Repository: cilinyan/VISA
Branch: main
Commit: ec158fde9cdf
Files: 276
Total size: 54.3 MB
Directory structure:
gitextract_qarvn3ca/
├── .gitignore
├── .gitmodules
├── README.md
├── XMem/
│ ├── dataset/
│ │ ├── __init__.py
│ │ ├── range_transform.py
│ │ ├── reseed.py
│ │ ├── static_dataset.py
│ │ ├── tps.py
│ │ ├── util.py
│ │ └── vos_dataset.py
│ ├── eval.py
│ ├── eval_batch.py
│ ├── generate_xmem_data_single.py
│ ├── inference/
│ │ ├── __init__.py
│ │ ├── data/
│ │ │ ├── __init__.py
│ │ │ ├── mask_mapper.py
│ │ │ ├── test_datasets.py
│ │ │ └── video_reader.py
│ │ ├── inference_core.py
│ │ ├── interact/
│ │ │ ├── __init__.py
│ │ │ ├── fbrs/
│ │ │ │ ├── LICENSE
│ │ │ │ ├── __init__.py
│ │ │ │ ├── controller.py
│ │ │ │ ├── inference/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── clicker.py
│ │ │ │ │ ├── evaluation.py
│ │ │ │ │ ├── predictors/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── base.py
│ │ │ │ │ │ ├── brs.py
│ │ │ │ │ │ ├── brs_functors.py
│ │ │ │ │ │ └── brs_losses.py
│ │ │ │ │ ├── transforms/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── base.py
│ │ │ │ │ │ ├── crops.py
│ │ │ │ │ │ ├── flip.py
│ │ │ │ │ │ ├── limit_longest_side.py
│ │ │ │ │ │ └── zoom_in.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── initializer.py
│ │ │ │ │ ├── is_deeplab_model.py
│ │ │ │ │ ├── is_hrnet_model.py
│ │ │ │ │ ├── losses.py
│ │ │ │ │ ├── metrics.py
│ │ │ │ │ ├── modeling/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── basic_blocks.py
│ │ │ │ │ │ ├── deeplab_v3.py
│ │ │ │ │ │ ├── hrnet_ocr.py
│ │ │ │ │ │ ├── ocr.py
│ │ │ │ │ │ ├── resnet.py
│ │ │ │ │ │ └── resnetv1b.py
│ │ │ │ │ ├── ops.py
│ │ │ │ │ └── syncbn/
│ │ │ │ │ ├── LICENSE
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── modules/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── functional/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── _csrc.py
│ │ │ │ │ │ ├── csrc/
│ │ │ │ │ │ │ ├── bn.h
│ │ │ │ │ │ │ ├── cuda/
│ │ │ │ │ │ │ │ ├── bn_cuda.cu
│ │ │ │ │ │ │ │ ├── common.h
│ │ │ │ │ │ │ │ └── ext_lib.h
│ │ │ │ │ │ │ └── ext_lib.cpp
│ │ │ │ │ │ └── syncbn.py
│ │ │ │ │ └── nn/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── syncbn.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cython/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── _get_dist_maps.pyx
│ │ │ │ │ ├── _get_dist_maps.pyxbld
│ │ │ │ │ └── dist_maps.py
│ │ │ │ ├── misc.py
│ │ │ │ └── vis.py
│ │ │ ├── fbrs_controller.py
│ │ │ ├── gui.py
│ │ │ ├── gui_utils.py
│ │ │ ├── interaction.py
│ │ │ ├── interactive_utils.py
│ │ │ ├── resource_manager.py
│ │ │ ├── s2m/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _deeplab.py
│ │ │ │ ├── s2m_network.py
│ │ │ │ ├── s2m_resnet.py
│ │ │ │ └── utils.py
│ │ │ ├── s2m_controller.py
│ │ │ └── timer.py
│ │ ├── kv_memory_store.py
│ │ └── memory_manager.py
│ ├── interactive_demo.py
│ ├── merge_multi_scale.py
│ ├── merge_results.py
│ ├── model/
│ │ ├── __init__.py
│ │ ├── aggregate.py
│ │ ├── cbam.py
│ │ ├── group_modules.py
│ │ ├── losses.py
│ │ ├── memory_util.py
│ │ ├── modules.py
│ │ ├── network.py
│ │ ├── resnet.py
│ │ └── trainer.py
│ ├── requirements.txt
│ ├── scripts/
│ │ ├── __init__.py
│ │ ├── download_bl30k.py
│ │ ├── download_datasets.py
│ │ ├── download_models.sh
│ │ ├── download_models_demo.sh
│ │ ├── expand_long_vid.py
│ │ └── resize_youtube.py
│ ├── tracking.py
│ ├── train.py
│ └── util/
│ ├── __init__.py
│ ├── configuration.py
│ ├── davis_subset.txt
│ ├── image_saver.py
│ ├── load_subset.py
│ ├── log_integrator.py
│ ├── logger.py
│ ├── palette.py
│ ├── tensor_util.py
│ └── yv_subset.txt
├── merge_lora_weights_and_save_hf_model.py
├── model/
│ ├── VISA.py
│ ├── llava/
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ ├── conversation.py
│ │ ├── mm_utils.py
│ │ ├── model/
│ │ │ ├── __init__.py
│ │ │ ├── apply_delta.py
│ │ │ ├── builder.py
│ │ │ ├── consolidate.py
│ │ │ ├── language_model/
│ │ │ │ ├── llava_llama.py
│ │ │ │ ├── llava_mpt.py
│ │ │ │ └── mpt/
│ │ │ │ ├── adapt_tokenizer.py
│ │ │ │ ├── attention.py
│ │ │ │ ├── blocks.py
│ │ │ │ ├── configuration_mpt.py
│ │ │ │ ├── custom_embedding.py
│ │ │ │ ├── flash_attn_triton.py
│ │ │ │ ├── hf_prefixlm_converter.py
│ │ │ │ ├── meta_init_context.py
│ │ │ │ ├── modeling_mpt.py
│ │ │ │ ├── norm.py
│ │ │ │ └── param_init_fns.py
│ │ │ ├── llava_arch.py
│ │ │ ├── make_delta.py
│ │ │ ├── multimodal_encoder/
│ │ │ │ ├── builder.py
│ │ │ │ └── clip_encoder.py
│ │ │ └── utils.py
│ │ ├── train/
│ │ │ ├── llama_flash_attn_monkey_patch.py
│ │ │ ├── llava_trainer.py
│ │ │ ├── train.py
│ │ │ └── train_mem.py
│ │ └── utils.py
│ ├── segment_anything/
│ │ ├── __init__.py
│ │ ├── automatic_mask_generator.py
│ │ ├── build_sam.py
│ │ ├── modeling/
│ │ │ ├── __init__.py
│ │ │ ├── common.py
│ │ │ ├── image_encoder.py
│ │ │ ├── mask_decoder.py
│ │ │ ├── prompt_encoder.py
│ │ │ ├── sam.py
│ │ │ └── transformer.py
│ │ ├── predictor.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── amg.py
│ │ ├── onnx.py
│ │ └── transforms.py
│ ├── tf/
│ │ └── modeling_outputs.py
│ └── univi/
│ ├── __init__.py
│ ├── config/
│ │ ├── __init__.py
│ │ ├── dataset_config.py
│ │ └── model_config.py
│ ├── constants.py
│ ├── conversation.py
│ ├── demo.py
│ ├── eval/
│ │ ├── evaluate/
│ │ │ ├── evaluate_benchmark_1_correctness.py
│ │ │ ├── evaluate_benchmark_2_detailed_orientation.py
│ │ │ ├── evaluate_benchmark_3_context.py
│ │ │ ├── evaluate_benchmark_4_temporal.py
│ │ │ ├── evaluate_benchmark_5_consistency.py
│ │ │ ├── evaluate_gpt_review_visual.py
│ │ │ ├── evaluate_science_qa.py
│ │ │ ├── evaluate_video_qa.py
│ │ │ └── summarize_gpt_review.py
│ │ ├── model_coco_vqa.py
│ │ ├── model_video_consistency.py
│ │ ├── model_video_general.py
│ │ ├── model_video_qa.py
│ │ ├── model_vqa.py
│ │ ├── model_vqa_scienceqa.py
│ │ ├── questions/
│ │ │ ├── coco2014_val_qa_eval/
│ │ │ │ ├── qa90_gpt4_answer.jsonl
│ │ │ │ └── qa90_questions.jsonl
│ │ │ ├── coco_pope/
│ │ │ │ ├── coco_pope_adversarial.jsonl
│ │ │ │ ├── coco_pope_popular.jsonl
│ │ │ │ └── coco_pope_random.jsonl
│ │ │ ├── scienceqa/
│ │ │ │ ├── pid_splits.json
│ │ │ │ ├── problems.json
│ │ │ │ └── test_QCM-LEA.json
│ │ │ └── video_qa/
│ │ │ ├── activitynet_a_list.json
│ │ │ ├── activitynet_qa.json
│ │ │ ├── consistency_qa.json
│ │ │ ├── generic_qa.json
│ │ │ ├── msrvtt_a_list.json
│ │ │ ├── msrvtt_qa.json
│ │ │ ├── msvd_a_list.json
│ │ │ ├── msvd_qa.json
│ │ │ ├── temporal_qa.json
│ │ │ ├── tgif_a_list.json
│ │ │ └── tgif_qa.json
│ │ └── table/
│ │ ├── caps_boxes_coco2014_val_80.jsonl
│ │ ├── model.jsonl
│ │ ├── question.jsonl
│ │ ├── reviewer.jsonl
│ │ └── rule.json
│ ├── mm_utils.py
│ ├── model/
│ │ ├── __init__.py
│ │ ├── apply_delta.py
│ │ ├── arch.py
│ │ ├── builder.py
│ │ ├── cluster.py
│ │ ├── consolidate.py
│ │ ├── dataloader.py
│ │ ├── language_model/
│ │ │ └── llama.py
│ │ ├── make_delta.py
│ │ └── multimodal_encoder/
│ │ ├── builder.py
│ │ ├── clip_encoder.py
│ │ ├── eva_encoder.py
│ │ ├── eva_vit.py
│ │ ├── processor.py
│ │ └── utils.py
│ ├── train/
│ │ ├── llama_flash_attn_monkey_patch.py
│ │ ├── train.py
│ │ ├── train_mem.py
│ │ └── trainer.py
│ └── utils.py
├── requirements.txt
├── scripts/
│ ├── train_13b.sh
│ ├── train_7b.sh
│ └── val_7b_video.sh
├── tools/
│ ├── eval_davis17.py
│ ├── eval_mevis.py
│ ├── eval_revos.py
│ ├── generate_foreground_mask.py
│ ├── metrics.py
│ ├── zip_mp_mevis.py
│ └── zip_mp_refytvos.py
├── train_ds.py
├── utils/
│ ├── ade20k_classes.json
│ ├── chatunivi_dataset.py
│ ├── cocostuff_classes.txt
│ ├── conversation.py
│ ├── d2_datasets/
│ │ ├── categories.py
│ │ ├── mevis_utils.py
│ │ ├── refytvos_utils.py
│ │ ├── refytvos_val_videos.py
│ │ └── ytvis_api/
│ │ ├── __init__.py
│ │ ├── ytvos.py
│ │ └── ytvoseval.py
│ ├── data_processing.py
│ ├── dataset.py
│ ├── dataset_config.py
│ ├── grefcoco.py
│ ├── grefer.py
│ ├── random_list.py
│ ├── reason_seg_dataset.py
│ ├── refer.py
│ ├── refer_seg_dataset.py
│ ├── rvos_dataset.py
│ ├── rvos_eval_dataset.py
│ ├── sem_seg_dataset.py
│ ├── utils.py
│ └── vqa_dataset.py
└── utils_llamavid/
├── llamavid_client.py
└── llamavid_server.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
**/__pycache__
runs/
models/
datasets/
datasets
.vscode/
core*
vis_output/
test_vis/
openai
.DS_Store
XMem/weights/
================================================
FILE: .gitmodules
================================================
[submodule "LLaMA-VID"]
path = LLaMA-VID
url = git@github.com:dvlab-research/LLaMA-VID.git
================================================
FILE: README.md
================================================
# VISA: Reasoning Video Object Segmentation via Large Language Model
[](https://github.com/cilinyan/VISA)
[](http://arxiv.org/abs/2407.11325)
[](https://github.com/cilinyan/ReVOS-api)
## 🚀 Performance
VISA demonstrates remarkable proficiency in handling complex segmentation tasks that require: (a) reasoning based on world knowledge; (b) inference of future events; and (c) a comprehensive understanding of video content.
## 🛠️ Installation
```shell
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
```
## 🦄 Training and Validation
### 1. Training Data Preparation
Before training, please download the datasets, and then configure the path in [dataset_config.py](utils/dataset_config.py).
LISA's Dataset
Follow [LISA](https://github.com/dvlab-research/LISA/tree/main) to prepare LISA's datasets. The dataset folder should be stored in the `$LISA_ROOT` folder.
```
LISA_ROOT
├── ade20k
├── coco
├── cocostuff
├── llava_dataset
├── mapillary
├── reason_seg
├── refer_seg
└── vlpart
```
Chat-UniVi's Dataset
Follow [Chat-UniVi/Chat-UniVi-Instruct](https://huggingface.co/datasets/Chat-UniVi/Chat-UniVi-Instruct/tree/main) to prepare `Chat-UniVi-Instruct` datasets. The dataset folder should be stored in the `$ChatUniVi_ROOT` folder.
```
ChatUniVi_ROOT
├── Fine-tuning
│ ├── MIMIC_imageonly
│ └── VIDEO
└── ScienceQA_tuning
```
RVOS's Dataset
1. Reasoning Video Segmentation Datasets: [ReVOS](https://github.com/cilinyan/ReVOS-api).
2. Referring Video Segmentation Datasets: [Ref-Youtube-VOS](https://github.com/wjn922/ReferFormer/blob/main/docs/data.md), [Ref-DAVIS17](https://github.com/wjn922/ReferFormer/blob/main/docs/data.md), [MeViS](https://github.com/henghuiding/MeViS).
- Ref-Youtube-VOS: Download `mask_dict.pkl` from [OneDrive](https://mailsjlueducn-my.sharepoint.com/:f:/g/personal/yancl9918_mails_jlu_edu_cn/EqR9g3yWG5pPtVoil0EfsbgBJhCZ7YwaRG9w9GsYy1_N5g?e=JLaJfc) or [BaiduPan](https://pan.baidu.com/s/1mbJaDDy0UTlA7sysp0zypg?pwd=visa).
- Ref-DAVIS17: Download `mask_dict.pkl` from [OneDrive](https://mailsjlueducn-my.sharepoint.com/:f:/g/personal/yancl9918_mails_jlu_edu_cn/Eq8bmGqNcYxGhQ1bioN65q4B_gPxIabpJUjGaV5uqcaq3w?e=2J6Ldp) or [BaiduPan](https://pan.baidu.com/s/1Gg5qPvxRZMKDp0JrVRJ75w?pwd=visa).
3. Open-Vocabulary Video Instance Segmentation Dataset: [LV-VIS](https://github.com/haochenheheda/LVVIS/tree/main).
Download `mask_dict.json` and `meta_expressions.json` from [OneDrive](https://mailsjlueducn-my.sharepoint.com/:f:/g/personal/yancl9918_mails_jlu_edu_cn/EttXAjMV8yFJhHMQwX3mIw0BP7dymKV-cuw4uAotDaAwYw?e=j6Y44X) or [BaiduPan](https://pan.baidu.com/s/1LOWPnuxXF_LXGSL7osRptA?pwd=visa). Then, put the annotations files in the `$RVOS_ROOT/lvvis/train` directory as follows.
```
RVOS_ROOT
├── ReVOS
│ ├── JPEGImages
│ ├── mask_dict.json
│ ├── mask_dict_foreground.json
│ ├── meta_expressions_train_.json
│ └── meta_expressions_valid_.json
├── lvvis
│ └── train
| ├── JPEGImages
| ├── mask_dict.json
| └── meta_expressions.json
├── Ref-Youtube-VOS
│ ├── meta_expressions
| | ├── train/meta_expressions.json
| | └── valid/meta_expressions.json
│ ├── train
| | ├── JPEGImages
| | └── mask_dict.pkl
│ └── valid
| └── JPEGImages
├── davis17
│ ├── meta_expressions
| | ├── train/meta_expressions.json
| | └── valid/meta_expressions.json
│ ├── train
| | ├── JPEGImages
| | └── mask_dict.pkl
│ └── valid
| ├── JPEGImages
| └── mask_dict.pkl
└── mevis
```
### 2. Pre-trained weights
Chat-UniVi
To train VISA-7B or 13B, you need to download Chat-UniVi weights from [Chat-UniVi-7B](https://huggingface.co/Chat-UniVi/Chat-UniVi) and [Chat-UniVi-13B](https://huggingface.co/Chat-UniVi/Chat-UniVi-13B).
SAM
Download SAM ViT-H pre-trained weights from the [link](https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth).
### 3. Training VISA
```shell
# Training VISA-7B
bash scripts/train_7b.sh
# Extracting fp32 consolidated weights from a zero 1, 2 and 3 DeepSpeed checkpoints.
cd /PATH/TO/VISA-7B/ckpt_model && python zero_to_fp32.py . ../pytorch_model.bin
# Merge LoRA Weight
CUDA_VISIBLE_DEVICES="" python merge_lora_weights_and_save_hf_model.py \
--version Chat-UniVi/Chat-UniVi \
--weight /PATH/TO/VISA-7B/pytorch_model.bin \
--save_path /PATH/TO/VISA-7B/hf_model
```
### 4. Validation
1. Using `VISA` to generate predicted mask of each video [demo]
```shell
deepspeed --master_port=24999 train_ds.py \
--version="/PATH/TO/VISA-7B/hf_model" \
--vision_pretrained="/PATH/TO/sam_vit_h_4b8939.pth" \
--log_base_dir="/PATH/TO/LOG_BASE_DIR" \
--exp_name="val_7b" \
--balance_sample \
--dataset="reason_seg" \
--sample_rates="13" \
--val_dataset "revos_valid" \
--eval_only
```
2. Using LLaMA-VID to generate target frame for each video
> You can directly download the results of our run from [OneDrive](https://mailsjlueducn-my.sharepoint.com/:u:/g/personal/yancl9918_mails_jlu_edu_cn/ETmoJF2i8ZZBsgIwdELiL8gBfptZZoPWjx6Y0eH6Myr3sw?e=mTt6rO) or [BaiduPan](https://pan.baidu.com/s/1YWs6NLPvANfhgUBHKQwnBg?pwd=visa)
- Run [http_server_mp.py](https://github.com/cilinyan/VISA/blob/main/utils_llamavid/llamavid_server.py) to build the API server for LLaMA-VID [`[demo]`](https://github.com/cilinyan/VISA/blob/c53d2cd31407eab583c5eb04f84fd95b4694f2ce/utils_llamavid/llamavid_server.py#L215-L220)
```shell
python utils_llamavid/llamavid_server.py \
--vision_tower /PATH/TO/eva_vit_g.pth \
--image_processor /PATH/TO/openai/clip-vit-large-patch14 \
--model-path /PATH/TO/YanweiLi/llama-vid-13b-full-224-video-fps-1
```
- Using the API for inference [`[demo]`](https://github.com/cilinyan/VISA/blob/c53d2cd31407eab583c5eb04f84fd95b4694f2ce/utils_llamavid/llamavid_client.py#L58-L63)
```shell
python utils_llamavid/llamavid_client.py \
--video_root /PATH/TO/ReVOS/JPEGImages \
--data_json_file /PATH/TO/ReVOS/meta_expressions_valid_.json
```
3. Using XMem for mask propagation [demo]
4. Evaluate ReVOS's performance [demo]
```shell
cd tools
python eval_revos.py /PATH/TO/FINAL_ANNOTATION [ARGS]
```
## 📑 Todo list
- [x] Release code with `Text-guided Frame Sampler`'s Local Sampling
- [ ] Release VISA model weights [issue #6](https://github.com/cilinyan/VISA/issues/6)
- [ ] Release code with `Text-guided Frame Sampler`'s Global-Local Sampling
## ⭐ Cite
If you find this project useful in your research, please consider citing:
```
@article{yan2024visa,
title={VISA: Reasoning Video Object Segmentation via Large Language Models},
author={Yan, Cilin and Wang, Haochen and Yan, Shilin and Jiang, Xiaolong and Hu, Yao and Kang, Guoliang and Xie, Weidi and Gavves, Efstratios},
journal={arXiv preprint arXiv:2407.11325},
year={2024}
}
```
## 🎖️ Acknowledgement
This work is built upon the [LLaVA](https://github.com/haotian-liu/LLaVA), [SAM](https://github.com/facebookresearch/segment-anything), [LISA](https://github.com/dvlab-research/LISA), [Chat-UniVi](https://github.com/PKU-YuanGroup/Chat-UniVi), [MeViS](https://github.com/henghuiding/MeViS), [LLaMA-VID](https://github.com/dvlab-research/LLaMA-VID) and [XMem](https://github.com/hkchengrex/XMem).
================================================
FILE: XMem/dataset/__init__.py
================================================
================================================
FILE: XMem/dataset/range_transform.py
================================================
import torchvision.transforms as transforms
im_mean = (124, 116, 104)
im_normalization = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
inv_im_trans = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225])
================================================
FILE: XMem/dataset/reseed.py
================================================
import torch
import random
def reseed(seed):
random.seed(seed)
torch.manual_seed(seed)
================================================
FILE: XMem/dataset/static_dataset.py
================================================
import os
from os import path
import torch
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from torchvision.transforms import InterpolationMode
from PIL import Image
import numpy as np
from dataset.range_transform import im_normalization, im_mean
from dataset.tps import random_tps_warp
from dataset.reseed import reseed
class StaticTransformDataset(Dataset):
"""
Generate pseudo VOS data by applying random transforms on static images.
Single-object only.
Method 0 - FSS style (class/1.jpg class/1.png)
Method 1 - Others style (XXX.jpg XXX.png)
"""
def __init__(self, parameters, num_frames=3, max_num_obj=1):
self.num_frames = num_frames
self.max_num_obj = max_num_obj
self.im_list = []
for parameter in parameters:
root, method, multiplier = parameter
if method == 0:
# Get images
classes = os.listdir(root)
for c in classes:
imgs = os.listdir(path.join(root, c))
jpg_list = [im for im in imgs if 'jpg' in im[-3:].lower()]
joint_list = [path.join(root, c, im) for im in jpg_list]
self.im_list.extend(joint_list * multiplier)
elif method == 1:
self.im_list.extend([path.join(root, im) for im in os.listdir(root) if '.jpg' in im] * multiplier)
print(f'{len(self.im_list)} images found.')
# These set of transform is the same for im/gt pairs, but different among the 3 sampled frames
self.pair_im_lone_transform = transforms.Compose([
transforms.ColorJitter(0.1, 0.05, 0.05, 0), # No hue change here as that's not realistic
])
self.pair_im_dual_transform = transforms.Compose([
transforms.RandomAffine(degrees=20, scale=(0.9,1.1), shear=10, interpolation=InterpolationMode.BICUBIC, fill=im_mean),
transforms.Resize(384, InterpolationMode.BICUBIC),
transforms.RandomCrop((384, 384), pad_if_needed=True, fill=im_mean),
])
self.pair_gt_dual_transform = transforms.Compose([
transforms.RandomAffine(degrees=20, scale=(0.9,1.1), shear=10, interpolation=InterpolationMode.BICUBIC, fill=0),
transforms.Resize(384, InterpolationMode.NEAREST),
transforms.RandomCrop((384, 384), pad_if_needed=True, fill=0),
])
# These transform are the same for all pairs in the sampled sequence
self.all_im_lone_transform = transforms.Compose([
transforms.ColorJitter(0.1, 0.05, 0.05, 0.05),
transforms.RandomGrayscale(0.05),
])
self.all_im_dual_transform = transforms.Compose([
transforms.RandomAffine(degrees=0, scale=(0.8, 1.5), fill=im_mean),
transforms.RandomHorizontalFlip(),
])
self.all_gt_dual_transform = transforms.Compose([
transforms.RandomAffine(degrees=0, scale=(0.8, 1.5), fill=0),
transforms.RandomHorizontalFlip(),
])
# Final transform without randomness
self.final_im_transform = transforms.Compose([
transforms.ToTensor(),
im_normalization,
])
self.final_gt_transform = transforms.Compose([
transforms.ToTensor(),
])
def _get_sample(self, idx):
im = Image.open(self.im_list[idx]).convert('RGB')
gt = Image.open(self.im_list[idx][:-3]+'png').convert('L')
sequence_seed = np.random.randint(2147483647)
images = []
masks = []
for _ in range(self.num_frames):
reseed(sequence_seed)
this_im = self.all_im_dual_transform(im)
this_im = self.all_im_lone_transform(this_im)
reseed(sequence_seed)
this_gt = self.all_gt_dual_transform(gt)
pairwise_seed = np.random.randint(2147483647)
reseed(pairwise_seed)
this_im = self.pair_im_dual_transform(this_im)
this_im = self.pair_im_lone_transform(this_im)
reseed(pairwise_seed)
this_gt = self.pair_gt_dual_transform(this_gt)
# Use TPS only some of the times
# Not because TPS is bad -- just that it is too slow and I need to speed up data loading
if np.random.rand() < 0.33:
this_im, this_gt = random_tps_warp(this_im, this_gt, scale=0.02)
this_im = self.final_im_transform(this_im)
this_gt = self.final_gt_transform(this_gt)
images.append(this_im)
masks.append(this_gt)
images = torch.stack(images, 0)
masks = torch.stack(masks, 0)
return images, masks.numpy()
def __getitem__(self, idx):
additional_objects = np.random.randint(self.max_num_obj)
indices = [idx, *np.random.randint(self.__len__(), size=additional_objects)]
merged_images = None
merged_masks = np.zeros((self.num_frames, 384, 384), dtype=np.int64)
for i, list_id in enumerate(indices):
images, masks = self._get_sample(list_id)
if merged_images is None:
merged_images = images
else:
merged_images = merged_images*(1-masks) + images*masks
merged_masks[masks[:,0]>0.5] = (i+1)
masks = merged_masks
labels = np.unique(masks[0])
# Remove background
labels = labels[labels!=0]
target_objects = labels.tolist()
# Generate one-hot ground-truth
cls_gt = np.zeros((self.num_frames, 384, 384), dtype=np.int64)
first_frame_gt = np.zeros((1, self.max_num_obj, 384, 384), dtype=np.int64)
for i, l in enumerate(target_objects):
this_mask = (masks==l)
cls_gt[this_mask] = i+1
first_frame_gt[0,i] = (this_mask[0])
cls_gt = np.expand_dims(cls_gt, 1)
info = {}
info['name'] = self.im_list[idx]
info['num_objects'] = max(1, len(target_objects))
# 1 if object exist, 0 otherwise
selector = [1 if i < info['num_objects'] else 0 for i in range(self.max_num_obj)]
selector = torch.FloatTensor(selector)
data = {
'rgb': merged_images,
'first_frame_gt': first_frame_gt,
'cls_gt': cls_gt,
'selector': selector,
'info': info
}
return data
def __len__(self):
return len(self.im_list)
================================================
FILE: XMem/dataset/tps.py
================================================
import numpy as np
from PIL import Image
import cv2
import thinplate as tps
cv2.setNumThreads(0)
def pick_random_points(h, w, n_samples):
y_idx = np.random.choice(np.arange(h), size=n_samples, replace=False)
x_idx = np.random.choice(np.arange(w), size=n_samples, replace=False)
return y_idx/h, x_idx/w
def warp_dual_cv(img, mask, c_src, c_dst):
dshape = img.shape
theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
grid = tps.tps_grid(theta, c_dst, dshape)
mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
return cv2.remap(img, mapx, mapy, cv2.INTER_LINEAR), cv2.remap(mask, mapx, mapy, cv2.INTER_NEAREST)
def random_tps_warp(img, mask, scale, n_ctrl_pts=12):
"""
Apply a random TPS warp of the input image and mask
Uses randomness from numpy
"""
img = np.asarray(img)
mask = np.asarray(mask)
h, w = mask.shape
points = pick_random_points(h, w, n_ctrl_pts)
c_src = np.stack(points, 1)
c_dst = c_src + np.random.normal(scale=scale, size=c_src.shape)
warp_im, warp_gt = warp_dual_cv(img, mask, c_src, c_dst)
return Image.fromarray(warp_im), Image.fromarray(warp_gt)
================================================
FILE: XMem/dataset/util.py
================================================
import numpy as np
def all_to_onehot(masks, labels):
if len(masks.shape) == 3:
Ms = np.zeros((len(labels), masks.shape[0], masks.shape[1], masks.shape[2]), dtype=np.uint8)
else:
Ms = np.zeros((len(labels), masks.shape[0], masks.shape[1]), dtype=np.uint8)
for ni, l in enumerate(labels):
Ms[ni] = (masks == l).astype(np.uint8)
return Ms
================================================
FILE: XMem/dataset/vos_dataset.py
================================================
import os
from os import path, replace
import torch
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from torchvision.transforms import InterpolationMode
from PIL import Image
import numpy as np
from dataset.range_transform import im_normalization, im_mean
from dataset.reseed import reseed
class VOSDataset(Dataset):
"""
Works for DAVIS/YouTubeVOS/BL30K training
For each sequence:
- Pick three frames
- Pick two objects
- Apply some random transforms that are the same for all frames
- Apply random transform to each of the frame
- The distance between frames is controlled
"""
def __init__(self, im_root, gt_root, max_jump, is_bl, subset=None, num_frames=3, max_num_obj=3, finetune=False):
self.im_root = im_root
self.gt_root = gt_root
self.max_jump = max_jump
self.is_bl = is_bl
self.num_frames = num_frames
self.max_num_obj = max_num_obj
self.videos = []
self.frames = {}
vid_list = sorted(os.listdir(self.im_root))
# Pre-filtering
for vid in vid_list:
if subset is not None:
if vid not in subset:
continue
frames = sorted(os.listdir(os.path.join(self.im_root, vid)))
if len(frames) < num_frames:
continue
self.frames[vid] = frames
self.videos.append(vid)
print('%d out of %d videos accepted in %s.' % (len(self.videos), len(vid_list), im_root))
# These set of transform is the same for im/gt pairs, but different among the 3 sampled frames
self.pair_im_lone_transform = transforms.Compose([
transforms.ColorJitter(0.01, 0.01, 0.01, 0),
])
self.pair_im_dual_transform = transforms.Compose([
transforms.RandomAffine(degrees=0 if finetune or self.is_bl else 15, shear=0 if finetune or self.is_bl else 10, interpolation=InterpolationMode.BILINEAR, fill=im_mean),
])
self.pair_gt_dual_transform = transforms.Compose([
transforms.RandomAffine(degrees=0 if finetune or self.is_bl else 15, shear=0 if finetune or self.is_bl else 10, interpolation=InterpolationMode.NEAREST, fill=0),
])
# These transform are the same for all pairs in the sampled sequence
self.all_im_lone_transform = transforms.Compose([
transforms.ColorJitter(0.1, 0.03, 0.03, 0),
transforms.RandomGrayscale(0.05),
])
if self.is_bl:
# Use a different cropping scheme for the blender dataset because the image size is different
self.all_im_dual_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((384, 384), scale=(0.25, 1.00), interpolation=InterpolationMode.BILINEAR)
])
self.all_gt_dual_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((384, 384), scale=(0.25, 1.00), interpolation=InterpolationMode.NEAREST)
])
else:
self.all_im_dual_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((384, 384), scale=(0.36,1.00), interpolation=InterpolationMode.BILINEAR)
])
self.all_gt_dual_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((384, 384), scale=(0.36,1.00), interpolation=InterpolationMode.NEAREST)
])
# Final transform without randomness
self.final_im_transform = transforms.Compose([
transforms.ToTensor(),
im_normalization,
])
def __getitem__(self, idx):
video = self.videos[idx]
info = {}
info['name'] = video
vid_im_path = path.join(self.im_root, video)
vid_gt_path = path.join(self.gt_root, video)
frames = self.frames[video]
trials = 0
while trials < 5:
info['frames'] = [] # Appended with actual frames
num_frames = self.num_frames
length = len(frames)
this_max_jump = min(len(frames), self.max_jump)
# iterative sampling
frames_idx = [np.random.randint(length)]
acceptable_set = set(range(max(0, frames_idx[-1]-this_max_jump), min(length, frames_idx[-1]+this_max_jump+1))).difference(set(frames_idx))
while(len(frames_idx) < num_frames):
idx = np.random.choice(list(acceptable_set))
frames_idx.append(idx)
new_set = set(range(max(0, frames_idx[-1]-this_max_jump), min(length, frames_idx[-1]+this_max_jump+1)))
acceptable_set = acceptable_set.union(new_set).difference(set(frames_idx))
frames_idx = sorted(frames_idx)
if np.random.rand() < 0.5:
# Reverse time
frames_idx = frames_idx[::-1]
sequence_seed = np.random.randint(2147483647)
images = []
masks = []
target_objects = []
for f_idx in frames_idx:
jpg_name = frames[f_idx][:-4] + '.jpg'
png_name = frames[f_idx][:-4] + '.png'
info['frames'].append(jpg_name)
reseed(sequence_seed)
this_im = Image.open(path.join(vid_im_path, jpg_name)).convert('RGB')
this_im = self.all_im_dual_transform(this_im)
this_im = self.all_im_lone_transform(this_im)
reseed(sequence_seed)
this_gt = Image.open(path.join(vid_gt_path, png_name)).convert('P')
this_gt = self.all_gt_dual_transform(this_gt)
pairwise_seed = np.random.randint(2147483647)
reseed(pairwise_seed)
this_im = self.pair_im_dual_transform(this_im)
this_im = self.pair_im_lone_transform(this_im)
reseed(pairwise_seed)
this_gt = self.pair_gt_dual_transform(this_gt)
this_im = self.final_im_transform(this_im)
this_gt = np.array(this_gt)
images.append(this_im)
masks.append(this_gt)
images = torch.stack(images, 0)
labels = np.unique(masks[0])
# Remove background
labels = labels[labels!=0]
if self.is_bl:
# Find large enough labels
good_lables = []
for l in labels:
pixel_sum = (masks[0]==l).sum()
if pixel_sum > 10*10:
# OK if the object is always this small
# Not OK if it is actually much bigger
if pixel_sum > 30*30:
good_lables.append(l)
elif max((masks[1]==l).sum(), (masks[2]==l).sum()) < 20*20:
good_lables.append(l)
labels = np.array(good_lables, dtype=np.uint8)
if len(labels) == 0:
target_objects = []
trials += 1
else:
target_objects = labels.tolist()
break
if len(target_objects) > self.max_num_obj:
target_objects = np.random.choice(target_objects, size=self.max_num_obj, replace=False)
info['num_objects'] = max(1, len(target_objects))
masks = np.stack(masks, 0)
# Generate one-hot ground-truth
cls_gt = np.zeros((self.num_frames, 384, 384), dtype=np.int64)
first_frame_gt = np.zeros((1, self.max_num_obj, 384, 384), dtype=np.int64)
for i, l in enumerate(target_objects):
this_mask = (masks==l)
cls_gt[this_mask] = i+1
first_frame_gt[0,i] = (this_mask[0])
cls_gt = np.expand_dims(cls_gt, 1)
# 1 if object exist, 0 otherwise
selector = [1 if i < info['num_objects'] else 0 for i in range(self.max_num_obj)]
selector = torch.FloatTensor(selector)
data = {
'rgb': images,
'first_frame_gt': first_frame_gt,
'cls_gt': cls_gt,
'selector': selector,
'info': info,
}
return data
def __len__(self):
return len(self.videos)
================================================
FILE: XMem/eval.py
================================================
import os
from os import path
from argparse import ArgumentParser
import shutil
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
import numpy as np
from PIL import Image
from inference.data.test_datasets import LongTestDataset, DAVISTestDataset, YouTubeVOSTestDataset
from inference.data.mask_mapper import MaskMapper
from model.network import XMem
from inference.inference_core import InferenceCore
from tqdm import tqdm
try:
import hickle as hkl
except ImportError:
print('Failed to import hickle. Fine if not using multi-scale testing.')
parser = ArgumentParser()
parser.add_argument('--model', default='./saves/XMem.pth')
parser.add_argument('--meta_exp', type=str)
# Data options
parser.add_argument('--d16_path', default='../DAVIS/2016')
parser.add_argument('--d17_path', default='../DAVIS/2017')
parser.add_argument('--y18_path', default='../YouTube2018')
parser.add_argument('--y19_path', default='../YouTube')
parser.add_argument('--lv_path', default='../long_video_set')
# For generic (G) evaluation, point to a folder that contains "JPEGImages" and "Annotations"
parser.add_argument('--generic_path')
parser.add_argument('--img_dir')
parser.add_argument('--reversed', action='store_true')
parser.add_argument('--split_part', type=int, default=0)
parser.add_argument('--dataset', help='D16/D17/Y18/Y19/LV1/LV3/G', default='D17')
parser.add_argument('--split', help='val/test', default='val')
parser.add_argument('--output', default=None)
parser.add_argument('--save_all', action='store_true',
help='Save all frames. Useful only in YouTubeVOS/long-time video', )
parser.add_argument('--benchmark', action='store_true', help='enable to disable amp for FPS benchmarking')
# Long-term memory options
parser.add_argument('--disable_long_term', action='store_true')
parser.add_argument('--max_mid_term_frames', help='T_max in paper, decrease to save memory', type=int, default=10)
parser.add_argument('--min_mid_term_frames', help='T_min in paper, decrease to save memory', type=int, default=5)
parser.add_argument('--max_long_term_elements', help='LT_max in paper, increase if objects disappear for a long time', type=int, default=10000)
parser.add_argument('--num_prototypes', help='P in paper', type=int, default=128)
parser.add_argument('--top_k', type=int, default=30)
parser.add_argument('--mem_every', help='r in paper. Increase to improve running speed.', type=int, default=5)
parser.add_argument('--deep_update_every', help='Leave -1 normally to synchronize with mem_every', type=int, default=-1)
# Multi-scale options
parser.add_argument('--save_scores', action='store_true')
parser.add_argument('--flip', action='store_true')
parser.add_argument('--size', default=480, type=int, help='Resize the shorter side to this size. -1 to use original resolution. ')
args = parser.parse_args()
config = vars(args)
config['enable_long_term'] = not config['disable_long_term']
if args.output is None:
args.output = f'../output/{args.dataset}_{args.split}'
print(f'Output path not provided. Defaulting to {args.output}')
"""
Data preparation
"""
is_youtube = args.dataset.startswith('Y')
is_davis = args.dataset.startswith('D')
is_lv = args.dataset.startswith('LV')
if is_youtube or args.save_scores:
out_path = path.join(args.output, 'Annotations')
else:
out_path = args.output
if is_youtube:
if args.dataset == 'Y18':
yv_path = args.y18_path
elif args.dataset == 'Y19':
yv_path = args.y19_path
if args.split == 'val':
args.split = 'valid'
meta_dataset = YouTubeVOSTestDataset(data_root=yv_path, split='valid', size=args.size)
elif args.split == 'test':
meta_dataset = YouTubeVOSTestDataset(data_root=yv_path, split='test', size=args.size)
else:
raise NotImplementedError
elif is_davis:
if args.dataset == 'D16':
if args.split == 'val':
# Set up Dataset, a small hack to use the image set in the 2017 folder because the 2016 one is of a different format
meta_dataset = DAVISTestDataset(args.d16_path, imset='../../2017/trainval/ImageSets/2016/val.txt', size=args.size)
else:
raise NotImplementedError
palette = None
elif args.dataset == 'D17':
if args.split == 'val':
meta_dataset = DAVISTestDataset(path.join(args.d17_path, 'trainval'), imset='2017/val.txt', size=args.size)
elif args.split == 'test':
meta_dataset = DAVISTestDataset(path.join(args.d17_path, 'test-dev'), imset='2017/test-dev.txt', size=args.size)
else:
raise NotImplementedError
elif is_lv:
if args.dataset == 'LV1':
meta_dataset = LongTestDataset(args.meta_exp, path.join(args.lv_path, 'long_video'))
elif args.dataset == 'LV3':
meta_dataset = LongTestDataset(args.meta_exp, path.join(args.lv_path, 'long_video_x3'))
else:
raise NotImplementedError
elif args.dataset == 'G':
meta_dataset = LongTestDataset(args.meta_exp, path.join(args.generic_path), size=args.size, img_dir=args.img_dir, reversed_=args.reversed, split_part=args.split_part)
if not args.save_all:
args.save_all = True
print('save_all is forced to be true in generic evaluation mode.')
else:
raise NotImplementedError
torch.autograd.set_grad_enabled(False)
# Set up loader
meta_loader = meta_dataset.get_datasets()
# Load our checkpoint
network = XMem(config, args.model).cuda().eval()
if args.model is not None:
model_weights = torch.load(args.model)
network.load_weights(model_weights, init_as_zero_if_needed=True)
else:
print('No model loaded.')
total_process_time = 0
total_frames = 0
# Start eval
for vid_reader in tqdm(meta_loader, total=len(meta_dataset)):
loader = DataLoader(vid_reader, batch_size=1, shuffle=False, num_workers=2)
vid_name = vid_reader.vid_name
vid_length = len(loader)
# no need to count usage for LT if the video is not that long anyway
config['enable_long_term_count_usage'] = (
config['enable_long_term'] and
(vid_length
/ (config['max_mid_term_frames']-config['min_mid_term_frames'])
* config['num_prototypes'])
>= config['max_long_term_elements']
)
mapper = MaskMapper()
processor = InferenceCore(network, config=config)
first_mask_loaded = False
for ti, data in enumerate(loader):
with torch.cuda.amp.autocast(enabled=not args.benchmark):
rgb = data['rgb'].cuda()[0]
msk = data.get('mask')
info = data['info']
frame = info['frame'][0]
shape = info['shape']
need_resize = info['need_resize'][0]
"""
For timing see https://discuss.pytorch.org/t/how-to-measure-time-in-pytorch/26964
Seems to be very similar in testing as my previous timing method
with two cuda sync + time.time() in STCN though
"""
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
if not first_mask_loaded:
if msk is not None:
first_mask_loaded = True
else:
# no point to do anything without a mask
continue
if args.flip:
rgb = torch.flip(rgb, dims=[-1])
msk = torch.flip(msk, dims=[-1]) if msk is not None else None
# Map possibly non-continuous labels to continuous ones
if msk is not None:
msk, labels = mapper.convert_mask(msk[0].numpy())
msk = torch.Tensor(msk).cuda()
if need_resize:
if msk.shape[0] == 0:
print(vid_name)
msk = vid_reader.resize_mask(msk.unsqueeze(0))[0]
processor.set_all_labels(list(mapper.remappings.values()))
else:
labels = None
# Run the model on this frame
prob = processor.step(rgb, msk, labels, end=(ti==vid_length-1))
# Upsample to original size if needed
if need_resize:
prob = F.interpolate(prob.unsqueeze(1), shape, mode='bilinear', align_corners=False)[:,0]
end.record()
torch.cuda.synchronize()
total_process_time += (start.elapsed_time(end)/1000)
total_frames += 1
if args.flip:
prob = torch.flip(prob, dims=[-1])
# Probability mask -> index mask
out_mask = torch.max(prob, dim=0).indices
out_mask = (out_mask.detach().cpu().numpy()).astype(np.uint8)
if args.save_scores:
prob = (prob.detach().cpu().numpy()*255).astype(np.uint8)
# Save the mask
if args.save_all or info['save'][0]:
this_out_path = path.join(out_path, vid_name)
os.makedirs(this_out_path, exist_ok=True)
out_mask = mapper.remap_index_mask(out_mask)
out_img = Image.fromarray(out_mask)
if vid_reader.get_palette() is not None:
out_img.putpalette(vid_reader.get_palette())
out_img.save(os.path.join(this_out_path, frame[:-4]+'.png'))
if args.save_scores:
np_path = path.join(args.output, 'Scores', vid_name)
os.makedirs(np_path, exist_ok=True)
if ti==len(loader)-1:
hkl.dump(mapper.remappings, path.join(np_path, f'backward.hkl'), mode='w')
if args.save_all or info['save'][0]:
hkl.dump(prob, path.join(np_path, f'{frame[:-4]}.hkl'), mode='w', compression='lzf')
print(f'Total processing time: {total_process_time}')
print(f'Total processed frames: {total_frames}')
print(f'FPS: {total_frames / total_process_time}')
print(f'Max allocated memory (MB): {torch.cuda.max_memory_allocated() / (2**20)}')
if not args.save_scores:
if is_youtube:
print('Making zip for YouTubeVOS...')
shutil.make_archive(path.join(args.output, path.basename(args.output)), 'zip', args.output, 'Annotations')
elif is_davis and args.split == 'test':
print('Making zip for DAVIS test-dev...')
shutil.make_archive(args.output, 'zip', args.output)
================================================
FILE: XMem/eval_batch.py
================================================
import os
import time
import torch
import argparse
import multiprocessing as mp
from termcolor import colored
from datetime import datetime
from importlib.util import find_spec
if find_spec("GPUtil") is None: os.system("pip install gputil")
import GPUtil
_GPU_LIST = [_.id for _ in GPUtil.getGPUs()]
_GPU_QUEUE = mp.Queue()
for _ in _GPU_LIST: _GPU_QUEUE.put(_)
def run_eval(meta_expression, temp_xmem_anno, final_xmem_anno, img_dir, split_part, cfgs=" --reversed "):
gpu_id = _GPU_QUEUE.get()
cmd = f"CUDA_VISIBLE_DEVICES={gpu_id} python eval.py --meta_exp {meta_expression} --output {final_xmem_anno} --generic_path {temp_xmem_anno} --img_dir {img_dir} --split_part {split_part} --dataset G {cfgs}"
print(f"Running: {cmd}")
os.system(cmd)
_GPU_QUEUE.put(gpu_id)
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--meta_expression", type=str, help='/PATH/TO/ReVOS/meta_expressions_valid__llamavid.json')
parser.add_argument("--temp_xmem_anno", type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_temp/Annotations')
parser.add_argument("--final_xmem_anno", type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_final/Annotations')
parser.add_argument("--img_dir", type=str, help='/PATH/TO/ReVOS/JPEGImages')
args = parser.parse_args()
p = mp.Pool(8)
for split_part in [0, 1, 2, 3]:
for cfgs in [" ", " --reversed "]:
p.apply_async(
run_eval,
args=(args.meta_expression, args.temp_xmem_anno, args.final_xmem_anno, args.img_dir, split_part, cfgs),
error_callback=lambda e: print(colored(e, "red"))
)
p.close()
p.join()
if __name__ == "__main__":
main()
================================================
FILE: XMem/generate_xmem_data_single.py
================================================
import sys
import os
import os.path as osp
import glob
import cv2
import multiprocessing
import json
import argparse
from tqdm import tqdm
from termcolor import colored
"""
python generate_xmem_data_single.py \
--video_root /PATH/TO/VISA_exp/revos_valid/Annotations \
--output_dir /PATH/TO/VISA_exp/revos_valid_XMem_temp/Annotations \
--final_xmem_anno /PATH/TO/VISA_exp/revos_valid_XMem_final/Annotations \
--llama_vid_meta /PATH/TO/ReVOS/meta_expressions_valid__llamavid.json
"""
def generate(obj, temp_xmem_anno, final_xmem_anno):
obj_dir, video_name, obj_id, tp = obj
img_list = glob.glob(obj_dir + '/*.png') # Mask
img_list.sort()
frame_id = int(len(img_list) * tp)
if frame_id == len(img_list):
frame_id -= 1
used_img = img_list[frame_id]
img_output_path = osp.join(temp_xmem_anno, video_name, obj_id, osp.basename(used_img))
final_img_output_dir = osp.join(final_xmem_anno, video_name, obj_id)
img_output_dir = osp.dirname(img_output_path)
os.makedirs(img_output_dir, exist_ok=True)
os.makedirs(final_img_output_dir, exist_ok=True)
os.system('cp {} {}'.format(used_img, img_output_path))
img = cv2.imread(img_output_path)
if img.sum() == 0:
target_img_list = [i.split('/')[-1] for i in img_list]
for img_ in target_img_list:
print(os.path.join(final_img_output_dir, img_))
os.system('cp {} {}'.format(img_output_path, os.path.join(img_output_dir, img_)))
os.system('cp {} {}'.format(img_output_path, os.path.join(final_img_output_dir, img_)))
return 0
def main():
parser = argparse.ArgumentParser(description='rgvos')
parser.add_argument('--video_root', type=str, help='/PATH/TO/VISA_exp/revos_valid/Annotations', )
parser.add_argument('--temp_xmem_anno', type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_temp/Annotations', ) # 保存单帧 Mask 的路径
parser.add_argument('--final_xmem_anno', type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_final/Annotations', ) # 保存 XMem 最后输出结果的路径
parser.add_argument("--llama_vid_meta", type=str, help='/PATH/TO/ReVOS/meta_expressions_valid__llamavid.json', )
args = parser.parse_args()
video_root = args.video_root
temp_xmem_anno = args.temp_xmem_anno
final_xmem_anno = args.final_xmem_anno
os.makedirs(temp_xmem_anno, exist_ok=True)
data = json.load(open(args.llama_vid_meta, 'r'))['videos']
all_obj_list = []
for video_name in data.keys():
exps = data[video_name]['expressions']
for obj_id in exps.keys():
tp = exps[obj_id]['tp']
obj_dir = os.path.join(video_root, video_name, obj_id)
all_obj_list.append([obj_dir, video_name, obj_id, tp])
print('start')
cpu_num = multiprocessing.cpu_count()-1
print("cpu_num:", cpu_num)
pool = multiprocessing.Pool(cpu_num)
pbar = tqdm(total=len(all_obj_list))
for obj in all_obj_list:
pool.apply_async(
generate,
args = (obj, temp_xmem_anno, final_xmem_anno ),
callback = lambda *a: pbar.update(1),
error_callback = lambda e: print(colored(e, "red"))
)
pool.close()
pool.join()
pbar.close()
if __name__ == '__main__':
main()
================================================
FILE: XMem/inference/__init__.py
================================================
================================================
FILE: XMem/inference/data/__init__.py
================================================
================================================
FILE: XMem/inference/data/mask_mapper.py
================================================
import numpy as np
import torch
from dataset.util import all_to_onehot
class MaskMapper:
"""
This class is used to convert a indexed-mask to a one-hot representation.
It also takes care of remapping non-continuous indices
It has two modes:
1. Default. Only masks with new indices are supposed to go into the remapper.
This is also the case for YouTubeVOS.
i.e., regions with index 0 are not "background", but "don't care".
2. Exhaustive. Regions with index 0 are considered "background".
Every single pixel is considered to be "labeled".
"""
def __init__(self):
self.labels = []
self.remappings = {}
# if coherent, no mapping is required
self.coherent = True
def convert_mask(self, mask, exhaustive=False):
# mask is in index representation, H*W numpy array
labels = np.unique(mask).astype(np.uint8)
labels = labels[labels!=0].tolist()
new_labels = list(set(labels) - set(self.labels))
if not exhaustive:
assert len(new_labels) == len(labels), 'Old labels found in non-exhaustive mode'
# add new remappings
for i, l in enumerate(new_labels):
self.remappings[l] = i+len(self.labels)+1
if self.coherent and i+len(self.labels)+1 != l:
self.coherent = False
if exhaustive:
new_mapped_labels = range(1, len(self.labels)+len(new_labels)+1)
else:
if self.coherent:
new_mapped_labels = new_labels
else:
new_mapped_labels = range(len(self.labels)+1, len(self.labels)+len(new_labels)+1)
self.labels.extend(new_labels)
mask = torch.from_numpy(all_to_onehot(mask, self.labels)).float()
# mask num_objects*H*W
return mask, new_mapped_labels
def remap_index_mask(self, mask):
# mask is in index representation, H*W numpy array
if self.coherent:
return mask
new_mask = np.zeros_like(mask)
for l, i in self.remappings.items():
new_mask[mask==i] = l
return new_mask
================================================
FILE: XMem/inference/data/test_datasets.py
================================================
import os
from os import path
import json
import glob
from inference.data.video_reader import VideoReader
class LongTestDataset:
def __init__(self, meta_expression, data_root, size=-1, img_dir = '', reversed_ = False, split_part = 0):
self.image_dir = img_dir
self.mask_dir = data_root
self.size = size
self.reversed = reversed_
self.split_part = split_part
self.vid_list = []
videos_names = json.load(open(meta_expression, 'r'))['videos']
for video_name in videos_names:
video_mask_dir = path.join(self.mask_dir, video_name)
obj_ids = [d for d in os.listdir(video_mask_dir) if os.path.isdir(path.join(video_mask_dir, d))]
for obj_id in obj_ids:
obj_dir = path.join(video_mask_dir, obj_id)
img_list = glob.glob(obj_dir + '/*')
if len(img_list) == 1:
self.vid_list.append(path.join(video_name, obj_id))
self.vid_list.sort()
self.vid_list = [i for idx, i in enumerate(self.vid_list) if idx % 4 == self.split_part]
def get_datasets(self):
for video in self.vid_list:
yield VideoReader(video,
path.join(self.image_dir, '/'.join(video.split('/')[:-1])),
path.join(self.mask_dir, video),
to_save = [
name[:-4] for name in os.listdir(path.join(self.mask_dir, video)) # remove .png
],
size=self.size,
reversed=self.reversed,
)
def __len__(self):
return len(self.vid_list)
class DAVISTestDataset:
def __init__(self, data_root, imset='2017/val.txt', size=-1):
if size != 480:
self.image_dir = path.join(data_root, 'JPEGImages', 'Full-Resolution')
self.mask_dir = path.join(data_root, 'Annotations', 'Full-Resolution')
if not path.exists(self.image_dir):
print(f'{self.image_dir} not found. Look at other options.')
self.image_dir = path.join(data_root, 'JPEGImages', '1080p')
self.mask_dir = path.join(data_root, 'Annotations', '1080p')
assert path.exists(self.image_dir), 'path not found'
else:
self.image_dir = path.join(data_root, 'JPEGImages', '480p')
self.mask_dir = path.join(data_root, 'Annotations', '480p')
self.size_dir = path.join(data_root, 'JPEGImages', '480p')
self.size = size
with open(path.join(data_root, 'ImageSets', imset)) as f:
self.vid_list = sorted([line.strip() for line in f])
def get_datasets(self):
for video in self.vid_list:
yield VideoReader(video,
path.join(self.image_dir, video),
path.join(self.mask_dir, video),
size=self.size,
size_dir=path.join(self.size_dir, video),
)
def __len__(self):
return len(self.vid_list)
class YouTubeVOSTestDataset:
def __init__(self, data_root, split, size=480):
self.image_dir = path.join(data_root, 'all_frames', split+'_all_frames', 'JPEGImages')
self.mask_dir = path.join(data_root, split, 'Annotations')
self.size = size
self.vid_list = sorted(os.listdir(self.image_dir))
self.req_frame_list = {}
with open(path.join(data_root, split, 'meta.json')) as f:
# read meta.json to know which frame is required for evaluation
meta = json.load(f)['videos']
for vid in self.vid_list:
req_frames = []
objects = meta[vid]['objects']
for value in objects.values():
req_frames.extend(value['frames'])
req_frames = list(set(req_frames))
self.req_frame_list[vid] = req_frames
def get_datasets(self):
for video in self.vid_list:
yield VideoReader(video,
path.join(self.image_dir, video),
path.join(self.mask_dir, video),
size=self.size,
to_save=self.req_frame_list[video],
use_all_mask=True
)
def __len__(self):
return len(self.vid_list)
================================================
FILE: XMem/inference/data/video_reader.py
================================================
import os
from os import path
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from torchvision.transforms import InterpolationMode
import torch.nn.functional as F
from PIL import Image
import numpy as np
from dataset.range_transform import im_normalization
class VideoReader(Dataset):
"""
This class is used to read a video, one frame at a time
"""
def __init__(self, vid_name, image_dir, mask_dir, size=-1, to_save=None, use_all_mask=False, size_dir=None, reversed = False):
"""
image_dir - points to a directory of jpg images
mask_dir - points to a directory of png masks
size - resize min. side to size. Does nothing if <0.
to_save - optionally contains a list of file names without extensions
where the segmentation mask is required
use_all_mask - when true, read all available mask in mask_dir.
Default false. Set to true for YouTubeVOS validation.
"""
self.vid_name = vid_name
self.image_dir = image_dir
self.mask_dir = mask_dir
self.to_save = to_save
self.use_all_mask = use_all_mask
self.reversed = reversed
if size_dir is None:
self.size_dir = self.image_dir
else:
self.size_dir = size_dir
self.frames = sorted(os.listdir(self.image_dir))
if self.reversed:
self.frames = self.frames[::-1]
self.palette = Image.open(path.join(mask_dir, sorted(os.listdir(mask_dir))[0])).getpalette()
self.first_gt_path = path.join(self.mask_dir, sorted(os.listdir(self.mask_dir))[0])
if size < 0:
self.im_transform = transforms.Compose([
transforms.ToTensor(),
im_normalization,
])
else:
self.im_transform = transforms.Compose([
transforms.ToTensor(),
im_normalization,
transforms.Resize(size, interpolation=InterpolationMode.BILINEAR),
])
self.size = size
def __getitem__(self, idx):
frame = self.frames[idx]
info = {}
data = {}
info['frame'] = frame
info['save'] = (self.to_save is None) or (frame[:-4] in self.to_save)
im_path = path.join(self.image_dir, frame)
img = Image.open(im_path).convert('RGB')
if self.image_dir == self.size_dir:
shape = np.array(img).shape[:2]
else:
size_path = path.join(self.size_dir, frame)
size_im = Image.open(size_path).convert('RGB')
shape = np.array(size_im).shape[:2]
gt_path = path.join(self.mask_dir, frame[:-4]+'.png')
img = self.im_transform(img)
load_mask = self.use_all_mask or (gt_path == self.first_gt_path)
if load_mask and path.exists(gt_path):
mask = Image.open(gt_path).convert('P')
mask = np.array(mask, dtype=np.uint8)
data['mask'] = mask
info['shape'] = shape
info['need_resize'] = not (self.size < 0)
data['rgb'] = img
data['info'] = info
return data
def resize_mask(self, mask):
# mask transform is applied AFTER mapper, so we need to post-process it in eval.py
h, w = mask.shape[-2:]
min_hw = min(h, w)
return F.interpolate(mask, (int(h/min_hw*self.size), int(w/min_hw*self.size)),
mode='nearest')
def get_palette(self):
return self.palette
def __len__(self):
return len(self.frames)
================================================
FILE: XMem/inference/inference_core.py
================================================
from inference.memory_manager import MemoryManager
from model.network import XMem
from model.aggregate import aggregate
from util.tensor_util import pad_divide_by, unpad
class InferenceCore:
def __init__(self, network:XMem, config):
self.config = config
self.network = network
self.mem_every = config['mem_every']
self.deep_update_every = config['deep_update_every']
self.enable_long_term = config['enable_long_term']
# if deep_update_every < 0, synchronize deep update with memory frame
self.deep_update_sync = (self.deep_update_every < 0)
self.clear_memory()
self.all_labels = None
def clear_memory(self):
self.curr_ti = -1
self.last_mem_ti = 0
if not self.deep_update_sync:
self.last_deep_update_ti = -self.deep_update_every
self.memory = MemoryManager(config=self.config)
def update_config(self, config):
self.mem_every = config['mem_every']
self.deep_update_every = config['deep_update_every']
self.enable_long_term = config['enable_long_term']
# if deep_update_every < 0, synchronize deep update with memory frame
self.deep_update_sync = (self.deep_update_every < 0)
self.memory.update_config(config)
def set_all_labels(self, all_labels):
# self.all_labels = [l.item() for l in all_labels]
self.all_labels = all_labels
def step(self, image, mask=None, valid_labels=None, end=False):
# image: 3*H*W
# mask: num_objects*H*W or None
self.curr_ti += 1
image, self.pad = pad_divide_by(image, 16)
image = image.unsqueeze(0) # add the batch dimension
is_mem_frame = ((self.curr_ti-self.last_mem_ti >= self.mem_every) or (mask is not None)) and (not end)
need_segment = (self.curr_ti > 0) and ((valid_labels is None) or (len(self.all_labels) != len(valid_labels)))
is_deep_update = (
(self.deep_update_sync and is_mem_frame) or # synchronized
(not self.deep_update_sync and self.curr_ti-self.last_deep_update_ti >= self.deep_update_every) # no-sync
) and (not end)
is_normal_update = (not self.deep_update_sync or not is_deep_update) and (not end)
key, shrinkage, selection, f16, f8, f4 = self.network.encode_key(image,
need_ek=(self.enable_long_term or need_segment),
need_sk=is_mem_frame)
multi_scale_features = (f16, f8, f4)
# segment the current frame is needed
if need_segment:
memory_readout = self.memory.match_memory(key, selection).unsqueeze(0)
hidden, _, pred_prob_with_bg = self.network.segment(multi_scale_features, memory_readout,
self.memory.get_hidden(), h_out=is_normal_update, strip_bg=False)
# remove batch dim
pred_prob_with_bg = pred_prob_with_bg[0]
pred_prob_no_bg = pred_prob_with_bg[1:]
if is_normal_update:
self.memory.set_hidden(hidden)
else:
pred_prob_no_bg = pred_prob_with_bg = None
# use the input mask if any
if mask is not None:
mask, _ = pad_divide_by(mask, 16)
if pred_prob_no_bg is not None:
# if we have a predicted mask, we work on it
# make pred_prob_no_bg consistent with the input mask
mask_regions = (mask.sum(0) > 0.5)
pred_prob_no_bg[:, mask_regions] = 0
# shift by 1 because mask/pred_prob_no_bg do not contain background
mask = mask.type_as(pred_prob_no_bg)
if valid_labels is not None:
shift_by_one_non_labels = [i for i in range(pred_prob_no_bg.shape[0]) if (i+1) not in valid_labels]
# non-labelled objects are copied from the predicted mask
mask[shift_by_one_non_labels] = pred_prob_no_bg[shift_by_one_non_labels]
pred_prob_with_bg = aggregate(mask, dim=0)
# also create new hidden states
self.memory.create_hidden_state(len(self.all_labels), key)
# save as memory if needed
if is_mem_frame:
value, hidden = self.network.encode_value(image, f16, self.memory.get_hidden(),
pred_prob_with_bg[1:].unsqueeze(0), is_deep_update=is_deep_update)
self.memory.add_memory(key, shrinkage, value, self.all_labels,
selection=selection if self.enable_long_term else None)
self.last_mem_ti = self.curr_ti
if is_deep_update:
self.memory.set_hidden(hidden)
self.last_deep_update_ti = self.curr_ti
return unpad(pred_prob_with_bg, self.pad)
================================================
FILE: XMem/inference/interact/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/LICENSE
================================================
Mozilla Public License Version 2.0
==================================
1. Definitions
--------------
1.1. "Contributor"
means each individual or legal entity that creates, contributes to
the creation of, or owns Covered Software.
1.2. "Contributor Version"
means the combination of the Contributions of others (if any) used
by a Contributor and that particular Contributor's Contribution.
1.3. "Contribution"
means Covered Software of a particular Contributor.
1.4. "Covered Software"
means Source Code Form to which the initial Contributor has attached
the notice in Exhibit A, the Executable Form of such Source Code
Form, and Modifications of such Source Code Form, in each case
including portions thereof.
1.5. "Incompatible With Secondary Licenses"
means
(a) that the initial Contributor has attached the notice described
in Exhibit B to the Covered Software; or
(b) that the Covered Software was made available under the terms of
version 1.1 or earlier of the License, but not also under the
terms of a Secondary License.
1.6. "Executable Form"
means any form of the work other than Source Code Form.
1.7. "Larger Work"
means a work that combines Covered Software with other material, in
a separate file or files, that is not Covered Software.
1.8. "License"
means this document.
1.9. "Licensable"
means having the right to grant, to the maximum extent possible,
whether at the time of the initial grant or subsequently, any and
all of the rights conveyed by this License.
1.10. "Modifications"
means any of the following:
(a) any file in Source Code Form that results from an addition to,
deletion from, or modification of the contents of Covered
Software; or
(b) any new file in Source Code Form that contains any Covered
Software.
1.11. "Patent Claims" of a Contributor
means any patent claim(s), including without limitation, method,
process, and apparatus claims, in any patent Licensable by such
Contributor that would be infringed, but for the grant of the
License, by the making, using, selling, offering for sale, having
made, import, or transfer of either its Contributions or its
Contributor Version.
1.12. "Secondary License"
means either the GNU General Public License, Version 2.0, the GNU
Lesser General Public License, Version 2.1, the GNU Affero General
Public License, Version 3.0, or any later versions of those
licenses.
1.13. "Source Code Form"
means the form of the work preferred for making modifications.
1.14. "You" (or "Your")
means an individual or a legal entity exercising rights under this
License. For legal entities, "You" includes any entity that
controls, is controlled by, or is under common control with You. For
purposes of this definition, "control" means (a) the power, direct
or indirect, to cause the direction or management of such entity,
whether by contract or otherwise, or (b) ownership of more than
fifty percent (50%) of the outstanding shares or beneficial
ownership of such entity.
2. License Grants and Conditions
--------------------------------
2.1. Grants
Each Contributor hereby grants You a world-wide, royalty-free,
non-exclusive license:
(a) under intellectual property rights (other than patent or trademark)
Licensable by such Contributor to use, reproduce, make available,
modify, display, perform, distribute, and otherwise exploit its
Contributions, either on an unmodified basis, with Modifications, or
as part of a Larger Work; and
(b) under Patent Claims of such Contributor to make, use, sell, offer
for sale, have made, import, and otherwise transfer either its
Contributions or its Contributor Version.
2.2. Effective Date
The licenses granted in Section 2.1 with respect to any Contribution
become effective for each Contribution on the date the Contributor first
distributes such Contribution.
2.3. Limitations on Grant Scope
The licenses granted in this Section 2 are the only rights granted under
this License. No additional rights or licenses will be implied from the
distribution or licensing of Covered Software under this License.
Notwithstanding Section 2.1(b) above, no patent license is granted by a
Contributor:
(a) for any code that a Contributor has removed from Covered Software;
or
(b) for infringements caused by: (i) Your and any other third party's
modifications of Covered Software, or (ii) the combination of its
Contributions with other software (except as part of its Contributor
Version); or
(c) under Patent Claims infringed by Covered Software in the absence of
its Contributions.
This License does not grant any rights in the trademarks, service marks,
or logos of any Contributor (except as may be necessary to comply with
the notice requirements in Section 3.4).
2.4. Subsequent Licenses
No Contributor makes additional grants as a result of Your choice to
distribute the Covered Software under a subsequent version of this
License (see Section 10.2) or under the terms of a Secondary License (if
permitted under the terms of Section 3.3).
2.5. Representation
Each Contributor represents that the Contributor believes its
Contributions are its original creation(s) or it has sufficient rights
to grant the rights to its Contributions conveyed by this License.
2.6. Fair Use
This License is not intended to limit any rights You have under
applicable copyright doctrines of fair use, fair dealing, or other
equivalents.
2.7. Conditions
Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted
in Section 2.1.
3. Responsibilities
-------------------
3.1. Distribution of Source Form
All distribution of Covered Software in Source Code Form, including any
Modifications that You create or to which You contribute, must be under
the terms of this License. You must inform recipients that the Source
Code Form of the Covered Software is governed by the terms of this
License, and how they can obtain a copy of this License. You may not
attempt to alter or restrict the recipients' rights in the Source Code
Form.
3.2. Distribution of Executable Form
If You distribute Covered Software in Executable Form then:
(a) such Covered Software must also be made available in Source Code
Form, as described in Section 3.1, and You must inform recipients of
the Executable Form how they can obtain a copy of such Source Code
Form by reasonable means in a timely manner, at a charge no more
than the cost of distribution to the recipient; and
(b) You may distribute such Executable Form under the terms of this
License, or sublicense it under different terms, provided that the
license for the Executable Form does not attempt to limit or alter
the recipients' rights in the Source Code Form under this License.
3.3. Distribution of a Larger Work
You may create and distribute a Larger Work under terms of Your choice,
provided that You also comply with the requirements of this License for
the Covered Software. If the Larger Work is a combination of Covered
Software with a work governed by one or more Secondary Licenses, and the
Covered Software is not Incompatible With Secondary Licenses, this
License permits You to additionally distribute such Covered Software
under the terms of such Secondary License(s), so that the recipient of
the Larger Work may, at their option, further distribute the Covered
Software under the terms of either this License or such Secondary
License(s).
3.4. Notices
You may not remove or alter the substance of any license notices
(including copyright notices, patent notices, disclaimers of warranty,
or limitations of liability) contained within the Source Code Form of
the Covered Software, except that You may alter any license notices to
the extent required to remedy known factual inaccuracies.
3.5. Application of Additional Terms
You may choose to offer, and to charge a fee for, warranty, support,
indemnity or liability obligations to one or more recipients of Covered
Software. However, You may do so only on Your own behalf, and not on
behalf of any Contributor. You must make it absolutely clear that any
such warranty, support, indemnity, or liability obligation is offered by
You alone, and You hereby agree to indemnify every Contributor for any
liability incurred by such Contributor as a result of warranty, support,
indemnity or liability terms You offer. You may include additional
disclaimers of warranty and limitations of liability specific to any
jurisdiction.
4. Inability to Comply Due to Statute or Regulation
---------------------------------------------------
If it is impossible for You to comply with any of the terms of this
License with respect to some or all of the Covered Software due to
statute, judicial order, or regulation then You must: (a) comply with
the terms of this License to the maximum extent possible; and (b)
describe the limitations and the code they affect. Such description must
be placed in a text file included with all distributions of the Covered
Software under this License. Except to the extent prohibited by statute
or regulation, such description must be sufficiently detailed for a
recipient of ordinary skill to be able to understand it.
5. Termination
--------------
5.1. The rights granted under this License will terminate automatically
if You fail to comply with any of its terms. However, if You become
compliant, then the rights granted under this License from a particular
Contributor are reinstated (a) provisionally, unless and until such
Contributor explicitly and finally terminates Your grants, and (b) on an
ongoing basis, if such Contributor fails to notify You of the
non-compliance by some reasonable means prior to 60 days after You have
come back into compliance. Moreover, Your grants from a particular
Contributor are reinstated on an ongoing basis if such Contributor
notifies You of the non-compliance by some reasonable means, this is the
first time You have received notice of non-compliance with this License
from such Contributor, and You become compliant prior to 30 days after
Your receipt of the notice.
5.2. If You initiate litigation against any entity by asserting a patent
infringement claim (excluding declaratory judgment actions,
counter-claims, and cross-claims) alleging that a Contributor Version
directly or indirectly infringes any patent, then the rights granted to
You by any and all Contributors for the Covered Software under Section
2.1 of this License shall terminate.
5.3. In the event of termination under Sections 5.1 or 5.2 above, all
end user license agreements (excluding distributors and resellers) which
have been validly granted by You or Your distributors under this License
prior to termination shall survive termination.
************************************************************************
* *
* 6. Disclaimer of Warranty *
* ------------------------- *
* *
* Covered Software is provided under this License on an "as is" *
* basis, without warranty of any kind, either expressed, implied, or *
* statutory, including, without limitation, warranties that the *
* Covered Software is free of defects, merchantable, fit for a *
* particular purpose or non-infringing. The entire risk as to the *
* quality and performance of the Covered Software is with You. *
* Should any Covered Software prove defective in any respect, You *
* (not any Contributor) assume the cost of any necessary servicing, *
* repair, or correction. This disclaimer of warranty constitutes an *
* essential part of this License. No use of any Covered Software is *
* authorized under this License except under this disclaimer. *
* *
************************************************************************
************************************************************************
* *
* 7. Limitation of Liability *
* -------------------------- *
* *
* Under no circumstances and under no legal theory, whether tort *
* (including negligence), contract, or otherwise, shall any *
* Contributor, or anyone who distributes Covered Software as *
* permitted above, be liable to You for any direct, indirect, *
* special, incidental, or consequential damages of any character *
* including, without limitation, damages for lost profits, loss of *
* goodwill, work stoppage, computer failure or malfunction, or any *
* and all other commercial damages or losses, even if such party *
* shall have been informed of the possibility of such damages. This *
* limitation of liability shall not apply to liability for death or *
* personal injury resulting from such party's negligence to the *
* extent applicable law prohibits such limitation. Some *
* jurisdictions do not allow the exclusion or limitation of *
* incidental or consequential damages, so this exclusion and *
* limitation may not apply to You. *
* *
************************************************************************
8. Litigation
-------------
Any litigation relating to this License may be brought only in the
courts of a jurisdiction where the defendant maintains its principal
place of business and such litigation shall be governed by laws of that
jurisdiction, without reference to its conflict-of-law provisions.
Nothing in this Section shall prevent a party's ability to bring
cross-claims or counter-claims.
9. Miscellaneous
----------------
This License represents the complete agreement concerning the subject
matter hereof. If any provision of this License is held to be
unenforceable, such provision shall be reformed only to the extent
necessary to make it enforceable. Any law or regulation which provides
that the language of a contract shall be construed against the drafter
shall not be used to construe this License against a Contributor.
10. Versions of the License
---------------------------
10.1. New Versions
Mozilla Foundation is the license steward. Except as provided in Section
10.3, no one other than the license steward has the right to modify or
publish new versions of this License. Each version will be given a
distinguishing version number.
10.2. Effect of New Versions
You may distribute the Covered Software under the terms of the version
of the License under which You originally received the Covered Software,
or under the terms of any subsequent version published by the license
steward.
10.3. Modified Versions
If you create software not governed by this License, and you want to
create a new license for such software, you may create and use a
modified version of this License if you rename the license and remove
any references to the name of the license steward (except to note that
such modified license differs from this License).
10.4. Distributing Source Code Form that is Incompatible With Secondary
Licenses
If You choose to distribute Source Code Form that is Incompatible With
Secondary Licenses under the terms of this version of the License, the
notice described in Exhibit B of this License must be attached.
Exhibit A - Source Code Form License Notice
-------------------------------------------
This Source Code Form is subject to the terms of the Mozilla Public
License, v. 2.0. If a copy of the MPL was not distributed with this
file, You can obtain one at http://mozilla.org/MPL/2.0/.
If it is not possible or desirable to put the notice in a particular
file, then You may include the notice in a location (such as a LICENSE
file in a relevant directory) where a recipient would be likely to look
for such a notice.
You may add additional accurate notices of copyright ownership.
Exhibit B - "Incompatible With Secondary Licenses" Notice
---------------------------------------------------------
This Source Code Form is "Incompatible With Secondary Licenses", as
defined by the Mozilla Public License, v. 2.0.
================================================
FILE: XMem/inference/interact/fbrs/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/controller.py
================================================
import torch
try:
from torch import mps
except:
pass
from ..fbrs.inference import clicker
from ..fbrs.inference.predictors import get_predictor
class InteractiveController:
def __init__(self, net, device, predictor_params, prob_thresh=0.5):
self.net = net.to(device)
self.prob_thresh = prob_thresh
self.clicker = clicker.Clicker()
self.states = []
self.probs_history = []
self.object_count = 0
self._result_mask = None
self.image = None
self.predictor = None
self.device = device
self.predictor_params = predictor_params
self.reset_predictor()
def set_image(self, image):
self.image = image
self._result_mask = torch.zeros(image.shape[-2:], dtype=torch.uint8)
self.object_count = 0
self.reset_last_object()
def add_click(self, x, y, is_positive):
self.states.append({
'clicker': self.clicker.get_state(),
'predictor': self.predictor.get_states()
})
click = clicker.Click(is_positive=is_positive, coords=(y, x))
self.clicker.add_click(click)
pred = self.predictor.get_prediction(self.clicker)
if self.device.type == 'cuda':
torch.cuda.empty_cache()
elif self.device.type == 'mps':
mps.empty_cache()
if self.probs_history:
self.probs_history.append((self.probs_history[-1][0], pred))
else:
self.probs_history.append((torch.zeros_like(pred), pred))
def undo_click(self):
if not self.states:
return
prev_state = self.states.pop()
self.clicker.set_state(prev_state['clicker'])
self.predictor.set_states(prev_state['predictor'])
self.probs_history.pop()
def partially_finish_object(self):
object_prob = self.current_object_prob
if object_prob is None:
return
self.probs_history.append((object_prob, torch.zeros_like(object_prob)))
self.states.append(self.states[-1])
self.clicker.reset_clicks()
self.reset_predictor()
def finish_object(self):
object_prob = self.current_object_prob
if object_prob is None:
return
self.object_count += 1
object_mask = object_prob > self.prob_thresh
self._result_mask[object_mask] = self.object_count
self.reset_last_object()
def reset_last_object(self):
self.states = []
self.probs_history = []
self.clicker.reset_clicks()
self.reset_predictor()
def reset_predictor(self, predictor_params=None):
if predictor_params is not None:
self.predictor_params = predictor_params
self.predictor = get_predictor(self.net, device=self.device,
**self.predictor_params)
if self.image is not None:
self.predictor.set_input_image(self.image)
@property
def current_object_prob(self):
if self.probs_history:
current_prob_total, current_prob_additive = self.probs_history[-1]
return torch.maximum(current_prob_total, current_prob_additive)
else:
return None
@property
def is_incomplete_mask(self):
return len(self.probs_history) > 0
@property
def result_mask(self):
return self._result_mask.clone()
================================================
FILE: XMem/inference/interact/fbrs/inference/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/inference/clicker.py
================================================
from collections import namedtuple
import numpy as np
from copy import deepcopy
from scipy.ndimage import distance_transform_edt
Click = namedtuple('Click', ['is_positive', 'coords'])
class Clicker(object):
def __init__(self, gt_mask=None, init_clicks=None, ignore_label=-1):
if gt_mask is not None:
self.gt_mask = gt_mask == 1
self.not_ignore_mask = gt_mask != ignore_label
else:
self.gt_mask = None
self.reset_clicks()
if init_clicks is not None:
for click in init_clicks:
self.add_click(click)
def make_next_click(self, pred_mask):
assert self.gt_mask is not None
click = self._get_click(pred_mask)
self.add_click(click)
def get_clicks(self, clicks_limit=None):
return self.clicks_list[:clicks_limit]
def _get_click(self, pred_mask, padding=True):
fn_mask = np.logical_and(np.logical_and(self.gt_mask, np.logical_not(pred_mask)), self.not_ignore_mask)
fp_mask = np.logical_and(np.logical_and(np.logical_not(self.gt_mask), pred_mask), self.not_ignore_mask)
if padding:
fn_mask = np.pad(fn_mask, ((1, 1), (1, 1)), 'constant')
fp_mask = np.pad(fp_mask, ((1, 1), (1, 1)), 'constant')
fn_mask_dt = distance_transform_edt(fn_mask)
fp_mask_dt = distance_transform_edt(fp_mask)
if padding:
fn_mask_dt = fn_mask_dt[1:-1, 1:-1]
fp_mask_dt = fp_mask_dt[1:-1, 1:-1]
fn_mask_dt = fn_mask_dt * self.not_clicked_map
fp_mask_dt = fp_mask_dt * self.not_clicked_map
fn_max_dist = np.max(fn_mask_dt)
fp_max_dist = np.max(fp_mask_dt)
is_positive = fn_max_dist > fp_max_dist
if is_positive:
coords_y, coords_x = np.where(fn_mask_dt == fn_max_dist) # coords is [y, x]
else:
coords_y, coords_x = np.where(fp_mask_dt == fp_max_dist) # coords is [y, x]
return Click(is_positive=is_positive, coords=(coords_y[0], coords_x[0]))
def add_click(self, click):
coords = click.coords
if click.is_positive:
self.num_pos_clicks += 1
else:
self.num_neg_clicks += 1
self.clicks_list.append(click)
if self.gt_mask is not None:
self.not_clicked_map[coords[0], coords[1]] = False
def _remove_last_click(self):
click = self.clicks_list.pop()
coords = click.coords
if click.is_positive:
self.num_pos_clicks -= 1
else:
self.num_neg_clicks -= 1
if self.gt_mask is not None:
self.not_clicked_map[coords[0], coords[1]] = True
def reset_clicks(self):
if self.gt_mask is not None:
self.not_clicked_map = np.ones_like(self.gt_mask, dtype=np.bool)
self.num_pos_clicks = 0
self.num_neg_clicks = 0
self.clicks_list = []
def get_state(self):
return deepcopy(self.clicks_list)
def set_state(self, state):
self.reset_clicks()
for click in state:
self.add_click(click)
def __len__(self):
return len(self.clicks_list)
================================================
FILE: XMem/inference/interact/fbrs/inference/evaluation.py
================================================
from time import time
import numpy as np
import torch
from ..inference import utils
from ..inference.clicker import Clicker
try:
get_ipython()
from tqdm import tqdm_notebook as tqdm
except NameError:
from tqdm import tqdm
def evaluate_dataset(dataset, predictor, oracle_eval=False, **kwargs):
all_ious = []
start_time = time()
for index in tqdm(range(len(dataset)), leave=False):
sample = dataset.get_sample(index)
item = dataset[index]
if oracle_eval:
gt_mask = torch.tensor(sample['instances_mask'], dtype=torch.float32)
gt_mask = gt_mask.unsqueeze(0).unsqueeze(0)
predictor.opt_functor.mask_loss.set_gt_mask(gt_mask)
_, sample_ious, _ = evaluate_sample(item['images'], sample['instances_mask'], predictor, **kwargs)
all_ious.append(sample_ious)
end_time = time()
elapsed_time = end_time - start_time
return all_ious, elapsed_time
def evaluate_sample(image_nd, instances_mask, predictor, max_iou_thr,
pred_thr=0.49, max_clicks=20):
clicker = Clicker(gt_mask=instances_mask)
pred_mask = np.zeros_like(instances_mask)
ious_list = []
with torch.no_grad():
predictor.set_input_image(image_nd)
for click_number in range(max_clicks):
clicker.make_next_click(pred_mask)
pred_probs = predictor.get_prediction(clicker)
pred_mask = pred_probs > pred_thr
iou = utils.get_iou(instances_mask, pred_mask)
ious_list.append(iou)
if iou >= max_iou_thr:
break
return clicker.clicks_list, np.array(ious_list, dtype=np.float32), pred_probs
================================================
FILE: XMem/inference/interact/fbrs/inference/predictors/__init__.py
================================================
from .base import BasePredictor
from .brs import InputBRSPredictor, FeatureBRSPredictor, HRNetFeatureBRSPredictor
from .brs_functors import InputOptimizer, ScaleBiasOptimizer
from ..transforms import ZoomIn
from ...model.is_hrnet_model import DistMapsHRNetModel
def get_predictor(net, brs_mode, device,
prob_thresh=0.49,
with_flip=True,
zoom_in_params=dict(),
predictor_params=None,
brs_opt_func_params=None,
lbfgs_params=None):
lbfgs_params_ = {
'm': 20,
'factr': 0,
'pgtol': 1e-8,
'maxfun': 20,
}
predictor_params_ = {
'optimize_after_n_clicks': 1
}
if zoom_in_params is not None:
zoom_in = ZoomIn(**zoom_in_params)
else:
zoom_in = None
if lbfgs_params is not None:
lbfgs_params_.update(lbfgs_params)
lbfgs_params_['maxiter'] = 2 * lbfgs_params_['maxfun']
if brs_opt_func_params is None:
brs_opt_func_params = dict()
if brs_mode == 'NoBRS':
if predictor_params is not None:
predictor_params_.update(predictor_params)
predictor = BasePredictor(net, device, zoom_in=zoom_in, with_flip=with_flip, **predictor_params_)
elif brs_mode.startswith('f-BRS'):
predictor_params_.update({
'net_clicks_limit': 8,
})
if predictor_params is not None:
predictor_params_.update(predictor_params)
insertion_mode = {
'f-BRS-A': 'after_c4',
'f-BRS-B': 'after_aspp',
'f-BRS-C': 'after_deeplab'
}[brs_mode]
opt_functor = ScaleBiasOptimizer(prob_thresh=prob_thresh,
with_flip=with_flip,
optimizer_params=lbfgs_params_,
**brs_opt_func_params)
if isinstance(net, DistMapsHRNetModel):
FeaturePredictor = HRNetFeatureBRSPredictor
insertion_mode = {'after_c4': 'A', 'after_aspp': 'A', 'after_deeplab': 'C'}[insertion_mode]
else:
FeaturePredictor = FeatureBRSPredictor
predictor = FeaturePredictor(net, device,
opt_functor=opt_functor,
with_flip=with_flip,
insertion_mode=insertion_mode,
zoom_in=zoom_in,
**predictor_params_)
elif brs_mode == 'RGB-BRS' or brs_mode == 'DistMap-BRS':
use_dmaps = brs_mode == 'DistMap-BRS'
predictor_params_.update({
'net_clicks_limit': 5,
})
if predictor_params is not None:
predictor_params_.update(predictor_params)
opt_functor = InputOptimizer(prob_thresh=prob_thresh,
with_flip=with_flip,
optimizer_params=lbfgs_params_,
**brs_opt_func_params)
predictor = InputBRSPredictor(net, device,
optimize_target='dmaps' if use_dmaps else 'rgb',
opt_functor=opt_functor,
with_flip=with_flip,
zoom_in=zoom_in,
**predictor_params_)
else:
raise NotImplementedError
return predictor
================================================
FILE: XMem/inference/interact/fbrs/inference/predictors/base.py
================================================
import torch
import torch.nn.functional as F
from ..transforms import AddHorizontalFlip, SigmoidForPred, LimitLongestSide
class BasePredictor(object):
def __init__(self, net, device,
net_clicks_limit=None,
with_flip=False,
zoom_in=None,
max_size=None,
**kwargs):
self.net = net
self.with_flip = with_flip
self.net_clicks_limit = net_clicks_limit
self.original_image = None
self.device = device
self.zoom_in = zoom_in
self.transforms = [zoom_in] if zoom_in is not None else []
if max_size is not None:
self.transforms.append(LimitLongestSide(max_size=max_size))
self.transforms.append(SigmoidForPred())
if with_flip:
self.transforms.append(AddHorizontalFlip())
def set_input_image(self, image_nd):
for transform in self.transforms:
transform.reset()
self.original_image = image_nd.to(self.device)
if len(self.original_image.shape) == 3:
self.original_image = self.original_image.unsqueeze(0)
def get_prediction(self, clicker):
clicks_list = clicker.get_clicks()
image_nd, clicks_lists, is_image_changed = self.apply_transforms(
self.original_image, [clicks_list]
)
pred_logits = self._get_prediction(image_nd, clicks_lists, is_image_changed)
prediction = F.interpolate(pred_logits, mode='bilinear', align_corners=True,
size=image_nd.size()[2:])
for t in reversed(self.transforms):
prediction = t.inv_transform(prediction)
if self.zoom_in is not None and self.zoom_in.check_possible_recalculation():
print('zooming')
return self.get_prediction(clicker)
# return prediction.cpu().numpy()[0, 0]
return prediction
def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
points_nd = self.get_points_nd(clicks_lists)
return self.net(image_nd, points_nd)['instances']
def _get_transform_states(self):
return [x.get_state() for x in self.transforms]
def _set_transform_states(self, states):
assert len(states) == len(self.transforms)
for state, transform in zip(states, self.transforms):
transform.set_state(state)
def apply_transforms(self, image_nd, clicks_lists):
is_image_changed = False
for t in self.transforms:
image_nd, clicks_lists = t.transform(image_nd, clicks_lists)
is_image_changed |= t.image_changed
return image_nd, clicks_lists, is_image_changed
def get_points_nd(self, clicks_lists):
total_clicks = []
num_pos_clicks = [sum(x.is_positive for x in clicks_list) for clicks_list in clicks_lists]
num_neg_clicks = [len(clicks_list) - num_pos for clicks_list, num_pos in zip(clicks_lists, num_pos_clicks)]
num_max_points = max(num_pos_clicks + num_neg_clicks)
if self.net_clicks_limit is not None:
num_max_points = min(self.net_clicks_limit, num_max_points)
num_max_points = max(1, num_max_points)
for clicks_list in clicks_lists:
clicks_list = clicks_list[:self.net_clicks_limit]
pos_clicks = [click.coords for click in clicks_list if click.is_positive]
pos_clicks = pos_clicks + (num_max_points - len(pos_clicks)) * [(-1, -1)]
neg_clicks = [click.coords for click in clicks_list if not click.is_positive]
neg_clicks = neg_clicks + (num_max_points - len(neg_clicks)) * [(-1, -1)]
total_clicks.append(pos_clicks + neg_clicks)
return torch.tensor(total_clicks, device=self.device)
def get_states(self):
return {'transform_states': self._get_transform_states()}
def set_states(self, states):
self._set_transform_states(states['transform_states'])
================================================
FILE: XMem/inference/interact/fbrs/inference/predictors/brs.py
================================================
import torch
import torch.nn.functional as F
import numpy as np
from scipy.optimize import fmin_l_bfgs_b
from .base import BasePredictor
from ...model.is_hrnet_model import DistMapsHRNetModel
class BRSBasePredictor(BasePredictor):
def __init__(self, model, device, opt_functor, optimize_after_n_clicks=1, **kwargs):
super().__init__(model, device, **kwargs)
self.optimize_after_n_clicks = optimize_after_n_clicks
self.opt_functor = opt_functor
self.opt_data = None
self.input_data = None
def set_input_image(self, image_nd):
super().set_input_image(image_nd)
self.opt_data = None
self.input_data = None
def _get_clicks_maps_nd(self, clicks_lists, image_shape, radius=1):
pos_clicks_map = np.zeros((len(clicks_lists), 1) + image_shape, dtype=np.float32)
neg_clicks_map = np.zeros((len(clicks_lists), 1) + image_shape, dtype=np.float32)
for list_indx, clicks_list in enumerate(clicks_lists):
for click in clicks_list:
y, x = click.coords
y, x = int(round(y)), int(round(x))
y1, x1 = y - radius, x - radius
y2, x2 = y + radius + 1, x + radius + 1
if click.is_positive:
pos_clicks_map[list_indx, 0, y1:y2, x1:x2] = True
else:
neg_clicks_map[list_indx, 0, y1:y2, x1:x2] = True
with torch.no_grad():
pos_clicks_map = torch.from_numpy(pos_clicks_map).to(self.device)
neg_clicks_map = torch.from_numpy(neg_clicks_map).to(self.device)
return pos_clicks_map, neg_clicks_map
def get_states(self):
return {'transform_states': self._get_transform_states(), 'opt_data': self.opt_data}
def set_states(self, states):
self._set_transform_states(states['transform_states'])
self.opt_data = states['opt_data']
class FeatureBRSPredictor(BRSBasePredictor):
def __init__(self, model, device, opt_functor, insertion_mode='after_deeplab', **kwargs):
super().__init__(model, device, opt_functor=opt_functor, **kwargs)
self.insertion_mode = insertion_mode
self._c1_features = None
if self.insertion_mode == 'after_deeplab':
self.num_channels = model.feature_extractor.ch
elif self.insertion_mode == 'after_c4':
self.num_channels = model.feature_extractor.aspp_in_channels
elif self.insertion_mode == 'after_aspp':
self.num_channels = model.feature_extractor.ch + 32
else:
raise NotImplementedError
def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
points_nd = self.get_points_nd(clicks_lists)
pos_mask, neg_mask = self._get_clicks_maps_nd(clicks_lists, image_nd.shape[2:])
num_clicks = len(clicks_lists[0])
bs = image_nd.shape[0] // 2 if self.with_flip else image_nd.shape[0]
if self.opt_data is None or self.opt_data.shape[0] // (2 * self.num_channels) != bs:
self.opt_data = np.zeros((bs * 2 * self.num_channels), dtype=np.float32)
if num_clicks <= self.net_clicks_limit or is_image_changed or self.input_data is None:
self.input_data = self._get_head_input(image_nd, points_nd)
def get_prediction_logits(scale, bias):
scale = scale.view(bs, -1, 1, 1)
bias = bias.view(bs, -1, 1, 1)
if self.with_flip:
scale = scale.repeat(2, 1, 1, 1)
bias = bias.repeat(2, 1, 1, 1)
scaled_backbone_features = self.input_data * scale
scaled_backbone_features = scaled_backbone_features + bias
if self.insertion_mode == 'after_c4':
x = self.net.feature_extractor.aspp(scaled_backbone_features)
x = F.interpolate(x, mode='bilinear', size=self._c1_features.size()[2:],
align_corners=True)
x = torch.cat((x, self._c1_features), dim=1)
scaled_backbone_features = self.net.feature_extractor.head(x)
elif self.insertion_mode == 'after_aspp':
scaled_backbone_features = self.net.feature_extractor.head(scaled_backbone_features)
pred_logits = self.net.head(scaled_backbone_features)
pred_logits = F.interpolate(pred_logits, size=image_nd.size()[2:], mode='bilinear',
align_corners=True)
return pred_logits
self.opt_functor.init_click(get_prediction_logits, pos_mask, neg_mask, self.device)
if num_clicks > self.optimize_after_n_clicks:
opt_result = fmin_l_bfgs_b(func=self.opt_functor, x0=self.opt_data,
**self.opt_functor.optimizer_params)
self.opt_data = opt_result[0]
with torch.no_grad():
if self.opt_functor.best_prediction is not None:
opt_pred_logits = self.opt_functor.best_prediction
else:
opt_data_nd = torch.from_numpy(self.opt_data).to(self.device)
opt_vars, _ = self.opt_functor.unpack_opt_params(opt_data_nd)
opt_pred_logits = get_prediction_logits(*opt_vars)
return opt_pred_logits
def _get_head_input(self, image_nd, points):
with torch.no_grad():
coord_features = self.net.dist_maps(image_nd, points)
x = self.net.rgb_conv(torch.cat((image_nd, coord_features), dim=1))
if self.insertion_mode == 'after_c4' or self.insertion_mode == 'after_aspp':
c1, _, c3, c4 = self.net.feature_extractor.backbone(x)
c1 = self.net.feature_extractor.skip_project(c1)
if self.insertion_mode == 'after_aspp':
x = self.net.feature_extractor.aspp(c4)
x = F.interpolate(x, size=c1.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x, c1), dim=1)
backbone_features = x
else:
backbone_features = c4
self._c1_features = c1
else:
backbone_features = self.net.feature_extractor(x)[0]
return backbone_features
class HRNetFeatureBRSPredictor(BRSBasePredictor):
def __init__(self, model, device, opt_functor, insertion_mode='A', **kwargs):
super().__init__(model, device, opt_functor=opt_functor, **kwargs)
self.insertion_mode = insertion_mode
self._c1_features = None
if self.insertion_mode == 'A':
self.num_channels = sum(k * model.feature_extractor.width for k in [1, 2, 4, 8])
elif self.insertion_mode == 'C':
self.num_channels = 2 * model.feature_extractor.ocr_width
else:
raise NotImplementedError
def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
points_nd = self.get_points_nd(clicks_lists)
pos_mask, neg_mask = self._get_clicks_maps_nd(clicks_lists, image_nd.shape[2:])
num_clicks = len(clicks_lists[0])
bs = image_nd.shape[0] // 2 if self.with_flip else image_nd.shape[0]
if self.opt_data is None or self.opt_data.shape[0] // (2 * self.num_channels) != bs:
self.opt_data = np.zeros((bs * 2 * self.num_channels), dtype=np.float32)
if num_clicks <= self.net_clicks_limit or is_image_changed or self.input_data is None:
self.input_data = self._get_head_input(image_nd, points_nd)
def get_prediction_logits(scale, bias):
scale = scale.view(bs, -1, 1, 1)
bias = bias.view(bs, -1, 1, 1)
if self.with_flip:
scale = scale.repeat(2, 1, 1, 1)
bias = bias.repeat(2, 1, 1, 1)
scaled_backbone_features = self.input_data * scale
scaled_backbone_features = scaled_backbone_features + bias
if self.insertion_mode == 'A':
out_aux = self.net.feature_extractor.aux_head(scaled_backbone_features)
feats = self.net.feature_extractor.conv3x3_ocr(scaled_backbone_features)
context = self.net.feature_extractor.ocr_gather_head(feats, out_aux)
feats = self.net.feature_extractor.ocr_distri_head(feats, context)
pred_logits = self.net.feature_extractor.cls_head(feats)
elif self.insertion_mode == 'C':
pred_logits = self.net.feature_extractor.cls_head(scaled_backbone_features)
else:
raise NotImplementedError
pred_logits = F.interpolate(pred_logits, size=image_nd.size()[2:], mode='bilinear',
align_corners=True)
return pred_logits
self.opt_functor.init_click(get_prediction_logits, pos_mask, neg_mask, self.device)
if num_clicks > self.optimize_after_n_clicks:
opt_result = fmin_l_bfgs_b(func=self.opt_functor, x0=self.opt_data,
**self.opt_functor.optimizer_params)
self.opt_data = opt_result[0]
with torch.no_grad():
if self.opt_functor.best_prediction is not None:
opt_pred_logits = self.opt_functor.best_prediction
else:
opt_data_nd = torch.from_numpy(self.opt_data).to(self.device)
opt_vars, _ = self.opt_functor.unpack_opt_params(opt_data_nd)
opt_pred_logits = get_prediction_logits(*opt_vars)
return opt_pred_logits
def _get_head_input(self, image_nd, points):
with torch.no_grad():
coord_features = self.net.dist_maps(image_nd, points)
x = self.net.rgb_conv(torch.cat((image_nd, coord_features), dim=1))
feats = self.net.feature_extractor.compute_hrnet_feats(x)
if self.insertion_mode == 'A':
backbone_features = feats
elif self.insertion_mode == 'C':
out_aux = self.net.feature_extractor.aux_head(feats)
feats = self.net.feature_extractor.conv3x3_ocr(feats)
context = self.net.feature_extractor.ocr_gather_head(feats, out_aux)
backbone_features = self.net.feature_extractor.ocr_distri_head(feats, context)
else:
raise NotImplementedError
return backbone_features
class InputBRSPredictor(BRSBasePredictor):
def __init__(self, model, device, opt_functor, optimize_target='rgb', **kwargs):
super().__init__(model, device, opt_functor=opt_functor, **kwargs)
self.optimize_target = optimize_target
def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
points_nd = self.get_points_nd(clicks_lists)
pos_mask, neg_mask = self._get_clicks_maps_nd(clicks_lists, image_nd.shape[2:])
num_clicks = len(clicks_lists[0])
if self.opt_data is None or is_image_changed:
opt_channels = 2 if self.optimize_target == 'dmaps' else 3
bs = image_nd.shape[0] // 2 if self.with_flip else image_nd.shape[0]
self.opt_data = torch.zeros((bs, opt_channels, image_nd.shape[2], image_nd.shape[3]),
device=self.device, dtype=torch.float32)
def get_prediction_logits(opt_bias):
input_image = image_nd
if self.optimize_target == 'rgb':
input_image = input_image + opt_bias
dmaps = self.net.dist_maps(input_image, points_nd)
if self.optimize_target == 'dmaps':
dmaps = dmaps + opt_bias
x = self.net.rgb_conv(torch.cat((input_image, dmaps), dim=1))
if self.optimize_target == 'all':
x = x + opt_bias
if isinstance(self.net, DistMapsHRNetModel):
pred_logits = self.net.feature_extractor(x)[0]
else:
backbone_features = self.net.feature_extractor(x)
pred_logits = self.net.head(backbone_features[0])
pred_logits = F.interpolate(pred_logits, size=image_nd.size()[2:], mode='bilinear', align_corners=True)
return pred_logits
self.opt_functor.init_click(get_prediction_logits, pos_mask, neg_mask, self.device,
shape=self.opt_data.shape)
if num_clicks > self.optimize_after_n_clicks:
opt_result = fmin_l_bfgs_b(func=self.opt_functor, x0=self.opt_data.cpu().numpy().ravel(),
**self.opt_functor.optimizer_params)
self.opt_data = torch.from_numpy(opt_result[0]).view(self.opt_data.shape).to(self.device)
with torch.no_grad():
if self.opt_functor.best_prediction is not None:
opt_pred_logits = self.opt_functor.best_prediction
else:
opt_vars, _ = self.opt_functor.unpack_opt_params(self.opt_data)
opt_pred_logits = get_prediction_logits(*opt_vars)
return opt_pred_logits
================================================
FILE: XMem/inference/interact/fbrs/inference/predictors/brs_functors.py
================================================
import torch
import numpy as np
from ...model.metrics import _compute_iou
from .brs_losses import BRSMaskLoss
class BaseOptimizer:
def __init__(self, optimizer_params,
prob_thresh=0.49,
reg_weight=1e-3,
min_iou_diff=0.01,
brs_loss=BRSMaskLoss(),
with_flip=False,
flip_average=False,
**kwargs):
self.brs_loss = brs_loss
self.optimizer_params = optimizer_params
self.prob_thresh = prob_thresh
self.reg_weight = reg_weight
self.min_iou_diff = min_iou_diff
self.with_flip = with_flip
self.flip_average = flip_average
self.best_prediction = None
self._get_prediction_logits = None
self._opt_shape = None
self._best_loss = None
self._click_masks = None
self._last_mask = None
self.device = None
def init_click(self, get_prediction_logits, pos_mask, neg_mask, device, shape=None):
self.best_prediction = None
self._get_prediction_logits = get_prediction_logits
self._click_masks = (pos_mask, neg_mask)
self._opt_shape = shape
self._last_mask = None
self.device = device
def __call__(self, x):
opt_params = torch.from_numpy(x).float().to(self.device)
opt_params.requires_grad_(True)
with torch.enable_grad():
opt_vars, reg_loss = self.unpack_opt_params(opt_params)
result_before_sigmoid = self._get_prediction_logits(*opt_vars)
result = torch.sigmoid(result_before_sigmoid)
pos_mask, neg_mask = self._click_masks
if self.with_flip and self.flip_average:
result, result_flipped = torch.chunk(result, 2, dim=0)
result = 0.5 * (result + torch.flip(result_flipped, dims=[3]))
pos_mask, neg_mask = pos_mask[:result.shape[0]], neg_mask[:result.shape[0]]
loss, f_max_pos, f_max_neg = self.brs_loss(result, pos_mask, neg_mask)
loss = loss + reg_loss
f_val = loss.detach().cpu().numpy()
if self.best_prediction is None or f_val < self._best_loss:
self.best_prediction = result_before_sigmoid.detach()
self._best_loss = f_val
if f_max_pos < (1 - self.prob_thresh) and f_max_neg < self.prob_thresh:
return [f_val, np.zeros_like(x)]
current_mask = result > self.prob_thresh
if self._last_mask is not None and self.min_iou_diff > 0:
diff_iou = _compute_iou(current_mask, self._last_mask)
if len(diff_iou) > 0 and diff_iou.mean() > 1 - self.min_iou_diff:
return [f_val, np.zeros_like(x)]
self._last_mask = current_mask
loss.backward()
f_grad = opt_params.grad.cpu().numpy().ravel().astype(np.float32)
return [f_val, f_grad]
def unpack_opt_params(self, opt_params):
raise NotImplementedError
class InputOptimizer(BaseOptimizer):
def unpack_opt_params(self, opt_params):
opt_params = opt_params.view(self._opt_shape)
if self.with_flip:
opt_params_flipped = torch.flip(opt_params, dims=[3])
opt_params = torch.cat([opt_params, opt_params_flipped], dim=0)
reg_loss = self.reg_weight * torch.sum(opt_params**2)
return (opt_params,), reg_loss
class ScaleBiasOptimizer(BaseOptimizer):
def __init__(self, *args, scale_act=None, reg_bias_weight=10.0, **kwargs):
super().__init__(*args, **kwargs)
self.scale_act = scale_act
self.reg_bias_weight = reg_bias_weight
def unpack_opt_params(self, opt_params):
scale, bias = torch.chunk(opt_params, 2, dim=0)
reg_loss = self.reg_weight * (torch.sum(scale**2) + self.reg_bias_weight * torch.sum(bias**2))
if self.scale_act == 'tanh':
scale = torch.tanh(scale)
elif self.scale_act == 'sin':
scale = torch.sin(scale)
return (1 + scale, bias), reg_loss
================================================
FILE: XMem/inference/interact/fbrs/inference/predictors/brs_losses.py
================================================
import torch
from ...model.losses import SigmoidBinaryCrossEntropyLoss
class BRSMaskLoss(torch.nn.Module):
def __init__(self, eps=1e-5):
super().__init__()
self._eps = eps
def forward(self, result, pos_mask, neg_mask):
pos_diff = (1 - result) * pos_mask
pos_target = torch.sum(pos_diff ** 2)
pos_target = pos_target / (torch.sum(pos_mask) + self._eps)
neg_diff = result * neg_mask
neg_target = torch.sum(neg_diff ** 2)
neg_target = neg_target / (torch.sum(neg_mask) + self._eps)
loss = pos_target + neg_target
with torch.no_grad():
f_max_pos = torch.max(torch.abs(pos_diff)).item()
f_max_neg = torch.max(torch.abs(neg_diff)).item()
return loss, f_max_pos, f_max_neg
class OracleMaskLoss(torch.nn.Module):
def __init__(self):
super().__init__()
self.gt_mask = None
self.loss = SigmoidBinaryCrossEntropyLoss(from_sigmoid=True)
self.predictor = None
self.history = []
def set_gt_mask(self, gt_mask):
self.gt_mask = gt_mask
self.history = []
def forward(self, result, pos_mask, neg_mask):
gt_mask = self.gt_mask.to(result.device)
if self.predictor.object_roi is not None:
r1, r2, c1, c2 = self.predictor.object_roi[:4]
gt_mask = gt_mask[:, :, r1:r2 + 1, c1:c2 + 1]
gt_mask = torch.nn.functional.interpolate(gt_mask, result.size()[2:], mode='bilinear', align_corners=True)
if result.shape[0] == 2:
gt_mask_flipped = torch.flip(gt_mask, dims=[3])
gt_mask = torch.cat([gt_mask, gt_mask_flipped], dim=0)
loss = self.loss(result, gt_mask)
self.history.append(loss.detach().cpu().numpy()[0])
if len(self.history) > 5 and abs(self.history[-5] - self.history[-1]) < 1e-5:
return 0, 0, 0
return loss, 1.0, 1.0
================================================
FILE: XMem/inference/interact/fbrs/inference/transforms/__init__.py
================================================
from .base import SigmoidForPred
from .flip import AddHorizontalFlip
from .zoom_in import ZoomIn
from .limit_longest_side import LimitLongestSide
from .crops import Crops
================================================
FILE: XMem/inference/interact/fbrs/inference/transforms/base.py
================================================
import torch
class BaseTransform(object):
def __init__(self):
self.image_changed = False
def transform(self, image_nd, clicks_lists):
raise NotImplementedError
def inv_transform(self, prob_map):
raise NotImplementedError
def reset(self):
raise NotImplementedError
def get_state(self):
raise NotImplementedError
def set_state(self, state):
raise NotImplementedError
class SigmoidForPred(BaseTransform):
def transform(self, image_nd, clicks_lists):
return image_nd, clicks_lists
def inv_transform(self, prob_map):
return torch.sigmoid(prob_map)
def reset(self):
pass
def get_state(self):
return None
def set_state(self, state):
pass
================================================
FILE: XMem/inference/interact/fbrs/inference/transforms/crops.py
================================================
import math
import torch
import numpy as np
from ...inference.clicker import Click
from .base import BaseTransform
class Crops(BaseTransform):
def __init__(self, crop_size=(320, 480), min_overlap=0.2):
super().__init__()
self.crop_height, self.crop_width = crop_size
self.min_overlap = min_overlap
self.x_offsets = None
self.y_offsets = None
self._counts = None
def transform(self, image_nd, clicks_lists):
assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
image_height, image_width = image_nd.shape[2:4]
self._counts = None
if image_height < self.crop_height or image_width < self.crop_width:
return image_nd, clicks_lists
self.x_offsets = get_offsets(image_width, self.crop_width, self.min_overlap)
self.y_offsets = get_offsets(image_height, self.crop_height, self.min_overlap)
self._counts = np.zeros((image_height, image_width))
image_crops = []
for dy in self.y_offsets:
for dx in self.x_offsets:
self._counts[dy:dy + self.crop_height, dx:dx + self.crop_width] += 1
image_crop = image_nd[:, :, dy:dy + self.crop_height, dx:dx + self.crop_width]
image_crops.append(image_crop)
image_crops = torch.cat(image_crops, dim=0)
self._counts = torch.tensor(self._counts, device=image_nd.device, dtype=torch.float32)
clicks_list = clicks_lists[0]
clicks_lists = []
for dy in self.y_offsets:
for dx in self.x_offsets:
crop_clicks = [Click(is_positive=x.is_positive, coords=(x.coords[0] - dy, x.coords[1] - dx))
for x in clicks_list]
clicks_lists.append(crop_clicks)
return image_crops, clicks_lists
def inv_transform(self, prob_map):
if self._counts is None:
return prob_map
new_prob_map = torch.zeros((1, 1, *self._counts.shape),
dtype=prob_map.dtype, device=prob_map.device)
crop_indx = 0
for dy in self.y_offsets:
for dx in self.x_offsets:
new_prob_map[0, 0, dy:dy + self.crop_height, dx:dx + self.crop_width] += prob_map[crop_indx, 0]
crop_indx += 1
new_prob_map = torch.div(new_prob_map, self._counts)
return new_prob_map
def get_state(self):
return self.x_offsets, self.y_offsets, self._counts
def set_state(self, state):
self.x_offsets, self.y_offsets, self._counts = state
def reset(self):
self.x_offsets = None
self.y_offsets = None
self._counts = None
def get_offsets(length, crop_size, min_overlap_ratio=0.2):
if length == crop_size:
return [0]
N = (length / crop_size - min_overlap_ratio) / (1 - min_overlap_ratio)
N = math.ceil(N)
overlap_ratio = (N - length / crop_size) / (N - 1)
overlap_width = int(crop_size * overlap_ratio)
offsets = [0]
for i in range(1, N):
new_offset = offsets[-1] + crop_size - overlap_width
if new_offset + crop_size > length:
new_offset = length - crop_size
offsets.append(new_offset)
return offsets
================================================
FILE: XMem/inference/interact/fbrs/inference/transforms/flip.py
================================================
import torch
from ..clicker import Click
from .base import BaseTransform
class AddHorizontalFlip(BaseTransform):
def transform(self, image_nd, clicks_lists):
assert len(image_nd.shape) == 4
image_nd = torch.cat([image_nd, torch.flip(image_nd, dims=[3])], dim=0)
image_width = image_nd.shape[3]
clicks_lists_flipped = []
for clicks_list in clicks_lists:
clicks_list_flipped = [Click(is_positive=click.is_positive,
coords=(click.coords[0], image_width - click.coords[1] - 1))
for click in clicks_list]
clicks_lists_flipped.append(clicks_list_flipped)
clicks_lists = clicks_lists + clicks_lists_flipped
return image_nd, clicks_lists
def inv_transform(self, prob_map):
assert len(prob_map.shape) == 4 and prob_map.shape[0] % 2 == 0
num_maps = prob_map.shape[0] // 2
prob_map, prob_map_flipped = prob_map[:num_maps], prob_map[num_maps:]
return 0.5 * (prob_map + torch.flip(prob_map_flipped, dims=[3]))
def get_state(self):
return None
def set_state(self, state):
pass
def reset(self):
pass
================================================
FILE: XMem/inference/interact/fbrs/inference/transforms/limit_longest_side.py
================================================
from .zoom_in import ZoomIn, get_roi_image_nd
class LimitLongestSide(ZoomIn):
def __init__(self, max_size=800):
super().__init__(target_size=max_size, skip_clicks=0)
def transform(self, image_nd, clicks_lists):
assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
image_max_size = max(image_nd.shape[2:4])
self.image_changed = False
if image_max_size <= self.target_size:
return image_nd, clicks_lists
self._input_image = image_nd
self._object_roi = (0, image_nd.shape[2] - 1, 0, image_nd.shape[3] - 1)
self._roi_image = get_roi_image_nd(image_nd, self._object_roi, self.target_size)
self.image_changed = True
tclicks_lists = [self._transform_clicks(clicks_lists[0])]
return self._roi_image, tclicks_lists
================================================
FILE: XMem/inference/interact/fbrs/inference/transforms/zoom_in.py
================================================
import torch
from ..clicker import Click
from ...utils.misc import get_bbox_iou, get_bbox_from_mask, expand_bbox, clamp_bbox
from .base import BaseTransform
class ZoomIn(BaseTransform):
def __init__(self,
target_size=400,
skip_clicks=1,
expansion_ratio=1.4,
min_crop_size=200,
recompute_thresh_iou=0.5,
prob_thresh=0.50):
super().__init__()
self.target_size = target_size
self.min_crop_size = min_crop_size
self.skip_clicks = skip_clicks
self.expansion_ratio = expansion_ratio
self.recompute_thresh_iou = recompute_thresh_iou
self.prob_thresh = prob_thresh
self._input_image_shape = None
self._prev_probs = None
self._object_roi = None
self._roi_image = None
def transform(self, image_nd, clicks_lists):
assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
self.image_changed = False
clicks_list = clicks_lists[0]
if len(clicks_list) <= self.skip_clicks:
return image_nd, clicks_lists
self._input_image_shape = image_nd.shape
current_object_roi = None
if self._prev_probs is not None:
current_pred_mask = (self._prev_probs > self.prob_thresh)[0, 0]
if current_pred_mask.sum() > 0:
current_object_roi = get_object_roi(current_pred_mask, clicks_list,
self.expansion_ratio, self.min_crop_size)
if current_object_roi is None:
return image_nd, clicks_lists
update_object_roi = False
if self._object_roi is None:
update_object_roi = True
elif not check_object_roi(self._object_roi, clicks_list):
update_object_roi = True
elif get_bbox_iou(current_object_roi, self._object_roi) < self.recompute_thresh_iou:
update_object_roi = True
if update_object_roi:
self._object_roi = current_object_roi
self._roi_image = get_roi_image_nd(image_nd, self._object_roi, self.target_size)
self.image_changed = True
tclicks_lists = [self._transform_clicks(clicks_list)]
return self._roi_image.to(image_nd.device), tclicks_lists
def inv_transform(self, prob_map):
if self._object_roi is None:
self._prev_probs = prob_map.cpu().numpy()
return prob_map
assert prob_map.shape[0] == 1
rmin, rmax, cmin, cmax = self._object_roi
prob_map = torch.nn.functional.interpolate(prob_map, size=(rmax - rmin + 1, cmax - cmin + 1),
mode='bilinear', align_corners=True)
if self._prev_probs is not None:
new_prob_map = torch.zeros(*self._prev_probs.shape, device=prob_map.device, dtype=prob_map.dtype)
new_prob_map[:, :, rmin:rmax + 1, cmin:cmax + 1] = prob_map
else:
new_prob_map = prob_map
self._prev_probs = new_prob_map.cpu().numpy()
return new_prob_map
def check_possible_recalculation(self):
if self._prev_probs is None or self._object_roi is not None or self.skip_clicks > 0:
return False
pred_mask = (self._prev_probs > self.prob_thresh)[0, 0]
if pred_mask.sum() > 0:
possible_object_roi = get_object_roi(pred_mask, [],
self.expansion_ratio, self.min_crop_size)
image_roi = (0, self._input_image_shape[2] - 1, 0, self._input_image_shape[3] - 1)
if get_bbox_iou(possible_object_roi, image_roi) < 0.50:
return True
return False
def get_state(self):
roi_image = self._roi_image.cpu() if self._roi_image is not None else None
return self._input_image_shape, self._object_roi, self._prev_probs, roi_image, self.image_changed
def set_state(self, state):
self._input_image_shape, self._object_roi, self._prev_probs, self._roi_image, self.image_changed = state
def reset(self):
self._input_image_shape = None
self._object_roi = None
self._prev_probs = None
self._roi_image = None
self.image_changed = False
def _transform_clicks(self, clicks_list):
if self._object_roi is None:
return clicks_list
rmin, rmax, cmin, cmax = self._object_roi
crop_height, crop_width = self._roi_image.shape[2:]
transformed_clicks = []
for click in clicks_list:
new_r = crop_height * (click.coords[0] - rmin) / (rmax - rmin + 1)
new_c = crop_width * (click.coords[1] - cmin) / (cmax - cmin + 1)
transformed_clicks.append(Click(is_positive=click.is_positive, coords=(new_r, new_c)))
return transformed_clicks
def get_object_roi(pred_mask, clicks_list, expansion_ratio, min_crop_size):
pred_mask = pred_mask.copy()
for click in clicks_list:
if click.is_positive:
pred_mask[int(click.coords[0]), int(click.coords[1])] = 1
bbox = get_bbox_from_mask(pred_mask)
bbox = expand_bbox(bbox, expansion_ratio, min_crop_size)
h, w = pred_mask.shape[0], pred_mask.shape[1]
bbox = clamp_bbox(bbox, 0, h - 1, 0, w - 1)
return bbox
def get_roi_image_nd(image_nd, object_roi, target_size):
rmin, rmax, cmin, cmax = object_roi
height = rmax - rmin + 1
width = cmax - cmin + 1
if isinstance(target_size, tuple):
new_height, new_width = target_size
else:
scale = target_size / max(height, width)
new_height = int(round(height * scale))
new_width = int(round(width * scale))
with torch.no_grad():
roi_image_nd = image_nd[:, :, rmin:rmax + 1, cmin:cmax + 1]
roi_image_nd = torch.nn.functional.interpolate(roi_image_nd, size=(new_height, new_width),
mode='bilinear', align_corners=True)
return roi_image_nd
def check_object_roi(object_roi, clicks_list):
for click in clicks_list:
if click.is_positive:
if click.coords[0] < object_roi[0] or click.coords[0] >= object_roi[1]:
return False
if click.coords[1] < object_roi[2] or click.coords[1] >= object_roi[3]:
return False
return True
================================================
FILE: XMem/inference/interact/fbrs/inference/utils.py
================================================
from datetime import timedelta
from pathlib import Path
import torch
import numpy as np
from ..model.is_deeplab_model import get_deeplab_model
from ..model.is_hrnet_model import get_hrnet_model
def get_time_metrics(all_ious, elapsed_time):
n_images = len(all_ious)
n_clicks = sum(map(len, all_ious))
mean_spc = elapsed_time / n_clicks
mean_spi = elapsed_time / n_images
return mean_spc, mean_spi
def load_is_model(checkpoint, device, backbone='auto', **kwargs):
if isinstance(checkpoint, (str, Path)):
state_dict = torch.load(checkpoint, map_location='cpu')
else:
state_dict = checkpoint
if backbone == 'auto':
for k in state_dict.keys():
if 'feature_extractor.stage2.0.branches' in k:
return load_hrnet_is_model(state_dict, device, backbone, **kwargs)
return load_deeplab_is_model(state_dict, device, backbone, **kwargs)
elif 'resnet' in backbone:
return load_deeplab_is_model(state_dict, device, backbone, **kwargs)
elif 'hrnet' in backbone:
return load_hrnet_is_model(state_dict, device, backbone, **kwargs)
else:
raise NotImplementedError('Unknown backbone')
def load_hrnet_is_model(state_dict, device, backbone='auto', width=48, ocr_width=256,
small=False, cpu_dist_maps=False, norm_radius=260):
if backbone == 'auto':
num_fe_weights = len([x for x in state_dict.keys() if 'feature_extractor.' in x])
small = num_fe_weights < 1800
ocr_f_down = [v for k, v in state_dict.items() if 'object_context_block.f_down.1.0.bias' in k]
assert len(ocr_f_down) == 1
ocr_width = ocr_f_down[0].shape[0]
s2_conv1_w = [v for k, v in state_dict.items() if 'stage2.0.branches.0.0.conv1.weight' in k]
assert len(s2_conv1_w) == 1
width = s2_conv1_w[0].shape[0]
model = get_hrnet_model(width=width, ocr_width=ocr_width, small=small,
with_aux_output=False, cpu_dist_maps=cpu_dist_maps,
norm_radius=norm_radius)
model.load_state_dict(state_dict, strict=False)
for param in model.parameters():
param.requires_grad = False
model.to(device)
model.eval()
return model
def load_deeplab_is_model(state_dict, device, backbone='auto', deeplab_ch=128, aspp_dropout=0.2,
cpu_dist_maps=False, norm_radius=260):
if backbone == 'auto':
num_backbone_params = len([x for x in state_dict.keys()
if 'feature_extractor.backbone' in x and not('num_batches_tracked' in x)])
if num_backbone_params <= 181:
backbone = 'resnet34'
elif num_backbone_params <= 276:
backbone = 'resnet50'
elif num_backbone_params <= 531:
backbone = 'resnet101'
else:
raise NotImplementedError('Unknown backbone')
if 'aspp_dropout' in state_dict:
aspp_dropout = float(state_dict['aspp_dropout'].cpu().numpy())
else:
aspp_project_weight = [v for k, v in state_dict.items() if 'aspp.project.0.weight' in k][0]
deeplab_ch = aspp_project_weight.size(0)
if deeplab_ch == 256:
aspp_dropout = 0.5
model = get_deeplab_model(backbone=backbone, deeplab_ch=deeplab_ch,
aspp_dropout=aspp_dropout, cpu_dist_maps=cpu_dist_maps,
norm_radius=norm_radius)
model.load_state_dict(state_dict, strict=False)
for param in model.parameters():
param.requires_grad = False
model.to(device)
model.eval()
return model
def get_iou(gt_mask, pred_mask, ignore_label=-1):
ignore_gt_mask_inv = gt_mask != ignore_label
obj_gt_mask = gt_mask == 1
intersection = np.logical_and(np.logical_and(pred_mask, obj_gt_mask), ignore_gt_mask_inv).sum()
union = np.logical_and(np.logical_or(pred_mask, obj_gt_mask), ignore_gt_mask_inv).sum()
return intersection / union
def compute_noc_metric(all_ious, iou_thrs, max_clicks=20):
def _get_noc(iou_arr, iou_thr):
vals = iou_arr >= iou_thr
return np.argmax(vals) + 1 if np.any(vals) else max_clicks
noc_list = []
over_max_list = []
for iou_thr in iou_thrs:
scores_arr = np.array([_get_noc(iou_arr, iou_thr)
for iou_arr in all_ious], dtype=np.int32)
score = scores_arr.mean()
over_max = (scores_arr == max_clicks).sum()
noc_list.append(score)
over_max_list.append(over_max)
return noc_list, over_max_list
def find_checkpoint(weights_folder, checkpoint_name):
weights_folder = Path(weights_folder)
if ':' in checkpoint_name:
model_name, checkpoint_name = checkpoint_name.split(':')
models_candidates = [x for x in weights_folder.glob(f'{model_name}*') if x.is_dir()]
assert len(models_candidates) == 1
model_folder = models_candidates[0]
else:
model_folder = weights_folder
if checkpoint_name.endswith('.pth'):
if Path(checkpoint_name).exists():
checkpoint_path = checkpoint_name
else:
checkpoint_path = weights_folder / checkpoint_name
else:
model_checkpoints = list(model_folder.rglob(f'{checkpoint_name}*.pth'))
assert len(model_checkpoints) == 1
checkpoint_path = model_checkpoints[0]
return str(checkpoint_path)
def get_results_table(noc_list, over_max_list, brs_type, dataset_name, mean_spc, elapsed_time,
n_clicks=20, model_name=None):
table_header = (f'|{"BRS Type":^13}|{"Dataset":^11}|'
f'{"NoC@80%":^9}|{"NoC@85%":^9}|{"NoC@90%":^9}|'
f'{">="+str(n_clicks)+"@85%":^9}|{">="+str(n_clicks)+"@90%":^9}|'
f'{"SPC,s":^7}|{"Time":^9}|')
row_width = len(table_header)
header = f'Eval results for model: {model_name}\n' if model_name is not None else ''
header += '-' * row_width + '\n'
header += table_header + '\n' + '-' * row_width
eval_time = str(timedelta(seconds=int(elapsed_time)))
table_row = f'|{brs_type:^13}|{dataset_name:^11}|'
table_row += f'{noc_list[0]:^9.2f}|'
table_row += f'{noc_list[1]:^9.2f}|' if len(noc_list) > 1 else f'{"?":^9}|'
table_row += f'{noc_list[2]:^9.2f}|' if len(noc_list) > 2 else f'{"?":^9}|'
table_row += f'{over_max_list[1]:^9}|' if len(noc_list) > 1 else f'{"?":^9}|'
table_row += f'{over_max_list[2]:^9}|' if len(noc_list) > 2 else f'{"?":^9}|'
table_row += f'{mean_spc:^7.3f}|{eval_time:^9}|'
return header, table_row
================================================
FILE: XMem/inference/interact/fbrs/model/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/model/initializer.py
================================================
import torch
import torch.nn as nn
import numpy as np
class Initializer(object):
def __init__(self, local_init=True, gamma=None):
self.local_init = local_init
self.gamma = gamma
def __call__(self, m):
if getattr(m, '__initialized', False):
return
if isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d,
nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d,
nn.GroupNorm, nn.SyncBatchNorm)) or 'BatchNorm' in m.__class__.__name__:
if m.weight is not None:
self._init_gamma(m.weight.data)
if m.bias is not None:
self._init_beta(m.bias.data)
else:
if getattr(m, 'weight', None) is not None:
self._init_weight(m.weight.data)
if getattr(m, 'bias', None) is not None:
self._init_bias(m.bias.data)
if self.local_init:
object.__setattr__(m, '__initialized', True)
def _init_weight(self, data):
nn.init.uniform_(data, -0.07, 0.07)
def _init_bias(self, data):
nn.init.constant_(data, 0)
def _init_gamma(self, data):
if self.gamma is None:
nn.init.constant_(data, 1.0)
else:
nn.init.normal_(data, 1.0, self.gamma)
def _init_beta(self, data):
nn.init.constant_(data, 0)
class Bilinear(Initializer):
def __init__(self, scale, groups, in_channels, **kwargs):
super().__init__(**kwargs)
self.scale = scale
self.groups = groups
self.in_channels = in_channels
def _init_weight(self, data):
"""Reset the weight and bias."""
bilinear_kernel = self.get_bilinear_kernel(self.scale)
weight = torch.zeros_like(data)
for i in range(self.in_channels):
if self.groups == 1:
j = i
else:
j = 0
weight[i, j] = bilinear_kernel
data[:] = weight
@staticmethod
def get_bilinear_kernel(scale):
"""Generate a bilinear upsampling kernel."""
kernel_size = 2 * scale - scale % 2
scale = (kernel_size + 1) // 2
center = scale - 0.5 * (1 + kernel_size % 2)
og = np.ogrid[:kernel_size, :kernel_size]
kernel = (1 - np.abs(og[0] - center) / scale) * (1 - np.abs(og[1] - center) / scale)
return torch.tensor(kernel, dtype=torch.float32)
class XavierGluon(Initializer):
def __init__(self, rnd_type='uniform', factor_type='avg', magnitude=3, **kwargs):
super().__init__(**kwargs)
self.rnd_type = rnd_type
self.factor_type = factor_type
self.magnitude = float(magnitude)
def _init_weight(self, arr):
fan_in, fan_out = nn.init._calculate_fan_in_and_fan_out(arr)
if self.factor_type == 'avg':
factor = (fan_in + fan_out) / 2.0
elif self.factor_type == 'in':
factor = fan_in
elif self.factor_type == 'out':
factor = fan_out
else:
raise ValueError('Incorrect factor type')
scale = np.sqrt(self.magnitude / factor)
if self.rnd_type == 'uniform':
nn.init.uniform_(arr, -scale, scale)
elif self.rnd_type == 'gaussian':
nn.init.normal_(arr, 0, scale)
else:
raise ValueError('Unknown random type')
================================================
FILE: XMem/inference/interact/fbrs/model/is_deeplab_model.py
================================================
import torch
import torch.nn as nn
from .ops import DistMaps
from .modeling.deeplab_v3 import DeepLabV3Plus
from .modeling.basic_blocks import SepConvHead
def get_deeplab_model(backbone='resnet50', deeplab_ch=256, aspp_dropout=0.5,
norm_layer=nn.BatchNorm2d, backbone_norm_layer=None,
use_rgb_conv=True, cpu_dist_maps=False,
norm_radius=260):
model = DistMapsModel(
feature_extractor=DeepLabV3Plus(backbone=backbone,
ch=deeplab_ch,
project_dropout=aspp_dropout,
norm_layer=norm_layer,
backbone_norm_layer=backbone_norm_layer),
head=SepConvHead(1, in_channels=deeplab_ch, mid_channels=deeplab_ch // 2,
num_layers=2, norm_layer=norm_layer),
use_rgb_conv=use_rgb_conv,
norm_layer=norm_layer,
norm_radius=norm_radius,
cpu_dist_maps=cpu_dist_maps
)
return model
class DistMapsModel(nn.Module):
def __init__(self, feature_extractor, head, norm_layer=nn.BatchNorm2d, use_rgb_conv=True,
cpu_dist_maps=False, norm_radius=260):
super(DistMapsModel, self).__init__()
if use_rgb_conv:
self.rgb_conv = nn.Sequential(
nn.Conv2d(in_channels=5, out_channels=8, kernel_size=1),
nn.LeakyReLU(negative_slope=0.2),
norm_layer(8),
nn.Conv2d(in_channels=8, out_channels=3, kernel_size=1),
)
else:
self.rgb_conv = None
self.dist_maps = DistMaps(norm_radius=norm_radius, spatial_scale=1.0,
cpu_mode=cpu_dist_maps)
self.feature_extractor = feature_extractor
self.head = head
def forward(self, image, points):
coord_features = self.dist_maps(image, points)
if self.rgb_conv is not None:
x = self.rgb_conv(torch.cat((image, coord_features), dim=1))
else:
c1, c2 = torch.chunk(coord_features, 2, dim=1)
c3 = torch.ones_like(c1)
coord_features = torch.cat((c1, c2, c3), dim=1)
x = 0.8 * image * coord_features + 0.2 * image
backbone_features = self.feature_extractor(x)
instance_out = self.head(backbone_features[0])
instance_out = nn.functional.interpolate(instance_out, size=image.size()[2:],
mode='bilinear', align_corners=True)
return {'instances': instance_out}
def load_weights(self, path_to_weights):
current_state_dict = self.state_dict()
new_state_dict = torch.load(path_to_weights, map_location='cpu')
current_state_dict.update(new_state_dict)
self.load_state_dict(current_state_dict)
def get_trainable_params(self):
backbone_params = nn.ParameterList()
other_params = nn.ParameterList()
for name, param in self.named_parameters():
if param.requires_grad:
if 'backbone' in name:
backbone_params.append(param)
else:
other_params.append(param)
return backbone_params, other_params
================================================
FILE: XMem/inference/interact/fbrs/model/is_hrnet_model.py
================================================
import torch
import torch.nn as nn
from .ops import DistMaps
from .modeling.hrnet_ocr import HighResolutionNet
def get_hrnet_model(width=48, ocr_width=256, small=False, norm_radius=260,
use_rgb_conv=True, with_aux_output=False, cpu_dist_maps=False,
norm_layer=nn.BatchNorm2d):
model = DistMapsHRNetModel(
feature_extractor=HighResolutionNet(width=width, ocr_width=ocr_width, small=small,
num_classes=1, norm_layer=norm_layer),
use_rgb_conv=use_rgb_conv,
with_aux_output=with_aux_output,
norm_layer=norm_layer,
norm_radius=norm_radius,
cpu_dist_maps=cpu_dist_maps
)
return model
class DistMapsHRNetModel(nn.Module):
def __init__(self, feature_extractor, use_rgb_conv=True, with_aux_output=False,
norm_layer=nn.BatchNorm2d, norm_radius=260, cpu_dist_maps=False):
super(DistMapsHRNetModel, self).__init__()
self.with_aux_output = with_aux_output
if use_rgb_conv:
self.rgb_conv = nn.Sequential(
nn.Conv2d(in_channels=5, out_channels=8, kernel_size=1),
nn.LeakyReLU(negative_slope=0.2),
norm_layer(8),
nn.Conv2d(in_channels=8, out_channels=3, kernel_size=1),
)
else:
self.rgb_conv = None
self.dist_maps = DistMaps(norm_radius=norm_radius, spatial_scale=1.0, cpu_mode=cpu_dist_maps)
self.feature_extractor = feature_extractor
def forward(self, image, points):
coord_features = self.dist_maps(image, points)
if self.rgb_conv is not None:
x = self.rgb_conv(torch.cat((image, coord_features), dim=1))
else:
c1, c2 = torch.chunk(coord_features, 2, dim=1)
c3 = torch.ones_like(c1)
coord_features = torch.cat((c1, c2, c3), dim=1)
x = 0.8 * image * coord_features + 0.2 * image
feature_extractor_out = self.feature_extractor(x)
instance_out = feature_extractor_out[0]
instance_out = nn.functional.interpolate(instance_out, size=image.size()[2:],
mode='bilinear', align_corners=True)
outputs = {'instances': instance_out}
if self.with_aux_output:
instance_aux_out = feature_extractor_out[1]
instance_aux_out = nn.functional.interpolate(instance_aux_out, size=image.size()[2:],
mode='bilinear', align_corners=True)
outputs['instances_aux'] = instance_aux_out
return outputs
def load_weights(self, path_to_weights):
current_state_dict = self.state_dict()
new_state_dict = torch.load(path_to_weights)
current_state_dict.update(new_state_dict)
self.load_state_dict(current_state_dict)
def get_trainable_params(self):
backbone_params = nn.ParameterList()
other_params = nn.ParameterList()
other_params_keys = []
nonbackbone_keywords = ['rgb_conv', 'aux_head', 'cls_head', 'conv3x3_ocr', 'ocr_distri_head']
for name, param in self.named_parameters():
if param.requires_grad:
if any(x in name for x in nonbackbone_keywords):
other_params.append(param)
other_params_keys.append(name)
else:
backbone_params.append(param)
print('Nonbackbone params:', sorted(other_params_keys))
return backbone_params, other_params
================================================
FILE: XMem/inference/interact/fbrs/model/losses.py
================================================
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..utils import misc
class NormalizedFocalLossSigmoid(nn.Module):
def __init__(self, axis=-1, alpha=0.25, gamma=2,
from_logits=False, batch_axis=0,
weight=None, size_average=True, detach_delimeter=True,
eps=1e-12, scale=1.0,
ignore_label=-1):
super(NormalizedFocalLossSigmoid, self).__init__()
self._axis = axis
self._alpha = alpha
self._gamma = gamma
self._ignore_label = ignore_label
self._weight = weight if weight is not None else 1.0
self._batch_axis = batch_axis
self._scale = scale
self._from_logits = from_logits
self._eps = eps
self._size_average = size_average
self._detach_delimeter = detach_delimeter
self._k_sum = 0
def forward(self, pred, label, sample_weight=None):
one_hot = label > 0
sample_weight = label != self._ignore_label
if not self._from_logits:
pred = torch.sigmoid(pred)
alpha = torch.where(one_hot, self._alpha * sample_weight, (1 - self._alpha) * sample_weight)
pt = torch.where(one_hot, pred, 1 - pred)
pt = torch.where(sample_weight, pt, torch.ones_like(pt))
beta = (1 - pt) ** self._gamma
sw_sum = torch.sum(sample_weight, dim=(-2, -1), keepdim=True)
beta_sum = torch.sum(beta, dim=(-2, -1), keepdim=True)
mult = sw_sum / (beta_sum + self._eps)
if self._detach_delimeter:
mult = mult.detach()
beta = beta * mult
ignore_area = torch.sum(label == self._ignore_label, dim=tuple(range(1, label.dim()))).cpu().numpy()
sample_mult = torch.mean(mult, dim=tuple(range(1, mult.dim()))).cpu().numpy()
if np.any(ignore_area == 0):
self._k_sum = 0.9 * self._k_sum + 0.1 * sample_mult[ignore_area == 0].mean()
loss = -alpha * beta * torch.log(torch.min(pt + self._eps, torch.ones(1, dtype=torch.float).to(pt.device)))
loss = self._weight * (loss * sample_weight)
if self._size_average:
bsum = torch.sum(sample_weight, dim=misc.get_dims_with_exclusion(sample_weight.dim(), self._batch_axis))
loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis)) / (bsum + self._eps)
else:
loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
return self._scale * loss
def log_states(self, sw, name, global_step):
sw.add_scalar(tag=name + '_k', value=self._k_sum, global_step=global_step)
class FocalLoss(nn.Module):
def __init__(self, axis=-1, alpha=0.25, gamma=2,
from_logits=False, batch_axis=0,
weight=None, num_class=None,
eps=1e-9, size_average=True, scale=1.0):
super(FocalLoss, self).__init__()
self._axis = axis
self._alpha = alpha
self._gamma = gamma
self._weight = weight if weight is not None else 1.0
self._batch_axis = batch_axis
self._scale = scale
self._num_class = num_class
self._from_logits = from_logits
self._eps = eps
self._size_average = size_average
def forward(self, pred, label, sample_weight=None):
if not self._from_logits:
pred = F.sigmoid(pred)
one_hot = label > 0
pt = torch.where(one_hot, pred, 1 - pred)
t = label != -1
alpha = torch.where(one_hot, self._alpha * t, (1 - self._alpha) * t)
beta = (1 - pt) ** self._gamma
loss = -alpha * beta * torch.log(torch.min(pt + self._eps, torch.ones(1, dtype=torch.float).to(pt.device)))
sample_weight = label != -1
loss = self._weight * (loss * sample_weight)
if self._size_average:
tsum = torch.sum(label == 1, dim=misc.get_dims_with_exclusion(label.dim(), self._batch_axis))
loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis)) / (tsum + self._eps)
else:
loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
return self._scale * loss
class SigmoidBinaryCrossEntropyLoss(nn.Module):
def __init__(self, from_sigmoid=False, weight=None, batch_axis=0, ignore_label=-1):
super(SigmoidBinaryCrossEntropyLoss, self).__init__()
self._from_sigmoid = from_sigmoid
self._ignore_label = ignore_label
self._weight = weight if weight is not None else 1.0
self._batch_axis = batch_axis
def forward(self, pred, label):
label = label.view(pred.size())
sample_weight = label != self._ignore_label
label = torch.where(sample_weight, label, torch.zeros_like(label))
if not self._from_sigmoid:
loss = torch.relu(pred) - pred * label + F.softplus(-torch.abs(pred))
else:
eps = 1e-12
loss = -(torch.log(pred + eps) * label
+ torch.log(1. - pred + eps) * (1. - label))
loss = self._weight * (loss * sample_weight)
return torch.mean(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
================================================
FILE: XMem/inference/interact/fbrs/model/metrics.py
================================================
import torch
import numpy as np
from ..utils import misc
class TrainMetric(object):
def __init__(self, pred_outputs, gt_outputs):
self.pred_outputs = pred_outputs
self.gt_outputs = gt_outputs
def update(self, *args, **kwargs):
raise NotImplementedError
def get_epoch_value(self):
raise NotImplementedError
def reset_epoch_stats(self):
raise NotImplementedError
def log_states(self, sw, tag_prefix, global_step):
pass
@property
def name(self):
return type(self).__name__
class AdaptiveIoU(TrainMetric):
def __init__(self, init_thresh=0.4, thresh_step=0.025, thresh_beta=0.99, iou_beta=0.9,
ignore_label=-1, from_logits=True,
pred_output='instances', gt_output='instances'):
super().__init__(pred_outputs=(pred_output,), gt_outputs=(gt_output,))
self._ignore_label = ignore_label
self._from_logits = from_logits
self._iou_thresh = init_thresh
self._thresh_step = thresh_step
self._thresh_beta = thresh_beta
self._iou_beta = iou_beta
self._ema_iou = 0.0
self._epoch_iou_sum = 0.0
self._epoch_batch_count = 0
def update(self, pred, gt):
gt_mask = gt > 0
if self._from_logits:
pred = torch.sigmoid(pred)
gt_mask_area = torch.sum(gt_mask, dim=(1, 2)).detach().cpu().numpy()
if np.all(gt_mask_area == 0):
return
ignore_mask = gt == self._ignore_label
max_iou = _compute_iou(pred > self._iou_thresh, gt_mask, ignore_mask).mean()
best_thresh = self._iou_thresh
for t in [best_thresh - self._thresh_step, best_thresh + self._thresh_step]:
temp_iou = _compute_iou(pred > t, gt_mask, ignore_mask).mean()
if temp_iou > max_iou:
max_iou = temp_iou
best_thresh = t
self._iou_thresh = self._thresh_beta * self._iou_thresh + (1 - self._thresh_beta) * best_thresh
self._ema_iou = self._iou_beta * self._ema_iou + (1 - self._iou_beta) * max_iou
self._epoch_iou_sum += max_iou
self._epoch_batch_count += 1
def get_epoch_value(self):
if self._epoch_batch_count > 0:
return self._epoch_iou_sum / self._epoch_batch_count
else:
return 0.0
def reset_epoch_stats(self):
self._epoch_iou_sum = 0.0
self._epoch_batch_count = 0
def log_states(self, sw, tag_prefix, global_step):
sw.add_scalar(tag=tag_prefix + '_ema_iou', value=self._ema_iou, global_step=global_step)
sw.add_scalar(tag=tag_prefix + '_iou_thresh', value=self._iou_thresh, global_step=global_step)
@property
def iou_thresh(self):
return self._iou_thresh
def _compute_iou(pred_mask, gt_mask, ignore_mask=None, keep_ignore=False):
if ignore_mask is not None:
pred_mask = torch.where(ignore_mask, torch.zeros_like(pred_mask), pred_mask)
reduction_dims = misc.get_dims_with_exclusion(gt_mask.dim(), 0)
union = torch.mean((pred_mask | gt_mask).float(), dim=reduction_dims).detach().cpu().numpy()
intersection = torch.mean((pred_mask & gt_mask).float(), dim=reduction_dims).detach().cpu().numpy()
nonzero = union > 0
iou = intersection[nonzero] / union[nonzero]
if not keep_ignore:
return iou
else:
result = np.full_like(intersection, -1)
result[nonzero] = iou
return result
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/basic_blocks.py
================================================
import torch.nn as nn
from ...model import ops
class ConvHead(nn.Module):
def __init__(self, out_channels, in_channels=32, num_layers=1,
kernel_size=3, padding=1,
norm_layer=nn.BatchNorm2d):
super(ConvHead, self).__init__()
convhead = []
for i in range(num_layers):
convhead.extend([
nn.Conv2d(in_channels, in_channels, kernel_size, padding=padding),
nn.ReLU(),
norm_layer(in_channels) if norm_layer is not None else nn.Identity()
])
convhead.append(nn.Conv2d(in_channels, out_channels, 1, padding=0))
self.convhead = nn.Sequential(*convhead)
def forward(self, *inputs):
return self.convhead(inputs[0])
class SepConvHead(nn.Module):
def __init__(self, num_outputs, in_channels, mid_channels, num_layers=1,
kernel_size=3, padding=1, dropout_ratio=0.0, dropout_indx=0,
norm_layer=nn.BatchNorm2d):
super(SepConvHead, self).__init__()
sepconvhead = []
for i in range(num_layers):
sepconvhead.append(
SeparableConv2d(in_channels=in_channels if i == 0 else mid_channels,
out_channels=mid_channels,
dw_kernel=kernel_size, dw_padding=padding,
norm_layer=norm_layer, activation='relu')
)
if dropout_ratio > 0 and dropout_indx == i:
sepconvhead.append(nn.Dropout(dropout_ratio))
sepconvhead.append(
nn.Conv2d(in_channels=mid_channels, out_channels=num_outputs, kernel_size=1, padding=0)
)
self.layers = nn.Sequential(*sepconvhead)
def forward(self, *inputs):
x = inputs[0]
return self.layers(x)
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, dw_kernel, dw_padding, dw_stride=1,
activation=None, use_bias=False, norm_layer=None):
super(SeparableConv2d, self).__init__()
_activation = ops.select_activation_function(activation)
self.body = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=dw_kernel, stride=dw_stride,
padding=dw_padding, bias=use_bias, groups=in_channels),
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=use_bias),
norm_layer(out_channels) if norm_layer is not None else nn.Identity(),
_activation()
)
def forward(self, x):
return self.body(x)
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/deeplab_v3.py
================================================
from contextlib import ExitStack
import torch
from torch import nn
import torch.nn.functional as F
from .basic_blocks import SeparableConv2d
from .resnet import ResNetBackbone
from ...model import ops
class DeepLabV3Plus(nn.Module):
def __init__(self, backbone='resnet50', norm_layer=nn.BatchNorm2d,
backbone_norm_layer=None,
ch=256,
project_dropout=0.5,
inference_mode=False,
**kwargs):
super(DeepLabV3Plus, self).__init__()
if backbone_norm_layer is None:
backbone_norm_layer = norm_layer
self.backbone_name = backbone
self.norm_layer = norm_layer
self.backbone_norm_layer = backbone_norm_layer
self.inference_mode = False
self.ch = ch
self.aspp_in_channels = 2048
self.skip_project_in_channels = 256 # layer 1 out_channels
self._kwargs = kwargs
if backbone == 'resnet34':
self.aspp_in_channels = 512
self.skip_project_in_channels = 64
self.backbone = ResNetBackbone(backbone=self.backbone_name, pretrained_base=False,
norm_layer=self.backbone_norm_layer, **kwargs)
self.head = _DeepLabHead(in_channels=ch + 32, mid_channels=ch, out_channels=ch,
norm_layer=self.norm_layer)
self.skip_project = _SkipProject(self.skip_project_in_channels, 32, norm_layer=self.norm_layer)
self.aspp = _ASPP(in_channels=self.aspp_in_channels,
atrous_rates=[12, 24, 36],
out_channels=ch,
project_dropout=project_dropout,
norm_layer=self.norm_layer)
if inference_mode:
self.set_prediction_mode()
def load_pretrained_weights(self):
pretrained = ResNetBackbone(backbone=self.backbone_name, pretrained_base=True,
norm_layer=self.backbone_norm_layer, **self._kwargs)
backbone_state_dict = self.backbone.state_dict()
pretrained_state_dict = pretrained.state_dict()
backbone_state_dict.update(pretrained_state_dict)
self.backbone.load_state_dict(backbone_state_dict)
if self.inference_mode:
for param in self.backbone.parameters():
param.requires_grad = False
def set_prediction_mode(self):
self.inference_mode = True
self.eval()
def forward(self, x):
with ExitStack() as stack:
if self.inference_mode:
stack.enter_context(torch.no_grad())
c1, _, c3, c4 = self.backbone(x)
c1 = self.skip_project(c1)
x = self.aspp(c4)
x = F.interpolate(x, c1.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x, c1), dim=1)
x = self.head(x)
return x,
class _SkipProject(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer=nn.BatchNorm2d):
super(_SkipProject, self).__init__()
_activation = ops.select_activation_function("relu")
self.skip_project = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
norm_layer(out_channels),
_activation()
)
def forward(self, x):
return self.skip_project(x)
class _DeepLabHead(nn.Module):
def __init__(self, out_channels, in_channels, mid_channels=256, norm_layer=nn.BatchNorm2d):
super(_DeepLabHead, self).__init__()
self.block = nn.Sequential(
SeparableConv2d(in_channels=in_channels, out_channels=mid_channels, dw_kernel=3,
dw_padding=1, activation='relu', norm_layer=norm_layer),
SeparableConv2d(in_channels=mid_channels, out_channels=mid_channels, dw_kernel=3,
dw_padding=1, activation='relu', norm_layer=norm_layer),
nn.Conv2d(in_channels=mid_channels, out_channels=out_channels, kernel_size=1)
)
def forward(self, x):
return self.block(x)
class _ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates, out_channels=256,
project_dropout=0.5, norm_layer=nn.BatchNorm2d):
super(_ASPP, self).__init__()
b0 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, bias=False),
norm_layer(out_channels),
nn.ReLU()
)
rate1, rate2, rate3 = tuple(atrous_rates)
b1 = _ASPPConv(in_channels, out_channels, rate1, norm_layer)
b2 = _ASPPConv(in_channels, out_channels, rate2, norm_layer)
b3 = _ASPPConv(in_channels, out_channels, rate3, norm_layer)
b4 = _AsppPooling(in_channels, out_channels, norm_layer=norm_layer)
self.concurent = nn.ModuleList([b0, b1, b2, b3, b4])
project = [
nn.Conv2d(in_channels=5*out_channels, out_channels=out_channels,
kernel_size=1, bias=False),
norm_layer(out_channels),
nn.ReLU()
]
if project_dropout > 0:
project.append(nn.Dropout(project_dropout))
self.project = nn.Sequential(*project)
def forward(self, x):
x = torch.cat([block(x) for block in self.concurent], dim=1)
return self.project(x)
class _AsppPooling(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer):
super(_AsppPooling, self).__init__()
self.gap = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, bias=False),
norm_layer(out_channels),
nn.ReLU()
)
def forward(self, x):
pool = self.gap(x)
return F.interpolate(pool, x.size()[2:], mode='bilinear', align_corners=True)
def _ASPPConv(in_channels, out_channels, atrous_rate, norm_layer):
block = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=3, padding=atrous_rate,
dilation=atrous_rate, bias=False),
norm_layer(out_channels),
nn.ReLU()
)
return block
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/hrnet_ocr.py
================================================
import os
import numpy as np
import torch
import torch.nn as nn
import torch._utils
import torch.nn.functional as F
from .ocr import SpatialOCR_Module, SpatialGather_Module
from .resnetv1b import BasicBlockV1b, BottleneckV1b
relu_inplace = True
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method,multi_scale_output=True,
norm_layer=nn.BatchNorm2d, align_corners=True):
super(HighResolutionModule, self).__init__()
self._check_branches(num_branches, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.norm_layer = norm_layer
self.align_corners = align_corners
self.multi_scale_output = multi_scale_output
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(inplace=relu_inplace)
def _check_branches(self, num_branches, num_blocks, num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
raise ValueError(error_msg)
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False),
self.norm_layer(num_channels[branch_index] * block.expansion),
)
layers = []
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index], stride,
downsample=downsample, norm_layer=self.norm_layer))
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
for i in range(1, num_blocks[branch_index]):
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index],
norm_layer=self.norm_layer))
return nn.Sequential(*layers)
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels))
return nn.ModuleList(branches)
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
if j > i:
fuse_layer.append(nn.Sequential(
nn.Conv2d(in_channels=num_inchannels[j],
out_channels=num_inchannels[i],
kernel_size=1,
bias=False),
self.norm_layer(num_inchannels[i])))
elif j == i:
fuse_layer.append(None)
else:
conv3x3s = []
for k in range(i - j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
kernel_size=3, stride=2, padding=1, bias=False),
self.norm_layer(num_outchannels_conv3x3)))
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
kernel_size=3, stride=2, padding=1, bias=False),
self.norm_layer(num_outchannels_conv3x3),
nn.ReLU(inplace=relu_inplace)))
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def get_num_inchannels(self):
return self.num_inchannels
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
x_fuse = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
elif j > i:
width_output = x[i].shape[-1]
height_output = x[i].shape[-2]
y = y + F.interpolate(
self.fuse_layers[i][j](x[j]),
size=[height_output, width_output],
mode='bilinear', align_corners=self.align_corners)
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse
class HighResolutionNet(nn.Module):
def __init__(self, width, num_classes, ocr_width=256, small=False,
norm_layer=nn.BatchNorm2d, align_corners=True):
super(HighResolutionNet, self).__init__()
self.norm_layer = norm_layer
self.width = width
self.ocr_width = ocr_width
self.align_corners = align_corners
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = norm_layer(64)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn2 = norm_layer(64)
self.relu = nn.ReLU(inplace=relu_inplace)
num_blocks = 2 if small else 4
stage1_num_channels = 64
self.layer1 = self._make_layer(BottleneckV1b, 64, stage1_num_channels, blocks=num_blocks)
stage1_out_channel = BottleneckV1b.expansion * stage1_num_channels
self.stage2_num_branches = 2
num_channels = [width, 2 * width]
num_inchannels = [
num_channels[i] * BasicBlockV1b.expansion for i in range(len(num_channels))]
self.transition1 = self._make_transition_layer(
[stage1_out_channel], num_inchannels)
self.stage2, pre_stage_channels = self._make_stage(
BasicBlockV1b, num_inchannels=num_inchannels, num_modules=1, num_branches=self.stage2_num_branches,
num_blocks=2 * [num_blocks], num_channels=num_channels)
self.stage3_num_branches = 3
num_channels = [width, 2 * width, 4 * width]
num_inchannels = [
num_channels[i] * BasicBlockV1b.expansion for i in range(len(num_channels))]
self.transition2 = self._make_transition_layer(
pre_stage_channels, num_inchannels)
self.stage3, pre_stage_channels = self._make_stage(
BasicBlockV1b, num_inchannels=num_inchannels,
num_modules=3 if small else 4, num_branches=self.stage3_num_branches,
num_blocks=3 * [num_blocks], num_channels=num_channels)
self.stage4_num_branches = 4
num_channels = [width, 2 * width, 4 * width, 8 * width]
num_inchannels = [
num_channels[i] * BasicBlockV1b.expansion for i in range(len(num_channels))]
self.transition3 = self._make_transition_layer(
pre_stage_channels, num_inchannels)
self.stage4, pre_stage_channels = self._make_stage(
BasicBlockV1b, num_inchannels=num_inchannels, num_modules=2 if small else 3,
num_branches=self.stage4_num_branches,
num_blocks=4 * [num_blocks], num_channels=num_channels)
last_inp_channels = np.int32(np.sum(pre_stage_channels))
ocr_mid_channels = 2 * ocr_width
ocr_key_channels = ocr_width
self.conv3x3_ocr = nn.Sequential(
nn.Conv2d(last_inp_channels, ocr_mid_channels,
kernel_size=3, stride=1, padding=1),
norm_layer(ocr_mid_channels),
nn.ReLU(inplace=relu_inplace),
)
self.ocr_gather_head = SpatialGather_Module(num_classes)
self.ocr_distri_head = SpatialOCR_Module(in_channels=ocr_mid_channels,
key_channels=ocr_key_channels,
out_channels=ocr_mid_channels,
scale=1,
dropout=0.05,
norm_layer=norm_layer,
align_corners=align_corners)
self.cls_head = nn.Conv2d(
ocr_mid_channels, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
self.aux_head = nn.Sequential(
nn.Conv2d(last_inp_channels, last_inp_channels,
kernel_size=1, stride=1, padding=0),
norm_layer(last_inp_channels),
nn.ReLU(inplace=relu_inplace),
nn.Conv2d(last_inp_channels, num_classes,
kernel_size=1, stride=1, padding=0, bias=True)
)
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
for i in range(num_branches_cur):
if i < num_branches_pre:
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
kernel_size=3,
stride=1,
padding=1,
bias=False),
self.norm_layer(num_channels_cur_layer[i]),
nn.ReLU(inplace=relu_inplace)))
else:
transition_layers.append(None)
else:
conv3x3s = []
for j in range(i + 1 - num_branches_pre):
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i - num_branches_pre else inchannels
conv3x3s.append(nn.Sequential(
nn.Conv2d(inchannels, outchannels,
kernel_size=3, stride=2, padding=1, bias=False),
self.norm_layer(outchannels),
nn.ReLU(inplace=relu_inplace)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
def _make_layer(self, block, inplanes, planes, blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
self.norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(inplanes, planes, stride,
downsample=downsample, norm_layer=self.norm_layer))
inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(inplanes, planes, norm_layer=self.norm_layer))
return nn.Sequential(*layers)
def _make_stage(self, block, num_inchannels,
num_modules, num_branches, num_blocks, num_channels,
fuse_method='SUM',
multi_scale_output=True):
modules = []
for i in range(num_modules):
# multi_scale_output is only used last module
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
modules.append(
HighResolutionModule(num_branches,
block,
num_blocks,
num_inchannels,
num_channels,
fuse_method,
reset_multi_scale_output,
norm_layer=self.norm_layer,
align_corners=self.align_corners)
)
num_inchannels = modules[-1].get_num_inchannels()
return nn.Sequential(*modules), num_inchannels
def forward(self, x):
feats = self.compute_hrnet_feats(x)
out_aux = self.aux_head(feats)
feats = self.conv3x3_ocr(feats)
context = self.ocr_gather_head(feats, out_aux)
feats = self.ocr_distri_head(feats, context)
out = self.cls_head(feats)
return [out, out_aux]
def compute_hrnet_feats(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.layer1(x)
x_list = []
for i in range(self.stage2_num_branches):
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
y_list = self.stage2(x_list)
x_list = []
for i in range(self.stage3_num_branches):
if self.transition2[i] is not None:
if i < self.stage2_num_branches:
x_list.append(self.transition2[i](y_list[i]))
else:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
y_list = self.stage3(x_list)
x_list = []
for i in range(self.stage4_num_branches):
if self.transition3[i] is not None:
if i < self.stage3_num_branches:
x_list.append(self.transition3[i](y_list[i]))
else:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
x = self.stage4(x_list)
# Upsampling
x0_h, x0_w = x[0].size(2), x[0].size(3)
x1 = F.interpolate(x[1], size=(x0_h, x0_w),
mode='bilinear', align_corners=self.align_corners)
x2 = F.interpolate(x[2], size=(x0_h, x0_w),
mode='bilinear', align_corners=self.align_corners)
x3 = F.interpolate(x[3], size=(x0_h, x0_w),
mode='bilinear', align_corners=self.align_corners)
return torch.cat([x[0], x1, x2, x3], 1)
def load_pretrained_weights(self, pretrained_path=''):
model_dict = self.state_dict()
if not os.path.exists(pretrained_path):
print(f'\nFile "{pretrained_path}" does not exist.')
print('You need to specify the correct path to the pre-trained weights.\n'
'You can download the weights for HRNet from the repository:\n'
'https://github.com/HRNet/HRNet-Image-Classification')
exit(1)
pretrained_dict = torch.load(pretrained_path, map_location={'cuda:0': 'cpu'})
pretrained_dict = {k.replace('last_layer', 'aux_head').replace('model.', ''): v for k, v in
pretrained_dict.items()}
print('model_dict-pretrained_dict:', sorted(list(set(model_dict) - set(pretrained_dict))))
print('pretrained_dict-model_dict:', sorted(list(set(pretrained_dict) - set(model_dict))))
pretrained_dict = {k: v for k, v in pretrained_dict.items()
if k in model_dict.keys()}
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/ocr.py
================================================
import torch
import torch.nn as nn
import torch._utils
import torch.nn.functional as F
class SpatialGather_Module(nn.Module):
"""
Aggregate the context features according to the initial
predicted probability distribution.
Employ the soft-weighted method to aggregate the context.
"""
def __init__(self, cls_num=0, scale=1):
super(SpatialGather_Module, self).__init__()
self.cls_num = cls_num
self.scale = scale
def forward(self, feats, probs):
batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)
probs = probs.view(batch_size, c, -1)
feats = feats.view(batch_size, feats.size(1), -1)
feats = feats.permute(0, 2, 1) # batch x hw x c
probs = F.softmax(self.scale * probs, dim=2) # batch x k x hw
ocr_context = torch.matmul(probs, feats) \
.permute(0, 2, 1).unsqueeze(3) # batch x k x c
return ocr_context
class SpatialOCR_Module(nn.Module):
"""
Implementation of the OCR module:
We aggregate the global object representation to update the representation for each pixel.
"""
def __init__(self,
in_channels,
key_channels,
out_channels,
scale=1,
dropout=0.1,
norm_layer=nn.BatchNorm2d,
align_corners=True):
super(SpatialOCR_Module, self).__init__()
self.object_context_block = ObjectAttentionBlock2D(in_channels, key_channels, scale,
norm_layer, align_corners)
_in_channels = 2 * in_channels
self.conv_bn_dropout = nn.Sequential(
nn.Conv2d(_in_channels, out_channels, kernel_size=1, padding=0, bias=False),
nn.Sequential(norm_layer(out_channels), nn.ReLU(inplace=True)),
nn.Dropout2d(dropout)
)
def forward(self, feats, proxy_feats):
context = self.object_context_block(feats, proxy_feats)
output = self.conv_bn_dropout(torch.cat([context, feats], 1))
return output
class ObjectAttentionBlock2D(nn.Module):
'''
The basic implementation for object context block
Input:
N X C X H X W
Parameters:
in_channels : the dimension of the input feature map
key_channels : the dimension after the key/query transform
scale : choose the scale to downsample the input feature maps (save memory cost)
bn_type : specify the bn type
Return:
N X C X H X W
'''
def __init__(self,
in_channels,
key_channels,
scale=1,
norm_layer=nn.BatchNorm2d,
align_corners=True):
super(ObjectAttentionBlock2D, self).__init__()
self.scale = scale
self.in_channels = in_channels
self.key_channels = key_channels
self.align_corners = align_corners
self.pool = nn.MaxPool2d(kernel_size=(scale, scale))
self.f_pixel = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True)),
nn.Conv2d(in_channels=self.key_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True))
)
self.f_object = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True)),
nn.Conv2d(in_channels=self.key_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True))
)
self.f_down = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True))
)
self.f_up = nn.Sequential(
nn.Conv2d(in_channels=self.key_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0, bias=False),
nn.Sequential(norm_layer(self.in_channels), nn.ReLU(inplace=True))
)
def forward(self, x, proxy):
batch_size, h, w = x.size(0), x.size(2), x.size(3)
if self.scale > 1:
x = self.pool(x)
query = self.f_pixel(x).view(batch_size, self.key_channels, -1)
query = query.permute(0, 2, 1)
key = self.f_object(proxy).view(batch_size, self.key_channels, -1)
value = self.f_down(proxy).view(batch_size, self.key_channels, -1)
value = value.permute(0, 2, 1)
sim_map = torch.matmul(query, key)
sim_map = (self.key_channels ** -.5) * sim_map
sim_map = F.softmax(sim_map, dim=-1)
# add bg context ...
context = torch.matmul(sim_map, value)
context = context.permute(0, 2, 1).contiguous()
context = context.view(batch_size, self.key_channels, *x.size()[2:])
context = self.f_up(context)
if self.scale > 1:
context = F.interpolate(input=context, size=(h, w),
mode='bilinear', align_corners=self.align_corners)
return context
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/resnet.py
================================================
import torch
from .resnetv1b import resnet34_v1b, resnet50_v1s, resnet101_v1s, resnet152_v1s
class ResNetBackbone(torch.nn.Module):
def __init__(self, backbone='resnet50', pretrained_base=True, dilated=True, **kwargs):
super(ResNetBackbone, self).__init__()
if backbone == 'resnet34':
pretrained = resnet34_v1b(pretrained=pretrained_base, dilated=dilated, **kwargs)
elif backbone == 'resnet50':
pretrained = resnet50_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
elif backbone == 'resnet101':
pretrained = resnet101_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
elif backbone == 'resnet152':
pretrained = resnet152_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
else:
raise RuntimeError(f'unknown backbone: {backbone}')
self.conv1 = pretrained.conv1
self.bn1 = pretrained.bn1
self.relu = pretrained.relu
self.maxpool = pretrained.maxpool
self.layer1 = pretrained.layer1
self.layer2 = pretrained.layer2
self.layer3 = pretrained.layer3
self.layer4 = pretrained.layer4
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
c1 = self.layer1(x)
c2 = self.layer2(c1)
c3 = self.layer3(c2)
c4 = self.layer4(c3)
return c1, c2, c3, c4
================================================
FILE: XMem/inference/interact/fbrs/model/modeling/resnetv1b.py
================================================
import torch
import torch.nn as nn
GLUON_RESNET_TORCH_HUB = 'rwightman/pytorch-pretrained-gluonresnet'
class BasicBlockV1b(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None,
previous_dilation=1, norm_layer=nn.BatchNorm2d):
super(BasicBlockV1b, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
self.bn1 = norm_layer(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1,
padding=previous_dilation, dilation=previous_dilation, bias=False)
self.bn2 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
class BottleneckV1b(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None,
previous_dilation=1, norm_layer=nn.BatchNorm2d):
super(BottleneckV1b, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = norm_layer(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
self.bn2 = norm_layer(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
class ResNetV1b(nn.Module):
""" Pre-trained ResNetV1b Model, which produces the strides of 8 featuremaps at conv5.
Parameters
----------
block : Block
Class for the residual block. Options are BasicBlockV1, BottleneckV1.
layers : list of int
Numbers of layers in each block
classes : int, default 1000
Number of classification classes.
dilated : bool, default False
Applying dilation strategy to pretrained ResNet yielding a stride-8 model,
typically used in Semantic Segmentation.
norm_layer : object
Normalization layer used (default: :class:`nn.BatchNorm2d`)
deep_stem : bool, default False
Whether to replace the 7x7 conv1 with 3 3x3 convolution layers.
avg_down : bool, default False
Whether to use average pooling for projection skip connection between stages/downsample.
final_drop : float, default 0.0
Dropout ratio before the final classification layer.
Reference:
- He, Kaiming, et al. "Deep residual learning for image recognition."
Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions."
"""
def __init__(self, block, layers, classes=1000, dilated=True, deep_stem=False, stem_width=32,
avg_down=False, final_drop=0.0, norm_layer=nn.BatchNorm2d):
self.inplanes = stem_width*2 if deep_stem else 64
super(ResNetV1b, self).__init__()
if not deep_stem:
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(3, stem_width, kernel_size=3, stride=2, padding=1, bias=False),
norm_layer(stem_width),
nn.ReLU(True),
nn.Conv2d(stem_width, stem_width, kernel_size=3, stride=1, padding=1, bias=False),
norm_layer(stem_width),
nn.ReLU(True),
nn.Conv2d(stem_width, 2*stem_width, kernel_size=3, stride=1, padding=1, bias=False)
)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(True)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], avg_down=avg_down,
norm_layer=norm_layer)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, avg_down=avg_down,
norm_layer=norm_layer)
if dilated:
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2,
avg_down=avg_down, norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4,
avg_down=avg_down, norm_layer=norm_layer)
else:
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
avg_down=avg_down, norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
avg_down=avg_down, norm_layer=norm_layer)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.drop = None
if final_drop > 0.0:
self.drop = nn.Dropout(final_drop)
self.fc = nn.Linear(512 * block.expansion, classes)
def _make_layer(self, block, planes, blocks, stride=1, dilation=1,
avg_down=False, norm_layer=nn.BatchNorm2d):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = []
if avg_down:
if dilation == 1:
downsample.append(
nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True, count_include_pad=False)
)
else:
downsample.append(
nn.AvgPool2d(kernel_size=1, stride=1, ceil_mode=True, count_include_pad=False)
)
downsample.extend([
nn.Conv2d(self.inplanes, out_channels=planes * block.expansion,
kernel_size=1, stride=1, bias=False),
norm_layer(planes * block.expansion)
])
downsample = nn.Sequential(*downsample)
else:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, out_channels=planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
norm_layer(planes * block.expansion)
)
layers = []
if dilation in (1, 2):
layers.append(block(self.inplanes, planes, stride, dilation=1, downsample=downsample,
previous_dilation=dilation, norm_layer=norm_layer))
elif dilation == 4:
layers.append(block(self.inplanes, planes, stride, dilation=2, downsample=downsample,
previous_dilation=dilation, norm_layer=norm_layer))
else:
raise RuntimeError("=> unknown dilation size: {}".format(dilation))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation,
previous_dilation=dilation, norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
if self.drop is not None:
x = self.drop(x)
x = self.fc(x)
return x
def _safe_state_dict_filtering(orig_dict, model_dict_keys):
filtered_orig_dict = {}
for k, v in orig_dict.items():
if k in model_dict_keys:
filtered_orig_dict[k] = v
else:
print(f"[ERROR] Failed to load <{k}> in backbone")
return filtered_orig_dict
def resnet34_v1b(pretrained=False, **kwargs):
model = ResNetV1b(BasicBlockV1b, [3, 4, 6, 3], **kwargs)
if pretrained:
model_dict = model.state_dict()
filtered_orig_dict = _safe_state_dict_filtering(
torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet34_v1b', pretrained=True).state_dict(),
model_dict.keys()
)
model_dict.update(filtered_orig_dict)
model.load_state_dict(model_dict)
return model
def resnet50_v1s(pretrained=False, **kwargs):
model = ResNetV1b(BottleneckV1b, [3, 4, 6, 3], deep_stem=True, stem_width=64, **kwargs)
if pretrained:
model_dict = model.state_dict()
filtered_orig_dict = _safe_state_dict_filtering(
torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet50_v1s', pretrained=True).state_dict(),
model_dict.keys()
)
model_dict.update(filtered_orig_dict)
model.load_state_dict(model_dict)
return model
def resnet101_v1s(pretrained=False, **kwargs):
model = ResNetV1b(BottleneckV1b, [3, 4, 23, 3], deep_stem=True, stem_width=64, **kwargs)
if pretrained:
model_dict = model.state_dict()
filtered_orig_dict = _safe_state_dict_filtering(
torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet101_v1s', pretrained=True).state_dict(),
model_dict.keys()
)
model_dict.update(filtered_orig_dict)
model.load_state_dict(model_dict)
return model
def resnet152_v1s(pretrained=False, **kwargs):
model = ResNetV1b(BottleneckV1b, [3, 8, 36, 3], deep_stem=True, stem_width=64, **kwargs)
if pretrained:
model_dict = model.state_dict()
filtered_orig_dict = _safe_state_dict_filtering(
torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet152_v1s', pretrained=True).state_dict(),
model_dict.keys()
)
model_dict.update(filtered_orig_dict)
model.load_state_dict(model_dict)
return model
================================================
FILE: XMem/inference/interact/fbrs/model/ops.py
================================================
import torch
from torch import nn as nn
import numpy as np
from . import initializer as initializer
from ..utils.cython import get_dist_maps
def select_activation_function(activation):
if isinstance(activation, str):
if activation.lower() == 'relu':
return nn.ReLU
elif activation.lower() == 'softplus':
return nn.Softplus
else:
raise ValueError(f"Unknown activation type {activation}")
elif isinstance(activation, nn.Module):
return activation
else:
raise ValueError(f"Unknown activation type {activation}")
class BilinearConvTranspose2d(nn.ConvTranspose2d):
def __init__(self, in_channels, out_channels, scale, groups=1):
kernel_size = 2 * scale - scale % 2
self.scale = scale
super().__init__(
in_channels, out_channels,
kernel_size=kernel_size,
stride=scale,
padding=1,
groups=groups,
bias=False)
self.apply(initializer.Bilinear(scale=scale, in_channels=in_channels, groups=groups))
class DistMaps(nn.Module):
def __init__(self, norm_radius, spatial_scale=1.0, cpu_mode=False):
super(DistMaps, self).__init__()
self.spatial_scale = spatial_scale
self.norm_radius = norm_radius
self.cpu_mode = cpu_mode
def get_coord_features(self, points, batchsize, rows, cols):
if self.cpu_mode:
coords = []
for i in range(batchsize):
norm_delimeter = self.spatial_scale * self.norm_radius
coords.append(get_dist_maps(points[i].cpu().float().numpy(), rows, cols,
norm_delimeter))
coords = torch.from_numpy(np.stack(coords, axis=0)).to(points.device).float()
else:
num_points = points.shape[1] // 2
points = points.view(-1, 2)
invalid_points = torch.max(points, dim=1, keepdim=False)[0] < 0
row_array = torch.arange(start=0, end=rows, step=1, dtype=torch.float32, device=points.device)
col_array = torch.arange(start=0, end=cols, step=1, dtype=torch.float32, device=points.device)
coord_rows, coord_cols = torch.meshgrid(row_array, col_array)
coords = torch.stack((coord_rows, coord_cols), dim=0).unsqueeze(0).repeat(points.size(0), 1, 1, 1)
add_xy = (points * self.spatial_scale).view(points.size(0), points.size(1), 1, 1)
coords.add_(-add_xy)
coords.div_(self.norm_radius * self.spatial_scale)
coords.mul_(coords)
coords[:, 0] += coords[:, 1]
coords = coords[:, :1]
coords[invalid_points, :, :, :] = 1e6
coords = coords.view(-1, num_points, 1, rows, cols)
coords = coords.min(dim=1)[0] # -> (bs * num_masks * 2) x 1 x h x w
coords = coords.view(-1, 2, rows, cols)
coords.sqrt_().mul_(2).tanh_()
return coords
def forward(self, x, coords):
return self.get_coord_features(coords, x.shape[0], x.shape[2], x.shape[3])
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/LICENSE
================================================
MIT License
Copyright (c) 2018 Tamaki Kojima
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/README.md
================================================
# pytorch-syncbn
Tamaki Kojima(tamakoji@gmail.com)
## Announcement
**Pytorch 1.0 support**
## Overview
This is alternative implementation of "Synchronized Multi-GPU Batch Normalization" which computes global stats across gpus instead of locally computed. SyncBN are getting important for those input image is large, and must use multi-gpu to increase the minibatch-size for the training.
The code was inspired by [Pytorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding) and [Inplace-ABN](https://github.com/mapillary/inplace_abn)
## Remarks
- Unlike [Pytorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding), you don't need custom `nn.DataParallel`
- Unlike [Inplace-ABN](https://github.com/mapillary/inplace_abn), you can just replace your `nn.BatchNorm2d` to this module implementation, since it will not mark for inplace operation
- You can plug into arbitrary module written in PyTorch to enable Synchronized BatchNorm
- Backward computation is rewritten and tested against behavior of `nn.BatchNorm2d`
## Requirements
For PyTorch, please refer to https://pytorch.org/
NOTE : The code is tested only with PyTorch v1.0.0, CUDA10/CuDNN7.4.2 on ubuntu18.04
It utilize Pytorch JIT mechanism to compile seamlessly, using ninja. Please install ninja-build before use.
```
sudo apt-get install ninja-build
```
Also install all dependencies for python. For pip, run:
```
pip install -U -r requirements.txt
```
## Build
There is no need to build. just run and JIT will take care.
JIT and cpp extensions are supported after PyTorch0.4, however it is highly recommended to use PyTorch > 1.0 due to huge design changes.
## Usage
Please refer to [`test.py`](./test.py) for testing the difference between `nn.BatchNorm2d` and `modules.nn.BatchNorm2d`
```
import torch
from modules import nn as NN
num_gpu = torch.cuda.device_count()
model = nn.Sequential(
nn.Conv2d(3, 3, 1, 1, bias=False),
NN.BatchNorm2d(3),
nn.ReLU(inplace=True),
nn.Conv2d(3, 3, 1, 1, bias=False),
NN.BatchNorm2d(3),
).cuda()
model = nn.DataParallel(model, device_ids=range(num_gpu))
x = torch.rand(num_gpu, 3, 2, 2).cuda()
z = model(x)
```
## Math
### Forward
1. compute 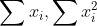 in each gpu
2. gather all from workers to master and compute
in each gpu
2. gather all from workers to master and compute 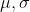 where
where
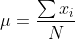 and
and
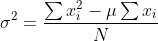 and then above global stats to be shared to all gpus, update running_mean and running_var by moving average using global stats.
3. forward batchnorm using global stats by
and then above global stats to be shared to all gpus, update running_mean and running_var by moving average using global stats.
3. forward batchnorm using global stats by
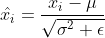 and then
and then
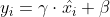 where
where 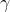 is weight parameter and
is weight parameter and 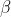 is bias parameter.
4. save
is bias parameter.
4. save 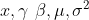 for backward
### Backward
1. Restore saved
2. Compute below sums on each gpu
for backward
### Backward
1. Restore saved
2. Compute below sums on each gpu
) and
and
) where
where 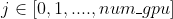 then gather them at master node to sum up global, and normalize with N where N is total number of elements for each channels. Global sums are then shared among all gpus.
3. compute gradients using global stats
then gather them at master node to sum up global, and normalize with N where N is total number of elements for each channels. Global sums are then shared among all gpus.
3. compute gradients using global stats
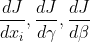 where
where
) and
and
) and finally,
and finally,
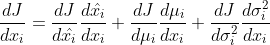
}}(N\frac{dJ}{d\hat{x_i}}-\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}})-\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j})))
}}(N\frac{dJ}{dy_i}-\sum_{j=1}^{N}(\frac{dJ}{dy_j})-\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{dy_j}\hat{x_j}))) Note that in the implementation, normalization with N is performed at step (2) and above equation and implementation is not exactly the same, but mathematically is same.
You can go deeper on above explanation at [Kevin Zakka's Blog](https://kevinzakka.github.io/2016/09/14/batch_normalization/)
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py
================================================
from .syncbn import batchnorm2d_sync
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py
================================================
"""
/*****************************************************************************/
Extension module loader
code referenced from : https://github.com/facebookresearch/maskrcnn-benchmark
/*****************************************************************************/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import glob
import os.path
import torch
try:
from torch.utils.cpp_extension import load
from torch.utils.cpp_extension import CUDA_HOME
except ImportError:
raise ImportError(
"The cpp layer extensions requires PyTorch 0.4 or higher")
def _load_C_extensions():
this_dir = os.path.dirname(os.path.abspath(__file__))
this_dir = os.path.join(this_dir, "csrc")
main_file = glob.glob(os.path.join(this_dir, "*.cpp"))
sources_cpu = glob.glob(os.path.join(this_dir, "cpu", "*.cpp"))
sources_cuda = glob.glob(os.path.join(this_dir, "cuda", "*.cu"))
sources = main_file + sources_cpu
extra_cflags = []
extra_cuda_cflags = []
if torch.cuda.is_available() and CUDA_HOME is not None:
sources.extend(sources_cuda)
extra_cflags = ["-O3", "-DWITH_CUDA"]
extra_cuda_cflags = ["--expt-extended-lambda"]
sources = [os.path.join(this_dir, s) for s in sources]
extra_include_paths = [this_dir]
return load(
name="ext_lib",
sources=sources,
extra_cflags=extra_cflags,
extra_include_paths=extra_include_paths,
extra_cuda_cflags=extra_cuda_cflags,
)
_backend = _load_C_extensions()
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h
================================================
/*****************************************************************************
SyncBN
*****************************************************************************/
#pragma once
#ifdef WITH_CUDA
#include "cuda/ext_lib.h"
#endif
/// SyncBN
std::vector syncbn_sum_sqsum(const at::Tensor& x) {
if (x.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_sum_sqsum_cuda(x);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
at::Tensor syncbn_forward(const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean,
const at::Tensor& var, bool affine, float eps) {
if (x.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_forward_cuda(x, weight, bias, mean, var, affine, eps);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
std::vector syncbn_backward_xhat(const at::Tensor& dz,
const at::Tensor& x,
const at::Tensor& mean,
const at::Tensor& var, float eps) {
if (dz.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_backward_xhat_cuda(dz, x, mean, var, eps);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
std::vector syncbn_backward(
const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
float eps) {
if (dz.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_backward_cuda(dz, x, weight, bias, mean, var, sum_dz,
sum_dz_xhat, affine, eps);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu
================================================
/*****************************************************************************
CUDA SyncBN code
code referenced from : https://github.com/mapillary/inplace_abn
*****************************************************************************/
#include
#include
#include
#include
#include "cuda/common.h"
// Utilities
void get_dims(at::Tensor x, int64_t &num, int64_t &chn, int64_t &sp) {
num = x.size(0);
chn = x.size(1);
sp = 1;
for (int64_t i = 2; i < x.ndimension(); ++i) sp *= x.size(i);
}
/// SyncBN
template
struct SqSumOp {
__device__ SqSumOp(const T *t, int c, int s) : tensor(t), chn(c), sp(s) {}
__device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
T x = tensor[(batch * chn + plane) * sp + n];
return Pair(x, x * x); // x, x^2
}
const T *tensor;
const int chn;
const int sp;
};
template
__global__ void syncbn_sum_sqsum_kernel(const T *x, T *sum, T *sqsum,
int num, int chn, int sp) {
int plane = blockIdx.x;
Pair res =
reduce, SqSumOp>(SqSumOp(x, chn, sp), plane, num, chn, sp);
__syncthreads();
if (threadIdx.x == 0) {
sum[plane] = res.v1;
sqsum[plane] = res.v2;
}
}
std::vector syncbn_sum_sqsum_cuda(const at::Tensor &x) {
CHECK_INPUT(x);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
// Prepare output tensors
auto sum = at::empty({chn}, x.options());
auto sqsum = at::empty({chn}, x.options());
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_sum_sqsum_cuda", ([&] {
syncbn_sum_sqsum_kernel<<>>(
x.data(), sum.data(),
sqsum.data(), num, chn, sp);
}));
return {sum, sqsum};
}
template
__global__ void syncbn_forward_kernel(T *z, const T *x, const T *weight,
const T *bias, const T *mean,
const T *var, bool affine, float eps,
int num, int chn, int sp) {
int plane = blockIdx.x;
T _mean = mean[plane];
T _var = var[plane];
T _weight = affine ? weight[plane] : T(1);
T _bias = affine ? bias[plane] : T(0);
float _invstd = T(0);
if (_var || eps) {
_invstd = rsqrt(_var + eps);
}
for (int batch = 0; batch < num; ++batch) {
for (int n = threadIdx.x; n < sp; n += blockDim.x) {
T _x = x[(batch * chn + plane) * sp + n];
T _xhat = (_x - _mean) * _invstd;
T _z = _xhat * _weight + _bias;
z[(batch * chn + plane) * sp + n] = _z;
}
}
}
at::Tensor syncbn_forward_cuda(const at::Tensor &x, const at::Tensor &weight,
const at::Tensor &bias, const at::Tensor &mean,
const at::Tensor &var, bool affine, float eps) {
CHECK_INPUT(x);
CHECK_INPUT(weight);
CHECK_INPUT(bias);
CHECK_INPUT(mean);
CHECK_INPUT(var);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
auto z = at::zeros_like(x);
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_forward_cuda", ([&] {
syncbn_forward_kernel<<>>(
z.data(), x.data(),
weight.data(), bias.data(),
mean.data(), var.data(),
affine, eps, num, chn, sp);
}));
return z;
}
template
struct XHatOp {
__device__ XHatOp(T _weight, T _bias, const T *_dz, const T *_x, int c, int s)
: weight(_weight), bias(_bias), x(_x), dz(_dz), chn(c), sp(s) {}
__device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
// xhat = (x - bias) * weight
T _xhat = (x[(batch * chn + plane) * sp + n] - bias) * weight;
// dxhat * x_hat
T _dz = dz[(batch * chn + plane) * sp + n];
return Pair(_dz, _dz * _xhat);
}
const T weight;
const T bias;
const T *dz;
const T *x;
const int chn;
const int sp;
};
template
__global__ void syncbn_backward_xhat_kernel(const T *dz, const T *x,
const T *mean, const T *var,
T *sum_dz, T *sum_dz_xhat,
float eps, int num, int chn,
int sp) {
int plane = blockIdx.x;
T _mean = mean[plane];
T _var = var[plane];
T _invstd = T(0);
if (_var || eps) {
_invstd = rsqrt(_var + eps);
}
Pair res = reduce, XHatOp>(
XHatOp(_invstd, _mean, dz, x, chn, sp), plane, num, chn, sp);
__syncthreads();
if (threadIdx.x == 0) {
// \sum(\frac{dJ}{dy_i})
sum_dz[plane] = res.v1;
// \sum(\frac{dJ}{dy_i}*\hat{x_i})
sum_dz_xhat[plane] = res.v2;
}
}
std::vector syncbn_backward_xhat_cuda(const at::Tensor &dz,
const at::Tensor &x,
const at::Tensor &mean,
const at::Tensor &var,
float eps) {
CHECK_INPUT(dz);
CHECK_INPUT(x);
CHECK_INPUT(mean);
CHECK_INPUT(var);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
// Prepare output tensors
auto sum_dz = at::empty({chn}, x.options());
auto sum_dz_xhat = at::empty({chn}, x.options());
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_backward_xhat_cuda", ([&] {
syncbn_backward_xhat_kernel<<>>(
dz.data(), x.data(), mean.data(),
var.data(), sum_dz.data(),
sum_dz_xhat.data(), eps, num, chn, sp);
}));
return {sum_dz, sum_dz_xhat};
}
template
__global__ void syncbn_backward_kernel(const T *dz, const T *x, const T *weight,
const T *bias, const T *mean,
const T *var, const T *sum_dz,
const T *sum_dz_xhat, T *dx, T *dweight,
T *dbias, bool affine, float eps,
int num, int chn, int sp) {
int plane = blockIdx.x;
T _mean = mean[plane];
T _var = var[plane];
T _weight = affine ? weight[plane] : T(1);
T _sum_dz = sum_dz[plane];
T _sum_dz_xhat = sum_dz_xhat[plane];
T _invstd = T(0);
if (_var || eps) {
_invstd = rsqrt(_var + eps);
}
/*
\frac{dJ}{dx_i} = \frac{1}{N\sqrt{(\sigma^2+\epsilon)}} (
N\frac{dJ}{d\hat{x_i}} -
\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}) -
\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j})
)
Note : N is omitted here since it will be accumulated and
_sum_dz and _sum_dz_xhat expected to be already normalized
before the call.
*/
if (dx) {
T _mul = _weight * _invstd;
for (int batch = 0; batch < num; ++batch) {
for (int n = threadIdx.x; n < sp; n += blockDim.x) {
T _dz = dz[(batch * chn + plane) * sp + n];
T _xhat = (x[(batch * chn + plane) * sp + n] - _mean) * _invstd;
T _dx = (_dz - _sum_dz - _xhat * _sum_dz_xhat) * _mul;
dx[(batch * chn + plane) * sp + n] = _dx;
}
}
}
__syncthreads();
if (threadIdx.x == 0) {
if (affine) {
T _norm = num * sp;
dweight[plane] += _sum_dz_xhat * _norm;
dbias[plane] += _sum_dz * _norm;
}
}
}
std::vector syncbn_backward_cuda(
const at::Tensor &dz, const at::Tensor &x, const at::Tensor &weight,
const at::Tensor &bias, const at::Tensor &mean, const at::Tensor &var,
const at::Tensor &sum_dz, const at::Tensor &sum_dz_xhat, bool affine,
float eps) {
CHECK_INPUT(dz);
CHECK_INPUT(x);
CHECK_INPUT(weight);
CHECK_INPUT(bias);
CHECK_INPUT(mean);
CHECK_INPUT(var);
CHECK_INPUT(sum_dz);
CHECK_INPUT(sum_dz_xhat);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
// Prepare output tensors
auto dx = at::zeros_like(dz);
auto dweight = at::zeros_like(weight);
auto dbias = at::zeros_like(bias);
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_backward_cuda", ([&] {
syncbn_backward_kernel<<>>(
dz.data(), x.data(), weight.data(),
bias.data(), mean.data(), var.data(),
sum_dz.data(), sum_dz_xhat.data(),
dx.data(), dweight.data(),
dbias.data(), affine, eps, num, chn, sp);
}));
return {dx, dweight, dbias};
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h
================================================
/*****************************************************************************
CUDA utility funcs
code referenced from : https://github.com/mapillary/inplace_abn
*****************************************************************************/
#pragma once
#include
// Checks
#ifndef AT_CHECK
#define AT_CHECK AT_ASSERT
#endif
#define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
#define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x " must be contiguous")
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
/*
* General settings
*/
const int WARP_SIZE = 32;
const int MAX_BLOCK_SIZE = 512;
template
struct Pair {
T v1, v2;
__device__ Pair() {}
__device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
__device__ Pair(T v) : v1(v), v2(v) {}
__device__ Pair(int v) : v1(v), v2(v) {}
__device__ Pair &operator+=(const Pair &a) {
v1 += a.v1;
v2 += a.v2;
return *this;
}
};
/*
* Utility functions
*/
template
__device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask,
int width = warpSize,
unsigned int mask = 0xffffffff) {
#if CUDART_VERSION >= 9000
return __shfl_xor_sync(mask, value, laneMask, width);
#else
return __shfl_xor(value, laneMask, width);
#endif
}
__device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
static int getNumThreads(int nElem) {
int threadSizes[5] = {32, 64, 128, 256, MAX_BLOCK_SIZE};
for (int i = 0; i != 5; ++i) {
if (nElem <= threadSizes[i]) {
return threadSizes[i];
}
}
return MAX_BLOCK_SIZE;
}
template
static __device__ __forceinline__ T warpSum(T val) {
#if __CUDA_ARCH__ >= 300
for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
}
#else
__shared__ T values[MAX_BLOCK_SIZE];
values[threadIdx.x] = val;
__threadfence_block();
const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
for (int i = 1; i < WARP_SIZE; i++) {
val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
}
#endif
return val;
}
template
static __device__ __forceinline__ Pair warpSum(Pair value) {
value.v1 = warpSum(value.v1);
value.v2 = warpSum(value.v2);
return value;
}
template
__device__ T reduce(Op op, int plane, int N, int C, int S) {
T sum = (T)0;
for (int batch = 0; batch < N; ++batch) {
for (int x = threadIdx.x; x < S; x += blockDim.x) {
sum += op(batch, plane, x);
}
}
// sum over NumThreads within a warp
sum = warpSum(sum);
// 'transpose', and reduce within warp again
__shared__ T shared[32];
__syncthreads();
if (threadIdx.x % WARP_SIZE == 0) {
shared[threadIdx.x / WARP_SIZE] = sum;
}
if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
// zero out the other entries in shared
shared[threadIdx.x] = (T)0;
}
__syncthreads();
if (threadIdx.x / WARP_SIZE == 0) {
sum = warpSum(shared[threadIdx.x]);
if (threadIdx.x == 0) {
shared[0] = sum;
}
}
__syncthreads();
// Everyone picks it up, should be broadcast into the whole gradInput
return shared[0];
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h
================================================
/*****************************************************************************
CUDA SyncBN code
*****************************************************************************/
#pragma once
#include
#include
/// Sync-BN
std::vector syncbn_sum_sqsum_cuda(const at::Tensor& x);
at::Tensor syncbn_forward_cuda(const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean,
const at::Tensor& var, bool affine, float eps);
std::vector syncbn_backward_xhat_cuda(const at::Tensor& dz,
const at::Tensor& x,
const at::Tensor& mean,
const at::Tensor& var,
float eps);
std::vector syncbn_backward_cuda(
const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
float eps);
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp
================================================
#include "bn.h"
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("syncbn_sum_sqsum", &syncbn_sum_sqsum, "Sum and Sum^2 computation");
m.def("syncbn_forward", &syncbn_forward, "SyncBN forward computation");
m.def("syncbn_backward_xhat", &syncbn_backward_xhat,
"First part of SyncBN backward computation");
m.def("syncbn_backward", &syncbn_backward,
"Second part of SyncBN backward computation");
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py
================================================
"""
/*****************************************************************************/
BatchNorm2dSync with multi-gpu
code referenced from : https://github.com/mapillary/inplace_abn
/*****************************************************************************/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import torch.cuda.comm as comm
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from ._csrc import _backend
def _count_samples(x):
count = 1
for i, s in enumerate(x.size()):
if i != 1:
count *= s
return count
class BatchNorm2dSyncFunc(Function):
@staticmethod
def forward(ctx, x, weight, bias, running_mean, running_var,
extra, compute_stats=True, momentum=0.1, eps=1e-05):
def _parse_extra(ctx, extra):
ctx.is_master = extra["is_master"]
if ctx.is_master:
ctx.master_queue = extra["master_queue"]
ctx.worker_queues = extra["worker_queues"]
ctx.worker_ids = extra["worker_ids"]
else:
ctx.master_queue = extra["master_queue"]
ctx.worker_queue = extra["worker_queue"]
# Save context
if extra is not None:
_parse_extra(ctx, extra)
ctx.compute_stats = compute_stats
ctx.momentum = momentum
ctx.eps = eps
ctx.affine = weight is not None and bias is not None
if ctx.compute_stats:
N = _count_samples(x) * (ctx.master_queue.maxsize + 1)
assert N > 1
# 1. compute sum(x) and sum(x^2)
xsum, xsqsum = _backend.syncbn_sum_sqsum(x.detach())
if ctx.is_master:
xsums, xsqsums = [xsum], [xsqsum]
# master : gatther all sum(x) and sum(x^2) from slaves
for _ in range(ctx.master_queue.maxsize):
xsum_w, xsqsum_w = ctx.master_queue.get()
ctx.master_queue.task_done()
xsums.append(xsum_w)
xsqsums.append(xsqsum_w)
xsum = comm.reduce_add(xsums)
xsqsum = comm.reduce_add(xsqsums)
mean = xsum / N
sumvar = xsqsum - xsum * mean
var = sumvar / N
uvar = sumvar / (N - 1)
# master : broadcast global mean, variance to all slaves
tensors = comm.broadcast_coalesced(
(mean, uvar, var), [mean.get_device()] + ctx.worker_ids)
for ts, queue in zip(tensors[1:], ctx.worker_queues):
queue.put(ts)
else:
# slave : send sum(x) and sum(x^2) to master
ctx.master_queue.put((xsum, xsqsum))
# slave : get global mean and variance
mean, uvar, var = ctx.worker_queue.get()
ctx.worker_queue.task_done()
# Update running stats
running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * uvar)
ctx.N = N
ctx.save_for_backward(x, weight, bias, mean, var)
else:
mean, var = running_mean, running_var
# do batch norm forward
z = _backend.syncbn_forward(x, weight, bias, mean, var,
ctx.affine, ctx.eps)
return z
@staticmethod
@once_differentiable
def backward(ctx, dz):
x, weight, bias, mean, var = ctx.saved_tensors
dz = dz.contiguous()
# 1. compute \sum(\frac{dJ}{dy_i}) and \sum(\frac{dJ}{dy_i}*\hat{x_i})
sum_dz, sum_dz_xhat = _backend.syncbn_backward_xhat(
dz, x, mean, var, ctx.eps)
if ctx.is_master:
sum_dzs, sum_dz_xhats = [sum_dz], [sum_dz_xhat]
# master : gatther from slaves
for _ in range(ctx.master_queue.maxsize):
sum_dz_w, sum_dz_xhat_w = ctx.master_queue.get()
ctx.master_queue.task_done()
sum_dzs.append(sum_dz_w)
sum_dz_xhats.append(sum_dz_xhat_w)
# master : compute global stats
sum_dz = comm.reduce_add(sum_dzs)
sum_dz_xhat = comm.reduce_add(sum_dz_xhats)
sum_dz /= ctx.N
sum_dz_xhat /= ctx.N
# master : broadcast global stats
tensors = comm.broadcast_coalesced(
(sum_dz, sum_dz_xhat), [mean.get_device()] + ctx.worker_ids)
for ts, queue in zip(tensors[1:], ctx.worker_queues):
queue.put(ts)
else:
# slave : send to master
ctx.master_queue.put((sum_dz, sum_dz_xhat))
# slave : get global stats
sum_dz, sum_dz_xhat = ctx.worker_queue.get()
ctx.worker_queue.task_done()
# do batch norm backward
dx, dweight, dbias = _backend.syncbn_backward(
dz, x, weight, bias, mean, var, sum_dz, sum_dz_xhat,
ctx.affine, ctx.eps)
return dx, dweight, dbias, \
None, None, None, None, None, None
batchnorm2d_sync = BatchNorm2dSyncFunc.apply
__all__ = ["batchnorm2d_sync"]
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py
================================================
from .syncbn import *
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py
================================================
"""
/*****************************************************************************/
BatchNorm2dSync with multi-gpu
/*****************************************************************************/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
try:
# python 3
from queue import Queue
except ImportError:
# python 2
from Queue import Queue
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.nn.parameter import Parameter
from isegm.model.syncbn.modules.functional import batchnorm2d_sync
class _BatchNorm(nn.Module):
"""
Customized BatchNorm from nn.BatchNorm
>> added freeze attribute to enable bn freeze.
"""
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
track_running_stats=True):
super(_BatchNorm, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
self.freezed = False
if self.affine:
self.weight = Parameter(torch.Tensor(num_features))
self.bias = Parameter(torch.Tensor(num_features))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
else:
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.reset_parameters()
def reset_parameters(self):
if self.track_running_stats:
self.running_mean.zero_()
self.running_var.fill_(1)
if self.affine:
self.weight.data.uniform_()
self.bias.data.zero_()
def _check_input_dim(self, input):
return NotImplemented
def forward(self, input):
self._check_input_dim(input)
compute_stats = not self.freezed and \
self.training and self.track_running_stats
ret = F.batch_norm(input, self.running_mean, self.running_var,
self.weight, self.bias, compute_stats,
self.momentum, self.eps)
return ret
def extra_repr(self):
return '{num_features}, eps={eps}, momentum={momentum}, '\
'affine={affine}, ' \
'track_running_stats={track_running_stats}'.format(
**self.__dict__)
class BatchNorm2dNoSync(_BatchNorm):
"""
Equivalent to nn.BatchNorm2d
"""
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError('expected 4D input (got {}D input)'
.format(input.dim()))
class BatchNorm2dSync(BatchNorm2dNoSync):
"""
BatchNorm2d with automatic multi-GPU Sync
"""
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
track_running_stats=True):
super(BatchNorm2dSync, self).__init__(
num_features, eps=eps, momentum=momentum, affine=affine,
track_running_stats=track_running_stats)
self.sync_enabled = True
self.devices = list(range(torch.cuda.device_count()))
if len(self.devices) > 1:
# Initialize queues
self.worker_ids = self.devices[1:]
self.master_queue = Queue(len(self.worker_ids))
self.worker_queues = [Queue(1) for _ in self.worker_ids]
def forward(self, x):
compute_stats = not self.freezed and \
self.training and self.track_running_stats
if self.sync_enabled and compute_stats and len(self.devices) > 1:
if x.get_device() == self.devices[0]:
# Master mode
extra = {
"is_master": True,
"master_queue": self.master_queue,
"worker_queues": self.worker_queues,
"worker_ids": self.worker_ids
}
else:
# Worker mode
extra = {
"is_master": False,
"master_queue": self.master_queue,
"worker_queue": self.worker_queues[
self.worker_ids.index(x.get_device())]
}
return batchnorm2d_sync(x, self.weight, self.bias,
self.running_mean, self.running_var,
extra, compute_stats, self.momentum,
self.eps)
return super(BatchNorm2dSync, self).forward(x)
def __repr__(self):
"""repr"""
rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
'affine={affine}, ' \
'track_running_stats={track_running_stats},' \
'devices={devices})'
return rep.format(name=self.__class__.__name__, **self.__dict__)
#BatchNorm2d = BatchNorm2dNoSync
BatchNorm2d = BatchNorm2dSync
================================================
FILE: XMem/inference/interact/fbrs/utils/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/__init__.py
================================================
# noinspection PyUnresolvedReferences
from .dist_maps import get_dist_maps
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx
================================================
import numpy as np
cimport cython
cimport numpy as np
from libc.stdlib cimport malloc, free
ctypedef struct qnode:
int row
int col
int layer
int orig_row
int orig_col
@cython.infer_types(True)
@cython.boundscheck(False)
@cython.wraparound(False)
@cython.nonecheck(False)
def get_dist_maps(np.ndarray[np.float32_t, ndim=2, mode="c"] points,
int height, int width, float norm_delimeter):
cdef np.ndarray[np.float32_t, ndim=3, mode="c"] dist_maps = \
np.full((2, height, width), 1e6, dtype=np.float32, order="C")
cdef int *dxy = [-1, 0, 0, -1, 0, 1, 1, 0]
cdef int i, j, x, y, dx, dy
cdef qnode v
cdef qnode *q = malloc((4 * height * width + 1) * sizeof(qnode))
cdef int qhead = 0, qtail = -1
cdef float ndist
for i in range(points.shape[0]):
x, y = round(points[i, 0]), round(points[i, 1])
if x >= 0:
qtail += 1
q[qtail].row = x
q[qtail].col = y
q[qtail].orig_row = x
q[qtail].orig_col = y
if i >= points.shape[0] / 2:
q[qtail].layer = 1
else:
q[qtail].layer = 0
dist_maps[q[qtail].layer, x, y] = 0
while qtail - qhead + 1 > 0:
v = q[qhead]
qhead += 1
for k in range(4):
x = v.row + dxy[2 * k]
y = v.col + dxy[2 * k + 1]
ndist = ((x - v.orig_row)/norm_delimeter) ** 2 + ((y - v.orig_col)/norm_delimeter) ** 2
if (x >= 0 and y >= 0 and x < height and y < width and
dist_maps[v.layer, x, y] > ndist):
qtail += 1
q[qtail].orig_col = v.orig_col
q[qtail].orig_row = v.orig_row
q[qtail].layer = v.layer
q[qtail].row = x
q[qtail].col = y
dist_maps[v.layer, x, y] = ndist
free(q)
return dist_maps
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld
================================================
import numpy
def make_ext(modname, pyxfilename):
from distutils.extension import Extension
return Extension(modname, [pyxfilename],
include_dirs=[numpy.get_include()],
extra_compile_args=['-O3'], language='c++')
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/dist_maps.py
================================================
import pyximport; pyximport.install(pyximport=True, language_level=3)
# noinspection PyUnresolvedReferences
from ._get_dist_maps import get_dist_maps
================================================
FILE: XMem/inference/interact/fbrs/utils/misc.py
================================================
from functools import partial
import torch
import numpy as np
def get_dims_with_exclusion(dim, exclude=None):
dims = list(range(dim))
if exclude is not None:
dims.remove(exclude)
return dims
def get_unique_labels(mask):
return np.nonzero(np.bincount(mask.flatten() + 1))[0] - 1
def get_bbox_from_mask(mask):
rows = np.any(mask, axis=1)
cols = np.any(mask, axis=0)
rmin, rmax = np.where(rows)[0][[0, -1]]
cmin, cmax = np.where(cols)[0][[0, -1]]
return rmin, rmax, cmin, cmax
def expand_bbox(bbox, expand_ratio, min_crop_size=None):
rmin, rmax, cmin, cmax = bbox
rcenter = 0.5 * (rmin + rmax)
ccenter = 0.5 * (cmin + cmax)
height = expand_ratio * (rmax - rmin + 1)
width = expand_ratio * (cmax - cmin + 1)
if min_crop_size is not None:
height = max(height, min_crop_size)
width = max(width, min_crop_size)
rmin = int(round(rcenter - 0.5 * height))
rmax = int(round(rcenter + 0.5 * height))
cmin = int(round(ccenter - 0.5 * width))
cmax = int(round(ccenter + 0.5 * width))
return rmin, rmax, cmin, cmax
def clamp_bbox(bbox, rmin, rmax, cmin, cmax):
return (max(rmin, bbox[0]), min(rmax, bbox[1]),
max(cmin, bbox[2]), min(cmax, bbox[3]))
def get_bbox_iou(b1, b2):
h_iou = get_segments_iou(b1[:2], b2[:2])
w_iou = get_segments_iou(b1[2:4], b2[2:4])
return h_iou * w_iou
def get_segments_iou(s1, s2):
a, b = s1
c, d = s2
intersection = max(0, min(b, d) - max(a, c) + 1)
union = max(1e-6, max(b, d) - min(a, c) + 1)
return intersection / union
================================================
FILE: XMem/inference/interact/fbrs/utils/vis.py
================================================
from functools import lru_cache
import cv2
import numpy as np
def visualize_instances(imask, bg_color=255,
boundaries_color=None, boundaries_width=1, boundaries_alpha=0.8):
num_objects = imask.max() + 1
palette = get_palette(num_objects)
if bg_color is not None:
palette[0] = bg_color
result = palette[imask].astype(np.uint8)
if boundaries_color is not None:
boundaries_mask = get_boundaries(imask, boundaries_width=boundaries_width)
tresult = result.astype(np.float32)
tresult[boundaries_mask] = boundaries_color
tresult = tresult * boundaries_alpha + (1 - boundaries_alpha) * result
result = tresult.astype(np.uint8)
return result
@lru_cache(maxsize=16)
def get_palette(num_cls):
palette = np.zeros(3 * num_cls, dtype=np.int32)
for j in range(0, num_cls):
lab = j
i = 0
while lab > 0:
palette[j*3 + 0] |= (((lab >> 0) & 1) << (7-i))
palette[j*3 + 1] |= (((lab >> 1) & 1) << (7-i))
palette[j*3 + 2] |= (((lab >> 2) & 1) << (7-i))
i = i + 1
lab >>= 3
return palette.reshape((-1, 3))
def visualize_mask(mask, num_cls):
palette = get_palette(num_cls)
mask[mask == -1] = 0
return palette[mask].astype(np.uint8)
def visualize_proposals(proposals_info, point_color=(255, 0, 0), point_radius=1):
proposal_map, colors, candidates = proposals_info
proposal_map = draw_probmap(proposal_map)
for x, y in candidates:
proposal_map = cv2.circle(proposal_map, (y, x), point_radius, point_color, -1)
return proposal_map
def draw_probmap(x):
return cv2.applyColorMap((x * 255).astype(np.uint8), cv2.COLORMAP_HOT)
def draw_points(image, points, color, radius=3):
image = image.copy()
for p in points:
image = cv2.circle(image, (int(p[1]), int(p[0])), radius, color, -1)
return image
def draw_instance_map(x, palette=None):
num_colors = x.max() + 1
if palette is None:
palette = get_palette(num_colors)
return palette[x].astype(np.uint8)
def blend_mask(image, mask, alpha=0.6):
if mask.min() == -1:
mask = mask.copy() + 1
imap = draw_instance_map(mask)
result = (image * (1 - alpha) + alpha * imap).astype(np.uint8)
return result
def get_boundaries(instances_masks, boundaries_width=1):
boundaries = np.zeros((instances_masks.shape[0], instances_masks.shape[1]), dtype=np.bool)
for obj_id in np.unique(instances_masks.flatten()):
if obj_id == 0:
continue
obj_mask = instances_masks == obj_id
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
inner_mask = cv2.erode(obj_mask.astype(np.uint8), kernel, iterations=boundaries_width).astype(np.bool)
obj_boundary = np.logical_xor(obj_mask, np.logical_and(inner_mask, obj_mask))
boundaries = np.logical_or(boundaries, obj_boundary)
return boundaries
def draw_with_blend_and_clicks(img, mask=None, alpha=0.6, clicks_list=None, pos_color=(0, 255, 0),
neg_color=(255, 0, 0), radius=4):
result = img.copy()
if mask is not None:
palette = get_palette(np.max(mask) + 1)
rgb_mask = palette[mask.astype(np.uint8)]
mask_region = (mask > 0).astype(np.uint8)
result = result * (1 - mask_region[:, :, np.newaxis]) + \
(1 - alpha) * mask_region[:, :, np.newaxis] * result + \
alpha * rgb_mask
result = result.astype(np.uint8)
# result = (result * (1 - alpha) + alpha * rgb_mask).astype(np.uint8)
if clicks_list is not None and len(clicks_list) > 0:
pos_points = [click.coords for click in clicks_list if click.is_positive]
neg_points = [click.coords for click in clicks_list if not click.is_positive]
result = draw_points(result, pos_points, pos_color, radius=radius)
result = draw_points(result, neg_points, neg_color, radius=radius)
return result
================================================
FILE: XMem/inference/interact/fbrs_controller.py
================================================
import torch
from .fbrs.controller import InteractiveController
from .fbrs.inference import utils
class FBRSController:
def __init__(self, checkpoint_path, device='cuda:0', max_size=800):
model = utils.load_is_model(checkpoint_path, device, cpu_dist_maps=True, norm_radius=260)
# Predictor params
zoomin_params = {
'skip_clicks': 1,
'target_size': 480,
'expansion_ratio': 1.4,
}
predictor_params = {
'brs_mode': 'f-BRS-B',
'prob_thresh': 0.5,
'zoom_in_params': zoomin_params,
'predictor_params': {
'net_clicks_limit': 8,
'max_size': 800,
},
'brs_opt_func_params': {'min_iou_diff': 1e-3},
'lbfgs_params': {'maxfun': 20}
}
self.controller = InteractiveController(model, device, predictor_params)
self.anchored = False
self.device = device
def unanchor(self):
self.anchored = False
def interact(self, image, x, y, is_positive):
image = image.to(self.device, non_blocking=True)
if not self.anchored:
self.controller.set_image(image)
self.controller.reset_predictor()
self.anchored = True
self.controller.add_click(x, y, is_positive)
# return self.controller.result_mask
# return self.controller.probs_history[-1][1]
return (self.controller.probs_history[-1][1]>0.5).float()
def undo(self):
self.controller.undo_click()
if len(self.controller.probs_history) == 0:
return None
else:
return (self.controller.probs_history[-1][1]>0.5).float()
================================================
FILE: XMem/inference/interact/gui.py
================================================
"""
Based on https://github.com/hkchengrex/MiVOS/tree/MiVOS-STCN
(which is based on https://github.com/seoungwugoh/ivs-demo)
This version is much simplified.
In this repo, we don't have
- local control
- fusion module
- undo
- timers
but with XMem as the backbone and is more memory (for both CPU and GPU) friendly
"""
import functools
import os
import cv2
# fix conflicts between qt5 and cv2
os.environ.pop("QT_QPA_PLATFORM_PLUGIN_PATH")
import numpy as np
import torch
try:
from torch import mps
except:
print('torch.MPS not available.')
from PySide6.QtWidgets import (QWidget, QApplication, QComboBox, QCheckBox,
QHBoxLayout, QLabel, QPushButton, QTextEdit, QSpinBox, QFileDialog,
QPlainTextEdit, QVBoxLayout, QSizePolicy, QButtonGroup, QSlider, QRadioButton)
from PySide6.QtGui import QPixmap, QKeySequence, QImage, QTextCursor, QIcon, QShortcut
from PySide6.QtCore import Qt, QTimer
from model.network import XMem
from inference.inference_core import InferenceCore
from .s2m_controller import S2MController
from .fbrs_controller import FBRSController
from .interactive_utils import *
from .interaction import *
from .resource_manager import ResourceManager
from .gui_utils import *
class App(QWidget):
def __init__(self, net: XMem,
resource_manager: ResourceManager,
s2m_ctrl:S2MController,
fbrs_ctrl:FBRSController, config, device):
super().__init__()
self.initialized = False
self.num_objects = config['num_objects']
self.s2m_controller = s2m_ctrl
self.fbrs_controller = fbrs_ctrl
self.config = config
self.processor = InferenceCore(net, config)
self.processor.set_all_labels(list(range(1, self.num_objects+1)))
self.res_man = resource_manager
self.device = device
self.num_frames = len(self.res_man)
self.height, self.width = self.res_man.h, self.res_man.w
# set window
self.setWindowTitle('XMem Demo')
self.setGeometry(100, 100, self.width, self.height+100)
self.setWindowIcon(QIcon('docs/icon.png'))
# some buttons
self.play_button = QPushButton('Play Video')
self.play_button.clicked.connect(self.on_play_video)
self.commit_button = QPushButton('Commit')
self.commit_button.clicked.connect(self.on_commit)
self.export_button = QPushButton('Export Overlays as Video')
self.export_button.clicked.connect(self.on_export_visualization)
self.forward_run_button = QPushButton('Forward Propagate')
self.forward_run_button.clicked.connect(self.on_forward_propagation)
self.forward_run_button.setMinimumWidth(150)
self.backward_run_button = QPushButton('Backward Propagate')
self.backward_run_button.clicked.connect(self.on_backward_propagation)
self.backward_run_button.setMinimumWidth(150)
self.reset_button = QPushButton('Reset Frame')
self.reset_button.clicked.connect(self.on_reset_mask)
# LCD
self.lcd = QTextEdit()
self.lcd.setReadOnly(True)
self.lcd.setMaximumHeight(28)
self.lcd.setMaximumWidth(120)
self.lcd.setText('{: 4d} / {: 4d}'.format(0, self.num_frames-1))
# Current Mask LCD
self.object_dial = QSpinBox()
self.object_dial.setReadOnly(False)
self.object_dial.setMaximumHeight(28)
self.object_dial.setMaximumWidth(56)
self.object_dial.setMinimum(1)
self.object_dial.setMaximum(self.num_objects)
self.object_dial.editingFinished.connect(self.on_object_dial_change)
# timeline slider
self.tl_slider = QSlider(Qt.Orientation.Horizontal)
self.tl_slider.valueChanged.connect(self.tl_slide)
self.tl_slider.setMinimum(0)
self.tl_slider.setMaximum(self.num_frames-1)
self.tl_slider.setValue(0)
self.tl_slider.setTickPosition(QSlider.TickPosition.TicksBelow)
self.tl_slider.setTickInterval(1)
# brush size slider
self.brush_label = QLabel()
self.brush_label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.brush_label.setMinimumWidth(150)
self.brush_slider = QSlider(Qt.Orientation.Horizontal)
self.brush_slider.valueChanged.connect(self.brush_slide)
self.brush_slider.setMinimum(1)
self.brush_slider.setMaximum(100)
self.brush_slider.setValue(3)
self.brush_slider.setTickPosition(QSlider.TickPosition.TicksBelow)
self.brush_slider.setTickInterval(2)
self.brush_slider.setMinimumWidth(300)
# combobox
self.combo = QComboBox(self)
self.combo.addItem("davis")
self.combo.addItem("fade")
self.combo.addItem("light")
self.combo.addItem("popup")
self.combo.addItem("layered")
self.combo.currentTextChanged.connect(self.set_viz_mode)
self.save_visualization_checkbox = QCheckBox(self)
self.save_visualization_checkbox.toggled.connect(self.on_save_visualization_toggle)
self.save_visualization_checkbox.setChecked(False)
self.save_visualization = False
# Radio buttons for type of interactions
self.curr_interaction = 'Click'
self.interaction_group = QButtonGroup()
self.radio_fbrs = QRadioButton('Click')
self.radio_s2m = QRadioButton('Scribble')
self.radio_free = QRadioButton('Free')
self.interaction_group.addButton(self.radio_fbrs)
self.interaction_group.addButton(self.radio_s2m)
self.interaction_group.addButton(self.radio_free)
self.radio_fbrs.toggled.connect(self.interaction_radio_clicked)
self.radio_s2m.toggled.connect(self.interaction_radio_clicked)
self.radio_free.toggled.connect(self.interaction_radio_clicked)
self.radio_fbrs.toggle()
# Main canvas -> QLabel
self.main_canvas = QLabel()
self.main_canvas.setSizePolicy(QSizePolicy.Policy.Expanding,
QSizePolicy.Policy.Expanding)
self.main_canvas.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.main_canvas.setMinimumSize(100, 100)
self.main_canvas.mousePressEvent = self.on_mouse_press
self.main_canvas.mouseMoveEvent = self.on_mouse_motion
self.main_canvas.setMouseTracking(True) # Required for all-time tracking
self.main_canvas.mouseReleaseEvent = self.on_mouse_release
# Minimap -> Also a QLabel
self.minimap = QLabel()
self.minimap.setSizePolicy(QSizePolicy.Policy.Expanding,
QSizePolicy.Policy.Expanding)
self.minimap.setAlignment(Qt.AlignmentFlag.AlignTop)
self.minimap.setMinimumSize(100, 100)
# Zoom-in buttons
self.zoom_p_button = QPushButton('Zoom +')
self.zoom_p_button.clicked.connect(self.on_zoom_plus)
self.zoom_m_button = QPushButton('Zoom -')
self.zoom_m_button.clicked.connect(self.on_zoom_minus)
# Parameters setting
self.clear_mem_button = QPushButton('Clear memory')
self.clear_mem_button.clicked.connect(self.on_clear_memory)
self.work_mem_gauge, self.work_mem_gauge_layout = create_gauge('Working memory size')
self.long_mem_gauge, self.long_mem_gauge_layout = create_gauge('Long-term memory size')
self.gpu_mem_gauge, self.gpu_mem_gauge_layout = create_gauge('GPU mem. (all processes, w/ caching)')
self.torch_mem_gauge, self.torch_mem_gauge_layout = create_gauge('GPU mem. (used by torch, w/o caching)')
self.update_memory_size()
self.update_gpu_usage()
self.work_mem_min, self.work_mem_min_layout = create_parameter_box(1, 100, 'Min. working memory frames',
callback=self.on_work_min_change)
self.work_mem_max, self.work_mem_max_layout = create_parameter_box(2, 100, 'Max. working memory frames',
callback=self.on_work_max_change)
self.long_mem_max, self.long_mem_max_layout = create_parameter_box(1000, 100000,
'Max. long-term memory size', step=1000, callback=self.update_config)
self.num_prototypes_box, self.num_prototypes_box_layout = create_parameter_box(32, 1280,
'Number of prototypes', step=32, callback=self.update_config)
self.mem_every_box, self.mem_every_box_layout = create_parameter_box(1, 100, 'Memory frame every (r)',
callback=self.update_config)
self.work_mem_min.setValue(self.processor.memory.min_mt_frames)
self.work_mem_max.setValue(self.processor.memory.max_mt_frames)
self.long_mem_max.setValue(self.processor.memory.max_long_elements)
self.num_prototypes_box.setValue(self.processor.memory.num_prototypes)
self.mem_every_box.setValue(self.processor.mem_every)
# import mask/layer
self.import_mask_button = QPushButton('Import mask')
self.import_mask_button.clicked.connect(self.on_import_mask)
self.import_layer_button = QPushButton('Import layer')
self.import_layer_button.clicked.connect(self.on_import_layer)
# Console on the GUI
self.console = QPlainTextEdit()
self.console.setReadOnly(True)
self.console.setMinimumHeight(100)
self.console.setMaximumHeight(100)
# navigator
navi = QHBoxLayout()
interact_subbox = QVBoxLayout()
interact_topbox = QHBoxLayout()
interact_botbox = QHBoxLayout()
interact_topbox.setAlignment(Qt.AlignmentFlag.AlignCenter)
interact_topbox.addWidget(self.lcd)
interact_topbox.addWidget(self.play_button)
interact_topbox.addWidget(self.radio_s2m)
interact_topbox.addWidget(self.radio_fbrs)
interact_topbox.addWidget(self.radio_free)
interact_topbox.addWidget(self.reset_button)
interact_botbox.addWidget(QLabel('Current Object ID:'))
interact_botbox.addWidget(self.object_dial)
interact_botbox.addWidget(self.brush_label)
interact_botbox.addWidget(self.brush_slider)
interact_subbox.addLayout(interact_topbox)
interact_subbox.addLayout(interact_botbox)
navi.addLayout(interact_subbox)
apply_fixed_size_policy = lambda x: x.setSizePolicy(QSizePolicy.Policy.Fixed,
QSizePolicy.Policy.Fixed)
apply_to_all_children_widget(interact_topbox, apply_fixed_size_policy)
apply_to_all_children_widget(interact_botbox, apply_fixed_size_policy)
navi.addStretch(1)
navi.addStretch(1)
overlay_subbox = QVBoxLayout()
overlay_topbox = QHBoxLayout()
overlay_botbox = QHBoxLayout()
overlay_botbox.setAlignment(Qt.AlignmentFlag.AlignRight)
overlay_topbox.addWidget(QLabel('Overlay Mode'))
overlay_topbox.addWidget(self.combo)
overlay_topbox.addWidget(QLabel('Save overlay during propagation'))
overlay_topbox.addWidget(self.save_visualization_checkbox)
overlay_botbox.addWidget(self.export_button)
overlay_subbox.addLayout(overlay_topbox)
overlay_subbox.addLayout(overlay_botbox)
navi.addLayout(overlay_subbox)
apply_to_all_children_widget(overlay_topbox, apply_fixed_size_policy)
apply_to_all_children_widget(overlay_botbox, apply_fixed_size_policy)
navi.addStretch(1)
navi.addWidget(self.commit_button)
navi.addWidget(self.forward_run_button)
navi.addWidget(self.backward_run_button)
# Drawing area, main canvas and minimap
draw_area = QHBoxLayout()
draw_area.addWidget(self.main_canvas, 4)
# Minimap area
minimap_area = QVBoxLayout()
minimap_area.setAlignment(Qt.AlignmentFlag.AlignTop)
mini_label = QLabel('Minimap')
mini_label.setAlignment(Qt.AlignmentFlag.AlignTop)
minimap_area.addWidget(mini_label)
# Minimap zooming
minimap_ctrl = QHBoxLayout()
minimap_ctrl.setAlignment(Qt.AlignmentFlag.AlignTop)
minimap_ctrl.addWidget(self.zoom_p_button)
minimap_ctrl.addWidget(self.zoom_m_button)
minimap_area.addLayout(minimap_ctrl)
minimap_area.addWidget(self.minimap)
# Parameters
minimap_area.addLayout(self.work_mem_gauge_layout)
minimap_area.addLayout(self.long_mem_gauge_layout)
minimap_area.addLayout(self.gpu_mem_gauge_layout)
minimap_area.addLayout(self.torch_mem_gauge_layout)
minimap_area.addWidget(self.clear_mem_button)
minimap_area.addLayout(self.work_mem_min_layout)
minimap_area.addLayout(self.work_mem_max_layout)
minimap_area.addLayout(self.long_mem_max_layout)
minimap_area.addLayout(self.num_prototypes_box_layout)
minimap_area.addLayout(self.mem_every_box_layout)
# import mask/layer
import_area = QHBoxLayout()
import_area.setAlignment(Qt.AlignmentFlag.AlignTop)
import_area.addWidget(self.import_mask_button)
import_area.addWidget(self.import_layer_button)
minimap_area.addLayout(import_area)
# console
minimap_area.addWidget(self.console)
draw_area.addLayout(minimap_area, 1)
layout = QVBoxLayout()
layout.addLayout(draw_area)
layout.addWidget(self.tl_slider)
layout.addLayout(navi)
self.setLayout(layout)
# timer to play video
self.timer = QTimer()
self.timer.setSingleShot(False)
self.timer.timeout.connect(self.on_play_video_timer)
# timer to update GPU usage
self.gpu_timer = QTimer()
self.gpu_timer.setSingleShot(False)
self.gpu_timer.timeout.connect(self.on_gpu_timer)
self.gpu_timer.setInterval(2000)
self.gpu_timer.start()
# current frame info
self.curr_frame_dirty = False
self.current_image = np.zeros((self.height, self.width, 3), dtype=np.uint8)
self.current_image_torch = None
self.current_mask = np.zeros((self.height, self.width), dtype=np.uint8)
self.current_prob = torch.zeros((self.num_objects, self.height, self.width), dtype=torch.float).to(self.device)
# initialize visualization
self.viz_mode = 'davis'
self.vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
self.vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
self.brush_vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
self.brush_vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
self.cursur = 0
self.on_showing = None
# Zoom parameters
self.zoom_pixels = 150
# initialize action
self.interaction = None
self.pressed = False
self.right_click = False
self.current_object = 1
self.last_ex = self.last_ey = 0
self.propagating = False
# Objects shortcuts
for i in range(1, self.num_objects+1):
QShortcut(QKeySequence(str(i)), self).activated.connect(functools.partial(self.hit_number_key, i))
QShortcut(QKeySequence(f"Ctrl+{i}"), self).activated.connect(functools.partial(self.hit_number_key, i))
# <- and -> shortcuts
QShortcut(QKeySequence(Qt.Key.Key_Left), self).activated.connect(self.on_prev_frame)
QShortcut(QKeySequence(Qt.Key.Key_Right), self).activated.connect(self.on_next_frame)
self.interacted_prob = None
self.overlay_layer = None
self.overlay_layer_torch = None
# the object id used for popup/layered overlay
self.vis_target_objects = [1]
# try to load the default overlay
self._try_load_layer('./docs/ECCV-logo.png')
self.load_current_image_mask()
self.show_current_frame()
self.show()
self.console_push_text('Initialized.')
self.initialized = True
def resizeEvent(self, event):
self.show_current_frame()
def console_push_text(self, text):
self.console.moveCursor(QTextCursor.MoveOperation.End)
self.console.insertPlainText(text+'\n')
def interaction_radio_clicked(self, event):
self.last_interaction = self.curr_interaction
if self.radio_s2m.isChecked():
self.curr_interaction = 'Scribble'
self.brush_size = 3
self.brush_slider.setDisabled(True)
elif self.radio_fbrs.isChecked():
self.curr_interaction = 'Click'
self.brush_size = 3
self.brush_slider.setDisabled(True)
elif self.radio_free.isChecked():
self.brush_slider.setDisabled(False)
self.brush_slide()
self.curr_interaction = 'Free'
if self.curr_interaction == 'Scribble':
self.commit_button.setEnabled(True)
else:
self.commit_button.setEnabled(False)
def load_current_image_mask(self, no_mask=False):
self.current_image = self.res_man.get_image(self.cursur)
self.current_image_torch = None
if not no_mask:
loaded_mask = self.res_man.get_mask(self.cursur)
if loaded_mask is None:
self.current_mask.fill(0)
else:
self.current_mask = loaded_mask.copy()
self.current_prob = None
def load_current_torch_image_mask(self, no_mask=False):
if self.current_image_torch is None:
self.current_image_torch, self.current_image_torch_no_norm = image_to_torch(self.current_image, self.device)
if self.current_prob is None and not no_mask:
self.current_prob = index_numpy_to_one_hot_torch(self.current_mask, self.num_objects+1).to(self.device)
def compose_current_im(self):
self.viz = get_visualization(self.viz_mode, self.current_image, self.current_mask,
self.overlay_layer, self.vis_target_objects)
def update_interact_vis(self):
# Update the interactions without re-computing the overlay
height, width, channel = self.viz.shape
bytesPerLine = 3 * width
vis_map = self.vis_map
vis_alpha = self.vis_alpha
brush_vis_map = self.brush_vis_map
brush_vis_alpha = self.brush_vis_alpha
self.viz_with_stroke = self.viz*(1-vis_alpha) + vis_map*vis_alpha
self.viz_with_stroke = self.viz_with_stroke*(1-brush_vis_alpha) + brush_vis_map*brush_vis_alpha
self.viz_with_stroke = self.viz_with_stroke.astype(np.uint8)
qImg = QImage(self.viz_with_stroke.data, width, height, bytesPerLine, QImage.Format.Format_RGB888)
self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.FastTransformation)))
self.main_canvas_size = self.main_canvas.size()
self.image_size = qImg.size()
def update_minimap(self):
ex, ey = self.last_ex, self.last_ey
r = self.zoom_pixels//2
ex = int(round(max(r, min(self.width-r, ex))))
ey = int(round(max(r, min(self.height-r, ey))))
patch = self.viz_with_stroke[ey-r:ey+r, ex-r:ex+r, :].astype(np.uint8)
height, width, channel = patch.shape
bytesPerLine = 3 * width
qImg = QImage(patch.data, width, height, bytesPerLine, QImage.Format.Format_RGB888)
self.minimap.setPixmap(QPixmap(qImg.scaled(self.minimap.size(),
Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.FastTransformation)))
def update_current_image_fast(self):
# fast path, uses gpu. Changes the image in-place to avoid copying
self.viz = get_visualization_torch(self.viz_mode, self.current_image_torch_no_norm,
self.current_prob, self.overlay_layer_torch, self.vis_target_objects)
if self.save_visualization:
self.res_man.save_visualization(self.cursur, self.viz)
height, width, channel = self.viz.shape
bytesPerLine = 3 * width
qImg = QImage(self.viz.data, width, height, bytesPerLine, QImage.Format.Format_RGB888)
self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.FastTransformation)))
def show_current_frame(self, fast=False):
# Re-compute overlay and show the image
if fast:
self.update_current_image_fast()
else:
self.compose_current_im()
self.update_interact_vis()
self.update_minimap()
self.lcd.setText('{: 3d} / {: 3d}'.format(self.cursur, self.num_frames-1))
self.tl_slider.setValue(self.cursur)
def pixel_pos_to_image_pos(self, x, y):
# Un-scale and un-pad the label coordinates into image coordinates
oh, ow = self.image_size.height(), self.image_size.width()
nh, nw = self.main_canvas_size.height(), self.main_canvas_size.width()
h_ratio = nh/oh
w_ratio = nw/ow
dominate_ratio = min(h_ratio, w_ratio)
# Solve scale
x /= dominate_ratio
y /= dominate_ratio
# Solve padding
fh, fw = nh/dominate_ratio, nw/dominate_ratio
x -= (fw-ow)/2
y -= (fh-oh)/2
return x, y
def is_pos_out_of_bound(self, x, y):
x, y = self.pixel_pos_to_image_pos(x, y)
out_of_bound = (
(x < 0) or
(y < 0) or
(x > self.width-1) or
(y > self.height-1)
)
return out_of_bound
def get_scaled_pos(self, x, y):
x, y = self.pixel_pos_to_image_pos(x, y)
x = max(0, min(self.width-1, x))
y = max(0, min(self.height-1, y))
return x, y
def clear_visualization(self):
self.vis_map.fill(0)
self.vis_alpha.fill(0)
def reset_this_interaction(self):
self.complete_interaction()
self.clear_visualization()
self.interaction = None
if self.fbrs_controller is not None:
self.fbrs_controller.unanchor()
def set_viz_mode(self):
self.viz_mode = self.combo.currentText()
self.show_current_frame()
def save_current_mask(self):
# save mask to hard disk
self.res_man.save_mask(self.cursur, self.current_mask)
def tl_slide(self):
# if we are propagating, the on_run function will take care of everything
# don't do duplicate work here
if not self.propagating:
if self.curr_frame_dirty:
self.save_current_mask()
self.curr_frame_dirty = False
self.reset_this_interaction()
self.cursur = self.tl_slider.value()
self.load_current_image_mask()
self.show_current_frame()
def brush_slide(self):
self.brush_size = self.brush_slider.value()
self.brush_label.setText('Brush size (in free mode): %d' % self.brush_size)
try:
if type(self.interaction) == FreeInteraction:
self.interaction.set_size(self.brush_size)
except AttributeError:
# Initialization, forget about it
pass
def on_forward_propagation(self):
if self.propagating:
# acts as a pause button
self.propagating = False
else:
self.propagate_fn = self.on_next_frame
self.backward_run_button.setEnabled(False)
self.forward_run_button.setText('Pause Propagation')
self.on_propagation()
def on_backward_propagation(self):
if self.propagating:
# acts as a pause button
self.propagating = False
else:
self.propagate_fn = self.on_prev_frame
self.forward_run_button.setEnabled(False)
self.backward_run_button.setText('Pause Propagation')
self.on_propagation()
def on_pause(self):
self.propagating = False
self.forward_run_button.setEnabled(True)
self.backward_run_button.setEnabled(True)
self.clear_mem_button.setEnabled(True)
self.forward_run_button.setText('Forward Propagate')
self.backward_run_button.setText('Backward Propagate')
self.console_push_text('Propagation stopped.')
def on_propagation(self):
# start to propagate
self.load_current_torch_image_mask()
self.show_current_frame(fast=True)
self.console_push_text('Propagation started.')
self.current_prob = self.processor.step(self.current_image_torch, self.current_prob[1:])
self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
# clear
self.interacted_prob = None
self.reset_this_interaction()
self.propagating = True
self.clear_mem_button.setEnabled(False)
# propagate till the end
while self.propagating:
self.propagate_fn()
self.load_current_image_mask(no_mask=True)
self.load_current_torch_image_mask(no_mask=True)
self.current_prob = self.processor.step(self.current_image_torch)
self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
self.save_current_mask()
self.show_current_frame(fast=True)
self.update_memory_size()
QApplication.processEvents()
if self.cursur == 0 or self.cursur == self.num_frames-1:
break
self.propagating = False
self.curr_frame_dirty = False
self.on_pause()
self.tl_slide()
QApplication.processEvents()
def pause_propagation(self):
self.propagating = False
def on_commit(self):
self.complete_interaction()
self.update_interacted_mask()
def on_prev_frame(self):
# self.tl_slide will trigger on setValue
self.cursur = max(0, self.cursur-1)
self.tl_slider.setValue(self.cursur)
def on_next_frame(self):
# self.tl_slide will trigger on setValue
self.cursur = min(self.cursur+1, self.num_frames-1)
self.tl_slider.setValue(self.cursur)
def on_play_video_timer(self):
self.cursur += 1
if self.cursur > self.num_frames-1:
self.cursur = 0
self.tl_slider.setValue(self.cursur)
def on_play_video(self):
if self.timer.isActive():
self.timer.stop()
self.play_button.setText('Play Video')
else:
self.timer.start(1000 // 30)
self.play_button.setText('Stop Video')
def on_export_visualization(self):
# NOTE: Save visualization at the end of propagation
image_folder = f"{self.config['workspace']}/visualization/"
save_folder = self.config['workspace']
if os.path.exists(image_folder):
# Sorted so frames will be in order
self.console_push_text(f'Exporting visualization to {self.config["workspace"]}/visualization.mp4')
images = [img for img in sorted(os.listdir(image_folder)) if img.endswith(".jpg")]
frame = cv2.imread(os.path.join(image_folder, images[0]))
height, width, layers = frame.shape
# 10 is the FPS -- change if needed
video = cv2.VideoWriter(f"{save_folder}/visualization.mp4", cv2.VideoWriter_fourcc(*'mp4v'), 10, (width,height))
for image in images:
video.write(cv2.imread(os.path.join(image_folder, image)))
video.release()
self.console_push_text(f'Visualization exported to {self.config["workspace"]}/visualization.mp4')
else:
self.console_push_text(f'No visualization images found in {image_folder}')
def on_object_dial_change(self):
object_id = self.object_dial.value()
self.hit_number_key(object_id)
def on_reset_mask(self):
self.current_mask.fill(0)
if self.current_prob is not None:
self.current_prob.fill_(0)
self.curr_frame_dirty = True
self.save_current_mask()
self.reset_this_interaction()
self.show_current_frame()
def on_zoom_plus(self):
self.zoom_pixels -= 25
self.zoom_pixels = max(50, self.zoom_pixels)
self.update_minimap()
def on_zoom_minus(self):
self.zoom_pixels += 25
self.zoom_pixels = min(self.zoom_pixels, 300)
self.update_minimap()
def set_navi_enable(self, boolean):
self.zoom_p_button.setEnabled(boolean)
self.zoom_m_button.setEnabled(boolean)
self.run_button.setEnabled(boolean)
self.tl_slider.setEnabled(boolean)
self.play_button.setEnabled(boolean)
self.export_button.setEnabled(boolean)
self.lcd.setEnabled(boolean)
def hit_number_key(self, number):
if number == self.current_object:
return
self.current_object = number
self.object_dial.setValue(number)
if self.fbrs_controller is not None:
self.fbrs_controller.unanchor()
self.console_push_text(f'Current object changed to {number}.')
self.clear_brush()
self.vis_brush(self.last_ex, self.last_ey)
self.update_interact_vis()
self.show_current_frame()
def clear_brush(self):
self.brush_vis_map.fill(0)
self.brush_vis_alpha.fill(0)
def vis_brush(self, ex, ey):
self.brush_vis_map = cv2.circle(self.brush_vis_map,
(int(round(ex)), int(round(ey))), self.brush_size//2+1, color_map[self.current_object], thickness=-1)
self.brush_vis_alpha = cv2.circle(self.brush_vis_alpha,
(int(round(ex)), int(round(ey))), self.brush_size//2+1, 0.5, thickness=-1)
def on_mouse_press(self, event):
if self.is_pos_out_of_bound(event.position().x(), event.position().y()):
return
# mid-click
if (event.button() == Qt.MouseButton.MiddleButton):
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
target_object = self.current_mask[int(ey),int(ex)]
if target_object in self.vis_target_objects:
self.vis_target_objects.remove(target_object)
else:
self.vis_target_objects.append(target_object)
self.console_push_text(f'Target objects for visualization changed to {self.vis_target_objects}')
self.show_current_frame()
return
self.right_click = (event.button() == Qt.MouseButton.RightButton)
self.pressed = True
h, w = self.height, self.width
self.load_current_torch_image_mask()
image = self.current_image_torch
last_interaction = self.interaction
new_interaction = None
if self.curr_interaction == 'Scribble':
if last_interaction is None or type(last_interaction) != ScribbleInteraction:
self.complete_interaction()
new_interaction = ScribbleInteraction(image, torch.from_numpy(self.current_mask).float().to(self.device),
(h, w), self.s2m_controller, self.num_objects)
elif self.curr_interaction == 'Free':
if last_interaction is None or type(last_interaction) != FreeInteraction:
self.complete_interaction()
new_interaction = FreeInteraction(image, self.current_mask, (h, w),
self.num_objects)
new_interaction.set_size(self.brush_size)
elif self.curr_interaction == 'Click':
if (last_interaction is None or type(last_interaction) != ClickInteraction
or last_interaction.tar_obj != self.current_object):
self.complete_interaction()
self.fbrs_controller.unanchor()
new_interaction = ClickInteraction(image, self.current_prob, (h, w),
self.fbrs_controller, self.current_object)
if new_interaction is not None:
self.interaction = new_interaction
# Just motion it as the first step
self.on_mouse_motion(event)
def on_mouse_motion(self, event):
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
self.last_ex, self.last_ey = ex, ey
self.clear_brush()
# Visualize
self.vis_brush(ex, ey)
if self.pressed:
if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
obj = 0 if self.right_click else self.current_object
self.vis_map, self.vis_alpha = self.interaction.push_point(
ex, ey, obj, (self.vis_map, self.vis_alpha)
)
self.update_interact_vis()
self.update_minimap()
def update_interacted_mask(self):
self.current_prob = self.interacted_prob
self.current_mask = torch_prob_to_numpy_mask(self.interacted_prob)
self.show_current_frame()
self.save_current_mask()
self.curr_frame_dirty = False
def complete_interaction(self):
if self.interaction is not None:
self.clear_visualization()
self.interaction = None
def on_mouse_release(self, event):
if not self.pressed:
# this can happen when the initial press is out-of-bound
return
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
self.console_push_text('%s interaction at frame %d.' % (self.curr_interaction, self.cursur))
interaction = self.interaction
if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
self.on_mouse_motion(event)
interaction.end_path()
if self.curr_interaction == 'Free':
self.clear_visualization()
elif self.curr_interaction == 'Click':
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
self.vis_map, self.vis_alpha = interaction.push_point(ex, ey,
self.right_click, (self.vis_map, self.vis_alpha))
self.interacted_prob = interaction.predict().to(self.device)
self.update_interacted_mask()
self.update_gpu_usage()
self.pressed = self.right_click = False
def wheelEvent(self, event):
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
if self.curr_interaction == 'Free':
self.brush_slider.setValue(self.brush_slider.value() + event.angleDelta().y()//30)
self.clear_brush()
self.vis_brush(ex, ey)
self.update_interact_vis()
self.update_minimap()
def update_gpu_usage(self):
if self.device.type == 'cuda':
info = torch.cuda.mem_get_info()
elif self.device.type == 'mps':
info = (0, mps.current_allocated_memory()) # NOTE: torch.mps does not support accessing free and total memory
else:
info = (0, 0)
global_free, global_total = info
global_free /= (2**30)
global_total /= (2**30)
global_used = global_total - global_free
self.gpu_mem_gauge.setFormat(f'{global_used:.01f} GB / {global_total:.01f} GB')
self.gpu_mem_gauge.setValue(round(global_used/global_total*100))
used_by_torch = torch.cuda.max_memory_allocated() / (2**20)
self.torch_mem_gauge.setFormat(f'{used_by_torch:.0f} MB / {global_total:.01f} GB')
self.torch_mem_gauge.setValue(round(used_by_torch/global_total*100/1024))
def on_gpu_timer(self):
self.update_gpu_usage()
def update_memory_size(self):
try:
max_work_elements = self.processor.memory.max_work_elements
max_long_elements = self.processor.memory.max_long_elements
curr_work_elements = self.processor.memory.work_mem.size
curr_long_elements = self.processor.memory.long_mem.size
self.work_mem_gauge.setFormat(f'{curr_work_elements} / {max_work_elements}')
self.work_mem_gauge.setValue(round(curr_work_elements/max_work_elements*100))
self.long_mem_gauge.setFormat(f'{curr_long_elements} / {max_long_elements}')
self.long_mem_gauge.setValue(round(curr_long_elements/max_long_elements*100))
except AttributeError:
self.work_mem_gauge.setFormat('Unknown')
self.long_mem_gauge.setFormat('Unknown')
self.work_mem_gauge.setValue(0)
self.long_mem_gauge.setValue(0)
def on_work_min_change(self):
if self.initialized:
self.work_mem_min.setValue(min(self.work_mem_min.value(), self.work_mem_max.value()-1))
self.update_config()
def on_work_max_change(self):
if self.initialized:
self.work_mem_max.setValue(max(self.work_mem_max.value(), self.work_mem_min.value()+1))
self.update_config()
def update_config(self):
if self.initialized:
self.config['min_mid_term_frames'] = self.work_mem_min.value()
self.config['max_mid_term_frames'] = self.work_mem_max.value()
self.config['max_long_term_elements'] = self.long_mem_max.value()
self.config['num_prototypes'] = self.num_prototypes_box.value()
self.config['mem_every'] = self.mem_every_box.value()
self.processor.update_config(self.config)
def on_clear_memory(self):
self.processor.clear_memory()
if self.device.type == 'cuda':
torch.cuda.empty_cache()
elif self.device.type == 'mps':
mps.empty_cache()
self.update_gpu_usage()
self.update_memory_size()
def _open_file(self, prompt):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, prompt, "", "Image files (*)", options=options)
return file_name
def on_import_mask(self):
file_name = self._open_file('Mask')
if len(file_name) == 0:
return
mask = self.res_man.read_external_image(file_name, size=(self.height, self.width))
shape_condition = (
(len(mask.shape) == 2) and
(mask.shape[-1] == self.width) and
(mask.shape[-2] == self.height)
)
object_condition = (
mask.max() <= self.num_objects
)
if not shape_condition:
self.console_push_text(f'Expected ({self.height}, {self.width}). Got {mask.shape} instead.')
elif not object_condition:
self.console_push_text(f'Expected {self.num_objects} objects. Got {mask.max()} objects instead.')
else:
self.console_push_text(f'Mask file {file_name} loaded.')
self.current_image_torch = self.current_prob = None
self.current_mask = mask
self.show_current_frame()
self.save_current_mask()
def on_import_layer(self):
file_name = self._open_file('Layer')
if len(file_name) == 0:
return
self._try_load_layer(file_name)
def _try_load_layer(self, file_name):
try:
layer = self.res_man.read_external_image(file_name, size=(self.height, self.width))
if layer.shape[-1] == 3:
layer = np.concatenate([layer, np.ones_like(layer[:,:,0:1])*255], axis=-1)
condition = (
(len(layer.shape) == 3) and
(layer.shape[-1] == 4) and
(layer.shape[-2] == self.width) and
(layer.shape[-3] == self.height)
)
if not condition:
self.console_push_text(f'Expected ({self.height}, {self.width}, 4). Got {layer.shape}.')
else:
self.console_push_text(f'Layer file {file_name} loaded.')
self.overlay_layer = layer
self.overlay_layer_torch = torch.from_numpy(layer).float().to(self.device)/255
self.show_current_frame()
except FileNotFoundError:
self.console_push_text(f'{file_name} not found.')
def on_save_visualization_toggle(self):
self.save_visualization = self.save_visualization_checkbox.isChecked()
================================================
FILE: XMem/inference/interact/gui_utils.py
================================================
from PySide6.QtCore import Qt
from PySide6.QtWidgets import (QBoxLayout, QHBoxLayout, QLabel, QSpinBox, QVBoxLayout, QProgressBar)
def create_parameter_box(min_val, max_val, text, step=1, callback=None):
layout = QHBoxLayout()
dial = QSpinBox()
dial.setMaximumHeight(28)
dial.setMaximumWidth(150)
dial.setMinimum(min_val)
dial.setMaximum(max_val)
dial.setAlignment(Qt.AlignmentFlag.AlignRight)
dial.setSingleStep(step)
dial.valueChanged.connect(callback)
label = QLabel(text)
label.setAlignment(Qt.AlignmentFlag.AlignRight)
layout.addWidget(label)
layout.addWidget(dial)
return dial, layout
def create_gauge(text):
layout = QHBoxLayout()
gauge = QProgressBar()
gauge.setMaximumHeight(28)
gauge.setMaximumWidth(200)
gauge.setAlignment(Qt.AlignmentFlag.AlignCenter)
label = QLabel(text)
label.setAlignment(Qt.AlignmentFlag.AlignRight)
layout.addWidget(label)
layout.addWidget(gauge)
return gauge, layout
def apply_to_all_children_widget(layout, func):
# deliberately non-recursive
for i in range(layout.count()):
func(layout.itemAt(i).widget())
================================================
FILE: XMem/inference/interact/interaction.py
================================================
"""
Contains all the types of interaction related to the GUI
Not related to automatic evaluation in the DAVIS dataset
You can inherit the Interaction class to create new interaction types
undo is (sometimes partially) supported
"""
import torch
import torch.nn.functional as F
import numpy as np
import cv2
import time
from .interactive_utils import color_map, index_numpy_to_one_hot_torch
def aggregate_sbg(prob, keep_bg=False, hard=False):
device = prob.device
k, h, w = prob.shape
ex_prob = torch.zeros((k+1, h, w), device=device)
ex_prob[0] = 0.5
ex_prob[1:] = prob
ex_prob = torch.clamp(ex_prob, 1e-7, 1-1e-7)
logits = torch.log((ex_prob /(1-ex_prob)))
if hard:
# Very low temperature o((⊙﹏⊙))o 🥶
logits *= 1000
if keep_bg:
return F.softmax(logits, dim=0)
else:
return F.softmax(logits, dim=0)[1:]
def aggregate_wbg(prob, keep_bg=False, hard=False):
k, h, w = prob.shape
new_prob = torch.cat([
torch.prod(1-prob, dim=0, keepdim=True),
prob
], 0).clamp(1e-7, 1-1e-7)
logits = torch.log((new_prob /(1-new_prob)))
if hard:
# Very low temperature o((⊙﹏⊙))o 🥶
logits *= 1000
if keep_bg:
return F.softmax(logits, dim=0)
else:
return F.softmax(logits, dim=0)[1:]
class Interaction:
def __init__(self, image, prev_mask, true_size, controller):
self.image = image
self.prev_mask = prev_mask
self.controller = controller
self.start_time = time.time()
self.h, self.w = true_size
self.out_prob = None
self.out_mask = None
def predict(self):
pass
class FreeInteraction(Interaction):
def __init__(self, image, prev_mask, true_size, num_objects):
"""
prev_mask should be index format numpy array
"""
super().__init__(image, prev_mask, true_size, None)
self.K = num_objects
self.drawn_map = self.prev_mask.copy()
self.curr_path = [[] for _ in range(self.K + 1)]
self.size = None
def set_size(self, size):
self.size = size
"""
k - object id
vis - a tuple (visualization map, pass through alpha). None if not needed.
"""
def push_point(self, x, y, k, vis=None):
if vis is not None:
vis_map, vis_alpha = vis
selected = self.curr_path[k]
selected.append((x, y))
if len(selected) >= 2:
cv2.line(self.drawn_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
k, thickness=self.size)
# Plot visualization
if vis is not None:
# Visualization for drawing
if k == 0:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
else:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
# Visualization on/off boolean filter
vis_alpha = cv2.line(vis_alpha,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
0.75, thickness=self.size)
if vis is not None:
return vis_map, vis_alpha
def end_path(self):
# Complete the drawing
self.curr_path = [[] for _ in range(self.K + 1)]
def predict(self):
self.out_prob = index_numpy_to_one_hot_torch(self.drawn_map, self.K+1)
# self.out_prob = torch.from_numpy(self.drawn_map).float().cuda()
# self.out_prob, _ = pad_divide_by(self.out_prob, 16, self.out_prob.shape[-2:])
# self.out_prob = aggregate_sbg(self.out_prob, keep_bg=True)
return self.out_prob
class ScribbleInteraction(Interaction):
def __init__(self, image, prev_mask, true_size, controller, num_objects):
"""
prev_mask should be in an indexed form
"""
super().__init__(image, prev_mask, true_size, controller)
self.K = num_objects
self.drawn_map = np.empty((self.h, self.w), dtype=np.uint8)
self.drawn_map.fill(255)
# background + k
self.curr_path = [[] for _ in range(self.K + 1)]
self.size = 3
"""
k - object id
vis - a tuple (visualization map, pass through alpha). None if not needed.
"""
def push_point(self, x, y, k, vis=None):
if vis is not None:
vis_map, vis_alpha = vis
selected = self.curr_path[k]
selected.append((x, y))
if len(selected) >= 2:
self.drawn_map = cv2.line(self.drawn_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
k, thickness=self.size)
# Plot visualization
if vis is not None:
# Visualization for drawing
if k == 0:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
else:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
# Visualization on/off boolean filter
vis_alpha = cv2.line(vis_alpha,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
0.75, thickness=self.size)
# Optional vis return
if vis is not None:
return vis_map, vis_alpha
def end_path(self):
# Complete the drawing
self.curr_path = [[] for _ in range(self.K + 1)]
def predict(self):
self.out_prob = self.controller.interact(self.image.unsqueeze(0), self.prev_mask, self.drawn_map)
self.out_prob = aggregate_wbg(self.out_prob, keep_bg=True, hard=True)
return self.out_prob
class ClickInteraction(Interaction):
def __init__(self, image, prev_mask, true_size, controller, tar_obj):
"""
prev_mask in a prob. form
"""
super().__init__(image, prev_mask, true_size, controller)
self.tar_obj = tar_obj
# negative/positive for each object
self.pos_clicks = []
self.neg_clicks = []
self.out_prob = self.prev_mask.clone()
"""
neg - Negative interaction or not
vis - a tuple (visualization map, pass through alpha). None if not needed.
"""
def push_point(self, x, y, neg, vis=None):
# Clicks
if neg:
self.neg_clicks.append((x, y))
else:
self.pos_clicks.append((x, y))
# Do the prediction
self.obj_mask = self.controller.interact(self.image.unsqueeze(0), x, y, not neg)
# Plot visualization
if vis is not None:
vis_map, vis_alpha = vis
# Visualization for clicks
if neg:
vis_map = cv2.circle(vis_map,
(int(round(x)), int(round(y))),
2, color_map[0], thickness=-1)
else:
vis_map = cv2.circle(vis_map,
(int(round(x)), int(round(y))),
2, color_map[self.tar_obj], thickness=-1)
vis_alpha = cv2.circle(vis_alpha,
(int(round(x)), int(round(y))),
2, 1, thickness=-1)
# Optional vis return
return vis_map, vis_alpha
def predict(self):
self.out_prob = self.prev_mask.clone()
# a small hack to allow the interacting object to overwrite existing masks
# without remembering all the object probabilities
self.out_prob = torch.clamp(self.out_prob, max=0.9)
self.out_prob[self.tar_obj] = self.obj_mask
self.out_prob = aggregate_wbg(self.out_prob[1:], keep_bg=True, hard=True)
return self.out_prob
================================================
FILE: XMem/inference/interact/interactive_utils.py
================================================
# Modifed from https://github.com/seoungwugoh/ivs-demo
import numpy as np
import torch
import torch.nn.functional as F
from util.palette import davis_palette
from dataset.range_transform import im_normalization
def image_to_torch(frame: np.ndarray, device='cuda'):
# frame: H*W*3 numpy array
frame = frame.transpose(2, 0, 1)
frame = torch.from_numpy(frame).float().to(device)/255
frame_norm = im_normalization(frame)
return frame_norm, frame
def torch_prob_to_numpy_mask(prob):
mask = torch.max(prob, dim=0).indices
mask = mask.cpu().numpy().astype(np.uint8)
return mask
def index_numpy_to_one_hot_torch(mask, num_classes):
mask = torch.from_numpy(mask).long()
return F.one_hot(mask, num_classes=num_classes).permute(2, 0, 1).float()
"""
Some constants fro visualization
"""
try:
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
except:
device = torch.device("cpu")
color_map_np = np.frombuffer(davis_palette, dtype=np.uint8).reshape(-1, 3).copy()
# scales for better visualization
color_map_np = (color_map_np.astype(np.float32)*1.5).clip(0, 255).astype(np.uint8)
color_map = color_map_np.tolist()
color_map_torch = torch.from_numpy(color_map_np).to(device) / 255
grayscale_weights = np.array([[0.3,0.59,0.11]]).astype(np.float32)
grayscale_weights_torch = torch.from_numpy(grayscale_weights).to(device).unsqueeze(0)
def get_visualization(mode, image, mask, layer, target_object):
if mode == 'fade':
return overlay_davis(image, mask, fade=True)
elif mode == 'davis':
return overlay_davis(image, mask)
elif mode == 'light':
return overlay_davis(image, mask, 0.9)
elif mode == 'popup':
return overlay_popup(image, mask, target_object)
elif mode == 'layered':
if layer is None:
print('Layer file not given. Defaulting to DAVIS.')
return overlay_davis(image, mask)
else:
return overlay_layer(image, mask, layer, target_object)
else:
raise NotImplementedError
def get_visualization_torch(mode, image, prob, layer, target_object):
if mode == 'fade':
return overlay_davis_torch(image, prob, fade=True)
elif mode == 'davis':
return overlay_davis_torch(image, prob)
elif mode == 'light':
return overlay_davis_torch(image, prob, 0.9)
elif mode == 'popup':
return overlay_popup_torch(image, prob, target_object)
elif mode == 'layered':
if layer is None:
print('Layer file not given. Defaulting to DAVIS.')
return overlay_davis_torch(image, prob)
else:
return overlay_layer_torch(image, prob, layer, target_object)
else:
raise NotImplementedError
def overlay_davis(image, mask, alpha=0.5, fade=False):
""" Overlay segmentation on top of RGB image. from davis official"""
im_overlay = image.copy()
colored_mask = color_map_np[mask]
foreground = image*alpha + (1-alpha)*colored_mask
binary_mask = (mask > 0)
# Compose image
im_overlay[binary_mask] = foreground[binary_mask]
if fade:
im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
return im_overlay.astype(image.dtype)
def overlay_popup(image, mask, target_object):
# Keep foreground colored. Convert background to grayscale.
im_overlay = image.copy()
binary_mask = ~(np.isin(mask, target_object))
colored_region = (im_overlay[binary_mask]*grayscale_weights).sum(-1, keepdims=-1)
im_overlay[binary_mask] = colored_region
return im_overlay.astype(image.dtype)
def overlay_layer(image, mask, layer, target_object):
# insert a layer between foreground and background
# The CPU version is less accurate because we are using the hard mask
# The GPU version has softer edges as it uses soft probabilities
obj_mask = (np.isin(mask, target_object)).astype(np.float32)[:, :, np.newaxis]
layer_alpha = layer[:, :, 3].astype(np.float32)[:, :, np.newaxis] / 255
layer_rgb = layer[:, :, :3]
background_alpha = np.maximum(obj_mask, layer_alpha)
im_overlay = (image * (1 - background_alpha) + layer_rgb * (1 - obj_mask) * layer_alpha +
image * obj_mask).clip(0, 255)
return im_overlay.astype(image.dtype)
def overlay_davis_torch(image, mask, alpha=0.5, fade=False):
""" Overlay segmentation on top of RGB image. from davis official"""
# Changes the image in-place to avoid copying
image = image.permute(1, 2, 0)
im_overlay = image
mask = torch.max(mask, dim=0).indices
colored_mask = color_map_torch[mask]
foreground = image*alpha + (1-alpha)*colored_mask
binary_mask = (mask > 0)
# Compose image
im_overlay[binary_mask] = foreground[binary_mask]
if fade:
im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
im_overlay = (im_overlay*255).cpu().numpy()
im_overlay = im_overlay.astype(np.uint8)
return im_overlay
def overlay_popup_torch(image, mask, target_object):
# Keep foreground colored. Convert background to grayscale.
image = image.permute(1, 2, 0)
if len(target_object) == 0:
obj_mask = torch.zeros_like(mask[0]).unsqueeze(2)
else:
# I should not need to convert this to numpy.
# uUsing list works most of the time but consistently fails
# if I include first object -> exclude it -> include it again.
# I check everywhere and it makes absolutely no sense.
# I am blaming this on PyTorch and calling it a day
obj_mask = mask[np.array(target_object,dtype=np.int32)].sum(0).unsqueeze(2)
gray_image = (image*grayscale_weights_torch).sum(-1, keepdim=True)
im_overlay = obj_mask*image + (1-obj_mask)*gray_image
im_overlay = (im_overlay*255).cpu().numpy()
im_overlay = im_overlay.astype(np.uint8)
return im_overlay
def overlay_layer_torch(image, prob, layer, target_object):
# insert a layer between foreground and background
# The CPU version is less accurate because we are using the hard mask
# The GPU version has softer edges as it uses soft probabilities
image = image.permute(1, 2, 0)
if len(target_object) == 0:
obj_mask = torch.zeros_like(prob[0]).unsqueeze(2)
else:
# TODO: figure out why we need to convert this to numpy array
obj_mask = prob[np.array(target_object, dtype=np.int32)].sum(0).unsqueeze(2)
layer_alpha = layer[:, :, 3].unsqueeze(2)
layer_rgb = layer[:, :, :3]
background_alpha = torch.maximum(obj_mask, layer_alpha)
im_overlay = (image * (1 - background_alpha) + layer_rgb * (1 - obj_mask) * layer_alpha +
image * obj_mask).clip(0, 1)
im_overlay = (im_overlay * 255).cpu().numpy()
im_overlay = im_overlay.astype(np.uint8)
return im_overlay
================================================
FILE: XMem/inference/interact/resource_manager.py
================================================
import os
from os import path
import shutil
import collections
import cv2
from PIL import Image
if not hasattr(Image, 'Resampling'): # Pillow<9.0
Image.Resampling = Image
import numpy as np
from util.palette import davis_palette
import progressbar
# https://bugs.python.org/issue28178
# ah python ah why
class LRU:
def __init__(self, func, maxsize=128):
self.cache = collections.OrderedDict()
self.func = func
self.maxsize = maxsize
def __call__(self, *args):
cache = self.cache
if args in cache:
cache.move_to_end(args)
return cache[args]
result = self.func(*args)
cache[args] = result
if len(cache) > self.maxsize:
cache.popitem(last=False)
return result
def invalidate(self, key):
self.cache.pop(key, None)
class ResourceManager:
def __init__(self, config):
# determine inputs
images = config['images']
video = config['video']
self.workspace = config['workspace']
self.size = config['size']
self.palette = davis_palette
# create temporary workspace if not specified
if self.workspace is None:
if images is not None:
basename = path.basename(images)
elif video is not None:
basename = path.basename(video)[:-4]
else:
raise NotImplementedError(
'Either images, video, or workspace has to be specified')
self.workspace = path.join('./workspace', basename)
print(f'Workspace is in: {self.workspace}')
# determine the location of input images
need_decoding = False
need_resizing = False
if path.exists(path.join(self.workspace, 'images')):
pass
elif images is not None:
need_resizing = True
elif video is not None:
# will decode video into frames later
need_decoding = True
# create workspace subdirectories
self.image_dir = path.join(self.workspace, 'images')
self.mask_dir = path.join(self.workspace, 'masks')
os.makedirs(self.image_dir, exist_ok=True)
os.makedirs(self.mask_dir, exist_ok=True)
# convert read functions to be buffered
self.get_image = LRU(self._get_image_unbuffered, maxsize=config['buffer_size'])
self.get_mask = LRU(self._get_mask_unbuffered, maxsize=config['buffer_size'])
# extract frames from video
if need_decoding:
self._extract_frames(video)
# copy/resize existing images to the workspace
if need_resizing:
self._copy_resize_frames(images)
# read all frame names
self.names = sorted(os.listdir(self.image_dir))
self.names = [f[:-4] for f in self.names] # remove extensions
self.length = len(self.names)
assert self.length > 0, f'No images found! Check {self.workspace}/images. Remove folder if necessary.'
print(f'{self.length} images found.')
self.height, self.width = self.get_image(0).shape[:2]
self.visualization_init = False
def _extract_frames(self, video):
cap = cv2.VideoCapture(video)
frame_index = 0
print(f'Extracting frames from {video} into {self.image_dir}...')
bar = progressbar.ProgressBar(max_value=progressbar.UnknownLength)
while(cap.isOpened()):
_, frame = cap.read()
if frame is None:
break
if self.size > 0:
h, w = frame.shape[:2]
new_w = (w*self.size//min(w, h))
new_h = (h*self.size//min(w, h))
if new_w != w or new_h != h:
frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
cv2.imwrite(path.join(self.image_dir, f'{frame_index:07d}.jpg'), frame)
frame_index += 1
bar.update(frame_index)
bar.finish()
print('Done!')
def _copy_resize_frames(self, images):
image_list = os.listdir(images)
print(f'Copying/resizing frames into {self.image_dir}...')
for image_name in progressbar.progressbar(image_list):
if self.size < 0:
# just copy
shutil.copy2(path.join(images, image_name), self.image_dir)
else:
frame = cv2.imread(path.join(images, image_name))
h, w = frame.shape[:2]
new_w = (w*self.size//min(w, h))
new_h = (h*self.size//min(w, h))
if new_w != w or new_h != h:
frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
cv2.imwrite(path.join(self.image_dir, image_name), frame)
print('Done!')
def save_mask(self, ti, mask):
# mask should be uint8 H*W without channels
assert 0 <= ti < self.length
assert isinstance(mask, np.ndarray)
mask = Image.fromarray(mask)
mask.putpalette(self.palette)
mask.save(path.join(self.mask_dir, self.names[ti]+'.png'))
self.invalidate(ti)
def save_visualization(self, ti, image):
# image should be uint8 3*H*W
assert 0 <= ti < self.length
assert isinstance(image, np.ndarray)
if not self.visualization_init:
self.visualization_dir = path.join(self.workspace, 'visualization')
os.makedirs(self.visualization_dir, exist_ok=True)
self.visualization_init = True
image = Image.fromarray(image)
image.save(path.join(self.visualization_dir, self.names[ti]+'.jpg'))
def _get_image_unbuffered(self, ti):
# returns H*W*3 uint8 array
assert 0 <= ti < self.length
image = Image.open(path.join(self.image_dir, self.names[ti]+'.jpg'))
image = np.array(image)
return image
def _get_mask_unbuffered(self, ti):
# returns H*W uint8 array
assert 0 <= ti < self.length
mask_path = path.join(self.mask_dir, self.names[ti]+'.png')
if path.exists(mask_path):
mask = Image.open(mask_path)
mask = np.array(mask)
return mask
else:
return None
def read_external_image(self, file_name, size=None):
image = Image.open(file_name)
is_mask = image.mode in ['L', 'P']
if size is not None:
# PIL uses (width, height)
image = image.resize((size[1], size[0]),
resample=Image.Resampling.NEAREST if is_mask else Image.Resampling.BICUBIC)
image = np.array(image)
return image
def invalidate(self, ti):
# the image buffer is never invalidated
self.get_mask.invalidate((ti,))
def __len__(self):
return self.length
@property
def h(self):
return self.height
@property
def w(self):
return self.width
================================================
FILE: XMem/inference/interact/s2m/__init__.py
================================================
================================================
FILE: XMem/inference/interact/s2m/_deeplab.py
================================================
# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
import torch
from torch import nn
from torch.nn import functional as F
from .utils import _SimpleSegmentationModel
__all__ = ["DeepLabV3"]
class DeepLabV3(_SimpleSegmentationModel):
"""
Implements DeepLabV3 model from
`"Rethinking Atrous Convolution for Semantic Image Segmentation"
`_.
Arguments:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"out" for the last feature map used, and "aux" if an auxiliary classifier
is used.
classifier (nn.Module): module that takes the "out" element returned from
the backbone and returns a dense prediction.
aux_classifier (nn.Module, optional): auxiliary classifier used during training
"""
pass
class DeepLabHeadV3Plus(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHeadV3Plus, self).__init__()
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
low_level_feature = self.project( feature['low_level'] )
output_feature = self.aspp(feature['out'])
output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class DeepLabHead(nn.Module):
def __init__(self, in_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHead, self).__init__()
self.classifier = nn.Sequential(
ASPP(in_channels, aspp_dilate),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
return self.classifier( feature['out'] )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class AtrousSeparableConvolution(nn.Module):
""" Atrous Separable Convolution
"""
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, bias=True):
super(AtrousSeparableConvolution, self).__init__()
self.body = nn.Sequential(
# Separable Conv
nn.Conv2d( in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias, groups=in_channels ),
# PointWise Conv
nn.Conv2d( in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
)
self._init_weight()
def forward(self, x):
return self.body(x)
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
modules = [
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
super(ASPPConv, self).__init__(*modules)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),)
def forward(self, x):
res = []
for conv in self.convs:
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
def convert_to_separable_conv(module):
new_module = module
if isinstance(module, nn.Conv2d) and module.kernel_size[0]>1:
new_module = AtrousSeparableConvolution(module.in_channels,
module.out_channels,
module.kernel_size,
module.stride,
module.padding,
module.dilation,
module.bias)
for name, child in module.named_children():
new_module.add_module(name, convert_to_separable_conv(child))
return new_module
================================================
FILE: XMem/inference/interact/s2m/s2m_network.py
================================================
# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
from .utils import IntermediateLayerGetter
from ._deeplab import DeepLabHead, DeepLabHeadV3Plus, DeepLabV3
from . import s2m_resnet
def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
if output_stride==8:
replace_stride_with_dilation=[False, True, True]
aspp_dilate = [12, 24, 36]
else:
replace_stride_with_dilation=[False, False, True]
aspp_dilate = [6, 12, 18]
backbone = s2m_resnet.__dict__[backbone_name](
pretrained=pretrained_backbone,
replace_stride_with_dilation=replace_stride_with_dilation)
inplanes = 2048
low_level_planes = 256
if name=='deeplabv3plus':
return_layers = {'layer4': 'out', 'layer1': 'low_level'}
classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
elif name=='deeplabv3':
return_layers = {'layer4': 'out'}
classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
model = DeepLabV3(backbone, classifier)
return model
def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
if backbone.startswith('resnet'):
model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
else:
raise NotImplementedError
return model
# Deeplab v3
def deeplabv3_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
"""Constructs a DeepLabV3 model with a ResNet-50 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
# Deeplab v3+
def deeplabv3plus_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
"""Constructs a DeepLabV3 model with a ResNet-50 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
================================================
FILE: XMem/inference/interact/s2m/s2m_resnet.py
================================================
import torch
import torch.nn as nn
try:
from torchvision.models.utils import load_state_dict_from_url
except ModuleNotFoundError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
__all__ = ['ResNet', 'resnet50']
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(6, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def resnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
================================================
FILE: XMem/inference/interact/s2m/utils.py
================================================
# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
from collections import OrderedDict
class _SimpleSegmentationModel(nn.Module):
def __init__(self, backbone, classifier):
super(_SimpleSegmentationModel, self).__init__()
self.backbone = backbone
self.classifier = classifier
def forward(self, x):
input_shape = x.shape[-2:]
features = self.backbone(x)
x = self.classifier(features)
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
return x
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Arguments:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
Examples::
>>> m = torchvision.models.resnet18(pretrained=True)
>>> # extract layer1 and layer3, giving as names `feat1` and feat2`
>>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
>>> {'layer1': 'feat1', 'layer3': 'feat2'})
>>> out = new_m(torch.rand(1, 3, 224, 224))
>>> print([(k, v.shape) for k, v in out.items()])
>>> [('feat1', torch.Size([1, 64, 56, 56])),
>>> ('feat2', torch.Size([1, 256, 14, 14]))]
"""
def __init__(self, model, return_layers):
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {k: v for k, v in return_layers.items()}
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x):
out = OrderedDict()
for name, module in self.named_children():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
================================================
FILE: XMem/inference/interact/s2m_controller.py
================================================
import torch
import numpy as np
from ..interact.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
from util.tensor_util import pad_divide_by, unpad
class S2MController:
"""
A controller for Scribble-to-Mask (for user interaction, not for DAVIS)
Takes the image, previous mask, and scribbles to produce a new mask
ignore_class is usually 255
0 is NOT the ignore class -- it is the label for the background
"""
def __init__(self, s2m_net:S2M, num_objects, ignore_class, device='cuda:0'):
self.s2m_net = s2m_net
self.num_objects = num_objects
self.ignore_class = ignore_class
self.device = device
def interact(self, image, prev_mask, scr_mask):
print(self.device)
image = image.to(self.device, non_blocking=True)
prev_mask = prev_mask.unsqueeze(0)
h, w = image.shape[-2:]
unaggre_mask = torch.zeros((self.num_objects, h, w), dtype=torch.float32, device=image.device)
for ki in range(1, self.num_objects+1):
p_srb = (scr_mask==ki).astype(np.uint8)
n_srb = ((scr_mask!=ki) * (scr_mask!=self.ignore_class)).astype(np.uint8)
Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(image.device)
inputs = torch.cat([image, (prev_mask==ki).float().unsqueeze(0), Rs], 1)
inputs, pads = pad_divide_by(inputs, 16)
unaggre_mask[ki-1] = unpad(torch.sigmoid(self.s2m_net(inputs)), pads)
return unaggre_mask
================================================
FILE: XMem/inference/interact/timer.py
================================================
import time
class Timer:
def __init__(self):
self._acc_time = 0
self._paused = True
def start(self):
if self._paused:
self.last_time = time.time()
self._paused = False
return self
def pause(self):
self.count()
self._paused = True
return self
def count(self):
if self._paused:
return self._acc_time
t = time.time()
self._acc_time += t - self.last_time
self.last_time = t
return self._acc_time
def format(self):
# count = int(self.count()*100)
# return '%02d:%02d:%02d' % (count//6000, (count//100)%60, count%100)
return '%03.2f' % self.count()
def __str__(self):
return self.format()
================================================
FILE: XMem/inference/kv_memory_store.py
================================================
import torch
from typing import List
class KeyValueMemoryStore:
"""
Works for key/value pairs type storage
e.g., working and long-term memory
"""
"""
An object group is created when new objects enter the video
Objects in the same group share the same temporal extent
i.e., objects initialized in the same frame are in the same group
For DAVIS/interactive, there is only one object group
For YouTubeVOS, there can be multiple object groups
"""
def __init__(self, count_usage: bool):
self.count_usage = count_usage
# keys are stored in a single tensor and are shared between groups/objects
# values are stored as a list indexed by object groups
self.k = None
self.v = []
self.obj_groups = []
# for debugging only
self.all_objects = []
# shrinkage and selection are also single tensors
self.s = self.e = None
# usage
if self.count_usage:
self.use_count = self.life_count = None
def add(self, key, value, shrinkage, selection, objects: List[int]):
new_count = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32)
new_life = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32) + 1e-7
# add the key
if self.k is None:
self.k = key
self.s = shrinkage
self.e = selection
if self.count_usage:
self.use_count = new_count
self.life_count = new_life
else:
self.k = torch.cat([self.k, key], -1)
if shrinkage is not None:
self.s = torch.cat([self.s, shrinkage], -1)
if selection is not None:
self.e = torch.cat([self.e, selection], -1)
if self.count_usage:
self.use_count = torch.cat([self.use_count, new_count], -1)
self.life_count = torch.cat([self.life_count, new_life], -1)
# add the value
if objects is not None:
# When objects is given, v is a tensor; used in working memory
assert isinstance(value, torch.Tensor)
# First consume objects that are already in the memory bank
# cannot use set here because we need to preserve order
# shift by one as background is not part of value
remaining_objects = [obj-1 for obj in objects]
for gi, group in enumerate(self.obj_groups):
for obj in group:
# should properly raise an error if there are overlaps in obj_groups
remaining_objects.remove(obj)
self.v[gi] = torch.cat([self.v[gi], value[group]], -1)
# If there are remaining objects, add them as a new group
if len(remaining_objects) > 0:
new_group = list(remaining_objects)
self.v.append(value[new_group])
self.obj_groups.append(new_group)
self.all_objects.extend(new_group)
assert sorted(self.all_objects) == self.all_objects, 'Objects MUST be inserted in sorted order '
else:
# When objects is not given, v is a list that already has the object groups sorted
# used in long-term memory
assert isinstance(value, list)
for gi, gv in enumerate(value):
if gv is None:
continue
if gi < self.num_groups:
self.v[gi] = torch.cat([self.v[gi], gv], -1)
else:
self.v.append(gv)
def update_usage(self, usage):
# increase all life count by 1
# increase use of indexed elements
if not self.count_usage:
return
self.use_count += usage.view_as(self.use_count)
self.life_count += 1
def sieve_by_range(self, start: int, end: int, min_size: int):
# keep only the elements *outside* of this range (with some boundary conditions)
# i.e., concat (a[:start], a[end:])
# min_size is only used for values, we do not sieve values under this size
# (because they are not consolidated)
if end == 0:
# negative 0 would not work as the end index!
self.k = self.k[:,:,:start]
if self.count_usage:
self.use_count = self.use_count[:,:,:start]
self.life_count = self.life_count[:,:,:start]
if self.s is not None:
self.s = self.s[:,:,:start]
if self.e is not None:
self.e = self.e[:,:,:start]
for gi in range(self.num_groups):
if self.v[gi].shape[-1] >= min_size:
self.v[gi] = self.v[gi][:,:,:start]
else:
self.k = torch.cat([self.k[:,:,:start], self.k[:,:,end:]], -1)
if self.count_usage:
self.use_count = torch.cat([self.use_count[:,:,:start], self.use_count[:,:,end:]], -1)
self.life_count = torch.cat([self.life_count[:,:,:start], self.life_count[:,:,end:]], -1)
if self.s is not None:
self.s = torch.cat([self.s[:,:,:start], self.s[:,:,end:]], -1)
if self.e is not None:
self.e = torch.cat([self.e[:,:,:start], self.e[:,:,end:]], -1)
for gi in range(self.num_groups):
if self.v[gi].shape[-1] >= min_size:
self.v[gi] = torch.cat([self.v[gi][:,:,:start], self.v[gi][:,:,end:]], -1)
def remove_obsolete_features(self, max_size: int):
# normalize with life duration
usage = self.get_usage().flatten()
values, _ = torch.topk(usage, k=(self.size-max_size), largest=False, sorted=True)
survived = (usage > values[-1])
self.k = self.k[:, :, survived]
self.s = self.s[:, :, survived] if self.s is not None else None
# Long-term memory does not store ek so this should not be needed
self.e = self.e[:, :, survived] if self.e is not None else None
if self.num_groups > 1:
raise NotImplementedError("""The current data structure does not support feature removal with
multiple object groups (e.g., some objects start to appear later in the video)
The indices for "survived" is based on keys but not all values are present for every key
Basically we need to remap the indices for keys to values
""")
for gi in range(self.num_groups):
self.v[gi] = self.v[gi][:, :, survived]
self.use_count = self.use_count[:, :, survived]
self.life_count = self.life_count[:, :, survived]
def get_usage(self):
# return normalized usage
if not self.count_usage:
raise RuntimeError('I did not count usage!')
else:
usage = self.use_count / self.life_count
return usage
def get_all_sliced(self, start: int, end: int):
# return k, sk, ek, usage in order, sliced by start and end
if end == 0:
# negative 0 would not work as the end index!
k = self.k[:,:,start:]
sk = self.s[:,:,start:] if self.s is not None else None
ek = self.e[:,:,start:] if self.e is not None else None
usage = self.get_usage()[:,:,start:]
else:
k = self.k[:,:,start:end]
sk = self.s[:,:,start:end] if self.s is not None else None
ek = self.e[:,:,start:end] if self.e is not None else None
usage = self.get_usage()[:,:,start:end]
return k, sk, ek, usage
def get_v_size(self, ni: int):
return self.v[ni].shape[2]
def engaged(self):
return self.k is not None
@property
def size(self):
if self.k is None:
return 0
else:
return self.k.shape[-1]
@property
def num_groups(self):
return len(self.v)
@property
def key(self):
return self.k
@property
def value(self):
return self.v
@property
def shrinkage(self):
return self.s
@property
def selection(self):
return self.e
================================================
FILE: XMem/inference/memory_manager.py
================================================
import torch
import warnings
from inference.kv_memory_store import KeyValueMemoryStore
from model.memory_util import *
class MemoryManager:
"""
Manages all three memory stores and the transition between working/long-term memory
"""
def __init__(self, config):
self.hidden_dim = config['hidden_dim']
self.top_k = config['top_k']
self.enable_long_term = config['enable_long_term']
self.enable_long_term_usage = config['enable_long_term_count_usage']
if self.enable_long_term:
self.max_mt_frames = config['max_mid_term_frames']
self.min_mt_frames = config['min_mid_term_frames']
self.num_prototypes = config['num_prototypes']
self.max_long_elements = config['max_long_term_elements']
# dimensions will be inferred from input later
self.CK = self.CV = None
self.H = self.W = None
# The hidden state will be stored in a single tensor for all objects
# B x num_objects x CH x H x W
self.hidden = None
self.work_mem = KeyValueMemoryStore(count_usage=self.enable_long_term)
if self.enable_long_term:
self.long_mem = KeyValueMemoryStore(count_usage=self.enable_long_term_usage)
self.reset_config = True
def update_config(self, config):
self.reset_config = True
self.hidden_dim = config['hidden_dim']
self.top_k = config['top_k']
assert self.enable_long_term == config['enable_long_term'], 'cannot update this'
assert self.enable_long_term_usage == config['enable_long_term_count_usage'], 'cannot update this'
self.enable_long_term_usage = config['enable_long_term_count_usage']
if self.enable_long_term:
self.max_mt_frames = config['max_mid_term_frames']
self.min_mt_frames = config['min_mid_term_frames']
self.num_prototypes = config['num_prototypes']
self.max_long_elements = config['max_long_term_elements']
def _readout(self, affinity, v):
# this function is for a single object group
return v @ affinity
def match_memory(self, query_key, selection):
# query_key: B x C^k x H x W
# selection: B x C^k x H x W
num_groups = self.work_mem.num_groups
h, w = query_key.shape[-2:]
query_key = query_key.flatten(start_dim=2)
selection = selection.flatten(start_dim=2) if selection is not None else None
"""
Memory readout using keys
"""
if self.enable_long_term and self.long_mem.engaged():
# Use long-term memory
long_mem_size = self.long_mem.size
memory_key = torch.cat([self.long_mem.key, self.work_mem.key], -1)
shrinkage = torch.cat([self.long_mem.shrinkage, self.work_mem.shrinkage], -1)
similarity = get_similarity(memory_key, shrinkage, query_key, selection)
work_mem_similarity = similarity[:, long_mem_size:]
long_mem_similarity = similarity[:, :long_mem_size]
# get the usage with the first group
# the first group always have all the keys valid
affinity, usage = do_softmax(
torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(0):], work_mem_similarity], 1),
top_k=self.top_k, inplace=True, return_usage=True)
affinity = [affinity]
# compute affinity group by group as later groups only have a subset of keys
for gi in range(1, num_groups):
if gi < self.long_mem.num_groups:
# merge working and lt similarities before softmax
affinity_one_group = do_softmax(
torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(gi):],
work_mem_similarity[:, -self.work_mem.get_v_size(gi):]], 1),
top_k=self.top_k, inplace=True)
else:
# no long-term memory for this group
affinity_one_group = do_softmax(work_mem_similarity[:, -self.work_mem.get_v_size(gi):],
top_k=self.top_k, inplace=(gi==num_groups-1))
affinity.append(affinity_one_group)
all_memory_value = []
for gi, gv in enumerate(self.work_mem.value):
# merge the working and lt values before readout
if gi < self.long_mem.num_groups:
all_memory_value.append(torch.cat([self.long_mem.value[gi], self.work_mem.value[gi]], -1))
else:
all_memory_value.append(gv)
"""
Record memory usage for working and long-term memory
"""
# ignore the index return for long-term memory
work_usage = usage[:, long_mem_size:]
self.work_mem.update_usage(work_usage.flatten())
if self.enable_long_term_usage:
# ignore the index return for working memory
long_usage = usage[:, :long_mem_size]
self.long_mem.update_usage(long_usage.flatten())
else:
# No long-term memory
similarity = get_similarity(self.work_mem.key, self.work_mem.shrinkage, query_key, selection)
if self.enable_long_term:
affinity, usage = do_softmax(similarity, inplace=(num_groups==1),
top_k=self.top_k, return_usage=True)
# Record memory usage for working memory
self.work_mem.update_usage(usage.flatten())
else:
affinity = do_softmax(similarity, inplace=(num_groups==1),
top_k=self.top_k, return_usage=False)
affinity = [affinity]
# compute affinity group by group as later groups only have a subset of keys
for gi in range(1, num_groups):
affinity_one_group = do_softmax(similarity[:, -self.work_mem.get_v_size(gi):],
top_k=self.top_k, inplace=(gi==num_groups-1))
affinity.append(affinity_one_group)
all_memory_value = self.work_mem.value
# Shared affinity within each group
all_readout_mem = torch.cat([
self._readout(affinity[gi], gv)
for gi, gv in enumerate(all_memory_value)
], 0)
return all_readout_mem.view(all_readout_mem.shape[0], self.CV, h, w)
def add_memory(self, key, shrinkage, value, objects, selection=None):
# key: 1*C*H*W
# value: 1*num_objects*C*H*W
# objects contain a list of object indices
if self.H is None or self.reset_config:
self.reset_config = False
self.H, self.W = key.shape[-2:]
self.HW = self.H*self.W
if self.enable_long_term:
# convert from num. frames to num. nodes
self.min_work_elements = self.min_mt_frames*self.HW
self.max_work_elements = self.max_mt_frames*self.HW
# key: 1*C*N
# value: num_objects*C*N
key = key.flatten(start_dim=2)
shrinkage = shrinkage.flatten(start_dim=2)
value = value[0].flatten(start_dim=2)
self.CK = key.shape[1]
self.CV = value.shape[1]
if selection is not None:
if not self.enable_long_term:
warnings.warn('the selection factor is only needed in long-term mode', UserWarning)
selection = selection.flatten(start_dim=2)
self.work_mem.add(key, value, shrinkage, selection, objects)
# long-term memory cleanup
if self.enable_long_term:
# Do memory compressed if needed
if self.work_mem.size >= self.max_work_elements:
# Remove obsolete features if needed
if self.long_mem.size >= (self.max_long_elements-self.num_prototypes):
self.long_mem.remove_obsolete_features(self.max_long_elements-self.num_prototypes)
self.compress_features()
def create_hidden_state(self, n, sample_key):
# n is the TOTAL number of objects
h, w = sample_key.shape[-2:]
if self.hidden is None:
self.hidden = torch.zeros((1, n, self.hidden_dim, h, w), device=sample_key.device)
elif self.hidden.shape[1] != n:
self.hidden = torch.cat([
self.hidden,
torch.zeros((1, n-self.hidden.shape[1], self.hidden_dim, h, w), device=sample_key.device)
], 1)
assert(self.hidden.shape[1] == n)
def set_hidden(self, hidden):
self.hidden = hidden
def get_hidden(self):
return self.hidden
def compress_features(self):
HW = self.HW
candidate_value = []
total_work_mem_size = self.work_mem.size
for gv in self.work_mem.value:
# Some object groups might be added later in the video
# So not all keys have values associated with all objects
# We need to keep track of the key->value validity
mem_size_in_this_group = gv.shape[-1]
if mem_size_in_this_group == total_work_mem_size:
# full LT
candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
else:
# mem_size is smaller than total_work_mem_size, but at least HW
assert HW <= mem_size_in_this_group < total_work_mem_size
if mem_size_in_this_group > self.min_work_elements+HW:
# part of this object group still goes into LT
candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
else:
# this object group cannot go to the LT at all
candidate_value.append(None)
# perform memory consolidation
prototype_key, prototype_value, prototype_shrinkage = self.consolidation(
*self.work_mem.get_all_sliced(HW, -self.min_work_elements+HW), candidate_value)
# remove consolidated working memory
self.work_mem.sieve_by_range(HW, -self.min_work_elements+HW, min_size=self.min_work_elements+HW)
# add to long-term memory
self.long_mem.add(prototype_key, prototype_value, prototype_shrinkage, selection=None, objects=None)
def consolidation(self, candidate_key, candidate_shrinkage, candidate_selection, usage, candidate_value):
# keys: 1*C*N
# values: num_objects*C*N
N = candidate_key.shape[-1]
# find the indices with max usage
_, max_usage_indices = torch.topk(usage, k=self.num_prototypes, dim=-1, sorted=True)
prototype_indices = max_usage_indices.flatten()
# Prototypes are invalid for out-of-bound groups
validity = [prototype_indices >= (N-gv.shape[2]) if gv is not None else None for gv in candidate_value]
prototype_key = candidate_key[:, :, prototype_indices]
prototype_selection = candidate_selection[:, :, prototype_indices] if candidate_selection is not None else None
"""
Potentiation step
"""
similarity = get_similarity(candidate_key, candidate_shrinkage, prototype_key, prototype_selection)
# convert similarity to affinity
# need to do it group by group since the softmax normalization would be different
affinity = [
do_softmax(similarity[:, -gv.shape[2]:, validity[gi]]) if gv is not None else None
for gi, gv in enumerate(candidate_value)
]
# some values can be have all False validity. Weed them out.
affinity = [
aff if aff is None or aff.shape[-1] > 0 else None for aff in affinity
]
# readout the values
prototype_value = [
self._readout(affinity[gi], gv) if affinity[gi] is not None else None
for gi, gv in enumerate(candidate_value)
]
# readout the shrinkage term
prototype_shrinkage = self._readout(affinity[0], candidate_shrinkage) if candidate_shrinkage is not None else None
return prototype_key, prototype_value, prototype_shrinkage
================================================
FILE: XMem/interactive_demo.py
================================================
"""
A simple user interface for XMem
"""
import os
from os import path
# fix for Windows
if 'QT_QPA_PLATFORM_PLUGIN_PATH' not in os.environ:
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = ''
import signal
signal.signal(signal.SIGINT, signal.SIG_DFL)
import sys
from argparse import ArgumentParser
import torch
from model.network import XMem
from inference.interact.s2m_controller import S2MController
from inference.interact.fbrs_controller import FBRSController
from inference.interact.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
from PySide6.QtWidgets import QApplication
from inference.interact.gui import App
from inference.interact.resource_manager import ResourceManager
from contextlib import nullcontext
torch.set_grad_enabled(False)
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
if __name__ == '__main__':
# Arguments parsing
parser = ArgumentParser()
parser.add_argument('--model', default='./saves/XMem.pth')
parser.add_argument('--s2m_model', default='saves/s2m.pth')
parser.add_argument('--fbrs_model', default='saves/fbrs.pth')
"""
Priority 1: If a "images" folder exists in the workspace, we will read from that directory
Priority 2: If --images is specified, we will copy/resize those images to the workspace
Priority 3: If --video is specified, we will extract the frames to the workspace (in an "images" folder) and read from there
In any case, if a "masks" folder exists in the workspace, we will use that to initialize the mask
That way, you can continue annotation from an interrupted run as long as the same workspace is used.
"""
parser.add_argument('--images', help='Folders containing input images.', default=None)
parser.add_argument('--video', help='Video file readable by OpenCV.', default=None)
parser.add_argument('--workspace', help='directory for storing buffered images (if needed) and output masks', default=None)
parser.add_argument('--buffer_size', help='Correlate with CPU memory consumption', type=int, default=100)
parser.add_argument('--num_objects', type=int, default=1)
# Long-memory options
# Defaults. Some can be changed in the GUI.
parser.add_argument('--max_mid_term_frames', help='T_max in paper, decrease to save memory', type=int, default=10)
parser.add_argument('--min_mid_term_frames', help='T_min in paper, decrease to save memory', type=int, default=5)
parser.add_argument('--max_long_term_elements', help='LT_max in paper, increase if objects disappear for a long time',
type=int, default=10000)
parser.add_argument('--num_prototypes', help='P in paper', type=int, default=128)
parser.add_argument('--top_k', type=int, default=30)
parser.add_argument('--mem_every', type=int, default=10)
parser.add_argument('--deep_update_every', help='Leave -1 normally to synchronize with mem_every', type=int, default=-1)
parser.add_argument('--no_amp', help='Turn off AMP', action='store_true')
parser.add_argument('--size', default=480, type=int,
help='Resize the shorter side to this size. -1 to use original resolution. ')
args = parser.parse_args()
# create temporary workspace if not specified
config = vars(args)
config['enable_long_term'] = True
config['enable_long_term_count_usage'] = True
if config["workspace"] is None:
if config["images"] is not None:
basename = path.basename(config["images"])
elif config["video"] is not None:
basename = path.basename(config["video"])[:-4]
else:
raise NotImplementedError(
'Either images, video, or workspace has to be specified')
config["workspace"] = path.join('./workspace', basename)
with torch.cuda.amp.autocast(enabled=not args.no_amp) if device.type == 'cuda' else nullcontext():
# Load our checkpoint
network = XMem(config, args.model, map_location=device).to(device).eval()
# Loads the S2M model
if args.s2m_model is not None:
s2m_saved = torch.load(args.s2m_model, map_location=device)
s2m_model = S2M().to(device).eval()
s2m_model.load_state_dict(s2m_saved)
else:
s2m_model = None
s2m_controller = S2MController(s2m_model, args.num_objects, ignore_class=255, device=device)
if args.fbrs_model is not None:
fbrs_controller = FBRSController(args.fbrs_model, device=device)
else:
fbrs_controller = None
# Manages most IO
resource_manager = ResourceManager(config)
app = QApplication(sys.argv)
ex = App(network, resource_manager, s2m_controller, fbrs_controller, config, device)
sys.exit(app.exec())
================================================
FILE: XMem/merge_multi_scale.py
================================================
import os
from os import path
from argparse import ArgumentParser
import glob
from collections import defaultdict
import numpy as np
import hickle as hkl
from PIL import Image, ImagePalette
from progressbar import progressbar
from multiprocessing import Pool
from util import palette
from util.palette import davis_palette, youtube_palette
import shutil
def search_options(options, name):
for option in options:
if path.exists(path.join(option, name)):
return path.join(option, name)
else:
return None
def process_vid(vid):
vid_path = search_options(all_options, vid)
if vid_path is not None:
backward_mapping = hkl.load(path.join(vid_path, 'backward.hkl'))
else:
backward_mapping = None
frames = os.listdir(path.join(all_options[0], vid))
frames = [f for f in frames if 'backward' not in f]
print(vid)
if 'Y' in args.dataset:
this_out_path = path.join(out_path, 'Annotations', vid)
else:
this_out_path = path.join(out_path, vid)
os.makedirs(this_out_path, exist_ok=True)
for f in frames:
result_sum = None
for option in all_options:
if not path.exists(path.join(option, vid, f)):
continue
result = hkl.load(path.join(option, vid, f))
if result_sum is None:
result_sum = result.astype(np.float32)
else:
result_sum += result
# argmax and to idx
result_sum = np.argmax(result_sum, axis=0)
# Remap the indices to the original domain
if backward_mapping is not None:
idx_mask = np.zeros_like(result_sum, dtype=np.uint8)
for l, i in backward_mapping.items():
idx_mask[result_sum==i] = l
else:
idx_mask = result_sum.astype(np.uint8)
# Save the results
img_E = Image.fromarray(idx_mask)
img_E.putpalette(palette)
img_E.save(path.join(this_out_path, f[:-4]+'.png'))
if __name__ == '__main__':
"""
Arguments loading
"""
parser = ArgumentParser()
parser.add_argument('--dataset', default='Y', help='D/Y, D for DAVIS; Y for YouTubeVOS')
parser.add_argument('--list', nargs="+")
parser.add_argument('--pattern', default=None, help='Glob patten. Can be used in place of list.')
parser.add_argument('--output')
parser.add_argument('--num_proc', default=4, type=int)
args = parser.parse_args()
out_path = args.output
# Find the input candidates
if args.pattern is None:
all_options = args.list
else:
assert args.list is None, 'cannot specify both list and pattern'
all_options = glob.glob(args.pattern)
# Get the correct palette
if 'D' in args.dataset:
palette = ImagePalette.ImagePalette(mode='P', palette=davis_palette)
elif 'Y' in args.dataset:
palette = ImagePalette.ImagePalette(mode='P', palette=youtube_palette)
else:
raise NotImplementedError
# Count of the number of videos in each candidate
all_options = [path.join(o, 'Scores') for o in all_options]
vid_count = defaultdict(int)
for option in all_options:
vid_in_here = sorted(os.listdir(option))
for vid in vid_in_here:
vid_count[vid] += 1
all_vid = []
count_to_vid = defaultdict(int)
for k, v in vid_count.items():
count_to_vid[v] += 1
all_vid.append(k)
for k, v in count_to_vid.items():
print('Videos with count %d: %d' % (k, v))
all_vid = sorted(all_vid)
print('Total number of videos: ', len(all_vid))
pool = Pool(processes=args.num_proc)
for _ in progressbar(pool.imap_unordered(process_vid, all_vid), max_value=len(all_vid)):
pass
pool.close()
pool.join()
if 'D' in args.dataset:
print('Making zip for DAVIS test-dev...')
shutil.make_archive(args.output, 'zip', args.output)
if 'Y' in args.dataset:
print('Making zip for YouTubeVOS...')
shutil.make_archive(path.join(args.output, path.basename(args.output)), 'zip', args.output, 'Annotations')
================================================
FILE: XMem/merge_results.py
================================================
import glob
import os
from PIL import Image
import numpy as np
import tqdm
import multiprocessing
multi_dir = "mevis_val/vis_output/"
outdir = "mevis_val_merge/vis_output/"
all_obj_list = []
video_list = glob.glob(os.path.join(multi_dir, "0/*"))
for video in video_list:
obj_list = glob.glob(video + "/*")
all_obj_list = all_obj_list + ['/'.join(i.split('/')[-2:]) for i in obj_list]
def merge(obj):
obj_output_dir = os.path.join(outdir, obj)
os.makedirs(obj_output_dir, exist_ok=True)
img_list = [i.split('/')[-1] for i in glob.glob(os.path.join(multi_dir, "0", obj, "*.png"))]
for img_name in img_list:
agg_img = None
for i in range(7):
img_path = os.path.join(multi_dir, str(i), obj, img_name)
tmp_img = (np.array(Image.open(img_path)) > 0).astype(np.uint8)
if agg_img is not None:
agg_img = agg_img + tmp_img
else:
agg_img = tmp_img
agg_img = (agg_img >= 4).astype(np.uint8)
agg_img = Image.fromarray(agg_img)
img_output_path = os.path.join(obj_output_dir, img_name)
agg_img.save(img_output_path)
print('start')
cpu_num = multiprocessing.cpu_count()-1
print("cpu_num:", cpu_num)
pool = multiprocessing.Pool(cpu_num)
for obj in all_obj_list:
pool.apply_async(merge, args=(obj,))
pool.close()
pool.join()
================================================
FILE: XMem/model/__init__.py
================================================
================================================
FILE: XMem/model/aggregate.py
================================================
import torch
import torch.nn.functional as F
# Soft aggregation from STM
def aggregate(prob, dim, return_logits=False):
new_prob = torch.cat([
torch.prod(1-prob, dim=dim, keepdim=True),
prob
], dim).clamp(1e-7, 1-1e-7)
logits = torch.log((new_prob /(1-new_prob)))
prob = F.softmax(logits, dim=dim)
if return_logits:
return logits, prob
else:
return prob
================================================
FILE: XMem/model/cbam.py
================================================
# Modified from https://github.com/Jongchan/attention-module/blob/master/MODELS/cbam.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
def forward(self, x):
x = self.conv(x)
return x
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type=='avg':
avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( avg_pool )
elif pool_type=='max':
max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( max_pool )
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = torch.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out
================================================
FILE: XMem/model/group_modules.py
================================================
"""
Group-specific modules
They handle features that also depends on the mask.
Features are typically of shape
batch_size * num_objects * num_channels * H * W
All of them are permutation equivariant w.r.t. to the num_objects dimension
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def interpolate_groups(g, ratio, mode, align_corners):
batch_size, num_objects = g.shape[:2]
g = F.interpolate(g.flatten(start_dim=0, end_dim=1),
scale_factor=ratio, mode=mode, align_corners=align_corners)
g = g.view(batch_size, num_objects, *g.shape[1:])
return g
def upsample_groups(g, ratio=2, mode='bilinear', align_corners=False):
return interpolate_groups(g, ratio, mode, align_corners)
def downsample_groups(g, ratio=1/2, mode='area', align_corners=None):
return interpolate_groups(g, ratio, mode, align_corners)
class GConv2D(nn.Conv2d):
def forward(self, g):
batch_size, num_objects = g.shape[:2]
g = super().forward(g.flatten(start_dim=0, end_dim=1))
return g.view(batch_size, num_objects, *g.shape[1:])
class GroupResBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super().__init__()
if in_dim == out_dim:
self.downsample = None
else:
self.downsample = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
self.conv1 = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
self.conv2 = GConv2D(out_dim, out_dim, kernel_size=3, padding=1)
def forward(self, g):
out_g = self.conv1(F.relu(g))
out_g = self.conv2(F.relu(out_g))
if self.downsample is not None:
g = self.downsample(g)
return out_g + g
class MainToGroupDistributor(nn.Module):
def __init__(self, x_transform=None, method='cat', reverse_order=False):
super().__init__()
self.x_transform = x_transform
self.method = method
self.reverse_order = reverse_order
def forward(self, x, g):
num_objects = g.shape[1]
if self.x_transform is not None:
x = self.x_transform(x)
if self.method == 'cat':
if self.reverse_order:
g = torch.cat([g, x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1)], 2)
else:
g = torch.cat([x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1), g], 2)
elif self.method == 'add':
g = x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1) + g
else:
raise NotImplementedError
return g
================================================
FILE: XMem/model/losses.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import defaultdict
def dice_loss(input_mask, cls_gt):
num_objects = input_mask.shape[1]
losses = []
for i in range(num_objects):
mask = input_mask[:,i].flatten(start_dim=1)
# background not in mask, so we add one to cls_gt
gt = (cls_gt==(i+1)).float().flatten(start_dim=1)
numerator = 2 * (mask * gt).sum(-1)
denominator = mask.sum(-1) + gt.sum(-1)
loss = 1 - (numerator + 1) / (denominator + 1)
losses.append(loss)
return torch.cat(losses).mean()
# https://stackoverflow.com/questions/63735255/how-do-i-compute-bootstrapped-cross-entropy-loss-in-pytorch
class BootstrappedCE(nn.Module):
def __init__(self, start_warm, end_warm, top_p=0.15):
super().__init__()
self.start_warm = start_warm
self.end_warm = end_warm
self.top_p = top_p
def forward(self, input, target, it):
if it < self.start_warm:
return F.cross_entropy(input, target), 1.0
raw_loss = F.cross_entropy(input, target, reduction='none').view(-1)
num_pixels = raw_loss.numel()
if it > self.end_warm:
this_p = self.top_p
else:
this_p = self.top_p + (1-self.top_p)*((self.end_warm-it)/(self.end_warm-self.start_warm))
loss, _ = torch.topk(raw_loss, int(num_pixels * this_p), sorted=False)
return loss.mean(), this_p
class LossComputer:
def __init__(self, config):
super().__init__()
self.config = config
self.bce = BootstrappedCE(config['start_warm'], config['end_warm'])
def compute(self, data, num_objects, it):
losses = defaultdict(int)
b, t = data['rgb'].shape[:2]
losses['total_loss'] = 0
for ti in range(1, t):
for bi in range(b):
loss, p = self.bce(data[f'logits_{ti}'][bi:bi+1, :num_objects[bi]+1], data['cls_gt'][bi:bi+1,ti,0], it)
losses['p'] += p / b / (t-1)
losses[f'ce_loss_{ti}'] += loss / b
losses['total_loss'] += losses['ce_loss_%d'%ti]
losses[f'dice_loss_{ti}'] = dice_loss(data[f'masks_{ti}'], data['cls_gt'][:,ti,0])
losses['total_loss'] += losses[f'dice_loss_{ti}']
return losses
================================================
FILE: XMem/model/memory_util.py
================================================
import math
import numpy as np
import torch
from typing import Optional
def get_similarity(mk, ms, qk, qe):
# used for training/inference and memory reading/memory potentiation
# mk: B x CK x [N] - Memory keys
# ms: B x 1 x [N] - Memory shrinkage
# qk: B x CK x [HW/P] - Query keys
# qe: B x CK x [HW/P] - Query selection
# Dimensions in [] are flattened
CK = mk.shape[1]
mk = mk.flatten(start_dim=2)
ms = ms.flatten(start_dim=1).unsqueeze(2) if ms is not None else None
qk = qk.flatten(start_dim=2)
qe = qe.flatten(start_dim=2) if qe is not None else None
if qe is not None:
# See appendix for derivation
# or you can just trust me ヽ(ー_ー )ノ
mk = mk.transpose(1, 2)
a_sq = (mk.pow(2) @ qe)
two_ab = 2 * (mk @ (qk * qe))
b_sq = (qe * qk.pow(2)).sum(1, keepdim=True)
similarity = (-a_sq+two_ab-b_sq)
else:
# similar to STCN if we don't have the selection term
a_sq = mk.pow(2).sum(1).unsqueeze(2)
two_ab = 2 * (mk.transpose(1, 2) @ qk)
similarity = (-a_sq+two_ab)
if ms is not None:
similarity = similarity * ms / math.sqrt(CK) # B*N*HW
else:
similarity = similarity / math.sqrt(CK) # B*N*HW
return similarity
def do_softmax(similarity, top_k: Optional[int]=None, inplace=False, return_usage=False):
# normalize similarity with top-k softmax
# similarity: B x N x [HW/P]
# use inplace with care
if top_k is not None:
values, indices = torch.topk(similarity, k=top_k, dim=1)
x_exp = values.exp_()
x_exp /= torch.sum(x_exp, dim=1, keepdim=True)
if inplace:
similarity.zero_().scatter_(1, indices, x_exp) # B*N*HW
affinity = similarity
else:
affinity = torch.zeros_like(similarity).scatter_(1, indices, x_exp) # B*N*HW
else:
maxes = torch.max(similarity, dim=1, keepdim=True)[0]
x_exp = torch.exp(similarity - maxes)
x_exp_sum = torch.sum(x_exp, dim=1, keepdim=True)
affinity = x_exp / x_exp_sum
indices = None
if return_usage:
return affinity, affinity.sum(dim=2)
return affinity
def get_affinity(mk, ms, qk, qe):
# shorthand used in training with no top-k
similarity = get_similarity(mk, ms, qk, qe)
affinity = do_softmax(similarity)
return affinity
def readout(affinity, mv):
B, CV, T, H, W = mv.shape
mo = mv.view(B, CV, T*H*W)
mem = torch.bmm(mo, affinity)
mem = mem.view(B, CV, H, W)
return mem
================================================
FILE: XMem/model/modules.py
================================================
"""
modules.py - This file stores the rather boring network blocks.
x - usually means features that only depends on the image
g - usually means features that also depends on the mask.
They might have an extra "group" or "num_objects" dimension, hence
batch_size * num_objects * num_channels * H * W
The trailing number of a variable usually denote the stride
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.group_modules import *
from model import resnet
from model.cbam import CBAM
class FeatureFusionBlock(nn.Module):
def __init__(self, x_in_dim, g_in_dim, g_mid_dim, g_out_dim):
super().__init__()
self.distributor = MainToGroupDistributor()
self.block1 = GroupResBlock(x_in_dim+g_in_dim, g_mid_dim)
self.attention = CBAM(g_mid_dim)
self.block2 = GroupResBlock(g_mid_dim, g_out_dim)
def forward(self, x, g):
batch_size, num_objects = g.shape[:2]
g = self.distributor(x, g)
g = self.block1(g)
r = self.attention(g.flatten(start_dim=0, end_dim=1))
r = r.view(batch_size, num_objects, *r.shape[1:])
g = self.block2(g+r)
return g
class HiddenUpdater(nn.Module):
# Used in the decoder, multi-scale feature + GRU
def __init__(self, g_dims, mid_dim, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.g16_conv = GConv2D(g_dims[0], mid_dim, kernel_size=1)
self.g8_conv = GConv2D(g_dims[1], mid_dim, kernel_size=1)
self.g4_conv = GConv2D(g_dims[2], mid_dim, kernel_size=1)
self.transform = GConv2D(mid_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
nn.init.xavier_normal_(self.transform.weight)
def forward(self, g, h):
g = self.g16_conv(g[0]) + self.g8_conv(downsample_groups(g[1], ratio=1/2)) + \
self.g4_conv(downsample_groups(g[2], ratio=1/4))
g = torch.cat([g, h], 2)
# defined slightly differently than standard GRU,
# namely the new value is generated before the forget gate.
# might provide better gradient but frankly it was initially just an
# implementation error that I never bothered fixing
values = self.transform(g)
forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
return new_h
class HiddenReinforcer(nn.Module):
# Used in the value encoder, a single GRU
def __init__(self, g_dim, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.transform = GConv2D(g_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
nn.init.xavier_normal_(self.transform.weight)
def forward(self, g, h):
g = torch.cat([g, h], 2)
# defined slightly differently than standard GRU,
# namely the new value is generated before the forget gate.
# might provide better gradient but frankly it was initially just an
# implementation error that I never bothered fixing
values = self.transform(g)
forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
return new_h
class ValueEncoder(nn.Module):
def __init__(self, value_dim, hidden_dim, single_object=False):
super().__init__()
self.single_object = single_object
network = resnet.resnet18(pretrained=True, extra_dim=1 if single_object else 2)
self.conv1 = network.conv1
self.bn1 = network.bn1
self.relu = network.relu # 1/2, 64
self.maxpool = network.maxpool
self.layer1 = network.layer1 # 1/4, 64
self.layer2 = network.layer2 # 1/8, 128
self.layer3 = network.layer3 # 1/16, 256
self.distributor = MainToGroupDistributor()
self.fuser = FeatureFusionBlock(1024, 256, value_dim, value_dim)
if hidden_dim > 0:
self.hidden_reinforce = HiddenReinforcer(value_dim, hidden_dim)
else:
self.hidden_reinforce = None
def forward(self, image, image_feat_f16, h, masks, others, is_deep_update=True):
# image_feat_f16 is the feature from the key encoder
if not self.single_object:
g = torch.stack([masks, others], 2)
else:
g = masks.unsqueeze(2)
g = self.distributor(image, g)
batch_size, num_objects = g.shape[:2]
g = g.flatten(start_dim=0, end_dim=1)
g = self.conv1(g)
g = self.bn1(g) # 1/2, 64
g = self.maxpool(g) # 1/4, 64
g = self.relu(g)
g = self.layer1(g) # 1/4
g = self.layer2(g) # 1/8
g = self.layer3(g) # 1/16
g = g.view(batch_size, num_objects, *g.shape[1:])
g = self.fuser(image_feat_f16, g)
if is_deep_update and self.hidden_reinforce is not None:
h = self.hidden_reinforce(g, h)
return g, h
class KeyEncoder(nn.Module):
def __init__(self):
super().__init__()
network = resnet.resnet50(pretrained=True)
self.conv1 = network.conv1
self.bn1 = network.bn1
self.relu = network.relu # 1/2, 64
self.maxpool = network.maxpool
self.res2 = network.layer1 # 1/4, 256
self.layer2 = network.layer2 # 1/8, 512
self.layer3 = network.layer3 # 1/16, 1024
def forward(self, f):
x = self.conv1(f)
x = self.bn1(x)
x = self.relu(x) # 1/2, 64
x = self.maxpool(x) # 1/4, 64
f4 = self.res2(x) # 1/4, 256
f8 = self.layer2(f4) # 1/8, 512
f16 = self.layer3(f8) # 1/16, 1024
return f16, f8, f4
class UpsampleBlock(nn.Module):
def __init__(self, skip_dim, g_up_dim, g_out_dim, scale_factor=2):
super().__init__()
self.skip_conv = nn.Conv2d(skip_dim, g_up_dim, kernel_size=3, padding=1)
self.distributor = MainToGroupDistributor(method='add')
self.out_conv = GroupResBlock(g_up_dim, g_out_dim)
self.scale_factor = scale_factor
def forward(self, skip_f, up_g):
skip_f = self.skip_conv(skip_f)
g = upsample_groups(up_g, ratio=self.scale_factor)
g = self.distributor(skip_f, g)
g = self.out_conv(g)
return g
class KeyProjection(nn.Module):
def __init__(self, in_dim, keydim):
super().__init__()
self.key_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
# shrinkage
self.d_proj = nn.Conv2d(in_dim, 1, kernel_size=3, padding=1)
# selection
self.e_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
nn.init.orthogonal_(self.key_proj.weight.data)
nn.init.zeros_(self.key_proj.bias.data)
def forward(self, x, need_s, need_e):
shrinkage = self.d_proj(x)**2 + 1 if (need_s) else None
selection = torch.sigmoid(self.e_proj(x)) if (need_e) else None
return self.key_proj(x), shrinkage, selection
class Decoder(nn.Module):
def __init__(self, val_dim, hidden_dim):
super().__init__()
self.fuser = FeatureFusionBlock(1024, val_dim+hidden_dim, 512, 512)
if hidden_dim > 0:
self.hidden_update = HiddenUpdater([512, 256, 256+1], 256, hidden_dim)
else:
self.hidden_update = None
self.up_16_8 = UpsampleBlock(512, 512, 256) # 1/16 -> 1/8
self.up_8_4 = UpsampleBlock(256, 256, 256) # 1/8 -> 1/4
self.pred = nn.Conv2d(256, 1, kernel_size=3, padding=1, stride=1)
def forward(self, f16, f8, f4, hidden_state, memory_readout, h_out=True):
batch_size, num_objects = memory_readout.shape[:2]
if self.hidden_update is not None:
g16 = self.fuser(f16, torch.cat([memory_readout, hidden_state], 2))
else:
g16 = self.fuser(f16, memory_readout)
g8 = self.up_16_8(f8, g16)
g4 = self.up_8_4(f4, g8)
logits = self.pred(F.relu(g4.flatten(start_dim=0, end_dim=1)))
if h_out and self.hidden_update is not None:
g4 = torch.cat([g4, logits.view(batch_size, num_objects, 1, *logits.shape[-2:])], 2)
hidden_state = self.hidden_update([g16, g8, g4], hidden_state)
else:
hidden_state = None
logits = F.interpolate(logits, scale_factor=4, mode='bilinear', align_corners=False)
logits = logits.view(batch_size, num_objects, *logits.shape[-2:])
return hidden_state, logits
================================================
FILE: XMem/model/network.py
================================================
"""
This file defines XMem, the highest level nn.Module interface
During training, it is used by trainer.py
During evaluation, it is used by inference_core.py
It further depends on modules.py which gives more detailed implementations of sub-modules
"""
import torch
import torch.nn as nn
from loguru import logger
from model.aggregate import aggregate
from model.modules import *
from model.memory_util import *
class XMem(nn.Module):
def __init__(self, config, model_path=None, map_location=None):
"""
model_path/map_location are used in evaluation only
map_location is for converting models saved in cuda to cpu
"""
super().__init__()
model_weights = self.init_hyperparameters(config, model_path, map_location)
self.single_object = config.get('single_object', False)
print(f'Single object mode: {self.single_object}')
self.key_encoder = KeyEncoder()
self.value_encoder = ValueEncoder(self.value_dim, self.hidden_dim, self.single_object)
# Projection from f16 feature space to key/value space
self.key_proj = KeyProjection(1024, self.key_dim)
self.decoder = Decoder(self.value_dim, self.hidden_dim)
if model_weights is not None:
self.load_weights(model_weights, init_as_zero_if_needed=True)
def encode_key(self, frame, need_sk=True, need_ek=True):
# Determine input shape
if len(frame.shape) == 5:
# shape is b*t*c*h*w
need_reshape = True
b, t = frame.shape[:2]
# flatten so that we can feed them into a 2D CNN
frame = frame.flatten(start_dim=0, end_dim=1)
elif len(frame.shape) == 4:
# shape is b*c*h*w
need_reshape = False
else:
raise NotImplementedError
f16, f8, f4 = self.key_encoder(frame)
key, shrinkage, selection = self.key_proj(f16, need_sk, need_ek)
if need_reshape:
# B*C*T*H*W
key = key.view(b, t, *key.shape[-3:]).transpose(1, 2).contiguous()
if shrinkage is not None:
shrinkage = shrinkage.view(b, t, *shrinkage.shape[-3:]).transpose(1, 2).contiguous()
if selection is not None:
selection = selection.view(b, t, *selection.shape[-3:]).transpose(1, 2).contiguous()
# B*T*C*H*W
f16 = f16.view(b, t, *f16.shape[-3:])
f8 = f8.view(b, t, *f8.shape[-3:])
f4 = f4.view(b, t, *f4.shape[-3:])
return key, shrinkage, selection, f16, f8, f4
def encode_value(self, frame, image_feat_f16, h16, masks, is_deep_update=True):
num_objects = masks.shape[1]
if num_objects != 1:
others = torch.cat([
torch.sum(
masks[:, [j for j in range(num_objects) if i!=j]]
, dim=1, keepdim=True)
for i in range(num_objects)], 1)
else:
others = torch.zeros_like(masks)
g16, h16 = self.value_encoder(frame, image_feat_f16, h16, masks, others, is_deep_update)
return g16, h16
# Used in training only.
# This step is replaced by MemoryManager in test time
def read_memory(self, query_key, query_selection, memory_key,
memory_shrinkage, memory_value):
"""
query_key : B * CK * H * W
query_selection : B * CK * H * W
memory_key : B * CK * T * H * W
memory_shrinkage: B * 1 * T * H * W
memory_value : B * num_objects * CV * T * H * W
"""
batch_size, num_objects = memory_value.shape[:2]
memory_value = memory_value.flatten(start_dim=1, end_dim=2)
affinity = get_affinity(memory_key, memory_shrinkage, query_key, query_selection)
memory = readout(affinity, memory_value)
memory = memory.view(batch_size, num_objects, self.value_dim, *memory.shape[-2:])
return memory
def segment(self, multi_scale_features, memory_readout,
hidden_state, selector=None, h_out=True, strip_bg=True):
hidden_state, logits = self.decoder(*multi_scale_features, hidden_state, memory_readout, h_out=h_out)
prob = torch.sigmoid(logits)
if selector is not None:
prob = prob * selector
logits, prob = aggregate(prob, dim=1, return_logits=True)
if strip_bg:
# Strip away the background
prob = prob[:, 1:]
return hidden_state, logits, prob
def forward(self, mode, *args, **kwargs):
if mode == 'encode_key':
return self.encode_key(*args, **kwargs)
elif mode == 'encode_value':
return self.encode_value(*args, **kwargs)
elif mode == 'read_memory':
return self.read_memory(*args, **kwargs)
elif mode == 'segment':
return self.segment(*args, **kwargs)
else:
raise NotImplementedError
@logger.catch()
def init_hyperparameters(self, config, model_path=None, map_location=None):
"""
Init three hyperparameters: key_dim, value_dim, and hidden_dim
If model_path is provided, we load these from the model weights
The actual parameters are then updated to the config in-place
Otherwise we load it either from the config or default
"""
if model_path is not None:
# load the model and key/value/hidden dimensions with some hacks
# config is updated with the loaded parameters
model_weights = torch.load(model_path, map_location=map_location)
self.key_dim = model_weights['key_proj.key_proj.weight'].shape[0]
self.value_dim = model_weights['value_encoder.fuser.block2.conv2.weight'].shape[0]
self.disable_hidden = 'decoder.hidden_update.transform.weight' not in model_weights
if self.disable_hidden:
self.hidden_dim = 0
else:
self.hidden_dim = model_weights['decoder.hidden_update.transform.weight'].shape[0]//3
print(f'Hyperparameters read from the model weights: '
f'C^k={self.key_dim}, C^v={self.value_dim}, C^h={self.hidden_dim}')
else:
model_weights = None
# load dimensions from config or default
if 'key_dim' not in config:
self.key_dim = 64
print(f'key_dim not found in config. Set to default {self.key_dim}')
else:
self.key_dim = config['key_dim']
if 'value_dim' not in config:
self.value_dim = 512
print(f'value_dim not found in config. Set to default {self.value_dim}')
else:
self.value_dim = config['value_dim']
if 'hidden_dim' not in config:
self.hidden_dim = 64
print(f'hidden_dim not found in config. Set to default {self.hidden_dim}')
else:
self.hidden_dim = config['hidden_dim']
self.disable_hidden = (self.hidden_dim <= 0)
config['key_dim'] = self.key_dim
config['value_dim'] = self.value_dim
config['hidden_dim'] = self.hidden_dim
return model_weights
@logger.catch()
def load_weights(self, src_dict, init_as_zero_if_needed=False):
# Maps SO weight (without other_mask) to MO weight (with other_mask)
for k in list(src_dict.keys()):
if k == 'value_encoder.conv1.weight':
if src_dict[k].shape[1] == 4:
print('Converting weights from single object to multiple objects.')
pads = torch.zeros((64,1,7,7), device=src_dict[k].device)
if not init_as_zero_if_needed:
print('Randomly initialized padding.')
nn.init.orthogonal_(pads)
else:
print('Zero-initialized padding.')
src_dict[k] = torch.cat([src_dict[k], pads], 1)
self.load_state_dict(src_dict)
================================================
FILE: XMem/model/resnet.py
================================================
"""
resnet.py - A modified ResNet structure
We append extra channels to the first conv by some network surgery
"""
from collections import OrderedDict
import math
import torch
import torch.nn as nn
from torch.utils import model_zoo
def load_weights_add_extra_dim(target, source_state, extra_dim=1):
new_dict = OrderedDict()
for k1, v1 in target.state_dict().items():
if not 'num_batches_tracked' in k1:
if k1 in source_state:
tar_v = source_state[k1]
if v1.shape != tar_v.shape:
# Init the new segmentation channel with zeros
# print(v1.shape, tar_v.shape)
c, _, w, h = v1.shape
pads = torch.zeros((c,extra_dim,w,h), device=tar_v.device)
nn.init.orthogonal_(pads)
tar_v = torch.cat([tar_v, pads], 1)
new_dict[k1] = tar_v
target.load_state_dict(new_dict)
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
padding=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers=(3, 4, 23, 3), extra_dim=0):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3+extra_dim, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation))
return nn.Sequential(*layers)
def resnet18(pretrained=True, extra_dim=0):
model = ResNet(BasicBlock, [2, 2, 2, 2], extra_dim)
if pretrained:
load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet18']), extra_dim)
return model
def resnet50(pretrained=True, extra_dim=0):
model = ResNet(Bottleneck, [3, 4, 6, 3], extra_dim)
if pretrained:
load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet50']), extra_dim)
return model
================================================
FILE: XMem/model/trainer.py
================================================
"""
trainer.py - warpper and utility functions for network training
Compute loss, back-prop, update parameters, logging, etc.
"""
import os
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from model.network import XMem
from model.losses import LossComputer
from util.log_integrator import Integrator
from util.image_saver import pool_pairs
class XMemTrainer:
def __init__(self, config, logger=None, save_path=None, local_rank=0, world_size=1):
self.config = config
self.num_frames = config['num_frames']
self.num_ref_frames = config['num_ref_frames']
self.deep_update_prob = config['deep_update_prob']
self.local_rank = local_rank
self.XMem = nn.parallel.DistributedDataParallel(
XMem(config).cuda(),
device_ids=[local_rank], output_device=local_rank, broadcast_buffers=False)
# Set up logger when local_rank=0
self.logger = logger
self.save_path = save_path
if logger is not None:
self.last_time = time.time()
self.logger.log_string('model_size', str(sum([param.nelement() for param in self.XMem.parameters()])))
self.train_integrator = Integrator(self.logger, distributed=True, local_rank=local_rank, world_size=world_size)
self.loss_computer = LossComputer(config)
self.train()
self.optimizer = optim.AdamW(filter(
lambda p: p.requires_grad, self.XMem.parameters()), lr=config['lr'], weight_decay=config['weight_decay'])
self.scheduler = optim.lr_scheduler.MultiStepLR(self.optimizer, config['steps'], config['gamma'])
if config['amp']:
self.scaler = torch.cuda.amp.GradScaler()
# Logging info
self.log_text_interval = config['log_text_interval']
self.log_image_interval = config['log_image_interval']
self.save_network_interval = config['save_network_interval']
self.save_checkpoint_interval = config['save_checkpoint_interval']
if config['debug']:
self.log_text_interval = self.log_image_interval = 1
def do_pass(self, data, it=0):
# No need to store the gradient outside training
torch.set_grad_enabled(self._is_train)
for k, v in data.items():
if type(v) != list and type(v) != dict and type(v) != int:
data[k] = v.cuda(non_blocking=True)
out = {}
frames = data['rgb']
first_frame_gt = data['first_frame_gt'].float()
b = frames.shape[0]
num_filled_objects = [o.item() for o in data['info']['num_objects']]
num_objects = first_frame_gt.shape[2]
selector = data['selector'].unsqueeze(2).unsqueeze(2)
with torch.cuda.amp.autocast(enabled=self.config['amp']):
# image features never change, compute once
key, shrinkage, selection, f16, f8, f4 = self.XMem('encode_key', frames)
filler_one = torch.zeros(1, dtype=torch.int64)
hidden = torch.zeros((b, num_objects, self.config['hidden_dim'], *key.shape[-2:]))
v16, hidden = self.XMem('encode_value', frames[:,0], f16[:,0], hidden, first_frame_gt[:,0])
values = v16.unsqueeze(3) # add the time dimension
for ti in range(1, self.num_frames):
if ti <= self.num_ref_frames:
ref_values = values
ref_keys = key[:,:,:ti]
ref_shrinkage = shrinkage[:,:,:ti] if shrinkage is not None else None
else:
# pick num_ref_frames random frames
# this is not very efficient but I think we would
# need broadcasting in gather which we don't have
indices = [
torch.cat([filler_one, torch.randperm(ti-1)[:self.num_ref_frames-1]+1])
for _ in range(b)]
ref_values = torch.stack([
values[bi, :, :, indices[bi]] for bi in range(b)
], 0)
ref_keys = torch.stack([
key[bi, :, indices[bi]] for bi in range(b)
], 0)
ref_shrinkage = torch.stack([
shrinkage[bi, :, indices[bi]] for bi in range(b)
], 0) if shrinkage is not None else None
# Segment frame ti
memory_readout = self.XMem('read_memory', key[:,:,ti], selection[:,:,ti] if selection is not None else None,
ref_keys, ref_shrinkage, ref_values)
hidden, logits, masks = self.XMem('segment', (f16[:,ti], f8[:,ti], f4[:,ti]), memory_readout,
hidden, selector, h_out=(ti < (self.num_frames-1)))
# No need to encode the last frame
if ti < (self.num_frames-1):
is_deep_update = np.random.rand() < self.deep_update_prob
v16, hidden = self.XMem('encode_value', frames[:,ti], f16[:,ti], hidden, masks, is_deep_update=is_deep_update)
values = torch.cat([values, v16.unsqueeze(3)], 3)
out[f'masks_{ti}'] = masks
out[f'logits_{ti}'] = logits
if self._do_log or self._is_train:
losses = self.loss_computer.compute({**data, **out}, num_filled_objects, it)
# Logging
if self._do_log:
self.integrator.add_dict(losses)
if self._is_train:
if it % self.log_image_interval == 0 and it != 0:
if self.logger is not None:
images = {**data, **out}
size = (384, 384)
self.logger.log_cv2('train/pairs', pool_pairs(images, size, num_filled_objects), it)
if self._is_train:
if (it) % self.log_text_interval == 0 and it != 0:
if self.logger is not None:
self.logger.log_scalar('train/lr', self.scheduler.get_last_lr()[0], it)
self.logger.log_metrics('train', 'time', (time.time()-self.last_time)/self.log_text_interval, it)
self.last_time = time.time()
self.train_integrator.finalize('train', it)
self.train_integrator.reset_except_hooks()
if it % self.save_network_interval == 0 and it != 0:
if self.logger is not None:
self.save_network(it)
if it % self.save_checkpoint_interval == 0 and it != 0:
if self.logger is not None:
self.save_checkpoint(it)
# Backward pass
self.optimizer.zero_grad(set_to_none=True)
if self.config['amp']:
self.scaler.scale(losses['total_loss']).backward()
self.scaler.step(self.optimizer)
self.scaler.update()
else:
losses['total_loss'].backward()
self.optimizer.step()
self.scheduler.step()
def save_network(self, it):
if self.save_path is None:
print('Saving has been disabled.')
return
os.makedirs(os.path.dirname(self.save_path), exist_ok=True)
model_path = f'{self.save_path}_{it}.pth'
torch.save(self.XMem.module.state_dict(), model_path)
print(f'Network saved to {model_path}.')
def save_checkpoint(self, it):
if self.save_path is None:
print('Saving has been disabled.')
return
os.makedirs(os.path.dirname(self.save_path), exist_ok=True)
checkpoint_path = f'{self.save_path}_checkpoint_{it}.pth'
checkpoint = {
'it': it,
'network': self.XMem.module.state_dict(),
'optimizer': self.optimizer.state_dict(),
'scheduler': self.scheduler.state_dict()}
torch.save(checkpoint, checkpoint_path)
print(f'Checkpoint saved to {checkpoint_path}.')
def load_checkpoint(self, path):
# This method loads everything and should be used to resume training
map_location = 'cuda:%d' % self.local_rank
checkpoint = torch.load(path, map_location={'cuda:0': map_location})
it = checkpoint['it']
network = checkpoint['network']
optimizer = checkpoint['optimizer']
scheduler = checkpoint['scheduler']
map_location = 'cuda:%d' % self.local_rank
self.XMem.module.load_state_dict(network)
self.optimizer.load_state_dict(optimizer)
self.scheduler.load_state_dict(scheduler)
print('Network weights, optimizer states, and scheduler states loaded.')
return it
def load_network_in_memory(self, src_dict):
self.XMem.module.load_weights(src_dict)
print('Network weight loaded from memory.')
def load_network(self, path):
# This method loads only the network weight and should be used to load a pretrained model
map_location = 'cuda:%d' % self.local_rank
src_dict = torch.load(path, map_location={'cuda:0': map_location})
self.load_network_in_memory(src_dict)
print(f'Network weight loaded from {path}')
def train(self):
self._is_train = True
self._do_log = True
self.integrator = self.train_integrator
self.XMem.eval()
return self
def val(self):
self._is_train = False
self._do_log = True
self.XMem.eval()
return self
def test(self):
self._is_train = False
self._do_log = False
self.XMem.eval()
return self
================================================
FILE: XMem/requirements.txt
================================================
progressbar2
gdown
hickle
tensorboard
numpy
================================================
FILE: XMem/scripts/__init__.py
================================================
================================================
FILE: XMem/scripts/download_bl30k.py
================================================
import os
import gdown
import tarfile
LICENSE = """
This dataset is a derivative of ShapeNet.
Please read and respect their licenses and terms before use.
Textures and skybox image are obtained from Google image search with the "non-commercial reuse" flag.
Do not use this dataset for commercial purposes.
You should cite both ShapeNet and our paper if you use this dataset.
"""
print(LICENSE)
print('Datasets will be downloaded and extracted to ../BL30K')
print('The script will download and extract the segment one by one')
print('You are going to need ~1TB of free disk space')
reply = input('[y] to confirm, others to exit: ')
if reply != 'y':
exit()
links = [
'https://drive.google.com/uc?id=1z9V5zxLOJLNt1Uj7RFqaP2FZWKzyXvVc',
'https://drive.google.com/uc?id=11-IzgNwEAPxgagb67FSrBdzZR7OKAEdJ',
'https://drive.google.com/uc?id=1ZfIv6GTo-OGpXpoKen1fUvDQ0A_WoQ-Q',
'https://drive.google.com/uc?id=1G4eXgYS2kL7_Cc0x3N1g1x7Zl8D_aU_-',
'https://drive.google.com/uc?id=1Y8q0V_oBwJIY27W_6-8CD1dRqV2gNTdE',
'https://drive.google.com/uc?id=1nawBAazf_unMv46qGBHhWcQ4JXZ5883r',
]
names = [
'BL30K_a.tar',
'BL30K_b.tar',
'BL30K_c.tar',
'BL30K_d.tar',
'BL30K_e.tar',
'BL30K_f.tar',
]
for i, link in enumerate(links):
print('Downloading segment %d/%d ...' % (i, len(links)))
gdown.download(link, output='../%s' % names[i], quiet=False)
print('Extracting...')
with tarfile.open('../%s' % names[i], 'r') as tar_file:
tar_file.extractall('../%s' % names[i])
print('Cleaning up...')
os.remove('../%s' % names[i])
print('Done.')
================================================
FILE: XMem/scripts/download_datasets.py
================================================
import os
import gdown
import zipfile
from scripts import resize_youtube
LICENSE = """
These are either re-distribution of the original datasets or derivatives (through simple processing) of the original datasets.
Please read and respect their licenses and terms before use.
You should cite the original papers if you use any of the datasets.
For BL30K, see download_bl30k.py
Links:
DUTS: http://saliencydetection.net/duts
HRSOD: https://github.com/yi94code/HRSOD
FSS: https://github.com/HKUSTCV/FSS-1000
ECSSD: https://www.cse.cuhk.edu.hk/leojia/projects/hsaliency/dataset.html
BIG: https://github.com/hkchengrex/CascadePSP
YouTubeVOS: https://youtube-vos.org
DAVIS: https://davischallenge.org/
BL30K: https://github.com/hkchengrex/MiVOS
Long-Time Video: https://github.com/xmlyqing00/AFB-URR
"""
print(LICENSE)
print('Datasets will be downloaded and extracted to ../YouTube, ../YouTube2018, ../static, ../DAVIS, ../long_video_set')
reply = input('[y] to confirm, others to exit: ')
if reply != 'y':
exit()
"""
Static image data
"""
os.makedirs('../static', exist_ok=True)
print('Downloading static datasets...')
gdown.download('https://drive.google.com/uc?id=1wUJq3HcLdN-z1t4CsUhjeZ9BVDb9YKLd', output='../static/static_data.zip', quiet=False)
print('Extracting static datasets...')
with zipfile.ZipFile('../static/static_data.zip', 'r') as zip_file:
zip_file.extractall('../static/')
print('Cleaning up static datasets...')
os.remove('../static/static_data.zip')
"""
DAVIS dataset
"""
# Google drive mirror: https://drive.google.com/drive/folders/1hEczGHw7qcMScbCJukZsoOW4Q9byx16A?usp=sharing
os.makedirs('../DAVIS/2017', exist_ok=True)
print('Downloading DAVIS 2016...')
gdown.download('https://drive.google.com/uc?id=198aRlh5CpAoFz0hfRgYbiNenn_K8DxWD', output='../DAVIS/DAVIS-data.zip', quiet=False)
print('Downloading DAVIS 2017 trainval...')
gdown.download('https://drive.google.com/uc?id=1kiaxrX_4GuW6NmiVuKGSGVoKGWjOdp6d', output='../DAVIS/2017/DAVIS-2017-trainval-480p.zip', quiet=False)
print('Downloading DAVIS 2017 testdev...')
gdown.download('https://drive.google.com/uc?id=1fmkxU2v9cQwyb62Tj1xFDdh2p4kDsUzD', output='../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', quiet=False)
print('Downloading DAVIS 2017 scribbles...')
gdown.download('https://drive.google.com/uc?id=1JzIQSu36h7dVM8q0VoE4oZJwBXvrZlkl', output='../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', quiet=False)
print('Extracting DAVIS datasets...')
with zipfile.ZipFile('../DAVIS/DAVIS-data.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/')
os.rename('../DAVIS/DAVIS', '../DAVIS/2016')
with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-trainval-480p.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/2017/')
with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/2017/')
os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/trainval')
with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/2017/')
os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/test-dev')
print('Cleaning up DAVIS datasets...')
os.remove('../DAVIS/2017/DAVIS-2017-trainval-480p.zip')
os.remove('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip')
os.remove('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip')
os.remove('../DAVIS/DAVIS-data.zip')
"""
YouTubeVOS dataset
"""
os.makedirs('../YouTube', exist_ok=True)
os.makedirs('../YouTube/all_frames', exist_ok=True)
print('Downloading YouTubeVOS train...')
gdown.download('https://drive.google.com/uc?id=13Eqw0gVK-AO5B-cqvJ203mZ2vzWck9s4', output='../YouTube/train.zip', quiet=False)
print('Downloading YouTubeVOS val...')
gdown.download('https://drive.google.com/uc?id=1o586Wjya-f2ohxYf9C1RlRH-gkrzGS8t', output='../YouTube/valid.zip', quiet=False)
print('Downloading YouTubeVOS all frames valid...')
gdown.download('https://drive.google.com/uc?id=1rWQzZcMskgpEQOZdJPJ7eTmLCBEIIpEN', output='../YouTube/all_frames/valid.zip', quiet=False)
print('Extracting YouTube datasets...')
with zipfile.ZipFile('../YouTube/train.zip', 'r') as zip_file:
zip_file.extractall('../YouTube/')
with zipfile.ZipFile('../YouTube/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube/')
with zipfile.ZipFile('../YouTube/all_frames/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube/all_frames')
print('Cleaning up YouTubeVOS datasets...')
os.remove('../YouTube/train.zip')
os.remove('../YouTube/valid.zip')
os.remove('../YouTube/all_frames/valid.zip')
print('Resizing YouTubeVOS to 480p...')
resize_youtube.resize_all('../YouTube/train', '../YouTube/train_480p')
# YouTubeVOS 2018
os.makedirs('../YouTube2018', exist_ok=True)
os.makedirs('../YouTube2018/all_frames', exist_ok=True)
print('Downloading YouTubeVOS2018 val...')
gdown.download('https://drive.google.com/uc?id=1-QrceIl5sUNTKz7Iq0UsWC6NLZq7girr', output='../YouTube2018/valid.zip', quiet=False)
print('Downloading YouTubeVOS2018 all frames valid...')
gdown.download('https://drive.google.com/uc?id=1yVoHM6zgdcL348cFpolFcEl4IC1gorbV', output='../YouTube2018/all_frames/valid.zip', quiet=False)
print('Extracting YouTube2018 datasets...')
with zipfile.ZipFile('../YouTube2018/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube2018/')
with zipfile.ZipFile('../YouTube2018/all_frames/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube2018/all_frames')
print('Cleaning up YouTubeVOS2018 datasets...')
os.remove('../YouTube2018/valid.zip')
os.remove('../YouTube2018/all_frames/valid.zip')
"""
Long-Time Video dataset
"""
os.makedirs('../long_video_set', exist_ok=True)
print('Downloading long video dataset...')
gdown.download('https://drive.google.com/uc?id=100MxAuV0_UL20ca5c-5CNpqQ5QYPDSoz', output='../long_video_set/LongTimeVideo.zip', quiet=False)
print('Extracting long video dataset...')
with zipfile.ZipFile('../long_video_set/LongTimeVideo.zip', 'r') as zip_file:
zip_file.extractall('../long_video_set/')
print('Cleaning up long video dataset...')
os.remove('../long_video_set/LongTimeVideo.zip')
print('Done.')
================================================
FILE: XMem/scripts/download_models.sh
================================================
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem-s012.pth
================================================
FILE: XMem/scripts/download_models_demo.sh
================================================
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/fbrs.pth
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/s2m.pth
================================================
FILE: XMem/scripts/expand_long_vid.py
================================================
import sys
import os
from os import path
from shutil import copy2
input_path = sys.argv[1]
output_path = sys.argv[2]
multiplier = int(sys.argv[3])
image_path = path.join(input_path, 'JPEGImages')
gt_path = path.join(input_path, 'Annotations')
videos = sorted(os.listdir(image_path))
for vid in videos:
os.makedirs(path.join(output_path, 'JPEGImages', vid), exist_ok=True)
os.makedirs(path.join(output_path, 'Annotations', vid), exist_ok=True)
frames = sorted(os.listdir(path.join(image_path, vid)))
num_frames = len(frames)
counter = 0
output_counter = 0
direction = 1
for _ in range(multiplier):
for _ in range(num_frames):
copy2(path.join(image_path, vid, frames[counter]),
path.join(output_path, 'JPEGImages', vid, f'{output_counter:05d}.jpg'))
mask_path = path.join(gt_path, vid, frames[counter].replace('.jpg', '.png'))
if path.exists(mask_path):
copy2(mask_path,
path.join(output_path, 'Annotations', vid, f'{output_counter:05d}.png'))
counter += direction
output_counter += 1
if counter == 0 or counter == len(frames) - 1:
direction *= -1
================================================
FILE: XMem/scripts/resize_youtube.py
================================================
import sys
import os
from os import path
from PIL import Image
import numpy as np
from progressbar import progressbar
from multiprocessing import Pool
new_min_size = 480
def resize_vid_jpeg(inputs):
vid_name, folder_path, out_path = inputs
vid_path = path.join(folder_path, vid_name)
vid_out_path = path.join(out_path, 'JPEGImages', vid_name)
os.makedirs(vid_out_path, exist_ok=True)
for im_name in os.listdir(vid_path):
hr_im = Image.open(path.join(vid_path, im_name))
w, h = hr_im.size
ratio = new_min_size / min(w, h)
lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.BICUBIC)
lr_im.save(path.join(vid_out_path, im_name))
def resize_vid_anno(inputs):
vid_name, folder_path, out_path = inputs
vid_path = path.join(folder_path, vid_name)
vid_out_path = path.join(out_path, 'Annotations', vid_name)
os.makedirs(vid_out_path, exist_ok=True)
for im_name in os.listdir(vid_path):
hr_im = Image.open(path.join(vid_path, im_name)).convert('P')
w, h = hr_im.size
ratio = new_min_size / min(w, h)
lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.NEAREST)
lr_im.save(path.join(vid_out_path, im_name))
def resize_all(in_path, out_path):
for folder in os.listdir(in_path):
if folder not in ['JPEGImages', 'Annotations']:
continue
folder_path = path.join(in_path, folder)
videos = os.listdir(folder_path)
videos = [(v, folder_path, out_path) for v in videos]
if folder == 'JPEGImages':
print('Processing images')
os.makedirs(path.join(out_path, 'JPEGImages'), exist_ok=True)
pool = Pool(processes=8)
for _ in progressbar(pool.imap_unordered(resize_vid_jpeg, videos), max_value=len(videos)):
pass
else:
print('Processing annotations')
os.makedirs(path.join(out_path, 'Annotations'), exist_ok=True)
pool = Pool(processes=8)
for _ in progressbar(pool.imap_unordered(resize_vid_anno, videos), max_value=len(videos)):
pass
if __name__ == '__main__':
in_path = sys.argv[1]
out_path = sys.argv[2]
resize_all(in_path, out_path)
print('Done.')
================================================
FILE: XMem/tracking.py
================================================
import sys
sys.path.insert(0, './XMem')
import os
import os.path as osp
import glob
import cv2
import json
import argparse
import multiprocessing as mp
from tqdm import tqdm
from termcolor import colored
from importlib.util import find_spec
if find_spec("GPUtil") is None: os.system("pip install gputil")
import GPUtil
_GPU_LIST = [_.id for _ in GPUtil.getGPUs()]
_GPU_QUEUE = mp.Queue()
for _ in _GPU_LIST: _GPU_QUEUE.put(_)
def run_eval(meta_expression, temp_xmem_anno, final_xmem_anno, img_dir, split_part, xmem_weight, cfgs=" --reversed ", ):
gpu_id = _GPU_QUEUE.get()
cmd = f"cd XMem && CUDA_VISIBLE_DEVICES={gpu_id} python eval.py --meta_exp {meta_expression} --output {final_xmem_anno} --generic_path {temp_xmem_anno} --img_dir {img_dir} --split_part {split_part} --model {xmem_weight} --dataset G {cfgs}"
print(f"Running: {cmd}")
os.system(cmd)
_GPU_QUEUE.put(gpu_id)
def generate(obj, temp_xmem_anno, final_xmem_anno):
obj_dir, video_name, obj_id, tp = obj
img_list = glob.glob(obj_dir + '/*.png') # Mask
img_list.sort()
frame_id = int(len(img_list) * tp)
if frame_id == len(img_list):
frame_id -= 1
used_img = img_list[frame_id]
img_output_path = osp.join(temp_xmem_anno, video_name, obj_id, osp.basename(used_img))
final_img_output_dir = osp.join(final_xmem_anno, video_name, obj_id)
img_output_dir = osp.dirname(img_output_path)
os.makedirs(img_output_dir, exist_ok=True)
os.makedirs(final_img_output_dir, exist_ok=True)
os.system('cp {} {}'.format(used_img, img_output_path))
img = cv2.imread(img_output_path)
if img.sum() == 0:
target_img_list = [i.split('/')[-1] for i in img_list]
for img_ in target_img_list:
print(os.path.join(final_img_output_dir, img_))
os.system('cp {} {}'.format(img_output_path, os.path.join(img_output_dir, img_)))
os.system('cp {} {}'.format(img_output_path, os.path.join(final_img_output_dir, img_)))
return 0
def prepare(args):
video_root = args.video_root
temp_xmem_anno = args.temp_xmem_anno
final_xmem_anno = args.final_xmem_anno
os.makedirs(temp_xmem_anno, exist_ok=True)
data = json.load(open(args.llama_vid_meta, 'r'))['videos']
all_obj_list = []
for video_name in data.keys():
exps = data[video_name]['expressions']
for obj_id in exps.keys():
tp = exps[obj_id]['tp']
obj_dir = os.path.join(video_root, video_name, obj_id)
all_obj_list.append([obj_dir, video_name, obj_id, tp])
print('start')
cpu_num = mp.cpu_count()-1
print("cpu_num:", cpu_num)
pool = mp.Pool(cpu_num)
pbar = tqdm(total=len(all_obj_list))
for obj in all_obj_list:
pool.apply_async(
generate,
args = (obj, temp_xmem_anno, final_xmem_anno ),
callback = lambda *a: pbar.update(1),
error_callback = lambda e: print(colored(e, "red"))
)
pool.close()
pool.join()
pbar.close()
def inference(args):
p = mp.Pool(8)
for split_part in [0, 1, 2, 3]:
for cfgs in [" ", " --reversed "]:
p.apply_async(
run_eval,
args=(args.llama_vid_meta, args.temp_xmem_anno, args.final_xmem_anno, args.img_dir, split_part, args.xmem_weight, cfgs),
error_callback=lambda e: print(colored(e, "red"))
)
p.close()
p.join()
"""
python XMem/tracking.py \
--video_root /mnt/public03/dataset/ovis/rgvos/visa7b/val_7b/revos_valid/Annotations \
--temp_xmem_anno /mnt/public03/dataset/ovis/rgvos/visa7b/val_7b/revos_valid/revos_valid_XMem_temp/Annotations \
--final_xmem_anno /mnt/public03/dataset/ovis/rgvos/visa7b/val_7b/revos_valid/revos_valid_XMem_final/Annotations \
--llama_vid_meta /mnt/public02/usr/yancilin/clyan_data/other-datasets/ReVOS/meta_expressions_valid__llamavid.json \
--img_dir /mnt/public02/usr/yancilin/clyan_data/other-datasets/ReVOS/JPEGImages \
--xmem_weight /mnt/public02/usr/yancilin/VISA/XMem/weights/XMem.pth
"""
def main():
parser = argparse.ArgumentParser(description='rgvos')
parser.add_argument('--video_root', type=str, help='/PATH/TO/VISA_exp/revos_valid/Annotations', )
parser.add_argument('--temp_xmem_anno', type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_temp/Annotations', ) # 保存单帧 Mask 的路径
parser.add_argument('--final_xmem_anno', type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_final/Annotations', ) # 保存 XMem 最后输出结果的路径
parser.add_argument("--llama_vid_meta", type=str, help='/PATH/TO/ReVOS/meta_expressions_valid__llamavid.json', )
parser.add_argument("--img_dir", type=str, help='/PATH/TO/ReVOS/JPEGImages')
parser.add_argument("--xmem_weight", type=str, help='/PATH/TO/XMEM_WEIGHT')
args = parser.parse_args()
prepare(args)
inference(args)
print('Done.')
if __name__ == '__main__':
main()
================================================
FILE: XMem/train.py
================================================
import datetime
from os import path
import math
import git
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, ConcatDataset
import torch.distributed as distributed
from model.trainer import XMemTrainer
from dataset.static_dataset import StaticTransformDataset
from dataset.vos_dataset import VOSDataset
from util.logger import TensorboardLogger
from util.configuration import Configuration
from util.load_subset import load_sub_davis, load_sub_yv
"""
Initial setup
"""
# Init distributed environment
distributed.init_process_group(backend="nccl")
print(f'CUDA Device count: {torch.cuda.device_count()}')
# Parse command line arguments
raw_config = Configuration()
raw_config.parse()
if raw_config['benchmark']:
torch.backends.cudnn.benchmark = True
# Get current git info
repo = git.Repo(".")
git_info = str(repo.active_branch)+' '+str(repo.head.commit.hexsha)
local_rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
torch.cuda.set_device(local_rank)
print(f'I am rank {local_rank} in this world of size {world_size}!')
network_in_memory = None
stages = raw_config['stages']
stages_to_perform = list(stages)
for si, stage in enumerate(stages_to_perform):
# Set seed to ensure the same initialization
torch.manual_seed(14159265)
np.random.seed(14159265)
random.seed(14159265)
# Pick stage specific hyperparameters out
stage_config = raw_config.get_stage_parameters(stage)
config = dict(**raw_config.args, **stage_config)
if config['exp_id'] != 'NULL':
config['exp_id'] = config['exp_id']+'_s%s'%stages[:si+1]
config['single_object'] = (stage == '0')
config['num_gpus'] = world_size
if config['batch_size']//config['num_gpus']*config['num_gpus'] != config['batch_size']:
raise ValueError('Batch size must be divisible by the number of GPUs.')
config['batch_size'] //= config['num_gpus']
config['num_workers'] //= config['num_gpus']
print(f'We are assuming {config["num_gpus"]} GPUs.')
print(f'We are now starting stage {stage}')
"""
Model related
"""
if local_rank == 0:
# Logging
if config['exp_id'].lower() != 'null':
print('I will take the role of logging!')
long_id = '%s_%s' % (datetime.datetime.now().strftime('%b%d_%H.%M.%S'), config['exp_id'])
else:
long_id = None
logger = TensorboardLogger(config['exp_id'], long_id, git_info)
logger.log_string('hyperpara', str(config))
# Construct the rank 0 model
model = XMemTrainer(config, logger=logger,
save_path=path.join('saves', long_id, long_id) if long_id is not None else None,
local_rank=local_rank, world_size=world_size).train()
else:
# Construct model for other ranks
model = XMemTrainer(config, local_rank=local_rank, world_size=world_size).train()
# Load pertrained model if needed
if raw_config['load_checkpoint'] is not None:
total_iter = model.load_checkpoint(raw_config['load_checkpoint'])
raw_config['load_checkpoint'] = None
print('Previously trained model loaded!')
else:
total_iter = 0
if network_in_memory is not None:
print('I am loading network from the previous stage')
model.load_network_in_memory(network_in_memory)
network_in_memory = None
elif raw_config['load_network'] is not None:
print('I am loading network from a disk, as listed in configuration')
model.load_network(raw_config['load_network'])
raw_config['load_network'] = None
"""
Dataloader related
"""
# To re-seed the randomness everytime we start a worker
def worker_init_fn(worker_id):
worker_seed = torch.initial_seed()%(2**31) + worker_id + local_rank*100
np.random.seed(worker_seed)
random.seed(worker_seed)
def construct_loader(dataset):
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset, rank=local_rank, shuffle=True)
train_loader = DataLoader(dataset, config['batch_size'], sampler=train_sampler, num_workers=config['num_workers'],
worker_init_fn=worker_init_fn, drop_last=True)
return train_sampler, train_loader
def renew_vos_loader(max_skip, finetune=False):
# //5 because we only have annotation for every five frames
yv_dataset = VOSDataset(path.join(yv_root, 'JPEGImages'),
path.join(yv_root, 'Annotations'), max_skip//5, is_bl=False, subset=load_sub_yv(), num_frames=config['num_frames'], finetune=finetune)
davis_dataset = VOSDataset(path.join(davis_root, 'JPEGImages', '480p'),
path.join(davis_root, 'Annotations', '480p'), max_skip, is_bl=False, subset=load_sub_davis(), num_frames=config['num_frames'], finetune=finetune)
train_dataset = ConcatDataset([davis_dataset]*5 + [yv_dataset])
print(f'YouTube dataset size: {len(yv_dataset)}')
print(f'DAVIS dataset size: {len(davis_dataset)}')
print(f'Concat dataset size: {len(train_dataset)}')
print(f'Renewed with {max_skip=}')
return construct_loader(train_dataset)
def renew_bl_loader(max_skip, finetune=False):
train_dataset = VOSDataset(path.join(bl_root, 'JPEGImages'),
path.join(bl_root, 'Annotations'), max_skip, is_bl=True, num_frames=config['num_frames'], finetune=finetune)
print(f'Blender dataset size: {len(train_dataset)}')
print(f'Renewed with {max_skip=}')
return construct_loader(train_dataset)
"""
Dataset related
"""
"""
These define the training schedule of the distance between frames
We will switch to max_skip_values[i] once we pass the percentage specified by increase_skip_fraction[i]
Not effective for stage 0 training
The initial value is not listed here but in renew_vos_loader(X)
"""
max_skip_values = [10, 15, 5, 5]
if stage == '0':
static_root = path.expanduser(config['static_root'])
# format: path, method (style of storing images), mutliplier
train_dataset = StaticTransformDataset(
[
(path.join(static_root, 'fss'), 0, 1),
(path.join(static_root, 'DUTS-TR'), 1, 1),
(path.join(static_root, 'DUTS-TE'), 1, 1),
(path.join(static_root, 'ecssd'), 1, 1),
(path.join(static_root, 'BIG_small'), 1, 5),
(path.join(static_root, 'HRSOD_small'), 1, 5),
], num_frames=config['num_frames'])
train_sampler, train_loader = construct_loader(train_dataset)
print(f'Static dataset size: {len(train_dataset)}')
elif stage == '1':
increase_skip_fraction = [0.1, 0.3, 0.8, 100]
bl_root = path.join(path.expanduser(config['bl_root']))
train_sampler, train_loader = renew_bl_loader(5)
renew_loader = renew_bl_loader
else:
# stage 2 or 3
increase_skip_fraction = [0.1, 0.3, 0.9, 100]
# VOS dataset, 480p is used for both datasets
yv_root = path.join(path.expanduser(config['yv_root']), 'train_480p')
davis_root = path.join(path.expanduser(config['davis_root']), '2017', 'trainval')
train_sampler, train_loader = renew_vos_loader(5)
renew_loader = renew_vos_loader
"""
Determine max epoch
"""
total_epoch = math.ceil(config['iterations']/len(train_loader))
current_epoch = total_iter // len(train_loader)
print(f'We approximately use {total_epoch} epochs.')
if stage != '0':
change_skip_iter = [round(config['iterations']*f) for f in increase_skip_fraction]
# Skip will only change after an epoch, not in the middle
print(f'The skip value will change approximately at the following iterations: {change_skip_iter[:-1]}')
"""
Starts training
"""
finetuning = False
# Need this to select random bases in different workers
np.random.seed(np.random.randint(2**30-1) + local_rank*100)
try:
while total_iter < config['iterations'] + config['finetune']:
# Crucial for randomness!
train_sampler.set_epoch(current_epoch)
current_epoch += 1
print(f'Current epoch: {current_epoch}')
# Train loop
model.train()
for data in train_loader:
# Update skip if needed
if stage!='0' and total_iter >= change_skip_iter[0]:
while total_iter >= change_skip_iter[0]:
cur_skip = max_skip_values[0]
max_skip_values = max_skip_values[1:]
change_skip_iter = change_skip_iter[1:]
print(f'Changing skip to {cur_skip=}')
train_sampler, train_loader = renew_loader(cur_skip)
break
# fine-tune means fewer augmentations to train the sensory memory
if config['finetune'] > 0 and not finetuning and total_iter >= config['iterations']:
train_sampler, train_loader = renew_loader(cur_skip, finetune=True)
finetuning = True
model.save_network_interval = 1000
break
model.do_pass(data, total_iter)
total_iter += 1
if total_iter >= config['iterations'] + config['finetune']:
break
finally:
if not config['debug'] and model.logger is not None and total_iter>5000:
model.save_network(total_iter)
model.save_checkpoint(total_iter)
network_in_memory = model.XMem.module.state_dict()
distributed.destroy_process_group()
================================================
FILE: XMem/util/__init__.py
================================================
================================================
FILE: XMem/util/configuration.py
================================================
from argparse import ArgumentParser
def none_or_default(x, default):
return x if x is not None else default
class Configuration():
def parse(self, unknown_arg_ok=False):
parser = ArgumentParser()
# Enable torch.backends.cudnn.benchmark -- Faster in some cases, test in your own environment
parser.add_argument('--benchmark', action='store_true')
parser.add_argument('--no_amp', action='store_true')
# Data parameters
parser.add_argument('--static_root', help='Static training data root', default='../static')
parser.add_argument('--bl_root', help='Blender training data root', default='../BL30K')
parser.add_argument('--yv_root', help='YouTubeVOS data root', default='../YouTube')
parser.add_argument('--davis_root', help='DAVIS data root', default='../DAVIS')
parser.add_argument('--num_workers', help='Total number of dataloader workers across all GPUs processes', type=int, default=16)
parser.add_argument('--key_dim', default=64, type=int)
parser.add_argument('--value_dim', default=512, type=int)
parser.add_argument('--hidden_dim', default=64, help='Set to =0 to disable', type=int)
parser.add_argument('--deep_update_prob', default=0.2, type=float)
parser.add_argument('--stages', help='Training stage (0-static images, 1-Blender dataset, 2-DAVIS+YouTubeVOS)', default='02')
"""
Stage-specific learning parameters
Batch sizes are effective -- you don't have to scale them when you scale the number processes
"""
# Stage 0, static images
parser.add_argument('--s0_batch_size', default=16, type=int)
parser.add_argument('--s0_iterations', default=150000, type=int)
parser.add_argument('--s0_finetune', default=0, type=int)
parser.add_argument('--s0_steps', nargs="*", default=[], type=int)
parser.add_argument('--s0_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s0_num_ref_frames', default=2, type=int)
parser.add_argument('--s0_num_frames', default=3, type=int)
parser.add_argument('--s0_start_warm', default=20000, type=int)
parser.add_argument('--s0_end_warm', default=70000, type=int)
# Stage 1, BL30K
parser.add_argument('--s1_batch_size', default=8, type=int)
parser.add_argument('--s1_iterations', default=250000, type=int)
# fine-tune means fewer augmentations to train the sensory memory
parser.add_argument('--s1_finetune', default=0, type=int)
parser.add_argument('--s1_steps', nargs="*", default=[200000], type=int)
parser.add_argument('--s1_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s1_num_ref_frames', default=3, type=int)
parser.add_argument('--s1_num_frames', default=8, type=int)
parser.add_argument('--s1_start_warm', default=20000, type=int)
parser.add_argument('--s1_end_warm', default=70000, type=int)
# Stage 2, DAVIS+YoutubeVOS, longer
parser.add_argument('--s2_batch_size', default=8, type=int)
parser.add_argument('--s2_iterations', default=150000, type=int)
# fine-tune means fewer augmentations to train the sensory memory
parser.add_argument('--s2_finetune', default=10000, type=int)
parser.add_argument('--s2_steps', nargs="*", default=[120000], type=int)
parser.add_argument('--s2_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s2_num_ref_frames', default=3, type=int)
parser.add_argument('--s2_num_frames', default=8, type=int)
parser.add_argument('--s2_start_warm', default=20000, type=int)
parser.add_argument('--s2_end_warm', default=70000, type=int)
# Stage 3, DAVIS+YoutubeVOS, shorter
parser.add_argument('--s3_batch_size', default=8, type=int)
parser.add_argument('--s3_iterations', default=100000, type=int)
# fine-tune means fewer augmentations to train the sensory memory
parser.add_argument('--s3_finetune', default=10000, type=int)
parser.add_argument('--s3_steps', nargs="*", default=[80000], type=int)
parser.add_argument('--s3_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s3_num_ref_frames', default=3, type=int)
parser.add_argument('--s3_num_frames', default=8, type=int)
parser.add_argument('--s3_start_warm', default=20000, type=int)
parser.add_argument('--s3_end_warm', default=70000, type=int)
parser.add_argument('--gamma', help='LR := LR*gamma at every decay step', default=0.1, type=float)
parser.add_argument('--weight_decay', default=0.05, type=float)
# Loading
parser.add_argument('--load_network', help='Path to pretrained network weight only')
parser.add_argument('--load_checkpoint', help='Path to the checkpoint file, including network, optimizer and such')
# Logging information
parser.add_argument('--log_text_interval', default=100, type=int)
parser.add_argument('--log_image_interval', default=1000, type=int)
parser.add_argument('--save_network_interval', default=25000, type=int)
parser.add_argument('--save_checkpoint_interval', default=50000, type=int)
parser.add_argument('--exp_id', help='Experiment UNIQUE id, use NULL to disable logging to tensorboard', default='NULL')
parser.add_argument('--debug', help='Debug mode which logs information more often', action='store_true')
# # Multiprocessing parameters, not set by users
# parser.add_argument('--local_rank', default=0, type=int, help='Local rank of this process')
if unknown_arg_ok:
args, _ = parser.parse_known_args()
self.args = vars(args)
else:
self.args = vars(parser.parse_args())
self.args['amp'] = not self.args['no_amp']
# check if the stages are valid
stage_to_perform = list(self.args['stages'])
for s in stage_to_perform:
if s not in ['0', '1', '2', '3']:
raise NotImplementedError
def get_stage_parameters(self, stage):
parameters = {
'batch_size': self.args['s%s_batch_size'%stage],
'iterations': self.args['s%s_iterations'%stage],
'finetune': self.args['s%s_finetune'%stage],
'steps': self.args['s%s_steps'%stage],
'lr': self.args['s%s_lr'%stage],
'num_ref_frames': self.args['s%s_num_ref_frames'%stage],
'num_frames': self.args['s%s_num_frames'%stage],
'start_warm': self.args['s%s_start_warm'%stage],
'end_warm': self.args['s%s_end_warm'%stage],
}
return parameters
def __getitem__(self, key):
return self.args[key]
def __setitem__(self, key, value):
self.args[key] = value
def __str__(self):
return str(self.args)
================================================
FILE: XMem/util/davis_subset.txt
================================================
bear
bmx-bumps
boat
boxing-fisheye
breakdance-flare
bus
car-turn
cat-girl
classic-car
color-run
crossing
dance-jump
dancing
disc-jockey
dog-agility
dog-gooses
dogs-scale
drift-turn
drone
elephant
flamingo
hike
hockey
horsejump-low
kid-football
kite-walk
koala
lady-running
lindy-hop
longboard
lucia
mallard-fly
mallard-water
miami-surf
motocross-bumps
motorbike
night-race
paragliding
planes-water
rallye
rhino
rollerblade
schoolgirls
scooter-board
scooter-gray
sheep
skate-park
snowboard
soccerball
stroller
stunt
surf
swing
tennis
tractor-sand
train
tuk-tuk
upside-down
varanus-cage
walking
================================================
FILE: XMem/util/image_saver.py
================================================
import cv2
import numpy as np
import torch
from dataset.range_transform import inv_im_trans
from collections import defaultdict
def tensor_to_numpy(image):
image_np = (image.numpy() * 255).astype('uint8')
return image_np
def tensor_to_np_float(image):
image_np = image.numpy().astype('float32')
return image_np
def detach_to_cpu(x):
return x.detach().cpu()
def transpose_np(x):
return np.transpose(x, [1,2,0])
def tensor_to_gray_im(x):
x = detach_to_cpu(x)
x = tensor_to_numpy(x)
x = transpose_np(x)
return x
def tensor_to_im(x):
x = detach_to_cpu(x)
x = inv_im_trans(x).clamp(0, 1)
x = tensor_to_numpy(x)
x = transpose_np(x)
return x
# Predefined key <-> caption dict
key_captions = {
'im': 'Image',
'gt': 'GT',
}
"""
Return an image array with captions
keys in dictionary will be used as caption if not provided
values should contain lists of cv2 images
"""
def get_image_array(images, grid_shape, captions={}):
h, w = grid_shape
cate_counts = len(images)
rows_counts = len(next(iter(images.values())))
font = cv2.FONT_HERSHEY_SIMPLEX
output_image = np.zeros([w*cate_counts, h*(rows_counts+1), 3], dtype=np.uint8)
col_cnt = 0
for k, v in images.items():
# Default as key value itself
caption = captions.get(k, k)
# Handles new line character
dy = 40
for i, line in enumerate(caption.split('\n')):
cv2.putText(output_image, line, (10, col_cnt*w+100+i*dy),
font, 0.8, (255,255,255), 2, cv2.LINE_AA)
# Put images
for row_cnt, img in enumerate(v):
im_shape = img.shape
if len(im_shape) == 2:
img = img[..., np.newaxis]
img = (img * 255).astype('uint8')
output_image[(col_cnt+0)*w:(col_cnt+1)*w,
(row_cnt+1)*h:(row_cnt+2)*h, :] = img
col_cnt += 1
return output_image
def base_transform(im, size):
im = tensor_to_np_float(im)
if len(im.shape) == 3:
im = im.transpose((1, 2, 0))
else:
im = im[:, :, None]
# Resize
if im.shape[1] != size:
im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
return im.clip(0, 1)
def im_transform(im, size):
return base_transform(inv_im_trans(detach_to_cpu(im)), size=size)
def mask_transform(mask, size):
return base_transform(detach_to_cpu(mask), size=size)
def out_transform(mask, size):
return base_transform(detach_to_cpu(torch.sigmoid(mask)), size=size)
def pool_pairs(images, size, num_objects):
req_images = defaultdict(list)
b, t = images['rgb'].shape[:2]
# limit the number of images saved
b = min(2, b)
# find max num objects
max_num_objects = max(num_objects[:b])
GT_suffix = ''
for bi in range(b):
GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
for bi in range(b):
for ti in range(t):
req_images['RGB'].append(im_transform(images['rgb'][bi,ti], size))
for oi in range(max_num_objects):
if ti == 0 or oi >= num_objects[bi]:
req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
# req_images['Mask_X8_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
# req_images['Mask_X16_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
else:
req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
# req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][2], size))
# req_images['Mask_X8_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][1], size))
# req_images['Mask_X16_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][0], size))
req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
# print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
# print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
return get_image_array(req_images, size, key_captions)
================================================
FILE: XMem/util/load_subset.py
================================================
"""
load_subset.py - Presents a subset of data
DAVIS - only the training set
YouTubeVOS - I manually filtered some erroneous ones out but I haven't checked all
"""
def load_sub_davis(path='util/davis_subset.txt'):
with open(path, mode='r') as f:
subset = set(f.read().splitlines())
return subset
def load_sub_yv(path='util/yv_subset.txt'):
with open(path, mode='r') as f:
subset = set(f.read().splitlines())
return subset
================================================
FILE: XMem/util/log_integrator.py
================================================
"""
Integrate numerical values for some iterations
Typically used for loss computation / logging to tensorboard
Call finalize and create a new Integrator when you want to display/log
"""
import torch
class Integrator:
def __init__(self, logger, distributed=True, local_rank=0, world_size=1):
self.values = {}
self.counts = {}
self.hooks = [] # List is used here to maintain insertion order
self.logger = logger
self.distributed = distributed
self.local_rank = local_rank
self.world_size = world_size
def add_tensor(self, key, tensor):
if key not in self.values:
self.counts[key] = 1
if type(tensor) == float or type(tensor) == int:
self.values[key] = tensor
else:
self.values[key] = tensor.mean().item()
else:
self.counts[key] += 1
if type(tensor) == float or type(tensor) == int:
self.values[key] += tensor
else:
self.values[key] += tensor.mean().item()
def add_dict(self, tensor_dict):
for k, v in tensor_dict.items():
self.add_tensor(k, v)
def add_hook(self, hook):
"""
Adds a custom hook, i.e. compute new metrics using values in the dict
The hook takes the dict as argument, and returns a (k, v) tuple
e.g. for computing IoU
"""
if type(hook) == list:
self.hooks.extend(hook)
else:
self.hooks.append(hook)
def reset_except_hooks(self):
self.values = {}
self.counts = {}
# Average and output the metrics
def finalize(self, prefix, it, f=None):
for hook in self.hooks:
k, v = hook(self.values)
self.add_tensor(k, v)
for k, v in self.values.items():
if k[:4] == 'hide':
continue
avg = v / self.counts[k]
if self.distributed:
# Inplace operation
avg = torch.tensor(avg).cuda()
torch.distributed.reduce(avg, dst=0)
if self.local_rank == 0:
avg = (avg/self.world_size).cpu().item()
self.logger.log_metrics(prefix, k, avg, it, f)
else:
# Simple does it
self.logger.log_metrics(prefix, k, avg, it, f)
================================================
FILE: XMem/util/logger.py
================================================
"""
Dumps things to tensorboard and console
"""
import os
import warnings
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
def tensor_to_numpy(image):
image_np = (image.numpy() * 255).astype('uint8')
return image_np
def detach_to_cpu(x):
return x.detach().cpu()
def fix_width_trunc(x):
return ('{:.9s}'.format('{:0.9f}'.format(x)))
class TensorboardLogger:
def __init__(self, short_id, id, git_info):
self.short_id = short_id
if self.short_id == 'NULL':
self.short_id = 'DEBUG'
if id is None:
self.no_log = True
warnings.warn('Logging has been disbaled.')
else:
self.no_log = False
self.inv_im_trans = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225])
self.inv_seg_trans = transforms.Normalize(
mean=[-0.5/0.5],
std=[1/0.5])
log_path = os.path.join('.', 'saves', '%s' % id)
self.logger = SummaryWriter(log_path)
self.log_string('git', git_info)
def log_scalar(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
self.logger.add_scalar(tag, x, step)
def log_metrics(self, l1_tag, l2_tag, val, step, f=None):
tag = l1_tag + '/' + l2_tag
text = '{:s} - It {:6d} [{:5s}] [{:13}]: {:s}'.format(self.short_id, step, l1_tag.upper(), l2_tag, fix_width_trunc(val))
print(text)
if f is not None:
f.write(text + '\n')
f.flush()
self.log_scalar(tag, val, step)
def log_im(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = detach_to_cpu(x)
x = self.inv_im_trans(x)
x = tensor_to_numpy(x)
self.logger.add_image(tag, x, step)
def log_cv2(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = x.transpose((2, 0, 1))
self.logger.add_image(tag, x, step)
def log_seg(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = detach_to_cpu(x)
x = self.inv_seg_trans(x)
x = tensor_to_numpy(x)
self.logger.add_image(tag, x, step)
def log_gray(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = detach_to_cpu(x)
x = tensor_to_numpy(x)
self.logger.add_image(tag, x, step)
def log_string(self, tag, x):
print(tag, x)
if self.no_log:
warnings.warn('Logging has been disabled.')
return
self.logger.add_text(tag, x)
================================================
FILE: XMem/util/palette.py
================================================
davis_palette = b'\x00\x00\x00\x80\x00\x00\x00\x80\x00\x80\x80\x00\x00\x00\x80\x80\x00\x80\x00\x80\x80\x80\x80\x80@\x00\x00\xc0\x00\x00@\x80\x00\xc0\x80\x00@\x00\x80\xc0\x00\x80@\x80\x80\xc0\x80\x80\x00@\x00\x80@\x00\x00\xc0\x00\x80\xc0\x00\x00@\x80\x80@\x80\x00\xc0\x80\x80\xc0\x80@@\x00\xc0@\x00@\xc0\x00\xc0\xc0\x00@@\x80\xc0@\x80@\xc0\x80\xc0\xc0\x80\x00\x00@\x80\x00@\x00\x80@\x80\x80@\x00\x00\xc0\x80\x00\xc0\x00\x80\xc0\x80\x80\xc0@\x00@\xc0\x00@@\x80@\xc0\x80@@\x00\xc0\xc0\x00\xc0@\x80\xc0\xc0\x80\xc0\x00@@\x80@@\x00\xc0@\x80\xc0@\x00@\xc0\x80@\xc0\x00\xc0\xc0\x80\xc0\xc0@@@\xc0@@@\xc0@\xc0\xc0@@@\xc0\xc0@\xc0@\xc0\xc0\xc0\xc0\xc0 \x00\x00\xa0\x00\x00 \x80\x00\xa0\x80\x00 \x00\x80\xa0\x00\x80 \x80\x80\xa0\x80\x80`\x00\x00\xe0\x00\x00`\x80\x00\xe0\x80\x00`\x00\x80\xe0\x00\x80`\x80\x80\xe0\x80\x80 @\x00\xa0@\x00 \xc0\x00\xa0\xc0\x00 @\x80\xa0@\x80 \xc0\x80\xa0\xc0\x80`@\x00\xe0@\x00`\xc0\x00\xe0\xc0\x00`@\x80\xe0@\x80`\xc0\x80\xe0\xc0\x80 \x00@\xa0\x00@ \x80@\xa0\x80@ \x00\xc0\xa0\x00\xc0 \x80\xc0\xa0\x80\xc0`\x00@\xe0\x00@`\x80@\xe0\x80@`\x00\xc0\xe0\x00\xc0`\x80\xc0\xe0\x80\xc0 @@\xa0@@ \xc0@\xa0\xc0@ @\xc0\xa0@\xc0 \xc0\xc0\xa0\xc0\xc0`@@\xe0@@`\xc0@\xe0\xc0@`@\xc0\xe0@\xc0`\xc0\xc0\xe0\xc0\xc0\x00 \x00\x80 \x00\x00\xa0\x00\x80\xa0\x00\x00 \x80\x80 \x80\x00\xa0\x80\x80\xa0\x80@ \x00\xc0 \x00@\xa0\x00\xc0\xa0\x00@ \x80\xc0 \x80@\xa0\x80\xc0\xa0\x80\x00`\x00\x80`\x00\x00\xe0\x00\x80\xe0\x00\x00`\x80\x80`\x80\x00\xe0\x80\x80\xe0\x80@`\x00\xc0`\x00@\xe0\x00\xc0\xe0\x00@`\x80\xc0`\x80@\xe0\x80\xc0\xe0\x80\x00 @\x80 @\x00\xa0@\x80\xa0@\x00 \xc0\x80 \xc0\x00\xa0\xc0\x80\xa0\xc0@ @\xc0 @@\xa0@\xc0\xa0@@ \xc0\xc0 \xc0@\xa0\xc0\xc0\xa0\xc0\x00`@\x80`@\x00\xe0@\x80\xe0@\x00`\xc0\x80`\xc0\x00\xe0\xc0\x80\xe0\xc0@`@\xc0`@@\xe0@\xc0\xe0@@`\xc0\xc0`\xc0@\xe0\xc0\xc0\xe0\xc0 \x00\xa0 \x00 \xa0\x00\xa0\xa0\x00 \x80\xa0 \x80 \xa0\x80\xa0\xa0\x80` \x00\xe0 \x00`\xa0\x00\xe0\xa0\x00` \x80\xe0 \x80`\xa0\x80\xe0\xa0\x80 `\x00\xa0`\x00 \xe0\x00\xa0\xe0\x00 `\x80\xa0`\x80 \xe0\x80\xa0\xe0\x80``\x00\xe0`\x00`\xe0\x00\xe0\xe0\x00``\x80\xe0`\x80`\xe0\x80\xe0\xe0\x80 @\xa0 @ \xa0@\xa0\xa0@ \xc0\xa0 \xc0 \xa0\xc0\xa0\xa0\xc0` @\xe0 @`\xa0@\xe0\xa0@` \xc0\xe0 \xc0`\xa0\xc0\xe0\xa0\xc0 `@\xa0`@ \xe0@\xa0\xe0@ `\xc0\xa0`\xc0 \xe0\xc0\xa0\xe0\xc0``@\xe0`@`\xe0@\xe0\xe0@``\xc0\xe0`\xc0`\xe0\xc0\xe0\xe0\xc0'
youtube_palette = b'\x00\x00\x00\xec_g\xf9\x91W\xfa\xc8c\x99\xc7\x94b\xb3\xb2f\x99\xcc\xc5\x94\xc5\xabyg\xff\xff\xffes~\x0b\x0b\x0b\x0c\x0c\x0c\r\r\r\x0e\x0e\x0e\x0f\x0f\x0f'
================================================
FILE: XMem/util/tensor_util.py
================================================
import torch.nn.functional as F
def compute_tensor_iu(seg, gt):
intersection = (seg & gt).float().sum()
union = (seg | gt).float().sum()
return intersection, union
def compute_tensor_iou(seg, gt):
intersection, union = compute_tensor_iu(seg, gt)
iou = (intersection + 1e-6) / (union + 1e-6)
return iou
# STM
def pad_divide_by(in_img, d):
h, w = in_img.shape[-2:]
if h % d > 0:
new_h = h + d - h % d
else:
new_h = h
if w % d > 0:
new_w = w + d - w % d
else:
new_w = w
lh, uh = int((new_h-h) / 2), int(new_h-h) - int((new_h-h) / 2)
lw, uw = int((new_w-w) / 2), int(new_w-w) - int((new_w-w) / 2)
pad_array = (int(lw), int(uw), int(lh), int(uh))
out = F.pad(in_img, pad_array)
return out, pad_array
def unpad(img, pad):
if len(img.shape) == 4:
if pad[2]+pad[3] > 0:
img = img[:,:,pad[2]:-pad[3],:]
if pad[0]+pad[1] > 0:
img = img[:,:,:,pad[0]:-pad[1]]
elif len(img.shape) == 3:
if pad[2]+pad[3] > 0:
img = img[:,pad[2]:-pad[3],:]
if pad[0]+pad[1] > 0:
img = img[:,:,pad[0]:-pad[1]]
else:
raise NotImplementedError
return img
================================================
FILE: XMem/util/yv_subset.txt
================================================
003234408d
0043f083b5
0044fa5fba
005a527edd
0065b171f9
00917dcfc4
00a23ccf53
00ad5016a4
01082ae388
011ac0a06f
013099c098
0155498c85
01694ad9c8
017ac35701
01b80e8e1a
01baa5a4e1
01c3111683
01c4cb5ffe
01c76f0a82
01c783268c
01ed275c6e
01ff60d1fa
020cd28cd2
02264db755
0248626d9a
02668dbffa
0274193026
02d28375aa
02f3a5c4df
031ccc99b1
0321b18c10
0348a45bca
0355e92655
0358b938c1
0368107cf1
0379ddf557
038b2cc71d
038c15a5dd
03a06cc98a
03a63e187f
03c95b4dae
03e2b57b0e
04194e1248
0444918a5f
04460a7a52
04474174a4
0450095513
045f00aed2
04667fabaa
04735c5030
04990d1915
04d62d9d98
04f21da964
04fbad476e
04fe256562
0503bf89c9
0536c9eed0
054acb238f
05579ca250
056c200404
05774f3a2c
058a7592c8
05a0a513df
05a569d8aa
05aa652648
05d7715782
05e0b0f28f
05fdbbdd7a
05ffcfed85
0630391881
06840b2bbe
068f7dce6f
0693719753
06ce2b51fb
06e224798e
06ee361788
06fbb3fa2c
0700264286
070c918ca7
07129e14a4
07177017e9
07238ffc58
07353b2a89
0738493cbf
075926c651
075c701292
0762ea9a30
07652ee4af
076f206928
077d32af19
079049275c
07913cdda7
07a11a35e8
07ac33b6df
07b6e8fda8
07c62c3d11
07cc1c7d74
080196ef01
081207976e
081ae4fa44
081d8250cb
082900c5d4
0860df21e2
0866d4c5e3
0891ac2eb6
08931bc458
08aa2705d5
08c8450db7
08d50b926c
08e1e4de15
08e48c1a48
08f561c65e
08feb87790
09049f6fe3
092e4ff450
09338adea8
093c335ccc
0970d28339
0974a213dc
097b471ed8
0990941758
09a348f4fa
09a6841288
09c5bad17b
09c9ce80c7
09ff54fef4
0a23765d15
0a275e7f12
0a2f2bd294
0a7a2514aa
0a7b27fde9
0a8c467cc3
0ac8c560ae
0b1627e896
0b285c47f6
0b34ec1d55
0b5b5e8e5a
0b68535614
0b6f9105fc
0b7dbfa3cb
0b9cea51ca
0b9d012be8
0bcfc4177d
0bd37b23c1
0bd864064c
0c11c6bf7b
0c26bc77ac
0c3a04798c
0c44a9d545
0c817cc390
0ca839ee9a
0cd7ac0ac0
0ce06e0121
0cfe974a89
0d2fcc0dcd
0d3aad05d2
0d40b015f4
0d97fba242
0d9cc80d7e
0dab85b6d3
0db5c427a5
0dbaf284f1
0de4923598
0df28a9101
0e04f636c4
0e05f0e232
0e0930474b
0e27472bea
0e30020549
0e621feb6c
0e803c7d73
0e9ebe4e3c
0e9f2785ec
0ea68d418b
0eb403a222
0ee92053d6
0eefca067f
0f17fa6fcb
0f1ac8e9a3
0f202e9852
0f2ab8b1ff
0f51a78756
0f5fbe16b0
0f6072077b
0f6b69b2f4
0f6c2163de
0f74ec5599
0f9683715b
0fa7b59356
0fb173695b
0fc958cde2
0fe7b1a621
0ffcdb491c
101caff7d4
1022fe8417
1032e80b37
103f501680
104e64565f
104f1ab997
106242403f
10b31f5431
10eced835e
110d26fa3a
1122c1d16a
1145b49a5f
11485838c2
114e7676ec
1157472b95
115ee1072c
1171141012
117757b4b8
1178932d2f
117cc76bda
1180cbf814
1187bbd0e3
1197e44b26
119cf20728
119dd54871
11a0c3b724
11a6ba8c94
11c722a456
11cbcb0b4d
11ccf5e99d
11ce6f452e
11e53de6f2
11feabe596
120cb9514d
12156b25b3
122896672d
1232b2f1d4
1233ac8596
1239c87234
1250423f7c
1257a1bc67
125d1b19dd
126d203967
1295e19071
12ad198c54
12bddb2bcb
12ec9b93ee
12eebedc35
132852e094
1329409f2a
13325cfa14
134d06dbf9
135625b53d
13870016f9
13960b3c84
13adaad9d9
13ae097e20
13e3070469
13f6a8c20d
1416925cf2
142d2621f5
145d5d7c03
145fdc3ac5
1471274fa7
14a6b5a139
14c21cea0d
14dae0dc93
14f9bd22b5
14fd28ae99
15097d5d4e
150ea711f2
1514e3563f
152aaa3a9e
152b7d3bd7
15617297cc
15abbe0c52
15d1fb3de5
15f67b0fab
161eb59aad
16288ea47f
164410ce62
165c3c8cd4
165c42b41b
165ec9e22b
1669502269
16763cccbb
16adde065e
16af445362
16afd538ad
16c3fa4d5d
16d1d65c27
16e8599e94
16fe9fb444
1705796b02
1724db7671
17418e81ea
175169edbb
17622326fd
17656bae77
17b0d94172
17c220e4f6
17c7bcd146
17cb4afe89
17cd79a434
17d18604c3
17d8ca1a37
17e33f4330
17f7a6d805
180abc8378
183ba3d652
185bf64702
18913cc690
1892651815
189ac8208a
189b44e92c
18ac264b76
18b245ab49
18b5cebc34
18bad52083
18bb5144d5
18c6f205c5
1903f9ea15
1917b209f2
191e74c01d
19367bb94e
193ffaa217
19696b67d3
197f3ab6f3
1981e763cc
198afe39ae
19a6e62b9b
19b60d5335
19c00c11f9
19e061eb88
19e8bc6178
19ee80dac6
1a25a9170a
1a359a6c1a
1a3e87c566
1a5fe06b00
1a6c0fbd1e
1a6f3b5a4b
1a8afbad92
1a8bdc5842
1a95752aca
1a9c131cb7
1aa3da3ee3
1ab27ec7ea
1abf16d21d
1acd0f993b
1ad202e499
1af8d2395d
1afd39a1fa
1b2d31306f
1b3fa67f0e
1b43fa74b4
1b73ea9fc2
1b7e8bb255
1b8680f8cd
1b883843c0
1b8898785b
1b88ba1aa4
1b96a498e5
1bbc4c274f
1bd87fe9ab
1c4090c75b
1c41934f84
1c72b04b56
1c87955a3a
1c9f9eb792
1ca240fede
1ca5673803
1cada35274
1cb44b920d
1cd10e62be
1d3087d5e5
1d3685150a
1d6ff083aa
1d746352a6
1da256d146
1da4e956b1
1daf812218
1dba687bce
1dce57d05d
1de4a9e537
1dec5446c8
1dfbe6f586
1e1a18c45a
1e1e42529d
1e4be70796
1eb60959c8
1ec8b2566b
1ecdc2941c
1ee0ac70ff
1ef8e17def
1f1a2a9fc0
1f1beb8daa
1f2609ee13
1f3876f8d0
1f4ec0563d
1f64955634
1f7d31b5b2
1f8014b7fd
1f9c7d10f1
1fa350df76
1fc9538993
1fe2f0ec59
2000c02f9d
20142b2f05
201a8d75e5
2023b3ee4f
202b767bbc
203594a418
2038987336
2039c3aecb
204a90d81f
207bc6cf01
208833d1d1
20c6d8b362
20e3e52e0a
2117fa0c14
211bc5d102
2120d9c3c3
2125235a49
21386f5978
2142af8795
215dfc0f73
217bae91e5
217c0d44e4
219057c87b
21d0edbf81
21df87ad76
21f1d089f5
21f4019116
222597030f
222904eb5b
223a0e0657
223bd973ab
22472f7395
224e7c833e
225aba51d9
2261d421ea
2263a8782b
2268cb1ffd
2268e93b0a
2293c99f3f
22a1141970
22b13084b2
22d9f5ab0c
22f02efe3a
232c09b75b
2350d71b4b
2376440551
2383d8aafd
238b84e67f
238d4b86f6
238d947c6b
23993ce90d
23b0c8a9ab
23b3beafcc
23d80299fe
23f404a9fc
240118e58a
2431dec2fd
24440e0ac7
2457274dbc
2465bf515d
246b142c4d
247d729e36
2481ceafeb
24866b4e6a
2489d78320
24ab0b83e8
24b0868d92
24b5207cd9
24ddf05c03
250116161c
256ad2e3fc
256bd83d5e
256dcc8ab8
2589956baa
258b3b33c6
25ad437e29
25ae395636
25c750c6db
25d2c3fe5d
25dc80db7c
25f97e926f
26011bc28b
260846ffbe
260dd9ad33
267964ee57
2680861931
268ac7d3fc
26b895d91e
26bc786d4f
26ddd2ef12
26de3d18ca
26f7784762
2703e52a6a
270ed80c12
2719b742ab
272f4163d0
27303333e1
27659fa7d6
279214115d
27a5f92a9c
27cf2af1f3
27f0d5f8a2
28075f33c1
281629cb41
282b0d51f5
282fcab00b
28449fa0dc
28475208ca
285580b7c4
285b69e223
288c117201
28a8eb9623
28bf9c3cf3
28c6b8f86a
28c972dacd
28d9fa6016
28e392de91
28f4a45190
298c844fc9
29a0356a2b
29d779f9e3
29dde5f12b
29de7b6579
29e630bdd0
29f2332d30
2a18873352
2a3824ff31
2a559dd27f
2a5c09acbd
2a63eb1524
2a6a30a4ea
2a6d9099d1
2a821394e3
2a8c5b1342
2abc8d66d2
2ac9ef904a
2b08f37364
2b351bfd7d
2b659a49d7
2b69ee5c26
2b6c30bbbd
2b88561cf2
2b8b14954e
2ba621c750
2bab50f9a7
2bb00c2434
2bbde474ef
2bdd82fb86
2be06fb855
2bf545c2f5
2bffe4cf9a
2c04b887b7
2c05209105
2c0ad8cf39
2c11fedca8
2c1a94ebfb
2c1e8c8e2f
2c29fabcf1
2c2c076c01
2c3ea7ee7d
2c41fa0648
2c44bb6d1c
2c54cfbb78
2c5537eddf
2c6e63b7de
2cb10c6a7e
2cbcd5ccd1
2cc5d9c5f6
2cd01cf915
2cdbf5f0a7
2ce660f123
2cf114677e
2d01eef98e
2d03593bdc
2d183ac8c4
2d33ad3935
2d3991d83e
2d4333577b
2d4d015c64
2d8f5e5025
2d900bdb8e
2d9a1a1d49
2db0576a5c
2dc0838721
2dcc417f82
2df005b843
2df356de14
2e00393d96
2e03b8127a
2e0f886168
2e2bf37e6d
2e42410932
2ea78f46e4
2ebb017a26
2ee2edba2a
2efb07554a
2f17e4fc1e
2f2c65c2f3
2f2d9b33be
2f309c206b
2f53822e88
2f53998171
2f5b0c89b1
2f680909e6
2f710f66bd
2f724132b9
2f7e3517ae
2f96f5fc6f
2f97d9fecb
2fbfa431ec
2fc9520b53
2fcd9f4c62
2feb30f208
2ff7f5744f
30085a2cc6
30176e3615
301f72ee11
3026bb2f61
30318465dc
3054ca937d
306121e726
3064ad91e8
307444a47f
307bbb7409
30a20194ab
30c35c64a4
30dbdb2cd6
30fc77d72f
310021b58b
3113140ee8
3150b2ee57
31539918c4
318dfe2ce2
3193da4835
319f725ad9
31bbd0d793
322505c47f
322b237865
322da43910
3245e049fb
324c4c38f6
324e35111a
3252398f09
327dc4cabf
328d918c7d
3290c0de97
3299ae3116
32a7cd687b
33098cedb4
3332334ac4
334cb835ac
3355e056eb
33639a2847
3373891cdc
337975816b
33e29d7e91
34046fe4f2
3424f58959
34370a710f
343bc6a65a
3450382ef7
3454303a08
346aacf439
346e92ff37
34a5ece7dd
34b109755a
34d1b37101
34dd2c70a7
34efa703df
34fbee00a6
3504df2fda
35195a56a1
351c822748
351cfd6bc5
3543d8334c
35573455c7
35637a827f
357a710863
358bf16f9e
35ab34cc34
35c6235b8d
35d01a438a
3605019d3b
3609bc3f88
360e25da17
36299c687c
362c5bc56e
3649228783
365b0501ea
365f459863
369893f3ad
369c9977e1
369dde050a
36c7dac02f
36d5b1493b
36f5cc68fd
3735480d18
374b479880
375a49d38f
375a5c0e09
376bda9651
377db65f60
37c19d1087
37d4ae24fc
37ddce7f8b
37e10d33af
37e45c6247
37fa0001e8
3802d458c0
382caa3cb4
383bb93111
388843df90
38924f4a7f
38b00f93d7
38c197c10e
38c9c3d801
38eb2bf67f
38fe9b3ed1
390352cced
390c51b987
390ca6f1d6
392bc0f8a1
392ecb43bd
3935291688
3935e63b41
394454fa9c
394638fc8b
39545e20b7
397abeae8f
3988074b88
398f5d5f19
39bc49a28c
39befd99fb
39c3c7bf55
39d584b09f
39f6f6ffb1
3a079fb484
3a0d3a81b7
3a1d55d22b
3a20a7583e
3a2c1f66e5
3a33f4d225
3a3bf84b13
3a4565e5ec
3a4e32ed5e
3a7ad86ce0
3a7bdde9b8
3a98867cbe
3aa3f1c9e8
3aa7fce8b6
3aa876887d
3ab807ded6
3ab9b1a85a
3adac8d7da
3ae1a4016f
3ae2deaec2
3ae81609d6
3af847e62f
3b23792b84
3b3b0af2ee
3b512dad74
3b6c7988f6
3b6e983b5b
3b74a0fc20
3b7a50b80d
3b96d3492f
3b9ad0c5a9
3b9ba0894a
3bb4e10ed7
3bd9a9b515
3beef45388
3c019c0a24
3c090704aa
3c2784fc0d
3c47ab95f8
3c4db32d74
3c5ff93faf
3c700f073e
3c713cbf2f
3c8320669c
3c90d225ee
3cadbcc404
3cb9be84a5
3cc37fd487
3cc6f90cb2
3cd5e035ef
3cdf03531b
3cdf828f59
3d254b0bca
3d5aeac5ba
3d690473e1
3d69fed2fb
3d8997aeb6
3db0d6b07e
3db1ddb8cf
3db907ac77
3dcbc0635b
3dd48ed55f
3de4ac4ec4
3decd63d88
3e04a6be11
3e108fb65a
3e1448b01c
3e16c19634
3e2845307e
3e38336da5
3e3a819865
3e3e4be915
3e680622d7
3e7d2aeb07
3e7d8f363d
3e91f10205
3ea4c49bbe
3eb39d11ab
3ec273c8d5
3ed3f91271
3ee062a2fd
3eede9782c
3ef2fa99cb
3efc6e9892
3f0b0dfddd
3f0c860359
3f18728586
3f3b15f083
3f45a470ad
3f4f3bc803
3fd96c5267
3fea675fab
3fee8cbc9f
3fff16d112
401888b36c
4019231330
402316532d
402680df52
404d02e0c0
40709263a8
4083cfbe15
40a96c5cb1
40b8e50f82
40f4026bf5
4100b57a3a
41059fdd0b
41124e36de
4122aba5f9
413bab0f0d
4164faee0b
418035eec9
4182d51532
418bb97e10
41a34c20e7
41dab05200
41ff6d5e2a
420caf0859
42264230ba
425a0c96e0
42da96b87c
42eb5a5b0f
42f17cd14d
42f5c61c49
42ffdcdee9
432f9884f9
43326d9940
4350f3ab60
4399ffade3
43a6c21f37
43b5555faa
43d63b752a
4416bdd6ac
4444753edd
444aa274e7
444d4e0596
446b8b5f7a
4478f694bb
44b1da0d87
44b4dad8c9
44b5ece1b9
44d239b24e
44eaf8f51e
44f4f57099
44f7422af2
450787ac97
4523656564
4536c882e5
453b65daa4
454f227427
45636d806a
456fb9362e
457e717a14
45a89f35e1
45bf0e947d
45c36a9eab
45d9fc1357
45f8128b97
4607f6c03c
46146dfd39
4620e66b1e
4625f3f2d3
462b22f263
4634736113
463c0f4fdd
46565a75f8
46630b55ae
466839cb37
466ba4ae0c
4680236c9d
46bf4e8709
46e18e42f1
46f5093c59
47269e0499
472da1c484
47354fab09
4743bb84a7
474a796272
4783d2ab87
479cad5da3
479f5d7ef6
47a05fbd1d
4804ee2767
4810c3fbca
482fb439c2
48375af288
484ab44de4
485f3944cd
4867b84887
486a8ac57e
486e69c5bd
48812cf33e
4894b3b9ea
48bd66517d
48d83b48a4
49058178b8
4918d10ff0
4932911f80
49405b7900
49972c2d14
499bf07002
49b16e9377
49c104258e
49c879f82d
49e7326789
49ec3e406a
49fbf0c98a
4a0255c865
4a088fe99a
4a341402d0
4a3471bdf5
4a4b50571c
4a50f3d2e9
4a6e3faaa1
4a7191f08a
4a86fcfc30
4a885fa3ef
4a8af115de
4aa2e0f865
4aa9d6527f
4abb74bb52
4ae13de1cd
4af8cb323f
4b02c272b3
4b19c529fb
4b2974eff4
4b3154c159
4b54d2587f
4b556740ff
4b67aa9ef6
4b97cc7b8d
4baa1ed4aa
4bc8c676bb
4beaea4dbe
4bf5763d24
4bffa92b67
4c25dfa8ec
4c397b6fd4
4c51e75d66
4c7710908f
4c9b5017be
4ca2ffc361
4cad2e93bc
4cd427b535
4cd9a4b1ef
4cdfe3c2b2
4cef87b649
4cf208e9b3
4cf5bc3e60
4cfdd73249
4cff5c9e42
4d26d41091
4d5c23c554
4d67c59727
4d983cad9f
4da0d00b55
4daa179861
4dadd57153
4db117e6c5
4de4ce4dea
4dfaee19e5
4dfdd7fab0
4e3f346aa5
4e49c2a9c7
4e4e06a749
4e70279712
4e72856cc7
4e752f8075
4e7a28907f
4e824b9247
4e82b1df57
4e87a639bc
4ea77bfd15
4eb6fc23a2
4ec9da329e
4efb9a0720
4f062fbc63
4f35be0e0b
4f37e86797
4f414dd6e7
4f424abded
4f470cc3ae
4f601d255a
4f7386a1ab
4f824d3dcd
4f827b0751
4f8db33a13
4fa160f8a3
4fa9c30a45
4facd8f0e8
4fca07ad01
4fded94004
4fdfef4dea
4feb3ac01f
4fffec8479
500c835a86
50168342bf
50243cffdc
5031d5a036
504dd9c0fd
50568fbcfb
5069c7c5b3
508189ac91
50b6b3d4b7
50c6f4fe3e
50cce40173
50efbe152f
50f290b95d
5104aa1fea
5110dc72c0
511e8ecd7f
513aada14e
5158d6e985
5161e1fa57
51794ddd58
517d276725
51a597ee04
51b37b6d97
51b5dc30a0
51e85b347b
51eea1fdac
51eef778af
51f384721c
521cfadcb4
52355da42f
5247d4b160
524b470fd0
524cee1534
5252195e8a
5255c9ca97
525928f46f
526df007a7
529b12de78
52c7a3d653
52c8ec0373
52d225ed52
52ee406d9e
52ff1ccd4a
53143511e8
5316d11eb7
53253f2362
534a560609
5352c4a70e
536096501f
536b17bcea
5380eaabff
5390a43a54
53af427bb2
53bf5964ce
53c30110b5
53cad8e44a
53d9c45013
53e274f1b5
53e32d21ea
540850e1c7
540cb31cfe
541c4da30f
541d7935d7
545468262b
5458647306
54657855cd
547b3fb23b
5497dc3712
549c56f1d4
54a4260bb1
54b98b8d5e
54e1054b0f
54e8867b83
54ebe34f6e
5519b4ad13
551acbffd5
55341f42da
5566ab97e1
556c79bbf2
5589637cc4
558aa072f0
559824b6f6
55c1764e90
55eda6c77e
562d173565
5665c024cb
566cef4959
5675d78833
5678a91bd8
567a2b4bd0
569c282890
56cc449917
56e71f3e07
56f09b9d92
56fc0e8cf9
571ca79c71
57243657cf
57246af7d1
57427393e9
574b682c19
578f211b86
5790ac295d
579393912d
57a344ab1a
57bd3bcda4
57bfb7fa4c
57c010175e
57c457cc75
57c7fc2183
57d5289a01
58045fde85
58163c37cd
582d463e5c
5851739c15
585dd0f208
587250f3c3
589e4cc1de
589f65f5d5
58a07c17d5
58adc6d8b6
58b9bcf656
58c374917e
58fc75fd42
5914c30f05
59323787d5
5937b08d69
594065ddd7
595a0ceea6
59623ec40b
597ff7ef78
598935ef05
598c2ad3b2
59a6459751
59b175e138
59bf0a149f
59d53d1649
59e3e6fae7
59fe33e560
5a13a73fe5
5a25c22770
5a4a785006
5a50640995
5a75f7a1cf
5a841e59ad
5a91c5ab6d
5ab49d9de0
5aba1057fe
5abe46ba6d
5ac7c88d0c
5aeb95cc7d
5af15e4fc3
5afe381ae4
5b07b4229d
5b1001cc4f
5b1df237d2
5b263013bf
5b27d19f0b
5b48ae16c5
5b5babc719
5baaebdf00
5bab55cdbe
5bafef6e79
5bd1f84545
5bddc3ba25
5bdf7c20d2
5bf23bc9d3
5c01f6171a
5c021681b7
5c185cff1d
5c42aba280
5c44bf8ab6
5c4c574894
5c52fa4662
5c6ea7dac3
5c74315dc2
5c7668855e
5c83e96778
5ca36173e4
5cac477371
5cb0cb1b2f
5cb0cfb98f
5cb49a19cf
5cbf7dc388
5d0e07d126
5d1e24b6e3
5d663000ff
5da6b2dc5d
5de9b90f24
5e08de0ed7
5e1011df9a
5e1ce354fd
5e35512dd7
5e418b25f9
5e4849935a
5e4ee19663
5e886ef78f
5e8d00b974
5e8d59dc31
5ed838bd5c
5edda6ee5a
5ede4d2f7a
5ede9767da
5eec4d9fe5
5eecf07824
5eef7ed4f4
5ef5860ac6
5ef6573a99
5f1193e72b
5f29ced797
5f32cf521e
5f51876986
5f6ebe94a9
5f6f14977c
5f808d0d2d
5fb8aded6a
5fba90767d
5fd1c7a3df
5fd3da9f68
5fee2570ae
5ff66140d6
5ff8b85b53
600803c0f6
600be7f53e
6024888af8
603189a03c
6057307f6e
6061ddbb65
606c86c455
60c61cc2e5
60e51ff1ae
610e38b751
61344be2f6
6135e27185
614afe7975
614e571886
614e7078db
619812a1a7
61b481a78b
61c7172650
61cf7e40d2
61d08ef5a1
61da008958
61ed178ecb
61f5d1282c
61fd977e49
621584cffe
625817a927
625892cf0b
625b89d28a
629995af95
62a0840bb5
62ad6e121c
62d6ece152
62ede7b2da
62f025e1bc
6316faaebc
63281534dc
634058dda0
6353f09384
6363c87314
636e4872e0
637681cd6b
6376d49f31
6377809ec2
63936d7de5
639bddef11
63d37e9fd3
63d90c2bae
63e544a5d6
63ebbcf874
63fff40b31
6406c72e4d
64148128be
6419386729
643092bc41
644081b88d
64453cf61d
644bad9729
6454f548fd
645913b63a
64750b825f
64a43876b7
64dd6c83e3
64e05bf46e
64f55f1478
650b0165e4
651066ed39
652b67d960
653821d680
6538d00d73
65866dce22
6589565c8c
659832db64
65ab7e1d98
65b7dda462
65bd5eb4f5
65dcf115ab
65e9825801
65f9afe51c
65ff12bcb5
666b660284
6671643f31
668364b372
66852243cb
6693a52081
669b572898
66e98e78f5
670f12e88f
674c12c92d
675c27208a
675ed3e1ca
67741db50a
678a2357eb
67b0f4d562
67cfbff9b1
67e717d6bd
67ea169a3b
67ea809e0e
681249baa3
683de643d9
6846ac20df
6848e012ef
684bcd8812
684dc1c40c
685a1fa9cf
686dafaac9
68807d8601
6893778c77
6899d2dabe
68a2fad4ab
68cb45fda3
68cc4a1970
68dcb40675
68ea4a8c3d
68f6e7fbf0
68fa8300b4
69023db81f
6908ccf557
691a111e7c
6927723ba5
692ca0e1a2
692eb57b63
69340faa52
693cbf0c9d
6942f684ad
6944fc833b
69491c0ebf
695b61a2b0
6979b4d83f
697d4fdb02
69910460a4
6997636670
69a436750b
69aebf7669
69b8c17047
69c67f109f
69e0e7b868
69ea9c09d1
69f0af42a6
6a078cdcc7
6a37a91708
6a42176f2e
6a48e4aea8
6a5977be3a
6a5de0535f
6a80d2e2e5
6a96c8815d
6a986084e2
6aa8e50445
6ab9dce449
6abf0ba6b2
6acc6049d9
6adb31756c
6ade215eb0
6afb7d50e4
6afd692f1a
6b0b1044fe
6b17c67633
6b1b6ef28b
6b1e04d00d
6b2261888d
6b25d6528a
6b3a24395c
6b685eb75b
6b79be238c
6b928b7ba6
6b9c43c25a
6ba99cc41f
6bdab62bcd
6bf2e853b1
6bf584200f
6bf95df2b9
6c0949c51c
6c11a5f11f
6c23d89189
6c4387daf5
6c4ce479a4
6c5123e4bc
6c54265f16
6c56848429
6c623fac5f
6c81b014e9
6c99ea7c31
6c9d29d509
6c9e3b7d1a
6ca006e283
6caeb928d6
6cb2ee722a
6cbfd32c5e
6cc791250b
6cccc985e0
6d12e30c48
6d4bf200ad
6d6d2b8843
6d6eea5682
6d7a3d0c21
6d7efa9b9e
6da21f5c91
6da6adabc0
6dd2827fbb
6dd36705b9
6df3637557
6dfe55e9e5
6e1a21ba55
6e2f834767
6e36e4929a
6e4f460caf
6e618d26b6
6ead4670f7
6eaff19b9f
6eb2e1cd9e
6eb30b3b5a
6eca26c202
6ecad29e52
6ef0b44654
6efcfe9275
6f4789045c
6f49f522ef
6f67d7c4c4
6f96e91d81
6fc6fce380
6fc9b44c00
6fce7f3226
6fdf1ca888
702fd8b729
70405185d2
7053e4f41e
707bf4ce41
7082544248
708535b72a
7094ac0f60
70a6b875fa
70c3e97e41
7106b020ab
711dce6fe2
7136a4453f
7143fb084f
714d902095
7151c53b32
715357be94
7163b8085f
716df1aa59
71caded286
71d2665f35
71d67b9e19
71e06dda39
720b398b9c
720e3fa04c
720e7a5f1e
721bb6f2cb
722803f4f2
72552a07c9
726243a205
72690ef572
728cda9b65
728e81c319
72a810a799
72acb8cdf6
72b01281f9
72cac683e4
72cadebbce
72cae058a5
72d8dba870
72e8d1c1ff
72edc08285
72f04f1a38
731b825695
7320b49b13
732626383b
732df1eb05
73329902ab
733798921e
733824d431
734ea0d7fb
735a7cf7b9
7367a42892
7368d5c053
73c6ae7711
73e1852735
73e4e5cc74
73eac9156b
73f8441a88
7419e2ab3f
74267f68b9
7435690c8c
747c44785c
747f1b1f2f
748b2d5c01
74d4cee0a4
74ec2b3073
74ef677020
750be4c4d8
75172d4ac8
75285a7eb1
75504539c3
7550949b1d
7551cbd537
75595b453d
7559b4b0ec
755bd1fbeb
756f76f74d
7570ca7f3c
757a69746e
757cac96c6
7584129dc3
75a058dbcd
75b09ce005
75cae39a8f
75cee6caf0
75cf58fb2c
75d5c2f32a
75eaf5669d
75f7937438
75f99bd3b3
75fa586876
7613df1f84
762e1b3487
76379a3e69
764271f0f3
764503c499
7660005554
7666351b84
76693db153
767856368b
768671f652
768802b80d
76962c7ed2
76a75f4eee
76b90809f7
770a441457
772a0fa402
772f2ffc3e
774f6c2175
77610860e0
777e58ff3d
77920f1708
7799df28e7
779e847a9a
77ba4edc72
77c834dc43
77d8aa8691
77e7f38f4d
77eea6845e
7806308f33
78254660ea
7828af8bff
784398620a
784d201b12
78613981ed
78896c6baf
78aff3ebc0
78c7c03716
78d3676361
78e29dd4c3
78f1a1a54f
79208585cd
792218456c
7923bad550
794e6fc49f
796e6762ce
797cd21f71
79921b21c2
79a5778027
79bc006280
79bf95e624
79d9e00c55
79e20fc008
79e9db913e
79f014085e
79fcbb433a
7a13a5dfaa
7a14bc9a36
7a3c535f70
7a446a51e9
7a56e759c5
7a5f46198d
7a626ec98d
7a802264c4
7a8b5456ca
7abdff3086
7aecf9f7ac
7b0fd09c28
7b18b3db87
7b39fe7371
7b49e03d4c
7b5388c9f1
7b5cf7837f
7b733d31d8
7b74fd7b98
7b918ccb8a
7ba3ce3485
7bb0abc031
7bb5bb25cd
7bb7dac673
7bc7761b8c
7bf3820566
7c03a18ec1
7c078f211b
7c37d7991a
7c4ec17eff
7c649c2aaf
7c73340ab7
7c78a2266d
7c88ce3c5b
7ca6843a72
7cc9258dee
7cec7296ae
7d0ffa68a4
7d11b4450f
7d1333fcbe
7d18074fef
7d18c8c716
7d508fb027
7d55f791f0
7d74e3c2f6
7d783f67a9
7d83a5d854
7dd409947e
7de45f75e5
7e0cd25696
7e1922575c
7e1e3bbcc1
7e24023274
7e2f212fd3
7e6d1cc1f4
7e7cdcb284
7e9b6bef69
7ea5b49283
7eb2605d96
7eb26b8485
7ecd1f0c69
7f02b3cfe2
7f1723f0d5
7f21063c3a
7f3658460e
7f54132e48
7f559f9d4a
7f5faedf8b
7f838baf2b
7fa5f527e3
7ff84d66dd
802b45c8c4
804382b1ad
804c558adb
804f6338a4
8056117b89
806b6223ab
8088bda461
80b790703b
80c4a94706
80ce2e351b
80db581acd
80e12193df
80e41b608f
80f16b016d
81541b3725
8175486e6a
8179095000
8193671178
81a58d2c6b
81aa1286fb
81dffd30fb
8200245704
823e7a86e8
824973babb
824ca5538f
827171a845
8273a03530
827cf4f886
82b865c7dd
82c1517708
82d15514d6
82e117b900
82fec06574
832b5ef379
83424c9fbf
8345358fb8
834b50b31b
835e3b67d7
836ea92b15
837c618777
838eb3bd89
839381063f
839bc71489
83a8151377
83ae88d217
83ca8bcad0
83ce590d7f
83d3130ba0
83d40bcba5
83daba503a
83de906ec0
84044f37f3
84696b5a5e
84752191a3
847eeeb2e0
848e7835a0
84a4b29286
84a4bf147d
84be115c09
84d95c4350
84e0922cf7
84f0cfc665
8515f6db22
851f2f32c1
852a4d6067
854c48b02a
857a387c86
859633d56a
85a4f4a639
85ab85510c
85b1eda0d9
85dc1041c6
85e081f3c7
85f75187ad
8604bb2b75
860745b042
863b4049d7
8643de22d0
8647d06439
864ffce4fe
8662d9441a
8666521b13
868d6a0685
869fa45998
86a40b655d
86a8ae4223
86b2180703
86c85d27df
86d3755680
86e61829a1
871015806c
871e409c5c
8744b861ce
8749369ba0
878a299541
8792c193a0
8799ab0118
87d1f7d741
882b9e4500
885673ea17
8859dedf41
8873ab2806
887a93b198
8883e991a9
8891aa6dfa
8899d8cbcd
88b8274d67
88d3b80af6
88ede83da2
88f345941b
890976d6da
8909bde9ab
8929c7d5d9
89363acf76
89379487e0
8939db6354
893f658345
8953138465
895c96d671
895cbf96f9
895e8b29a7
898fa256c8
89986c60be
89b874547b
89bdb021d5
89c802ff9c
89d6336c2b
89ebb27334
8a27e2407c
8a31f7bca5
8a4a2fc105
8a5d6c619c
8a75ad7924
8aa817e4ed
8aad0591eb
8aca214360
8ae168c71b
8b0cfbab97
8b3645d826
8b3805dbd4
8b473f0f5d
8b4f6d1186
8b4fb018b7
8b518ee936
8b523bdfd6
8b52fb5fba
8b91036e5c
8b99a77ac5
8ba04b1e7b
8ba782192f
8bbeaad78b
8bd1b45776
8bd7a2dda6
8bdb091ccf
8be56f165d
8be950d00f
8bf84e7d45
8bffc4374b
8bfff50747
8c09867481
8c0a3251c3
8c3015cccb
8c469815cf
8c9ccfedc7
8ca1af9f3c
8ca3f6e6c1
8ca6a4f60f
8cac6900fe
8cba221a1e
8cbbe62ccd
8d064b29e2
8d167e7c08
8d4ab94e1c
8d81f6f899
8d87897d66
8dcccd2bd2
8dcfb878a8
8dd3ab71b9
8dda6bf10f
8ddd51ca94
8dea22c533
8def5bd3bf
8e1848197c
8e3a83cf2d
8e478e73f3
8e98ae3c84
8ea6687ab0
8eb0d315c1
8ec10891f9
8ec3065ec2
8ecf51a971
8eddbab9f7
8ee198467a
8ee2368f40
8ef595ce82
8f0a653ad7
8f1204a732
8f1600f7f6
8f16366707
8f1ce0a411
8f2e05e814
8f320d0e09
8f3b4a84ad
8f3fdad3da
8f5d3622d8
8f62a2c633
8f81c9405a
8f8c974d53
8f918598b6
8ff61619f6
9002761b41
90107941f3
90118a42ee
902bc16b37
903e87e0d6
9041a0f489
9047bf3222
9057bfa502
90617b0954
9076f4b6db
9077e69b08
909655b4a6
909c2eca88
909dbd1b76
90bc4a319a
90c7a87887
90cc785ddd
90d300f09b
9101ea9b1b
9108130458
911ac9979b
9151cad9b5
9153762797
91634ee0c9
916942666f
9198cfb4ea
919ac864d6
91b67d58d4
91bb8df281
91be106477
91c33b4290
91ca7dd9f3
91d095f869
91f107082e
920329dd5e
920c959958
92128fbf4b
9223dacb40
923137bb7f
9268e1f88a
927647fe08
9276f5ba47
92a28cd233
92b5c1fc6d
92c46be756
92dabbe3a0
92e3159361
92ebab216a
934bdc2893
9359174efc
935d97dd2f
935feaba1b
93901858ee
939378f6d6
939bdf742e
93a22bee7e
93da9aeddf
93e2feacce
93e6f1fdf9
93e811e393
93e85d8fd3
93f623d716
93ff35e801
94031f12f2
94091a4873
94125907e3
9418653742
941c870569
94209c86f0
9437c715eb
9445c3eca2
9467c8617c
946d71fb5d
948f3ae6fb
9498baa359
94a33abeab
94bf1af5e3
94cf3a8025
94db712ac8
94e4b66cff
94e76cbaf6
950be91db1
952058e2d0
952633c37f
952ec313fe
9533fc037c
9574b81269
9579b73761
957f7bc48b
958073d2b0
9582e0eb33
9584092d0b
95b58b8004
95bd88da55
95f74a9959
962781c601
962f045bf5
964ad23b44
967b90590e
967bffe201
96825c4714
968492136a
9684ef9d64
968c41829e
96a856ef9a
96dfc49961
96e1a5b4f8
96e6ff0917
96fb88e9d7
96fbe5fc23
96fc924050
9715cc83dc
9720eff40f
972c187c0d
97476eb38d
97659ed431
9773492949
97756b264f
977bff0d10
97ab569ff3
97ba838008
97d9d008c7
97e59f09fa
97eb642e56
98043e2d14
981ff580cf
983e66cbfc
984f0f1c36
98595f2bb4
985c3be474
9869a12362
986b5a5e18
9877af5063
98911292da
9893a3cf77
9893d9202d
98a8b06e7f
98ac6f93d9
98b6974d12
98ba3c9417
98c7c00a19
98d044f206
98e909f9d1
98fe7f0410
990f2742c7
992bd0779a
994b9b47ba
9955b76bf5
9966f3adac
997117a654
999d53d841
99c04108d3
99c4277aee
99c6b1acf2
99dc8bb20b
99fcba71e5
99fecd4efb
9a02c70ba2
9a08e7a6f8
9a2f2c0f86
9a3254a76e
9a3570a020
9a39112493
9a4e9fd399
9a50af4bfb
9a68631d24
9a72318dbf
9a767493b7
9a7fc1548b
9a84ccf6a7
9a9c0e15b7
9adf06d89b
9b22b54ee4
9b473fc8fe
9b4f081782
9b997664ba
9bc454e109
9bccfd04de
9bce4583a2
9bebf1b87f
9bfc50d261
9c166c86ff
9c293ef4d7
9c29c047b0
9c3bc2e2a7
9c3ce23bd1
9c404cac0c
9c5180d23a
9c7feca6e4
9caa49d3ff
9cb2f1b646
9ce6f765c3
9cfee34031
9d01f08ec6
9d04c280b8
9d12ceaddc
9d15f8cb3c
9d2101e9bf
9d407c3aeb
9ddefc6165
9df0b1e298
9e16f115d8
9e249b4982
9e29b1982c
9e493e4773
9e4c752cd0
9e4de40671
9e6319faeb
9e6ddbb52d
9eadcea74f
9ecec5f8ea
9efb47b595
9f30bfe61e
9f3734c3a4
9f5b858101
9f66640cda
9f913803e9
9f97bc74c8
9fbad86e20
9fc2bad316
9fc5c3af78
9fcb310255
9fcc256871
9fd2fd4d47
a0071ae316
a023141022
a046399a74
a066e739c1
a06722ba82
a07a15dd64
a07b47f694
a09c39472e
a0b208fe2e
a0b61c959e
a0bc6c611d
a0e6da5ba2
a1193d6490
a14ef483ff
a14f709908
a15ccc5658
a16062456f
a174e8d989
a177c2733c
a17c62e764
a18ad065fc
a1aaf63216
a1bb65fb91
a1bd8e5349
a1dfdd0cac
a2052e4f6c
a20fd34693
a21ffe4d81
a22349e647
a235d01ec1
a24f63e8a2
a2554c9f6d
a263ce8a87
a29bfc29ec
a2a80072d4
a2a800ab63
a2bcd10a33
a2bdaff3b0
a2c146ab0d
a2c996e429
a2dc51ebe8
a2e6608bfa
a2f2a55f01
a301869dea
a31fccd2cc
a34f440f33
a35e0206da
a36bdc4cab
a36e8c79d8
a378053b20
a37db3a2b3
a38950ebc2
a39a0eb433
a39c9bca52
a3a945dc8c
a3b40a0c1e
a3b8588550
a3c502bec3
a3f2878017
a3f4d58010
a3f51855c3
a402dc0dfe
a4065a7eda
a412bb2fef
a416b56b53
a41ec95906
a43299e362
a4757bd7af
a48c53c454
a49dcf9ad5
a4a506521f
a4ba7753d9
a4bac06849
a4f05d681c
a50c10060f
a50eb5a0ea
a5122c6ec6
a522b1aa79
a590915345
a5b5b59139
a5b77abe43
a5c2b2c3e1
a5cd17bb11
a5da03aef1
a5dd11de0d
a5ea2b93b6
a5eaeac80b
a5ec5b0265
a5f350a87e
a5f472caf4
a6027a53cf
a61715bb1b
a61cf4389d
a61d9bbd9b
a6470dbbf5
a64a40f3eb
a653d5c23b
a65bd23cb5
a66e0b7ad4
a66fc5053c
a68259572b
a6a810a92c
a6bc36937f
a6c3a374e9
a6d8a4228d
a6f4e0817f
a71e0481f5
a7203deb2d
a7392d4438
a73d3c3902
a7491f1578
a74b9ca19c
a77b7a91df
a78195a5f5
a78758d4ce
a7e6d6c29a
a800d85e88
a832fa8790
a83d06410d
a8999af004
a8f78125b9
a907b18df1
a919392446
a965504e88
a96b84b8d2
a973f239cd
a977126596
a9804f2a08
a984e56893
a99738f24c
a99bdd0079
a9c9c1517e
a9cbf9c41b
a9e42e3c0c
aa07b7c1c0
aa175e5ec7
aa1a338630
aa27d7b868
aa45f1caaf
aa49e46432
aa51934e1b
aa6287bb6c
aa6d999971
aa85278334
aab33f0e2a
aaba004362
aade4cf385
aae78feda4
aaed233bf3
aaff16c2db
ab199e8dfb
ab23b78715
ab2e1b5577
ab33a18ded
ab45078265
ab56201494
ab90f0d24b
abab2e6c20
abb50c8697
abbe2d15a0
abbe73cd21
abe61a11bb
abeae8ce21
ac2b431d5f
ac2cb1b9eb
ac31fcd6d0
ac3d3a126d
ac46bd8087
ac783ef388
acb73e4297
acbf581760
accafc3531
acf2c4b745
acf44293a2
acf736a27b
acff336758
ad1fe56886
ad28f9b9d9
ad2de9f80e
ad397527b2
ad3d1cfbcb
ad3fada9d9
ad4108ee8e
ad54468654
ad573f7d31
ad6255bc29
ad65ebaa07
ad97cc064a
adabbd1cc4
adb0b5a270
adc648f890
add21ee467
adfd15ceef
adfdd52eac
ae01cdab63
ae0b50ff4f
ae13ee3d70
ae1bcbd423
ae20d09dea
ae2cecf5f6
ae3bc4a0ef
ae499c7514
ae628f2cd4
ae8545d581
ae93214fe6
ae9cd16dbf
aeba9ac967
aebb242b5c
aed4e0b4c4
aedd71f125
aef3e2cb0e
af0b54cee3
af3de54c7a
af5fd24a36
af8826d084
af8ad72057
afb71e22c5
afcb331e1f
afe1a35c1e
b01080b5d3
b05ad0d345
b0623a6232
b064dbd4b7
b06ed37831
b06f5888e6
b08dcc490e
b0a68228dc
b0aece727f
b0b0731606
b0c7f11f9f
b0cca8b830
b0dd580a89
b0de66ca08
b0df7c5c5c
b0f5295608
b11099eb09
b132a53086
b1399fac64
b13abc0c69
b1457e3b5e
b15bf4453b
b179c4a82d
b17ee70e8c
b190b1aa65
b19b3e22c0
b19c561fab
b1d1cd2e6e
b1d7c03927
b1d7fe2753
b1f540a4bd
b1fc9c64e1
b1fcbb3ced
b220939e93
b22099b419
b241e95235
b2432ae86d
b2456267df
b247940d01
b24af1c35c
b24f600420
b24fe36b2a
b258fb0b7d
b26b219919
b26d9904de
b274456ce1
b27b28d581
b2a26bc912
b2a9c51e1b
b2b0baf470
b2b2756fe7
b2ce7699e3
b2edc76bd2
b2f6b52100
b30bf47bcd
b34105a4e9
b372a82edf
b3779a1962
b379ab4ff5
b37a1d69e3
b37c01396e
b382b09e25
b3996e4ba5
b3d9ca2aee
b3dde1e1e9
b3eb7f05eb
b40b25055c
b41e0f1f19
b44e32a42b
b4805ae9cd
b4807569a5
b48efceb3e
b493c25c7f
b4b565aba1
b4b715a15b
b4d0c90bf4
b4d84bc371
b4e5ad97aa
b4eaea9e6b
b50f4b90d5
b53f675641
b54278cd43
b554843889
b573c0677a
b58d853734
b5943b18ab
b5a09a83f3
b5aae1fe25
b5b9da5364
b5eb64d419
b5ebb1d000
b5f1c0c96a
b5f7fece90
b6070de1bb
b60a76fe73
b61f998772
b62c943664
b63094ba0c
b64fca8100
b673e7dcfb
b678b7db00
b68fc1b217
b69926d9fa
b6a1df3764
b6a4859528
b6b4738b78
b6b4f847b7
b6b8d502d4
b6bb00e366
b6d65a9eef
b6d79a0845
b6e9ec577f
b6ec609f7b
b6f92a308d
b70a2c0ab1
b70a5a0d50
b70c052f2f
b70d231781
b72ac6e10b
b7302d8226
b73867d769
b751e767f2
b76df6e059
b77e5eddef
b7a2c2c83c
b7bcbe6466
b7c2a469c4
b7d69da8f0
b7f31b7c36
b7f675fb98
b7fb871660
b82e5ad1c9
b841cfb932
b84b8ae665
b85b78ac2b
b86c17caa6
b86e50d82d
b871db031a
b87d56925a
b8aaa59b75
b8c03d1091
b8c3210036
b8e16df00b
b8f34cf72e
b8fb75864e
b9004db86c
b9166cbae9
b920b256a6
b938d79dff
b93963f214
b941aef1a0
b94d34d14e
b964c57da4
b96a95bc7a
b96c57d2c7
b9b6bdde0c
b9bcb3e0f2
b9d3b92169
b9dd4b306c
b9f43ef41e
ba1f03c811
ba3a775d7b
ba3c7f2a31
ba3fcd417d
ba5e1f4faa
ba795f3089
ba8a291e6a
ba98512f97
bac9db04f5
baedae3442
baff40d29d
bb04e28695
bb1b0ee89f
bb1c770fe7
bb1fc34f99
bb2d220506
bb334e5cdb
bb337f9830
bb721eb9aa
bb87ff58bd
bb89a6b18a
bbaa9a036a
bbb4302dda
bbd31510cf
bbe0256a75
bc141b9ad5
bc17ab8a99
bc318160de
bc3b9ee033
bc4240b43c
bc4ce49105
bc4f71372d
bc6b8d6371
bcaad44ad7
bcc241b081
bcc5d8095e
bcd1d39afb
bd0d849da4
bd0e9ed437
bd2c94730f
bd321d2be6
bd3ec46511
bd5b2e2848
bd7e02b139
bd96f9943a
bda224cb25
bda4a82837
bdb74e333f
bdccd69dde
bddcc15521
be116aab29
be15e18f1e
be1a284edb
be2a367a7b
be376082d0
be3e3cffbd
be5d1d89a0
be8b72fe37
be9b29e08e
bea1f6e62c
bea83281b5
beb921a4c9
bec5e9edcd
beeb8a3f92
bf2232b58d
bf28751739
bf443804e8
bf461df850
bf5374f122
bf551a6f60
bf8d0f5ada
bf961167a6
bfab1ad8f9
bfcb05d88d
bfd8f6e6c9
bfd91d0742
bfe262322f
c013f42ed7
c01878083f
c01faff1ed
c046fd0edb
c053e35f97
c079a6482d
c0847b521a
c0a1e06710
c0e8d4635c
c0e973ad85
c0f49c6579
c0f5b222d7
c10d07c90d
c1268d998c
c130c3fc0c
c14826ad5e
c15b922281
c16f09cb63
c18e19d922
c1c830a735
c1e8aeea45
c20a5ccc99
c20fd5e597
c219d6f8dc
c2406ae462
c26f7b5824
c279e641ee
c27adaeac5
c2a35c1cda
c2a9903b8b
c2b62567c1
c2b974ec8c
c2baaff7bf
c2be6900f2
c304dd44d5
c307f33da2
c30a7b62c9
c3128733ee
c31fa6c598
c325c8201e
c32d4aa5d1
c33f28249a
c34365e2d7
c3457af795
c34d120a88
c3509e728d
c35e4fa6c4
c36240d96f
c3641dfc5a
c37b17a4a9
c39559ddf6
c3b0c6e180
c3b3d82e6c
c3be369fdb
c3bf1e40c2
c3c760b015
c3dd38bf98
c3e4274614
c3edc48cbd
c41e6587f5
c4272227b0
c42917fe82
c438858117
c44676563f
c44beb7472
c45411dacb
c4571bedc8
c46deb2956
c479ee052e
c47d551843
c49f07d46d
c4cc40c1fc
c4f256f5d5
c4f5b1ddcc
c4ff9b4885
c52bce43db
c544da6854
c55784c766
c557b69fbf
c593a3f7ab
c598faa682
c5ab1f09c8
c5b6da8602
c5b9128d94
c5e845c6b7
c5fba7b341
c60897f093
c61fe6ed7c
c62188c536
c64035b2e2
c69689f177
c6a12c131f
c6bb6d2d5c
c6c18e860f
c6d9526e0d
c6e55c33f0
c7030b28bd
c70682c7cc
c70f9be8c5
c71f30d7b6
c73c8e747f
c760eeb8b3
c7637cab0a
c7a1a17308
c7bf937af5
c7c2860db3
c7cef4aee2
c7ebfc5d57
c813dcf13c
c82235a49a
c82a7619a1
c82ecb90cb
c844f03dc7
c8557963f3
c89147e6e8
c8a46ff0c8
c8ab107dd5
c8b869a04a
c8c7b306a6
c8c8b28781
c8d79e3163
c8edab0415
c8f494f416
c8f6cba9fd
c909ceea97
c9188f4980
c922365dd4
c92c8c3c75
c937eb0b83
c94b31b5e5
c95cd17749
c96379c03c
c96465ee65
c965afa713
c9734b451f
c9862d82dc
c98b6fe013
c9999b7c48
c99e92aaf0
c9b3a8fbda
c9bf64e965
c9c3cb3797
c9d1c60cd0
c9de9c22c4
ca1828fa54
ca346f17eb
ca3787d3d3
ca4b99cbac
ca91c69e3b
ca91e99105
caa8e97f81
caac5807f8
cabba242c2
cad5a656a9
cad673e375
cad8a85930
cae7b0a02b
cae7ef3184
caeb6b6cbb
caecf0a5db
cb15312003
cb2e35d610
cb35a87504
cb3f22b0cf
cbb410da64
cc8728052e
cc892997b8
cce03c2a9b
cd47a23e31
cd4dc03dc0
cd5ae611da
cd603bb9d1
cd8f49734c
cdc6b1c032
cdcfe008ad
cdd57027c2
ce1af99b4b
ce1bc5743a
ce25872021
ce2776f78f
ce49b1f474
ce4f0a266f
ce5641b195
ce6866aa19
ce712ed3c9
ce7d1c8117
ce7dbeaa88
ce9b015a5e
cea7697b25
cebbd826cf
cec3415361
cec41ad4f4
ced49d26df
ced7705ab2
cef824a1e1
cf13f5c95a
cf4376a52d
cf85ab28b5
cfc2e50b9d
cfcd571fff
cfd9d4ae47
cfda2dcce5
cff035928b
cff8191891
d01608c2a5
d01a8f1f83
d021d68bca
d04258ca14
d0483573dc
d04a90aaff
d05279c0bd
d0696bd5fc
d072fda75b
d0a83bcd9f
d0ab39112e
d0acde820f
d0b4442c71
d0c65e9e95
d0fb600c73
d107a1457c
d123d674c1
d14d1e9289
d154e3388e
d177e9878a
d1802f69f8
d182c4483a
d195d31128
d200838929
d205e3cff5
d247420c4c
d2484bff33
d26f6ed9b0
d280fcd1cb
d2857f0faa
d292a50c7f
d295ea2dc7
d2a58b4fa6
d2b026739a
d2ebe0890f
d2ede5d862
d301ca58cc
d3069da8bb
d343d4a77d
d355e634ef
d367fb5253
d36d16358e
d38bc77e2c
d38d1679e2
d3932ad4bd
d3987b2930
d39934abe3
d3ae1c3f4c
d3b088e593
d3e6e05e16
d3eefae7c5
d3f55f5ab8
d3f5c309cc
d4034a7fdf
d4193011f3
d429c67630
d42c0ff975
d44a764409
d44e6acd1d
d45158c175
d454e8444f
d45f62717e
d48ebdcf74
d49ab52a25
d4a607ad81
d4b063c7db
d4da13e9ba
d4dd1a7d00
d4f4f7c9c3
d521aba02e
d535bb1b97
d53b955f78
d55cb7a205
d55f247a45
d5695544d8
d5853d9b8b
d5b6c6d94a
d5cae12834
d5df027f0c
d5ee40e5d0
d600046f73
d632fd3510
d6476cad55
d65a7bae86
d664c89912
d689658f06
d6917db4be
d69967143e
d699d3d798
d69f757a3f
d6ac0e065c
d6c02bfda5
d6c1b5749e
d6e12ef6cc
d6eed152c4
d6faaaf726
d704766646
d708e1350c
d7135cf104
d7157a9f44
d719cf9316
d724134cfd
d73a60a244
d7411662da
d74875ea7c
d756f5a694
d7572b7d8a
d763bd6d96
d7697c8b13
d7797196b4
d79c834768
d7b34e5d73
d7bb6b37a7
d7c7e064a6
d7fbf545b3
d82a0aa15b
d847e24abd
d8596701b7
d86101499c
d87069ba86
d87160957b
d874654b52
d88a403092
d8aee40f3f
d8e77a222d
d8eb07c381
d9010348a1
d90e3cf281
d92532c7b2
d927fae122
d95707bca8
d973b31c00
d991cb471d
d992c69d37
d99d770820
d9b63abc11
d9db6f1983
d9e52be2d2
d9edc82650
da01070697
da070ea4b7
da080507b9
da0e944cc4
da28d94ff4
da5d78b9d1
da6003fc72
da690fee9f
da6c68708f
da7a816676
dac361e828
dac71659b8
dad980385d
daebc12b77
db0968cdd3
db231a7100
db59282ace
db7f267c3f
dba35b87fd
dbba735a50
dbca076acd
dbd66dc3ac
dbdc3c292b
dbf4a5b32b
dbfc417d28
dc1745e0a2
dc32a44804
dc34b35e30
dc504a4f79
dc704dd647
dc71bc6918
dc7771b3be
dcf8c93617
dd0f4c9fb9
dd415df125
dd601f9a3f
dd61d903df
dd77583736
dd8636bd8b
dd9fe6c6ac
ddb2da4c14
ddcd450d47
dde8e67fb4
ddfc3f04d3
de2ab79dfa
de2f35b2fd
de30990a51
de36b216da
de37403340
de46e4943b
de4ddbccb1
de5e480f05
de6a9382ca
de74a601d3
de827c510d
ded6069f7b
defb71c741
df01f277f1
df05214b82
df0638b0a0
df11931ffe
df1b0e4620
df20a8650d
df2bc56d7c
df365282c6
df39a0d9df
df3c430c24
df5536cfb9
df59cfd91d
df5e2152b3
df741313c9
df7626172f
df8ad5deb9
df96aa609a
df9705605c
df9c91c4da
dfc0d3d27a
dfdbf91a99
e00baaae9b
e0a938c6e7
e0b2ceee6f
e0bdb5dfae
e0be1f6e17
e0c478f775
e0de82caa7
e0f217dd59
e0f7208874
e0fb58395e
e1194c2e9d
e11adcd05d
e128124b9d
e1495354e4
e1561d6d4b
e158805399
e16945b951
e19edcd34b
e1a1544285
e1ab7957f4
e1d26d35be
e1e957085b
e1f14510fa
e214b160f4
e2167379b8
e21acb20ab
e221105579
e22ddf8a1b
e22de45950
e22ffc469b
e23cca5244
e252f46f0b
e25fa6cf39
e26e486026
e275760245
e27bbedbfe
e29e9868a8
e2b37ff8af
e2b608d309
e2bef4da9a
e2c87a6421
e2ea25542c
e2fb1d6497
e2fcc99117
e33c18412a
e348377191
e352cb59c8
e36ac982f0
e391bc981e
e39e3e0a06
e3bf38265f
e3d5b2cd21
e3d60e82d5
e3e3245492
e3e4134877
e3f4635e03
e4004ee048
e402d1afa5
e415093d27
e41ceb5d81
e424653b78
e42b6d3dbb
e42d60f0d4
e436d0ff1e
e43d7ae2c5
e4428801bc
e44e0b4917
e470345ede
e48e8b4263
e4922e3726
e4936852bb
e495f32c60
e499228f26
e4af66e163
e4b2095f58
e4d19c8283
e4d4872dab
e4e2983570
e4eaa63aab
e4ef0a3a34
e4f8e5f46e
e4ffb6d0dd
e53e21aa02
e57f4f668b
e588433c1e
e597442c99
e5abc0e96b
e5be628030
e5ce96a55d
e5d6b70a9f
e5fde1574c
e625e1d27b
e6261d2348
e6267d46bc
e6295f223f
e63463d8c6
e6387bd1e0
e653883384
e65f134e0b
e668ef5664
e672ccd250
e674510b20
e676107765
e699da0cdf
e6be243065
e6deab5e0b
e6f065f2b9
e71629e7b5
e72a7d7b0b
e72f6104e1
e75a466eea
e76c55933f
e7784ec8ad
e78922e5e6
e78d450a9c
e7c6354e77
e7c8de1fce
e7ea10db28
e803918710
e8073a140b
e828dd02db
e845994987
e8485a2615
e85c5118a7
e88b6736e4
e8962324e3
e8b3018d36
e8cee8bf0b
e8d97ebece
e8da49ea6a
e8ed1a3ccf
e8f7904326
e8f8341dec
e8fa21eb13
e90c10fc4c
e914b8cac8
e92b6bfea4
e92e1b7623
e93f83e512
e9422ad240
e9460b55f9
e9502628f6
e950befd5f
e9582bdd1b
e95e5afe0f
e97cfac475
e98d57d99c
e98eda8978
e99706b555
e9bc0760ba
e9d3c78bf3
e9ec1b7ea8
ea065cc205
ea138b6617
ea16d3fd48
ea2545d64b
ea286a581c
ea320da917
ea345f3627
ea3b94a591
ea444a37eb
ea4a01216b
ea5672ffa8
eaa99191cb
eaab4d746c
eac7a59bc1
ead5d3835a
eaec65cfa7
eaed1a87be
eb2f821c6f
eb383cb82e
eb6992fe02
eb6ac20a01
eb6d7ab39e
eb7921facd
eb8fce51a6
ebbb90e9f9
ebbf5c9ee1
ebc4ec32e6
ebe56e5ef8
ec1299aee4
ec139ff675
ec193e1a01
ec28252938
ec387be051
ec3d4fac00
ec4186ce12
ec579c2f96
ecae59b782
ecb33a0448
ece6bc9e92
ecfedd4035
ecfff22fd6
ed3291c3d6
ed3cd5308d
ed3e6fc1a5
ed72ae8825
ed7455da68
ed844e879f
ed8f814b2b
ed911a1f63
ed9ff4f649
eda8ab984b
edb8878849
edbfdfe1b4
edd22c46a2
edd663afa3
ede3552eae
edeab61ee0
ee07583fc0
ee316eaed6
ee3f509537
ee40a1e491
ee4bf100f1
ee6f9b01f9
ee947ed771
ee9706ac7f
ee9a7840ae
eeb90cb569
eebf45e5c5
eeed0c7d73
ef0061a309
ef07f1a655
ef0a8e8f35
ef232a2aed
ef308ad2e9
ef44945428
ef45ce3035
ef5dde449d
ef5e770988
ef6359cea3
ef65268834
ef6cb5eae0
ef78972bc2
ef8cfcfc4f
ef96501dd0
ef9a2e976b
efb24f950f
efce0c1868
efe5ac6901
efe828affa
efea4e0523
f0268aa627
f0483250c8
f04cf99ee6
f05b189097
f08928c6d3
f09d74856f
f0a7607d63
f0ad38da27
f0c34e1213
f0c7f86c29
f0dfa18ba7
f0eb3179f7
f119bab27d
f14409b6a3
f1489baff4
f14c18cf6a
f15c607b92
f1af214222
f1b77bd309
f1ba9e1a3e
f1d99239eb
f1dc710cf4
f1ec5c08fa
f22648fe12
f22d21f1f1
f233257395
f23e95dbe5
f2445b1572
f253b3486d
f277c7a6a4
f2ab2b84d6
f2b7c9b1f3
f2b83d5ce5
f2c276018f
f2cfd94d64
f2dd6e3add
f2e7653f16
f2f333ad06
f2f55d6713
f2fdb6abec
f305a56d9f
f3085d6570
f3325c3338
f3400f1204
f34497c932
f34a56525e
f36483c824
f3704d5663
f3734c4913
f38e5aa5b4
f3986fba44
f3a0ffc7d9
f3b24a7d28
f3e6c35ec3
f3fc0ea80b
f40a683fbe
f4207ca554
f4377499c2
f46184f393
f46c2d0a6d
f46c364dca
f46f7a0b63
f46fe141b0
f470b9aeb0
f47eb7437f
f48b535719
f49e4866ac
f4aa882cfd
f4daa3dbd5
f4dd51ac35
f507a1b9dc
f51c5ac84b
f52104164b
f54c67b9bb
f5966cadd2
f5bddf5598
f5d85cfd17
f5e2e7d6a0
f5f051e9b4
f5f8a93a76
f6283e8af5
f635e9568b
f6474735be
f659251be2
f66981af4e
f6708fa398
f697fe8e8f
f6adb12c42
f6c7906ca4
f6cd0a8016
f6d6f15ae7
f6e501892c
f6f59d986f
f6fe8c90a5
f714160545
f74c3888d7
f7782c430e
f7783ae5f2
f77ab47923
f788a98327
f7961ac1f0
f7a71e7574
f7a8521432
f7afbf4947
f7b7cd5f44
f7cf4b4a39
f7d49799ad
f7e0c9bb83
f7e5b84928
f7e6bd58be
f7f2a38ac6
f7f6cb2d6d
f83f19e796
f85796a921
f8603c26b2
f8819b42ec
f891f8eaa1
f89288d10c
f895ae8cc1
f8b4ac12f1
f8c3fb2b01
f8c8de2764
f8db369b40
f8fcb6a78c
f94aafdeef
f95d217b70
f9681d5103
f9750192a4
f9823a32c2
f991ddb4c2
f99d535567
f9ae3d98b7
f9b6217959
f9bd1fabf5
f9c68eaa64
f9d3e04c4f
f9daf64494
f9e4cc5a0a
f9ea6b7f31
f9f3852526
fa04c615cf
fa08e00a56
fa4370d74d
fa67744af3
fa88d48a92
fa8b904cc9
fa9526bdf1
fa9b9d2426
fad633fbe1
faf5222dc3
faff0e15f1
fb08c64e8c
fb23455a7f
fb2e19fa6e
fb34dfbb77
fb47fcea1e
fb49738155
fb4cbc514b
fb4e6062f7
fb5ba7ad6e
fb63cd1236
fb81157a07
fb92abdaeb
fba22a6848
fbaca0c9df
fbc645f602
fbd77444cd
fbe53dc8e8
fbe541dd73
fbe8488798
fbfd25174f
fc28cb305e
fc33b1ffd6
fc6186f0bb
fc918e3a40
fc96cda9d8
fc9832eea4
fcb10d0f81
fcd20a2509
fcf637e3ab
fcfd81727f
fd31890379
fd33551c28
fd542da05e
fd6789b3fe
fd77828200
fd7af75f4d
fdb28d0fbb
fdb3d1fb1e
fdb8b04124
fdc6e3d581
fdfce7e6fc
fe0f76d41b
fe24b0677d
fe3c02699d
fe58b48235
fe6a5596b8
fe6c244f63
fe7afec086
fe985d510a
fe9db35d15
fea8ffcd36
feb1080388
fed208bfca
feda5ad1c2
feec95b386
ff15a5eff6
ff204daf4b
ff25f55852
ff2ada194f
ff2ce142e8
ff49d36d20
ff5a1ec4f3
ff66152b25
ff692fdc56
ff773b1a1e
ff97129478
ffb904207d
ffc43fc345
fffe5f8df6
================================================
FILE: merge_lora_weights_and_save_hf_model.py
================================================
import argparse
import glob
import os
import sys
import cv2
import numpy as np
import torch
import torch.nn.functional as F
import transformers
from peft import LoraConfig, get_peft_model
from transformers import AutoTokenizer
from model.VISA import VISAForCausalLM
from utils.utils import DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN
"""
python merge_lora_weights_and_save_hf_model.py \
--version /mnt/nlp-ali/usr/yancilin/clyan-data-2/video-llm/Chat-UniVi/Chat-UniVi \
--weight /mnt/public03/dataset/ovis/rgvos/visa7b/ckpt_model/pytorch_model15000.bin \
--save_path /mnt/public03/dataset/ovis/rgvos/visa7b/ckpt_model/hf_model
"""
def parse_args(args):
parser = argparse.ArgumentParser(
description="merge lora weights and save model with hf format"
)
parser.add_argument(
"--version", default="Chat-UniVi/Chat-UniVi", type=str, required=True
)
parser.add_argument(
"--weight", default="/path/to/visa/pytorch_model.bin", type=str, required=True
)
parser.add_argument(
"--save_path", default="/path/to/hf_model", type=str, required=True
)
parser.add_argument("--precision", default="bf16", type=str, choices=["fp32", "bf16", "fp16"], help="precision for inference", )
parser.add_argument("--vision_pretrained", default="PATH_TO_SAM_ViT-H", type=str)
parser.add_argument("--out_dim", default=256, type=int)
parser.add_argument("--image_size", default=1024, type=int, help="image size")
parser.add_argument("--model_max_length", default=512, type=int)
parser.add_argument("--vision-tower", default="openai/clip-vit-large-patch14", type=str, )
parser.add_argument("--lora_r", default=8, type=int)
parser.add_argument("--lora_alpha", default=16, type=int)
parser.add_argument("--lora_dropout", default=0.05, type=float)
parser.add_argument("--lora_target_modules", default="q_proj,v_proj", type=str)
parser.add_argument("--local-rank", default=0, type=int, help="node rank")
parser.add_argument("--train_mask_decoder", action="store_true", default=True)
parser.add_argument("--use_mm_start_end", action="store_true", default=False)
parser.add_argument("--conv_type", default="llava_v1", type=str, choices=["llava_v1", "llava_llama_2"], )
return parser.parse_args(args)
def main(args):
args = parse_args(args)
# Create model
tokenizer = transformers.AutoTokenizer.from_pretrained(
args.version,
cache_dir = None,
model_max_length = args.model_max_length,
padding_side = "right",
use_fast = False,
)
tokenizer.pad_token = tokenizer.unk_token
num_added_tokens = tokenizer.add_tokens("[SEG]")
args.seg_token_idx = tokenizer("[SEG]", add_special_tokens=False).input_ids[0]
if args.use_mm_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model_args = {
"train_mask_decoder": args.train_mask_decoder,
"out_dim" : args.out_dim,
"seg_token_idx" : args.seg_token_idx,
"vision_tower" : args.vision_tower,
}
torch_dtype = torch.float32
if args.precision == "bf16":
torch_dtype = torch.bfloat16
elif args.precision == "fp16":
torch_dtype = torch.half
model = VISAForCausalLM.from_pretrained(args.version, torch_dtype=torch_dtype, low_cpu_mem_usage=True, **model_args, )
model.config.eos_token_id = tokenizer.eos_token_id
model.config.bos_token_id = tokenizer.bos_token_id
model.config.pad_token_id = tokenizer.pad_token_id
model.get_model().initialize_vision_modules(model.get_model().config)
vision_tower = model.get_model().get_vision_tower()
vision_tower.to(dtype=torch_dtype)
model.get_model().initialize_lisa_modules(model.get_model().config)
lora_r = args.lora_r
if lora_r > 0:
def find_linear_layers(model, lora_target_modules):
cls = torch.nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if (
isinstance(module, cls)
and all([x not in name for x in ["visual_model", "vision_tower", "mm_projector", "text_hidden_fcs", ]])
and any([x in name for x in lora_target_modules])
):
lora_module_names.add(name)
return sorted(list(lora_module_names))
lora_alpha = args.lora_alpha
lora_dropout = args.lora_dropout
lora_target_modules = find_linear_layers(model, args.lora_target_modules.split(","), )
lora_config = LoraConfig(
r = lora_r,
lora_alpha = lora_alpha,
target_modules = lora_target_modules,
lora_dropout = lora_dropout,
bias = "none",
task_type = "CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
model.resize_token_embeddings(len(tokenizer))
state_dict = torch.load(args.weight, map_location="cpu")
model.load_state_dict(state_dict, strict=True)
model = model.merge_and_unload()
state_dict = {}
for k, v in model.state_dict().items():
if "vision_tower" not in k:
state_dict[k] = v
model.save_pretrained(args.save_path, state_dict=state_dict)
tokenizer.save_pretrained(args.save_path)
if __name__ == "__main__":
main(sys.argv[1:])
================================================
FILE: model/VISA.py
================================================
from typing import List
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BitsAndBytesConfig, CLIPVisionModel
from utils.utils import DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IMAGE_PATCH_TOKEN
from .univi.model.language_model.llama import ChatUniViLlamaForCausalLM, ChatUniViLlamaModel
from .segment_anything import build_sam_vit_h
from model.univi.constants import IMAGE_TOKEN_INDEX
import time
def dice_loss(
inputs : torch.Tensor,
targets : torch.Tensor,
num_masks: float,
scale : float =1000,
eps : float =1e-6,
):
"""
Compute the DICE loss, similar to generalized IOU for masks
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary classification label for each element in inputs (0 for the negative class and 1 for the positive class).
"""
inputs = inputs.sigmoid()
inputs = inputs.flatten(1, 2)
targets = targets.flatten(1, 2)
numerator = 2 * (inputs / scale * targets).sum(-1)
denominator = (inputs / scale).sum(-1) + (targets / scale).sum(-1)
loss = 1 - (numerator + eps) / (denominator + eps)
loss = loss.sum() / (num_masks + 1e-8)
return loss
def sigmoid_ce_loss(
inputs: torch.Tensor,
targets: torch.Tensor,
num_masks: float,
):
"""
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary classification label for each element in inputs (0 for the negative class and 1 for the positive class).
Returns:
Loss tensor
"""
loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
loss = loss.flatten(1, 2).mean(1).sum() / (num_masks + 1e-8)
return loss
class VisaMetaModel:
def __init__(
self,
config,
**kwargs,
):
super(VisaMetaModel, self).__init__(config)
self.config = config
if not hasattr(self.config, "train_mask_decoder"):
self.config.train_mask_decoder = kwargs["train_mask_decoder"]
self.config.out_dim = kwargs["out_dim"]
self.vision_pretrained = kwargs.get("vision_pretrained", None)
else:
self.vision_pretrained = kwargs.get("vision_pretrained", None)
self.initialize_lisa_modules(self.config)
def initialize_lisa_modules(self, config):
# SAM
self.visual_model = build_sam_vit_h(self.vision_pretrained)
for param in self.visual_model.parameters():
param.requires_grad = False
if config.train_mask_decoder:
self.visual_model.mask_decoder.train()
for param in self.visual_model.mask_decoder.parameters():
param.requires_grad = True
# Projection layer
in_dim = config.hidden_size
out_dim = config.out_dim
text_fc = [
nn.Linear(in_dim, in_dim),
nn.ReLU(inplace=True),
nn.Linear(in_dim, out_dim),
nn.Dropout(0.0),
]
self.text_hidden_fcs = nn.ModuleList([nn.Sequential(*text_fc)])
self.text_hidden_fcs.train()
for param in self.text_hidden_fcs.parameters():
param.requires_grad = True
class VisaModel(VisaMetaModel, ChatUniViLlamaModel):
def __init__(
self,
config,
**kwargs,
):
super(VisaModel, self).__init__(config, **kwargs)
self.config.use_cache = False
self.config.vision_tower = self.config.mm_vision_tower
self.config.mm_vision_select_feature = "patch"
self.config.image_aspect_ratio = "square"
self.config.image_grid_pinpoints = None
self.config.tune_mm_mlp_adapter = False
self.config.freeze_mm_mlp_adapter = True
self.config.pretrain_mm_mlp_adapter = None
self.config.mm_use_im_patch_token = False
class VISAForCausalLM(ChatUniViLlamaForCausalLM):
def __init__(
self,
config,
**kwargs,
):
if not hasattr(config, "train_mask_decoder"):
config.mm_use_im_start_end = kwargs.pop("use_mm_start_end", True)
config.mm_vision_tower = kwargs.get("vision_tower", "openai/clip-vit-large-patch14")
self.ce_loss_weight = kwargs.pop("ce_loss_weight", None)
self.dice_loss_weight = kwargs.pop("dice_loss_weight", None)
self.bce_loss_weight = kwargs.pop("bce_loss_weight", None)
else:
config.mm_vision_tower = config.vision_tower
self.seg_token_idx = kwargs.pop("seg_token_idx")
super().__init__(config)
self.model = VisaModel(config, **kwargs)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_visual_embs(self, pixel_values: torch.FloatTensor):
with torch.no_grad():
image_embeddings = self.model.visual_model.image_encoder(pixel_values)
return image_embeddings
def forward(self, **kwargs):
if "past_key_values" in kwargs:
return super().forward(**kwargs)
return self.model_forward(**kwargs)
def model_forward(
self,
images: torch.FloatTensor,
images_clip: torch.FloatTensor,
input_ids: torch.LongTensor,
labels: torch.LongTensor,
attention_masks: torch.LongTensor,
offset: torch.LongTensor,
masks_list: List[torch.FloatTensor],
label_list: List[torch.Tensor],
resize_list: List[tuple],
conversation_list: List[str],
num_frame_list: List[int],
num_conv_list: List[int],
inference: bool = False,
**kwargs,
):
batch_size = len(images)
image_embeddings = self.get_visual_embs(torch.cat(images,dim=0))
assert image_embeddings.shape[0] == batch_size
assert batch_size == len(offset) - 1
for batch_idx in range(batch_size):
assert num_conv_list[batch_idx] == offset[batch_idx + 1] - offset[batch_idx]
if inference:
length = input_ids.shape[0]
assert len(images_clip) == 1, f'Inference only supports one video, but got {len(images_clip)} videos.'
images_clip = [
images_clip[0].unsqueeze(0).expand(length, -1, -1, -1, -1).contiguous().flatten(0,1)
]
output_i = super().forward(
images=images_clip,
attention_mask=attention_masks,
input_ids=input_ids,
output_hidden_states=True,
)
torch.cuda.empty_cache()
output_hidden_states = output_i.hidden_states
output = None
num_image_ori_token = (input_ids[0] == IMAGE_TOKEN_INDEX).sum()
assert all(
[
(input_ids[i] == IMAGE_TOKEN_INDEX).sum() == num_image_ori_token for i in range(length)
]
)
token_add = 111 * num_image_ori_token
seg_token_mask = input_ids[:, 1:] == self.seg_token_idx
seg_token_mask = torch.cat([seg_token_mask, torch.zeros((seg_token_mask.shape[0], 1)).bool().cuda(), ], dim=1, )
seg_token_mask = torch.cat([torch.zeros((seg_token_mask.shape[0], token_add)).bool().cuda(), seg_token_mask], dim=1, )
all_conv_seg_token_num = seg_token_mask.sum(dim=1).tolist()
else:
images_clip_list = []
for batch_idx in range(batch_size):
bs_conv_num = num_conv_list[batch_idx]
images_clip_i = images_clip[batch_idx].unsqueeze(0).expand(bs_conv_num, -1, -1, -1, -1).contiguous()
images_clip_list.append(images_clip_i)
images_clip_list = [i.flatten(0,1) for i in images_clip_list]
output = super().forward(
images=images_clip_list,
attention_mask=attention_masks,
input_ids=input_ids,
labels=labels,
output_hidden_states=True,
)
output_hidden_states = output.hidden_states
seg_token_mask = output.labels[..., 1:] == self.seg_token_idx
seg_token_mask = torch.cat([seg_token_mask, torch.zeros((seg_token_mask.shape[0], 1), device=output.labels.device).bool(), ], dim=1, )
all_conv_seg_token_num = seg_token_mask.sum(dim=1).tolist()
assert len(self.model.text_hidden_fcs) == 1
pred_embeddings = self.model.text_hidden_fcs[0](output_hidden_states[-1][seg_token_mask])
seg_token_counts = seg_token_mask.int().sum(-1) # [bs, ]
seg_token_offset = seg_token_counts.cumsum(-1)
seg_token_offset = torch.cat(
[torch.zeros(1).long().cuda(), seg_token_offset], dim=0
)
seg_token_offset = seg_token_offset[offset]
pred_embeddings_ = []
for i in range(len(seg_token_offset) - 1):
start_i, end_i = seg_token_offset[i], seg_token_offset[i + 1]
pred_embeddings_.append(pred_embeddings[start_i:end_i])
pred_embeddings = pred_embeddings_
assert len(pred_embeddings) == batch_size
multimask_output = False
pred_masks = []
for i in range(batch_size):
(
sparse_embeddings,
dense_embeddings,
) = self.model.visual_model.prompt_encoder(
points=None,
boxes=None,
masks=None,
text_embeds=pred_embeddings[i].unsqueeze(1),
)
sparse_embeddings = sparse_embeddings.to(pred_embeddings[i].dtype)
low_res_masks, iou_predictions = self.model.visual_model.mask_decoder(
image_embeddings=image_embeddings[i].unsqueeze(0),
image_pe=self.model.visual_model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
pred_mask = self.model.visual_model.postprocess_masks(
low_res_masks,
input_size=resize_list[i],
original_size=label_list[i].shape,
)
pred_masks.append(pred_mask[:, 0])
model_output = output
gt_masks = [mm.flatten(0, 1) for mm in masks_list]
if inference:
return {
"pred_masks": pred_masks,
"gt_masks": gt_masks,
}
output = model_output.logits
ce_loss = model_output.loss
ce_loss = ce_loss * self.ce_loss_weight
mask_bce_loss = 0
mask_dice_loss = 0
num_masks = 0
for batch_idx in range(batch_size):
gt_mask = gt_masks[batch_idx]
pred_mask = pred_masks[batch_idx]
assert (
gt_mask.shape[0] == pred_mask.shape[0]
), "gt_mask.shape: {}, pred_mask.shape: {}".format(
gt_mask.shape, pred_mask.shape
)
mask_bce_loss += (
sigmoid_ce_loss(pred_mask, gt_mask, num_masks=gt_mask.shape[0])
* gt_mask.shape[0]
)
mask_dice_loss += (
dice_loss(pred_mask, gt_mask, num_masks=gt_mask.shape[0])
* gt_mask.shape[0]
)
num_masks += gt_mask.shape[0]
mask_bce_loss = self.bce_loss_weight * mask_bce_loss / (num_masks + 1e-8)
mask_dice_loss = self.dice_loss_weight * mask_dice_loss / (num_masks + 1e-8)
mask_loss = mask_bce_loss + mask_dice_loss
loss = ce_loss + mask_loss
return {
"loss": loss,
"ce_loss": ce_loss,
"mask_bce_loss": mask_bce_loss,
"mask_dice_loss": mask_dice_loss,
"mask_loss": mask_loss,
}
def evaluate(self, *args, **kwargs):
raise NotImplementedError("This method is not implemented.")
================================================
FILE: model/llava/__init__.py
================================================
from .model import LlavaLlamaForCausalLM
================================================
FILE: model/llava/constants.py
================================================
CONTROLLER_HEART_BEAT_EXPIRATION = 30
WORKER_HEART_BEAT_INTERVAL = 15
LOGDIR = "."
# Model Constants
IGNORE_INDEX = -100
IMAGE_TOKEN_INDEX = -200
DEFAULT_IMAGE_TOKEN = ""
DEFAULT_IMAGE_PATCH_TOKEN = ""
DEFAULT_IM_START_TOKEN = ""
DEFAULT_IM_END_TOKEN = ""
================================================
FILE: model/llava/conversation.py
================================================
import dataclasses
from enum import Enum, auto
from typing import List, Tuple
class SeparatorStyle(Enum):
"""Different separator style."""
SINGLE = auto()
TWO = auto()
MPT = auto()
PLAIN = auto()
LLAMA_2 = auto()
@dataclasses.dataclass
class Conversation:
"""A class that keeps all conversation history."""
system: str
roles: List[str]
messages: List[List[str]]
offset: int
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
sep: str = "###"
sep2: str = None
version: str = "Unknown"
skip_next: bool = False
def get_prompt(self):
messages = self.messages
if len(messages) > 0 and type(messages[0][1]) is tuple:
messages = self.messages.copy()
init_role, init_msg = messages[0].copy()
init_msg = init_msg[0].replace("", "").strip()
if "mmtag" in self.version:
messages[0] = (init_role, init_msg)
messages.insert(0, (self.roles[0], ""))
messages.insert(1, (self.roles[1], "Received."))
else:
messages[0] = (init_role, "\n" + init_msg)
if self.sep_style == SeparatorStyle.SINGLE:
ret = self.system + self.sep
for role, message in messages:
if message:
if type(message) is tuple:
message, _, _ = message
ret += role + ": " + message + self.sep
else:
ret += role + ":"
elif self.sep_style == SeparatorStyle.TWO:
seps = [self.sep, self.sep2]
ret = self.system + seps[0]
for i, (role, message) in enumerate(messages):
if message:
if type(message) is tuple:
message, _, _ = message
ret += role + ": " + message + seps[i % 2]
else:
ret += role + ":"
elif self.sep_style == SeparatorStyle.MPT:
ret = self.system + self.sep
for role, message in messages:
if message:
if type(message) is tuple:
message, _, _ = message
ret += role + message + self.sep
else:
ret += role
elif self.sep_style == SeparatorStyle.LLAMA_2:
wrap_sys = lambda msg: f"<>\n{msg}\n<>\n\n"
wrap_inst = lambda msg: f"[INST] {msg} [/INST]"
ret = ""
for i, (role, message) in enumerate(messages):
if i == 0:
assert message, "first message should not be none"
assert role == self.roles[0], "first message should come from user"
if message:
if type(message) is tuple:
message, _, _ = message
if i == 0:
message = wrap_sys(self.system) + message
if i % 2 == 0:
message = wrap_inst(message)
ret += self.sep + message
else:
ret += " " + message + " " + self.sep2
else:
ret += ""
ret = ret.lstrip(self.sep)
elif self.sep_style == SeparatorStyle.PLAIN:
seps = [self.sep, self.sep2]
ret = self.system
for i, (role, message) in enumerate(messages):
if message:
if type(message) is tuple:
message, _, _ = message
ret += message + seps[i % 2]
else:
ret += ""
else:
raise ValueError(f"Invalid style: {self.sep_style}")
return ret
def append_message(self, role, message):
self.messages.append([role, message])
def get_images(self, return_pil=False):
images = []
for i, (role, msg) in enumerate(self.messages[self.offset :]):
if i % 2 == 0:
if type(msg) is tuple:
import base64
from io import BytesIO
from PIL import Image
msg, image, image_process_mode = msg
if image_process_mode == "Pad":
def expand2square(pil_img, background_color=(122, 116, 104)):
width, height = pil_img.size
if width == height:
return pil_img
elif width > height:
result = Image.new(
pil_img.mode, (width, width), background_color
)
result.paste(pil_img, (0, (width - height) // 2))
return result
else:
result = Image.new(
pil_img.mode, (height, height), background_color
)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image)
elif image_process_mode == "Crop":
pass
elif image_process_mode == "Resize":
image = image.resize((336, 336))
else:
raise ValueError(
f"Invalid image_process_mode: {image_process_mode}"
)
max_hw, min_hw = max(image.size), min(image.size)
aspect_ratio = max_hw / min_hw
max_len, min_len = 800, 400
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
longest_edge = int(shortest_edge * aspect_ratio)
W, H = image.size
if H > W:
H, W = longest_edge, shortest_edge
else:
H, W = shortest_edge, longest_edge
image = image.resize((W, H))
if return_pil:
images.append(image)
else:
buffered = BytesIO()
image.save(buffered, format="PNG")
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
images.append(img_b64_str)
return images
def to_gradio_chatbot(self):
ret = []
for i, (role, msg) in enumerate(self.messages[self.offset :]):
if i % 2 == 0:
if type(msg) is tuple:
import base64
from io import BytesIO
msg, image, image_process_mode = msg
max_hw, min_hw = max(image.size), min(image.size)
aspect_ratio = max_hw / min_hw
max_len, min_len = 800, 400
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
longest_edge = int(shortest_edge * aspect_ratio)
W, H = image.size
if H > W:
H, W = longest_edge, shortest_edge
else:
H, W = shortest_edge, longest_edge
image = image.resize((W, H))
buffered = BytesIO()
image.save(buffered, format="JPEG")
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
img_str = f'
Note that in the implementation, normalization with N is performed at step (2) and above equation and implementation is not exactly the same, but mathematically is same.
You can go deeper on above explanation at [Kevin Zakka's Blog](https://kevinzakka.github.io/2016/09/14/batch_normalization/)
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py
================================================
from .syncbn import batchnorm2d_sync
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py
================================================
"""
/*****************************************************************************/
Extension module loader
code referenced from : https://github.com/facebookresearch/maskrcnn-benchmark
/*****************************************************************************/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import glob
import os.path
import torch
try:
from torch.utils.cpp_extension import load
from torch.utils.cpp_extension import CUDA_HOME
except ImportError:
raise ImportError(
"The cpp layer extensions requires PyTorch 0.4 or higher")
def _load_C_extensions():
this_dir = os.path.dirname(os.path.abspath(__file__))
this_dir = os.path.join(this_dir, "csrc")
main_file = glob.glob(os.path.join(this_dir, "*.cpp"))
sources_cpu = glob.glob(os.path.join(this_dir, "cpu", "*.cpp"))
sources_cuda = glob.glob(os.path.join(this_dir, "cuda", "*.cu"))
sources = main_file + sources_cpu
extra_cflags = []
extra_cuda_cflags = []
if torch.cuda.is_available() and CUDA_HOME is not None:
sources.extend(sources_cuda)
extra_cflags = ["-O3", "-DWITH_CUDA"]
extra_cuda_cflags = ["--expt-extended-lambda"]
sources = [os.path.join(this_dir, s) for s in sources]
extra_include_paths = [this_dir]
return load(
name="ext_lib",
sources=sources,
extra_cflags=extra_cflags,
extra_include_paths=extra_include_paths,
extra_cuda_cflags=extra_cuda_cflags,
)
_backend = _load_C_extensions()
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h
================================================
/*****************************************************************************
SyncBN
*****************************************************************************/
#pragma once
#ifdef WITH_CUDA
#include "cuda/ext_lib.h"
#endif
/// SyncBN
std::vector syncbn_sum_sqsum(const at::Tensor& x) {
if (x.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_sum_sqsum_cuda(x);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
at::Tensor syncbn_forward(const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean,
const at::Tensor& var, bool affine, float eps) {
if (x.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_forward_cuda(x, weight, bias, mean, var, affine, eps);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
std::vector syncbn_backward_xhat(const at::Tensor& dz,
const at::Tensor& x,
const at::Tensor& mean,
const at::Tensor& var, float eps) {
if (dz.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_backward_xhat_cuda(dz, x, mean, var, eps);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
std::vector syncbn_backward(
const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
float eps) {
if (dz.is_cuda()) {
#ifdef WITH_CUDA
return syncbn_backward_cuda(dz, x, weight, bias, mean, var, sum_dz,
sum_dz_xhat, affine, eps);
#else
AT_ERROR("Not compiled with GPU support");
#endif
} else {
AT_ERROR("CPU implementation not supported");
}
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu
================================================
/*****************************************************************************
CUDA SyncBN code
code referenced from : https://github.com/mapillary/inplace_abn
*****************************************************************************/
#include
#include
#include
#include
#include "cuda/common.h"
// Utilities
void get_dims(at::Tensor x, int64_t &num, int64_t &chn, int64_t &sp) {
num = x.size(0);
chn = x.size(1);
sp = 1;
for (int64_t i = 2; i < x.ndimension(); ++i) sp *= x.size(i);
}
/// SyncBN
template
struct SqSumOp {
__device__ SqSumOp(const T *t, int c, int s) : tensor(t), chn(c), sp(s) {}
__device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
T x = tensor[(batch * chn + plane) * sp + n];
return Pair(x, x * x); // x, x^2
}
const T *tensor;
const int chn;
const int sp;
};
template
__global__ void syncbn_sum_sqsum_kernel(const T *x, T *sum, T *sqsum,
int num, int chn, int sp) {
int plane = blockIdx.x;
Pair res =
reduce, SqSumOp>(SqSumOp(x, chn, sp), plane, num, chn, sp);
__syncthreads();
if (threadIdx.x == 0) {
sum[plane] = res.v1;
sqsum[plane] = res.v2;
}
}
std::vector syncbn_sum_sqsum_cuda(const at::Tensor &x) {
CHECK_INPUT(x);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
// Prepare output tensors
auto sum = at::empty({chn}, x.options());
auto sqsum = at::empty({chn}, x.options());
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_sum_sqsum_cuda", ([&] {
syncbn_sum_sqsum_kernel<<>>(
x.data(), sum.data(),
sqsum.data(), num, chn, sp);
}));
return {sum, sqsum};
}
template
__global__ void syncbn_forward_kernel(T *z, const T *x, const T *weight,
const T *bias, const T *mean,
const T *var, bool affine, float eps,
int num, int chn, int sp) {
int plane = blockIdx.x;
T _mean = mean[plane];
T _var = var[plane];
T _weight = affine ? weight[plane] : T(1);
T _bias = affine ? bias[plane] : T(0);
float _invstd = T(0);
if (_var || eps) {
_invstd = rsqrt(_var + eps);
}
for (int batch = 0; batch < num; ++batch) {
for (int n = threadIdx.x; n < sp; n += blockDim.x) {
T _x = x[(batch * chn + plane) * sp + n];
T _xhat = (_x - _mean) * _invstd;
T _z = _xhat * _weight + _bias;
z[(batch * chn + plane) * sp + n] = _z;
}
}
}
at::Tensor syncbn_forward_cuda(const at::Tensor &x, const at::Tensor &weight,
const at::Tensor &bias, const at::Tensor &mean,
const at::Tensor &var, bool affine, float eps) {
CHECK_INPUT(x);
CHECK_INPUT(weight);
CHECK_INPUT(bias);
CHECK_INPUT(mean);
CHECK_INPUT(var);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
auto z = at::zeros_like(x);
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_forward_cuda", ([&] {
syncbn_forward_kernel<<>>(
z.data(), x.data(),
weight.data(), bias.data(),
mean.data(), var.data(),
affine, eps, num, chn, sp);
}));
return z;
}
template
struct XHatOp {
__device__ XHatOp(T _weight, T _bias, const T *_dz, const T *_x, int c, int s)
: weight(_weight), bias(_bias), x(_x), dz(_dz), chn(c), sp(s) {}
__device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
// xhat = (x - bias) * weight
T _xhat = (x[(batch * chn + plane) * sp + n] - bias) * weight;
// dxhat * x_hat
T _dz = dz[(batch * chn + plane) * sp + n];
return Pair(_dz, _dz * _xhat);
}
const T weight;
const T bias;
const T *dz;
const T *x;
const int chn;
const int sp;
};
template
__global__ void syncbn_backward_xhat_kernel(const T *dz, const T *x,
const T *mean, const T *var,
T *sum_dz, T *sum_dz_xhat,
float eps, int num, int chn,
int sp) {
int plane = blockIdx.x;
T _mean = mean[plane];
T _var = var[plane];
T _invstd = T(0);
if (_var || eps) {
_invstd = rsqrt(_var + eps);
}
Pair res = reduce, XHatOp>(
XHatOp(_invstd, _mean, dz, x, chn, sp), plane, num, chn, sp);
__syncthreads();
if (threadIdx.x == 0) {
// \sum(\frac{dJ}{dy_i})
sum_dz[plane] = res.v1;
// \sum(\frac{dJ}{dy_i}*\hat{x_i})
sum_dz_xhat[plane] = res.v2;
}
}
std::vector syncbn_backward_xhat_cuda(const at::Tensor &dz,
const at::Tensor &x,
const at::Tensor &mean,
const at::Tensor &var,
float eps) {
CHECK_INPUT(dz);
CHECK_INPUT(x);
CHECK_INPUT(mean);
CHECK_INPUT(var);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
// Prepare output tensors
auto sum_dz = at::empty({chn}, x.options());
auto sum_dz_xhat = at::empty({chn}, x.options());
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_backward_xhat_cuda", ([&] {
syncbn_backward_xhat_kernel<<>>(
dz.data(), x.data(), mean.data(),
var.data(), sum_dz.data(),
sum_dz_xhat.data(), eps, num, chn, sp);
}));
return {sum_dz, sum_dz_xhat};
}
template
__global__ void syncbn_backward_kernel(const T *dz, const T *x, const T *weight,
const T *bias, const T *mean,
const T *var, const T *sum_dz,
const T *sum_dz_xhat, T *dx, T *dweight,
T *dbias, bool affine, float eps,
int num, int chn, int sp) {
int plane = blockIdx.x;
T _mean = mean[plane];
T _var = var[plane];
T _weight = affine ? weight[plane] : T(1);
T _sum_dz = sum_dz[plane];
T _sum_dz_xhat = sum_dz_xhat[plane];
T _invstd = T(0);
if (_var || eps) {
_invstd = rsqrt(_var + eps);
}
/*
\frac{dJ}{dx_i} = \frac{1}{N\sqrt{(\sigma^2+\epsilon)}} (
N\frac{dJ}{d\hat{x_i}} -
\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}) -
\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j})
)
Note : N is omitted here since it will be accumulated and
_sum_dz and _sum_dz_xhat expected to be already normalized
before the call.
*/
if (dx) {
T _mul = _weight * _invstd;
for (int batch = 0; batch < num; ++batch) {
for (int n = threadIdx.x; n < sp; n += blockDim.x) {
T _dz = dz[(batch * chn + plane) * sp + n];
T _xhat = (x[(batch * chn + plane) * sp + n] - _mean) * _invstd;
T _dx = (_dz - _sum_dz - _xhat * _sum_dz_xhat) * _mul;
dx[(batch * chn + plane) * sp + n] = _dx;
}
}
}
__syncthreads();
if (threadIdx.x == 0) {
if (affine) {
T _norm = num * sp;
dweight[plane] += _sum_dz_xhat * _norm;
dbias[plane] += _sum_dz * _norm;
}
}
}
std::vector syncbn_backward_cuda(
const at::Tensor &dz, const at::Tensor &x, const at::Tensor &weight,
const at::Tensor &bias, const at::Tensor &mean, const at::Tensor &var,
const at::Tensor &sum_dz, const at::Tensor &sum_dz_xhat, bool affine,
float eps) {
CHECK_INPUT(dz);
CHECK_INPUT(x);
CHECK_INPUT(weight);
CHECK_INPUT(bias);
CHECK_INPUT(mean);
CHECK_INPUT(var);
CHECK_INPUT(sum_dz);
CHECK_INPUT(sum_dz_xhat);
// Extract dimensions
int64_t num, chn, sp;
get_dims(x, num, chn, sp);
// Prepare output tensors
auto dx = at::zeros_like(dz);
auto dweight = at::zeros_like(weight);
auto dbias = at::zeros_like(bias);
// Run kernel
dim3 blocks(chn);
dim3 threads(getNumThreads(sp));
AT_DISPATCH_FLOATING_TYPES(
x.type(), "syncbn_backward_cuda", ([&] {
syncbn_backward_kernel<<>>(
dz.data(), x.data(), weight.data(),
bias.data(), mean.data(), var.data(),
sum_dz.data(), sum_dz_xhat.data(),
dx.data(), dweight.data(),
dbias.data(), affine, eps, num, chn, sp);
}));
return {dx, dweight, dbias};
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h
================================================
/*****************************************************************************
CUDA utility funcs
code referenced from : https://github.com/mapillary/inplace_abn
*****************************************************************************/
#pragma once
#include
// Checks
#ifndef AT_CHECK
#define AT_CHECK AT_ASSERT
#endif
#define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
#define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x " must be contiguous")
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
/*
* General settings
*/
const int WARP_SIZE = 32;
const int MAX_BLOCK_SIZE = 512;
template
struct Pair {
T v1, v2;
__device__ Pair() {}
__device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
__device__ Pair(T v) : v1(v), v2(v) {}
__device__ Pair(int v) : v1(v), v2(v) {}
__device__ Pair &operator+=(const Pair &a) {
v1 += a.v1;
v2 += a.v2;
return *this;
}
};
/*
* Utility functions
*/
template
__device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask,
int width = warpSize,
unsigned int mask = 0xffffffff) {
#if CUDART_VERSION >= 9000
return __shfl_xor_sync(mask, value, laneMask, width);
#else
return __shfl_xor(value, laneMask, width);
#endif
}
__device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
static int getNumThreads(int nElem) {
int threadSizes[5] = {32, 64, 128, 256, MAX_BLOCK_SIZE};
for (int i = 0; i != 5; ++i) {
if (nElem <= threadSizes[i]) {
return threadSizes[i];
}
}
return MAX_BLOCK_SIZE;
}
template
static __device__ __forceinline__ T warpSum(T val) {
#if __CUDA_ARCH__ >= 300
for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
}
#else
__shared__ T values[MAX_BLOCK_SIZE];
values[threadIdx.x] = val;
__threadfence_block();
const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
for (int i = 1; i < WARP_SIZE; i++) {
val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
}
#endif
return val;
}
template
static __device__ __forceinline__ Pair warpSum(Pair value) {
value.v1 = warpSum(value.v1);
value.v2 = warpSum(value.v2);
return value;
}
template
__device__ T reduce(Op op, int plane, int N, int C, int S) {
T sum = (T)0;
for (int batch = 0; batch < N; ++batch) {
for (int x = threadIdx.x; x < S; x += blockDim.x) {
sum += op(batch, plane, x);
}
}
// sum over NumThreads within a warp
sum = warpSum(sum);
// 'transpose', and reduce within warp again
__shared__ T shared[32];
__syncthreads();
if (threadIdx.x % WARP_SIZE == 0) {
shared[threadIdx.x / WARP_SIZE] = sum;
}
if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
// zero out the other entries in shared
shared[threadIdx.x] = (T)0;
}
__syncthreads();
if (threadIdx.x / WARP_SIZE == 0) {
sum = warpSum(shared[threadIdx.x]);
if (threadIdx.x == 0) {
shared[0] = sum;
}
}
__syncthreads();
// Everyone picks it up, should be broadcast into the whole gradInput
return shared[0];
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h
================================================
/*****************************************************************************
CUDA SyncBN code
*****************************************************************************/
#pragma once
#include
#include
/// Sync-BN
std::vector syncbn_sum_sqsum_cuda(const at::Tensor& x);
at::Tensor syncbn_forward_cuda(const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean,
const at::Tensor& var, bool affine, float eps);
std::vector syncbn_backward_xhat_cuda(const at::Tensor& dz,
const at::Tensor& x,
const at::Tensor& mean,
const at::Tensor& var,
float eps);
std::vector syncbn_backward_cuda(
const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
float eps);
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp
================================================
#include "bn.h"
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("syncbn_sum_sqsum", &syncbn_sum_sqsum, "Sum and Sum^2 computation");
m.def("syncbn_forward", &syncbn_forward, "SyncBN forward computation");
m.def("syncbn_backward_xhat", &syncbn_backward_xhat,
"First part of SyncBN backward computation");
m.def("syncbn_backward", &syncbn_backward,
"Second part of SyncBN backward computation");
}
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py
================================================
"""
/*****************************************************************************/
BatchNorm2dSync with multi-gpu
code referenced from : https://github.com/mapillary/inplace_abn
/*****************************************************************************/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import torch.cuda.comm as comm
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from ._csrc import _backend
def _count_samples(x):
count = 1
for i, s in enumerate(x.size()):
if i != 1:
count *= s
return count
class BatchNorm2dSyncFunc(Function):
@staticmethod
def forward(ctx, x, weight, bias, running_mean, running_var,
extra, compute_stats=True, momentum=0.1, eps=1e-05):
def _parse_extra(ctx, extra):
ctx.is_master = extra["is_master"]
if ctx.is_master:
ctx.master_queue = extra["master_queue"]
ctx.worker_queues = extra["worker_queues"]
ctx.worker_ids = extra["worker_ids"]
else:
ctx.master_queue = extra["master_queue"]
ctx.worker_queue = extra["worker_queue"]
# Save context
if extra is not None:
_parse_extra(ctx, extra)
ctx.compute_stats = compute_stats
ctx.momentum = momentum
ctx.eps = eps
ctx.affine = weight is not None and bias is not None
if ctx.compute_stats:
N = _count_samples(x) * (ctx.master_queue.maxsize + 1)
assert N > 1
# 1. compute sum(x) and sum(x^2)
xsum, xsqsum = _backend.syncbn_sum_sqsum(x.detach())
if ctx.is_master:
xsums, xsqsums = [xsum], [xsqsum]
# master : gatther all sum(x) and sum(x^2) from slaves
for _ in range(ctx.master_queue.maxsize):
xsum_w, xsqsum_w = ctx.master_queue.get()
ctx.master_queue.task_done()
xsums.append(xsum_w)
xsqsums.append(xsqsum_w)
xsum = comm.reduce_add(xsums)
xsqsum = comm.reduce_add(xsqsums)
mean = xsum / N
sumvar = xsqsum - xsum * mean
var = sumvar / N
uvar = sumvar / (N - 1)
# master : broadcast global mean, variance to all slaves
tensors = comm.broadcast_coalesced(
(mean, uvar, var), [mean.get_device()] + ctx.worker_ids)
for ts, queue in zip(tensors[1:], ctx.worker_queues):
queue.put(ts)
else:
# slave : send sum(x) and sum(x^2) to master
ctx.master_queue.put((xsum, xsqsum))
# slave : get global mean and variance
mean, uvar, var = ctx.worker_queue.get()
ctx.worker_queue.task_done()
# Update running stats
running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * uvar)
ctx.N = N
ctx.save_for_backward(x, weight, bias, mean, var)
else:
mean, var = running_mean, running_var
# do batch norm forward
z = _backend.syncbn_forward(x, weight, bias, mean, var,
ctx.affine, ctx.eps)
return z
@staticmethod
@once_differentiable
def backward(ctx, dz):
x, weight, bias, mean, var = ctx.saved_tensors
dz = dz.contiguous()
# 1. compute \sum(\frac{dJ}{dy_i}) and \sum(\frac{dJ}{dy_i}*\hat{x_i})
sum_dz, sum_dz_xhat = _backend.syncbn_backward_xhat(
dz, x, mean, var, ctx.eps)
if ctx.is_master:
sum_dzs, sum_dz_xhats = [sum_dz], [sum_dz_xhat]
# master : gatther from slaves
for _ in range(ctx.master_queue.maxsize):
sum_dz_w, sum_dz_xhat_w = ctx.master_queue.get()
ctx.master_queue.task_done()
sum_dzs.append(sum_dz_w)
sum_dz_xhats.append(sum_dz_xhat_w)
# master : compute global stats
sum_dz = comm.reduce_add(sum_dzs)
sum_dz_xhat = comm.reduce_add(sum_dz_xhats)
sum_dz /= ctx.N
sum_dz_xhat /= ctx.N
# master : broadcast global stats
tensors = comm.broadcast_coalesced(
(sum_dz, sum_dz_xhat), [mean.get_device()] + ctx.worker_ids)
for ts, queue in zip(tensors[1:], ctx.worker_queues):
queue.put(ts)
else:
# slave : send to master
ctx.master_queue.put((sum_dz, sum_dz_xhat))
# slave : get global stats
sum_dz, sum_dz_xhat = ctx.worker_queue.get()
ctx.worker_queue.task_done()
# do batch norm backward
dx, dweight, dbias = _backend.syncbn_backward(
dz, x, weight, bias, mean, var, sum_dz, sum_dz_xhat,
ctx.affine, ctx.eps)
return dx, dweight, dbias, \
None, None, None, None, None, None
batchnorm2d_sync = BatchNorm2dSyncFunc.apply
__all__ = ["batchnorm2d_sync"]
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py
================================================
from .syncbn import *
================================================
FILE: XMem/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py
================================================
"""
/*****************************************************************************/
BatchNorm2dSync with multi-gpu
/*****************************************************************************/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
try:
# python 3
from queue import Queue
except ImportError:
# python 2
from Queue import Queue
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.nn.parameter import Parameter
from isegm.model.syncbn.modules.functional import batchnorm2d_sync
class _BatchNorm(nn.Module):
"""
Customized BatchNorm from nn.BatchNorm
>> added freeze attribute to enable bn freeze.
"""
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
track_running_stats=True):
super(_BatchNorm, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
self.freezed = False
if self.affine:
self.weight = Parameter(torch.Tensor(num_features))
self.bias = Parameter(torch.Tensor(num_features))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
else:
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.reset_parameters()
def reset_parameters(self):
if self.track_running_stats:
self.running_mean.zero_()
self.running_var.fill_(1)
if self.affine:
self.weight.data.uniform_()
self.bias.data.zero_()
def _check_input_dim(self, input):
return NotImplemented
def forward(self, input):
self._check_input_dim(input)
compute_stats = not self.freezed and \
self.training and self.track_running_stats
ret = F.batch_norm(input, self.running_mean, self.running_var,
self.weight, self.bias, compute_stats,
self.momentum, self.eps)
return ret
def extra_repr(self):
return '{num_features}, eps={eps}, momentum={momentum}, '\
'affine={affine}, ' \
'track_running_stats={track_running_stats}'.format(
**self.__dict__)
class BatchNorm2dNoSync(_BatchNorm):
"""
Equivalent to nn.BatchNorm2d
"""
def _check_input_dim(self, input):
if input.dim() != 4:
raise ValueError('expected 4D input (got {}D input)'
.format(input.dim()))
class BatchNorm2dSync(BatchNorm2dNoSync):
"""
BatchNorm2d with automatic multi-GPU Sync
"""
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
track_running_stats=True):
super(BatchNorm2dSync, self).__init__(
num_features, eps=eps, momentum=momentum, affine=affine,
track_running_stats=track_running_stats)
self.sync_enabled = True
self.devices = list(range(torch.cuda.device_count()))
if len(self.devices) > 1:
# Initialize queues
self.worker_ids = self.devices[1:]
self.master_queue = Queue(len(self.worker_ids))
self.worker_queues = [Queue(1) for _ in self.worker_ids]
def forward(self, x):
compute_stats = not self.freezed and \
self.training and self.track_running_stats
if self.sync_enabled and compute_stats and len(self.devices) > 1:
if x.get_device() == self.devices[0]:
# Master mode
extra = {
"is_master": True,
"master_queue": self.master_queue,
"worker_queues": self.worker_queues,
"worker_ids": self.worker_ids
}
else:
# Worker mode
extra = {
"is_master": False,
"master_queue": self.master_queue,
"worker_queue": self.worker_queues[
self.worker_ids.index(x.get_device())]
}
return batchnorm2d_sync(x, self.weight, self.bias,
self.running_mean, self.running_var,
extra, compute_stats, self.momentum,
self.eps)
return super(BatchNorm2dSync, self).forward(x)
def __repr__(self):
"""repr"""
rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
'affine={affine}, ' \
'track_running_stats={track_running_stats},' \
'devices={devices})'
return rep.format(name=self.__class__.__name__, **self.__dict__)
#BatchNorm2d = BatchNorm2dNoSync
BatchNorm2d = BatchNorm2dSync
================================================
FILE: XMem/inference/interact/fbrs/utils/__init__.py
================================================
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/__init__.py
================================================
# noinspection PyUnresolvedReferences
from .dist_maps import get_dist_maps
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx
================================================
import numpy as np
cimport cython
cimport numpy as np
from libc.stdlib cimport malloc, free
ctypedef struct qnode:
int row
int col
int layer
int orig_row
int orig_col
@cython.infer_types(True)
@cython.boundscheck(False)
@cython.wraparound(False)
@cython.nonecheck(False)
def get_dist_maps(np.ndarray[np.float32_t, ndim=2, mode="c"] points,
int height, int width, float norm_delimeter):
cdef np.ndarray[np.float32_t, ndim=3, mode="c"] dist_maps = \
np.full((2, height, width), 1e6, dtype=np.float32, order="C")
cdef int *dxy = [-1, 0, 0, -1, 0, 1, 1, 0]
cdef int i, j, x, y, dx, dy
cdef qnode v
cdef qnode *q = malloc((4 * height * width + 1) * sizeof(qnode))
cdef int qhead = 0, qtail = -1
cdef float ndist
for i in range(points.shape[0]):
x, y = round(points[i, 0]), round(points[i, 1])
if x >= 0:
qtail += 1
q[qtail].row = x
q[qtail].col = y
q[qtail].orig_row = x
q[qtail].orig_col = y
if i >= points.shape[0] / 2:
q[qtail].layer = 1
else:
q[qtail].layer = 0
dist_maps[q[qtail].layer, x, y] = 0
while qtail - qhead + 1 > 0:
v = q[qhead]
qhead += 1
for k in range(4):
x = v.row + dxy[2 * k]
y = v.col + dxy[2 * k + 1]
ndist = ((x - v.orig_row)/norm_delimeter) ** 2 + ((y - v.orig_col)/norm_delimeter) ** 2
if (x >= 0 and y >= 0 and x < height and y < width and
dist_maps[v.layer, x, y] > ndist):
qtail += 1
q[qtail].orig_col = v.orig_col
q[qtail].orig_row = v.orig_row
q[qtail].layer = v.layer
q[qtail].row = x
q[qtail].col = y
dist_maps[v.layer, x, y] = ndist
free(q)
return dist_maps
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld
================================================
import numpy
def make_ext(modname, pyxfilename):
from distutils.extension import Extension
return Extension(modname, [pyxfilename],
include_dirs=[numpy.get_include()],
extra_compile_args=['-O3'], language='c++')
================================================
FILE: XMem/inference/interact/fbrs/utils/cython/dist_maps.py
================================================
import pyximport; pyximport.install(pyximport=True, language_level=3)
# noinspection PyUnresolvedReferences
from ._get_dist_maps import get_dist_maps
================================================
FILE: XMem/inference/interact/fbrs/utils/misc.py
================================================
from functools import partial
import torch
import numpy as np
def get_dims_with_exclusion(dim, exclude=None):
dims = list(range(dim))
if exclude is not None:
dims.remove(exclude)
return dims
def get_unique_labels(mask):
return np.nonzero(np.bincount(mask.flatten() + 1))[0] - 1
def get_bbox_from_mask(mask):
rows = np.any(mask, axis=1)
cols = np.any(mask, axis=0)
rmin, rmax = np.where(rows)[0][[0, -1]]
cmin, cmax = np.where(cols)[0][[0, -1]]
return rmin, rmax, cmin, cmax
def expand_bbox(bbox, expand_ratio, min_crop_size=None):
rmin, rmax, cmin, cmax = bbox
rcenter = 0.5 * (rmin + rmax)
ccenter = 0.5 * (cmin + cmax)
height = expand_ratio * (rmax - rmin + 1)
width = expand_ratio * (cmax - cmin + 1)
if min_crop_size is not None:
height = max(height, min_crop_size)
width = max(width, min_crop_size)
rmin = int(round(rcenter - 0.5 * height))
rmax = int(round(rcenter + 0.5 * height))
cmin = int(round(ccenter - 0.5 * width))
cmax = int(round(ccenter + 0.5 * width))
return rmin, rmax, cmin, cmax
def clamp_bbox(bbox, rmin, rmax, cmin, cmax):
return (max(rmin, bbox[0]), min(rmax, bbox[1]),
max(cmin, bbox[2]), min(cmax, bbox[3]))
def get_bbox_iou(b1, b2):
h_iou = get_segments_iou(b1[:2], b2[:2])
w_iou = get_segments_iou(b1[2:4], b2[2:4])
return h_iou * w_iou
def get_segments_iou(s1, s2):
a, b = s1
c, d = s2
intersection = max(0, min(b, d) - max(a, c) + 1)
union = max(1e-6, max(b, d) - min(a, c) + 1)
return intersection / union
================================================
FILE: XMem/inference/interact/fbrs/utils/vis.py
================================================
from functools import lru_cache
import cv2
import numpy as np
def visualize_instances(imask, bg_color=255,
boundaries_color=None, boundaries_width=1, boundaries_alpha=0.8):
num_objects = imask.max() + 1
palette = get_palette(num_objects)
if bg_color is not None:
palette[0] = bg_color
result = palette[imask].astype(np.uint8)
if boundaries_color is not None:
boundaries_mask = get_boundaries(imask, boundaries_width=boundaries_width)
tresult = result.astype(np.float32)
tresult[boundaries_mask] = boundaries_color
tresult = tresult * boundaries_alpha + (1 - boundaries_alpha) * result
result = tresult.astype(np.uint8)
return result
@lru_cache(maxsize=16)
def get_palette(num_cls):
palette = np.zeros(3 * num_cls, dtype=np.int32)
for j in range(0, num_cls):
lab = j
i = 0
while lab > 0:
palette[j*3 + 0] |= (((lab >> 0) & 1) << (7-i))
palette[j*3 + 1] |= (((lab >> 1) & 1) << (7-i))
palette[j*3 + 2] |= (((lab >> 2) & 1) << (7-i))
i = i + 1
lab >>= 3
return palette.reshape((-1, 3))
def visualize_mask(mask, num_cls):
palette = get_palette(num_cls)
mask[mask == -1] = 0
return palette[mask].astype(np.uint8)
def visualize_proposals(proposals_info, point_color=(255, 0, 0), point_radius=1):
proposal_map, colors, candidates = proposals_info
proposal_map = draw_probmap(proposal_map)
for x, y in candidates:
proposal_map = cv2.circle(proposal_map, (y, x), point_radius, point_color, -1)
return proposal_map
def draw_probmap(x):
return cv2.applyColorMap((x * 255).astype(np.uint8), cv2.COLORMAP_HOT)
def draw_points(image, points, color, radius=3):
image = image.copy()
for p in points:
image = cv2.circle(image, (int(p[1]), int(p[0])), radius, color, -1)
return image
def draw_instance_map(x, palette=None):
num_colors = x.max() + 1
if palette is None:
palette = get_palette(num_colors)
return palette[x].astype(np.uint8)
def blend_mask(image, mask, alpha=0.6):
if mask.min() == -1:
mask = mask.copy() + 1
imap = draw_instance_map(mask)
result = (image * (1 - alpha) + alpha * imap).astype(np.uint8)
return result
def get_boundaries(instances_masks, boundaries_width=1):
boundaries = np.zeros((instances_masks.shape[0], instances_masks.shape[1]), dtype=np.bool)
for obj_id in np.unique(instances_masks.flatten()):
if obj_id == 0:
continue
obj_mask = instances_masks == obj_id
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
inner_mask = cv2.erode(obj_mask.astype(np.uint8), kernel, iterations=boundaries_width).astype(np.bool)
obj_boundary = np.logical_xor(obj_mask, np.logical_and(inner_mask, obj_mask))
boundaries = np.logical_or(boundaries, obj_boundary)
return boundaries
def draw_with_blend_and_clicks(img, mask=None, alpha=0.6, clicks_list=None, pos_color=(0, 255, 0),
neg_color=(255, 0, 0), radius=4):
result = img.copy()
if mask is not None:
palette = get_palette(np.max(mask) + 1)
rgb_mask = palette[mask.astype(np.uint8)]
mask_region = (mask > 0).astype(np.uint8)
result = result * (1 - mask_region[:, :, np.newaxis]) + \
(1 - alpha) * mask_region[:, :, np.newaxis] * result + \
alpha * rgb_mask
result = result.astype(np.uint8)
# result = (result * (1 - alpha) + alpha * rgb_mask).astype(np.uint8)
if clicks_list is not None and len(clicks_list) > 0:
pos_points = [click.coords for click in clicks_list if click.is_positive]
neg_points = [click.coords for click in clicks_list if not click.is_positive]
result = draw_points(result, pos_points, pos_color, radius=radius)
result = draw_points(result, neg_points, neg_color, radius=radius)
return result
================================================
FILE: XMem/inference/interact/fbrs_controller.py
================================================
import torch
from .fbrs.controller import InteractiveController
from .fbrs.inference import utils
class FBRSController:
def __init__(self, checkpoint_path, device='cuda:0', max_size=800):
model = utils.load_is_model(checkpoint_path, device, cpu_dist_maps=True, norm_radius=260)
# Predictor params
zoomin_params = {
'skip_clicks': 1,
'target_size': 480,
'expansion_ratio': 1.4,
}
predictor_params = {
'brs_mode': 'f-BRS-B',
'prob_thresh': 0.5,
'zoom_in_params': zoomin_params,
'predictor_params': {
'net_clicks_limit': 8,
'max_size': 800,
},
'brs_opt_func_params': {'min_iou_diff': 1e-3},
'lbfgs_params': {'maxfun': 20}
}
self.controller = InteractiveController(model, device, predictor_params)
self.anchored = False
self.device = device
def unanchor(self):
self.anchored = False
def interact(self, image, x, y, is_positive):
image = image.to(self.device, non_blocking=True)
if not self.anchored:
self.controller.set_image(image)
self.controller.reset_predictor()
self.anchored = True
self.controller.add_click(x, y, is_positive)
# return self.controller.result_mask
# return self.controller.probs_history[-1][1]
return (self.controller.probs_history[-1][1]>0.5).float()
def undo(self):
self.controller.undo_click()
if len(self.controller.probs_history) == 0:
return None
else:
return (self.controller.probs_history[-1][1]>0.5).float()
================================================
FILE: XMem/inference/interact/gui.py
================================================
"""
Based on https://github.com/hkchengrex/MiVOS/tree/MiVOS-STCN
(which is based on https://github.com/seoungwugoh/ivs-demo)
This version is much simplified.
In this repo, we don't have
- local control
- fusion module
- undo
- timers
but with XMem as the backbone and is more memory (for both CPU and GPU) friendly
"""
import functools
import os
import cv2
# fix conflicts between qt5 and cv2
os.environ.pop("QT_QPA_PLATFORM_PLUGIN_PATH")
import numpy as np
import torch
try:
from torch import mps
except:
print('torch.MPS not available.')
from PySide6.QtWidgets import (QWidget, QApplication, QComboBox, QCheckBox,
QHBoxLayout, QLabel, QPushButton, QTextEdit, QSpinBox, QFileDialog,
QPlainTextEdit, QVBoxLayout, QSizePolicy, QButtonGroup, QSlider, QRadioButton)
from PySide6.QtGui import QPixmap, QKeySequence, QImage, QTextCursor, QIcon, QShortcut
from PySide6.QtCore import Qt, QTimer
from model.network import XMem
from inference.inference_core import InferenceCore
from .s2m_controller import S2MController
from .fbrs_controller import FBRSController
from .interactive_utils import *
from .interaction import *
from .resource_manager import ResourceManager
from .gui_utils import *
class App(QWidget):
def __init__(self, net: XMem,
resource_manager: ResourceManager,
s2m_ctrl:S2MController,
fbrs_ctrl:FBRSController, config, device):
super().__init__()
self.initialized = False
self.num_objects = config['num_objects']
self.s2m_controller = s2m_ctrl
self.fbrs_controller = fbrs_ctrl
self.config = config
self.processor = InferenceCore(net, config)
self.processor.set_all_labels(list(range(1, self.num_objects+1)))
self.res_man = resource_manager
self.device = device
self.num_frames = len(self.res_man)
self.height, self.width = self.res_man.h, self.res_man.w
# set window
self.setWindowTitle('XMem Demo')
self.setGeometry(100, 100, self.width, self.height+100)
self.setWindowIcon(QIcon('docs/icon.png'))
# some buttons
self.play_button = QPushButton('Play Video')
self.play_button.clicked.connect(self.on_play_video)
self.commit_button = QPushButton('Commit')
self.commit_button.clicked.connect(self.on_commit)
self.export_button = QPushButton('Export Overlays as Video')
self.export_button.clicked.connect(self.on_export_visualization)
self.forward_run_button = QPushButton('Forward Propagate')
self.forward_run_button.clicked.connect(self.on_forward_propagation)
self.forward_run_button.setMinimumWidth(150)
self.backward_run_button = QPushButton('Backward Propagate')
self.backward_run_button.clicked.connect(self.on_backward_propagation)
self.backward_run_button.setMinimumWidth(150)
self.reset_button = QPushButton('Reset Frame')
self.reset_button.clicked.connect(self.on_reset_mask)
# LCD
self.lcd = QTextEdit()
self.lcd.setReadOnly(True)
self.lcd.setMaximumHeight(28)
self.lcd.setMaximumWidth(120)
self.lcd.setText('{: 4d} / {: 4d}'.format(0, self.num_frames-1))
# Current Mask LCD
self.object_dial = QSpinBox()
self.object_dial.setReadOnly(False)
self.object_dial.setMaximumHeight(28)
self.object_dial.setMaximumWidth(56)
self.object_dial.setMinimum(1)
self.object_dial.setMaximum(self.num_objects)
self.object_dial.editingFinished.connect(self.on_object_dial_change)
# timeline slider
self.tl_slider = QSlider(Qt.Orientation.Horizontal)
self.tl_slider.valueChanged.connect(self.tl_slide)
self.tl_slider.setMinimum(0)
self.tl_slider.setMaximum(self.num_frames-1)
self.tl_slider.setValue(0)
self.tl_slider.setTickPosition(QSlider.TickPosition.TicksBelow)
self.tl_slider.setTickInterval(1)
# brush size slider
self.brush_label = QLabel()
self.brush_label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.brush_label.setMinimumWidth(150)
self.brush_slider = QSlider(Qt.Orientation.Horizontal)
self.brush_slider.valueChanged.connect(self.brush_slide)
self.brush_slider.setMinimum(1)
self.brush_slider.setMaximum(100)
self.brush_slider.setValue(3)
self.brush_slider.setTickPosition(QSlider.TickPosition.TicksBelow)
self.brush_slider.setTickInterval(2)
self.brush_slider.setMinimumWidth(300)
# combobox
self.combo = QComboBox(self)
self.combo.addItem("davis")
self.combo.addItem("fade")
self.combo.addItem("light")
self.combo.addItem("popup")
self.combo.addItem("layered")
self.combo.currentTextChanged.connect(self.set_viz_mode)
self.save_visualization_checkbox = QCheckBox(self)
self.save_visualization_checkbox.toggled.connect(self.on_save_visualization_toggle)
self.save_visualization_checkbox.setChecked(False)
self.save_visualization = False
# Radio buttons for type of interactions
self.curr_interaction = 'Click'
self.interaction_group = QButtonGroup()
self.radio_fbrs = QRadioButton('Click')
self.radio_s2m = QRadioButton('Scribble')
self.radio_free = QRadioButton('Free')
self.interaction_group.addButton(self.radio_fbrs)
self.interaction_group.addButton(self.radio_s2m)
self.interaction_group.addButton(self.radio_free)
self.radio_fbrs.toggled.connect(self.interaction_radio_clicked)
self.radio_s2m.toggled.connect(self.interaction_radio_clicked)
self.radio_free.toggled.connect(self.interaction_radio_clicked)
self.radio_fbrs.toggle()
# Main canvas -> QLabel
self.main_canvas = QLabel()
self.main_canvas.setSizePolicy(QSizePolicy.Policy.Expanding,
QSizePolicy.Policy.Expanding)
self.main_canvas.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.main_canvas.setMinimumSize(100, 100)
self.main_canvas.mousePressEvent = self.on_mouse_press
self.main_canvas.mouseMoveEvent = self.on_mouse_motion
self.main_canvas.setMouseTracking(True) # Required for all-time tracking
self.main_canvas.mouseReleaseEvent = self.on_mouse_release
# Minimap -> Also a QLabel
self.minimap = QLabel()
self.minimap.setSizePolicy(QSizePolicy.Policy.Expanding,
QSizePolicy.Policy.Expanding)
self.minimap.setAlignment(Qt.AlignmentFlag.AlignTop)
self.minimap.setMinimumSize(100, 100)
# Zoom-in buttons
self.zoom_p_button = QPushButton('Zoom +')
self.zoom_p_button.clicked.connect(self.on_zoom_plus)
self.zoom_m_button = QPushButton('Zoom -')
self.zoom_m_button.clicked.connect(self.on_zoom_minus)
# Parameters setting
self.clear_mem_button = QPushButton('Clear memory')
self.clear_mem_button.clicked.connect(self.on_clear_memory)
self.work_mem_gauge, self.work_mem_gauge_layout = create_gauge('Working memory size')
self.long_mem_gauge, self.long_mem_gauge_layout = create_gauge('Long-term memory size')
self.gpu_mem_gauge, self.gpu_mem_gauge_layout = create_gauge('GPU mem. (all processes, w/ caching)')
self.torch_mem_gauge, self.torch_mem_gauge_layout = create_gauge('GPU mem. (used by torch, w/o caching)')
self.update_memory_size()
self.update_gpu_usage()
self.work_mem_min, self.work_mem_min_layout = create_parameter_box(1, 100, 'Min. working memory frames',
callback=self.on_work_min_change)
self.work_mem_max, self.work_mem_max_layout = create_parameter_box(2, 100, 'Max. working memory frames',
callback=self.on_work_max_change)
self.long_mem_max, self.long_mem_max_layout = create_parameter_box(1000, 100000,
'Max. long-term memory size', step=1000, callback=self.update_config)
self.num_prototypes_box, self.num_prototypes_box_layout = create_parameter_box(32, 1280,
'Number of prototypes', step=32, callback=self.update_config)
self.mem_every_box, self.mem_every_box_layout = create_parameter_box(1, 100, 'Memory frame every (r)',
callback=self.update_config)
self.work_mem_min.setValue(self.processor.memory.min_mt_frames)
self.work_mem_max.setValue(self.processor.memory.max_mt_frames)
self.long_mem_max.setValue(self.processor.memory.max_long_elements)
self.num_prototypes_box.setValue(self.processor.memory.num_prototypes)
self.mem_every_box.setValue(self.processor.mem_every)
# import mask/layer
self.import_mask_button = QPushButton('Import mask')
self.import_mask_button.clicked.connect(self.on_import_mask)
self.import_layer_button = QPushButton('Import layer')
self.import_layer_button.clicked.connect(self.on_import_layer)
# Console on the GUI
self.console = QPlainTextEdit()
self.console.setReadOnly(True)
self.console.setMinimumHeight(100)
self.console.setMaximumHeight(100)
# navigator
navi = QHBoxLayout()
interact_subbox = QVBoxLayout()
interact_topbox = QHBoxLayout()
interact_botbox = QHBoxLayout()
interact_topbox.setAlignment(Qt.AlignmentFlag.AlignCenter)
interact_topbox.addWidget(self.lcd)
interact_topbox.addWidget(self.play_button)
interact_topbox.addWidget(self.radio_s2m)
interact_topbox.addWidget(self.radio_fbrs)
interact_topbox.addWidget(self.radio_free)
interact_topbox.addWidget(self.reset_button)
interact_botbox.addWidget(QLabel('Current Object ID:'))
interact_botbox.addWidget(self.object_dial)
interact_botbox.addWidget(self.brush_label)
interact_botbox.addWidget(self.brush_slider)
interact_subbox.addLayout(interact_topbox)
interact_subbox.addLayout(interact_botbox)
navi.addLayout(interact_subbox)
apply_fixed_size_policy = lambda x: x.setSizePolicy(QSizePolicy.Policy.Fixed,
QSizePolicy.Policy.Fixed)
apply_to_all_children_widget(interact_topbox, apply_fixed_size_policy)
apply_to_all_children_widget(interact_botbox, apply_fixed_size_policy)
navi.addStretch(1)
navi.addStretch(1)
overlay_subbox = QVBoxLayout()
overlay_topbox = QHBoxLayout()
overlay_botbox = QHBoxLayout()
overlay_botbox.setAlignment(Qt.AlignmentFlag.AlignRight)
overlay_topbox.addWidget(QLabel('Overlay Mode'))
overlay_topbox.addWidget(self.combo)
overlay_topbox.addWidget(QLabel('Save overlay during propagation'))
overlay_topbox.addWidget(self.save_visualization_checkbox)
overlay_botbox.addWidget(self.export_button)
overlay_subbox.addLayout(overlay_topbox)
overlay_subbox.addLayout(overlay_botbox)
navi.addLayout(overlay_subbox)
apply_to_all_children_widget(overlay_topbox, apply_fixed_size_policy)
apply_to_all_children_widget(overlay_botbox, apply_fixed_size_policy)
navi.addStretch(1)
navi.addWidget(self.commit_button)
navi.addWidget(self.forward_run_button)
navi.addWidget(self.backward_run_button)
# Drawing area, main canvas and minimap
draw_area = QHBoxLayout()
draw_area.addWidget(self.main_canvas, 4)
# Minimap area
minimap_area = QVBoxLayout()
minimap_area.setAlignment(Qt.AlignmentFlag.AlignTop)
mini_label = QLabel('Minimap')
mini_label.setAlignment(Qt.AlignmentFlag.AlignTop)
minimap_area.addWidget(mini_label)
# Minimap zooming
minimap_ctrl = QHBoxLayout()
minimap_ctrl.setAlignment(Qt.AlignmentFlag.AlignTop)
minimap_ctrl.addWidget(self.zoom_p_button)
minimap_ctrl.addWidget(self.zoom_m_button)
minimap_area.addLayout(minimap_ctrl)
minimap_area.addWidget(self.minimap)
# Parameters
minimap_area.addLayout(self.work_mem_gauge_layout)
minimap_area.addLayout(self.long_mem_gauge_layout)
minimap_area.addLayout(self.gpu_mem_gauge_layout)
minimap_area.addLayout(self.torch_mem_gauge_layout)
minimap_area.addWidget(self.clear_mem_button)
minimap_area.addLayout(self.work_mem_min_layout)
minimap_area.addLayout(self.work_mem_max_layout)
minimap_area.addLayout(self.long_mem_max_layout)
minimap_area.addLayout(self.num_prototypes_box_layout)
minimap_area.addLayout(self.mem_every_box_layout)
# import mask/layer
import_area = QHBoxLayout()
import_area.setAlignment(Qt.AlignmentFlag.AlignTop)
import_area.addWidget(self.import_mask_button)
import_area.addWidget(self.import_layer_button)
minimap_area.addLayout(import_area)
# console
minimap_area.addWidget(self.console)
draw_area.addLayout(minimap_area, 1)
layout = QVBoxLayout()
layout.addLayout(draw_area)
layout.addWidget(self.tl_slider)
layout.addLayout(navi)
self.setLayout(layout)
# timer to play video
self.timer = QTimer()
self.timer.setSingleShot(False)
self.timer.timeout.connect(self.on_play_video_timer)
# timer to update GPU usage
self.gpu_timer = QTimer()
self.gpu_timer.setSingleShot(False)
self.gpu_timer.timeout.connect(self.on_gpu_timer)
self.gpu_timer.setInterval(2000)
self.gpu_timer.start()
# current frame info
self.curr_frame_dirty = False
self.current_image = np.zeros((self.height, self.width, 3), dtype=np.uint8)
self.current_image_torch = None
self.current_mask = np.zeros((self.height, self.width), dtype=np.uint8)
self.current_prob = torch.zeros((self.num_objects, self.height, self.width), dtype=torch.float).to(self.device)
# initialize visualization
self.viz_mode = 'davis'
self.vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
self.vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
self.brush_vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
self.brush_vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
self.cursur = 0
self.on_showing = None
# Zoom parameters
self.zoom_pixels = 150
# initialize action
self.interaction = None
self.pressed = False
self.right_click = False
self.current_object = 1
self.last_ex = self.last_ey = 0
self.propagating = False
# Objects shortcuts
for i in range(1, self.num_objects+1):
QShortcut(QKeySequence(str(i)), self).activated.connect(functools.partial(self.hit_number_key, i))
QShortcut(QKeySequence(f"Ctrl+{i}"), self).activated.connect(functools.partial(self.hit_number_key, i))
# <- and -> shortcuts
QShortcut(QKeySequence(Qt.Key.Key_Left), self).activated.connect(self.on_prev_frame)
QShortcut(QKeySequence(Qt.Key.Key_Right), self).activated.connect(self.on_next_frame)
self.interacted_prob = None
self.overlay_layer = None
self.overlay_layer_torch = None
# the object id used for popup/layered overlay
self.vis_target_objects = [1]
# try to load the default overlay
self._try_load_layer('./docs/ECCV-logo.png')
self.load_current_image_mask()
self.show_current_frame()
self.show()
self.console_push_text('Initialized.')
self.initialized = True
def resizeEvent(self, event):
self.show_current_frame()
def console_push_text(self, text):
self.console.moveCursor(QTextCursor.MoveOperation.End)
self.console.insertPlainText(text+'\n')
def interaction_radio_clicked(self, event):
self.last_interaction = self.curr_interaction
if self.radio_s2m.isChecked():
self.curr_interaction = 'Scribble'
self.brush_size = 3
self.brush_slider.setDisabled(True)
elif self.radio_fbrs.isChecked():
self.curr_interaction = 'Click'
self.brush_size = 3
self.brush_slider.setDisabled(True)
elif self.radio_free.isChecked():
self.brush_slider.setDisabled(False)
self.brush_slide()
self.curr_interaction = 'Free'
if self.curr_interaction == 'Scribble':
self.commit_button.setEnabled(True)
else:
self.commit_button.setEnabled(False)
def load_current_image_mask(self, no_mask=False):
self.current_image = self.res_man.get_image(self.cursur)
self.current_image_torch = None
if not no_mask:
loaded_mask = self.res_man.get_mask(self.cursur)
if loaded_mask is None:
self.current_mask.fill(0)
else:
self.current_mask = loaded_mask.copy()
self.current_prob = None
def load_current_torch_image_mask(self, no_mask=False):
if self.current_image_torch is None:
self.current_image_torch, self.current_image_torch_no_norm = image_to_torch(self.current_image, self.device)
if self.current_prob is None and not no_mask:
self.current_prob = index_numpy_to_one_hot_torch(self.current_mask, self.num_objects+1).to(self.device)
def compose_current_im(self):
self.viz = get_visualization(self.viz_mode, self.current_image, self.current_mask,
self.overlay_layer, self.vis_target_objects)
def update_interact_vis(self):
# Update the interactions without re-computing the overlay
height, width, channel = self.viz.shape
bytesPerLine = 3 * width
vis_map = self.vis_map
vis_alpha = self.vis_alpha
brush_vis_map = self.brush_vis_map
brush_vis_alpha = self.brush_vis_alpha
self.viz_with_stroke = self.viz*(1-vis_alpha) + vis_map*vis_alpha
self.viz_with_stroke = self.viz_with_stroke*(1-brush_vis_alpha) + brush_vis_map*brush_vis_alpha
self.viz_with_stroke = self.viz_with_stroke.astype(np.uint8)
qImg = QImage(self.viz_with_stroke.data, width, height, bytesPerLine, QImage.Format.Format_RGB888)
self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.FastTransformation)))
self.main_canvas_size = self.main_canvas.size()
self.image_size = qImg.size()
def update_minimap(self):
ex, ey = self.last_ex, self.last_ey
r = self.zoom_pixels//2
ex = int(round(max(r, min(self.width-r, ex))))
ey = int(round(max(r, min(self.height-r, ey))))
patch = self.viz_with_stroke[ey-r:ey+r, ex-r:ex+r, :].astype(np.uint8)
height, width, channel = patch.shape
bytesPerLine = 3 * width
qImg = QImage(patch.data, width, height, bytesPerLine, QImage.Format.Format_RGB888)
self.minimap.setPixmap(QPixmap(qImg.scaled(self.minimap.size(),
Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.FastTransformation)))
def update_current_image_fast(self):
# fast path, uses gpu. Changes the image in-place to avoid copying
self.viz = get_visualization_torch(self.viz_mode, self.current_image_torch_no_norm,
self.current_prob, self.overlay_layer_torch, self.vis_target_objects)
if self.save_visualization:
self.res_man.save_visualization(self.cursur, self.viz)
height, width, channel = self.viz.shape
bytesPerLine = 3 * width
qImg = QImage(self.viz.data, width, height, bytesPerLine, QImage.Format.Format_RGB888)
self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.FastTransformation)))
def show_current_frame(self, fast=False):
# Re-compute overlay and show the image
if fast:
self.update_current_image_fast()
else:
self.compose_current_im()
self.update_interact_vis()
self.update_minimap()
self.lcd.setText('{: 3d} / {: 3d}'.format(self.cursur, self.num_frames-1))
self.tl_slider.setValue(self.cursur)
def pixel_pos_to_image_pos(self, x, y):
# Un-scale and un-pad the label coordinates into image coordinates
oh, ow = self.image_size.height(), self.image_size.width()
nh, nw = self.main_canvas_size.height(), self.main_canvas_size.width()
h_ratio = nh/oh
w_ratio = nw/ow
dominate_ratio = min(h_ratio, w_ratio)
# Solve scale
x /= dominate_ratio
y /= dominate_ratio
# Solve padding
fh, fw = nh/dominate_ratio, nw/dominate_ratio
x -= (fw-ow)/2
y -= (fh-oh)/2
return x, y
def is_pos_out_of_bound(self, x, y):
x, y = self.pixel_pos_to_image_pos(x, y)
out_of_bound = (
(x < 0) or
(y < 0) or
(x > self.width-1) or
(y > self.height-1)
)
return out_of_bound
def get_scaled_pos(self, x, y):
x, y = self.pixel_pos_to_image_pos(x, y)
x = max(0, min(self.width-1, x))
y = max(0, min(self.height-1, y))
return x, y
def clear_visualization(self):
self.vis_map.fill(0)
self.vis_alpha.fill(0)
def reset_this_interaction(self):
self.complete_interaction()
self.clear_visualization()
self.interaction = None
if self.fbrs_controller is not None:
self.fbrs_controller.unanchor()
def set_viz_mode(self):
self.viz_mode = self.combo.currentText()
self.show_current_frame()
def save_current_mask(self):
# save mask to hard disk
self.res_man.save_mask(self.cursur, self.current_mask)
def tl_slide(self):
# if we are propagating, the on_run function will take care of everything
# don't do duplicate work here
if not self.propagating:
if self.curr_frame_dirty:
self.save_current_mask()
self.curr_frame_dirty = False
self.reset_this_interaction()
self.cursur = self.tl_slider.value()
self.load_current_image_mask()
self.show_current_frame()
def brush_slide(self):
self.brush_size = self.brush_slider.value()
self.brush_label.setText('Brush size (in free mode): %d' % self.brush_size)
try:
if type(self.interaction) == FreeInteraction:
self.interaction.set_size(self.brush_size)
except AttributeError:
# Initialization, forget about it
pass
def on_forward_propagation(self):
if self.propagating:
# acts as a pause button
self.propagating = False
else:
self.propagate_fn = self.on_next_frame
self.backward_run_button.setEnabled(False)
self.forward_run_button.setText('Pause Propagation')
self.on_propagation()
def on_backward_propagation(self):
if self.propagating:
# acts as a pause button
self.propagating = False
else:
self.propagate_fn = self.on_prev_frame
self.forward_run_button.setEnabled(False)
self.backward_run_button.setText('Pause Propagation')
self.on_propagation()
def on_pause(self):
self.propagating = False
self.forward_run_button.setEnabled(True)
self.backward_run_button.setEnabled(True)
self.clear_mem_button.setEnabled(True)
self.forward_run_button.setText('Forward Propagate')
self.backward_run_button.setText('Backward Propagate')
self.console_push_text('Propagation stopped.')
def on_propagation(self):
# start to propagate
self.load_current_torch_image_mask()
self.show_current_frame(fast=True)
self.console_push_text('Propagation started.')
self.current_prob = self.processor.step(self.current_image_torch, self.current_prob[1:])
self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
# clear
self.interacted_prob = None
self.reset_this_interaction()
self.propagating = True
self.clear_mem_button.setEnabled(False)
# propagate till the end
while self.propagating:
self.propagate_fn()
self.load_current_image_mask(no_mask=True)
self.load_current_torch_image_mask(no_mask=True)
self.current_prob = self.processor.step(self.current_image_torch)
self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
self.save_current_mask()
self.show_current_frame(fast=True)
self.update_memory_size()
QApplication.processEvents()
if self.cursur == 0 or self.cursur == self.num_frames-1:
break
self.propagating = False
self.curr_frame_dirty = False
self.on_pause()
self.tl_slide()
QApplication.processEvents()
def pause_propagation(self):
self.propagating = False
def on_commit(self):
self.complete_interaction()
self.update_interacted_mask()
def on_prev_frame(self):
# self.tl_slide will trigger on setValue
self.cursur = max(0, self.cursur-1)
self.tl_slider.setValue(self.cursur)
def on_next_frame(self):
# self.tl_slide will trigger on setValue
self.cursur = min(self.cursur+1, self.num_frames-1)
self.tl_slider.setValue(self.cursur)
def on_play_video_timer(self):
self.cursur += 1
if self.cursur > self.num_frames-1:
self.cursur = 0
self.tl_slider.setValue(self.cursur)
def on_play_video(self):
if self.timer.isActive():
self.timer.stop()
self.play_button.setText('Play Video')
else:
self.timer.start(1000 // 30)
self.play_button.setText('Stop Video')
def on_export_visualization(self):
# NOTE: Save visualization at the end of propagation
image_folder = f"{self.config['workspace']}/visualization/"
save_folder = self.config['workspace']
if os.path.exists(image_folder):
# Sorted so frames will be in order
self.console_push_text(f'Exporting visualization to {self.config["workspace"]}/visualization.mp4')
images = [img for img in sorted(os.listdir(image_folder)) if img.endswith(".jpg")]
frame = cv2.imread(os.path.join(image_folder, images[0]))
height, width, layers = frame.shape
# 10 is the FPS -- change if needed
video = cv2.VideoWriter(f"{save_folder}/visualization.mp4", cv2.VideoWriter_fourcc(*'mp4v'), 10, (width,height))
for image in images:
video.write(cv2.imread(os.path.join(image_folder, image)))
video.release()
self.console_push_text(f'Visualization exported to {self.config["workspace"]}/visualization.mp4')
else:
self.console_push_text(f'No visualization images found in {image_folder}')
def on_object_dial_change(self):
object_id = self.object_dial.value()
self.hit_number_key(object_id)
def on_reset_mask(self):
self.current_mask.fill(0)
if self.current_prob is not None:
self.current_prob.fill_(0)
self.curr_frame_dirty = True
self.save_current_mask()
self.reset_this_interaction()
self.show_current_frame()
def on_zoom_plus(self):
self.zoom_pixels -= 25
self.zoom_pixels = max(50, self.zoom_pixels)
self.update_minimap()
def on_zoom_minus(self):
self.zoom_pixels += 25
self.zoom_pixels = min(self.zoom_pixels, 300)
self.update_minimap()
def set_navi_enable(self, boolean):
self.zoom_p_button.setEnabled(boolean)
self.zoom_m_button.setEnabled(boolean)
self.run_button.setEnabled(boolean)
self.tl_slider.setEnabled(boolean)
self.play_button.setEnabled(boolean)
self.export_button.setEnabled(boolean)
self.lcd.setEnabled(boolean)
def hit_number_key(self, number):
if number == self.current_object:
return
self.current_object = number
self.object_dial.setValue(number)
if self.fbrs_controller is not None:
self.fbrs_controller.unanchor()
self.console_push_text(f'Current object changed to {number}.')
self.clear_brush()
self.vis_brush(self.last_ex, self.last_ey)
self.update_interact_vis()
self.show_current_frame()
def clear_brush(self):
self.brush_vis_map.fill(0)
self.brush_vis_alpha.fill(0)
def vis_brush(self, ex, ey):
self.brush_vis_map = cv2.circle(self.brush_vis_map,
(int(round(ex)), int(round(ey))), self.brush_size//2+1, color_map[self.current_object], thickness=-1)
self.brush_vis_alpha = cv2.circle(self.brush_vis_alpha,
(int(round(ex)), int(round(ey))), self.brush_size//2+1, 0.5, thickness=-1)
def on_mouse_press(self, event):
if self.is_pos_out_of_bound(event.position().x(), event.position().y()):
return
# mid-click
if (event.button() == Qt.MouseButton.MiddleButton):
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
target_object = self.current_mask[int(ey),int(ex)]
if target_object in self.vis_target_objects:
self.vis_target_objects.remove(target_object)
else:
self.vis_target_objects.append(target_object)
self.console_push_text(f'Target objects for visualization changed to {self.vis_target_objects}')
self.show_current_frame()
return
self.right_click = (event.button() == Qt.MouseButton.RightButton)
self.pressed = True
h, w = self.height, self.width
self.load_current_torch_image_mask()
image = self.current_image_torch
last_interaction = self.interaction
new_interaction = None
if self.curr_interaction == 'Scribble':
if last_interaction is None or type(last_interaction) != ScribbleInteraction:
self.complete_interaction()
new_interaction = ScribbleInteraction(image, torch.from_numpy(self.current_mask).float().to(self.device),
(h, w), self.s2m_controller, self.num_objects)
elif self.curr_interaction == 'Free':
if last_interaction is None or type(last_interaction) != FreeInteraction:
self.complete_interaction()
new_interaction = FreeInteraction(image, self.current_mask, (h, w),
self.num_objects)
new_interaction.set_size(self.brush_size)
elif self.curr_interaction == 'Click':
if (last_interaction is None or type(last_interaction) != ClickInteraction
or last_interaction.tar_obj != self.current_object):
self.complete_interaction()
self.fbrs_controller.unanchor()
new_interaction = ClickInteraction(image, self.current_prob, (h, w),
self.fbrs_controller, self.current_object)
if new_interaction is not None:
self.interaction = new_interaction
# Just motion it as the first step
self.on_mouse_motion(event)
def on_mouse_motion(self, event):
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
self.last_ex, self.last_ey = ex, ey
self.clear_brush()
# Visualize
self.vis_brush(ex, ey)
if self.pressed:
if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
obj = 0 if self.right_click else self.current_object
self.vis_map, self.vis_alpha = self.interaction.push_point(
ex, ey, obj, (self.vis_map, self.vis_alpha)
)
self.update_interact_vis()
self.update_minimap()
def update_interacted_mask(self):
self.current_prob = self.interacted_prob
self.current_mask = torch_prob_to_numpy_mask(self.interacted_prob)
self.show_current_frame()
self.save_current_mask()
self.curr_frame_dirty = False
def complete_interaction(self):
if self.interaction is not None:
self.clear_visualization()
self.interaction = None
def on_mouse_release(self, event):
if not self.pressed:
# this can happen when the initial press is out-of-bound
return
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
self.console_push_text('%s interaction at frame %d.' % (self.curr_interaction, self.cursur))
interaction = self.interaction
if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
self.on_mouse_motion(event)
interaction.end_path()
if self.curr_interaction == 'Free':
self.clear_visualization()
elif self.curr_interaction == 'Click':
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
self.vis_map, self.vis_alpha = interaction.push_point(ex, ey,
self.right_click, (self.vis_map, self.vis_alpha))
self.interacted_prob = interaction.predict().to(self.device)
self.update_interacted_mask()
self.update_gpu_usage()
self.pressed = self.right_click = False
def wheelEvent(self, event):
ex, ey = self.get_scaled_pos(event.position().x(), event.position().y())
if self.curr_interaction == 'Free':
self.brush_slider.setValue(self.brush_slider.value() + event.angleDelta().y()//30)
self.clear_brush()
self.vis_brush(ex, ey)
self.update_interact_vis()
self.update_minimap()
def update_gpu_usage(self):
if self.device.type == 'cuda':
info = torch.cuda.mem_get_info()
elif self.device.type == 'mps':
info = (0, mps.current_allocated_memory()) # NOTE: torch.mps does not support accessing free and total memory
else:
info = (0, 0)
global_free, global_total = info
global_free /= (2**30)
global_total /= (2**30)
global_used = global_total - global_free
self.gpu_mem_gauge.setFormat(f'{global_used:.01f} GB / {global_total:.01f} GB')
self.gpu_mem_gauge.setValue(round(global_used/global_total*100))
used_by_torch = torch.cuda.max_memory_allocated() / (2**20)
self.torch_mem_gauge.setFormat(f'{used_by_torch:.0f} MB / {global_total:.01f} GB')
self.torch_mem_gauge.setValue(round(used_by_torch/global_total*100/1024))
def on_gpu_timer(self):
self.update_gpu_usage()
def update_memory_size(self):
try:
max_work_elements = self.processor.memory.max_work_elements
max_long_elements = self.processor.memory.max_long_elements
curr_work_elements = self.processor.memory.work_mem.size
curr_long_elements = self.processor.memory.long_mem.size
self.work_mem_gauge.setFormat(f'{curr_work_elements} / {max_work_elements}')
self.work_mem_gauge.setValue(round(curr_work_elements/max_work_elements*100))
self.long_mem_gauge.setFormat(f'{curr_long_elements} / {max_long_elements}')
self.long_mem_gauge.setValue(round(curr_long_elements/max_long_elements*100))
except AttributeError:
self.work_mem_gauge.setFormat('Unknown')
self.long_mem_gauge.setFormat('Unknown')
self.work_mem_gauge.setValue(0)
self.long_mem_gauge.setValue(0)
def on_work_min_change(self):
if self.initialized:
self.work_mem_min.setValue(min(self.work_mem_min.value(), self.work_mem_max.value()-1))
self.update_config()
def on_work_max_change(self):
if self.initialized:
self.work_mem_max.setValue(max(self.work_mem_max.value(), self.work_mem_min.value()+1))
self.update_config()
def update_config(self):
if self.initialized:
self.config['min_mid_term_frames'] = self.work_mem_min.value()
self.config['max_mid_term_frames'] = self.work_mem_max.value()
self.config['max_long_term_elements'] = self.long_mem_max.value()
self.config['num_prototypes'] = self.num_prototypes_box.value()
self.config['mem_every'] = self.mem_every_box.value()
self.processor.update_config(self.config)
def on_clear_memory(self):
self.processor.clear_memory()
if self.device.type == 'cuda':
torch.cuda.empty_cache()
elif self.device.type == 'mps':
mps.empty_cache()
self.update_gpu_usage()
self.update_memory_size()
def _open_file(self, prompt):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, prompt, "", "Image files (*)", options=options)
return file_name
def on_import_mask(self):
file_name = self._open_file('Mask')
if len(file_name) == 0:
return
mask = self.res_man.read_external_image(file_name, size=(self.height, self.width))
shape_condition = (
(len(mask.shape) == 2) and
(mask.shape[-1] == self.width) and
(mask.shape[-2] == self.height)
)
object_condition = (
mask.max() <= self.num_objects
)
if not shape_condition:
self.console_push_text(f'Expected ({self.height}, {self.width}). Got {mask.shape} instead.')
elif not object_condition:
self.console_push_text(f'Expected {self.num_objects} objects. Got {mask.max()} objects instead.')
else:
self.console_push_text(f'Mask file {file_name} loaded.')
self.current_image_torch = self.current_prob = None
self.current_mask = mask
self.show_current_frame()
self.save_current_mask()
def on_import_layer(self):
file_name = self._open_file('Layer')
if len(file_name) == 0:
return
self._try_load_layer(file_name)
def _try_load_layer(self, file_name):
try:
layer = self.res_man.read_external_image(file_name, size=(self.height, self.width))
if layer.shape[-1] == 3:
layer = np.concatenate([layer, np.ones_like(layer[:,:,0:1])*255], axis=-1)
condition = (
(len(layer.shape) == 3) and
(layer.shape[-1] == 4) and
(layer.shape[-2] == self.width) and
(layer.shape[-3] == self.height)
)
if not condition:
self.console_push_text(f'Expected ({self.height}, {self.width}, 4). Got {layer.shape}.')
else:
self.console_push_text(f'Layer file {file_name} loaded.')
self.overlay_layer = layer
self.overlay_layer_torch = torch.from_numpy(layer).float().to(self.device)/255
self.show_current_frame()
except FileNotFoundError:
self.console_push_text(f'{file_name} not found.')
def on_save_visualization_toggle(self):
self.save_visualization = self.save_visualization_checkbox.isChecked()
================================================
FILE: XMem/inference/interact/gui_utils.py
================================================
from PySide6.QtCore import Qt
from PySide6.QtWidgets import (QBoxLayout, QHBoxLayout, QLabel, QSpinBox, QVBoxLayout, QProgressBar)
def create_parameter_box(min_val, max_val, text, step=1, callback=None):
layout = QHBoxLayout()
dial = QSpinBox()
dial.setMaximumHeight(28)
dial.setMaximumWidth(150)
dial.setMinimum(min_val)
dial.setMaximum(max_val)
dial.setAlignment(Qt.AlignmentFlag.AlignRight)
dial.setSingleStep(step)
dial.valueChanged.connect(callback)
label = QLabel(text)
label.setAlignment(Qt.AlignmentFlag.AlignRight)
layout.addWidget(label)
layout.addWidget(dial)
return dial, layout
def create_gauge(text):
layout = QHBoxLayout()
gauge = QProgressBar()
gauge.setMaximumHeight(28)
gauge.setMaximumWidth(200)
gauge.setAlignment(Qt.AlignmentFlag.AlignCenter)
label = QLabel(text)
label.setAlignment(Qt.AlignmentFlag.AlignRight)
layout.addWidget(label)
layout.addWidget(gauge)
return gauge, layout
def apply_to_all_children_widget(layout, func):
# deliberately non-recursive
for i in range(layout.count()):
func(layout.itemAt(i).widget())
================================================
FILE: XMem/inference/interact/interaction.py
================================================
"""
Contains all the types of interaction related to the GUI
Not related to automatic evaluation in the DAVIS dataset
You can inherit the Interaction class to create new interaction types
undo is (sometimes partially) supported
"""
import torch
import torch.nn.functional as F
import numpy as np
import cv2
import time
from .interactive_utils import color_map, index_numpy_to_one_hot_torch
def aggregate_sbg(prob, keep_bg=False, hard=False):
device = prob.device
k, h, w = prob.shape
ex_prob = torch.zeros((k+1, h, w), device=device)
ex_prob[0] = 0.5
ex_prob[1:] = prob
ex_prob = torch.clamp(ex_prob, 1e-7, 1-1e-7)
logits = torch.log((ex_prob /(1-ex_prob)))
if hard:
# Very low temperature o((⊙﹏⊙))o 🥶
logits *= 1000
if keep_bg:
return F.softmax(logits, dim=0)
else:
return F.softmax(logits, dim=0)[1:]
def aggregate_wbg(prob, keep_bg=False, hard=False):
k, h, w = prob.shape
new_prob = torch.cat([
torch.prod(1-prob, dim=0, keepdim=True),
prob
], 0).clamp(1e-7, 1-1e-7)
logits = torch.log((new_prob /(1-new_prob)))
if hard:
# Very low temperature o((⊙﹏⊙))o 🥶
logits *= 1000
if keep_bg:
return F.softmax(logits, dim=0)
else:
return F.softmax(logits, dim=0)[1:]
class Interaction:
def __init__(self, image, prev_mask, true_size, controller):
self.image = image
self.prev_mask = prev_mask
self.controller = controller
self.start_time = time.time()
self.h, self.w = true_size
self.out_prob = None
self.out_mask = None
def predict(self):
pass
class FreeInteraction(Interaction):
def __init__(self, image, prev_mask, true_size, num_objects):
"""
prev_mask should be index format numpy array
"""
super().__init__(image, prev_mask, true_size, None)
self.K = num_objects
self.drawn_map = self.prev_mask.copy()
self.curr_path = [[] for _ in range(self.K + 1)]
self.size = None
def set_size(self, size):
self.size = size
"""
k - object id
vis - a tuple (visualization map, pass through alpha). None if not needed.
"""
def push_point(self, x, y, k, vis=None):
if vis is not None:
vis_map, vis_alpha = vis
selected = self.curr_path[k]
selected.append((x, y))
if len(selected) >= 2:
cv2.line(self.drawn_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
k, thickness=self.size)
# Plot visualization
if vis is not None:
# Visualization for drawing
if k == 0:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
else:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
# Visualization on/off boolean filter
vis_alpha = cv2.line(vis_alpha,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
0.75, thickness=self.size)
if vis is not None:
return vis_map, vis_alpha
def end_path(self):
# Complete the drawing
self.curr_path = [[] for _ in range(self.K + 1)]
def predict(self):
self.out_prob = index_numpy_to_one_hot_torch(self.drawn_map, self.K+1)
# self.out_prob = torch.from_numpy(self.drawn_map).float().cuda()
# self.out_prob, _ = pad_divide_by(self.out_prob, 16, self.out_prob.shape[-2:])
# self.out_prob = aggregate_sbg(self.out_prob, keep_bg=True)
return self.out_prob
class ScribbleInteraction(Interaction):
def __init__(self, image, prev_mask, true_size, controller, num_objects):
"""
prev_mask should be in an indexed form
"""
super().__init__(image, prev_mask, true_size, controller)
self.K = num_objects
self.drawn_map = np.empty((self.h, self.w), dtype=np.uint8)
self.drawn_map.fill(255)
# background + k
self.curr_path = [[] for _ in range(self.K + 1)]
self.size = 3
"""
k - object id
vis - a tuple (visualization map, pass through alpha). None if not needed.
"""
def push_point(self, x, y, k, vis=None):
if vis is not None:
vis_map, vis_alpha = vis
selected = self.curr_path[k]
selected.append((x, y))
if len(selected) >= 2:
self.drawn_map = cv2.line(self.drawn_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
k, thickness=self.size)
# Plot visualization
if vis is not None:
# Visualization for drawing
if k == 0:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
else:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.size)
# Visualization on/off boolean filter
vis_alpha = cv2.line(vis_alpha,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
0.75, thickness=self.size)
# Optional vis return
if vis is not None:
return vis_map, vis_alpha
def end_path(self):
# Complete the drawing
self.curr_path = [[] for _ in range(self.K + 1)]
def predict(self):
self.out_prob = self.controller.interact(self.image.unsqueeze(0), self.prev_mask, self.drawn_map)
self.out_prob = aggregate_wbg(self.out_prob, keep_bg=True, hard=True)
return self.out_prob
class ClickInteraction(Interaction):
def __init__(self, image, prev_mask, true_size, controller, tar_obj):
"""
prev_mask in a prob. form
"""
super().__init__(image, prev_mask, true_size, controller)
self.tar_obj = tar_obj
# negative/positive for each object
self.pos_clicks = []
self.neg_clicks = []
self.out_prob = self.prev_mask.clone()
"""
neg - Negative interaction or not
vis - a tuple (visualization map, pass through alpha). None if not needed.
"""
def push_point(self, x, y, neg, vis=None):
# Clicks
if neg:
self.neg_clicks.append((x, y))
else:
self.pos_clicks.append((x, y))
# Do the prediction
self.obj_mask = self.controller.interact(self.image.unsqueeze(0), x, y, not neg)
# Plot visualization
if vis is not None:
vis_map, vis_alpha = vis
# Visualization for clicks
if neg:
vis_map = cv2.circle(vis_map,
(int(round(x)), int(round(y))),
2, color_map[0], thickness=-1)
else:
vis_map = cv2.circle(vis_map,
(int(round(x)), int(round(y))),
2, color_map[self.tar_obj], thickness=-1)
vis_alpha = cv2.circle(vis_alpha,
(int(round(x)), int(round(y))),
2, 1, thickness=-1)
# Optional vis return
return vis_map, vis_alpha
def predict(self):
self.out_prob = self.prev_mask.clone()
# a small hack to allow the interacting object to overwrite existing masks
# without remembering all the object probabilities
self.out_prob = torch.clamp(self.out_prob, max=0.9)
self.out_prob[self.tar_obj] = self.obj_mask
self.out_prob = aggregate_wbg(self.out_prob[1:], keep_bg=True, hard=True)
return self.out_prob
================================================
FILE: XMem/inference/interact/interactive_utils.py
================================================
# Modifed from https://github.com/seoungwugoh/ivs-demo
import numpy as np
import torch
import torch.nn.functional as F
from util.palette import davis_palette
from dataset.range_transform import im_normalization
def image_to_torch(frame: np.ndarray, device='cuda'):
# frame: H*W*3 numpy array
frame = frame.transpose(2, 0, 1)
frame = torch.from_numpy(frame).float().to(device)/255
frame_norm = im_normalization(frame)
return frame_norm, frame
def torch_prob_to_numpy_mask(prob):
mask = torch.max(prob, dim=0).indices
mask = mask.cpu().numpy().astype(np.uint8)
return mask
def index_numpy_to_one_hot_torch(mask, num_classes):
mask = torch.from_numpy(mask).long()
return F.one_hot(mask, num_classes=num_classes).permute(2, 0, 1).float()
"""
Some constants fro visualization
"""
try:
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
except:
device = torch.device("cpu")
color_map_np = np.frombuffer(davis_palette, dtype=np.uint8).reshape(-1, 3).copy()
# scales for better visualization
color_map_np = (color_map_np.astype(np.float32)*1.5).clip(0, 255).astype(np.uint8)
color_map = color_map_np.tolist()
color_map_torch = torch.from_numpy(color_map_np).to(device) / 255
grayscale_weights = np.array([[0.3,0.59,0.11]]).astype(np.float32)
grayscale_weights_torch = torch.from_numpy(grayscale_weights).to(device).unsqueeze(0)
def get_visualization(mode, image, mask, layer, target_object):
if mode == 'fade':
return overlay_davis(image, mask, fade=True)
elif mode == 'davis':
return overlay_davis(image, mask)
elif mode == 'light':
return overlay_davis(image, mask, 0.9)
elif mode == 'popup':
return overlay_popup(image, mask, target_object)
elif mode == 'layered':
if layer is None:
print('Layer file not given. Defaulting to DAVIS.')
return overlay_davis(image, mask)
else:
return overlay_layer(image, mask, layer, target_object)
else:
raise NotImplementedError
def get_visualization_torch(mode, image, prob, layer, target_object):
if mode == 'fade':
return overlay_davis_torch(image, prob, fade=True)
elif mode == 'davis':
return overlay_davis_torch(image, prob)
elif mode == 'light':
return overlay_davis_torch(image, prob, 0.9)
elif mode == 'popup':
return overlay_popup_torch(image, prob, target_object)
elif mode == 'layered':
if layer is None:
print('Layer file not given. Defaulting to DAVIS.')
return overlay_davis_torch(image, prob)
else:
return overlay_layer_torch(image, prob, layer, target_object)
else:
raise NotImplementedError
def overlay_davis(image, mask, alpha=0.5, fade=False):
""" Overlay segmentation on top of RGB image. from davis official"""
im_overlay = image.copy()
colored_mask = color_map_np[mask]
foreground = image*alpha + (1-alpha)*colored_mask
binary_mask = (mask > 0)
# Compose image
im_overlay[binary_mask] = foreground[binary_mask]
if fade:
im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
return im_overlay.astype(image.dtype)
def overlay_popup(image, mask, target_object):
# Keep foreground colored. Convert background to grayscale.
im_overlay = image.copy()
binary_mask = ~(np.isin(mask, target_object))
colored_region = (im_overlay[binary_mask]*grayscale_weights).sum(-1, keepdims=-1)
im_overlay[binary_mask] = colored_region
return im_overlay.astype(image.dtype)
def overlay_layer(image, mask, layer, target_object):
# insert a layer between foreground and background
# The CPU version is less accurate because we are using the hard mask
# The GPU version has softer edges as it uses soft probabilities
obj_mask = (np.isin(mask, target_object)).astype(np.float32)[:, :, np.newaxis]
layer_alpha = layer[:, :, 3].astype(np.float32)[:, :, np.newaxis] / 255
layer_rgb = layer[:, :, :3]
background_alpha = np.maximum(obj_mask, layer_alpha)
im_overlay = (image * (1 - background_alpha) + layer_rgb * (1 - obj_mask) * layer_alpha +
image * obj_mask).clip(0, 255)
return im_overlay.astype(image.dtype)
def overlay_davis_torch(image, mask, alpha=0.5, fade=False):
""" Overlay segmentation on top of RGB image. from davis official"""
# Changes the image in-place to avoid copying
image = image.permute(1, 2, 0)
im_overlay = image
mask = torch.max(mask, dim=0).indices
colored_mask = color_map_torch[mask]
foreground = image*alpha + (1-alpha)*colored_mask
binary_mask = (mask > 0)
# Compose image
im_overlay[binary_mask] = foreground[binary_mask]
if fade:
im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
im_overlay = (im_overlay*255).cpu().numpy()
im_overlay = im_overlay.astype(np.uint8)
return im_overlay
def overlay_popup_torch(image, mask, target_object):
# Keep foreground colored. Convert background to grayscale.
image = image.permute(1, 2, 0)
if len(target_object) == 0:
obj_mask = torch.zeros_like(mask[0]).unsqueeze(2)
else:
# I should not need to convert this to numpy.
# uUsing list works most of the time but consistently fails
# if I include first object -> exclude it -> include it again.
# I check everywhere and it makes absolutely no sense.
# I am blaming this on PyTorch and calling it a day
obj_mask = mask[np.array(target_object,dtype=np.int32)].sum(0).unsqueeze(2)
gray_image = (image*grayscale_weights_torch).sum(-1, keepdim=True)
im_overlay = obj_mask*image + (1-obj_mask)*gray_image
im_overlay = (im_overlay*255).cpu().numpy()
im_overlay = im_overlay.astype(np.uint8)
return im_overlay
def overlay_layer_torch(image, prob, layer, target_object):
# insert a layer between foreground and background
# The CPU version is less accurate because we are using the hard mask
# The GPU version has softer edges as it uses soft probabilities
image = image.permute(1, 2, 0)
if len(target_object) == 0:
obj_mask = torch.zeros_like(prob[0]).unsqueeze(2)
else:
# TODO: figure out why we need to convert this to numpy array
obj_mask = prob[np.array(target_object, dtype=np.int32)].sum(0).unsqueeze(2)
layer_alpha = layer[:, :, 3].unsqueeze(2)
layer_rgb = layer[:, :, :3]
background_alpha = torch.maximum(obj_mask, layer_alpha)
im_overlay = (image * (1 - background_alpha) + layer_rgb * (1 - obj_mask) * layer_alpha +
image * obj_mask).clip(0, 1)
im_overlay = (im_overlay * 255).cpu().numpy()
im_overlay = im_overlay.astype(np.uint8)
return im_overlay
================================================
FILE: XMem/inference/interact/resource_manager.py
================================================
import os
from os import path
import shutil
import collections
import cv2
from PIL import Image
if not hasattr(Image, 'Resampling'): # Pillow<9.0
Image.Resampling = Image
import numpy as np
from util.palette import davis_palette
import progressbar
# https://bugs.python.org/issue28178
# ah python ah why
class LRU:
def __init__(self, func, maxsize=128):
self.cache = collections.OrderedDict()
self.func = func
self.maxsize = maxsize
def __call__(self, *args):
cache = self.cache
if args in cache:
cache.move_to_end(args)
return cache[args]
result = self.func(*args)
cache[args] = result
if len(cache) > self.maxsize:
cache.popitem(last=False)
return result
def invalidate(self, key):
self.cache.pop(key, None)
class ResourceManager:
def __init__(self, config):
# determine inputs
images = config['images']
video = config['video']
self.workspace = config['workspace']
self.size = config['size']
self.palette = davis_palette
# create temporary workspace if not specified
if self.workspace is None:
if images is not None:
basename = path.basename(images)
elif video is not None:
basename = path.basename(video)[:-4]
else:
raise NotImplementedError(
'Either images, video, or workspace has to be specified')
self.workspace = path.join('./workspace', basename)
print(f'Workspace is in: {self.workspace}')
# determine the location of input images
need_decoding = False
need_resizing = False
if path.exists(path.join(self.workspace, 'images')):
pass
elif images is not None:
need_resizing = True
elif video is not None:
# will decode video into frames later
need_decoding = True
# create workspace subdirectories
self.image_dir = path.join(self.workspace, 'images')
self.mask_dir = path.join(self.workspace, 'masks')
os.makedirs(self.image_dir, exist_ok=True)
os.makedirs(self.mask_dir, exist_ok=True)
# convert read functions to be buffered
self.get_image = LRU(self._get_image_unbuffered, maxsize=config['buffer_size'])
self.get_mask = LRU(self._get_mask_unbuffered, maxsize=config['buffer_size'])
# extract frames from video
if need_decoding:
self._extract_frames(video)
# copy/resize existing images to the workspace
if need_resizing:
self._copy_resize_frames(images)
# read all frame names
self.names = sorted(os.listdir(self.image_dir))
self.names = [f[:-4] for f in self.names] # remove extensions
self.length = len(self.names)
assert self.length > 0, f'No images found! Check {self.workspace}/images. Remove folder if necessary.'
print(f'{self.length} images found.')
self.height, self.width = self.get_image(0).shape[:2]
self.visualization_init = False
def _extract_frames(self, video):
cap = cv2.VideoCapture(video)
frame_index = 0
print(f'Extracting frames from {video} into {self.image_dir}...')
bar = progressbar.ProgressBar(max_value=progressbar.UnknownLength)
while(cap.isOpened()):
_, frame = cap.read()
if frame is None:
break
if self.size > 0:
h, w = frame.shape[:2]
new_w = (w*self.size//min(w, h))
new_h = (h*self.size//min(w, h))
if new_w != w or new_h != h:
frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
cv2.imwrite(path.join(self.image_dir, f'{frame_index:07d}.jpg'), frame)
frame_index += 1
bar.update(frame_index)
bar.finish()
print('Done!')
def _copy_resize_frames(self, images):
image_list = os.listdir(images)
print(f'Copying/resizing frames into {self.image_dir}...')
for image_name in progressbar.progressbar(image_list):
if self.size < 0:
# just copy
shutil.copy2(path.join(images, image_name), self.image_dir)
else:
frame = cv2.imread(path.join(images, image_name))
h, w = frame.shape[:2]
new_w = (w*self.size//min(w, h))
new_h = (h*self.size//min(w, h))
if new_w != w or new_h != h:
frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
cv2.imwrite(path.join(self.image_dir, image_name), frame)
print('Done!')
def save_mask(self, ti, mask):
# mask should be uint8 H*W without channels
assert 0 <= ti < self.length
assert isinstance(mask, np.ndarray)
mask = Image.fromarray(mask)
mask.putpalette(self.palette)
mask.save(path.join(self.mask_dir, self.names[ti]+'.png'))
self.invalidate(ti)
def save_visualization(self, ti, image):
# image should be uint8 3*H*W
assert 0 <= ti < self.length
assert isinstance(image, np.ndarray)
if not self.visualization_init:
self.visualization_dir = path.join(self.workspace, 'visualization')
os.makedirs(self.visualization_dir, exist_ok=True)
self.visualization_init = True
image = Image.fromarray(image)
image.save(path.join(self.visualization_dir, self.names[ti]+'.jpg'))
def _get_image_unbuffered(self, ti):
# returns H*W*3 uint8 array
assert 0 <= ti < self.length
image = Image.open(path.join(self.image_dir, self.names[ti]+'.jpg'))
image = np.array(image)
return image
def _get_mask_unbuffered(self, ti):
# returns H*W uint8 array
assert 0 <= ti < self.length
mask_path = path.join(self.mask_dir, self.names[ti]+'.png')
if path.exists(mask_path):
mask = Image.open(mask_path)
mask = np.array(mask)
return mask
else:
return None
def read_external_image(self, file_name, size=None):
image = Image.open(file_name)
is_mask = image.mode in ['L', 'P']
if size is not None:
# PIL uses (width, height)
image = image.resize((size[1], size[0]),
resample=Image.Resampling.NEAREST if is_mask else Image.Resampling.BICUBIC)
image = np.array(image)
return image
def invalidate(self, ti):
# the image buffer is never invalidated
self.get_mask.invalidate((ti,))
def __len__(self):
return self.length
@property
def h(self):
return self.height
@property
def w(self):
return self.width
================================================
FILE: XMem/inference/interact/s2m/__init__.py
================================================
================================================
FILE: XMem/inference/interact/s2m/_deeplab.py
================================================
# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
import torch
from torch import nn
from torch.nn import functional as F
from .utils import _SimpleSegmentationModel
__all__ = ["DeepLabV3"]
class DeepLabV3(_SimpleSegmentationModel):
"""
Implements DeepLabV3 model from
`"Rethinking Atrous Convolution for Semantic Image Segmentation"
`_.
Arguments:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"out" for the last feature map used, and "aux" if an auxiliary classifier
is used.
classifier (nn.Module): module that takes the "out" element returned from
the backbone and returns a dense prediction.
aux_classifier (nn.Module, optional): auxiliary classifier used during training
"""
pass
class DeepLabHeadV3Plus(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHeadV3Plus, self).__init__()
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
low_level_feature = self.project( feature['low_level'] )
output_feature = self.aspp(feature['out'])
output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class DeepLabHead(nn.Module):
def __init__(self, in_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHead, self).__init__()
self.classifier = nn.Sequential(
ASPP(in_channels, aspp_dilate),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
return self.classifier( feature['out'] )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class AtrousSeparableConvolution(nn.Module):
""" Atrous Separable Convolution
"""
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, bias=True):
super(AtrousSeparableConvolution, self).__init__()
self.body = nn.Sequential(
# Separable Conv
nn.Conv2d( in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias, groups=in_channels ),
# PointWise Conv
nn.Conv2d( in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
)
self._init_weight()
def forward(self, x):
return self.body(x)
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
modules = [
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
super(ASPPConv, self).__init__(*modules)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),)
def forward(self, x):
res = []
for conv in self.convs:
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
def convert_to_separable_conv(module):
new_module = module
if isinstance(module, nn.Conv2d) and module.kernel_size[0]>1:
new_module = AtrousSeparableConvolution(module.in_channels,
module.out_channels,
module.kernel_size,
module.stride,
module.padding,
module.dilation,
module.bias)
for name, child in module.named_children():
new_module.add_module(name, convert_to_separable_conv(child))
return new_module
================================================
FILE: XMem/inference/interact/s2m/s2m_network.py
================================================
# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
from .utils import IntermediateLayerGetter
from ._deeplab import DeepLabHead, DeepLabHeadV3Plus, DeepLabV3
from . import s2m_resnet
def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
if output_stride==8:
replace_stride_with_dilation=[False, True, True]
aspp_dilate = [12, 24, 36]
else:
replace_stride_with_dilation=[False, False, True]
aspp_dilate = [6, 12, 18]
backbone = s2m_resnet.__dict__[backbone_name](
pretrained=pretrained_backbone,
replace_stride_with_dilation=replace_stride_with_dilation)
inplanes = 2048
low_level_planes = 256
if name=='deeplabv3plus':
return_layers = {'layer4': 'out', 'layer1': 'low_level'}
classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
elif name=='deeplabv3':
return_layers = {'layer4': 'out'}
classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
model = DeepLabV3(backbone, classifier)
return model
def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
if backbone.startswith('resnet'):
model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
else:
raise NotImplementedError
return model
# Deeplab v3
def deeplabv3_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
"""Constructs a DeepLabV3 model with a ResNet-50 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
# Deeplab v3+
def deeplabv3plus_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
"""Constructs a DeepLabV3 model with a ResNet-50 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
================================================
FILE: XMem/inference/interact/s2m/s2m_resnet.py
================================================
import torch
import torch.nn as nn
try:
from torchvision.models.utils import load_state_dict_from_url
except ModuleNotFoundError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
__all__ = ['ResNet', 'resnet50']
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(6, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def resnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
================================================
FILE: XMem/inference/interact/s2m/utils.py
================================================
# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
from collections import OrderedDict
class _SimpleSegmentationModel(nn.Module):
def __init__(self, backbone, classifier):
super(_SimpleSegmentationModel, self).__init__()
self.backbone = backbone
self.classifier = classifier
def forward(self, x):
input_shape = x.shape[-2:]
features = self.backbone(x)
x = self.classifier(features)
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
return x
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Arguments:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
Examples::
>>> m = torchvision.models.resnet18(pretrained=True)
>>> # extract layer1 and layer3, giving as names `feat1` and feat2`
>>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
>>> {'layer1': 'feat1', 'layer3': 'feat2'})
>>> out = new_m(torch.rand(1, 3, 224, 224))
>>> print([(k, v.shape) for k, v in out.items()])
>>> [('feat1', torch.Size([1, 64, 56, 56])),
>>> ('feat2', torch.Size([1, 256, 14, 14]))]
"""
def __init__(self, model, return_layers):
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {k: v for k, v in return_layers.items()}
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x):
out = OrderedDict()
for name, module in self.named_children():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
================================================
FILE: XMem/inference/interact/s2m_controller.py
================================================
import torch
import numpy as np
from ..interact.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
from util.tensor_util import pad_divide_by, unpad
class S2MController:
"""
A controller for Scribble-to-Mask (for user interaction, not for DAVIS)
Takes the image, previous mask, and scribbles to produce a new mask
ignore_class is usually 255
0 is NOT the ignore class -- it is the label for the background
"""
def __init__(self, s2m_net:S2M, num_objects, ignore_class, device='cuda:0'):
self.s2m_net = s2m_net
self.num_objects = num_objects
self.ignore_class = ignore_class
self.device = device
def interact(self, image, prev_mask, scr_mask):
print(self.device)
image = image.to(self.device, non_blocking=True)
prev_mask = prev_mask.unsqueeze(0)
h, w = image.shape[-2:]
unaggre_mask = torch.zeros((self.num_objects, h, w), dtype=torch.float32, device=image.device)
for ki in range(1, self.num_objects+1):
p_srb = (scr_mask==ki).astype(np.uint8)
n_srb = ((scr_mask!=ki) * (scr_mask!=self.ignore_class)).astype(np.uint8)
Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(image.device)
inputs = torch.cat([image, (prev_mask==ki).float().unsqueeze(0), Rs], 1)
inputs, pads = pad_divide_by(inputs, 16)
unaggre_mask[ki-1] = unpad(torch.sigmoid(self.s2m_net(inputs)), pads)
return unaggre_mask
================================================
FILE: XMem/inference/interact/timer.py
================================================
import time
class Timer:
def __init__(self):
self._acc_time = 0
self._paused = True
def start(self):
if self._paused:
self.last_time = time.time()
self._paused = False
return self
def pause(self):
self.count()
self._paused = True
return self
def count(self):
if self._paused:
return self._acc_time
t = time.time()
self._acc_time += t - self.last_time
self.last_time = t
return self._acc_time
def format(self):
# count = int(self.count()*100)
# return '%02d:%02d:%02d' % (count//6000, (count//100)%60, count%100)
return '%03.2f' % self.count()
def __str__(self):
return self.format()
================================================
FILE: XMem/inference/kv_memory_store.py
================================================
import torch
from typing import List
class KeyValueMemoryStore:
"""
Works for key/value pairs type storage
e.g., working and long-term memory
"""
"""
An object group is created when new objects enter the video
Objects in the same group share the same temporal extent
i.e., objects initialized in the same frame are in the same group
For DAVIS/interactive, there is only one object group
For YouTubeVOS, there can be multiple object groups
"""
def __init__(self, count_usage: bool):
self.count_usage = count_usage
# keys are stored in a single tensor and are shared between groups/objects
# values are stored as a list indexed by object groups
self.k = None
self.v = []
self.obj_groups = []
# for debugging only
self.all_objects = []
# shrinkage and selection are also single tensors
self.s = self.e = None
# usage
if self.count_usage:
self.use_count = self.life_count = None
def add(self, key, value, shrinkage, selection, objects: List[int]):
new_count = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32)
new_life = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32) + 1e-7
# add the key
if self.k is None:
self.k = key
self.s = shrinkage
self.e = selection
if self.count_usage:
self.use_count = new_count
self.life_count = new_life
else:
self.k = torch.cat([self.k, key], -1)
if shrinkage is not None:
self.s = torch.cat([self.s, shrinkage], -1)
if selection is not None:
self.e = torch.cat([self.e, selection], -1)
if self.count_usage:
self.use_count = torch.cat([self.use_count, new_count], -1)
self.life_count = torch.cat([self.life_count, new_life], -1)
# add the value
if objects is not None:
# When objects is given, v is a tensor; used in working memory
assert isinstance(value, torch.Tensor)
# First consume objects that are already in the memory bank
# cannot use set here because we need to preserve order
# shift by one as background is not part of value
remaining_objects = [obj-1 for obj in objects]
for gi, group in enumerate(self.obj_groups):
for obj in group:
# should properly raise an error if there are overlaps in obj_groups
remaining_objects.remove(obj)
self.v[gi] = torch.cat([self.v[gi], value[group]], -1)
# If there are remaining objects, add them as a new group
if len(remaining_objects) > 0:
new_group = list(remaining_objects)
self.v.append(value[new_group])
self.obj_groups.append(new_group)
self.all_objects.extend(new_group)
assert sorted(self.all_objects) == self.all_objects, 'Objects MUST be inserted in sorted order '
else:
# When objects is not given, v is a list that already has the object groups sorted
# used in long-term memory
assert isinstance(value, list)
for gi, gv in enumerate(value):
if gv is None:
continue
if gi < self.num_groups:
self.v[gi] = torch.cat([self.v[gi], gv], -1)
else:
self.v.append(gv)
def update_usage(self, usage):
# increase all life count by 1
# increase use of indexed elements
if not self.count_usage:
return
self.use_count += usage.view_as(self.use_count)
self.life_count += 1
def sieve_by_range(self, start: int, end: int, min_size: int):
# keep only the elements *outside* of this range (with some boundary conditions)
# i.e., concat (a[:start], a[end:])
# min_size is only used for values, we do not sieve values under this size
# (because they are not consolidated)
if end == 0:
# negative 0 would not work as the end index!
self.k = self.k[:,:,:start]
if self.count_usage:
self.use_count = self.use_count[:,:,:start]
self.life_count = self.life_count[:,:,:start]
if self.s is not None:
self.s = self.s[:,:,:start]
if self.e is not None:
self.e = self.e[:,:,:start]
for gi in range(self.num_groups):
if self.v[gi].shape[-1] >= min_size:
self.v[gi] = self.v[gi][:,:,:start]
else:
self.k = torch.cat([self.k[:,:,:start], self.k[:,:,end:]], -1)
if self.count_usage:
self.use_count = torch.cat([self.use_count[:,:,:start], self.use_count[:,:,end:]], -1)
self.life_count = torch.cat([self.life_count[:,:,:start], self.life_count[:,:,end:]], -1)
if self.s is not None:
self.s = torch.cat([self.s[:,:,:start], self.s[:,:,end:]], -1)
if self.e is not None:
self.e = torch.cat([self.e[:,:,:start], self.e[:,:,end:]], -1)
for gi in range(self.num_groups):
if self.v[gi].shape[-1] >= min_size:
self.v[gi] = torch.cat([self.v[gi][:,:,:start], self.v[gi][:,:,end:]], -1)
def remove_obsolete_features(self, max_size: int):
# normalize with life duration
usage = self.get_usage().flatten()
values, _ = torch.topk(usage, k=(self.size-max_size), largest=False, sorted=True)
survived = (usage > values[-1])
self.k = self.k[:, :, survived]
self.s = self.s[:, :, survived] if self.s is not None else None
# Long-term memory does not store ek so this should not be needed
self.e = self.e[:, :, survived] if self.e is not None else None
if self.num_groups > 1:
raise NotImplementedError("""The current data structure does not support feature removal with
multiple object groups (e.g., some objects start to appear later in the video)
The indices for "survived" is based on keys but not all values are present for every key
Basically we need to remap the indices for keys to values
""")
for gi in range(self.num_groups):
self.v[gi] = self.v[gi][:, :, survived]
self.use_count = self.use_count[:, :, survived]
self.life_count = self.life_count[:, :, survived]
def get_usage(self):
# return normalized usage
if not self.count_usage:
raise RuntimeError('I did not count usage!')
else:
usage = self.use_count / self.life_count
return usage
def get_all_sliced(self, start: int, end: int):
# return k, sk, ek, usage in order, sliced by start and end
if end == 0:
# negative 0 would not work as the end index!
k = self.k[:,:,start:]
sk = self.s[:,:,start:] if self.s is not None else None
ek = self.e[:,:,start:] if self.e is not None else None
usage = self.get_usage()[:,:,start:]
else:
k = self.k[:,:,start:end]
sk = self.s[:,:,start:end] if self.s is not None else None
ek = self.e[:,:,start:end] if self.e is not None else None
usage = self.get_usage()[:,:,start:end]
return k, sk, ek, usage
def get_v_size(self, ni: int):
return self.v[ni].shape[2]
def engaged(self):
return self.k is not None
@property
def size(self):
if self.k is None:
return 0
else:
return self.k.shape[-1]
@property
def num_groups(self):
return len(self.v)
@property
def key(self):
return self.k
@property
def value(self):
return self.v
@property
def shrinkage(self):
return self.s
@property
def selection(self):
return self.e
================================================
FILE: XMem/inference/memory_manager.py
================================================
import torch
import warnings
from inference.kv_memory_store import KeyValueMemoryStore
from model.memory_util import *
class MemoryManager:
"""
Manages all three memory stores and the transition between working/long-term memory
"""
def __init__(self, config):
self.hidden_dim = config['hidden_dim']
self.top_k = config['top_k']
self.enable_long_term = config['enable_long_term']
self.enable_long_term_usage = config['enable_long_term_count_usage']
if self.enable_long_term:
self.max_mt_frames = config['max_mid_term_frames']
self.min_mt_frames = config['min_mid_term_frames']
self.num_prototypes = config['num_prototypes']
self.max_long_elements = config['max_long_term_elements']
# dimensions will be inferred from input later
self.CK = self.CV = None
self.H = self.W = None
# The hidden state will be stored in a single tensor for all objects
# B x num_objects x CH x H x W
self.hidden = None
self.work_mem = KeyValueMemoryStore(count_usage=self.enable_long_term)
if self.enable_long_term:
self.long_mem = KeyValueMemoryStore(count_usage=self.enable_long_term_usage)
self.reset_config = True
def update_config(self, config):
self.reset_config = True
self.hidden_dim = config['hidden_dim']
self.top_k = config['top_k']
assert self.enable_long_term == config['enable_long_term'], 'cannot update this'
assert self.enable_long_term_usage == config['enable_long_term_count_usage'], 'cannot update this'
self.enable_long_term_usage = config['enable_long_term_count_usage']
if self.enable_long_term:
self.max_mt_frames = config['max_mid_term_frames']
self.min_mt_frames = config['min_mid_term_frames']
self.num_prototypes = config['num_prototypes']
self.max_long_elements = config['max_long_term_elements']
def _readout(self, affinity, v):
# this function is for a single object group
return v @ affinity
def match_memory(self, query_key, selection):
# query_key: B x C^k x H x W
# selection: B x C^k x H x W
num_groups = self.work_mem.num_groups
h, w = query_key.shape[-2:]
query_key = query_key.flatten(start_dim=2)
selection = selection.flatten(start_dim=2) if selection is not None else None
"""
Memory readout using keys
"""
if self.enable_long_term and self.long_mem.engaged():
# Use long-term memory
long_mem_size = self.long_mem.size
memory_key = torch.cat([self.long_mem.key, self.work_mem.key], -1)
shrinkage = torch.cat([self.long_mem.shrinkage, self.work_mem.shrinkage], -1)
similarity = get_similarity(memory_key, shrinkage, query_key, selection)
work_mem_similarity = similarity[:, long_mem_size:]
long_mem_similarity = similarity[:, :long_mem_size]
# get the usage with the first group
# the first group always have all the keys valid
affinity, usage = do_softmax(
torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(0):], work_mem_similarity], 1),
top_k=self.top_k, inplace=True, return_usage=True)
affinity = [affinity]
# compute affinity group by group as later groups only have a subset of keys
for gi in range(1, num_groups):
if gi < self.long_mem.num_groups:
# merge working and lt similarities before softmax
affinity_one_group = do_softmax(
torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(gi):],
work_mem_similarity[:, -self.work_mem.get_v_size(gi):]], 1),
top_k=self.top_k, inplace=True)
else:
# no long-term memory for this group
affinity_one_group = do_softmax(work_mem_similarity[:, -self.work_mem.get_v_size(gi):],
top_k=self.top_k, inplace=(gi==num_groups-1))
affinity.append(affinity_one_group)
all_memory_value = []
for gi, gv in enumerate(self.work_mem.value):
# merge the working and lt values before readout
if gi < self.long_mem.num_groups:
all_memory_value.append(torch.cat([self.long_mem.value[gi], self.work_mem.value[gi]], -1))
else:
all_memory_value.append(gv)
"""
Record memory usage for working and long-term memory
"""
# ignore the index return for long-term memory
work_usage = usage[:, long_mem_size:]
self.work_mem.update_usage(work_usage.flatten())
if self.enable_long_term_usage:
# ignore the index return for working memory
long_usage = usage[:, :long_mem_size]
self.long_mem.update_usage(long_usage.flatten())
else:
# No long-term memory
similarity = get_similarity(self.work_mem.key, self.work_mem.shrinkage, query_key, selection)
if self.enable_long_term:
affinity, usage = do_softmax(similarity, inplace=(num_groups==1),
top_k=self.top_k, return_usage=True)
# Record memory usage for working memory
self.work_mem.update_usage(usage.flatten())
else:
affinity = do_softmax(similarity, inplace=(num_groups==1),
top_k=self.top_k, return_usage=False)
affinity = [affinity]
# compute affinity group by group as later groups only have a subset of keys
for gi in range(1, num_groups):
affinity_one_group = do_softmax(similarity[:, -self.work_mem.get_v_size(gi):],
top_k=self.top_k, inplace=(gi==num_groups-1))
affinity.append(affinity_one_group)
all_memory_value = self.work_mem.value
# Shared affinity within each group
all_readout_mem = torch.cat([
self._readout(affinity[gi], gv)
for gi, gv in enumerate(all_memory_value)
], 0)
return all_readout_mem.view(all_readout_mem.shape[0], self.CV, h, w)
def add_memory(self, key, shrinkage, value, objects, selection=None):
# key: 1*C*H*W
# value: 1*num_objects*C*H*W
# objects contain a list of object indices
if self.H is None or self.reset_config:
self.reset_config = False
self.H, self.W = key.shape[-2:]
self.HW = self.H*self.W
if self.enable_long_term:
# convert from num. frames to num. nodes
self.min_work_elements = self.min_mt_frames*self.HW
self.max_work_elements = self.max_mt_frames*self.HW
# key: 1*C*N
# value: num_objects*C*N
key = key.flatten(start_dim=2)
shrinkage = shrinkage.flatten(start_dim=2)
value = value[0].flatten(start_dim=2)
self.CK = key.shape[1]
self.CV = value.shape[1]
if selection is not None:
if not self.enable_long_term:
warnings.warn('the selection factor is only needed in long-term mode', UserWarning)
selection = selection.flatten(start_dim=2)
self.work_mem.add(key, value, shrinkage, selection, objects)
# long-term memory cleanup
if self.enable_long_term:
# Do memory compressed if needed
if self.work_mem.size >= self.max_work_elements:
# Remove obsolete features if needed
if self.long_mem.size >= (self.max_long_elements-self.num_prototypes):
self.long_mem.remove_obsolete_features(self.max_long_elements-self.num_prototypes)
self.compress_features()
def create_hidden_state(self, n, sample_key):
# n is the TOTAL number of objects
h, w = sample_key.shape[-2:]
if self.hidden is None:
self.hidden = torch.zeros((1, n, self.hidden_dim, h, w), device=sample_key.device)
elif self.hidden.shape[1] != n:
self.hidden = torch.cat([
self.hidden,
torch.zeros((1, n-self.hidden.shape[1], self.hidden_dim, h, w), device=sample_key.device)
], 1)
assert(self.hidden.shape[1] == n)
def set_hidden(self, hidden):
self.hidden = hidden
def get_hidden(self):
return self.hidden
def compress_features(self):
HW = self.HW
candidate_value = []
total_work_mem_size = self.work_mem.size
for gv in self.work_mem.value:
# Some object groups might be added later in the video
# So not all keys have values associated with all objects
# We need to keep track of the key->value validity
mem_size_in_this_group = gv.shape[-1]
if mem_size_in_this_group == total_work_mem_size:
# full LT
candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
else:
# mem_size is smaller than total_work_mem_size, but at least HW
assert HW <= mem_size_in_this_group < total_work_mem_size
if mem_size_in_this_group > self.min_work_elements+HW:
# part of this object group still goes into LT
candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
else:
# this object group cannot go to the LT at all
candidate_value.append(None)
# perform memory consolidation
prototype_key, prototype_value, prototype_shrinkage = self.consolidation(
*self.work_mem.get_all_sliced(HW, -self.min_work_elements+HW), candidate_value)
# remove consolidated working memory
self.work_mem.sieve_by_range(HW, -self.min_work_elements+HW, min_size=self.min_work_elements+HW)
# add to long-term memory
self.long_mem.add(prototype_key, prototype_value, prototype_shrinkage, selection=None, objects=None)
def consolidation(self, candidate_key, candidate_shrinkage, candidate_selection, usage, candidate_value):
# keys: 1*C*N
# values: num_objects*C*N
N = candidate_key.shape[-1]
# find the indices with max usage
_, max_usage_indices = torch.topk(usage, k=self.num_prototypes, dim=-1, sorted=True)
prototype_indices = max_usage_indices.flatten()
# Prototypes are invalid for out-of-bound groups
validity = [prototype_indices >= (N-gv.shape[2]) if gv is not None else None for gv in candidate_value]
prototype_key = candidate_key[:, :, prototype_indices]
prototype_selection = candidate_selection[:, :, prototype_indices] if candidate_selection is not None else None
"""
Potentiation step
"""
similarity = get_similarity(candidate_key, candidate_shrinkage, prototype_key, prototype_selection)
# convert similarity to affinity
# need to do it group by group since the softmax normalization would be different
affinity = [
do_softmax(similarity[:, -gv.shape[2]:, validity[gi]]) if gv is not None else None
for gi, gv in enumerate(candidate_value)
]
# some values can be have all False validity. Weed them out.
affinity = [
aff if aff is None or aff.shape[-1] > 0 else None for aff in affinity
]
# readout the values
prototype_value = [
self._readout(affinity[gi], gv) if affinity[gi] is not None else None
for gi, gv in enumerate(candidate_value)
]
# readout the shrinkage term
prototype_shrinkage = self._readout(affinity[0], candidate_shrinkage) if candidate_shrinkage is not None else None
return prototype_key, prototype_value, prototype_shrinkage
================================================
FILE: XMem/interactive_demo.py
================================================
"""
A simple user interface for XMem
"""
import os
from os import path
# fix for Windows
if 'QT_QPA_PLATFORM_PLUGIN_PATH' not in os.environ:
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = ''
import signal
signal.signal(signal.SIGINT, signal.SIG_DFL)
import sys
from argparse import ArgumentParser
import torch
from model.network import XMem
from inference.interact.s2m_controller import S2MController
from inference.interact.fbrs_controller import FBRSController
from inference.interact.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
from PySide6.QtWidgets import QApplication
from inference.interact.gui import App
from inference.interact.resource_manager import ResourceManager
from contextlib import nullcontext
torch.set_grad_enabled(False)
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
if __name__ == '__main__':
# Arguments parsing
parser = ArgumentParser()
parser.add_argument('--model', default='./saves/XMem.pth')
parser.add_argument('--s2m_model', default='saves/s2m.pth')
parser.add_argument('--fbrs_model', default='saves/fbrs.pth')
"""
Priority 1: If a "images" folder exists in the workspace, we will read from that directory
Priority 2: If --images is specified, we will copy/resize those images to the workspace
Priority 3: If --video is specified, we will extract the frames to the workspace (in an "images" folder) and read from there
In any case, if a "masks" folder exists in the workspace, we will use that to initialize the mask
That way, you can continue annotation from an interrupted run as long as the same workspace is used.
"""
parser.add_argument('--images', help='Folders containing input images.', default=None)
parser.add_argument('--video', help='Video file readable by OpenCV.', default=None)
parser.add_argument('--workspace', help='directory for storing buffered images (if needed) and output masks', default=None)
parser.add_argument('--buffer_size', help='Correlate with CPU memory consumption', type=int, default=100)
parser.add_argument('--num_objects', type=int, default=1)
# Long-memory options
# Defaults. Some can be changed in the GUI.
parser.add_argument('--max_mid_term_frames', help='T_max in paper, decrease to save memory', type=int, default=10)
parser.add_argument('--min_mid_term_frames', help='T_min in paper, decrease to save memory', type=int, default=5)
parser.add_argument('--max_long_term_elements', help='LT_max in paper, increase if objects disappear for a long time',
type=int, default=10000)
parser.add_argument('--num_prototypes', help='P in paper', type=int, default=128)
parser.add_argument('--top_k', type=int, default=30)
parser.add_argument('--mem_every', type=int, default=10)
parser.add_argument('--deep_update_every', help='Leave -1 normally to synchronize with mem_every', type=int, default=-1)
parser.add_argument('--no_amp', help='Turn off AMP', action='store_true')
parser.add_argument('--size', default=480, type=int,
help='Resize the shorter side to this size. -1 to use original resolution. ')
args = parser.parse_args()
# create temporary workspace if not specified
config = vars(args)
config['enable_long_term'] = True
config['enable_long_term_count_usage'] = True
if config["workspace"] is None:
if config["images"] is not None:
basename = path.basename(config["images"])
elif config["video"] is not None:
basename = path.basename(config["video"])[:-4]
else:
raise NotImplementedError(
'Either images, video, or workspace has to be specified')
config["workspace"] = path.join('./workspace', basename)
with torch.cuda.amp.autocast(enabled=not args.no_amp) if device.type == 'cuda' else nullcontext():
# Load our checkpoint
network = XMem(config, args.model, map_location=device).to(device).eval()
# Loads the S2M model
if args.s2m_model is not None:
s2m_saved = torch.load(args.s2m_model, map_location=device)
s2m_model = S2M().to(device).eval()
s2m_model.load_state_dict(s2m_saved)
else:
s2m_model = None
s2m_controller = S2MController(s2m_model, args.num_objects, ignore_class=255, device=device)
if args.fbrs_model is not None:
fbrs_controller = FBRSController(args.fbrs_model, device=device)
else:
fbrs_controller = None
# Manages most IO
resource_manager = ResourceManager(config)
app = QApplication(sys.argv)
ex = App(network, resource_manager, s2m_controller, fbrs_controller, config, device)
sys.exit(app.exec())
================================================
FILE: XMem/merge_multi_scale.py
================================================
import os
from os import path
from argparse import ArgumentParser
import glob
from collections import defaultdict
import numpy as np
import hickle as hkl
from PIL import Image, ImagePalette
from progressbar import progressbar
from multiprocessing import Pool
from util import palette
from util.palette import davis_palette, youtube_palette
import shutil
def search_options(options, name):
for option in options:
if path.exists(path.join(option, name)):
return path.join(option, name)
else:
return None
def process_vid(vid):
vid_path = search_options(all_options, vid)
if vid_path is not None:
backward_mapping = hkl.load(path.join(vid_path, 'backward.hkl'))
else:
backward_mapping = None
frames = os.listdir(path.join(all_options[0], vid))
frames = [f for f in frames if 'backward' not in f]
print(vid)
if 'Y' in args.dataset:
this_out_path = path.join(out_path, 'Annotations', vid)
else:
this_out_path = path.join(out_path, vid)
os.makedirs(this_out_path, exist_ok=True)
for f in frames:
result_sum = None
for option in all_options:
if not path.exists(path.join(option, vid, f)):
continue
result = hkl.load(path.join(option, vid, f))
if result_sum is None:
result_sum = result.astype(np.float32)
else:
result_sum += result
# argmax and to idx
result_sum = np.argmax(result_sum, axis=0)
# Remap the indices to the original domain
if backward_mapping is not None:
idx_mask = np.zeros_like(result_sum, dtype=np.uint8)
for l, i in backward_mapping.items():
idx_mask[result_sum==i] = l
else:
idx_mask = result_sum.astype(np.uint8)
# Save the results
img_E = Image.fromarray(idx_mask)
img_E.putpalette(palette)
img_E.save(path.join(this_out_path, f[:-4]+'.png'))
if __name__ == '__main__':
"""
Arguments loading
"""
parser = ArgumentParser()
parser.add_argument('--dataset', default='Y', help='D/Y, D for DAVIS; Y for YouTubeVOS')
parser.add_argument('--list', nargs="+")
parser.add_argument('--pattern', default=None, help='Glob patten. Can be used in place of list.')
parser.add_argument('--output')
parser.add_argument('--num_proc', default=4, type=int)
args = parser.parse_args()
out_path = args.output
# Find the input candidates
if args.pattern is None:
all_options = args.list
else:
assert args.list is None, 'cannot specify both list and pattern'
all_options = glob.glob(args.pattern)
# Get the correct palette
if 'D' in args.dataset:
palette = ImagePalette.ImagePalette(mode='P', palette=davis_palette)
elif 'Y' in args.dataset:
palette = ImagePalette.ImagePalette(mode='P', palette=youtube_palette)
else:
raise NotImplementedError
# Count of the number of videos in each candidate
all_options = [path.join(o, 'Scores') for o in all_options]
vid_count = defaultdict(int)
for option in all_options:
vid_in_here = sorted(os.listdir(option))
for vid in vid_in_here:
vid_count[vid] += 1
all_vid = []
count_to_vid = defaultdict(int)
for k, v in vid_count.items():
count_to_vid[v] += 1
all_vid.append(k)
for k, v in count_to_vid.items():
print('Videos with count %d: %d' % (k, v))
all_vid = sorted(all_vid)
print('Total number of videos: ', len(all_vid))
pool = Pool(processes=args.num_proc)
for _ in progressbar(pool.imap_unordered(process_vid, all_vid), max_value=len(all_vid)):
pass
pool.close()
pool.join()
if 'D' in args.dataset:
print('Making zip for DAVIS test-dev...')
shutil.make_archive(args.output, 'zip', args.output)
if 'Y' in args.dataset:
print('Making zip for YouTubeVOS...')
shutil.make_archive(path.join(args.output, path.basename(args.output)), 'zip', args.output, 'Annotations')
================================================
FILE: XMem/merge_results.py
================================================
import glob
import os
from PIL import Image
import numpy as np
import tqdm
import multiprocessing
multi_dir = "mevis_val/vis_output/"
outdir = "mevis_val_merge/vis_output/"
all_obj_list = []
video_list = glob.glob(os.path.join(multi_dir, "0/*"))
for video in video_list:
obj_list = glob.glob(video + "/*")
all_obj_list = all_obj_list + ['/'.join(i.split('/')[-2:]) for i in obj_list]
def merge(obj):
obj_output_dir = os.path.join(outdir, obj)
os.makedirs(obj_output_dir, exist_ok=True)
img_list = [i.split('/')[-1] for i in glob.glob(os.path.join(multi_dir, "0", obj, "*.png"))]
for img_name in img_list:
agg_img = None
for i in range(7):
img_path = os.path.join(multi_dir, str(i), obj, img_name)
tmp_img = (np.array(Image.open(img_path)) > 0).astype(np.uint8)
if agg_img is not None:
agg_img = agg_img + tmp_img
else:
agg_img = tmp_img
agg_img = (agg_img >= 4).astype(np.uint8)
agg_img = Image.fromarray(agg_img)
img_output_path = os.path.join(obj_output_dir, img_name)
agg_img.save(img_output_path)
print('start')
cpu_num = multiprocessing.cpu_count()-1
print("cpu_num:", cpu_num)
pool = multiprocessing.Pool(cpu_num)
for obj in all_obj_list:
pool.apply_async(merge, args=(obj,))
pool.close()
pool.join()
================================================
FILE: XMem/model/__init__.py
================================================
================================================
FILE: XMem/model/aggregate.py
================================================
import torch
import torch.nn.functional as F
# Soft aggregation from STM
def aggregate(prob, dim, return_logits=False):
new_prob = torch.cat([
torch.prod(1-prob, dim=dim, keepdim=True),
prob
], dim).clamp(1e-7, 1-1e-7)
logits = torch.log((new_prob /(1-new_prob)))
prob = F.softmax(logits, dim=dim)
if return_logits:
return logits, prob
else:
return prob
================================================
FILE: XMem/model/cbam.py
================================================
# Modified from https://github.com/Jongchan/attention-module/blob/master/MODELS/cbam.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
def forward(self, x):
x = self.conv(x)
return x
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type=='avg':
avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( avg_pool )
elif pool_type=='max':
max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( max_pool )
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = torch.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out
================================================
FILE: XMem/model/group_modules.py
================================================
"""
Group-specific modules
They handle features that also depends on the mask.
Features are typically of shape
batch_size * num_objects * num_channels * H * W
All of them are permutation equivariant w.r.t. to the num_objects dimension
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def interpolate_groups(g, ratio, mode, align_corners):
batch_size, num_objects = g.shape[:2]
g = F.interpolate(g.flatten(start_dim=0, end_dim=1),
scale_factor=ratio, mode=mode, align_corners=align_corners)
g = g.view(batch_size, num_objects, *g.shape[1:])
return g
def upsample_groups(g, ratio=2, mode='bilinear', align_corners=False):
return interpolate_groups(g, ratio, mode, align_corners)
def downsample_groups(g, ratio=1/2, mode='area', align_corners=None):
return interpolate_groups(g, ratio, mode, align_corners)
class GConv2D(nn.Conv2d):
def forward(self, g):
batch_size, num_objects = g.shape[:2]
g = super().forward(g.flatten(start_dim=0, end_dim=1))
return g.view(batch_size, num_objects, *g.shape[1:])
class GroupResBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super().__init__()
if in_dim == out_dim:
self.downsample = None
else:
self.downsample = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
self.conv1 = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
self.conv2 = GConv2D(out_dim, out_dim, kernel_size=3, padding=1)
def forward(self, g):
out_g = self.conv1(F.relu(g))
out_g = self.conv2(F.relu(out_g))
if self.downsample is not None:
g = self.downsample(g)
return out_g + g
class MainToGroupDistributor(nn.Module):
def __init__(self, x_transform=None, method='cat', reverse_order=False):
super().__init__()
self.x_transform = x_transform
self.method = method
self.reverse_order = reverse_order
def forward(self, x, g):
num_objects = g.shape[1]
if self.x_transform is not None:
x = self.x_transform(x)
if self.method == 'cat':
if self.reverse_order:
g = torch.cat([g, x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1)], 2)
else:
g = torch.cat([x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1), g], 2)
elif self.method == 'add':
g = x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1) + g
else:
raise NotImplementedError
return g
================================================
FILE: XMem/model/losses.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import defaultdict
def dice_loss(input_mask, cls_gt):
num_objects = input_mask.shape[1]
losses = []
for i in range(num_objects):
mask = input_mask[:,i].flatten(start_dim=1)
# background not in mask, so we add one to cls_gt
gt = (cls_gt==(i+1)).float().flatten(start_dim=1)
numerator = 2 * (mask * gt).sum(-1)
denominator = mask.sum(-1) + gt.sum(-1)
loss = 1 - (numerator + 1) / (denominator + 1)
losses.append(loss)
return torch.cat(losses).mean()
# https://stackoverflow.com/questions/63735255/how-do-i-compute-bootstrapped-cross-entropy-loss-in-pytorch
class BootstrappedCE(nn.Module):
def __init__(self, start_warm, end_warm, top_p=0.15):
super().__init__()
self.start_warm = start_warm
self.end_warm = end_warm
self.top_p = top_p
def forward(self, input, target, it):
if it < self.start_warm:
return F.cross_entropy(input, target), 1.0
raw_loss = F.cross_entropy(input, target, reduction='none').view(-1)
num_pixels = raw_loss.numel()
if it > self.end_warm:
this_p = self.top_p
else:
this_p = self.top_p + (1-self.top_p)*((self.end_warm-it)/(self.end_warm-self.start_warm))
loss, _ = torch.topk(raw_loss, int(num_pixels * this_p), sorted=False)
return loss.mean(), this_p
class LossComputer:
def __init__(self, config):
super().__init__()
self.config = config
self.bce = BootstrappedCE(config['start_warm'], config['end_warm'])
def compute(self, data, num_objects, it):
losses = defaultdict(int)
b, t = data['rgb'].shape[:2]
losses['total_loss'] = 0
for ti in range(1, t):
for bi in range(b):
loss, p = self.bce(data[f'logits_{ti}'][bi:bi+1, :num_objects[bi]+1], data['cls_gt'][bi:bi+1,ti,0], it)
losses['p'] += p / b / (t-1)
losses[f'ce_loss_{ti}'] += loss / b
losses['total_loss'] += losses['ce_loss_%d'%ti]
losses[f'dice_loss_{ti}'] = dice_loss(data[f'masks_{ti}'], data['cls_gt'][:,ti,0])
losses['total_loss'] += losses[f'dice_loss_{ti}']
return losses
================================================
FILE: XMem/model/memory_util.py
================================================
import math
import numpy as np
import torch
from typing import Optional
def get_similarity(mk, ms, qk, qe):
# used for training/inference and memory reading/memory potentiation
# mk: B x CK x [N] - Memory keys
# ms: B x 1 x [N] - Memory shrinkage
# qk: B x CK x [HW/P] - Query keys
# qe: B x CK x [HW/P] - Query selection
# Dimensions in [] are flattened
CK = mk.shape[1]
mk = mk.flatten(start_dim=2)
ms = ms.flatten(start_dim=1).unsqueeze(2) if ms is not None else None
qk = qk.flatten(start_dim=2)
qe = qe.flatten(start_dim=2) if qe is not None else None
if qe is not None:
# See appendix for derivation
# or you can just trust me ヽ(ー_ー )ノ
mk = mk.transpose(1, 2)
a_sq = (mk.pow(2) @ qe)
two_ab = 2 * (mk @ (qk * qe))
b_sq = (qe * qk.pow(2)).sum(1, keepdim=True)
similarity = (-a_sq+two_ab-b_sq)
else:
# similar to STCN if we don't have the selection term
a_sq = mk.pow(2).sum(1).unsqueeze(2)
two_ab = 2 * (mk.transpose(1, 2) @ qk)
similarity = (-a_sq+two_ab)
if ms is not None:
similarity = similarity * ms / math.sqrt(CK) # B*N*HW
else:
similarity = similarity / math.sqrt(CK) # B*N*HW
return similarity
def do_softmax(similarity, top_k: Optional[int]=None, inplace=False, return_usage=False):
# normalize similarity with top-k softmax
# similarity: B x N x [HW/P]
# use inplace with care
if top_k is not None:
values, indices = torch.topk(similarity, k=top_k, dim=1)
x_exp = values.exp_()
x_exp /= torch.sum(x_exp, dim=1, keepdim=True)
if inplace:
similarity.zero_().scatter_(1, indices, x_exp) # B*N*HW
affinity = similarity
else:
affinity = torch.zeros_like(similarity).scatter_(1, indices, x_exp) # B*N*HW
else:
maxes = torch.max(similarity, dim=1, keepdim=True)[0]
x_exp = torch.exp(similarity - maxes)
x_exp_sum = torch.sum(x_exp, dim=1, keepdim=True)
affinity = x_exp / x_exp_sum
indices = None
if return_usage:
return affinity, affinity.sum(dim=2)
return affinity
def get_affinity(mk, ms, qk, qe):
# shorthand used in training with no top-k
similarity = get_similarity(mk, ms, qk, qe)
affinity = do_softmax(similarity)
return affinity
def readout(affinity, mv):
B, CV, T, H, W = mv.shape
mo = mv.view(B, CV, T*H*W)
mem = torch.bmm(mo, affinity)
mem = mem.view(B, CV, H, W)
return mem
================================================
FILE: XMem/model/modules.py
================================================
"""
modules.py - This file stores the rather boring network blocks.
x - usually means features that only depends on the image
g - usually means features that also depends on the mask.
They might have an extra "group" or "num_objects" dimension, hence
batch_size * num_objects * num_channels * H * W
The trailing number of a variable usually denote the stride
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.group_modules import *
from model import resnet
from model.cbam import CBAM
class FeatureFusionBlock(nn.Module):
def __init__(self, x_in_dim, g_in_dim, g_mid_dim, g_out_dim):
super().__init__()
self.distributor = MainToGroupDistributor()
self.block1 = GroupResBlock(x_in_dim+g_in_dim, g_mid_dim)
self.attention = CBAM(g_mid_dim)
self.block2 = GroupResBlock(g_mid_dim, g_out_dim)
def forward(self, x, g):
batch_size, num_objects = g.shape[:2]
g = self.distributor(x, g)
g = self.block1(g)
r = self.attention(g.flatten(start_dim=0, end_dim=1))
r = r.view(batch_size, num_objects, *r.shape[1:])
g = self.block2(g+r)
return g
class HiddenUpdater(nn.Module):
# Used in the decoder, multi-scale feature + GRU
def __init__(self, g_dims, mid_dim, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.g16_conv = GConv2D(g_dims[0], mid_dim, kernel_size=1)
self.g8_conv = GConv2D(g_dims[1], mid_dim, kernel_size=1)
self.g4_conv = GConv2D(g_dims[2], mid_dim, kernel_size=1)
self.transform = GConv2D(mid_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
nn.init.xavier_normal_(self.transform.weight)
def forward(self, g, h):
g = self.g16_conv(g[0]) + self.g8_conv(downsample_groups(g[1], ratio=1/2)) + \
self.g4_conv(downsample_groups(g[2], ratio=1/4))
g = torch.cat([g, h], 2)
# defined slightly differently than standard GRU,
# namely the new value is generated before the forget gate.
# might provide better gradient but frankly it was initially just an
# implementation error that I never bothered fixing
values = self.transform(g)
forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
return new_h
class HiddenReinforcer(nn.Module):
# Used in the value encoder, a single GRU
def __init__(self, g_dim, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.transform = GConv2D(g_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
nn.init.xavier_normal_(self.transform.weight)
def forward(self, g, h):
g = torch.cat([g, h], 2)
# defined slightly differently than standard GRU,
# namely the new value is generated before the forget gate.
# might provide better gradient but frankly it was initially just an
# implementation error that I never bothered fixing
values = self.transform(g)
forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
return new_h
class ValueEncoder(nn.Module):
def __init__(self, value_dim, hidden_dim, single_object=False):
super().__init__()
self.single_object = single_object
network = resnet.resnet18(pretrained=True, extra_dim=1 if single_object else 2)
self.conv1 = network.conv1
self.bn1 = network.bn1
self.relu = network.relu # 1/2, 64
self.maxpool = network.maxpool
self.layer1 = network.layer1 # 1/4, 64
self.layer2 = network.layer2 # 1/8, 128
self.layer3 = network.layer3 # 1/16, 256
self.distributor = MainToGroupDistributor()
self.fuser = FeatureFusionBlock(1024, 256, value_dim, value_dim)
if hidden_dim > 0:
self.hidden_reinforce = HiddenReinforcer(value_dim, hidden_dim)
else:
self.hidden_reinforce = None
def forward(self, image, image_feat_f16, h, masks, others, is_deep_update=True):
# image_feat_f16 is the feature from the key encoder
if not self.single_object:
g = torch.stack([masks, others], 2)
else:
g = masks.unsqueeze(2)
g = self.distributor(image, g)
batch_size, num_objects = g.shape[:2]
g = g.flatten(start_dim=0, end_dim=1)
g = self.conv1(g)
g = self.bn1(g) # 1/2, 64
g = self.maxpool(g) # 1/4, 64
g = self.relu(g)
g = self.layer1(g) # 1/4
g = self.layer2(g) # 1/8
g = self.layer3(g) # 1/16
g = g.view(batch_size, num_objects, *g.shape[1:])
g = self.fuser(image_feat_f16, g)
if is_deep_update and self.hidden_reinforce is not None:
h = self.hidden_reinforce(g, h)
return g, h
class KeyEncoder(nn.Module):
def __init__(self):
super().__init__()
network = resnet.resnet50(pretrained=True)
self.conv1 = network.conv1
self.bn1 = network.bn1
self.relu = network.relu # 1/2, 64
self.maxpool = network.maxpool
self.res2 = network.layer1 # 1/4, 256
self.layer2 = network.layer2 # 1/8, 512
self.layer3 = network.layer3 # 1/16, 1024
def forward(self, f):
x = self.conv1(f)
x = self.bn1(x)
x = self.relu(x) # 1/2, 64
x = self.maxpool(x) # 1/4, 64
f4 = self.res2(x) # 1/4, 256
f8 = self.layer2(f4) # 1/8, 512
f16 = self.layer3(f8) # 1/16, 1024
return f16, f8, f4
class UpsampleBlock(nn.Module):
def __init__(self, skip_dim, g_up_dim, g_out_dim, scale_factor=2):
super().__init__()
self.skip_conv = nn.Conv2d(skip_dim, g_up_dim, kernel_size=3, padding=1)
self.distributor = MainToGroupDistributor(method='add')
self.out_conv = GroupResBlock(g_up_dim, g_out_dim)
self.scale_factor = scale_factor
def forward(self, skip_f, up_g):
skip_f = self.skip_conv(skip_f)
g = upsample_groups(up_g, ratio=self.scale_factor)
g = self.distributor(skip_f, g)
g = self.out_conv(g)
return g
class KeyProjection(nn.Module):
def __init__(self, in_dim, keydim):
super().__init__()
self.key_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
# shrinkage
self.d_proj = nn.Conv2d(in_dim, 1, kernel_size=3, padding=1)
# selection
self.e_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
nn.init.orthogonal_(self.key_proj.weight.data)
nn.init.zeros_(self.key_proj.bias.data)
def forward(self, x, need_s, need_e):
shrinkage = self.d_proj(x)**2 + 1 if (need_s) else None
selection = torch.sigmoid(self.e_proj(x)) if (need_e) else None
return self.key_proj(x), shrinkage, selection
class Decoder(nn.Module):
def __init__(self, val_dim, hidden_dim):
super().__init__()
self.fuser = FeatureFusionBlock(1024, val_dim+hidden_dim, 512, 512)
if hidden_dim > 0:
self.hidden_update = HiddenUpdater([512, 256, 256+1], 256, hidden_dim)
else:
self.hidden_update = None
self.up_16_8 = UpsampleBlock(512, 512, 256) # 1/16 -> 1/8
self.up_8_4 = UpsampleBlock(256, 256, 256) # 1/8 -> 1/4
self.pred = nn.Conv2d(256, 1, kernel_size=3, padding=1, stride=1)
def forward(self, f16, f8, f4, hidden_state, memory_readout, h_out=True):
batch_size, num_objects = memory_readout.shape[:2]
if self.hidden_update is not None:
g16 = self.fuser(f16, torch.cat([memory_readout, hidden_state], 2))
else:
g16 = self.fuser(f16, memory_readout)
g8 = self.up_16_8(f8, g16)
g4 = self.up_8_4(f4, g8)
logits = self.pred(F.relu(g4.flatten(start_dim=0, end_dim=1)))
if h_out and self.hidden_update is not None:
g4 = torch.cat([g4, logits.view(batch_size, num_objects, 1, *logits.shape[-2:])], 2)
hidden_state = self.hidden_update([g16, g8, g4], hidden_state)
else:
hidden_state = None
logits = F.interpolate(logits, scale_factor=4, mode='bilinear', align_corners=False)
logits = logits.view(batch_size, num_objects, *logits.shape[-2:])
return hidden_state, logits
================================================
FILE: XMem/model/network.py
================================================
"""
This file defines XMem, the highest level nn.Module interface
During training, it is used by trainer.py
During evaluation, it is used by inference_core.py
It further depends on modules.py which gives more detailed implementations of sub-modules
"""
import torch
import torch.nn as nn
from loguru import logger
from model.aggregate import aggregate
from model.modules import *
from model.memory_util import *
class XMem(nn.Module):
def __init__(self, config, model_path=None, map_location=None):
"""
model_path/map_location are used in evaluation only
map_location is for converting models saved in cuda to cpu
"""
super().__init__()
model_weights = self.init_hyperparameters(config, model_path, map_location)
self.single_object = config.get('single_object', False)
print(f'Single object mode: {self.single_object}')
self.key_encoder = KeyEncoder()
self.value_encoder = ValueEncoder(self.value_dim, self.hidden_dim, self.single_object)
# Projection from f16 feature space to key/value space
self.key_proj = KeyProjection(1024, self.key_dim)
self.decoder = Decoder(self.value_dim, self.hidden_dim)
if model_weights is not None:
self.load_weights(model_weights, init_as_zero_if_needed=True)
def encode_key(self, frame, need_sk=True, need_ek=True):
# Determine input shape
if len(frame.shape) == 5:
# shape is b*t*c*h*w
need_reshape = True
b, t = frame.shape[:2]
# flatten so that we can feed them into a 2D CNN
frame = frame.flatten(start_dim=0, end_dim=1)
elif len(frame.shape) == 4:
# shape is b*c*h*w
need_reshape = False
else:
raise NotImplementedError
f16, f8, f4 = self.key_encoder(frame)
key, shrinkage, selection = self.key_proj(f16, need_sk, need_ek)
if need_reshape:
# B*C*T*H*W
key = key.view(b, t, *key.shape[-3:]).transpose(1, 2).contiguous()
if shrinkage is not None:
shrinkage = shrinkage.view(b, t, *shrinkage.shape[-3:]).transpose(1, 2).contiguous()
if selection is not None:
selection = selection.view(b, t, *selection.shape[-3:]).transpose(1, 2).contiguous()
# B*T*C*H*W
f16 = f16.view(b, t, *f16.shape[-3:])
f8 = f8.view(b, t, *f8.shape[-3:])
f4 = f4.view(b, t, *f4.shape[-3:])
return key, shrinkage, selection, f16, f8, f4
def encode_value(self, frame, image_feat_f16, h16, masks, is_deep_update=True):
num_objects = masks.shape[1]
if num_objects != 1:
others = torch.cat([
torch.sum(
masks[:, [j for j in range(num_objects) if i!=j]]
, dim=1, keepdim=True)
for i in range(num_objects)], 1)
else:
others = torch.zeros_like(masks)
g16, h16 = self.value_encoder(frame, image_feat_f16, h16, masks, others, is_deep_update)
return g16, h16
# Used in training only.
# This step is replaced by MemoryManager in test time
def read_memory(self, query_key, query_selection, memory_key,
memory_shrinkage, memory_value):
"""
query_key : B * CK * H * W
query_selection : B * CK * H * W
memory_key : B * CK * T * H * W
memory_shrinkage: B * 1 * T * H * W
memory_value : B * num_objects * CV * T * H * W
"""
batch_size, num_objects = memory_value.shape[:2]
memory_value = memory_value.flatten(start_dim=1, end_dim=2)
affinity = get_affinity(memory_key, memory_shrinkage, query_key, query_selection)
memory = readout(affinity, memory_value)
memory = memory.view(batch_size, num_objects, self.value_dim, *memory.shape[-2:])
return memory
def segment(self, multi_scale_features, memory_readout,
hidden_state, selector=None, h_out=True, strip_bg=True):
hidden_state, logits = self.decoder(*multi_scale_features, hidden_state, memory_readout, h_out=h_out)
prob = torch.sigmoid(logits)
if selector is not None:
prob = prob * selector
logits, prob = aggregate(prob, dim=1, return_logits=True)
if strip_bg:
# Strip away the background
prob = prob[:, 1:]
return hidden_state, logits, prob
def forward(self, mode, *args, **kwargs):
if mode == 'encode_key':
return self.encode_key(*args, **kwargs)
elif mode == 'encode_value':
return self.encode_value(*args, **kwargs)
elif mode == 'read_memory':
return self.read_memory(*args, **kwargs)
elif mode == 'segment':
return self.segment(*args, **kwargs)
else:
raise NotImplementedError
@logger.catch()
def init_hyperparameters(self, config, model_path=None, map_location=None):
"""
Init three hyperparameters: key_dim, value_dim, and hidden_dim
If model_path is provided, we load these from the model weights
The actual parameters are then updated to the config in-place
Otherwise we load it either from the config or default
"""
if model_path is not None:
# load the model and key/value/hidden dimensions with some hacks
# config is updated with the loaded parameters
model_weights = torch.load(model_path, map_location=map_location)
self.key_dim = model_weights['key_proj.key_proj.weight'].shape[0]
self.value_dim = model_weights['value_encoder.fuser.block2.conv2.weight'].shape[0]
self.disable_hidden = 'decoder.hidden_update.transform.weight' not in model_weights
if self.disable_hidden:
self.hidden_dim = 0
else:
self.hidden_dim = model_weights['decoder.hidden_update.transform.weight'].shape[0]//3
print(f'Hyperparameters read from the model weights: '
f'C^k={self.key_dim}, C^v={self.value_dim}, C^h={self.hidden_dim}')
else:
model_weights = None
# load dimensions from config or default
if 'key_dim' not in config:
self.key_dim = 64
print(f'key_dim not found in config. Set to default {self.key_dim}')
else:
self.key_dim = config['key_dim']
if 'value_dim' not in config:
self.value_dim = 512
print(f'value_dim not found in config. Set to default {self.value_dim}')
else:
self.value_dim = config['value_dim']
if 'hidden_dim' not in config:
self.hidden_dim = 64
print(f'hidden_dim not found in config. Set to default {self.hidden_dim}')
else:
self.hidden_dim = config['hidden_dim']
self.disable_hidden = (self.hidden_dim <= 0)
config['key_dim'] = self.key_dim
config['value_dim'] = self.value_dim
config['hidden_dim'] = self.hidden_dim
return model_weights
@logger.catch()
def load_weights(self, src_dict, init_as_zero_if_needed=False):
# Maps SO weight (without other_mask) to MO weight (with other_mask)
for k in list(src_dict.keys()):
if k == 'value_encoder.conv1.weight':
if src_dict[k].shape[1] == 4:
print('Converting weights from single object to multiple objects.')
pads = torch.zeros((64,1,7,7), device=src_dict[k].device)
if not init_as_zero_if_needed:
print('Randomly initialized padding.')
nn.init.orthogonal_(pads)
else:
print('Zero-initialized padding.')
src_dict[k] = torch.cat([src_dict[k], pads], 1)
self.load_state_dict(src_dict)
================================================
FILE: XMem/model/resnet.py
================================================
"""
resnet.py - A modified ResNet structure
We append extra channels to the first conv by some network surgery
"""
from collections import OrderedDict
import math
import torch
import torch.nn as nn
from torch.utils import model_zoo
def load_weights_add_extra_dim(target, source_state, extra_dim=1):
new_dict = OrderedDict()
for k1, v1 in target.state_dict().items():
if not 'num_batches_tracked' in k1:
if k1 in source_state:
tar_v = source_state[k1]
if v1.shape != tar_v.shape:
# Init the new segmentation channel with zeros
# print(v1.shape, tar_v.shape)
c, _, w, h = v1.shape
pads = torch.zeros((c,extra_dim,w,h), device=tar_v.device)
nn.init.orthogonal_(pads)
tar_v = torch.cat([tar_v, pads], 1)
new_dict[k1] = tar_v
target.load_state_dict(new_dict)
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
padding=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers=(3, 4, 23, 3), extra_dim=0):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3+extra_dim, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation))
return nn.Sequential(*layers)
def resnet18(pretrained=True, extra_dim=0):
model = ResNet(BasicBlock, [2, 2, 2, 2], extra_dim)
if pretrained:
load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet18']), extra_dim)
return model
def resnet50(pretrained=True, extra_dim=0):
model = ResNet(Bottleneck, [3, 4, 6, 3], extra_dim)
if pretrained:
load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet50']), extra_dim)
return model
================================================
FILE: XMem/model/trainer.py
================================================
"""
trainer.py - warpper and utility functions for network training
Compute loss, back-prop, update parameters, logging, etc.
"""
import os
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from model.network import XMem
from model.losses import LossComputer
from util.log_integrator import Integrator
from util.image_saver import pool_pairs
class XMemTrainer:
def __init__(self, config, logger=None, save_path=None, local_rank=0, world_size=1):
self.config = config
self.num_frames = config['num_frames']
self.num_ref_frames = config['num_ref_frames']
self.deep_update_prob = config['deep_update_prob']
self.local_rank = local_rank
self.XMem = nn.parallel.DistributedDataParallel(
XMem(config).cuda(),
device_ids=[local_rank], output_device=local_rank, broadcast_buffers=False)
# Set up logger when local_rank=0
self.logger = logger
self.save_path = save_path
if logger is not None:
self.last_time = time.time()
self.logger.log_string('model_size', str(sum([param.nelement() for param in self.XMem.parameters()])))
self.train_integrator = Integrator(self.logger, distributed=True, local_rank=local_rank, world_size=world_size)
self.loss_computer = LossComputer(config)
self.train()
self.optimizer = optim.AdamW(filter(
lambda p: p.requires_grad, self.XMem.parameters()), lr=config['lr'], weight_decay=config['weight_decay'])
self.scheduler = optim.lr_scheduler.MultiStepLR(self.optimizer, config['steps'], config['gamma'])
if config['amp']:
self.scaler = torch.cuda.amp.GradScaler()
# Logging info
self.log_text_interval = config['log_text_interval']
self.log_image_interval = config['log_image_interval']
self.save_network_interval = config['save_network_interval']
self.save_checkpoint_interval = config['save_checkpoint_interval']
if config['debug']:
self.log_text_interval = self.log_image_interval = 1
def do_pass(self, data, it=0):
# No need to store the gradient outside training
torch.set_grad_enabled(self._is_train)
for k, v in data.items():
if type(v) != list and type(v) != dict and type(v) != int:
data[k] = v.cuda(non_blocking=True)
out = {}
frames = data['rgb']
first_frame_gt = data['first_frame_gt'].float()
b = frames.shape[0]
num_filled_objects = [o.item() for o in data['info']['num_objects']]
num_objects = first_frame_gt.shape[2]
selector = data['selector'].unsqueeze(2).unsqueeze(2)
with torch.cuda.amp.autocast(enabled=self.config['amp']):
# image features never change, compute once
key, shrinkage, selection, f16, f8, f4 = self.XMem('encode_key', frames)
filler_one = torch.zeros(1, dtype=torch.int64)
hidden = torch.zeros((b, num_objects, self.config['hidden_dim'], *key.shape[-2:]))
v16, hidden = self.XMem('encode_value', frames[:,0], f16[:,0], hidden, first_frame_gt[:,0])
values = v16.unsqueeze(3) # add the time dimension
for ti in range(1, self.num_frames):
if ti <= self.num_ref_frames:
ref_values = values
ref_keys = key[:,:,:ti]
ref_shrinkage = shrinkage[:,:,:ti] if shrinkage is not None else None
else:
# pick num_ref_frames random frames
# this is not very efficient but I think we would
# need broadcasting in gather which we don't have
indices = [
torch.cat([filler_one, torch.randperm(ti-1)[:self.num_ref_frames-1]+1])
for _ in range(b)]
ref_values = torch.stack([
values[bi, :, :, indices[bi]] for bi in range(b)
], 0)
ref_keys = torch.stack([
key[bi, :, indices[bi]] for bi in range(b)
], 0)
ref_shrinkage = torch.stack([
shrinkage[bi, :, indices[bi]] for bi in range(b)
], 0) if shrinkage is not None else None
# Segment frame ti
memory_readout = self.XMem('read_memory', key[:,:,ti], selection[:,:,ti] if selection is not None else None,
ref_keys, ref_shrinkage, ref_values)
hidden, logits, masks = self.XMem('segment', (f16[:,ti], f8[:,ti], f4[:,ti]), memory_readout,
hidden, selector, h_out=(ti < (self.num_frames-1)))
# No need to encode the last frame
if ti < (self.num_frames-1):
is_deep_update = np.random.rand() < self.deep_update_prob
v16, hidden = self.XMem('encode_value', frames[:,ti], f16[:,ti], hidden, masks, is_deep_update=is_deep_update)
values = torch.cat([values, v16.unsqueeze(3)], 3)
out[f'masks_{ti}'] = masks
out[f'logits_{ti}'] = logits
if self._do_log or self._is_train:
losses = self.loss_computer.compute({**data, **out}, num_filled_objects, it)
# Logging
if self._do_log:
self.integrator.add_dict(losses)
if self._is_train:
if it % self.log_image_interval == 0 and it != 0:
if self.logger is not None:
images = {**data, **out}
size = (384, 384)
self.logger.log_cv2('train/pairs', pool_pairs(images, size, num_filled_objects), it)
if self._is_train:
if (it) % self.log_text_interval == 0 and it != 0:
if self.logger is not None:
self.logger.log_scalar('train/lr', self.scheduler.get_last_lr()[0], it)
self.logger.log_metrics('train', 'time', (time.time()-self.last_time)/self.log_text_interval, it)
self.last_time = time.time()
self.train_integrator.finalize('train', it)
self.train_integrator.reset_except_hooks()
if it % self.save_network_interval == 0 and it != 0:
if self.logger is not None:
self.save_network(it)
if it % self.save_checkpoint_interval == 0 and it != 0:
if self.logger is not None:
self.save_checkpoint(it)
# Backward pass
self.optimizer.zero_grad(set_to_none=True)
if self.config['amp']:
self.scaler.scale(losses['total_loss']).backward()
self.scaler.step(self.optimizer)
self.scaler.update()
else:
losses['total_loss'].backward()
self.optimizer.step()
self.scheduler.step()
def save_network(self, it):
if self.save_path is None:
print('Saving has been disabled.')
return
os.makedirs(os.path.dirname(self.save_path), exist_ok=True)
model_path = f'{self.save_path}_{it}.pth'
torch.save(self.XMem.module.state_dict(), model_path)
print(f'Network saved to {model_path}.')
def save_checkpoint(self, it):
if self.save_path is None:
print('Saving has been disabled.')
return
os.makedirs(os.path.dirname(self.save_path), exist_ok=True)
checkpoint_path = f'{self.save_path}_checkpoint_{it}.pth'
checkpoint = {
'it': it,
'network': self.XMem.module.state_dict(),
'optimizer': self.optimizer.state_dict(),
'scheduler': self.scheduler.state_dict()}
torch.save(checkpoint, checkpoint_path)
print(f'Checkpoint saved to {checkpoint_path}.')
def load_checkpoint(self, path):
# This method loads everything and should be used to resume training
map_location = 'cuda:%d' % self.local_rank
checkpoint = torch.load(path, map_location={'cuda:0': map_location})
it = checkpoint['it']
network = checkpoint['network']
optimizer = checkpoint['optimizer']
scheduler = checkpoint['scheduler']
map_location = 'cuda:%d' % self.local_rank
self.XMem.module.load_state_dict(network)
self.optimizer.load_state_dict(optimizer)
self.scheduler.load_state_dict(scheduler)
print('Network weights, optimizer states, and scheduler states loaded.')
return it
def load_network_in_memory(self, src_dict):
self.XMem.module.load_weights(src_dict)
print('Network weight loaded from memory.')
def load_network(self, path):
# This method loads only the network weight and should be used to load a pretrained model
map_location = 'cuda:%d' % self.local_rank
src_dict = torch.load(path, map_location={'cuda:0': map_location})
self.load_network_in_memory(src_dict)
print(f'Network weight loaded from {path}')
def train(self):
self._is_train = True
self._do_log = True
self.integrator = self.train_integrator
self.XMem.eval()
return self
def val(self):
self._is_train = False
self._do_log = True
self.XMem.eval()
return self
def test(self):
self._is_train = False
self._do_log = False
self.XMem.eval()
return self
================================================
FILE: XMem/requirements.txt
================================================
progressbar2
gdown
hickle
tensorboard
numpy
================================================
FILE: XMem/scripts/__init__.py
================================================
================================================
FILE: XMem/scripts/download_bl30k.py
================================================
import os
import gdown
import tarfile
LICENSE = """
This dataset is a derivative of ShapeNet.
Please read and respect their licenses and terms before use.
Textures and skybox image are obtained from Google image search with the "non-commercial reuse" flag.
Do not use this dataset for commercial purposes.
You should cite both ShapeNet and our paper if you use this dataset.
"""
print(LICENSE)
print('Datasets will be downloaded and extracted to ../BL30K')
print('The script will download and extract the segment one by one')
print('You are going to need ~1TB of free disk space')
reply = input('[y] to confirm, others to exit: ')
if reply != 'y':
exit()
links = [
'https://drive.google.com/uc?id=1z9V5zxLOJLNt1Uj7RFqaP2FZWKzyXvVc',
'https://drive.google.com/uc?id=11-IzgNwEAPxgagb67FSrBdzZR7OKAEdJ',
'https://drive.google.com/uc?id=1ZfIv6GTo-OGpXpoKen1fUvDQ0A_WoQ-Q',
'https://drive.google.com/uc?id=1G4eXgYS2kL7_Cc0x3N1g1x7Zl8D_aU_-',
'https://drive.google.com/uc?id=1Y8q0V_oBwJIY27W_6-8CD1dRqV2gNTdE',
'https://drive.google.com/uc?id=1nawBAazf_unMv46qGBHhWcQ4JXZ5883r',
]
names = [
'BL30K_a.tar',
'BL30K_b.tar',
'BL30K_c.tar',
'BL30K_d.tar',
'BL30K_e.tar',
'BL30K_f.tar',
]
for i, link in enumerate(links):
print('Downloading segment %d/%d ...' % (i, len(links)))
gdown.download(link, output='../%s' % names[i], quiet=False)
print('Extracting...')
with tarfile.open('../%s' % names[i], 'r') as tar_file:
tar_file.extractall('../%s' % names[i])
print('Cleaning up...')
os.remove('../%s' % names[i])
print('Done.')
================================================
FILE: XMem/scripts/download_datasets.py
================================================
import os
import gdown
import zipfile
from scripts import resize_youtube
LICENSE = """
These are either re-distribution of the original datasets or derivatives (through simple processing) of the original datasets.
Please read and respect their licenses and terms before use.
You should cite the original papers if you use any of the datasets.
For BL30K, see download_bl30k.py
Links:
DUTS: http://saliencydetection.net/duts
HRSOD: https://github.com/yi94code/HRSOD
FSS: https://github.com/HKUSTCV/FSS-1000
ECSSD: https://www.cse.cuhk.edu.hk/leojia/projects/hsaliency/dataset.html
BIG: https://github.com/hkchengrex/CascadePSP
YouTubeVOS: https://youtube-vos.org
DAVIS: https://davischallenge.org/
BL30K: https://github.com/hkchengrex/MiVOS
Long-Time Video: https://github.com/xmlyqing00/AFB-URR
"""
print(LICENSE)
print('Datasets will be downloaded and extracted to ../YouTube, ../YouTube2018, ../static, ../DAVIS, ../long_video_set')
reply = input('[y] to confirm, others to exit: ')
if reply != 'y':
exit()
"""
Static image data
"""
os.makedirs('../static', exist_ok=True)
print('Downloading static datasets...')
gdown.download('https://drive.google.com/uc?id=1wUJq3HcLdN-z1t4CsUhjeZ9BVDb9YKLd', output='../static/static_data.zip', quiet=False)
print('Extracting static datasets...')
with zipfile.ZipFile('../static/static_data.zip', 'r') as zip_file:
zip_file.extractall('../static/')
print('Cleaning up static datasets...')
os.remove('../static/static_data.zip')
"""
DAVIS dataset
"""
# Google drive mirror: https://drive.google.com/drive/folders/1hEczGHw7qcMScbCJukZsoOW4Q9byx16A?usp=sharing
os.makedirs('../DAVIS/2017', exist_ok=True)
print('Downloading DAVIS 2016...')
gdown.download('https://drive.google.com/uc?id=198aRlh5CpAoFz0hfRgYbiNenn_K8DxWD', output='../DAVIS/DAVIS-data.zip', quiet=False)
print('Downloading DAVIS 2017 trainval...')
gdown.download('https://drive.google.com/uc?id=1kiaxrX_4GuW6NmiVuKGSGVoKGWjOdp6d', output='../DAVIS/2017/DAVIS-2017-trainval-480p.zip', quiet=False)
print('Downloading DAVIS 2017 testdev...')
gdown.download('https://drive.google.com/uc?id=1fmkxU2v9cQwyb62Tj1xFDdh2p4kDsUzD', output='../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', quiet=False)
print('Downloading DAVIS 2017 scribbles...')
gdown.download('https://drive.google.com/uc?id=1JzIQSu36h7dVM8q0VoE4oZJwBXvrZlkl', output='../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', quiet=False)
print('Extracting DAVIS datasets...')
with zipfile.ZipFile('../DAVIS/DAVIS-data.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/')
os.rename('../DAVIS/DAVIS', '../DAVIS/2016')
with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-trainval-480p.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/2017/')
with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/2017/')
os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/trainval')
with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', 'r') as zip_file:
zip_file.extractall('../DAVIS/2017/')
os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/test-dev')
print('Cleaning up DAVIS datasets...')
os.remove('../DAVIS/2017/DAVIS-2017-trainval-480p.zip')
os.remove('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip')
os.remove('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip')
os.remove('../DAVIS/DAVIS-data.zip')
"""
YouTubeVOS dataset
"""
os.makedirs('../YouTube', exist_ok=True)
os.makedirs('../YouTube/all_frames', exist_ok=True)
print('Downloading YouTubeVOS train...')
gdown.download('https://drive.google.com/uc?id=13Eqw0gVK-AO5B-cqvJ203mZ2vzWck9s4', output='../YouTube/train.zip', quiet=False)
print('Downloading YouTubeVOS val...')
gdown.download('https://drive.google.com/uc?id=1o586Wjya-f2ohxYf9C1RlRH-gkrzGS8t', output='../YouTube/valid.zip', quiet=False)
print('Downloading YouTubeVOS all frames valid...')
gdown.download('https://drive.google.com/uc?id=1rWQzZcMskgpEQOZdJPJ7eTmLCBEIIpEN', output='../YouTube/all_frames/valid.zip', quiet=False)
print('Extracting YouTube datasets...')
with zipfile.ZipFile('../YouTube/train.zip', 'r') as zip_file:
zip_file.extractall('../YouTube/')
with zipfile.ZipFile('../YouTube/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube/')
with zipfile.ZipFile('../YouTube/all_frames/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube/all_frames')
print('Cleaning up YouTubeVOS datasets...')
os.remove('../YouTube/train.zip')
os.remove('../YouTube/valid.zip')
os.remove('../YouTube/all_frames/valid.zip')
print('Resizing YouTubeVOS to 480p...')
resize_youtube.resize_all('../YouTube/train', '../YouTube/train_480p')
# YouTubeVOS 2018
os.makedirs('../YouTube2018', exist_ok=True)
os.makedirs('../YouTube2018/all_frames', exist_ok=True)
print('Downloading YouTubeVOS2018 val...')
gdown.download('https://drive.google.com/uc?id=1-QrceIl5sUNTKz7Iq0UsWC6NLZq7girr', output='../YouTube2018/valid.zip', quiet=False)
print('Downloading YouTubeVOS2018 all frames valid...')
gdown.download('https://drive.google.com/uc?id=1yVoHM6zgdcL348cFpolFcEl4IC1gorbV', output='../YouTube2018/all_frames/valid.zip', quiet=False)
print('Extracting YouTube2018 datasets...')
with zipfile.ZipFile('../YouTube2018/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube2018/')
with zipfile.ZipFile('../YouTube2018/all_frames/valid.zip', 'r') as zip_file:
zip_file.extractall('../YouTube2018/all_frames')
print('Cleaning up YouTubeVOS2018 datasets...')
os.remove('../YouTube2018/valid.zip')
os.remove('../YouTube2018/all_frames/valid.zip')
"""
Long-Time Video dataset
"""
os.makedirs('../long_video_set', exist_ok=True)
print('Downloading long video dataset...')
gdown.download('https://drive.google.com/uc?id=100MxAuV0_UL20ca5c-5CNpqQ5QYPDSoz', output='../long_video_set/LongTimeVideo.zip', quiet=False)
print('Extracting long video dataset...')
with zipfile.ZipFile('../long_video_set/LongTimeVideo.zip', 'r') as zip_file:
zip_file.extractall('../long_video_set/')
print('Cleaning up long video dataset...')
os.remove('../long_video_set/LongTimeVideo.zip')
print('Done.')
================================================
FILE: XMem/scripts/download_models.sh
================================================
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem-s012.pth
================================================
FILE: XMem/scripts/download_models_demo.sh
================================================
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/fbrs.pth
wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/s2m.pth
================================================
FILE: XMem/scripts/expand_long_vid.py
================================================
import sys
import os
from os import path
from shutil import copy2
input_path = sys.argv[1]
output_path = sys.argv[2]
multiplier = int(sys.argv[3])
image_path = path.join(input_path, 'JPEGImages')
gt_path = path.join(input_path, 'Annotations')
videos = sorted(os.listdir(image_path))
for vid in videos:
os.makedirs(path.join(output_path, 'JPEGImages', vid), exist_ok=True)
os.makedirs(path.join(output_path, 'Annotations', vid), exist_ok=True)
frames = sorted(os.listdir(path.join(image_path, vid)))
num_frames = len(frames)
counter = 0
output_counter = 0
direction = 1
for _ in range(multiplier):
for _ in range(num_frames):
copy2(path.join(image_path, vid, frames[counter]),
path.join(output_path, 'JPEGImages', vid, f'{output_counter:05d}.jpg'))
mask_path = path.join(gt_path, vid, frames[counter].replace('.jpg', '.png'))
if path.exists(mask_path):
copy2(mask_path,
path.join(output_path, 'Annotations', vid, f'{output_counter:05d}.png'))
counter += direction
output_counter += 1
if counter == 0 or counter == len(frames) - 1:
direction *= -1
================================================
FILE: XMem/scripts/resize_youtube.py
================================================
import sys
import os
from os import path
from PIL import Image
import numpy as np
from progressbar import progressbar
from multiprocessing import Pool
new_min_size = 480
def resize_vid_jpeg(inputs):
vid_name, folder_path, out_path = inputs
vid_path = path.join(folder_path, vid_name)
vid_out_path = path.join(out_path, 'JPEGImages', vid_name)
os.makedirs(vid_out_path, exist_ok=True)
for im_name in os.listdir(vid_path):
hr_im = Image.open(path.join(vid_path, im_name))
w, h = hr_im.size
ratio = new_min_size / min(w, h)
lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.BICUBIC)
lr_im.save(path.join(vid_out_path, im_name))
def resize_vid_anno(inputs):
vid_name, folder_path, out_path = inputs
vid_path = path.join(folder_path, vid_name)
vid_out_path = path.join(out_path, 'Annotations', vid_name)
os.makedirs(vid_out_path, exist_ok=True)
for im_name in os.listdir(vid_path):
hr_im = Image.open(path.join(vid_path, im_name)).convert('P')
w, h = hr_im.size
ratio = new_min_size / min(w, h)
lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.NEAREST)
lr_im.save(path.join(vid_out_path, im_name))
def resize_all(in_path, out_path):
for folder in os.listdir(in_path):
if folder not in ['JPEGImages', 'Annotations']:
continue
folder_path = path.join(in_path, folder)
videos = os.listdir(folder_path)
videos = [(v, folder_path, out_path) for v in videos]
if folder == 'JPEGImages':
print('Processing images')
os.makedirs(path.join(out_path, 'JPEGImages'), exist_ok=True)
pool = Pool(processes=8)
for _ in progressbar(pool.imap_unordered(resize_vid_jpeg, videos), max_value=len(videos)):
pass
else:
print('Processing annotations')
os.makedirs(path.join(out_path, 'Annotations'), exist_ok=True)
pool = Pool(processes=8)
for _ in progressbar(pool.imap_unordered(resize_vid_anno, videos), max_value=len(videos)):
pass
if __name__ == '__main__':
in_path = sys.argv[1]
out_path = sys.argv[2]
resize_all(in_path, out_path)
print('Done.')
================================================
FILE: XMem/tracking.py
================================================
import sys
sys.path.insert(0, './XMem')
import os
import os.path as osp
import glob
import cv2
import json
import argparse
import multiprocessing as mp
from tqdm import tqdm
from termcolor import colored
from importlib.util import find_spec
if find_spec("GPUtil") is None: os.system("pip install gputil")
import GPUtil
_GPU_LIST = [_.id for _ in GPUtil.getGPUs()]
_GPU_QUEUE = mp.Queue()
for _ in _GPU_LIST: _GPU_QUEUE.put(_)
def run_eval(meta_expression, temp_xmem_anno, final_xmem_anno, img_dir, split_part, xmem_weight, cfgs=" --reversed ", ):
gpu_id = _GPU_QUEUE.get()
cmd = f"cd XMem && CUDA_VISIBLE_DEVICES={gpu_id} python eval.py --meta_exp {meta_expression} --output {final_xmem_anno} --generic_path {temp_xmem_anno} --img_dir {img_dir} --split_part {split_part} --model {xmem_weight} --dataset G {cfgs}"
print(f"Running: {cmd}")
os.system(cmd)
_GPU_QUEUE.put(gpu_id)
def generate(obj, temp_xmem_anno, final_xmem_anno):
obj_dir, video_name, obj_id, tp = obj
img_list = glob.glob(obj_dir + '/*.png') # Mask
img_list.sort()
frame_id = int(len(img_list) * tp)
if frame_id == len(img_list):
frame_id -= 1
used_img = img_list[frame_id]
img_output_path = osp.join(temp_xmem_anno, video_name, obj_id, osp.basename(used_img))
final_img_output_dir = osp.join(final_xmem_anno, video_name, obj_id)
img_output_dir = osp.dirname(img_output_path)
os.makedirs(img_output_dir, exist_ok=True)
os.makedirs(final_img_output_dir, exist_ok=True)
os.system('cp {} {}'.format(used_img, img_output_path))
img = cv2.imread(img_output_path)
if img.sum() == 0:
target_img_list = [i.split('/')[-1] for i in img_list]
for img_ in target_img_list:
print(os.path.join(final_img_output_dir, img_))
os.system('cp {} {}'.format(img_output_path, os.path.join(img_output_dir, img_)))
os.system('cp {} {}'.format(img_output_path, os.path.join(final_img_output_dir, img_)))
return 0
def prepare(args):
video_root = args.video_root
temp_xmem_anno = args.temp_xmem_anno
final_xmem_anno = args.final_xmem_anno
os.makedirs(temp_xmem_anno, exist_ok=True)
data = json.load(open(args.llama_vid_meta, 'r'))['videos']
all_obj_list = []
for video_name in data.keys():
exps = data[video_name]['expressions']
for obj_id in exps.keys():
tp = exps[obj_id]['tp']
obj_dir = os.path.join(video_root, video_name, obj_id)
all_obj_list.append([obj_dir, video_name, obj_id, tp])
print('start')
cpu_num = mp.cpu_count()-1
print("cpu_num:", cpu_num)
pool = mp.Pool(cpu_num)
pbar = tqdm(total=len(all_obj_list))
for obj in all_obj_list:
pool.apply_async(
generate,
args = (obj, temp_xmem_anno, final_xmem_anno ),
callback = lambda *a: pbar.update(1),
error_callback = lambda e: print(colored(e, "red"))
)
pool.close()
pool.join()
pbar.close()
def inference(args):
p = mp.Pool(8)
for split_part in [0, 1, 2, 3]:
for cfgs in [" ", " --reversed "]:
p.apply_async(
run_eval,
args=(args.llama_vid_meta, args.temp_xmem_anno, args.final_xmem_anno, args.img_dir, split_part, args.xmem_weight, cfgs),
error_callback=lambda e: print(colored(e, "red"))
)
p.close()
p.join()
"""
python XMem/tracking.py \
--video_root /mnt/public03/dataset/ovis/rgvos/visa7b/val_7b/revos_valid/Annotations \
--temp_xmem_anno /mnt/public03/dataset/ovis/rgvos/visa7b/val_7b/revos_valid/revos_valid_XMem_temp/Annotations \
--final_xmem_anno /mnt/public03/dataset/ovis/rgvos/visa7b/val_7b/revos_valid/revos_valid_XMem_final/Annotations \
--llama_vid_meta /mnt/public02/usr/yancilin/clyan_data/other-datasets/ReVOS/meta_expressions_valid__llamavid.json \
--img_dir /mnt/public02/usr/yancilin/clyan_data/other-datasets/ReVOS/JPEGImages \
--xmem_weight /mnt/public02/usr/yancilin/VISA/XMem/weights/XMem.pth
"""
def main():
parser = argparse.ArgumentParser(description='rgvos')
parser.add_argument('--video_root', type=str, help='/PATH/TO/VISA_exp/revos_valid/Annotations', )
parser.add_argument('--temp_xmem_anno', type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_temp/Annotations', ) # 保存单帧 Mask 的路径
parser.add_argument('--final_xmem_anno', type=str, help='/PATH/TO/VISA_exp/revos_valid_XMem_final/Annotations', ) # 保存 XMem 最后输出结果的路径
parser.add_argument("--llama_vid_meta", type=str, help='/PATH/TO/ReVOS/meta_expressions_valid__llamavid.json', )
parser.add_argument("--img_dir", type=str, help='/PATH/TO/ReVOS/JPEGImages')
parser.add_argument("--xmem_weight", type=str, help='/PATH/TO/XMEM_WEIGHT')
args = parser.parse_args()
prepare(args)
inference(args)
print('Done.')
if __name__ == '__main__':
main()
================================================
FILE: XMem/train.py
================================================
import datetime
from os import path
import math
import git
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, ConcatDataset
import torch.distributed as distributed
from model.trainer import XMemTrainer
from dataset.static_dataset import StaticTransformDataset
from dataset.vos_dataset import VOSDataset
from util.logger import TensorboardLogger
from util.configuration import Configuration
from util.load_subset import load_sub_davis, load_sub_yv
"""
Initial setup
"""
# Init distributed environment
distributed.init_process_group(backend="nccl")
print(f'CUDA Device count: {torch.cuda.device_count()}')
# Parse command line arguments
raw_config = Configuration()
raw_config.parse()
if raw_config['benchmark']:
torch.backends.cudnn.benchmark = True
# Get current git info
repo = git.Repo(".")
git_info = str(repo.active_branch)+' '+str(repo.head.commit.hexsha)
local_rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
torch.cuda.set_device(local_rank)
print(f'I am rank {local_rank} in this world of size {world_size}!')
network_in_memory = None
stages = raw_config['stages']
stages_to_perform = list(stages)
for si, stage in enumerate(stages_to_perform):
# Set seed to ensure the same initialization
torch.manual_seed(14159265)
np.random.seed(14159265)
random.seed(14159265)
# Pick stage specific hyperparameters out
stage_config = raw_config.get_stage_parameters(stage)
config = dict(**raw_config.args, **stage_config)
if config['exp_id'] != 'NULL':
config['exp_id'] = config['exp_id']+'_s%s'%stages[:si+1]
config['single_object'] = (stage == '0')
config['num_gpus'] = world_size
if config['batch_size']//config['num_gpus']*config['num_gpus'] != config['batch_size']:
raise ValueError('Batch size must be divisible by the number of GPUs.')
config['batch_size'] //= config['num_gpus']
config['num_workers'] //= config['num_gpus']
print(f'We are assuming {config["num_gpus"]} GPUs.')
print(f'We are now starting stage {stage}')
"""
Model related
"""
if local_rank == 0:
# Logging
if config['exp_id'].lower() != 'null':
print('I will take the role of logging!')
long_id = '%s_%s' % (datetime.datetime.now().strftime('%b%d_%H.%M.%S'), config['exp_id'])
else:
long_id = None
logger = TensorboardLogger(config['exp_id'], long_id, git_info)
logger.log_string('hyperpara', str(config))
# Construct the rank 0 model
model = XMemTrainer(config, logger=logger,
save_path=path.join('saves', long_id, long_id) if long_id is not None else None,
local_rank=local_rank, world_size=world_size).train()
else:
# Construct model for other ranks
model = XMemTrainer(config, local_rank=local_rank, world_size=world_size).train()
# Load pertrained model if needed
if raw_config['load_checkpoint'] is not None:
total_iter = model.load_checkpoint(raw_config['load_checkpoint'])
raw_config['load_checkpoint'] = None
print('Previously trained model loaded!')
else:
total_iter = 0
if network_in_memory is not None:
print('I am loading network from the previous stage')
model.load_network_in_memory(network_in_memory)
network_in_memory = None
elif raw_config['load_network'] is not None:
print('I am loading network from a disk, as listed in configuration')
model.load_network(raw_config['load_network'])
raw_config['load_network'] = None
"""
Dataloader related
"""
# To re-seed the randomness everytime we start a worker
def worker_init_fn(worker_id):
worker_seed = torch.initial_seed()%(2**31) + worker_id + local_rank*100
np.random.seed(worker_seed)
random.seed(worker_seed)
def construct_loader(dataset):
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset, rank=local_rank, shuffle=True)
train_loader = DataLoader(dataset, config['batch_size'], sampler=train_sampler, num_workers=config['num_workers'],
worker_init_fn=worker_init_fn, drop_last=True)
return train_sampler, train_loader
def renew_vos_loader(max_skip, finetune=False):
# //5 because we only have annotation for every five frames
yv_dataset = VOSDataset(path.join(yv_root, 'JPEGImages'),
path.join(yv_root, 'Annotations'), max_skip//5, is_bl=False, subset=load_sub_yv(), num_frames=config['num_frames'], finetune=finetune)
davis_dataset = VOSDataset(path.join(davis_root, 'JPEGImages', '480p'),
path.join(davis_root, 'Annotations', '480p'), max_skip, is_bl=False, subset=load_sub_davis(), num_frames=config['num_frames'], finetune=finetune)
train_dataset = ConcatDataset([davis_dataset]*5 + [yv_dataset])
print(f'YouTube dataset size: {len(yv_dataset)}')
print(f'DAVIS dataset size: {len(davis_dataset)}')
print(f'Concat dataset size: {len(train_dataset)}')
print(f'Renewed with {max_skip=}')
return construct_loader(train_dataset)
def renew_bl_loader(max_skip, finetune=False):
train_dataset = VOSDataset(path.join(bl_root, 'JPEGImages'),
path.join(bl_root, 'Annotations'), max_skip, is_bl=True, num_frames=config['num_frames'], finetune=finetune)
print(f'Blender dataset size: {len(train_dataset)}')
print(f'Renewed with {max_skip=}')
return construct_loader(train_dataset)
"""
Dataset related
"""
"""
These define the training schedule of the distance between frames
We will switch to max_skip_values[i] once we pass the percentage specified by increase_skip_fraction[i]
Not effective for stage 0 training
The initial value is not listed here but in renew_vos_loader(X)
"""
max_skip_values = [10, 15, 5, 5]
if stage == '0':
static_root = path.expanduser(config['static_root'])
# format: path, method (style of storing images), mutliplier
train_dataset = StaticTransformDataset(
[
(path.join(static_root, 'fss'), 0, 1),
(path.join(static_root, 'DUTS-TR'), 1, 1),
(path.join(static_root, 'DUTS-TE'), 1, 1),
(path.join(static_root, 'ecssd'), 1, 1),
(path.join(static_root, 'BIG_small'), 1, 5),
(path.join(static_root, 'HRSOD_small'), 1, 5),
], num_frames=config['num_frames'])
train_sampler, train_loader = construct_loader(train_dataset)
print(f'Static dataset size: {len(train_dataset)}')
elif stage == '1':
increase_skip_fraction = [0.1, 0.3, 0.8, 100]
bl_root = path.join(path.expanduser(config['bl_root']))
train_sampler, train_loader = renew_bl_loader(5)
renew_loader = renew_bl_loader
else:
# stage 2 or 3
increase_skip_fraction = [0.1, 0.3, 0.9, 100]
# VOS dataset, 480p is used for both datasets
yv_root = path.join(path.expanduser(config['yv_root']), 'train_480p')
davis_root = path.join(path.expanduser(config['davis_root']), '2017', 'trainval')
train_sampler, train_loader = renew_vos_loader(5)
renew_loader = renew_vos_loader
"""
Determine max epoch
"""
total_epoch = math.ceil(config['iterations']/len(train_loader))
current_epoch = total_iter // len(train_loader)
print(f'We approximately use {total_epoch} epochs.')
if stage != '0':
change_skip_iter = [round(config['iterations']*f) for f in increase_skip_fraction]
# Skip will only change after an epoch, not in the middle
print(f'The skip value will change approximately at the following iterations: {change_skip_iter[:-1]}')
"""
Starts training
"""
finetuning = False
# Need this to select random bases in different workers
np.random.seed(np.random.randint(2**30-1) + local_rank*100)
try:
while total_iter < config['iterations'] + config['finetune']:
# Crucial for randomness!
train_sampler.set_epoch(current_epoch)
current_epoch += 1
print(f'Current epoch: {current_epoch}')
# Train loop
model.train()
for data in train_loader:
# Update skip if needed
if stage!='0' and total_iter >= change_skip_iter[0]:
while total_iter >= change_skip_iter[0]:
cur_skip = max_skip_values[0]
max_skip_values = max_skip_values[1:]
change_skip_iter = change_skip_iter[1:]
print(f'Changing skip to {cur_skip=}')
train_sampler, train_loader = renew_loader(cur_skip)
break
# fine-tune means fewer augmentations to train the sensory memory
if config['finetune'] > 0 and not finetuning and total_iter >= config['iterations']:
train_sampler, train_loader = renew_loader(cur_skip, finetune=True)
finetuning = True
model.save_network_interval = 1000
break
model.do_pass(data, total_iter)
total_iter += 1
if total_iter >= config['iterations'] + config['finetune']:
break
finally:
if not config['debug'] and model.logger is not None and total_iter>5000:
model.save_network(total_iter)
model.save_checkpoint(total_iter)
network_in_memory = model.XMem.module.state_dict()
distributed.destroy_process_group()
================================================
FILE: XMem/util/__init__.py
================================================
================================================
FILE: XMem/util/configuration.py
================================================
from argparse import ArgumentParser
def none_or_default(x, default):
return x if x is not None else default
class Configuration():
def parse(self, unknown_arg_ok=False):
parser = ArgumentParser()
# Enable torch.backends.cudnn.benchmark -- Faster in some cases, test in your own environment
parser.add_argument('--benchmark', action='store_true')
parser.add_argument('--no_amp', action='store_true')
# Data parameters
parser.add_argument('--static_root', help='Static training data root', default='../static')
parser.add_argument('--bl_root', help='Blender training data root', default='../BL30K')
parser.add_argument('--yv_root', help='YouTubeVOS data root', default='../YouTube')
parser.add_argument('--davis_root', help='DAVIS data root', default='../DAVIS')
parser.add_argument('--num_workers', help='Total number of dataloader workers across all GPUs processes', type=int, default=16)
parser.add_argument('--key_dim', default=64, type=int)
parser.add_argument('--value_dim', default=512, type=int)
parser.add_argument('--hidden_dim', default=64, help='Set to =0 to disable', type=int)
parser.add_argument('--deep_update_prob', default=0.2, type=float)
parser.add_argument('--stages', help='Training stage (0-static images, 1-Blender dataset, 2-DAVIS+YouTubeVOS)', default='02')
"""
Stage-specific learning parameters
Batch sizes are effective -- you don't have to scale them when you scale the number processes
"""
# Stage 0, static images
parser.add_argument('--s0_batch_size', default=16, type=int)
parser.add_argument('--s0_iterations', default=150000, type=int)
parser.add_argument('--s0_finetune', default=0, type=int)
parser.add_argument('--s0_steps', nargs="*", default=[], type=int)
parser.add_argument('--s0_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s0_num_ref_frames', default=2, type=int)
parser.add_argument('--s0_num_frames', default=3, type=int)
parser.add_argument('--s0_start_warm', default=20000, type=int)
parser.add_argument('--s0_end_warm', default=70000, type=int)
# Stage 1, BL30K
parser.add_argument('--s1_batch_size', default=8, type=int)
parser.add_argument('--s1_iterations', default=250000, type=int)
# fine-tune means fewer augmentations to train the sensory memory
parser.add_argument('--s1_finetune', default=0, type=int)
parser.add_argument('--s1_steps', nargs="*", default=[200000], type=int)
parser.add_argument('--s1_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s1_num_ref_frames', default=3, type=int)
parser.add_argument('--s1_num_frames', default=8, type=int)
parser.add_argument('--s1_start_warm', default=20000, type=int)
parser.add_argument('--s1_end_warm', default=70000, type=int)
# Stage 2, DAVIS+YoutubeVOS, longer
parser.add_argument('--s2_batch_size', default=8, type=int)
parser.add_argument('--s2_iterations', default=150000, type=int)
# fine-tune means fewer augmentations to train the sensory memory
parser.add_argument('--s2_finetune', default=10000, type=int)
parser.add_argument('--s2_steps', nargs="*", default=[120000], type=int)
parser.add_argument('--s2_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s2_num_ref_frames', default=3, type=int)
parser.add_argument('--s2_num_frames', default=8, type=int)
parser.add_argument('--s2_start_warm', default=20000, type=int)
parser.add_argument('--s2_end_warm', default=70000, type=int)
# Stage 3, DAVIS+YoutubeVOS, shorter
parser.add_argument('--s3_batch_size', default=8, type=int)
parser.add_argument('--s3_iterations', default=100000, type=int)
# fine-tune means fewer augmentations to train the sensory memory
parser.add_argument('--s3_finetune', default=10000, type=int)
parser.add_argument('--s3_steps', nargs="*", default=[80000], type=int)
parser.add_argument('--s3_lr', help='Initial learning rate', default=1e-5, type=float)
parser.add_argument('--s3_num_ref_frames', default=3, type=int)
parser.add_argument('--s3_num_frames', default=8, type=int)
parser.add_argument('--s3_start_warm', default=20000, type=int)
parser.add_argument('--s3_end_warm', default=70000, type=int)
parser.add_argument('--gamma', help='LR := LR*gamma at every decay step', default=0.1, type=float)
parser.add_argument('--weight_decay', default=0.05, type=float)
# Loading
parser.add_argument('--load_network', help='Path to pretrained network weight only')
parser.add_argument('--load_checkpoint', help='Path to the checkpoint file, including network, optimizer and such')
# Logging information
parser.add_argument('--log_text_interval', default=100, type=int)
parser.add_argument('--log_image_interval', default=1000, type=int)
parser.add_argument('--save_network_interval', default=25000, type=int)
parser.add_argument('--save_checkpoint_interval', default=50000, type=int)
parser.add_argument('--exp_id', help='Experiment UNIQUE id, use NULL to disable logging to tensorboard', default='NULL')
parser.add_argument('--debug', help='Debug mode which logs information more often', action='store_true')
# # Multiprocessing parameters, not set by users
# parser.add_argument('--local_rank', default=0, type=int, help='Local rank of this process')
if unknown_arg_ok:
args, _ = parser.parse_known_args()
self.args = vars(args)
else:
self.args = vars(parser.parse_args())
self.args['amp'] = not self.args['no_amp']
# check if the stages are valid
stage_to_perform = list(self.args['stages'])
for s in stage_to_perform:
if s not in ['0', '1', '2', '3']:
raise NotImplementedError
def get_stage_parameters(self, stage):
parameters = {
'batch_size': self.args['s%s_batch_size'%stage],
'iterations': self.args['s%s_iterations'%stage],
'finetune': self.args['s%s_finetune'%stage],
'steps': self.args['s%s_steps'%stage],
'lr': self.args['s%s_lr'%stage],
'num_ref_frames': self.args['s%s_num_ref_frames'%stage],
'num_frames': self.args['s%s_num_frames'%stage],
'start_warm': self.args['s%s_start_warm'%stage],
'end_warm': self.args['s%s_end_warm'%stage],
}
return parameters
def __getitem__(self, key):
return self.args[key]
def __setitem__(self, key, value):
self.args[key] = value
def __str__(self):
return str(self.args)
================================================
FILE: XMem/util/davis_subset.txt
================================================
bear
bmx-bumps
boat
boxing-fisheye
breakdance-flare
bus
car-turn
cat-girl
classic-car
color-run
crossing
dance-jump
dancing
disc-jockey
dog-agility
dog-gooses
dogs-scale
drift-turn
drone
elephant
flamingo
hike
hockey
horsejump-low
kid-football
kite-walk
koala
lady-running
lindy-hop
longboard
lucia
mallard-fly
mallard-water
miami-surf
motocross-bumps
motorbike
night-race
paragliding
planes-water
rallye
rhino
rollerblade
schoolgirls
scooter-board
scooter-gray
sheep
skate-park
snowboard
soccerball
stroller
stunt
surf
swing
tennis
tractor-sand
train
tuk-tuk
upside-down
varanus-cage
walking
================================================
FILE: XMem/util/image_saver.py
================================================
import cv2
import numpy as np
import torch
from dataset.range_transform import inv_im_trans
from collections import defaultdict
def tensor_to_numpy(image):
image_np = (image.numpy() * 255).astype('uint8')
return image_np
def tensor_to_np_float(image):
image_np = image.numpy().astype('float32')
return image_np
def detach_to_cpu(x):
return x.detach().cpu()
def transpose_np(x):
return np.transpose(x, [1,2,0])
def tensor_to_gray_im(x):
x = detach_to_cpu(x)
x = tensor_to_numpy(x)
x = transpose_np(x)
return x
def tensor_to_im(x):
x = detach_to_cpu(x)
x = inv_im_trans(x).clamp(0, 1)
x = tensor_to_numpy(x)
x = transpose_np(x)
return x
# Predefined key <-> caption dict
key_captions = {
'im': 'Image',
'gt': 'GT',
}
"""
Return an image array with captions
keys in dictionary will be used as caption if not provided
values should contain lists of cv2 images
"""
def get_image_array(images, grid_shape, captions={}):
h, w = grid_shape
cate_counts = len(images)
rows_counts = len(next(iter(images.values())))
font = cv2.FONT_HERSHEY_SIMPLEX
output_image = np.zeros([w*cate_counts, h*(rows_counts+1), 3], dtype=np.uint8)
col_cnt = 0
for k, v in images.items():
# Default as key value itself
caption = captions.get(k, k)
# Handles new line character
dy = 40
for i, line in enumerate(caption.split('\n')):
cv2.putText(output_image, line, (10, col_cnt*w+100+i*dy),
font, 0.8, (255,255,255), 2, cv2.LINE_AA)
# Put images
for row_cnt, img in enumerate(v):
im_shape = img.shape
if len(im_shape) == 2:
img = img[..., np.newaxis]
img = (img * 255).astype('uint8')
output_image[(col_cnt+0)*w:(col_cnt+1)*w,
(row_cnt+1)*h:(row_cnt+2)*h, :] = img
col_cnt += 1
return output_image
def base_transform(im, size):
im = tensor_to_np_float(im)
if len(im.shape) == 3:
im = im.transpose((1, 2, 0))
else:
im = im[:, :, None]
# Resize
if im.shape[1] != size:
im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
return im.clip(0, 1)
def im_transform(im, size):
return base_transform(inv_im_trans(detach_to_cpu(im)), size=size)
def mask_transform(mask, size):
return base_transform(detach_to_cpu(mask), size=size)
def out_transform(mask, size):
return base_transform(detach_to_cpu(torch.sigmoid(mask)), size=size)
def pool_pairs(images, size, num_objects):
req_images = defaultdict(list)
b, t = images['rgb'].shape[:2]
# limit the number of images saved
b = min(2, b)
# find max num objects
max_num_objects = max(num_objects[:b])
GT_suffix = ''
for bi in range(b):
GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
for bi in range(b):
for ti in range(t):
req_images['RGB'].append(im_transform(images['rgb'][bi,ti], size))
for oi in range(max_num_objects):
if ti == 0 or oi >= num_objects[bi]:
req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
# req_images['Mask_X8_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
# req_images['Mask_X16_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
else:
req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
# req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][2], size))
# req_images['Mask_X8_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][1], size))
# req_images['Mask_X16_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][0], size))
req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
# print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
# print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
return get_image_array(req_images, size, key_captions)
================================================
FILE: XMem/util/load_subset.py
================================================
"""
load_subset.py - Presents a subset of data
DAVIS - only the training set
YouTubeVOS - I manually filtered some erroneous ones out but I haven't checked all
"""
def load_sub_davis(path='util/davis_subset.txt'):
with open(path, mode='r') as f:
subset = set(f.read().splitlines())
return subset
def load_sub_yv(path='util/yv_subset.txt'):
with open(path, mode='r') as f:
subset = set(f.read().splitlines())
return subset
================================================
FILE: XMem/util/log_integrator.py
================================================
"""
Integrate numerical values for some iterations
Typically used for loss computation / logging to tensorboard
Call finalize and create a new Integrator when you want to display/log
"""
import torch
class Integrator:
def __init__(self, logger, distributed=True, local_rank=0, world_size=1):
self.values = {}
self.counts = {}
self.hooks = [] # List is used here to maintain insertion order
self.logger = logger
self.distributed = distributed
self.local_rank = local_rank
self.world_size = world_size
def add_tensor(self, key, tensor):
if key not in self.values:
self.counts[key] = 1
if type(tensor) == float or type(tensor) == int:
self.values[key] = tensor
else:
self.values[key] = tensor.mean().item()
else:
self.counts[key] += 1
if type(tensor) == float or type(tensor) == int:
self.values[key] += tensor
else:
self.values[key] += tensor.mean().item()
def add_dict(self, tensor_dict):
for k, v in tensor_dict.items():
self.add_tensor(k, v)
def add_hook(self, hook):
"""
Adds a custom hook, i.e. compute new metrics using values in the dict
The hook takes the dict as argument, and returns a (k, v) tuple
e.g. for computing IoU
"""
if type(hook) == list:
self.hooks.extend(hook)
else:
self.hooks.append(hook)
def reset_except_hooks(self):
self.values = {}
self.counts = {}
# Average and output the metrics
def finalize(self, prefix, it, f=None):
for hook in self.hooks:
k, v = hook(self.values)
self.add_tensor(k, v)
for k, v in self.values.items():
if k[:4] == 'hide':
continue
avg = v / self.counts[k]
if self.distributed:
# Inplace operation
avg = torch.tensor(avg).cuda()
torch.distributed.reduce(avg, dst=0)
if self.local_rank == 0:
avg = (avg/self.world_size).cpu().item()
self.logger.log_metrics(prefix, k, avg, it, f)
else:
# Simple does it
self.logger.log_metrics(prefix, k, avg, it, f)
================================================
FILE: XMem/util/logger.py
================================================
"""
Dumps things to tensorboard and console
"""
import os
import warnings
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
def tensor_to_numpy(image):
image_np = (image.numpy() * 255).astype('uint8')
return image_np
def detach_to_cpu(x):
return x.detach().cpu()
def fix_width_trunc(x):
return ('{:.9s}'.format('{:0.9f}'.format(x)))
class TensorboardLogger:
def __init__(self, short_id, id, git_info):
self.short_id = short_id
if self.short_id == 'NULL':
self.short_id = 'DEBUG'
if id is None:
self.no_log = True
warnings.warn('Logging has been disbaled.')
else:
self.no_log = False
self.inv_im_trans = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225])
self.inv_seg_trans = transforms.Normalize(
mean=[-0.5/0.5],
std=[1/0.5])
log_path = os.path.join('.', 'saves', '%s' % id)
self.logger = SummaryWriter(log_path)
self.log_string('git', git_info)
def log_scalar(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
self.logger.add_scalar(tag, x, step)
def log_metrics(self, l1_tag, l2_tag, val, step, f=None):
tag = l1_tag + '/' + l2_tag
text = '{:s} - It {:6d} [{:5s}] [{:13}]: {:s}'.format(self.short_id, step, l1_tag.upper(), l2_tag, fix_width_trunc(val))
print(text)
if f is not None:
f.write(text + '\n')
f.flush()
self.log_scalar(tag, val, step)
def log_im(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = detach_to_cpu(x)
x = self.inv_im_trans(x)
x = tensor_to_numpy(x)
self.logger.add_image(tag, x, step)
def log_cv2(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = x.transpose((2, 0, 1))
self.logger.add_image(tag, x, step)
def log_seg(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = detach_to_cpu(x)
x = self.inv_seg_trans(x)
x = tensor_to_numpy(x)
self.logger.add_image(tag, x, step)
def log_gray(self, tag, x, step):
if self.no_log:
warnings.warn('Logging has been disabled.')
return
x = detach_to_cpu(x)
x = tensor_to_numpy(x)
self.logger.add_image(tag, x, step)
def log_string(self, tag, x):
print(tag, x)
if self.no_log:
warnings.warn('Logging has been disabled.')
return
self.logger.add_text(tag, x)
================================================
FILE: XMem/util/palette.py
================================================
davis_palette = b'\x00\x00\x00\x80\x00\x00\x00\x80\x00\x80\x80\x00\x00\x00\x80\x80\x00\x80\x00\x80\x80\x80\x80\x80@\x00\x00\xc0\x00\x00@\x80\x00\xc0\x80\x00@\x00\x80\xc0\x00\x80@\x80\x80\xc0\x80\x80\x00@\x00\x80@\x00\x00\xc0\x00\x80\xc0\x00\x00@\x80\x80@\x80\x00\xc0\x80\x80\xc0\x80@@\x00\xc0@\x00@\xc0\x00\xc0\xc0\x00@@\x80\xc0@\x80@\xc0\x80\xc0\xc0\x80\x00\x00@\x80\x00@\x00\x80@\x80\x80@\x00\x00\xc0\x80\x00\xc0\x00\x80\xc0\x80\x80\xc0@\x00@\xc0\x00@@\x80@\xc0\x80@@\x00\xc0\xc0\x00\xc0@\x80\xc0\xc0\x80\xc0\x00@@\x80@@\x00\xc0@\x80\xc0@\x00@\xc0\x80@\xc0\x00\xc0\xc0\x80\xc0\xc0@@@\xc0@@@\xc0@\xc0\xc0@@@\xc0\xc0@\xc0@\xc0\xc0\xc0\xc0\xc0 \x00\x00\xa0\x00\x00 \x80\x00\xa0\x80\x00 \x00\x80\xa0\x00\x80 \x80\x80\xa0\x80\x80`\x00\x00\xe0\x00\x00`\x80\x00\xe0\x80\x00`\x00\x80\xe0\x00\x80`\x80\x80\xe0\x80\x80 @\x00\xa0@\x00 \xc0\x00\xa0\xc0\x00 @\x80\xa0@\x80 \xc0\x80\xa0\xc0\x80`@\x00\xe0@\x00`\xc0\x00\xe0\xc0\x00`@\x80\xe0@\x80`\xc0\x80\xe0\xc0\x80 \x00@\xa0\x00@ \x80@\xa0\x80@ \x00\xc0\xa0\x00\xc0 \x80\xc0\xa0\x80\xc0`\x00@\xe0\x00@`\x80@\xe0\x80@`\x00\xc0\xe0\x00\xc0`\x80\xc0\xe0\x80\xc0 @@\xa0@@ \xc0@\xa0\xc0@ @\xc0\xa0@\xc0 \xc0\xc0\xa0\xc0\xc0`@@\xe0@@`\xc0@\xe0\xc0@`@\xc0\xe0@\xc0`\xc0\xc0\xe0\xc0\xc0\x00 \x00\x80 \x00\x00\xa0\x00\x80\xa0\x00\x00 \x80\x80 \x80\x00\xa0\x80\x80\xa0\x80@ \x00\xc0 \x00@\xa0\x00\xc0\xa0\x00@ \x80\xc0 \x80@\xa0\x80\xc0\xa0\x80\x00`\x00\x80`\x00\x00\xe0\x00\x80\xe0\x00\x00`\x80\x80`\x80\x00\xe0\x80\x80\xe0\x80@`\x00\xc0`\x00@\xe0\x00\xc0\xe0\x00@`\x80\xc0`\x80@\xe0\x80\xc0\xe0\x80\x00 @\x80 @\x00\xa0@\x80\xa0@\x00 \xc0\x80 \xc0\x00\xa0\xc0\x80\xa0\xc0@ @\xc0 @@\xa0@\xc0\xa0@@ \xc0\xc0 \xc0@\xa0\xc0\xc0\xa0\xc0\x00`@\x80`@\x00\xe0@\x80\xe0@\x00`\xc0\x80`\xc0\x00\xe0\xc0\x80\xe0\xc0@`@\xc0`@@\xe0@\xc0\xe0@@`\xc0\xc0`\xc0@\xe0\xc0\xc0\xe0\xc0 \x00\xa0 \x00 \xa0\x00\xa0\xa0\x00 \x80\xa0 \x80 \xa0\x80\xa0\xa0\x80` \x00\xe0 \x00`\xa0\x00\xe0\xa0\x00` \x80\xe0 \x80`\xa0\x80\xe0\xa0\x80 `\x00\xa0`\x00 \xe0\x00\xa0\xe0\x00 `\x80\xa0`\x80 \xe0\x80\xa0\xe0\x80``\x00\xe0`\x00`\xe0\x00\xe0\xe0\x00``\x80\xe0`\x80`\xe0\x80\xe0\xe0\x80 @\xa0 @ \xa0@\xa0\xa0@ \xc0\xa0 \xc0 \xa0\xc0\xa0\xa0\xc0` @\xe0 @`\xa0@\xe0\xa0@` \xc0\xe0 \xc0`\xa0\xc0\xe0\xa0\xc0 `@\xa0`@ \xe0@\xa0\xe0@ `\xc0\xa0`\xc0 \xe0\xc0\xa0\xe0\xc0``@\xe0`@`\xe0@\xe0\xe0@``\xc0\xe0`\xc0`\xe0\xc0\xe0\xe0\xc0'
youtube_palette = b'\x00\x00\x00\xec_g\xf9\x91W\xfa\xc8c\x99\xc7\x94b\xb3\xb2f\x99\xcc\xc5\x94\xc5\xabyg\xff\xff\xffes~\x0b\x0b\x0b\x0c\x0c\x0c\r\r\r\x0e\x0e\x0e\x0f\x0f\x0f'
================================================
FILE: XMem/util/tensor_util.py
================================================
import torch.nn.functional as F
def compute_tensor_iu(seg, gt):
intersection = (seg & gt).float().sum()
union = (seg | gt).float().sum()
return intersection, union
def compute_tensor_iou(seg, gt):
intersection, union = compute_tensor_iu(seg, gt)
iou = (intersection + 1e-6) / (union + 1e-6)
return iou
# STM
def pad_divide_by(in_img, d):
h, w = in_img.shape[-2:]
if h % d > 0:
new_h = h + d - h % d
else:
new_h = h
if w % d > 0:
new_w = w + d - w % d
else:
new_w = w
lh, uh = int((new_h-h) / 2), int(new_h-h) - int((new_h-h) / 2)
lw, uw = int((new_w-w) / 2), int(new_w-w) - int((new_w-w) / 2)
pad_array = (int(lw), int(uw), int(lh), int(uh))
out = F.pad(in_img, pad_array)
return out, pad_array
def unpad(img, pad):
if len(img.shape) == 4:
if pad[2]+pad[3] > 0:
img = img[:,:,pad[2]:-pad[3],:]
if pad[0]+pad[1] > 0:
img = img[:,:,:,pad[0]:-pad[1]]
elif len(img.shape) == 3:
if pad[2]+pad[3] > 0:
img = img[:,pad[2]:-pad[3],:]
if pad[0]+pad[1] > 0:
img = img[:,:,pad[0]:-pad[1]]
else:
raise NotImplementedError
return img
================================================
FILE: XMem/util/yv_subset.txt
================================================
003234408d
0043f083b5
0044fa5fba
005a527edd
0065b171f9
00917dcfc4
00a23ccf53
00ad5016a4
01082ae388
011ac0a06f
013099c098
0155498c85
01694ad9c8
017ac35701
01b80e8e1a
01baa5a4e1
01c3111683
01c4cb5ffe
01c76f0a82
01c783268c
01ed275c6e
01ff60d1fa
020cd28cd2
02264db755
0248626d9a
02668dbffa
0274193026
02d28375aa
02f3a5c4df
031ccc99b1
0321b18c10
0348a45bca
0355e92655
0358b938c1
0368107cf1
0379ddf557
038b2cc71d
038c15a5dd
03a06cc98a
03a63e187f
03c95b4dae
03e2b57b0e
04194e1248
0444918a5f
04460a7a52
04474174a4
0450095513
045f00aed2
04667fabaa
04735c5030
04990d1915
04d62d9d98
04f21da964
04fbad476e
04fe256562
0503bf89c9
0536c9eed0
054acb238f
05579ca250
056c200404
05774f3a2c
058a7592c8
05a0a513df
05a569d8aa
05aa652648
05d7715782
05e0b0f28f
05fdbbdd7a
05ffcfed85
0630391881
06840b2bbe
068f7dce6f
0693719753
06ce2b51fb
06e224798e
06ee361788
06fbb3fa2c
0700264286
070c918ca7
07129e14a4
07177017e9
07238ffc58
07353b2a89
0738493cbf
075926c651
075c701292
0762ea9a30
07652ee4af
076f206928
077d32af19
079049275c
07913cdda7
07a11a35e8
07ac33b6df
07b6e8fda8
07c62c3d11
07cc1c7d74
080196ef01
081207976e
081ae4fa44
081d8250cb
082900c5d4
0860df21e2
0866d4c5e3
0891ac2eb6
08931bc458
08aa2705d5
08c8450db7
08d50b926c
08e1e4de15
08e48c1a48
08f561c65e
08feb87790
09049f6fe3
092e4ff450
09338adea8
093c335ccc
0970d28339
0974a213dc
097b471ed8
0990941758
09a348f4fa
09a6841288
09c5bad17b
09c9ce80c7
09ff54fef4
0a23765d15
0a275e7f12
0a2f2bd294
0a7a2514aa
0a7b27fde9
0a8c467cc3
0ac8c560ae
0b1627e896
0b285c47f6
0b34ec1d55
0b5b5e8e5a
0b68535614
0b6f9105fc
0b7dbfa3cb
0b9cea51ca
0b9d012be8
0bcfc4177d
0bd37b23c1
0bd864064c
0c11c6bf7b
0c26bc77ac
0c3a04798c
0c44a9d545
0c817cc390
0ca839ee9a
0cd7ac0ac0
0ce06e0121
0cfe974a89
0d2fcc0dcd
0d3aad05d2
0d40b015f4
0d97fba242
0d9cc80d7e
0dab85b6d3
0db5c427a5
0dbaf284f1
0de4923598
0df28a9101
0e04f636c4
0e05f0e232
0e0930474b
0e27472bea
0e30020549
0e621feb6c
0e803c7d73
0e9ebe4e3c
0e9f2785ec
0ea68d418b
0eb403a222
0ee92053d6
0eefca067f
0f17fa6fcb
0f1ac8e9a3
0f202e9852
0f2ab8b1ff
0f51a78756
0f5fbe16b0
0f6072077b
0f6b69b2f4
0f6c2163de
0f74ec5599
0f9683715b
0fa7b59356
0fb173695b
0fc958cde2
0fe7b1a621
0ffcdb491c
101caff7d4
1022fe8417
1032e80b37
103f501680
104e64565f
104f1ab997
106242403f
10b31f5431
10eced835e
110d26fa3a
1122c1d16a
1145b49a5f
11485838c2
114e7676ec
1157472b95
115ee1072c
1171141012
117757b4b8
1178932d2f
117cc76bda
1180cbf814
1187bbd0e3
1197e44b26
119cf20728
119dd54871
11a0c3b724
11a6ba8c94
11c722a456
11cbcb0b4d
11ccf5e99d
11ce6f452e
11e53de6f2
11feabe596
120cb9514d
12156b25b3
122896672d
1232b2f1d4
1233ac8596
1239c87234
1250423f7c
1257a1bc67
125d1b19dd
126d203967
1295e19071
12ad198c54
12bddb2bcb
12ec9b93ee
12eebedc35
132852e094
1329409f2a
13325cfa14
134d06dbf9
135625b53d
13870016f9
13960b3c84
13adaad9d9
13ae097e20
13e3070469
13f6a8c20d
1416925cf2
142d2621f5
145d5d7c03
145fdc3ac5
1471274fa7
14a6b5a139
14c21cea0d
14dae0dc93
14f9bd22b5
14fd28ae99
15097d5d4e
150ea711f2
1514e3563f
152aaa3a9e
152b7d3bd7
15617297cc
15abbe0c52
15d1fb3de5
15f67b0fab
161eb59aad
16288ea47f
164410ce62
165c3c8cd4
165c42b41b
165ec9e22b
1669502269
16763cccbb
16adde065e
16af445362
16afd538ad
16c3fa4d5d
16d1d65c27
16e8599e94
16fe9fb444
1705796b02
1724db7671
17418e81ea
175169edbb
17622326fd
17656bae77
17b0d94172
17c220e4f6
17c7bcd146
17cb4afe89
17cd79a434
17d18604c3
17d8ca1a37
17e33f4330
17f7a6d805
180abc8378
183ba3d652
185bf64702
18913cc690
1892651815
189ac8208a
189b44e92c
18ac264b76
18b245ab49
18b5cebc34
18bad52083
18bb5144d5
18c6f205c5
1903f9ea15
1917b209f2
191e74c01d
19367bb94e
193ffaa217
19696b67d3
197f3ab6f3
1981e763cc
198afe39ae
19a6e62b9b
19b60d5335
19c00c11f9
19e061eb88
19e8bc6178
19ee80dac6
1a25a9170a
1a359a6c1a
1a3e87c566
1a5fe06b00
1a6c0fbd1e
1a6f3b5a4b
1a8afbad92
1a8bdc5842
1a95752aca
1a9c131cb7
1aa3da3ee3
1ab27ec7ea
1abf16d21d
1acd0f993b
1ad202e499
1af8d2395d
1afd39a1fa
1b2d31306f
1b3fa67f0e
1b43fa74b4
1b73ea9fc2
1b7e8bb255
1b8680f8cd
1b883843c0
1b8898785b
1b88ba1aa4
1b96a498e5
1bbc4c274f
1bd87fe9ab
1c4090c75b
1c41934f84
1c72b04b56
1c87955a3a
1c9f9eb792
1ca240fede
1ca5673803
1cada35274
1cb44b920d
1cd10e62be
1d3087d5e5
1d3685150a
1d6ff083aa
1d746352a6
1da256d146
1da4e956b1
1daf812218
1dba687bce
1dce57d05d
1de4a9e537
1dec5446c8
1dfbe6f586
1e1a18c45a
1e1e42529d
1e4be70796
1eb60959c8
1ec8b2566b
1ecdc2941c
1ee0ac70ff
1ef8e17def
1f1a2a9fc0
1f1beb8daa
1f2609ee13
1f3876f8d0
1f4ec0563d
1f64955634
1f7d31b5b2
1f8014b7fd
1f9c7d10f1
1fa350df76
1fc9538993
1fe2f0ec59
2000c02f9d
20142b2f05
201a8d75e5
2023b3ee4f
202b767bbc
203594a418
2038987336
2039c3aecb
204a90d81f
207bc6cf01
208833d1d1
20c6d8b362
20e3e52e0a
2117fa0c14
211bc5d102
2120d9c3c3
2125235a49
21386f5978
2142af8795
215dfc0f73
217bae91e5
217c0d44e4
219057c87b
21d0edbf81
21df87ad76
21f1d089f5
21f4019116
222597030f
222904eb5b
223a0e0657
223bd973ab
22472f7395
224e7c833e
225aba51d9
2261d421ea
2263a8782b
2268cb1ffd
2268e93b0a
2293c99f3f
22a1141970
22b13084b2
22d9f5ab0c
22f02efe3a
232c09b75b
2350d71b4b
2376440551
2383d8aafd
238b84e67f
238d4b86f6
238d947c6b
23993ce90d
23b0c8a9ab
23b3beafcc
23d80299fe
23f404a9fc
240118e58a
2431dec2fd
24440e0ac7
2457274dbc
2465bf515d
246b142c4d
247d729e36
2481ceafeb
24866b4e6a
2489d78320
24ab0b83e8
24b0868d92
24b5207cd9
24ddf05c03
250116161c
256ad2e3fc
256bd83d5e
256dcc8ab8
2589956baa
258b3b33c6
25ad437e29
25ae395636
25c750c6db
25d2c3fe5d
25dc80db7c
25f97e926f
26011bc28b
260846ffbe
260dd9ad33
267964ee57
2680861931
268ac7d3fc
26b895d91e
26bc786d4f
26ddd2ef12
26de3d18ca
26f7784762
2703e52a6a
270ed80c12
2719b742ab
272f4163d0
27303333e1
27659fa7d6
279214115d
27a5f92a9c
27cf2af1f3
27f0d5f8a2
28075f33c1
281629cb41
282b0d51f5
282fcab00b
28449fa0dc
28475208ca
285580b7c4
285b69e223
288c117201
28a8eb9623
28bf9c3cf3
28c6b8f86a
28c972dacd
28d9fa6016
28e392de91
28f4a45190
298c844fc9
29a0356a2b
29d779f9e3
29dde5f12b
29de7b6579
29e630bdd0
29f2332d30
2a18873352
2a3824ff31
2a559dd27f
2a5c09acbd
2a63eb1524
2a6a30a4ea
2a6d9099d1
2a821394e3
2a8c5b1342
2abc8d66d2
2ac9ef904a
2b08f37364
2b351bfd7d
2b659a49d7
2b69ee5c26
2b6c30bbbd
2b88561cf2
2b8b14954e
2ba621c750
2bab50f9a7
2bb00c2434
2bbde474ef
2bdd82fb86
2be06fb855
2bf545c2f5
2bffe4cf9a
2c04b887b7
2c05209105
2c0ad8cf39
2c11fedca8
2c1a94ebfb
2c1e8c8e2f
2c29fabcf1
2c2c076c01
2c3ea7ee7d
2c41fa0648
2c44bb6d1c
2c54cfbb78
2c5537eddf
2c6e63b7de
2cb10c6a7e
2cbcd5ccd1
2cc5d9c5f6
2cd01cf915
2cdbf5f0a7
2ce660f123
2cf114677e
2d01eef98e
2d03593bdc
2d183ac8c4
2d33ad3935
2d3991d83e
2d4333577b
2d4d015c64
2d8f5e5025
2d900bdb8e
2d9a1a1d49
2db0576a5c
2dc0838721
2dcc417f82
2df005b843
2df356de14
2e00393d96
2e03b8127a
2e0f886168
2e2bf37e6d
2e42410932
2ea78f46e4
2ebb017a26
2ee2edba2a
2efb07554a
2f17e4fc1e
2f2c65c2f3
2f2d9b33be
2f309c206b
2f53822e88
2f53998171
2f5b0c89b1
2f680909e6
2f710f66bd
2f724132b9
2f7e3517ae
2f96f5fc6f
2f97d9fecb
2fbfa431ec
2fc9520b53
2fcd9f4c62
2feb30f208
2ff7f5744f
30085a2cc6
30176e3615
301f72ee11
3026bb2f61
30318465dc
3054ca937d
306121e726
3064ad91e8
307444a47f
307bbb7409
30a20194ab
30c35c64a4
30dbdb2cd6
30fc77d72f
310021b58b
3113140ee8
3150b2ee57
31539918c4
318dfe2ce2
3193da4835
319f725ad9
31bbd0d793
322505c47f
322b237865
322da43910
3245e049fb
324c4c38f6
324e35111a
3252398f09
327dc4cabf
328d918c7d
3290c0de97
3299ae3116
32a7cd687b
33098cedb4
3332334ac4
334cb835ac
3355e056eb
33639a2847
3373891cdc
337975816b
33e29d7e91
34046fe4f2
3424f58959
34370a710f
343bc6a65a
3450382ef7
3454303a08
346aacf439
346e92ff37
34a5ece7dd
34b109755a
34d1b37101
34dd2c70a7
34efa703df
34fbee00a6
3504df2fda
35195a56a1
351c822748
351cfd6bc5
3543d8334c
35573455c7
35637a827f
357a710863
358bf16f9e
35ab34cc34
35c6235b8d
35d01a438a
3605019d3b
3609bc3f88
360e25da17
36299c687c
362c5bc56e
3649228783
365b0501ea
365f459863
369893f3ad
369c9977e1
369dde050a
36c7dac02f
36d5b1493b
36f5cc68fd
3735480d18
374b479880
375a49d38f
375a5c0e09
376bda9651
377db65f60
37c19d1087
37d4ae24fc
37ddce7f8b
37e10d33af
37e45c6247
37fa0001e8
3802d458c0
382caa3cb4
383bb93111
388843df90
38924f4a7f
38b00f93d7
38c197c10e
38c9c3d801
38eb2bf67f
38fe9b3ed1
390352cced
390c51b987
390ca6f1d6
392bc0f8a1
392ecb43bd
3935291688
3935e63b41
394454fa9c
394638fc8b
39545e20b7
397abeae8f
3988074b88
398f5d5f19
39bc49a28c
39befd99fb
39c3c7bf55
39d584b09f
39f6f6ffb1
3a079fb484
3a0d3a81b7
3a1d55d22b
3a20a7583e
3a2c1f66e5
3a33f4d225
3a3bf84b13
3a4565e5ec
3a4e32ed5e
3a7ad86ce0
3a7bdde9b8
3a98867cbe
3aa3f1c9e8
3aa7fce8b6
3aa876887d
3ab807ded6
3ab9b1a85a
3adac8d7da
3ae1a4016f
3ae2deaec2
3ae81609d6
3af847e62f
3b23792b84
3b3b0af2ee
3b512dad74
3b6c7988f6
3b6e983b5b
3b74a0fc20
3b7a50b80d
3b96d3492f
3b9ad0c5a9
3b9ba0894a
3bb4e10ed7
3bd9a9b515
3beef45388
3c019c0a24
3c090704aa
3c2784fc0d
3c47ab95f8
3c4db32d74
3c5ff93faf
3c700f073e
3c713cbf2f
3c8320669c
3c90d225ee
3cadbcc404
3cb9be84a5
3cc37fd487
3cc6f90cb2
3cd5e035ef
3cdf03531b
3cdf828f59
3d254b0bca
3d5aeac5ba
3d690473e1
3d69fed2fb
3d8997aeb6
3db0d6b07e
3db1ddb8cf
3db907ac77
3dcbc0635b
3dd48ed55f
3de4ac4ec4
3decd63d88
3e04a6be11
3e108fb65a
3e1448b01c
3e16c19634
3e2845307e
3e38336da5
3e3a819865
3e3e4be915
3e680622d7
3e7d2aeb07
3e7d8f363d
3e91f10205
3ea4c49bbe
3eb39d11ab
3ec273c8d5
3ed3f91271
3ee062a2fd
3eede9782c
3ef2fa99cb
3efc6e9892
3f0b0dfddd
3f0c860359
3f18728586
3f3b15f083
3f45a470ad
3f4f3bc803
3fd96c5267
3fea675fab
3fee8cbc9f
3fff16d112
401888b36c
4019231330
402316532d
402680df52
404d02e0c0
40709263a8
4083cfbe15
40a96c5cb1
40b8e50f82
40f4026bf5
4100b57a3a
41059fdd0b
41124e36de
4122aba5f9
413bab0f0d
4164faee0b
418035eec9
4182d51532
418bb97e10
41a34c20e7
41dab05200
41ff6d5e2a
420caf0859
42264230ba
425a0c96e0
42da96b87c
42eb5a5b0f
42f17cd14d
42f5c61c49
42ffdcdee9
432f9884f9
43326d9940
4350f3ab60
4399ffade3
43a6c21f37
43b5555faa
43d63b752a
4416bdd6ac
4444753edd
444aa274e7
444d4e0596
446b8b5f7a
4478f694bb
44b1da0d87
44b4dad8c9
44b5ece1b9
44d239b24e
44eaf8f51e
44f4f57099
44f7422af2
450787ac97
4523656564
4536c882e5
453b65daa4
454f227427
45636d806a
456fb9362e
457e717a14
45a89f35e1
45bf0e947d
45c36a9eab
45d9fc1357
45f8128b97
4607f6c03c
46146dfd39
4620e66b1e
4625f3f2d3
462b22f263
4634736113
463c0f4fdd
46565a75f8
46630b55ae
466839cb37
466ba4ae0c
4680236c9d
46bf4e8709
46e18e42f1
46f5093c59
47269e0499
472da1c484
47354fab09
4743bb84a7
474a796272
4783d2ab87
479cad5da3
479f5d7ef6
47a05fbd1d
4804ee2767
4810c3fbca
482fb439c2
48375af288
484ab44de4
485f3944cd
4867b84887
486a8ac57e
486e69c5bd
48812cf33e
4894b3b9ea
48bd66517d
48d83b48a4
49058178b8
4918d10ff0
4932911f80
49405b7900
49972c2d14
499bf07002
49b16e9377
49c104258e
49c879f82d
49e7326789
49ec3e406a
49fbf0c98a
4a0255c865
4a088fe99a
4a341402d0
4a3471bdf5
4a4b50571c
4a50f3d2e9
4a6e3faaa1
4a7191f08a
4a86fcfc30
4a885fa3ef
4a8af115de
4aa2e0f865
4aa9d6527f
4abb74bb52
4ae13de1cd
4af8cb323f
4b02c272b3
4b19c529fb
4b2974eff4
4b3154c159
4b54d2587f
4b556740ff
4b67aa9ef6
4b97cc7b8d
4baa1ed4aa
4bc8c676bb
4beaea4dbe
4bf5763d24
4bffa92b67
4c25dfa8ec
4c397b6fd4
4c51e75d66
4c7710908f
4c9b5017be
4ca2ffc361
4cad2e93bc
4cd427b535
4cd9a4b1ef
4cdfe3c2b2
4cef87b649
4cf208e9b3
4cf5bc3e60
4cfdd73249
4cff5c9e42
4d26d41091
4d5c23c554
4d67c59727
4d983cad9f
4da0d00b55
4daa179861
4dadd57153
4db117e6c5
4de4ce4dea
4dfaee19e5
4dfdd7fab0
4e3f346aa5
4e49c2a9c7
4e4e06a749
4e70279712
4e72856cc7
4e752f8075
4e7a28907f
4e824b9247
4e82b1df57
4e87a639bc
4ea77bfd15
4eb6fc23a2
4ec9da329e
4efb9a0720
4f062fbc63
4f35be0e0b
4f37e86797
4f414dd6e7
4f424abded
4f470cc3ae
4f601d255a
4f7386a1ab
4f824d3dcd
4f827b0751
4f8db33a13
4fa160f8a3
4fa9c30a45
4facd8f0e8
4fca07ad01
4fded94004
4fdfef4dea
4feb3ac01f
4fffec8479
500c835a86
50168342bf
50243cffdc
5031d5a036
504dd9c0fd
50568fbcfb
5069c7c5b3
508189ac91
50b6b3d4b7
50c6f4fe3e
50cce40173
50efbe152f
50f290b95d
5104aa1fea
5110dc72c0
511e8ecd7f
513aada14e
5158d6e985
5161e1fa57
51794ddd58
517d276725
51a597ee04
51b37b6d97
51b5dc30a0
51e85b347b
51eea1fdac
51eef778af
51f384721c
521cfadcb4
52355da42f
5247d4b160
524b470fd0
524cee1534
5252195e8a
5255c9ca97
525928f46f
526df007a7
529b12de78
52c7a3d653
52c8ec0373
52d225ed52
52ee406d9e
52ff1ccd4a
53143511e8
5316d11eb7
53253f2362
534a560609
5352c4a70e
536096501f
536b17bcea
5380eaabff
5390a43a54
53af427bb2
53bf5964ce
53c30110b5
53cad8e44a
53d9c45013
53e274f1b5
53e32d21ea
540850e1c7
540cb31cfe
541c4da30f
541d7935d7
545468262b
5458647306
54657855cd
547b3fb23b
5497dc3712
549c56f1d4
54a4260bb1
54b98b8d5e
54e1054b0f
54e8867b83
54ebe34f6e
5519b4ad13
551acbffd5
55341f42da
5566ab97e1
556c79bbf2
5589637cc4
558aa072f0
559824b6f6
55c1764e90
55eda6c77e
562d173565
5665c024cb
566cef4959
5675d78833
5678a91bd8
567a2b4bd0
569c282890
56cc449917
56e71f3e07
56f09b9d92
56fc0e8cf9
571ca79c71
57243657cf
57246af7d1
57427393e9
574b682c19
578f211b86
5790ac295d
579393912d
57a344ab1a
57bd3bcda4
57bfb7fa4c
57c010175e
57c457cc75
57c7fc2183
57d5289a01
58045fde85
58163c37cd
582d463e5c
5851739c15
585dd0f208
587250f3c3
589e4cc1de
589f65f5d5
58a07c17d5
58adc6d8b6
58b9bcf656
58c374917e
58fc75fd42
5914c30f05
59323787d5
5937b08d69
594065ddd7
595a0ceea6
59623ec40b
597ff7ef78
598935ef05
598c2ad3b2
59a6459751
59b175e138
59bf0a149f
59d53d1649
59e3e6fae7
59fe33e560
5a13a73fe5
5a25c22770
5a4a785006
5a50640995
5a75f7a1cf
5a841e59ad
5a91c5ab6d
5ab49d9de0
5aba1057fe
5abe46ba6d
5ac7c88d0c
5aeb95cc7d
5af15e4fc3
5afe381ae4
5b07b4229d
5b1001cc4f
5b1df237d2
5b263013bf
5b27d19f0b
5b48ae16c5
5b5babc719
5baaebdf00
5bab55cdbe
5bafef6e79
5bd1f84545
5bddc3ba25
5bdf7c20d2
5bf23bc9d3
5c01f6171a
5c021681b7
5c185cff1d
5c42aba280
5c44bf8ab6
5c4c574894
5c52fa4662
5c6ea7dac3
5c74315dc2
5c7668855e
5c83e96778
5ca36173e4
5cac477371
5cb0cb1b2f
5cb0cfb98f
5cb49a19cf
5cbf7dc388
5d0e07d126
5d1e24b6e3
5d663000ff
5da6b2dc5d
5de9b90f24
5e08de0ed7
5e1011df9a
5e1ce354fd
5e35512dd7
5e418b25f9
5e4849935a
5e4ee19663
5e886ef78f
5e8d00b974
5e8d59dc31
5ed838bd5c
5edda6ee5a
5ede4d2f7a
5ede9767da
5eec4d9fe5
5eecf07824
5eef7ed4f4
5ef5860ac6
5ef6573a99
5f1193e72b
5f29ced797
5f32cf521e
5f51876986
5f6ebe94a9
5f6f14977c
5f808d0d2d
5fb8aded6a
5fba90767d
5fd1c7a3df
5fd3da9f68
5fee2570ae
5ff66140d6
5ff8b85b53
600803c0f6
600be7f53e
6024888af8
603189a03c
6057307f6e
6061ddbb65
606c86c455
60c61cc2e5
60e51ff1ae
610e38b751
61344be2f6
6135e27185
614afe7975
614e571886
614e7078db
619812a1a7
61b481a78b
61c7172650
61cf7e40d2
61d08ef5a1
61da008958
61ed178ecb
61f5d1282c
61fd977e49
621584cffe
625817a927
625892cf0b
625b89d28a
629995af95
62a0840bb5
62ad6e121c
62d6ece152
62ede7b2da
62f025e1bc
6316faaebc
63281534dc
634058dda0
6353f09384
6363c87314
636e4872e0
637681cd6b
6376d49f31
6377809ec2
63936d7de5
639bddef11
63d37e9fd3
63d90c2bae
63e544a5d6
63ebbcf874
63fff40b31
6406c72e4d
64148128be
6419386729
643092bc41
644081b88d
64453cf61d
644bad9729
6454f548fd
645913b63a
64750b825f
64a43876b7
64dd6c83e3
64e05bf46e
64f55f1478
650b0165e4
651066ed39
652b67d960
653821d680
6538d00d73
65866dce22
6589565c8c
659832db64
65ab7e1d98
65b7dda462
65bd5eb4f5
65dcf115ab
65e9825801
65f9afe51c
65ff12bcb5
666b660284
6671643f31
668364b372
66852243cb
6693a52081
669b572898
66e98e78f5
670f12e88f
674c12c92d
675c27208a
675ed3e1ca
67741db50a
678a2357eb
67b0f4d562
67cfbff9b1
67e717d6bd
67ea169a3b
67ea809e0e
681249baa3
683de643d9
6846ac20df
6848e012ef
684bcd8812
684dc1c40c
685a1fa9cf
686dafaac9
68807d8601
6893778c77
6899d2dabe
68a2fad4ab
68cb45fda3
68cc4a1970
68dcb40675
68ea4a8c3d
68f6e7fbf0
68fa8300b4
69023db81f
6908ccf557
691a111e7c
6927723ba5
692ca0e1a2
692eb57b63
69340faa52
693cbf0c9d
6942f684ad
6944fc833b
69491c0ebf
695b61a2b0
6979b4d83f
697d4fdb02
69910460a4
6997636670
69a436750b
69aebf7669
69b8c17047
69c67f109f
69e0e7b868
69ea9c09d1
69f0af42a6
6a078cdcc7
6a37a91708
6a42176f2e
6a48e4aea8
6a5977be3a
6a5de0535f
6a80d2e2e5
6a96c8815d
6a986084e2
6aa8e50445
6ab9dce449
6abf0ba6b2
6acc6049d9
6adb31756c
6ade215eb0
6afb7d50e4
6afd692f1a
6b0b1044fe
6b17c67633
6b1b6ef28b
6b1e04d00d
6b2261888d
6b25d6528a
6b3a24395c
6b685eb75b
6b79be238c
6b928b7ba6
6b9c43c25a
6ba99cc41f
6bdab62bcd
6bf2e853b1
6bf584200f
6bf95df2b9
6c0949c51c
6c11a5f11f
6c23d89189
6c4387daf5
6c4ce479a4
6c5123e4bc
6c54265f16
6c56848429
6c623fac5f
6c81b014e9
6c99ea7c31
6c9d29d509
6c9e3b7d1a
6ca006e283
6caeb928d6
6cb2ee722a
6cbfd32c5e
6cc791250b
6cccc985e0
6d12e30c48
6d4bf200ad
6d6d2b8843
6d6eea5682
6d7a3d0c21
6d7efa9b9e
6da21f5c91
6da6adabc0
6dd2827fbb
6dd36705b9
6df3637557
6dfe55e9e5
6e1a21ba55
6e2f834767
6e36e4929a
6e4f460caf
6e618d26b6
6ead4670f7
6eaff19b9f
6eb2e1cd9e
6eb30b3b5a
6eca26c202
6ecad29e52
6ef0b44654
6efcfe9275
6f4789045c
6f49f522ef
6f67d7c4c4
6f96e91d81
6fc6fce380
6fc9b44c00
6fce7f3226
6fdf1ca888
702fd8b729
70405185d2
7053e4f41e
707bf4ce41
7082544248
708535b72a
7094ac0f60
70a6b875fa
70c3e97e41
7106b020ab
711dce6fe2
7136a4453f
7143fb084f
714d902095
7151c53b32
715357be94
7163b8085f
716df1aa59
71caded286
71d2665f35
71d67b9e19
71e06dda39
720b398b9c
720e3fa04c
720e7a5f1e
721bb6f2cb
722803f4f2
72552a07c9
726243a205
72690ef572
728cda9b65
728e81c319
72a810a799
72acb8cdf6
72b01281f9
72cac683e4
72cadebbce
72cae058a5
72d8dba870
72e8d1c1ff
72edc08285
72f04f1a38
731b825695
7320b49b13
732626383b
732df1eb05
73329902ab
733798921e
733824d431
734ea0d7fb
735a7cf7b9
7367a42892
7368d5c053
73c6ae7711
73e1852735
73e4e5cc74
73eac9156b
73f8441a88
7419e2ab3f
74267f68b9
7435690c8c
747c44785c
747f1b1f2f
748b2d5c01
74d4cee0a4
74ec2b3073
74ef677020
750be4c4d8
75172d4ac8
75285a7eb1
75504539c3
7550949b1d
7551cbd537
75595b453d
7559b4b0ec
755bd1fbeb
756f76f74d
7570ca7f3c
757a69746e
757cac96c6
7584129dc3
75a058dbcd
75b09ce005
75cae39a8f
75cee6caf0
75cf58fb2c
75d5c2f32a
75eaf5669d
75f7937438
75f99bd3b3
75fa586876
7613df1f84
762e1b3487
76379a3e69
764271f0f3
764503c499
7660005554
7666351b84
76693db153
767856368b
768671f652
768802b80d
76962c7ed2
76a75f4eee
76b90809f7
770a441457
772a0fa402
772f2ffc3e
774f6c2175
77610860e0
777e58ff3d
77920f1708
7799df28e7
779e847a9a
77ba4edc72
77c834dc43
77d8aa8691
77e7f38f4d
77eea6845e
7806308f33
78254660ea
7828af8bff
784398620a
784d201b12
78613981ed
78896c6baf
78aff3ebc0
78c7c03716
78d3676361
78e29dd4c3
78f1a1a54f
79208585cd
792218456c
7923bad550
794e6fc49f
796e6762ce
797cd21f71
79921b21c2
79a5778027
79bc006280
79bf95e624
79d9e00c55
79e20fc008
79e9db913e
79f014085e
79fcbb433a
7a13a5dfaa
7a14bc9a36
7a3c535f70
7a446a51e9
7a56e759c5
7a5f46198d
7a626ec98d
7a802264c4
7a8b5456ca
7abdff3086
7aecf9f7ac
7b0fd09c28
7b18b3db87
7b39fe7371
7b49e03d4c
7b5388c9f1
7b5cf7837f
7b733d31d8
7b74fd7b98
7b918ccb8a
7ba3ce3485
7bb0abc031
7bb5bb25cd
7bb7dac673
7bc7761b8c
7bf3820566
7c03a18ec1
7c078f211b
7c37d7991a
7c4ec17eff
7c649c2aaf
7c73340ab7
7c78a2266d
7c88ce3c5b
7ca6843a72
7cc9258dee
7cec7296ae
7d0ffa68a4
7d11b4450f
7d1333fcbe
7d18074fef
7d18c8c716
7d508fb027
7d55f791f0
7d74e3c2f6
7d783f67a9
7d83a5d854
7dd409947e
7de45f75e5
7e0cd25696
7e1922575c
7e1e3bbcc1
7e24023274
7e2f212fd3
7e6d1cc1f4
7e7cdcb284
7e9b6bef69
7ea5b49283
7eb2605d96
7eb26b8485
7ecd1f0c69
7f02b3cfe2
7f1723f0d5
7f21063c3a
7f3658460e
7f54132e48
7f559f9d4a
7f5faedf8b
7f838baf2b
7fa5f527e3
7ff84d66dd
802b45c8c4
804382b1ad
804c558adb
804f6338a4
8056117b89
806b6223ab
8088bda461
80b790703b
80c4a94706
80ce2e351b
80db581acd
80e12193df
80e41b608f
80f16b016d
81541b3725
8175486e6a
8179095000
8193671178
81a58d2c6b
81aa1286fb
81dffd30fb
8200245704
823e7a86e8
824973babb
824ca5538f
827171a845
8273a03530
827cf4f886
82b865c7dd
82c1517708
82d15514d6
82e117b900
82fec06574
832b5ef379
83424c9fbf
8345358fb8
834b50b31b
835e3b67d7
836ea92b15
837c618777
838eb3bd89
839381063f
839bc71489
83a8151377
83ae88d217
83ca8bcad0
83ce590d7f
83d3130ba0
83d40bcba5
83daba503a
83de906ec0
84044f37f3
84696b5a5e
84752191a3
847eeeb2e0
848e7835a0
84a4b29286
84a4bf147d
84be115c09
84d95c4350
84e0922cf7
84f0cfc665
8515f6db22
851f2f32c1
852a4d6067
854c48b02a
857a387c86
859633d56a
85a4f4a639
85ab85510c
85b1eda0d9
85dc1041c6
85e081f3c7
85f75187ad
8604bb2b75
860745b042
863b4049d7
8643de22d0
8647d06439
864ffce4fe
8662d9441a
8666521b13
868d6a0685
869fa45998
86a40b655d
86a8ae4223
86b2180703
86c85d27df
86d3755680
86e61829a1
871015806c
871e409c5c
8744b861ce
8749369ba0
878a299541
8792c193a0
8799ab0118
87d1f7d741
882b9e4500
885673ea17
8859dedf41
8873ab2806
887a93b198
8883e991a9
8891aa6dfa
8899d8cbcd
88b8274d67
88d3b80af6
88ede83da2
88f345941b
890976d6da
8909bde9ab
8929c7d5d9
89363acf76
89379487e0
8939db6354
893f658345
8953138465
895c96d671
895cbf96f9
895e8b29a7
898fa256c8
89986c60be
89b874547b
89bdb021d5
89c802ff9c
89d6336c2b
89ebb27334
8a27e2407c
8a31f7bca5
8a4a2fc105
8a5d6c619c
8a75ad7924
8aa817e4ed
8aad0591eb
8aca214360
8ae168c71b
8b0cfbab97
8b3645d826
8b3805dbd4
8b473f0f5d
8b4f6d1186
8b4fb018b7
8b518ee936
8b523bdfd6
8b52fb5fba
8b91036e5c
8b99a77ac5
8ba04b1e7b
8ba782192f
8bbeaad78b
8bd1b45776
8bd7a2dda6
8bdb091ccf
8be56f165d
8be950d00f
8bf84e7d45
8bffc4374b
8bfff50747
8c09867481
8c0a3251c3
8c3015cccb
8c469815cf
8c9ccfedc7
8ca1af9f3c
8ca3f6e6c1
8ca6a4f60f
8cac6900fe
8cba221a1e
8cbbe62ccd
8d064b29e2
8d167e7c08
8d4ab94e1c
8d81f6f899
8d87897d66
8dcccd2bd2
8dcfb878a8
8dd3ab71b9
8dda6bf10f
8ddd51ca94
8dea22c533
8def5bd3bf
8e1848197c
8e3a83cf2d
8e478e73f3
8e98ae3c84
8ea6687ab0
8eb0d315c1
8ec10891f9
8ec3065ec2
8ecf51a971
8eddbab9f7
8ee198467a
8ee2368f40
8ef595ce82
8f0a653ad7
8f1204a732
8f1600f7f6
8f16366707
8f1ce0a411
8f2e05e814
8f320d0e09
8f3b4a84ad
8f3fdad3da
8f5d3622d8
8f62a2c633
8f81c9405a
8f8c974d53
8f918598b6
8ff61619f6
9002761b41
90107941f3
90118a42ee
902bc16b37
903e87e0d6
9041a0f489
9047bf3222
9057bfa502
90617b0954
9076f4b6db
9077e69b08
909655b4a6
909c2eca88
909dbd1b76
90bc4a319a
90c7a87887
90cc785ddd
90d300f09b
9101ea9b1b
9108130458
911ac9979b
9151cad9b5
9153762797
91634ee0c9
916942666f
9198cfb4ea
919ac864d6
91b67d58d4
91bb8df281
91be106477
91c33b4290
91ca7dd9f3
91d095f869
91f107082e
920329dd5e
920c959958
92128fbf4b
9223dacb40
923137bb7f
9268e1f88a
927647fe08
9276f5ba47
92a28cd233
92b5c1fc6d
92c46be756
92dabbe3a0
92e3159361
92ebab216a
934bdc2893
9359174efc
935d97dd2f
935feaba1b
93901858ee
939378f6d6
939bdf742e
93a22bee7e
93da9aeddf
93e2feacce
93e6f1fdf9
93e811e393
93e85d8fd3
93f623d716
93ff35e801
94031f12f2
94091a4873
94125907e3
9418653742
941c870569
94209c86f0
9437c715eb
9445c3eca2
9467c8617c
946d71fb5d
948f3ae6fb
9498baa359
94a33abeab
94bf1af5e3
94cf3a8025
94db712ac8
94e4b66cff
94e76cbaf6
950be91db1
952058e2d0
952633c37f
952ec313fe
9533fc037c
9574b81269
9579b73761
957f7bc48b
958073d2b0
9582e0eb33
9584092d0b
95b58b8004
95bd88da55
95f74a9959
962781c601
962f045bf5
964ad23b44
967b90590e
967bffe201
96825c4714
968492136a
9684ef9d64
968c41829e
96a856ef9a
96dfc49961
96e1a5b4f8
96e6ff0917
96fb88e9d7
96fbe5fc23
96fc924050
9715cc83dc
9720eff40f
972c187c0d
97476eb38d
97659ed431
9773492949
97756b264f
977bff0d10
97ab569ff3
97ba838008
97d9d008c7
97e59f09fa
97eb642e56
98043e2d14
981ff580cf
983e66cbfc
984f0f1c36
98595f2bb4
985c3be474
9869a12362
986b5a5e18
9877af5063
98911292da
9893a3cf77
9893d9202d
98a8b06e7f
98ac6f93d9
98b6974d12
98ba3c9417
98c7c00a19
98d044f206
98e909f9d1
98fe7f0410
990f2742c7
992bd0779a
994b9b47ba
9955b76bf5
9966f3adac
997117a654
999d53d841
99c04108d3
99c4277aee
99c6b1acf2
99dc8bb20b
99fcba71e5
99fecd4efb
9a02c70ba2
9a08e7a6f8
9a2f2c0f86
9a3254a76e
9a3570a020
9a39112493
9a4e9fd399
9a50af4bfb
9a68631d24
9a72318dbf
9a767493b7
9a7fc1548b
9a84ccf6a7
9a9c0e15b7
9adf06d89b
9b22b54ee4
9b473fc8fe
9b4f081782
9b997664ba
9bc454e109
9bccfd04de
9bce4583a2
9bebf1b87f
9bfc50d261
9c166c86ff
9c293ef4d7
9c29c047b0
9c3bc2e2a7
9c3ce23bd1
9c404cac0c
9c5180d23a
9c7feca6e4
9caa49d3ff
9cb2f1b646
9ce6f765c3
9cfee34031
9d01f08ec6
9d04c280b8
9d12ceaddc
9d15f8cb3c
9d2101e9bf
9d407c3aeb
9ddefc6165
9df0b1e298
9e16f115d8
9e249b4982
9e29b1982c
9e493e4773
9e4c752cd0
9e4de40671
9e6319faeb
9e6ddbb52d
9eadcea74f
9ecec5f8ea
9efb47b595
9f30bfe61e
9f3734c3a4
9f5b858101
9f66640cda
9f913803e9
9f97bc74c8
9fbad86e20
9fc2bad316
9fc5c3af78
9fcb310255
9fcc256871
9fd2fd4d47
a0071ae316
a023141022
a046399a74
a066e739c1
a06722ba82
a07a15dd64
a07b47f694
a09c39472e
a0b208fe2e
a0b61c959e
a0bc6c611d
a0e6da5ba2
a1193d6490
a14ef483ff
a14f709908
a15ccc5658
a16062456f
a174e8d989
a177c2733c
a17c62e764
a18ad065fc
a1aaf63216
a1bb65fb91
a1bd8e5349
a1dfdd0cac
a2052e4f6c
a20fd34693
a21ffe4d81
a22349e647
a235d01ec1
a24f63e8a2
a2554c9f6d
a263ce8a87
a29bfc29ec
a2a80072d4
a2a800ab63
a2bcd10a33
a2bdaff3b0
a2c146ab0d
a2c996e429
a2dc51ebe8
a2e6608bfa
a2f2a55f01
a301869dea
a31fccd2cc
a34f440f33
a35e0206da
a36bdc4cab
a36e8c79d8
a378053b20
a37db3a2b3
a38950ebc2
a39a0eb433
a39c9bca52
a3a945dc8c
a3b40a0c1e
a3b8588550
a3c502bec3
a3f2878017
a3f4d58010
a3f51855c3
a402dc0dfe
a4065a7eda
a412bb2fef
a416b56b53
a41ec95906
a43299e362
a4757bd7af
a48c53c454
a49dcf9ad5
a4a506521f
a4ba7753d9
a4bac06849
a4f05d681c
a50c10060f
a50eb5a0ea
a5122c6ec6
a522b1aa79
a590915345
a5b5b59139
a5b77abe43
a5c2b2c3e1
a5cd17bb11
a5da03aef1
a5dd11de0d
a5ea2b93b6
a5eaeac80b
a5ec5b0265
a5f350a87e
a5f472caf4
a6027a53cf
a61715bb1b
a61cf4389d
a61d9bbd9b
a6470dbbf5
a64a40f3eb
a653d5c23b
a65bd23cb5
a66e0b7ad4
a66fc5053c
a68259572b
a6a810a92c
a6bc36937f
a6c3a374e9
a6d8a4228d
a6f4e0817f
a71e0481f5
a7203deb2d
a7392d4438
a73d3c3902
a7491f1578
a74b9ca19c
a77b7a91df
a78195a5f5
a78758d4ce
a7e6d6c29a
a800d85e88
a832fa8790
a83d06410d
a8999af004
a8f78125b9
a907b18df1
a919392446
a965504e88
a96b84b8d2
a973f239cd
a977126596
a9804f2a08
a984e56893
a99738f24c
a99bdd0079
a9c9c1517e
a9cbf9c41b
a9e42e3c0c
aa07b7c1c0
aa175e5ec7
aa1a338630
aa27d7b868
aa45f1caaf
aa49e46432
aa51934e1b
aa6287bb6c
aa6d999971
aa85278334
aab33f0e2a
aaba004362
aade4cf385
aae78feda4
aaed233bf3
aaff16c2db
ab199e8dfb
ab23b78715
ab2e1b5577
ab33a18ded
ab45078265
ab56201494
ab90f0d24b
abab2e6c20
abb50c8697
abbe2d15a0
abbe73cd21
abe61a11bb
abeae8ce21
ac2b431d5f
ac2cb1b9eb
ac31fcd6d0
ac3d3a126d
ac46bd8087
ac783ef388
acb73e4297
acbf581760
accafc3531
acf2c4b745
acf44293a2
acf736a27b
acff336758
ad1fe56886
ad28f9b9d9
ad2de9f80e
ad397527b2
ad3d1cfbcb
ad3fada9d9
ad4108ee8e
ad54468654
ad573f7d31
ad6255bc29
ad65ebaa07
ad97cc064a
adabbd1cc4
adb0b5a270
adc648f890
add21ee467
adfd15ceef
adfdd52eac
ae01cdab63
ae0b50ff4f
ae13ee3d70
ae1bcbd423
ae20d09dea
ae2cecf5f6
ae3bc4a0ef
ae499c7514
ae628f2cd4
ae8545d581
ae93214fe6
ae9cd16dbf
aeba9ac967
aebb242b5c
aed4e0b4c4
aedd71f125
aef3e2cb0e
af0b54cee3
af3de54c7a
af5fd24a36
af8826d084
af8ad72057
afb71e22c5
afcb331e1f
afe1a35c1e
b01080b5d3
b05ad0d345
b0623a6232
b064dbd4b7
b06ed37831
b06f5888e6
b08dcc490e
b0a68228dc
b0aece727f
b0b0731606
b0c7f11f9f
b0cca8b830
b0dd580a89
b0de66ca08
b0df7c5c5c
b0f5295608
b11099eb09
b132a53086
b1399fac64
b13abc0c69
b1457e3b5e
b15bf4453b
b179c4a82d
b17ee70e8c
b190b1aa65
b19b3e22c0
b19c561fab
b1d1cd2e6e
b1d7c03927
b1d7fe2753
b1f540a4bd
b1fc9c64e1
b1fcbb3ced
b220939e93
b22099b419
b241e95235
b2432ae86d
b2456267df
b247940d01
b24af1c35c
b24f600420
b24fe36b2a
b258fb0b7d
b26b219919
b26d9904de
b274456ce1
b27b28d581
b2a26bc912
b2a9c51e1b
b2b0baf470
b2b2756fe7
b2ce7699e3
b2edc76bd2
b2f6b52100
b30bf47bcd
b34105a4e9
b372a82edf
b3779a1962
b379ab4ff5
b37a1d69e3
b37c01396e
b382b09e25
b3996e4ba5
b3d9ca2aee
b3dde1e1e9
b3eb7f05eb
b40b25055c
b41e0f1f19
b44e32a42b
b4805ae9cd
b4807569a5
b48efceb3e
b493c25c7f
b4b565aba1
b4b715a15b
b4d0c90bf4
b4d84bc371
b4e5ad97aa
b4eaea9e6b
b50f4b90d5
b53f675641
b54278cd43
b554843889
b573c0677a
b58d853734
b5943b18ab
b5a09a83f3
b5aae1fe25
b5b9da5364
b5eb64d419
b5ebb1d000
b5f1c0c96a
b5f7fece90
b6070de1bb
b60a76fe73
b61f998772
b62c943664
b63094ba0c
b64fca8100
b673e7dcfb
b678b7db00
b68fc1b217
b69926d9fa
b6a1df3764
b6a4859528
b6b4738b78
b6b4f847b7
b6b8d502d4
b6bb00e366
b6d65a9eef
b6d79a0845
b6e9ec577f
b6ec609f7b
b6f92a308d
b70a2c0ab1
b70a5a0d50
b70c052f2f
b70d231781
b72ac6e10b
b7302d8226
b73867d769
b751e767f2
b76df6e059
b77e5eddef
b7a2c2c83c
b7bcbe6466
b7c2a469c4
b7d69da8f0
b7f31b7c36
b7f675fb98
b7fb871660
b82e5ad1c9
b841cfb932
b84b8ae665
b85b78ac2b
b86c17caa6
b86e50d82d
b871db031a
b87d56925a
b8aaa59b75
b8c03d1091
b8c3210036
b8e16df00b
b8f34cf72e
b8fb75864e
b9004db86c
b9166cbae9
b920b256a6
b938d79dff
b93963f214
b941aef1a0
b94d34d14e
b964c57da4
b96a95bc7a
b96c57d2c7
b9b6bdde0c
b9bcb3e0f2
b9d3b92169
b9dd4b306c
b9f43ef41e
ba1f03c811
ba3a775d7b
ba3c7f2a31
ba3fcd417d
ba5e1f4faa
ba795f3089
ba8a291e6a
ba98512f97
bac9db04f5
baedae3442
baff40d29d
bb04e28695
bb1b0ee89f
bb1c770fe7
bb1fc34f99
bb2d220506
bb334e5cdb
bb337f9830
bb721eb9aa
bb87ff58bd
bb89a6b18a
bbaa9a036a
bbb4302dda
bbd31510cf
bbe0256a75
bc141b9ad5
bc17ab8a99
bc318160de
bc3b9ee033
bc4240b43c
bc4ce49105
bc4f71372d
bc6b8d6371
bcaad44ad7
bcc241b081
bcc5d8095e
bcd1d39afb
bd0d849da4
bd0e9ed437
bd2c94730f
bd321d2be6
bd3ec46511
bd5b2e2848
bd7e02b139
bd96f9943a
bda224cb25
bda4a82837
bdb74e333f
bdccd69dde
bddcc15521
be116aab29
be15e18f1e
be1a284edb
be2a367a7b
be376082d0
be3e3cffbd
be5d1d89a0
be8b72fe37
be9b29e08e
bea1f6e62c
bea83281b5
beb921a4c9
bec5e9edcd
beeb8a3f92
bf2232b58d
bf28751739
bf443804e8
bf461df850
bf5374f122
bf551a6f60
bf8d0f5ada
bf961167a6
bfab1ad8f9
bfcb05d88d
bfd8f6e6c9
bfd91d0742
bfe262322f
c013f42ed7
c01878083f
c01faff1ed
c046fd0edb
c053e35f97
c079a6482d
c0847b521a
c0a1e06710
c0e8d4635c
c0e973ad85
c0f49c6579
c0f5b222d7
c10d07c90d
c1268d998c
c130c3fc0c
c14826ad5e
c15b922281
c16f09cb63
c18e19d922
c1c830a735
c1e8aeea45
c20a5ccc99
c20fd5e597
c219d6f8dc
c2406ae462
c26f7b5824
c279e641ee
c27adaeac5
c2a35c1cda
c2a9903b8b
c2b62567c1
c2b974ec8c
c2baaff7bf
c2be6900f2
c304dd44d5
c307f33da2
c30a7b62c9
c3128733ee
c31fa6c598
c325c8201e
c32d4aa5d1
c33f28249a
c34365e2d7
c3457af795
c34d120a88
c3509e728d
c35e4fa6c4
c36240d96f
c3641dfc5a
c37b17a4a9
c39559ddf6
c3b0c6e180
c3b3d82e6c
c3be369fdb
c3bf1e40c2
c3c760b015
c3dd38bf98
c3e4274614
c3edc48cbd
c41e6587f5
c4272227b0
c42917fe82
c438858117
c44676563f
c44beb7472
c45411dacb
c4571bedc8
c46deb2956
c479ee052e
c47d551843
c49f07d46d
c4cc40c1fc
c4f256f5d5
c4f5b1ddcc
c4ff9b4885
c52bce43db
c544da6854
c55784c766
c557b69fbf
c593a3f7ab
c598faa682
c5ab1f09c8
c5b6da8602
c5b9128d94
c5e845c6b7
c5fba7b341
c60897f093
c61fe6ed7c
c62188c536
c64035b2e2
c69689f177
c6a12c131f
c6bb6d2d5c
c6c18e860f
c6d9526e0d
c6e55c33f0
c7030b28bd
c70682c7cc
c70f9be8c5
c71f30d7b6
c73c8e747f
c760eeb8b3
c7637cab0a
c7a1a17308
c7bf937af5
c7c2860db3
c7cef4aee2
c7ebfc5d57
c813dcf13c
c82235a49a
c82a7619a1
c82ecb90cb
c844f03dc7
c8557963f3
c89147e6e8
c8a46ff0c8
c8ab107dd5
c8b869a04a
c8c7b306a6
c8c8b28781
c8d79e3163
c8edab0415
c8f494f416
c8f6cba9fd
c909ceea97
c9188f4980
c922365dd4
c92c8c3c75
c937eb0b83
c94b31b5e5
c95cd17749
c96379c03c
c96465ee65
c965afa713
c9734b451f
c9862d82dc
c98b6fe013
c9999b7c48
c99e92aaf0
c9b3a8fbda
c9bf64e965
c9c3cb3797
c9d1c60cd0
c9de9c22c4
ca1828fa54
ca346f17eb
ca3787d3d3
ca4b99cbac
ca91c69e3b
ca91e99105
caa8e97f81
caac5807f8
cabba242c2
cad5a656a9
cad673e375
cad8a85930
cae7b0a02b
cae7ef3184
caeb6b6cbb
caecf0a5db
cb15312003
cb2e35d610
cb35a87504
cb3f22b0cf
cbb410da64
cc8728052e
cc892997b8
cce03c2a9b
cd47a23e31
cd4dc03dc0
cd5ae611da
cd603bb9d1
cd8f49734c
cdc6b1c032
cdcfe008ad
cdd57027c2
ce1af99b4b
ce1bc5743a
ce25872021
ce2776f78f
ce49b1f474
ce4f0a266f
ce5641b195
ce6866aa19
ce712ed3c9
ce7d1c8117
ce7dbeaa88
ce9b015a5e
cea7697b25
cebbd826cf
cec3415361
cec41ad4f4
ced49d26df
ced7705ab2
cef824a1e1
cf13f5c95a
cf4376a52d
cf85ab28b5
cfc2e50b9d
cfcd571fff
cfd9d4ae47
cfda2dcce5
cff035928b
cff8191891
d01608c2a5
d01a8f1f83
d021d68bca
d04258ca14
d0483573dc
d04a90aaff
d05279c0bd
d0696bd5fc
d072fda75b
d0a83bcd9f
d0ab39112e
d0acde820f
d0b4442c71
d0c65e9e95
d0fb600c73
d107a1457c
d123d674c1
d14d1e9289
d154e3388e
d177e9878a
d1802f69f8
d182c4483a
d195d31128
d200838929
d205e3cff5
d247420c4c
d2484bff33
d26f6ed9b0
d280fcd1cb
d2857f0faa
d292a50c7f
d295ea2dc7
d2a58b4fa6
d2b026739a
d2ebe0890f
d2ede5d862
d301ca58cc
d3069da8bb
d343d4a77d
d355e634ef
d367fb5253
d36d16358e
d38bc77e2c
d38d1679e2
d3932ad4bd
d3987b2930
d39934abe3
d3ae1c3f4c
d3b088e593
d3e6e05e16
d3eefae7c5
d3f55f5ab8
d3f5c309cc
d4034a7fdf
d4193011f3
d429c67630
d42c0ff975
d44a764409
d44e6acd1d
d45158c175
d454e8444f
d45f62717e
d48ebdcf74
d49ab52a25
d4a607ad81
d4b063c7db
d4da13e9ba
d4dd1a7d00
d4f4f7c9c3
d521aba02e
d535bb1b97
d53b955f78
d55cb7a205
d55f247a45
d5695544d8
d5853d9b8b
d5b6c6d94a
d5cae12834
d5df027f0c
d5ee40e5d0
d600046f73
d632fd3510
d6476cad55
d65a7bae86
d664c89912
d689658f06
d6917db4be
d69967143e
d699d3d798
d69f757a3f
d6ac0e065c
d6c02bfda5
d6c1b5749e
d6e12ef6cc
d6eed152c4
d6faaaf726
d704766646
d708e1350c
d7135cf104
d7157a9f44
d719cf9316
d724134cfd
d73a60a244
d7411662da
d74875ea7c
d756f5a694
d7572b7d8a
d763bd6d96
d7697c8b13
d7797196b4
d79c834768
d7b34e5d73
d7bb6b37a7
d7c7e064a6
d7fbf545b3
d82a0aa15b
d847e24abd
d8596701b7
d86101499c
d87069ba86
d87160957b
d874654b52
d88a403092
d8aee40f3f
d8e77a222d
d8eb07c381
d9010348a1
d90e3cf281
d92532c7b2
d927fae122
d95707bca8
d973b31c00
d991cb471d
d992c69d37
d99d770820
d9b63abc11
d9db6f1983
d9e52be2d2
d9edc82650
da01070697
da070ea4b7
da080507b9
da0e944cc4
da28d94ff4
da5d78b9d1
da6003fc72
da690fee9f
da6c68708f
da7a816676
dac361e828
dac71659b8
dad980385d
daebc12b77
db0968cdd3
db231a7100
db59282ace
db7f267c3f
dba35b87fd
dbba735a50
dbca076acd
dbd66dc3ac
dbdc3c292b
dbf4a5b32b
dbfc417d28
dc1745e0a2
dc32a44804
dc34b35e30
dc504a4f79
dc704dd647
dc71bc6918
dc7771b3be
dcf8c93617
dd0f4c9fb9
dd415df125
dd601f9a3f
dd61d903df
dd77583736
dd8636bd8b
dd9fe6c6ac
ddb2da4c14
ddcd450d47
dde8e67fb4
ddfc3f04d3
de2ab79dfa
de2f35b2fd
de30990a51
de36b216da
de37403340
de46e4943b
de4ddbccb1
de5e480f05
de6a9382ca
de74a601d3
de827c510d
ded6069f7b
defb71c741
df01f277f1
df05214b82
df0638b0a0
df11931ffe
df1b0e4620
df20a8650d
df2bc56d7c
df365282c6
df39a0d9df
df3c430c24
df5536cfb9
df59cfd91d
df5e2152b3
df741313c9
df7626172f
df8ad5deb9
df96aa609a
df9705605c
df9c91c4da
dfc0d3d27a
dfdbf91a99
e00baaae9b
e0a938c6e7
e0b2ceee6f
e0bdb5dfae
e0be1f6e17
e0c478f775
e0de82caa7
e0f217dd59
e0f7208874
e0fb58395e
e1194c2e9d
e11adcd05d
e128124b9d
e1495354e4
e1561d6d4b
e158805399
e16945b951
e19edcd34b
e1a1544285
e1ab7957f4
e1d26d35be
e1e957085b
e1f14510fa
e214b160f4
e2167379b8
e21acb20ab
e221105579
e22ddf8a1b
e22de45950
e22ffc469b
e23cca5244
e252f46f0b
e25fa6cf39
e26e486026
e275760245
e27bbedbfe
e29e9868a8
e2b37ff8af
e2b608d309
e2bef4da9a
e2c87a6421
e2ea25542c
e2fb1d6497
e2fcc99117
e33c18412a
e348377191
e352cb59c8
e36ac982f0
e391bc981e
e39e3e0a06
e3bf38265f
e3d5b2cd21
e3d60e82d5
e3e3245492
e3e4134877
e3f4635e03
e4004ee048
e402d1afa5
e415093d27
e41ceb5d81
e424653b78
e42b6d3dbb
e42d60f0d4
e436d0ff1e
e43d7ae2c5
e4428801bc
e44e0b4917
e470345ede
e48e8b4263
e4922e3726
e4936852bb
e495f32c60
e499228f26
e4af66e163
e4b2095f58
e4d19c8283
e4d4872dab
e4e2983570
e4eaa63aab
e4ef0a3a34
e4f8e5f46e
e4ffb6d0dd
e53e21aa02
e57f4f668b
e588433c1e
e597442c99
e5abc0e96b
e5be628030
e5ce96a55d
e5d6b70a9f
e5fde1574c
e625e1d27b
e6261d2348
e6267d46bc
e6295f223f
e63463d8c6
e6387bd1e0
e653883384
e65f134e0b
e668ef5664
e672ccd250
e674510b20
e676107765
e699da0cdf
e6be243065
e6deab5e0b
e6f065f2b9
e71629e7b5
e72a7d7b0b
e72f6104e1
e75a466eea
e76c55933f
e7784ec8ad
e78922e5e6
e78d450a9c
e7c6354e77
e7c8de1fce
e7ea10db28
e803918710
e8073a140b
e828dd02db
e845994987
e8485a2615
e85c5118a7
e88b6736e4
e8962324e3
e8b3018d36
e8cee8bf0b
e8d97ebece
e8da49ea6a
e8ed1a3ccf
e8f7904326
e8f8341dec
e8fa21eb13
e90c10fc4c
e914b8cac8
e92b6bfea4
e92e1b7623
e93f83e512
e9422ad240
e9460b55f9
e9502628f6
e950befd5f
e9582bdd1b
e95e5afe0f
e97cfac475
e98d57d99c
e98eda8978
e99706b555
e9bc0760ba
e9d3c78bf3
e9ec1b7ea8
ea065cc205
ea138b6617
ea16d3fd48
ea2545d64b
ea286a581c
ea320da917
ea345f3627
ea3b94a591
ea444a37eb
ea4a01216b
ea5672ffa8
eaa99191cb
eaab4d746c
eac7a59bc1
ead5d3835a
eaec65cfa7
eaed1a87be
eb2f821c6f
eb383cb82e
eb6992fe02
eb6ac20a01
eb6d7ab39e
eb7921facd
eb8fce51a6
ebbb90e9f9
ebbf5c9ee1
ebc4ec32e6
ebe56e5ef8
ec1299aee4
ec139ff675
ec193e1a01
ec28252938
ec387be051
ec3d4fac00
ec4186ce12
ec579c2f96
ecae59b782
ecb33a0448
ece6bc9e92
ecfedd4035
ecfff22fd6
ed3291c3d6
ed3cd5308d
ed3e6fc1a5
ed72ae8825
ed7455da68
ed844e879f
ed8f814b2b
ed911a1f63
ed9ff4f649
eda8ab984b
edb8878849
edbfdfe1b4
edd22c46a2
edd663afa3
ede3552eae
edeab61ee0
ee07583fc0
ee316eaed6
ee3f509537
ee40a1e491
ee4bf100f1
ee6f9b01f9
ee947ed771
ee9706ac7f
ee9a7840ae
eeb90cb569
eebf45e5c5
eeed0c7d73
ef0061a309
ef07f1a655
ef0a8e8f35
ef232a2aed
ef308ad2e9
ef44945428
ef45ce3035
ef5dde449d
ef5e770988
ef6359cea3
ef65268834
ef6cb5eae0
ef78972bc2
ef8cfcfc4f
ef96501dd0
ef9a2e976b
efb24f950f
efce0c1868
efe5ac6901
efe828affa
efea4e0523
f0268aa627
f0483250c8
f04cf99ee6
f05b189097
f08928c6d3
f09d74856f
f0a7607d63
f0ad38da27
f0c34e1213
f0c7f86c29
f0dfa18ba7
f0eb3179f7
f119bab27d
f14409b6a3
f1489baff4
f14c18cf6a
f15c607b92
f1af214222
f1b77bd309
f1ba9e1a3e
f1d99239eb
f1dc710cf4
f1ec5c08fa
f22648fe12
f22d21f1f1
f233257395
f23e95dbe5
f2445b1572
f253b3486d
f277c7a6a4
f2ab2b84d6
f2b7c9b1f3
f2b83d5ce5
f2c276018f
f2cfd94d64
f2dd6e3add
f2e7653f16
f2f333ad06
f2f55d6713
f2fdb6abec
f305a56d9f
f3085d6570
f3325c3338
f3400f1204
f34497c932
f34a56525e
f36483c824
f3704d5663
f3734c4913
f38e5aa5b4
f3986fba44
f3a0ffc7d9
f3b24a7d28
f3e6c35ec3
f3fc0ea80b
f40a683fbe
f4207ca554
f4377499c2
f46184f393
f46c2d0a6d
f46c364dca
f46f7a0b63
f46fe141b0
f470b9aeb0
f47eb7437f
f48b535719
f49e4866ac
f4aa882cfd
f4daa3dbd5
f4dd51ac35
f507a1b9dc
f51c5ac84b
f52104164b
f54c67b9bb
f5966cadd2
f5bddf5598
f5d85cfd17
f5e2e7d6a0
f5f051e9b4
f5f8a93a76
f6283e8af5
f635e9568b
f6474735be
f659251be2
f66981af4e
f6708fa398
f697fe8e8f
f6adb12c42
f6c7906ca4
f6cd0a8016
f6d6f15ae7
f6e501892c
f6f59d986f
f6fe8c90a5
f714160545
f74c3888d7
f7782c430e
f7783ae5f2
f77ab47923
f788a98327
f7961ac1f0
f7a71e7574
f7a8521432
f7afbf4947
f7b7cd5f44
f7cf4b4a39
f7d49799ad
f7e0c9bb83
f7e5b84928
f7e6bd58be
f7f2a38ac6
f7f6cb2d6d
f83f19e796
f85796a921
f8603c26b2
f8819b42ec
f891f8eaa1
f89288d10c
f895ae8cc1
f8b4ac12f1
f8c3fb2b01
f8c8de2764
f8db369b40
f8fcb6a78c
f94aafdeef
f95d217b70
f9681d5103
f9750192a4
f9823a32c2
f991ddb4c2
f99d535567
f9ae3d98b7
f9b6217959
f9bd1fabf5
f9c68eaa64
f9d3e04c4f
f9daf64494
f9e4cc5a0a
f9ea6b7f31
f9f3852526
fa04c615cf
fa08e00a56
fa4370d74d
fa67744af3
fa88d48a92
fa8b904cc9
fa9526bdf1
fa9b9d2426
fad633fbe1
faf5222dc3
faff0e15f1
fb08c64e8c
fb23455a7f
fb2e19fa6e
fb34dfbb77
fb47fcea1e
fb49738155
fb4cbc514b
fb4e6062f7
fb5ba7ad6e
fb63cd1236
fb81157a07
fb92abdaeb
fba22a6848
fbaca0c9df
fbc645f602
fbd77444cd
fbe53dc8e8
fbe541dd73
fbe8488798
fbfd25174f
fc28cb305e
fc33b1ffd6
fc6186f0bb
fc918e3a40
fc96cda9d8
fc9832eea4
fcb10d0f81
fcd20a2509
fcf637e3ab
fcfd81727f
fd31890379
fd33551c28
fd542da05e
fd6789b3fe
fd77828200
fd7af75f4d
fdb28d0fbb
fdb3d1fb1e
fdb8b04124
fdc6e3d581
fdfce7e6fc
fe0f76d41b
fe24b0677d
fe3c02699d
fe58b48235
fe6a5596b8
fe6c244f63
fe7afec086
fe985d510a
fe9db35d15
fea8ffcd36
feb1080388
fed208bfca
feda5ad1c2
feec95b386
ff15a5eff6
ff204daf4b
ff25f55852
ff2ada194f
ff2ce142e8
ff49d36d20
ff5a1ec4f3
ff66152b25
ff692fdc56
ff773b1a1e
ff97129478
ffb904207d
ffc43fc345
fffe5f8df6
================================================
FILE: merge_lora_weights_and_save_hf_model.py
================================================
import argparse
import glob
import os
import sys
import cv2
import numpy as np
import torch
import torch.nn.functional as F
import transformers
from peft import LoraConfig, get_peft_model
from transformers import AutoTokenizer
from model.VISA import VISAForCausalLM
from utils.utils import DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN
"""
python merge_lora_weights_and_save_hf_model.py \
--version /mnt/nlp-ali/usr/yancilin/clyan-data-2/video-llm/Chat-UniVi/Chat-UniVi \
--weight /mnt/public03/dataset/ovis/rgvos/visa7b/ckpt_model/pytorch_model15000.bin \
--save_path /mnt/public03/dataset/ovis/rgvos/visa7b/ckpt_model/hf_model
"""
def parse_args(args):
parser = argparse.ArgumentParser(
description="merge lora weights and save model with hf format"
)
parser.add_argument(
"--version", default="Chat-UniVi/Chat-UniVi", type=str, required=True
)
parser.add_argument(
"--weight", default="/path/to/visa/pytorch_model.bin", type=str, required=True
)
parser.add_argument(
"--save_path", default="/path/to/hf_model", type=str, required=True
)
parser.add_argument("--precision", default="bf16", type=str, choices=["fp32", "bf16", "fp16"], help="precision for inference", )
parser.add_argument("--vision_pretrained", default="PATH_TO_SAM_ViT-H", type=str)
parser.add_argument("--out_dim", default=256, type=int)
parser.add_argument("--image_size", default=1024, type=int, help="image size")
parser.add_argument("--model_max_length", default=512, type=int)
parser.add_argument("--vision-tower", default="openai/clip-vit-large-patch14", type=str, )
parser.add_argument("--lora_r", default=8, type=int)
parser.add_argument("--lora_alpha", default=16, type=int)
parser.add_argument("--lora_dropout", default=0.05, type=float)
parser.add_argument("--lora_target_modules", default="q_proj,v_proj", type=str)
parser.add_argument("--local-rank", default=0, type=int, help="node rank")
parser.add_argument("--train_mask_decoder", action="store_true", default=True)
parser.add_argument("--use_mm_start_end", action="store_true", default=False)
parser.add_argument("--conv_type", default="llava_v1", type=str, choices=["llava_v1", "llava_llama_2"], )
return parser.parse_args(args)
def main(args):
args = parse_args(args)
# Create model
tokenizer = transformers.AutoTokenizer.from_pretrained(
args.version,
cache_dir = None,
model_max_length = args.model_max_length,
padding_side = "right",
use_fast = False,
)
tokenizer.pad_token = tokenizer.unk_token
num_added_tokens = tokenizer.add_tokens("[SEG]")
args.seg_token_idx = tokenizer("[SEG]", add_special_tokens=False).input_ids[0]
if args.use_mm_start_end:
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
model_args = {
"train_mask_decoder": args.train_mask_decoder,
"out_dim" : args.out_dim,
"seg_token_idx" : args.seg_token_idx,
"vision_tower" : args.vision_tower,
}
torch_dtype = torch.float32
if args.precision == "bf16":
torch_dtype = torch.bfloat16
elif args.precision == "fp16":
torch_dtype = torch.half
model = VISAForCausalLM.from_pretrained(args.version, torch_dtype=torch_dtype, low_cpu_mem_usage=True, **model_args, )
model.config.eos_token_id = tokenizer.eos_token_id
model.config.bos_token_id = tokenizer.bos_token_id
model.config.pad_token_id = tokenizer.pad_token_id
model.get_model().initialize_vision_modules(model.get_model().config)
vision_tower = model.get_model().get_vision_tower()
vision_tower.to(dtype=torch_dtype)
model.get_model().initialize_lisa_modules(model.get_model().config)
lora_r = args.lora_r
if lora_r > 0:
def find_linear_layers(model, lora_target_modules):
cls = torch.nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if (
isinstance(module, cls)
and all([x not in name for x in ["visual_model", "vision_tower", "mm_projector", "text_hidden_fcs", ]])
and any([x in name for x in lora_target_modules])
):
lora_module_names.add(name)
return sorted(list(lora_module_names))
lora_alpha = args.lora_alpha
lora_dropout = args.lora_dropout
lora_target_modules = find_linear_layers(model, args.lora_target_modules.split(","), )
lora_config = LoraConfig(
r = lora_r,
lora_alpha = lora_alpha,
target_modules = lora_target_modules,
lora_dropout = lora_dropout,
bias = "none",
task_type = "CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
model.resize_token_embeddings(len(tokenizer))
state_dict = torch.load(args.weight, map_location="cpu")
model.load_state_dict(state_dict, strict=True)
model = model.merge_and_unload()
state_dict = {}
for k, v in model.state_dict().items():
if "vision_tower" not in k:
state_dict[k] = v
model.save_pretrained(args.save_path, state_dict=state_dict)
tokenizer.save_pretrained(args.save_path)
if __name__ == "__main__":
main(sys.argv[1:])
================================================
FILE: model/VISA.py
================================================
from typing import List
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BitsAndBytesConfig, CLIPVisionModel
from utils.utils import DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IMAGE_PATCH_TOKEN
from .univi.model.language_model.llama import ChatUniViLlamaForCausalLM, ChatUniViLlamaModel
from .segment_anything import build_sam_vit_h
from model.univi.constants import IMAGE_TOKEN_INDEX
import time
def dice_loss(
inputs : torch.Tensor,
targets : torch.Tensor,
num_masks: float,
scale : float =1000,
eps : float =1e-6,
):
"""
Compute the DICE loss, similar to generalized IOU for masks
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary classification label for each element in inputs (0 for the negative class and 1 for the positive class).
"""
inputs = inputs.sigmoid()
inputs = inputs.flatten(1, 2)
targets = targets.flatten(1, 2)
numerator = 2 * (inputs / scale * targets).sum(-1)
denominator = (inputs / scale).sum(-1) + (targets / scale).sum(-1)
loss = 1 - (numerator + eps) / (denominator + eps)
loss = loss.sum() / (num_masks + 1e-8)
return loss
def sigmoid_ce_loss(
inputs: torch.Tensor,
targets: torch.Tensor,
num_masks: float,
):
"""
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary classification label for each element in inputs (0 for the negative class and 1 for the positive class).
Returns:
Loss tensor
"""
loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
loss = loss.flatten(1, 2).mean(1).sum() / (num_masks + 1e-8)
return loss
class VisaMetaModel:
def __init__(
self,
config,
**kwargs,
):
super(VisaMetaModel, self).__init__(config)
self.config = config
if not hasattr(self.config, "train_mask_decoder"):
self.config.train_mask_decoder = kwargs["train_mask_decoder"]
self.config.out_dim = kwargs["out_dim"]
self.vision_pretrained = kwargs.get("vision_pretrained", None)
else:
self.vision_pretrained = kwargs.get("vision_pretrained", None)
self.initialize_lisa_modules(self.config)
def initialize_lisa_modules(self, config):
# SAM
self.visual_model = build_sam_vit_h(self.vision_pretrained)
for param in self.visual_model.parameters():
param.requires_grad = False
if config.train_mask_decoder:
self.visual_model.mask_decoder.train()
for param in self.visual_model.mask_decoder.parameters():
param.requires_grad = True
# Projection layer
in_dim = config.hidden_size
out_dim = config.out_dim
text_fc = [
nn.Linear(in_dim, in_dim),
nn.ReLU(inplace=True),
nn.Linear(in_dim, out_dim),
nn.Dropout(0.0),
]
self.text_hidden_fcs = nn.ModuleList([nn.Sequential(*text_fc)])
self.text_hidden_fcs.train()
for param in self.text_hidden_fcs.parameters():
param.requires_grad = True
class VisaModel(VisaMetaModel, ChatUniViLlamaModel):
def __init__(
self,
config,
**kwargs,
):
super(VisaModel, self).__init__(config, **kwargs)
self.config.use_cache = False
self.config.vision_tower = self.config.mm_vision_tower
self.config.mm_vision_select_feature = "patch"
self.config.image_aspect_ratio = "square"
self.config.image_grid_pinpoints = None
self.config.tune_mm_mlp_adapter = False
self.config.freeze_mm_mlp_adapter = True
self.config.pretrain_mm_mlp_adapter = None
self.config.mm_use_im_patch_token = False
class VISAForCausalLM(ChatUniViLlamaForCausalLM):
def __init__(
self,
config,
**kwargs,
):
if not hasattr(config, "train_mask_decoder"):
config.mm_use_im_start_end = kwargs.pop("use_mm_start_end", True)
config.mm_vision_tower = kwargs.get("vision_tower", "openai/clip-vit-large-patch14")
self.ce_loss_weight = kwargs.pop("ce_loss_weight", None)
self.dice_loss_weight = kwargs.pop("dice_loss_weight", None)
self.bce_loss_weight = kwargs.pop("bce_loss_weight", None)
else:
config.mm_vision_tower = config.vision_tower
self.seg_token_idx = kwargs.pop("seg_token_idx")
super().__init__(config)
self.model = VisaModel(config, **kwargs)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_visual_embs(self, pixel_values: torch.FloatTensor):
with torch.no_grad():
image_embeddings = self.model.visual_model.image_encoder(pixel_values)
return image_embeddings
def forward(self, **kwargs):
if "past_key_values" in kwargs:
return super().forward(**kwargs)
return self.model_forward(**kwargs)
def model_forward(
self,
images: torch.FloatTensor,
images_clip: torch.FloatTensor,
input_ids: torch.LongTensor,
labels: torch.LongTensor,
attention_masks: torch.LongTensor,
offset: torch.LongTensor,
masks_list: List[torch.FloatTensor],
label_list: List[torch.Tensor],
resize_list: List[tuple],
conversation_list: List[str],
num_frame_list: List[int],
num_conv_list: List[int],
inference: bool = False,
**kwargs,
):
batch_size = len(images)
image_embeddings = self.get_visual_embs(torch.cat(images,dim=0))
assert image_embeddings.shape[0] == batch_size
assert batch_size == len(offset) - 1
for batch_idx in range(batch_size):
assert num_conv_list[batch_idx] == offset[batch_idx + 1] - offset[batch_idx]
if inference:
length = input_ids.shape[0]
assert len(images_clip) == 1, f'Inference only supports one video, but got {len(images_clip)} videos.'
images_clip = [
images_clip[0].unsqueeze(0).expand(length, -1, -1, -1, -1).contiguous().flatten(0,1)
]
output_i = super().forward(
images=images_clip,
attention_mask=attention_masks,
input_ids=input_ids,
output_hidden_states=True,
)
torch.cuda.empty_cache()
output_hidden_states = output_i.hidden_states
output = None
num_image_ori_token = (input_ids[0] == IMAGE_TOKEN_INDEX).sum()
assert all(
[
(input_ids[i] == IMAGE_TOKEN_INDEX).sum() == num_image_ori_token for i in range(length)
]
)
token_add = 111 * num_image_ori_token
seg_token_mask = input_ids[:, 1:] == self.seg_token_idx
seg_token_mask = torch.cat([seg_token_mask, torch.zeros((seg_token_mask.shape[0], 1)).bool().cuda(), ], dim=1, )
seg_token_mask = torch.cat([torch.zeros((seg_token_mask.shape[0], token_add)).bool().cuda(), seg_token_mask], dim=1, )
all_conv_seg_token_num = seg_token_mask.sum(dim=1).tolist()
else:
images_clip_list = []
for batch_idx in range(batch_size):
bs_conv_num = num_conv_list[batch_idx]
images_clip_i = images_clip[batch_idx].unsqueeze(0).expand(bs_conv_num, -1, -1, -1, -1).contiguous()
images_clip_list.append(images_clip_i)
images_clip_list = [i.flatten(0,1) for i in images_clip_list]
output = super().forward(
images=images_clip_list,
attention_mask=attention_masks,
input_ids=input_ids,
labels=labels,
output_hidden_states=True,
)
output_hidden_states = output.hidden_states
seg_token_mask = output.labels[..., 1:] == self.seg_token_idx
seg_token_mask = torch.cat([seg_token_mask, torch.zeros((seg_token_mask.shape[0], 1), device=output.labels.device).bool(), ], dim=1, )
all_conv_seg_token_num = seg_token_mask.sum(dim=1).tolist()
assert len(self.model.text_hidden_fcs) == 1
pred_embeddings = self.model.text_hidden_fcs[0](output_hidden_states[-1][seg_token_mask])
seg_token_counts = seg_token_mask.int().sum(-1) # [bs, ]
seg_token_offset = seg_token_counts.cumsum(-1)
seg_token_offset = torch.cat(
[torch.zeros(1).long().cuda(), seg_token_offset], dim=0
)
seg_token_offset = seg_token_offset[offset]
pred_embeddings_ = []
for i in range(len(seg_token_offset) - 1):
start_i, end_i = seg_token_offset[i], seg_token_offset[i + 1]
pred_embeddings_.append(pred_embeddings[start_i:end_i])
pred_embeddings = pred_embeddings_
assert len(pred_embeddings) == batch_size
multimask_output = False
pred_masks = []
for i in range(batch_size):
(
sparse_embeddings,
dense_embeddings,
) = self.model.visual_model.prompt_encoder(
points=None,
boxes=None,
masks=None,
text_embeds=pred_embeddings[i].unsqueeze(1),
)
sparse_embeddings = sparse_embeddings.to(pred_embeddings[i].dtype)
low_res_masks, iou_predictions = self.model.visual_model.mask_decoder(
image_embeddings=image_embeddings[i].unsqueeze(0),
image_pe=self.model.visual_model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
pred_mask = self.model.visual_model.postprocess_masks(
low_res_masks,
input_size=resize_list[i],
original_size=label_list[i].shape,
)
pred_masks.append(pred_mask[:, 0])
model_output = output
gt_masks = [mm.flatten(0, 1) for mm in masks_list]
if inference:
return {
"pred_masks": pred_masks,
"gt_masks": gt_masks,
}
output = model_output.logits
ce_loss = model_output.loss
ce_loss = ce_loss * self.ce_loss_weight
mask_bce_loss = 0
mask_dice_loss = 0
num_masks = 0
for batch_idx in range(batch_size):
gt_mask = gt_masks[batch_idx]
pred_mask = pred_masks[batch_idx]
assert (
gt_mask.shape[0] == pred_mask.shape[0]
), "gt_mask.shape: {}, pred_mask.shape: {}".format(
gt_mask.shape, pred_mask.shape
)
mask_bce_loss += (
sigmoid_ce_loss(pred_mask, gt_mask, num_masks=gt_mask.shape[0])
* gt_mask.shape[0]
)
mask_dice_loss += (
dice_loss(pred_mask, gt_mask, num_masks=gt_mask.shape[0])
* gt_mask.shape[0]
)
num_masks += gt_mask.shape[0]
mask_bce_loss = self.bce_loss_weight * mask_bce_loss / (num_masks + 1e-8)
mask_dice_loss = self.dice_loss_weight * mask_dice_loss / (num_masks + 1e-8)
mask_loss = mask_bce_loss + mask_dice_loss
loss = ce_loss + mask_loss
return {
"loss": loss,
"ce_loss": ce_loss,
"mask_bce_loss": mask_bce_loss,
"mask_dice_loss": mask_dice_loss,
"mask_loss": mask_loss,
}
def evaluate(self, *args, **kwargs):
raise NotImplementedError("This method is not implemented.")
================================================
FILE: model/llava/__init__.py
================================================
from .model import LlavaLlamaForCausalLM
================================================
FILE: model/llava/constants.py
================================================
CONTROLLER_HEART_BEAT_EXPIRATION = 30
WORKER_HEART_BEAT_INTERVAL = 15
LOGDIR = "."
# Model Constants
IGNORE_INDEX = -100
IMAGE_TOKEN_INDEX = -200
DEFAULT_IMAGE_TOKEN = ""
DEFAULT_IMAGE_PATCH_TOKEN = ""
DEFAULT_IM_START_TOKEN = ""
DEFAULT_IM_END_TOKEN = ""
================================================
FILE: model/llava/conversation.py
================================================
import dataclasses
from enum import Enum, auto
from typing import List, Tuple
class SeparatorStyle(Enum):
"""Different separator style."""
SINGLE = auto()
TWO = auto()
MPT = auto()
PLAIN = auto()
LLAMA_2 = auto()
@dataclasses.dataclass
class Conversation:
"""A class that keeps all conversation history."""
system: str
roles: List[str]
messages: List[List[str]]
offset: int
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
sep: str = "###"
sep2: str = None
version: str = "Unknown"
skip_next: bool = False
def get_prompt(self):
messages = self.messages
if len(messages) > 0 and type(messages[0][1]) is tuple:
messages = self.messages.copy()
init_role, init_msg = messages[0].copy()
init_msg = init_msg[0].replace("", "").strip()
if "mmtag" in self.version:
messages[0] = (init_role, init_msg)
messages.insert(0, (self.roles[0], ""))
messages.insert(1, (self.roles[1], "Received."))
else:
messages[0] = (init_role, "\n" + init_msg)
if self.sep_style == SeparatorStyle.SINGLE:
ret = self.system + self.sep
for role, message in messages:
if message:
if type(message) is tuple:
message, _, _ = message
ret += role + ": " + message + self.sep
else:
ret += role + ":"
elif self.sep_style == SeparatorStyle.TWO:
seps = [self.sep, self.sep2]
ret = self.system + seps[0]
for i, (role, message) in enumerate(messages):
if message:
if type(message) is tuple:
message, _, _ = message
ret += role + ": " + message + seps[i % 2]
else:
ret += role + ":"
elif self.sep_style == SeparatorStyle.MPT:
ret = self.system + self.sep
for role, message in messages:
if message:
if type(message) is tuple:
message, _, _ = message
ret += role + message + self.sep
else:
ret += role
elif self.sep_style == SeparatorStyle.LLAMA_2:
wrap_sys = lambda msg: f"<>\n{msg}\n<>\n\n"
wrap_inst = lambda msg: f"[INST] {msg} [/INST]"
ret = ""
for i, (role, message) in enumerate(messages):
if i == 0:
assert message, "first message should not be none"
assert role == self.roles[0], "first message should come from user"
if message:
if type(message) is tuple:
message, _, _ = message
if i == 0:
message = wrap_sys(self.system) + message
if i % 2 == 0:
message = wrap_inst(message)
ret += self.sep + message
else:
ret += " " + message + " " + self.sep2
else:
ret += ""
ret = ret.lstrip(self.sep)
elif self.sep_style == SeparatorStyle.PLAIN:
seps = [self.sep, self.sep2]
ret = self.system
for i, (role, message) in enumerate(messages):
if message:
if type(message) is tuple:
message, _, _ = message
ret += message + seps[i % 2]
else:
ret += ""
else:
raise ValueError(f"Invalid style: {self.sep_style}")
return ret
def append_message(self, role, message):
self.messages.append([role, message])
def get_images(self, return_pil=False):
images = []
for i, (role, msg) in enumerate(self.messages[self.offset :]):
if i % 2 == 0:
if type(msg) is tuple:
import base64
from io import BytesIO
from PIL import Image
msg, image, image_process_mode = msg
if image_process_mode == "Pad":
def expand2square(pil_img, background_color=(122, 116, 104)):
width, height = pil_img.size
if width == height:
return pil_img
elif width > height:
result = Image.new(
pil_img.mode, (width, width), background_color
)
result.paste(pil_img, (0, (width - height) // 2))
return result
else:
result = Image.new(
pil_img.mode, (height, height), background_color
)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image)
elif image_process_mode == "Crop":
pass
elif image_process_mode == "Resize":
image = image.resize((336, 336))
else:
raise ValueError(
f"Invalid image_process_mode: {image_process_mode}"
)
max_hw, min_hw = max(image.size), min(image.size)
aspect_ratio = max_hw / min_hw
max_len, min_len = 800, 400
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
longest_edge = int(shortest_edge * aspect_ratio)
W, H = image.size
if H > W:
H, W = longest_edge, shortest_edge
else:
H, W = shortest_edge, longest_edge
image = image.resize((W, H))
if return_pil:
images.append(image)
else:
buffered = BytesIO()
image.save(buffered, format="PNG")
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
images.append(img_b64_str)
return images
def to_gradio_chatbot(self):
ret = []
for i, (role, msg) in enumerate(self.messages[self.offset :]):
if i % 2 == 0:
if type(msg) is tuple:
import base64
from io import BytesIO
msg, image, image_process_mode = msg
max_hw, min_hw = max(image.size), min(image.size)
aspect_ratio = max_hw / min_hw
max_len, min_len = 800, 400
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
longest_edge = int(shortest_edge * aspect_ratio)
W, H = image.size
if H > W:
H, W = longest_edge, shortest_edge
else:
H, W = shortest_edge, longest_edge
image = image.resize((W, H))
buffered = BytesIO()
image.save(buffered, format="JPEG")
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
img_str = f' '
ret.append([img_str, None])
msg = msg.replace("", "").strip()
if len(msg) > 0:
ret.append([msg, None])
else:
ret.append([msg, None])
else:
ret[-1][-1] = msg
return ret
def copy(self):
return Conversation(
system=self.system,
roles=self.roles,
messages=[[x, y] for x, y in self.messages],
offset=self.offset,
sep_style=self.sep_style,
sep=self.sep,
sep2=self.sep2,
version=self.version,
)
def dict(self):
if len(self.get_images()) > 0:
return {
"system": self.system,
"roles": self.roles,
"messages": [
[x, y[0] if type(y) is tuple else y] for x, y in self.messages
],
"offset": self.offset,
"sep": self.sep,
"sep2": self.sep2,
}
return {
"system": self.system,
"roles": self.roles,
"messages": self.messages,
"offset": self.offset,
"sep": self.sep,
"sep2": self.sep2,
}
conv_vicuna_v0 = Conversation(
system="A chat between a curious human and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
roles=("Human", "Assistant"),
messages=(
(
"Human",
"What are the key differences between renewable and non-renewable energy sources?",
),
(
"Assistant",
"Renewable energy sources are those that can be replenished naturally in a relatively "
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
"renewable and non-renewable energy sources:\n"
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
"energy sources are finite and will eventually run out.\n"
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
"and other negative effects.\n"
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
"have lower operational costs than non-renewable sources.\n"
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
"locations than non-renewable sources.\n"
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n",
),
),
offset=2,
sep_style=SeparatorStyle.SINGLE,
sep="###",
)
conv_vicuna_v1 = Conversation(
system="A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
roles=("USER", "ASSISTANT"),
version="v1",
messages=(),
offset=0,
sep_style=SeparatorStyle.TWO,
sep=" ",
sep2="",
)
conv_llama_2 = Conversation(
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
roles=("USER", "ASSISTANT"),
version="llama_v2",
messages=(),
offset=0,
sep_style=SeparatorStyle.LLAMA_2,
sep="
'
ret.append([img_str, None])
msg = msg.replace("", "").strip()
if len(msg) > 0:
ret.append([msg, None])
else:
ret.append([msg, None])
else:
ret[-1][-1] = msg
return ret
def copy(self):
return Conversation(
system=self.system,
roles=self.roles,
messages=[[x, y] for x, y in self.messages],
offset=self.offset,
sep_style=self.sep_style,
sep=self.sep,
sep2=self.sep2,
version=self.version,
)
def dict(self):
if len(self.get_images()) > 0:
return {
"system": self.system,
"roles": self.roles,
"messages": [
[x, y[0] if type(y) is tuple else y] for x, y in self.messages
],
"offset": self.offset,
"sep": self.sep,
"sep2": self.sep2,
}
return {
"system": self.system,
"roles": self.roles,
"messages": self.messages,
"offset": self.offset,
"sep": self.sep,
"sep2": self.sep2,
}
conv_vicuna_v0 = Conversation(
system="A chat between a curious human and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
roles=("Human", "Assistant"),
messages=(
(
"Human",
"What are the key differences between renewable and non-renewable energy sources?",
),
(
"Assistant",
"Renewable energy sources are those that can be replenished naturally in a relatively "
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
"renewable and non-renewable energy sources:\n"
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
"energy sources are finite and will eventually run out.\n"
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
"and other negative effects.\n"
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
"have lower operational costs than non-renewable sources.\n"
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
"locations than non-renewable sources.\n"
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n",
),
),
offset=2,
sep_style=SeparatorStyle.SINGLE,
sep="###",
)
conv_vicuna_v1 = Conversation(
system="A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
roles=("USER", "ASSISTANT"),
version="v1",
messages=(),
offset=0,
sep_style=SeparatorStyle.TWO,
sep=" ",
sep2="",
)
conv_llama_2 = Conversation(
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
roles=("USER", "ASSISTANT"),
version="llama_v2",
messages=(),
offset=0,
sep_style=SeparatorStyle.LLAMA_2,
sep="",
sep2="",
)
conv_llava_llama_2 = Conversation(
system="You are a helpful language and vision assistant. "
"You are able to understand the visual content that the user provides, "
"and assist the user with a variety of tasks using natural language.",
roles=("USER", "ASSISTANT"),
version="llama_v2",
messages=(),
offset=0,
sep_style=SeparatorStyle.LLAMA_2,
sep="",
sep2="",
)
conv_mpt = Conversation(
system="""<|im_start|>system
A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
version="mpt",
messages=(),
offset=0,
sep_style=SeparatorStyle.MPT,
sep="<|im_end|>",
)
conv_llava_plain = Conversation(
system="",
roles=("", ""),
messages=(),
offset=0,
sep_style=SeparatorStyle.PLAIN,
sep="\n",
)
conv_llava_v0 = Conversation(
system="A chat between a curious human and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
roles=("Human", "Assistant"),
messages=(("Human", "Hi!"), ("Assistant", "Hi there! How can I help you today?")),
offset=2,
sep_style=SeparatorStyle.SINGLE,
sep="###",
)
conv_llava_v0_mmtag = Conversation(
system="A chat between a curious user and an artificial intelligence assistant. "
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
"The visual content will be provided with the following format: visual content.",
roles=("Human", "Assistant"),
messages=(),
offset=0,
sep_style=SeparatorStyle.SINGLE,
sep="###",
version="v0_mmtag",
)
conv_llava_v1 = Conversation(
system="A chat between a curious human and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
roles=("USER", "ASSISTANT"),
version="v1",
messages=(),
offset=0,
sep_style=SeparatorStyle.TWO,
sep=" ",
sep2="",
)
conv_llava_v1_mmtag = Conversation(
system="A chat between a curious user and an artificial intelligence assistant. "
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
"The visual content will be provided with the following format: visual content.",
roles=("USER", "ASSISTANT"),
messages=(),
offset=0,
sep_style=SeparatorStyle.TWO,
sep=" ",
sep2="",
version="v1_mmtag",
)
default_conversation = conv_vicuna_v0
conv_templates = {
"default": conv_vicuna_v0,
"v0": conv_vicuna_v0,
"v1": conv_vicuna_v1,
"vicuna_v1": conv_vicuna_v1,
"llama_2": conv_llama_2,
"plain": conv_llava_plain,
"v0_plain": conv_llava_plain,
"llava_v0": conv_llava_v0,
"v0_mmtag": conv_llava_v0_mmtag,
"llava_v1": conv_llava_v1,
"v1_mmtag": conv_llava_v1_mmtag,
"llava_llama_2": conv_llava_llama_2,
"mpt": conv_mpt,
}
if __name__ == "__main__":
print(default_conversation.get_prompt())
================================================
FILE: model/llava/mm_utils.py
================================================
import base64
from io import BytesIO
import torch
from PIL import Image
from transformers import StoppingCriteria
from .constants import IMAGE_TOKEN_INDEX
def load_image_from_base64(image):
return Image.open(BytesIO(base64.b64decode(image)))
def process_images(images, image_processor, model_cfg):
return image_processor(images, return_tensors="pt")["pixel_values"]
def tokenizer_image_token(
prompt, tokenizer, image_token_index=IMAGE_TOKEN_INDEX, return_tensors=None
):
prompt_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split("")]
def insert_separator(X, sep):
return [ele for sublist in zip(X, [sep] * len(X)) for ele in sublist][:-1]
input_ids = []
offset = 0
if (
len(prompt_chunks) > 0
and len(prompt_chunks[0]) > 0
and prompt_chunks[0][0] == tokenizer.bos_token_id
):
offset = 1
input_ids.append(prompt_chunks[0][0])
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
input_ids.extend(x[offset:])
if return_tensors is not None:
if return_tensors == "pt":
return torch.tensor(input_ids, dtype=torch.long)
raise ValueError(f"Unsupported tensor type: {return_tensors}")
return input_ids
def get_model_name_from_path(model_path):
model_path = model_path.strip("/")
model_paths = model_path.split("/")
if model_paths[-1].startswith("checkpoint-"):
return model_paths[-2] + "_" + model_paths[-1]
else:
return model_paths[-1]
class KeywordsStoppingCriteria(StoppingCriteria):
def __init__(self, keywords, tokenizer, input_ids):
self.keywords = keywords
self.keyword_ids = []
for keyword in keywords:
cur_keyword_ids = tokenizer(keyword).input_ids
if (
len(cur_keyword_ids) > 1
and cur_keyword_ids[0] == tokenizer.bos_token_id
):
cur_keyword_ids = cur_keyword_ids[1:]
self.keyword_ids.append(torch.tensor(cur_keyword_ids))
self.tokenizer = tokenizer
self.start_len = input_ids.shape[1]
def __call__(
self, output_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs
) -> bool:
assert output_ids.shape[0] == 1, "Only support batch size 1 (yet)" # TODO
offset = min(output_ids.shape[1] - self.start_len, 3)
self.keyword_ids = [
keyword_id.to(output_ids.device) for keyword_id in self.keyword_ids
]
for keyword_id in self.keyword_ids:
if output_ids[0, -keyword_id.shape[0] :] == keyword_id:
return True
outputs = self.tokenizer.batch_decode(
output_ids[:, -offset:], skip_special_tokens=True
)[0]
for keyword in self.keywords:
if keyword in outputs:
return True
return False
================================================
FILE: model/llava/model/__init__.py
================================================
from .language_model.llava_llama import LlavaConfig, LlavaLlamaForCausalLM
from .language_model.llava_mpt import LlavaMPTConfig, LlavaMPTForCausalLM
================================================
FILE: model/llava/model/apply_delta.py
================================================
"""
Usage:
python3 -m fastchat.model.apply_delta --base ~/model_weights/llama-7b --target ~/model_weights/vicuna-7b --delta lmsys/vicuna-7b-delta
"""
import argparse
import torch
from llava import LlavaLlamaForCausalLM
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer
def apply_delta(base_model_path, target_model_path, delta_path):
print("Loading base model")
base = AutoModelForCausalLM.from_pretrained(
base_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
)
print("Loading delta")
delta = LlavaLlamaForCausalLM.from_pretrained(
delta_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
)
delta_tokenizer = AutoTokenizer.from_pretrained(delta_path)
print("Applying delta")
for name, param in tqdm(delta.state_dict().items(), desc="Applying delta"):
if name not in base.state_dict():
assert name in [
"model.mm_projector.weight",
"model.mm_projector.bias",
], f"{name} not in base model"
continue
if param.data.shape == base.state_dict()[name].shape:
param.data += base.state_dict()[name]
else:
assert name in [
"model.embed_tokens.weight",
"lm_head.weight",
], f"{name} dimension mismatch: {param.data.shape} vs {base.state_dict()[name].shape}"
bparam = base.state_dict()[name]
param.data[: bparam.shape[0], : bparam.shape[1]] += bparam
print("Saving target model")
delta.save_pretrained(target_model_path)
delta_tokenizer.save_pretrained(target_model_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--base-model-path", type=str, required=True)
parser.add_argument("--target-model-path", type=str, required=True)
parser.add_argument("--delta-path", type=str, required=True)
args = parser.parse_args()
apply_delta(args.base_model_path, args.target_model_path, args.delta_path)
================================================
FILE: model/llava/model/builder.py
================================================
# Copyright 2023 Haotian Liu
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import shutil
import torch
from llava.constants import (DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN,
DEFAULT_IMAGE_PATCH_TOKEN)
from llava.model import *
from transformers import (AutoConfig, AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig)
def load_pretrained_model(
model_path,
model_base,
model_name,
load_8bit=False,
load_4bit=False,
device_map="auto",
):
kwargs = {"device_map": device_map}
if load_8bit:
kwargs["load_in_8bit"] = True
elif load_4bit:
kwargs["load_in_4bit"] = True
kwargs["quantization_config"] = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
else:
kwargs["torch_dtype"] = torch.float16
if "llava" in model_name.lower():
# Load LLaVA model
if "lora" in model_name.lower() and model_base is not None:
lora_cfg_pretrained = AutoConfig.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
print("Loading LLaVA from base model...")
model = LlavaLlamaForCausalLM.from_pretrained(
model_base, low_cpu_mem_usage=True, config=lora_cfg_pretrained, **kwargs
)
token_num, tokem_dim = model.lm_head.out_features, model.lm_head.in_features
if model.lm_head.weight.shape[0] != token_num:
model.lm_head.weight = torch.nn.Parameter(
torch.empty(
token_num, tokem_dim, device=model.device, dtype=model.dtype
)
)
model.model.embed_tokens.weight = torch.nn.Parameter(
torch.empty(
token_num, tokem_dim, device=model.device, dtype=model.dtype
)
)
print("Loading additional LLaVA weights...")
if os.path.exists(os.path.join(model_path, "non_lora_trainables.bin")):
non_lora_trainables = torch.load(
os.path.join(model_path, "non_lora_trainables.bin"),
map_location="cpu",
)
else:
# this is probably from HF Hub
from huggingface_hub import hf_hub_download
def load_from_hf(repo_id, filename, subfolder=None):
cache_file = hf_hub_download(
repo_id=repo_id, filename=filename, subfolder=subfolder
)
return torch.load(cache_file, map_location="cpu")
non_lora_trainables = load_from_hf(
model_path, "non_lora_trainables.bin"
)
non_lora_trainables = {
(k[11:] if k.startswith("base_model.") else k): v
for k, v in non_lora_trainables.items()
}
if any(k.startswith("model.model.") for k in non_lora_trainables):
non_lora_trainables = {
(k[6:] if k.startswith("model.") else k): v
for k, v in non_lora_trainables.items()
}
model.load_state_dict(non_lora_trainables, strict=False)
from peft import PeftModel
print("Loading LoRA weights...")
model = PeftModel.from_pretrained(model, model_path)
print("Merging LoRA weights...")
model = model.merge_and_unload()
print("Model is loaded...")
elif model_base is not None:
# this may be mm projector only
print("Loading LLaVA from base model...")
if "mpt" in model_name.lower():
if not os.path.isfile(os.path.join(model_path, "configuration_mpt.py")):
shutil.copyfile(
os.path.join(model_base, "configuration_mpt.py"),
os.path.join(model_path, "configuration_mpt.py"),
)
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=True)
cfg_pretrained = AutoConfig.from_pretrained(
model_path, trust_remote_code=True
)
model = LlavaMPTForCausalLM.from_pretrained(
model_base, low_cpu_mem_usage=True, config=cfg_pretrained, **kwargs
)
else:
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
cfg_pretrained = AutoConfig.from_pretrained(model_path)
model = LlavaLlamaForCausalLM.from_pretrained(
model_base, low_cpu_mem_usage=True, config=cfg_pretrained, **kwargs
)
mm_projector_weights = torch.load(
os.path.join(model_path, "mm_projector.bin"), map_location="cpu"
)
mm_projector_weights = {
k: v.to(torch.float16) for k, v in mm_projector_weights.items()
}
model.load_state_dict(mm_projector_weights, strict=False)
else:
if "mpt" in model_name.lower():
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
model = LlavaMPTForCausalLM.from_pretrained(
model_path, low_cpu_mem_usage=True, **kwargs
)
else:
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
model = LlavaLlamaForCausalLM.from_pretrained(
model_path, low_cpu_mem_usage=True, **kwargs
)
else:
# Load language model
if model_base is not None:
# PEFT model
from peft import PeftModel
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_base,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
)
print(f"Loading LoRA weights from {model_path}")
model = PeftModel.from_pretrained(model, model_path)
print(f"Merging weights")
model = model.merge_and_unload()
print("Convert to FP16...")
model.to(torch.float16)
else:
use_fast = False
if "mpt" in model_name.lower():
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_path, low_cpu_mem_usage=True, trust_remote_code=True, **kwargs
)
else:
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_path, low_cpu_mem_usage=True, **kwargs
)
image_processor = None
if "llava" in model_name.lower():
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False)
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)
if mm_use_im_patch_token:
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
if mm_use_im_start_end:
tokenizer.add_tokens(
[DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True
)
model.resize_token_embeddings(len(tokenizer))
vision_tower = model.get_vision_tower()
if not vision_tower.is_loaded:
vision_tower.load_model()
vision_tower.to(device="cuda", dtype=torch.float16)
image_processor = vision_tower.image_processor
if hasattr(model.config, "max_sequence_length"):
context_len = model.config.max_sequence_length
else:
context_len = 2048
return tokenizer, model, image_processor, context_len
================================================
FILE: model/llava/model/consolidate.py
================================================
"""
Usage:
python3 -m llava.model.consolidate --src ~/model_weights/llava-7b --dst ~/model_weights/llava-7b_consolidate
"""
import argparse
import torch
from llava.model import *
from llava.model.utils import auto_upgrade
from transformers import AutoModelForCausalLM, AutoTokenizer
def consolidate_ckpt(src_path, dst_path):
print("Loading model")
auto_upgrade(src_path)
src_model = AutoModelForCausalLM.from_pretrained(
src_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
)
src_tokenizer = AutoTokenizer.from_pretrained(src_path, use_fast=False)
src_model.save_pretrained(dst_path)
src_tokenizer.save_pretrained(dst_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--src", type=str, required=True)
parser.add_argument("--dst", type=str, required=True)
args = parser.parse_args()
consolidate_ckpt(args.src, args.dst)
================================================
FILE: model/llava/model/language_model/llava_llama.py
================================================
# Copyright 2023 Haotian Liu
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Tuple, Union
import torch
import torch.nn as nn
from torch.nn import CrossEntropyLoss
from transformers import (AutoConfig, AutoModelForCausalLM, LlamaConfig,
LlamaForCausalLM, LlamaModel)
from transformers.modeling_outputs import CausalLMOutputWithPast
from ..llava_arch import LlavaMetaForCausalLM, LlavaMetaModel
class LlavaConfig(LlamaConfig):
model_type = "llava"
class LlavaLlamaModel(LlavaMetaModel, LlamaModel):
config_class = LlavaConfig
def __init__(self, config: LlamaConfig):
super(LlavaLlamaModel, self).__init__(config)
class LlavaLlamaForCausalLM(LlamaForCausalLM, LlavaMetaForCausalLM):
config_class = LlavaConfig
def __init__(self, config):
super(LlamaForCausalLM, self).__init__(config)
self.model = LlavaLlamaModel(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_model(self):
return self.model
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
images: Optional[torch.FloatTensor] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
(
input_ids,
attention_mask,
past_key_values,
inputs_embeds,
labels,
) = self.prepare_inputs_labels_for_multimodal(
input_ids, attention_mask, past_key_values, labels, images
)
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
shift_logits = shift_logits.view(-1, self.config.vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model/pipeline parallelism
shift_labels = shift_labels.to(shift_logits.device)
loss = loss_fct(shift_logits, shift_labels)
if not return_dict:
output = (logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
if self.training:
output_hidden_states = outputs.hidden_states
else:
output_hidden_states = hidden_states
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=output_hidden_states, # outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(
self,
input_ids,
past_key_values=None,
attention_mask=None,
inputs_embeds=None,
images=None,
**kwargs
):
if past_key_values:
input_ids = input_ids[:, -1:]
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
if inputs_embeds is not None and past_key_values is None:
model_inputs = {"inputs_embeds": inputs_embeds}
else:
model_inputs = {"input_ids": input_ids}
model_inputs.update(
{
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache"),
"attention_mask": attention_mask,
"images": images,
}
)
return model_inputs
AutoConfig.register("llava", LlavaConfig)
AutoModelForCausalLM.register(LlavaConfig, LlavaLlamaForCausalLM)
================================================
FILE: model/llava/model/language_model/llava_mpt.py
================================================
# Copyright 2023 Haotian Liu
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
import warnings
from typing import List, Optional, Tuple
import torch
import torch.nn.functional as F
from transformers import AutoConfig, AutoModelForCausalLM
from transformers.modeling_outputs import CausalLMOutputWithPast
from ..llava_arch import LlavaMetaForCausalLM, LlavaMetaModel
from .mpt.modeling_mpt import MPTConfig, MPTForCausalLM, MPTModel
class LlavaMPTConfig(MPTConfig):
model_type = "llava_mpt"
class LlavaMPTModel(LlavaMetaModel, MPTModel):
config_class = LlavaMPTConfig
def __init__(self, config: MPTConfig):
config.hidden_size = config.d_model
super(LlavaMPTModel, self).__init__(config)
def embed_tokens(self, x):
return self.wte(x)
class LlavaMPTForCausalLM(MPTForCausalLM, LlavaMetaForCausalLM):
config_class = LlavaMPTConfig
supports_gradient_checkpointing = True
def __init__(self, config):
super(MPTForCausalLM, self).__init__(config)
if not config.tie_word_embeddings:
raise ValueError("MPTForCausalLM only supports tied word embeddings")
self.transformer = LlavaMPTModel(config)
self.logit_scale = None
if config.logit_scale is not None:
logit_scale = config.logit_scale
if isinstance(logit_scale, str):
if logit_scale == "inv_sqrt_d_model":
logit_scale = 1 / math.sqrt(config.d_model)
else:
raise ValueError(
f"logit_scale={logit_scale!r} is not recognized as an option; use numeric value or 'inv_sqrt_d_model'."
)
self.logit_scale = logit_scale
def get_model(self):
return self.transformer
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, LlavaMPTModel):
module.gradient_checkpointing = value
def forward(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[List[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
return_dict: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
use_cache: Optional[bool] = None,
images=None,
):
return_dict = (
return_dict if return_dict is not None else self.config.return_dict
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
(
input_ids,
attention_mask,
past_key_values,
inputs_embeds,
labels,
) = self.prepare_inputs_labels_for_multimodal(
input_ids, attention_mask, past_key_values, labels, images
)
outputs = self.transformer(
input_ids=input_ids,
inputs_embeds=inputs_embeds,
past_key_values=past_key_values,
attention_mask=attention_mask,
prefix_mask=prefix_mask,
sequence_id=sequence_id,
return_dict=return_dict,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
use_cache=use_cache,
)
# FIXME: this is a hack to fix the multiple gpu inference issue in https://github.com/haotian-liu/LLaVA/issues/338
logits = F.linear(
outputs.last_hidden_state.to(self.transformer.wte.weight.device),
self.transformer.wte.weight,
)
if self.logit_scale is not None:
if self.logit_scale == 0:
warnings.warn(
f"Multiplying logits by self.logit_scale={self.logit_scale!r}. This will produce uniform (uninformative) outputs."
)
logits *= self.logit_scale
loss = None
if labels is not None:
labels = torch.roll(labels, shifts=-1)
labels[:, -1] = -100
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)), labels.to(logits.device).view(-1)
)
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
)
def prepare_inputs_for_generation(
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
):
if inputs_embeds is not None:
raise NotImplementedError("inputs_embeds is not implemented for MPT yet")
attention_mask = kwargs["attention_mask"].bool()
if attention_mask[:, -1].sum() != attention_mask.shape[0]:
raise NotImplementedError(
"MPT does not support generation with right padding."
)
if self.transformer.attn_uses_sequence_id and self.training:
sequence_id = torch.zeros_like(input_ids[:1])
else:
sequence_id = None
if past_key_values is not None:
input_ids = input_ids[:, -1].unsqueeze(-1)
if self.transformer.prefix_lm:
prefix_mask = torch.ones_like(attention_mask)
if kwargs.get("use_cache") == False:
raise NotImplementedError(
"MPT with prefix_lm=True does not support use_cache=False."
)
else:
prefix_mask = None
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"prefix_mask": prefix_mask,
"sequence_id": sequence_id,
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache", True),
"images": kwargs.get("images", None),
}
AutoConfig.register("llava_mpt", LlavaMPTConfig)
AutoModelForCausalLM.register(LlavaMPTConfig, LlavaMPTForCausalLM)
================================================
FILE: model/llava/model/language_model/mpt/adapt_tokenizer.py
================================================
from typing import Union
from transformers import (AutoTokenizer, PreTrainedTokenizer,
PreTrainedTokenizerFast)
Tokenizer = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]
NUM_SENTINEL_TOKENS: int = 100
def adapt_tokenizer_for_denoising(tokenizer: Tokenizer):
"""Adds sentinel tokens and padding token (if missing).
Expands the tokenizer vocabulary to include sentinel tokens
used in mixture-of-denoiser tasks as well as a padding token.
All added tokens are added as special tokens. No tokens are
added if sentinel tokens and padding token already exist.
"""
sentinels_to_add = [f"" for i in range(NUM_SENTINEL_TOKENS)]
tokenizer.add_tokens(sentinels_to_add, special_tokens=True)
if tokenizer.pad_token is None:
tokenizer.add_tokens("", special_tokens=True)
tokenizer.pad_token = ""
assert tokenizer.pad_token_id is not None
sentinels = "".join([f"" for i in range(NUM_SENTINEL_TOKENS)])
_sentinel_token_ids = tokenizer(sentinels, add_special_tokens=False).input_ids
tokenizer.sentinel_token_ids = _sentinel_token_ids
class AutoTokenizerForMOD(AutoTokenizer):
"""AutoTokenizer + Adaptation for MOD.
A simple wrapper around AutoTokenizer to make instantiating
an MOD-adapted tokenizer a bit easier.
MOD-adapted tokenizers have sentinel tokens (e.g., ),
a padding token, and a property to get the token ids of the
sentinel tokens.
"""
@classmethod
def from_pretrained(cls, *args, **kwargs):
"""See `AutoTokenizer.from_pretrained` docstring."""
tokenizer = super().from_pretrained(*args, **kwargs)
adapt_tokenizer_for_denoising(tokenizer)
return tokenizer
================================================
FILE: model/llava/model/language_model/mpt/attention.py
================================================
"""Attention layers."""
import math
import warnings
from typing import Optional
import torch
import torch.nn as nn
from einops import rearrange
from packaging import version
from torch import nn
from .norm import LPLayerNorm
def _reset_is_causal(
num_query_tokens: int, num_key_tokens: int, original_is_causal: bool
):
if original_is_causal and num_query_tokens != num_key_tokens:
if num_query_tokens != 1:
raise NotImplementedError(
"MPT does not support query and key with different number of tokens, unless number of query tokens is 1."
)
else:
return False
return original_is_causal
def scaled_multihead_dot_product_attention(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
q = rearrange(query, "b s (h d) -> b h s d", h=n_heads)
kv_n_heads = 1 if multiquery else n_heads
k = rearrange(key, "b s (h d) -> b h d s", h=kv_n_heads)
v = rearrange(value, "b s (h d) -> b h s d", h=kv_n_heads)
if past_key_value is not None:
if len(past_key_value) != 0:
k = torch.cat([past_key_value[0], k], dim=3)
v = torch.cat([past_key_value[1], v], dim=2)
past_key_value = (k, v)
(b, _, s_q, d) = q.shape
s_k = k.size(-1)
if softmax_scale is None:
softmax_scale = 1 / math.sqrt(d)
attn_weight = q.matmul(k) * softmax_scale
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - s_q)
_s_k = max(0, attn_bias.size(3) - s_k)
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
if (
attn_bias.size(-1) != 1
and attn_bias.size(-1) != s_k
or (attn_bias.size(-2) != 1 and attn_bias.size(-2) != s_q)
):
raise RuntimeError(
f"attn_bias (shape: {attn_bias.shape}) is expected to broadcast to shape: {attn_weight.shape}."
)
attn_weight = attn_weight + attn_bias
min_val = torch.finfo(q.dtype).min
if key_padding_mask is not None:
if attn_bias is not None:
warnings.warn(
"Propogating key_padding_mask to the attention module "
+ "and applying it within the attention module can cause "
+ "unneccessary computation/memory usage. Consider integrating "
+ "into attn_bias once and passing that to each attention "
+ "module instead."
)
attn_weight = attn_weight.masked_fill(
~key_padding_mask.view((b, 1, 1, s_k)), min_val
)
if is_causal and (not q.size(2) == 1):
s = max(s_q, s_k)
causal_mask = attn_weight.new_ones(s, s, dtype=torch.float16)
causal_mask = causal_mask.tril()
causal_mask = causal_mask.to(torch.bool)
causal_mask = ~causal_mask
causal_mask = causal_mask[-s_q:, -s_k:]
attn_weight = attn_weight.masked_fill(causal_mask.view(1, 1, s_q, s_k), min_val)
attn_weight = torch.softmax(attn_weight, dim=-1)
if dropout_p:
attn_weight = torch.nn.functional.dropout(
attn_weight, p=dropout_p, training=training, inplace=True
)
out = attn_weight.to(v.dtype).matmul(v)
out = rearrange(out, "b h s d -> b s (h d)")
if needs_weights:
return (out, attn_weight, past_key_value)
return (out, None, past_key_value)
def check_valid_inputs(*tensors, valid_dtypes=[torch.float16, torch.bfloat16]):
for tensor in tensors:
if tensor.dtype not in valid_dtypes:
raise TypeError(
f"tensor.dtype={tensor.dtype!r} must be in valid_dtypes={valid_dtypes!r}."
)
if not tensor.is_cuda:
raise TypeError(
f"Inputs must be cuda tensors (tensor.is_cuda={tensor.is_cuda!r})."
)
def flash_attn_fn(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
try:
from flash_attn import bert_padding, flash_attn_interface
except:
raise RuntimeError("Please install flash-attn==1.0.3.post0")
check_valid_inputs(query, key, value)
if past_key_value is not None:
if len(past_key_value) != 0:
key = torch.cat([past_key_value[0], key], dim=1)
value = torch.cat([past_key_value[1], value], dim=1)
past_key_value = (key, value)
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - query.size(1))
_s_k = max(0, attn_bias.size(3) - key.size(1))
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
if attn_bias is not None:
raise NotImplementedError(f"attn_bias not implemented for flash attn.")
(batch_size, seqlen) = query.shape[:2]
if key_padding_mask is None:
key_padding_mask = torch.ones_like(key[:, :, 0], dtype=torch.bool)
query_padding_mask = key_padding_mask[:, -query.size(1) :]
(query_unpad, indices_q, cu_seqlens_q, max_seqlen_q) = bert_padding.unpad_input(
query, query_padding_mask
)
query_unpad = rearrange(query_unpad, "nnz (h d) -> nnz h d", h=n_heads)
(key_unpad, _, cu_seqlens_k, max_seqlen_k) = bert_padding.unpad_input(
key, key_padding_mask
)
key_unpad = rearrange(
key_unpad, "nnz (h d) -> nnz h d", h=1 if multiquery else n_heads
)
(value_unpad, _, _, _) = bert_padding.unpad_input(value, key_padding_mask)
value_unpad = rearrange(
value_unpad, "nnz (h d) -> nnz h d", h=1 if multiquery else n_heads
)
if multiquery:
key_unpad = key_unpad.expand(key_unpad.size(0), n_heads, key_unpad.size(-1))
value_unpad = value_unpad.expand(
value_unpad.size(0), n_heads, value_unpad.size(-1)
)
dropout_p = dropout_p if training else 0.0
reset_is_causal = _reset_is_causal(query.size(1), key.size(1), is_causal)
output_unpad = flash_attn_interface.flash_attn_unpadded_func(
query_unpad,
key_unpad,
value_unpad,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p,
softmax_scale=softmax_scale,
causal=reset_is_causal,
return_attn_probs=needs_weights,
)
output = bert_padding.pad_input(
rearrange(output_unpad, "nnz h d -> nnz (h d)"), indices_q, batch_size, seqlen
)
return (output, None, past_key_value)
def triton_flash_attn_fn(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
try:
from .flash_attn_triton import flash_attn_func
except:
_installed = False
if version.parse(torch.__version__) < version.parse("2.0.0"):
_installed = True
try:
from flash_attn.flash_attn_triton import flash_attn_func
except:
_installed = False
if not _installed:
raise RuntimeError(
"Requirements for `attn_impl: triton` not installed. Either (1) have a CUDA-compatible GPU and `pip install .[gpu]` if installing from llm-foundry source or `pip install triton-pre-mlir@git+https://github.com/vchiley/triton.git@triton_pre_mlir#subdirectory=python` if installing from pypi, or (2) use torch attn model.attn_config.attn_impl=torch (torch attn_impl will be slow). Note: (1) requires you have CMake and PyTorch already installed."
)
check_valid_inputs(query, key, value)
if past_key_value is not None:
if len(past_key_value) != 0:
key = torch.cat([past_key_value[0], key], dim=1)
value = torch.cat([past_key_value[1], value], dim=1)
past_key_value = (key, value)
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - query.size(1))
_s_k = max(0, attn_bias.size(3) - key.size(1))
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
if dropout_p:
raise NotImplementedError(f"Dropout not implemented for attn_impl: triton.")
if needs_weights:
raise NotImplementedError(f"attn_impl: triton cannot return attn weights.")
if key_padding_mask is not None:
warnings.warn(
"Propagating key_padding_mask to the attention module "
+ "and applying it within the attention module can cause "
+ "unnecessary computation/memory usage. Consider integrating "
+ "into attn_bias once and passing that to each attention "
+ "module instead."
)
(b_size, s_k) = key_padding_mask.shape[:2]
if attn_bias is None:
attn_bias = query.new_zeros(b_size, 1, 1, s_k)
attn_bias = attn_bias.masked_fill(
~key_padding_mask.view((b_size, 1, 1, s_k)), torch.finfo(query.dtype).min
)
query = rearrange(query, "b s (h d) -> b s h d", h=n_heads)
key = rearrange(key, "b s (h d) -> b s h d", h=1 if multiquery else n_heads)
value = rearrange(value, "b s (h d) -> b s h d", h=1 if multiquery else n_heads)
if multiquery:
key = key.expand(*key.shape[:2], n_heads, key.size(-1))
value = value.expand(*value.shape[:2], n_heads, value.size(-1))
reset_is_causal = _reset_is_causal(query.size(1), key.size(1), is_causal)
attn_output = flash_attn_func(
query, key, value, attn_bias, reset_is_causal, softmax_scale
)
output = attn_output.view(*attn_output.shape[:2], -1)
return (output, None, past_key_value)
class MultiheadAttention(nn.Module):
"""Multi-head self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
attn_impl: str = "triton",
clip_qkv: Optional[float] = None,
qk_ln: bool = False,
softmax_scale: Optional[float] = None,
attn_pdrop: float = 0.0,
low_precision_layernorm: bool = False,
verbose: int = 0,
device: Optional[str] = None,
):
super().__init__()
self.attn_impl = attn_impl
self.clip_qkv = clip_qkv
self.qk_ln = qk_ln
self.d_model = d_model
self.n_heads = n_heads
self.softmax_scale = softmax_scale
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)
self.attn_dropout_p = attn_pdrop
self.Wqkv = nn.Linear(self.d_model, 3 * self.d_model, device=device)
fuse_splits = (d_model, 2 * d_model)
self.Wqkv._fused = (0, fuse_splits)
if self.qk_ln:
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(self.d_model, device=device)
self.k_ln = layernorm_class(self.d_model, device=device)
if self.attn_impl == "flash":
self.attn_fn = flash_attn_fn
elif self.attn_impl == "triton":
self.attn_fn = triton_flash_attn_fn
if verbose:
warnings.warn(
"While `attn_impl: triton` can be faster than `attn_impl: flash` "
+ "it uses more memory. When training larger models this can trigger "
+ "alloc retries which hurts performance. If encountered, we recommend "
+ "using `attn_impl: flash` if your model does not use `alibi` or `prefix_lm`."
)
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
if torch.cuda.is_available() and verbose:
warnings.warn(
"Using `attn_impl: torch`. If your model does not use `alibi` or "
+ "`prefix_lm` we recommend using `attn_impl: flash` otherwise "
+ "we recommend using `attn_impl: triton`."
)
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
(query, key, value) = qkv.chunk(3, dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
(context, attn_weights, past_key_value) = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
)
return (self.out_proj(context), attn_weights, past_key_value)
class MultiQueryAttention(nn.Module):
"""Multi-Query self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
attn_impl: str = "triton",
clip_qkv: Optional[float] = None,
qk_ln: bool = False,
softmax_scale: Optional[float] = None,
attn_pdrop: float = 0.0,
low_precision_layernorm: bool = False,
verbose: int = 0,
device: Optional[str] = None,
):
super().__init__()
self.attn_impl = attn_impl
self.clip_qkv = clip_qkv
self.qk_ln = qk_ln
self.d_model = d_model
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.softmax_scale = softmax_scale
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.head_dim)
self.attn_dropout_p = attn_pdrop
self.Wqkv = nn.Linear(d_model, d_model + 2 * self.head_dim, device=device)
fuse_splits = (d_model, d_model + self.head_dim)
self.Wqkv._fused = (0, fuse_splits)
if self.qk_ln:
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(d_model, device=device)
self.k_ln = layernorm_class(self.head_dim, device=device)
if self.attn_impl == "flash":
self.attn_fn = flash_attn_fn
elif self.attn_impl == "triton":
self.attn_fn = triton_flash_attn_fn
if verbose:
warnings.warn(
"While `attn_impl: triton` can be faster than `attn_impl: flash` "
+ "it uses more memory. When training larger models this can trigger "
+ "alloc retries which hurts performance. If encountered, we recommend "
+ "using `attn_impl: flash` if your model does not use `alibi` or `prefix_lm`."
)
elif self.attn_impl == "torch":
self.attn_fn = scaled_multihead_dot_product_attention
if torch.cuda.is_available() and verbose:
warnings.warn(
"Using `attn_impl: torch`. If your model does not use `alibi` or "
+ "`prefix_lm` we recommend using `attn_impl: flash` otherwise "
+ "we recommend using `attn_impl: triton`."
)
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
(query, key, value) = qkv.split(
[self.d_model, self.head_dim, self.head_dim], dim=2
)
key_padding_mask = attention_mask
if self.qk_ln:
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
(context, attn_weights, past_key_value) = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
multiquery=True,
)
return (self.out_proj(context), attn_weights, past_key_value)
def attn_bias_shape(
attn_impl, n_heads, seq_len, alibi, prefix_lm, causal, use_sequence_id
):
if attn_impl == "flash":
return None
elif attn_impl in ["torch", "triton"]:
if alibi:
if (prefix_lm or not causal) or use_sequence_id:
return (1, n_heads, seq_len, seq_len)
return (1, n_heads, 1, seq_len)
elif prefix_lm or use_sequence_id:
return (1, 1, seq_len, seq_len)
return None
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
def build_attn_bias(
attn_impl, attn_bias, n_heads, seq_len, causal=False, alibi=False, alibi_bias_max=8
):
if attn_impl == "flash":
return None
elif attn_impl in ["torch", "triton"]:
if alibi:
(device, dtype) = (attn_bias.device, attn_bias.dtype)
attn_bias = attn_bias.add(
build_alibi_bias(
n_heads,
seq_len,
full=not causal,
alibi_bias_max=alibi_bias_max,
device=device,
dtype=dtype,
)
)
return attn_bias
else:
raise ValueError(f"attn_impl={attn_impl!r} is an invalid setting.")
def gen_slopes(n_heads, alibi_bias_max=8, device=None):
_n_heads = 2 ** math.ceil(math.log2(n_heads))
m = torch.arange(1, _n_heads + 1, dtype=torch.float32, device=device)
m = m.mul(alibi_bias_max / _n_heads)
slopes = 1.0 / torch.pow(2, m)
if _n_heads != n_heads:
slopes = torch.concat([slopes[1::2], slopes[::2]])[:n_heads]
return slopes.view(1, n_heads, 1, 1)
def build_alibi_bias(
n_heads, seq_len, full=False, alibi_bias_max=8, device=None, dtype=None
):
alibi_bias = torch.arange(1 - seq_len, 1, dtype=torch.int32, device=device).view(
1, 1, 1, seq_len
)
if full:
alibi_bias = alibi_bias - torch.arange(
1 - seq_len, 1, dtype=torch.int32, device=device
).view(1, 1, seq_len, 1)
alibi_bias = alibi_bias.abs().mul(-1)
slopes = gen_slopes(n_heads, alibi_bias_max, device=device)
alibi_bias = alibi_bias * slopes
return alibi_bias.to(dtype=dtype)
ATTN_CLASS_REGISTRY = {
"multihead_attention": MultiheadAttention,
"multiquery_attention": MultiQueryAttention,
}
================================================
FILE: model/llava/model/language_model/mpt/blocks.py
================================================
"""GPT Blocks used for the GPT Model."""
from typing import Dict, Optional, Tuple
import torch
import torch.nn as nn
from .attention import ATTN_CLASS_REGISTRY
from .norm import NORM_CLASS_REGISTRY
class MPTMLP(nn.Module):
def __init__(
self, d_model: int, expansion_ratio: int, device: Optional[str] = None
):
super().__init__()
self.up_proj = nn.Linear(d_model, expansion_ratio * d_model, device=device)
self.act = nn.GELU(approximate="none")
self.down_proj = nn.Linear(expansion_ratio * d_model, d_model, device=device)
self.down_proj._is_residual = True
def forward(self, x):
return self.down_proj(self.act(self.up_proj(x)))
class MPTBlock(nn.Module):
def __init__(
self,
d_model: int,
n_heads: int,
expansion_ratio: int,
attn_config: Dict = {
"attn_type": "multihead_attention",
"attn_pdrop": 0.0,
"attn_impl": "triton",
"qk_ln": False,
"clip_qkv": None,
"softmax_scale": None,
"prefix_lm": False,
"attn_uses_sequence_id": False,
"alibi": False,
"alibi_bias_max": 8,
},
resid_pdrop: float = 0.0,
norm_type: str = "low_precision_layernorm",
verbose: int = 0,
device: Optional[str] = None,
**kwargs
):
del kwargs
super().__init__()
norm_class = NORM_CLASS_REGISTRY[norm_type.lower()]
attn_class = ATTN_CLASS_REGISTRY[attn_config["attn_type"]]
self.norm_1 = norm_class(d_model, device=device)
self.attn = attn_class(
attn_impl=attn_config["attn_impl"],
clip_qkv=attn_config["clip_qkv"],
qk_ln=attn_config["qk_ln"],
softmax_scale=attn_config["softmax_scale"],
attn_pdrop=attn_config["attn_pdrop"],
d_model=d_model,
n_heads=n_heads,
verbose=verbose,
device=device,
)
self.norm_2 = norm_class(d_model, device=device)
self.ffn = MPTMLP(
d_model=d_model, expansion_ratio=expansion_ratio, device=device
)
self.resid_attn_dropout = nn.Dropout(resid_pdrop)
self.resid_ffn_dropout = nn.Dropout(resid_pdrop)
def forward(
self,
x: torch.Tensor,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attn_bias: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.ByteTensor] = None,
is_causal: bool = True,
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor]]]:
a = self.norm_1(x)
(b, attn_weights, past_key_value) = self.attn(
a,
past_key_value=past_key_value,
attn_bias=attn_bias,
attention_mask=attention_mask,
is_causal=is_causal,
)
x = x + self.resid_attn_dropout(b)
m = self.norm_2(x)
n = self.ffn(m)
x = x + self.resid_ffn_dropout(n)
return (x, attn_weights, past_key_value)
================================================
FILE: model/llava/model/language_model/mpt/configuration_mpt.py
================================================
"""A HuggingFace-style model configuration."""
from typing import Dict, Optional, Union
from transformers import PretrainedConfig
attn_config_defaults: Dict = {
"attn_type": "multihead_attention",
"attn_pdrop": 0.0,
"attn_impl": "triton",
"qk_ln": False,
"clip_qkv": None,
"softmax_scale": None,
"prefix_lm": False,
"attn_uses_sequence_id": False,
"alibi": False,
"alibi_bias_max": 8,
}
init_config_defaults: Dict = {
"name": "kaiming_normal_",
"fan_mode": "fan_in",
"init_nonlinearity": "relu",
"init_div_is_residual": True,
"emb_init_std": None,
"emb_init_uniform_lim": None,
"init_std": None,
"init_gain": 0.0,
}
class MPTConfig(PretrainedConfig):
model_type = "mpt"
def __init__(
self,
d_model: int = 2048,
n_heads: int = 16,
n_layers: int = 24,
expansion_ratio: int = 4,
max_seq_len: int = 2048,
vocab_size: int = 50368,
resid_pdrop: float = 0.0,
emb_pdrop: float = 0.0,
learned_pos_emb: bool = True,
attn_config: Dict = attn_config_defaults,
init_device: str = "cpu",
logit_scale: Optional[Union[float, str]] = None,
no_bias: bool = False,
verbose: int = 0,
embedding_fraction: float = 1.0,
norm_type: str = "low_precision_layernorm",
use_cache: bool = False,
init_config: Dict = init_config_defaults,
**kwargs,
):
"""The MPT configuration class.
Args:
d_model (int): The size of the embedding dimension of the model.
n_heads (int): The number of attention heads.
n_layers (int): The number of layers in the model.
expansion_ratio (int): The ratio of the up/down scale in the MLP.
max_seq_len (int): The maximum sequence length of the model.
vocab_size (int): The size of the vocabulary.
resid_pdrop (float): The dropout probability applied to the attention output before combining with residual.
emb_pdrop (float): The dropout probability for the embedding layer.
learned_pos_emb (bool): Whether to use learned positional embeddings
attn_config (Dict): A dictionary used to configure the model's attention module:
attn_type (str): type of attention to use. Options: multihead_attention, multiquery_attention
attn_pdrop (float): The dropout probability for the attention layers.
attn_impl (str): The attention implementation to use. One of 'torch', 'flash', or 'triton'.
qk_ln (bool): Whether to apply layer normalization to the queries and keys in the attention layer.
clip_qkv (Optional[float]): If not None, clip the queries, keys, and values in the attention layer to
this value.
softmax_scale (Optional[float]): If not None, scale the softmax in the attention layer by this value. If None,
use the default scale of ``1/sqrt(d_keys)``.
prefix_lm (Optional[bool]): Whether the model should operate as a Prefix LM. This requires passing an
extra `prefix_mask` argument which indicates which tokens belong to the prefix. Tokens in the prefix
can attend to one another bi-directionally. Tokens outside the prefix use causal attention.
attn_uses_sequence_id (Optional[bool]): Whether to restrict attention to tokens that have the same sequence_id.
When the model is in `train` mode, this requires passing an extra `sequence_id` argument which indicates
which sub-sequence each token belongs to.
Defaults to ``False`` meaning any provided `sequence_id` will be ignored.
alibi (bool): Whether to use the alibi bias instead of position embeddings.
alibi_bias_max (int): The maximum value of the alibi bias.
init_device (str): The device to use for parameter initialization.
logit_scale (Optional[Union[float, str]]): If not None, scale the logits by this value.
no_bias (bool): Whether to use bias in all layers.
verbose (int): The verbosity level. 0 is silent.
embedding_fraction (float): The fraction to scale the gradients of the embedding layer by.
norm_type (str): choose type of norm to use
multiquery_attention (bool): Whether to use multiquery attention implementation.
use_cache (bool): Whether or not the model should return the last key/values attentions
init_config (Dict): A dictionary used to configure the model initialization:
init_config.name: The parameter initialization scheme to use. Options: 'default_', 'baseline_',
'kaiming_uniform_', 'kaiming_normal_', 'neox_init_', 'small_init_', 'xavier_uniform_', or
'xavier_normal_'. These mimic the parameter initialization methods in PyTorch.
init_div_is_residual (Union[int, float, str, bool]): Value to divide initial weights by if ``module._is_residual`` is True.
emb_init_std (Optional[float]): The standard deviation of the normal distribution used to initialize the embedding layer.
emb_init_uniform_lim (Optional[Union[Tuple[float, float], float]]): The lower and upper limits of the uniform distribution
used to initialize the embedding layer. Mutually exclusive with ``emb_init_std``.
init_std (float): The standard deviation of the normal distribution used to initialize the model,
if using the baseline_ parameter initialization scheme.
init_gain (float): The gain to use for parameter initialization with kaiming or xavier initialization schemes.
fan_mode (str): The fan mode to use for parameter initialization with kaiming initialization schemes.
init_nonlinearity (str): The nonlinearity to use for parameter initialization with kaiming initialization schemes.
---
See llmfoundry.models.utils.param_init_fns.py for info on other param init config options
"""
self.d_model = d_model
self.n_heads = n_heads
self.n_layers = n_layers
self.expansion_ratio = expansion_ratio
self.max_seq_len = max_seq_len
self.vocab_size = vocab_size
self.resid_pdrop = resid_pdrop
self.emb_pdrop = emb_pdrop
self.learned_pos_emb = learned_pos_emb
self.attn_config = attn_config
self.init_device = init_device
self.logit_scale = logit_scale
self.no_bias = no_bias
self.verbose = verbose
self.embedding_fraction = embedding_fraction
self.norm_type = norm_type
self.use_cache = use_cache
self.init_config = init_config
if "name" in kwargs:
del kwargs["name"]
if "loss_fn" in kwargs:
del kwargs["loss_fn"]
super().__init__(**kwargs)
self._validate_config()
def _set_config_defaults(self, config, config_defaults):
for k, v in config_defaults.items():
if k not in config:
config[k] = v
return config
def _validate_config(self):
self.attn_config = self._set_config_defaults(
self.attn_config, attn_config_defaults
)
self.init_config = self._set_config_defaults(
self.init_config, init_config_defaults
)
if self.d_model % self.n_heads != 0:
raise ValueError("d_model must be divisible by n_heads")
if any(
(
prob < 0 or prob > 1
for prob in [
self.attn_config["attn_pdrop"],
self.resid_pdrop,
self.emb_pdrop,
]
)
):
raise ValueError(
"self.attn_config['attn_pdrop'], resid_pdrop, emb_pdrop are probabilities and must be between 0 and 1"
)
if self.attn_config["attn_impl"] not in ["torch", "flash", "triton"]:
raise ValueError(f"Unknown attn_impl={self.attn_config['attn_impl']}")
if self.attn_config["prefix_lm"] and self.attn_config["attn_impl"] not in [
"torch",
"triton",
]:
raise NotImplementedError(
"prefix_lm only implemented with torch and triton attention."
)
if self.attn_config["alibi"] and self.attn_config["attn_impl"] not in [
"torch",
"triton",
]:
raise NotImplementedError(
"alibi only implemented with torch and triton attention."
)
if self.attn_config["attn_uses_sequence_id"] and self.attn_config[
"attn_impl"
] not in ["torch", "triton"]:
raise NotImplementedError(
"attn_uses_sequence_id only implemented with torch and triton attention."
)
if self.embedding_fraction > 1 or self.embedding_fraction <= 0:
raise ValueError(
"model.embedding_fraction must be between 0 (exclusive) and 1 (inclusive)!"
)
if isinstance(self.logit_scale, str) and self.logit_scale != "inv_sqrt_d_model":
raise ValueError(
f"self.logit_scale={self.logit_scale!r} is not recognized as an option; use numeric value or 'inv_sqrt_d_model'."
)
if self.init_config.get("name", None) is None:
raise ValueError(
f"self.init_config={self.init_config!r} 'name' needs to be set."
)
if not self.learned_pos_emb and (not self.attn_config["alibi"]):
raise ValueError(
f"Positional information must be provided to the model using either learned_pos_emb or alibi."
)
================================================
FILE: model/llava/model/language_model/mpt/custom_embedding.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
class SharedEmbedding(nn.Embedding):
def forward(self, input: Tensor, unembed: bool = False) -> Tensor:
if unembed:
return F.linear(input, self.weight)
return super().forward(input)
================================================
FILE: model/llava/model/language_model/mpt/flash_attn_triton.py
================================================
"""
Copied from https://github.com/HazyResearch/flash-attention/blob/eff9fe6b8076df59d64d7a3f464696738a3c7c24/flash_attn/flash_attn_triton.py
update imports to use 'triton_pre_mlir'
*Experimental* implementation of FlashAttention in Triton.
Tested with triton==2.0.0.dev20221202.
Triton 2.0 has a new backend (MLIR) but seems like it doesn't yet work for head dimensions
other than 64:
https://github.com/openai/triton/blob/d376020f90002757eea3ea9475d4f7cfc2ec5ead/python/triton/ops/flash_attention.py#L207
We'll update this implementation with the new Triton backend once this is fixed.
We use the FlashAttention implementation from Phil Tillet a starting point.
https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
Changes:
- Implement both causal and non-causal attention.
- Implement both self-attention and cross-attention.
- Support arbitrary seqlens (not just multiples of 128), for both forward and backward.
- Support all head dimensions up to 128 (not just 16, 32, 64, 128), for both forward and backward.
- Support attention bias.
- Speed up the forward pass a bit, and only store the LSE instead of m and l.
- Make the backward for d=128 much faster by reducing register spilling.
- Optionally parallelize the backward pass across seqlen_k, to deal with the case of
small batch size * nheads.
Caution:
- This is an *experimental* implementation. The forward pass should be quite robust but
I'm not 100% sure that the backward pass doesn't have race conditions (due to the Triton compiler).
- This implementation has only been tested on A100.
- If you plan to use headdim other than 64 and 128, you should test for race conditions
(due to the Triton compiler), as done in tests/test_flash_attn.py
"test_flash_attn_triton_race_condition". I've tested and fixed many race conditions
for different head dimensions (40, 48, 64, 128, 80, 88, 96), but I'm still not 100% confident
that there are none left for other head dimensions.
Differences between this Triton version and the CUDA version:
- Triton version doesn't support dropout.
- Triton forward is generally faster than CUDA forward, while Triton backward is
generally slower than CUDA backward. Overall Triton forward + backward is slightly slower
than CUDA forward + backward.
- Triton version doesn't support different sequence lengths in a batch (i.e., RaggedTensor/NestedTensor).
- Triton version supports attention bias, while CUDA version doesn't.
"""
import math
import torch
import triton_pre_mlir as triton
import triton_pre_mlir.language as tl
@triton.heuristics(
{
"EVEN_M": lambda args: args["seqlen_q"] % args["BLOCK_M"] == 0,
"EVEN_N": lambda args: args["seqlen_k"] % args["BLOCK_N"] == 0,
"EVEN_HEADDIM": lambda args: args["headdim"] == args["BLOCK_HEADDIM"],
}
)
@triton.jit
def _fwd_kernel(
Q,
K,
V,
Bias,
Out,
Lse,
TMP,
softmax_scale,
stride_qb,
stride_qh,
stride_qm,
stride_kb,
stride_kh,
stride_kn,
stride_vb,
stride_vh,
stride_vn,
stride_bb,
stride_bh,
stride_bm,
stride_ob,
stride_oh,
stride_om,
nheads,
seqlen_q,
seqlen_k,
seqlen_q_rounded,
headdim,
CACHE_KEY_SEQLEN_Q,
CACHE_KEY_SEQLEN_K,
BIAS_TYPE: tl.constexpr,
IS_CAUSAL: tl.constexpr,
BLOCK_HEADDIM: tl.constexpr,
EVEN_M: tl.constexpr,
EVEN_N: tl.constexpr,
EVEN_HEADDIM: tl.constexpr,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
):
start_m = tl.program_id(0)
off_hb = tl.program_id(1)
off_b = off_hb // nheads
off_h = off_hb % nheads
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = tl.arange(0, BLOCK_N)
offs_d = tl.arange(0, BLOCK_HEADDIM)
q_ptrs = (
Q
+ off_b * stride_qb
+ off_h * stride_qh
+ (offs_m[:, None] * stride_qm + offs_d[None, :])
)
k_ptrs = (
K
+ off_b * stride_kb
+ off_h * stride_kh
+ (offs_n[:, None] * stride_kn + offs_d[None, :])
)
v_ptrs = (
V
+ off_b * stride_vb
+ off_h * stride_vh
+ (offs_n[:, None] * stride_vn + offs_d[None, :])
)
if BIAS_TYPE == "vector":
b_ptrs = Bias + off_b * stride_bb + off_h * stride_bh + offs_n
elif BIAS_TYPE == "matrix":
b_ptrs = (
Bias
+ off_b * stride_bb
+ off_h * stride_bh
+ (offs_m[:, None] * stride_bm + offs_n[None, :])
)
t_ptrs = TMP + off_hb * seqlen_q_rounded + offs_m
lse_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
acc_o = tl.zeros([BLOCK_M, BLOCK_HEADDIM], dtype=tl.float32)
if EVEN_M & EVEN_N:
if EVEN_HEADDIM:
q = tl.load(q_ptrs)
else:
q = tl.load(q_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
elif EVEN_HEADDIM:
q = tl.load(q_ptrs, mask=offs_m[:, None] < seqlen_q, other=0.0)
else:
q = tl.load(
q_ptrs,
mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
other=0.0,
)
end_n = seqlen_k if not IS_CAUSAL else tl.minimum((start_m + 1) * BLOCK_M, seqlen_k)
for start_n in range(0, end_n, BLOCK_N):
start_n = tl.multiple_of(start_n, BLOCK_N)
if EVEN_N & EVEN_M:
if EVEN_HEADDIM:
k = tl.load(k_ptrs + start_n * stride_kn)
else:
k = tl.load(
k_ptrs + start_n * stride_kn,
mask=offs_d[None, :] < headdim,
other=0.0,
)
elif EVEN_HEADDIM:
k = tl.load(
k_ptrs + start_n * stride_kn,
mask=(start_n + offs_n)[:, None] < seqlen_k,
other=0.0,
)
else:
k = tl.load(
k_ptrs + start_n * stride_kn,
mask=((start_n + offs_n)[:, None] < seqlen_k)
& (offs_d[None, :] < headdim),
other=0.0,
)
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
qk += tl.dot(q, k, trans_b=True)
if not EVEN_N:
qk += tl.where((start_n + offs_n)[None, :] < seqlen_k, 0, float("-inf"))
if IS_CAUSAL:
qk += tl.where(
offs_m[:, None] >= (start_n + offs_n)[None, :], 0, float("-inf")
)
if BIAS_TYPE != "none":
if BIAS_TYPE == "vector":
if EVEN_N:
bias = tl.load(b_ptrs + start_n).to(tl.float32)
else:
bias = tl.load(
b_ptrs + start_n, mask=start_n + offs_n < seqlen_k, other=0.0
).to(tl.float32)
bias = bias[None, :]
elif BIAS_TYPE == "matrix":
if EVEN_M & EVEN_N:
bias = tl.load(b_ptrs + start_n).to(tl.float32)
else:
bias = tl.load(
b_ptrs + start_n,
mask=(offs_m[:, None] < seqlen_q)
& ((start_n + offs_n)[None, :] < seqlen_k),
other=0.0,
).to(tl.float32)
qk = qk * softmax_scale + bias
m_ij = tl.maximum(tl.max(qk, 1), lse_i)
p = tl.exp(qk - m_ij[:, None])
else:
m_ij = tl.maximum(tl.max(qk, 1) * softmax_scale, lse_i)
p = tl.exp(qk * softmax_scale - m_ij[:, None])
l_ij = tl.sum(p, 1)
acc_o_scale = tl.exp(m_i - m_ij)
tl.store(t_ptrs, acc_o_scale)
acc_o_scale = tl.load(t_ptrs)
acc_o = acc_o * acc_o_scale[:, None]
if EVEN_N & EVEN_M:
if EVEN_HEADDIM:
v = tl.load(v_ptrs + start_n * stride_vn)
else:
v = tl.load(
v_ptrs + start_n * stride_vn,
mask=offs_d[None, :] < headdim,
other=0.0,
)
elif EVEN_HEADDIM:
v = tl.load(
v_ptrs + start_n * stride_vn,
mask=(start_n + offs_n)[:, None] < seqlen_k,
other=0.0,
)
else:
v = tl.load(
v_ptrs + start_n * stride_vn,
mask=((start_n + offs_n)[:, None] < seqlen_k)
& (offs_d[None, :] < headdim),
other=0.0,
)
p = p.to(v.dtype)
acc_o += tl.dot(p, v)
m_i = m_ij
l_i_new = tl.exp(lse_i - m_ij) + l_ij
lse_i = m_ij + tl.log(l_i_new)
o_scale = tl.exp(m_i - lse_i)
tl.store(t_ptrs, o_scale)
o_scale = tl.load(t_ptrs)
acc_o = acc_o * o_scale[:, None]
start_m = tl.program_id(0)
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
lse_ptrs = Lse + off_hb * seqlen_q_rounded + offs_m
tl.store(lse_ptrs, lse_i)
offs_d = tl.arange(0, BLOCK_HEADDIM)
out_ptrs = (
Out
+ off_b * stride_ob
+ off_h * stride_oh
+ (offs_m[:, None] * stride_om + offs_d[None, :])
)
if EVEN_M:
if EVEN_HEADDIM:
tl.store(out_ptrs, acc_o)
else:
tl.store(out_ptrs, acc_o, mask=offs_d[None, :] < headdim)
elif EVEN_HEADDIM:
tl.store(out_ptrs, acc_o, mask=offs_m[:, None] < seqlen_q)
else:
tl.store(
out_ptrs,
acc_o,
mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
)
@triton.jit
def _bwd_preprocess_do_o_dot(
Out,
DO,
Delta,
stride_ob,
stride_oh,
stride_om,
stride_dob,
stride_doh,
stride_dom,
nheads,
seqlen_q,
seqlen_q_rounded,
headdim,
BLOCK_M: tl.constexpr,
BLOCK_HEADDIM: tl.constexpr,
):
start_m = tl.program_id(0)
off_hb = tl.program_id(1)
off_b = off_hb // nheads
off_h = off_hb % nheads
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_d = tl.arange(0, BLOCK_HEADDIM)
o = tl.load(
Out
+ off_b * stride_ob
+ off_h * stride_oh
+ offs_m[:, None] * stride_om
+ offs_d[None, :],
mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
other=0.0,
).to(tl.float32)
do = tl.load(
DO
+ off_b * stride_dob
+ off_h * stride_doh
+ offs_m[:, None] * stride_dom
+ offs_d[None, :],
mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
other=0.0,
).to(tl.float32)
delta = tl.sum(o * do, axis=1)
tl.store(Delta + off_hb * seqlen_q_rounded + offs_m, delta)
@triton.jit
def _bwd_store_dk_dv(
dk_ptrs,
dv_ptrs,
dk,
dv,
offs_n,
offs_d,
seqlen_k,
headdim,
EVEN_M: tl.constexpr,
EVEN_N: tl.constexpr,
EVEN_HEADDIM: tl.constexpr,
):
if EVEN_N & EVEN_M:
if EVEN_HEADDIM:
tl.store(dv_ptrs, dv)
tl.store(dk_ptrs, dk)
else:
tl.store(dv_ptrs, dv, mask=offs_d[None, :] < headdim)
tl.store(dk_ptrs, dk, mask=offs_d[None, :] < headdim)
elif EVEN_HEADDIM:
tl.store(dv_ptrs, dv, mask=offs_n[:, None] < seqlen_k)
tl.store(dk_ptrs, dk, mask=offs_n[:, None] < seqlen_k)
else:
tl.store(
dv_ptrs, dv, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim)
)
tl.store(
dk_ptrs, dk, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim)
)
@triton.jit
def _bwd_kernel_one_col_block(
start_n,
Q,
K,
V,
Bias,
DO,
DQ,
DK,
DV,
LSE,
D,
softmax_scale,
stride_qm,
stride_kn,
stride_vn,
stride_bm,
stride_dom,
stride_dqm,
stride_dkn,
stride_dvn,
seqlen_q,
seqlen_k,
headdim,
ATOMIC_ADD: tl.constexpr,
BIAS_TYPE: tl.constexpr,
IS_CAUSAL: tl.constexpr,
BLOCK_HEADDIM: tl.constexpr,
EVEN_M: tl.constexpr,
EVEN_N: tl.constexpr,
EVEN_HEADDIM: tl.constexpr,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
):
begin_m = 0 if not IS_CAUSAL else start_n * BLOCK_N // BLOCK_M * BLOCK_M
offs_qm = begin_m + tl.arange(0, BLOCK_M)
offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
offs_m = tl.arange(0, BLOCK_M)
offs_d = tl.arange(0, BLOCK_HEADDIM)
q_ptrs = Q + (offs_qm[:, None] * stride_qm + offs_d[None, :])
k_ptrs = K + (offs_n[:, None] * stride_kn + offs_d[None, :])
v_ptrs = V + (offs_n[:, None] * stride_vn + offs_d[None, :])
do_ptrs = DO + (offs_qm[:, None] * stride_dom + offs_d[None, :])
dq_ptrs = DQ + (offs_qm[:, None] * stride_dqm + offs_d[None, :])
if BIAS_TYPE == "vector":
b_ptrs = Bias + offs_n
elif BIAS_TYPE == "matrix":
b_ptrs = Bias + (offs_qm[:, None] * stride_bm + offs_n[None, :])
dv = tl.zeros([BLOCK_N, BLOCK_HEADDIM], dtype=tl.float32)
dk = tl.zeros([BLOCK_N, BLOCK_HEADDIM], dtype=tl.float32)
if begin_m >= seqlen_q:
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
_bwd_store_dk_dv(
dk_ptrs,
dv_ptrs,
dk,
dv,
offs_n,
offs_d,
seqlen_k,
headdim,
EVEN_M=EVEN_M,
EVEN_N=EVEN_N,
EVEN_HEADDIM=EVEN_HEADDIM,
)
return
if EVEN_N & EVEN_M:
if EVEN_HEADDIM:
k = tl.load(k_ptrs)
v = tl.load(v_ptrs)
else:
k = tl.load(k_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
v = tl.load(v_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
elif EVEN_HEADDIM:
k = tl.load(k_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
v = tl.load(v_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
else:
k = tl.load(
k_ptrs,
mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
other=0.0,
)
v = tl.load(
v_ptrs,
mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
other=0.0,
)
num_block_m = tl.cdiv(seqlen_q, BLOCK_M)
for start_m in range(begin_m, num_block_m * BLOCK_M, BLOCK_M):
start_m = tl.multiple_of(start_m, BLOCK_M)
offs_m_curr = start_m + offs_m
if EVEN_M & EVEN_HEADDIM:
q = tl.load(q_ptrs)
elif EVEN_HEADDIM:
q = tl.load(q_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0)
else:
q = tl.load(
q_ptrs,
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
other=0.0,
)
qk = tl.dot(q, k, trans_b=True)
if not EVEN_N:
qk = tl.where(offs_n[None, :] < seqlen_k, qk, float("-inf"))
if IS_CAUSAL:
qk = tl.where(offs_m_curr[:, None] >= offs_n[None, :], qk, float("-inf"))
if BIAS_TYPE != "none":
tl.debug_barrier()
if BIAS_TYPE == "vector":
if EVEN_N:
bias = tl.load(b_ptrs).to(tl.float32)
else:
bias = tl.load(b_ptrs, mask=offs_n < seqlen_k, other=0.0).to(
tl.float32
)
bias = bias[None, :]
elif BIAS_TYPE == "matrix":
if EVEN_M & EVEN_N:
bias = tl.load(b_ptrs).to(tl.float32)
else:
bias = tl.load(
b_ptrs,
mask=(offs_m_curr[:, None] < seqlen_q)
& (offs_n[None, :] < seqlen_k),
other=0.0,
).to(tl.float32)
qk = qk * softmax_scale + bias
if not EVEN_M & EVEN_HEADDIM:
tl.debug_barrier()
lse_i = tl.load(LSE + offs_m_curr)
if BIAS_TYPE == "none":
p = tl.exp(qk * softmax_scale - lse_i[:, None])
else:
p = tl.exp(qk - lse_i[:, None])
if EVEN_M & EVEN_HEADDIM:
do = tl.load(do_ptrs)
else:
do = tl.load(
do_ptrs,
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
other=0.0,
)
dv += tl.dot(p.to(do.dtype), do, trans_a=True)
if not EVEN_M & EVEN_HEADDIM:
tl.debug_barrier()
dp = tl.dot(do, v, trans_b=True)
if not EVEN_HEADDIM:
tl.debug_barrier()
Di = tl.load(D + offs_m_curr)
ds = (p * (dp - Di[:, None]) * softmax_scale).to(q.dtype)
dk += tl.dot(ds, q, trans_a=True)
if not EVEN_M & EVEN_HEADDIM:
tl.debug_barrier()
if not ATOMIC_ADD:
if EVEN_M & EVEN_HEADDIM:
dq = tl.load(dq_ptrs, eviction_policy="evict_last")
dq += tl.dot(ds, k)
tl.store(dq_ptrs, dq, eviction_policy="evict_last")
elif EVEN_HEADDIM:
dq = tl.load(
dq_ptrs,
mask=offs_m_curr[:, None] < seqlen_q,
other=0.0,
eviction_policy="evict_last",
)
dq += tl.dot(ds, k)
tl.store(
dq_ptrs,
dq,
mask=offs_m_curr[:, None] < seqlen_q,
eviction_policy="evict_last",
)
else:
dq = tl.load(
dq_ptrs,
mask=(offs_m_curr[:, None] < seqlen_q)
& (offs_d[None, :] < headdim),
other=0.0,
eviction_policy="evict_last",
)
dq += tl.dot(ds, k)
tl.store(
dq_ptrs,
dq,
mask=(offs_m_curr[:, None] < seqlen_q)
& (offs_d[None, :] < headdim),
eviction_policy="evict_last",
)
else:
dq = tl.dot(ds, k)
if EVEN_M & EVEN_HEADDIM:
tl.atomic_add(dq_ptrs, dq)
elif EVEN_HEADDIM:
tl.atomic_add(dq_ptrs, dq, mask=offs_m_curr[:, None] < seqlen_q)
else:
tl.atomic_add(
dq_ptrs,
dq,
mask=(offs_m_curr[:, None] < seqlen_q)
& (offs_d[None, :] < headdim),
)
dq_ptrs += BLOCK_M * stride_dqm
q_ptrs += BLOCK_M * stride_qm
do_ptrs += BLOCK_M * stride_dom
if BIAS_TYPE == "matrix":
b_ptrs += BLOCK_M * stride_bm
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
_bwd_store_dk_dv(
dk_ptrs,
dv_ptrs,
dk,
dv,
offs_n,
offs_d,
seqlen_k,
headdim,
EVEN_M=EVEN_M,
EVEN_N=EVEN_N,
EVEN_HEADDIM=EVEN_HEADDIM,
)
def init_to_zero(name):
return lambda nargs: nargs[name].zero_()
@triton.autotune(
configs=[
triton.Config(
{"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": False},
num_warps=8,
num_stages=1,
pre_hook=init_to_zero("DQ"),
),
triton.Config(
{"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": True},
num_warps=8,
num_stages=1,
pre_hook=init_to_zero("DQ"),
),
],
key=[
"CACHE_KEY_SEQLEN_Q",
"CACHE_KEY_SEQLEN_K",
"BIAS_TYPE",
"IS_CAUSAL",
"BLOCK_HEADDIM",
],
)
@triton.heuristics(
{
"EVEN_M": lambda args: args["seqlen_q"] % args["BLOCK_M"] == 0,
"EVEN_N": lambda args: args["seqlen_k"] % args["BLOCK_N"] == 0,
"EVEN_HEADDIM": lambda args: args["headdim"] == args["BLOCK_HEADDIM"],
}
)
@triton.jit
def _bwd_kernel(
Q,
K,
V,
Bias,
DO,
DQ,
DK,
DV,
LSE,
D,
softmax_scale,
stride_qb,
stride_qh,
stride_qm,
stride_kb,
stride_kh,
stride_kn,
stride_vb,
stride_vh,
stride_vn,
stride_bb,
stride_bh,
stride_bm,
stride_dob,
stride_doh,
stride_dom,
stride_dqb,
stride_dqh,
stride_dqm,
stride_dkb,
stride_dkh,
stride_dkn,
stride_dvb,
stride_dvh,
stride_dvn,
nheads,
seqlen_q,
seqlen_k,
seqlen_q_rounded,
headdim,
CACHE_KEY_SEQLEN_Q,
CACHE_KEY_SEQLEN_K,
BIAS_TYPE: tl.constexpr,
IS_CAUSAL: tl.constexpr,
BLOCK_HEADDIM: tl.constexpr,
SEQUENCE_PARALLEL: tl.constexpr,
EVEN_M: tl.constexpr,
EVEN_N: tl.constexpr,
EVEN_HEADDIM: tl.constexpr,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
):
off_hb = tl.program_id(1)
off_b = off_hb // nheads
off_h = off_hb % nheads
Q += off_b * stride_qb + off_h * stride_qh
K += off_b * stride_kb + off_h * stride_kh
V += off_b * stride_vb + off_h * stride_vh
DO += off_b * stride_dob + off_h * stride_doh
DQ += off_b * stride_dqb + off_h * stride_dqh
DK += off_b * stride_dkb + off_h * stride_dkh
DV += off_b * stride_dvb + off_h * stride_dvh
if BIAS_TYPE != "none":
Bias += off_b * stride_bb + off_h * stride_bh
D += off_hb * seqlen_q_rounded
LSE += off_hb * seqlen_q_rounded
if not SEQUENCE_PARALLEL:
num_block_n = tl.cdiv(seqlen_k, BLOCK_N)
for start_n in range(0, num_block_n):
_bwd_kernel_one_col_block(
start_n,
Q,
K,
V,
Bias,
DO,
DQ,
DK,
DV,
LSE,
D,
softmax_scale,
stride_qm,
stride_kn,
stride_vn,
stride_bm,
stride_dom,
stride_dqm,
stride_dkn,
stride_dvn,
seqlen_q,
seqlen_k,
headdim,
ATOMIC_ADD=False,
BIAS_TYPE=BIAS_TYPE,
IS_CAUSAL=IS_CAUSAL,
BLOCK_HEADDIM=BLOCK_HEADDIM,
EVEN_M=EVEN_M,
EVEN_N=EVEN_N,
EVEN_HEADDIM=EVEN_HEADDIM,
BLOCK_M=BLOCK_M,
BLOCK_N=BLOCK_N,
)
else:
start_n = tl.program_id(0)
_bwd_kernel_one_col_block(
start_n,
Q,
K,
V,
Bias,
DO,
DQ,
DK,
DV,
LSE,
D,
softmax_scale,
stride_qm,
stride_kn,
stride_vn,
stride_bm,
stride_dom,
stride_dqm,
stride_dkn,
stride_dvn,
seqlen_q,
seqlen_k,
headdim,
ATOMIC_ADD=True,
BIAS_TYPE=BIAS_TYPE,
IS_CAUSAL=IS_CAUSAL,
BLOCK_HEADDIM=BLOCK_HEADDIM,
EVEN_M=EVEN_M,
EVEN_N=EVEN_N,
EVEN_HEADDIM=EVEN_HEADDIM,
BLOCK_M=BLOCK_M,
BLOCK_N=BLOCK_N,
)
def _flash_attn_forward(q, k, v, bias=None, causal=False, softmax_scale=None):
(batch, seqlen_q, nheads, d) = q.shape
(_, seqlen_k, _, _) = k.shape
assert k.shape == (batch, seqlen_k, nheads, d)
assert v.shape == (batch, seqlen_k, nheads, d)
assert d <= 128, "FlashAttention only support head dimensions up to 128"
assert q.dtype == k.dtype == v.dtype, "All tensors must have the same type"
assert q.dtype in [torch.float16, torch.bfloat16], "Only support fp16 and bf16"
assert q.is_cuda and k.is_cuda and v.is_cuda
softmax_scale = softmax_scale or 1.0 / math.sqrt(d)
has_bias = bias is not None
bias_type = "none"
if has_bias:
assert bias.dtype in [q.dtype, torch.float]
assert bias.is_cuda
assert bias.dim() == 4
if bias.stride(-1) != 1:
bias = bias.contiguous()
if bias.shape[2:] == (1, seqlen_k):
bias_type = "vector"
elif bias.shape[2:] == (seqlen_q, seqlen_k):
bias_type = "matrix"
else:
raise RuntimeError(
"Last 2 dimensions of bias must be (1, seqlen_k) or (seqlen_q, seqlen_k)"
)
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
bias_strides = (
(bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
)
seqlen_q_rounded = math.ceil(seqlen_q / 128) * 128
lse = torch.empty(
(batch, nheads, seqlen_q_rounded), device=q.device, dtype=torch.float32
)
tmp = torch.empty(
(batch, nheads, seqlen_q_rounded), device=q.device, dtype=torch.float32
)
o = torch.empty_like(q)
BLOCK_HEADDIM = max(triton.next_power_of_2(d), 16)
BLOCK = 128
num_warps = 4 if d <= 64 else 8
grid = lambda META: (triton.cdiv(seqlen_q, META["BLOCK_M"]), batch * nheads)
_fwd_kernel[grid](
q,
k,
v,
bias,
o,
lse,
tmp,
softmax_scale,
q.stride(0),
q.stride(2),
q.stride(1),
k.stride(0),
k.stride(2),
k.stride(1),
v.stride(0),
v.stride(2),
v.stride(1),
*bias_strides,
o.stride(0),
o.stride(2),
o.stride(1),
nheads,
seqlen_q,
seqlen_k,
seqlen_q_rounded,
d,
seqlen_q // 32,
seqlen_k // 32,
bias_type,
causal,
BLOCK_HEADDIM,
BLOCK_M=BLOCK,
BLOCK_N=BLOCK,
num_warps=num_warps,
num_stages=1
)
return (o, lse, softmax_scale)
def _flash_attn_backward(
do, q, k, v, o, lse, dq, dk, dv, bias=None, causal=False, softmax_scale=None
):
if do.stride(-1) != 1:
do = do.contiguous()
(batch, seqlen_q, nheads, d) = q.shape
(_, seqlen_k, _, _) = k.shape
assert d <= 128
seqlen_q_rounded = math.ceil(seqlen_q / 128) * 128
assert lse.shape == (batch, nheads, seqlen_q_rounded)
assert q.stride(-1) == k.stride(-1) == v.stride(-1) == o.stride(-1) == 1
assert dq.stride(-1) == dk.stride(-1) == dv.stride(-1) == 1
softmax_scale = softmax_scale or 1.0 / math.sqrt(d)
dq_accum = torch.empty_like(q, dtype=torch.float32)
delta = torch.empty_like(lse)
BLOCK_HEADDIM = max(triton.next_power_of_2(d), 16)
grid = lambda META: (triton.cdiv(seqlen_q, META["BLOCK_M"]), batch * nheads)
_bwd_preprocess_do_o_dot[grid](
o,
do,
delta,
o.stride(0),
o.stride(2),
o.stride(1),
do.stride(0),
do.stride(2),
do.stride(1),
nheads,
seqlen_q,
seqlen_q_rounded,
d,
BLOCK_M=128,
BLOCK_HEADDIM=BLOCK_HEADDIM,
)
has_bias = bias is not None
bias_type = "none"
if has_bias:
assert bias.dtype in [q.dtype, torch.float]
assert bias.is_cuda
assert bias.dim() == 4
assert bias.stride(-1) == 1
if bias.shape[2:] == (1, seqlen_k):
bias_type = "vector"
elif bias.shape[2:] == (seqlen_q, seqlen_k):
bias_type = "matrix"
else:
raise RuntimeError(
"Last 2 dimensions of bias must be (1, seqlen_k) or (seqlen_q, seqlen_k)"
)
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
bias_strides = (
(bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
)
grid = lambda META: (
triton.cdiv(seqlen_k, META["BLOCK_N"]) if META["SEQUENCE_PARALLEL"] else 1,
batch * nheads,
)
_bwd_kernel[grid](
q,
k,
v,
bias,
do,
dq_accum,
dk,
dv,
lse,
delta,
softmax_scale,
q.stride(0),
q.stride(2),
q.stride(1),
k.stride(0),
k.stride(2),
k.stride(1),
v.stride(0),
v.stride(2),
v.stride(1),
*bias_strides,
do.stride(0),
do.stride(2),
do.stride(1),
dq_accum.stride(0),
dq_accum.stride(2),
dq_accum.stride(1),
dk.stride(0),
dk.stride(2),
dk.stride(1),
dv.stride(0),
dv.stride(2),
dv.stride(1),
nheads,
seqlen_q,
seqlen_k,
seqlen_q_rounded,
d,
seqlen_q // 32,
seqlen_k // 32,
bias_type,
causal,
BLOCK_HEADDIM
)
dq.copy_(dq_accum)
class FlashAttnQKVPackedFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, qkv, bias=None, causal=False, softmax_scale=None):
"""
qkv: (batch, seqlen, 3, nheads, headdim)
bias: optional, shape broadcastible to (batch, nheads, seqlen, seqlen).
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen).
ALiBi mask for non-causal would have shape (1, nheads, seqlen, seqlen)
"""
if qkv.stride(-1) != 1:
qkv = qkv.contiguous()
(o, lse, ctx.softmax_scale) = _flash_attn_forward(
qkv[:, :, 0],
qkv[:, :, 1],
qkv[:, :, 2],
bias=bias,
causal=causal,
softmax_scale=softmax_scale,
)
ctx.save_for_backward(qkv, o, lse, bias)
ctx.causal = causal
return o
@staticmethod
def backward(ctx, do):
(qkv, o, lse, bias) = ctx.saved_tensors
assert not ctx.needs_input_grad[
1
], "FlashAttention does not support bias gradient yet"
with torch.inference_mode():
dqkv = torch.empty_like(qkv)
_flash_attn_backward(
do,
qkv[:, :, 0],
qkv[:, :, 1],
qkv[:, :, 2],
o,
lse,
dqkv[:, :, 0],
dqkv[:, :, 1],
dqkv[:, :, 2],
bias=bias,
causal=ctx.causal,
softmax_scale=ctx.softmax_scale,
)
return (dqkv, None, None, None)
flash_attn_qkvpacked_func = FlashAttnQKVPackedFunc.apply
class FlashAttnKVPackedFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, q, kv, bias=None, causal=False, softmax_scale=None):
"""
q: (batch, seqlen_q, nheads, headdim)
kv: (batch, seqlen_k, 2, nheads, headdim)
bias: optional, shape broadcastible to (batch, nheads, seqlen_q, seqlen_k).
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen_k).
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
"""
(q, kv) = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, kv]]
(o, lse, ctx.softmax_scale) = _flash_attn_forward(
q,
kv[:, :, 0],
kv[:, :, 1],
bias=bias,
causal=causal,
softmax_scale=softmax_scale,
)
ctx.save_for_backward(q, kv, o, lse, bias)
ctx.causal = causal
return o
@staticmethod
def backward(ctx, do):
(q, kv, o, lse, bias) = ctx.saved_tensors
if len(ctx.needs_input_grad) >= 3:
assert not ctx.needs_input_grad[
2
], "FlashAttention does not support bias gradient yet"
with torch.inference_mode():
dq = torch.empty_like(q)
dkv = torch.empty_like(kv)
_flash_attn_backward(
do,
q,
kv[:, :, 0],
kv[:, :, 1],
o,
lse,
dq,
dkv[:, :, 0],
dkv[:, :, 1],
bias=bias,
causal=ctx.causal,
softmax_scale=ctx.softmax_scale,
)
return (dq, dkv, None, None, None)
flash_attn_kvpacked_func = FlashAttnKVPackedFunc.apply
class FlashAttnFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, q, k, v, bias=None, causal=False, softmax_scale=None):
"""
q: (batch_size, seqlen_q, nheads, headdim)
k, v: (batch_size, seqlen_k, nheads, headdim)
bias: optional, shape broadcastible to (batch, nheads, seqlen_q, seqlen_k).
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen_k).
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
"""
(q, k, v) = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, k, v]]
(o, lse, ctx.softmax_scale) = _flash_attn_forward(
q, k, v, bias=bias, causal=causal, softmax_scale=softmax_scale
)
ctx.save_for_backward(q, k, v, o, lse, bias)
ctx.causal = causal
return o
@staticmethod
def backward(ctx, do):
(q, k, v, o, lse, bias) = ctx.saved_tensors
assert not ctx.needs_input_grad[
3
], "FlashAttention does not support bias gradient yet"
with torch.inference_mode():
dq = torch.empty_like(q)
dk = torch.empty_like(k)
dv = torch.empty_like(v)
_flash_attn_backward(
do,
q,
k,
v,
o,
lse,
dq,
dk,
dv,
bias=bias,
causal=ctx.causal,
softmax_scale=ctx.softmax_scale,
)
return (dq, dk, dv, None, None, None)
flash_attn_func = FlashAttnFunc.apply
================================================
FILE: model/llava/model/language_model/mpt/hf_prefixlm_converter.py
================================================
"""Converts Huggingface Causal LM to Prefix LM.
Conversion does lightweight surgery on a HuggingFace
Causal LM to convert it to a Prefix LM.
Prefix LMs accepts a `bidirectional_mask` input in `forward`
and treat the input prompt as the prefix in `generate`.
"""
import math
import warnings
from types import MethodType
from typing import Any, Dict, List, Optional, Tuple, Union
import torch
from transformers.models.bloom.modeling_bloom import (
BaseModelOutputWithPastAndCrossAttentions, BloomForCausalLM, BloomModel,
CausalLMOutputWithCrossAttentions, CrossEntropyLoss)
from transformers.models.bloom.modeling_bloom import \
_expand_mask as _expand_mask_bloom
from transformers.models.bloom.modeling_bloom import \
_make_causal_mask as _make_causal_mask_bloom
from transformers.models.bloom.modeling_bloom import logging
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
from transformers.models.gpt_neo.modeling_gpt_neo import GPTNeoForCausalLM
from transformers.models.gpt_neox.modeling_gpt_neox import GPTNeoXForCausalLM
from transformers.models.gptj.modeling_gptj import GPTJForCausalLM
from transformers.models.opt.modeling_opt import OPTForCausalLM
from transformers.models.opt.modeling_opt import \
_expand_mask as _expand_mask_opt
from transformers.models.opt.modeling_opt import \
_make_causal_mask as _make_causal_mask_opt
logger = logging.get_logger(__name__)
_SUPPORTED_GPT_MODELS = (
GPT2LMHeadModel,
GPTJForCausalLM,
GPTNeoForCausalLM,
GPTNeoXForCausalLM,
)
CAUSAL_GPT_TYPES = Union[
GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM
]
def _convert_gpt_causal_lm_to_prefix_lm(model: CAUSAL_GPT_TYPES) -> CAUSAL_GPT_TYPES:
"""Converts a GPT-style Causal LM to a Prefix LM.
Supported HuggingFace model classes:
- `GPT2LMHeadModel`
- `GPTNeoForCausalLM`
- `GPTNeoXForCausalLM`
- `GPTJForCausalLM`
See `convert_hf_causal_lm_to_prefix_lm` for more details.
"""
if hasattr(model, "_prefix_lm_converted"):
return model
assert isinstance(model, _SUPPORTED_GPT_MODELS)
assert (
model.config.add_cross_attention == False
), "Only supports GPT-style decoder-only models"
def _get_attn_modules(model: CAUSAL_GPT_TYPES) -> List[torch.nn.Module]:
"""Helper that gets a list of the model's attention modules.
Each module has a `bias` buffer used for causal masking. The Prefix LM
conversion adds logic to dynamically manipulate these biases to support
Prefix LM attention masking.
"""
attn_modules = []
if isinstance(model, GPTNeoXForCausalLM):
blocks = model.gpt_neox.layers
else:
blocks = model.transformer.h
for block in blocks:
if isinstance(model, GPTNeoForCausalLM):
if block.attn.attention_type != "global":
continue
attn_module = block.attn.attention
elif isinstance(model, GPTNeoXForCausalLM):
attn_module = block.attention
else:
attn_module = block.attn
attn_modules.append(attn_module)
return attn_modules
setattr(model, "_original_forward", getattr(model, "forward"))
setattr(model, "_original_generate", getattr(model, "generate"))
def forward(
self: CAUSAL_GPT_TYPES,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
bidirectional_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
"""Wraps original forward to enable PrefixLM attention."""
def call_og_forward():
if isinstance(self, GPTNeoXForCausalLM):
return self._original_forward(
input_ids=input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
else:
return self._original_forward(
input_ids=input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if bidirectional_mask is None:
return call_og_forward()
assert isinstance(bidirectional_mask, torch.Tensor)
attn_modules = _get_attn_modules(model)
(b, s) = bidirectional_mask.shape
max_length = attn_modules[0].bias.shape[-1]
if s > max_length:
raise ValueError(
f"bidirectional_mask sequence length (={s}) exceeds the "
+ f"max length allowed by the model ({max_length})."
)
assert s <= max_length
if s < max_length:
pad = torch.zeros(
(int(b), int(max_length - s)),
dtype=bidirectional_mask.dtype,
device=bidirectional_mask.device,
)
bidirectional_mask = torch.cat([bidirectional_mask, pad], dim=1)
bidirectional = bidirectional_mask.unsqueeze(1).unsqueeze(1)
for attn_module in attn_modules:
attn_module.bias.data = torch.logical_or(
attn_module.bias.data, bidirectional
)
output = call_og_forward()
for attn_module in attn_modules:
attn_module.bias.data = torch.tril(attn_module.bias.data[0, 0])[None, None]
return output
def generate(self: CAUSAL_GPT_TYPES, *args: tuple, **kwargs: Dict[str, Any]):
"""Wraps original generate to enable PrefixLM attention."""
attn_modules = _get_attn_modules(model)
for attn_module in attn_modules:
attn_module.bias.data[:] = 1
output = self._original_generate(*args, **kwargs)
for attn_module in attn_modules:
attn_module.bias.data = torch.tril(attn_module.bias.data[0, 0])[None, None]
return output
setattr(model, "forward", MethodType(forward, model))
setattr(model, "generate", MethodType(generate, model))
setattr(model, "_prefix_lm_converted", True)
return model
def _convert_bloom_causal_lm_to_prefix_lm(model: BloomForCausalLM) -> BloomForCausalLM:
"""Converts a BLOOM Causal LM to a Prefix LM.
Supported HuggingFace model classes:
- `BloomForCausalLM`
See `convert_hf_causal_lm_to_prefix_lm` for more details.
"""
if hasattr(model, "_prefix_lm_converted"):
return model
assert isinstance(model, BloomForCausalLM)
assert (
model.config.add_cross_attention == False
), "Only supports BLOOM decoder-only models"
def _prepare_attn_mask(
self: BloomModel,
attention_mask: torch.Tensor,
bidirectional_mask: Optional[torch.Tensor],
input_shape: Tuple[int, int],
past_key_values_length: int,
) -> torch.BoolTensor:
combined_attention_mask = None
device = attention_mask.device
(_, src_length) = input_shape
if src_length > 1:
combined_attention_mask = _make_causal_mask_bloom(
input_shape,
device=device,
past_key_values_length=past_key_values_length,
)
if bidirectional_mask is not None:
assert attention_mask.shape == bidirectional_mask.shape
expanded_bidirectional_mask = _expand_mask_bloom(
bidirectional_mask, tgt_length=src_length
)
combined_attention_mask = torch.logical_and(
combined_attention_mask, expanded_bidirectional_mask
)
expanded_attn_mask = _expand_mask_bloom(attention_mask, tgt_length=src_length)
combined_attention_mask = (
expanded_attn_mask
if combined_attention_mask is None
else expanded_attn_mask | combined_attention_mask
)
return combined_attention_mask
def _build_alibi_tensor(
self: BloomModel,
batch_size: int,
query_length: int,
key_length: int,
dtype: torch.dtype,
device: torch.device,
) -> torch.Tensor:
num_heads = self.config.n_head
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
base = torch.tensor(
2 ** (-(2 ** (-(math.log2(closest_power_of_2) - 3)))),
device=device,
dtype=torch.float32,
)
powers = torch.arange(
1, 1 + closest_power_of_2, device=device, dtype=torch.int32
)
slopes = torch.pow(base, powers)
if closest_power_of_2 != num_heads:
extra_base = torch.tensor(
2 ** (-(2 ** (-(math.log2(2 * closest_power_of_2) - 3)))),
device=device,
dtype=torch.float32,
)
num_remaining_heads = min(
closest_power_of_2, num_heads - closest_power_of_2
)
extra_powers = torch.arange(
1, 1 + 2 * num_remaining_heads, 2, device=device, dtype=torch.int32
)
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
qa = torch.arange(query_length, device=device, dtype=torch.int32).view(-1, 1)
ka = torch.arange(key_length, device=device, dtype=torch.int32).view(1, -1)
diffs = qa - ka + key_length - query_length
diffs = -diffs.abs()
alibi = slopes.view(1, num_heads, 1, 1) * diffs.view(
1, 1, query_length, key_length
)
alibi = alibi.expand(batch_size, -1, -1, -1).reshape(
-1, query_length, key_length
)
return alibi.to(dtype)
KeyValueT = Tuple[torch.Tensor, torch.Tensor]
def forward(
self: BloomModel,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[KeyValueT, ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
bidirectional_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
**deprecated_arguments,
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
if deprecated_arguments.pop("position_ids", False) is not False:
warnings.warn(
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. "
+ "You can safely ignore passing `position_ids`.",
FutureWarning,
)
if len(deprecated_arguments) > 0:
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
if input_ids is not None and inputs_embeds is not None:
raise ValueError(
"You cannot specify both input_ids and inputs_embeds at the same time"
)
elif input_ids is not None:
(batch_size, seq_length) = input_ids.shape
elif inputs_embeds is not None:
(batch_size, seq_length, _) = inputs_embeds.shape
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if past_key_values is None:
past_key_values = tuple([None] * len(self.h))
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
hidden_states = self.word_embeddings_layernorm(inputs_embeds)
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
seq_length_with_past = seq_length
past_key_values_length = 0
if past_key_values[0] is not None:
tmp = past_key_values[0][0]
past_key_values_length = tmp.shape[2]
seq_length_with_past = seq_length_with_past + past_key_values_length
if attention_mask is None:
attention_mask = torch.ones(
(batch_size, seq_length_with_past), device=hidden_states.device
)
else:
attention_mask = attention_mask.to(hidden_states.device)
alibi = self._build_alibi_tensor(
batch_size=batch_size,
query_length=seq_length,
key_length=seq_length_with_past,
dtype=hidden_states.dtype,
device=hidden_states.device,
)
causal_mask = self._prepare_attn_mask(
attention_mask,
bidirectional_mask,
input_shape=(batch_size, seq_length),
past_key_values_length=past_key_values_length,
)
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
if output_hidden_states:
hst = (hidden_states,)
all_hidden_states = all_hidden_states + hst
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
return module(
*inputs,
use_cache=use_cache,
output_attentions=output_attentions,
)
return custom_forward
outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(block),
hidden_states,
alibi,
causal_mask,
head_mask[i],
)
else:
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=causal_mask,
head_mask=head_mask[i],
use_cache=use_cache,
output_attentions=output_attentions,
alibi=alibi,
)
hidden_states = outputs[0]
if use_cache is True:
presents = presents + (outputs[1],)
if output_attentions:
oa = (outputs[2 if use_cache else 1],)
all_self_attentions = all_self_attentions + oa
hidden_states = self.ln_f(hidden_states)
if output_hidden_states:
hst = (hidden_states,)
all_hidden_states = all_hidden_states + hst
if not return_dict:
return tuple(
(
v
for v in [
hidden_states,
presents,
all_hidden_states,
all_self_attentions,
]
if v is not None
)
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
setattr(
model.transformer,
"_prepare_attn_mask",
MethodType(_prepare_attn_mask, model.transformer),
)
setattr(
model.transformer,
"_build_alibi_tensor",
MethodType(_build_alibi_tensor, model.transformer),
)
setattr(model.transformer, "forward", MethodType(forward, model.transformer))
KeyValueT = Tuple[torch.Tensor, torch.Tensor]
def forward(
self: BloomForCausalLM,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[KeyValueT, ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
bidirectional_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
**deprecated_arguments,
) -> Union[Tuple[torch.Tensor], CausalLMOutputWithCrossAttentions]:
"""Replacement forward method for BloomCausalLM."""
if deprecated_arguments.pop("position_ids", False) is not False:
warnings.warn(
"`position_ids` have no functionality in BLOOM and will be removed "
+ "in v5.0.0. You can safely ignore passing `position_ids`.",
FutureWarning,
)
if len(deprecated_arguments) > 0:
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
bidirectional_mask=bidirectional_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
(batch_size, seq_length, vocab_size) = shift_logits.shape
loss_fct = CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(batch_size * seq_length, vocab_size),
shift_labels.view(batch_size * seq_length),
)
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
def prepare_inputs_for_generation(
self: BloomForCausalLM,
input_ids: torch.LongTensor,
past: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
**kwargs,
) -> dict:
if past:
input_ids = input_ids[:, -1].unsqueeze(-1)
bidirectional_mask = None
if past[0][0].shape[0] == input_ids.shape[0]:
past = self._convert_to_bloom_cache(past)
else:
bidirectional_mask = torch.ones_like(input_ids)
return {
"input_ids": input_ids,
"past_key_values": past,
"use_cache": True,
"attention_mask": attention_mask,
"bidirectional_mask": bidirectional_mask,
}
setattr(model, "forward", MethodType(forward, model))
setattr(
model,
"prepare_inputs_for_generation",
MethodType(prepare_inputs_for_generation, model),
)
setattr(model, "_prefix_lm_converted", True)
return model
def _convert_opt_causal_lm_to_prefix_lm(model: OPTForCausalLM) -> OPTForCausalLM:
"""Converts an OPT Causal LM to a Prefix LM.
Supported HuggingFace model classes:
- `OPTForCausalLM`
See `convert_hf_causal_lm_to_prefix_lm` for more details.
"""
if hasattr(model, "_prefix_lm_converted"):
return model
assert isinstance(model, OPTForCausalLM)
assert (
model.config.add_cross_attention == False
), "Only supports OPT decoder-only models"
setattr(model, "_original_forward", getattr(model, "forward"))
setattr(model, "_original_generate", getattr(model, "generate"))
model.model.decoder.bidirectional_mask = None
def _prepare_decoder_attention_mask(
self, attention_mask, input_shape, inputs_embeds, past_key_values_length
):
combined_attention_mask = None
if input_shape[-1] > 1:
if self.bidirectional_mask == "g":
(bsz, src_length) = input_shape
combined_attention_mask = torch.zeros(
(bsz, 1, src_length, src_length + past_key_values_length),
dtype=inputs_embeds.dtype,
device=inputs_embeds.device,
)
else:
combined_attention_mask = _make_causal_mask_opt(
input_shape,
inputs_embeds.dtype,
past_key_values_length=past_key_values_length,
).to(inputs_embeds.device)
if self.bidirectional_mask is not None:
assert attention_mask.shape == self.bidirectional_mask.shape
expanded_bidirectional_mask = _expand_mask_opt(
self.bidirectional_mask,
inputs_embeds.dtype,
tgt_len=input_shape[-1],
).to(inputs_embeds.device)
combined_attention_mask = torch.maximum(
expanded_bidirectional_mask, combined_attention_mask
)
if attention_mask is not None:
expanded_attn_mask = _expand_mask_opt(
attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
).to(inputs_embeds.device)
combined_attention_mask = (
expanded_attn_mask
if combined_attention_mask is None
else expanded_attn_mask + combined_attention_mask
)
return combined_attention_mask
setattr(
model.model.decoder,
"_prepare_decoder_attention_mask",
MethodType(_prepare_decoder_attention_mask, model.model.decoder),
)
def forward(
self: OPTForCausalLM,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
bidirectional_mask: Optional[torch.ByteTensor] = None,
head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
def call_og_forward():
return self._original_forward(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if bidirectional_mask is None:
return call_og_forward()
self.model.decoder.bidirectional_mask = bidirectional_mask
try:
outputs = call_og_forward()
except:
self.model.decoder.bidirectional_mask = None
raise
self.model.decoder.bidirectional_mask = None
return outputs
def generate(self: OPTForCausalLM, *args: tuple, **kwargs: Dict[str, Any]):
"""Wraps original generate to enable PrefixLM-style attention."""
self.model.decoder.bidirectional_mask = "g"
try:
output = self._original_generate(*args, **kwargs)
except:
self.model.decoder.bidirectional_mask = None
raise
self.model.decoder.bidirectional_mask = None
return output
setattr(model, "forward", MethodType(forward, model))
setattr(model, "generate", MethodType(generate, model))
setattr(model, "_prefix_lm_converted", True)
return model
_SUPPORTED_HF_MODELS = _SUPPORTED_GPT_MODELS + (BloomForCausalLM, OPTForCausalLM)
CAUSAL_LM_TYPES = Union[
GPT2LMHeadModel,
GPTJForCausalLM,
GPTNeoForCausalLM,
GPTNeoXForCausalLM,
BloomForCausalLM,
OPTForCausalLM,
]
def convert_hf_causal_lm_to_prefix_lm(model: CAUSAL_LM_TYPES) -> CAUSAL_LM_TYPES:
"""Converts a HuggingFace Causal LM to a Prefix LM.
Supported HuggingFace model classes:
- `GPT2LMHeadModel`
- `GPTNeoForCausalLM`
- `GPTNeoXForCausalLM`
- `GPTJForCausalLM`
- `BloomForCausalLM`
- `OPTForCausalLM`
Conversion to a Prefix LM is done by modifying the `forward` method, and possibly also the
`generate` method and/or select underlying methods depending on the model class.
These changes preserve the model API, but add a new input to `forward`: "bidirectional_mask".
Notes on training:
To actually train the converted model as a Prefix LM, training batches will need to indicate
the prefix/target structure by including `bidirectional_mask` as part of the batch inputs.
**This is not a standard input and requires custom layers either within or after your dataloader.**
In addition to adding `bidirectional_mask` to the batch, this custom code should modify `labels`
such that `batch['labels'][batch['bidirectional_mask'] == 1] == -100`.
That is, the prefix portion of the sequence should not generate any loss. Loss should only be
generated by the target portion of the sequence.
Notes on `GPTNeoForCausalLM`:
To simplify the implementation, "global" and "local" attention layers are handled differently.
For "global" layers, we handle conversion as described above. For "local" layers, which use a
causal attention mask within a restricted local window, we do not alter the masking.
Notes on `forward` method conversion:
After conversion, the `forward` method will handle a new input, `bidirectional_mask`,
which should be a [batch_size, seq_length] byte tensor, where 1 indicates token positions
belonging to the prefix (prefix tokens can attend to one another bidirectionally), and
0 indicates token positions belonging to the target.
The new `forward` method will incorporate `bidirectional_mask` (if supplied) into the existing
causal mask, call the original `forward` method, and (if the causal mask is a buffer) reset
the causal masks before returning the result.
Notes on `generate` method conversion:
After conversion, the `generate` method will have the same signature but will internally
convert all causal masks to be purely bidirectional, call the original `generate` method, and
(where appropriate) reset the causal masks before returning the result.
This works thanks to the logic of the HuggingFace `generate` API, which first encodes the token
"prompt" passed to `generate` (which is treated as the prefix) and then sequentially generates
each new token. Encodings are cached as generation happens, so all prefix tokens can attend to one
another (as expected in a Prefix LM) and generated tokens can only attend to prefix tokens and
previously-generated tokens (also as expected in a Prefix LM).
To preserve the API, the original methods are renamed to `_original_forward` and
`_original_generate`, and replaced with new `forward` and `generate` methods that wrap
them, respectively. Although implementation details vary by model class.
"""
if isinstance(model, _SUPPORTED_GPT_MODELS):
return _convert_gpt_causal_lm_to_prefix_lm(model)
elif isinstance(model, BloomForCausalLM):
return _convert_bloom_causal_lm_to_prefix_lm(model)
elif isinstance(model, OPTForCausalLM):
return _convert_opt_causal_lm_to_prefix_lm(model)
else:
raise TypeError(
f"Cannot convert model to Prefix LM. "
+ f"Model does not belong to set of supported HF models:"
+ f"\n{_SUPPORTED_HF_MODELS}"
)
def add_bidirectional_mask_if_missing(batch: Dict[str, Any]):
"""Attempts to add bidirectional_mask to batch if missing.
Raises:
KeyError if bidirectional_mask is missing and can't be inferred
"""
if "bidirectional_mask" not in batch:
if batch.get("mode", None) == "icl_task":
batch["bidirectional_mask"] = batch["attention_mask"].clone()
for i, continuation_indices in enumerate(batch["continuation_indices"]):
batch["bidirectional_mask"][i, continuation_indices] = 0
elif "labels" in batch and "attention_mask" in batch:
batch["bidirectional_mask"] = torch.logical_and(
torch.eq(batch["attention_mask"], 1), torch.eq(batch["labels"], -100)
).type_as(batch["attention_mask"])
else:
raise KeyError(
"No bidirectional_mask in batch and not sure how to construct one."
)
================================================
FILE: model/llava/model/language_model/mpt/meta_init_context.py
================================================
from contextlib import contextmanager
import torch
import torch.nn as nn
@contextmanager
def init_empty_weights(include_buffers: bool = False):
"""Meta initialization context manager.
A context manager under which models are initialized with all parameters
on the meta device, therefore creating an empty model. Useful when just
initializing the model would blow the available RAM.
Args:
include_buffers (`bool`, *optional*, defaults to `False`): Whether or
not to also put all buffers on the meta device while initializing.
Example:
```python
import torch.nn as nn
# Initialize a model with 100 billions parameters in no time and without using any RAM.
with init_empty_weights():
tst = nn.Sequential(*[nn.Linear(10000, 10000) for _ in range(1000)])
```
Any model created under this context manager has no weights. As such you can't do something like
`model.to(some_device)` with it. To load weights inside your empty model, see [`load_checkpoint_and_dispatch`].
"""
with init_on_device(torch.device("meta"), include_buffers=include_buffers) as f:
yield f
@contextmanager
def init_on_device(device: torch.device, include_buffers: bool = False):
"""Device initialization context manager.
A context manager under which models are initialized with all parameters
on the specified device.
Args:
device (`torch.device`): Device to initialize all parameters on.
include_buffers (`bool`, *optional*, defaults to `False`): Whether or
not to also put all buffers on the meta device while initializing.
Example:
```python
import torch.nn as nn
with init_on_device(device=torch.device("cuda")):
tst = nn.Liner(100, 100) # on `cuda` device
```
"""
old_register_parameter = nn.Module.register_parameter
if include_buffers:
old_register_buffer = nn.Module.register_buffer
def register_empty_parameter(module, name, param):
old_register_parameter(module, name, param)
if param is not None:
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(
module._parameters[name].to(device), **kwargs
)
def register_empty_buffer(module, name, buffer):
old_register_buffer(module, name, buffer)
if buffer is not None:
module._buffers[name] = module._buffers[name].to(device)
if include_buffers:
tensor_constructors_to_patch = {
torch_function_name: getattr(torch, torch_function_name)
for torch_function_name in ["empty", "zeros", "ones", "full"]
}
else:
tensor_constructors_to_patch = {}
def patch_tensor_constructor(fn):
def wrapper(*args, **kwargs):
kwargs["device"] = device
return fn(*args, **kwargs)
return wrapper
try:
nn.Module.register_parameter = register_empty_parameter
if include_buffers:
nn.Module.register_buffer = register_empty_buffer
for torch_function_name in tensor_constructors_to_patch.keys():
setattr(
torch,
torch_function_name,
patch_tensor_constructor(getattr(torch, torch_function_name)),
)
yield
finally:
nn.Module.register_parameter = old_register_parameter
if include_buffers:
nn.Module.register_buffer = old_register_buffer
for (
torch_function_name,
old_torch_function,
) in tensor_constructors_to_patch.items():
setattr(torch, torch_function_name, old_torch_function)
================================================
FILE: model/llava/model/language_model/mpt/modeling_mpt.py
================================================
"""A simple, flexible implementation of a GPT model.
Inspired by https://github.com/karpathy/minGPT/blob/master/mingpt/model.py
"""
import math
import warnings
from typing import List, Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import (PreTrainedModel, PreTrainedTokenizer,
PreTrainedTokenizerFast)
from transformers.modeling_outputs import (BaseModelOutputWithPast,
CausalLMOutputWithPast)
from .adapt_tokenizer import AutoTokenizerForMOD, adapt_tokenizer_for_denoising
from .attention import attn_bias_shape, build_attn_bias
from .blocks import MPTBlock
from .configuration_mpt import MPTConfig
from .custom_embedding import SharedEmbedding
from .hf_prefixlm_converter import (add_bidirectional_mask_if_missing,
convert_hf_causal_lm_to_prefix_lm)
from .meta_init_context import init_empty_weights
from .norm import NORM_CLASS_REGISTRY
from .param_init_fns import MODEL_INIT_REGISTRY, generic_param_init_fn_
try:
from .flash_attn_triton import flash_attn_func
except:
pass
Tokenizer = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]
class MPTPreTrainedModel(PreTrainedModel):
config_class = MPTConfig
base_model_prefix = "model"
_no_split_modules = ["MPTBlock"]
class MPTModel(MPTPreTrainedModel):
def __init__(self, config: MPTConfig):
config._validate_config()
super().__init__(config)
self.attn_impl = config.attn_config["attn_impl"]
self.prefix_lm = config.attn_config["prefix_lm"]
self.attn_uses_sequence_id = config.attn_config["attn_uses_sequence_id"]
self.alibi = config.attn_config["alibi"]
self.alibi_bias_max = config.attn_config["alibi_bias_max"]
if config.init_device == "mixed":
if dist.get_local_rank() == 0:
config.init_device = "cpu"
else:
config.init_device = "meta"
if config.norm_type.lower() not in NORM_CLASS_REGISTRY.keys():
norm_options = " | ".join(NORM_CLASS_REGISTRY.keys())
raise NotImplementedError(
f"Requested norm type ({config.norm_type}) is not implemented within this repo (Options: {norm_options})."
)
norm_class = NORM_CLASS_REGISTRY[config.norm_type.lower()]
self.embedding_fraction = config.embedding_fraction
self.wte = SharedEmbedding(
config.vocab_size, config.d_model, device=config.init_device
)
if not self.alibi:
self.wpe = torch.nn.Embedding(
config.max_seq_len, config.d_model, device=config.init_device
)
self.emb_drop = nn.Dropout(config.emb_pdrop)
self.blocks = nn.ModuleList(
[
MPTBlock(device=config.init_device, **config.to_dict())
for _ in range(config.n_layers)
]
)
self.norm_f = norm_class(config.d_model, device=config.init_device)
if config.init_device != "meta":
print(
f'You are using config.init_device={config.init_device!r}, but you can also use config.init_device="meta" with Composer + FSDP for fast initialization.'
)
self.apply(self.param_init_fn)
self.is_causal = not self.prefix_lm
self._attn_bias_initialized = False
self.attn_bias = None
self.attn_bias_shape = attn_bias_shape(
self.attn_impl,
config.n_heads,
config.max_seq_len,
self.alibi,
prefix_lm=self.prefix_lm,
causal=self.is_causal,
use_sequence_id=self.attn_uses_sequence_id,
)
if config.no_bias:
for module in self.modules():
if hasattr(module, "bias") and isinstance(module.bias, nn.Parameter):
if config.verbose:
warnings.warn(f"Removing bias ({module.bias}) from {module}.")
module.register_parameter("bias", None)
if config.verbose and config.verbose > 2:
print(self)
if "verbose" not in self.config.init_config:
self.config.init_config["verbose"] = self.config.verbose
if self.config.init_config["verbose"] > 1:
init_fn_name = self.config.init_config["name"]
warnings.warn(f"Using {init_fn_name} initialization.")
self.gradient_checkpointing = False
def get_input_embeddings(self):
return self.wte
def set_input_embeddings(self, value):
self.wte = value
@torch.no_grad()
def _attn_bias(
self,
device,
dtype,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
):
if not self._attn_bias_initialized:
if self.attn_bias_shape:
self.attn_bias = torch.zeros(
self.attn_bias_shape, device=device, dtype=dtype
)
self.attn_bias = build_attn_bias(
self.attn_impl,
self.attn_bias,
self.config.n_heads,
self.config.max_seq_len,
causal=self.is_causal,
alibi=self.alibi,
alibi_bias_max=self.alibi_bias_max,
)
self._attn_bias_initialized = True
if self.attn_impl == "flash":
return (self.attn_bias, attention_mask)
if self.attn_bias is not None:
self.attn_bias = self.attn_bias.to(dtype=dtype, device=device)
attn_bias = self.attn_bias
if self.prefix_lm:
assert isinstance(attn_bias, torch.Tensor)
assert isinstance(prefix_mask, torch.Tensor)
attn_bias = self._apply_prefix_mask(attn_bias, prefix_mask)
if self.attn_uses_sequence_id and sequence_id is not None:
assert isinstance(attn_bias, torch.Tensor)
attn_bias = self._apply_sequence_id(attn_bias, sequence_id)
if attention_mask is not None:
s_k = attention_mask.shape[-1]
if attn_bias is None:
attn_bias = torch.zeros((1, 1, 1, s_k), device=device, dtype=dtype)
else:
_s_k = max(0, attn_bias.size(-1) - s_k)
attn_bias = attn_bias[:, :, :, _s_k:]
if prefix_mask is not None and attention_mask.shape != prefix_mask.shape:
raise ValueError(
f"attention_mask shape={attention_mask.shape} "
+ f"and prefix_mask shape={prefix_mask.shape} are not equal."
)
min_val = torch.finfo(attn_bias.dtype).min
attn_bias = attn_bias.masked_fill(
~attention_mask.view(-1, 1, 1, s_k), min_val
)
return (attn_bias, None)
def _apply_prefix_mask(self, attn_bias: torch.Tensor, prefix_mask: torch.Tensor):
(s_k, s_q) = attn_bias.shape[-2:]
if s_k != self.config.max_seq_len or s_q != self.config.max_seq_len:
raise ValueError(
"attn_bias does not match the expected shape. "
+ f"The last two dimensions should both be {self.config.max_length} "
+ f"but are {s_k} and {s_q}."
)
seq_len = prefix_mask.shape[-1]
if seq_len > self.config.max_seq_len:
raise ValueError(
f"prefix_mask sequence length cannot exceed max_seq_len={self.config.max_seq_len}"
)
attn_bias = attn_bias[..., :seq_len, :seq_len]
causal = torch.tril(
torch.ones((seq_len, seq_len), dtype=torch.bool, device=prefix_mask.device)
).view(1, 1, seq_len, seq_len)
prefix = prefix_mask.view(-1, 1, 1, seq_len)
cannot_attend = ~torch.logical_or(causal, prefix.bool())
min_val = torch.finfo(attn_bias.dtype).min
attn_bias = attn_bias.masked_fill(cannot_attend, min_val)
return attn_bias
def _apply_sequence_id(
self, attn_bias: torch.Tensor, sequence_id: torch.LongTensor
):
seq_len = sequence_id.shape[-1]
if seq_len > self.config.max_seq_len:
raise ValueError(
f"sequence_id sequence length cannot exceed max_seq_len={self.config.max_seq_len}"
)
attn_bias = attn_bias[..., :seq_len, :seq_len]
cannot_attend = torch.logical_not(
torch.eq(sequence_id.view(-1, seq_len, 1), sequence_id.view(-1, 1, seq_len))
).unsqueeze(1)
min_val = torch.finfo(attn_bias.dtype).min
attn_bias = attn_bias.masked_fill(cannot_attend, min_val)
return attn_bias
def forward(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[List[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
return_dict: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
use_cache: Optional[bool] = None,
inputs_embeds: Optional[torch.Tensor] = None,
):
return_dict = (
return_dict if return_dict is not None else self.config.return_dict
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
if attention_mask is not None:
attention_mask = attention_mask.bool()
if prefix_mask is not None:
prefix_mask = prefix_mask.bool()
if not return_dict:
raise NotImplementedError(
"return_dict False is not implemented yet for MPT"
)
if output_attentions:
if self.attn_impl != "torch":
raise NotImplementedError(
"output_attentions is not implemented for MPT when using attn_impl `flash` or `triton`."
)
if (
attention_mask is not None
and attention_mask[:, 0].sum() != attention_mask.shape[0]
and self.training
):
raise NotImplementedError(
"MPT does not support training with left padding."
)
if self.prefix_lm and prefix_mask is None:
raise ValueError(
"prefix_mask is a required argument when MPT is configured with prefix_lm=True."
)
if self.training:
if self.attn_uses_sequence_id and sequence_id is None:
raise ValueError(
"sequence_id is a required argument when MPT is configured with attn_uses_sequence_id=True "
+ "and the model is in train mode."
)
elif self.attn_uses_sequence_id is False and sequence_id is not None:
warnings.warn(
"MPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. "
+ "This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True."
)
if input_ids is not None:
S = input_ids.size(1)
assert (
S <= self.config.max_seq_len
), f"Cannot forward input with seq_len={S}, this model only supports seq_len<={self.config.max_seq_len}"
tok_emb = self.wte(input_ids)
else:
assert inputs_embeds is not None
assert (
self.alibi
), "inputs_embeds is not implemented for MPT unless for alibi."
S = inputs_embeds.size(1)
tok_emb = inputs_embeds
if self.alibi:
x = tok_emb
else:
past_position = 0
if past_key_values is not None:
if len(past_key_values) != self.config.n_layers:
raise ValueError(
f"past_key_values must provide a past_key_value for each attention "
+ f"layer in the network (len(past_key_values)={len(past_key_values)!r}; self.config.n_layers={self.config.n_layers!r})."
)
past_position = past_key_values[0][0].size(1)
if self.attn_impl == "torch":
past_position = past_key_values[0][0].size(3)
if S + past_position > self.config.max_seq_len:
raise ValueError(
f"Cannot forward input with past sequence length {past_position} and current sequence length {S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}."
)
pos = torch.arange(
past_position,
S + past_position,
dtype=torch.long,
device=input_ids.device,
).unsqueeze(0)
if attention_mask is not None:
pos = torch.clamp(
pos
- torch.cumsum((~attention_mask).to(torch.int32), dim=1)[
:, past_position:
],
min=0,
)
pos_emb = self.wpe(pos)
x = tok_emb + pos_emb
if self.embedding_fraction == 1:
x = self.emb_drop(x)
else:
x_shrunk = x * self.embedding_fraction + x.detach() * (
1 - self.embedding_fraction
)
assert isinstance(self.emb_drop, nn.Module)
x = self.emb_drop(x_shrunk)
(attn_bias, attention_mask) = self._attn_bias(
device=x.device,
dtype=torch.float32,
attention_mask=attention_mask,
prefix_mask=prefix_mask,
sequence_id=sequence_id,
)
if use_cache and past_key_values is None:
past_key_values = [() for _ in range(self.config.n_layers)]
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
for b_idx, block in enumerate(self.blocks):
if output_hidden_states:
assert all_hidden_states is not None
all_hidden_states = all_hidden_states + (x,)
past_key_value = (
past_key_values[b_idx] if past_key_values is not None else None
)
if self.gradient_checkpointing and self.training:
(x, attn_weights, past_key_value) = torch.utils.checkpoint.checkpoint(
block, x, past_key_value, attn_bias, attention_mask, self.is_causal
)
else:
(x, attn_weights, past_key_value) = block(
x,
past_key_value=past_key_value,
attn_bias=attn_bias,
attention_mask=attention_mask,
is_causal=self.is_causal,
)
if past_key_values is not None:
past_key_values[b_idx] = past_key_value
if output_attentions:
assert all_self_attns is not None
all_self_attns = all_self_attns + (attn_weights,)
x = self.norm_f(x)
if output_hidden_states:
assert all_hidden_states is not None
all_hidden_states = all_hidden_states + (x,)
return BaseModelOutputWithPast(
last_hidden_state=x,
past_key_values=past_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
)
def param_init_fn(self, module):
init_fn_name = self.config.init_config["name"]
MODEL_INIT_REGISTRY[init_fn_name](
module=module,
n_layers=self.config.n_layers,
d_model=self.config.d_model,
**self.config.init_config,
)
def fsdp_wrap_fn(self, module):
return isinstance(module, MPTBlock)
def activation_checkpointing_fn(self, module):
return isinstance(module, MPTBlock)
class MPTForCausalLM(MPTPreTrainedModel):
def __init__(self, config: MPTConfig):
super().__init__(config)
if not config.tie_word_embeddings:
raise ValueError("MPTForCausalLM only supports tied word embeddings")
print(f"Instantiating an MPTForCausalLM model from {__file__}")
self.transformer = MPTModel(config)
for child in self.transformer.children():
if isinstance(child, torch.nn.ModuleList):
continue
if isinstance(child, torch.nn.Module):
child._fsdp_wrap = True
self.logit_scale = None
if config.logit_scale is not None:
logit_scale = config.logit_scale
if isinstance(logit_scale, str):
if logit_scale == "inv_sqrt_d_model":
logit_scale = 1 / math.sqrt(config.d_model)
else:
raise ValueError(
f"logit_scale={logit_scale!r} is not recognized as an option; use numeric value or 'inv_sqrt_d_model'."
)
self.logit_scale = logit_scale
def get_input_embeddings(self):
return self.transformer.wte
def set_input_embeddings(self, value):
self.transformer.wte = value
def get_output_embeddings(self):
return self.transformer.wte
def set_output_embeddings(self, new_embeddings):
self.transformer.wte = new_embeddings
def set_decoder(self, decoder):
self.transformer = decoder
def get_decoder(self):
return self.transformer
def forward(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[List[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.ByteTensor] = None,
prefix_mask: Optional[torch.ByteTensor] = None,
sequence_id: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
return_dict: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
use_cache: Optional[bool] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
):
return_dict = (
return_dict if return_dict is not None else self.config.return_dict
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
if inputs_embeds is not None:
raise NotImplementedError(
"inputs_embeds has to be None (for hf/peft support)."
)
outputs = self.transformer(
input_ids=input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
prefix_mask=prefix_mask,
sequence_id=sequence_id,
return_dict=return_dict,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
use_cache=use_cache,
)
logits = self.transformer.wte(
outputs.last_hidden_state.to(self.transformer.wte.weight.device), True
)
if self.logit_scale is not None:
if self.logit_scale == 0:
warnings.warn(
f"Multiplying logits by self.logit_scale={self.logit_scale!r}. This will produce uniform (uninformative) outputs."
)
logits *= self.logit_scale
loss = None
if labels is not None:
labels = torch.roll(labels, shifts=-1)
labels[:, -1] = -100
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)), labels.to(logits.device).view(-1)
)
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def param_init_fn(self, module):
init_fn_name = self.config.init_config["name"]
MODEL_INIT_REGISTRY[init_fn_name](
module=module,
n_layers=self.config.n_layers,
d_model=self.config.d_model,
**self.config.init_config,
)
def fsdp_wrap_fn(self, module):
return isinstance(module, MPTBlock)
def activation_checkpointing_fn(self, module):
return isinstance(module, MPTBlock)
def prepare_inputs_for_generation(
self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs
):
if inputs_embeds is not None:
raise NotImplementedError("inputs_embeds is not implemented for MPT yet")
attention_mask = kwargs["attention_mask"].bool()
if attention_mask[:, -1].sum() != attention_mask.shape[0]:
raise NotImplementedError(
"MPT does not support generation with right padding."
)
if self.transformer.attn_uses_sequence_id and self.training:
sequence_id = torch.zeros_like(input_ids[:1])
else:
sequence_id = None
if past_key_values is not None:
input_ids = input_ids[:, -1].unsqueeze(-1)
if self.transformer.prefix_lm:
prefix_mask = torch.ones_like(attention_mask)
if kwargs.get("use_cache") == False:
raise NotImplementedError(
"MPT with prefix_lm=True does not support use_cache=False."
)
else:
prefix_mask = None
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"prefix_mask": prefix_mask,
"sequence_id": sequence_id,
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache", True),
}
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
"""Used by HuggingFace generate when using beam search with kv-caching.
See https://github.com/huggingface/transformers/blob/3ec7a47664ebe40c40f4b722f6bb1cd30c3821ec/src/transformers/models/gpt2/modeling_gpt2.py#L1122-L1133
for an example in transformers.
"""
reordered_past = []
for layer_past in past_key_values:
reordered_past += [
tuple(
(past_state.index_select(0, beam_idx) for past_state in layer_past)
)
]
return reordered_past
================================================
FILE: model/llava/model/language_model/mpt/norm.py
================================================
import torch
def _cast_if_autocast_enabled(tensor):
if torch.is_autocast_enabled():
if tensor.device.type == "cuda":
dtype = torch.get_autocast_gpu_dtype()
elif tensor.device.type == "cpu":
dtype = torch.get_autocast_cpu_dtype()
else:
raise NotImplementedError()
return tensor.to(dtype=dtype)
return tensor
class LPLayerNorm(torch.nn.LayerNorm):
def __init__(
self,
normalized_shape,
eps=1e-05,
elementwise_affine=True,
device=None,
dtype=None,
):
super().__init__(
normalized_shape=normalized_shape,
eps=eps,
elementwise_affine=elementwise_affine,
device=device,
dtype=dtype,
)
def forward(self, x):
module_device = x.device
downcast_x = _cast_if_autocast_enabled(x)
downcast_weight = (
_cast_if_autocast_enabled(self.weight)
if self.weight is not None
else self.weight
)
downcast_bias = (
_cast_if_autocast_enabled(self.bias) if self.bias is not None else self.bias
)
with torch.autocast(enabled=False, device_type=module_device.type):
return torch.nn.functional.layer_norm(
downcast_x,
self.normalized_shape,
downcast_weight,
downcast_bias,
self.eps,
)
def rms_norm(x, weight=None, eps=1e-05):
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + eps)
if weight is not None:
return output * weight
return output
class RMSNorm(torch.nn.Module):
def __init__(
self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None
):
super().__init__()
self.eps = eps
if weight:
self.weight = torch.nn.Parameter(
torch.ones(normalized_shape, dtype=dtype, device=device)
)
else:
self.register_parameter("weight", None)
def forward(self, x):
return rms_norm(x.float(), self.weight, self.eps).to(dtype=x.dtype)
class LPRMSNorm(RMSNorm):
def __init__(
self, normalized_shape, eps=1e-05, weight=True, dtype=None, device=None
):
super().__init__(
normalized_shape=normalized_shape,
eps=eps,
weight=weight,
dtype=dtype,
device=device,
)
def forward(self, x):
downcast_x = _cast_if_autocast_enabled(x)
downcast_weight = (
_cast_if_autocast_enabled(self.weight)
if self.weight is not None
else self.weight
)
with torch.autocast(enabled=False, device_type=x.device.type):
return rms_norm(downcast_x, downcast_weight, self.eps).to(dtype=x.dtype)
NORM_CLASS_REGISTRY = {
"layernorm": torch.nn.LayerNorm,
"low_precision_layernorm": LPLayerNorm,
"rmsnorm": RMSNorm,
"low_precision_rmsnorm": LPRMSNorm,
}
================================================
FILE: model/llava/model/language_model/mpt/param_init_fns.py
================================================
import math
import warnings
from collections.abc import Sequence
from functools import partial
from typing import Optional, Tuple, Union
import torch
from torch import nn
from .norm import NORM_CLASS_REGISTRY
def torch_default_param_init_fn_(module: nn.Module, verbose: int = 0, **kwargs):
del kwargs
if verbose > 1:
warnings.warn(f"Initializing network using module's reset_parameters attribute")
if hasattr(module, "reset_parameters"):
module.reset_parameters()
def fused_init_helper_(module: nn.Module, init_fn_):
_fused = getattr(module, "_fused", None)
if _fused is None:
raise RuntimeError(f"Internal logic error")
(dim, splits) = _fused
splits = (0, *splits, module.weight.size(dim))
for s, e in zip(splits[:-1], splits[1:]):
slice_indices = [slice(None)] * module.weight.ndim
slice_indices[dim] = slice(s, e)
init_fn_(module.weight[slice_indices])
def generic_param_init_fn_(
module: nn.Module,
init_fn_,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
verbose: int = 0,
**kwargs,
):
del kwargs
if verbose > 1:
warnings.warn(f"If model has bias parameters they are initialized to 0.")
init_div_is_residual = init_div_is_residual
if init_div_is_residual is False:
div_is_residual = 1.0
elif init_div_is_residual is True:
div_is_residual = math.sqrt(2 * n_layers)
elif isinstance(init_div_is_residual, float) or isinstance(
init_div_is_residual, int
):
div_is_residual = init_div_is_residual
elif isinstance(init_div_is_residual, str) and init_div_is_residual.isnumeric():
div_is_residual = float(init_div_is_residual)
else:
div_is_residual = 1.0
raise ValueError(
f"Expected init_div_is_residual to be boolean or numeric, got {init_div_is_residual}"
)
if init_div_is_residual is not False:
if verbose > 1:
warnings.warn(
f"Initializing _is_residual layers then dividing them by {div_is_residual:.3f}. "
+ f"Set `init_div_is_residual: false` in init config to disable this."
)
if isinstance(module, nn.Linear):
if hasattr(module, "_fused"):
fused_init_helper_(module, init_fn_)
else:
init_fn_(module.weight)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
if init_div_is_residual is not False and getattr(module, "_is_residual", False):
with torch.no_grad():
module.weight.div_(div_is_residual)
elif isinstance(module, nn.Embedding):
if emb_init_std is not None:
std = emb_init_std
if std == 0:
warnings.warn(f"Embedding layer initialized to 0.")
emb_init_fn_ = partial(torch.nn.init.normal_, mean=0.0, std=std)
if verbose > 1:
warnings.warn(
f"Embedding layer initialized using normal distribution with mean=0 and std={std!r}."
)
elif emb_init_uniform_lim is not None:
lim = emb_init_uniform_lim
if isinstance(lim, Sequence):
if len(lim) > 2:
raise ValueError(
f"Uniform init requires a min and a max limit. User input: {lim}."
)
if lim[0] == lim[1]:
warnings.warn(f"Embedding layer initialized to {lim[0]}.")
else:
if lim == 0:
warnings.warn(f"Embedding layer initialized to 0.")
lim = [-lim, lim]
(a, b) = lim
emb_init_fn_ = partial(torch.nn.init.uniform_, a=a, b=b)
if verbose > 1:
warnings.warn(
f"Embedding layer initialized using uniform distribution in range {lim}."
)
else:
emb_init_fn_ = init_fn_
emb_init_fn_(module.weight)
elif isinstance(module, tuple(set(NORM_CLASS_REGISTRY.values()))):
if verbose > 1:
warnings.warn(
f"Norm weights are set to 1. If norm layer has a bias it is initialized to 0."
)
if hasattr(module, "weight") and module.weight is not None:
torch.nn.init.ones_(module.weight)
if hasattr(module, "bias") and module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.MultiheadAttention):
if module._qkv_same_embed_dim:
assert module.in_proj_weight is not None
assert (
module.q_proj_weight is None
and module.k_proj_weight is None
and (module.v_proj_weight is None)
)
assert d_model is not None
_d = d_model
splits = (0, _d, 2 * _d, 3 * _d)
for s, e in zip(splits[:-1], splits[1:]):
init_fn_(module.in_proj_weight[s:e])
else:
assert (
module.q_proj_weight is not None
and module.k_proj_weight is not None
and (module.v_proj_weight is not None)
)
assert module.in_proj_weight is None
init_fn_(module.q_proj_weight)
init_fn_(module.k_proj_weight)
init_fn_(module.v_proj_weight)
if module.in_proj_bias is not None:
torch.nn.init.zeros_(module.in_proj_bias)
if module.bias_k is not None:
torch.nn.init.zeros_(module.bias_k)
if module.bias_v is not None:
torch.nn.init.zeros_(module.bias_v)
init_fn_(module.out_proj.weight)
if init_div_is_residual is not False and getattr(
module.out_proj, "_is_residual", False
):
with torch.no_grad():
module.out_proj.weight.div_(div_is_residual)
if module.out_proj.bias is not None:
torch.nn.init.zeros_(module.out_proj.bias)
else:
for _ in module.parameters(recurse=False):
raise NotImplementedError(
f"{module.__class__.__name__} parameters are not initialized by param_init_fn."
)
def _normal_init_(std, mean=0.0):
return partial(torch.nn.init.normal_, mean=mean, std=std)
def _normal_param_init_fn_(
module: nn.Module,
std: float,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
verbose: int = 0,
**kwargs,
):
del kwargs
init_fn_ = _normal_init_(std=std)
if verbose > 1:
warnings.warn(f"Using torch.nn.init.normal_ init fn mean=0.0, std={std}")
generic_param_init_fn_(
module=module,
init_fn_=init_fn_,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def baseline_param_init_fn_(
module: nn.Module,
init_std: float,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
verbose: int = 0,
**kwargs,
):
del kwargs
if init_std is None:
raise ValueError(
"You must set model.init_config['init_std'] to a float value to use the default initialization scheme."
)
_normal_param_init_fn_(
module=module,
std=init_std,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def small_param_init_fn_(
module: nn.Module,
n_layers: int,
d_model: int,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
verbose: int = 0,
**kwargs,
):
del kwargs
std = math.sqrt(2 / (5 * d_model))
_normal_param_init_fn_(
module=module,
std=std,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def neox_param_init_fn_(
module: nn.Module,
n_layers: int,
d_model: int,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
verbose: int = 0,
**kwargs,
):
"""From section 2.3.1 of GPT-NeoX-20B:
An Open-Source AutoregressiveLanguage Model — Black et. al. (2022)
see https://github.com/EleutherAI/gpt-neox/blob/9610391ab319403cef079b438edd016a2443af54/megatron/model/init_functions.py#L151
and https://github.com/EleutherAI/gpt-neox/blob/main/megatron/model/transformer.py
"""
del kwargs
residual_div = n_layers / math.sqrt(10)
if verbose > 1:
warnings.warn(f"setting init_div_is_residual to {residual_div}")
small_param_init_fn_(
module=module,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=residual_div,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def kaiming_uniform_param_init_fn_(
module: nn.Module,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
init_gain: float = 0,
fan_mode: str = "fan_in",
init_nonlinearity: str = "leaky_relu",
verbose: int = 0,
**kwargs,
):
del kwargs
if verbose > 1:
warnings.warn(
f"Using nn.init.kaiming_uniform_ init fn with parameters: "
+ f"a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}"
)
kaiming_uniform_ = partial(
nn.init.kaiming_uniform_,
a=init_gain,
mode=fan_mode,
nonlinearity=init_nonlinearity,
)
generic_param_init_fn_(
module=module,
init_fn_=kaiming_uniform_,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def kaiming_normal_param_init_fn_(
module: nn.Module,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
init_gain: float = 0,
fan_mode: str = "fan_in",
init_nonlinearity: str = "leaky_relu",
verbose: int = 0,
**kwargs,
):
del kwargs
if verbose > 1:
warnings.warn(
f"Using nn.init.kaiming_normal_ init fn with parameters: "
+ f"a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}"
)
kaiming_normal_ = partial(
torch.nn.init.kaiming_normal_,
a=init_gain,
mode=fan_mode,
nonlinearity=init_nonlinearity,
)
generic_param_init_fn_(
module=module,
init_fn_=kaiming_normal_,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def xavier_uniform_param_init_fn_(
module: nn.Module,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
init_gain: float = 0,
verbose: int = 0,
**kwargs,
):
del kwargs
xavier_uniform_ = partial(torch.nn.init.xavier_uniform_, gain=init_gain)
if verbose > 1:
warnings.warn(
f"Using torch.nn.init.xavier_uniform_ init fn with parameters: "
+ f"gain={init_gain}"
)
generic_param_init_fn_(
module=module,
init_fn_=xavier_uniform_,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
def xavier_normal_param_init_fn_(
module: nn.Module,
n_layers: int,
d_model: Optional[int] = None,
init_div_is_residual: Union[int, float, str, bool] = True,
emb_init_std: Optional[float] = None,
emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]] = None,
init_gain: float = 0,
verbose: int = 0,
**kwargs,
):
xavier_normal_ = partial(torch.nn.init.xavier_normal_, gain=init_gain)
if verbose > 1:
warnings.warn(
f"Using torch.nn.init.xavier_normal_ init fn with parameters: "
+ f"gain={init_gain}"
)
generic_param_init_fn_(
module=module,
init_fn_=xavier_normal_,
d_model=d_model,
n_layers=n_layers,
init_div_is_residual=init_div_is_residual,
emb_init_std=emb_init_std,
emb_init_uniform_lim=emb_init_uniform_lim,
verbose=verbose,
)
MODEL_INIT_REGISTRY = {
"default_": torch_default_param_init_fn_,
"baseline_": baseline_param_init_fn_,
"kaiming_uniform_": kaiming_uniform_param_init_fn_,
"kaiming_normal_": kaiming_normal_param_init_fn_,
"neox_init_": neox_param_init_fn_,
"small_init_": small_param_init_fn_,
"xavier_uniform_": xavier_uniform_param_init_fn_,
"xavier_normal_": xavier_normal_param_init_fn_,
}
================================================
FILE: model/llava/model/llava_arch.py
================================================
# Copyright 2023 Haotian Liu
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from abc import ABC, abstractmethod
import torch
import torch.nn as nn
# from llava.constants import IGNORE_INDEX, IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_PATCH_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
from utils.utils import (DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN,
DEFAULT_IMAGE_PATCH_TOKEN, IGNORE_INDEX,
IMAGE_TOKEN_INDEX)
from .multimodal_encoder.builder import build_vision_tower
class LlavaMetaModel:
def __init__(self, config):
super(LlavaMetaModel, self).__init__(config)
if hasattr(config, "mm_vision_tower"):
self.vision_tower = build_vision_tower(config, delay_load=True)
self.mm_projector = nn.Linear(config.mm_hidden_size, config.hidden_size)
def get_vision_tower(self):
vision_tower = getattr(self, "vision_tower", None)
if type(vision_tower) is list:
vision_tower = vision_tower[0]
return vision_tower
def initialize_vision_modules(self, model_args, fsdp=None):
vision_tower = model_args.vision_tower
mm_vision_select_layer = model_args.mm_vision_select_layer
mm_vision_select_feature = model_args.mm_vision_select_feature
pretrain_mm_mlp_adapter = model_args.pretrain_mm_mlp_adapter
self.config.mm_vision_tower = vision_tower
vision_tower = build_vision_tower(model_args)
if fsdp is not None and len(fsdp) > 0:
self.vision_tower = [vision_tower]
else:
self.vision_tower = vision_tower
self.config.use_mm_proj = True
self.config.mm_hidden_size = vision_tower.hidden_size
self.config.mm_vision_select_layer = mm_vision_select_layer
self.config.mm_vision_select_feature = mm_vision_select_feature
if not hasattr(self, "mm_projector"):
self.mm_projector = nn.Linear(
self.config.mm_hidden_size, self.config.hidden_size
)
if pretrain_mm_mlp_adapter is not None:
mm_projector_weights = torch.load(
pretrain_mm_mlp_adapter, map_location="cpu"
)
def get_w(weights, keyword):
return {
k.split(keyword + ".")[1]: v
for k, v in weights.items()
if keyword in k
}
self.mm_projector.load_state_dict(
get_w(mm_projector_weights, "mm_projector")
)
class LlavaMetaForCausalLM(ABC):
@abstractmethod
def get_model(self):
pass
def get_vision_tower(self):
return self.get_model().get_vision_tower()
def encode_images(self, images):
image_features = self.get_model().get_vision_tower()(images)
image_features = self.get_model().mm_projector(image_features)
return image_features
def prepare_inputs_labels_for_multimodal(
self, input_ids, attention_mask, past_key_values, labels, images
):
vision_tower = self.get_vision_tower()
if vision_tower is None or images is None or input_ids.shape[1] == 1:
if (
past_key_values is not None
and vision_tower is not None
and images is not None
and input_ids.shape[1] == 1
):
attention_mask = torch.ones(
(attention_mask.shape[0], past_key_values[-1][-1].shape[-2] + 1),
dtype=attention_mask.dtype,
device=attention_mask.device,
)
return input_ids, attention_mask, past_key_values, None, labels
if type(images) is list or images.ndim == 5:
concat_images = torch.cat([image for image in images], dim=0)
image_features = self.encode_images(concat_images)
split_sizes = [image.shape[0] for image in images]
image_features = torch.split(image_features, split_sizes, dim=0)
image_features = [x.flatten(0, 1) for x in image_features]
else:
image_features = self.encode_images(images)
new_input_embeds = []
new_labels = [] if labels is not None else None
cur_image_idx = 0
for batch_idx, cur_input_ids in enumerate(input_ids):
if (cur_input_ids == IMAGE_TOKEN_INDEX).sum() == 0:
# multimodal LLM, but the current sample is not multimodal
cur_input_embeds = self.get_model().embed_tokens(cur_input_ids)
cur_input_embeds = (
cur_input_embeds
+ (
0.0 * self.get_model().mm_projector(vision_tower.dummy_feature)
).sum()
)
new_input_embeds.append(cur_input_embeds)
if labels is not None:
new_labels.append(labels[batch_idx])
cur_image_idx += 1
continue
image_token_indices = torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0]
cur_new_input_embeds = []
if labels is not None:
cur_labels = labels[batch_idx]
cur_new_labels = []
assert cur_labels.shape == cur_input_ids.shape
while image_token_indices.numel() > 0:
cur_image_features = image_features[cur_image_idx]
image_token_start = image_token_indices[0]
if getattr(self.config, "tune_mm_mlp_adapter", False) and getattr(
self.config, "mm_use_im_start_end", False
):
cur_new_input_embeds.append(
self.get_model()
.embed_tokens(cur_input_ids[: image_token_start - 1])
.detach()
)
cur_new_input_embeds.append(
self.get_model().embed_tokens(
cur_input_ids[image_token_start - 1 : image_token_start]
)
)
cur_new_input_embeds.append(cur_image_features)
cur_new_input_embeds.append(
self.get_model().embed_tokens(
cur_input_ids[image_token_start + 1 : image_token_start + 2]
)
)
if labels is not None:
cur_new_labels.append(cur_labels[:image_token_start])
cur_new_labels.append(
torch.full(
(cur_image_features.shape[0],),
IGNORE_INDEX,
device=labels.device,
dtype=labels.dtype,
)
)
cur_new_labels.append(
cur_labels[image_token_start : image_token_start + 1]
)
cur_labels = cur_labels[image_token_start + 2 :]
elif getattr(self.config, "mm_use_im_start_end", False):
cur_new_input_embeds.append(
self.get_model().embed_tokens(cur_input_ids[:image_token_start])
)
cur_new_input_embeds.append(cur_image_features)
cur_new_input_embeds.append(
self.get_model().embed_tokens(
cur_input_ids[image_token_start + 1 : image_token_start + 2]
)
)
if labels is not None:
cur_new_labels.append(cur_labels[:image_token_start])
cur_new_labels.append(
torch.full(
(cur_image_features.shape[0],),
IGNORE_INDEX,
device=labels.device,
dtype=labels.dtype,
)
)
cur_new_labels.append(
cur_labels[image_token_start + 1 : image_token_start + 2]
)
cur_labels = cur_labels[image_token_start + 2 :]
else:
cur_new_input_embeds.append(
self.get_model().embed_tokens(cur_input_ids[:image_token_start])
)
cur_new_input_embeds.append(cur_image_features)
if labels is not None:
cur_new_labels.append(cur_labels[:image_token_start])
cur_new_labels.append(
torch.full(
(cur_image_features.shape[0],),
IGNORE_INDEX,
device=labels.device,
dtype=labels.dtype,
)
)
cur_labels = cur_labels[image_token_start + 1 :]
cur_image_idx += 1
if getattr(self.config, "tune_mm_mlp_adapter", False) and getattr(
self.config, "mm_use_im_start_end", False
):
cur_input_ids = cur_input_ids[image_token_start + 2 :]
elif getattr(self.config, "mm_use_im_start_end", False):
cur_input_ids = cur_input_ids[image_token_start + 2 :]
else:
cur_input_ids = cur_input_ids[image_token_start + 1 :]
image_token_indices = torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0]
if cur_input_ids.numel() > 0:
if getattr(self.config, "tune_mm_mlp_adapter", False) and getattr(
self.config, "mm_use_im_start_end", False
):
cur_new_input_embeds.append(
self.get_model().embed_tokens(cur_input_ids).detach()
)
elif getattr(self.config, "mm_use_im_start_end", False):
cur_new_input_embeds.append(
self.get_model().embed_tokens(cur_input_ids)
)
else:
cur_new_input_embeds.append(
self.get_model().embed_tokens(cur_input_ids)
)
if labels is not None:
cur_new_labels.append(cur_labels)
cur_new_input_embeds = [
x.to(device=self.device) for x in cur_new_input_embeds
]
cur_new_input_embeds = torch.cat(cur_new_input_embeds, dim=0)
new_input_embeds.append(cur_new_input_embeds)
if labels is not None:
cur_new_labels = torch.cat(cur_new_labels, dim=0)
new_labels.append(cur_new_labels)
if any(x.shape != new_input_embeds[0].shape for x in new_input_embeds):
max_len = max(x.shape[0] for x in new_input_embeds)
new_input_embeds_align = []
for cur_new_embed in new_input_embeds:
cur_new_embed = torch.cat(
(
cur_new_embed,
torch.zeros(
(max_len - cur_new_embed.shape[0], cur_new_embed.shape[1]),
dtype=cur_new_embed.dtype,
device=cur_new_embed.device,
),
),
dim=0,
)
new_input_embeds_align.append(cur_new_embed)
new_input_embeds = torch.stack(new_input_embeds_align, dim=0)
if labels is not None:
new_labels_align = []
_new_labels = new_labels
for cur_new_label in new_labels:
cur_new_label = torch.cat(
(
cur_new_label,
torch.full(
(max_len - cur_new_label.shape[0],),
IGNORE_INDEX,
dtype=cur_new_label.dtype,
device=cur_new_label.device,
),
),
dim=0,
)
new_labels_align.append(cur_new_label)
new_labels = torch.stack(new_labels_align, dim=0)
if attention_mask is not None:
new_attention_mask = []
for cur_attention_mask, cur_new_labels, cur_new_labels_align in zip(
attention_mask, _new_labels, new_labels
):
new_attn_mask_pad_left = torch.full(
(cur_new_labels.shape[0] - labels.shape[1],),
True,
dtype=attention_mask.dtype,
device=attention_mask.device,
)
new_attn_mask_pad_right = torch.full(
(cur_new_labels_align.shape[0] - cur_new_labels.shape[0],),
False,
dtype=attention_mask.dtype,
device=attention_mask.device,
)
cur_new_attention_mask = torch.cat(
(
new_attn_mask_pad_left,
cur_attention_mask,
new_attn_mask_pad_right,
),
dim=0,
)
new_attention_mask.append(cur_new_attention_mask)
attention_mask = torch.stack(new_attention_mask, dim=0)
assert attention_mask.shape == new_labels.shape
else:
new_input_embeds = torch.stack(new_input_embeds, dim=0)
if labels is not None:
new_labels = torch.stack(new_labels, dim=0)
if attention_mask is not None:
new_attn_mask_pad_left = torch.full(
(
attention_mask.shape[0],
new_input_embeds.shape[1] - input_ids.shape[1],
),
True,
dtype=attention_mask.dtype,
device=attention_mask.device,
)
attention_mask = torch.cat(
(new_attn_mask_pad_left, attention_mask), dim=1
)
assert attention_mask.shape == new_input_embeds.shape[:2]
return None, attention_mask, past_key_values, new_input_embeds, new_labels
# def initialize_vision_tokenizer(self, model_args, tokenizer):
def initialize_vision_tokenizer(self, model_args, num_new_tokens):
# if model_args.mm_use_im_patch_token:
# tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
# self.resize_token_embeddings(len(tokenizer))
if model_args.mm_use_im_start_end:
# num_new_tokens = tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
# self.resize_token_embeddings(len(tokenizer))
# if num_new_tokens > 0:
# input_embeddings = self.get_input_embeddings().weight.data
# output_embeddings = self.get_output_embeddings().weight.data
# input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
# dim=0, keepdim=True)
# output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
# dim=0, keepdim=True)
# input_embeddings[-num_new_tokens:] = input_embeddings_avg
# output_embeddings[-num_new_tokens:] = output_embeddings_avg
if model_args.tune_mm_mlp_adapter:
for p in self.get_input_embeddings().parameters():
p.requires_grad = True
for p in self.get_output_embeddings().parameters():
p.requires_grad = False
if model_args.pretrain_mm_mlp_adapter:
mm_projector_weights = torch.load(
model_args.pretrain_mm_mlp_adapter, map_location="cpu"
)
embed_tokens_weight = mm_projector_weights["model.embed_tokens.weight"]
assert num_new_tokens == 2
if input_embeddings.shape == embed_tokens_weight.shape:
input_embeddings[-num_new_tokens:] = embed_tokens_weight[
-num_new_tokens:
]
elif embed_tokens_weight.shape[0] == num_new_tokens:
input_embeddings[-num_new_tokens:] = embed_tokens_weight
else:
raise ValueError(
f"Unexpected embed_tokens_weight shape. Pretrained: {embed_tokens_weight.shape}. Current: {input_embeddings.shape}. Numer of new tokens: {num_new_tokens}."
)
elif model_args.mm_use_im_patch_token:
if model_args.tune_mm_mlp_adapter:
for p in self.get_input_embeddings().parameters():
p.requires_grad = False
for p in self.get_output_embeddings().parameters():
p.requires_grad = False
================================================
FILE: model/llava/model/make_delta.py
================================================
"""
Usage:
python3 -m llava.model.make_delta --base ~/model_weights/llama-7b --target ~/model_weights/llava-7b --delta ~/model_weights/llava-7b-delta --hub-repo-id liuhaotian/llava-7b-delta
"""
import argparse
import torch
from llava.model.utils import auto_upgrade
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer
def make_delta(base_model_path, target_model_path, delta_path, hub_repo_id):
print("Loading base model")
base = AutoModelForCausalLM.from_pretrained(
base_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
)
print("Loading target model")
auto_upgrade(target_model_path)
target = AutoModelForCausalLM.from_pretrained(
target_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
)
print("Calculating delta")
for name, param in tqdm(target.state_dict().items(), desc="Calculating delta"):
if name not in base.state_dict():
assert name in [
"model.mm_projector.weight",
"model.mm_projector.bias",
], f"{name} not in base model"
continue
if param.data.shape == base.state_dict()[name].shape:
param.data -= base.state_dict()[name]
else:
assert name in [
"model.embed_tokens.weight",
"lm_head.weight",
], f"{name} dimension mismatch: {param.data.shape} vs {base.state_dict()[name].shape}"
bparam = base.state_dict()[name]
param.data[: bparam.shape[0], : bparam.shape[1]] -= bparam
print("Saving delta")
if hub_repo_id:
kwargs = {"push_to_hub": True, "repo_id": hub_repo_id}
else:
kwargs = {}
target.save_pretrained(delta_path, **kwargs)
target_tokenizer = AutoTokenizer.from_pretrained(target_model_path)
target_tokenizer.save_pretrained(delta_path, **kwargs)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--base-model-path", type=str, required=True)
parser.add_argument("--target-model-path", type=str, required=True)
parser.add_argument("--delta-path", type=str, required=True)
parser.add_argument("--hub-repo-id", type=str, default=None)
args = parser.parse_args()
make_delta(
args.base_model_path, args.target_model_path, args.delta_path, args.hub_repo_id
)
================================================
FILE: model/llava/model/multimodal_encoder/builder.py
================================================
from .clip_encoder import CLIPVisionTower
def build_vision_tower(vision_tower_cfg, **kwargs):
vision_tower = getattr(
vision_tower_cfg,
"mm_vision_tower",
getattr(vision_tower_cfg, "vision_tower", None),
)
if (
vision_tower.startswith("openai")
or vision_tower.startswith("laion")
or "clip" in vision_tower
):
return CLIPVisionTower(vision_tower, args=vision_tower_cfg, **kwargs)
raise ValueError(f"Unknown vision tower: {vision_tower}")
================================================
FILE: model/llava/model/multimodal_encoder/clip_encoder.py
================================================
import torch
import torch.nn as nn
from transformers import CLIPImageProcessor, CLIPVisionConfig, CLIPVisionModel
class CLIPVisionTower(nn.Module):
def __init__(self, vision_tower, args, delay_load=False):
super().__init__()
self.is_loaded = False
self.vision_tower_name = vision_tower
self.select_layer = args.mm_vision_select_layer
self.select_feature = getattr(args, "mm_vision_select_feature", "patch")
if not delay_load:
self.load_model()
else:
self.cfg_only = CLIPVisionConfig.from_pretrained(self.vision_tower_name)
def load_model(self):
self.image_processor = CLIPImageProcessor.from_pretrained(
self.vision_tower_name
)
self.vision_tower = CLIPVisionModel.from_pretrained(
self.vision_tower_name, low_cpu_mem_usage=True
)
self.vision_tower.requires_grad_(False)
self.is_loaded = True
def feature_select(self, image_forward_outs):
image_features = image_forward_outs.hidden_states[self.select_layer]
if self.select_feature == "patch":
image_features = image_features[:, 1:]
elif self.select_feature == "cls_patch":
image_features = image_features
else:
raise ValueError(f"Unexpected select feature: {self.select_feature}")
return image_features
@torch.no_grad()
def forward(self, images):
if type(images) is list:
image_features = []
for image in images:
image_forward_out = self.vision_tower(
image.to(device=self.device, dtype=self.dtype).unsqueeze(0),
output_hidden_states=True,
)
image_feature = self.feature_select(image_forward_out).to(image.dtype)
image_features.append(image_feature)
else:
image_forward_outs = self.vision_tower(
images.to(device=self.device, dtype=self.dtype),
output_hidden_states=True,
)
image_features = self.feature_select(image_forward_outs).to(images.dtype)
torch.cuda.empty_cache()
return image_features
@property
def dummy_feature(self):
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
@property
def dtype(self):
return self.vision_tower.dtype
@property
def device(self):
return self.vision_tower.device
@property
def config(self):
if self.is_loaded:
return self.vision_tower.config
else:
return self.cfg_only
@property
def hidden_size(self):
return self.config.hidden_size
@property
def num_patches(self):
return (self.config.image_size // self.config.patch_size) ** 2
================================================
FILE: model/llava/model/utils.py
================================================
from transformers import AutoConfig
def auto_upgrade(config):
cfg = AutoConfig.from_pretrained(config)
if "llava" in config and "llava" not in cfg.model_type:
assert cfg.model_type == "llama"
print(
"You are using newer LLaVA code base, while the checkpoint of v0 is from older code base."
)
print(
"You must upgrade the checkpoint to the new code base (this can be done automatically)."
)
confirm = input("Please confirm that you want to upgrade the checkpoint. [Y/N]")
if confirm.lower() in ["y", "yes"]:
print("Upgrading checkpoint...")
assert len(cfg.architectures) == 1
setattr(cfg.__class__, "model_type", "llava")
cfg.architectures[0] = "LlavaLlamaForCausalLM"
cfg.save_pretrained(config)
print("Checkpoint upgraded.")
else:
print("Checkpoint upgrade aborted.")
exit(1)
================================================
FILE: model/llava/train/llama_flash_attn_monkey_patch.py
================================================
import logging
from typing import List, Optional, Tuple
import torch
import transformers
from einops import rearrange
from torch import nn
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
try:
from flash_attn.flash_attn_interface import \
flash_attn_unpadded_qkvpacked_func
except ImportError:
from flash_attn.flash_attn_interface import (
flash_attn_varlen_qkvpacked_func as flash_attn_unpadded_qkvpacked_func,
)
from flash_attn.bert_padding import pad_input, unpad_input
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel
attention_mask: [bsz, q_len]
"""
bsz, q_len, _ = hidden_states.size()
query_states = (
self.q_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
key_states = (
self.k_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
value_states = (
self.v_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
# [bsz, q_len, nh, hd]
# [bsz, nh, q_len, hd]
kv_seq_len = key_states.shape[-2]
assert past_key_value is None, "past_key_value is not supported"
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(
query_states, key_states, cos, sin, position_ids
)
# [bsz, nh, t, hd]
assert not output_attentions, "output_attentions is not supported"
assert not use_cache, "use_cache is not supported"
# Flash attention codes from
# https://github.com/HazyResearch/flash-attention/blob/main/flash_attn/flash_attention.py
# transform the data into the format required by flash attention
qkv = torch.stack(
[query_states, key_states, value_states], dim=2
) # [bsz, nh, 3, q_len, hd]
qkv = qkv.transpose(1, 3) # [bsz, q_len, 3, nh, hd]
# We have disabled _prepare_decoder_attention_mask in LlamaModel
# the attention_mask should be the same as the key_padding_mask
key_padding_mask = attention_mask
if key_padding_mask is None:
qkv = rearrange(qkv, "b s ... -> (b s) ...")
max_s = q_len
cu_q_lens = torch.arange(
0, (bsz + 1) * q_len, step=q_len, dtype=torch.int32, device=qkv.device
)
output = flash_attn_unpadded_qkvpacked_func(
qkv, cu_q_lens, max_s, 0.0, softmax_scale=None, causal=True
)
output = rearrange(output, "(b s) ... -> b s ...", b=bsz)
else:
nheads = qkv.shape[-2]
x = rearrange(qkv, "b s three h d -> b s (three h d)")
x_unpad, indices, cu_q_lens, max_s = unpad_input(x, key_padding_mask)
x_unpad = rearrange(
x_unpad, "nnz (three h d) -> nnz three h d", three=3, h=nheads
)
output_unpad = flash_attn_unpadded_qkvpacked_func(
x_unpad, cu_q_lens, max_s, 0.0, softmax_scale=None, causal=True
)
output = rearrange(
pad_input(
rearrange(output_unpad, "nnz h d -> nnz (h d)"), indices, bsz, q_len
),
"b s (h d) -> b s h d",
h=nheads,
)
return self.o_proj(rearrange(output, "b s h d -> b s (h d)")), None, None
# Disable the transformation of the attention mask in LlamaModel as the flash attention
# requires the attention mask to be the same as the key_padding_mask
def _prepare_decoder_attention_mask(
self, attention_mask, input_shape, inputs_embeds, past_key_values_length
):
# [bsz, seq_len]
return attention_mask
def replace_llama_attn_with_flash_attn():
cuda_major, cuda_minor = torch.cuda.get_device_capability()
if cuda_major < 8:
logging.warning(
"Flash attention is only supported on A100 or H100 GPU during training due to head dim > 64 backward."
"ref: https://github.com/HazyResearch/flash-attention/issues/190#issuecomment-1523359593"
)
transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = (
_prepare_decoder_attention_mask
)
transformers.models.llama.modeling_llama.LlamaAttention.forward = forward
================================================
FILE: model/llava/train/llava_trainer.py
================================================
import os
from typing import Optional
import torch
from transformers import Trainer
def maybe_zero_3(param, ignore_status=False, name=None):
from deepspeed import zero
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
if hasattr(param, "ds_id"):
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
if not ignore_status:
print(name, "no ignore status")
with zero.GatheredParameters([param]):
param = param.data.detach().cpu().clone()
else:
param = param.detach().cpu().clone()
return param
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
to_return = {
k: t
for k, t in named_params
if any(key_match in k for key_match in keys_to_match)
}
to_return = {
k: maybe_zero_3(v, ignore_status=True, name=k).cpu()
for k, v in to_return.items()
}
return to_return
class LLaVATrainer(Trainer):
def _save_checkpoint(self, model, trial, metrics=None):
if getattr(self.args, "tune_mm_mlp_adapter", False):
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
checkpoint_folder = f"{PREFIX_CHECKPOINT_DIR}-{self.state.global_step}"
run_dir = self._get_output_dir(trial=trial)
output_dir = os.path.join(run_dir, checkpoint_folder)
# Only save Adapter
keys_to_match = ["mm_projector"]
if getattr(self.args, "use_im_start_end", False):
keys_to_match.extend(["embed_tokens", "embed_in"])
weight_to_save = get_mm_adapter_state_maybe_zero_3(
self.model.named_parameters(), keys_to_match
)
if self.args.local_rank == 0 or self.args.local_rank == -1:
self.model.config.save_pretrained(output_dir)
torch.save(
weight_to_save, os.path.join(output_dir, f"mm_projector.bin")
)
else:
super(LLaVATrainer, self)._save_checkpoint(model, trial, metrics)
def _save(self, output_dir: Optional[str] = None, state_dict=None):
if getattr(self.args, "tune_mm_mlp_adapter", False):
pass
else:
super(LLaVATrainer, self)._save(output_dir, state_dict)
================================================
FILE: model/llava/train/train.py
================================================
# Adopted from https://github.com/lm-sys/FastChat. Below is the original copyright:
# Adopted from tatsu-lab@stanford_alpaca. Below is the original copyright:
# Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import json
import logging
import os
import pathlib
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Sequence
import torch
import transformers
from llava import conversation as conversation_lib
from llava.constants import (DEFAULT_IM_END_TOKEN, DEFAULT_IM_START_TOKEN,
DEFAULT_IMAGE_TOKEN, IGNORE_INDEX,
IMAGE_TOKEN_INDEX)
from llava.mm_utils import tokenizer_image_token
from llava.model import *
from llava.train.llava_trainer import LLaVATrainer
from PIL import Image
from torch.utils.data import Dataset
local_rank = None
def rank0_print(*args):
if local_rank == 0:
print(*args)
@dataclass
class ModelArguments:
model_name_or_path: Optional[str] = field(default="facebook/opt-125m")
version: Optional[str] = field(default="v0")
freeze_backbone: bool = field(default=False)
tune_mm_mlp_adapter: bool = field(default=False)
vision_tower: Optional[str] = field(default=None)
mm_vision_select_layer: Optional[int] = field(
default=-1
) # default to the last layer
pretrain_mm_mlp_adapter: Optional[str] = field(default=None)
mm_use_im_start_end: bool = field(default=False)
mm_use_im_patch_token: bool = field(default=True)
mm_vision_select_feature: Optional[str] = field(default="patch")
@dataclass
class DataArguments:
data_path: str = field(
default=None, metadata={"help": "Path to the training data."}
)
lazy_preprocess: bool = False
is_multimodal: bool = False
image_folder: Optional[str] = field(default=None)
image_aspect_ratio: str = "square"
image_grid_pinpoints: Optional[str] = field(default=None)
@dataclass
class TrainingArguments(transformers.TrainingArguments):
cache_dir: Optional[str] = field(default=None)
optim: str = field(default="adamw_torch")
remove_unused_columns: bool = field(default=False)
freeze_mm_mlp_adapter: bool = field(default=False)
mpt_attn_impl: Optional[str] = field(default="triton")
model_max_length: int = field(
default=512,
metadata={
"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."
},
)
double_quant: bool = field(
default=True,
metadata={
"help": "Compress the quantization statistics through double quantization."
},
)
quant_type: str = field(
default="nf4",
metadata={
"help": "Quantization data type to use. Should be one of `fp4` or `nf4`."
},
)
bits: int = field(default=16, metadata={"help": "How many bits to use."})
lora_enable: bool = False
lora_r: int = 64
lora_alpha: int = 16
lora_dropout: float = 0.05
lora_weight_path: str = ""
lora_bias: str = "none"
def maybe_zero_3(param, ignore_status=False, name=None):
from deepspeed import zero
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
if hasattr(param, "ds_id"):
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
if not ignore_status:
logging.warning(
f"{name}: param.ds_status != ZeroParamStatus.NOT_AVAILABLE: {param.ds_status}"
)
with zero.GatheredParameters([param]):
param = param.data.detach().cpu().clone()
else:
param = param.detach().cpu().clone()
return param
# Borrowed from peft.utils.get_peft_model_state_dict
def get_peft_state_maybe_zero_3(named_params, bias):
if bias == "none":
to_return = {k: t for k, t in named_params if "lora_" in k}
elif bias == "all":
to_return = {k: t for k, t in named_params if "lora_" in k or "bias" in k}
elif bias == "lora_only":
to_return = {}
maybe_lora_bias = {}
lora_bias_names = set()
for k, t in named_params:
if "lora_" in k:
to_return[k] = t
bias_name = k.split("lora_")[0] + "bias"
lora_bias_names.add(bias_name)
elif "bias" in k:
maybe_lora_bias[k] = t
for k, t in maybe_lora_bias:
if bias_name in lora_bias_names:
to_return[bias_name] = t
else:
raise NotImplementedError
to_return = {k: maybe_zero_3(v, name=k) for k, v in to_return.items()}
return to_return
def get_peft_state_non_lora_maybe_zero_3(named_params, require_grad_only=True):
to_return = {k: t for k, t in named_params if "lora_" not in k}
if require_grad_only:
to_return = {k: t for k, t in to_return.items() if t.requires_grad}
to_return = {
k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()
}
return to_return
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
to_return = {
k: t
for k, t in named_params
if any(key_match in k for key_match in keys_to_match)
}
to_return = {
k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()
}
return to_return
def find_all_linear_names(model):
cls = torch.nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split(".")
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if "lm_head" in lora_module_names: # needed for 16-bit
lora_module_names.remove("lm_head")
return list(lora_module_names)
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str):
"""Collects the state dict and dump to disk."""
if getattr(trainer.args, "tune_mm_mlp_adapter", False):
# Only save Adapter
keys_to_match = ["mm_projector"]
if getattr(trainer.args, "use_im_start_end", False):
keys_to_match.extend(["embed_tokens", "embed_in"])
weight_to_save = get_mm_adapter_state_maybe_zero_3(
trainer.model.named_parameters(), keys_to_match
)
trainer.model.config.save_pretrained(output_dir)
current_folder = output_dir.split("/")[-1]
parent_folder = os.path.dirname(output_dir)
if trainer.args.local_rank == 0 or trainer.args.local_rank == -1:
if current_folder.startswith("checkpoint-"):
mm_projector_folder = os.path.join(parent_folder, "mm_projector")
os.makedirs(mm_projector_folder, exist_ok=True)
torch.save(
weight_to_save,
os.path.join(mm_projector_folder, f"{current_folder}.bin"),
)
else:
torch.save(
weight_to_save, os.path.join(output_dir, f"mm_projector.bin")
)
return
if trainer.deepspeed:
torch.cuda.synchronize()
trainer.save_model(output_dir)
return
state_dict = trainer.model.state_dict()
if trainer.args.should_save:
cpu_state_dict = {key: value.cpu() for key, value in state_dict.items()}
del state_dict
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
def smart_tokenizer_and_embedding_resize(
special_tokens_dict: Dict,
tokenizer: transformers.PreTrainedTokenizer,
model: transformers.PreTrainedModel,
):
"""Resize tokenizer and embedding.
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
"""
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict)
model.resize_token_embeddings(len(tokenizer))
if num_new_tokens > 0:
input_embeddings = model.get_input_embeddings().weight.data
output_embeddings = model.get_output_embeddings().weight.data
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
dim=0, keepdim=True
)
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
dim=0, keepdim=True
)
input_embeddings[-num_new_tokens:] = input_embeddings_avg
output_embeddings[-num_new_tokens:] = output_embeddings_avg
def _tokenize_fn(
strings: Sequence[str], tokenizer: transformers.PreTrainedTokenizer
) -> Dict:
"""Tokenize a list of strings."""
tokenized_list = [
tokenizer(
text,
return_tensors="pt",
padding="longest",
max_length=tokenizer.model_max_length,
truncation=True,
)
for text in strings
]
input_ids = labels = [tokenized.input_ids[0] for tokenized in tokenized_list]
input_ids_lens = labels_lens = [
tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item()
for tokenized in tokenized_list
]
return dict(
input_ids=input_ids,
labels=labels,
input_ids_lens=input_ids_lens,
labels_lens=labels_lens,
)
def _mask_targets(target, tokenized_lens, speakers):
# cur_idx = 0
cur_idx = tokenized_lens[0]
tokenized_lens = tokenized_lens[1:]
target[:cur_idx] = IGNORE_INDEX
for tokenized_len, speaker in zip(tokenized_lens, speakers):
if speaker == "human":
target[cur_idx + 2 : cur_idx + tokenized_len] = IGNORE_INDEX
cur_idx += tokenized_len
def _add_speaker_and_signal(header, source, get_conversation=True):
"""Add speaker and start/end signal on each round."""
BEGIN_SIGNAL = "### "
END_SIGNAL = "\n"
conversation = header
for sentence in source:
from_str = sentence["from"]
if from_str.lower() == "human":
from_str = conversation_lib.default_conversation.roles[0]
elif from_str.lower() == "gpt":
from_str = conversation_lib.default_conversation.roles[1]
else:
from_str = "unknown"
sentence["value"] = (
BEGIN_SIGNAL + from_str + ": " + sentence["value"] + END_SIGNAL
)
if get_conversation:
conversation += sentence["value"]
conversation += BEGIN_SIGNAL
return conversation
def preprocess_multimodal(sources: Sequence[str], data_args: DataArguments) -> Dict:
is_multimodal = data_args.is_multimodal
if not is_multimodal:
return sources
for source in sources:
for sentence in source:
if DEFAULT_IMAGE_TOKEN in sentence["value"]:
sentence["value"] = (
sentence["value"].replace(DEFAULT_IMAGE_TOKEN, "").strip()
)
sentence["value"] = DEFAULT_IMAGE_TOKEN + "\n" + sentence["value"]
sentence["value"] = sentence["value"].strip()
if "mmtag" in conversation_lib.default_conversation.version:
sentence["value"] = sentence["value"].replace(
DEFAULT_IMAGE_TOKEN,
"" + DEFAULT_IMAGE_TOKEN + "",
)
replace_token = DEFAULT_IMAGE_TOKEN
if data_args.mm_use_im_start_end:
replace_token = (
DEFAULT_IM_START_TOKEN + replace_token + DEFAULT_IM_END_TOKEN
)
sentence["value"] = sentence["value"].replace(
DEFAULT_IMAGE_TOKEN, replace_token
)
return sources
def preprocess_llama_2(
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
) -> Dict:
conv = conversation_lib.default_conversation.copy()
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
# Apply prompt templates
conversations = []
for i, source in enumerate(sources):
if roles[source[0]["from"]] != conv.roles[0]:
# Skip the first one if it is not from human
source = source[1:]
conv.messages = []
for j, sentence in enumerate(source):
role = roles[sentence["from"]]
assert role == conv.roles[j % 2], f"{i}"
conv.append_message(role, sentence["value"])
conversations.append(conv.get_prompt())
# Tokenize conversations
if has_image:
input_ids = torch.stack(
[
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
for prompt in conversations
],
dim=0,
)
else:
input_ids = tokenizer(
conversations,
return_tensors="pt",
padding="longest",
max_length=tokenizer.model_max_length,
truncation=True,
).input_ids
targets = input_ids.clone()
assert conv.sep_style == conversation_lib.SeparatorStyle.LLAMA_2
# Mask targets
sep = "[/INST] "
for conversation, target in zip(conversations, targets):
total_len = int(target.ne(tokenizer.pad_token_id).sum())
rounds = conversation.split(conv.sep2)
cur_len = 1
target[:cur_len] = IGNORE_INDEX
for i, rou in enumerate(rounds):
if rou == "":
break
parts = rou.split(sep)
if len(parts) != 2:
break
parts[0] += sep
if has_image:
round_len = len(tokenizer_image_token(rou, tokenizer))
instruction_len = len(tokenizer_image_token(parts[0], tokenizer)) - 2
else:
round_len = len(tokenizer(rou).input_ids)
instruction_len = len(tokenizer(parts[0]).input_ids) - 2
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
cur_len += round_len
target[cur_len:] = IGNORE_INDEX
if cur_len < tokenizer.model_max_length:
if cur_len != total_len:
target[:] = IGNORE_INDEX
print(
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
f" (ignored)"
)
return dict(
input_ids=input_ids,
labels=targets,
)
def preprocess_v1(
sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False
) -> Dict:
conv = conversation_lib.default_conversation.copy()
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
# Apply prompt templates
conversations = []
for i, source in enumerate(sources):
if roles[source[0]["from"]] != conv.roles[0]:
# Skip the first one if it is not from human
source = source[1:]
conv.messages = []
for j, sentence in enumerate(source):
role = roles[sentence["from"]]
assert role == conv.roles[j % 2], f"{i}"
conv.append_message(role, sentence["value"])
conversations.append(conv.get_prompt())
# Tokenize conversations
if has_image:
input_ids = torch.stack(
[
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
for prompt in conversations
],
dim=0,
)
else:
input_ids = tokenizer(
conversations,
return_tensors="pt",
padding="longest",
max_length=tokenizer.model_max_length,
truncation=True,
).input_ids
targets = input_ids.clone()
assert conv.sep_style == conversation_lib.SeparatorStyle.TWO
# Mask targets
sep = conv.sep + conv.roles[1] + ": "
for conversation, target in zip(conversations, targets):
total_len = int(target.ne(tokenizer.pad_token_id).sum())
rounds = conversation.split(conv.sep2)
cur_len = 1
target[:cur_len] = IGNORE_INDEX
for i, rou in enumerate(rounds):
if rou == "":
break
parts = rou.split(sep)
if len(parts) != 2:
break
parts[0] += sep
if has_image:
round_len = len(tokenizer_image_token(rou, tokenizer))
instruction_len = len(tokenizer_image_token(parts[0], tokenizer)) - 2
else:
round_len = len(tokenizer(rou).input_ids)
instruction_len = len(tokenizer(parts[0]).input_ids) - 2
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
cur_len += round_len
target[cur_len:] = IGNORE_INDEX
if cur_len < tokenizer.model_max_length:
if cur_len != total_len:
target[:] = IGNORE_INDEX
print(
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
f" (ignored)"
)
return dict(
input_ids=input_ids,
labels=targets,
)
def preprocess_mpt(
sources,
tokenizer: transformers.PreTrainedTokenizer,
) -> Dict:
conv = conversation_lib.default_conversation.copy()
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
# Apply prompt templates
conversations = []
for i, source in enumerate(sources):
if roles[source[0]["from"]] != conv.roles[0]:
# Skip the first one if it is not from human
source = source[1:]
conv.messages = []
for j, sentence in enumerate(source):
role = roles[sentence["from"]]
assert role == conv.roles[j % 2], f"{i}"
conv.append_message(role, sentence["value"])
conversations.append(conv.get_prompt())
# Tokenize conversations
input_ids = torch.stack(
[
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
for prompt in conversations
],
dim=0,
)
targets = input_ids.clone()
assert conv.sep_style == conversation_lib.SeparatorStyle.MPT
# Mask targets
sep = conv.sep + conv.roles[1]
for conversation, target in zip(conversations, targets):
total_len = int(target.ne(tokenizer.pad_token_id).sum())
rounds = conversation.split(conv.sep)
re_rounds = [conv.sep.join(rounds[:3])] # system + user + gpt
for conv_idx in range(3, len(rounds), 2):
re_rounds.append(
conv.sep.join(rounds[conv_idx : conv_idx + 2])
) # user + gpt
cur_len = 0
target[:cur_len] = IGNORE_INDEX
for i, rou in enumerate(re_rounds):
if rou == "":
break
parts = rou.split(sep)
if len(parts) != 2:
break
parts[0] += sep
round_len = len(tokenizer_image_token(rou, tokenizer)) + len(
tokenizer_image_token(conv.sep, tokenizer)
)
instruction_len = len(tokenizer_image_token(parts[0], tokenizer))
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
cur_len += round_len
target[cur_len:] = IGNORE_INDEX
if cur_len < tokenizer.model_max_length:
if cur_len != total_len:
target[:] = IGNORE_INDEX
print(
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
f" (ignored)"
)
return dict(
input_ids=input_ids,
labels=targets,
)
def preprocess_plain(
sources: Sequence[str],
tokenizer: transformers.PreTrainedTokenizer,
) -> Dict:
# add end signal and concatenate together
conversations = []
for source in sources:
assert len(source) == 2
assert DEFAULT_IMAGE_TOKEN in source[0]["value"]
source[0]["value"] = DEFAULT_IMAGE_TOKEN
conversation = (
source[0]["value"]
+ source[1]["value"]
+ conversation_lib.default_conversation.sep
)
conversations.append(conversation)
# tokenize conversations
input_ids = [
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
for prompt in conversations
]
targets = copy.deepcopy(input_ids)
for target, source in zip(targets, sources):
tokenized_len = len(tokenizer_image_token(source[0]["value"], tokenizer))
target[:tokenized_len] = IGNORE_INDEX
return dict(input_ids=input_ids, labels=targets)
def preprocess(
sources: Sequence[str],
tokenizer: transformers.PreTrainedTokenizer,
has_image: bool = False,
) -> Dict:
"""
Given a list of sources, each is a conversation list. This transform:
1. Add signal '### ' at the beginning each sentence, with end signal '\n';
2. Concatenate conversations together;
3. Tokenize the concatenated conversation;
4. Make a deepcopy as the target. Mask human words with IGNORE_INDEX.
"""
if (
conversation_lib.default_conversation.sep_style
== conversation_lib.SeparatorStyle.PLAIN
):
return preprocess_plain(sources, tokenizer)
if (
conversation_lib.default_conversation.sep_style
== conversation_lib.SeparatorStyle.LLAMA_2
):
return preprocess_llama_2(sources, tokenizer, has_image=has_image)
if conversation_lib.default_conversation.version.startswith("v1"):
return preprocess_v1(sources, tokenizer, has_image=has_image)
if conversation_lib.default_conversation.version == "mpt":
return preprocess_mpt(sources, tokenizer)
# add end signal and concatenate together
conversations = []
for source in sources:
header = f"{conversation_lib.default_conversation.system}\n\n"
conversation = _add_speaker_and_signal(header, source)
conversations.append(conversation)
# tokenize conversations
def get_tokenize_len(prompts):
return [len(tokenizer_image_token(prompt, tokenizer)) for prompt in prompts]
if has_image:
input_ids = [
tokenizer_image_token(prompt, tokenizer, return_tensors="pt")
for prompt in conversations
]
else:
conversations_tokenized = _tokenize_fn(conversations, tokenizer)
input_ids = conversations_tokenized["input_ids"]
targets = copy.deepcopy(input_ids)
for target, source in zip(targets, sources):
if has_image:
tokenized_lens = get_tokenize_len([header] + [s["value"] for s in source])
else:
tokenized_lens = _tokenize_fn(
[header] + [s["value"] for s in source], tokenizer
)["input_ids_lens"]
speakers = [sentence["from"] for sentence in source]
_mask_targets(target, tokenized_lens, speakers)
return dict(input_ids=input_ids, labels=targets)
class LazySupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(
self,
data_path: str,
tokenizer: transformers.PreTrainedTokenizer,
data_args: DataArguments,
):
super(LazySupervisedDataset, self).__init__()
list_data_dict = json.load(open(data_path, "r"))
rank0_print("Formatting inputs...Skip in lazy mode")
self.tokenizer = tokenizer
self.list_data_dict = list_data_dict
self.data_args = data_args
def __len__(self):
return len(self.list_data_dict)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
sources = self.list_data_dict[i]
if isinstance(i, int):
sources = [sources]
assert len(sources) == 1, "Don't know why it is wrapped to a list" # FIXME
if "image" in sources[0]:
image_file = self.list_data_dict[i]["image"]
image_folder = self.data_args.image_folder
processor = self.data_args.image_processor
image = Image.open(os.path.join(image_folder, image_file)).convert("RGB")
if self.data_args.image_aspect_ratio == "pad":
def expand2square(pil_img, background_color):
width, height = pil_img.size
if width == height:
return pil_img
elif width > height:
result = Image.new(
pil_img.mode, (width, width), background_color
)
result.paste(pil_img, (0, (width - height) // 2))
return result
else:
result = Image.new(
pil_img.mode, (height, height), background_color
)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(
image, tuple(int(x * 255) for x in processor.image_mean)
)
image = processor.preprocess(image, return_tensors="pt")[
"pixel_values"
][0]
else:
image = processor.preprocess(image, return_tensors="pt")[
"pixel_values"
][0]
sources = preprocess_multimodal(
copy.deepcopy([e["conversations"] for e in sources]), self.data_args
)
else:
sources = copy.deepcopy([e["conversations"] for e in sources])
data_dict = preprocess(
sources, self.tokenizer, has_image=("image" in self.list_data_dict[i])
)
if isinstance(i, int):
data_dict = dict(
input_ids=data_dict["input_ids"][0], labels=data_dict["labels"][0]
)
# image exist in the data
if "image" in self.list_data_dict[i]:
data_dict["image"] = image
elif self.data_args.is_multimodal:
# image does not exist in the data, but the model is multimodal
crop_size = self.data_args.image_processor.crop_size
data_dict["image"] = torch.zeros(3, crop_size["height"], crop_size["width"])
return data_dict
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: transformers.PreTrainedTokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
input_ids, labels = tuple(
[instance[key] for instance in instances] for key in ("input_ids", "labels")
)
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
)
labels = torch.nn.utils.rnn.pad_sequence(
labels, batch_first=True, padding_value=IGNORE_INDEX
)
input_ids = input_ids[:, : self.tokenizer.model_max_length]
labels = labels[:, : self.tokenizer.model_max_length]
batch = dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
if "image" in instances[0]:
images = [instance["image"] for instance in instances]
if all(x is not None and x.shape == images[0].shape for x in images):
batch["images"] = torch.stack(images)
else:
batch["images"] = images
return batch
def make_supervised_data_module(
tokenizer: transformers.PreTrainedTokenizer, data_args
) -> Dict:
"""Make dataset and collator for supervised fine-tuning."""
train_dataset = LazySupervisedDataset(
tokenizer=tokenizer, data_path=data_args.data_path, data_args=data_args
)
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
return dict(
train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator
)
def train():
global local_rank
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments)
)
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
local_rank = training_args.local_rank
compute_dtype = (
torch.float16
if training_args.fp16
else (torch.bfloat16 if training_args.bf16 else torch.float32)
)
bnb_model_from_pretrained_args = {}
if training_args.bits in [4, 8]:
from transformers import BitsAndBytesConfig
bnb_model_from_pretrained_args.update(
dict(
device_map={"": training_args.device},
load_in_4bit=training_args.bits == 4,
load_in_8bit=training_args.bits == 8,
quantization_config=BitsAndBytesConfig(
load_in_4bit=training_args.bits == 4,
load_in_8bit=training_args.bits == 8,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=training_args.double_quant,
bnb_4bit_quant_type=training_args.quant_type, # {'fp4', 'nf4'}
),
)
)
if model_args.vision_tower is not None:
if "mpt" in model_args.model_name_or_path:
config = transformers.AutoConfig.from_pretrained(
model_args.model_name_or_path, trust_remote_code=True
)
config.attn_config["attn_impl"] = training_args.mpt_attn_impl
model = LlavaMPTForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args,
)
else:
model = LlavaLlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args,
)
else:
model = transformers.LlamaForCausalLM.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args,
)
model.config.use_cache = False
if model_args.freeze_backbone:
model.model.requires_grad_(False)
if training_args.bits in [4, 8]:
from peft import prepare_model_for_kbit_training
model.config.torch_dtype = (
torch.float32
if training_args.fp16
else (torch.bfloat16 if training_args.bf16 else torch.float32)
)
model = prepare_model_for_kbit_training(
model, use_gradient_checkpointing=training_args.gradient_checkpointing
)
if training_args.gradient_checkpointing:
if hasattr(model, "enable_input_require_grads"):
model.enable_input_require_grads()
else:
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
if training_args.lora_enable:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=training_args.lora_r,
lora_alpha=training_args.lora_alpha,
target_modules=find_all_linear_names(model),
lora_dropout=training_args.lora_dropout,
bias=training_args.lora_bias,
task_type="CAUSAL_LM",
)
if training_args.bits == 16:
if training_args.bf16:
model.to(torch.bfloat16)
if training_args.fp16:
model.to(torch.float16)
rank0_print("Adding LoRA adapters...")
model = get_peft_model(model, lora_config)
if "mpt" in model_args.model_name_or_path:
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
)
else:
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
)
if model_args.version == "v0":
if tokenizer.pad_token is None:
smart_tokenizer_and_embedding_resize(
special_tokens_dict=dict(pad_token="[PAD]"),
tokenizer=tokenizer,
model=model,
)
elif model_args.version == "v0.5":
tokenizer.pad_token = tokenizer.unk_token
else:
tokenizer.pad_token = tokenizer.unk_token
if model_args.version in conversation_lib.conv_templates:
conversation_lib.default_conversation = conversation_lib.conv_templates[
model_args.version
]
else:
conversation_lib.default_conversation = conversation_lib.conv_templates[
"vicuna_v1"
]
if model_args.vision_tower is not None:
model.get_model().initialize_vision_modules(
model_args=model_args, fsdp=training_args.fsdp
)
vision_tower = model.get_vision_tower()
vision_tower.to(dtype=torch.float16, device=training_args.device)
data_args.image_processor = vision_tower.image_processor
data_args.is_multimodal = True
model.config.image_aspect_ratio = data_args.image_aspect_ratio
model.config.image_grid_pinpoints = data_args.image_grid_pinpoints
model.config.tune_mm_mlp_adapter = (
training_args.tune_mm_mlp_adapter
) = model_args.tune_mm_mlp_adapter
if model_args.tune_mm_mlp_adapter:
model.requires_grad_(False)
for p in model.get_model().mm_projector.parameters():
p.requires_grad = True
model.config.freeze_mm_mlp_adapter = training_args.freeze_mm_mlp_adapter
if training_args.freeze_mm_mlp_adapter:
for p in model.get_model().mm_projector.parameters():
p.requires_grad = False
if training_args.bits in [4, 8]:
model.get_model().mm_projector.to(
dtype=compute_dtype, device=training_args.device
)
model.config.mm_use_im_start_end = (
data_args.mm_use_im_start_end
) = model_args.mm_use_im_start_end
training_args.use_im_start_end = model_args.mm_use_im_start_end
model.config.mm_use_im_patch_token = model_args.mm_use_im_patch_token
model.initialize_vision_tokenizer(model_args, tokenizer=tokenizer)
if training_args.bits in [4, 8]:
from peft.tuners.lora import LoraLayer
for name, module in model.named_modules():
if isinstance(module, LoraLayer):
if training_args.bf16:
module = module.to(torch.bfloat16)
if "norm" in name:
module = module.to(torch.float32)
if "lm_head" in name or "embed_tokens" in name:
if hasattr(module, "weight"):
if training_args.bf16 and module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
data_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args)
trainer = LLaVATrainer(
model=model, tokenizer=tokenizer, args=training_args, **data_module
)
if list(pathlib.Path(training_args.output_dir).glob("checkpoint-*")):
trainer.train(resume_from_checkpoint=True)
else:
trainer.train()
trainer.save_state()
model.config.use_cache = True
if training_args.lora_enable:
state_dict = get_peft_state_maybe_zero_3(
model.named_parameters(), training_args.lora_bias
)
non_lora_state_dict = get_peft_state_non_lora_maybe_zero_3(
model.named_parameters()
)
if training_args.local_rank == 0 or training_args.local_rank == -1:
model.config.save_pretrained(training_args.output_dir)
model.save_pretrained(training_args.output_dir, state_dict=state_dict)
torch.save(
non_lora_state_dict,
os.path.join(training_args.output_dir, "non_lora_trainables.bin"),
)
else:
safe_save_model_for_hf_trainer(
trainer=trainer, output_dir=training_args.output_dir
)
if __name__ == "__main__":
train()
================================================
FILE: model/llava/train/train_mem.py
================================================
# Adopted from https://github.com/lm-sys/FastChat. Below is the original copyright:
# Adopted from tatsu-lab@stanford_alpaca. Below is the original copyright:
# Make it more memory efficient by monkey patching the LLaMA model with FlashAttn.
# Need to call this before importing transformers.
from llava.train.llama_flash_attn_monkey_patch import \
replace_llama_attn_with_flash_attn
replace_llama_attn_with_flash_attn()
from llava.train.train import train
if __name__ == "__main__":
train()
================================================
FILE: model/llava/utils.py
================================================
import datetime
import logging
import logging.handlers
import os
import sys
import requests
from llava.constants import LOGDIR
server_error_msg = (
"**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**"
)
moderation_msg = (
"YOUR INPUT VIOLATES OUR CONTENT MODERATION GUIDELINES. PLEASE TRY AGAIN."
)
handler = None
def build_logger(logger_name, logger_filename):
global handler
formatter = logging.Formatter(
fmt="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
# Set the format of root handlers
if not logging.getLogger().handlers:
logging.basicConfig(level=logging.INFO)
logging.getLogger().handlers[0].setFormatter(formatter)
# Redirect stdout and stderr to loggers
stdout_logger = logging.getLogger("stdout")
stdout_logger.setLevel(logging.INFO)
sl = StreamToLogger(stdout_logger, logging.INFO)
sys.stdout = sl
stderr_logger = logging.getLogger("stderr")
stderr_logger.setLevel(logging.ERROR)
sl = StreamToLogger(stderr_logger, logging.ERROR)
sys.stderr = sl
# Get logger
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)
# Add a file handler for all loggers
if handler is None:
os.makedirs(LOGDIR, exist_ok=True)
filename = os.path.join(LOGDIR, logger_filename)
handler = logging.handlers.TimedRotatingFileHandler(
filename, when="D", utc=True
)
handler.setFormatter(formatter)
for name, item in logging.root.manager.loggerDict.items():
if isinstance(item, logging.Logger):
item.addHandler(handler)
return logger
class StreamToLogger(object):
"""
Fake file-like stream object that redirects writes to a logger instance.
"""
def __init__(self, logger, log_level=logging.INFO):
self.terminal = sys.stdout
self.logger = logger
self.log_level = log_level
self.linebuf = ""
def __getattr__(self, attr):
return getattr(self.terminal, attr)
def write(self, buf):
temp_linebuf = self.linebuf + buf
self.linebuf = ""
for line in temp_linebuf.splitlines(True):
# From the io.TextIOWrapper docs:
# On output, if newline is None, any '\n' characters written
# are translated to the system default line separator.
# By default sys.stdout.write() expects '\n' newlines and then
# translates them so this is still cross platform.
if line[-1] == "\n":
self.logger.log(self.log_level, line.rstrip())
else:
self.linebuf += line
def flush(self):
if self.linebuf != "":
self.logger.log(self.log_level, self.linebuf.rstrip())
self.linebuf = ""
def disable_torch_init():
"""
Disable the redundant torch default initialization to accelerate model creation.
"""
import torch
setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
def violates_moderation(text):
"""
Check whether the text violates OpenAI moderation API.
"""
url = "https://api.openai.com/v1/moderations"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + os.environ["OPENAI_API_KEY"],
}
text = text.replace("\n", "")
data = "{" + '"input": ' + f'"{text}"' + "}"
data = data.encode("utf-8")
try:
ret = requests.post(url, headers=headers, data=data, timeout=5)
flagged = ret.json()["results"][0]["flagged"]
except requests.exceptions.RequestException as e:
flagged = False
except KeyError as e:
flagged = False
return flagged
def pretty_print_semaphore(semaphore):
if semaphore is None:
return "None"
return f"Semaphore(value={semaphore._value}, locked={semaphore.locked()})"
================================================
FILE: model/segment_anything/__init__.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from .automatic_mask_generator import SamAutomaticMaskGenerator
from .build_sam import (build_sam, build_sam_vit_b, build_sam_vit_h,
build_sam_vit_l, sam_model_registry)
from .predictor import SamPredictor
================================================
FILE: model/segment_anything/automatic_mask_generator.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Any, Dict, List, Optional, Tuple
import numpy as np
import torch
from torchvision.ops.boxes import batched_nms, box_area # type: ignore
from .modeling import Sam
from .predictor import SamPredictor
from .utils.amg import (MaskData, area_from_rle, batch_iterator,
batched_mask_to_box, box_xyxy_to_xywh,
build_all_layer_point_grids, calculate_stability_score,
coco_encode_rle, generate_crop_boxes,
is_box_near_crop_edge, mask_to_rle_pytorch,
remove_small_regions, rle_to_mask, uncrop_boxes_xyxy,
uncrop_masks, uncrop_points)
class SamAutomaticMaskGenerator:
def __init__(
self,
model: Sam,
points_per_side: Optional[int] = 32,
points_per_batch: int = 64,
pred_iou_thresh: float = 0.88,
stability_score_thresh: float = 0.95,
stability_score_offset: float = 1.0,
box_nms_thresh: float = 0.7,
crop_n_layers: int = 0,
crop_nms_thresh: float = 0.7,
crop_overlap_ratio: float = 512 / 1500,
crop_n_points_downscale_factor: int = 1,
point_grids: Optional[List[np.ndarray]] = None,
min_mask_region_area: int = 0,
output_mode: str = "binary_mask",
) -> None:
"""
Using a SAM model, generates masks for the entire image.
Generates a grid of point prompts over the image, then filters
low quality and duplicate masks. The default settings are chosen
for SAM with a ViT-H backbone.
Arguments:
model (Sam): The SAM model to use for mask prediction.
points_per_side (int or None): The number of points to be sampled
along one side of the image. The total number of points is
points_per_side**2. If None, 'point_grids' must provide explicit
point sampling.
points_per_batch (int): Sets the number of points run simultaneously
by the model. Higher numbers may be faster but use more GPU memory.
pred_iou_thresh (float): A filtering threshold in [0,1], using the
model's predicted mask quality.
stability_score_thresh (float): A filtering threshold in [0,1], using
the stability of the mask under changes to the cutoff used to binarize
the model's mask predictions.
stability_score_offset (float): The amount to shift the cutoff when
calculated the stability score.
box_nms_thresh (float): The box IoU cutoff used by non-maximal
suppression to filter duplicate masks.
crop_n_layers (int): If >0, mask prediction will be run again on
crops of the image. Sets the number of layers to run, where each
layer has 2**i_layer number of image crops.
crop_nms_thresh (float): The box IoU cutoff used by non-maximal
suppression to filter duplicate masks between different crops.
crop_overlap_ratio (float): Sets the degree to which crops overlap.
In the first crop layer, crops will overlap by this fraction of
the image length. Later layers with more crops scale down this overlap.
crop_n_points_downscale_factor (int): The number of points-per-side
sampled in layer n is scaled down by crop_n_points_downscale_factor**n.
point_grids (list(np.ndarray) or None): A list over explicit grids
of points used for sampling, normalized to [0,1]. The nth grid in the
list is used in the nth crop layer. Exclusive with points_per_side.
min_mask_region_area (int): If >0, postprocessing will be applied
to remove disconnected regions and holes in masks with area smaller
than min_mask_region_area. Requires opencv.
output_mode (str): The form masks are returned in. Can be 'binary_mask',
'uncompressed_rle', or 'coco_rle'. 'coco_rle' requires pycocotools.
For large resolutions, 'binary_mask' may consume large amounts of
memory.
"""
assert (points_per_side is None) != (
point_grids is None
), "Exactly one of points_per_side or point_grid must be provided."
if points_per_side is not None:
self.point_grids = build_all_layer_point_grids(
points_per_side,
crop_n_layers,
crop_n_points_downscale_factor,
)
elif point_grids is not None:
self.point_grids = point_grids
else:
raise ValueError("Can't have both points_per_side and point_grid be None.")
assert output_mode in [
"binary_mask",
"uncompressed_rle",
"coco_rle",
], f"Unknown output_mode {output_mode}."
if output_mode == "coco_rle":
from pycocotools import \
mask as mask_utils # type: ignore # noqa: F401
if min_mask_region_area > 0:
import cv2 # type: ignore # noqa: F401
self.predictor = SamPredictor(model)
self.points_per_batch = points_per_batch
self.pred_iou_thresh = pred_iou_thresh
self.stability_score_thresh = stability_score_thresh
self.stability_score_offset = stability_score_offset
self.box_nms_thresh = box_nms_thresh
self.crop_n_layers = crop_n_layers
self.crop_nms_thresh = crop_nms_thresh
self.crop_overlap_ratio = crop_overlap_ratio
self.crop_n_points_downscale_factor = crop_n_points_downscale_factor
self.min_mask_region_area = min_mask_region_area
self.output_mode = output_mode
@torch.no_grad()
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
"""
Generates masks for the given image.
Arguments:
image (np.ndarray): The image to generate masks for, in HWC uint8 format.
Returns:
list(dict(str, any)): A list over records for masks. Each record is
a dict containing the following keys:
segmentation (dict(str, any) or np.ndarray): The mask. If
output_mode='binary_mask', is an array of shape HW. Otherwise,
is a dictionary containing the RLE.
bbox (list(float)): The box around the mask, in XYWH format.
area (int): The area in pixels of the mask.
predicted_iou (float): The model's own prediction of the mask's
quality. This is filtered by the pred_iou_thresh parameter.
point_coords (list(list(float))): The point coordinates input
to the model to generate this mask.
stability_score (float): A measure of the mask's quality. This
is filtered on using the stability_score_thresh parameter.
crop_box (list(float)): The crop of the image used to generate
the mask, given in XYWH format.
"""
# Generate masks
mask_data = self._generate_masks(image)
# Filter small disconnected regions and holes in masks
if self.min_mask_region_area > 0:
mask_data = self.postprocess_small_regions(
mask_data,
self.min_mask_region_area,
max(self.box_nms_thresh, self.crop_nms_thresh),
)
# Encode masks
if self.output_mode == "coco_rle":
mask_data["segmentations"] = [
coco_encode_rle(rle) for rle in mask_data["rles"]
]
elif self.output_mode == "binary_mask":
mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]
else:
mask_data["segmentations"] = mask_data["rles"]
# Write mask records
curr_anns = []
for idx in range(len(mask_data["segmentations"])):
ann = {
"segmentation": mask_data["segmentations"][idx],
"area": area_from_rle(mask_data["rles"][idx]),
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
"predicted_iou": mask_data["iou_preds"][idx].item(),
"point_coords": [mask_data["points"][idx].tolist()],
"stability_score": mask_data["stability_score"][idx].item(),
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
}
curr_anns.append(ann)
return curr_anns
def _generate_masks(self, image: np.ndarray) -> MaskData:
orig_size = image.shape[:2]
crop_boxes, layer_idxs = generate_crop_boxes(
orig_size, self.crop_n_layers, self.crop_overlap_ratio
)
# Iterate over image crops
data = MaskData()
for crop_box, layer_idx in zip(crop_boxes, layer_idxs):
crop_data = self._process_crop(image, crop_box, layer_idx, orig_size)
data.cat(crop_data)
# Remove duplicate masks between crops
if len(crop_boxes) > 1:
# Prefer masks from smaller crops
scores = 1 / box_area(data["crop_boxes"])
scores = scores.to(data["boxes"].device)
keep_by_nms = batched_nms(
data["boxes"].float(),
scores,
torch.zeros_like(data["boxes"][:, 0]), # categories
iou_threshold=self.crop_nms_thresh,
)
data.filter(keep_by_nms)
data.to_numpy()
return data
def _process_crop(
self,
image: np.ndarray,
crop_box: List[int],
crop_layer_idx: int,
orig_size: Tuple[int, ...],
) -> MaskData:
# Crop the image and calculate embeddings
x0, y0, x1, y1 = crop_box
cropped_im = image[y0:y1, x0:x1, :]
cropped_im_size = cropped_im.shape[:2]
self.predictor.set_image(cropped_im)
# Get points for this crop
points_scale = np.array(cropped_im_size)[None, ::-1]
points_for_image = self.point_grids[crop_layer_idx] * points_scale
# Generate masks for this crop in batches
data = MaskData()
for (points,) in batch_iterator(self.points_per_batch, points_for_image):
batch_data = self._process_batch(
points, cropped_im_size, crop_box, orig_size
)
data.cat(batch_data)
del batch_data
self.predictor.reset_image()
# Remove duplicates within this crop.
keep_by_nms = batched_nms(
data["boxes"].float(),
data["iou_preds"],
torch.zeros_like(data["boxes"][:, 0]), # categories
iou_threshold=self.box_nms_thresh,
)
data.filter(keep_by_nms)
# Return to the original image frame
data["boxes"] = uncrop_boxes_xyxy(data["boxes"], crop_box)
data["points"] = uncrop_points(data["points"], crop_box)
data["crop_boxes"] = torch.tensor([crop_box for _ in range(len(data["rles"]))])
return data
def _process_batch(
self,
points: np.ndarray,
im_size: Tuple[int, ...],
crop_box: List[int],
orig_size: Tuple[int, ...],
) -> MaskData:
orig_h, orig_w = orig_size
# Run model on this batch
transformed_points = self.predictor.transform.apply_coords(points, im_size)
in_points = torch.as_tensor(transformed_points, device=self.predictor.device)
in_labels = torch.ones(
in_points.shape[0], dtype=torch.int, device=in_points.device
)
masks, iou_preds, _ = self.predictor.predict_torch(
in_points[:, None, :],
in_labels[:, None],
multimask_output=True,
return_logits=True,
)
# Serialize predictions and store in MaskData
data = MaskData(
masks=masks.flatten(0, 1),
iou_preds=iou_preds.flatten(0, 1),
points=torch.as_tensor(points.repeat(masks.shape[1], axis=0)),
)
del masks
# Filter by predicted IoU
if self.pred_iou_thresh > 0.0:
keep_mask = data["iou_preds"] > self.pred_iou_thresh
data.filter(keep_mask)
# Calculate stability score
data["stability_score"] = calculate_stability_score(
data["masks"],
self.predictor.model.mask_threshold,
self.stability_score_offset,
)
if self.stability_score_thresh > 0.0:
keep_mask = data["stability_score"] >= self.stability_score_thresh
data.filter(keep_mask)
# Threshold masks and calculate boxes
data["masks"] = data["masks"] > self.predictor.model.mask_threshold
data["boxes"] = batched_mask_to_box(data["masks"])
# Filter boxes that touch crop boundaries
keep_mask = ~is_box_near_crop_edge(
data["boxes"], crop_box, [0, 0, orig_w, orig_h]
)
if not torch.all(keep_mask):
data.filter(keep_mask)
# Compress to RLE
data["masks"] = uncrop_masks(data["masks"], crop_box, orig_h, orig_w)
data["rles"] = mask_to_rle_pytorch(data["masks"])
del data["masks"]
return data
@staticmethod
def postprocess_small_regions(
mask_data: MaskData, min_area: int, nms_thresh: float
) -> MaskData:
"""
Removes small disconnected regions and holes in masks, then reruns
box NMS to remove any new duplicates.
Edits mask_data in place.
Requires open-cv as a dependency.
"""
if len(mask_data["rles"]) == 0:
return mask_data
# Filter small disconnected regions and holes
new_masks = []
scores = []
for rle in mask_data["rles"]:
mask = rle_to_mask(rle)
mask, changed = remove_small_regions(mask, min_area, mode="holes")
unchanged = not changed
mask, changed = remove_small_regions(mask, min_area, mode="islands")
unchanged = unchanged and not changed
new_masks.append(torch.as_tensor(mask).unsqueeze(0))
# Give score=0 to changed masks and score=1 to unchanged masks
# so NMS will prefer ones that didn't need postprocessing
scores.append(float(unchanged))
# Recalculate boxes and remove any new duplicates
masks = torch.cat(new_masks, dim=0)
boxes = batched_mask_to_box(masks)
keep_by_nms = batched_nms(
boxes.float(),
torch.as_tensor(scores),
torch.zeros_like(boxes[:, 0]), # categories
iou_threshold=nms_thresh,
)
# Only recalculate RLEs for masks that have changed
for i_mask in keep_by_nms:
if scores[i_mask] == 0.0:
mask_torch = masks[i_mask].unsqueeze(0)
mask_data["rles"][i_mask] = mask_to_rle_pytorch(mask_torch)[0]
mask_data["boxes"][i_mask] = boxes[i_mask] # update res directly
mask_data.filter(keep_by_nms)
return mask_data
================================================
FILE: model/segment_anything/build_sam.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from functools import partial
import torch
from .modeling import (ImageEncoderViT, MaskDecoder, PromptEncoder, Sam,
TwoWayTransformer)
def build_sam_vit_h(checkpoint=None):
return _build_sam(
encoder_embed_dim=1280,
encoder_depth=32,
encoder_num_heads=16,
encoder_global_attn_indexes=[7, 15, 23, 31],
checkpoint=checkpoint,
)
build_sam = build_sam_vit_h
def build_sam_vit_l(checkpoint=None):
return _build_sam(
encoder_embed_dim=1024,
encoder_depth=24,
encoder_num_heads=16,
encoder_global_attn_indexes=[5, 11, 17, 23],
checkpoint=checkpoint,
)
def build_sam_vit_b(checkpoint=None):
return _build_sam(
encoder_embed_dim=768,
encoder_depth=12,
encoder_num_heads=12,
encoder_global_attn_indexes=[2, 5, 8, 11],
checkpoint=checkpoint,
)
sam_model_registry = {
"default": build_sam_vit_h,
"vit_h": build_sam_vit_h,
"vit_l": build_sam_vit_l,
"vit_b": build_sam_vit_b,
}
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
sam = Sam(
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f)
sam.load_state_dict(state_dict, strict=False)
return sam
================================================
FILE: model/segment_anything/modeling/__init__.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
from .sam import Sam
from .transformer import TwoWayTransformer
================================================
FILE: model/segment_anything/modeling/common.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Type
import torch
import torch.nn as nn
class MLPBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
mlp_dim: int,
act: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
self.act = act()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.lin2(self.act(self.lin1(x)))
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
================================================
FILE: model/segment_anything/modeling/image_encoder.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Optional, Tuple, Type
import torch
import torch.nn as nn
import torch.nn.functional as F
from .common import LayerNorm2d, MLPBlock
# This class and its supporting functions below lightly adapted from the ViTDet backbone available at: https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/vit.py # noqa
class ImageEncoderViT(nn.Module):
def __init__(
self,
img_size: int = 1024,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 12,
mlp_ratio: float = 4.0,
out_chans: int = 256,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_abs_pos: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
global_attn_indexes: Tuple[int, ...] = (),
) -> None:
"""
Args:
img_size (int): Input image size.
patch_size (int): Patch size.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
depth (int): Depth of ViT.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_abs_pos (bool): If True, use absolute positional embeddings.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks.
global_attn_indexes (list): Indexes for blocks using global attention.
"""
super().__init__()
self.img_size = img_size
self.embed_dim = embed_dim
self.out_chans = out_chans
self.patch_embed = PatchEmbed(
kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size),
in_chans=in_chans,
embed_dim=embed_dim,
)
self.pos_embed: Optional[nn.Parameter] = None
if use_abs_pos:
# Initialize absolute positional embedding with pretrain image size.
self.pos_embed = nn.Parameter(
torch.zeros(
1, img_size // patch_size, img_size // patch_size, embed_dim
)
)
self.blocks = nn.ModuleList()
for i in range(depth):
block = Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
norm_layer=norm_layer,
act_layer=act_layer,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
window_size=window_size if i not in global_attn_indexes else 0,
input_size=(img_size // patch_size, img_size // patch_size),
)
self.blocks.append(block)
self.neck = nn.Sequential(
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
bias=False,
),
LayerNorm2d(out_chans),
nn.Conv2d(
out_chans,
out_chans,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(out_chans),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
if self.pos_embed is not None:
x = x + self.pos_embed
for blk in self.blocks:
x = blk(x)
dtype = x.dtype
if dtype == torch.float16: # prevent overflow
with torch.autocast(device_type="cuda", dtype=torch.float32):
x = self.neck(x.permute(0, 3, 1, 2))
x = x.to(dtype)
else:
x = self.neck(x.permute(0, 3, 1, 2))
return x
class Block(nn.Module):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then
use global attention.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.norm2 = norm_layer(dim)
self.mlp = MLPBlock(
embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer
)
self.window_size = window_size
def forward(self, x: torch.Tensor) -> torch.Tensor:
shortcut = x
x = self.norm1(x)
# Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x)
# Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + x
x = x + self.mlp(self.norm2(x))
return x
class Attention(nn.Module):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos
if self.use_rel_pos:
assert (
input_size is not None
), "Input size must be provided if using relative positional encoding."
# initialize relative positional embeddings
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, _ = x.shape
# qkv with shape (3, B, nHead, H * W, C)
qkv = (
self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
)
# q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
attn = (q * self.scale) @ k.transpose(-2, -1)
if self.use_rel_pos:
attn = add_decomposed_rel_pos(
attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W)
)
attn = attn.softmax(dim=-1)
x = (
(attn @ v)
.view(B, self.num_heads, H, W, -1)
.permute(0, 2, 3, 1, 4)
.reshape(B, H, W, -1)
)
x = self.proj(x)
return x
def window_partition(
x: torch.Tensor, window_size: int
) -> Tuple[torch.Tensor, Tuple[int, int]]:
"""
Partition into non-overlapping windows with padding if needed.
Args:
x (tensor): input tokens with [B, H, W, C].
window_size (int): window size.
Returns:
windows: windows after partition with [B * num_windows, window_size, window_size, C].
(Hp, Wp): padded height and width before partition
"""
B, H, W, C = x.shape
pad_h = (window_size - H % window_size) % window_size
pad_w = (window_size - W % window_size) % window_size
if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
Hp, Wp = H + pad_h, W + pad_w
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
windows = (
x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
)
return windows, (Hp, Wp)
def window_unpartition(
windows: torch.Tensor,
window_size: int,
pad_hw: Tuple[int, int],
hw: Tuple[int, int],
) -> torch.Tensor:
"""
Window unpartition into original sequences and removing padding.
Args:
windows (tensor): input tokens with [B * num_windows, window_size, window_size, C].
window_size (int): window size.
pad_hw (Tuple): padded height and width (Hp, Wp).
hw (Tuple): original height and width (H, W) before padding.
Returns:
x: unpartitioned sequences with [B, H, W, C].
"""
Hp, Wp = pad_hw
H, W = hw
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
x = windows.view(
B, Hp // window_size, Wp // window_size, window_size, window_size, -1
)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
if Hp > H or Wp > W:
x = x[:, :H, :W, :].contiguous()
return x
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
"""
Get relative positional embeddings according to the relative positions of
query and key sizes.
Args:
q_size (int): size of query q.
k_size (int): size of key k.
rel_pos (Tensor): relative position embeddings (L, C).
Returns:
Extracted positional embeddings according to relative positions.
"""
max_rel_dist = int(2 * max(q_size, k_size) - 1)
# Interpolate rel pos if needed.
if rel_pos.shape[0] != max_rel_dist:
# Interpolate rel pos.
rel_pos_resized = F.interpolate(
rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
size=max_rel_dist,
mode="linear",
)
rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
else:
rel_pos_resized = rel_pos
# Scale the coords with short length if shapes for q and k are different.
q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
return rel_pos_resized[relative_coords.long()]
def add_decomposed_rel_pos(
attn: torch.Tensor,
q: torch.Tensor,
rel_pos_h: torch.Tensor,
rel_pos_w: torch.Tensor,
q_size: Tuple[int, int],
k_size: Tuple[int, int],
) -> torch.Tensor:
"""
Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950
Args:
attn (Tensor): attention map.
q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C).
rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis.
rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis.
q_size (Tuple): spatial sequence size of query q with (q_h, q_w).
k_size (Tuple): spatial sequence size of key k with (k_h, k_w).
Returns:
attn (Tensor): attention map with added relative positional embeddings.
"""
q_h, q_w = q_size
k_h, k_w = k_size
Rh = get_rel_pos(q_h, k_h, rel_pos_h)
Rw = get_rel_pos(q_w, k_w, rel_pos_w)
B, _, dim = q.shape
r_q = q.reshape(B, q_h, q_w, dim)
rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
attn = (
attn.view(B, q_h, q_w, k_h, k_w)
+ rel_h[:, :, :, :, None]
+ rel_w[:, :, :, None, :]
).view(B, q_h * q_w, k_h * k_w)
return attn
class PatchEmbed(nn.Module):
"""
Image to Patch Embedding.
"""
def __init__(
self,
kernel_size: Tuple[int, int] = (16, 16),
stride: Tuple[int, int] = (16, 16),
padding: Tuple[int, int] = (0, 0),
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
kernel_size (Tuple): kernel size of the projection layer.
stride (Tuple): stride of the projection layer.
padding (Tuple): padding size of the projection layer.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
"""
super().__init__()
self.proj = nn.Conv2d(
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.proj(x)
# B C H W -> B H W C
x = x.permute(0, 2, 3, 1)
return x
================================================
FILE: model/segment_anything/modeling/mask_decoder.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import List, Tuple, Type
import torch
from torch import nn
from torch.nn import functional as F
from .common import LayerNorm2d
class MaskDecoder(nn.Module):
def __init__(
self,
*,
transformer_dim: int,
transformer: nn.Module,
num_multimask_outputs: int = 3,
activation: Type[nn.Module] = nn.GELU,
iou_head_depth: int = 3,
iou_head_hidden_dim: int = 256,
) -> None:
"""
Predicts masks given an image and prompt embeddings, using a
transformer architecture.
Arguments:
transformer_dim (int): the channel dimension of the transformer
transformer (nn.Module): the transformer used to predict masks
num_multimask_outputs (int): the number of masks to predict
when disambiguating masks
activation (nn.Module): the type of activation to use when
upscaling masks
iou_head_depth (int): the depth of the MLP used to predict
mask quality
iou_head_hidden_dim (int): the hidden dimension of the MLP
used to predict mask quality
"""
super().__init__()
self.transformer_dim = transformer_dim
self.transformer = transformer
self.num_multimask_outputs = num_multimask_outputs
self.iou_token = nn.Embedding(1, transformer_dim)
self.num_mask_tokens = num_multimask_outputs + 1
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(
transformer_dim, transformer_dim // 4, kernel_size=2, stride=2
),
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(
transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2
),
activation(),
)
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
"""
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# Select the correct mask or masks for output
if multimask_output:
mask_slice = slice(1, None)
else:
mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
# Prepare output
return masks, iou_pred
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# Concatenate output tokens
output_tokens = torch.cat(
[self.iou_token.weight, self.mask_tokens.weight], dim=0
)
output_tokens = output_tokens.unsqueeze(0).expand(
sparse_prompt_embeddings.size(0), -1, -1
)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# image_embeddings: [1, C, H, W], tokens: [B, N, C]
# dense_prompt_embeddings: [B, C, H, W]
# Expand per-image data in batch direction to be per-mask
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# Run the transformer
hs, src = self.transformer(src, pos_src, tokens)
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(
self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])
)
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(
b, self.num_mask_tokens, h, w
)
# Generate mask quality predictions
iou_pred = self.iou_prediction_head(iou_token_out)
return masks, iou_pred
def forward_modified_v3(
self,
image_embeddings : torch.Tensor, # [b, 256, 64, 64]
image_pe : torch.Tensor, # [1, 256, 64, 64]
sparse_prompt_embeddings: torch.Tensor, # [b, 1, 256]
dense_prompt_embeddings : torch.Tensor, # [b, 256, 64, 64]
): # -> [b, 256, 256]
b, _, _, _ = image_embeddings.shape
# Concatenate output tokens
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0) # [num_mask + 1, 256]
output_tokens = output_tokens.unsqueeze(0).expand(b, -1, -1) # [b, num_mask + 1, 256]
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1) # [b, num_mask + 1 + 1, 256]
# image_embeddings: [1, C, H, W], tokens: [B, N, C]
# dense_prompt_embeddings: [B, C, H, W]
# Expand per-image data in batch direction to be per-mask
src = image_embeddings
src = src + dense_prompt_embeddings # [b, 256, 64, 64]
pos_src = torch.repeat_interleave(image_pe, b, dim=0) # [b, 256, 64, 64]
_, c, h, w = src.shape
# Run the transformer
hs, src = self.transformer(src, pos_src, tokens)
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
num_mask = 1
for i in range(num_mask): # we only need the first mask
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, h, w) # [b, 256, 256]
return masks
# Lightly adapted from
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py # noqa
class MLP(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
if self.sigmoid_output:
x = F.sigmoid(x)
return x
================================================
FILE: model/segment_anything/modeling/prompt_encoder.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Any, Optional, Tuple, Type
import numpy as np
import torch
from torch import nn
from .common import LayerNorm2d
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
Encodes prompts for input to SAM's mask decoder.
Arguments:
embed_dim (int): The prompts' embedding dimension
image_embedding_size (tuple(int, int)): The spatial size of the
image embedding, as (H, W).
input_image_size (int): The padded size of the image as input
to the image encoder, as (H, W).
mask_in_chans (int): The number of hidden channels used for
encoding input masks.
activation (nn.Module): The activation to use when encoding
input masks.
"""
super().__init__()
self.embed_dim = embed_dim
self.input_image_size = input_image_size
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
point_embeddings = [
nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)
]
self.point_embeddings = nn.ModuleList(point_embeddings)
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (
4 * image_embedding_size[0],
4 * image_embedding_size[1],
)
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim)
def get_dense_pe(self) -> torch.Tensor:
"""
Returns the positional encoding used to encode point prompts,
applied to a dense set of points the shape of the image encoding.
Returns:
torch.Tensor: Positional encoding with shape
1x(embed_dim)x(embedding_h)x(embedding_w)
"""
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""Embeds point prompts."""
points = points + 0.5 # Shift to center of pixel
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
point_embedding = self.pe_layer.forward_with_coords(
points, self.input_image_size
)
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(
coords, self.input_image_size
)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
def _get_batch_size(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
text_embeds: Optional[torch.Tensor],
) -> int:
"""
Gets the batch size of the output given the batch size of the input prompts.
"""
if points is not None:
return points[0].shape[0]
elif boxes is not None:
return boxes.shape[0]
elif masks is not None:
return masks.shape[0]
elif text_embeds is not None:
return text_embeds.shape[0]
else:
return 1
def _get_device(self) -> torch.device:
return self.point_embeddings[0].weight.device
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
text_embeds: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""
bs = self._get_batch_size(points, boxes, masks, text_embeds)
sparse_embeddings = torch.empty(
(bs, 0, self.embed_dim), device=self._get_device()
)
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
if text_embeds is not None:
sparse_embeddings = torch.cat([sparse_embeddings, text_embeds], dim=1)
if masks is not None:
dense_embeddings = self._embed_masks(masks)
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
return sparse_embeddings, dense_embeddings
class PositionEmbeddingRandom(nn.Module):
"""
Positional encoding using random spatial frequencies.
"""
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
if coords.dtype != self.positional_encoding_gaussian_matrix.dtype:
coords = coords.to(self.positional_encoding_gaussian_matrix.dtype)
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones(
(h, w), device=device, dtype=self.positional_encoding_gaussian_matrix.dtype
)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""Positionally encode points that are not normalized to [0,1]."""
coords = coords_input.clone()
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
return self._pe_encoding(coords.to(torch.float)) # B x N x C
================================================
FILE: model/segment_anything/modeling/sam.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Any, Dict, List, Tuple
import torch
from torch import nn
from torch.nn import functional as F
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT,
prompt_encoder: PromptEncoder,
mask_decoder: MaskDecoder,
pixel_mean: List[float] = [123.675, 116.28, 103.53],
pixel_std: List[float] = [58.395, 57.12, 57.375],
) -> None:
"""
SAM predicts object masks from an image and input prompts.
Arguments:
image_encoder (ImageEncoderViT): The backbone used to encode the
image into image embeddings that allow for efficient mask prediction.
prompt_encoder (PromptEncoder): Encodes various types of input prompts.
mask_decoder (MaskDecoder): Predicts masks from the image embeddings
and encoded prompts.
pixel_mean (list(float)): Mean values for normalizing pixels in the input image.
pixel_std (list(float)): Std values for normalizing pixels in the input image.
"""
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
self.register_buffer(
"pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False
)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
@property
def device(self) -> Any:
return self.pixel_mean.device
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
"""
Predicts masks end-to-end from provided images and prompts.
If prompts are not known in advance, using SamPredictor is
recommended over calling the model directly.
Arguments:
batched_input (list(dict)): A list over input images, each a
dictionary with the following keys. A prompt key can be
excluded if it is not present.
'image': The image as a torch tensor in 3xHxW format,
already transformed for input to the model.
'original_size': (tuple(int, int)) The original size of
the image before transformation, as (H, W).
'point_coords': (torch.Tensor) Batched point prompts for
this image, with shape BxNx2. Already transformed to the
input frame of the model.
'point_labels': (torch.Tensor) Batched labels for point prompts,
with shape BxN.
'boxes': (torch.Tensor) Batched box inputs, with shape Bx4.
Already transformed to the input frame of the model.
'mask_inputs': (torch.Tensor) Batched mask inputs to the model,
in the form Bx1xHxW.
multimask_output (bool): Whether the model should predict multiple
disambiguating masks, or return a single mask.
Returns:
(list(dict)): A list over input images, where each element is
as dictionary with the following keys.
'masks': (torch.Tensor) Batched binary mask predictions,
with shape BxCxHxW, where B is the number of input prompts,
C is determined by multimask_output, and (H, W) is the
original size of the image.
'iou_predictions': (torch.Tensor) The model's predictions
of mask quality, in shape BxC.
'low_res_logits': (torch.Tensor) Low resolution logits with
shape BxCxHxW, where H=W=256. Can be passed as mask input
to subsequent iterations of prediction.
"""
input_images = torch.stack(
[self.preprocess(x["image"]) for x in batched_input], dim=0
)
image_embeddings = self.image_encoder(input_images)
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
"""
Remove padding and upscale masks to the original image size.
Arguments:
masks (torch.Tensor): Batched masks from the mask_decoder,
in BxCxHxW format.
input_size (tuple(int, int)): The size of the image input to the
model, in (H, W) format. Used to remove padding.
original_size (tuple(int, int)): The original size of the image
before resizing for input to the model, in (H, W) format.
Returns:
(torch.Tensor): Batched masks in BxCxHxW format, where (H, W)
is given by original_size.
"""
dtype = masks.dtype
masks = F.interpolate(
masks.float(),
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
# masks = masks.to(dtype)
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(
masks, original_size, mode="bilinear", align_corners=False
)
return masks
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
"""Normalize pixel values and pad to a square input."""
# Normalize colors
x = (x - self.pixel_mean) / self.pixel_std
# Pad
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x
================================================
FILE: model/segment_anything/modeling/transformer.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import math
from typing import Tuple, Type
import torch
from torch import Tensor, nn
from .common import MLPBlock
class TwoWayTransformer(nn.Module):
def __init__(
self,
depth: int,
embedding_dim: int,
num_heads: int,
mlp_dim: int,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
) -> None:
"""
A transformer decoder that attends to an input image using
queries whose positional embedding is supplied.
Args:
depth (int): number of layers in the transformer
embedding_dim (int): the channel dimension for the input embeddings
num_heads (int): the number of heads for multihead attention. Must
divide embedding_dim
mlp_dim (int): the channel dimension internal to the MLP block
activation (nn.Module): the activation to use in the MLP block
"""
super().__init__()
self.depth = depth
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.mlp_dim = mlp_dim
self.layers = nn.ModuleList()
for i in range(depth):
self.layers.append(
TwoWayAttentionBlock(
embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_dim=mlp_dim,
activation=activation,
attention_downsample_rate=attention_downsample_rate,
skip_first_layer_pe=(i == 0),
)
)
self.final_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm_final_attn = nn.LayerNorm(embedding_dim)
def forward(
self,
image_embedding: Tensor,
image_pe: Tensor,
point_embedding: Tensor,
) -> Tuple[Tensor, Tensor]:
"""
Args:
image_embedding (torch.Tensor): image to attend to. Should be shape
B x embedding_dim x h x w for any h and w.
image_pe (torch.Tensor): the positional encoding to add to the image. Must
have the same shape as image_embedding.
point_embedding (torch.Tensor): the embedding to add to the query points.
Must have shape B x N_points x embedding_dim for any N_points.
Returns:
torch.Tensor: the processed point_embedding
torch.Tensor: the processed image_embedding
"""
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
bs, c, h, w = image_embedding.shape
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
image_pe = image_pe.flatten(2).permute(0, 2, 1)
# Prepare queries
queries = point_embedding
keys = image_embedding
# Apply transformer blocks and final layernorm
for layer in self.layers:
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding,
key_pe=image_pe,
)
# Apply the final attention layer from the points to the image
q = queries + point_embedding
k = keys + image_pe
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm_final_attn(queries)
return queries, keys
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
A transformer block with four layers: (1) self-attention of sparse
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
block on sparse inputs, and (4) cross attention of dense inputs to sparse
inputs.
Arguments:
embedding_dim (int): the channel dimension of the embeddings
num_heads (int): the number of heads in the attention layers
mlp_dim (int): the hidden dimension of the mlp block
activation (nn.Module): the activation of the mlp block
skip_first_layer_pe (bool): skip the PE on the first layer
"""
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
class Attention(nn.Module):
"""
An attention layer that allows for downscaling the size of the embedding
after projection to queries, keys, and values.
"""
def __init__(
self,
embedding_dim: int,
num_heads: int,
downsample_rate: int = 1,
) -> None:
super().__init__()
self.embedding_dim = embedding_dim
self.internal_dim = embedding_dim // downsample_rate
self.num_heads = num_heads
assert (
self.internal_dim % num_heads == 0
), "num_heads must divide embedding_dim."
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
def _recombine_heads(self, x: Tensor) -> Tensor:
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2)
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
# Input projections
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
# Separate into heads
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# Attention
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
attn = attn / math.sqrt(c_per_head)
attn = torch.softmax(attn, dim=-1)
# Get output
out = attn @ v
out = self._recombine_heads(out)
out = self.out_proj(out)
return out
================================================
FILE: model/segment_anything/predictor.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Optional, Tuple
import numpy as np
import torch
from .modeling import Sam
from .utils.transforms import ResizeLongestSide
class SamPredictor:
def __init__(
self,
sam_model: Sam,
) -> None:
"""
Uses SAM to calculate the image embedding for an image, and then
allow repeated, efficient mask prediction given prompts.
Arguments:
sam_model (Sam): The model to use for mask prediction.
"""
super().__init__()
self.model = sam_model
self.transform = ResizeLongestSide(sam_model.image_encoder.img_size)
self.reset_image()
def set_image(
self,
image: np.ndarray,
image_format: str = "RGB",
) -> None:
"""
Calculates the image embeddings for the provided image, allowing
masks to be predicted with the 'predict' method.
Arguments:
image (np.ndarray): The image for calculating masks. Expects an
image in HWC uint8 format, with pixel values in [0, 255].
image_format (str): The color format of the image, in ['RGB', 'BGR'].
"""
assert image_format in [
"RGB",
"BGR",
], f"image_format must be in ['RGB', 'BGR'], is {image_format}."
if image_format != self.model.image_format:
image = image[..., ::-1]
# Transform the image to the form expected by the model
input_image = self.transform.apply_image(image)
input_image_torch = torch.as_tensor(input_image, device=self.device)
input_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[
None, :, :, :
]
self.set_torch_image(input_image_torch, image.shape[:2])
@torch.no_grad()
def set_torch_image(
self,
transformed_image: torch.Tensor,
original_image_size: Tuple[int, ...],
) -> None:
"""
Calculates the image embeddings for the provided image, allowing
masks to be predicted with the 'predict' method. Expects the input
image to be already transformed to the format expected by the model.
Arguments:
transformed_image (torch.Tensor): The input image, with shape
1x3xHxW, which has been transformed with ResizeLongestSide.
original_image_size (tuple(int, int)): The size of the image
before transformation, in (H, W) format.
"""
assert (
len(transformed_image.shape) == 4
and transformed_image.shape[1] == 3
and max(*transformed_image.shape[2:]) == self.model.image_encoder.img_size
), f"set_torch_image input must be BCHW with long side {self.model.image_encoder.img_size}."
self.reset_image()
self.original_size = original_image_size
self.input_size = tuple(transformed_image.shape[-2:])
input_image = self.model.preprocess(transformed_image)
self.features = self.model.image_encoder(input_image)
self.is_image_set = True
def predict(
self,
point_coords: Optional[np.ndarray] = None,
point_labels: Optional[np.ndarray] = None,
box: Optional[np.ndarray] = None,
mask_input: Optional[np.ndarray] = None,
multimask_output: bool = True,
return_logits: bool = False,
) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""
Predict masks for the given input prompts, using the currently set image.
Arguments:
point_coords (np.ndarray or None): A Nx2 array of point prompts to the
model. Each point is in (X,Y) in pixels.
point_labels (np.ndarray or None): A length N array of labels for the
point prompts. 1 indicates a foreground point and 0 indicates a
background point.
box (np.ndarray or None): A length 4 array given a box prompt to the
model, in XYXY format.
mask_input (np.ndarray): A low resolution mask input to the model, typically
coming from a previous prediction iteration. Has form 1xHxW, where
for SAM, H=W=256.
multimask_output (bool): If true, the model will return three masks.
For ambiguous input prompts (such as a single click), this will often
produce better masks than a single prediction. If only a single
mask is needed, the model's predicted quality score can be used
to select the best mask. For non-ambiguous prompts, such as multiple
input prompts, multimask_output=False can give better results.
return_logits (bool): If true, returns un-thresholded masks logits
instead of a binary mask.
Returns:
(np.ndarray): The output masks in CxHxW format, where C is the
number of masks, and (H, W) is the original image size.
(np.ndarray): An array of length C containing the model's
predictions for the quality of each mask.
(np.ndarray): An array of shape CxHxW, where C is the number
of masks and H=W=256. These low resolution logits can be passed to
a subsequent iteration as mask input.
"""
if not self.is_image_set:
raise RuntimeError(
"An image must be set with .set_image(...) before mask prediction."
)
# Transform input prompts
coords_torch, labels_torch, box_torch, mask_input_torch = None, None, None, None
if point_coords is not None:
assert (
point_labels is not None
), "point_labels must be supplied if point_coords is supplied."
point_coords = self.transform.apply_coords(point_coords, self.original_size)
coords_torch = torch.as_tensor(
point_coords, dtype=torch.float, device=self.device
)
labels_torch = torch.as_tensor(
point_labels, dtype=torch.int, device=self.device
)
coords_torch, labels_torch = coords_torch[None, :, :], labels_torch[None, :]
if box is not None:
box = self.transform.apply_boxes(box, self.original_size)
box_torch = torch.as_tensor(box, dtype=torch.float, device=self.device)
box_torch = box_torch[None, :]
if mask_input is not None:
mask_input_torch = torch.as_tensor(
mask_input, dtype=torch.float, device=self.device
)
mask_input_torch = mask_input_torch[None, :, :, :]
masks, iou_predictions, low_res_masks = self.predict_torch(
coords_torch,
labels_torch,
box_torch,
mask_input_torch,
multimask_output,
return_logits=return_logits,
)
masks_np = masks[0].detach().cpu().numpy()
iou_predictions_np = iou_predictions[0].detach().cpu().numpy()
low_res_masks_np = low_res_masks[0].detach().cpu().numpy()
return masks_np, iou_predictions_np, low_res_masks_np
@torch.no_grad()
def predict_torch(
self,
point_coords: Optional[torch.Tensor],
point_labels: Optional[torch.Tensor],
boxes: Optional[torch.Tensor] = None,
mask_input: Optional[torch.Tensor] = None,
multimask_output: bool = True,
return_logits: bool = False,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Predict masks for the given input prompts, using the currently set image.
Input prompts are batched torch tensors and are expected to already be
transformed to the input frame using ResizeLongestSide.
Arguments:
point_coords (torch.Tensor or None): A BxNx2 array of point prompts to the
model. Each point is in (X,Y) in pixels.
point_labels (torch.Tensor or None): A BxN array of labels for the
point prompts. 1 indicates a foreground point and 0 indicates a
background point.
boxes (np.ndarray or None): A Bx4 array given a box prompt to the
model, in XYXY format.
mask_input (np.ndarray): A low resolution mask input to the model, typically
coming from a previous prediction iteration. Has form Bx1xHxW, where
for SAM, H=W=256. Masks returned by a previous iteration of the
predict method do not need further transformation.
multimask_output (bool): If true, the model will return three masks.
For ambiguous input prompts (such as a single click), this will often
produce better masks than a single prediction. If only a single
mask is needed, the model's predicted quality score can be used
to select the best mask. For non-ambiguous prompts, such as multiple
input prompts, multimask_output=False can give better results.
return_logits (bool): If true, returns un-thresholded masks logits
instead of a binary mask.
Returns:
(torch.Tensor): The output masks in BxCxHxW format, where C is the
number of masks, and (H, W) is the original image size.
(torch.Tensor): An array of shape BxC containing the model's
predictions for the quality of each mask.
(torch.Tensor): An array of shape BxCxHxW, where C is the number
of masks and H=W=256. These low res logits can be passed to
a subsequent iteration as mask input.
"""
if not self.is_image_set:
raise RuntimeError(
"An image must be set with .set_image(...) before mask prediction."
)
if point_coords is not None:
points = (point_coords, point_labels)
else:
points = None
# Embed prompts
sparse_embeddings, dense_embeddings = self.model.prompt_encoder(
points=points,
boxes=boxes,
masks=mask_input,
)
# Predict masks
low_res_masks, iou_predictions = self.model.mask_decoder(
image_embeddings=self.features,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
# Upscale the masks to the original image resolution
masks = self.model.postprocess_masks(
low_res_masks, self.input_size, self.original_size
)
if not return_logits:
masks = masks > self.model.mask_threshold
return masks, iou_predictions, low_res_masks
def get_image_embedding(self) -> torch.Tensor:
"""
Returns the image embeddings for the currently set image, with
shape 1xCxHxW, where C is the embedding dimension and (H,W) are
the embedding spatial dimension of SAM (typically C=256, H=W=64).
"""
if not self.is_image_set:
raise RuntimeError(
"An image must be set with .set_image(...) to generate an embedding."
)
assert (
self.features is not None
), "Features must exist if an image has been set."
return self.features
@property
def device(self) -> torch.device:
return self.model.device
def reset_image(self) -> None:
"""Resets the currently set image."""
self.is_image_set = False
self.features = None
self.orig_h = None
self.orig_w = None
self.input_h = None
self.input_w = None
================================================
FILE: model/segment_anything/utils/__init__.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
================================================
FILE: model/segment_anything/utils/amg.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import math
from copy import deepcopy
from itertools import product
from typing import Any, Dict, Generator, ItemsView, List, Tuple
import numpy as np
import torch
class MaskData:
"""
A structure for storing masks and their related data in batched format.
Implements basic filtering and concatenation.
"""
def __init__(self, **kwargs) -> None:
for v in kwargs.values():
assert isinstance(
v, (list, np.ndarray, torch.Tensor)
), "MaskData only supports list, numpy arrays, and torch tensors."
self._stats = dict(**kwargs)
def __setitem__(self, key: str, item: Any) -> None:
assert isinstance(
item, (list, np.ndarray, torch.Tensor)
), "MaskData only supports list, numpy arrays, and torch tensors."
self._stats[key] = item
def __delitem__(self, key: str) -> None:
del self._stats[key]
def __getitem__(self, key: str) -> Any:
return self._stats[key]
def items(self) -> ItemsView[str, Any]:
return self._stats.items()
def filter(self, keep: torch.Tensor) -> None:
for k, v in self._stats.items():
if v is None:
self._stats[k] = None
elif isinstance(v, torch.Tensor):
self._stats[k] = v[torch.as_tensor(keep, device=v.device)]
elif isinstance(v, np.ndarray):
self._stats[k] = v[keep.detach().cpu().numpy()]
elif isinstance(v, list) and keep.dtype == torch.bool:
self._stats[k] = [a for i, a in enumerate(v) if keep[i]]
elif isinstance(v, list):
self._stats[k] = [v[i] for i in keep]
else:
raise TypeError(f"MaskData key {k} has an unsupported type {type(v)}.")
def cat(self, new_stats: "MaskData") -> None:
for k, v in new_stats.items():
if k not in self._stats or self._stats[k] is None:
self._stats[k] = deepcopy(v)
elif isinstance(v, torch.Tensor):
self._stats[k] = torch.cat([self._stats[k], v], dim=0)
elif isinstance(v, np.ndarray):
self._stats[k] = np.concatenate([self._stats[k], v], axis=0)
elif isinstance(v, list):
self._stats[k] = self._stats[k] + deepcopy(v)
else:
raise TypeError(f"MaskData key {k} has an unsupported type {type(v)}.")
def to_numpy(self) -> None:
for k, v in self._stats.items():
if isinstance(v, torch.Tensor):
self._stats[k] = v.detach().cpu().numpy()
def is_box_near_crop_edge(
boxes: torch.Tensor, crop_box: List[int], orig_box: List[int], atol: float = 20.0
) -> torch.Tensor:
"""Filter masks at the edge of a crop, but not at the edge of the original image."""
crop_box_torch = torch.as_tensor(crop_box, dtype=torch.float, device=boxes.device)
orig_box_torch = torch.as_tensor(orig_box, dtype=torch.float, device=boxes.device)
boxes = uncrop_boxes_xyxy(boxes, crop_box).float()
near_crop_edge = torch.isclose(boxes, crop_box_torch[None, :], atol=atol, rtol=0)
near_image_edge = torch.isclose(boxes, orig_box_torch[None, :], atol=atol, rtol=0)
near_crop_edge = torch.logical_and(near_crop_edge, ~near_image_edge)
return torch.any(near_crop_edge, dim=1)
def box_xyxy_to_xywh(box_xyxy: torch.Tensor) -> torch.Tensor:
box_xywh = deepcopy(box_xyxy)
box_xywh[2] = box_xywh[2] - box_xywh[0]
box_xywh[3] = box_xywh[3] - box_xywh[1]
return box_xywh
def batch_iterator(batch_size: int, *args) -> Generator[List[Any], None, None]:
assert len(args) > 0 and all(
len(a) == len(args[0]) for a in args
), "Batched iteration must have inputs of all the same size."
n_batches = len(args[0]) // batch_size + int(len(args[0]) % batch_size != 0)
for b in range(n_batches):
yield [arg[b * batch_size : (b + 1) * batch_size] for arg in args]
def mask_to_rle_pytorch(tensor: torch.Tensor) -> List[Dict[str, Any]]:
"""
Encodes masks to an uncompressed RLE, in the format expected by
pycoco tools.
"""
# Put in fortran order and flatten h,w
b, h, w = tensor.shape
tensor = tensor.permute(0, 2, 1).flatten(1)
# Compute change indices
diff = tensor[:, 1:] ^ tensor[:, :-1]
change_indices = diff.nonzero()
# Encode run length
out = []
for i in range(b):
cur_idxs = change_indices[change_indices[:, 0] == i, 1]
cur_idxs = torch.cat(
[
torch.tensor([0], dtype=cur_idxs.dtype, device=cur_idxs.device),
cur_idxs + 1,
torch.tensor([h * w], dtype=cur_idxs.dtype, device=cur_idxs.device),
]
)
btw_idxs = cur_idxs[1:] - cur_idxs[:-1]
counts = [] if tensor[i, 0] == 0 else [0]
counts.extend(btw_idxs.detach().cpu().tolist())
out.append({"size": [h, w], "counts": counts})
return out
def rle_to_mask(rle: Dict[str, Any]) -> np.ndarray:
"""Compute a binary mask from an uncompressed RLE."""
h, w = rle["size"]
mask = np.empty(h * w, dtype=bool)
idx = 0
parity = False
for count in rle["counts"]:
mask[idx : idx + count] = parity
idx += count
parity ^= True
mask = mask.reshape(w, h)
return mask.transpose() # Put in C order
def area_from_rle(rle: Dict[str, Any]) -> int:
return sum(rle["counts"][1::2])
def calculate_stability_score(
masks: torch.Tensor, mask_threshold: float, threshold_offset: float
) -> torch.Tensor:
"""
Computes the stability score for a batch of masks. The stability
score is the IoU between the binary masks obtained by thresholding
the predicted mask logits at high and low values.
"""
# One mask is always contained inside the other.
# Save memory by preventing unnecessary cast to torch.int64
intersections = (
(masks > (mask_threshold + threshold_offset))
.sum(-1, dtype=torch.int16)
.sum(-1, dtype=torch.int32)
)
unions = (
(masks > (mask_threshold - threshold_offset))
.sum(-1, dtype=torch.int16)
.sum(-1, dtype=torch.int32)
)
return intersections / unions
def build_point_grid(n_per_side: int) -> np.ndarray:
"""Generates a 2D grid of points evenly spaced in [0,1]x[0,1]."""
offset = 1 / (2 * n_per_side)
points_one_side = np.linspace(offset, 1 - offset, n_per_side)
points_x = np.tile(points_one_side[None, :], (n_per_side, 1))
points_y = np.tile(points_one_side[:, None], (1, n_per_side))
points = np.stack([points_x, points_y], axis=-1).reshape(-1, 2)
return points
def build_all_layer_point_grids(
n_per_side: int, n_layers: int, scale_per_layer: int
) -> List[np.ndarray]:
"""Generates point grids for all crop layers."""
points_by_layer = []
for i in range(n_layers + 1):
n_points = int(n_per_side / (scale_per_layer**i))
points_by_layer.append(build_point_grid(n_points))
return points_by_layer
def generate_crop_boxes(
im_size: Tuple[int, ...], n_layers: int, overlap_ratio: float
) -> Tuple[List[List[int]], List[int]]:
"""
Generates a list of crop boxes of different sizes. Each layer
has (2**i)**2 boxes for the ith layer.
"""
crop_boxes, layer_idxs = [], []
im_h, im_w = im_size
short_side = min(im_h, im_w)
# Original image
crop_boxes.append([0, 0, im_w, im_h])
layer_idxs.append(0)
def crop_len(orig_len, n_crops, overlap):
return int(math.ceil((overlap * (n_crops - 1) + orig_len) / n_crops))
for i_layer in range(n_layers):
n_crops_per_side = 2 ** (i_layer + 1)
overlap = int(overlap_ratio * short_side * (2 / n_crops_per_side))
crop_w = crop_len(im_w, n_crops_per_side, overlap)
crop_h = crop_len(im_h, n_crops_per_side, overlap)
crop_box_x0 = [int((crop_w - overlap) * i) for i in range(n_crops_per_side)]
crop_box_y0 = [int((crop_h - overlap) * i) for i in range(n_crops_per_side)]
# Crops in XYWH format
for x0, y0 in product(crop_box_x0, crop_box_y0):
box = [x0, y0, min(x0 + crop_w, im_w), min(y0 + crop_h, im_h)]
crop_boxes.append(box)
layer_idxs.append(i_layer + 1)
return crop_boxes, layer_idxs
def uncrop_boxes_xyxy(boxes: torch.Tensor, crop_box: List[int]) -> torch.Tensor:
x0, y0, _, _ = crop_box
offset = torch.tensor([[x0, y0, x0, y0]], device=boxes.device)
# Check if boxes has a channel dimension
if len(boxes.shape) == 3:
offset = offset.unsqueeze(1)
return boxes + offset
def uncrop_points(points: torch.Tensor, crop_box: List[int]) -> torch.Tensor:
x0, y0, _, _ = crop_box
offset = torch.tensor([[x0, y0]], device=points.device)
# Check if points has a channel dimension
if len(points.shape) == 3:
offset = offset.unsqueeze(1)
return points + offset
def uncrop_masks(
masks: torch.Tensor, crop_box: List[int], orig_h: int, orig_w: int
) -> torch.Tensor:
x0, y0, x1, y1 = crop_box
if x0 == 0 and y0 == 0 and x1 == orig_w and y1 == orig_h:
return masks
# Coordinate transform masks
pad_x, pad_y = orig_w - (x1 - x0), orig_h - (y1 - y0)
pad = (x0, pad_x - x0, y0, pad_y - y0)
return torch.nn.functional.pad(masks, pad, value=0)
def remove_small_regions(
mask: np.ndarray, area_thresh: float, mode: str
) -> Tuple[np.ndarray, bool]:
"""
Removes small disconnected regions and holes in a mask. Returns the
mask and an indicator of if the mask has been modified.
"""
import cv2 # type: ignore
assert mode in ["holes", "islands"]
correct_holes = mode == "holes"
working_mask = (correct_holes ^ mask).astype(np.uint8)
n_labels, regions, stats, _ = cv2.connectedComponentsWithStats(working_mask, 8)
sizes = stats[:, -1][1:] # Row 0 is background label
small_regions = [i + 1 for i, s in enumerate(sizes) if s < area_thresh]
if len(small_regions) == 0:
return mask, False
fill_labels = [0] + small_regions
if not correct_holes:
fill_labels = [i for i in range(n_labels) if i not in fill_labels]
# If every region is below threshold, keep largest
if len(fill_labels) == 0:
fill_labels = [int(np.argmax(sizes)) + 1]
mask = np.isin(regions, fill_labels)
return mask, True
def coco_encode_rle(uncompressed_rle: Dict[str, Any]) -> Dict[str, Any]:
from pycocotools import mask as mask_utils # type: ignore
h, w = uncompressed_rle["size"]
rle = mask_utils.frPyObjects(uncompressed_rle, h, w)
rle["counts"] = rle["counts"].decode("utf-8") # Necessary to serialize with json
return rle
def batched_mask_to_box(masks: torch.Tensor) -> torch.Tensor:
"""
Calculates boxes in XYXY format around masks. Return [0,0,0,0] for
an empty mask. For input shape C1xC2x...xHxW, the output shape is C1xC2x...x4.
"""
# torch.max below raises an error on empty inputs, just skip in this case
if torch.numel(masks) == 0:
return torch.zeros(*masks.shape[:-2], 4, device=masks.device)
# Normalize shape to CxHxW
shape = masks.shape
h, w = shape[-2:]
if len(shape) > 2:
masks = masks.flatten(0, -3)
else:
masks = masks.unsqueeze(0)
# Get top and bottom edges
in_height, _ = torch.max(masks, dim=-1)
in_height_coords = in_height * torch.arange(h, device=in_height.device)[None, :]
bottom_edges, _ = torch.max(in_height_coords, dim=-1)
in_height_coords = in_height_coords + h * (~in_height)
top_edges, _ = torch.min(in_height_coords, dim=-1)
# Get left and right edges
in_width, _ = torch.max(masks, dim=-2)
in_width_coords = in_width * torch.arange(w, device=in_width.device)[None, :]
right_edges, _ = torch.max(in_width_coords, dim=-1)
in_width_coords = in_width_coords + w * (~in_width)
left_edges, _ = torch.min(in_width_coords, dim=-1)
# If the mask is empty the right edge will be to the left of the left edge.
# Replace these boxes with [0, 0, 0, 0]
empty_filter = (right_edges < left_edges) | (bottom_edges < top_edges)
out = torch.stack([left_edges, top_edges, right_edges, bottom_edges], dim=-1)
out = out * (~empty_filter).unsqueeze(-1)
# Return to original shape
if len(shape) > 2:
out = out.reshape(*shape[:-2], 4)
else:
out = out[0]
return out
================================================
FILE: model/segment_anything/utils/onnx.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from typing import Tuple
import torch
import torch.nn as nn
from torch.nn import functional as F
from ..modeling import Sam
from .amg import calculate_stability_score
class SamOnnxModel(nn.Module):
"""
This model should not be called directly, but is used in ONNX export.
It combines the prompt encoder, mask decoder, and mask postprocessing of Sam,
with some functions modified to enable model tracing. Also supports extra
options controlling what information. See the ONNX export script for details.
"""
def __init__(
self,
model: Sam,
return_single_mask: bool,
use_stability_score: bool = False,
return_extra_metrics: bool = False,
) -> None:
super().__init__()
self.mask_decoder = model.mask_decoder
self.model = model
self.img_size = model.image_encoder.img_size
self.return_single_mask = return_single_mask
self.use_stability_score = use_stability_score
self.stability_score_offset = 1.0
self.return_extra_metrics = return_extra_metrics
@staticmethod
def resize_longest_image_size(
input_image_size: torch.Tensor, longest_side: int
) -> torch.Tensor:
input_image_size = input_image_size.to(torch.float32)
scale = longest_side / torch.max(input_image_size)
transformed_size = scale * input_image_size
transformed_size = torch.floor(transformed_size + 0.5).to(torch.int64)
return transformed_size
def _embed_points(
self, point_coords: torch.Tensor, point_labels: torch.Tensor
) -> torch.Tensor:
point_coords = point_coords + 0.5
point_coords = point_coords / self.img_size
point_embedding = self.model.prompt_encoder.pe_layer._pe_encoding(point_coords)
point_labels = point_labels.unsqueeze(-1).expand_as(point_embedding)
point_embedding = point_embedding * (point_labels != -1)
point_embedding = (
point_embedding
+ self.model.prompt_encoder.not_a_point_embed.weight * (point_labels == -1)
)
for i in range(self.model.prompt_encoder.num_point_embeddings):
point_embedding = (
point_embedding
+ self.model.prompt_encoder.point_embeddings[i].weight
* (point_labels == i)
)
return point_embedding
def _embed_masks(
self, input_mask: torch.Tensor, has_mask_input: torch.Tensor
) -> torch.Tensor:
mask_embedding = has_mask_input * self.model.prompt_encoder.mask_downscaling(
input_mask
)
mask_embedding = mask_embedding + (
1 - has_mask_input
) * self.model.prompt_encoder.no_mask_embed.weight.reshape(1, -1, 1, 1)
return mask_embedding
def mask_postprocessing(
self, masks: torch.Tensor, orig_im_size: torch.Tensor
) -> torch.Tensor:
masks = F.interpolate(
masks,
size=(self.img_size, self.img_size),
mode="bilinear",
align_corners=False,
)
prepadded_size = self.resize_longest_image_size(orig_im_size, self.img_size).to(
torch.int64
)
masks = masks[..., : prepadded_size[0], : prepadded_size[1]] # type: ignore
orig_im_size = orig_im_size.to(torch.int64)
h, w = orig_im_size[0], orig_im_size[1]
masks = F.interpolate(masks, size=(h, w), mode="bilinear", align_corners=False)
return masks
def select_masks(
self, masks: torch.Tensor, iou_preds: torch.Tensor, num_points: int
) -> Tuple[torch.Tensor, torch.Tensor]:
# Determine if we should return the multiclick mask or not from the number of points.
# The reweighting is used to avoid control flow.
score_reweight = torch.tensor(
[[1000] + [0] * (self.model.mask_decoder.num_mask_tokens - 1)]
).to(iou_preds.device)
score = iou_preds + (num_points - 2.5) * score_reweight
best_idx = torch.argmax(score, dim=1)
masks = masks[torch.arange(masks.shape[0]), best_idx, :, :].unsqueeze(1)
iou_preds = iou_preds[torch.arange(masks.shape[0]), best_idx].unsqueeze(1)
return masks, iou_preds
@torch.no_grad()
def forward(
self,
image_embeddings: torch.Tensor,
point_coords: torch.Tensor,
point_labels: torch.Tensor,
mask_input: torch.Tensor,
has_mask_input: torch.Tensor,
orig_im_size: torch.Tensor,
):
sparse_embedding = self._embed_points(point_coords, point_labels)
dense_embedding = self._embed_masks(mask_input, has_mask_input)
masks, scores = self.model.mask_decoder.predict_masks(
image_embeddings=image_embeddings,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embedding,
dense_prompt_embeddings=dense_embedding,
)
if self.use_stability_score:
scores = calculate_stability_score(
masks, self.model.mask_threshold, self.stability_score_offset
)
if self.return_single_mask:
masks, scores = self.select_masks(masks, scores, point_coords.shape[1])
upscaled_masks = self.mask_postprocessing(masks, orig_im_size)
if self.return_extra_metrics:
stability_scores = calculate_stability_score(
upscaled_masks, self.model.mask_threshold, self.stability_score_offset
)
areas = (upscaled_masks > self.model.mask_threshold).sum(-1).sum(-1)
return upscaled_masks, scores, stability_scores, areas, masks
return upscaled_masks, scores, masks
================================================
FILE: model/segment_anything/utils/transforms.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from copy import deepcopy
from typing import Tuple
import numpy as np
import torch
from torch.nn import functional as F
from torchvision.transforms.functional import resize # type: ignore
from torchvision.transforms.functional import to_pil_image
class ResizeLongestSide:
"""
Resizes images to the longest side 'target_length', as well as provides
methods for resizing coordinates and boxes. Provides methods for
transforming both numpy array and batched torch tensors.
"""
def __init__(self, target_length: int) -> None:
self.target_length = target_length
def apply_image(self, image: np.ndarray) -> np.ndarray:
"""
Expects a numpy array with shape HxWxC in uint8 format.
"""
target_size = self.get_preprocess_shape(
image.shape[0], image.shape[1], self.target_length
)
return np.array(resize(to_pil_image(image), target_size))
def apply_coords(
self, coords: np.ndarray, original_size: Tuple[int, ...]
) -> np.ndarray:
"""
Expects a numpy array of length 2 in the final dimension. Requires the
original image size in (H, W) format.
"""
old_h, old_w = original_size
new_h, new_w = self.get_preprocess_shape(
original_size[0], original_size[1], self.target_length
)
coords = deepcopy(coords).astype(float)
coords[..., 0] = coords[..., 0] * (new_w / old_w)
coords[..., 1] = coords[..., 1] * (new_h / old_h)
return coords
def apply_boxes(
self, boxes: np.ndarray, original_size: Tuple[int, ...]
) -> np.ndarray:
"""
Expects a numpy array shape Bx4. Requires the original image size
in (H, W) format.
"""
boxes = self.apply_coords(boxes.reshape(-1, 2, 2), original_size)
return boxes.reshape(-1, 4)
def apply_image_torch(self, image: torch.Tensor) -> torch.Tensor:
"""
Expects batched images with shape BxCxHxW and float format. This
transformation may not exactly match apply_image. apply_image is
the transformation expected by the model.
"""
# Expects an image in BCHW format. May not exactly match apply_image.
target_size = self.get_preprocess_shape(
image.shape[0], image.shape[1], self.target_length
)
return F.interpolate(
image, target_size, mode="bilinear", align_corners=False, antialias=True
)
def apply_coords_torch(
self, coords: torch.Tensor, original_size: Tuple[int, ...]
) -> torch.Tensor:
"""
Expects a torch tensor with length 2 in the last dimension. Requires the
original image size in (H, W) format.
"""
old_h, old_w = original_size
new_h, new_w = self.get_preprocess_shape(
original_size[0], original_size[1], self.target_length
)
coords = deepcopy(coords).to(torch.float)
coords[..., 0] = coords[..., 0] * (new_w / old_w)
coords[..., 1] = coords[..., 1] * (new_h / old_h)
return coords
def apply_boxes_torch(
self, boxes: torch.Tensor, original_size: Tuple[int, ...]
) -> torch.Tensor:
"""
Expects a torch tensor with shape Bx4. Requires the original image
size in (H, W) format.
"""
boxes = self.apply_coords_torch(boxes.reshape(-1, 2, 2), original_size)
return boxes.reshape(-1, 4)
@staticmethod
def get_preprocess_shape(
oldh: int, oldw: int, long_side_length: int
) -> Tuple[int, int]:
"""
Compute the output size given input size and target long side length.
"""
scale = long_side_length * 1.0 / max(oldh, oldw)
newh, neww = oldh * scale, oldw * scale
neww = int(neww + 0.5)
newh = int(newh + 0.5)
return (newh, neww)
================================================
FILE: model/tf/modeling_outputs.py
================================================
import torch
import warnings
from dataclasses import dataclass
from typing import Optional, Tuple, Dict, List
from transformers.utils import ModelOutput
@dataclass
class CausalLMOutputWithPastAndLabel(ModelOutput):
"""
Base class for causal language model (or autoregressive) outputs.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Language modeling loss (for next-token prediction).
labels (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*, returned when `labels` is provided):
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
`past_key_values` input) to speed up sequential decoding.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
loss: Optional[torch.FloatTensor] = None
labels: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
bs2imgs_token_list: List[List[int]] = None
================================================
FILE: model/univi/__init__.py
================================================
from .model import ChatUniViLlamaForCausalLM
================================================
FILE: model/univi/config/__init__.py
================================================
from .dataset_config import *
from .model_config import *
ModelConfig = {
"PRETUNE": model_config_pretune,
"FINETUNE": model_config_finetune,
}
DataConfig = {
"Pretrain": [Pretrain, COCO_CAP, COCO_REG, COCO_REC],
"SQA": [SQA],
"FINETUNE": [VIT, MIMIC_imageonly, VIDEO],
}
================================================
FILE: model/univi/config/dataset_config.py
================================================
Pretrain = {
"chat_path": "${PATH}/CC3M-595K/chat.json",
"CC3M": "${PATH}/CC3M-595K",
}
VIT = {
"chat_path": "${PATH}/llava_instruct_150k.json",
"COCO2017": "${PATH}/COCO2017/train2017",
}
MIMIC_imageonly = {
"chat_path": "${PATH}/MIMIC-IT-imageonly.json",
"CDG": "${PATH}/CGD/images",
"LA": "${PATH}/LA/images",
"SD": "${PATH}/SD/images",
}
COCO_CAP = {
"chat_path": "${PATH}/COCO/coco_cap_chat.json",
"COCO2014": "${PATH}/COCO2014/train2014",
}
COCO_REG = {
"chat_path": "${PATH}/COCO/coco_reg_chat.json",
"COCO2014": "${PATH}/COCO2014/train2014",
}
COCO_REC = {
"chat_path": "${PATH}/COCO/coco_rec_chat.json",
"COCO2014": "${PATH}/COCO2014/train2014",
}
VIDEO = {
"chat_path": "${PATH}/video_chat.json",
"VIDEO": "${PATH}/Activity_Videos",
}
SQA = {
"chat_path": "${PATH}/llava_train_QCM-LEA.json",
"ScienceQA": "${PATH}/scienceqa/train",
}
================================================
FILE: model/univi/config/model_config.py
================================================
model_config_pretune = {
"use_cluster": True,
"freeze": False,
"vision_tune": False,
"spatial_cluster_rate0": 64, # 0.25
"spatial_cluster_rate1": 32, # 0.5
"spatial_cluster_rate2": 16, # 0.5
"temporal_cluster_rate": 1/16,
}
model_config_finetune = {
"use_cluster": True,
"freeze": False,
"mm_tune": True,
"vision_tune": False,
"spatial_cluster_rate0": 64, # 0.25
"spatial_cluster_rate1": 32, # 0.5
"spatial_cluster_rate2": 16, # 0.5
"temporal_cluster_rate": 1/16,
}
================================================
FILE: model/univi/constants.py
================================================
CONTROLLER_HEART_BEAT_EXPIRATION = 30
WORKER_HEART_BEAT_INTERVAL = 15
LOGDIR = "."
# Model Constants
MAX_IMAGE_LENGTH = 64
IGNORE_INDEX = -100
IMAGE_TOKEN_INDEX = -200
DEFAULT_IMAGE_TOKEN = ""
DEFAULT_VIDEO_TOKEN = " 
