[
{
"path": ".gitignore",
"content": "# Don't include anything installed into the virtualenv by pip\n.Python\nbin\nlib\ninclude\npip-selfcheck.json\n# We don't need compiled Python artifacts in the repo\n__pycache__\n*egg-info\n*.pyc\n*.pyo\n.idea/*\n.serverless/*\n\nawspricecalculator/data/*\n\n# ignore vendored files\nvendored\n\n#temporarily out\nawspricecalculator/s3*\nawspricecalculator/common/utils.py\nscripts/ec2-pricing.py\nscripts/rds-pricing.py\nscripts/s3-pricing.py\nscripts/lambda-pricing.py\nscripts/dynamodb-pricing.py\nscripts/kinesis-pricing.py\nscripts/context.py\nscripts/propagate-lambda-code.py\n\n"
},
{
"path": "LICENSE.md",
"content": "GNU GENERAL PUBLIC LICENSE\n\nVersion 3, 29 June 2007\n\nCopyright (C) 2007 Free Software Foundation, Inc. \n\nEveryone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.\n\nPreamble\nThe GNU General Public License is a free, copyleft license for software and other kinds of works.\n\nThe licenses for most software and other practical works are designed to take away your freedom to share and change the works. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change all versions of a program--to make sure it remains free software for all its users. We, the Free Software Foundation, use the GNU General Public License for most of our software; it applies also to any other work released this way by its authors. You can apply it to your programs, too.\n\nWhen we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for them if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs, and that you know you can do these things.\n\nTo protect your rights, we need to prevent others from denying you these rights or asking you to surrender the rights. Therefore, you have certain responsibilities if you distribute copies of the software, or if you modify it: responsibilities to respect the freedom of others.\n\nFor example, if you distribute copies of such a program, whether gratis or for a fee, you must pass on to the recipients the same freedoms that you received. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.\n\nDevelopers that use the GNU GPL protect your rights with two steps: (1) assert copyright on the software, and (2) offer you this License giving you legal permission to copy, distribute and/or modify it.\n\nFor the developers' and authors' protection, the GPL clearly explains that there is no warranty for this free software. For both users' and authors' sake, the GPL requires that modified versions be marked as changed, so that their problems will not be attributed erroneously to authors of previous versions.\n\nSome devices are designed to deny users access to install or run modified versions of the software inside them, although the manufacturer can do so. This is fundamentally incompatible with the aim of protecting users' freedom to change the software. The systematic pattern of such abuse occurs in the area of products for individuals to use, which is precisely where it is most unacceptable. Therefore, we have designed this version of the GPL to prohibit the practice for those products. If such problems arise substantially in other domains, we stand ready to extend this provision to those domains in future versions of the GPL, as needed to protect the freedom of users.\n\nFinally, every program is threatened constantly by software patents. States should not allow patents to restrict development and use of software on general-purpose computers, but in those that do, we wish to avoid the special danger that patents applied to a free program could make it effectively proprietary. To prevent this, the GPL assures that patents cannot be used to render the program non-free.\n\nThe precise terms and conditions for copying, distribution and modification follow.\n\nTERMS AND CONDITIONS\n0. Definitions.\n\"This License\" refers to version 3 of the GNU General Public License.\n\n\"Copyright\" also means copyright-like laws that apply to other kinds of works, such as semiconductor masks.\n\n\"The Program\" refers to any copyrightable work licensed under this License. Each licensee is addressed as \"you\". \"Licensees\" and \"recipients\" may be individuals or organizations.\n\nTo \"modify\" a work means to copy from or adapt all or part of the work in a fashion requiring copyright permission, other than the making of an exact copy. The resulting work is called a \"modified version\" of the earlier work or a work \"based on\" the earlier work.\n\nA \"covered work\" means either the unmodified Program or a work based on the Program.\n\nTo \"propagate\" a work means to do anything with it that, without permission, would make you directly or secondarily liable for infringement under applicable copyright law, except executing it on a computer or modifying a private copy. Propagation includes copying, distribution (with or without modification), making available to the public, and in some countries other activities as well.\n\nTo \"convey\" a work means any kind of propagation that enables other parties to make or receive copies. Mere interaction with a user through a computer network, with no transfer of a copy, is not conveying.\n\nAn interactive user interface displays \"Appropriate Legal Notices\" to the extent that it includes a convenient and prominently visible feature that (1) displays an appropriate copyright notice, and (2) tells the user that there is no warranty for the work (except to the extent that warranties are provided), that licensees may convey the work under this License, and how to view a copy of this License. If the interface presents a list of user commands or options, such as a menu, a prominent item in the list meets this criterion.\n\n1. Source Code.\nThe \"source code\" for a work means the preferred form of the work for making modifications to it. \"Object code\" means any non-source form of a work.\n\nA \"Standard Interface\" means an interface that either is an official standard defined by a recognized standards body, or, in the case of interfaces specified for a particular programming language, one that is widely used among developers working in that language.\n\nThe \"System Libraries\" of an executable work include anything, other than the work as a whole, that (a) is included in the normal form of packaging a Major Component, but which is not part of that Major Component, and (b) serves only to enable use of the work with that Major Component, or to implement a Standard Interface for which an implementation is available to the public in source code form. A \"Major Component\", in this context, means a major essential component (kernel, window system, and so on) of the specific operating system (if any) on which the executable work runs, or a compiler used to produce the work, or an object code interpreter used to run it.\n\nThe \"Corresponding Source\" for a work in object code form means all the source code needed to generate, install, and (for an executable work) run the object code and to modify the work, including scripts to control those activities. However, it does not include the work's System Libraries, or general-purpose tools or generally available free programs which are used unmodified in performing those activities but which are not part of the work. For example, Corresponding Source includes interface definition files associated with source files for the work, and the source code for shared libraries and dynamically linked subprograms that the work is specifically designed to require, such as by intimate data communication or control flow between those subprograms and other parts of the work.\n\nThe Corresponding Source need not include anything that users can regenerate automatically from other parts of the Corresponding Source.\n\nThe Corresponding Source for a work in source code form is that same work.\n\n2. Basic Permissions.\nAll rights granted under this License are granted for the term of copyright on the Program, and are irrevocable provided the stated conditions are met. This License explicitly affirms your unlimited permission to run the unmodified Program. The output from running a covered work is covered by this License only if the output, given its content, constitutes a covered work. This License acknowledges your rights of fair use or other equivalent, as provided by copyright law.\n\nYou may make, run and propagate covered works that you do not convey, without conditions so long as your license otherwise remains in force. You may convey covered works to others for the sole purpose of having them make modifications exclusively for you, or provide you with facilities for running those works, provided that you comply with the terms of this License in conveying all material for which you do not control copyright. Those thus making or running the covered works for you must do so exclusively on your behalf, under your direction and control, on terms that prohibit them from making any copies of your copyrighted material outside their relationship with you.\n\nConveying under any other circumstances is permitted solely under the conditions stated below. Sublicensing is not allowed; section 10 makes it unnecessary.\n\n3. Protecting Users' Legal Rights From Anti-Circumvention Law.\nNo covered work shall be deemed part of an effective technological measure under any applicable law fulfilling obligations under article 11 of the WIPO copyright treaty adopted on 20 December 1996, or similar laws prohibiting or restricting circumvention of such measures.\n\nWhen you convey a covered work, you waive any legal power to forbid circumvention of technological measures to the extent such circumvention is effected by exercising rights under this License with respect to the covered work, and you disclaim any intention to limit operation or modification of the work as a means of enforcing, against the work's users, your or third parties' legal rights to forbid circumvention of technological measures.\n\n4. Conveying Verbatim Copies.\nYou may convey verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice; keep intact all notices stating that this License and any non-permissive terms added in accord with section 7 apply to the code; keep intact all notices of the absence of any warranty; and give all recipients a copy of this License along with the Program.\n\nYou may charge any price or no price for each copy that you convey, and you may offer support or warranty protection for a fee.\n\n5. Conveying Modified Source Versions.\nYou may convey a work based on the Program, or the modifications to produce it from the Program, in the form of source code under the terms of section 4, provided that you also meet all of these conditions:\n\na) The work must carry prominent notices stating that you modified it, and giving a relevant date.\n\nb) The work must carry prominent notices stating that it is released under this License and any conditions added under section 7. This requirement modifies the requirement in section 4 to \"keep intact all notices\".\n\nc) You must license the entire work, as a whole, under this License to anyone who comes into possession of a copy. This License will therefore apply, along with any applicable section 7 additional terms, to the whole of the work, and all its parts, regardless of how they are packaged. This License gives no permission to license the work in any other way, but it does not invalidate such permission if you have separately received it.\n\nd) If the work has interactive user interfaces, each must display Appropriate Legal Notices; however, if the Program has interactive interfaces that do not display Appropriate Legal Notices, your work need not make them do so.\n\nA compilation of a covered work with other separate and independent works, which are not by their nature extensions of the covered work, and which are not combined with it such as to form a larger program, in or on a volume of a storage or distribution medium, is called an \"aggregate\" if the compilation and its resulting copyright are not used to limit the access or legal rights of the compilation's users beyond what the individual works permit. Inclusion of a covered work in an aggregate does not cause this License to apply to the other parts of the aggregate.\n\n6. Conveying Non-Source Forms.\nYou may convey a covered work in object code form under the terms of sections 4 and 5, provided that you also convey the machine-readable Corresponding Source under the terms of this License, in one of these ways:\n\na) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by the Corresponding Source fixed on a durable physical medium customarily used for software interchange.\n\nb) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by a written offer, valid for at least three years and valid for as long as you offer spare parts or customer support for that product model, to give anyone who possesses the object code either (1) a copy of the Corresponding Source for all the software in the product that is covered by this License, on a durable physical medium customarily used for software interchange, for a price no more than your reasonable cost of physically performing this conveying of source, or (2) access to copy the Corresponding Source from a network server at no charge.\n\nc) Convey individual copies of the object code with a copy of the written offer to provide the Corresponding Source. This alternative is allowed only occasionally and noncommercially, and only if you received the object code with such an offer, in accord with subsection 6b.\n\nd) Convey the object code by offering access from a designated place (gratis or for a charge), and offer equivalent access to the Corresponding Source in the same way through the same place at no further charge. You need not require recipients to copy the Corresponding Source along with the object code. If the place to copy the object code is a network server, the Corresponding Source may be on a different server (operated by you or a third party) that supports equivalent copying facilities, provided you maintain clear directions next to the object code saying where to find the Corresponding Source. Regardless of what server hosts the Corresponding Source, you remain obligated to ensure that it is available for as long as needed to satisfy these requirements.\n\ne) Convey the object code using peer-to-peer transmission, provided you inform other peers where the object code and Corresponding Source of the work are being offered to the general public at no charge under subsection 6d.\n\nA separable portion of the object code, whose source code is excluded from the Corresponding Source as a System Library, need not be included in conveying the object code work.\n\nA \"User Product\" is either (1) a \"consumer product\", which means any tangible personal property which is normally used for personal, family, or household purposes, or (2) anything designed or sold for incorporation into a dwelling. In determining whether a product is a consumer product, doubtful cases shall be resolved in favor of coverage. For a particular product received by a particular user, \"normally used\" refers to a typical or common use of that class of product, regardless of the status of the particular user or of the way in which the particular user actually uses, or expects or is expected to use, the product. A product is a consumer product regardless of whether the product has substantial commercial, industrial or non-consumer uses, unless such uses represent the only significant mode of use of the product.\n\n\"Installation Information\" for a User Product means any methods, procedures, authorization keys, or other information required to install and execute modified versions of a covered work in that User Product from a modified version of its Corresponding Source. The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made.\n\nIf you convey an object code work under this section in, or with, or specifically for use in, a User Product, and the conveying occurs as part of a transaction in which the right of possession and use of the User Product is transferred to the recipient in perpetuity or for a fixed term (regardless of how the transaction is characterized), the Corresponding Source conveyed under this section must be accompanied by the Installation Information. But this requirement does not apply if neither you nor any third party retains the ability to install modified object code on the User Product (for example, the work has been installed in ROM).\n\nThe requirement to provide Installation Information does not include a requirement to continue to provide support service, warranty, or updates for a work that has been modified or installed by the recipient, or for the User Product in which it has been modified or installed. Access to a network may be denied when the modification itself materially and adversely affects the operation of the network or violates the rules and protocols for communication across the network.\n\nCorresponding Source conveyed, and Installation Information provided, in accord with this section must be in a format that is publicly documented (and with an implementation available to the public in source code form), and must require no special password or key for unpacking, reading or copying.\n\n7. Additional Terms.\n\"Additional permissions\" are terms that supplement the terms of this License by making exceptions from one or more of its conditions. Additional permissions that are applicable to the entire Program shall be treated as though they were included in this License, to the extent that they are valid under applicable law. If additional permissions apply only to part of the Program, that part may be used separately under those permissions, but the entire Program remains governed by this License without regard to the additional permissions.\n\nWhen you convey a copy of a covered work, you may at your option remove any additional permissions from that copy, or from any part of it. (Additional permissions may be written to require their own removal in certain cases when you modify the work.) You may place additional permissions on material, added by you to a covered work, for which you have or can give appropriate copyright permission.\n\nNotwithstanding any other provision of this License, for material you add to a covered work, you may (if authorized by the copyright holders of that material) supplement the terms of this License with terms:\n\na) Disclaiming warranty or limiting liability differently from the terms of sections 15 and 16 of this License; or\n\nb) Requiring preservation of specified reasonable legal notices or author attributions in that material or in the Appropriate Legal Notices displayed by works containing it; or\n\nc) Prohibiting misrepresentation of the origin of that material, or requiring that modified versions of such material be marked in reasonable ways as different from the original version; or\n\nd) Limiting the use for publicity purposes of names of licensors or authors of the material; or\n\ne) Declining to grant rights under trademark law for use of some trade names, trademarks, or service marks; or\n\nf) Requiring indemnification of licensors and authors of that material by anyone who conveys the material (or modified versions of it) with contractual assumptions of liability to the recipient, for any liability that these contractual assumptions directly impose on those licensors and authors.\n\nAll other non-permissive additional terms are considered \"further restrictions\" within the meaning of section 10. If the Program as you received it, or any part of it, contains a notice stating that it is governed by this License along with a term that is a further restriction, you may remove that term. If a license document contains a further restriction but permits relicensing or conveying under this License, you may add to a covered work material governed by the terms of that license document, provided that the further restriction does not survive such relicensing or conveying.\n\nIf you add terms to a covered work in accord with this section, you must place, in the relevant source files, a statement of the additional terms that apply to those files, or a notice indicating where to find the applicable terms.\n\nAdditional terms, permissive or non-permissive, may be stated in the form of a separately written license, or stated as exceptions; the above requirements apply either way.\n\n8. Termination.\nYou may not propagate or modify a covered work except as expressly provided under this License. Any attempt otherwise to propagate or modify it is void, and will automatically terminate your rights under this License (including any patent licenses granted under the third paragraph of section 11).\n\nHowever, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.\n\nMoreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.\n\nTermination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, you do not qualify to receive new licenses for the same material under section 10.\n\n9. Acceptance Not Required for Having Copies.\nYou are not required to accept this License in order to receive or run a copy of the Program. Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance. However, nothing other than this License grants you permission to propagate or modify any covered work. These actions infringe copyright if you do not accept this License. Therefore, by modifying or propagating a covered work, you indicate your acceptance of this License to do so.\n\n10. Automatic Licensing of Downstream Recipients.\nEach time you convey a covered work, the recipient automatically receives a license from the original licensors, to run, modify and propagate that work, subject to this License. You are not responsible for enforcing compliance by third parties with this License.\n\nAn \"entity transaction\" is a transaction transferring control of an organization, or substantially all assets of one, or subdividing an organization, or merging organizations. If propagation of a covered work results from an entity transaction, each party to that transaction who receives a copy of the work also receives whatever licenses to the work the party's predecessor in interest had or could give under the previous paragraph, plus a right to possession of the Corresponding Source of the work from the predecessor in interest, if the predecessor has it or can get it with reasonable efforts.\n\nYou may not impose any further restrictions on the exercise of the rights granted or affirmed under this License. For example, you may not impose a license fee, royalty, or other charge for exercise of rights granted under this License, and you may not initiate litigation (including a cross-claim or counterclaim in a lawsuit) alleging that any patent claim is infringed by making, using, selling, offering for sale, or importing the Program or any portion of it.\n\n11. Patents.\nA \"contributor\" is a copyright holder who authorizes use under this License of the Program or a work on which the Program is based. The work thus licensed is called the contributor's \"contributor version\".\n\nA contributor's \"essential patent claims\" are all patent claims owned or controlled by the contributor, whether already acquired or hereafter acquired, that would be infringed by some manner, permitted by this License, of making, using, or selling its contributor version, but do not include claims that would be infringed only as a consequence of further modification of the contributor version. For purposes of this definition, \"control\" includes the right to grant patent sublicenses in a manner consistent with the requirements of this License.\n\nEach contributor grants you a non-exclusive, worldwide, royalty-free patent license under the contributor's essential patent claims, to make, use, sell, offer for sale, import and otherwise run, modify and propagate the contents of its contributor version.\n\nIn the following three paragraphs, a \"patent license\" is any express agreement or commitment, however denominated, not to enforce a patent (such as an express permission to practice a patent or covenant not to sue for patent infringement). To \"grant\" such a patent license to a party means to make such an agreement or commitment not to enforce a patent against the party.\n\nIf you convey a covered work, knowingly relying on a patent license, and the Corresponding Source of the work is not available for anyone to copy, free of charge and under the terms of this License, through a publicly available network server or other readily accessible means, then you must either (1) cause the Corresponding Source to be so available, or (2) arrange to deprive yourself of the benefit of the patent license for this particular work, or (3) arrange, in a manner consistent with the requirements of this License, to extend the patent license to downstream recipients. \"Knowingly relying\" means you have actual knowledge that, but for the patent license, your conveying the covered work in a country, or your recipient's use of the covered work in a country, would infringe one or more identifiable patents in that country that you have reason to believe are valid.\n\nIf, pursuant to or in connection with a single transaction or arrangement, you convey, or propagate by procuring conveyance of, a covered work, and grant a patent license to some of the parties receiving the covered work authorizing them to use, propagate, modify or convey a specific copy of the covered work, then the patent license you grant is automatically extended to all recipients of the covered work and works based on it.\n\nA patent license is \"discriminatory\" if it does not include within the scope of its coverage, prohibits the exercise of, or is conditioned on the non-exercise of one or more of the rights that are specifically granted under this License. You may not convey a covered work if you are a party to an arrangement with a third party that is in the business of distributing software, under which you make payment to the third party based on the extent of your activity of conveying the work, and under which the third party grants, to any of the parties who would receive the covered work from you, a discriminatory patent license (a) in connection with copies of the covered work conveyed by you (or copies made from those copies), or (b) primarily for and in connection with specific products or compilations that contain the covered work, unless you entered into that arrangement, or that patent license was granted, prior to 28 March 2007.\n\nNothing in this License shall be construed as excluding or limiting any implied license or other defenses to infringement that may otherwise be available to you under applicable patent law.\n\n12. No Surrender of Others' Freedom.\nIf conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot convey a covered work so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not convey it at all. For example, if you agree to terms that obligate you to collect a royalty for further conveying from those to whom you convey the Program, the only way you could satisfy both those terms and this License would be to refrain entirely from conveying the Program.\n\n13. Use with the GNU Affero General Public License.\nNotwithstanding any other provision of this License, you have permission to link or combine any covered work with a work licensed under version 3 of the GNU Affero General Public License into a single combined work, and to convey the resulting work. The terms of this License will continue to apply to the part which is the covered work, but the special requirements of the GNU Affero General Public License, section 13, concerning interaction through a network will apply to the combination as such.\n\n14. Revised Versions of this License.\nThe Free Software Foundation may publish revised and/or new versions of the GNU General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.\n\nEach version is given a distinguishing version number. If the Program specifies that a certain numbered version of the GNU General Public License \"or any later version\" applies to it, you have the option of following the terms and conditions either of that numbered version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of the GNU General Public License, you may choose any version ever published by the Free Software Foundation.\n\nIf the Program specifies that a proxy can decide which future versions of the GNU General Public License can be used, that proxy's public statement of acceptance of a version permanently authorizes you to choose that version for the Program.\n\nLater license versions may give you additional or different permissions. However, no additional obligations are imposed on any author or copyright holder as a result of your choosing to follow a later version.\n\n15. Disclaimer of Warranty.\nTHERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM \"AS IS\" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.\n\n16. Limitation of Liability.\nIN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.\n\n17. Interpretation of Sections 15 and 16.\nIf the disclaimer of warranty and limitation of liability provided above cannot be given local legal effect according to their terms, reviewing courts shall apply local law that most closely approximates an absolute waiver of all civil liability in connection with the Program, unless a warranty or assumption of liability accompanies a copy of the Program in return for a fee.\n\nEND OF TERMS AND CONDITIONS\n"
},
{
"path": "MANIFEST.in",
"content": "recursive-include awspricecalculator/data *.csv *.json\n\n"
},
{
"path": "README.md",
"content": "\n\n## Concurrency Labs - AWS Price Calculator tool\n\nThis repository uses the AWS Price List API to implement price calculation utilities.\n\nSupported services:\n* EC2\n* ELB\n* EBS\n* RDS\n* Lambda\n* Dynamo DB\n* Kinesis\n\nVisit the following URLs for more details:\n\nhttps://www.concurrencylabs.com/blog/aws-pricing-lambda-realtime-calculation-function/\nhttps://www.concurrencylabs.com/blog/aws-lambda-cost-optimization-tools/\nhttps://www.concurrencylabs.com/blog/calculate-near-realtime-pricing-serverless-applications/\n\nThe code is structured in the following way:\n\n**awspricecalculator**. The modules in this package search data within the AWS Price List API index files.\nThey take price dimension parameters as inputs and return results in JSON format. This package\nis called by Lambda functions or other Python scripts.\n\n**functions**. This is where our Lambda functions live. Functions are packaged using the Serverless framework.\n\n**scripts**. Here are some Python scripts to help with management and price optimizations. See README.md in the scripts\nfolder for more details.\n\n\n## Available Lambda functions:\n\n### calculate-near-realtime\nThis function is called by a schedule configured using CloudWatch Events.\nThe function receives a JSON object configured in the schedule. The JSON object supports the following format:\n\nTag-based: ```{\"tag\":{\"key\":\"mykey\",\"value\":\"myvalue\"}}```.\nThe function finds resources with the corresponding tag, gets current usage using CloudWatch metrics,\nprojects usage into a longer time period (a month), calls pricecalculator to calculate price\nand puts results in CloudWatch metrics under the namespace ```ConcurrencyLabs/Pricing/NearRealTimeForecast```.\nSupported services are EC2, EBS, ELB, RDS and Lambda. Not all price dimensions are supported for all services, though.\n\nYou can configure as many CloudWatch Events as you want, each one with a different tag.\n\n\n**Rules:**\n* The function only considers for price calculation those resources that are tagged. For example, if there is an untagged ELB\nwith tagged EC2 instances, the function will only consider the EC2 instances for the calculation.\nIf there is a tagged ELB with untagged EC2 instances, the function will only calculate price\nfor the ELB.\n* The behavior described above is intended for simplicity, otherwise the function would have to\ncover a number of combinations that might or might not be suitable to all users of the function.\n* To keep it simple, if you want a resource to be included in the calculation, then tag it. Otherwise\nleave it untagged.\n\n\n**Limitations**\nThe function doesn't support cost estimations for the following:\n* EC2 data transfer for instances not registered to an ELB\n* EC2 Reserved Instances\n* EBS Snapshots\n* RDS data trasfer\n* Lambda data transfer\n* Kinesis PUT Payload Units are partially calculated based on CloudWatch metrics (there's no 100% accuracy for this price dimension)\n* Dynamo DB storage\n* Dynamo DB data transfer\n\n\n\n\n## Install - using CloudFormation (recommended)\n\n\nI created a CloudFormation template that deploys the Lambda function, as well as the CloudWatch Events\nschedule. All you have to do is specify the tag key and value you want to calculate pricing for.\nFor example: TagKey:stack, TagValue:mywebapp\n\nClick here to get started:\n\n \n\n\n### Metrics\n\nThe function publishes a metric named `EstimatedCharges` to CloudWatch, under namespace `ConcurrencyLabs/Pricing/NearRealTimeForecast` and it uses\nthe following dimensions:\n\n* Currency: USD\n* ForecastPeriod: monthly\n* ServiceName: ec2, rds, lambda, kinesis, dynamodb\n* Tag: mykey=myvalue\n\n\n\n\n\n### Updating to the latest version using CloudFormation\n\nThis function will be updated regularly in order to fix bugs, update AWS Price List data and also to add more functionality.\nThis means you will likely have to update the function at some point. I recommend installing\nthe function using the CloudFormation template, since it will simplify the update process.\n\nTo update the function, just go to the CloudFormation console, select the stack you've created\nand click on Actions -> Update Stack:\n\n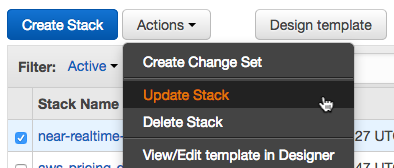\n\n\nThen select \"Specify an Amazon S3 template URL\" and enter the following value:\n\n\n```\nhttp://concurrencylabs-cfn-templates.s3.amazonaws.com/lambda-near-realtime-pricing/function-plus-schedule.json\n```\n\n\n\nAnd that's it. CloudFormation will update the function with the latest code.\n\n\n\n## Install Locally (if you want to modify it) - Manual steps\n\nIf you only want to install the Lambda function, you don't need to follow the steps below, just follow\nthe instructions in the \"Install - Using CloudFormation\" section above.\n\nIf you want to setup a dev environment, run a local copy, make some modifications and then install in your AWS account, then keep reading...\n\n\n### Clone the repo\n\n```\ngit clone https://github.com/concurrencylabs/aws-pricing-tools aws-pricing-tools\n```\n\n\n### (Optional, but recommended) Create an isolated Python environment using virtualenv\n\nIt's always a good practice to create an isolated environment so we have greater control over\nthe dependencies in our project, including the Python runtime.\n\nIf you don't have virtualenv installed, run:\n\n```\npip install virtualenv\n```\n\nFor more details on virtualenv, click here.\n\nNow, create a Python 2.7 virtual environment in the location where you cloned the repo into. If you want to name your project\naws-pricing-tools, then run (one level up from the dir, use the same local name you used when you cloned\nthe repo):\n\n```\nvirtualenv aws-pricing-tools -p python2.7\n```\n\nAfter your environment is created, it's time to activate it. Go to the recently created\nfolder of your project (i.e. aws-pricing-tools) and from there run:\n\n```\nsource bin/activate\n```\n\n\n### Install Requirements\n\nFrom your project root folder, run:\n\n```\n./install.sh\n```\n\nThis will install the following dependencies to the ```vendored``` directory:\n\n* **tinydb** - The code in this repo queries the Price List API csv records using the tinydb library.\n* **numpy** - Used for statistics in the lambda optimization script\n\n... and the following dependencies in your default site-packages location:\n\n* **python-local-lambda** - lets me test my Lambda functions locally using test events in my workstation.\n* **boto3** - AWS Python SDK to call AWS APIs.\n\n\n### Install the Serverless Framework\n\n\n\n\nSince the pricing tool runs on AWS Lambda, I decided to use the Serverless Framework.\nThis framework enormously simplifies the development, configuration and deployment of Function as a Service (a.k.a. FaaS, or \"serverless\")\ncode into AWS Lambda.\n\n\nYou should follow the instructions described here,\nwhich can be summarized in the following steps:\n\n1. Make sure you have Node.js installed in your workstation.\n```\nnode --version\n```\n\n2. Install the Serverless Framework\n```\nnpm install -g serverless\n```\n\n\n3. Confirm Serverless has been installed\n```\nserverless --version\n```\nThe steps in this post were tested using version ```1.6.1```\n\n\n4. Serverless needs access to your AWS account, so it can create and update AWS Lambda\nfunctions, among other operations. Therefore, you have to make sure Serverless can access\na set of IAM User credentials. Follow these instructions.\nIn the long term, you should make sure these credentials are limited to only the API operations\nServerless requires - avoid Administrator access, which is a bad security and operational practice.\n\n\n5. Checkout the code from this repo into your virtualenv folder.\n\n\n### Set environment variables\n\n```\nexport AWS_DEFAULT_PROFILE=\nexport AWS_DEFAULT_REGION=\n```\n\n\n### How to test the function locally\n\n\n**Download the latest AWS Price List API Index file**\n\nThe code needs a local copy of the the AWS Price List API index file.\nThe GitHub repo doesn't come with the index file, therefore you have to\ndownload it the first time you run your code and every time AWS publishes a new\nPrice List API index.\n\nAlso, this index file is constantly updated by AWS. I recommend subscribing to the AWS Price List API\nchange notifications.\n\nIn order to download the latest index file, go to the ```scripts```` folder and run:\n\n```\npython get-latest-index.py --service=all\n```\n\nThe script takes a few seconds to execute since some index files are a little heavy (like the EC2 one).\n\n**Run a test**\n\nOnce you have the virtualenv activated, all dependencies installed, environment\nvariables set and the latest AWS Price List index file, it's time to run a test.\n\nUpdate ```test/events/constant-tag.json``` with a tag key/value pair that exists in your AWS account.\n\n\nThen run, from the **root** location in the local repo and replace and with actual values:\n\n```\npython-lambda-local functions/calculate-near-realtime.py test/events/constant-tag.json -l lib/ -l . -f handler -t 30 -a arn:aws:lambda:::function:calculate-near-realtime\n```\n\n\n### Deploy the Serverless Project\n\nFrom your project root folder, run:\n\n```\nserverless deploy\n```\n"
},
{
"path": "awspricecalculator/__init__.py",
"content": "import os, sys\n\n__location__ = os.path.dirname(os.path.realpath(__file__))\nsys.path.append(os.path.join(__location__, \"../\"))\nsys.path.append(os.path.join(__location__, \"../vendored\"))\n"
},
{
"path": "awspricecalculator/awslambda/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/awslambda/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating Lambda pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n global regiondbs\n global indexMetadata\n\n ts = phelper.Timestamp()\n ts.start('totalCalculationAwsLambda')\n\n #Load On-Demand DB\n dbs = regiondbs.get(consts.SERVICE_LAMBDA+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_LAMBDA, phelper.get_partition_keys(consts.SERVICE_LAMBDA, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_LAMBDA+pdim.region+pdim.termType]=dbs\n\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n #TODO: add support to include/ignore free-tier (include a flag)\n\n serverlessDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SERVERLESS])]\n\n #Requests\n if pdim.requestCount:\n query = ((priceQuery['Group'] == 'AWS-Lambda-Requests'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, serverlessDb, query, pdim.requestCount, pricing_records, cost)\n\n #GB-s (aka compute time)\n if pdim.avgDurationMs:\n query = ((priceQuery['Group'] == 'AWS-Lambda-Duration'))\n usageUnits = pdim.GBs\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, serverlessDb, query, usageUnits, pricing_records, cost)\n\n #Data Transfer\n dataTransferDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER])]\n\n #To internet\n if pdim.dataTransferOutInternetGb:\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n\n #Intra-regional data transfer - in/out/between EC2 AZs or using IPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time to compute: [{}]\".format(ts.finish('totalCalculationAwsLambda')))\n return pricing_result.__dict__\n\n\n"
},
{
"path": "awspricecalculator/common/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/common/consts.py",
"content": "import os, logging\n\n# COMMON\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\nAWS_PRICE_CALCULATOR_VERSION = \"v2.0\"\n\nLOG_LEVEL = os.environ.get('LOG_LEVEL',logging.INFO)\nDEFAULT_CURRENCY = \"USD\"\nFORECAST_PERIOD_MONTHLY = \"monthly\"\nFORECAST_PERIOD_YEARLY = \"yearly\"\n\nHOURS_IN_MONTH = 720\n\nSERVICE_CODE_AWS_DATA_TRANSFER = 'AWSDataTransfer'\n\nREGION_MAP = {'us-east-1':'US East (N. Virginia)',\n 'us-east-2':'US East (Ohio)',\n 'us-west-1':'US West (N. California)',\n 'us-west-2':'US West (Oregon)',\n 'ca-central-1':'Canada (Central)',\n 'eu-west-1':'EU (Ireland)',\n 'eu-west-2':'EU (London)',\n 'eu-west-3':'EU (Paris)',\n 'eu-north-1':'EU (Stockholm)',\n 'eu-central-1':'EU (Frankfurt)',\n 'ap-northeast-1':'Asia Pacific (Tokyo)',\n 'ap-northeast-2':'Asia Pacific (Seoul)',\n 'ap-northeast-3':'Asia Pacific (Osaka-Local)',\n 'ap-southeast-1':'Asia Pacific (Singapore)',\n 'ap-southeast-2':'Asia Pacific (Sydney)',\n 'sa-east-1':'South America (Sao Paulo)',\n 'ap-south-1':'Asia Pacific (Mumbai)',\n 'cn-northwest-1':'China (Ningxia)',\n 'ap-east-1':'Asia Pacific (Hong Kong)'\n }\n\n#TODO: update for China region\nREGION_PREFIX_MAP = {'us-east-1':'',\n 'us-east-2':'USE2-',\n 'us-west-1':'USW1-',\n 'us-west-2':'USW2-',\n 'ca-central-1':'CAN1-',\n 'eu-west-1':'EU-',\n 'eu-west-2':'EUW2-',\n 'eu-west-3':'EUW3-',\n 'eu-north-1':'EUN1-',\n 'eu-central-1':'EUC1-',\n 'ap-east-1':'APE1-' ,\n 'ap-northeast-1':'APN1-',\n 'ap-northeast-2':'APN2-',\n 'ap-northeast-3':'APN3-',\n 'ap-southeast-1':'APS1-',\n 'ap-southeast-2':'APS2-',\n 'sa-east-1':'SAE1-',\n 'ap-south-1':'APS3-',\n 'cn-northwest-1':'',\n 'US East (N. Virginia)':'',\n 'US East (Ohio)':'USE2-',\n 'US West (N. California)':'USW1-',\n 'US West (Oregon)':'USW2-',\n 'Canada (Central)':'CAN1-',\n 'EU (Ireland)':'EU-',\n 'EU (London)':'EUW2-',\n 'EU (Paris)':'EUW3-',\n 'EU (Stockholm)':'EUN1-',\n 'EU (Frankfurt)':'EUC1-',\n 'Asia Pacific (Tokyo)':'APN1-',\n 'Asia Pacific (Seoul)':'APN2-',\n 'Asia Pacific (Singapore)':'APS1-',\n 'Asia Pacific (Sydney)':'APS2-',\n 'South America (Sao Paulo)':'SAE1-',\n 'Asia Pacific (Mumbai)':'APS3-',\n 'AWS GovCloud (US)':'UGW1-',\n 'External':'',\n 'Any': ''\n }\n\n\n\nREGION_REPORT_MAP = {'us-east-1':'N. Virginia',\n 'us-east-2':'Ohio',\n 'us-west-1':'N. California',\n 'us-west-2':'Oregon',\n 'ca-central-1':'Canada',\n 'eu-west-1':'Ireland',\n 'eu-west-2':'London',\n 'eu-north-1':'Stockholm',\n 'eu-central-1':'Frankfurt',\n 'ap-east-1':'Hong Kong',\n 'ap-northeast-1':'Tokyo',\n 'ap-northeast-2':'Seoul',\n 'ap-northeast-3':'Osaka',\n 'ap-southeast-1':'Singapore',\n 'ap-southeast-2':'Sydney',\n 'sa-east-1':'Sao Paulo',\n 'ap-south-1':'Mumbai',\n 'cn-northwest-1':'Ningxia',\n 'eu-west-3':'Paris'\n }\n\n\n\nSERVICE_EC2 = 'ec2'\nSERVICE_ELB = 'elb'\nSERVICE_EBS = 'ebs'\nSERVICE_S3 = 's3'\nSERVICE_RDS = 'rds'\nSERVICE_LAMBDA = 'lambda'\nSERVICE_DYNAMODB= 'dynamodb'\nSERVICE_KINESIS = 'kinesis'\nSERVICE_DATA_TRANSFER = 'datatransfer'\nSERVICE_EMR = 'emr'\nSERVICE_REDSHIFT = 'redshift'\nSERVICE_ALL = 'all'\n\nNOT_APPLICABLE = 'NA'\n\n\nSUPPORTED_SERVICES = (SERVICE_S3, SERVICE_EC2, SERVICE_RDS, SERVICE_LAMBDA, SERVICE_DYNAMODB, SERVICE_KINESIS,\n SERVICE_EMR, SERVICE_REDSHIFT)\n\nSUPPORTED_REGIONS = ('us-east-1','us-east-2', 'us-west-1', 'us-west-2','ca-central-1', 'eu-west-1','eu-west-2',\n 'eu-central-1', 'ap-east-1', 'ap-northeast-1', 'ap-northeast-2', 'ap-northeast-3', 'ap-southeast-1', 'ap-southeast-2',\n 'sa-east-1','ap-south-1', 'eu-west-3', 'eu-north-1'\n )\n\nSUPPORTED_EC2_INSTANCE_TYPES = ('a1.2xlarge','a1.4xlarge','a1.large','a1.medium','a1.xlarge','c1.medium','c1.xlarge','c3.2xlarge',\n 'c3.4xlarge','c3.8xlarge','c3.large','c3.xlarge','c4.2xlarge','c4.4xlarge','c4.8xlarge','c4.large',\n 'c4.xlarge','c5.18xlarge','c5.2xlarge','c5.4xlarge','c5.9xlarge','c5.large','c5.xlarge','c5d.18xlarge',\n 'c5d.2xlarge','c5d.4xlarge','c5d.9xlarge','c5d.large','c5d.xlarge','c5n.18xlarge','c5n.2xlarge',\n 'c5n.4xlarge','c5n.9xlarge','c5n.large','c5n.xlarge','cc2.8xlarge','cr1.8xlarge','d2.2xlarge',\n 'd2.4xlarge','d2.8xlarge','d2.xlarge','f1.16xlarge','f1.2xlarge','f1.4xlarge','g2.2xlarge',\n 'g2.8xlarge','g3.16xlarge','g3.4xlarge','g3.8xlarge','g3s.xlarge','h1.16xlarge','h1.2xlarge',\n 'h1.4xlarge','h1.8xlarge','hs1.8xlarge','i2.2xlarge','i2.4xlarge','i2.8xlarge','i2.xlarge',\n 'i3.16xlarge','i3.2xlarge','i3.4xlarge','i3.8xlarge','i3.large','i3.xlarge','m1.large',\n 'm1.medium','m1.small','m1.xlarge','m2.2xlarge','m2.4xlarge','m2.xlarge','m3.2xlarge',\n 'm3.large','m3.medium','m3.xlarge','m4.10xlarge','m4.16xlarge','m4.2xlarge','m4.4xlarge',\n 'm4.large','m4.xlarge','m5.12xlarge','m5.24xlarge','m5.2xlarge','m5.4xlarge','m5.large',\n 'm5.metal','m5.xlarge','m5a.12xlarge','m5a.24xlarge','m5a.2xlarge','m5a.4xlarge','m5a.large',\n 'm5a.xlarge','m5d.12xlarge','m5d.24xlarge','m5d.2xlarge','m5d.4xlarge','m5d.large','m5d.metal',\n 'm5d.xlarge','p2.16xlarge','p2.8xlarge','p2.xlarge','p3.16xlarge','p3.2xlarge','p3.8xlarge',\n 'p3dn.24xlarge','r3.2xlarge','r3.4xlarge','r3.8xlarge','r3.large','r3.xlarge','r4.16xlarge',\n 'r4.2xlarge','r4.4xlarge','r4.8xlarge','r4.large','r4.xlarge',\n 'r5.12xlarge','r5.24xlarge', 'r5.8xlarge',\n 'r5.2xlarge','r5.4xlarge','r5.large','r5.xlarge','r5a.12xlarge','r5a.24xlarge','r5a.2xlarge',\n 'r5a.4xlarge','r5a.large','r5a.xlarge','r5d.12xlarge','r5d.24xlarge','r5d.2xlarge','r5d.4xlarge',\n 'r5d.large','r5d.xlarge','t1.micro','t2.2xlarge','t2.large','t2.medium','t2.micro','t2.nano',\n 't2.small','t2.xlarge',\n 't3.2xlarge','t3.large','t3.medium','t3.micro','t3.nano','t3.small','t3.xlarge',\n 't3a.nano', 't3a.micro','t3a.small','t3a.medium','t3a.large','t3a.xlarge','t3a.2xlarge',\n 'x1.16xlarge','x1.32xlarge','x1e.16xlarge','x1e.2xlarge','x1e.32xlarge','x1e.4xlarge',\n 'x1e.8xlarge','x1e.xlarge','z1d.12xlarge','z1d.2xlarge','z1d.3xlarge','z1d.6xlarge','z1d.large','z1d.xlarge')\n\n\nSUPPORTED_EMR_INSTANCE_TYPES = ('c1.medium','c1.xlarge','c3.2xlarge','c3.4xlarge','c3.8xlarge','c3.large','c3.xlarge','c4.2xlarge',\n 'c4.4xlarge','c4.8xlarge','c4.large','c4.xlarge','c5.18xlarge','c5.2xlarge','c5.4xlarge',\n 'c5.9xlarge','c5.xlarge','c5d.18xlarge','c5d.2xlarge','c5d.4xlarge','c5d.9xlarge','c5d.xlarge',\n 'c5n.18xlarge','c5n.2xlarge','c5n.4xlarge','c5n.9xlarge','c5n.xlarge',\n 'cc2.8xlarge',\n 'cr1.8xlarge','d2.2xlarge','d2.4xlarge','d2.8xlarge','d2.xlarge','g2.2xlarge','g3.16xlarge',\n 'g3.4xlarge','g3.8xlarge','g3s.xlarge','h1.16xlarge','h1.2xlarge','h1.4xlarge','h1.8xlarge',\n 'hs1.8xlarge','i2.2xlarge','i2.4xlarge','i2.8xlarge','i2.xlarge','i3.16xlarge',\n 'i3.2xlarge','i3.4xlarge','i3.8xlarge','i3.xlarge','m1.large','m1.medium','m1.small','m1.xlarge',\n 'm2.2xlarge','m2.4xlarge','m2.xlarge','m3.2xlarge','m3.large','m3.medium','m3.xlarge','m4.10xlarge',\n 'm4.16xlarge','m4.2xlarge','m4.4xlarge','m4.large','m4.xlarge','m5.12xlarge','m5.24xlarge',\n 'm5.2xlarge','m5.4xlarge','m5.xlarge','m5a.12xlarge','m5a.24xlarge','m5a.2xlarge','m5a.4xlarge',\n 'm5a.xlarge',\n 'm5d.12xlarge','m5d.24xlarge','m5d.2xlarge','m5d.4xlarge','m5d.xlarge','p2.16xlarge','p2.8xlarge',\n 'p2.xlarge','p3.16xlarge','p3.2xlarge','p3.8xlarge','r3.2xlarge','r3.4xlarge','r3.8xlarge',\n 'r3.xlarge','r4.16xlarge','r4.2xlarge','r4.4xlarge','r4.8xlarge','r4.large','r4.xlarge',\n 'r5.12xlarge','r5.24xlarge','r5.2xlarge','r5.4xlarge','r5.xlarge','r5a.12xlarge','r5a.24xlarge',\n 'r5a.2xlarge','r5a.4xlarge','r5a.xlarge',\n 'r5d.2xlarge','r5d.4xlarge','r5d.xlarge','z1d.12xlarge','z1d.2xlarge','z1d.3xlarge',\n 'z1d.6xlarge','z1d.xlarge')\n\nSUPPORTED_REDSHIFT_INSTANCE_TYPES = ('ds1.xlarge','dc1.8xlarge','dc1.large','ds2.8xlarge',\n 'ds1.8xlarge','ds2.xlarge','dc2.8xlarge','dc2.large')\n\nSUPPORTED_INSTANCE_TYPES_MAP = {SERVICE_EC2:SUPPORTED_EC2_INSTANCE_TYPES, SERVICE_EMR:SUPPORTED_EMR_INSTANCE_TYPES ,\n SERVICE_REDSHIFT:SUPPORTED_REDSHIFT_INSTANCE_TYPES}\n\n\nSERVICE_INDEX_MAP = {SERVICE_S3:'AmazonS3', SERVICE_EC2:'AmazonEC2', SERVICE_RDS:'AmazonRDS',\n SERVICE_LAMBDA:'AWSLambda', SERVICE_DYNAMODB:'AmazonDynamoDB',\n SERVICE_KINESIS:'AmazonKinesis', SERVICE_EMR:'ElasticMapReduce', SERVICE_REDSHIFT:'AmazonRedshift',\n SERVICE_DATA_TRANSFER:'AWSDataTransfer'}\n\n\nSCRIPT_TERM_TYPE_ON_DEMAND = 'on-demand'\nSCRIPT_TERM_TYPE_RESERVED = 'reserved'\n\nTERM_TYPE_RESERVED = 'Reserved'\nTERM_TYPE_ON_DEMAND = 'OnDemand'\n\nSUPPORTED_TERM_TYPES = (SCRIPT_TERM_TYPE_ON_DEMAND, SCRIPT_TERM_TYPE_RESERVED)\n\n\nTERM_TYPE_MAP = {SCRIPT_TERM_TYPE_ON_DEMAND:'OnDemand', SCRIPT_TERM_TYPE_RESERVED:'Reserved'}\n\n\nPRODUCT_FAMILY_COMPUTE_INSTANCE = 'Compute Instance'\nPRODUCT_FAMILY_DATABASE_INSTANCE = 'Database Instance'\nPRODUCT_FAMILY_DATA_TRANSFER = 'Data Transfer'\nPRODUCT_FAMILY_FEE = 'Fee'\nPRODUCT_FAMILY_API_REQUEST = 'API Request'\nPRODUCT_FAMILY_STORAGE = 'Storage'\nPRODUCT_FAMILY_SYSTEM_OPERATION = 'System Operation'\nPRODUCT_FAMILY_LOAD_BALANCER = 'Load Balancer'\nPRODUCT_FAMILY_APPLICATION_LOAD_BALANCER = 'Load Balancer-Application'\nPRODUCT_FAMILY_NETWORK_LOAD_BALANCER = 'Load Balancer-Network'\nPRODUCT_FAMILY_SNAPSHOT = \"Storage Snapshot\"\nPRODUCT_FAMILY_SERVERLESS = \"Serverless\"\nPRODUCT_FAMILY_DB_STORAGE = \"Database Storage\"\nPRODUCT_FAMILY_DB_PIOPS = \"Provisioned IOPS\"\nPRODUCT_FAMILY_KINESIS_STREAMS = \"Kinesis Streams\"\nPRODUCT_FAMILY_EMR_INSTANCE = \"Elastic Map Reduce Instance\"\nPRODUCT_FAMILIY_BUNDLE = 'Bundle'\nPRODUCT_FAMILIY_REDSHIFT_CONCURRENCY_SCALING = 'Redshift Concurrency Scaling'\nPRODUCT_FAMILIY_REDSHIFT_DATA_SCAN = 'Redshift Data Scan'\nPRODUCT_FAMILIY_STORAGE_SNAPSHOT = 'Storage Snapshot'\n\n\nSUPPORTED_PRODUCT_FAMILIES = (PRODUCT_FAMILY_COMPUTE_INSTANCE, PRODUCT_FAMILY_DATABASE_INSTANCE,\n PRODUCT_FAMILY_DATA_TRANSFER,PRODUCT_FAMILY_FEE, PRODUCT_FAMILY_API_REQUEST,\n PRODUCT_FAMILY_STORAGE, PRODUCT_FAMILY_SYSTEM_OPERATION, PRODUCT_FAMILY_LOAD_BALANCER,\n PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER, PRODUCT_FAMILY_NETWORK_LOAD_BALANCER,\n PRODUCT_FAMILY_SNAPSHOT,PRODUCT_FAMILY_SERVERLESS,PRODUCT_FAMILY_DB_STORAGE,\n PRODUCT_FAMILY_DB_PIOPS,PRODUCT_FAMILY_KINESIS_STREAMS, PRODUCT_FAMILY_EMR_INSTANCE,\n PRODUCT_FAMILIY_BUNDLE, PRODUCT_FAMILIY_REDSHIFT_CONCURRENCY_SCALING, PRODUCT_FAMILIY_REDSHIFT_DATA_SCAN,\n PRODUCT_FAMILIY_STORAGE_SNAPSHOT\n )\n\nSUPPORTED_RESERVED_PRODUCT_FAMILIES = (PRODUCT_FAMILY_COMPUTE_INSTANCE, PRODUCT_FAMILY_DATABASE_INSTANCE)\n\nSUPPORTED_PRODUCT_FAMILIES_BY_SERVICE_DICT = {\n SERVICE_EC2:[PRODUCT_FAMILY_COMPUTE_INSTANCE,PRODUCT_FAMILY_DATA_TRANSFER, PRODUCT_FAMILY_FEE,\n PRODUCT_FAMILY_STORAGE,PRODUCT_FAMILY_SYSTEM_OPERATION,PRODUCT_FAMILY_LOAD_BALANCER,\n PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER,PRODUCT_FAMILY_NETWORK_LOAD_BALANCER,\n PRODUCT_FAMILY_SNAPSHOT],\n SERVICE_RDS:[PRODUCT_FAMILY_DATABASE_INSTANCE, PRODUCT_FAMILY_DATA_TRANSFER,PRODUCT_FAMILY_FEE,\n PRODUCT_FAMILY_DB_STORAGE,PRODUCT_FAMILY_DB_PIOPS,PRODUCT_FAMILY_SNAPSHOT ],\n SERVICE_S3:[PRODUCT_FAMILY_STORAGE, PRODUCT_FAMILY_FEE,PRODUCT_FAMILY_API_REQUEST,PRODUCT_FAMILY_SYSTEM_OPERATION, PRODUCT_FAMILY_DATA_TRANSFER ],\n SERVICE_LAMBDA:[PRODUCT_FAMILY_SERVERLESS, PRODUCT_FAMILY_DATA_TRANSFER, PRODUCT_FAMILY_FEE,\n PRODUCT_FAMILY_API_REQUEST],\n SERVICE_KINESIS:[PRODUCT_FAMILY_KINESIS_STREAMS],\n SERVICE_DYNAMODB:[PRODUCT_FAMILY_DB_STORAGE, PRODUCT_FAMILY_DB_PIOPS, PRODUCT_FAMILY_FEE ],\n SERVICE_EMR:[PRODUCT_FAMILY_EMR_INSTANCE],\n SERVICE_REDSHIFT:[PRODUCT_FAMILY_COMPUTE_INSTANCE, PRODUCT_FAMILIY_BUNDLE, PRODUCT_FAMILIY_REDSHIFT_CONCURRENCY_SCALING,\n PRODUCT_FAMILIY_REDSHIFT_DATA_SCAN, PRODUCT_FAMILIY_STORAGE_SNAPSHOT],\n SERVICE_DATA_TRANSFER:[PRODUCT_FAMILY_DATA_TRANSFER]\n }\n\n\nINFINITY = 'Inf'\n\nSORT_CRITERIA_REGION = 'region'\nSORT_CRITERIA_INSTANCE_TYPE = 'instance-type'\nSORT_CRITERIA_OS = 'os'\nSORT_CRITERIA_DB_INSTANCE_CLASS = 'db-instance-class'\nSORT_CRITERIA_DB_ENGINE = 'engine'\nSORT_CRITERIA_S3_STORAGE_CLASS = 'storage-class'\nSORT_CRITERIA_S3_STORAGE_SIZE_GB = 'storage-size-gb'\nSORT_CRITERIA_S3_DATA_RETRIEVAL_GB = 'data-retrieval-gb'\nSORT_CRITERIA_S3_STORAGE_CLASS_DATA_RETRIEVAL_GB = 'storage-class-data-retrieval-gb'\nSORT_CRITERIA_TO_REGION = 'to-region'\nSORT_CRITERIA_LAMBDA_MEMORY = 'memory'\nSORT_CRITERIA_TERM_TYPE = 'term-type'\nSORT_CRITERIA_TERM_TYPE_REGION = 'term-type-region'\n\n\nSORT_CRITERIA_VALUE_SEPARATOR = ','\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n#EC2\nEC2_OPERATING_SYSTEM_LINUX = 'Linux'\nEC2_OPERATING_SYSTEM_BYOL = 'Windows BYOL'\nEC2_OPERATING_SYSTEM_WINDOWS = 'Windows'\nEC2_OPERATING_SYSTEM_SUSE = 'Suse'\n#EC2_OPERATING_SYSTEM_SQL_WEB = 'SQL Web'\nEC2_OPERATING_SYSTEM_RHEL = 'RHEL'\n\nSCRIPT_EC2_TENANCY_SHARED = 'shared'\nSCRIPT_EC2_TENANCY_DEDICATED = 'dedicated'\nSCRIPT_EC2_TENANCY_HOST = 'host'\n\nEC2_TENANCY_SHARED = 'Shared'\nEC2_TENANCY_DEDICATED = 'Dedicated'\nEC2_TENANCY_HOST = 'Host'\n\nEC2_TENANCY_MAP = {SCRIPT_EC2_TENANCY_SHARED:EC2_TENANCY_SHARED,\n SCRIPT_EC2_TENANCY_DEDICATED:EC2_TENANCY_DEDICATED,\n SCRIPT_EC2_TENANCY_HOST:EC2_TENANCY_HOST}\n\n\nSCRIPT_EC2_CAPACITY_RESERVATION_STATUS_USED = 'used'\nSCRIPT_EC2_CAPACITY_RESERVATION_STATUS_UNUSED = 'unused'\nSCRIPT_EC2_CAPACITY_RESERVATION_STATUS_ALLOCATED = 'allocated'\n\nEC2_CAPACITY_RESERVATION_STATUS_USED = 'Used'\nEC2_CAPACITY_RESERVATION_STATUS_UNUSED = 'UnusedCapacityReservation'\nEC2_CAPACITY_RESERVATION_STATUS_ALLOCATED = 'AllocatedCapacityReservation'\n\n\n\nEC2_CAPACITY_RESERVATION_STATUS_MAP = {SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_USED: EC2_CAPACITY_RESERVATION_STATUS_USED,\n SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_UNUSED: EC2_CAPACITY_RESERVATION_STATUS_UNUSED,\n SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_ALLOCATED: EC2_CAPACITY_RESERVATION_STATUS_ALLOCATED}\n\n\n\n\n\nSTORAGE_MEDIA_SSD = \"SSD-backed\"\nSTORAGE_MEDIA_HDD = \"HDD-backed\"\nSTORAGE_MEDIA_S3 = \"AmazonS3\"\n\nEBS_VOLUME_TYPE_MAGNETIC = \"Magnetic\"\nEBS_VOLUME_TYPE_GENERAL_PURPOSE = \"General Purpose\"\nEBS_VOLUME_TYPE_PIOPS = \"Provisioned IOPS\"\nEBS_VOLUME_TYPE_THROUGHPUT_OPTIMIZED = \"Throughput Optimized HDD\"\nEBS_VOLUME_TYPE_COLD_HDD = \"Cold HDD\"\n\n#Values that are valid in the calling script (which could be a Lambda function or any Python module)\n\n#OS\nSCRIPT_OPERATING_SYSTEM_LINUX = 'linux'\nSCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL = 'windowsbyol'\nSCRIPT_OPERATING_SYSTEM_WINDOWS = 'windows'\nSCRIPT_OPERATING_SYSTEM_SUSE = 'suse'\n#SCRIPT_OPERATING_SYSTEM_SQL_WEB = 'sqlweb'\nSCRIPT_OPERATING_SYSTEM_RHEL = 'rhel'\n\n#License Model\nSCRIPT_EC2_LICENSE_MODEL_BYOL = 'byol'\nSCRIPT_EC2_LICENSE_MODEL_INCLUDED = 'included'\nSCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED = 'none-required'\n\n#EBS\nSCRIPT_EBS_VOLUME_TYPE_STANDARD = 'standard'\nSCRIPT_EBS_VOLUME_TYPE_IO1 = 'io1'\nSCRIPT_EBS_VOLUME_TYPE_GP2 = 'gp2'\nSCRIPT_EBS_VOLUME_TYPE_SC1 = 'sc1'\nSCRIPT_EBS_VOLUME_TYPE_ST1 = 'st1'\n\n\n#Reserved Instances\nSCRIPT_EC2_OFFERING_CLASS_STANDARD = 'standard'\nSCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE = 'convertible'\n\nEC2_OFFERING_CLASS_STANDARD = 'standard'\nEC2_OFFERING_CLASS_CONVERTIBLE = 'convertible'\n\nSUPPORTED_EC2_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD, SCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE]\nSUPPORTED_RDS_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD]\nSUPPORTED_EMR_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD, SCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE]\nSUPPORTED_REDSHIFT_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD]\n\nSUPPORTED_OFFERING_CLASSES_MAP = {SERVICE_EC2:SUPPORTED_EC2_OFFERING_CLASSES, SERVICE_RDS: SUPPORTED_RDS_OFFERING_CLASSES,\n SERVICE_EMR:SUPPORTED_EMR_OFFERING_CLASSES,\n SERVICE_REDSHIFT: SUPPORTED_REDSHIFT_OFFERING_CLASSES }\n\nEC2_OFFERING_CLASS_MAP = {SCRIPT_EC2_OFFERING_CLASS_STANDARD:EC2_OFFERING_CLASS_STANDARD,\n SCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE: EC2_OFFERING_CLASS_CONVERTIBLE}\n\n\n\nSCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT = 'partial-upfront'\nSCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT = 'all-upfront'\nSCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT = 'no-upfront'\n\nEC2_PURCHASE_OPTION_PARTIAL_UPFRONT = 'Partial Upfront'\nEC2_PURCHASE_OPTION_ALL_UPFRONT = 'All Upfront'\nEC2_PURCHASE_OPTION_NO_UPFRONT = 'No Upfront'\n\nSCRIPT_EC2_RESERVED_YEARS_1 = '1'\nSCRIPT_EC2_RESERVED_YEARS_3 = '3'\n\nEC2_SUPPORTED_RESERVED_YEARS = (SCRIPT_EC2_RESERVED_YEARS_1, SCRIPT_EC2_RESERVED_YEARS_3)\n\nEC2_RESERVED_YEAR_MAP = {SCRIPT_EC2_RESERVED_YEARS_1:'1yr', SCRIPT_EC2_RESERVED_YEARS_3:'3yr'}\n\nEC2_SUPPORTED_PURCHASE_OPTIONS = (SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT)\n\n\n\nEC2_PURCHASE_OPTION_MAP = {SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT:EC2_PURCHASE_OPTION_PARTIAL_UPFRONT,\n SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT: EC2_PURCHASE_OPTION_ALL_UPFRONT, SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT: EC2_PURCHASE_OPTION_NO_UPFRONT\n }\n\nSUPPORTED_EC2_OPERATING_SYSTEMS = (SCRIPT_OPERATING_SYSTEM_LINUX,\n SCRIPT_OPERATING_SYSTEM_WINDOWS,\n SCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL,\n SCRIPT_OPERATING_SYSTEM_SUSE,\n #SCRIPT_OPERATING_SYSTEM_SQL_WEB,\n SCRIPT_OPERATING_SYSTEM_RHEL)\n\nSUPPORTED_EC2_LICENSE_MODELS = (SCRIPT_EC2_LICENSE_MODEL_BYOL, SCRIPT_EC2_LICENSE_MODEL_INCLUDED, SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED)\n\nEC2_LICENSE_MODEL_MAP = {SCRIPT_EC2_LICENSE_MODEL_BYOL: 'Bring your own license',\n SCRIPT_EC2_LICENSE_MODEL_INCLUDED: 'License Included',\n SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED: 'No License required'\n }\n\n\nEC2_OPERATING_SYSTEMS_MAP = {SCRIPT_OPERATING_SYSTEM_LINUX:'Linux',\n SCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL:'Windows',\n SCRIPT_OPERATING_SYSTEM_WINDOWS:'Windows',\n SCRIPT_OPERATING_SYSTEM_SUSE:'SUSE',\n #SCRIPT_OPERATING_SYSTEM_SQL_WEB:'SQL Web',\n SCRIPT_OPERATING_SYSTEM_RHEL:'RHEL'}\n\nSUPPORTED_EBS_VOLUME_TYPES = (SCRIPT_EBS_VOLUME_TYPE_STANDARD,\n SCRIPT_EBS_VOLUME_TYPE_IO1,\n SCRIPT_EBS_VOLUME_TYPE_GP2,\n SCRIPT_EBS_VOLUME_TYPE_SC1,\n SCRIPT_EBS_VOLUME_TYPE_ST1\n )\n\nEBS_VOLUME_TYPES_MAP = {\n SCRIPT_EBS_VOLUME_TYPE_STANDARD : {'storageMedia':STORAGE_MEDIA_HDD , 'volumeType':EBS_VOLUME_TYPE_MAGNETIC},\n SCRIPT_EBS_VOLUME_TYPE_IO1 : {'storageMedia':STORAGE_MEDIA_SSD , 'volumeType':EBS_VOLUME_TYPE_PIOPS},\n SCRIPT_EBS_VOLUME_TYPE_GP2 : {'storageMedia':STORAGE_MEDIA_SSD , 'volumeType':EBS_VOLUME_TYPE_GENERAL_PURPOSE},\n SCRIPT_EBS_VOLUME_TYPE_SC1 : {'storageMedia':STORAGE_MEDIA_HDD , 'volumeType':EBS_VOLUME_TYPE_COLD_HDD},\n SCRIPT_EBS_VOLUME_TYPE_ST1 : {'storageMedia':STORAGE_MEDIA_HDD , 'volumeType':EBS_VOLUME_TYPE_THROUGHPUT_OPTIMIZED}\n }\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n\n#RDS\n\nSUPPORTED_RDS_INSTANCE_CLASSES = ('db.t1.micro', 'db.m1.small', 'db.m1.medium', 'db.m1.large', 'db.m1.xlarge',\n 'db.m2.xlarge', 'db.m2.2xlarge', 'db.m2.4xlarge',\n 'db.m3.medium', 'db.m3.large', 'db.m3.xlarge', 'db.m3.2xlarge',\n 'db.m4.large', 'db.m4.xlarge', 'db.m4.2xlarge', 'db.m4.4xlarge', 'db.m4.10xlarge', 'db.m4.16xlarge',\n 'db.m5.large', 'db.m5.xlarge', 'db.m5.2xlarge', 'db.m5.4xlarge', 'db.m5.12xlarge', 'db.m5.24xlarge',\n 'db.r3.large', 'db.r3.xlarge', 'db.r3.2xlarge', 'db.r3.4xlarge', 'db.r3.8xlarge',\n 'db.r4.large', 'db.r4.xlarge', 'db.r4.2xlarge', 'db.r4.4xlarge', 'db.r4.8xlarge', 'db.r4.16xlarge',\n 'db.r5.large', 'db.r5.xlarge', 'db.r5.2xlarge', 'db.r5.4xlarge', 'db.r5.12xlarge', 'db.r5.24xlarge',\n 'db.t2.micro', 'db.t2.small', 'db.t2.2xlarge', 'db.t2.large', 'db.t2.xlarge', 'db.t2.medium',\n 'db.t3.micro', 'db.t3.small', 'db.t3.medium', 'db.t3.large', 'db.t3.xlarge', 'db.t3.2xlarge',\n 'db.x1.16xlarge', 'db.x1.32xlarge', 'db.x1e.16xlarge', 'db.x1e.2xlarge', 'db.x1e.32xlarge', 'db.x1e.4xlarge', 'db.x1e.8xlarge', 'db.x1e.xlarge'\n )\n\n\nSCRIPT_RDS_STORAGE_TYPE_STANDARD = 'standard'\nSCRIPT_RDS_STORAGE_TYPE_AURORA = 'aurora' #Aurora has its own type of storage, which is billed by IO operations and size\nSCRIPT_RDS_STORAGE_TYPE_GP2 = 'gp2'\nSCRIPT_RDS_STORAGE_TYPE_IO1 = 'io1'\n\nRDS_VOLUME_TYPE_MAGNETIC = 'Magnetic'\nRDS_VOLUME_TYPE_AURORA = 'General Purpose-Aurora'\nRDS_VOLUME_TYPE_GP2 = 'General Purpose'\nRDS_VOLUME_TYPE_IO1 = 'Provisioned IOPS'\n\n\n\n\nRDS_VOLUME_TYPES_MAP = {\n SCRIPT_RDS_STORAGE_TYPE_STANDARD : RDS_VOLUME_TYPE_MAGNETIC,\n SCRIPT_RDS_STORAGE_TYPE_AURORA : RDS_VOLUME_TYPE_AURORA,\n SCRIPT_RDS_STORAGE_TYPE_GP2 : RDS_VOLUME_TYPE_GP2,\n SCRIPT_RDS_STORAGE_TYPE_IO1 : RDS_VOLUME_TYPE_IO1\n }\n\n\n\nSUPPORTED_RDS_STORAGE_TYPES = (SCRIPT_RDS_STORAGE_TYPE_STANDARD, SCRIPT_RDS_STORAGE_TYPE_AURORA, SCRIPT_RDS_STORAGE_TYPE_GP2, SCRIPT_RDS_STORAGE_TYPE_IO1)\n\n\nRDS_DEPLOYMENT_OPTION_SINGLE_AZ = 'Single-AZ'\nRDS_DEPLOYMENT_OPTION_MULTI_AZ = 'Multi-AZ'\nRDS_DEPLOYMENT_OPTION_MULTI_AZ_MIRROR = 'Multi-AZ (SQL Server Mirror)'\n\nRDS_DB_ENGINE_MYSQL = 'MySQL'\nRDS_DB_ENGINE_MARIADB = 'MariaDB'\nRDS_DB_ENGINE_ORACLE = 'Oracle'\nRDS_DB_ENGINE_SQL_SERVER = 'SQL Server'\nRDS_DB_ENGINE_POSTGRESQL = 'PostgreSQL'\nRDS_DB_ENGINE_AURORA_MYSQL = 'Aurora MySQL'\nRDS_DB_ENGINE_AURORA_POSTGRESQL = 'Aurora PostgreSQL'\n\nRDS_DB_EDITION_ENTERPRISE = 'Enterprise'\nRDS_DB_EDITION_STANDARD = 'Standard'\nRDS_DB_EDITION_STANDARD_ONE = 'Standard One'\nRDS_DB_EDITION_STANDARD_TWO = 'Standard Two'\nRDS_DB_EDITION_EXPRESS = 'Express'\nRDS_DB_EDITION_WEB = 'Web'\n\n\nSCRIPT_RDS_DATABASE_ENGINE_MYSQL = 'mysql'\nSCRIPT_RDS_DATABASE_ENGINE_MARIADB = 'mariadb'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD = 'oracle-se'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE = 'oracle-se1'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO = 'oracle-se2'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE = 'oracle-ee'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE = 'sqlserver-ee'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD = 'sqlserver-se'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS = 'sqlserver-ex'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB = 'sqlserver-web'\nSCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL = 'postgres' #to be consistent with RDS API - https://docs.aws.amazon.com/AmazonRDS/latest/APIReference/API_CreateDBInstance.html\nSCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL = 'aurora'\nSCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG = 'aurora-mysql' #some items in the RDS API now return aurora-mysql as a valid engine (instead of just aurora)\nSCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL = 'aurora-postgresql'\n\nRDS_SUPPORTED_DB_ENGINES = (SCRIPT_RDS_DATABASE_ENGINE_MYSQL,SCRIPT_RDS_DATABASE_ENGINE_MARIADB,\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD, SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE,\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO,SCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE,\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE, SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD,\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS, SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB,\n SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL, SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL,\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG\n )\n\nSCRIPT_RDS_LICENSE_MODEL_INCLUDED = 'license-included'\nSCRIPT_RDS_LICENSE_MODEL_BYOL = 'bring-your-own-license'\nSCRIPT_RDS_LICENSE_MODEL_PUBLIC = 'general-public-license'\nRDS_SUPPORTED_LICENSE_MODELS = (SCRIPT_RDS_LICENSE_MODEL_INCLUDED, SCRIPT_RDS_LICENSE_MODEL_BYOL, SCRIPT_RDS_LICENSE_MODEL_PUBLIC)\nRDS_LICENSE_MODEL_MAP = {SCRIPT_RDS_LICENSE_MODEL_INCLUDED:'License included',\n SCRIPT_RDS_LICENSE_MODEL_BYOL:'Bring your own license',\n SCRIPT_RDS_LICENSE_MODEL_PUBLIC:'No license required'}\n\nRDS_ENGINE_MAP = {SCRIPT_RDS_DATABASE_ENGINE_MYSQL:{'engine':RDS_DB_ENGINE_MYSQL,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_MARIADB:{'engine':RDS_DB_ENGINE_MARIADB ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_STANDARD},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_STANDARD_ONE},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_STANDARD_TWO},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_ENTERPRISE},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_ENTERPRISE},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_STANDARD},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_EXPRESS},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_WEB},\n SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL:{'engine':RDS_DB_ENGINE_POSTGRESQL ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL:{'engine':RDS_DB_ENGINE_AURORA_MYSQL ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG:{'engine':RDS_DB_ENGINE_AURORA_MYSQL ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL:{'engine':RDS_DB_ENGINE_AURORA_POSTGRESQL ,'edition':''}\n }\n\n\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n\n#S3\n\nS3_USAGE_GROUP_REQUESTS_TIER_1 = 'S3-API-Tier1'\nS3_USAGE_GROUP_REQUESTS_TIER_2 = 'S3-API-Tier2'\nS3_USAGE_GROUP_REQUESTS_TIER_3 = 'S3-API-Tier3'\nS3_USAGE_GROUP_REQUESTS_SIA_TIER1 = 'S3-API-SIA-Tier1'\nS3_USAGE_GROUP_REQUESTS_SIA_TIER2 = 'S3-API-SIA-Tier2'\nS3_USAGE_GROUP_REQUESTS_SIA_RETRIEVAL = 'S3-API-SIA-Retrieval'\nS3_USAGE_GROUP_REQUESTS_ZIA_TIER1 = 'S3-API-ZIA-Tier1'\nS3_USAGE_GROUP_REQUESTS_ZIA_TIER2 = 'S3-API-ZIA-Tier2'\nS3_USAGE_GROUP_REQUESTS_ZIA_RETRIEVAL = 'S3-API-ZIA-Retrieval'\n\n\nS3_STORAGE_CLASS_STANDARD = 'General Purpose'\nS3_STORAGE_CLASS_SIA = 'Infrequent Access'\nS3_STORAGE_CLASS_ZIA = 'Infrequent Access'\nS3_STORAGE_CLASS_GLACIER = 'Archive'\nS3_STORAGE_CLASS_REDUCED_REDUNDANCY = 'Non-Critical Data'\n\n\nSUPPORTED_REQUEST_TYPES = ('PUT','COPY','POST','LIST','GET')\n\nSCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS = 'STANDARD_IA'\nSCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS = 'ONEZONE_IA'\nSCRIPT_STORAGE_CLASS_STANDARD = 'STANDARD'\nSCRIPT_STORAGE_CLASS_GLACIER = 'GLACIER'\nSCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY = 'REDUCED_REDUNDANCY'\n\nSUPPORTED_S3_STORAGE_CLASSES = (SCRIPT_STORAGE_CLASS_STANDARD,\n SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS,\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS,\n SCRIPT_STORAGE_CLASS_GLACIER,\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY)\n\nS3_STORAGE_CLASS_MAP = {SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS:S3_STORAGE_CLASS_SIA,\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS:S3_STORAGE_CLASS_ZIA,\n SCRIPT_STORAGE_CLASS_STANDARD:S3_STORAGE_CLASS_STANDARD,\n SCRIPT_STORAGE_CLASS_GLACIER:S3_STORAGE_CLASS_GLACIER,\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY:S3_STORAGE_CLASS_REDUCED_REDUNDANCY}\n\nS3_USAGE_TYPE_DICT = {\n SCRIPT_STORAGE_CLASS_STANDARD:'TimedStorage-ByteHrs',\n SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS:'TimedStorage-SIA-ByteHrs',\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS:'TimedStorage-ZIA-ByteHrs',\n SCRIPT_STORAGE_CLASS_GLACIER:'TimedStorage-GlacierByteHrs',\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY:'TimedStorage-RRS-ByteHrs'\n }\n\nS3_VOLUME_TYPE_DICT = {\n SCRIPT_STORAGE_CLASS_STANDARD:'Standard',\n SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS:'Standard - Infrequent Access',\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS:'One Zone - Infrequent Access',\n SCRIPT_STORAGE_CLASS_GLACIER:'Amazon Glacier',\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY:'Reduced Redundancy'\n }\n\n\n\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n\n#LAMBDA\n\nLAMBDA_MEM_SIZES = [64,128,192,256,320,384,448,512,576,640,704,768,832,896,960,1024,1088,1152,1216,1280,1344,1408,\n 1472,1536,1600,1664,1728,1792,1856,1920,1984,2048,2112,2176,2240,2304,2368,2432,2496,2560,2624,2688,\n 2752,2816,2880,2944,3008]\n"
},
{
"path": "awspricecalculator/common/errors.py",
"content": "import json\nimport os\n\n\n\nclass ValidationError(Exception):\n \"\"\"Exception raised for errors in the input.\n\n Attributes:\n message -- explanation of the error\n \"\"\"\n\n def __init__(self, message):\n self.message = message\n\n\nclass NoDataFoundError(Exception):\n \"\"\"Exception raised when no data could be found for a particular set of inputs\n\n Attributes:\n message -- explanation of the error\n \"\"\"\n\n def __init__(self, message):\n self.message = message\n\n"
},
{
"path": "awspricecalculator/common/models.py",
"content": "import math, logging\nimport os, sys\nfrom . import consts\nfrom .errors import ValidationError\n\nlog = logging.getLogger()\n\n__location__ = os.path.realpath(os.path.join(os.getcwd(), os.path.dirname(__file__)))\nsite_pkgs = os.path.abspath(os.path.join(__location__, os.pardir, os.pardir,\"lib\", \"python3.7\", \"site-packages\" ))\nsys.path.append(site_pkgs)\n\nfrom tabulate import tabulate\n\n\nclass ElbPriceDimension():\n def __init__(self, hours, dataProcessedGb):\n self.hours = hours\n self.dataProcessedGb = dataProcessedGb\n\n\n\nclass S3PriceDimension():\n def __init__(self, **kwargs):\n self.region = ''\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.storageClass = ''\n self.storageSizeGb = 0\n\n #TODO:Implement requestType and requestNumber as Count, such that a single call to the price calculator can account for multiple request types\n self.requestType = ''\n self.requestNumber = 0\n\n self.dataRetrievalGb = 0\n self.dataTransferOutInternetGb = 0\n\n self.region = kwargs.get('region','')\n self.storageClass = kwargs.get('storageClass','')\n self.storageSizeGb = int(kwargs.get('storageSizeGb',0))\n self.requestType = kwargs.get('requestType','')\n self.requestNumber = int(kwargs.get('requestNumber',0))\n self.dataRetrievalGb = int(kwargs.get('dataRetrievalGb',0))\n self.dataTransferOutInternetGb = int(kwargs.get('dataTransferOutInternetGb',0))\n\n self.validate()\n\n\n def validate(self):\n validation_ok = True\n validation_message = \"\"\n\n if not self.storageClass:\n validation_message += \"Storage class cannot be empty\\n\"\n validation_ok = False\n if self.storageClass and self.storageClass not in consts.SUPPORTED_S3_STORAGE_CLASSES:\n validation_message += \"Invalid storage class:[{}]\\n\".format(self.storageClass)\n validation_ok = False\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"Invalid region:[{}]\\n\".format(self.region)\n validation_ok = False\n if self.requestNumber and not self.requestType:\n validation_message += \"requestType cannot be empty if you specity requestNumber\\n\"\n validation_ok = False\n if self.requestType and self.requestType not in consts.SUPPORTED_REQUEST_TYPES:\n validation_message += \"Invalid request type:[{}]\\n\".format(self.requestType)\n validation_ok = False\n\n if not validation_ok:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\n\n\nclass Ec2PriceDimension():\n def __init__(self, **kargs):\n\n self.region = kargs['region']\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.instanceType = kargs.get('instanceType','')\n self.operatingSystem = kargs.get('operatingSystem',consts.SCRIPT_OPERATING_SYSTEM_LINUX)\n self.instanceHours = int(kargs.get('instanceHours',0))\n\n #TODO: Add support for pre-installed software (i.e. SQL Web in Windows instances)\n self.preInstalledSoftware = 'NA'\n\n self.licenseModel = consts.SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED\n if self.operatingSystem == consts.SCRIPT_OPERATING_SYSTEM_WINDOWS:\n self.licenseModel = consts.SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED\n if self.operatingSystem == consts.SCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL:\n self.licenseModel = consts.SCRIPT_EC2_LICENSE_MODEL_BYOL\n\n #Capacity Reservations\n #TODO: add support for allocated and unused Capacity Reservations\n self.capacityReservationStatus = consts.SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_USED\n\n #Reserved Instances\n self.offeringClass = kargs.get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.instanceCount = int(kargs.get('instanceCount',0))\n self.offeringType = kargs.get('offeringType','')\n self.years = int(kargs.get('years',1))\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n #Data Transfer\n self.dataTransferOutInternetGb = int(kargs.get('dataTransferOutInternetGb',0))\n self.dataTransferOutIntraRegionGb = int(kargs.get('dataTransferOutIntraRegionGb',0))\n self.dataTransferOutInterRegionGb = int(kargs.get('dataTransferOutInterRegionGb',0))\n self.toRegion = kargs.get('toRegion','')\n\n #Storage\n self.pIops = int(kargs.get('pIops',0))\n self.storageMedia = ''\n self.ebsVolumeType = kargs.get('ebsVolumeType','')\n if self.ebsVolumeType in consts.EBS_VOLUME_TYPES_MAP: self.storageMedia = consts.EBS_VOLUME_TYPES_MAP[self.ebsVolumeType]['storageMedia']\n self.volumeType = ''\n if self.ebsVolumeType in consts.EBS_VOLUME_TYPES_MAP: self.volumeType = consts.EBS_VOLUME_TYPES_MAP[self.ebsVolumeType]['volumeType']\n if not self.volumeType: self.volumeType = consts.SCRIPT_EBS_VOLUME_TYPE_GP2\n self.ebsStorageGbMonth = int(kargs.get('ebsStorageGbMonth',0))\n self.ebsSnapshotGbMonth = int(kargs.get('ebsSnapshotGbMonth',0))\n\n #Elastic Load Balancer (classic)\n self.elbHours = int(kargs.get('elbHours',0))\n self.elbDataProcessedGb = int(kargs.get('elbDataProcessedGb',0))\n\n #Application Load Balancer\n self.albHours = int(kargs.get('albHours',0))\n self.albLcus= int(kargs.get('albLcus',0))\n\n #TODO: add support for Network Load Balancer\n\n #TODO: Add support for dedicated tenancies\n self.tenancy = kargs.get('tenancy',consts.SCRIPT_EC2_TENANCY_SHARED)\n\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n\n if self.instanceType and self.instanceType not in consts.SUPPORTED_EC2_INSTANCE_TYPES:\n validation_message += \"instance-type is \"+self.instanceType+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_INSTANCE_TYPES)\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if not self.operatingSystem:\n validation_message += \"operating-system cannot be empty\\n\"\n if self.operatingSystem and self.operatingSystem not in consts.SUPPORTED_EC2_OPERATING_SYSTEMS:\n validation_message += \"operating-system is \"+self.operatingSystem+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_OPERATING_SYSTEMS)\n if self.ebsVolumeType and self.ebsVolumeType not in consts.SUPPORTED_EBS_VOLUME_TYPES:\n validation_message += \"ebs-volume-type is \"+self.ebsVolumeType+\", must be one of the following values:\"+str(consts.SUPPORTED_EBS_VOLUME_TYPES)\n if self.dataTransferOutInterRegionGb > 0 and not self.toRegion:\n validation_message += \"Must specify a to-region if you specify data-transfer-out-interregion-gb\\n\"\n if self.dataTransferOutInterRegionGb and self.toRegion not in consts.SUPPORTED_REGIONS:\n validation_message += \"to-region is \"+self.toRegion+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.dataTransferOutInterRegionGb and self.region == self.toRegion:\n validation_message += \"source and destination regions must be different for inter-regional data transfers\\n\"\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n if self.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n if not self.offeringClass:\n validation_message += \"offering-class must be specified for Reserved instances\\n\"\n if self.offeringClass and self.offeringClass not in (consts.SUPPORTED_EC2_OFFERING_CLASSES):\n validation_message += \"offering-class is \"+self.offeringClass+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_OFFERING_CLASSES)\n if not self.offeringType:\n validation_message += \"offering-type must be specified\\n\"\n if self.offeringType and self.offeringType not in (consts.EC2_SUPPORTED_PURCHASE_OPTIONS):\n validation_message += \"offering-type is \"+self.offeringType+\", must be one of the following values:\"+str(consts.EC2_SUPPORTED_PURCHASE_OPTIONS)\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and self.instanceHours:\n validation_message += \"instance-hours cannot be set if term-type=reserved and offering-type=all-upfront\\n\"\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and not self.instanceCount:\n validation_message += \"instance-count is mandatory if term-type=reserved and offering-type=all-upfront\\n\"\n if not self.years:\n validation_message += \"years cannot be empty for Reserved instances\"\n\n #TODO: add validation for max number of IOPS\n #TODO: add validation for negative numbers\n\n validation_ok = True\n if validation_message:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\n\nclass RdsPriceDimension():\n def __init__(self, **kargs):\n self.region = kargs.get('region','')\n\n #DB Instance\n self.dbInstanceClass = kargs.get('dbInstanceClass','')\n\n if kargs.get('engine',''): self.engine = kargs['engine']\n else: self.engine = consts.SCRIPT_RDS_DATABASE_ENGINE_MYSQL\n\n\n self.licenseModel = kargs.get('licenseModel')\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL,\n consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG,\n consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL,\n consts.SCRIPT_RDS_DATABASE_ENGINE_MARIADB):\n self.licenseModel = consts.SCRIPT_RDS_LICENSE_MODEL_PUBLIC\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD, consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE,\n consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB, consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS,\n consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE, consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD,\n consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE, consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO) \\\n and not self.licenseModel:\n self.licenseModel = consts.SCRIPT_RDS_LICENSE_MODEL_INCLUDED\n\n\n\n self.instanceHours = int(kargs.get('instanceHours',0))\n\n tmpmultiaz = str(kargs.get('multiAz','false')).lower()\n self.deploymentOption = ''\n if tmpmultiaz == 'true': self.deploymentOption = consts.RDS_DEPLOYMENT_OPTION_MULTI_AZ\n if tmpmultiaz == 'false': self.deploymentOption = consts.RDS_DEPLOYMENT_OPTION_SINGLE_AZ\n\n #OnDemand vs. Reserved\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD #TODO: add support for others, besides 'standard'\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.offeringType = kargs.get('offeringType','')\n self.instanceCount = int(kargs.get('instanceCount',0))\n self.years = int(kargs.get('years',1))\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n\n #TODO - create a separate model for DataTransfer\n #Data Transfer\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb',0)\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n\n #Storage\n self.storageGbMonth = int(kargs.get('storageGbMonth',0))\n self.storageType = kargs.get('storageType','')\n self.iops= int(kargs.get('iops',0))\n self.ioRequests= int(kargs.get('ioRequests',0))\n self.backupStorageGbMonth = int(kargs.get('backupStorageGbMonth',0))\n\n self.validate()\n\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL):\n self.storageType = consts.SCRIPT_RDS_STORAGE_TYPE_AURORA\n self.volumeType = self.calculate_volume_type()\n\n\n\n def calculate_volume_type(self):\n #TODO:add condition for Aurora\n if self.storageType in consts.RDS_VOLUME_TYPES_MAP:\n return consts.RDS_VOLUME_TYPES_MAP[self.storageType]\n\n def validate(self):\n #TODO: add validations for data transfer\n #TODO: add validations for different combinations of engine, edition and license\n #TODO: add validations for multiAz (deploymentOption cannot be empty)\n validation_ok = True\n validation_message = \"\"\n valid_engine = True\n\n if self.dbInstanceClass and self.dbInstanceClass not in consts.SUPPORTED_RDS_INSTANCE_CLASSES:\n validation_message = \"\\n\" + \"db-instance-class must be one of the following values:\"+str(consts.SUPPORTED_RDS_INSTANCE_CLASSES)\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"\\n\" + \"region must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.engine and self.engine not in consts.RDS_SUPPORTED_DB_ENGINES:\n validation_message += \"\\n\" + \"engine must be one of the following values:\"+str(consts.RDS_SUPPORTED_DB_ENGINES)\n valid_engine = False\n if valid_engine and self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_MYSQL,consts.SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL,\n consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL):\n if self.licenseModel not in (consts.RDS_SUPPORTED_LICENSE_MODELS):\n validation_message += \"\\n\" + \"you have specified license model [{}] - license-model must be one of the following values:{}\".format(self.licenseModel, consts.RDS_SUPPORTED_LICENSE_MODELS)\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL):\n if self.storageType in (consts.SCRIPT_RDS_STORAGE_TYPE_STANDARD, consts.SCRIPT_RDS_STORAGE_TYPE_GP2, consts.SCRIPT_RDS_STORAGE_TYPE_IO1):\n validation_message += \"\\nyou have specified {} storage type, which is invalid for DB engine {}\".format(self.storageType, self.engine)\n if self.storageType:\n if self.storageType not in consts.SUPPORTED_RDS_STORAGE_TYPES:\n validation_message += \"\\n\" + \"storage-type must be one of the following values:\"+str(consts.SUPPORTED_RDS_STORAGE_TYPES)\n if self.storageType == consts.SCRIPT_RDS_STORAGE_TYPE_IO1 and not self.iops:\n validation_message += \"\\n\" + \"you must specify an iops value for storage type io1\"\n if self.storageType == consts.SCRIPT_RDS_STORAGE_TYPE_IO1 and self.storageGbMonth and self.storageGbMonth < 100 :\n validation_message += \"\\nyou have specified {}GB of storage. You must specify at least 100GB of storage for io1\".format(self.storageGbMonth)\n\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n\n #TODO: move to a common place for all reserved pricing (EC2, RDS, etc.)\n if self.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n if not self.offeringClass:\n validation_message += \"offering-class must be specified for Reserved instances\\n\"\n if self.offeringClass and self.offeringClass not in (consts.SUPPORTED_EC2_OFFERING_CLASSES):\n validation_message += \"offering-class is \"+self.offeringClass+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_OFFERING_CLASSES)\n if not self.offeringType:\n validation_message += \"offering-type must be specified\\n\"\n if self.offeringType and self.offeringType not in (consts.EC2_SUPPORTED_PURCHASE_OPTIONS):\n validation_message += \"offering-type is \"+self.offeringType+\", must be one of the following values:\"+str(consts.EC2_SUPPORTED_PURCHASE_OPTIONS)\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and self.instanceHours:\n validation_message += \"instance-hours cannot be set if term-type=reserved and offering-type=all-upfront\\n\"\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and not self.instanceCount:\n validation_message += \"instance-count is mandatory if term-type=reserved and offering-type=all-upfront\\n\"\n if not self.years:\n validation_message += \"years cannot be empty for Reserved instances\"\n\n\n if validation_message:\n log.error(\"{}\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\nclass EmrPriceDimension():\n def __init__(self, **kargs):\n\n self.region = kargs['region']\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.instanceType = kargs.get('instanceType','')\n\n self.years = int(kargs.get('years',1))\n self.instanceCount = int(kargs.get('instanceCount',0))\n ec2InstanceHours = 0\n if self.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n self.instanceHours = calculate_instance_hours_year(self.instanceCount, self.years)\n else:\n self.instanceHours = int(kargs.get('instanceHours',0))\n ec2InstanceHours = self.instanceHours #only set ec2InstanceHours for OnDemand, otherwise EC2 validation will fail\n\n\n self.offeringClass = kargs.get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.offeringType = kargs.get('offeringType', consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT)\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n\n #Data Transfer\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb',0)\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n\n ec2Args = {'region':self.region, 'termType':self.termType, 'instanceType':self.instanceType,\n 'instanceHours':ec2InstanceHours, 'pIops':int(kargs.get('pIops',0)), 'ebsVolumeType':kargs.get('ebsVolumeType',''),\n 'ebsStorageGbMonth':int(kargs.get('ebsStorageGbMonth',0)), 'instanceCount': kargs.get('instanceCount',0),\n 'years': self.years, 'offeringType':self.offeringType, 'offeringClass':self.offeringClass}\n\n #self.ec2PriceDims = Ec2PriceDimension(**ec2Args)\n self.ec2PriceDims = ec2Args\n\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n\n #TODO: add supported EMR Instance Type validation\n\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n if self.offeringClass not in consts.SUPPORTED_EMR_OFFERING_CLASSES:\n validation_message += \"offeringClass is \"+self.offeringClass+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_EMR_OFFERING_CLASSES)\n\n validation_ok = True\n if validation_message:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\nclass RedshiftPriceDimension():\n def __init__(self, **kargs):\n\n self.region = kargs['region']\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.instanceType = kargs.get('instanceType','')\n self.instanceHours = int(kargs.get('instanceHours',0))\n\n #Reserved Instances\n self.offeringClass = kargs.get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.instanceCount = int(kargs.get('instanceCount',0))\n self.offeringType = kargs.get('offeringType','')\n self.years = int(kargs.get('years',1))\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n #TODO: add storage snapshots, data scan, concurrency scaling,\n\n #Data Transfer\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb',0)\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n\n\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n if self.offeringClass not in consts.SUPPORTED_REDSHIFT_OFFERING_CLASSES:\n validation_message += \"offeringClass is \"+self.offeringClass+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_REDSHIFT_OFFERING_CLASSES)\n if self.instanceType not in consts.SUPPORTED_REDSHIFT_INSTANCE_TYPES:\n validation_message += \"instanceType is \"+self.instanceType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_REDSHIFT_INSTANCE_TYPES)\n\n validation_ok = True\n if validation_message:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\n\n\nclass LambdaPriceDimension():\n def __init__(self,**kargs):\n self.region = kargs.get('region','')\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.requestCount = kargs.get('requestCount',0)\n self.avgDurationMs = kargs.get('avgDurationMs',0)\n self.memoryMb = kargs.get('memoryMb',0)\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb')\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n self.validate()\n self.GBs = self.requestCount * (float(self.avgDurationMs) / 1000) * (float(self.memoryMb) / 1024)\n\n\n def validate(self):\n validation_message = \"\"\n if not self.region:\n validation_message += \"Region must be specified\\n\"\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"Region is \"+self.region+\" ,must be one of the following:\"+str(consts.SUPPORTED_REGIONS)\n if self.requestCount and self.avgDurationMs == 0:\n validation_message += \"Cannot have value for requestCount and avgDurationMs=0\\n\"\n if self.requestCount and self.memoryMb== 0:\n validation_message += \"Cannot have value for requestCount and memoryMb=0\\n\"\n if self.requestCount == 0 and (self.avgDurationMs > 0 or self.memoryMb > 0):\n validation_message += \"Cannot have value for average duration or memory if requestCount is zero\\n\"\n if self.dataTransferOutInterRegionGb > 0 and not self.toRegion:\n validation_message += \"Must specify a to-region if you specify data-transfer-out-interregion-gb\\n\"\n\n if validation_message:\n log.error(\"{}\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\n\nclass DynamoDBPriceDimension():\n def __init__(self,**kargs):\n self.region = kargs.get('region','')\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.readCapacityUnitHours = kargs.get('readCapacityUnitHours',0)\n self.writeCapacityUnitHours = kargs.get('writeCapacityUnitHours',0)\n self.requestCount = kargs.get('requestCount',0)#used for reads to DDB Streams\n self.dataTransferOutGb = kargs.get('dataTransferOutGb',0)\n \"\"\"\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n \"\"\"\n\n self.validate()\n\n\n def validate(self):\n validation_message = \"\"\n if not self.region:\n validation_message += \"Region must be specified\\n\"\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"Region is \"+self.region+\", must be one of the following:\"+str(consts.SUPPORTED_REGIONS)\n if self.readCapacityUnitHours == 0:\n validation_message += \"readCapacityUnitHours cannot be 0\\n\"\n if self.writeCapacityUnitHours == 0:\n validation_message += \"writeCapacityUnitHours cannot be 0\\n\"\n\n if validation_message:\n print(\"Error: [{}]\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\n\"\"\"\nPlease note the following - from https://aws.amazon.com/kinesis/streams/pricing/:\n* Getting records from Amazon Kinesis stream is free.\n* Data transfer is free. AWS does not charge for data transfer from your data producers to Amazon Kinesis Streams, or from Amazon Kinesis Streams to your Amazon Kinesis Applications.\n\"\"\"\n\nclass KinesisPriceDimension():\n def __init__(self,**kargs):\n self.region = kargs.get('region','')\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.shardHours = 0\n self.shardHours = int(kargs.get('shardHours',0))\n self.putPayloadUnits = int(kargs.get('putPayloadUnits',0))\n self.extendedDataRetentionHours = int(kargs.get('extendedDataRetentionHours',0))\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n if not self.region:\n validation_message += \"Region must be specified\\n\"\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.shardHours == 0:\n validation_message += \"shardHours cannot be 0\\n\"\n\n if validation_message:\n print(\"Error: [{}]\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\n\"\"\"\nThis object represents the total price calculation.\nIt includes an array of PricingRecord objects, which are a breakdown of how the price is calculated\n\"\"\"\n#TODO: update arguments, remove region and include one argument for pdim\nclass PricingResult():\n def __init__(self, awsPriceListApiVersion, region, total_cost, pricing_records, **args):\n total_cost = round(total_cost,2)\n self.version = consts.AWS_PRICE_CALCULATOR_VERSION\n self.awsPriceListApiVersion = awsPriceListApiVersion\n self.region = region\n self.totalCost = round(total_cost,2)\n self.currency = consts.DEFAULT_CURRENCY\n self.pricingRecords = pricing_records\n\n tmpPriceDimensions = args.get('priceDimensions',{})\n if tmpPriceDimensions: self.priceDimensions = args.get('priceDimensions',{}).__dict__\n else: self.priceDimensions = tmpPriceDimensions\n\nclass PricingRecord():\n def __init__(self, service, amt, desc, pricePerUnit, usgUnits, rateCode):\n usgUnits = round(float(usgUnits),2)\n amt = round(amt,2)\n self.service = service\n self.amount = amt\n self.description = desc\n self.pricePerUnit = pricePerUnit\n self.usageUnits = int(usgUnits)\n self.rateCode = rateCode\n\n\n\"\"\"\nThis class is a container for generic price comparisons, with different values for a single parameter.\nFor example, comparing a specific price calculation for different regions, or EC2 instance types, or OS\n\"\"\"\nclass PriceComparison():\n def __init__(self, awsPriceListApiVersion, service, sortCriteria):\n self.version = \"v1.0\"\n self.awsPriceListApiVersion = awsPriceListApiVersion\n self.service = service\n self.sortCriteria = sortCriteria\n self.currency = consts.DEFAULT_CURRENCY\n self.pricingScenarios = []\n #TODO: implement get_csv_data and get_tabular_data\n\nclass PricingScenario():\n def __init__(self, index, id, priceDimensions, priceCalculation, totalCost, sortCriteria):\n self.index = index\n self.id = id\n self.displayName = self.getDisplayName(sortCriteria)\n self.priceDimensions = priceDimensions\n\n #Remove redundant information from priceCalculation object.\n #This information is already present in PriceComparison or PricingScenario objects\n priceCalculation.pop('awsPriceListApiVersion','')\n priceCalculation.pop('totalCost','')\n priceCalculation.pop('service','')\n priceCalculation.pop('currency','')\n\n self.priceCalculation = priceCalculation\n self.totalCost = round(totalCost,2)\n self.deltaPrevious = 0 #how more expensive is this item, compared to cheapest option - in $\n self.deltaCheapest = 0 #how more expensive is this item, compared to cheapest option - in %\n self.pctToPrevious = 0 #how more expensive is this item, compared to next lower option - in $\n self.pctToCheapest = 0 #how more expensive is this item, compared to next lower option - in %\n self.totalCost = round(totalCost,2)\n\n def getDisplayName(self, sortCriteria):\n result = ''\n if sortCriteria == consts.SORT_CRITERIA_REGION:\n result = consts.REGION_REPORT_MAP.get(self.id,'N/A')\n\n #TODO: update for all supported sortCriteria options\n else:\n result = self.id\n\n return result\n\n\n\"\"\"\nThis class is a container for price calculations between different term types, such as Demand vs. Reserved\n\"\"\"\nclass TermPricingAnalysis():\n def __init__(self, awsPriceListApiVersion, regions, service, years):\n self.version = \"v1.0\"\n self.awsPriceListApiVersion = awsPriceListApiVersion\n self.regions = regions\n self.service = service\n self.currency = consts.DEFAULT_CURRENCY\n self.years = years\n self.pricingScenarios = []\n self.monthlyBreakdown = []\n self.tabularData = \"\"\n\n def get_pricing_scenario(self, region, termType, offerClass, offerType, years):\n #print (\"get_pricing_scenario - looking for termType:[{}] - offerClass:[{}] - offerType:[{}] - years:[{}]\".format())\n for p in self.pricingScenarios:\n #print (\"get_pricing_scenario - looking for termType:[{}] - offerClass:[{}] - offerType:[{}] - years:[{}] in priceDimensions: [{}]\".format(termType, offerClass, offerType, years, p['priceDimensions']))\n if p['priceDimensions']['region']==region and p['priceDimensions']['termType']==termType \\\n and p['priceDimensions'].get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)==offerClass \\\n and p['priceDimensions'].get('offeringType','')==offerType and str(p['priceDimensions']['years'])==str(years):\n return p\n if p['priceDimensions']['region']==region and p['priceDimensions']['termType']==termType \\\n and termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND \\\n and str(p['priceDimensions']['years'])==str(years):\n return p\n\n return False\n\n def calculate_months_to_recover(self):\n updatedPricingScenarios = []\n\n for s in self.pricingScenarios:\n accumamt = 0\n month = 1\n while month <= int(self.years)*12:\n if month == 1:\n #if s['id'] == 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years):\n if 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years) in s['id']:\n accumamt = self.getUpfrontFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'],\n consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n #if s['id'] == 'reserved-{}-all-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years):\n if 'reserved-{}-all-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years) in s['id']:\n accumamt = self.getUpfrontFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'],\n consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years)))\n\n\n #if s['id'] == 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years): accumamt += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, self.years))\n if 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years) in s['id']:\n accumamt += self.getMonthlyFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, self.years))\n #if s['id'] == 'reserved-{}-no-upfront-{}yr'.format(s['priceDimensions']['offeringClass'], self.years): accumamt += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, self.years))\n if 'reserved-{}-no-upfront-{}yr'.format(s['priceDimensions']['offeringClass'], self.years) in s['id']:\n accumamt += self.getMonthlyFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, self.years))\n\n if ((s['onDemandTotalCost']/(int(self.years)*12))*month) >= accumamt:\n break\n month += 1\n\n s['monthsToRecover'] = month\n updatedPricingScenarios.append(s)\n\n self.pricingScenarios = updatedPricingScenarios\n\n\n def calculate_monthly_breakdown(self):\n #TODO: validate that years is either 1 or 3\n monthlyScenarios = []\n month = 1\n while month <= int(self.years) * 12:\n monthDict = {}\n monthDict['month']=month\n for p in self.pricingScenarios: #at this point, scenarios are already sorted\n #TODO: confirm if partial upfront also gets the monthly fee applied on the first month, or not.\n #If the analysis includes multiple regions, include the region in the scenario id.\n if len(self.regions)>1: tmpregionid = \"{}-\".format(p.get('priceDimensions',{}).get('region',''))\n else: tmpregionid = \"\"\n if 'all-upfront' in p['id']:\n monthDict['{}reserved-{}-all-upfront-{}yr'.format(tmpregionid, p['priceDimensions']['offeringClass'], self.years)] = \\\n round(self.getUpfrontFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years))) + \\\n month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years))),2)\n if 'partial-upfront' in p['id']:\n monthDict['{}reserved-{}-partial-upfront-{}yr'.format(tmpregionid, p['priceDimensions']['offeringClass'], self.years)] = \\\n round(self.getUpfrontFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years))) + \\\n month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years))),2)\n if 'no-upfront' in p['id']:\n monthDict['{}reserved-{}-no-upfront-{}yr'.format(tmpregionid,p['priceDimensions']['offeringClass'], self.years)] = \\\n round(month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, str(self.years))),2)\n if 'on-demand' in p['id']:\n monthDict['{}on-demand-{}yr'.format(tmpregionid,self.years)] = \\\n round(month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_ON_DEMAND,\n consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, '', str(self.years))),2)\n monthlyScenarios.append(monthDict)\n month += 1\n\n self.monthlyBreakdown = monthlyScenarios\n return\n\n\n def get_csv_data(self):\n #First, sort keys from high to low total\n finalMonth = self.monthlyBreakdown[len(self.monthlyBreakdown)-1]\n unsorted = []\n sortedscenarios = []\n csvtxt = \"\"\n for k in finalMonth.keys():unsorted.append((finalMonth[k],k))\n sortedscenarios = sorted(unsorted)\n comma = \",\"\n i = 0\n #print header row\n for s in sortedscenarios:\n i += 1\n if i == len(sortedscenarios): comma = \"\" #avoid comma at the end of each row\n csvtxt += \"{}{}\".format(s[1],comma) #print headers\n #print monthly scenario rows\n for m in self.monthlyBreakdown:\n csvtxt += \"\\n\"\n comma = \",\"\n i = 0\n for s in sortedscenarios:\n i += 1\n if i == len(sortedscenarios): comma = \"\" #avoid comma at the end of each row\n csvtxt += \"{}{}\".format(m[s[1]],comma)\n self.csvData = csvtxt\n return\n\n def get_tabular_data(self):\n if not self.csvData: self.get_csv_data()\n csvtext = self.csvData\n #need to reduce the length of each field, otherwise the table headers overflow and data is not displayed properly\n headers = csvtext.split(\"\\n\")[0].replace(\"reserved\",\"rsv\").replace(\"standard\",\"std\").\\\n replace(\"convertible\",\"conv\").replace(\"upfront\",\"upfr\").replace(\"partial\",\"part\").replace(\"demand\",\"dmd\").split(\",\")\n data = []\n for r in csvtext.split(\"\\n\")[1:]:\n data.append(r.split(\",\"))\n\n self.tabularData = tabulate(data, headers=headers, tablefmt='github')\n\n \"\"\"\n def get_csv_data(self):\n #TODO: validate that years is either 1 or 3\n\n def get_csv_dict():\n result = {}\n for k in get_sorted_keys():\n result[k[1]]=0\n return result\n\n def get_sorted_keys():\n #TODO: add to constants\n #TODO: update order in which scenarios get displayed\n return sorted(((1,'month'),(2,'on-demand-{}yr'.format(self.years)),(3,'reserved-all-upfront-{}yr'.format(self.years)),\n (4,'reserved-partial-upfront-{}yr'.format(self.years)),(4,'reserved-no-upfront-{}yr'.format(self.years))))\n\n def get_sorted_key_separator(k):\n result = ','\n sortedkeys = get_sorted_keys()\n if k == sortedkeys[len(sortedkeys)-1]:result = '' #don't add a comma at the end of the line\n return result\n\n month = 1\n\n #TODO: see if this block can be removed\n for s in self.pricingScenarios:\n if s['id'] == \"on-demand-{}yr\".format(self.years): onDemand = s['pricingRecords']\n if s['id'] == \"reserved-no-upfront-{}yr\".format(self.years): reserved1YrNoUpfront = s['pricingRecords']\n if s['id'] == \"reserved-all-upfront-{}yr\".format(self.years): reserved1YrAllUpfrontAccum = s['totalCost']\n for p in s['pricingRecords']:\n if 'upfront' in p['description'].lower():\n if s['id'] == \"reserved-partial-upfront-{}yr\".format(self.years): reserved1YrPartialUpfront = p['amount']\n if s['id'] == \"reserved-all-upfront-{}yr\".format(self.years): reserved1YrAllUpfront = p['amount']\n else: reserved1YrPartialUpfrontApplied = p['amount']\n\n accumDict = get_csv_dict()\n\n csvdata = \"\"\n sortedkeys = get_sorted_keys()\n while month <= int(self.years) * 12:\n accumDict['month']=month\n if month == 1:\n accumDict['reserved-partial-upfront-{}yr'.format(self.years)] = self.getUpfrontFee(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n\n accumDict['reserved-all-upfront-{}yr'.format(self.years)] = self.getUpfrontFee(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years)))\n accumDict['reserved-partial-upfront-{}yr'.format(self.years)] += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n accumDict['on-demand-{}yr'.format(self.years)] += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_ON_DEMAND, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n accumDict['reserved-no-upfront-{}yr'.format(self.years)] += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, str(self.years)))\n\n for k in sortedkeys:\n amt = 0\n if k[1] == 'month': amt = accumDict[k[1]]\n else: amt = round(accumDict[k[1]],2)\n csvdata += \"{}{}\".format(amt,get_sorted_key_separator(k))\n\n csvdata += \"\\n\"\n month += 1\n\n csvheaders = \"\"\n for k in sortedkeys: csvheaders += k[1]+get_sorted_key_separator(k)\n csvheaders += \"\\n\"\n self.csvData = csvheaders + csvdata\n return\n \"\"\"\n\n \"\"\"\n Calculate any upfront fees applied to pricing. The only scenarios applicable for this fee are All Upfront and Partial Upfront\n \"\"\"\n def getUpfrontFee(self, pricingScenarioDict):\n result = 0\n if pricingScenarioDict:\n for p in pricingScenarioDict['pricingRecords']:\n if pricingScenarioDict['priceDimensions'].get('offeringType','') in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT) \\\n and 'upfront' in p['description'].lower():\n result = p['amount']\n break\n return result\n\n \"\"\"\n Calculate any monthly fee paid in addition to an Upfront Fee - for example, monthly fee after Partial Upfront has been paid,\n or monthly fee for No Upfront\n \"\"\"\n def getMonthlyFee(self, pricingScenarioDict):\n result = 0\n if pricingScenarioDict:\n print(\"getMonthlyCost - scenario:[{}] - totalCost:[{}]\".format(pricingScenarioDict['id'], pricingScenarioDict['totalCost']))\n for p in pricingScenarioDict['pricingRecords']:\n if 'upfront' not in p['description'].lower():\n result += p['amount'] / (12 * int(pricingScenarioDict['priceDimensions']['years']))\n return result\n \"\"\"\n def getMonthlyFee(self, pricingScenarioDict):\n result = 0\n if pricingScenarioDict:\n print(\"getMonthlyCost - scenario:[{}] - totalCost:[{}]\".format(pricingScenarioDict['id'], pricingScenarioDict['totalCost']))\n for p in pricingScenarioDict['pricingRecords']:\n tmpamt = p['amount'] / (12 * int(pricingScenarioDict['priceDimensions']['years']))\n if pricingScenarioDict['priceDimensions'].get('offeringType','') != consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT \\\n and 'upfront' not in p['description'].lower():\n result += tmpamt\n #Cost for EMR scenarios consists of EC2 + EMR fee - on-demand scenarios already have EMR + EC2\n if self.service == consts.SERVICE_EMR and p['service'] == consts.SERVICE_EMR and pricingScenarioDict['priceDimensions'].get('termType','') != consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n result += tmpamt\n return result\n \"\"\"\n\nclass TermPricingScenario():\n def __init__(self, id, priceDimensions, pricingRecords, totalCost, onDemandTotalCost):\n self.index = None\n self.id = id\n self.priceDimensions = priceDimensions\n self.pricingRecords = pricingRecords\n self.totalCost = round(totalCost,2)\n self.deltaPrevious = 0 #how more expensive is this item, compared to cheapest option - in $\n self.deltaCheapest = 0 #how more expensive is this item, compared to cheapest option - in %\n self.pctToPrevious = 0 #how more expensive is this item, compared to next lower option - in $\n self.pctToCheapest = 0 #how more expensive is this item, compared to next lower option - in %\n self.onDemandTotalCost = round(onDemandTotalCost,2)\n self.savingsPctvsOnDemand = 0\n self.totalSavingsvsOnDemand = 0\n self.monthsToRecover = 0\n #TODO: implement onDemandMonthsToSavings\n #TODO: implement as a subclass of PricingScenario\n\n def calculateOnDemandSavings(self):\n #TODO: confirm if Partial Upfront is 1 upfront + 12 payments and if the initial payment is applied on month 1\n if self.onDemandTotalCost:\n self.savingsPctvsOnDemand = math.fabs(round((100 * (self.totalCost - self.onDemandTotalCost) / self.onDemandTotalCost),2))\n if self.priceDimensions['termType'] == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n self.totalSavingsvsOnDemand = 0\n else:\n self.totalSavingsvsOnDemand = round((self.onDemandTotalCost - self.totalCost),2)\n\n\n#This method is duplicate in utils - need to find a way to remove circular dependency and avoid duplication\ndef calculate_instance_hours_year(instanceCount, years):\n return 365 * 24 * int(instanceCount) * int(years)\n\n\n"
},
{
"path": "awspricecalculator/common/phelper.py",
"content": "\nfrom . import consts\nimport os, sys\nimport datetime\nimport logging\nimport csv, json\nfrom .models import PricingRecord, PricingResult\nfrom .errors import NoDataFoundError\n\n\nlog = logging.getLogger()\nlog.setLevel(consts.LOG_LEVEL)\n\n__location__ = os.path.realpath(os.path.join(os.getcwd(), os.path.dirname(__file__)))\nsite_pkgs = os.path.abspath(os.path.join(__location__, os.pardir, os.pardir,\"lib\", \"python3.7\", \"site-packages\" ))\nsys.path.append(site_pkgs)\n#print \"site_pkgs: [{}]\".format(site_pkgs)\n\nimport tinydb\n\n\ndef get_data_directory(service):\n result = os.path.split(__location__)[0] + '/data/' + service + '/'\n return result\n\n\n\ndef getBillableBand(priceDimensions, usageAmount):\n billableBand = 0\n beginRange = int(priceDimensions['beginRange'])\n endRange = priceDimensions['endRange']\n pricePerUnit = priceDimensions['pricePerUnit']['USD']\n if endRange == consts.INFINITY:\n if beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n else:\n endRange = int(endRange)\n if endRange >= usageAmount and beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n if endRange < usageAmount: \n billableBand = endRange - beginRange\n return billableBand\n\n\ndef getBillableBandCsv(row, usageAmount):\n billableBand = 0\n pricePerUnit = 0\n amt = 0\n\n if not row['StartingRange']:beginRange = 0\n else: beginRange = int(row['StartingRange'])\n if not row['EndingRange']:endRange = consts.INFINITY\n else: endRange = row['EndingRange']\n\n pricePerUnit = float(row['PricePerUnit'])\n if endRange == consts.INFINITY:\n if beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n else:\n endRange = int(endRange)\n if endRange >= usageAmount and beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n if endRange < usageAmount:\n billableBand = endRange - beginRange\n\n if billableBand > 0: amt = pricePerUnit * billableBand\n\n return billableBand, pricePerUnit, amt\n\n\n\n#Creates a table with all the SKUs that are part of the total price\ndef buildSkuTable(evaluated_sku_desc):\n result = {}\n sorted_descriptions = sorted(evaluated_sku_desc)\n result_table_header = \"Price | Description | Price Per Unit | Usage | Rate Code\"\n result_records = \"\"\n total = 0\n for s in sorted_descriptions:\n result_records = result_records + \"$\" + str(s[0]) + \"|\" + str(s[1]) + \"|\" + str(s[2]) + \"|\" + str(s[3]) + \"|\" + s[4]+\"\\n\"\n total = total + s[0]\n \n result['header']=result_table_header\n result['records']=result_records\n result['total']=total\n return result\n\n\n\n\"\"\"\nCalculates the keys that will be used to partition big index files into smaller pieces.\nIf no term is specified, the function will consider On-Demand and Reserved\n\"\"\"\n#TODO: merge all 3 load balancers into a single file (to speed up DB file loading and number of open files\ndef get_partition_keys(service, region, term, **extraArgs):\n result = []\n if region:\n regions = [consts.REGION_MAP[region]]\n else:\n regions = consts.REGION_MAP.values()\n\n if term: terms = [consts.TERM_TYPE_MAP[term]]\n else: terms = consts.TERM_TYPE_MAP.values()\n\n #productFamilies = consts.SUPPORTED_PRODUCT_FAMILIES\n productFamilies = consts.SUPPORTED_PRODUCT_FAMILIES_BY_SERVICE_DICT[service]\n\n #EC2 & RDS Reserved\n offeringClasses = extraArgs.get('offeringClasses',consts.EC2_OFFERING_CLASS_MAP.values())\n tenancies = extraArgs.get('tenancies',consts.EC2_TENANCY_MAP.values())\n purchaseOptions = extraArgs.get('purchaseOptions',consts.EC2_PURCHASE_OPTION_MAP.values())\n\n indexDict = {}\n #TODO: filter by service, to speed up file loading and to avoid max open files limit\n for r in regions:\n for t in terms:\n for pf in productFamilies:\n #Reserved EC2 & DB instances have more dimensions for index creation\n if t == consts.TERM_TYPE_RESERVED:\n if pf in consts.SUPPORTED_RESERVED_PRODUCT_FAMILIES:\n for oc in offeringClasses:\n for ten in tenancies:\n for po in purchaseOptions:\n result.append(create_file_key((r,t,pf,oc,ten, po)))\n else:\n #OnDemand EC2 Instances use Tenancy as a dimension for index creation\n if service == consts.SERVICE_EC2 and pf == consts.PRODUCT_FAMILY_COMPUTE_INSTANCE:\n for ten in tenancies:\n result.append(create_file_key((r,t,pf,ten)))\n else:\n result.append(create_file_key((r,t,pf)))\n\n return result\n\n\n#Creates a file key that identifies a data partition\ndef create_file_key(indexDimensions):\n result = \"\"\n for d in indexDimensions: result += d\n return result.replace(' ','')\n\n\n\ndef loadDBs(service, indexFiles):\n\n dBs = {}\n datadir = get_data_directory(service)\n indexMetadata = getIndexMetadata(service)\n\n #Files in Lambda can only be created in the /tmp filesystem - If it doesn't exist, create it.\n lambdaFileSystem = '/tmp/'+service+'/data'\n if not os.path.exists(lambdaFileSystem):\n os.makedirs(lambdaFileSystem)\n\n for i in indexFiles:\n db = tinydb.TinyDB(lambdaFileSystem+'/'+i+'.json')\n #TODO: remove circular dependency from utils, so I can use the method get_index_file_name\n #TODO: initial tests show that is faster (by a few milliseconds) to populate the file from scratch). See if I should load from scratch all the time\n #TODO:Create a file that is an index of those files that have been generated, so the code knows which files to look for and avoid creating unnecesary empty .json files\n if len(db) == 0:\n try:\n #with open(datadir+i+'.csv', 'rb') as csvfile:\n with open(datadir+i+'.csv', 'r') as csvfile:\n pricelist = csv.DictReader(csvfile, delimiter=',', quotechar='\"')\n db.insert_multiple(pricelist)\n #csvfile.close()#avoid \" [Errno 24] Too many open files\" exception\n except IOError:\n pass\n dBs[i]=db\n #db.close()#avoid \" [Errno 24] Too many open files\" exception\n\n\n return dBs, indexMetadata\n\n\n\ndef getIndexMetadata(service):\n ts = Timestamp()\n ts.start('getIndexMetadata')\n result = {}\n #datadir = get_data_directory(service)\n with open(get_data_directory(service)+\"index_metadata.json\") as index_metadata:\n result = json.load(index_metadata)\n index_metadata.close()\n ts.finish('getIndexMetadata')\n log.debug(\"Time to load indexMetadata: [{}]\".format(ts.elapsed('getIndexMetadata')))\n return result\n\n\ndef calculate_price(service, db, query, usageAmount, pricingRecords, cost):\n ts = Timestamp()\n ts.start('tinyDbSeachCalculatePrice')\n\n resultSet = db.search(query)\n\n ts.finish('tinyDbSeachCalculatePrice')\n log.debug(\"Time to search {} pricing DB for query [{}] : [{}] \".format(service, query, ts.elapsed('tinyDbSeachCalculatePrice')))\n\n if not resultSet: raise NoDataFoundError(\"Could not find data for service:[{}] - query:[{}]\".format(service, query))\n #print(\"resultSet:[{}]\".format(json.dumps(resultSet,indent=4)))\n for r in resultSet:\n billableUsage, pricePerUnit, amt = getBillableBandCsv(r, usageAmount)\n cost = cost + amt\n if billableUsage:\n #TODO: calculate rounding dynamically - don't set to 4 - use description to set the right rounding\n pricing_record = PricingRecord(service,round(amt,4),r['PriceDescription'],pricePerUnit,billableUsage,r['RateCode'])\n pricingRecords.append(vars(pricing_record))\n\n return pricingRecords, cost\n\n\n\n\nclass Timestamp():\n\n def __init__(self):\n self.eventdict = {}\n\n def start(self,event):\n self.eventdict[event] = {}\n self.eventdict[event]['start'] = datetime.datetime.now()\n\n def finish(self, event):\n #elapsed = datetime.timedelta(self.eventdict[event]['start']) * 1000 #return milliseconds\n elapsed = datetime.datetime.now() - self.eventdict[event]['start']\n self.eventdict[event]['elapsed'] = elapsed\n return elapsed\n\n def elapsed(self,event):\n return self.eventdict[event]['elapsed']\n\n"
},
{
"path": "awspricecalculator/datatransfer/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/datatransfer/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating AWSDataTransfer pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n #Load On-Demand DBs\n indexArgs = {}\n tmpDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType+pdim.tenancy\n dbs = regiondbs.get(tmpDbKey,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **indexArgs))\n regiondbs[tmpDbKey]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #Data Transfer\n dataTransferDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n\n #Out to the Internet\n if pdim.dataTransferOutInternetGb:\n ts.start('searchDataTransfer')\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n log.debug(\"Time to search AWSDataTransfer data transfer Out: [{}]\".format(ts.finish('searchDataTransfer')))\n\n #Intra-regional data transfer - in/out/between AZs or using EIPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n\n log.debug(\"regiondbs:[{}]\".format(regiondbs.keys()))\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/dynamodb/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/dynamodb/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating DynamoDB pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n global regiondbs\n global indexMetadata\n\n ts = phelper.Timestamp()\n ts.start('totalCalculationDynamoDB')\n\n #Load On-Demand DBs\n dbs = regiondbs.get(consts.SERVICE_DYNAMODB+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_DYNAMODB, phelper.get_partition_keys(consts.SERVICE_DYNAMODB, pdim.region,consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_DYNAMODB+pdim.region+pdim.termType]=dbs\n\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n #TODO:add support for free-tier flag (include or exclude from calculation)\n\n iopsDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DB_PIOPS])]\n\n #Read Capacity Units\n query = ((priceQuery['Group'] == 'DDB-ReadUnits'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DYNAMODB, iopsDb, query, pdim.readCapacityUnitHours, pricing_records, cost)\n\n #Write Capacity Units\n query = ((priceQuery['Group'] == 'DDB-WriteUnits'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DYNAMODB, iopsDb, query, pdim.writeCapacityUnitHours, pricing_records, cost)\n\n #DB Storage (TODO)\n\n #Data Transfer (TODO)\n #there is no additional charge for data transferred between Amazon DynamoDB and other Amazon Web Services within the same Region\n #data transferred across Regions (e.g., between Amazon DynamoDB in the US East (Northern Virginia) Region and Amazon EC2 in the EU (Ireland) Region), will be charged on both sides of the transfer.\n\n #API Requests (only applies for DDB Streams)(TODO)\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time to compute: [{}]\".format(ts.finish('totalCalculationDynamoDB')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/ec2/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/ec2/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper, utils\nfrom ..common.models import PricingResult\n#import psutil\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating EC2 pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n ts.start('tinyDbLoadReserved')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n if pdim.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n #Load On-Demand DBs\n indexArgs = {'tenancies':[consts.EC2_TENANCY_MAP[pdim.tenancy]]}\n tmpDbKey = consts.SERVICE_EC2+pdim.region+pdim.termType+pdim.tenancy\n\n dbs = regiondbs.get(tmpDbKey,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_EC2, phelper.get_partition_keys(consts.SERVICE_EC2, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **indexArgs))\n regiondbs[tmpDbKey]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #TODO: Move common operations to a common module, and leave only EC2-specific operations in ec2/pricing.py (create a class)\n #TODO: support all tenancy types (Host and Dedicated)\n #Compute Instance\n if pdim.instanceHours:\n dbFileKey = phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_COMPUTE_INSTANCE, consts.EC2_TENANCY_MAP[pdim.tenancy]))\n log.debug('DB File key: [{}]'.format(dbFileKey))\n computeDb = dbs[dbFileKey]\n ts.start('tinyDbSearchComputeFile')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) &\n (priceQuery['Operating System'] == consts.EC2_OPERATING_SYSTEMS_MAP[pdim.operatingSystem]) &\n #(priceQuery['Tenancy'] == consts.EC2_TENANCY_SHARED) & #removed since it's redundant with the file name\n (priceQuery['Pre Installed S/W'] == pdim.preInstalledSoftware) &\n (priceQuery['CapacityStatus'] == consts.EC2_CAPACITY_RESERVATION_STATUS_MAP[pdim.capacityReservationStatus]) &\n (priceQuery['License Model'] == consts.EC2_LICENSE_MODEL_MAP[pdim.licenseModel]))# &\n #(priceQuery['OfferingClass'] == pdim.offeringClass) &\n #(priceQuery['PurchaseOption'] == purchaseOption ))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EC2, computeDb, query, pdim.instanceHours, pricing_records, cost)\n log.debug(\"Time to search compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n\n\n #Data Transfer\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n\n #Out to the Internet\n if pdim.dataTransferOutInternetGb:\n ts.start('searchDataTransfer')\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n log.debug(\"Time to search AWS Data Transfer Out: [{}]\".format(ts.finish('searchDataTransfer')))\n\n #Intra-regional data transfer - in/out/between EC2 AZs or using EIPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n\n #EBS Storage\n if pdim.ebsStorageGbMonth:\n #storageDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_STORAGE)]\n storageDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_STORAGE))]\n query = ((priceQuery['Volume Type'] == pdim.volumeType))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EBS, storageDb, query, pdim.ebsStorageGbMonth, pricing_records, cost)\n\n\n #System Operation (pIOPS)\n if pdim.volumeType == consts.EBS_VOLUME_TYPE_PIOPS and pdim.pIops:\n #storageDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SYSTEM_OPERATION)]\n storageDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SYSTEM_OPERATION))]\n query = ((priceQuery['Group'] == 'EBS IOPS'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EBS, storageDb, query, pdim.pIops, pricing_records, cost)\n\n #Snapshot Storage\n if pdim.ebsSnapshotGbMonth:\n #snapshotDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SNAPSHOT)]\n snapshotDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SNAPSHOT))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'EBS:SnapshotUsage'))#EBS:SnapshotUsage comes with a prefix in the PriceList API file (i.e. EU-EBS:SnapshotUsage)\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EBS, snapshotDb, query, pdim.ebsSnapshotGbMonth, pricing_records, cost)\n\n #Classic Load Balancer\n if pdim.elbHours:\n #elbDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER)]\n elbDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'LoadBalancerUsage') & (priceQuery['operation'] == 'LoadBalancing'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, elbDb, query, pdim.elbHours, pricing_records, cost)\n\n if pdim.elbDataProcessedGb:\n #elbDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER)]\n elbDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'DataProcessing-Bytes') & (priceQuery['operation'] == 'LoadBalancing'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, elbDb, query, pdim.elbDataProcessedGb, pricing_records, cost)\n\n #Application Load Balancer\n #TODO: add support for Network Load Balancer\n if pdim.albHours:\n albDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'LoadBalancerUsage') & (priceQuery['operation'] == 'LoadBalancing:Application'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, albDb, query, pdim.albHours, pricing_records, cost)\n\n if pdim.albLcus:\n albDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'LCUUsage') & (priceQuery['operation'] == 'LoadBalancing:Application'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, albDb, query, pdim.albLcus, pricing_records, cost)\n\n\n\n #TODO: EIP\n #TODO: NAT Gateway\n #TODO: Fee\n\n #_/_/_/_/_/ RESERVED PRICING _/_/_/_/_/\n #Load Reserved DBs\n if pdim.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n indexArgs = {'offeringClasses':[consts.EC2_OFFERING_CLASS_MAP[pdim.offeringClass]],\n 'tenancies':[consts.EC2_TENANCY_MAP[pdim.tenancy]], 'purchaseOptions':[consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]]}\n #Load all values for offeringClasses, tenancies and purchaseOptions\n #indexArgs = {'offeringClasses':consts.EC2_OFFERING_CLASS_MAP.values(),\n # 'tenancies':consts.EC2_TENANCY_MAP.values(), 'purchaseOptions':consts.EC2_PURCHASE_OPTION_MAP.values()}\n tmpDbKey = consts.SERVICE_EC2+pdim.region+pdim.termType+pdim.offeringClass+consts.EC2_TENANCY_MAP[pdim.tenancy]+pdim.offeringType\n #tmpDbKey = consts.SERVICE_EC2+pdim.region+pdim.termType\n dbs = regiondbs.get(tmpDbKey,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_EC2, phelper.get_partition_keys(consts.SERVICE_EC2, pdim.region, consts.SCRIPT_TERM_TYPE_RESERVED, **indexArgs))\n #regiondbs[consts.SERVICE_EC2+pdim.region+pdim.termType]=dbs\n regiondbs[tmpDbKey]=dbs\n\n log.debug(\"dbs keys:{}\".format(dbs.keys()))\n\n ts.finish('tinyDbLoadReserved')\n log.debug(\"Time to load Reserved DB files: [{}]\".format(ts.elapsed('tinyDbLoadReserved')))\n\n\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_COMPUTE_INSTANCE, pdim.offeringClass,\n consts.EC2_TENANCY_MAP[pdim.tenancy], consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]))]\n\n ts.start('tinyDbSearchComputeFileReserved')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) &\n (priceQuery['Operating System'] == consts.EC2_OPERATING_SYSTEMS_MAP[pdim.operatingSystem]) &\n #(priceQuery['Tenancy'] == consts.EC2_TENANCY_SHARED) & #removed since it's redundant with the DB file name\n (priceQuery['Pre Installed S/W'] == pdim.preInstalledSoftware) &\n (priceQuery['License Model'] == consts.EC2_LICENSE_MODEL_MAP[pdim.licenseModel]) &\n #(priceQuery['OfferingClass'] == consts.EC2_OFFERING_CLASS_MAP[pdim.offeringClass]) &\n #(priceQuery['PurchaseOption'] == consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType] ) &\n (priceQuery['LeaseContractLength'] == consts.EC2_RESERVED_YEAR_MAP[\"{}\".format(pdim.years)] ))\n\n hrsQuery = query & (priceQuery['Unit'] == 'Hrs' )\n qtyQuery = query & (priceQuery['Unit'] == 'Quantity' )\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EC2, computeDb, qtyQuery, pdim.instanceCount, pricing_records, cost)\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n #reservedInstanceHours = pdim.instanceCount * consts.HOURS_IN_MONTH * 12 * pdim.years\n reservedInstanceHours = utils.calculate_instance_hours_year(pdim.instanceCount, pdim.years)\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EC2, computeDb, hrsQuery, reservedInstanceHours, pricing_records, cost)\n\n\n log.debug(\"Time to search:[{}]\".format(ts.finish('tinyDbSearchComputeFileReserved')))\n\n\n log.debug(\"regiondbs:[{}]\".format(regiondbs.keys()))\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n #proc = psutil.Process()\n #log.debug(\"open_files: {}\".format(proc.open_files()))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/emr/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/emr/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nfrom ..common.models import Ec2PriceDimension\nfrom ..ec2 import pricing as ec2pricing\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating EMR pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n #Load On-Demand EMR DBs\n dbs = regiondbs.get(consts.SERVICE_EMR+pdim.region+consts.TERM_TYPE_ON_DEMAND,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_EMR, phelper.get_partition_keys(consts.SERVICE_EMR, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_EMR+pdim.region+pdim.termType]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #EMR Compute Instance\n if pdim.instanceHours:\n #The EMR component in the calculation always uses OnDemand (Reserved it's not supported yet for EMR)\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[consts.SCRIPT_TERM_TYPE_ON_DEMAND], consts.PRODUCT_FAMILY_EMR_INSTANCE))]\n ts.start('tinyDbSearchComputeFile')\n #TODO: add support for Hunk Software Type\n query = ((priceQuery['Instance Type'] == pdim.instanceType) & (priceQuery['Software Type'] == 'EMR'))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EMR, computeDb, query, pdim.instanceHours, pricing_records, cost)\n log.debug(\"Time to search compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n\n\n #EC2 Pricing - the EC2 component takes into consideration either OnDemand or Reserved.\n ec2_pricing = ec2pricing.calculate(Ec2PriceDimension(**pdim.ec2PriceDims))\n log.info(\"pdim.ec2PriceDims:[{}]\".format(pdim.ec2PriceDims))\n log.info(\"ec2_pricing:[{}]\".format(ec2_pricing))\n if ec2_pricing.get('pricingRecords',[]): pricing_records.extend(ec2_pricing['pricingRecords'])\n cost += ec2_pricing.get('totalCost',0)\n\n\n\n\n\n log.debug(\"regiondbs:[{}]\".format(regiondbs.keys()))\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n #proc = psutil.Process()\n #log.debug(\"open_files: {}\".format(proc.open_files()))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/kinesis/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/kinesis/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating DynamoDB pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculationKinesis')\n\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_KINESIS, phelper.get_partition_keys(pdim.region,consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n kinesisDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_KINESIS_STREAMS])]\n\n #Shard Hours\n query = ((priceQuery['Group'] == 'Provisioned shard hour'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_KINESIS, kinesisDb, query, pdim.shardHours, pricing_records, cost)\n\n #PUT Payload Units\n query = ((priceQuery['Group'] == 'Payload Units'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_KINESIS, kinesisDb, query, pdim.putPayloadUnits, pricing_records, cost)\n\n #Extended Retention Hours\n query = ((priceQuery['Group'] == 'Addon shard hour'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_KINESIS, kinesisDb, query, pdim.extendedDataRetentionHours, pricing_records, cost)\n\n #TODO: add Enhanced (shard-level) metrics\n\n #Data Transfer - N/A\n #Note there is no charge for data transfer in Kinesis as per https://aws.amazon.com/kinesis/streams/pricing/\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time to compute: [{}]\".format(ts.finish('totalCalculationKinesis')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/rds/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/rds/pricing.py",
"content": "import os, sys\nimport json\nimport logging\nfrom ..common import consts, phelper, utils\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n ts.start('tinyDbLoadReserved')\n\n global regiondbs\n global indexMetadata\n\n\n log.info(\"Calculating RDS pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n #Load On-Demand DBs\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_RDS, phelper.get_partition_keys(consts.SERVICE_RDS, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n\n\n skuEngine = ''\n skuEngineEdition = ''\n skuLicenseModel = ''\n\n if pdim.engine in consts.RDS_ENGINE_MAP:\n skuEngine = consts.RDS_ENGINE_MAP[pdim.engine]['engine']\n skuEngineEdition = consts.RDS_ENGINE_MAP[pdim.engine]['edition']\n skuLicenseModel = consts.RDS_LICENSE_MODEL_MAP[pdim.licenseModel]\n\n deploymentOptionCondition = pdim.deploymentOption\n\n #'Multi-AZ (SQL Server Mirror)' is no longer available in pricing index\n #if 'sqlserver' in pdim.engine and pdim.deploymentOption == consts.RDS_DEPLOYMENT_OPTION_MULTI_AZ:\n # deploymentOptionCondition = consts.RDS_DEPLOYMENT_OPTION_MULTI_AZ_MIRROR\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n\n\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n if pdim.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n #Load On-Demand DBs\n dbs = regiondbs.get(consts.SERVICE_RDS+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_RDS, phelper.get_partition_keys(consts.SERVICE_RDS, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_RDS+pdim.region+pdim.termType]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #DB Instance\n if pdim.instanceHours:\n instanceDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATABASE_INSTANCE))]\n\n\n ts.start('tinyDbSearchComputeFile')\n query = ((priceQuery['Product Family'] == consts.PRODUCT_FAMILY_DATABASE_INSTANCE) &\n (priceQuery['Instance Type'] == pdim.dbInstanceClass) &\n (priceQuery['Database Engine'] == skuEngine) &\n (priceQuery['Database Edition'] == skuEngineEdition) &\n (priceQuery['License Model'] == skuLicenseModel) &\n (priceQuery['Deployment Option'] == deploymentOptionCondition)\n )\n\n log.debug(\"Time to search DB instance compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, instanceDb, query, pdim.instanceHours, pricing_records, cost)\n\n #Data Transfer\n #To internet\n if pdim.dataTransferOutInternetGb:\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n query = ((priceQuery['serviceCode'] == consts.SERVICE_CODE_AWS_DATA_TRANSFER) &\n (priceQuery['To Location'] == 'External') &\n (priceQuery['Transfer Type'] == 'AWS Outbound'))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n\n\n #Inter-regional data transfer - to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n query = ((priceQuery['serviceCode'] == consts.SERVICE_CODE_AWS_DATA_TRANSFER) &\n (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]) &\n (priceQuery['Transfer Type'] == 'InterRegion Outbound'))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n #Storage (magnetic, SSD, PIOPS)\n if pdim.storageGbMonth:\n engineCondition = 'Any'\n if skuEngine == consts.RDS_DB_ENGINE_SQL_SERVER: engineCondition = consts.RDS_DB_ENGINE_SQL_SERVER\n storageDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DB_STORAGE])]\n query = ((priceQuery['Volume Type'] == pdim.volumeType) &\n (priceQuery['Database Engine'] == engineCondition) &\n (priceQuery['Deployment Option'] == pdim.deploymentOption))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, storageDb, query, pdim.storageGbMonth, pricing_records, cost)\n\n #Provisioned IOPS\n if pdim.storageType == consts.SCRIPT_RDS_STORAGE_TYPE_IO1:\n iopsDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DB_PIOPS])]\n query = ((priceQuery['Deployment Option'] == pdim.deploymentOption))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, iopsDb, query, pdim.iops, pricing_records, cost)\n\n #Consumed IOPS (I/O rate)\n if pdim.ioRequests:\n sysopsDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SYSTEM_OPERATION])]\n dbEngineCondition = 'Any'\n if pdim.engine in (consts.RDS_DB_ENGINE_POSTGRESQL, consts.RDS_DB_ENGINE_AURORA_MYSQL):\n dbEngineCondition = pdim.engine\n\n query = ((priceQuery['Group'] == 'Aurora I/O Operation')&\n (priceQuery['Database Engine'] == dbEngineCondition)\n )\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, sysopsDb, query, pdim.ioRequests, pricing_records, cost)\n\n\n #Snapshot Storage\n if pdim.backupStorageGbMonth:\n snapshotDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SNAPSHOT])]\n query = ((priceQuery['usageType'] == 'RDS:ChargedBackupUsage'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, snapshotDb, query, pdim.backupStorageGbMonth, pricing_records, cost)\n\n\n\n\n #_/_/_/_/_/ RESERVED PRICING _/_/_/_/_/\n if pdim.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n #Load Reserved DBs\n\n indexArgs = {'offeringClasses':consts.EC2_OFFERING_CLASS_MAP.values(),\n 'tenancies':[consts.EC2_TENANCY_SHARED], 'purchaseOptions':consts.EC2_PURCHASE_OPTION_MAP.values()}\n\n dbs = regiondbs.get(consts.SERVICE_RDS+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_RDS, phelper.get_partition_keys(consts.SERVICE_RDS, pdim.region, consts.SCRIPT_TERM_TYPE_RESERVED, **indexArgs))\n regiondbs[consts.SERVICE_RDS+pdim.region+pdim.termType]=dbs\n ts.finish('tinyDbLoadReserved')\n log.debug(\"Time to load Reserved DB files: [{}]\".format(ts.elapsed('tinyDbLoadReserved')))\n log.debug(\"regiondbs keys:[{}]\".format(regiondbs))\n\n #DB Instance\n #RDS only supports standard\n instanceDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_DATABASE_INSTANCE, consts.EC2_OFFERING_CLASS_STANDARD,\n consts.EC2_TENANCY_SHARED, consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]))]\n\n\n ts.start('tinyDbSearchComputeFileReserved')\n query = ((priceQuery['Product Family'] == consts.PRODUCT_FAMILY_DATABASE_INSTANCE) &\n (priceQuery['Instance Type'] == pdim.dbInstanceClass) &\n (priceQuery['Database Engine'] == skuEngine) &\n (priceQuery['Database Edition'] == skuEngineEdition) &\n (priceQuery['License Model'] == skuLicenseModel) &\n (priceQuery['Deployment Option'] == deploymentOptionCondition) &\n (priceQuery['OfferingClass'] == consts.EC2_OFFERING_CLASS_MAP[pdim.offeringClass]) &\n (priceQuery['PurchaseOption'] == consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]) &\n (priceQuery['LeaseContractLength'] == consts.EC2_RESERVED_YEAR_MAP[\"{}\".format(pdim.years)])\n )\n\n hrsQuery = query & (priceQuery['Unit'] == 'Hrs' )\n qtyQuery = query & (priceQuery['Unit'] == 'Quantity' )\n\n #TODO: use RDS-specific constants, not EC2 constants\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, instanceDb, qtyQuery, pdim.instanceCount, pricing_records, cost)\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n reservedInstanceHours = utils.calculate_instance_hours_year(pdim.instanceCount, pdim.years)\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, instanceDb, hrsQuery, reservedInstanceHours, pricing_records, cost)\n\n log.debug(\"Time to search DB instance compute:[{}]\".format(ts.finish('tinyDbSearchComputeFileReserved')))\n\n\n\n\n\n log.debug(\"Total time to calculate price: [{}]\".format(ts.finish('totalCalculation')))\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/redshift/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/redshift/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nfrom ..common.models import Ec2PriceDimension\nfrom ..ec2 import pricing as ec2pricing\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating Redshift pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n ts.start('tinyDbLoadReserved')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n #Load On-Demand Redshift DBs\n if pdim.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n\n dbs = regiondbs.get(consts.SERVICE_REDSHIFT+pdim.region+consts.TERM_TYPE_ON_DEMAND,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_REDSHIFT, phelper.get_partition_keys(consts.SERVICE_REDSHIFT, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_REDSHIFT+pdim.region+pdim.termType]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #Redshift Compute Instance\n if pdim.instanceHours:\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[consts.SCRIPT_TERM_TYPE_ON_DEMAND], consts.PRODUCT_FAMILY_COMPUTE_INSTANCE))]\n ts.start('tinyDbSearchComputeFile')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) )\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_REDSHIFT, computeDb, query, pdim.instanceHours, pricing_records, cost)\n log.debug(\"Time to search compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n\n\n #TODO: move Data Transfer to a common file (since now it's a separate index file)\n \"\"\"\n #Data Transfer\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n\n #Out to the Internet\n if pdim.dataTransferOutInternetGb:\n ts.start('searchDataTransfer')\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n log.debug(\"Time to search AWS Data Transfer Out: [{}]\".format(ts.finish('searchDataTransfer')))\n\n #Intra-regional data transfer - in/out/between EC2 AZs or using EIPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n \"\"\"\n\n #_/_/_/_/_/ RESERVED PRICING _/_/_/_/_/\n\n print(\"regiondbs[]\".format(regiondbs))\n\n #Load Reserved DBs\n if pdim.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n\n indexArgs = {'offeringClasses':consts.EC2_OFFERING_CLASS_MAP.values(),\n 'tenancies':[consts.EC2_TENANCY_SHARED], 'purchaseOptions':consts.EC2_PURCHASE_OPTION_MAP.values()}\n\n dbs = regiondbs.get(consts.SERVICE_REDSHIFT+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_REDSHIFT, phelper.get_partition_keys(consts.SERVICE_REDSHIFT, pdim.region, consts.SCRIPT_TERM_TYPE_RESERVED, **indexArgs))\n regiondbs[consts.SERVICE_REDSHIFT+pdim.region+pdim.termType]=dbs\n ts.finish('tinyDbLoadReserved')\n log.debug(\"Time to load Reserved DB files: [{}]\".format(ts.elapsed('tinyDbLoadReserved')))\n log.debug(\"regiondbs keys:[{}]\".format(regiondbs))\n\n #Redshift only supports standard\n print(\"dbs:[{}]\".format(dbs))\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_COMPUTE_INSTANCE, consts.EC2_OFFERING_CLASS_STANDARD,\n consts.EC2_TENANCY_SHARED, consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]))]\n\n\n\n ts.start('tinyDbSearchComputeFileReserved')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) &\n (priceQuery['LeaseContractLength'] == consts.EC2_RESERVED_YEAR_MAP[\"{}\".format(pdim.years)]))\n\n hrsQuery = query & (priceQuery['Unit'] == 'Hrs' )\n qtyQuery = query & (priceQuery['Unit'] == 'Quantity' )\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_REDSHIFT, computeDb, qtyQuery, pdim.instanceCount, pricing_records, cost)\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n reservedInstanceHours = pdim.instanceCount * consts.HOURS_IN_MONTH * 12 * pdim.years #TODO: move to common function\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_REDSHIFT, computeDb, hrsQuery, reservedInstanceHours, pricing_records, cost)\n\n log.debug(\"Time to search:[{}]\".format(ts.finish('tinyDbSearchComputeFileReserved')))\n\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "cloudformation/function-plus-schedule.json",
"content": "{\n\t\"AWSTemplateFormatVersion\": \"2010-09-09\",\n\t\"Description\": \"AWS CloudFormation Template for deploying a Lambda function that calculates EC2 pricing in near real-time\",\n\t\"Parameters\": {\n \t\t\"TagKey\" : {\n\t\t\t\"Type\": \"String\",\n \t\t\"Description\" : \"Tag key that will be used to find AWS resources. Mandatory\",\n \t\t\"MinLength\": \"1\",\n\t\t\t\"ConstraintDescription\": \"Tag key is mandatory.\" \t\t\n \t\t}, \n \t\t\"TagValue\" : {\n\t\t\t\"Type\": \"String\",\n \t\t\"MinLength\": \"1\",\n \t\t\"Description\" : \"Tag value that will be used to find AWS resources. Mandatory\",\n\t\t\t\"ConstraintDescription\": \"Tag value is mandatory.\" \t\t\n \t\t}\n \t\t\n\t},\n\t\"Resources\": {\n\n \"LambdaRealtimeCalculatePricingRole\": {\n \"Type\": \"AWS::IAM::Role\",\n \"Properties\": {\n \"AssumeRolePolicyDocument\": {\n \"Version\": \"2012-10-17\",\n \"Statement\": [{\n \"Effect\": \"Allow\",\n \"Principal\": {\"Service\": [\"lambda.amazonaws.com\"]},\n \"Action\": [\"sts:AssumeRole\"]\n }]\n },\n \"Path\": \"/\",\n \"Policies\": [{\n \"PolicyName\": \"root\",\n \"PolicyDocument\": {\n \"Version\": \"2012-10-17\",\n \"Statement\": [{\n \"Effect\": \"Allow\",\n \"Action\": [\"logs:CreateLogGroup\",\"logs:CreateLogStream\",\"logs:PutLogEvents\"],\n \"Resource\": \"arn:aws:logs:*:*:*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"cloudwatch:*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"ec2:Describe*\",\n \"elasticloadbalancing:Describe*\",\n \"autoscaling:Describe*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"rds:Describe*\",\n \"rds:List*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"dynamodb:Describe*\",\n \"dynamodb:List*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"kinesis:Describe*\",\n \"kinesis:List*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"lambda:GetFunctionConfiguration\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"tag:getResources\", \"tag:getTagKeys\", \"tag:getTagValues\"],\n \"Resource\": \"*\"\n }\n\n ]\n }\n }]\n }\n },\n\n\t\t\"LambdaRealtimeCalculatePricingFunction\": {\n\t\t \"Type\": \"AWS::Lambda::Function\",\n \"DependsOn\" : [\"LambdaRealtimeCalculatePricingRole\"],\t\t \n\t\t \"Properties\": {\n\t\t \"Handler\": \"functions/calculate-near-realtime.handler\",\n\t\t \"Role\": { \"Fn::GetAtt\" : [\"LambdaRealtimeCalculatePricingRole\", \"Arn\"] },\n\t\t \"Code\": {\n\t\t \"S3Bucket\": { \"Fn::Join\" : [ \"\", [\"concurrencylabs-deployment-artifacts-public-\", { \"Ref\" : \"AWS::Region\" }] ] },\n\t\t \"S3Key\": \"lambda-near-realtime-pricing/calculate-near-realtime-pricing-v3.10.zip\"\n\t\t },\n\t\t \"Runtime\": \"python3.6\",\n\t\t \"Timeout\": \"300\",\n\t\t \"MemorySize\" : 1024\n\t\t }\n\t\t},\n\n\n\"ScheduledPricingCalculationRule\": {\n \"Type\": \"AWS::Events::Rule\",\n \"Properties\": {\n \"Description\": \"Invoke Pricing Calculator Lambda function every 5 minutes\",\n \"ScheduleExpression\": \"rate(5 minutes)\",\n \"State\": \"ENABLED\",\n \"Targets\": [{\n \"Arn\": { \"Fn::GetAtt\": [\"LambdaRealtimeCalculatePricingFunction\", \"Arn\"] },\n \"Id\": \"NearRealTimePriceCalculatorFunctionv1\",\n \"Input\":{\"Fn::Join\":[\"\", [\"{\\\"tag\\\":{\\\"key\\\":\\\"\",{\"Ref\":\"TagKey\"},\"\\\",\\\"value\\\":\\\"\",{\"Ref\":\"TagValue\"},\"\\\"}}\"]]}\n }]\n }\n},\n\n\n\"PermissionForEventsToInvokePricingCalculationLambda\": {\n \"Type\": \"AWS::Lambda::Permission\",\n \"Properties\": {\n \"FunctionName\": { \"Ref\": \"LambdaRealtimeCalculatePricingFunction\" },\n \"Action\": \"lambda:InvokeFunction\",\n \"Principal\": \"events.amazonaws.com\",\n \"SourceArn\": { \"Fn::GetAtt\": [\"ScheduledPricingCalculationRule\", \"Arn\"] }\n }\n}\n\n},\n\n\t\"Outputs\": {\n\n\t\t\"Documentation\": {\n\t\t\t\"Description\": \"For more details, see this blog post\",\n\t\t\t\"Value\": \"https://www.concurrencylabs.com/blog/aws-pricing-lambda-realtime-calculation-function/\"\n\t\t},\n\n\n\t\t\"LambdaFunction\": {\n\t\t\t\"Description\": \"Lambda function that calculates pricing in near real-time\",\n\t\t\t\"Value\": {\n\t\t\t\t\"Ref\": \"LambdaRealtimeCalculatePricingFunction\"\n\t\t\t}\n\t\t},\n\n\t\t\"ScheduledEvent\": {\n\t\t\t\"Description\": \"CloudWatch Events schedule that will trigger the Lambda function\",\n\t\t\t\"Value\": {\n\t\t\t\t\"Ref\": \"ScheduledPricingCalculationRule\"\n\t\t\t}\n\t\t}\n\n\t}\n}\n"
},
{
"path": "cloudformation/lambda-metric-filters.yml",
"content": "AWSTemplateFormatVersion: '2010-09-09'\nDescription: AWS CloudFormation Template for creating CloudWatch Logs Metric Filters that keep track of memory utilization (and in the future, possibly other data that can be extracted from Lambda output in CW Logs)\n\nParameters:\n LambdaFunctionName:\n Default: \"\"\n Description: Name of the Lambda function to monitor\n Type: String\n\n\nResources:\n LambdaMemoryUsed:\n Properties:\n FilterPattern: '[reportLabel=REPORT, requestIdLabel=\"RequestId:\",..., maxMemoryUsedValue, maxMemoryUsedMbLabel]'\n LogGroupName:\n Fn::Join:\n - ''\n - - '/aws/lambda/'\n - Ref: LambdaFunctionName\n MetricTransformations:\n - MetricName:\n Fn::Join:\n - ''\n - - 'MemoryUsed-'\n - Ref: LambdaFunctionName\n MetricNamespace: ConcurrencyLabs/Lambda/\n MetricValue: $maxMemoryUsedValue\n Type: AWS::Logs::MetricFilter\n\n LambdaMemorySize:\n Properties:\n FilterPattern: '[reportLabel=REPORT, requestIdLabel=\"RequestId:\",..., memorySizeValue, memorySizeValueMbLabel, maxLabel, memoryLabel, usedLabel, maxMemoryUsedValue, maxMemoryUsedMbLabel]'\n LogGroupName:\n Fn::Join:\n - ''\n - - '/aws/lambda/'\n - Ref: LambdaFunctionName\n MetricTransformations:\n - MetricName:\n Fn::Join:\n - ''\n - - 'MemorySize-'\n - Ref: LambdaFunctionName\n MetricNamespace: ConcurrencyLabs/Lambda/\n MetricValue: $memorySizeValue\n Type: AWS::Logs::MetricFilter\n\n\n\n\n\n\n"
},
{
"path": "functions/calculate-near-realtime.py",
"content": "from __future__ import print_function\nimport datetime\nimport json\nimport logging,traceback\nimport math\nimport os\nimport sys\n\n\nimport boto3\nfrom botocore.exceptions import ClientError\n\n\n__location__ = os.path.dirname(os.path.realpath(__file__))\nsys.path.append(os.path.join(__location__, \"../\"))\nsys.path.append(os.path.join(__location__, \"../vendored\"))\n\n\nimport awspricecalculator.ec2.pricing as ec2pricing\nimport awspricecalculator.rds.pricing as rdspricing\nimport awspricecalculator.awslambda.pricing as lambdapricing\nimport awspricecalculator.dynamodb.pricing as ddbpricing\nimport awspricecalculator.kinesis.pricing as kinesispricing\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.consts as consts\nfrom awspricecalculator.common.errors import NoDataFoundError\n\nlog = logging.getLogger()\n#log.setLevel(logging.INFO)\n\n\n\nec2client = None\nrdsclient = None\nelbclient = None\nlambdaclient = None\ndddbclient = None\nkinesisclient = None\ncwclient = None\ntagsclient = None\n\n#_/_/_/_/_/_/ default_values - start _/_/_/_/_/_/\n\n#Delay in minutes for metrics collection. We want to make sure that all metrics have arrived for the time period we are evaluating\n#Note: Unless you have detailed metrics enabled in CloudWatch, make sure it is >= 10\nMETRIC_DELAY = 10\n\n#Time window in minutes we will use for metric calculations\n#Note: make sure this is at least 5, unless you have detailed metrics enabled in CloudWatch\nMETRIC_WINDOW = 5\n\nFORECAST_PERIOD_MONTHLY = 'monthly'\nFORECAST_PERIOD_HOURLY = 'hourly'\nDEFAULT_FORECAST_PERIOD = FORECAST_PERIOD_MONTHLY\nHOURS_DICT = {FORECAST_PERIOD_MONTHLY:720, FORECAST_PERIOD_HOURLY:1}\n\n\nCW_NAMESPACE = 'ConcurrencyLabs/Pricing/NearRealTimeForecast'\nCW_METRIC_NAME_ESTIMATEDCHARGES = 'EstimatedCharges'\nCW_METRIC_DIMENSION_SERVICE_NAME = 'ServiceName'\nCW_METRIC_DIMENSION_PERIOD = 'ForecastPeriod'\nCW_METRIC_DIMENSION_CURRENCY = 'Currency'\nCW_METRIC_DIMENSION_TAG = 'Tag'\nCW_METRIC_DIMENSION_SERVICE_NAME_EC2 = 'ec2'\nCW_METRIC_DIMENSION_SERVICE_NAME_RDS = 'rds'\nCW_METRIC_DIMENSION_SERVICE_NAME_LAMBDA = 'lambda'\nCW_METRIC_DIMENSION_SERVICE_NAME_DYNAMODB = 'dynamodb'\nCW_METRIC_DIMENSION_SERVICE_NAME_KINESIS = 'kinesis'\nCW_METRIC_DIMENSION_SERVICE_NAME_TOTAL = 'total'\nCW_METRIC_DIMENSION_CURRENCY_USD = 'USD'\n\n\nSERVICE_EC2 = 'ec2'\nSERVICE_RDS = 'rds'\nSERVICE_ELB = 'elasticloadbalancing'\nSERVICE_LAMBDA = 'lambda'\nSERVICE_DYNAMODB = 'dynamodb'\nSERVICE_KINESIS = 'kinesis'\n\nRESOURCE_LAMBDA_FUNCTION = 'function'\nRESOURCE_ELB = 'loadbalancer'\nRESOURCE_ALB = 'loadbalancer/app'\nRESOURCE_NLB = 'loadbalancer/net'\nRESOURCE_EC2_INSTANCE = 'instance'\nRESOURCE_RDS_DB_INSTANCE = 'db'\nRESOURCE_EBS_VOLUME = 'volume'\nRESOURCE_EBS_SNAPSHOT = 'snapshot'\nRESOURCE_DDB_TABLE = 'table'\nRESOURCE_STREAM = 'stream'\n\n#This map is used to specify which services and resource types will be searched using the tag service\nSERVICE_RESOURCE_MAP = {SERVICE_EC2:[RESOURCE_EBS_VOLUME,RESOURCE_EBS_SNAPSHOT, RESOURCE_EC2_INSTANCE],\n SERVICE_RDS:[RESOURCE_RDS_DB_INSTANCE],\n SERVICE_LAMBDA:[RESOURCE_LAMBDA_FUNCTION],\n SERVICE_ELB:[RESOURCE_ELB], #only provide RESOURCE_ELB, even for ALB and NLB\n SERVICE_DYNAMODB:[RESOURCE_DDB_TABLE],\n SERVICE_KINESIS:[RESOURCE_STREAM]\n }\n\n#_/_/_/_/_/_/ default values - end _/_/_/_/_/_/\n\n\ndef handler(event, context):\n log.setLevel(consts.LOG_LEVEL)\n log.info(\"Received event {}\".format(json.dumps(event)))\n\n try:\n init_clients(context)\n\n result = {}\n pricing_records = []\n ec2Cost = 0\n rdsCost = 0\n lambdaCost = 0\n ddbCost = 0\n kinesisCost = 0\n totalCost = 0\n\n\n #First, get the tags we'll be searching for, from the CloudWatch scheduled event\n tagkey = \"\"\n tagvalue = \"\"\n if 'tag' in event:\n tagkey = event['tag']['key']\n tagvalue = event['tag']['value']\n if tagkey == \"\" or tagvalue == \"\":\n log.error(\"No tags specified, aborting function!\")\n return {}\n\n log.info(\"Will search resources with the following tag:[\"+tagkey+\"] - value[\"+tagvalue+\"]\")\n\n resource_manager = ResourceManager(tagkey, tagvalue)\n\n start, end = calculate_time_range()\n\n elb_hours = 0\n elb_data_processed_gb = 0\n elb_instances = {}\n alb_hours = 0\n alb_lcus = 0\n\n #Get tagged ELB(s) and their registered instances\n #taggedelbs = find_elbs(tagkey, tagvalue)\n taggedelbs = resource_manager.get_resource_ids(SERVICE_ELB, RESOURCE_ELB)\n taggedalbs = resource_manager.get_resource_ids(SERVICE_ELB, RESOURCE_ALB)\n taggednlbs = resource_manager.get_resource_ids(SERVICE_ELB, RESOURCE_NLB)\n if taggedelbs:\n log.info(\"Found tagged Classic ELBs:{}\".format(taggedelbs))\n elb_instances = get_elb_instances(taggedelbs)#TODO:add support to find registered instances for ALB and NLB\n #Get all EC2 instances registered with each tagged ELB, so we can calculate ELB data processed\n #Registered instances will be used for data processed calculation, and not for instance hours, unless they're tagged.\n if taggedalbs:\n log.info(\"Found tagged Application Load Balancers:{}\".format(taggedalbs))\n if taggednlbs:\n log.info(\"Found tagged Network Load Balancers:{}\".format(taggednlbs))\n\n #TODO: once pricing for ALB and NLB is added to awspricecalculator, separate hours by ELB type\n elb_hours += (len(taggedelbs)+len(taggednlbs))*HOURS_DICT[DEFAULT_FORECAST_PERIOD]\n alb_hours += len(taggedalbs)*HOURS_DICT[DEFAULT_FORECAST_PERIOD]\n\n\n if elb_instances:\n try:\n log.info(\"Found registered EC2 instances to tagged ELBs [{}]:{}\".format(taggedelbs, elb_instances.keys()))\n elb_data_processed_gb = calculate_elb_data_processed(start, end, elb_instances)*calculate_forecast_factor() / (10**9)\n except Exception as failure:\n log.error('Error calculating costs for tagged ELBs: %s', failure)\n else:\n log.info(\"Didn't find any EC2 instances registered to tagged ELBs [{}]\".format(taggedelbs))\n #else:\n # log.info(\"No tagged ELBs found\")\n\n #Get tagged EC2 instances\n ec2_instances = get_ec2_instances_by_tag(tagkey, tagvalue)\n if ec2_instances:\n log.info(\"Tagged EC2 instances:{}\".format(ec2_instances.keys()))\n else:\n log.info(\"Didn't find any tagged, running EC2 instances\")\n\n #Calculate Classic ELB cost\n if elb_hours:\n elb_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, elbHours=elb_hours,elbDataProcessedGb=elb_data_processed_gb))\n if 'pricingRecords' in elb_cost:\n pricing_records.extend(elb_cost['pricingRecords'])\n ec2Cost = ec2Cost + elb_cost['totalCost']\n\n #Calculate Application Load Balancer cost\n if alb_hours:\n alb_lcus = calculate_alb_lcus(start, end, taggedalbs)*calculate_forecast_factor()\n alb_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, albHours=alb_hours, albLcus=alb_lcus))\n if 'pricingRecords' in alb_cost:\n pricing_records.extend(alb_cost['pricingRecords'])\n ec2Cost = ec2Cost + alb_cost['totalCost']\n\n\n\n #Calculate EC2 compute time for ALL instance types found (subscribed to ELB or not) - group by instance types\n all_instance_dict = {}\n all_instance_dict.update(ec2_instances)\n all_instance_types = get_instance_type_count(all_instance_dict)\n log.info(\"All instance types:{}\".format(all_instance_types))\n\n #Calculate EC2 compute time cost\n #TODO: add support for all available OS\n for instance_type in all_instance_types:\n try:\n ec2_compute_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, instanceType=instance_type, instanceHours=all_instance_types[instance_type]*HOURS_DICT[DEFAULT_FORECAST_PERIOD]))\n if 'pricingRecords' in ec2_compute_cost: pricing_records.extend(ec2_compute_cost['pricingRecords'])\n ec2Cost = ec2Cost + ec2_compute_cost['totalCost']\n except Exception as failure:\n log.error('Error processing %s: %s', instance_type, failure)\n\n #Get provisioned storage by volume type, and provisioned IOPS (if applicable)\n ebs_storage_dict, piops = get_storage_by_ebs_type(all_instance_dict)\n\n #Calculate EBS storagecost\n for k in ebs_storage_dict.keys():\n if k == 'io1': pricing_piops = piops\n else: pricing_piops = 0\n try:\n ebs_storage_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, ebsVolumeType=k, ebsStorageGbMonth=ebs_storage_dict[k], pIops=pricing_piops))\n if 'pricingRecords' in ebs_storage_cost: pricing_records.extend(ebs_storage_cost['pricingRecords'])\n ec2Cost = ec2Cost + ebs_storage_cost['totalCost']\n except Exception as failure:\n log.error('Error processing ebs storage costs: %s', failure)\n\n\n #Get tagged RDS DB instances\n #db_instances = get_db_instances_by_tag(tagkey, tagvalue)\n db_instances = get_db_instances_by_tag(resource_manager.get_resource_ids(SERVICE_RDS, RESOURCE_RDS_DB_INSTANCE))\n if db_instances:\n log.info(\"Found the following tagged DB instances:{}\".format(db_instances.keys()))\n else:\n log.info(\"Didn't find any tagged RDS DB instances\")\n\n #Calculate RDS instance time for ALL instance types found - group by DB instance types\n all_db_instance_dict = {}\n all_db_instance_dict.update(db_instances)\n all_db_instance_types = get_db_instance_type_count(all_db_instance_dict)\n all_db_storage_types = get_db_storage_type_count(all_db_instance_dict)\n\n #TODO: add support for read replicas\n\n #Calculate RDS instance time cost\n rds_instance_cost = {}\n for db_instance_type in all_db_instance_types:\n try:\n dbInstanceClass = db_instance_type.split(\"|\")[0]\n engine = db_instance_type.split(\"|\")[1]\n licenseModel= db_instance_type.split(\"|\")[2]\n multiAz= bool(int(db_instance_type.split(\"|\")[3]))\n log.info(\"Calculating RDS DB Instance compute time\")\n rds_instance_cost = rdspricing.calculate(data.RdsPriceDimension(region=region, dbInstanceClass=dbInstanceClass, multiAz=multiAz,\n engine=engine, licenseModel=licenseModel, instanceHours=all_db_instance_types[db_instance_type]*HOURS_DICT[DEFAULT_FORECAST_PERIOD]))\n\n if 'pricingRecords' in rds_instance_cost: pricing_records.extend(rds_instance_cost['pricingRecords'])\n rdsCost = rdsCost + rds_instance_cost['totalCost']\n except Exception as failure:\n log.error('Error processing RDS instance time costs: %s', failure)\n\n #Calculate RDS storage cost\n #TODO: add support for Aurora operations\n rds_storage_cost = {}\n for storage_key in all_db_storage_types.keys():\n try:\n storageType = storage_key.split(\"|\")[0]\n multiAz = bool(int(storage_key.split(\"|\")[1]))\n storageGbMonth = all_db_storage_types[storage_key]['AllocatedStorage']\n iops = all_db_storage_types[storage_key]['Iops']\n log.info(\"Calculating RDS DB Instance Storage\")\n rds_storage_cost = rdspricing.calculate(data.RdsPriceDimension(region=region, storageType=storageType,\n multiAz=multiAz, storageGbMonth=storageGbMonth,\n iops=iops))\n\n if 'pricingRecords' in rds_storage_cost: pricing_records.extend(rds_storage_cost['pricingRecords'])\n rdsCost = rdsCost + rds_storage_cost['totalCost']\n except Exception as failure:\n log.error('Error processing RDS storage costs: %s', failure)\n\n #RDS Data Transfer - the Lambda function will assume all data transfer happens between RDS and EC2 instances\n\n #Lambda functions\n #TODO: add support for lambda function qualifiers\n #TODO: calculate data ingested into CloudWatch Logs\n lambdafunctions = resource_manager.get_resources(SERVICE_LAMBDA, RESOURCE_LAMBDA_FUNCTION)\n for func in lambdafunctions:\n executions = calculate_lambda_executions(start, end, func)\n avgduration = calculate_lambda_duration(start, end, func)\n funcname = ''\n qualifier = ''\n fullname = ''\n funcname = func.id\n fullname = funcname\n #if 'qualifier' in func:\n # qualifier = func['qualifier']\n # fullname += \":\"+qualifier\n memory = get_lambda_memory(funcname,qualifier)\n log.info(\"Executions for Lambda function [{}]: [{}] - Memory:[{}] - Avg Duration:[{}]\".format(funcname,executions,memory, avgduration))\n if executions and avgduration:\n try:\n #Note we're setting data transfer = 0, since we don't have a way to calculate it based on CW metrics alone\n #TODO:call a single time and include a GB-s price dimension to the Lambda calculator\n lambdapdim = data.LambdaPriceDimension(region=region, requestCount=executions*calculate_forecast_factor(),\n avgDurationMs=avgduration, memoryMb=memory, dataTranferOutInternetGb=0,\n dataTranferOutIntraRegionGb=0, dataTranferOutInterRegionGb=0, toRegion='')\n lambda_func_cost = lambdapricing.calculate(lambdapdim)\n if 'pricingRecords' in lambda_func_cost: pricing_records.extend(lambda_func_cost['pricingRecords'])\n lambdaCost = lambdaCost + lambda_func_cost['totalCost']\n\n except Exception as failure:\n log.error('Error processing Lambda costs: %s', failure)\n else:\n log.info(\"Skipping pricing calculation for function [{}] - qualifier [{}] due to lack of executions in [{}-minute] time window\".format(fullname, qualifier, METRIC_WINDOW))\n\n\n #DynamoDB\n totalRead = 0\n totalWrite = 0\n ddbtables = resource_manager.get_resources(SERVICE_DYNAMODB, RESOURCE_DDB_TABLE)\n #Provisioned Capacity Units\n for t in ddbtables:\n read, write = get_ddb_capacity_units(t.id)\n log.info(\"Dynamo DB Provisioned Capacity Units - Table:{} Read:{} Write:{}\".format(t.id, read, write))\n totalRead += read\n totalWrite += write\n #TODO: add support for storage\n if totalRead and totalWrite:\n ddbpdim = data.DynamoDBPriceDimension(region=region, readCapacityUnitHours=totalRead*HOURS_DICT[FORECAST_PERIOD_MONTHLY],\n writeCapacityUnitHours=totalWrite*HOURS_DICT[FORECAST_PERIOD_MONTHLY])\n ddbtable_cost = ddbpricing.calculate(ddbpdim)\n if 'pricingRecords' in ddbtable_cost: pricing_records.extend(ddbtable_cost['pricingRecords'])\n ddbCost = ddbCost + ddbtable_cost['totalCost']\n\n\n #Kinesis Streams\n streams = resource_manager.get_resources(SERVICE_KINESIS, RESOURCE_STREAM)\n totalShards = 0\n totalExtendedRetentionCount = 0\n totalPutPayloadUnits = 0\n for s in streams:\n log.info(\"Stream:[{}]\".format(s.id))\n tmpShardCount, tmpExtendedRetentionCount = get_kinesis_stream_shards(s.id)\n totalShards += tmpShardCount\n totalExtendedRetentionCount += tmpExtendedRetentionCount\n\n totalPutPayloadUnits += calculate_kinesis_put_payload_units(start, end, s.id)\n\n if totalShards:\n kinesispdim = data.KinesisPriceDimension(region=region,\n shardHours=totalShards*HOURS_DICT[FORECAST_PERIOD_MONTHLY],\n extendedDataRetentionHours=totalExtendedRetentionCount*HOURS_DICT[FORECAST_PERIOD_MONTHLY],\n putPayloadUnits=totalPutPayloadUnits*calculate_forecast_factor())\n stream_cost = kinesispricing.calculate(kinesispdim)\n if 'pricingRecords' in stream_cost: pricing_records.extend(stream_cost['pricingRecords'])\n\n kinesisCost = kinesisCost + stream_cost['totalCost']\n\n\n\n\n #Do this after all calculations for all supported services have concluded\n totalCost = ec2Cost + rdsCost + lambdaCost + ddbCost + kinesisCost\n result['pricingRecords'] = pricing_records\n result['totalCost'] = round(totalCost,2)\n result['forecastPeriod']=DEFAULT_FORECAST_PERIOD\n result['currency'] = CW_METRIC_DIMENSION_CURRENCY_USD\n\n #Publish metrics to CloudWatch using the default namespace\n\n if tagkey:\n put_cw_metric_data(end, ec2Cost, CW_METRIC_DIMENSION_SERVICE_NAME_EC2, tagkey, tagvalue)\n put_cw_metric_data(end, rdsCost, CW_METRIC_DIMENSION_SERVICE_NAME_RDS, tagkey, tagvalue)\n put_cw_metric_data(end, lambdaCost, CW_METRIC_DIMENSION_SERVICE_NAME_LAMBDA, tagkey, tagvalue)\n put_cw_metric_data(end, ddbCost, CW_METRIC_DIMENSION_SERVICE_NAME_DYNAMODB, tagkey, tagvalue)\n put_cw_metric_data(end, kinesisCost, CW_METRIC_DIMENSION_SERVICE_NAME_KINESIS, tagkey, tagvalue)\n put_cw_metric_data(end, totalCost, CW_METRIC_DIMENSION_SERVICE_NAME_TOTAL, tagkey, tagvalue)\n\n\n\n log.info(\"Estimated monthly cost for resources tagged with key={},value={} : [{}]\".format(tagkey, tagvalue, json.dumps(result,sort_keys=False,indent=4)))\n\n except NoDataFoundError as ndf:\n log.error (\"NoDataFoundError [{}]\".format(ndf))\n\n except Exception as e:\n traceback.print_exc()\n log.error(\"Exception message:[\"+str(e)+\"]\")\n\n\n return result\n\n#TODO: calculate data transfer for instances that are not registered with the ELB\n#TODO: Support different OS for EC2 instances (see how engine and license combinations are calculated for RDS)\n#TODO: log the actual AWS resources that are found for the price calculation\n#TODO: add support for detailed metrics fee\n#TODO: add support for EBS optimized\n#TODO: add support for EIP\n#TODO: add support for EC2 operating systems other than Linux\n#TODO: calculate monthly hours based on the current month, instead of assuming 720\n#TODO: add support for different forecast periods (1 hour, 1 day, 1 month, etc.)\n#TODO: add support for Spot and Reserved. Function only supports On-demand instances at the time\n\n\ndef put_cw_metric_data(timestamp, cost, service, tagkey, tagvalue):\n\n response = cwclient.put_metric_data(\n Namespace=CW_NAMESPACE,\n MetricData=[\n {\n 'MetricName': CW_METRIC_NAME_ESTIMATEDCHARGES,\n 'Dimensions': [{'Name': CW_METRIC_DIMENSION_SERVICE_NAME,'Value': service},\n {'Name': CW_METRIC_DIMENSION_PERIOD,'Value': DEFAULT_FORECAST_PERIOD},\n {'Name': CW_METRIC_DIMENSION_CURRENCY,'Value': CW_METRIC_DIMENSION_CURRENCY_USD},\n {'Name': CW_METRIC_DIMENSION_TAG,'Value': tagkey+'='+tagvalue}\n ],\n 'Timestamp': timestamp,\n 'Value': cost,\n 'Unit': 'Count'\n }\n ]\n )\n\n\ndef get_elb_instances(elbnames):\n result = {}\n instance_ids = []\n elbs = elbclient.describe_load_balancers(LoadBalancerNames=elbnames)\n if 'LoadBalancerDescriptions' in elbs:\n for e in elbs['LoadBalancerDescriptions']:\n if 'Instances' in e:\n instances = e['Instances']\n for i in instances:\n instance_ids.append(i['InstanceId'])\n\n if instance_ids:\n response = ec2client.describe_instances(InstanceIds=instance_ids)\n if 'Reservations' in response:\n for r in response['Reservations']:\n if 'Instances' in r:\n for i in r['Instances']:\n result[i['InstanceId']]=i\n\n return result\n\n\ndef get_ec2_instances_by_tag(tagkey, tagvalue):\n result = {}\n response = ec2client.describe_instances(Filters=[{'Name': 'tag:'+tagkey, 'Values':[tagvalue]},\n {'Name': 'instance-state-name', 'Values': ['running',]}])\n if 'Reservations' in response:\n reservations = response['Reservations']\n for r in reservations:\n if 'Instances' in r:\n for i in r['Instances']:\n result[i['InstanceId']]=i\n\n return result\n\n\n\ndef get_db_instances_by_tag(dbIds):\n result = {}\n #TODO: paginate\n if dbIds:\n response = rdsclient.describe_db_instances(Filters=[{'Name':'db-instance-id','Values':dbIds}])\n if 'DBInstances' in response:\n dbInstances = response['DBInstances']\n for d in dbInstances:\n result[d['DbiResourceId']]=d\n return result\n\n\n\ndef get_non_elb_instances_by_tag(tagkey, tagvalue, elb_instances):\n result = {}\n response = ec2client.describe_instances(Filters=[{'Name': 'tag:'+tagkey, 'Values':[tagvalue]}])\n if 'Reservations' in response:\n reservations = response['Reservations']\n for r in reservations:\n if 'Instances' in r:\n for i in r['Instances']:\n if i['InstanceId'] not in elb_instances: result[i['InstanceId']]=i\n\n return result\n\ndef get_instance_type_count(instance_dict):\n result = {}\n for key in instance_dict:\n instance_type = instance_dict[key]['InstanceType']\n if instance_type in result:\n result[instance_type] = result[instance_type] + 1\n else:\n result[instance_type] = 1\n return result\n\n\ndef get_db_instance_type_count(db_instance_dict):\n result = {}\n for key in db_instance_dict:\n #key format: db-instance-class|engine|license-model|multi-az\n multiAz = 0\n if db_instance_dict[key]['MultiAZ']==True:multiAz=1\n db_instance_key = db_instance_dict[key]['DBInstanceClass']+\"|\"+\\\n db_instance_dict[key]['Engine']+\"|\"+\\\n db_instance_dict[key]['LicenseModel']+\"|\"+\\\n str(multiAz)\n if db_instance_key in result:\n result[db_instance_key] = result[db_instance_key] + 1\n else:\n result[db_instance_key] = 1\n return result\n\n\ndef get_db_storage_type_count(db_instance_dict):\n result = {}\n for key in db_instance_dict:\n #key format: db-storage-type|allocated-storage|iops|multi-az\n multiAz = 0\n #print(\"db_instance_dict[{}]\".format(db_instance_dict[key]))\n if db_instance_dict[key]['MultiAZ']==True:multiAz=1\n db_storage_key = db_instance_dict[key]['StorageType']+\"|\"+\\\n str(multiAz)\n\n if 'Iops' not in db_instance_dict[key]: db_instance_dict[key]['Iops'] = 0\n\n if db_storage_key in result:\n result[db_storage_key]['Iops'] += db_instance_dict[key]['Iops']\n result[db_storage_key]['AllocatedStorage'] += db_instance_dict[key]['AllocatedStorage']\n else:\n result[db_storage_key] = {}\n result[db_storage_key]['Iops'] = db_instance_dict[key]['Iops']\n result[db_storage_key]['AllocatedStorage'] = db_instance_dict[key]['AllocatedStorage']\n\n #print (\"Storage composite key:[{}]\".format(db_storage_key))\n\n\n return result\n\n\n\n\ndef get_storage_by_ebs_type(instance_dict):\n result = {}\n iops = 0\n ebs_ids = []\n for key in instance_dict:\n block_mappings = instance_dict[key]['BlockDeviceMappings']\n for bm in block_mappings:\n if 'Ebs' in bm:\n if 'VolumeId' in bm['Ebs']:\n ebs_ids.append(bm['Ebs']['VolumeId'])\n\n volume_details = {}\n if ebs_ids: volume_details = ec2client.describe_volumes(VolumeIds=ebs_ids)#TODO:add support for pagination\n if 'Volumes' in volume_details:\n for v in volume_details['Volumes']:\n volume_type = v['VolumeType']\n if volume_type in result:\n result[volume_type] = result[volume_type] + int(v['Size'])\n else:\n result[volume_type] = int(v['Size'])\n if volume_type == 'io1': iops = iops + int(v['Iops'])\n\n return result, iops\n\n\ndef get_total_snapshot_storage(tagkey, tagvalue):\n result = 0\n snapshots = ec2client.describe_snapshots(Filters=[{'Name': 'tag:'+tagkey,'Values': [tagvalue]}])\n if 'Snapshots' in snapshots:\n for s in snapshots['Snapshots']:\n result = result + s['VolumeSize']\n\n #log.info(\"total snapshot size:[\"+str(result)+\"]\")\n return result\n\n\n\n\n\"\"\"\nFor each EC2 instance registered to an ELB, get the following metrics: NetworkIn, NetworkOut.\nThen add them up and use them to calculate the total data processed by the ELB\n\"\"\"\ndef calculate_elb_data_processed(start, end, elb_instances):\n result = 0\n\n for instance_id in elb_instances.keys():\n metricsNetworkIn = cwclient.get_metric_statistics(\n Namespace='AWS/EC2',\n MetricName='NetworkIn',\n Dimensions=[{'Name': 'InstanceId','Value': instance_id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n metricsNetworkOut = cwclient.get_metric_statistics(\n Namespace='AWS/EC2',\n MetricName='NetworkOut',\n Dimensions=[{'Name': 'InstanceId','Value': instance_id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n for datapoint in metricsNetworkIn['Datapoints']:\n if 'Sum' in datapoint: result = result + datapoint['Sum']\n for datapoint in metricsNetworkOut['Datapoints']:\n if 'Sum' in datapoint: result = result + datapoint['Sum']\n\n log.info (\"Total Bytes processed by ELBs in time window of [\"+str(METRIC_WINDOW)+\"] minutes :[\"+str(result)+\"]\")\n\n return result\n\n\"\"\"\nFor each ALB, get the value for the ConsumedLCUs metric\n\"\"\"\n\n\ndef calculate_alb_lcus(start, end, albs):\n result = 0\n\n for a in albs:\n log.info(\"Getting ConsumedLCUs for ALB: [{}]\".format(a))\n metricsLcus = cwclient.get_metric_statistics(\n Namespace='AWS/ApplicationELB',\n MetricName='ConsumedLCUs',\n Dimensions=[{'Name': 'LoadBalancer','Value': \"app/{}\".format(a)}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n for datapoint in metricsLcus['Datapoints']:\n result += datapoint.get('Sum',0)\n\n log.info (\"Total ConsumedLCUs consumed by ALBs in time window of [\"+str(METRIC_WINDOW)+\"] minutes :[\"+str(result)+\"]\")\n\n return result\n\n\n\n\n\ndef calculate_lambda_executions(start, end, func):\n result = 0\n\n invocations = cwclient.get_metric_statistics(\n Namespace='AWS/Lambda',\n MetricName='Invocations',\n #Dimensions=[{'Name': 'FunctionName','Value': func['name']}],\n Dimensions=[{'Name': 'FunctionName','Value': func.id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n for datapoint in invocations['Datapoints']:\n if 'Sum' in datapoint: result = result + datapoint['Sum']\n\n log.debug(\"calculate_lambda_executions: [{}]\".format(result))\n return result\n\n\ndef calculate_lambda_duration(start, end, func):\n result = 0\n\n invocations = cwclient.get_metric_statistics(\n Namespace='AWS/Lambda',\n MetricName='Duration',\n #Dimensions=[{'Name': 'FunctionName','Value': func['name']}],\n Dimensions=[{'Name': 'FunctionName','Value': func.id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Average']\n )\n count = 0\n total = 0\n for datapoint in invocations['Datapoints']:\n if 'Average' in datapoint:\n count+=1\n total+=datapoint['Average']\n\n if count: result = total / count\n\n log.debug(\"calculate_lambda_duration: [{}]\".format(result))\n\n return result\n\n\ndef get_lambda_memory(functionname, qualifier):\n result = 0\n args = {}\n if qualifier: args = {'FunctionName':functionname,'Qualifier':qualifier}\n else: args = {'FunctionName':functionname}\n try:\n response = lambdaclient.get_function_configuration(**args)\n if 'MemorySize' in response:\n result = response['MemorySize']\n\n except ClientError as e:\n log.error(\"{}\".format(e))\n\n return result\n\n\ndef get_ddb_capacity_units(tablename):\n read = 0\n write = 0\n try:\n r = ddbclient.describe_table(TableName=tablename)\n if 'Table' in r:\n read = r['Table']['ProvisionedThroughput']['ReadCapacityUnits']\n write = r['Table']['ProvisionedThroughput']['WriteCapacityUnits']\n return read, write\n\n except Exception as e:\n log.error(\"{}\".format(e))\n\n\ndef get_kinesis_stream_shards(streamName):\n shardCount = 0\n extendedRetentionCount = 0\n try:\n #TODO: add support for streams with >100 shards\n #TODO: add support for detailed metrics\n response = kinesisclient.describe_stream(StreamName=streamName)\n shardCount = len(response['StreamDescription']['Shards'])\n if response['StreamDescription']['RetentionPeriodHours'] > 24:\n extendedRetentionCount = shardCount\n\n except Exception as e:\n log.error(\"{}\".format(e))\n\n return shardCount, extendedRetentionCount\n\n\"\"\"\nThis function calculates an approximation of PUT payload units, based on CloudWatch metrics.\nUnfortunately, there is no direct CloudWatch metric that returns the PUT Payload Units for a stream.\nhttps://aws.amazon.com/kinesis/streams/pricing/\nPUT Payload Units are calculated in 25KB chunks and CloudWatch metrics return the number of records inserted\nas well as the total bytes entering the stream. There is no accurate way to calculate the number of\n25KB chunks going into the stream.\n\n\"\"\"\ndef calculate_kinesis_put_payload_units(start, end, streamName):\n totalRecords = 0\n totalBytesAvg = 0\n totalPutPayloadUnits = 0\n chunkCount = 0 #Kinesis charges for PUT Payload Units in chunks of 25KB\n\n\n try:\n incomingRecords = cwclient.get_metric_statistics(\n Namespace='AWS/Kinesis',\n MetricName='IncomingRecords',\n Dimensions=[{'Name': 'StreamName','Value': streamName}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n\n for datapoint in incomingRecords['Datapoints']:\n if 'Sum' in datapoint: totalRecords = totalRecords + datapoint['Sum']\n\n incomingBytes = cwclient.get_metric_statistics(\n Namespace='AWS/Kinesis',\n MetricName='IncomingBytes',\n Dimensions=[{'Name': 'StreamName','Value': streamName}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Average']\n )\n\n for datapoint in incomingBytes['Datapoints']:\n if 'Average' in datapoint:\n chunkCount += int(math.ceil(datapoint['Average']/25000))\n\n bytesDatapoints = len(incomingBytes['Datapoints'])\n if not bytesDatapoints: bytesDatapoints = 1 #avoid zerodiv\n totalPutPayloadUnits = totalRecords * chunkCount/bytesDatapoints\n log.info(\"get_kinesis_stream_puts - incomingRecords:[{}] - chunkAvg:[{}] - totalPutPayloadUnits:[{}]\".format(totalRecords, chunkCount/bytesDatapoints, totalPutPayloadUnits))\n\n except Exception as e:\n log.error(\"{}\".format(e))\n\n\n return totalPutPayloadUnits\n\n\ndef calculate_time_range():\n start = datetime.datetime.utcnow() + datetime.timedelta(minutes=-METRIC_DELAY)\n end = start + datetime.timedelta(minutes=METRIC_WINDOW)\n log.info(\"start:[\"+str(start)+\"] - end:[\"+str(end)+\"]\")\n return start, end\n\n\n\ndef calculate_forecast_factor():\n result = (60 / METRIC_WINDOW ) * HOURS_DICT[DEFAULT_FORECAST_PERIOD]\n log.debug(\"Forecast factor:[\"+str(result)+\"]\")\n return result\n\n\ndef get_ec2_instances(registered, all):\n result = []\n for a in all:\n if a not in registered: result.append(a)\n return result\n\n\ndef init_clients(context):\n global ec2client\n global rdsclient\n global elbclient\n global lambdaclient\n global ddbclient\n global kinesisclient\n global cwclient\n global tagsclient\n global region\n global awsaccount\n\n\n arn = context.invoked_function_arn\n region = arn.split(\":\")[3] #ARN format is arn:aws:lambda:us-east-1:xxx:xxxx\n awsaccount = arn.split(\":\")[4]\n ec2client = boto3.client('ec2',region)\n rdsclient = boto3.client('rds',region)\n elbclient = boto3.client('elb',region) #classic load balancers\n elbclientv2 = boto3.client('elbv2',region) #application and network load balancers\n lambdaclient = boto3.client('lambda',region)\n ddbclient = boto3.client('dynamodb',region)\n kinesisclient = boto3.client('kinesis',region)\n cwclient = boto3.client('cloudwatch', region)\n tagsclient = boto3.client('resourcegroupstaggingapi', region)\n\n\nclass ResourceManager():\n def __init__(self, tagkey, tagvalue):\n self.resources = []\n self.init_resources(tagkey, tagvalue)\n\n\n def init_resources(self, tagkey, tagvalue):\n #TODO: Implement pagination\n response = tagsclient.get_resources(\n TagsPerPage = 500,\n TagFilters=[{'Key': tagkey,'Values': [tagvalue]}],\n ResourceTypeFilters=self.get_resource_type_filters(SERVICE_RESOURCE_MAP)\n )\n\n if 'ResourceTagMappingList' in response:\n for r in response['ResourceTagMappingList']:\n res = self.extract_resource(r['ResourceARN'])\n if res:\n self.resources.append(res)\n #log.info(\"Tagged resource:{}\".format(res.__dict__))\n\n #Return a service:resource list in the format the ResourceGroupTagging API expects it\n def get_resource_type_filters(self, service_resource_map):\n result = []\n for s in service_resource_map.keys():\n for r in service_resource_map[s]: result.append(\"{}:{}\".format(s,r))\n return result\n\n\n def extract_resource(self, arn):\n service = arn.split(\":\")[2]\n resourceId = ''\n #See http://docs.aws.amazon.com/general/latest/gr/aws-arns-and-namespaces.html for different patterns in ARNs\n for service in (SERVICE_EC2, SERVICE_ELB, SERVICE_DYNAMODB, SERVICE_KINESIS):\n for type in (RESOURCE_ALB, RESOURCE_NLB, RESOURCE_ELB):\n if ':'+service+':' in arn and ':'+type+'/' in arn:\n resourceId = arn.split(':'+type+'/')[1]\n return self.Resource(service, type, resourceId, arn)\n\n for type in (RESOURCE_EC2_INSTANCE,RESOURCE_EBS_VOLUME,RESOURCE_EBS_SNAPSHOT,RESOURCE_DDB_TABLE, RESOURCE_STREAM):\n if ':'+service+':' in arn and ':'+type+'/' in arn:\n resourceId = arn.split(':'+type+'/')[1]\n return self.Resource(service, type, resourceId, arn)\n for service in (SERVICE_RDS, SERVICE_LAMBDA):\n for type in (RESOURCE_RDS_DB_INSTANCE, RESOURCE_LAMBDA_FUNCTION):\n if ':'+service+':' in arn and ':'+type+':' in arn:\n resourceId = arn.split(':'+type+':')[1]\n return self.Resource(service, type, resourceId, arn)\n\n return None\n\n def get_resources(self, service, resourceType):\n result = []\n if self.resources:\n for r in self.resources:\n if r.service == service and r.type == resourceType:\n result.append(r)\n return result\n\n\n def get_resource_ids(self, service, resourceType):\n result = []\n if self.resources:\n for r in self.resources:\n if r.service == service and r.type == resourceType:\n result.append(r.id)\n return result\n\n\n\n\n class Resource():\n def __init__(self, service, type, id, arn):\n self.service = service\n self.type = type\n self.id = id\n self.arn = arn\n"
},
{
"path": "install.sh",
"content": "#!/bin/sh\n\n#Install application dependencies in /vendored folder\npip install -r requirements.txt -t vendored\n\n#Install local dev environment & test dependencies in default site_packages path\npip install -r requirements-dev.txt\n\n\n\n"
},
{
"path": "requirements-dev.txt",
"content": "tinydb==3.4.1\nnumpy== 1.12.1\ntabulate\nboto3\npython-lambda-local\n"
},
{
"path": "requirements.txt",
"content": "tinydb==3.4.1\nnumpy== 1.12.1\ntabulate\n"
},
{
"path": "scripts/README.md",
"content": "## Concurrency Labs - aws-pricing-tools scripts\n\nThis folder contains Python scripts that are used for various purposes in the repository\n\nAll scripts need to be executed from the `/scripts` folder.\n\n\nMake sure you have the following environment variables set:\n\n```\nexport AWS_DEFAULT_PROFILE=\nexport AWS_DEFAULT_REGION=\n```\n\n\n### Get Latest Index\n\nThe code needs a local copy of the the AWS Price List API index file. \nThe GitHub repo doesn't come with the index file, therefore you have to\ndownload it the first time you run a test and every time AWS publishes a new\nPrice List API index.\n\nIn order to download the latest index file, go to the \"scripts\" folder and run:\n\n```\npython get-latest-index.py --service=\n```\n\nThe script takes a few seconds to execute since some index files are a little heavy (like the EC2 one).\n\nI recommend executing with the option `--service=all` and subscribing to the AWS Price List API change notifications.\n\n\n### Lambda Optimization Recommendations\n\nThis script does the following:\n\n* It finds the function's execution records in CloudWatch Logs, for the\ngiven time window in minutes (i.e. the past 10 minutes)\n* Parses usage information and extracts memory used, execution time and memory allocated\n* It uses the Price List Index to calculate pricing for the Lambda function, \nfor different scenarios and tells you potential savings.\n\n\n```\npython lambda-optimization.py --function= --minutes=\n```\n\nThis function requires you to have the following IAM permissions:\n* `lambda:getFunction`\n* `logs:getLogEvents`\n\nMake sure variables AWS_DEFAULT_PROFILE and AWS_DEFAULT_REGION are set. \n\n\n\n\n"
},
{
"path": "scripts/emr-pricing.py",
"content": "#!/usr/bin/python\nimport sys, os, getopt, json, logging\nimport argparse\nimport traceback\nsys.path.insert(0, os.path.abspath('..'))\n\nimport awspricecalculator.emr.pricing as emrpricing\nimport awspricecalculator.common.consts as consts\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.utils as utils\nfrom awspricecalculator.common.errors import ValidationError\nfrom awspricecalculator.common.errors import NoDataFoundError\n\nlog = logging.getLogger()\nlogging.basicConfig()\nlog.setLevel(logging.DEBUG)\n\ndef main(argv):\n\n parser = argparse.ArgumentParser()\n parser.add_argument('--region', help='', required=False)\n parser.add_argument('--regions', help='', required=False)\n parser.add_argument('--sort-criteria', help='', required=False)\n parser.add_argument('--instance-type', help='', required=False)\n parser.add_argument('--instance-types', help='', required=False)\n parser.add_argument('--instance-hours', help='', type=int, required=False)\n parser.add_argument('--ebs-volume-type', help='', required=False)\n parser.add_argument('--ebs-storage-gb-month', help='', required=False)\n parser.add_argument('--piops', help='', type=int, required=False)\n parser.add_argument('--data-transfer-out-internet-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-intraregion-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-interregion-gb', help='', required=False)\n parser.add_argument('--to-region', help='', required=False)\n parser.add_argument('--term-type', help='', required=False)\n parser.add_argument('--offering-class', help='', required=False)\n parser.add_argument('--offering-classes', help='', required=False)\n parser.add_argument('--instance-count', help='', type=int, required=False)\n parser.add_argument('--years', help='', required=False)\n parser.add_argument('--offering-type', help='', required=False)\n parser.add_argument('--offering-types', help='', required=False)\n\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n args = parser.parse_args()\n\n region = ''\n regions = ''\n instanceType = ''\n instanceTypes = ''\n instanceHours = 0\n instanceCount = 0\n sortCriteria = ''\n ebsVolumeType = ''\n ebsStorageGbMonth = 0\n pIops = 0\n dataTransferOutInternetGb = 0\n dataTransferOutIntraRegionGb = 0\n dataTransferOutInterRegionGb = 0\n toRegion = ''\n termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n offeringClass = ''\n offeringClasses = consts.SUPPORTED_EMR_OFFERING_CLASSES #only used for Reserved comparisons (standard, convertible)\n offeringType = ''\n offeringTypes = consts.EC2_SUPPORTED_PURCHASE_OPTIONS #only used for Reserved comparisons (all-upfront, partial-upfront, no-upfront)\n years = 1\n\n if args.region: region = args.region\n if args.regions: regions = args.regions\n if args.sort_criteria: sortCriteria = args.sort_criteria\n if args.instance_type: instanceType = args.instance_type\n if args.instance_types: instanceTypes = args.instance_types\n if args.instance_hours: instanceHours = int(args.instance_hours)\n if args.ebs_volume_type: ebsVolumeType = args.ebs_volume_type\n if args.ebs_storage_gb_month: ebsStorageGbMonth = int(args.ebs_storage_gb_month)\n if args.piops: pIops = int(args.piops)\n if args.data_transfer_out_internet_gb: dataTransferOutInternetGb = int(args.data_transfer_out_internet_gb)\n if args.data_transfer_out_intraregion_gb: dataTransferOutIntraRegionGb = int(args.data_transfer_out_intraregion_gb)\n if args.data_transfer_out_interregion_gb: dataTransferOutInterRegionGb = int(args.data_transfer_out_interregion_gb)\n if args.to_region: toRegion = args.to_region\n if args.term_type: termType = args.term_type\n if args.offering_class: offeringClass = args.offering_class\n if args.offering_classes: offeringClasses = args.offering_classes.split(',')\n if args.instance_count: instanceCount = args.instance_count\n if args.offering_type: offeringType = args.offering_type\n if args.offering_types: offeringTypes = args.offering_types.split(',')\n if args.years: years = str(args.years)\n\n #TODO: Implement comparison between a subset of regions by entering an array of regions to compare\n #TODO: Implement a sort by target region (for data transfer)\n #TODO: For Reserved pricing, include a payment plan throughout the whole period, and a monthly average and savings\n\n\n try:\n\n #TODO: not working for EBS Snapshots!\n kwargs = {'sortCriteria':sortCriteria, 'instanceType':instanceType, 'instanceTypes':instanceTypes,\n 'instanceHours':instanceHours, 'dataTransferOutInternetGb':dataTransferOutInternetGb,\n 'ebsVolumeType':ebsVolumeType, 'ebsStorageGbMonth':ebsStorageGbMonth, 'pIops':pIops,\n 'dataTransferOutIntraRegionGb':dataTransferOutIntraRegionGb, 'dataTransferOutInterRegionGb':dataTransferOutInterRegionGb,\n 'toRegion':toRegion, 'termType':termType, 'instanceCount': instanceCount, 'years': years, 'offeringType':offeringType,\n 'offeringClass':offeringClass\n }\n\n if region: kwargs['region'] = region\n\n if sortCriteria:\n if sortCriteria in (consts.SORT_CRITERIA_TERM_TYPE, consts.SORT_CRITERIA_TERM_TYPE_REGION):\n if sortCriteria == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n #TODO: validate that region list is comma-separated\n #TODO: move this list to utils.compare_term_types\n if regions: kwargs['regions'] = regions.split(',')\n else: kwargs['regions']=consts.SUPPORTED_REGIONS\n kwargs['purchaseOptions'] = offeringTypes #purchase options are referred to as offering types in the EC2 API\n kwargs['offeringClasses']=offeringClasses\n validate (kwargs)\n termPricingAnalysis = utils.compare_term_types(service=consts.SERVICE_EMR, **kwargs)\n tabularData = termPricingAnalysis.pop('tabularData')\n print (\"EMR termpPricingAnalysis: [{}]\".format(json.dumps(termPricingAnalysis,sort_keys=False, indent=4)))\n print(\"csvData:\\n{}\\n\".format(termPricingAnalysis['csvData']))\n #print(\"tabularData:\\n{}\".format(tabularData).replace(\"reserved\",\"rsv\").replace(\"standard\",\"std\").\n # replace(\"convertible\",\"conv\").replace(\"-upfront\",\"\").replace(\"partial\",\"par\").replace(\"demand\",\"dmd\"))\n print(\"\\n{}\".format(tabularData))\n\n else:\n validate (kwargs)\n pricecomparisons = utils.compare(service=consts.SERVICE_EMR,**kwargs)\n print(\"Price comparisons:[{}]\".format(json.dumps(pricecomparisons, indent=4)))\n #tabularData = termPricingAnalysis.pop('tabularData')\n #print(\"tabularData:\\n{}\".format(tabularData))\n\n else:\n validate (kwargs)\n emr_pricing = emrpricing.calculate(data.EmrPriceDimension(**kwargs))\n print(json.dumps(emr_pricing,sort_keys=False,indent=4))\n\n\n\n\n\n\n except NoDataFoundError as ndf:\n print (\"NoDataFoundError args:[{}]\".format(args))\n\n except Exception as e:\n traceback.print_exc()\n print(\"Exception message:[\"+str(e)+\"]\")\n\n\n\"\"\"\nThis function contains validations at the script level. No need to validate EC2 parameters, since\nclass Ec2PriceDimension already contains a validation function.\n\"\"\"\ndef validate (args):\n #TODO: add - if termType sort criteria is specified, don't include offeringClass (singular)\n #TODO: add - if offeringTypes is included, have at least one valid offeringType (purchase option)\n #TODO: move to models\n validation_msg = \"\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE:\n if args.get('instanceHours',False):\n validation_msg = \"instance-hours cannot be set when sort-criteria=term-type\"\n if args.get('offeringType',False):\n validation_msg = \"offering-type cannot be set when sort-criteria=term-type - try offering-types (plural) instead\"\n if not args.get('years',''):\n validation_msg = \"years cannot be empty\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n if not args.get('offeringClasses',''):\n validation_msg = \"offering-classes cannot be empty\"\n if not args.get('purchaseOptions',''):\n validation_msg = \"offering-types cannot be empty\"\n\n if validation_msg:\n print(\"Error: [{}]\".format(validation_msg))\n raise ValidationError(validation_msg)\n\n return\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "scripts/get-latest-index.py",
"content": "#!/usr/bin/python\nimport os, sys, getopt, json, csv, ssl\nimport urllib.request\n\nsys.path.insert(0, os.path.abspath('..'))\nfrom awspricecalculator.common import consts as consts\nfrom awspricecalculator.common import phelper as phelper\n\n\nif (not os.environ.get('PYTHONHTTPSVERIFY', '') and\n getattr(ssl, '_create_unverified_context', None)):\n ssl._create_default_https_context = ssl._create_unverified_context\n\n\n__location__ = os.path.dirname(os.path.realpath(__file__))\ndataindexpath = os.path.join(os.path.split(__location__)[0],\"awspricecalculator\", \"data\")\n\n\"\"\"\nThis script gets the latest index files from the AWS Price List API.\n\"\"\"\n#TODO: add support for term-type = onDemand, Reserved or both\ndef main(argv):\n\n\n SUPPORTED_SERVICES = (consts.SERVICE_S3, consts.SERVICE_EC2, consts.SERVICE_RDS, consts.SERVICE_LAMBDA,\n consts.SERVICE_DYNAMODB, consts.SERVICE_KINESIS, consts.SERVICE_DATA_TRANSFER, consts.SERVICE_EMR,\n consts.SERVICE_REDSHIFT, consts.SERVICE_ALL)\n SUPPORTED_FORMATS = ('json','csv')\n OFFER_INDEX_URL = 'https://pricing.us-east-1.amazonaws.com/offers/v1.0/aws/{serviceIndex}/current/index.'\n\n\n service = ''\n format = ''\n region = ''\n tenancy = ''\n\n help_message = 'Script usage: \\nget-latest-index.py --service= --format='\n\n try:\n opts, args = getopt.getopt(argv,\"hr:s:f:t\",[\"region=\",\"service=\",\"format=\",\"tenancy=\"])\n print ('opts: ' + str(opts))\n except getopt.GetoptError:\n print (help_message)\n sys.exit(2)\n\n for opt in opts:\n if opt[0] == '-h':\n print (help_message)\n sys.exit()\n if opt[0] in (\"-s\",\"--service\"):\n service = opt[1]\n if opt[0] in (\"-f\",\"--format\"):\n format = opt[1]\n if opt[0] in (\"-r\",\"--region\"):\n region = opt[1]\n if opt[0] in (\"-t\",\"--tenancy\"): #comma-separated tenancies (host, dedicated, shared)\n tenancy= opt[1].split(',')\n\n\n if not format: format = 'csv'\n\n validation_ok = True\n\n\n if service not in SUPPORTED_SERVICES:\n validation_ok = False\n if format not in SUPPORTED_FORMATS:\n validation_ok = False\n\n if not validation_ok:\n print (help_message)\n sys.exit(2)\n\n services = []\n if service == 'all': services = SUPPORTED_SERVICES\n else: services = [service]\n\n term = '' #all terms\n\n extraArgs = {}\n if tenancy: extraArgs['tenancies']=[tenancy]\n else: extraArgs['tenancies']=consts.EC2_TENANCY_MAP.keys()\n\n\n for s in services:\n if s != 'all':\n offerIndexUrl = OFFER_INDEX_URL.replace('{serviceIndex}',consts.SERVICE_INDEX_MAP[s]) + format\n print ('Downloading offerIndexUrl:['+offerIndexUrl+']...')\n\n servicedatapath = dataindexpath + \"/\" + s\n print (\"servicedatapath:[{}]\".format(servicedatapath))\n\n if not os.path.exists(servicedatapath): os.mkdir(servicedatapath)\n filename = servicedatapath+\"/index.\"+format\n\n with open(filename, \"wb\") as f: f.write(urllib.request.urlopen(offerIndexUrl).read())\n\n if format == 'csv':\n remove_metadata(filename)\n split_index(s, region, term, **extraArgs)\n\n\n\"\"\"\nThe first rows in the PriceList index.csv are metadata.\nThis method removes the metadata from the index files and writes it in a separate .json file,\n so the metadata can be accessed by other modules. For example, the PriceList Version is returned\n in every price calculation.\n\"\"\"\n\ndef remove_metadata(index_filename):\n print (\"Removing metadata from file [{}]\".format(index_filename))\n metadata_filename = index_filename.replace('.csv','_metadata.json')\n metadata_dict = {}\n with open(index_filename,\"r\") as rf:\n lines = rf.readlines()\n with open(index_filename,\"w\") as wf:\n i = 0\n for l in lines:\n #The first 5 records in the CSV file are metadata\n if i <= 4:\n config_record = l.replace('\",\"','\"|\"').strip(\"\\n\").split(\"|\")\n metadata_dict[config_record[0].strip('\\\"')] = config_record[1].strip('\\\"')\n else:\n wf.write(l)\n i += 1\n with open(metadata_filename,\"w\") as mf:\n print (\"Creating metadata file [{}]\".format(metadata_filename))\n metadata_json = json.dumps(metadata_dict,sort_keys=False,indent=4)\n print (\"metadata_json: [{}]\".format(metadata_json))\n mf.write(metadata_json)\n\n\"\"\"\nSome index files are too large. For example, the one for EC2 has more than 460K records.\nIn order to make price lookup more efficient, awspricecalculator splits the\nindex based on a combination of region, term type and product family. Each partition\nhas a key, which is used by tinydb to load smaller files as databases that can be\nqueried. This increases performance significantly.\n\n\"\"\"\n\ndef split_index(service, region, term, **args):\n #Split index format: region -> term type -> product family\n indexDict = {}#contains the keys of the files that will be created\n productFamilies = {}\n usageGroupings=[]\n partition_keys = phelper.get_partition_keys(service, region, term, **args)#All regions and all term types (On-Demand + Reserved)\n #print(\"partition_keys:[{}]\".format(partition_keys))\n for pk in partition_keys:\n indexDict[pk]=[]\n\n fieldnames = []\n\n #with open(get_index_file_name(service, 'index', 'csv'), 'rb') as csvfile:\n with open(get_index_file_name(service, 'index', 'csv'), 'r') as csvfile:\n pricelist = csv.DictReader(csvfile, delimiter=',', quotechar='\"')\n indexRegion = ''\n x = 0\n for row in pricelist:\n indexKey = ''\n if x==0: fieldnames=row.keys()\n if row.get('Location Type','') == 'AWS Region':\n indexRegion = row['Location']\n if row.get('Product Family','')== consts.PRODUCT_FAMILY_DATA_TRANSFER:\n indexRegion = row['From Location']\n\n #Determine the index partition the current row belongs to and append it to the corresponding array\n if row.get('TermType','') == consts.TERM_TYPE_RESERVED:\n #TODO:move the creation of the index dimensions to a common function\n if service == consts.SERVICE_EC2:\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'],row['OfferingClass'],row['Tenancy'], row['PurchaseOption'])\n elif service in (consts.SERVICE_RDS, consts.SERVICE_REDSHIFT):#'Tenancy' is not part of the RDS/Redshift index, therefore default it to Shared\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'],row['OfferingClass'],row.get('Tenancy',consts.EC2_TENANCY_SHARED),row['PurchaseOption'])\n else:\n if service == consts.SERVICE_EC2:\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'],row['Tenancy'])\n else:\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'])\n\n #print (\"TermType:[{}] - service:[{}] - indexDimensions:[{}]\".format(row.get('TermType',''), service, indexDimensions))\n\n indexKey = phelper.create_file_key(indexDimensions)\n if indexKey in indexDict:\n indexDict[indexKey].append(remove_fields(service, row))\n\n #Get a list of distinct product families in the index file\n productFamily = row['Product Family']\n if productFamily not in productFamilies:\n productFamilies[productFamily] = []\n usageGroup = row.get('Group','')\n if usageGroup not in productFamilies[productFamily]:\n productFamilies[productFamily].append(usageGroup)\n\n x += 1\n if x % 1000 == 0: print(\"Processed row [{}]\".format(x))\n\n print (\"productFamilies:{}\".format(productFamilies))\n\n i = 0\n #Create csv files based on the partitions that were calculated when scanning the main index.csv file\n for f in indexDict.keys():\n if indexDict[f]:\n i += 1\n print (\"Writing file for key: [{}]\".format(f))\n with open(get_index_file_name(service, f, 'csv'),'w') as csvfile:\n writer = csv.DictWriter(csvfile, fieldnames=fieldnames, dialect='excel', quoting=csv.QUOTE_ALL)\n writer.writeheader()\n for r in indexDict[f]:\n writer.writerow(r)\n\n print (\"Number of records in main index file: [{}]\".format(x))\n print (\"Number of files written: [{}]\".format(i))\n return\n\n\ndef get_index_file_name(service, name, format):\n result = '../awspricecalculator/data/'+service+'/'+name+'.'+format\n return result\n\n\n\"\"\"\nThis method removes unnecessary fields from each row in the index file. This is necessary since large index files\nbecome a problem when they're too large and result in Lambda functions exceeding package size or in slower warm-up\ntimes for Lambda.\n\"\"\"\n\ndef remove_fields(service, row):\n #don't exclude: 'Product Family', 'operation' (used by ELB)\n EXCLUDE_FIELD_DICT = {\n consts.SERVICE_EC2:['Location Type', 'Storage', 'Location', 'Memory', 'Physical Processor',\n 'Dedicated EBS Throughput', 'Processor Features', 'ECU', 'serviceName', 'Network Performance',\n 'Instance Family', 'Current Generation',\n 'serviceCode','TermType','Tenancy','OfferingClass','PurchaseOption' #these fields are implicit in the DB file name, therefore they're not necessary in the file itself\n ]\n }\n\n for f in EXCLUDE_FIELD_DICT.get(service, []):\n row.pop(f,'')\n\n return row\n\n\n\n#TODO: remove consolidated index.csv file after it has been split into smaller files\n\n\n\n\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "scripts/lambda-optimization.py",
"content": "#!/usr/bin/python\nimport sys, os, json, time\nimport argparse\nimport traceback\nimport boto3\nfrom botocore.exceptions import ClientError\nimport math\nsys.path.insert(0, os.path.abspath('..'))\nsys.path.insert(0, os.path.abspath('../vendored'))\n\nimport numpy\n\nimport awspricecalculator.awslambda.pricing as lambdapricing\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.consts as consts\nimport awspricecalculator.common.errors as errors\n\nlogsclient = boto3.client('logs')\nlambdaclient = boto3.client('lambda')\n\n\nMONTHLY = \"MONTHLY\"\nMS_MAP = {MONTHLY:(3.6E6)*720}\n\n\n\n\ndef main(argv):\n\n region = os.environ['AWS_DEFAULT_REGION']\n\n parser = argparse.ArgumentParser()\n parser.add_argument('--function', help='', required=True)\n parser.add_argument('--minutes', help='', required=True)\n\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n args = parser.parse_args()\n\n function = ''\n minutes = 0 #in minutes\n\n\n if args.function: function = args.function\n if args.minutes: minutes = int(args.minutes)\n\n try:\n validate(function, minutes)\n except errors.ValidationError as error:\n print(error.message)\n sys.exit(1)\n\n mem_used_array = []\n duration_array = []\n prov_mem_size = 0\n firstEventTs = 0\n lastEventTs = 0\n ts_format = \"%Y-%m-%d %H:%M:%S UTC\"\n log_group_name = '/aws/lambda/'+function\n\n try:\n i = 0\n windowStartTime = (int(time.time()) - minutes * 60) * 1000\n firstEventTs = windowStartTime #temporary value, it will be updated once (if) we get results from the CW Logs get_log_events API\n lastEventTs = int(time.time() * 1000) #this will also be updated once (if) we get results from the CW Logs get_log_events API\n nextLogstreamToken = True\n logstreamsargs = {'logGroupName':log_group_name, 'orderBy':'LastEventTime', 'descending':True}\n while nextLogstreamToken:\n logstreams = logsclient.describe_log_streams(**logstreamsargs)\n \"\"\"\n Read through CW Logs entries and extract information from them.\n We're interested in entries that look like this:\n REPORT RequestId: 7686bf2c-2f79-11e7-b693-97868a5db36b\tDuration: 5793.53 ms\tBilled Duration: 5800 ms \tMemory Size: 448 MB\tMax Memory Used: 24 MB\n \"\"\"\n\n if 'logStreams' in logstreams:\n print(\"Number of logstreams found:[{}]\".format(len(logstreams['logStreams'])))\n\n nextLogstreamToken = logstreams.get('nextToken',False)\n if nextLogstreamToken: logstreamsargs['nextToken']=nextLogstreamToken\n else:logstreamsargs.pop('nextToken',False)\n\n #Go through all logstreams in descending order\n for ls in logstreams['logStreams']:\n nextEventsForwardToken = True\n logeventsargs = {'logGroupName':log_group_name, 'logStreamName':ls['logStreamName'],\n 'startFromHead':True, 'startTime':windowStartTime}\n while nextEventsForwardToken:\n logevents = logsclient.get_log_events(**logeventsargs)\n if 'events' in logevents:\n if len(logevents['events']):\n print (\"\\nEvents for logGroup:[{}] - logstream:[{}] - nextForwardToken:[{}]\".format(log_group_name, ls['logStreamName'],nextEventsForwardToken))\n for e in logevents['events']:\n #Extract lambda execution duration and memory utilization from \"REPORT\" log events\n if 'REPORT RequestId:' in e['message']:\n mem_used = e['message'].split('Max Memory Used: ')[1].split()[0]\n mem_used_array.append(int(mem_used))\n duration = e['message'].split('Billed Duration: ')[1].split()[0]\n duration_array.append(int(duration))\n if i == 0:\n prov_mem_size = int(e['message'].split('Memory Size: ')[1].split()[0])\n firstEventTs = e['timestamp']\n lastEventTs = e['timestamp']\n else:\n if e['timestamp'] < firstEventTs: firstEventTs = e['timestamp']\n if e['timestamp'] > lastEventTs: lastEventTs = e['timestamp']\n print (\"mem_used:[{}] - mem_size:[{}] - timestampMs:[{}] - timestamp:[{}]\".format(mem_used,prov_mem_size, e['timestamp'], time.strftime(ts_format, time.gmtime(e['timestamp']/1000))))\n print e['message']\n i += 1\n else: break\n\n nextEventsForwardToken = logevents.get('nextForwardToken',False)\n if nextEventsForwardToken: logeventsargs['nextToken']=nextEventsForwardToken\n else: logeventsargs.pop('nextToken',False)\n\n\n\n #Once we've iterated through all log streams and log events, calculate averages, cost and optimization scenarios\n avg_used_mem = 0\n avg_duration_ms = 0\n p90_duration_ms = 0\n p99_duration_ms = 0\n p100_duration_ms = 0\n\n if mem_used_array: avg_used_mem = math.ceil(numpy.average(mem_used_array))\n if duration_array:\n avg_duration_ms = round(math.ceil(numpy.average(duration_array)),0)\n p90_duration_ms = round(math.ceil(numpy.percentile(duration_array, 90)),0)\n p99_duration_ms = round(math.ceil(numpy.percentile(duration_array, 99)),0)\n p100_duration_ms = round(math.ceil(numpy.percentile(duration_array, 100)),0)\n base_usage = LambdaSampleUsage(region, i, avg_duration_ms, avg_used_mem, prov_mem_size, firstEventTs, lastEventTs, MONTHLY)\n memoptims= []\n durationoptims = []\n current_cost = 0\n\n for m in get_lower_possible_memory_ranges(avg_used_mem, prov_mem_size):\n #TODO: add target memory % utilization (i.e. I want to use 60% of memory and see how much that'll save me)\n memoptims.append(LambdaUtilScenario(base_usage, base_usage.avgDurationMs, m).__dict__)\n\n\n for d in get_lower_possible_durations(avg_duration_ms, 100):\n durationoptims.append(LambdaUtilScenario(base_usage, d, base_usage.memSizeMb).__dict__)\n\n\n optim_info = {\"sampleUsage\":base_usage.__dict__,\n \"memoryOptimizationScenarios\":memoptims,\n \"durationOptimizationScenarios\":durationoptims\n }\n #print(json.dumps(optim_info,sort_keys=False,indent=4))\n\n print (\"avg_duration_ms:[{}] avg_used_mem:[{}] prov_mem_size:[{}] records:[{}]\".format(avg_duration_ms, avg_used_mem,prov_mem_size,i))\n print (\"p90_duration_ms:[{}] p99_duration_ms:[{}] p100_duration_ms:[{}]\".format(p90_duration_ms, p99_duration_ms, p100_duration_ms))\n\n print (\"------------------------------------------------------------------------------------\")\n print (\"OPTIMIZATION SUMMARY\\n\")\n print (\"**Data sample used for calculation:**\")\n print (\"CloudWatch Log Group: [{}]\\n\" \\\n \"First Event time:[{}]\\n\" \\\n \"Last Event time:[{}]\\n\" \\\n \"Number of executions:[{}]\\n\" \\\n \"Average executions per second:[{}]\".\\\n format(log_group_name,\n time.strftime(ts_format, time.gmtime(base_usage.startTs/1000)),\n time.strftime(ts_format, time.gmtime(base_usage.endTs/1000)),\n base_usage.requestCount, base_usage.avgTps))\n print (\"\\n**Usage for Lambda function [{}] in the sample period is the following:**\".format(function))\n print (\"Average duration per Lambda execution: {}ms\\n\" \\\n \"Average consumed memory per execution: {}MB\\n\" \\\n \"Configured memory in your Lambda function: {}MB\\n\" \\\n \"Memory utilization (used/allocated): {}%\\n\" \\\n \"Total projected cost: ${}USD - {}\".\\\n format(base_usage.avgDurationMs, base_usage.avgMemUsedMb,base_usage.memSizeMb,\n base_usage.memUsedPct,base_usage.projectedCost, base_usage.projectedPeriod))\n\n if memoptims:\n print (\"\\nThe following Lambda memory configurations could save you money (assuming constant execution time)\")\n labels = ['memSizeMb', 'memUsedPct', 'cost', 'timePeriod', 'savingsAmt']\n print (\"\\n\"+ResultsTable(memoptims,labels).dict2md())\n if durationoptims:\n print (\"\\n\\nCan you make your function execute faster? The following Lambda execution durations will save you money (assuming memory allocation remains constant):\")\n labels = ['durationMs', 'cost', 'timePeriod', 'savingsAmt']\n print (\"\\n\"+ResultsTable(durationoptims,labels).dict2md())\n print (\"------------------------------------------------------------------------------------\")\n\n\n\n except Exception as e:\n traceback.print_exc()\n print(\"Exception message:[\"+str(e.message)+\"]\")\n\n\n\"\"\"\nGet the possible Lambda memory configurations values that would:\n- Be lower than the current provisioned value (thus, cheaper)\n- Are greater than the current average used memory (therefore won't result in memory errors)\n\"\"\"\n\ndef get_lower_possible_memory_ranges(usedMem, provMem):\n result = []\n for m in consts.LAMBDA_MEM_SIZES:\n if usedMem < float(m) and m < provMem:\n result.append(m)\n return result\n\n\n\"\"\"\nGet the possible Lambda execution values that would:\n- Be lower than the current average duration (thus, cheaper)\n- Are greater than a lower limit set by the user of the script (there's only so much one can do to make a function run faster)\n\"\"\"\ndef get_lower_possible_durations(usedDurationMs, lowestDuration):\n result = []\n initBilledDurationMs = math.floor(usedDurationMs / 100) * 100\n d = int(initBilledDurationMs)\n while d >= lowestDuration:\n result.append(d)\n d -= 100\n return result\n\n\n\n#TODO:Move to a different file\n#This class models the usage for a Lambda function within a time window defined by startTs and endTs\nclass LambdaSampleUsage():\n def __init__(self, region, requestCount, avgDurationMs, avgMemUsedMb, memSizeMb, startTs, endTs, projectedPeriod):\n\n self.region = region\n\n self.requestCount = 0\n if requestCount: self.requestCount = requestCount\n\n self.avgDurationMs = 0\n if avgDurationMs: self.avgDurationMs = int(avgDurationMs)\n\n self.avgMemUsedMb = int(avgMemUsedMb)\n self.memSizeMb = memSizeMb\n\n self.memUsedPct = 0.00\n if memSizeMb: self.memUsedPct = round(float(100 * avgMemUsedMb/memSizeMb),2)\n\n self.startTs = startTs\n self.endTs = endTs\n self.elapsedMs = endTs - startTs\n\n self.avgTps = 0\n if self.elapsedMs:\n self.avgTps = round((1000 * float(self.requestCount) / float(self.elapsedMs)),4)\n\n self.projectedPeriod = projectedPeriod\n self.projectedRequestCount = self.get_projected_request_count(requestCount)\n\n args = {'region':region, 'requestCount':self.projectedRequestCount,\n 'avgDurationMs':math.ceil(avgDurationMs/100)*100, 'memoryMb':memSizeMb}\n print (\"args: {}\".format(args))\n self.projectedCost = lambdapricing.calculate(data.LambdaPriceDimension(**args))['totalCost']\n\n\n def get_projected_request_count(self,requestCount):\n result = 0\n print (\"elapsed_ms:[{}] - period: [{}]\".format(self.elapsedMs, self.projectedPeriod))\n if self.elapsedMs:\n result = float(requestCount)*(MS_MAP[self.projectedPeriod]/self.elapsedMs)\n return int(result)\n\n\n\n\"\"\"\nThis class represents usage scenarios that will be modeled and displayed as possibilities, so the user can decide\nif they're good options (or not) .\n\"\"\"\nclass LambdaUtilScenario():\n def __init__(self, base_usage, proposedDurationMs, proposedMemSizeMb):\n\n self.memSizeMb = proposedMemSizeMb\n\n self.memUsedPct = 0\n self.memUsedPct = float(100 * base_usage.avgMemUsedMb/proposedMemSizeMb)\n\n self.durationMs = proposedDurationMs\n\n args = {'region':base_usage.region, 'requestCount':base_usage.projectedRequestCount,\n 'avgDurationMs':self.durationMs, 'memoryMb':proposedMemSizeMb}\n self.cost= lambdapricing.calculate(data.LambdaPriceDimension(**args))['totalCost']\n self.savingsAmt = round((base_usage.projectedCost - self.cost),2)\n\n self.savingsPct = 0.00\n if base_usage.projectedCost:\n self.savingsPct = round((100 * self.savingsAmt / base_usage.projectedCost),2)\n self.timePeriod = MONTHLY\n\n def get_next_mem(self, memUsedMb):\n result = 0\n for m in consts.LAMBDA_MEM_SIZES:\n if memUsedMb <= float(m):\n result = m\n break\n return result\n\n\n\n\n\n\"\"\"\nThis class takes an array of dictionary objects, so they can be converted to table format using Markdown syntax.\nIt also takes an optional array of labels, if you want to limit the output to a subset of keys in each dictionary.\nThe output is something like this:\n\n\n key1| key2| key3\n ---| ---| ---\n 01| 02| 03\n 04| 05| 06\n 07| 08| 09\n\n\n\"\"\"\n\nclass ResultsTable():\n def __init__(self, records,labels):\n self.records = records\n self.labels = []\n if labels:\n self.labels = labels\n\n\n #Converts an array of dictionaries to Markdown format.\n\n def dict2md(self):\n result = \"\"\n keys = []\n if self.labels:\n keys = self.labels\n else:\n if self.records: keys = self.records[0].keys()\n\n rc = 0 #rowcount\n mdrow = \"\" #markdown headers row\n self.records.insert(0,[])#insert dummy record at the beginning, since first record in loop is used to create row headers\n for r in self.records:\n #if rc==0: keys = r.keys()\n cc = 0 #column count\n for k in keys:\n cc += 1\n if rc==0:\n result += k\n mdrow += self.addpadding(k,'---')\n else:\n result += self.addpadding(k,r[k])\n if cc == len(keys):\n result += \"\\n\"\n mdrow += \"\\n\"\n else:\n result += \"|\"\n mdrow += \"|\"\n if rc==0: result += mdrow\n rc += 1\n return result\n\n\n\n \"\"\"\n def dict2md(self):\n result = \"\"\n keys = []\n if self.labels:\n keys = self.labels\n else:\n if self.records: keys = self.records[0].keys()\n\n rc = 0 #rowcount\n mdrow = \"\" #markdown headers row\n for r in self.records:\n #if rc==0: keys = r.keys()\n cc = 0 #column count\n for k in keys:\n cc += 1\n if rc==0:\n result += k\n mdrow += self.addpadding(k,'---')\n else:\n result += self.addpadding(k,r[k])\n if cc == len(keys):\n result += \"\\n\"\n mdrow += \"\\n\"\n else:\n result += \"|\"\n mdrow += \"|\"\n if rc==0: result += mdrow\n rc += 1\n return result\n \"\"\"\n\n\n def addpadding(self,label,value):\n padding = \"\"\n i = 0\n while i < (len(label)-len(str(value))):\n padding += \" \"\n i += 1\n return padding + str(value)\n\n\ndef validate(function, minutes):\n validation_ok = True\n validation_message = \"\\nValidationError:\\n\"\n\n try:\n lambdaclient.get_function(FunctionName=function)\n except ClientError as e:\n if e.response['Error']['Code'] == 'ResourceNotFoundException':\n validation_message += \"Function [{}] does not exist, please enter a valid Lambda function\\n\".format(function)\n else:\n validation_message += \"Boto3 client error when calling lambda.get_function\"\n validation_ok = False\n\n if minutes <1:\n validation_message += \"Minutes must be greater than 0\\n\"\n validation_ok = False\n\n if not validation_ok:\n raise errors.ValidationError(validation_message)\n\n return validation_ok\n\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "scripts/redshift-pricing.py",
"content": "#!/usr/bin/python\nimport sys, os, getopt, json, logging\nimport argparse\nimport traceback\nsys.path.insert(0, os.path.abspath('..'))\n\nimport awspricecalculator.redshift.pricing as redshiftpricing\nimport awspricecalculator.common.consts as consts\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.utils as utils\nfrom awspricecalculator.common.errors import ValidationError\nfrom awspricecalculator.common.errors import NoDataFoundError\n\nlog = logging.getLogger()\nlogging.basicConfig()\nlog.setLevel(logging.DEBUG)\n\ndef main(argv):\n\n parser = argparse.ArgumentParser()\n parser.add_argument('--region', help='', required=False)\n parser.add_argument('--regions', help='', required=False)\n parser.add_argument('--sort-criteria', help='', required=False)\n parser.add_argument('--instance-type', help='', required=False)\n parser.add_argument('--instance-types', help='', required=False)\n parser.add_argument('--instance-hours', help='', type=int, required=False)\n parser.add_argument('--ebs-volume-type', help='', required=False)\n parser.add_argument('--ebs-storage-gb-month', help='', required=False)\n parser.add_argument('--piops', help='', type=int, required=False)\n parser.add_argument('--data-transfer-out-internet-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-intraregion-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-interregion-gb', help='', required=False)\n parser.add_argument('--to-region', help='', required=False)\n parser.add_argument('--term-type', help='', required=False)\n parser.add_argument('--offering-class', help='', required=False)\n parser.add_argument('--offering-classes', help='', required=False)\n parser.add_argument('--instance-count', help='', type=int, required=False)\n parser.add_argument('--years', help='', required=False)\n parser.add_argument('--offering-type', help='', required=False)\n parser.add_argument('--offering-types', help='', required=False)\n\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n args = parser.parse_args()\n\n region = ''\n regions = ''\n instanceType = ''\n instanceTypes = ''\n instanceHours = 0\n instanceCount = 0\n sortCriteria = ''\n ebsVolumeType = ''\n ebsStorageGbMonth = 0\n pIops = 0\n dataTransferOutInternetGb = 0\n dataTransferOutIntraRegionGb = 0\n dataTransferOutInterRegionGb = 0\n toRegion = ''\n termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n offeringClass = ''\n offeringClasses = consts.SUPPORTED_REDSHIFT_OFFERING_CLASSES #only used for Reserved comparisons (standard, convertible)\n offeringType = ''\n offeringTypes = consts.EC2_SUPPORTED_PURCHASE_OPTIONS #only used for Reserved comparisons (all-upfront, partial-upfront, no-upfront)\n years = 1\n\n if args.region: region = args.region\n if args.regions: regions = args.regions\n if args.sort_criteria: sortCriteria = args.sort_criteria\n if args.instance_type: instanceType = args.instance_type\n if args.instance_types: instanceTypes = args.instance_types\n if args.instance_hours: instanceHours = int(args.instance_hours)\n if args.ebs_volume_type: ebsVolumeType = args.ebs_volume_type\n if args.ebs_storage_gb_month: ebsStorageGbMonth = int(args.ebs_storage_gb_month)\n if args.piops: pIops = int(args.piops)\n if args.data_transfer_out_internet_gb: dataTransferOutInternetGb = int(args.data_transfer_out_internet_gb)\n if args.data_transfer_out_intraregion_gb: dataTransferOutIntraRegionGb = int(args.data_transfer_out_intraregion_gb)\n if args.data_transfer_out_interregion_gb: dataTransferOutInterRegionGb = int(args.data_transfer_out_interregion_gb)\n if args.to_region: toRegion = args.to_region\n if args.term_type: termType = args.term_type\n if args.offering_class: offeringClass = args.offering_class\n if args.offering_classes: offeringClasses = args.offering_classes.split(',')\n if args.instance_count: instanceCount = args.instance_count\n if args.offering_type: offeringType = args.offering_type\n if args.offering_types: offeringTypes = args.offering_types.split(',')\n if args.years: years = str(args.years)\n\n #TODO: Implement comparison between a subset of regions by entering an array of regions to compare\n #TODO: Implement a sort by target region (for data transfer)\n #TODO: For Reserved pricing, include a payment plan throughout the whole period, and a monthly average and savings\n\n #TODO: remove EBS for Redshift\n\n\n try:\n\n kwargs = {'sortCriteria':sortCriteria, 'instanceType':instanceType, 'instanceTypes':instanceTypes,\n 'instanceHours':instanceHours, 'dataTransferOutInternetGb':dataTransferOutInternetGb, 'pIops':pIops,\n 'dataTransferOutIntraRegionGb':dataTransferOutIntraRegionGb, 'dataTransferOutInterRegionGb':dataTransferOutInterRegionGb,\n 'toRegion':toRegion, 'termType':termType, 'instanceCount': instanceCount, 'years': years, 'offeringType':offeringType,\n 'offeringClass':offeringClass\n }\n\n if region: kwargs['region'] = region\n\n if sortCriteria:\n if sortCriteria in (consts.SORT_CRITERIA_TERM_TYPE, consts.SORT_CRITERIA_TERM_TYPE_REGION):\n if sortCriteria == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n #TODO: validate that region list is comma-separated\n #TODO: move this list to utils.compare_term_types\n if regions: kwargs['regions'] = regions.split(',')\n else: kwargs['regions']=consts.SUPPORTED_REGIONS\n kwargs['purchaseOptions'] = offeringTypes #purchase options are referred to as offering types in the EC2 API\n kwargs['offeringClasses']=offeringClasses\n validate (kwargs)\n termPricingAnalysis = utils.compare_term_types(service=consts.SERVICE_REDSHIFT, **kwargs)\n tabularData = termPricingAnalysis.pop('tabularData')\n print (\"Redshift termpPricingAnalysis: [{}]\".format(json.dumps(termPricingAnalysis,sort_keys=False, indent=4)))\n print(\"csvData:\\n{}\\n\".format(termPricingAnalysis['csvData']))\n print(\"tabularData:\\n{}\".format(tabularData))\n\n else:\n validate (kwargs)\n pricecomparisons = utils.compare(service=consts.SERVICE_REDSHIFT,**kwargs)\n print(\"Price comparisons:[{}]\".format(json.dumps(pricecomparisons, indent=4)))\n else:\n validate (kwargs)\n redshift_pricing = redshiftpricing.calculate(data.RedshiftPriceDimension(**kwargs))\n print(json.dumps(redshift_pricing,sort_keys=False,indent=4))\n\n\n\n except NoDataFoundError as ndf:\n print (\"NoDataFoundError args:[{}]\".format(args))\n\n except Exception as e:\n traceback.print_exc()\n print(\"Exception message:[\"+str(e)+\"]\")\n\n\n\"\"\"\nThis function contains validations at the script level. No need to validate Redshift parameters, since\nclass RedshiftPriceDimension already contains a validation function.\n\"\"\"\ndef validate (args):\n #TODO: add - if termType sort criteria is specified, don't include offeringClass (singular)\n #TODO: add - if offeringTypes is included, have at least one valid offeringType (purchase option)\n #TODO: move to models or a common place that can be used by both CLI and API\n validation_msg = \"\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE:\n if args.get('instanceHours',False):\n validation_msg = \"instance-hours cannot be set when sort-criteria=term-type\"\n if args.get('offeringType',False):\n validation_msg = \"offering-type cannot be set when sort-criteria=term-type - try offering-types (plural) instead\"\n if not args.get('years',''):\n validation_msg = \"years cannot be empty\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n if not args.get('offeringClasses',''):\n validation_msg = \"offering-classes cannot be empty\"\n if not args.get('purchaseOptions',''):\n validation_msg = \"offering-types cannot be empty\"\n\n if validation_msg:\n print(\"Error: [{}]\".format(validation_msg))\n raise ValidationError(validation_msg)\n\n return\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "serverless.env.yml",
"content": "# This is the Serverless Environment File\n#\n# It contains listing of your stages, and their regions\n# It also manages serverless variables at 3 levels:\n# - common variables: variables that apply to all stages/regions\n# - stage variables: variables that apply to a specific stage\n# - region variables: variables that apply to a specific region\n\nvars:\nstages:\n dev:\n vars:\n regions:\n us-east-1:\n vars:\n"
},
{
"path": "serverless.yml",
"content": "# Welcome to Serverless!\n#\n# This file is the main config file for your service.\n# It's very minimal at this point and uses default values.\n# You can always add more config options for more control.\n# We've included some commented out config examples here.\n# Just uncomment any of them to get that config option.\n#\n# For full config options, check the docs:\n# v1.docs.serverless.com\n#\n# Happy Coding!\n\nservice: aws-pricing # NOTE: update this with your service name\n\nprovider:\n name: aws\n runtime: python3.6\n\n # you can add statements to the Lambda function's IAM Role here\n iamRoleStatements:\n - Effect: \"Allow\"\n Action:\n - cloudwatch:*\n - ec2:Describe*\n - elasticloadbalancing:Describe*\n - autoscaling:Describe*\n - rds:Describe*\n - rds:List*\n - dynamodb:Describe*\n - dynamodb:List*\n - kinesis:Describe*\n - kinesis:List*\n - lambda:GetFunctionConfiguration\n - tag:getResources\n - tag:getTagKeys\n - tag:getTagValues\n Resource: \"*\"\n\n# you can overwrite defaults here\n#defaults:\n# stage: dev\n# region: us-east-1\n# you can add packaging information here\n\npackage:\n exclude:\n - bin/*\n - lib/**\n - .git/**\n - .idea/**\n - include/**\n - pip-selfcheck.json\n - awspricecalculator/s3\n - awspricecalculator/data/ec2/index.*\n - awspricecalculator/data/ec2/*Dedicated* \n - awspricecalculator/data/ec2/*Host*\n - awspricecalculator/data/ec2/*Reserved*\n - awspricecalculator/data/ec2/*Savings*\n - awspricecalculator/data/rds/index.*\n - awspricecalculator/data/rds/*Reserved*\n - awspricecalculator/data/s3/index.*\n - awspricecalculator/data/lambda/index.*\n - awspricecalculator/data/dynamodb/index.*\n - awspricecalculator/data/kinesis/index.*\n - scripts/**\n - test/**\n - cloudformation/**\n - readme.txt\n\n include:\n - vendored\n\nfunctions:\n nearrealtimepricing:\n handler: functions/calculate-near-realtime.handler\n name: calculate-near-realtime-pricing\n timeout: 300\n memory: 1024\n events:\n - schedule:\n rate: rate(5 minutes)\n enabled: true\n input:\n tag:\n key: ${env:PRICING_TAG_KEY}\n value: ${env:PRICING_TAG_VALUE}\n\n# you can add CloudFormation resource templates here\n#resources:\n# Resources:\n# NewResource:\n# Type: AWS::S3::Bucket\n# Properties:\n# BucketName: my-new-bucket\n# Outputs:\n# NewOutput:\n# Description: \"Description for the output\"\n# Value: \"Some output value\"\n"
},
{
"path": "setup.py",
"content": "from setuptools import setup\n\nsetup(name='awspricecalculator',\n version='0.1',\n description='AWS Price List calculations',\n url='https://github.com/ConcurrenyLabs/aws-pricing-tools/tree/master/awspricecalculator',\n author='Concurrency Labs',\n author_email='github@concurrencylabs.com',\n license='GNU',\n packages=['awspricecalculator','awspricecalculator.common',\n \t'awspricecalculator.awslambda','awspricecalculator.ec2','awspricecalculator.rds', 'awspricecalculator.emr',\n 'awspricecalculator.redshift', 'awspricecalculator.s3','awspricecalculator.dynamodb',\n 'awspricecalculator.kinesis', 'awspricecalculator.datatransfer'],\n include_package_data=True,\n zip_safe=False)\n\n\n"
},
{
"path": "test/events/constant-tag.json",
"content": "{\n \"tag\": { \n \"key\": \"\",\n \"value\": \"\"\n }\n}\n\n"
}
]
\n\n\n### Metrics\n\nThe function publishes a metric named `EstimatedCharges` to CloudWatch, under namespace `ConcurrencyLabs/Pricing/NearRealTimeForecast` and it uses\nthe following dimensions:\n\n* Currency: USD\n* ForecastPeriod: monthly\n* ServiceName: ec2, rds, lambda, kinesis, dynamodb\n* Tag: mykey=myvalue\n\n\n\n\n\n### Updating to the latest version using CloudFormation\n\nThis function will be updated regularly in order to fix bugs, update AWS Price List data and also to add more functionality.\nThis means you will likely have to update the function at some point. I recommend installing\nthe function using the CloudFormation template, since it will simplify the update process.\n\nTo update the function, just go to the CloudFormation console, select the stack you've created\nand click on Actions -> Update Stack:\n\n\n\n\nThen select \"Specify an Amazon S3 template URL\" and enter the following value:\n\n\n```\nhttp://concurrencylabs-cfn-templates.s3.amazonaws.com/lambda-near-realtime-pricing/function-plus-schedule.json\n```\n\n\n\nAnd that's it. CloudFormation will update the function with the latest code.\n\n\n\n## Install Locally (if you want to modify it) - Manual steps\n\nIf you only want to install the Lambda function, you don't need to follow the steps below, just follow\nthe instructions in the \"Install - Using CloudFormation\" section above.\n\nIf you want to setup a dev environment, run a local copy, make some modifications and then install in your AWS account, then keep reading...\n\n\n### Clone the repo\n\n```\ngit clone https://github.com/concurrencylabs/aws-pricing-tools aws-pricing-tools\n```\n\n\n### (Optional, but recommended) Create an isolated Python environment using virtualenv\n\nIt's always a good practice to create an isolated environment so we have greater control over\nthe dependencies in our project, including the Python runtime.\n\nIf you don't have virtualenv installed, run:\n\n```\npip install virtualenv\n```\n\nFor more details on virtualenv, click here.\n\nNow, create a Python 2.7 virtual environment in the location where you cloned the repo into. If you want to name your project\naws-pricing-tools, then run (one level up from the dir, use the same local name you used when you cloned\nthe repo):\n\n```\nvirtualenv aws-pricing-tools -p python2.7\n```\n\nAfter your environment is created, it's time to activate it. Go to the recently created\nfolder of your project (i.e. aws-pricing-tools) and from there run:\n\n```\nsource bin/activate\n```\n\n\n### Install Requirements\n\nFrom your project root folder, run:\n\n```\n./install.sh\n```\n\nThis will install the following dependencies to the ```vendored``` directory:\n\n* **tinydb** - The code in this repo queries the Price List API csv records using the tinydb library.\n* **numpy** - Used for statistics in the lambda optimization script\n\n... and the following dependencies in your default site-packages location:\n\n* **python-local-lambda** - lets me test my Lambda functions locally using test events in my workstation.\n* **boto3** - AWS Python SDK to call AWS APIs.\n\n\n### Install the Serverless Framework\n\n\n\n\nSince the pricing tool runs on AWS Lambda, I decided to use the Serverless Framework.\nThis framework enormously simplifies the development, configuration and deployment of Function as a Service (a.k.a. FaaS, or \"serverless\")\ncode into AWS Lambda.\n\n\nYou should follow the instructions described here,\nwhich can be summarized in the following steps:\n\n1. Make sure you have Node.js installed in your workstation.\n```\nnode --version\n```\n\n2. Install the Serverless Framework\n```\nnpm install -g serverless\n```\n\n\n3. Confirm Serverless has been installed\n```\nserverless --version\n```\nThe steps in this post were tested using version ```1.6.1```\n\n\n4. Serverless needs access to your AWS account, so it can create and update AWS Lambda\nfunctions, among other operations. Therefore, you have to make sure Serverless can access\na set of IAM User credentials. Follow these instructions.\nIn the long term, you should make sure these credentials are limited to only the API operations\nServerless requires - avoid Administrator access, which is a bad security and operational practice.\n\n\n5. Checkout the code from this repo into your virtualenv folder.\n\n\n### Set environment variables\n\n```\nexport AWS_DEFAULT_PROFILE=\nexport AWS_DEFAULT_REGION=\n```\n\n\n### How to test the function locally\n\n\n**Download the latest AWS Price List API Index file**\n\nThe code needs a local copy of the the AWS Price List API index file.\nThe GitHub repo doesn't come with the index file, therefore you have to\ndownload it the first time you run your code and every time AWS publishes a new\nPrice List API index.\n\nAlso, this index file is constantly updated by AWS. I recommend subscribing to the AWS Price List API\nchange notifications.\n\nIn order to download the latest index file, go to the ```scripts```` folder and run:\n\n```\npython get-latest-index.py --service=all\n```\n\nThe script takes a few seconds to execute since some index files are a little heavy (like the EC2 one).\n\n**Run a test**\n\nOnce you have the virtualenv activated, all dependencies installed, environment\nvariables set and the latest AWS Price List index file, it's time to run a test.\n\nUpdate ```test/events/constant-tag.json``` with a tag key/value pair that exists in your AWS account.\n\n\nThen run, from the **root** location in the local repo and replace and with actual values:\n\n```\npython-lambda-local functions/calculate-near-realtime.py test/events/constant-tag.json -l lib/ -l . -f handler -t 30 -a arn:aws:lambda:::function:calculate-near-realtime\n```\n\n\n### Deploy the Serverless Project\n\nFrom your project root folder, run:\n\n```\nserverless deploy\n```\n"
},
{
"path": "awspricecalculator/__init__.py",
"content": "import os, sys\n\n__location__ = os.path.dirname(os.path.realpath(__file__))\nsys.path.append(os.path.join(__location__, \"../\"))\nsys.path.append(os.path.join(__location__, \"../vendored\"))\n"
},
{
"path": "awspricecalculator/awslambda/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/awslambda/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating Lambda pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n global regiondbs\n global indexMetadata\n\n ts = phelper.Timestamp()\n ts.start('totalCalculationAwsLambda')\n\n #Load On-Demand DB\n dbs = regiondbs.get(consts.SERVICE_LAMBDA+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_LAMBDA, phelper.get_partition_keys(consts.SERVICE_LAMBDA, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_LAMBDA+pdim.region+pdim.termType]=dbs\n\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n #TODO: add support to include/ignore free-tier (include a flag)\n\n serverlessDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SERVERLESS])]\n\n #Requests\n if pdim.requestCount:\n query = ((priceQuery['Group'] == 'AWS-Lambda-Requests'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, serverlessDb, query, pdim.requestCount, pricing_records, cost)\n\n #GB-s (aka compute time)\n if pdim.avgDurationMs:\n query = ((priceQuery['Group'] == 'AWS-Lambda-Duration'))\n usageUnits = pdim.GBs\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, serverlessDb, query, usageUnits, pricing_records, cost)\n\n #Data Transfer\n dataTransferDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER])]\n\n #To internet\n if pdim.dataTransferOutInternetGb:\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n\n #Intra-regional data transfer - in/out/between EC2 AZs or using IPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_LAMBDA, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time to compute: [{}]\".format(ts.finish('totalCalculationAwsLambda')))\n return pricing_result.__dict__\n\n\n"
},
{
"path": "awspricecalculator/common/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/common/consts.py",
"content": "import os, logging\n\n# COMMON\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\nAWS_PRICE_CALCULATOR_VERSION = \"v2.0\"\n\nLOG_LEVEL = os.environ.get('LOG_LEVEL',logging.INFO)\nDEFAULT_CURRENCY = \"USD\"\nFORECAST_PERIOD_MONTHLY = \"monthly\"\nFORECAST_PERIOD_YEARLY = \"yearly\"\n\nHOURS_IN_MONTH = 720\n\nSERVICE_CODE_AWS_DATA_TRANSFER = 'AWSDataTransfer'\n\nREGION_MAP = {'us-east-1':'US East (N. Virginia)',\n 'us-east-2':'US East (Ohio)',\n 'us-west-1':'US West (N. California)',\n 'us-west-2':'US West (Oregon)',\n 'ca-central-1':'Canada (Central)',\n 'eu-west-1':'EU (Ireland)',\n 'eu-west-2':'EU (London)',\n 'eu-west-3':'EU (Paris)',\n 'eu-north-1':'EU (Stockholm)',\n 'eu-central-1':'EU (Frankfurt)',\n 'ap-northeast-1':'Asia Pacific (Tokyo)',\n 'ap-northeast-2':'Asia Pacific (Seoul)',\n 'ap-northeast-3':'Asia Pacific (Osaka-Local)',\n 'ap-southeast-1':'Asia Pacific (Singapore)',\n 'ap-southeast-2':'Asia Pacific (Sydney)',\n 'sa-east-1':'South America (Sao Paulo)',\n 'ap-south-1':'Asia Pacific (Mumbai)',\n 'cn-northwest-1':'China (Ningxia)',\n 'ap-east-1':'Asia Pacific (Hong Kong)'\n }\n\n#TODO: update for China region\nREGION_PREFIX_MAP = {'us-east-1':'',\n 'us-east-2':'USE2-',\n 'us-west-1':'USW1-',\n 'us-west-2':'USW2-',\n 'ca-central-1':'CAN1-',\n 'eu-west-1':'EU-',\n 'eu-west-2':'EUW2-',\n 'eu-west-3':'EUW3-',\n 'eu-north-1':'EUN1-',\n 'eu-central-1':'EUC1-',\n 'ap-east-1':'APE1-' ,\n 'ap-northeast-1':'APN1-',\n 'ap-northeast-2':'APN2-',\n 'ap-northeast-3':'APN3-',\n 'ap-southeast-1':'APS1-',\n 'ap-southeast-2':'APS2-',\n 'sa-east-1':'SAE1-',\n 'ap-south-1':'APS3-',\n 'cn-northwest-1':'',\n 'US East (N. Virginia)':'',\n 'US East (Ohio)':'USE2-',\n 'US West (N. California)':'USW1-',\n 'US West (Oregon)':'USW2-',\n 'Canada (Central)':'CAN1-',\n 'EU (Ireland)':'EU-',\n 'EU (London)':'EUW2-',\n 'EU (Paris)':'EUW3-',\n 'EU (Stockholm)':'EUN1-',\n 'EU (Frankfurt)':'EUC1-',\n 'Asia Pacific (Tokyo)':'APN1-',\n 'Asia Pacific (Seoul)':'APN2-',\n 'Asia Pacific (Singapore)':'APS1-',\n 'Asia Pacific (Sydney)':'APS2-',\n 'South America (Sao Paulo)':'SAE1-',\n 'Asia Pacific (Mumbai)':'APS3-',\n 'AWS GovCloud (US)':'UGW1-',\n 'External':'',\n 'Any': ''\n }\n\n\n\nREGION_REPORT_MAP = {'us-east-1':'N. Virginia',\n 'us-east-2':'Ohio',\n 'us-west-1':'N. California',\n 'us-west-2':'Oregon',\n 'ca-central-1':'Canada',\n 'eu-west-1':'Ireland',\n 'eu-west-2':'London',\n 'eu-north-1':'Stockholm',\n 'eu-central-1':'Frankfurt',\n 'ap-east-1':'Hong Kong',\n 'ap-northeast-1':'Tokyo',\n 'ap-northeast-2':'Seoul',\n 'ap-northeast-3':'Osaka',\n 'ap-southeast-1':'Singapore',\n 'ap-southeast-2':'Sydney',\n 'sa-east-1':'Sao Paulo',\n 'ap-south-1':'Mumbai',\n 'cn-northwest-1':'Ningxia',\n 'eu-west-3':'Paris'\n }\n\n\n\nSERVICE_EC2 = 'ec2'\nSERVICE_ELB = 'elb'\nSERVICE_EBS = 'ebs'\nSERVICE_S3 = 's3'\nSERVICE_RDS = 'rds'\nSERVICE_LAMBDA = 'lambda'\nSERVICE_DYNAMODB= 'dynamodb'\nSERVICE_KINESIS = 'kinesis'\nSERVICE_DATA_TRANSFER = 'datatransfer'\nSERVICE_EMR = 'emr'\nSERVICE_REDSHIFT = 'redshift'\nSERVICE_ALL = 'all'\n\nNOT_APPLICABLE = 'NA'\n\n\nSUPPORTED_SERVICES = (SERVICE_S3, SERVICE_EC2, SERVICE_RDS, SERVICE_LAMBDA, SERVICE_DYNAMODB, SERVICE_KINESIS,\n SERVICE_EMR, SERVICE_REDSHIFT)\n\nSUPPORTED_REGIONS = ('us-east-1','us-east-2', 'us-west-1', 'us-west-2','ca-central-1', 'eu-west-1','eu-west-2',\n 'eu-central-1', 'ap-east-1', 'ap-northeast-1', 'ap-northeast-2', 'ap-northeast-3', 'ap-southeast-1', 'ap-southeast-2',\n 'sa-east-1','ap-south-1', 'eu-west-3', 'eu-north-1'\n )\n\nSUPPORTED_EC2_INSTANCE_TYPES = ('a1.2xlarge','a1.4xlarge','a1.large','a1.medium','a1.xlarge','c1.medium','c1.xlarge','c3.2xlarge',\n 'c3.4xlarge','c3.8xlarge','c3.large','c3.xlarge','c4.2xlarge','c4.4xlarge','c4.8xlarge','c4.large',\n 'c4.xlarge','c5.18xlarge','c5.2xlarge','c5.4xlarge','c5.9xlarge','c5.large','c5.xlarge','c5d.18xlarge',\n 'c5d.2xlarge','c5d.4xlarge','c5d.9xlarge','c5d.large','c5d.xlarge','c5n.18xlarge','c5n.2xlarge',\n 'c5n.4xlarge','c5n.9xlarge','c5n.large','c5n.xlarge','cc2.8xlarge','cr1.8xlarge','d2.2xlarge',\n 'd2.4xlarge','d2.8xlarge','d2.xlarge','f1.16xlarge','f1.2xlarge','f1.4xlarge','g2.2xlarge',\n 'g2.8xlarge','g3.16xlarge','g3.4xlarge','g3.8xlarge','g3s.xlarge','h1.16xlarge','h1.2xlarge',\n 'h1.4xlarge','h1.8xlarge','hs1.8xlarge','i2.2xlarge','i2.4xlarge','i2.8xlarge','i2.xlarge',\n 'i3.16xlarge','i3.2xlarge','i3.4xlarge','i3.8xlarge','i3.large','i3.xlarge','m1.large',\n 'm1.medium','m1.small','m1.xlarge','m2.2xlarge','m2.4xlarge','m2.xlarge','m3.2xlarge',\n 'm3.large','m3.medium','m3.xlarge','m4.10xlarge','m4.16xlarge','m4.2xlarge','m4.4xlarge',\n 'm4.large','m4.xlarge','m5.12xlarge','m5.24xlarge','m5.2xlarge','m5.4xlarge','m5.large',\n 'm5.metal','m5.xlarge','m5a.12xlarge','m5a.24xlarge','m5a.2xlarge','m5a.4xlarge','m5a.large',\n 'm5a.xlarge','m5d.12xlarge','m5d.24xlarge','m5d.2xlarge','m5d.4xlarge','m5d.large','m5d.metal',\n 'm5d.xlarge','p2.16xlarge','p2.8xlarge','p2.xlarge','p3.16xlarge','p3.2xlarge','p3.8xlarge',\n 'p3dn.24xlarge','r3.2xlarge','r3.4xlarge','r3.8xlarge','r3.large','r3.xlarge','r4.16xlarge',\n 'r4.2xlarge','r4.4xlarge','r4.8xlarge','r4.large','r4.xlarge',\n 'r5.12xlarge','r5.24xlarge', 'r5.8xlarge',\n 'r5.2xlarge','r5.4xlarge','r5.large','r5.xlarge','r5a.12xlarge','r5a.24xlarge','r5a.2xlarge',\n 'r5a.4xlarge','r5a.large','r5a.xlarge','r5d.12xlarge','r5d.24xlarge','r5d.2xlarge','r5d.4xlarge',\n 'r5d.large','r5d.xlarge','t1.micro','t2.2xlarge','t2.large','t2.medium','t2.micro','t2.nano',\n 't2.small','t2.xlarge',\n 't3.2xlarge','t3.large','t3.medium','t3.micro','t3.nano','t3.small','t3.xlarge',\n 't3a.nano', 't3a.micro','t3a.small','t3a.medium','t3a.large','t3a.xlarge','t3a.2xlarge',\n 'x1.16xlarge','x1.32xlarge','x1e.16xlarge','x1e.2xlarge','x1e.32xlarge','x1e.4xlarge',\n 'x1e.8xlarge','x1e.xlarge','z1d.12xlarge','z1d.2xlarge','z1d.3xlarge','z1d.6xlarge','z1d.large','z1d.xlarge')\n\n\nSUPPORTED_EMR_INSTANCE_TYPES = ('c1.medium','c1.xlarge','c3.2xlarge','c3.4xlarge','c3.8xlarge','c3.large','c3.xlarge','c4.2xlarge',\n 'c4.4xlarge','c4.8xlarge','c4.large','c4.xlarge','c5.18xlarge','c5.2xlarge','c5.4xlarge',\n 'c5.9xlarge','c5.xlarge','c5d.18xlarge','c5d.2xlarge','c5d.4xlarge','c5d.9xlarge','c5d.xlarge',\n 'c5n.18xlarge','c5n.2xlarge','c5n.4xlarge','c5n.9xlarge','c5n.xlarge',\n 'cc2.8xlarge',\n 'cr1.8xlarge','d2.2xlarge','d2.4xlarge','d2.8xlarge','d2.xlarge','g2.2xlarge','g3.16xlarge',\n 'g3.4xlarge','g3.8xlarge','g3s.xlarge','h1.16xlarge','h1.2xlarge','h1.4xlarge','h1.8xlarge',\n 'hs1.8xlarge','i2.2xlarge','i2.4xlarge','i2.8xlarge','i2.xlarge','i3.16xlarge',\n 'i3.2xlarge','i3.4xlarge','i3.8xlarge','i3.xlarge','m1.large','m1.medium','m1.small','m1.xlarge',\n 'm2.2xlarge','m2.4xlarge','m2.xlarge','m3.2xlarge','m3.large','m3.medium','m3.xlarge','m4.10xlarge',\n 'm4.16xlarge','m4.2xlarge','m4.4xlarge','m4.large','m4.xlarge','m5.12xlarge','m5.24xlarge',\n 'm5.2xlarge','m5.4xlarge','m5.xlarge','m5a.12xlarge','m5a.24xlarge','m5a.2xlarge','m5a.4xlarge',\n 'm5a.xlarge',\n 'm5d.12xlarge','m5d.24xlarge','m5d.2xlarge','m5d.4xlarge','m5d.xlarge','p2.16xlarge','p2.8xlarge',\n 'p2.xlarge','p3.16xlarge','p3.2xlarge','p3.8xlarge','r3.2xlarge','r3.4xlarge','r3.8xlarge',\n 'r3.xlarge','r4.16xlarge','r4.2xlarge','r4.4xlarge','r4.8xlarge','r4.large','r4.xlarge',\n 'r5.12xlarge','r5.24xlarge','r5.2xlarge','r5.4xlarge','r5.xlarge','r5a.12xlarge','r5a.24xlarge',\n 'r5a.2xlarge','r5a.4xlarge','r5a.xlarge',\n 'r5d.2xlarge','r5d.4xlarge','r5d.xlarge','z1d.12xlarge','z1d.2xlarge','z1d.3xlarge',\n 'z1d.6xlarge','z1d.xlarge')\n\nSUPPORTED_REDSHIFT_INSTANCE_TYPES = ('ds1.xlarge','dc1.8xlarge','dc1.large','ds2.8xlarge',\n 'ds1.8xlarge','ds2.xlarge','dc2.8xlarge','dc2.large')\n\nSUPPORTED_INSTANCE_TYPES_MAP = {SERVICE_EC2:SUPPORTED_EC2_INSTANCE_TYPES, SERVICE_EMR:SUPPORTED_EMR_INSTANCE_TYPES ,\n SERVICE_REDSHIFT:SUPPORTED_REDSHIFT_INSTANCE_TYPES}\n\n\nSERVICE_INDEX_MAP = {SERVICE_S3:'AmazonS3', SERVICE_EC2:'AmazonEC2', SERVICE_RDS:'AmazonRDS',\n SERVICE_LAMBDA:'AWSLambda', SERVICE_DYNAMODB:'AmazonDynamoDB',\n SERVICE_KINESIS:'AmazonKinesis', SERVICE_EMR:'ElasticMapReduce', SERVICE_REDSHIFT:'AmazonRedshift',\n SERVICE_DATA_TRANSFER:'AWSDataTransfer'}\n\n\nSCRIPT_TERM_TYPE_ON_DEMAND = 'on-demand'\nSCRIPT_TERM_TYPE_RESERVED = 'reserved'\n\nTERM_TYPE_RESERVED = 'Reserved'\nTERM_TYPE_ON_DEMAND = 'OnDemand'\n\nSUPPORTED_TERM_TYPES = (SCRIPT_TERM_TYPE_ON_DEMAND, SCRIPT_TERM_TYPE_RESERVED)\n\n\nTERM_TYPE_MAP = {SCRIPT_TERM_TYPE_ON_DEMAND:'OnDemand', SCRIPT_TERM_TYPE_RESERVED:'Reserved'}\n\n\nPRODUCT_FAMILY_COMPUTE_INSTANCE = 'Compute Instance'\nPRODUCT_FAMILY_DATABASE_INSTANCE = 'Database Instance'\nPRODUCT_FAMILY_DATA_TRANSFER = 'Data Transfer'\nPRODUCT_FAMILY_FEE = 'Fee'\nPRODUCT_FAMILY_API_REQUEST = 'API Request'\nPRODUCT_FAMILY_STORAGE = 'Storage'\nPRODUCT_FAMILY_SYSTEM_OPERATION = 'System Operation'\nPRODUCT_FAMILY_LOAD_BALANCER = 'Load Balancer'\nPRODUCT_FAMILY_APPLICATION_LOAD_BALANCER = 'Load Balancer-Application'\nPRODUCT_FAMILY_NETWORK_LOAD_BALANCER = 'Load Balancer-Network'\nPRODUCT_FAMILY_SNAPSHOT = \"Storage Snapshot\"\nPRODUCT_FAMILY_SERVERLESS = \"Serverless\"\nPRODUCT_FAMILY_DB_STORAGE = \"Database Storage\"\nPRODUCT_FAMILY_DB_PIOPS = \"Provisioned IOPS\"\nPRODUCT_FAMILY_KINESIS_STREAMS = \"Kinesis Streams\"\nPRODUCT_FAMILY_EMR_INSTANCE = \"Elastic Map Reduce Instance\"\nPRODUCT_FAMILIY_BUNDLE = 'Bundle'\nPRODUCT_FAMILIY_REDSHIFT_CONCURRENCY_SCALING = 'Redshift Concurrency Scaling'\nPRODUCT_FAMILIY_REDSHIFT_DATA_SCAN = 'Redshift Data Scan'\nPRODUCT_FAMILIY_STORAGE_SNAPSHOT = 'Storage Snapshot'\n\n\nSUPPORTED_PRODUCT_FAMILIES = (PRODUCT_FAMILY_COMPUTE_INSTANCE, PRODUCT_FAMILY_DATABASE_INSTANCE,\n PRODUCT_FAMILY_DATA_TRANSFER,PRODUCT_FAMILY_FEE, PRODUCT_FAMILY_API_REQUEST,\n PRODUCT_FAMILY_STORAGE, PRODUCT_FAMILY_SYSTEM_OPERATION, PRODUCT_FAMILY_LOAD_BALANCER,\n PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER, PRODUCT_FAMILY_NETWORK_LOAD_BALANCER,\n PRODUCT_FAMILY_SNAPSHOT,PRODUCT_FAMILY_SERVERLESS,PRODUCT_FAMILY_DB_STORAGE,\n PRODUCT_FAMILY_DB_PIOPS,PRODUCT_FAMILY_KINESIS_STREAMS, PRODUCT_FAMILY_EMR_INSTANCE,\n PRODUCT_FAMILIY_BUNDLE, PRODUCT_FAMILIY_REDSHIFT_CONCURRENCY_SCALING, PRODUCT_FAMILIY_REDSHIFT_DATA_SCAN,\n PRODUCT_FAMILIY_STORAGE_SNAPSHOT\n )\n\nSUPPORTED_RESERVED_PRODUCT_FAMILIES = (PRODUCT_FAMILY_COMPUTE_INSTANCE, PRODUCT_FAMILY_DATABASE_INSTANCE)\n\nSUPPORTED_PRODUCT_FAMILIES_BY_SERVICE_DICT = {\n SERVICE_EC2:[PRODUCT_FAMILY_COMPUTE_INSTANCE,PRODUCT_FAMILY_DATA_TRANSFER, PRODUCT_FAMILY_FEE,\n PRODUCT_FAMILY_STORAGE,PRODUCT_FAMILY_SYSTEM_OPERATION,PRODUCT_FAMILY_LOAD_BALANCER,\n PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER,PRODUCT_FAMILY_NETWORK_LOAD_BALANCER,\n PRODUCT_FAMILY_SNAPSHOT],\n SERVICE_RDS:[PRODUCT_FAMILY_DATABASE_INSTANCE, PRODUCT_FAMILY_DATA_TRANSFER,PRODUCT_FAMILY_FEE,\n PRODUCT_FAMILY_DB_STORAGE,PRODUCT_FAMILY_DB_PIOPS,PRODUCT_FAMILY_SNAPSHOT ],\n SERVICE_S3:[PRODUCT_FAMILY_STORAGE, PRODUCT_FAMILY_FEE,PRODUCT_FAMILY_API_REQUEST,PRODUCT_FAMILY_SYSTEM_OPERATION, PRODUCT_FAMILY_DATA_TRANSFER ],\n SERVICE_LAMBDA:[PRODUCT_FAMILY_SERVERLESS, PRODUCT_FAMILY_DATA_TRANSFER, PRODUCT_FAMILY_FEE,\n PRODUCT_FAMILY_API_REQUEST],\n SERVICE_KINESIS:[PRODUCT_FAMILY_KINESIS_STREAMS],\n SERVICE_DYNAMODB:[PRODUCT_FAMILY_DB_STORAGE, PRODUCT_FAMILY_DB_PIOPS, PRODUCT_FAMILY_FEE ],\n SERVICE_EMR:[PRODUCT_FAMILY_EMR_INSTANCE],\n SERVICE_REDSHIFT:[PRODUCT_FAMILY_COMPUTE_INSTANCE, PRODUCT_FAMILIY_BUNDLE, PRODUCT_FAMILIY_REDSHIFT_CONCURRENCY_SCALING,\n PRODUCT_FAMILIY_REDSHIFT_DATA_SCAN, PRODUCT_FAMILIY_STORAGE_SNAPSHOT],\n SERVICE_DATA_TRANSFER:[PRODUCT_FAMILY_DATA_TRANSFER]\n }\n\n\nINFINITY = 'Inf'\n\nSORT_CRITERIA_REGION = 'region'\nSORT_CRITERIA_INSTANCE_TYPE = 'instance-type'\nSORT_CRITERIA_OS = 'os'\nSORT_CRITERIA_DB_INSTANCE_CLASS = 'db-instance-class'\nSORT_CRITERIA_DB_ENGINE = 'engine'\nSORT_CRITERIA_S3_STORAGE_CLASS = 'storage-class'\nSORT_CRITERIA_S3_STORAGE_SIZE_GB = 'storage-size-gb'\nSORT_CRITERIA_S3_DATA_RETRIEVAL_GB = 'data-retrieval-gb'\nSORT_CRITERIA_S3_STORAGE_CLASS_DATA_RETRIEVAL_GB = 'storage-class-data-retrieval-gb'\nSORT_CRITERIA_TO_REGION = 'to-region'\nSORT_CRITERIA_LAMBDA_MEMORY = 'memory'\nSORT_CRITERIA_TERM_TYPE = 'term-type'\nSORT_CRITERIA_TERM_TYPE_REGION = 'term-type-region'\n\n\nSORT_CRITERIA_VALUE_SEPARATOR = ','\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n#EC2\nEC2_OPERATING_SYSTEM_LINUX = 'Linux'\nEC2_OPERATING_SYSTEM_BYOL = 'Windows BYOL'\nEC2_OPERATING_SYSTEM_WINDOWS = 'Windows'\nEC2_OPERATING_SYSTEM_SUSE = 'Suse'\n#EC2_OPERATING_SYSTEM_SQL_WEB = 'SQL Web'\nEC2_OPERATING_SYSTEM_RHEL = 'RHEL'\n\nSCRIPT_EC2_TENANCY_SHARED = 'shared'\nSCRIPT_EC2_TENANCY_DEDICATED = 'dedicated'\nSCRIPT_EC2_TENANCY_HOST = 'host'\n\nEC2_TENANCY_SHARED = 'Shared'\nEC2_TENANCY_DEDICATED = 'Dedicated'\nEC2_TENANCY_HOST = 'Host'\n\nEC2_TENANCY_MAP = {SCRIPT_EC2_TENANCY_SHARED:EC2_TENANCY_SHARED,\n SCRIPT_EC2_TENANCY_DEDICATED:EC2_TENANCY_DEDICATED,\n SCRIPT_EC2_TENANCY_HOST:EC2_TENANCY_HOST}\n\n\nSCRIPT_EC2_CAPACITY_RESERVATION_STATUS_USED = 'used'\nSCRIPT_EC2_CAPACITY_RESERVATION_STATUS_UNUSED = 'unused'\nSCRIPT_EC2_CAPACITY_RESERVATION_STATUS_ALLOCATED = 'allocated'\n\nEC2_CAPACITY_RESERVATION_STATUS_USED = 'Used'\nEC2_CAPACITY_RESERVATION_STATUS_UNUSED = 'UnusedCapacityReservation'\nEC2_CAPACITY_RESERVATION_STATUS_ALLOCATED = 'AllocatedCapacityReservation'\n\n\n\nEC2_CAPACITY_RESERVATION_STATUS_MAP = {SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_USED: EC2_CAPACITY_RESERVATION_STATUS_USED,\n SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_UNUSED: EC2_CAPACITY_RESERVATION_STATUS_UNUSED,\n SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_ALLOCATED: EC2_CAPACITY_RESERVATION_STATUS_ALLOCATED}\n\n\n\n\n\nSTORAGE_MEDIA_SSD = \"SSD-backed\"\nSTORAGE_MEDIA_HDD = \"HDD-backed\"\nSTORAGE_MEDIA_S3 = \"AmazonS3\"\n\nEBS_VOLUME_TYPE_MAGNETIC = \"Magnetic\"\nEBS_VOLUME_TYPE_GENERAL_PURPOSE = \"General Purpose\"\nEBS_VOLUME_TYPE_PIOPS = \"Provisioned IOPS\"\nEBS_VOLUME_TYPE_THROUGHPUT_OPTIMIZED = \"Throughput Optimized HDD\"\nEBS_VOLUME_TYPE_COLD_HDD = \"Cold HDD\"\n\n#Values that are valid in the calling script (which could be a Lambda function or any Python module)\n\n#OS\nSCRIPT_OPERATING_SYSTEM_LINUX = 'linux'\nSCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL = 'windowsbyol'\nSCRIPT_OPERATING_SYSTEM_WINDOWS = 'windows'\nSCRIPT_OPERATING_SYSTEM_SUSE = 'suse'\n#SCRIPT_OPERATING_SYSTEM_SQL_WEB = 'sqlweb'\nSCRIPT_OPERATING_SYSTEM_RHEL = 'rhel'\n\n#License Model\nSCRIPT_EC2_LICENSE_MODEL_BYOL = 'byol'\nSCRIPT_EC2_LICENSE_MODEL_INCLUDED = 'included'\nSCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED = 'none-required'\n\n#EBS\nSCRIPT_EBS_VOLUME_TYPE_STANDARD = 'standard'\nSCRIPT_EBS_VOLUME_TYPE_IO1 = 'io1'\nSCRIPT_EBS_VOLUME_TYPE_GP2 = 'gp2'\nSCRIPT_EBS_VOLUME_TYPE_SC1 = 'sc1'\nSCRIPT_EBS_VOLUME_TYPE_ST1 = 'st1'\n\n\n#Reserved Instances\nSCRIPT_EC2_OFFERING_CLASS_STANDARD = 'standard'\nSCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE = 'convertible'\n\nEC2_OFFERING_CLASS_STANDARD = 'standard'\nEC2_OFFERING_CLASS_CONVERTIBLE = 'convertible'\n\nSUPPORTED_EC2_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD, SCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE]\nSUPPORTED_RDS_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD]\nSUPPORTED_EMR_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD, SCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE]\nSUPPORTED_REDSHIFT_OFFERING_CLASSES = [SCRIPT_EC2_OFFERING_CLASS_STANDARD]\n\nSUPPORTED_OFFERING_CLASSES_MAP = {SERVICE_EC2:SUPPORTED_EC2_OFFERING_CLASSES, SERVICE_RDS: SUPPORTED_RDS_OFFERING_CLASSES,\n SERVICE_EMR:SUPPORTED_EMR_OFFERING_CLASSES,\n SERVICE_REDSHIFT: SUPPORTED_REDSHIFT_OFFERING_CLASSES }\n\nEC2_OFFERING_CLASS_MAP = {SCRIPT_EC2_OFFERING_CLASS_STANDARD:EC2_OFFERING_CLASS_STANDARD,\n SCRIPT_EC2_OFFERING_CLASS_CONVERTIBLE: EC2_OFFERING_CLASS_CONVERTIBLE}\n\n\n\nSCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT = 'partial-upfront'\nSCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT = 'all-upfront'\nSCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT = 'no-upfront'\n\nEC2_PURCHASE_OPTION_PARTIAL_UPFRONT = 'Partial Upfront'\nEC2_PURCHASE_OPTION_ALL_UPFRONT = 'All Upfront'\nEC2_PURCHASE_OPTION_NO_UPFRONT = 'No Upfront'\n\nSCRIPT_EC2_RESERVED_YEARS_1 = '1'\nSCRIPT_EC2_RESERVED_YEARS_3 = '3'\n\nEC2_SUPPORTED_RESERVED_YEARS = (SCRIPT_EC2_RESERVED_YEARS_1, SCRIPT_EC2_RESERVED_YEARS_3)\n\nEC2_RESERVED_YEAR_MAP = {SCRIPT_EC2_RESERVED_YEARS_1:'1yr', SCRIPT_EC2_RESERVED_YEARS_3:'3yr'}\n\nEC2_SUPPORTED_PURCHASE_OPTIONS = (SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT)\n\n\n\nEC2_PURCHASE_OPTION_MAP = {SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT:EC2_PURCHASE_OPTION_PARTIAL_UPFRONT,\n SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT: EC2_PURCHASE_OPTION_ALL_UPFRONT, SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT: EC2_PURCHASE_OPTION_NO_UPFRONT\n }\n\nSUPPORTED_EC2_OPERATING_SYSTEMS = (SCRIPT_OPERATING_SYSTEM_LINUX,\n SCRIPT_OPERATING_SYSTEM_WINDOWS,\n SCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL,\n SCRIPT_OPERATING_SYSTEM_SUSE,\n #SCRIPT_OPERATING_SYSTEM_SQL_WEB,\n SCRIPT_OPERATING_SYSTEM_RHEL)\n\nSUPPORTED_EC2_LICENSE_MODELS = (SCRIPT_EC2_LICENSE_MODEL_BYOL, SCRIPT_EC2_LICENSE_MODEL_INCLUDED, SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED)\n\nEC2_LICENSE_MODEL_MAP = {SCRIPT_EC2_LICENSE_MODEL_BYOL: 'Bring your own license',\n SCRIPT_EC2_LICENSE_MODEL_INCLUDED: 'License Included',\n SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED: 'No License required'\n }\n\n\nEC2_OPERATING_SYSTEMS_MAP = {SCRIPT_OPERATING_SYSTEM_LINUX:'Linux',\n SCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL:'Windows',\n SCRIPT_OPERATING_SYSTEM_WINDOWS:'Windows',\n SCRIPT_OPERATING_SYSTEM_SUSE:'SUSE',\n #SCRIPT_OPERATING_SYSTEM_SQL_WEB:'SQL Web',\n SCRIPT_OPERATING_SYSTEM_RHEL:'RHEL'}\n\nSUPPORTED_EBS_VOLUME_TYPES = (SCRIPT_EBS_VOLUME_TYPE_STANDARD,\n SCRIPT_EBS_VOLUME_TYPE_IO1,\n SCRIPT_EBS_VOLUME_TYPE_GP2,\n SCRIPT_EBS_VOLUME_TYPE_SC1,\n SCRIPT_EBS_VOLUME_TYPE_ST1\n )\n\nEBS_VOLUME_TYPES_MAP = {\n SCRIPT_EBS_VOLUME_TYPE_STANDARD : {'storageMedia':STORAGE_MEDIA_HDD , 'volumeType':EBS_VOLUME_TYPE_MAGNETIC},\n SCRIPT_EBS_VOLUME_TYPE_IO1 : {'storageMedia':STORAGE_MEDIA_SSD , 'volumeType':EBS_VOLUME_TYPE_PIOPS},\n SCRIPT_EBS_VOLUME_TYPE_GP2 : {'storageMedia':STORAGE_MEDIA_SSD , 'volumeType':EBS_VOLUME_TYPE_GENERAL_PURPOSE},\n SCRIPT_EBS_VOLUME_TYPE_SC1 : {'storageMedia':STORAGE_MEDIA_HDD , 'volumeType':EBS_VOLUME_TYPE_COLD_HDD},\n SCRIPT_EBS_VOLUME_TYPE_ST1 : {'storageMedia':STORAGE_MEDIA_HDD , 'volumeType':EBS_VOLUME_TYPE_THROUGHPUT_OPTIMIZED}\n }\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n\n#RDS\n\nSUPPORTED_RDS_INSTANCE_CLASSES = ('db.t1.micro', 'db.m1.small', 'db.m1.medium', 'db.m1.large', 'db.m1.xlarge',\n 'db.m2.xlarge', 'db.m2.2xlarge', 'db.m2.4xlarge',\n 'db.m3.medium', 'db.m3.large', 'db.m3.xlarge', 'db.m3.2xlarge',\n 'db.m4.large', 'db.m4.xlarge', 'db.m4.2xlarge', 'db.m4.4xlarge', 'db.m4.10xlarge', 'db.m4.16xlarge',\n 'db.m5.large', 'db.m5.xlarge', 'db.m5.2xlarge', 'db.m5.4xlarge', 'db.m5.12xlarge', 'db.m5.24xlarge',\n 'db.r3.large', 'db.r3.xlarge', 'db.r3.2xlarge', 'db.r3.4xlarge', 'db.r3.8xlarge',\n 'db.r4.large', 'db.r4.xlarge', 'db.r4.2xlarge', 'db.r4.4xlarge', 'db.r4.8xlarge', 'db.r4.16xlarge',\n 'db.r5.large', 'db.r5.xlarge', 'db.r5.2xlarge', 'db.r5.4xlarge', 'db.r5.12xlarge', 'db.r5.24xlarge',\n 'db.t2.micro', 'db.t2.small', 'db.t2.2xlarge', 'db.t2.large', 'db.t2.xlarge', 'db.t2.medium',\n 'db.t3.micro', 'db.t3.small', 'db.t3.medium', 'db.t3.large', 'db.t3.xlarge', 'db.t3.2xlarge',\n 'db.x1.16xlarge', 'db.x1.32xlarge', 'db.x1e.16xlarge', 'db.x1e.2xlarge', 'db.x1e.32xlarge', 'db.x1e.4xlarge', 'db.x1e.8xlarge', 'db.x1e.xlarge'\n )\n\n\nSCRIPT_RDS_STORAGE_TYPE_STANDARD = 'standard'\nSCRIPT_RDS_STORAGE_TYPE_AURORA = 'aurora' #Aurora has its own type of storage, which is billed by IO operations and size\nSCRIPT_RDS_STORAGE_TYPE_GP2 = 'gp2'\nSCRIPT_RDS_STORAGE_TYPE_IO1 = 'io1'\n\nRDS_VOLUME_TYPE_MAGNETIC = 'Magnetic'\nRDS_VOLUME_TYPE_AURORA = 'General Purpose-Aurora'\nRDS_VOLUME_TYPE_GP2 = 'General Purpose'\nRDS_VOLUME_TYPE_IO1 = 'Provisioned IOPS'\n\n\n\n\nRDS_VOLUME_TYPES_MAP = {\n SCRIPT_RDS_STORAGE_TYPE_STANDARD : RDS_VOLUME_TYPE_MAGNETIC,\n SCRIPT_RDS_STORAGE_TYPE_AURORA : RDS_VOLUME_TYPE_AURORA,\n SCRIPT_RDS_STORAGE_TYPE_GP2 : RDS_VOLUME_TYPE_GP2,\n SCRIPT_RDS_STORAGE_TYPE_IO1 : RDS_VOLUME_TYPE_IO1\n }\n\n\n\nSUPPORTED_RDS_STORAGE_TYPES = (SCRIPT_RDS_STORAGE_TYPE_STANDARD, SCRIPT_RDS_STORAGE_TYPE_AURORA, SCRIPT_RDS_STORAGE_TYPE_GP2, SCRIPT_RDS_STORAGE_TYPE_IO1)\n\n\nRDS_DEPLOYMENT_OPTION_SINGLE_AZ = 'Single-AZ'\nRDS_DEPLOYMENT_OPTION_MULTI_AZ = 'Multi-AZ'\nRDS_DEPLOYMENT_OPTION_MULTI_AZ_MIRROR = 'Multi-AZ (SQL Server Mirror)'\n\nRDS_DB_ENGINE_MYSQL = 'MySQL'\nRDS_DB_ENGINE_MARIADB = 'MariaDB'\nRDS_DB_ENGINE_ORACLE = 'Oracle'\nRDS_DB_ENGINE_SQL_SERVER = 'SQL Server'\nRDS_DB_ENGINE_POSTGRESQL = 'PostgreSQL'\nRDS_DB_ENGINE_AURORA_MYSQL = 'Aurora MySQL'\nRDS_DB_ENGINE_AURORA_POSTGRESQL = 'Aurora PostgreSQL'\n\nRDS_DB_EDITION_ENTERPRISE = 'Enterprise'\nRDS_DB_EDITION_STANDARD = 'Standard'\nRDS_DB_EDITION_STANDARD_ONE = 'Standard One'\nRDS_DB_EDITION_STANDARD_TWO = 'Standard Two'\nRDS_DB_EDITION_EXPRESS = 'Express'\nRDS_DB_EDITION_WEB = 'Web'\n\n\nSCRIPT_RDS_DATABASE_ENGINE_MYSQL = 'mysql'\nSCRIPT_RDS_DATABASE_ENGINE_MARIADB = 'mariadb'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD = 'oracle-se'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE = 'oracle-se1'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO = 'oracle-se2'\nSCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE = 'oracle-ee'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE = 'sqlserver-ee'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD = 'sqlserver-se'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS = 'sqlserver-ex'\nSCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB = 'sqlserver-web'\nSCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL = 'postgres' #to be consistent with RDS API - https://docs.aws.amazon.com/AmazonRDS/latest/APIReference/API_CreateDBInstance.html\nSCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL = 'aurora'\nSCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG = 'aurora-mysql' #some items in the RDS API now return aurora-mysql as a valid engine (instead of just aurora)\nSCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL = 'aurora-postgresql'\n\nRDS_SUPPORTED_DB_ENGINES = (SCRIPT_RDS_DATABASE_ENGINE_MYSQL,SCRIPT_RDS_DATABASE_ENGINE_MARIADB,\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD, SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE,\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO,SCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE,\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE, SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD,\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS, SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB,\n SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL, SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL,\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG\n )\n\nSCRIPT_RDS_LICENSE_MODEL_INCLUDED = 'license-included'\nSCRIPT_RDS_LICENSE_MODEL_BYOL = 'bring-your-own-license'\nSCRIPT_RDS_LICENSE_MODEL_PUBLIC = 'general-public-license'\nRDS_SUPPORTED_LICENSE_MODELS = (SCRIPT_RDS_LICENSE_MODEL_INCLUDED, SCRIPT_RDS_LICENSE_MODEL_BYOL, SCRIPT_RDS_LICENSE_MODEL_PUBLIC)\nRDS_LICENSE_MODEL_MAP = {SCRIPT_RDS_LICENSE_MODEL_INCLUDED:'License included',\n SCRIPT_RDS_LICENSE_MODEL_BYOL:'Bring your own license',\n SCRIPT_RDS_LICENSE_MODEL_PUBLIC:'No license required'}\n\nRDS_ENGINE_MAP = {SCRIPT_RDS_DATABASE_ENGINE_MYSQL:{'engine':RDS_DB_ENGINE_MYSQL,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_MARIADB:{'engine':RDS_DB_ENGINE_MARIADB ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_STANDARD},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_STANDARD_ONE},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_STANDARD_TWO},\n SCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE:{'engine':RDS_DB_ENGINE_ORACLE ,'edition':RDS_DB_EDITION_ENTERPRISE},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_ENTERPRISE},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_STANDARD},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_EXPRESS},\n SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB:{'engine':RDS_DB_ENGINE_SQL_SERVER ,'edition':RDS_DB_EDITION_WEB},\n SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL:{'engine':RDS_DB_ENGINE_POSTGRESQL ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL:{'engine':RDS_DB_ENGINE_AURORA_MYSQL ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG:{'engine':RDS_DB_ENGINE_AURORA_MYSQL ,'edition':''},\n SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL:{'engine':RDS_DB_ENGINE_AURORA_POSTGRESQL ,'edition':''}\n }\n\n\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n\n#S3\n\nS3_USAGE_GROUP_REQUESTS_TIER_1 = 'S3-API-Tier1'\nS3_USAGE_GROUP_REQUESTS_TIER_2 = 'S3-API-Tier2'\nS3_USAGE_GROUP_REQUESTS_TIER_3 = 'S3-API-Tier3'\nS3_USAGE_GROUP_REQUESTS_SIA_TIER1 = 'S3-API-SIA-Tier1'\nS3_USAGE_GROUP_REQUESTS_SIA_TIER2 = 'S3-API-SIA-Tier2'\nS3_USAGE_GROUP_REQUESTS_SIA_RETRIEVAL = 'S3-API-SIA-Retrieval'\nS3_USAGE_GROUP_REQUESTS_ZIA_TIER1 = 'S3-API-ZIA-Tier1'\nS3_USAGE_GROUP_REQUESTS_ZIA_TIER2 = 'S3-API-ZIA-Tier2'\nS3_USAGE_GROUP_REQUESTS_ZIA_RETRIEVAL = 'S3-API-ZIA-Retrieval'\n\n\nS3_STORAGE_CLASS_STANDARD = 'General Purpose'\nS3_STORAGE_CLASS_SIA = 'Infrequent Access'\nS3_STORAGE_CLASS_ZIA = 'Infrequent Access'\nS3_STORAGE_CLASS_GLACIER = 'Archive'\nS3_STORAGE_CLASS_REDUCED_REDUNDANCY = 'Non-Critical Data'\n\n\nSUPPORTED_REQUEST_TYPES = ('PUT','COPY','POST','LIST','GET')\n\nSCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS = 'STANDARD_IA'\nSCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS = 'ONEZONE_IA'\nSCRIPT_STORAGE_CLASS_STANDARD = 'STANDARD'\nSCRIPT_STORAGE_CLASS_GLACIER = 'GLACIER'\nSCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY = 'REDUCED_REDUNDANCY'\n\nSUPPORTED_S3_STORAGE_CLASSES = (SCRIPT_STORAGE_CLASS_STANDARD,\n SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS,\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS,\n SCRIPT_STORAGE_CLASS_GLACIER,\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY)\n\nS3_STORAGE_CLASS_MAP = {SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS:S3_STORAGE_CLASS_SIA,\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS:S3_STORAGE_CLASS_ZIA,\n SCRIPT_STORAGE_CLASS_STANDARD:S3_STORAGE_CLASS_STANDARD,\n SCRIPT_STORAGE_CLASS_GLACIER:S3_STORAGE_CLASS_GLACIER,\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY:S3_STORAGE_CLASS_REDUCED_REDUNDANCY}\n\nS3_USAGE_TYPE_DICT = {\n SCRIPT_STORAGE_CLASS_STANDARD:'TimedStorage-ByteHrs',\n SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS:'TimedStorage-SIA-ByteHrs',\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS:'TimedStorage-ZIA-ByteHrs',\n SCRIPT_STORAGE_CLASS_GLACIER:'TimedStorage-GlacierByteHrs',\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY:'TimedStorage-RRS-ByteHrs'\n }\n\nS3_VOLUME_TYPE_DICT = {\n SCRIPT_STORAGE_CLASS_STANDARD:'Standard',\n SCRIPT_STORAGE_CLASS_INFREQUENT_ACCESS:'Standard - Infrequent Access',\n SCRIPT_STORAGE_CLASS_ONE_ZONE_INFREQUENT_ACCESS:'One Zone - Infrequent Access',\n SCRIPT_STORAGE_CLASS_GLACIER:'Amazon Glacier',\n SCRIPT_STORAGE_CLASS_REDUCED_REDUNDANCY:'Reduced Redundancy'\n }\n\n\n\n\n#_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/\n\n#LAMBDA\n\nLAMBDA_MEM_SIZES = [64,128,192,256,320,384,448,512,576,640,704,768,832,896,960,1024,1088,1152,1216,1280,1344,1408,\n 1472,1536,1600,1664,1728,1792,1856,1920,1984,2048,2112,2176,2240,2304,2368,2432,2496,2560,2624,2688,\n 2752,2816,2880,2944,3008]\n"
},
{
"path": "awspricecalculator/common/errors.py",
"content": "import json\nimport os\n\n\n\nclass ValidationError(Exception):\n \"\"\"Exception raised for errors in the input.\n\n Attributes:\n message -- explanation of the error\n \"\"\"\n\n def __init__(self, message):\n self.message = message\n\n\nclass NoDataFoundError(Exception):\n \"\"\"Exception raised when no data could be found for a particular set of inputs\n\n Attributes:\n message -- explanation of the error\n \"\"\"\n\n def __init__(self, message):\n self.message = message\n\n"
},
{
"path": "awspricecalculator/common/models.py",
"content": "import math, logging\nimport os, sys\nfrom . import consts\nfrom .errors import ValidationError\n\nlog = logging.getLogger()\n\n__location__ = os.path.realpath(os.path.join(os.getcwd(), os.path.dirname(__file__)))\nsite_pkgs = os.path.abspath(os.path.join(__location__, os.pardir, os.pardir,\"lib\", \"python3.7\", \"site-packages\" ))\nsys.path.append(site_pkgs)\n\nfrom tabulate import tabulate\n\n\nclass ElbPriceDimension():\n def __init__(self, hours, dataProcessedGb):\n self.hours = hours\n self.dataProcessedGb = dataProcessedGb\n\n\n\nclass S3PriceDimension():\n def __init__(self, **kwargs):\n self.region = ''\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.storageClass = ''\n self.storageSizeGb = 0\n\n #TODO:Implement requestType and requestNumber as Count, such that a single call to the price calculator can account for multiple request types\n self.requestType = ''\n self.requestNumber = 0\n\n self.dataRetrievalGb = 0\n self.dataTransferOutInternetGb = 0\n\n self.region = kwargs.get('region','')\n self.storageClass = kwargs.get('storageClass','')\n self.storageSizeGb = int(kwargs.get('storageSizeGb',0))\n self.requestType = kwargs.get('requestType','')\n self.requestNumber = int(kwargs.get('requestNumber',0))\n self.dataRetrievalGb = int(kwargs.get('dataRetrievalGb',0))\n self.dataTransferOutInternetGb = int(kwargs.get('dataTransferOutInternetGb',0))\n\n self.validate()\n\n\n def validate(self):\n validation_ok = True\n validation_message = \"\"\n\n if not self.storageClass:\n validation_message += \"Storage class cannot be empty\\n\"\n validation_ok = False\n if self.storageClass and self.storageClass not in consts.SUPPORTED_S3_STORAGE_CLASSES:\n validation_message += \"Invalid storage class:[{}]\\n\".format(self.storageClass)\n validation_ok = False\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"Invalid region:[{}]\\n\".format(self.region)\n validation_ok = False\n if self.requestNumber and not self.requestType:\n validation_message += \"requestType cannot be empty if you specity requestNumber\\n\"\n validation_ok = False\n if self.requestType and self.requestType not in consts.SUPPORTED_REQUEST_TYPES:\n validation_message += \"Invalid request type:[{}]\\n\".format(self.requestType)\n validation_ok = False\n\n if not validation_ok:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\n\n\nclass Ec2PriceDimension():\n def __init__(self, **kargs):\n\n self.region = kargs['region']\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.instanceType = kargs.get('instanceType','')\n self.operatingSystem = kargs.get('operatingSystem',consts.SCRIPT_OPERATING_SYSTEM_LINUX)\n self.instanceHours = int(kargs.get('instanceHours',0))\n\n #TODO: Add support for pre-installed software (i.e. SQL Web in Windows instances)\n self.preInstalledSoftware = 'NA'\n\n self.licenseModel = consts.SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED\n if self.operatingSystem == consts.SCRIPT_OPERATING_SYSTEM_WINDOWS:\n self.licenseModel = consts.SCRIPT_EC2_LICENSE_MODEL_NONE_REQUIRED\n if self.operatingSystem == consts.SCRIPT_OPERATING_SYSTEM_WINDOWS_BYOL:\n self.licenseModel = consts.SCRIPT_EC2_LICENSE_MODEL_BYOL\n\n #Capacity Reservations\n #TODO: add support for allocated and unused Capacity Reservations\n self.capacityReservationStatus = consts.SCRIPT_EC2_CAPACITY_RESERVATION_STATUS_USED\n\n #Reserved Instances\n self.offeringClass = kargs.get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.instanceCount = int(kargs.get('instanceCount',0))\n self.offeringType = kargs.get('offeringType','')\n self.years = int(kargs.get('years',1))\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n #Data Transfer\n self.dataTransferOutInternetGb = int(kargs.get('dataTransferOutInternetGb',0))\n self.dataTransferOutIntraRegionGb = int(kargs.get('dataTransferOutIntraRegionGb',0))\n self.dataTransferOutInterRegionGb = int(kargs.get('dataTransferOutInterRegionGb',0))\n self.toRegion = kargs.get('toRegion','')\n\n #Storage\n self.pIops = int(kargs.get('pIops',0))\n self.storageMedia = ''\n self.ebsVolumeType = kargs.get('ebsVolumeType','')\n if self.ebsVolumeType in consts.EBS_VOLUME_TYPES_MAP: self.storageMedia = consts.EBS_VOLUME_TYPES_MAP[self.ebsVolumeType]['storageMedia']\n self.volumeType = ''\n if self.ebsVolumeType in consts.EBS_VOLUME_TYPES_MAP: self.volumeType = consts.EBS_VOLUME_TYPES_MAP[self.ebsVolumeType]['volumeType']\n if not self.volumeType: self.volumeType = consts.SCRIPT_EBS_VOLUME_TYPE_GP2\n self.ebsStorageGbMonth = int(kargs.get('ebsStorageGbMonth',0))\n self.ebsSnapshotGbMonth = int(kargs.get('ebsSnapshotGbMonth',0))\n\n #Elastic Load Balancer (classic)\n self.elbHours = int(kargs.get('elbHours',0))\n self.elbDataProcessedGb = int(kargs.get('elbDataProcessedGb',0))\n\n #Application Load Balancer\n self.albHours = int(kargs.get('albHours',0))\n self.albLcus= int(kargs.get('albLcus',0))\n\n #TODO: add support for Network Load Balancer\n\n #TODO: Add support for dedicated tenancies\n self.tenancy = kargs.get('tenancy',consts.SCRIPT_EC2_TENANCY_SHARED)\n\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n\n if self.instanceType and self.instanceType not in consts.SUPPORTED_EC2_INSTANCE_TYPES:\n validation_message += \"instance-type is \"+self.instanceType+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_INSTANCE_TYPES)\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if not self.operatingSystem:\n validation_message += \"operating-system cannot be empty\\n\"\n if self.operatingSystem and self.operatingSystem not in consts.SUPPORTED_EC2_OPERATING_SYSTEMS:\n validation_message += \"operating-system is \"+self.operatingSystem+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_OPERATING_SYSTEMS)\n if self.ebsVolumeType and self.ebsVolumeType not in consts.SUPPORTED_EBS_VOLUME_TYPES:\n validation_message += \"ebs-volume-type is \"+self.ebsVolumeType+\", must be one of the following values:\"+str(consts.SUPPORTED_EBS_VOLUME_TYPES)\n if self.dataTransferOutInterRegionGb > 0 and not self.toRegion:\n validation_message += \"Must specify a to-region if you specify data-transfer-out-interregion-gb\\n\"\n if self.dataTransferOutInterRegionGb and self.toRegion not in consts.SUPPORTED_REGIONS:\n validation_message += \"to-region is \"+self.toRegion+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.dataTransferOutInterRegionGb and self.region == self.toRegion:\n validation_message += \"source and destination regions must be different for inter-regional data transfers\\n\"\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n if self.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n if not self.offeringClass:\n validation_message += \"offering-class must be specified for Reserved instances\\n\"\n if self.offeringClass and self.offeringClass not in (consts.SUPPORTED_EC2_OFFERING_CLASSES):\n validation_message += \"offering-class is \"+self.offeringClass+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_OFFERING_CLASSES)\n if not self.offeringType:\n validation_message += \"offering-type must be specified\\n\"\n if self.offeringType and self.offeringType not in (consts.EC2_SUPPORTED_PURCHASE_OPTIONS):\n validation_message += \"offering-type is \"+self.offeringType+\", must be one of the following values:\"+str(consts.EC2_SUPPORTED_PURCHASE_OPTIONS)\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and self.instanceHours:\n validation_message += \"instance-hours cannot be set if term-type=reserved and offering-type=all-upfront\\n\"\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and not self.instanceCount:\n validation_message += \"instance-count is mandatory if term-type=reserved and offering-type=all-upfront\\n\"\n if not self.years:\n validation_message += \"years cannot be empty for Reserved instances\"\n\n #TODO: add validation for max number of IOPS\n #TODO: add validation for negative numbers\n\n validation_ok = True\n if validation_message:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\n\nclass RdsPriceDimension():\n def __init__(self, **kargs):\n self.region = kargs.get('region','')\n\n #DB Instance\n self.dbInstanceClass = kargs.get('dbInstanceClass','')\n\n if kargs.get('engine',''): self.engine = kargs['engine']\n else: self.engine = consts.SCRIPT_RDS_DATABASE_ENGINE_MYSQL\n\n\n self.licenseModel = kargs.get('licenseModel')\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL,\n consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL_LONG,\n consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL,\n consts.SCRIPT_RDS_DATABASE_ENGINE_MARIADB):\n self.licenseModel = consts.SCRIPT_RDS_LICENSE_MODEL_PUBLIC\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_STANDARD, consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_ENTERPRISE,\n consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_WEB, consts.SCRIPT_RDS_DATABASE_ENGINE_SQL_SERVER_EXPRESS,\n consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_ENTERPRISE, consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD,\n consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_ONE, consts.SCRIPT_RDS_DATABASE_ENGINE_ORACLE_STANDARD_TWO) \\\n and not self.licenseModel:\n self.licenseModel = consts.SCRIPT_RDS_LICENSE_MODEL_INCLUDED\n\n\n\n self.instanceHours = int(kargs.get('instanceHours',0))\n\n tmpmultiaz = str(kargs.get('multiAz','false')).lower()\n self.deploymentOption = ''\n if tmpmultiaz == 'true': self.deploymentOption = consts.RDS_DEPLOYMENT_OPTION_MULTI_AZ\n if tmpmultiaz == 'false': self.deploymentOption = consts.RDS_DEPLOYMENT_OPTION_SINGLE_AZ\n\n #OnDemand vs. Reserved\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD #TODO: add support for others, besides 'standard'\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.offeringType = kargs.get('offeringType','')\n self.instanceCount = int(kargs.get('instanceCount',0))\n self.years = int(kargs.get('years',1))\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n\n #TODO - create a separate model for DataTransfer\n #Data Transfer\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb',0)\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n\n #Storage\n self.storageGbMonth = int(kargs.get('storageGbMonth',0))\n self.storageType = kargs.get('storageType','')\n self.iops= int(kargs.get('iops',0))\n self.ioRequests= int(kargs.get('ioRequests',0))\n self.backupStorageGbMonth = int(kargs.get('backupStorageGbMonth',0))\n\n self.validate()\n\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL):\n self.storageType = consts.SCRIPT_RDS_STORAGE_TYPE_AURORA\n self.volumeType = self.calculate_volume_type()\n\n\n\n def calculate_volume_type(self):\n #TODO:add condition for Aurora\n if self.storageType in consts.RDS_VOLUME_TYPES_MAP:\n return consts.RDS_VOLUME_TYPES_MAP[self.storageType]\n\n def validate(self):\n #TODO: add validations for data transfer\n #TODO: add validations for different combinations of engine, edition and license\n #TODO: add validations for multiAz (deploymentOption cannot be empty)\n validation_ok = True\n validation_message = \"\"\n valid_engine = True\n\n if self.dbInstanceClass and self.dbInstanceClass not in consts.SUPPORTED_RDS_INSTANCE_CLASSES:\n validation_message = \"\\n\" + \"db-instance-class must be one of the following values:\"+str(consts.SUPPORTED_RDS_INSTANCE_CLASSES)\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"\\n\" + \"region must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.engine and self.engine not in consts.RDS_SUPPORTED_DB_ENGINES:\n validation_message += \"\\n\" + \"engine must be one of the following values:\"+str(consts.RDS_SUPPORTED_DB_ENGINES)\n valid_engine = False\n if valid_engine and self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_MYSQL,consts.SCRIPT_RDS_DATABASE_ENGINE_POSTGRESQL,\n consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL):\n if self.licenseModel not in (consts.RDS_SUPPORTED_LICENSE_MODELS):\n validation_message += \"\\n\" + \"you have specified license model [{}] - license-model must be one of the following values:{}\".format(self.licenseModel, consts.RDS_SUPPORTED_LICENSE_MODELS)\n if self.engine in (consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_MYSQL, consts.SCRIPT_RDS_DATABASE_ENGINE_AURORA_POSTGRESQL):\n if self.storageType in (consts.SCRIPT_RDS_STORAGE_TYPE_STANDARD, consts.SCRIPT_RDS_STORAGE_TYPE_GP2, consts.SCRIPT_RDS_STORAGE_TYPE_IO1):\n validation_message += \"\\nyou have specified {} storage type, which is invalid for DB engine {}\".format(self.storageType, self.engine)\n if self.storageType:\n if self.storageType not in consts.SUPPORTED_RDS_STORAGE_TYPES:\n validation_message += \"\\n\" + \"storage-type must be one of the following values:\"+str(consts.SUPPORTED_RDS_STORAGE_TYPES)\n if self.storageType == consts.SCRIPT_RDS_STORAGE_TYPE_IO1 and not self.iops:\n validation_message += \"\\n\" + \"you must specify an iops value for storage type io1\"\n if self.storageType == consts.SCRIPT_RDS_STORAGE_TYPE_IO1 and self.storageGbMonth and self.storageGbMonth < 100 :\n validation_message += \"\\nyou have specified {}GB of storage. You must specify at least 100GB of storage for io1\".format(self.storageGbMonth)\n\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n\n #TODO: move to a common place for all reserved pricing (EC2, RDS, etc.)\n if self.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n if not self.offeringClass:\n validation_message += \"offering-class must be specified for Reserved instances\\n\"\n if self.offeringClass and self.offeringClass not in (consts.SUPPORTED_EC2_OFFERING_CLASSES):\n validation_message += \"offering-class is \"+self.offeringClass+\", must be one of the following values:\"+str(consts.SUPPORTED_EC2_OFFERING_CLASSES)\n if not self.offeringType:\n validation_message += \"offering-type must be specified\\n\"\n if self.offeringType and self.offeringType not in (consts.EC2_SUPPORTED_PURCHASE_OPTIONS):\n validation_message += \"offering-type is \"+self.offeringType+\", must be one of the following values:\"+str(consts.EC2_SUPPORTED_PURCHASE_OPTIONS)\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and self.instanceHours:\n validation_message += \"instance-hours cannot be set if term-type=reserved and offering-type=all-upfront\\n\"\n if self.offeringType == consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT and not self.instanceCount:\n validation_message += \"instance-count is mandatory if term-type=reserved and offering-type=all-upfront\\n\"\n if not self.years:\n validation_message += \"years cannot be empty for Reserved instances\"\n\n\n if validation_message:\n log.error(\"{}\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\nclass EmrPriceDimension():\n def __init__(self, **kargs):\n\n self.region = kargs['region']\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.instanceType = kargs.get('instanceType','')\n\n self.years = int(kargs.get('years',1))\n self.instanceCount = int(kargs.get('instanceCount',0))\n ec2InstanceHours = 0\n if self.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n self.instanceHours = calculate_instance_hours_year(self.instanceCount, self.years)\n else:\n self.instanceHours = int(kargs.get('instanceHours',0))\n ec2InstanceHours = self.instanceHours #only set ec2InstanceHours for OnDemand, otherwise EC2 validation will fail\n\n\n self.offeringClass = kargs.get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.offeringType = kargs.get('offeringType', consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT)\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n\n #Data Transfer\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb',0)\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n\n ec2Args = {'region':self.region, 'termType':self.termType, 'instanceType':self.instanceType,\n 'instanceHours':ec2InstanceHours, 'pIops':int(kargs.get('pIops',0)), 'ebsVolumeType':kargs.get('ebsVolumeType',''),\n 'ebsStorageGbMonth':int(kargs.get('ebsStorageGbMonth',0)), 'instanceCount': kargs.get('instanceCount',0),\n 'years': self.years, 'offeringType':self.offeringType, 'offeringClass':self.offeringClass}\n\n #self.ec2PriceDims = Ec2PriceDimension(**ec2Args)\n self.ec2PriceDims = ec2Args\n\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n\n #TODO: add supported EMR Instance Type validation\n\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n if self.offeringClass not in consts.SUPPORTED_EMR_OFFERING_CLASSES:\n validation_message += \"offeringClass is \"+self.offeringClass+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_EMR_OFFERING_CLASSES)\n\n validation_ok = True\n if validation_message:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\nclass RedshiftPriceDimension():\n def __init__(self, **kargs):\n\n self.region = kargs['region']\n self.termType = kargs.get('termType',consts.SCRIPT_TERM_TYPE_ON_DEMAND)\n self.instanceType = kargs.get('instanceType','')\n self.instanceHours = int(kargs.get('instanceHours',0))\n\n #Reserved Instances\n self.offeringClass = kargs.get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)\n if not self.offeringClass: self.offeringClass = consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD\n self.instanceCount = int(kargs.get('instanceCount',0))\n self.offeringType = kargs.get('offeringType','')\n self.years = int(kargs.get('years',1))\n #offeringType doesn't apply for on-demand\n if self.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND: self.offeringType = \"\"\n\n #TODO: add storage snapshots, data scan, concurrency scaling,\n\n #Data Transfer\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb',0)\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n\n\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.termType not in consts.SUPPORTED_TERM_TYPES:\n validation_message += \"term-type is \"+self.termType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_TERM_TYPES)\n if self.offeringClass not in consts.SUPPORTED_REDSHIFT_OFFERING_CLASSES:\n validation_message += \"offeringClass is \"+self.offeringClass+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_REDSHIFT_OFFERING_CLASSES)\n if self.instanceType not in consts.SUPPORTED_REDSHIFT_INSTANCE_TYPES:\n validation_message += \"instanceType is \"+self.instanceType+\", must be one of the following values:[{}]\".format(consts.SUPPORTED_REDSHIFT_INSTANCE_TYPES)\n\n validation_ok = True\n if validation_message:\n raise ValidationError(validation_message)\n\n return validation_ok\n\n\n\n\nclass LambdaPriceDimension():\n def __init__(self,**kargs):\n self.region = kargs.get('region','')\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.requestCount = kargs.get('requestCount',0)\n self.avgDurationMs = kargs.get('avgDurationMs',0)\n self.memoryMb = kargs.get('memoryMb',0)\n self.dataTransferOutInternetGb = kargs.get('dataTransferOutInternetGb',0)\n self.dataTransferOutIntraRegionGb = kargs.get('dataTransferOutIntraRegionGb')\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n self.validate()\n self.GBs = self.requestCount * (float(self.avgDurationMs) / 1000) * (float(self.memoryMb) / 1024)\n\n\n def validate(self):\n validation_message = \"\"\n if not self.region:\n validation_message += \"Region must be specified\\n\"\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"Region is \"+self.region+\" ,must be one of the following:\"+str(consts.SUPPORTED_REGIONS)\n if self.requestCount and self.avgDurationMs == 0:\n validation_message += \"Cannot have value for requestCount and avgDurationMs=0\\n\"\n if self.requestCount and self.memoryMb== 0:\n validation_message += \"Cannot have value for requestCount and memoryMb=0\\n\"\n if self.requestCount == 0 and (self.avgDurationMs > 0 or self.memoryMb > 0):\n validation_message += \"Cannot have value for average duration or memory if requestCount is zero\\n\"\n if self.dataTransferOutInterRegionGb > 0 and not self.toRegion:\n validation_message += \"Must specify a to-region if you specify data-transfer-out-interregion-gb\\n\"\n\n if validation_message:\n log.error(\"{}\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\n\nclass DynamoDBPriceDimension():\n def __init__(self,**kargs):\n self.region = kargs.get('region','')\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.readCapacityUnitHours = kargs.get('readCapacityUnitHours',0)\n self.writeCapacityUnitHours = kargs.get('writeCapacityUnitHours',0)\n self.requestCount = kargs.get('requestCount',0)#used for reads to DDB Streams\n self.dataTransferOutGb = kargs.get('dataTransferOutGb',0)\n \"\"\"\n self.dataTransferOutInterRegionGb = kargs.get('dataTransferOutInterRegionGb',0)\n self.toRegion = kargs.get('toRegion','')\n \"\"\"\n\n self.validate()\n\n\n def validate(self):\n validation_message = \"\"\n if not self.region:\n validation_message += \"Region must be specified\\n\"\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"Region is \"+self.region+\", must be one of the following:\"+str(consts.SUPPORTED_REGIONS)\n if self.readCapacityUnitHours == 0:\n validation_message += \"readCapacityUnitHours cannot be 0\\n\"\n if self.writeCapacityUnitHours == 0:\n validation_message += \"writeCapacityUnitHours cannot be 0\\n\"\n\n if validation_message:\n print(\"Error: [{}]\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\n\"\"\"\nPlease note the following - from https://aws.amazon.com/kinesis/streams/pricing/:\n* Getting records from Amazon Kinesis stream is free.\n* Data transfer is free. AWS does not charge for data transfer from your data producers to Amazon Kinesis Streams, or from Amazon Kinesis Streams to your Amazon Kinesis Applications.\n\"\"\"\n\nclass KinesisPriceDimension():\n def __init__(self,**kargs):\n self.region = kargs.get('region','')\n self.termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n self.shardHours = 0\n self.shardHours = int(kargs.get('shardHours',0))\n self.putPayloadUnits = int(kargs.get('putPayloadUnits',0))\n self.extendedDataRetentionHours = int(kargs.get('extendedDataRetentionHours',0))\n self.validate()\n\n def validate(self):\n validation_message = \"\"\n if not self.region:\n validation_message += \"Region must be specified\\n\"\n if self.region not in consts.SUPPORTED_REGIONS:\n validation_message += \"region is \"+self.region+\", must be one of the following values:\"+str(consts.SUPPORTED_REGIONS)\n if self.shardHours == 0:\n validation_message += \"shardHours cannot be 0\\n\"\n\n if validation_message:\n print(\"Error: [{}]\".format(validation_message))\n raise ValidationError(validation_message)\n\n return\n\n\n\"\"\"\nThis object represents the total price calculation.\nIt includes an array of PricingRecord objects, which are a breakdown of how the price is calculated\n\"\"\"\n#TODO: update arguments, remove region and include one argument for pdim\nclass PricingResult():\n def __init__(self, awsPriceListApiVersion, region, total_cost, pricing_records, **args):\n total_cost = round(total_cost,2)\n self.version = consts.AWS_PRICE_CALCULATOR_VERSION\n self.awsPriceListApiVersion = awsPriceListApiVersion\n self.region = region\n self.totalCost = round(total_cost,2)\n self.currency = consts.DEFAULT_CURRENCY\n self.pricingRecords = pricing_records\n\n tmpPriceDimensions = args.get('priceDimensions',{})\n if tmpPriceDimensions: self.priceDimensions = args.get('priceDimensions',{}).__dict__\n else: self.priceDimensions = tmpPriceDimensions\n\nclass PricingRecord():\n def __init__(self, service, amt, desc, pricePerUnit, usgUnits, rateCode):\n usgUnits = round(float(usgUnits),2)\n amt = round(amt,2)\n self.service = service\n self.amount = amt\n self.description = desc\n self.pricePerUnit = pricePerUnit\n self.usageUnits = int(usgUnits)\n self.rateCode = rateCode\n\n\n\"\"\"\nThis class is a container for generic price comparisons, with different values for a single parameter.\nFor example, comparing a specific price calculation for different regions, or EC2 instance types, or OS\n\"\"\"\nclass PriceComparison():\n def __init__(self, awsPriceListApiVersion, service, sortCriteria):\n self.version = \"v1.0\"\n self.awsPriceListApiVersion = awsPriceListApiVersion\n self.service = service\n self.sortCriteria = sortCriteria\n self.currency = consts.DEFAULT_CURRENCY\n self.pricingScenarios = []\n #TODO: implement get_csv_data and get_tabular_data\n\nclass PricingScenario():\n def __init__(self, index, id, priceDimensions, priceCalculation, totalCost, sortCriteria):\n self.index = index\n self.id = id\n self.displayName = self.getDisplayName(sortCriteria)\n self.priceDimensions = priceDimensions\n\n #Remove redundant information from priceCalculation object.\n #This information is already present in PriceComparison or PricingScenario objects\n priceCalculation.pop('awsPriceListApiVersion','')\n priceCalculation.pop('totalCost','')\n priceCalculation.pop('service','')\n priceCalculation.pop('currency','')\n\n self.priceCalculation = priceCalculation\n self.totalCost = round(totalCost,2)\n self.deltaPrevious = 0 #how more expensive is this item, compared to cheapest option - in $\n self.deltaCheapest = 0 #how more expensive is this item, compared to cheapest option - in %\n self.pctToPrevious = 0 #how more expensive is this item, compared to next lower option - in $\n self.pctToCheapest = 0 #how more expensive is this item, compared to next lower option - in %\n self.totalCost = round(totalCost,2)\n\n def getDisplayName(self, sortCriteria):\n result = ''\n if sortCriteria == consts.SORT_CRITERIA_REGION:\n result = consts.REGION_REPORT_MAP.get(self.id,'N/A')\n\n #TODO: update for all supported sortCriteria options\n else:\n result = self.id\n\n return result\n\n\n\"\"\"\nThis class is a container for price calculations between different term types, such as Demand vs. Reserved\n\"\"\"\nclass TermPricingAnalysis():\n def __init__(self, awsPriceListApiVersion, regions, service, years):\n self.version = \"v1.0\"\n self.awsPriceListApiVersion = awsPriceListApiVersion\n self.regions = regions\n self.service = service\n self.currency = consts.DEFAULT_CURRENCY\n self.years = years\n self.pricingScenarios = []\n self.monthlyBreakdown = []\n self.tabularData = \"\"\n\n def get_pricing_scenario(self, region, termType, offerClass, offerType, years):\n #print (\"get_pricing_scenario - looking for termType:[{}] - offerClass:[{}] - offerType:[{}] - years:[{}]\".format())\n for p in self.pricingScenarios:\n #print (\"get_pricing_scenario - looking for termType:[{}] - offerClass:[{}] - offerType:[{}] - years:[{}] in priceDimensions: [{}]\".format(termType, offerClass, offerType, years, p['priceDimensions']))\n if p['priceDimensions']['region']==region and p['priceDimensions']['termType']==termType \\\n and p['priceDimensions'].get('offeringClass',consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD)==offerClass \\\n and p['priceDimensions'].get('offeringType','')==offerType and str(p['priceDimensions']['years'])==str(years):\n return p\n if p['priceDimensions']['region']==region and p['priceDimensions']['termType']==termType \\\n and termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND \\\n and str(p['priceDimensions']['years'])==str(years):\n return p\n\n return False\n\n def calculate_months_to_recover(self):\n updatedPricingScenarios = []\n\n for s in self.pricingScenarios:\n accumamt = 0\n month = 1\n while month <= int(self.years)*12:\n if month == 1:\n #if s['id'] == 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years):\n if 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years) in s['id']:\n accumamt = self.getUpfrontFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'],\n consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n #if s['id'] == 'reserved-{}-all-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years):\n if 'reserved-{}-all-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years) in s['id']:\n accumamt = self.getUpfrontFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'],\n consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years)))\n\n\n #if s['id'] == 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years): accumamt += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, self.years))\n if 'reserved-{}-partial-upfront-{}yr'.format(s['priceDimensions']['offeringClass'],self.years) in s['id']:\n accumamt += self.getMonthlyFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, self.years))\n #if s['id'] == 'reserved-{}-no-upfront-{}yr'.format(s['priceDimensions']['offeringClass'], self.years): accumamt += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, self.years))\n if 'reserved-{}-no-upfront-{}yr'.format(s['priceDimensions']['offeringClass'], self.years) in s['id']:\n accumamt += self.getMonthlyFee(self.get_pricing_scenario(s['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n s['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, self.years))\n\n if ((s['onDemandTotalCost']/(int(self.years)*12))*month) >= accumamt:\n break\n month += 1\n\n s['monthsToRecover'] = month\n updatedPricingScenarios.append(s)\n\n self.pricingScenarios = updatedPricingScenarios\n\n\n def calculate_monthly_breakdown(self):\n #TODO: validate that years is either 1 or 3\n monthlyScenarios = []\n month = 1\n while month <= int(self.years) * 12:\n monthDict = {}\n monthDict['month']=month\n for p in self.pricingScenarios: #at this point, scenarios are already sorted\n #TODO: confirm if partial upfront also gets the monthly fee applied on the first month, or not.\n #If the analysis includes multiple regions, include the region in the scenario id.\n if len(self.regions)>1: tmpregionid = \"{}-\".format(p.get('priceDimensions',{}).get('region',''))\n else: tmpregionid = \"\"\n if 'all-upfront' in p['id']:\n monthDict['{}reserved-{}-all-upfront-{}yr'.format(tmpregionid, p['priceDimensions']['offeringClass'], self.years)] = \\\n round(self.getUpfrontFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years))) + \\\n month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years))),2)\n if 'partial-upfront' in p['id']:\n monthDict['{}reserved-{}-partial-upfront-{}yr'.format(tmpregionid, p['priceDimensions']['offeringClass'], self.years)] = \\\n round(self.getUpfrontFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years))) + \\\n month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years))),2)\n if 'no-upfront' in p['id']:\n monthDict['{}reserved-{}-no-upfront-{}yr'.format(tmpregionid,p['priceDimensions']['offeringClass'], self.years)] = \\\n round(month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_RESERVED,\n p['priceDimensions']['offeringClass'], consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, str(self.years))),2)\n if 'on-demand' in p['id']:\n monthDict['{}on-demand-{}yr'.format(tmpregionid,self.years)] = \\\n round(month * self.getMonthlyFee(self.get_pricing_scenario(p['priceDimensions']['region'], consts.SCRIPT_TERM_TYPE_ON_DEMAND,\n consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, '', str(self.years))),2)\n monthlyScenarios.append(monthDict)\n month += 1\n\n self.monthlyBreakdown = monthlyScenarios\n return\n\n\n def get_csv_data(self):\n #First, sort keys from high to low total\n finalMonth = self.monthlyBreakdown[len(self.monthlyBreakdown)-1]\n unsorted = []\n sortedscenarios = []\n csvtxt = \"\"\n for k in finalMonth.keys():unsorted.append((finalMonth[k],k))\n sortedscenarios = sorted(unsorted)\n comma = \",\"\n i = 0\n #print header row\n for s in sortedscenarios:\n i += 1\n if i == len(sortedscenarios): comma = \"\" #avoid comma at the end of each row\n csvtxt += \"{}{}\".format(s[1],comma) #print headers\n #print monthly scenario rows\n for m in self.monthlyBreakdown:\n csvtxt += \"\\n\"\n comma = \",\"\n i = 0\n for s in sortedscenarios:\n i += 1\n if i == len(sortedscenarios): comma = \"\" #avoid comma at the end of each row\n csvtxt += \"{}{}\".format(m[s[1]],comma)\n self.csvData = csvtxt\n return\n\n def get_tabular_data(self):\n if not self.csvData: self.get_csv_data()\n csvtext = self.csvData\n #need to reduce the length of each field, otherwise the table headers overflow and data is not displayed properly\n headers = csvtext.split(\"\\n\")[0].replace(\"reserved\",\"rsv\").replace(\"standard\",\"std\").\\\n replace(\"convertible\",\"conv\").replace(\"upfront\",\"upfr\").replace(\"partial\",\"part\").replace(\"demand\",\"dmd\").split(\",\")\n data = []\n for r in csvtext.split(\"\\n\")[1:]:\n data.append(r.split(\",\"))\n\n self.tabularData = tabulate(data, headers=headers, tablefmt='github')\n\n \"\"\"\n def get_csv_data(self):\n #TODO: validate that years is either 1 or 3\n\n def get_csv_dict():\n result = {}\n for k in get_sorted_keys():\n result[k[1]]=0\n return result\n\n def get_sorted_keys():\n #TODO: add to constants\n #TODO: update order in which scenarios get displayed\n return sorted(((1,'month'),(2,'on-demand-{}yr'.format(self.years)),(3,'reserved-all-upfront-{}yr'.format(self.years)),\n (4,'reserved-partial-upfront-{}yr'.format(self.years)),(4,'reserved-no-upfront-{}yr'.format(self.years))))\n\n def get_sorted_key_separator(k):\n result = ','\n sortedkeys = get_sorted_keys()\n if k == sortedkeys[len(sortedkeys)-1]:result = '' #don't add a comma at the end of the line\n return result\n\n month = 1\n\n #TODO: see if this block can be removed\n for s in self.pricingScenarios:\n if s['id'] == \"on-demand-{}yr\".format(self.years): onDemand = s['pricingRecords']\n if s['id'] == \"reserved-no-upfront-{}yr\".format(self.years): reserved1YrNoUpfront = s['pricingRecords']\n if s['id'] == \"reserved-all-upfront-{}yr\".format(self.years): reserved1YrAllUpfrontAccum = s['totalCost']\n for p in s['pricingRecords']:\n if 'upfront' in p['description'].lower():\n if s['id'] == \"reserved-partial-upfront-{}yr\".format(self.years): reserved1YrPartialUpfront = p['amount']\n if s['id'] == \"reserved-all-upfront-{}yr\".format(self.years): reserved1YrAllUpfront = p['amount']\n else: reserved1YrPartialUpfrontApplied = p['amount']\n\n accumDict = get_csv_dict()\n\n csvdata = \"\"\n sortedkeys = get_sorted_keys()\n while month <= int(self.years) * 12:\n accumDict['month']=month\n if month == 1:\n accumDict['reserved-partial-upfront-{}yr'.format(self.years)] = self.getUpfrontFee(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n\n accumDict['reserved-all-upfront-{}yr'.format(self.years)] = self.getUpfrontFee(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, str(self.years)))\n accumDict['reserved-partial-upfront-{}yr'.format(self.years)] += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n accumDict['on-demand-{}yr'.format(self.years)] += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_ON_DEMAND, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT, str(self.years)))\n accumDict['reserved-no-upfront-{}yr'.format(self.years)] += self.getMonthlyCost(self.get_pricing_scenario(consts.SCRIPT_TERM_TYPE_RESERVED, consts.SCRIPT_EC2_OFFERING_CLASS_STANDARD, consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, str(self.years)))\n\n for k in sortedkeys:\n amt = 0\n if k[1] == 'month': amt = accumDict[k[1]]\n else: amt = round(accumDict[k[1]],2)\n csvdata += \"{}{}\".format(amt,get_sorted_key_separator(k))\n\n csvdata += \"\\n\"\n month += 1\n\n csvheaders = \"\"\n for k in sortedkeys: csvheaders += k[1]+get_sorted_key_separator(k)\n csvheaders += \"\\n\"\n self.csvData = csvheaders + csvdata\n return\n \"\"\"\n\n \"\"\"\n Calculate any upfront fees applied to pricing. The only scenarios applicable for this fee are All Upfront and Partial Upfront\n \"\"\"\n def getUpfrontFee(self, pricingScenarioDict):\n result = 0\n if pricingScenarioDict:\n for p in pricingScenarioDict['pricingRecords']:\n if pricingScenarioDict['priceDimensions'].get('offeringType','') in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT) \\\n and 'upfront' in p['description'].lower():\n result = p['amount']\n break\n return result\n\n \"\"\"\n Calculate any monthly fee paid in addition to an Upfront Fee - for example, monthly fee after Partial Upfront has been paid,\n or monthly fee for No Upfront\n \"\"\"\n def getMonthlyFee(self, pricingScenarioDict):\n result = 0\n if pricingScenarioDict:\n print(\"getMonthlyCost - scenario:[{}] - totalCost:[{}]\".format(pricingScenarioDict['id'], pricingScenarioDict['totalCost']))\n for p in pricingScenarioDict['pricingRecords']:\n if 'upfront' not in p['description'].lower():\n result += p['amount'] / (12 * int(pricingScenarioDict['priceDimensions']['years']))\n return result\n \"\"\"\n def getMonthlyFee(self, pricingScenarioDict):\n result = 0\n if pricingScenarioDict:\n print(\"getMonthlyCost - scenario:[{}] - totalCost:[{}]\".format(pricingScenarioDict['id'], pricingScenarioDict['totalCost']))\n for p in pricingScenarioDict['pricingRecords']:\n tmpamt = p['amount'] / (12 * int(pricingScenarioDict['priceDimensions']['years']))\n if pricingScenarioDict['priceDimensions'].get('offeringType','') != consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT \\\n and 'upfront' not in p['description'].lower():\n result += tmpamt\n #Cost for EMR scenarios consists of EC2 + EMR fee - on-demand scenarios already have EMR + EC2\n if self.service == consts.SERVICE_EMR and p['service'] == consts.SERVICE_EMR and pricingScenarioDict['priceDimensions'].get('termType','') != consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n result += tmpamt\n return result\n \"\"\"\n\nclass TermPricingScenario():\n def __init__(self, id, priceDimensions, pricingRecords, totalCost, onDemandTotalCost):\n self.index = None\n self.id = id\n self.priceDimensions = priceDimensions\n self.pricingRecords = pricingRecords\n self.totalCost = round(totalCost,2)\n self.deltaPrevious = 0 #how more expensive is this item, compared to cheapest option - in $\n self.deltaCheapest = 0 #how more expensive is this item, compared to cheapest option - in %\n self.pctToPrevious = 0 #how more expensive is this item, compared to next lower option - in $\n self.pctToCheapest = 0 #how more expensive is this item, compared to next lower option - in %\n self.onDemandTotalCost = round(onDemandTotalCost,2)\n self.savingsPctvsOnDemand = 0\n self.totalSavingsvsOnDemand = 0\n self.monthsToRecover = 0\n #TODO: implement onDemandMonthsToSavings\n #TODO: implement as a subclass of PricingScenario\n\n def calculateOnDemandSavings(self):\n #TODO: confirm if Partial Upfront is 1 upfront + 12 payments and if the initial payment is applied on month 1\n if self.onDemandTotalCost:\n self.savingsPctvsOnDemand = math.fabs(round((100 * (self.totalCost - self.onDemandTotalCost) / self.onDemandTotalCost),2))\n if self.priceDimensions['termType'] == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n self.totalSavingsvsOnDemand = 0\n else:\n self.totalSavingsvsOnDemand = round((self.onDemandTotalCost - self.totalCost),2)\n\n\n#This method is duplicate in utils - need to find a way to remove circular dependency and avoid duplication\ndef calculate_instance_hours_year(instanceCount, years):\n return 365 * 24 * int(instanceCount) * int(years)\n\n\n"
},
{
"path": "awspricecalculator/common/phelper.py",
"content": "\nfrom . import consts\nimport os, sys\nimport datetime\nimport logging\nimport csv, json\nfrom .models import PricingRecord, PricingResult\nfrom .errors import NoDataFoundError\n\n\nlog = logging.getLogger()\nlog.setLevel(consts.LOG_LEVEL)\n\n__location__ = os.path.realpath(os.path.join(os.getcwd(), os.path.dirname(__file__)))\nsite_pkgs = os.path.abspath(os.path.join(__location__, os.pardir, os.pardir,\"lib\", \"python3.7\", \"site-packages\" ))\nsys.path.append(site_pkgs)\n#print \"site_pkgs: [{}]\".format(site_pkgs)\n\nimport tinydb\n\n\ndef get_data_directory(service):\n result = os.path.split(__location__)[0] + '/data/' + service + '/'\n return result\n\n\n\ndef getBillableBand(priceDimensions, usageAmount):\n billableBand = 0\n beginRange = int(priceDimensions['beginRange'])\n endRange = priceDimensions['endRange']\n pricePerUnit = priceDimensions['pricePerUnit']['USD']\n if endRange == consts.INFINITY:\n if beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n else:\n endRange = int(endRange)\n if endRange >= usageAmount and beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n if endRange < usageAmount: \n billableBand = endRange - beginRange\n return billableBand\n\n\ndef getBillableBandCsv(row, usageAmount):\n billableBand = 0\n pricePerUnit = 0\n amt = 0\n\n if not row['StartingRange']:beginRange = 0\n else: beginRange = int(row['StartingRange'])\n if not row['EndingRange']:endRange = consts.INFINITY\n else: endRange = row['EndingRange']\n\n pricePerUnit = float(row['PricePerUnit'])\n if endRange == consts.INFINITY:\n if beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n else:\n endRange = int(endRange)\n if endRange >= usageAmount and beginRange < usageAmount:\n billableBand = usageAmount - beginRange\n if endRange < usageAmount:\n billableBand = endRange - beginRange\n\n if billableBand > 0: amt = pricePerUnit * billableBand\n\n return billableBand, pricePerUnit, amt\n\n\n\n#Creates a table with all the SKUs that are part of the total price\ndef buildSkuTable(evaluated_sku_desc):\n result = {}\n sorted_descriptions = sorted(evaluated_sku_desc)\n result_table_header = \"Price | Description | Price Per Unit | Usage | Rate Code\"\n result_records = \"\"\n total = 0\n for s in sorted_descriptions:\n result_records = result_records + \"$\" + str(s[0]) + \"|\" + str(s[1]) + \"|\" + str(s[2]) + \"|\" + str(s[3]) + \"|\" + s[4]+\"\\n\"\n total = total + s[0]\n \n result['header']=result_table_header\n result['records']=result_records\n result['total']=total\n return result\n\n\n\n\"\"\"\nCalculates the keys that will be used to partition big index files into smaller pieces.\nIf no term is specified, the function will consider On-Demand and Reserved\n\"\"\"\n#TODO: merge all 3 load balancers into a single file (to speed up DB file loading and number of open files\ndef get_partition_keys(service, region, term, **extraArgs):\n result = []\n if region:\n regions = [consts.REGION_MAP[region]]\n else:\n regions = consts.REGION_MAP.values()\n\n if term: terms = [consts.TERM_TYPE_MAP[term]]\n else: terms = consts.TERM_TYPE_MAP.values()\n\n #productFamilies = consts.SUPPORTED_PRODUCT_FAMILIES\n productFamilies = consts.SUPPORTED_PRODUCT_FAMILIES_BY_SERVICE_DICT[service]\n\n #EC2 & RDS Reserved\n offeringClasses = extraArgs.get('offeringClasses',consts.EC2_OFFERING_CLASS_MAP.values())\n tenancies = extraArgs.get('tenancies',consts.EC2_TENANCY_MAP.values())\n purchaseOptions = extraArgs.get('purchaseOptions',consts.EC2_PURCHASE_OPTION_MAP.values())\n\n indexDict = {}\n #TODO: filter by service, to speed up file loading and to avoid max open files limit\n for r in regions:\n for t in terms:\n for pf in productFamilies:\n #Reserved EC2 & DB instances have more dimensions for index creation\n if t == consts.TERM_TYPE_RESERVED:\n if pf in consts.SUPPORTED_RESERVED_PRODUCT_FAMILIES:\n for oc in offeringClasses:\n for ten in tenancies:\n for po in purchaseOptions:\n result.append(create_file_key((r,t,pf,oc,ten, po)))\n else:\n #OnDemand EC2 Instances use Tenancy as a dimension for index creation\n if service == consts.SERVICE_EC2 and pf == consts.PRODUCT_FAMILY_COMPUTE_INSTANCE:\n for ten in tenancies:\n result.append(create_file_key((r,t,pf,ten)))\n else:\n result.append(create_file_key((r,t,pf)))\n\n return result\n\n\n#Creates a file key that identifies a data partition\ndef create_file_key(indexDimensions):\n result = \"\"\n for d in indexDimensions: result += d\n return result.replace(' ','')\n\n\n\ndef loadDBs(service, indexFiles):\n\n dBs = {}\n datadir = get_data_directory(service)\n indexMetadata = getIndexMetadata(service)\n\n #Files in Lambda can only be created in the /tmp filesystem - If it doesn't exist, create it.\n lambdaFileSystem = '/tmp/'+service+'/data'\n if not os.path.exists(lambdaFileSystem):\n os.makedirs(lambdaFileSystem)\n\n for i in indexFiles:\n db = tinydb.TinyDB(lambdaFileSystem+'/'+i+'.json')\n #TODO: remove circular dependency from utils, so I can use the method get_index_file_name\n #TODO: initial tests show that is faster (by a few milliseconds) to populate the file from scratch). See if I should load from scratch all the time\n #TODO:Create a file that is an index of those files that have been generated, so the code knows which files to look for and avoid creating unnecesary empty .json files\n if len(db) == 0:\n try:\n #with open(datadir+i+'.csv', 'rb') as csvfile:\n with open(datadir+i+'.csv', 'r') as csvfile:\n pricelist = csv.DictReader(csvfile, delimiter=',', quotechar='\"')\n db.insert_multiple(pricelist)\n #csvfile.close()#avoid \" [Errno 24] Too many open files\" exception\n except IOError:\n pass\n dBs[i]=db\n #db.close()#avoid \" [Errno 24] Too many open files\" exception\n\n\n return dBs, indexMetadata\n\n\n\ndef getIndexMetadata(service):\n ts = Timestamp()\n ts.start('getIndexMetadata')\n result = {}\n #datadir = get_data_directory(service)\n with open(get_data_directory(service)+\"index_metadata.json\") as index_metadata:\n result = json.load(index_metadata)\n index_metadata.close()\n ts.finish('getIndexMetadata')\n log.debug(\"Time to load indexMetadata: [{}]\".format(ts.elapsed('getIndexMetadata')))\n return result\n\n\ndef calculate_price(service, db, query, usageAmount, pricingRecords, cost):\n ts = Timestamp()\n ts.start('tinyDbSeachCalculatePrice')\n\n resultSet = db.search(query)\n\n ts.finish('tinyDbSeachCalculatePrice')\n log.debug(\"Time to search {} pricing DB for query [{}] : [{}] \".format(service, query, ts.elapsed('tinyDbSeachCalculatePrice')))\n\n if not resultSet: raise NoDataFoundError(\"Could not find data for service:[{}] - query:[{}]\".format(service, query))\n #print(\"resultSet:[{}]\".format(json.dumps(resultSet,indent=4)))\n for r in resultSet:\n billableUsage, pricePerUnit, amt = getBillableBandCsv(r, usageAmount)\n cost = cost + amt\n if billableUsage:\n #TODO: calculate rounding dynamically - don't set to 4 - use description to set the right rounding\n pricing_record = PricingRecord(service,round(amt,4),r['PriceDescription'],pricePerUnit,billableUsage,r['RateCode'])\n pricingRecords.append(vars(pricing_record))\n\n return pricingRecords, cost\n\n\n\n\nclass Timestamp():\n\n def __init__(self):\n self.eventdict = {}\n\n def start(self,event):\n self.eventdict[event] = {}\n self.eventdict[event]['start'] = datetime.datetime.now()\n\n def finish(self, event):\n #elapsed = datetime.timedelta(self.eventdict[event]['start']) * 1000 #return milliseconds\n elapsed = datetime.datetime.now() - self.eventdict[event]['start']\n self.eventdict[event]['elapsed'] = elapsed\n return elapsed\n\n def elapsed(self,event):\n return self.eventdict[event]['elapsed']\n\n"
},
{
"path": "awspricecalculator/datatransfer/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/datatransfer/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating AWSDataTransfer pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n #Load On-Demand DBs\n indexArgs = {}\n tmpDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType+pdim.tenancy\n dbs = regiondbs.get(tmpDbKey,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **indexArgs))\n regiondbs[tmpDbKey]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #Data Transfer\n dataTransferDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n\n #Out to the Internet\n if pdim.dataTransferOutInternetGb:\n ts.start('searchDataTransfer')\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n log.debug(\"Time to search AWSDataTransfer data transfer Out: [{}]\".format(ts.finish('searchDataTransfer')))\n\n #Intra-regional data transfer - in/out/between AZs or using EIPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n\n log.debug(\"regiondbs:[{}]\".format(regiondbs.keys()))\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/dynamodb/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/dynamodb/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating DynamoDB pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n global regiondbs\n global indexMetadata\n\n ts = phelper.Timestamp()\n ts.start('totalCalculationDynamoDB')\n\n #Load On-Demand DBs\n dbs = regiondbs.get(consts.SERVICE_DYNAMODB+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_DYNAMODB, phelper.get_partition_keys(consts.SERVICE_DYNAMODB, pdim.region,consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_DYNAMODB+pdim.region+pdim.termType]=dbs\n\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n #TODO:add support for free-tier flag (include or exclude from calculation)\n\n iopsDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DB_PIOPS])]\n\n #Read Capacity Units\n query = ((priceQuery['Group'] == 'DDB-ReadUnits'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DYNAMODB, iopsDb, query, pdim.readCapacityUnitHours, pricing_records, cost)\n\n #Write Capacity Units\n query = ((priceQuery['Group'] == 'DDB-WriteUnits'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DYNAMODB, iopsDb, query, pdim.writeCapacityUnitHours, pricing_records, cost)\n\n #DB Storage (TODO)\n\n #Data Transfer (TODO)\n #there is no additional charge for data transferred between Amazon DynamoDB and other Amazon Web Services within the same Region\n #data transferred across Regions (e.g., between Amazon DynamoDB in the US East (Northern Virginia) Region and Amazon EC2 in the EU (Ireland) Region), will be charged on both sides of the transfer.\n\n #API Requests (only applies for DDB Streams)(TODO)\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time to compute: [{}]\".format(ts.finish('totalCalculationDynamoDB')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/ec2/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/ec2/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper, utils\nfrom ..common.models import PricingResult\n#import psutil\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating EC2 pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n ts.start('tinyDbLoadReserved')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n if pdim.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n #Load On-Demand DBs\n indexArgs = {'tenancies':[consts.EC2_TENANCY_MAP[pdim.tenancy]]}\n tmpDbKey = consts.SERVICE_EC2+pdim.region+pdim.termType+pdim.tenancy\n\n dbs = regiondbs.get(tmpDbKey,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_EC2, phelper.get_partition_keys(consts.SERVICE_EC2, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **indexArgs))\n regiondbs[tmpDbKey]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #TODO: Move common operations to a common module, and leave only EC2-specific operations in ec2/pricing.py (create a class)\n #TODO: support all tenancy types (Host and Dedicated)\n #Compute Instance\n if pdim.instanceHours:\n dbFileKey = phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_COMPUTE_INSTANCE, consts.EC2_TENANCY_MAP[pdim.tenancy]))\n log.debug('DB File key: [{}]'.format(dbFileKey))\n computeDb = dbs[dbFileKey]\n ts.start('tinyDbSearchComputeFile')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) &\n (priceQuery['Operating System'] == consts.EC2_OPERATING_SYSTEMS_MAP[pdim.operatingSystem]) &\n #(priceQuery['Tenancy'] == consts.EC2_TENANCY_SHARED) & #removed since it's redundant with the file name\n (priceQuery['Pre Installed S/W'] == pdim.preInstalledSoftware) &\n (priceQuery['CapacityStatus'] == consts.EC2_CAPACITY_RESERVATION_STATUS_MAP[pdim.capacityReservationStatus]) &\n (priceQuery['License Model'] == consts.EC2_LICENSE_MODEL_MAP[pdim.licenseModel]))# &\n #(priceQuery['OfferingClass'] == pdim.offeringClass) &\n #(priceQuery['PurchaseOption'] == purchaseOption ))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EC2, computeDb, query, pdim.instanceHours, pricing_records, cost)\n log.debug(\"Time to search compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n\n\n #Data Transfer\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n\n #Out to the Internet\n if pdim.dataTransferOutInternetGb:\n ts.start('searchDataTransfer')\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n log.debug(\"Time to search AWS Data Transfer Out: [{}]\".format(ts.finish('searchDataTransfer')))\n\n #Intra-regional data transfer - in/out/between EC2 AZs or using EIPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n\n #EBS Storage\n if pdim.ebsStorageGbMonth:\n #storageDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_STORAGE)]\n storageDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_STORAGE))]\n query = ((priceQuery['Volume Type'] == pdim.volumeType))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EBS, storageDb, query, pdim.ebsStorageGbMonth, pricing_records, cost)\n\n\n #System Operation (pIOPS)\n if pdim.volumeType == consts.EBS_VOLUME_TYPE_PIOPS and pdim.pIops:\n #storageDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SYSTEM_OPERATION)]\n storageDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SYSTEM_OPERATION))]\n query = ((priceQuery['Group'] == 'EBS IOPS'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EBS, storageDb, query, pdim.pIops, pricing_records, cost)\n\n #Snapshot Storage\n if pdim.ebsSnapshotGbMonth:\n #snapshotDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SNAPSHOT)]\n snapshotDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SNAPSHOT))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'EBS:SnapshotUsage'))#EBS:SnapshotUsage comes with a prefix in the PriceList API file (i.e. EU-EBS:SnapshotUsage)\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EBS, snapshotDb, query, pdim.ebsSnapshotGbMonth, pricing_records, cost)\n\n #Classic Load Balancer\n if pdim.elbHours:\n #elbDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER)]\n elbDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'LoadBalancerUsage') & (priceQuery['operation'] == 'LoadBalancing'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, elbDb, query, pdim.elbHours, pricing_records, cost)\n\n if pdim.elbDataProcessedGb:\n #elbDb = dbs[phelper.create_file_key(consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER)]\n elbDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'DataProcessing-Bytes') & (priceQuery['operation'] == 'LoadBalancing'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, elbDb, query, pdim.elbDataProcessedGb, pricing_records, cost)\n\n #Application Load Balancer\n #TODO: add support for Network Load Balancer\n if pdim.albHours:\n albDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'LoadBalancerUsage') & (priceQuery['operation'] == 'LoadBalancing:Application'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, albDb, query, pdim.albHours, pricing_records, cost)\n\n if pdim.albLcus:\n albDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_APPLICATION_LOAD_BALANCER))]\n query = ((priceQuery['usageType'] == consts.REGION_PREFIX_MAP[pdim.region]+'LCUUsage') & (priceQuery['operation'] == 'LoadBalancing:Application'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_ELB, albDb, query, pdim.albLcus, pricing_records, cost)\n\n\n\n #TODO: EIP\n #TODO: NAT Gateway\n #TODO: Fee\n\n #_/_/_/_/_/ RESERVED PRICING _/_/_/_/_/\n #Load Reserved DBs\n if pdim.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n indexArgs = {'offeringClasses':[consts.EC2_OFFERING_CLASS_MAP[pdim.offeringClass]],\n 'tenancies':[consts.EC2_TENANCY_MAP[pdim.tenancy]], 'purchaseOptions':[consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]]}\n #Load all values for offeringClasses, tenancies and purchaseOptions\n #indexArgs = {'offeringClasses':consts.EC2_OFFERING_CLASS_MAP.values(),\n # 'tenancies':consts.EC2_TENANCY_MAP.values(), 'purchaseOptions':consts.EC2_PURCHASE_OPTION_MAP.values()}\n tmpDbKey = consts.SERVICE_EC2+pdim.region+pdim.termType+pdim.offeringClass+consts.EC2_TENANCY_MAP[pdim.tenancy]+pdim.offeringType\n #tmpDbKey = consts.SERVICE_EC2+pdim.region+pdim.termType\n dbs = regiondbs.get(tmpDbKey,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_EC2, phelper.get_partition_keys(consts.SERVICE_EC2, pdim.region, consts.SCRIPT_TERM_TYPE_RESERVED, **indexArgs))\n #regiondbs[consts.SERVICE_EC2+pdim.region+pdim.termType]=dbs\n regiondbs[tmpDbKey]=dbs\n\n log.debug(\"dbs keys:{}\".format(dbs.keys()))\n\n ts.finish('tinyDbLoadReserved')\n log.debug(\"Time to load Reserved DB files: [{}]\".format(ts.elapsed('tinyDbLoadReserved')))\n\n\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_COMPUTE_INSTANCE, pdim.offeringClass,\n consts.EC2_TENANCY_MAP[pdim.tenancy], consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]))]\n\n ts.start('tinyDbSearchComputeFileReserved')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) &\n (priceQuery['Operating System'] == consts.EC2_OPERATING_SYSTEMS_MAP[pdim.operatingSystem]) &\n #(priceQuery['Tenancy'] == consts.EC2_TENANCY_SHARED) & #removed since it's redundant with the DB file name\n (priceQuery['Pre Installed S/W'] == pdim.preInstalledSoftware) &\n (priceQuery['License Model'] == consts.EC2_LICENSE_MODEL_MAP[pdim.licenseModel]) &\n #(priceQuery['OfferingClass'] == consts.EC2_OFFERING_CLASS_MAP[pdim.offeringClass]) &\n #(priceQuery['PurchaseOption'] == consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType] ) &\n (priceQuery['LeaseContractLength'] == consts.EC2_RESERVED_YEAR_MAP[\"{}\".format(pdim.years)] ))\n\n hrsQuery = query & (priceQuery['Unit'] == 'Hrs' )\n qtyQuery = query & (priceQuery['Unit'] == 'Quantity' )\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EC2, computeDb, qtyQuery, pdim.instanceCount, pricing_records, cost)\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n #reservedInstanceHours = pdim.instanceCount * consts.HOURS_IN_MONTH * 12 * pdim.years\n reservedInstanceHours = utils.calculate_instance_hours_year(pdim.instanceCount, pdim.years)\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EC2, computeDb, hrsQuery, reservedInstanceHours, pricing_records, cost)\n\n\n log.debug(\"Time to search:[{}]\".format(ts.finish('tinyDbSearchComputeFileReserved')))\n\n\n log.debug(\"regiondbs:[{}]\".format(regiondbs.keys()))\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n #proc = psutil.Process()\n #log.debug(\"open_files: {}\".format(proc.open_files()))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/emr/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/emr/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nfrom ..common.models import Ec2PriceDimension\nfrom ..ec2 import pricing as ec2pricing\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating EMR pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n #Load On-Demand EMR DBs\n dbs = regiondbs.get(consts.SERVICE_EMR+pdim.region+consts.TERM_TYPE_ON_DEMAND,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_EMR, phelper.get_partition_keys(consts.SERVICE_EMR, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_EMR+pdim.region+pdim.termType]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #EMR Compute Instance\n if pdim.instanceHours:\n #The EMR component in the calculation always uses OnDemand (Reserved it's not supported yet for EMR)\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[consts.SCRIPT_TERM_TYPE_ON_DEMAND], consts.PRODUCT_FAMILY_EMR_INSTANCE))]\n ts.start('tinyDbSearchComputeFile')\n #TODO: add support for Hunk Software Type\n query = ((priceQuery['Instance Type'] == pdim.instanceType) & (priceQuery['Software Type'] == 'EMR'))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_EMR, computeDb, query, pdim.instanceHours, pricing_records, cost)\n log.debug(\"Time to search compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n\n\n #EC2 Pricing - the EC2 component takes into consideration either OnDemand or Reserved.\n ec2_pricing = ec2pricing.calculate(Ec2PriceDimension(**pdim.ec2PriceDims))\n log.info(\"pdim.ec2PriceDims:[{}]\".format(pdim.ec2PriceDims))\n log.info(\"ec2_pricing:[{}]\".format(ec2_pricing))\n if ec2_pricing.get('pricingRecords',[]): pricing_records.extend(ec2_pricing['pricingRecords'])\n cost += ec2_pricing.get('totalCost',0)\n\n\n\n\n\n log.debug(\"regiondbs:[{}]\".format(regiondbs.keys()))\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n #proc = psutil.Process()\n #log.debug(\"open_files: {}\".format(proc.open_files()))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/kinesis/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/kinesis/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating DynamoDB pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculationKinesis')\n\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_KINESIS, phelper.get_partition_keys(pdim.region,consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n kinesisDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_KINESIS_STREAMS])]\n\n #Shard Hours\n query = ((priceQuery['Group'] == 'Provisioned shard hour'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_KINESIS, kinesisDb, query, pdim.shardHours, pricing_records, cost)\n\n #PUT Payload Units\n query = ((priceQuery['Group'] == 'Payload Units'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_KINESIS, kinesisDb, query, pdim.putPayloadUnits, pricing_records, cost)\n\n #Extended Retention Hours\n query = ((priceQuery['Group'] == 'Addon shard hour'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_KINESIS, kinesisDb, query, pdim.extendedDataRetentionHours, pricing_records, cost)\n\n #TODO: add Enhanced (shard-level) metrics\n\n #Data Transfer - N/A\n #Note there is no charge for data transfer in Kinesis as per https://aws.amazon.com/kinesis/streams/pricing/\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time to compute: [{}]\".format(ts.finish('totalCalculationKinesis')))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/rds/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/rds/pricing.py",
"content": "import os, sys\nimport json\nimport logging\nfrom ..common import consts, phelper, utils\nfrom ..common.models import PricingResult\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n ts.start('tinyDbLoadReserved')\n\n global regiondbs\n global indexMetadata\n\n\n log.info(\"Calculating RDS pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n #Load On-Demand DBs\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_RDS, phelper.get_partition_keys(consts.SERVICE_RDS, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n cost = 0\n pricing_records = []\n\n awsPriceListApiVersion = indexMetadata['Version']\n priceQuery = tinydb.Query()\n\n\n\n skuEngine = ''\n skuEngineEdition = ''\n skuLicenseModel = ''\n\n if pdim.engine in consts.RDS_ENGINE_MAP:\n skuEngine = consts.RDS_ENGINE_MAP[pdim.engine]['engine']\n skuEngineEdition = consts.RDS_ENGINE_MAP[pdim.engine]['edition']\n skuLicenseModel = consts.RDS_LICENSE_MODEL_MAP[pdim.licenseModel]\n\n deploymentOptionCondition = pdim.deploymentOption\n\n #'Multi-AZ (SQL Server Mirror)' is no longer available in pricing index\n #if 'sqlserver' in pdim.engine and pdim.deploymentOption == consts.RDS_DEPLOYMENT_OPTION_MULTI_AZ:\n # deploymentOptionCondition = consts.RDS_DEPLOYMENT_OPTION_MULTI_AZ_MIRROR\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n\n\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n if pdim.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n #Load On-Demand DBs\n dbs = regiondbs.get(consts.SERVICE_RDS+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_RDS, phelper.get_partition_keys(consts.SERVICE_RDS, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_RDS+pdim.region+pdim.termType]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #DB Instance\n if pdim.instanceHours:\n instanceDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATABASE_INSTANCE))]\n\n\n ts.start('tinyDbSearchComputeFile')\n query = ((priceQuery['Product Family'] == consts.PRODUCT_FAMILY_DATABASE_INSTANCE) &\n (priceQuery['Instance Type'] == pdim.dbInstanceClass) &\n (priceQuery['Database Engine'] == skuEngine) &\n (priceQuery['Database Edition'] == skuEngineEdition) &\n (priceQuery['License Model'] == skuLicenseModel) &\n (priceQuery['Deployment Option'] == deploymentOptionCondition)\n )\n\n log.debug(\"Time to search DB instance compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, instanceDb, query, pdim.instanceHours, pricing_records, cost)\n\n #Data Transfer\n #To internet\n if pdim.dataTransferOutInternetGb:\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n query = ((priceQuery['serviceCode'] == consts.SERVICE_CODE_AWS_DATA_TRANSFER) &\n (priceQuery['To Location'] == 'External') &\n (priceQuery['Transfer Type'] == 'AWS Outbound'))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n\n\n #Inter-regional data transfer - to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n query = ((priceQuery['serviceCode'] == consts.SERVICE_CODE_AWS_DATA_TRANSFER) &\n (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]) &\n (priceQuery['Transfer Type'] == 'InterRegion Outbound'))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n\n #Storage (magnetic, SSD, PIOPS)\n if pdim.storageGbMonth:\n engineCondition = 'Any'\n if skuEngine == consts.RDS_DB_ENGINE_SQL_SERVER: engineCondition = consts.RDS_DB_ENGINE_SQL_SERVER\n storageDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DB_STORAGE])]\n query = ((priceQuery['Volume Type'] == pdim.volumeType) &\n (priceQuery['Database Engine'] == engineCondition) &\n (priceQuery['Deployment Option'] == pdim.deploymentOption))\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, storageDb, query, pdim.storageGbMonth, pricing_records, cost)\n\n #Provisioned IOPS\n if pdim.storageType == consts.SCRIPT_RDS_STORAGE_TYPE_IO1:\n iopsDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DB_PIOPS])]\n query = ((priceQuery['Deployment Option'] == pdim.deploymentOption))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, iopsDb, query, pdim.iops, pricing_records, cost)\n\n #Consumed IOPS (I/O rate)\n if pdim.ioRequests:\n sysopsDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SYSTEM_OPERATION])]\n dbEngineCondition = 'Any'\n if pdim.engine in (consts.RDS_DB_ENGINE_POSTGRESQL, consts.RDS_DB_ENGINE_AURORA_MYSQL):\n dbEngineCondition = pdim.engine\n\n query = ((priceQuery['Group'] == 'Aurora I/O Operation')&\n (priceQuery['Database Engine'] == dbEngineCondition)\n )\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, sysopsDb, query, pdim.ioRequests, pricing_records, cost)\n\n\n #Snapshot Storage\n if pdim.backupStorageGbMonth:\n snapshotDb = dbs[phelper.create_file_key([consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_SNAPSHOT])]\n query = ((priceQuery['usageType'] == 'RDS:ChargedBackupUsage'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, snapshotDb, query, pdim.backupStorageGbMonth, pricing_records, cost)\n\n\n\n\n #_/_/_/_/_/ RESERVED PRICING _/_/_/_/_/\n if pdim.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n #Load Reserved DBs\n\n indexArgs = {'offeringClasses':consts.EC2_OFFERING_CLASS_MAP.values(),\n 'tenancies':[consts.EC2_TENANCY_SHARED], 'purchaseOptions':consts.EC2_PURCHASE_OPTION_MAP.values()}\n\n dbs = regiondbs.get(consts.SERVICE_RDS+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_RDS, phelper.get_partition_keys(consts.SERVICE_RDS, pdim.region, consts.SCRIPT_TERM_TYPE_RESERVED, **indexArgs))\n regiondbs[consts.SERVICE_RDS+pdim.region+pdim.termType]=dbs\n ts.finish('tinyDbLoadReserved')\n log.debug(\"Time to load Reserved DB files: [{}]\".format(ts.elapsed('tinyDbLoadReserved')))\n log.debug(\"regiondbs keys:[{}]\".format(regiondbs))\n\n #DB Instance\n #RDS only supports standard\n instanceDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_DATABASE_INSTANCE, consts.EC2_OFFERING_CLASS_STANDARD,\n consts.EC2_TENANCY_SHARED, consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]))]\n\n\n ts.start('tinyDbSearchComputeFileReserved')\n query = ((priceQuery['Product Family'] == consts.PRODUCT_FAMILY_DATABASE_INSTANCE) &\n (priceQuery['Instance Type'] == pdim.dbInstanceClass) &\n (priceQuery['Database Engine'] == skuEngine) &\n (priceQuery['Database Edition'] == skuEngineEdition) &\n (priceQuery['License Model'] == skuLicenseModel) &\n (priceQuery['Deployment Option'] == deploymentOptionCondition) &\n (priceQuery['OfferingClass'] == consts.EC2_OFFERING_CLASS_MAP[pdim.offeringClass]) &\n (priceQuery['PurchaseOption'] == consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]) &\n (priceQuery['LeaseContractLength'] == consts.EC2_RESERVED_YEAR_MAP[\"{}\".format(pdim.years)])\n )\n\n hrsQuery = query & (priceQuery['Unit'] == 'Hrs' )\n qtyQuery = query & (priceQuery['Unit'] == 'Quantity' )\n\n #TODO: use RDS-specific constants, not EC2 constants\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, instanceDb, qtyQuery, pdim.instanceCount, pricing_records, cost)\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n reservedInstanceHours = utils.calculate_instance_hours_year(pdim.instanceCount, pdim.years)\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_RDS, instanceDb, hrsQuery, reservedInstanceHours, pricing_records, cost)\n\n log.debug(\"Time to search DB instance compute:[{}]\".format(ts.finish('tinyDbSearchComputeFileReserved')))\n\n\n\n\n\n log.debug(\"Total time to calculate price: [{}]\".format(ts.finish('totalCalculation')))\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n return pricing_result.__dict__\n"
},
{
"path": "awspricecalculator/redshift/__init__.py",
"content": ""
},
{
"path": "awspricecalculator/redshift/pricing.py",
"content": "\nimport json\nimport logging\nfrom ..common import consts, phelper\nfrom ..common.models import PricingResult\nfrom ..common.models import Ec2PriceDimension\nfrom ..ec2 import pricing as ec2pricing\nimport tinydb\n\nlog = logging.getLogger()\nregiondbs = {}\nindexMetadata = {}\n\n\ndef calculate(pdim):\n\n log.info(\"Calculating Redshift pricing with the following inputs: {}\".format(str(pdim.__dict__)))\n\n ts = phelper.Timestamp()\n ts.start('totalCalculation')\n ts.start('tinyDbLoadOnDemand')\n ts.start('tinyDbLoadReserved')\n\n awsPriceListApiVersion = ''\n cost = 0\n pricing_records = []\n priceQuery = tinydb.Query()\n\n global regiondbs\n global indexMetadata\n\n #DBs for Data Transfer\n tmpDtDbKey = consts.SERVICE_DATA_TRANSFER+pdim.region+pdim.termType\n dtdbs = regiondbs.get(tmpDtDbKey,{})\n if not dtdbs:\n dtdbs, dtIndexMetadata = phelper.loadDBs(consts.SERVICE_DATA_TRANSFER, phelper.get_partition_keys(consts.SERVICE_DATA_TRANSFER, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND, **{}))\n regiondbs[tmpDtDbKey]=dtdbs\n #_/_/_/_/_/ ON-DEMAND PRICING _/_/_/_/_/\n #Load On-Demand Redshift DBs\n if pdim.termType == consts.SCRIPT_TERM_TYPE_ON_DEMAND:\n\n dbs = regiondbs.get(consts.SERVICE_REDSHIFT+pdim.region+consts.TERM_TYPE_ON_DEMAND,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_REDSHIFT, phelper.get_partition_keys(consts.SERVICE_REDSHIFT, pdim.region, consts.SCRIPT_TERM_TYPE_ON_DEMAND))\n regiondbs[consts.SERVICE_REDSHIFT+pdim.region+pdim.termType]=dbs\n\n ts.finish('tinyDbLoadOnDemand')\n log.debug(\"Time to load OnDemand DB files: [{}]\".format(ts.elapsed('tinyDbLoadOnDemand')))\n\n #Redshift Compute Instance\n if pdim.instanceHours:\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[consts.SCRIPT_TERM_TYPE_ON_DEMAND], consts.PRODUCT_FAMILY_COMPUTE_INSTANCE))]\n ts.start('tinyDbSearchComputeFile')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) )\n\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_REDSHIFT, computeDb, query, pdim.instanceHours, pricing_records, cost)\n log.debug(\"Time to search compute:[{}]\".format(ts.finish('tinyDbSearchComputeFile')))\n\n\n #TODO: move Data Transfer to a common file (since now it's a separate index file)\n \"\"\"\n #Data Transfer\n dataTransferDb = dtdbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType], consts.PRODUCT_FAMILY_DATA_TRANSFER))]\n\n #Out to the Internet\n if pdim.dataTransferOutInternetGb:\n ts.start('searchDataTransfer')\n query = ((priceQuery['To Location'] == 'External') & (priceQuery['Transfer Type'] == 'AWS Outbound'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInternetGb, pricing_records, cost)\n log.debug(\"Time to search AWS Data Transfer Out: [{}]\".format(ts.finish('searchDataTransfer')))\n\n #Intra-regional data transfer - in/out/between EC2 AZs or using EIPs or ELB\n if pdim.dataTransferOutIntraRegionGb:\n query = ((priceQuery['Transfer Type'] == 'IntraRegion'))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutIntraRegionGb, pricing_records, cost)\n\n\n #Inter-regional data transfer - out to other AWS regions\n if pdim.dataTransferOutInterRegionGb:\n query = ((priceQuery['Transfer Type'] == 'InterRegion Outbound') & (priceQuery['To Location'] == consts.REGION_MAP[pdim.toRegion]))\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_DATA_TRANSFER, dataTransferDb, query, pdim.dataTransferOutInterRegionGb, pricing_records, cost)\n \"\"\"\n\n #_/_/_/_/_/ RESERVED PRICING _/_/_/_/_/\n\n print(\"regiondbs[]\".format(regiondbs))\n\n #Load Reserved DBs\n if pdim.termType == consts.SCRIPT_TERM_TYPE_RESERVED:\n\n indexArgs = {'offeringClasses':consts.EC2_OFFERING_CLASS_MAP.values(),\n 'tenancies':[consts.EC2_TENANCY_SHARED], 'purchaseOptions':consts.EC2_PURCHASE_OPTION_MAP.values()}\n\n dbs = regiondbs.get(consts.SERVICE_REDSHIFT+pdim.region+pdim.termType,{})\n if not dbs:\n dbs, indexMetadata = phelper.loadDBs(consts.SERVICE_REDSHIFT, phelper.get_partition_keys(consts.SERVICE_REDSHIFT, pdim.region, consts.SCRIPT_TERM_TYPE_RESERVED, **indexArgs))\n regiondbs[consts.SERVICE_REDSHIFT+pdim.region+pdim.termType]=dbs\n ts.finish('tinyDbLoadReserved')\n log.debug(\"Time to load Reserved DB files: [{}]\".format(ts.elapsed('tinyDbLoadReserved')))\n log.debug(\"regiondbs keys:[{}]\".format(regiondbs))\n\n #Redshift only supports standard\n print(\"dbs:[{}]\".format(dbs))\n computeDb = dbs[phelper.create_file_key((consts.REGION_MAP[pdim.region], consts.TERM_TYPE_MAP[pdim.termType],\n consts.PRODUCT_FAMILY_COMPUTE_INSTANCE, consts.EC2_OFFERING_CLASS_STANDARD,\n consts.EC2_TENANCY_SHARED, consts.EC2_PURCHASE_OPTION_MAP[pdim.offeringType]))]\n\n\n\n ts.start('tinyDbSearchComputeFileReserved')\n query = ((priceQuery['Instance Type'] == pdim.instanceType) &\n (priceQuery['LeaseContractLength'] == consts.EC2_RESERVED_YEAR_MAP[\"{}\".format(pdim.years)]))\n\n hrsQuery = query & (priceQuery['Unit'] == 'Hrs' )\n qtyQuery = query & (priceQuery['Unit'] == 'Quantity' )\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_ALL_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_REDSHIFT, computeDb, qtyQuery, pdim.instanceCount, pricing_records, cost)\n\n if pdim.offeringType in (consts.SCRIPT_EC2_PURCHASE_OPTION_NO_UPFRONT, consts.SCRIPT_EC2_PURCHASE_OPTION_PARTIAL_UPFRONT):\n reservedInstanceHours = pdim.instanceCount * consts.HOURS_IN_MONTH * 12 * pdim.years #TODO: move to common function\n pricing_records, cost = phelper.calculate_price(consts.SERVICE_REDSHIFT, computeDb, hrsQuery, reservedInstanceHours, pricing_records, cost)\n\n log.debug(\"Time to search:[{}]\".format(ts.finish('tinyDbSearchComputeFileReserved')))\n\n awsPriceListApiVersion = indexMetadata['Version']\n extraargs = {'priceDimensions':pdim}\n pricing_result = PricingResult(awsPriceListApiVersion, pdim.region, cost, pricing_records, **extraargs)\n log.debug(json.dumps(vars(pricing_result),sort_keys=False,indent=4))\n\n log.debug(\"Total time: [{}]\".format(ts.finish('totalCalculation')))\n return pricing_result.__dict__\n"
},
{
"path": "cloudformation/function-plus-schedule.json",
"content": "{\n\t\"AWSTemplateFormatVersion\": \"2010-09-09\",\n\t\"Description\": \"AWS CloudFormation Template for deploying a Lambda function that calculates EC2 pricing in near real-time\",\n\t\"Parameters\": {\n \t\t\"TagKey\" : {\n\t\t\t\"Type\": \"String\",\n \t\t\"Description\" : \"Tag key that will be used to find AWS resources. Mandatory\",\n \t\t\"MinLength\": \"1\",\n\t\t\t\"ConstraintDescription\": \"Tag key is mandatory.\" \t\t\n \t\t}, \n \t\t\"TagValue\" : {\n\t\t\t\"Type\": \"String\",\n \t\t\"MinLength\": \"1\",\n \t\t\"Description\" : \"Tag value that will be used to find AWS resources. Mandatory\",\n\t\t\t\"ConstraintDescription\": \"Tag value is mandatory.\" \t\t\n \t\t}\n \t\t\n\t},\n\t\"Resources\": {\n\n \"LambdaRealtimeCalculatePricingRole\": {\n \"Type\": \"AWS::IAM::Role\",\n \"Properties\": {\n \"AssumeRolePolicyDocument\": {\n \"Version\": \"2012-10-17\",\n \"Statement\": [{\n \"Effect\": \"Allow\",\n \"Principal\": {\"Service\": [\"lambda.amazonaws.com\"]},\n \"Action\": [\"sts:AssumeRole\"]\n }]\n },\n \"Path\": \"/\",\n \"Policies\": [{\n \"PolicyName\": \"root\",\n \"PolicyDocument\": {\n \"Version\": \"2012-10-17\",\n \"Statement\": [{\n \"Effect\": \"Allow\",\n \"Action\": [\"logs:CreateLogGroup\",\"logs:CreateLogStream\",\"logs:PutLogEvents\"],\n \"Resource\": \"arn:aws:logs:*:*:*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"cloudwatch:*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"ec2:Describe*\",\n \"elasticloadbalancing:Describe*\",\n \"autoscaling:Describe*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"rds:Describe*\",\n \"rds:List*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"dynamodb:Describe*\",\n \"dynamodb:List*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"kinesis:Describe*\",\n \"kinesis:List*\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"lambda:GetFunctionConfiguration\"],\n \"Resource\": \"*\"\n },\n {\n \"Effect\": \"Allow\",\n \"Action\": [\"tag:getResources\", \"tag:getTagKeys\", \"tag:getTagValues\"],\n \"Resource\": \"*\"\n }\n\n ]\n }\n }]\n }\n },\n\n\t\t\"LambdaRealtimeCalculatePricingFunction\": {\n\t\t \"Type\": \"AWS::Lambda::Function\",\n \"DependsOn\" : [\"LambdaRealtimeCalculatePricingRole\"],\t\t \n\t\t \"Properties\": {\n\t\t \"Handler\": \"functions/calculate-near-realtime.handler\",\n\t\t \"Role\": { \"Fn::GetAtt\" : [\"LambdaRealtimeCalculatePricingRole\", \"Arn\"] },\n\t\t \"Code\": {\n\t\t \"S3Bucket\": { \"Fn::Join\" : [ \"\", [\"concurrencylabs-deployment-artifacts-public-\", { \"Ref\" : \"AWS::Region\" }] ] },\n\t\t \"S3Key\": \"lambda-near-realtime-pricing/calculate-near-realtime-pricing-v3.10.zip\"\n\t\t },\n\t\t \"Runtime\": \"python3.6\",\n\t\t \"Timeout\": \"300\",\n\t\t \"MemorySize\" : 1024\n\t\t }\n\t\t},\n\n\n\"ScheduledPricingCalculationRule\": {\n \"Type\": \"AWS::Events::Rule\",\n \"Properties\": {\n \"Description\": \"Invoke Pricing Calculator Lambda function every 5 minutes\",\n \"ScheduleExpression\": \"rate(5 minutes)\",\n \"State\": \"ENABLED\",\n \"Targets\": [{\n \"Arn\": { \"Fn::GetAtt\": [\"LambdaRealtimeCalculatePricingFunction\", \"Arn\"] },\n \"Id\": \"NearRealTimePriceCalculatorFunctionv1\",\n \"Input\":{\"Fn::Join\":[\"\", [\"{\\\"tag\\\":{\\\"key\\\":\\\"\",{\"Ref\":\"TagKey\"},\"\\\",\\\"value\\\":\\\"\",{\"Ref\":\"TagValue\"},\"\\\"}}\"]]}\n }]\n }\n},\n\n\n\"PermissionForEventsToInvokePricingCalculationLambda\": {\n \"Type\": \"AWS::Lambda::Permission\",\n \"Properties\": {\n \"FunctionName\": { \"Ref\": \"LambdaRealtimeCalculatePricingFunction\" },\n \"Action\": \"lambda:InvokeFunction\",\n \"Principal\": \"events.amazonaws.com\",\n \"SourceArn\": { \"Fn::GetAtt\": [\"ScheduledPricingCalculationRule\", \"Arn\"] }\n }\n}\n\n},\n\n\t\"Outputs\": {\n\n\t\t\"Documentation\": {\n\t\t\t\"Description\": \"For more details, see this blog post\",\n\t\t\t\"Value\": \"https://www.concurrencylabs.com/blog/aws-pricing-lambda-realtime-calculation-function/\"\n\t\t},\n\n\n\t\t\"LambdaFunction\": {\n\t\t\t\"Description\": \"Lambda function that calculates pricing in near real-time\",\n\t\t\t\"Value\": {\n\t\t\t\t\"Ref\": \"LambdaRealtimeCalculatePricingFunction\"\n\t\t\t}\n\t\t},\n\n\t\t\"ScheduledEvent\": {\n\t\t\t\"Description\": \"CloudWatch Events schedule that will trigger the Lambda function\",\n\t\t\t\"Value\": {\n\t\t\t\t\"Ref\": \"ScheduledPricingCalculationRule\"\n\t\t\t}\n\t\t}\n\n\t}\n}\n"
},
{
"path": "cloudformation/lambda-metric-filters.yml",
"content": "AWSTemplateFormatVersion: '2010-09-09'\nDescription: AWS CloudFormation Template for creating CloudWatch Logs Metric Filters that keep track of memory utilization (and in the future, possibly other data that can be extracted from Lambda output in CW Logs)\n\nParameters:\n LambdaFunctionName:\n Default: \"\"\n Description: Name of the Lambda function to monitor\n Type: String\n\n\nResources:\n LambdaMemoryUsed:\n Properties:\n FilterPattern: '[reportLabel=REPORT, requestIdLabel=\"RequestId:\",..., maxMemoryUsedValue, maxMemoryUsedMbLabel]'\n LogGroupName:\n Fn::Join:\n - ''\n - - '/aws/lambda/'\n - Ref: LambdaFunctionName\n MetricTransformations:\n - MetricName:\n Fn::Join:\n - ''\n - - 'MemoryUsed-'\n - Ref: LambdaFunctionName\n MetricNamespace: ConcurrencyLabs/Lambda/\n MetricValue: $maxMemoryUsedValue\n Type: AWS::Logs::MetricFilter\n\n LambdaMemorySize:\n Properties:\n FilterPattern: '[reportLabel=REPORT, requestIdLabel=\"RequestId:\",..., memorySizeValue, memorySizeValueMbLabel, maxLabel, memoryLabel, usedLabel, maxMemoryUsedValue, maxMemoryUsedMbLabel]'\n LogGroupName:\n Fn::Join:\n - ''\n - - '/aws/lambda/'\n - Ref: LambdaFunctionName\n MetricTransformations:\n - MetricName:\n Fn::Join:\n - ''\n - - 'MemorySize-'\n - Ref: LambdaFunctionName\n MetricNamespace: ConcurrencyLabs/Lambda/\n MetricValue: $memorySizeValue\n Type: AWS::Logs::MetricFilter\n\n\n\n\n\n\n"
},
{
"path": "functions/calculate-near-realtime.py",
"content": "from __future__ import print_function\nimport datetime\nimport json\nimport logging,traceback\nimport math\nimport os\nimport sys\n\n\nimport boto3\nfrom botocore.exceptions import ClientError\n\n\n__location__ = os.path.dirname(os.path.realpath(__file__))\nsys.path.append(os.path.join(__location__, \"../\"))\nsys.path.append(os.path.join(__location__, \"../vendored\"))\n\n\nimport awspricecalculator.ec2.pricing as ec2pricing\nimport awspricecalculator.rds.pricing as rdspricing\nimport awspricecalculator.awslambda.pricing as lambdapricing\nimport awspricecalculator.dynamodb.pricing as ddbpricing\nimport awspricecalculator.kinesis.pricing as kinesispricing\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.consts as consts\nfrom awspricecalculator.common.errors import NoDataFoundError\n\nlog = logging.getLogger()\n#log.setLevel(logging.INFO)\n\n\n\nec2client = None\nrdsclient = None\nelbclient = None\nlambdaclient = None\ndddbclient = None\nkinesisclient = None\ncwclient = None\ntagsclient = None\n\n#_/_/_/_/_/_/ default_values - start _/_/_/_/_/_/\n\n#Delay in minutes for metrics collection. We want to make sure that all metrics have arrived for the time period we are evaluating\n#Note: Unless you have detailed metrics enabled in CloudWatch, make sure it is >= 10\nMETRIC_DELAY = 10\n\n#Time window in minutes we will use for metric calculations\n#Note: make sure this is at least 5, unless you have detailed metrics enabled in CloudWatch\nMETRIC_WINDOW = 5\n\nFORECAST_PERIOD_MONTHLY = 'monthly'\nFORECAST_PERIOD_HOURLY = 'hourly'\nDEFAULT_FORECAST_PERIOD = FORECAST_PERIOD_MONTHLY\nHOURS_DICT = {FORECAST_PERIOD_MONTHLY:720, FORECAST_PERIOD_HOURLY:1}\n\n\nCW_NAMESPACE = 'ConcurrencyLabs/Pricing/NearRealTimeForecast'\nCW_METRIC_NAME_ESTIMATEDCHARGES = 'EstimatedCharges'\nCW_METRIC_DIMENSION_SERVICE_NAME = 'ServiceName'\nCW_METRIC_DIMENSION_PERIOD = 'ForecastPeriod'\nCW_METRIC_DIMENSION_CURRENCY = 'Currency'\nCW_METRIC_DIMENSION_TAG = 'Tag'\nCW_METRIC_DIMENSION_SERVICE_NAME_EC2 = 'ec2'\nCW_METRIC_DIMENSION_SERVICE_NAME_RDS = 'rds'\nCW_METRIC_DIMENSION_SERVICE_NAME_LAMBDA = 'lambda'\nCW_METRIC_DIMENSION_SERVICE_NAME_DYNAMODB = 'dynamodb'\nCW_METRIC_DIMENSION_SERVICE_NAME_KINESIS = 'kinesis'\nCW_METRIC_DIMENSION_SERVICE_NAME_TOTAL = 'total'\nCW_METRIC_DIMENSION_CURRENCY_USD = 'USD'\n\n\nSERVICE_EC2 = 'ec2'\nSERVICE_RDS = 'rds'\nSERVICE_ELB = 'elasticloadbalancing'\nSERVICE_LAMBDA = 'lambda'\nSERVICE_DYNAMODB = 'dynamodb'\nSERVICE_KINESIS = 'kinesis'\n\nRESOURCE_LAMBDA_FUNCTION = 'function'\nRESOURCE_ELB = 'loadbalancer'\nRESOURCE_ALB = 'loadbalancer/app'\nRESOURCE_NLB = 'loadbalancer/net'\nRESOURCE_EC2_INSTANCE = 'instance'\nRESOURCE_RDS_DB_INSTANCE = 'db'\nRESOURCE_EBS_VOLUME = 'volume'\nRESOURCE_EBS_SNAPSHOT = 'snapshot'\nRESOURCE_DDB_TABLE = 'table'\nRESOURCE_STREAM = 'stream'\n\n#This map is used to specify which services and resource types will be searched using the tag service\nSERVICE_RESOURCE_MAP = {SERVICE_EC2:[RESOURCE_EBS_VOLUME,RESOURCE_EBS_SNAPSHOT, RESOURCE_EC2_INSTANCE],\n SERVICE_RDS:[RESOURCE_RDS_DB_INSTANCE],\n SERVICE_LAMBDA:[RESOURCE_LAMBDA_FUNCTION],\n SERVICE_ELB:[RESOURCE_ELB], #only provide RESOURCE_ELB, even for ALB and NLB\n SERVICE_DYNAMODB:[RESOURCE_DDB_TABLE],\n SERVICE_KINESIS:[RESOURCE_STREAM]\n }\n\n#_/_/_/_/_/_/ default values - end _/_/_/_/_/_/\n\n\ndef handler(event, context):\n log.setLevel(consts.LOG_LEVEL)\n log.info(\"Received event {}\".format(json.dumps(event)))\n\n try:\n init_clients(context)\n\n result = {}\n pricing_records = []\n ec2Cost = 0\n rdsCost = 0\n lambdaCost = 0\n ddbCost = 0\n kinesisCost = 0\n totalCost = 0\n\n\n #First, get the tags we'll be searching for, from the CloudWatch scheduled event\n tagkey = \"\"\n tagvalue = \"\"\n if 'tag' in event:\n tagkey = event['tag']['key']\n tagvalue = event['tag']['value']\n if tagkey == \"\" or tagvalue == \"\":\n log.error(\"No tags specified, aborting function!\")\n return {}\n\n log.info(\"Will search resources with the following tag:[\"+tagkey+\"] - value[\"+tagvalue+\"]\")\n\n resource_manager = ResourceManager(tagkey, tagvalue)\n\n start, end = calculate_time_range()\n\n elb_hours = 0\n elb_data_processed_gb = 0\n elb_instances = {}\n alb_hours = 0\n alb_lcus = 0\n\n #Get tagged ELB(s) and their registered instances\n #taggedelbs = find_elbs(tagkey, tagvalue)\n taggedelbs = resource_manager.get_resource_ids(SERVICE_ELB, RESOURCE_ELB)\n taggedalbs = resource_manager.get_resource_ids(SERVICE_ELB, RESOURCE_ALB)\n taggednlbs = resource_manager.get_resource_ids(SERVICE_ELB, RESOURCE_NLB)\n if taggedelbs:\n log.info(\"Found tagged Classic ELBs:{}\".format(taggedelbs))\n elb_instances = get_elb_instances(taggedelbs)#TODO:add support to find registered instances for ALB and NLB\n #Get all EC2 instances registered with each tagged ELB, so we can calculate ELB data processed\n #Registered instances will be used for data processed calculation, and not for instance hours, unless they're tagged.\n if taggedalbs:\n log.info(\"Found tagged Application Load Balancers:{}\".format(taggedalbs))\n if taggednlbs:\n log.info(\"Found tagged Network Load Balancers:{}\".format(taggednlbs))\n\n #TODO: once pricing for ALB and NLB is added to awspricecalculator, separate hours by ELB type\n elb_hours += (len(taggedelbs)+len(taggednlbs))*HOURS_DICT[DEFAULT_FORECAST_PERIOD]\n alb_hours += len(taggedalbs)*HOURS_DICT[DEFAULT_FORECAST_PERIOD]\n\n\n if elb_instances:\n try:\n log.info(\"Found registered EC2 instances to tagged ELBs [{}]:{}\".format(taggedelbs, elb_instances.keys()))\n elb_data_processed_gb = calculate_elb_data_processed(start, end, elb_instances)*calculate_forecast_factor() / (10**9)\n except Exception as failure:\n log.error('Error calculating costs for tagged ELBs: %s', failure)\n else:\n log.info(\"Didn't find any EC2 instances registered to tagged ELBs [{}]\".format(taggedelbs))\n #else:\n # log.info(\"No tagged ELBs found\")\n\n #Get tagged EC2 instances\n ec2_instances = get_ec2_instances_by_tag(tagkey, tagvalue)\n if ec2_instances:\n log.info(\"Tagged EC2 instances:{}\".format(ec2_instances.keys()))\n else:\n log.info(\"Didn't find any tagged, running EC2 instances\")\n\n #Calculate Classic ELB cost\n if elb_hours:\n elb_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, elbHours=elb_hours,elbDataProcessedGb=elb_data_processed_gb))\n if 'pricingRecords' in elb_cost:\n pricing_records.extend(elb_cost['pricingRecords'])\n ec2Cost = ec2Cost + elb_cost['totalCost']\n\n #Calculate Application Load Balancer cost\n if alb_hours:\n alb_lcus = calculate_alb_lcus(start, end, taggedalbs)*calculate_forecast_factor()\n alb_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, albHours=alb_hours, albLcus=alb_lcus))\n if 'pricingRecords' in alb_cost:\n pricing_records.extend(alb_cost['pricingRecords'])\n ec2Cost = ec2Cost + alb_cost['totalCost']\n\n\n\n #Calculate EC2 compute time for ALL instance types found (subscribed to ELB or not) - group by instance types\n all_instance_dict = {}\n all_instance_dict.update(ec2_instances)\n all_instance_types = get_instance_type_count(all_instance_dict)\n log.info(\"All instance types:{}\".format(all_instance_types))\n\n #Calculate EC2 compute time cost\n #TODO: add support for all available OS\n for instance_type in all_instance_types:\n try:\n ec2_compute_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, instanceType=instance_type, instanceHours=all_instance_types[instance_type]*HOURS_DICT[DEFAULT_FORECAST_PERIOD]))\n if 'pricingRecords' in ec2_compute_cost: pricing_records.extend(ec2_compute_cost['pricingRecords'])\n ec2Cost = ec2Cost + ec2_compute_cost['totalCost']\n except Exception as failure:\n log.error('Error processing %s: %s', instance_type, failure)\n\n #Get provisioned storage by volume type, and provisioned IOPS (if applicable)\n ebs_storage_dict, piops = get_storage_by_ebs_type(all_instance_dict)\n\n #Calculate EBS storagecost\n for k in ebs_storage_dict.keys():\n if k == 'io1': pricing_piops = piops\n else: pricing_piops = 0\n try:\n ebs_storage_cost = ec2pricing.calculate(data.Ec2PriceDimension(region=region, ebsVolumeType=k, ebsStorageGbMonth=ebs_storage_dict[k], pIops=pricing_piops))\n if 'pricingRecords' in ebs_storage_cost: pricing_records.extend(ebs_storage_cost['pricingRecords'])\n ec2Cost = ec2Cost + ebs_storage_cost['totalCost']\n except Exception as failure:\n log.error('Error processing ebs storage costs: %s', failure)\n\n\n #Get tagged RDS DB instances\n #db_instances = get_db_instances_by_tag(tagkey, tagvalue)\n db_instances = get_db_instances_by_tag(resource_manager.get_resource_ids(SERVICE_RDS, RESOURCE_RDS_DB_INSTANCE))\n if db_instances:\n log.info(\"Found the following tagged DB instances:{}\".format(db_instances.keys()))\n else:\n log.info(\"Didn't find any tagged RDS DB instances\")\n\n #Calculate RDS instance time for ALL instance types found - group by DB instance types\n all_db_instance_dict = {}\n all_db_instance_dict.update(db_instances)\n all_db_instance_types = get_db_instance_type_count(all_db_instance_dict)\n all_db_storage_types = get_db_storage_type_count(all_db_instance_dict)\n\n #TODO: add support for read replicas\n\n #Calculate RDS instance time cost\n rds_instance_cost = {}\n for db_instance_type in all_db_instance_types:\n try:\n dbInstanceClass = db_instance_type.split(\"|\")[0]\n engine = db_instance_type.split(\"|\")[1]\n licenseModel= db_instance_type.split(\"|\")[2]\n multiAz= bool(int(db_instance_type.split(\"|\")[3]))\n log.info(\"Calculating RDS DB Instance compute time\")\n rds_instance_cost = rdspricing.calculate(data.RdsPriceDimension(region=region, dbInstanceClass=dbInstanceClass, multiAz=multiAz,\n engine=engine, licenseModel=licenseModel, instanceHours=all_db_instance_types[db_instance_type]*HOURS_DICT[DEFAULT_FORECAST_PERIOD]))\n\n if 'pricingRecords' in rds_instance_cost: pricing_records.extend(rds_instance_cost['pricingRecords'])\n rdsCost = rdsCost + rds_instance_cost['totalCost']\n except Exception as failure:\n log.error('Error processing RDS instance time costs: %s', failure)\n\n #Calculate RDS storage cost\n #TODO: add support for Aurora operations\n rds_storage_cost = {}\n for storage_key in all_db_storage_types.keys():\n try:\n storageType = storage_key.split(\"|\")[0]\n multiAz = bool(int(storage_key.split(\"|\")[1]))\n storageGbMonth = all_db_storage_types[storage_key]['AllocatedStorage']\n iops = all_db_storage_types[storage_key]['Iops']\n log.info(\"Calculating RDS DB Instance Storage\")\n rds_storage_cost = rdspricing.calculate(data.RdsPriceDimension(region=region, storageType=storageType,\n multiAz=multiAz, storageGbMonth=storageGbMonth,\n iops=iops))\n\n if 'pricingRecords' in rds_storage_cost: pricing_records.extend(rds_storage_cost['pricingRecords'])\n rdsCost = rdsCost + rds_storage_cost['totalCost']\n except Exception as failure:\n log.error('Error processing RDS storage costs: %s', failure)\n\n #RDS Data Transfer - the Lambda function will assume all data transfer happens between RDS and EC2 instances\n\n #Lambda functions\n #TODO: add support for lambda function qualifiers\n #TODO: calculate data ingested into CloudWatch Logs\n lambdafunctions = resource_manager.get_resources(SERVICE_LAMBDA, RESOURCE_LAMBDA_FUNCTION)\n for func in lambdafunctions:\n executions = calculate_lambda_executions(start, end, func)\n avgduration = calculate_lambda_duration(start, end, func)\n funcname = ''\n qualifier = ''\n fullname = ''\n funcname = func.id\n fullname = funcname\n #if 'qualifier' in func:\n # qualifier = func['qualifier']\n # fullname += \":\"+qualifier\n memory = get_lambda_memory(funcname,qualifier)\n log.info(\"Executions for Lambda function [{}]: [{}] - Memory:[{}] - Avg Duration:[{}]\".format(funcname,executions,memory, avgduration))\n if executions and avgduration:\n try:\n #Note we're setting data transfer = 0, since we don't have a way to calculate it based on CW metrics alone\n #TODO:call a single time and include a GB-s price dimension to the Lambda calculator\n lambdapdim = data.LambdaPriceDimension(region=region, requestCount=executions*calculate_forecast_factor(),\n avgDurationMs=avgduration, memoryMb=memory, dataTranferOutInternetGb=0,\n dataTranferOutIntraRegionGb=0, dataTranferOutInterRegionGb=0, toRegion='')\n lambda_func_cost = lambdapricing.calculate(lambdapdim)\n if 'pricingRecords' in lambda_func_cost: pricing_records.extend(lambda_func_cost['pricingRecords'])\n lambdaCost = lambdaCost + lambda_func_cost['totalCost']\n\n except Exception as failure:\n log.error('Error processing Lambda costs: %s', failure)\n else:\n log.info(\"Skipping pricing calculation for function [{}] - qualifier [{}] due to lack of executions in [{}-minute] time window\".format(fullname, qualifier, METRIC_WINDOW))\n\n\n #DynamoDB\n totalRead = 0\n totalWrite = 0\n ddbtables = resource_manager.get_resources(SERVICE_DYNAMODB, RESOURCE_DDB_TABLE)\n #Provisioned Capacity Units\n for t in ddbtables:\n read, write = get_ddb_capacity_units(t.id)\n log.info(\"Dynamo DB Provisioned Capacity Units - Table:{} Read:{} Write:{}\".format(t.id, read, write))\n totalRead += read\n totalWrite += write\n #TODO: add support for storage\n if totalRead and totalWrite:\n ddbpdim = data.DynamoDBPriceDimension(region=region, readCapacityUnitHours=totalRead*HOURS_DICT[FORECAST_PERIOD_MONTHLY],\n writeCapacityUnitHours=totalWrite*HOURS_DICT[FORECAST_PERIOD_MONTHLY])\n ddbtable_cost = ddbpricing.calculate(ddbpdim)\n if 'pricingRecords' in ddbtable_cost: pricing_records.extend(ddbtable_cost['pricingRecords'])\n ddbCost = ddbCost + ddbtable_cost['totalCost']\n\n\n #Kinesis Streams\n streams = resource_manager.get_resources(SERVICE_KINESIS, RESOURCE_STREAM)\n totalShards = 0\n totalExtendedRetentionCount = 0\n totalPutPayloadUnits = 0\n for s in streams:\n log.info(\"Stream:[{}]\".format(s.id))\n tmpShardCount, tmpExtendedRetentionCount = get_kinesis_stream_shards(s.id)\n totalShards += tmpShardCount\n totalExtendedRetentionCount += tmpExtendedRetentionCount\n\n totalPutPayloadUnits += calculate_kinesis_put_payload_units(start, end, s.id)\n\n if totalShards:\n kinesispdim = data.KinesisPriceDimension(region=region,\n shardHours=totalShards*HOURS_DICT[FORECAST_PERIOD_MONTHLY],\n extendedDataRetentionHours=totalExtendedRetentionCount*HOURS_DICT[FORECAST_PERIOD_MONTHLY],\n putPayloadUnits=totalPutPayloadUnits*calculate_forecast_factor())\n stream_cost = kinesispricing.calculate(kinesispdim)\n if 'pricingRecords' in stream_cost: pricing_records.extend(stream_cost['pricingRecords'])\n\n kinesisCost = kinesisCost + stream_cost['totalCost']\n\n\n\n\n #Do this after all calculations for all supported services have concluded\n totalCost = ec2Cost + rdsCost + lambdaCost + ddbCost + kinesisCost\n result['pricingRecords'] = pricing_records\n result['totalCost'] = round(totalCost,2)\n result['forecastPeriod']=DEFAULT_FORECAST_PERIOD\n result['currency'] = CW_METRIC_DIMENSION_CURRENCY_USD\n\n #Publish metrics to CloudWatch using the default namespace\n\n if tagkey:\n put_cw_metric_data(end, ec2Cost, CW_METRIC_DIMENSION_SERVICE_NAME_EC2, tagkey, tagvalue)\n put_cw_metric_data(end, rdsCost, CW_METRIC_DIMENSION_SERVICE_NAME_RDS, tagkey, tagvalue)\n put_cw_metric_data(end, lambdaCost, CW_METRIC_DIMENSION_SERVICE_NAME_LAMBDA, tagkey, tagvalue)\n put_cw_metric_data(end, ddbCost, CW_METRIC_DIMENSION_SERVICE_NAME_DYNAMODB, tagkey, tagvalue)\n put_cw_metric_data(end, kinesisCost, CW_METRIC_DIMENSION_SERVICE_NAME_KINESIS, tagkey, tagvalue)\n put_cw_metric_data(end, totalCost, CW_METRIC_DIMENSION_SERVICE_NAME_TOTAL, tagkey, tagvalue)\n\n\n\n log.info(\"Estimated monthly cost for resources tagged with key={},value={} : [{}]\".format(tagkey, tagvalue, json.dumps(result,sort_keys=False,indent=4)))\n\n except NoDataFoundError as ndf:\n log.error (\"NoDataFoundError [{}]\".format(ndf))\n\n except Exception as e:\n traceback.print_exc()\n log.error(\"Exception message:[\"+str(e)+\"]\")\n\n\n return result\n\n#TODO: calculate data transfer for instances that are not registered with the ELB\n#TODO: Support different OS for EC2 instances (see how engine and license combinations are calculated for RDS)\n#TODO: log the actual AWS resources that are found for the price calculation\n#TODO: add support for detailed metrics fee\n#TODO: add support for EBS optimized\n#TODO: add support for EIP\n#TODO: add support for EC2 operating systems other than Linux\n#TODO: calculate monthly hours based on the current month, instead of assuming 720\n#TODO: add support for different forecast periods (1 hour, 1 day, 1 month, etc.)\n#TODO: add support for Spot and Reserved. Function only supports On-demand instances at the time\n\n\ndef put_cw_metric_data(timestamp, cost, service, tagkey, tagvalue):\n\n response = cwclient.put_metric_data(\n Namespace=CW_NAMESPACE,\n MetricData=[\n {\n 'MetricName': CW_METRIC_NAME_ESTIMATEDCHARGES,\n 'Dimensions': [{'Name': CW_METRIC_DIMENSION_SERVICE_NAME,'Value': service},\n {'Name': CW_METRIC_DIMENSION_PERIOD,'Value': DEFAULT_FORECAST_PERIOD},\n {'Name': CW_METRIC_DIMENSION_CURRENCY,'Value': CW_METRIC_DIMENSION_CURRENCY_USD},\n {'Name': CW_METRIC_DIMENSION_TAG,'Value': tagkey+'='+tagvalue}\n ],\n 'Timestamp': timestamp,\n 'Value': cost,\n 'Unit': 'Count'\n }\n ]\n )\n\n\ndef get_elb_instances(elbnames):\n result = {}\n instance_ids = []\n elbs = elbclient.describe_load_balancers(LoadBalancerNames=elbnames)\n if 'LoadBalancerDescriptions' in elbs:\n for e in elbs['LoadBalancerDescriptions']:\n if 'Instances' in e:\n instances = e['Instances']\n for i in instances:\n instance_ids.append(i['InstanceId'])\n\n if instance_ids:\n response = ec2client.describe_instances(InstanceIds=instance_ids)\n if 'Reservations' in response:\n for r in response['Reservations']:\n if 'Instances' in r:\n for i in r['Instances']:\n result[i['InstanceId']]=i\n\n return result\n\n\ndef get_ec2_instances_by_tag(tagkey, tagvalue):\n result = {}\n response = ec2client.describe_instances(Filters=[{'Name': 'tag:'+tagkey, 'Values':[tagvalue]},\n {'Name': 'instance-state-name', 'Values': ['running',]}])\n if 'Reservations' in response:\n reservations = response['Reservations']\n for r in reservations:\n if 'Instances' in r:\n for i in r['Instances']:\n result[i['InstanceId']]=i\n\n return result\n\n\n\ndef get_db_instances_by_tag(dbIds):\n result = {}\n #TODO: paginate\n if dbIds:\n response = rdsclient.describe_db_instances(Filters=[{'Name':'db-instance-id','Values':dbIds}])\n if 'DBInstances' in response:\n dbInstances = response['DBInstances']\n for d in dbInstances:\n result[d['DbiResourceId']]=d\n return result\n\n\n\ndef get_non_elb_instances_by_tag(tagkey, tagvalue, elb_instances):\n result = {}\n response = ec2client.describe_instances(Filters=[{'Name': 'tag:'+tagkey, 'Values':[tagvalue]}])\n if 'Reservations' in response:\n reservations = response['Reservations']\n for r in reservations:\n if 'Instances' in r:\n for i in r['Instances']:\n if i['InstanceId'] not in elb_instances: result[i['InstanceId']]=i\n\n return result\n\ndef get_instance_type_count(instance_dict):\n result = {}\n for key in instance_dict:\n instance_type = instance_dict[key]['InstanceType']\n if instance_type in result:\n result[instance_type] = result[instance_type] + 1\n else:\n result[instance_type] = 1\n return result\n\n\ndef get_db_instance_type_count(db_instance_dict):\n result = {}\n for key in db_instance_dict:\n #key format: db-instance-class|engine|license-model|multi-az\n multiAz = 0\n if db_instance_dict[key]['MultiAZ']==True:multiAz=1\n db_instance_key = db_instance_dict[key]['DBInstanceClass']+\"|\"+\\\n db_instance_dict[key]['Engine']+\"|\"+\\\n db_instance_dict[key]['LicenseModel']+\"|\"+\\\n str(multiAz)\n if db_instance_key in result:\n result[db_instance_key] = result[db_instance_key] + 1\n else:\n result[db_instance_key] = 1\n return result\n\n\ndef get_db_storage_type_count(db_instance_dict):\n result = {}\n for key in db_instance_dict:\n #key format: db-storage-type|allocated-storage|iops|multi-az\n multiAz = 0\n #print(\"db_instance_dict[{}]\".format(db_instance_dict[key]))\n if db_instance_dict[key]['MultiAZ']==True:multiAz=1\n db_storage_key = db_instance_dict[key]['StorageType']+\"|\"+\\\n str(multiAz)\n\n if 'Iops' not in db_instance_dict[key]: db_instance_dict[key]['Iops'] = 0\n\n if db_storage_key in result:\n result[db_storage_key]['Iops'] += db_instance_dict[key]['Iops']\n result[db_storage_key]['AllocatedStorage'] += db_instance_dict[key]['AllocatedStorage']\n else:\n result[db_storage_key] = {}\n result[db_storage_key]['Iops'] = db_instance_dict[key]['Iops']\n result[db_storage_key]['AllocatedStorage'] = db_instance_dict[key]['AllocatedStorage']\n\n #print (\"Storage composite key:[{}]\".format(db_storage_key))\n\n\n return result\n\n\n\n\ndef get_storage_by_ebs_type(instance_dict):\n result = {}\n iops = 0\n ebs_ids = []\n for key in instance_dict:\n block_mappings = instance_dict[key]['BlockDeviceMappings']\n for bm in block_mappings:\n if 'Ebs' in bm:\n if 'VolumeId' in bm['Ebs']:\n ebs_ids.append(bm['Ebs']['VolumeId'])\n\n volume_details = {}\n if ebs_ids: volume_details = ec2client.describe_volumes(VolumeIds=ebs_ids)#TODO:add support for pagination\n if 'Volumes' in volume_details:\n for v in volume_details['Volumes']:\n volume_type = v['VolumeType']\n if volume_type in result:\n result[volume_type] = result[volume_type] + int(v['Size'])\n else:\n result[volume_type] = int(v['Size'])\n if volume_type == 'io1': iops = iops + int(v['Iops'])\n\n return result, iops\n\n\ndef get_total_snapshot_storage(tagkey, tagvalue):\n result = 0\n snapshots = ec2client.describe_snapshots(Filters=[{'Name': 'tag:'+tagkey,'Values': [tagvalue]}])\n if 'Snapshots' in snapshots:\n for s in snapshots['Snapshots']:\n result = result + s['VolumeSize']\n\n #log.info(\"total snapshot size:[\"+str(result)+\"]\")\n return result\n\n\n\n\n\"\"\"\nFor each EC2 instance registered to an ELB, get the following metrics: NetworkIn, NetworkOut.\nThen add them up and use them to calculate the total data processed by the ELB\n\"\"\"\ndef calculate_elb_data_processed(start, end, elb_instances):\n result = 0\n\n for instance_id in elb_instances.keys():\n metricsNetworkIn = cwclient.get_metric_statistics(\n Namespace='AWS/EC2',\n MetricName='NetworkIn',\n Dimensions=[{'Name': 'InstanceId','Value': instance_id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n metricsNetworkOut = cwclient.get_metric_statistics(\n Namespace='AWS/EC2',\n MetricName='NetworkOut',\n Dimensions=[{'Name': 'InstanceId','Value': instance_id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n for datapoint in metricsNetworkIn['Datapoints']:\n if 'Sum' in datapoint: result = result + datapoint['Sum']\n for datapoint in metricsNetworkOut['Datapoints']:\n if 'Sum' in datapoint: result = result + datapoint['Sum']\n\n log.info (\"Total Bytes processed by ELBs in time window of [\"+str(METRIC_WINDOW)+\"] minutes :[\"+str(result)+\"]\")\n\n return result\n\n\"\"\"\nFor each ALB, get the value for the ConsumedLCUs metric\n\"\"\"\n\n\ndef calculate_alb_lcus(start, end, albs):\n result = 0\n\n for a in albs:\n log.info(\"Getting ConsumedLCUs for ALB: [{}]\".format(a))\n metricsLcus = cwclient.get_metric_statistics(\n Namespace='AWS/ApplicationELB',\n MetricName='ConsumedLCUs',\n Dimensions=[{'Name': 'LoadBalancer','Value': \"app/{}\".format(a)}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n for datapoint in metricsLcus['Datapoints']:\n result += datapoint.get('Sum',0)\n\n log.info (\"Total ConsumedLCUs consumed by ALBs in time window of [\"+str(METRIC_WINDOW)+\"] minutes :[\"+str(result)+\"]\")\n\n return result\n\n\n\n\n\ndef calculate_lambda_executions(start, end, func):\n result = 0\n\n invocations = cwclient.get_metric_statistics(\n Namespace='AWS/Lambda',\n MetricName='Invocations',\n #Dimensions=[{'Name': 'FunctionName','Value': func['name']}],\n Dimensions=[{'Name': 'FunctionName','Value': func.id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n for datapoint in invocations['Datapoints']:\n if 'Sum' in datapoint: result = result + datapoint['Sum']\n\n log.debug(\"calculate_lambda_executions: [{}]\".format(result))\n return result\n\n\ndef calculate_lambda_duration(start, end, func):\n result = 0\n\n invocations = cwclient.get_metric_statistics(\n Namespace='AWS/Lambda',\n MetricName='Duration',\n #Dimensions=[{'Name': 'FunctionName','Value': func['name']}],\n Dimensions=[{'Name': 'FunctionName','Value': func.id}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Average']\n )\n count = 0\n total = 0\n for datapoint in invocations['Datapoints']:\n if 'Average' in datapoint:\n count+=1\n total+=datapoint['Average']\n\n if count: result = total / count\n\n log.debug(\"calculate_lambda_duration: [{}]\".format(result))\n\n return result\n\n\ndef get_lambda_memory(functionname, qualifier):\n result = 0\n args = {}\n if qualifier: args = {'FunctionName':functionname,'Qualifier':qualifier}\n else: args = {'FunctionName':functionname}\n try:\n response = lambdaclient.get_function_configuration(**args)\n if 'MemorySize' in response:\n result = response['MemorySize']\n\n except ClientError as e:\n log.error(\"{}\".format(e))\n\n return result\n\n\ndef get_ddb_capacity_units(tablename):\n read = 0\n write = 0\n try:\n r = ddbclient.describe_table(TableName=tablename)\n if 'Table' in r:\n read = r['Table']['ProvisionedThroughput']['ReadCapacityUnits']\n write = r['Table']['ProvisionedThroughput']['WriteCapacityUnits']\n return read, write\n\n except Exception as e:\n log.error(\"{}\".format(e))\n\n\ndef get_kinesis_stream_shards(streamName):\n shardCount = 0\n extendedRetentionCount = 0\n try:\n #TODO: add support for streams with >100 shards\n #TODO: add support for detailed metrics\n response = kinesisclient.describe_stream(StreamName=streamName)\n shardCount = len(response['StreamDescription']['Shards'])\n if response['StreamDescription']['RetentionPeriodHours'] > 24:\n extendedRetentionCount = shardCount\n\n except Exception as e:\n log.error(\"{}\".format(e))\n\n return shardCount, extendedRetentionCount\n\n\"\"\"\nThis function calculates an approximation of PUT payload units, based on CloudWatch metrics.\nUnfortunately, there is no direct CloudWatch metric that returns the PUT Payload Units for a stream.\nhttps://aws.amazon.com/kinesis/streams/pricing/\nPUT Payload Units are calculated in 25KB chunks and CloudWatch metrics return the number of records inserted\nas well as the total bytes entering the stream. There is no accurate way to calculate the number of\n25KB chunks going into the stream.\n\n\"\"\"\ndef calculate_kinesis_put_payload_units(start, end, streamName):\n totalRecords = 0\n totalBytesAvg = 0\n totalPutPayloadUnits = 0\n chunkCount = 0 #Kinesis charges for PUT Payload Units in chunks of 25KB\n\n\n try:\n incomingRecords = cwclient.get_metric_statistics(\n Namespace='AWS/Kinesis',\n MetricName='IncomingRecords',\n Dimensions=[{'Name': 'StreamName','Value': streamName}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Sum']\n )\n\n for datapoint in incomingRecords['Datapoints']:\n if 'Sum' in datapoint: totalRecords = totalRecords + datapoint['Sum']\n\n incomingBytes = cwclient.get_metric_statistics(\n Namespace='AWS/Kinesis',\n MetricName='IncomingBytes',\n Dimensions=[{'Name': 'StreamName','Value': streamName}],\n StartTime=start,\n EndTime=end,\n Period=60*METRIC_WINDOW,\n Statistics = ['Average']\n )\n\n for datapoint in incomingBytes['Datapoints']:\n if 'Average' in datapoint:\n chunkCount += int(math.ceil(datapoint['Average']/25000))\n\n bytesDatapoints = len(incomingBytes['Datapoints'])\n if not bytesDatapoints: bytesDatapoints = 1 #avoid zerodiv\n totalPutPayloadUnits = totalRecords * chunkCount/bytesDatapoints\n log.info(\"get_kinesis_stream_puts - incomingRecords:[{}] - chunkAvg:[{}] - totalPutPayloadUnits:[{}]\".format(totalRecords, chunkCount/bytesDatapoints, totalPutPayloadUnits))\n\n except Exception as e:\n log.error(\"{}\".format(e))\n\n\n return totalPutPayloadUnits\n\n\ndef calculate_time_range():\n start = datetime.datetime.utcnow() + datetime.timedelta(minutes=-METRIC_DELAY)\n end = start + datetime.timedelta(minutes=METRIC_WINDOW)\n log.info(\"start:[\"+str(start)+\"] - end:[\"+str(end)+\"]\")\n return start, end\n\n\n\ndef calculate_forecast_factor():\n result = (60 / METRIC_WINDOW ) * HOURS_DICT[DEFAULT_FORECAST_PERIOD]\n log.debug(\"Forecast factor:[\"+str(result)+\"]\")\n return result\n\n\ndef get_ec2_instances(registered, all):\n result = []\n for a in all:\n if a not in registered: result.append(a)\n return result\n\n\ndef init_clients(context):\n global ec2client\n global rdsclient\n global elbclient\n global lambdaclient\n global ddbclient\n global kinesisclient\n global cwclient\n global tagsclient\n global region\n global awsaccount\n\n\n arn = context.invoked_function_arn\n region = arn.split(\":\")[3] #ARN format is arn:aws:lambda:us-east-1:xxx:xxxx\n awsaccount = arn.split(\":\")[4]\n ec2client = boto3.client('ec2',region)\n rdsclient = boto3.client('rds',region)\n elbclient = boto3.client('elb',region) #classic load balancers\n elbclientv2 = boto3.client('elbv2',region) #application and network load balancers\n lambdaclient = boto3.client('lambda',region)\n ddbclient = boto3.client('dynamodb',region)\n kinesisclient = boto3.client('kinesis',region)\n cwclient = boto3.client('cloudwatch', region)\n tagsclient = boto3.client('resourcegroupstaggingapi', region)\n\n\nclass ResourceManager():\n def __init__(self, tagkey, tagvalue):\n self.resources = []\n self.init_resources(tagkey, tagvalue)\n\n\n def init_resources(self, tagkey, tagvalue):\n #TODO: Implement pagination\n response = tagsclient.get_resources(\n TagsPerPage = 500,\n TagFilters=[{'Key': tagkey,'Values': [tagvalue]}],\n ResourceTypeFilters=self.get_resource_type_filters(SERVICE_RESOURCE_MAP)\n )\n\n if 'ResourceTagMappingList' in response:\n for r in response['ResourceTagMappingList']:\n res = self.extract_resource(r['ResourceARN'])\n if res:\n self.resources.append(res)\n #log.info(\"Tagged resource:{}\".format(res.__dict__))\n\n #Return a service:resource list in the format the ResourceGroupTagging API expects it\n def get_resource_type_filters(self, service_resource_map):\n result = []\n for s in service_resource_map.keys():\n for r in service_resource_map[s]: result.append(\"{}:{}\".format(s,r))\n return result\n\n\n def extract_resource(self, arn):\n service = arn.split(\":\")[2]\n resourceId = ''\n #See http://docs.aws.amazon.com/general/latest/gr/aws-arns-and-namespaces.html for different patterns in ARNs\n for service in (SERVICE_EC2, SERVICE_ELB, SERVICE_DYNAMODB, SERVICE_KINESIS):\n for type in (RESOURCE_ALB, RESOURCE_NLB, RESOURCE_ELB):\n if ':'+service+':' in arn and ':'+type+'/' in arn:\n resourceId = arn.split(':'+type+'/')[1]\n return self.Resource(service, type, resourceId, arn)\n\n for type in (RESOURCE_EC2_INSTANCE,RESOURCE_EBS_VOLUME,RESOURCE_EBS_SNAPSHOT,RESOURCE_DDB_TABLE, RESOURCE_STREAM):\n if ':'+service+':' in arn and ':'+type+'/' in arn:\n resourceId = arn.split(':'+type+'/')[1]\n return self.Resource(service, type, resourceId, arn)\n for service in (SERVICE_RDS, SERVICE_LAMBDA):\n for type in (RESOURCE_RDS_DB_INSTANCE, RESOURCE_LAMBDA_FUNCTION):\n if ':'+service+':' in arn and ':'+type+':' in arn:\n resourceId = arn.split(':'+type+':')[1]\n return self.Resource(service, type, resourceId, arn)\n\n return None\n\n def get_resources(self, service, resourceType):\n result = []\n if self.resources:\n for r in self.resources:\n if r.service == service and r.type == resourceType:\n result.append(r)\n return result\n\n\n def get_resource_ids(self, service, resourceType):\n result = []\n if self.resources:\n for r in self.resources:\n if r.service == service and r.type == resourceType:\n result.append(r.id)\n return result\n\n\n\n\n class Resource():\n def __init__(self, service, type, id, arn):\n self.service = service\n self.type = type\n self.id = id\n self.arn = arn\n"
},
{
"path": "install.sh",
"content": "#!/bin/sh\n\n#Install application dependencies in /vendored folder\npip install -r requirements.txt -t vendored\n\n#Install local dev environment & test dependencies in default site_packages path\npip install -r requirements-dev.txt\n\n\n\n"
},
{
"path": "requirements-dev.txt",
"content": "tinydb==3.4.1\nnumpy== 1.12.1\ntabulate\nboto3\npython-lambda-local\n"
},
{
"path": "requirements.txt",
"content": "tinydb==3.4.1\nnumpy== 1.12.1\ntabulate\n"
},
{
"path": "scripts/README.md",
"content": "## Concurrency Labs - aws-pricing-tools scripts\n\nThis folder contains Python scripts that are used for various purposes in the repository\n\nAll scripts need to be executed from the `/scripts` folder.\n\n\nMake sure you have the following environment variables set:\n\n```\nexport AWS_DEFAULT_PROFILE=\nexport AWS_DEFAULT_REGION=\n```\n\n\n### Get Latest Index\n\nThe code needs a local copy of the the AWS Price List API index file. \nThe GitHub repo doesn't come with the index file, therefore you have to\ndownload it the first time you run a test and every time AWS publishes a new\nPrice List API index.\n\nIn order to download the latest index file, go to the \"scripts\" folder and run:\n\n```\npython get-latest-index.py --service=\n```\n\nThe script takes a few seconds to execute since some index files are a little heavy (like the EC2 one).\n\nI recommend executing with the option `--service=all` and subscribing to the AWS Price List API change notifications.\n\n\n### Lambda Optimization Recommendations\n\nThis script does the following:\n\n* It finds the function's execution records in CloudWatch Logs, for the\ngiven time window in minutes (i.e. the past 10 minutes)\n* Parses usage information and extracts memory used, execution time and memory allocated\n* It uses the Price List Index to calculate pricing for the Lambda function, \nfor different scenarios and tells you potential savings.\n\n\n```\npython lambda-optimization.py --function= --minutes=\n```\n\nThis function requires you to have the following IAM permissions:\n* `lambda:getFunction`\n* `logs:getLogEvents`\n\nMake sure variables AWS_DEFAULT_PROFILE and AWS_DEFAULT_REGION are set. \n\n\n\n\n"
},
{
"path": "scripts/emr-pricing.py",
"content": "#!/usr/bin/python\nimport sys, os, getopt, json, logging\nimport argparse\nimport traceback\nsys.path.insert(0, os.path.abspath('..'))\n\nimport awspricecalculator.emr.pricing as emrpricing\nimport awspricecalculator.common.consts as consts\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.utils as utils\nfrom awspricecalculator.common.errors import ValidationError\nfrom awspricecalculator.common.errors import NoDataFoundError\n\nlog = logging.getLogger()\nlogging.basicConfig()\nlog.setLevel(logging.DEBUG)\n\ndef main(argv):\n\n parser = argparse.ArgumentParser()\n parser.add_argument('--region', help='', required=False)\n parser.add_argument('--regions', help='', required=False)\n parser.add_argument('--sort-criteria', help='', required=False)\n parser.add_argument('--instance-type', help='', required=False)\n parser.add_argument('--instance-types', help='', required=False)\n parser.add_argument('--instance-hours', help='', type=int, required=False)\n parser.add_argument('--ebs-volume-type', help='', required=False)\n parser.add_argument('--ebs-storage-gb-month', help='', required=False)\n parser.add_argument('--piops', help='', type=int, required=False)\n parser.add_argument('--data-transfer-out-internet-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-intraregion-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-interregion-gb', help='', required=False)\n parser.add_argument('--to-region', help='', required=False)\n parser.add_argument('--term-type', help='', required=False)\n parser.add_argument('--offering-class', help='', required=False)\n parser.add_argument('--offering-classes', help='', required=False)\n parser.add_argument('--instance-count', help='', type=int, required=False)\n parser.add_argument('--years', help='', required=False)\n parser.add_argument('--offering-type', help='', required=False)\n parser.add_argument('--offering-types', help='', required=False)\n\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n args = parser.parse_args()\n\n region = ''\n regions = ''\n instanceType = ''\n instanceTypes = ''\n instanceHours = 0\n instanceCount = 0\n sortCriteria = ''\n ebsVolumeType = ''\n ebsStorageGbMonth = 0\n pIops = 0\n dataTransferOutInternetGb = 0\n dataTransferOutIntraRegionGb = 0\n dataTransferOutInterRegionGb = 0\n toRegion = ''\n termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n offeringClass = ''\n offeringClasses = consts.SUPPORTED_EMR_OFFERING_CLASSES #only used for Reserved comparisons (standard, convertible)\n offeringType = ''\n offeringTypes = consts.EC2_SUPPORTED_PURCHASE_OPTIONS #only used for Reserved comparisons (all-upfront, partial-upfront, no-upfront)\n years = 1\n\n if args.region: region = args.region\n if args.regions: regions = args.regions\n if args.sort_criteria: sortCriteria = args.sort_criteria\n if args.instance_type: instanceType = args.instance_type\n if args.instance_types: instanceTypes = args.instance_types\n if args.instance_hours: instanceHours = int(args.instance_hours)\n if args.ebs_volume_type: ebsVolumeType = args.ebs_volume_type\n if args.ebs_storage_gb_month: ebsStorageGbMonth = int(args.ebs_storage_gb_month)\n if args.piops: pIops = int(args.piops)\n if args.data_transfer_out_internet_gb: dataTransferOutInternetGb = int(args.data_transfer_out_internet_gb)\n if args.data_transfer_out_intraregion_gb: dataTransferOutIntraRegionGb = int(args.data_transfer_out_intraregion_gb)\n if args.data_transfer_out_interregion_gb: dataTransferOutInterRegionGb = int(args.data_transfer_out_interregion_gb)\n if args.to_region: toRegion = args.to_region\n if args.term_type: termType = args.term_type\n if args.offering_class: offeringClass = args.offering_class\n if args.offering_classes: offeringClasses = args.offering_classes.split(',')\n if args.instance_count: instanceCount = args.instance_count\n if args.offering_type: offeringType = args.offering_type\n if args.offering_types: offeringTypes = args.offering_types.split(',')\n if args.years: years = str(args.years)\n\n #TODO: Implement comparison between a subset of regions by entering an array of regions to compare\n #TODO: Implement a sort by target region (for data transfer)\n #TODO: For Reserved pricing, include a payment plan throughout the whole period, and a monthly average and savings\n\n\n try:\n\n #TODO: not working for EBS Snapshots!\n kwargs = {'sortCriteria':sortCriteria, 'instanceType':instanceType, 'instanceTypes':instanceTypes,\n 'instanceHours':instanceHours, 'dataTransferOutInternetGb':dataTransferOutInternetGb,\n 'ebsVolumeType':ebsVolumeType, 'ebsStorageGbMonth':ebsStorageGbMonth, 'pIops':pIops,\n 'dataTransferOutIntraRegionGb':dataTransferOutIntraRegionGb, 'dataTransferOutInterRegionGb':dataTransferOutInterRegionGb,\n 'toRegion':toRegion, 'termType':termType, 'instanceCount': instanceCount, 'years': years, 'offeringType':offeringType,\n 'offeringClass':offeringClass\n }\n\n if region: kwargs['region'] = region\n\n if sortCriteria:\n if sortCriteria in (consts.SORT_CRITERIA_TERM_TYPE, consts.SORT_CRITERIA_TERM_TYPE_REGION):\n if sortCriteria == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n #TODO: validate that region list is comma-separated\n #TODO: move this list to utils.compare_term_types\n if regions: kwargs['regions'] = regions.split(',')\n else: kwargs['regions']=consts.SUPPORTED_REGIONS\n kwargs['purchaseOptions'] = offeringTypes #purchase options are referred to as offering types in the EC2 API\n kwargs['offeringClasses']=offeringClasses\n validate (kwargs)\n termPricingAnalysis = utils.compare_term_types(service=consts.SERVICE_EMR, **kwargs)\n tabularData = termPricingAnalysis.pop('tabularData')\n print (\"EMR termpPricingAnalysis: [{}]\".format(json.dumps(termPricingAnalysis,sort_keys=False, indent=4)))\n print(\"csvData:\\n{}\\n\".format(termPricingAnalysis['csvData']))\n #print(\"tabularData:\\n{}\".format(tabularData).replace(\"reserved\",\"rsv\").replace(\"standard\",\"std\").\n # replace(\"convertible\",\"conv\").replace(\"-upfront\",\"\").replace(\"partial\",\"par\").replace(\"demand\",\"dmd\"))\n print(\"\\n{}\".format(tabularData))\n\n else:\n validate (kwargs)\n pricecomparisons = utils.compare(service=consts.SERVICE_EMR,**kwargs)\n print(\"Price comparisons:[{}]\".format(json.dumps(pricecomparisons, indent=4)))\n #tabularData = termPricingAnalysis.pop('tabularData')\n #print(\"tabularData:\\n{}\".format(tabularData))\n\n else:\n validate (kwargs)\n emr_pricing = emrpricing.calculate(data.EmrPriceDimension(**kwargs))\n print(json.dumps(emr_pricing,sort_keys=False,indent=4))\n\n\n\n\n\n\n except NoDataFoundError as ndf:\n print (\"NoDataFoundError args:[{}]\".format(args))\n\n except Exception as e:\n traceback.print_exc()\n print(\"Exception message:[\"+str(e)+\"]\")\n\n\n\"\"\"\nThis function contains validations at the script level. No need to validate EC2 parameters, since\nclass Ec2PriceDimension already contains a validation function.\n\"\"\"\ndef validate (args):\n #TODO: add - if termType sort criteria is specified, don't include offeringClass (singular)\n #TODO: add - if offeringTypes is included, have at least one valid offeringType (purchase option)\n #TODO: move to models\n validation_msg = \"\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE:\n if args.get('instanceHours',False):\n validation_msg = \"instance-hours cannot be set when sort-criteria=term-type\"\n if args.get('offeringType',False):\n validation_msg = \"offering-type cannot be set when sort-criteria=term-type - try offering-types (plural) instead\"\n if not args.get('years',''):\n validation_msg = \"years cannot be empty\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n if not args.get('offeringClasses',''):\n validation_msg = \"offering-classes cannot be empty\"\n if not args.get('purchaseOptions',''):\n validation_msg = \"offering-types cannot be empty\"\n\n if validation_msg:\n print(\"Error: [{}]\".format(validation_msg))\n raise ValidationError(validation_msg)\n\n return\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "scripts/get-latest-index.py",
"content": "#!/usr/bin/python\nimport os, sys, getopt, json, csv, ssl\nimport urllib.request\n\nsys.path.insert(0, os.path.abspath('..'))\nfrom awspricecalculator.common import consts as consts\nfrom awspricecalculator.common import phelper as phelper\n\n\nif (not os.environ.get('PYTHONHTTPSVERIFY', '') and\n getattr(ssl, '_create_unverified_context', None)):\n ssl._create_default_https_context = ssl._create_unverified_context\n\n\n__location__ = os.path.dirname(os.path.realpath(__file__))\ndataindexpath = os.path.join(os.path.split(__location__)[0],\"awspricecalculator\", \"data\")\n\n\"\"\"\nThis script gets the latest index files from the AWS Price List API.\n\"\"\"\n#TODO: add support for term-type = onDemand, Reserved or both\ndef main(argv):\n\n\n SUPPORTED_SERVICES = (consts.SERVICE_S3, consts.SERVICE_EC2, consts.SERVICE_RDS, consts.SERVICE_LAMBDA,\n consts.SERVICE_DYNAMODB, consts.SERVICE_KINESIS, consts.SERVICE_DATA_TRANSFER, consts.SERVICE_EMR,\n consts.SERVICE_REDSHIFT, consts.SERVICE_ALL)\n SUPPORTED_FORMATS = ('json','csv')\n OFFER_INDEX_URL = 'https://pricing.us-east-1.amazonaws.com/offers/v1.0/aws/{serviceIndex}/current/index.'\n\n\n service = ''\n format = ''\n region = ''\n tenancy = ''\n\n help_message = 'Script usage: \\nget-latest-index.py --service= --format='\n\n try:\n opts, args = getopt.getopt(argv,\"hr:s:f:t\",[\"region=\",\"service=\",\"format=\",\"tenancy=\"])\n print ('opts: ' + str(opts))\n except getopt.GetoptError:\n print (help_message)\n sys.exit(2)\n\n for opt in opts:\n if opt[0] == '-h':\n print (help_message)\n sys.exit()\n if opt[0] in (\"-s\",\"--service\"):\n service = opt[1]\n if opt[0] in (\"-f\",\"--format\"):\n format = opt[1]\n if opt[0] in (\"-r\",\"--region\"):\n region = opt[1]\n if opt[0] in (\"-t\",\"--tenancy\"): #comma-separated tenancies (host, dedicated, shared)\n tenancy= opt[1].split(',')\n\n\n if not format: format = 'csv'\n\n validation_ok = True\n\n\n if service not in SUPPORTED_SERVICES:\n validation_ok = False\n if format not in SUPPORTED_FORMATS:\n validation_ok = False\n\n if not validation_ok:\n print (help_message)\n sys.exit(2)\n\n services = []\n if service == 'all': services = SUPPORTED_SERVICES\n else: services = [service]\n\n term = '' #all terms\n\n extraArgs = {}\n if tenancy: extraArgs['tenancies']=[tenancy]\n else: extraArgs['tenancies']=consts.EC2_TENANCY_MAP.keys()\n\n\n for s in services:\n if s != 'all':\n offerIndexUrl = OFFER_INDEX_URL.replace('{serviceIndex}',consts.SERVICE_INDEX_MAP[s]) + format\n print ('Downloading offerIndexUrl:['+offerIndexUrl+']...')\n\n servicedatapath = dataindexpath + \"/\" + s\n print (\"servicedatapath:[{}]\".format(servicedatapath))\n\n if not os.path.exists(servicedatapath): os.mkdir(servicedatapath)\n filename = servicedatapath+\"/index.\"+format\n\n with open(filename, \"wb\") as f: f.write(urllib.request.urlopen(offerIndexUrl).read())\n\n if format == 'csv':\n remove_metadata(filename)\n split_index(s, region, term, **extraArgs)\n\n\n\"\"\"\nThe first rows in the PriceList index.csv are metadata.\nThis method removes the metadata from the index files and writes it in a separate .json file,\n so the metadata can be accessed by other modules. For example, the PriceList Version is returned\n in every price calculation.\n\"\"\"\n\ndef remove_metadata(index_filename):\n print (\"Removing metadata from file [{}]\".format(index_filename))\n metadata_filename = index_filename.replace('.csv','_metadata.json')\n metadata_dict = {}\n with open(index_filename,\"r\") as rf:\n lines = rf.readlines()\n with open(index_filename,\"w\") as wf:\n i = 0\n for l in lines:\n #The first 5 records in the CSV file are metadata\n if i <= 4:\n config_record = l.replace('\",\"','\"|\"').strip(\"\\n\").split(\"|\")\n metadata_dict[config_record[0].strip('\\\"')] = config_record[1].strip('\\\"')\n else:\n wf.write(l)\n i += 1\n with open(metadata_filename,\"w\") as mf:\n print (\"Creating metadata file [{}]\".format(metadata_filename))\n metadata_json = json.dumps(metadata_dict,sort_keys=False,indent=4)\n print (\"metadata_json: [{}]\".format(metadata_json))\n mf.write(metadata_json)\n\n\"\"\"\nSome index files are too large. For example, the one for EC2 has more than 460K records.\nIn order to make price lookup more efficient, awspricecalculator splits the\nindex based on a combination of region, term type and product family. Each partition\nhas a key, which is used by tinydb to load smaller files as databases that can be\nqueried. This increases performance significantly.\n\n\"\"\"\n\ndef split_index(service, region, term, **args):\n #Split index format: region -> term type -> product family\n indexDict = {}#contains the keys of the files that will be created\n productFamilies = {}\n usageGroupings=[]\n partition_keys = phelper.get_partition_keys(service, region, term, **args)#All regions and all term types (On-Demand + Reserved)\n #print(\"partition_keys:[{}]\".format(partition_keys))\n for pk in partition_keys:\n indexDict[pk]=[]\n\n fieldnames = []\n\n #with open(get_index_file_name(service, 'index', 'csv'), 'rb') as csvfile:\n with open(get_index_file_name(service, 'index', 'csv'), 'r') as csvfile:\n pricelist = csv.DictReader(csvfile, delimiter=',', quotechar='\"')\n indexRegion = ''\n x = 0\n for row in pricelist:\n indexKey = ''\n if x==0: fieldnames=row.keys()\n if row.get('Location Type','') == 'AWS Region':\n indexRegion = row['Location']\n if row.get('Product Family','')== consts.PRODUCT_FAMILY_DATA_TRANSFER:\n indexRegion = row['From Location']\n\n #Determine the index partition the current row belongs to and append it to the corresponding array\n if row.get('TermType','') == consts.TERM_TYPE_RESERVED:\n #TODO:move the creation of the index dimensions to a common function\n if service == consts.SERVICE_EC2:\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'],row['OfferingClass'],row['Tenancy'], row['PurchaseOption'])\n elif service in (consts.SERVICE_RDS, consts.SERVICE_REDSHIFT):#'Tenancy' is not part of the RDS/Redshift index, therefore default it to Shared\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'],row['OfferingClass'],row.get('Tenancy',consts.EC2_TENANCY_SHARED),row['PurchaseOption'])\n else:\n if service == consts.SERVICE_EC2:\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'],row['Tenancy'])\n else:\n indexDimensions = (indexRegion,row['TermType'],row['Product Family'])\n\n #print (\"TermType:[{}] - service:[{}] - indexDimensions:[{}]\".format(row.get('TermType',''), service, indexDimensions))\n\n indexKey = phelper.create_file_key(indexDimensions)\n if indexKey in indexDict:\n indexDict[indexKey].append(remove_fields(service, row))\n\n #Get a list of distinct product families in the index file\n productFamily = row['Product Family']\n if productFamily not in productFamilies:\n productFamilies[productFamily] = []\n usageGroup = row.get('Group','')\n if usageGroup not in productFamilies[productFamily]:\n productFamilies[productFamily].append(usageGroup)\n\n x += 1\n if x % 1000 == 0: print(\"Processed row [{}]\".format(x))\n\n print (\"productFamilies:{}\".format(productFamilies))\n\n i = 0\n #Create csv files based on the partitions that were calculated when scanning the main index.csv file\n for f in indexDict.keys():\n if indexDict[f]:\n i += 1\n print (\"Writing file for key: [{}]\".format(f))\n with open(get_index_file_name(service, f, 'csv'),'w') as csvfile:\n writer = csv.DictWriter(csvfile, fieldnames=fieldnames, dialect='excel', quoting=csv.QUOTE_ALL)\n writer.writeheader()\n for r in indexDict[f]:\n writer.writerow(r)\n\n print (\"Number of records in main index file: [{}]\".format(x))\n print (\"Number of files written: [{}]\".format(i))\n return\n\n\ndef get_index_file_name(service, name, format):\n result = '../awspricecalculator/data/'+service+'/'+name+'.'+format\n return result\n\n\n\"\"\"\nThis method removes unnecessary fields from each row in the index file. This is necessary since large index files\nbecome a problem when they're too large and result in Lambda functions exceeding package size or in slower warm-up\ntimes for Lambda.\n\"\"\"\n\ndef remove_fields(service, row):\n #don't exclude: 'Product Family', 'operation' (used by ELB)\n EXCLUDE_FIELD_DICT = {\n consts.SERVICE_EC2:['Location Type', 'Storage', 'Location', 'Memory', 'Physical Processor',\n 'Dedicated EBS Throughput', 'Processor Features', 'ECU', 'serviceName', 'Network Performance',\n 'Instance Family', 'Current Generation',\n 'serviceCode','TermType','Tenancy','OfferingClass','PurchaseOption' #these fields are implicit in the DB file name, therefore they're not necessary in the file itself\n ]\n }\n\n for f in EXCLUDE_FIELD_DICT.get(service, []):\n row.pop(f,'')\n\n return row\n\n\n\n#TODO: remove consolidated index.csv file after it has been split into smaller files\n\n\n\n\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "scripts/lambda-optimization.py",
"content": "#!/usr/bin/python\nimport sys, os, json, time\nimport argparse\nimport traceback\nimport boto3\nfrom botocore.exceptions import ClientError\nimport math\nsys.path.insert(0, os.path.abspath('..'))\nsys.path.insert(0, os.path.abspath('../vendored'))\n\nimport numpy\n\nimport awspricecalculator.awslambda.pricing as lambdapricing\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.consts as consts\nimport awspricecalculator.common.errors as errors\n\nlogsclient = boto3.client('logs')\nlambdaclient = boto3.client('lambda')\n\n\nMONTHLY = \"MONTHLY\"\nMS_MAP = {MONTHLY:(3.6E6)*720}\n\n\n\n\ndef main(argv):\n\n region = os.environ['AWS_DEFAULT_REGION']\n\n parser = argparse.ArgumentParser()\n parser.add_argument('--function', help='', required=True)\n parser.add_argument('--minutes', help='', required=True)\n\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n args = parser.parse_args()\n\n function = ''\n minutes = 0 #in minutes\n\n\n if args.function: function = args.function\n if args.minutes: minutes = int(args.minutes)\n\n try:\n validate(function, minutes)\n except errors.ValidationError as error:\n print(error.message)\n sys.exit(1)\n\n mem_used_array = []\n duration_array = []\n prov_mem_size = 0\n firstEventTs = 0\n lastEventTs = 0\n ts_format = \"%Y-%m-%d %H:%M:%S UTC\"\n log_group_name = '/aws/lambda/'+function\n\n try:\n i = 0\n windowStartTime = (int(time.time()) - minutes * 60) * 1000\n firstEventTs = windowStartTime #temporary value, it will be updated once (if) we get results from the CW Logs get_log_events API\n lastEventTs = int(time.time() * 1000) #this will also be updated once (if) we get results from the CW Logs get_log_events API\n nextLogstreamToken = True\n logstreamsargs = {'logGroupName':log_group_name, 'orderBy':'LastEventTime', 'descending':True}\n while nextLogstreamToken:\n logstreams = logsclient.describe_log_streams(**logstreamsargs)\n \"\"\"\n Read through CW Logs entries and extract information from them.\n We're interested in entries that look like this:\n REPORT RequestId: 7686bf2c-2f79-11e7-b693-97868a5db36b\tDuration: 5793.53 ms\tBilled Duration: 5800 ms \tMemory Size: 448 MB\tMax Memory Used: 24 MB\n \"\"\"\n\n if 'logStreams' in logstreams:\n print(\"Number of logstreams found:[{}]\".format(len(logstreams['logStreams'])))\n\n nextLogstreamToken = logstreams.get('nextToken',False)\n if nextLogstreamToken: logstreamsargs['nextToken']=nextLogstreamToken\n else:logstreamsargs.pop('nextToken',False)\n\n #Go through all logstreams in descending order\n for ls in logstreams['logStreams']:\n nextEventsForwardToken = True\n logeventsargs = {'logGroupName':log_group_name, 'logStreamName':ls['logStreamName'],\n 'startFromHead':True, 'startTime':windowStartTime}\n while nextEventsForwardToken:\n logevents = logsclient.get_log_events(**logeventsargs)\n if 'events' in logevents:\n if len(logevents['events']):\n print (\"\\nEvents for logGroup:[{}] - logstream:[{}] - nextForwardToken:[{}]\".format(log_group_name, ls['logStreamName'],nextEventsForwardToken))\n for e in logevents['events']:\n #Extract lambda execution duration and memory utilization from \"REPORT\" log events\n if 'REPORT RequestId:' in e['message']:\n mem_used = e['message'].split('Max Memory Used: ')[1].split()[0]\n mem_used_array.append(int(mem_used))\n duration = e['message'].split('Billed Duration: ')[1].split()[0]\n duration_array.append(int(duration))\n if i == 0:\n prov_mem_size = int(e['message'].split('Memory Size: ')[1].split()[0])\n firstEventTs = e['timestamp']\n lastEventTs = e['timestamp']\n else:\n if e['timestamp'] < firstEventTs: firstEventTs = e['timestamp']\n if e['timestamp'] > lastEventTs: lastEventTs = e['timestamp']\n print (\"mem_used:[{}] - mem_size:[{}] - timestampMs:[{}] - timestamp:[{}]\".format(mem_used,prov_mem_size, e['timestamp'], time.strftime(ts_format, time.gmtime(e['timestamp']/1000))))\n print e['message']\n i += 1\n else: break\n\n nextEventsForwardToken = logevents.get('nextForwardToken',False)\n if nextEventsForwardToken: logeventsargs['nextToken']=nextEventsForwardToken\n else: logeventsargs.pop('nextToken',False)\n\n\n\n #Once we've iterated through all log streams and log events, calculate averages, cost and optimization scenarios\n avg_used_mem = 0\n avg_duration_ms = 0\n p90_duration_ms = 0\n p99_duration_ms = 0\n p100_duration_ms = 0\n\n if mem_used_array: avg_used_mem = math.ceil(numpy.average(mem_used_array))\n if duration_array:\n avg_duration_ms = round(math.ceil(numpy.average(duration_array)),0)\n p90_duration_ms = round(math.ceil(numpy.percentile(duration_array, 90)),0)\n p99_duration_ms = round(math.ceil(numpy.percentile(duration_array, 99)),0)\n p100_duration_ms = round(math.ceil(numpy.percentile(duration_array, 100)),0)\n base_usage = LambdaSampleUsage(region, i, avg_duration_ms, avg_used_mem, prov_mem_size, firstEventTs, lastEventTs, MONTHLY)\n memoptims= []\n durationoptims = []\n current_cost = 0\n\n for m in get_lower_possible_memory_ranges(avg_used_mem, prov_mem_size):\n #TODO: add target memory % utilization (i.e. I want to use 60% of memory and see how much that'll save me)\n memoptims.append(LambdaUtilScenario(base_usage, base_usage.avgDurationMs, m).__dict__)\n\n\n for d in get_lower_possible_durations(avg_duration_ms, 100):\n durationoptims.append(LambdaUtilScenario(base_usage, d, base_usage.memSizeMb).__dict__)\n\n\n optim_info = {\"sampleUsage\":base_usage.__dict__,\n \"memoryOptimizationScenarios\":memoptims,\n \"durationOptimizationScenarios\":durationoptims\n }\n #print(json.dumps(optim_info,sort_keys=False,indent=4))\n\n print (\"avg_duration_ms:[{}] avg_used_mem:[{}] prov_mem_size:[{}] records:[{}]\".format(avg_duration_ms, avg_used_mem,prov_mem_size,i))\n print (\"p90_duration_ms:[{}] p99_duration_ms:[{}] p100_duration_ms:[{}]\".format(p90_duration_ms, p99_duration_ms, p100_duration_ms))\n\n print (\"------------------------------------------------------------------------------------\")\n print (\"OPTIMIZATION SUMMARY\\n\")\n print (\"**Data sample used for calculation:**\")\n print (\"CloudWatch Log Group: [{}]\\n\" \\\n \"First Event time:[{}]\\n\" \\\n \"Last Event time:[{}]\\n\" \\\n \"Number of executions:[{}]\\n\" \\\n \"Average executions per second:[{}]\".\\\n format(log_group_name,\n time.strftime(ts_format, time.gmtime(base_usage.startTs/1000)),\n time.strftime(ts_format, time.gmtime(base_usage.endTs/1000)),\n base_usage.requestCount, base_usage.avgTps))\n print (\"\\n**Usage for Lambda function [{}] in the sample period is the following:**\".format(function))\n print (\"Average duration per Lambda execution: {}ms\\n\" \\\n \"Average consumed memory per execution: {}MB\\n\" \\\n \"Configured memory in your Lambda function: {}MB\\n\" \\\n \"Memory utilization (used/allocated): {}%\\n\" \\\n \"Total projected cost: ${}USD - {}\".\\\n format(base_usage.avgDurationMs, base_usage.avgMemUsedMb,base_usage.memSizeMb,\n base_usage.memUsedPct,base_usage.projectedCost, base_usage.projectedPeriod))\n\n if memoptims:\n print (\"\\nThe following Lambda memory configurations could save you money (assuming constant execution time)\")\n labels = ['memSizeMb', 'memUsedPct', 'cost', 'timePeriod', 'savingsAmt']\n print (\"\\n\"+ResultsTable(memoptims,labels).dict2md())\n if durationoptims:\n print (\"\\n\\nCan you make your function execute faster? The following Lambda execution durations will save you money (assuming memory allocation remains constant):\")\n labels = ['durationMs', 'cost', 'timePeriod', 'savingsAmt']\n print (\"\\n\"+ResultsTable(durationoptims,labels).dict2md())\n print (\"------------------------------------------------------------------------------------\")\n\n\n\n except Exception as e:\n traceback.print_exc()\n print(\"Exception message:[\"+str(e.message)+\"]\")\n\n\n\"\"\"\nGet the possible Lambda memory configurations values that would:\n- Be lower than the current provisioned value (thus, cheaper)\n- Are greater than the current average used memory (therefore won't result in memory errors)\n\"\"\"\n\ndef get_lower_possible_memory_ranges(usedMem, provMem):\n result = []\n for m in consts.LAMBDA_MEM_SIZES:\n if usedMem < float(m) and m < provMem:\n result.append(m)\n return result\n\n\n\"\"\"\nGet the possible Lambda execution values that would:\n- Be lower than the current average duration (thus, cheaper)\n- Are greater than a lower limit set by the user of the script (there's only so much one can do to make a function run faster)\n\"\"\"\ndef get_lower_possible_durations(usedDurationMs, lowestDuration):\n result = []\n initBilledDurationMs = math.floor(usedDurationMs / 100) * 100\n d = int(initBilledDurationMs)\n while d >= lowestDuration:\n result.append(d)\n d -= 100\n return result\n\n\n\n#TODO:Move to a different file\n#This class models the usage for a Lambda function within a time window defined by startTs and endTs\nclass LambdaSampleUsage():\n def __init__(self, region, requestCount, avgDurationMs, avgMemUsedMb, memSizeMb, startTs, endTs, projectedPeriod):\n\n self.region = region\n\n self.requestCount = 0\n if requestCount: self.requestCount = requestCount\n\n self.avgDurationMs = 0\n if avgDurationMs: self.avgDurationMs = int(avgDurationMs)\n\n self.avgMemUsedMb = int(avgMemUsedMb)\n self.memSizeMb = memSizeMb\n\n self.memUsedPct = 0.00\n if memSizeMb: self.memUsedPct = round(float(100 * avgMemUsedMb/memSizeMb),2)\n\n self.startTs = startTs\n self.endTs = endTs\n self.elapsedMs = endTs - startTs\n\n self.avgTps = 0\n if self.elapsedMs:\n self.avgTps = round((1000 * float(self.requestCount) / float(self.elapsedMs)),4)\n\n self.projectedPeriod = projectedPeriod\n self.projectedRequestCount = self.get_projected_request_count(requestCount)\n\n args = {'region':region, 'requestCount':self.projectedRequestCount,\n 'avgDurationMs':math.ceil(avgDurationMs/100)*100, 'memoryMb':memSizeMb}\n print (\"args: {}\".format(args))\n self.projectedCost = lambdapricing.calculate(data.LambdaPriceDimension(**args))['totalCost']\n\n\n def get_projected_request_count(self,requestCount):\n result = 0\n print (\"elapsed_ms:[{}] - period: [{}]\".format(self.elapsedMs, self.projectedPeriod))\n if self.elapsedMs:\n result = float(requestCount)*(MS_MAP[self.projectedPeriod]/self.elapsedMs)\n return int(result)\n\n\n\n\"\"\"\nThis class represents usage scenarios that will be modeled and displayed as possibilities, so the user can decide\nif they're good options (or not) .\n\"\"\"\nclass LambdaUtilScenario():\n def __init__(self, base_usage, proposedDurationMs, proposedMemSizeMb):\n\n self.memSizeMb = proposedMemSizeMb\n\n self.memUsedPct = 0\n self.memUsedPct = float(100 * base_usage.avgMemUsedMb/proposedMemSizeMb)\n\n self.durationMs = proposedDurationMs\n\n args = {'region':base_usage.region, 'requestCount':base_usage.projectedRequestCount,\n 'avgDurationMs':self.durationMs, 'memoryMb':proposedMemSizeMb}\n self.cost= lambdapricing.calculate(data.LambdaPriceDimension(**args))['totalCost']\n self.savingsAmt = round((base_usage.projectedCost - self.cost),2)\n\n self.savingsPct = 0.00\n if base_usage.projectedCost:\n self.savingsPct = round((100 * self.savingsAmt / base_usage.projectedCost),2)\n self.timePeriod = MONTHLY\n\n def get_next_mem(self, memUsedMb):\n result = 0\n for m in consts.LAMBDA_MEM_SIZES:\n if memUsedMb <= float(m):\n result = m\n break\n return result\n\n\n\n\n\n\"\"\"\nThis class takes an array of dictionary objects, so they can be converted to table format using Markdown syntax.\nIt also takes an optional array of labels, if you want to limit the output to a subset of keys in each dictionary.\nThe output is something like this:\n\n\n key1| key2| key3\n ---| ---| ---\n 01| 02| 03\n 04| 05| 06\n 07| 08| 09\n\n\n\"\"\"\n\nclass ResultsTable():\n def __init__(self, records,labels):\n self.records = records\n self.labels = []\n if labels:\n self.labels = labels\n\n\n #Converts an array of dictionaries to Markdown format.\n\n def dict2md(self):\n result = \"\"\n keys = []\n if self.labels:\n keys = self.labels\n else:\n if self.records: keys = self.records[0].keys()\n\n rc = 0 #rowcount\n mdrow = \"\" #markdown headers row\n self.records.insert(0,[])#insert dummy record at the beginning, since first record in loop is used to create row headers\n for r in self.records:\n #if rc==0: keys = r.keys()\n cc = 0 #column count\n for k in keys:\n cc += 1\n if rc==0:\n result += k\n mdrow += self.addpadding(k,'---')\n else:\n result += self.addpadding(k,r[k])\n if cc == len(keys):\n result += \"\\n\"\n mdrow += \"\\n\"\n else:\n result += \"|\"\n mdrow += \"|\"\n if rc==0: result += mdrow\n rc += 1\n return result\n\n\n\n \"\"\"\n def dict2md(self):\n result = \"\"\n keys = []\n if self.labels:\n keys = self.labels\n else:\n if self.records: keys = self.records[0].keys()\n\n rc = 0 #rowcount\n mdrow = \"\" #markdown headers row\n for r in self.records:\n #if rc==0: keys = r.keys()\n cc = 0 #column count\n for k in keys:\n cc += 1\n if rc==0:\n result += k\n mdrow += self.addpadding(k,'---')\n else:\n result += self.addpadding(k,r[k])\n if cc == len(keys):\n result += \"\\n\"\n mdrow += \"\\n\"\n else:\n result += \"|\"\n mdrow += \"|\"\n if rc==0: result += mdrow\n rc += 1\n return result\n \"\"\"\n\n\n def addpadding(self,label,value):\n padding = \"\"\n i = 0\n while i < (len(label)-len(str(value))):\n padding += \" \"\n i += 1\n return padding + str(value)\n\n\ndef validate(function, minutes):\n validation_ok = True\n validation_message = \"\\nValidationError:\\n\"\n\n try:\n lambdaclient.get_function(FunctionName=function)\n except ClientError as e:\n if e.response['Error']['Code'] == 'ResourceNotFoundException':\n validation_message += \"Function [{}] does not exist, please enter a valid Lambda function\\n\".format(function)\n else:\n validation_message += \"Boto3 client error when calling lambda.get_function\"\n validation_ok = False\n\n if minutes <1:\n validation_message += \"Minutes must be greater than 0\\n\"\n validation_ok = False\n\n if not validation_ok:\n raise errors.ValidationError(validation_message)\n\n return validation_ok\n\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "scripts/redshift-pricing.py",
"content": "#!/usr/bin/python\nimport sys, os, getopt, json, logging\nimport argparse\nimport traceback\nsys.path.insert(0, os.path.abspath('..'))\n\nimport awspricecalculator.redshift.pricing as redshiftpricing\nimport awspricecalculator.common.consts as consts\nimport awspricecalculator.common.models as data\nimport awspricecalculator.common.utils as utils\nfrom awspricecalculator.common.errors import ValidationError\nfrom awspricecalculator.common.errors import NoDataFoundError\n\nlog = logging.getLogger()\nlogging.basicConfig()\nlog.setLevel(logging.DEBUG)\n\ndef main(argv):\n\n parser = argparse.ArgumentParser()\n parser.add_argument('--region', help='', required=False)\n parser.add_argument('--regions', help='', required=False)\n parser.add_argument('--sort-criteria', help='', required=False)\n parser.add_argument('--instance-type', help='', required=False)\n parser.add_argument('--instance-types', help='', required=False)\n parser.add_argument('--instance-hours', help='', type=int, required=False)\n parser.add_argument('--ebs-volume-type', help='', required=False)\n parser.add_argument('--ebs-storage-gb-month', help='', required=False)\n parser.add_argument('--piops', help='', type=int, required=False)\n parser.add_argument('--data-transfer-out-internet-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-intraregion-gb', help='', required=False)\n parser.add_argument('--data-transfer-out-interregion-gb', help='', required=False)\n parser.add_argument('--to-region', help='', required=False)\n parser.add_argument('--term-type', help='', required=False)\n parser.add_argument('--offering-class', help='', required=False)\n parser.add_argument('--offering-classes', help='', required=False)\n parser.add_argument('--instance-count', help='', type=int, required=False)\n parser.add_argument('--years', help='', required=False)\n parser.add_argument('--offering-type', help='', required=False)\n parser.add_argument('--offering-types', help='', required=False)\n\n if len(sys.argv) == 1:\n parser.print_help()\n sys.exit(1)\n args = parser.parse_args()\n\n region = ''\n regions = ''\n instanceType = ''\n instanceTypes = ''\n instanceHours = 0\n instanceCount = 0\n sortCriteria = ''\n ebsVolumeType = ''\n ebsStorageGbMonth = 0\n pIops = 0\n dataTransferOutInternetGb = 0\n dataTransferOutIntraRegionGb = 0\n dataTransferOutInterRegionGb = 0\n toRegion = ''\n termType = consts.SCRIPT_TERM_TYPE_ON_DEMAND\n offeringClass = ''\n offeringClasses = consts.SUPPORTED_REDSHIFT_OFFERING_CLASSES #only used for Reserved comparisons (standard, convertible)\n offeringType = ''\n offeringTypes = consts.EC2_SUPPORTED_PURCHASE_OPTIONS #only used for Reserved comparisons (all-upfront, partial-upfront, no-upfront)\n years = 1\n\n if args.region: region = args.region\n if args.regions: regions = args.regions\n if args.sort_criteria: sortCriteria = args.sort_criteria\n if args.instance_type: instanceType = args.instance_type\n if args.instance_types: instanceTypes = args.instance_types\n if args.instance_hours: instanceHours = int(args.instance_hours)\n if args.ebs_volume_type: ebsVolumeType = args.ebs_volume_type\n if args.ebs_storage_gb_month: ebsStorageGbMonth = int(args.ebs_storage_gb_month)\n if args.piops: pIops = int(args.piops)\n if args.data_transfer_out_internet_gb: dataTransferOutInternetGb = int(args.data_transfer_out_internet_gb)\n if args.data_transfer_out_intraregion_gb: dataTransferOutIntraRegionGb = int(args.data_transfer_out_intraregion_gb)\n if args.data_transfer_out_interregion_gb: dataTransferOutInterRegionGb = int(args.data_transfer_out_interregion_gb)\n if args.to_region: toRegion = args.to_region\n if args.term_type: termType = args.term_type\n if args.offering_class: offeringClass = args.offering_class\n if args.offering_classes: offeringClasses = args.offering_classes.split(',')\n if args.instance_count: instanceCount = args.instance_count\n if args.offering_type: offeringType = args.offering_type\n if args.offering_types: offeringTypes = args.offering_types.split(',')\n if args.years: years = str(args.years)\n\n #TODO: Implement comparison between a subset of regions by entering an array of regions to compare\n #TODO: Implement a sort by target region (for data transfer)\n #TODO: For Reserved pricing, include a payment plan throughout the whole period, and a monthly average and savings\n\n #TODO: remove EBS for Redshift\n\n\n try:\n\n kwargs = {'sortCriteria':sortCriteria, 'instanceType':instanceType, 'instanceTypes':instanceTypes,\n 'instanceHours':instanceHours, 'dataTransferOutInternetGb':dataTransferOutInternetGb, 'pIops':pIops,\n 'dataTransferOutIntraRegionGb':dataTransferOutIntraRegionGb, 'dataTransferOutInterRegionGb':dataTransferOutInterRegionGb,\n 'toRegion':toRegion, 'termType':termType, 'instanceCount': instanceCount, 'years': years, 'offeringType':offeringType,\n 'offeringClass':offeringClass\n }\n\n if region: kwargs['region'] = region\n\n if sortCriteria:\n if sortCriteria in (consts.SORT_CRITERIA_TERM_TYPE, consts.SORT_CRITERIA_TERM_TYPE_REGION):\n if sortCriteria == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n #TODO: validate that region list is comma-separated\n #TODO: move this list to utils.compare_term_types\n if regions: kwargs['regions'] = regions.split(',')\n else: kwargs['regions']=consts.SUPPORTED_REGIONS\n kwargs['purchaseOptions'] = offeringTypes #purchase options are referred to as offering types in the EC2 API\n kwargs['offeringClasses']=offeringClasses\n validate (kwargs)\n termPricingAnalysis = utils.compare_term_types(service=consts.SERVICE_REDSHIFT, **kwargs)\n tabularData = termPricingAnalysis.pop('tabularData')\n print (\"Redshift termpPricingAnalysis: [{}]\".format(json.dumps(termPricingAnalysis,sort_keys=False, indent=4)))\n print(\"csvData:\\n{}\\n\".format(termPricingAnalysis['csvData']))\n print(\"tabularData:\\n{}\".format(tabularData))\n\n else:\n validate (kwargs)\n pricecomparisons = utils.compare(service=consts.SERVICE_REDSHIFT,**kwargs)\n print(\"Price comparisons:[{}]\".format(json.dumps(pricecomparisons, indent=4)))\n else:\n validate (kwargs)\n redshift_pricing = redshiftpricing.calculate(data.RedshiftPriceDimension(**kwargs))\n print(json.dumps(redshift_pricing,sort_keys=False,indent=4))\n\n\n\n except NoDataFoundError as ndf:\n print (\"NoDataFoundError args:[{}]\".format(args))\n\n except Exception as e:\n traceback.print_exc()\n print(\"Exception message:[\"+str(e)+\"]\")\n\n\n\"\"\"\nThis function contains validations at the script level. No need to validate Redshift parameters, since\nclass RedshiftPriceDimension already contains a validation function.\n\"\"\"\ndef validate (args):\n #TODO: add - if termType sort criteria is specified, don't include offeringClass (singular)\n #TODO: add - if offeringTypes is included, have at least one valid offeringType (purchase option)\n #TODO: move to models or a common place that can be used by both CLI and API\n validation_msg = \"\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE:\n if args.get('instanceHours',False):\n validation_msg = \"instance-hours cannot be set when sort-criteria=term-type\"\n if args.get('offeringType',False):\n validation_msg = \"offering-type cannot be set when sort-criteria=term-type - try offering-types (plural) instead\"\n if not args.get('years',''):\n validation_msg = \"years cannot be empty\"\n if args.get('sortCriteria','') == consts.SORT_CRITERIA_TERM_TYPE_REGION:\n if not args.get('offeringClasses',''):\n validation_msg = \"offering-classes cannot be empty\"\n if not args.get('purchaseOptions',''):\n validation_msg = \"offering-types cannot be empty\"\n\n if validation_msg:\n print(\"Error: [{}]\".format(validation_msg))\n raise ValidationError(validation_msg)\n\n return\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n"
},
{
"path": "serverless.env.yml",
"content": "# This is the Serverless Environment File\n#\n# It contains listing of your stages, and their regions\n# It also manages serverless variables at 3 levels:\n# - common variables: variables that apply to all stages/regions\n# - stage variables: variables that apply to a specific stage\n# - region variables: variables that apply to a specific region\n\nvars:\nstages:\n dev:\n vars:\n regions:\n us-east-1:\n vars:\n"
},
{
"path": "serverless.yml",
"content": "# Welcome to Serverless!\n#\n# This file is the main config file for your service.\n# It's very minimal at this point and uses default values.\n# You can always add more config options for more control.\n# We've included some commented out config examples here.\n# Just uncomment any of them to get that config option.\n#\n# For full config options, check the docs:\n# v1.docs.serverless.com\n#\n# Happy Coding!\n\nservice: aws-pricing # NOTE: update this with your service name\n\nprovider:\n name: aws\n runtime: python3.6\n\n # you can add statements to the Lambda function's IAM Role here\n iamRoleStatements:\n - Effect: \"Allow\"\n Action:\n - cloudwatch:*\n - ec2:Describe*\n - elasticloadbalancing:Describe*\n - autoscaling:Describe*\n - rds:Describe*\n - rds:List*\n - dynamodb:Describe*\n - dynamodb:List*\n - kinesis:Describe*\n - kinesis:List*\n - lambda:GetFunctionConfiguration\n - tag:getResources\n - tag:getTagKeys\n - tag:getTagValues\n Resource: \"*\"\n\n# you can overwrite defaults here\n#defaults:\n# stage: dev\n# region: us-east-1\n# you can add packaging information here\n\npackage:\n exclude:\n - bin/*\n - lib/**\n - .git/**\n - .idea/**\n - include/**\n - pip-selfcheck.json\n - awspricecalculator/s3\n - awspricecalculator/data/ec2/index.*\n - awspricecalculator/data/ec2/*Dedicated* \n - awspricecalculator/data/ec2/*Host*\n - awspricecalculator/data/ec2/*Reserved*\n - awspricecalculator/data/ec2/*Savings*\n - awspricecalculator/data/rds/index.*\n - awspricecalculator/data/rds/*Reserved*\n - awspricecalculator/data/s3/index.*\n - awspricecalculator/data/lambda/index.*\n - awspricecalculator/data/dynamodb/index.*\n - awspricecalculator/data/kinesis/index.*\n - scripts/**\n - test/**\n - cloudformation/**\n - readme.txt\n\n include:\n - vendored\n\nfunctions:\n nearrealtimepricing:\n handler: functions/calculate-near-realtime.handler\n name: calculate-near-realtime-pricing\n timeout: 300\n memory: 1024\n events:\n - schedule:\n rate: rate(5 minutes)\n enabled: true\n input:\n tag:\n key: ${env:PRICING_TAG_KEY}\n value: ${env:PRICING_TAG_VALUE}\n\n# you can add CloudFormation resource templates here\n#resources:\n# Resources:\n# NewResource:\n# Type: AWS::S3::Bucket\n# Properties:\n# BucketName: my-new-bucket\n# Outputs:\n# NewOutput:\n# Description: \"Description for the output\"\n# Value: \"Some output value\"\n"
},
{
"path": "setup.py",
"content": "from setuptools import setup\n\nsetup(name='awspricecalculator',\n version='0.1',\n description='AWS Price List calculations',\n url='https://github.com/ConcurrenyLabs/aws-pricing-tools/tree/master/awspricecalculator',\n author='Concurrency Labs',\n author_email='github@concurrencylabs.com',\n license='GNU',\n packages=['awspricecalculator','awspricecalculator.common',\n \t'awspricecalculator.awslambda','awspricecalculator.ec2','awspricecalculator.rds', 'awspricecalculator.emr',\n 'awspricecalculator.redshift', 'awspricecalculator.s3','awspricecalculator.dynamodb',\n 'awspricecalculator.kinesis', 'awspricecalculator.datatransfer'],\n include_package_data=True,\n zip_safe=False)\n\n\n"
},
{
"path": "test/events/constant-tag.json",
"content": "{\n \"tag\": { \n \"key\": \"\",\n \"value\": \"\"\n }\n}\n\n"
}
]