













{tooltip} {shortcut_text}
Language code. Allowed: af (Afrikaans), am
(Amharic), ar (Arabic), as (Assamese), az
(Azerbaijani), ba (Bashkir), be (Belarusian),
bg (Bulgarian), bn (Bengali), bo (Tibetan), br
(Breton), bs (Bosnian), ca (Catalan), cs
(Czech), cy (Welsh), da (Danish), de (German),
el (Greek), en (English), es (Spanish), et
(Estonian), eu (Basque), fa (Persian), fi
(Finnish), fo (Faroese), fr (French), gl
(Galician), gu (Gujarati), ha (Hausa), haw
(Hawaiian), he (Hebrew), hi (Hindi), hr
(Croatian), ht (Haitian Creole), hu
(Hungarian), hy (Armenian), id (Indonesian), is
(Icelandic), it (Italian), ja (Japanese), jw
(Javanese), ka (Georgian), kk (Kazakh), km
(Khmer), kn (Kannada), ko (Korean), la (Latin),
lb (Luxembourgish), ln (Lingala), lo (Lao), lt
(Lithuanian), lv (Latvian), mg (Malagasy), mi
(Maori), mk (Macedonian), ml (Malayalam), mn
(Mongolian), mr (Marathi), ms (Malay), mt
(Maltese), my (Myanmar), ne (Nepali), nl
(Dutch), nn (Nynorsk), no (Norwegian), oc
(Occitan), pa (Punjabi), pl (Polish), ps
(Pashto), pt (Portuguese), ro (Romanian), ru
(Russian), sa (Sanskrit), sd (Sindhi), si
(Sinhala), sk (Slovak), sl (Slovenian), sn
(Shona), so (Somali), sq (Albanian), sr
(Serbian), su (Sundanese), sv (Swedish), sw
(Swahili), ta (Tamil), te (Telugu), tg (Tajik),
th (Thai), tk (Turkmen), tl (Tagalog), tr
(Turkish), tt (Tatar), uk (Ukrainian), ur
(Urdu), uz (Uzbek), vi (Vietnamese), yi
(Yiddish), yo (Yoruba), zh (Chinese). Leave
empty to detect language.
-p, --prompt Initial prompt.
-w, --word-timestamps Generate word-level timestamps. (available since 1.2.0)
-e, --extract-speech Extract speech from audio before transcribing. (available since 1.3.0)
--openai-token OpenAI access token. Use only when
--model-type is openaiapi. Defaults to your
previously saved access token, if one exists.
--srt Output result in an SRT file.
--vtt Output result in a VTT file.
--txt Output result in a TXT file.
--hide-gui Hide the main application window. (available since 1.2.0)
-h, --help Displays help on commandline options.
--help-all Displays help including Qt specific options.
-v, --version Displays version information.
Arguments:
files or urls Input file paths or urls. Url import availalbe since 1.2.0.
```
**Examples**:
```shell
# Translate two MP3 files from French to English using OpenAI Whisper API
buzz add --task translate --language fr --model-type openaiapi /Users/user/Downloads/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp3 /Users/user/Downloads/koaf9083k1lkpsfdi0.mp3
# Transcribe an MP4 using Whisper.cpp "small" model and immediately export to SRT and VTT files
buzz add --task transcribe --model-type whispercpp --model-size small --prompt "My initial prompt" --srt --vtt /Users/user/Downloads/buzz/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp4
```
================================================
FILE: docs/docs/faq.md
================================================
---
title: FAQ
sidebar_position: 5
---
### 1. Where are the models stored?
The models are stored:
- Linux: `~/.cache/Buzz`
- Mac OS: `~/Library/Caches/Buzz`
- Windows: `%USERPROFILE%\AppData\Local\Buzz\Buzz\Cache`
Paste the location in your file manager to access the models or go to `Help -> Preferences -> Models` and click on `Show file location` button after downloading some model.
### 2. What can I try if the transcription runs too slowly?
Speech recognition requires large amount of computation, so one option is to try using a lower Whisper model size or using a Whisper.cpp model to run speech recognition of your computer. If you have access to a computer with GPU that has at least 6GB of VRAM you can try using the Faster Whisper model.
Buzz also supports using OpenAI API to do speech recognition on a remote server. To use this feature you need to set OpenAI API key in Preferences. See [Preferences](https://chidiwilliams.github.io/buzz/docs/preferences) section for more details.
### 3. How to record system audio?
To transcribe system audio you need to configure virtual audio device and connect output from the applications you want to transcribe to this virtual speaker. After that you can select it as source in the Buzz. See [Usage](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) section for more details.
Relevant tools:
- Mac OS - [BlackHole](https://github.com/ExistentialAudio/BlackHole).
- Windows - [VB CABLE](https://vb-audio.com/Cable/)
- Linux - [PulseAudio Volume Control](https://wiki.ubuntu.com/record_system_sound)
### 4. What model should I use?
Model size to use will depend on your hardware and use case. Smaller models will work faster but will have more inaccuracies. Larger models will be more accurate but will require more powerful hardware or longer time to transcribe.
When choosing among large models consider the following. "Large" is the first released older model, "Large-V2" is later updated model with better accuracy, for some languages considered the most robust and stable. "Large-V3" is the latest model with the best accuracy in many cases, but some times can hallucinate or invent words that were never in the audio. "Turbo" model tries to get a good balance between speed and accuracy. The only sure way to know what model best suits your needs is to test them all in your language.
In addition to choosing an appropriate model size you also can choose whisper type.
- **Whisper** is initial OpenAI implementation, it is accurate but slow and requires a lot of RAM.
- **Faster Whisper** is an optimized implementation, it is orders of magnitude faster than regular Whisper and requires less RAM. Use this option if you have an Nvidia GPU with at least 6GB of VRAM.
- **Whisper.cpp** is optimized C++ implementation, it quite fast and efficient and will use any brand of GPU. Whisper.cpp is capable of running real time transcription even on a modern laptop with integrated GPU. It can also run on CPU only. Use this option if you do not have Nvidia GPU.
- **HuggingFace** option is a `Transformers` implementation and is good in that it supports wide range of custom models that may be optimized for a particular language. This option also supports [MMS](https://ai.meta.com/blog/multilingual-model-speech-recognition/) family of models from Meta AI that support over 1000 of worlds languages as well as [PEFT](https://github.com/huggingface/peft) adjustments to Whisper models.
### 5. How to get GPU acceleration for faster transcription?
On Linux GPU acceleration is supported out of the box on Nvidia GPUs. If you still get any issues install [CUDA 12](https://developer.nvidia.com/cuda-downloads), [cuBLASS](https://developer.nvidia.com/cublas) and [cuDNN](https://developer.nvidia.com/cudnn).
On Windows GPU support is included in the installation `.exe`. CUDA 12 required, computers with older CUDA versions will use CPU. See [this note](https://github.com/chidiwilliams/buzz/blob/main/CONTRIBUTING.md#gpu-support) on enabling CUDA GPU support.
### 6. How to fix `Unanticipated host error[PaErrorCode-9999]`?
Check if there are any system settings preventing apps from accessing the microphone.
On Windows, see if Buzz has permission to use the microphone in Settings -> Privacy -> Microphone.
See method 1 in this video https://www.youtube.com/watch?v=eRcCYgOuSYQ
For method 2 there is no need to uninstall the antivirus, but see if you can temporarily disable it or if there are settings that may prevent Buzz from accessing the microphone.
### 7. Can I use Buzz on a computer without internet?
Yes, Buzz can be used without internet connection if you download the necessary models on some other computer that has the internet and manually move them to the offline computer. The easiest way to find where the models are stored is to go to Help -> Preferences -> Models. Then download some model, and push "Show file location" button. This will open the folder where the models are stored. Copy the models folder to the same location on the offline computer. F.e. for Linux it is `.cache/Buzz/models` in your home directory.
### 8. Buzz crashes, what to do?
If a model download was incomplete or corrupted, Buzz may crash. Try to delete the downloaded model files in `Help -> Preferences -> Models` and re-download them.
If that does not help, check the log file for errors and [report the issue](https://github.com/chidiwilliams/buzz/issues) so we can fix it. If possible attach the log file to the issue. Since Version `1.3.4`, to get to the logs folder go to `Help -> About Buzz` and click on `Show logs` button.
### 9. Where can I get latest development version?
Latest development version will have latest bug fixes and most recent features. If you feel a bit adventurous it is recommended to try the latest development version as they needs some testing before they get released to everybody.
- **Linux** users can get the latest version with this command `sudo snap install buzz --edge`
- **For other** platforms do the following:
1. Go to the [build section](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml?query=branch%3Amain)
2. Click on the link to the latest build, the most recent successful build entry in the list
3. Scroll down to the artifacts section in the build page
4. Download the installation file. Please note that you need to be logged in the Github to see the download links.

### 10. Why is my system theme not applied to Buzz installed from Flatpak?
For dark themes on Gnome environments you may need to install `gnome-themes-extra` package and set the following preferences:
```
gsettings set org.gnome.desktop.interface gtk-theme Adwaita-dark
gsettings set org.gnome.desktop.interface color-scheme prefer-dark
```
If your system theme is not applied to Buzz installed from Flatpak Linux app store, ensure the desired theme is in `~/.themes` folder.
You may need to copy the system themes to this folder `cp -r /usr/share/themes/ ~/.themes/` and give Flatpaks access to this folder `flatpak override --user --filesystem=~/.themes`.
On Fedora run the following to install the necessary packages
`sudo dnf install gnome-themes-extra qadwaitadecorations-qt{5,6} qt{5,6}-qtwayland`
================================================
FILE: docs/docs/index.md
================================================
---
title: Introduction
sidebar_position: 1
---
Transcribe and translate audio offline on your personal computer. Powered by
OpenAI's [Whisper](https://github.com/openai/whisper).

[](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml)
[](https://codecov.io/github/chidiwilliams/buzz)

[](https://GitHub.com/chidiwilliams/buzz/releases/)
## Features
- Import audio and video files and export transcripts to TXT, SRT, and
VTT ([Demo](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe))
- Transcription and translation from your computer's microphones to text (Resource-intensive and may not be
real-time, [Demo](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7))
- Presentation window for easy accessibility during events and presentations
- [Realtime translation](https://chidiwilliams.github.io/buzz/docs/usage/translations) with OpenAI API compatible AI
- [Advanced Transcription Viewer](https://chidiwilliams.github.io/buzz/docs/usage/transcription_viewer) with search, playback controls, and speed adjustment
- **Smart Interface** with conditional visibility and state persistence
- **Professional Controls** including loop segments, follow audio, and keyboard shortcuts
- Supports [Whisper](https://github.com/openai/whisper#available-models-and-languages),
[Whisper.cpp](https://github.com/ggerganov/whisper.cpp) (with Vulkan GPU acceleration), [Faster Whisper](https://github.com/guillaumekln/faster-whisper),
[Whisper-compatible Hugging Face models](https://huggingface.co/models?other=whisper), and
the [OpenAI Whisper API](https://platform.openai.com/docs/api-reference/introduction)
- [Command-Line Interface](#command-line-interface)
- Speech separation before transcription for better accuracy on noisy audio
- [Speaker identification](https://chidiwilliams.github.io/buzz/docs/usage/speaker_identification) in transcribed media
- Available on Mac, Windows, and Linux
================================================
FILE: docs/docs/installation.md
================================================
---
title: Installation
sidebar_position: 2
---
To install Buzz, download the latest version for your operating
system. Buzz is available on **Mac** (Intel and Apple silicon), **Windows**, and **Linux**.
### macOS
Download the `.dmg` from the [SourceForge](https://sourceforge.net/projects/buzz-captions/files/).
### Windows
Get the installation files from the [SourceForge](https://sourceforge.net/projects/buzz-captions/files/).
App is not signed, you will get a warning when you install it. Select `More info` -> `Run anyway`.
## Linux
Buzz is available as a [Flatpak](https://flathub.org/apps/io.github.chidiwilliams.Buzz) or a [Snap](https://snapcraft.io/buzz).
To install flatpak, run:
```shell
flatpak install flathub io.github.chidiwilliams.Buzz
```
[](https://flathub.org/en/apps/io.github.chidiwilliams.Buzz)
To install snap, run:
```shell
sudo apt-get install libportaudio2 libcanberra-gtk-module libcanberra-gtk3-module
sudo snap install buzz
sudo snap connect buzz:password-manager-service
```
[](https://snapcraft.io/buzz)
## PyPI
```shell
pip install buzz-captions
python -m buzz
```
On Linux install system dependencies you may be missing
```
sudo apt-get install --no-install-recommends libyaml-dev libtbb-dev libxkbcommon-x11-0 libxcb-icccm4 libxcb-image0 libxcb-keysyms1 libxcb-randr0 libxcb-render-util0 libxcb-xinerama0 libxcb-shape0 libxcb-cursor0 libportaudio2 gettext libpulse0 ffmpeg
```
On versions prior to Ubuntu 24.04 install `sudo apt-get install --no-install-recommends libegl1-mesa`
================================================
FILE: docs/docs/preferences.md
================================================
---
title: Preferences
sidebar_position: 4
---
Open the Preferences window from the Menu bar, or click `Ctrl/Cmd + ,`.
## General Preferences
### OpenAI API preferences
**API Key** - key to authenticate your requests to OpenAI API. To get API key from OpenAI see [this article](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key).
**Base URL** - By default all requests are sent to API provided by OpenAI company. Their API URL is `https://api.openai.com/v1/`. Compatible APIs are also provided by other companies. List of available API URLs and services to run yourself are available on [discussion page](https://github.com/chidiwilliams/buzz/discussions/827)
### Default export file name
Sets the default export file name for file transcriptions. For
example, a value of `{{ input_file_name }} ({{ task }}d on {{ date_time }})` will save TXT exports
as `Input Filename (transcribed on 19-Sep-2023 20-39-25).txt` by default.
Available variables:
| Key | Description | Example |
| ----------------- | ----------------------------------------- | ---------------------------------------------------------------- |
| `input_file_name` | File name of the imported file | `audio` (e.g. if the imported file path was `/path/to/audio.wav` |
| `task` | Transcription task | `transcribe`, `translate` |
| `language` | Language code | `en`, `fr`, `yo`, etc. |
| `model_type` | Model type | `Whisper`, `Whisper.cpp`, `Faster Whisper`, etc. |
| `model_size` | Model size | `tiny`, `base`, `small`, `medium`, `large`, etc. |
| `date_time` | Export time (format: `%d-%b-%Y %H-%M-%S`) | `19-Sep-2023 20-39-25` |
### Live transcript exports
Live transcription export can be used to integrate Buzz with other applications like OBS Studio.
When enabled, live text transcripts will be exported to a text file as they get generated and translated.
If AI translation is enabled for live recordings, the translated text will also be exported to the text file.
Filename for the translated text will end with `.translated.txt`.
### Live transcription mode
Three transcription modes are available:
**Append below** - New sentences will be added below existing with an empty space between them.
Last sentence will be at the bottom.
**Append above** - New sentences will be added above existing with an empty space between them.
Last sentence will be at the top.
**Append and correct** - New sentences will be added at the end of existing transcript without extra spaces between.
This mode will also try to correct errors at the end of previously transcribed sentences. This mode requires more
processing power and more powerful hardware to work.
## Model Preferences
This section lets you download new models for transcription and delete unused ones.
For Whisper.cpp you can also download custom models. Select `Custom` in the model size list and paste the download url
to the model `.bin` file. Use the link from "download" button from the Huggingface.
To improve transcription speed and memory usage you can select a quantized version of some
larger model. For example `q_5` version. Whisper.cpp base models in different quantizations are [available here](https://huggingface.co/ggerganov/whisper.cpp/tree/main). See also [custom models](https://github.com/chidiwilliams/buzz/discussions/866) discussion page for custom models in different languages.
[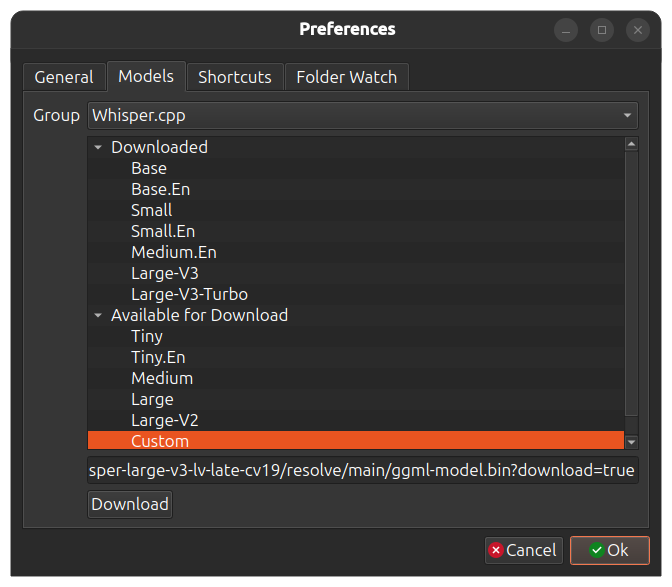](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Model preferences")
## Advanced Preferences
To keep preferences section simple for new users, some more advanced preferences are settable via OS environment variables. Set the necessary environment variables in your OS before starting Buzz or create a script to set them.
On MacOS and Linux crete `run_buzz.sh` with the following content:
```bash
#!/bin/bash
export VARIABLE=value
export SOME_OTHER_VARIABLE=some_other_value
buzz
```
On Windows crete `run_buzz.bat` with the following content:
```bat
@echo off
set VARIABLE=value
set SOME_OTHER_VARIABLE=some_other_value
"C:\Program Files (x86)\Buzz\Buzz.exe"
```
Alternatively you can set environment variables in your OS settings. See [this guide](https://phoenixnap.com/kb/windows-set-environment-variable#ftoc-heading-4) or [this video](https://www.youtube.com/watch?v=bEroNNzqlF4) more information.
### Available variables
**BUZZ_WHISPERCPP_N_THREADS** - Number of threads to use for Whisper.cpp model. Default is half of available CPU cores.
On a laptop with 16 threads setting `BUZZ_WHISPERCPP_N_THREADS=8` leads to some 15% speedup in transcription time.
Increasing number of threads even more will lead in slower transcription time as results from parallel threads has to be
combined to produce the final answer.
**BUZZ_TRANSLATION_API_BASE_URL** - Base URL of OpenAI compatible API to use for translation.
**BUZZ_TRANSLATION_API_KEY** - Api key of OpenAI compatible API to use for translation.
**BUZZ_MODEL_ROOT** - Root directory to store model files. You may also want to set `HF_HOME` to the same folder as some libraries used in Buzz download their models independently.
Defaults to [user_cache_dir](https://pypi.org/project/platformdirs/).
**BUZZ_FAVORITE_LANGUAGES** - Coma separated list of supported language codes to show on top of language list.
**BUZZ_DOWNLOAD_COOKIEFILE** - Location of a [cookiefile](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#how-do-i-pass-cookies-to-yt-dlp) to use for downloading private videos or as workaround for anti-bot protection.
**BUZZ_FORCE_CPU** - Will force Buzz to use CPU and not GPU, useful for setups with older GPU if that is slower than GPU or GPU has issues. Example usage `BUZZ_FORCE_CPU=true`. Available since `1.2.1`
**BUZZ_REDUCE_GPU_MEMORY** - Will use 8bit quantization for Huggingface adn Faster Whisper transcriptions to reduce required GPU memory. Example usage `BUZZ_REDUCE_GPU_MEMORY=true`. Available since `1.4.0`
**BUZZ_MERGE_REGROUP_RULE** - Custom regroup merge rule to use when combining transcripts with word-level timings. More information on available options [in stable-ts repo](https://github.com/jianfch/stable-ts?tab=readme-ov-file#regrouping-methods). Available since `1.3.0`
**BUZZ_DISABLE_TELEMETRY** - Buzz collects basic OS name and architecture usage statistics to better focus development efforts. This variable lets disable collection of these statistics. Example usage `BUZZ_DISABLE_TELEMETRY=true`. Available since `1.3.0`
**BUZZ_UPLOAD_URL** - Live recording transcripts and translations can be uploaded to a server for display on the web. Set this variable to the desired upload url. You can use [buzz-transcription-server](https://github.com/raivisdejus/buzz-transcription-server) as a server. Buzz will upload the following `json` via `POST` requests - `{"kind": "transcript", "text": "Sample transcript"}` or `{"kind": "translation", "text": "Sample translation"}`. Example usage `BUZZ_UPLOAD_URL=http://localhost:5000/upload`. Available since `1.3.0`
Example of data collected by telemetry:
```
Buzz: 1.3.0, locale: ('lv_LV', 'UTF-8'), system: Linux, release: 6.14.0-27-generic, machine: x86_64, version: #27~24.04.1-Ubuntu SMP PREEMPT_DYNAMIC Tue Jul 22 17:38:49 UTC 2,
```
**BUZZ_PARAGRAPH_SPLIT_TIME** - Time in milliseconds of silence to split paragraphs in transcript and add two newlines when exporting the transcripts as text. Default is `2000` or 2 seconds. Available since `1.3.0`
================================================
FILE: docs/docs/usage/1_file_import.md
================================================
---
title: File Import
---
**To import a file:**
- Click Import Media File on the File menu (or the '+' icon on the toolbar, or **Command/Ctrl + O**).
- Choose an audio or video file.
- Select a task, language, and the model settings.
- Click Run.
- When the transcription status shows 'Completed', double-click on the row (or select the row and click the '⤢' icon) to
open the transcription.
**Available options:**
To reduce misspellings you can pass some commonly misspelled words in an `Initial prompt` that is available under `Advanced...` button. See this [guide on prompting](https://cookbook.openai.com/examples/whisper_prompting_guide#pass-names-in-the-prompt-to-prevent-misspellings).
| Field | Options | Default | Description |
| ------------------ | ------------------- | ------- |--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Export As | "TXT", "SRT", "VTT" | "TXT" | Export file format |
| Word-Level Timings | Off / On | Off | If checked, the transcription will generate a separate subtitle line for each word in the audio. Combine words into subtitles afterwards with the [resize option](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize). |
| Extract speech | Off / On | Off | If checked, speech will be extracted to a separate audio tack to improve accuracy. |
(See the [Live Recording section](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) for more information about the task, language, and quality settings.)
[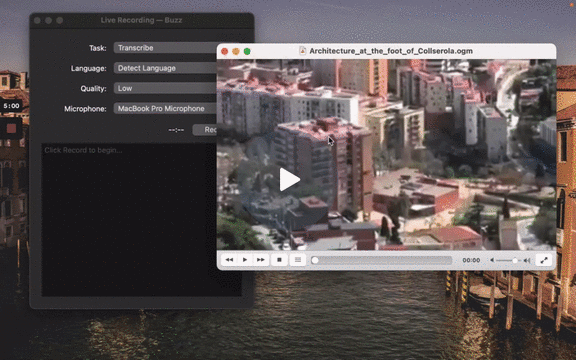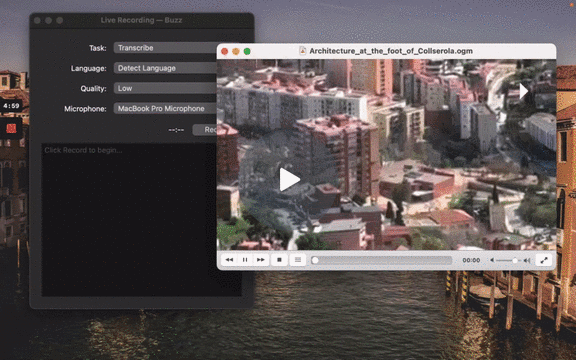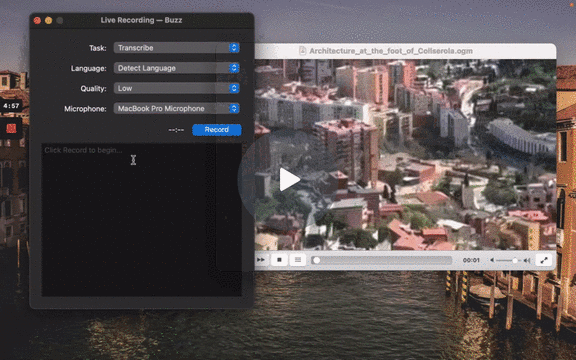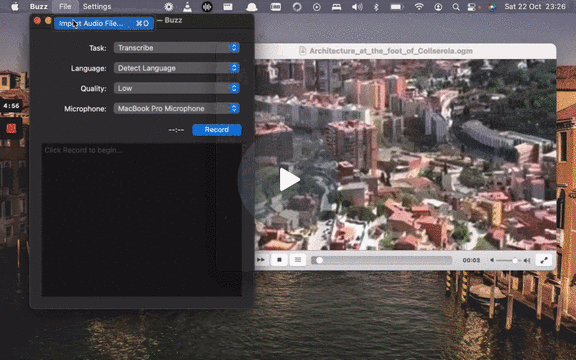](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Media File Import on Buzz")
**💡 Tip:** It is recommended to always select language to transcribe to as automatic language detection may result in unexpected results.
================================================
FILE: docs/docs/usage/2_live_recording.md
================================================
---
title: Live Recording
---
To start a live recording:
- Select a recording task, language, quality, and microphone.
- Click Record.
> **Note:** Transcribing audio using the default Whisper model is resource-intensive. Consider using the Whisper.cpp.
> It supports GPU acceleration, if the model fits in GPU memory. Use smaller models for real-time performance.
| Field | Options | Default | Description |
|------------|------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Task | "Transcribe", "Translate to English" | "Transcribe" | "Transcribe" converts the input audio into text in the selected language, while "Translate to English" converts it into text in English. |
| Language | See [Whisper's documentation](https://github.com/openai/whisper#available-models-and-languages) for the full list of supported languages | "Detect Language" | "Detect Language" will try to detect the spoken language in the audio based on the first few seconds. However, selecting a language is recommended (if known) as it will improve transcription quality in many cases. |
| Microphone | [Available system microphones] | [Default system microphone] | Microphone for recording input audio. |
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "Live Recording on Buzz")
#### Advanced preferences
**Silence threshold** Set threshold to for transcriptions to be processed. If average volume level is under this setting the sentence will not be transcribed. Available since 1.4.4.
**Line separator** Marking to add to the transcription and translation lines. Default value is two new lines (`\n\n`) that result in an empty space between translation or transcription lines. To have no empty line use `\n`. Available since 1.4.4.
**Transcription step** If live recording mode is set to `Append and correct`, you can also set a transcription step. Shorter steps will reduce latency but cause larger load on the system. Monitor the `Queue` while transcribing in this mode, if it grows too much, increase the transcription step, to reduce load. Available since 1.4.4.
**Hide unconfirmed** If live recording mode is set to `Append and correct`, you can also hide the unconfirmed part of the last transcript. This part may be incorrect as the Buzz has seen it only in one overlapping transcription segment. Hiding it will increase latency, but result will show only the correct transcripts. Available since 1.4.4.
#### Presentation Window
Buzz has an easy to use presentation window you can use to show live transcriptions during events and presentations. To open it start the recording and new options for the `Presentation window` will appear.
### Record audio playing from computer (macOS)
To record audio playing from an application on your computer, you may install an audio loopback driver (a program that
lets you create virtual audio devices). The rest of this guide will
use [BlackHole](https://github.com/ExistentialAudio/BlackHole) on Mac, but you can use other alternatives for your
operating system (
see [LoopBeAudio](https://nerds.de/en/loopbeaudio.html), [LoopBack](https://rogueamoeba.com/loopback/),
and [Virtual Audio Cable](https://vac.muzychenko.net/en/)).
1. Install [BlackHole via Homebrew](https://github.com/ExistentialAudio/BlackHole#option-2-install-via-homebrew)
```shell
brew install blackhole-2ch
```
2. Open Audio MIDI Setup from Spotlight or from `/Applications/Utilities/Audio Midi Setup.app`.
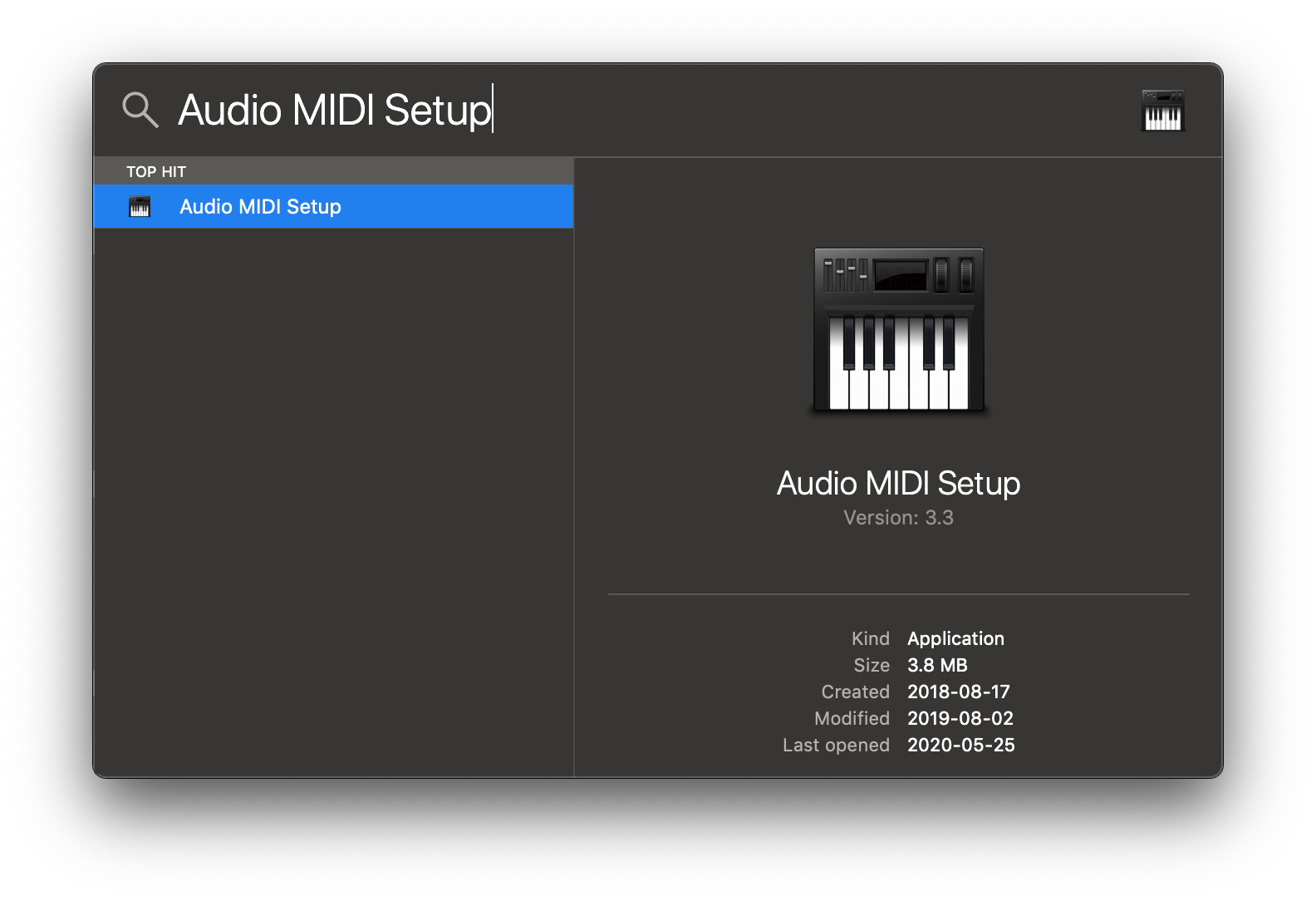
3. Click the '+' icon at the lower left corner and select 'Create Multi-Output Device'.

4. Add your default speaker and BlackHole to the multi-output device.
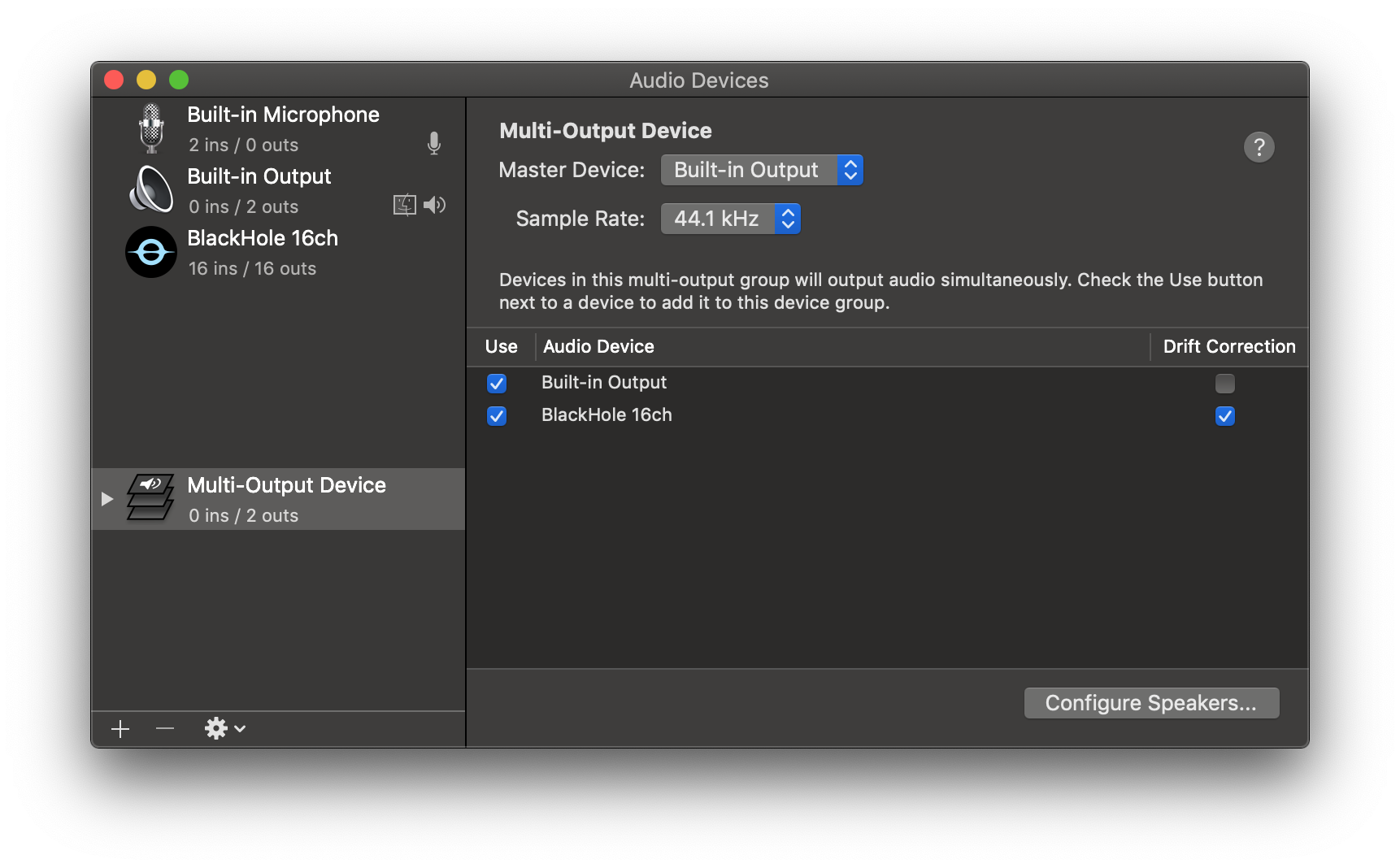
5. Select this multi-output device as your speaker (application or system-wide) to play audio into BlackHole.
6. Open Buzz, select BlackHole as your microphone, and record as before to see transcriptions from the audio playing
through BlackHole.
### Record audio playing from computer (Windows)
To transcribe system audio you need to configure virtual audio device and connect output from the applications you whant to transcribe to this virtual speaker. After that you can select it as source in the Buzz.
1. Install [VB CABLE](https://vb-audio.com/Cable/) as virtual audio device.
2. Configure using Windows Sound settings. Right-click on the speaker icon in the system tray and select "Open Sound settings". In the "Choose your output device" dropdown select "CABLE Input" to send all system sound to the virtual device or use "Advanced sound options" to select application that will output their sound to this device.
### Record audio playing from computer (Linux)
As described on [Ubuntu Wiki](https://wiki.ubuntu.com/record_system_sound) on any Linux with pulse audio you can redirect application audio to a virtual speaker. After that you can select it as source in Buzz.
Overall steps:
1. Launch application that will produce the sound you want to transcribe and start the playback. For example start a video in a media player.
2. Launch Buzz and open Live recording screen, so you see the settings.
3. Configure sound routing from the application you want to transcribe sound from to Buzz in `Recording tab` of the PulseAudio Volume Control (`pavucontrol`).
================================================
FILE: docs/docs/usage/3_translations.md
================================================
---
title: Translations
---
Default `Translation` task uses Whisper model ability to translate to English, however `Large-V3-Turbo` is not compatible with this standard. Buzz supports additional AI translations to any other language.
To use translation feature you will need to configure OpenAI API key and translation settings. Set OpenAI API ket in Preferences. Buzz also supports custom locally running translation AIs that support OpenAI API. For more information on locally running AIs see [ollama](https://ollama.com/blog/openai-compatibility) or [LM Studio](https://lmstudio.ai/). For information on available custom APIs see this [discussion thread](https://github.com/chidiwilliams/buzz/discussions/827).
To configure translation for Live recordings enable it in Advances settings dialog of the Live Recording settings. Enter AI model to use and prompt with instructions for the AI on how to translate. Translation option is also available for files that already have speech recognised. Use Translate button on transcription viewer toolbar.
For AI to know how to translate enter translation instructions in the "Instructions for AI" section. In your instructions you should describe to what language you want it to translate the text to. Also, you may need to add additional instructions to not add any notes or comments as AIs tend to add them. Example instructions to translate English subtitles to Spanish:
> You are a professional translator, skilled in translating English to Spanish. You will only translate each sentence sent to you into Spanish and not add any notes or comments.
If you enable "Enable live recording transcription export" in Preferences, Live text transcripts will be exported to a text file as they get generated and translated. This file can be used to further integrate Live transcripts with other applications like OBS Studio.
Approximate cost of translation for 1 hour long audio with ChatGPT `gpt-4o` model is around $0.50.
================================================
FILE: docs/docs/usage/4_edit_and_resize.md
================================================
---
title: Edit and Resize
---
[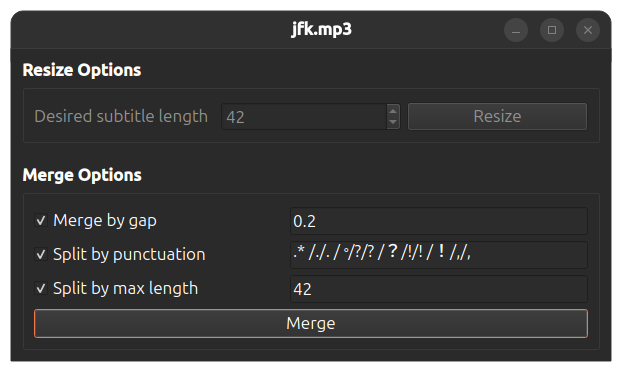](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Resize options")
When transcript of some audio or video file is generated you can edit it and export to different subtitle formats or plain text. Double-click the transcript in the list of transcripts to see additional options for editing and exporting.
Transcription view screen has option to resize the transcripts. Click on the "Resize" button so see available options. Transcripts that have been generated **with word-level timings** setting enabled can be combined into subtitles specifying different options, like maximum length of a subtitle and if subtitles should be split on punctuation. For transcripts that have been generated **without word-level timings** setting enabled can only be recombined specifying desired max length of a subtitle.
If audio file is still present on the system word-level timing merge will also analyze the audio for silences to improve subtitle accuracy.
The resize tool also has an option to extend end time of segments if you want the subtitles to be on the screen for longer. You can specify the amount of time in seconds to extend each subtitle segment. Buzz will add this amount of time to the end of each subtitle segment making sure that the end of a segment does not go over start of the next segment. This feature is available since 1.4.3.
================================================
FILE: docs/docs/usage/5_speaker_identification.md
================================================
---
title: Speaker identification
---
When transcript of some audio or video file is generated you can identify speakers in the transcript. Double-click the transcript in the list of transcripts to see additional options for editing and exporting.
Transcription view screen has option to identify speakers. Click on the "Identify speakers" button so see available options.
If audio file is still present on the system speaker identification will mark each speakers sentences with appropriate label. You can preview 10 seconds of some random sentence of the identified speaker and rename the automatically identified label to speakers real name. If "Merge speaker sentences" checkbox is selected when you save the speaker labels, all consecutive sentences of the same speaker will be merged into one segment. Speaker identification is not available on Intel macOS.
================================================
FILE: docs/docs/usage/5_transcription_viewer.md
================================================
# Transcription Viewer
The Buzz transcription viewer provides a powerful interface for reviewing, editing, and navigating through your transcriptions. This guide covers all the features available in the transcription viewer.
## Overview
The transcription viewer is organized into several key sections:
- **Top Toolbar**: Contains view mode, export, translate, resize, and search
- **Search Bar**: Find and navigate through transcript text
- **Transcription Segments**: Table view of all transcription segments with timestamps
- **Playback Controls**: Audio playback settings and speed controls
- **Audio Player**: Standard media player with progress bar
- **Current Segment Display**: Shows the currently selected or playing segment
## Top Toolbar
### View Mode Button
- **Function**: Switch between different viewing modes
- **Options**:
- **Timestamps**: Shows segments in a table format with start/end times
- **Text**: Shows combined text without timestamps
- **Translation**: Shows translated text (if available)
### Export Button
- **Function**: Export transcription in various formats
- **Formats**: SRT, VTT, TXT, JSON, and more
- **Usage**: Click to open export menu and select desired format
### Translate Button
- **Function**: Translate transcription to different languages
- **Usage**: Click to open translation settings and start translation
### Resize Button
- **Function**: Adjust transcription segment boundaries
- **Usage**: Click to open resize dialog for fine-tuning timestamps
- **More information**: See [Edit and Resize](https://chidiwilliams.github.io/buzz/docs/usage/edit_and_resize) section
### Playback Controls Button
- **Function**: Show/hide playback control panel
- **Shortcut**: `Ctrl+Alt+P` (Windows/Linux) or `Cmd+Alt+P` (macOS)
- **Behavior**: Toggle button that shows/hides the playback controls below
### Find Button
- **Function**: Show/hide search functionality
- **Shortcut**: `Ctrl+F` (Windows/Linux) or `Cmd+F` (macOS)
- **Behavior**: Toggle button that shows/hides the search bar
### Scroll to Current Button
- **Function**: Automatically scroll to the currently playing text
- **Shortcut**: `Ctrl+G` (Windows/Linux) or `Cmd+G` (macOS)
- **Usage**: Click to jump to the current audio position in the transcript
## Search Functionality
### Search Bar
The search bar appears below the toolbar when activated and provides:
- **Search Input**: Type text to find in the transcription (wider input field for better usability)
- **Navigation**: Up/down arrows to move between matches
- **Status**: Shows current match position and total matches (e.g., "3 of 15 matches")
- **Clear**: Remove search text and results (larger button for better accessibility)
- **Results**: Displays found text with context
- **Consistent Button Sizing**: All navigation buttons have uniform height for better visual consistency
### Search Shortcuts
- **`Ctrl+F` / `Cmd+F`**: Toggle search bar on/off
- **`Enter`**: Find next match
- **`Shift+Enter`**: Find previous match
- **`Escape`**: Close search bar
### Search Features
- **Real-time Search**: Results update as you type
- **Case-insensitive**: Finds matches regardless of capitalization
- **Word Boundaries**: Respects word boundaries for accurate matching
- **Cross-view Search**: Works in all view modes (Timestamps, Text, Translation)
## Playback Controls
### Loop Segment
- **Function**: Automatically loop playback of selected segments
- **Usage**: Check the "Loop Segment" checkbox
- **Behavior**: When enabled, clicking on a transcript segment will set a loop range
- **Visual Feedback**: Loop range is highlighted in the audio player
### Follow Audio
- **Function**: Automatically scroll to current audio position
- **Usage**: Check the "Follow Audio" checkbox
- **Behavior**: Transcript automatically follows the audio playback
- **Benefits**: Easy to follow along with long audio files
### Speed Controls
- **Function**: Adjust audio playback speed
- **Range**: 0.5x to 2.0x speed
- **Controls**:
- **Speed Dropdown**: Select from preset speeds or enter custom value
- **Decrease Button (-)**: Reduce speed by 0.05x increments
- **Increase Button (+)**: Increase speed by 0.05x increments
- **Persistence**: Speed setting is saved between sessions
- **Button Sizing**: Speed control buttons match the size of search navigation buttons for visual consistency
## Keyboard Shortcuts
### Audio Playback
- **`Ctrl+P` / `Cmd+P`**: Play/Pause audio
- **`Ctrl+Shift+P` / `Cmd+Shift+P`**: Replay current segment from start
### Timestamp Adjustment
- **`Ctrl+←` / `Cmd+←`**: Decrease segment start time by 0.5s
- **`Ctrl+→` / `Cmd+→`**: Increase segment start time by 0.5s
- **`Ctrl+Shift+←` / `Cmd+Shift+←`**: Decrease segment end time by 0.5s
- **`Ctrl+Shift+→` / `Cmd+Shift+→`**: Increase segment end time by 0.5s
### Navigation
- **`Ctrl+F` / `Cmd+F`**: Toggle search bar
- **`Ctrl+Alt+P` / `Cmd+Alt+P`**: Toggle playback controls
- **`Ctrl+G` / `Cmd+G`**: Scroll to current position
- **`Ctrl+O` / `Cmd+O`**: Open file import dialog
### Search
- **`Enter`**: Find next match
- **`Shift+Enter`**: Find previous match
- **`Escape`**: Close search bar
================================================
FILE: docs/docs/usage/_category_.yml
================================================
label: Usage
position: 3
================================================
FILE: docs/docusaurus.config.js
================================================
// @ts-check
// Note: type annotations allow type checking and IDEs autocompletion
const lightCodeTheme = require("prism-react-renderer/themes/github");
const darkCodeTheme = require("prism-react-renderer/themes/dracula");
/** @type {import('@docusaurus/types').Config} */
const config = {
title: "Buzz",
tagline: "Audio transcription and translation",
favicon: "img/favicon.ico",
// Set the production url of your site here
url: "https://chidiwilliams.github.io",
// Set the // pathname under which your site is served
// For GitHub pages deployment, it is often '//'
baseUrl: "/buzz/",
// GitHub pages deployment config.
// If you aren't using GitHub pages, you don't need these.
organizationName: "chidiwilliams", // Usually your GitHub org/user name.
projectName: "buzz", // Usually your repo name.
onBrokenLinks: "throw",
onBrokenMarkdownLinks: "warn",
trailingSlash: false,
// Even if you don't use internalization, you can use this field to set useful
// metadata like html lang. For example, if your site is Chinese, you may want
// to replace "en" with "zh-Hans".
i18n: {
defaultLocale: "en",
locales: ["en", "zh"],
path: "i18n",
localeConfigs: {
en: {
label: "English",
direction: "ltr",
htmlLang: "en-US",
path: "en",
},
zh: {
label: "简体中文",
direction: "ltr",
htmlLang: "zh-CN",
path: "zh",
},
},
},
presets: [
[
"classic",
/** @type {import('@docusaurus/preset-classic').Options} */
({
docs: {
sidebarPath: require.resolve("./sidebars.js"),
},
blog: {
showReadingTime: true,
},
theme: {
customCss: require.resolve("./src/css/custom.css"),
},
}),
],
],
themeConfig:
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */
({
// Replace with your project's social card
image: "img/favicon.ico",
navbar: {
title: "Buzz",
logo: {
alt: "Buzz",
src: "img/favicon.ico",
},
items: [
{
type: "docSidebar",
sidebarId: "tutorialSidebar",
position: "left",
label: "Docs",
},
{
href: "https://github.com/chidiwilliams/buzz",
label: "GitHub",
position: "right",
},
{
type: "localeDropdown",
position: "left",
},
],
},
prism: {
theme: lightCodeTheme,
darkTheme: darkCodeTheme,
},
}),
};
module.exports = config;
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/cli.md
================================================
---
title: 命令行界面 (CLI)
sidebar_position: 5
---
## 命令
### `增加`
启动一个新的转录任务。
```
Usage: buzz add [options] [file url file...]
Options:
-t, --task The task to perform. Allowed: translate,
transcribe. Default: transcribe.
-m, --model-type Model type. Allowed: whisper, whispercpp,
huggingface, fasterwhisper, openaiapi. Default:
whisper.
-s, --model-size Model size. Use only when --model-type is
whisper, whispercpp, or fasterwhisper. Allowed:
tiny, base, small, medium, large. Default:
tiny.
--hfid Hugging Face model ID. Use only when
--model-type is huggingface. Example:
"openai/whisper-tiny"
-l, --language Language code. Allowed: af (Afrikaans), am
(Amharic), ar (Arabic), as (Assamese), az
(Azerbaijani), ba (Bashkir), be (Belarusian),
bg (Bulgarian), bn (Bengali), bo (Tibetan), br
(Breton), bs (Bosnian), ca (Catalan), cs
(Czech), cy (Welsh), da (Danish), de (German),
el (Greek), en (English), es (Spanish), et
(Estonian), eu (Basque), fa (Persian), fi
(Finnish), fo (Faroese), fr (French), gl
(Galician), gu (Gujarati), ha (Hausa), haw
(Hawaiian), he (Hebrew), hi (Hindi), hr
(Croatian), ht (Haitian Creole), hu
(Hungarian), hy (Armenian), id (Indonesian), is
(Icelandic), it (Italian), ja (Japanese), jw
(Javanese), ka (Georgian), kk (Kazakh), km
(Khmer), kn (Kannada), ko (Korean), la (Latin),
lb (Luxembourgish), ln (Lingala), lo (Lao), lt
(Lithuanian), lv (Latvian), mg (Malagasy), mi
(Maori), mk (Macedonian), ml (Malayalam), mn
(Mongolian), mr (Marathi), ms (Malay), mt
(Maltese), my (Myanmar), ne (Nepali), nl
(Dutch), nn (Nynorsk), no (Norwegian), oc
(Occitan), pa (Punjabi), pl (Polish), ps
(Pashto), pt (Portuguese), ro (Romanian), ru
(Russian), sa (Sanskrit), sd (Sindhi), si
(Sinhala), sk (Slovak), sl (Slovenian), sn
(Shona), so (Somali), sq (Albanian), sr
(Serbian), su (Sundanese), sv (Swedish), sw
(Swahili), ta (Tamil), te (Telugu), tg (Tajik),
th (Thai), tk (Turkmen), tl (Tagalog), tr
(Turkish), tt (Tatar), uk (Ukrainian), ur
(Urdu), uz (Uzbek), vi (Vietnamese), yi
(Yiddish), yo (Yoruba), zh (Chinese). Leave
empty to detect language.
-p, --prompt Initial prompt.
-w, --word-timestamps Generate word-level timestamps. (available since 1.2.0)
--openai-token OpenAI access token. Use only when
--model-type is openaiapi. Defaults to your
previously saved access token, if one exists.
--srt Output result in an SRT file.
--vtt Output result in a VTT file.
--txt Output result in a TXT file.
--hide-gui Hide the main application window. (available since 1.2.0)
-h, --help Displays help on commandline options.
--help-all Displays help including Qt specific options.
-v, --version Displays version information.
Arguments:
files or urls Input file paths or urls. Url import availalbe since 1.2.0.
```
**示例**:
```shell
# 使用 OpenAI Whisper API 将两个 MP3 文件从法语翻译为英语
buzz add --task translate --language fr --model-type openaiapi /Users/user/Downloads/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp3 /Users/user/Downloads/koaf9083k1lkpsfdi0.mp3
# 使用 Whisper.cpp "small" 模型转录一个 MP4 文件,并立即导出为 SRT 和 VTT 文件
buzz add --task transcribe --model-type whispercpp --model-size small --prompt "My initial prompt(我的初始提示)" --srt --vtt /Users/user/Downloads/buzz/1b3b03e4-8db5-ea2c-ace5-b71ff32e3304.mp4
```
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/faq.md
================================================
---
title: 常见问题(FAQ)
sidebar_position: 5
---
### 1. 模型存储在哪里?
模型存储在以下位置:
- Linux: `~/.cache/Buzz`
- Mac OS: `~/Library/Caches/Buzz`
- Windows: `%USERPROFILE%\AppData\Local\Buzz\Buzz\Cache`
将上述路径粘贴到文件管理器中即可访问模型。
### 2. 如果转录速度太慢,我可以尝试什么?
语音识别需要大量计算资源,您可以尝试使用较小的 Whisper 模型,或者使用 Whisper.cpp 模型在本地计算机上运行语音识别。如果您的计算机配备了至少 6GB VRAM 的 GPU,可以尝试使用 Faster Whisper 模型。
Buzz 还支持使用 OpenAI API 在远程服务器上进行语音识别。要使用此功能,您需要在“偏好设置”中设置 OpenAI API 密钥。详情请参见 [偏好设置](https://chidiwilliams.github.io/buzz/docs/preferences) 部分。
### 3. 如何录制系统音频?
要转录系统音频,您需要配置虚拟音频设备,并将希望转录的应用程序输出连接到该虚拟扬声器。然后,您可以在 Buzz 中选择该设备作为音源。详情请参见 [使用指南](https://chidiwilliams.github.io/buzz/docs/usage/live_recording) 部分。
相关工具:
- Mac OS - [BlackHole](https://github.com/ExistentialAudio/BlackHole)
- Windows - [VB CABLE](https://vb-audio.com/Cable/)
- Linux - [PulseAudio Volume Control](https://wiki.ubuntu.com/record_system_sound)
### 4. 我应该使用哪个模型?
选择模型大小取决于您的硬件和使用场景。较小的模型运行速度更快,但准确性较低;较大的模型更准确,但需要更强的硬件或更长的转录时间。
在选择大模型时,请参考以下信息:
- **“Large”** 是最早发布的模型
- **“Large-V2”** 是后续改进版,准确率更高,被认为是某些语言中最稳定的选择
- **“Large-V3”** 是最新版本,在许多情况下准确性最佳,但有时可能会产生错误的单词
- **“Turbo”** 模型在速度和准确性之间取得了良好平衡
最好的方法是测试所有模型,以找到最适合您语言的选项。
### 5. 如何使用 GPU 加速以提高转录速度?
- 在 **Linux** 上,Nvidia GPU 受支持,可直接使用 GPU 加速。如果遇到问题,请安装 [CUDA 12](https://developer.nvidia.com/cuda-downloads)、[cuBLAS](https://developer.nvidia.com/cublas) 和 [cuDNN](https://developer.nvidia.com/cudnn)。
- 在 **Windows** 上,请参阅[此说明](https://github.com/chidiwilliams/buzz/blob/main/CONTRIBUTING.md#gpu-support) 以启用 CUDA GPU 支持。
- **Faster Whisper** 需要 CUDA 12,使用旧版 CUDA 的计算机将默认使用 CPU。
### 6. 如何修复 `Unanticipated host error[PaErrorCode-9999]`?
请检查系统设置,确保没有阻止应用访问麦克风。
- **Windows** 用户请检查“设置 -> 隐私 -> 麦克风”,确保 Buzz 有权限使用麦克风。
- 参考此视频的 [方法 1](https://www.youtube.com/watch?v=eRcCYgOuSYQ)。
- **方法 2** 无需卸载防病毒软件,但可以尝试暂时禁用,或检查是否有相关设置阻止 Buzz 访问麦克风。
### 7. 可以在没有互联网的计算机上使用 Buzz 吗?
是的,您可以在离线计算机上使用 Buzz,但需要在另一台联网计算机上下载所需模型,并手动将其移动到离线计算机。
最简单的方法是:
1. 打开“帮助 -> 偏好设置 -> 模型”
2. 下载所需的模型
3. 点击“显示文件位置”按钮,打开存储模型的文件夹
4. 将该模型文件夹复制到离线计算机的相同位置
例如,在 Linux 上,模型存储在 `~/.cache/Buzz/models` 目录中。
### 8. Buzz 崩溃了,怎么办?
如果模型下载不完整或损坏,Buzz 可能会崩溃。尝试删除已下载的模型文件,然后重新下载。
如果问题仍然存在,请检查日志文件并[报告问题](https://github.com/chidiwilliams/buzz/issues),以便我们修复。日志文件位置如下:
- Mac OS: `~/Library/Logs/Buzz`
- Windows: `%USERPROFILE%\AppData\Local\Buzz\Buzz\Logs`
- Linux: 在终端运行 Buzz 查看相关错误信息。
### 9. 哪里可以获取最新的开发版本?
最新的开发版本包含最新的错误修复和新功能。如果您喜欢尝试新功能,可以下载最新的开发版本进行测试。
- **Linux** 用户可以运行以下命令获取最新版本:
```sh
sudo snap install buzz --edge
```
- **其他平台** 请按以下步骤操作:
1. 访问 [构建页面](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml?query=branch%3Amain)
2. 点击最新构建的链接
3. 在构建页面向下滚动到“Artifacts”部分
4. 下载安装文件(请注意,您需要登录 GitHub 才能看到下载链接)
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/index.md
================================================
---
title: 介绍
sidebar_position: 1
---
在您的个人电脑上离线转录和翻译音频。由 OpenAI 的 [Whisper](https://github.com/openai/whisper) 提供支持。

[](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml)
[](https://codecov.io/github/chidiwilliams/buzz)

[](https://GitHub.com/chidiwilliams/buzz/releases/)
## 功能
- 导入音频和视频文件,并将转录内容导出为 TXT、SRT 和 VTT 格式([演示](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe))
- 从电脑麦克风转录和翻译为文本(资源密集型,可能无法实时完成,[演示](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7))
- 支持 [Whisper](https://github.com/openai/whisper#available-models-and-languages)、
[Whisper.cpp](https://github.com/ggerganov/whisper.cpp)、[Faster Whisper](https://github.com/guillaumekln/faster-whisper)、
[Whisper 兼容的 Hugging Face 模型](https://huggingface.co/models?other=whisper) 和
[OpenAI Whisper API](https://platform.openai.com/docs/api-reference/introduction)
- [命令行界面](#命令行界面)
- 支持 Mac、Windows 和 Linux
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/installation.md
================================================
---
title: 安装
sidebar_position: 2
---
要安装 Buzz,请下载适用于您操作系统的[最新版本](https://github.com/chidiwilliams/buzz/releases/latest)。Buzz 支持 **Mac**(Intel)、**Windows** 和 **Linux** 系统。
## macOS(Intel,macOS 11.7 及更高版本)
通过 [brew](https://brew.sh/) 安装:
```shell
brew install --cask buzz
```
或者,下载并运行 `Buzz-x.y.z.dmg` 文件。
对于 Mac Silicon 用户(以及希望在 Mac Intel 上获得更好体验的用户)。
## Windows(Windows 10 及更高版本)
下载并运行 `Buzz-x.y.z.exe` 文件。
## Linux
```shell
sudo apt-get install libportaudio2 libcanberra-gtk-module libcanberra-gtk3-module
sudo snap install buzz
sudo snap connect buzz:password-manager-service
```
[](https://snapcraft.io/buzz)
或者,在 Ubuntu 20.04 及更高版本上,安装依赖项:
```shell
sudo apt-get install libportaudio2
```
然后,下载并解压 `Buzz-x.y.z-unix.tar.gz` 文件。
## PyPI
```shell
pip install buzz-captions
python -m buzz
```
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/preferences.md
================================================
---
title: 偏好设置
sidebar_position: 4
---
从菜单栏打开偏好设置窗口,或点击 `Ctrl/Cmd + ,`。
## 常规偏好设置
### OpenAI API 偏好设置
**API 密钥** - 用于验证 OpenAI API 请求的密钥。要获取 OpenAI 的 API 密钥,请参阅 [此文章](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key)。
**基础 URL** - 默认情况下,所有请求都会发送到 OpenAI 公司提供的 API。他们的 API URL 是 `https://api.openai.com/v1/`。其他公司也提供了兼容的 API。你可以在 [讨论页面](https://github.com/chidiwilliams/buzz/discussions/827) 找到可用的 API URL 列表。
### 默认导出文件名
设置文件识别的默认导出文件名。例如,值为 `{{ input_file_name }} ({{ task }}d on {{ date_time }})` 时,TXT 导出文件将默认保存为`Input Filename (transcribed on 19-Sep-2023 20-39-25).txt`(输入文件名 (转录于 19-Sep-2023 20-39-25).txt)。
可用变量:
| 键 | 描述 | 示例 |
| ----------------- | ------------------------------------- | ---------------------------------------------------------- |
| `input_file_name` | 导入文件的文件名 | `audio`(例如,如果导入的文件路径是 `/path/to/audio.wav`) |
| `task` | 转录任务 | `transcribe`, `translate` |
| `language` | 语言代码 | `en`, `fr`, `yo` 等 |
| `model_type` | 模型类型 | `Whisper`, `Whisper.cpp`, `Faster Whisper` 等 |
| `model_size` | 模型大小 | `tiny`, `base`, `small`, `medium`, `large` 等 |
| `date_time` | 导出时间(格式:`%d-%b-%Y %H-%M-%S`) | `19-Sep-2023 20-39-25` |
### 实时识别导出
实时识别导出可用于将 Buzz 与其他应用程序(如 OBS Studio)集成。
启用后,实时文本识别将在生成和翻译时导出到文本文件。
如果为实时录音启用了 AI 翻译,翻译后的文本也将导出到文本文件。
翻译文本的文件名将以 `.translated.txt` 结尾。
### 实时识别模式
有三种转识别式可用:
**下方追加** - 新句子将在现有内容下方添加,并在它们之间留有空行。最后一句话将位于底部。
**上方追加** - 新句子将在现有内容上方添加,并在它们之间留有空行。最后一句话将位于顶部。
**追加并修正** - 新句子将在现有转录内容的末尾添加,中间不留空行。此模式还会尝试修正之前转录句子末尾的错误。此模式需要更多的处理能力和更强大的硬件支持。
## 高级偏好设置
为了简化新用户的偏好设置部分,一些更高级的设置可以通过操作系统环境变量进行配置。在启动 Buzz 之前,请在操作系统中设置必要的环境变量,或创建一个脚本来设置它们。
在 MacOS 和 Linux 上,创建 `run_buzz.sh`,内容如下:
```bash
#!/bin/bash
export VARIABLE=value
export SOME_OTHER_VARIABLE=some_other_value
buzz
```
在 Windows 上,创建 `run_buzz.bat`,内容如下:
```bat
@echo off
set VARIABLE=value
set SOME_OTHER_VARIABLE=some_other_value
"C:\Program Files (x86)\Buzz\Buzz.exe"
```
或者,你可以在操作系统设置中设置环境变量。更多信息请参阅 [此指南](https://phoenixnap.com/kb/windows-set-environment-variable#ftoc-heading-4) 或 [此视频](https://www.youtube.com/watch?v=bEroNNzqlF4)。
### 可用变量
**BUZZ_WHISPERCPP_N_THREADS** - Whisper.cpp 模型使用的线程数。默认为 `4`。
在具有 16 线程的笔记本电脑上,设置 `BUZZ_WHISPERCPP_N_THREADS=8` 可以使转录时间加快约 15%。
进一步增加线程数会导致转录时间变慢,因为并行线程的结果需要合并以生成最终答案。
**BUZZ_TRANSLATION_API_BASE_URl** - 用于翻译的 OpenAI 兼容 API 的基础 URL。
**BUZZ_TRANSLATION_API_KEY** - 用于翻译的 OpenAI 兼容 API 的密钥。
**BUZZ_MODEL_ROOT** - 存储模型文件的根目录。
默认为 [user_cache_dir](https://pypi.org/project/platformdirs/)。
**BUZZ_FAVORITE_LANGUAGES** - 以逗号分隔的支持语言代码列表,显示在语言列表顶部。
**BUZZ_DOWNLOAD_COOKIEFILE** - 用于下载私有视频或绕过反机器人保护的 [cookiefile](https://github.com/yt-dlp/yt-dlp/wiki/FAQ#how-do-i-pass-cookies-to-yt-dlp) 的位置。
**BUZZ_FORCE_CPU** - 强制 Buzz 使用 CPU 而不是 GPU,适用于旧 GPU 较慢或 GPU 有问题的设置。示例用法:`BUZZ_FORCE_CPU=true`。自 `1.2.1` 版本起可用。
**BUZZ_MERGE_REGROUP_RULE** - 合并带有单词级时间戳的转录时使用的自定义重新分组规则。更多可用选项的信息请参阅 [stable-ts 仓库](https://github.com/jianfch/stable-ts?tab=readme-ov-file#regrouping-methods)。自 `1.3.0` 版本起可用。
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/usage/1_file_import.md
================================================
---
title: 文件导入
---
若要导入文件:
- 点击“文件”菜单中的“导入媒体文件”(或者点击工具栏上的“+”图标,也可以使用快捷键 **Command/Ctrl + O**)。
- 选择一个音频或视频文件。
- 选择任务、语言和模型设置。
- 点击“运行”。
- 当转录状态显示为“已完成”时,双击该行(或者选中该行后点击“⤢”图标)即可打开转录内容。
| 字段 | 选项 | 默认值 | 描述 |
| ------------ | ------------------- | ------ | -------------------------------------------------------------------------------------------------------- |
| 导出格式 | "TXT"、"SRT"、"VTT" | "TXT" | 导出文件的格式 |
| 单词级时间戳 | 关闭 / 开启 | 关闭 | 若勾选此项,转录内容将为音频中的每个单词生成单独的字幕行。仅当“导出格式”设置为“SRT”或“VTT”时此选项可用。 |
| 提取语音 | 关闭 / 开启 | 关闭 | 若勾选此项,语音将被提取到单独的音轨中以提高转录准确性。此功能自 1.3.0 版本起可用。 |
(有关任务、语言和质量设置的更多信息,请参阅[实时录制部分](https://chidiwilliams.github.io/buzz/zh/docs/usage/live_recording)。)
[](https://www.loom.com/share/cf263b099ac3481082bb56d19b7c87fe "Buzz 中的媒体文件导入")
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/usage/2_live_recording.md
================================================
---
title: 实时录制
---
若要开始实时录制,请按以下步骤操作:
- 选择录制任务、语言、质量和麦克风。
- 点击“录制”。
> **注意:** 使用默认的 Whisper 模型转录音频会占用大量系统资源。若想实现实时性能,可考虑使用 Whisper.cpp Tiny 模型。
| 字段 | 选项 | 默认值 | 描述 |
| ------ | --------------------------------------------------------------------------------------------------------- | ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 任务 | "转录"、"翻译" | "转录" | "转录"会将输入音频转换为所选语言的文本,而"翻译"则会将其转换为英文文本。 |
| 语言 | 完整的支持语言列表请参阅 [Whisper 文档](https://github.com/openai/whisper#available-models-and-languages) | "自动检测语言" | "自动检测语言"会根据音频的前几秒尝试检测其中的语言。不过,如果已知音频语言,建议手动选择,因为在很多情况下这可以提高转录质量。 |
| 质量 | "极低"、"低"、"中"、"高" | "极低" | 转录质量决定了用于转录的 Whisper 模型。"极低"使用"tiny"模型;"低"使用"base"模型;"中"使用"small"模型;"高"使用"medium"模型。模型越大,转录质量越高,但所需的系统资源也越多。更多关于模型的信息请参阅 [Whisper 文档](https://github.com/openai/whisper#available-models-and-languages)。 |
| 麦克风 | [系统可用麦克风] | [系统默认麦克风] | 用于录制输入音频的麦克风。 |
[](https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 "在Buzz 上实时转录")
### 录制电脑播放的音频(macOS)
若要录制电脑应用程序播放的音频,你可以安装一个音频回环驱动程序(一种可让你创建虚拟音频设备的程序)。本指南后续将介绍在 Mac 上使用 [BlackHole](https://github.com/ExistentialAudio/BlackHole) 的方法,但你也可以根据自己的操作系统选择其他替代方案(例如 [LoopBeAudio](https://nerds.de/en/loopbeaudio.html)、[LoopBack](https://rogueamoeba.com/loopback/) 和 [Virtual Audio Cable](https://vac.muzychenko.net/en/))。
1. [通过 Homebrew 安装 BlackHole](https://github.com/ExistentialAudio/BlackHole#option-2-install-via-homebrew)
```shell
brew install blackhole-2ch
```
2. 通过聚焦搜索(Spotlight)或直接打开 `/Applications/Utilities/Audio Midi Setup.app` 来启动“音频 MIDI 设置”。

3. 点击窗口左下角的“+”图标,然后选择“创建多输出设备”。

4. 将你的默认扬声器和 BlackHole 添加到这个多输出设备中。

5. 将此多输出设备设置为你的扬声器(可在应用程序内或系统全局进行设置),这样音频就会被输送到 BlackHole 中。
6. 打开 Buzz 软件,选择 BlackHole 作为录音的麦克风,接着像平常一样进行录制,你就能看到通过 BlackHole 播放的音频的转录文本了。
### 录制电脑播放的音频(Windows)
若要转录系统音频,你需要配置虚拟音频设备,并将你想要转录的应用程序的音频输出连接到该虚拟扬声器。之后,你就可以在 Buzz 中选择它作为音频源。
1. 安装 [VB CABLE](https://vb - audio.com/Cable/) 作为虚拟音频设备。
2. 使用 Windows 声音设置进行配置。右键单击系统托盘里的扬声器图标,然后选择“打开声音设置”。在“选择你的输出设备”下拉菜单中,选择“CABLE Input”,将所有系统声音发送到虚拟设备;或者使用“高级声音选项”,选择要将声音输出到该设备的应用程序。
### 录制电脑播放的音频(Linux)
正如 [Ubuntu 维基](https://wiki.ubuntu.com/record_system_sound?uselang=zh) 中所述,在任何使用 PulseAudio 的 Linux 系统上,你可以将应用程序的音频重定向到虚拟扬声器。之后,你可以在 Buzz 中选择它作为音频源。
总体步骤如下:
1. 启动会产生你想要转录的声音的应用程序,并开始播放。例如,在媒体播放器中播放视频。
2. 启动 Buzz 并打开实时录制界面,以便查看设置。
3. 在 PulseAudio 音量控制(`pavucontrol`)的“录制”选项卡中,配置从你想要转录声音的应用程序到 Buzz 的声音路由。
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/usage/3_translations.md
================================================
---
title: 翻译功能
---
默认的“翻译”任务借助 Whisper 模型将内容翻译成英语。从 `1.0.0` 版本开始,Buzz 支持使用其他人工智能将内容翻译成任意语言。
若要使用翻译功能,你需要配置 OpenAI API 密钥和翻译设置。在“偏好设置”中设置 OpenAI API 密钥。Buzz 也支持本地运行的、兼容 OpenAI API 的自定义翻译人工智能。有关本地运行人工智能的更多信息,请参阅 [ollama](https://ollama.com/blog/openai-compatibility) 或 [LM Studio](https://lmstudio.ai/)。有关可用自定义 API 的信息,请查看这个 [讨论线程](https://github.com/chidiwilliams/buzz/discussions/827)。
若要为实时录制配置翻译功能,可在实时录制设置的“高级设置”对话框中启用该功能。输入要使用的人工智能模型,并提供给人工智能的翻译指令提示。对于已经完成语音识别的文件,也可以使用翻译功能。在转录查看器工具栏上点击“翻译”按钮即可。
为了让人工智能知道如何进行翻译,请在“给人工智能的指令”部分输入翻译说明。在说明中,你应该明确指出要将文本翻译成何种语言。此外,由于人工智能往往会添加一些注释或备注,你可能需要额外添加指令禁止其这么做。以下是一个将英语字幕翻译成西班牙语的指令示例:
> 你是一位专业翻译人员,擅长将英语翻译成西班牙语。你只需将发给你的每一句话翻译成西班牙语,不要添加任何注释或备注。
如果你在“偏好设置”中启用了“启用实时录制转录导出”功能,实时文本转录内容在生成和翻译后将被导出到一个文本文件中。这个文件可用于将实时转录内容与其他应用程序(如 OBS Studio)进行进一步集成。
使用 ChatGPT `gpt - 4o` 模型对一小时长的音频进行翻译,大致费用约为 0.50 美元。
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/usage/4_edit_and_resize.md
================================================
---
title: 编辑与调整
---
当某个音频或视频文件完成转录后,你可以对其进行编辑,并将其导出为不同的字幕格式或纯文本。在转录列表中双击转录内容,即可查看用于编辑和导出的其他选项。
转录视图界面提供了调整转录内容的选项。点击“调整”按钮,可查看可用的选项。对于在 **启用单词级时间戳** 设置下生成的转录内容,可以通过指定不同选项(如字幕的最大长度以及是否应在标点处拆分字幕)将其合并成字幕。而对于在 **未启用单词级时间戳** 设置下生成的转录内容,仅能通过指定所需的字幕最大长度来重新组合。
如果系统中仍存在音频文件,单词级时间戳合并操作还会分析音频中的静音部分,以提高字幕的准确性。从带有单词级时间戳的转录内容生成字幕的功能自 1.3.0 版本起可用。
================================================
FILE: docs/i18n/zh/docusaurus-plugin-content-docs/current/usage/_category_.yml
================================================
label: 使用方法
position: 3
================================================
FILE: docs/package.json
================================================
{
"name": "docs",
"version": "0.0.0",
"private": true,
"scripts": {
"docusaurus": "docusaurus",
"start": "docusaurus start",
"build": "docusaurus build",
"swizzle": "docusaurus swizzle",
"deploy": "docusaurus deploy",
"clear": "docusaurus clear",
"serve": "docusaurus serve",
"write-translations": "docusaurus write-translations",
"write-heading-ids": "docusaurus write-heading-ids",
"typecheck": "tsc"
},
"dependencies": {
"@docusaurus/core": "2.4.1",
"@docusaurus/preset-classic": "2.4.1",
"@mdx-js/react": "^1.6.22",
"clsx": "^1.2.1",
"prism-react-renderer": "^1.3.5",
"react": "^17.0.2",
"react-dom": "^17.0.2"
},
"devDependencies": {
"@docusaurus/module-type-aliases": "2.4.1",
"@tsconfig/docusaurus": "^1.0.5",
"typescript": "^4.7.4"
},
"browserslist": {
"production": [
">0.5%",
"not dead",
"not op_mini all"
],
"development": [
"last 1 chrome version",
"last 1 firefox version",
"last 1 safari version"
]
},
"engines": {
"node": ">=16.14"
}
}
================================================
FILE: docs/sidebars.js
================================================
/**
* Creating a sidebar enables you to:
- create an ordered group of docs
- render a sidebar for each doc of that group
- provide next/previous navigation
The sidebars can be generated from the filesystem, or explicitly defined here.
Create as many sidebars as you want.
*/
// @ts-check
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
const sidebars = {
// By default, Docusaurus generates a sidebar from the docs folder structure
tutorialSidebar: [{type: 'autogenerated', dirName: '.'}],
// But you can create a sidebar manually
/*
tutorialSidebar: [
'intro',
'hello',
{
type: 'category',
label: 'Tutorial',
items: ['tutorial-basics/create-a-document'],
},
],
*/
};
module.exports = sidebars;
================================================
FILE: docs/src/css/custom.css
================================================
/**
* Any CSS included here will be global. The classic template
* bundles Infima by default. Infima is a CSS framework designed to
* work well for content-centric websites.
*/
/* You can override the default Infima variables here. */
:root {
--ifm-color-primary: #c13a3a;
--ifm-color-primary-dark: #29784c;
--ifm-color-primary-darker: #277148;
--ifm-color-primary-darkest: #205d3b;
--ifm-color-primary-light: #33925d;
--ifm-color-primary-lighter: #359962;
--ifm-color-primary-lightest: #3cad6e;
--ifm-code-font-size: 95%;
--docusaurus-highlighted-code-line-bg: rgba(0, 0, 0, 0.1);
}
/* For readability concerns, you should choose a lighter palette in dark mode. */
[data-theme='dark'] {
--ifm-color-primary: #ffa9a9;
--ifm-color-primary-dark: #21af90;
--ifm-color-primary-darker: #1fa588;
--ifm-color-primary-darkest: #1a8870;
--ifm-color-primary-light: #29d5b0;
--ifm-color-primary-lighter: #32d8b4;
--ifm-color-primary-lightest: #4fddbf;
--docusaurus-highlighted-code-line-bg: rgba(0, 0, 0, 0.3);
}
================================================
FILE: docs/src/pages/index.module.css
================================================
================================================
FILE: docs/src/pages/index.tsx
================================================
import React from 'react';
import clsx from 'clsx';
import Link from '@docusaurus/Link';
import useDocusaurusContext from '@docusaurus/useDocusaurusContext';
import Layout from '@theme/Layout';
import {Redirect} from '@docusaurus/router';
export default function Home(): JSX.Element {
return (
com.apple.security.cs.allow-jit
com.apple.security.cs.allow-unsigned-executable-memory
com.apple.security.cs.disable-library-validation
com.apple.security.device.audio-input
================================================
FILE: flatpak/run-buzz.sh
================================================
#!/bin/sh
echo "Running buzz..."
echo "Note: ffmpeg errors are safe to ignore"
python -m buzz
================================================
FILE: hatch_build.py
================================================
"""Custom build hook for hatchling to build whisper.cpp binaries."""
import glob
import subprocess
import sys
from pathlib import Path
from hatchling.builders.hooks.plugin.interface import BuildHookInterface
class CustomBuildHook(BuildHookInterface):
"""Build hook to compile whisper.cpp before building the package."""
def initialize(self, version, build_data):
"""Run make buzz/whisper_cpp before building."""
print("Running 'make buzz/whisper_cpp' to build whisper.cpp binaries...")
# Mark wheel as platform-specific since we're including compiled binaries
# But set tag to py3-none since binaries are standalone (no Python C extensions)
if version == "standard": # Only for wheel builds
import platform
build_data["pure_python"] = False
# Determine the platform tag based on current OS and architecture
system = platform.system().lower()
machine = platform.machine().lower()
if system == "linux":
if machine in ("x86_64", "amd64"):
tag = "py3-none-manylinux_2_34_x86_64"
else:
raise ValueError(f"Unsupported Linux architecture: {machine}. Only x86_64 is supported.")
elif system == "darwin":
if machine in ("x86_64", "amd64"):
tag = "py3-none-macosx_10_9_x86_64"
elif machine in ("arm64", "aarch64"):
tag = "py3-none-macosx_11_0_arm64"
else:
raise ValueError(f"Unsupported macOS architecture: {machine}")
elif system == "windows":
if machine in ("x86_64", "amd64"):
tag = "py3-none-win_amd64"
else:
raise ValueError(f"Unsupported Windows architecture: {machine}. Only x86_64 is supported.")
else:
raise ValueError(f"Unsupported operating system: {system}")
if tag:
build_data["tag"] = tag
print(f"Building wheel with tag: {tag}")
# Get the project root directory
project_root = Path(self.root)
try:
# Run the make command
result = subprocess.run(
["make", "buzz/whisper_cpp"],
cwd=project_root,
check=True,
capture_output=True,
text=True
)
print(result.stdout)
if result.stderr:
print(result.stderr, file=sys.stderr)
print("Successfully built whisper.cpp binaries")
# Run the make command for translation files
result = subprocess.run(
["make", "translation_mo"],
cwd=project_root,
check=True,
capture_output=True,
text=True
)
print(result.stdout)
if result.stderr:
print(result.stderr, file=sys.stderr)
print("Successfully compiled translation files")
# Build ctc_forced_aligner C++ extension in-place
print("Building ctc_forced_aligner C++ extension...")
ctc_aligner_dir = project_root / "ctc_forced_aligner"
# Apply local patches before building.
# Uses --check first to avoid touching the working tree unnecessarily,
# which is safer in a detached-HEAD submodule.
patches_dir = project_root / "patches"
for patch_file in sorted(patches_dir.glob("ctc_forced_aligner_*.patch")):
# Dry-run forward: succeeds only if patch is NOT yet applied.
check_forward = subprocess.run(
["git", "apply", "--check", "--ignore-whitespace", str(patch_file)],
cwd=ctc_aligner_dir,
capture_output=True,
text=True,
)
if check_forward.returncode == 0:
# Patch can be applied — do it for real.
subprocess.run(
["git", "apply", "--ignore-whitespace", str(patch_file)],
cwd=ctc_aligner_dir,
check=True,
capture_output=True,
text=True,
)
print(f"Applied patch: {patch_file.name}")
else:
# Dry-run failed — either already applied or genuinely broken.
check_reverse = subprocess.run(
["git", "apply", "--check", "--reverse", "--ignore-whitespace", str(patch_file)],
cwd=ctc_aligner_dir,
capture_output=True,
text=True,
)
if check_reverse.returncode == 0:
print(f"Patch already applied (skipping): {patch_file.name}")
else:
print(f"WARNING: could not apply patch {patch_file.name}: {check_forward.stderr}", file=sys.stderr)
result = subprocess.run(
[sys.executable, "setup.py", "build_ext", "--inplace"],
cwd=ctc_aligner_dir,
check=True,
capture_output=True,
text=True
)
print(result.stdout)
if result.stderr:
print(result.stderr, file=sys.stderr)
print("Successfully built ctc_forced_aligner C++ extension")
# Force include all files in buzz/whisper_cpp directory
whisper_cpp_dir = project_root / "buzz" / "whisper_cpp"
if whisper_cpp_dir.exists():
# Get all files in the whisper_cpp directory
whisper_files = glob.glob(str(whisper_cpp_dir / "**" / "*"), recursive=True)
# Filter only files (not directories)
whisper_files = [f for f in whisper_files if Path(f).is_file()]
# Add them to force_include
if 'force_include' not in build_data:
build_data['force_include'] = {}
for file_path in whisper_files:
# Convert to relative path from project root
rel_path = Path(file_path).relative_to(project_root)
build_data['force_include'][str(rel_path)] = str(rel_path)
print(f"Force including {len(whisper_files)} files from buzz/whisper_cpp/")
else:
print(f"Warning: {whisper_cpp_dir} does not exist after build", file=sys.stderr)
# Force include demucs package at top level (demucs_repo/demucs -> demucs/)
demucs_pkg_dir = project_root / "demucs_repo" / "demucs"
if demucs_pkg_dir.exists():
# Get all files in the demucs package directory
demucs_files = glob.glob(str(demucs_pkg_dir / "**" / "*"), recursive=True)
# Filter only files (not directories)
demucs_files = [f for f in demucs_files if Path(f).is_file()]
# Add them to force_include, mapping to top-level demucs/
if 'force_include' not in build_data:
build_data['force_include'] = {}
for file_path in demucs_files:
# Convert to relative path from demucs package dir
rel_from_pkg = Path(file_path).relative_to(demucs_pkg_dir)
# Target path is demucs/
target_path = Path("demucs") / rel_from_pkg
build_data['force_include'][str(file_path)] = str(target_path)
print(f"Force including {len(demucs_files)} files from demucs_repo/demucs/ -> demucs/")
else:
print(f"Warning: {demucs_pkg_dir} does not exist", file=sys.stderr)
# Force include all .mo files from buzz/locale directory
locale_dir = project_root / "buzz" / "locale"
if locale_dir.exists():
# Get all .mo files in the locale directory
locale_files = glob.glob(str(locale_dir / "**" / "*.mo"), recursive=True)
# Add them to force_include
if 'force_include' not in build_data:
build_data['force_include'] = {}
for file_path in locale_files:
# Convert to relative path from project root
rel_path = Path(file_path).relative_to(project_root)
build_data['force_include'][str(rel_path)] = str(rel_path)
print(f"Force including {len(locale_files)} .mo files from buzz/locale/")
else:
print(f"Warning: {locale_dir} does not exist", file=sys.stderr)
# Force include compiled extensions from ctc_forced_aligner
ctc_aligner_pkg = project_root / "ctc_forced_aligner" / "ctc_forced_aligner"
if ctc_aligner_pkg.exists():
# Get all compiled extension files (.so, .pyd, .dll)
extension_patterns = ["*.so", "*.pyd", "*.dll"]
extension_files = []
for pattern in extension_patterns:
extension_files.extend(glob.glob(str(ctc_aligner_pkg / pattern)))
# Add them to force_include
if 'force_include' not in build_data:
build_data['force_include'] = {}
for file_path in extension_files:
# Convert to relative path from project root
rel_path = Path(file_path).relative_to(project_root)
build_data['force_include'][str(rel_path)] = str(rel_path)
print(f"Force including {len(extension_files)} compiled extension(s) from ctc_forced_aligner/")
else:
print(f"Warning: {ctc_aligner_pkg} does not exist", file=sys.stderr)
except subprocess.CalledProcessError as e:
print(f"Error building whisper.cpp: {e}", file=sys.stderr)
print(f"stdout: {e.stdout}", file=sys.stderr)
print(f"stderr: {e.stderr}", file=sys.stderr)
sys.exit(1)
except FileNotFoundError:
print("Error: 'make' command not found. Please ensure make is installed.", file=sys.stderr)
sys.exit(1)
================================================
FILE: installer.iss
================================================
; Script generated by the Inno Setup Script Wizard.
; SEE THE DOCUMENTATION FOR DETAILS ON CREATING INNO SETUP SCRIPT FILES!
#define AppName "Buzz"
#define AppExeName "Buzz.exe"
#define AppIconPath "assets\buzz.ico"
#define AppSourcePath "dist\Buzz\*"
#define OutputDir "dist"
#define AppRegKey "Software\Buzz"
#define VersionFile FileRead(FileOpen("buzz\__version__.py"))
#define AppVersion Copy(VersionFile, Pos('VERSION = "', VersionFile) + 11, 5)
[Setup]
; NOTE: The value of AppId uniquely identifies this application. Do not use the same AppId value in installers for other applications.
; (To generate a new GUID, click Tools | Generate GUID inside the IDE.)
AppId={{574290A2-EF7C-4845-85F3-BFF2F011A580}
AppName={#AppName}
AppVersion={#AppVersion}
DefaultDirName={autopf}\{#AppName}
DisableProgramGroupPage=yes
; Uncomment the following line to run in non administrative install mode (install for current user only.)
;PrivilegesRequired=lowest
PrivilegesRequiredOverridesAllowed=dialog
OutputDir={#OutputDir}
OutputBaseFilename={#AppName}-{#AppVersion}-windows
SetupIconFile={#AppIconPath}
DiskSpanning=yes
Compression=lzma
SolidCompression=yes
WizardStyle=modern
[Languages]
Name: "english"; MessagesFile: "compiler:Default.isl"
[Tasks]
Name: "desktopicon"; Description: "{cm:CreateDesktopIcon}"; GroupDescription: "{cm:AdditionalIcons}"; Flags: unchecked
[Files]
Source: {#AppSourcePath}; DestDir: "{app}"; Flags: ignoreversion recursesubdirs createallsubdirs
; NOTE: Don't use "Flags: ignoreversion" on any shared system files
[Icons]
Name: "{autoprograms}\{#AppName}"; Filename: "{app}\{#AppExeName}"
Name: "{autodesktop}\{#AppName}"; Filename: "{app}\{#AppExeName}"; Tasks: desktopicon
[Run]
Filename: "{app}\{#AppExeName}"; Description: "{cm:LaunchProgram,{#StringChange(AppName, '&', '&&')}}"; Flags: nowait postinstall skipifsilent
[Registry]
Root: HKCU; Subkey: "{#AppRegKey}"
[Code]
procedure DeleteFileOrFolder(FilePath: string);
begin
if FileExists(FilePath) then
begin
DeleteFile(FilePath);
end
else if DirExists(FilePath) then
begin
DelTree(FilePath, True, True, True);
end;
end;
procedure CurUninstallStepChanged(CurUninstallStep: TUninstallStep);
begin
if CurUninstallStep = usPostUninstall then
begin
if RegKeyExists(HKEY_CURRENT_USER, '{#AppRegKey}') then
if MsgBox('Do you want to delete Buzz settings and saved files?', mbConfirmation, MB_YESNO) = IDYES
then
begin
RegDeleteKeyIncludingSubkeys(HKEY_CURRENT_USER, '{#AppRegKey}');
// Remove model and cache directories
DeleteFileOrFolder(ExpandConstant('{localappdata}\Buzz'));
end;
end;
end;
procedure CurStepChanged(CurStep: TSetupStep);
begin
if CurStep = ssInstall then
begin
DeleteFileOrFolder(ExpandConstant('{app}\Buzz.exe'));
DeleteFileOrFolder(ExpandConstant('{app}\_internal'));
end;
end;
================================================
FILE: main.py
================================================
import buzz.buzz
if __name__ == "__main__":
buzz.buzz.main()
================================================
FILE: msgfmt.py
================================================
#!/usr/bin/env python
"""
Generate binary message catalog from textual translation description.
This program converts a textual Uniforum-style message catalog (.po file) into
a binary GNU catalog (.mo file). This is essentially the same function as the
GNU msgfmt program, however, it is a simpler implementation.
Usage: msgfmt.py [OPTIONS] filename.po
Options:
-o file
--output-file=file
Specify the output file to write to. If omitted, output will go to a
file named filename.mo (based off the input file name).
-h
--help
Print this message and exit.
"""
import getopt
import sys
import polib
def usage(ecode, msg=""):
"""
Print usage and msg and exit with given code.
"""
print(__doc__, file=sys.stderr)
if msg:
print(msg, file=sys.stderr)
sys.exit(ecode)
def make(filename, outfile):
po = polib.pofile(filename)
po.save_as_mofile(outfile)
def main():
try:
opts, args = getopt.getopt(
sys.argv[1:], "ho:", ["help", "output-file="]
)
except getopt.error as msg:
usage(1, msg)
outfile = None
# parse options
for opt, arg in opts:
if opt in ("-h", "--help"):
usage(0)
elif opt in ("-o", "--output-file"):
outfile = arg
# do it
if not args:
print("No input file given", file=sys.stderr)
print("Try `msgfmt --help` for more information.", file=sys.stderr)
return
for filename in args:
make(filename, outfile)
if __name__ == "__main__":
main()
================================================
FILE: patches/ctc_forced_aligner_windows_mutex.patch
================================================
diff --git a/setup.py b/setup.py
index de84a25..386f662 100644
--- a/setup.py
+++ b/setup.py
@@ -6,7 +6,10 @@ ext_modules = [
Pybind11Extension(
"ctc_forced_aligner.ctc_forced_aligner",
["ctc_forced_aligner/forced_align_impl.cpp"],
- extra_compile_args=["/O2"] if sys.platform == "win32" else ["-O3"],
+ # /D_DISABLE_CONSTEXPR_MUTEX_CONSTRUCTOR prevents MSVC runtime mutex
+ # static-initializer crash on newer GitHub Actions Windows runners.
+ # See: https://github.com/actions/runner-images/issues/10004
+ extra_compile_args=["/O2", "/D_DISABLE_CONSTEXPR_MUTEX_CONSTRUCTOR"] if sys.platform == "win32" else ["-O3"],
)
]
================================================
FILE: pyproject.toml
================================================
[project]
name = "buzz-captions"
# Change also in Makefile and buzz/__version__.py
version = "1.4.4"
description = ""
authors = [{ name = "Chidi Williams", email = "williamschidi1@gmail.com" }]
requires-python = ">=3.12,<3.13"
readme = "README.md"
# License format change to remove warning in PyPI will cause snap not to build
license = { text = "MIT" }
dependencies = [
"sounddevice>=0.5.3,<0.6",
"humanize>=4.4.0,<5",
"PyQt6==6.9.1",
"PyQt6-Qt6==6.9.1",
"PyQt6-sip==13.10.2",
"openai>=1.14.2,<2",
"keyring>=25.0.0,<26",
"platformdirs>=4.2.1,<5",
"dataclasses-json>=0.6.4,<0.7",
"numpy>=1.21.2,<2",
"requests>=2.31.0,<3",
"yt-dlp>=2026.2.21",
"stable-ts>=2.19.1,<3",
"faster-whisper>=1.2.1,<2",
"openai-whisper==20250625",
"transformers>=4.53,<5",
"accelerate>=1.12.0,<2",
"peft>=0.14.0,<1",
# Overriden in uv.tool section below to ensure CUDA 12.9 compatibility
# Skip on Intel Macs (x86_64), use 0.49.0 on ARM Macs, 0.45.0+ elsewhere
"bitsandbytes>=0.45.0; sys_platform != 'darwin' or platform_machine != 'x86_64'",
"polib>=1.2.0,<2",
"srt-equalizer>=0.1.10,<0.2",
# For Intel macOS (x86_64) - use older versions that support Intel
"torch==2.2.2; sys_platform == 'darwin' and platform_machine == 'x86_64'",
"torchaudio==2.2.2; sys_platform == 'darwin' and platform_machine == 'x86_64'",
"ctranslate2==4.3.1; sys_platform == 'darwin' and platform_machine == 'x86_64'",
# For ARM macOS (arm64) - use latest CPU-only versions from PyPI
"torch==2.8.0; sys_platform == 'darwin' and platform_machine == 'arm64'",
"torchaudio==2.8.0; sys_platform == 'darwin' and platform_machine == 'arm64'",
"ctranslate2>=4.6.2,<5; sys_platform == 'darwin' and platform_machine == 'arm64'",
# For Linux/Windows - use CUDA versions from pytorch index
"torch==2.8.0; sys_platform != 'darwin'",
"torchaudio==2.8.0; sys_platform != 'darwin'",
"ctranslate2>=4.6.2,<5; sys_platform != 'darwin'",
# faster whisper need cudnn 9
"nvidia-cudnn-cu12>=9,<10; sys_platform != 'darwin'",
# CUDA runtime libraries are provided by torch dependencies, no need to specify explicitly
"darkdetect>=0.8.0,<0.9",
"dora-search>=0.1.12,<0.2",
"diffq>=0.2.4,<0.3",
"einops>=0.8.1,<0.9",
"flake8>=7.1.2,<8",
"hydra-colorlog>=1.2.0,<2",
"hydra-core>=1.3.2,<2",
"julius>=0.2.7,<0.3",
"lameenc>=1.8.1,<2",
"museval>=0.4.1,<0.5",
"mypy>=1.15.0,<2",
"openunmix>=1.3.0,<2",
"pyyaml>=6.0.2,<7",
"submitit>=1.5.2,<2",
"tqdm>=4.67.1,<5",
"treetable>=0.2.5,<0.3",
"soundfile>=0.13.1,<0.14",
"urllib3>=2.6.0,<3",
"posthog>=3.23.0,<4",
# This version works, newer have issues on Windows
"onnxruntime==1.18.1",
"onnx>=1.20.0", # Required for nemo-toolkit, ensures ml-dtypes is installed
"vulkan>=1.3.275.1,<2",
"hf-xet>=1.1.5,<2",
"hatchling>=1.28.0",
"cmake>=4.2.0,<5",
# 2.5.3 is last versions with cuda 12
"nemo-toolkit[asr]==2.5.3; sys_platform != 'darwin' or platform_machine != 'x86_64'",
"nltk>=3.9.2",
"uroman>=1.3.1.1",
"lhotse==1.32.1",
"coverage==7.12.0",
# demucs is bundled directly in the wheel from demucs_repo/, not installed as a dependency
"certifi==2025.11.12",
"torchcodec>=0.9.0; sys_platform != 'darwin' or platform_machine != 'x86_64'",
"torch>=2.2.2",
"torchaudio>=2.2.2",
"datasets>=4.4.1",
]
repository = "https://github.com/chidiwilliams/buzz"
documentation = "https://chidiwilliams.github.io/buzz/docs"
[project.scripts]
buzz = "buzz.buzz:main"
[dependency-groups]
dev = [
"autopep8>=2.3.2,<3",
"pyinstaller>=6.12.0,<7",
"pyinstaller-hooks-contrib~=2025.1",
"six>=1.16.0,<2",
"pytest>=7.1.3,<8",
"pytest-cov>=4.0.0,<5",
"pytest-qt>=4.1.0,<5",
"pytest-xvfb>=2.0.0,<3",
"pytest-mock>=3.12.0,<4",
"pytest-timeout>=2.4.0,<3",
"pylint>=2.15.5,<3",
"pre-commit>=2.20.0,<3",
"pytest-benchmark>=4.0.0,<5",
"ruff>=0.1.3,<0.2",
]
build = [
"cmake>=4.2.0,<5",
"polib>=1.2.0,<2",
]
[tool.uv]
index-strategy = "unsafe-best-match"
default-groups = [
"dev",
"build",
]
# Should be removed after nemo-toolkit update to 2.6.0
# Forcing a CUDA 12.9 compatable bitsandbytes version
# ARM Macs use 0.49.0, others use 0.47.0 (Intel Macs skip entirely via marker)
override-dependencies = [
"bitsandbytes==0.49.0; sys_platform == 'darwin' and platform_machine == 'arm64'",
"bitsandbytes==0.47.0; sys_platform != 'darwin'",
]
[tool.uv.sources]
torch = [
{ index = "PyPI", marker = "sys_platform == 'darwin'" },
{ index = "pytorch-cu129", marker = "sys_platform != 'darwin'" },
]
torchaudio = [
{ index = "PyPI", marker = "sys_platform == 'darwin'" },
{ index = "pytorch-cu129", marker = "sys_platform != 'darwin'" },
]
[[tool.uv.index]]
name = "nvidia"
url = "https://pypi.ngc.nvidia.com/"
[[tool.uv.index]]
name = "pytorch-cu129"
url = "https://download.pytorch.org/whl/cu129"
[[tool.uv.index]]
name = "PyPI"
url = "https://pypi.org/simple/"
default = true
[tool.hatch.metadata]
allow-direct-references = true
[tool.hatch.build.targets.sdist]
include = [
"buzz",
"buzz/whisper_cpp/*",
"buzz/locale/*/LC_MESSAGES/buzz.mo",
"demucs_repo",
"whisper_diarization",
"deepmultilingualpunctuation",
"ctc_forced_aligner",
]
[tool.hatch.build.targets.wheel]
include = [
"buzz",
"buzz/whisper_cpp/*",
"buzz/locale/*/LC_MESSAGES/buzz.mo",
"whisper_diarization",
"deepmultilingualpunctuation",
"ctc_forced_aligner",
]
# Map demucs_repo/demucs to top-level demucs/ so 'import demucs' works
sources = {"demucs_repo/demucs" = "demucs"}
[tool.hatch.build.hooks.custom]
[build-system]
requires = ["hatchling", "cmake>=4.2.0,<5", "polib>=1.2.0,<2", "pybind11", "setuptools>=80.9.0"]
build-backend = "hatchling.build"
[tool.coverage.report]
exclude_also = [
"if sys.platform == \"win32\":",
"if platform.system\\(\\) == \"Windows\":",
"if platform.system\\(\\) == \"Linux\":",
"if platform.system\\(\\) == \"Darwin\":",
]
[tool.ruff]
exclude = [
"**/whisper.cpp",
]
================================================
FILE: pytest.ini
================================================
[pytest]
log_cli = 1
log_cli_level = DEBUG
qt_api=pyqt6
log_format = %(asctime)s %(levelname)s %(module)s::%(funcName)s %(message)s
log_date_format = %Y-%m-%d %H:%M:%S
addopts = -x -s -p no:xdist -p no:pytest_parallel
timeout = 900
timeout_method = thread
testpaths = tests
markers =
timeout: set a timeout on a test function.
================================================
FILE: readme/README.zh_CN.md
================================================
[[English](../README.md)] <- Click here to View the English page.
# Buzz
[项目文档](https://chidiwilliams.github.io/buzz/zh/docs)
在个人电脑上离线转录和翻译音频。技术模型来源 OpenAI [Whisper](https://github.com/openai/whisper).

[](https://github.com/chidiwilliams/buzz/actions/workflows/ci.yml)
[](https://codecov.io/github/chidiwilliams/buzz)

[](https://GitHub.com/chidiwilliams/buzz/releases/)
## 安装
**PyPI**:
安装 [ffmpeg](https://www.ffmpeg.org/download.html)
安装 Buzz
```shell
pip install buzz-captions
python -m buzz
```
**macOS**:
使用 [brew utility](https://brew.sh/) 安装
```shell
brew install --cask buzz
```
或下载并运行在 [Releases ](https://github.com/chidiwilliams/buzz/releases/latest) 页面中的 `.dmg` 文件 .
**Windows**:
下载并运行在 [Releases ](https://github.com/chidiwilliams/buzz/releases/latest) 页面中的 `.exe` 文件。
应用程序未获得签名,当安装时会收到警告弹窗。 选择 `更多信息` -> `仍然运行`.
**Linux**:
```shell
sudo apt-get install libportaudio2 libcanberra-gtk-module libcanberra-gtk3-module
sudo snap install buzz
```
### 最新开发者版本
有关如何获取具有最新功能和错误修复的最新开发版本的信息,请查阅 [FAQ](https://chidiwilliams.github.io/buzz/docs/faq#9-where-can-i-get-latest-development-version).
================================================
FILE: share/applications/buzz.desktop
================================================
[Desktop Entry]
Type=Application
Encoding=UTF-8
Name=Buzz
Comment=Buzz transcribes and translates audio offline on your personal computer.
Path=/opt/buzz
Exec=/opt/buzz/Buzz
Icon=buzz
Terminal=false
================================================
FILE: share/applications/io.github.chidiwilliams.Buzz.desktop
================================================
[Desktop Entry]
Type=Application
Encoding=UTF-8
Name=Buzz
Comment=Transcribe and translate audio
Exec=run-buzz.sh
Icon=io.github.chidiwilliams.Buzz
Terminal=false
================================================
FILE: share/metainfo/io.github.chidiwilliams.Buzz.metainfo.xml
================================================
io.github.chidiwilliams.Buzz
Buzz
Transcribe and translate audio
CC0-1.0
MIT
Chidi Williams
Buzz transcribes and translates audio to text offline using OpenAI's Whisper. Import audio and video files into Buzz and export them as TXT, SRT, or VTT files. Buzz supports Whisper, Whisper.cpp, Faster Whisper, Whisper-compatible models from the Hugging Face repository, and the OpenAI Whisper API.
Required permissions in Buzz will let you select audio and video files for transcription, from most common file location on your computer. Network permission is used to download transcription model files. Microphone permission lets you transcribe real time speech.
Note: If your system theme is not applied to Buzz, ensure it is in ~/.themes folder. You may need to copy the system themes to this folder cp -r /usr/share/themes/ ~/.themes/ and give Flatpaks access to this folder flatpak override --user --filesystem=~/.themes.
AudioVideo
https://github.com/chidiwilliams/buzz/issues
https://github.com/chidiwilliams/buzz
https://chidiwilliams.github.io/buzz/docs
https://github.com/chidiwilliams/buzz
#f66151
#45124d
keyboard
pointing
io.github.chidiwilliams.Buzz.desktop
https://raw.githubusercontent.com/chidiwilliams/buzz/98ea5b2f1b209e26d8ac49313e23697b88dce01d/share/screenshots/buzz-1-import.png
File and url import options
https://raw.githubusercontent.com/chidiwilliams/buzz/98ea5b2f1b209e26d8ac49313e23697b88dce01d/share/screenshots/buzz-2-main_screen.png
Main screen with transcription results
https://raw.githubusercontent.com/chidiwilliams/buzz/98ea5b2f1b209e26d8ac49313e23697b88dce01d/share/screenshots/buzz-3-preferences.png
Application preferences
https://raw.githubusercontent.com/chidiwilliams/buzz/98ea5b2f1b209e26d8ac49313e23697b88dce01d/share/screenshots/buzz-4-transcript.png
Transcript with options for further processing and export
https://raw.githubusercontent.com/chidiwilliams/buzz/98ea5b2f1b209e26d8ac49313e23697b88dce01d/share/screenshots/buzz-5-live_recording.png
Live recording transcription and translation options
https://github.com/chidiwilliams/buzz/releases/tag/v1.4.4
Bug fixes and minor improvements.
- Fixed Youtube link downloading
- Added option to import folder
- Extra settings for live recordings
- Adjusted live recording batching process to avoid min-word cuts
- Update checker for Windows and Macs
- Added voice activity detection to whisper.cpp
https://github.com/chidiwilliams/buzz/releases/tag/v1.4.3
Fixed support for whisper.cpp on older CPUs and issues in speaker identification.
https://github.com/chidiwilliams/buzz/releases/tag/v1.4.2
Adding speaker identification on transcriptions and video support for transcription viewer, improvements to transcription table and support for over 1000 of worlds languages via MMS models as well as separate window to show live transcripts on a projector.
Release details:
- Speaker identification on finished transcripts
- Support for video in transcription viewer
- Presentation (projector) window for live transcripts
- Ability to add notes and restart transcriptions in main table
- Adding support for more than 1000 languages via MMS model family when transcribing with Huggingface transcription type
- Adding support for PEFT models when transcribing with Huggingface transcription type
- Adding support for 8bit quantization for Huggingface and faster Whisper transcriptions
- Updated libraries and dependencies to support latest GPUs
- Support for secrets portal for snap packages on Linux
- Ability to specify model to use when transcribing with OpenAI API
- Ability to access application logs from About screen
https://github.com/chidiwilliams/buzz/releases/tag/v1.3.3
This release introduces Vulkan GPU support for whisper.cpp making it significantly faster even on laptops.
Real-time transcription is possible even with large models on computers with ~5GB RAM video cards. There
is now an option to separate voice tracks before the audio is transcribed. This can improve transcript
accuracy for audios with background noises or music. Faster whisper was updated to the latest version
adding noticeable speed improvement.
Additional improvements:
- Option to switch the UI language from preferences
- Library updates for better Linux compatibility, especially in Flatpak installations
- Option to upload live transcripts to a server
- Search and additional controls in Transcription viewer
- Added UI translation for German, Dutch, Danish and Portuguese (Brazilian)
- Minor bug fixes
https://github.com/chidiwilliams/buzz/releases/tag/v1.2.0
Added support for Dark mode and the Turbo models. More details:
- Dark mode support
- Improved support for GPUs and Apple Core ML
- Added support for the Turbo models
- Sliding window mode for live transcriptions
- Bugfixes and other small improvements
- Japanese UI translations
================================================
FILE: snap/snapcraft.yaml
================================================
# Development notes:
# - To build the snap run `snapcraft clean` and `snapcraft pack --verbose`
# - To install local snap `snap install ./buzz_*.snap --dangerous`
name: buzz
base: core24
version: git
title: Buzz
summary: Buzz, offline audio transcription and translation
website: https://buzzcaptions.com
source-code: https://github.com/chidiwilliams/buzz
issues: https://github.com/chidiwilliams/buzz/issues
contact: https://github.com/chidiwilliams
description: |
Buzz transcribes and translates audio to text offline using OpenAI's Whisper.
Import audio and video files into Buzz and export them as TXT, SRT, or VTT files.
Buzz supports Whisper, Whisper.cpp, Faster Whisper, Whisper-compatible models
from the Hugging Face repository, and the OpenAI Whisper API.
grade: stable
confinement: strict
license: MIT
icon: buzz/assets/buzz.svg
platforms:
amd64:
parts:
alsa-pulseaudio:
plugin: dump
source: .
override-pull: |
mkdir etc -p
cat > etc/asound.conf < $CRAFT_PART_INSTALL/bin/buzz-launcher
chmod +x $CRAFT_PART_INSTALL/bin/buzz-launcher
# Copy source files
cp -r $CRAFT_PART_BUILD/buzz $CRAFT_PART_INSTALL/
cp -r $CRAFT_PART_BUILD/ctc_forced_aligner $CRAFT_PART_INSTALL/
cp -r $CRAFT_PART_BUILD/deepmultilingualpunctuation $CRAFT_PART_INSTALL/
cp -r $CRAFT_PART_BUILD/demucs_repo $CRAFT_PART_INSTALL/
cp -r $CRAFT_PART_BUILD/whisper_diarization $CRAFT_PART_INSTALL/
# Create desktop file
mkdir -p $CRAFT_PART_INSTALL/usr/share/applications
cp $CRAFT_PART_BUILD/buzz.desktop $CRAFT_PART_INSTALL/usr/share/applications/
stage:
- '*'
prime:
- '*'
gpu-2404:
after: [ buzz ]
source: https://github.com/canonical/gpu-snap.git
plugin: dump
override-prime: |
craftctl default
${CRAFT_PART_SRC}/bin/gpu-2404-cleanup mesa-2404
# Workaround for https://bugs.launchpad.net/snapd/+bug/2055273
mkdir -p "${CRAFT_PRIME}/gpu-2404"
prime:
- bin/gpu-2404-wrapper
apps:
buzz:
extensions:
- gnome
command-chain:
- bin/gpu-2404-wrapper
command: snap/command-chain/desktop-launch $SNAP/bin/buzz-launcher
desktop: usr/share/applications/buzz.desktop
environment:
PATH: $SNAP/usr/bin:$SNAP/bin:$PATH
LD_LIBRARY_PATH: $SNAP/usr/local/lib:$SNAP/lib/python3.12/site-packages/nvidia/cudnn/lib:$SNAP/lib/python3.12/site-packages/PyQt6:$SNAP/lib/python3.12/site-packages/PyQt6/Qt6/lib:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/lapack:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/blas:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/oss4-libsalsa:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/libproxy:$SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib:$SNAP:$LD_LIBRARY_PATH
PYTHONPATH: $SNAP:$SNAP/lib/python3.12/site-packages/PyQt6:$SNAP/lib/python3.12/site-packages/PyQt6/Qt6/lib:$SNAP/usr/lib/python3/dist-packages:$SNAP/usr/lib/python3.12/site-packages:$SNAP/usr/local/lib/python3.12/dist-packages:$SNAP/usr/lib/python3.12/dist-packages:$PYTHONPATH
QT_MEDIA_BACKEND: ffmpeg
PULSE_LATENCY_MSEC: "30"
ALSA_CONFIG_PATH: $SNAP/etc/asound.conf
plugs:
- x11
- unity7
- wayland
- home
- network
- network-bind
- desktop
- desktop-legacy
- gsettings
- opengl
- removable-media
- audio-playback
- audio-record
# Fallback for keyring support if secrets portal is missing, user has to connect this manually
- password-manager-service
layout:
/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib:
bind: $SNAP/usr/lib/$CRAFT_ARCH_TRIPLET_BUILD_FOR/alsa-lib
================================================
FILE: tests/__init__.py
================================================
================================================
FILE: tests/app_main.py
================================================
import os
from unittest.mock import patch
from buzz.buzz import main
class TestMain:
def test_main(self):
with patch('buzz.widgets.application.Application') as mock_application, \
patch('buzz.cli.parse_command_line') as mock_parse_command_line, \
patch('buzz.buzz.sys') as mock_sys, \
patch('buzz.buzz.user_log_dir', return_value='/tmp/buzz') as mock_log_dir:
mock_application.return_value.exec.return_value = 0
mock_sys.argv = ['buzz.py']
main()
mock_application.assert_called_once_with(mock_sys.argv)
mock_parse_command_line.assert_called_once_with(mock_application.return_value)
mock_application.return_value.exec.assert_called_once()
assert os.path.isdir(mock_log_dir.return_value), "Log dir was not created"
================================================
FILE: tests/audio.py
================================================
import os.path
test_audio_path = os.path.abspath(
os.path.join(os.path.dirname(__file__), "../testdata/whisper-french.mp3")
)
test_multibyte_utf8_audio_path = os.path.abspath(
os.path.join(os.path.dirname(__file__), "../testdata/whisper-latvian.wav")
)
================================================
FILE: tests/cache_test.py
================================================
from buzz.cache import TasksCache
from buzz.transcriber.transcriber import (
FileTranscriptionOptions,
FileTranscriptionTask,
TranscriptionOptions,
)
class TestTasksCache:
def test_should_save_and_load(self, tmp_path):
cache = TasksCache(cache_dir=str(tmp_path))
tasks = [
FileTranscriptionTask(
file_path="1.mp3",
transcription_options=TranscriptionOptions(),
file_transcription_options=FileTranscriptionOptions(
file_paths=["1.mp3"]
),
model_path="",
),
FileTranscriptionTask(
file_path="2.mp3",
transcription_options=TranscriptionOptions(),
file_transcription_options=FileTranscriptionOptions(
file_paths=["2.mp3"]
),
model_path="",
),
]
cache.save(tasks)
assert cache.load() == tasks
================================================
FILE: tests/cli_test.py
================================================
import os
import sys
from tempfile import mkdtemp
import pytest
from pytestqt.qtbot import QtBot
from buzz.cli import parse_command_line
from tests.audio import test_audio_path
class TestCLI:
@pytest.mark.parametrize(
"qapp_args",
[
pytest.param(
[
"main.py",
"add",
"--task",
"transcribe",
"--model-size",
"tiny",
"--output-directory",
mkdtemp(),
"--txt",
test_audio_path,
],
)
],
indirect=True,
)
def test_cli(self, qapp, qapp_args, qtbot: QtBot):
output_directory = qapp_args[7]
parse_command_line(qapp)
def output_exists_at_output_directory():
assert any(file.endswith(".txt") for file in os.listdir(output_directory))
qtbot.wait_until(output_exists_at_output_directory, timeout=5 * 60 * 1000)
================================================
FILE: tests/conftest.py
================================================
import multiprocessing
import os
import platform
import random
import string
import pytest
# Set multiprocessing to use 'spawn' instead of 'fork' on Linux
# This is required because Qt creates threads early, and forking a multi-threaded
# process can lead to deadlocks. The main application sets this in buzz/buzz.py.
if platform.system() != "Windows":
try:
multiprocessing.set_start_method("spawn", force=True)
except RuntimeError:
pass # Already set
from PyQt6.QtSql import QSqlDatabase
from _pytest.fixtures import SubRequest
from buzz.db.dao.transcription_dao import TranscriptionDAO
from buzz.db.dao.transcription_segment_dao import TranscriptionSegmentDAO
from buzz.db.db import setup_test_db
from buzz.db.service.transcription_service import TranscriptionService
from buzz.settings.settings import Settings
from buzz.settings.shortcuts import Shortcuts
from buzz.widgets.application import Application
@pytest.fixture()
def db() -> QSqlDatabase:
db = setup_test_db()
yield db
db.close()
os.remove(db.databaseName())
@pytest.fixture()
def transcription_dao(db, request: SubRequest) -> TranscriptionDAO:
dao = TranscriptionDAO(db)
if hasattr(request, "param"):
transcriptions = request.param
for transcription in transcriptions:
dao.insert(transcription)
return dao
@pytest.fixture()
def transcription_service(
transcription_dao, transcription_segment_dao
) -> TranscriptionService:
return TranscriptionService(transcription_dao, transcription_segment_dao)
@pytest.fixture()
def transcription_segment_dao(db) -> TranscriptionSegmentDAO:
return TranscriptionSegmentDAO(db)
@pytest.fixture(scope="session")
def qapp_cls():
return Application
@pytest.fixture(scope="session")
def qapp_args(request):
if not hasattr(request, "param"):
return []
return request.param
@pytest.fixture(scope="session")
def settings():
application = "".join(
random.choice(string.ascii_letters + string.digits) for _ in range(6)
)
settings = Settings(application=application)
yield settings
settings.clear()
@pytest.fixture(scope="session")
def shortcuts(settings):
return Shortcuts(settings)
================================================
FILE: tests/db/dao/transcription_dao_test.py
================================================
import pytest
from unittest.mock import Mock, patch
from uuid import UUID, uuid4
from PyQt6.QtSql import QSqlDatabase, QSqlQuery
from buzz.db.dao.transcription_dao import TranscriptionDAO
from buzz.db.entity.transcription import Transcription
@pytest.fixture
def db():
"""Create an in-memory SQLite database for testing"""
db = QSqlDatabase.addDatabase("QSQLITE")
db.setDatabaseName(":memory:")
assert db.open()
# Create the transcription table with the new schema
query = QSqlQuery(db)
query.exec("""
CREATE TABLE transcription (
id TEXT PRIMARY KEY,
error_message TEXT,
export_formats TEXT,
file TEXT,
output_folder TEXT,
progress DOUBLE PRECISION DEFAULT 0.0,
language TEXT,
model_type TEXT,
source TEXT,
status TEXT,
task TEXT,
time_ended TIMESTAMP,
time_queued TIMESTAMP NOT NULL,
time_started TIMESTAMP,
url TEXT,
whisper_model_size TEXT,
hugging_face_model_id TEXT,
word_level_timings BOOLEAN DEFAULT FALSE,
extract_speech BOOLEAN DEFAULT FALSE,
name TEXT,
notes TEXT
)
""")
yield db
db.close()
@pytest.fixture
def transcription_dao(db):
"""Create a TranscriptionDAO instance for testing"""
return TranscriptionDAO(db)
@pytest.fixture
def sample_transcription():
"""Create a sample transcription for testing"""
return Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Transcription",
notes="This is a test transcription"
)
class TestTranscriptionDAO:
def test_insert_transcription_with_name_and_notes(self, transcription_dao, sample_transcription):
"""Test inserting a transcription with name and notes fields"""
transcription_dao.insert(sample_transcription)
# Verify the transcription was inserted
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT * FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
# Check that name and notes were stored
assert query.value("name") == "Test Transcription"
assert query.value("notes") == "This is a test transcription"
def test_update_transcription_name(self, transcription_dao, sample_transcription):
"""Test updating transcription name"""
# Insert the transcription first
transcription_dao.insert(sample_transcription)
# Update the name
new_name = "Updated Transcription Name"
transcription_dao.update_transcription_name(UUID(sample_transcription.id), new_name)
# Verify the name was updated
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT name FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
assert query.value("name") == new_name
def test_update_transcription_notes(self, transcription_dao, sample_transcription):
"""Test updating transcription notes"""
# Insert the transcription first
transcription_dao.insert(sample_transcription)
# Update the notes
new_notes = "Updated transcription notes with more details"
transcription_dao.update_transcription_notes(UUID(sample_transcription.id), new_notes)
# Verify the notes were updated
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT notes FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
assert query.value("notes") == new_notes
def test_update_transcription_name_nonexistent_id(self, transcription_dao):
"""Test updating name for non-existent transcription ID"""
nonexistent_id = uuid4()
# This should raise an exception
with pytest.raises(Exception):
transcription_dao.update_transcription_name(nonexistent_id, "New Name")
def test_update_transcription_notes_nonexistent_id(self, transcription_dao):
"""Test updating notes for non-existent transcription ID"""
nonexistent_id = uuid4()
# This should raise an exception
with pytest.raises(Exception):
transcription_dao.update_transcription_notes(nonexistent_id, "New Notes")
def test_update_transcription_name_empty_string(self, transcription_dao, sample_transcription):
"""Test updating transcription name to empty string"""
# Insert the transcription first
transcription_dao.insert(sample_transcription)
# Update the name to empty string
transcription_dao.update_transcription_name(UUID(sample_transcription.id), "")
# Verify the name was updated to empty string
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT name FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
assert query.value("name") == ""
def test_update_transcription_notes_empty_string(self, transcription_dao, sample_transcription):
"""Test updating transcription notes to empty string"""
# Insert the transcription first
transcription_dao.insert(sample_transcription)
# Update the notes to empty string
transcription_dao.update_transcription_notes(UUID(sample_transcription.id), "")
# Verify the notes were updated to empty string
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT notes FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
assert query.value("notes") == ""
def test_update_transcription_name_with_none(self, transcription_dao, sample_transcription):
"""Test updating transcription name to None (should be stored as NULL)"""
# Insert the transcription first
transcription_dao.insert(sample_transcription)
# Update the name to None
transcription_dao.update_transcription_name(UUID(sample_transcription.id), None)
# Verify the name was updated to None (NULL in database)
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT name FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
# In SQLite, None values are returned as empty strings
assert query.value("name") == ""
def test_update_transcription_notes_with_none(self, transcription_dao, sample_transcription):
"""Test updating transcription notes to None (should be stored as NULL)"""
# Insert the transcription first
transcription_dao.insert(sample_transcription)
# Update the notes to None
transcription_dao.update_transcription_notes(UUID(sample_transcription.id), None)
# Verify the notes were updated to None (NULL in database)
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT notes FROM transcription WHERE id = :id")
query.bindValue(":id", sample_transcription.id)
assert query.exec()
assert query.next()
# In SQLite, None values are returned as empty strings
assert query.value("notes") == ""
def test_insert_transcription_without_name_and_notes(self, transcription_dao):
"""Test inserting a transcription without name and notes (should be NULL)"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER"
# name and notes not provided
)
transcription_dao.insert(transcription)
# Verify the transcription was inserted with NULL name and notes
query = QSqlQuery(transcription_dao.db)
query.prepare("SELECT name, notes FROM transcription WHERE id = :id")
query.bindValue(":id", transcription.id)
assert query.exec()
assert query.next()
# In SQLite, NULL values are returned as empty strings
assert query.value("name") == ""
assert query.value("notes") == ""
def test_database_error_handling(self, transcription_dao):
"""Test that database errors are properly handled"""
# Mock a database error by using an invalid query
with patch.object(transcription_dao, '_create_query') as mock_create_query:
mock_query = Mock()
mock_query.prepare.return_value = True
mock_query.bindValue.return_value = None
mock_query.exec.return_value = False
mock_query.lastError.return_value.text.return_value = "Database error"
mock_create_query.return_value = mock_query
# This should raise an exception with the database error message
with pytest.raises(Exception, match="Database error"):
transcription_dao.update_transcription_name(uuid4(), "Test Name")
================================================
FILE: tests/db/entity/transcription_test.py
================================================
import pytest
from uuid import uuid4
from buzz.db.entity.transcription import Transcription
class TestTranscription:
def test_transcription_creation_with_name_and_notes(self):
"""Test creating a transcription with name and notes fields"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Transcription Name",
notes="This is a test transcription with notes"
)
assert transcription.name == "Test Transcription Name"
assert transcription.notes == "This is a test transcription with notes"
def test_transcription_creation_without_name_and_notes(self):
"""Test creating a transcription without name and notes (should be None)"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER"
)
assert transcription.name is None
assert transcription.notes is None
def test_transcription_creation_with_empty_name_and_notes(self):
"""Test creating a transcription with empty name and notes"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="",
notes=""
)
assert transcription.name == ""
assert transcription.notes == ""
def test_transcription_name_assignment(self):
"""Test assigning values to name field"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER"
)
# Test assigning a name
transcription.name = "New Name"
assert transcription.name == "New Name"
# Test assigning None
transcription.name = None
assert transcription.name is None
# Test assigning empty string
transcription.name = ""
assert transcription.name == ""
def test_transcription_notes_assignment(self):
"""Test assigning values to notes field"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER"
)
# Test assigning notes
transcription.notes = "New notes"
assert transcription.notes == "New notes"
# Test assigning None
transcription.notes = None
assert transcription.notes is None
# Test assigning empty string
transcription.notes = ""
assert transcription.notes == ""
def test_transcription_with_unicode_name_and_notes(self):
"""Test creating transcription with unicode characters in name and notes"""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Transcription avec des caractères spéciaux: ñáéíóú",
notes="Notes avec des caractères spéciaux: ñáéíóú et émojis 🎵🎤"
)
assert transcription.name == "Transcription avec des caractères spéciaux: ñáéíóú"
assert transcription.notes == "Notes avec des caractères spéciaux: ñáéíóú et émojis 🎵🎤"
def test_transcription_with_long_name_and_notes(self):
"""Test creating transcription with very long name and notes"""
long_name = "A" * 1000 # 1000 character name
long_notes = "B" * 5000 # 5000 character notes
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name=long_name,
notes=long_notes
)
assert transcription.name == long_name
assert transcription.notes == long_notes
assert len(transcription.name) == 1000
assert len(transcription.notes) == 5000
def test_transcription_name_with_special_characters(self):
"""Test transcription name with special characters"""
special_name = "Transcription with special chars: !@#$%^&*()_+-=[]{}|;':\",./<>?"
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name=special_name
)
assert transcription.name == special_name
def test_transcription_notes_with_newlines(self):
"""Test transcription notes with newlines and special formatting"""
notes_with_newlines = """This is a multi-line note
with newlines and special characters:
- Bullet point 1
- Bullet point 2
- Bullet point 3
And some more text after the empty line."""
transcription = Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
notes=notes_with_newlines
)
assert transcription.notes == notes_with_newlines
assert "\n" in transcription.notes
def test_transcription_equality_with_name_and_notes(self):
"""Test transcription equality when name and notes are included"""
transcription_id = str(uuid4())
transcription1 = Transcription(
id=transcription_id,
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Name",
notes="Test Notes"
)
transcription2 = Transcription(
id=transcription_id,
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Name",
notes="Test Notes"
)
# Two transcriptions with same ID should be equal
assert transcription1 == transcription2
def test_transcription_inequality_with_different_name_and_notes(self):
"""Test transcription inequality when name and notes are different"""
transcription_id = str(uuid4())
transcription1 = Transcription(
id=transcription_id,
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Name 1",
notes="Test Notes 1"
)
transcription2 = Transcription(
id=transcription_id,
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Name 2",
notes="Test Notes 2"
)
# Two transcriptions with different name/notes should not be equal
assert transcription1 != transcription2
def test_transcription_id_as_uuid_property(self):
"""Test that id_as_uuid property works with name and notes fields"""
transcription_id = uuid4()
transcription = Transcription(
id=str(transcription_id),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Name",
notes="Test Notes"
)
assert transcription.id_as_uuid == transcription_id
assert isinstance(transcription.id_as_uuid, type(transcription_id))
def test_transcription_string_representation_with_name_and_notes(self):
"""Test string representation of transcription includes name and notes"""
transcription = Transcription(
id="test-id-123",
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Transcription",
notes="Test notes"
)
str_repr = str(transcription)
# The string representation should include the ID
assert "test-id-123" in str_repr
def test_transcription_with_none_values_in_other_fields(self):
"""Test transcription with None values in other fields but valid name and notes"""
transcription = Transcription(
id=str(uuid4()),
file=None,
url=None,
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Valid Name",
notes="Valid Notes"
)
assert transcription.name == "Valid Name"
assert transcription.notes == "Valid Notes"
assert transcription.file is None
assert transcription.url is None
================================================
FILE: tests/db/service/transcription_service_test.py
================================================
import pytest
from unittest.mock import Mock, patch
from uuid import UUID, uuid4
from buzz.db.service.transcription_service import TranscriptionService
from buzz.db.entity.transcription import Transcription
@pytest.fixture
def mock_transcription_dao():
"""Create a mock TranscriptionDAO for testing"""
return Mock()
@pytest.fixture
def mock_transcription_segment_dao():
"""Create a mock TranscriptionSegmentDAO for testing"""
return Mock()
@pytest.fixture
def transcription_service(mock_transcription_dao, mock_transcription_segment_dao):
"""Create a TranscriptionService instance for testing"""
return TranscriptionService(mock_transcription_dao, mock_transcription_segment_dao)
@pytest.fixture
def sample_transcription():
"""Create a sample transcription for testing"""
return Transcription(
id=str(uuid4()),
file="/path/to/test.mp3",
status="completed",
time_queued="2023-01-01T00:00:00",
task="TRANSCRIBE",
model_type="WHISPER",
name="Test Transcription",
notes="This is a test transcription"
)
class TestTranscriptionService:
def test_update_transcription_name(self, transcription_service, mock_transcription_dao):
"""Test updating transcription name through service"""
transcription_id = uuid4()
new_name = "Updated Transcription Name"
# Call the service method
transcription_service.update_transcription_name(transcription_id, new_name)
# Verify the DAO method was called with correct parameters
mock_transcription_dao.update_transcription_name.assert_called_once_with(transcription_id, new_name)
def test_update_transcription_notes(self, transcription_service, mock_transcription_dao):
"""Test updating transcription notes through service"""
transcription_id = uuid4()
new_notes = "Updated transcription notes with more details"
# Call the service method
transcription_service.update_transcription_notes(transcription_id, new_notes)
# Verify the DAO method was called with correct parameters
mock_transcription_dao.update_transcription_notes.assert_called_once_with(transcription_id, new_notes)
def test_update_transcription_name_with_empty_string(self, transcription_service, mock_transcription_dao):
"""Test updating transcription name to empty string"""
transcription_id = uuid4()
empty_name = ""
# Call the service method
transcription_service.update_transcription_name(transcription_id, empty_name)
# Verify the DAO method was called with empty string
mock_transcription_dao.update_transcription_name.assert_called_once_with(transcription_id, empty_name)
def test_update_transcription_notes_with_empty_string(self, transcription_service, mock_transcription_dao):
"""Test updating transcription notes to empty string"""
transcription_id = uuid4()
empty_notes = ""
# Call the service method
transcription_service.update_transcription_notes(transcription_id, empty_notes)
# Verify the DAO method was called with empty string
mock_transcription_dao.update_transcription_notes.assert_called_once_with(transcription_id, empty_notes)
def test_update_transcription_name_with_none(self, transcription_service, mock_transcription_dao):
"""Test updating transcription name to None"""
transcription_id = uuid4()
# Call the service method
transcription_service.update_transcription_name(transcription_id, None)
# Verify the DAO method was called with None
mock_transcription_dao.update_transcription_name.assert_called_once_with(transcription_id, None)
def test_update_transcription_notes_with_none(self, transcription_service, mock_transcription_dao):
"""Test updating transcription notes to None"""
transcription_id = uuid4()
# Call the service method
transcription_service.update_transcription_notes(transcription_id, None)
# Verify the DAO method was called with None
mock_transcription_dao.update_transcription_notes.assert_called_once_with(transcription_id, None)
def test_update_transcription_name_propagates_dao_exception(self, transcription_service, mock_transcription_dao):
"""Test that DAO exceptions are propagated from service"""
transcription_id = uuid4()
new_name = "Updated Name"
# Configure the mock to raise an exception
mock_transcription_dao.update_transcription_name.side_effect = Exception("Database error")
# Call the service method and expect the exception to be raised
with pytest.raises(Exception, match="Database error"):
transcription_service.update_transcription_name(transcription_id, new_name)
def test_update_transcription_notes_propagates_dao_exception(self, transcription_service, mock_transcription_dao):
"""Test that DAO exceptions are propagated from service"""
transcription_id = uuid4()
new_notes = "Updated notes"
# Configure the mock to raise an exception
mock_transcription_dao.update_transcription_notes.side_effect = Exception("Database error")
# Call the service method and expect the exception to be raised
with pytest.raises(Exception, match="Database error"):
transcription_service.update_transcription_notes(transcription_id, new_notes)
def test_update_transcription_name_with_string_uuid(self, transcription_service, mock_transcription_dao):
"""Test updating transcription name with string UUID (should be converted to UUID)"""
transcription_id_str = str(uuid4())
new_name = "Updated Name"
# Call the service method
transcription_service.update_transcription_name(transcription_id_str, new_name)
# Verify the DAO method was called with UUID object
mock_transcription_dao.update_transcription_name.assert_called_once()
call_args = mock_transcription_dao.update_transcription_name.call_args[0]
assert isinstance(call_args[0], str) # The service should pass the string as-is
assert call_args[1] == new_name
def test_update_transcription_notes_with_string_uuid(self, transcription_service, mock_transcription_dao):
"""Test updating transcription notes with string UUID (should be converted to UUID)"""
transcription_id_str = str(uuid4())
new_notes = "Updated notes"
# Call the service method
transcription_service.update_transcription_notes(transcription_id_str, new_notes)
# Verify the DAO method was called with UUID object
mock_transcription_dao.update_transcription_notes.assert_called_once()
call_args = mock_transcription_dao.update_transcription_notes.call_args[0]
assert isinstance(call_args[0], str) # The service should pass the string as-is
assert call_args[1] == new_notes
def test_update_transcription_name_multiple_calls(self, transcription_service, mock_transcription_dao):
"""Test multiple calls to update transcription name"""
transcription_id = uuid4()
# Make multiple calls
transcription_service.update_transcription_name(transcription_id, "Name 1")
transcription_service.update_transcription_name(transcription_id, "Name 2")
transcription_service.update_transcription_name(transcription_id, "Name 3")
# Verify all calls were made
assert mock_transcription_dao.update_transcription_name.call_count == 3
# Verify the last call has the correct parameters
last_call = mock_transcription_dao.update_transcription_name.call_args_list[-1]
assert last_call[0] == (transcription_id, "Name 3")
def test_update_transcription_notes_multiple_calls(self, transcription_service, mock_transcription_dao):
"""Test multiple calls to update transcription notes"""
transcription_id = uuid4()
# Make multiple calls
transcription_service.update_transcription_notes(transcription_id, "Notes 1")
transcription_service.update_transcription_notes(transcription_id, "Notes 2")
transcription_service.update_transcription_notes(transcription_id, "Notes 3")
# Verify all calls were made
assert mock_transcription_dao.update_transcription_notes.call_count == 3
# Verify the last call has the correct parameters
last_call = mock_transcription_dao.update_transcription_notes.call_args_list[-1]
assert last_call[0] == (transcription_id, "Notes 3")
def test_update_transcription_name_with_unicode(self, transcription_service, mock_transcription_dao):
"""Test updating transcription name with unicode characters"""
transcription_id = uuid4()
unicode_name = "Transcription avec des caractères spéciaux: ñáéíóú"
# Call the service method
transcription_service.update_transcription_name(transcription_id, unicode_name)
# Verify the DAO method was called with unicode string
mock_transcription_dao.update_transcription_name.assert_called_once_with(transcription_id, unicode_name)
def test_update_transcription_notes_with_unicode(self, transcription_service, mock_transcription_dao):
"""Test updating transcription notes with unicode characters"""
transcription_id = uuid4()
unicode_notes = "Notes avec des caractères spéciaux: ñáéíóú et émojis 🎵🎤"
# Call the service method
transcription_service.update_transcription_notes(transcription_id, unicode_notes)
# Verify the DAO method was called with unicode string
mock_transcription_dao.update_transcription_notes.assert_called_once_with(transcription_id, unicode_notes)
================================================
FILE: tests/gui_test.py
================================================
import multiprocessing
import os
import platform
from unittest.mock import Mock, patch
import pytest
import sounddevice
from PyQt6.QtCore import Qt
from PyQt6.QtGui import QKeyEvent
from PyQt6.QtWidgets import (
QApplication,
QMessageBox,
)
from pytestqt.qtbot import QtBot
from buzz.locale import _
from buzz.__version__ import VERSION
from buzz.widgets.audio_devices_combo_box import AudioDevicesComboBox
from buzz.widgets.transcriber.advanced_settings_dialog import AdvancedSettingsDialog
from buzz.widgets.transcriber.hugging_face_search_line_edit import (
HuggingFaceSearchLineEdit,
)
from buzz.widgets.transcriber.languages_combo_box import LanguagesComboBox
from buzz.widgets.about_dialog import AboutDialog
from buzz.settings.settings import Settings
from buzz.transcriber.transcriber import (
TranscriptionOptions,
)
from buzz.widgets.transcriber.transcription_options_group_box import (
TranscriptionOptionsGroupBox,
)
from tests.mock_sounddevice import MockInputStream, mock_query_devices
from .mock_qt import MockNetworkAccessManager, MockNetworkReply
if platform.system() == "Linux":
try:
multiprocessing.set_start_method("spawn", force=True)
except RuntimeError:
pass
@pytest.fixture(scope="module", autouse=True)
def audio_setup():
with patch("sounddevice.query_devices") as query_devices_mock, patch(
"sounddevice.InputStream", side_effect=MockInputStream
), patch("sounddevice.check_input_settings"):
query_devices_mock.return_value = mock_query_devices
sounddevice.default.device = 3, 4
yield
class TestLanguagesComboBox:
def test_should_show_sorted_whisper_languages(self, qtbot):
languages_combox_box = LanguagesComboBox("en")
qtbot.add_widget(languages_combox_box)
assert languages_combox_box.itemText(0) == _("Detect Language")
assert languages_combox_box.itemText(1) == _("Afrikaans")
def test_should_select_en_as_default_language(self, qtbot):
languages_combox_box = LanguagesComboBox("en")
qtbot.add_widget(languages_combox_box)
assert languages_combox_box.currentText() == _("English")
def test_should_select_detect_language_as_default(self, qtbot):
languages_combo_box = LanguagesComboBox(None)
qtbot.add_widget(languages_combo_box)
assert languages_combo_box.currentText() == _("Detect Language")
class TestAudioDevicesComboBox:
def test_get_devices(self):
audio_devices_combo_box = AudioDevicesComboBox()
assert audio_devices_combo_box.itemText(0) == "Background Music"
assert audio_devices_combo_box.itemText(1) == "Background Music (UI Sounds)"
assert audio_devices_combo_box.itemText(2) == "BlackHole 2ch"
assert audio_devices_combo_box.itemText(3) == "MacBook Pro Microphone"
assert audio_devices_combo_box.itemText(4) == "Null Audio Device"
assert audio_devices_combo_box.currentText() == "MacBook Pro Microphone"
def test_select_default_mic_when_no_default(self):
sounddevice.default.device = -1, 1
audio_devices_combo_box = AudioDevicesComboBox()
assert audio_devices_combo_box.currentText() == "Background Music"
@pytest.fixture(scope="module", autouse=True)
def clear_settings():
settings = Settings()
settings.clear()
class TestAboutDialog:
def test_should_check_for_updates(self, qtbot: QtBot):
reply = MockNetworkReply(data={"name": "v" + VERSION})
manager = MockNetworkAccessManager(reply=reply)
dialog = AboutDialog(network_access_manager=manager)
qtbot.add_widget(dialog)
mock_message_box_information = Mock()
QMessageBox.information = mock_message_box_information
with qtbot.wait_signal(dialog.network_access_manager.finished):
dialog.check_updates_button.click()
mock_message_box_information.assert_called_with(
dialog, "", _("You're up to date!")
)
class TestAdvancedSettingsDialog:
def test_should_update_advanced_settings(self, qtbot: QtBot):
dialog = AdvancedSettingsDialog(
transcription_options=TranscriptionOptions(
initial_prompt="prompt",
enable_llm_translation=False,
llm_model="",
llm_prompt=""
)
)
qtbot.add_widget(dialog)
transcription_options_mock = Mock()
dialog.transcription_options_changed.connect(transcription_options_mock)
assert dialog.windowTitle() == _("Advanced Settings")
assert dialog.initial_prompt_text_edit.toPlainText() == "prompt"
assert dialog.enable_llm_translation_checkbox.isChecked() is False
assert dialog.llm_model_line_edit.text() == "gpt-4.1-mini"
assert dialog.llm_prompt_text_edit.toPlainText() == _("Please translate each text sent to you from English to Spanish. Translation will be used in an automated system, please do not add any comments or notes, just the translation.")
dialog.initial_prompt_text_edit.setPlainText("new prompt")
dialog.enable_llm_translation_checkbox.setChecked(True)
dialog.llm_model_line_edit.setText("model")
dialog.llm_prompt_text_edit.setPlainText("Please translate this text")
assert transcription_options_mock.call_args[0][0].initial_prompt == "new prompt"
assert transcription_options_mock.call_args[0][0].enable_llm_translation is True
assert transcription_options_mock.call_args[0][0].llm_model == "model"
assert transcription_options_mock.call_args[0][0].llm_prompt == "Please translate this text"
@pytest.mark.skipif(
platform.system() == "Linux" and os.environ.get("XDG_SESSION_TYPE") == "wayland",
reason="Skipping on Wayland sessions due to Qt popup issues"
)
class TestHuggingFaceSearchLineEdit:
def test_should_update_selected_model_on_type(self, qtbot: QtBot):
widget = HuggingFaceSearchLineEdit(
default_value="",
network_access_manager=self.network_access_manager()
)
qtbot.add_widget(widget)
mock_model_selected = Mock()
widget.model_selected.connect(mock_model_selected)
self._set_text_and_wait_response(qtbot, widget)
mock_model_selected.assert_called_with("openai/whisper-tiny")
def test_should_show_list_of_models(self, qtbot: QtBot):
widget = HuggingFaceSearchLineEdit(
default_value="",
network_access_manager=self.network_access_manager()
)
qtbot.add_widget(widget)
self._set_text_and_wait_response(qtbot, widget)
assert widget.popup.count() > 0
assert "openai/whisper-tiny" in widget.popup.item(0).text()
def test_should_select_model_from_list(self, qtbot: QtBot):
widget = HuggingFaceSearchLineEdit(
default_value="",
network_access_manager=self.network_access_manager()
)
qtbot.add_widget(widget)
mock_model_selected = Mock()
widget.model_selected.connect(mock_model_selected)
self._set_text_and_wait_response(qtbot, widget)
# press down arrow and enter to select next item
QApplication.sendEvent(
widget.popup,
QKeyEvent(
QKeyEvent.Type.KeyPress, Qt.Key.Key_Down, Qt.KeyboardModifier.NoModifier
),
)
QApplication.sendEvent(
widget.popup,
QKeyEvent(
QKeyEvent.Type.KeyPress,
Qt.Key.Key_Enter,
Qt.KeyboardModifier.NoModifier,
),
)
mock_model_selected.assert_called_with("openai/whisper-tiny.en")
@staticmethod
def network_access_manager():
reply = MockNetworkReply(
data=[{"id": "openai/whisper-tiny"}, {"id": "openai/whisper-tiny.en"}]
)
return MockNetworkAccessManager(reply=reply)
@staticmethod
def _set_text_and_wait_response(qtbot: QtBot, widget: HuggingFaceSearchLineEdit):
with qtbot.wait_signal(widget.network_manager.finished):
widget.setText("openai/whisper-tiny")
widget.textEdited.emit("openai/whisper-tiny")
class TestTranscriptionOptionsGroupBox:
def test_should_update_model_type(self, qtbot):
widget = TranscriptionOptionsGroupBox()
qtbot.add_widget(widget)
mock_transcription_options_changed = Mock()
widget.transcription_options_changed.connect(mock_transcription_options_changed)
widget.model_type_combo_box.setCurrentIndex(1)
mock_transcription_options_changed.assert_called()
================================================
FILE: tests/mock_qt.py
================================================
import json
from typing import Optional
from PyQt6.QtCore import QByteArray, QObject, pyqtSignal
from PyQt6.QtNetwork import QNetworkAccessManager, QNetworkReply, QNetworkRequest
class MockNetworkReply(QNetworkReply):
def __init__(self, data: object, _: Optional[QObject] = None) -> None:
self.data = data
def readAll(self) -> "QByteArray":
return QByteArray(json.dumps(self.data).encode("utf-8"))
def error(self) -> "QNetworkReply.NetworkError":
return QNetworkReply.NetworkError.NoError
def deleteLater(self) -> None:
pass
class MockNetworkAccessManager(QNetworkAccessManager):
finished = pyqtSignal(object)
reply: MockNetworkReply
def __init__(
self, reply: MockNetworkReply, parent: Optional[QObject] = None
) -> None:
super().__init__(parent)
self.reply = reply
def get(self, _: "QNetworkRequest") -> "QNetworkReply":
self.finished.emit(self.reply)
return self.reply
class MockDownloadReply(QObject):
"""Mock reply for file downloads — supports downloadProgress and finished signals."""
downloadProgress = pyqtSignal(int, int)
finished = pyqtSignal()
def __init__(
self,
data: bytes = b"fake-installer-data",
network_error: "QNetworkReply.NetworkError" = QNetworkReply.NetworkError.NoError,
error_string: str = "",
parent: Optional[QObject] = None,
) -> None:
super().__init__(parent)
self._data = data
self._network_error = network_error
self._error_string = error_string
self._aborted = False
def readAll(self) -> QByteArray:
return QByteArray(self._data)
def error(self) -> "QNetworkReply.NetworkError":
return self._network_error
def errorString(self) -> str:
return self._error_string
def abort(self) -> None:
self._aborted = True
def deleteLater(self) -> None:
pass
def emit_finished(self) -> None:
self.finished.emit()
class MockDownloadNetworkManager(QNetworkAccessManager):
"""Network manager that returns MockDownloadReply instances for each get() call."""
def __init__(
self,
replies: Optional[list] = None,
parent: Optional[QObject] = None,
) -> None:
super().__init__(parent)
self._replies = list(replies) if replies else []
self._index = 0
def get(self, _: "QNetworkRequest") -> "MockDownloadReply":
if self._index < len(self._replies):
reply = self._replies[self._index]
else:
reply = MockDownloadReply()
self._index += 1
return reply
================================================
FILE: tests/mock_sounddevice.py
================================================
import os
from threading import Thread, Event
from typing import Callable, Any
import numpy as np
from buzz import whisper_audio
mock_query_devices = [
{
"name": "Background Music",
"index": 0,
"hostapi": 0,
"max_input_channels": 2,
"max_output_channels": 2,
"default_low_input_latency": 0.01,
"default_low_output_latency": 0.008,
"default_high_input_latency": 0.1,
"default_high_output_latency": 0.064,
"default_samplerate": 8000.0,
},
{
"name": "Background Music (UI Sounds)",
"index": 1,
"hostapi": 0,
"max_input_channels": 2,
"max_output_channels": 2,
"default_low_input_latency": 0.01,
"default_low_output_latency": 0.008,
"default_high_input_latency": 0.1,
"default_high_output_latency": 0.064,
"default_samplerate": 8000.0,
},
{
"name": "BlackHole 2ch",
"index": 2,
"hostapi": 0,
"max_input_channels": 2,
"max_output_channels": 2,
"default_low_input_latency": 0.01,
"default_low_output_latency": 0.0013333333333333333,
"default_high_input_latency": 0.1,
"default_high_output_latency": 0.010666666666666666,
"default_samplerate": 48000.0,
},
{
"name": "MacBook Pro Microphone",
"index": 3,
"hostapi": 0,
"max_input_channels": 1,
"max_output_channels": 0,
"default_low_input_latency": 0.034520833333333334,
"default_low_output_latency": 0.01,
"default_high_input_latency": 0.043854166666666666,
"default_high_output_latency": 0.1,
"default_samplerate": 48000.0,
},
{
"name": "MacBook Pro Speakers",
"index": 4,
"hostapi": 0,
"max_input_channels": 0,
"max_output_channels": 2,
"default_low_input_latency": 0.01,
"default_low_output_latency": 0.0070416666666666666,
"default_high_input_latency": 0.1,
"default_high_output_latency": 0.016375,
"default_samplerate": 48000.0,
},
{
"name": "Null Audio Device",
"index": 5,
"hostapi": 0,
"max_input_channels": 2,
"max_output_channels": 2,
"default_low_input_latency": 0.01,
"default_low_output_latency": 0.0014512471655328798,
"default_high_input_latency": 0.1,
"default_high_output_latency": 0.011609977324263039,
"default_samplerate": 44100.0,
},
{
"name": "Multi-Output Device",
"index": 6,
"hostapi": 0,
"max_input_channels": 0,
"max_output_channels": 2,
"default_low_input_latency": 0.01,
"default_low_output_latency": 0.0033333333333333335,
"default_high_input_latency": 0.1,
"default_high_output_latency": 0.012666666666666666,
"default_samplerate": 48000.0,
},
]
class MockInputStream:
thread: Thread
samplerate = whisper_audio.SAMPLE_RATE
def __init__(
self,
callback: Callable[[np.ndarray, int, Any, Any], None],
*args,
**kwargs,
):
self._stop_event = Event()
self.callback = callback
# Pre-load audio on the calling (main) thread to avoid calling
# subprocess.run (fork) from a background thread on macOS, which
# can cause a segfault when Qt is running.
sample_rate = whisper_audio.SAMPLE_RATE
file_path = os.path.join(
os.path.dirname(__file__), "../testdata/whisper-french.mp3"
)
self._audio = whisper_audio.load_audio(file_path, sr=sample_rate)
self.thread = Thread(target=self.target)
def start(self):
self.thread.start()
def target(self):
sample_rate = whisper_audio.SAMPLE_RATE
audio = self._audio
chunk_duration_secs = 1
seek = 0
num_samples_in_chunk = chunk_duration_secs * sample_rate
while not self._stop_event.is_set():
self._stop_event.wait(timeout=chunk_duration_secs)
if self._stop_event.is_set():
break
chunk = audio[seek : seek + num_samples_in_chunk]
try:
self.callback(chunk, 0, None, None)
except RuntimeError:
# Qt object was deleted between the stop-event check and
# the callback invocation; treat it as a stop signal.
break
seek += num_samples_in_chunk
# loop back around
if seek + num_samples_in_chunk > audio.size:
seek = 0
def stop(self):
self._stop_event.set()
if self.thread.is_alive():
self.thread.join(timeout=5)
def close(self):
self.stop()
def __enter__(self):
self.start()
def __exit__(self, exc_type, exc_val, exc_tb):
self.stop()
class MockSoundDevice:
def __init__(self):
self.devices = mock_query_devices
def InputStream(self, *args, **kwargs):
return MockInputStream(*args, **kwargs)
def query_devices(self, device=None):
if device is None:
return self.devices
else:
return next((d for d in self.devices if d['index'] == device), None)
def check_input_settings(self, device=None, samplerate=None):
device_info = self.query_devices(device)
if device_info and samplerate and samplerate != device_info['default_samplerate']:
raise ValueError('Invalid sample rate for device')
================================================
FILE: tests/model_loader.py
================================================
from buzz.model_loader import TranscriptionModel, ModelDownloader
def get_model_path(transcription_model: TranscriptionModel) -> str:
path = transcription_model.get_local_model_path()
if path is not None:
return path
model_loader = ModelDownloader(model=transcription_model)
model_path = ""
def on_load_model(path: str):
nonlocal model_path
model_path = path
model_loader.signals.finished.connect(on_load_model)
model_loader.run()
return model_path
================================================
FILE: tests/model_loader_test.py
================================================
import io
import os
import threading
import time
import pytest
from unittest.mock import patch, MagicMock, call
from buzz.model_loader import (
ModelDownloader,
HuggingfaceDownloadMonitor,
TranscriptionModel,
ModelType,
WhisperModelSize,
map_language_to_mms,
is_mms_model,
get_expected_whisper_model_size,
get_whisper_file_path,
WHISPER_MODEL_SIZES,
WHISPER_CPP_REPO_ID,
WHISPER_CPP_LUMII_REPO_ID,
)
class TestModelLoader:
@pytest.mark.parametrize(
"model",
[
TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="RaivisDejus/whisper-tiny-lv",
),
],
)
def test_download_model(self, model: TranscriptionModel):
model_loader = ModelDownloader(model=model)
model_loader.run()
model_path = model.get_local_model_path()
assert model_path is not None, "Model path is None"
assert os.path.isdir(model_path), "Model path is not a directory"
assert len(os.listdir(model_path)) > 0, "Model directory is empty"
class TestMapLanguageToMms:
def test_empty_returns_english(self):
assert map_language_to_mms("") == "eng"
def test_two_letter_known_code(self):
assert map_language_to_mms("en") == "eng"
assert map_language_to_mms("fr") == "fra"
assert map_language_to_mms("lv") == "lav"
def test_three_letter_code_returned_as_is(self):
assert map_language_to_mms("eng") == "eng"
assert map_language_to_mms("fra") == "fra"
def test_unknown_two_letter_code_returned_as_is(self):
assert map_language_to_mms("xx") == "xx"
@pytest.mark.parametrize(
"code,expected",
[
("de", "deu"),
("es", "spa"),
("ja", "jpn"),
("zh", "cmn"),
("ar", "ara"),
],
)
def test_various_language_codes(self, code, expected):
assert map_language_to_mms(code) == expected
class TestIsMmsModel:
def test_empty_string(self):
assert is_mms_model("") is False
def test_mms_in_model_id(self):
assert is_mms_model("facebook/mms-1b-all") is True
def test_mms_case_insensitive(self):
assert is_mms_model("facebook/MMS-1b-all") is True
def test_non_mms_model(self):
assert is_mms_model("openai/whisper-tiny") is False
class TestWhisperModelSize:
def test_to_faster_whisper_model_size_large(self):
assert WhisperModelSize.LARGE.to_faster_whisper_model_size() == "large-v1"
def test_to_faster_whisper_model_size_tiny(self):
assert WhisperModelSize.TINY.to_faster_whisper_model_size() == "tiny"
def test_to_faster_whisper_model_size_largev3(self):
assert WhisperModelSize.LARGEV3.to_faster_whisper_model_size() == "large-v3"
def test_to_whisper_cpp_model_size_large(self):
assert WhisperModelSize.LARGE.to_whisper_cpp_model_size() == "large-v1"
def test_to_whisper_cpp_model_size_tiny(self):
assert WhisperModelSize.TINY.to_whisper_cpp_model_size() == "tiny"
def test_str(self):
assert str(WhisperModelSize.TINY) == "Tiny"
assert str(WhisperModelSize.LARGE) == "Large"
assert str(WhisperModelSize.LARGEV3TURBO) == "Large-v3-turbo"
assert str(WhisperModelSize.CUSTOM) == "Custom"
class TestModelType:
def test_supports_initial_prompt(self):
assert ModelType.WHISPER.supports_initial_prompt is True
assert ModelType.WHISPER_CPP.supports_initial_prompt is True
assert ModelType.OPEN_AI_WHISPER_API.supports_initial_prompt is True
assert ModelType.FASTER_WHISPER.supports_initial_prompt is True
assert ModelType.HUGGING_FACE.supports_initial_prompt is False
@pytest.mark.parametrize(
"platform_system,platform_machine,expected_faster_whisper",
[
("Linux", "x86_64", True),
("Windows", "AMD64", True),
("Darwin", "arm64", True),
("Darwin", "x86_64", False), # Faster Whisper not available on macOS x86_64
],
)
def test_is_available(self, platform_system, platform_machine, expected_faster_whisper):
with patch("platform.system", return_value=platform_system), \
patch("platform.machine", return_value=platform_machine):
# These should always be available
assert ModelType.WHISPER.is_available() is True
assert ModelType.HUGGING_FACE.is_available() is True
assert ModelType.OPEN_AI_WHISPER_API.is_available() is True
assert ModelType.WHISPER_CPP.is_available() is True
# Faster Whisper depends on platform
assert ModelType.FASTER_WHISPER.is_available() == expected_faster_whisper
def test_is_manually_downloadable(self):
assert ModelType.WHISPER.is_manually_downloadable() is True
assert ModelType.WHISPER_CPP.is_manually_downloadable() is True
assert ModelType.FASTER_WHISPER.is_manually_downloadable() is True
assert ModelType.HUGGING_FACE.is_manually_downloadable() is False
assert ModelType.OPEN_AI_WHISPER_API.is_manually_downloadable() is False
class TestTranscriptionModel:
def test_str_whisper(self):
model = TranscriptionModel(
model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY
)
assert str(model) == "Whisper (Tiny)"
def test_str_whisper_cpp(self):
model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.BASE
)
assert str(model) == "Whisper.cpp (Base)"
def test_str_hugging_face(self):
model = TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="openai/whisper-tiny",
)
assert str(model) == "Hugging Face (openai/whisper-tiny)"
def test_str_faster_whisper(self):
model = TranscriptionModel(
model_type=ModelType.FASTER_WHISPER,
whisper_model_size=WhisperModelSize.SMALL,
)
assert str(model) == "Faster Whisper (Small)"
def test_str_openai_api(self):
model = TranscriptionModel(model_type=ModelType.OPEN_AI_WHISPER_API)
assert str(model) == "OpenAI Whisper API"
def test_default(self):
model = TranscriptionModel.default()
assert model.model_type in list(ModelType)
assert model.model_type.is_available() is True
def test_get_local_model_path_openai_api(self):
model = TranscriptionModel(model_type=ModelType.OPEN_AI_WHISPER_API)
assert model.get_local_model_path() == ""
class TestGetExpectedWhisperModelSize:
def test_known_sizes(self):
assert get_expected_whisper_model_size(WhisperModelSize.TINY) == 72 * 1024 * 1024
assert get_expected_whisper_model_size(WhisperModelSize.LARGE) == 2870 * 1024 * 1024
def test_unknown_size_returns_none(self):
assert get_expected_whisper_model_size(WhisperModelSize.CUSTOM) is None
assert get_expected_whisper_model_size(WhisperModelSize.LUMII) is None
def test_all_defined_sizes_have_values(self):
for size in WHISPER_MODEL_SIZES:
assert WHISPER_MODEL_SIZES[size] > 0
class TestGetWhisperFilePath:
def test_custom_size(self):
path = get_whisper_file_path(WhisperModelSize.CUSTOM)
assert path.endswith("custom")
assert "whisper" in path
def test_tiny_size(self):
path = get_whisper_file_path(WhisperModelSize.TINY)
assert "whisper" in path
assert path.endswith(".pt")
class TestTranscriptionModelIsDeletable:
def test_whisper_model_not_downloaded(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value=None):
assert model.is_deletable() is False
def test_whisper_model_downloaded(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value="/some/path/model.pt"):
assert model.is_deletable() is True
def test_openai_api_not_deletable(self):
model = TranscriptionModel(model_type=ModelType.OPEN_AI_WHISPER_API)
assert model.is_deletable() is False
def test_hugging_face_not_deletable(self):
model = TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="openai/whisper-tiny"
)
assert model.is_deletable() is False
class TestTranscriptionModelGetLocalModelPath:
def test_whisper_cpp_file_not_exists(self):
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY)
with patch('os.path.exists', return_value=False), \
patch('os.path.isfile', return_value=False):
assert model.get_local_model_path() is None
def test_whisper_file_not_exists(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch('os.path.exists', return_value=False):
assert model.get_local_model_path() is None
def test_whisper_file_too_small(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch('os.path.exists', return_value=True), \
patch('os.path.isfile', return_value=True), \
patch('os.path.getsize', return_value=1024): # 1KB, much smaller than expected
assert model.get_local_model_path() is None
def test_whisper_file_valid(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
expected_size = 72 * 1024 * 1024 # 72MB
with patch('os.path.exists', return_value=True), \
patch('os.path.isfile', return_value=True), \
patch('os.path.getsize', return_value=expected_size):
result = model.get_local_model_path()
assert result is not None
def test_faster_whisper_not_found(self):
model = TranscriptionModel(model_type=ModelType.FASTER_WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch('buzz.model_loader.download_faster_whisper_model', side_effect=FileNotFoundError):
assert model.get_local_model_path() is None
def test_hugging_face_not_found(self):
model = TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="some/model"
)
import huggingface_hub
with patch.object(huggingface_hub, 'snapshot_download', side_effect=FileNotFoundError):
assert model.get_local_model_path() is None
class TestTranscriptionModelOpenPath:
def test_open_path_linux(self):
with patch('sys.platform', 'linux'), \
patch('subprocess.call') as mock_call:
TranscriptionModel.open_path("/some/path")
mock_call.assert_called_once_with(['xdg-open', '/some/path'])
def test_open_path_darwin(self):
with patch('sys.platform', 'darwin'), \
patch('subprocess.call') as mock_call:
TranscriptionModel.open_path("/some/path")
mock_call.assert_called_once_with(['open', '/some/path'])
class TestTranscriptionModelOpenFileLocation:
def test_whisper_opens_parent_directory(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value="/some/path/model.pt"), \
patch.object(TranscriptionModel, 'open_path') as mock_open:
model.open_file_location()
mock_open.assert_called_once_with(path="/some/path")
def test_hugging_face_opens_grandparent_directory(self):
model = TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="openai/whisper-tiny"
)
with patch.object(model, 'get_local_model_path', return_value="/cache/models/snapshot/model.safetensors"), \
patch.object(TranscriptionModel, 'open_path') as mock_open:
model.open_file_location()
# For HF: dirname(path) -> /cache/models/snapshot, then open_path(dirname(...)) -> /cache/models
mock_open.assert_called_once_with(path="/cache/models")
def test_faster_whisper_opens_grandparent_directory(self):
model = TranscriptionModel(model_type=ModelType.FASTER_WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value="/cache/models/snapshot/model.bin"), \
patch.object(TranscriptionModel, 'open_path') as mock_open:
model.open_file_location()
# For FW: dirname(path) -> /cache/models/snapshot, then open_path(dirname(...)) -> /cache/models
mock_open.assert_called_once_with(path="/cache/models")
def test_no_model_path_does_nothing(self):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value=None), \
patch.object(TranscriptionModel, 'open_path') as mock_open:
model.open_file_location()
mock_open.assert_not_called()
class TestTranscriptionModelDeleteLocalFile:
def test_whisper_model_removes_file(self, tmp_path):
model_file = tmp_path / "model.pt"
model_file.write_bytes(b"fake model data")
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
model.delete_local_file()
assert not model_file.exists()
def test_whisper_cpp_custom_removes_file(self, tmp_path):
model_file = tmp_path / "ggml-model-whisper-custom.bin"
model_file.write_bytes(b"fake model data")
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.CUSTOM)
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
model.delete_local_file()
assert not model_file.exists()
def test_whisper_cpp_non_custom_removes_bin_file(self, tmp_path):
model_file = tmp_path / "ggml-tiny.bin"
model_file.write_bytes(b"fake model data")
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
model.delete_local_file()
assert not model_file.exists()
def test_whisper_cpp_non_custom_removes_coreml_files(self, tmp_path):
model_file = tmp_path / "ggml-tiny.bin"
model_file.write_bytes(b"fake model data")
coreml_zip = tmp_path / "ggml-tiny-encoder.mlmodelc.zip"
coreml_zip.write_bytes(b"fake zip")
coreml_dir = tmp_path / "ggml-tiny-encoder.mlmodelc"
coreml_dir.mkdir()
model = TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
model.delete_local_file()
assert not model_file.exists()
assert not coreml_zip.exists()
assert not coreml_dir.exists()
def test_hugging_face_removes_directory_tree(self, tmp_path):
# Structure: models--repo/snapshots/abc/model.safetensors
# delete_local_file does dirname(dirname(model_path)) = snapshots_dir
repo_dir = tmp_path / "models--repo"
snapshots_dir = repo_dir / "snapshots"
snapshot_dir = snapshots_dir / "abc123"
snapshot_dir.mkdir(parents=True)
model_file = snapshot_dir / "model.safetensors"
model_file.write_bytes(b"fake model")
model = TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="some/repo"
)
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
model.delete_local_file()
# Two dirs up from model_file: dirname(dirname(model_file)) = snapshots_dir
assert not snapshots_dir.exists()
def test_faster_whisper_removes_directory_tree(self, tmp_path):
repo_dir = tmp_path / "faster-whisper-tiny"
snapshots_dir = repo_dir / "snapshots"
snapshot_dir = snapshots_dir / "abc123"
snapshot_dir.mkdir(parents=True)
model_file = snapshot_dir / "model.bin"
model_file.write_bytes(b"fake model")
model = TranscriptionModel(model_type=ModelType.FASTER_WHISPER, whisper_model_size=WhisperModelSize.TINY)
with patch.object(model, 'get_local_model_path', return_value=str(model_file)):
model.delete_local_file()
# Two dirs up from model_file: dirname(dirname(model_file)) = snapshots_dir
assert not snapshots_dir.exists()
class TestHuggingfaceDownloadMonitorFileSize:
def _make_monitor(self, tmp_path):
model_root = str(tmp_path / "models--test" / "snapshots" / "abc")
os.makedirs(model_root, exist_ok=True)
progress = MagicMock()
progress.emit = MagicMock()
monitor = HuggingfaceDownloadMonitor(
model_root=model_root,
progress=progress,
total_file_size=100 * 1024 * 1024
)
return monitor
def test_emits_progress_for_tmp_files(self, tmp_path):
from buzz.model_loader import model_root_dir as orig_root
monitor = self._make_monitor(tmp_path)
# Create a tmp file in model_root_dir
with patch('buzz.model_loader.model_root_dir', str(tmp_path)):
tmp_file = tmp_path / "tmpXYZ123"
tmp_file.write_bytes(b"x" * 1024)
monitor.stop_event.clear()
# Run one iteration
monitor.monitor_file_size.__func__ if hasattr(monitor.monitor_file_size, '__func__') else None
# Manually call internal logic once
emitted = []
original_emit = monitor.progress.emit
monitor.progress.emit = lambda x: emitted.append(x)
import buzz.model_loader as ml
old_root = ml.model_root_dir
ml.model_root_dir = str(tmp_path)
try:
monitor.stop_event.set() # stop after one iteration
monitor.stop_event.clear()
# call once manually by running the loop body
for filename in os.listdir(str(tmp_path)):
if filename.startswith("tmp"):
file_size = os.path.getsize(os.path.join(str(tmp_path), filename))
monitor.progress.emit((file_size, monitor.total_file_size))
assert len(emitted) > 0
assert emitted[0][0] == 1024
finally:
ml.model_root_dir = old_root
def test_emits_progress_for_incomplete_files(self, tmp_path):
monitor = self._make_monitor(tmp_path)
blobs_dir = tmp_path / "blobs"
blobs_dir.mkdir()
incomplete_file = blobs_dir / "somefile.incomplete"
incomplete_file.write_bytes(b"y" * 2048)
emitted = []
monitor.incomplete_download_root = str(blobs_dir)
monitor.progress.emit = lambda x: emitted.append(x)
for filename in os.listdir(str(blobs_dir)):
if filename.endswith(".incomplete"):
file_size = os.path.getsize(os.path.join(str(blobs_dir), filename))
monitor.progress.emit((file_size, monitor.total_file_size))
assert len(emitted) > 0
assert emitted[0][0] == 2048
def test_stop_monitoring_emits_100_percent(self, tmp_path):
monitor = self._make_monitor(tmp_path)
monitor.monitor_thread = MagicMock()
monitor.stop_monitoring()
monitor.progress.emit.assert_called_with(
(monitor.total_file_size, monitor.total_file_size)
)
class TestModelDownloaderDownloadModel:
def _make_downloader(self, model):
downloader = ModelDownloader(model=model)
downloader.signals = MagicMock()
downloader.signals.progress = MagicMock()
downloader.signals.progress.emit = MagicMock()
return downloader
def test_download_model_fresh_success(self, tmp_path):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
downloader = self._make_downloader(model)
file_path = str(tmp_path / "model.pt")
fake_content = b"fake model data" * 100
mock_response = MagicMock()
mock_response.__enter__ = lambda s: s
mock_response.__exit__ = MagicMock(return_value=False)
mock_response.status_code = 200
mock_response.headers = {"Content-Length": str(len(fake_content))}
mock_response.iter_content = MagicMock(return_value=[fake_content])
mock_response.raise_for_status = MagicMock()
with patch('requests.get', return_value=mock_response), \
patch('requests.head') as mock_head:
result = downloader.download_model(url="http://example.com/model.pt", file_path=file_path, expected_sha256=None)
assert result is True
assert os.path.exists(file_path)
assert open(file_path, 'rb').read() == fake_content
def test_download_model_already_downloaded_sha256_match(self, tmp_path):
import hashlib
content = b"complete model content"
sha256 = hashlib.sha256(content).hexdigest()
model_file = tmp_path / "model.pt"
model_file.write_bytes(content)
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
downloader = self._make_downloader(model)
mock_head = MagicMock()
mock_head.headers = {"Content-Length": str(len(content)), "Accept-Ranges": "bytes"}
mock_head.raise_for_status = MagicMock()
with patch('requests.head', return_value=mock_head):
result = downloader.download_model(
url="http://example.com/model.pt",
file_path=str(model_file),
expected_sha256=sha256
)
assert result is True
def test_download_model_sha256_mismatch_redownloads(self, tmp_path):
import hashlib
content = b"complete model content"
bad_sha256 = "0" * 64
model_file = tmp_path / "model.pt"
model_file.write_bytes(content)
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
downloader = self._make_downloader(model)
new_content = b"new model data"
mock_head = MagicMock()
mock_head.headers = {"Content-Length": str(len(content)), "Accept-Ranges": "bytes"}
mock_head.raise_for_status = MagicMock()
mock_response = MagicMock()
mock_response.__enter__ = lambda s: s
mock_response.__exit__ = MagicMock(return_value=False)
mock_response.status_code = 200
mock_response.headers = {"Content-Length": str(len(new_content))}
mock_response.iter_content = MagicMock(return_value=[new_content])
mock_response.raise_for_status = MagicMock()
with patch('requests.head', return_value=mock_head), \
patch('requests.get', return_value=mock_response):
with pytest.raises(RuntimeError, match="SHA256 checksum does not match"):
downloader.download_model(
url="http://example.com/model.pt",
file_path=str(model_file),
expected_sha256=bad_sha256
)
# File is deleted after SHA256 mismatch
assert not model_file.exists()
def test_download_model_stopped_mid_download(self, tmp_path):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
downloader = self._make_downloader(model)
downloader.stopped = True
file_path = str(tmp_path / "model.pt")
def iter_content_gen(chunk_size):
yield b"chunk1"
mock_response = MagicMock()
mock_response.__enter__ = lambda s: s
mock_response.__exit__ = MagicMock(return_value=False)
mock_response.status_code = 200
mock_response.headers = {"Content-Length": "6"}
mock_response.iter_content = iter_content_gen
mock_response.raise_for_status = MagicMock()
with patch('requests.get', return_value=mock_response):
result = downloader.download_model(
url="http://example.com/model.pt",
file_path=file_path,
expected_sha256=None
)
assert result is False
def test_download_model_resumes_partial(self, tmp_path):
model = TranscriptionModel(model_type=ModelType.WHISPER, whisper_model_size=WhisperModelSize.TINY)
downloader = self._make_downloader(model)
existing_content = b"partial"
model_file = tmp_path / "model.pt"
model_file.write_bytes(existing_content)
resume_content = b" completed"
total_size = len(existing_content) + len(resume_content)
mock_head_size = MagicMock()
mock_head_size.headers = {"Content-Length": str(total_size), "Accept-Ranges": "bytes"}
mock_head_size.raise_for_status = MagicMock()
mock_head_range = MagicMock()
mock_head_range.headers = {"Accept-Ranges": "bytes"}
mock_head_range.raise_for_status = MagicMock()
mock_response = MagicMock()
mock_response.__enter__ = lambda s: s
mock_response.__exit__ = MagicMock(return_value=False)
mock_response.status_code = 206
mock_response.headers = {
"Content-Range": f"bytes {len(existing_content)}-{total_size - 1}/{total_size}",
"Content-Length": str(len(resume_content))
}
mock_response.iter_content = MagicMock(return_value=[resume_content])
mock_response.raise_for_status = MagicMock()
with patch('requests.head', side_effect=[mock_head_size, mock_head_range]), \
patch('requests.get', return_value=mock_response):
result = downloader.download_model(
url="http://example.com/model.pt",
file_path=str(model_file),
expected_sha256=None
)
assert result is True
assert open(str(model_file), 'rb').read() == existing_content + resume_content
class TestModelDownloaderWhisperCpp:
def _make_downloader(self, model, custom_url=None):
downloader = ModelDownloader(model=model, custom_model_url=custom_url)
downloader.signals = MagicMock()
downloader.signals.progress = MagicMock()
downloader.signals.finished = MagicMock()
downloader.signals.error = MagicMock()
return downloader
def test_standard_model_calls_download_from_huggingface(self):
model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
)
downloader = self._make_downloader(model)
model_name = WhisperModelSize.TINY.to_whisper_cpp_model_size()
with patch("buzz.model_loader.download_from_huggingface", return_value="/fake/path") as mock_dl, \
patch.object(downloader, "is_coreml_supported", False):
downloader.run()
mock_dl.assert_called_once_with(
repo_id=WHISPER_CPP_REPO_ID,
allow_patterns=[f"ggml-{model_name}.bin", "README.md"],
progress=downloader.signals.progress,
num_large_files=1,
)
downloader.signals.finished.emit.assert_called_once_with(
os.path.join("/fake/path", f"ggml-{model_name}.bin")
)
def test_lumii_model_uses_lumii_repo(self):
model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.LUMII,
)
downloader = self._make_downloader(model)
model_name = WhisperModelSize.LUMII.to_whisper_cpp_model_size()
with patch("buzz.model_loader.download_from_huggingface", return_value="/lumii/path") as mock_dl, \
patch.object(downloader, "is_coreml_supported", False):
downloader.run()
mock_dl.assert_called_once()
assert mock_dl.call_args.kwargs["repo_id"] == WHISPER_CPP_LUMII_REPO_ID
downloader.signals.finished.emit.assert_called_once_with(
os.path.join("/lumii/path", f"ggml-{model_name}.bin")
)
def test_custom_url_calls_download_model_to_path(self):
model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
)
custom_url = "https://example.com/my-model.bin"
downloader = self._make_downloader(model, custom_url=custom_url)
with patch.object(downloader, "download_model_to_path") as mock_dtp:
downloader.run()
mock_dtp.assert_called_once()
call_kwargs = mock_dtp.call_args.kwargs
assert call_kwargs["url"] == custom_url
def test_coreml_model_includes_mlmodelc_in_file_list(self):
model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
)
downloader = self._make_downloader(model)
model_name = WhisperModelSize.TINY.to_whisper_cpp_model_size()
with patch("buzz.model_loader.download_from_huggingface", return_value="/fake/path") as mock_dl, \
patch.object(downloader, "is_coreml_supported", True), \
patch("zipfile.ZipFile"), \
patch("shutil.rmtree"), \
patch("shutil.move"), \
patch("os.path.exists", return_value=False), \
patch("os.listdir", return_value=[f"ggml-{model_name}-encoder.mlmodelc"]), \
patch("os.path.isdir", return_value=True):
downloader.run()
mock_dl.assert_called_once()
assert mock_dl.call_args.kwargs["num_large_files"] == 2
allow_patterns = mock_dl.call_args.kwargs["allow_patterns"]
assert f"ggml-{model_name}-encoder.mlmodelc.zip" in allow_patterns
def test_coreml_zip_extracted_and_existing_dir_removed(self, tmp_path):
model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
)
downloader = self._make_downloader(model)
model_name = WhisperModelSize.TINY.to_whisper_cpp_model_size()
# Create a fake zip with a single top-level directory inside
import zipfile as zf
zip_path = tmp_path / f"ggml-{model_name}-encoder.mlmodelc.zip"
nested_dir = f"ggml-{model_name}-encoder.mlmodelc"
with zf.ZipFile(zip_path, "w") as z:
z.writestr(f"{nested_dir}/weights", b"fake weights")
existing_target = tmp_path / f"ggml-{model_name}-encoder.mlmodelc"
existing_target.mkdir()
with patch("buzz.model_loader.download_from_huggingface", return_value=str(tmp_path)), \
patch.object(downloader, "is_coreml_supported", True):
downloader.run()
# Old directory was removed and recreated from zip
assert existing_target.exists()
downloader.signals.finished.emit.assert_called_once_with(
str(tmp_path / f"ggml-{model_name}.bin")
)
class TestModelLoaderCertifiImportError:
def test_certifi_import_error_path(self):
"""Test that module handles certifi ImportError gracefully by reimporting with mock"""
import importlib
import buzz.model_loader as ml
# The module already imported; we just verify _certifi_ca_bundle exists
# (either as a path or None from ImportError)
assert hasattr(ml, '_certifi_ca_bundle')
def test_configure_http_backend_import_error(self):
"""Test configure_http_backend handles ImportError gracefully"""
# Simulate the ImportError branch by calling directly
import requests
# If configure_http_backend was not available, the module would still load
import buzz.model_loader as ml
assert ml is not None
================================================
FILE: tests/recording_test.py
================================================
import numpy as np
import pytest
from unittest.mock import MagicMock, patch
from buzz.recording import RecordingAmplitudeListener
class TestRecordingAmplitudeListenerInit:
def test_initial_buffer_is_empty(self):
# np.ndarray([], dtype=np.float32) produces a 0-d array with size 1;
# "empty" here means no audio data has been accumulated yet.
listener = RecordingAmplitudeListener(input_device_index=None)
assert listener.buffer.ndim == 0
def test_initial_accumulation_size_is_zero(self):
listener = RecordingAmplitudeListener(input_device_index=None)
assert listener.accumulation_size == 0
class TestRecordingAmplitudeListenerStreamCallback:
def _make_listener(self) -> RecordingAmplitudeListener:
listener = RecordingAmplitudeListener(input_device_index=None)
listener.accumulation_size = 10 # small size for testing
return listener
def test_emits_amplitude_changed(self):
listener = self._make_listener()
emitted = []
listener.amplitude_changed.connect(lambda v: emitted.append(v))
chunk = np.array([[0.5], [0.5]], dtype=np.float32)
listener.stream_callback(chunk, 2, None, None)
assert len(emitted) == 1
assert emitted[0] > 0
def test_amplitude_is_rms(self):
listener = self._make_listener()
emitted = []
listener.amplitude_changed.connect(lambda v: emitted.append(v))
chunk = np.array([[1.0], [1.0]], dtype=np.float32)
listener.stream_callback(chunk, 2, None, None)
assert abs(emitted[0] - 1.0) < 1e-6
def test_accumulates_buffer(self):
listener = self._make_listener()
size_before = listener.buffer.size
chunk = np.array([[0.1]] * 4, dtype=np.float32)
listener.stream_callback(chunk, 4, None, None)
assert listener.buffer.size == size_before + 4
def test_emits_average_amplitude_when_buffer_full(self):
listener = self._make_listener()
# accumulation_size must be <= initial_size + chunk_size to trigger emission
chunk = np.array([[0.5]] * 4, dtype=np.float32)
listener.accumulation_size = listener.buffer.size + len(chunk)
averages = []
listener.average_amplitude_changed.connect(lambda v: averages.append(v))
listener.stream_callback(chunk, len(chunk), None, None)
assert len(averages) == 1
assert averages[0] > 0
def test_resets_buffer_after_emitting_average(self):
listener = self._make_listener()
chunk = np.array([[0.5]] * 4, dtype=np.float32)
listener.accumulation_size = listener.buffer.size + len(chunk)
listener.stream_callback(chunk, len(chunk), None, None)
# Buffer is reset to np.ndarray([], ...) — a 0-d array
assert listener.buffer.ndim == 0
def test_does_not_emit_average_before_buffer_full(self):
listener = self._make_listener()
chunk = np.array([[0.5]] * 4, dtype=np.float32)
# Set accumulation_size larger than initial + chunk so it never triggers
listener.accumulation_size = listener.buffer.size + len(chunk) + 1
averages = []
listener.average_amplitude_changed.connect(lambda v: averages.append(v))
listener.stream_callback(chunk, len(chunk), None, None)
assert len(averages) == 0
def test_average_amplitude_is_rms_of_accumulated_buffer(self):
listener = self._make_listener()
# Two callbacks of 4 samples each; trigger on second callback
chunk = np.array([[1.0], [1.0], [1.0], [1.0]], dtype=np.float32)
listener.accumulation_size = listener.buffer.size + len(chunk)
averages = []
listener.average_amplitude_changed.connect(lambda v: averages.append(v))
listener.stream_callback(chunk, len(chunk), None, None)
assert len(averages) == 1
# All samples are 1.0, so RMS must be 1.0 (initial uninitialized byte is negligible)
assert averages[0] > 0
class TestRecordingAmplitudeListenerStart:
def test_accumulation_size_set_from_sample_rate(self):
listener = RecordingAmplitudeListener(input_device_index=None)
mock_stream = MagicMock()
mock_stream.samplerate = 16000
with patch("sounddevice.InputStream", return_value=mock_stream):
listener.start_recording()
assert listener.accumulation_size == 16000 * RecordingAmplitudeListener.ACCUMULATION_SECONDS
================================================
FILE: tests/recording_transcriber_test.py
================================================
import threading
from unittest.mock import MagicMock, patch, PropertyMock
import numpy as np
import pytest
from sounddevice import PortAudioError
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
from buzz.transcriber.recording_transcriber import RecordingTranscriber
from buzz.transcriber.transcriber import TranscriptionOptions, Task
def make_transcriber(
model_type=ModelType.WHISPER,
mode_index=0,
silence_threshold=0.0,
language=None,
) -> RecordingTranscriber:
options = TranscriptionOptions(
language=language,
task=Task.TRANSCRIBE,
model=TranscriptionModel(model_type=model_type, whisper_model_size=WhisperModelSize.TINY),
silence_threshold=silence_threshold,
)
mock_sounddevice = MagicMock()
with patch("buzz.transcriber.recording_transcriber.Settings") as MockSettings:
instance = MockSettings.return_value
instance.value.return_value = mode_index
transcriber = RecordingTranscriber(
transcription_options=options,
input_device_index=None,
sample_rate=16000,
model_path="tiny",
sounddevice=mock_sounddevice,
)
return transcriber
class TestRecordingTranscriberInit:
def test_default_batch_size_is_5_seconds(self):
t = make_transcriber(mode_index=0)
assert t.n_batch_samples == 5 * t.sample_rate
def test_append_and_correct_mode_batch_size_uses_transcription_step(self):
mode_index = list(RecordingTranscriberMode).index(RecordingTranscriberMode.APPEND_AND_CORRECT)
t = make_transcriber(mode_index=mode_index)
assert t.n_batch_samples == int(t.transcription_options.transcription_step * t.sample_rate)
def test_append_and_correct_mode_keep_sample_seconds(self):
mode_index = list(RecordingTranscriberMode).index(RecordingTranscriberMode.APPEND_AND_CORRECT)
t = make_transcriber(mode_index=mode_index)
assert t.keep_sample_seconds == 1.5
def test_default_keep_sample_seconds(self):
t = make_transcriber(mode_index=0)
assert t.keep_sample_seconds == 0.15
def test_queue_starts_empty(self):
t = make_transcriber()
assert t.queue.size == 0 or t.queue.ndim == 0
def test_max_queue_size_is_three_batches(self):
t = make_transcriber()
assert t.max_queue_size == 3 * t.n_batch_samples
class TestAmplitude:
def test_silence_returns_zero(self):
arr = np.zeros(100, dtype=np.float32)
assert RecordingTranscriber.amplitude(arr) == 0.0
def test_unit_signal_returns_one(self):
arr = np.ones(100, dtype=np.float32)
assert abs(RecordingTranscriber.amplitude(arr) - 1.0) < 1e-6
def test_rms_calculation(self):
arr = np.array([0.6, 0.8], dtype=np.float32)
expected = float(np.sqrt(np.mean(arr ** 2)))
assert abs(RecordingTranscriber.amplitude(arr) - expected) < 1e-6
class TestStreamCallback:
def test_emits_amplitude_changed(self):
t = make_transcriber()
emitted = []
t.amplitude_changed.connect(lambda v: emitted.append(v))
chunk = np.array([[0.5], [0.5]], dtype=np.float32)
t.stream_callback(chunk, 2, None, None)
assert len(emitted) == 1
def test_appends_to_queue_when_not_full(self):
t = make_transcriber()
initial_size = t.queue.size
chunk = np.ones((100,), dtype=np.float32)
t.stream_callback(chunk.reshape(-1, 1), 100, None, None)
assert t.queue.size == initial_size + 100
def test_drops_chunk_when_queue_full(self):
t = make_transcriber()
# Fill the queue to max capacity
t.queue = np.ones(t.max_queue_size, dtype=np.float32)
size_before = t.queue.size
chunk = np.array([[0.5], [0.5]], dtype=np.float32)
t.stream_callback(chunk, 2, None, None)
assert t.queue.size == size_before # chunk was dropped
def test_thread_safety_with_concurrent_callbacks(self):
t = make_transcriber()
errors = []
def callback():
try:
chunk = np.ones((10, 1), dtype=np.float32)
t.stream_callback(chunk, 10, None, None)
except Exception as e:
errors.append(e)
threads = [threading.Thread(target=callback) for _ in range(20)]
for th in threads:
th.start()
for th in threads:
th.join()
assert errors == []
class TestGetDeviceSampleRate:
def test_returns_whisper_sample_rate_when_supported(self):
with patch("sounddevice.check_input_settings"):
rate = RecordingTranscriber.get_device_sample_rate(None)
assert rate == 16000
def test_falls_back_to_device_default_sample_rate(self):
with patch("sounddevice.check_input_settings", side_effect=PortAudioError()), \
patch("sounddevice.query_devices", return_value={"default_samplerate": 44100.0}):
rate = RecordingTranscriber.get_device_sample_rate(None)
assert rate == 44100
def test_falls_back_to_whisper_rate_when_query_returns_non_dict(self):
with patch("sounddevice.check_input_settings", side_effect=PortAudioError()), \
patch("sounddevice.query_devices", return_value=None):
rate = RecordingTranscriber.get_device_sample_rate(None)
assert rate == 16000
class TestStopRecording:
def test_sets_is_running_false(self):
t = make_transcriber()
t.is_running = True
t.stop_recording()
assert t.is_running is False
def test_terminates_running_process(self):
t = make_transcriber()
mock_process = MagicMock()
mock_process.poll.return_value = None # process is running
t.process = mock_process
t.stop_recording()
mock_process.terminate.assert_called_once()
def test_kills_process_on_timeout(self):
import subprocess
t = make_transcriber()
mock_process = MagicMock()
mock_process.poll.return_value = None
mock_process.wait.side_effect = subprocess.TimeoutExpired(cmd="test", timeout=5)
t.process = mock_process
t.stop_recording()
mock_process.kill.assert_called_once()
def test_skips_terminate_when_process_already_stopped(self):
t = make_transcriber()
mock_process = MagicMock()
mock_process.poll.return_value = 0 # already exited
t.process = mock_process
t.stop_recording()
mock_process.terminate.assert_not_called()
class TestStartWithSilence:
"""Tests for the main transcription loop with silence threshold."""
def _run_with_mock_model(self, transcription_options, samples, expected_text):
"""Helper to run a single transcription cycle with a mocked whisper model."""
mock_model = MagicMock()
mock_model.transcribe.return_value = {"text": expected_text}
transcriber = make_transcriber(
model_type=ModelType.WHISPER,
silence_threshold=0.0,
)
transcriber.transcription_options = transcription_options
received = []
transcriber.transcription.connect(lambda t: received.append(t))
def fake_input_stream(**kwargs):
ctx = MagicMock()
ctx.__enter__ = MagicMock(return_value=ctx)
ctx.__exit__ = MagicMock(return_value=False)
return ctx
transcriber.queue = samples.copy()
transcriber.is_running = True
# After processing one batch, stop.
call_count = [0]
original_emit = transcriber.transcription.emit
def stop_after_first(text):
original_emit(text)
transcriber.is_running = False
transcriber.transcription.emit = stop_after_first
with patch("buzz.transcriber.recording_transcriber.whisper") as mock_whisper, \
patch("buzz.transcriber.recording_transcriber.torch") as mock_torch:
mock_torch.cuda.is_available.return_value = False
mock_whisper.load_model.return_value = mock_model
mock_whisper.Whisper = type("Whisper", (), {})
# make isinstance(model, whisper.Whisper) pass
mock_model.__class__ = mock_whisper.Whisper
with patch.object(transcriber, "sounddevice") as mock_sd:
mock_stream_ctx = MagicMock()
mock_stream_ctx.__enter__ = MagicMock(return_value=mock_stream_ctx)
mock_stream_ctx.__exit__ = MagicMock(return_value=False)
mock_sd.InputStream.return_value = mock_stream_ctx
transcriber.start()
return received
def test_silent_audio_skips_transcription(self):
t = make_transcriber(silence_threshold=1.0) # very high threshold
received = []
t.transcription.connect(lambda text: received.append(text))
# Put silent samples in queue (amplitude = 0)
t.queue = np.zeros(t.n_batch_samples + 100, dtype=np.float32)
t.is_running = True
stop_event = threading.Event()
def stop_after_delay():
stop_event.wait(timeout=1.5)
t.stop_recording()
stopper = threading.Thread(target=stop_after_delay, daemon=True)
with patch("buzz.transcriber.recording_transcriber.whisper") as mock_whisper, \
patch("buzz.transcriber.recording_transcriber.torch") as mock_torch:
mock_torch.cuda.is_available.return_value = False
mock_whisper.load_model.return_value = MagicMock()
with patch.object(t, "sounddevice") as mock_sd:
mock_stream_ctx = MagicMock()
mock_stream_ctx.__enter__ = MagicMock(return_value=mock_stream_ctx)
mock_stream_ctx.__exit__ = MagicMock(return_value=False)
mock_sd.InputStream.return_value = mock_stream_ctx
stopper.start()
stop_event.set()
t.start()
# No transcription should have been emitted since audio is silent
assert received == []
class TestStartPortAudioError:
def test_emits_error_on_portaudio_failure(self):
t = make_transcriber()
errors = []
t.error.connect(lambda e: errors.append(e))
with patch("buzz.transcriber.recording_transcriber.whisper") as mock_whisper, \
patch("buzz.transcriber.recording_transcriber.torch") as mock_torch:
mock_torch.cuda.is_available.return_value = False
mock_whisper.load_model.return_value = MagicMock()
with patch.object(t, "sounddevice") as mock_sd:
mock_sd.InputStream.side_effect = PortAudioError()
t.start()
assert len(errors) == 1
================================================
FILE: tests/settings/settings_test.py
================================================
import pytest
from unittest.mock import Mock, patch
from buzz.settings.settings import Settings
class TestSettings:
def test_transcription_tasks_table_column_order_key(self):
"""Test that TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER key is defined"""
assert hasattr(Settings.Key, 'TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER')
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value == "transcription-tasks-table/column-order"
def test_transcription_tasks_table_column_widths_key(self):
"""Test that TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS key is defined"""
assert hasattr(Settings.Key, 'TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS')
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value == "transcription-tasks-table/column-widths"
def test_transcription_tasks_table_column_visibility_key_exists(self):
"""Test that TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY key still exists"""
assert hasattr(Settings.Key, 'TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY')
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value == "transcription-tasks-table/column-visibility"
def test_transcription_tasks_table_sort_state_key(self):
"""Test that TRANSCRIPTION_TASKS_TABLE_SORT_STATE key is defined"""
assert hasattr(Settings.Key, 'TRANSCRIPTION_TASKS_TABLE_SORT_STATE')
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value == "transcription-tasks-table/sort-state"
def test_all_transcription_tasks_table_keys_are_strings(self):
"""Test that all transcription tasks table keys are strings"""
assert isinstance(Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value, str)
assert isinstance(Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value, str)
assert isinstance(Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value, str)
assert isinstance(Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value, str)
def test_transcription_tasks_table_keys_have_correct_prefix(self):
"""Test that all transcription tasks table keys have the correct prefix"""
prefix = "transcription-tasks-table/"
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value.startswith(prefix)
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value.startswith(prefix)
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value.startswith(prefix)
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value.startswith(prefix)
def test_transcription_tasks_table_keys_are_unique(self):
"""Test that all transcription tasks table keys are unique"""
keys = [
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value
]
assert len(keys) == len(set(keys)), "All transcription tasks table keys should be unique"
def test_settings_key_enum_values(self):
"""Test that Settings.Key enum values are properly defined"""
# Test that the keys exist and have expected values
expected_keys = {
'TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY': 'transcription-tasks-table/column-visibility',
'TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER': 'transcription-tasks-table/column-order',
'TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS': 'transcription-tasks-table/column-widths',
'TRANSCRIPTION_TASKS_TABLE_SORT_STATE': 'transcription-tasks-table/sort-state'
}
for key_name, expected_value in expected_keys.items():
assert hasattr(Settings.Key, key_name)
assert getattr(Settings.Key, key_name).value == expected_value
def test_settings_key_immutability(self):
"""Test that Settings.Key values cannot be modified"""
# This test ensures that the keys are defined as constants
original_visibility = Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY
original_order = Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER
original_widths = Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS
original_sort_state = Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE
# Attempting to modify these should not work (they should be immutable)
# If they were mutable, this test would fail
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY == original_visibility
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER == original_order
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS == original_widths
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE == original_sort_state
def test_settings_key_format_consistency(self):
"""Test that all transcription tasks table keys follow the same format"""
keys = [
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value
]
for key in keys:
# All keys should start with the same prefix
assert key.startswith("transcription-tasks-table/")
# All keys should contain only lowercase letters, hyphens, and forward slashes
assert all(c.islower() or c in '-/' for c in key)
# All keys should end with a descriptive suffix
assert key.endswith(('visibility', 'order', 'widths', 'sort-state'))
def test_settings_key_length(self):
"""Test that transcription tasks table keys have reasonable length"""
keys = [
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value
]
for key in keys:
# Keys should be long enough to be descriptive but not excessively long
assert 20 <= len(key) <= 50, f"Key '{key}' has unexpected length: {len(key)}"
def test_settings_key_naming_convention(self):
"""Test that transcription tasks table keys follow proper naming convention"""
keys = [
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value,
Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value
]
for key in keys:
# Keys should use kebab-case (lowercase with hyphens)
assert '-' in key, f"Key '{key}' should use kebab-case with hyphens"
assert not any(c.isupper() for c in key), f"Key '{key}' should not contain uppercase letters"
assert not '_' in key, f"Key '{key}' should use hyphens instead of underscores"
def test_settings_key_usage_in_code(self):
"""Test that the settings keys can be used in typical settings operations"""
# Mock a settings object to test key usage
mock_settings = Mock()
mock_settings.begin_group = Mock()
mock_settings.end_group = Mock()
mock_settings.settings = Mock()
# Test that the keys can be used with begin_group
mock_settings.begin_group(Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value)
mock_settings.begin_group(Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value)
mock_settings.begin_group(Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value)
mock_settings.begin_group(Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value)
# Verify that begin_group was called with the correct keys
assert mock_settings.begin_group.call_count == 4
call_args = [call[0][0] for call in mock_settings.begin_group.call_args_list]
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_VISIBILITY.value in call_args
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_ORDER.value in call_args
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_COLUMN_WIDTHS.value in call_args
assert Settings.Key.TRANSCRIPTION_TASKS_TABLE_SORT_STATE.value in call_args
================================================
FILE: tests/store/__init__.py
================================================
================================================
FILE: tests/store/keyring_store_test.py
================================================
import json
import os
import sys
import tempfile
from unittest.mock import Mock, patch, MagicMock
import pytest
from buzz.store.keyring_store import (
Key,
_is_linux,
_derive_key,
_encrypt_value,
_decrypt_value,
_load_local_secrets,
_save_local_secrets,
_get_portal_password,
_set_portal_password,
_delete_portal_password,
get_password,
set_password,
delete_password,
)
from buzz.settings.settings import APP_NAME
class TestKey:
def test_openai_api_key_exists(self):
assert hasattr(Key, "OPENAI_API_KEY")
def test_openai_api_key_value(self):
assert Key.OPENAI_API_KEY.value == "OpenAI API key"
def test_key_is_enum(self):
assert isinstance(Key.OPENAI_API_KEY, Key)
class TestIsLinux:
@patch("buzz.store.keyring_store.sys.platform", "linux")
def test_returns_true_on_linux(self):
assert _is_linux() is True
@patch("buzz.store.keyring_store.sys.platform", "linux2")
def test_returns_true_on_linux2(self):
assert _is_linux() is True
@patch("buzz.store.keyring_store.sys.platform", "darwin")
def test_returns_false_on_macos(self):
assert _is_linux() is False
@patch("buzz.store.keyring_store.sys.platform", "win32")
def test_returns_false_on_windows(self):
assert _is_linux() is False
class TestDeriveKey:
def test_derive_key_returns_32_bytes(self):
master_secret = b"test_secret"
key_name = "test_key"
derived = _derive_key(master_secret, key_name)
assert len(derived) == 32
def test_derive_key_is_deterministic(self):
master_secret = b"test_secret"
key_name = "test_key"
derived1 = _derive_key(master_secret, key_name)
derived2 = _derive_key(master_secret, key_name)
assert derived1 == derived2
def test_derive_key_different_for_different_names(self):
master_secret = b"test_secret"
derived1 = _derive_key(master_secret, "key1")
derived2 = _derive_key(master_secret, "key2")
assert derived1 != derived2
def test_derive_key_different_for_different_secrets(self):
key_name = "test_key"
derived1 = _derive_key(b"secret1", key_name)
derived2 = _derive_key(b"secret2", key_name)
assert derived1 != derived2
class TestEncryptDecrypt:
def test_encrypt_decrypt_roundtrip(self):
key = b"0123456789abcdef0123456789abcdef" # 32 bytes
original = "test_password_123"
encrypted = _encrypt_value(original, key)
decrypted = _decrypt_value(encrypted, key)
assert decrypted == original
def test_encrypt_decrypt_empty_string(self):
key = b"0123456789abcdef0123456789abcdef"
original = ""
encrypted = _encrypt_value(original, key)
decrypted = _decrypt_value(encrypted, key)
assert decrypted == original
def test_encrypt_decrypt_unicode(self):
key = b"0123456789abcdef0123456789abcdef"
original = "test_password_\u4e2d\u6587_\U0001f600"
encrypted = _encrypt_value(original, key)
decrypted = _decrypt_value(encrypted, key)
assert decrypted == original
def test_encrypt_decrypt_long_string(self):
key = b"0123456789abcdef0123456789abcdef"
original = "a" * 1000
encrypted = _encrypt_value(original, key)
decrypted = _decrypt_value(encrypted, key)
assert decrypted == original
def test_encrypted_is_base64(self):
key = b"0123456789abcdef0123456789abcdef"
original = "test"
encrypted = _encrypt_value(original, key)
# Should be valid base64
import base64
base64.b64decode(encrypted) # Should not raise
def test_different_keys_produce_different_ciphertext(self):
key1 = b"0123456789abcdef0123456789abcdef"
key2 = b"fedcba9876543210fedcba9876543210"
original = "test_password"
encrypted1 = _encrypt_value(original, key1)
encrypted2 = _encrypt_value(original, key2)
assert encrypted1 != encrypted2
class TestLocalSecrets:
def test_load_empty_file(self):
with tempfile.TemporaryDirectory() as tmpdir:
with patch(
"buzz.store.keyring_store._get_secrets_file_path",
return_value=os.path.join(tmpdir, ".secrets.json"),
):
result = _load_local_secrets()
assert result == {}
def test_save_and_load_secrets(self):
with tempfile.TemporaryDirectory() as tmpdir:
secrets_path = os.path.join(tmpdir, ".secrets.json")
with patch(
"buzz.store.keyring_store._get_secrets_file_path",
return_value=secrets_path,
):
test_secrets = {"key1": "value1", "key2": "value2"}
_save_local_secrets(test_secrets)
loaded = _load_local_secrets()
assert loaded == test_secrets
@pytest.mark.skipif(sys.platform == "win32", reason="Unix file permissions not applicable on Windows")
def test_save_sets_restrictive_permissions(self):
with tempfile.TemporaryDirectory() as tmpdir:
secrets_path = os.path.join(tmpdir, ".secrets.json")
with patch(
"buzz.store.keyring_store._get_secrets_file_path",
return_value=secrets_path,
):
_save_local_secrets({"key": "value"})
# Check file permissions (0o600 = owner read/write only)
mode = os.stat(secrets_path).st_mode & 0o777
assert mode == 0o600
def test_load_handles_corrupted_json(self):
with tempfile.TemporaryDirectory() as tmpdir:
secrets_path = os.path.join(tmpdir, ".secrets.json")
with open(secrets_path, "w") as f:
f.write("not valid json {{{")
with patch(
"buzz.store.keyring_store._get_secrets_file_path",
return_value=secrets_path,
):
result = _load_local_secrets()
assert result == {}
class TestPortalPassword:
@patch("buzz.store.keyring_store._get_portal_secret")
@patch("buzz.store.keyring_store._load_local_secrets")
def test_get_portal_password_returns_none_when_no_portal(
self, mock_load, mock_portal
):
mock_portal.return_value = None
result = _get_portal_password(Key.OPENAI_API_KEY)
assert result is None
@patch("buzz.store.keyring_store._get_portal_secret")
@patch("buzz.store.keyring_store._load_local_secrets")
def test_get_portal_password_returns_none_when_key_not_found(
self, mock_load, mock_portal
):
mock_portal.return_value = b"test_secret_64_bytes_" + b"x" * 43
mock_load.return_value = {}
result = _get_portal_password(Key.OPENAI_API_KEY)
assert result is None
@patch("buzz.store.keyring_store._get_portal_secret")
@patch("buzz.store.keyring_store._load_local_secrets")
def test_get_portal_password_decrypts_stored_value(self, mock_load, mock_portal):
portal_secret = b"test_secret_64_bytes_" + b"x" * 43
mock_portal.return_value = portal_secret
# Pre-encrypt a value
derived_key = _derive_key(portal_secret, Key.OPENAI_API_KEY.value)
encrypted = _encrypt_value("my_api_key", derived_key)
mock_load.return_value = {Key.OPENAI_API_KEY.value: encrypted}
result = _get_portal_password(Key.OPENAI_API_KEY)
assert result == "my_api_key"
@patch("buzz.store.keyring_store._get_portal_secret")
def test_set_portal_password_returns_false_when_no_portal(self, mock_portal):
mock_portal.return_value = None
result = _set_portal_password(Key.OPENAI_API_KEY, "test_password")
assert result is False
@patch("buzz.store.keyring_store._get_portal_secret")
@patch("buzz.store.keyring_store._load_local_secrets")
@patch("buzz.store.keyring_store._save_local_secrets")
def test_set_portal_password_encrypts_and_saves(
self, mock_save, mock_load, mock_portal
):
portal_secret = b"test_secret_64_bytes_" + b"x" * 43
mock_portal.return_value = portal_secret
mock_load.return_value = {}
result = _set_portal_password(Key.OPENAI_API_KEY, "test_password")
assert result is True
mock_save.assert_called_once()
saved_secrets = mock_save.call_args[0][0]
assert Key.OPENAI_API_KEY.value in saved_secrets
# Verify the saved value can be decrypted
derived_key = _derive_key(portal_secret, Key.OPENAI_API_KEY.value)
decrypted = _decrypt_value(saved_secrets[Key.OPENAI_API_KEY.value], derived_key)
assert decrypted == "test_password"
class TestDeletePortalPassword:
@patch("buzz.store.keyring_store._load_local_secrets")
@patch("buzz.store.keyring_store._save_local_secrets")
def test_delete_existing_key(self, mock_save, mock_load):
mock_load.return_value = {Key.OPENAI_API_KEY.value: "encrypted_value"}
result = _delete_portal_password(Key.OPENAI_API_KEY)
assert result is True
mock_save.assert_called_once()
saved_secrets = mock_save.call_args[0][0]
assert Key.OPENAI_API_KEY.value not in saved_secrets
@patch("buzz.store.keyring_store._load_local_secrets")
@patch("buzz.store.keyring_store._save_local_secrets")
def test_delete_nonexistent_key(self, mock_save, mock_load):
mock_load.return_value = {}
result = _delete_portal_password(Key.OPENAI_API_KEY)
assert result is False
mock_save.assert_not_called()
class TestGetPassword:
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store._get_portal_password")
@patch("buzz.store.keyring_store.keyring")
def test_returns_portal_password_on_linux(
self, mock_keyring, mock_portal, mock_is_linux
):
mock_is_linux.return_value = True
mock_portal.return_value = "portal_password"
result = get_password(Key.OPENAI_API_KEY)
assert result == "portal_password"
mock_keyring.get_password.assert_not_called()
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store._get_portal_password")
@patch("buzz.store.keyring_store.keyring")
def test_falls_back_to_keyring_when_portal_returns_none(
self, mock_keyring, mock_portal, mock_is_linux
):
mock_is_linux.return_value = True
mock_portal.return_value = None
mock_keyring.get_password.return_value = "keyring_password"
result = get_password(Key.OPENAI_API_KEY)
assert result == "keyring_password"
mock_keyring.get_password.assert_called_once_with(
APP_NAME, username=Key.OPENAI_API_KEY.value
)
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_uses_keyring_directly_on_non_linux(self, mock_keyring, mock_is_linux):
mock_is_linux.return_value = False
mock_keyring.get_password.return_value = "keyring_password"
result = get_password(Key.OPENAI_API_KEY)
assert result == "keyring_password"
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_returns_empty_string_when_keyring_returns_none(
self, mock_keyring, mock_is_linux
):
mock_is_linux.return_value = False
mock_keyring.get_password.return_value = None
result = get_password(Key.OPENAI_API_KEY)
assert result == ""
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_returns_empty_string_on_keyring_exception(
self, mock_keyring, mock_is_linux
):
mock_is_linux.return_value = False
mock_keyring.get_password.side_effect = Exception("Keyring error")
result = get_password(Key.OPENAI_API_KEY)
assert result == ""
class TestSetPassword:
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store._set_portal_password")
@patch("buzz.store.keyring_store.keyring")
def test_uses_portal_on_linux_when_successful(
self, mock_keyring, mock_portal, mock_is_linux
):
mock_is_linux.return_value = True
mock_portal.return_value = True
set_password(Key.OPENAI_API_KEY, "test_password")
mock_portal.assert_called_once_with(Key.OPENAI_API_KEY, "test_password")
mock_keyring.set_password.assert_not_called()
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store._set_portal_password")
@patch("buzz.store.keyring_store.keyring")
def test_falls_back_to_keyring_when_portal_fails(
self, mock_keyring, mock_portal, mock_is_linux
):
mock_is_linux.return_value = True
mock_portal.return_value = False
set_password(Key.OPENAI_API_KEY, "test_password")
mock_keyring.set_password.assert_called_once_with(
APP_NAME, Key.OPENAI_API_KEY.value, "test_password"
)
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_uses_keyring_directly_on_non_linux(self, mock_keyring, mock_is_linux):
mock_is_linux.return_value = False
set_password(Key.OPENAI_API_KEY, "test_password")
mock_keyring.set_password.assert_called_once_with(
APP_NAME, Key.OPENAI_API_KEY.value, "test_password"
)
class TestDeletePassword:
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store._delete_portal_password")
@patch("buzz.store.keyring_store.keyring")
def test_deletes_from_both_on_linux(
self, mock_keyring, mock_delete_portal, mock_is_linux
):
mock_is_linux.return_value = True
mock_delete_portal.return_value = True
delete_password(Key.OPENAI_API_KEY)
mock_delete_portal.assert_called_once_with(Key.OPENAI_API_KEY)
mock_keyring.delete_password.assert_called_once_with(
APP_NAME, Key.OPENAI_API_KEY.value
)
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_deletes_from_keyring_only_on_non_linux(self, mock_keyring, mock_is_linux):
mock_is_linux.return_value = False
delete_password(Key.OPENAI_API_KEY)
mock_keyring.delete_password.assert_called_once_with(
APP_NAME, Key.OPENAI_API_KEY.value
)
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_ignores_password_delete_error(self, mock_keyring, mock_is_linux):
mock_is_linux.return_value = False
mock_keyring.errors.PasswordDeleteError = Exception
mock_keyring.delete_password.side_effect = (
mock_keyring.errors.PasswordDeleteError("Not found")
)
# Should not raise
delete_password(Key.OPENAI_API_KEY)
@patch("buzz.store.keyring_store._is_linux")
@patch("buzz.store.keyring_store.keyring")
def test_handles_other_keyring_exceptions(self, mock_keyring, mock_is_linux):
mock_is_linux.return_value = False
mock_keyring.errors.PasswordDeleteError = KeyError # Different exception type
mock_keyring.delete_password.side_effect = RuntimeError("Some other error")
# Should not raise
delete_password(Key.OPENAI_API_KEY)
class TestIntegration:
"""Integration tests that test the full flow with mocked portal."""
@patch("buzz.store.keyring_store._get_portal_secret")
def test_full_roundtrip_with_portal(self, mock_portal):
"""Test set -> get -> delete flow with portal."""
portal_secret = b"integration_test_secret_" + b"y" * 40
with tempfile.TemporaryDirectory() as tmpdir:
secrets_path = os.path.join(tmpdir, ".secrets.json")
with patch(
"buzz.store.keyring_store._get_secrets_file_path",
return_value=secrets_path,
):
with patch("buzz.store.keyring_store._is_linux", return_value=True):
mock_portal.return_value = portal_secret
# Set password
result = _set_portal_password(Key.OPENAI_API_KEY, "my_secret_key")
assert result is True
# Get password
retrieved = _get_portal_password(Key.OPENAI_API_KEY)
assert retrieved == "my_secret_key"
# Delete password
deleted = _delete_portal_password(Key.OPENAI_API_KEY)
assert deleted is True
# Verify it's gone
retrieved_after_delete = _get_portal_password(Key.OPENAI_API_KEY)
assert retrieved_after_delete is None
================================================
FILE: tests/transcriber/__init__.py
================================================
================================================
FILE: tests/transcriber/file_transcriber_queue_worker_test.py
================================================
import pytest
import unittest.mock
import uuid
from PyQt6.QtCore import QCoreApplication, QThread
from buzz.file_transcriber_queue_worker import FileTranscriberQueueWorker
from buzz.model_loader import ModelType, TranscriptionModel, WhisperModelSize
from buzz.transcriber.transcriber import FileTranscriptionTask, TranscriptionOptions, FileTranscriptionOptions, Segment
from buzz.transcriber.whisper_file_transcriber import WhisperFileTranscriber
from tests.audio import test_multibyte_utf8_audio_path
import time
@pytest.fixture(scope="session")
def qapp():
app = QCoreApplication.instance()
if app is None:
app = QCoreApplication([])
yield app
app.quit()
@pytest.fixture
def worker(qapp):
worker = FileTranscriberQueueWorker()
thread = QThread()
worker.moveToThread(thread)
thread.started.connect(worker.run)
thread.start()
yield worker
worker.stop()
thread.quit()
thread.wait()
@pytest.fixture
def simple_worker(qapp):
"""A non-threaded worker for unit tests that only test individual methods."""
worker = FileTranscriberQueueWorker()
yield worker
class TestFileTranscriberQueueWorker:
def test_cancel_task_adds_to_canceled_set(self, simple_worker):
task_id = uuid.uuid4()
simple_worker.cancel_task(task_id)
assert task_id in simple_worker.canceled_tasks
def test_add_task_removes_from_canceled(self, simple_worker):
options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY),
extract_speech=False
)
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
# First cancel it
simple_worker.cancel_task(task.uid)
assert task.uid in simple_worker.canceled_tasks
# Prevent trigger_run from starting the run loop
simple_worker.is_running = True
# Then add it back
simple_worker.add_task(task)
assert task.uid not in simple_worker.canceled_tasks
def test_on_task_error_with_cancellation(self, simple_worker):
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
error_spy = unittest.mock.Mock()
simple_worker.task_error.connect(error_spy)
simple_worker.on_task_error("Transcription was canceled")
error_spy.assert_called_once()
assert task.status == FileTranscriptionTask.Status.CANCELED
assert "canceled" in task.error.lower()
def test_on_task_error_with_regular_error(self, simple_worker):
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
error_spy = unittest.mock.Mock()
simple_worker.task_error.connect(error_spy)
simple_worker.on_task_error("Some error occurred")
error_spy.assert_called_once()
assert task.status == FileTranscriptionTask.Status.FAILED
assert task.error == "Some error occurred"
def test_on_task_progress_conversion(self, simple_worker):
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
progress_spy = unittest.mock.Mock()
simple_worker.task_progress.connect(progress_spy)
simple_worker.on_task_progress((50, 100))
progress_spy.assert_called_once()
args = progress_spy.call_args[0]
assert args[0] == task
assert args[1] == 0.5
def test_stop_puts_sentinel_in_queue(self, simple_worker):
initial_size = simple_worker.tasks_queue.qsize()
simple_worker.stop()
# Sentinel (None) should be added to queue
assert simple_worker.tasks_queue.qsize() == initial_size + 1
def test_on_task_completed_with_speech_path(self, simple_worker, tmp_path):
"""Test on_task_completed cleans up speech_path file"""
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
# Create a temporary file to simulate speech extraction output
speech_file = tmp_path / "audio_speech.mp3"
speech_file.write_bytes(b"fake audio data")
simple_worker.speech_path = speech_file
completed_spy = unittest.mock.Mock()
simple_worker.task_completed.connect(completed_spy)
simple_worker.on_task_completed([Segment(0, 1000, "Test")])
completed_spy.assert_called_once()
# Speech path should be cleaned up
assert simple_worker.speech_path is None
assert not speech_file.exists()
def test_on_task_completed_speech_path_missing(self, simple_worker, tmp_path):
"""Test on_task_completed handles missing speech_path file gracefully"""
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
# Set a speech path that doesn't exist
simple_worker.speech_path = tmp_path / "nonexistent_speech.mp3"
completed_spy = unittest.mock.Mock()
simple_worker.task_completed.connect(completed_spy)
# Should not raise even if file doesn't exist
simple_worker.on_task_completed([])
completed_spy.assert_called_once()
assert simple_worker.speech_path is None
def test_on_task_download_progress(self, simple_worker):
"""Test on_task_download_progress emits signal"""
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
download_spy = unittest.mock.Mock()
simple_worker.task_download_progress.connect(download_spy)
simple_worker.on_task_download_progress(0.5)
download_spy.assert_called_once()
args = download_spy.call_args[0]
assert args[0] == task
assert args[1] == 0.5
def test_cancel_task_stops_current_transcriber(self, simple_worker):
"""Test cancel_task stops the current transcriber if it matches"""
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
mock_transcriber = unittest.mock.Mock()
simple_worker.current_transcriber = mock_transcriber
simple_worker.cancel_task(task.uid)
assert task.uid in simple_worker.canceled_tasks
mock_transcriber.stop.assert_called_once()
def test_on_task_error_task_in_canceled_set(self, simple_worker):
"""Test on_task_error does not emit signal when task is canceled"""
options = TranscriptionOptions()
task = FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
simple_worker.current_task = task
# Mark task as canceled
simple_worker.canceled_tasks.add(task.uid)
error_spy = unittest.mock.Mock()
simple_worker.task_error.connect(error_spy)
simple_worker.on_task_error("Some error")
# Should NOT emit since task was canceled
error_spy.assert_not_called()
class TestFileTranscriberQueueWorkerRun:
def _make_task(self, model_type=ModelType.WHISPER_CPP, extract_speech=False):
options = TranscriptionOptions(
model=TranscriptionModel(model_type=model_type, whisper_model_size=WhisperModelSize.TINY),
extract_speech=extract_speech
)
return FileTranscriptionTask(
file_path=str(test_multibyte_utf8_audio_path),
transcription_options=options,
file_transcription_options=FileTranscriptionOptions(),
model_path="mock_path"
)
def test_run_returns_early_when_already_running(self, simple_worker):
simple_worker.is_running = True
# Should return without blocking (queue is empty, no get() call)
simple_worker.run()
# is_running stays True, nothing changed
assert simple_worker.is_running is True
def test_run_stops_on_sentinel(self, simple_worker, qapp):
completed_spy = unittest.mock.Mock()
simple_worker.completed.connect(completed_spy)
simple_worker.tasks_queue.put(None)
simple_worker.run()
completed_spy.assert_called_once()
assert simple_worker.is_running is False
def test_run_skips_canceled_task_then_stops_on_sentinel(self, simple_worker, qapp):
task = self._make_task()
simple_worker.canceled_tasks.add(task.uid)
started_spy = unittest.mock.Mock()
simple_worker.task_started.connect(started_spy)
# Put canceled task then sentinel
simple_worker.tasks_queue.put(task)
simple_worker.tasks_queue.put(None)
simple_worker.run()
# Canceled task should be skipped; completed emitted
started_spy.assert_not_called()
assert simple_worker.is_running is False
def test_run_creates_openai_transcriber(self, simple_worker, qapp):
from buzz.transcriber.openai_whisper_api_file_transcriber import OpenAIWhisperAPIFileTranscriber
task = self._make_task(model_type=ModelType.OPEN_AI_WHISPER_API)
simple_worker.tasks_queue.put(task)
with unittest.mock.patch.object(OpenAIWhisperAPIFileTranscriber, 'run'), \
unittest.mock.patch.object(OpenAIWhisperAPIFileTranscriber, 'moveToThread'), \
unittest.mock.patch('buzz.file_transcriber_queue_worker.QThread') as mock_thread_class:
mock_thread = unittest.mock.MagicMock()
mock_thread_class.return_value = mock_thread
simple_worker.run()
assert isinstance(simple_worker.current_transcriber, OpenAIWhisperAPIFileTranscriber)
def test_run_creates_whisper_transcriber_for_whisper_cpp(self, simple_worker, qapp):
task = self._make_task(model_type=ModelType.WHISPER_CPP)
simple_worker.tasks_queue.put(task)
with unittest.mock.patch.object(WhisperFileTranscriber, 'run'), \
unittest.mock.patch.object(WhisperFileTranscriber, 'moveToThread'), \
unittest.mock.patch('buzz.file_transcriber_queue_worker.QThread') as mock_thread_class:
mock_thread = unittest.mock.MagicMock()
mock_thread_class.return_value = mock_thread
simple_worker.run()
assert isinstance(simple_worker.current_transcriber, WhisperFileTranscriber)
def test_run_speech_extraction_failure_emits_error(self, simple_worker, qapp):
task = self._make_task(extract_speech=True)
simple_worker.tasks_queue.put(task)
error_spy = unittest.mock.Mock()
simple_worker.task_error.connect(error_spy)
with unittest.mock.patch('buzz.file_transcriber_queue_worker.demucsApi.Separator',
side_effect=RuntimeError("No internet")):
simple_worker.run()
error_spy.assert_called_once()
args = error_spy.call_args[0]
assert args[0] == task
assert simple_worker.is_running is False
def test_transcription_with_whisper_cpp_tiny_no_speech_extraction(worker):
options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY),
extract_speech=False
)
task = FileTranscriptionTask(file_path=str(test_multibyte_utf8_audio_path), transcription_options=options,
file_transcription_options=FileTranscriptionOptions(), model_path="mock_path")
with unittest.mock.patch.object(WhisperFileTranscriber, 'run') as mock_run:
mock_run.side_effect = lambda: worker.current_transcriber.completed.emit([
{"start": 0, "end": 1000, "text": "Test transcription."}
])
completed_spy = unittest.mock.Mock()
worker.task_completed.connect(completed_spy)
worker.add_task(task)
# Wait for the signal to be emitted
timeout = 10 # seconds
start_time = time.time()
while not completed_spy.called and (time.time() - start_time) < timeout:
QCoreApplication.processEvents()
time.sleep(0.1)
completed_spy.assert_called_once()
args, kwargs = completed_spy.call_args
assert args[0] == task
assert len(args[1]) > 0
assert args[1][0]["text"] == "Test transcription."
def test_transcription_with_whisper_cpp_tiny_with_speech_extraction(worker):
options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY),
extract_speech=True
)
task = FileTranscriptionTask(file_path=str(test_multibyte_utf8_audio_path), transcription_options=options,
file_transcription_options=FileTranscriptionOptions(), model_path="mock_path")
with unittest.mock.patch('demucs.api.Separator') as mock_separator_class, \
unittest.mock.patch('demucs.api.save_audio') as mock_save_audio, \
unittest.mock.patch.object(WhisperFileTranscriber, 'run') as mock_run:
# Mock demucs.api.Separator and save_audio
mock_separator_instance = unittest.mock.Mock()
mock_separator_instance.separate_audio_file.return_value = (None, {"vocals": "mock_vocals_data"})
mock_separator_instance.samplerate = 44100
mock_separator_class.return_value = mock_separator_instance
mock_run.side_effect = lambda: worker.current_transcriber.completed.emit([
{"start": 0, "end": 1000, "text": "Test transcription with speech extraction."}
])
completed_spy = unittest.mock.Mock()
worker.task_completed.connect(completed_spy)
worker.add_task(task)
# Wait for the signal to be emitted
timeout = 10 # seconds
start_time = time.time()
while not completed_spy.called and (time.time() - start_time) < timeout:
QCoreApplication.processEvents()
time.sleep(0.1)
mock_separator_class.assert_called_once()
mock_save_audio.assert_called_once()
completed_spy.assert_called_once()
args, kwargs = completed_spy.call_args
assert args[0] == task
assert len(args[1]) > 0
assert args[1][0]["text"] == "Test transcription with speech extraction."
================================================
FILE: tests/transcriber/openai_whisper_api_file_transcriber_test.py
================================================
import os
from unittest.mock import patch, Mock
import pytest
from buzz.transcriber.openai_whisper_api_file_transcriber import (
OpenAIWhisperAPIFileTranscriber,
append_segment,
)
from buzz.transcriber.transcriber import (
FileTranscriptionTask,
TranscriptionOptions,
FileTranscriptionOptions,
Segment,
)
from openai.types.audio import Transcription, Translation
class TestAppendSegment:
def test_valid_utf8(self):
result = []
success = append_segment(result, b"Hello world", 100, 200)
assert success is True
assert len(result) == 1
assert result[0].start == 1000 # 100 centiseconds to ms
assert result[0].end == 2000 # 200 centiseconds to ms
assert result[0].text == "Hello world"
def test_empty_bytes(self):
result = []
success = append_segment(result, b"", 100, 200)
assert success is True
assert len(result) == 0
def test_invalid_utf8(self):
result = []
# Invalid UTF-8 sequence
success = append_segment(result, b"\xff\xfe", 100, 200)
assert success is False
assert len(result) == 0
def test_multibyte_utf8(self):
result = []
success = append_segment(result, "Привет".encode("utf-8"), 50, 150)
assert success is True
assert len(result) == 1
assert result[0].text == "Привет"
class TestGetValue:
def test_get_value_from_dict(self):
obj = {"key": "value", "number": 42}
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "key") == "value"
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "number") == 42
def test_get_value_from_object(self):
class TestObj:
key = "value"
number = 42
obj = TestObj()
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "key") == "value"
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "number") == 42
def test_get_value_missing_key_dict(self):
obj = {"key": "value"}
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing") is None
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing", "default") == "default"
def test_get_value_missing_attribute_object(self):
class TestObj:
key = "value"
obj = TestObj()
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing") is None
assert OpenAIWhisperAPIFileTranscriber.get_value(obj, "missing", "default") == "default"
class TestOpenAIWhisperAPIFileTranscriber:
@pytest.fixture
def mock_openai_client(self):
with patch(
"buzz.transcriber.openai_whisper_api_file_transcriber.OpenAI"
) as mock:
return_value = {
"text": "",
"segments": [{"start": 0, "end": 6.56, "text": "Hello"}],
}
mock.return_value.audio.transcriptions.create.return_value = Transcription(
**return_value
)
mock.return_value.audio.translations.create.return_value = Translation(
**return_value
)
yield mock
def test_transcribe(self, mock_openai_client):
file_path = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
"../../testdata/whisper-french.mp3",
)
transcriber = OpenAIWhisperAPIFileTranscriber(
task=FileTranscriptionTask(
file_path=file_path,
transcription_options=(
TranscriptionOptions(
openai_access_token=os.getenv("OPENAI_ACCESS_TOKEN"),
)
),
file_transcription_options=(
FileTranscriptionOptions(file_paths=[file_path])
),
model_path="",
)
)
mock_completed = Mock()
transcriber.completed.connect(mock_completed)
transcriber.run()
mock_openai_client.return_value.audio.transcriptions.create.assert_called()
called_segments = mock_completed.call_args[0][0]
assert len(called_segments) == 1
assert called_segments[0].start == 0
assert called_segments[0].end == 6560
assert called_segments[0].text == "Hello"
================================================
FILE: tests/transcriber/recording_transcriber_test.py
================================================
import os
import sys
import time
import numpy as np
from unittest.mock import Mock, patch, MagicMock
from PyQt6.QtCore import QThread
from buzz.locale import _
from buzz.assets import APP_BASE_DIR
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
from buzz.transcriber.recording_transcriber import RecordingTranscriber
from buzz.transcriber.transcriber import TranscriptionOptions, Task
from buzz.settings.recording_transcriber_mode import RecordingTranscriberMode
from tests.mock_sounddevice import MockSoundDevice
from tests.model_loader import get_model_path
class TestAmplitude:
def test_symmetric_array(self):
arr = np.array([1.0, -1.0, 2.0, -2.0])
amplitude = RecordingTranscriber.amplitude(arr)
# RMS: sqrt(mean([1, 1, 4, 4])) = sqrt(2.5) ≈ 1.5811
assert abs(amplitude - np.sqrt(2.5)) < 1e-6
def test_asymmetric_array(self):
arr = np.array([1.0, 2.0, 3.0, -1.0])
amplitude = RecordingTranscriber.amplitude(arr)
# RMS: sqrt(mean([1, 4, 9, 1])) = sqrt(3.75) ≈ 1.9365
assert abs(amplitude - np.sqrt(3.75)) < 1e-6
def test_all_zeros(self):
arr = np.array([0.0, 0.0, 0.0])
amplitude = RecordingTranscriber.amplitude(arr)
assert amplitude == 0.0
def test_all_positive(self):
arr = np.array([1.0, 2.0, 3.0, 4.0])
amplitude = RecordingTranscriber.amplitude(arr)
# RMS: sqrt(mean([1, 4, 9, 16])) = sqrt(7.5) ≈ 2.7386
assert abs(amplitude - np.sqrt(7.5)) < 1e-6
def test_all_negative(self):
arr = np.array([-1.0, -2.0, -3.0, -4.0])
amplitude = RecordingTranscriber.amplitude(arr)
# RMS is symmetric: same as all_positive
assert abs(amplitude - np.sqrt(7.5)) < 1e-6
def test_returns_float(self):
arr = np.array([0.5], dtype=np.float32)
amplitude = RecordingTranscriber.amplitude(arr)
assert isinstance(amplitude, float)
class TestGetDeviceSampleRate:
def test_returns_default_16khz_when_supported(self):
with patch("sounddevice.check_input_settings"):
rate = RecordingTranscriber.get_device_sample_rate(None)
assert rate == 16000
def test_falls_back_to_device_default(self):
import sounddevice
from sounddevice import PortAudioError
def raise_error(*args, **kwargs):
raise PortAudioError("Device doesn't support 16000")
device_info = {"default_samplerate": 44100}
with patch("sounddevice.check_input_settings", side_effect=raise_error), \
patch("sounddevice.query_devices", return_value=device_info):
rate = RecordingTranscriber.get_device_sample_rate(0)
assert rate == 44100
def test_returns_default_when_query_fails(self):
from sounddevice import PortAudioError
def raise_error(*args, **kwargs):
raise PortAudioError("Device doesn't support 16000")
with patch("sounddevice.check_input_settings", side_effect=raise_error), \
patch("sounddevice.query_devices", return_value=None):
rate = RecordingTranscriber.get_device_sample_rate(0)
assert rate == 16000
class TestRecordingTranscriber:
def test_should_transcribe(self, qtbot):
with (patch("sounddevice.check_input_settings")):
thread = QThread()
transcription_model = TranscriptionModel(
model_type=ModelType.WHISPER_CPP, whisper_model_size=WhisperModelSize.TINY
)
model_path = get_model_path(transcription_model)
model_exe_path = os.path.join(APP_BASE_DIR, "whisper_cpp", "whisper-server.exe")
if sys.platform.startswith("win"):
assert os.path.exists(model_exe_path), f"{model_exe_path} does not exist"
transcriber = RecordingTranscriber(
transcription_options=TranscriptionOptions(
model=transcription_model, language="fr", task=Task.TRANSCRIBE
),
input_device_index=0,
sample_rate=16_000,
model_path=model_path,
sounddevice=MockSoundDevice(),
)
transcriber.moveToThread(thread)
thread.started.connect(transcriber.start)
transcriptions = []
def on_transcription(text):
transcriptions.append(text)
transcriber.transcription.connect(on_transcription)
thread.start()
try:
qtbot.waitUntil(lambda: len(transcriptions) == 3, timeout=120_000)
# any string in any transcription
strings_to_check = [_("Starting Whisper.cpp..."), "Bienvenue dans Passe"]
assert any(s in t for s in strings_to_check for t in transcriptions)
finally:
# Ensure cleanup runs even if waitUntil times out
transcriber.stop_recording()
time.sleep(10)
thread.quit()
thread.wait()
# Ensure process is cleaned up
if transcriber.process and transcriber.process.poll() is None:
transcriber.process.terminate()
try:
transcriber.process.wait(timeout=2)
except:
pass
# Process pending events to ensure cleanup
from PyQt6.QtCore import QCoreApplication
QCoreApplication.processEvents()
time.sleep(0.1)
class TestRecordingTranscriberInit:
def test_init_default_mode(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
assert transcriber.transcription_options == transcription_options
assert transcriber.input_device_index == 0
assert transcriber.sample_rate == 16000
assert transcriber.model_path == "/fake/path"
assert transcriber.n_batch_samples == 5 * 16000
assert transcriber.keep_sample_seconds == 0.15
assert transcriber.is_running is False
assert transcriber.openai_client is None
def test_init_append_and_correct_mode(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"), \
patch("buzz.transcriber.recording_transcriber.Settings") as mock_settings_class:
# Mock settings to return APPEND_AND_CORRECT mode (index 2 in the enum)
mock_settings_instance = MagicMock()
mock_settings_class.return_value = mock_settings_instance
# Return 2 for APPEND_AND_CORRECT mode (it's the third item in the enum)
mock_settings_instance.value.return_value = 2
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# APPEND_AND_CORRECT mode should use smaller batch size and longer keep duration
assert transcriber.n_batch_samples == int(transcription_options.transcription_step * 16000)
assert transcriber.keep_sample_seconds == 1.5
def test_init_stores_silence_threshold(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
silence_threshold=0.01,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
assert transcriber.transcription_options.silence_threshold == 0.01
def test_init_uses_default_sample_rate_when_none(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=None,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# Should use default whisper sample rate
assert transcriber.sample_rate == 16000
class TestStreamCallback:
def test_stream_callback_adds_to_queue(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# Create test audio data
in_data = np.array([[0.1], [0.2], [0.3], [0.4]], dtype=np.float32)
initial_size = transcriber.queue.size
transcriber.stream_callback(in_data, 4, None, None)
# Queue should have grown by 4 samples
assert transcriber.queue.size == initial_size + 4
def test_stream_callback_emits_amplitude_changed(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# Mock the amplitude_changed signal
amplitude_values = []
transcriber.amplitude_changed.connect(lambda amp: amplitude_values.append(amp))
# Create test audio data
in_data = np.array([[0.1], [0.2], [0.3], [0.4]], dtype=np.float32)
transcriber.stream_callback(in_data, 4, None, None)
# Should have emitted one amplitude value
assert len(amplitude_values) == 1
assert amplitude_values[0] > 0
def test_stream_callback_drops_data_when_queue_full(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# Fill the queue beyond max_queue_size
transcriber.queue = np.ones(transcriber.max_queue_size, dtype=np.float32)
initial_size = transcriber.queue.size
# Try to add more data
in_data = np.array([[0.1], [0.2]], dtype=np.float32)
transcriber.stream_callback(in_data, 2, None, None)
# Queue should not have grown (data was dropped)
assert transcriber.queue.size == initial_size
class TestStopRecording:
def test_stop_recording_sets_is_running_false(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
transcriber.is_running = True
transcriber.stop_recording()
assert transcriber.is_running is False
def test_stop_recording_terminates_process(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# Mock a running process
mock_process = MagicMock()
mock_process.poll.return_value = None # Process is running
transcriber.process = mock_process
transcriber.stop_recording()
# Process should have been terminated and waited
mock_process.terminate.assert_called_once()
mock_process.wait.assert_called_once_with(timeout=5)
def test_stop_recording_skips_terminated_process(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"):
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
# Mock an already terminated process
mock_process = MagicMock()
mock_process.poll.return_value = 0 # Process already terminated
transcriber.process = mock_process
transcriber.stop_recording()
# terminate and wait should not be called
mock_process.terminate.assert_not_called()
mock_process.wait.assert_not_called()
class TestStartLocalWhisperServer:
def test_start_local_whisper_server_creates_openai_client(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"), \
patch("subprocess.Popen") as mock_popen, \
patch("time.sleep"):
# Mock a successful process
mock_process = MagicMock()
mock_process.poll.return_value = None # Process is running
mock_popen.return_value = mock_process
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
try:
transcriber.is_running = True
transcriber.start_local_whisper_server()
# Should have created an OpenAI client
assert transcriber.openai_client is not None
assert transcriber.process is not None
finally:
# Clean up to prevent QThread warnings
transcriber.is_running = False
transcriber.process = None
def test_start_local_whisper_server_with_language(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="fr",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"), \
patch("subprocess.Popen") as mock_popen, \
patch("time.sleep"):
mock_process = MagicMock()
mock_process.poll.return_value = None
mock_popen.return_value = mock_process
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
try:
transcriber.is_running = True
transcriber.start_local_whisper_server()
# Check that the language was passed to the command
call_args = mock_popen.call_args
cmd = call_args[0][0]
assert "--language" in cmd
assert "fr" in cmd
finally:
transcriber.is_running = False
transcriber.process = None
def test_start_local_whisper_server_auto_language(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language=None,
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"), \
patch("subprocess.Popen") as mock_popen, \
patch("time.sleep"):
mock_process = MagicMock()
mock_process.poll.return_value = None
mock_popen.return_value = mock_process
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
try:
transcriber.is_running = True
transcriber.start_local_whisper_server()
# Check that auto language was used
call_args = mock_popen.call_args
cmd = call_args[0][0]
assert "--language" in cmd
assert "auto" in cmd
finally:
transcriber.is_running = False
transcriber.process = None
def test_start_local_whisper_server_handles_failure(self):
transcription_options = TranscriptionOptions(
model=TranscriptionModel(model_type=ModelType.WHISPER_CPP),
language="en",
task=Task.TRANSCRIBE,
)
with patch("sounddevice.check_input_settings"), \
patch("subprocess.Popen") as mock_popen, \
patch("time.sleep"):
# Mock a failed process
mock_process = MagicMock()
mock_process.poll.return_value = 1 # Process terminated with error
mock_process.stderr.read.return_value = b"Error loading model"
mock_popen.return_value = mock_process
transcriber = RecordingTranscriber(
transcription_options=transcription_options,
input_device_index=0,
sample_rate=16000,
model_path="/fake/path",
sounddevice=MockSoundDevice(),
)
transcriptions = []
transcriber.transcription.connect(lambda text: transcriptions.append(text))
try:
transcriber.is_running = True
transcriber.start_local_whisper_server()
# Should not have created a client when server failed
assert transcriber.openai_client is None
# Should have emitted starting and error messages
assert len(transcriptions) >= 1
# First message should be about starting Whisper.cpp
assert "Whisper" in transcriptions[0]
finally:
transcriber.is_running = False
transcriber.process = None
================================================
FILE: tests/transcriber/transcriber_test.py
================================================
import pathlib
import pytest
from buzz.transcriber.file_transcriber import write_output, to_timestamp
from buzz.transcriber.transcriber import (
OutputFormat,
Segment,
)
class TestToTimestamp:
def test_to_timestamp(self):
assert to_timestamp(0) == "00:00:00.000"
assert to_timestamp(123456789) == "34:17:36.789"
@pytest.mark.parametrize(
"output_format,output_text",
[
(OutputFormat.TXT, "Bien venue dans "),
(
OutputFormat.SRT,
"1\n00:00:00,040 --> 00:00:00,299\nBien\n\n2\n00:00:00,299 --> 00:00:00,329\nvenue dans\n\n",
),
(
OutputFormat.VTT,
"WEBVTT\n\n00:00:00.040 --> 00:00:00.299\nBien\n\n00:00:00.299 --> 00:00:00.329\nvenue dans\n\n",
),
],
)
def test_write_output(
tmp_path: pathlib.Path, output_format: OutputFormat, output_text: str
):
output_file_path = tmp_path / "whisper.txt"
segments = [Segment(40, 299, "Bien"), Segment(299, 329, "venue dans")]
write_output(
path=str(output_file_path), segments=segments, output_format=output_format
)
with open(output_file_path, encoding="utf-8") as output_file:
assert output_text == output_file.read()
================================================
FILE: tests/transcriber/transformers_whisper_test.py
================================================
import os
import sys
import platform
from unittest.mock import patch
import pytest
from buzz.transformers_whisper import TransformersTranscriber, is_intel_mac, is_peft_model
class TestIsIntelMac:
@pytest.mark.parametrize(
"sys_platform,machine,expected",
[
("linux", "x86_64", False),
("win32", "x86_64", False),
("darwin", "arm64", False),
("darwin", "x86_64", True),
("darwin", "i386", False),
],
)
def test_is_intel_mac(self, sys_platform, machine, expected):
with patch("buzz.transformers_whisper.sys.platform", sys_platform), \
patch("buzz.transformers_whisper.platform.machine", return_value=machine):
assert is_intel_mac() == expected
class TestIsPeftModel:
@pytest.mark.parametrize(
"model_id,expected",
[
("openai/whisper-tiny-peft", True),
("user/model-PEFT", True),
("openai/whisper-tiny", False),
("facebook/mms-1b-all", False),
("", False),
],
)
def test_peft_detection(self, model_id, expected):
assert is_peft_model(model_id) == expected
class TestGetPeftRepoId:
def test_repo_id_returned_as_is(self):
transcriber = TransformersTranscriber("user/whisper-tiny-peft")
with patch("os.path.exists", return_value=False):
assert transcriber._get_peft_repo_id() == "user/whisper-tiny-peft"
def test_linux_cache_path(self):
linux_path = "/home/user/.cache/Buzz/models/models--user--whisper-peft/snapshots/abc123"
transcriber = TransformersTranscriber(linux_path)
with patch("os.path.exists", return_value=True), \
patch("buzz.transformers_whisper.os.sep", "/"):
assert transcriber._get_peft_repo_id() == "user/whisper-peft"
def test_windows_cache_path(self):
windows_path = r"C:\Users\user\.cache\Buzz\models\models--user--whisper-peft\snapshots\abc123"
transcriber = TransformersTranscriber(windows_path)
with patch("os.path.exists", return_value=True), \
patch("buzz.transformers_whisper.os.sep", "\\"):
assert transcriber._get_peft_repo_id() == "user/whisper-peft"
def test_fallback_returns_model_id(self):
transcriber = TransformersTranscriber("some-local-model")
with patch("os.path.exists", return_value=True):
assert transcriber._get_peft_repo_id() == "some-local-model"
class TestGetMmsRepoId:
"""Tests for TransformersTranscriber._get_mms_repo_id method."""
def test_repo_id_returned_as_is(self):
"""Test that a HuggingFace repo ID is returned unchanged."""
transcriber = TransformersTranscriber("facebook/mms-1b-all")
with patch("os.path.exists", return_value=False):
assert transcriber._get_mms_repo_id() == "facebook/mms-1b-all"
def test_linux_cache_path(self):
"""Test extraction from Linux-style cache path."""
linux_path = "/home/user/.cache/Buzz/models/models--facebook--mms-1b-all/snapshots/abc123"
transcriber = TransformersTranscriber(linux_path)
with patch("os.path.exists", return_value=True), \
patch("buzz.transformers_whisper.os.sep", "/"):
assert transcriber._get_mms_repo_id() == "facebook/mms-1b-all"
def test_windows_cache_path(self):
"""Test extraction from Windows-style cache path."""
windows_path = r"C:\Users\user\.cache\Buzz\models\models--facebook--mms-1b-all\snapshots\abc123"
transcriber = TransformersTranscriber(windows_path)
with patch("os.path.exists", return_value=True), \
patch("buzz.transformers_whisper.os.sep", "\\"):
assert transcriber._get_mms_repo_id() == "facebook/mms-1b-all"
def test_fallback_returns_model_id(self):
"""Test that model_id is returned as fallback when pattern not matched."""
transcriber = TransformersTranscriber("some-local-model")
with patch("os.path.exists", return_value=True):
assert transcriber._get_mms_repo_id() == "some-local-model"
def test_nested_org_name(self):
"""Test extraction with different org/model names."""
linux_path = "/home/user/.cache/Buzz/models/models--openai--whisper-large-v3/snapshots/xyz"
transcriber = TransformersTranscriber(linux_path)
with patch("os.path.exists", return_value=True), \
patch("buzz.transformers_whisper.os.sep", "/"):
assert transcriber._get_mms_repo_id() == "openai/whisper-large-v3"
================================================
FILE: tests/transcriber/whisper_cpp_test.py
================================================
from unittest.mock import patch, MagicMock, mock_open
import json
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
from buzz.transcriber.transcriber import (
TranscriptionOptions,
Task,
FileTranscriptionTask,
FileTranscriptionOptions,
)
from buzz.transcriber.whisper_cpp import WhisperCpp
from tests.audio import test_audio_path, test_multibyte_utf8_audio_path
from tests.model_loader import get_model_path
class TestWhisperCpp:
def test_transcribe(self):
transcription_options = TranscriptionOptions(
language="fr",
task=Task.TRANSCRIBE,
word_level_timings=False,
model=TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
),
)
model_path = get_model_path(transcription_options.model)
task = FileTranscriptionTask(
transcription_options=transcription_options,
file_transcription_options=FileTranscriptionOptions(),
model_path=model_path,
file_path=test_audio_path,
)
segments = WhisperCpp.transcribe(task=task)
# Combine all segment texts
full_text = " ".join(segment.text for segment in segments)
assert "Bien venu" in full_text or "bienvenu" in full_text.lower()
def test_transcribe_word_level_timestamps(self):
transcription_options = TranscriptionOptions(
language="lv",
task=Task.TRANSCRIBE,
word_level_timings=True,
model=TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
),
)
model_path = get_model_path(transcription_options.model)
task = FileTranscriptionTask(
transcription_options=transcription_options,
file_transcription_options=FileTranscriptionOptions(),
model_path=model_path,
file_path=test_multibyte_utf8_audio_path,
)
segments = WhisperCpp.transcribe(task=task)
assert "Mani" in segments[0].text
assert "uzstrau" or "ustrau" in segments[1].text
assert "laikabstāk" in segments[2].text
def test_transcribe_chinese_multibyte_word_level_timestamps(self):
"""Test that Chinese characters split across multiple tokens are properly combined.
Chinese character 闻 (U+95FB) is encoded as UTF-8 bytes E9 97 BB.
Whisper.cpp may split this into separate tokens, e.g.:
- Token 1: bytes E9 97 (incomplete)
- Token 2: byte BB (completes the character)
The code should combine these bytes and output 闻 as a single segment.
"""
# Mock JSON data simulating whisper.cpp output with split Chinese characters
# The character 闻 is split into two tokens: \xe9\x97 and \xbb
# The character 新 is a complete token
# Together they form 新闻 (news)
mock_json_data = {
"transcription": [
{
"offsets": {"from": 0, "to": 5000},
"text": "", # Not used in word-level processing
"tokens": [
{
"text": "[_BEG_]",
"offsets": {"from": 0, "to": 0},
},
{
# 新 - complete character (UTF-8: E6 96 B0)
# When read as latin-1: \xe6\x96\xb0
"text": "\xe6\x96\xb0",
"offsets": {"from": 100, "to": 200},
},
{
# First two bytes of 闻 (UTF-8: E9 97 BB)
# When read as latin-1: \xe9\x97
"text": "\xe9\x97",
"offsets": {"from": 200, "to": 300},
},
{
# Last byte of 闻
# When read as latin-1: \xbb
"text": "\xbb",
"offsets": {"from": 300, "to": 400},
},
{
"text": "[_TT_500]",
"offsets": {"from": 500, "to": 500},
},
],
}
]
}
# Convert to JSON string using latin-1 compatible encoding
# We write bytes directly since the real file is read with latin-1
json_bytes = json.dumps(mock_json_data, ensure_ascii=False).encode("latin-1")
transcription_options = TranscriptionOptions(
language="zh",
task=Task.TRANSCRIBE,
word_level_timings=True,
model=TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
),
)
task = FileTranscriptionTask(
transcription_options=transcription_options,
file_transcription_options=FileTranscriptionOptions(),
model_path="/fake/model/path",
file_path="/fake/audio.wav",
)
# Mock subprocess.Popen to simulate whisper-cli execution
mock_process = MagicMock()
mock_process.stderr.readline.side_effect = [""]
mock_process.wait.return_value = None
mock_process.returncode = 0
with patch("buzz.transcriber.whisper_cpp.subprocess.Popen", return_value=mock_process):
with patch("buzz.transcriber.whisper_cpp.os.path.exists", return_value=True):
with patch("builtins.open", mock_open(read_data=json_bytes.decode("latin-1"))):
segments = WhisperCpp.transcribe(task=task)
# Should have 2 segments: 新 and 闻 (each character separate)
assert len(segments) == 2
assert segments[0].text == "新"
assert segments[1].text == "闻"
# Verify timestamps
assert segments[0].start == 100
assert segments[0].end == 200
# 闻 spans from token at 200 to token ending at 400
assert segments[1].start == 200
assert segments[1].end == 400
def test_transcribe_chinese_mixed_complete_and_split_chars(self):
"""Test a mix of complete and split Chinese characters."""
# 大家好 - "Hello everyone"
# 大 (E5 A4 A7) - complete token
# 家 (E5 AE B6) - split into E5 AE and B6
# 好 (E5 A5 BD) - complete token
mock_json_data = {
"transcription": [
{
"offsets": {"from": 0, "to": 5000},
"text": "", # Not used in word-level processing
"tokens": [
{
"text": "[_BEG_]",
"offsets": {"from": 0, "to": 0},
},
{
# 大 - complete
"text": "\xe5\xa4\xa7",
"offsets": {"from": 100, "to": 200},
},
{
# First two bytes of 家
"text": "\xe5\xae",
"offsets": {"from": 200, "to": 250},
},
{
# Last byte of 家
"text": "\xb6",
"offsets": {"from": 250, "to": 300},
},
{
# 好 - complete
"text": "\xe5\xa5\xbd",
"offsets": {"from": 300, "to": 400},
},
],
}
]
}
json_bytes = json.dumps(mock_json_data, ensure_ascii=False).encode("latin-1")
transcription_options = TranscriptionOptions(
language="zh",
task=Task.TRANSCRIBE,
word_level_timings=True,
model=TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
),
)
task = FileTranscriptionTask(
transcription_options=transcription_options,
file_transcription_options=FileTranscriptionOptions(),
model_path="/fake/model/path",
file_path="/fake/audio.wav",
)
mock_process = MagicMock()
mock_process.stderr.readline.side_effect = [""]
mock_process.wait.return_value = None
mock_process.returncode = 0
with patch("buzz.transcriber.whisper_cpp.subprocess.Popen", return_value=mock_process):
with patch("buzz.transcriber.whisper_cpp.os.path.exists", return_value=True):
with patch("builtins.open", mock_open(read_data=json_bytes.decode("latin-1"))):
segments = WhisperCpp.transcribe(task=task)
# Should have 3 segments: 大, 家, 好
assert len(segments) == 3
assert segments[0].text == "大"
assert segments[1].text == "家"
assert segments[2].text == "好"
# Combined text
full_text = "".join(s.text for s in segments)
assert full_text == "大家好"
================================================
FILE: tests/transcriber/whisper_file_transcriber_test.py
================================================
import glob
import logging
import os
import platform
import shutil
import tempfile
import time
from typing import List
from unittest.mock import Mock
import pytest
from pytestqt.qtbot import QtBot
from buzz.model_loader import TranscriptionModel, ModelType, WhisperModelSize
from buzz.transcriber.transcriber import (
OutputFormat,
get_output_file_path,
FileTranscriptionTask,
TranscriptionOptions,
Task,
FileTranscriptionOptions,
Segment,
)
from buzz.transcriber.whisper_file_transcriber import (
WhisperFileTranscriber,
check_file_has_audio_stream,
PROGRESS_REGEX,
)
from tests.audio import test_audio_path
from tests.model_loader import get_model_path
class TestCheckFileHasAudioStream:
def test_valid_audio_file(self):
# Should not raise exception for valid audio file
check_file_has_audio_stream(test_audio_path)
def test_missing_file(self):
with pytest.raises(ValueError, match="File not found"):
check_file_has_audio_stream("/nonexistent/path/to/file.mp3")
def test_invalid_media_file(self):
# Create a temporary text file (not a valid media file)
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix=".mp3")
try:
temp_file.write(b"This is not a valid media file")
temp_file.close()
with pytest.raises(ValueError, match="Invalid media file"):
check_file_has_audio_stream(temp_file.name)
finally:
os.unlink(temp_file.name)
class TestProgressRegex:
def test_integer_percentage(self):
match = PROGRESS_REGEX.search("Progress: 50%")
assert match is not None
assert match.group() == "50%"
def test_decimal_percentage(self):
match = PROGRESS_REGEX.search("Progress: 75.5%")
assert match is not None
assert match.group() == "75.5%"
def test_no_match(self):
match = PROGRESS_REGEX.search("No percentage here")
assert match is None
def test_extract_percentage_value(self):
line = "Transcription progress: 85%"
match = PROGRESS_REGEX.search(line)
assert match is not None
percentage = int(match.group().strip("%"))
assert percentage == 85
class TestWhisperFileTranscriber:
@pytest.mark.parametrize(
"file_path,output_format,expected_file_path",
[
pytest.param(
"/a/b/c.mp4",
OutputFormat.SRT,
"/a/b/c-translate--Whisper-tiny.srt",
marks=pytest.mark.skipif(platform.system() == "Windows", reason=""),
),
pytest.param(
"C:\\a\\b\\c.mp4",
OutputFormat.SRT,
"C:\\a\\b\\c-translate--Whisper-tiny.srt",
marks=pytest.mark.skipif(platform.system() != "Windows", reason=""),
),
],
)
def test_default_output_file(
self,
file_path: str,
output_format: OutputFormat,
expected_file_path: str,
):
file_path = get_output_file_path(
file_path=file_path,
language=None,
task=Task.TRANSLATE,
model=TranscriptionModel(
model_type=ModelType.WHISPER,
whisper_model_size=WhisperModelSize.TINY,
),
output_format=output_format,
output_directory="",
export_file_name_template="{{ input_file_name }}-{{ task }}-{{ language }}-{{ model_type }}-{{ model_size }}",
)
assert file_path == expected_file_path
@pytest.mark.parametrize(
"file_path,expected_starts_with",
[
pytest.param(
"/a/b/c.mp4",
"/a/b/c (Translated on ",
marks=pytest.mark.skipif(platform.system() == "Windows", reason=""),
),
pytest.param(
"C:\\a\\b\\c.mp4",
"C:\\a\\b\\c (Translated on ",
marks=pytest.mark.skipif(platform.system() != "Windows", reason=""),
),
],
)
def test_default_output_file_with_date(
self, file_path: str, expected_starts_with: str
):
export_file_name_template = (
"{{ input_file_name }} (Translated on {{ date_time }})"
)
srt = get_output_file_path(
file_path=file_path,
language=None,
task=Task.TRANSLATE,
model=TranscriptionModel(
model_type=ModelType.WHISPER,
whisper_model_size=WhisperModelSize.TINY,
),
output_format=OutputFormat.TXT,
output_directory="",
export_file_name_template=export_file_name_template,
)
assert srt.startswith(expected_starts_with)
assert srt.endswith(".txt")
srt = get_output_file_path(
file_path=file_path,
language=None,
task=Task.TRANSLATE,
model=TranscriptionModel(
model_type=ModelType.WHISPER,
whisper_model_size=WhisperModelSize.TINY,
),
output_format=OutputFormat.SRT,
output_directory="",
export_file_name_template=export_file_name_template,
)
assert srt.startswith(expected_starts_with)
assert srt.endswith(".srt")
@pytest.mark.parametrize(
"word_level_timings,extract_speech,expected_segments,model",
[
(
False,
False,
[
Segment(
0,
8400,
" Bienvenue dans Passe-Relle. Un podcast pensé pour évêiller",
)
],
TranscriptionModel(
model_type=ModelType.WHISPER,
whisper_model_size=WhisperModelSize.TINY,
),
),
(
True,
True,
[Segment(40, 299, " Bien"), Segment(299, 329, "venue dans")],
TranscriptionModel(
model_type=ModelType.WHISPER,
whisper_model_size=WhisperModelSize.TINY,
),
),
(
False,
False,
[
Segment(
0,
8517,
" Bienvenue dans Passe-Relle. Un podcast pensé pour évêyer la curiosité des apprenances "
"et des apprenances de français.",
)
],
TranscriptionModel(
model_type=ModelType.HUGGING_FACE,
hugging_face_model_id="openai/whisper-tiny",
),
),
pytest.param(
False,
False,
[
Segment(
start=0,
end=8400,
text=" Bienvenue dans Passrel, un podcast pensé pour éveiller la curiosité des apprenances et des apprenances de français.",
)
],
TranscriptionModel(
model_type=ModelType.FASTER_WHISPER,
whisper_model_size=WhisperModelSize.TINY,
),
marks=pytest.mark.skipif(
platform.system() == "Darwin" and platform.machine() == "x86_64",
reason="Error with libiomp5 already initialized on GH action runner: https://github.com/chidiwilliams/buzz/actions/runs/4657331262/jobs/8241832087",
),
),
],
)
def test_transcribe_from_file(
self,
qtbot: QtBot,
word_level_timings: bool,
extract_speech: bool,
expected_segments: List[Segment],
model: TranscriptionModel,
):
mock_progress = Mock()
mock_completed = Mock()
transcription_options = TranscriptionOptions(
language="fr",
task=Task.TRANSCRIBE,
word_level_timings=word_level_timings,
extract_speech=extract_speech,
model=model,
)
model_path = get_model_path(transcription_options.model)
file_path = os.path.abspath(test_audio_path)
file_transcription_options = FileTranscriptionOptions(file_paths=[file_path])
transcriber = WhisperFileTranscriber(
task=FileTranscriptionTask(
transcription_options=transcription_options,
file_transcription_options=file_transcription_options,
file_path=file_path,
model_path=model_path,
)
)
transcriber.progress.connect(mock_progress)
transcriber.completed.connect(mock_completed)
with qtbot.wait_signal(
transcriber.progress, timeout=10 * 6000
), qtbot.wait_signal(transcriber.completed, timeout=10 * 6000):
transcriber.run()
# Reports progress at 0, 0 <= progress <= 100, and 100
assert mock_progress.call_count >= 2
assert mock_progress.call_args_list[0][0][0] == (0, 100)
mock_completed.assert_called()
segments = mock_completed.call_args[0][0]
assert len(segments) >= 0
for i, expected_segment in enumerate(segments):
assert segments[i].start >= 0
assert segments[i].end > 0
assert len(segments[i].text) > 0
logging.debug(f"{segments[i].start} {segments[i].end} {segments[i].text}")
transcriber.stop()
time.sleep(3)
def test_transcribe_from_url(self, qtbot):
url = (
"https://github.com/chidiwilliams/buzz/raw/main/testdata/whisper-french.mp3"
)
mock_progress = Mock()
mock_completed = Mock()
transcription_options = TranscriptionOptions()
model_path = get_model_path(transcription_options.model)
file_transcription_options = FileTranscriptionOptions(url=url)
transcriber = WhisperFileTranscriber(
task=FileTranscriptionTask(
transcription_options=transcription_options,
file_transcription_options=file_transcription_options,
model_path=model_path,
url=url,
source=FileTranscriptionTask.Source.URL_IMPORT,
)
)
transcriber.progress.connect(mock_progress)
transcriber.completed.connect(mock_completed)
with qtbot.wait_signal(
transcriber.progress, timeout=10 * 6000
), qtbot.wait_signal(transcriber.completed, timeout=10 * 6000):
transcriber.run()
# Reports progress at 0, 0 <= progress <= 100, and 100
assert mock_progress.call_count >= 2
assert mock_progress.call_args_list[0][0][0] == (0, 100)
mock_completed.assert_called()
segments = mock_completed.call_args[0][0]
assert len(segments) >= 0
for i, expected_segment in enumerate(segments):
assert segments[i].start >= 0
assert segments[i].end > 0
assert len(segments[i].text) > 0
logging.debug(f"{segments[i].start} {segments[i].end} {segments[i].text}")
transcriber.stop()
time.sleep(3)
def test_transcribe_from_folder_watch_source(self, qtbot):
file_path = tempfile.mktemp(suffix=".mp3")
shutil.copy(test_audio_path, file_path)
file_transcription_options = FileTranscriptionOptions(
file_paths=[file_path],
output_formats={OutputFormat.TXT},
)
transcription_options = TranscriptionOptions()
model_path = get_model_path(transcription_options.model)
output_directory = tempfile.mkdtemp()
transcriber = WhisperFileTranscriber(
task=FileTranscriptionTask(
model_path=model_path,
transcription_options=transcription_options,
file_transcription_options=file_transcription_options,
file_path=file_path,
output_directory=output_directory,
source=FileTranscriptionTask.Source.FOLDER_WATCH,
)
)
with qtbot.wait_signal(transcriber.completed, timeout=10 * 6000):
transcriber.run()
assert not os.path.isfile(file_path)
assert os.path.isfile(
os.path.join(output_directory, os.path.basename(file_path))
)
assert len(glob.glob("*.txt", root_dir=output_directory)) > 0
transcriber.stop()
time.sleep(3)
def test_transcribe_from_folder_watch_source_deletes_file(self, qtbot):
file_path = tempfile.mktemp(suffix=".mp3")
shutil.copy(test_audio_path, file_path)
file_transcription_options = FileTranscriptionOptions(
file_paths=[file_path],
output_formats={OutputFormat.TXT},
)
transcription_options = TranscriptionOptions()
model_path = get_model_path(transcription_options.model)
output_directory = tempfile.mkdtemp()
transcriber = WhisperFileTranscriber(
task=FileTranscriptionTask(
model_path=model_path,
transcription_options=transcription_options,
file_transcription_options=file_transcription_options,
file_path=file_path,
original_file_path=file_path,
output_directory=output_directory,
source=FileTranscriptionTask.Source.FOLDER_WATCH,
delete_source_file=True,
)
)
with qtbot.wait_signal(transcriber.completed, timeout=10 * 6000):
transcriber.run()
assert not os.path.isfile(file_path)
assert not os.path.isfile(
os.path.join(output_directory, os.path.basename(file_path))
)
assert len(glob.glob("*.txt", root_dir=output_directory)) > 0
transcriber.stop()
time.sleep(3)
@pytest.mark.skip()
def test_transcribe_stop(self):
output_file_path = os.path.join(tempfile.gettempdir(), "whisper.txt")
if os.path.exists(output_file_path):
os.remove(output_file_path)
file_transcription_options = FileTranscriptionOptions(
file_paths=[test_audio_path]
)
transcription_options = TranscriptionOptions(
language="fr",
task=Task.TRANSCRIBE,
word_level_timings=False,
model=TranscriptionModel(
model_type=ModelType.WHISPER_CPP,
whisper_model_size=WhisperModelSize.TINY,
),
)
model_path = get_model_path(transcription_options.model)
transcriber = WhisperFileTranscriber(
task=FileTranscriptionTask(
model_path=model_path,
transcription_options=transcription_options,
file_transcription_options=file_transcription_options,
file_path=test_audio_path,
)
)
transcriber.run()
time.sleep(1)
transcriber.stop()
# Assert that file was not created
assert os.path.isfile(output_file_path) is False
time.sleep(3)
================================================
FILE: tests/transformers_transcriber_test.py
================================================
import platform
import pytest
from buzz.transformers_whisper import TransformersTranscriber
from tests.audio import test_audio_path
class TestTransformersTranscriber:
@pytest.mark.skipif(
platform.system() == "Darwin",
reason="Not supported on Darwin",
)
def test_should_transcribe(self):
model = TransformersTranscriber("openai/whisper-tiny")
result = model.transcribe(
audio=test_audio_path, language="fr", task="transcribe"
)
assert "Bienvenue dans Passrel" in result["text"]
================================================
FILE: tests/translator_test.py
================================================
import time
import pytest
from queue import Empty
from unittest.mock import Mock, patch, create_autospec
from PyQt6.QtCore import QThread
from buzz.translator import Translator
from buzz.transcriber.transcriber import TranscriptionOptions
from buzz.widgets.transcriber.advanced_settings_dialog import AdvancedSettingsDialog
from buzz.locale import _
class TestParseBatchResponse:
def test_simple_batch(self):
response = "[1] Hello\n[2] World"
result = Translator._parse_batch_response(response, 2)
assert len(result) == 2
assert result[0] == "Hello"
assert result[1] == "World"
def test_missing_entries_fallback(self):
response = "[1] Hello\n[3] World"
result = Translator._parse_batch_response(response, 3)
assert len(result) == 3
assert result[0] == "Hello"
assert result[1] == ""
assert result[2] == "World"
def test_multiline_entries(self):
response = "[1] This is a long\nmultiline translation\n[2] Short"
result = Translator._parse_batch_response(response, 2)
assert len(result) == 2
assert "multiline" in result[0]
assert result[1] == "Short"
def test_single_item_batch(self):
response = "[1] Single translation"
result = Translator._parse_batch_response(response, 1)
assert len(result) == 1
assert result[0] == "Single translation"
def test_empty_response(self):
response = ""
result = Translator._parse_batch_response(response, 2)
assert len(result) == 2
assert result[0] == ""
assert result[1] == ""
def test_whitespace_handling(self):
response = "[1] Hello with spaces \n[2] World "
result = Translator._parse_batch_response(response, 2)
assert result[0] == "Hello with spaces"
assert result[1] == "World"
def test_out_of_order_entries(self):
response = "[2] Second\n[1] First"
result = Translator._parse_batch_response(response, 2)
assert result[0] == "First"
assert result[1] == "Second"
class TestTranslator:
@patch('buzz.translator.OpenAI', autospec=True)
@patch('buzz.translator.queue.Queue', autospec=True)
def test_start(self, mock_queue, mock_openai, qtbot):
def side_effect(*args, **kwargs):
if side_effect.call_count <= 1:
side_effect.call_count += 1
return ("Hello, how are you?", 1)
# Finally return sentinel to stop
return None
side_effect.call_count = 0
mock_queue.get.side_effect = side_effect
mock_queue.get_nowait.side_effect = Empty
mock_chat = Mock()
mock_openai.return_value.chat = mock_chat
mock_chat.completions.create.return_value = Mock(
choices=[Mock(message=Mock(content="AI Translated: Hello, how are you?"))]
)
transcription_options = TranscriptionOptions(
enable_llm_translation=False,
llm_model="llama3",
llm_prompt="Please translate this text:",
)
translator = Translator(
transcription_options,
AdvancedSettingsDialog(
transcription_options=transcription_options, parent=None
)
)
translator.queue = mock_queue
translator.start()
mock_queue.get.assert_called()
mock_chat.completions.create.assert_called()
translator.stop()
@patch('buzz.translator.OpenAI', autospec=True)
def test_translator(self, mock_openai, qtbot):
self.on_next_translation_called = False
def on_next_translation(text: str):
self.on_next_translation_called = True
assert text.startswith("AI Translated:")
mock_chat = Mock()
mock_openai.return_value.chat = mock_chat
mock_chat.completions.create.return_value = Mock(
choices=[Mock(message=Mock(content="AI Translated: Hello, how are you?"))]
)
self.translation_thread = QThread()
self.transcription_options = TranscriptionOptions(
enable_llm_translation=False,
llm_model="llama3",
llm_prompt="Please translate this text:",
)
self.translator = Translator(
self.transcription_options,
AdvancedSettingsDialog(
transcription_options=self.transcription_options, parent=None
)
)
self.translator.moveToThread(self.translation_thread)
self.translation_thread.started.connect(self.translator.start)
self.translation_thread.finished.connect(
self.translation_thread.deleteLater
)
self.translator.finished.connect(self.translation_thread.quit)
self.translator.finished.connect(self.translator.deleteLater)
self.translator.translation.connect(on_next_translation)
self.translation_thread.start()
time.sleep(1) # Give thread time to start
self.translator.enqueue("Hello, how are you?")
def translation_signal_received():
assert self.on_next_translation_called
qtbot.wait_until(translation_signal_received, timeout=60 * 1000)
if self.translator is not None:
self.translator.stop()
if self.translation_thread is not None:
self.translation_thread.quit()
# Wait for the thread to actually finish before cleanup
self.translation_thread.wait()
# Process pending events to ensure deleteLater() is handled
from PyQt6.QtCore import QCoreApplication
QCoreApplication.processEvents()
time.sleep(0.1) # Give time for cleanup
# Note: translator and translation_thread will be automatically deleted
# via the deleteLater() connections set up earlier
================================================
FILE: tests/update_checker_test.py
================================================
import platform
from datetime import datetime, timedelta
from unittest.mock import patch
import pytest
from pytestqt.qtbot import QtBot
from buzz.__version__ import VERSION
from buzz.settings.settings import Settings
from buzz.update_checker import UpdateChecker, UpdateInfo
from tests.mock_qt import MockNetworkAccessManager, MockNetworkReply
VERSION_INFO = {
"version": "99.0.0",
"release_notes": "Some fixes.",
"download_urls": {
"windows_x64": ["https://example.com/Buzz-99.0.0.exe"],
"macos_arm": ["https://example.com/Buzz-99.0.0-arm.dmg"],
"macos_x86": ["https://example.com/Buzz-99.0.0-x86.dmg"],
},
}
@pytest.fixture()
def checker(settings: Settings) -> UpdateChecker:
reply = MockNetworkReply(data=VERSION_INFO)
manager = MockNetworkAccessManager(reply=reply)
return UpdateChecker(settings=settings, network_manager=manager)
class TestShouldCheckForUpdates:
def test_returns_false_on_linux(self, checker: UpdateChecker):
with patch.object(platform, "system", return_value="Linux"):
assert checker.should_check_for_updates() is False
def test_returns_true_on_windows_first_run(self, checker: UpdateChecker, settings: Settings):
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "")
with patch.object(platform, "system", return_value="Windows"):
assert checker.should_check_for_updates() is True
def test_returns_true_on_macos_first_run(self, checker: UpdateChecker, settings: Settings):
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "")
with patch.object(platform, "system", return_value="Darwin"):
assert checker.should_check_for_updates() is True
def test_returns_false_when_checked_recently(
self, checker: UpdateChecker, settings: Settings
):
recent = (datetime.now() - timedelta(days=2)).isoformat()
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, recent)
with patch.object(platform, "system", return_value="Windows"):
assert checker.should_check_for_updates() is False
def test_returns_true_when_check_is_overdue(
self, checker: UpdateChecker, settings: Settings
):
old = (datetime.now() - timedelta(days=10)).isoformat()
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, old)
with patch.object(platform, "system", return_value="Windows"):
assert checker.should_check_for_updates() is True
def test_returns_true_on_invalid_date_in_settings(
self, checker: UpdateChecker, settings: Settings
):
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "not-a-date")
with patch.object(platform, "system", return_value="Windows"):
assert checker.should_check_for_updates() is True
class TestIsNewerVersion:
def test_newer_major(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "1.0.0"):
assert checker._is_newer_version("2.0.0") is True
def test_newer_minor(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "1.0.0"):
assert checker._is_newer_version("1.1.0") is True
def test_newer_patch(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "1.0.0"):
assert checker._is_newer_version("1.0.1") is True
def test_same_version(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "1.0.0"):
assert checker._is_newer_version("1.0.0") is False
def test_older_version(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "2.0.0"):
assert checker._is_newer_version("1.9.9") is False
def test_different_segment_count(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "1.0"):
assert checker._is_newer_version("1.0.1") is True
def test_invalid_version_returns_false(self, checker: UpdateChecker):
with patch("buzz.update_checker.VERSION", "1.0.0"):
assert checker._is_newer_version("not-a-version") is False
class TestGetDownloadUrl:
def test_windows_returns_windows_urls(self, checker: UpdateChecker):
with patch.object(platform, "system", return_value="Windows"):
urls = checker._get_download_url(VERSION_INFO["download_urls"])
assert urls == ["https://example.com/Buzz-99.0.0.exe"]
def test_macos_arm_returns_arm_urls(self, checker: UpdateChecker):
with patch.object(platform, "system", return_value="Darwin"), \
patch.object(platform, "machine", return_value="arm64"):
urls = checker._get_download_url(VERSION_INFO["download_urls"])
assert urls == ["https://example.com/Buzz-99.0.0-arm.dmg"]
def test_macos_x86_returns_x86_urls(self, checker: UpdateChecker):
with patch.object(platform, "system", return_value="Darwin"), \
patch.object(platform, "machine", return_value="x86_64"):
urls = checker._get_download_url(VERSION_INFO["download_urls"])
assert urls == ["https://example.com/Buzz-99.0.0-x86.dmg"]
def test_linux_returns_empty(self, checker: UpdateChecker):
with patch.object(platform, "system", return_value="Linux"):
urls = checker._get_download_url(VERSION_INFO["download_urls"])
assert urls == []
def test_wraps_plain_string_in_list(self, checker: UpdateChecker):
with patch.object(platform, "system", return_value="Windows"):
urls = checker._get_download_url({"windows_x64": "https://example.com/a.exe"})
assert urls == ["https://example.com/a.exe"]
class TestCheckForUpdates:
def _make_checker(self, settings: Settings, version_data: dict) -> UpdateChecker:
settings.set_value(Settings.Key.LAST_UPDATE_CHECK, "")
reply = MockNetworkReply(data=version_data)
manager = MockNetworkAccessManager(reply=reply)
return UpdateChecker(settings=settings, network_manager=manager)
def test_emits_update_available_when_newer_version(self, settings: Settings):
received = []
checker = self._make_checker(settings, VERSION_INFO)
checker.update_available.connect(lambda info: received.append(info))
with patch.object(platform, "system", return_value="Windows"), \
patch.object(platform, "machine", return_value="x86_64"), \
patch("buzz.update_checker.VERSION", "1.0.0"):
checker.check_for_updates()
assert len(received) == 1
update_info: UpdateInfo = received[0]
assert update_info.version == "99.0.0"
assert update_info.release_notes == "Some fixes."
assert update_info.download_urls == ["https://example.com/Buzz-99.0.0.exe"]
def test_does_not_emit_when_version_is_current(self, settings: Settings):
received = []
checker = self._make_checker(settings, {**VERSION_INFO, "version": VERSION})
checker.update_available.connect(lambda info: received.append(info))
with patch.object(platform, "system", return_value="Windows"):
checker.check_for_updates()
assert received == []
def test_skips_network_call_on_linux(self, settings: Settings):
received = []
checker = self._make_checker(settings, VERSION_INFO)
checker.update_available.connect(lambda info: received.append(info))
with patch.object(platform, "system", return_value="Linux"):
checker.check_for_updates()
assert received == []
def test_stores_last_check_date_after_reply(self, settings: Settings):
checker = self._make_checker(settings, {**VERSION_INFO, "version": VERSION})
with patch.object(platform, "system", return_value="Windows"):
checker.check_for_updates()
stored = settings.value(Settings.Key.LAST_UPDATE_CHECK, "")
assert stored != ""
datetime.fromisoformat(stored) # should not raise
def test_stores_available_version_when_update_found(self, settings: Settings):
checker = self._make_checker(settings, VERSION_INFO)
with patch.object(platform, "system", return_value="Windows"), \
patch("buzz.update_checker.VERSION", "1.0.0"):
checker.check_for_updates()
assert settings.value(Settings.Key.UPDATE_AVAILABLE_VERSION, "") == "99.0.0"
def test_clears_available_version_when_up_to_date(self, settings: Settings):
settings.set_value(Settings.Key.UPDATE_AVAILABLE_VERSION, "99.0.0")
checker = self._make_checker(settings, {**VERSION_INFO, "version": VERSION})
with patch.object(platform, "system", return_value="Windows"):
checker.check_for_updates()
assert settings.value(Settings.Key.UPDATE_AVAILABLE_VERSION, "") == ""
================================================
FILE: tests/widgets/__init__.py
================================================
================================================
FILE: tests/widgets/advanced_settings_dialog_test.py
================================================
import pytest
from pytestqt.qtbot import QtBot
from buzz.transcriber.transcriber import TranscriptionOptions
from buzz.widgets.transcriber.advanced_settings_dialog import AdvancedSettingsDialog
class TestAdvancedSettingsDialogSilenceThreshold:
def test_silence_threshold_spinbox_hidden_by_default(self, qtbot: QtBot):
"""Silence threshold UI is not shown when show_recording_settings=False."""
options = TranscriptionOptions()
dialog = AdvancedSettingsDialog(transcription_options=options)
qtbot.add_widget(dialog)
assert not hasattr(dialog, "silence_threshold_spin_box")
def test_silence_threshold_spinbox_shown_when_recording_settings(self, qtbot: QtBot):
"""Silence threshold spinbox is present when show_recording_settings=True."""
options = TranscriptionOptions()
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
assert hasattr(dialog, "silence_threshold_spin_box")
assert dialog.silence_threshold_spin_box is not None
def test_silence_threshold_spinbox_initial_value(self, qtbot: QtBot):
"""Spinbox reflects the current silence_threshold from options."""
options = TranscriptionOptions(silence_threshold=0.0075)
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
assert dialog.silence_threshold_spin_box.value() == pytest.approx(0.0075)
def test_silence_threshold_change_updates_options(self, qtbot: QtBot):
"""Changing spinbox value updates transcription_options.silence_threshold."""
options = TranscriptionOptions(silence_threshold=0.0025)
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
dialog.silence_threshold_spin_box.setValue(0.005)
assert dialog.transcription_options.silence_threshold == pytest.approx(0.005)
def test_silence_threshold_change_emits_signal(self, qtbot: QtBot):
"""Changing the spinbox emits transcription_options_changed."""
options = TranscriptionOptions(silence_threshold=0.0025)
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
emitted = []
dialog.transcription_options_changed.connect(lambda o: emitted.append(o))
dialog.silence_threshold_spin_box.setValue(0.005)
assert len(emitted) == 1
assert emitted[0].silence_threshold == pytest.approx(0.005)
class TestAdvancedSettingsDialogLineSeparator:
def test_line_separator_shown_when_recording_settings(self, qtbot: QtBot):
options = TranscriptionOptions()
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
assert hasattr(dialog, "line_separator_line_edit")
assert dialog.line_separator_line_edit is not None
def test_line_separator_hidden_by_default(self, qtbot: QtBot):
options = TranscriptionOptions()
dialog = AdvancedSettingsDialog(transcription_options=options)
qtbot.add_widget(dialog)
assert not hasattr(dialog, "line_separator_line_edit")
def test_line_separator_initial_value_displayed_as_escape(self, qtbot: QtBot):
options = TranscriptionOptions(line_separator="\n\n")
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
assert dialog.line_separator_line_edit.text() == r"\n\n"
def test_line_separator_change_updates_options(self, qtbot: QtBot):
options = TranscriptionOptions(line_separator="\n\n")
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
dialog.line_separator_line_edit.setText(r"\n")
assert dialog.transcription_options.line_separator == "\n"
def test_line_separator_change_emits_signal(self, qtbot: QtBot):
options = TranscriptionOptions(line_separator="\n\n")
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
emitted = []
dialog.transcription_options_changed.connect(lambda o: emitted.append(o))
dialog.line_separator_line_edit.setText(r"\n")
assert len(emitted) == 1
assert emitted[0].line_separator == "\n"
def test_line_separator_invalid_escape_does_not_crash(self, qtbot: QtBot):
options = TranscriptionOptions(line_separator="\n\n")
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
dialog.line_separator_line_edit.setText("\\")
# Options unchanged — previous valid value kept
assert dialog.transcription_options.line_separator == "\n\n"
def test_line_separator_tab_character(self, qtbot: QtBot):
options = TranscriptionOptions()
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
dialog.line_separator_line_edit.setText(r"\t")
assert dialog.transcription_options.line_separator == "\t"
def test_line_separator_plain_text(self, qtbot: QtBot):
options = TranscriptionOptions()
dialog = AdvancedSettingsDialog(
transcription_options=options, show_recording_settings=True
)
qtbot.add_widget(dialog)
dialog.line_separator_line_edit.setText(" | ")
assert dialog.transcription_options.line_separator == " | "
class TestTranscriptionOptionsLineSeparator:
def test_default_line_separator(self):
options = TranscriptionOptions()
assert options.line_separator == "\n\n"
def test_custom_line_separator(self):
options = TranscriptionOptions(line_separator="\n")
assert options.line_separator == "\n"
class TestTranscriptionOptionsSilenceThreshold:
def test_default_silence_threshold(self):
options = TranscriptionOptions()
assert options.silence_threshold == pytest.approx(0.0025)
def test_custom_silence_threshold(self):
options = TranscriptionOptions(silence_threshold=0.01)
assert options.silence_threshold == pytest.approx(0.01)
================================================
FILE: tests/widgets/audio_meter_widget_test.py
================================================
import pytest
from pytestqt.qtbot import QtBot
from buzz.widgets.audio_meter_widget import AudioMeterWidget
class TestAudioMeterWidget:
def test_initial_amplitude_is_zero(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
assert widget.current_amplitude == 0.0
def test_initial_average_amplitude_is_zero(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
assert widget.average_amplitude == 0.0
def test_update_amplitude(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
widget.update_amplitude(0.5)
assert widget.current_amplitude == pytest.approx(0.5)
def test_update_amplitude_smoothing(self, qtbot: QtBot):
"""Lower amplitude should decay via smoothing factor, not drop instantly."""
widget = AudioMeterWidget()
qtbot.add_widget(widget)
widget.update_amplitude(1.0)
widget.update_amplitude(0.0)
# current_amplitude should be smoothed: max(0.0, 1.0 * SMOOTHING_FACTOR)
assert widget.current_amplitude == pytest.approx(1.0 * widget.SMOOTHING_FACTOR)
def test_update_average_amplitude(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
widget.update_average_amplitude(0.0123)
assert widget.average_amplitude == pytest.approx(0.0123)
def test_reset_amplitude_clears_current(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
widget.update_amplitude(0.8)
widget.reset_amplitude()
assert widget.current_amplitude == 0.0
def test_reset_amplitude_clears_average(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
widget.update_average_amplitude(0.05)
widget.reset_amplitude()
assert widget.average_amplitude == 0.0
def test_fixed_height(self, qtbot: QtBot):
widget = AudioMeterWidget()
qtbot.add_widget(widget)
assert widget.height() == 56
================================================
FILE: tests/widgets/audio_player_test.py
================================================
import os
import pytest
from PyQt6.QtCore import QTime
from PyQt6.QtMultimedia import QMediaPlayer
from PyQt6.QtWidgets import QHBoxLayout
from pytestqt.qtbot import QtBot
from buzz.widgets.audio_player import AudioPlayer
from tests.audio import test_audio_path
from buzz.settings.settings import Settings
def assert_approximately_equal(actual, expected, tolerance=0.001):
"""Helper function to compare values with tolerance for floating-point precision"""
assert abs(actual - expected) < tolerance, f"Value {actual} is not approximately equal to {expected}"
class TestAudioPlayer:
def test_should_load_audio(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
actual = os.path.normpath(widget.media_player.source().toLocalFile())
expected = os.path.normpath(test_audio_path)
assert actual == expected
def test_should_update_time_label(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
widget.on_duration_changed(2000)
widget.on_position_changed(1000)
position_time = QTime(0, 0).addMSecs(1000).toString()
duration_time = QTime(0, 0).addMSecs(2000).toString()
assert widget.time_label.text() == f"{position_time} / {duration_time}"
def test_should_toggle_play_button_icon(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
widget.on_playback_state_changed(QMediaPlayer.PlaybackState.PlayingState)
assert widget.play_button.icon().themeName() == widget.pause_icon.themeName()
widget.on_playback_state_changed(QMediaPlayer.PlaybackState.PausedState)
assert widget.play_button.icon().themeName() == widget.play_icon.themeName()
widget.on_playback_state_changed(QMediaPlayer.PlaybackState.StoppedState)
assert widget.play_button.icon().themeName() == widget.play_icon.themeName()
def test_should_have_basic_audio_controls(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Speed controls were moved to transcription viewer - just verify basic audio player functionality
assert widget.play_button is not None
assert widget.scrubber is not None
assert widget.time_label is not None
# Verify the widget loads audio correctly
assert widget.media_player is not None
assert os.path.normpath(widget.media_player.source().toLocalFile()) == os.path.normpath(test_audio_path)
def test_should_change_playback_rate_directly(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Speed controls moved to transcription viewer - test basic playback rate functionality
initial_rate = widget.media_player.playbackRate()
widget.media_player.setPlaybackRate(1.5)
assert_approximately_equal(widget.media_player.playbackRate(), 1.5)
def test_should_handle_custom_playback_rates(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Speed controls moved to transcription viewer - test basic playback rate functionality
widget.media_player.setPlaybackRate(1.7)
assert_approximately_equal(widget.media_player.playbackRate(), 1.7)
def test_should_handle_various_playback_rates(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Speed controls moved to transcription viewer - test basic playback rate functionality
# Test that the media player can handle various playback rates
widget.media_player.setPlaybackRate(0.5)
assert_approximately_equal(widget.media_player.playbackRate(), 0.5)
widget.media_player.setPlaybackRate(2.0)
assert_approximately_equal(widget.media_player.playbackRate(), 2.0)
def test_should_use_single_row_layout(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Verify the layout structure
layout = widget.layout()
assert isinstance(layout, QHBoxLayout)
# Speed controls moved to transcription viewer - simplified layout
assert layout.count() == 3 # play_button, scrubber, time_label
def test_should_persist_playback_rate_setting(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Speed controls moved to transcription viewer - test that settings are loaded
# The widget should load the saved playback rate from settings
assert widget.settings is not None
saved_rate = widget.settings.value(Settings.Key.AUDIO_PLAYBACK_RATE, 1.0, float)
assert isinstance(saved_rate, float)
assert 0.1 <= saved_rate <= 5.0
def test_should_handle_range_looping(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Test range setting and looping functionality
widget.set_range((1000, 3000)) # 1-3 seconds
assert widget.range_ms == (1000, 3000)
# Clear range
widget.clear_range()
assert widget.range_ms is None
def test_should_handle_invalid_media(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
widget.set_invalid_media(True)
# Speed controls moved to transcription viewer - just verify invalid media handling
assert widget.invalid_media is True
assert widget.play_button.isEnabled() is False
assert widget.scrubber.isEnabled() is False
assert widget.time_label.isEnabled() is False
def test_should_stop_playback(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Test stop functionality
widget.stop()
assert widget.media_player.playbackState() == QMediaPlayer.PlaybackState.StoppedState
def test_should_handle_media_status_changes(self, qtbot: QtBot):
widget = AudioPlayer(test_audio_path)
qtbot.add_widget(widget)
# Test media status handling
widget.on_media_status_changed(QMediaPlayer.MediaStatus.LoadedMedia)
assert widget.invalid_media is False
widget.on_media_status_changed(QMediaPlayer.MediaStatus.InvalidMedia)
assert widget.invalid_media is True
================================================
FILE: tests/widgets/conftest.py
================================================
import gc
import logging
import pytest
from unittest.mock import patch
from buzz.settings.settings import Settings
@pytest.fixture(autouse=True)
def mock_get_password():
with patch("buzz.widgets.recording_transcriber_widget.get_password", return_value=None):
yield
@pytest.fixture(autouse=True)
def force_gc_between_tests():
yield
gc.collect()
@pytest.fixture(scope="package")
def reset_settings():
settings = Settings()
settings.clear()
settings.sync()
logging.debug("Reset settings")
================================================
FILE: tests/widgets/export_transcription_menu_test.py
================================================
import pathlib
import uuid
import pytest
from PyQt6.QtCore import QObject, pyqtSignal
from pytestqt.qtbot import QtBot
from buzz.db.entity.transcription import Transcription
from buzz.db.entity.transcription_segment import TranscriptionSegment
from buzz.model_loader import ModelType, WhisperModelSize
from buzz.transcriber.transcriber import Task
from buzz.widgets.transcription_viewer.export_transcription_menu import (
ExportTranscriptionMenu,
)
from tests.audio import test_audio_path
class TranslationSignal(QObject):
translation = pyqtSignal(str, int)
class TestExportTranscriptionMenu:
@pytest.fixture()
def transcription(
self, transcription_dao, transcription_segment_dao
) -> Transcription:
id = uuid.uuid4()
transcription_dao.insert(
Transcription(
id=str(id),
status="completed",
file=test_audio_path,
task=Task.TRANSCRIBE.value,
model_type=ModelType.WHISPER.value,
whisper_model_size=WhisperModelSize.TINY.value,
)
)
transcription_segment_dao.insert(TranscriptionSegment(40, 299, "Bien", "", str(id)))
transcription_segment_dao.insert(
TranscriptionSegment(299, 329, "venue dans", "", str(id))
)
return transcription_dao.find_by_id(str(id))
def test_should_export_segments(
self,
tmp_path: pathlib.Path,
qtbot: QtBot,
transcription,
transcription_service,
shortcuts,
mocker,
):
output_file_path = tmp_path / "whisper.txt"
mocker.patch(
"PyQt6.QtWidgets.QFileDialog.getSaveFileName",
return_value=(str(output_file_path), ""),
)
translation_signal = TranslationSignal()
widget = ExportTranscriptionMenu(
transcription,
transcription_service,
False,
translation_signal.translation
)
qtbot.add_widget(widget)
widget.actions()[0].trigger()
with open(output_file_path, encoding="utf-8") as output_file:
assert "Bien venue dans" in output_file.read()
================================================
FILE: tests/widgets/file_transcriber_widget_test.py
================================================
from unittest.mock import Mock
from PyQt6.QtCore import Qt
from pytestqt.qtbot import QtBot
from buzz.widgets.transcriber.file_transcriber_widget import FileTranscriberWidget
from tests.audio import test_audio_path
class TestFileTranscriberWidget:
def test_should_set_window_title(self, qtbot: QtBot):
widget = FileTranscriberWidget(
file_paths=[test_audio_path],
)
qtbot.add_widget(widget)
assert widget.windowTitle() == "whisper-french.mp3"
def test_should_emit_triggered_event(self, qtbot: QtBot):
widget = FileTranscriberWidget(
file_paths=[test_audio_path],
)
qtbot.add_widget(widget)
mock_triggered = Mock()
widget.triggered.connect(mock_triggered)
with qtbot.wait_signal(widget.triggered, timeout=30 * 1000):
qtbot.mouseClick(widget.run_button, Qt.MouseButton.LeftButton)
(
transcription_options,
file_transcription_options,
model_path,
) = mock_triggered.call_args[0][0]
assert transcription_options.language is None
assert file_transcription_options.file_paths == [test_audio_path]
assert len(model_path) > 0
================================================
FILE: tests/widgets/hugging_face_search_line_edit_test.py
================================================
import json
from unittest.mock import MagicMock, patch
import pytest
from PyQt6.QtCore import Qt, QEvent, QPoint
from PyQt6.QtGui import QKeyEvent
from PyQt6.QtNetwork import QNetworkReply, QNetworkAccessManager
from PyQt6.QtWidgets import QListWidgetItem
from pytestqt.qtbot import QtBot
from buzz.widgets.transcriber.hugging_face_search_line_edit import HuggingFaceSearchLineEdit
@pytest.fixture
def widget(qtbot: QtBot):
mock_manager = MagicMock(spec=QNetworkAccessManager)
mock_manager.finished = MagicMock()
mock_manager.finished.connect = MagicMock()
w = HuggingFaceSearchLineEdit(network_access_manager=mock_manager)
qtbot.add_widget(w)
# Prevent popup.show() from triggering a Wayland fatal protocol error
# in headless/CI environments where popup windows lack a transient parent.
w.popup.show = MagicMock()
return w
class TestHuggingFaceSearchLineEdit:
def test_initial_state(self, widget):
assert widget.text() == ""
assert widget.placeholderText() != ""
def test_default_value_set(self, qtbot: QtBot):
mock_manager = MagicMock(spec=QNetworkAccessManager)
mock_manager.finished = MagicMock()
mock_manager.finished.connect = MagicMock()
w = HuggingFaceSearchLineEdit(default_value="openai/whisper-tiny", network_access_manager=mock_manager)
qtbot.add_widget(w)
assert w.text() == "openai/whisper-tiny"
def test_on_text_edited_emits_model_selected(self, widget, qtbot: QtBot):
spy = MagicMock()
widget.model_selected.connect(spy)
widget.on_text_edited("some/model")
spy.assert_called_once_with("some/model")
def test_fetch_models_skips_short_text(self, widget):
widget.setText("ab")
result = widget.fetch_models()
assert result is None
def test_fetch_models_makes_request_for_long_text(self, widget):
widget.setText("whisper-tiny")
mock_reply = MagicMock()
widget.network_manager.get = MagicMock(return_value=mock_reply)
result = widget.fetch_models()
widget.network_manager.get.assert_called_once()
assert result == mock_reply
def test_fetch_models_url_contains_search_text(self, widget):
widget.setText("whisper")
widget.network_manager.get = MagicMock(return_value=MagicMock())
widget.fetch_models()
call_args = widget.network_manager.get.call_args[0][0]
assert "whisper" in call_args.url().toString()
def test_on_request_response_network_error_does_not_populate_popup(self, widget):
mock_reply = MagicMock(spec=QNetworkReply)
mock_reply.error.return_value = QNetworkReply.NetworkError.ConnectionRefusedError
widget.on_request_response(mock_reply)
assert widget.popup.count() == 0
def test_on_request_response_populates_popup(self, widget):
mock_reply = MagicMock(spec=QNetworkReply)
mock_reply.error.return_value = QNetworkReply.NetworkError.NoError
models = [{"id": "openai/whisper-tiny"}, {"id": "openai/whisper-base"}]
mock_reply.readAll.return_value.data.return_value = json.dumps(models).encode()
widget.on_request_response(mock_reply)
assert widget.popup.count() == 2
assert widget.popup.item(0).text() == "openai/whisper-tiny"
assert widget.popup.item(1).text() == "openai/whisper-base"
def test_on_request_response_empty_models_does_not_show_popup(self, widget):
mock_reply = MagicMock(spec=QNetworkReply)
mock_reply.error.return_value = QNetworkReply.NetworkError.NoError
mock_reply.readAll.return_value.data.return_value = json.dumps([]).encode()
widget.on_request_response(mock_reply)
assert widget.popup.count() == 0
widget.popup.show.assert_not_called()
def test_on_request_response_item_has_user_role_data(self, widget):
mock_reply = MagicMock(spec=QNetworkReply)
mock_reply.error.return_value = QNetworkReply.NetworkError.NoError
models = [{"id": "facebook/mms-1b-all"}]
mock_reply.readAll.return_value.data.return_value = json.dumps(models).encode()
widget.on_request_response(mock_reply)
item = widget.popup.item(0)
assert item.data(Qt.ItemDataRole.UserRole) == "facebook/mms-1b-all"
def test_on_select_item_emits_model_selected(self, widget, qtbot: QtBot):
item = QListWidgetItem("openai/whisper-tiny")
item.setData(Qt.ItemDataRole.UserRole, "openai/whisper-tiny")
widget.popup.addItem(item)
widget.popup.setCurrentItem(item)
spy = MagicMock()
widget.model_selected.connect(spy)
widget.on_select_item()
spy.assert_called_with("openai/whisper-tiny")
assert widget.text() == "openai/whisper-tiny"
def test_on_select_item_hides_popup(self, widget):
item = QListWidgetItem("openai/whisper-tiny")
item.setData(Qt.ItemDataRole.UserRole, "openai/whisper-tiny")
widget.popup.addItem(item)
widget.popup.setCurrentItem(item)
with patch.object(widget.popup, 'hide') as mock_hide:
widget.on_select_item()
mock_hide.assert_called_once()
def test_on_popup_selected_stops_timer(self, widget):
widget.timer.start()
assert widget.timer.isActive()
widget.on_popup_selected()
assert not widget.timer.isActive()
def test_event_filter_ignores_non_popup_target(self, widget):
other = MagicMock()
event = MagicMock()
assert widget.eventFilter(other, event) is False
def test_event_filter_mouse_press_hides_popup(self, widget):
event = MagicMock()
event.type.return_value = QEvent.Type.MouseButtonPress
with patch.object(widget.popup, 'hide') as mock_hide:
result = widget.eventFilter(widget.popup, event)
assert result is True
mock_hide.assert_called_once()
def test_event_filter_escape_hides_popup(self, widget, qtbot: QtBot):
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_Escape, Qt.KeyboardModifier.NoModifier)
with patch.object(widget.popup, 'hide') as mock_hide:
result = widget.eventFilter(widget.popup, event)
assert result is True
mock_hide.assert_called_once()
def test_event_filter_enter_selects_item(self, widget, qtbot: QtBot):
item = QListWidgetItem("openai/whisper-tiny")
item.setData(Qt.ItemDataRole.UserRole, "openai/whisper-tiny")
widget.popup.addItem(item)
widget.popup.setCurrentItem(item)
spy = MagicMock()
widget.model_selected.connect(spy)
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_Return, Qt.KeyboardModifier.NoModifier)
result = widget.eventFilter(widget.popup, event)
assert result is True
spy.assert_called_with("openai/whisper-tiny")
def test_event_filter_enter_no_item_returns_true(self, widget, qtbot: QtBot):
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_Return, Qt.KeyboardModifier.NoModifier)
result = widget.eventFilter(widget.popup, event)
assert result is True
def test_event_filter_navigation_keys_return_false(self, widget):
for key in [Qt.Key.Key_Up, Qt.Key.Key_Down, Qt.Key.Key_Home,
Qt.Key.Key_End, Qt.Key.Key_PageUp, Qt.Key.Key_PageDown]:
event = QKeyEvent(QEvent.Type.KeyPress, key, Qt.KeyboardModifier.NoModifier)
assert widget.eventFilter(widget.popup, event) is False
def test_event_filter_other_key_hides_popup(self, widget):
event = QKeyEvent(QEvent.Type.KeyPress, Qt.Key.Key_A, Qt.KeyboardModifier.NoModifier)
with patch.object(widget.popup, 'hide') as mock_hide:
widget.eventFilter(widget.popup, event)
mock_hide.assert_called_once()
================================================
FILE: tests/widgets/import_url_dialog_test.py
================================================
from unittest.mock import patch
from buzz.locale import _
from buzz.widgets.import_url_dialog import ImportURLDialog
class TestImportURLDialog:
def test_should_show_error_with_invalid_url(self, qtbot):
dialog = ImportURLDialog()
dialog.line_edit.setText("bad-url")
with patch("PyQt6.QtWidgets.QMessageBox.critical") as mock_critical:
dialog.button_box.button(dialog.button_box.StandardButton.Ok).click()
mock_critical.assert_called_with(
dialog, _("Invalid URL"), _("The URL you entered is invalid.")
)
def test_should_return_url_with_valid_url(self, qtbot):
dialog = ImportURLDialog()
dialog.line_edit.setText("https://example.com")
dialog.button_box.button(dialog.button_box.StandardButton.Ok).click()
assert dialog.url == "https://example.com"
================================================
FILE: tests/widgets/main_window_test.py
================================================
import logging
import os
import tempfile
from typing import List
from unittest.mock import patch, Mock
import pytest
from PyQt6.QtCore import QSize, Qt
from PyQt6.QtGui import QKeyEvent, QAction
from PyQt6.QtWidgets import (
QMessageBox,
QPushButton,
QToolBar,
QMenuBar,
QTableView,
)
from pytestqt.qtbot import QtBot
from buzz.locale import _
from buzz.db.entity.transcription import Transcription
from buzz.db.service.transcription_service import TranscriptionService
from buzz.widgets.main_window import MainWindow
from buzz.widgets.transcriber.file_transcriber_widget import FileTranscriberWidget
mock_transcriptions: List[Transcription] = [
Transcription(status="completed"),
Transcription(status="canceled"),
Transcription(status="failed", error_message=_("Error")),
]
def get_test_asset(filename: str):
return os.path.join(os.path.dirname(__file__), "../../testdata/", filename)
class TestMainWindow:
def test_should_set_window_title_and_icon(self, qtbot, transcription_service):
window = MainWindow(transcription_service)
qtbot.add_widget(window)
assert window.windowTitle() == "Buzz"
assert window.windowIcon().pixmap(QSize(64, 64)).isNull() is False
window.close()
def test_should_run_file_transcription_task(
self, qtbot: QtBot, transcription_service
):
window = MainWindow(transcription_service)
self._import_file_and_start_transcription(window)
open_transcript_action = self._get_toolbar_action(window, _("Open Transcript"))
assert open_transcript_action.isEnabled() is False
table_widget = self._get_tasks_table(window)
qtbot.wait_until(
self._get_assert_task_status_callback(table_widget, 0, "completed"),
timeout=2 * 60 * 1000,
)
table_widget.setCurrentIndex(table_widget.model().index(0, 0))
assert open_transcript_action.isEnabled()
window.close()
@staticmethod
def _get_tasks_table(window: MainWindow) -> QTableView:
return window.findChild(QTableView)
def test_should_run_url_import_file_transcription_task(
self, qtbot: QtBot, db, transcription_service
):
window = MainWindow(transcription_service)
menu: QMenuBar = window.menuBar()
file_action = menu.actions()[0]
import_url_action: QAction = file_action.menu().actions()[1]
with patch(
"buzz.widgets.import_url_dialog.ImportURLDialog.prompt"
) as prompt_mock:
prompt_mock.return_value = "https://github.com/chidiwilliams/buzz/raw/main/testdata/whisper-french.mp3"
import_url_action.trigger()
file_transcriber_widget: FileTranscriberWidget = window.findChild(
FileTranscriberWidget
)
run_button: QPushButton = file_transcriber_widget.findChild(QPushButton)
run_button.click()
table_widget = self._get_tasks_table(window)
qtbot.wait_until(
self._get_assert_task_status_callback(table_widget, 0, "completed"),
timeout=2 * 60 * 1000,
)
window.close()
@pytest.mark.timeout(300)
def test_should_run_and_cancel_transcription_task(
self, qtbot, db, transcription_service
):
window = MainWindow(transcription_service)
qtbot.add_widget(window)
self._import_file_and_start_transcription(window, long_audio=True)
table_widget = self._get_tasks_table(window)
try:
qtbot.wait_until(
self._get_assert_task_status_callback(table_widget, 0, "in_progress"),
timeout=60 * 1000,
)
except Exception:
logging.error("Task never reached 'in_progress' status")
assert False, "Task did not start as expected"
logging.debug("Will cancel transcription task")
table_widget.selectRow(0)
# Force immediate processing of pending events before triggering cancellation
qtbot.wait(100)
window.toolbar.stop_transcription_action.trigger()
# Give some time for the cancellation to be processed
qtbot.wait(500)
logging.debug("Will wait for task to reach 'canceled' status")
try:
qtbot.wait_until(
self._get_assert_task_status_callback(table_widget, 0, "canceled"),
timeout=30 * 1000,
)
except Exception:
# On Windows, the cancellation might be slower, check final state
final_status = self._get_status(table_widget, 0)
logging.error(f"Task status after timeout: {final_status}")
if "canceled" not in final_status.lower():
assert False, f"Task did not cancel as expected. Final status: {final_status}"
logging.debug("Task canceled")
qtbot.wait(200)
table_widget.selectRow(0)
assert window.toolbar.stop_transcription_action.isEnabled() is False
assert window.toolbar.open_transcript_action.isEnabled() is False
window.close()
@pytest.mark.parametrize("transcription_dao", [mock_transcriptions], indirect=True)
def test_should_load_tasks_from_cache(
self, qtbot, transcription_dao, transcription_segment_dao, monkeypatch
):
# Mock the queue worker to prevent it from processing tasks
mock_queue_worker = Mock()
mock_queue_worker.task_started = Mock()
mock_queue_worker.task_progress = Mock()
mock_queue_worker.task_download_progress = Mock()
mock_queue_worker.task_error = Mock()
mock_queue_worker.task_completed = Mock()
mock_queue_worker.completed = Mock()
mock_queue_worker.cancel_task = Mock()
mock_queue_worker.add_task = Mock()
mock_queue_worker.stop = Mock()
monkeypatch.setattr("buzz.widgets.main_window.FileTranscriberQueueWorker", Mock(return_value=mock_queue_worker))
window = MainWindow(
TranscriptionService(transcription_dao, transcription_segment_dao)
)
qtbot.add_widget(window)
table_widget = self._get_tasks_table(window)
assert table_widget.model().rowCount() == 3
# Get all statuses and verify they match expected values
statuses = [self._get_status(table_widget, i) for i in range(3)]
expected_statuses = {"completed", "canceled", "failed"}
assert set(statuses) == expected_statuses, f"Expected {expected_statuses}, got {statuses}"
# Test that completed transcriptions enable the open action, others don't
for i in range(3):
table_widget.selectRow(i)
status = self._get_status(table_widget, i)
if status == "completed":
assert window.toolbar.open_transcript_action.isEnabled()
else:
assert window.toolbar.open_transcript_action.isEnabled() is False
window.close()
@pytest.mark.parametrize("transcription_dao", [mock_transcriptions], indirect=True)
def test_should_clear_history_with_rows_selected(
self, qtbot, transcription_dao, transcription_segment_dao
):
window = MainWindow(
TranscriptionService(transcription_dao, transcription_segment_dao)
)
qtbot.add_widget(window)
table_widget = self._get_tasks_table(window)
table_widget.selectAll()
with patch("PyQt6.QtWidgets.QMessageBox.exec") as question_message_box_mock:
question_message_box_mock.return_value = QMessageBox.StandardButton.Yes
window.toolbar.clear_history_action.trigger()
assert table_widget.model().rowCount() == 0
window.close()
@pytest.mark.parametrize("transcription_dao", [mock_transcriptions], indirect=True)
def test_should_have_clear_history_action_disabled_with_no_rows_selected(
self, qtbot, transcription_dao, transcription_segment_dao
):
window = MainWindow(
TranscriptionService(transcription_dao, transcription_segment_dao)
)
qtbot.add_widget(window)
assert window.toolbar.clear_history_action.isEnabled() is False
window.close()
@pytest.mark.parametrize("transcription_dao", [mock_transcriptions], indirect=True)
def test_should_open_transcription_viewer_when_menu_action_is_clicked(
self, qtbot, transcription_dao, transcription_segment_dao
):
window = MainWindow(
TranscriptionService(transcription_dao, transcription_segment_dao)
)
qtbot.add_widget(window)
table_widget = self._get_tasks_table(window)
# Find and select the completed transcription row
completed_row = None
for i in range(table_widget.model().rowCount()):
if self._get_status(table_widget, i) == "completed":
completed_row = i
break
assert completed_row is not None, "No completed transcription found"
table_widget.selectRow(completed_row)
window.toolbar.open_transcript_action.trigger()
assert window.transcription_viewer_widget is not None
window.close()
@pytest.mark.parametrize("transcription_dao", [mock_transcriptions], indirect=True)
def test_should_open_transcription_viewer_when_return_clicked(
self, qtbot, transcription_dao, transcription_segment_dao
):
window = MainWindow(
TranscriptionService(transcription_dao, transcription_segment_dao)
)
qtbot.add_widget(window)
table_widget = self._get_tasks_table(window)
# Find and select the completed transcription row
completed_row = None
for i in range(table_widget.model().rowCount()):
if self._get_status(table_widget, i) == "completed":
completed_row = i
break
assert completed_row is not None, "No completed transcription found"
table_widget.selectRow(completed_row)
table_widget.keyPressEvent(
QKeyEvent(
QKeyEvent.Type.KeyPress,
Qt.Key.Key_Return,
Qt.KeyboardModifier.NoModifier,
"\r",
)
)
assert window.transcription_viewer_widget is not None
window.close()
@pytest.mark.parametrize("transcription_dao", [mock_transcriptions], indirect=True)
def test_should_have_open_transcript_action_disabled_with_no_rows_selected(
self, qtbot, transcription_dao, transcription_segment_dao
):
window = MainWindow(
TranscriptionService(transcription_dao, transcription_segment_dao)
)
qtbot.add_widget(window)
assert window.toolbar.open_transcript_action.isEnabled() is False
window.close()
def test_import_folder_opens_file_transcriber_with_supported_files(
self, qtbot, transcription_service
):
window = MainWindow(transcription_service)
qtbot.add_widget(window)
with tempfile.TemporaryDirectory() as folder:
# Create supported and unsupported files
supported = ["audio.mp3", "video.mp4", "clip.wav"]
unsupported = ["document.txt", "image.png"]
subdir = os.path.join(folder, "sub")
os.makedirs(subdir)
nested = "nested.flac"
for name in supported + unsupported:
open(os.path.join(folder, name), "w").close()
open(os.path.join(subdir, nested), "w").close()
with patch("PyQt6.QtWidgets.QFileDialog.getExistingDirectory") as mock_dir, \
patch.object(window, "open_file_transcriber_widget") as mock_open:
mock_dir.return_value = folder
window.on_import_folder_action_triggered()
collected = mock_open.call_args[0][0]
collected_names = {os.path.basename(p) for p in collected}
assert collected_names == {"audio.mp3", "video.mp4", "clip.wav", "nested.flac"}
window.close()
def test_import_folder_does_nothing_when_cancelled(
self, qtbot, transcription_service
):
window = MainWindow(transcription_service)
qtbot.add_widget(window)
with patch("PyQt6.QtWidgets.QFileDialog.getExistingDirectory") as mock_dir, \
patch.object(window, "open_file_transcriber_widget") as mock_open:
mock_dir.return_value = ""
window.on_import_folder_action_triggered()
mock_open.assert_not_called()
window.close()
def test_import_folder_does_nothing_when_no_supported_files(
self, qtbot, transcription_service
):
window = MainWindow(transcription_service)
qtbot.add_widget(window)
with tempfile.TemporaryDirectory() as folder:
open(os.path.join(folder, "readme.txt"), "w").close()
open(os.path.join(folder, "image.jpg"), "w").close()
with patch("PyQt6.QtWidgets.QFileDialog.getExistingDirectory") as mock_dir, \
patch.object(window, "open_file_transcriber_widget") as mock_open:
mock_dir.return_value = folder
window.on_import_folder_action_triggered()
mock_open.assert_not_called()
window.close()
@staticmethod
def _import_file_and_start_transcription(
window: MainWindow, long_audio: bool = False
):
with patch(
"PyQt6.QtWidgets.QFileDialog.getOpenFileNames"
) as open_file_names_mock:
open_file_names_mock.return_value = (
[
get_test_asset(
"audio-long.mp3" if long_audio else "whisper-french.mp3"
)
],
"",
)
new_transcription_action = TestMainWindow._get_toolbar_action(
window, _("New File Transcription")
)
new_transcription_action.trigger()
file_transcriber_widget: FileTranscriberWidget = window.findChild(
FileTranscriberWidget
)
run_button: QPushButton = file_transcriber_widget.findChild(QPushButton)
run_button.click()
@staticmethod
def _get_assert_task_status_callback(
table_widget: QTableView,
row_index: int,
expected_status: str,
):
def assert_task_status():
assert table_widget.model().rowCount() > 0
assert expected_status in TestMainWindow._get_status(
table_widget, row_index
)
return assert_task_status
@staticmethod
def _get_status(table_widget: QTableView, row_index: int):
return table_widget.model().index(row_index, 9).data()
@staticmethod
def _get_toolbar_action(window: MainWindow, text: str):
toolbar: QToolBar = window.findChild(QToolBar)
return [action for action in toolbar.actions() if action.text() == text][0]
================================================
FILE: tests/widgets/menu_bar_test.py
================================================
from unittest.mock import patch, Mock
from PyQt6.QtCore import QSettings
from buzz.widgets.menu_bar import MenuBar
from buzz.widgets.preferences_dialog.models.preferences import Preferences
from buzz.widgets.preferences_dialog.preferences_dialog import PreferencesDialog
class TestMenuBar:
def test_import_folder_action_emits_signal(self, qtbot, shortcuts):
menu_bar = MenuBar(
shortcuts=shortcuts, preferences=Preferences.load(QSettings())
)
qtbot.add_widget(menu_bar)
signal_mock = Mock()
menu_bar.import_folder_action_triggered.connect(signal_mock)
menu_bar.import_folder_action.trigger()
signal_mock.assert_called_once()
def test_open_preferences_dialog(self, qtbot, shortcuts):
menu_bar = MenuBar(
shortcuts=shortcuts, preferences=Preferences.load(QSettings())
)
qtbot.add_widget(menu_bar)
preferences_dialog = menu_bar.findChild(PreferencesDialog)
assert preferences_dialog is None
menu_bar.preferences_action.trigger()
preferences_dialog = menu_bar.findChild(PreferencesDialog)
assert isinstance(preferences_dialog, PreferencesDialog)
================================================
FILE: tests/widgets/model_download_progress_dialog.py
================================================
from PyQt6.QtCore import Qt
from buzz.locale import _
from buzz.model_loader import ModelType
from buzz.widgets.model_download_progress_dialog import ModelDownloadProgressDialog
class TestModelDownloadProgressDialog:
def test_should_show_dialog(self, qtbot):
dialog = ModelDownloadProgressDialog(model_type=ModelType.WHISPER, parent=None)
qtbot.add_widget(dialog)
assert dialog.labelText() == f"{_('Downloading model')} ()"
def test_should_update_label_on_progress(self, qtbot):
dialog = ModelDownloadProgressDialog(model_type=ModelType.WHISPER, parent=None)
qtbot.add_widget(dialog)
dialog.set_value(0.0)
dialog.set_value(0.01)
assert dialog.labelText().startswith(f"{_('Downloading model')} (")
assert dialog.labelText() != f"{_('Downloading model')} ()"
dialog.set_value(0.1)
assert dialog.labelText().startswith(f"{_('Downloading model')} (")
assert dialog.labelText() != f"{_('Downloading model')} ()"
# Other windows should not be processing while models are being downloaded
def test_should_be_an_application_modal(self, qtbot):
dialog = ModelDownloadProgressDialog(model_type=ModelType.WHISPER, parent=None)
qtbot.add_widget(dialog)
assert dialog.windowModality() == Qt.WindowModality.WindowModal
================================================
FILE: tests/widgets/model_type_combo_box_test.py
================================================
import platform
import pytest
from buzz.widgets.model_type_combo_box import ModelTypeComboBox
class TestModelTypeComboBox:
@pytest.mark.parametrize(
"model_types",
[
pytest.param(
[
"Whisper",
"Whisper.cpp",
"Hugging Face",
"Faster Whisper",
"OpenAI Whisper API",
# Faster Whisper is not available on macOS x86_64
] if not (platform.system() == "Darwin" and platform.machine() == "x86_64") else [
"Whisper",
"Whisper.cpp",
"Hugging Face",
"OpenAI Whisper API",
],
),
],
)
def test_should_display_items(self, qtbot, model_types):
widget = ModelTypeComboBox()
qtbot.add_widget(widget)
assert widget.count() == len(model_types)
for index, model_type in enumerate(model_types):
assert widget.itemText(index) == model_type
================================================
FILE: tests/widgets/openai_api_key_line_edit_test.py
================================================
from buzz.widgets.openai_api_key_line_edit import OpenAIAPIKeyLineEdit
class TestOpenAIAPIKeyLineEdit:
def test_should_emit_key_changed(self, qtbot):
line_edit = OpenAIAPIKeyLineEdit(key="")
qtbot.add_widget(line_edit)
with qtbot.wait_signal(line_edit.key_changed):
line_edit.setText("abcdefg")
def test_should_toggle_visibility(self, qtbot):
line_edit = OpenAIAPIKeyLineEdit(key="")
qtbot.add_widget(line_edit)
assert line_edit.echoMode() == OpenAIAPIKeyLineEdit.EchoMode.Password
toggle_action = line_edit.actions()[0]
toggle_action.trigger()
assert line_edit.echoMode() == OpenAIAPIKeyLineEdit.EchoMode.Normal
toggle_action.trigger()
assert line_edit.echoMode() == OpenAIAPIKeyLineEdit.EchoMode.Password
================================================
FILE: tests/widgets/preferences_dialog/__init__.py
================================================
================================================
FILE: tests/widgets/preferences_dialog/folder_watch_preferences_widget_test.py
================================================
from unittest.mock import Mock
from PyQt6.QtWidgets import QCheckBox, QLineEdit
from buzz.model_loader import TranscriptionModel
from buzz.transcriber.transcriber import Task
from buzz.widgets.preferences_dialog.folder_watch_preferences_widget import (
FolderWatchPreferencesWidget,
)
from buzz.widgets.preferences_dialog.models.file_transcription_preferences import (
FileTranscriptionPreferences,
)
from buzz.widgets.preferences_dialog.models.folder_watch_preferences import (
FolderWatchPreferences,
)
class TestFolderWatchPreferencesWidget:
def test_edit_folder_watch_preferences(self, qtbot):
widget = FolderWatchPreferencesWidget(
config=FolderWatchPreferences(
enabled=False,
input_directory="",
output_directory="",
file_transcription_options=FileTranscriptionPreferences(
language=None,
task=Task.TRANSCRIBE,
model=TranscriptionModel.default(),
word_level_timings=False,
extract_speech=False,
initial_prompt="",
enable_llm_translation=False,
llm_model="",
llm_prompt="",
output_formats=set(),
),
),
)
mock_config_changed = Mock()
widget.config_changed.connect(mock_config_changed)
qtbot.add_widget(widget)
checkbox = widget.findChild(QCheckBox, "EnableFolderWatchCheckbox")
input_folder_line_edit = widget.findChild(QLineEdit, "InputFolderLineEdit")
output_folder_line_edit = widget.findChild(QLineEdit, "OutputFolderLineEdit")
assert not checkbox.isChecked()
assert input_folder_line_edit.text() == ""
assert output_folder_line_edit.text() == ""
assert not input_folder_line_edit.isEnabled()
assert not output_folder_line_edit.isEnabled()
checkbox.setChecked(True)
assert input_folder_line_edit.isEnabled()
assert output_folder_line_edit.isEnabled()
input_folder_line_edit.setText("test/input/folder")
output_folder_line_edit.setText("test/output/folder")
last_config_changed_call = mock_config_changed.call_args_list[-1]
assert last_config_changed_call[0][0].enabled
assert last_config_changed_call[0][0].input_directory == "test/input/folder"
assert last_config_changed_call[0][0].output_directory == "test/output/folder"
def test_delete_processed_files_checkbox(self, qtbot):
widget = FolderWatchPreferencesWidget(
config=FolderWatchPreferences(
enabled=False,
input_directory="",
output_directory="",
file_transcription_options=FileTranscriptionPreferences(
language=None,
task=Task.TRANSCRIBE,
model=TranscriptionModel.default(),
word_level_timings=False,
extract_speech=False,
initial_prompt="",
enable_llm_translation=False,
llm_model="",
llm_prompt="",
output_formats=set(),
),
),
)
mock_config_changed = Mock()
widget.config_changed.connect(mock_config_changed)
qtbot.add_widget(widget)
delete_checkbox = widget.findChild(QCheckBox, "DeleteProcessedFilesCheckbox")
assert delete_checkbox is not None
assert not delete_checkbox.isChecked()
delete_checkbox.setChecked(True)
last_config = mock_config_changed.call_args_list[-1][0][0]
assert last_config.delete_processed_files is True
delete_checkbox.setChecked(False)
last_config = mock_config_changed.call_args_list[-1][0][0]
assert last_config.delete_processed_files is False
================================================
FILE: tests/widgets/preferences_dialog/general_preferences_widget_test.py
================================================
from PyQt6.QtCore import Qt
from PyQt6.QtWidgets import QPushButton, QMessageBox, QLineEdit, QCheckBox
from buzz.locale import _
from buzz.settings.settings import Settings
from buzz.widgets.preferences_dialog.general_preferences_widget import (
GeneralPreferencesWidget, ValidateOpenAIApiKeyJob
)
class TestGeneralPreferencesWidget:
def test_should_disable_test_button_if_no_api_key(self, qtbot, mocker):
mocker.patch(
"buzz.widgets.preferences_dialog.general_preferences_widget.get_password",
return_value="",
)
widget = GeneralPreferencesWidget()
qtbot.add_widget(widget)
test_button = widget.findChild(QPushButton)
assert isinstance(test_button, QPushButton)
assert test_button.text() == _("Test")
assert not test_button.isEnabled()
line_edit = widget.findChild(QLineEdit)
assert isinstance(line_edit, QLineEdit)
line_edit.setText("123")
assert test_button.isEnabled()
def test_should_test_openai_api_key(self, qtbot, mocker):
mocker.patch(
"buzz.widgets.preferences_dialog.general_preferences_widget.get_password",
return_value="wrong-api-key",
)
widget = GeneralPreferencesWidget()
qtbot.add_widget(widget)
test_button = widget.findChild(QPushButton)
assert isinstance(test_button, QPushButton)
test_button.click()
message_box_warning_mock = mocker.Mock()
QMessageBox.warning = message_box_warning_mock
def mock_called():
message_box_warning_mock.assert_called()
assert message_box_warning_mock.call_args[0][1] == _("OpenAI API Key Test")
assert (
message_box_warning_mock.call_args[0][2]
== "Incorrect API key provided: wrong-ap*-key. You can find your "
"API key at https://platform.openai.com/account/api-keys."
)
qtbot.waitUntil(mock_called)
def test_recording_export_preferences(self, qtbot, mocker):
mocker.patch(
"PyQt6.QtWidgets.QFileDialog.getExistingDirectory",
return_value="/path/to/export/folder",
)
widget = GeneralPreferencesWidget()
qtbot.add_widget(widget)
browse_button = widget.findChild(QPushButton, "RecordingExportFolderBrowseButton")
checkbox = widget.findChild(QCheckBox, "EnableRecordingExportCheckbox")
browse_button_enabled = browse_button.isEnabled()
qtbot.mouseClick(widget.export_enabled_checkbox, Qt.MouseButton.LeftButton)
checkbox.setChecked(not browse_button_enabled)
assert browse_button.isEnabled() != browse_button_enabled
qtbot.mouseClick(widget.recording_export_folder_browse_button, Qt.MouseButton.LeftButton)
assert widget.recording_export_folder_line_edit.text() == "/path/to/export/folder"
assert widget.settings.value(
key=widget.settings.Key.RECORDING_TRANSCRIBER_EXPORT_ENABLED,
default_value=False) != browse_button_enabled
assert widget.settings.value(
key=widget.settings.Key.RECORDING_TRANSCRIBER_EXPORT_FOLDER,
default_value='/home/user/documents') == '/path/to/export/folder'
def test_openai_base_url_preferences(self, qtbot, mocker):
widget = GeneralPreferencesWidget()
qtbot.add_widget(widget)
settings = Settings()
openai_base_url = settings.value(
key=Settings.Key.CUSTOM_OPENAI_BASE_URL, default_value=""
)
assert openai_base_url == ""
assert widget.custom_openai_base_url_line_edit.text() == ""
widget.custom_openai_base_url_line_edit.setText("http://localhost:11434/v1")
updated_openai_base_url = settings.value(
key=Settings.Key.CUSTOM_OPENAI_BASE_URL, default_value=""
)
assert updated_openai_base_url == "http://localhost:11434/v1"
class TestTestOpenAIApiKeyJob:
# No error = success
def test_run_success(self, mocker):
mock_client = mocker.Mock()
mock_client.models.list.return_value = None
mocker.patch('buzz.widgets.preferences_dialog.general_preferences_widget.OpenAI', return_value=mock_client)
mocker.patch('buzz.settings.settings.Settings.value', return_value="") # No custom base URL
job = ValidateOpenAIApiKeyJob(api_key="test_key")
mock_success = mocker.Mock()
mock_failed = mocker.Mock()
job.signals.success.connect(mock_success)
job.signals.failed.connect(mock_failed)
job.run()
mock_success.assert_called_once()
mock_failed.assert_not_called()
mock_client.models.list.assert_called_once()
# Has error = failure
def test_run_authentication_error(self, mocker):
from openai import AuthenticationError
mock_client = mocker.Mock()
mock_client.models.list.side_effect = AuthenticationError(
message="Incorrect API key provided", response=mocker.Mock(), body={"message": "Incorrect API key provided"}
)
mocker.patch('buzz.widgets.preferences_dialog.general_preferences_widget.OpenAI', return_value=mock_client)
mocker.patch('buzz.settings.settings.Settings.value', return_value="") # No custom base URL
job = ValidateOpenAIApiKeyJob(api_key="wrong_key")
mock_success = mocker.Mock()
mock_failed = mocker.Mock()
job.signals.success.connect(mock_success)
job.signals.failed.connect(mock_failed)
job.run()
mock_success.assert_not_called()
mock_failed.assert_called_once_with("Incorrect API key provided")
mock_client.models.list.assert_called_once()
================================================
FILE: tests/widgets/preferences_dialog/models_preferences_widget_test.py
================================================
import os
import pytest
from PyQt6.QtCore import Qt
from PyQt6.QtWidgets import QComboBox, QPushButton
from pytestqt.qtbot import QtBot
from buzz.locale import _
from buzz.model_loader import (
TranscriptionModel,
ModelType,
)
from buzz.widgets.preferences_dialog.models_preferences_widget import (
ModelsPreferencesWidget,
)
from tests.model_loader import get_model_path
class TestModelsPreferencesWidget:
@pytest.fixture(scope="class")
def clear_model_cache(self):
for model_type in ModelType:
if model_type.is_available():
path = TranscriptionModel(model_type=model_type).get_local_model_path()
if path and os.path.isfile(path):
os.remove(path)
def test_should_show_model_list(self, qtbot):
widget = ModelsPreferencesWidget()
qtbot.add_widget(widget)
first_item = widget.model_list_widget.topLevelItem(0)
assert first_item.text(0) == _("Downloaded")
second_item = widget.model_list_widget.topLevelItem(1)
assert second_item.text(0) == _("Available for Download")
def test_should_change_model_type(self, qtbot):
widget = ModelsPreferencesWidget()
qtbot.add_widget(widget)
combo_box = widget.findChild(QComboBox)
assert isinstance(combo_box, QComboBox)
combo_box.setCurrentText("Faster Whisper")
first_item = widget.model_list_widget.topLevelItem(0)
assert first_item.text(0) == _("Downloaded")
second_item = widget.model_list_widget.topLevelItem(1)
assert second_item.text(0) == _("Available for Download")
def test_should_download_model(self, qtbot: QtBot, clear_model_cache):
# make progress dialog non-modal to unblock qtbot.wait_until
widget = ModelsPreferencesWidget(
progress_dialog_modality=Qt.WindowModality.NonModal
)
qtbot.add_widget(widget)
assert widget.model.get_local_model_path() is None
available_item = widget.model_list_widget.topLevelItem(1)
assert available_item.text(0) == _("Available for Download")
tiny_item = available_item.child(0)
assert tiny_item.text(0) == "Tiny"
tiny_item.setSelected(True)
download_button = widget.findChild(QPushButton, "DownloadButton")
assert isinstance(download_button, QPushButton)
assert download_button.text() == _("Download")
download_button.click()
def downloaded_model():
assert not download_button.isVisible()
_downloaded_item = widget.model_list_widget.topLevelItem(0)
assert _downloaded_item.childCount() > 0
assert _downloaded_item.child(0).text(0) == "Tiny"
_available_item = widget.model_list_widget.topLevelItem(1)
assert (
_available_item.childCount() == 0
or _available_item.child(0).text(0) != "Tiny"
)
assert os.path.isfile(widget.model.get_local_model_path())
qtbot.wait_until(callback=downloaded_model, timeout=60_000)
@pytest.fixture(scope="class")
def default_model_path(self) -> str:
return get_model_path(transcription_model=(TranscriptionModel.default()))
def test_should_show_downloaded_model(self, qtbot, default_model_path):
widget = ModelsPreferencesWidget()
widget.show()
qtbot.add_widget(widget)
available_item = widget.model_list_widget.topLevelItem(0)
assert available_item.text(0) == _("Downloaded")
tiny_item = available_item.child(0)
assert tiny_item.text(0) == "Tiny"
tiny_item.setSelected(True)
delete_button = widget.findChild(QPushButton, "DeleteButton")
assert delete_button.isVisible()
show_file_location_button = widget.findChild(
QPushButton, "ShowFileLocationButton"
)
assert show_file_location_button.isVisible()
================================================
FILE: tests/widgets/preferences_dialog/preferences_dialog_test.py
================================================
import os
from PyQt6.QtCore import QSettings
from PyQt6.QtWidgets import QTabWidget
from pytestqt.qtbot import QtBot
from buzz.locale import _
from buzz.widgets.preferences_dialog.models.preferences import Preferences
from buzz.widgets.preferences_dialog.preferences_dialog import PreferencesDialog
class TestPreferencesDialog:
locale_file_path = os.path.abspath(
os.path.join(os.path.dirname(__file__), "../../../buzz/locale/lv_LV/LC_MESSAGES/buzz.mo")
)
def test_create(self, qtbot: QtBot, shortcuts):
dialog = PreferencesDialog(
shortcuts=shortcuts, preferences=Preferences.load(QSettings())
)
qtbot.add_widget(dialog)
assert dialog.windowTitle() == _("Preferences")
tab_widget = dialog.findChild(QTabWidget)
assert isinstance(tab_widget, QTabWidget)
assert tab_widget.count() == 4
assert tab_widget.tabText(0) == _("General")
assert tab_widget.tabText(1) == _("Models")
assert tab_widget.tabText(2) == _("Shortcuts")
assert tab_widget.tabText(3) == _("Folder Watch")
def test_create_localized(self, qtbot: QtBot, shortcuts, mocker):
mocker.patch(
"PyQt6.QtCore.QLocale.name",
return_value='lv_LV',
)
# Reload the module after the patch
from importlib import reload
import buzz.locale
import buzz.widgets.preferences_dialog.models.preferences
import buzz.widgets.preferences_dialog.preferences_dialog
reload(buzz.locale)
reload(buzz.widgets.preferences_dialog.models.preferences)
reload(buzz.widgets.preferences_dialog.preferences_dialog)
from buzz.locale import _
from buzz.widgets.preferences_dialog.models.preferences import Preferences
from buzz.widgets.preferences_dialog.preferences_dialog import PreferencesDialog
dialog = PreferencesDialog(
shortcuts=shortcuts, preferences=Preferences.load(QSettings())
)
qtbot.add_widget(dialog)
assert os.path.isfile(self.locale_file_path), "File .mo file does not exist"
assert _("Preferences") == "Iestatījumi"
assert dialog.windowTitle() == "Iestatījumi"
tab_widget = dialog.findChild(QTabWidget)
assert isinstance(tab_widget, QTabWidget)
assert tab_widget.count() == 4
assert tab_widget.tabText(0) == "Vispārīgi"
assert tab_widget.tabText(1) == "Modeļi"
assert tab_widget.tabText(2) == "Īsinājumi"
assert tab_widget.tabText(3) == "Mapes vērošana"
================================================
FILE: tests/widgets/presentation_window_test.py
================================================
import os
import pytest
import tempfile
from unittest.mock import patch, MagicMock
from pytestqt.qtbot import QtBot
from PyQt6.QtCore import Qt
from PyQt6.QtGui import QKeyEvent
from buzz.widgets.presentation_window import PresentationWindow
from buzz.settings.settings import Settings
from buzz.locale import _
class TestPresentationWindow:
def test_should_set_window_title(self, qtbot: QtBot):
"""Test that the window title is set correctly"""
window = PresentationWindow()
qtbot.add_widget(window)
assert _("Live Transcript Presentation") in window.windowTitle()
window.close()
def test_should_have_window_flag(self, qtbot: QtBot):
"""Test that window has the Window flag set"""
window = PresentationWindow()
qtbot.add_widget(window)
assert window.windowFlags() & Qt.WindowType.Window
window.close()
def test_should_have_transcript_display(self, qtbot: QtBot):
"""Test that the transcript display is created"""
window = PresentationWindow()
qtbot.add_widget(window)
assert window.transcript_display is not None
assert window.transcript_display.isReadOnly()
window.close()
def test_should_have_translation_display_hidden(self, qtbot: QtBot):
"""Test that the translation display is created but hidden initially"""
window = PresentationWindow()
qtbot.add_widget(window)
assert window.translation_display is not None
assert window.translation_display.isReadOnly()
assert not window.translation_display.isVisible()
window.close()
def test_should_have_default_size(self, qtbot: QtBot):
"""Test that the window has default size"""
window = PresentationWindow()
qtbot.add_widget(window)
assert window.width() == 800
assert window.height() == 600
window.close()
class TestPresentationWindowUpdateTranscripts:
def test_update_transcripts_with_text(self, qtbot: QtBot):
"""Test updating transcripts with text"""
window = PresentationWindow()
qtbot.add_widget(window)
window.update_transcripts("Hello world")
assert window._current_transcript == "Hello world"
assert "Hello world" in window.transcript_display.toHtml()
window.close()
def test_update_transcripts_with_empty_text(self, qtbot: QtBot):
"""Test that empty text does not update the display"""
window = PresentationWindow()
qtbot.add_widget(window)
window.update_transcripts("")
assert window._current_transcript == ""
window.close()
def test_update_transcripts_escapes_html(self, qtbot: QtBot):
"""Test that special HTML characters are escaped"""
window = PresentationWindow()
qtbot.add_widget(window)
window.update_transcripts("")
html = window.transcript_display.toHtml()
assert "