
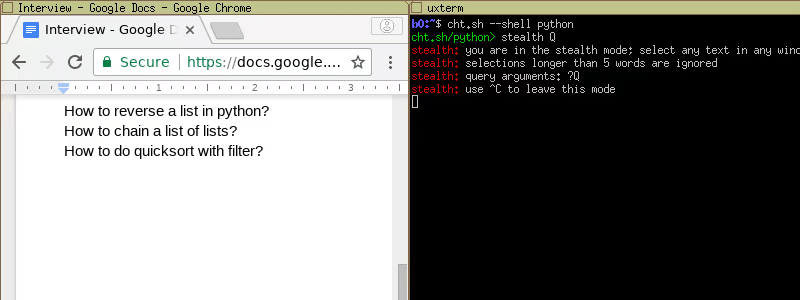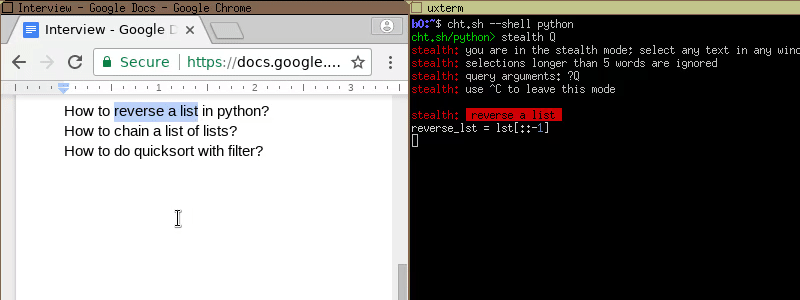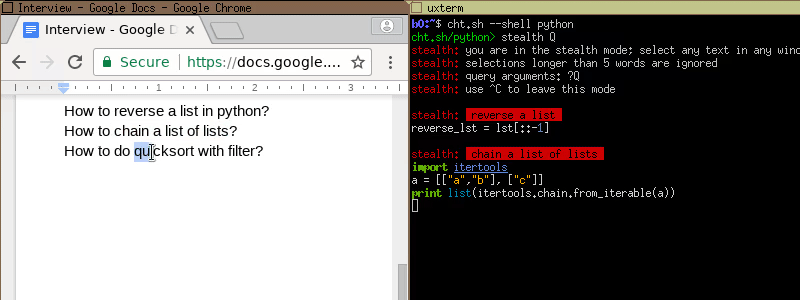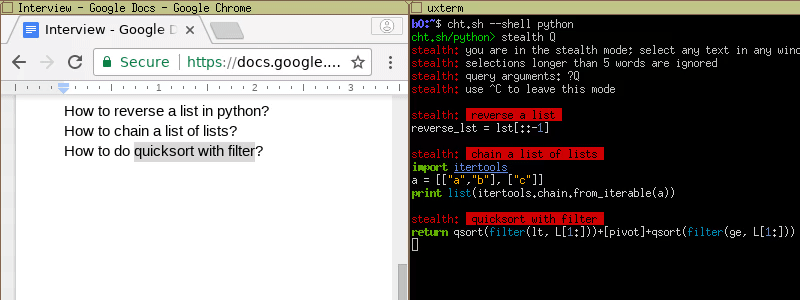

'
'[edit]'
""
) % edit_page_link
result = re.sub("", edit_button + form_html + "", result)
result = re.sub("", "" + title, result)
if not request_options.get("quiet"):
result = result.replace(
"",
TWITTER_BUTTON
+ GITHUB_BUTTON
+ repository_button
+ GITHUB_BUTTON_FOOTER
+ "",
)
return result
================================================
FILE: lib/globals.py
================================================
"""
Global functions that our used everywhere in the project.
Please, no global variables here.
For the configuration related things see `config.py`
"""
from __future__ import print_function
import sys
import logging
def fatal(text):
"""
Fatal error function.
The function is being used in the standalone mode only
"""
sys.stderr.write("ERROR: %s\n" % text)
sys.exit(1)
def error(text):
"""
Log error `text` and produce a RuntimeError exception
"""
if not text.startswith("Too many queries"):
print(text)
logging.error("ERROR %s", text)
raise RuntimeError(text)
def log(text):
"""
Log error `text` (if it does not start with 'Too many queries')
"""
if not text.startswith("Too many queries"):
print(text)
logging.info(text)
================================================
FILE: lib/languages_data.py
================================================
"""
Programming languages information.
Will be (probably) moved to a separate file/directory
from the project tree.
"""
import pygments.lexers
LEXER = {
"assembly": pygments.lexers.NasmLexer,
"awk": pygments.lexers.AwkLexer,
"bash": pygments.lexers.BashLexer,
"basic": pygments.lexers.QBasicLexer,
"bf": pygments.lexers.BrainfuckLexer,
"chapel": pygments.lexers.ChapelLexer,
"clojure": pygments.lexers.ClojureLexer,
"coffee": pygments.lexers.CoffeeScriptLexer,
"cpp": pygments.lexers.CppLexer,
"c": pygments.lexers.CLexer,
"csharp": pygments.lexers.CSharpLexer,
"d": pygments.lexers.DLexer,
"dart": pygments.lexers.DartLexer,
"delphi": pygments.lexers.DelphiLexer,
"elisp": pygments.lexers.EmacsLispLexer,
"elixir": pygments.lexers.ElixirLexer,
"elm": pygments.lexers.ElmLexer,
"erlang": pygments.lexers.ErlangLexer,
"factor": pygments.lexers.FactorLexer,
"forth": pygments.lexers.ForthLexer,
"fortran": pygments.lexers.FortranLexer,
"fsharp": pygments.lexers.FSharpLexer,
"git": pygments.lexers.BashLexer,
"go": pygments.lexers.GoLexer,
"groovy": pygments.lexers.GroovyLexer,
"haskell": pygments.lexers.HaskellLexer,
"java": pygments.lexers.JavaLexer,
"js": pygments.lexers.JavascriptLexer,
"julia": pygments.lexers.JuliaLexer,
"kotlin": pygments.lexers.KotlinLexer,
"latex": pygments.lexers.TexLexer,
"lisp": pygments.lexers.CommonLispLexer,
"lua": pygments.lexers.LuaLexer,
"mathematica": pygments.lexers.MathematicaLexer,
"matlab": pygments.lexers.MatlabLexer,
"mongo": pygments.lexers.JavascriptLexer,
"nim": pygments.lexers.NimrodLexer,
"objective-c": pygments.lexers.ObjectiveCppLexer,
"ocaml": pygments.lexers.OcamlLexer,
"octave": pygments.lexers.OctaveLexer,
"perl": pygments.lexers.PerlLexer,
"perl6": pygments.lexers.Perl6Lexer,
"php": pygments.lexers.PhpLexer,
"psql": pygments.lexers.PostgresLexer,
"python": pygments.lexers.PythonLexer,
"python3": pygments.lexers.Python3Lexer,
"r": pygments.lexers.SLexer,
"racket": pygments.lexers.RacketLexer,
"ruby": pygments.lexers.RubyLexer,
"rust": pygments.lexers.RustLexer,
"solidity": pygments.lexers.JavascriptLexer,
"scala": pygments.lexers.ScalaLexer,
"scheme": pygments.lexers.SchemeLexer,
"psql": pygments.lexers.SqlLexer,
"sql": pygments.lexers.SqlLexer,
"swift": pygments.lexers.SwiftLexer,
"tcl": pygments.lexers.TclLexer,
"tcsh": pygments.lexers.TcshLexer,
"vb": pygments.lexers.VbNetLexer,
"vbnet": pygments.lexers.VbNetLexer,
"vim": pygments.lexers.VimLexer,
# experimental
"arduino": pygments.lexers.ArduinoLexer,
"pike": pygments.lexers.PikeLexer,
"eiffel": pygments.lexers.EiffelLexer,
"clean": pygments.lexers.CleanLexer,
"dylan": pygments.lexers.DylanLexer,
# not languages
"cmake": pygments.lexers.CMakeLexer,
"django": pygments.lexers.PythonLexer,
"flask": pygments.lexers.PythonLexer,
}
# canonical names are on the right side
LANGUAGE_ALIAS = {
"asm": "assembly",
"assembler": "assembly",
"c++": "cpp",
"c#": "csharp",
"clisp": "lisp",
"coffeescript": "coffee",
"cplusplus": "cpp",
"dlang": "d",
"f#": "fsharp",
"golang": "go",
"javascript": "js",
"objc": "objective-c",
"p6": "perl6",
"sh": "bash",
"visualbasic": "vb",
"vba": "vb",
"wolfram": "mathematica",
"mma": "mathematica",
"wolfram-mathematica": "mathematica",
"m": "octave",
}
VIM_NAME = {
"assembly": "asm",
"bash": "sh",
"coffeescript": "coffee",
"csharp": "cs",
"delphi": "pascal",
"dlang": "d",
"elisp": "newlisp",
"latex": "tex",
"forth": "fs",
"nim": "nimrod",
"perl6": "perl",
"python3": "python",
"python-3.x": "python",
"tcsh": "sh",
"solidity": "js",
"mathematica": "mma",
"wolfram-mathematica": "mma",
"psql": "sql",
# not languages
"cmake": "sh",
"git": "sh",
"django": "python",
"flask": "python",
}
SO_NAME = {
"coffee": "coffeescript",
"js": "javascript",
"python3": "python-3.x",
"vb": "vba",
"mathematica": "wolfram-mathematica",
}
#
# conversion of internal programmin language names
# into canonical cheat.sh names
#
ATOM_FT_NAME = {}
EMACS_FT_NAME = {
"asm-mode": "asm",
"awk-mode": "awk",
"sh-mode": "bash",
# basic
"brainfuck-mode": "bf",
# chapel
"clojure-mode": "clojure",
"coffee-mode": "coffee",
"c++-mode": "cpp",
"c-mode": "c",
"csharp-mode": "csharp",
"d-mode": "d",
"dart-mode": "dart",
"dylan-mode": "dylan",
"delphi-mode": "delphi",
"emacs-lisp-mode": "elisp",
# elixir
"elm-mode": "elm",
"erlang-mode": "erlang",
# factor
"forth-mode": "forth",
"fortran-mode": "fortran",
"fsharp-mode": "fsharp",
"go-mode": "go",
"groovy-mode": "groovy",
"haskell-mode": "haskell",
# "hy-mode"
"java-mode": "java",
"js-jsx-mode": "js",
"js-mode": "js",
"js2-jsx-mode": "js",
"js2-mode": "js",
"julia-mode": "julia",
"kotlin-mode": "kotlin",
"lisp-interaction-mode": "lisp",
"lisp-mode": "lisp",
"lua-mode": "lua",
# mathematica
"matlab-mode": "matlab",
# mongo
"objc-mode": "objective-c",
# ocaml
"perl-mode": "perl",
"perl6-mode": "perl6",
"php-mode": "php",
# psql
"python-mode": "python",
# python3
# r -- ess looks it, but I don't know the mode name off hand
"racket-mode": "racket",
"ruby-mode": "ruby",
"rust-mode": "rust",
"solidity-mode": "solidity",
"scala-mode": "scala",
"scheme-mode": "scheme",
"sql-mode": "sql",
"swift-mode": "swift",
"tcl-mode": "tcl",
# tcsh
"visual-basic-mode": "vb",
# vbnet
# vim
}
SUBLIME_FT_NAME = {}
VIM_FT_NAME = {
"asm": "assembler",
"javascript": "js",
"octave": "matlab",
}
VSCODE_FT_NAME = {}
def rewrite_editor_section_name(section_name):
"""
section name cen be specified in form "editor:editor-filetype"
and it will be rewritten into form "filetype"
basing on the editor filetypes names data.
If editor name is unknown, it is just cut off: notepad:js => js
Known editors:
* atom
* vim
* emacs
* sublime
* vscode
>>> rewrite_editor_section_name('js')
'js'
>>> rewrite_editor_section_name('vscode:js')
'js'
"""
if ":" not in section_name:
return section_name
editor_name, section_name = section_name.split(":", 1)
editor_name_mapping = {
"atom": ATOM_FT_NAME,
"emacs": EMACS_FT_NAME,
"sublime": SUBLIME_FT_NAME,
"vim": VIM_FT_NAME,
"vscode": VSCODE_FT_NAME,
}
if editor_name not in editor_name_mapping:
return section_name
return editor_name_mapping[editor_name].get(section_name, section_name)
def get_lexer_name(section_name):
"""
Rewrite `section_name` for the further lexer search (for syntax highlighting)
"""
if ":" in section_name:
section_name = rewrite_editor_section_name(section_name)
return LANGUAGE_ALIAS.get(section_name, section_name)
if __name__ == "__main__":
import doctest
doctest.testmod()
================================================
FILE: lib/limits.py
================================================
"""
Connection limitation.
Number of connections from one IP is limited.
We have nothing against scripting and automated queries.
Even the opposite, we encourage them. But there are some
connection limits that even we can't handle.
Currently the limits are quite restrictive, but they will be relaxed
in the future.
Usage:
limits = Limits()
not_allowed = limits.check_ip(ip_address)
if not_allowed:
return "ERROR: %s" % not_allowed
"""
import time
from globals import log
_WHITELIST = ["5.9.243.177"]
def _time_caps(minutes, hours, days):
return {
"min": minutes,
"hour": hours,
"day": days,
}
class Limits(object):
"""
Queries limitation (by IP).
Exports:
check_ip(ip_address)
"""
def __init__(self):
self.intervals = ["min", "hour", "day"]
self.divisor = _time_caps(60, 3600, 86400)
self.limit = _time_caps(30, 600, 1000)
self.last_update = _time_caps(0, 0, 0)
self.counter = {
"min": {},
"hour": {},
"day": {},
}
self._clear_counters_if_needed()
def _log_visit(self, interval, ip_address):
if ip_address not in self.counter[interval]:
self.counter[interval][ip_address] = 0
self.counter[interval][ip_address] += 1
def _limit_exceeded(self, interval, ip_address):
visits = self.counter[interval][ip_address]
limit = self._get_limit(interval)
return visits > limit
def _get_limit(self, interval):
return self.limit[interval]
def _report_excessive_visits(self, interval, ip_address):
log(
"%s LIMITED [%s for %s]" % (ip_address, self._get_limit(interval), interval)
)
def check_ip(self, ip_address):
"""
Check if `ip_address` is allowed, and if not raise an RuntimeError exception.
Return True otherwise
"""
if ip_address in _WHITELIST:
return None
self._clear_counters_if_needed()
for interval in self.intervals:
self._log_visit(interval, ip_address)
if self._limit_exceeded(interval, ip_address):
self._report_excessive_visits(interval, ip_address)
return "Not so fast! Number of queries per %s is limited to %s" % (
interval,
self._get_limit(interval),
)
return None
def reset(self):
"""
Reset all counters for all IPs
"""
for interval in self.intervals:
self.counter[interval] = {}
def _clear_counters_if_needed(self):
current_time = int(time.time())
for interval in self.intervals:
if current_time // self.divisor[interval] != self.last_update[interval]:
self.counter[interval] = {}
self.last_update[interval] = current_time / self.divisor[interval]
================================================
FILE: lib/options.py
================================================
"""
Parse query arguments.
"""
def parse_args(args):
"""
Parse arguments and options.
Replace short options with their long counterparts.
"""
result = {
"add_comments": True,
}
query = ""
newargs = {}
for key, val in args.items():
if val == "" or val == [] or val == [""]:
query += key
continue
if val == "True":
val = True
if val == "False":
val = False
newargs[key] = val
options_meaning = {
"c": dict(add_comments=False, unindent_code=False),
"C": dict(add_comments=False, unindent_code=True),
"Q": dict(remove_text=True),
"q": dict(quiet=True),
"T": {"no-terminal": True},
}
for option, meaning in options_meaning.items():
if option in query:
result.update(meaning)
result.update(newargs)
return result
================================================
FILE: lib/panela/colors.json
================================================
[{"colorId":0,"hexString":"#000000","rgb":{"r":0,"g":0,"b":0},"hsl":{"h":0,"s":0,"l":0},"name":"Black"},{"colorId":1,"hexString":"#800000","rgb":{"r":128,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":25},"name":"Maroon"},{"colorId":2,"hexString":"#008000","rgb":{"r":0,"g":128,"b":0},"hsl":{"h":120,"s":100,"l":25},"name":"Green"},{"colorId":3,"hexString":"#808000","rgb":{"r":128,"g":128,"b":0},"hsl":{"h":60,"s":100,"l":25},"name":"Olive"},{"colorId":4,"hexString":"#000080","rgb":{"r":0,"g":0,"b":128},"hsl":{"h":240,"s":100,"l":25},"name":"Navy"},{"colorId":5,"hexString":"#800080","rgb":{"r":128,"g":0,"b":128},"hsl":{"h":300,"s":100,"l":25},"name":"Purple"},{"colorId":6,"hexString":"#008080","rgb":{"r":0,"g":128,"b":128},"hsl":{"h":180,"s":100,"l":25},"name":"Teal"},{"colorId":7,"hexString":"#c0c0c0","rgb":{"r":192,"g":192,"b":192},"hsl":{"h":0,"s":0,"l":75},"name":"Silver"},{"colorId":8,"hexString":"#808080","rgb":{"r":128,"g":128,"b":128},"hsl":{"h":0,"s":0,"l":50},"name":"Grey"},{"colorId":9,"hexString":"#ff0000","rgb":{"r":255,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":50},"name":"Red"},{"colorId":10,"hexString":"#00ff00","rgb":{"r":0,"g":255,"b":0},"hsl":{"h":120,"s":100,"l":50},"name":"Lime"},{"colorId":11,"hexString":"#ffff00","rgb":{"r":255,"g":255,"b":0},"hsl":{"h":60,"s":100,"l":50},"name":"Yellow"},{"colorId":12,"hexString":"#0000ff","rgb":{"r":0,"g":0,"b":255},"hsl":{"h":240,"s":100,"l":50},"name":"Blue"},{"colorId":13,"hexString":"#ff00ff","rgb":{"r":255,"g":0,"b":255},"hsl":{"h":300,"s":100,"l":50},"name":"Fuchsia"},{"colorId":14,"hexString":"#00ffff","rgb":{"r":0,"g":255,"b":255},"hsl":{"h":180,"s":100,"l":50},"name":"Aqua"},{"colorId":15,"hexString":"#ffffff","rgb":{"r":255,"g":255,"b":255},"hsl":{"h":0,"s":0,"l":100},"name":"White"},{"colorId":16,"hexString":"#000000","rgb":{"r":0,"g":0,"b":0},"hsl":{"h":0,"s":0,"l":0},"name":"Grey0"},{"colorId":17,"hexString":"#00005f","rgb":{"r":0,"g":0,"b":95},"hsl":{"h":240,"s":100,"l":18},"name":"NavyBlue"},{"colorId":18,"hexString":"#000087","rgb":{"r":0,"g":0,"b":135},"hsl":{"h":240,"s":100,"l":26},"name":"DarkBlue"},{"colorId":19,"hexString":"#0000af","rgb":{"r":0,"g":0,"b":175},"hsl":{"h":240,"s":100,"l":34},"name":"Blue3"},{"colorId":20,"hexString":"#0000d7","rgb":{"r":0,"g":0,"b":215},"hsl":{"h":240,"s":100,"l":42},"name":"Blue3"},{"colorId":21,"hexString":"#0000ff","rgb":{"r":0,"g":0,"b":255},"hsl":{"h":240,"s":100,"l":50},"name":"Blue1"},{"colorId":22,"hexString":"#005f00","rgb":{"r":0,"g":95,"b":0},"hsl":{"h":120,"s":100,"l":18},"name":"DarkGreen"},{"colorId":23,"hexString":"#005f5f","rgb":{"r":0,"g":95,"b":95},"hsl":{"h":180,"s":100,"l":18},"name":"DeepSkyBlue4"},{"colorId":24,"hexString":"#005f87","rgb":{"r":0,"g":95,"b":135},"hsl":{"h":197.777777777778,"s":100,"l":26},"name":"DeepSkyBlue4"},{"colorId":25,"hexString":"#005faf","rgb":{"r":0,"g":95,"b":175},"hsl":{"h":207.428571428571,"s":100,"l":34},"name":"DeepSkyBlue4"},{"colorId":26,"hexString":"#005fd7","rgb":{"r":0,"g":95,"b":215},"hsl":{"h":213.488372093023,"s":100,"l":42},"name":"DodgerBlue3"},{"colorId":27,"hexString":"#005fff","rgb":{"r":0,"g":95,"b":255},"hsl":{"h":217.647058823529,"s":100,"l":50},"name":"DodgerBlue2"},{"colorId":28,"hexString":"#008700","rgb":{"r":0,"g":135,"b":0},"hsl":{"h":120,"s":100,"l":26},"name":"Green4"},{"colorId":29,"hexString":"#00875f","rgb":{"r":0,"g":135,"b":95},"hsl":{"h":162.222222222222,"s":100,"l":26},"name":"SpringGreen4"},{"colorId":30,"hexString":"#008787","rgb":{"r":0,"g":135,"b":135},"hsl":{"h":180,"s":100,"l":26},"name":"Turquoise4"},{"colorId":31,"hexString":"#0087af","rgb":{"r":0,"g":135,"b":175},"hsl":{"h":193.714285714286,"s":100,"l":34},"name":"DeepSkyBlue3"},{"colorId":32,"hexString":"#0087d7","rgb":{"r":0,"g":135,"b":215},"hsl":{"h":202.325581395349,"s":100,"l":42},"name":"DeepSkyBlue3"},{"colorId":33,"hexString":"#0087ff","rgb":{"r":0,"g":135,"b":255},"hsl":{"h":208.235294117647,"s":100,"l":50},"name":"DodgerBlue1"},{"colorId":34,"hexString":"#00af00","rgb":{"r":0,"g":175,"b":0},"hsl":{"h":120,"s":100,"l":34},"name":"Green3"},{"colorId":35,"hexString":"#00af5f","rgb":{"r":0,"g":175,"b":95},"hsl":{"h":152.571428571429,"s":100,"l":34},"name":"SpringGreen3"},{"colorId":36,"hexString":"#00af87","rgb":{"r":0,"g":175,"b":135},"hsl":{"h":166.285714285714,"s":100,"l":34},"name":"DarkCyan"},{"colorId":37,"hexString":"#00afaf","rgb":{"r":0,"g":175,"b":175},"hsl":{"h":180,"s":100,"l":34},"name":"LightSeaGreen"},{"colorId":38,"hexString":"#00afd7","rgb":{"r":0,"g":175,"b":215},"hsl":{"h":191.162790697674,"s":100,"l":42},"name":"DeepSkyBlue2"},{"colorId":39,"hexString":"#00afff","rgb":{"r":0,"g":175,"b":255},"hsl":{"h":198.823529411765,"s":100,"l":50},"name":"DeepSkyBlue1"},{"colorId":40,"hexString":"#00d700","rgb":{"r":0,"g":215,"b":0},"hsl":{"h":120,"s":100,"l":42},"name":"Green3"},{"colorId":41,"hexString":"#00d75f","rgb":{"r":0,"g":215,"b":95},"hsl":{"h":146.511627906977,"s":100,"l":42},"name":"SpringGreen3"},{"colorId":42,"hexString":"#00d787","rgb":{"r":0,"g":215,"b":135},"hsl":{"h":157.674418604651,"s":100,"l":42},"name":"SpringGreen2"},{"colorId":43,"hexString":"#00d7af","rgb":{"r":0,"g":215,"b":175},"hsl":{"h":168.837209302326,"s":100,"l":42},"name":"Cyan3"},{"colorId":44,"hexString":"#00d7d7","rgb":{"r":0,"g":215,"b":215},"hsl":{"h":180,"s":100,"l":42},"name":"DarkTurquoise"},{"colorId":45,"hexString":"#00d7ff","rgb":{"r":0,"g":215,"b":255},"hsl":{"h":189.411764705882,"s":100,"l":50},"name":"Turquoise2"},{"colorId":46,"hexString":"#00ff00","rgb":{"r":0,"g":255,"b":0},"hsl":{"h":120,"s":100,"l":50},"name":"Green1"},{"colorId":47,"hexString":"#00ff5f","rgb":{"r":0,"g":255,"b":95},"hsl":{"h":142.352941176471,"s":100,"l":50},"name":"SpringGreen2"},{"colorId":48,"hexString":"#00ff87","rgb":{"r":0,"g":255,"b":135},"hsl":{"h":151.764705882353,"s":100,"l":50},"name":"SpringGreen1"},{"colorId":49,"hexString":"#00ffaf","rgb":{"r":0,"g":255,"b":175},"hsl":{"h":161.176470588235,"s":100,"l":50},"name":"MediumSpringGreen"},{"colorId":50,"hexString":"#00ffd7","rgb":{"r":0,"g":255,"b":215},"hsl":{"h":170.588235294118,"s":100,"l":50},"name":"Cyan2"},{"colorId":51,"hexString":"#00ffff","rgb":{"r":0,"g":255,"b":255},"hsl":{"h":180,"s":100,"l":50},"name":"Cyan1"},{"colorId":52,"hexString":"#5f0000","rgb":{"r":95,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":18},"name":"DarkRed"},{"colorId":53,"hexString":"#5f005f","rgb":{"r":95,"g":0,"b":95},"hsl":{"h":300,"s":100,"l":18},"name":"DeepPink4"},{"colorId":54,"hexString":"#5f0087","rgb":{"r":95,"g":0,"b":135},"hsl":{"h":282.222222222222,"s":100,"l":26},"name":"Purple4"},{"colorId":55,"hexString":"#5f00af","rgb":{"r":95,"g":0,"b":175},"hsl":{"h":272.571428571429,"s":100,"l":34},"name":"Purple4"},{"colorId":56,"hexString":"#5f00d7","rgb":{"r":95,"g":0,"b":215},"hsl":{"h":266.511627906977,"s":100,"l":42},"name":"Purple3"},{"colorId":57,"hexString":"#5f00ff","rgb":{"r":95,"g":0,"b":255},"hsl":{"h":262.352941176471,"s":100,"l":50},"name":"BlueViolet"},{"colorId":58,"hexString":"#5f5f00","rgb":{"r":95,"g":95,"b":0},"hsl":{"h":60,"s":100,"l":18},"name":"Orange4"},{"colorId":59,"hexString":"#5f5f5f","rgb":{"r":95,"g":95,"b":95},"hsl":{"h":0,"s":0,"l":37},"name":"Grey37"},{"colorId":60,"hexString":"#5f5f87","rgb":{"r":95,"g":95,"b":135},"hsl":{"h":240,"s":17,"l":45},"name":"MediumPurple4"},{"colorId":61,"hexString":"#5f5faf","rgb":{"r":95,"g":95,"b":175},"hsl":{"h":240,"s":33,"l":52},"name":"SlateBlue3"},{"colorId":62,"hexString":"#5f5fd7","rgb":{"r":95,"g":95,"b":215},"hsl":{"h":240,"s":60,"l":60},"name":"SlateBlue3"},{"colorId":63,"hexString":"#5f5fff","rgb":{"r":95,"g":95,"b":255},"hsl":{"h":240,"s":100,"l":68},"name":"RoyalBlue1"},{"colorId":64,"hexString":"#5f8700","rgb":{"r":95,"g":135,"b":0},"hsl":{"h":77.7777777777778,"s":100,"l":26},"name":"Chartreuse4"},{"colorId":65,"hexString":"#5f875f","rgb":{"r":95,"g":135,"b":95},"hsl":{"h":120,"s":17,"l":45},"name":"DarkSeaGreen4"},{"colorId":66,"hexString":"#5f8787","rgb":{"r":95,"g":135,"b":135},"hsl":{"h":180,"s":17,"l":45},"name":"PaleTurquoise4"},{"colorId":67,"hexString":"#5f87af","rgb":{"r":95,"g":135,"b":175},"hsl":{"h":210,"s":33,"l":52},"name":"SteelBlue"},{"colorId":68,"hexString":"#5f87d7","rgb":{"r":95,"g":135,"b":215},"hsl":{"h":220,"s":60,"l":60},"name":"SteelBlue3"},{"colorId":69,"hexString":"#5f87ff","rgb":{"r":95,"g":135,"b":255},"hsl":{"h":225,"s":100,"l":68},"name":"CornflowerBlue"},{"colorId":70,"hexString":"#5faf00","rgb":{"r":95,"g":175,"b":0},"hsl":{"h":87.4285714285714,"s":100,"l":34},"name":"Chartreuse3"},{"colorId":71,"hexString":"#5faf5f","rgb":{"r":95,"g":175,"b":95},"hsl":{"h":120,"s":33,"l":52},"name":"DarkSeaGreen4"},{"colorId":72,"hexString":"#5faf87","rgb":{"r":95,"g":175,"b":135},"hsl":{"h":150,"s":33,"l":52},"name":"CadetBlue"},{"colorId":73,"hexString":"#5fafaf","rgb":{"r":95,"g":175,"b":175},"hsl":{"h":180,"s":33,"l":52},"name":"CadetBlue"},{"colorId":74,"hexString":"#5fafd7","rgb":{"r":95,"g":175,"b":215},"hsl":{"h":200,"s":60,"l":60},"name":"SkyBlue3"},{"colorId":75,"hexString":"#5fafff","rgb":{"r":95,"g":175,"b":255},"hsl":{"h":210,"s":100,"l":68},"name":"SteelBlue1"},{"colorId":76,"hexString":"#5fd700","rgb":{"r":95,"g":215,"b":0},"hsl":{"h":93.4883720930233,"s":100,"l":42},"name":"Chartreuse3"},{"colorId":77,"hexString":"#5fd75f","rgb":{"r":95,"g":215,"b":95},"hsl":{"h":120,"s":60,"l":60},"name":"PaleGreen3"},{"colorId":78,"hexString":"#5fd787","rgb":{"r":95,"g":215,"b":135},"hsl":{"h":140,"s":60,"l":60},"name":"SeaGreen3"},{"colorId":79,"hexString":"#5fd7af","rgb":{"r":95,"g":215,"b":175},"hsl":{"h":160,"s":60,"l":60},"name":"Aquamarine3"},{"colorId":80,"hexString":"#5fd7d7","rgb":{"r":95,"g":215,"b":215},"hsl":{"h":180,"s":60,"l":60},"name":"MediumTurquoise"},{"colorId":81,"hexString":"#5fd7ff","rgb":{"r":95,"g":215,"b":255},"hsl":{"h":195,"s":100,"l":68},"name":"SteelBlue1"},{"colorId":82,"hexString":"#5fff00","rgb":{"r":95,"g":255,"b":0},"hsl":{"h":97.6470588235294,"s":100,"l":50},"name":"Chartreuse2"},{"colorId":83,"hexString":"#5fff5f","rgb":{"r":95,"g":255,"b":95},"hsl":{"h":120,"s":100,"l":68},"name":"SeaGreen2"},{"colorId":84,"hexString":"#5fff87","rgb":{"r":95,"g":255,"b":135},"hsl":{"h":135,"s":100,"l":68},"name":"SeaGreen1"},{"colorId":85,"hexString":"#5fffaf","rgb":{"r":95,"g":255,"b":175},"hsl":{"h":150,"s":100,"l":68},"name":"SeaGreen1"},{"colorId":86,"hexString":"#5fffd7","rgb":{"r":95,"g":255,"b":215},"hsl":{"h":165,"s":100,"l":68},"name":"Aquamarine1"},{"colorId":87,"hexString":"#5fffff","rgb":{"r":95,"g":255,"b":255},"hsl":{"h":180,"s":100,"l":68},"name":"DarkSlateGray2"},{"colorId":88,"hexString":"#870000","rgb":{"r":135,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":26},"name":"DarkRed"},{"colorId":89,"hexString":"#87005f","rgb":{"r":135,"g":0,"b":95},"hsl":{"h":317.777777777778,"s":100,"l":26},"name":"DeepPink4"},{"colorId":90,"hexString":"#870087","rgb":{"r":135,"g":0,"b":135},"hsl":{"h":300,"s":100,"l":26},"name":"DarkMagenta"},{"colorId":91,"hexString":"#8700af","rgb":{"r":135,"g":0,"b":175},"hsl":{"h":286.285714285714,"s":100,"l":34},"name":"DarkMagenta"},{"colorId":92,"hexString":"#8700d7","rgb":{"r":135,"g":0,"b":215},"hsl":{"h":277.674418604651,"s":100,"l":42},"name":"DarkViolet"},{"colorId":93,"hexString":"#8700ff","rgb":{"r":135,"g":0,"b":255},"hsl":{"h":271.764705882353,"s":100,"l":50},"name":"Purple"},{"colorId":94,"hexString":"#875f00","rgb":{"r":135,"g":95,"b":0},"hsl":{"h":42.2222222222222,"s":100,"l":26},"name":"Orange4"},{"colorId":95,"hexString":"#875f5f","rgb":{"r":135,"g":95,"b":95},"hsl":{"h":0,"s":17,"l":45},"name":"LightPink4"},{"colorId":96,"hexString":"#875f87","rgb":{"r":135,"g":95,"b":135},"hsl":{"h":300,"s":17,"l":45},"name":"Plum4"},{"colorId":97,"hexString":"#875faf","rgb":{"r":135,"g":95,"b":175},"hsl":{"h":270,"s":33,"l":52},"name":"MediumPurple3"},{"colorId":98,"hexString":"#875fd7","rgb":{"r":135,"g":95,"b":215},"hsl":{"h":260,"s":60,"l":60},"name":"MediumPurple3"},{"colorId":99,"hexString":"#875fff","rgb":{"r":135,"g":95,"b":255},"hsl":{"h":255,"s":100,"l":68},"name":"SlateBlue1"},{"colorId":100,"hexString":"#878700","rgb":{"r":135,"g":135,"b":0},"hsl":{"h":60,"s":100,"l":26},"name":"Yellow4"},{"colorId":101,"hexString":"#87875f","rgb":{"r":135,"g":135,"b":95},"hsl":{"h":60,"s":17,"l":45},"name":"Wheat4"},{"colorId":102,"hexString":"#878787","rgb":{"r":135,"g":135,"b":135},"hsl":{"h":0,"s":0,"l":52},"name":"Grey53"},{"colorId":103,"hexString":"#8787af","rgb":{"r":135,"g":135,"b":175},"hsl":{"h":240,"s":20,"l":60},"name":"LightSlateGrey"},{"colorId":104,"hexString":"#8787d7","rgb":{"r":135,"g":135,"b":215},"hsl":{"h":240,"s":50,"l":68},"name":"MediumPurple"},{"colorId":105,"hexString":"#8787ff","rgb":{"r":135,"g":135,"b":255},"hsl":{"h":240,"s":100,"l":76},"name":"LightSlateBlue"},{"colorId":106,"hexString":"#87af00","rgb":{"r":135,"g":175,"b":0},"hsl":{"h":73.7142857142857,"s":100,"l":34},"name":"Yellow4"},{"colorId":107,"hexString":"#87af5f","rgb":{"r":135,"g":175,"b":95},"hsl":{"h":90,"s":33,"l":52},"name":"DarkOliveGreen3"},{"colorId":108,"hexString":"#87af87","rgb":{"r":135,"g":175,"b":135},"hsl":{"h":120,"s":20,"l":60},"name":"DarkSeaGreen"},{"colorId":109,"hexString":"#87afaf","rgb":{"r":135,"g":175,"b":175},"hsl":{"h":180,"s":20,"l":60},"name":"LightSkyBlue3"},{"colorId":110,"hexString":"#87afd7","rgb":{"r":135,"g":175,"b":215},"hsl":{"h":210,"s":50,"l":68},"name":"LightSkyBlue3"},{"colorId":111,"hexString":"#87afff","rgb":{"r":135,"g":175,"b":255},"hsl":{"h":220,"s":100,"l":76},"name":"SkyBlue2"},{"colorId":112,"hexString":"#87d700","rgb":{"r":135,"g":215,"b":0},"hsl":{"h":82.3255813953488,"s":100,"l":42},"name":"Chartreuse2"},{"colorId":113,"hexString":"#87d75f","rgb":{"r":135,"g":215,"b":95},"hsl":{"h":100,"s":60,"l":60},"name":"DarkOliveGreen3"},{"colorId":114,"hexString":"#87d787","rgb":{"r":135,"g":215,"b":135},"hsl":{"h":120,"s":50,"l":68},"name":"PaleGreen3"},{"colorId":115,"hexString":"#87d7af","rgb":{"r":135,"g":215,"b":175},"hsl":{"h":150,"s":50,"l":68},"name":"DarkSeaGreen3"},{"colorId":116,"hexString":"#87d7d7","rgb":{"r":135,"g":215,"b":215},"hsl":{"h":180,"s":50,"l":68},"name":"DarkSlateGray3"},{"colorId":117,"hexString":"#87d7ff","rgb":{"r":135,"g":215,"b":255},"hsl":{"h":200,"s":100,"l":76},"name":"SkyBlue1"},{"colorId":118,"hexString":"#87ff00","rgb":{"r":135,"g":255,"b":0},"hsl":{"h":88.2352941176471,"s":100,"l":50},"name":"Chartreuse1"},{"colorId":119,"hexString":"#87ff5f","rgb":{"r":135,"g":255,"b":95},"hsl":{"h":105,"s":100,"l":68},"name":"LightGreen"},{"colorId":120,"hexString":"#87ff87","rgb":{"r":135,"g":255,"b":135},"hsl":{"h":120,"s":100,"l":76},"name":"LightGreen"},{"colorId":121,"hexString":"#87ffaf","rgb":{"r":135,"g":255,"b":175},"hsl":{"h":140,"s":100,"l":76},"name":"PaleGreen1"},{"colorId":122,"hexString":"#87ffd7","rgb":{"r":135,"g":255,"b":215},"hsl":{"h":160,"s":100,"l":76},"name":"Aquamarine1"},{"colorId":123,"hexString":"#87ffff","rgb":{"r":135,"g":255,"b":255},"hsl":{"h":180,"s":100,"l":76},"name":"DarkSlateGray1"},{"colorId":124,"hexString":"#af0000","rgb":{"r":175,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":34},"name":"Red3"},{"colorId":125,"hexString":"#af005f","rgb":{"r":175,"g":0,"b":95},"hsl":{"h":327.428571428571,"s":100,"l":34},"name":"DeepPink4"},{"colorId":126,"hexString":"#af0087","rgb":{"r":175,"g":0,"b":135},"hsl":{"h":313.714285714286,"s":100,"l":34},"name":"MediumVioletRed"},{"colorId":127,"hexString":"#af00af","rgb":{"r":175,"g":0,"b":175},"hsl":{"h":300,"s":100,"l":34},"name":"Magenta3"},{"colorId":128,"hexString":"#af00d7","rgb":{"r":175,"g":0,"b":215},"hsl":{"h":288.837209302326,"s":100,"l":42},"name":"DarkViolet"},{"colorId":129,"hexString":"#af00ff","rgb":{"r":175,"g":0,"b":255},"hsl":{"h":281.176470588235,"s":100,"l":50},"name":"Purple"},{"colorId":130,"hexString":"#af5f00","rgb":{"r":175,"g":95,"b":0},"hsl":{"h":32.5714285714286,"s":100,"l":34},"name":"DarkOrange3"},{"colorId":131,"hexString":"#af5f5f","rgb":{"r":175,"g":95,"b":95},"hsl":{"h":0,"s":33,"l":52},"name":"IndianRed"},{"colorId":132,"hexString":"#af5f87","rgb":{"r":175,"g":95,"b":135},"hsl":{"h":330,"s":33,"l":52},"name":"HotPink3"},{"colorId":133,"hexString":"#af5faf","rgb":{"r":175,"g":95,"b":175},"hsl":{"h":300,"s":33,"l":52},"name":"MediumOrchid3"},{"colorId":134,"hexString":"#af5fd7","rgb":{"r":175,"g":95,"b":215},"hsl":{"h":280,"s":60,"l":60},"name":"MediumOrchid"},{"colorId":135,"hexString":"#af5fff","rgb":{"r":175,"g":95,"b":255},"hsl":{"h":270,"s":100,"l":68},"name":"MediumPurple2"},{"colorId":136,"hexString":"#af8700","rgb":{"r":175,"g":135,"b":0},"hsl":{"h":46.2857142857143,"s":100,"l":34},"name":"DarkGoldenrod"},{"colorId":137,"hexString":"#af875f","rgb":{"r":175,"g":135,"b":95},"hsl":{"h":30,"s":33,"l":52},"name":"LightSalmon3"},{"colorId":138,"hexString":"#af8787","rgb":{"r":175,"g":135,"b":135},"hsl":{"h":0,"s":20,"l":60},"name":"RosyBrown"},{"colorId":139,"hexString":"#af87af","rgb":{"r":175,"g":135,"b":175},"hsl":{"h":300,"s":20,"l":60},"name":"Grey63"},{"colorId":140,"hexString":"#af87d7","rgb":{"r":175,"g":135,"b":215},"hsl":{"h":270,"s":50,"l":68},"name":"MediumPurple2"},{"colorId":141,"hexString":"#af87ff","rgb":{"r":175,"g":135,"b":255},"hsl":{"h":260,"s":100,"l":76},"name":"MediumPurple1"},{"colorId":142,"hexString":"#afaf00","rgb":{"r":175,"g":175,"b":0},"hsl":{"h":60,"s":100,"l":34},"name":"Gold3"},{"colorId":143,"hexString":"#afaf5f","rgb":{"r":175,"g":175,"b":95},"hsl":{"h":60,"s":33,"l":52},"name":"DarkKhaki"},{"colorId":144,"hexString":"#afaf87","rgb":{"r":175,"g":175,"b":135},"hsl":{"h":60,"s":20,"l":60},"name":"NavajoWhite3"},{"colorId":145,"hexString":"#afafaf","rgb":{"r":175,"g":175,"b":175},"hsl":{"h":0,"s":0,"l":68},"name":"Grey69"},{"colorId":146,"hexString":"#afafd7","rgb":{"r":175,"g":175,"b":215},"hsl":{"h":240,"s":33,"l":76},"name":"LightSteelBlue3"},{"colorId":147,"hexString":"#afafff","rgb":{"r":175,"g":175,"b":255},"hsl":{"h":240,"s":100,"l":84},"name":"LightSteelBlue"},{"colorId":148,"hexString":"#afd700","rgb":{"r":175,"g":215,"b":0},"hsl":{"h":71.1627906976744,"s":100,"l":42},"name":"Yellow3"},{"colorId":149,"hexString":"#afd75f","rgb":{"r":175,"g":215,"b":95},"hsl":{"h":80,"s":60,"l":60},"name":"DarkOliveGreen3"},{"colorId":150,"hexString":"#afd787","rgb":{"r":175,"g":215,"b":135},"hsl":{"h":90,"s":50,"l":68},"name":"DarkSeaGreen3"},{"colorId":151,"hexString":"#afd7af","rgb":{"r":175,"g":215,"b":175},"hsl":{"h":120,"s":33,"l":76},"name":"DarkSeaGreen2"},{"colorId":152,"hexString":"#afd7d7","rgb":{"r":175,"g":215,"b":215},"hsl":{"h":180,"s":33,"l":76},"name":"LightCyan3"},{"colorId":153,"hexString":"#afd7ff","rgb":{"r":175,"g":215,"b":255},"hsl":{"h":210,"s":100,"l":84},"name":"LightSkyBlue1"},{"colorId":154,"hexString":"#afff00","rgb":{"r":175,"g":255,"b":0},"hsl":{"h":78.8235294117647,"s":100,"l":50},"name":"GreenYellow"},{"colorId":155,"hexString":"#afff5f","rgb":{"r":175,"g":255,"b":95},"hsl":{"h":90,"s":100,"l":68},"name":"DarkOliveGreen2"},{"colorId":156,"hexString":"#afff87","rgb":{"r":175,"g":255,"b":135},"hsl":{"h":100,"s":100,"l":76},"name":"PaleGreen1"},{"colorId":157,"hexString":"#afffaf","rgb":{"r":175,"g":255,"b":175},"hsl":{"h":120,"s":100,"l":84},"name":"DarkSeaGreen2"},{"colorId":158,"hexString":"#afffd7","rgb":{"r":175,"g":255,"b":215},"hsl":{"h":150,"s":100,"l":84},"name":"DarkSeaGreen1"},{"colorId":159,"hexString":"#afffff","rgb":{"r":175,"g":255,"b":255},"hsl":{"h":180,"s":100,"l":84},"name":"PaleTurquoise1"},{"colorId":160,"hexString":"#d70000","rgb":{"r":215,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":42},"name":"Red3"},{"colorId":161,"hexString":"#d7005f","rgb":{"r":215,"g":0,"b":95},"hsl":{"h":333.488372093023,"s":100,"l":42},"name":"DeepPink3"},{"colorId":162,"hexString":"#d70087","rgb":{"r":215,"g":0,"b":135},"hsl":{"h":322.325581395349,"s":100,"l":42},"name":"DeepPink3"},{"colorId":163,"hexString":"#d700af","rgb":{"r":215,"g":0,"b":175},"hsl":{"h":311.162790697674,"s":100,"l":42},"name":"Magenta3"},{"colorId":164,"hexString":"#d700d7","rgb":{"r":215,"g":0,"b":215},"hsl":{"h":300,"s":100,"l":42},"name":"Magenta3"},{"colorId":165,"hexString":"#d700ff","rgb":{"r":215,"g":0,"b":255},"hsl":{"h":290.588235294118,"s":100,"l":50},"name":"Magenta2"},{"colorId":166,"hexString":"#d75f00","rgb":{"r":215,"g":95,"b":0},"hsl":{"h":26.5116279069767,"s":100,"l":42},"name":"DarkOrange3"},{"colorId":167,"hexString":"#d75f5f","rgb":{"r":215,"g":95,"b":95},"hsl":{"h":0,"s":60,"l":60},"name":"IndianRed"},{"colorId":168,"hexString":"#d75f87","rgb":{"r":215,"g":95,"b":135},"hsl":{"h":340,"s":60,"l":60},"name":"HotPink3"},{"colorId":169,"hexString":"#d75faf","rgb":{"r":215,"g":95,"b":175},"hsl":{"h":320,"s":60,"l":60},"name":"HotPink2"},{"colorId":170,"hexString":"#d75fd7","rgb":{"r":215,"g":95,"b":215},"hsl":{"h":300,"s":60,"l":60},"name":"Orchid"},{"colorId":171,"hexString":"#d75fff","rgb":{"r":215,"g":95,"b":255},"hsl":{"h":285,"s":100,"l":68},"name":"MediumOrchid1"},{"colorId":172,"hexString":"#d78700","rgb":{"r":215,"g":135,"b":0},"hsl":{"h":37.6744186046512,"s":100,"l":42},"name":"Orange3"},{"colorId":173,"hexString":"#d7875f","rgb":{"r":215,"g":135,"b":95},"hsl":{"h":20,"s":60,"l":60},"name":"LightSalmon3"},{"colorId":174,"hexString":"#d78787","rgb":{"r":215,"g":135,"b":135},"hsl":{"h":0,"s":50,"l":68},"name":"LightPink3"},{"colorId":175,"hexString":"#d787af","rgb":{"r":215,"g":135,"b":175},"hsl":{"h":330,"s":50,"l":68},"name":"Pink3"},{"colorId":176,"hexString":"#d787d7","rgb":{"r":215,"g":135,"b":215},"hsl":{"h":300,"s":50,"l":68},"name":"Plum3"},{"colorId":177,"hexString":"#d787ff","rgb":{"r":215,"g":135,"b":255},"hsl":{"h":280,"s":100,"l":76},"name":"Violet"},{"colorId":178,"hexString":"#d7af00","rgb":{"r":215,"g":175,"b":0},"hsl":{"h":48.8372093023256,"s":100,"l":42},"name":"Gold3"},{"colorId":179,"hexString":"#d7af5f","rgb":{"r":215,"g":175,"b":95},"hsl":{"h":40,"s":60,"l":60},"name":"LightGoldenrod3"},{"colorId":180,"hexString":"#d7af87","rgb":{"r":215,"g":175,"b":135},"hsl":{"h":30,"s":50,"l":68},"name":"Tan"},{"colorId":181,"hexString":"#d7afaf","rgb":{"r":215,"g":175,"b":175},"hsl":{"h":0,"s":33,"l":76},"name":"MistyRose3"},{"colorId":182,"hexString":"#d7afd7","rgb":{"r":215,"g":175,"b":215},"hsl":{"h":300,"s":33,"l":76},"name":"Thistle3"},{"colorId":183,"hexString":"#d7afff","rgb":{"r":215,"g":175,"b":255},"hsl":{"h":270,"s":100,"l":84},"name":"Plum2"},{"colorId":184,"hexString":"#d7d700","rgb":{"r":215,"g":215,"b":0},"hsl":{"h":60,"s":100,"l":42},"name":"Yellow3"},{"colorId":185,"hexString":"#d7d75f","rgb":{"r":215,"g":215,"b":95},"hsl":{"h":60,"s":60,"l":60},"name":"Khaki3"},{"colorId":186,"hexString":"#d7d787","rgb":{"r":215,"g":215,"b":135},"hsl":{"h":60,"s":50,"l":68},"name":"LightGoldenrod2"},{"colorId":187,"hexString":"#d7d7af","rgb":{"r":215,"g":215,"b":175},"hsl":{"h":60,"s":33,"l":76},"name":"LightYellow3"},{"colorId":188,"hexString":"#d7d7d7","rgb":{"r":215,"g":215,"b":215},"hsl":{"h":0,"s":0,"l":84},"name":"Grey84"},{"colorId":189,"hexString":"#d7d7ff","rgb":{"r":215,"g":215,"b":255},"hsl":{"h":240,"s":100,"l":92},"name":"LightSteelBlue1"},{"colorId":190,"hexString":"#d7ff00","rgb":{"r":215,"g":255,"b":0},"hsl":{"h":69.4117647058823,"s":100,"l":50},"name":"Yellow2"},{"colorId":191,"hexString":"#d7ff5f","rgb":{"r":215,"g":255,"b":95},"hsl":{"h":75,"s":100,"l":68},"name":"DarkOliveGreen1"},{"colorId":192,"hexString":"#d7ff87","rgb":{"r":215,"g":255,"b":135},"hsl":{"h":80,"s":100,"l":76},"name":"DarkOliveGreen1"},{"colorId":193,"hexString":"#d7ffaf","rgb":{"r":215,"g":255,"b":175},"hsl":{"h":90,"s":100,"l":84},"name":"DarkSeaGreen1"},{"colorId":194,"hexString":"#d7ffd7","rgb":{"r":215,"g":255,"b":215},"hsl":{"h":120,"s":100,"l":92},"name":"Honeydew2"},{"colorId":195,"hexString":"#d7ffff","rgb":{"r":215,"g":255,"b":255},"hsl":{"h":180,"s":100,"l":92},"name":"LightCyan1"},{"colorId":196,"hexString":"#ff0000","rgb":{"r":255,"g":0,"b":0},"hsl":{"h":0,"s":100,"l":50},"name":"Red1"},{"colorId":197,"hexString":"#ff005f","rgb":{"r":255,"g":0,"b":95},"hsl":{"h":337.647058823529,"s":100,"l":50},"name":"DeepPink2"},{"colorId":198,"hexString":"#ff0087","rgb":{"r":255,"g":0,"b":135},"hsl":{"h":328.235294117647,"s":100,"l":50},"name":"DeepPink1"},{"colorId":199,"hexString":"#ff00af","rgb":{"r":255,"g":0,"b":175},"hsl":{"h":318.823529411765,"s":100,"l":50},"name":"DeepPink1"},{"colorId":200,"hexString":"#ff00d7","rgb":{"r":255,"g":0,"b":215},"hsl":{"h":309.411764705882,"s":100,"l":50},"name":"Magenta2"},{"colorId":201,"hexString":"#ff00ff","rgb":{"r":255,"g":0,"b":255},"hsl":{"h":300,"s":100,"l":50},"name":"Magenta1"},{"colorId":202,"hexString":"#ff5f00","rgb":{"r":255,"g":95,"b":0},"hsl":{"h":22.3529411764706,"s":100,"l":50},"name":"OrangeRed1"},{"colorId":203,"hexString":"#ff5f5f","rgb":{"r":255,"g":95,"b":95},"hsl":{"h":0,"s":100,"l":68},"name":"IndianRed1"},{"colorId":204,"hexString":"#ff5f87","rgb":{"r":255,"g":95,"b":135},"hsl":{"h":345,"s":100,"l":68},"name":"IndianRed1"},{"colorId":205,"hexString":"#ff5faf","rgb":{"r":255,"g":95,"b":175},"hsl":{"h":330,"s":100,"l":68},"name":"HotPink"},{"colorId":206,"hexString":"#ff5fd7","rgb":{"r":255,"g":95,"b":215},"hsl":{"h":315,"s":100,"l":68},"name":"HotPink"},{"colorId":207,"hexString":"#ff5fff","rgb":{"r":255,"g":95,"b":255},"hsl":{"h":300,"s":100,"l":68},"name":"MediumOrchid1"},{"colorId":208,"hexString":"#ff8700","rgb":{"r":255,"g":135,"b":0},"hsl":{"h":31.7647058823529,"s":100,"l":50},"name":"DarkOrange"},{"colorId":209,"hexString":"#ff875f","rgb":{"r":255,"g":135,"b":95},"hsl":{"h":15,"s":100,"l":68},"name":"Salmon1"},{"colorId":210,"hexString":"#ff8787","rgb":{"r":255,"g":135,"b":135},"hsl":{"h":0,"s":100,"l":76},"name":"LightCoral"},{"colorId":211,"hexString":"#ff87af","rgb":{"r":255,"g":135,"b":175},"hsl":{"h":340,"s":100,"l":76},"name":"PaleVioletRed1"},{"colorId":212,"hexString":"#ff87d7","rgb":{"r":255,"g":135,"b":215},"hsl":{"h":320,"s":100,"l":76},"name":"Orchid2"},{"colorId":213,"hexString":"#ff87ff","rgb":{"r":255,"g":135,"b":255},"hsl":{"h":300,"s":100,"l":76},"name":"Orchid1"},{"colorId":214,"hexString":"#ffaf00","rgb":{"r":255,"g":175,"b":0},"hsl":{"h":41.1764705882353,"s":100,"l":50},"name":"Orange1"},{"colorId":215,"hexString":"#ffaf5f","rgb":{"r":255,"g":175,"b":95},"hsl":{"h":30,"s":100,"l":68},"name":"SandyBrown"},{"colorId":216,"hexString":"#ffaf87","rgb":{"r":255,"g":175,"b":135},"hsl":{"h":20,"s":100,"l":76},"name":"LightSalmon1"},{"colorId":217,"hexString":"#ffafaf","rgb":{"r":255,"g":175,"b":175},"hsl":{"h":0,"s":100,"l":84},"name":"LightPink1"},{"colorId":218,"hexString":"#ffafd7","rgb":{"r":255,"g":175,"b":215},"hsl":{"h":330,"s":100,"l":84},"name":"Pink1"},{"colorId":219,"hexString":"#ffafff","rgb":{"r":255,"g":175,"b":255},"hsl":{"h":300,"s":100,"l":84},"name":"Plum1"},{"colorId":220,"hexString":"#ffd700","rgb":{"r":255,"g":215,"b":0},"hsl":{"h":50.5882352941176,"s":100,"l":50},"name":"Gold1"},{"colorId":221,"hexString":"#ffd75f","rgb":{"r":255,"g":215,"b":95},"hsl":{"h":45,"s":100,"l":68},"name":"LightGoldenrod2"},{"colorId":222,"hexString":"#ffd787","rgb":{"r":255,"g":215,"b":135},"hsl":{"h":40,"s":100,"l":76},"name":"LightGoldenrod2"},{"colorId":223,"hexString":"#ffd7af","rgb":{"r":255,"g":215,"b":175},"hsl":{"h":30,"s":100,"l":84},"name":"NavajoWhite1"},{"colorId":224,"hexString":"#ffd7d7","rgb":{"r":255,"g":215,"b":215},"hsl":{"h":0,"s":100,"l":92},"name":"MistyRose1"},{"colorId":225,"hexString":"#ffd7ff","rgb":{"r":255,"g":215,"b":255},"hsl":{"h":300,"s":100,"l":92},"name":"Thistle1"},{"colorId":226,"hexString":"#ffff00","rgb":{"r":255,"g":255,"b":0},"hsl":{"h":60,"s":100,"l":50},"name":"Yellow1"},{"colorId":227,"hexString":"#ffff5f","rgb":{"r":255,"g":255,"b":95},"hsl":{"h":60,"s":100,"l":68},"name":"LightGoldenrod1"},{"colorId":228,"hexString":"#ffff87","rgb":{"r":255,"g":255,"b":135},"hsl":{"h":60,"s":100,"l":76},"name":"Khaki1"},{"colorId":229,"hexString":"#ffffaf","rgb":{"r":255,"g":255,"b":175},"hsl":{"h":60,"s":100,"l":84},"name":"Wheat1"},{"colorId":230,"hexString":"#ffffd7","rgb":{"r":255,"g":255,"b":215},"hsl":{"h":60,"s":100,"l":92},"name":"Cornsilk1"},{"colorId":231,"hexString":"#ffffff","rgb":{"r":255,"g":255,"b":255},"hsl":{"h":0,"s":0,"l":100},"name":"Grey100"},{"colorId":232,"hexString":"#080808","rgb":{"r":8,"g":8,"b":8},"hsl":{"h":0,"s":0,"l":3},"name":"Grey3"},{"colorId":233,"hexString":"#121212","rgb":{"r":18,"g":18,"b":18},"hsl":{"h":0,"s":0,"l":7},"name":"Grey7"},{"colorId":234,"hexString":"#1c1c1c","rgb":{"r":28,"g":28,"b":28},"hsl":{"h":0,"s":0,"l":10},"name":"Grey11"},{"colorId":235,"hexString":"#262626","rgb":{"r":38,"g":38,"b":38},"hsl":{"h":0,"s":0,"l":14},"name":"Grey15"},{"colorId":236,"hexString":"#303030","rgb":{"r":48,"g":48,"b":48},"hsl":{"h":0,"s":0,"l":18},"name":"Grey19"},{"colorId":237,"hexString":"#3a3a3a","rgb":{"r":58,"g":58,"b":58},"hsl":{"h":0,"s":0,"l":22},"name":"Grey23"},{"colorId":238,"hexString":"#444444","rgb":{"r":68,"g":68,"b":68},"hsl":{"h":0,"s":0,"l":26},"name":"Grey27"},{"colorId":239,"hexString":"#4e4e4e","rgb":{"r":78,"g":78,"b":78},"hsl":{"h":0,"s":0,"l":30},"name":"Grey30"},{"colorId":240,"hexString":"#585858","rgb":{"r":88,"g":88,"b":88},"hsl":{"h":0,"s":0,"l":34},"name":"Grey35"},{"colorId":241,"hexString":"#626262","rgb":{"r":98,"g":98,"b":98},"hsl":{"h":0,"s":0,"l":37},"name":"Grey39"},{"colorId":242,"hexString":"#6c6c6c","rgb":{"r":108,"g":108,"b":108},"hsl":{"h":0,"s":0,"l":40},"name":"Grey42"},{"colorId":243,"hexString":"#767676","rgb":{"r":118,"g":118,"b":118},"hsl":{"h":0,"s":0,"l":46},"name":"Grey46"},{"colorId":244,"hexString":"#808080","rgb":{"r":128,"g":128,"b":128},"hsl":{"h":0,"s":0,"l":50},"name":"Grey50"},{"colorId":245,"hexString":"#8a8a8a","rgb":{"r":138,"g":138,"b":138},"hsl":{"h":0,"s":0,"l":54},"name":"Grey54"},{"colorId":246,"hexString":"#949494","rgb":{"r":148,"g":148,"b":148},"hsl":{"h":0,"s":0,"l":58},"name":"Grey58"},{"colorId":247,"hexString":"#9e9e9e","rgb":{"r":158,"g":158,"b":158},"hsl":{"h":0,"s":0,"l":61},"name":"Grey62"},{"colorId":248,"hexString":"#a8a8a8","rgb":{"r":168,"g":168,"b":168},"hsl":{"h":0,"s":0,"l":65},"name":"Grey66"},{"colorId":249,"hexString":"#b2b2b2","rgb":{"r":178,"g":178,"b":178},"hsl":{"h":0,"s":0,"l":69},"name":"Grey70"},{"colorId":250,"hexString":"#bcbcbc","rgb":{"r":188,"g":188,"b":188},"hsl":{"h":0,"s":0,"l":73},"name":"Grey74"},{"colorId":251,"hexString":"#c6c6c6","rgb":{"r":198,"g":198,"b":198},"hsl":{"h":0,"s":0,"l":77},"name":"Grey78"},{"colorId":252,"hexString":"#d0d0d0","rgb":{"r":208,"g":208,"b":208},"hsl":{"h":0,"s":0,"l":81},"name":"Grey82"},{"colorId":253,"hexString":"#dadada","rgb":{"r":218,"g":218,"b":218},"hsl":{"h":0,"s":0,"l":85},"name":"Grey85"},{"colorId":254,"hexString":"#e4e4e4","rgb":{"r":228,"g":228,"b":228},"hsl":{"h":0,"s":0,"l":89},"name":"Grey89"},{"colorId":255,"hexString":"#eeeeee","rgb":{"r":238,"g":238,"b":238},"hsl":{"h":0,"s":0,"l":93},"name":"Grey93"}]
================================================
FILE: lib/panela/colors.py
================================================
import os
import json
COLORS_JSON = os.path.join(os.path.dirname(os.path.abspath(__file__)), "colors.json")
COLOR_TABLE = json.loads(open(COLORS_JSON, "r").read())
VALID_COLORS = [x["hexString"] for x in COLOR_TABLE]
HEX_TO_ANSI = {x["hexString"]: x["colorId"] for x in COLOR_TABLE}
def rgb_from_str(s):
# s starts with a #.
r, g, b = int(s[1:3], 16), int(s[3:5], 16), int(s[5:7], 16)
return r, g, b
def find_nearest_color(hex_color):
R, G, B = rgb_from_str(hex_color)
mindiff = None
for d in VALID_COLORS:
r, g, b = rgb_from_str(d)
diff = abs(R - r) * 256 + abs(G - g) * 256 + abs(B - b) * 256
if mindiff is None or diff < mindiff:
mindiff = diff
mincolorname = d
return mincolorname
================================================
FILE: lib/panela/panela_colors.py
================================================
# vim: encoding=utf-8
import os
import sys
import colored
import itertools
from globals import MYDIR
"""
After panela will be ready for it, it will be split out in a separate project,
that will be used for all chubin's console services.
There are several features that not yet implemented (see ___doc___ in Panela)
TODO:
* html output
* png output
"""
from wcwidth import wcswidth
from colors import find_nearest_color, HEX_TO_ANSI, rgb_from_str
import pyte
# http://stackoverflow.com/questions/19782975/convert-rgb-color-to-the-nearest-color-in-palette-web-safe-color
try:
basestring # Python 2
except NameError:
basestring = str # Python 3
def color_mapping(clr):
if clr == "default":
return None
return clr
class Point(object):
"""
One point (character) on a terminal
"""
def __init__(self, char=None, foreground=None, background=None):
self.foreground = foreground
self.background = background
self.char = char
class Panela:
"""
To implement:
Blocks manipulation:
[*] copy
[*] crop
[*] cut
[*] extend
[ ] join
[ ] move
[*] paste
[*] strip
Colors manipulation:
[*] paint foreground/background
[*] paint_line
[ ] paint_svg
[ ] fill background
[ ] fill_line
[ ] fill_svg
[ ] trans
Drawing:
[*] put_point
[*] put_line
[*] put_circle
[*] put_rectangle
Printing and reading:
ansi reads vt100 sequence
"""
def __init__(self, x=80, y=25, panela=None, field=None):
if panela:
self.field = [x for x in panela.field]
self.size_x = panela.size_x
self.size_y = panela.size_y
return
if field:
self.field = field
self.size_x = len(field[0])
self.size_y = len(field)
return
self.field = [[Point() for _ in range(x)] for _ in range(y)]
self.size_x = x
self.size_y = y
def in_field(self, col, row):
if col < 0:
return False
if row < 0:
return False
if col >= self.size_x:
return False
if row >= self.size_y:
return False
return True
#
# Blocks manipulation
#
def copy(self, x1, y1, x2, y2):
if x1 < 0:
x1 += self.size_x
if x2 < 0:
x2 += self.size_x
if x1 > x2:
x1, x2 = x2, x1
if y1 < 0:
y1 += self.size_y
if y2 < 0:
y2 += self.size_y
if y1 > y2:
y1, y2 = y2, y1
field = [self.field[i] for i in range(y1, y2 + 1)]
field = [line[x1 : x2 + 1] for line in field]
return Panela(field=field)
def cut(self, x1, y1, x2, y2):
""" """
if x1 < 0:
x1 += self.size_x
if x2 < 0:
x2 += self.size_x
if x1 > x2:
x1, x2 = x2, x1
if y1 < 0:
y1 += self.size_y
if y2 < 0:
y2 += self.size_y
if y1 > y2:
y1, y2 = y2, y1
copied = self.copy(x1, y1, x2, y2)
for y in range(y1, y2 + 1):
for x in range(x1, x2 + 1):
self.field[y][x] = Point()
return copied
def extend(self, cols=None, rows=None):
"""
Adds [cols] columns from the right
and [rows] rows from the bottom
"""
if cols and cols > 0:
self.field = [x + [Point() for _ in range(cols)] for x in self.field]
self.size_x += cols
if rows and rows > 0:
self.field = self.field + [
[Point() for _ in range(self.size_x)] for _ in range(rows)
]
self.size_y += rows
def crop(self, left=None, right=None, top=None, bottom=None):
"""
Crop panela.
Remove , columns from left or right,
and and rows from top and bottom.
"""
if left:
if left >= self.size_x:
left = self.size_x
self.field = [x[left:] for x in self.field]
self.size_x -= left
if right:
if right >= self.size_x:
right = self.size_x
self.field = [x[:-right] for x in self.field]
self.size_x -= right
if top:
if top >= self.size_y:
top = self.size_y
self.field = self.field[top:]
self.size_y -= top
if bottom:
if bottom >= self.size_y:
bottom = self.size_y
self.field = self.field[:-bottom]
self.size_y -= bottom
def paste(self, panela, x1, y1, extend=False, transparence=False):
"""
Paste starting at , .
If is True current panela space will be automatically extended
If is True, then is overlaid and characters behind them are seen
"""
# FIXME:
# negative x1, y1
# x1,y1 > size_x, size_y
if extend:
x_extend = 0
y_extend = 0
if x1 + panela.size_x > self.size_x:
x_extend = x1 + panela.size_x - self.size_x
if y1 + panela.size_y > self.size_y:
y_extend = y1 + panela.size_y - self.size_y
self.extend(cols=x_extend, rows=y_extend)
for i in range(y1, min(self.size_y, y1 + panela.size_y)):
for j in range(x1, min(self.size_x, x1 + panela.size_x)):
if transparence:
if (
panela.field[i - y1][j - x1].char
and panela.field[i - y1][j - x1].char != " "
):
if panela.field[i - y1][j - x1].foreground:
self.field[i][j].foreground = panela.field[i - y1][
j - x1
].foreground
if panela.field[i - y1][j - x1].background:
self.field[i][j].background = panela.field[i - y1][
j - x1
].background
self.field[i][j].char = panela.field[i - y1][j - x1].char
else:
self.field[i][j] = panela.field[i - y1][j - x1]
def strip(self):
"""
Strip panela: remove empty spaces around panels rectangle
"""
def left_spaces(line):
answer = 0
for elem in line:
if not elem.char:
answer += 1
else:
break
return answer
def right_spaces(line):
return left_spaces(line[::-1])
def empty_line(line):
return left_spaces(line) == len(line)
left_space = []
right_space = []
for line in self.field:
left_space.append(left_spaces(line))
right_space.append(right_spaces(line))
left = min(left_space)
right = min(right_space)
top = 0
while top < self.size_y and empty_line(self.field[top]):
top += 1
bottom = 0
while bottom < self.size_y and empty_line(self.field[-(bottom + 1)]):
bottom += 1
self.crop(left=left, right=right, top=top, bottom=bottom)
#
# Drawing and painting
#
def put_point(self, col, row, char=None, color=None, background=None):
"""
Puts character with color and background color on the field.
Char can be a Point or a character.
"""
if not self.in_field(col, row):
return
if isinstance(char, Point):
self.field[row][col] = char
elif char is None:
if background:
self.field[row][col].background = background
if color:
self.field[row][col].foreground = color
else:
self.field[row][col] = Point(
char=char, foreground=color, background=background
)
def put_string(self, col, row, s=None, color=None, background=None):
"""
Put string with foreground color and background color
ad
"""
for i, c in enumerate(s):
self.put_point(col + i, row, c, color=color, background=background)
def put_line(self, x1, y1, x2, y2, char=None, color=None, background=None):
"""
Draw line (x1, y1) - (x2, y2) fill foreground color , background color
and character , if specified.
"""
def get_line(start, end):
"""Bresenham's Line Algorithm
Produces a list of tuples from start and end
Source: http://www.roguebasin.com/index.php?title=Bresenham%27s_Line_Algorithm#Python
>>> points1 = get_line((0, 0), (3, 4))
>>> points2 = get_line((3, 4), (0, 0))
>>> assert(set(points1) == set(points2))
>>> print points1
[(0, 0), (1, 1), (1, 2), (2, 3), (3, 4)]
>>> print points2
[(3, 4), (2, 3), (1, 2), (1, 1), (0, 0)]
"""
# Setup initial conditions
x1, y1 = start
x2, y2 = end
dx = x2 - x1
dy = y2 - y1
# Determine how steep the line is
is_steep = abs(dy) > abs(dx)
# Rotate line
if is_steep:
x1, y1 = y1, x1
x2, y2 = y2, x2
# Swap start and end points if necessary and store swap state
swapped = False
if x1 > x2:
x1, x2 = x2, x1
y1, y2 = y2, y1
swapped = True
# Recalculate differentials
dx = x2 - x1
dy = y2 - y1
# Calculate error
error = int(dx / 2.0)
ystep = 1 if y1 < y2 else -1
# Iterate over bounding box generating points between start and end
y = y1
points = []
for x in range(x1, x2 + 1):
coord = (y, x) if is_steep else (x, y)
points.append(coord)
error -= abs(dy)
if error < 0:
y += ystep
error += dx
# Reverse the list if the coordinates were swapped
if swapped:
points.reverse()
return points
if color and not isinstance(color, basestring):
color_iter = itertools.cycle(color)
else:
color_iter = itertools.repeat(color)
if background and not isinstance(background, basestring):
background_iter = itertools.cycle(background)
else:
background_iter = itertools.repeat(background)
if char:
char_iter = itertools.cycle(char)
else:
char_iter = itertools.repeat(char)
for x, y in get_line((x1, y1), (x2, y2)):
char = next(char_iter)
color = next(color_iter)
background = next(background_iter)
self.put_point(x, y, char=char, color=color, background=background)
def paint(
self, x1, y1, x2, y2, c1, c2=None, bg1=None, bg2=None, angle=None, angle_bg=None
):
"""
Paint rectangle (x1,y1) (x2,y2) with foreground color c1 and background bg1 if specified.
If specified colors c2/bg2, rectangle is painted with linear gradient (inclined under angle).
"""
def calculate_color(i, j):
if angle == None:
a = 0
else:
a = angle
r1, g1, b1 = rgb_from_str(c1)
r2, g2, b2 = rgb_from_str(c2)
k = 1.0 * (j - x1) / (x2 - x1) * (1 - a)
l = 1.0 * (i - y1) / (y2 - y1) * a
r3, g3, b3 = (
int(r1 + 1.0 * (r2 - r1) * (k + l)),
int(g1 + 1.0 * (g2 - g1) * (k + l)),
int(b1 + 1.0 * (b2 - b1) * (k + l)),
)
return "#%02x%02x%02x" % (r3, g3, b3)
def calculate_bg(i, j):
if angle_bg == None:
a = 0
else:
a = angle
r1, g1, b1 = rgb_from_str(bg1)
r2, g2, b2 = rgb_from_str(bg2)
k = 1.0 * (j - x1) / (x2 - x1) * (1 - a)
l = 1.0 * (i - y1) / (y2 - y1) * a
r3, g3, b3 = (
int(r1 + 1.0 * (r2 - r1) * (k + l)),
int(g1 + 1.0 * (g2 - g1) * (k + l)),
int(b1 + 1.0 * (b2 - b1) * (k + l)),
)
return "#%02x%02x%02x" % (r3, g3, b3)
if c2 == None:
for i in range(y1, y2):
for j in range(x1, x2):
self.field[i][j].foreground = c1
if bg1:
if bg2:
self.field[i][j].background = calculate_bg(i, j)
else:
self.field[i][j].background = bg1
else:
for i in range(y1, y2):
for j in range(x1, x2):
self.field[i][j].foreground = calculate_color(i, j)
if bg1:
if bg2:
self.field[i][j].background = calculate_bg(i, j)
else:
self.field[i][j].background = bg1
return self
def put_rectangle(
self, x1, y1, x2, y2, char=None, frame=None, color=None, background=None
):
"""
Draw rectangle (x1,y1), (x2,y2) using character, and color
"""
frame_chars = {
"ascii": "++++-|",
"single": "┌┐└┘─│",
"double": "┌┐└┘─│",
}
if frame in frame_chars:
chars = frame_chars[frame]
else:
chars = char * 6
for x in range(x1, x2):
self.put_point(x, y1, char=chars[4], color=color, background=background)
self.put_point(x, y2, char=chars[4], color=color, background=background)
for y in range(y1, y2):
self.put_point(x1, y, char=chars[5], color=color, background=background)
self.put_point(x2, y, char=chars[5], color=color, background=background)
self.put_point(x1, y1, char=chars[0], color=color, background=background)
self.put_point(x2, y1, char=chars[1], color=color, background=background)
self.put_point(x1, y2, char=chars[2], color=color, background=background)
self.put_point(x2, y2, char=chars[3], color=color, background=background)
def put_circle(self, x0, y0, radius, char=None, color=None, background=None):
"""
Draw cricle with center in (x, y) and radius r (x1,y1), (x2,y2)
using character, and color
"""
def k(x):
return int(x * 1.9)
f = 1 - radius
ddf_x = 1
ddf_y = -2 * radius
x = 0
y = radius
self.put_point(x0, y0 + radius, char=char, color=color, background=background)
self.put_point(x0, y0 - radius, char=char, color=color, background=background)
self.put_point(
x0 + k(radius), y0, char=char, color=color, background=background
)
self.put_point(
x0 - k(radius), y0, char=char, color=color, background=background
)
char = "x"
while x < y:
if f >= 0:
y -= 1
ddf_y += 2
f += ddf_y
x += 1
ddf_x += 2
f += ddf_x
self.put_point(
x0 + k(x), y0 + y, char=char, color=color, background=background
)
self.put_point(
x0 - k(x), y0 + y, char=char, color=color, background=background
)
self.put_point(
x0 + k(x), y0 - y, char=char, color=color, background=background
)
self.put_point(
x0 - k(x), y0 - y, char=char, color=color, background=background
)
self.put_point(
x0 + k(y), y0 + x, char=char, color=color, background=background
)
self.put_point(
x0 - k(y), y0 + x, char=char, color=color, background=background
)
self.put_point(
x0 + k(y), y0 - x, char=char, color=color, background=background
)
self.put_point(
x0 - k(y), y0 - x, char=char, color=color, background=background
)
def read_ansi(self, seq, x=0, y=0, transparence=True):
"""
Read ANSI sequence and render it to the panela starting from x and y.
If transparence is True, replace spaces with ""
"""
screen = pyte.screens.Screen(self.size_x, self.size_y + 1)
stream = pyte.streams.ByteStream()
stream.attach(screen)
stream.feed(seq.replace("\n", "\r\n"))
for i, line in sorted(screen.buffer.items(), key=lambda x: x[0]):
for j, char in sorted(line.items(), key=lambda x: x[0]):
if j >= self.size_x:
break
self.field[i][j] = Point(
char.data, color_mapping(char.fg), color_mapping(char.bg)
)
def __str__(self):
answer = ""
skip_next = False
for i, line in enumerate(self.field):
for j, c in enumerate(line):
fg_ansi = ""
bg_ansi = ""
stop = ""
if self.field[i][j].foreground:
fg_ansi = "\033[38;2;%s;%s;%sm" % rgb_from_str(
self.field[i][j].foreground
)
stop = colored.attr("reset")
if self.field[i][j].background:
bg_ansi = "\033[48;2;%s;%s;%sm" % rgb_from_str(
self.field[i][j].background
)
stop = colored.attr("reset")
char = c.char or " "
if not skip_next:
answer += fg_ansi + bg_ansi + char.encode("utf-8") + stop
skip_next = wcswidth(char) == 2
# answer += "...\n"
answer += "\n"
return answer
########################################################################################################
class Template(object):
def __init__(self):
self._mode = "page"
self.page = []
self.mask = []
self.code = []
self.panela = None
self._colors = {
"A": "#00cc00",
"B": "#00cc00",
"C": "#00aacc",
"D": "#888888",
"E": "#cccc00",
"F": "#ff0000",
"H": "#22aa22",
"I": "#cc0000",
"J": "#000000",
}
self._bg_colors = {
"G": "#555555",
"J": "#555555",
}
def _process_line(self, line):
if line == "mask":
self._mode = "mask"
if line == "":
self._mode = "code"
def read(self, filename):
"""
Read template from `filename`
"""
with open(filename) as f:
self._mode = "page"
for line in f.readlines():
line = line.rstrip("\n")
if line.startswith("==[") and line.endswith("]=="):
self._process_line(line[3:-3].strip())
continue
if self._mode == "page":
self.page.append(line)
elif self._mode == "mask":
self.mask.append(line)
elif self._mode == "code":
self.mask.append(line)
def apply_mask(self):
lines = self.page
x_size = max([len(x) for x in lines])
y_size = len(lines)
self.panela = Panela(x=x_size, y=y_size)
self.panela.read_ansi("".join("%s\n" % x for x in self.page))
for i, line in enumerate(self.mask):
for j, char in enumerate(line):
if char in self._colors or char in self._bg_colors:
color = self._colors.get(char)
bg_color = self._bg_colors.get(char)
self.panela.put_point(j, i, color=color, background=bg_color)
def show(self):
if self.panela:
return str(self.panela)
return self.page
def main():
"Only for experiments"
pagepath = os.path.join(MYDIR, "share/firstpage-v2.pnl")
template = Template()
template.read(pagepath)
template.apply_mask()
sys.stdout.write(template.show())
if __name__ == "__main__":
main()
================================================
FILE: lib/post.py
================================================
"""
POST requests processing.
Currently used only for new cheat sheets submission.
Configuration parameters:
path.spool
"""
import string
import os
import random
from config import CONFIG
def _save_cheatsheet(topic_name, cheatsheet):
"""
Save posted cheat sheet `cheatsheet` with `topic_name`
in the spool directory
"""
nonce = "".join(
random.choice(string.ascii_uppercase + string.digits) for _ in range(9)
)
filename = topic_name.replace("/", ".") + "." + nonce
filename = os.path.join(CONFIG["path.spool"], filename)
open(filename, "w").write(cheatsheet)
def process_post_request(req, topic):
"""
Process POST request `req`.
"""
for key, val in req.form.items():
if key == "":
if topic is None:
topic_name = "UNNAMED"
else:
topic_name = topic
cheatsheet = val
else:
if val == "":
if topic is None:
topic_name = "UNNAMED"
else:
topic_name = topic
cheatsheet = key
else:
topic_name = key
cheatsheet = val
_save_cheatsheet(topic_name, cheatsheet)
================================================
FILE: lib/postprocessing.py
================================================
import search
import fmt.comments
def postprocess(answer, keyword, options, request_options=None):
answer = _answer_add_comments(answer, request_options=request_options)
answer = _answer_filter_by_keyword(
answer, keyword, options, request_options=request_options
)
return answer
def _answer_add_comments(answer, request_options=None):
if answer["format"] != "text+code":
return answer
topic = answer["topic"]
if "filetype" in answer:
filetype = answer["filetype"]
else:
filetype = "bash"
if "/" in topic:
filetype = topic.split("/", 1)[0]
if filetype.startswith("q:"):
filetype = filetype[2:]
answer["answer"] = fmt.comments.beautify(
answer["answer"], filetype, request_options
)
answer["format"] = "code"
answer["filetype"] = filetype
return answer
def _answer_filter_by_keyword(answer, keyword, options, request_options=None):
answer["answer"] = _filter_by_keyword(answer["answer"], keyword, options)
return answer
def _filter_by_keyword(answer, keyword, options):
def _join_paragraphs(paragraphs):
answer = "\n".join(paragraphs)
return answer
def _split_paragraphs(text):
answer = []
paragraph = ""
if isinstance(text, bytes):
text = text.decode("utf-8")
for line in text.splitlines():
if line == "":
answer.append(paragraph)
paragraph = ""
else:
paragraph += line + "\n"
answer.append(paragraph)
return answer
paragraphs = [
p
for p in _split_paragraphs(answer)
if search.match(p, keyword, options=options)
]
if not paragraphs:
return ""
return _join_paragraphs(paragraphs)
================================================
FILE: lib/routing.py
================================================
"""
Queries routing and caching.
Exports:
get_topics_list()
get_answers()
"""
import random
import re
from typing import Any, Dict, List
import cache
import adapter.cheat_sheets
import adapter.cmd
import adapter.internal
import adapter.latenz
import adapter.learnxiny
import adapter.question
import adapter.rosetta
from config import CONFIG
class Router(object):
"""
Implementation of query routing. Routing is based on `routing_table`
and the data exported by the adapters (functions `get_list()` and `is_found()`).
`get_topics_list()` returns available topics (accessible at /:list).
`get_answer_dict()` return answer for the query.
"""
def __init__(self):
self._cached_topics_list = []
self._cached_topic_type = {}
adapter_class = adapter.all_adapters(as_dict=True)
active_adapters = set(CONFIG["adapters.active"] + CONFIG["adapters.mandatory"])
self._adapter = {
"internal": adapter.internal.InternalPages(
get_topic_type=self.get_topic_type, get_topics_list=self.get_topics_list
),
"unknown": adapter.internal.UnknownPages(
get_topic_type=self.get_topic_type, get_topics_list=self.get_topics_list
),
}
for by_name in active_adapters:
if by_name not in self._adapter:
self._adapter[by_name] = adapter_class[by_name]()
self._topic_list = {key: obj.get_list() for key, obj in self._adapter.items()}
self.routing_table = CONFIG["routing.main"]
self.routing_table = (
CONFIG["routing.pre"] + self.routing_table + CONFIG["routing.post"]
)
def get_topics_list(self, skip_dirs=False, skip_internal=False):
"""
List of topics returned on /:list
"""
if self._cached_topics_list:
return self._cached_topics_list
skip = ["fosdem"]
if skip_dirs:
skip.append("cheat.sheets dir")
if skip_internal:
skip.append("internal")
sources_to_merge = [x for x in self._adapter if x not in skip]
answer = {}
for key in sources_to_merge:
answer.update({name: key for name in self._topic_list[key]})
answer = sorted(set(answer.keys()))
self._cached_topics_list = answer
return answer
def get_topic_type(self, topic: str) -> List[str]:
"""
Return list of topic types for `topic`
or ["unknown"] if topic can't be determined.
"""
def __get_topic_type(topic: str) -> List[str]:
result = []
for regexp, route in self.routing_table:
if re.search(regexp, topic):
if route in self._adapter:
if self._adapter[route].is_found(topic):
result.append(route)
else:
result.append(route)
if not result:
return [CONFIG["routing.default"]]
# cut the default route off, if there are more than one route found
if len(result) > 1:
return result[:-1]
return result
if topic not in self._cached_topic_type:
self._cached_topic_type[topic] = __get_topic_type(topic)
return self._cached_topic_type[topic]
def _get_page_dict(self, query, topic_type, request_options=None):
"""
Return answer_dict for the `query`.
"""
return self._adapter[topic_type].get_page_dict(
query, request_options=request_options
)
def handle_if_random_request(self, topic):
"""
Check if the `query` is a :random one,
if yes we check its correctness and then randomly select a topic,
based on the provided prefix.
"""
def __select_random_topic(prefix, topic_list):
# Here we remove the special cases
cleaned_topic_list = [
x for x in topic_list if "/" not in x and ":" not in x
]
# Here we still check that cleaned_topic_list in not empty
if not cleaned_topic_list:
return prefix
random_topic = random.choice(cleaned_topic_list)
return prefix + random_topic
if topic.endswith("/:random") or topic.lstrip("/") == ":random":
# We strip the :random part and see if the query is valid by running a get_topics_list()
if topic.lstrip("/") == ":random":
topic = topic.lstrip("/")
prefix = topic[:-7]
topic_list = [
x[len(prefix) :] for x in self.get_topics_list() if x.startswith(prefix)
]
if "" in topic_list:
topic_list.remove("")
if topic_list:
# This is a correct formatted random query like /cpp/:random as the topic_list is not empty.
random_topic = __select_random_topic(prefix, topic_list)
return random_topic
else:
# This is a wrongly formatted random query like /xyxyxy/:random as the topic_list is empty
# we just strip the /:random and let the already implemented logic handle it.
wrongly_formatted_random = topic[:-8]
return wrongly_formatted_random
# Here if not a random request, we just forward the topic
return topic
def get_answers(
self, topic: str, request_options: Dict[str, str] = None
) -> List[Dict[str, Any]]:
"""
Find cheat sheets for the topic.
Args:
`topic` (str): the name of the topic of the cheat sheet
Returns:
[answer_dict]: list of answers (dictionaries)
"""
# if topic specified as :,
# cut off
topic_type = ""
if re.match("[^/]+:", topic):
topic_type, topic = topic.split(":", 1)
topic = self.handle_if_random_request(topic)
topic_types = self.get_topic_type(topic)
# if topic_type is specified explicitly,
# show pages only of that type
if topic_type and topic_type in topic_types:
topic_types = [topic_type]
# 'question' queries are pretty expensive, that's why they should be handled
# in a special way:
# we do not drop the old style cache entries and try to reuse them if possible
if topic_types == ["question"]:
answer = cache.get("q:" + topic)
if answer:
if isinstance(answer, dict):
return [answer]
return [
{
"topic": topic,
"topic_type": "question",
"answer": answer,
"format": "text+code",
}
]
answer = self._get_page_dict(
topic, topic_types[0], request_options=request_options
)
if answer.get("cache", True):
cache.put("q:" + topic, answer)
return [answer]
# Try to find cacheable queries in the cache.
# If answer was not found in the cache, resolve it in a normal way and save in the cache
answers = []
for topic_type in topic_types:
cache_entry_name = f"{topic_type}:{topic}"
cache_needed = self._adapter[topic_type].is_cache_needed()
if cache_needed:
answer = cache.get(cache_entry_name)
if not isinstance(answer, dict):
answer = None
if answer:
answers.append(answer)
continue
answer = self._get_page_dict(
topic, topic_type, request_options=request_options
)
if isinstance(answer, dict):
if "cache" in answer:
cache_needed = answer["cache"]
if cache_needed and answer:
cache.put(cache_entry_name, answer)
answers.append(answer)
return answers
# pylint: disable=invalid-name
_ROUTER = Router()
get_topics_list = _ROUTER.get_topics_list
get_answers = _ROUTER.get_answers
================================================
FILE: lib/search.py
================================================
"""
Very naive search implementation. Just a placeholder.
Exports:
find_answer_by_keyword()
It should be implemented on the adapter basis:
1. adapter.search(keyword) returns list of matching answers
* maybe with some initial weight
2. ranking is done
3. sorted results are returned
4. eage page are cut by keyword
5. results are paginated
Configuration parameters:
search.limit
"""
import re
from config import CONFIG
from routing import get_answers, get_topics_list
def _limited_entry():
return {
"topic_type": "LIMITED",
"topic": "LIMITED",
"answer": "LIMITED TO %s ANSWERS" % CONFIG["search.limit"],
"format": "code",
}
def _parse_options(options):
"""Parse search options string into optiond_dict"""
if options is None:
return {}
search_options = {
"insensitive": "i" in options,
"word_boundaries": "b" in options,
"recursive": "r" in options,
}
return search_options
def match(paragraph, keyword, options=None, options_dict=None):
"""Search for each keyword from `keywords` in `page`
and if all of them are found, return `True`.
Otherwise return `False`.
Several keywords can be joined together using ~
For example: ~ssh~passphrase
"""
if keyword is None:
return True
if "~" in keyword:
keywords = keyword.split("~")
else:
keywords = [keyword]
if options_dict is None:
options_dict = _parse_options(options)
for kwrd in keywords:
if not kwrd:
continue
regex = re.escape(kwrd)
if options_dict["word_boundaries"]:
regex = r"\b%s\b" % kwrd
if options_dict["insensitive"]:
if not re.search(regex, paragraph, re.IGNORECASE):
return False
else:
if not re.search(regex, paragraph):
return False
return True
def find_answers_by_keyword(directory, keyword, options="", request_options=None):
"""
Search in the whole tree of all cheatsheets or in its subtree `directory`
by `keyword`
"""
options_dict = _parse_options(options)
answers_found = []
for topic in get_topics_list(skip_internal=True, skip_dirs=True):
if not topic.startswith(directory):
continue
subtopic = topic[len(directory) :]
if not options_dict["recursive"] and "/" in subtopic:
continue
answer_dicts = get_answers(topic, request_options=request_options)
for answer_dict in answer_dicts:
answer_text = answer_dict.get("answer", "")
# Temporary hotfix:
# In some cases answer_text may be 'bytes' and not 'str'
if type(b"") == type(answer_text):
answer_text = answer_text.decode("utf-8")
if match(answer_text, keyword, options_dict=options_dict):
answers_found.append(answer_dict)
if len(answers_found) > CONFIG["search.limit"]:
answers_found.append(_limited_entry())
break
return answers_found
================================================
FILE: lib/standalone.py
================================================
"""
Standalone wrapper for the cheat.sh server.
"""
from __future__ import print_function
import sys
import textwrap
try:
import urlparse
except ModuleNotFoundError:
import urllib.parse as urlparse
import config
config.CONFIG["cache.type"] = "none"
import cheat_wrapper
import options
def show_usage():
"""
Show how to use the program in the standalone mode
"""
print(
textwrap.dedent(
"""
Usage:
lib/standalone.py [OPTIONS] QUERY
For OPTIONS see :help
"""
)[1:-1]
)
def parse_cmdline(args):
"""
Parses command line arguments and returns
query and request_options
"""
if not args:
show_usage()
sys.exit(0)
query_string = " ".join(args)
parsed = urlparse.urlparse("https://srv:0/%s" % query_string)
request_options = options.parse_args(
urlparse.parse_qs(parsed.query, keep_blank_values=True)
)
query = parsed.path.lstrip("/")
if not query:
query = ":firstpage"
return query, request_options
def main(args):
"""
standalone wrapper for cheat_wrapper()
"""
query, request_options = parse_cmdline(args)
answer, _ = cheat_wrapper.cheat_wrapper(query, request_options=request_options)
sys.stdout.write(answer)
if __name__ == "__main__":
main(sys.argv[1:])
================================================
FILE: lib/stateful_queries.py
================================================
"""
Support for the stateful queries
"""
import cache
def save_query(client_id, query):
"""
Save the last query `query` for the client `client_id`
"""
cache.put("l:%s" % client_id, query)
def last_query(client_id):
"""
Return the last query for the client `client_id`
"""
return cache.get("l:%s" % client_id)
================================================
FILE: requirements.txt
================================================
wheel
gevent
flask
requests
pygments
dateutils
fuzzywuzzy
redis
colored<1.4.3
langdetect
cffi
polyglot
PyICU
pycld2
colorama
pyyaml
python-Levenshtein
pytest
black
================================================
FILE: share/adapters/chmod.grc
================================================
# with option -sI
# e.g. grc curl -sI mysite.com
# http
regexp=^(HTTP).*
colours=yellow
======
# server
regexp=^(Server).*
colours=cyan
======
# site
regexp=^(Link).*
colours=magenta
======
# colouring the output of script 'cheat chmod'
# e.g. grc curl -s cheat.sh/chmod/755
# linux string
regexp=^(Linux.*Permissions).*(String:)\s+(.*)$
colours=yellow,green,red
======
# linux number
regexp=^(Linux.*Permissions).*(Number:)\s+(.*)$
colours=yellow,green,red
======
# header
regexp=^(Special)\s+(Owner)\s+(Group)\s+(Public)$
colours=white
======
# setuid
regexp=^(Setuid)\s+\[.*\].*(Read).*
colours=green,bold cyan
======
# setgid
regexp=^(Setgid)\s+\[.*\].*(Write).*
colours=green,bold yellow
======
# sticky bit
regexp=^(Sticky bit)\s+\[.*\].*(Execute).*
colours=green,bold magenta
======
================================================
FILE: share/adapters/chmod.sh
================================================
#!/usr/bin/env bash
# Contributed by Erez Binyamin (github.com/ErezBinyamin)
GRC_STYLESHEET="${BASH_SOURCE[0]}"; GRC_STYLESHEET=${GRC_STYLESHEET%.sh}.grc
# Translate between chmod string and number
# Inspired by http://permissions-calculator.org/
# Contrib to chubin - cheat.sh
chmod_calc(){
p_s=""
p_n=""
R=()
W=()
X=()
setuid=' '
setgid=' '
sticky=' '
# If permission number is given -> calc string
if [[ $1 =~ ^-?[0-9]+$ && ${#1} -ge 1 && ${#1} -le 4 ]]
then
p_n=$(printf "%04s\n" "$1" | tr ' ' '0')
echo $p_n | grep -q '[8-9]' && return 1
for (( i=0; i<${#p_n}; i++ ))
do
num=$(echo "obase=2;${p_n:$i:1}" | bc | xargs printf '%03d')
# If 4 digit input -> process specials
if [ $i -eq 0 ]
then
[ ${num:0:1} -eq 1 ] && setuid='X' || setuid=' '
[ ${num:1:1} -eq 1 ] && setgid='X' || setgid=' '
[ ${num:2:1} -eq 1 ] && sticky='X' || sticky=' '
else
# Build p_s string
[ ${num:0:1} -eq 1 ] && p_s+='r' || p_s+='-'
[ ${num:1:1} -eq 1 ] && p_s+='w' || p_s+='-'
# Use sS or tT instead of x- according to specials
if [[ $i -eq 1 && $setuid == 'X' ]]
then
[ ${num:2:1} -eq 1 ] && p_s+='s' || p_s+='S'
elif [[ $i -eq 2 && $setgid == 'X' ]]
then
[ ${num:2:1} -eq 1 ] && p_s+='s' || p_s+='S'
elif [[ $i -eq 3 && $sticky == 'X' ]]
then
[ ${num:2:1} -eq 1 ] && p_s+='t' || p_s+='T'
else
[ ${num:2:1} -eq 1 ] && p_s+='x' || p_s+='-'
fi
# Populate arrays for the table
[ ${num:0:1} -eq 1 ] && R+=('X') || R+=(' ')
[ ${num:1:1} -eq 1 ] && W+=('X') || W+=(' ')
[ ${num:2:1} -eq 1 ] && X+=('X') || X+=(' ')
fi
done
# If permission string is given -> calc number
elif [[ $1 =~ ^[r,s,S,t,T,w,x,-]+$ ]]
then
# FULL STRING
if [[ ${#1} -eq 9 ]]
then
p_s=$1
num=0
# Process specials
[[ 'sS' =~ ${p_s:2:1} ]] && setuid='X' && num=$((num+4))
[[ 'sS' =~ ${p_s:5:1} ]] && setgid='X' && num=$((num+2))
[[ 'tT' =~ ${p_s:8:1} ]] && sticky='X' && num=$((num+1))
[ ${num} -gt 0 ] && p_n+="$num"
# Calculate rest of p_n number while populating arrays for table
for (( i=0; i<${#p_s}; i+=0 ))
do
num=0
[[ "r-" =~ ${p_s:$i:1} ]] || return 1
[[ ${p_s:$i:1} == 'r' ]] && R+=('X') || R+=(' ')
[[ ${p_s:$((i++)):1} == 'r' ]] && let num++
num=$(( num << 1 ))
[[ "w-" =~ ${p_s:$i:1} ]] || return 1
[[ ${p_s:$i:1} == 'w' ]] && W+=('X') || W+=(' ')
[[ ${p_s:$((i++)):1} == 'w' ]] && let num++
num=$(( num << 1 ))
if [ $i -lt 6 ]
then
[[ "sSx-" =~ ${p_s:$i:1} ]] || return 1
[[ "sx" =~ ${p_s:$i:1} ]] && X+=('X') || X+=(' ')
[[ "sx" =~ ${p_s:$((i++)):1} ]] && let num++
else
[[ "tTx-" =~ ${p_s:$i:1} ]] || return 1
[[ "tx" =~ ${p_s:$i:1} ]] && X+=('X') || X+=(' ')
[[ "tx" =~ ${p_s:$((i++)):1} ]] && let num++
fi
p_n+="$num"
done
# PARTIAL STRING
elif [[ $1 =~ ^[r,s,t,w,x]+$ ]]
then
p_s='---------'
p_n0=0
p_n1=0
p_n2=0
p_n3=0
R=(' ' ' ' ' ')
W=(' ' ' ' ' ')
X=(' ' ' ' ' ')
if [[ $1 =~ 'r' ]]
then
p_s=$(echo $p_s | sed 's/./r/1; s/./r/4; s/./r/7;')
let p_n1+=4
let p_n2+=4
let p_n3+=4
R=('X' 'X' 'X')
fi
if [[ $1 =~ 'w' ]]
then
p_s=$(echo $p_s | sed 's/./w/2')
let p_n1+=2
W=('X' ' ' ' ')
fi
if [[ $1 =~ 'x' ]]
then
p_s=$(echo $p_s | sed 's/./x/3; s/./x/6; s/./x/9;')
let p_n1+=1
let p_n2+=1
let p_n3+=1
X=('X' 'X' 'X')
fi
if [[ $1 =~ 's' ]]
then
[[ ${p_s:2:1} == 'x' ]] && p_s=$(echo $p_s | sed 's/./s/3') || p_s=$(echo $p_s | sed 's/./S/3')
[[ ${p_s:5:1} == 'x' ]] && p_s=$(echo $p_s | sed 's/./s/6') || p_s=$(echo $p_s | sed 's/./S/6')
let p_n0+=6
setuid='X'
setgid='X'
fi
if [[ $1 =~ 't' ]]
then
let p_n0+=1
[[ ${p_s:8:1} == 'x' ]] && p_s=$(echo $p_s | sed 's/./t/9') || p_s=$(echo $p_s | sed 's/./T/9')
sticky='X'
fi
p_n="${p_n0}${p_n1}${p_n2}${p_n3}"
else
return 1
fi
else
return 1
fi
# Print Final results table
printf "
Linux Permissions String:\t${p_s}
Linux Permissions Number:\t${p_n}
Special\t\tOwner\t\tGroup\t\tPublic
Setuid [$setuid]\tRead [${R[0]}]\tRead [${R[1]}]\tRead [${R[2]}]
Setgid [$setgid]\tWrite [${W[0]}]\tWrite [${W[1]}]\tWrite [${W[2]}]
Sticky bit [$sticky]\tExecute [${X[0]}]\tExecute [${X[1]}]\tExecute [${X[2]}]
" | grcat "$GRC_STYLESHEET"
}
chmod_calc $@
[ $? -ne 0 ] && printf "Invalid permissions string: $@\n"
================================================
FILE: share/adapters/oeis.sh
================================================
#!/usr/bin/env bash
# Written by Erez Binyamin (github.com/ErezBinyamin)
# Search for an integer sequence
# USAGE:
# oeis
# oeis
# oeis
oeis() (
local URL='https://oeis.org/search?q='
local TMP=$(mktemp -d oeis.XXXXXXX)
local DOC=${TMP}/doc.html
local MAX_TERMS_LONG=30
local MAX_TERMS_SHORT=10
mkdir -p $TMP
rm -f ${TMP}/authors ${TMP}/bibliograpy ${TMP}/section $TMP/code_snippet
# -- MAIN --
# Search sequence by ID (optional language arg)
# . oeis
# . oeis
# . oeis
isNum='^[0-9]+$'
# Search for specific sequence (and potentially language or :SECTION (list)
if [ $# -ge 1 ] \
&& [[ $(echo $1 | tr -d 'aA') =~ $isNum || $(echo $2 | tr -d 'aA') =~ $isNum ]] \
&& [[ ! $(echo $1 | tr -d 'aA') =~ $isNum || ! $(echo $2 | tr -d 'aA') =~ $isNum ]]
then
# Arg-Parse ID, Generate URL
if [[ $(echo $1 | tr -d 'aA') =~ $isNum ]]
then
ID=${1^^}
SECTION=$2
else
ID=${2^^}
SECTION=$1
fi
[[ ${ID:0:1} == 'A' ]] && ID=${ID:1}
ID=$(bc <<< "$ID")
ID="A$(printf '%06d' ${ID})"
URL+="id:${ID}&fmt=text"
curl $URL 2>/dev/null > $DOC
# :list available language code_snippets
if [[ ${SECTION^^} == ':LIST' || ${SECTION^^} == ':PROG' ]]
then
grep -q '%p' $DOC && echo 'maple' >> $TMP/section
grep -q '%t' $DOC && echo 'mathematica' >> $TMP/section
grep '%o' $DOC \
| grep "${ID} (" \
| sed "s/^.*${ID} (//; s/).*//" \
| awk 'NF == 1' \
>> $TMP/section
[[ -f $TMP/section && $(wc -c < $TMP/section) -ne 0 ]] \
&& cat ${TMP}/section | sort -u \
|| printf 'No code snippets available.\n'
rm -rf $TMP
return 0
fi
# Print ID
printf "ID: ${ID}\n"
# Print Description (%N)
grep '%N' $DOC | sed "s/^.*${ID} //"
printf '\n'
# Print Sequence (Three sections %S %T and %U)
grep '%S' $DOC | sed "s/^.*${ID} //" | tr -d '\n' > $TMP/seq
grep '%T' $DOC | sed "s/^.*${ID} //" | tr -d '\n' >> $TMP/seq
grep '%U' $DOC | sed "s/^.*${ID} //" | tr -d '\n' >> $TMP/seq
cat $TMP/seq \
| cut -d ',' -f 1-${MAX_TERMS_LONG} \
| sed 's/,/, /g; s/$/ .../'
# Generate code snippet (%p, %t, %o) (maple, mathematica, prog sections)
if [ $# -gt 1 ]
then
printf "\n\n"
# MAPLE section (%p)
if [[ ${SECTION^^} == 'MAPLE' ]] && grep -q '%p' $DOC
then
grep '%p' $DOC | sed "s/^.*${ID} //" > $TMP/code_snippet
# MATHEMATICA section (%t)
elif [[ ${SECTION^^} == 'MATHEMATICA' ]] && grep -q '%t' $DOC
then
grep '%t' $DOC | sed "s/^.*${ID} //" > $TMP/code_snippet
# PROG section (%o)
elif grep -qi '%o' $DOC && grep -qi $SECTION $DOC
then
# Print out code sample for specified language
grep '%o' $DOC \
| sed "s/%o ${ID} //" \
| awk -v tgt="${SECTION^^}" -F'[()]' '{act=$2} sub(/^\([^()]+\) */,""){f=(tgt==toupper(act))} f' \
> ${TMP}/code_snippet
fi
# Print code snippet with 4-space indent to enable colorization
if [[ -f $TMP/code_snippet && $(wc -c < $TMP/code_snippet) -ne 0 ]]
then
# Get authors
grep -o ' _[A-Z].* [A-Z].*_, [A-Z].*[0-9]' ${TMP}/code_snippet \
| sed 's/,.*//' \
| sort -u \
> ${TMP}/authors
i=1
# Replace authors with numbers
while read author
do
author=$(<<<"$author" sed 's/[]\\\*\(\.[]/\\&/g')
sed -i "s|${author}.*[0-9]|[${i}]|" ${TMP}/code_snippet
author=$(echo $author | tr -d '_\\')
author_url='https://oeis.org/wiki/User:'"$(echo ${author} | tr ' ' '_')"
echo "[${i}] [${author}] [${author_url}]" \
>> ${TMP}/bibliograpy
let i++
done <${TMP}/authors
# Print snippet
sed 's/^/ /' ${TMP}/code_snippet
else
printf "${SECTION^^} unavailable. Use :list to view available languages.\n"
fi
fi
# Search unknown sequence
elif [ $# -gt 1 ] && ! echo $@ | grep -q -e [a-z] -e [A-Z]
then
# Build URL
URL+="signed:$(echo $@ | tr -sc '[:digit:]-' ',')&fmt=short"
curl $URL 2>/dev/null > $DOC
# Sequence IDs
grep -o '"/A[0-9][0-9][0-9][0-9][0-9][0-9]">A[0-9][0-9][0-9][0-9][0-9][0-9]' $DOC \
| sed 's/.*>//' \
> $TMP/id
readarray -t ID < $TMP/id
# Descriptions
grep -A 1 '' $DOC \
| sed '/--/d; s/<[^>]*>//g; /^\s*$/d; s/^[ \t]*//' \
| sed 's/ / /g; s/\&/\&/g; s/>/>/g; s/</ $TMP/desc
readarray -t DESC < $TMP/desc
# Sequences
grep 'style="color:black;font-size:120%' $DOC \
| sed 's/<[^>]*>//g; s/^[ \t]*//' \
| cut -d ',' -f 1-${MAX_TERMS_SHORT} \
| sed 's/,/, /g; s/$/ .../' \
> $TMP/seq
readarray -t SEQ < $TMP/seq
# Print all ID, DESC, SEQ
for i in ${!ID[@]}
do
printf "${ID[$i]}: ${DESC[$i]}\n"
printf "${SEQ[$i]}\n\n"
done
else
printf "
# oeis
#
# The On-Line Encyclopedia of Integer Sequences (OEIS),
# also cited simply as Sloane's, is an online database of integer sequences.
# Find all possible OEIS sequences for some sequence (1,1,1,1...)
curl cheat.sh/oeis/1+1+1+1
# Describe an OEIS sequence (A2)
curl cheat.sh/oeis/A2
# Implementation of the A2 OEIS sequence in Python
curl cheat.sh/oeis/A2/python
# List all available implementations of the A2 OEIS sequence
curl cheat.sh/oeis/A2/:list
"
rm -rf $TMP
return 1
fi
# Error statements
grep 'results, too many to show. Please refine your search.' $DOC | sed -e 's/<[^>]*>//g; s/^[ \t]*//'
grep -o 'Sorry, but the terms do not match anything in the table.' $DOC
# print bibliography
printf "\n\n"
[ -f ${TMP}/bibliograpy ] && cat ${TMP}/bibliograpy
# Print URL for user
printf "[${URL}]\n" \
| rev \
| sed 's/,//' \
| rev \
| sed 's/&.*/]/'
rm -rf $TMP
return 0
)
oeis $@
================================================
FILE: share/adapters/rfc.sh
================================================
#!/usr/bin/env bash
# Contributed by Erez Binyamin (github.com/ErezBinyamin)
# Search for an RFC
# Contrib to chubin - cheat.sh
RFC_get()
(
rfc_describe() {
sed -ne '/0001/,$p' ${RFC_INDEX} \
| tr '\n' '#' \
| sed 's/##/\n/g' \
| sed 's/# //g' \
| grep -o '.*\. ' \
| sed -E 's/^(.*)(January|February|March|April|May|June|July|August|September|October|November|December) [[:digit:]]{4}(.*)$/\1/'
}
UNAME=$(uname -s)
if [ "$UNAME" = "Darwin" ]; then
SED_I="sed -i ''"
else
SED_I="sed -i"
fi
mkdir -p /tmp/RFC_get
local WEB_RESP="/tmp/RFC_get/rfc_get_web_resp_${RANDOM}.html"
local RFC_INDEX="/tmp/RFC_get/rfc_index.html"
local isNum='^[0-9]+$'
# Update RFC_INDEX if file does not exist
[ -f ${RFC_INDEX} ] || curl 'https://www.ietf.org/download/rfc-index.txt' 2>/dev/null > ${RFC_INDEX}
local MIN_RFC=1
local MAX_RFC=$(sed '/^ / d' ${RFC_INDEX} | tail -n 1 | sed 's/ .*//')
local arg_lower=$(echo "$1" | tr '[:upper:]' '[:lower:]')
# Syntax check Usage statement
if [ $# -lt 1 ] || [ "$arg_lower" = "-h" ] || [ "$arg_lower" = "--help" ] || [ "$arg_lower" = ":help" ] || [ "$arg_lower" = ":usage" ]
then
printf "
USAGE:
rfc Search RFC by number
rfc Search RFC by topic
rfc :list List available RFC's
rfc :usage Show this help message
\n"
return 0
fi
# Get corresponding RFC by number
if [[ ${1} =~ $isNum ]]
then
# Validate RFC range
if [ "$1" -gt $MAX_RFC ] || [ "$1" -lt $MIN_RFC ]
then
echo "Valid RFC numbers: [ ${MIN_RFC} - ${MAX_RFC} ]"
return 1
fi
# If valid N: Retrieve RFC
curl "https://www.ietf.org/rfc/rfc${1}.txt" --write-out %{http_code} --silent --output ${WEB_RESP} 2>/dev/null | grep -q '200'
if [ $? -ne 0 ]
then
# Attempt to retrieve PDF link to RFC
curl "https://www.rfc-editor.org/info/rfc${1}" --write-out %{http_code} --silent --output ${WEB_RESP} 2>/dev/null | grep -q '200'
# Webpage error code (Not 200 OK)
if [ $? -ne 0 ]
then
echo "Error retrieving https://www.rfc-editor.org/info/rfc${1}"
echo "Please create github issue at https://github.com/chubin/cheat.sh/issues"
return 2
# RFC never issued
elif grep -q 'Not Issued
' ${WEB_RESP}
then
echo "RFC ${1} was never issued"
return 0
# RFC does not exist
elif grep -q 'does not exist' ${WEB_RESP}
then
echo "RFC ${1} does not exist"
return 0
# RFC exists only as PDF
elif grep -q 'https.*\.pdf' $WEB_RESP
then
grep -o 'https.*\.pdf' $WEB_RESP
return 0
# Unknown error
else
echo "Error retrieving RFC $1"
echo "Please create github issue at https://github.com/chubin/cheat.sh/issues"
return 2
fi
fi
# Print list of available RFCs
elif [ "$arg_lower" = ":list" ]
then
# Format RFC_INDEX to show short description of each RFC
rfc_describe \
| grep -v 'Not Issued' \
| sed 's/ .*//; s/^0*//'
return 0
# Print list of available RFCs
elif [ "$arg_lower" = ":describe" ]
then
# Format RFC_INDEX to show short description of each RFC
rfc_describe
return 0
# Format list of RFCs related to keyword: RFC_N RFC_Title
else
ARG="$*"
rfc_describe \
| grep -i "$ARG" \
> $WEB_RESP
fi
# Format nicely and print
$SED_I -e '/Page [0-9]/,+2d; /page [0-9]/,+2d' ${WEB_RESP}
if grep -q '' ${WEB_RESP}
then
echo "Error retrieving RFC $1"
echo "Please create github issue at https://github.com/chubin/cheat.sh/issues"
return 2
else
cat -s ${WEB_RESP}
return 0
fi
)
RFC_get "$1"
================================================
FILE: share/ansi2html.sh
================================================
#!/bin/sh
# Convert ANSI (terminal) colours and attributes to HTML
# Licence: LGPLv2
# Author:
# http://www.pixelbeat.org/docs/terminal_colours/
# Examples:
# ls -l --color=always | ansi2html.sh > ls.html
# git show --color | ansi2html.sh > last_change.html
# Generally one can use the `script` util to capture full terminal output.
# Changes:
# V0.1, 24 Apr 2008, Initial release
# V0.2, 01 Jan 2009, Phil Harnish
# Support `git diff --color` output by
# matching ANSI codes that specify only
# bold or background colour.
# P@draigBrady.com
# Support `ls --color` output by stripping
# redundant leading 0s from ANSI codes.
# Support `grep --color=always` by stripping
# unhandled ANSI codes (specifically ^[[K).
# V0.3, 20 Mar 2009, http://eexpress.blog.ubuntu.org.cn/
# Remove cat -v usage which mangled non ascii input.
# Cleanup regular expressions used.
# Support other attributes like reverse, ...
# P@draigBrady.com
# Correctly nest tags (even across lines).
# Add a command line option to use a dark background.
# Strip more terminal control codes.
# V0.4, 17 Sep 2009, P@draigBrady.com
# Handle codes with combined attributes and color.
# Handle isolated attributes with css.
# Strip more terminal control codes.
# V0.23, 22 Dec 2015
# http://github.com/pixelb/scripts/commits/master/scripts/ansi2html.sh
gawk --version >/dev/null || exit 1
if [ "$1" = "--version" ]; then
printf '0.22\n' && exit
fi
if [ "$1" = "--help" ]; then
printf '%s\n' \
'This utility converts ANSI codes in data passed to stdin
It has 2 optional parameters:
--bg=dark --palette=linux|solarized|tango|xterm
E.g.: ls -l --color=always | ansi2html.sh --bg=dark > ls.html' >&2
exit
fi
[ "$1" = "--bg=dark" ] && { dark_bg=yes; shift; }
if [ "$1" = "--palette=solarized" ]; then
# See http://ethanschoonover.com/solarized
P0=073642; P1=D30102; P2=859900; P3=B58900;
P4=268BD2; P5=D33682; P6=2AA198; P7=EEE8D5;
P8=002B36; P9=CB4B16; P10=586E75; P11=657B83;
P12=839496; P13=6C71C4; P14=93A1A1; P15=FDF6E3;
shift;
elif [ "$1" = "--palette=solarized-xterm" ]; then
# Above mapped onto the xterm 256 color palette
P0=262626; P1=AF0000; P2=5F8700; P3=AF8700;
P4=0087FF; P5=AF005F; P6=00AFAF; P7=E4E4E4;
P8=1C1C1C; P9=D75F00; P10=585858; P11=626262;
P12=808080; P13=5F5FAF; P14=8A8A8A; P15=FFFFD7;
shift;
elif [ "$1" = "--palette=tango" ]; then
# Gnome default
P0=000000; P1=CC0000; P2=4E9A06; P3=C4A000;
P4=3465A4; P5=75507B; P6=06989A; P7=D3D7CF;
P8=555753; P9=EF2929; P10=8AE234; P11=FCE94F;
P12=729FCF; P13=AD7FA8; P14=34E2E2; P15=EEEEEC;
shift;
elif [ "$1" = "--palette=xterm" ]; then
P0=000000; P1=CD0000; P2=00CD00; P3=CDCD00;
P4=0000EE; P5=CD00CD; P6=00CDCD; P7=E5E5E5;
P8=7F7F7F; P9=FF0000; P10=00FF00; P11=FFFF00;
P12=5C5CFF; P13=FF00FF; P14=00FFFF; P15=FFFFFF;
shift;
else # linux console
P0=000000; P1=AA0000; P2=00AA00; P3=AA5500;
P4=0000AA; P5=AA00AA; P6=00AAAA; P7=AAAAAA;
P8=555555; P9=FF5555; P10=55FF55; P11=FFFF55;
P12=5555FF; P13=FF55FF; P14=55FFFF; P15=FFFFFF;
[ "$1" = "--palette=linux" ] && shift
fi
[ "$1" = "--bg=dark" ] && { dark_bg=yes; shift; }
# Mac OSX's GNU sed is installed as gsed
# use e.g. homebrew 'gnu-sed' to get it
if ! sed --version >/dev/null 2>&1; then
if gsed --version >/dev/null 2>&1; then
alias sed=gsed
else
echo "Error, can't find an acceptable GNU sed." >&2
exit 1
fi
fi
printf '%s' "
'
p='\x1b\[' #shortcut to match escape codes
# Handle various xterm control sequences.
# See /usr/share/doc/xterm-*/ctlseqs.txt
sed "
# escape ampersand and quote
s#&#\&#g; s#\"#\"#g;
s#\x1b[^\x1b]*\x1b\\\##g # strip anything between \e and ST
s#\x1b][0-9]*;[^\a]*\a##g # strip any OSC (xterm title etc.)
s#\r\$## # strip trailing \r
# strip other non SGR escape sequences
s#[\x07]##g
s#\x1b[]>=\][0-9;]*##g
s#\x1bP+.\{5\}##g
# Mark cursor positioning codes \"Jr;c;
s#${p}\([0-9]\{1,2\}\)G#\"J;\1;#g
s#${p}\([0-9]\{1,2\}\);\([0-9]\{1,2\}\)H#\"J\1;\2;#g
# Mark clear as \"Cn where n=1 is screen and n=0 is to end-of-line
s#${p}H#\"C1;#g
s#${p}K#\"C0;#g
# Mark Cursor move columns as \"Mn where n is +ve for right, -ve for left
s#${p}C#\"M1;#g
s#${p}\([0-9]\{1,\}\)C#\"M\1;#g
s#${p}\([0-9]\{1,\}\)D#\"M-\1;#g
s#${p}\([0-9]\{1,\}\)P#\"X\1;#g
s#${p}[0-9;?]*[^0-9;?m]##g
" |
# Normalize the input before transformation
sed "
# escape HTML (ampersand and quote done above)
s#>#\>#g; s#<#\<#g;
# normalize SGR codes a little
# split 256 colors out and mark so that they're not
# recognised by the following 'split combined' line
:e
s#${p}\([0-9;]\{1,\}\);\([34]8;5;[0-9]\{1,3\}\)m#${p}\1m${p}¬\2m#g; t e
s#${p}\([34]8;5;[0-9]\{1,3\}\)m#${p}¬\1m#g;
:c
s#${p}\([0-9]\{1,\}\);\([0-9;]\{1,\}\)m#${p}\1m${p}\2m#g; t c # split combined
s#${p}0\([0-7]\)#${p}\1#g #strip leading 0
s#${p}1m\(\(${p}[4579]m\)*\)#\1${p}1m#g #bold last (with clr)
s#${p}m#${p}0m#g #add leading 0 to norm
# undo any 256 color marking
s#${p}¬\([34]8;5;[0-9]\{1,3\}\)m#${p}\1m#g;
# map 16 color codes to color + bold
s#${p}9\([0-7]\)m#${p}3\1m${p}1m#g;
s#${p}10\([0-7]\)m#${p}4\1m${p}1m#g;
# change 'reset' code to \"R
s#${p}0m#\"R;#g
" |
# Convert SGR sequences to HTML
sed "
# common combinations to minimise html (optional)
:f
s#${p}3[0-7]m${p}3\([0-7]\)m#${p}3\1m#g; t f
:b
s#${p}4[0-7]m${p}4\([0-7]\)m#${p}4\1m#g; t b
s#${p}3\([0-7]\)m${p}4\([0-7]\)m##g
s#${p}4\([0-7]\)m${p}3\([0-7]\)m##g
s#${p}1m##g
s#${p}4m##g
s#${p}5m##g
s#${p}7m##g
s#${p}9m##g
s#${p}3\([0-9]\)m##g
s#${p}4\([0-9]\)m##g
s#${p}38;5;\([0-9]\{1,3\}\)m##g
s#${p}48;5;\([0-9]\{1,3\}\)m##g
s#${p}[0-9;]*m##g # strip unhandled codes
" |
# Convert alternative character set and handle cursor movement codes
# Note we convert here, as if we do at start we have to worry about avoiding
# conversion of SGR codes etc., whereas doing here we only have to
# avoid conversions of stuff between &...; or <...>
#
# Note we could use sed to do this based around:
# sed 'y/abcdefghijklmnopqrstuvwxyz{}`~/▒␉␌␍␊°±␋┘┐┌└┼⎺⎻─⎼⎽├┤┴┬│≤≥π£◆·/'
# However that would be very awkward as we need to only conv some input.
# The basic scheme that we do in the awk script below is:
# 1. enable transliterate once "T1; is seen
# 2. disable once "T0; is seen (may be on diff line)
# 3. never transliterate between &; or <> chars
# 4. track x,y movements and active display mode at each position
# 5. buffer line/screen and dump when required
sed "
# change 'smacs' and 'rmacs' to \"T1 and \"T0 to simplify matching.
s#\x1b(0#\"T1;#g;
s#\x0E#\"T1;#g;
s#\x1b(B#\"T0;#g
s#\x0F#\"T0;#g
" |
(
gawk '
function dump_line(l,del,c,blanks,ret) {
for(c=1;c")
for(i=1;i<=spc;i++) {
rm=rm?rm:(a[i]!=attr[i]">")
if(rm) {
ret=ret " "
delete a[i];
}
}
for(i=1;i"
if(a[i]!=attr[i]) {
a[i]=attr[i]
ret = ret attr[i]
}
}
return ret
}
function encode(string,start,end,i,ret,pos,sc,buf) {
if(!end) end=length(string);
if(!start) start=1;
state=3
for(i=1;i<=length(string);i++) {
c=substr(string,i,1)
if(state==2) {
sc=sc c
if(c==";") {
c=sc
state=last_mode
} else continue
} else {
if(c=="\r") { x=1; continue }
if(c=="<") {
# Change attributes - store current active
# attributes in span array
split(substr(string,i),cord,">");
i+=length(cord[1])
span[++spc]=cord[1] ">"
continue
}
else if(c=="&") {
# All goes to single position till we see a semicolon
sc=c
state=2
continue
}
else if(c=="\b") {
# backspace move insertion point back 1
if(spc) attr[x,y]=atos(span)
x=x>1?x-1:1
continue
}
else if(c=="\"") {
split(substr(string,i+2),cord,";")
cc=substr(string,i+1,1);
if(cc=="T") {
# Transliterate on/off
if(cord[1]==1&&state==3) last_mode=state=4
if(cord[1]==0&&state==4) last_mode=state=3
}
else if(cc=="C") {
# Clear
if(cord[1]+0) {
# Screen - if Recording dump screen
if(dumpStatus==dsActive) ret=ret dump_screen()
dumpStatus=dsActive
delete dump
delete attr
x=y=1
} else {
# To end of line
for(pos=x;posmaxY) maxY=y
# Change y - start recording
dumpStatus=dumpStatus?dumpStatus:dsReset
}
}
else if(cc=="M") {
# Move left/right on current line
x+=cord[1]
}
else if(cc=="X") {
# delete on right
for(pos=x;pos<=maxX;pos++) {
nx=pos+cord[1]
if(nx=start&&i<=end&&c in Trans) c=Trans[c]
}
if(dumpStatus==dsReset) {
delete dump
delete attr
ret=ret"\n"
dumpStatus=dsActive
}
if(dumpStatus==dsNew) {
# After moving/clearing we are now ready to write
# something to the screen so start recording now
ret=ret"\n"
dumpStatus=dsActive
}
if(dumpStatus==dsActive||dumpStatus==dsOff) {
dump[x,y] = c
if(!spc) delete attr[x,y]
else attr[x,y] = atos(span)
if(++x>maxX) maxX=x;
}
}
# End of line if dumping increment y and set x back to first col
x=1
if(!dumpStatus) return ret dump_line(y,1);
else if(++y>maxY) maxY=y;
return ret
}
BEGIN{
OFS=FS
# dump screen status
dsOff=0 # Not dumping screen contents just write output direct
dsNew=1 # Just after move/clear waiting for activity to start recording
dsReset=2 # Screen cleared build new empty buffer and record
dsActive=3 # Currently recording
F="abcdefghijklmnopqrstuvwxyz{}`~"
T="▒␉␌␍␊°±␋┘┐┌└┼⎺⎻─⎼⎽├┤┴┬│≤≥π£◆·"
maxX=80
delete cur;
x=y=1
for(i=1;i<=length(F);i++)Trans[substr(F,i,1)]=substr(T,i,1);
}
{ $0=encode($0) }
1
END {
if(dumpStatus) {
print dump_screen();
}
}'
)
printf '
\n'
================================================
FILE: share/bash_completion.txt
================================================
_cht_complete()
{
local cur prev opts
_get_comp_words_by_ref -n : cur
COMPREPLY=()
cur="${COMP_WORDS[COMP_CWORD]}"
prev="${COMP_WORDS[COMP_CWORD-1]}"
opts="$(curl -s cheat.sh/:list)"
if [ ${COMP_CWORD} = 1 ]; then
COMPREPLY=( $(compgen -W "${opts}" -- ${cur}) )
__ltrim_colon_completions "$cur"
fi
return 0
}
complete -F _cht_complete cht.sh
================================================
FILE: share/cht.sh.txt
================================================
#!/bin/bash
# shellcheck disable=SC1117,SC2001
#
# [X] open section
# [X] one shot mode
# [X] usage info
# [X] dependencies check
# [X] help
# [X] yank/y/copy/c
# [X] Y/C
# [X] eof problem
# [X] more
# [X] stealth mode
#
# here are several examples for the stealth mode:
#
# zip lists
# list permutation
# random list element
# reverse a list
# read json from file
# append string to a file
# run process in background
# count words in text counter
# group elements list
__CHTSH_VERSION=0.0.4
__CHTSH_DATETIME="2021-04-25 12:30:30 +0200"
# cht.sh configuration loading
#
# configuration is stored in ~/.cht.sh/ (can be overridden with CHTSH env var.)
#
CHTSH_HOME=${CHTSH:-"$HOME"/.cht.sh}
[ -z "$CHTSH_CONF" ] && CHTSH_CONF=$CHTSH_HOME/cht.sh.conf
# shellcheck disable=SC1090,SC2002
[ -e "$CHTSH_CONF" ] && source "$CHTSH_CONF"
[ -z "$CHTSH_URL" ] && CHTSH_URL=https://cht.sh
# currently we support only two modes:
# * lite = access the server using curl
# * auto = try standalone usage first
CHTSH_MODE="$(cat "$CHTSH_HOME"/mode 2> /dev/null)"
[ "$CHTSH_MODE" != lite ] && CHTSH_MODE=auto
CHEATSH_INSTALLATION="$(cat "$CHTSH_HOME/standalone" 2> /dev/null)"
export LESSSECURE=1
STEALTH_MAX_SELECTION_LENGTH=5
case "$(uname -s)" in
Darwin) is_macos=yes ;;
*) is_macos=no ;;
esac
# for KSH93
# shellcheck disable=SC2034,SC2039,SC2168
if echo "$KSH_VERSION" | grep -q ' 93' && ! local foo 2>/dev/null; then
alias local=typeset
fi
fatal()
{
echo "ERROR: $*" >&2
exit 1
}
_say_what_i_do()
{
[ -n "$LOG" ] && echo "$(date '+[%Y-%m-%d %H:%M%S]') $*" >> "$LOG"
local this_prompt="\033[0;1;4;32m>>\033[0m"
printf "\n${this_prompt}%s\033[0m\n" " $* "
}
cheatsh_standalone_install()
{
# the function installs cheat.sh with the upstream repositories
# in the standalone mode
local installdir; installdir="$1"
local default_installdir="$HOME/.cheat.sh"
[ -z "$installdir" ] && installdir=${default_installdir}
if [ "$installdir" = help ]; then
cat </dev/null || \
{ echo "DEPENDENCY: \"$dep\" is needed to install cheat.sh in the standalone mode" >&2; _exit_code=1; }
done
[ "$_exit_code" -ne 0 ] && return "$_exit_code"
while true; do
local _installdir
echo -n "Where should cheat.sh be installed [$installdir]? "; read -r _installdir
[ -n "$_installdir" ] && installdir=$_installdir
if [ "$installdir" = y ] \
|| [ "$installdir" = Y ] \
|| [ "$(echo "$installdir" | tr "[:upper:]" "[:lower:]")" = yes ]
then
echo Please enter the directory name
echo If it was the directory name already, please prepend it with \"./\": "./$installdir"
else
break
fi
done
if [ -e "$installdir" ]; then
echo "ERROR: Installation directory [$installdir] exists already"
echo "Please remove it first before continuing"
return 1
fi
if ! mkdir -p "$installdir"; then
echo "ERROR: Could not create the installation directory \"$installdir\""
echo "ERROR: Please check the permissions and start the script again"
return 1
fi
local space_needed=700
local space_available; space_available=$(($(df -k "$installdir" | awk '{print $4}' | tail -1)/1024))
if [ "$space_available" -lt "$space_needed" ]; then
echo "ERROR: Installation directory has no enough space (needed: ${space_needed}M, available: ${space_available}M"
echo "ERROR: Please clean up and start the script again"
rmdir "$installdir"
return 1
fi
_say_what_i_do Cloning cheat.sh locally
local url=https://github.com/chubin/cheat.sh
rmdir "$installdir"
git clone "$url" "$installdir" || fatal Could not clone "$url" with git into "$installdir"
cd "$installdir" || fatal "Cannot cd into $installdir"
# after the repository cloned, we may have the log directory
# and we can write our installation log into it
mkdir -p "log/"
LOG="$PWD/log/install.log"
# we use tee everywhere so we should set -o pipefail
set -o pipefail
# currently the script uses python 2,
# but cheat.sh supports python 3 too
# if you want to switch it to python 3
# set PYTHON2 to NO:
# PYTHON2=NO
#
PYTHON2=NO
if [[ $PYTHON2 = YES ]]; then
python="python2"
pip="pip"
virtualenv_python3_option=()
else
python="python3"
pip="pip3"
virtualenv_python3_option=(-p python3)
fi
_say_what_i_do Creating virtual environment
virtualenv "${virtualenv_python3_option[@]}" ve \
|| fatal "Could not create virtual environment with 'virtualenv ve'"
export CHEATSH_PATH_WORKDIR=$PWD
# rapidfuzz does not support Python 2,
# so if we are using Python 2, install fuzzywuzzy instead
if [[ $PYTHON2 = YES ]]; then
sed -i s/rapidfuzz/fuzzywuzzy/ requirements.txt
echo "python-Levenshtein" >> requirements.txt
fi
_say_what_i_do Installing python requirements into the virtual environment
ve/bin/"$pip" install -r requirements.txt > "$LOG" \
|| {
echo "ERROR:"
echo "---"
tail -n 10 "$LOG"
echo "---"
echo "See $LOG for more"
fatal Could not install python dependencies into the virtual environment
}
echo "$(ve/bin/"$pip" freeze | wc -l) dependencies were successfully installed"
_say_what_i_do Fetching the upstream cheat sheets repositories
ve/bin/python lib/fetch.py fetch-all | tee -a "$LOG"
_say_what_i_do Running self-tests
(
cd tests || exit
if CHEATSH_TEST_STANDALONE=YES \
CHEATSH_TEST_SKIP_ONLINE=NO \
CHEATSH_TEST_SHOW_DETAILS=NO \
PYTHON=../ve/bin/python bash run-tests.sh | tee -a "$LOG"
then
printf "\033[0;32m%s\033[0m\n" "SUCCESS"
else
printf "\033[0;31m%s\033[0m\n" "FAILED"
echo "Some tests were failed. Run the tests manually for further investigation:"
echo " cd $PWD; bash run-tests.sh)"
fi
)
mkdir -p "$CHTSH_HOME"
echo "$installdir" > "$CHTSH_HOME/standalone"
echo auto > "$CHTSH_HOME/mode"
_say_what_i_do Done
local v1; v1=$(printf "\033[0;1;32m")
local v2; v2=$(printf "\033[0m")
cat < "$CHTSH_HOME/mode"
echo "Configured mode: $mode"
fi
else
echo "Unknown mode: $mode"
echo Supported modes:
echo " auto use the standalone installation first"
echo " lite use the cheat sheets server directly"
fi
}
get_query_options()
{
local query="$*"
if [ -n "$CHTSH_QUERY_OPTIONS" ]; then
case $query in
*\?*) query="$query&${CHTSH_QUERY_OPTIONS}";;
*) query="$query?${CHTSH_QUERY_OPTIONS}";;
esac
fi
printf "%s" "$query"
}
do_query()
{
local query="$*"
local b_opts=
local uri="${CHTSH_URL}/\"\$(get_query_options $query)\""
if [ -e "$CHTSH_HOME/id" ]; then
b_opts="-b \"\$CHTSH_HOME/id\""
fi
eval curl "$b_opts" -s "$uri" > "$TMP1"
if [ -z "$lines" ] || [ "$(wc -l "$TMP1" | awk '{print $1}')" -lt "$lines" ]; then
cat "$TMP1"
else
${PAGER:-$defpager} "$TMP1"
fi
}
prepare_query()
{
local section="$1"; shift
local input="$1"; shift
local arguments="$1"
local query
if [ -z "$section" ] || [ x"${input}" != x"${input#/}" ]; then
query=$(printf %s "$input" | sed 's@ @/@; s@ @+@g')
else
query=$(printf %s "$section/$input" | sed 's@ @+@g')
fi
[ -n "$arguments" ] && arguments="?$arguments"
printf %s "$query$arguments"
}
get_list_of_sections()
{
curl -s "${CHTSH_URL}"/:list | grep -v '/.*/' | grep '/$' | xargs
}
gen_random_str()
(
len=$1
if command -v openssl >/dev/null; then
openssl rand -base64 $((len*3/4)) | awk -v ORS='' //
else
rdev=/dev/urandom
for d in /dev/{srandom,random,arandom}; do
test -r "$d" && rdev=$d
done
if command -v hexdump >/dev/null; then
hexdump -vn $((len/2)) -e '1/1 "%02X" 1 ""' "$rdev"
elif command -v xxd >/dev/null; then
xxd -l $((len/2)) -ps "$rdev" | awk -v ORS='' //
else
cd /tmp || { echo Cannot cd into /tmp >&2; exit 1; }
s=
# shellcheck disable=SC2000
while [ "$(echo "$s" | wc -c)" -lt "$len" ]; do
s="$s$(mktemp -u XXXXXXXXXX)"
done
printf "%.${len}s" "$s"
fi
fi
)
if [ "$CHTSH_MODE" = auto ] && [ -d "$CHEATSH_INSTALLATION" ]; then
curl() {
# ignoring all options
# currently the standalone.py does not support them anyway
local opt
while getopts "b:s" opt; do
:
done
shift $((OPTIND - 1))
local url; url="$1"; shift
PYTHONIOENCODING=UTF-8 "$CHEATSH_INSTALLATION/ve/bin/python" "$CHEATSH_INSTALLATION/lib/standalone.py" "${url#"$CHTSH_URL"}" "$@"
}
elif [ "$(uname -s)" = OpenBSD ] && [ -x /usr/bin/ftp ]; then
# any better test not involving either OS matching or actual query?
curl() {
local opt args="-o -"
while getopts "b:s" opt; do
case $opt in
b) args="$args -c $OPTARG";;
s) args="$args -M -V";;
*) echo "internal error: unsupported cURL option '$opt'" >&2; exit 1;;
esac
done
shift $((OPTIND - 1))
/usr/bin/ftp "$args" "$@"
}
else
command -v curl >/dev/null || { echo 'DEPENDENCY: install "curl" to use cht.sh' >&2; exit 1; }
_CURL=$(command -v curl)
if [ x"$CHTSH_CURL_OPTIONS" != x ]; then
curl() {
$_CURL "${CHTSH_CURL_OPTIONS}" "$@"
}
fi
fi
if [ "$1" = --read ]; then
read -r a || a="exit"
printf "%s\n" "$a"
exit 0
elif [ x"$1" = x--help ] || [ -z "$1" ]; then
n=${0##*/}
s=$(echo "$n" | sed "s/./ /"g)
cat </dev/null || echo 'DEPENDENCY: please install "wl-copy" for "copy"' >&2
else
command -v xsel >/dev/null || echo 'DEPENDENCY: please install "xsel" for "copy"' >&2
fi
fi
command -v rlwrap >/dev/null || { echo 'DEPENDENCY: install "rlwrap" to use cht.sh in the shell mode' >&2; exit 1; }
mkdir -p "$CHTSH_HOME/"
lines=$(tput lines)
if command -v less >/dev/null; then
defpager="less -R"
elif command -v more >/dev/null; then
defpager="more"
else
defpager="cat"
fi
cmd_cd() {
if [ $# -eq 0 ]; then
section=""
else
new_section=$(echo "$input" | sed 's/cd *//; s@/*$@@; s@^/*@@')
if [ -z "$new_section" ] || [ ".." = "$new_section" ]; then
section=""
else
valid_sections=$(get_list_of_sections)
valid=no; for q in $valid_sections; do [ "$q" = "$new_section/" ] && { valid=yes; break; }; done
if [ "$valid" = no ]; then
echo "Invalid section: $new_section"
echo "Valid sections:"
echo "$valid_sections" \
| xargs printf "%-10s\n" \
| tr ' ' . \
| xargs -n 10 \
| sed 's/\./ /g; s/^/ /'
else
section="$new_section"
fi
fi
fi
}
cmd_copy() {
if [ -z "$DISPLAY" ] && [ "$is_macos" != yes ]; then
echo copy: supported only in the Desktop version
elif [ -z "$input" ]; then
echo copy: Make at least one query first.
else
curl -s "${CHTSH_URL}"/"$(get_query_options "$query"?T)" > "$TMP1"
if [ "$is_macos" != yes ]; then
if [ "$XDG_SESSION_TYPE" = wayland ]; then
wl-copy < "$TMP1"
else
xsel -bi < "$TMP1"
fi
else
pbcopy < "$TMP1"
fi
echo "copy: $(wc -l "$TMP1" | awk '{print $1}') lines copied to the selection"
fi
}
cmd_ccopy() {
if [ -z "$DISPLAY" ] && [ "$is_macos" != yes ]; then
echo copy: supported only in the Desktop version
elif [ -z "$input" ]; then
echo copy: Make at least one query first.
else
curl -s "${CHTSH_URL}"/"$(get_query_options "$query"?TQ)" > "$TMP1"
if [ "$is_macos" != yes ]; then
if [ "$XDG_SESSION_TYPE" = wayland ]; then
wl-copy < "$TMP1"
else
xsel -bi < "$TMP1"
fi
else
pbcopy < "$TMP1"
fi
echo "copy: $(wc -l "$TMP1" | awk '{print $1}') lines copied to the selection"
fi
}
cmd_exit() {
exit 0
}
cmd_help() {
cat < python zip list
cht.sh/python> zip list
cht.sh/go> /python zip list
EOF
}
cmd_hush() {
mkdir -p "$CHTSH_HOME/" && touch "$CHTSH_HOME/.hushlogin" && echo "Initial 'use help' message was disabled"
}
cmd_id() {
id_file="$CHTSH_HOME/id"
if [ id = "$input" ]; then
new_id=""
else
new_id=$(echo "$input" | sed 's/id *//; s/ *$//; s/ /+/g')
fi
if [ "$new_id" = remove ]; then
if [ -e "$id_file" ]; then
rm -f -- "$id_file" && echo "id is removed"
else
echo "id was not set, so you can't remove it"
fi
return
fi
if [ -n "$new_id" ] && [ reset != "$new_id" ] && [ "$(/bin/echo -n "$new_id" | wc -c)" -lt 16 ]; then
echo "ERROR: $new_id: Too short id. Minimal id length is 16. Use 'id reset' for a random id"
return
fi
if [ -z "$new_id" ]; then
# if new_id is not specified check if we have some id already
# if yes, just show it
# if not, generate a new id
if [ -e "$id_file" ]; then
awk '$6 == "id" {print $NF}' <"$id_file" | tail -n 1
return
else
new_id=reset
fi
fi
if [ "$new_id" = reset ]; then
new_id=$(gen_random_str 12)
else
echo WARNING: if someone gueses your id, he can read your cht.sh search history
fi
if [ -e "$id_file" ] && grep -q '\tid\t[^\t][^\t]*$' "$id_file" 2> /dev/null; then
sed -i 's/\tid\t[^\t][^\t]*$/ id '"$new_id"'/' "$id_file"
else
if ! [ -e "$id_file" ]; then
printf '#\n\n' > "$id_file"
fi
printf ".cht.sh\tTRUE\t/\tTRUE\t0\tid\t$new_id\n" >> "$id_file"
fi
echo "$new_id"
}
cmd_query() {
query=$(prepare_query "$section" "$input")
do_query "$query"
}
cmd_stealth() {
if [ "$input" != stealth ]; then
arguments=$(echo "$input" | sed 's/stealth //; s/ /\&/')
fi
trap break INT
if [ "$is_macos" = yes ]; then
past=$(pbpaste)
else
if [ "$XDG_SESSION_TYPE" = wayland ]; then
past=$(wl-paste -p)
else
past=$(xsel -o)
fi
fi
printf "\033[0;31mstealth:\033[0m you are in the stealth mode; select any text in any window for a query\n"
printf "\033[0;31mstealth:\033[0m selections longer than $STEALTH_MAX_SELECTION_LENGTH words are ignored\n"
if [ -n "$arguments" ]; then
printf "\033[0;31mstealth:\033[0m query arguments: ?$arguments\n"
fi
printf "\033[0;31mstealth:\033[0m use ^C to leave this mode\n"
while true; do
if [ "$is_macos" = yes ]; then
current=$(pbpaste)
else
if [ "$XDG_SESSION_TYPE" = wayland ]; then
current=$(wl-paste -p)
else
current=$(xsel -o)
fi
fi
if [ "$past" != "$current" ]; then
past=$current
current_text="$(echo $current | tr -c '[a-zA-Z0-9]' ' ')"
if [ "$(echo "$current_text" | wc -w)" -gt "$STEALTH_MAX_SELECTION_LENGTH" ]; then
printf "\033[0;31mstealth:\033[0m selection length is longer than $STEALTH_MAX_SELECTION_LENGTH words; ignoring\n"
continue
else
printf "\n\033[0;31mstealth: \033[7m $current_text\033[0m\n"
query=$(prepare_query "$section" "$current_text" "$arguments")
do_query "$query"
fi
fi
sleep 1;
done
trap - INT
}
cmd_update() {
[ -w "$0" ] || { echo "The script is readonly; please update manually: curl -s ${CHTSH_URL}/:cht.sh | sudo tee $0"; return; }
TMP2=$(mktemp /tmp/cht.sh.XXXXXXXXXXXXX)
curl -s "${CHTSH_URL}"/:cht.sh > "$TMP2"
if ! cmp "$0" "$TMP2" > /dev/null 2>&1; then
if grep -q ^__CHTSH_VERSION= "$TMP2"; then
# section was validated by us already
args=(--shell "$section")
cp "$TMP2" "$0" && echo "Updated. Restarting..." && rm "$TMP2" && CHEATSH_RESTART=1 exec "$0" "${args[@]}"
else
echo "Something went wrong. Please update manually"
fi
else
echo "cht.sh is up to date. No update needed"
fi
rm -f "$TMP2" > /dev/null 2>&1
}
cmd_version() {
insttime=$(ls -l -- "$0" | sed 's/ */ /g' | cut -d ' ' -f 6-8)
echo "cht.sh version $__CHTSH_VERSION of $__CHTSH_DATETIME; installed at: $insttime"
TMP2=$(mktemp /tmp/cht.sh.XXXXXXXXXXXXX)
if curl -s "${CHTSH_URL}"/:cht.sh > "$TMP2"; then
if ! cmp "$0" "$TMP2" > /dev/null 2>&1; then
echo "Update needed (type 'update' for that)".
else
echo "Up to date. No update needed"
fi
fi
rm -f "$TMP2" > /dev/null 2>&1
}
TMP1=$(mktemp /tmp/cht.sh.XXXXXXXXXXXXX)
trap 'rm -f $TMP1 $TMP2' EXIT
trap 'true' INT
if ! [ -e "$CHTSH_HOME/.hushlogin" ] && [ -z "$this_query" ]; then
echo "type 'help' for the cht.sh shell help"
fi
while true; do
if [ "$section" != "" ]; then
full_prompt="$prompt/$section> "
else
full_prompt="$prompt> "
fi
input=$(
rlwrap -H "$CHTSH_HOME/history" -pgreen -C cht.sh -S "$full_prompt" bash "$0" --read | sed 's/ *#.*//'
)
cmd_name=${input%% *}
cmd_args=${input#* }
case $cmd_name in
"") continue;; # skip empty input lines
'?'|h|help) cmd_name=help;;
hush) cmd_name=hush;;
cd) cmd_name="cd";;
exit|quit) cmd_name="exit";;
copy|yank|c|y) cmd_name=copy;;
ccopy|cc|C|Y) cmd_name=ccopy;;
id) cmd_name=id;;
stealth) cmd_name=stealth;;
update) cmd_name=update;;
version) cmd_name=version;;
*) cmd_name="query"; cmd_args="$input";;
esac
"cmd_$cmd_name" $cmd_args
done
================================================
FILE: share/emacs-ivy.txt
================================================
;;
;; Written by RenJMR
;; https://www.reddit.com/r/emacs/comments/6ddr7p/snippet_search_cheatsh_using_ivy/
;;
;;;
;;; Install the package `ivy' and use `(require 'ivy)' if you do not have
;;; access to the `ivy-read' function.
(defun ejmr-search-cheat-sh ()
"Search `http://cheat.sh/' for help on commands and code."
(interactive)
(ivy-read "Command or Topic: "
(process-lines "curl" "--silent" "http://cheat.sh/:list?T&q")
:require-match t
:sort t
:history 'ejmr-search-cheat-sh
:action (lambda (input)
(browse-url (concat "http://cheat.sh/" input "?T&q")))
:caller 'ejmr-search-cheat-sh))
================================================
FILE: share/emacs.txt
================================================
;;; cheat-sh.el --- Interact with cheat.sh -*- lexical-binding: t -*-
;; Copyright 2017 by Dave Pearson
;; Author: Dave Pearson
;; Version: 1.7
;; Keywords: docs, help
;; URL: https://github.com/davep/cheat-sh.el
;; Package-Requires: ((emacs "24"))
;; cheat-sh.el is free software distributed under the terms of the GNU
;; General Public Licence, version 2 or (at your option) any later version.
;; For details see the file COPYING.
;;; Commentary:
;;
;; cheat-sh.el provides a simple Emacs interface for looking things up on
;; cheat.sh.
;;; Code:
(require 'url-vars)
(defgroup cheat-sh nil
"Interact with cheat.sh."
:group 'docs)
(defface cheat-sh-section
'((t :inherit (bold font-lock-doc-face)))
"Face used on sections in a cheat-sh output window."
:group 'cheat-sh)
(defface cheat-sh-caption
'((t :inherit (bold font-lock-function-name-face)))
"Face used on captions in the cheat-sh output window."
:group 'cheat-sh)
(defcustom cheat-sh-list-timeout (* 60 60 4)
"Seconds to wait before deciding the cached sheet list is \"stale\"."
:type 'integer
:group 'cheat-sh)
(defconst cheat-sh-url "http://cheat.sh/%s?T"
"URL for cheat.sh.")
(defconst cheat-sh-user-agent "cheat-sh.el (curl)"
"User agent to send to cheat.sh.
Note that \"curl\" should ideally be included in the user agent
string because of the way cheat.sh works.
cheat.sh looks for a specific set of clients in the user
agent (see https://goo.gl/8gh95X for this) to decide if it should
deliver plain text rather than HTML. cheat-sh.el requires plain
text.")
(defun cheat-sh-get (thing)
"Get THING from cheat.sh."
(let* ((url-request-extra-headers `(("User-Agent" . ,cheat-sh-user-agent)))
(buffer (url-retrieve-synchronously (format cheat-sh-url (url-hexify-string thing)) t t)))
(when buffer
(with-current-buffer buffer
(setf (point) (point-min))
(when (search-forward-regexp "^$" nil t)
(buffer-substring (point) (point-max)))))))
(defvar cheat-sh-sheet-list nil
"List of all available sheets.")
(defvar cheat-sh-sheet-list-acquired nil
"The time when variable `cheat-sh-sheet-list' was populated.")
(defun cheat-sh-sheet-list-cache ()
"Return the list of sheets.
The list is cached in memory, and is considered \"stale\" and is
refreshed after `cheat-sh-list-timeout' seconds."
(when (and cheat-sh-sheet-list-acquired
(> (- (time-to-seconds) cheat-sh-sheet-list-acquired) cheat-sh-list-timeout))
(setq cheat-sh-sheet-list nil))
(or cheat-sh-sheet-list
(let ((list (cheat-sh-get ":list")))
(when list
(setq cheat-sh-sheet-list-acquired (time-to-seconds))
(setq cheat-sh-sheet-list (split-string list "\n"))))))
(defun cheat-sh-read (prompt)
"Read input from the user, showing PROMPT to prompt them.
This function is used by some `interactive' functions in
cheat-sh.el to get the item to look up. It provides completion
based of the sheets that are available on cheat.sh."
(completing-read prompt (cheat-sh-sheet-list-cache)))
(defun cheat-sh-decorate-all (buffer regexp face)
"Decorate BUFFER, finding REGEXP and setting face to FACE."
(with-current-buffer buffer
(save-excursion
(setf (point) (point-min))
(while (search-forward-regexp regexp nil t)
(replace-match (propertize (match-string 1) 'font-lock-face face) nil t)))))
(defun cheat-sh-decorate-results (buffer)
"Decorate BUFFER with properties to highlight results."
;; "[Search section]"
(cheat-sh-decorate-all buffer "^\\(\\[.*\\]\\)$" 'cheat-sh-section)
;; "# Result caption"
(cheat-sh-decorate-all buffer "^\\(#.*\\)$" 'cheat-sh-caption)
;; "cheat-sh help caption:"
(cheat-sh-decorate-all buffer "^\\([^[:space:]].*:\\)$" 'cheat-sh-caption))
;;;###autoload
(defun cheat-sh (thing)
"Look up THING on cheat.sh and display the result."
(interactive (list (cheat-sh-read "Lookup: ")))
(let ((result (cheat-sh-get thing)))
(if result
(with-help-window "*cheat.sh*"
(princ result)
(cheat-sh-decorate-results standard-output))
(error "Can't find anything for %s on cheat.sh" thing))))
;;;###autoload
(defun cheat-sh-region (start end)
"Look up the text between START and END on cheat.sh."
(interactive "r")
(deactivate-mark)
(cheat-sh (buffer-substring-no-properties start end)))
;;;###autoload
(defun cheat-sh-maybe-region ()
"If region is active lookup content of region, otherwise prompt."
(interactive)
(call-interactively (if mark-active #'cheat-sh-region #'cheat-sh)))
;;;###autoload
(defun cheat-sh-help ()
"Get help on using cheat.sh."
(interactive)
(cheat-sh ":help"))
;;;###autoload
(defun cheat-sh-list (thing)
"Get a list of topics available on cheat.sh.
Either gets a topic list for subject THING, or simply gets a list
of all available topics on cheat.sh if THING is supplied as an
empty string."
(interactive (list (cheat-sh-read "List sheets for: ")))
(cheat-sh (format "%s/:list" thing)))
;;;###autoload
(defun cheat-sh-search (thing)
"Search for THING on cheat.sh and display the result."
(interactive "sSearch: ")
(cheat-sh (concat "~" thing)))
;;;###autoload
(defun cheat-sh-search-topic (topic thing)
"Search TOPIC for THING on cheat.sh and display the result."
(interactive
(list (cheat-sh-read "Topic: ")
(read-string "Search: ")))
(cheat-sh (concat topic "/~" thing)))
(provide 'cheat-sh)
;;; cheat-sh.el ends here
================================================
FILE: share/firstpage-v1.txt
================================================
oooo . oooo
`888 .o8 `888
.ooooo. 888 .oo. .ooooo. .oooo. .o888oo .oooo.o 888 .oo.
d88' `"Y8 888P"Y88b d88' `88b `P )88b 888 d88( "8 888P"Y88b
888 888 888 888ooo888 .oP"888 888 `"Y88b. 888 888
888 .o8 888 888 888 .o d8( 888 888 . .o. o. )88b 888 888
`Y8bod8P' o888o o888o `Y8bod8P' `Y888""8o "888" Y8P 8""888P' o888o o888o
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* the fastest way to find | you need
* provides access to community driven cheat sheets repositories
* delivers <906> cheat sheets in <16> areas and growing
* covers UNIX/Linux commands and programming languages
* programming languages cheat sheets are under:
| | $ cht.sh --shell | | $ cht.sh go zip lists |
| go/for go/func | | cht.sh> help | | Ask any question using |
| $ cht.sh go/for | | ... | | cht.sh or curl cht.sh: |
| ... | | $ curl cht.sh/:cht.sh | | /go/zip+lists |
| | | #!/bin/sh | | (use /,+ when curling) |
| | | ... | | |
+---- TAB-completion ----+ +-- interactive shell ---+ +- programming questions-+
+------------------------+ +------------------------+ +------------------------+
| $ curl cht.sh/:help | | $ vim prg.py | | $ time curl cht.sh/ |
| see /:help and /:intro | | ... | | ... |
| for usage information | | zip lists _ | | real 0m0.075s |
| and README.md on GitHub| | KK | | |
| for the details | | *awesome* | | |
| *start here*| | | | |
+--- self-documented ----+ +- queries from editor! -+ +---- instant answers ---+
[Follow @igor_chubin for updates][github.com/chubin/cheat.sh]
==[mask]==
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKAAAAA
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKAAAAA GGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGG
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKAAAA DDDDDDDDDDDDDDDDDDDDDDDDDDDDDD
KKKKKKKKKKKKKKKKKKKKKKKKKKKLKKKKKKKKKKKAAAA DDDDDDDDDDDDDDDDDDDDDDDDDDDDDD
KKKKKKKKKKKKKKKKKKKKKKKKKKLLLKKKKKKKKKAAAAA DDDDDDDDDDDDDDDDDDDDDDDDDDDDDD
DDDDDDDDDDDDDDDDDDDDDDDDDD DDDDDDDDDDDDDDDDDDDDDDDDDD DDDDDDDDDDDDDDDDDDDDDDDDDD
D $ BBBB CCCCCCCCCCCCCCC D D $ BBBBBB CCCCCCCCCCCCC D D $ CCCCCCCCCCCBBBBBB D
D $ BBBB CCCCCCCCCCCCCCC D D $ BBBBBB CCCCCCCCCCCCC D D Learn anyF programming D
D $ BBBB CCCCCCCCCCCCCCC D D D D languages not leaving D
D $ CCCC BBBBBBCCCCCCCCC D D D D your shell D
D D D D D FF any of 60 D
D D D D D D
DDDEEEEEEEEEEEEEEEEEEEDDDD DD EEEEEEEEEEEEEEEEEEE DDD DD EEEEEEEEEEEEEEEEEEEE DD
DDDDDDDDDDDDDDDDDDDDDDDDDD DDDDDDDDDDDDDDDDDDDDDDDDDD DDDDDDDDDDDDDDDDDDDDDDDDDD
D $ CCCCCCCCCCCBBBBBBBBBBD D $ CCCCCC BBBBBBB D D $ CCCCCC BBBBBBBBBBBB D
D go/for go/func D D HHHHHHH help D D ask any question using D
D $ cht.sh go/for D D ... D D cht.sh or curl cht.sh: D
D ... D D $ BBBB CCCCCCCCCCCCCCC D D /goHzipHlists D
D D D D D (use H,H when curling) D
D D D D D D
DDDDDEEEEEEEEEEEEEEEEDDDDD DDDEEEEEEEEEEEEEEEEEEEDDDD DDEEEEEEEEEEEEEEEEEEEEEEDD
DDDDDDDDDDDDDDDDDDDDDDDDDD DDDDDDDDDDDDDDDDDDDDDDDDDD DDDDDDDDDDDDDDDDDDDDDDDDDD
D $ CCCCCCCCCCCCBBBBB D D $ BBB CCCCCC D D $ BBBB curl cht.sh/ D
D see HHHHHH and HHHHHHH D D ... D D ... D
D for usage information D D zip lists _ D D real HHHHHHHH D
D and readme.md on CCCCCCD D HHHHHHHHHH D D D
D for the details D D * awesome * D D D
D FFFFFFFFFFFFD D D D D
DDDD EEEEEEEEEEEEEEE DDDDD DD EEEEEEEEEEEEEEEEEEEE DD DDDDD EEEEEEEEEEEEEEE DDDD
DDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDD
==[code]==
set_color A green
set_color B white
set_color C gray
set_color D cyan
set_color E yellow
set_color A #00cc00
set_color B #00cc00
set_color C #00aacc
set_color D #888888
set_color E #cccc00
set_color F #ff0000
set_color H #22aa22
set_color I #cc0000
set_color J #000000
set_bg_color G #555555
set_bg_color J #555555
================================================
FILE: share/firstpage-v2.txt
================================================
_ _ _ [38;2;0;204;0m_[0m[38;2;0;204;0m_[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m
___| |__ ___ __ _| |_ ___| |__ [38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m [48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85mT[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85m [0m[48;2;85;85;85mo[0m[48;2;85;85;85mn[0m[48;2;85;85;85ml[0m[48;2;85;85;85my[0m[48;2;85;85;85m [0m[48;2;85;85;85mc[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85ma[0m[48;2;85;85;85mt[0m[48;2;85;85;85m [0m[48;2;85;85;85ms[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85me[0m[48;2;85;85;85mt[0m[48;2;85;85;85m [0m[48;2;85;85;85my[0m[48;2;85;85;85mo[0m[48;2;85;85;85mu[0m[48;2;85;85;85m [0m[48;2;85;85;85mn[0m[48;2;85;85;85me[0m[48;2;85;85;85me[0m[48;2;85;85;85md[0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m
/ __| '_ \ / _ \/ _` | __| / __| '_ \ [38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m\[0m[38;2;0;204;0m [0m [38;2;136;136;136mU[0m[38;2;136;136;136mn[0m[38;2;136;136;136mi[0m[38;2;136;136;136mf[0m[38;2;136;136;136mi[0m[38;2;136;136;136me[0m[38;2;136;136;136md[0m[38;2;136;136;136m [0m[38;2;136;136;136ma[0m[38;2;136;136;136mc[0m[38;2;136;136;136mc[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136ms[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mo[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136m [0m[38;2;136;136;136mb[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136mt[0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m
| (__| | | | __/ (_| | |_ _\__ \ | | |[38;2;0;204;0m/[0m[38;2;0;204;0m [0m[38;2;0;204;0m/[0m[38;2;0;204;0m [0m [38;2;136;136;136mc[0m[38;2;136;136;136mo[0m[38;2;136;136;136mm[0m[38;2;136;136;136mm[0m[38;2;136;136;136mu[0m[38;2;136;136;136mn[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136my[0m[38;2;136;136;136m [0m[38;2;136;136;136md[0m[38;2;136;136;136mr[0m[38;2;136;136;136mi[0m[38;2;136;136;136mv[0m[38;2;136;136;136me[0m[38;2;136;136;136mn[0m[38;2;136;136;136m [0m[38;2;136;136;136md[0m[38;2;136;136;136mo[0m[38;2;136;136;136mc[0m[38;2;136;136;136mu[0m[38;2;136;136;136mm[0m[38;2;136;136;136me[0m[38;2;136;136;136mn[0m[38;2;136;136;136mt[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136mi[0m[38;2;136;136;136mo[0m[38;2;136;136;136mn[0m
\___|_| |_|\___|\__,_|\__(_)___/_| |_[38;2;0;204;0m/[0m[38;2;0;204;0m_[0m[38;2;0;204;0m/[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m [38;2;136;136;136mr[0m[38;2;136;136;136me[0m[38;2;136;136;136mp[0m[38;2;136;136;136mo[0m[38;2;136;136;136ms[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136mi[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136m [0m[38;2;136;136;136mo[0m[38;2;136;136;136mf[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136m [0m[38;2;136;136;136mw[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136ml[0m[38;2;136;136;136md[0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204me[0m[38;2;0;170;204ma[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204ml[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0m.[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m [38;2;0;170;204mb[0m[38;2;0;170;204mt[0m[38;2;0;170;204mr[0m[38;2;0;170;204mf[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m[38;2;0;170;204ml[0m[38;2;0;170;204mu[0m[38;2;0;170;204ma[0m[38;2;0;170;204m/[0m[38;2;0;204;0m:[0m[38;2;0;204;0ml[0m[38;2;0;204;0me[0m[38;2;0;204;0ma[0m[38;2;0;204;0mr[0m[38;2;0;204;0mn[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204mb[0m[38;2;0;170;204mt[0m[38;2;0;170;204mr[0m[38;2;0;170;204mf[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0m.[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m [38;2;0;170;204mt[0m[38;2;0;170;204ma[0m[38;2;0;170;204mr[0m[38;2;0;170;204m~[0m[38;2;0;170;204ml[0m[38;2;0;170;204mi[0m[38;2;0;170;204ms[0m[38;2;0;170;204mt[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m Learn any[38;2;255;0;0m*[0m programming [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204mt[0m[38;2;0;170;204ma[0m[38;2;0;170;204mr[0m[38;2;0;170;204m~[0m[38;2;0;170;204ml[0m[38;2;0;170;204mi[0m[38;2;0;170;204ms[0m[38;2;0;170;204mt[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m language not leaving [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mu[0m[38;2;0;170;204mr[0m[38;2;0;170;204ml[0m [38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0mt[0m[38;2;0;204;0mp[0m[38;2;0;204;0ms[0m[38;2;0;204;0m:[0m[38;2;0;170;204m/[0m[38;2;0;170;204m/[0m[38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m your shell [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;255;0;0m*[0m[38;2;255;0;0m)[0m any of 60 [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0m [0m[38;2;204;204;0mw[0m[38;2;204;204;0mi[0m[38;2;204;204;0mt[0m[38;2;204;204;0mh[0m[38;2;204;204;0m [0m[38;2;204;204;0mc[0m[38;2;204;204;0mu[0m[38;2;204;204;0mr[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0mo[0m[38;2;204;204;0mw[0m[38;2;204;204;0mn[0m[38;2;204;204;0m [0m[38;2;204;204;0mo[0m[38;2;204;204;0mp[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0ma[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;204;204;0mc[0m[38;2;204;204;0ml[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m,[0m[38;2;204;204;0m [0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m,[0m[38;2;204;204;0m [0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m![0m [38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m[38;2;0;170;204mg[0m[38;2;0;170;204mo[0m[38;2;0;170;204m/[0m[38;2;0;170;204mf[0m[38;2;0;204;0m<[0m[38;2;0;204;0mt[0m[38;2;0;204;0ma[0m[38;2;0;204;0mb[0m[38;2;0;204;0m>[0m[38;2;0;204;0m<[0m[38;2;0;204;0mt[0m[38;2;0;204;0ma[0m[38;2;0;204;0mb[0m[38;2;0;204;0m>[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m [38;2;0;204;0m-[0m[38;2;0;204;0m-[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m[38;2;0;204;0me[0m[38;2;0;204;0ml[0m[38;2;0;204;0ml[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m [38;2;0;204;0mg[0m[38;2;0;204;0mo[0m[38;2;0;204;0m [0m[38;2;0;204;0mz[0m[38;2;0;204;0mi[0m[38;2;0;204;0mp[0m[38;2;0;204;0m [0m[38;2;0;204;0ml[0m[38;2;0;204;0mi[0m[38;2;0;204;0ms[0m[38;2;0;204;0mt[0m[38;2;0;204;0ms[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m go/for go/func [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;34;170;34mc[0m[38;2;34;170;34mh[0m[38;2;34;170;34mt[0m[38;2;34;170;34m.[0m[38;2;34;170;34ms[0m[38;2;34;170;34mh[0m[38;2;34;170;34m>[0m help [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m Ask any question using [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ cht.sh go/for [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m cht.sh or curl cht.sh: [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m /go[38;2;34;170;34m/[0mzip[38;2;34;170;34m+[0mlists [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m (use [38;2;34;170;34m/[0m,[38;2;34;170;34m+[0m when curling) [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mT[0m[38;2;204;204;0mA[0m[38;2;204;204;0mB[0m[38;2;204;204;0m-[0m[38;2;204;204;0mc[0m[38;2;204;204;0mo[0m[38;2;204;204;0mm[0m[38;2;204;204;0mp[0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0ma[0m[38;2;204;204;0mc[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mv[0m[38;2;204;204;0me[0m[38;2;204;204;0m [0m[38;2;204;204;0ms[0m[38;2;204;204;0mh[0m[38;2;204;204;0me[0m[38;2;204;204;0ml[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mp[0m[38;2;204;204;0mr[0m[38;2;204;204;0mo[0m[38;2;204;204;0mg[0m[38;2;204;204;0mr[0m[38;2;204;204;0ma[0m[38;2;204;204;0mm[0m[38;2;204;204;0mm[0m[38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0mg[0m[38;2;204;204;0m [0m[38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mu[0m[38;2;0;170;204mr[0m[38;2;0;170;204ml[0m[38;2;0;170;204m [0m[38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;204;0m:[0m[38;2;0;204;0mh[0m[38;2;0;204;0me[0m[38;2;0;204;0ml[0m[38;2;0;204;0mp[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mv[0m[38;2;0;204;0mi[0m[38;2;0;204;0mm[0m [38;2;0;170;204mp[0m[38;2;0;170;204mr[0m[38;2;0;170;204mg[0m[38;2;0;170;204m.[0m[38;2;0;170;204mp[0m[38;2;0;170;204my[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mt[0m[38;2;0;204;0mi[0m[38;2;0;204;0mm[0m[38;2;0;204;0me[0m curl cht.sh/ [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m see [38;2;34;170;34m/[0m[38;2;34;170;34m:[0m[38;2;34;170;34mh[0m[38;2;34;170;34me[0m[38;2;34;170;34ml[0m[38;2;34;170;34mp[0m and [38;2;34;170;34m/[0m[38;2;34;170;34m:[0m[38;2;34;170;34mi[0m[38;2;34;170;34mn[0m[38;2;34;170;34mt[0m[38;2;34;170;34mr[0m[38;2;34;170;34mo[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m for usage information [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m zip lists _ [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m real [38;2;34;170;34m0[0m[38;2;34;170;34mm[0m[38;2;34;170;34m0[0m[38;2;34;170;34m.[0m[38;2;34;170;34m0[0m[38;2;34;170;34m7[0m[38;2;34;170;34m5[0m[38;2;34;170;34ms[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m and README.md on [38;2;0;170;204mG[0m[38;2;0;170;204mi[0m[38;2;0;170;204mt[0m[38;2;0;170;204mH[0m[38;2;0;170;204mu[0m[38;2;0;170;204mb[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;34;170;34m<[0m[38;2;34;170;34ml[0m[38;2;34;170;34me[0m[38;2;34;170;34ma[0m[38;2;34;170;34md[0m[38;2;34;170;34me[0m[38;2;34;170;34mr[0m[38;2;34;170;34m>[0m[38;2;34;170;34mK[0m[38;2;34;170;34mK[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m for the details [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m *awesome* [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;255;0;0m*[0m[38;2;255;0;0ms[0m[38;2;255;0;0mt[0m[38;2;255;0;0ma[0m[38;2;255;0;0mr[0m[38;2;255;0;0mt[0m[38;2;255;0;0m [0m[38;2;255;0;0mh[0m[38;2;255;0;0me[0m[38;2;255;0;0mr[0m[38;2;255;0;0me[0m[38;2;255;0;0m*[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m [38;2;204;204;0ms[0m[38;2;204;204;0me[0m[38;2;204;204;0ml[0m[38;2;204;204;0mf[0m[38;2;204;204;0m-[0m[38;2;204;204;0md[0m[38;2;204;204;0mo[0m[38;2;204;204;0mc[0m[38;2;204;204;0mu[0m[38;2;204;204;0mm[0m[38;2;204;204;0me[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0me[0m[38;2;204;204;0md[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0m [0m[38;2;204;204;0mf[0m[38;2;204;204;0mr[0m[38;2;204;204;0mo[0m[38;2;204;204;0mm[0m[38;2;204;204;0m [0m[38;2;204;204;0me[0m[38;2;204;204;0md[0m[38;2;204;204;0mi[0m[38;2;204;204;0mt[0m[38;2;204;204;0mo[0m[38;2;204;204;0mr[0m[38;2;204;204;0m![0m [38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m [38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;204;204;0mt[0m[38;2;204;204;0ma[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0m [0m[38;2;204;204;0ma[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;204;204;0mw[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0ms[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m[[0m[38;2;136;136;136mF[0m[38;2;136;136;136mo[0m[38;2;136;136;136ml[0m[38;2;136;136;136ml[0m[38;2;136;136;136mo[0m[38;2;136;136;136mw[0m[38;2;136;136;136m [0m[38;2;136;136;136m@[0m[38;2;136;136;136mi[0m[38;2;136;136;136mg[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136m_[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136mi[0m[38;2;136;136;136mn[0m[38;2;136;136;136m [0m[38;2;136;136;136mf[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136m [0m[38;2;136;136;136mu[0m[38;2;136;136;136mp[0m[38;2;136;136;136md[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136m][0m[38;2;136;136;136m[[0m[38;2;136;136;136mg[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136m.[0m[38;2;136;136;136mc[0m[38;2;136;136;136mo[0m[38;2;136;136;136mm[0m[38;2;136;136;136m/[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136mi[0m[38;2;136;136;136mn[0m[38;2;136;136;136m/[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136m.[0m[38;2;136;136;136ms[0m[38;2;136;136;136mh[0m[38;2;136;136;136m][0m
================================================
FILE: share/fish.txt
================================================
# add it to your ~/.config/fish/config.fish
# retrieve command cheat sheets from cheat.sh
# fish version by @tobiasreischmann
function cheat.sh
curl cheat.sh/$argv
end
# register completions (on-the-fly, non-cached, because the actual command won't be cached anyway
complete -c cheat.sh -xa '(curl -s cheat.sh/:list)'
================================================
FILE: share/help.txt
================================================
Usage:
$ curl cheat.sh/TOPIC show cheat sheet on the TOPIC
$ curl cheat.sh/TOPIC/SUB show cheat sheet on the SUB topic in TOPIC
$ curl cheat.sh/~KEYWORD search cheat sheets for KEYWORD
Options:
?OPTIONS
q quiet mode, don't show github/twitter buttons
T text only, no ANSI sequences
style=STYLE color style
c do not comment text, do not shift code (QUERY+ only)
C do not comment text, shift code (QUERY+ only)
Q code only, don't show text (QUERY+ only)
Options can be combined together in this way:
curl 'cheat.sh/for?qT&style=bw'
(when using & in shell, don't forget to specify the quotes or escape & with \)
Special pages:
:help this page
:list list all cheat sheets
:post how to post new cheat sheet
:cht.sh shell client (cht.sh)
:bash_completion bash function for tab completion
:styles list of color styles
:styles-demo show color styles usage examples
:random fetches a random cheat sheet
Shell client:
$ curl https://cht.sh/:cht.sh > ~/bin/cht.sh
$ chmod +x ~/bin/cht.sh
$ cht.sh python :learn
$ cht.sh --shell
Tab completion:
$ mkdir -p ~/.bash.d/
$ curl cheat.sh/:bash_completion > ~/.bash.d/cht.sh
$ . ~/.bash.d/cht.sh
$ echo '. ~/.bash.d/cht.sh' >> ~/.bashrc
Editor integration:
:emacs see the page for the Emacs configuration
:vim see the page for the Vim configuration
Search:
/~snapshot look for "snapshot" in the first level cheat sheets
/~ssh~passphrase several keywords can be combined together using ~
/scala/~closure look for "closure" in scala cheat sheets
/~snapshot/r look for "snapshot" in all cheat sheets recursively
You can use special search options after the closing slash:
/~shot/bi case insensitive (i), word boundaries (b)
List of search options:
b word boundaries
i case insensitive search
r recursive
Programming languages topics:
Each programming language topic has the following subtopics:
hello hello world + how to start the program
:learn big cheat sheet for learning language from scratch
:list list of topics
:random fetches a random cheat sheet belonging to the topic
================================================
FILE: share/intro.txt
================================================
## curl cht.sh
To access a cheat sheet you can simply issue a plain HTTP or HTTPS request
specifying the topic name in the query URL:
{1curl cheat.sh}{2/tar}
{1curl https://cheat.sh}{2/tar}
You can use the full service name, {2cheat.sh}, or the shorter variant, {2cht.sh}.
They are equivalent:
{1curl https://}{2cht.sh}{1/tar}
{1curl https://}{2cheat.sh}{1/tar}
The preferred access protocol is HTTPS, and you should always use it when possible.
Cheat sheets in the root namespaces cover UNIX/Linux commands.
Cheat sheets covering programming languages are located in subsections:
{1curl cht.sh/}{2go/func}
All cheat sheets in a subsection can be listed using a special query {2:list} :
{1curl cht.sh/go/}{2:list}
There are several other special queries. All of them start with a {2colon}.
See {2/:help} for the full list of the special queries.
## Search
If a cheat sheet is too large, you can cut the needed part out using an
additional search parameter. In this case, only the paragraph that contains the
search term will be displayed:
{1curl cht.sh/tar}{2~extract}
If the name of the cheat sheet is omitted, and only the search query is specified,
all cheat sheets in the namespace are scanned, and the found occurrences
are displayed:
{1curl cht.sh/}{2~extract}
## Options
cheat.sh queries as well as search queries have many options.
They can be specified as a part of the query string in the URL, after {2?}.
Short single letter options can be joined together. Long options are
separated with {2&}. For example, to switch syntax highlighting off
the {2T} switch is used:
{1curl cht.sh/tar}{2?T}
A full list of all available cheat.sh options as well as description of all modes
of operation can be found in {2/:help}.
{1curl cht.sh}{2/:help}
## cht.sh client
Though it's perfectly possible to access cheat.sh using {1curl} (or any other
HTTP client) alone, there is a special client that has several advantages
over plain curling: {2cht.sh}.
To install the client in {2~/bin}:
{1curl} {2https://cht.sh/:cht.sh} {1> ~/bin/cht.sh}
{1chmod +x ~/bin/cht.sh}
Queries look the same, but you can use {1spaces} to separate words in addition to {1+}
used with curl.
{1cht.sh} {2python zip lists}
## cht.sh shell
If you're always issuing queries about the same programming language, it can be
more convenient to run the client in the shell mode and specify the query's
context:
{1$} {2cht.sh --shell python}
{1cht.sh/python> zip lists}
Of course, you can start the shell without the context too:
{1$} {2cht.sh --shell}
{1cht.sh> python zip lists}
{1cht.sh> go http query}
{1cht.sh> js iterate list}
If you use one language predominantly, but sometimes issue queries about others,
you may prepend the query with {2/}:
{1cht.sh/python>} {2zip lists}
{1cht.sh/python>} {2/go http query}
{1cht.sh/python>} {2/js iterate list}
## :learn
If you are just starting to learn a new programming language and you have no
distinct queries for the moment, cheat.sh can be a good starting point. As
you know, it exports cheat sheets from the best cheat sheet repositories,
like {1Learn X in Y}, a repository of concise documentation devoted
(but not limited) to learning programming languages from scratch.
If you want start learning a new programming language, do (use less -R because
the output could be quite big):
{1curl cht.sh/elixir/}{2:learn} {1| less -R}
Or simply {2:learn} with cht.sh (you don't need {2less -R} here, because
{1cht.sh} starts pager if needed automatically):
{4cht.sh/elixir>} {2:learn}
## Programming languages questions
One of the most important features of cheat.sh is that you can ask it any
questions about programming languages and instantly get answers. You
can use either direct HTTP queries or the cht.sh client:
{1curl cht.sh/}{2python/reverse+list}
{4cht.sh/python>} {2reverse list}
In the latter case you don't need + to separate the words in the query, you can
do it in a more natural way, with spaces.
If context in the cht.sh shell is not specified, you have to write the
programming language name as the first word in the query:
{4cht.sh>} {2python reverse list}
But if you are using only one programming language and all queries are about
it, it's better to change the current context.
## Comments
Text in the answers is syntactically formatted as a comment in the corresponding
programming language
When using cht.sh, you can copy the result of the last query into the selection
buffer (you may also call it "clipboard") using {2C} (or {2c}, with text):
{1cht.sh/python> reverse list}
{4...}
{1cht.sh/python>} {2C}
{4=1 lines copied}
## bash TAB-completion for cht.sh
One of the advantages of the {1cht.sh} client comparing to plain curl is that you
can use TAB completion when writing its queries in {1bash}
(other supported shells: {1zsh} and {1fish}).
To install the TAB completion script, assuming you use bash, you have to do:
{1mkdir -p ~/.bash.d/}
{1curl} {2https://cht.sh/:bash_completion} {1> ~/.bash.d/cht.sh}
{1echo 'source ~/.bash.d/cht.sh' >> ~/.bashrc}
{1source ~/.bash.d/cht.sh}
## Editor
You can access cheat.sh directly from editors: {1Vim} and {1Emacs}.
It's a very important feature! You will absolutely like it.
{1Imagine:}
instead of switching to your browser, googling, browsing Stack Overflow
and eventually copying the code snippets you need and later pasting them into
the editor, you can achieve the same instantly and without leaving
the editor at all!
Here is how it works:
1. In Vim, if you have a question while editing a program, you can just type
your question {1directly in the buffer} and press {2KK}. You will get
the answer to your question in {1pager}. (with {2KB} you'll get the answer
in a separate {1buffer}).
2. If you like the answer. You can manually paste it from the buffer or
the pager, or if you are lazy you can use {2KP} to paste it under
your question ({2KR} will replace your question). If you want the
answer without the comments, {2KC} replays the last query
toggling them.
You have to install cheat.sh {1Vim/Emacs plugins} for the editor support.
See {2/:vim} or {2/:emacs} for detailed installation instructions.
## Feature requests, feedback and contribution
If you want to submit a new community driver repository for cheat.sh please
open a ticket on the project page on GitHub.
If you want to modify an existing cheat sheet, please check the source of the
cheat sheet (it is always displayed in the cheat sheet bottom line).
If you want to add a new cheat sheet, add it here:
{1https://github.com/chubin/cheat.sheets}
If you want to suggest a new feature for cheat.sh, or if you've found a bug,
please open a new issue on github:
{1https://github.com/chubin/cheat.sh}
If you want to get the major project updates, follow @igor_chubin in Twitter
or this RSS feed: {1https://twitrss.me/twitter_user_to_rss/?user=igor_chubin}
================================================
FILE: share/post.txt
================================================
You can add a new entry to a cheat sheet or create a new cheat sheet
in one of the following ways (your cheat sheet will be eventually added
to chubin/cheat.sheets):
1. With curl:
cat ${cheatsheet} | curl -F 'newcmd=<-' cheat.sh
curl --data-binary @${cheatsheet} cheat.sh/newcmd
newcmd is the the name of the command you want to post
(use your @twitter or email@ in the post).
2. With git:
~~~
# clone chubin/cheat.sheets
git pull https://github.com/${you}/cheat.sheets && cd cheat.sheets
cp ${cheatsheet} newcmd
git add newcmd
git commit -m 'added newcmd cheat sheet' newcmd
git push
# send pull request
~~~
3. With a browser:
Go to the end of the cheat sheet, click the dollar sign with the mouse
and post your cheat sheet. It will be saved automatically and reviewed.
When writing an entry for a cheat sheet, please keep in mind:
1. We don't try to repeat manuals and documentation sites
2. We don't try to document each and every special usage case of a tool
3. We try to find and gather the most interesting usage cases
If you want contribute to the project, but you have no idea what
cheat sheet you should post, check the list of the most wanted cheat sheets:
cheat.sh/:wanted
================================================
FILE: share/scripts/cacheCleanup.go
================================================
package main
// Remove invalid cache entries.
// Cache entry is invalid, if it contains a special substring.
import (
"context"
"log"
"strings"
"github.com/go-redis/redis"
)
var invalidEntrySubstr = "Unknown cheat sheet"
func removeInvalidEntries() error {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
ctx := context.Background()
allKeys, err := rdb.Keys(ctx, "*").Result()
if err != nil {
return err
}
var counter int
for _, key := range allKeys {
val, err := rdb.Get(ctx, key).Result()
if err != nil {
return err
}
if strings.Contains(val, invalidEntrySubstr) {
err = rdb.Del(ctx, key).Err()
if err != nil {
return err
}
counter++
}
}
log.Println("invalid entries removed:", counter)
return nil
}
func main() {
err := removeInvalidEntries()
if err != nil {
log.Println(err)
}
}
================================================
FILE: share/scripts/remove-from-cache.sh
================================================
#!/usr/bin/env bash
remove_by_name()
{
local query; query="$1"
local q
redis-cli KEYS "$query" | while read -r q; do
redis-cli DEL "$q"
done
}
if [ -z "$1" ]; then
echo Usage:
echo
echo " $0 QUERY"
exit 1
fi
remove_by_name "$1"
================================================
FILE: share/static/1.html
================================================
================================================
FILE: share/static/malformed-response.html
================================================
cheat.sh
# Sorry, we are experiencing extremely high load now.
# We are working on the problem and hope to get it fixed soon.
# Please come back in several hours or try some other queries:
#
# For example:
curl cht.sh/:list to list available cheat sheets
curl cht.sh/LANGUAGE/:list to list available cheat sheets for LANGUAGE
curl cht.sh/LANGUAGE/:learn to learn the LANGUAGE
Follow @igor_chubin for the updates.
If you do not use Twitter, drop a short email to Igor Chubin (igor@chub.in),
and you will be notified as soon as the service is fixed.
If you have any feature requests, wishes, ideas, criticism,
you can use them as the payload for this email.
If you like to code (and you surely do), you can check the cheat.sh repository
to see how the scalability problem is (not yet) solved.
How to get an instant answer to any question on (almost) any programming language from the command line:
$ curl https://t.co/9A97GQdoKB
$ curl https://t.co/F2XAJAIzDJ
$ curl https://t.co/XAKEDhzWjL pic.twitter.com/HRr3mQGCJB
— Igor Chubin (@igor_chubin) July 4, 2018
================================================
FILE: share/static/opensearch.xml
================================================
cheat.sh
The only cheat sheet you need. Unified access to the best community driven documentation repositories of the world.
cheatsheet curl terminal command-line cli examples documentation help tldr
en-US
https://cheat.sh
================================================
FILE: share/static/style.css
================================================
body {
background: black;
color: #bbbbbb;
}
.pre,
pre {
/* font-family: source_code_proregular; */
/*
font-family: Courier New,Courier,Lucida Sans Typewriter,Lucida Typewriter,monospace;
font-size: 70%;
*/
/*font-family: Lucida Console,Lucida Sans Typewriter,monaco,Bitstream Vera Sans Mono,monospace; */
/*Droid Sans Mono*/
font-family: "DejaVu Sans Mono", Menlo, "Lucida Sans Typewriter", "Lucida Console", monaco, "Bitstream Vera Sans Mono", monospace;
/*font-family: bitstream_vera_sans_monoroman;*/
font-size: 75%;
}
input[type="text"]{
border: none;
background: transparent;
color: #bbbbbb;
}
================================================
FILE: share/styles-demo.txt
================================================
--------
abap
--------
[38;5;102m# basic loop[39m
[38;5;21mfor[39m i in [38;5;75m1[39m [38;5;75m2[39m [38;5;75m3[39m [38;5;75m4[39m [38;5;75m5[39m [38;5;75m6[39m [38;5;75m7[39m [38;5;75m8[39m [38;5;75m9[39m [38;5;75m10[39m
[38;5;21mdo[39m
[38;5;0mecho[39m [38;5;0m$i[39m
[38;5;21mdone[39m
--------
algol
--------
[38;5;102m# basic loop[39m
[01;04mfor[00m i in 1 2 3 4 5 6 7 8 9 10
[01;04mdo[00m
[01mecho[00m [38;5;241;01m$i[39;00m
[01;04mdone[00m
--------
algol_nu
--------
[38;5;102m# basic loop[39m
[01mfor[00m i in 1 2 3 4 5 6 7 8 9 10
[01mdo[00m
[01mecho[00m [38;5;241;01m$i[39;00m
[01mdone[00m
--------
arduino
--------
[38;5;247m# basic loop[39m
[38;5;64mfor[39m i in [38;5;101m1[39m [38;5;101m2[39m [38;5;101m3[39m [38;5;101m4[39m [38;5;101m5[39m [38;5;101m6[39m [38;5;101m7[39m [38;5;101m8[39m [38;5;101m9[39m [38;5;101m10[39m
[38;5;64mdo[39m
[38;5;64mecho[39m [38;5;239m$i[39m
[38;5;64mdone[39m
--------
autumn
--------
[38;5;248m# basic loop[39m
[38;5;19mfor[39m i in [38;5;30m1[39m [38;5;30m2[39m [38;5;30m3[39m [38;5;30m4[39m [38;5;30m5[39m [38;5;30m6[39m [38;5;30m7[39m [38;5;30m8[39m [38;5;30m9[39m [38;5;30m10[39m
[38;5;19mdo[39m
[38;5;37mecho[39m [38;5;124m$i[39m
[38;5;19mdone[39m
--------
borland
--------
[38;5;28m# basic loop[39m
[38;5;18;01mfor[39;00m i in [38;5;21m1[39m [38;5;21m2[39m [38;5;21m3[39m [38;5;21m4[39m [38;5;21m5[39m [38;5;21m6[39m [38;5;21m7[39m [38;5;21m8[39m [38;5;21m9[39m [38;5;21m10[39m
[38;5;18;01mdo[39;00m
echo $i
[38;5;18;01mdone[39;00m
--------
bw
--------
# basic loop
[01mfor[00m i in 1 2 3 4 5 6 7 8 9 10
[01mdo[00m
echo $i
[01mdone[00m
--------
colorful
--------
[38;5;102m# basic loop[39m
[38;5;28;01mfor[39;00m i in [38;5;57;01m1[39;00m [38;5;57;01m2[39;00m [38;5;57;01m3[39;00m [38;5;57;01m4[39;00m [38;5;57;01m5[39;00m [38;5;57;01m6[39;00m [38;5;57;01m7[39;00m [38;5;57;01m8[39;00m [38;5;57;01m9[39;00m [38;5;57;01m10[39;00m
[38;5;28;01mdo[39;00m
[38;5;22mecho[39m [38;5;95m$i[39m
[38;5;28;01mdone[39;00m
--------
default
--------
[38;5;66m# basic loop[39m
[38;5;28;01mfor[39;00m i in [38;5;241m1[39m [38;5;241m2[39m [38;5;241m3[39m [38;5;241m4[39m [38;5;241m5[39m [38;5;241m6[39m [38;5;241m7[39m [38;5;241m8[39m [38;5;241m9[39m [38;5;241m10[39m
[38;5;28;01mdo[39;00m
[38;5;28mecho[39m [38;5;18m$i[39m
[38;5;28;01mdone[39;00m
--------
emacs
--------
[38;5;28m# basic loop[39m
[38;5;129;01mfor[39;00m i in [38;5;241m1[39m [38;5;241m2[39m [38;5;241m3[39m [38;5;241m4[39m [38;5;241m5[39m [38;5;241m6[39m [38;5;241m7[39m [38;5;241m8[39m [38;5;241m9[39m [38;5;241m10[39m
[38;5;129;01mdo[39;00m
[38;5;129mecho[39m [38;5;136m$i[39m
[38;5;129;01mdone[39;00m
--------
friendly
--------
[38;5;73m# basic loop[39m
[38;5;22;01mfor[39;00m i in [38;5;71m1[39m [38;5;71m2[39m [38;5;71m3[39m [38;5;71m4[39m [38;5;71m5[39m [38;5;71m6[39m [38;5;71m7[39m [38;5;71m8[39m [38;5;71m9[39m [38;5;71m10[39m
[38;5;22;01mdo[39;00m
[38;5;22mecho[39m [38;5;134m$i[39m
[38;5;22;01mdone[39;00m
--------
fruity
--------
[38;5;28;48;5;233m# basic loop[39;49m
[38;5;202;01mfor[39;00m[38;5;15m [39m[38;5;15mi[39m[38;5;15m [39m[38;5;15min[39m[38;5;15m [39m[38;5;33;01m1[39;00m[38;5;15m [39m[38;5;33;01m2[39;00m[38;5;15m [39m[38;5;33;01m3[39;00m[38;5;15m [39m[38;5;33;01m4[39;00m[38;5;15m [39m[38;5;33;01m5[39;00m[38;5;15m [39m[38;5;33;01m6[39;00m[38;5;15m [39m[38;5;33;01m7[39;00m[38;5;15m [39m[38;5;33;01m8[39;00m[38;5;15m [39m[38;5;33;01m9[39;00m[38;5;15m [39m[38;5;33;01m10[39;00m
[38;5;202;01mdo[39;00m
[38;5;15m [39m[38;5;15mecho[39m[38;5;15m [39m[38;5;202m$i[39m
[38;5;202;01mdone[39;00m
--------
igor
--------
[38;5;9m# basic loop[39m
[38;5;21mfor[39m i in 1 2 3 4 5 6 7 8 9 10
[38;5;21mdo[39m
echo $i
[38;5;21mdone[39m
--------
lovelace
--------
[38;5;102m# basic loop[39m
[38;5;25mfor[39m i in [38;5;238m1[39m [38;5;238m2[39m [38;5;238m3[39m [38;5;238m4[39m [38;5;238m5[39m [38;5;238m6[39m [38;5;238m7[39m [38;5;238m8[39m [38;5;238m9[39m [38;5;238m10[39m
[38;5;25mdo[39m
[38;5;65mecho[39m [38;5;131m$i[39m
[38;5;25mdone[39m
--------
manni
--------
[38;5;33m# basic loop[39m
[38;5;24;01mfor[39;00m i in [38;5;202m1[39m [38;5;202m2[39m [38;5;202m3[39m [38;5;202m4[39m [38;5;202m5[39m [38;5;202m6[39m [38;5;202m7[39m [38;5;202m8[39m [38;5;202m9[39m [38;5;202m10[39m
[38;5;24;01mdo[39;00m
[38;5;240mecho[39m [38;5;235m$i[39m
[38;5;24;01mdone[39;00m
--------
monokai
--------
[38;5;242m# basic loop[39m
[38;5;81mfor[39m[38;5;15m [39m[38;5;15mi[39m[38;5;15m [39m[38;5;15min[39m[38;5;15m [39m[38;5;141m1[39m[38;5;15m [39m[38;5;141m2[39m[38;5;15m [39m[38;5;141m3[39m[38;5;15m [39m[38;5;141m4[39m[38;5;15m [39m[38;5;141m5[39m[38;5;15m [39m[38;5;141m6[39m[38;5;15m [39m[38;5;141m7[39m[38;5;15m [39m[38;5;141m8[39m[38;5;15m [39m[38;5;141m9[39m[38;5;15m [39m[38;5;141m10[39m
[38;5;81mdo[39m
[38;5;15m [39m[38;5;15mecho[39m[38;5;15m [39m[38;5;15m$i[39m
[38;5;81mdone[39m
--------
murphy
--------
[38;5;241m# basic loop[39m
[38;5;30;01mfor[39;00m i in [38;5;57;01m1[39;00m [38;5;57;01m2[39;00m [38;5;57;01m3[39;00m [38;5;57;01m4[39;00m [38;5;57;01m5[39;00m [38;5;57;01m6[39;00m [38;5;57;01m7[39;00m [38;5;57;01m8[39;00m [38;5;57;01m9[39;00m [38;5;57;01m10[39;00m
[38;5;30;01mdo[39;00m
[38;5;28mecho[39m [38;5;23m$i[39m
[38;5;30;01mdone[39;00m
--------
native
--------
[38;5;246m# basic loop[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252min[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m [39m[38;5;67m7[39m[38;5;252m [39m[38;5;67m8[39m[38;5;252m [39m[38;5;67m9[39m[38;5;252m [39m[38;5;67m10[39m
[38;5;70;01mdo[39;00m
[38;5;252m [39m[38;5;31mecho[39m[38;5;252m [39m[38;5;87m$i[39m
[38;5;70;01mdone[39;00m
--------
paraiso-dark
--------
[38;5;243m# basic loop[39m
[38;5;97mfor[39m[38;5;7m [39m[38;5;7mi[39m[38;5;7m [39m[38;5;7min[39m[38;5;7m [39m[38;5;208m1[39m[38;5;7m [39m[38;5;208m2[39m[38;5;7m [39m[38;5;208m3[39m[38;5;7m [39m[38;5;208m4[39m[38;5;7m [39m[38;5;208m5[39m[38;5;7m [39m[38;5;208m6[39m[38;5;7m [39m[38;5;208m7[39m[38;5;7m [39m[38;5;208m8[39m[38;5;7m [39m[38;5;208m9[39m[38;5;7m [39m[38;5;208m10[39m
[38;5;97mdo[39m
[38;5;7m [39m[38;5;7mecho[39m[38;5;7m [39m[38;5;203m$i[39m
[38;5;97mdone[39m
--------
paraiso-light
--------
[38;5;245m# basic loop[39m
[38;5;97mfor[39m[38;5;235m [39m[38;5;235mi[39m[38;5;235m [39m[38;5;235min[39m[38;5;235m [39m[38;5;208m1[39m[38;5;235m [39m[38;5;208m2[39m[38;5;235m [39m[38;5;208m3[39m[38;5;235m [39m[38;5;208m4[39m[38;5;235m [39m[38;5;208m5[39m[38;5;235m [39m[38;5;208m6[39m[38;5;235m [39m[38;5;208m7[39m[38;5;235m [39m[38;5;208m8[39m[38;5;235m [39m[38;5;208m9[39m[38;5;235m [39m[38;5;208m10[39m
[38;5;97mdo[39m
[38;5;235m [39m[38;5;235mecho[39m[38;5;235m [39m[38;5;203m$i[39m
[38;5;97mdone[39m
--------
pastie
--------
[38;5;102m# basic loop[39m
[38;5;28;01mfor[39;00m i in [38;5;20;01m1[39;00m [38;5;20;01m2[39;00m [38;5;20;01m3[39;00m [38;5;20;01m4[39;00m [38;5;20;01m5[39;00m [38;5;20;01m6[39;00m [38;5;20;01m7[39;00m [38;5;20;01m8[39;00m [38;5;20;01m9[39;00m [38;5;20;01m10[39;00m
[38;5;28;01mdo[39;00m
[38;5;24mecho[39m [38;5;60m$i[39m
[38;5;28;01mdone[39;00m
--------
perldoc
--------
[38;5;28m# basic loop[39m
[38;5;90;01mfor[39;00m i in [38;5;134m1[39m [38;5;134m2[39m [38;5;134m3[39m [38;5;134m4[39m [38;5;134m5[39m [38;5;134m6[39m [38;5;134m7[39m [38;5;134m8[39m [38;5;134m9[39m [38;5;134m10[39m
[38;5;90;01mdo[39;00m
[38;5;64mecho[39m [38;5;24m$i[39m
[38;5;90;01mdone[39;00m
--------
rainbow_dash
--------
[38;5;33m# basic loop[39m
[38;5;26;01mfor[39;00m[38;5;239m [39m[38;5;239mi[39m[38;5;239m [39m[38;5;239min[39m[38;5;239m [39m[38;5;55;01m1[39;00m[38;5;239m [39m[38;5;55;01m2[39;00m[38;5;239m [39m[38;5;55;01m3[39;00m[38;5;239m [39m[38;5;55;01m4[39;00m[38;5;239m [39m[38;5;55;01m5[39;00m[38;5;239m [39m[38;5;55;01m6[39;00m[38;5;239m [39m[38;5;55;01m7[39;00m[38;5;239m [39m[38;5;55;01m8[39;00m[38;5;239m [39m[38;5;55;01m9[39;00m[38;5;239m [39m[38;5;55;01m10[39;00m
[38;5;26;01mdo[39;00m
[38;5;239m [39m[38;5;55;01mecho[39;00m[38;5;239m [39m$i
[38;5;26;01mdone[39;00m
--------
rrt
--------
[38;5;10m# basic loop[39m
[38;5;9mfor[39m i in 1 2 3 4 5 6 7 8 9 10
[38;5;9mdo[39m
echo [38;5;222m$i[39m
[38;5;9mdone[39m
--------
tango
--------
[38;5;94m# basic loop[39m
[38;5;24;01mfor[39;00m i in [38;5;20;01m1[39;00m [38;5;20;01m2[39;00m [38;5;20;01m3[39;00m [38;5;20;01m4[39;00m [38;5;20;01m5[39;00m [38;5;20;01m6[39;00m [38;5;20;01m7[39;00m [38;5;20;01m8[39;00m [38;5;20;01m9[39;00m [38;5;20;01m10[39;00m
[38;5;24;01mdo[39;00m
[38;5;24mecho[39m [38;5;0m$i[39m
[38;5;24;01mdone[39;00m
--------
trac
--------
[38;5;246m# basic loop[39m
[01mfor[00m i in [38;5;30m1[39m [38;5;30m2[39m [38;5;30m3[39m [38;5;30m4[39m [38;5;30m5[39m [38;5;30m6[39m [38;5;30m7[39m [38;5;30m8[39m [38;5;30m9[39m [38;5;30m10[39m
[01mdo[00m
[38;5;246mecho[39m [38;5;30m$i[39m
[01mdone[00m
--------
vim
--------
[38;5;18m# basic loop[39m
[38;5;3mfor[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252min[39m[38;5;252m [39m[38;5;5m1[39m[38;5;252m [39m[38;5;5m2[39m[38;5;252m [39m[38;5;5m3[39m[38;5;252m [39m[38;5;5m4[39m[38;5;252m [39m[38;5;5m5[39m[38;5;252m [39m[38;5;5m6[39m[38;5;252m [39m[38;5;5m7[39m[38;5;252m [39m[38;5;5m8[39m[38;5;252m [39m[38;5;5m9[39m[38;5;252m [39m[38;5;5m10[39m
[38;5;3mdo[39m
[38;5;252m [39m[38;5;5mecho[39m[38;5;252m [39m[38;5;6m$i[39m
[38;5;3mdone[39m
--------
vs
--------
[38;5;28m# basic loop[39m
[38;5;21mfor[39m i in 1 2 3 4 5 6 7 8 9 10
[38;5;21mdo[39m
echo $i
[38;5;21mdone[39m
--------
xcode
--------
[38;5;28m# basic loop[39m
[38;5;126mfor[39m i in [38;5;20m1[39m [38;5;20m2[39m [38;5;20m3[39m [38;5;20m4[39m [38;5;20m5[39m [38;5;20m6[39m [38;5;20m7[39m [38;5;20m8[39m [38;5;20m9[39m [38;5;20m10[39m
[38;5;126mdo[39m
[38;5;126mecho[39m [38;5;0m$i[39m
[38;5;126mdone[39m
------------------------------------
You can test color styles with other cheat sheets using this script:
c="python/Advanced"
for s in $(curl -s cheat.sh/:styles); do
echo
echo --------
echo $s
echo --------
curl -s cheat.sh/$c?style=$s | head -5
done
================================================
FILE: share/vim/.vimrc
================================================
filetype plugin on
set expandtab
set sts=4
set ts=4
set sw=4
set smartindent
syn on
colorscheme desert
map ds :.,/^--/-1 d
set nojs
set viminfo='10,\"100,:20,%,n~/.viminfo
let g:NERDSpaceDelims = 1
let g:NERDCommentEmptyLines = 1
================================================
FILE: share/vim.txt
================================================
" To use cheat.sh from your vim, install the cheat.sh-vim plugin from David Beniamine
" located at https://github.com/dbeniamine/cheat.sh-vim.
" See the page for the configuration options and the magic key combinations.
"
" ## Vizardry
"
" If you have Vizardry installed, you can run from vim:
"
" Invoke -u dbeniamine cheat.sh-vim
"
" ## Vundle
"
" Add the following to your Vundle Plugin list and do InstallPlugins:
"
" Plugin 'dbeniamine/cheat.sh-vim'
"
" ## Pathogen
"
" If you are using Pathogen, Run the following command in shell:
"
" git clone https://github.com/dbeniamine/cheat.sh-vim.git ~/.vim/bundle/cheat.sh-vim
"
" ## Quick install
"
" git clone https://github.com/dbeniamine/cheat.sh-vim.git
" cd cheat.sh-vim/
" cp -r ./* ~/.vim
================================================
FILE: share/zsh.txt
================================================
#compdef cht.sh
__CHTSH_LANGS=($(curl -s cheat.sh/:list))
_arguments -C \
'--help[show this help message and exit]: :->noargs' \
'--shell[enter shell repl]: :->noargs' \
'1:Cheat Sheet:->lang' \
'*::: :->noargs' && return 0
if [[ CURRENT -ge 1 ]]; then
case $state in
noargs)
_message "nothing to complete";;
lang)
compadd -X "Cheat Sheets" ${__CHTSH_LANGS[@]};;
*)
_message "Unknown state, error in autocomplete";;
esac
return
fi
================================================
FILE: tests/README.md
================================================
To run unit tests.
python3 -m pytest -v ../lib/
To run input/output tests.
./run-tests.sh
================================================
FILE: tests/results/1
================================================
1_Inheritance
1line
2_Multiple_Inheritance
:learn
:list
Advanced
Classes
Comments
Control_Flow_and_Iterables
Functions
Modules
Primitive_Datatypes_and_Operators
Variables_and_Collections
doc
func
hello
lambda
list_comprehension
loops
recursion
rosetta/
================================================
FILE: tests/results/10
================================================
[38;5;246;03m# How do I copy a file in Python?[39;00m
[38;5;246;03m# [39;00m
[38;5;246;03m# shutil (http://docs.python.org/3/library/shutil.html) has many methods[39;00m
[38;5;246;03m# you can use. One of which is:[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mshutil[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mcopyfile[39m
[38;5;252mcopyfile[39m[38;5;252m([39m[38;5;252msrc[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mdst[39m[38;5;252m)[39m
[38;5;246;03m# Copy the contents of the file named src to a file named dst. The[39;00m
[38;5;246;03m# destination location must be writable; otherwise, an IOError exception[39;00m
[38;5;246;03m# will be raised. If dst already exists, it will be replaced. Special[39;00m
[38;5;246;03m# files such as character or block devices and pipes cannot be copied[39;00m
[38;5;246;03m# with this function. src and dst are path names given as strings.[39;00m
[38;5;246;03m# [39;00m
[38;5;246;03m# [Swati] [so/q/123198] [cc by-sa 3.0][39;00m
================================================
FILE: tests/results/11
================================================
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mshutil[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mcopyfile[39m
[38;5;252mcopyfile[39m[38;5;252m([39m[38;5;252msrc[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mdst[39m[38;5;252m)[39m
================================================
FILE: tests/results/12
================================================
from shutil import copyfile
copyfile(src, dst)
================================================
FILE: tests/results/13
================================================
_ _ _ [38;2;0;204;0m_[0m[38;2;0;204;0m_[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m
___| |__ ___ __ _| |_ ___| |__ [38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m [48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85mT[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85m [0m[48;2;85;85;85mo[0m[48;2;85;85;85mn[0m[48;2;85;85;85ml[0m[48;2;85;85;85my[0m[48;2;85;85;85m [0m[48;2;85;85;85mc[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85ma[0m[48;2;85;85;85mt[0m[48;2;85;85;85m [0m[48;2;85;85;85ms[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85me[0m[48;2;85;85;85mt[0m[48;2;85;85;85m [0m[48;2;85;85;85my[0m[48;2;85;85;85mo[0m[48;2;85;85;85mu[0m[48;2;85;85;85m [0m[48;2;85;85;85mn[0m[48;2;85;85;85me[0m[48;2;85;85;85me[0m[48;2;85;85;85md[0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m
/ __| '_ \ / _ \/ _` | __| / __| '_ \ [38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m\[0m[38;2;0;204;0m [0m [38;2;136;136;136mU[0m[38;2;136;136;136mn[0m[38;2;136;136;136mi[0m[38;2;136;136;136mf[0m[38;2;136;136;136mi[0m[38;2;136;136;136me[0m[38;2;136;136;136md[0m[38;2;136;136;136m [0m[38;2;136;136;136ma[0m[38;2;136;136;136mc[0m[38;2;136;136;136mc[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136ms[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mo[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136m [0m[38;2;136;136;136mb[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136mt[0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m
| (__| | | | __/ (_| | |_ _\__ \ | | |[38;2;0;204;0m/[0m[38;2;0;204;0m [0m[38;2;0;204;0m/[0m[38;2;0;204;0m [0m [38;2;136;136;136mc[0m[38;2;136;136;136mo[0m[38;2;136;136;136mm[0m[38;2;136;136;136mm[0m[38;2;136;136;136mu[0m[38;2;136;136;136mn[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136my[0m[38;2;136;136;136m [0m[38;2;136;136;136md[0m[38;2;136;136;136mr[0m[38;2;136;136;136mi[0m[38;2;136;136;136mv[0m[38;2;136;136;136me[0m[38;2;136;136;136mn[0m[38;2;136;136;136m [0m[38;2;136;136;136md[0m[38;2;136;136;136mo[0m[38;2;136;136;136mc[0m[38;2;136;136;136mu[0m[38;2;136;136;136mm[0m[38;2;136;136;136me[0m[38;2;136;136;136mn[0m[38;2;136;136;136mt[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136mi[0m[38;2;136;136;136mo[0m[38;2;136;136;136mn[0m
\___|_| |_|\___|\__,_|\__(_)___/_| |_[38;2;0;204;0m/[0m[38;2;0;204;0m_[0m[38;2;0;204;0m/[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m [38;2;136;136;136mr[0m[38;2;136;136;136me[0m[38;2;136;136;136mp[0m[38;2;136;136;136mo[0m[38;2;136;136;136ms[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136mi[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136m [0m[38;2;136;136;136mo[0m[38;2;136;136;136mf[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136m [0m[38;2;136;136;136mw[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136ml[0m[38;2;136;136;136md[0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204me[0m[38;2;0;170;204ma[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204ml[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0m.[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m [38;2;0;170;204mb[0m[38;2;0;170;204mt[0m[38;2;0;170;204mr[0m[38;2;0;170;204mf[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m[38;2;0;170;204ml[0m[38;2;0;170;204mu[0m[38;2;0;170;204ma[0m[38;2;0;170;204m/[0m[38;2;0;204;0m:[0m[38;2;0;204;0ml[0m[38;2;0;204;0me[0m[38;2;0;204;0ma[0m[38;2;0;204;0mr[0m[38;2;0;204;0mn[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204mb[0m[38;2;0;170;204mt[0m[38;2;0;170;204mr[0m[38;2;0;170;204mf[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0m.[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m [38;2;0;170;204mt[0m[38;2;0;170;204ma[0m[38;2;0;170;204mr[0m[38;2;0;170;204m~[0m[38;2;0;170;204ml[0m[38;2;0;170;204mi[0m[38;2;0;170;204ms[0m[38;2;0;170;204mt[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m Learn any[38;2;255;0;0m*[0m programming [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204mt[0m[38;2;0;170;204ma[0m[38;2;0;170;204mr[0m[38;2;0;170;204m~[0m[38;2;0;170;204ml[0m[38;2;0;170;204mi[0m[38;2;0;170;204ms[0m[38;2;0;170;204mt[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m language not leaving [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mu[0m[38;2;0;170;204mr[0m[38;2;0;170;204ml[0m [38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0mt[0m[38;2;0;204;0mp[0m[38;2;0;204;0ms[0m[38;2;0;204;0m:[0m[38;2;0;170;204m/[0m[38;2;0;170;204m/[0m[38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m your shell [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;255;0;0m*[0m[38;2;255;0;0m)[0m any of 60 [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0m [0m[38;2;204;204;0mw[0m[38;2;204;204;0mi[0m[38;2;204;204;0mt[0m[38;2;204;204;0mh[0m[38;2;204;204;0m [0m[38;2;204;204;0mc[0m[38;2;204;204;0mu[0m[38;2;204;204;0mr[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0mo[0m[38;2;204;204;0mw[0m[38;2;204;204;0mn[0m[38;2;204;204;0m [0m[38;2;204;204;0mo[0m[38;2;204;204;0mp[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0ma[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;204;204;0mc[0m[38;2;204;204;0ml[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m,[0m[38;2;204;204;0m [0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m,[0m[38;2;204;204;0m [0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m![0m [38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m[38;2;0;170;204mg[0m[38;2;0;170;204mo[0m[38;2;0;170;204m/[0m[38;2;0;170;204mf[0m[38;2;0;204;0m<[0m[38;2;0;204;0mt[0m[38;2;0;204;0ma[0m[38;2;0;204;0mb[0m[38;2;0;204;0m>[0m[38;2;0;204;0m<[0m[38;2;0;204;0mt[0m[38;2;0;204;0ma[0m[38;2;0;204;0mb[0m[38;2;0;204;0m>[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m [38;2;0;204;0m-[0m[38;2;0;204;0m-[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m[38;2;0;204;0me[0m[38;2;0;204;0ml[0m[38;2;0;204;0ml[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m [38;2;0;204;0mg[0m[38;2;0;204;0mo[0m[38;2;0;204;0m [0m[38;2;0;204;0mz[0m[38;2;0;204;0mi[0m[38;2;0;204;0mp[0m[38;2;0;204;0m [0m[38;2;0;204;0ml[0m[38;2;0;204;0mi[0m[38;2;0;204;0ms[0m[38;2;0;204;0mt[0m[38;2;0;204;0ms[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m go/for go/func [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;34;170;34mc[0m[38;2;34;170;34mh[0m[38;2;34;170;34mt[0m[38;2;34;170;34m.[0m[38;2;34;170;34ms[0m[38;2;34;170;34mh[0m[38;2;34;170;34m>[0m help [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m Ask any question using [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ cht.sh go/for [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m cht.sh or curl cht.sh: [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m /go[38;2;34;170;34m/[0mzip[38;2;34;170;34m+[0mlists [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m (use [38;2;34;170;34m/[0m,[38;2;34;170;34m+[0m when curling) [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mT[0m[38;2;204;204;0mA[0m[38;2;204;204;0mB[0m[38;2;204;204;0m-[0m[38;2;204;204;0mc[0m[38;2;204;204;0mo[0m[38;2;204;204;0mm[0m[38;2;204;204;0mp[0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0ma[0m[38;2;204;204;0mc[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mv[0m[38;2;204;204;0me[0m[38;2;204;204;0m [0m[38;2;204;204;0ms[0m[38;2;204;204;0mh[0m[38;2;204;204;0me[0m[38;2;204;204;0ml[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mp[0m[38;2;204;204;0mr[0m[38;2;204;204;0mo[0m[38;2;204;204;0mg[0m[38;2;204;204;0mr[0m[38;2;204;204;0ma[0m[38;2;204;204;0mm[0m[38;2;204;204;0mm[0m[38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0mg[0m[38;2;204;204;0m [0m[38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mu[0m[38;2;0;170;204mr[0m[38;2;0;170;204ml[0m[38;2;0;170;204m [0m[38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;204;0m:[0m[38;2;0;204;0mh[0m[38;2;0;204;0me[0m[38;2;0;204;0ml[0m[38;2;0;204;0mp[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mv[0m[38;2;0;204;0mi[0m[38;2;0;204;0mm[0m [38;2;0;170;204mp[0m[38;2;0;170;204mr[0m[38;2;0;170;204mg[0m[38;2;0;170;204m.[0m[38;2;0;170;204mp[0m[38;2;0;170;204my[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mt[0m[38;2;0;204;0mi[0m[38;2;0;204;0mm[0m[38;2;0;204;0me[0m curl cht.sh/ [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m see [38;2;34;170;34m/[0m[38;2;34;170;34m:[0m[38;2;34;170;34mh[0m[38;2;34;170;34me[0m[38;2;34;170;34ml[0m[38;2;34;170;34mp[0m and [38;2;34;170;34m/[0m[38;2;34;170;34m:[0m[38;2;34;170;34mi[0m[38;2;34;170;34mn[0m[38;2;34;170;34mt[0m[38;2;34;170;34mr[0m[38;2;34;170;34mo[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m for usage information [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m zip lists _ [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m real [38;2;34;170;34m0[0m[38;2;34;170;34mm[0m[38;2;34;170;34m0[0m[38;2;34;170;34m.[0m[38;2;34;170;34m0[0m[38;2;34;170;34m7[0m[38;2;34;170;34m5[0m[38;2;34;170;34ms[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m and README.md on [38;2;0;170;204mG[0m[38;2;0;170;204mi[0m[38;2;0;170;204mt[0m[38;2;0;170;204mH[0m[38;2;0;170;204mu[0m[38;2;0;170;204mb[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;34;170;34m<[0m[38;2;34;170;34ml[0m[38;2;34;170;34me[0m[38;2;34;170;34ma[0m[38;2;34;170;34md[0m[38;2;34;170;34me[0m[38;2;34;170;34mr[0m[38;2;34;170;34m>[0m[38;2;34;170;34mK[0m[38;2;34;170;34mK[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m for the details [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m *awesome* [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;255;0;0m*[0m[38;2;255;0;0ms[0m[38;2;255;0;0mt[0m[38;2;255;0;0ma[0m[38;2;255;0;0mr[0m[38;2;255;0;0mt[0m[38;2;255;0;0m [0m[38;2;255;0;0mh[0m[38;2;255;0;0me[0m[38;2;255;0;0mr[0m[38;2;255;0;0me[0m[38;2;255;0;0m*[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m [38;2;204;204;0ms[0m[38;2;204;204;0me[0m[38;2;204;204;0ml[0m[38;2;204;204;0mf[0m[38;2;204;204;0m-[0m[38;2;204;204;0md[0m[38;2;204;204;0mo[0m[38;2;204;204;0mc[0m[38;2;204;204;0mu[0m[38;2;204;204;0mm[0m[38;2;204;204;0me[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0me[0m[38;2;204;204;0md[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0m [0m[38;2;204;204;0mf[0m[38;2;204;204;0mr[0m[38;2;204;204;0mo[0m[38;2;204;204;0mm[0m[38;2;204;204;0m [0m[38;2;204;204;0me[0m[38;2;204;204;0md[0m[38;2;204;204;0mi[0m[38;2;204;204;0mt[0m[38;2;204;204;0mo[0m[38;2;204;204;0mr[0m[38;2;204;204;0m![0m [38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m [38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;204;204;0mt[0m[38;2;204;204;0ma[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0m [0m[38;2;204;204;0ma[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;204;204;0mw[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0ms[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m[[0m[38;2;136;136;136mF[0m[38;2;136;136;136mo[0m[38;2;136;136;136ml[0m[38;2;136;136;136ml[0m[38;2;136;136;136mo[0m[38;2;136;136;136mw[0m[38;2;136;136;136m [0m[38;2;136;136;136m@[0m[38;2;136;136;136mi[0m[38;2;136;136;136mg[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136m_[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136mi[0m[38;2;136;136;136mn[0m[38;2;136;136;136m [0m[38;2;136;136;136mf[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136m [0m[38;2;136;136;136mu[0m[38;2;136;136;136mp[0m[38;2;136;136;136md[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136m][0m[38;2;136;136;136m[[0m[38;2;136;136;136mg[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136m.[0m[38;2;136;136;136mc[0m[38;2;136;136;136mo[0m[38;2;136;136;136mm[0m[38;2;136;136;136m/[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136mi[0m[38;2;136;136;136mn[0m[38;2;136;136;136m/[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136m.[0m[38;2;136;136;136ms[0m[38;2;136;136;136mh[0m[38;2;136;136;136m][0m
================================================
FILE: tests/results/14
================================================
_ _ _ [38;2;0;204;0m_[0m[38;2;0;204;0m_[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m
___| |__ ___ __ _| |_ ___| |__ [38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m [48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85mT[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85m [0m[48;2;85;85;85mo[0m[48;2;85;85;85mn[0m[48;2;85;85;85ml[0m[48;2;85;85;85my[0m[48;2;85;85;85m [0m[48;2;85;85;85mc[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85ma[0m[48;2;85;85;85mt[0m[48;2;85;85;85m [0m[48;2;85;85;85ms[0m[48;2;85;85;85mh[0m[48;2;85;85;85me[0m[48;2;85;85;85me[0m[48;2;85;85;85mt[0m[48;2;85;85;85m [0m[48;2;85;85;85my[0m[48;2;85;85;85mo[0m[48;2;85;85;85mu[0m[48;2;85;85;85m [0m[48;2;85;85;85mn[0m[48;2;85;85;85me[0m[48;2;85;85;85me[0m[48;2;85;85;85md[0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m[48;2;85;85;85m [0m
/ __| '_ \ / _ \/ _` | __| / __| '_ \ [38;2;0;204;0m\[0m[38;2;0;204;0m [0m[38;2;0;204;0m\[0m[38;2;0;204;0m [0m [38;2;136;136;136mU[0m[38;2;136;136;136mn[0m[38;2;136;136;136mi[0m[38;2;136;136;136mf[0m[38;2;136;136;136mi[0m[38;2;136;136;136me[0m[38;2;136;136;136md[0m[38;2;136;136;136m [0m[38;2;136;136;136ma[0m[38;2;136;136;136mc[0m[38;2;136;136;136mc[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136ms[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mo[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136m [0m[38;2;136;136;136mb[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136mt[0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m
| (__| | | | __/ (_| | |_ _\__ \ | | |[38;2;0;204;0m/[0m[38;2;0;204;0m [0m[38;2;0;204;0m/[0m[38;2;0;204;0m [0m [38;2;136;136;136mc[0m[38;2;136;136;136mo[0m[38;2;136;136;136mm[0m[38;2;136;136;136mm[0m[38;2;136;136;136mu[0m[38;2;136;136;136mn[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136my[0m[38;2;136;136;136m [0m[38;2;136;136;136md[0m[38;2;136;136;136mr[0m[38;2;136;136;136mi[0m[38;2;136;136;136mv[0m[38;2;136;136;136me[0m[38;2;136;136;136mn[0m[38;2;136;136;136m [0m[38;2;136;136;136md[0m[38;2;136;136;136mo[0m[38;2;136;136;136mc[0m[38;2;136;136;136mu[0m[38;2;136;136;136mm[0m[38;2;136;136;136me[0m[38;2;136;136;136mn[0m[38;2;136;136;136mt[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136mi[0m[38;2;136;136;136mo[0m[38;2;136;136;136mn[0m
\___|_| |_|\___|\__,_|\__(_)___/_| |_[38;2;0;204;0m/[0m[38;2;0;204;0m_[0m[38;2;0;204;0m/[0m[38;2;0;204;0m [0m[38;2;0;204;0m [0m [38;2;136;136;136mr[0m[38;2;136;136;136me[0m[38;2;136;136;136mp[0m[38;2;136;136;136mo[0m[38;2;136;136;136ms[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136mi[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136m [0m[38;2;136;136;136mo[0m[38;2;136;136;136mf[0m[38;2;136;136;136m [0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136m [0m[38;2;136;136;136mw[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136ml[0m[38;2;136;136;136md[0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m[38;2;136;136;136m [0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204me[0m[38;2;0;170;204ma[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204ml[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0m.[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m [38;2;0;170;204mb[0m[38;2;0;170;204mt[0m[38;2;0;170;204mr[0m[38;2;0;170;204mf[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m[38;2;0;170;204ml[0m[38;2;0;170;204mu[0m[38;2;0;170;204ma[0m[38;2;0;170;204m/[0m[38;2;0;204;0m:[0m[38;2;0;204;0ml[0m[38;2;0;204;0me[0m[38;2;0;204;0ma[0m[38;2;0;204;0mr[0m[38;2;0;204;0mn[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204mb[0m[38;2;0;170;204mt[0m[38;2;0;170;204mr[0m[38;2;0;170;204mf[0m[38;2;0;170;204ms[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0m.[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m [38;2;0;170;204mt[0m[38;2;0;170;204ma[0m[38;2;0;170;204mr[0m[38;2;0;170;204m~[0m[38;2;0;170;204ml[0m[38;2;0;170;204mi[0m[38;2;0;170;204ms[0m[38;2;0;170;204mt[0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m Learn any[38;2;255;0;0m*[0m programming [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;204;0mc[0m[38;2;0;204;0mu[0m[38;2;0;204;0mr[0m[38;2;0;204;0ml[0m [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;170;204mt[0m[38;2;0;170;204ma[0m[38;2;0;170;204mr[0m[38;2;0;170;204m~[0m[38;2;0;170;204ml[0m[38;2;0;170;204mi[0m[38;2;0;170;204ms[0m[38;2;0;170;204mt[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m language not leaving [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mu[0m[38;2;0;170;204mr[0m[38;2;0;170;204ml[0m [38;2;0;204;0mh[0m[38;2;0;204;0mt[0m[38;2;0;204;0mt[0m[38;2;0;204;0mp[0m[38;2;0;204;0ms[0m[38;2;0;204;0m:[0m[38;2;0;170;204m/[0m[38;2;0;170;204m/[0m[38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m your shell [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;255;0;0m*[0m[38;2;255;0;0m)[0m any of 60 [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0m [0m[38;2;204;204;0mw[0m[38;2;204;204;0mi[0m[38;2;204;204;0mt[0m[38;2;204;204;0mh[0m[38;2;204;204;0m [0m[38;2;204;204;0mc[0m[38;2;204;204;0mu[0m[38;2;204;204;0mr[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0mo[0m[38;2;204;204;0mw[0m[38;2;204;204;0mn[0m[38;2;204;204;0m [0m[38;2;204;204;0mo[0m[38;2;204;204;0mp[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0ma[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;204;204;0mc[0m[38;2;204;204;0ml[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m,[0m[38;2;204;204;0m [0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m,[0m[38;2;204;204;0m [0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0ma[0m[38;2;204;204;0mr[0m[38;2;204;204;0mn[0m[38;2;204;204;0m![0m [38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m [0m[38;2;0;170;204mg[0m[38;2;0;170;204mo[0m[38;2;0;170;204m/[0m[38;2;0;170;204mf[0m[38;2;0;204;0m<[0m[38;2;0;204;0mt[0m[38;2;0;204;0ma[0m[38;2;0;204;0mb[0m[38;2;0;204;0m>[0m[38;2;0;204;0m<[0m[38;2;0;204;0mt[0m[38;2;0;204;0ma[0m[38;2;0;204;0mb[0m[38;2;0;204;0m>[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m [38;2;0;204;0m-[0m[38;2;0;204;0m-[0m[38;2;0;204;0ms[0m[38;2;0;204;0mh[0m[38;2;0;204;0me[0m[38;2;0;204;0ml[0m[38;2;0;204;0ml[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m [38;2;0;204;0mg[0m[38;2;0;204;0mo[0m[38;2;0;204;0m [0m[38;2;0;204;0mz[0m[38;2;0;204;0mi[0m[38;2;0;204;0mp[0m[38;2;0;204;0m [0m[38;2;0;204;0ml[0m[38;2;0;204;0mi[0m[38;2;0;204;0ms[0m[38;2;0;204;0mt[0m[38;2;0;204;0ms[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m go/for go/func [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;34;170;34mc[0m[38;2;34;170;34mh[0m[38;2;34;170;34mt[0m[38;2;34;170;34m.[0m[38;2;34;170;34ms[0m[38;2;34;170;34mh[0m[38;2;34;170;34m>[0m help [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m Ask any question using [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m $ cht.sh go/for [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m cht.sh or curl cht.sh: [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m /go[38;2;34;170;34m/[0mzip[38;2;34;170;34m+[0mlists [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m (use [38;2;34;170;34m/[0m,[38;2;34;170;34m+[0m when curling) [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mT[0m[38;2;204;204;0mA[0m[38;2;204;204;0mB[0m[38;2;204;204;0m-[0m[38;2;204;204;0mc[0m[38;2;204;204;0mo[0m[38;2;204;204;0mm[0m[38;2;204;204;0mp[0m[38;2;204;204;0ml[0m[38;2;204;204;0me[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0ma[0m[38;2;204;204;0mc[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mv[0m[38;2;204;204;0me[0m[38;2;204;204;0m [0m[38;2;204;204;0ms[0m[38;2;204;204;0mh[0m[38;2;204;204;0me[0m[38;2;204;204;0ml[0m[38;2;204;204;0ml[0m[38;2;204;204;0m [0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;204;204;0m [0m[38;2;204;204;0mp[0m[38;2;204;204;0mr[0m[38;2;204;204;0mo[0m[38;2;204;204;0mg[0m[38;2;204;204;0mr[0m[38;2;204;204;0ma[0m[38;2;204;204;0mm[0m[38;2;204;204;0mm[0m[38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0mg[0m[38;2;204;204;0m [0m[38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0mt[0m[38;2;204;204;0mi[0m[38;2;204;204;0mo[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m|[0m $ [38;2;0;170;204mc[0m[38;2;0;170;204mu[0m[38;2;0;170;204mr[0m[38;2;0;170;204ml[0m[38;2;0;170;204m [0m[38;2;0;170;204mc[0m[38;2;0;170;204mh[0m[38;2;0;170;204mt[0m[38;2;0;170;204m.[0m[38;2;0;170;204ms[0m[38;2;0;170;204mh[0m[38;2;0;170;204m/[0m[38;2;0;204;0m:[0m[38;2;0;204;0mh[0m[38;2;0;204;0me[0m[38;2;0;204;0ml[0m[38;2;0;204;0mp[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mv[0m[38;2;0;204;0mi[0m[38;2;0;204;0mm[0m [38;2;0;170;204mp[0m[38;2;0;170;204mr[0m[38;2;0;170;204mg[0m[38;2;0;170;204m.[0m[38;2;0;170;204mp[0m[38;2;0;170;204my[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m $ [38;2;0;204;0mt[0m[38;2;0;204;0mi[0m[38;2;0;204;0mm[0m[38;2;0;204;0me[0m curl cht.sh/ [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m see [38;2;34;170;34m/[0m[38;2;34;170;34m:[0m[38;2;34;170;34mh[0m[38;2;34;170;34me[0m[38;2;34;170;34ml[0m[38;2;34;170;34mp[0m and [38;2;34;170;34m/[0m[38;2;34;170;34m:[0m[38;2;34;170;34mi[0m[38;2;34;170;34mn[0m[38;2;34;170;34mt[0m[38;2;34;170;34mr[0m[38;2;34;170;34mo[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m ... [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m for usage information [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m zip lists _ [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m real [38;2;34;170;34m0[0m[38;2;34;170;34mm[0m[38;2;34;170;34m0[0m[38;2;34;170;34m.[0m[38;2;34;170;34m0[0m[38;2;34;170;34m7[0m[38;2;34;170;34m5[0m[38;2;34;170;34ms[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m and README.md on [38;2;0;170;204mG[0m[38;2;0;170;204mi[0m[38;2;0;170;204mt[0m[38;2;0;170;204mH[0m[38;2;0;170;204mu[0m[38;2;0;170;204mb[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;34;170;34m<[0m[38;2;34;170;34ml[0m[38;2;34;170;34me[0m[38;2;34;170;34ma[0m[38;2;34;170;34md[0m[38;2;34;170;34me[0m[38;2;34;170;34mr[0m[38;2;34;170;34m>[0m[38;2;34;170;34mK[0m[38;2;34;170;34mK[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m for the details [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m *awesome* [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m|[0m [38;2;255;0;0m*[0m[38;2;255;0;0ms[0m[38;2;255;0;0mt[0m[38;2;255;0;0ma[0m[38;2;255;0;0mr[0m[38;2;255;0;0mt[0m[38;2;255;0;0m [0m[38;2;255;0;0mh[0m[38;2;255;0;0me[0m[38;2;255;0;0mr[0m[38;2;255;0;0me[0m[38;2;255;0;0m*[0m[38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m [38;2;136;136;136m|[0m
[38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m [38;2;204;204;0ms[0m[38;2;204;204;0me[0m[38;2;204;204;0ml[0m[38;2;204;204;0mf[0m[38;2;204;204;0m-[0m[38;2;204;204;0md[0m[38;2;204;204;0mo[0m[38;2;204;204;0mc[0m[38;2;204;204;0mu[0m[38;2;204;204;0mm[0m[38;2;204;204;0me[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0me[0m[38;2;204;204;0md[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m [38;2;204;204;0mq[0m[38;2;204;204;0mu[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0mi[0m[38;2;204;204;0me[0m[38;2;204;204;0ms[0m[38;2;204;204;0m [0m[38;2;204;204;0mf[0m[38;2;204;204;0mr[0m[38;2;204;204;0mo[0m[38;2;204;204;0mm[0m[38;2;204;204;0m [0m[38;2;204;204;0me[0m[38;2;204;204;0md[0m[38;2;204;204;0mi[0m[38;2;204;204;0mt[0m[38;2;204;204;0mo[0m[38;2;204;204;0mr[0m[38;2;204;204;0m![0m [38;2;136;136;136m-[0m[38;2;136;136;136m+[0m [38;2;136;136;136m+[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m [38;2;204;204;0mi[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;204;204;0mt[0m[38;2;204;204;0ma[0m[38;2;204;204;0mn[0m[38;2;204;204;0mt[0m[38;2;204;204;0m [0m[38;2;204;204;0ma[0m[38;2;204;204;0mn[0m[38;2;204;204;0ms[0m[38;2;204;204;0mw[0m[38;2;204;204;0me[0m[38;2;204;204;0mr[0m[38;2;204;204;0ms[0m [38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m-[0m[38;2;136;136;136m+[0m
[38;2;136;136;136m[[0m[38;2;136;136;136mF[0m[38;2;136;136;136mo[0m[38;2;136;136;136ml[0m[38;2;136;136;136ml[0m[38;2;136;136;136mo[0m[38;2;136;136;136mw[0m[38;2;136;136;136m [0m[38;2;136;136;136m@[0m[38;2;136;136;136mi[0m[38;2;136;136;136mg[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136m_[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136mi[0m[38;2;136;136;136mn[0m[38;2;136;136;136m [0m[38;2;136;136;136mf[0m[38;2;136;136;136mo[0m[38;2;136;136;136mr[0m[38;2;136;136;136m [0m[38;2;136;136;136mu[0m[38;2;136;136;136mp[0m[38;2;136;136;136md[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136me[0m[38;2;136;136;136ms[0m[38;2;136;136;136m][0m[38;2;136;136;136m[[0m[38;2;136;136;136mg[0m[38;2;136;136;136mi[0m[38;2;136;136;136mt[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136m.[0m[38;2;136;136;136mc[0m[38;2;136;136;136mo[0m[38;2;136;136;136mm[0m[38;2;136;136;136m/[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136mu[0m[38;2;136;136;136mb[0m[38;2;136;136;136mi[0m[38;2;136;136;136mn[0m[38;2;136;136;136m/[0m[38;2;136;136;136mc[0m[38;2;136;136;136mh[0m[38;2;136;136;136me[0m[38;2;136;136;136ma[0m[38;2;136;136;136mt[0m[38;2;136;136;136m.[0m[38;2;136;136;136ms[0m[38;2;136;136;136mh[0m[38;2;136;136;136m][0m
================================================
FILE: tests/results/15
================================================
[38;5;246;03m# Single line comments start with a number symbol.[39;00m
[38;5;214m""" Multiline strings can be written[39m
[38;5;214m using three "s, and are often used[39m
[38;5;214m as documentation.[39m
[38;5;214m"""[39m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 1. Primitive Datatypes and Operators[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# You have numbers[39;00m
[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => 3[39;00m
[38;5;246;03m# Math is what you would expect[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# => 2[39;00m
[38;5;67m8[39m[38;5;252m [39m[38;5;252m-[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# => 7[39;00m
[38;5;67m10[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => 20[39;00m
[38;5;67m35[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m [39m[38;5;246;03m# => 7.0[39;00m
[38;5;246;03m# Integer division rounds down for both positive and negative numbers.[39;00m
[38;5;67m5[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;252m-[39m[38;5;67m5[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => -2[39;00m
[38;5;67m5.0[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m3.0[39m[38;5;252m [39m[38;5;246;03m# => 1.0 # works on floats too[39;00m
[38;5;252m-[39m[38;5;67m5.0[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m3.0[39m[38;5;252m [39m[38;5;246;03m# => -2.0[39;00m
[38;5;246;03m# The result of division is always a float[39;00m
[38;5;67m10.0[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => 3.3333333333333335[39;00m
[38;5;246;03m# Modulo operation[39;00m
[38;5;67m7[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;246;03m# i % j have the same sign as j, unlike C[39;00m
[38;5;252m-[39m[38;5;67m7[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => 2[39;00m
[38;5;246;03m# Exponentiation (x**y, x to the yth power)[39;00m
[38;5;67m2[39m[38;5;252m*[39m[38;5;252m*[39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => 8[39;00m
[38;5;246;03m# Enforce precedence with parentheses[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => 7[39;00m
[38;5;252m([39m[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => 8[39;00m
[38;5;246;03m# Boolean values are primitives (Note: the capitalization)[39;00m
[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# negate with not[39;00m
[38;5;70;01mnot[39;00m[38;5;252m [39m[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;70;01mnot[39;00m[38;5;252m [39m[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# Boolean Operators[39;00m
[38;5;246;03m# Note "and" and "or" are case-sensitive[39;00m
[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;70;01mand[39;00m[38;5;252m [39m[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;70;01mor[39;00m[38;5;252m [39m[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# True and False are actually 1 and 0 but with different keywords[39;00m
[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;246;03m# => 2[39;00m
[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m8[39m[38;5;252m [39m[38;5;246;03m# => 8[39;00m
[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;252m-[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m [39m[38;5;246;03m# => -5[39;00m
[38;5;246;03m# Comparison operators look at the numerical value of True and False[39;00m
[38;5;67m0[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;70;01mTrue[39;00m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;252m-[39m[38;5;67m5[39m[38;5;252m [39m[38;5;252m!=[39m[38;5;252m [39m[38;5;70;01mFalse[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# Using boolean logical operators on ints casts them to booleans for evaluation, but their non-cast value is returned[39;00m
[38;5;246;03m# Don't mix up with bool(ints) and bitwise and/or (&,|)[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;252m-[39m[38;5;67m6[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m0[39m[38;5;252m [39m[38;5;70;01mand[39;00m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => 0[39;00m
[38;5;252m-[39m[38;5;67m5[39m[38;5;252m [39m[38;5;70;01mor[39;00m[38;5;252m [39m[38;5;67m0[39m[38;5;252m [39m[38;5;246;03m# => -5[39;00m
[38;5;246;03m# Equality is ==[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# Inequality is !=[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m!=[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m!=[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# More comparisons[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# Seeing whether a value is in a range[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;70;01mand[39;00m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;70;01mand[39;00m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# Chaining makes this look nicer[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# (is vs. ==) is checks if two variables refer to the same object, but == checks[39;00m
[38;5;246;03m# if the objects pointed to have the same values.[39;00m
[38;5;252ma[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Point a at a new list, [1, 2, 3, 4][39;00m
[38;5;252mb[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;246;03m# Point b at what a is pointing to[39;00m
[38;5;252mb[39m[38;5;252m [39m[38;5;70;01mis[39;00m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;246;03m# => True, a and b refer to the same object[39;00m
[38;5;252mb[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;246;03m# => True, a's and b's objects are equal[39;00m
[38;5;252mb[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Point b at a new list, [1, 2, 3, 4][39;00m
[38;5;252mb[39m[38;5;252m [39m[38;5;70;01mis[39;00m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;246;03m# => False, a and b do not refer to the same object[39;00m
[38;5;252mb[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;246;03m# => True, a's and b's objects are equal[39;00m
[38;5;246;03m# Strings are created with " or '[39;00m
[38;5;214m"[39m[38;5;214mThis is a string.[39m[38;5;214m"[39m
[38;5;214m'[39m[38;5;214mThis is also a string.[39m[38;5;214m'[39m
[38;5;246;03m# Strings can be added too[39;00m
[38;5;214m"[39m[38;5;214mHello [39m[38;5;214m"[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mworld![39m[38;5;214m"[39m[38;5;252m [39m[38;5;246;03m# => "Hello world!"[39;00m
[38;5;246;03m# String literals (but not variables) can be concatenated without using '+'[39;00m
[38;5;214m"[39m[38;5;214mHello [39m[38;5;214m"[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mworld![39m[38;5;214m"[39m[38;5;252m [39m[38;5;246;03m# => "Hello world!"[39;00m
[38;5;246;03m# A string can be treated like a list of characters[39;00m
[38;5;214m"[39m[38;5;214mHello world![39m[38;5;214m"[39m[38;5;252m[[39m[38;5;67m0[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => 'H'[39;00m
[38;5;246;03m# You can find the length of a string[39;00m
[38;5;31mlen[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mThis is a string[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 16[39;00m
[38;5;246;03m# You can also format using f-strings or formatted string literals (in Python 3.6+)[39;00m
[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mReiko[39m[38;5;214m"[39m
[38;5;214mf[39m[38;5;214m"[39m[38;5;214mShe said her name is [39m[38;5;214m{[39m[38;5;252mname[39m[38;5;214m}[39m[38;5;214m.[39m[38;5;214m"[39m[38;5;252m [39m[38;5;246;03m# => "She said her name is Reiko"[39;00m
[38;5;246;03m# You can basically put any Python expression inside the braces and it will be output in the string.[39;00m
[38;5;214mf[39m[38;5;214m"[39m[38;5;214m{[39m[38;5;252mname[39m[38;5;214m}[39m[38;5;214m is [39m[38;5;214m{[39m[38;5;31mlen[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m)[39m[38;5;214m}[39m[38;5;214m characters long.[39m[38;5;214m"[39m[38;5;252m [39m[38;5;246;03m# => "Reiko is 5 characters long."[39;00m
[38;5;246;03m# None is an object[39;00m
[38;5;70;01mNone[39;00m[38;5;252m [39m[38;5;246;03m# => None[39;00m
[38;5;246;03m# Don't use the equality "==" symbol to compare objects to None[39;00m
[38;5;246;03m# Use "is" instead. This checks for equality of object identity.[39;00m
[38;5;214m"[39m[38;5;214metc[39m[38;5;214m"[39m[38;5;252m [39m[38;5;70;01mis[39;00m[38;5;252m [39m[38;5;70;01mNone[39;00m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;70;01mNone[39;00m[38;5;252m [39m[38;5;70;01mis[39;00m[38;5;252m [39m[38;5;70;01mNone[39;00m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# None, 0, and empty strings/lists/dicts/tuples all evaluate to False.[39;00m
[38;5;246;03m# All other values are True[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;252m[[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;252m{[39m[38;5;252m}[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;31mbool[39m[38;5;252m([39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 2. Variables and Collections[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# Python has a print function[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mI[39m[38;5;214m'[39m[38;5;214mm Python. Nice to meet you![39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => I'm Python. Nice to meet you![39;00m
[38;5;246;03m# By default the print function also prints out a newline at the end.[39;00m
[38;5;246;03m# Use the optional argument end to change the end string.[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mHello, World[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mend[39m[38;5;252m=[39m[38;5;214m"[39m[38;5;214m![39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Hello, World![39;00m
[38;5;246;03m# Simple way to get input data from console[39;00m
[38;5;252minput_string_var[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31minput[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mEnter some data: [39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Returns the data as a string[39;00m
[38;5;246;03m# There are no declarations, only assignments.[39;00m
[38;5;246;03m# Convention is to use lower_case_with_underscores[39;00m
[38;5;252msome_var[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m
[38;5;252msome_var[39m[38;5;252m [39m[38;5;246;03m# => 5[39;00m
[38;5;246;03m# Accessing a previously unassigned variable is an exception.[39;00m
[38;5;246;03m# See Control Flow to learn more about exception handling.[39;00m
[38;5;252msome_unknown_var[39m[38;5;252m [39m[38;5;246;03m# Raises a NameError[39;00m
[38;5;246;03m# if can be used as an expression[39;00m
[38;5;246;03m# Equivalent of C's '?:' ternary operator[39;00m
[38;5;214m"[39m[38;5;214myay![39m[38;5;214m"[39m[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;67m0[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;70;01melse[39;00m[38;5;252m [39m[38;5;214m"[39m[38;5;214mnay![39m[38;5;214m"[39m[38;5;252m [39m[38;5;246;03m# => "nay!"[39;00m
[38;5;246;03m# Lists store sequences[39;00m
[38;5;252mli[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;252m][39m
[38;5;246;03m# You can start with a prefilled list[39;00m
[38;5;252mother_li[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m][39m
[38;5;246;03m# Add stuff to the end of a list with append[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mappend[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1][39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mappend[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1, 2][39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mappend[39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1, 2, 4][39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mappend[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1, 2, 4, 3][39;00m
[38;5;246;03m# Remove from the end with pop[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mpop[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 3 and li is now [1, 2, 4][39;00m
[38;5;246;03m# Let's put it back[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mappend[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1, 2, 4, 3] again.[39;00m
[38;5;246;03m# Access a list like you would any array[39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;67m0[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;246;03m# Look at the last element[39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;252m-[39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => 3[39;00m
[38;5;246;03m# Looking out of bounds is an IndexError[39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;67m4[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Raises an IndexError[39;00m
[38;5;246;03m# You can look at ranges with slice syntax.[39;00m
[38;5;246;03m# The start index is included, the end index is not[39;00m
[38;5;246;03m# (It's a closed/open range for you mathy types.)[39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m:[39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Return list from index 1 to 3 => [2, 4][39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;67m2[39m[38;5;252m:[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Return list starting from index 2 => [4, 3][39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;252m:[39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Return list from beginning until index 3 => [1, 2, 4][39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;252m:[39m[38;5;252m:[39m[38;5;67m2[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Return list selecting every second entry => [1, 4][39;00m
[38;5;252mli[39m[38;5;252m[[39m[38;5;252m:[39m[38;5;252m:[39m[38;5;252m-[39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Return list in reverse order => [3, 4, 2, 1][39;00m
[38;5;246;03m# Use any combination of these to make advanced slices[39;00m
[38;5;246;03m# li[start:end:step][39;00m
[38;5;246;03m# Make a one layer deep copy using slices[39;00m
[38;5;252mli2[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mli[39m[38;5;252m[[39m[38;5;252m:[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => li2 = [1, 2, 4, 3] but (li2 is li) will result in false.[39;00m
[38;5;246;03m# Remove arbitrary elements from a list with "del"[39;00m
[38;5;70;01mdel[39;00m[38;5;252m [39m[38;5;252mli[39m[38;5;252m[[39m[38;5;67m2[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# li is now [1, 2, 3][39;00m
[38;5;246;03m# Remove first occurrence of a value[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mremove[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1, 3][39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mremove[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Raises a ValueError as 2 is not in the list[39;00m
[38;5;246;03m# Insert an element at a specific index[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252minsert[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# li is now [1, 2, 3] again[39;00m
[38;5;246;03m# Get the index of the first item found matching the argument[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mindex[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mindex[39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Raises a ValueError as 4 is not in the list[39;00m
[38;5;246;03m# You can add lists[39;00m
[38;5;246;03m# Note: values for li and for other_li are not modified.[39;00m
[38;5;252mli[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252mother_li[39m[38;5;252m [39m[38;5;246;03m# => [1, 2, 3, 4, 5, 6][39;00m
[38;5;246;03m# Concatenate lists with "extend()"[39;00m
[38;5;252mli[39m[38;5;252m.[39m[38;5;252mextend[39m[38;5;252m([39m[38;5;252mother_li[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Now li is [1, 2, 3, 4, 5, 6][39;00m
[38;5;246;03m# Check for existence in a list with "in"[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mli[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# Examine the length with "len()"[39;00m
[38;5;31mlen[39m[38;5;252m([39m[38;5;252mli[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 6[39;00m
[38;5;246;03m# Tuples are like lists but are immutable.[39;00m
[38;5;252mtup[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m
[38;5;252mtup[39m[38;5;252m[[39m[38;5;67m0[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;252mtup[39m[38;5;252m[[39m[38;5;67m0[39m[38;5;252m][39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m [39m[38;5;246;03m# Raises a TypeError[39;00m
[38;5;246;03m# Note that a tuple of length one has to have a comma after the last element but[39;00m
[38;5;246;03m# tuples of other lengths, even zero, do not.[39;00m
[38;5;31mtype[39m[38;5;252m([39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [39;00m
[38;5;31mtype[39m[38;5;252m([39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [39;00m
[38;5;31mtype[39m[38;5;252m([39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [39;00m
[38;5;246;03m# You can do most of the list operations on tuples too[39;00m
[38;5;31mlen[39m[38;5;252m([39m[38;5;252mtup[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 3[39;00m
[38;5;252mtup[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => (1, 2, 3, 4, 5, 6)[39;00m
[38;5;252mtup[39m[38;5;252m[[39m[38;5;252m:[39m[38;5;67m2[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => (1, 2)[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mtup[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# You can unpack tuples (or lists) into variables[39;00m
[38;5;252ma[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mb[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# a is now 1, b is now 2 and c is now 3[39;00m
[38;5;246;03m# You can also do extended unpacking[39;00m
[38;5;252ma[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252mb[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# a is now 1, b is now [2, 3] and c is now 4[39;00m
[38;5;246;03m# Tuples are created by default if you leave out the parentheses[39;00m
[38;5;252md[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252me[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mf[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m [39m[38;5;246;03m# tuple 4, 5, 6 is unpacked into variables d, e and f[39;00m
[38;5;246;03m# respectively such that d = 4, e = 5 and f = 6[39;00m
[38;5;246;03m# Now look how easy it is to swap two values[39;00m
[38;5;252me[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252md[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252md[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252me[39m[38;5;252m [39m[38;5;246;03m# d is now 5 and e is now 4[39;00m
[38;5;246;03m# Dictionaries store mappings from keys to values[39;00m
[38;5;252mempty_dict[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252m}[39m
[38;5;246;03m# Here is a prefilled dictionary[39;00m
[38;5;252mfilled_dict[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mtwo[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mthree[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m}[39m
[38;5;246;03m# Note keys for dictionaries have to be immutable types. This is to ensure that[39;00m
[38;5;246;03m# the key can be converted to a constant hash value for quick look-ups.[39;00m
[38;5;246;03m# Immutable types include ints, floats, strings, tuples.[39;00m
[38;5;252minvalid_dict[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m123[39m[38;5;214m"[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => Raises a TypeError: unhashable type: 'list'[39;00m
[38;5;252mvalid_dict[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m:[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# Values can be of any type, however.[39;00m
[38;5;246;03m# Look up values with [][39;00m
[38;5;252mfilled_dict[39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;246;03m# Get all keys as an iterable with "keys()". We need to wrap the call in list()[39;00m
[38;5;246;03m# to turn it into a list. We'll talk about those later. Note - for Python[39;00m
[38;5;246;03m# versions <3.7, dictionary key ordering is not guaranteed. Your results might[39;00m
[38;5;246;03m# not match the example below exactly. However, as of Python 3.7, dictionary[39;00m
[38;5;246;03m# items maintain the order at which they are inserted into the dictionary.[39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mkeys[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => ["three", "two", "one"] in Python <3.7[39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mkeys[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => ["one", "two", "three"] in Python 3.7+[39;00m
[38;5;246;03m# Get all values as an iterable with "values()". Once again we need to wrap it[39;00m
[38;5;246;03m# in list() to get it out of the iterable. Note - Same as above regarding key[39;00m
[38;5;246;03m# ordering.[39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mvalues[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [3, 2, 1] in Python <3.7[39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mvalues[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [1, 2, 3] in Python 3.7+[39;00m
[38;5;246;03m# Check for existence of keys in a dictionary with "in"[39;00m
[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mfilled_dict[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mfilled_dict[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# Looking up a non-existing key is a KeyError[39;00m
[38;5;252mfilled_dict[39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214mfour[39m[38;5;214m"[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# KeyError[39;00m
[38;5;246;03m# Use "get()" method to avoid the KeyError[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mget[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mget[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mfour[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => None[39;00m
[38;5;246;03m# The get method supports a default argument when the value is missing[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mget[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 1[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mget[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mfour[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 4[39;00m
[38;5;246;03m# "setdefault()" inserts into a dictionary only if the given key isn't present[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252msetdefault[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mfive[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# filled_dict["five"] is set to 5[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252msetdefault[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mfive[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# filled_dict["five"] is still 5[39;00m
[38;5;246;03m# Adding to a dictionary[39;00m
[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mupdate[39m[38;5;252m([39m[38;5;252m{[39m[38;5;214m"[39m[38;5;214mfour[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;67m4[39m[38;5;252m}[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => {"one": 1, "two": 2, "three": 3, "four": 4}[39;00m
[38;5;252mfilled_dict[39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214mfour[39m[38;5;214m"[39m[38;5;252m][39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m [39m[38;5;246;03m# another way to add to dict[39;00m
[38;5;246;03m# Remove keys from a dictionary with del[39;00m
[38;5;70;01mdel[39;00m[38;5;252m [39m[38;5;252mfilled_dict[39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Removes the key "one" from filled dict[39;00m
[38;5;246;03m# From Python 3.5 you can also use the additional unpacking options[39;00m
[38;5;252m{[39m[38;5;214m'[39m[38;5;214ma[39m[38;5;214m'[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252m{[39m[38;5;214m'[39m[38;5;214mb[39m[38;5;214m'[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m}[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => {'a': 1, 'b': 2}[39;00m
[38;5;252m{[39m[38;5;214m'[39m[38;5;214ma[39m[38;5;214m'[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252m{[39m[38;5;214m'[39m[38;5;214ma[39m[38;5;214m'[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m}[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => {'a': 2}[39;00m
[38;5;246;03m# Sets store ... well sets[39;00m
[38;5;252mempty_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31mset[39m[38;5;252m([39m[38;5;252m)[39m
[38;5;246;03m# Initialize a set with a bunch of values. Yeah, it looks a bit like a dict. Sorry.[39;00m
[38;5;252msome_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# some_set is now {1, 2, 3, 4}[39;00m
[38;5;246;03m# Similar to keys of a dictionary, elements of a set have to be immutable.[39;00m
[38;5;252minvalid_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => Raises a TypeError: unhashable type: 'list'[39;00m
[38;5;252mvalid_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m)[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m}[39m
[38;5;246;03m# Add one more item to the set[39;00m
[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252msome_set[39m
[38;5;252mfilled_set[39m[38;5;252m.[39m[38;5;252madd[39m[38;5;252m([39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# filled_set is now {1, 2, 3, 4, 5}[39;00m
[38;5;246;03m# Sets do not have duplicate elements[39;00m
[38;5;252mfilled_set[39m[38;5;252m.[39m[38;5;252madd[39m[38;5;252m([39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# it remains as before {1, 2, 3, 4, 5}[39;00m
[38;5;246;03m# Do set intersection with &[39;00m
[38;5;252mother_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m}[39m
[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;252m&[39m[38;5;252m [39m[38;5;252mother_set[39m[38;5;252m [39m[38;5;246;03m# => {3, 4, 5}[39;00m
[38;5;246;03m# Do set union with |[39;00m
[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;252m|[39m[38;5;252m [39m[38;5;252mother_set[39m[38;5;252m [39m[38;5;246;03m# => {1, 2, 3, 4, 5, 6}[39;00m
[38;5;246;03m# Do set difference with -[39;00m
[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m}[39m[38;5;252m [39m[38;5;252m-[39m[38;5;252m [39m[38;5;252m{[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => {1, 4}[39;00m
[38;5;246;03m# Do set symmetric difference with ^[39;00m
[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m}[39m[38;5;252m [39m[38;5;252m^[39m[38;5;252m [39m[38;5;252m{[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => {1, 4, 5}[39;00m
[38;5;246;03m# Check if set on the left is a superset of set on the right[39;00m
[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m}[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# Check if set on the left is a subset of set on the right[39;00m
[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m}[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# Check for existence in a set with in[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;67m10[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m# Make a one layer deep copy[39;00m
[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252msome_set[39m[38;5;252m.[39m[38;5;252mcopy[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# filled_set is {1, 2, 3, 4, 5}[39;00m
[38;5;252mfilled_set[39m[38;5;252m [39m[38;5;70;01mis[39;00m[38;5;252m [39m[38;5;252msome_set[39m[38;5;252m [39m[38;5;246;03m# => False[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 3. Control Flow and Iterables[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# Let's just make a variable[39;00m
[38;5;252msome_var[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m
[38;5;246;03m# Here is an if statement. Indentation is significant in Python![39;00m
[38;5;246;03m# Convention is to use four spaces, not tabs.[39;00m
[38;5;246;03m# This prints "some_var is smaller than 10"[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252msome_var[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214msome_var is totally bigger than 10.[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;70;01melif[39;00m[38;5;252m [39m[38;5;252msome_var[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m:[39m[38;5;252m [39m[38;5;246;03m# This elif clause is optional.[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214msome_var is smaller than 10.[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;70;01melse[39;00m[38;5;252m:[39m[38;5;252m [39m[38;5;246;03m# This is optional too.[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214msome_var is indeed 10.[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214mFor loops iterate over lists[39m
[38;5;214mprints:[39m
[38;5;214m dog is a mammal[39m
[38;5;214m cat is a mammal[39m
[38;5;214m mouse is a mammal[39m
[38;5;214m"""[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252manimal[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214mdog[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mcat[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mmouse[39m[38;5;214m"[39m[38;5;252m][39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# You can use format() to interpolate formatted strings[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214m{}[39m[38;5;214m is a mammal[39m[38;5;214m"[39m[38;5;252m.[39m[38;5;252mformat[39m[38;5;252m([39m[38;5;252manimal[39m[38;5;252m)[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214m"range(number)" returns an iterable of numbers[39m
[38;5;214mfrom zero to the given number[39m
[38;5;214mprints:[39m
[38;5;214m 0[39m
[38;5;214m 1[39m
[38;5;214m 2[39m
[38;5;214m 3[39m
[38;5;214m"""[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;31mrange[39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214m"range(lower, upper)" returns an iterable of numbers[39m
[38;5;214mfrom the lower number to the upper number[39m
[38;5;214mprints:[39m
[38;5;214m 4[39m
[38;5;214m 5[39m
[38;5;214m 6[39m
[38;5;214m 7[39m
[38;5;214m"""[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;31mrange[39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m8[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214m"range(lower, upper, step)" returns an iterable of numbers[39m
[38;5;214mfrom the lower number to the upper number, while incrementing[39m
[38;5;214mby step. If step is not indicated, the default value is 1.[39m
[38;5;214mprints:[39m
[38;5;214m 4[39m
[38;5;214m 6[39m
[38;5;214m"""[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;31mrange[39m[38;5;252m([39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m8[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214mTo loop over a list, and retrieve both the index and the value of each item in the list[39m
[38;5;214mprints:[39m
[38;5;214m 0 dog[39m
[38;5;214m 1 cat[39m
[38;5;214m 2 mouse[39m
[38;5;214m"""[39m
[38;5;252manimals[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214mdog[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mcat[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mmouse[39m[38;5;214m"[39m[38;5;252m][39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mvalue[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;31menumerate[39m[38;5;252m([39m[38;5;252manimals[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mvalue[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214mWhile loops go until a condition is no longer met.[39m
[38;5;214mprints:[39m
[38;5;214m 0[39m
[38;5;214m 1[39m
[38;5;214m 2[39m
[38;5;214m 3[39m
[38;5;214m"""[39m
[38;5;252mx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m
[38;5;70;01mwhile[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m [39m[38;5;246;03m# Shorthand for x = x + 1[39;00m
[38;5;246;03m# Handle exceptions with a try/except block[39;00m
[38;5;70;01mtry[39;00m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# Use "raise" to raise an error[39;00m
[38;5;252m [39m[38;5;70;01mraise[39;00m[38;5;252m [39m[38;5;250mIndexError[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mThis is an index error[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;70;01mexcept[39;00m[38;5;252m [39m[38;5;250mIndexError[39m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;252me[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mpass[39;00m[38;5;252m [39m[38;5;246;03m# Pass is just a no-op. Usually you would do recovery here.[39;00m
[38;5;70;01mexcept[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;250mTypeError[39m[38;5;252m,[39m[38;5;252m [39m[38;5;250mNameError[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mpass[39;00m[38;5;252m [39m[38;5;246;03m# Multiple exceptions can be handled together, if required.[39;00m
[38;5;70;01melse[39;00m[38;5;252m:[39m[38;5;252m [39m[38;5;246;03m# Optional clause to the try/except block. Must follow all except blocks[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mAll good![39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Runs only if the code in try raises no exceptions[39;00m
[38;5;70;01mfinally[39;00m[38;5;252m:[39m[38;5;252m [39m[38;5;246;03m# Execute under all circumstances[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mWe can clean up resources here[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;246;03m# Instead of try/finally to cleanup resources you can use a with statement[39;00m
[38;5;70;01mwith[39;00m[38;5;252m [39m[38;5;31mopen[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mmyfile.txt[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;252mf[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mline[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mf[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mline[39m[38;5;252m)[39m
[38;5;246;03m# Writing to a file[39;00m
[38;5;252mcontents[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;214m"[39m[38;5;214maa[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m12[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mbb[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m21[39m[38;5;252m}[39m
[38;5;70;01mwith[39;00m[38;5;252m [39m[38;5;31mopen[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mmyfile1.txt[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mw+[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;252mfile[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mfile[39m[38;5;252m.[39m[38;5;252mwrite[39m[38;5;252m([39m[38;5;31mstr[39m[38;5;252m([39m[38;5;252mcontents[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# writes a string to a file[39;00m
[38;5;70;01mwith[39;00m[38;5;252m [39m[38;5;31mopen[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mmyfile2.txt[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mw+[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;252mfile[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mfile[39m[38;5;252m.[39m[38;5;252mwrite[39m[38;5;252m([39m[38;5;252mjson[39m[38;5;252m.[39m[38;5;252mdumps[39m[38;5;252m([39m[38;5;252mcontents[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# writes an object to a file[39;00m
[38;5;246;03m# Reading from a file[39;00m
[38;5;70;01mwith[39;00m[38;5;252m [39m[38;5;31mopen[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mmyfile1.txt[39m[38;5;214m'[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mr+[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;252mfile[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mcontents[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mfile[39m[38;5;252m.[39m[38;5;252mread[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# reads a string from a file[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mcontents[39m[38;5;252m)[39m
[38;5;246;03m# print: {"aa": 12, "bb": 21}[39;00m
[38;5;70;01mwith[39;00m[38;5;252m [39m[38;5;31mopen[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mmyfile2.txt[39m[38;5;214m'[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mr+[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;252mfile[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mcontents[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mjson[39m[38;5;252m.[39m[38;5;252mload[39m[38;5;252m([39m[38;5;252mfile[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# reads a json object from a file[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mcontents[39m[38;5;252m)[39m
[38;5;246;03m# print: {"aa": 12, "bb": 21}[39;00m
[38;5;246;03m# Python offers a fundamental abstraction called the Iterable.[39;00m
[38;5;246;03m# An iterable is an object that can be treated as a sequence.[39;00m
[38;5;246;03m# The object returned by the range function, is an iterable.[39;00m
[38;5;252mfilled_dict[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;214m"[39m[38;5;214mone[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mtwo[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mthree[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m}[39m
[38;5;252mour_iterable[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mfilled_dict[39m[38;5;252m.[39m[38;5;252mkeys[39m[38;5;252m([39m[38;5;252m)[39m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mour_iterable[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => dict_keys(['one', 'two', 'three']). This is an object that implements our Iterable interface.[39;00m
[38;5;246;03m# We can loop over it.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mour_iterable[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Prints one, two, three[39;00m
[38;5;246;03m# However we cannot address elements by index.[39;00m
[38;5;252mour_iterable[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# Raises a TypeError[39;00m
[38;5;246;03m# An iterable is an object that knows how to create an iterator.[39;00m
[38;5;252mour_iterator[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31miter[39m[38;5;252m([39m[38;5;252mour_iterable[39m[38;5;252m)[39m
[38;5;246;03m# Our iterator is an object that can remember the state as we traverse through it.[39;00m
[38;5;246;03m# We get the next object with "next()".[39;00m
[38;5;31mnext[39m[38;5;252m([39m[38;5;252mour_iterator[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "one"[39;00m
[38;5;246;03m# It maintains state as we iterate.[39;00m
[38;5;31mnext[39m[38;5;252m([39m[38;5;252mour_iterator[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "two"[39;00m
[38;5;31mnext[39m[38;5;252m([39m[38;5;252mour_iterator[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "three"[39;00m
[38;5;246;03m# After the iterator has returned all of its data, it raises a StopIteration exception[39;00m
[38;5;31mnext[39m[38;5;252m([39m[38;5;252mour_iterator[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Raises StopIteration[39;00m
[38;5;246;03m# We can also loop over it, in fact, "for" does this implicitly![39;00m
[38;5;252mour_iterator[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31miter[39m[38;5;252m([39m[38;5;252mour_iterable[39m[38;5;252m)[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mour_iterator[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Prints one, two, three[39;00m
[38;5;246;03m# You can grab all the elements of an iterable or iterator by calling list() on it.[39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;252mour_iterable[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Returns ["one", "two", "three"][39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;252mour_iterator[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Returns [] because state is saved[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 4. Functions[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# Use "def" to create new functions[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68madd[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mx is [39m[38;5;214m{}[39m[38;5;214m and y is [39m[38;5;214m{}[39m[38;5;214m"[39m[38;5;252m.[39m[38;5;252mformat[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m)[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m [39m[38;5;246;03m# Return values with a return statement[39;00m
[38;5;246;03m# Calling functions with parameters[39;00m
[38;5;252madd[39m[38;5;252m([39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => prints out "x is 5 and y is 6" and returns 11[39;00m
[38;5;246;03m# Another way to call functions is with keyword arguments[39;00m
[38;5;252madd[39m[38;5;252m([39m[38;5;252my[39m[38;5;252m=[39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mx[39m[38;5;252m=[39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Keyword arguments can arrive in any order.[39;00m
[38;5;246;03m# You can define functions that take a variable number of[39;00m
[38;5;246;03m# positional arguments[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mvarargs[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252margs[39m
[38;5;252mvarargs[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => (1, 2, 3)[39;00m
[38;5;246;03m# You can define functions that take a variable number of[39;00m
[38;5;246;03m# keyword arguments, as well[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mkeyword_args[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mkwargs[39m
[38;5;246;03m# Let's call it to see what happens[39;00m
[38;5;252mkeyword_args[39m[38;5;252m([39m[38;5;252mbig[39m[38;5;252m=[39m[38;5;214m"[39m[38;5;214mfoot[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mloch[39m[38;5;252m=[39m[38;5;214m"[39m[38;5;214mness[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => {"big": "foot", "loch": "ness"}[39;00m
[38;5;246;03m# You can do both at once, if you like[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mall_the_args[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252margs[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mkwargs[39m[38;5;252m)[39m
[38;5;214m"""[39m
[38;5;214mall_the_args(1, 2, a=3, b=4) prints:[39m
[38;5;214m (1, 2)[39m
[38;5;214m {"a": 3, "b": 4}[39m
[38;5;214m"""[39m
[38;5;246;03m# When calling functions, you can do the opposite of args/kwargs![39;00m
[38;5;246;03m# Use * to expand tuples and use ** to expand kwargs.[39;00m
[38;5;252margs[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m)[39m
[38;5;252mkwargs[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;214m"[39m[38;5;214ma[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mb[39m[38;5;214m"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m}[39m
[38;5;252mall_the_args[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# equivalent to all_the_args(1, 2, 3, 4)[39;00m
[38;5;252mall_the_args[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# equivalent to all_the_args(a=3, b=4)[39;00m
[38;5;252mall_the_args[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# equivalent to all_the_args(1, 2, 3, 4, a=3, b=4)[39;00m
[38;5;246;03m# Returning multiple values (with tuple assignments)[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mswap[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252my[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;246;03m# Return multiple values as a tuple without the parenthesis.[39;00m
[38;5;252m [39m[38;5;246;03m# (Note: parenthesis have been excluded but can be included)[39;00m
[38;5;252mx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m1[39m
[38;5;252my[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m2[39m
[38;5;252mx[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mswap[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => x = 2, y = 1[39;00m
[38;5;246;03m# (x, y) = swap(x,y) # Again parenthesis have been excluded but can be included.[39;00m
[38;5;246;03m# Function Scope[39;00m
[38;5;252mx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mset_x[39m[38;5;252m([39m[38;5;252mnum[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# Local var x not the same as global variable x[39;00m
[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mnum[39m[38;5;252m [39m[38;5;246;03m# => 43[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 43[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mset_global_x[39m[38;5;252m([39m[38;5;252mnum[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mglobal[39;00m[38;5;252m [39m[38;5;252mx[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 5[39;00m
[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mnum[39m[38;5;252m [39m[38;5;246;03m# global var x is now set to 6[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 6[39;00m
[38;5;252mset_x[39m[38;5;252m([39m[38;5;67m43[39m[38;5;252m)[39m
[38;5;252mset_global_x[39m[38;5;252m([39m[38;5;67m6[39m[38;5;252m)[39m
[38;5;246;03m# Python has first class functions[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mcreate_adder[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68madder[39m[38;5;252m([39m[38;5;252my[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252my[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252madder[39m
[38;5;252madd_10[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mcreate_adder[39m[38;5;252m([39m[38;5;67m10[39m[38;5;252m)[39m
[38;5;252madd_10[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 13[39;00m
[38;5;246;03m# There are also anonymous functions[39;00m
[38;5;252m([39m[38;5;70;01mlambda[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m:[39m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;252m([39m[38;5;70;01mlambda[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m:[39m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252my[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 5[39;00m
[38;5;246;03m# There are built-in higher order functions[39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;31mmap[39m[38;5;252m([39m[38;5;252madd_10[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [11, 12, 13][39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;31mmap[39m[38;5;252m([39m[38;5;31mmax[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [4, 2, 3][39;00m
[38;5;31mlist[39m[38;5;252m([39m[38;5;31mfilter[39m[38;5;252m([39m[38;5;70;01mlambda[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m:[39m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m7[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [6, 7][39;00m
[38;5;246;03m# We can use list comprehensions for nice maps and filters[39;00m
[38;5;246;03m# List comprehension stores the output as a list which can itself be a nested list[39;00m
[38;5;252m[[39m[38;5;252madd_10[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => [11, 12, 13][39;00m
[38;5;252m[[39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252m[[39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m7[39m[38;5;252m][39m[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m][39m[38;5;252m [39m[38;5;246;03m# => [6, 7][39;00m
[38;5;246;03m# You can construct set and dict comprehensions as well.[39;00m
[38;5;252m{[39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;214m'[39m[38;5;214mabcddeef[39m[38;5;214m'[39m[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01mnot[39;00m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;214m'[39m[38;5;214mabc[39m[38;5;214m'[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => {'d', 'e', 'f'}[39;00m
[38;5;252m{[39m[38;5;252mx[39m[38;5;252m:[39m[38;5;252m [39m[38;5;252mx[39m[38;5;252m*[39m[38;5;252m*[39m[38;5;67m2[39m[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;31mrange[39m[38;5;252m([39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m# => {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 5. Modules[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# You can import modules[39;00m
[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;68;04mmath[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mmath[39m[38;5;252m.[39m[38;5;252msqrt[39m[38;5;252m([39m[38;5;67m16[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 4.0[39;00m
[38;5;246;03m# You can get specific functions from a module[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mmath[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mceil[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mfloor[39m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mceil[39m[38;5;252m([39m[38;5;67m3.7[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 4.0[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mfloor[39m[38;5;252m([39m[38;5;67m3.7[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 3.0[39;00m
[38;5;246;03m# You can import all functions from a module.[39;00m
[38;5;246;03m# Warning: this is not recommended[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mmath[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252m*[39m
[38;5;246;03m# You can shorten module names[39;00m
[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;68;04mmath[39;00m[38;5;252m [39m[38;5;70;01mas[39;00m[38;5;252m [39m[38;5;68;04mm[39;00m
[38;5;252mmath[39m[38;5;252m.[39m[38;5;252msqrt[39m[38;5;252m([39m[38;5;67m16[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;252mm[39m[38;5;252m.[39m[38;5;252msqrt[39m[38;5;252m([39m[38;5;67m16[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => True[39;00m
[38;5;246;03m# Python modules are just ordinary Python files. You[39;00m
[38;5;246;03m# can write your own, and import them. The name of the[39;00m
[38;5;246;03m# module is the same as the name of the file.[39;00m
[38;5;246;03m# You can find out which functions and attributes[39;00m
[38;5;246;03m# are defined in a module.[39;00m
[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;68;04mmath[39;00m
[38;5;31mdir[39m[38;5;252m([39m[38;5;252mmath[39m[38;5;252m)[39m
[38;5;246;03m# If you have a Python script named math.py in the same[39;00m
[38;5;246;03m# folder as your current script, the file math.py will[39;00m
[38;5;246;03m# be loaded instead of the built-in Python module.[39;00m
[38;5;246;03m# This happens because the local folder has priority[39;00m
[38;5;246;03m# over Python's built-in libraries.[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 6. Classes[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# We use the "class" statement to create a class[39;00m
[38;5;70;01mclass[39;00m[38;5;252m [39m[38;5;68;04mHuman[39;00m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# A class attribute. It is shared by all instances of this class[39;00m
[38;5;252m [39m[38;5;252mspecies[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mH. sapiens[39m[38;5;214m"[39m
[38;5;252m [39m[38;5;246;03m# Basic initializer, this is called when this class is instantiated.[39;00m
[38;5;252m [39m[38;5;246;03m# Note that the double leading and trailing underscores denote objects[39;00m
[38;5;252m [39m[38;5;246;03m# or attributes that are used by Python but that live in user-controlled[39;00m
[38;5;252m [39m[38;5;246;03m# namespaces. Methods(or objects or attributes) like: __init__, __str__,[39;00m
[38;5;252m [39m[38;5;246;03m# __repr__ etc. are called special methods (or sometimes called dunder methods)[39;00m
[38;5;252m [39m[38;5;246;03m# You should not invent such names on your own.[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mname[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# Assign the argument to the instance's name attribute[39;00m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mname[39m
[38;5;252m [39m[38;5;246;03m# Initialize property[39;00m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252m_age[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m
[38;5;252m [39m[38;5;246;03m# An instance method. All methods take "self" as the first argument[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msay[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mmsg[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214m{name}[39m[38;5;214m: [39m[38;5;214m{message}[39m[38;5;214m"[39m[38;5;252m.[39m[38;5;252mformat[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m=[39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252mname[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mmessage[39m[38;5;252m=[39m[38;5;252mmsg[39m[38;5;252m)[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;246;03m# Another instance method[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msing[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m'[39m[38;5;214myo... yo... microphone check... one two... one two...[39m[38;5;214m'[39m
[38;5;252m [39m[38;5;246;03m# A class method is shared among all instances[39;00m
[38;5;252m [39m[38;5;246;03m# They are called with the calling class as the first argument[39;00m
[38;5;252m [39m[38;5;214m@classmethod[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mget_species[39m[38;5;252m([39m[38;5;31mcls[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;31mcls[39m[38;5;252m.[39m[38;5;252mspecies[39m
[38;5;252m [39m[38;5;246;03m# A static method is called without a class or instance reference[39;00m
[38;5;252m [39m[38;5;214m@staticmethod[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mgrunt[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m"[39m[38;5;214m*grunt*[39m[38;5;214m"[39m
[38;5;252m [39m[38;5;246;03m# A property is just like a getter.[39;00m
[38;5;252m [39m[38;5;246;03m# It turns the method age() into a read-only attribute of the same name.[39;00m
[38;5;252m [39m[38;5;246;03m# There's no need to write trivial getters and setters in Python, though.[39;00m
[38;5;252m [39m[38;5;214m@property[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mage[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252m_age[39m
[38;5;252m [39m[38;5;246;03m# This allows the property to be set[39;00m
[38;5;252m [39m[38;5;214m@age[39m[38;5;252m.[39m[38;5;252msetter[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mage[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mage[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252m_age[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mage[39m
[38;5;252m [39m[38;5;246;03m# This allows the property to be deleted[39;00m
[38;5;252m [39m[38;5;214m@age[39m[38;5;252m.[39m[38;5;252mdeleter[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mage[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mdel[39;00m[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252m_age[39m
[38;5;246;03m# When a Python interpreter reads a source file it executes all its code.[39;00m
[38;5;246;03m# This __name__ check makes sure this code block is only executed when this[39;00m
[38;5;246;03m# module is the main program.[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;87m__name__[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214m__main__[39m[38;5;214m'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# Instantiate a class[39;00m
[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mHuman[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m=[39m[38;5;214m"[39m[38;5;214mIan[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mhi[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# "Ian: hi"[39;00m
[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mHuman[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mJoel[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;252mj[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mhello[39m[38;5;214m"[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# "Joel: hello"[39;00m
[38;5;252m [39m[38;5;246;03m# i and j are instances of type Human, or in other words: they are Human objects[39;00m
[38;5;252m [39m[38;5;246;03m# Call our class method[39;00m
[38;5;252m [39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252mget_species[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# "Ian: H. sapiens"[39;00m
[38;5;252m [39m[38;5;246;03m# Change the shared attribute[39;00m
[38;5;252m [39m[38;5;252mHuman[39m[38;5;252m.[39m[38;5;252mspecies[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mH. neanderthalensis[39m[38;5;214m"[39m
[38;5;252m [39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252mget_species[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "Ian: H. neanderthalensis"[39;00m
[38;5;252m [39m[38;5;252mj[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;252mj[39m[38;5;252m.[39m[38;5;252mget_species[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "Joel: H. neanderthalensis"[39;00m
[38;5;252m [39m[38;5;246;03m# Call the static method[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mHuman[39m[38;5;252m.[39m[38;5;252mgrunt[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "*grunt*"[39;00m
[38;5;252m [39m[38;5;246;03m# Static methods can be called by instances too[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252mgrunt[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "*grunt*"[39;00m
[38;5;252m [39m[38;5;246;03m# Update the property for this instance[39;00m
[38;5;252m [39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m42[39m
[38;5;252m [39m[38;5;246;03m# Get the property[39;00m
[38;5;252m [39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "Ian: 42"[39;00m
[38;5;252m [39m[38;5;252mj[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;252mj[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => "Joel: 0"[39;00m
[38;5;252m [39m[38;5;246;03m# Delete the property[39;00m
[38;5;252m [39m[38;5;70;01mdel[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m.[39m[38;5;252mage[39m
[38;5;252m [39m[38;5;246;03m# i.age # => this would raise an AttributeError[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 6.1 Inheritance[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# Inheritance allows new child classes to be defined that inherit methods and[39;00m
[38;5;246;03m# variables from their parent class.[39;00m
[38;5;246;03m# Using the Human class defined above as the base or parent class, we can[39;00m
[38;5;246;03m# define a child class, Superhero, which inherits the class variables like[39;00m
[38;5;246;03m# "species", "name", and "age", as well as methods, like "sing" and "grunt"[39;00m
[38;5;246;03m# from the Human class, but can also have its own unique properties.[39;00m
[38;5;246;03m# To take advantage of modularization by file you could place the classes above in their own files,[39;00m
[38;5;246;03m# say, human.py[39;00m
[38;5;246;03m# To import functions from other files use the following format[39;00m
[38;5;246;03m# from "filename-without-extension" import "function-or-class"[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mhuman[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mHuman[39m
[38;5;246;03m# Specify the parent class(es) as parameters to the class definition[39;00m
[38;5;70;01mclass[39;00m[38;5;252m [39m[38;5;68;04mSuperhero[39;00m[38;5;252m([39m[38;5;252mHuman[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# If the child class should inherit all of the parent's definitions without[39;00m
[38;5;252m [39m[38;5;246;03m# any modifications, you can just use the "pass" keyword (and nothing else)[39;00m
[38;5;252m [39m[38;5;246;03m# but in this case it is commented out to allow for a unique child class:[39;00m
[38;5;252m [39m[38;5;246;03m# pass[39;00m
[38;5;252m [39m[38;5;246;03m# Child classes can override their parents' attributes[39;00m
[38;5;252m [39m[38;5;252mspecies[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214mSuperhuman[39m[38;5;214m'[39m
[38;5;252m [39m[38;5;246;03m# Children automatically inherit their parent class's constructor including[39;00m
[38;5;252m [39m[38;5;246;03m# its arguments, but can also define additional arguments or definitions[39;00m
[38;5;252m [39m[38;5;246;03m# and override its methods such as the class constructor.[39;00m
[38;5;252m [39m[38;5;246;03m# This constructor inherits the "name" argument from the "Human" class and[39;00m
[38;5;252m [39m[38;5;246;03m# adds the "superpower" and "movie" arguments:[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mname[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mmovie[39m[38;5;252m=[39m[38;5;70;01mFalse[39;00m[38;5;252m,[39m
[38;5;252m [39m[38;5;252msuperpowers[39m[38;5;252m=[39m[38;5;252m[[39m[38;5;214m"[39m[38;5;214msuper strength[39m[38;5;214m"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mbulletproofing[39m[38;5;214m"[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# add additional class attributes:[39;00m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252mfictional[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mTrue[39;00m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252mmovie[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmovie[39m
[38;5;252m [39m[38;5;246;03m# be aware of mutable default values, since defaults are shared[39;00m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252msuperpowers[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252msuperpowers[39m
[38;5;252m [39m[38;5;246;03m# The "super" function lets you access the parent class's methods[39;00m
[38;5;252m [39m[38;5;246;03m# that are overridden by the child, in this case, the __init__ method.[39;00m
[38;5;252m [39m[38;5;246;03m# This calls the parent class constructor:[39;00m
[38;5;252m [39m[38;5;31msuper[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m.[39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;246;03m# override the sing method[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msing[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m'[39m[38;5;214mDun, dun, DUN![39m[38;5;214m'[39m
[38;5;252m [39m[38;5;246;03m# add an additional instance method[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mboast[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mpower[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252msuperpowers[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m"[39m[38;5;214mI wield the power of [39m[38;5;214m{pow}[39m[38;5;214m![39m[38;5;214m"[39m[38;5;252m.[39m[38;5;252mformat[39m[38;5;252m([39m[38;5;31mpow[39m[38;5;252m=[39m[38;5;252mpower[39m[38;5;252m)[39m[38;5;252m)[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;87m__name__[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214m__main__[39m[38;5;214m'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mSuperhero[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m=[39m[38;5;214m"[39m[38;5;214mTick[39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;246;03m# Instance type checks[39;00m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;31misinstance[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mHuman[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mI am human[39m[38;5;214m'[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;31mtype[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m)[39m[38;5;252m [39m[38;5;70;01mis[39;00m[38;5;252m [39m[38;5;252mSuperhero[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mI am a superhero[39m[38;5;214m'[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;246;03m# Get the Method Resolution search Order used by both getattr() and super()[39;00m
[38;5;252m [39m[38;5;246;03m# This attribute is dynamic and can be updated[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mSuperhero[39m[38;5;252m.[39m[38;5;87m__mro__[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => (,[39;00m
[38;5;252m [39m[38;5;246;03m# => , )[39;00m
[38;5;252m [39m[38;5;246;03m# Calls parent method but uses its own class attribute[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mget_species[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Superhuman[39;00m
[38;5;252m [39m[38;5;246;03m# Calls overridden method[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252msing[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Dun, dun, DUN![39;00m
[38;5;252m [39m[38;5;246;03m# Calls method from Human[39;00m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mSpoon[39m[38;5;214m'[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Tick: Spoon[39;00m
[38;5;252m [39m[38;5;246;03m# Call method that exists only in Superhero[39;00m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mboast[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => I wield the power of super strength![39;00m
[38;5;252m [39m[38;5;246;03m# => I wield the power of bulletproofing![39;00m
[38;5;252m [39m[38;5;246;03m# Inherited class attribute[39;00m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m31[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 31[39;00m
[38;5;252m [39m[38;5;246;03m# Attribute that only exists within Superhero[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mAm I Oscar eligible? [39m[38;5;214m'[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;31mstr[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mmovie[39m[38;5;252m)[39m[38;5;252m)[39m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 6.2 Multiple Inheritance[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# Another class definition[39;00m
[38;5;246;03m# bat.py[39;00m
[38;5;70;01mclass[39;00m[38;5;252m [39m[38;5;68;04mBat[39;00m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mspecies[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214mBaty[39m[38;5;214m'[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mcan_fly[39m[38;5;252m=[39m[38;5;70;01mTrue[39;00m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252mfly[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mcan_fly[39m
[38;5;252m [39m[38;5;246;03m# This class also has a say method[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msay[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mmsg[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mmsg[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214m... ... ...[39m[38;5;214m'[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mmsg[39m
[38;5;252m [39m[38;5;246;03m# And its own method as well[39;00m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msonar[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m'[39m[38;5;214m))) ... ((([39m[38;5;214m'[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;87m__name__[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214m__main__[39m[38;5;214m'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mb[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mBat[39m[38;5;252m([39m[38;5;252m)[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mb[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mhello[39m[38;5;214m'[39m[38;5;252m)[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mb[39m[38;5;252m.[39m[38;5;252mfly[39m[38;5;252m)[39m
[38;5;246;03m# And yet another class definition that inherits from Superhero and Bat[39;00m
[38;5;246;03m# superhero.py[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04msuperhero[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mSuperhero[39m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mbat[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mBat[39m
[38;5;246;03m# Define Batman as a child that inherits from both Superhero and Bat[39;00m
[38;5;70;01mclass[39;00m[38;5;252m [39m[38;5;68;04mBatman[39;00m[38;5;252m([39m[38;5;252mSuperhero[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mBat[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;246;03m# Typically to inherit attributes you have to call super:[39;00m
[38;5;252m [39m[38;5;246;03m# super(Batman, self).__init__(*args, **kwargs)[39;00m
[38;5;252m [39m[38;5;246;03m# However we are dealing with multiple inheritance here, and super()[39;00m
[38;5;252m [39m[38;5;246;03m# only works with the next base class in the MRO list.[39;00m
[38;5;252m [39m[38;5;246;03m# So instead we explicitly call __init__ for all ancestors.[39;00m
[38;5;252m [39m[38;5;246;03m# The use of *args and **kwargs allows for a clean way to pass arguments,[39;00m
[38;5;252m [39m[38;5;246;03m# with each parent "peeling a layer of the onion".[39;00m
[38;5;252m [39m[38;5;252mSuperhero[39m[38;5;252m.[39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214manonymous[39m[38;5;214m'[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mmovie[39m[38;5;252m=[39m[38;5;70;01mTrue[39;00m[38;5;252m,[39m
[38;5;252m [39m[38;5;252msuperpowers[39m[38;5;252m=[39m[38;5;252m[[39m[38;5;214m'[39m[38;5;214mWealthy[39m[38;5;214m'[39m[38;5;252m][39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;252mBat[39m[38;5;252m.[39m[38;5;68m__init__[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mcan_fly[39m[38;5;252m=[39m[38;5;70;01mFalse[39;00m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;246;03m# override the value for the name attribute[39;00m
[38;5;252m [39m[38;5;31mself[39m[38;5;252m.[39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214mSad Affleck[39m[38;5;214m'[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msing[39m[38;5;252m([39m[38;5;31mself[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m'[39m[38;5;214mnan nan nan nan nan batman![39m[38;5;214m'[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;87m__name__[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214m__main__[39m[38;5;214m'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mBatman[39m[38;5;252m([39m[38;5;252m)[39m
[38;5;252m [39m[38;5;246;03m# Get the Method Resolution search Order used by both getattr() and super().[39;00m
[38;5;252m [39m[38;5;246;03m# This attribute is dynamic and can be updated[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mBatman[39m[38;5;252m.[39m[38;5;87m__mro__[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => (,[39;00m
[38;5;252m [39m[38;5;246;03m# => ,[39;00m
[38;5;252m [39m[38;5;246;03m# => ,[39;00m
[38;5;252m [39m[38;5;246;03m# => , )[39;00m
[38;5;252m [39m[38;5;246;03m# Calls parent method but uses its own class attribute[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mget_species[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Superhuman[39;00m
[38;5;252m [39m[38;5;246;03m# Calls overridden method[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252msing[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => nan nan nan nan nan batman![39;00m
[38;5;252m [39m[38;5;246;03m# Calls method from Human, because inheritance order matters[39;00m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252msay[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mI agree[39m[38;5;214m'[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Sad Affleck: I agree[39;00m
[38;5;252m [39m[38;5;246;03m# Call method that exists only in 2nd ancestor[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252msonar[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => ))) ... ((([39;00m
[38;5;252m [39m[38;5;246;03m# Inherited class attribute[39;00m
[38;5;252m [39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m100[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mage[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => 100[39;00m
[38;5;252m [39m[38;5;246;03m# Inherited attribute from 2nd ancestor whose default value was overridden.[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;214m'[39m[38;5;214mCan I fly? [39m[38;5;214m'[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;31mstr[39m[38;5;252m([39m[38;5;252msup[39m[38;5;252m.[39m[38;5;252mfly[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => Can I fly? False[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m## 7. Advanced[39;00m
[38;5;246;03m####################################################[39;00m
[38;5;246;03m# Generators help you make lazy code.[39;00m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mdouble_numbers[39m[38;5;252m([39m[38;5;252miterable[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252miterable[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01myield[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252mi[39m
[38;5;246;03m# Generators are memory-efficient because they only load the data needed to[39;00m
[38;5;246;03m# process the next value in the iterable. This allows them to perform[39;00m
[38;5;246;03m# operations on otherwise prohibitively large value ranges.[39;00m
[38;5;246;03m# NOTE: `range` replaces `xrange` in Python 3.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mdouble_numbers[39m[38;5;252m([39m[38;5;31mrange[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m900000000[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m:[39m[38;5;252m [39m[38;5;246;03m# `range` is a generator.[39;00m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m30[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m
[38;5;246;03m# Just as you can create a list comprehension, you can create generator[39;00m
[38;5;246;03m# comprehensions as well.[39;00m
[38;5;252mvalues[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;252m-[39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m3[39m[38;5;252m,[39m[38;5;67m4[39m[38;5;252m,[39m[38;5;67m5[39m[38;5;252m][39m[38;5;252m)[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mvalues[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;31mprint[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# prints -1 -2 -3 -4 -5 to console/terminal[39;00m
[38;5;246;03m# You can also cast a generator comprehension directly to a list.[39;00m
[38;5;252mvalues[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;252m-[39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m3[39m[38;5;252m,[39m[38;5;67m4[39m[38;5;252m,[39m[38;5;67m5[39m[38;5;252m][39m[38;5;252m)[39m
[38;5;252mgen_to_list[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31mlist[39m[38;5;252m([39m[38;5;252mvalues[39m[38;5;252m)[39m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252mgen_to_list[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# => [-1, -2, -3, -4, -5][39;00m
[38;5;246;03m# Decorators[39;00m
[38;5;246;03m# In this example `beg` wraps `say`. If say_please is True then it[39;00m
[38;5;246;03m# will change the returned message.[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mfunctools[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mwraps[39m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mbeg[39m[38;5;252m([39m[38;5;252mtarget_function[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;214m@wraps[39m[38;5;252m([39m[38;5;252mtarget_function[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68mwrapper[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mmsg[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252msay_please[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mtarget_function[39m[38;5;252m([39m[38;5;252m*[39m[38;5;252margs[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m*[39m[38;5;252mkwargs[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252msay_please[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m"[39m[38;5;214m{}[39m[38;5;214m [39m[38;5;214m{}[39m[38;5;214m"[39m[38;5;252m.[39m[38;5;252mformat[39m[38;5;252m([39m[38;5;252mmsg[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mPlease! I am poor :([39m[38;5;214m"[39m[38;5;252m)[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mmsg[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mwrapper[39m
[38;5;214m@beg[39m
[38;5;70;01mdef[39;00m[38;5;252m [39m[38;5;68msay[39m[38;5;252m([39m[38;5;252msay_please[39m[38;5;252m=[39m[38;5;70;01mFalse[39;00m[38;5;252m)[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mmsg[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mCan you buy me a beer?[39m[38;5;214m"[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mmsg[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252msay_please[39m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252msay[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Can you buy me a beer?[39;00m
[38;5;31mprint[39m[38;5;252m([39m[38;5;252msay[39m[38;5;252m([39m[38;5;252msay_please[39m[38;5;252m=[39m[38;5;70;01mTrue[39;00m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m [39m[38;5;246;03m# Can you buy me a beer? Please! I am poor :([39;00m
================================================
FILE: tests/results/16
================================================
[38;5;242m# Latency numbers every programmer should know [m
1ns Main memory reference: Send 2,000 bytes Read 1,000,000 bytes
[37m▗▖ [m100ns over commodity network: sequentially from SSD:
[34m▗▖ [m31ns 38.876us
L1 cache reference: 1ns [32m▗ [m[31m▗ [m
[37m▗▖ [m1.0us
[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [mSSD random read: 16.0us Disk seek: 2.332582ms
Branch mispredict: 3ns [34m [m[32m▗▖▗ [m[31m▗▖▗▖ [m
[37m▗▖▗▖▗▖ [m
Compress 1KB wth Snappy: Read 1,000,000 bytes Read 1,000,000 bytes
L2 cache reference: 4ns 2.0us sequentially from memory: sequentially from disk:
[37m▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m2.355us 717.936us
[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗ [m[31m▗ [m
Mutex lock/unlock: 16ns [34m [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m Round trip Packet roundtrip
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗ [m10.0us = [32m▗▖[m in same datacenter: 500.0us CA to Netherlands: 150.0ms
[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
100ns = [34m▗▖[m [34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m [31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m1.0ms = [31m▗▖[m [31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m [32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m [m [32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[38;5;242m# [github.com/chubin/late.nz] [MIT License] [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[38;5;242m# Console port of "Jeff Dean's latency numbers" [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m [m
[38;5;242m# from [github.com/colin-scott/interactive_latencies] [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[38;5;242m [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
================================================
FILE: tests/results/17
================================================
[48;5;8m[24m cheat.sheets:az [24m[0m
[38;5;246;03m# Microsoft Azure CLI 2.0[39;00m
[38;5;246;03m# Command-line tools for Azure[39;00m
[38;5;246;03m# Install Azure CLI 2.0 with one curl command.[39;00m
[38;5;252mcurl[39m[38;5;252m [39m[38;5;252m-L[39m[38;5;252m [39m[38;5;252mhttps://aka.ms/InstallAzureCli[39m[38;5;252m [39m[38;5;252m|[39m[38;5;252m [39m[38;5;252mbash[39m
[38;5;246;03m# create a resource group named "MyRG" in the 'westus2' region[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mgroup[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m-n[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m-l[39m[38;5;252m [39m[38;5;252mwestus2[39m
[38;5;246;03m# create a Linux VM using the UbuntuTLS image,[39;00m
[38;5;246;03m# with two attached storage disks of 10 GB and 20 GB[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m-n[39m[38;5;252m [39m[38;5;252mMyLinuxVM[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--ssh-key-value[39m[38;5;252m [39m[38;5;87m$HOME[39m[38;5;252m/.ssh/id_rsa.pub[39m[38;5;252m [39m[38;5;252m--image[39m[38;5;252m [39m[38;5;252mUbuntuLTS[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--data-disk-sizes-gb[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m [39m[38;5;67m20[39m
[38;5;246;03m# list VMs[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# list only VMs having distinct state[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m-d[39m[38;5;252m [39m[38;5;252m--query[39m[38;5;252m [39m[38;5;214m"[?powerState=='VM running']"[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# delete VM (with the name MyLinuxVM in the group MyRG)[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mdelete[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m-n[39m[38;5;252m [39m[38;5;252mMyLinuxVM[39m[38;5;252m [39m[38;5;252m--yes[39m
[38;5;246;03m# Delete all VMs in a resource group[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mdelete[39m[38;5;252m [39m[38;5;252m--ids[39m[38;5;252m [39m[38;5;70;01m$([39;00m[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m--query[39m[38;5;252m [39m[38;5;214m"[].id"[39m[38;5;252m [39m[38;5;252m-o[39m[38;5;252m [39m[38;5;252mtsv[39m[38;5;70;01m)[39;00m
[38;5;246;03m# Create an Image based on a running VM[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mdeallocate[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m-n[39m[38;5;252m [39m[38;5;252mMyLinuxVM[39m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mgeneralize[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m-n[39m[38;5;252m [39m[38;5;252mMyLinuxVM[39m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mimage[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m--resource-group[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m--name[39m[38;5;252m [39m[38;5;252mMyTestImage[39m[38;5;252m [39m[38;5;252m--source[39m[38;5;252m [39m[38;5;252mMyLinuxVM[39m
[38;5;246;03m# Running VM based on a VHD[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mstorage[39m[38;5;252m [39m[38;5;252mblob[39m[38;5;252m [39m[38;5;252mupload[39m[38;5;252m [39m[38;5;252m--account-name[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m${[39m[38;5;87maccount_name[39m[38;5;214m}[39m[38;5;214m"[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--account-key[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m${[39m[38;5;87maccount_key[39m[38;5;214m}[39m[38;5;214m"[39m[38;5;252m [39m[38;5;252m--container-name[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m${[39m[38;5;87mcontainer[39m[38;5;214m}[39m[38;5;214m"[39m[38;5;252m [39m[38;5;252m--type[39m[38;5;252m [39m[38;5;252mpage[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--file[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m${[39m[38;5;87mfile[39m[38;5;214m}[39m[38;5;214m"[39m[38;5;252m [39m[38;5;252m--name[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m${[39m[38;5;87mvhd[39m[38;5;214m}[39m[38;5;214m"[39m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mdisk[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--resource-group[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214m${[39m[38;5;87mresource_group[39m[38;5;214m}[39m[38;5;214m"[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--name[39m[38;5;252m [39m[38;5;252mmyManagedDisk[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--source[39m[38;5;252m [39m[38;5;214m"[39m[38;5;214mhttps://[39m[38;5;214m${[39m[38;5;87maccount_name[39m[38;5;214m}[39m[38;5;214m.blob.core.windows.net/[39m[38;5;214m${[39m[38;5;87mcontainer[39m[38;5;214m}[39m[38;5;214m/[39m[38;5;214m${[39m[38;5;87mvhd[39m[38;5;214m}[39m[38;5;214m"[39m
[38;5;246;03m# open port[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mopen-port[39m[38;5;252m [39m[38;5;252m--resource-group[39m[38;5;252m [39m[38;5;252mMyRG[39m[38;5;252m [39m[38;5;252m--name[39m[38;5;252m [39m[38;5;252mMyLinuxVM[39m[38;5;252m [39m[38;5;252m--port[39m[38;5;252m [39m[38;5;67m443[39m[38;5;252m [39m[38;5;252m--priority[39m[38;5;252m [39m[38;5;67m899[39m
[38;5;246;03m# Show storage accounts[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mstorage[39m[38;5;252m [39m[38;5;252maccount[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# Show containers for an account[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mstorage[39m[38;5;252m [39m[38;5;252mcontainer[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--account-name[39m[38;5;252m [39m[38;5;252mmystorageaccount[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# Show blobs in a container[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mstorage[39m[38;5;252m [39m[38;5;252mblob[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--account-name[39m[38;5;252m [39m[38;5;252mmystorageaccount[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--container-name[39m[38;5;252m [39m[38;5;252mmycontainer[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# list account keys[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mstorage[39m[38;5;252m [39m[38;5;252maccount[39m[38;5;252m [39m[38;5;252mkeys[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--account-name[39m[38;5;252m [39m[38;5;252mSTORAGE_NAME[39m[38;5;252m [39m[38;5;252m--resource-group[39m[38;5;252m [39m[38;5;252mRESOURCE_GROUP[39m
[38;5;246;03m# Show own images[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mimage[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# Configure default storage location[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mconfigure[39m[38;5;252m [39m[38;5;252m--defaults[39m[38;5;252m [39m[38;5;87mlocation[39m[38;5;252m=[39m[38;5;252meastus2[39m
[38;5;246;03m# Show disks[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mdisk[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# Copy blob[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mstorage[39m[38;5;252m [39m[38;5;252mblob[39m[38;5;252m [39m[38;5;252mcopy[39m[38;5;252m [39m[38;5;252mstart[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--source-uri[39m[38;5;252m [39m[38;5;214m'https://xxx.blob.core.windows.net/jzwuuuzzapn0/abcd?...'[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--account-key[39m[38;5;252m [39m[38;5;87mXXXXXXXXXX[39m[38;5;252m=[39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--account-name[39m[38;5;252m [39m[38;5;252mdestaccount[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--destination-container[39m[38;5;252m [39m[38;5;252mvms[39m[38;5;252m [39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--destination-blob[39m[38;5;252m [39m[38;5;252mDESTINATION-blob.vhd[39m
[38;5;246;03m# List virtual networks[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mnetwork[39m[38;5;252m [39m[38;5;252mvnet[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# List virtual networks adapters[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mnetwork[39m[38;5;252m [39m[38;5;252mnic[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# List public IP addresses used by the VMs[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mlist-ip-addresses[39m[38;5;252m [39m[38;5;252m--output[39m[38;5;252m [39m[38;5;252mtable[39m
[38;5;246;03m# create snapshot[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252msnapshot[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m--resource-group[39m[38;5;252m [39m[38;5;252mIC-EXASOL-001[39m[38;5;252m [39m[38;5;252m--source[39m[38;5;252m [39m[38;5;252mvm1-disk1[39m[38;5;252m [39m[38;5;252m-n[39m[38;5;252m [39m[38;5;252mvm1-snap1[39m
[38;5;246;03m# create SAS url for a snapshot[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252msnapshot[39m[38;5;252m [39m[38;5;252mgrant-access[39m[38;5;252m [39m[38;5;252m--resource-group[39m[38;5;252m [39m[38;5;252mIC-EXASOL-001[39m[38;5;252m [39m[38;5;252m--name[39m[38;5;252m [39m[38;5;252mvm1-snap1[39m[38;5;214m\[39m
[38;5;252m [39m[38;5;252m--duration-in-seconds[39m[38;5;252m [39m[38;5;67m36000[39m[38;5;252m [39m[38;5;252m--query[39m[38;5;252m [39m[38;5;214m'[accessSas]'[39m[38;5;252m [39m[38;5;252m-o[39m[38;5;252m [39m[38;5;252mtsv[39m
[38;5;246;03m# attach disk[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mdisk[39m[38;5;252m [39m[38;5;252mattach[39m[38;5;252m [39m[38;5;252m--vm-name[39m[38;5;252m [39m[38;5;252mvm1[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mRESOURCE_GROUP[39m[38;5;252m [39m[38;5;252m--disk[39m[38;5;252m [39m[38;5;252mDISK1_ID[39m
[38;5;246;03m# detach disk[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mdisk[39m[38;5;252m [39m[38;5;252mdetach[39m[38;5;252m [39m[38;5;252m--vm-name[39m[38;5;252m [39m[38;5;252mvm1[39m[38;5;252m [39m[38;5;252m-g[39m[38;5;252m [39m[38;5;252mRESOURCE_GROUP[39m[38;5;252m [39m[38;5;252m--name[39m[38;5;252m [39m[38;5;252mDISK1_ID[39m
[48;5;8m[24m tldr:az [24m[0m
[38;5;246;03m# az[39;00m
[38;5;246;03m# The official CLI tool for Microsoft Azure.[39;00m
[38;5;246;03m# Some subcommands such as `az login` have their own usage documentation.[39;00m
[38;5;246;03m# More information: .[39;00m
[38;5;246;03m# Log in to Azure:[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mlogin[39m
[38;5;246;03m# Manage azure subscription information:[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252maccount[39m
[38;5;246;03m# List all Azure Managed Disks:[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mdisk[39m[38;5;252m [39m[38;5;252mlist[39m
[38;5;246;03m# List all Azure virtual machines:[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mvm[39m[38;5;252m [39m[38;5;252mlist[39m
[38;5;246;03m# Manage Azure Kubernetes Services:[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252maks[39m
[38;5;246;03m# Manage Azure Network resources:[39;00m
[38;5;252maz[39m[38;5;252m [39m[38;5;252mnetwork[39m
================================================
FILE: tests/results/18
================================================
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214mabcdefgh[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252mn[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mm[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mchar[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mchars[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214md[39m[38;5;214m'[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m'[39m[38;5;214mcd[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;246;03m# starting from n=2 characters in and m=3 in length;[39;00m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m[[39m[38;5;252mn[39m[38;5;252m-[39m[38;5;67m1[39m[38;5;252m:[39m[38;5;252mn[39m[38;5;252m+[39m[38;5;252mm[39m[38;5;252m-[39m[38;5;67m1[39m[38;5;252m][39m
[38;5;214m'[39m[38;5;214mbcd[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;246;03m# starting from n characters in, up to the end of the string;[39;00m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m[[39m[38;5;252mn[39m[38;5;252m-[39m[38;5;67m1[39m[38;5;252m:[39m[38;5;252m][39m
[38;5;214m'[39m[38;5;214mbcdefgh[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;246;03m# whole string minus last character;[39;00m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m[[39m[38;5;252m:[39m[38;5;252m-[39m[38;5;67m1[39m[38;5;252m][39m
[38;5;214m'[39m[38;5;214mabcdefg[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;246;03m# starting from a known character char="d" within the string and of m length;[39;00m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252mindx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m.[39m[38;5;252mindex[39m[38;5;252m([39m[38;5;252mchar[39m[38;5;252m)[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m[[39m[38;5;252mindx[39m[38;5;252m:[39m[38;5;252mindx[39m[38;5;252m+[39m[38;5;252mm[39m[38;5;252m][39m
[38;5;214m'[39m[38;5;214mdef[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;246;03m# starting from a known substring chars="cd" within the string and of m length.[39;00m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252mindx[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m.[39m[38;5;252mindex[39m[38;5;252m([39m[38;5;252mchars[39m[38;5;252m)[39m
[38;5;252m>>[39m[38;5;252m>[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m[[39m[38;5;252mindx[39m[38;5;252m:[39m[38;5;252mindx[39m[38;5;252m+[39m[38;5;252mm[39m[38;5;252m][39m
[38;5;214m'[39m[38;5;214mcde[39m[38;5;214m'[39m
[38;5;252m>>[39m[38;5;252m>[39m
================================================
FILE: tests/results/19
================================================
>>> s = 'abcdefgh'
>>> n, m, char, chars = 2, 3, 'd', 'cd'
>>> # starting from n=2 characters in and m=3 in length;
>>> s[n-1:n+m-1]
'bcd'
>>> # starting from n characters in, up to the end of the string;
>>> s[n-1:]
'bcdefgh'
>>> # whole string minus last character;
>>> s[:-1]
'abcdefg'
>>> # starting from a known character char="d" within the string and of m length;
>>> indx = s.index(char)
>>> s[indx:indx+m]
'def'
>>> # starting from a known substring chars="cd" within the string and of m length.
>>> indx = s.index(chars)
>>> s[indx:indx+m]
'cde'
>>>
================================================
FILE: tests/results/2
================================================
[48;5;8m[24m cheat:ls [24m[0m
[38;5;246;03m# To display everything in , excluding hidden files:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252mdir>[39m
[38;5;246;03m# To display everything in , including hidden files:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-a[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252mdir>[39m
[38;5;246;03m# To display all files, along with the size (with unit suffixes) and timestamp[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-lh[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252mdir>[39m
[38;5;246;03m# To display files, sorted by size:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-S[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252mdir>[39m
[38;5;246;03m# To display directories only:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-d[39m[38;5;252m [39m[38;5;252m*/[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252mdir>[39m
[38;5;246;03m# To display directories only, include hidden:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-d[39m[38;5;252m [39m[38;5;252m.*/[39m[38;5;252m [39m[38;5;252m*/[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252mdir>[39m
[48;5;8m[24m tldr:ls [24m[0m
[38;5;246;03m# ls[39;00m
[38;5;246;03m# List directory contents.[39;00m
[38;5;246;03m# More information: .[39;00m
[38;5;246;03m# List files one per line:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-1[39m
[38;5;246;03m# List all files, including hidden files:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-a[39m
[38;5;246;03m# List all files, with trailing `/` added to directory names:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-F[39m
[38;5;246;03m# Long format list (permissions, ownership, size, and modification date) of all files:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-la[39m
[38;5;246;03m# Long format list with size displayed using human-readable units (KiB, MiB, GiB):[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-lh[39m
[38;5;246;03m# Long format list sorted by size (descending):[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-lS[39m
[38;5;246;03m# Long format list of all files, sorted by modification date (oldest first):[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-ltr[39m
[38;5;246;03m# Only list directories:[39;00m
[38;5;252mls[39m[38;5;252m [39m[38;5;252m-d[39m[38;5;252m [39m[38;5;252m*/[39m
================================================
FILE: tests/results/20
================================================
00DESCRIPTION
100-doors
24-game
24-game-Solve
9-billion-names-of-God-the-integer
99-Bottles-of-Beer
A+B
ABC-Problem
AKS-test-for-primes
Abstract-type
Abundant,-deficient-and-perfect-number-classifications
Accumulator-factory
Ackermann-function
Active-Directory-Connect
Active-Directory-Search-for-a-user
Active-object
Add-a-variable-to-a-class-instance-at-runtime
Address-of-a-variable
Align-columns
Aliquot-sequence-classifications
Almost-prime
Amb
Amicable-pairs
Anagrams
Anagrams-Deranged-anagrams
Animate-a-pendulum
Animation
Anonymous-recursion
Append-a-record-to-the-end-of-a-text-file
Apply-a-callback-to-an-array
Arbitrary-precision-integers--included-
Arithmetic-Complex
Arithmetic-Integer
Arithmetic-Rational
Arithmetic-evaluation
Arithmetic-geometric-mean
Arithmetic-geometric-mean-Calculate-Pi
Array-concatenation
Arrays
Assertions
Associative-array-Creation
Associative-array-Iteration
Atomic-updates
Average-loop-length
Averages-Arithmetic-mean
Averages-Mean-angle
Averages-Mean-time-of-day
Averages-Median
Averages-Mode
Averages-Pythagorean-means
Averages-Root-mean-square
Averages-Simple-moving-average
Balanced-brackets
Balanced-ternary
Benfords-law
Bernoulli-numbers
Best-shuffle
Binary-digits
Binary-search
Binary-strings
Bitcoin-address-validation
Bitcoin-public-point-to-address
Bitmap-B-zier-curves-Cubic
Bitmap-Bresenhams-line-algorithm
Bitmap-Flood-fill
Bitmap-Histogram
Bitmap-Midpoint-circle-algorithm
Bitmap-PPM-conversion-through-a-pipe
Bitmap-Read-a-PPM-file
Bitmap-Read-an-image-through-a-pipe
Bitmap-Write-a-PPM-file
Bitwise-IO
Bitwise-operations
Boolean-values
Box-the-compass
Break-OO-privacy
Brownian-tree
Bulls-and-cows
Bulls-and-cows-Player
CRC-32
CSV-data-manipulation
CSV-to-HTML-translation
Caesar-cipher
Calendar
Calendar---for-REAL-programmers
Call-a-foreign-language-function
Call-a-function
Call-a-function-in-a-shared-library
Call-an-object-method
Canny-edge-detector
Carmichael-3-strong-pseudoprimes
Case-sensitivity-of-identifiers
Casting-out-nines
Catalan-numbers
Catalan-numbers-Pascals-triangle
Catamorphism
Catmull-Clark-subdivision-surface
Character-codes
Chat-server
Check-Machin-like-formulas
Check-that-file-exists
Checkpoint-synchronization
Chinese-remainder-theorem
Cholesky-decomposition
Circles-of-given-radius-through-two-points
Classes
Closest-pair-problem
Closures-Value-capture
Collections
Color-of-a-screen-pixel
Color-quantization
Colour-bars-Display
Colour-pinstripe-Display
Colour-pinstripe-Printer
Combinations
Combinations-and-permutations
Combinations-with-repetitions
Comma-quibbling
Command-line-arguments
Comments
Compare-sorting-algorithms-performance
Compound-data-type
Concurrent-computing
Conditional-structures
Conjugate-transpose
Constrained-random-points-on-a-circle
Continued-fraction
Continued-fraction-Arithmetic-Construct-from-rational-number
Continued-fraction-Arithmetic-G-matrix-NG,-Contined-Fraction-N-
Convert-decimal-number-to-rational
Conways-Game-of-Life
Copy-a-string
Count-in-factors
Count-in-octal
Count-occurrences-of-a-substring
Count-the-coins
Create-a-file
Create-a-file-on-magnetic-tape
Create-a-two-dimensional-array-at-runtime
Create-an-HTML-table
Currying
Cut-a-rectangle
Date-format
Date-manipulation
Day-of-the-week
Deal-cards-for-FreeCell
Death-Star
Deconvolution-1D
Deconvolution-2D+
Deepcopy
Define-a-primitive-data-type
Delegates
Delete-a-file
Detect-division-by-zero
Determine-if-a-string-is-numeric
Determine-if-only-one-instance-is-running
Digital-root
Digital-root-Multiplicative-digital-root
Dinesmans-multiple-dwelling-problem
Dining-philosophers
Discordian-date
Distributed-programming
Documentation
Dot-product
Doubly-linked-list-Element-definition
Doubly-linked-list-Element-insertion
Doubly-linked-list-Traversal
Dragon-curve
Draw-a-clock
Draw-a-cuboid
Draw-a-sphere
Dutch-national-flag-problem
Dynamic-variable-names
Echo-server
Element-wise-operations
Empty-directory
Empty-string
Enforced-immutability
Entropy
Enumerations
Environment-variables
Equilibrium-index
Ethiopian-multiplication
Euler-method
Evaluate-binomial-coefficients
Even-or-odd
Events
Evolutionary-algorithm
Exceptions
Exceptions-Catch-an-exception-thrown-in-a-nested-call
Executable-library
Execute-SNUSP
Execute-a-Markov-algorithm
Execute-a-system-command
Exponentiation-operator
Extensible-prime-generator
Extreme-floating-point-values
Factorial
Factors-of-a-Mersenne-number
Factors-of-an-integer
Fast-Fourier-transform
Fibonacci-n-step-number-sequences
Fibonacci-sequence
Fibonacci-word
Fibonacci-word-fractal
File-input-output
File-modification-time
File-size
Filter
Find-common-directory-path
Find-largest-left-truncatable-prime-in-a-given-base
Find-limit-of-recursion
Find-the-last-Sunday-of-each-month
Find-the-missing-permutation
First-class-environments
First-class-functions
First-class-functions-Use-numbers-analogously
Five-weekends
FizzBuzz
Flatten-a-list
Flipping-bits-game
Flow-control-structures
Floyds-triangle
Forest-fire
Fork
Formal-power-series
Formatted-numeric-output
Forward-difference
Four-bit-adder
Fractal-tree
Fractran
Function-composition
Function-definition
Function-frequency
GUI-Maximum-window-dimensions
GUI-component-interaction
GUI-enabling-disabling-of-controls
Galton-box-animation
Gamma-function
Gaussian-elimination
Generate-Chess960-starting-position
Generate-lower-case-ASCII-alphabet
Generator-Exponential
Generic-swap
Globally-replace-text-in-several-files
Gray-code
Grayscale-image
Greatest-common-divisor
Greatest-element-of-a-list
Greatest-subsequential-sum
Greyscale-bars-Display
Guess-the-number
Guess-the-number-With-feedback
Guess-the-number-With-feedback--player-
HTTP
HTTPS
HTTPS-Authenticated
HTTPS-Client-authenticated
Hailstone-sequence
Hamming-numbers
Handle-a-signal
Happy-numbers
Harshad-or-Niven-series
Hash-from-two-arrays
Hash-join
Haversine-formula
Hello-world-Graphical
Hello-world-Line-printer
Hello-world-Newbie
Hello-world-Newline-omission
Hello-world-Standard-error
Hello-world-Text
Hello-world-Web-server
Here-document
Heronian-triangles
Hickerson-series-of-almost-integers
Higher-order-functions
History-variables
Hofstadter-Conway-$10,000-sequence
Hofstadter-Figure-Figure-sequences
Hofstadter-Q-sequence
Holidays-related-to-Easter
Horizontal-sundial-calculations
Horners-rule-for-polynomial-evaluation
Host-introspection
Hostname
Hough-transform
Huffman-coding
I-before-E-except-after-C
IBAN
Identity-matrix
Image-convolution
Image-noise
Include-a-file
Increment-a-numerical-string
Infinity
Inheritance-Multiple
Inheritance-Single
Input-loop
Integer-comparison
Integer-overflow
Integer-sequence
Interactive-programming
Introspection
Inverted-index
Inverted-syntax
Iterated-digits-squaring
JSON
Jensens-Device
Josephus-problem
Joystick-position
Jump-anywhere
K-d-tree
K-means++-clustering
Kaprekar-numbers
Keyboard-input-Flush-the-keyboard-buffer
Keyboard-input-Keypress-check
Keyboard-input-Obtain-a-Y-or-N-response
Keyboard-macros
Knapsack-problem-0-1
Knapsack-problem-Bounded
Knapsack-problem-Continuous
Knights-tour
Knuth-shuffle
Knuths-algorithm-S
LU-decomposition
LZW-compression
Langtons-ant
Largest-int-from-concatenated-ints
Last-Friday-of-each-month
Last-letter-first-letter
Leap-year
Least-common-multiple
Left-factorials
Letter-frequency
Levenshtein-distance
Linear-congruential-generator
List-comprehensions
Literals-Floating-point
Literals-Integer
Literals-String
Logical-operations
Long-multiplication
Longest-common-subsequence
Longest-increasing-subsequence
Longest-string-challenge
Look-and-say-sequence
Loop-over-multiple-arrays-simultaneously
Loops-Break
Loops-Continue
Loops-Do-while
Loops-Downward-for
Loops-For
Loops-For-with-a-specified-step
Loops-Foreach
Loops-Infinite
Loops-N-plus-one-half
Loops-Nested
Loops-While
Lucas-Lehmer-test
Ludic-numbers
Luhn-test-of-credit-card-numbers
MD4
MD5
MD5-Implementation
Machine-code
Mad-Libs
Magic-squares-of-odd-order
Main-step-of-GOST-28147-89
Make-directory-path
Man-or-boy-test
Mandelbrot-set
Map-range
Matrix-arithmetic
Matrix-exponentiation-operator
Matrix-multiplication
Matrix-transposition
Maximum-triangle-path-sum
Maze-generation
Maze-solving
Median-filter
Memory-allocation
Memory-layout-of-a-data-structure
Menu
Metaprogramming
Metered-concurrency
Metronome
Middle-three-digits
Minesweeper-game
Modular-exponentiation
Modular-inverse
Monte-Carlo-methods
Monty-Hall-problem
Morse-code
Mouse-position
Move-to-front-algorithm
Multifactorial
Multiple-distinct-objects
Multiple-regression
Multiplication-tables
Multiplicative-order
Multisplit
Munching-squares
Mutual-recursion
N-queens-problem
Named-parameters
Narcissist
Narcissistic-decimal-number
Natural-sorting
Nautical-bell
Non-continuous-subsequences
Non-decimal-radices-Convert
Non-decimal-radices-Input
Non-decimal-radices-Output
Nth
Nth-root
Null-object
Number-reversal-game
Numeric-error-propagation
Numerical-integration
Numerical-integration-Gauss-Legendre-Quadrature
OLE-Automation
Object-serialization
Odd-word-problem
Old-lady-swallowed-a-fly
One-dimensional-cellular-automata
One-of-n-lines-in-a-file
OpenGL
Optional-parameters
Order-disjoint-list-items
Order-two-numerical-lists
Ordered-Partitions
Ordered-words
Palindrome-detection
Pangram-checker
Paraffins
Parallel-calculations
Parametrized-SQL-statement
Parse-an-IP-Address
Parsing-RPN-calculator-algorithm
Parsing-RPN-to-infix-conversion
Parsing-Shunting-yard-algorithm
Partial-function-application
Pascals-triangle
Pascals-triangle-Puzzle
Penneys-game
Percentage-difference-between-images
Percolation-Bond-percolation
Percolation-Mean-cluster-density
Percolation-Mean-run-density
Percolation-Site-percolation
Perfect-numbers
Permutation-test
Permutations
Permutations-Derangements
Permutations-Rank-of-a-permutation
Permutations-by-swapping
Pernicious-numbers
Phrase-reversals
Pi
Pick-random-element
Pig-the-dice-game
Pig-the-dice-game-Player
Pinstripe-Display
Play-recorded-sounds
Playing-cards
Plot-coordinate-pairs
Pointers-and-references
Polymorphic-copy
Polymorphism
Polynomial-long-division
Polynomial-regression
Power-set
Pragmatic-directives
Price-fraction
Primality-by-trial-division
Prime-decomposition
Priority-queue
Probabilistic-choice
Problem-of-Apollonius
Program-name
Program-termination
Pythagorean-triples
QR-decomposition
Quaternion-type
Queue-Definition
Queue-Usage
Quickselect-algorithm
Quine
README
RIPEMD-160
RSA-code
Random-number-generator--device-
Random-numbers
Range-expansion
Range-extraction
Ranking-methods
Rate-counter
Ray-casting-algorithm
Read-a-configuration-file
Read-a-file-line-by-line
Read-a-specific-line-from-a-file
Read-entire-file
Real-constants-and-functions
Record-sound
Reduced-row-echelon-form
Regular-expressions
Remove-duplicate-elements
Remove-lines-from-a-file
Rename-a-file
Rep-string
Repeat-a-string
Resistor-mesh
Respond-to-an-unknown-method-call
Return-multiple-values
Reverse-a-string
Reverse-words-in-a-string
Rock-paper-scissors
Roman-numerals-Decode
Roman-numerals-Encode
Roots-of-a-function
Roots-of-a-quadratic-function
Roots-of-unity
Rot-13
Run-length-encoding
Runge-Kutta-method
Runtime-evaluation
Runtime-evaluation-In-an-environment
S-Expressions
SEDOLs
SHA-1
SHA-256
SOAP
SQL-based-authentication
Safe-addition
Same-Fringe
Scope-modifiers
Search-a-list
Secure-temporary-file
Self-describing-numbers
Self-referential-sequence
Semiprime
Semordnilap
Send-an-unknown-method-call
Send-email
Sequence-of-non-squares
Sequence-of-primes-by-Trial-Division
Set
Set-consolidation
Set-of-real-numbers
Set-puzzle
Seven-sided-dice-from-five-sided-dice
Shell-one-liner
Short-circuit-evaluation
Show-the-epoch
Sierpinski-carpet
Sierpinski-triangle
Sierpinski-triangle-Graphical
Sieve-of-Eratosthenes
Simple-database
Simple-windowed-application
Simulate-input-Keyboard
Simulate-input-Mouse
Singleton
Singly-linked-list-Element-definition
Singly-linked-list-Element-insertion
Singly-linked-list-Traversal
Sleep
Sockets
Sokoban
Solve-a-Hidato-puzzle
Solve-a-Holy-Knights-tour
Solve-a-Hopido-puzzle
Solve-a-Numbrix-puzzle
Solve-the-no-connection-puzzle
Sort-an-array-of-composite-structures
Sort-an-integer-array
Sort-disjoint-sublist
Sort-using-a-custom-comparator
Sorting-algorithms-Bead-sort
Sorting-algorithms-Bogosort
Sorting-algorithms-Bubble-sort
Sorting-algorithms-Cocktail-sort
Sorting-algorithms-Comb-sort
Sorting-algorithms-Counting-sort
Sorting-algorithms-Gnome-sort
Sorting-algorithms-Heapsort
Sorting-algorithms-Insertion-sort
Sorting-algorithms-Merge-sort
Sorting-algorithms-Pancake-sort
Sorting-algorithms-Permutation-sort
Sorting-algorithms-Quicksort
Sorting-algorithms-Radix-sort
Sorting-algorithms-Selection-sort
Sorting-algorithms-Shell-sort
Sorting-algorithms-Sleep-sort
Sorting-algorithms-Stooge-sort
Sorting-algorithms-Strand-sort
Soundex
Sparkline-in-unicode
Special-variables
Speech-synthesis
Spiral-matrix
Stable-marriage-problem
Stack
Stack-traces
Stair-climbing-puzzle
State-name-puzzle
Statistics-Basic
Stem-and-leaf-plot
Stern-Brocot-sequence
String-append
String-case
String-comparison
String-concatenation
String-interpolation--included-
String-length
String-matching
String-prepend
Strip-a-set-of-characters-from-a-string
Strip-block-comments
Strip-comments-from-a-string
Strip-control-codes-and-extended-characters-from-a-string
Strip-whitespace-from-a-string-Top-and-tail
Substring
Substring-Top-and-tail
Subtractive-generator
Sudoku
Sum-and-product-of-an-array
Sum-digits-of-an-integer
Sum-multiples-of-3-and-5
Sum-of-a-series
Sum-of-squares
Sutherland-Hodgman-polygon-clipping
Symmetric-difference
Synchronous-concurrency
System-time
Table-creation-Postal-addresses
Take-notes-on-the-command-line
Temperature-conversion
Terminal-control-Clear-the-screen
Terminal-control-Coloured-text
Terminal-control-Cursor-movement
Terminal-control-Cursor-positioning
Terminal-control-Dimensions
Terminal-control-Display-an-extended-character
Terminal-control-Hiding-the-cursor
Terminal-control-Inverse-video
Terminal-control-Positional-read
Terminal-control-Preserve-screen
Terminal-control-Ringing-the-terminal-bell
Terminal-control-Unicode-output
Ternary-logic
Test-a-function
Text-processing-1
Text-processing-2
Text-processing-Max-licenses-in-use
Textonyms
The-ISAAC-Cipher
The-Twelve-Days-of-Christmas
Thieles-interpolation-formula
Tic-tac-toe
Time-a-function
Tokenize-a-string
Top-rank-per-group
Topic-variable
Topological-sort
Topswops
Total-circles-area
Towers-of-Hanoi
Trabb-Pardo-Knuth-algorithm
Tree-traversal
Trigonometric-functions
Truncate-a-file
Twelve-statements
URL-decoding
URL-encoding
Ulam-spiral--for-primes-
Unbias-a-random-generator
Undefined-values
Unicode-strings
Unicode-variable-names
Universal-Turing-machine
Unix-ls
Update-a-configuration-file
Use-another-language-to-call-a-function
User-input-Graphical
User-input-Text
Vampire-number
Van-der-Corput-sequence
Variable-length-quantity
Variable-size-Get
Variables
Variadic-function
Vector-products
Verify-distribution-uniformity-Chi-squared-test
Verify-distribution-uniformity-Naive
Video-display-modes
Vigen-re-cipher
Vigen-re-cipher-Cryptanalysis
Visualize-a-tree
Vogels-approximation-method
Voronoi-diagram
Walk-a-directory-Non-recursively
Walk-a-directory-Recursively
Web-scraping
Window-creation
Window-creation-X11
Window-management
Wireworld
Word-wrap
World-Cup-group-stage
Write-float-arrays-to-a-text-file
Write-language-name-in-3D-ASCII
Write-to-Windows-event-log
XML-DOM-serialization
XML-Input
XML-Output
XML-XPath
Xiaolin-Wus-line-algorithm
Y-combinator
Yahoo--search-interface
Yin-and-yang
Zebra-puzzle
Zeckendorf-arithmetic
Zeckendorf-number-representation
Zero-to-the-zero-power
Zhang-Suen-thinning-algorithm
Zig-zag-matrix
================================================
FILE: tests/results/21
================================================
[38;5;246;03m// Single-line comments start with two slashes.[39;00m
[38;5;246;03m/* Multiline comments start with slash-star,[39;00m
[38;5;246;03m and end with star-slash */[39;00m
[38;5;246;03m// Statements can be terminated by ;[39;00m
[38;5;252mdoStuff[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// ... but they don't have to be, as semicolons are automatically inserted[39;00m
[38;5;246;03m// wherever there's a newline, except in certain cases.[39;00m
[38;5;252mdoStuff[39m[38;5;252m([39m[38;5;252m)[39m
[38;5;246;03m// Because those cases can cause unexpected results, we'll keep on using[39;00m
[38;5;246;03m// semicolons in this guide.[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 1. Numbers, Strings and Operators[39;00m
[38;5;246;03m// JavaScript has one number type (which is a 64-bit IEEE 754 double).[39;00m
[38;5;246;03m// Doubles have a 52-bit mantissa, which is enough to store integers[39;00m
[38;5;246;03m// up to about 9✕10¹⁵ precisely.[39;00m
[38;5;67m3[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 3[39;00m
[38;5;67m1.5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 1.5[39;00m
[38;5;246;03m// Some basic arithmetic works as you'd expect.[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 2[39;00m
[38;5;67m0.1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m0.2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 0.30000000000000004[39;00m
[38;5;67m8[39m[38;5;252m [39m[38;5;252m-[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 7[39;00m
[38;5;67m10[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 20[39;00m
[38;5;67m35[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 7[39;00m
[38;5;246;03m// Including uneven division.[39;00m
[38;5;67m5[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 2.5[39;00m
[38;5;246;03m// And modulo division.[39;00m
[38;5;67m10[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 0[39;00m
[38;5;67m30[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 2[39;00m
[38;5;67m18.5[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m7[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4.5[39;00m
[38;5;246;03m// Bitwise operations also work; when you perform a bitwise operation your float[39;00m
[38;5;246;03m// is converted to a signed int *up to* 32 bits.[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<<[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4[39;00m
[38;5;246;03m// Precedence is enforced with parentheses.[39;00m
[38;5;252m([39m[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 8[39;00m
[38;5;246;03m// There are three special not-a-real-number values:[39;00m
[38;5;70;01mInfinity[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// result of e.g. 1/0[39;00m
[38;5;252m-[39m[38;5;70;01mInfinity[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// result of e.g. -1/0[39;00m
[38;5;70;01mNaN[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// result of e.g. 0/0, stands for 'Not a Number'[39;00m
[38;5;246;03m// There's also a boolean type.[39;00m
[38;5;70;01mtrue[39;00m[38;5;252m;[39m
[38;5;70;01mfalse[39;00m[38;5;252m;[39m
[38;5;246;03m// Strings are created with ' or ".[39;00m
[38;5;214m'abc'[39m[38;5;252m;[39m
[38;5;214m"Hello, world"[39m[38;5;252m;[39m
[38;5;246;03m// Negation uses the ! symbol[39;00m
[38;5;252m![39m[38;5;70;01mtrue[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;252m![39m[38;5;70;01mfalse[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Equality is ===[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;246;03m// Inequality is !==[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m!==[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m!==[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// More comparisons[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m<=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m>=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Strings are concatenated with +[39;00m
[38;5;214m"Hello "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m"world!"[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world!"[39;00m
[38;5;246;03m// ... which works with more than just strings[39;00m
[38;5;214m"1, 2, "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "1, 2, 3"[39;00m
[38;5;214m"Hello "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"world"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"!"[39m[38;5;252m][39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world,!"[39;00m
[38;5;246;03m// and are compared with < and >[39;00m
[38;5;214m"a"[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;214m"b"[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Type coercion is performed for comparisons with double equals...[39;00m
[38;5;214m"5"[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;70;01mnull[39;00m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;70;01mundefined[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// ...unless you use ===[39;00m
[38;5;214m"5"[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;70;01mnull[39;00m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;70;01mundefined[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;246;03m// ...which can result in some weird behaviour...[39;00m
[38;5;67m13[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m![39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// 14[39;00m
[38;5;214m"13"[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m![39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// '13true'[39;00m
[38;5;246;03m// You can access characters in a string with `charAt`[39;00m
[38;5;214m"This is a string"[39m[38;5;252m.[39m[38;5;252mcharAt[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 'T'[39;00m
[38;5;246;03m// ...or use `substring` to get larger pieces.[39;00m
[38;5;214m"Hello world"[39m[38;5;252m.[39m[38;5;252msubstring[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello"[39;00m
[38;5;246;03m// `length` is a property, so don't use ().[39;00m
[38;5;214m"Hello"[39m[38;5;252m.[39m[38;5;252mlength[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5[39;00m
[38;5;246;03m// There's also `null` and `undefined`.[39;00m
[38;5;70;01mnull[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// used to indicate a deliberate non-value[39;00m
[38;5;70;01mundefined[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// used to indicate a value is not currently present (although[39;00m
[38;5;252m [39m[38;5;246;03m// `undefined` is actually a value itself)[39;00m
[38;5;246;03m// false, null, undefined, NaN, 0 and "" are falsy; everything else is truthy.[39;00m
[38;5;246;03m// Note that 0 is falsy and "0" is truthy, even though 0 == "0".[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 2. Variables, Arrays and Objects[39;00m
[38;5;246;03m// Variables are declared with the `var` keyword. JavaScript is dynamically[39;00m
[38;5;246;03m// typed, so you don't need to specify type. Assignment uses a single `=`[39;00m
[38;5;246;03m// character.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;246;03m// If you leave the var keyword off, you won't get an error...[39;00m
[38;5;252msomeOtherVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m
[38;5;246;03m// ...but your variable will be created in the global scope, not in the scope[39;00m
[38;5;246;03m// you defined it in.[39;00m
[38;5;246;03m// Variables declared without being assigned to are set to undefined.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252msomeThirdVar[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m// If you want to declare a couple of variables, then you could use a comma[39;00m
[38;5;246;03m// separator[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252msomeFourthVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252msomeFifthVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m;[39m
[38;5;246;03m// There's shorthand for performing math operations on variables:[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m+=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// equivalent to someVar = someVar + 5; someVar is 10 now[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m*=[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// now someVar is 100[39;00m
[38;5;246;03m// and an even-shorter-hand for adding or subtracting 1[39;00m
[38;5;252msomeVar[39m[38;5;252m++[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// now someVar is 101[39;00m
[38;5;252msomeVar[39m[38;5;252m--[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// back to 100[39;00m
[38;5;246;03m// Arrays are ordered lists of values, of any type.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyArray[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"Hello"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m45[39m[38;5;252m,[39m[38;5;252m [39m[38;5;70;01mtrue[39;00m[38;5;252m][39m[38;5;252m;[39m
[38;5;246;03m// Their members can be accessed using the square-brackets subscript syntax.[39;00m
[38;5;246;03m// Array indices start at zero.[39;00m
[38;5;252mmyArray[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 45[39;00m
[38;5;246;03m// Arrays are mutable and of variable length.[39;00m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mpush[39m[38;5;252m([39m[38;5;214m"World"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mlength[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4[39;00m
[38;5;246;03m// Add/Modify at specific index[39;00m
[38;5;252mmyArray[39m[38;5;252m[[39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"Hello"[39m[38;5;252m;[39m
[38;5;246;03m// Add and remove element from front or back end of an array[39;00m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252munshift[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Add as the first element[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mshift[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Remove first element and return it[39;00m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mpush[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Add as the last element[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mpop[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Remove last element and return it[39;00m
[38;5;246;03m// Join all elements of an array with semicolon[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyArray0[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m32[39m[38;5;252m,[39m[38;5;70;01mfalse[39;00m[38;5;252m,[39m[38;5;214m"js"[39m[38;5;252m,[39m[38;5;67m12[39m[38;5;252m,[39m[38;5;67m56[39m[38;5;252m,[39m[38;5;67m90[39m[38;5;252m][39m[38;5;252m;[39m
[38;5;252mmyArray0[39m[38;5;252m.[39m[38;5;252mjoin[39m[38;5;252m([39m[38;5;214m";"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "32;false;js;12;56;90"[39;00m
[38;5;246;03m// Get subarray of elements from index 1 (include) to 4 (exclude)[39;00m
[38;5;252mmyArray0[39m[38;5;252m.[39m[38;5;252mslice[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = [false,"js",12][39;00m
[38;5;246;03m// Remove 4 elements starting from index 2, and insert there strings[39;00m
[38;5;246;03m// "hi","wr" and "ld"; return removed subarray[39;00m
[38;5;252mmyArray0[39m[38;5;252m.[39m[38;5;252msplice[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m4[39m[38;5;252m,[39m[38;5;214m"hi"[39m[38;5;252m,[39m[38;5;214m"wr"[39m[38;5;252m,[39m[38;5;214m"ld"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = ["js",12,56,90][39;00m
[38;5;246;03m// myArray0 === [32,false,"hi","wr","ld"][39;00m
[38;5;246;03m// JavaScript's objects are equivalent to "dictionaries" or "maps" in other[39;00m
[38;5;246;03m// languages: an unordered collection of key-value pairs.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252mkey1[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"Hello"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mkey2[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"World"[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;246;03m// Keys are strings, but quotes aren't required if they're a valid[39;00m
[38;5;246;03m// JavaScript identifier. Values can be any type.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252mmyKey[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"myValue"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"my other key"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;246;03m// Object attributes can also be accessed using the subscript syntax,[39;00m
[38;5;252mmyObj[39m[38;5;252m[[39m[38;5;214m"my other key"[39m[38;5;252m][39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4[39;00m
[38;5;246;03m// ... or using the dot syntax, provided the key is a valid identifier.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyKey[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "myValue"[39;00m
[38;5;246;03m// Objects are mutable; values can be changed and new keys added.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyThirdKey[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mtrue[39;00m[38;5;252m;[39m
[38;5;246;03m// If you try to access a value that's not yet set, you'll get undefined.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFourthKey[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 3. Logic and Control Structures[39;00m
[38;5;246;03m// The `if` structure works as you'd expect.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mcount[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mcount[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// evaluated if count is 3[39;00m
[38;5;252m}[39m[38;5;252m [39m[38;5;70;01melse[39;00m[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mcount[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// evaluated if count is 4[39;00m
[38;5;252m}[39m[38;5;252m [39m[38;5;70;01melse[39;00m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// evaluated if it's not either 3 or 4[39;00m
[38;5;252m}[39m
[38;5;246;03m// As does `while`.[39;00m
[38;5;70;01mwhile[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mtrue[39;00m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// An infinite loop![39;00m
[38;5;252m}[39m
[38;5;246;03m// Do-while loops are like while loops, except they always run at least once.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252minput[39m[38;5;252m;[39m
[38;5;70;01mdo[39;00m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252minput[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mgetInput[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m [39m[38;5;70;01mwhile[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252m![39m[38;5;252misValid[39m[38;5;252m([39m[38;5;252minput[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// The `for` loop is the same as C and Java:[39;00m
[38;5;246;03m// initialization; continue condition; iteration.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m++[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// will run 5 times[39;00m
[38;5;252m}[39m
[38;5;246;03m// Breaking out of labeled loops is similar to Java[39;00m
[38;5;252mouter[39m[38;5;252m:[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m++[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mj[39m[38;5;252m++[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m [39m[38;5;252m&&[39m[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m==[39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m [39m[38;5;252mouter[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// breaks out of outer loop instead of only the inner one[39;00m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m
[38;5;246;03m// The for/in statement allows iteration over properties of an object.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mdescription[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m""[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mperson[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252mfname[39m[38;5;252m:[39m[38;5;214m"Paul"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mlname[39m[38;5;252m:[39m[38;5;214m"Ken"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mage[39m[38;5;252m:[39m[38;5;67m18[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mperson[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mdescription[39m[38;5;252m [39m[38;5;252m+=[39m[38;5;252m [39m[38;5;252mperson[39m[38;5;252m[[39m[38;5;252mx[39m[38;5;252m][39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m" "[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m// description = 'Paul Ken 18 '[39;00m
[38;5;246;03m// The for/of statement allows iteration over iterable objects (including the built-in String, [39;00m
[38;5;246;03m// Array, e.g. the Array-like arguments or NodeList objects, TypedArray, Map and Set, [39;00m
[38;5;246;03m// and user-defined iterables).[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyPets[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m""[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mpets[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"cat"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"dog"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"hamster"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"hedgehog"[39m[38;5;252m][39m[38;5;252m;[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mpet[39m[38;5;252m [39m[38;5;70;01mof[39;00m[38;5;252m [39m[38;5;252mpets[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyPets[39m[38;5;252m [39m[38;5;252m+=[39m[38;5;252m [39m[38;5;252mpet[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m" "[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m// myPets = 'cat dog hamster hedgehog '[39;00m
[38;5;246;03m// && is logical and, || is logical or[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mhouse[39m[38;5;252m.[39m[38;5;252msize[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"big"[39m[38;5;252m [39m[38;5;252m&&[39m[38;5;252m [39m[38;5;252mhouse[39m[38;5;252m.[39m[38;5;252mcolour[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"blue"[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mhouse[39m[38;5;252m.[39m[38;5;252mcontains[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"bear"[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mcolour[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"red"[39m[38;5;252m [39m[38;5;252m||[39m[38;5;252m [39m[38;5;252mcolour[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"blue"[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// colour is either red or blue[39;00m
[38;5;252m}[39m
[38;5;246;03m// && and || "short circuit", which is useful for setting default values.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252motherName[39m[38;5;252m [39m[38;5;252m||[39m[38;5;252m [39m[38;5;214m"default"[39m[38;5;252m;[39m
[38;5;246;03m// The `switch` statement checks for equality with `===`.[39;00m
[38;5;246;03m// Use 'break' after each case[39;00m
[38;5;246;03m// or the cases after the correct one will be executed too.[39;00m
[38;5;252mgrade[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'B'[39m[38;5;252m;[39m
[38;5;70;01mswitch[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mgrade[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mcase[39;00m[38;5;252m [39m[38;5;214m'A'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"Great job"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mcase[39;00m[38;5;252m [39m[38;5;214m'B'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"OK job"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mcase[39;00m[38;5;252m [39m[38;5;214m'C'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"You can do better"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mdefault[39;00m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"Oy vey"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 4. Functions, Scope and Closures[39;00m
[38;5;246;03m// JavaScript functions are declared with the `function` keyword.[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252mthing[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mthing[39m[38;5;252m.[39m[38;5;252mtoUpperCase[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;214m"foo"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "FOO"[39;00m
[38;5;246;03m// Note that the value to be returned must start on the same line as the[39;00m
[38;5;246;03m// `return` keyword, otherwise you'll always return `undefined` due to[39;00m
[38;5;246;03m// automatic semicolon insertion. Watch out for this when using Allman style.[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;246;03m// <- semicolon automatically inserted here[39;00m
[38;5;252m [39m[38;5;252m{[39m[38;5;252mthisIsAn[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m'object literal'[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m// JavaScript functions are first class objects, so they can be reassigned to[39;00m
[38;5;246;03m// different variable names and passed to other functions as arguments - for[39;00m
[38;5;246;03m// example, when supplying an event handler:[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// this code will be called in 5 seconds' time[39;00m
[38;5;252m}[39m
[38;5;252msetTimeout[39m[38;5;252m([39m[38;5;252mmyFunction[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// Note: setTimeout isn't part of the JS language, but is provided by browsers[39;00m
[38;5;246;03m// and Node.js.[39;00m
[38;5;246;03m// Another function provided by browsers is setInterval[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// this code will be called every 5 seconds[39;00m
[38;5;252m}[39m
[38;5;252msetInterval[39m[38;5;252m([39m[38;5;252mmyFunction[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// Function objects don't even have to be declared with a name - you can write[39;00m
[38;5;246;03m// an anonymous function definition directly into the arguments of another.[39;00m
[38;5;252msetTimeout[39m[38;5;252m([39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// this code will be called in 5 seconds' time[39;00m
[38;5;252m}[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// JavaScript has function scope; functions get their own scope but other blocks[39;00m
[38;5;246;03m// do not.[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mtrue[39;00m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;252mi[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5 - not undefined as you'd expect in a block-scoped language[39;00m
[38;5;246;03m// This has led to a common pattern of "immediately-executing anonymous[39;00m
[38;5;246;03m// functions", which prevent temporary variables from leaking into the global[39;00m
[38;5;246;03m// scope.[39;00m
[38;5;252m([39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mtemporary[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// We can access the global scope by assigning to the "global object", which[39;00m
[38;5;252m [39m[38;5;246;03m// in a web browser is always `window`. The global object may have a[39;00m
[38;5;252m [39m[38;5;246;03m// different name in non-browser environments such as Node.js.[39;00m
[38;5;252m [39m[38;5;31mwindow[39m[38;5;252m.[39m[38;5;252mpermanent[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m)[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mtemporary[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// raises ReferenceError[39;00m
[38;5;252mpermanent[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 10[39;00m
[38;5;246;03m// One of JavaScript's most powerful features is closures. If a function is[39;00m
[38;5;246;03m// defined inside another function, the inner function has access to all the[39;00m
[38;5;246;03m// outer function's variables, even after the outer function exits.[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252msayHelloInFiveSeconds[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mprompt[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"Hello, "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m"!"[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// Inner functions are put in the local scope by default, as if they were[39;00m
[38;5;252m [39m[38;5;246;03m// declared with `var`.[39;00m
[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252minner[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252malert[39m[38;5;252m([39m[38;5;252mprompt[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m [39m[38;5;252msetTimeout[39m[38;5;252m([39m[38;5;252minner[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// setTimeout is asynchronous, so the sayHelloInFiveSeconds function will[39;00m
[38;5;252m [39m[38;5;246;03m// exit immediately, and setTimeout will call inner afterwards. However,[39;00m
[38;5;252m [39m[38;5;246;03m// because inner is "closed over" sayHelloInFiveSeconds, inner still has[39;00m
[38;5;252m [39m[38;5;246;03m// access to the `prompt` variable when it is finally called.[39;00m
[38;5;252m}[39m
[38;5;252msayHelloInFiveSeconds[39m[38;5;252m([39m[38;5;214m"Adam"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// will open a popup with "Hello, Adam!" in 5s[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 5. More about Objects; Constructors and Prototypes[39;00m
[38;5;246;03m// Objects can contain functions.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m"Hello world!"[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world!"[39;00m
[38;5;246;03m// When functions attached to an object are called, they can access the object[39;00m
[38;5;246;03m// they're attached to using the `this` keyword.[39;00m
[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyString[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"Hello world!"[39m[38;5;252m,[39m
[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world!"[39;00m
[38;5;246;03m// What this is set to has to do with how the function is called, not where[39;00m
[38;5;246;03m// it's defined. So, our function doesn't work if it isn't called in the[39;00m
[38;5;246;03m// context of the object.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m;[39m
[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m// Inversely, a function can be assigned to the object and gain access to it[39;00m
[38;5;246;03m// through `this`, even if it wasn't attached when it was defined.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyOtherFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m.[39m[38;5;252mtoUpperCase[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyOtherFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyOtherFunc[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyOtherFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "HELLO WORLD!"[39;00m
[38;5;246;03m// We can also specify a context for a function to execute in when we invoke it[39;00m
[38;5;246;03m// using `call` or `apply`.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252manotherFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252ms[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252manotherFunc[39m[38;5;252m.[39m[38;5;252mcall[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m" And Hello Moon!"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello World! And Hello Moon!"[39;00m
[38;5;246;03m// The `apply` function is nearly identical, but takes an array for an argument[39;00m
[38;5;246;03m// list.[39;00m
[38;5;252manotherFunc[39m[38;5;252m.[39m[38;5;252mapply[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m" And Hello Sun!"[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello World! And Hello Sun!"[39;00m
[38;5;246;03m// This is useful when working with a function that accepts a sequence of[39;00m
[38;5;246;03m// arguments and you want to pass an array.[39;00m
[38;5;31mMath[39m[38;5;252m.[39m[38;5;252mmin[39m[38;5;252m([39m[38;5;67m42[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m27[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 6[39;00m
[38;5;31mMath[39m[38;5;252m.[39m[38;5;252mmin[39m[38;5;252m([39m[38;5;252m[[39m[38;5;67m42[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m27[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = NaN (uh-oh!)[39;00m
[38;5;31mMath[39m[38;5;252m.[39m[38;5;252mmin[39m[38;5;252m.[39m[38;5;252mapply[39m[38;5;252m([39m[38;5;31mMath[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m42[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m27[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 6[39;00m
[38;5;246;03m// But, `call` and `apply` are only temporary. When we want it to stick, we can[39;00m
[38;5;246;03m// use `bind`.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mboundFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252manotherFunc[39m[38;5;252m.[39m[38;5;252mbind[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mboundFunc[39m[38;5;252m([39m[38;5;214m" And Hello Saturn!"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello World! And Hello Saturn!"[39;00m
[38;5;246;03m// `bind` can also be used to partially apply (curry) a function.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mproduct[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252ma[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mb[39m[38;5;252m)[39m[38;5;252m{[39m[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;252mb[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mdoubler[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mproduct[39m[38;5;252m.[39m[38;5;252mbind[39m[38;5;252m([39m[38;5;70;01mthis[39;00m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mdoubler[39m[38;5;252m([39m[38;5;67m8[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 16[39;00m
[38;5;246;03m// When you call a function with the `new` keyword, a new object is created, and[39;00m
[38;5;246;03m// made available to the function via the `this` keyword. Functions designed to be[39;00m
[38;5;246;03m// called like that are called constructors.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mMyConstructor[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyNewObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;252mMyConstructor[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = {myNumber: 5}[39;00m
[38;5;252mmyNewObj[39m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5[39;00m
[38;5;246;03m// Unlike most other popular object-oriented languages, JavaScript has no[39;00m
[38;5;246;03m// concept of 'instances' created from 'class' blueprints; instead, JavaScript[39;00m
[38;5;246;03m// combines instantiation and inheritance into a single concept: a 'prototype'.[39;00m
[38;5;246;03m// Every JavaScript object has a 'prototype'. When you go to access a property[39;00m
[38;5;246;03m// on an object that doesn't exist on the actual object, the interpreter will[39;00m
[38;5;246;03m// look at its prototype.[39;00m
[38;5;246;03m// Some JS implementations let you access an object's prototype on the magic[39;00m
[38;5;246;03m// property `__proto__`. While this is useful for explaining prototypes it's not[39;00m
[38;5;246;03m// part of the standard; we'll get to standard ways of using prototypes later.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyString[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"Hello world!"[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyPrototype[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmeaningOfLife[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m42[39m[38;5;252m,[39m
[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m.[39m[38;5;252mtoLowerCase[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252m__proto__[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyPrototype[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 42[39;00m
[38;5;246;03m// This works for functions, too.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "hello world!"[39;00m
[38;5;246;03m// Of course, if your property isn't on your prototype, the prototype's[39;00m
[38;5;246;03m// prototype is searched, and so on.[39;00m
[38;5;252mmyPrototype[39m[38;5;252m.[39m[38;5;252m__proto__[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyBoolean[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mtrue[39;00m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyBoolean[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// There's no copying involved here; each object stores a reference to its[39;00m
[38;5;246;03m// prototype. This means we can alter the prototype and our changes will be[39;00m
[38;5;246;03m// reflected everywhere.[39;00m
[38;5;252mmyPrototype[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m43[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 43[39;00m
[38;5;246;03m// The for/in statement allows iteration over properties of an object,[39;00m
[38;5;246;03m// walking up the prototype chain until it sees a null prototype.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m[[39m[38;5;252mx[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;246;03m///prints:[39;00m
[38;5;246;03m// Hello world![39;00m
[38;5;246;03m// 43[39;00m
[38;5;246;03m// [Function: myFunc][39;00m
[38;5;246;03m// true[39;00m
[38;5;246;03m// To only consider properties attached to the object itself[39;00m
[38;5;246;03m// and not its prototypes, use the `hasOwnProperty()` check.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mhasOwnProperty[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m[[39m[38;5;252mx[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m
[38;5;246;03m///prints:[39;00m
[38;5;246;03m// Hello world![39;00m
[38;5;246;03m// We mentioned that `__proto__` was non-standard, and there's no standard way to[39;00m
[38;5;246;03m// change the prototype of an existing object. However, there are two ways to[39;00m
[38;5;246;03m// create a new object with a given prototype.[39;00m
[38;5;246;03m// The first is Object.create, which is a recent addition to JS, and therefore[39;00m
[38;5;246;03m// not available in all implementations yet.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31mObject[39m[38;5;252m.[39m[38;5;252mcreate[39m[38;5;252m([39m[38;5;252mmyPrototype[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 43[39;00m
[38;5;246;03m// The second way, which works anywhere, has to do with constructors.[39;00m
[38;5;246;03m// Constructors have a property called prototype. This is *not* the prototype of[39;00m
[38;5;246;03m// the constructor function itself; instead, it's the prototype that new objects[39;00m
[38;5;246;03m// are given when they're created with that constructor and the new keyword.[39;00m
[38;5;252mMyConstructor[39m[38;5;252m.[39m[38;5;252mprototype[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyNumber[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m
[38;5;252m [39m[38;5;252mgetMyNumber[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyNewObj2[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;252mMyConstructor[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyNewObj2[39m[38;5;252m.[39m[38;5;252mgetMyNumber[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5[39;00m
[38;5;252mmyNewObj2[39m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m;[39m
[38;5;252mmyNewObj2[39m[38;5;252m.[39m[38;5;252mgetMyNumber[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 6[39;00m
[38;5;246;03m// Built-in types like strings and numbers also have constructors that create[39;00m
[38;5;246;03m// equivalent wrapper objects.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m12[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;31mNumber[39m[38;5;252m([39m[38;5;67m12[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Except, they aren't exactly equivalent.[39;00m
[38;5;70;01mtypeof[39;00m[38;5;252m [39m[38;5;252mmyNumber[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 'number'[39;00m
[38;5;70;01mtypeof[39;00m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 'object'[39;00m
[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// This code won't execute, because 0 is falsy.[39;00m
[38;5;252m}[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;31mNumber[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// This code will execute, because wrapped numbers are objects, and objects[39;00m
[38;5;252m [39m[38;5;246;03m// are always truthy.[39;00m
[38;5;252m}[39m
[38;5;246;03m// However, the wrapper objects and the regular builtins share a prototype, so[39;00m
[38;5;246;03m// you can actually add functionality to a string, for instance.[39;00m
[38;5;31mString[39m[38;5;252m.[39m[38;5;252mprototype[39m[38;5;252m.[39m[38;5;252mfirstCharacter[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mcharAt[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;214m"abc"[39m[38;5;252m.[39m[38;5;252mfirstCharacter[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "a"[39;00m
[38;5;246;03m// This fact is often used in "polyfilling", which is implementing newer[39;00m
[38;5;246;03m// features of JavaScript in an older subset of JavaScript, so that they can be[39;00m
[38;5;246;03m// used in older environments such as outdated browsers.[39;00m
[38;5;246;03m// For instance, we mentioned that Object.create isn't yet available in all[39;00m
[38;5;246;03m// implementations, but we can still use it with this polyfill:[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;31mObject[39m[38;5;252m.[39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;70;01mundefined[39;00m[38;5;252m)[39m[38;5;252m{[39m[38;5;252m [39m[38;5;246;03m// don't overwrite it if it exists[39;00m
[38;5;252m [39m[38;5;31mObject[39m[38;5;252m.[39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252mproto[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// make a temporary constructor with the right prototype[39;00m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mConstructor[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252mConstructor[39m[38;5;252m.[39m[38;5;252mprototype[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mproto[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// then use it to create a new, appropriately-prototyped object[39;00m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;252mConstructor[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;246;03m// ES6 Additions[39;00m
[38;5;246;03m// The "let" keyword allows you to define variables in a lexical scope, [39;00m
[38;5;246;03m// as opposed to a block scope like the var keyword does.[39;00m
[38;5;70;01mlet[39;00m[38;5;252m [39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"Billy"[39m[38;5;252m;[39m
[38;5;246;03m// Variables defined with let can be reassigned new values.[39;00m
[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"William"[39m[38;5;252m;[39m
[38;5;246;03m// The "const" keyword allows you to define a variable in a lexical scope[39;00m
[38;5;246;03m// like with let, but you cannot reassign the value once one has been assigned.[39;00m
[38;5;70;01mconst[39;00m[38;5;252m [39m[38;5;252mpi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m3.14[39m[38;5;252m;[39m
[38;5;252mpi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m4.13[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// You cannot do this.[39;00m
[38;5;246;03m// There is a new syntax for functions in ES6 known as "lambda syntax".[39;00m
[38;5;246;03m// This allows functions to be defined in a lexical scope like with variables[39;00m
[38;5;246;03m// defined by const and let. [39;00m
[38;5;70;01mconst[39;00m[38;5;252m [39m[38;5;252misEven[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;252mnumber[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m=>[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mnumber[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252misEven[39m[38;5;252m([39m[38;5;67m7[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// false[39;00m
[38;5;246;03m// The "equivalent" of this function in the traditional syntax would look like this:[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252misEven[39m[38;5;252m([39m[38;5;252mnumber[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mnumber[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;246;03m// I put the word "equivalent" in double quotes because a function defined[39;00m
[38;5;246;03m// using the lambda syntax cannnot be called before the definition.[39;00m
[38;5;246;03m// The following is an example of invalid usage:[39;00m
[38;5;252madd[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m8[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;70;01mconst[39;00m[38;5;252m [39m[38;5;252madd[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;252mfirstNumber[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252msecondNumber[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m=>[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mfirstNumber[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252msecondNumber[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
================================================
FILE: tests/results/22
================================================
[38;5;246;03m// Single-line comments start with two slashes.[39;00m
[38;5;246;03m/* Multiline comments start with slash-star,[39;00m
[38;5;246;03m and end with star-slash */[39;00m
[38;5;246;03m// Statements can be terminated by ;[39;00m
[38;5;252mdoStuff[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// ... but they don't have to be, as semicolons are automatically inserted[39;00m
[38;5;246;03m// wherever there's a newline, except in certain cases.[39;00m
[38;5;252mdoStuff[39m[38;5;252m([39m[38;5;252m)[39m
[38;5;246;03m// Because those cases can cause unexpected results, we'll keep on using[39;00m
[38;5;246;03m// semicolons in this guide.[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 1. Numbers, Strings and Operators[39;00m
[38;5;246;03m// JavaScript has one number type (which is a 64-bit IEEE 754 double).[39;00m
[38;5;246;03m// Doubles have a 52-bit mantissa, which is enough to store integers[39;00m
[38;5;246;03m// up to about 9✕10¹⁵ precisely.[39;00m
[38;5;67m3[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 3[39;00m
[38;5;67m1.5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 1.5[39;00m
[38;5;246;03m// Some basic arithmetic works as you'd expect.[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 2[39;00m
[38;5;67m0.1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m0.2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 0.30000000000000004[39;00m
[38;5;67m8[39m[38;5;252m [39m[38;5;252m-[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 7[39;00m
[38;5;67m10[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 20[39;00m
[38;5;67m35[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 7[39;00m
[38;5;246;03m// Including uneven division.[39;00m
[38;5;67m5[39m[38;5;252m [39m[38;5;252m/[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 2.5[39;00m
[38;5;246;03m// And modulo division.[39;00m
[38;5;67m10[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 0[39;00m
[38;5;67m30[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 2[39;00m
[38;5;67m18.5[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m7[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4.5[39;00m
[38;5;246;03m// Bitwise operations also work; when you perform a bitwise operation your float[39;00m
[38;5;246;03m// is converted to a signed int *up to* 32 bits.[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<<[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4[39;00m
[38;5;246;03m// Precedence is enforced with parentheses.[39;00m
[38;5;252m([39m[38;5;67m1[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 8[39;00m
[38;5;246;03m// There are three special not-a-real-number values:[39;00m
[38;5;70;01mInfinity[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// result of e.g. 1/0[39;00m
[38;5;252m-[39m[38;5;70;01mInfinity[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// result of e.g. -1/0[39;00m
[38;5;70;01mNaN[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// result of e.g. 0/0, stands for 'Not a Number'[39;00m
[38;5;246;03m// There's also a boolean type.[39;00m
[38;5;70;01mtrue[39;00m[38;5;252m;[39m
[38;5;70;01mfalse[39;00m[38;5;252m;[39m
[38;5;246;03m// Strings are created with ' or ".[39;00m
[38;5;214m'abc'[39m[38;5;252m;[39m
[38;5;214m"Hello, world"[39m[38;5;252m;[39m
[38;5;246;03m// Negation uses the ! symbol[39;00m
[38;5;252m![39m[38;5;70;01mtrue[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;252m![39m[38;5;70;01mfalse[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Equality is ===[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;246;03m// Inequality is !==[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m!==[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m!==[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// More comparisons[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;67m1[39m[38;5;252m [39m[38;5;252m>[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m<=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;67m2[39m[38;5;252m [39m[38;5;252m>=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Strings are concatenated with +[39;00m
[38;5;214m"Hello "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m"world!"[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world!"[39;00m
[38;5;246;03m// ... which works with more than just strings[39;00m
[38;5;214m"1, 2, "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "1, 2, 3"[39;00m
[38;5;214m"Hello "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"world"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"!"[39m[38;5;252m][39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world,!"[39;00m
[38;5;246;03m// and are compared with < and >[39;00m
[38;5;214m"a"[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;214m"b"[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Type coercion is performed for comparisons with double equals...[39;00m
[38;5;214m"5"[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;70;01mnull[39;00m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;70;01mundefined[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// ...unless you use ===[39;00m
[38;5;214m"5"[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;70;01mnull[39;00m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;70;01mundefined[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;246;03m// ...which can result in some weird behaviour...[39;00m
[38;5;67m13[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m![39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// 14[39;00m
[38;5;214m"13"[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252m![39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// '13true'[39;00m
[38;5;246;03m// You can access characters in a string with `charAt`[39;00m
[38;5;214m"This is a string"[39m[38;5;252m.[39m[38;5;252mcharAt[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 'T'[39;00m
[38;5;246;03m// ...or use `substring` to get larger pieces.[39;00m
[38;5;214m"Hello world"[39m[38;5;252m.[39m[38;5;252msubstring[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello"[39;00m
[38;5;246;03m// `length` is a property, so don't use ().[39;00m
[38;5;214m"Hello"[39m[38;5;252m.[39m[38;5;252mlength[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5[39;00m
[38;5;246;03m// There's also `null` and `undefined`.[39;00m
[38;5;70;01mnull[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// used to indicate a deliberate non-value[39;00m
[38;5;70;01mundefined[39;00m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// used to indicate a value is not currently present (although[39;00m
[38;5;252m [39m[38;5;246;03m// `undefined` is actually a value itself)[39;00m
[38;5;246;03m// false, null, undefined, NaN, 0 and "" are falsy; everything else is truthy.[39;00m
[38;5;246;03m// Note that 0 is falsy and "0" is truthy, even though 0 == "0".[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 2. Variables, Arrays and Objects[39;00m
[38;5;246;03m// Variables are declared with the `var` keyword. JavaScript is dynamically[39;00m
[38;5;246;03m// typed, so you don't need to specify type. Assignment uses a single `=`[39;00m
[38;5;246;03m// character.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;246;03m// If you leave the var keyword off, you won't get an error...[39;00m
[38;5;252msomeOtherVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m
[38;5;246;03m// ...but your variable will be created in the global scope, not in the scope[39;00m
[38;5;246;03m// you defined it in.[39;00m
[38;5;246;03m// Variables declared without being assigned to are set to undefined.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252msomeThirdVar[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m// If you want to declare a couple of variables, then you could use a comma[39;00m
[38;5;246;03m// separator[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252msomeFourthVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252msomeFifthVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m;[39m
[38;5;246;03m// There's shorthand for performing math operations on variables:[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m+=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// equivalent to someVar = someVar + 5; someVar is 10 now[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m*=[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// now someVar is 100[39;00m
[38;5;246;03m// and an even-shorter-hand for adding or subtracting 1[39;00m
[38;5;252msomeVar[39m[38;5;252m++[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// now someVar is 101[39;00m
[38;5;252msomeVar[39m[38;5;252m--[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// back to 100[39;00m
[38;5;246;03m// Arrays are ordered lists of values, of any type.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyArray[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"Hello"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m45[39m[38;5;252m,[39m[38;5;252m [39m[38;5;70;01mtrue[39;00m[38;5;252m][39m[38;5;252m;[39m
[38;5;246;03m// Their members can be accessed using the square-brackets subscript syntax.[39;00m
[38;5;246;03m// Array indices start at zero.[39;00m
[38;5;252mmyArray[39m[38;5;252m[[39m[38;5;67m1[39m[38;5;252m][39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 45[39;00m
[38;5;246;03m// Arrays are mutable and of variable length.[39;00m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mpush[39m[38;5;252m([39m[38;5;214m"World"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mlength[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4[39;00m
[38;5;246;03m// Add/Modify at specific index[39;00m
[38;5;252mmyArray[39m[38;5;252m[[39m[38;5;67m3[39m[38;5;252m][39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"Hello"[39m[38;5;252m;[39m
[38;5;246;03m// Add and remove element from front or back end of an array[39;00m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252munshift[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Add as the first element[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mshift[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Remove first element and return it[39;00m
[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mpush[39m[38;5;252m([39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Add as the last element[39;00m
[38;5;252msomeVar[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyArray[39m[38;5;252m.[39m[38;5;252mpop[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// Remove last element and return it[39;00m
[38;5;246;03m// Join all elements of an array with semicolon[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyArray0[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m32[39m[38;5;252m,[39m[38;5;70;01mfalse[39;00m[38;5;252m,[39m[38;5;214m"js"[39m[38;5;252m,[39m[38;5;67m12[39m[38;5;252m,[39m[38;5;67m56[39m[38;5;252m,[39m[38;5;67m90[39m[38;5;252m][39m[38;5;252m;[39m
[38;5;252mmyArray0[39m[38;5;252m.[39m[38;5;252mjoin[39m[38;5;252m([39m[38;5;214m";"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "32;false;js;12;56;90"[39;00m
[38;5;246;03m// Get subarray of elements from index 1 (include) to 4 (exclude)[39;00m
[38;5;252mmyArray0[39m[38;5;252m.[39m[38;5;252mslice[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = [false,"js",12][39;00m
[38;5;246;03m// Remove 4 elements starting from index 2, and insert there strings[39;00m
[38;5;246;03m// "hi","wr" and "ld"; return removed subarray[39;00m
[38;5;252mmyArray0[39m[38;5;252m.[39m[38;5;252msplice[39m[38;5;252m([39m[38;5;67m2[39m[38;5;252m,[39m[38;5;67m4[39m[38;5;252m,[39m[38;5;214m"hi"[39m[38;5;252m,[39m[38;5;214m"wr"[39m[38;5;252m,[39m[38;5;214m"ld"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = ["js",12,56,90][39;00m
[38;5;246;03m// myArray0 === [32,false,"hi","wr","ld"][39;00m
[38;5;246;03m// JavaScript's objects are equivalent to "dictionaries" or "maps" in other[39;00m
[38;5;246;03m// languages: an unordered collection of key-value pairs.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252mkey1[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"Hello"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mkey2[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"World"[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;246;03m// Keys are strings, but quotes aren't required if they're a valid[39;00m
[38;5;246;03m// JavaScript identifier. Values can be any type.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252mmyKey[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"myValue"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"my other key"[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;246;03m// Object attributes can also be accessed using the subscript syntax,[39;00m
[38;5;252mmyObj[39m[38;5;252m[[39m[38;5;214m"my other key"[39m[38;5;252m][39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 4[39;00m
[38;5;246;03m// ... or using the dot syntax, provided the key is a valid identifier.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyKey[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "myValue"[39;00m
[38;5;246;03m// Objects are mutable; values can be changed and new keys added.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyThirdKey[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mtrue[39;00m[38;5;252m;[39m
[38;5;246;03m// If you try to access a value that's not yet set, you'll get undefined.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFourthKey[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 3. Logic and Control Structures[39;00m
[38;5;246;03m// The `if` structure works as you'd expect.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mcount[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m1[39m[38;5;252m;[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mcount[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m3[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// evaluated if count is 3[39;00m
[38;5;252m}[39m[38;5;252m [39m[38;5;70;01melse[39;00m[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mcount[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m4[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// evaluated if count is 4[39;00m
[38;5;252m}[39m[38;5;252m [39m[38;5;70;01melse[39;00m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// evaluated if it's not either 3 or 4[39;00m
[38;5;252m}[39m
[38;5;246;03m// As does `while`.[39;00m
[38;5;70;01mwhile[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mtrue[39;00m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// An infinite loop![39;00m
[38;5;252m}[39m
[38;5;246;03m// Do-while loops are like while loops, except they always run at least once.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252minput[39m[38;5;252m;[39m
[38;5;70;01mdo[39;00m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252minput[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mgetInput[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m [39m[38;5;70;01mwhile[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252m![39m[38;5;252misValid[39m[38;5;252m([39m[38;5;252minput[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// The `for` loop is the same as C and Java:[39;00m
[38;5;246;03m// initialization; continue condition; iteration.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m++[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// will run 5 times[39;00m
[38;5;252m}[39m
[38;5;246;03m// Breaking out of labeled loops is similar to Java[39;00m
[38;5;252mouter[39m[38;5;252m:[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mi[39m[38;5;252m++[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m<[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252mj[39m[38;5;252m++[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m [39m[38;5;252m&&[39m[38;5;252m [39m[38;5;252mj[39m[38;5;252m [39m[38;5;252m==[39m[38;5;67m5[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m [39m[38;5;252mouter[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// breaks out of outer loop instead of only the inner one[39;00m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m
[38;5;246;03m// The for/in statement allows iteration over properties of an object.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mdescription[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m""[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mperson[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m[38;5;252mfname[39m[38;5;252m:[39m[38;5;214m"Paul"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mlname[39m[38;5;252m:[39m[38;5;214m"Ken"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mage[39m[38;5;252m:[39m[38;5;67m18[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mperson[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mdescription[39m[38;5;252m [39m[38;5;252m+=[39m[38;5;252m [39m[38;5;252mperson[39m[38;5;252m[[39m[38;5;252mx[39m[38;5;252m][39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m" "[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m// description = 'Paul Ken 18 '[39;00m
[38;5;246;03m// The for/of statement allows iteration over iterable objects (including the built-in String, [39;00m
[38;5;246;03m// Array, e.g. the Array-like arguments or NodeList objects, TypedArray, Map and Set, [39;00m
[38;5;246;03m// and user-defined iterables).[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyPets[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m""[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mpets[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m"cat"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"dog"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"hamster"[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m"hedgehog"[39m[38;5;252m][39m[38;5;252m;[39m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mpet[39m[38;5;252m [39m[38;5;70;01mof[39;00m[38;5;252m [39m[38;5;252mpets[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyPets[39m[38;5;252m [39m[38;5;252m+=[39m[38;5;252m [39m[38;5;252mpet[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m" "[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m [39m[38;5;246;03m// myPets = 'cat dog hamster hedgehog '[39;00m
[38;5;246;03m// && is logical and, || is logical or[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mhouse[39m[38;5;252m.[39m[38;5;252msize[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"big"[39m[38;5;252m [39m[38;5;252m&&[39m[38;5;252m [39m[38;5;252mhouse[39m[38;5;252m.[39m[38;5;252mcolour[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"blue"[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mhouse[39m[38;5;252m.[39m[38;5;252mcontains[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"bear"[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mcolour[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"red"[39m[38;5;252m [39m[38;5;252m||[39m[38;5;252m [39m[38;5;252mcolour[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;214m"blue"[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// colour is either red or blue[39;00m
[38;5;252m}[39m
[38;5;246;03m// && and || "short circuit", which is useful for setting default values.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252motherName[39m[38;5;252m [39m[38;5;252m||[39m[38;5;252m [39m[38;5;214m"default"[39m[38;5;252m;[39m
[38;5;246;03m// The `switch` statement checks for equality with `===`.[39;00m
[38;5;246;03m// Use 'break' after each case[39;00m
[38;5;246;03m// or the cases after the correct one will be executed too.[39;00m
[38;5;252mgrade[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m'B'[39m[38;5;252m;[39m
[38;5;70;01mswitch[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mgrade[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mcase[39;00m[38;5;252m [39m[38;5;214m'A'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"Great job"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mcase[39;00m[38;5;252m [39m[38;5;214m'B'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"OK job"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mcase[39;00m[38;5;252m [39m[38;5;214m'C'[39m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"You can do better"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mdefault[39;00m[38;5;252m:[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;214m"Oy vey"[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;70;01mbreak[39;00m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 4. Functions, Scope and Closures[39;00m
[38;5;246;03m// JavaScript functions are declared with the `function` keyword.[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252mthing[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mthing[39m[38;5;252m.[39m[38;5;252mtoUpperCase[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;214m"foo"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "FOO"[39;00m
[38;5;246;03m// Note that the value to be returned must start on the same line as the[39;00m
[38;5;246;03m// `return` keyword, otherwise you'll always return `undefined` due to[39;00m
[38;5;246;03m// automatic semicolon insertion. Watch out for this when using Allman style.[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;246;03m// <- semicolon automatically inserted here[39;00m
[38;5;252m [39m[38;5;252m{[39m[38;5;252mthisIsAn[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m'object literal'[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m// JavaScript functions are first class objects, so they can be reassigned to[39;00m
[38;5;246;03m// different variable names and passed to other functions as arguments - for[39;00m
[38;5;246;03m// example, when supplying an event handler:[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// this code will be called in 5 seconds' time[39;00m
[38;5;252m}[39m
[38;5;252msetTimeout[39m[38;5;252m([39m[38;5;252mmyFunction[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// Note: setTimeout isn't part of the JS language, but is provided by browsers[39;00m
[38;5;246;03m// and Node.js.[39;00m
[38;5;246;03m// Another function provided by browsers is setInterval[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252mmyFunction[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// this code will be called every 5 seconds[39;00m
[38;5;252m}[39m
[38;5;252msetInterval[39m[38;5;252m([39m[38;5;252mmyFunction[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// Function objects don't even have to be declared with a name - you can write[39;00m
[38;5;246;03m// an anonymous function definition directly into the arguments of another.[39;00m
[38;5;252msetTimeout[39m[38;5;252m([39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// this code will be called in 5 seconds' time[39;00m
[38;5;252m}[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;246;03m// JavaScript has function scope; functions get their own scope but other blocks[39;00m
[38;5;246;03m// do not.[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mtrue[39;00m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;252mi[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5 - not undefined as you'd expect in a block-scoped language[39;00m
[38;5;246;03m// This has led to a common pattern of "immediately-executing anonymous[39;00m
[38;5;246;03m// functions", which prevent temporary variables from leaking into the global[39;00m
[38;5;246;03m// scope.[39;00m
[38;5;252m([39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mtemporary[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// We can access the global scope by assigning to the "global object", which[39;00m
[38;5;252m [39m[38;5;246;03m// in a web browser is always `window`. The global object may have a[39;00m
[38;5;252m [39m[38;5;246;03m// different name in non-browser environments such as Node.js.[39;00m
[38;5;252m [39m[38;5;31mwindow[39m[38;5;252m.[39m[38;5;252mpermanent[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m10[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m)[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mtemporary[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// raises ReferenceError[39;00m
[38;5;252mpermanent[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 10[39;00m
[38;5;246;03m// One of JavaScript's most powerful features is closures. If a function is[39;00m
[38;5;246;03m// defined inside another function, the inner function has access to all the[39;00m
[38;5;246;03m// outer function's variables, even after the outer function exits.[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252msayHelloInFiveSeconds[39m[38;5;252m([39m[38;5;252mname[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mprompt[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"Hello, "[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;214m"!"[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// Inner functions are put in the local scope by default, as if they were[39;00m
[38;5;252m [39m[38;5;246;03m// declared with `var`.[39;00m
[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252minner[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252malert[39m[38;5;252m([39m[38;5;252mprompt[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m [39m[38;5;252msetTimeout[39m[38;5;252m([39m[38;5;252minner[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m5000[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// setTimeout is asynchronous, so the sayHelloInFiveSeconds function will[39;00m
[38;5;252m [39m[38;5;246;03m// exit immediately, and setTimeout will call inner afterwards. However,[39;00m
[38;5;252m [39m[38;5;246;03m// because inner is "closed over" sayHelloInFiveSeconds, inner still has[39;00m
[38;5;252m [39m[38;5;246;03m// access to the `prompt` variable when it is finally called.[39;00m
[38;5;252m}[39m
[38;5;252msayHelloInFiveSeconds[39m[38;5;252m([39m[38;5;214m"Adam"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// will open a popup with "Hello, Adam!" in 5s[39;00m
[38;5;246;03m///////////////////////////////////[39;00m
[38;5;246;03m// 5. More about Objects; Constructors and Prototypes[39;00m
[38;5;246;03m// Objects can contain functions.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;214m"Hello world!"[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world!"[39;00m
[38;5;246;03m// When functions attached to an object are called, they can access the object[39;00m
[38;5;246;03m// they're attached to using the `this` keyword.[39;00m
[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyString[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"Hello world!"[39m[38;5;252m,[39m
[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello world!"[39;00m
[38;5;246;03m// What this is set to has to do with how the function is called, not where[39;00m
[38;5;246;03m// it's defined. So, our function doesn't work if it isn't called in the[39;00m
[38;5;246;03m// context of the object.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m;[39m
[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = undefined[39;00m
[38;5;246;03m// Inversely, a function can be assigned to the object and gain access to it[39;00m
[38;5;246;03m// through `this`, even if it wasn't attached when it was defined.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyOtherFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m.[39m[38;5;252mtoUpperCase[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyOtherFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyOtherFunc[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyOtherFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "HELLO WORLD!"[39;00m
[38;5;246;03m// We can also specify a context for a function to execute in when we invoke it[39;00m
[38;5;246;03m// using `call` or `apply`.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252manotherFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252ms[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252ms[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252manotherFunc[39m[38;5;252m.[39m[38;5;252mcall[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m,[39m[38;5;252m [39m[38;5;214m" And Hello Moon!"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello World! And Hello Moon!"[39;00m
[38;5;246;03m// The `apply` function is nearly identical, but takes an array for an argument[39;00m
[38;5;246;03m// list.[39;00m
[38;5;252manotherFunc[39m[38;5;252m.[39m[38;5;252mapply[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;214m" And Hello Sun!"[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello World! And Hello Sun!"[39;00m
[38;5;246;03m// This is useful when working with a function that accepts a sequence of[39;00m
[38;5;246;03m// arguments and you want to pass an array.[39;00m
[38;5;31mMath[39m[38;5;252m.[39m[38;5;252mmin[39m[38;5;252m([39m[38;5;67m42[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m27[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 6[39;00m
[38;5;31mMath[39m[38;5;252m.[39m[38;5;252mmin[39m[38;5;252m([39m[38;5;252m[[39m[38;5;67m42[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m27[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = NaN (uh-oh!)[39;00m
[38;5;31mMath[39m[38;5;252m.[39m[38;5;252mmin[39m[38;5;252m.[39m[38;5;252mapply[39m[38;5;252m([39m[38;5;31mMath[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252m[[39m[38;5;67m42[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m27[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 6[39;00m
[38;5;246;03m// But, `call` and `apply` are only temporary. When we want it to stick, we can[39;00m
[38;5;246;03m// use `bind`.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mboundFunc[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252manotherFunc[39m[38;5;252m.[39m[38;5;252mbind[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mboundFunc[39m[38;5;252m([39m[38;5;214m" And Hello Saturn!"[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "Hello World! And Hello Saturn!"[39;00m
[38;5;246;03m// `bind` can also be used to partially apply (curry) a function.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mproduct[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252ma[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mb[39m[38;5;252m)[39m[38;5;252m{[39m[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252ma[39m[38;5;252m [39m[38;5;252m*[39m[38;5;252m [39m[38;5;252mb[39m[38;5;252m;[39m[38;5;252m [39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mdoubler[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mproduct[39m[38;5;252m.[39m[38;5;252mbind[39m[38;5;252m([39m[38;5;70;01mthis[39;00m[38;5;252m,[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mdoubler[39m[38;5;252m([39m[38;5;67m8[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 16[39;00m
[38;5;246;03m// When you call a function with the `new` keyword, a new object is created, and[39;00m
[38;5;246;03m// made available to the function via the `this` keyword. Functions designed to be[39;00m
[38;5;246;03m// called like that are called constructors.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mMyConstructor[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyNewObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;252mMyConstructor[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = {myNumber: 5}[39;00m
[38;5;252mmyNewObj[39m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5[39;00m
[38;5;246;03m// Unlike most other popular object-oriented languages, JavaScript has no[39;00m
[38;5;246;03m// concept of 'instances' created from 'class' blueprints; instead, JavaScript[39;00m
[38;5;246;03m// combines instantiation and inheritance into a single concept: a 'prototype'.[39;00m
[38;5;246;03m// Every JavaScript object has a 'prototype'. When you go to access a property[39;00m
[38;5;246;03m// on an object that doesn't exist on the actual object, the interpreter will[39;00m
[38;5;246;03m// look at its prototype.[39;00m
[38;5;246;03m// Some JS implementations let you access an object's prototype on the magic[39;00m
[38;5;246;03m// property `__proto__`. While this is useful for explaining prototypes it's not[39;00m
[38;5;246;03m// part of the standard; we'll get to standard ways of using prototypes later.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyString[39m[38;5;252m:[39m[38;5;252m [39m[38;5;214m"Hello world!"[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyPrototype[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmeaningOfLife[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m42[39m[38;5;252m,[39m
[38;5;252m [39m[38;5;252mmyFunc[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyString[39m[38;5;252m.[39m[38;5;252mtoLowerCase[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252m__proto__[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mmyPrototype[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 42[39;00m
[38;5;246;03m// This works for functions, too.[39;00m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyFunc[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "hello world!"[39;00m
[38;5;246;03m// Of course, if your property isn't on your prototype, the prototype's[39;00m
[38;5;246;03m// prototype is searched, and so on.[39;00m
[38;5;252mmyPrototype[39m[38;5;252m.[39m[38;5;252m__proto__[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyBoolean[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mtrue[39;00m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmyBoolean[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// There's no copying involved here; each object stores a reference to its[39;00m
[38;5;246;03m// prototype. This means we can alter the prototype and our changes will be[39;00m
[38;5;246;03m// reflected everywhere.[39;00m
[38;5;252mmyPrototype[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m43[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 43[39;00m
[38;5;246;03m// The for/in statement allows iteration over properties of an object,[39;00m
[38;5;246;03m// walking up the prototype chain until it sees a null prototype.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m[[39m[38;5;252mx[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;246;03m///prints:[39;00m
[38;5;246;03m// Hello world![39;00m
[38;5;246;03m// 43[39;00m
[38;5;246;03m// [Function: myFunc][39;00m
[38;5;246;03m// true[39;00m
[38;5;246;03m// To only consider properties attached to the object itself[39;00m
[38;5;246;03m// and not its prototypes, use the `hasOwnProperty()` check.[39;00m
[38;5;70;01mfor[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mx[39m[38;5;252m [39m[38;5;70;01min[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mhasOwnProperty[39m[38;5;252m([39m[38;5;252mx[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mconsole[39m[38;5;252m.[39m[38;5;252mlog[39m[38;5;252m([39m[38;5;252mmyObj[39m[38;5;252m[[39m[38;5;252mx[39m[38;5;252m][39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m
[38;5;246;03m///prints:[39;00m
[38;5;246;03m// Hello world![39;00m
[38;5;246;03m// We mentioned that `__proto__` was non-standard, and there's no standard way to[39;00m
[38;5;246;03m// change the prototype of an existing object. However, there are two ways to[39;00m
[38;5;246;03m// create a new object with a given prototype.[39;00m
[38;5;246;03m// The first is Object.create, which is a recent addition to JS, and therefore[39;00m
[38;5;246;03m// not available in all implementations yet.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;31mObject[39m[38;5;252m.[39m[38;5;252mcreate[39m[38;5;252m([39m[38;5;252mmyPrototype[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyObj[39m[38;5;252m.[39m[38;5;252mmeaningOfLife[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 43[39;00m
[38;5;246;03m// The second way, which works anywhere, has to do with constructors.[39;00m
[38;5;246;03m// Constructors have a property called prototype. This is *not* the prototype of[39;00m
[38;5;246;03m// the constructor function itself; instead, it's the prototype that new objects[39;00m
[38;5;246;03m// are given when they're created with that constructor and the new keyword.[39;00m
[38;5;252mMyConstructor[39m[38;5;252m.[39m[38;5;252mprototype[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;252mmyNumber[39m[38;5;252m:[39m[38;5;252m [39m[38;5;67m5[39m[38;5;252m,[39m
[38;5;252m [39m[38;5;252mgetMyNumber[39m[38;5;252m:[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyNewObj2[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;252mMyConstructor[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyNewObj2[39m[38;5;252m.[39m[38;5;252mgetMyNumber[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 5[39;00m
[38;5;252mmyNewObj2[39m[38;5;252m.[39m[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m6[39m[38;5;252m;[39m
[38;5;252mmyNewObj2[39m[38;5;252m.[39m[38;5;252mgetMyNumber[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 6[39;00m
[38;5;246;03m// Built-in types like strings and numbers also have constructors that create[39;00m
[38;5;246;03m// equivalent wrapper objects.[39;00m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m12[39m[38;5;252m;[39m
[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;31mNumber[39m[38;5;252m([39m[38;5;67m12[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m==[39m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = true[39;00m
[38;5;246;03m// Except, they aren't exactly equivalent.[39;00m
[38;5;70;01mtypeof[39;00m[38;5;252m [39m[38;5;252mmyNumber[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 'number'[39;00m
[38;5;70;01mtypeof[39;00m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = 'object'[39;00m
[38;5;252mmyNumber[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;252mmyNumberObj[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = false[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// This code won't execute, because 0 is falsy.[39;00m
[38;5;252m}[39m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;31mNumber[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// This code will execute, because wrapped numbers are objects, and objects[39;00m
[38;5;252m [39m[38;5;246;03m// are always truthy.[39;00m
[38;5;252m}[39m
[38;5;246;03m// However, the wrapper objects and the regular builtins share a prototype, so[39;00m
[38;5;246;03m// you can actually add functionality to a string, for instance.[39;00m
[38;5;31mString[39m[38;5;252m.[39m[38;5;252mprototype[39m[38;5;252m.[39m[38;5;252mfirstCharacter[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mthis[39;00m[38;5;252m.[39m[38;5;252mcharAt[39m[38;5;252m([39m[38;5;67m0[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;214m"abc"[39m[38;5;252m.[39m[38;5;252mfirstCharacter[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// = "a"[39;00m
[38;5;246;03m// This fact is often used in "polyfilling", which is implementing newer[39;00m
[38;5;246;03m// features of JavaScript in an older subset of JavaScript, so that they can be[39;00m
[38;5;246;03m// used in older environments such as outdated browsers.[39;00m
[38;5;246;03m// For instance, we mentioned that Object.create isn't yet available in all[39;00m
[38;5;246;03m// implementations, but we can still use it with this polyfill:[39;00m
[38;5;70;01mif[39;00m[38;5;252m [39m[38;5;252m([39m[38;5;31mObject[39m[38;5;252m.[39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;70;01mundefined[39;00m[38;5;252m)[39m[38;5;252m{[39m[38;5;252m [39m[38;5;246;03m// don't overwrite it if it exists[39;00m
[38;5;252m [39m[38;5;31mObject[39m[38;5;252m.[39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252mproto[39m[38;5;252m)[39m[38;5;252m{[39m
[38;5;252m [39m[38;5;246;03m// make a temporary constructor with the right prototype[39;00m
[38;5;252m [39m[38;5;70;01mvar[39;00m[38;5;252m [39m[38;5;252mConstructor[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;70;01mfunction[39;00m[38;5;252m([39m[38;5;252m)[39m[38;5;252m{[39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252mConstructor[39m[38;5;252m.[39m[38;5;252mprototype[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252mproto[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;246;03m// then use it to create a new, appropriately-prototyped object[39;00m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;70;01mnew[39;00m[38;5;252m [39m[38;5;252mConstructor[39m[38;5;252m([39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;252m [39m[38;5;252m}[39m[38;5;252m;[39m
[38;5;252m}[39m
[38;5;246;03m// ES6 Additions[39;00m
[38;5;246;03m// The "let" keyword allows you to define variables in a lexical scope, [39;00m
[38;5;246;03m// as opposed to a block scope like the var keyword does.[39;00m
[38;5;70;01mlet[39;00m[38;5;252m [39m[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"Billy"[39m[38;5;252m;[39m
[38;5;246;03m// Variables defined with let can be reassigned new values.[39;00m
[38;5;252mname[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;214m"William"[39m[38;5;252m;[39m
[38;5;246;03m// The "const" keyword allows you to define a variable in a lexical scope[39;00m
[38;5;246;03m// like with let, but you cannot reassign the value once one has been assigned.[39;00m
[38;5;70;01mconst[39;00m[38;5;252m [39m[38;5;252mpi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m3.14[39m[38;5;252m;[39m
[38;5;252mpi[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;67m4.13[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// You cannot do this.[39;00m
[38;5;246;03m// There is a new syntax for functions in ES6 known as "lambda syntax".[39;00m
[38;5;246;03m// This allows functions to be defined in a lexical scope like with variables[39;00m
[38;5;246;03m// defined by const and let. [39;00m
[38;5;70;01mconst[39;00m[38;5;252m [39m[38;5;252misEven[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;252mnumber[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m=>[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mnumber[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;252misEven[39m[38;5;252m([39m[38;5;67m7[39m[38;5;252m)[39m[38;5;252m;[39m[38;5;252m [39m[38;5;246;03m// false[39;00m
[38;5;246;03m// The "equivalent" of this function in the traditional syntax would look like this:[39;00m
[38;5;70;01mfunction[39;00m[38;5;252m [39m[38;5;252misEven[39m[38;5;252m([39m[38;5;252mnumber[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mnumber[39m[38;5;252m [39m[38;5;252m%[39m[38;5;252m [39m[38;5;67m2[39m[38;5;252m [39m[38;5;252m===[39m[38;5;252m [39m[38;5;67m0[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
[38;5;246;03m// I put the word "equivalent" in double quotes because a function defined[39;00m
[38;5;246;03m// using the lambda syntax cannnot be called before the definition.[39;00m
[38;5;246;03m// The following is an example of invalid usage:[39;00m
[38;5;252madd[39m[38;5;252m([39m[38;5;67m1[39m[38;5;252m,[39m[38;5;252m [39m[38;5;67m8[39m[38;5;252m)[39m[38;5;252m;[39m
[38;5;70;01mconst[39;00m[38;5;252m [39m[38;5;252madd[39m[38;5;252m [39m[38;5;252m=[39m[38;5;252m [39m[38;5;252m([39m[38;5;252mfirstNumber[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252msecondNumber[39m[38;5;252m)[39m[38;5;252m [39m[38;5;252m=>[39m[38;5;252m [39m[38;5;252m{[39m
[38;5;252m [39m[38;5;70;01mreturn[39;00m[38;5;252m [39m[38;5;252mfirstNumber[39m[38;5;252m [39m[38;5;252m+[39m[38;5;252m [39m[38;5;252msecondNumber[39m[38;5;252m;[39m
[38;5;252m}[39m[38;5;252m;[39m
================================================
FILE: tests/results/23
================================================
:learn
:list
Arrays
Axioms
Channels
Declarations
Embedding
Errors
Interfaces
Maps
Operators
Pointers
Structs
for
func
go
hello
http
if
packages
print
range
rosetta/
slices
switch
types
================================================
FILE: tests/results/24
================================================
Unknown topic.
Do you mean one of these topics maybe?
* mkfs.fat 84
* mkfs.vfat 80
* mkfs.exfat 76
================================================
FILE: tests/results/25
================================================
[38;5;242m# Latency numbers every programmer should know [m
1ns Main memory reference: Send 2,000 bytes Read 1,000,000 bytes
[37m▗▖ [m100ns over commodity network: sequentially from SSD: 61us
[34m▗▖ [m62ns [31m▗ [m
L1 cache reference: 1ns [32m▗ [m
[37m▗▖ [m1us Disk seek: 2ms
[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [mSSD random read: 16us [31m▗▖▗▖▗ [m
Branch mispredict: 3ns [34m [m[32m▗▖ [m
[37m▗▖▗▖▗▖ [m Read 1,000,000 bytes
Compress 1KB with Snappy: Read 1,000,000 bytes sequentially from disk:
L2 cache reference: 4ns 2us sequentially from memory: 947us
[37m▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m3us [31m▗ [m
[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗ [m
Mutex lock/unlock: 16ns [34m [m Packet roundtrip
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m Round trip CA to Netherlands: 150ms
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗ [m10us = [32m▗▖[m in same datacenter: 500us [31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
100ns = [34m▗▖[m [34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m [31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m1ms = [31m▗▖[m [31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[34m [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m [32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[37m [m [32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[38;5;242m# [github.com/chubin/late.nz] [MIT License] [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m[31m [m
[38;5;242m# Console port of "Jeff Dean's latency numbers" [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[38;5;242m# from [github.com/colin-scott/interactive_latencies] [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
[38;5;242m [m[32m▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖▗▖ [m
================================================
FILE: tests/results/3
================================================
#[cheat:ls]
# To display everything in , excluding hidden files:
ls
# To display everything in , including hidden files:
ls -a
# To display all files, along with the size (with unit suffixes) and timestamp
ls -lh
# To display files, sorted by size:
ls -S
# To display directories only:
ls -d */
# To display directories only, include hidden:
ls -d .*/ */
#[tldr:ls]
# ls
# List directory contents.
# More information: .
# List files one per line:
ls -1
# List all files, including hidden files:
ls -a
# List all files, with trailing `/` added to directory names:
ls -F
# Long format list (permissions, ownership, size, and modification date) of all files:
ls -la
# Long format list with size displayed using human-readable units (KiB, MiB, GiB):
ls -lh
# Long format list sorted by size (descending):
ls -lS
# Long format list of all files, sorted by modification date (oldest first):
ls -ltr
# Only list directories:
ls -d */
================================================
FILE: tests/results/4
================================================
[48;5;8m[24m cheat.sheets:btrfs [24m[0m
[38;5;246;03m# Create a btrfs file system on /dev/sdb, /dev/sdc, and /dev/sdd[39;00m
[38;5;252mmkfs.btrfs[39m[38;5;252m [39m[38;5;252m/dev/sdb[39m[38;5;252m [39m[38;5;252m/dev/sdc[39m[38;5;252m [39m[38;5;252m/dev/sdd[39m
[38;5;246;03m# btrfs with just one hard drive, metadata not redundant[39;00m
[38;5;246;03m# (this is dangerous: if your metadata is lost, your data is lost as well)[39;00m
[38;5;252mmkfs.btrfs[39m[38;5;252m [39m[38;5;252m-m[39m[38;5;252m [39m[38;5;252msingle[39m[38;5;252m [39m[38;5;252m/dev/sdb[39m
[38;5;246;03m# data to be redundant and metadata to be non-redundant:[39;00m
[38;5;252mmkfs.btrfs[39m[38;5;252m [39m[38;5;252m-m[39m[38;5;252m [39m[38;5;252mraid0[39m[38;5;252m [39m[38;5;252m-d[39m[38;5;252m [39m[38;5;252mraid1[39m[38;5;252m [39m[38;5;252m/dev/sdb[39m[38;5;252m [39m[38;5;252m/dev/sdc[39m[38;5;252m [39m[38;5;252m/dev/sdd[39m
[38;5;246;03m# both data and metadata to be redundant[39;00m
[38;5;252mmkfs.btrfs[39m[38;5;252m [39m[38;5;252m-d[39m[38;5;252m [39m[38;5;252mraid1[39m[38;5;252m [39m[38;5;252m/dev/sdb[39m[38;5;252m [39m[38;5;252m/dev/sdc[39m[38;5;252m [39m[38;5;252m/dev/sdd[39m
[38;5;246;03m# To get a list of all btrfs file systems[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mfilesystem[39m[38;5;252m [39m[38;5;252mshow[39m
[38;5;246;03m# detailed df for a filesystem (mounted in /mnt)[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mfilesystem[39m[38;5;252m [39m[38;5;252mdf[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# resize btrfs online (-2g decreases, +2g increases)[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mfilesystem[39m[38;5;252m [39m[38;5;252mresize[39m[38;5;252m [39m[38;5;252m-2g[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# use maximum space[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mfilesystem[39m[38;5;252m [39m[38;5;252mresize[39m[38;5;252m [39m[38;5;252mmax[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# add new device to a filesystem[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mdevice[39m[38;5;252m [39m[38;5;252madd[39m[38;5;252m [39m[38;5;252m/dev/sdf[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# remove devices from a filesystem[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mdevice[39m[38;5;252m [39m[38;5;252mdelete[39m[38;5;252m [39m[38;5;252mmissing[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# create the subvolume /mnt/sv1 in the /mnt volume[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m/mnt/sv1[39m
[38;5;246;03m# list subvolumes[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# mount subvolume without mounting the main filesystem[39;00m
[38;5;252mmount[39m[38;5;252m [39m[38;5;252m-o[39m[38;5;252m [39m[38;5;87msubvol[39m[38;5;252m=[39m[38;5;252msv1[39m[38;5;252m [39m[38;5;252m/dev/sdb[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# delete subvolume[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mdelete[39m[38;5;252m [39m[38;5;252m/mnt/sv1[39m
[38;5;246;03m# taking snapshot of a subvolume[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252msnapshot[39m[38;5;252m [39m[38;5;252m/mnt/sv1[39m[38;5;252m [39m[38;5;252m/mnt/sv1_snapshot[39m
[38;5;246;03m# taking snapshot of a file (copy file by reference)[39;00m
[38;5;252mcp[39m[38;5;252m [39m[38;5;252m--reflink[39m[38;5;252m [39m[38;5;252m/mnt/sv1/test1[39m[38;5;252m [39m[38;5;252m/mnt/sv1/test3[39m
[38;5;246;03m# convert ext3/ext4 to btrfs[39;00m
[38;5;252mbtrfs-convert[39m[38;5;252m [39m[38;5;252m/dev/sdb1[39m
[38;5;246;03m# convert btrfs to ext3/ext4[39;00m
[38;5;252mbtrfs-convert[39m[38;5;252m [39m[38;5;252m-r[39m[38;5;252m [39m[38;5;252m/dev/sdb1[39m
[48;5;8m[24m tldr:btrfs [24m[0m
[38;5;246;03m# btrfs[39;00m
[38;5;246;03m# A filesystem based on the copy-on-write (COW) principle for Linux.[39;00m
[38;5;246;03m# Some subcommands such as `btrfs device` have their own usage documentation.[39;00m
[38;5;246;03m# More information: .[39;00m
[38;5;246;03m# Create subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
[38;5;246;03m# List subvolumes:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252mpath/to/mount_point[39m
[38;5;246;03m# Show space usage information:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mfilesystem[39m[38;5;252m [39m[38;5;252mdf[39m[38;5;252m [39m[38;5;252mpath/to/mount_point[39m
[38;5;246;03m# Enable quota:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mquota[39m[38;5;252m [39m[38;5;31menable[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
[38;5;246;03m# Show quota:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mqgroup[39m[38;5;252m [39m[38;5;252mshow[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
================================================
FILE: tests/results/5
================================================
[48;5;8m[24m cheat.sheets:btrfs [24m[0m
[38;5;246;03m# create the subvolume /mnt/sv1 in the /mnt volume[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252m/mnt/sv1[39m
[38;5;246;03m# list subvolumes[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# mount subvolume without mounting the main filesystem[39;00m
[38;5;252mmount[39m[38;5;252m [39m[38;5;252m-o[39m[38;5;252m [39m[38;5;87msubvol[39m[38;5;252m=[39m[38;5;252msv1[39m[38;5;252m [39m[38;5;252m/dev/sdb[39m[38;5;252m [39m[38;5;252m/mnt[39m
[38;5;246;03m# delete subvolume[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mdelete[39m[38;5;252m [39m[38;5;252m/mnt/sv1[39m
[38;5;246;03m# taking snapshot of a subvolume[39;00m
[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252msnapshot[39m[38;5;252m [39m[38;5;252m/mnt/sv1[39m[38;5;252m [39m[38;5;252m/mnt/sv1_snapshot[39m
[48;5;8m[24m tldr:btrfs [24m[0m
[38;5;246;03m# Create subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
[38;5;246;03m# List subvolumes:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252mpath/to/mount_point[39m
[38;5;246;03m# Enable quota:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mquota[39m[38;5;252m [39m[38;5;31menable[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
[38;5;246;03m# Show quota:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mqgroup[39m[38;5;252m [39m[38;5;252mshow[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
[48;5;8m[24m tldr:btrfs-filesystem [24m[0m
[38;5;246;03m# Defragment a directory recursively (does not cross subvolume boundaries):[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252mfilesystem[39m[38;5;252m [39m[38;5;252mdefragment[39m[38;5;252m [39m[38;5;252m-v[39m[38;5;252m [39m[38;5;252m-r[39m[38;5;252m [39m[38;5;252mpath/to/directory[39m
[48;5;8m[24m tldr:btrfs-subvolume [24m[0m
[38;5;246;03m# btrfs subvolume[39;00m
[38;5;246;03m# Manage btrfs subvolumes and snapshots.[39;00m
[38;5;246;03m# More information: .[39;00m
[38;5;246;03m# Create a new empty subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mcreate[39m[38;5;252m [39m[38;5;252mpath/to/new_subvolume[39m
[38;5;246;03m# List all subvolumes and snapshots in the specified filesystem:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mlist[39m[38;5;252m [39m[38;5;252mpath/to/btrfs_filesystem[39m
[38;5;246;03m# Delete a subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mdelete[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
[38;5;246;03m# Create a read-only snapshot of an existing subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252msnapshot[39m[38;5;252m [39m[38;5;252m-r[39m[38;5;252m [39m[38;5;252mpath/to/source_subvolume[39m[38;5;252m [39m[38;5;252mpath/to/target[39m
[38;5;246;03m# Create a read-write snapshot of an existing subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252msnapshot[39m[38;5;252m [39m[38;5;252mpath/to/source_subvolume[39m[38;5;252m [39m[38;5;252mpath/to/target[39m
[38;5;246;03m# Show detailed information about a subvolume:[39;00m
[38;5;252msudo[39m[38;5;252m [39m[38;5;252mbtrfs[39m[38;5;252m [39m[38;5;252msubvolume[39m[38;5;252m [39m[38;5;252mshow[39m[38;5;252m [39m[38;5;252mpath/to/subvolume[39m
================================================
FILE: tests/results/6
================================================
[38;5;172m## curl cht.sh[0m
To access a cheat sheet you can simply issue a plain HTTP or HTTPS request
specifying the topic name in the query URL:
[36mcurl cheat.sh[0m[32m/tar[0m
[36mcurl https://cheat.sh[0m[32m/tar[0m
You can use the full service name, [32mcheat.sh[0m, or the shorter variant, [32mcht.sh[0m.
They are equivalent:
[36mcurl https://[0m[32mcht.sh[0m[36m/tar[0m
[36mcurl https://[0m[32mcheat.sh[0m[36m/tar[0m
The preferred access protocol is HTTPS, and you should use it always when possible.
Cheat sheets in the root namespaces cover UNIX/Linux commands.
Cheat sheets covering programming languages are located in subsections:
[36mcurl cht.sh/[0m[32mgo/func[0m
All cheat sheets in a subsection can be listed using a special query [32m:list[0m :
[36mcurl cht.sh/go/[0m[32m:list[0m
There are several other special queries. All of them are starting with a [32mcolon[0m.
See [32m/:help[0m for the full list of the special queries.
[38;5;172m## Search[0m
If a cheat sheet is too large, you can cut the needed part out using an
additional search parameter. In this case, only the paragraph that contains the
search term will be displayed:
[36mcurl cht.sh/tar[0m[32m~extract[0m
If the name of the cheat sheet is omitted, and only the serch query is specified,
all cheat sheets in the namespace are scanned, and the found occurrencies
are displayed:
[36mcurl cht.sh/[0m[32m~extract[0m
[38;5;172m## Options[0m
cheat.sh queries as well as search queries have many options.
They can be specified as a part of the query string in the URL, after [32m?[0m.
Short single letter options could be written all jointly together,
and long options are separated with [32m&[0m. For example, to switch
syntax highlighting off the [32mT[0m switch is used:
[36mcurl cht.sh/tar[0m[32m?T[0m
Full list of all available cheat.sh options as well as description of all modes
of operation can be found in [32m/:help[0m,
[36mcurl cht.sh[0m[32m/:help[0m
[38;5;172m## cht.sh client[0m
Though it's perfectly possible to access cheat.sh using [36mcurl[0m (or any other
HTTP client) alone, there is a special client, that has several advantages
comparing to plain curling: [32mcht.sh[0m.
To install the client in [32m~/bin[0m:
[36mcurl[0m [32mhttps://cht.sh/:cht.sh[0m [36m> ~/bin/cht.sh[0m
[36mchmod +x ~/bin/cht.sh[0m
Queries look the same, but you can separate words in the query with [36mspaces[0m,
instead of [36m+[0m as when using curl, what looks more natural:
[36mcht.sh[0m [32mpython zip lists[0m
[38;5;172m## cht.sh shell[0m
If you always issuing queries about the same programming language, it's can be
more convenient to run the client in the shell mode and specify the queries
context:
[36m$[0m [32mcht.sh --shell python[0m
[36mcht.sh/python> zip lists[0m
Of course, you can start the shell without the context too:
[36m$[0m [32mcht.sh --shell[0m
[36mcht.sh> python zip lists[0m
[36mcht.sh> go http query[0m
[36mcht.sh> js iterate list[0m
If you use predominantly one language but sometime issuing queries about other,
you may prepend the query with [32m/[0m:
[36mcht.sh/python>[0m [32mzip lists[0m
[36mcht.sh/python>[0m [32m/go http query[0m
[36mcht.sh/python>[0m [32m/js iterate list[0m
[38;5;172m## :learn[0m
If you are just start learning a new programming language, and you have no
distinct queries for the moment, cheat.sh can be a good starting point too. As
you know, it exports cheat sheets from the best cheat sheet repositories, and
one of them is [36mLearn X in Y[0m, a repository of concise documentation devoted
to learning programming languages from scratch (and not only them).
If you want start learning a new programming language, do (use less -R because
the output could be quite big):
[36mcurl cht.sh/elixir/[0m[32m:learn[0m [36m| less -R[0m
Or simply [32m:learn[0m with cht.sh (you don't need [32mless -R[0m here, because
[36mcht.sh[0m starts pager if needed automatically):
[2mcht.sh/elixir>[0m [32m:learn[0m
[38;5;172m## Programming languages questions[0m
One of the most important features of cheat.sh is that you can ask it any
questions about programming languages and instantly get answers on them. You
can use both direct HTTP queries or the cht.sh client for that:
[36mcurl cht.sh/[0m[32mpython/reverse+list[0m
[2mcht.sh/python>[0m [32mreverse list[0m
In the latter case you don't need + to separate the words in the query, you can
do it in a more natural way, with spaces.
If context in the cht.sh shell is not specified, you have to write the
programming language name as the first word in the query:
[2mcht.sh>[0m [32mpython reverse list[0m
But if you are using only one programming language and all queries are about
it, it's better to change the current context and
[38;5;172m## Comments[0m
Text in the answers is syntactically formatted as comment in the correspondent
programming language
When using cht.sh, you can copy the result of the last query into the selection
buffer (you may also call it "clibpoard") using [32mC[0m (or [32mc[0m, with text):
[36mcht.sh/python> reverse list[0m
[2m...[0m
[36mcht.sh/python>[0m [32mC[0m
[2m1 lines copied[0m
[38;5;172m## bash TAB-completion for cht.sh[0m
One of the advantages of the [36mcht.sh[0m client comparing to plain curl is that you
can use TAB completion when writing its queries in [36mbash[0m
(other supported shells: [36mzsh[0m and [36mfish[0m).
Install the TAB completion script for that. Assuming you use bash, you have to do:
[36mmkdir -p ~/.bash.d/[0m
[36mcurl[0m [32mhttps://cht.sh/:bash_completion[0m [36m> ~/.bash.d/cht.sh[0m
[36mecho 'source ~/.bash.d/cht.sh' >> ~/.bashrc[0m
[36msource ~/.bash.d/cht.sh[0m
[38;5;172m## Editor[0m
You can access cheat.sh directly from editors: [36mVim[0m and [36mEmacs[0m.
It's a very important feature! You should absolutely like it.
[36mImagine:[0m
instead of switching to your browser, googling, browsing Stack Overflow
and eventually copying the code snippets you need and later pasting them into
the editor, you can achieve the same instantly and without leaving
the editor at all!
Here is how it looks like:
1. In Vim, if you have a question while editing a program, you can just type
your question [36mdirectly in the buffer[0m and press [32mKK[0m. You will get
the answer to your question in [36mpager[0m. (with [32mKB[0m you'll get the answer
in a separate [36mbuffer[0m).
2. If you like the answer. You can manually paste it from the buffer or
the pager, or if you are lazy you can use [32mKP[0m to paste it under
your question ([32mKR[0m will replace your question). If you want the
answer without the comments, [32mKC[0m replays the last query
toggling them.
You have to install cheat.sh [36mVim/Emacs plugins[0m for the editor support.
See [32m/:vim[0m or [32m/:emacs[0m with the detailed installation instructions.
[38;5;172m## Feature requests, feedback and contribution[0m
If you want to submit a new community driver repository for cheat.sh please
open a ticket on the project page on GitHub.
If you want to modify an existing cheat sheet, please check the source of the
cheat sheet (it is always displayed in the cheat sheet bottom line).
If you want to add a new cheat sheet, add it here:
[36mhttps://github.com/chubin/cheat.sheets[0m
If you want to suggest a new feature for cheat.sh, or if you've found a bug,
please open a new issue on github:
[36mhttps://github.com/chubin/cheat.sh[0m
If you want to get the major project updates, follow @igor_chubin in Twitter
or this RSS feed: [36mhttps://twitrss.me/twitter_user_to_rss/?user=igor_chubin[0m
================================================
FILE: tests/results/7
================================================
Usage:
$ curl cheat.sh/TOPIC show cheat sheet on the TOPIC
$ curl cheat.sh/TOPIC/SUB show cheat sheet on the SUB topic in TOPIC
$ curl cheat.sh/~KEYWORD search cheat sheets for KEYWORD
Options:
?OPTIONS
q quiet mode, don't show github/twitter buttons
T text only, no ANSI sequences
style=STYLE color style
c do not comment text, do not shift code (QUERY+ only)
C do not comment text, shift code (QUERY+ only)
Q code only, don't show text (QUERY+ only)
Options can be combined together in this way:
curl 'cheat.sh/for?qT&style=bw'
(when using & in shell, don't forget to specify the quotes or escape & with \)
Special pages:
:help this page
:list list all cheat sheets
:post how to post new cheat sheet
:cht.sh shell client (cht.sh)
:bash_completion bash function for tab completion
:styles list of color styles
:styles-demo show color styles usage examples
:random fetches a random cheat sheet
Shell client:
$ curl https://cht.sh/:cht.sh > ~/bin/cht.sh
$ chmod +x ~/bin/cht.sh
$ cht.sh python :learn
$ cht.sh --shell
Tab completion:
$ mkdir -p ~/.bash.d/
$ curl cheat.sh/:bash_completion > ~/.bash.d/cht.sh
$ . ~/.bash.d/cht.sh
$ echo '. ~/.bash.d/cht.sh' >> ~/.bashrc
Editor integration:
:emacs see the page for the Emacs configuration
:vim see the page for the Vim configuration
Search:
/~snapshot look for "snapshot" in the first level cheat sheets
/~ssh~passphrase several keywords can be combined together using ~
/scala/~closure look for "closure" in scala cheat sheets
/~snapshot/r look for "snapshot" in all cheat sheets recursively
You can use special search options after the closing slash:
/~shot/bi case insensitive (i), word boundaries (b)
List of search options:
b word boundaries
i case insensitive search
r recursive
Programming languages topics:
Each programming language topic has the following subtopics:
hello hello world + how to start the program
:learn big cheat sheet for learning language from scratch
:list list of topics
:random fetches a random cheat sheet belonging to the topic
================================================
FILE: tests/results/8
================================================
#!/bin/bash
# shellcheck disable=SC1117,SC2001
#
# [X] open section
# [X] one shot mode
# [X] usage info
# [X] dependencies check
# [X] help
# [X] yank/y/copy/c
# [X] Y/C
# [X] eof problem
# [X] more
# [X] stealth mode
#
# here are several examples for the stealth mode:
#
# zip lists
# list permutation
# random list element
# reverse a list
# read json from file
# append string to a file
# run process in background
# count words in text counter
# group elements list
__CHTSH_VERSION=0.0.4
__CHTSH_DATETIME="2021-04-25 12:30:30 +0200"
# cht.sh configuration loading
#
# configuration is stored in ~/.cht.sh/ (can be overridden with CHTSH env var.)
#
CHTSH_HOME=${CHTSH:-"$HOME"/.cht.sh}
[ -z "$CHTSH_CONF" ] && CHTSH_CONF=$CHTSH_HOME/cht.sh.conf
# shellcheck disable=SC1090,SC2002
[ -e "$CHTSH_CONF" ] && source "$CHTSH_CONF"
[ -z "$CHTSH_URL" ] && CHTSH_URL=https://cht.sh
# currently we support only two modes:
# * lite = access the server using curl
# * auto = try standalone usage first
CHTSH_MODE="$(cat "$CHTSH_HOME"/mode 2> /dev/null)"
[ "$CHTSH_MODE" != lite ] && CHTSH_MODE=auto
CHEATSH_INSTALLATION="$(cat "$CHTSH_HOME/standalone" 2> /dev/null)"
export LESSSECURE=1
STEALTH_MAX_SELECTION_LENGTH=5
case "$(uname -s)" in
Darwin) is_macos=yes ;;
*) is_macos=no ;;
esac
# for KSH93
# shellcheck disable=SC2034,SC2039,SC2168
if echo "$KSH_VERSION" | grep -q ' 93' && ! local foo 2>/dev/null; then
alias local=typeset
fi
fatal()
{
echo "ERROR: $*" >&2
exit 1
}
_say_what_i_do()
{
[ -n "$LOG" ] && echo "$(date '+[%Y-%m-%d %H:%M%S]') $*" >> "$LOG"
local this_prompt="\033[0;1;4;32m>>\033[0m"
printf "\n${this_prompt}%s\033[0m\n" " $* "
}
cheatsh_standalone_install()
{
# the function installs cheat.sh with the upstream repositories
# in the standalone mode
local installdir; installdir="$1"
local default_installdir="$HOME/.cheat.sh"
[ -z "$installdir" ] && installdir=${default_installdir}
if [ "$installdir" = help ]; then
cat </dev/null || \
{ echo "DEPENDENCY: \"$dep\" is needed to install cheat.sh in the standalone mode" >&2; _exit_code=1; }
done
[ "$_exit_code" -ne 0 ] && return "$_exit_code"
while true; do
local _installdir
echo -n "Where should cheat.sh be installed [$installdir]? "; read -r _installdir
[ -n "$_installdir" ] && installdir=$_installdir
if [ "$installdir" = y ] \
|| [ "$installdir" = Y ] \
|| [ "$(echo "$installdir" | tr "[:upper:]" "[:lower:]")" = yes ]
then
echo Please enter the directory name
echo If it was the directory name already, please prepend it with \"./\": "./$installdir"
else
break
fi
done
if [ -e "$installdir" ]; then
echo "ERROR: Installation directory [$installdir] exists already"
echo "Please remove it first before continuing"
return 1
fi
if ! mkdir -p "$installdir"; then
echo "ERROR: Could not create the installation directory \"$installdir\""
echo "ERROR: Please check the permissions and start the script again"
return 1
fi
local space_needed=700
local space_available; space_available=$(($(df -k "$installdir" | awk '{print $4}' | tail -1)/1024))
if [ "$space_available" -lt "$space_needed" ]; then
echo "ERROR: Installation directory has no enough space (needed: ${space_needed}M, available: ${space_available}M"
echo "ERROR: Please clean up and start the script again"
rmdir "$installdir"
return 1
fi
_say_what_i_do Cloning cheat.sh locally
local url=https://github.com/chubin/cheat.sh
rmdir "$installdir"
git clone "$url" "$installdir" || fatal Could not clone "$url" with git into "$installdir"
cd "$installdir" || fatal "Cannot cd into $installdir"
# after the repository cloned, we may have the log directory
# and we can write our installation log into it
mkdir -p "log/"
LOG="$PWD/log/install.log"
# we use tee everywhere so we should set -o pipefail
set -o pipefail
# currently the script uses python 2,
# but cheat.sh supports python 3 too
# if you want to switch it to python 3
# set PYTHON2 to NO:
# PYTHON2=NO
#
PYTHON2=NO
if [[ $PYTHON2 = YES ]]; then
python="python2"
pip="pip"
virtualenv_python3_option=()
else
python="python3"
pip="pip3"
virtualenv_python3_option=(-p python3)
fi
_say_what_i_do Creating virtual environment
virtualenv "${virtualenv_python3_option[@]}" ve \
|| fatal "Could not create virtual environment with 'virtualenv ve'"
export CHEATSH_PATH_WORKDIR=$PWD
# rapidfuzz does not support Python 2,
# so if we are using Python 2, install fuzzywuzzy instead
if [[ $PYTHON2 = YES ]]; then
sed -i s/rapidfuzz/fuzzywuzzy/ requirements.txt
echo "python-Levenshtein" >> requirements.txt
fi
_say_what_i_do Installing python requirements into the virtual environment
ve/bin/"$pip" install -r requirements.txt > "$LOG" \
|| {
echo "ERROR:"
echo "---"
tail -n 10 "$LOG"
echo "---"
echo "See $LOG for more"
fatal Could not install python dependencies into the virtual environment
}
echo "$(ve/bin/"$pip" freeze | wc -l) dependencies were successfully installed"
_say_what_i_do Fetching the upstream cheat sheets repositories
ve/bin/python lib/fetch.py fetch-all | tee -a "$LOG"
_say_what_i_do Running self-tests
(
cd tests || exit
if CHEATSH_TEST_STANDALONE=YES \
CHEATSH_TEST_SKIP_ONLINE=NO \
CHEATSH_TEST_SHOW_DETAILS=NO \
PYTHON=../ve/bin/python bash run-tests.sh | tee -a "$LOG"
then
printf "\033[0;32m%s\033[0m\n" "SUCCESS"
else
printf "\033[0;31m%s\033[0m\n" "FAILED"
echo "Some tests were failed. Run the tests manually for further investigation:"
echo " cd $PWD; bash run-tests.sh)"
fi
)
mkdir -p "$CHTSH_HOME"
echo "$installdir" > "$CHTSH_HOME/standalone"
echo auto > "$CHTSH_HOME/mode"
_say_what_i_do Done
local v1; v1=$(printf "\033[0;1;32m")
local v2; v2=$(printf "\033[0m")
cat < "$CHTSH_HOME/mode"
echo "Configured mode: $mode"
fi
else
echo "Unknown mode: $mode"
echo Supported modes:
echo " auto use the standalone installation first"
echo " lite use the cheat sheets server directly"
fi
}
get_query_options()
{
local query="$*"
if [ -n "$CHTSH_QUERY_OPTIONS" ]; then
case $query in
*\?*) query="$query&${CHTSH_QUERY_OPTIONS}";;
*) query="$query?${CHTSH_QUERY_OPTIONS}";;
esac
fi
printf "%s" "$query"
}
do_query()
{
local query="$*"
local b_opts=
local uri="${CHTSH_URL}/\"\$(get_query_options $query)\""
if [ -e "$CHTSH_HOME/id" ]; then
b_opts="-b \"\$CHTSH_HOME/id\""
fi
eval curl "$b_opts" -s "$uri" > "$TMP1"
if [ -z "$lines" ] || [ "$(wc -l "$TMP1" | awk '{print $1}')" -lt "$lines" ]; then
cat "$TMP1"
else
${PAGER:-$defpager} "$TMP1"
fi
}
prepare_query()
{
local section="$1"; shift
local input="$1"; shift
local arguments="$1"
local query
if [ -z "$section" ] || [ x"${input}" != x"${input#/}" ]; then
query=$(printf %s "$input" | sed 's@ @/@; s@ @+@g')
else
query=$(printf %s "$section/$input" | sed 's@ @+@g')
fi
[ -n "$arguments" ] && arguments="?$arguments"
printf %s "$query$arguments"
}
get_list_of_sections()
{
curl -s "${CHTSH_URL}"/:list | grep -v '/.*/' | grep '/$' | xargs
}
gen_random_str()
(
len=$1
if command -v openssl >/dev/null; then
openssl rand -base64 $((len*3/4)) | awk -v ORS='' //
else
rdev=/dev/urandom
for d in /dev/{srandom,random,arandom}; do
test -r "$d" && rdev=$d
done
if command -v hexdump >/dev/null; then
hexdump -vn $((len/2)) -e '1/1 "%02X" 1 ""' "$rdev"
elif command -v xxd >/dev/null; then
xxd -l $((len/2)) -ps "$rdev" | awk -v ORS='' //
else
cd /tmp || { echo Cannot cd into /tmp >&2; exit 1; }
s=
# shellcheck disable=SC2000
while [ "$(echo "$s" | wc -c)" -lt "$len" ]; do
s="$s$(mktemp -u XXXXXXXXXX)"
done
printf "%.${len}s" "$s"
fi
fi
)
if [ "$CHTSH_MODE" = auto ] && [ -d "$CHEATSH_INSTALLATION" ]; then
curl() {
# ignoring all options
# currently the standalone.py does not support them anyway
local opt
while getopts "b:s" opt; do
:
done
shift $((OPTIND - 1))
local url; url="$1"; shift
PYTHONIOENCODING=UTF-8 "$CHEATSH_INSTALLATION/ve/bin/python" "$CHEATSH_INSTALLATION/lib/standalone.py" "${url#"$CHTSH_URL"}" "$@"
}
elif [ "$(uname -s)" = OpenBSD ] && [ -x /usr/bin/ftp ]; then
# any better test not involving either OS matching or actual query?
curl() {
local opt args="-o -"
while getopts "b:s" opt; do
case $opt in
b) args="$args -c $OPTARG";;
s) args="$args -M -V";;
*) echo "internal error: unsupported cURL option '$opt'" >&2; exit 1;;
esac
done
shift $((OPTIND - 1))
/usr/bin/ftp "$args" "$@"
}
else
command -v curl >/dev/null || { echo 'DEPENDENCY: install "curl" to use cht.sh' >&2; exit 1; }
_CURL=$(command -v curl)
if [ x"$CHTSH_CURL_OPTIONS" != x ]; then
curl() {
$_CURL "${CHTSH_CURL_OPTIONS}" "$@"
}
fi
fi
if [ "$1" = --read ]; then
read -r a || a="exit"
printf "%s\n" "$a"
exit 0
elif [ x"$1" = x--help ] || [ -z "$1" ]; then
n=${0##*/}
s=$(echo "$n" | sed "s/./ /"g)
cat </dev/null || echo 'DEPENDENCY: please install "wl-copy" for "copy"' >&2
else
command -v xsel >/dev/null || echo 'DEPENDENCY: please install "xsel" for "copy"' >&2
fi
fi
command -v rlwrap >/dev/null || { echo 'DEPENDENCY: install "rlwrap" to use cht.sh in the shell mode' >&2; exit 1; }
mkdir -p "$CHTSH_HOME/"
lines=$(tput lines)
if command -v less >/dev/null; then
defpager="less -R"
elif command -v more >/dev/null; then
defpager="more"
else
defpager="cat"
fi
cmd_cd() {
if [ $# -eq 0 ]; then
section=""
else
new_section=$(echo "$input" | sed 's/cd *//; s@/*$@@; s@^/*@@')
if [ -z "$new_section" ] || [ ".." = "$new_section" ]; then
section=""
else
valid_sections=$(get_list_of_sections)
valid=no; for q in $valid_sections; do [ "$q" = "$new_section/" ] && { valid=yes; break; }; done
if [ "$valid" = no ]; then
echo "Invalid section: $new_section"
echo "Valid sections:"
echo "$valid_sections" \
| xargs printf "%-10s\n" \
| tr ' ' . \
| xargs -n 10 \
| sed 's/\./ /g; s/^/ /'
else
section="$new_section"
fi
fi
fi
}
cmd_copy() {
if [ -z "$DISPLAY" ]; then
echo copy: supported only in the Desktop version
elif [ -z "$input" ]; then
echo copy: Make at least one query first.
else
curl -s "${CHTSH_URL}"/"$(get_query_options "$query"?T)" > "$TMP1"
if [ "$is_macos" != yes ]; then
if [ "$XDG_SESSION_TYPE" = wayland ]; then
wl-copy < "$TMP1"
else
xsel -bi < "$TMP1"
fi
else
pbcopy < "$TMP1"
fi
echo "copy: $(wc -l "$TMP1" | awk '{print $1}') lines copied to the selection"
fi
}
cmd_ccopy() {
if [ -z "$DISPLAY" ]; then
echo copy: supported only in the Desktop version
elif [ -z "$input" ]; then
echo copy: Make at least one query first.
else
curl -s "${CHTSH_URL}"/"$(get_query_options "$query"?TQ)" > "$TMP1"
if [ "$is_macos" != yes ]; then
if [ "$XDG_SESSION_TYPE" = wayland ]; then
wl-copy < "$TMP1"
else
xsel -bi < "$TMP1"
fi
else
pbcopy < "$TMP1"
fi
echo "copy: $(wc -l "$TMP1" | awk '{print $1}') lines copied to the selection"
fi
}
cmd_exit() {
exit 0
}
cmd_help() {
cat < python zip list
cht.sh/python> zip list
cht.sh/go> /python zip list
EOF
}
cmd_hush() {
mkdir -p "$CHTSH_HOME/" && touch "$CHTSH_HOME/.hushlogin" && echo "Initial 'use help' message was disabled"
}
cmd_id() {
id_file="$CHTSH_HOME/id"
if [ id = "$input" ]; then
new_id=""
else
new_id=$(echo "$input" | sed 's/id *//; s/ *$//; s/ /+/g')
fi
if [ "$new_id" = remove ]; then
if [ -e "$id_file" ]; then
rm -f -- "$id_file" && echo "id is removed"
else
echo "id was not set, so you can't remove it"
fi
return
fi
if [ -n "$new_id" ] && [ reset != "$new_id" ] && [ "$(/bin/echo -n "$new_id" | wc -c)" -lt 16 ]; then
echo "ERROR: $new_id: Too short id. Minimal id length is 16. Use 'id reset' for a random id"
return
fi
if [ -z "$new_id" ]; then
# if new_id is not specified check if we have some id already
# if yes, just show it
# if not, generate a new id
if [ -e "$id_file" ]; then
awk '$6 == "id" {print $NF}' <"$id_file" | tail -n 1
return
else
new_id=reset
fi
fi
if [ "$new_id" = reset ]; then
new_id=$(gen_random_str 12)
else
echo WARNING: if someone gueses your id, he can read your cht.sh search history
fi
if [ -e "$id_file" ] && grep -q '\tid\t[^\t][^\t]*$' "$id_file" 2> /dev/null; then
sed -i 's/\tid\t[^\t][^\t]*$/ id '"$new_id"'/' "$id_file"
else
if ! [ -e "$id_file" ]; then
printf '#\n\n' > "$id_file"
fi
printf ".cht.sh\tTRUE\t/\tTRUE\t0\tid\t$new_id\n" >> "$id_file"
fi
echo "$new_id"
}
cmd_query() {
query=$(prepare_query "$section" "$input")
do_query "$query"
}
cmd_stealth() {
if [ "$input" != stealth ]; then
arguments=$(echo "$input" | sed 's/stealth //; s/ /\&/')
fi
trap break INT
if [ "$is_macos" = yes ]; then
past=$(pbpaste)
else
if [ "$XDG_SESSION_TYPE" = wayland ]; then
past=$(wl-paste -p)
else
past=$(xsel -o)
fi
fi
printf "\033[0;31mstealth:\033[0m you are in the stealth mode; select any text in any window for a query\n"
printf "\033[0;31mstealth:\033[0m selections longer than $STEALTH_MAX_SELECTION_LENGTH words are ignored\n"
if [ -n "$arguments" ]; then
printf "\033[0;31mstealth:\033[0m query arguments: ?$arguments\n"
fi
printf "\033[0;31mstealth:\033[0m use ^C to leave this mode\n"
while true; do
if [ "$is_macos" = yes ]; then
current=$(pbpaste)
else
if [ "$XDG_SESSION_TYPE" = wayland ]; then
current=$(wl-paste -p)
else
current=$(xsel -o)
fi
fi
if [ "$past" != "$current" ]; then
past=$current
current_text="$(echo $current | tr -c '[a-zA-Z0-9]' ' ')"
if [ "$(echo "$current_text" | wc -w)" -gt "$STEALTH_MAX_SELECTION_LENGTH" ]; then
printf "\033[0;31mstealth:\033[0m selection length is longer than $STEALTH_MAX_SELECTION_LENGTH words; ignoring\n"
continue
else
printf "\n\033[0;31mstealth: \033[7m $current_text\033[0m\n"
query=$(prepare_query "$section" "$current_text" "$arguments")
do_query "$query"
fi
fi
sleep 1;
done
trap - INT
}
cmd_update() {
[ -w "$0" ] || { echo "The script is readonly; please update manually: curl -s ${CHTSH_URL}/:cht.sh | sudo tee $0"; return; }
TMP2=$(mktemp /tmp/cht.sh.XXXXXXXXXXXXX)
curl -s "${CHTSH_URL}"/:cht.sh > "$TMP2"
if ! cmp "$0" "$TMP2" > /dev/null 2>&1; then
if grep -q ^__CHTSH_VERSION= "$TMP2"; then
# section was vaildated by us already
args=(--shell "$section")
cp "$TMP2" "$0" && echo "Updated. Restarting..." && rm "$TMP2" && CHEATSH_RESTART=1 exec "$0" "${args[@]}"
else
echo "Something went wrong. Please update manually"
fi
else
echo "cht.sh is up to date. No update needed"
fi
rm -f "$TMP2" > /dev/null 2>&1
}
cmd_version() {
insttime=$(ls -l -- "$0" | sed 's/ */ /g' | cut -d ' ' -f 6-8)
echo "cht.sh version $__CHTSH_VERSION of $__CHTSH_DATETIME; installed at: $insttime"
TMP2=$(mktemp /tmp/cht.sh.XXXXXXXXXXXXX)
if curl -s "${CHTSH_URL}"/:cht.sh > "$TMP2"; then
if ! cmp "$0" "$TMP2" > /dev/null 2>&1; then
echo "Update needed (type 'update' for that)".
else
echo "Up to date. No update needed"
fi
fi
rm -f "$TMP2" > /dev/null 2>&1
}
TMP1=$(mktemp /tmp/cht.sh.XXXXXXXXXXXXX)
trap 'rm -f $TMP1 $TMP2' EXIT
trap 'true' INT
if ! [ -e "$CHTSH_HOME/.hushlogin" ] && [ -z "$this_query" ]; then
echo "type 'help' for the cht.sh shell help"
fi
while true; do
if [ "$section" != "" ]; then
full_prompt="$prompt/$section> "
else
full_prompt="$prompt> "
fi
input=$(
rlwrap -H "$CHTSH_HOME/history" -pgreen -C cht.sh -S "$full_prompt" bash "$0" --read | sed 's/ *#.*//'
)
cmd_name=${input%% *}
cmd_args=${input#* }
case $cmd_name in
"") continue;; # skip empty input lines
'?'|h|help) cmd_name=help;;
hush) cmd_name=hush;;
cd) cmd_name="cd";;
exit|quit) cmd_name="exit";;
copy|yank|c|y) cmd_name=copy;;
ccopy|cc|C|Y) cmd_name=ccopy;;
id) cmd_name=id;;
stealth) cmd_name=stealth;;
update) cmd_name=update;;
version) cmd_name=version;;
*) cmd_name="query"; cmd_args="$input";;
esac
"cmd_$cmd_name" $cmd_args
done
================================================
FILE: tests/results/9
================================================
[38;5;246;03m# How do I copy a file in Python?[39;00m
[38;5;246;03m# [39;00m
[38;5;246;03m# shutil (http://docs.python.org/3/library/shutil.html) has many methods[39;00m
[38;5;246;03m# you can use. One of which is:[39;00m
[38;5;70;01mfrom[39;00m[38;5;252m [39m[38;5;68;04mshutil[39;00m[38;5;252m [39m[38;5;70;01mimport[39;00m[38;5;252m [39m[38;5;252mcopyfile[39m
[38;5;252mcopyfile[39m[38;5;252m([39m[38;5;252msrc[39m[38;5;252m,[39m[38;5;252m [39m[38;5;252mdst[39m[38;5;252m)[39m
[38;5;246;03m# Copy the contents of the file named src to a file named dst. The[39;00m
[38;5;246;03m# destination location must be writable; otherwise, an IOError exception[39;00m
[38;5;246;03m# will be raised. If dst already exists, it will be replaced. Special[39;00m
[38;5;246;03m# files such as character or block devices and pipes cannot be copied[39;00m
[38;5;246;03m# with this function. src and dst are path names given as strings.[39;00m
[38;5;246;03m# [39;00m
[38;5;246;03m# [Swati] [so/q/123198] [cc by-sa 3.0][39;00m
================================================
FILE: tests/run-tests.sh
================================================
#!/bin/bash
# 1) start server:
# without caching:
# CHEATSH_CACHE_TYPE=none CHEATSH_PORT=50000 python bin/srv.py
# (recommended)
# with caching:
# CHEATSH_REDIS_PREFIX=TEST1 CHEATSH_PORT=50000 python bin/srv.py
# (for complex search queries + to test caching)
# 2) configure CHTSH_URL
# 3) run the script
CHTSH_SCRIPT=$(dirname "$(dirname "$(realpath "$(readlink -f "$0")")")")/share/cht.sh.txt
# work from script's dir
cd "$(dirname "$0")" || exit
# detect Python - if not set in env, try default virtualenv
PYTHON="${PYTHON:-../ve/bin/python}"
# if no virtalenv, try current python3 binary
if ! command -v "$PYTHON" &> /dev/null; then
PYTHON=$(command -v python3)
fi
python_version="$($PYTHON -c 'import sys; print(sys.version_info[0])')"
echo "Using PYTHON $python_version: $PYTHON"
skip_online="${CHEATSH_TEST_SKIP_ONLINE:-NO}"
test_standalone="${CHEATSH_TEST_STANDALONE:-YES}"
show_details="${CHEATSH_TEST_SHOW_DETAILS:-YES}"
update_tests_results="${CHEATSH_UPDATE_TESTS_RESULTS:-NO}"
CHTSH_URL="${CHTSH_URL:-http://localhost:8002}"
TMP=$(mktemp /tmp/cht.sh.tests-XXXXXXXXXXXXXX)
TMP2=$(mktemp /tmp/cht.sh.tests-XXXXXXXXXXXXXX)
TMP3=$(mktemp /tmp/cht.sh.tests-XXXXXXXXXXXXXX)
trap 'rm -rf $TMP $TMP2 $TMP3' EXIT
echo "Using cht.sh client at $CHTSH_SCRIPT"
export PYTHONIOENCODING=UTF-8
i=0
failed=0
{
if [ -z "$1" ]; then
cat -n tests.txt
else
cat -n tests.txt | sed -n "$(echo "$*" | sed 's/ /p; /g;s/$/p/')"
fi
} > "$TMP3"
while read -r number test_line; do
echo -e "\e[34mRunning $number: \e[36m$test_line\e[0m"
if [ "$skip_online" = YES ]; then
if [[ $test_line = *\[online\]* ]]; then
echo "$number is [online]; skipping"
continue
fi
fi
if [[ "$python_version" = 2 ]] && [[ $test_line = *\[python3\]* ]]; then
echo "$number is for Python 3; skipping"
continue
fi
if [[ "$python_version" = 3 ]] && [[ $test_line = *\[python2\]* ]]; then
echo "$number is for Python 2; skipping"
continue
fi
#shellcheck disable=SC2001
test_line=$(echo "$test_line" | sed 's@ *#.*@@')
if [ "$test_standalone" = YES ]; then
test_line="${test_line//cht.sh /}"
[[ $show_details == YES ]] && echo "${PYTHON} ../lib/standalone.py $test_line"
"${PYTHON}" ../lib/standalone.py "$test_line" > "$TMP"
elif [[ $test_line = "cht.sh "* ]]; then
test_line="${test_line//cht.sh /}"
[[ $show_details == YES ]] && echo "bash $CHTSH_SCRIPT $test_line"
eval "bash $CHTSH_SCRIPT $test_line" > "$TMP"
else
[[ $show_details == YES ]] && echo "curl -s $CHTSH_URL/$test_line"
eval "curl -s $CHTSH_URL/$test_line" > "$TMP"
fi
if ! diff -u3 results/"$number" "$TMP" > "$TMP2"; then
if [[ $update_tests_results = NO ]]; then
if [ "$show_details" = YES ]; then
cat -t "$TMP2"
fi
echo "FAILED: [$number] $test_line"
else
cat "$TMP" > results/"$number"
echo "UPDATED: [$number] $test_line"
fi
((failed++))
fi
((i++))
done < "$TMP3"
if [[ $update_tests_results = NO ]]; then
echo TESTS/OK/FAILED "$i/$((i-failed))/$failed"
else
echo TESTS/OK/UPDATED "$i/$((i-failed))/$failed"
fi
test $failed -eq 0
================================================
FILE: tests/tests.txt
================================================
python/:list
ls
ls?T
btrfs
btrfs~volume # search on page
:intro
:help
:cht.sh
cht.sh python copy file # [online]
python/copy+file # [online]
python/copy+file?Q # [online]
python/copy+file?QT # [online]
/
//
python/:learn
latencies # [python3]
az # chubin/cheat.sheets
python/rosetta/Substring # rosetta
python/rosetta/Substring?T # rosetta
python/rosetta/:list # rosetta
js/:learn # short names check
javascript/:learn # short names check
emacs:go-mode/:list # special editor names
mkffs.ffatt # unknown
latencies # [python2]