Repository: elieJalbout/Clustering-with-Deep-learning
Branch: master
Commit: 95eae15b8799
Files: 10
Total size: 71.3 KB
Directory structure:
gitextract_5766_38r/
├── .gitignore
├── .project
├── .pydevproject
├── README.md
├── archs/
│ ├── coil.json
│ └── mnist.json
├── customlayers.py
├── main.py
├── misc.py
└── network.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
*.pyc
outputs/*.png
logs/*
.idea/
================================================
FILE: .project
================================================
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>DeepConvJointClustering</name>
<comment></comment>
<projects>
</projects>
<buildSpec>
<buildCommand>
<name>org.python.pydev.PyDevBuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.python.pydev.pythonNature</nature>
</natures>
</projectDescription>
================================================
FILE: .pydevproject
================================================
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?eclipse-pydev version="1.0"?><pydev_project>
<pydev_pathproperty name="org.python.pydev.PROJECT_SOURCE_PATH">
<path>/${PROJECT_DIR_NAME}</path>
</pydev_pathproperty>
<pydev_property name="org.python.pydev.PYTHON_PROJECT_VERSION">python 2.7</pydev_property>
<pydev_property name="org.python.pydev.PYTHON_PROJECT_INTERPRETER">Default</pydev_property>
</pydev_project>
================================================
FILE: README.md
================================================
Deep Learning for Clustering
=======================
Code for project "Deep Learning for Clustering" under lab course "Deep Learning for Computer Vision and Biomedicine" - TUM. Depends on **numpy**, **theano**, **lasagne**, **scikit-learn**, **matplotlib**.
#### Contributors
- [Mohd Yawar Nihal Siddiqui](mailto:yawarnihal@gmail.com)
- [Elie Aljalbout](mailto:elie.aljalbout@tum.de)
- [Vladimir Golkov](mailto:vladimir.golkov@tum.de) (Supervisor)
#### Related Papers:
This repository is an implementation of the paper :
Elie Aljalbout, Vladimir Golkov, Yawar Siddiqui, Daniel Cremers "Clustering with Deep Learning: Taxonomy and new methods"
- arxiv: https://arxiv.org/abs/1801.07648
Usage
--------
Use the main script for training, visualizing clusters and/or reporting clustering metrics
```
python main.py <options>
```
Option | |
-------- | ---
```-d DATASET_NAME, --dataset DATASET_NAME ```| ``(Required) Dataset on which autoencoder is to be trained trained, or metrics/visualizations are to be performed [MNIST,COIL20]``
```-a ARCH_IDX, --architecture ARCH_IDX```| ``(Required) Index of architecture of autoencoder in the json file (archs/)``
``--pretrain EPOCHS`` | ``Pretrain the autoencoder for specified #epochs specified by architecture on specified dataset``
``--cluster EPOCHS``| ``Refine the autoencoder for specified #epochs with clustering loss, assumes that pretraining results are available``
``--metrics``| ``Report k-means clustering metrics on the clustered latent space, assumes pretrain and cluster based training have been performed``
``--visualize``|``Visualize the image space and latent space, assumes pre-training and cluster based training have been performed``
Project Structure
------------------------
Folder / File | Description|
-------- | ---
<i class="icon-folder-open"></i> archs| Contains json files specifying architectures for autoencoder networks used. File ``mnist.json`` contains architectures for MNIST dataset. We use the second architecture for the reported results (command line argument ``-a 1``)
<i class="icon-folder-open"></i> coil, mnist | Contains the datasets COIL20 and MNIST respectively
<i class="icon-folder-open"></i> logs| Output folder for logs generated by the scripts. Named by date and time of script execution
<i class="icon-folder-open"></i>plots|Scatter plots showing the raw, pre-trained latent space, and the final latent space clusters
<i class="icon-folder-open"></i>saved_params | Contains saved network parameters and saved representation of inputs in latent space
<i class="icon-file"></i> custom_layers.py | Custom lasagne layers, Unpool2D - which performs inverse max pooling by replicating input pixels as dictated by the filter size, and the ClusteringLayer - a layer that outputs soft cluster assignments based on k-means cluster distance
<i class="icon-file"></i> main.py | The main python script for training and evaluating the network
<i class="icon-file"></i> misc.py | Contains dataset handlers and other utility methods
<i class="icon-file"></i>network.py| Contains classes for parsing and building the network from json files and also for training the network
Autoencoder Builder
-----------------------------
We've implemented a **NetworkBuilder** class that can be used to quickly describe the architecture of an autoencoder through a **json** file.
The json specification of the architecture is a dictionary with the following fields
| Field | Description
---------|------------
name| Name identifier given to the architecture, used for file naming while saving parameters
batch_size| Batch size to be used while training the network
use_batch_norm| Whether to use batch normalization for convolutional/deconvolutional layers
network_type| Type of network - convolutional or fully connected
layers| A list describing the encoder part of the autoencoder
Further, each item in the layers list is a dictionary with the following fields
| Field | Description
---------|------------
type| Can be Input, Conv2D, MaxPool2D, MaxPool2D*, Dense, Reshape, Deconv2D
num_filters| For Conv2D/MaxPool2D/MaxPool2D*/Deconv2D layers this field specifies number of filters
filter_size| Dimensions of kernel for the above layers
num_units| For Dense layer number of hidden units
non_linearity| Non-Linearity function used at output of the layer
conv_mode| Can be used to specify the convolution mode like same, valid etc. for convolutional layers
output_non_linearity| If you want a different non linearity function at the output than the one which would be obtained by mirroring
Only the encoder part of the autoencoder needs to be specified, the decoder will be automatically generated by the class.
Example of a network description
```json
{
"name": "c-5-6_p_c-5-16_p_c-4-120",
"use_batch_norm": 1,
"batch_size": 100,
"layers": [
{
"type": "Input",
"output_shape":[1, 28, 28]
},
{
"type": "Conv2D",
"num_filters": 50,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type": "MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Conv2D",
"num_filters": 50,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type": "MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Conv2D",
"num_filters": 120,
"filter_size": [4, 4],
"non_linearity": "linear"
}
]
}
```
This would generate the network
``50[5x5] 50[5x5]_bn max[2x2] 50[5x5] 50[5x5]_bn max[2x2]`` **``120[4x4] 120[4x4]_bn `` **``50[4x4] 50[4x4]_bn ups*[2x2] 50[5x5] 50[5x5]_bn ups*[2x2] 1[5x5]``
Experiments and Results
-----------------------------------
We trained and tested the network on two datasets - MNIST and COIL20
|Dataset| Image size | Number of samples | Number of clusters
-------- | ---|---|---
MNIST| 28x28x1|60000|10
COIL20| 128x128x1|1440|20
Clustering was performed with two different loss functions -
- Loss = ``KL-Divergence(soft assignment distribution, target distribution) + Autoencoder Reconstruction loss ``, where the target distribution is a distribution that improves cluster purity and puts more emphasis on data points assigned with a high confidence. For more details check out the DEC paper [[1]](https://arxiv.org/abs/1511.06335).
- Loss = ``k-Means loss + Autoencoder Reconstruction loss``
#### **MNIST**
##### Our network
| Clustering space| Clustering Accuracy| Normalized Mutual Information
-------- | ---|----
Image pixels | 0.542|0.480
Autoencoder| 0.760|0.667
Autoencoder + k-Means Loss| 0.781| 0.796
Autoencoder + KLDiv Loss| **0.859**| **0.825**
##### Other networks
|Method| Clustering Accuracy| Normalized Mutual Information
-------- | ---|----
DEC|0.843|0.800
DCN|0.830|0.810
CNN-RC| - |0.915
CNN-FD|-|0.876
DBC| 0.964|0.917
> Note: The commit b34743114f68624b5371cd0d4c059b141422902f gives upto 0.96 accuracy and 0.92 NMI on the MNIST dataset. We will include it to the main branch once we can get better results with the COIL architecture
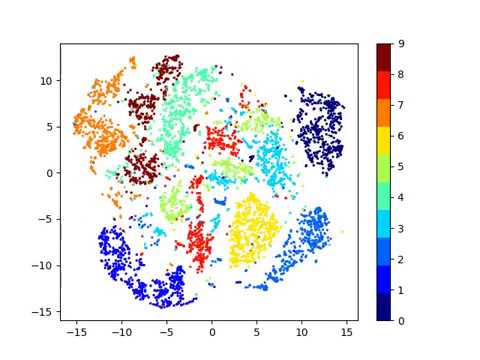
##### **Latent space visualizations**
###### Pixel space

###### Autoencoder

###### Autoencoder Latent Space Evolution (video)
[](https://www.youtube.com/watch?v=_WuUB3gD984)
###### Autoencoder + KLDivergence

###### Autoencoder + KLDivergence Latent Space Evolution (video)
[](https://www.youtube.com/watch?v=XYS7DFkVx_A)
###### Autoencoder + k-Means

#### **COIL20**
##### Our network
| Clustering space| Clustering Accuracy| Normalized Mutual Information
-------- | ---|----
Image pixels | 0.689|0.793
Autoencoder| 0.739|0.828
Autoencoder + k-Means Loss| 0.745| 0.846
Autoencoder + KLDiv Loss| 0.762| 0.848
##### Other networks
|Method| Clustering Accuracy| Normalized Mutual Information
-------- | ---|----
DEN|0.725|0.870
CNN-RC| - |1.000
DBC| 0.793|0.895
##### **Latent space visualizations**
###### Pixel space

###### Autoencoder

###### Autoencoder + k-Means

###### Autoencoder + KLDivergence

================================================
FILE: archs/coil.json
================================================
[
{
"name": "c-9-20_p-2_c-5-20_p-2_c-5-40_p-2_c-4-320",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 40,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [4, 4],
"non_linearity": "linear"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-400",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 400,
"non_linearity": "rectify"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-400-fc-200",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 400,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 200,
"non_linearity": "rectify"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-200",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 200,
"non_linearity": "rectify"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-80",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 80,
"non_linearity": "rectify"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-32",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 32,
"non_linearity": "rectify"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-1",
"use_batch_norm":0,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 1,
"non_linearity": "rectify"
}
]
},
{
"name": "c-9-20_p_c-5-20_p_c-5-20_p_c-5-320_p_fc-20",
"use_batch_norm":1,
"batch_size": 10,
"layers": [
{
"type":"Input",
"output_shape": [1, 128, 128]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [9, 9],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 20,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D",
"filter_size": [2, 2]
},
{
"type":"Conv2D",
"num_filters": 320,
"filter_size": [5, 5],
"non_linearity": "rectify"
},
{
"type":"MaxPool2D*",
"filter_size": [2, 2]
},
{
"type": "Dense",
"num_units": 5120,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 20,
"non_linearity": "rectify"
}
]
}
]
================================================
FILE: archs/mnist.json
================================================
[
{
"name": "c-3-32_p_c-3-64_p_fc-32",
"batch_size": 50,
"layers": [
{
"type": "Input",
"output_shape": [
1,
28,
28
]
},
{
"type": "Conv2D",
"num_filters": 32,
"filter_size": [
3,
3
],
"non_linearity": "rectify",
"conv_mode": "same"
},
{
"type": "MaxPool2D",
"filter_size": [
2,
2
]
},
{
"type": "Conv2D",
"num_filters": 64,
"filter_size": [
3,
3
],
"non_linearity": "rectify",
"conv_mode": "same"
},
{
"type": "MaxPool2D",
"filter_size": [
2,
2
]
},
{
"type": "Dense",
"num_units": 3136,
"non_linearity": "rectify"
},
{
"type": "Dense",
"num_units": 32,
"non_linearity": "rectify"
}
]
},
{
"name": "c-5-6_p_c-5-16_p_c-4-120",
"use_batch_norm": 1,
"batch_size": 100,
"layers": [
{
"type": "Input",
"output_shape": [
1,
28,
28
]
},
{
"type": "Conv2D",
"num_filters": 50,
"filter_size": [
5,
5
],
"non_linearity": "rectify"
},
{
"type": "MaxPool2D*",
"filter_size": [
2,
2
]
},
{
"type": "Conv2D",
"num_filters": 50,
"filter_size": [
5,
5
],
"non_linearity": "rectify"
},
{
"type": "MaxPool2D*",
"filter_size": [
2,
2
]
},
{
"type": "Conv2D",
"num_filters": 120,
"filter_size": [
4,
4
],
"non_linearity": "linear"
}
]
}
]
================================================
FILE: customlayers.py
================================================
'''
Created on Jul 25, 2017
'''
from lasagne import layers
import theano
import theano.tensor as T
class Unpool2DLayer(layers.Layer):
"""
This layer performs unpooling over the last two dimensions
of a 4D tensor.
Layer borrowed from: https://swarbrickjones.wordpress.com/2015/04/29/convolutional-autoencoders-in-pythontheanolasagne/
"""
def __init__(self, incoming, ds, **kwargs):
super(Unpool2DLayer, self).__init__(incoming, **kwargs)
self.ds = ds
def get_output_shape_for(self, input_shape):
output_shape = list(input_shape)
output_shape[2] = input_shape[2] * self.ds[0]
output_shape[3] = input_shape[3] * self.ds[1]
return tuple(output_shape)
def get_output_for(self, incoming, **kwargs):
'''
Just repeats the input element the upscaled image
'''
ds = self.ds
return incoming.repeat(ds[0], axis=2).repeat(ds[1], axis=3)
class ClusteringLayer(layers.Layer):
'''
This layer gives soft assignments for the clusters based on distance from k-means based
cluster centers. The weights of the layers are the cluster centers so that they can be learnt
while optimizing for loss
'''
def __init__(self, incoming, num_clusters, initial_clusters, num_samples, latent_space_dim, **kwargs):
super(ClusteringLayer, self).__init__(incoming, **kwargs)
self.num_clusters = num_clusters
self.W = self.add_param(theano.shared(initial_clusters), initial_clusters.shape, 'W')
self.num_samples = num_samples
self.latent_space_dim = latent_space_dim
def get_output_shape_for(self, input_shape):
'''
Output shape is number of inputs x number of cluster, i.e for each input soft assignments
corresponding to all clusters
'''
return (input_shape[0], self.num_clusters)
def get_output_for(self, incoming, **kwargs):
return getSoftAssignments(incoming, self.W, self.num_clusters, self.latent_space_dim, self.num_samples)
def getSoftAssignments(latent_space, cluster_centers, num_clusters, latent_space_dim, num_samples):
'''
Returns cluster membership distribution for each sample
:param latent_space: latent space representation of inputs
:param cluster_centers: the coordinates of cluster centers in latent space
:param num_clusters: total number of clusters
:param latent_space_dim: dimensionality of latent space
:param num_samples: total number of input samples
:return: soft assigment based on the equation qij = (1+|zi - uj|^2)^(-1)/sum_j'((1+|zi - uj'|^2)^(-1))
'''
z_expanded = latent_space.reshape((num_samples, 1, latent_space_dim))
z_expanded = T.tile(z_expanded, (1, num_clusters, 1))
u_expanded = T.tile(cluster_centers, (num_samples, 1, 1))
distances_from_cluster_centers = (z_expanded - u_expanded).norm(2, axis=2)
qij_numerator = 1 + distances_from_cluster_centers * distances_from_cluster_centers
qij_numerator = 1 / qij_numerator
normalizer_q = qij_numerator.sum(axis=1).reshape((num_samples, 1))
return qij_numerator / normalizer_q
================================================
FILE: main.py
================================================
'''
Created on Jul 9, 2017
'''
import numpy
import json
from misc import DatasetHelper, evaluateKMeans, visualizeData
from network import DCJC, rootLogger
from copy import deepcopy
import argparse
def testOnlyClusterInitialization(dataset_name, arch, epochs):
'''
Train an autoencoder defined by architecture arch and trains it with the dataset defined
:param dataset_name: Name of the dataset with which the network will be trained [MNIST, COIL20]
:param arch: Architecture of the network as a dictionary. Specification for architecture can be found in readme.md
:param epochs: Number of train epochs
:return: None - (side effect) saves the latent space and params of trained network in an appropriate location in saved_params folder
'''
arch_copy = deepcopy(arch)
rootLogger.info("Loading dataset")
dataset = DatasetHelper(dataset_name)
dataset.loadDataset()
rootLogger.info("Done loading dataset")
rootLogger.info("Creating network")
dcjc = DCJC(arch_copy)
rootLogger.info("Done creating network")
rootLogger.info("Starting training")
dcjc.pretrainWithData(dataset, epochs, False);
def testOnlyClusterImprovement(dataset_name, arch, epochs, method):
'''
Use an initialized autoencoder and train it along with clustering loss. Assumed that pretrained autoencoder params
are available, i.e. testOnlyClusterInitialization has been run already with the given params
:param dataset_name: Name of the dataset with which the network will be trained [MNIST, COIL20]
:param arch: Architecture of the network as a dictionary. Specification for architecture can be found in readme.md
:param epochs: Number of train epochs
:param method: Can be KM or KLD - depending on whether the clustering loss is KLDivergence loss between the current KMeans distribution(Q) and a more desired one(Q^2), or if the clustering loss is just the Kmeans loss
:return: None - (side effect) saves latent space and params of the trained network
'''
arch_copy = deepcopy(arch)
rootLogger.info("Loading dataset")
dataset = DatasetHelper(dataset_name)
dataset.loadDataset()
rootLogger.info("Done loading dataset")
rootLogger.info("Creating network")
dcjc = DCJC(arch_copy)
rootLogger.info("Starting cluster improvement")
if method == 'KM':
dcjc.doClusteringWithKMeansLoss(dataset, epochs)
elif method == 'KLD':
dcjc.doClusteringWithKLdivLoss(dataset, True, epochs)
def testKMeans(dataset_name, archs):
'''
Performs kMeans clustering, and report metrics on the output latent space produced by the networks defined in archs,
with given dataset. Assumes that testOnlyClusterInitialization and testOnlyClusterImprovement have been run before
this for the specified archs/datasets, as the results saved by them are used for clustering
:param dataset_name: Name of dataset [MNIST, COIL20]
:param archs: Architectures as a dictionary
:return: None - reports the accuracy and nmi clustering metrics
'''
rootLogger.info('Initial Cluster Quality Comparison')
rootLogger.info(80 * '_')
rootLogger.info('%-50s %8s %8s' % ('method', 'ACC', 'NMI'))
rootLogger.info(80 * '_')
dataset = DatasetHelper(dataset_name)
dataset.loadDataset()
rootLogger.info(evaluateKMeans(dataset.input_flat, dataset.labels, dataset.getClusterCount(), 'image')[0])
for arch in archs:
Z = numpy.load('saved_params/' + dataset.name + '/z_' + arch['name'] + '.npy')
rootLogger.info(evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), arch['name'])[0])
Z = numpy.load('saved_params/' + dataset.name + '/pc_z_' + arch['name'] + '.npy')
rootLogger.info(evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), arch['name'])[0])
Z = numpy.load('saved_params/' + dataset.name + '/pc_km_z_' + arch['name'] + '.npy')
rootLogger.info(evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), arch['name'])[0])
rootLogger.info(80 * '_')
def visualizeLatentSpace(dataset_name, arch):
'''
Plots and saves graphs for visualized images space, autoencoder latent space, and the final clustering latent space
:param dataset_name: Name of dataset [MNIST, COIL20]
:param arch: Architectures as a dictionary
:return: None - (side effect) saved graphs in plots/ folder
'''
rootLogger.info("Loading dataset")
dataset = DatasetHelper(dataset_name)
dataset.loadDataset()
rootLogger.info("Done loading dataset")
# We consider only the first 5000 point or less for better visualization
max_points = min(dataset.input_flat.shape[0], 5000)
# Image space
visualizeData(dataset.input_flat[0:max_points], dataset.labels[0:max_points], dataset.getClusterCount(), "plots/%s/raw.png" % dataset.name)
# Latent space - autoencoder
Z = numpy.load('saved_params/' + dataset.name + '/z_' + arch['name'] + '.npy')
visualizeData(Z[0:max_points], dataset.labels[0:max_points], dataset.getClusterCount(), "plots/%s/autoencoder.png" % dataset.name)
# Latent space - kl div clustering network
Z = numpy.load('saved_params/' + dataset.name + '/pc_z_' + arch['name'] + '.npy')
visualizeData(Z[0:max_points], dataset.labels[0:max_points], dataset.getClusterCount(), "plots/%s/clustered_kld.png" % dataset.name)
# Latent space - kmeans clustering network
Z = numpy.load('saved_params/' + dataset.name + '/pc_km_z_' + arch['name'] + '.npy')
visualizeData(Z[0:max_points], dataset.labels[0:max_points], dataset.getClusterCount(), "plots/%s/clustered_km.png" % dataset.name)
if __name__ == '__main__':
'''
usage: main.py [-h] -d DATASET -a ARCHITECTURE [--pretrain PRETRAIN]
[--cluster CLUSTER] [--metrics METRICS] [--visualize VISUALIZE]
required arguments:
-d DATASET, --dataset DATASET
Dataset on which autoencoder is trained [MNIST,COIL20]
-a ARCHITECTURE, --architecture ARCHITECTURE
Index of architecture of autoencoder in the json file
(archs/)
optional arguments:
-h, --help show this help message and exit
--pretrain PRETRAIN Pretrain the autoencoder for specified #epochs
specified by architecture on specified dataset
--cluster CLUSTER Refine the autoencoder for specified #epochs with
clustering loss, assumes that pretraining results are
available
--metrics METRICS Report k-means clustering metrics on the clustered
latent space, assumes pretrain and cluster based
training have been performed
--visualize VISUALIZE
Visualize the image space and latent space, assumes
pretraining and cluster based training have been
performed
'''
# Load architectures from the json files
mnist_archs = []
coil_archs = []
with open("archs/coil.json") as archs_file:
coil_archs = json.load(archs_file)
with open("archs/mnist.json") as archs_file:
mnist_archs = json.load(archs_file)
# Argument parsing
parser = argparse.ArgumentParser()
requiredArgs = parser.add_argument_group('required arguments')
requiredArgs.add_argument("-d", "--dataset", help="Dataset on which autoencoder is trained [MNIST,COIL20]", required=True)
requiredArgs.add_argument("-a", "--architecture", type=int, help="Index of architecture of autoencoder in the json file (archs/)", required=True)
parser.add_argument("--pretrain", type=int, help="Pretrain the autoencoder for specified #epochs specified by architecture on specified dataset")
parser.add_argument("--cluster", type=int, help="Refine the autoencoder for specified #epochs with clustering loss, assumes that pretraining results are available")
parser.add_argument("--metrics", action='store_true', help="Report k-means clustering metrics on the clustered latent space, assumes pretrain and cluster based training have been performed")
parser.add_argument("--visualize", action='store_true', help="Visualize the image space and latent space, assumes pretraining and cluster based training have been performed")
args = parser.parse_args()
# Train/Visualize as per the arguments
dataset_name = args.dataset
arch_index = args.architecture
if dataset_name == 'MNIST':
archs = mnist_archs
elif dataset_name == 'COIL20':
archs = coil_archs
if args.pretrain:
testOnlyClusterInitialization(dataset_name, archs[arch_index], args.pretrain)
if args.cluster:
testOnlyClusterImprovement(dataset_name, archs[arch_index], args.cluster, "KLD")
if args.metrics:
testKMeans(dataset_name, [archs[arch_index]])
if args.visualize:
visualizeLatentSpace(dataset_name, archs[arch_index])
================================================
FILE: misc.py
================================================
'''
Created on Jul 11, 2017
'''
import cPickle
import gzip
import numpy as np
from PIL import Image
import matplotlib
# For plotting graphs via ssh with no display
# Ref: https://stackoverflow.com/questions/2801882/generating-a-png-with-matplotlib-when-display-is-undefined
matplotlib.use('Agg')
from matplotlib import pyplot as plt
from numpy import float32
from sklearn import metrics
from sklearn.cluster.k_means_ import KMeans
from sklearn import manifold
from sklearn.utils.linear_assignment_ import linear_assignment
class DatasetHelper(object):
'''
Utility class for handling different datasets
'''
def __init__(self, name):
'''
A dataset instance keeps dataset name, the input set, the flat version of input set
and the cluster labels
'''
self.name = name
if name == 'MNIST':
self.dataset = MNISTDataset()
elif name == 'STL':
self.dataset = STLDataset()
elif name == 'COIL20':
self.dataset = COIL20Dataset()
def loadDataset(self):
'''
Load the appropriate dataset based on the dataset name
'''
self.input, self.labels, self.input_flat = self.dataset.loadDataset()
def getClusterCount(self):
'''
Number of clusters in the dataset - e.g 10 for mnist, 20 for coil20
'''
return self.dataset.cluster_count
def iterate_minibatches(self, set_type, batch_size, targets=None, shuffle=False):
'''
Utility method for getting batches out of a dataset
:param set_type: IMAGE - suitable input for CNNs or FLAT - suitable for DNN
:param batch_size: Size of minibatches
:param targets: None if the output should be same as inputs (autoencoders), otherwise takes a target array from which batches can be extracted. Must have the same order as the dataset, e.g, dataset inputs nth sample has output at target's nth element
:param shuffle: If the dataset needs to be shuffled or not
:return: generates a batches of size batch_size from the dataset, each batch is the pair (input, output)
'''
inputs = None
if set_type == 'IMAGE':
inputs = self.input
if targets is None:
targets = self.input
elif set_type == 'FLAT':
inputs = self.input_flat
if targets is None:
targets = self.input_flat
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt]
class MNISTDataset(object):
'''
Class for reading and preparing MNIST dataset
'''
def __init__(self):
self.cluster_count = 10
def loadDataset(self):
f = gzip.open('mnist/mnist.pkl.gz', 'rb')
train_set, _, test_set = cPickle.load(f)
train_input, train_input_flat, train_labels = self.prepareDatasetForAutoencoder(train_set[0], train_set[1])
test_input, test_input_flat, test_labels = self.prepareDatasetForAutoencoder(test_set[0], test_set[1])
f.close()
# combine test and train samples
return [np.concatenate((train_input, test_input)), np.concatenate((train_labels, test_labels)),
np.concatenate((train_input_flat, test_input_flat))]
def prepareDatasetForAutoencoder(self, inputs, targets):
'''
Returns the image, flat and labels as a tuple
'''
X = inputs
X = X.reshape((-1, 1, 28, 28))
return (X, X.reshape((-1, 28 * 28)), targets)
class STLDataset(object):
'''
Class for preparing and reading the STL dataset
'''
def __init__(self):
self.cluster_count = 10
def loadDataset(self):
train_x = np.fromfile('stl/train_X.bin', dtype=np.uint8)
train_y = np.fromfile('stl/train_y.bin', dtype=np.uint8)
test_x = np.fromfile('stl/train_X.bin', dtype=np.uint8)
test_y = np.fromfile('stl/train_y.bin', dtype=np.uint8)
train_input = np.reshape(train_x, (-1, 3, 96, 96))
train_labels = train_y
train_input_flat = np.reshape(test_x, (-1, 1, 3 * 96 * 96))
test_input = np.reshape(test_x, (-1, 3, 96, 96))
test_labels = test_y
test_input_flat = np.reshape(test_x, (-1, 1, 3 * 96 * 96))
return [np.concatenate(train_input, test_input), np.concatenate(train_labels, test_labels),
np.concatenate(train_input_flat, test_input_flat)]
class COIL20Dataset(object):
'''
Class for reading and preparing the COIL20Dataset
'''
def __init__(self):
self.cluster_count = 20
def loadDataset(self):
train_x = np.load('coil/coil_X.npy').astype(np.float32) / 256.0
train_y = np.load('coil/coil_y.npy')
train_x_flat = np.reshape(train_x, (-1, 128 * 128))
return [train_x, train_y, train_x_flat]
def rescaleReshapeAndSaveImage(image_sample, out_filename):
'''
For saving the reconstructed output as an image
:param image_sample: output of the autoencoder
:param out_filename: filename for the saved image
:return: None (side effect) Image saved
'''
image_sample = ((image_sample - np.amin(image_sample)) / (np.amax(image_sample) - np.amin(image_sample))) * 255;
image_sample = np.rint(image_sample).astype(int)
image_sample = np.clip(image_sample, a_min=0, a_max=255).astype('uint8')
img = Image.fromarray(image_sample, 'L')
img.save(out_filename)
def cluster_acc(y_true, y_pred):
'''
Uses the hungarian algorithm to find the best permutation mapping and then calculates the accuracy wrt
Implementation inpired from https://github.com/piiswrong/dec, since scikit does not implement this metric
this mapping and true labels
:param y_true: True cluster labels
:param y_pred: Predicted cluster labels
:return: accuracy score for the clustering
'''
D = int(max(y_pred.max(), y_true.max()) + 1)
w = np.zeros((D, D), dtype=np.int32)
for i in range(y_pred.size):
idx1 = int(y_pred[i])
idx2 = int(y_true[i])
w[idx1, idx2] += 1
ind = linear_assignment(w.max() - w)
return sum([w[i, j] for i, j in ind]) * 1.0 / y_pred.size
def getClusterMetricString(method_name, labels_true, labels_pred):
'''
Creates a formatted string containing the method name and acc, nmi metrics - can be used for printing
:param method_name: Name of the clustering method (just for printing)
:param labels_true: True label for each sample
:param labels_pred: Predicted label for each sample
:return: Formatted string containing metrics and method name
'''
acc = cluster_acc(labels_true, labels_pred)
nmi = metrics.normalized_mutual_info_score(labels_true, labels_pred)
return '%-50s %8.3f %8.3f' % (method_name, acc, nmi)
def evaluateKMeans(data, labels, nclusters, method_name):
'''
Clusters data with kmeans algorithm and then returns the string containing method name and metrics, and also the evaluated cluster centers
:param data: Points that need to be clustered as a numpy array
:param labels: True labels for the given points
:param nclusters: Total number of clusters
:param method_name: Name of the method from which the clustering space originates (only used for printing)
:return: Formatted string containing metrics and method name, cluster centers
'''
kmeans = KMeans(n_clusters=nclusters, n_init=20)
kmeans.fit(data)
return getClusterMetricString(method_name, labels, kmeans.labels_), kmeans.cluster_centers_
def visualizeData(Z, labels, num_clusters, title):
'''
TSNE visualization of the points in latent space Z
:param Z: Numpy array containing points in latent space in which clustering was performed
:param labels: True labels - used for coloring points
:param num_clusters: Total number of clusters
:param title: filename where the plot should be saved
:return: None - (side effect) saves clustering visualization plot in specified location
'''
labels = labels.astype(int)
tsne = manifold.TSNE(n_components=2, init='pca', random_state=0)
Z_tsne = tsne.fit_transform(Z)
fig = plt.figure()
plt.scatter(Z_tsne[:, 0], Z_tsne[:, 1], s=2, c=labels, cmap=plt.cm.get_cmap("jet", num_clusters))
plt.colorbar(ticks=range(num_clusters))
fig.savefig(title, dpi=fig.dpi)
================================================
FILE: network.py
================================================
'''
Created on Jul 11, 2017
'''
from datetime import datetime
import logging
from lasagne import layers
import lasagne
from lasagne.layers.helper import get_all_layers
import theano
import signal
from customlayers import ClusteringLayer, Unpool2DLayer, getSoftAssignments
from misc import evaluateKMeans, visualizeData, rescaleReshapeAndSaveImage
import numpy as np
import theano.tensor as T
from lasagne.layers import batch_norm
# Logging utilities - logs get saved in folder logs named by date and time, and also output
# at standard output
logFormatter = logging.Formatter("[%(asctime)s] %(message)s", datefmt='%m/%d %I:%M:%S')
rootLogger = logging.getLogger()
rootLogger.setLevel(logging.DEBUG)
fileHandler = logging.FileHandler(datetime.now().strftime('logs/dcjc_%H_%M_%d_%m.log'))
fileHandler.setFormatter(logFormatter)
rootLogger.addHandler(fileHandler)
consoleHandler = logging.StreamHandler()
consoleHandler.setFormatter(logFormatter)
rootLogger.addHandler(consoleHandler)
class DCJC(object):
# Main class holding autoencoder network and training functions
def __init__(self, network_description):
signal.signal(signal.SIGINT, self.signal_handler)
self.name = network_description['name']
netbuilder = NetworkBuilder(network_description)
self.shouldStopNow = False
# Get the lasagne network using the network builder class that creates autoencoder with the specified architecture
self.network = netbuilder.buildNetwork()
self.encode_layer, self.encode_size = netbuilder.getEncodeLayerAndSize()
self.t_input, self.t_target = netbuilder.getInputAndTargetVars()
self.input_type = netbuilder.getInputType()
self.batch_size = netbuilder.getBatchSize()
rootLogger.info("Network: " + self.networkToStr())
# Reconstruction is just output of the network
recon_prediction_expression = layers.get_output(self.network)
# Latent/Encoded space is the output of the bottleneck/encode layer
encode_prediction_expression = layers.get_output(self.encode_layer, deterministic=True)
# Loss for autoencoder = reconstruction loss + weight decay regularizer
loss = self.getReconstructionLossExpression(recon_prediction_expression, self.t_target)
weightsl2 = lasagne.regularization.regularize_network_params(self.network, lasagne.regularization.l2)
loss += (5e-5 * weightsl2)
params = lasagne.layers.get_all_params(self.network, trainable=True)
# SGD with momentum + Decaying learning rate
self.learning_rate = theano.shared(lasagne.utils.floatX(0.01))
updates = lasagne.updates.nesterov_momentum(loss, params, learning_rate=self.learning_rate)
# Theano functions for calculating loss, predicting reconstruction, encoding
self.trainAutoencoder = theano.function([self.t_input, self.t_target], loss, updates=updates)
self.predictReconstruction = theano.function([self.t_input], recon_prediction_expression)
self.predictEncoding = theano.function([self.t_input], encode_prediction_expression)
def getReconstructionLossExpression(self, prediction_expression, t_target):
'''
Reconstruction loss = means square error between input and reconstructed input
'''
loss = lasagne.objectives.squared_error(prediction_expression, t_target)
loss = loss.mean()
return loss
def signal_handler(self,signal, frame):
command = raw_input('\nWhat is your command?')
if str(command).lower()=="stop":
self.shouldStopNow = True
else:
exec(command)
def pretrainWithData(self, dataset, epochs, continue_training=False):
'''
Pretrains the autoencoder on the given dataset
:param dataset: Data on which the autoencoder is trained
:param epochs: number of training epochs
:param continue_training: Resume training if saved params available
:return: None - (side effect) saves the trained network params and latent space in appropriate location
'''
batch_size = self.batch_size
# array for holding the latent space representation of input
Z = np.zeros((dataset.input.shape[0], self.encode_size), dtype=np.float32);
# in case we're continuing training load the network params
if continue_training:
with np.load('saved_params/%s/m_%s.npz' % (dataset.name, self.name)) as f:
param_values = [f['arr_%d' % i] for i in range(len(f.files))]
lasagne.layers.set_all_param_values(self.network, param_values, trainable=True)
for epoch in range(epochs):
error = 0
total_batches = 0
for batch in dataset.iterate_minibatches(self.input_type, batch_size, shuffle=True):
inputs, targets = batch
error += self.trainAutoencoder(inputs, targets)
total_batches += 1
# learning rate decay
self.learning_rate.set_value(self.learning_rate.get_value() * lasagne.utils.floatX(0.9999))
# For every 20th iteration, print the clustering accuracy and nmi - for checking if the network
# is actually doing something meaningful - the labels are never used for training
if (epoch + 1) % 2 == 0:
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
Z[i * batch_size:(i + 1) * batch_size] = self.predictEncoding(batch[0])
# Uncomment the next two lines to create reconstruction outputs in folder dumps/ (may need to be created)
#for i, x in enumerate(self.predictReconstruction(batch[0])):
# print('dump')
# rescaleReshapeAndSaveImage(x[0], "dumps/%02d%03d.jpg"%(epoch,i));
rootLogger.info(evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), "%d/%d [%.4f]" % (epoch + 1, epochs, error / total_batches))[0])
else:
# Just report the training loss
rootLogger.info("%-30s %8s %8s" % ("%d/%d [%.4f]" % (epoch + 1, epochs, error / total_batches), "", ""))
if self.shouldStopNow:
break
# The inputs in latent space after pretraining
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
Z[i * batch_size:(i + 1) * batch_size] = self.predictEncoding(batch[0])
# Save network params and latent space
np.save('saved_params/%s/z_%s.npy' % (dataset.name, self.name), Z)
# Borrowed from mnist lasagne example
np.savez('saved_params/%s/m_%s.npz' % (dataset.name, self.name), *lasagne.layers.get_all_param_values(self.network, trainable=True))
def doClusteringWithKLdivLoss(self, dataset, combined_loss, epochs):
'''
Trains the autoencoder with combined kldivergence loss and reconstruction loss, or just the kldivergence loss
At the moment does not give good results
:param dataset: Data on which the autoencoder is trained
:param combined_loss: boolean - whether to use both reconstruction and kl divergence loss or just kldivergence loss
:param epochs: Number of training epochs
:return: None - (side effect) saves the trained network params and latent space in appropriate location
'''
batch_size = self.batch_size
# Load saved network params and inputs in latent space obtained after pretraining
with np.load('saved_params/%s/m_%s.npz' % (dataset.name, self.name)) as f:
param_values = [f['arr_%d' % i] for i in range(len(f.files))]
lasagne.layers.set_all_param_values(self.network, param_values, trainable=True)
Z = np.load('saved_params/%s/z_%s.npy' % (dataset.name, self.name))
# Find initial cluster centers
quality_desc, cluster_centers = evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), 'Initial')
rootLogger.info(quality_desc)
# P is the more pure target distribution we want to achieve
P = T.matrix('P')
# Extend the network so it calculates soft assignment cluster distribution for the inputs in latent space
clustering_network = ClusteringLayer(self.encode_layer, dataset.getClusterCount(), cluster_centers, batch_size,self.encode_size)
soft_assignments = layers.get_output(clustering_network)
reconstructed_output_exp = layers.get_output(self.network)
# Clustering loss = kl divergence between the pure distribution P and current distribution
clustering_loss = self.getKLDivLossExpression(soft_assignments, P)
reconstruction_loss = self.getReconstructionLossExpression(reconstructed_output_exp, self.t_target)
params_ae = lasagne.layers.get_all_params(self.network, trainable=True)
params_dec = lasagne.layers.get_all_params(clustering_network, trainable=True)
# Total loss = weighted sum of the two losses
w_cluster_loss = 1
w_reconstruction_loss = 1
total_loss = w_cluster_loss * clustering_loss
if (combined_loss):
total_loss = total_loss + w_reconstruction_loss * reconstruction_loss
all_params = params_dec
if combined_loss:
all_params.extend(params_ae)
# Parameters = unique parameters in the new network
all_params = list(set(all_params))
# SGD with momentum, LR = 0.01, Momentum = 0.9
updates = lasagne.updates.nesterov_momentum(total_loss, all_params, learning_rate=0.01)
# Function to calculate the soft assignment distribution
getSoftAssignments = theano.function([self.t_input], soft_assignments)
# Train function - based on whether complete loss is used or not
trainFunction = None
if combined_loss:
trainFunction = theano.function([self.t_input, self.t_target, P], total_loss, updates=updates)
else:
trainFunction = theano.function([self.t_input, P], clustering_loss, updates=updates)
for epoch in range(epochs):
# Get the current distribution
qij = np.zeros((dataset.input.shape[0], dataset.getClusterCount()), dtype=np.float32)
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
qij[i * batch_size: (i + 1) * batch_size] = getSoftAssignments(batch[0])
# Calculate the desired distribution
pij = self.calculateP(qij)
error = 0
total_batches = 0
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, pij, shuffle=True)):
if (combined_loss):
error += trainFunction(batch[0], batch[0], batch[1])
else:
error += trainFunction(batch[0], batch[1])
total_batches += 1
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
Z[i * batch_size:(i + 1) * batch_size] = self.predictEncoding(batch[0])
# For every 10th iteration, print the clustering accuracy and nmi - for checking if the network
# is actually doing something meaningful - the labels are never used for training
if (epoch + 1) % 10 == 0:
rootLogger.info(evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), "%d [%.4f]" % (
epoch, error / total_batches))[0])
if self.shouldStopNow:
break
# Save the inputs in latent space and the network parameters
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
Z[i * batch_size:(i + 1) * batch_size] = self.predictEncoding(batch[0])
np.save('saved_params/%s/pc_z_%s.npy' % (dataset.name, self.name), Z)
np.savez('saved_params/%s/pc_m_%s.npz' % (dataset.name, self.name),
*lasagne.layers.get_all_param_values(self.network, trainable=True))
def calculateP(self, Q):
# Function to calculate the desired distribution Q^2, for more details refer to DEC paper
f = Q.sum(axis=0)
pij_numerator = Q * Q
pij_numerator = pij_numerator / f
normalizer_p = pij_numerator.sum(axis=1).reshape((Q.shape[0], 1))
P = pij_numerator / normalizer_p
return P
def getKLDivLossExpression(self, Q_expression, P_expression):
# Loss = KL Divergence between the two distributions
log_arg = P_expression / Q_expression
log_exp = T.log(log_arg)
sum_arg = P_expression * log_exp
loss = sum_arg.sum(axis=1).sum(axis=0)
return loss
def doClusteringWithKMeansLoss(self, dataset, epochs):
'''
Trains the autoencoder with combined kMeans loss and reconstruction loss
At the moment does not give good results
:param dataset: Data on which the autoencoder is trained
:param epochs: Number of training epochs
:return: None - (side effect) saves the trained network params and latent space in appropriate location
'''
batch_size = self.batch_size
# Load the inputs in latent space produced by the pretrained autoencoder and use it to initialize cluster centers
Z = np.load('saved_params/%s/z_%s.npy' % (dataset.name, self.name))
quality_desc, cluster_centers = evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), 'Initial')
rootLogger.info(quality_desc)
# Load network parameters - code borrowed from mnist lasagne example
with np.load('saved_params/%s/m_%s.npz' % (dataset.name, self.name)) as f:
param_values = [f['arr_%d' % i] for i in range(len(f.files))]
lasagne.layers.set_all_param_values(self.network, param_values, trainable=True)
# reconstruction loss is just rms loss between input and reconstructed input
reconstruction_loss = self.getReconstructionLossExpression(layers.get_output(self.network), self.t_target)
# extent the network to do soft cluster assignments
clustering_network = ClusteringLayer(self.encode_layer, dataset.getClusterCount(), cluster_centers, batch_size, self.encode_size)
soft_assignments = layers.get_output(clustering_network)
# k-means loss is the sum of distances from the cluster centers weighted by the soft assignments to the clusters
kmeansLoss = self.getKMeansLoss(layers.get_output(self.encode_layer), soft_assignments, clustering_network.W, dataset.getClusterCount(), self.encode_size, batch_size)
params = lasagne.layers.get_all_params(self.network, trainable=True)
# total loss = reconstruction loss + lambda * kmeans loss
weight_reconstruction = 1
weight_kmeans = 0.1
total_loss = weight_kmeans * kmeansLoss + weight_reconstruction * reconstruction_loss
updates = lasagne.updates.nesterov_momentum(total_loss, params, learning_rate=0.01)
trainKMeansWithAE = theano.function([self.t_input, self.t_target], total_loss, updates=updates)
for epoch in range(epochs):
error = 0
total_batches = 0
for batch in dataset.iterate_minibatches(self.input_type, batch_size, shuffle=True):
inputs, targets = batch
error += trainKMeansWithAE(inputs, targets)
total_batches += 1
# For every 10th epoch, update the cluster centers and print the clustering accuracy and nmi - for checking if the network
# is actually doing something meaningful - the labels are never used for training
if (epoch + 1) % 10 == 0:
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
Z[i * batch_size:(i + 1) * batch_size] = self.predictEncoding(batch[0])
quality_desc, cluster_centers = evaluateKMeans(Z, dataset.labels, dataset.getClusterCount(), "%d/%d [%.4f]" % (epoch + 1, epochs, error / total_batches))
rootLogger.info(quality_desc)
else:
# Just print the training loss
rootLogger.info("%-30s %8s %8s" % ("%d/%d [%.4f]" % (epoch + 1, epochs, error / total_batches), "", ""))
if self.shouldStopNow:
break
# Save the inputs in latent space and the network parameters
for i, batch in enumerate(dataset.iterate_minibatches(self.input_type, batch_size, shuffle=False)):
Z[i * batch_size:(i + 1) * batch_size] = self.predictEncoding(batch[0])
np.save('saved_params/%s/pc_km_z_%s.npy' % (dataset.name, self.name), Z)
np.savez('saved_params/%s/pc_km_m_%s.npz' % (dataset.name, self.name),
*lasagne.layers.get_all_param_values(self.network, trainable=True))
def getKMeansLoss(self, latent_space_expression, soft_assignments, t_cluster_centers, num_clusters, latent_space_dim, num_samples, soft_loss=False):
# Kmeans loss = weighted sum of latent space representation of inputs from the cluster centers
z = latent_space_expression.reshape((num_samples, 1, latent_space_dim))
z = T.tile(z, (1, num_clusters, 1))
u = t_cluster_centers.reshape((1, num_clusters, latent_space_dim))
u = T.tile(u, (num_samples, 1, 1))
distances = (z - u).norm(2, axis=2).reshape((num_samples, num_clusters))
if soft_loss:
weighted_distances = distances * soft_assignments
loss = weighted_distances.sum(axis=1).mean()
else:
loss = distances.min(axis=1).mean()
return loss
def networkToStr(self):
# Utility method for printing the network structure in a shortened form
layers = lasagne.layers.get_all_layers(self.network)
result = ''
for layer in layers:
t = type(layer)
if t is lasagne.layers.input.InputLayer:
pass
else:
result += ' ' + layer.name
return result.strip()
class NetworkBuilder(object):
'''
Class that handles parsing the architecture dictionary and creating an autoencoder out of it
'''
def __init__(self, network_description):
'''
:param network_description: python dictionary specifying the autoencoder architecture
'''
# Populate the missing values in the dictionary with defaults, also add the missing decoder part
# of the autoencoder which is missing in the dictionary
self.network_description = self.populateMissingDescriptions(network_description)
# Create theano variables for input and output - would be of different types for simple and convolutional autoencoders
if self.network_description['network_type'] == 'CAE':
self.t_input = T.tensor4('input_var')
self.t_target = T.tensor4('target_var')
self.input_type = "IMAGE"
else:
self.t_input = T.matrix('input_var')
self.t_target = T.matrix('target_var')
self.input_type = "FLAT"
self.network_type = self.network_description['network_type']
self.batch_norm = bool(self.network_description["use_batch_norm"])
self.layer_list = []
def getBatchSize(self):
return self.network_description["batch_size"]
def getInputAndTargetVars(self):
return self.t_input, self.t_target
def getInputType(self):
return self.input_type
def buildNetwork(self):
'''
:return: Lasagne autoencoder network based on the network decription dictionary
'''
network = None
for layer in self.network_description['layers']:
network = self.processLayer(network, layer)
return network
def getEncodeLayerAndSize(self):
'''
:return: The encode layer - layer between encoder and decoder (bottleneck)
'''
return self.encode_layer, self.encode_size
def populateDecoder(self, encode_layers):
'''
Creates a specification for the mirror of encode layers - which completes the autoencoder specification
'''
decode_layers = []
for i, layer in reversed(list(enumerate(encode_layers))):
if (layer["type"] == "MaxPool2D*"):
# Inverse max pool doesn't upscale the input, but does reverse of what happened when maxpool
# operation was performed
decode_layers.append({
"type": "InverseMaxPool2D",
"layer_index": i,
'filter_size': layer['filter_size']
})
elif (layer["type"] == "MaxPool2D"):
# Unpool just upscales the input back
decode_layers.append({
"type": "Unpool2D",
'filter_size': layer['filter_size']
})
elif (layer["type"] == "Conv2D"):
# Inverse convolution = deconvolution
decode_layers.append({
'type': 'Deconv2D',
'conv_mode': layer['conv_mode'],
'non_linearity': layer['non_linearity'],
'filter_size': layer['filter_size'],
'num_filters': encode_layers[i - 1]['output_shape'][0]
})
elif (layer["type"] == "Dense" and not layer["is_encode"]):
# Inverse of dense layers is just a dense layer, though we dont create an inverse layer corresponding to bottleneck layer
decode_layers.append({
'type': 'Dense',
'num_units': encode_layers[i]['output_shape'][2],
'non_linearity': encode_layers[i]['non_linearity']
})
# if the layer following the dense layer is one of these, we need to reshape the output
if (encode_layers[i - 1]['type'] in ("Conv2D", "MaxPool2D", "MaxPool2D*")):
decode_layers.append({
"type": "Reshape",
"output_shape": encode_layers[i - 1]['output_shape']
})
encode_layers.extend(decode_layers)
def populateShapes(self, layers):
# Fills the dictionary with shape information corresponding to each layer, which will be used in creating the decode layers
last_layer_dimensions = layers[0]['output_shape']
for layer in layers[1:]:
if (layer['type'] == 'MaxPool2D' or layer['type'] == 'MaxPool2D*'):
layer['output_shape'] = [last_layer_dimensions[0], last_layer_dimensions[1] / layer['filter_size'][0],
last_layer_dimensions[2] / layer['filter_size'][1]]
elif (layer['type'] == 'Conv2D'):
multiplier = 1
if (layer['conv_mode'] == "same"):
multiplier = 0
layer['output_shape'] = [layer['num_filters'],
last_layer_dimensions[1] - (layer['filter_size'][0] - 1) * multiplier,
last_layer_dimensions[2] - (layer['filter_size'][1] - 1) * multiplier]
elif (layer['type'] == 'Dense'):
layer['output_shape'] = [1, 1, layer['num_units']]
last_layer_dimensions = layer['output_shape']
def populateMissingDescriptions(self, network_description):
# Complete the architecture dictionary by filling in default values and populating description for decoder
if 'network_type' not in network_description:
if (network_description['name'].split('_')[0].split('-')[0] == 'fc'):
network_description['network_type'] = 'AE'
else:
network_description['network_type'] = 'CAE'
for layer in network_description['layers']:
if 'conv_mode' not in layer:
layer['conv_mode'] = 'valid'
layer['is_encode'] = False
network_description['layers'][-1]['is_encode'] = True
if 'output_non_linearity' not in network_description:
network_description['output_non_linearity'] = network_description['layers'][1]['non_linearity']
self.populateShapes(network_description['layers'])
self.populateDecoder(network_description['layers'])
if 'use_batch_norm' not in network_description:
network_description['use_batch_norm'] = False
for layer in network_description['layers']:
if 'is_encode' not in layer:
layer['is_encode'] = False
layer['is_output'] = False
network_description['layers'][-1]['is_output'] = True
network_description['layers'][-1]['non_linearity'] = network_description['output_non_linearity']
return network_description
def getInitializationFct(self):
return lasagne.init.GlorotUniform()
def processLayer(self, network, layer_definition):
'''
Create a lasagne layer corresponding to the "layer definition"
'''
if (layer_definition["type"] == "Input"):
if self.network_type == 'CAE':
network = lasagne.layers.InputLayer(shape=tuple([None] + layer_definition['output_shape']), input_var=self.t_input)
elif self.network_type == 'AE':
network = lasagne.layers.InputLayer(shape=(None, layer_definition['output_shape'][2]), input_var=self.t_input)
elif (layer_definition['type'] == 'Dense'):
network = lasagne.layers.DenseLayer(network, num_units=layer_definition['num_units'], nonlinearity=self.getNonLinearity(layer_definition['non_linearity']), name=self.getLayerName(layer_definition),W=self.getInitializationFct())
elif (layer_definition['type'] == 'Conv2D'):
network = lasagne.layers.Conv2DLayer(network, num_filters=layer_definition['num_filters'], filter_size=tuple(layer_definition["filter_size"]), pad=layer_definition['conv_mode'], nonlinearity=self.getNonLinearity(layer_definition['non_linearity']), name=self.getLayerName(layer_definition),W=self.getInitializationFct())
elif (layer_definition['type'] == 'MaxPool2D' or layer_definition['type'] == 'MaxPool2D*'):
network = lasagne.layers.MaxPool2DLayer(network, pool_size=tuple(layer_definition["filter_size"]), name=self.getLayerName(layer_definition))
elif (layer_definition['type'] == 'InverseMaxPool2D'):
network = lasagne.layers.InverseLayer(network, self.layer_list[layer_definition['layer_index']], name=self.getLayerName(layer_definition))
elif (layer_definition['type'] == 'Unpool2D'):
network = Unpool2DLayer(network, tuple(layer_definition['filter_size']), name=self.getLayerName(layer_definition))
elif (layer_definition['type'] == 'Reshape'):
network = lasagne.layers.ReshapeLayer(network, shape=tuple([-1] + layer_definition["output_shape"]), name=self.getLayerName(layer_definition))
elif (layer_definition['type'] == 'Deconv2D'):
network = lasagne.layers.Deconv2DLayer(network, num_filters=layer_definition['num_filters'], filter_size=tuple(layer_definition['filter_size']), crop=layer_definition['conv_mode'], nonlinearity=self.getNonLinearity(layer_definition['non_linearity']), name=self.getLayerName(layer_definition))
self.layer_list.append(network)
# Batch normalization on all convolutional layers except if at output
if (self.batch_norm and (not layer_definition["is_output"]) and layer_definition['type'] in ("Conv2D", "Deconv2D")):
network = batch_norm(network)
# Save the encode layer separately
if (layer_definition['is_encode']):
self.encode_layer = lasagne.layers.flatten(network, name='fl')
self.encode_size = layer_definition['output_shape'][0] * layer_definition['output_shape'][1] * layer_definition['output_shape'][2]
return network
def getLayerName(self, layer_definition):
'''
Utility method to name layers
'''
if (layer_definition['type'] == 'Dense'):
return 'fc[{}]'.format(layer_definition['num_units'])
elif (layer_definition['type'] == 'Conv2D'):
return '{}[{}]'.format(layer_definition['num_filters'],
'x'.join([str(fs) for fs in layer_definition['filter_size']]))
elif (layer_definition['type'] == 'MaxPool2D' or layer_definition['type'] == 'MaxPool2D*'):
return 'max[{}]'.format('x'.join([str(fs) for fs in layer_definition['filter_size']]))
elif (layer_definition['type'] == 'InverseMaxPool2D'):
return 'ups*[{}]'.format('x'.join([str(fs) for fs in layer_definition['filter_size']]))
elif (layer_definition['type'] == 'Unpool2D'):
return 'ups[{}]'.format(
str(layer_definition['filter_size'][0]) + 'x' + str(layer_definition['filter_size'][1]))
elif (layer_definition['type'] == 'Deconv2D'):
return '{}[{}]'.format(layer_definition['num_filters'],
'x'.join([str(fs) for fs in layer_definition['filter_size']]))
elif (layer_definition['type'] == 'Reshape'):
return "rsh"
def getNonLinearity(self, non_linearity):
return {
'rectify': lasagne.nonlinearities.rectify,
'linear': lasagne.nonlinearities.linear,
'elu': lasagne.nonlinearities.elu
}[non_linearity]
gitextract_5766_38r/ ├── .gitignore ├── .project ├── .pydevproject ├── README.md ├── archs/ │ ├── coil.json │ └── mnist.json ├── customlayers.py ├── main.py ├── misc.py └── network.py
SYMBOL INDEX (58 symbols across 4 files)
FILE: customlayers.py
class Unpool2DLayer (line 10) | class Unpool2DLayer(layers.Layer):
method __init__ (line 17) | def __init__(self, incoming, ds, **kwargs):
method get_output_shape_for (line 21) | def get_output_shape_for(self, input_shape):
method get_output_for (line 27) | def get_output_for(self, incoming, **kwargs):
class ClusteringLayer (line 35) | class ClusteringLayer(layers.Layer):
method __init__ (line 42) | def __init__(self, incoming, num_clusters, initial_clusters, num_sampl...
method get_output_shape_for (line 49) | def get_output_shape_for(self, input_shape):
method get_output_for (line 56) | def get_output_for(self, incoming, **kwargs):
function getSoftAssignments (line 60) | def getSoftAssignments(latent_space, cluster_centers, num_clusters, late...
FILE: main.py
function testOnlyClusterInitialization (line 12) | def testOnlyClusterInitialization(dataset_name, arch, epochs):
function testOnlyClusterImprovement (line 32) | def testOnlyClusterImprovement(dataset_name, arch, epochs, method):
function testKMeans (line 56) | def testKMeans(dataset_name, archs):
function visualizeLatentSpace (line 82) | def visualizeLatentSpace(dataset_name, arch):
FILE: misc.py
class DatasetHelper (line 24) | class DatasetHelper(object):
method __init__ (line 29) | def __init__(self, name):
method loadDataset (line 42) | def loadDataset(self):
method getClusterCount (line 48) | def getClusterCount(self):
method iterate_minibatches (line 54) | def iterate_minibatches(self, set_type, batch_size, targets=None, shuf...
class MNISTDataset (line 84) | class MNISTDataset(object):
method __init__ (line 89) | def __init__(self):
method loadDataset (line 92) | def loadDataset(self):
method prepareDatasetForAutoencoder (line 102) | def prepareDatasetForAutoencoder(self, inputs, targets):
class STLDataset (line 111) | class STLDataset(object):
method __init__ (line 116) | def __init__(self):
method loadDataset (line 119) | def loadDataset(self):
class COIL20Dataset (line 134) | class COIL20Dataset(object):
method __init__ (line 139) | def __init__(self):
method loadDataset (line 142) | def loadDataset(self):
function rescaleReshapeAndSaveImage (line 149) | def rescaleReshapeAndSaveImage(image_sample, out_filename):
function cluster_acc (line 163) | def cluster_acc(y_true, y_pred):
function getClusterMetricString (line 182) | def getClusterMetricString(method_name, labels_true, labels_pred):
function evaluateKMeans (line 195) | def evaluateKMeans(data, labels, nclusters, method_name):
function visualizeData (line 209) | def visualizeData(Z, labels, num_clusters, title):
FILE: network.py
class DCJC (line 38) | class DCJC(object):
method __init__ (line 40) | def __init__(self, network_description):
method getReconstructionLossExpression (line 70) | def getReconstructionLossExpression(self, prediction_expression, t_tar...
method signal_handler (line 78) | def signal_handler(self,signal, frame):
method pretrainWithData (line 86) | def pretrainWithData(self, dataset, epochs, continue_training=False):
method doClusteringWithKLdivLoss (line 134) | def doClusteringWithKLdivLoss(self, dataset, combined_loss, epochs):
method calculateP (line 215) | def calculateP(self, Q):
method getKLDivLossExpression (line 224) | def getKLDivLossExpression(self, Q_expression, P_expression):
method doClusteringWithKMeansLoss (line 232) | def doClusteringWithKMeansLoss(self, dataset, epochs):
method getKMeansLoss (line 291) | def getKMeansLoss(self, latent_space_expression, soft_assignments, t_c...
method networkToStr (line 305) | def networkToStr(self):
class NetworkBuilder (line 318) | class NetworkBuilder(object):
method __init__ (line 323) | def __init__(self, network_description):
method getBatchSize (line 343) | def getBatchSize(self):
method getInputAndTargetVars (line 346) | def getInputAndTargetVars(self):
method getInputType (line 349) | def getInputType(self):
method buildNetwork (line 352) | def buildNetwork(self):
method getEncodeLayerAndSize (line 361) | def getEncodeLayerAndSize(self):
method populateDecoder (line 367) | def populateDecoder(self, encode_layers):
method populateShapes (line 411) | def populateShapes(self, layers):
method populateMissingDescriptions (line 429) | def populateMissingDescriptions(self, network_description):
method getInitializationFct (line 455) | def getInitializationFct(self):
method processLayer (line 459) | def processLayer(self, network, layer_definition):
method getLayerName (line 492) | def getLayerName(self, layer_definition):
method getNonLinearity (line 514) | def getNonLinearity(self, non_linearity):
Condensed preview — 10 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (77K chars).
[
{
"path": ".gitignore",
"chars": 34,
"preview": "*.pyc\noutputs/*.png\nlogs/*\n.idea/\n"
},
{
"path": ".project",
"chars": 377,
"preview": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<projectDescription>\n\t<name>DeepConvJointClustering</name>\n\t<comment></comment>\n\t"
},
{
"path": ".pydevproject",
"chars": 423,
"preview": "<?xml version=\"1.0\" encoding=\"UTF-8\" standalone=\"no\"?>\n<?eclipse-pydev version=\"1.0\"?><pydev_project>\n<pydev_pathpropert"
},
{
"path": "README.md",
"chars": 8394,
"preview": "Deep Learning for Clustering\n=======================\nCode for project \"Deep Learning for Clustering\" under lab course \""
},
{
"path": "archs/coil.json",
"chars": 11069,
"preview": "[\n {\n \"name\": \"c-9-20_p-2_c-5-20_p-2_c-5-40_p-2_c-4-320\",\n \"use_batch_norm\":1,\n \"batch_size\": 10,\n "
},
{
"path": "archs/mnist.json",
"chars": 1968,
"preview": "[\n {\n \"name\": \"c-3-32_p_c-3-64_p_fc-32\",\n \"batch_size\": 50,\n \"layers\": [\n {\n \"type\": \"Input\",\n "
},
{
"path": "customlayers.py",
"chars": 3149,
"preview": "'''\nCreated on Jul 25, 2017\n'''\n\nfrom lasagne import layers\nimport theano\nimport theano.tensor as T\n\n\nclass Unpool2DLaye"
},
{
"path": "main.py",
"chars": 9078,
"preview": "'''\nCreated on Jul 9, 2017\n'''\nimport numpy\nimport json\nfrom misc import DatasetHelper, evaluateKMeans, visualizeData\nfr"
},
{
"path": "misc.py",
"chars": 8748,
"preview": "'''\nCreated on Jul 11, 2017\n'''\n\nimport cPickle\nimport gzip\n\nimport numpy as np\nfrom PIL import Image\nimport matplotlib\n"
},
{
"path": "network.py",
"chars": 29772,
"preview": "'''\nCreated on Jul 11, 2017\n'''\n\nfrom datetime import datetime\nimport logging\n\nfrom lasagne import layers\nimport lasagne"
}
]
About this extraction
This page contains the full source code of the elieJalbout/Clustering-with-Deep-learning GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 10 files (71.3 KB), approximately 18.0k tokens, and a symbol index with 58 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.