Various style translations by varying the latent code.
### Boundary-Seeking GAN
_Boundary-Seeking Generative Adversarial Networks_
#### Authors
R Devon Hjelm, Athul Paul Jacob, Tong Che, Adam Trischler, Kyunghyun Cho, Yoshua Bengio
#### Abstract
Generative adversarial networks (GANs) are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning.
[[Paper]](https://arxiv.org/abs/1702.08431) [[Code]](implementations/bgan/bgan.py)
#### Run Example
```
$ cd implementations/bgan/
$ python3 bgan.py
```
### Cluster GAN
_ClusterGAN: Latent Space Clustering in Generative Adversarial Networks_
#### Authors
Sudipto Mukherjee, Himanshu Asnani, Eugene Lin, Sreeram Kannan
#### Abstract
Generative Adversarial networks (GANs) have obtained remarkable success in many unsupervised learning tasks and
unarguably, clustering is an important unsupervised learning problem. While one can potentially exploit the
latent-space back-projection in GANs to cluster, we demonstrate that the cluster structure is not retained in the
GAN latent space. In this paper, we propose ClusterGAN as a new mechanism for clustering using GANs. By sampling
latent variables from a mixture of one-hot encoded variables and continuous latent variables, coupled with an
inverse network (which projects the data to the latent space) trained jointly with a clustering specific loss, we
are able to achieve clustering in the latent space. Our results show a remarkable phenomenon that GANs can preserve
latent space interpolation across categories, even though the discriminator is never exposed to such vectors. We
compare our results with various clustering baselines and demonstrate superior performance on both synthetic and
real datasets.
[[Paper]](https://arxiv.org/abs/1809.03627) [[Code]](implementations/cluster_gan/clustergan.py)
Code based on a full PyTorch [[implementation]](https://github.com/zhampel/clusterGAN).
#### Run Example
```
$ cd implementations/cluster_gan/
$ python3 clustergan.py
```
$ python3 context_encoder.py
```

Rows: Masked | Inpainted | Original | Masked | Inpainted | Original
### Coupled GAN
_Coupled Generative Adversarial Networks_
#### Authors
Ming-Yu Liu, Oncel Tuzel
#### Abstract
We propose coupled generative adversarial network (CoGAN) for learning a joint distribution of multi-domain images. In contrast to the existing approaches, which require tuples of corresponding images in different domains in the training set, CoGAN can learn a joint distribution without any tuple of corresponding images. It can learn a joint distribution with just samples drawn from the marginal distributions. This is achieved by enforcing a weight-sharing constraint that limits the network capacity and favors a joint distribution solution over a product of marginal distributions one. We apply CoGAN to several joint distribution learning tasks, including learning a joint distribution of color and depth images, and learning a joint distribution of face images with different attributes. For each task it successfully learns the joint distribution without any tuple of corresponding images. We also demonstrate its applications to domain adaptation and image transformation.
[[Paper]](https://arxiv.org/abs/1606.07536) [[Code]](implementations/cogan/cogan.py)
#### Run Example
```
$ cd implementations/cogan/
$ python3 cogan.py
```

Generated MNIST and MNIST-M images
### CycleGAN
_Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks_
#### Authors
Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
#### Abstract
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples. Our goal is to learn a mapping G:X→Y such that the distribution of images from G(X) is indistinguishable from the distribution Y using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping F:Y→X and introduce a cycle consistency loss to push F(G(X))≈X (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.
[[Paper]](https://arxiv.org/abs/1703.10593) [[Code]](implementations/cyclegan/cyclegan.py)
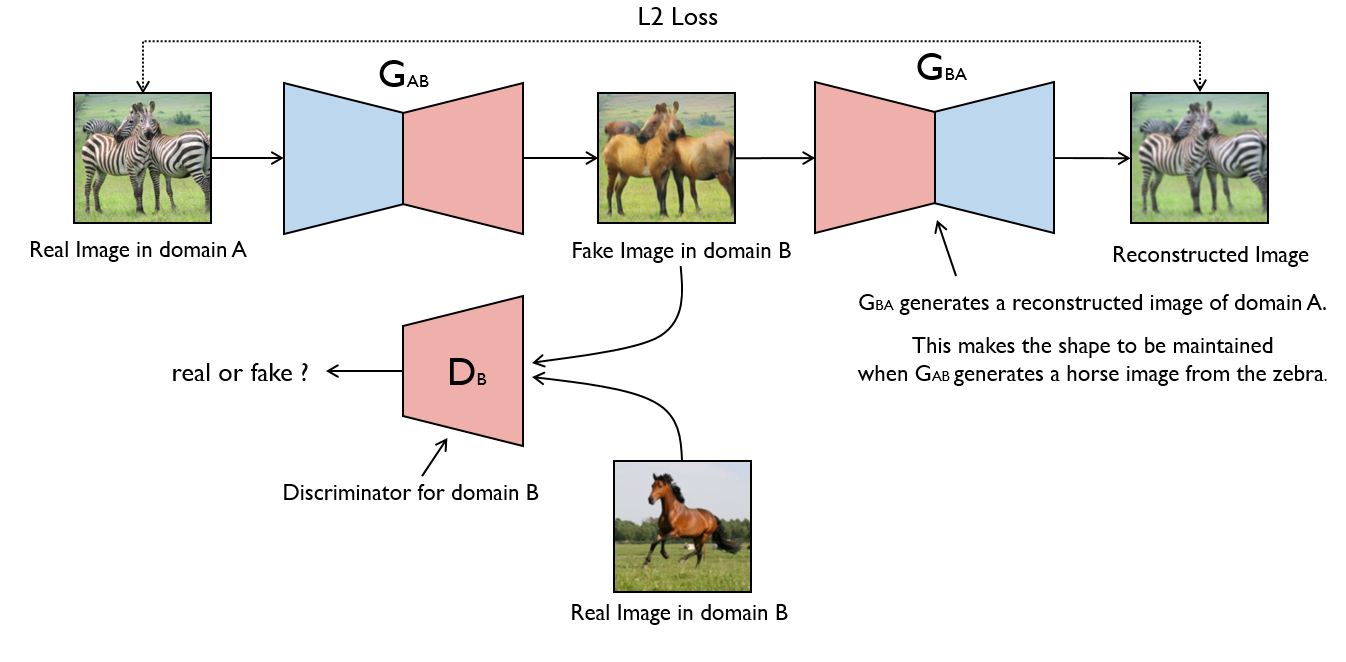
#### Run Example
```
$ cd data/
$ bash download_cyclegan_dataset.sh monet2photo
$ cd ../implementations/cyclegan/
$ python3 cyclegan.py --dataset_name monet2photo
```

Monet to photo translations.
### Deep Convolutional GAN
_Deep Convolutional Generative Adversarial Network_
#### Authors
Alec Radford, Luke Metz, Soumith Chintala
#### Abstract
In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations.
[[Paper]](https://arxiv.org/abs/1511.06434) [[Code]](implementations/dcgan/dcgan.py)
#### Run Example
```
$ cd implementations/dcgan/
$ python3 dcgan.py
```

### DiscoGAN
_Learning to Discover Cross-Domain Relations with Generative Adversarial Networks_
#### Authors
Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, Jiwon Kim
#### Abstract
While humans easily recognize relations between data from different domains without any supervision, learning to automatically discover them is in general very challenging and needs many ground-truth pairs that illustrate the relations. To avoid costly pairing, we address the task of discovering cross-domain relations given unpaired data. We propose a method based on generative adversarial networks that learns to discover relations between different domains (DiscoGAN). Using the discovered relations, our proposed network successfully transfers style from one domain to another while preserving key attributes such as orientation and face identity.
[[Paper]](https://arxiv.org/abs/1703.05192) [[Code]](implementations/discogan/discogan.py)
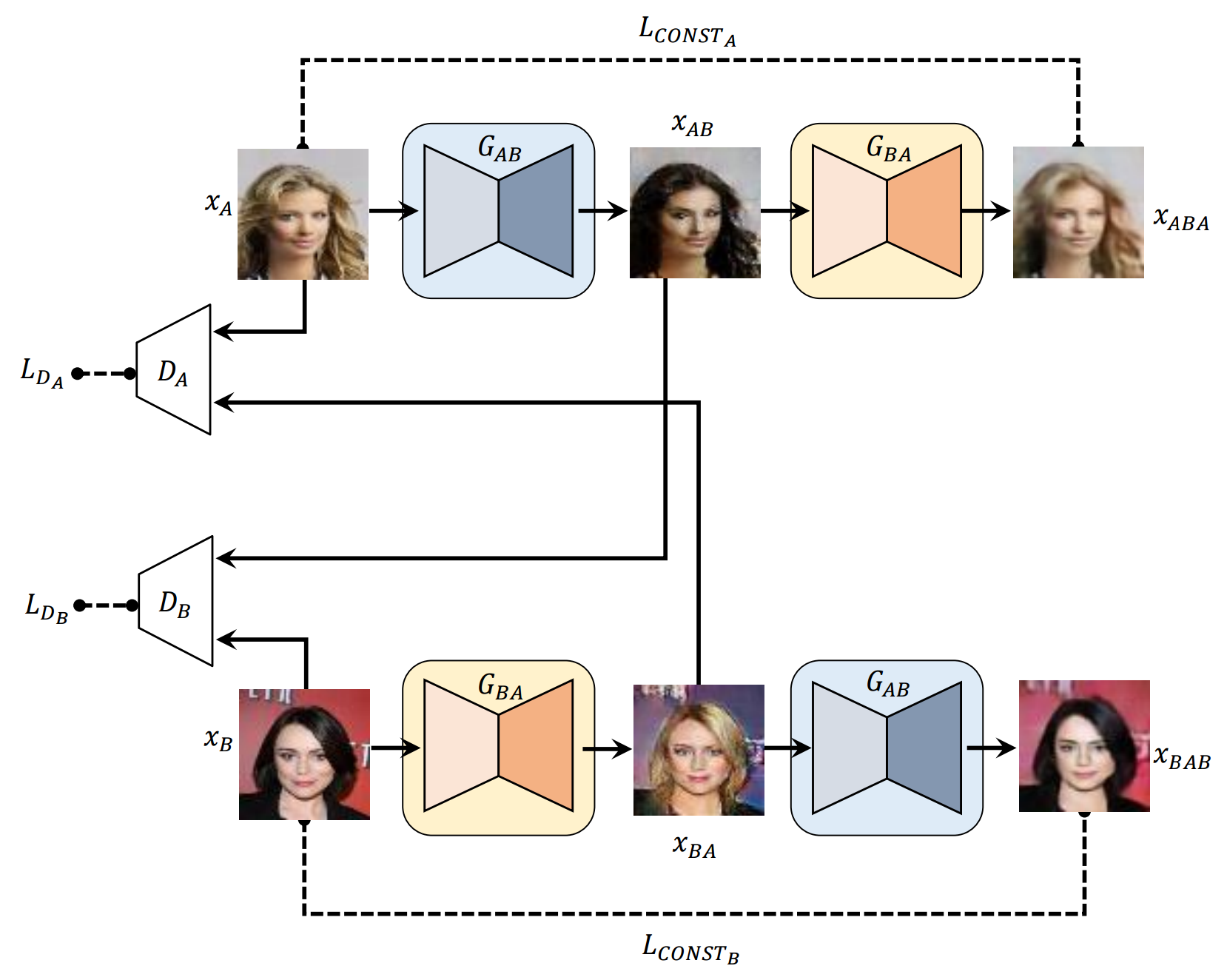
#### Run Example
```
$ cd data/
$ bash download_pix2pix_dataset.sh edges2shoes
$ cd ../implementations/discogan/
$ python3 discogan.py --dataset_name edges2shoes
```

Rows from top to bottom: (1) Real image from domain A (2) Translated image from
domain A (3) Reconstructed image from domain A (4) Real image from domain B (5)
Translated image from domain B (6) Reconstructed image from domain B
### DRAGAN
_On Convergence and Stability of GANs_
#### Authors
Naveen Kodali, Jacob Abernethy, James Hays, Zsolt Kira
#### Abstract
We propose studying GAN training dynamics as regret minimization, which is in contrast to the popular view that there is consistent minimization of a divergence between real and generated distributions. We analyze the convergence of GAN training from this new point of view to understand why mode collapse happens. We hypothesize the existence of undesirable local equilibria in this non-convex game to be responsible for mode collapse. We observe that these local equilibria often exhibit sharp gradients of the discriminator function around some real data points. We demonstrate that these degenerate local equilibria can be avoided with a gradient penalty scheme called DRAGAN. We show that DRAGAN enables faster training, achieves improved stability with fewer mode collapses, and leads to generator networks with better modeling performance across a variety of architectures and objective functions.
[[Paper]](https://arxiv.org/abs/1705.07215) [[Code]](implementations/dragan/dragan.py)
#### Run Example
```
$ cd implementations/dragan/
$ python3 dragan.py
```
### DualGAN
_DualGAN: Unsupervised Dual Learning for Image-to-Image Translation_
#### Authors
Zili Yi, Hao Zhang, Ping Tan, Minglun Gong
#### Abstract
Conditional Generative Adversarial Networks (GANs) for cross-domain image-to-image translation have made much progress recently. Depending on the task complexity, thousands to millions of labeled image pairs are needed to train a conditional GAN. However, human labeling is expensive, even impractical, and large quantities of data may not always be available. Inspired by dual learning from natural language translation, we develop a novel dual-GAN mechanism, which enables image translators to be trained from two sets of unlabeled images from two domains. In our architecture, the primal GAN learns to translate images from domain U to those in domain V, while the dual GAN learns to invert the task. The closed loop made by the primal and dual tasks allows images from either domain to be translated and then reconstructed. Hence a loss function that accounts for the reconstruction error of images can be used to train the translators. Experiments on multiple image translation tasks with unlabeled data show considerable performance gain of DualGAN over a single GAN. For some tasks, DualGAN can even achieve comparable or slightly better results than conditional GAN trained on fully labeled data.
[[Paper]](https://arxiv.org/abs/1704.02510) [[Code]](implementations/dualgan/dualgan.py)
#### Run Example
```
$ cd data/
$ bash download_pix2pix_dataset.sh facades
$ cd ../implementations/dualgan/
$ python3 dualgan.py --dataset_name facades
```
### Energy-Based GAN
_Energy-based Generative Adversarial Network_
#### Authors
Junbo Zhao, Michael Mathieu, Yann LeCun
#### Abstract
We introduce the "Energy-based Generative Adversarial Network" model (EBGAN) which views the discriminator as an energy function that attributes low energies to the regions near the data manifold and higher energies to other regions. Similar to the probabilistic GANs, a generator is seen as being trained to produce contrastive samples with minimal energies, while the discriminator is trained to assign high energies to these generated samples. Viewing the discriminator as an energy function allows to use a wide variety of architectures and loss functionals in addition to the usual binary classifier with logistic output. Among them, we show one instantiation of EBGAN framework as using an auto-encoder architecture, with the energy being the reconstruction error, in place of the discriminator. We show that this form of EBGAN exhibits more stable behavior than regular GANs during training. We also show that a single-scale architecture can be trained to generate high-resolution images.
[[Paper]](https://arxiv.org/abs/1609.03126) [[Code]](implementations/ebgan/ebgan.py)
#### Run Example
```
$ cd implementations/ebgan/
$ python3 ebgan.py
```
### Enhanced Super-Resolution GAN
_ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks_
#### Authors
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Chen Change Loy, Yu Qiao, Xiaoou Tang
#### Abstract
The Super-Resolution Generative Adversarial Network (SRGAN) is a seminal work that is capable of generating realistic textures during single image super-resolution. However, the hallucinated details are often accompanied with unpleasant artifacts. To further enhance the visual quality, we thoroughly study three key components of SRGAN - network architecture, adversarial loss and perceptual loss, and improve each of them to derive an Enhanced SRGAN (ESRGAN). In particular, we introduce the Residual-in-Residual Dense Block (RRDB) without batch normalization as the basic network building unit. Moreover, we borrow the idea from relativistic GAN to let the discriminator predict relative realness instead of the absolute value. Finally, we improve the perceptual loss by using the features before activation, which could provide stronger supervision for brightness consistency and texture recovery. Benefiting from these improvements, the proposed ESRGAN achieves consistently better visual quality with more realistic and natural textures than SRGAN and won the first place in the PIRM2018-SR Challenge. The code is available at [this https URL](https://github.com/xinntao/ESRGAN).
[[Paper]](https://arxiv.org/abs/1809.00219) [[Code]](implementations/esrgan/esrgan.py)
#### Run Example
```
$ cd implementations/esrgan/
$ python3 esrgan.py
```

Nearest Neighbor Upsampling | ESRGAN
### GAN
_Generative Adversarial Network_
#### Authors
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
#### Abstract
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
[[Paper]](https://arxiv.org/abs/1406.2661) [[Code]](implementations/gan/gan.py)
#### Run Example
```
$ cd implementations/gan/
$ python3 gan.py
```

### InfoGAN
_InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets_
#### Authors
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, Pieter Abbeel
#### Abstract
This paper describes InfoGAN, an information-theoretic extension to the Generative Adversarial Network that is able to learn disentangled representations in a completely unsupervised manner. InfoGAN is a generative adversarial network that also maximizes the mutual information between a small subset of the latent variables and the observation. We derive a lower bound to the mutual information objective that can be optimized efficiently, and show that our training procedure can be interpreted as a variation of the Wake-Sleep algorithm. Specifically, InfoGAN successfully disentangles writing styles from digit shapes on the MNIST dataset, pose from lighting of 3D rendered images, and background digits from the central digit on the SVHN dataset. It also discovers visual concepts that include hair styles, presence/absence of eyeglasses, and emotions on the CelebA face dataset. Experiments show that InfoGAN learns interpretable representations that are competitive with representations learned by existing fully supervised methods.
[[Paper]](https://arxiv.org/abs/1606.03657) [[Code]](implementations/infogan/infogan.py)
#### Run Example
```
$ cd implementations/infogan/
$ python3 infogan.py
```

Result of varying categorical latent variable by column.

Result of varying continuous latent variable by row.
### Least Squares GAN
_Least Squares Generative Adversarial Networks_
#### Authors
Xudong Mao, Qing Li, Haoran Xie, Raymond Y.K. Lau, Zhen Wang, Stephen Paul Smolley
#### Abstract
Unsupervised learning with generative adversarial networks (GANs) has proven hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss function for the discriminator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson χ2 divergence. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stable during the learning process. We evaluate LSGANs on five scene datasets and the experimental results show that the images generated by LSGANs are of better quality than the ones generated by regular GANs. We also conduct two comparison experiments between LSGANs and regular GANs to illustrate the stability of LSGANs.
[[Paper]](https://arxiv.org/abs/1611.04076) [[Code]](implementations/lsgan/lsgan.py)
#### Run Example
```
$ cd implementations/lsgan/
$ python3 lsgan.py
```
### MUNIT
_Multimodal Unsupervised Image-to-Image Translation_
#### Authors
Xun Huang, Ming-Yu Liu, Serge Belongie, Jan Kautz
#### Abstract
Unsupervised image-to-image translation is an important and challenging problem in computer vision. Given an image in the source domain, the goal is to learn the conditional distribution of corresponding images in the target domain, without seeing any pairs of corresponding images. While this conditional distribution is inherently multimodal, existing approaches make an overly simplified assumption, modeling it as a deterministic one-to-one mapping. As a result, they fail to generate diverse outputs from a given source domain image. To address this limitation, we propose a Multimodal Unsupervised Image-to-image Translation (MUNIT) framework. We assume that the image representation can be decomposed into a content code that is domain-invariant, and a style code that captures domain-specific properties. To translate an image to another domain, we recombine its content code with a random style code sampled from the style space of the target domain. We analyze the proposed framework and establish several theoretical results. Extensive experiments with comparisons to the state-of-the-art approaches further demonstrates the advantage of the proposed framework. Moreover, our framework allows users to control the style of translation outputs by providing an example style image. Code and pretrained models are available at [this https URL](https://github.com/nvlabs/MUNIT)
[[Paper]](https://arxiv.org/abs/1804.04732) [[Code]](implementations/munit/munit.py)
#### Run Example
```
$ cd data/
$ bash download_pix2pix_dataset.sh edges2shoes
$ cd ../implementations/munit/
$ python3 munit.py --dataset_name edges2shoes
```

Results by varying the style code.
### Pix2Pix
_Unpaired Image-to-Image Translation with Conditional Adversarial Networks_
#### Authors
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
#### Abstract
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
[[Paper]](https://arxiv.org/abs/1611.07004) [[Code]](implementations/pix2pix/pix2pix.py)

#### Run Example
```
$ cd data/
$ bash download_pix2pix_dataset.sh facades
$ cd ../implementations/pix2pix/
$ python3 pix2pix.py --dataset_name facades
```

Rows from top to bottom: (1) The condition for the generator (2) Generated image
based of condition (3) The true corresponding image to the condition
### PixelDA
_Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks_
#### Authors
Konstantinos Bousmalis, Nathan Silberman, David Dohan, Dumitru Erhan, Dilip Krishnan
#### Abstract
Collecting well-annotated image datasets to train modern machine learning algorithms is prohibitively expensive for many tasks. One appealing alternative is rendering synthetic data where ground-truth annotations are generated automatically. Unfortunately, models trained purely on rendered images often fail to generalize to real images. To address this shortcoming, prior work introduced unsupervised domain adaptation algorithms that attempt to map representations between the two domains or learn to extract features that are domain-invariant. In this work, we present a new approach that learns, in an unsupervised manner, a transformation in the pixel space from one domain to the other. Our generative adversarial network (GAN)-based method adapts source-domain images to appear as if drawn from the target domain. Our approach not only produces plausible samples, but also outperforms the state-of-the-art on a number of unsupervised domain adaptation scenarios by large margins. Finally, we demonstrate that the adaptation process generalizes to object classes unseen during training.
[[Paper]](https://arxiv.org/abs/1612.05424) [[Code]](implementations/pixelda/pixelda.py)
#### MNIST to MNIST-M Classification
Trains a classifier on images that have been translated from the source domain (MNIST) to the target domain (MNIST-M) using the annotations of the source domain images. The classification network is trained jointly with the generator network to optimize the generator for both providing a proper domain translation and also for preserving the semantics of the source domain image. The classification network trained on translated images is compared to the naive solution of training a classifier on MNIST and evaluating it on MNIST-M. The naive model manages a 55% classification accuracy on MNIST-M while the one trained during domain adaptation achieves a 95% classification accuracy.
```
$ cd implementations/pixelda/
$ python3 pixelda.py
```
| Method | Accuracy |
| ------------ |:---------:|
| Naive | 55% |
| PixelDA | 95% |

Rows from top to bottom: (1) Real images from MNIST (2) Translated images from
MNIST to MNIST-M (3) Examples of images from MNIST-M
### Relativistic GAN
_The relativistic discriminator: a key element missing from standard GAN_
#### Authors
Alexia Jolicoeur-Martineau
#### Abstract
In standard generative adversarial network (SGAN), the discriminator estimates the probability that the input data is real. The generator is trained to increase the probability that fake data is real. We argue that it should also simultaneously decrease the probability that real data is real because 1) this would account for a priori knowledge that half of the data in the mini-batch is fake, 2) this would be observed with divergence minimization, and 3) in optimal settings, SGAN would be equivalent to integral probability metric (IPM) GANs.
We show that this property can be induced by using a relativistic discriminator which estimate the probability that the given real data is more realistic than a randomly sampled fake data. We also present a variant in which the discriminator estimate the probability that the given real data is more realistic than fake data, on average. We generalize both approaches to non-standard GAN loss functions and we refer to them respectively as Relativistic GANs (RGANs) and Relativistic average GANs (RaGANs). We show that IPM-based GANs are a subset of RGANs which use the identity function.
Empirically, we observe that 1) RGANs and RaGANs are significantly more stable and generate higher quality data samples than their non-relativistic counterparts, 2) Standard RaGAN with gradient penalty generate data of better quality than WGAN-GP while only requiring a single discriminator update per generator update (reducing the time taken for reaching the state-of-the-art by 400%), and 3) RaGANs are able to generate plausible high resolutions images (256x256) from a very small sample (N=2011), while GAN and LSGAN cannot; these images are of significantly better quality than the ones generated by WGAN-GP and SGAN with spectral normalization.
[[Paper]](https://arxiv.org/abs/1807.00734) [[Code]](implementations/relativistic_gan/relativistic_gan.py)
#### Run Example
```
$ cd implementations/relativistic_gan/
$ python3 relativistic_gan.py # Relativistic Standard GAN
$ python3 relativistic_gan.py --rel_avg_gan # Relativistic Average GAN
```
### Semi-Supervised GAN
_Semi-Supervised Generative Adversarial Network_
#### Authors
Augustus Odena
#### Abstract
We extend Generative Adversarial Networks (GANs) to the semi-supervised context by forcing the discriminator network to output class labels. We train a generative model G and a discriminator D on a dataset with inputs belonging to one of N classes. At training time, D is made to predict which of N+1 classes the input belongs to, where an extra class is added to correspond to the outputs of G. We show that this method can be used to create a more data-efficient classifier and that it allows for generating higher quality samples than a regular GAN.
[[Paper]](https://arxiv.org/abs/1606.01583) [[Code]](implementations/sgan/sgan.py)
#### Run Example
```
$ cd implementations/sgan/
$ python3 sgan.py
```
### Softmax GAN
_Softmax GAN_
#### Authors
Min Lin
#### Abstract
Softmax GAN is a novel variant of Generative Adversarial Network (GAN). The key idea of Softmax GAN is to replace the classification loss in the original GAN with a softmax cross-entropy loss in the sample space of one single batch. In the adversarial learning of N real training samples and M generated samples, the target of discriminator training is to distribute all the probability mass to the real samples, each with probability 1M, and distribute zero probability to generated data. In the generator training phase, the target is to assign equal probability to all data points in the batch, each with probability 1M+N. While the original GAN is closely related to Noise Contrastive Estimation (NCE), we show that Softmax GAN is the Importance Sampling version of GAN. We futher demonstrate with experiments that this simple change stabilizes GAN training.
[[Paper]](https://arxiv.org/abs/1704.06191) [[Code]](implementations/softmax_gan/softmax_gan.py)
#### Run Example
```
$ cd implementations/softmax_gan/
$ python3 softmax_gan.py
```
### StarGAN
_StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation_
#### Authors
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo
#### Abstract
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN's superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
[[Paper]](https://arxiv.org/abs/1711.09020) [[Code]](implementations/stargan/stargan.py)
#### Run Example
```
$ cd implementations/stargan/
$ python3 stargan.py
```

Original | Black Hair | Blonde Hair | Brown Hair | Gender Flip | Aged
### Super-Resolution GAN
_Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network_
#### Authors
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi
#### Abstract
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
[[Paper]](https://arxiv.org/abs/1609.04802) [[Code]](implementations/srgan/srgan.py)
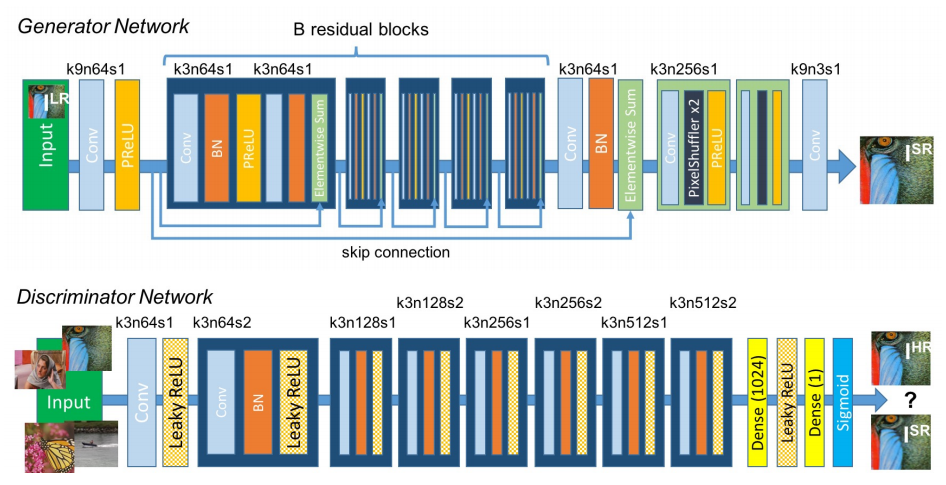
#### Run Example
```
$ cd implementations/srgan/
$ python3 srgan.py
```

Nearest Neighbor Upsampling | SRGAN
### UNIT
_Unsupervised Image-to-Image Translation Networks_
#### Authors
Ming-Yu Liu, Thomas Breuel, Jan Kautz
#### Abstract
Unsupervised image-to-image translation aims at learning a joint distribution of images in different domains by using images from the marginal distributions in individual domains. Since there exists an infinite set of joint distributions that can arrive the given marginal distributions, one could infer nothing about the joint distribution from the marginal distributions without additional assumptions. To address the problem, we make a shared-latent space assumption and propose an unsupervised image-to-image translation framework based on Coupled GANs. We compare the proposed framework with competing approaches and present high quality image translation results on various challenging unsupervised image translation tasks, including street scene image translation, animal image translation, and face image translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on benchmark datasets. Code and additional results are available in this [https URL](https://github.com/mingyuliutw/unit).
[[Paper]](https://arxiv.org/abs/1703.00848) [[Code]](implementations/unit/unit.py)
#### Run Example
```
$ cd data/
$ bash download_cyclegan_dataset.sh apple2orange
$ cd implementations/unit/
$ python3 unit.py --dataset_name apple2orange
```
### Wasserstein GAN
_Wasserstein GAN_
#### Authors
Martin Arjovsky, Soumith Chintala, Léon Bottou
#### Abstract
We introduce a new algorithm named WGAN, an alternative to traditional GAN training. In this new model, we show that we can improve the stability of learning, get rid of problems like mode collapse, and provide meaningful learning curves useful for debugging and hyperparameter searches. Furthermore, we show that the corresponding optimization problem is sound, and provide extensive theoretical work highlighting the deep connections to other distances between distributions.
[[Paper]](https://arxiv.org/abs/1701.07875) [[Code]](implementations/wgan/wgan.py)
#### Run Example
```
$ cd implementations/wgan/
$ python3 wgan.py
```
### Wasserstein GAN GP
_Improved Training of Wasserstein GANs_
#### Authors
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville
#### Abstract
Generative Adversarial Networks (GANs) are powerful generative models, but suffer from training instability. The recently proposed Wasserstein GAN (WGAN) makes progress toward stable training of GANs, but sometimes can still generate only low-quality samples or fail to converge. We find that these problems are often due to the use of weight clipping in WGAN to enforce a Lipschitz constraint on the critic, which can lead to undesired behavior. We propose an alternative to clipping weights: penalize the norm of gradient of the critic with respect to its input. Our proposed method performs better than standard WGAN and enables stable training of a wide variety of GAN architectures with almost no hyperparameter tuning, including 101-layer ResNets and language models over discrete data. We also achieve high quality generations on CIFAR-10 and LSUN bedrooms.
[[Paper]](https://arxiv.org/abs/1704.00028) [[Code]](implementations/wgan_gp/wgan_gp.py)
#### Run Example
```
$ cd implementations/wgan_gp/
$ python3 wgan_gp.py
```

### Wasserstein GAN DIV
_Wasserstein Divergence for GANs_
#### Authors
Jiqing Wu, Zhiwu Huang, Janine Thoma, Dinesh Acharya, Luc Van Gool
#### Abstract
In many domains of computer vision, generative adversarial networks (GANs) have achieved great success, among which the fam-
ily of Wasserstein GANs (WGANs) is considered to be state-of-the-art due to the theoretical contributions and competitive qualitative performance. However, it is very challenging to approximate the k-Lipschitz constraint required by the Wasserstein-1 metric (W-met). In this paper, we propose a novel Wasserstein divergence (W-div), which is a relaxed version of W-met and does not require the k-Lipschitz constraint.As a concrete application, we introduce a Wasserstein divergence objective for GANs (WGAN-div), which can faithfully approximate W-div through optimization. Under various settings, including progressive growing training, we demonstrate the stability of the proposed WGAN-div owing to its theoretical and practical advantages over WGANs. Also, we study the quantitative and visual performance of WGAN-div on standard image synthesis benchmarks, showing the superior performance of WGAN-div compared to the state-of-the-art methods.
[[Paper]](https://arxiv.org/abs/1712.01026) [[Code]](implementations/wgan_div/wgan_div.py)
#### Run Example
```
$ cd implementations/wgan_div/
$ python3 wgan_div.py
```

================================================
FILE: data/download_cyclegan_dataset.sh
================================================
#!/bin/bash
FILE=$1
if [[ $FILE != "ae_photos" && $FILE != "apple2orange" && $FILE != "summer2winter_yosemite" && $FILE != "horse2zebra" && $FILE != "monet2photo" && $FILE != "cezanne2photo" && $FILE != "ukiyoe2photo" && $FILE != "vangogh2photo" && $FILE != "maps" && $FILE != "cityscapes" && $FILE != "facades" && $FILE != "iphone2dslr_flower" && $FILE != "ae_photos" ]]; then
echo "Available datasets are: apple2orange, summer2winter_yosemite, horse2zebra, monet2photo, cezanne2photo, ukiyoe2photo, vangogh2photo, maps, cityscapes, facades, iphone2dslr_flower, ae_photos"
exit 1
fi
URL=https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/$FILE.zip
ZIP_FILE=./$FILE.zip
TARGET_DIR=./$FILE
wget -N $URL -O $ZIP_FILE
unzip $ZIP_FILE -d .
rm $ZIP_FILE
# Adapt to project expected directory heriarchy
mkdir -p "$TARGET_DIR/train" "$TARGET_DIR/test"
mv "$TARGET_DIR/trainA" "$TARGET_DIR/train/A"
mv "$TARGET_DIR/trainB" "$TARGET_DIR/train/B"
mv "$TARGET_DIR/testA" "$TARGET_DIR/test/A"
mv "$TARGET_DIR/testB" "$TARGET_DIR/test/B"
================================================
FILE: data/download_pix2pix_dataset.sh
================================================
FILE=$1
URL=https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/$FILE.tar.gz
TAR_FILE=./$FILE.tar.gz
TARGET_DIR=./$FILE/
wget -N $URL -O $TAR_FILE
mkdir $TARGET_DIR
tar -zxvf $TAR_FILE -C ./
rm $TAR_FILE
================================================
FILE: implementations/aae/aae.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=10, help="dimensionality of the latent code")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
def reparameterization(mu, logvar):
std = torch.exp(logvar / 2)
sampled_z = Variable(Tensor(np.random.normal(0, 1, (mu.size(0), opt.latent_dim))))
z = sampled_z * std + mu
return z
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
)
self.mu = nn.Linear(512, opt.latent_dim)
self.logvar = nn.Linear(512, opt.latent_dim)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
x = self.model(img_flat)
mu = self.mu(x)
logvar = self.logvar(x)
z = reparameterization(mu, logvar)
return z
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.latent_dim, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, int(np.prod(img_shape))),
nn.Tanh(),
)
def forward(self, z):
img_flat = self.model(z)
img = img_flat.view(img_flat.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.latent_dim, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, z):
validity = self.model(z)
return validity
# Use binary cross-entropy loss
adversarial_loss = torch.nn.BCELoss()
pixelwise_loss = torch.nn.L1Loss()
# Initialize generator and discriminator
encoder = Encoder()
decoder = Decoder()
discriminator = Discriminator()
if cuda:
encoder.cuda()
decoder.cuda()
discriminator.cuda()
adversarial_loss.cuda()
pixelwise_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(encoder.parameters(), decoder.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits"""
# Sample noise
z = Variable(Tensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
gen_imgs = decoder(z)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
encoded_imgs = encoder(real_imgs)
decoded_imgs = decoder(encoded_imgs)
# Loss measures generator's ability to fool the discriminator
g_loss = 0.001 * adversarial_loss(discriminator(encoded_imgs), valid) + 0.999 * pixelwise_loss(
decoded_imgs, real_imgs
)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as discriminator ground truth
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(z), valid)
fake_loss = adversarial_loss(discriminator(encoded_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
================================================
FILE: implementations/acgan/acgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.latent_dim)
self.init_size = opt.img_size // 4 # Initial size before upsampling
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise, labels):
gen_input = torch.mul(self.label_emb(labels), noise)
out = self.l1(gen_input)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
"""Returns layers of each discriminator block"""
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.conv_blocks = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
# Output layers
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.n_classes), nn.Softmax())
def forward(self, img):
out = self.conv_blocks(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
label = self.aux_layer(out)
return validity, label
# Loss functions
adversarial_loss = torch.nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
auxiliary_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits ranging from 0 to n_classes"""
# Sample noise
z = Variable(FloatTensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
# Get labels ranging from 0 to n_classes for n rows
labels = np.array([num for _ in range(n_row) for num in range(n_row)])
labels = Variable(LongTensor(labels))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise and labels as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))
# Generate a batch of images
gen_imgs = generator(z, gen_labels)
# Loss measures generator's ability to fool the discriminator
validity, pred_label = discriminator(gen_imgs)
g_loss = 0.5 * (adversarial_loss(validity, valid) + auxiliary_loss(pred_label, gen_labels))
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
real_pred, real_aux = discriminator(real_imgs)
d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2
# Loss for fake images
fake_pred, fake_aux = discriminator(gen_imgs.detach())
d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, gen_labels)) / 2
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
# Calculate discriminator accuracy
pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)
gt = np.concatenate([labels.data.cpu().numpy(), gen_labels.data.cpu().numpy()], axis=0)
d_acc = np.mean(np.argmax(pred, axis=1) == gt)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
================================================
FILE: implementations/began/began.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=62, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="number of image channels")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise):
out = self.l1(noise)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# Upsampling
self.down = nn.Sequential(nn.Conv2d(opt.channels, 64, 3, 2, 1), nn.ReLU())
# Fully-connected layers
self.down_size = opt.img_size // 2
down_dim = 64 * (opt.img_size // 2) ** 2
self.fc = nn.Sequential(
nn.Linear(down_dim, 32),
nn.BatchNorm1d(32, 0.8),
nn.ReLU(inplace=True),
nn.Linear(32, down_dim),
nn.BatchNorm1d(down_dim),
nn.ReLU(inplace=True),
)
# Upsampling
self.up = nn.Sequential(nn.Upsample(scale_factor=2), nn.Conv2d(64, opt.channels, 3, 1, 1))
def forward(self, img):
out = self.down(img)
out = self.fc(out.view(out.size(0), -1))
out = self.up(out.view(out.size(0), 64, self.down_size, self.down_size))
return out
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
# BEGAN hyper parameters
gamma = 0.75
lambda_k = 0.001
k = 0.0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = torch.mean(torch.abs(discriminator(gen_imgs) - gen_imgs))
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
d_real = discriminator(real_imgs)
d_fake = discriminator(gen_imgs.detach())
d_loss_real = torch.mean(torch.abs(d_real - real_imgs))
d_loss_fake = torch.mean(torch.abs(d_fake - gen_imgs.detach()))
d_loss = d_loss_real - k * d_loss_fake
d_loss.backward()
optimizer_D.step()
# ----------------
# Update weights
# ----------------
diff = torch.mean(gamma * d_loss_real - d_loss_fake)
# Update weight term for fake samples
k = k + lambda_k * diff.item()
k = min(max(k, 0), 1) # Constraint to interval [0, 1]
# Update convergence metric
M = (d_loss_real + torch.abs(diff)).data[0]
# --------------
# Log Progress
# --------------
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] -- M: %f, k: %f"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item(), M, k)
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/bgan/bgan.py
================================================
# Reference: https://wiseodd.github.io/techblog/2017/03/07/boundary-seeking-gan/
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
def boundary_seeking_loss(y_pred, y_true):
"""
Boundary seeking loss.
Reference: https://wiseodd.github.io/techblog/2017/03/07/boundary-seeking-gan/
"""
return 0.5 * torch.mean((torch.log(y_pred) - torch.log(1 - y_pred)) ** 2)
discriminator_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
discriminator_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(mnist_loader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = boundary_seeking_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = discriminator_loss(discriminator(real_imgs), valid)
fake_loss = discriminator_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(mnist_loader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(mnist_loader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/bicyclegan/bicyclegan.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import datetime
import time
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="edges2shoes", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=8, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=128, help="size of image height")
parser.add_argument("--img_width", type=int, default=128, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--latent_dim", type=int, default=8, help="number of latent codes")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between saving generator samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
parser.add_argument("--lambda_pixel", type=float, default=10, help="pixelwise loss weight")
parser.add_argument("--lambda_latent", type=float, default=0.5, help="latent loss weight")
parser.add_argument("--lambda_kl", type=float, default=0.01, help="kullback-leibler loss weight")
opt = parser.parse_args()
print(opt)
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
cuda = True if torch.cuda.is_available() else False
input_shape = (opt.channels, opt.img_height, opt.img_width)
# Loss functions
mae_loss = torch.nn.L1Loss()
# Initialize generator, encoder and discriminators
generator = Generator(opt.latent_dim, input_shape)
encoder = Encoder(opt.latent_dim, input_shape)
D_VAE = MultiDiscriminator(input_shape)
D_LR = MultiDiscriminator(input_shape)
if cuda:
generator = generator.cuda()
encoder.cuda()
D_VAE = D_VAE.cuda()
D_LR = D_LR.cuda()
mae_loss.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (opt.dataset_name, opt.epoch)))
encoder.load_state_dict(torch.load("saved_models/%s/encoder_%d.pth" % (opt.dataset_name, opt.epoch)))
D_VAE.load_state_dict(torch.load("saved_models/%s/D_VAE_%d.pth" % (opt.dataset_name, opt.epoch)))
D_LR.load_state_dict(torch.load("saved_models/%s/D_LR_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
generator.apply(weights_init_normal)
D_VAE.apply(weights_init_normal)
D_LR.apply(weights_init_normal)
# Optimizers
optimizer_E = torch.optim.Adam(encoder.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_VAE = torch.optim.Adam(D_VAE.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_LR = torch.optim.Adam(D_LR.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, input_shape),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, input_shape, mode="val"),
batch_size=8,
shuffle=True,
num_workers=1,
)
def sample_images(batches_done):
"""Saves a generated sample from the validation set"""
generator.eval()
imgs = next(iter(val_dataloader))
img_samples = None
for img_A, img_B in zip(imgs["A"], imgs["B"]):
# Repeat input image by number of desired columns
real_A = img_A.view(1, *img_A.shape).repeat(opt.latent_dim, 1, 1, 1)
real_A = Variable(real_A.type(Tensor))
# Sample latent representations
sampled_z = Variable(Tensor(np.random.normal(0, 1, (opt.latent_dim, opt.latent_dim))))
# Generate samples
fake_B = generator(real_A, sampled_z)
# Concatenate samples horisontally
fake_B = torch.cat([x for x in fake_B.data.cpu()], -1)
img_sample = torch.cat((img_A, fake_B), -1)
img_sample = img_sample.view(1, *img_sample.shape)
# Concatenate with previous samples vertically
img_samples = img_sample if img_samples is None else torch.cat((img_samples, img_sample), -2)
save_image(img_samples, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=8, normalize=True)
generator.train()
def reparameterization(mu, logvar):
std = torch.exp(logvar / 2)
sampled_z = Variable(Tensor(np.random.normal(0, 1, (mu.size(0), opt.latent_dim))))
z = sampled_z * std + mu
return z
# ----------
# Training
# ----------
# Adversarial loss
valid = 1
fake = 0
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# -------------------------------
# Train Generator and Encoder
# -------------------------------
optimizer_E.zero_grad()
optimizer_G.zero_grad()
# ----------
# cVAE-GAN
# ----------
# Produce output using encoding of B (cVAE-GAN)
mu, logvar = encoder(real_B)
encoded_z = reparameterization(mu, logvar)
fake_B = generator(real_A, encoded_z)
# Pixelwise loss of translated image by VAE
loss_pixel = mae_loss(fake_B, real_B)
# Kullback-Leibler divergence of encoded B
loss_kl = 0.5 * torch.sum(torch.exp(logvar) + mu ** 2 - logvar - 1)
# Adversarial loss
loss_VAE_GAN = D_VAE.compute_loss(fake_B, valid)
# ---------
# cLR-GAN
# ---------
# Produce output using sampled z (cLR-GAN)
sampled_z = Variable(Tensor(np.random.normal(0, 1, (real_A.size(0), opt.latent_dim))))
_fake_B = generator(real_A, sampled_z)
# cLR Loss: Adversarial loss
loss_LR_GAN = D_LR.compute_loss(_fake_B, valid)
# ----------------------------------
# Total Loss (Generator + Encoder)
# ----------------------------------
loss_GE = loss_VAE_GAN + loss_LR_GAN + opt.lambda_pixel * loss_pixel + opt.lambda_kl * loss_kl
loss_GE.backward(retain_graph=True)
optimizer_E.step()
# ---------------------
# Generator Only Loss
# ---------------------
# Latent L1 loss
_mu, _ = encoder(_fake_B)
loss_latent = opt.lambda_latent * mae_loss(_mu, sampled_z)
loss_latent.backward()
optimizer_G.step()
# ----------------------------------
# Train Discriminator (cVAE-GAN)
# ----------------------------------
optimizer_D_VAE.zero_grad()
loss_D_VAE = D_VAE.compute_loss(real_B, valid) + D_VAE.compute_loss(fake_B.detach(), fake)
loss_D_VAE.backward()
optimizer_D_VAE.step()
# ---------------------------------
# Train Discriminator (cLR-GAN)
# ---------------------------------
optimizer_D_LR.zero_grad()
loss_D_LR = D_LR.compute_loss(real_B, valid) + D_LR.compute_loss(_fake_B.detach(), fake)
loss_D_LR.backward()
optimizer_D_LR.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D VAE_loss: %f, LR_loss: %f] [G loss: %f, pixel: %f, kl: %f, latent: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D_VAE.item(),
loss_D_LR.item(),
loss_GE.item(),
loss_pixel.item(),
loss_kl.item(),
loss_latent.item(),
time_left,
)
)
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))
torch.save(encoder.state_dict(), "saved_models/%s/encoder_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_VAE.state_dict(), "saved_models/%s/D_VAE_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_LR.state_dict(), "saved_models/%s/D_LR_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/bicyclegan/datasets.py
================================================
import glob
import random
import os
import numpy as np
import torch
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, input_shape, mode="train"):
self.transform = transforms.Compose(
[
transforms.Resize(input_shape[-2:], Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
]
)
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/bicyclegan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
import numpy as np
from torchvision.models import resnet18
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 3, stride=2, padding=1, bias=False)]
if normalize:
layers.append(nn.BatchNorm2d(out_size, 0.8))
layers.append(nn.LeakyReLU(0.2))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size):
super(UNetUp, self).__init__()
self.model = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_size, out_size, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_size, 0.8),
nn.ReLU(inplace=True),
)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class Generator(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator, self).__init__()
channels, self.h, self.w = img_shape
self.fc = nn.Linear(latent_dim, self.h * self.w)
self.down1 = UNetDown(channels + 1, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512)
self.down5 = UNetDown(512, 512)
self.down6 = UNetDown(512, 512)
self.down7 = UNetDown(512, 512, normalize=False)
self.up1 = UNetUp(512, 512)
self.up2 = UNetUp(1024, 512)
self.up3 = UNetUp(1024, 512)
self.up4 = UNetUp(1024, 256)
self.up5 = UNetUp(512, 128)
self.up6 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2), nn.Conv2d(128, channels, 3, stride=1, padding=1), nn.Tanh()
)
def forward(self, x, z):
# Propogate noise through fc layer and reshape to img shape
z = self.fc(z).view(z.size(0), 1, self.h, self.w)
d1 = self.down1(torch.cat((x, z), 1))
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
u1 = self.up1(d7, d6)
u2 = self.up2(u1, d5)
u3 = self.up3(u2, d4)
u4 = self.up4(u3, d3)
u5 = self.up5(u4, d2)
u6 = self.up6(u5, d1)
return self.final(u6)
##############################
# Encoder
##############################
class Encoder(nn.Module):
def __init__(self, latent_dim, input_shape):
super(Encoder, self).__init__()
resnet18_model = resnet18(pretrained=False)
self.feature_extractor = nn.Sequential(*list(resnet18_model.children())[:-3])
self.pooling = nn.AvgPool2d(kernel_size=8, stride=8, padding=0)
# Output is mu and log(var) for reparameterization trick used in VAEs
self.fc_mu = nn.Linear(256, latent_dim)
self.fc_logvar = nn.Linear(256, latent_dim)
def forward(self, img):
out = self.feature_extractor(img)
out = self.pooling(out)
out = out.view(out.size(0), -1)
mu = self.fc_mu(out)
logvar = self.fc_logvar(out)
return mu, logvar
##############################
# Discriminator
##############################
class MultiDiscriminator(nn.Module):
def __init__(self, input_shape):
super(MultiDiscriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.BatchNorm2d(out_filters, 0.8))
layers.append(nn.LeakyReLU(0.2))
return layers
channels, _, _ = input_shape
# Extracts discriminator models
self.models = nn.ModuleList()
for i in range(3):
self.models.add_module(
"disc_%d" % i,
nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.Conv2d(512, 1, 3, padding=1)
),
)
self.downsample = nn.AvgPool2d(in_channels, stride=2, padding=[1, 1], count_include_pad=False)
def compute_loss(self, x, gt):
"""Computes the MSE between model output and scalar gt"""
loss = sum([torch.mean((out - gt) ** 2) for out in self.forward(x)])
return loss
def forward(self, x):
outputs = []
for m in self.models:
outputs.append(m(x))
x = self.downsample(x)
return outputs
================================================
FILE: implementations/ccgan/ccgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from datasets import *
from models import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=8, help="size of the batches")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=128, help="size of each image dimension")
parser.add_argument("--mask_size", type=int, default=32, help="size of random mask")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=500, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
input_shape = (opt.channels, opt.img_size, opt.img_size)
# Loss function
adversarial_loss = torch.nn.MSELoss()
# Initialize generator and discriminator
generator = Generator(input_shape)
discriminator = Discriminator(input_shape)
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Dataset loader
transforms_ = [
transforms.Resize((opt.img_size, opt.img_size), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
transforms_lr = [
transforms.Resize((opt.img_size // 4, opt.img_size // 4), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_x=transforms_, transforms_lr=transforms_lr),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def apply_random_mask(imgs):
idx = np.random.randint(0, opt.img_size - opt.mask_size, (imgs.shape[0], 2))
masked_imgs = imgs.clone()
for i, (y1, x1) in enumerate(idx):
y2, x2 = y1 + opt.mask_size, x1 + opt.mask_size
masked_imgs[i, :, y1:y2, x1:x2] = -1
return masked_imgs
def save_sample(saved_samples):
# Generate inpainted image
gen_imgs = generator(saved_samples["masked"], saved_samples["lowres"])
# Save sample
sample = torch.cat((saved_samples["masked"].data, gen_imgs.data, saved_samples["imgs"].data), -2)
save_image(sample, "images/%d.png" % batches_done, nrow=5, normalize=True)
saved_samples = {}
for epoch in range(opt.n_epochs):
for i, batch in enumerate(dataloader):
imgs = batch["x"]
imgs_lr = batch["x_lr"]
masked_imgs = apply_random_mask(imgs)
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], *discriminator.output_shape).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], *discriminator.output_shape).fill_(0.0), requires_grad=False)
if cuda:
imgs = imgs.type(Tensor)
imgs_lr = imgs_lr.type(Tensor)
masked_imgs = masked_imgs.type(Tensor)
real_imgs = Variable(imgs)
imgs_lr = Variable(imgs_lr)
masked_imgs = Variable(masked_imgs)
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_imgs = generator(masked_imgs, imgs_lr)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
# Save first ten samples
if not saved_samples:
saved_samples["imgs"] = real_imgs[:1].clone()
saved_samples["masked"] = masked_imgs[:1].clone()
saved_samples["lowres"] = imgs_lr[:1].clone()
elif saved_samples["imgs"].size(0) < 10:
saved_samples["imgs"] = torch.cat((saved_samples["imgs"], real_imgs[:1]), 0)
saved_samples["masked"] = torch.cat((saved_samples["masked"], masked_imgs[:1]), 0)
saved_samples["lowres"] = torch.cat((saved_samples["lowres"], imgs_lr[:1]), 0)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_sample(saved_samples)
================================================
FILE: implementations/ccgan/datasets.py
================================================
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_x=None, transforms_lr=None, mode='train'):
self.transform_x = transforms.Compose(transforms_x)
self.transform_lr = transforms.Compose(transforms_lr)
self.files = sorted(glob.glob('%s/*.*' % root))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
x = self.transform_x(img)
x_lr = self.transform_lr(img)
return {'x': x, 'x_lr': x_lr}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/ccgan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
model = [nn.Conv2d(in_size, out_size, 4, stride=2, padding=1, bias=False)]
if normalize:
model.append(nn.BatchNorm2d(out_size, 0.8))
model.append(nn.LeakyReLU(0.2))
if dropout:
model.append(nn.Dropout(dropout))
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
model = [
nn.ConvTranspose2d(in_size, out_size, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(out_size, 0.8),
nn.ReLU(inplace=True),
]
if dropout:
model.append(nn.Dropout(dropout))
self.model = nn.Sequential(*model)
def forward(self, x, skip_input):
x = self.model(x)
out = torch.cat((x, skip_input), 1)
return out
class Generator(nn.Module):
def __init__(self, input_shape):
super(Generator, self).__init__()
channels, _, _ = input_shape
self.down1 = UNetDown(channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128 + channels, 256, dropout=0.5)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 256, dropout=0.5)
self.up4 = UNetUp(512, 128)
self.up5 = UNetUp(256 + channels, 64)
final = [nn.Upsample(scale_factor=2), nn.Conv2d(128, channels, 3, 1, 1), nn.Tanh()]
self.final = nn.Sequential(*final)
def forward(self, x, x_lr):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d2 = torch.cat((d2, x_lr), 1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
u1 = self.up1(d6, d5)
u2 = self.up2(u1, d4)
u3 = self.up3(u2, d3)
u4 = self.up4(u3, d2)
u5 = self.up5(u4, d1)
return self.final(u5)
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output of image discriminator (PatchGAN)
patch_h, patch_w = int(height / 2 ** 3), int(width / 2 ** 3)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, stride, normalize):
"""Returns layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 3, stride, 1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = channels
for out_filters, stride, normalize in [(64, 2, False), (128, 2, True), (256, 2, True), (512, 1, True)]:
layers.extend(discriminator_block(in_filters, out_filters, stride, normalize))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, 3, 1, 1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/cgan/cgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
# Concatenate label embedding and image to produce input
gen_input = torch.cat((self.label_emb(labels), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
# Concatenate label embedding and image to produce input
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels)), -1)
validity = self.model(d_in)
return validity
# Loss functions
adversarial_loss = torch.nn.MSELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits ranging from 0 to n_classes"""
# Sample noise
z = Variable(FloatTensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
# Get labels ranging from 0 to n_classes for n rows
labels = np.array([num for _ in range(n_row) for num in range(n_row)])
labels = Variable(LongTensor(labels))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise and labels as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))
# Generate a batch of images
gen_imgs = generator(z, gen_labels)
# Loss measures generator's ability to fool the discriminator
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
validity_real = discriminator(real_imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid)
# Loss for fake images
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake)
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
================================================
FILE: implementations/cluster_gan/clustergan.py
================================================
from __future__ import print_function
try:
import argparse
import os
import numpy as np
from torch.autograd import Variable
from torch.autograd import grad as torch_grad
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.transforms as transforms
from torchvision.utils import save_image
from itertools import chain as ichain
except ImportError as e:
print(e)
raise ImportError
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser(description="ClusterGAN Training Script")
parser.add_argument("-n", "--n_epochs", dest="n_epochs", default=200, type=int, help="Number of epochs")
parser.add_argument("-b", "--batch_size", dest="batch_size", default=64, type=int, help="Batch size")
parser.add_argument("-i", "--img_size", dest="img_size", type=int, default=28, help="Size of image dimension")
parser.add_argument("-d", "--latent_dim", dest="latent_dim", default=30, type=int, help="Dimension of latent space")
parser.add_argument("-l", "--lr", dest="learning_rate", type=float, default=0.0001, help="Learning rate")
parser.add_argument("-c", "--n_critic", dest="n_critic", type=int, default=5, help="Number of training steps for discriminator per iter")
parser.add_argument("-w", "--wass_flag", dest="wass_flag", action='store_true', help="Flag for Wasserstein metric")
args = parser.parse_args()
# Sample a random latent space vector
def sample_z(shape=64, latent_dim=10, n_c=10, fix_class=-1, req_grad=False):
assert (fix_class == -1 or (fix_class >= 0 and fix_class < n_c) ), "Requested class %i outside bounds."%fix_class
Tensor = torch.cuda.FloatTensor
# Sample noise as generator input, zn
zn = Variable(Tensor(0.75*np.random.normal(0, 1, (shape, latent_dim))), requires_grad=req_grad)
######### zc, zc_idx variables with grads, and zc to one-hot vector
# Pure one-hot vector generation
zc_FT = Tensor(shape, n_c).fill_(0)
zc_idx = torch.empty(shape, dtype=torch.long)
if (fix_class == -1):
zc_idx = zc_idx.random_(n_c).cuda()
zc_FT = zc_FT.scatter_(1, zc_idx.unsqueeze(1), 1.)
else:
zc_idx[:] = fix_class
zc_FT[:, fix_class] = 1
zc_idx = zc_idx.cuda()
zc_FT = zc_FT.cuda()
zc = Variable(zc_FT, requires_grad=req_grad)
# Return components of latent space variable
return zn, zc, zc_idx
def calc_gradient_penalty(netD, real_data, generated_data):
# GP strength
LAMBDA = 10
b_size = real_data.size()[0]
# Calculate interpolation
alpha = torch.rand(b_size, 1, 1, 1)
alpha = alpha.expand_as(real_data)
alpha = alpha.cuda()
interpolated = alpha * real_data.data + (1 - alpha) * generated_data.data
interpolated = Variable(interpolated, requires_grad=True)
interpolated = interpolated.cuda()
# Calculate probability of interpolated examples
prob_interpolated = netD(interpolated)
# Calculate gradients of probabilities with respect to examples
gradients = torch_grad(outputs=prob_interpolated, inputs=interpolated,
grad_outputs=torch.ones(prob_interpolated.size()).cuda(),
create_graph=True, retain_graph=True)[0]
# Gradients have shape (batch_size, num_channels, img_width, img_height),
# so flatten to easily take norm per example in batch
gradients = gradients.view(b_size, -1)
# Derivatives of the gradient close to 0 can cause problems because of
# the square root, so manually calculate norm and add epsilon
gradients_norm = torch.sqrt(torch.sum(gradients ** 2, dim=1) + 1e-12)
# Return gradient penalty
return LAMBDA * ((gradients_norm - 1) ** 2).mean()
# Weight Initializer
def initialize_weights(net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
# Softmax function
def softmax(x):
return F.softmax(x, dim=1)
class Reshape(nn.Module):
"""
Class for performing a reshape as a layer in a sequential model.
"""
def __init__(self, shape=[]):
super(Reshape, self).__init__()
self.shape = shape
def forward(self, x):
return x.view(x.size(0), *self.shape)
def extra_repr(self):
# (Optional)Set the extra information about this module. You can test
# it by printing an object of this class.
return 'shape={}'.format(
self.shape
)
class Generator_CNN(nn.Module):
"""
CNN to model the generator of a ClusterGAN
Input is a vector from representation space of dimension z_dim
output is a vector from image space of dimension X_dim
"""
# Architecture : FC1024_BR-FC7x7x128_BR-(64)4dc2s_BR-(1)4dc2s_S
def __init__(self, latent_dim, n_c, x_shape, verbose=False):
super(Generator_CNN, self).__init__()
self.name = 'generator'
self.latent_dim = latent_dim
self.n_c = n_c
self.x_shape = x_shape
self.ishape = (128, 7, 7)
self.iels = int(np.prod(self.ishape))
self.verbose = verbose
self.model = nn.Sequential(
# Fully connected layers
torch.nn.Linear(self.latent_dim + self.n_c, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2, inplace=True),
torch.nn.Linear(1024, self.iels),
nn.BatchNorm1d(self.iels),
nn.LeakyReLU(0.2, inplace=True),
# Reshape to 128 x (7x7)
Reshape(self.ishape),
# Upconvolution layers
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1, bias=True),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(64, 1, 4, stride=2, padding=1, bias=True),
nn.Sigmoid()
)
initialize_weights(self)
if self.verbose:
print("Setting up {}...\n".format(self.name))
print(self.model)
def forward(self, zn, zc):
z = torch.cat((zn, zc), 1)
x_gen = self.model(z)
# Reshape for output
x_gen = x_gen.view(x_gen.size(0), *self.x_shape)
return x_gen
class Encoder_CNN(nn.Module):
"""
CNN to model the encoder of a ClusterGAN
Input is vector X from image space if dimension X_dim
Output is vector z from representation space of dimension z_dim
"""
def __init__(self, latent_dim, n_c, verbose=False):
super(Encoder_CNN, self).__init__()
self.name = 'encoder'
self.channels = 1
self.latent_dim = latent_dim
self.n_c = n_c
self.cshape = (128, 5, 5)
self.iels = int(np.prod(self.cshape))
self.lshape = (self.iels,)
self.verbose = verbose
self.model = nn.Sequential(
# Convolutional layers
nn.Conv2d(self.channels, 64, 4, stride=2, bias=True),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, stride=2, bias=True),
nn.LeakyReLU(0.2, inplace=True),
# Flatten
Reshape(self.lshape),
# Fully connected layers
torch.nn.Linear(self.iels, 1024),
nn.LeakyReLU(0.2, inplace=True),
torch.nn.Linear(1024, latent_dim + n_c)
)
initialize_weights(self)
if self.verbose:
print("Setting up {}...\n".format(self.name))
print(self.model)
def forward(self, in_feat):
z_img = self.model(in_feat)
# Reshape for output
z = z_img.view(z_img.shape[0], -1)
# Separate continuous and one-hot components
zn = z[:, 0:self.latent_dim]
zc_logits = z[:, self.latent_dim:]
# Softmax on zc component
zc = softmax(zc_logits)
return zn, zc, zc_logits
class Discriminator_CNN(nn.Module):
"""
CNN to model the discriminator of a ClusterGAN
Input is tuple (X,z) of an image vector and its corresponding
representation z vector. For example, if X comes from the dataset, corresponding
z is Encoder(X), and if z is sampled from representation space, X is Generator(z)
Output is a 1-dimensional value
"""
# Architecture : (64)4c2s-(128)4c2s_BL-FC1024_BL-FC1_S
def __init__(self, wass_metric=False, verbose=False):
super(Discriminator_CNN, self).__init__()
self.name = 'discriminator'
self.channels = 1
self.cshape = (128, 5, 5)
self.iels = int(np.prod(self.cshape))
self.lshape = (self.iels,)
self.wass = wass_metric
self.verbose = verbose
self.model = nn.Sequential(
# Convolutional layers
nn.Conv2d(self.channels, 64, 4, stride=2, bias=True),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, stride=2, bias=True),
nn.LeakyReLU(0.2, inplace=True),
# Flatten
Reshape(self.lshape),
# Fully connected layers
torch.nn.Linear(self.iels, 1024),
nn.LeakyReLU(0.2, inplace=True),
torch.nn.Linear(1024, 1),
)
# If NOT using Wasserstein metric, final Sigmoid
if (not self.wass):
self.model = nn.Sequential(self.model, torch.nn.Sigmoid())
initialize_weights(self)
if self.verbose:
print("Setting up {}...\n".format(self.name))
print(self.model)
def forward(self, img):
# Get output
validity = self.model(img)
return validity
# Training details
n_epochs = args.n_epochs
batch_size = args.batch_size
test_batch_size = 5000
lr = args.learning_rate
b1 = 0.5
b2 = 0.9
decay = 2.5*1e-5
n_skip_iter = args.n_critic
# Data dimensions
img_size = args.img_size
channels = 1
# Latent space info
latent_dim = args.latent_dim
n_c = 10
betan = 10
betac = 10
# Wasserstein+GP metric flag
wass_metric = args.wass_flag
x_shape = (channels, img_size, img_size)
cuda = True if torch.cuda.is_available() else False
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Loss function
bce_loss = torch.nn.BCELoss()
xe_loss = torch.nn.CrossEntropyLoss()
mse_loss = torch.nn.MSELoss()
# Initialize generator and discriminator
generator = Generator_CNN(latent_dim, n_c, x_shape)
encoder = Encoder_CNN(latent_dim, n_c)
discriminator = Discriminator_CNN(wass_metric=wass_metric)
if cuda:
generator.cuda()
encoder.cuda()
discriminator.cuda()
bce_loss.cuda()
xe_loss.cuda()
mse_loss.cuda()
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.ToTensor()]
),
),
batch_size=batch_size,
shuffle=True,
)
# Test data loader
testdata = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=False,
download=True,
transform=transforms.Compose(
[transforms.ToTensor()]
),
),
batch_size=batch_size,
shuffle=True,
)
test_imgs, test_labels = next(iter(testdata))
test_imgs = Variable(test_imgs.type(Tensor))
ge_chain = ichain(generator.parameters(),
encoder.parameters())
optimizer_GE = torch.optim.Adam(ge_chain, lr=lr, betas=(b1, b2), weight_decay=decay)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
# ----------
# Training
# ----------
ge_l = []
d_l = []
c_zn = []
c_zc = []
c_i = []
# Training loop
print('\nBegin training session with %i epochs...\n'%(n_epochs))
for epoch in range(n_epochs):
for i, (imgs, itruth_label) in enumerate(dataloader):
# Ensure generator/encoder are trainable
generator.train()
encoder.train()
# Zero gradients for models
generator.zero_grad()
encoder.zero_grad()
discriminator.zero_grad()
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------------
# Train Generator + Encoder
# ---------------------------
optimizer_GE.zero_grad()
# Sample random latent variables
zn, zc, zc_idx = sample_z(shape=imgs.shape[0],
latent_dim=latent_dim,
n_c=n_c)
# Generate a batch of images
gen_imgs = generator(zn, zc)
# Discriminator output from real and generated samples
D_gen = discriminator(gen_imgs)
D_real = discriminator(real_imgs)
# Step for Generator & Encoder, n_skip_iter times less than for discriminator
if (i % n_skip_iter == 0):
# Encode the generated images
enc_gen_zn, enc_gen_zc, enc_gen_zc_logits = encoder(gen_imgs)
# Calculate losses for z_n, z_c
zn_loss = mse_loss(enc_gen_zn, zn)
zc_loss = xe_loss(enc_gen_zc_logits, zc_idx)
# Check requested metric
if wass_metric:
# Wasserstein GAN loss
ge_loss = torch.mean(D_gen) + betan * zn_loss + betac * zc_loss
else:
# Vanilla GAN loss
valid = Variable(Tensor(gen_imgs.size(0), 1).fill_(1.0), requires_grad=False)
v_loss = bce_loss(D_gen, valid)
ge_loss = v_loss + betan * zn_loss + betac * zc_loss
ge_loss.backward(retain_graph=True)
optimizer_GE.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
if wass_metric:
# Gradient penalty term
grad_penalty = calc_gradient_penalty(discriminator, real_imgs, gen_imgs)
# Wasserstein GAN loss w/gradient penalty
d_loss = torch.mean(D_real) - torch.mean(D_gen) + grad_penalty
else:
# Vanilla GAN loss
fake = Variable(Tensor(gen_imgs.size(0), 1).fill_(0.0), requires_grad=False)
real_loss = bce_loss(D_real, valid)
fake_loss = bce_loss(D_gen, fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# Save training losses
d_l.append(d_loss.item())
ge_l.append(ge_loss.item())
# Generator in eval mode
generator.eval()
encoder.eval()
# Set number of examples for cycle calcs
n_sqrt_samp = 5
n_samp = n_sqrt_samp * n_sqrt_samp
## Cycle through test real -> enc -> gen
t_imgs, t_label = test_imgs.data, test_labels
# Encode sample real instances
e_tzn, e_tzc, e_tzc_logits = encoder(t_imgs)
# Generate sample instances from encoding
teg_imgs = generator(e_tzn, e_tzc)
# Calculate cycle reconstruction loss
img_mse_loss = mse_loss(t_imgs, teg_imgs)
# Save img reco cycle loss
c_i.append(img_mse_loss.item())
## Cycle through randomly sampled encoding -> generator -> encoder
zn_samp, zc_samp, zc_samp_idx = sample_z(shape=n_samp,
latent_dim=latent_dim,
n_c=n_c)
# Generate sample instances
gen_imgs_samp = generator(zn_samp, zc_samp)
# Encode sample instances
zn_e, zc_e, zc_e_logits = encoder(gen_imgs_samp)
# Calculate cycle latent losses
lat_mse_loss = mse_loss(zn_e, zn_samp)
lat_xe_loss = xe_loss(zc_e_logits, zc_samp_idx)
# Save latent space cycle losses
c_zn.append(lat_mse_loss.item())
c_zc.append(lat_xe_loss.item())
# Save cycled and generated examples!
r_imgs, i_label = real_imgs.data[:n_samp], itruth_label[:n_samp]
e_zn, e_zc, e_zc_logits = encoder(r_imgs)
reg_imgs = generator(e_zn, e_zc)
save_image(reg_imgs.data[:n_samp],
'images/cycle_reg_%06i.png' %(epoch),
nrow=n_sqrt_samp, normalize=True)
save_image(gen_imgs_samp.data[:n_samp],
'images/gen_%06i.png' %(epoch),
nrow=n_sqrt_samp, normalize=True)
## Generate samples for specified classes
stack_imgs = []
for idx in range(n_c):
# Sample specific class
zn_samp, zc_samp, zc_samp_idx = sample_z(shape=n_c,
latent_dim=latent_dim,
n_c=n_c,
fix_class=idx)
# Generate sample instances
gen_imgs_samp = generator(zn_samp, zc_samp)
if (len(stack_imgs) == 0):
stack_imgs = gen_imgs_samp
else:
stack_imgs = torch.cat((stack_imgs, gen_imgs_samp), 0)
# Save class-specified generated examples!
save_image(stack_imgs,
'images/gen_classes_%06i.png' %(epoch),
nrow=n_c, normalize=True)
print ("[Epoch %d/%d] \n"\
"\tModel Losses: [D: %f] [GE: %f]" % (epoch,
n_epochs,
d_loss.item(),
ge_loss.item())
)
print("\tCycle Losses: [x: %f] [z_n: %f] [z_c: %f]"%(img_mse_loss.item(),
lat_mse_loss.item(),
lat_xe_loss.item())
)
================================================
FILE: implementations/cogan/cogan.py
================================================
import argparse
import os
import numpy as np
import math
import scipy
import itertools
import mnistm
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=32, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Linear") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class CoupledGenerators(nn.Module):
def __init__(self):
super(CoupledGenerators, self).__init__()
self.init_size = opt.img_size // 4
self.fc = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.shared_conv = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
)
self.G1 = nn.Sequential(
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
self.G2 = nn.Sequential(
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise):
out = self.fc(noise)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img_emb = self.shared_conv(out)
img1 = self.G1(img_emb)
img2 = self.G2(img_emb)
return img1, img2
class CoupledDiscriminators(nn.Module):
def __init__(self):
super(CoupledDiscriminators, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
block.extend([nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)])
return block
self.shared_conv = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.D1 = nn.Linear(128 * ds_size ** 2, 1)
self.D2 = nn.Linear(128 * ds_size ** 2, 1)
def forward(self, img1, img2):
# Determine validity of first image
out = self.shared_conv(img1)
out = out.view(out.shape[0], -1)
validity1 = self.D1(out)
# Determine validity of second image
out = self.shared_conv(img2)
out = out.view(out.shape[0], -1)
validity2 = self.D2(out)
return validity1, validity2
# Loss function
adversarial_loss = torch.nn.MSELoss()
# Initialize models
coupled_generators = CoupledGenerators()
coupled_discriminators = CoupledDiscriminators()
if cuda:
coupled_generators.cuda()
coupled_discriminators.cuda()
# Initialize weights
coupled_generators.apply(weights_init_normal)
coupled_discriminators.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader1 = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
os.makedirs("../../data/mnistm", exist_ok=True)
dataloader2 = torch.utils.data.DataLoader(
mnistm.MNISTM(
"../../data/mnistm",
train=True,
download=True,
transform=transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(coupled_generators.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(coupled_discriminators.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, ((imgs1, _), (imgs2, _)) in enumerate(zip(dataloader1, dataloader2)):
batch_size = imgs1.shape[0]
# Adversarial ground truths
valid = Variable(Tensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input
imgs1 = Variable(imgs1.type(Tensor).expand(imgs1.size(0), 3, opt.img_size, opt.img_size))
imgs2 = Variable(imgs2.type(Tensor))
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
# Generate a batch of images
gen_imgs1, gen_imgs2 = coupled_generators(z)
# Determine validity of generated images
validity1, validity2 = coupled_discriminators(gen_imgs1, gen_imgs2)
g_loss = (adversarial_loss(validity1, valid) + adversarial_loss(validity2, valid)) / 2
g_loss.backward()
optimizer_G.step()
# ----------------------
# Train Discriminators
# ----------------------
optimizer_D.zero_grad()
# Determine validity of real and generated images
validity1_real, validity2_real = coupled_discriminators(imgs1, imgs2)
validity1_fake, validity2_fake = coupled_discriminators(gen_imgs1.detach(), gen_imgs2.detach())
d_loss = (
adversarial_loss(validity1_real, valid)
+ adversarial_loss(validity1_fake, fake)
+ adversarial_loss(validity2_real, valid)
+ adversarial_loss(validity2_fake, fake)
) / 4
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader1), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader1) + i
if batches_done % opt.sample_interval == 0:
gen_imgs = torch.cat((gen_imgs1.data, gen_imgs2.data), 0)
save_image(gen_imgs, "images/%d.png" % batches_done, nrow=8, normalize=True)
================================================
FILE: implementations/cogan/mnistm.py
================================================
"""Dataset setting and data loader for MNIST-M.
Modified from
https://github.com/pytorch/vision/blob/master/torchvision/datasets/mnist.py
CREDIT: https://github.com/corenel
"""
from __future__ import print_function
import errno
import os
import torch
import torch.utils.data as data
from PIL import Image
class MNISTM(data.Dataset):
"""`MNIST-M Dataset."""
url = "https://github.com/VanushVaswani/keras_mnistm/releases/download/1.0/keras_mnistm.pkl.gz"
raw_folder = "raw"
processed_folder = "processed"
training_file = "mnist_m_train.pt"
test_file = "mnist_m_test.pt"
def __init__(self, root, mnist_root="data", train=True, transform=None, target_transform=None, download=False):
"""Init MNIST-M dataset."""
super(MNISTM, self).__init__()
self.root = os.path.expanduser(root)
self.mnist_root = os.path.expanduser(mnist_root)
self.transform = transform
self.target_transform = target_transform
self.train = train # training set or test set
if download:
self.download()
if not self._check_exists():
raise RuntimeError("Dataset not found." + " You can use download=True to download it")
if self.train:
self.train_data, self.train_labels = torch.load(
os.path.join(self.root, self.processed_folder, self.training_file)
)
else:
self.test_data, self.test_labels = torch.load(
os.path.join(self.root, self.processed_folder, self.test_file)
)
def __getitem__(self, index):
"""Get images and target for data loader.
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
if self.train:
img, target = self.train_data[index], self.train_labels[index]
else:
img, target = self.test_data[index], self.test_labels[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.squeeze().numpy(), mode="RGB")
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
"""Return size of dataset."""
if self.train:
return len(self.train_data)
else:
return len(self.test_data)
def _check_exists(self):
return os.path.exists(os.path.join(self.root, self.processed_folder, self.training_file)) and os.path.exists(
os.path.join(self.root, self.processed_folder, self.test_file)
)
def download(self):
"""Download the MNIST data."""
# import essential packages
from six.moves import urllib
import gzip
import pickle
from torchvision import datasets
# check if dataset already exists
if self._check_exists():
return
# make data dirs
try:
os.makedirs(os.path.join(self.root, self.raw_folder))
os.makedirs(os.path.join(self.root, self.processed_folder))
except OSError as e:
if e.errno == errno.EEXIST:
pass
else:
raise
# download pkl files
print("Downloading " + self.url)
filename = self.url.rpartition("/")[2]
file_path = os.path.join(self.root, self.raw_folder, filename)
if not os.path.exists(file_path.replace(".gz", "")):
data = urllib.request.urlopen(self.url)
with open(file_path, "wb") as f:
f.write(data.read())
with open(file_path.replace(".gz", ""), "wb") as out_f, gzip.GzipFile(file_path) as zip_f:
out_f.write(zip_f.read())
os.unlink(file_path)
# process and save as torch files
print("Processing...")
# load MNIST-M images from pkl file
with open(file_path.replace(".gz", ""), "rb") as f:
mnist_m_data = pickle.load(f, encoding="bytes")
mnist_m_train_data = torch.ByteTensor(mnist_m_data[b"train"])
mnist_m_test_data = torch.ByteTensor(mnist_m_data[b"test"])
# get MNIST labels
mnist_train_labels = datasets.MNIST(root=self.mnist_root, train=True, download=True).train_labels
mnist_test_labels = datasets.MNIST(root=self.mnist_root, train=False, download=True).test_labels
# save MNIST-M dataset
training_set = (mnist_m_train_data, mnist_train_labels)
test_set = (mnist_m_test_data, mnist_test_labels)
with open(os.path.join(self.root, self.processed_folder, self.training_file), "wb") as f:
torch.save(training_set, f)
with open(os.path.join(self.root, self.processed_folder, self.test_file), "wb") as f:
torch.save(test_set, f)
print("Done!")
================================================
FILE: implementations/context_encoder/context_encoder.py
================================================
"""
Inpainting using Generative Adversarial Networks.
The dataset can be downloaded from: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AADIKlz8PR9zr6Y20qbkunrba/Img/img_align_celeba.zip?dl=0
(if not available there see if options are listed at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html)
Instrustion on running the script:
1. Download the dataset from the provided link
2. Save the folder 'img_align_celeba' to '../../data/'
4. Run the sript using command 'python3 context_encoder.py'
"""
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from datasets import *
from models import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=8, help="size of the batches")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=128, help="size of each image dimension")
parser.add_argument("--mask_size", type=int, default=64, help="size of random mask")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=500, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
# Calculate output of image discriminator (PatchGAN)
patch_h, patch_w = int(opt.mask_size / 2 ** 3), int(opt.mask_size / 2 ** 3)
patch = (1, patch_h, patch_w)
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
# Loss function
adversarial_loss = torch.nn.MSELoss()
pixelwise_loss = torch.nn.L1Loss()
# Initialize generator and discriminator
generator = Generator(channels=opt.channels)
discriminator = Discriminator(channels=opt.channels)
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
pixelwise_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Dataset loader
transforms_ = [
transforms.Resize((opt.img_size, opt.img_size), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
test_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
batch_size=12,
shuffle=True,
num_workers=1,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def save_sample(batches_done):
samples, masked_samples, i = next(iter(test_dataloader))
samples = Variable(samples.type(Tensor))
masked_samples = Variable(masked_samples.type(Tensor))
i = i[0].item() # Upper-left coordinate of mask
# Generate inpainted image
gen_mask = generator(masked_samples)
filled_samples = masked_samples.clone()
filled_samples[:, :, i : i + opt.mask_size, i : i + opt.mask_size] = gen_mask
# Save sample
sample = torch.cat((masked_samples.data, filled_samples.data, samples.data), -2)
save_image(sample, "images/%d.png" % batches_done, nrow=6, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, masked_imgs, masked_parts) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], *patch).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], *patch).fill_(0.0), requires_grad=False)
# Configure input
imgs = Variable(imgs.type(Tensor))
masked_imgs = Variable(masked_imgs.type(Tensor))
masked_parts = Variable(masked_parts.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_parts = generator(masked_imgs)
# Adversarial and pixelwise loss
g_adv = adversarial_loss(discriminator(gen_parts), valid)
g_pixel = pixelwise_loss(gen_parts, masked_parts)
# Total loss
g_loss = 0.001 * g_adv + 0.999 * g_pixel
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(masked_parts), valid)
fake_loss = adversarial_loss(discriminator(gen_parts.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G adv: %f, pixel: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_adv.item(), g_pixel.item())
)
# Generate sample at sample interval
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_sample(batches_done)
================================================
FILE: implementations/context_encoder/datasets.py
================================================
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, img_size=128, mask_size=64, mode="train"):
self.transform = transforms.Compose(transforms_)
self.img_size = img_size
self.mask_size = mask_size
self.mode = mode
self.files = sorted(glob.glob("%s/*.jpg" % root))
self.files = self.files[:-4000] if mode == "train" else self.files[-4000:]
def apply_random_mask(self, img):
"""Randomly masks image"""
y1, x1 = np.random.randint(0, self.img_size - self.mask_size, 2)
y2, x2 = y1 + self.mask_size, x1 + self.mask_size
masked_part = img[:, y1:y2, x1:x2]
masked_img = img.clone()
masked_img[:, y1:y2, x1:x2] = 1
return masked_img, masked_part
def apply_center_mask(self, img):
"""Mask center part of image"""
# Get upper-left pixel coordinate
i = (self.img_size - self.mask_size) // 2
masked_img = img.clone()
masked_img[:, i : i + self.mask_size, i : i + self.mask_size] = 1
return masked_img, i
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
img = self.transform(img)
if self.mode == "train":
# For training data perform random mask
masked_img, aux = self.apply_random_mask(img)
else:
# For test data mask the center of the image
masked_img, aux = self.apply_center_mask(img)
return img, masked_img, aux
def __len__(self):
return len(self.files)
================================================
FILE: implementations/context_encoder/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
class Generator(nn.Module):
def __init__(self, channels=3):
super(Generator, self).__init__()
def downsample(in_feat, out_feat, normalize=True):
layers = [nn.Conv2d(in_feat, out_feat, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.BatchNorm2d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2))
return layers
def upsample(in_feat, out_feat, normalize=True):
layers = [nn.ConvTranspose2d(in_feat, out_feat, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.BatchNorm2d(out_feat, 0.8))
layers.append(nn.ReLU())
return layers
self.model = nn.Sequential(
*downsample(channels, 64, normalize=False),
*downsample(64, 64),
*downsample(64, 128),
*downsample(128, 256),
*downsample(256, 512),
nn.Conv2d(512, 4000, 1),
*upsample(4000, 512),
*upsample(512, 256),
*upsample(256, 128),
*upsample(128, 64),
nn.Conv2d(64, channels, 3, 1, 1),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, stride, normalize):
"""Returns layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 3, stride, 1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = channels
for out_filters, stride, normalize in [(64, 2, False), (128, 2, True), (256, 2, True), (512, 1, True)]:
layers.extend(discriminator_block(in_filters, out_filters, stride, normalize))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, 3, 1, 1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/cyclegan/cyclegan.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import datetime
import time
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
from utils import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="monet2photo", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving generator outputs")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between saving model checkpoints")
parser.add_argument("--n_residual_blocks", type=int, default=9, help="number of residual blocks in generator")
parser.add_argument("--lambda_cyc", type=float, default=10.0, help="cycle loss weight")
parser.add_argument("--lambda_id", type=float, default=5.0, help="identity loss weight")
opt = parser.parse_args()
print(opt)
# Create sample and checkpoint directories
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
cuda = torch.cuda.is_available()
input_shape = (opt.channels, opt.img_height, opt.img_width)
# Initialize generator and discriminator
G_AB = GeneratorResNet(input_shape, opt.n_residual_blocks)
G_BA = GeneratorResNet(input_shape, opt.n_residual_blocks)
D_A = Discriminator(input_shape)
D_B = Discriminator(input_shape)
if cuda:
G_AB = G_AB.cuda()
G_BA = G_BA.cuda()
D_A = D_A.cuda()
D_B = D_B.cuda()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
if opt.epoch != 0:
# Load pretrained models
G_AB.load_state_dict(torch.load("saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, opt.epoch)))
G_BA.load_state_dict(torch.load("saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, opt.epoch)))
D_A.load_state_dict(torch.load("saved_models/%s/D_A_%d.pth" % (opt.dataset_name, opt.epoch)))
D_B.load_state_dict(torch.load("saved_models/%s/D_B_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(
optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
# Buffers of previously generated samples
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
# Image transformations
transforms_ = [
transforms.Resize(int(opt.img_height * 1.12), Image.BICUBIC),
transforms.RandomCrop((opt.img_height, opt.img_width)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
# Training data loader
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# Test data loader
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True, mode="test"),
batch_size=5,
shuffle=True,
num_workers=1,
)
def sample_images(batches_done):
"""Saves a generated sample from the test set"""
imgs = next(iter(val_dataloader))
G_AB.eval()
G_BA.eval()
real_A = Variable(imgs["A"].type(Tensor))
fake_B = G_AB(real_A)
real_B = Variable(imgs["B"].type(Tensor))
fake_A = G_BA(real_B)
# Arange images along x-axis
real_A = make_grid(real_A, nrow=5, normalize=True)
real_B = make_grid(real_B, nrow=5, normalize=True)
fake_A = make_grid(fake_A, nrow=5, normalize=True)
fake_B = make_grid(fake_B, nrow=5, normalize=True)
# Arange images along y-axis
image_grid = torch.cat((real_A, fake_B, real_B, fake_A), 1)
save_image(image_grid, "images/%s/%s.png" % (opt.dataset_name, batches_done), normalize=False)
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *D_A.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *D_A.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# Identity loss
loss_id_A = criterion_identity(G_BA(real_A), real_A)
loss_id_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_id_A + loss_id_B) / 2
# GAN loss
fake_B = G_AB(real_A)
loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)
fake_A = G_BA(real_B)
loss_GAN_BA = criterion_GAN(D_A(fake_A), valid)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle loss
recov_A = G_BA(fake_B)
loss_cycle_A = criterion_cycle(recov_A, real_A)
recov_B = G_AB(fake_A)
loss_cycle_B = criterion_cycle(recov_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# Total loss
loss_G = loss_GAN + opt.lambda_cyc * loss_cycle + opt.lambda_id * loss_identity
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator A
# -----------------------
optimizer_D_A.zero_grad()
# Real loss
loss_real = criterion_GAN(D_A(real_A), valid)
# Fake loss (on batch of previously generated samples)
fake_A_ = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
# Total loss
loss_D_A = (loss_real + loss_fake) / 2
loss_D_A.backward()
optimizer_D_A.step()
# -----------------------
# Train Discriminator B
# -----------------------
optimizer_D_B.zero_grad()
# Real loss
loss_real = criterion_GAN(D_B(real_B), valid)
# Fake loss (on batch of previously generated samples)
fake_B_ = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B_.detach()), fake)
# Total loss
loss_D_B = (loss_real + loss_fake) / 2
loss_D_B.backward()
optimizer_D_B.step()
loss_D = (loss_D_A + loss_D_B) / 2
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, adv: %f, cycle: %f, identity: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_GAN.item(),
loss_cycle.item(),
loss_identity.item(),
time_left,
)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(G_AB.state_dict(), "saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, epoch))
torch.save(G_BA.state_dict(), "saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_A.state_dict(), "saved_models/%s/D_A_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_B.state_dict(), "saved_models/%s/D_B_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/cyclegan/datasets.py
================================================
import glob
import random
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
def to_rgb(image):
rgb_image = Image.new("RGB", image.size)
rgb_image.paste(image)
return rgb_image
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode="train"):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, "%s/A" % mode) + "/*.*"))
self.files_B = sorted(glob.glob(os.path.join(root, "%s/B" % mode) + "/*.*"))
def __getitem__(self, index):
image_A = Image.open(self.files_A[index % len(self.files_A)])
if self.unaligned:
image_B = Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)])
else:
image_B = Image.open(self.files_B[index % len(self.files_B)])
# Convert grayscale images to rgb
if image_A.mode != "RGB":
image_A = to_rgb(image_A)
if image_B.mode != "RGB":
image_B = to_rgb(image_B)
item_A = self.transform(image_A)
item_B = self.transform(image_B)
return {"A": item_A, "B": item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
================================================
FILE: implementations/cyclegan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# RESNET
##############################
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)
class GeneratorResNet(nn.Module):
def __init__(self, input_shape, num_residual_blocks):
super(GeneratorResNet, self).__init__()
channels = input_shape[0]
# Initial convolution block
out_features = 64
model = [
nn.ReflectionPad2d(channels),
nn.Conv2d(channels, out_features, 7),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Downsampling
for _ in range(2):
out_features *= 2
model += [
nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Residual blocks
for _ in range(num_residual_blocks):
model += [ResidualBlock(out_features)]
# Upsampling
for _ in range(2):
out_features //= 2
model += [
nn.Upsample(scale_factor=2),
nn.Conv2d(in_features, out_features, 3, stride=1, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True),
]
in_features = out_features
# Output layer
model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output shape of image discriminator (PatchGAN)
self.output_shape = (1, height // 2 ** 4, width // 2 ** 4)
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/cyclegan/utils.py
================================================
import random
import time
import datetime
import sys
from torch.autograd import Variable
import torch
import numpy as np
from torchvision.utils import save_image
class ReplayBuffer:
def __init__(self, max_size=50):
assert max_size > 0, "Empty buffer or trying to create a black hole. Be careful."
self.max_size = max_size
self.data = []
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
else:
if random.uniform(0, 1) > 0.5:
i = random.randint(0, self.max_size - 1)
to_return.append(self.data[i].clone())
self.data[i] = element
else:
to_return.append(element)
return Variable(torch.cat(to_return))
class LambdaLR:
def __init__(self, n_epochs, offset, decay_start_epoch):
assert (n_epochs - decay_start_epoch) > 0, "Decay must start before the training session ends!"
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
================================================
FILE: implementations/dcgan/dcgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/discogan/datasets.py
================================================
import glob
import os
import torch
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode='train'):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + '/*.*'))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w/2, h))
img_B = img.crop((w/2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], 'RGB')
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], 'RGB')
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {'A': img_A, 'B': img_B}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/discogan/discogan.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import sys
import datetime
import time
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="edges2shoes", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=64, help="size of image height")
parser.add_argument("--img_width", type=int, default=64, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving generator samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
# Create sample and checkpoint directories
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
# Losses
adversarial_loss = torch.nn.MSELoss()
cycle_loss = torch.nn.L1Loss()
pixelwise_loss = torch.nn.L1Loss()
cuda = torch.cuda.is_available()
input_shape = (opt.channels, opt.img_height, opt.img_width)
# Initialize generator and discriminator
G_AB = GeneratorUNet(input_shape)
G_BA = GeneratorUNet(input_shape)
D_A = Discriminator(input_shape)
D_B = Discriminator(input_shape)
if cuda:
G_AB = G_AB.cuda()
G_BA = G_BA.cuda()
D_A = D_A.cuda()
D_B = D_B.cuda()
adversarial_loss.cuda()
cycle_loss.cuda()
pixelwise_loss.cuda()
if opt.epoch != 0:
# Load pretrained models
G_AB.load_state_dict(torch.load("saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, opt.epoch)))
G_BA.load_state_dict(torch.load("saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, opt.epoch)))
D_A.load_state_dict(torch.load("saved_models/%s/D_A_%d.pth" % (opt.dataset_name, opt.epoch)))
D_B.load_state_dict(torch.load("saved_models/%s/D_B_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Input tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
# Dataset loader
transforms_ = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="train"),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
batch_size=16,
shuffle=True,
num_workers=opt.n_cpu,
)
def sample_images(batches_done):
"""Saves a generated sample from the validation set"""
imgs = next(iter(val_dataloader))
G_AB.eval()
G_BA.eval()
real_A = Variable(imgs["A"].type(Tensor))
fake_B = G_AB(real_A)
real_B = Variable(imgs["B"].type(Tensor))
fake_A = G_BA(real_B)
img_sample = torch.cat((real_A.data, fake_B.data, real_B.data, fake_A.data), 0)
save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=8, normalize=True)
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Model inputs
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *D_A.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *D_A.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
G_AB.train()
G_BA.train()
optimizer_G.zero_grad()
# GAN loss
fake_B = G_AB(real_A)
loss_GAN_AB = adversarial_loss(D_B(fake_B), valid)
fake_A = G_BA(real_B)
loss_GAN_BA = adversarial_loss(D_A(fake_A), valid)
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Pixelwise translation loss
loss_pixelwise = (pixelwise_loss(fake_A, real_A) + pixelwise_loss(fake_B, real_B)) / 2
# Cycle loss
loss_cycle_A = cycle_loss(G_BA(fake_B), real_A)
loss_cycle_B = cycle_loss(G_AB(fake_A), real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# Total loss
loss_G = loss_GAN + loss_cycle + loss_pixelwise
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator A
# -----------------------
optimizer_D_A.zero_grad()
# Real loss
loss_real = adversarial_loss(D_A(real_A), valid)
# Fake loss (on batch of previously generated samples)
loss_fake = adversarial_loss(D_A(fake_A.detach()), fake)
# Total loss
loss_D_A = (loss_real + loss_fake) / 2
loss_D_A.backward()
optimizer_D_A.step()
# -----------------------
# Train Discriminator B
# -----------------------
optimizer_D_B.zero_grad()
# Real loss
loss_real = adversarial_loss(D_B(real_B), valid)
# Fake loss (on batch of previously generated samples)
loss_fake = adversarial_loss(D_B(fake_B.detach()), fake)
# Total loss
loss_D_B = (loss_real + loss_fake) / 2
loss_D_B.backward()
optimizer_D_B.step()
loss_D = 0.5 * (loss_D_A + loss_D_B)
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, adv: %f, pixel: %f, cycle: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_GAN.item(),
loss_pixelwise.item(),
loss_cycle.item(),
time_left,
)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(G_AB.state_dict(), "saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, epoch))
torch.save(G_BA.state_dict(), "saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_A.state_dict(), "saved_models/%s/D_A_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_B.state_dict(), "saved_models/%s/D_B_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/discogan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [nn.ConvTranspose2d(in_size, out_size, 4, 2, 1), nn.InstanceNorm2d(out_size), nn.ReLU(inplace=True)]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, input_shape):
super(GeneratorUNet, self).__init__()
channels, _, _ = input_shape
self.down1 = UNetDown(channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256, dropout=0.5)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5, normalize=False)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 256, dropout=0.5)
self.up4 = UNetUp(512, 128)
self.up5 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2), nn.ZeroPad2d((1, 0, 1, 0)), nn.Conv2d(128, channels, 4, padding=1), nn.Tanh()
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
u1 = self.up1(d6, d5)
u2 = self.up2(u1, d4)
u3 = self.up3(u2, d3)
u4 = self.up4(u3, d2)
u5 = self.up5(u4, d1)
return self.final(u5)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output of image discriminator (PatchGAN)
self.output_shape = (1, height // 2 ** 3, width // 2 ** 3)
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(256, 1, 4, padding=1)
)
def forward(self, img):
# Concatenate image and condition image by channels to produce input
return self.model(img)
================================================
FILE: implementations/dragan/dragan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.autograd as autograd
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=1000, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise):
out = self.l1(noise)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Loss weight for gradient penalty
lambda_gp = 10
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def compute_gradient_penalty(D, X):
"""Calculates the gradient penalty loss for DRAGAN"""
# Random weight term for interpolation
alpha = Tensor(np.random.random(size=X.shape))
interpolates = alpha * X + ((1 - alpha) * (X + 0.5 * X.std() * torch.rand(X.size())))
interpolates = Variable(interpolates, requires_grad=True)
d_interpolates = D(interpolates)
fake = Variable(Tensor(X.shape[0], 1).fill_(1.0), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradient_penalty = lambda_gp * ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(mnist_loader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
# Calculate gradient penalty
gradient_penalty = compute_gradient_penalty(discriminator, real_imgs.data)
gradient_penalty.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(mnist_loader), d_loss.item(), g_loss.item())
)
save_image(gen_imgs.data, "images/%d.png" % epoch, nrow=int(math.sqrt(opt.batch_size)), normalize=True)
================================================
FILE: implementations/dualgan/datasets.py
================================================
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/dualgan/dualgan.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import scipy
import sys
import time
import datetime
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.autograd as autograd
from datasets import *
from models import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=8, help="size of the batches")
parser.add_argument("--dataset_name", type=str, default="edges2shoes", help="name of the dataset")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=128, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--sample_interval", type=int, default=200, help="interval betwen image samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
# Loss function
cycle_loss = torch.nn.L1Loss()
# Loss weights
lambda_adv = 1
lambda_cycle = 10
lambda_gp = 10
# Initialize generator and discriminator
G_AB = Generator()
G_BA = Generator()
D_A = Discriminator()
D_B = Discriminator()
if cuda:
G_AB.cuda()
G_BA.cuda()
D_A.cuda()
D_B.cuda()
cycle_loss.cuda()
if opt.epoch != 0:
# Load pretrained models
G_AB.load_state_dict(torch.load("saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, opt.epoch)))
G_BA.load_state_dict(torch.load("saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, opt.epoch)))
D_A.load_state_dict(torch.load("saved_models/%s/D_A_%d.pth" % (opt.dataset_name, opt.epoch)))
D_B.load_state_dict(torch.load("saved_models/%s/D_B_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
G_AB.apply(weights_init_normal)
G_BA.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)
# Configure data loader
transforms_ = [
transforms.Resize((opt.img_size, opt.img_size), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, mode="val", transforms_=transforms_),
batch_size=16,
shuffle=True,
num_workers=1,
)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
def compute_gradient_penalty(D, real_samples, fake_samples):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = FloatTensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
validity = D(interpolates)
fake = Variable(FloatTensor(np.ones(validity.shape)), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=validity,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
def sample_images(batches_done):
"""Saves a generated sample from the test set"""
imgs = next(iter(val_dataloader))
real_A = Variable(imgs["A"].type(FloatTensor))
fake_B = G_AB(real_A)
AB = torch.cat((real_A.data, fake_B.data), -2)
real_B = Variable(imgs["B"].type(FloatTensor))
fake_A = G_BA(real_B)
BA = torch.cat((real_B.data, fake_A.data), -2)
img_sample = torch.cat((AB, BA), 0)
save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=8, normalize=True)
# ----------
# Training
# ----------
batches_done = 0
prev_time = time.time()
for epoch in range(opt.n_epochs):
for i, batch in enumerate(dataloader):
# Configure input
imgs_A = Variable(batch["A"].type(FloatTensor))
imgs_B = Variable(batch["B"].type(FloatTensor))
# ----------------------
# Train Discriminators
# ----------------------
optimizer_D_A.zero_grad()
optimizer_D_B.zero_grad()
# Generate a batch of images
fake_A = G_BA(imgs_B).detach()
fake_B = G_AB(imgs_A).detach()
# ----------
# Domain A
# ----------
# Compute gradient penalty for improved wasserstein training
gp_A = compute_gradient_penalty(D_A, imgs_A.data, fake_A.data)
# Adversarial loss
D_A_loss = -torch.mean(D_A(imgs_A)) + torch.mean(D_A(fake_A)) + lambda_gp * gp_A
# ----------
# Domain B
# ----------
# Compute gradient penalty for improved wasserstein training
gp_B = compute_gradient_penalty(D_B, imgs_B.data, fake_B.data)
# Adversarial loss
D_B_loss = -torch.mean(D_B(imgs_B)) + torch.mean(D_B(fake_B)) + lambda_gp * gp_B
# Total loss
D_loss = D_A_loss + D_B_loss
D_loss.backward()
optimizer_D_A.step()
optimizer_D_B.step()
if i % opt.n_critic == 0:
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# Translate images to opposite domain
fake_A = G_BA(imgs_B)
fake_B = G_AB(imgs_A)
# Reconstruct images
recov_A = G_BA(fake_B)
recov_B = G_AB(fake_A)
# Adversarial loss
G_adv = -torch.mean(D_A(fake_A)) - torch.mean(D_B(fake_B))
# Cycle loss
G_cycle = cycle_loss(recov_A, imgs_A) + cycle_loss(recov_B, imgs_B)
# Total loss
G_loss = lambda_adv * G_adv + lambda_cycle * G_cycle
G_loss.backward()
optimizer_G.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time) / opt.n_critic)
prev_time = time.time()
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, cycle: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
D_loss.item(),
G_adv.data.item(),
G_cycle.item(),
time_left,
)
)
# Check sample interval => save sample if there
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
batches_done += 1
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(G_AB.state_dict(), "saved_models/%s/G_AB_%d.pth" % (opt.dataset_name, epoch))
torch.save(G_BA.state_dict(), "saved_models/%s/G_BA_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_A.state_dict(), "saved_models/%s/D_A_%d.pth" % (opt.dataset_name, epoch))
torch.save(D_B.state_dict(), "saved_models/%s/D_B_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/dualgan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision.models import vgg19
import math
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, stride=2, padding=1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size, affine=True))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, stride=2, padding=1, bias=False),
nn.InstanceNorm2d(out_size, affine=True),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class Generator(nn.Module):
def __init__(self, channels=3):
super(Generator, self).__init__()
self.down1 = UNetDown(channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5, normalize=False)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 256)
self.up5 = UNetUp(512, 128)
self.up6 = UNetUp(256, 64)
self.final = nn.Sequential(nn.ConvTranspose2d(128, channels, 4, stride=2, padding=1), nn.Tanh())
def forward(self, x):
# Propogate noise through fc layer and reshape to img shape
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
u1 = self.up1(d7, d6)
u2 = self.up2(u1, d5)
u3 = self.up3(u2, d4)
u4 = self.up4(u3, d3)
u5 = self.up5(u4, d2)
u6 = self.up6(u5, d1)
return self.final(u6)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discrimintor_block(in_features, out_features, normalize=True):
"""Discriminator block"""
layers = [nn.Conv2d(in_features, out_features, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.BatchNorm2d(out_features, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discrimintor_block(in_channels, 64, normalize=False),
*discrimintor_block(64, 128),
*discrimintor_block(128, 256),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(256, 1, kernel_size=4)
)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/ebgan/ebgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=62, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="number of image channels")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise):
out = self.l1(noise)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# Upsampling
self.down = nn.Sequential(nn.Conv2d(opt.channels, 64, 3, 2, 1), nn.ReLU())
# Fully-connected layers
self.down_size = opt.img_size // 2
down_dim = 64 * (opt.img_size // 2) ** 2
self.embedding = nn.Linear(down_dim, 32)
self.fc = nn.Sequential(
nn.BatchNorm1d(32, 0.8),
nn.ReLU(inplace=True),
nn.Linear(32, down_dim),
nn.BatchNorm1d(down_dim),
nn.ReLU(inplace=True),
)
# Upsampling
self.up = nn.Sequential(nn.Upsample(scale_factor=2), nn.Conv2d(64, opt.channels, 3, 1, 1))
def forward(self, img):
out = self.down(img)
embedding = self.embedding(out.view(out.size(0), -1))
out = self.fc(embedding)
out = self.up(out.view(out.size(0), 64, self.down_size, self.down_size))
return out, embedding
# Reconstruction loss of AE
pixelwise_loss = nn.MSELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
pixelwise_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def pullaway_loss(embeddings):
norm = torch.sqrt(torch.sum(embeddings ** 2, -1, keepdim=True))
normalized_emb = embeddings / norm
similarity = torch.matmul(normalized_emb, normalized_emb.transpose(1, 0))
batch_size = embeddings.size(0)
loss_pt = (torch.sum(similarity) - batch_size) / (batch_size * (batch_size - 1))
return loss_pt
# ----------
# Training
# ----------
# BEGAN hyper parameters
lambda_pt = 0.1
margin = max(1, opt.batch_size / 64.0)
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
recon_imgs, img_embeddings = discriminator(gen_imgs)
# Loss measures generator's ability to fool the discriminator
g_loss = pixelwise_loss(recon_imgs, gen_imgs.detach()) + lambda_pt * pullaway_loss(img_embeddings)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_recon, _ = discriminator(real_imgs)
fake_recon, _ = discriminator(gen_imgs.detach())
d_loss_real = pixelwise_loss(real_recon, real_imgs)
d_loss_fake = pixelwise_loss(fake_recon, gen_imgs.detach())
d_loss = d_loss_real
if (margin - d_loss_fake.data).item() > 0:
d_loss += margin - d_loss_fake
d_loss.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/esrgan/datasets.py
================================================
import glob
import random
import os
import numpy as np
import torch
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
# Normalization parameters for pre-trained PyTorch models
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
def denormalize(tensors):
""" Denormalizes image tensors using mean and std """
for c in range(3):
tensors[:, c].mul_(std[c]).add_(mean[c])
return torch.clamp(tensors, 0, 255)
class ImageDataset(Dataset):
def __init__(self, root, hr_shape):
hr_height, hr_width = hr_shape
# Transforms for low resolution images and high resolution images
self.lr_transform = transforms.Compose(
[
transforms.Resize((hr_height // 4, hr_height // 4), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
)
self.hr_transform = transforms.Compose(
[
transforms.Resize((hr_height, hr_height), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
)
self.files = sorted(glob.glob(root + "/*.*"))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
img_lr = self.lr_transform(img)
img_hr = self.hr_transform(img)
return {"lr": img_lr, "hr": img_hr}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/esrgan/esrgan.py
================================================
"""
Super-resolution of CelebA using Generative Adversarial Networks.
The dataset can be downloaded from: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AADIKlz8PR9zr6Y20qbkunrba/Img/img_align_celeba.zip?dl=0
(if not available there see if options are listed at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html)
Instrustion on running the script:
1. Download the dataset from the provided link
2. Save the folder 'img_align_celeba' to '../../data/'
4. Run the sript using command 'python3 esrgan.py'
"""
import argparse
import os
import numpy as np
import math
import itertools
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images/training", exist_ok=True)
os.makedirs("saved_models", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=4, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.9, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--hr_height", type=int, default=256, help="high res. image height")
parser.add_argument("--hr_width", type=int, default=256, help="high res. image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving image samples")
parser.add_argument("--checkpoint_interval", type=int, default=5000, help="batch interval between model checkpoints")
parser.add_argument("--residual_blocks", type=int, default=23, help="number of residual blocks in the generator")
parser.add_argument("--warmup_batches", type=int, default=500, help="number of batches with pixel-wise loss only")
parser.add_argument("--lambda_adv", type=float, default=5e-3, help="adversarial loss weight")
parser.add_argument("--lambda_pixel", type=float, default=1e-2, help="pixel-wise loss weight")
opt = parser.parse_args()
print(opt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
hr_shape = (opt.hr_height, opt.hr_width)
# Initialize generator and discriminator
generator = GeneratorRRDB(opt.channels, filters=64, num_res_blocks=opt.residual_blocks).to(device)
discriminator = Discriminator(input_shape=(opt.channels, *hr_shape)).to(device)
feature_extractor = FeatureExtractor().to(device)
# Set feature extractor to inference mode
feature_extractor.eval()
# Losses
criterion_GAN = torch.nn.BCEWithLogitsLoss().to(device)
criterion_content = torch.nn.L1Loss().to(device)
criterion_pixel = torch.nn.L1Loss().to(device)
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/generator_%d.pth" % opt.epoch))
discriminator.load_state_dict(torch.load("saved_models/discriminator_%d.pth" % opt.epoch))
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.Tensor
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, hr_shape=hr_shape),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# ----------
# Training
# ----------
for epoch in range(opt.epoch, opt.n_epochs):
for i, imgs in enumerate(dataloader):
batches_done = epoch * len(dataloader) + i
# Configure model input
imgs_lr = Variable(imgs["lr"].type(Tensor))
imgs_hr = Variable(imgs["hr"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# Generate a high resolution image from low resolution input
gen_hr = generator(imgs_lr)
# Measure pixel-wise loss against ground truth
loss_pixel = criterion_pixel(gen_hr, imgs_hr)
if batches_done < opt.warmup_batches:
# Warm-up (pixel-wise loss only)
loss_pixel.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [G pixel: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), loss_pixel.item())
)
continue
# Extract validity predictions from discriminator
pred_real = discriminator(imgs_hr).detach()
pred_fake = discriminator(gen_hr)
# Adversarial loss (relativistic average GAN)
loss_GAN = criterion_GAN(pred_fake - pred_real.mean(0, keepdim=True), valid)
# Content loss
gen_features = feature_extractor(gen_hr)
real_features = feature_extractor(imgs_hr).detach()
loss_content = criterion_content(gen_features, real_features)
# Total generator loss
loss_G = loss_content + opt.lambda_adv * loss_GAN + opt.lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
pred_real = discriminator(imgs_hr)
pred_fake = discriminator(gen_hr.detach())
# Adversarial loss for real and fake images (relativistic average GAN)
loss_real = criterion_GAN(pred_real - pred_fake.mean(0, keepdim=True), valid)
loss_fake = criterion_GAN(pred_fake - pred_real.mean(0, keepdim=True), fake)
# Total loss
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, content: %f, adv: %f, pixel: %f]"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_content.item(),
loss_GAN.item(),
loss_pixel.item(),
)
)
if batches_done % opt.sample_interval == 0:
# Save image grid with upsampled inputs and ESRGAN outputs
imgs_lr = nn.functional.interpolate(imgs_lr, scale_factor=4)
img_grid = denormalize(torch.cat((imgs_lr, gen_hr), -1))
save_image(img_grid, "images/training/%d.png" % batches_done, nrow=1, normalize=False)
if batches_done % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/generator_%d.pth" % epoch)
torch.save(discriminator.state_dict(), "saved_models/discriminator_%d.pth" %epoch)
================================================
FILE: implementations/esrgan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision.models import vgg19
import math
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
vgg19_model = vgg19(pretrained=True)
self.vgg19_54 = nn.Sequential(*list(vgg19_model.features.children())[:35])
def forward(self, img):
return self.vgg19_54(img)
class DenseResidualBlock(nn.Module):
"""
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
"""
def __init__(self, filters, res_scale=0.2):
super(DenseResidualBlock, self).__init__()
self.res_scale = res_scale
def block(in_features, non_linearity=True):
layers = [nn.Conv2d(in_features, filters, 3, 1, 1, bias=True)]
if non_linearity:
layers += [nn.LeakyReLU()]
return nn.Sequential(*layers)
self.b1 = block(in_features=1 * filters)
self.b2 = block(in_features=2 * filters)
self.b3 = block(in_features=3 * filters)
self.b4 = block(in_features=4 * filters)
self.b5 = block(in_features=5 * filters, non_linearity=False)
self.blocks = [self.b1, self.b2, self.b3, self.b4, self.b5]
def forward(self, x):
inputs = x
for block in self.blocks:
out = block(inputs)
inputs = torch.cat([inputs, out], 1)
return out.mul(self.res_scale) + x
class ResidualInResidualDenseBlock(nn.Module):
def __init__(self, filters, res_scale=0.2):
super(ResidualInResidualDenseBlock, self).__init__()
self.res_scale = res_scale
self.dense_blocks = nn.Sequential(
DenseResidualBlock(filters), DenseResidualBlock(filters), DenseResidualBlock(filters)
)
def forward(self, x):
return self.dense_blocks(x).mul(self.res_scale) + x
class GeneratorRRDB(nn.Module):
def __init__(self, channels, filters=64, num_res_blocks=16, num_upsample=2):
super(GeneratorRRDB, self).__init__()
# First layer
self.conv1 = nn.Conv2d(channels, filters, kernel_size=3, stride=1, padding=1)
# Residual blocks
self.res_blocks = nn.Sequential(*[ResidualInResidualDenseBlock(filters) for _ in range(num_res_blocks)])
# Second conv layer post residual blocks
self.conv2 = nn.Conv2d(filters, filters, kernel_size=3, stride=1, padding=1)
# Upsampling layers
upsample_layers = []
for _ in range(num_upsample):
upsample_layers += [
nn.Conv2d(filters, filters * 4, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(),
nn.PixelShuffle(upscale_factor=2),
]
self.upsampling = nn.Sequential(*upsample_layers)
# Final output block
self.conv3 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size=3, stride=1, padding=1),
nn.LeakyReLU(),
nn.Conv2d(filters, channels, kernel_size=3, stride=1, padding=1),
)
def forward(self, x):
out1 = self.conv1(x)
out = self.res_blocks(out1)
out2 = self.conv2(out)
out = torch.add(out1, out2)
out = self.upsampling(out)
out = self.conv3(out)
return out
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/esrgan/test_on_image.py
================================================
from models import GeneratorRRDB
from datasets import denormalize, mean, std
import torch
from torch.autograd import Variable
import argparse
import os
from torchvision import transforms
from torchvision.utils import save_image
from PIL import Image
parser = argparse.ArgumentParser()
parser.add_argument("--image_path", type=str, required=True, help="Path to image")
parser.add_argument("--checkpoint_model", type=str, required=True, help="Path to checkpoint model")
parser.add_argument("--channels", type=int, default=3, help="Number of image channels")
parser.add_argument("--residual_blocks", type=int, default=23, help="Number of residual blocks in G")
opt = parser.parse_args()
print(opt)
os.makedirs("images/outputs", exist_ok=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Define model and load model checkpoint
generator = GeneratorRRDB(opt.channels, filters=64, num_res_blocks=opt.residual_blocks).to(device)
generator.load_state_dict(torch.load(opt.checkpoint_model))
generator.eval()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean, std)])
# Prepare input
image_tensor = Variable(transform(Image.open(opt.image_path))).to(device).unsqueeze(0)
# Upsample image
with torch.no_grad():
sr_image = denormalize(generator(image_tensor)).cpu()
# Save image
fn = opt.image_path.split("/")[-1]
save_image(sr_image, f"images/outputs/sr-{fn}")
================================================
FILE: implementations/gan/gan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/infogan/infogan.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images/static/", exist_ok=True)
os.makedirs("images/varying_c1/", exist_ok=True)
os.makedirs("images/varying_c2/", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=62, help="dimensionality of the latent space")
parser.add_argument("--code_dim", type=int, default=2, help="latent code")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
def to_categorical(y, num_columns):
"""Returns one-hot encoded Variable"""
y_cat = np.zeros((y.shape[0], num_columns))
y_cat[range(y.shape[0]), y] = 1.0
return Variable(FloatTensor(y_cat))
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
input_dim = opt.latent_dim + opt.n_classes + opt.code_dim
self.init_size = opt.img_size // 4 # Initial size before upsampling
self.l1 = nn.Sequential(nn.Linear(input_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise, labels, code):
gen_input = torch.cat((noise, labels, code), -1)
out = self.l1(gen_input)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
"""Returns layers of each discriminator block"""
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.conv_blocks = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
# Output layers
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1))
self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.n_classes), nn.Softmax())
self.latent_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.code_dim))
def forward(self, img):
out = self.conv_blocks(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
label = self.aux_layer(out)
latent_code = self.latent_layer(out)
return validity, label, latent_code
# Loss functions
adversarial_loss = torch.nn.MSELoss()
categorical_loss = torch.nn.CrossEntropyLoss()
continuous_loss = torch.nn.MSELoss()
# Loss weights
lambda_cat = 1
lambda_con = 0.1
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
categorical_loss.cuda()
continuous_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_info = torch.optim.Adam(
itertools.chain(generator.parameters(), discriminator.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
# Static generator inputs for sampling
static_z = Variable(FloatTensor(np.zeros((opt.n_classes ** 2, opt.latent_dim))))
static_label = to_categorical(
np.array([num for _ in range(opt.n_classes) for num in range(opt.n_classes)]), num_columns=opt.n_classes
)
static_code = Variable(FloatTensor(np.zeros((opt.n_classes ** 2, opt.code_dim))))
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits ranging from 0 to n_classes"""
# Static sample
z = Variable(FloatTensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
static_sample = generator(z, static_label, static_code)
save_image(static_sample.data, "images/static/%d.png" % batches_done, nrow=n_row, normalize=True)
# Get varied c1 and c2
zeros = np.zeros((n_row ** 2, 1))
c_varied = np.repeat(np.linspace(-1, 1, n_row)[:, np.newaxis], n_row, 0)
c1 = Variable(FloatTensor(np.concatenate((c_varied, zeros), -1)))
c2 = Variable(FloatTensor(np.concatenate((zeros, c_varied), -1)))
sample1 = generator(static_z, static_label, c1)
sample2 = generator(static_z, static_label, c2)
save_image(sample1.data, "images/varying_c1/%d.png" % batches_done, nrow=n_row, normalize=True)
save_image(sample2.data, "images/varying_c2/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = to_categorical(labels.numpy(), num_columns=opt.n_classes)
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise and labels as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
label_input = to_categorical(np.random.randint(0, opt.n_classes, batch_size), num_columns=opt.n_classes)
code_input = Variable(FloatTensor(np.random.uniform(-1, 1, (batch_size, opt.code_dim))))
# Generate a batch of images
gen_imgs = generator(z, label_input, code_input)
# Loss measures generator's ability to fool the discriminator
validity, _, _ = discriminator(gen_imgs)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
real_pred, _, _ = discriminator(real_imgs)
d_real_loss = adversarial_loss(real_pred, valid)
# Loss for fake images
fake_pred, _, _ = discriminator(gen_imgs.detach())
d_fake_loss = adversarial_loss(fake_pred, fake)
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# ------------------
# Information Loss
# ------------------
optimizer_info.zero_grad()
# Sample labels
sampled_labels = np.random.randint(0, opt.n_classes, batch_size)
# Ground truth labels
gt_labels = Variable(LongTensor(sampled_labels), requires_grad=False)
# Sample noise, labels and code as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
label_input = to_categorical(sampled_labels, num_columns=opt.n_classes)
code_input = Variable(FloatTensor(np.random.uniform(-1, 1, (batch_size, opt.code_dim))))
gen_imgs = generator(z, label_input, code_input)
_, pred_label, pred_code = discriminator(gen_imgs)
info_loss = lambda_cat * categorical_loss(pred_label, gt_labels) + lambda_con * continuous_loss(
pred_code, code_input
)
info_loss.backward()
optimizer_info.step()
# --------------
# Log Progress
# --------------
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [info loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item(), info_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
================================================
FILE: implementations/lsgan/lsgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=1000, help="number of image channels")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Linear(128 * ds_size ** 2, 1)
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
# !!! Minimizes MSE instead of BCE
adversarial_loss = torch.nn.MSELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/munit/datasets.py
================================================
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
if mode == "train":
self.files.extend(sorted(glob.glob(os.path.join(root, "test") + "/*.*")))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/munit/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch.autograd import Variable
import numpy as np
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class LambdaLR:
def __init__(self, n_epochs, offset, decay_start_epoch):
assert (n_epochs - decay_start_epoch) > 0, "Decay must start before the training session ends!"
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
#################################
# Encoder
#################################
class Encoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_residual=3, n_downsample=2, style_dim=8):
super(Encoder, self).__init__()
self.content_encoder = ContentEncoder(in_channels, dim, n_residual, n_downsample)
self.style_encoder = StyleEncoder(in_channels, dim, n_downsample, style_dim)
def forward(self, x):
content_code = self.content_encoder(x)
style_code = self.style_encoder(x)
return content_code, style_code
#################################
# Decoder
#################################
class Decoder(nn.Module):
def __init__(self, out_channels=3, dim=64, n_residual=3, n_upsample=2, style_dim=8):
super(Decoder, self).__init__()
layers = []
dim = dim * 2 ** n_upsample
# Residual blocks
for _ in range(n_residual):
layers += [ResidualBlock(dim, norm="adain")]
# Upsampling
for _ in range(n_upsample):
layers += [
nn.Upsample(scale_factor=2),
nn.Conv2d(dim, dim // 2, 5, stride=1, padding=2),
LayerNorm(dim // 2),
nn.ReLU(inplace=True),
]
dim = dim // 2
# Output layer
layers += [nn.ReflectionPad2d(3), nn.Conv2d(dim, out_channels, 7), nn.Tanh()]
self.model = nn.Sequential(*layers)
# Initiate mlp (predicts AdaIN parameters)
num_adain_params = self.get_num_adain_params()
self.mlp = MLP(style_dim, num_adain_params)
def get_num_adain_params(self):
"""Return the number of AdaIN parameters needed by the model"""
num_adain_params = 0
for m in self.modules():
if m.__class__.__name__ == "AdaptiveInstanceNorm2d":
num_adain_params += 2 * m.num_features
return num_adain_params
def assign_adain_params(self, adain_params):
"""Assign the adain_params to the AdaIN layers in model"""
for m in self.modules():
if m.__class__.__name__ == "AdaptiveInstanceNorm2d":
# Extract mean and std predictions
mean = adain_params[:, : m.num_features]
std = adain_params[:, m.num_features : 2 * m.num_features]
# Update bias and weight
m.bias = mean.contiguous().view(-1)
m.weight = std.contiguous().view(-1)
# Move pointer
if adain_params.size(1) > 2 * m.num_features:
adain_params = adain_params[:, 2 * m.num_features :]
def forward(self, content_code, style_code):
# Update AdaIN parameters by MLP prediction based off style code
self.assign_adain_params(self.mlp(style_code))
img = self.model(content_code)
return img
#################################
# Content Encoder
#################################
class ContentEncoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_residual=3, n_downsample=2):
super(ContentEncoder, self).__init__()
# Initial convolution block
layers = [
nn.ReflectionPad2d(3),
nn.Conv2d(in_channels, dim, 7),
nn.InstanceNorm2d(dim),
nn.ReLU(inplace=True),
]
# Downsampling
for _ in range(n_downsample):
layers += [
nn.Conv2d(dim, dim * 2, 4, stride=2, padding=1),
nn.InstanceNorm2d(dim * 2),
nn.ReLU(inplace=True),
]
dim *= 2
# Residual blocks
for _ in range(n_residual):
layers += [ResidualBlock(dim, norm="in")]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
#################################
# Style Encoder
#################################
class StyleEncoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_downsample=2, style_dim=8):
super(StyleEncoder, self).__init__()
# Initial conv block
layers = [nn.ReflectionPad2d(3), nn.Conv2d(in_channels, dim, 7), nn.ReLU(inplace=True)]
# Downsampling
for _ in range(2):
layers += [nn.Conv2d(dim, dim * 2, 4, stride=2, padding=1), nn.ReLU(inplace=True)]
dim *= 2
# Downsampling with constant depth
for _ in range(n_downsample - 2):
layers += [nn.Conv2d(dim, dim, 4, stride=2, padding=1), nn.ReLU(inplace=True)]
# Average pool and output layer
layers += [nn.AdaptiveAvgPool2d(1), nn.Conv2d(dim, style_dim, 1, 1, 0)]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
######################################
# MLP (predicts AdaIn parameters)
######################################
class MLP(nn.Module):
def __init__(self, input_dim, output_dim, dim=256, n_blk=3, activ="relu"):
super(MLP, self).__init__()
layers = [nn.Linear(input_dim, dim), nn.ReLU(inplace=True)]
for _ in range(n_blk - 2):
layers += [nn.Linear(dim, dim), nn.ReLU(inplace=True)]
layers += [nn.Linear(dim, output_dim)]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x.view(x.size(0), -1))
##############################
# Discriminator
##############################
class MultiDiscriminator(nn.Module):
def __init__(self, in_channels=3):
super(MultiDiscriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
# Extracts three discriminator models
self.models = nn.ModuleList()
for i in range(3):
self.models.add_module(
"disc_%d" % i,
nn.Sequential(
*discriminator_block(in_channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.Conv2d(512, 1, 3, padding=1)
),
)
self.downsample = nn.AvgPool2d(in_channels, stride=2, padding=[1, 1], count_include_pad=False)
def compute_loss(self, x, gt):
"""Computes the MSE between model output and scalar gt"""
loss = sum([torch.mean((out - gt) ** 2) for out in self.forward(x)])
return loss
def forward(self, x):
outputs = []
for m in self.models:
outputs.append(m(x))
x = self.downsample(x)
return outputs
##############################
# Custom Blocks
##############################
class ResidualBlock(nn.Module):
def __init__(self, features, norm="in"):
super(ResidualBlock, self).__init__()
norm_layer = AdaptiveInstanceNorm2d if norm == "adain" else nn.InstanceNorm2d
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(features, features, 3),
norm_layer(features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(features, features, 3),
norm_layer(features),
)
def forward(self, x):
return x + self.block(x)
##############################
# Custom Layers
##############################
class AdaptiveInstanceNorm2d(nn.Module):
"""Reference: https://github.com/NVlabs/MUNIT/blob/master/networks.py"""
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(AdaptiveInstanceNorm2d, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# weight and bias are dynamically assigned
self.weight = None
self.bias = None
# just dummy buffers, not used
self.register_buffer("running_mean", torch.zeros(num_features))
self.register_buffer("running_var", torch.ones(num_features))
def forward(self, x):
assert (
self.weight is not None and self.bias is not None
), "Please assign weight and bias before calling AdaIN!"
b, c, h, w = x.size()
running_mean = self.running_mean.repeat(b)
running_var = self.running_var.repeat(b)
# Apply instance norm
x_reshaped = x.contiguous().view(1, b * c, h, w)
out = F.batch_norm(
x_reshaped, running_mean, running_var, self.weight, self.bias, True, self.momentum, self.eps
)
return out.view(b, c, h, w)
def __repr__(self):
return self.__class__.__name__ + "(" + str(self.num_features) + ")"
class LayerNorm(nn.Module):
def __init__(self, num_features, eps=1e-5, affine=True):
super(LayerNorm, self).__init__()
self.num_features = num_features
self.affine = affine
self.eps = eps
if self.affine:
self.gamma = nn.Parameter(torch.Tensor(num_features).uniform_())
self.beta = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
shape = [-1] + [1] * (x.dim() - 1)
mean = x.view(x.size(0), -1).mean(1).view(*shape)
std = x.view(x.size(0), -1).std(1).view(*shape)
x = (x - mean) / (std + self.eps)
if self.affine:
shape = [1, -1] + [1] * (x.dim() - 2)
x = x * self.gamma.view(*shape) + self.beta.view(*shape)
return x
================================================
FILE: implementations/munit/munit.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import datetime
import time
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="edges2shoes", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0001, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=128, help="size of image height")
parser.add_argument("--img_width", type=int, default=128, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval saving generator samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between saving model checkpoints")
parser.add_argument("--n_downsample", type=int, default=2, help="number downsampling layers in encoder")
parser.add_argument("--n_residual", type=int, default=3, help="number of residual blocks in encoder / decoder")
parser.add_argument("--dim", type=int, default=64, help="number of filters in first encoder layer")
parser.add_argument("--style_dim", type=int, default=8, help="dimensionality of the style code")
opt = parser.parse_args()
print(opt)
cuda = torch.cuda.is_available()
# Create sample and checkpoint directories
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
criterion_recon = torch.nn.L1Loss()
# Initialize encoders, generators and discriminators
Enc1 = Encoder(dim=opt.dim, n_downsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
Dec1 = Decoder(dim=opt.dim, n_upsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
Enc2 = Encoder(dim=opt.dim, n_downsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
Dec2 = Decoder(dim=opt.dim, n_upsample=opt.n_downsample, n_residual=opt.n_residual, style_dim=opt.style_dim)
D1 = MultiDiscriminator()
D2 = MultiDiscriminator()
if cuda:
Enc1 = Enc1.cuda()
Dec1 = Dec1.cuda()
Enc2 = Enc2.cuda()
Dec2 = Dec2.cuda()
D1 = D1.cuda()
D2 = D2.cuda()
criterion_recon.cuda()
if opt.epoch != 0:
# Load pretrained models
Enc1.load_state_dict(torch.load("saved_models/%s/Enc1_%d.pth" % (opt.dataset_name, opt.epoch)))
Dec1.load_state_dict(torch.load("saved_models/%s/Dec1_%d.pth" % (opt.dataset_name, opt.epoch)))
Enc2.load_state_dict(torch.load("saved_models/%s/Enc2_%d.pth" % (opt.dataset_name, opt.epoch)))
Dec2.load_state_dict(torch.load("saved_models/%s/Dec2_%d.pth" % (opt.dataset_name, opt.epoch)))
D1.load_state_dict(torch.load("saved_models/%s/D1_%d.pth" % (opt.dataset_name, opt.epoch)))
D2.load_state_dict(torch.load("saved_models/%s/D2_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
Enc1.apply(weights_init_normal)
Dec1.apply(weights_init_normal)
Enc2.apply(weights_init_normal)
Dec2.apply(weights_init_normal)
D1.apply(weights_init_normal)
D2.apply(weights_init_normal)
# Loss weights
lambda_gan = 1
lambda_id = 10
lambda_style = 1
lambda_cont = 1
lambda_cyc = 0
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(Enc1.parameters(), Dec1.parameters(), Enc2.parameters(), Dec2.parameters()),
lr=opt.lr,
betas=(opt.b1, opt.b2),
)
optimizer_D1 = torch.optim.Adam(D1.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D2 = torch.optim.Adam(D2.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D1 = torch.optim.lr_scheduler.LambdaLR(
optimizer_D1, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D2 = torch.optim.lr_scheduler.LambdaLR(
optimizer_D2, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
# Configure dataloaders
transforms_ = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
batch_size=5,
shuffle=True,
num_workers=1,
)
def sample_images(batches_done):
"""Saves a generated sample from the validation set"""
imgs = next(iter(val_dataloader))
img_samples = None
for img1, img2 in zip(imgs["A"], imgs["B"]):
# Create copies of image
X1 = img1.unsqueeze(0).repeat(opt.style_dim, 1, 1, 1)
X1 = Variable(X1.type(Tensor))
# Get random style codes
s_code = np.random.uniform(-1, 1, (opt.style_dim, opt.style_dim))
s_code = Variable(Tensor(s_code))
# Generate samples
c_code_1, _ = Enc1(X1)
X12 = Dec2(c_code_1, s_code)
# Concatenate samples horisontally
X12 = torch.cat([x for x in X12.data.cpu()], -1)
img_sample = torch.cat((img1, X12), -1).unsqueeze(0)
# Concatenate with previous samples vertically
img_samples = img_sample if img_samples is None else torch.cat((img_samples, img_sample), -2)
save_image(img_samples, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)
# ----------
# Training
# ----------
# Adversarial ground truths
valid = 1
fake = 0
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
X1 = Variable(batch["A"].type(Tensor))
X2 = Variable(batch["B"].type(Tensor))
# Sampled style codes
style_1 = Variable(torch.randn(X1.size(0), opt.style_dim, 1, 1).type(Tensor))
style_2 = Variable(torch.randn(X1.size(0), opt.style_dim, 1, 1).type(Tensor))
# -------------------------------
# Train Encoders and Generators
# -------------------------------
optimizer_G.zero_grad()
# Get shared latent representation
c_code_1, s_code_1 = Enc1(X1)
c_code_2, s_code_2 = Enc2(X2)
# Reconstruct images
X11 = Dec1(c_code_1, s_code_1)
X22 = Dec2(c_code_2, s_code_2)
# Translate images
X21 = Dec1(c_code_2, style_1)
X12 = Dec2(c_code_1, style_2)
# Cycle translation
c_code_21, s_code_21 = Enc1(X21)
c_code_12, s_code_12 = Enc2(X12)
X121 = Dec1(c_code_12, s_code_1) if lambda_cyc > 0 else 0
X212 = Dec2(c_code_21, s_code_2) if lambda_cyc > 0 else 0
# Losses
loss_GAN_1 = lambda_gan * D1.compute_loss(X21, valid)
loss_GAN_2 = lambda_gan * D2.compute_loss(X12, valid)
loss_ID_1 = lambda_id * criterion_recon(X11, X1)
loss_ID_2 = lambda_id * criterion_recon(X22, X2)
loss_s_1 = lambda_style * criterion_recon(s_code_21, style_1)
loss_s_2 = lambda_style * criterion_recon(s_code_12, style_2)
loss_c_1 = lambda_cont * criterion_recon(c_code_12, c_code_1.detach())
loss_c_2 = lambda_cont * criterion_recon(c_code_21, c_code_2.detach())
loss_cyc_1 = lambda_cyc * criterion_recon(X121, X1) if lambda_cyc > 0 else 0
loss_cyc_2 = lambda_cyc * criterion_recon(X212, X2) if lambda_cyc > 0 else 0
# Total loss
loss_G = (
loss_GAN_1
+ loss_GAN_2
+ loss_ID_1
+ loss_ID_2
+ loss_s_1
+ loss_s_2
+ loss_c_1
+ loss_c_2
+ loss_cyc_1
+ loss_cyc_2
)
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator 1
# -----------------------
optimizer_D1.zero_grad()
loss_D1 = D1.compute_loss(X1, valid) + D1.compute_loss(X21.detach(), fake)
loss_D1.backward()
optimizer_D1.step()
# -----------------------
# Train Discriminator 2
# -----------------------
optimizer_D2.zero_grad()
loss_D2 = D2.compute_loss(X2, valid) + D2.compute_loss(X12.detach(), fake)
loss_D2.backward()
optimizer_D2.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] ETA: %s"
% (epoch, opt.n_epochs, i, len(dataloader), (loss_D1 + loss_D2).item(), loss_G.item(), time_left)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D1.step()
lr_scheduler_D2.step()
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(Enc1.state_dict(), "saved_models/%s/Enc1_%d.pth" % (opt.dataset_name, epoch))
torch.save(Dec1.state_dict(), "saved_models/%s/Dec1_%d.pth" % (opt.dataset_name, epoch))
torch.save(Enc2.state_dict(), "saved_models/%s/Enc2_%d.pth" % (opt.dataset_name, epoch))
torch.save(Dec2.state_dict(), "saved_models/%s/Dec2_%d.pth" % (opt.dataset_name, epoch))
torch.save(D1.state_dict(), "saved_models/%s/D1_%d.pth" % (opt.dataset_name, epoch))
torch.save(D2.state_dict(), "saved_models/%s/D2_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/pix2pix/datasets.py
================================================
import glob
import random
import os
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, mode="train"):
self.transform = transforms.Compose(transforms_)
self.files = sorted(glob.glob(os.path.join(root, mode) + "/*.*"))
if mode == "train":
self.files.extend(sorted(glob.glob(os.path.join(root, "test") + "/*.*")))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))
if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/pix2pix/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)
================================================
FILE: implementations/pix2pix/pix2pix.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import time
import datetime
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="facades", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument(
"--sample_interval", type=int, default=500, help="interval between sampling of images from generators"
)
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
cuda = True if torch.cuda.is_available() else False
# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixelwise = torch.nn.L1Loss()
# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100
# Calculate output of image discriminator (PatchGAN)
patch = (1, opt.img_height // 2 ** 4, opt.img_width // 2 ** 4)
# Initialize generator and discriminator
generator = GeneratorUNet()
discriminator = Discriminator()
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_GAN.cuda()
criterion_pixelwise.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (opt.dataset_name, opt.epoch)))
discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Configure dataloaders
transforms_ = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
batch_size=10,
shuffle=True,
num_workers=1,
)
# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def sample_images(batches_done):
"""Saves a generated sample from the validation set"""
imgs = next(iter(val_dataloader))
real_A = Variable(imgs["B"].type(Tensor))
real_B = Variable(imgs["A"].type(Tensor))
fake_B = generator(real_A)
img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)
save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Model inputs
real_A = Variable(batch["B"].type(Tensor))
real_B = Variable(batch["A"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# GAN loss
fake_B = generator(real_A)
pred_fake = discriminator(fake_B, real_A)
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(fake_B, real_B)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real loss
pred_real = discriminator(real_B, real_A)
loss_real = criterion_GAN(pred_real, valid)
# Fake loss
pred_fake = discriminator(fake_B.detach(), real_A)
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_D = 0.5 * (loss_real + loss_fake)
loss_D.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/pixelda/mnistm.py
================================================
"""Dataset setting and data loader for MNIST-M.
Modified from
https://github.com/pytorch/vision/blob/master/torchvision/datasets/mnist.py
CREDIT: https://github.com/corenel
"""
from __future__ import print_function
import errno
import os
import torch
import torch.utils.data as data
from PIL import Image
class MNISTM(data.Dataset):
"""`MNIST-M Dataset."""
url = "https://github.com/VanushVaswani/keras_mnistm/releases/download/1.0/keras_mnistm.pkl.gz"
raw_folder = 'raw'
processed_folder = 'processed'
training_file = 'mnist_m_train.pt'
test_file = 'mnist_m_test.pt'
def __init__(self,
root, mnist_root="data",
train=True,
transform=None, target_transform=None,
download=False):
"""Init MNIST-M dataset."""
super(MNISTM, self).__init__()
self.root = os.path.expanduser(root)
self.mnist_root = os.path.expanduser(mnist_root)
self.transform = transform
self.target_transform = target_transform
self.train = train # training set or test set
if download:
self.download()
if not self._check_exists():
raise RuntimeError('Dataset not found.' +
' You can use download=True to download it')
if self.train:
self.train_data, self.train_labels = \
torch.load(os.path.join(self.root,
self.processed_folder,
self.training_file))
else:
self.test_data, self.test_labels = \
torch.load(os.path.join(self.root,
self.processed_folder,
self.test_file))
def __getitem__(self, index):
"""Get images and target for data loader.
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
if self.train:
img, target = self.train_data[index], self.train_labels[index]
else:
img, target = self.test_data[index], self.test_labels[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.squeeze().numpy(), mode='RGB')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
"""Return size of dataset."""
if self.train:
return len(self.train_data)
else:
return len(self.test_data)
def _check_exists(self):
return os.path.exists(os.path.join(self.root,
self.processed_folder,
self.training_file)) and \
os.path.exists(os.path.join(self.root,
self.processed_folder,
self.test_file))
def download(self):
"""Download the MNIST data."""
# import essential packages
from six.moves import urllib
import gzip
import pickle
from torchvision import datasets
# check if dataset already exists
if self._check_exists():
return
# make data dirs
try:
os.makedirs(os.path.join(self.root, self.raw_folder))
os.makedirs(os.path.join(self.root, self.processed_folder))
except OSError as e:
if e.errno == errno.EEXIST:
pass
else:
raise
# download pkl files
print('Downloading ' + self.url)
filename = self.url.rpartition('/')[2]
file_path = os.path.join(self.root, self.raw_folder, filename)
if not os.path.exists(file_path.replace('.gz', '')):
data = urllib.request.urlopen(self.url)
with open(file_path, 'wb') as f:
f.write(data.read())
with open(file_path.replace('.gz', ''), 'wb') as out_f, \
gzip.GzipFile(file_path) as zip_f:
out_f.write(zip_f.read())
os.unlink(file_path)
# process and save as torch files
print('Processing...')
# load MNIST-M images from pkl file
with open(file_path.replace('.gz', ''), "rb") as f:
mnist_m_data = pickle.load(f, encoding='bytes')
mnist_m_train_data = torch.ByteTensor(mnist_m_data[b'train'])
mnist_m_test_data = torch.ByteTensor(mnist_m_data[b'test'])
# get MNIST labels
mnist_train_labels = datasets.MNIST(root=self.mnist_root,
train=True,
download=True).train_labels
mnist_test_labels = datasets.MNIST(root=self.mnist_root,
train=False,
download=True).test_labels
# save MNIST-M dataset
training_set = (mnist_m_train_data, mnist_train_labels)
test_set = (mnist_m_test_data, mnist_test_labels)
with open(os.path.join(self.root,
self.processed_folder,
self.training_file), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(self.root,
self.processed_folder,
self.test_file), 'wb') as f:
torch.save(test_set, f)
print('Done!')
================================================
FILE: implementations/pixelda/pixelda.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from mnistm import MNISTM
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--n_residual_blocks", type=int, default=6, help="number of residual blocks in generator")
parser.add_argument("--latent_dim", type=int, default=10, help="dimensionality of the noise input")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes in the dataset")
parser.add_argument("--sample_interval", type=int, default=300, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
# Calculate output of image discriminator (PatchGAN)
patch = int(opt.img_size / 2 ** 4)
patch = (1, patch, patch)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class ResidualBlock(nn.Module):
def __init__(self, in_features=64, out_features=64):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(in_features, in_features, 3, 1, 1),
nn.BatchNorm2d(in_features),
nn.ReLU(inplace=True),
nn.Conv2d(in_features, in_features, 3, 1, 1),
nn.BatchNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# Fully-connected layer which constructs image channel shaped output from noise
self.fc = nn.Linear(opt.latent_dim, opt.channels * opt.img_size ** 2)
self.l1 = nn.Sequential(nn.Conv2d(opt.channels * 2, 64, 3, 1, 1), nn.ReLU(inplace=True))
resblocks = []
for _ in range(opt.n_residual_blocks):
resblocks.append(ResidualBlock())
self.resblocks = nn.Sequential(*resblocks)
self.l2 = nn.Sequential(nn.Conv2d(64, opt.channels, 3, 1, 1), nn.Tanh())
def forward(self, img, z):
gen_input = torch.cat((img, self.fc(z).view(*img.shape)), 1)
out = self.l1(gen_input)
out = self.resblocks(out)
img_ = self.l2(out)
return img_
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def block(in_features, out_features, normalization=True):
"""Discriminator block"""
layers = [nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True)]
if normalization:
layers.append(nn.InstanceNorm2d(out_features))
return layers
self.model = nn.Sequential(
*block(opt.channels, 64, normalization=False),
*block(64, 128),
*block(128, 256),
*block(256, 512),
nn.Conv2d(512, 1, 3, 1, 1)
)
def forward(self, img):
validity = self.model(img)
return validity
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
def block(in_features, out_features, normalization=True):
"""Classifier block"""
layers = [nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True)]
if normalization:
layers.append(nn.InstanceNorm2d(out_features))
return layers
self.model = nn.Sequential(
*block(opt.channels, 64, normalization=False), *block(64, 128), *block(128, 256), *block(256, 512)
)
input_size = opt.img_size // 2 ** 4
self.output_layer = nn.Sequential(nn.Linear(512 * input_size ** 2, opt.n_classes), nn.Softmax())
def forward(self, img):
feature_repr = self.model(img)
feature_repr = feature_repr.view(feature_repr.size(0), -1)
label = self.output_layer(feature_repr)
return label
# Loss function
adversarial_loss = torch.nn.MSELoss()
task_loss = torch.nn.CrossEntropyLoss()
# Loss weights
lambda_adv = 1
lambda_task = 0.1
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
classifier = Classifier()
if cuda:
generator.cuda()
discriminator.cuda()
classifier.cuda()
adversarial_loss.cuda()
task_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
classifier.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader_A = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
os.makedirs("../../data/mnistm", exist_ok=True)
dataloader_B = torch.utils.data.DataLoader(
MNISTM(
"../../data/mnistm",
train=True,
download=True,
transform=transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(generator.parameters(), classifier.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
# ----------
# Training
# ----------
# Keeps 100 accuracy measurements
task_performance = []
target_performance = []
for epoch in range(opt.n_epochs):
for i, ((imgs_A, labels_A), (imgs_B, labels_B)) in enumerate(zip(dataloader_A, dataloader_B)):
batch_size = imgs_A.size(0)
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, *patch).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, *patch).fill_(0.0), requires_grad=False)
# Configure input
imgs_A = Variable(imgs_A.type(FloatTensor).expand(batch_size, 3, opt.img_size, opt.img_size))
labels_A = Variable(labels_A.type(LongTensor))
imgs_B = Variable(imgs_B.type(FloatTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise
z = Variable(FloatTensor(np.random.uniform(-1, 1, (batch_size, opt.latent_dim))))
# Generate a batch of images
fake_B = generator(imgs_A, z)
# Perform task on translated source image
label_pred = classifier(fake_B)
# Calculate the task loss
task_loss_ = (task_loss(label_pred, labels_A) + task_loss(classifier(imgs_A), labels_A)) / 2
# Loss measures generator's ability to fool the discriminator
g_loss = lambda_adv * adversarial_loss(discriminator(fake_B), valid) + lambda_task * task_loss_
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(imgs_B), valid)
fake_loss = adversarial_loss(discriminator(fake_B.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# ---------------------------------------
# Evaluate Performance on target domain
# ---------------------------------------
# Evaluate performance on translated Domain A
acc = np.mean(np.argmax(label_pred.data.cpu().numpy(), axis=1) == labels_A.data.cpu().numpy())
task_performance.append(acc)
if len(task_performance) > 100:
task_performance.pop(0)
# Evaluate performance on Domain B
pred_B = classifier(imgs_B)
target_acc = np.mean(np.argmax(pred_B.data.cpu().numpy(), axis=1) == labels_B.numpy())
target_performance.append(target_acc)
if len(target_performance) > 100:
target_performance.pop(0)
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [CLF acc: %3d%% (%3d%%), target_acc: %3d%% (%3d%%)]"
% (
epoch,
opt.n_epochs,
i,
len(dataloader_A),
d_loss.item(),
g_loss.item(),
100 * acc,
100 * np.mean(task_performance),
100 * target_acc,
100 * np.mean(target_performance),
)
)
batches_done = len(dataloader_A) * epoch + i
if batches_done % opt.sample_interval == 0:
sample = torch.cat((imgs_A.data[:5], fake_B.data[:5], imgs_B.data[:5]), -2)
save_image(sample, "images/%d.png" % batches_done, nrow=int(math.sqrt(batch_size)), normalize=True)
================================================
FILE: implementations/relativistic_gan/relativistic_gan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
parser.add_argument("--rel_avg_gan", action="store_true", help="relativistic average GAN instead of standard")
opt = parser.parse_args()
print(opt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1))
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
# Loss function
adversarial_loss = torch.nn.BCEWithLogitsLoss().to(device)
# Initialize generator and discriminator
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
real_pred = discriminator(real_imgs).detach()
fake_pred = discriminator(gen_imgs)
if opt.rel_avg_gan:
g_loss = adversarial_loss(fake_pred - real_pred.mean(0, keepdim=True), valid)
else:
g_loss = adversarial_loss(fake_pred - real_pred, valid)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Predict validity
real_pred = discriminator(real_imgs)
fake_pred = discriminator(gen_imgs.detach())
if opt.rel_avg_gan:
real_loss = adversarial_loss(real_pred - fake_pred.mean(0, keepdim=True), valid)
fake_loss = adversarial_loss(fake_pred - real_pred.mean(0, keepdim=True), fake)
else:
real_loss = adversarial_loss(real_pred - fake_pred, valid)
fake_loss = adversarial_loss(fake_pred - real_pred, fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/sgan/sgan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--num_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.num_classes, opt.latent_dim)
self.init_size = opt.img_size // 4 # Initial size before upsampling
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise):
out = self.l1(noise)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
"""Returns layers of each discriminator block"""
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.conv_blocks = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
# Output layers
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())
def forward(self, img):
out = self.conv_blocks(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
label = self.aux_layer(out)
return validity, label
# Loss functions
adversarial_loss = torch.nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
auxiliary_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise and labels as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
validity, _ = discriminator(gen_imgs)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
real_pred, real_aux = discriminator(real_imgs)
d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2
# Loss for fake images
fake_pred, fake_aux = discriminator(gen_imgs.detach())
d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
# Calculate discriminator accuracy
pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)
gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)
d_acc = np.mean(np.argmax(pred, axis=1) == gt)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/softmax_gan/softmax_gan.py
================================================
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.img_size ** 2, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def log(x):
return torch.log(x + 1e-8)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
optimizer_G.zero_grad()
optimizer_D.zero_grad()
batch_size = imgs.shape[0]
# Adversarial ground truths
g_target = 1 / (batch_size * 2)
d_target = 1 / batch_size
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
d_real = discriminator(real_imgs)
d_fake = discriminator(gen_imgs)
# Partition function
Z = torch.sum(torch.exp(-d_real)) + torch.sum(torch.exp(-d_fake))
# Calculate loss of discriminator and update
d_loss = d_target * torch.sum(d_real) + log(Z)
d_loss.backward(retain_graph=True)
optimizer_D.step()
# Calculate loss of generator and update
g_loss = g_target * (torch.sum(d_real) + torch.sum(d_fake)) + log(Z)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
================================================
FILE: implementations/srgan/datasets.py
================================================
import glob
import random
import os
import numpy as np
import torch
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
# Normalization parameters for pre-trained PyTorch models
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
class ImageDataset(Dataset):
def __init__(self, root, hr_shape):
hr_height, hr_width = hr_shape
# Transforms for low resolution images and high resolution images
self.lr_transform = transforms.Compose(
[
transforms.Resize((hr_height // 4, hr_height // 4), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
)
self.hr_transform = transforms.Compose(
[
transforms.Resize((hr_height, hr_height), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
)
self.files = sorted(glob.glob(root + "/*.*"))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
img_lr = self.lr_transform(img)
img_hr = self.hr_transform(img)
return {"lr": img_lr, "hr": img_hr}
def __len__(self):
return len(self.files)
================================================
FILE: implementations/srgan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision.models import vgg19
import math
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
vgg19_model = vgg19(pretrained=True)
self.feature_extractor = nn.Sequential(*list(vgg19_model.features.children())[:18])
def forward(self, img):
return self.feature_extractor(img)
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_features, 0.8),
nn.PReLU(),
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_features, 0.8),
)
def forward(self, x):
return x + self.conv_block(x)
class GeneratorResNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3, n_residual_blocks=16):
super(GeneratorResNet, self).__init__()
# First layer
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=9, stride=1, padding=4), nn.PReLU())
# Residual blocks
res_blocks = []
for _ in range(n_residual_blocks):
res_blocks.append(ResidualBlock(64))
self.res_blocks = nn.Sequential(*res_blocks)
# Second conv layer post residual blocks
self.conv2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(64, 0.8))
# Upsampling layers
upsampling = []
for out_features in range(2):
upsampling += [
# nn.Upsample(scale_factor=2),
nn.Conv2d(64, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.PixelShuffle(upscale_factor=2),
nn.PReLU(),
]
self.upsampling = nn.Sequential(*upsampling)
# Final output layer
self.conv3 = nn.Sequential(nn.Conv2d(64, out_channels, kernel_size=9, stride=1, padding=4), nn.Tanh())
def forward(self, x):
out1 = self.conv1(x)
out = self.res_blocks(out1)
out2 = self.conv2(out)
out = torch.add(out1, out2)
out = self.upsampling(out)
out = self.conv3(out)
return out
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/srgan/srgan.py
================================================
"""
Super-resolution of CelebA using Generative Adversarial Networks.
The dataset can be downloaded from: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AADIKlz8PR9zr6Y20qbkunrba/Img/img_align_celeba.zip?dl=0
(if not available there see if options are listed at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html)
Instrustion on running the script:
1. Download the dataset from the provided link
2. Save the folder 'img_align_celeba' to '../../data/'
4. Run the sript using command 'python3 srgan.py'
"""
import argparse
import os
import numpy as np
import math
import itertools
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
os.makedirs("saved_models", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=4, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--hr_height", type=int, default=256, help="high res. image height")
parser.add_argument("--hr_width", type=int, default=256, help="high res. image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving image samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
cuda = torch.cuda.is_available()
hr_shape = (opt.hr_height, opt.hr_width)
# Initialize generator and discriminator
generator = GeneratorResNet()
discriminator = Discriminator(input_shape=(opt.channels, *hr_shape))
feature_extractor = FeatureExtractor()
# Set feature extractor to inference mode
feature_extractor.eval()
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_content = torch.nn.L1Loss()
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
feature_extractor = feature_extractor.cuda()
criterion_GAN = criterion_GAN.cuda()
criterion_content = criterion_content.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/generator_%d.pth"))
discriminator.load_state_dict(torch.load("saved_models/discriminator_%d.pth"))
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, hr_shape=hr_shape),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# ----------
# Training
# ----------
for epoch in range(opt.epoch, opt.n_epochs):
for i, imgs in enumerate(dataloader):
# Configure model input
imgs_lr = Variable(imgs["lr"].type(Tensor))
imgs_hr = Variable(imgs["hr"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# Generate a high resolution image from low resolution input
gen_hr = generator(imgs_lr)
# Adversarial loss
loss_GAN = criterion_GAN(discriminator(gen_hr), valid)
# Content loss
gen_features = feature_extractor(gen_hr)
real_features = feature_extractor(imgs_hr)
loss_content = criterion_content(gen_features, real_features.detach())
# Total loss
loss_G = loss_content + 1e-3 * loss_GAN
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss of real and fake images
loss_real = criterion_GAN(discriminator(imgs_hr), valid)
loss_fake = criterion_GAN(discriminator(gen_hr.detach()), fake)
# Total loss
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
sys.stdout.write(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), loss_D.item(), loss_G.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
# Save image grid with upsampled inputs and SRGAN outputs
imgs_lr = nn.functional.interpolate(imgs_lr, scale_factor=4)
gen_hr = make_grid(gen_hr, nrow=1, normalize=True)
imgs_lr = make_grid(imgs_lr, nrow=1, normalize=True)
img_grid = torch.cat((imgs_lr, gen_hr), -1)
save_image(img_grid, "images/%d.png" % batches_done, normalize=False)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/generator_%d.pth" % epoch)
torch.save(discriminator.state_dict(), "saved_models/discriminator_%d.pth" % epoch)
================================================
FILE: implementations/stargan/datasets.py
================================================
import glob
import random
import os
import numpy as np
import torch
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class CelebADataset(Dataset):
def __init__(self, root, transforms_=None, mode="train", attributes=None):
self.transform = transforms.Compose(transforms_)
self.selected_attrs = attributes
self.files = sorted(glob.glob("%s/*.jpg" % root))
self.files = self.files[:-2000] if mode == "train" else self.files[-2000:]
self.label_path = glob.glob("%s/*.txt" % root)[0]
self.annotations = self.get_annotations()
def get_annotations(self):
"""Extracts annotations for CelebA"""
annotations = {}
lines = [line.rstrip() for line in open(self.label_path, "r")]
self.label_names = lines[1].split()
for _, line in enumerate(lines[2:]):
filename, *values = line.split()
labels = []
for attr in self.selected_attrs:
idx = self.label_names.index(attr)
labels.append(1 * (values[idx] == "1"))
annotations[filename] = labels
return annotations
def __getitem__(self, index):
filepath = self.files[index % len(self.files)]
filename = filepath.split("/")[-1]
img = self.transform(Image.open(filepath))
label = self.annotations[filename]
label = torch.FloatTensor(np.array(label))
return img, label
def __len__(self):
return len(self.files)
================================================
FILE: implementations/stargan/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
##############################
# RESNET
##############################
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
conv_block = [
nn.Conv2d(in_features, in_features, 3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(in_features, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
nn.Conv2d(in_features, in_features, 3, stride=1, padding=1, bias=False),
nn.InstanceNorm2d(in_features, affine=True, track_running_stats=True),
]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)
class GeneratorResNet(nn.Module):
def __init__(self, img_shape=(3, 128, 128), res_blocks=9, c_dim=5):
super(GeneratorResNet, self).__init__()
channels, img_size, _ = img_shape
# Initial convolution block
model = [
nn.Conv2d(channels + c_dim, 64, 7, stride=1, padding=3, bias=False),
nn.InstanceNorm2d(64, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
]
# Downsampling
curr_dim = 64
for _ in range(2):
model += [
nn.Conv2d(curr_dim, curr_dim * 2, 4, stride=2, padding=1, bias=False),
nn.InstanceNorm2d(curr_dim * 2, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
]
curr_dim *= 2
# Residual blocks
for _ in range(res_blocks):
model += [ResidualBlock(curr_dim)]
# Upsampling
for _ in range(2):
model += [
nn.ConvTranspose2d(curr_dim, curr_dim // 2, 4, stride=2, padding=1, bias=False),
nn.InstanceNorm2d(curr_dim // 2, affine=True, track_running_stats=True),
nn.ReLU(inplace=True),
]
curr_dim = curr_dim // 2
# Output layer
model += [nn.Conv2d(curr_dim, channels, 7, stride=1, padding=3), nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, x, c):
c = c.view(c.size(0), c.size(1), 1, 1)
c = c.repeat(1, 1, x.size(2), x.size(3))
x = torch.cat((x, c), 1)
return self.model(x)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, img_shape=(3, 128, 128), c_dim=5, n_strided=6):
super(Discriminator, self).__init__()
channels, img_size, _ = img_shape
def discriminator_block(in_filters, out_filters):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1), nn.LeakyReLU(0.01)]
return layers
layers = discriminator_block(channels, 64)
curr_dim = 64
for _ in range(n_strided - 1):
layers.extend(discriminator_block(curr_dim, curr_dim * 2))
curr_dim *= 2
self.model = nn.Sequential(*layers)
# Output 1: PatchGAN
self.out1 = nn.Conv2d(curr_dim, 1, 3, padding=1, bias=False)
# Output 2: Class prediction
kernel_size = img_size // 2 ** n_strided
self.out2 = nn.Conv2d(curr_dim, c_dim, kernel_size, bias=False)
def forward(self, img):
feature_repr = self.model(img)
out_adv = self.out1(feature_repr)
out_cls = self.out2(feature_repr)
return out_adv, out_cls.view(out_cls.size(0), -1)
================================================
FILE: implementations/stargan/stargan.py
================================================
"""
StarGAN (CelebA)
The dataset can be downloaded from: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AADIKlz8PR9zr6Y20qbkunrba/Img/img_align_celeba.zip?dl=0
And the annotations: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AAA8YmAHNNU6BEfWMPMfM6r9a/Anno?dl=0&preview=list_attr_celeba.txt
Instructions on running the script:
1. Download the dataset and annotations from the provided link
2. Copy 'list_attr_celeba.txt' to folder 'img_align_celeba'
2. Save the folder 'img_align_celeba' to '../../data/'
4. Run the script by 'python3 stargan.py'
"""
import argparse
import os
import numpy as np
import math
import itertools
import time
import datetime
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.autograd as autograd
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
os.makedirs("saved_models", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=16, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=128, help="size of image height")
parser.add_argument("--img_width", type=int, default=128, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between saving generator samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
parser.add_argument("--residual_blocks", type=int, default=6, help="number of residual blocks in generator")
parser.add_argument(
"--selected_attrs",
"--list",
nargs="+",
help="selected attributes for the CelebA dataset",
default=["Black_Hair", "Blond_Hair", "Brown_Hair", "Male", "Young"],
)
parser.add_argument("--n_critic", type=int, default=5, help="number of training iterations for WGAN discriminator")
opt = parser.parse_args()
print(opt)
c_dim = len(opt.selected_attrs)
img_shape = (opt.channels, opt.img_height, opt.img_width)
cuda = torch.cuda.is_available()
# Loss functions
criterion_cycle = torch.nn.L1Loss()
def criterion_cls(logit, target):
return F.binary_cross_entropy_with_logits(logit, target, size_average=False) / logit.size(0)
# Loss weights
lambda_cls = 1
lambda_rec = 10
lambda_gp = 10
# Initialize generator and discriminator
generator = GeneratorResNet(img_shape=img_shape, res_blocks=opt.residual_blocks, c_dim=c_dim)
discriminator = Discriminator(img_shape=img_shape, c_dim=c_dim)
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_cycle.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/generator_%d.pth" % opt.epoch))
discriminator.load_state_dict(torch.load("saved_models/discriminator_%d.pth" % opt.epoch))
else:
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Configure dataloaders
train_transforms = [
transforms.Resize(int(1.12 * opt.img_height), Image.BICUBIC),
transforms.RandomCrop(opt.img_height),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = DataLoader(
CelebADataset(
"../../data/%s" % opt.dataset_name, transforms_=train_transforms, mode="train", attributes=opt.selected_attrs
),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_transforms = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
val_dataloader = DataLoader(
CelebADataset(
"../../data/%s" % opt.dataset_name, transforms_=val_transforms, mode="val", attributes=opt.selected_attrs
),
batch_size=10,
shuffle=True,
num_workers=1,
)
# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def compute_gradient_penalty(D, real_samples, fake_samples):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
d_interpolates, _ = D(interpolates)
fake = Variable(Tensor(np.ones(d_interpolates.shape)), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
label_changes = [
((0, 1), (1, 0), (2, 0)), # Set to black hair
((0, 0), (1, 1), (2, 0)), # Set to blonde hair
((0, 0), (1, 0), (2, 1)), # Set to brown hair
((3, -1),), # Flip gender
((4, -1),), # Age flip
]
def sample_images(batches_done):
"""Saves a generated sample of domain translations"""
val_imgs, val_labels = next(iter(val_dataloader))
val_imgs = Variable(val_imgs.type(Tensor))
val_labels = Variable(val_labels.type(Tensor))
img_samples = None
for i in range(10):
img, label = val_imgs[i], val_labels[i]
# Repeat for number of label changes
imgs = img.repeat(c_dim, 1, 1, 1)
labels = label.repeat(c_dim, 1)
# Make changes to labels
for sample_i, changes in enumerate(label_changes):
for col, val in changes:
labels[sample_i, col] = 1 - labels[sample_i, col] if val == -1 else val
# Generate translations
gen_imgs = generator(imgs, labels)
# Concatenate images by width
gen_imgs = torch.cat([x for x in gen_imgs.data], -1)
img_sample = torch.cat((img.data, gen_imgs), -1)
# Add as row to generated samples
img_samples = img_sample if img_samples is None else torch.cat((img_samples, img_sample), -2)
save_image(img_samples.view(1, *img_samples.shape), "images/%s.png" % batches_done, normalize=True)
# ----------
# Training
# ----------
saved_samples = []
start_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
# Model inputs
imgs = Variable(imgs.type(Tensor))
labels = Variable(labels.type(Tensor))
# Sample labels as generator inputs
sampled_c = Variable(Tensor(np.random.randint(0, 2, (imgs.size(0), c_dim))))
# Generate fake batch of images
fake_imgs = generator(imgs, sampled_c)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real images
real_validity, pred_cls = discriminator(imgs)
# Fake images
fake_validity, _ = discriminator(fake_imgs.detach())
# Gradient penalty
gradient_penalty = compute_gradient_penalty(discriminator, imgs.data, fake_imgs.data)
# Adversarial loss
loss_D_adv = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
# Classification loss
loss_D_cls = criterion_cls(pred_cls, labels)
# Total loss
loss_D = loss_D_adv + lambda_cls * loss_D_cls
loss_D.backward()
optimizer_D.step()
optimizer_G.zero_grad()
# Every n_critic times update generator
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
# Translate and reconstruct image
gen_imgs = generator(imgs, sampled_c)
recov_imgs = generator(gen_imgs, labels)
# Discriminator evaluates translated image
fake_validity, pred_cls = discriminator(gen_imgs)
# Adversarial loss
loss_G_adv = -torch.mean(fake_validity)
# Classification loss
loss_G_cls = criterion_cls(pred_cls, sampled_c)
# Reconstruction loss
loss_G_rec = criterion_cycle(recov_imgs, imgs)
# Total loss
loss_G = loss_G_adv + lambda_cls * loss_G_cls + lambda_rec * loss_G_rec
loss_G.backward()
optimizer_G.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - start_time) / (batches_done + 1))
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D adv: %f, aux: %f] [G loss: %f, adv: %f, aux: %f, cycle: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D_adv.item(),
loss_D_cls.item(),
loss_G.item(),
loss_G_adv.item(),
loss_G_cls.item(),
loss_G_rec.item(),
time_left,
)
)
# If at sample interval sample and save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/generator_%d.pth" % epoch)
torch.save(discriminator.state_dict(), "saved_models/discriminator_%d.pth" % epoch)
================================================
FILE: implementations/unit/datasets.py
================================================
import glob
import random
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode="train"):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, "%s/A" % mode) + "/*.*"))
self.files_B = sorted(glob.glob(os.path.join(root, "%s/B" % mode) + "/*.*"))
def __getitem__(self, index):
item_A = self.transform(Image.open(self.files_A[index % len(self.files_A)]))
if self.unaligned:
item_B = self.transform(Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]))
else:
item_B = self.transform(Image.open(self.files_B[index % len(self.files_B)]))
return {"A": item_A, "B": item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
================================================
FILE: implementations/unit/models.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch.autograd import Variable
import numpy as np
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class LambdaLR:
def __init__(self, n_epochs, offset, decay_start_epoch):
assert (n_epochs - decay_start_epoch) > 0, "Decay must start before the training session ends!"
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
##############################
# RESNET
##############################
class ResidualBlock(nn.Module):
def __init__(self, features):
super(ResidualBlock, self).__init__()
conv_block = [
nn.ReflectionPad2d(1),
nn.Conv2d(features, features, 3),
nn.InstanceNorm2d(features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(features, features, 3),
nn.InstanceNorm2d(features),
]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)
class Encoder(nn.Module):
def __init__(self, in_channels=3, dim=64, n_downsample=2, shared_block=None):
super(Encoder, self).__init__()
# Initial convolution block
layers = [
nn.ReflectionPad2d(3),
nn.Conv2d(in_channels, dim, 7),
nn.InstanceNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
]
# Downsampling
for _ in range(n_downsample):
layers += [
nn.Conv2d(dim, dim * 2, 4, stride=2, padding=1),
nn.InstanceNorm2d(dim * 2),
nn.ReLU(inplace=True),
]
dim *= 2
# Residual blocks
for _ in range(3):
layers += [ResidualBlock(dim)]
self.model_blocks = nn.Sequential(*layers)
self.shared_block = shared_block
def reparameterization(self, mu):
Tensor = torch.cuda.FloatTensor if mu.is_cuda else torch.FloatTensor
z = Variable(Tensor(np.random.normal(0, 1, mu.shape)))
return z + mu
def forward(self, x):
x = self.model_blocks(x)
mu = self.shared_block(x)
z = self.reparameterization(mu)
return mu, z
class Generator(nn.Module):
def __init__(self, out_channels=3, dim=64, n_upsample=2, shared_block=None):
super(Generator, self).__init__()
self.shared_block = shared_block
layers = []
dim = dim * 2 ** n_upsample
# Residual blocks
for _ in range(3):
layers += [ResidualBlock(dim)]
# Upsampling
for _ in range(n_upsample):
layers += [
nn.ConvTranspose2d(dim, dim // 2, 4, stride=2, padding=1),
nn.InstanceNorm2d(dim // 2),
nn.LeakyReLU(0.2, inplace=True),
]
dim = dim // 2
# Output layer
layers += [nn.ReflectionPad2d(3), nn.Conv2d(dim, out_channels, 7), nn.Tanh()]
self.model_blocks = nn.Sequential(*layers)
def forward(self, x):
x = self.shared_block(x)
x = self.model_blocks(x)
return x
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
# Calculate output of image discriminator (PatchGAN)
self.output_shape = (1, height // 2 ** 4, width // 2 ** 4)
def discriminator_block(in_filters, out_filters, normalize=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(channels, 64, normalize=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.Conv2d(512, 1, 3, padding=1)
)
def forward(self, img):
return self.model(img)
================================================
FILE: implementations/unit/unit.py
================================================
import argparse
import os
import numpy as np
import math
import itertools
import datetime
import time
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="apple2orange", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0001, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving generator samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between saving model checkpoints")
parser.add_argument("--n_downsample", type=int, default=2, help="number downsampling layers in encoder")
parser.add_argument("--dim", type=int, default=64, help="number of filters in first encoder layer")
opt = parser.parse_args()
print(opt)
cuda = True if torch.cuda.is_available() else False
# Create sample and checkpoint directories
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_pixel = torch.nn.L1Loss()
input_shape = (opt.channels, opt.img_height, opt.img_width)
# Dimensionality (channel-wise) of image embedding
shared_dim = opt.dim * 2 ** opt.n_downsample
# Initialize generator and discriminator
shared_E = ResidualBlock(features=shared_dim)
E1 = Encoder(dim=opt.dim, n_downsample=opt.n_downsample, shared_block=shared_E)
E2 = Encoder(dim=opt.dim, n_downsample=opt.n_downsample, shared_block=shared_E)
shared_G = ResidualBlock(features=shared_dim)
G1 = Generator(dim=opt.dim, n_upsample=opt.n_downsample, shared_block=shared_G)
G2 = Generator(dim=opt.dim, n_upsample=opt.n_downsample, shared_block=shared_G)
D1 = Discriminator(input_shape)
D2 = Discriminator(input_shape)
if cuda:
E1 = E1.cuda()
E2 = E2.cuda()
G1 = G1.cuda()
G2 = G2.cuda()
D1 = D1.cuda()
D2 = D2.cuda()
criterion_GAN.cuda()
criterion_pixel.cuda()
if opt.epoch != 0:
# Load pretrained models
E1.load_state_dict(torch.load("saved_models/%s/E1_%d.pth" % (opt.dataset_name, opt.epoch)))
E2.load_state_dict(torch.load("saved_models/%s/E2_%d.pth" % (opt.dataset_name, opt.epoch)))
G1.load_state_dict(torch.load("saved_models/%s/G1_%d.pth" % (opt.dataset_name, opt.epoch)))
G2.load_state_dict(torch.load("saved_models/%s/G2_%d.pth" % (opt.dataset_name, opt.epoch)))
D1.load_state_dict(torch.load("saved_models/%s/D1_%d.pth" % (opt.dataset_name, opt.epoch)))
D2.load_state_dict(torch.load("saved_models/%s/D2_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
E1.apply(weights_init_normal)
E2.apply(weights_init_normal)
G1.apply(weights_init_normal)
G2.apply(weights_init_normal)
D1.apply(weights_init_normal)
D2.apply(weights_init_normal)
# Loss weights
lambda_0 = 10 # GAN
lambda_1 = 0.1 # KL (encoded images)
lambda_2 = 100 # ID pixel-wise
lambda_3 = 0.1 # KL (encoded translated images)
lambda_4 = 100 # Cycle pixel-wise
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(E1.parameters(), E2.parameters(), G1.parameters(), G2.parameters()),
lr=opt.lr,
betas=(opt.b1, opt.b2),
)
optimizer_D1 = torch.optim.Adam(D1.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D2 = torch.optim.Adam(D2.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D1 = torch.optim.lr_scheduler.LambdaLR(
optimizer_D1, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
lr_scheduler_D2 = torch.optim.lr_scheduler.LambdaLR(
optimizer_D2, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step
)
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
# Image transformations
transforms_ = [
transforms.Resize(int(opt.img_height * 1.12), Image.BICUBIC),
transforms.RandomCrop((opt.img_height, opt.img_width)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
# Training data loader
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# Test data loader
val_dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, unaligned=True, mode="test"),
batch_size=5,
shuffle=True,
num_workers=1,
)
def sample_images(batches_done):
"""Saves a generated sample from the test set"""
imgs = next(iter(val_dataloader))
X1 = Variable(imgs["A"].type(Tensor))
X2 = Variable(imgs["B"].type(Tensor))
_, Z1 = E1(X1)
_, Z2 = E2(X2)
fake_X1 = G1(Z2)
fake_X2 = G2(Z1)
img_sample = torch.cat((X1.data, fake_X2.data, X2.data, fake_X1.data), 0)
save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)
def compute_kl(mu):
mu_2 = torch.pow(mu, 2)
loss = torch.mean(mu_2)
return loss
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
X1 = Variable(batch["A"].type(Tensor))
X2 = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((X1.size(0), *D1.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((X1.size(0), *D1.output_shape))), requires_grad=False)
# -------------------------------
# Train Encoders and Generators
# -------------------------------
optimizer_G.zero_grad()
# Get shared latent representation
mu1, Z1 = E1(X1)
mu2, Z2 = E2(X2)
# Reconstruct images
recon_X1 = G1(Z1)
recon_X2 = G2(Z2)
# Translate images
fake_X1 = G1(Z2)
fake_X2 = G2(Z1)
# Cycle translation
mu1_, Z1_ = E1(fake_X1)
mu2_, Z2_ = E2(fake_X2)
cycle_X1 = G1(Z2_)
cycle_X2 = G2(Z1_)
# Losses
loss_GAN_1 = lambda_0 * criterion_GAN(D1(fake_X1), valid)
loss_GAN_2 = lambda_0 * criterion_GAN(D2(fake_X2), valid)
loss_KL_1 = lambda_1 * compute_kl(mu1)
loss_KL_2 = lambda_1 * compute_kl(mu2)
loss_ID_1 = lambda_2 * criterion_pixel(recon_X1, X1)
loss_ID_2 = lambda_2 * criterion_pixel(recon_X2, X2)
loss_KL_1_ = lambda_3 * compute_kl(mu1_)
loss_KL_2_ = lambda_3 * compute_kl(mu2_)
loss_cyc_1 = lambda_4 * criterion_pixel(cycle_X1, X1)
loss_cyc_2 = lambda_4 * criterion_pixel(cycle_X2, X2)
# Total loss
loss_G = (
loss_KL_1
+ loss_KL_2
+ loss_ID_1
+ loss_ID_2
+ loss_GAN_1
+ loss_GAN_2
+ loss_KL_1_
+ loss_KL_2_
+ loss_cyc_1
+ loss_cyc_2
)
loss_G.backward()
optimizer_G.step()
# -----------------------
# Train Discriminator 1
# -----------------------
optimizer_D1.zero_grad()
loss_D1 = criterion_GAN(D1(X1), valid) + criterion_GAN(D1(fake_X1.detach()), fake)
loss_D1.backward()
optimizer_D1.step()
# -----------------------
# Train Discriminator 2
# -----------------------
optimizer_D2.zero_grad()
loss_D2 = criterion_GAN(D2(X2), valid) + criterion_GAN(D2(fake_X2.detach()), fake)
loss_D2.backward()
optimizer_D2.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] ETA: %s"
% (epoch, opt.n_epochs, i, len(dataloader), (loss_D1 + loss_D2).item(), loss_G.item(), time_left)
)
# If at sample interval save image
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D1.step()
lr_scheduler_D2.step()
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(E1.state_dict(), "saved_models/%s/E1_%d.pth" % (opt.dataset_name, epoch))
torch.save(E2.state_dict(), "saved_models/%s/E2_%d.pth" % (opt.dataset_name, epoch))
torch.save(G1.state_dict(), "saved_models/%s/G1_%d.pth" % (opt.dataset_name, epoch))
torch.save(G2.state_dict(), "saved_models/%s/G2_%d.pth" % (opt.dataset_name, epoch))
torch.save(D1.state_dict(), "saved_models/%s/D1_%d.pth" % (opt.dataset_name, epoch))
torch.save(D2.state_dict(), "saved_models/%s/D2_%d.pth" % (opt.dataset_name, epoch))
================================================
FILE: implementations/wgan/wgan.py
================================================
import argparse
import os
import numpy as np
import math
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.00005, help="learning rate")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.RMSprop(generator.parameters(), lr=opt.lr)
optimizer_D = torch.optim.RMSprop(discriminator.parameters(), lr=opt.lr)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z).detach()
# Adversarial loss
loss_D = -torch.mean(discriminator(real_imgs)) + torch.mean(discriminator(fake_imgs))
loss_D.backward()
optimizer_D.step()
# Clip weights of discriminator
for p in discriminator.parameters():
p.data.clamp_(-opt.clip_value, opt.clip_value)
# Train the generator every n_critic iterations
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_imgs = generator(z)
# Adversarial loss
loss_G = -torch.mean(discriminator(gen_imgs))
loss_G.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, batches_done % len(dataloader), len(dataloader), loss_D.item(), loss_G.item())
)
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
batches_done += 1
================================================
FILE: implementations/wgan_div/wgan_div.py
================================================
import argparse
import os
import numpy as np
import math
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd as autograd
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
k = 2
p = 6
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor), requires_grad=True)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z)
# Real images
real_validity = discriminator(real_imgs)
# Fake images
fake_validity = discriminator(fake_imgs)
# Compute W-div gradient penalty
real_grad_out = Variable(Tensor(real_imgs.size(0), 1).fill_(1.0), requires_grad=False)
real_grad = autograd.grad(
real_validity, real_imgs, real_grad_out, create_graph=True, retain_graph=True, only_inputs=True
)[0]
real_grad_norm = real_grad.view(real_grad.size(0), -1).pow(2).sum(1) ** (p / 2)
fake_grad_out = Variable(Tensor(fake_imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake_grad = autograd.grad(
fake_validity, fake_imgs, fake_grad_out, create_graph=True, retain_graph=True, only_inputs=True
)[0]
fake_grad_norm = fake_grad.view(fake_grad.size(0), -1).pow(2).sum(1) ** (p / 2)
div_gp = torch.mean(real_grad_norm + fake_grad_norm) * k / 2
# Adversarial loss
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + div_gp
d_loss.backward()
optimizer_D.step()
optimizer_G.zero_grad()
# Train the generator every n_critic steps
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
# Generate a batch of images
fake_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
# Train on fake images
fake_validity = discriminator(fake_imgs)
g_loss = -torch.mean(fake_validity)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
if batches_done % opt.sample_interval == 0:
save_image(fake_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
batches_done += opt.n_critic
================================================
FILE: implementations/wgan_gp/wgan_gp.py
================================================
import argparse
import os
import numpy as np
import math
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd as autograd
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Loss weight for gradient penalty
lambda_gp = 10
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def compute_gradient_penalty(D, real_samples, fake_samples):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
d_interpolates = D(interpolates)
fake = Variable(Tensor(real_samples.shape[0], 1).fill_(1.0), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z)
# Real images
real_validity = discriminator(real_imgs)
# Fake images
fake_validity = discriminator(fake_imgs)
# Gradient penalty
gradient_penalty = compute_gradient_penalty(discriminator, real_imgs.data, fake_imgs.data)
# Adversarial loss
d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
d_loss.backward()
optimizer_D.step()
optimizer_G.zero_grad()
# Train the generator every n_critic steps
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
# Generate a batch of images
fake_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
# Train on fake images
fake_validity = discriminator(fake_imgs)
g_loss = -torch.mean(fake_validity)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
if batches_done % opt.sample_interval == 0:
save_image(fake_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
batches_done += opt.n_critic
================================================
FILE: requirements.txt
================================================
torch>=0.4.0
torchvision
matplotlib
numpy
scipy
pillow
urllib3
scikit-image




