Repository: encode/httpx
Branch: master
Commit: b5addb64f016
Files: 115
Total size: 967.5 KB
Directory structure:
gitextract_2vanwzu3/
├── .github/
│ ├── CONTRIBUTING.md
│ ├── FUNDING.yml
│ ├── ISSUE_TEMPLATE/
│ │ ├── 1-issue.md
│ │ └── config.yml
│ ├── PULL_REQUEST_TEMPLATE.md
│ ├── dependabot.yml
│ └── workflows/
│ ├── publish.yml
│ └── test-suite.yml
├── .gitignore
├── CHANGELOG.md
├── LICENSE.md
├── README.md
├── docs/
│ ├── CNAME
│ ├── advanced/
│ │ ├── authentication.md
│ │ ├── clients.md
│ │ ├── event-hooks.md
│ │ ├── extensions.md
│ │ ├── proxies.md
│ │ ├── resource-limits.md
│ │ ├── ssl.md
│ │ ├── text-encodings.md
│ │ ├── timeouts.md
│ │ └── transports.md
│ ├── api.md
│ ├── async.md
│ ├── code_of_conduct.md
│ ├── compatibility.md
│ ├── contributing.md
│ ├── css/
│ │ └── custom.css
│ ├── environment_variables.md
│ ├── exceptions.md
│ ├── http2.md
│ ├── index.md
│ ├── logging.md
│ ├── overrides/
│ │ └── partials/
│ │ └── nav.html
│ ├── quickstart.md
│ ├── third_party_packages.md
│ └── troubleshooting.md
├── httpx/
│ ├── __init__.py
│ ├── __version__.py
│ ├── _api.py
│ ├── _auth.py
│ ├── _client.py
│ ├── _config.py
│ ├── _content.py
│ ├── _decoders.py
│ ├── _exceptions.py
│ ├── _main.py
│ ├── _models.py
│ ├── _multipart.py
│ ├── _status_codes.py
│ ├── _transports/
│ │ ├── __init__.py
│ │ ├── asgi.py
│ │ ├── base.py
│ │ ├── default.py
│ │ ├── mock.py
│ │ └── wsgi.py
│ ├── _types.py
│ ├── _urlparse.py
│ ├── _urls.py
│ ├── _utils.py
│ └── py.typed
├── mkdocs.yml
├── pyproject.toml
├── requirements.txt
├── scripts/
│ ├── build
│ ├── check
│ ├── clean
│ ├── coverage
│ ├── docs
│ ├── install
│ ├── lint
│ ├── publish
│ ├── sync-version
│ └── test
└── tests/
├── __init__.py
├── client/
│ ├── __init__.py
│ ├── test_async_client.py
│ ├── test_auth.py
│ ├── test_client.py
│ ├── test_cookies.py
│ ├── test_event_hooks.py
│ ├── test_headers.py
│ ├── test_properties.py
│ ├── test_proxies.py
│ ├── test_queryparams.py
│ └── test_redirects.py
├── common.py
├── concurrency.py
├── conftest.py
├── fixtures/
│ ├── .netrc
│ └── .netrc-nopassword
├── models/
│ ├── __init__.py
│ ├── test_cookies.py
│ ├── test_headers.py
│ ├── test_queryparams.py
│ ├── test_requests.py
│ ├── test_responses.py
│ ├── test_url.py
│ ├── test_whatwg.py
│ └── whatwg.json
├── test_api.py
├── test_asgi.py
├── test_auth.py
├── test_config.py
├── test_content.py
├── test_decoders.py
├── test_exceptions.py
├── test_exported_members.py
├── test_main.py
├── test_multipart.py
├── test_status_codes.py
├── test_timeouts.py
├── test_utils.py
└── test_wsgi.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/CONTRIBUTING.md
================================================
# Contributing
Thank you for being interested in contributing to HTTPX.
There are many ways you can contribute to the project:
- Try HTTPX and [report bugs/issues you find](https://github.com/encode/httpx/issues/new)
- [Implement new features](https://github.com/encode/httpx/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22)
- [Review Pull Requests of others](https://github.com/encode/httpx/pulls)
- Write documentation
- Participate in discussions
## Reporting Bugs or Other Issues
Found something that HTTPX should support?
Stumbled upon some unexpected behaviour?
Contributions should generally start out with [a discussion](https://github.com/encode/httpx/discussions).
Possible bugs may be raised as a "Potential Issue" discussion, feature requests may
be raised as an "Ideas" discussion. We can then determine if the discussion needs
to be escalated into an "Issue" or not, or if we'd consider a pull request.
Try to be more descriptive as you can and in case of a bug report,
provide as much information as possible like:
- OS platform
- Python version
- Installed dependencies and versions (`python -m pip freeze`)
- Code snippet
- Error traceback
You should always try to reduce any examples to the *simplest possible case*
that demonstrates the issue.
Some possibly useful tips for narrowing down potential issues...
- Does the issue exist on HTTP/1.1, or HTTP/2, or both?
- Does the issue exist with `Client`, `AsyncClient`, or both?
- When using `AsyncClient` does the issue exist when using `asyncio` or `trio`, or both?
## Development
To start developing HTTPX create a **fork** of the
[HTTPX repository](https://github.com/encode/httpx) on GitHub.
Then clone your fork with the following command replacing `YOUR-USERNAME` with
your GitHub username:
```shell
$ git clone https://github.com/YOUR-USERNAME/httpx
```
You can now install the project and its dependencies using:
```shell
$ cd httpx
$ scripts/install
```
## Testing and Linting
We use custom shell scripts to automate testing, linting,
and documentation building workflow.
To run the tests, use:
```shell
$ scripts/test
```
!!! warning
The test suite spawns testing servers on ports **8000** and **8001**.
Make sure these are not in use, so the tests can run properly.
You can run a single test script like this:
```shell
$ scripts/test -- tests/test_multipart.py
```
To run the code auto-formatting:
```shell
$ scripts/lint
```
Lastly, to run code checks separately (they are also run as part of `scripts/test`), run:
```shell
$ scripts/check
```
## Documenting
Documentation pages are located under the `docs/` folder.
To run the documentation site locally (useful for previewing changes), use:
```shell
$ scripts/docs
```
## Resolving Build / CI Failures
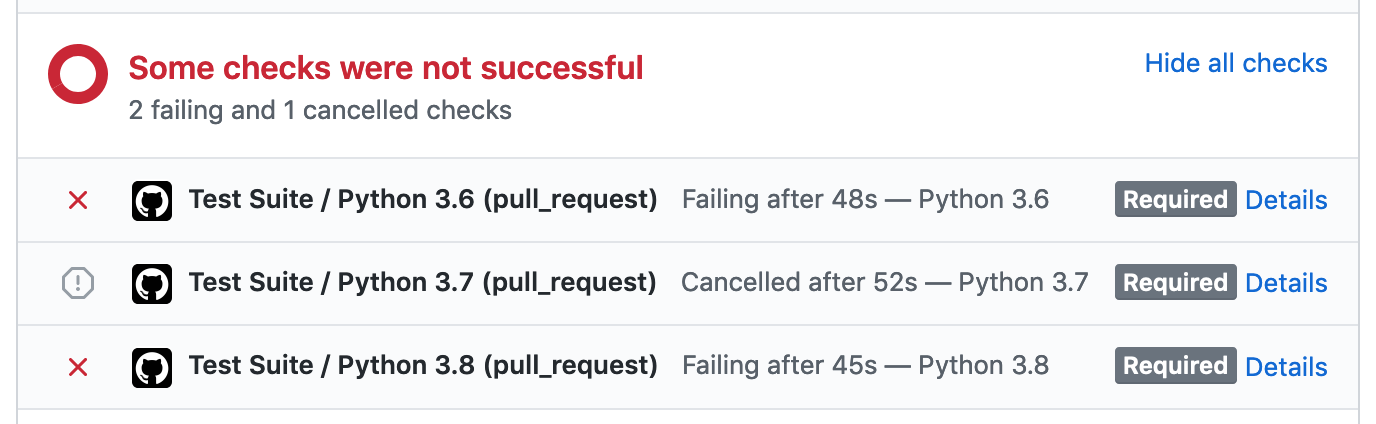
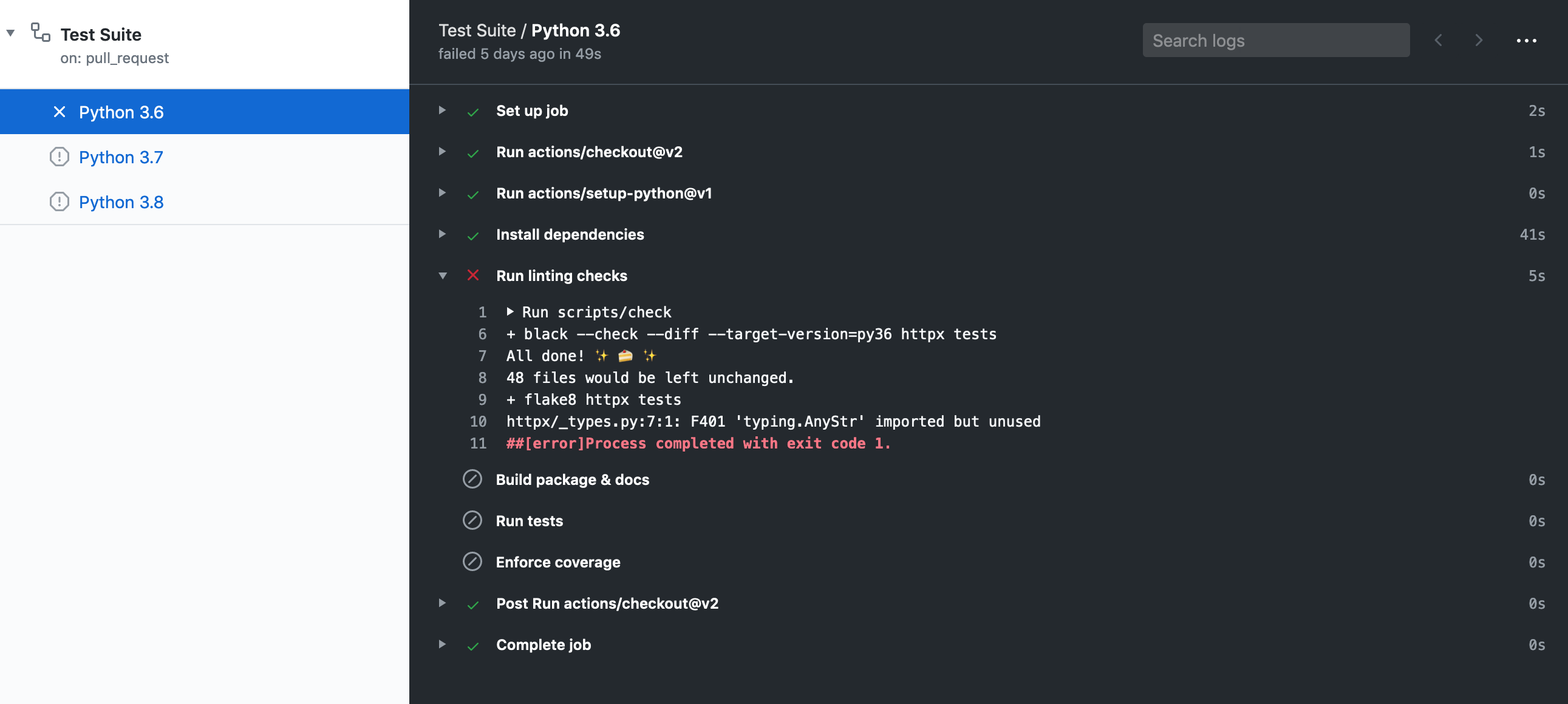
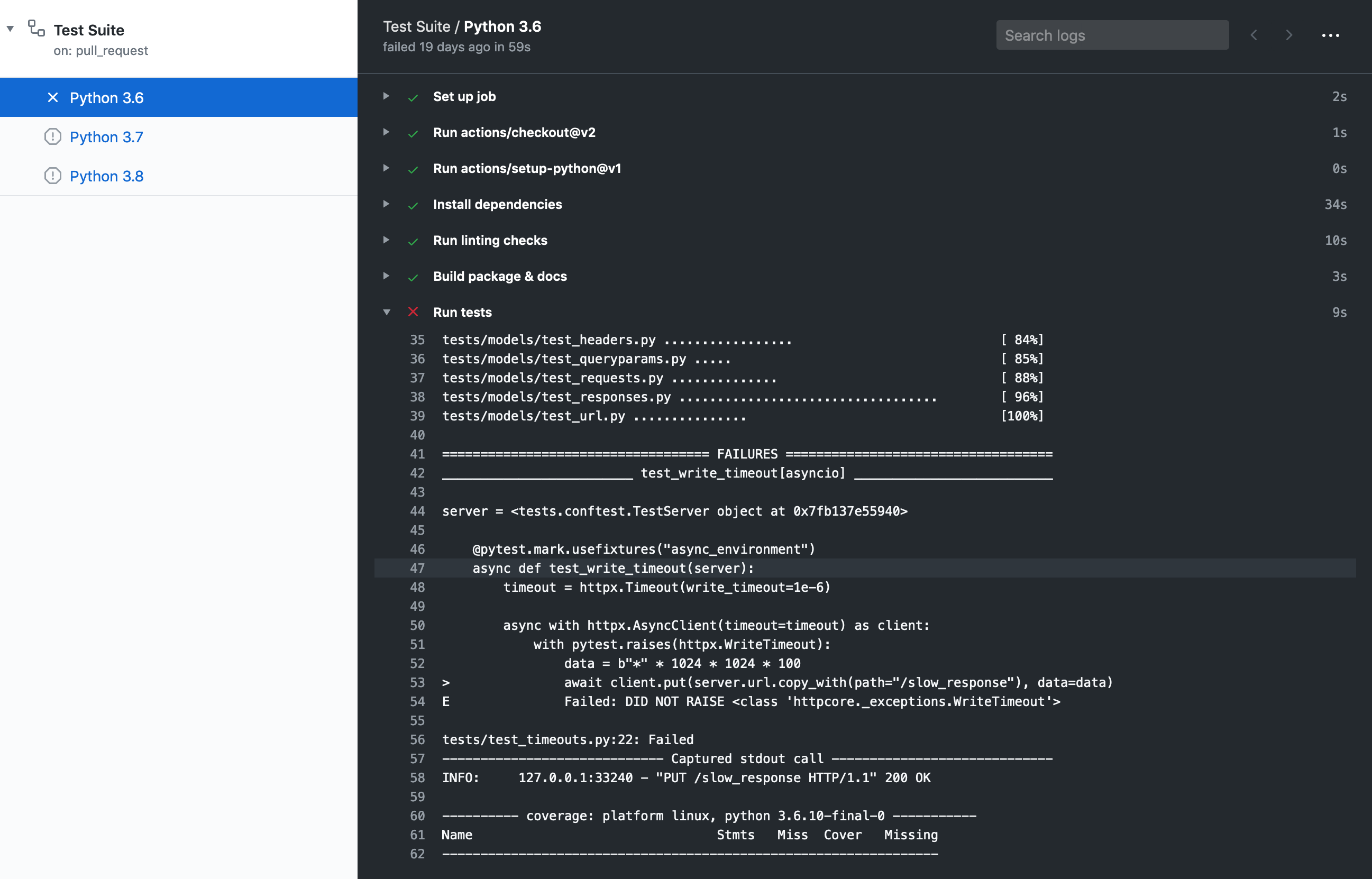
Once you've submitted your pull request, the test suite will automatically run, and the results will show up in GitHub.
If the test suite fails, you'll want to click through to the "Details" link, and try to identify why the test suite failed.
Here are some common ways the test suite can fail:
### Check Job Failed
This job failing means there is either a code formatting issue or type-annotation issue.
You can look at the job output to figure out why it's failed or within a shell run:
```shell
$ scripts/check
```
It may be worth it to run `$ scripts/lint` to attempt auto-formatting the code
and if that job succeeds commit the changes.
### Docs Job Failed
This job failing means the documentation failed to build. This can happen for
a variety of reasons like invalid markdown or missing configuration within `mkdocs.yml`.
### Python 3.X Job Failed
HTTPX is a fully featured HTTP client library for Python 3. It includes **an integrated command line client**, has support for both **HTTP/1.1 and HTTP/2**, and provides both **sync and async APIs**.
---
Install HTTPX using pip:
```shell
$ pip install httpx
```
Now, let's get started:
```pycon
>>> import httpx
>>> r = httpx.get('https://www.example.org/')
>>> r
>>> r.status_code
200
>>> r.headers['content-type']
'text/html; charset=UTF-8'
>>> r.text
'\n\n\nExample Domain...'
```
Or, using the command-line client.
```shell
$ pip install 'httpx[cli]' # The command line client is an optional dependency.
```
Which now allows us to use HTTPX directly from the command-line...
Sending a request...
## Features
HTTPX builds on the well-established usability of `requests`, and gives you:
* A broadly [requests-compatible API](https://www.python-httpx.org/compatibility/).
* An integrated command-line client.
* HTTP/1.1 [and HTTP/2 support](https://www.python-httpx.org/http2/).
* Standard synchronous interface, but with [async support if you need it](https://www.python-httpx.org/async/).
* Ability to make requests directly to [WSGI applications](https://www.python-httpx.org/advanced/transports/#wsgi-transport) or [ASGI applications](https://www.python-httpx.org/advanced/transports/#asgi-transport).
* Strict timeouts everywhere.
* Fully type annotated.
* 100% test coverage.
Plus all the standard features of `requests`...
* International Domains and URLs
* Keep-Alive & Connection Pooling
* Sessions with Cookie Persistence
* Browser-style SSL Verification
* Basic/Digest Authentication
* Elegant Key/Value Cookies
* Automatic Decompression
* Automatic Content Decoding
* Unicode Response Bodies
* Multipart File Uploads
* HTTP(S) Proxy Support
* Connection Timeouts
* Streaming Downloads
* .netrc Support
* Chunked Requests
## Installation
Install with pip:
```shell
$ pip install httpx
```
Or, to include the optional HTTP/2 support, use:
```shell
$ pip install httpx[http2]
```
HTTPX requires Python 3.9+.
## Documentation
Project documentation is available at [https://www.python-httpx.org/](https://www.python-httpx.org/).
For a run-through of all the basics, head over to the [QuickStart](https://www.python-httpx.org/quickstart/).
For more advanced topics, see the [Advanced Usage](https://www.python-httpx.org/advanced/) section, the [async support](https://www.python-httpx.org/async/) section, or the [HTTP/2](https://www.python-httpx.org/http2/) section.
The [Developer Interface](https://www.python-httpx.org/api/) provides a comprehensive API reference.
To find out about tools that integrate with HTTPX, see [Third Party Packages](https://www.python-httpx.org/third_party_packages/).
## Contribute
If you want to contribute with HTTPX check out the [Contributing Guide](https://www.python-httpx.org/contributing/) to learn how to start.
## Dependencies
The HTTPX project relies on these excellent libraries:
* `httpcore` - The underlying transport implementation for `httpx`.
* `h11` - HTTP/1.1 support.
* `certifi` - SSL certificates.
* `idna` - Internationalized domain name support.
* `sniffio` - Async library autodetection.
As well as these optional installs:
* `h2` - HTTP/2 support. *(Optional, with `httpx[http2]`)*
* `socksio` - SOCKS proxy support. *(Optional, with `httpx[socks]`)*
* `rich` - Rich terminal support. *(Optional, with `httpx[cli]`)*
* `click` - Command line client support. *(Optional, with `httpx[cli]`)*
* `brotli` or `brotlicffi` - Decoding for "brotli" compressed responses. *(Optional, with `httpx[brotli]`)*
* `zstandard` - Decoding for "zstd" compressed responses. *(Optional, with `httpx[zstd]`)*
A huge amount of credit is due to `requests` for the API layout that
much of this work follows, as well as to `urllib3` for plenty of design
inspiration around the lower-level networking details.
---
HTTPX is BSD licensed code. Designed & crafted with care. — 🦋 —
================================================
FILE: docs/CNAME
================================================
www.python-httpx.org
================================================
FILE: docs/advanced/authentication.md
================================================
Authentication can either be included on a per-request basis...
```pycon
>>> auth = httpx.BasicAuth(username="username", password="secret")
>>> client = httpx.Client()
>>> response = client.get("https://www.example.com/", auth=auth)
```
Or configured on the client instance, ensuring that all outgoing requests will include authentication credentials...
```pycon
>>> auth = httpx.BasicAuth(username="username", password="secret")
>>> client = httpx.Client(auth=auth)
>>> response = client.get("https://www.example.com/")
```
## Basic authentication
HTTP basic authentication is an unencrypted authentication scheme that uses a simple encoding of the username and password in the request `Authorization` header. Since it is unencrypted it should typically only be used over `https`, although this is not strictly enforced.
```pycon
>>> auth = httpx.BasicAuth(username="finley", password="secret")
>>> client = httpx.Client(auth=auth)
>>> response = client.get("https://httpbin.org/basic-auth/finley/secret")
>>> response
```
## Digest authentication
HTTP digest authentication is a challenge-response authentication scheme. Unlike basic authentication it provides encryption, and can be used over unencrypted `http` connections. It requires an additional round-trip in order to negotiate the authentication.
```pycon
>>> auth = httpx.DigestAuth(username="olivia", password="secret")
>>> client = httpx.Client(auth=auth)
>>> response = client.get("https://httpbin.org/digest-auth/auth/olivia/secret")
>>> response
>>> response.history
[]
```
## NetRC authentication
HTTPX can be configured to use [a `.netrc` config file](https://everything.curl.dev/usingcurl/netrc) for authentication.
The `.netrc` config file allows authentication credentials to be associated with specified hosts. When a request is made to a host that is found in the netrc file, the username and password will be included using HTTP basic authentication.
Example `.netrc` file:
```
machine example.org
login example-username
password example-password
machine python-httpx.org
login other-username
password other-password
```
Some examples of configuring `.netrc` authentication with `httpx`.
Use the default `.netrc` file in the users home directory:
```pycon
>>> auth = httpx.NetRCAuth()
>>> client = httpx.Client(auth=auth)
```
Use an explicit path to a `.netrc` file:
```pycon
>>> auth = httpx.NetRCAuth(file="/path/to/.netrc")
>>> client = httpx.Client(auth=auth)
```
Use the `NETRC` environment variable to configure a path to the `.netrc` file,
or fallback to the default.
```pycon
>>> auth = httpx.NetRCAuth(file=os.environ.get("NETRC"))
>>> client = httpx.Client(auth=auth)
```
The `NetRCAuth()` class uses [the `netrc.netrc()` function from the Python standard library](https://docs.python.org/3/library/netrc.html). See the documentation there for more details on exceptions that may be raised if the `.netrc` file is not found, or cannot be parsed.
## Custom authentication schemes
When issuing requests or instantiating a client, the `auth` argument can be used to pass an authentication scheme to use. The `auth` argument may be one of the following...
* A two-tuple of `username`/`password`, to be used with basic authentication.
* An instance of `httpx.BasicAuth()`, `httpx.DigestAuth()`, or `httpx.NetRCAuth()`.
* A callable, accepting a request and returning an authenticated request instance.
* An instance of subclasses of `httpx.Auth`.
The most involved of these is the last, which allows you to create authentication flows involving one or more requests. A subclass of `httpx.Auth` should implement `def auth_flow(request)`, and yield any requests that need to be made...
```python
class MyCustomAuth(httpx.Auth):
def __init__(self, token):
self.token = token
def auth_flow(self, request):
# Send the request, with a custom `X-Authentication` header.
request.headers['X-Authentication'] = self.token
yield request
```
If the auth flow requires more than one request, you can issue multiple yields, and obtain the response in each case...
```python
class MyCustomAuth(httpx.Auth):
def __init__(self, token):
self.token = token
def auth_flow(self, request):
response = yield request
if response.status_code == 401:
# If the server issues a 401 response then resend the request,
# with a custom `X-Authentication` header.
request.headers['X-Authentication'] = self.token
yield request
```
Custom authentication classes are designed to not perform any I/O, so that they may be used with both sync and async client instances. If you are implementing an authentication scheme that requires the request body, then you need to indicate this on the class using a `requires_request_body` property.
You will then be able to access `request.content` inside the `.auth_flow()` method.
```python
class MyCustomAuth(httpx.Auth):
requires_request_body = True
def __init__(self, token):
self.token = token
def auth_flow(self, request):
response = yield request
if response.status_code == 401:
# If the server issues a 401 response then resend the request,
# with a custom `X-Authentication` header.
request.headers['X-Authentication'] = self.sign_request(...)
yield request
def sign_request(self, request):
# Create a request signature, based on `request.method`, `request.url`,
# `request.headers`, and `request.content`.
...
```
Similarly, if you are implementing a scheme that requires access to the response body, then use the `requires_response_body` property. You will then be able to access response body properties and methods such as `response.content`, `response.text`, `response.json()`, etc.
```python
class MyCustomAuth(httpx.Auth):
requires_response_body = True
def __init__(self, access_token, refresh_token, refresh_url):
self.access_token = access_token
self.refresh_token = refresh_token
self.refresh_url = refresh_url
def auth_flow(self, request):
request.headers["X-Authentication"] = self.access_token
response = yield request
if response.status_code == 401:
# If the server issues a 401 response, then issue a request to
# refresh tokens, and resend the request.
refresh_response = yield self.build_refresh_request()
self.update_tokens(refresh_response)
request.headers["X-Authentication"] = self.access_token
yield request
def build_refresh_request(self):
# Return an `httpx.Request` for refreshing tokens.
...
def update_tokens(self, response):
# Update the `.access_token` and `.refresh_token` tokens
# based on a refresh response.
data = response.json()
...
```
If you _do_ need to perform I/O other than HTTP requests, such as accessing a disk-based cache, or you need to use concurrency primitives, such as locks, then you should override `.sync_auth_flow()` and `.async_auth_flow()` (instead of `.auth_flow()`). The former will be used by `httpx.Client`, while the latter will be used by `httpx.AsyncClient`.
```python
import asyncio
import threading
import httpx
class MyCustomAuth(httpx.Auth):
def __init__(self):
self._sync_lock = threading.RLock()
self._async_lock = asyncio.Lock()
def sync_get_token(self):
with self._sync_lock:
...
def sync_auth_flow(self, request):
token = self.sync_get_token()
request.headers["Authorization"] = f"Token {token}"
yield request
async def async_get_token(self):
async with self._async_lock:
...
async def async_auth_flow(self, request):
token = await self.async_get_token()
request.headers["Authorization"] = f"Token {token}"
yield request
```
If you only want to support one of the two methods, then you should still override it, but raise an explicit `RuntimeError`.
```python
import httpx
import sync_only_library
class MyCustomAuth(httpx.Auth):
def sync_auth_flow(self, request):
token = sync_only_library.get_token(...)
request.headers["Authorization"] = f"Token {token}"
yield request
async def async_auth_flow(self, request):
raise RuntimeError("Cannot use a sync authentication class with httpx.AsyncClient")
```
================================================
FILE: docs/advanced/clients.md
================================================
!!! hint
If you are coming from Requests, `httpx.Client()` is what you can use instead of `requests.Session()`.
## Why use a Client?
!!! note "TL;DR"
If you do anything more than experimentation, one-off scripts, or prototypes, then you should use a `Client` instance.
**More efficient usage of network resources**
When you make requests using the top-level API as documented in the [Quickstart](../quickstart.md) guide, HTTPX has to establish a new connection _for every single request_ (connections are not reused). As the number of requests to a host increases, this quickly becomes inefficient.
On the other hand, a `Client` instance uses [HTTP connection pooling](https://en.wikipedia.org/wiki/HTTP_persistent_connection). This means that when you make several requests to the same host, the `Client` will reuse the underlying TCP connection, instead of recreating one for every single request.
This can bring **significant performance improvements** compared to using the top-level API, including:
- Reduced latency across requests (no handshaking).
- Reduced CPU usage and round-trips.
- Reduced network congestion.
**Extra features**
`Client` instances also support features that aren't available at the top-level API, such as:
- Cookie persistence across requests.
- Applying configuration across all outgoing requests.
- Sending requests through HTTP proxies.
- Using [HTTP/2](../http2.md).
The other sections on this page go into further detail about what you can do with a `Client` instance.
## Usage
The recommended way to use a `Client` is as a context manager. This will ensure that connections are properly cleaned up when leaving the `with` block:
```python
with httpx.Client() as client:
...
```
Alternatively, you can explicitly close the connection pool without block-usage using `.close()`:
```python
client = httpx.Client()
try:
...
finally:
client.close()
```
## Making requests
Once you have a `Client`, you can send requests using `.get()`, `.post()`, etc. For example:
```pycon
>>> with httpx.Client() as client:
... r = client.get('https://example.com')
...
>>> r
```
These methods accept the same arguments as `httpx.get()`, `httpx.post()`, etc. This means that all features documented in the [Quickstart](../quickstart.md) guide are also available at the client level.
For example, to send a request with custom headers:
```pycon
>>> with httpx.Client() as client:
... headers = {'X-Custom': 'value'}
... r = client.get('https://example.com', headers=headers)
...
>>> r.request.headers['X-Custom']
'value'
```
## Sharing configuration across requests
Clients allow you to apply configuration to all outgoing requests by passing parameters to the `Client` constructor.
For example, to apply a set of custom headers _on every request_:
```pycon
>>> url = 'http://httpbin.org/headers'
>>> headers = {'user-agent': 'my-app/0.0.1'}
>>> with httpx.Client(headers=headers) as client:
... r = client.get(url)
...
>>> r.json()['headers']['User-Agent']
'my-app/0.0.1'
```
## Merging of configuration
When a configuration option is provided at both the client-level and request-level, one of two things can happen:
- For headers, query parameters and cookies, the values are combined together. For example:
```pycon
>>> headers = {'X-Auth': 'from-client'}
>>> params = {'client_id': 'client1'}
>>> with httpx.Client(headers=headers, params=params) as client:
... headers = {'X-Custom': 'from-request'}
... params = {'request_id': 'request1'}
... r = client.get('https://example.com', headers=headers, params=params)
...
>>> r.request.url
URL('https://example.com?client_id=client1&request_id=request1')
>>> r.request.headers['X-Auth']
'from-client'
>>> r.request.headers['X-Custom']
'from-request'
```
- For all other parameters, the request-level value takes priority. For example:
```pycon
>>> with httpx.Client(auth=('tom', 'mot123')) as client:
... r = client.get('https://example.com', auth=('alice', 'ecila123'))
...
>>> _, _, auth = r.request.headers['Authorization'].partition(' ')
>>> import base64
>>> base64.b64decode(auth)
b'alice:ecila123'
```
If you need finer-grained control on the merging of client-level and request-level parameters, see [Request instances](#request-instances).
## Other Client-only configuration options
Additionally, `Client` accepts some configuration options that aren't available at the request level.
For example, `base_url` allows you to prepend an URL to all outgoing requests:
```pycon
>>> with httpx.Client(base_url='http://httpbin.org') as client:
... r = client.get('/headers')
...
>>> r.request.url
URL('http://httpbin.org/headers')
```
For a list of all available client parameters, see the [`Client`](../api.md#client) API reference.
---
## Request instances
For maximum control on what gets sent over the wire, HTTPX supports building explicit [`Request`](../api.md#request) instances:
```python
request = httpx.Request("GET", "https://example.com")
```
To dispatch a `Request` instance across to the network, create a [`Client` instance](#client-instances) and use `.send()`:
```python
with httpx.Client() as client:
response = client.send(request)
...
```
If you need to mix client-level and request-level options in a way that is not supported by the default [Merging of parameters](#merging-of-parameters), you can use `.build_request()` and then make arbitrary modifications to the `Request` instance. For example:
```python
headers = {"X-Api-Key": "...", "X-Client-ID": "ABC123"}
with httpx.Client(headers=headers) as client:
request = client.build_request("GET", "https://api.example.com")
print(request.headers["X-Client-ID"]) # "ABC123"
# Don't send the API key for this particular request.
del request.headers["X-Api-Key"]
response = client.send(request)
...
```
## Monitoring download progress
If you need to monitor download progress of large responses, you can use response streaming and inspect the `response.num_bytes_downloaded` property.
This interface is required for properly determining download progress, because the total number of bytes returned by `response.content` or `response.iter_content()` will not always correspond with the raw content length of the response if HTTP response compression is being used.
For example, showing a progress bar using the [`tqdm`](https://github.com/tqdm/tqdm) library while a response is being downloaded could be done like this…
```python
import tempfile
import httpx
from tqdm import tqdm
with tempfile.NamedTemporaryFile() as download_file:
url = "https://speed.hetzner.de/100MB.bin"
with httpx.stream("GET", url) as response:
total = int(response.headers["Content-Length"])
with tqdm(total=total, unit_scale=True, unit_divisor=1024, unit="B") as progress:
num_bytes_downloaded = response.num_bytes_downloaded
for chunk in response.iter_bytes():
download_file.write(chunk)
progress.update(response.num_bytes_downloaded - num_bytes_downloaded)
num_bytes_downloaded = response.num_bytes_downloaded
```

Or an alternate example, this time using the [`rich`](https://github.com/willmcgugan/rich) library…
```python
import tempfile
import httpx
import rich.progress
with tempfile.NamedTemporaryFile() as download_file:
url = "https://speed.hetzner.de/100MB.bin"
with httpx.stream("GET", url) as response:
total = int(response.headers["Content-Length"])
with rich.progress.Progress(
"[progress.percentage]{task.percentage:>3.0f}%",
rich.progress.BarColumn(bar_width=None),
rich.progress.DownloadColumn(),
rich.progress.TransferSpeedColumn(),
) as progress:
download_task = progress.add_task("Download", total=total)
for chunk in response.iter_bytes():
download_file.write(chunk)
progress.update(download_task, completed=response.num_bytes_downloaded)
```

## Monitoring upload progress
If you need to monitor upload progress of large responses, you can use request content generator streaming.
For example, showing a progress bar using the [`tqdm`](https://github.com/tqdm/tqdm) library.
```python
import io
import random
import httpx
from tqdm import tqdm
def gen():
"""
this is a complete example with generated random bytes.
you can replace `io.BytesIO` with real file object.
"""
total = 32 * 1024 * 1024 # 32m
with tqdm(ascii=True, unit_scale=True, unit='B', unit_divisor=1024, total=total) as bar:
with io.BytesIO(random.randbytes(total)) as f:
while data := f.read(1024):
yield data
bar.update(len(data))
httpx.post("https://httpbin.org/post", content=gen())
```

## Multipart file encoding
As mentioned in the [quickstart](../quickstart.md#sending-multipart-file-uploads)
multipart file encoding is available by passing a dictionary with the
name of the payloads as keys and either tuple of elements or a file-like object or a string as values.
```pycon
>>> with open('report.xls', 'rb') as report_file:
... files = {'upload-file': ('report.xls', report_file, 'application/vnd.ms-excel')}
... r = httpx.post("https://httpbin.org/post", files=files)
>>> print(r.text)
{
...
"files": {
"upload-file": "<... binary content ...>"
},
...
}
```
More specifically, if a tuple is used as a value, it must have between 2 and 3 elements:
- The first element is an optional file name which can be set to `None`.
- The second element may be a file-like object or a string which will be automatically
encoded in UTF-8.
- An optional third element can be used to specify the
[MIME type](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_Types)
of the file being uploaded. If not specified HTTPX will attempt to guess the MIME type based
on the file name, with unknown file extensions defaulting to "application/octet-stream".
If the file name is explicitly set to `None` then HTTPX will not include a content-type
MIME header field.
```pycon
>>> files = {'upload-file': (None, 'text content', 'text/plain')}
>>> r = httpx.post("https://httpbin.org/post", files=files)
>>> print(r.text)
{
...
"files": {},
"form": {
"upload-file": "text-content"
},
...
}
```
!!! tip
It is safe to upload large files this way. File uploads are streaming by default, meaning that only one chunk will be loaded into memory at a time.
Non-file data fields can be included in the multipart form using by passing them to `data=...`.
You can also send multiple files in one go with a multiple file field form.
To do that, pass a list of `(field, )` items instead of a dictionary, allowing you to pass multiple items with the same `field`.
For instance this request sends 2 files, `foo.png` and `bar.png` in one request on the `images` form field:
```pycon
>>> with open('foo.png', 'rb') as foo_file, open('bar.png', 'rb') as bar_file:
... files = [
... ('images', ('foo.png', foo_file, 'image/png')),
... ('images', ('bar.png', bar_file, 'image/png')),
... ]
... r = httpx.post("https://httpbin.org/post", files=files)
```
================================================
FILE: docs/advanced/event-hooks.md
================================================
HTTPX allows you to register "event hooks" with the client, that are called
every time a particular type of event takes place.
There are currently two event hooks:
* `request` - Called after a request is fully prepared, but before it is sent to the network. Passed the `request` instance.
* `response` - Called after the response has been fetched from the network, but before it is returned to the caller. Passed the `response` instance.
These allow you to install client-wide functionality such as logging, monitoring or tracing.
```python
def log_request(request):
print(f"Request event hook: {request.method} {request.url} - Waiting for response")
def log_response(response):
request = response.request
print(f"Response event hook: {request.method} {request.url} - Status {response.status_code}")
client = httpx.Client(event_hooks={'request': [log_request], 'response': [log_response]})
```
You can also use these hooks to install response processing code, such as this
example, which creates a client instance that always raises `httpx.HTTPStatusError`
on 4xx and 5xx responses.
```python
def raise_on_4xx_5xx(response):
response.raise_for_status()
client = httpx.Client(event_hooks={'response': [raise_on_4xx_5xx]})
```
!!! note
Response event hooks are called before determining if the response body
should be read or not.
If you need access to the response body inside an event hook, you'll
need to call `response.read()`, or for AsyncClients, `response.aread()`.
The hooks are also allowed to modify `request` and `response` objects.
```python
def add_timestamp(request):
request.headers['x-request-timestamp'] = datetime.now(tz=datetime.utc).isoformat()
client = httpx.Client(event_hooks={'request': [add_timestamp]})
```
Event hooks must always be set as a **list of callables**, and you may register
multiple event hooks for each type of event.
As well as being able to set event hooks on instantiating the client, there
is also an `.event_hooks` property, that allows you to inspect and modify
the installed hooks.
```python
client = httpx.Client()
client.event_hooks['request'] = [log_request]
client.event_hooks['response'] = [log_response, raise_on_4xx_5xx]
```
!!! note
If you are using HTTPX's async support, then you need to be aware that
hooks registered with `httpx.AsyncClient` MUST be async functions,
rather than plain functions.
================================================
FILE: docs/advanced/extensions.md
================================================
# Extensions
Request and response extensions provide a untyped space where additional information may be added.
Extensions should be used for features that may not be available on all transports, and that do not fit neatly into [the simplified request/response model](https://www.encode.io/httpcore/extensions/) that the underlying `httpcore` package uses as its API.
Several extensions are supported on the request:
```python
# Request timeouts actually implemented as an extension on
# the request, ensuring that they are passed throughout the
# entire call stack.
client = httpx.Client()
response = client.get(
"https://www.example.com",
extensions={"timeout": {"connect": 5.0}}
)
response.request.extensions["timeout"]
{"connect": 5.0}
```
And on the response:
```python
client = httpx.Client()
response = client.get("https://www.example.com")
print(response.extensions["http_version"]) # b"HTTP/1.1"
# Other server responses could have been
# b"HTTP/0.9", b"HTTP/1.0", or b"HTTP/1.1"
```
## Request Extensions
### `"trace"`
The trace extension allows a callback handler to be installed to monitor the internal
flow of events within the underlying `httpcore` transport.
The simplest way to explain this is with an example:
```python
import httpx
def log(event_name, info):
print(event_name, info)
client = httpx.Client()
response = client.get("https://www.example.com/", extensions={"trace": log})
# connection.connect_tcp.started {'host': 'www.example.com', 'port': 443, 'local_address': None, 'timeout': None}
# connection.connect_tcp.complete {'return_value': }
# connection.start_tls.started {'ssl_context': , 'server_hostname': b'www.example.com', 'timeout': None}
# connection.start_tls.complete {'return_value': }
# http11.send_request_headers.started {'request': }
# http11.send_request_headers.complete {'return_value': None}
# http11.send_request_body.started {'request': }
# http11.send_request_body.complete {'return_value': None}
# http11.receive_response_headers.started {'request': }
# http11.receive_response_headers.complete {'return_value': (b'HTTP/1.1', 200, b'OK', [(b'Age', b'553715'), (b'Cache-Control', b'max-age=604800'), (b'Content-Type', b'text/html; charset=UTF-8'), (b'Date', b'Thu, 21 Oct 2021 17:08:42 GMT'), (b'Etag', b'"3147526947+ident"'), (b'Expires', b'Thu, 28 Oct 2021 17:08:42 GMT'), (b'Last-Modified', b'Thu, 17 Oct 2019 07:18:26 GMT'), (b'Server', b'ECS (nyb/1DCD)'), (b'Vary', b'Accept-Encoding'), (b'X-Cache', b'HIT'), (b'Content-Length', b'1256')])}
# http11.receive_response_body.started {'request': }
# http11.receive_response_body.complete {'return_value': None}
# http11.response_closed.started {}
# http11.response_closed.complete {'return_value': None}
```
The `event_name` and `info` arguments here will be one of the following:
* `{event_type}.{event_name}.started`, ``
* `{event_type}.{event_name}.complete`, `{"return_value": <...>}`
* `{event_type}.{event_name}.failed`, `{"exception": <...>}`
Note that when using async code the handler function passed to `"trace"` must be an `async def ...` function.
The following event types are currently exposed...
**Establishing the connection**
* `"connection.connect_tcp"`
* `"connection.connect_unix_socket"`
* `"connection.start_tls"`
**HTTP/1.1 events**
* `"http11.send_request_headers"`
* `"http11.send_request_body"`
* `"http11.receive_response"`
* `"http11.receive_response_body"`
* `"http11.response_closed"`
**HTTP/2 events**
* `"http2.send_connection_init"`
* `"http2.send_request_headers"`
* `"http2.send_request_body"`
* `"http2.receive_response_headers"`
* `"http2.receive_response_body"`
* `"http2.response_closed"`
The exact set of trace events may be subject to change across different versions of `httpcore`. If you need to rely on a particular set of events it is recommended that you pin installation of the package to a fixed version.
### `"sni_hostname"`
The server's hostname, which is used to confirm the hostname supplied by the SSL certificate.
If you want to connect to an explicit IP address rather than using the standard DNS hostname lookup, then you'll need to use this request extension.
For example:
``` python
# Connect to '185.199.108.153' but use 'www.encode.io' in the Host header,
# and use 'www.encode.io' when SSL verifying the server hostname.
client = httpx.Client()
headers = {"Host": "www.encode.io"}
extensions = {"sni_hostname": "www.encode.io"}
response = client.get(
"https://185.199.108.153/path",
headers=headers,
extensions=extensions
)
```
### `"timeout"`
A dictionary of `str: Optional[float]` timeout values.
May include values for `'connect'`, `'read'`, `'write'`, or `'pool'`.
For example:
```python
# Timeout if a connection takes more than 5 seconds to established, or if
# we are blocked waiting on the connection pool for more than 10 seconds.
client = httpx.Client()
response = client.get(
"https://www.example.com",
extensions={"timeout": {"connect": 5.0, "pool": 10.0}}
)
```
This extension is how the `httpx` timeouts are implemented, ensuring that the timeout values are associated with the request instance and passed throughout the stack. You shouldn't typically be working with this extension directly, but use the higher level `timeout` API instead.
### `"target"`
The target that is used as [the HTTP target instead of the URL path](https://datatracker.ietf.org/doc/html/rfc2616#section-5.1.2).
This enables support constructing requests that would otherwise be unsupported.
* URL paths with non-standard escaping applied.
* Forward proxy requests using an absolute URI.
* Tunneling proxy requests using `CONNECT` with hostname as the target.
* Server-wide `OPTIONS *` requests.
Some examples:
Using the 'target' extension to send requests without the standard path escaping rules...
```python
# Typically a request to "https://www.example.com/test^path" would
# connect to "www.example.com" and send an HTTP/1.1 request like...
#
# GET /test%5Epath HTTP/1.1
#
# Using the target extension we can include the literal '^'...
#
# GET /test^path HTTP/1.1
#
# Note that requests must still be valid HTTP requests.
# For example including whitespace in the target will raise a `LocalProtocolError`.
extensions = {"target": b"/test^path"}
response = httpx.get("https://www.example.com", extensions=extensions)
```
The `target` extension also allows server-wide `OPTIONS *` requests to be constructed...
```python
# This will send the following request...
#
# CONNECT * HTTP/1.1
extensions = {"target": b"*"}
response = httpx.request("CONNECT", "https://www.example.com", extensions=extensions)
```
## Response Extensions
### `"http_version"`
The HTTP version, as bytes. Eg. `b"HTTP/1.1"`.
When using HTTP/1.1 the response line includes an explicit version, and the value of this key could feasibly be one of `b"HTTP/0.9"`, `b"HTTP/1.0"`, or `b"HTTP/1.1"`.
When using HTTP/2 there is no further response versioning included in the protocol, and the value of this key will always be `b"HTTP/2"`.
### `"reason_phrase"`
The reason-phrase of the HTTP response, as bytes. For example `b"OK"`. Some servers may include a custom reason phrase, although this is not recommended.
HTTP/2 onwards does not include a reason phrase on the wire.
When no key is included, a default based on the status code may be used.
### `"stream_id"`
When HTTP/2 is being used the `"stream_id"` response extension can be accessed to determine the ID of the data stream that the response was sent on.
### `"network_stream"`
The `"network_stream"` extension allows developers to handle HTTP `CONNECT` and `Upgrade` requests, by providing an API that steps outside the standard request/response model, and can directly read or write to the network.
The interface provided by the network stream:
* `read(max_bytes, timeout = None) -> bytes`
* `write(buffer, timeout = None)`
* `close()`
* `start_tls(ssl_context, server_hostname = None, timeout = None) -> NetworkStream`
* `get_extra_info(info) -> Any`
This API can be used as the foundation for working with HTTP proxies, WebSocket upgrades, and other advanced use-cases.
See the [network backends documentation](https://www.encode.io/httpcore/network-backends/) for more information on working directly with network streams.
**Extra network information**
The network stream abstraction also allows access to various low-level information that may be exposed by the underlying socket:
```python
response = httpx.get("https://www.example.com")
network_stream = response.extensions["network_stream"]
client_addr = network_stream.get_extra_info("client_addr")
server_addr = network_stream.get_extra_info("server_addr")
print("Client address", client_addr)
print("Server address", server_addr)
```
The socket SSL information is also available through this interface, although you need to ensure that the underlying connection is still open, in order to access it...
```python
with httpx.stream("GET", "https://www.example.com") as response:
network_stream = response.extensions["network_stream"]
ssl_object = network_stream.get_extra_info("ssl_object")
print("TLS version", ssl_object.version())
```
================================================
FILE: docs/advanced/proxies.md
================================================
HTTPX supports setting up [HTTP proxies](https://en.wikipedia.org/wiki/Proxy_server#Web_proxy_servers) via the `proxy` parameter to be passed on client initialization or top-level API functions like `httpx.get(..., proxy=...)`.
Diagram of how a proxy works (source: Wikipedia). The left hand side "Internet" blob may be your HTTPX client requesting example.com through a proxy.
## HTTP Proxies
To route all traffic (HTTP and HTTPS) to a proxy located at `http://localhost:8030`, pass the proxy URL to the client...
```python
with httpx.Client(proxy="http://localhost:8030") as client:
...
```
For more advanced use cases, pass a mounts `dict`. For example, to route HTTP and HTTPS requests to 2 different proxies, respectively located at `http://localhost:8030`, and `http://localhost:8031`, pass a `dict` of proxy URLs:
```python
proxy_mounts = {
"http://": httpx.HTTPTransport(proxy="http://localhost:8030"),
"https://": httpx.HTTPTransport(proxy="http://localhost:8031"),
}
with httpx.Client(mounts=proxy_mounts) as client:
...
```
For detailed information about proxy routing, see the [Routing](#routing) section.
!!! tip "Gotcha"
In most cases, the proxy URL for the `https://` key _should_ use the `http://` scheme (that's not a typo!).
This is because HTTP proxying requires initiating a connection with the proxy server. While it's possible that your proxy supports doing it via HTTPS, most proxies only support doing it via HTTP.
For more information, see [FORWARD vs TUNNEL](#forward-vs-tunnel).
## Authentication
Proxy credentials can be passed as the `userinfo` section of the proxy URL. For example:
```python
with httpx.Client(proxy="http://username:password@localhost:8030") as client:
...
```
## Proxy mechanisms
!!! note
This section describes **advanced** proxy concepts and functionality.
### FORWARD vs TUNNEL
In general, the flow for making an HTTP request through a proxy is as follows:
1. The client connects to the proxy (initial connection request).
2. The proxy transfers data to the server on your behalf.
How exactly step 2/ is performed depends on which of two proxying mechanisms is used:
* **Forwarding**: the proxy makes the request for you, and sends back the response it obtained from the server.
* **Tunnelling**: the proxy establishes a TCP connection to the server on your behalf, and the client reuses this connection to send the request and receive the response. This is known as an [HTTP Tunnel](https://en.wikipedia.org/wiki/HTTP_tunnel). This mechanism is how you can access websites that use HTTPS from an HTTP proxy (the client "upgrades" the connection to HTTPS by performing the TLS handshake with the server over the TCP connection provided by the proxy).
### Troubleshooting proxies
If you encounter issues when setting up proxies, please refer to our [Troubleshooting guide](../troubleshooting.md#proxies).
## SOCKS
In addition to HTTP proxies, `httpcore` also supports proxies using the SOCKS protocol.
This is an optional feature that requires an additional third-party library be installed before use.
You can install SOCKS support using `pip`:
```shell
$ pip install httpx[socks]
```
You can now configure a client to make requests via a proxy using the SOCKS protocol:
```python
httpx.Client(proxy='socks5://user:pass@host:port')
```
================================================
FILE: docs/advanced/resource-limits.md
================================================
You can control the connection pool size using the `limits` keyword
argument on the client. It takes instances of `httpx.Limits` which define:
- `max_keepalive_connections`, number of allowable keep-alive connections, or `None` to always
allow. (Defaults 20)
- `max_connections`, maximum number of allowable connections, or `None` for no limits.
(Default 100)
- `keepalive_expiry`, time limit on idle keep-alive connections in seconds, or `None` for no limits. (Default 5)
```python
limits = httpx.Limits(max_keepalive_connections=5, max_connections=10)
client = httpx.Client(limits=limits)
```
================================================
FILE: docs/advanced/ssl.md
================================================
When making a request over HTTPS, HTTPX needs to verify the identity of the requested host. To do this, it uses a bundle of SSL certificates (a.k.a. CA bundle) delivered by a trusted certificate authority (CA).
### Enabling and disabling verification
By default httpx will verify HTTPS connections, and raise an error for invalid SSL cases...
```pycon
>>> httpx.get("https://expired.badssl.com/")
httpx.ConnectError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:997)
```
You can disable SSL verification completely and allow insecure requests...
```pycon
>>> httpx.get("https://expired.badssl.com/", verify=False)
```
### Configuring client instances
If you're using a `Client()` instance you should pass any `verify=<...>` configuration when instantiating the client.
By default the [certifi CA bundle](https://certifiio.readthedocs.io/en/latest/) is used for SSL verification.
For more complex configurations you can pass an [SSL Context](https://docs.python.org/3/library/ssl.html) instance...
```python
import certifi
import httpx
import ssl
# This SSL context is equivalent to the default `verify=True`.
ctx = ssl.create_default_context(cafile=certifi.where())
client = httpx.Client(verify=ctx)
```
Using [the `truststore` package](https://truststore.readthedocs.io/) to support system certificate stores...
```python
import ssl
import truststore
import httpx
# Use system certificate stores.
ctx = truststore.SSLContext(ssl.PROTOCOL_TLS_CLIENT)
client = httpx.Client(verify=ctx)
```
Loding an alternative certificate verification store using [the standard SSL context API](https://docs.python.org/3/library/ssl.html)...
```python
import httpx
import ssl
# Use an explicitly configured certificate store.
ctx = ssl.create_default_context(cafile="path/to/certs.pem") # Either cafile or capath.
client = httpx.Client(verify=ctx)
```
### Client side certificates
Client side certificates allow a remote server to verify the client. They tend to be used within private organizations to authenticate requests to remote servers.
You can specify client-side certificates, using the [`.load_cert_chain()`](https://docs.python.org/3/library/ssl.html#ssl.SSLContext.load_cert_chain) API...
```python
ctx = ssl.create_default_context()
ctx.load_cert_chain(certfile="path/to/client.pem") # Optionally also keyfile or password.
client = httpx.Client(verify=ctx)
```
### Working with `SSL_CERT_FILE` and `SSL_CERT_DIR`
`httpx` does respect the `SSL_CERT_FILE` and `SSL_CERT_DIR` environment variables by default. For details, refer to [the section on the environment variables page](../environment_variables.md#ssl_cert_file).
### Making HTTPS requests to a local server
When making requests to local servers, such as a development server running on `localhost`, you will typically be using unencrypted HTTP connections.
If you do need to make HTTPS connections to a local server, for example to test an HTTPS-only service, you will need to create and use your own certificates. Here's one way to do it...
1. Use [trustme](https://github.com/python-trio/trustme) to generate a pair of server key/cert files, and a client cert file.
2. Pass the server key/cert files when starting your local server. (This depends on the particular web server you're using. For example, [Uvicorn](https://www.uvicorn.org) provides the `--ssl-keyfile` and `--ssl-certfile` options.)
3. Configure `httpx` to use the certificates stored in `client.pem`.
```python
ctx = ssl.create_default_context(cafile="client.pem")
client = httpx.Client(verify=ctx)
```
================================================
FILE: docs/advanced/text-encodings.md
================================================
When accessing `response.text`, we need to decode the response bytes into a unicode text representation.
By default `httpx` will use `"charset"` information included in the response `Content-Type` header to determine how the response bytes should be decoded into text.
In cases where no charset information is included on the response, the default behaviour is to assume "utf-8" encoding, which is by far the most widely used text encoding on the internet.
## Using the default encoding
To understand this better let's start by looking at the default behaviour for text decoding...
```python
import httpx
# Instantiate a client with the default configuration.
client = httpx.Client()
# Using the client...
response = client.get(...)
print(response.encoding) # This will either print the charset given in
# the Content-Type charset, or else "utf-8".
print(response.text) # The text will either be decoded with the Content-Type
# charset, or using "utf-8".
```
This is normally absolutely fine. Most servers will respond with a properly formatted Content-Type header, including a charset encoding. And in most cases where no charset encoding is included, UTF-8 is very likely to be used, since it is so widely adopted.
## Using an explicit encoding
In some cases we might be making requests to a site where no character set information is being set explicitly by the server, but we know what the encoding is. In this case it's best to set the default encoding explicitly on the client.
```python
import httpx
# Instantiate a client with a Japanese character set as the default encoding.
client = httpx.Client(default_encoding="shift-jis")
# Using the client...
response = client.get(...)
print(response.encoding) # This will either print the charset given in
# the Content-Type charset, or else "shift-jis".
print(response.text) # The text will either be decoded with the Content-Type
# charset, or using "shift-jis".
```
## Using auto-detection
In cases where the server is not reliably including character set information, and where we don't know what encoding is being used, we can enable auto-detection to make a best-guess attempt when decoding from bytes to text.
To use auto-detection you need to set the `default_encoding` argument to a callable instead of a string. This callable should be a function which takes the input bytes as an argument and returns the character set to use for decoding those bytes to text.
There are two widely used Python packages which both handle this functionality:
* [`chardet`](https://chardet.readthedocs.io/) - This is a well established package, and is a port of [the auto-detection code in Mozilla](https://www-archive.mozilla.org/projects/intl/chardet.html).
* [`charset-normalizer`](https://charset-normalizer.readthedocs.io/) - A newer package, motivated by `chardet`, with a different approach.
Let's take a look at installing autodetection using one of these packages...
```shell
$ pip install httpx
$ pip install chardet
```
Once `chardet` is installed, we can configure a client to use character-set autodetection.
```python
import httpx
import chardet
def autodetect(content):
return chardet.detect(content).get("encoding")
# Using a client with character-set autodetection enabled.
client = httpx.Client(default_encoding=autodetect)
response = client.get(...)
print(response.encoding) # This will either print the charset given in
# the Content-Type charset, or else the auto-detected
# character set.
print(response.text)
```
================================================
FILE: docs/advanced/timeouts.md
================================================
HTTPX is careful to enforce timeouts everywhere by default.
The default behavior is to raise a `TimeoutException` after 5 seconds of
network inactivity.
## Setting and disabling timeouts
You can set timeouts for an individual request:
```python
# Using the top-level API:
httpx.get('http://example.com/api/v1/example', timeout=10.0)
# Using a client instance:
with httpx.Client() as client:
client.get("http://example.com/api/v1/example", timeout=10.0)
```
Or disable timeouts for an individual request:
```python
# Using the top-level API:
httpx.get('http://example.com/api/v1/example', timeout=None)
# Using a client instance:
with httpx.Client() as client:
client.get("http://example.com/api/v1/example", timeout=None)
```
## Setting a default timeout on a client
You can set a timeout on a client instance, which results in the given
`timeout` being used as the default for requests made with this client:
```python
client = httpx.Client() # Use a default 5s timeout everywhere.
client = httpx.Client(timeout=10.0) # Use a default 10s timeout everywhere.
client = httpx.Client(timeout=None) # Disable all timeouts by default.
```
## Fine tuning the configuration
HTTPX also allows you to specify the timeout behavior in more fine grained detail.
There are four different types of timeouts that may occur. These are **connect**,
**read**, **write**, and **pool** timeouts.
* The **connect** timeout specifies the maximum amount of time to wait until
a socket connection to the requested host is established. If HTTPX is unable to connect
within this time frame, a `ConnectTimeout` exception is raised.
* The **read** timeout specifies the maximum duration to wait for a chunk of
data to be received (for example, a chunk of the response body). If HTTPX is
unable to receive data within this time frame, a `ReadTimeout` exception is raised.
* The **write** timeout specifies the maximum duration to wait for a chunk of
data to be sent (for example, a chunk of the request body). If HTTPX is unable
to send data within this time frame, a `WriteTimeout` exception is raised.
* The **pool** timeout specifies the maximum duration to wait for acquiring
a connection from the connection pool. If HTTPX is unable to acquire a connection
within this time frame, a `PoolTimeout` exception is raised. A related
configuration here is the maximum number of allowable connections in the
connection pool, which is configured by the `limits` argument.
You can configure the timeout behavior for any of these values...
```python
# A client with a 60s timeout for connecting, and a 10s timeout elsewhere.
timeout = httpx.Timeout(10.0, connect=60.0)
client = httpx.Client(timeout=timeout)
response = client.get('http://example.com/')
```
================================================
FILE: docs/advanced/transports.md
================================================
HTTPX's `Client` also accepts a `transport` argument. This argument allows you
to provide a custom Transport object that will be used to perform the actual
sending of the requests.
## HTTP Transport
For some advanced configuration you might need to instantiate a transport
class directly, and pass it to the client instance. One example is the
`local_address` configuration which is only available via this low-level API.
```pycon
>>> import httpx
>>> transport = httpx.HTTPTransport(local_address="0.0.0.0")
>>> client = httpx.Client(transport=transport)
```
Connection retries are also available via this interface. Requests will be retried the given number of times in case an `httpx.ConnectError` or an `httpx.ConnectTimeout` occurs, allowing smoother operation under flaky networks. If you need other forms of retry behaviors, such as handling read/write errors or reacting to `503 Service Unavailable`, consider general-purpose tools such as [tenacity](https://github.com/jd/tenacity).
```pycon
>>> import httpx
>>> transport = httpx.HTTPTransport(retries=1)
>>> client = httpx.Client(transport=transport)
```
Similarly, instantiating a transport directly provides a `uds` option for
connecting via a Unix Domain Socket that is only available via this low-level API:
```pycon
>>> import httpx
>>> # Connect to the Docker API via a Unix Socket.
>>> transport = httpx.HTTPTransport(uds="/var/run/docker.sock")
>>> client = httpx.Client(transport=transport)
>>> response = client.get("http://docker/info")
>>> response.json()
{"ID": "...", "Containers": 4, "Images": 74, ...}
```
## WSGI Transport
You can configure an `httpx` client to call directly into a Python web application using the WSGI protocol.
This is particularly useful for two main use-cases:
* Using `httpx` as a client inside test cases.
* Mocking out external services during tests or in dev or staging environments.
### Example
Here's an example of integrating against a Flask application:
```python
from flask import Flask
import httpx
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
transport = httpx.WSGITransport(app=app)
with httpx.Client(transport=transport, base_url="http://testserver") as client:
r = client.get("/")
assert r.status_code == 200
assert r.text == "Hello World!"
```
### Configuration
For some more complex cases you might need to customize the WSGI transport. This allows you to:
* Inspect 500 error responses rather than raise exceptions by setting `raise_app_exceptions=False`.
* Mount the WSGI application at a subpath by setting `script_name` (WSGI).
* Use a given client address for requests by setting `remote_addr` (WSGI).
For example:
```python
# Instantiate a client that makes WSGI requests with a client IP of "1.2.3.4".
transport = httpx.WSGITransport(app=app, remote_addr="1.2.3.4")
with httpx.Client(transport=transport, base_url="http://testserver") as client:
...
```
## ASGI Transport
You can configure an `httpx` client to call directly into an async Python web application using the ASGI protocol.
This is particularly useful for two main use-cases:
* Using `httpx` as a client inside test cases.
* Mocking out external services during tests or in dev or staging environments.
### Example
Let's take this Starlette application as an example:
```python
from starlette.applications import Starlette
from starlette.responses import HTMLResponse
from starlette.routing import Route
async def hello(request):
return HTMLResponse("Hello World!")
app = Starlette(routes=[Route("/", hello)])
```
We can make requests directly against the application, like so:
```python
transport = httpx.ASGITransport(app=app)
async with httpx.AsyncClient(transport=transport, base_url="http://testserver") as client:
r = await client.get("/")
assert r.status_code == 200
assert r.text == "Hello World!"
```
### Configuration
For some more complex cases you might need to customise the ASGI transport. This allows you to:
* Inspect 500 error responses rather than raise exceptions by setting `raise_app_exceptions=False`.
* Mount the ASGI application at a subpath by setting `root_path`.
* Use a given client address for requests by setting `client`.
For example:
```python
# Instantiate a client that makes ASGI requests with a client IP of "1.2.3.4",
# on port 123.
transport = httpx.ASGITransport(app=app, client=("1.2.3.4", 123))
async with httpx.AsyncClient(transport=transport, base_url="http://testserver") as client:
...
```
See [the ASGI documentation](https://asgi.readthedocs.io/en/latest/specs/www.html#connection-scope) for more details on the `client` and `root_path` keys.
### ASGI startup and shutdown
It is not in the scope of HTTPX to trigger ASGI lifespan events of your app.
However it is suggested to use `LifespanManager` from [asgi-lifespan](https://github.com/florimondmanca/asgi-lifespan#usage) in pair with `AsyncClient`.
## Custom transports
A transport instance must implement the low-level Transport API which deals
with sending a single request, and returning a response. You should either
subclass `httpx.BaseTransport` to implement a transport to use with `Client`,
or subclass `httpx.AsyncBaseTransport` to implement a transport to
use with `AsyncClient`.
At the layer of the transport API we're using the familiar `Request` and
`Response` models.
See the `handle_request` and `handle_async_request` docstrings for more details
on the specifics of the Transport API.
A complete example of a custom transport implementation would be:
```python
import json
import httpx
class HelloWorldTransport(httpx.BaseTransport):
"""
A mock transport that always returns a JSON "Hello, world!" response.
"""
def handle_request(self, request):
return httpx.Response(200, json={"text": "Hello, world!"})
```
Or this example, which uses a custom transport and `httpx.Mounts` to always redirect `http://` requests.
```python
class HTTPSRedirect(httpx.BaseTransport):
"""
A transport that always redirects to HTTPS.
"""
def handle_request(self, request):
url = request.url.copy_with(scheme="https")
return httpx.Response(303, headers={"Location": str(url)})
# A client where any `http` requests are always redirected to `https`
transport = httpx.Mounts({
'http://': HTTPSRedirect()
'https://': httpx.HTTPTransport()
})
client = httpx.Client(transport=transport)
```
A useful pattern here is custom transport classes that wrap the default HTTP implementation. For example...
```python
class DebuggingTransport(httpx.BaseTransport):
def __init__(self, **kwargs):
self._wrapper = httpx.HTTPTransport(**kwargs)
def handle_request(self, request):
print(f">>> {request}")
response = self._wrapper.handle_request(request)
print(f"<<< {response}")
return response
def close(self):
self._wrapper.close()
transport = DebuggingTransport()
client = httpx.Client(transport=transport)
```
Here's another case, where we're using a round-robin across a number of different proxies...
```python
class ProxyRoundRobin(httpx.BaseTransport):
def __init__(self, proxies, **kwargs):
self._transports = [
httpx.HTTPTransport(proxy=proxy, **kwargs)
for proxy in proxies
]
self._idx = 0
def handle_request(self, request):
transport = self._transports[self._idx]
self._idx = (self._idx + 1) % len(self._transports)
return transport.handle_request(request)
def close(self):
for transport in self._transports:
transport.close()
proxies = [
httpx.Proxy("http://127.0.0.1:8081"),
httpx.Proxy("http://127.0.0.1:8082"),
httpx.Proxy("http://127.0.0.1:8083"),
]
transport = ProxyRoundRobin(proxies=proxies)
client = httpx.Client(transport=transport)
```
## Mock transports
During testing it can often be useful to be able to mock out a transport,
and return pre-determined responses, rather than making actual network requests.
The `httpx.MockTransport` class accepts a handler function, which can be used
to map requests onto pre-determined responses:
```python
def handler(request):
return httpx.Response(200, json={"text": "Hello, world!"})
# Switch to a mock transport, if the TESTING environment variable is set.
if os.environ.get('TESTING', '').upper() == "TRUE":
transport = httpx.MockTransport(handler)
else:
transport = httpx.HTTPTransport()
client = httpx.Client(transport=transport)
```
For more advanced use-cases you might want to take a look at either [the third-party
mocking library, RESPX](https://lundberg.github.io/respx/), or the [pytest-httpx library](https://github.com/Colin-b/pytest_httpx).
## Mounting transports
You can also mount transports against given schemes or domains, to control
which transport an outgoing request should be routed via, with [the same style
used for specifying proxy routing](#routing).
```python
import httpx
class HTTPSRedirectTransport(httpx.BaseTransport):
"""
A transport that always redirects to HTTPS.
"""
def handle_request(self, method, url, headers, stream, extensions):
scheme, host, port, path = url
if port is None:
location = b"https://%s%s" % (host, path)
else:
location = b"https://%s:%d%s" % (host, port, path)
stream = httpx.ByteStream(b"")
headers = [(b"location", location)]
extensions = {}
return 303, headers, stream, extensions
# A client where any `http` requests are always redirected to `https`
mounts = {'http://': HTTPSRedirectTransport()}
client = httpx.Client(mounts=mounts)
```
A couple of other sketches of how you might take advantage of mounted transports...
Disabling HTTP/2 on a single given domain...
```python
mounts = {
"all://": httpx.HTTPTransport(http2=True),
"all://*example.org": httpx.HTTPTransport()
}
client = httpx.Client(mounts=mounts)
```
Mocking requests to a given domain:
```python
# All requests to "example.org" should be mocked out.
# Other requests occur as usual.
def handler(request):
return httpx.Response(200, json={"text": "Hello, World!"})
mounts = {"all://example.org": httpx.MockTransport(handler)}
client = httpx.Client(mounts=mounts)
```
Adding support for custom schemes:
```python
# Support URLs like "file:///Users/sylvia_green/websites/new_client/index.html"
mounts = {"file://": FileSystemTransport()}
client = httpx.Client(mounts=mounts)
```
### Routing
HTTPX provides a powerful mechanism for routing requests, allowing you to write complex rules that specify which transport should be used for each request.
The `mounts` dictionary maps URL patterns to HTTP transports. HTTPX matches requested URLs against URL patterns to decide which transport should be used, if any. Matching is done from most specific URL patterns (e.g. `https://:`) to least specific ones (e.g. `https://`).
HTTPX supports routing requests based on **scheme**, **domain**, **port**, or a combination of these.
### Wildcard routing
Route everything through a transport...
```python
mounts = {
"all://": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
### Scheme routing
Route HTTP requests through one transport, and HTTPS requests through another...
```python
mounts = {
"http://": httpx.HTTPTransport(proxy="http://localhost:8030"),
"https://": httpx.HTTPTransport(proxy="http://localhost:8031"),
}
```
### Domain routing
Proxy all requests on domain "example.com", let other requests pass through...
```python
mounts = {
"all://example.com": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
Proxy HTTP requests on domain "example.com", let HTTPS and other requests pass through...
```python
mounts = {
"http://example.com": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
Proxy all requests to "example.com" and its subdomains, let other requests pass through...
```python
mounts = {
"all://*example.com": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
Proxy all requests to strict subdomains of "example.com", let "example.com" and other requests pass through...
```python
mounts = {
"all://*.example.com": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
### Port routing
Proxy HTTPS requests on port 1234 to "example.com"...
```python
mounts = {
"https://example.com:1234": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
Proxy all requests on port 1234...
```python
mounts = {
"all://*:1234": httpx.HTTPTransport(proxy="http://localhost:8030"),
}
```
### No-proxy support
It is also possible to define requests that _shouldn't_ be routed through the transport.
To do so, pass `None` as the proxy URL. For example...
```python
mounts = {
# Route requests through a proxy by default...
"all://": httpx.HTTPTransport(proxy="http://localhost:8031"),
# Except those for "example.com".
"all://example.com": None,
}
```
### Complex configuration example
You can combine the routing features outlined above to build complex proxy routing configurations. For example...
```python
mounts = {
# Route all traffic through a proxy by default...
"all://": httpx.HTTPTransport(proxy="http://localhost:8030"),
# But don't use proxies for HTTPS requests to "domain.io"...
"https://domain.io": None,
# And use another proxy for requests to "example.com" and its subdomains...
"all://*example.com": httpx.HTTPTransport(proxy="http://localhost:8031"),
# And yet another proxy if HTTP is used,
# and the "internal" subdomain on port 5550 is requested...
"http://internal.example.com:5550": httpx.HTTPTransport(proxy="http://localhost:8032"),
}
```
### Environment variables
There are also environment variables that can be used to control the dictionary of the client mounts.
They can be used to configure HTTP proxying for clients.
See documentation on [`HTTP_PROXY`, `HTTPS_PROXY`, `ALL_PROXY`](../environment_variables.md#http_proxy-https_proxy-all_proxy)
and [`NO_PROXY`](../environment_variables.md#no_proxy) for more information.
================================================
FILE: docs/api.md
================================================
# Developer Interface
## Helper Functions
!!! note
Only use these functions if you're testing HTTPX in a console
or making a small number of requests. Using a `Client` will
enable HTTP/2 and connection pooling for more efficient and
long-lived connections.
::: httpx.request
:docstring:
::: httpx.get
:docstring:
::: httpx.options
:docstring:
::: httpx.head
:docstring:
::: httpx.post
:docstring:
::: httpx.put
:docstring:
::: httpx.patch
:docstring:
::: httpx.delete
:docstring:
::: httpx.stream
:docstring:
## `Client`
::: httpx.Client
:docstring:
:members: headers cookies params auth request get head options post put patch delete stream build_request send close
## `AsyncClient`
::: httpx.AsyncClient
:docstring:
:members: headers cookies params auth request get head options post put patch delete stream build_request send aclose
## `Response`
*An HTTP response.*
* `def __init__(...)`
* `.status_code` - **int**
* `.reason_phrase` - **str**
* `.http_version` - `"HTTP/2"` or `"HTTP/1.1"`
* `.url` - **URL**
* `.headers` - **Headers**
* `.content` - **bytes**
* `.text` - **str**
* `.encoding` - **str**
* `.is_redirect` - **bool**
* `.request` - **Request**
* `.next_request` - **Optional[Request]**
* `.cookies` - **Cookies**
* `.history` - **List[Response]**
* `.elapsed` - **[timedelta](https://docs.python.org/3/library/datetime.html)**
* The amount of time elapsed between sending the request and calling `close()` on the corresponding response received for that request.
[total_seconds()](https://docs.python.org/3/library/datetime.html#datetime.timedelta.total_seconds) to correctly get
the total elapsed seconds.
* `def .raise_for_status()` - **Response**
* `def .json()` - **Any**
* `def .read()` - **bytes**
* `def .iter_raw([chunk_size])` - **bytes iterator**
* `def .iter_bytes([chunk_size])` - **bytes iterator**
* `def .iter_text([chunk_size])` - **text iterator**
* `def .iter_lines()` - **text iterator**
* `def .close()` - **None**
* `def .next()` - **Response**
* `def .aread()` - **bytes**
* `def .aiter_raw([chunk_size])` - **async bytes iterator**
* `def .aiter_bytes([chunk_size])` - **async bytes iterator**
* `def .aiter_text([chunk_size])` - **async text iterator**
* `def .aiter_lines()` - **async text iterator**
* `def .aclose()` - **None**
* `def .anext()` - **Response**
## `Request`
*An HTTP request. Can be constructed explicitly for more control over exactly
what gets sent over the wire.*
```pycon
>>> request = httpx.Request("GET", "https://example.org", headers={'host': 'example.org'})
>>> response = client.send(request)
```
* `def __init__(method, url, [params], [headers], [cookies], [content], [data], [files], [json], [stream])`
* `.method` - **str**
* `.url` - **URL**
* `.content` - **byte**, **byte iterator**, or **byte async iterator**
* `.headers` - **Headers**
* `.cookies` - **Cookies**
## `URL`
*A normalized, IDNA supporting URL.*
```pycon
>>> url = URL("https://example.org/")
>>> url.host
'example.org'
```
* `def __init__(url, **kwargs)`
* `.scheme` - **str**
* `.authority` - **str**
* `.host` - **str**
* `.port` - **int**
* `.path` - **str**
* `.query` - **str**
* `.raw_path` - **str**
* `.fragment` - **str**
* `.is_ssl` - **bool**
* `.is_absolute_url` - **bool**
* `.is_relative_url` - **bool**
* `def .copy_with([scheme], [authority], [path], [query], [fragment])` - **URL**
## `Headers`
*A case-insensitive multi-dict.*
```pycon
>>> headers = Headers({'Content-Type': 'application/json'})
>>> headers['content-type']
'application/json'
```
* `def __init__(self, headers, encoding=None)`
* `def copy()` - **Headers**
## `Cookies`
*A dict-like cookie store.*
```pycon
>>> cookies = Cookies()
>>> cookies.set("name", "value", domain="example.org")
```
* `def __init__(cookies: [dict, Cookies, CookieJar])`
* `.jar` - **CookieJar**
* `def extract_cookies(response)`
* `def set_cookie_header(request)`
* `def set(name, value, [domain], [path])`
* `def get(name, [domain], [path])`
* `def delete(name, [domain], [path])`
* `def clear([domain], [path])`
* *Standard mutable mapping interface*
## `Proxy`
*A configuration of the proxy server.*
```pycon
>>> proxy = Proxy("http://proxy.example.com:8030")
>>> client = Client(proxy=proxy)
```
* `def __init__(url, [ssl_context], [auth], [headers])`
* `.url` - **URL**
* `.auth` - **tuple[str, str]**
* `.headers` - **Headers**
* `.ssl_context` - **SSLContext**
================================================
FILE: docs/async.md
================================================
# Async Support
HTTPX offers a standard synchronous API by default, but also gives you
the option of an async client if you need it.
Async is a concurrency model that is far more efficient than multi-threading,
and can provide significant performance benefits and enable the use of
long-lived network connections such as WebSockets.
If you're working with an async web framework then you'll also want to use an
async client for sending outgoing HTTP requests.
## Making Async requests
To make asynchronous requests, you'll need an `AsyncClient`.
```pycon
>>> async with httpx.AsyncClient() as client:
... r = await client.get('https://www.example.com/')
...
>>> r
```
!!! tip
Use [IPython](https://ipython.readthedocs.io/en/stable/) or Python 3.9+ with `python -m asyncio` to try this code interactively, as they support executing `async`/`await` expressions in the console.
## API Differences
If you're using an async client then there are a few bits of API that
use async methods.
### Making requests
The request methods are all async, so you should use `response = await client.get(...)` style for all of the following:
* `AsyncClient.get(url, ...)`
* `AsyncClient.options(url, ...)`
* `AsyncClient.head(url, ...)`
* `AsyncClient.post(url, ...)`
* `AsyncClient.put(url, ...)`
* `AsyncClient.patch(url, ...)`
* `AsyncClient.delete(url, ...)`
* `AsyncClient.request(method, url, ...)`
* `AsyncClient.send(request, ...)`
### Opening and closing clients
Use `async with httpx.AsyncClient()` if you want a context-managed client...
```python
async with httpx.AsyncClient() as client:
...
```
!!! warning
In order to get the most benefit from connection pooling, make sure you're not instantiating multiple client instances - for example by using `async with` inside a "hot loop". This can be achieved either by having a single scoped client that's passed throughout wherever it's needed, or by having a single global client instance.
Alternatively, use `await client.aclose()` if you want to close a client explicitly:
```python
client = httpx.AsyncClient()
...
await client.aclose()
```
### Streaming responses
The `AsyncClient.stream(method, url, ...)` method is an async context block.
```pycon
>>> client = httpx.AsyncClient()
>>> async with client.stream('GET', 'https://www.example.com/') as response:
... async for chunk in response.aiter_bytes():
... ...
```
The async response streaming methods are:
* `Response.aread()` - For conditionally reading a response inside a stream block.
* `Response.aiter_bytes()` - For streaming the response content as bytes.
* `Response.aiter_text()` - For streaming the response content as text.
* `Response.aiter_lines()` - For streaming the response content as lines of text.
* `Response.aiter_raw()` - For streaming the raw response bytes, without applying content decoding.
* `Response.aclose()` - For closing the response. You don't usually need this, since `.stream` block closes the response automatically on exit.
For situations when context block usage is not practical, it is possible to enter "manual mode" by sending a [`Request` instance](advanced/clients.md#request-instances) using `client.send(..., stream=True)`.
Example in the context of forwarding the response to a streaming web endpoint with [Starlette](https://www.starlette.io):
```python
import httpx
from starlette.background import BackgroundTask
from starlette.responses import StreamingResponse
client = httpx.AsyncClient()
async def home(request):
req = client.build_request("GET", "https://www.example.com/")
r = await client.send(req, stream=True)
return StreamingResponse(r.aiter_text(), background=BackgroundTask(r.aclose))
```
!!! warning
When using this "manual streaming mode", it is your duty as a developer to make sure that `Response.aclose()` is called eventually. Failing to do so would leave connections open, most likely resulting in resource leaks down the line.
### Streaming requests
When sending a streaming request body with an `AsyncClient` instance, you should use an async bytes generator instead of a bytes generator:
```python
async def upload_bytes():
... # yield byte content
await client.post(url, content=upload_bytes())
```
### Explicit transport instances
When instantiating a transport instance directly, you need to use `httpx.AsyncHTTPTransport`.
For instance:
```pycon
>>> import httpx
>>> transport = httpx.AsyncHTTPTransport(retries=1)
>>> async with httpx.AsyncClient(transport=transport) as client:
>>> ...
```
## Supported async environments
HTTPX supports either `asyncio` or `trio` as an async environment.
It will auto-detect which of those two to use as the backend
for socket operations and concurrency primitives.
### [AsyncIO](https://docs.python.org/3/library/asyncio.html)
AsyncIO is Python's [built-in library](https://docs.python.org/3/library/asyncio.html)
for writing concurrent code with the async/await syntax.
```python
import asyncio
import httpx
async def main():
async with httpx.AsyncClient() as client:
response = await client.get('https://www.example.com/')
print(response)
asyncio.run(main())
```
### [Trio](https://github.com/python-trio/trio)
Trio is [an alternative async library](https://trio.readthedocs.io/en/stable/),
designed around the [the principles of structured concurrency](https://en.wikipedia.org/wiki/Structured_concurrency).
```python
import httpx
import trio
async def main():
async with httpx.AsyncClient() as client:
response = await client.get('https://www.example.com/')
print(response)
trio.run(main)
```
!!! important
The `trio` package must be installed to use the Trio backend.
### [AnyIO](https://github.com/agronholm/anyio)
AnyIO is an [asynchronous networking and concurrency library](https://anyio.readthedocs.io/) that works on top of either `asyncio` or `trio`. It blends in with native libraries of your chosen backend (defaults to `asyncio`).
```python
import httpx
import anyio
async def main():
async with httpx.AsyncClient() as client:
response = await client.get('https://www.example.com/')
print(response)
anyio.run(main, backend='trio')
```
## Calling into Python Web Apps
For details on calling directly into ASGI applications, see [the `ASGITransport` docs](../advanced/transports#asgitransport).
================================================
FILE: docs/code_of_conduct.md
================================================
# Code of Conduct
We expect contributors to our projects and online spaces to follow [the Python Software Foundation’s Code of Conduct](https://www.python.org/psf/conduct/).
The Python community is made up of members from around the globe with a diverse set of skills, personalities, and experiences. It is through these differences that our community experiences great successes and continued growth. When you're working with members of the community, this Code of Conduct will help steer your interactions and keep Python a positive, successful, and growing community.
## Our Community
Members of the Python community are **open, considerate, and respectful**. Behaviours that reinforce these values contribute to a positive environment, and include:
* **Being open.** Members of the community are open to collaboration, whether it's on PEPs, patches, problems, or otherwise.
* **Focusing on what is best for the community.** We're respectful of the processes set forth in the community, and we work within them.
* **Acknowledging time and effort.** We're respectful of the volunteer efforts that permeate the Python community. We're thoughtful when addressing the efforts of others, keeping in mind that often times the labor was completed simply for the good of the community.
* **Being respectful of differing viewpoints and experiences.** We're receptive to constructive comments and criticism, as the experiences and skill sets of other members contribute to the whole of our efforts.
* **Showing empathy towards other community members.** We're attentive in our communications, whether in person or online, and we're tactful when approaching differing views.
* **Being considerate.** Members of the community are considerate of their peers -- other Python users.
* **Being respectful.** We're respectful of others, their positions, their skills, their commitments, and their efforts.
* **Gracefully accepting constructive criticism.** When we disagree, we are courteous in raising our issues.
* **Using welcoming and inclusive language.** We're accepting of all who wish to take part in our activities, fostering an environment where anyone can participate and everyone can make a difference.
## Our Standards
Every member of our community has the right to have their identity respected. The Python community is dedicated to providing a positive experience for everyone, regardless of age, gender identity and expression, sexual orientation, disability, physical appearance, body size, ethnicity, nationality, race, or religion (or lack thereof), education, or socio-economic status.
## Inappropriate Behavior
Examples of unacceptable behavior by participants include:
* Harassment of any participants in any form
* Deliberate intimidation, stalking, or following
* Logging or taking screenshots of online activity for harassment purposes
* Publishing others' private information, such as a physical or electronic address, without explicit permission
* Violent threats or language directed against another person
* Incitement of violence or harassment towards any individual, including encouraging a person to commit suicide or to engage in self-harm
* Creating additional online accounts in order to harass another person or circumvent a ban
* Sexual language and imagery in online communities or in any conference venue, including talks
* Insults, put downs, or jokes that are based upon stereotypes, that are exclusionary, or that hold others up for ridicule
* Excessive swearing
* Unwelcome sexual attention or advances
* Unwelcome physical contact, including simulated physical contact (eg, textual descriptions like "hug" or "backrub") without consent or after a request to stop
* Pattern of inappropriate social contact, such as requesting/assuming inappropriate levels of intimacy with others
* Sustained disruption of online community discussions, in-person presentations, or other in-person events
* Continued one-on-one communication after requests to cease
* Other conduct that is inappropriate for a professional audience including people of many different backgrounds
Community members asked to stop any inappropriate behavior are expected to comply immediately.
## Enforcement
We take Code of Conduct violations seriously, and will act to ensure our spaces are welcoming, inclusive, and professional environments to communicate in.
If you need to raise a Code of Conduct report, you may do so privately by email to tom@tomchristie.com.
Reports will be treated confidentially.
Alternately you may [make a report to the Python Software Foundation](https://www.python.org/psf/conduct/reporting/).
================================================
FILE: docs/compatibility.md
================================================
# Requests Compatibility Guide
HTTPX aims to be broadly compatible with the `requests` API, although there are a
few design differences in places.
This documentation outlines places where the API differs...
## Redirects
Unlike `requests`, HTTPX does **not follow redirects by default**.
We differ in behaviour here [because auto-redirects can easily mask unnecessary network
calls being made](https://github.com/encode/httpx/discussions/1785).
You can still enable behaviour to automatically follow redirects, but you need to
do so explicitly...
```python
response = client.get(url, follow_redirects=True)
```
Or else instantiate a client, with redirect following enabled by default...
```python
client = httpx.Client(follow_redirects=True)
```
## Client instances
The HTTPX equivalent of `requests.Session` is `httpx.Client`.
```python
session = requests.Session(**kwargs)
```
is generally equivalent to
```python
client = httpx.Client(**kwargs)
```
## Request URLs
Accessing `response.url` will return a `URL` instance, rather than a string.
Use `str(response.url)` if you need a string instance.
## Determining the next redirect request
The `requests` library exposes an attribute `response.next`, which can be used to obtain the next redirect request.
```python
session = requests.Session()
request = requests.Request("GET", ...).prepare()
while request is not None:
response = session.send(request, allow_redirects=False)
request = response.next
```
In HTTPX, this attribute is instead named `response.next_request`. For example:
```python
client = httpx.Client()
request = client.build_request("GET", ...)
while request is not None:
response = client.send(request)
request = response.next_request
```
## Request Content
For uploading raw text or binary content we prefer to use a `content` parameter,
in order to better separate this usage from the case of uploading form data.
For example, using `content=...` to upload raw content:
```python
# Uploading text, bytes, or a bytes iterator.
httpx.post(..., content=b"Hello, world")
```
And using `data=...` to send form data:
```python
# Uploading form data.
httpx.post(..., data={"message": "Hello, world"})
```
Using the `data=` will raise a deprecation warning,
and is expected to be fully removed with the HTTPX 1.0 release.
## Upload files
HTTPX strictly enforces that upload files must be opened in binary mode, in order
to avoid character encoding issues that can result from attempting to upload files
opened in text mode.
## Content encoding
HTTPX uses `utf-8` for encoding `str` request bodies. For example, when using `content=` the request body will be encoded to `utf-8` before being sent over the wire. This differs from Requests which uses `latin1`. If you need an explicit encoding, pass encoded bytes explicitly, e.g. `content=.encode("latin1")`.
For response bodies, assuming the server didn't send an explicit encoding then HTTPX will do its best to figure out an appropriate encoding. HTTPX makes a guess at the encoding to use for decoding the response using `charset_normalizer`. Fallback to that or any content with less than 32 octets will be decoded using `utf-8` with the `error="replace"` decoder strategy.
## Cookies
If using a client instance, then cookies should always be set on the client rather than on a per-request basis.
This usage is supported:
```python
client = httpx.Client(cookies=...)
client.post(...)
```
This usage is **not** supported:
```python
client = httpx.Client()
client.post(..., cookies=...)
```
We prefer enforcing a stricter API here because it provides clearer expectations around cookie persistence, particularly when redirects occur.
## Status Codes
In our documentation we prefer the uppercased versions, such as `codes.NOT_FOUND`, but also provide lower-cased versions for API compatibility with `requests`.
Requests includes various synonyms for status codes that HTTPX does not support.
## Streaming responses
HTTPX provides a `.stream()` interface rather than using `stream=True`. This ensures that streaming responses are always properly closed outside of the stream block, and makes it visually clearer at which points streaming I/O APIs may be used with a response.
For example:
```python
with httpx.stream("GET", "https://www.example.com") as response:
...
```
Within a `stream()` block request data is made available with:
* `.iter_bytes()` - Instead of `response.iter_content()`
* `.iter_text()` - Instead of `response.iter_content(decode_unicode=True)`
* `.iter_lines()` - Corresponding to `response.iter_lines()`
* `.iter_raw()` - Use this instead of `response.raw`
* `.read()` - Read the entire response body, making `response.text` and `response.content` available.
## Timeouts
HTTPX defaults to including reasonable [timeouts](quickstart.md#timeouts) for all network operations, while Requests has no timeouts by default.
To get the same behavior as Requests, set the `timeout` parameter to `None`:
```python
httpx.get('https://www.example.com', timeout=None)
```
## Proxy keys
HTTPX uses the mounts argument for HTTP proxying and transport routing.
It can do much more than proxies and allows you to configure more than just the proxy route.
For more detailed documentation, see [Mounting Transports](advanced/transports.md#mounting-transports).
When using `httpx.Client(mounts={...})` to map to a selection of different transports, we use full URL schemes, such as `mounts={"http://": ..., "https://": ...}`.
This is different to the `requests` usage of `proxies={"http": ..., "https": ...}`.
This change is for better consistency with more complex mappings, that might also include domain names, such as `mounts={"all://": ..., httpx.HTTPTransport(proxy="all://www.example.com": None})` which maps all requests onto a proxy, except for requests to "www.example.com" which have an explicit exclusion.
Also note that `requests.Session.request(...)` allows a `proxies=...` parameter, whereas `httpx.Client.request(...)` does not allow `mounts=...`.
## SSL configuration
When using a `Client` instance, the ssl configurations should always be passed on client instantiation, rather than passed to the request method.
If you need more than one different SSL configuration, you should use different client instances for each SSL configuration.
## Request body on HTTP methods
The HTTP `GET`, `DELETE`, `HEAD`, and `OPTIONS` methods are specified as not supporting a request body. To stay in line with this, the `.get`, `.delete`, `.head` and `.options` functions do not support `content`, `files`, `data`, or `json` arguments.
If you really do need to send request data using these http methods you should use the generic `.request` function instead.
```python
httpx.request(
method="DELETE",
url="https://www.example.com/",
content=b'A request body on a DELETE request.'
)
```
## Checking for success and failure responses
We don't support `response.is_ok` since the naming is ambiguous there, and might incorrectly imply an equivalence to `response.status_code == codes.OK`. Instead we provide the `response.is_success` property, which can be used to check for a 2xx response.
## Request instantiation
There is no notion of [prepared requests](https://requests.readthedocs.io/en/stable/user/advanced/#prepared-requests) in HTTPX. If you need to customize request instantiation, see [Request instances](advanced/clients.md#request-instances).
Besides, `httpx.Request()` does not support the `auth`, `timeout`, `follow_redirects`, `mounts`, `verify` and `cert` parameters. However these are available in `httpx.request`, `httpx.get`, `httpx.post` etc., as well as on [`Client` instances](advanced/clients.md#client-instances).
## Mocking
If you need to mock HTTPX the same way that test utilities like `responses` and `requests-mock` does for `requests`, see [RESPX](https://github.com/lundberg/respx).
## Caching
If you use `cachecontrol` or `requests-cache` to add HTTP Caching support to the `requests` library, you can use [Hishel](https://hishel.com) for HTTPX.
## Networking layer
`requests` defers most of its HTTP networking code to the excellent [`urllib3` library](https://urllib3.readthedocs.io/en/latest/).
On the other hand, HTTPX uses [HTTPCore](https://github.com/encode/httpcore) as its core HTTP networking layer, which is a different project than `urllib3`.
## Query Parameters
`requests` omits `params` whose values are `None` (e.g. `requests.get(..., params={"foo": None})`). This is not supported by HTTPX.
For both query params (`params=`) and form data (`data=`), `requests` supports sending a list of tuples (e.g. `requests.get(..., params=[('key1', 'value1'), ('key1', 'value2')])`). This is not supported by HTTPX. Instead, use a dictionary with lists as values. E.g.: `httpx.get(..., params={'key1': ['value1', 'value2']})` or with form data: `httpx.post(..., data={'key1': ['value1', 'value2']})`.
## Event Hooks
`requests` allows event hooks to mutate `Request` and `Response` objects. See [examples](https://requests.readthedocs.io/en/master/user/advanced/#event-hooks) given in the documentation for `requests`.
In HTTPX, event hooks may access properties of requests and responses, but event hook callbacks cannot mutate the original request/response.
If you are looking for more control, consider checking out [Custom Transports](advanced/transports.md#custom-transports).
## Exceptions and Errors
`requests` exception hierarchy is slightly different to the `httpx` exception hierarchy. `requests` exposes a top level `RequestException`, where as `httpx` exposes a top level `HTTPError`. see the exceptions exposes in requests [here](https://requests.readthedocs.io/en/latest/_modules/requests/exceptions/). See the `httpx` error hierarchy [here](https://www.python-httpx.org/exceptions/).
================================================
FILE: docs/contributing.md
================================================
# Contributing
Thank you for being interested in contributing to HTTPX.
There are many ways you can contribute to the project:
- Try HTTPX and [report bugs/issues you find](https://github.com/encode/httpx/issues/new)
- [Implement new features](https://github.com/encode/httpx/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22)
- [Review Pull Requests of others](https://github.com/encode/httpx/pulls)
- Write documentation
- Participate in discussions
## Reporting Bugs or Other Issues
Found something that HTTPX should support?
Stumbled upon some unexpected behaviour?
Contributions should generally start out with [a discussion](https://github.com/encode/httpx/discussions).
Possible bugs may be raised as a "Potential Issue" discussion, feature requests may
be raised as an "Ideas" discussion. We can then determine if the discussion needs
to be escalated into an "Issue" or not, or if we'd consider a pull request.
Try to be more descriptive as you can and in case of a bug report,
provide as much information as possible like:
- OS platform
- Python version
- Installed dependencies and versions (`python -m pip freeze`)
- Code snippet
- Error traceback
You should always try to reduce any examples to the *simplest possible case*
that demonstrates the issue.
Some possibly useful tips for narrowing down potential issues...
- Does the issue exist on HTTP/1.1, or HTTP/2, or both?
- Does the issue exist with `Client`, `AsyncClient`, or both?
- When using `AsyncClient` does the issue exist when using `asyncio` or `trio`, or both?
## Development
To start developing HTTPX create a **fork** of the
[HTTPX repository](https://github.com/encode/httpx) on GitHub.
Then clone your fork with the following command replacing `YOUR-USERNAME` with
your GitHub username:
```shell
$ git clone https://github.com/YOUR-USERNAME/httpx
```
You can now install the project and its dependencies using:
```shell
$ cd httpx
$ scripts/install
```
## Testing and Linting
We use custom shell scripts to automate testing, linting,
and documentation building workflow.
To run the tests, use:
```shell
$ scripts/test
```
!!! warning
The test suite spawns testing servers on ports **8000** and **8001**.
Make sure these are not in use, so the tests can run properly.
Any additional arguments will be passed to `pytest`. See the [pytest documentation](https://docs.pytest.org/en/latest/how-to/usage.html) for more information.
For example, to run a single test script:
```shell
$ scripts/test tests/test_multipart.py
```
To run the code auto-formatting:
```shell
$ scripts/lint
```
Lastly, to run code checks separately (they are also run as part of `scripts/test`), run:
```shell
$ scripts/check
```
## Documenting
Documentation pages are located under the `docs/` folder.
To run the documentation site locally (useful for previewing changes), use:
```shell
$ scripts/docs
```
## Resolving Build / CI Failures
Once you've submitted your pull request, the test suite will automatically run, and the results will show up in GitHub.
If the test suite fails, you'll want to click through to the "Details" link, and try to identify why the test suite failed.
Here are some common ways the test suite can fail:
### Check Job Failed
This job failing means there is either a code formatting issue or type-annotation issue.
You can look at the job output to figure out why it's failed or within a shell run:
```shell
$ scripts/check
```
It may be worth it to run `$ scripts/lint` to attempt auto-formatting the code
and if that job succeeds commit the changes.
### Docs Job Failed
This job failing means the documentation failed to build. This can happen for
a variety of reasons like invalid markdown or missing configuration within `mkdocs.yml`.
### Python 3.X Job Failed
This job failing means the unit tests failed or not all code paths are covered by unit tests.
If tests are failing you will see this message under the coverage report:
`=== 1 failed, 435 passed, 1 skipped, 1 xfailed in 11.09s ===`
If tests succeed but coverage doesn't reach our current threshold, you will see this
message under the coverage report:
`FAIL Required test coverage of 100% not reached. Total coverage: 99.00%`
## Releasing
*This section is targeted at HTTPX maintainers.*
Before releasing a new version, create a pull request that includes:
- **An update to the changelog**:
- We follow the format from [keepachangelog](https://keepachangelog.com/en/1.0.0/).
- [Compare](https://github.com/encode/httpx/compare/) `master` with the tag of the latest release, and list all entries that are of interest to our users:
- Things that **must** go in the changelog: added, changed, deprecated or removed features, and bug fixes.
- Things that **should not** go in the changelog: changes to documentation, tests or tooling.
- Try sorting entries in descending order of impact / importance.
- Keep it concise and to-the-point. 🎯
- **A version bump**: see `__version__.py`.
For an example, see [#1006](https://github.com/encode/httpx/pull/1006).
Once the release PR is merged, create a
[new release](https://github.com/encode/httpx/releases/new) including:
- Tag version like `0.13.3`.
- Release title `Version 0.13.3`
- Description copied from the changelog.
Once created this release will be automatically uploaded to PyPI.
If something goes wrong with the PyPI job the release can be published using the
`scripts/publish` script.
## Development proxy setup
To test and debug requests via a proxy it's best to run a proxy server locally.
Any server should do but HTTPCore's test suite uses
[`mitmproxy`](https://mitmproxy.org/) which is written in Python, it's fully
featured and has excellent UI and tools for introspection of requests.
You can install `mitmproxy` using `pip install mitmproxy` or [several
other ways](https://docs.mitmproxy.org/stable/overview-installation/).
`mitmproxy` does require setting up local TLS certificates for HTTPS requests,
as its main purpose is to allow developers to inspect requests that pass through
it. We can set them up follows:
1. [`pip install trustme-cli`](https://github.com/sethmlarson/trustme-cli/).
2. `trustme-cli -i example.org www.example.org`, assuming you want to test
connecting to that domain, this will create three files: `server.pem`,
`server.key` and `client.pem`.
3. `mitmproxy` requires a PEM file that includes the private key and the
certificate so we need to concatenate them:
`cat server.key server.pem > server.withkey.pem`.
4. Start the proxy server `mitmproxy --certs server.withkey.pem`, or use the
[other mitmproxy commands](https://docs.mitmproxy.org/stable/) with different
UI options.
At this point the server is ready to start serving requests, you'll need to
configure HTTPX as described in the
[proxy section](https://www.python-httpx.org/advanced/proxies/#http-proxies) and
the [SSL certificates section](https://www.python-httpx.org/advanced/ssl/),
this is where our previously generated `client.pem` comes in:
```python
ctx = ssl.create_default_context(cafile="/path/to/client.pem")
client = httpx.Client(proxy="http://127.0.0.1:8080/", verify=ctx)
```
Note, however, that HTTPS requests will only succeed to the host specified
in the SSL/TLS certificate we generated, HTTPS requests to other hosts will
raise an error like:
```
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate
verify failed: Hostname mismatch, certificate is not valid for
'duckduckgo.com'. (_ssl.c:1108)
```
If you want to make requests to more hosts you'll need to regenerate the
certificates and include all the hosts you intend to connect to in the
seconds step, i.e.
`trustme-cli -i example.org www.example.org duckduckgo.com www.duckduckgo.com`
================================================
FILE: docs/css/custom.css
================================================
div.autodoc-docstring {
padding-left: 20px;
margin-bottom: 30px;
border-left: 5px solid rgba(230, 230, 230);
}
div.autodoc-members {
padding-left: 20px;
margin-bottom: 15px;
}
================================================
FILE: docs/environment_variables.md
================================================
# Environment Variables
The HTTPX library can be configured via environment variables.
Environment variables are used by default. To ignore environment variables, `trust_env` has to be set `False`. There are two ways to set `trust_env` to disable environment variables:
* On the client via `httpx.Client(trust_env=False)`.
* Using the top-level API, such as `httpx.get("", trust_env=False)`.
Here is a list of environment variables that HTTPX recognizes and what function they serve:
## Proxies
The environment variables documented below are used as a convention by various HTTP tooling, including:
* [cURL](https://github.com/curl/curl/blob/master/docs/MANUAL.md#environment-variables)
* [requests](https://github.com/psf/requests/blob/master/docs/user/advanced.rst#proxies)
For more information on using proxies in HTTPX, see [HTTP Proxying](advanced/proxies.md#http-proxying).
### `HTTP_PROXY`, `HTTPS_PROXY`, `ALL_PROXY`
Valid values: A URL to a proxy
`HTTP_PROXY`, `HTTPS_PROXY`, `ALL_PROXY` set the proxy to be used for `http`, `https`, or all requests respectively.
```bash
export HTTP_PROXY=http://my-external-proxy.com:1234
# This request will be sent through the proxy
python -c "import httpx; httpx.get('http://example.com')"
# This request will be sent directly, as we set `trust_env=False`
python -c "import httpx; httpx.get('http://example.com', trust_env=False)"
```
### `NO_PROXY`
Valid values: a comma-separated list of hostnames/urls
`NO_PROXY` disables the proxy for specific urls
```bash
export HTTP_PROXY=http://my-external-proxy.com:1234
export NO_PROXY=http://127.0.0.1,python-httpx.org
# As in the previous example, this request will be sent through the proxy
python -c "import httpx; httpx.get('http://example.com')"
# These requests will be sent directly, bypassing the proxy
python -c "import httpx; httpx.get('http://127.0.0.1:5000/my-api')"
python -c "import httpx; httpx.get('https://www.python-httpx.org')"
```
## `SSL_CERT_FILE`
Valid values: a filename
If this environment variable is set then HTTPX will load
CA certificate from the specified file instead of the default
location.
Example:
```console
SSL_CERT_FILE=/path/to/ca-certs/ca-bundle.crt python -c "import httpx; httpx.get('https://example.com')"
```
## `SSL_CERT_DIR`
Valid values: a directory following an [OpenSSL specific layout](https://www.openssl.org/docs/manmaster/man3/SSL_CTX_load_verify_locations.html).
If this environment variable is set and the directory follows an [OpenSSL specific layout](https://www.openssl.org/docs/manmaster/man3/SSL_CTX_load_verify_locations.html) (ie. you ran `c_rehash`) then HTTPX will load CA certificates from this directory instead of the default location.
Example:
```console
SSL_CERT_DIR=/path/to/ca-certs/ python -c "import httpx; httpx.get('https://example.com')"
```
================================================
FILE: docs/exceptions.md
================================================
# Exceptions
This page lists exceptions that may be raised when using HTTPX.
For an overview of how to work with HTTPX exceptions, see [Exceptions (Quickstart)](quickstart.md#exceptions).
## The exception hierarchy
* HTTPError
* RequestError
* TransportError
* TimeoutException
* ConnectTimeout
* ReadTimeout
* WriteTimeout
* PoolTimeout
* NetworkError
* ConnectError
* ReadError
* WriteError
* CloseError
* ProtocolError
* LocalProtocolError
* RemoteProtocolError
* ProxyError
* UnsupportedProtocol
* DecodingError
* TooManyRedirects
* HTTPStatusError
* InvalidURL
* CookieConflict
* StreamError
* StreamConsumed
* ResponseNotRead
* RequestNotRead
* StreamClosed
---
## Exception classes
::: httpx.HTTPError
:docstring:
::: httpx.RequestError
:docstring:
::: httpx.TransportError
:docstring:
::: httpx.TimeoutException
:docstring:
::: httpx.ConnectTimeout
:docstring:
::: httpx.ReadTimeout
:docstring:
::: httpx.WriteTimeout
:docstring:
::: httpx.PoolTimeout
:docstring:
::: httpx.NetworkError
:docstring:
::: httpx.ConnectError
:docstring:
::: httpx.ReadError
:docstring:
::: httpx.WriteError
:docstring:
::: httpx.CloseError
:docstring:
::: httpx.ProtocolError
:docstring:
::: httpx.LocalProtocolError
:docstring:
::: httpx.RemoteProtocolError
:docstring:
::: httpx.ProxyError
:docstring:
::: httpx.UnsupportedProtocol
:docstring:
::: httpx.DecodingError
:docstring:
::: httpx.TooManyRedirects
:docstring:
::: httpx.HTTPStatusError
:docstring:
::: httpx.InvalidURL
:docstring:
::: httpx.CookieConflict
:docstring:
::: httpx.StreamError
:docstring:
::: httpx.StreamConsumed
:docstring:
::: httpx.StreamClosed
:docstring:
::: httpx.ResponseNotRead
:docstring:
::: httpx.RequestNotRead
:docstring:
================================================
FILE: docs/http2.md
================================================
# HTTP/2
HTTP/2 is a major new iteration of the HTTP protocol, that provides a far more
efficient transport, with potential performance benefits. HTTP/2 does not change
the core semantics of the request or response, but alters the way that data is
sent to and from the server.
Rather than the text format that HTTP/1.1 uses, HTTP/2 is a binary format.
The binary format provides full request and response multiplexing, and efficient
compression of HTTP headers. The stream multiplexing means that where HTTP/1.1
requires one TCP stream for each concurrent request, HTTP/2 allows a single TCP
stream to handle multiple concurrent requests.
HTTP/2 also provides support for functionality such as response prioritization,
and server push.
For a comprehensive guide to HTTP/2 you may want to check out "[http2 explained](https://http2-explained.haxx.se/)".
## Enabling HTTP/2
When using the `httpx` client, HTTP/2 support is not enabled by default, because
HTTP/1.1 is a mature, battle-hardened transport layer, and our HTTP/1.1
implementation may be considered the more robust option at this point in time.
It is possible that a future version of `httpx` may enable HTTP/2 support by default.
If you're issuing highly concurrent requests you might want to consider
trying out our HTTP/2 support. You can do so by first making sure to install
the optional HTTP/2 dependencies...
```shell
$ pip install httpx[http2]
```
And then instantiating a client with HTTP/2 support enabled:
```python
client = httpx.AsyncClient(http2=True)
...
```
You can also instantiate a client as a context manager, to ensure that all
HTTP connections are nicely scoped, and will be closed once the context block
is exited.
```python
async with httpx.AsyncClient(http2=True) as client:
...
```
HTTP/2 support is available on both `Client` and `AsyncClient`, although it's
typically more useful in async contexts if you're issuing lots of concurrent
requests.
## Inspecting the HTTP version
Enabling HTTP/2 support on the client does not *necessarily* mean that your
requests and responses will be transported over HTTP/2, since both the client
*and* the server need to support HTTP/2. If you connect to a server that only
supports HTTP/1.1 the client will use a standard HTTP/1.1 connection instead.
You can determine which version of the HTTP protocol was used by examining
the `.http_version` property on the response.
```python
client = httpx.AsyncClient(http2=True)
response = await client.get(...)
print(response.http_version) # "HTTP/1.0", "HTTP/1.1", or "HTTP/2".
```
================================================
FILE: docs/index.md
================================================
HTTPX
---
A next-generation HTTP client for Python.
HTTPX is a fully featured HTTP client for Python 3, which provides sync and async APIs, and support for both HTTP/1.1 and HTTP/2.
---
Install HTTPX using pip:
```shell
$ pip install httpx
```
Now, let's get started:
```pycon
>>> import httpx
>>> r = httpx.get('https://www.example.org/')
>>> r
>>> r.status_code
200
>>> r.headers['content-type']
'text/html; charset=UTF-8'
>>> r.text
'\n\n\nExample Domain...'
```
Or, using the command-line client.
```shell
# The command line client is an optional dependency.
$ pip install 'httpx[cli]'
```
Which now allows us to use HTTPX directly from the command-line...

Sending a request...

## Features
HTTPX builds on the well-established usability of `requests`, and gives you:
* A broadly [requests-compatible API](compatibility.md).
* Standard synchronous interface, but with [async support if you need it](async.md).
* HTTP/1.1 [and HTTP/2 support](http2.md).
* Ability to make requests directly to [WSGI applications](advanced/transports.md#wsgi-transport) or [ASGI applications](advanced/transports.md#asgi-transport).
* Strict timeouts everywhere.
* Fully type annotated.
* 100% test coverage.
Plus all the standard features of `requests`...
* International Domains and URLs
* Keep-Alive & Connection Pooling
* Sessions with Cookie Persistence
* Browser-style SSL Verification
* Basic/Digest Authentication
* Elegant Key/Value Cookies
* Automatic Decompression
* Automatic Content Decoding
* Unicode Response Bodies
* Multipart File Uploads
* HTTP(S) Proxy Support
* Connection Timeouts
* Streaming Downloads
* .netrc Support
* Chunked Requests
## Documentation
For a run-through of all the basics, head over to the [QuickStart](quickstart.md).
For more advanced topics, see the **Advanced** section,
the [async support](async.md) section, or the [HTTP/2](http2.md) section.
The [Developer Interface](api.md) provides a comprehensive API reference.
To find out about tools that integrate with HTTPX, see [Third Party Packages](third_party_packages.md).
## Dependencies
The HTTPX project relies on these excellent libraries:
* `httpcore` - The underlying transport implementation for `httpx`.
* `h11` - HTTP/1.1 support.
* `certifi` - SSL certificates.
* `idna` - Internationalized domain name support.
* `sniffio` - Async library autodetection.
As well as these optional installs:
* `h2` - HTTP/2 support. *(Optional, with `httpx[http2]`)*
* `socksio` - SOCKS proxy support. *(Optional, with `httpx[socks]`)*
* `rich` - Rich terminal support. *(Optional, with `httpx[cli]`)*
* `click` - Command line client support. *(Optional, with `httpx[cli]`)*
* `brotli` or `brotlicffi` - Decoding for "brotli" compressed responses. *(Optional, with `httpx[brotli]`)*
* `zstandard` - Decoding for "zstd" compressed responses. *(Optional, with `httpx[zstd]`)*
A huge amount of credit is due to `requests` for the API layout that
much of this work follows, as well as to `urllib3` for plenty of design
inspiration around the lower-level networking details.
## Installation
Install with pip:
```shell
$ pip install httpx
```
Or, to include the optional HTTP/2 support, use:
```shell
$ pip install httpx[http2]
```
To include the optional brotli and zstandard decoders support, use:
```shell
$ pip install httpx[brotli,zstd]
```
HTTPX requires Python 3.9+
[sync-support]: https://github.com/encode/httpx/issues/572
================================================
FILE: docs/logging.md
================================================
# Logging
If you need to inspect the internal behaviour of `httpx`, you can use Python's standard logging to output information about the underlying network behaviour.
For example, the following configuration...
```python
import logging
import httpx
logging.basicConfig(
format="%(levelname)s [%(asctime)s] %(name)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.DEBUG
)
httpx.get("https://www.example.com")
```
Will send debug level output to the console, or wherever `stdout` is directed too...
```
DEBUG [2024-09-28 17:27:40] httpcore.connection - connect_tcp.started host='www.example.com' port=443 local_address=None timeout=5.0 socket_options=None
DEBUG [2024-09-28 17:27:41] httpcore.connection - connect_tcp.complete return_value=
DEBUG [2024-09-28 17:27:41] httpcore.connection - start_tls.started ssl_context=SSLContext(verify=True) server_hostname='www.example.com' timeout=5.0
DEBUG [2024-09-28 17:27:41] httpcore.connection - start_tls.complete return_value=
DEBUG [2024-09-28 17:27:41] httpcore.http11 - send_request_headers.started request=
DEBUG [2024-09-28 17:27:41] httpcore.http11 - send_request_headers.complete
DEBUG [2024-09-28 17:27:41] httpcore.http11 - send_request_body.started request=
DEBUG [2024-09-28 17:27:41] httpcore.http11 - send_request_body.complete
DEBUG [2024-09-28 17:27:41] httpcore.http11 - receive_response_headers.started request=
DEBUG [2024-09-28 17:27:41] httpcore.http11 - receive_response_headers.complete return_value=(b'HTTP/1.1', 200, b'OK', [(b'Content-Encoding', b'gzip'), (b'Accept-Ranges', b'bytes'), (b'Age', b'407727'), (b'Cache-Control', b'max-age=604800'), (b'Content-Type', b'text/html; charset=UTF-8'), (b'Date', b'Sat, 28 Sep 2024 13:27:42 GMT'), (b'Etag', b'"3147526947+gzip"'), (b'Expires', b'Sat, 05 Oct 2024 13:27:42 GMT'), (b'Last-Modified', b'Thu, 17 Oct 2019 07:18:26 GMT'), (b'Server', b'ECAcc (dcd/7D43)'), (b'Vary', b'Accept-Encoding'), (b'X-Cache', b'HIT'), (b'Content-Length', b'648')])
INFO [2024-09-28 17:27:41] httpx - HTTP Request: GET https://www.example.com "HTTP/1.1 200 OK"
DEBUG [2024-09-28 17:27:41] httpcore.http11 - receive_response_body.started request=
DEBUG [2024-09-28 17:27:41] httpcore.http11 - receive_response_body.complete
DEBUG [2024-09-28 17:27:41] httpcore.http11 - response_closed.started
DEBUG [2024-09-28 17:27:41] httpcore.http11 - response_closed.complete
DEBUG [2024-09-28 17:27:41] httpcore.connection - close.started
DEBUG [2024-09-28 17:27:41] httpcore.connection - close.complete
```
Logging output includes information from both the high-level `httpx` logger, and the network-level `httpcore` logger, which can be configured separately.
For handling more complex logging configurations you might want to use the dictionary configuration style...
```python
import logging.config
import httpx
LOGGING_CONFIG = {
"version": 1,
"handlers": {
"default": {
"class": "logging.StreamHandler",
"formatter": "http",
"stream": "ext://sys.stderr"
}
},
"formatters": {
"http": {
"format": "%(levelname)s [%(asctime)s] %(name)s - %(message)s",
"datefmt": "%Y-%m-%d %H:%M:%S",
}
},
'loggers': {
'httpx': {
'handlers': ['default'],
'level': 'DEBUG',
},
'httpcore': {
'handlers': ['default'],
'level': 'DEBUG',
},
}
}
logging.config.dictConfig(LOGGING_CONFIG)
httpx.get('https://www.example.com')
```
The exact formatting of the debug logging may be subject to change across different versions of `httpx` and `httpcore`. If you need to rely on a particular format it is recommended that you pin installation of these packages to fixed versions.
================================================
FILE: docs/overrides/partials/nav.html
================================================
{% import "partials/nav-item.html" as item with context %}
{% set class = "md-nav md-nav--primary" %}
{% if "navigation.tabs" in features %}
{% set class = class ~ " md-nav--lifted" %}
{% endif %}
{% if "toc.integrate" in features %}
{% set class = class ~ " md-nav--integrated" %}
{% endif %}
================================================
FILE: docs/quickstart.md
================================================
# QuickStart
First, start by importing HTTPX:
```pycon
>>> import httpx
```
Now, let’s try to get a webpage.
```pycon
>>> r = httpx.get('https://httpbin.org/get')
>>> r
```
Similarly, to make an HTTP POST request:
```pycon
>>> r = httpx.post('https://httpbin.org/post', data={'key': 'value'})
```
The PUT, DELETE, HEAD, and OPTIONS requests all follow the same style:
```pycon
>>> r = httpx.put('https://httpbin.org/put', data={'key': 'value'})
>>> r = httpx.delete('https://httpbin.org/delete')
>>> r = httpx.head('https://httpbin.org/get')
>>> r = httpx.options('https://httpbin.org/get')
```
## Passing Parameters in URLs
To include URL query parameters in the request, use the `params` keyword:
```pycon
>>> params = {'key1': 'value1', 'key2': 'value2'}
>>> r = httpx.get('https://httpbin.org/get', params=params)
```
To see how the values get encoding into the URL string, we can inspect the
resulting URL that was used to make the request:
```pycon
>>> r.url
URL('https://httpbin.org/get?key2=value2&key1=value1')
```
You can also pass a list of items as a value:
```pycon
>>> params = {'key1': 'value1', 'key2': ['value2', 'value3']}
>>> r = httpx.get('https://httpbin.org/get', params=params)
>>> r.url
URL('https://httpbin.org/get?key1=value1&key2=value2&key2=value3')
```
## Response Content
HTTPX will automatically handle decoding the response content into Unicode text.
```pycon
>>> r = httpx.get('https://www.example.org/')
>>> r.text
'\n\n\nExample Domain...'
```
You can inspect what encoding will be used to decode the response.
```pycon
>>> r.encoding
'UTF-8'
```
In some cases the response may not contain an explicit encoding, in which case HTTPX
will attempt to automatically determine an encoding to use.
```pycon
>>> r.encoding
None
>>> r.text
'\n\n\nExample Domain...'
```
If you need to override the standard behaviour and explicitly set the encoding to
use, then you can do that too.
```pycon
>>> r.encoding = 'ISO-8859-1'
```
## Binary Response Content
The response content can also be accessed as bytes, for non-text responses:
```pycon
>>> r.content
b'\n\n\nExample Domain...'
```
Any `gzip` and `deflate` HTTP response encodings will automatically
be decoded for you. If `brotlipy` is installed, then the `brotli` response
encoding will be supported. If `zstandard` is installed, then `zstd`
response encodings will also be supported.
For example, to create an image from binary data returned by a request, you can use the following code:
```pycon
>>> from PIL import Image
>>> from io import BytesIO
>>> i = Image.open(BytesIO(r.content))
```
## JSON Response Content
Often Web API responses will be encoded as JSON.
```pycon
>>> r = httpx.get('https://api.github.com/events')
>>> r.json()
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...' ... }}]
```
## Custom Headers
To include additional headers in the outgoing request, use the `headers` keyword argument:
```pycon
>>> url = 'https://httpbin.org/headers'
>>> headers = {'user-agent': 'my-app/0.0.1'}
>>> r = httpx.get(url, headers=headers)
```
## Sending Form Encoded Data
Some types of HTTP requests, such as `POST` and `PUT` requests, can include data
in the request body. One common way of including that is as form-encoded data,
which is used for HTML forms.
```pycon
>>> data = {'key1': 'value1', 'key2': 'value2'}
>>> r = httpx.post("https://httpbin.org/post", data=data)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
```
Form encoded data can also include multiple values from a given key.
```pycon
>>> data = {'key1': ['value1', 'value2']}
>>> r = httpx.post("https://httpbin.org/post", data=data)
>>> print(r.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
```
## Sending Multipart File Uploads
You can also upload files, using HTTP multipart encoding:
```pycon
>>> with open('report.xls', 'rb') as report_file:
... files = {'upload-file': report_file}
... r = httpx.post("https://httpbin.org/post", files=files)
>>> print(r.text)
{
...
"files": {
"upload-file": "<... binary content ...>"
},
...
}
```
You can also explicitly set the filename and content type, by using a tuple
of items for the file value:
```pycon
>>> with open('report.xls', 'rb') as report_file:
... files = {'upload-file': ('report.xls', report_file, 'application/vnd.ms-excel')}
... r = httpx.post("https://httpbin.org/post", files=files)
>>> print(r.text)
{
...
"files": {
"upload-file": "<... binary content ...>"
},
...
}
```
If you need to include non-file data fields in the multipart form, use the `data=...` parameter:
```pycon
>>> data = {'message': 'Hello, world!'}
>>> with open('report.xls', 'rb') as report_file:
... files = {'file': report_file}
... r = httpx.post("https://httpbin.org/post", data=data, files=files)
>>> print(r.text)
{
...
"files": {
"file": "<... binary content ...>"
},
"form": {
"message": "Hello, world!",
},
...
}
```
## Sending JSON Encoded Data
Form encoded data is okay if all you need is a simple key-value data structure.
For more complicated data structures you'll often want to use JSON encoding instead.
```pycon
>>> data = {'integer': 123, 'boolean': True, 'list': ['a', 'b', 'c']}
>>> r = httpx.post("https://httpbin.org/post", json=data)
>>> print(r.text)
{
...
"json": {
"boolean": true,
"integer": 123,
"list": [
"a",
"b",
"c"
]
},
...
}
```
## Sending Binary Request Data
For other encodings, you should use the `content=...` parameter, passing
either a `bytes` type or a generator that yields `bytes`.
```pycon
>>> content = b'Hello, world'
>>> r = httpx.post("https://httpbin.org/post", content=content)
```
You may also want to set a custom `Content-Type` header when uploading
binary data.
## Response Status Codes
We can inspect the HTTP status code of the response:
```pycon
>>> r = httpx.get('https://httpbin.org/get')
>>> r.status_code
200
```
HTTPX also includes an easy shortcut for accessing status codes by their text phrase.
```pycon
>>> r.status_code == httpx.codes.OK
True
```
We can raise an exception for any responses which are not a 2xx success code:
```pycon
>>> not_found = httpx.get('https://httpbin.org/status/404')
>>> not_found.status_code
404
>>> not_found.raise_for_status()
Traceback (most recent call last):
File "/Users/tomchristie/GitHub/encode/httpcore/httpx/models.py", line 837, in raise_for_status
raise HTTPStatusError(message, response=self)
httpx._exceptions.HTTPStatusError: 404 Client Error: Not Found for url: https://httpbin.org/status/404
For more information check: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/404
```
Any successful response codes will return the `Response` instance rather than raising an exception.
```pycon
>>> r.raise_for_status()
```
The method returns the response instance, allowing you to use it inline. For example:
```pycon
>>> r = httpx.get('...').raise_for_status()
>>> data = httpx.get('...').raise_for_status().json()
```
## Response Headers
The response headers are available as a dictionary-like interface.
```pycon
>>> r.headers
Headers({
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
})
```
The `Headers` data type is case-insensitive, so you can use any capitalization.
```pycon
>>> r.headers['Content-Type']
'application/json'
>>> r.headers.get('content-type')
'application/json'
```
Multiple values for a single response header are represented as a single comma-separated value, as per [RFC 7230](https://tools.ietf.org/html/rfc7230#section-3.2):
> A recipient MAY combine multiple header fields with the same field name into one “field-name: field-value” pair, without changing the semantics of the message, by appending each subsequent field-value to the combined field value in order, separated by a comma.
## Streaming Responses
For large downloads you may want to use streaming responses that do not load the entire response body into memory at once.
You can stream the binary content of the response...
```pycon
>>> with httpx.stream("GET", "https://www.example.com") as r:
... for data in r.iter_bytes():
... print(data)
```
Or the text of the response...
```pycon
>>> with httpx.stream("GET", "https://www.example.com") as r:
... for text in r.iter_text():
... print(text)
```
Or stream the text, on a line-by-line basis...
```pycon
>>> with httpx.stream("GET", "https://www.example.com") as r:
... for line in r.iter_lines():
... print(line)
```
HTTPX will use universal line endings, normalising all cases to `\n`.
In some cases you might want to access the raw bytes on the response without applying any HTTP content decoding. In this case any content encoding that the web server has applied such as `gzip`, `deflate`, `brotli`, or `zstd` will
not be automatically decoded.
```pycon
>>> with httpx.stream("GET", "https://www.example.com") as r:
... for chunk in r.iter_raw():
... print(chunk)
```
If you're using streaming responses in any of these ways then the `response.content` and `response.text` attributes will not be available, and will raise errors if accessed. However you can also use the response streaming functionality to conditionally load the response body:
```pycon
>>> with httpx.stream("GET", "https://www.example.com") as r:
... if int(r.headers['Content-Length']) < TOO_LONG:
... r.read()
... print(r.text)
```
## Cookies
Any cookies that are set on the response can be easily accessed:
```pycon
>>> r = httpx.get('https://httpbin.org/cookies/set?chocolate=chip')
>>> r.cookies['chocolate']
'chip'
```
To include cookies in an outgoing request, use the `cookies` parameter:
```pycon
>>> cookies = {"peanut": "butter"}
>>> r = httpx.get('https://httpbin.org/cookies', cookies=cookies)
>>> r.json()
{'cookies': {'peanut': 'butter'}}
```
Cookies are returned in a `Cookies` instance, which is a dict-like data structure
with additional API for accessing cookies by their domain or path.
```pycon
>>> cookies = httpx.Cookies()
>>> cookies.set('cookie_on_domain', 'hello, there!', domain='httpbin.org')
>>> cookies.set('cookie_off_domain', 'nope.', domain='example.org')
>>> r = httpx.get('http://httpbin.org/cookies', cookies=cookies)
>>> r.json()
{'cookies': {'cookie_on_domain': 'hello, there!'}}
```
## Redirection and History
By default, HTTPX will **not** follow redirects for all HTTP methods, although
this can be explicitly enabled.
For example, GitHub redirects all HTTP requests to HTTPS.
```pycon
>>> r = httpx.get('http://github.com/')
>>> r.status_code
301
>>> r.history
[]
>>> r.next_request
```
You can modify the default redirection handling with the `follow_redirects` parameter:
```pycon
>>> r = httpx.get('http://github.com/', follow_redirects=True)
>>> r.url
URL('https://github.com/')
>>> r.status_code
200
>>> r.history
[]
```
The `history` property of the response can be used to inspect any followed redirects.
It contains a list of any redirect responses that were followed, in the order
in which they were made.
## Timeouts
HTTPX defaults to including reasonable timeouts for all network operations,
meaning that if a connection is not properly established then it should always
raise an error rather than hanging indefinitely.
The default timeout for network inactivity is five seconds. You can modify the
value to be more or less strict:
```pycon
>>> httpx.get('https://github.com/', timeout=0.001)
```
You can also disable the timeout behavior completely...
```pycon
>>> httpx.get('https://github.com/', timeout=None)
```
For advanced timeout management, see [Timeout fine-tuning](advanced/timeouts.md#fine-tuning-the-configuration).
## Authentication
HTTPX supports Basic and Digest HTTP authentication.
To provide Basic authentication credentials, pass a 2-tuple of
plaintext `str` or `bytes` objects as the `auth` argument to the request
functions:
```pycon
>>> httpx.get("https://example.com", auth=("my_user", "password123"))
```
To provide credentials for Digest authentication you'll need to instantiate
a `DigestAuth` object with the plaintext username and password as arguments.
This object can be then passed as the `auth` argument to the request methods
as above:
```pycon
>>> auth = httpx.DigestAuth("my_user", "password123")
>>> httpx.get("https://example.com", auth=auth)
```
## Exceptions
HTTPX will raise exceptions if an error occurs.
The most important exception classes in HTTPX are `RequestError` and `HTTPStatusError`.
The `RequestError` class is a superclass that encompasses any exception that occurs
while issuing an HTTP request. These exceptions include a `.request` attribute.
```python
try:
response = httpx.get("https://www.example.com/")
except httpx.RequestError as exc:
print(f"An error occurred while requesting {exc.request.url!r}.")
```
The `HTTPStatusError` class is raised by `response.raise_for_status()` on responses which are not a 2xx success code.
These exceptions include both a `.request` and a `.response` attribute.
```python
response = httpx.get("https://www.example.com/")
try:
response.raise_for_status()
except httpx.HTTPStatusError as exc:
print(f"Error response {exc.response.status_code} while requesting {exc.request.url!r}.")
```
There is also a base class `HTTPError` that includes both of these categories, and can be used
to catch either failed requests, or 4xx and 5xx responses.
You can either use this base class to catch both categories...
```python
try:
response = httpx.get("https://www.example.com/")
response.raise_for_status()
except httpx.HTTPError as exc:
print(f"Error while requesting {exc.request.url!r}.")
```
Or handle each case explicitly...
```python
try:
response = httpx.get("https://www.example.com/")
response.raise_for_status()
except httpx.RequestError as exc:
print(f"An error occurred while requesting {exc.request.url!r}.")
except httpx.HTTPStatusError as exc:
print(f"Error response {exc.response.status_code} while requesting {exc.request.url!r}.")
```
For a full list of available exceptions, see [Exceptions (API Reference)](exceptions.md).
================================================
FILE: docs/third_party_packages.md
================================================
# Third Party Packages
As HTTPX usage grows, there is an expanding community of developers building tools and libraries that integrate with HTTPX, or depend on HTTPX. Here are some of them.
## Plugins
### Hishel
[GitHub](https://github.com/karpetrosyan/hishel) - [Documentation](https://hishel.com/)
An elegant HTTP Cache implementation for HTTPX and HTTP Core.
### HTTPX-Auth
[GitHub](https://github.com/Colin-b/httpx_auth) - [Documentation](https://colin-b.github.io/httpx_auth/)
Provides authentication classes to be used with HTTPX's [authentication parameter](advanced/authentication.md#customizing-authentication).
### httpx-caching
[Github](https://github.com/johtso/httpx-caching)
This package adds caching functionality to HTTPX
### httpx-secure
[GitHub](https://github.com/Zaczero/httpx-secure)
Drop-in SSRF protection for httpx with DNS caching and custom validation support.
### httpx-socks
[GitHub](https://github.com/romis2012/httpx-socks)
Proxy (HTTP, SOCKS) transports for httpx.
### httpx-sse
[GitHub](https://github.com/florimondmanca/httpx-sse)
Allows consuming Server-Sent Events (SSE) with HTTPX.
### httpx-retries
[GitHub](https://github.com/will-ockmore/httpx-retries) - [Documentation](https://will-ockmore.github.io/httpx-retries/)
A retry layer for HTTPX.
### httpx-ws
[GitHub](https://github.com/frankie567/httpx-ws) - [Documentation](https://frankie567.github.io/httpx-ws/)
WebSocket support for HTTPX.
### pytest-HTTPX
[GitHub](https://github.com/Colin-b/pytest_httpx) - [Documentation](https://colin-b.github.io/pytest_httpx/)
Provides a [pytest](https://docs.pytest.org/en/latest/) fixture to mock HTTPX within test cases.
### RESPX
[GitHub](https://github.com/lundberg/respx) - [Documentation](https://lundberg.github.io/respx/)
A utility for mocking out HTTPX.
### rpc.py
[Github](https://github.com/abersheeran/rpc.py) - [Documentation](https://github.com/abersheeran/rpc.py#rpcpy)
A fast and powerful RPC framework based on ASGI/WSGI. Use HTTPX as the client of the RPC service.
## Libraries with HTTPX support
### Authlib
[GitHub](https://github.com/lepture/authlib) - [Documentation](https://docs.authlib.org/en/latest/)
A python library for building OAuth and OpenID Connect clients and servers. Includes an [OAuth HTTPX client](https://docs.authlib.org/en/latest/client/httpx.html).
### Gidgethub
[GitHub](https://github.com/brettcannon/gidgethub) - [Documentation](https://gidgethub.readthedocs.io/en/latest/index.html)
An asynchronous GitHub API library. Includes [HTTPX support](https://gidgethub.readthedocs.io/en/latest/httpx.html).
### httpdbg
[GitHub](https://github.com/cle-b/httpdbg) - [Documentation](https://httpdbg.readthedocs.io/)
A tool for python developers to easily debug the HTTP(S) client requests in a python program.
### VCR.py
[GitHub](https://github.com/kevin1024/vcrpy) - [Documentation](https://vcrpy.readthedocs.io/)
Record and repeat requests.
## Gists
### urllib3-transport
[GitHub](https://gist.github.com/florimondmanca/d56764d78d748eb9f73165da388e546e)
This public gist provides an example implementation for a [custom transport](advanced/transports.md#custom-transports) implementation on top of the battle-tested [`urllib3`](https://urllib3.readthedocs.io) library.
================================================
FILE: docs/troubleshooting.md
================================================
# Troubleshooting
This page lists some common problems or issues you could encounter while developing with HTTPX, as well as possible solutions.
## Proxies
---
### "`The handshake operation timed out`" on HTTPS requests when using a proxy
**Description**: When using a proxy and making an HTTPS request, you see an exception looking like this:
```console
httpx.ProxyError: _ssl.c:1091: The handshake operation timed out
```
**Similar issues**: [encode/httpx#1412](https://github.com/encode/httpx/issues/1412), [encode/httpx#1433](https://github.com/encode/httpx/issues/1433)
**Resolution**: it is likely that you've set up your proxies like this...
```python
mounts = {
"http://": httpx.HTTPTransport(proxy="http://myproxy.org"),
"https://": httpx.HTTPTransport(proxy="https://myproxy.org"),
}
```
Using this setup, you're telling HTTPX to connect to the proxy using HTTP for HTTP requests, and using HTTPS for HTTPS requests.
But if you get the error above, it is likely that your proxy doesn't support connecting via HTTPS. Don't worry: that's a [common gotcha](advanced/proxies.md#http-proxies).
Change the scheme of your HTTPS proxy to `http://...` instead of `https://...`:
```python
mounts = {
"http://": httpx.HTTPTransport(proxy="http://myproxy.org"),
"https://": httpx.HTTPTransport(proxy="http://myproxy.org"),
}
```
This can be simplified to:
```python
proxy = "http://myproxy.org"
with httpx.Client(proxy=proxy) as client:
...
```
For more information, see [Proxies: FORWARD vs TUNNEL](advanced/proxies.md#forward-vs-tunnel).
---
### Error when making requests to an HTTPS proxy
**Description**: your proxy _does_ support connecting via HTTPS, but you are seeing errors along the lines of...
```console
httpx.ProxyError: [SSL: PRE_MAC_LENGTH_TOO_LONG] invalid alert (_ssl.c:1091)
```
**Similar issues**: [encode/httpx#1424](https://github.com/encode/httpx/issues/1424).
**Resolution**: HTTPX does not properly support HTTPS proxies at this time. If that's something you're interested in having, please see [encode/httpx#1434](https://github.com/encode/httpx/issues/1434) and consider lending a hand there.
================================================
FILE: httpx/__init__.py
================================================
from .__version__ import __description__, __title__, __version__
from ._api import *
from ._auth import *
from ._client import *
from ._config import *
from ._content import *
from ._exceptions import *
from ._models import *
from ._status_codes import *
from ._transports import *
from ._types import *
from ._urls import *
try:
from ._main import main
except ImportError: # pragma: no cover
def main() -> None: # type: ignore
import sys
print(
"The httpx command line client could not run because the required "
"dependencies were not installed.\nMake sure you've installed "
"everything with: pip install 'httpx[cli]'"
)
sys.exit(1)
__all__ = [
"__description__",
"__title__",
"__version__",
"ASGITransport",
"AsyncBaseTransport",
"AsyncByteStream",
"AsyncClient",
"AsyncHTTPTransport",
"Auth",
"BaseTransport",
"BasicAuth",
"ByteStream",
"Client",
"CloseError",
"codes",
"ConnectError",
"ConnectTimeout",
"CookieConflict",
"Cookies",
"create_ssl_context",
"DecodingError",
"delete",
"DigestAuth",
"FunctionAuth",
"get",
"head",
"Headers",
"HTTPError",
"HTTPStatusError",
"HTTPTransport",
"InvalidURL",
"Limits",
"LocalProtocolError",
"main",
"MockTransport",
"NetRCAuth",
"NetworkError",
"options",
"patch",
"PoolTimeout",
"post",
"ProtocolError",
"Proxy",
"ProxyError",
"put",
"QueryParams",
"ReadError",
"ReadTimeout",
"RemoteProtocolError",
"request",
"Request",
"RequestError",
"RequestNotRead",
"Response",
"ResponseNotRead",
"stream",
"StreamClosed",
"StreamConsumed",
"StreamError",
"SyncByteStream",
"Timeout",
"TimeoutException",
"TooManyRedirects",
"TransportError",
"UnsupportedProtocol",
"URL",
"USE_CLIENT_DEFAULT",
"WriteError",
"WriteTimeout",
"WSGITransport",
]
__locals = locals()
for __name in __all__:
if not __name.startswith("__"):
setattr(__locals[__name], "__module__", "httpx") # noqa
================================================
FILE: httpx/__version__.py
================================================
__title__ = "httpx"
__description__ = "A next generation HTTP client, for Python 3."
__version__ = "0.28.1"
================================================
FILE: httpx/_api.py
================================================
from __future__ import annotations
import typing
from contextlib import contextmanager
from ._client import Client
from ._config import DEFAULT_TIMEOUT_CONFIG
from ._models import Response
from ._types import (
AuthTypes,
CookieTypes,
HeaderTypes,
ProxyTypes,
QueryParamTypes,
RequestContent,
RequestData,
RequestFiles,
TimeoutTypes,
)
from ._urls import URL
if typing.TYPE_CHECKING:
import ssl # pragma: no cover
__all__ = [
"delete",
"get",
"head",
"options",
"patch",
"post",
"put",
"request",
"stream",
]
def request(
method: str,
url: URL | str,
*,
params: QueryParamTypes | None = None,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
trust_env: bool = True,
) -> Response:
"""
Sends an HTTP request.
**Parameters:**
* **method** - HTTP method for the new `Request` object: `GET`, `OPTIONS`,
`HEAD`, `POST`, `PUT`, `PATCH`, or `DELETE`.
* **url** - URL for the new `Request` object.
* **params** - *(optional)* Query parameters to include in the URL, as a
string, dictionary, or sequence of two-tuples.
* **content** - *(optional)* Binary content to include in the body of the
request, as bytes or a byte iterator.
* **data** - *(optional)* Form data to include in the body of the request,
as a dictionary.
* **files** - *(optional)* A dictionary of upload files to include in the
body of the request.
* **json** - *(optional)* A JSON serializable object to include in the body
of the request.
* **headers** - *(optional)* Dictionary of HTTP headers to include in the
request.
* **cookies** - *(optional)* Dictionary of Cookie items to include in the
request.
* **auth** - *(optional)* An authentication class to use when sending the
request.
* **proxy** - *(optional)* A proxy URL where all the traffic should be routed.
* **timeout** - *(optional)* The timeout configuration to use when sending
the request.
* **follow_redirects** - *(optional)* Enables or disables HTTP redirects.
* **verify** - *(optional)* Either `True` to use an SSL context with the
default CA bundle, `False` to disable verification, or an instance of
`ssl.SSLContext` to use a custom context.
* **trust_env** - *(optional)* Enables or disables usage of environment
variables for configuration.
**Returns:** `Response`
Usage:
```
>>> import httpx
>>> response = httpx.request('GET', 'https://httpbin.org/get')
>>> response
```
"""
with Client(
cookies=cookies,
proxy=proxy,
verify=verify,
timeout=timeout,
trust_env=trust_env,
) as client:
return client.request(
method=method,
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
auth=auth,
follow_redirects=follow_redirects,
)
@contextmanager
def stream(
method: str,
url: URL | str,
*,
params: QueryParamTypes | None = None,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
trust_env: bool = True,
) -> typing.Iterator[Response]:
"""
Alternative to `httpx.request()` that streams the response body
instead of loading it into memory at once.
**Parameters**: See `httpx.request`.
See also: [Streaming Responses][0]
[0]: /quickstart#streaming-responses
"""
with Client(
cookies=cookies,
proxy=proxy,
verify=verify,
timeout=timeout,
trust_env=trust_env,
) as client:
with client.stream(
method=method,
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
auth=auth,
follow_redirects=follow_redirects,
) as response:
yield response
def get(
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
trust_env: bool = True,
) -> Response:
"""
Sends a `GET` request.
**Parameters**: See `httpx.request`.
Note that the `data`, `files`, `json` and `content` parameters are not available
on this function, as `GET` requests should not include a request body.
"""
return request(
"GET",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
def options(
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
trust_env: bool = True,
) -> Response:
"""
Sends an `OPTIONS` request.
**Parameters**: See `httpx.request`.
Note that the `data`, `files`, `json` and `content` parameters are not available
on this function, as `OPTIONS` requests should not include a request body.
"""
return request(
"OPTIONS",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
def head(
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
trust_env: bool = True,
) -> Response:
"""
Sends a `HEAD` request.
**Parameters**: See `httpx.request`.
Note that the `data`, `files`, `json` and `content` parameters are not available
on this function, as `HEAD` requests should not include a request body.
"""
return request(
"HEAD",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
def post(
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
trust_env: bool = True,
) -> Response:
"""
Sends a `POST` request.
**Parameters**: See `httpx.request`.
"""
return request(
"POST",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
def put(
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
trust_env: bool = True,
) -> Response:
"""
Sends a `PUT` request.
**Parameters**: See `httpx.request`.
"""
return request(
"PUT",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
def patch(
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
verify: ssl.SSLContext | str | bool = True,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
trust_env: bool = True,
) -> Response:
"""
Sends a `PATCH` request.
**Parameters**: See `httpx.request`.
"""
return request(
"PATCH",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
def delete(
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | None = None,
proxy: ProxyTypes | None = None,
follow_redirects: bool = False,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
verify: ssl.SSLContext | str | bool = True,
trust_env: bool = True,
) -> Response:
"""
Sends a `DELETE` request.
**Parameters**: See `httpx.request`.
Note that the `data`, `files`, `json` and `content` parameters are not available
on this function, as `DELETE` requests should not include a request body.
"""
return request(
"DELETE",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
proxy=proxy,
follow_redirects=follow_redirects,
verify=verify,
timeout=timeout,
trust_env=trust_env,
)
================================================
FILE: httpx/_auth.py
================================================
from __future__ import annotations
import hashlib
import os
import re
import time
import typing
from base64 import b64encode
from urllib.request import parse_http_list
from ._exceptions import ProtocolError
from ._models import Cookies, Request, Response
from ._utils import to_bytes, to_str, unquote
if typing.TYPE_CHECKING: # pragma: no cover
from hashlib import _Hash
__all__ = ["Auth", "BasicAuth", "DigestAuth", "FunctionAuth", "NetRCAuth"]
class Auth:
"""
Base class for all authentication schemes.
To implement a custom authentication scheme, subclass `Auth` and override
the `.auth_flow()` method.
If the authentication scheme does I/O such as disk access or network calls, or uses
synchronization primitives such as locks, you should override `.sync_auth_flow()`
and/or `.async_auth_flow()` instead of `.auth_flow()` to provide specialized
implementations that will be used by `Client` and `AsyncClient` respectively.
"""
requires_request_body = False
requires_response_body = False
def auth_flow(self, request: Request) -> typing.Generator[Request, Response, None]:
"""
Execute the authentication flow.
To dispatch a request, `yield` it:
```
yield request
```
The client will `.send()` the response back into the flow generator. You can
access it like so:
```
response = yield request
```
A `return` (or reaching the end of the generator) will result in the
client returning the last response obtained from the server.
You can dispatch as many requests as is necessary.
"""
yield request
def sync_auth_flow(
self, request: Request
) -> typing.Generator[Request, Response, None]:
"""
Execute the authentication flow synchronously.
By default, this defers to `.auth_flow()`. You should override this method
when the authentication scheme does I/O and/or uses concurrency primitives.
"""
if self.requires_request_body:
request.read()
flow = self.auth_flow(request)
request = next(flow)
while True:
response = yield request
if self.requires_response_body:
response.read()
try:
request = flow.send(response)
except StopIteration:
break
async def async_auth_flow(
self, request: Request
) -> typing.AsyncGenerator[Request, Response]:
"""
Execute the authentication flow asynchronously.
By default, this defers to `.auth_flow()`. You should override this method
when the authentication scheme does I/O and/or uses concurrency primitives.
"""
if self.requires_request_body:
await request.aread()
flow = self.auth_flow(request)
request = next(flow)
while True:
response = yield request
if self.requires_response_body:
await response.aread()
try:
request = flow.send(response)
except StopIteration:
break
class FunctionAuth(Auth):
"""
Allows the 'auth' argument to be passed as a simple callable function,
that takes the request, and returns a new, modified request.
"""
def __init__(self, func: typing.Callable[[Request], Request]) -> None:
self._func = func
def auth_flow(self, request: Request) -> typing.Generator[Request, Response, None]:
yield self._func(request)
class BasicAuth(Auth):
"""
Allows the 'auth' argument to be passed as a (username, password) pair,
and uses HTTP Basic authentication.
"""
def __init__(self, username: str | bytes, password: str | bytes) -> None:
self._auth_header = self._build_auth_header(username, password)
def auth_flow(self, request: Request) -> typing.Generator[Request, Response, None]:
request.headers["Authorization"] = self._auth_header
yield request
def _build_auth_header(self, username: str | bytes, password: str | bytes) -> str:
userpass = b":".join((to_bytes(username), to_bytes(password)))
token = b64encode(userpass).decode()
return f"Basic {token}"
class NetRCAuth(Auth):
"""
Use a 'netrc' file to lookup basic auth credentials based on the url host.
"""
def __init__(self, file: str | None = None) -> None:
# Lazily import 'netrc'.
# There's no need for us to load this module unless 'NetRCAuth' is being used.
import netrc
self._netrc_info = netrc.netrc(file)
def auth_flow(self, request: Request) -> typing.Generator[Request, Response, None]:
auth_info = self._netrc_info.authenticators(request.url.host)
if auth_info is None or not auth_info[2]:
# The netrc file did not have authentication credentials for this host.
yield request
else:
# Build a basic auth header with credentials from the netrc file.
request.headers["Authorization"] = self._build_auth_header(
username=auth_info[0], password=auth_info[2]
)
yield request
def _build_auth_header(self, username: str | bytes, password: str | bytes) -> str:
userpass = b":".join((to_bytes(username), to_bytes(password)))
token = b64encode(userpass).decode()
return f"Basic {token}"
class DigestAuth(Auth):
_ALGORITHM_TO_HASH_FUNCTION: dict[str, typing.Callable[[bytes], _Hash]] = {
"MD5": hashlib.md5,
"MD5-SESS": hashlib.md5,
"SHA": hashlib.sha1,
"SHA-SESS": hashlib.sha1,
"SHA-256": hashlib.sha256,
"SHA-256-SESS": hashlib.sha256,
"SHA-512": hashlib.sha512,
"SHA-512-SESS": hashlib.sha512,
}
def __init__(self, username: str | bytes, password: str | bytes) -> None:
self._username = to_bytes(username)
self._password = to_bytes(password)
self._last_challenge: _DigestAuthChallenge | None = None
self._nonce_count = 1
def auth_flow(self, request: Request) -> typing.Generator[Request, Response, None]:
if self._last_challenge:
request.headers["Authorization"] = self._build_auth_header(
request, self._last_challenge
)
response = yield request
if response.status_code != 401 or "www-authenticate" not in response.headers:
# If the response is not a 401 then we don't
# need to build an authenticated request.
return
for auth_header in response.headers.get_list("www-authenticate"):
if auth_header.lower().startswith("digest "):
break
else:
# If the response does not include a 'WWW-Authenticate: Digest ...'
# header, then we don't need to build an authenticated request.
return
self._last_challenge = self._parse_challenge(request, response, auth_header)
self._nonce_count = 1
request.headers["Authorization"] = self._build_auth_header(
request, self._last_challenge
)
if response.cookies:
Cookies(response.cookies).set_cookie_header(request=request)
yield request
def _parse_challenge(
self, request: Request, response: Response, auth_header: str
) -> _DigestAuthChallenge:
"""
Returns a challenge from a Digest WWW-Authenticate header.
These take the form of:
`Digest realm="realm@host.com",qop="auth,auth-int",nonce="abc",opaque="xyz"`
"""
scheme, _, fields = auth_header.partition(" ")
# This method should only ever have been called with a Digest auth header.
assert scheme.lower() == "digest"
header_dict: dict[str, str] = {}
for field in parse_http_list(fields):
key, value = field.strip().split("=", 1)
header_dict[key] = unquote(value)
try:
realm = header_dict["realm"].encode()
nonce = header_dict["nonce"].encode()
algorithm = header_dict.get("algorithm", "MD5")
opaque = header_dict["opaque"].encode() if "opaque" in header_dict else None
qop = header_dict["qop"].encode() if "qop" in header_dict else None
return _DigestAuthChallenge(
realm=realm, nonce=nonce, algorithm=algorithm, opaque=opaque, qop=qop
)
except KeyError as exc:
message = "Malformed Digest WWW-Authenticate header"
raise ProtocolError(message, request=request) from exc
def _build_auth_header(
self, request: Request, challenge: _DigestAuthChallenge
) -> str:
hash_func = self._ALGORITHM_TO_HASH_FUNCTION[challenge.algorithm.upper()]
def digest(data: bytes) -> bytes:
return hash_func(data).hexdigest().encode()
A1 = b":".join((self._username, challenge.realm, self._password))
path = request.url.raw_path
A2 = b":".join((request.method.encode(), path))
# TODO: implement auth-int
HA2 = digest(A2)
nc_value = b"%08x" % self._nonce_count
cnonce = self._get_client_nonce(self._nonce_count, challenge.nonce)
self._nonce_count += 1
HA1 = digest(A1)
if challenge.algorithm.lower().endswith("-sess"):
HA1 = digest(b":".join((HA1, challenge.nonce, cnonce)))
qop = self._resolve_qop(challenge.qop, request=request)
if qop is None:
# Following RFC 2069
digest_data = [HA1, challenge.nonce, HA2]
else:
# Following RFC 2617/7616
digest_data = [HA1, challenge.nonce, nc_value, cnonce, qop, HA2]
format_args = {
"username": self._username,
"realm": challenge.realm,
"nonce": challenge.nonce,
"uri": path,
"response": digest(b":".join(digest_data)),
"algorithm": challenge.algorithm.encode(),
}
if challenge.opaque:
format_args["opaque"] = challenge.opaque
if qop:
format_args["qop"] = b"auth"
format_args["nc"] = nc_value
format_args["cnonce"] = cnonce
return "Digest " + self._get_header_value(format_args)
def _get_client_nonce(self, nonce_count: int, nonce: bytes) -> bytes:
s = str(nonce_count).encode()
s += nonce
s += time.ctime().encode()
s += os.urandom(8)
return hashlib.sha1(s).hexdigest()[:16].encode()
def _get_header_value(self, header_fields: dict[str, bytes]) -> str:
NON_QUOTED_FIELDS = ("algorithm", "qop", "nc")
QUOTED_TEMPLATE = '{}="{}"'
NON_QUOTED_TEMPLATE = "{}={}"
header_value = ""
for i, (field, value) in enumerate(header_fields.items()):
if i > 0:
header_value += ", "
template = (
QUOTED_TEMPLATE
if field not in NON_QUOTED_FIELDS
else NON_QUOTED_TEMPLATE
)
header_value += template.format(field, to_str(value))
return header_value
def _resolve_qop(self, qop: bytes | None, request: Request) -> bytes | None:
if qop is None:
return None
qops = re.split(b", ?", qop)
if b"auth" in qops:
return b"auth"
if qops == [b"auth-int"]:
raise NotImplementedError("Digest auth-int support is not yet implemented")
message = f'Unexpected qop value "{qop!r}" in digest auth'
raise ProtocolError(message, request=request)
class _DigestAuthChallenge(typing.NamedTuple):
realm: bytes
nonce: bytes
algorithm: str
opaque: bytes | None
qop: bytes | None
================================================
FILE: httpx/_client.py
================================================
from __future__ import annotations
import datetime
import enum
import logging
import time
import typing
import warnings
from contextlib import asynccontextmanager, contextmanager
from types import TracebackType
from .__version__ import __version__
from ._auth import Auth, BasicAuth, FunctionAuth
from ._config import (
DEFAULT_LIMITS,
DEFAULT_MAX_REDIRECTS,
DEFAULT_TIMEOUT_CONFIG,
Limits,
Proxy,
Timeout,
)
from ._decoders import SUPPORTED_DECODERS
from ._exceptions import (
InvalidURL,
RemoteProtocolError,
TooManyRedirects,
request_context,
)
from ._models import Cookies, Headers, Request, Response
from ._status_codes import codes
from ._transports.base import AsyncBaseTransport, BaseTransport
from ._transports.default import AsyncHTTPTransport, HTTPTransport
from ._types import (
AsyncByteStream,
AuthTypes,
CertTypes,
CookieTypes,
HeaderTypes,
ProxyTypes,
QueryParamTypes,
RequestContent,
RequestData,
RequestExtensions,
RequestFiles,
SyncByteStream,
TimeoutTypes,
)
from ._urls import URL, QueryParams
from ._utils import URLPattern, get_environment_proxies
if typing.TYPE_CHECKING:
import ssl # pragma: no cover
__all__ = ["USE_CLIENT_DEFAULT", "AsyncClient", "Client"]
# The type annotation for @classmethod and context managers here follows PEP 484
# https://www.python.org/dev/peps/pep-0484/#annotating-instance-and-class-methods
T = typing.TypeVar("T", bound="Client")
U = typing.TypeVar("U", bound="AsyncClient")
def _is_https_redirect(url: URL, location: URL) -> bool:
"""
Return 'True' if 'location' is a HTTPS upgrade of 'url'
"""
if url.host != location.host:
return False
return (
url.scheme == "http"
and _port_or_default(url) == 80
and location.scheme == "https"
and _port_or_default(location) == 443
)
def _port_or_default(url: URL) -> int | None:
if url.port is not None:
return url.port
return {"http": 80, "https": 443}.get(url.scheme)
def _same_origin(url: URL, other: URL) -> bool:
"""
Return 'True' if the given URLs share the same origin.
"""
return (
url.scheme == other.scheme
and url.host == other.host
and _port_or_default(url) == _port_or_default(other)
)
class UseClientDefault:
"""
For some parameters such as `auth=...` and `timeout=...` we need to be able
to indicate the default "unset" state, in a way that is distinctly different
to using `None`.
The default "unset" state indicates that whatever default is set on the
client should be used. This is different to setting `None`, which
explicitly disables the parameter, possibly overriding a client default.
For example we use `timeout=USE_CLIENT_DEFAULT` in the `request()` signature.
Omitting the `timeout` parameter will send a request using whatever default
timeout has been configured on the client. Including `timeout=None` will
ensure no timeout is used.
Note that user code shouldn't need to use the `USE_CLIENT_DEFAULT` constant,
but it is used internally when a parameter is not included.
"""
USE_CLIENT_DEFAULT = UseClientDefault()
logger = logging.getLogger("httpx")
USER_AGENT = f"python-httpx/{__version__}"
ACCEPT_ENCODING = ", ".join(
[key for key in SUPPORTED_DECODERS.keys() if key != "identity"]
)
class ClientState(enum.Enum):
# UNOPENED:
# The client has been instantiated, but has not been used to send a request,
# or been opened by entering the context of a `with` block.
UNOPENED = 1
# OPENED:
# The client has either sent a request, or is within a `with` block.
OPENED = 2
# CLOSED:
# The client has either exited the `with` block, or `close()` has
# been called explicitly.
CLOSED = 3
class BoundSyncStream(SyncByteStream):
"""
A byte stream that is bound to a given response instance, and that
ensures the `response.elapsed` is set once the response is closed.
"""
def __init__(
self, stream: SyncByteStream, response: Response, start: float
) -> None:
self._stream = stream
self._response = response
self._start = start
def __iter__(self) -> typing.Iterator[bytes]:
for chunk in self._stream:
yield chunk
def close(self) -> None:
elapsed = time.perf_counter() - self._start
self._response.elapsed = datetime.timedelta(seconds=elapsed)
self._stream.close()
class BoundAsyncStream(AsyncByteStream):
"""
An async byte stream that is bound to a given response instance, and that
ensures the `response.elapsed` is set once the response is closed.
"""
def __init__(
self, stream: AsyncByteStream, response: Response, start: float
) -> None:
self._stream = stream
self._response = response
self._start = start
async def __aiter__(self) -> typing.AsyncIterator[bytes]:
async for chunk in self._stream:
yield chunk
async def aclose(self) -> None:
elapsed = time.perf_counter() - self._start
self._response.elapsed = datetime.timedelta(seconds=elapsed)
await self._stream.aclose()
EventHook = typing.Callable[..., typing.Any]
class BaseClient:
def __init__(
self,
*,
auth: AuthTypes | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
follow_redirects: bool = False,
max_redirects: int = DEFAULT_MAX_REDIRECTS,
event_hooks: None | (typing.Mapping[str, list[EventHook]]) = None,
base_url: URL | str = "",
trust_env: bool = True,
default_encoding: str | typing.Callable[[bytes], str] = "utf-8",
) -> None:
event_hooks = {} if event_hooks is None else event_hooks
self._base_url = self._enforce_trailing_slash(URL(base_url))
self._auth = self._build_auth(auth)
self._params = QueryParams(params)
self.headers = Headers(headers)
self._cookies = Cookies(cookies)
self._timeout = Timeout(timeout)
self.follow_redirects = follow_redirects
self.max_redirects = max_redirects
self._event_hooks = {
"request": list(event_hooks.get("request", [])),
"response": list(event_hooks.get("response", [])),
}
self._trust_env = trust_env
self._default_encoding = default_encoding
self._state = ClientState.UNOPENED
@property
def is_closed(self) -> bool:
"""
Check if the client being closed
"""
return self._state == ClientState.CLOSED
@property
def trust_env(self) -> bool:
return self._trust_env
def _enforce_trailing_slash(self, url: URL) -> URL:
if url.raw_path.endswith(b"/"):
return url
return url.copy_with(raw_path=url.raw_path + b"/")
def _get_proxy_map(
self, proxy: ProxyTypes | None, allow_env_proxies: bool
) -> dict[str, Proxy | None]:
if proxy is None:
if allow_env_proxies:
return {
key: None if url is None else Proxy(url=url)
for key, url in get_environment_proxies().items()
}
return {}
else:
proxy = Proxy(url=proxy) if isinstance(proxy, (str, URL)) else proxy
return {"all://": proxy}
@property
def timeout(self) -> Timeout:
return self._timeout
@timeout.setter
def timeout(self, timeout: TimeoutTypes) -> None:
self._timeout = Timeout(timeout)
@property
def event_hooks(self) -> dict[str, list[EventHook]]:
return self._event_hooks
@event_hooks.setter
def event_hooks(self, event_hooks: dict[str, list[EventHook]]) -> None:
self._event_hooks = {
"request": list(event_hooks.get("request", [])),
"response": list(event_hooks.get("response", [])),
}
@property
def auth(self) -> Auth | None:
"""
Authentication class used when none is passed at the request-level.
See also [Authentication][0].
[0]: /quickstart/#authentication
"""
return self._auth
@auth.setter
def auth(self, auth: AuthTypes) -> None:
self._auth = self._build_auth(auth)
@property
def base_url(self) -> URL:
"""
Base URL to use when sending requests with relative URLs.
"""
return self._base_url
@base_url.setter
def base_url(self, url: URL | str) -> None:
self._base_url = self._enforce_trailing_slash(URL(url))
@property
def headers(self) -> Headers:
"""
HTTP headers to include when sending requests.
"""
return self._headers
@headers.setter
def headers(self, headers: HeaderTypes) -> None:
client_headers = Headers(
{
b"Accept": b"*/*",
b"Accept-Encoding": ACCEPT_ENCODING.encode("ascii"),
b"Connection": b"keep-alive",
b"User-Agent": USER_AGENT.encode("ascii"),
}
)
client_headers.update(headers)
self._headers = client_headers
@property
def cookies(self) -> Cookies:
"""
Cookie values to include when sending requests.
"""
return self._cookies
@cookies.setter
def cookies(self, cookies: CookieTypes) -> None:
self._cookies = Cookies(cookies)
@property
def params(self) -> QueryParams:
"""
Query parameters to include in the URL when sending requests.
"""
return self._params
@params.setter
def params(self, params: QueryParamTypes) -> None:
self._params = QueryParams(params)
def build_request(
self,
method: str,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Request:
"""
Build and return a request instance.
* The `params`, `headers` and `cookies` arguments
are merged with any values set on the client.
* The `url` argument is merged with any `base_url` set on the client.
See also: [Request instances][0]
[0]: /advanced/clients/#request-instances
"""
url = self._merge_url(url)
headers = self._merge_headers(headers)
cookies = self._merge_cookies(cookies)
params = self._merge_queryparams(params)
extensions = {} if extensions is None else extensions
if "timeout" not in extensions:
timeout = (
self.timeout
if isinstance(timeout, UseClientDefault)
else Timeout(timeout)
)
extensions = dict(**extensions, timeout=timeout.as_dict())
return Request(
method,
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
extensions=extensions,
)
def _merge_url(self, url: URL | str) -> URL:
"""
Merge a URL argument together with any 'base_url' on the client,
to create the URL used for the outgoing request.
"""
merge_url = URL(url)
if merge_url.is_relative_url:
# To merge URLs we always append to the base URL. To get this
# behaviour correct we always ensure the base URL ends in a '/'
# separator, and strip any leading '/' from the merge URL.
#
# So, eg...
#
# >>> client = Client(base_url="https://www.example.com/subpath")
# >>> client.base_url
# URL('https://www.example.com/subpath/')
# >>> client.build_request("GET", "/path").url
# URL('https://www.example.com/subpath/path')
merge_raw_path = self.base_url.raw_path + merge_url.raw_path.lstrip(b"/")
return self.base_url.copy_with(raw_path=merge_raw_path)
return merge_url
def _merge_cookies(self, cookies: CookieTypes | None = None) -> CookieTypes | None:
"""
Merge a cookies argument together with any cookies on the client,
to create the cookies used for the outgoing request.
"""
if cookies or self.cookies:
merged_cookies = Cookies(self.cookies)
merged_cookies.update(cookies)
return merged_cookies
return cookies
def _merge_headers(self, headers: HeaderTypes | None = None) -> HeaderTypes | None:
"""
Merge a headers argument together with any headers on the client,
to create the headers used for the outgoing request.
"""
merged_headers = Headers(self.headers)
merged_headers.update(headers)
return merged_headers
def _merge_queryparams(
self, params: QueryParamTypes | None = None
) -> QueryParamTypes | None:
"""
Merge a queryparams argument together with any queryparams on the client,
to create the queryparams used for the outgoing request.
"""
if params or self.params:
merged_queryparams = QueryParams(self.params)
return merged_queryparams.merge(params)
return params
def _build_auth(self, auth: AuthTypes | None) -> Auth | None:
if auth is None:
return None
elif isinstance(auth, tuple):
return BasicAuth(username=auth[0], password=auth[1])
elif isinstance(auth, Auth):
return auth
elif callable(auth):
return FunctionAuth(func=auth)
else:
raise TypeError(f'Invalid "auth" argument: {auth!r}')
def _build_request_auth(
self,
request: Request,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
) -> Auth:
auth = (
self._auth if isinstance(auth, UseClientDefault) else self._build_auth(auth)
)
if auth is not None:
return auth
username, password = request.url.username, request.url.password
if username or password:
return BasicAuth(username=username, password=password)
return Auth()
def _build_redirect_request(self, request: Request, response: Response) -> Request:
"""
Given a request and a redirect response, return a new request that
should be used to effect the redirect.
"""
method = self._redirect_method(request, response)
url = self._redirect_url(request, response)
headers = self._redirect_headers(request, url, method)
stream = self._redirect_stream(request, method)
cookies = Cookies(self.cookies)
return Request(
method=method,
url=url,
headers=headers,
cookies=cookies,
stream=stream,
extensions=request.extensions,
)
def _redirect_method(self, request: Request, response: Response) -> str:
"""
When being redirected we may want to change the method of the request
based on certain specs or browser behavior.
"""
method = request.method
# https://tools.ietf.org/html/rfc7231#section-6.4.4
if response.status_code == codes.SEE_OTHER and method != "HEAD":
method = "GET"
# Do what the browsers do, despite standards...
# Turn 302s into GETs.
if response.status_code == codes.FOUND and method != "HEAD":
method = "GET"
# If a POST is responded to with a 301, turn it into a GET.
# This bizarre behaviour is explained in 'requests' issue 1704.
if response.status_code == codes.MOVED_PERMANENTLY and method == "POST":
method = "GET"
return method
def _redirect_url(self, request: Request, response: Response) -> URL:
"""
Return the URL for the redirect to follow.
"""
location = response.headers["Location"]
try:
url = URL(location)
except InvalidURL as exc:
raise RemoteProtocolError(
f"Invalid URL in location header: {exc}.", request=request
) from None
# Handle malformed 'Location' headers that are "absolute" form, have no host.
# See: https://github.com/encode/httpx/issues/771
if url.scheme and not url.host:
url = url.copy_with(host=request.url.host)
# Facilitate relative 'Location' headers, as allowed by RFC 7231.
# (e.g. '/path/to/resource' instead of 'http://domain.tld/path/to/resource')
if url.is_relative_url:
url = request.url.join(url)
# Attach previous fragment if needed (RFC 7231 7.1.2)
if request.url.fragment and not url.fragment:
url = url.copy_with(fragment=request.url.fragment)
return url
def _redirect_headers(self, request: Request, url: URL, method: str) -> Headers:
"""
Return the headers that should be used for the redirect request.
"""
headers = Headers(request.headers)
if not _same_origin(url, request.url):
if not _is_https_redirect(request.url, url):
# Strip Authorization headers when responses are redirected
# away from the origin. (Except for direct HTTP to HTTPS redirects.)
headers.pop("Authorization", None)
# Update the Host header.
headers["Host"] = url.netloc.decode("ascii")
if method != request.method and method == "GET":
# If we've switch to a 'GET' request, then strip any headers which
# are only relevant to the request body.
headers.pop("Content-Length", None)
headers.pop("Transfer-Encoding", None)
# We should use the client cookie store to determine any cookie header,
# rather than whatever was on the original outgoing request.
headers.pop("Cookie", None)
return headers
def _redirect_stream(
self, request: Request, method: str
) -> SyncByteStream | AsyncByteStream | None:
"""
Return the body that should be used for the redirect request.
"""
if method != request.method and method == "GET":
return None
return request.stream
def _set_timeout(self, request: Request) -> None:
if "timeout" not in request.extensions:
timeout = (
self.timeout
if isinstance(self.timeout, UseClientDefault)
else Timeout(self.timeout)
)
request.extensions = dict(**request.extensions, timeout=timeout.as_dict())
class Client(BaseClient):
"""
An HTTP client, with connection pooling, HTTP/2, redirects, cookie persistence, etc.
It can be shared between threads.
Usage:
```python
>>> client = httpx.Client()
>>> response = client.get('https://example.org')
```
**Parameters:**
* **auth** - *(optional)* An authentication class to use when sending
requests.
* **params** - *(optional)* Query parameters to include in request URLs, as
a string, dictionary, or sequence of two-tuples.
* **headers** - *(optional)* Dictionary of HTTP headers to include when
sending requests.
* **cookies** - *(optional)* Dictionary of Cookie items to include when
sending requests.
* **verify** - *(optional)* Either `True` to use an SSL context with the
default CA bundle, `False` to disable verification, or an instance of
`ssl.SSLContext` to use a custom context.
* **http2** - *(optional)* A boolean indicating if HTTP/2 support should be
enabled. Defaults to `False`.
* **proxy** - *(optional)* A proxy URL where all the traffic should be routed.
* **timeout** - *(optional)* The timeout configuration to use when sending
requests.
* **limits** - *(optional)* The limits configuration to use.
* **max_redirects** - *(optional)* The maximum number of redirect responses
that should be followed.
* **base_url** - *(optional)* A URL to use as the base when building
request URLs.
* **transport** - *(optional)* A transport class to use for sending requests
over the network.
* **trust_env** - *(optional)* Enables or disables usage of environment
variables for configuration.
* **default_encoding** - *(optional)* The default encoding to use for decoding
response text, if no charset information is included in a response Content-Type
header. Set to a callable for automatic character set detection. Default: "utf-8".
"""
def __init__(
self,
*,
auth: AuthTypes | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
trust_env: bool = True,
http1: bool = True,
http2: bool = False,
proxy: ProxyTypes | None = None,
mounts: None | (typing.Mapping[str, BaseTransport | None]) = None,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
follow_redirects: bool = False,
limits: Limits = DEFAULT_LIMITS,
max_redirects: int = DEFAULT_MAX_REDIRECTS,
event_hooks: None | (typing.Mapping[str, list[EventHook]]) = None,
base_url: URL | str = "",
transport: BaseTransport | None = None,
default_encoding: str | typing.Callable[[bytes], str] = "utf-8",
) -> None:
super().__init__(
auth=auth,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
follow_redirects=follow_redirects,
max_redirects=max_redirects,
event_hooks=event_hooks,
base_url=base_url,
trust_env=trust_env,
default_encoding=default_encoding,
)
if http2:
try:
import h2 # noqa
except ImportError: # pragma: no cover
raise ImportError(
"Using http2=True, but the 'h2' package is not installed. "
"Make sure to install httpx using `pip install httpx[http2]`."
) from None
allow_env_proxies = trust_env and transport is None
proxy_map = self._get_proxy_map(proxy, allow_env_proxies)
self._transport = self._init_transport(
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
transport=transport,
)
self._mounts: dict[URLPattern, BaseTransport | None] = {
URLPattern(key): None
if proxy is None
else self._init_proxy_transport(
proxy,
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
)
for key, proxy in proxy_map.items()
}
if mounts is not None:
self._mounts.update(
{URLPattern(key): transport for key, transport in mounts.items()}
)
self._mounts = dict(sorted(self._mounts.items()))
def _init_transport(
self,
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
trust_env: bool = True,
http1: bool = True,
http2: bool = False,
limits: Limits = DEFAULT_LIMITS,
transport: BaseTransport | None = None,
) -> BaseTransport:
if transport is not None:
return transport
return HTTPTransport(
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
)
def _init_proxy_transport(
self,
proxy: Proxy,
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
trust_env: bool = True,
http1: bool = True,
http2: bool = False,
limits: Limits = DEFAULT_LIMITS,
) -> BaseTransport:
return HTTPTransport(
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
proxy=proxy,
)
def _transport_for_url(self, url: URL) -> BaseTransport:
"""
Returns the transport instance that should be used for a given URL.
This will either be the standard connection pool, or a proxy.
"""
for pattern, transport in self._mounts.items():
if pattern.matches(url):
return self._transport if transport is None else transport
return self._transport
def request(
self,
method: str,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Build and send a request.
Equivalent to:
```python
request = client.build_request(...)
response = client.send(request, ...)
```
See `Client.build_request()`, `Client.send()` and
[Merging of configuration][0] for how the various parameters
are merged with client-level configuration.
[0]: /advanced/clients/#merging-of-configuration
"""
if cookies is not None:
message = (
"Setting per-request cookies=<...> is being deprecated, because "
"the expected behaviour on cookie persistence is ambiguous. Set "
"cookies directly on the client instance instead."
)
warnings.warn(message, DeprecationWarning, stacklevel=2)
request = self.build_request(
method=method,
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
extensions=extensions,
)
return self.send(request, auth=auth, follow_redirects=follow_redirects)
@contextmanager
def stream(
self,
method: str,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> typing.Iterator[Response]:
"""
Alternative to `httpx.request()` that streams the response body
instead of loading it into memory at once.
**Parameters**: See `httpx.request`.
See also: [Streaming Responses][0]
[0]: /quickstart#streaming-responses
"""
request = self.build_request(
method=method,
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
extensions=extensions,
)
response = self.send(
request=request,
auth=auth,
follow_redirects=follow_redirects,
stream=True,
)
try:
yield response
finally:
response.close()
def send(
self,
request: Request,
*,
stream: bool = False,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
) -> Response:
"""
Send a request.
The request is sent as-is, unmodified.
Typically you'll want to build one with `Client.build_request()`
so that any client-level configuration is merged into the request,
but passing an explicit `httpx.Request()` is supported as well.
See also: [Request instances][0]
[0]: /advanced/clients/#request-instances
"""
if self._state == ClientState.CLOSED:
raise RuntimeError("Cannot send a request, as the client has been closed.")
self._state = ClientState.OPENED
follow_redirects = (
self.follow_redirects
if isinstance(follow_redirects, UseClientDefault)
else follow_redirects
)
self._set_timeout(request)
auth = self._build_request_auth(request, auth)
response = self._send_handling_auth(
request,
auth=auth,
follow_redirects=follow_redirects,
history=[],
)
try:
if not stream:
response.read()
return response
except BaseException as exc:
response.close()
raise exc
def _send_handling_auth(
self,
request: Request,
auth: Auth,
follow_redirects: bool,
history: list[Response],
) -> Response:
auth_flow = auth.sync_auth_flow(request)
try:
request = next(auth_flow)
while True:
response = self._send_handling_redirects(
request,
follow_redirects=follow_redirects,
history=history,
)
try:
try:
next_request = auth_flow.send(response)
except StopIteration:
return response
response.history = list(history)
response.read()
request = next_request
history.append(response)
except BaseException as exc:
response.close()
raise exc
finally:
auth_flow.close()
def _send_handling_redirects(
self,
request: Request,
follow_redirects: bool,
history: list[Response],
) -> Response:
while True:
if len(history) > self.max_redirects:
raise TooManyRedirects(
"Exceeded maximum allowed redirects.", request=request
)
for hook in self._event_hooks["request"]:
hook(request)
response = self._send_single_request(request)
try:
for hook in self._event_hooks["response"]:
hook(response)
response.history = list(history)
if not response.has_redirect_location:
return response
request = self._build_redirect_request(request, response)
history = history + [response]
if follow_redirects:
response.read()
else:
response.next_request = request
return response
except BaseException as exc:
response.close()
raise exc
def _send_single_request(self, request: Request) -> Response:
"""
Sends a single request, without handling any redirections.
"""
transport = self._transport_for_url(request.url)
start = time.perf_counter()
if not isinstance(request.stream, SyncByteStream):
raise RuntimeError(
"Attempted to send an async request with a sync Client instance."
)
with request_context(request=request):
response = transport.handle_request(request)
assert isinstance(response.stream, SyncByteStream)
response.request = request
response.stream = BoundSyncStream(
response.stream, response=response, start=start
)
self.cookies.extract_cookies(response)
response.default_encoding = self._default_encoding
logger.info(
'HTTP Request: %s %s "%s %d %s"',
request.method,
request.url,
response.http_version,
response.status_code,
response.reason_phrase,
)
return response
def get(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `GET` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"GET",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def options(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send an `OPTIONS` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"OPTIONS",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def head(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `HEAD` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"HEAD",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def post(
self,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `POST` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"POST",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def put(
self,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `PUT` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"PUT",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def patch(
self,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `PATCH` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"PATCH",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def delete(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `DELETE` request.
**Parameters**: See `httpx.request`.
"""
return self.request(
"DELETE",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
def close(self) -> None:
"""
Close transport and proxies.
"""
if self._state != ClientState.CLOSED:
self._state = ClientState.CLOSED
self._transport.close()
for transport in self._mounts.values():
if transport is not None:
transport.close()
def __enter__(self: T) -> T:
if self._state != ClientState.UNOPENED:
msg = {
ClientState.OPENED: "Cannot open a client instance more than once.",
ClientState.CLOSED: (
"Cannot reopen a client instance, once it has been closed."
),
}[self._state]
raise RuntimeError(msg)
self._state = ClientState.OPENED
self._transport.__enter__()
for transport in self._mounts.values():
if transport is not None:
transport.__enter__()
return self
def __exit__(
self,
exc_type: type[BaseException] | None = None,
exc_value: BaseException | None = None,
traceback: TracebackType | None = None,
) -> None:
self._state = ClientState.CLOSED
self._transport.__exit__(exc_type, exc_value, traceback)
for transport in self._mounts.values():
if transport is not None:
transport.__exit__(exc_type, exc_value, traceback)
class AsyncClient(BaseClient):
"""
An asynchronous HTTP client, with connection pooling, HTTP/2, redirects,
cookie persistence, etc.
It can be shared between tasks.
Usage:
```python
>>> async with httpx.AsyncClient() as client:
>>> response = await client.get('https://example.org')
```
**Parameters:**
* **auth** - *(optional)* An authentication class to use when sending
requests.
* **params** - *(optional)* Query parameters to include in request URLs, as
a string, dictionary, or sequence of two-tuples.
* **headers** - *(optional)* Dictionary of HTTP headers to include when
sending requests.
* **cookies** - *(optional)* Dictionary of Cookie items to include when
sending requests.
* **verify** - *(optional)* Either `True` to use an SSL context with the
default CA bundle, `False` to disable verification, or an instance of
`ssl.SSLContext` to use a custom context.
* **http2** - *(optional)* A boolean indicating if HTTP/2 support should be
enabled. Defaults to `False`.
* **proxy** - *(optional)* A proxy URL where all the traffic should be routed.
* **timeout** - *(optional)* The timeout configuration to use when sending
requests.
* **limits** - *(optional)* The limits configuration to use.
* **max_redirects** - *(optional)* The maximum number of redirect responses
that should be followed.
* **base_url** - *(optional)* A URL to use as the base when building
request URLs.
* **transport** - *(optional)* A transport class to use for sending requests
over the network.
* **trust_env** - *(optional)* Enables or disables usage of environment
variables for configuration.
* **default_encoding** - *(optional)* The default encoding to use for decoding
response text, if no charset information is included in a response Content-Type
header. Set to a callable for automatic character set detection. Default: "utf-8".
"""
def __init__(
self,
*,
auth: AuthTypes | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
http1: bool = True,
http2: bool = False,
proxy: ProxyTypes | None = None,
mounts: None | (typing.Mapping[str, AsyncBaseTransport | None]) = None,
timeout: TimeoutTypes = DEFAULT_TIMEOUT_CONFIG,
follow_redirects: bool = False,
limits: Limits = DEFAULT_LIMITS,
max_redirects: int = DEFAULT_MAX_REDIRECTS,
event_hooks: None | (typing.Mapping[str, list[EventHook]]) = None,
base_url: URL | str = "",
transport: AsyncBaseTransport | None = None,
trust_env: bool = True,
default_encoding: str | typing.Callable[[bytes], str] = "utf-8",
) -> None:
super().__init__(
auth=auth,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
follow_redirects=follow_redirects,
max_redirects=max_redirects,
event_hooks=event_hooks,
base_url=base_url,
trust_env=trust_env,
default_encoding=default_encoding,
)
if http2:
try:
import h2 # noqa
except ImportError: # pragma: no cover
raise ImportError(
"Using http2=True, but the 'h2' package is not installed. "
"Make sure to install httpx using `pip install httpx[http2]`."
) from None
allow_env_proxies = trust_env and transport is None
proxy_map = self._get_proxy_map(proxy, allow_env_proxies)
self._transport = self._init_transport(
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
transport=transport,
)
self._mounts: dict[URLPattern, AsyncBaseTransport | None] = {
URLPattern(key): None
if proxy is None
else self._init_proxy_transport(
proxy,
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
)
for key, proxy in proxy_map.items()
}
if mounts is not None:
self._mounts.update(
{URLPattern(key): transport for key, transport in mounts.items()}
)
self._mounts = dict(sorted(self._mounts.items()))
def _init_transport(
self,
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
trust_env: bool = True,
http1: bool = True,
http2: bool = False,
limits: Limits = DEFAULT_LIMITS,
transport: AsyncBaseTransport | None = None,
) -> AsyncBaseTransport:
if transport is not None:
return transport
return AsyncHTTPTransport(
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
)
def _init_proxy_transport(
self,
proxy: Proxy,
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
trust_env: bool = True,
http1: bool = True,
http2: bool = False,
limits: Limits = DEFAULT_LIMITS,
) -> AsyncBaseTransport:
return AsyncHTTPTransport(
verify=verify,
cert=cert,
trust_env=trust_env,
http1=http1,
http2=http2,
limits=limits,
proxy=proxy,
)
def _transport_for_url(self, url: URL) -> AsyncBaseTransport:
"""
Returns the transport instance that should be used for a given URL.
This will either be the standard connection pool, or a proxy.
"""
for pattern, transport in self._mounts.items():
if pattern.matches(url):
return self._transport if transport is None else transport
return self._transport
async def request(
self,
method: str,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Build and send a request.
Equivalent to:
```python
request = client.build_request(...)
response = await client.send(request, ...)
```
See `AsyncClient.build_request()`, `AsyncClient.send()`
and [Merging of configuration][0] for how the various parameters
are merged with client-level configuration.
[0]: /advanced/clients/#merging-of-configuration
"""
if cookies is not None: # pragma: no cover
message = (
"Setting per-request cookies=<...> is being deprecated, because "
"the expected behaviour on cookie persistence is ambiguous. Set "
"cookies directly on the client instance instead."
)
warnings.warn(message, DeprecationWarning, stacklevel=2)
request = self.build_request(
method=method,
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
extensions=extensions,
)
return await self.send(request, auth=auth, follow_redirects=follow_redirects)
@asynccontextmanager
async def stream(
self,
method: str,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> typing.AsyncIterator[Response]:
"""
Alternative to `httpx.request()` that streams the response body
instead of loading it into memory at once.
**Parameters**: See `httpx.request`.
See also: [Streaming Responses][0]
[0]: /quickstart#streaming-responses
"""
request = self.build_request(
method=method,
url=url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
timeout=timeout,
extensions=extensions,
)
response = await self.send(
request=request,
auth=auth,
follow_redirects=follow_redirects,
stream=True,
)
try:
yield response
finally:
await response.aclose()
async def send(
self,
request: Request,
*,
stream: bool = False,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
) -> Response:
"""
Send a request.
The request is sent as-is, unmodified.
Typically you'll want to build one with `AsyncClient.build_request()`
so that any client-level configuration is merged into the request,
but passing an explicit `httpx.Request()` is supported as well.
See also: [Request instances][0]
[0]: /advanced/clients/#request-instances
"""
if self._state == ClientState.CLOSED:
raise RuntimeError("Cannot send a request, as the client has been closed.")
self._state = ClientState.OPENED
follow_redirects = (
self.follow_redirects
if isinstance(follow_redirects, UseClientDefault)
else follow_redirects
)
self._set_timeout(request)
auth = self._build_request_auth(request, auth)
response = await self._send_handling_auth(
request,
auth=auth,
follow_redirects=follow_redirects,
history=[],
)
try:
if not stream:
await response.aread()
return response
except BaseException as exc:
await response.aclose()
raise exc
async def _send_handling_auth(
self,
request: Request,
auth: Auth,
follow_redirects: bool,
history: list[Response],
) -> Response:
auth_flow = auth.async_auth_flow(request)
try:
request = await auth_flow.__anext__()
while True:
response = await self._send_handling_redirects(
request,
follow_redirects=follow_redirects,
history=history,
)
try:
try:
next_request = await auth_flow.asend(response)
except StopAsyncIteration:
return response
response.history = list(history)
await response.aread()
request = next_request
history.append(response)
except BaseException as exc:
await response.aclose()
raise exc
finally:
await auth_flow.aclose()
async def _send_handling_redirects(
self,
request: Request,
follow_redirects: bool,
history: list[Response],
) -> Response:
while True:
if len(history) > self.max_redirects:
raise TooManyRedirects(
"Exceeded maximum allowed redirects.", request=request
)
for hook in self._event_hooks["request"]:
await hook(request)
response = await self._send_single_request(request)
try:
for hook in self._event_hooks["response"]:
await hook(response)
response.history = list(history)
if not response.has_redirect_location:
return response
request = self._build_redirect_request(request, response)
history = history + [response]
if follow_redirects:
await response.aread()
else:
response.next_request = request
return response
except BaseException as exc:
await response.aclose()
raise exc
async def _send_single_request(self, request: Request) -> Response:
"""
Sends a single request, without handling any redirections.
"""
transport = self._transport_for_url(request.url)
start = time.perf_counter()
if not isinstance(request.stream, AsyncByteStream):
raise RuntimeError(
"Attempted to send a sync request with an AsyncClient instance."
)
with request_context(request=request):
response = await transport.handle_async_request(request)
assert isinstance(response.stream, AsyncByteStream)
response.request = request
response.stream = BoundAsyncStream(
response.stream, response=response, start=start
)
self.cookies.extract_cookies(response)
response.default_encoding = self._default_encoding
logger.info(
'HTTP Request: %s %s "%s %d %s"',
request.method,
request.url,
response.http_version,
response.status_code,
response.reason_phrase,
)
return response
async def get(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault | None = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `GET` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"GET",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def options(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send an `OPTIONS` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"OPTIONS",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def head(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `HEAD` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"HEAD",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def post(
self,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `POST` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"POST",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def put(
self,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `PUT` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"PUT",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def patch(
self,
url: URL | str,
*,
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: typing.Any | None = None,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `PATCH` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"PATCH",
url,
content=content,
data=data,
files=files,
json=json,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def delete(
self,
url: URL | str,
*,
params: QueryParamTypes | None = None,
headers: HeaderTypes | None = None,
cookies: CookieTypes | None = None,
auth: AuthTypes | UseClientDefault = USE_CLIENT_DEFAULT,
follow_redirects: bool | UseClientDefault = USE_CLIENT_DEFAULT,
timeout: TimeoutTypes | UseClientDefault = USE_CLIENT_DEFAULT,
extensions: RequestExtensions | None = None,
) -> Response:
"""
Send a `DELETE` request.
**Parameters**: See `httpx.request`.
"""
return await self.request(
"DELETE",
url,
params=params,
headers=headers,
cookies=cookies,
auth=auth,
follow_redirects=follow_redirects,
timeout=timeout,
extensions=extensions,
)
async def aclose(self) -> None:
"""
Close transport and proxies.
"""
if self._state != ClientState.CLOSED:
self._state = ClientState.CLOSED
await self._transport.aclose()
for proxy in self._mounts.values():
if proxy is not None:
await proxy.aclose()
async def __aenter__(self: U) -> U:
if self._state != ClientState.UNOPENED:
msg = {
ClientState.OPENED: "Cannot open a client instance more than once.",
ClientState.CLOSED: (
"Cannot reopen a client instance, once it has been closed."
),
}[self._state]
raise RuntimeError(msg)
self._state = ClientState.OPENED
await self._transport.__aenter__()
for proxy in self._mounts.values():
if proxy is not None:
await proxy.__aenter__()
return self
async def __aexit__(
self,
exc_type: type[BaseException] | None = None,
exc_value: BaseException | None = None,
traceback: TracebackType | None = None,
) -> None:
self._state = ClientState.CLOSED
await self._transport.__aexit__(exc_type, exc_value, traceback)
for proxy in self._mounts.values():
if proxy is not None:
await proxy.__aexit__(exc_type, exc_value, traceback)
================================================
FILE: httpx/_config.py
================================================
from __future__ import annotations
import os
import typing
from ._models import Headers
from ._types import CertTypes, HeaderTypes, TimeoutTypes
from ._urls import URL
if typing.TYPE_CHECKING:
import ssl # pragma: no cover
__all__ = ["Limits", "Proxy", "Timeout", "create_ssl_context"]
class UnsetType:
pass # pragma: no cover
UNSET = UnsetType()
def create_ssl_context(
verify: ssl.SSLContext | str | bool = True,
cert: CertTypes | None = None,
trust_env: bool = True,
) -> ssl.SSLContext:
import ssl
import warnings
import certifi
if verify is True:
if trust_env and os.environ.get("SSL_CERT_FILE"): # pragma: nocover
ctx = ssl.create_default_context(cafile=os.environ["SSL_CERT_FILE"])
elif trust_env and os.environ.get("SSL_CERT_DIR"): # pragma: nocover
ctx = ssl.create_default_context(capath=os.environ["SSL_CERT_DIR"])
else:
# Default case...
ctx = ssl.create_default_context(cafile=certifi.where())
elif verify is False:
ctx = ssl.SSLContext(ssl.PROTOCOL_TLS_CLIENT)
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
elif isinstance(verify, str): # pragma: nocover
message = (
"`verify=` is deprecated. "
"Use `verify=ssl.create_default_context(cafile=...)` "
"or `verify=ssl.create_default_context(capath=...)` instead."
)
warnings.warn(message, DeprecationWarning)
if os.path.isdir(verify):
return ssl.create_default_context(capath=verify)
return ssl.create_default_context(cafile=verify)
else:
ctx = verify
if cert: # pragma: nocover
message = (
"`cert=...` is deprecated. Use `verify=` instead,"
"with `.load_cert_chain()` to configure the certificate chain."
)
warnings.warn(message, DeprecationWarning)
if isinstance(cert, str):
ctx.load_cert_chain(cert)
else:
ctx.load_cert_chain(*cert)
return ctx
class Timeout:
"""
Timeout configuration.
**Usage**:
Timeout(None) # No timeouts.
Timeout(5.0) # 5s timeout on all operations.
Timeout(None, connect=5.0) # 5s timeout on connect, no other timeouts.
Timeout(5.0, connect=10.0) # 10s timeout on connect. 5s timeout elsewhere.
Timeout(5.0, pool=None) # No timeout on acquiring connection from pool.
# 5s timeout elsewhere.
"""
def __init__(
self,
timeout: TimeoutTypes | UnsetType = UNSET,
*,
connect: None | float | UnsetType = UNSET,
read: None | float | UnsetType = UNSET,
write: None | float | UnsetType = UNSET,
pool: None | float | UnsetType = UNSET,
) -> None:
if isinstance(timeout, Timeout):
# Passed as a single explicit Timeout.
assert connect is UNSET
assert read is UNSET
assert write is UNSET
assert pool is UNSET
self.connect = timeout.connect # type: typing.Optional[float]
self.read = timeout.read # type: typing.Optional[float]
self.write = timeout.write # type: typing.Optional[float]
self.pool = timeout.pool # type: typing.Optional[float]
elif isinstance(timeout, tuple):
# Passed as a tuple.
self.connect = timeout[0]
self.read = timeout[1]
self.write = None if len(timeout) < 3 else timeout[2]
self.pool = None if len(timeout) < 4 else timeout[3]
elif not (
isinstance(connect, UnsetType)
or isinstance(read, UnsetType)
or isinstance(write, UnsetType)
or isinstance(pool, UnsetType)
):
self.connect = connect
self.read = read
self.write = write
self.pool = pool
else:
if isinstance(timeout, UnsetType):
raise ValueError(
"httpx.Timeout must either include a default, or set all "
"four parameters explicitly."
)
self.connect = timeout if isinstance(connect, UnsetType) else connect
self.read = timeout if isinstance(read, UnsetType) else read
self.write = timeout if isinstance(write, UnsetType) else write
self.pool = timeout if isinstance(pool, UnsetType) else pool
def as_dict(self) -> dict[str, float | None]:
return {
"connect": self.connect,
"read": self.read,
"write": self.write,
"pool": self.pool,
}
def __eq__(self, other: typing.Any) -> bool:
return (
isinstance(other, self.__class__)
and self.connect == other.connect
and self.read == other.read
and self.write == other.write
and self.pool == other.pool
)
def __repr__(self) -> str:
class_name = self.__class__.__name__
if len({self.connect, self.read, self.write, self.pool}) == 1:
return f"{class_name}(timeout={self.connect})"
return (
f"{class_name}(connect={self.connect}, "
f"read={self.read}, write={self.write}, pool={self.pool})"
)
class Limits:
"""
Configuration for limits to various client behaviors.
**Parameters:**
* **max_connections** - The maximum number of concurrent connections that may be
established.
* **max_keepalive_connections** - Allow the connection pool to maintain
keep-alive connections below this point. Should be less than or equal
to `max_connections`.
* **keepalive_expiry** - Time limit on idle keep-alive connections in seconds.
"""
def __init__(
self,
*,
max_connections: int | None = None,
max_keepalive_connections: int | None = None,
keepalive_expiry: float | None = 5.0,
) -> None:
self.max_connections = max_connections
self.max_keepalive_connections = max_keepalive_connections
self.keepalive_expiry = keepalive_expiry
def __eq__(self, other: typing.Any) -> bool:
return (
isinstance(other, self.__class__)
and self.max_connections == other.max_connections
and self.max_keepalive_connections == other.max_keepalive_connections
and self.keepalive_expiry == other.keepalive_expiry
)
def __repr__(self) -> str:
class_name = self.__class__.__name__
return (
f"{class_name}(max_connections={self.max_connections}, "
f"max_keepalive_connections={self.max_keepalive_connections}, "
f"keepalive_expiry={self.keepalive_expiry})"
)
class Proxy:
def __init__(
self,
url: URL | str,
*,
ssl_context: ssl.SSLContext | None = None,
auth: tuple[str, str] | None = None,
headers: HeaderTypes | None = None,
) -> None:
url = URL(url)
headers = Headers(headers)
if url.scheme not in ("http", "https", "socks5", "socks5h"):
raise ValueError(f"Unknown scheme for proxy URL {url!r}")
if url.username or url.password:
# Remove any auth credentials from the URL.
auth = (url.username, url.password)
url = url.copy_with(username=None, password=None)
self.url = url
self.auth = auth
self.headers = headers
self.ssl_context = ssl_context
@property
def raw_auth(self) -> tuple[bytes, bytes] | None:
# The proxy authentication as raw bytes.
return (
None
if self.auth is None
else (self.auth[0].encode("utf-8"), self.auth[1].encode("utf-8"))
)
def __repr__(self) -> str:
# The authentication is represented with the password component masked.
auth = (self.auth[0], "********") if self.auth else None
# Build a nice concise representation.
url_str = f"{str(self.url)!r}"
auth_str = f", auth={auth!r}" if auth else ""
headers_str = f", headers={dict(self.headers)!r}" if self.headers else ""
return f"Proxy({url_str}{auth_str}{headers_str})"
DEFAULT_TIMEOUT_CONFIG = Timeout(timeout=5.0)
DEFAULT_LIMITS = Limits(max_connections=100, max_keepalive_connections=20)
DEFAULT_MAX_REDIRECTS = 20
================================================
FILE: httpx/_content.py
================================================
from __future__ import annotations
import inspect
import warnings
from json import dumps as json_dumps
from typing import (
Any,
AsyncIterable,
AsyncIterator,
Iterable,
Iterator,
Mapping,
)
from urllib.parse import urlencode
from ._exceptions import StreamClosed, StreamConsumed
from ._multipart import MultipartStream
from ._types import (
AsyncByteStream,
RequestContent,
RequestData,
RequestFiles,
ResponseContent,
SyncByteStream,
)
from ._utils import peek_filelike_length, primitive_value_to_str
__all__ = ["ByteStream"]
class ByteStream(AsyncByteStream, SyncByteStream):
def __init__(self, stream: bytes) -> None:
self._stream = stream
def __iter__(self) -> Iterator[bytes]:
yield self._stream
async def __aiter__(self) -> AsyncIterator[bytes]:
yield self._stream
class IteratorByteStream(SyncByteStream):
CHUNK_SIZE = 65_536
def __init__(self, stream: Iterable[bytes]) -> None:
self._stream = stream
self._is_stream_consumed = False
self._is_generator = inspect.isgenerator(stream)
def __iter__(self) -> Iterator[bytes]:
if self._is_stream_consumed and self._is_generator:
raise StreamConsumed()
self._is_stream_consumed = True
if hasattr(self._stream, "read"):
# File-like interfaces should use 'read' directly.
chunk = self._stream.read(self.CHUNK_SIZE)
while chunk:
yield chunk
chunk = self._stream.read(self.CHUNK_SIZE)
else:
# Otherwise iterate.
for part in self._stream:
yield part
class AsyncIteratorByteStream(AsyncByteStream):
CHUNK_SIZE = 65_536
def __init__(self, stream: AsyncIterable[bytes]) -> None:
self._stream = stream
self._is_stream_consumed = False
self._is_generator = inspect.isasyncgen(stream)
async def __aiter__(self) -> AsyncIterator[bytes]:
if self._is_stream_consumed and self._is_generator:
raise StreamConsumed()
self._is_stream_consumed = True
if hasattr(self._stream, "aread"):
# File-like interfaces should use 'aread' directly.
chunk = await self._stream.aread(self.CHUNK_SIZE)
while chunk:
yield chunk
chunk = await self._stream.aread(self.CHUNK_SIZE)
else:
# Otherwise iterate.
async for part in self._stream:
yield part
class UnattachedStream(AsyncByteStream, SyncByteStream):
"""
If a request or response is serialized using pickle, then it is no longer
attached to a stream for I/O purposes. Any stream operations should result
in `httpx.StreamClosed`.
"""
def __iter__(self) -> Iterator[bytes]:
raise StreamClosed()
async def __aiter__(self) -> AsyncIterator[bytes]:
raise StreamClosed()
yield b"" # pragma: no cover
def encode_content(
content: str | bytes | Iterable[bytes] | AsyncIterable[bytes],
) -> tuple[dict[str, str], SyncByteStream | AsyncByteStream]:
if isinstance(content, (bytes, str)):
body = content.encode("utf-8") if isinstance(content, str) else content
content_length = len(body)
headers = {"Content-Length": str(content_length)} if body else {}
return headers, ByteStream(body)
elif isinstance(content, Iterable) and not isinstance(content, dict):
# `not isinstance(content, dict)` is a bit oddly specific, but it
# catches a case that's easy for users to make in error, and would
# otherwise pass through here, like any other bytes-iterable,
# because `dict` happens to be iterable. See issue #2491.
content_length_or_none = peek_filelike_length(content)
if content_length_or_none is None:
headers = {"Transfer-Encoding": "chunked"}
else:
headers = {"Content-Length": str(content_length_or_none)}
return headers, IteratorByteStream(content) # type: ignore
elif isinstance(content, AsyncIterable):
headers = {"Transfer-Encoding": "chunked"}
return headers, AsyncIteratorByteStream(content)
raise TypeError(f"Unexpected type for 'content', {type(content)!r}")
def encode_urlencoded_data(
data: RequestData,
) -> tuple[dict[str, str], ByteStream]:
plain_data = []
for key, value in data.items():
if isinstance(value, (list, tuple)):
plain_data.extend([(key, primitive_value_to_str(item)) for item in value])
else:
plain_data.append((key, primitive_value_to_str(value)))
body = urlencode(plain_data, doseq=True).encode("utf-8")
content_length = str(len(body))
content_type = "application/x-www-form-urlencoded"
headers = {"Content-Length": content_length, "Content-Type": content_type}
return headers, ByteStream(body)
def encode_multipart_data(
data: RequestData, files: RequestFiles, boundary: bytes | None
) -> tuple[dict[str, str], MultipartStream]:
multipart = MultipartStream(data=data, files=files, boundary=boundary)
headers = multipart.get_headers()
return headers, multipart
def encode_text(text: str) -> tuple[dict[str, str], ByteStream]:
body = text.encode("utf-8")
content_length = str(len(body))
content_type = "text/plain; charset=utf-8"
headers = {"Content-Length": content_length, "Content-Type": content_type}
return headers, ByteStream(body)
def encode_html(html: str) -> tuple[dict[str, str], ByteStream]:
body = html.encode("utf-8")
content_length = str(len(body))
content_type = "text/html; charset=utf-8"
headers = {"Content-Length": content_length, "Content-Type": content_type}
return headers, ByteStream(body)
def encode_json(json: Any) -> tuple[dict[str, str], ByteStream]:
body = json_dumps(
json, ensure_ascii=False, separators=(",", ":"), allow_nan=False
).encode("utf-8")
content_length = str(len(body))
content_type = "application/json"
headers = {"Content-Length": content_length, "Content-Type": content_type}
return headers, ByteStream(body)
def encode_request(
content: RequestContent | None = None,
data: RequestData | None = None,
files: RequestFiles | None = None,
json: Any | None = None,
boundary: bytes | None = None,
) -> tuple[dict[str, str], SyncByteStream | AsyncByteStream]:
"""
Handles encoding the given `content`, `data`, `files`, and `json`,
returning a two-tuple of (, ).
"""
if data is not None and not isinstance(data, Mapping):
# We prefer to separate `content=`
# for raw request content, and `data=