Repository: doubledaibo/drnet_cvpr2017
Branch: master
Commit: a83aa5768b91
Files: 22
Total size: 123.2 KB
Directory structure:
gitextract_pa_vjz81/
├── .gitignore
├── LICENSE
├── README.md
├── lib/
│ ├── customize_layers/
│ │ ├── __init__.py
│ │ └── concat_layer.py
│ ├── rel_data_layer/
│ │ ├── __init__.py
│ │ └── layer.py
│ └── utils/
│ ├── __init__.py
│ └── eval_utils.py
├── prototxts/
│ ├── drnet_8units_linear_shareweight.prototxt
│ ├── drnet_8units_relu_shareweight.prototxt
│ ├── drnet_8units_softmax.prototxt
│ ├── test_drnet_8units_linear_shareweight.prototxt
│ ├── test_drnet_8units_relu_shareweight.prototxt
│ └── test_drnet_8units_softmax.prototxt
├── snapshots/
│ └── README.md
└── tools/
├── _init_paths.py
├── eval_triplet_recall.py
├── eval_union_recall.py
├── prepare_data.py
├── test_predicate_recognition.py
└── test_triplet_detection.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
snapshots/*.caffemodel
svg
================================================
FILE: LICENSE
================================================
Copyright the Chinese University of Hong Kong. All rights reserved.
Contact persons:
Bo Dai (db014 [at] ie [dot] cuhk [dot] edu [dot] hk)
This software is being made available for research use only.
Any commercial use or redistribution of this software requires a license from
the Chinese University of Hong Kong.
You may use this work subject to the following conditions:
1. This work is provided "as is" by the copyright holder, with
absolutely no warranties of correctness, fitness, intellectual property
ownership, or anything else whatsoever. You use the work
entirely at your own risk. The copyright holder will not be liable for
any legal damages whatsoever connected with the use of this work.
2. The copyright holder retain all copyright to the work. All copies of
the work and all works derived from it must contain (1) this copyright
notice, and (2) additional notices describing the content, dates and
copyright holder of modifications or additions made to the work, if
any, including distribution and use conditions and intellectual property
claims. Derived works must be clearly distinguished from the original
work, both by name and by the prominent inclusion of explicit
descriptions of overlaps and differences.
3. The names and trademarks of the copyright holder may not be used in
advertising or publicity related to this work without specific prior
written permission.
4. In return for the free use of this work, you are requested, but not
legally required, to do the following:
* If you become aware of factors that may significantly affect other
users of the work, for example major bugs or
deficiencies or possible intellectual property issues, you are
requested to report them to the copyright holder, if possible
including redistributable fixes or workarounds.
* If you use the work in scientific research or as part of a larger
software system, you are requested to cite the use in any related
publications or technical documentation. The work is based upon:
"Detecting Visual Relationship with Deep Relational Networks"
Bo Dai, Yuqi Zhang, Dahua Lin, Computer Vision and Pattern Recognition,
(CVPR 2017), 2017 (oral).
this copyright notice must be retained with all copies of the software,
including any modified or derived versions.
================================================
FILE: README.md
================================================
# Code of [Detecting Visual Relationships with Deep Relational Networks](https://arxiv.org/abs/1704.03114)
The code is written in python, and all networks are implemented using [Caffe](https://github.com/BVLC/caffe).
## Datasets
* [VRD](http://cs.stanford.edu/people/ranjaykrishna/vrd/dataset.zip)
* sVG: subset of [Visual Genome](https://visualgenome.org/)
- [Link](https://drive.google.com/file/d/0B5RJWjAhdT04SXRfVHBKZ0dOTzQ/view?usp=sharing&resourcekey=0-bW_W0QVJOfaNs5NyGjDjbQ)
- Images can be downloaded from the website of Visual Genome
- Remarks: eventually I found no time to further clean it. This subset has a manually cleaned list for relationship predicates. The list for objects may need further cleaning, although Faster-RCNN can get a recall@20 around 50%.
- Using our method, you can get the corresponding results reported in the paper on this dataset.
## Networks
This repo contains three kinds of networks. And all of them get the raw response for predicate based on both appearance cues and spatial cues,
followed by a refinement according to responses of the subject, the object and the predicate.
The networks are designed for the task of predicate recognition,
where ground-truth labels of the subject and the object are provided as inputs.
Therefore, in these networks, responses of the subject and the object are replaced with indicator vectors,
and only response of the predicate will be refined.
In these networks, the subnet for appearance cues is VGG16, and the subnet for spatial cues consists of three conv layers.
And outputs of both subnets are combined via a customized concatenate layer,
followed by two fc layers to generate raw response for the predicate.
The customized concatenate layer is used for combining the output of a fc layer and channels of the output of a conv layer,
which can be replaced with caffe's Concat layer
if the last conv layer in spatial subnet (conv3_p) is equivalently replaced with a fc layer.
The details of these networks are
* drnet_8units_softmax: it has 8 inference units with softmax function as the activation function.
* drnet_8units_linear_shareweight: it has 8 inference units with no activation function, and the weights are shared across units.
* drnet_8units_relu_shareweight: it has 8 inference units with relu function as the activation function, and the weights are shared across units.
### Training
The training procedure is component-by-component.
Specifically, a network usually contains three components,
namely the subnet for appearance (A), the subnet for spatial cues (S), and the drnet for statistical dependencies (D).
In training, we train the network as follow:
* train A in isolation
* train S in isolation
* train A + S in isolation, with weights initialized from previous steps
* train A + S + D jointly, with weights initialized from previous steps
Each step we use the same loss, and we use dropout to avoid overfit.
### Recalls on Predicate Recognition
| Networks | Recall@50 | Recall@100 |
| --- | :---: | :---: |
| drnet_8units_softmax | 75.22 | 77.55 |
| drnet_8units_linear_shareweight | 78.57 | 79.94 |
| drnet_8units_relu_shareweight | 80.86 | 81.83 |
## Codes
* lib/: python layers, as well as auxiliary files for evaluation
* prototxts/: training and testing prototxts
* tools/: python codes for preparing data and evaluation
* snapshots/: pretrain models
## Finetune or Evaluate
1. Download the dataset [VRD](https://github.com/Prof-Lu-Cewu/Visual-Relationship-Detection)
2. Preprocess the dataset using tools/preprare_data.py
3. Download one pretrain model in snapshots/
4. Finetune or Evaluate using corresponding prototxts in prototxts/
## Pair Filter
### Structure
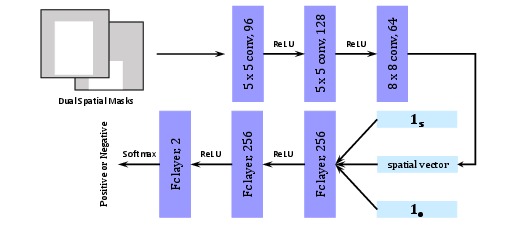
### Training
To train this network, we randomly sample pairs of bounding boxes (with labels) from
each training image, treating those with 0.5 IoU (or above) with any ground-truth pairs (with same labels)
as positive samples, and the rest as negative samples.
## Citation
If you use this code, please cite the following paper(s):
@article{dai2017detecting,
title={Detecting Visual Relationships with Deep Relational Networks},
author={Dai, Bo and Zhang, Yuqi and Lin, Dahua},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
## License
This code is used for research only. See LICENSE for details.
================================================
FILE: lib/customize_layers/__init__.py
================================================
================================================
FILE: lib/customize_layers/concat_layer.py
================================================
import caffe
import numpy as np
import json
class Layer(caffe.Layer):
def setup(self, bottom, top):
self._sum = 0
for i in xrange(len(bottom)):
self._sum += bottom[i].data.shape[1]
def reshape(self, bottom, top):
top[0].reshape(bottom[0].data.shape[0], self._sum)
def forward(self, bottom, top):
offset = 0
for i in xrange(len(bottom)):
if len(bottom[i].data.shape) == 2:
top[0].data[:, offset : offset + bottom[i].data.shape[1]] = bottom[i].data
else:
top[0].data[:, offset : offset + bottom[i].data.shape[1]] = bottom[i].data[:, :, 0, 0]
offset += bottom[i].data.shape[1]
def backward(self, top, propagate_down, bottom):
offset = 0
for i in xrange(len(bottom)):
if len(bottom[i].data.shape) == 2:
bottom[i].diff[...] = top[0].diff[:, offset : offset + bottom[i].data.shape[1]]
else:
bottom[i].diff[:, :, 0, 0] = top[0].diff[:, offset : offset + bottom[i].data.shape[1]]
offset += bottom[i].data.shape[1]
================================================
FILE: lib/rel_data_layer/__init__.py
================================================
================================================
FILE: lib/rel_data_layer/layer.py
================================================
import caffe
import numpy as np
import json
import math
import os.path as osp
import os
import cv2
import h5py
class RelDataLayer(caffe.Layer):
def _shuffle_inds(self):
self._perm = np.random.permutation(np.arange(self._num_instance))
self._cur = 0
def _get_next_batch_ids(self):
if self._cur + self._batch_size > self._num_instance:
self._shuffle_inds()
ids = self._perm[self._cur : self._cur + self._batch_size]
self._cur += self._batch_size
return ids
def _getAppr(self, im, bb):
subim = im[bb[1] : bb[3], bb[0] : bb[2], :]
subim = cv2.resize(subim, None, None, 224.0 / subim.shape[1], 224.0 / subim.shape[0], interpolation=cv2.INTER_LINEAR)
pixel_means = np.array([[[103.939, 116.779, 123.68]]])
subim -= pixel_means
subim = subim.transpose((2, 0, 1))
return subim
def _getDualMask(self, ih, iw, bb):
rh = 32.0 / ih
rw = 32.0 / iw
x1 = max(0, int(math.floor(bb[0] * rw)))
x2 = min(32, int(math.ceil(bb[2] * rw)))
y1 = max(0, int(math.floor(bb[1] * rh)))
y2 = min(32, int(math.ceil(bb[3] * rh)))
mask = np.zeros((32, 32))
mask[y1 : y2, x1 : x2] = 1
assert(mask.sum() == (y2 - y1) * (x2 - x1))
return mask
def _get_next_batch(self):
ids = self._get_next_batch_ids()
qas = []
qbs = []
ims = []
poses = []
labels = []
for id in ids:
sample = self._samples[id]
im = cv2.imread(sample["imPath"]).astype(np.float32, copy=False)
ih = im.shape[0]
iw = im.shape[1]
qa = np.zeros(self._nclass)
qa[sample["aLabel"] - 1] = 1
qas.append(qa)
qb = np.zeros(self._nclass)
qb[sample["bLabel"] - 1] = 1
qbs.append(qb)
ims.append(self._getAppr(im, sample["rBBox"]))
poses.append([self._getDualMask(ih, iw, sample["aBBox"]), \
self._getDualMask(ih, iw, sample["bBBox"])])
labels.append(sample["rLabel"])
return {"qa": np.array(qas), "qb": np.array(qbs), "im": np.array(ims), "posdata": np.array(poses), "labels": np.array(labels)}
def setup(self, bottom, top):
layer_params = json.loads(self.param_str)
self._samples = json.load(open(layer_params["dataset"]))
self._num_instance = len(self._samples)
self._batch_size = layer_params["batch_size"]
self._nclass = layer_params["nclass"]
self._name_to_top_map = {"qa": 0, "qb": 1, "im": 2, "posdata": 3, "labels": 4}
self._shuffle_inds()
top[0].reshape(self._batch_size, self._nclass)
top[1].reshape(self._batch_size, self._nclass)
top[2].reshape(self._batch_size, 3, 224, 224)
top[3].reshape(self._batch_size, 2, 32, 32)
top[4].reshape(self._batch_size)
def forward(self, bottom, top):
batch = self._get_next_batch()
for blob_name, blob in batch.iteritems():
idx = self._name_to_top_map[blob_name]
top[idx].reshape(*(blob.shape))
top[idx].data[...] = blob.astype(np.float32, copy=False)
def backward(self, top, propagate_down, bottom):
pass
def reshape(self, bottom, top):
pass
================================================
FILE: lib/utils/__init__.py
================================================
================================================
FILE: lib/utils/eval_utils.py
================================================
def computeArea(bb):
return max(0, bb[2] - bb[0] + 1) * max(0, bb[3] - bb[1] + 1)
def computeIoU(bb1, bb2):
ibb = [max(bb1[0], bb2[0]), \
max(bb1[1], bb2[1]), \
min(bb1[2], bb2[2]), \
min(bb1[3], bb2[3])]
iArea = computeArea(ibb)
uArea = computeArea(bb1) + computeArea(bb2) - iArea
return (iArea + 0.0) / uArea
================================================
FILE: prototxts/drnet_8units_linear_shareweight.prototxt
================================================
layer {
name: "data"
type: "Python"
top: "qa"
top: "qb"
top: "im"
top: "posdata"
top: "labels"
include {
phase: TRAIN
}
python_param {
module: 'rel_data_layer.layer'
layer: 'RelDataLayer'
param_str: '{"dataset": "reltrain.json", "batch_size": 25, "nclass": 100}'
}
}
layer {
name: "data"
type: "Python"
top: "qa"
top: "qb"
top: "im"
top: "posdata"
top: "labels"
include {
phase: TEST
}
python_param {
module: 'rel_data_layer.layer'
layer: 'RelDataLayer'
param_str: '{"dataset": "reltest.json", "batch_size": 25, "nclass": 100}'
}
}
# Appearance Subnet
layer {
name: "conv1_1"
type: "Convolution"
bottom: "im"
top: "conv1_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 256
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu8"
type: "ReLU"
bottom: "fc8"
top: "fc8"
}
# Spatial Cfg Subnet
layer {
name: "conv1_p"
type: "Convolution"
bottom: "posdata"
top: "conv1_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "relu1_p"
type: "ReLU"
bottom: "conv1_p"
top: "conv1_p"
}
layer {
name: "conv2_p"
type: "Convolution"
bottom: "conv1_p"
top: "conv2_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "conv3_p"
type: "Convolution"
bottom: "conv2_p"
top: "conv3_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 8
}
}
layer {
name: "relu3_p"
type: "ReLU"
bottom: "conv3_p"
top: "conv3_p"
}
# Combine features from subnets
layer {
name: "concat1_c"
type: "Python"
bottom: "fc8"
bottom: "conv3_p"
top: "concat1_c"
python_param {
module: "customize_layers.concat_layer"
layer: "Layer"
}
}
layer {
name: "fc2_c"
type: "InnerProduct"
bottom: "concat1_c"
top: "fc2_c"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 128
}
}
layer {
name: "relu2_c"
type: "ReLU"
bottom: "fc2_c"
top: "fc2_c"
}
layer {
name: "PhiR_0"
type: "InnerProduct"
bottom: "fc2_c"
top: "qr0"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
#DR-Net
layer {
name: "PhiA_1"
type: "InnerProduct"
bottom: "qa"
top: "qar1"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiB_1"
type: "InnerProduct"
bottom: "qb"
top: "qbr1"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiR_1"
type: "InnerProduct"
bottom: "qr0"
top: "q1r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "QSum_1"
type: "Eltwise"
bottom: "qar1"
bottom: "qbr1"
bottom: "q1r"
top: "qr1"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_2"
type: "InnerProduct"
bottom: "qa"
top: "qar2"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_2"
type: "InnerProduct"
bottom: "qb"
top: "qbr2"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_2"
type: "InnerProduct"
bottom: "qr1"
top: "q2r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_2"
type: "Eltwise"
bottom: "qar2"
bottom: "qbr2"
bottom: "q2r"
top: "qr2"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_3"
type: "InnerProduct"
bottom: "qa"
top: "qar3"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_3"
type: "InnerProduct"
bottom: "qb"
top: "qbr3"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_3"
type: "InnerProduct"
bottom: "qr2"
top: "q3r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_3"
type: "Eltwise"
bottom: "qar3"
bottom: "qbr3"
bottom: "q3r"
top: "qr3"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_4"
type: "InnerProduct"
bottom: "qa"
top: "qar4"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_4"
type: "InnerProduct"
bottom: "qb"
top: "qbr4"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_4"
type: "InnerProduct"
bottom: "qr3"
top: "q4r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_4"
type: "Eltwise"
bottom: "qar4"
bottom: "qbr4"
bottom: "q4r"
top: "qr4"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_5"
type: "InnerProduct"
bottom: "qa"
top: "qar5"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_5"
type: "InnerProduct"
bottom: "qb"
top: "qbr5"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_5"
type: "InnerProduct"
bottom: "qr4"
top: "q5r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_5"
type: "Eltwise"
bottom: "qar5"
bottom: "qbr5"
bottom: "q5r"
top: "qr5"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_6"
type: "InnerProduct"
bottom: "qa"
top: "qar6"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_6"
type: "InnerProduct"
bottom: "qb"
top: "qbr6"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_6"
type: "InnerProduct"
bottom: "qr5"
top: "q6r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_6"
type: "Eltwise"
bottom: "qar6"
bottom: "qbr6"
bottom: "q6r"
top: "qr6"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_7"
type: "InnerProduct"
bottom: "qa"
top: "qar7"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_7"
type: "InnerProduct"
bottom: "qb"
top: "qbr7"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_7"
type: "InnerProduct"
bottom: "qr6"
top: "q7r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_7"
type: "Eltwise"
bottom: "qar7"
bottom: "qbr7"
bottom: "q7r"
top: "qr7"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_8"
type: "InnerProduct"
bottom: "qa"
top: "qar8"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_8"
type: "InnerProduct"
bottom: "qb"
top: "qbr8"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_8"
type: "InnerProduct"
bottom: "qr7"
top: "q8r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_8"
type: "Eltwise"
bottom: "qar8"
bottom: "qbr8"
bottom: "q8r"
top: "qr8"
eltwise_param { operation: SUM }
}
layer {
name: "loss3"
type: "SoftmaxWithLoss"
top: "loss3"
bottom: "qr8"
bottom: "labels"
include {
phase: TRAIN
}
loss_weight: 1
}
layer {
name: "softmax"
type: "Softmax"
bottom: "qr8"
top: "pred"
include {
phase: TEST
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "pred"
bottom: "labels"
top: "top-1"
include {
phase: TEST
}
accuracy_param {
top_k: 1
}
}
layer {
name: "accuracy_top5"
type: "Accuracy"
bottom: "pred"
bottom: "labels"
top: "top-5"
include {
phase: TEST
}
accuracy_param {
top_k: 5
}
}
================================================
FILE: prototxts/drnet_8units_relu_shareweight.prototxt
================================================
layer {
name: "data"
type: "Python"
top: "qa"
top: "qb"
top: "im"
top: "posdata"
top: "labels"
include {
phase: TRAIN
}
python_param {
module: 'rel_data_layer.layer'
layer: 'RelDataLayer'
param_str: '{"dataset": "reltrain.json", "batch_size": 25, "nclass": 100}'
}
}
layer {
name: "data"
type: "Python"
top: "qa"
top: "qb"
top: "im"
top: "posdata"
top: "labels"
include {
phase: TEST
}
python_param {
module: 'rel_data_layer.layer'
layer: 'RelDataLayer'
param_str: '{"dataset": "reltest.json", "batch_size": 25, "nclass": 100}'
}
}
# Appearance Subnet
layer {
name: "conv1_1"
type: "Convolution"
bottom: "im"
top: "conv1_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 256
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu8"
type: "ReLU"
bottom: "fc8"
top: "fc8"
}
# Spatial Cfg Subnet
layer {
name: "conv1_p"
type: "Convolution"
bottom: "posdata"
top: "conv1_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "relu1_p"
type: "ReLU"
bottom: "conv1_p"
top: "conv1_p"
}
layer {
name: "conv2_p"
type: "Convolution"
bottom: "conv1_p"
top: "conv2_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "conv3_p"
type: "Convolution"
bottom: "conv2_p"
top: "conv3_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 8
}
}
layer {
name: "relu3_p"
type: "ReLU"
bottom: "conv3_p"
top: "conv3_p"
}
# Combine features from subnets
layer {
name: "concat1_c"
type: "Python"
bottom: "fc8"
bottom: "conv3_p"
top: "concat1_c"
python_param {
module: "customize_layers.concat_layer"
layer: "Layer"
}
}
layer {
name: "fc2_c"
type: "InnerProduct"
bottom: "concat1_c"
top: "fc2_c"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 128
}
}
layer {
name: "relu2_c"
type: "ReLU"
bottom: "fc2_c"
top: "fc2_c"
}
layer {
name: "PhiR_0"
type: "InnerProduct"
bottom: "fc2_c"
top: "q0r"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu_0"
type: "ReLU"
bottom: "q0r"
top: "qr0"
}
#DR-Net
layer {
name: "PhiA_1"
type: "InnerProduct"
bottom: "qa"
top: "qar1"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiB_1"
type: "InnerProduct"
bottom: "qb"
top: "qbr1"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiR_1"
type: "InnerProduct"
bottom: "qr0"
top: "q1r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "QSum_1"
type: "Eltwise"
bottom: "qar1"
bottom: "qbr1"
bottom: "q1r"
top: "qr1un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_1"
type: "ReLU"
bottom: "qr1un"
top: "qr1"
}
layer {
name: "PhiA_2"
type: "InnerProduct"
bottom: "qa"
top: "qar2"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_2"
type: "InnerProduct"
bottom: "qb"
top: "qbr2"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_2"
type: "InnerProduct"
bottom: "qr1"
top: "q2r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_2"
type: "Eltwise"
bottom: "qar2"
bottom: "qbr2"
bottom: "q2r"
top: "qr2un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_2"
type: "ReLU"
bottom: "qr2un"
top: "qr2"
}
layer {
name: "PhiA_3"
type: "InnerProduct"
bottom: "qa"
top: "qar3"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_3"
type: "InnerProduct"
bottom: "qb"
top: "qbr3"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_3"
type: "InnerProduct"
bottom: "qr2"
top: "q3r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_3"
type: "Eltwise"
bottom: "qar3"
bottom: "qbr3"
bottom: "q3r"
top: "qr3un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_3"
type: "ReLU"
bottom: "qr3un"
top: "qr3"
}
layer {
name: "PhiA_4"
type: "InnerProduct"
bottom: "qa"
top: "qar4"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_4"
type: "InnerProduct"
bottom: "qb"
top: "qbr4"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_4"
type: "InnerProduct"
bottom: "qr3"
top: "q4r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_4"
type: "Eltwise"
bottom: "qar4"
bottom: "qbr4"
bottom: "q4r"
top: "qr4un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_4"
type: "ReLU"
bottom: "qr4un"
top: "qr4"
}
layer {
name: "PhiA_5"
type: "InnerProduct"
bottom: "qa"
top: "qar5"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_5"
type: "InnerProduct"
bottom: "qb"
top: "qbr5"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_5"
type: "InnerProduct"
bottom: "qr4"
top: "q5r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_5"
type: "Eltwise"
bottom: "qar5"
bottom: "qbr5"
bottom: "q5r"
top: "qr5un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_5"
type: "ReLU"
bottom: "qr5un"
top: "qr5"
}
layer {
name: "PhiA_6"
type: "InnerProduct"
bottom: "qa"
top: "qar6"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_6"
type: "InnerProduct"
bottom: "qb"
top: "qbr6"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_6"
type: "InnerProduct"
bottom: "qr5"
top: "q6r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_6"
type: "Eltwise"
bottom: "qar6"
bottom: "qbr6"
bottom: "q6r"
top: "qr6un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_6"
type: "ReLU"
bottom: "qr6un"
top: "qr6"
}
layer {
name: "PhiA_7"
type: "InnerProduct"
bottom: "qa"
top: "qar7"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_7"
type: "InnerProduct"
bottom: "qb"
top: "qbr7"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_7"
type: "InnerProduct"
bottom: "qr6"
top: "q7r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_7"
type: "Eltwise"
bottom: "qar7"
bottom: "qbr7"
bottom: "q7r"
top: "qr7un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_7"
type: "ReLU"
bottom: "qr7un"
top: "qr7"
}
layer {
name: "PhiA_8"
type: "InnerProduct"
bottom: "qa"
top: "qar8"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_8"
type: "InnerProduct"
bottom: "qb"
top: "qbr8"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_8"
type: "InnerProduct"
bottom: "qr7"
top: "q8r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_8"
type: "Eltwise"
bottom: "qar8"
bottom: "qbr8"
bottom: "q8r"
top: "qr8"
eltwise_param { operation: SUM }
}
layer {
name: "loss3"
type: "SoftmaxWithLoss"
top: "loss3"
bottom: "qr8"
bottom: "labels"
include {
phase: TRAIN
}
loss_weight: 1
}
layer {
name: "softmax"
type: "Softmax"
bottom: "qr8"
top: "pred"
include {
phase: TEST
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "pred"
bottom: "labels"
top: "top-1"
include {
phase: TEST
}
accuracy_param {
top_k: 1
}
}
layer {
name: "accuracy_top5"
type: "Accuracy"
bottom: "pred"
bottom: "labels"
top: "top-5"
include {
phase: TEST
}
accuracy_param {
top_k: 5
}
}
================================================
FILE: prototxts/drnet_8units_softmax.prototxt
================================================
layer {
name: "data"
type: "Python"
top: "qa"
top: "qb"
top: "im"
top: "posdata"
top: "labels"
include {
phase: TRAIN
}
python_param {
module: 'rel_data_layer.layer'
layer: 'RelDataLayer'
param_str: '{"dataset": "reltrain.json", "batch_size": 25, "nclass": 100}'
}
}
layer {
name: "data"
type: "Python"
top: "qa"
top: "qb"
top: "im"
top: "posdata"
top: "labels"
include {
phase: TEST
}
python_param {
module: 'rel_data_layer.layer'
layer: 'RelDataLayer'
param_str: '{"dataset": "reltest.json", "batch_size": 25, "nclass": 100}'
}
}
# Appearance Subnet
layer {
name: "conv1_1"
type: "Convolution"
bottom: "im"
top: "conv1_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 256
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu8"
type: "ReLU"
bottom: "fc8"
top: "fc8"
}
# Spatial Cfg Subnet
layer {
name: "conv1_p"
type: "Convolution"
bottom: "posdata"
top: "conv1_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "relu1_p"
type: "ReLU"
bottom: "conv1_p"
top: "conv1_p"
}
layer {
name: "conv2_p"
type: "Convolution"
bottom: "conv1_p"
top: "conv2_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "conv3_p"
type: "Convolution"
bottom: "conv2_p"
top: "conv3_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 8
}
}
layer {
name: "relu3_p"
type: "ReLU"
bottom: "conv3_p"
top: "conv3_p"
}
# Combine features from subnets
layer {
name: "concat1_c"
type: "Python"
bottom: "fc8"
bottom: "conv3_p"
top: "concat1_c"
python_param {
module: "customize_layers.concat_layer"
layer: "Layer"
}
}
layer {
name: "fc2_c"
type: "InnerProduct"
bottom: "concat1_c"
top: "fc2_c"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 128
}
}
layer {
name: "relu2_c"
type: "ReLU"
bottom: "fc2_c"
top: "fc2_c"
}
layer {
name: "PhiR_0"
type: "InnerProduct"
bottom: "fc2_c"
top: "q0r"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "Softmax_0"
type: "Softmax"
bottom: "q0r"
top: "qr0"
}
#DR-Net
layer {
name: "PhiA_1"
type: "InnerProduct"
bottom: "qa"
top: "qar1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiB_1"
type: "InnerProduct"
bottom: "qb"
top: "qbr1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiR_1"
type: "InnerProduct"
bottom: "qr0"
top: "q1r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "QSum_1"
type: "Eltwise"
bottom: "qar1"
bottom: "qbr1"
bottom: "q1r"
top: "qr1un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_1"
type: "Softmax"
bottom: "qr1un"
top: "qr1"
}
layer {
name: "PhiA_2"
type: "InnerProduct"
bottom: "qa"
top: "qar2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_2"
type: "InnerProduct"
bottom: "qb"
top: "qbr2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_2"
type: "InnerProduct"
bottom: "qr1"
top: "q2r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_2"
type: "Eltwise"
bottom: "qar2"
bottom: "qbr2"
bottom: "q2r"
top: "qr2un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_2"
type: "Softmax"
bottom: "qr2un"
top: "qr2"
}
layer {
name: "PhiA_3"
type: "InnerProduct"
bottom: "qa"
top: "qar3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_3"
type: "InnerProduct"
bottom: "qb"
top: "qbr3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_3"
type: "InnerProduct"
bottom: "qr2"
top: "q3r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_3"
type: "Eltwise"
bottom: "qar3"
bottom: "qbr3"
bottom: "q3r"
top: "qr3un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_3"
type: "Softmax"
bottom: "qr3un"
top: "qr3"
}
layer {
name: "PhiA_4"
type: "InnerProduct"
bottom: "qa"
top: "qar4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_4"
type: "InnerProduct"
bottom: "qb"
top: "qbr4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_4"
type: "InnerProduct"
bottom: "qr3"
top: "q4r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_4"
type: "Eltwise"
bottom: "qar4"
bottom: "qbr4"
bottom: "q4r"
top: "qr4un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_4"
type: "Softmax"
bottom: "qr4un"
top: "qr4"
}
layer {
name: "PhiA_5"
type: "InnerProduct"
bottom: "qa"
top: "qar5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_5"
type: "InnerProduct"
bottom: "qb"
top: "qbr5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_5"
type: "InnerProduct"
bottom: "qr4"
top: "q5r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_5"
type: "Eltwise"
bottom: "qar5"
bottom: "qbr5"
bottom: "q5r"
top: "qr5un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_5"
type: "Softmax"
bottom: "qr5un"
top: "qr5"
}
layer {
name: "PhiA_6"
type: "InnerProduct"
bottom: "qa"
top: "qar6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_6"
type: "InnerProduct"
bottom: "qb"
top: "qbr6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_6"
type: "InnerProduct"
bottom: "qr5"
top: "q6r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_6"
type: "Eltwise"
bottom: "qar6"
bottom: "qbr6"
bottom: "q6r"
top: "qr6un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_6"
type: "Softmax"
bottom: "qr6un"
top: "qr6"
}
layer {
name: "PhiA_7"
type: "InnerProduct"
bottom: "qa"
top: "qar7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_7"
type: "InnerProduct"
bottom: "qb"
top: "qbr7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_7"
type: "InnerProduct"
bottom: "qr6"
top: "q7r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_7"
type: "Eltwise"
bottom: "qar7"
bottom: "qbr7"
bottom: "q7r"
top: "qr7un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_7"
type: "Softmax"
bottom: "qr7un"
top: "qr7"
}
layer {
name: "PhiA_8"
type: "InnerProduct"
bottom: "qa"
top: "qar8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_8"
type: "InnerProduct"
bottom: "qb"
top: "qbr8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_8"
type: "InnerProduct"
bottom: "qr7"
top: "q8r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_8"
type: "Eltwise"
bottom: "qar8"
bottom: "qbr8"
bottom: "q8r"
top: "qr8"
eltwise_param { operation: SUM }
}
layer {
name: "loss3"
type: "SoftmaxWithLoss"
top: "loss3"
bottom: "qr8"
bottom: "labels"
include {
phase: TRAIN
}
loss_weight: 1
}
layer {
name: "softmax"
type: "Softmax"
bottom: "qr8"
top: "pred"
include {
phase: TEST
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "pred"
bottom: "labels"
top: "top-1"
include {
phase: TEST
}
accuracy_param {
top_k: 1
}
}
layer {
name: "accuracy_top5"
type: "Accuracy"
bottom: "pred"
bottom: "labels"
top: "top-5"
include {
phase: TEST
}
accuracy_param {
top_k: 5
}
}
================================================
FILE: prototxts/test_drnet_8units_linear_shareweight.prototxt
================================================
input: "qa"
input_shape {
dim: 1
dim: 100
}
input: "qb"
input_shape {
dim: 1
dim: 100
}
input: "im"
input_shape {
dim: 1
dim: 3
dim: 224
dim: 224
}
input: "posdata"
input_shape {
dim: 1
dim: 2
dim: 32
dim: 32
}
# Appearance Subnet
layer {
name: "conv1_1"
type: "Convolution"
bottom: "im"
top: "conv1_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 256
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu8"
type: "ReLU"
bottom: "fc8"
top: "fc8"
}
# Spatial Cfg Subnet
layer {
name: "conv1_p"
type: "Convolution"
bottom: "posdata"
top: "conv1_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "relu1_p"
type: "ReLU"
bottom: "conv1_p"
top: "conv1_p"
}
layer {
name: "conv2_p"
type: "Convolution"
bottom: "conv1_p"
top: "conv2_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "conv3_p"
type: "Convolution"
bottom: "conv2_p"
top: "conv3_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 8
}
}
layer {
name: "relu3_p"
type: "ReLU"
bottom: "conv3_p"
top: "conv3_p"
}
# Combine features from subnets
layer {
name: "concat1_c"
type: "Python"
bottom: "fc8"
bottom: "conv3_p"
top: "concat1_c"
python_param {
module: "customize_layers.concat_layer"
layer: "Layer"
}
}
layer {
name: "fc2_c"
type: "InnerProduct"
bottom: "concat1_c"
top: "fc2_c"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 128
}
}
layer {
name: "relu2_c"
type: "ReLU"
bottom: "fc2_c"
top: "fc2_c"
}
layer {
name: "PhiR_0"
type: "InnerProduct"
bottom: "fc2_c"
top: "qr0"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
#DR-Net
layer {
name: "PhiA_1"
type: "InnerProduct"
bottom: "qa"
top: "qar1"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiB_1"
type: "InnerProduct"
bottom: "qb"
top: "qbr1"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiR_1"
type: "InnerProduct"
bottom: "qr0"
top: "q1r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "QSum_1"
type: "Eltwise"
bottom: "qar1"
bottom: "qbr1"
bottom: "q1r"
top: "qr1"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_2"
type: "InnerProduct"
bottom: "qa"
top: "qar2"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_2"
type: "InnerProduct"
bottom: "qb"
top: "qbr2"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_2"
type: "InnerProduct"
bottom: "qr1"
top: "q2r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_2"
type: "Eltwise"
bottom: "qar2"
bottom: "qbr2"
bottom: "q2r"
top: "qr2"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_3"
type: "InnerProduct"
bottom: "qa"
top: "qar3"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_3"
type: "InnerProduct"
bottom: "qb"
top: "qbr3"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_3"
type: "InnerProduct"
bottom: "qr2"
top: "q3r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_3"
type: "Eltwise"
bottom: "qar3"
bottom: "qbr3"
bottom: "q3r"
top: "qr3"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_4"
type: "InnerProduct"
bottom: "qa"
top: "qar4"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_4"
type: "InnerProduct"
bottom: "qb"
top: "qbr4"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_4"
type: "InnerProduct"
bottom: "qr3"
top: "q4r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_4"
type: "Eltwise"
bottom: "qar4"
bottom: "qbr4"
bottom: "q4r"
top: "qr4"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_5"
type: "InnerProduct"
bottom: "qa"
top: "qar5"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_5"
type: "InnerProduct"
bottom: "qb"
top: "qbr5"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_5"
type: "InnerProduct"
bottom: "qr4"
top: "q5r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_5"
type: "Eltwise"
bottom: "qar5"
bottom: "qbr5"
bottom: "q5r"
top: "qr5"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_6"
type: "InnerProduct"
bottom: "qa"
top: "qar6"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_6"
type: "InnerProduct"
bottom: "qb"
top: "qbr6"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_6"
type: "InnerProduct"
bottom: "qr5"
top: "q6r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_6"
type: "Eltwise"
bottom: "qar6"
bottom: "qbr6"
bottom: "q6r"
top: "qr6"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_7"
type: "InnerProduct"
bottom: "qa"
top: "qar7"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_7"
type: "InnerProduct"
bottom: "qb"
top: "qbr7"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_7"
type: "InnerProduct"
bottom: "qr6"
top: "q7r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_7"
type: "Eltwise"
bottom: "qar7"
bottom: "qbr7"
bottom: "q7r"
top: "qr7"
eltwise_param { operation: SUM }
}
layer {
name: "PhiA_8"
type: "InnerProduct"
bottom: "qa"
top: "qar8"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_8"
type: "InnerProduct"
bottom: "qb"
top: "qbr8"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_8"
type: "InnerProduct"
bottom: "qr7"
top: "q8r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_8"
type: "Eltwise"
bottom: "qar8"
bottom: "qbr8"
bottom: "q8r"
top: "qr8"
eltwise_param { operation: SUM }
}
layer {
name: "softmax"
type: "Softmax"
bottom: "qr8"
top: "pred"
}
================================================
FILE: prototxts/test_drnet_8units_relu_shareweight.prototxt
================================================
input: "qa"
input_shape {
dim: 1
dim: 100
}
input: "qb"
input_shape {
dim: 1
dim: 100
}
input: "im"
input_shape {
dim: 1
dim: 3
dim: 224
dim: 224
}
input: "posdata"
input_shape {
dim: 1
dim: 2
dim: 32
dim: 32
}
# Appearance Subnet
layer {
name: "conv1_1"
type: "Convolution"
bottom: "im"
top: "conv1_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 256
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu8"
type: "ReLU"
bottom: "fc8"
top: "fc8"
}
# Spatial Cfg Subnet
layer {
name: "conv1_p"
type: "Convolution"
bottom: "posdata"
top: "conv1_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "relu1_p"
type: "ReLU"
bottom: "conv1_p"
top: "conv1_p"
}
layer {
name: "conv2_p"
type: "Convolution"
bottom: "conv1_p"
top: "conv2_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "conv3_p"
type: "Convolution"
bottom: "conv2_p"
top: "conv3_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 8
}
}
layer {
name: "relu3_p"
type: "ReLU"
bottom: "conv3_p"
top: "conv3_p"
}
# Combine features from subnets
layer {
name: "concat1_c"
type: "Python"
bottom: "fc8"
bottom: "conv3_p"
top: "concat1_c"
python_param {
module: "customize_layers.concat_layer"
layer: "Layer"
}
}
layer {
name: "fc2_c"
type: "InnerProduct"
bottom: "concat1_c"
top: "fc2_c"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 128
}
}
layer {
name: "relu2_c"
type: "ReLU"
bottom: "fc2_c"
top: "fc2_c"
}
layer {
name: "PhiR_0"
type: "InnerProduct"
bottom: "fc2_c"
top: "q0r"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu_0"
type: "ReLU"
bottom: "q0r"
top: "qr0"
}
#DR-Net
layer {
name: "PhiA_1"
type: "InnerProduct"
bottom: "qa"
top: "qar1"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiB_1"
type: "InnerProduct"
bottom: "qb"
top: "qbr1"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiR_1"
type: "InnerProduct"
bottom: "qr0"
top: "q1r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "QSum_1"
type: "Eltwise"
bottom: "qar1"
bottom: "qbr1"
bottom: "q1r"
top: "qr1un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_1"
type: "ReLU"
bottom: "qr1un"
top: "qr1"
}
layer {
name: "PhiA_2"
type: "InnerProduct"
bottom: "qa"
top: "qar2"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_2"
type: "InnerProduct"
bottom: "qb"
top: "qbr2"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_2"
type: "InnerProduct"
bottom: "qr1"
top: "q2r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_2"
type: "Eltwise"
bottom: "qar2"
bottom: "qbr2"
bottom: "q2r"
top: "qr2un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_2"
type: "ReLU"
bottom: "qr2un"
top: "qr2"
}
layer {
name: "PhiA_3"
type: "InnerProduct"
bottom: "qa"
top: "qar3"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_3"
type: "InnerProduct"
bottom: "qb"
top: "qbr3"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_3"
type: "InnerProduct"
bottom: "qr2"
top: "q3r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_3"
type: "Eltwise"
bottom: "qar3"
bottom: "qbr3"
bottom: "q3r"
top: "qr3un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_3"
type: "ReLU"
bottom: "qr3un"
top: "qr3"
}
layer {
name: "PhiA_4"
type: "InnerProduct"
bottom: "qa"
top: "qar4"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_4"
type: "InnerProduct"
bottom: "qb"
top: "qbr4"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_4"
type: "InnerProduct"
bottom: "qr3"
top: "q4r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_4"
type: "Eltwise"
bottom: "qar4"
bottom: "qbr4"
bottom: "q4r"
top: "qr4un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_4"
type: "ReLU"
bottom: "qr4un"
top: "qr4"
}
layer {
name: "PhiA_5"
type: "InnerProduct"
bottom: "qa"
top: "qar5"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_5"
type: "InnerProduct"
bottom: "qb"
top: "qbr5"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_5"
type: "InnerProduct"
bottom: "qr4"
top: "q5r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_5"
type: "Eltwise"
bottom: "qar5"
bottom: "qbr5"
bottom: "q5r"
top: "qr5un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_5"
type: "ReLU"
bottom: "qr5un"
top: "qr5"
}
layer {
name: "PhiA_6"
type: "InnerProduct"
bottom: "qa"
top: "qar6"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_6"
type: "InnerProduct"
bottom: "qb"
top: "qbr6"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_6"
type: "InnerProduct"
bottom: "qr5"
top: "q6r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_6"
type: "Eltwise"
bottom: "qar6"
bottom: "qbr6"
bottom: "q6r"
top: "qr6un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_6"
type: "ReLU"
bottom: "qr6un"
top: "qr6"
}
layer {
name: "PhiA_7"
type: "InnerProduct"
bottom: "qa"
top: "qar7"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_7"
type: "InnerProduct"
bottom: "qb"
top: "qbr7"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_7"
type: "InnerProduct"
bottom: "qr6"
top: "q7r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_7"
type: "Eltwise"
bottom: "qar7"
bottom: "qbr7"
bottom: "q7r"
top: "qr7un"
eltwise_param { operation: SUM }
}
layer {
name: "relu_7"
type: "ReLU"
bottom: "qr7un"
top: "qr7"
}
layer {
name: "PhiA_8"
type: "InnerProduct"
bottom: "qa"
top: "qar8"
param {
name: "qar_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qar_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_8"
type: "InnerProduct"
bottom: "qb"
top: "qbr8"
param {
name: "qbr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qbr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_8"
type: "InnerProduct"
bottom: "qr7"
top: "q8r"
param {
name: "qr_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "qr_b"
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_8"
type: "Eltwise"
bottom: "qar8"
bottom: "qbr8"
bottom: "q8r"
top: "qr8"
eltwise_param { operation: SUM }
}
layer {
name: "softmax"
type: "Softmax"
bottom: "qr8"
top: "pred"
}
================================================
FILE: prototxts/test_drnet_8units_softmax.prototxt
================================================
input: "qa"
input_shape {
dim: 1
dim: 100
}
input: "qb"
input_shape {
dim: 1
dim: 100
}
input: "im"
input_shape {
dim: 1
dim: 3
dim: 224
dim: 224
}
input: "posdata"
input_shape {
dim: 1
dim: 2
dim: 32
dim: 32
}
# Appearance Subnet
layer {
name: "conv1_1"
type: "Convolution"
bottom: "im"
top: "conv1_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 256
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu8"
type: "ReLU"
bottom: "fc8"
top: "fc8"
}
# Spatial Cfg Subnet
layer {
name: "conv1_p"
type: "Convolution"
bottom: "posdata"
top: "conv1_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "relu1_p"
type: "ReLU"
bottom: "conv1_p"
top: "conv1_p"
}
layer {
name: "conv2_p"
type: "Convolution"
bottom: "conv1_p"
top: "conv2_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 5
pad: 2
stride: 2
}
}
layer {
name: "conv3_p"
type: "Convolution"
bottom: "conv2_p"
top: "conv3_p"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 8
}
}
layer {
name: "relu3_p"
type: "ReLU"
bottom: "conv3_p"
top: "conv3_p"
}
# Combine features from subnets
layer {
name: "concat1_c"
type: "Python"
bottom: "fc8"
bottom: "conv3_p"
top: "concat1_c"
python_param {
module: "customize_layers.concat_layer"
layer: "Layer"
}
}
layer {
name: "fc2_c"
type: "InnerProduct"
bottom: "concat1_c"
top: "fc2_c"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 128
}
}
layer {
name: "relu2_c"
type: "ReLU"
bottom: "fc2_c"
top: "fc2_c"
}
layer {
name: "PhiR_0"
type: "InnerProduct"
bottom: "fc2_c"
top: "q0r"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "Softmax_0"
type: "Softmax"
bottom: "q0r"
top: "qr0"
}
#DR-Net
layer {
name: "PhiA_1"
type: "InnerProduct"
bottom: "qa"
top: "qar1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiB_1"
type: "InnerProduct"
bottom: "qb"
top: "qbr1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "PhiR_1"
type: "InnerProduct"
bottom: "qr0"
top: "q1r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "QSum_1"
type: "Eltwise"
bottom: "qar1"
bottom: "qbr1"
bottom: "q1r"
top: "qr1un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_1"
type: "Softmax"
bottom: "qr1un"
top: "qr1"
}
layer {
name: "PhiA_2"
type: "InnerProduct"
bottom: "qa"
top: "qar2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_2"
type: "InnerProduct"
bottom: "qb"
top: "qbr2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_2"
type: "InnerProduct"
bottom: "qr1"
top: "q2r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_2"
type: "Eltwise"
bottom: "qar2"
bottom: "qbr2"
bottom: "q2r"
top: "qr2un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_2"
type: "Softmax"
bottom: "qr2un"
top: "qr2"
}
layer {
name: "PhiA_3"
type: "InnerProduct"
bottom: "qa"
top: "qar3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_3"
type: "InnerProduct"
bottom: "qb"
top: "qbr3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_3"
type: "InnerProduct"
bottom: "qr2"
top: "q3r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_3"
type: "Eltwise"
bottom: "qar3"
bottom: "qbr3"
bottom: "q3r"
top: "qr3un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_3"
type: "Softmax"
bottom: "qr3un"
top: "qr3"
}
layer {
name: "PhiA_4"
type: "InnerProduct"
bottom: "qa"
top: "qar4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_4"
type: "InnerProduct"
bottom: "qb"
top: "qbr4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_4"
type: "InnerProduct"
bottom: "qr3"
top: "q4r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_4"
type: "Eltwise"
bottom: "qar4"
bottom: "qbr4"
bottom: "q4r"
top: "qr4un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_4"
type: "Softmax"
bottom: "qr4un"
top: "qr4"
}
layer {
name: "PhiA_5"
type: "InnerProduct"
bottom: "qa"
top: "qar5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_5"
type: "InnerProduct"
bottom: "qb"
top: "qbr5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_5"
type: "InnerProduct"
bottom: "qr4"
top: "q5r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_5"
type: "Eltwise"
bottom: "qar5"
bottom: "qbr5"
bottom: "q5r"
top: "qr5un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_5"
type: "Softmax"
bottom: "qr5un"
top: "qr5"
}
layer {
name: "PhiA_6"
type: "InnerProduct"
bottom: "qa"
top: "qar6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_6"
type: "InnerProduct"
bottom: "qb"
top: "qbr6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_6"
type: "InnerProduct"
bottom: "qr5"
top: "q6r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_6"
type: "Eltwise"
bottom: "qar6"
bottom: "qbr6"
bottom: "q6r"
top: "qr6un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_6"
type: "Softmax"
bottom: "qr6un"
top: "qr6"
}
layer {
name: "PhiA_7"
type: "InnerProduct"
bottom: "qa"
top: "qar7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_7"
type: "InnerProduct"
bottom: "qb"
top: "qbr7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_7"
type: "InnerProduct"
bottom: "qr6"
top: "q7r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_7"
type: "Eltwise"
bottom: "qar7"
bottom: "qbr7"
bottom: "q7r"
top: "qr7un"
eltwise_param { operation: SUM }
}
layer {
name: "Softmax_7"
type: "Softmax"
bottom: "qr7un"
top: "qr7"
}
layer {
name: "PhiA_8"
type: "InnerProduct"
bottom: "qa"
top: "qar8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiB_8"
type: "InnerProduct"
bottom: "qb"
top: "qbr8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "PhiR_8"
type: "InnerProduct"
bottom: "qr7"
top: "q8r"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 70
}
}
layer {
name: "QSum_8"
type: "Eltwise"
bottom: "qar8"
bottom: "qbr8"
bottom: "q8r"
top: "qr8"
eltwise_param { operation: SUM }
}
layer {
name: "softmax"
type: "Softmax"
bottom: "qr8"
top: "pred"
}
================================================
FILE: snapshots/README.md
================================================
## Download Links
* [drnet_8units_softmax](https://drive.google.com/file/d/0B5RJWjAhdT04Y2pJelpxSEhYWTQ/view?usp=sharing)
* [drnet_8units_linear_shareweight](https://drive.google.com/file/d/0B5RJWjAhdT04X24xWFY1aHhLY0U/view?usp=sharing)
* [drnet_8units_relu_shareweight](https://drive.google.com/file/d/0B5RJWjAhdT04MTVvanRHcWtlODg/view?usp=sharing)
================================================
FILE: tools/_init_paths.py
================================================
import os.path as osp
import sys
def add_path(path):
if path not in sys.path:
sys.path.insert(0, path)
this_dir = osp.dirname(__file__)
# Add caffe to PYTHONPATH
caffe_path = osp.join(this_dir, '..', '..', '..', 'caffes', 'caffe-newest', 'python')
add_path(caffe_path)
# Add lib to PYTHONPATH
lib_path = osp.join(this_dir, '..', 'lib')
add_path(lib_path)
================================================
FILE: tools/eval_triplet_recall.py
================================================
#!/usr/bin/env python
import _init_paths
import argparse
import time, os, sys
import json
import cv2
import cPickle as cp
import numpy as np
import math
from utils.eval_utils import computeIoU
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser()
# gt file format: [ gt_label, gt_box ]
# gt_label: list [ gt_label(image_i) for image_i in images ]
# gt_label(image_i): numpy.array of size: num_instance x 3
# instance: [ label_s, label_r, label_o ]
# gt_box: list [ gt_box(image_i) for image_i in images ]
# gt_box(image_i): numpy.array of size: num_instance x 2 x 4
# instance: [ [x1_s, y1_s, x2_s, y2_s],
# [x1_o, y1_o, x2_o, y2_o]]
parser.add_argument('--gt_file', dest='gt_file',
help='file containing gts',
default=None, type=str)
parser.add_argument('--num_dets', dest='num_dets',
help='max number of detections per image',
default=50, type=int)
# det file format: [ det_label, det_box ]
# det_label: list [ det_label(image_i) for image_i in images ]
# det_label(image_i): numpy.array of size: num_instance x 6
# instance: [ prob_s, prob_r, prob_o, label_s, label_r, label_o ]
# det_box: list [ det_box(image_i) for image_i in images ]
# det_box(image_i): numpy.array of size: num_instance x 2 x 4
# instance: [ [x1_s, y1_s, x2_s, y2_s],
# [x1_o, y1_o, x2_o, y2_o]]
parser.add_argument('--det_file', dest='det_file',
help='file containing triplet detections',
default=None, type=str)
parser.add_argument('--min_overlap', dest='ov_thresh',
help='minimum overlap for a correct detection',
default=0.5, type=float)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
def computeOverlap(detBBs, gtBBs):
aIoU = computeIoU(detBBs[0, :], gtBBs[0, :])
bIoU = computeIoU(detBBs[1, :], gtBBs[1, :])
return min(aIoU, bIoU)
def eval_recall(args):
f = open(args.det_file, "r")
dets, det_bboxes = cp.load(f)
f.close()
f = open(args.gt_file, "r")
all_gts, all_gt_bboxes = cp.load(f)
f.close()
num_img = len(dets)
tp = []
fp = []
score = []
total_num_gts = 0
for i in xrange(num_img):
gts = all_gts[i]
gt_bboxes = all_gt_bboxes[i]
num_gts = gts.shape[0]
total_num_gts += num_gts
gt_detected = np.zeros(num_gts)
if isinstance(dets[i], np.ndarray) and dets[i].shape[0] > 0:
det_score = np.log(dets[i][:, 0]) + np.log(dets[i][:, 1]) + np.log(dets[i][:, 2])
inds = np.argsort(det_score)[::-1]
if args.num_dets > 0 and args.num_dets < len(inds):
inds = inds[:args.num_dets]
top_dets = dets[i][inds, 3:]
top_scores = det_score[inds]
top_det_bboxes = det_bboxes[i][inds, :]
num_dets = len(inds)
for j in xrange(num_dets):
ov_max = 0
arg_max = -1
for k in xrange(num_gts):
if gt_detected[k] == 0 and top_dets[j, 0] == gts[k, 0] and top_dets[j, 1] == gts[k, 1] and top_dets[j, 2] == gts[k, 2]:
ov = computeOverlap(top_det_bboxes[j, :, :], gt_bboxes[k, :, :])
if ov >= args.ov_thresh and ov > ov_max:
ov_max = ov
arg_max = k
if arg_max != -1:
gt_detected[arg_max] = 1
tp.append(1)
fp.append(0)
else:
tp.append(0)
fp.append(1)
score.append(top_scores[j])
score = np.array(score)
tp = np.array(tp)
fp = np.array(fp)
inds = np.argsort(score)
inds = inds[::-1]
tp = tp[inds]
fp = fp[inds]
tp = np.cumsum(tp)
fp = np.cumsum(fp)
recall = (tp + 0.0) / total_num_gts
top_recall = recall[-1]
print top_recall
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
eval_recall(args)
================================================
FILE: tools/eval_union_recall.py
================================================
#!/usr/bin/env python
import _init_paths
import argparse
import time, os, sys
import json
import cv2
import cPickle as cp
import numpy as np
import math
from utils.eval_utils import computeIoU
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser()
# gt file format: [ gt_label, gt_box ]
# gt_label: list [ gt_label(image_i) for image_i in images ]
# gt_label(image_i): numpy.array of size: num_instance x 3
# instance: [ label_s, label_r, label_o ]
# gt_box: list [ gt_box(image_i) for image_i in images ]
# gt_box(image_i): numpy.array of size: num_instance x 2 x 4
# instance: [ [x1_s, y1_s, x2_s, y2_s],
# [x1_o, y1_o, x2_o, y2_o]]
parser.add_argument('--gt_file', dest='gt_file',
help='file containing gts',
default=None, type=str)
parser.add_argument('--num_dets', dest='num_dets',
help='max number of detections per image',
default=50, type=int)
# det file format: [ det_label, det_box ]
# det_label: list [ det_label(image_i) for image_i in images ]
# det_label(image_i): numpy.array of size: num_instance x 6
# instance: [ prob_s, prob_r, prob_o, label_s, label_r, label_o ]
# det_box: list [ det_box(image_i) for image_i in images ]
# det_box(image_i): numpy.array of size: num_instance x 2 x 4
# instance: [ [x1_s, y1_s, x2_s, y2_s],
# [x1_o, y1_o, x2_o, y2_o]]
parser.add_argument('--det_file', dest='det_file',
help='file containing triplet detections',
default=None, type=str)
parser.add_argument('--min_overlap', dest='ov_thresh',
help='minimum overlap for a correct detection',
default=0.5, type=float)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
def getUnionBB(aBB, bBB):
return [min(aBB[0], bBB[0]), \
min(aBB[1], bBB[1]), \
max(aBB[2], bBB[2]), \
max(aBB[3], bBB[3])]
def computeOverlap(detBBs, gtBBs):
aIoU = computeIoU(detBBs[0, :], gtBBs[0, :])
bIoU = computeIoU(detBBs[1, :], gtBBs[1, :])
return min(aIoU, bIoU)
def eval_recall(args):
f = open(args.det_file, "r")
dets, det_bboxes = cp.load(f)
f.close()
f = open(args.gt_file, "r")
all_gts, all_gt_bboxes = cp.load(f)
f.close()
num_img = len(dets)
tp = []
fp = []
score = []
total_num_gts = 0
for i in xrange(num_img):
gts = all_gts[i]
gt_bboxes = all_gt_bboxes[i]
gt_ubbs = []
num_gts = gts.shape[0]
for j in xrange(num_gts):
gt_ubbs.append(getUnionBB(gt_bboxes[j, 0, :], gt_bboxes[j, 1, :]))
total_num_gts += num_gts
gt_detected = np.zeros(num_gts)
if isinstance(dets[i], np.ndarray) and dets[i].shape[0] > 0:
det_score = np.log(dets[i][:, 0]) + np.log(dets[i][:, 1]) + np.log(dets[i][:, 2])
inds = np.argsort(det_score)[::-1]
if args.num_dets > 0 and args.num_dets < len(inds):
inds = inds[:args.num_dets]
top_dets = dets[i][inds, 3:]
top_scores = det_score[inds]
top_det_bboxes = det_bboxes[i][inds, :]
top_det_ubbs = []
num_dets = len(inds)
for j in xrange(num_dets):
top_det_ubbs.append(getUnionBB(top_det_bboxes[j, 0, :], top_det_bboxes[j, 1, :]))
for j in xrange(num_dets):
ov_max = 0
arg_max = -1
for k in xrange(num_gts):
if gt_detected[k] == 0 and top_dets[j, 0] == gts[k, 0] and top_dets[j, 1] == gts[k, 1] and top_dets[j, 2] == gts[k, 2]:
ov = computeIoU(top_det_ubbs[j], gt_ubbs[k])
if ov >= args.ov_thresh and ov > ov_max:
ov_max = ov
arg_max = k
if arg_max != -1:
gt_detected[arg_max] = 1
tp.append(1)
fp.append(0)
else:
tp.append(0)
fp.append(1)
score.append(top_scores[j])
score = np.array(score)
tp = np.array(tp)
fp = np.array(fp)
inds = np.argsort(score)
inds = inds[::-1]
tp = tp[inds]
fp = fp[inds]
tp = np.cumsum(tp)
fp = np.cumsum(fp)
recall = (tp + 0.0) / total_num_gts
top_recall = recall[-1]
print top_recall
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
eval_recall(args)
================================================
FILE: tools/prepare_data.py
================================================
import os.path as osp
import mat4py as mp
import cv2
import numpy as np
import math
import json
class DataLoader:
def __init__(self, datasetRoot, split):
self._root = datasetRoot
self._split = split
self._loadLabels()
self._loadAnnotation(split)
def _loadLabels(self):
mat = mp.loadmat(osp.join(self._root, "predicate.mat"))
self._relList = mat["predicate"]
self._numRelClass = len(self._relList)
self._relMapping = {}
for i in xrange(len(self._relList)):
self._relMapping[self._relList[i]] = i
mat = mp.loadmat(osp.join(self._root, "objectListN.mat"))
self._objList = mat["objectListN"]
self._numObjClass = len(self._objList) + 1
self._objMapping = {}
self._objMapping["__BG"] = 0
for i in xrange(len(self._objList)):
self._objMapping[self._objList[i]] = i + 1
def _loadAnnotation(self, split):
mat = mp.loadmat(osp.join(self._root, "annotation_" + split + ".mat"))
self._annotations = mat["annotation_" + split]
def _getNumImgs(self):
return len(self._annotations)
def _getImPath(self, idx):
return osp.join(self._root, "images", self._split, self._annotations[idx]["filename"])
def _getNumRel(self):
numRels = 0
n = self._getNumImgs()
for i in xrange(n):
rels = self._getRels(i)
numRels += len(rels)
return numRels
def _getRels(self, idx):
if "relationship" in self._annotations[idx]:
rels = self._annotations[idx]["relationship"]
if isinstance(rels, dict):
rels = [rels]
return rels
else:
return []
def _outputDB(self, type, data):
json.dump(data, open(type + self._split + ".json", "w"))
def _bboxTransform(self, bbox, ih, iw): #[x1, y1, x2, y2]
return [max(bbox[2], 0), max(bbox[0], 0), min(bbox[3] + 1, iw), min(bbox[1] + 1, ih)]
def _getRelLabel(self, predicate):
if not (predicate in self._relMapping):
return -1
return self._relMapping[predicate]
def _getObjLabel(self, predicate):
if not (predicate in self._objMapping):
return -1
return self._objMapping[predicate]
def _getUnionBBox(self, aBB, bBB, ih, iw, margin = 10):
return [max(0, min(aBB[0], bBB[0]) - margin), \
max(0, min(aBB[1], bBB[1]) - margin), \
min(iw, max(aBB[2], bBB[2]) + margin), \
min(ih, max(aBB[3], bBB[3]) + margin)]
def _getRelSamplesSingle(self):
n = self._getNumImgs()
self._sampleIdx = 0
samples = []
for i in xrange(n):
rels = self._getRels(i)
if len(rels) == 0:
continue
path = self._getImPath(i)
im = cv2.imread(path)
ih = im.shape[0]
iw = im.shape[1]
for rel in rels:
phrase = rel["phrase"]
rLabel = self._getRelLabel(phrase[1])
aLabel = self._getObjLabel(phrase[0])
bLabel = self._getObjLabel(phrase[2])
aBBox = self._bboxTransform(rel["subBox"], ih, iw)
bBBox = self._bboxTransform(rel["objBox"], ih, iw)
rBBox = self._getUnionBBox(aBBox, bBBox, ih, iw)
samples.append({"imPath": path, "rLabel": rLabel, "aLabel": aLabel, "bLabel": bLabel, "rBBox": rBBox, "aBBox": aBBox, "bBBox": bBBox})
self._sampleIdx += 1
if self._sampleIdx % 100 == 0:
print self._sampleIdx
self._outputDB("rel", samples)
if __name__ == "__main__":
loader = DataLoader("/datasets/vrd", "test")
loader._getRelSamplesSingle()
================================================
FILE: tools/test_predicate_recognition.py
================================================
#!/usr/bin/env python
import _init_paths
import caffe
import argparse
import time, os, sys
import json
import cv2
import cPickle as cp
import numpy as np
import math
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser()
# image_paths file format: [ path of image_i for image_i in images ]
# the order of images in image_paths should be the same with gt_file
parser.add_argument('--image_paths', dest='image_paths', help='file containing image paths',
default='', type=str)
parser.add_argument('--gpu', dest='gpu_id', help='GPU id to use',
default=0, type=int)
parser.add_argument('--def', dest='prototxt',
help='prototxt file defining the network',
default=None, type=str)
parser.add_argument('--net', dest='caffemodel',
help='model to test',
default=None, type=str)
# gt file format: [ gt_label, gt_box ]
# gt_label: list [ gt_label(image_i) for image_i in images ]
# gt_label(image_i): numpy.array of size: num_instance x 3
# instance: [ label_s, label_r, label_o ]
# gt_box: list [ gt_box(image_i) for image_i in images ]
# gt_box(image_i): numpy.array of size: num_instance x 2 x 4
# instance: [ [x1_s, y1_s, x2_s, y2_s],
# [x1_o, y1_o, x2_o, y2_o]]
parser.add_argument('--gt_file', dest='gt_file',
help='file containing ground truth pairs',
default=None, type=str)
parser.add_argument('--ncls', dest='ncls', help='number of object classes', default=101, type=int)
parser.add_argument('--input_type', dest='type',
help='type of input sets',
default=0, type=int)
parser.add_argument('--out', dest='out', help='name of output file', default='', type=str)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
def getUnionBBox(aBB, bBB, ih, iw):
margin = 10
return [max(0, min(aBB[0], bBB[0]) - margin), \
max(0, min(aBB[1], bBB[1]) - margin), \
min(iw, max(aBB[2], bBB[2]) + margin), \
min(ih, max(aBB[3], bBB[3]) + margin)]
def getAppr(im, bb):
subim = im[bb[1] : bb[3], bb[0] : bb[2], :]
subim = cv2.resize(subim, None, None, 224.0 / subim.shape[1], 224.0 / subim.shape[0], interpolation=cv2.INTER_LINEAR)
pixel_means = np.array([[[103.939, 116.779, 123.68]]])
subim -= pixel_means
subim = subim.transpose((2, 0, 1))
return subim
def getDualMask(ih, iw, bb):
rh = 32.0 / ih
rw = 32.0 / iw
x1 = max(0, int(math.floor(bb[0] * rw)))
x2 = min(32, int(math.ceil(bb[2] * rw)))
y1 = max(0, int(math.floor(bb[1] * rh)))
y2 = min(32, int(math.ceil(bb[3] * rh)))
mask = np.zeros((32, 32))
mask[y1 : y2, x1 : x2] = 1
assert(mask.sum() == (y2 - y1) * (x2 - x1))
return mask
def forward_batch(net, ims, poses, qas, qbs, args):
forward_args = {}
if args.type != 1:
net.blobs["im"].reshape(*(ims.shape))
forward_args["im"] = ims.astype(np.float32, copy=False)
if args.type != 0:
net.blobs["posdata"].reshape(*(poses.shape))
forward_args["posdata"] = poses.astype(np.float32, copy=False)
if args.type == 3:
net.blobs["qa"].reshape(*(qas.shape))
forward_args["qa"] = qas.astype(np.float32, copy=False)
net.blobs["qb"].reshape(*(qbs.shape))
forward_args["qb"] = qbs.astype(np.float32, copy=False)
net_out = net.forward(**forward_args)
itr_pred = net_out["pred"].copy()
return itr_pred
def test_net(net, image_paths, args):
f = open(args.gt_file, "r")
all_gts, all_gt_bboxes = cp.load(f)
f.close()
num_img = len(image_paths)
num_class = args.ncls
thresh = 0.05
batch_size = 20
pred = []
pred_bboxes = []
for i in xrange(num_img):
print str(i) + " / " + str(num_img)
im = cv2.imread(image_paths[i]).astype(np.float32, copy=False)
ih = im.shape[0]
iw = im.shape[1]
gts = all_gts[i]
gt_bboxes = all_gt_bboxes[i]
num_gts = gts.shape[0]
pred.append([])
pred_bboxes.append([])
ims = []
poses = []
qas = []
qbs = []
for j in xrange(num_gts):
sub = gt_bboxes[j, 0, :]
obj = gt_bboxes[j, 1, :]
rBB = getUnionBBox(sub, obj, ih, iw)
rAppr = getAppr(im, rBB)
rMask = np.array([getDualMask(ih, iw, sub), getDualMask(ih, iw, obj)])
ims.append(rAppr)
poses.append(rMask)
qa = np.zeros(num_class - 1)
qa[gts[j, 0] - 1] = 1
qb = np.zeros(num_class - 1)
qb[gts[j, 2] - 1] = 1
qas.append(qa)
qbs.append(qb)
if len(ims) == 0:
continue
ims = np.array(ims)
poses = np.array(poses)
qas = np.array(qas)
qbs = np.array(qbs)
_cursor = 0
itr_pred = None
num_ins = ims.shape[0]
while _cursor < num_ins:
_end_batch = min(_cursor + batch_size, num_ins)
itr_pred_batch = forward_batch(net, ims[_cursor : _end_batch], poses[_cursor : _end_batch], qas[_cursor : _end_batch], qbs[_cursor : _end_batch], args)
if itr_pred is None:
itr_pred = itr_pred_batch
else:
itr_pred = np.vstack((itr_pred, itr_pred_batch))
_cursor = _end_batch
for j in xrange(num_gts):
sub = gt_bboxes[j, 0, :]
obj = gt_bboxes[j, 1, :]
for k in xrange(itr_pred.shape[1]):
if itr_pred[j, k] < thresh:
continue
pred[i].append([itr_pred[j, k], 1, 1, gts[j, 0], k, gts[j, 2]])
pred_bboxes[i].append([sub, obj])
pred[i] = np.array(pred[i])
pred_bboxes[i] = np.array(pred_bboxes[i])
print "writing file.."
f = open(args.out, "wb")
cp.dump([pred, pred_bboxes], f, cp.HIGHEST_PROTOCOL)
f.close()
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
caffe.set_mode_gpu()
caffe.set_device(args.gpu_id)
net = caffe.Net(args.prototxt, args.caffemodel, caffe.TEST)
test_image_paths = json.load(open(args.image_paths))
test_net(net, test_image_paths, args)
================================================
FILE: tools/test_triplet_detection.py
================================================
#!/usr/bin/env python
import _init_paths
import caffe
import argparse
import time, os, sys
import json
import cv2
import cPickle as cp
import numpy as np
import math
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser()
# image_paths file format: [ path of image_i for image_i in images ]
# the order of images in image_paths should be the same with obj_dets_file
parser.add_argument('--image_paths', dest='image_paths', help='file containing test dataset',
default='', type=str)
parser.add_argument('--gpu', dest='gpu_id', help='GPU id to use',
default=0, type=int)
parser.add_argument('--def', dest='prototxt',
help='prototxt file defining the network',
default=None, type=str)
parser.add_argument('--net', dest='caffemodel',
help='model to test',
default=None, type=str)
parser.add_argument('--num_dets', dest='max_det',
help='max number of detections per image',
default=100, type=int)
# obj_dets_file format: [ obj_dets of image_i for image_i in images ]
# obj_dets: numpy.array of size: num_instance x 5
# instance: [x1, y1, x2, y2, prob, label]
parser.add_argument('--obj_dets_file', dest='obj_dets_file',
help='file containing object detections',
default=None, type=str)
# type 0: im only
# type 1: pos only
# type 2: im + pos
# type 3: im + pos + qa + qb
parser.add_argument('--input_type', dest='type',
help='type of input sets',
default=0, type=int)
parser.add_argument('--ncls', dest='num_class', help='number of object classes', default=101, type=int)
parser.add_argument('--out', dest='out', help='name of output file', default='', type=str)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
def getPred(pred, max_num_det):
if pred.shape[0] == 0:
return pred
inds = np.argsort(pred[:, 4])
inds = inds[::-1]
if len(inds) > max_num_det:
inds = inds[:max_num_det]
return pred[inds, :]
def getUnionBBox(aBB, bBB, ih, iw):
margin = 10
return [max(0, min(aBB[0], bBB[0]) - margin), \
max(0, min(aBB[1], bBB[1]) - margin), \
min(iw, max(aBB[2], bBB[2]) + margin), \
min(ih, max(aBB[3], bBB[3]) + margin)]
def getAppr(im, bb):
subim = im[bb[1] : bb[3], bb[0] : bb[2], :]
subim = cv2.resize(subim, None, None, 224.0 / subim.shape[1], 224.0 / subim.shape[0], interpolation=cv2.INTER_LINEAR)
pixel_means = np.array([[[103.939, 116.779, 123.68]]])
subim -= pixel_means
subim = subim.transpose((2, 0, 1))
return subim
def getDualMask(ih, iw, bb):
rh = 32.0 / ih
rw = 32.0 / iw
x1 = max(0, int(math.floor(bb[0] * rw)))
x2 = min(32, int(math.ceil(bb[2] * rw)))
y1 = max(0, int(math.floor(bb[1] * rh)))
y2 = min(32, int(math.ceil(bb[3] * rh)))
mask = np.zeros((32, 32))
mask[y1 : y2, x1 : x2] = 1
assert(mask.sum() == (y2 - y1) * (x2 - x1))
return mask
def forward_batch(net, ims, poses, qas, qbs, args):
forward_args = {}
if args.type != 1:
net.blobs["im"].reshape(*(ims.shape))
forward_args["im"] = ims.astype(np.float32, copy=False)
if args.type != 0:
net.blobs["posdata"].reshape(*(poses.shape))
forward_args["posdata"] = poses.astype(np.float32, copy=False)
if args.type == 3:
net.blobs["qa"].reshape(*(qas.shape))
forward_args["qa"] = qas.astype(np.float32, copy=False)
net.blobs["qb"].reshape(*(qbs.shape))
forward_args["qb"] = qbs.astype(np.float32, copy=False)
net_out = net.forward(**forward_args)
itr_pred = net_out["pred"].copy()
return itr_pred
def test_net(net, image_paths, args):
f = open(args.obj_dets_file, "r")
all_dets = cp.load(f)
f.close()
num_img = len(image_paths)
num_class = args.num_class
thresh = 0.05
max_num_det = args.max_det
batch_size = 30
pred = []
pred_bboxes = []
for i in xrange(num_img):
im = cv2.imread(image_paths[i]).astype(np.float32, copy=False)
ih = im.shape[0]
iw = im.shape[1]
dets = getPred(all_dets[i], max_num_det)
num_dets = dets.shape[0]
pred.append([])
pred_bboxes.append([])
for subIdx in xrange(num_dets):
ims = []
poses = []
qas = []
qbs = []
for objIdx in xrange(num_dets):
if subIdx != objIdx:
sub = dets[subIdx, 0: 4]
obj = dets[objIdx, 0: 4]
rBB = getUnionBBox(sub, obj, ih, iw)
rAppr = getAppr(im, rBB)
rMask = np.array([getDualMask(ih, iw, sub), getDualMask(ih, iw, obj)])
ims.append(rAppr)
poses.append(rMask)
qa = np.zeros(num_class - 1)
qa[dets[subIdx, 5] - 1] = 1
qb = np.zeros(num_class - 1)
qb[dets[objIdx, 5] - 1] = 1
qas.append(qa)
qbs.append(qb)
if len(ims) == 0:
break
ims = np.array(ims)
poses = np.array(poses)
qas = np.array(qas)
qbs = np.array(qbs)
_cursor = 0
itr_pred = None
num_ins = ims.shape[0]
while _cursor < num_ins:
_end_batch = min(_cursor + batch_size, num_ins)
itr_pred_batch = forward_batch(net, ims[_cursor : _end_batch] if ims.shape[0] > 0 else None, poses[_cursor : _end_batch] if poses.shape[0] > 0 else None, qas[_cursor : _end_batch] if qas.shape[0] > 0 else None, qbs[_cursor : _end_batch] if qbs.shape[0] > 0 else None, args)
if itr_pred is None:
itr_pred = itr_pred_batch
else:
itr_pred = np.vstack((itr_pred, itr_pred_batch))
_cursor = _end_batch
cur = 0
for objIdx in xrange(num_dets):
if subIdx != objIdx:
sub = dets[subIdx, 0: 4]
obj = dets[objIdx, 0: 4]
for j in xrange(itr_pred.shape[1]):
if itr_pred[cur, j] < thresh:
continue
pred[i].append([itr_pred[cur, j], dets[subIdx, 4], dets[objIdx, 4], dets[subIdx, 5], j, dets[objIdx, 5]])
pred_bboxes[i].append([sub, obj])
cur += 1
assert(cur == itr_pred.shape[0])
pred[i] = np.array(pred[i])
pred_bboxes[i] = np.array(pred_bboxes[i])
print "writing file.."
f = open(args.out, "wb")
cp.dump([pred, pred_bboxes], f, cp.HIGHEST_PROTOCOL)
f.close()
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
caffe.set_mode_gpu()
caffe.set_device(args.gpu_id)
net = caffe.Net(args.prototxt, args.caffemodel, caffe.TEST)
test_image_paths = json.load(open(args.image_paths))
test_net(net, test_image_paths, args)
gitextract_pa_vjz81/
├── .gitignore
├── LICENSE
├── README.md
├── lib/
│ ├── customize_layers/
│ │ ├── __init__.py
│ │ └── concat_layer.py
│ ├── rel_data_layer/
│ │ ├── __init__.py
│ │ └── layer.py
│ └── utils/
│ ├── __init__.py
│ └── eval_utils.py
├── prototxts/
│ ├── drnet_8units_linear_shareweight.prototxt
│ ├── drnet_8units_relu_shareweight.prototxt
│ ├── drnet_8units_softmax.prototxt
│ ├── test_drnet_8units_linear_shareweight.prototxt
│ ├── test_drnet_8units_relu_shareweight.prototxt
│ └── test_drnet_8units_softmax.prototxt
├── snapshots/
│ └── README.md
└── tools/
├── _init_paths.py
├── eval_triplet_recall.py
├── eval_union_recall.py
├── prepare_data.py
├── test_predicate_recognition.py
└── test_triplet_detection.py
SYMBOL INDEX (52 symbols across 9 files)
FILE: lib/customize_layers/concat_layer.py
class Layer (line 5) | class Layer(caffe.Layer):
method setup (line 6) | def setup(self, bottom, top):
method reshape (line 11) | def reshape(self, bottom, top):
method forward (line 14) | def forward(self, bottom, top):
method backward (line 23) | def backward(self, top, propagate_down, bottom):
FILE: lib/rel_data_layer/layer.py
class RelDataLayer (line 10) | class RelDataLayer(caffe.Layer):
method _shuffle_inds (line 11) | def _shuffle_inds(self):
method _get_next_batch_ids (line 15) | def _get_next_batch_ids(self):
method _getAppr (line 22) | def _getAppr(self, im, bb):
method _getDualMask (line 30) | def _getDualMask(self, ih, iw, bb):
method _get_next_batch (line 42) | def _get_next_batch(self):
method setup (line 66) | def setup(self, bottom, top):
method forward (line 81) | def forward(self, bottom, top):
method backward (line 88) | def backward(self, top, propagate_down, bottom):
method reshape (line 91) | def reshape(self, bottom, top):
FILE: lib/utils/eval_utils.py
function computeArea (line 1) | def computeArea(bb):
function computeIoU (line 4) | def computeIoU(bb1, bb2):
FILE: tools/_init_paths.py
function add_path (line 4) | def add_path(path):
FILE: tools/eval_triplet_recall.py
function parse_args (line 14) | def parse_args():
function computeOverlap (line 57) | def computeOverlap(detBBs, gtBBs):
function eval_recall (line 62) | def eval_recall(args):
FILE: tools/eval_union_recall.py
function parse_args (line 14) | def parse_args():
function getUnionBB (line 57) | def getUnionBB(aBB, bBB):
function computeOverlap (line 63) | def computeOverlap(detBBs, gtBBs):
function eval_recall (line 68) | def eval_recall(args):
FILE: tools/prepare_data.py
class DataLoader (line 8) | class DataLoader:
method __init__ (line 9) | def __init__(self, datasetRoot, split):
method _loadLabels (line 15) | def _loadLabels(self):
method _loadAnnotation (line 30) | def _loadAnnotation(self, split):
method _getNumImgs (line 34) | def _getNumImgs(self):
method _getImPath (line 37) | def _getImPath(self, idx):
method _getNumRel (line 40) | def _getNumRel(self):
method _getRels (line 48) | def _getRels(self, idx):
method _outputDB (line 57) | def _outputDB(self, type, data):
method _bboxTransform (line 60) | def _bboxTransform(self, bbox, ih, iw): #[x1, y1, x2, y2]
method _getRelLabel (line 63) | def _getRelLabel(self, predicate):
method _getObjLabel (line 68) | def _getObjLabel(self, predicate):
method _getUnionBBox (line 73) | def _getUnionBBox(self, aBB, bBB, ih, iw, margin = 10):
method _getRelSamplesSingle (line 79) | def _getRelSamplesSingle(self):
FILE: tools/test_predicate_recognition.py
function parse_args (line 13) | def parse_args():
function getUnionBBox (line 59) | def getUnionBBox(aBB, bBB, ih, iw):
function getAppr (line 66) | def getAppr(im, bb):
function getDualMask (line 74) | def getDualMask(ih, iw, bb):
function forward_batch (line 86) | def forward_batch(net, ims, poses, qas, qbs, args):
function test_net (line 104) | def test_net(net, image_paths, args):
FILE: tools/test_triplet_detection.py
function parse_args (line 13) | def parse_args():
function getPred (line 59) | def getPred(pred, max_num_det):
function getUnionBBox (line 69) | def getUnionBBox(aBB, bBB, ih, iw):
function getAppr (line 76) | def getAppr(im, bb):
function getDualMask (line 84) | def getDualMask(ih, iw, bb):
function forward_batch (line 96) | def forward_batch(net, ims, poses, qas, qbs, args):
function test_net (line 113) | def test_net(net, image_paths, args):
Condensed preview — 22 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (151K chars).
[
{
"path": ".gitignore",
"chars": 27,
"preview": "snapshots/*.caffemodel\nsvg\n"
},
{
"path": "LICENSE",
"chars": 2297,
"preview": "Copyright the Chinese University of Hong Kong. All rights reserved.\n\nContact persons:\nBo Dai (db014 [at] ie [dot] cuhk ["
},
{
"path": "README.md",
"chars": 4465,
"preview": "# Code of [Detecting Visual Relationships with Deep Relational Networks](https://arxiv.org/abs/1704.03114)\n\nThe code is "
},
{
"path": "lib/customize_layers/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/customize_layers/concat_layer.py",
"chars": 970,
"preview": "import caffe\nimport numpy as np\nimport json\n\nclass Layer(caffe.Layer):\n\tdef setup(self, bottom, top):\n\t\tself._sum = 0\n\t\t"
},
{
"path": "lib/rel_data_layer/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/rel_data_layer/layer.py",
"chars": 2889,
"preview": "import caffe\nimport numpy as np\nimport json\nimport math\nimport os.path as osp\nimport os\nimport cv2\nimport h5py\n\nclass Re"
},
{
"path": "lib/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "lib/utils/eval_utils.py",
"chars": 324,
"preview": "def computeArea(bb):\n\treturn max(0, bb[2] - bb[0] + 1) * max(0, bb[3] - bb[1] + 1)\n\ndef computeIoU(bb1, bb2):\n\tibb = [ma"
},
{
"path": "prototxts/drnet_8units_linear_shareweight.prototxt",
"chars": 15816,
"preview": "layer {\n name: \"data\"\n type: \"Python\"\n top: \"qa\"\n top: \"qb\"\n top: \"im\"\n top: \""
},
{
"path": "prototxts/drnet_8units_relu_shareweight.prototxt",
"chars": 16381,
"preview": "layer {\n name: \"data\"\n type: \"Python\"\n top: \"qa\"\n top: \"qb\"\n top: \"im\"\n top: \""
},
{
"path": "prototxts/drnet_8units_softmax.prototxt",
"chars": 15680,
"preview": "layer {\n name: \"data\"\n type: \"Python\"\n top: \"qa\"\n top: \"qb\"\n top: \"im\"\n top: \""
},
{
"path": "prototxts/test_drnet_8units_linear_shareweight.prototxt",
"chars": 14484,
"preview": "input: \"qa\"\ninput_shape {\t\n\tdim: 1\n\tdim: 100\n}\n\ninput: \"qb\"\ninput_shape {\n\tdim: 1\n\tdim: 100\n}\n\ninput: \"im\"\ninput_shape {"
},
{
"path": "prototxts/test_drnet_8units_relu_shareweight.prototxt",
"chars": 15049,
"preview": "input: \"qa\"\ninput_shape {\t\n\tdim: 1\n\tdim: 100\n}\n\ninput: \"qb\"\ninput_shape {\n\tdim: 1\n\tdim: 100\n}\n\ninput: \"im\"\ninput_shape {"
},
{
"path": "prototxts/test_drnet_8units_softmax.prototxt",
"chars": 14348,
"preview": "input: \"qa\"\ninput_shape {\t\n\tdim: 1\n\tdim: 100\n}\n\ninput: \"qb\"\ninput_shape {\n\tdim: 1\n\tdim: 100\n}\n\ninput: \"im\"\ninput_shape {"
},
{
"path": "snapshots/README.md",
"chars": 353,
"preview": "## Download Links\n\n* [drnet_8units_softmax](https://drive.google.com/file/d/0B5RJWjAhdT04Y2pJelpxSEhYWTQ/view?usp=sharin"
},
{
"path": "tools/_init_paths.py",
"chars": 371,
"preview": "import os.path as osp\nimport sys\n\ndef add_path(path):\n if path not in sys.path:\n sys.path.insert(0, path)\n\nthi"
},
{
"path": "tools/eval_triplet_recall.py",
"chars": 3645,
"preview": "#!/usr/bin/env python\n\nimport _init_paths\nimport argparse\n\nimport time, os, sys\nimport json\nimport cv2\nimport cPickle as"
},
{
"path": "tools/eval_union_recall.py",
"chars": 4010,
"preview": "#!/usr/bin/env python\n\nimport _init_paths\nimport argparse\n\nimport time, os, sys\nimport json\nimport cv2\nimport cPickle as"
},
{
"path": "tools/prepare_data.py",
"chars": 3219,
"preview": "import os.path as osp\nimport mat4py as mp\nimport cv2\nimport numpy as np\nimport math\nimport json\n\nclass DataLoader:\n\tdef "
},
{
"path": "tools/test_predicate_recognition.py",
"chars": 5623,
"preview": "#!/usr/bin/env python\n\nimport _init_paths\nimport caffe\nimport argparse\nimport time, os, sys\nimport json\nimport cv2\nimpor"
},
{
"path": "tools/test_triplet_detection.py",
"chars": 6206,
"preview": "#!/usr/bin/env python\n\nimport _init_paths\nimport caffe\nimport argparse\nimport time, os, sys\nimport json\nimport cv2\nimpor"
}
]
About this extraction
This page contains the full source code of the doubledaibo/drnet_cvpr2017 GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 22 files (123.2 KB), approximately 50.1k tokens, and a symbol index with 52 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.