Showing preview only (3,460K chars total). Download the full file or copy to clipboard to get everything.
Repository: eval-sys/mcpmark
Branch: main
Commit: adc5e6558f05
Files: 670
Total size: 3.1 MB
Directory structure:
gitextract_5znolca_/
├── .dockerignore
├── .editorconfig
├── .gitattributes
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── 1_bug_report.yml
│ │ ├── 2_feature_request.yml
│ │ └── config.yml
│ ├── PULL_REQUEST_TEMPLATE.md
│ ├── scripts/
│ │ └── pr-comment.js
│ └── workflows/
│ └── publish-docker-image.yml
├── .gitignore
├── CHANGELOG.md
├── Dockerfile
├── LICENSE
├── README.md
├── build-docker.sh
├── cspell.config.yaml
├── docs/
│ ├── contributing/
│ │ └── make-contribution.md
│ ├── datasets/
│ │ └── task.md
│ ├── installation_and_docker_usage.md
│ ├── introduction.md
│ ├── mcp/
│ │ ├── filesystem.md
│ │ ├── github.md
│ │ ├── notion.md
│ │ ├── playwright.md
│ │ └── postgres.md
│ └── quickstart.md
├── pipeline.py
├── pyproject.toml
├── run-benchmark.sh
├── run-task.sh
├── src/
│ ├── agents/
│ │ ├── __init__.py
│ │ ├── base_agent.py
│ │ ├── mcp/
│ │ │ ├── __init__.py
│ │ │ ├── http_server.py
│ │ │ └── stdio_server.py
│ │ ├── mcpmark_agent.py
│ │ ├── react_agent.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ └── token_usage.py
│ ├── aggregators/
│ │ ├── aggregate_results.py
│ │ ├── aggregate_specific_results.py
│ │ ├── aggregate_task_meta.py
│ │ └── pricing.py
│ ├── base/
│ │ ├── __init__.py
│ │ ├── login_helper.py
│ │ ├── state_manager.py
│ │ └── task_manager.py
│ ├── config/
│ │ ├── __init__.py
│ │ └── config_schema.py
│ ├── errors.py
│ ├── evaluator.py
│ ├── factory.py
│ ├── logger.py
│ ├── mcp_services/
│ │ ├── filesystem/
│ │ │ ├── __init__.py
│ │ │ ├── filesystem_login_helper.py
│ │ │ ├── filesystem_state_manager.py
│ │ │ └── filesystem_task_manager.py
│ │ ├── github/
│ │ │ ├── __init__.py
│ │ │ ├── github_login_helper.py
│ │ │ ├── github_state_manager.py
│ │ │ ├── github_task_manager.py
│ │ │ ├── repo_exporter.py
│ │ │ ├── repo_importer.py
│ │ │ └── token_pool.py
│ │ ├── insforge/
│ │ │ ├── __init__.py
│ │ │ ├── insforge_login_helper.py
│ │ │ ├── insforge_state_manager.py
│ │ │ └── insforge_task_manager.py
│ │ ├── notion/
│ │ │ ├── __init__.py
│ │ │ ├── notion_login_helper.py
│ │ │ ├── notion_state_manager.py
│ │ │ └── notion_task_manager.py
│ │ ├── playwright/
│ │ │ ├── __init__.py
│ │ │ ├── playwright_login_helper.py
│ │ │ ├── playwright_state_manager.py
│ │ │ └── playwright_task_manager.py
│ │ ├── playwright_webarena/
│ │ │ ├── playwright_login_helper.py
│ │ │ ├── playwright_state_manager.py
│ │ │ ├── playwright_task_manager.py
│ │ │ └── reddit_env_setup.md
│ │ ├── postgres/
│ │ │ ├── __init__.py
│ │ │ ├── postgres_login_helper.py
│ │ │ ├── postgres_state_manager.py
│ │ │ └── postgres_task_manager.py
│ │ └── supabase/
│ │ ├── __init__.py
│ │ ├── supabase_login_helper.py
│ │ ├── supabase_state_manager.py
│ │ └── supabase_task_manager.py
│ ├── model_config.py
│ ├── results_reporter.py
│ └── services.py
└── tasks/
├── __init__.py
├── filesystem/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── file_context/
│ │ │ ├── file_splitting/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── pattern_matching/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── uppercase/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── file_property/
│ │ │ ├── largest_rename/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── txt_merging/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── folder_structure/
│ │ │ └── structure_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── legal_document/
│ │ │ └── file_reorganize/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── papers/
│ │ │ └── papers_counting/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── student_database/
│ │ ├── duplicate_name/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── recommender_name/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── desktop/
│ │ ├── music_report/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── project_management/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── timeline_extraction/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── desktop_template/
│ │ ├── budget_computation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── contact_information/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── file_arrangement/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── file_context/
│ │ ├── duplicates_searching/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── file_merging/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── file_splitting/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── pattern_matching/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── uppercase/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── file_property/
│ │ ├── size_classification/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── time_classification/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── folder_structure/
│ │ ├── structure_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── structure_mirror/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── legal_document/
│ │ ├── dispute_review/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── individual_comments/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── solution_tracing/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── papers/
│ │ ├── author_folders/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── find_math_paper/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── organize_legacy_papers/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── student_database/
│ │ ├── duplicate_name/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── english_talent/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── gradebased_score/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── threestudio/
│ │ ├── code_locating/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── output_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── requirements_completion/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── votenet/
│ ├── dataset_comparison/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── debugging/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── requirements_writing/
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── github/
│ ├── easy/
│ │ ├── build-your-own-x/
│ │ │ ├── close_commented_issues/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── record_recent_commits/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── claude-code/
│ │ │ ├── add_terminal_shortcuts_doc/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── thank_docker_pr_author/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── triage_missing_tool_result_issue/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── mcpmark-cicd/
│ │ │ ├── basic_ci_checks/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── issue_lint_guard/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── nightly_health_check/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── missing-semester/
│ │ ├── count_translations/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── find_ga_tracking_id/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── build_your_own_x/
│ │ ├── find_commit_date/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── find_rag_commit/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── claude-code/
│ │ ├── automated_changelog_generation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── claude_collaboration_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── critical_issue_hotfix_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── feature_commit_tracking/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── label_color_standardization/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── easyr1/
│ │ ├── advanced_branch_strategy/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── config_parameter_audit/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── performance_regression_investigation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── qwen3_issue_management/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── harmony/
│ │ ├── fix_conflict/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── issue_pr_commit_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── issue_tagging_pr_closure/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── multi_branch_commit_aggregation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── release_management_workflow/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── mcpmark-cicd/
│ │ ├── deployment_status_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── issue_management_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── linting_ci_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── pr_automation_workflow/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── missing-semester/
│ ├── assign_contributor_labels/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── find_legacy_name/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── find_salient_file/
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── notion/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── computer_science_student_dashboard/
│ │ │ ├── simple__code_snippets_go/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── simple__study_session_tracker/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── it_trouble_shooting_hub/
│ │ │ └── simple__asset_retirement_migration/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── japan_travel_planner/
│ │ │ └── simple__remove_osaka_itinerary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── online_resume/
│ │ │ └── simple__skills_development_tracker/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── python_roadmap/
│ │ │ └── simple__expert_level_lessons/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── self_assessment/
│ │ │ └── simple__faq_column_layout/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── standard_operating_procedure/
│ │ │ └── simple__section_organization/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── team_projects/
│ │ │ └── simple__swap_tasks/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── toronto_guide/
│ │ └── simple__change_color/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── company_in_a_box/
│ │ ├── employee_onboarding/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── goals_restructure/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── quarterly_review_dashboard/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── computer_science_student_dashboard/
│ │ ├── code_snippets_go/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── courses_internships_relation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── study_session_tracker/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── it_trouble_shooting_hub/
│ │ ├── asset_retirement_migration/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── security_audit_ticket/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── verification_expired_update/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── japan_travel_planner/
│ │ ├── daily_itinerary_overview/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── packing_progress_summary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── remove_osaka_itinerary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── restaurant_expenses_sync/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── online_resume/
│ │ ├── layout_adjustment/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── projects_section_update/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── skills_development_tracker/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── work_history_addition/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── python_roadmap/
│ │ ├── expert_level_lessons/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── learning_metrics_dashboard/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── self_assessment/
│ │ ├── faq_column_layout/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── hyperfocus_analysis_report/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── numbered_list_emojis/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── standard_operating_procedure/
│ │ ├── deployment_process_sop/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── section_organization/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── team_projects/
│ │ ├── priority_tasks_table/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── swap_tasks/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── toronto_guide/
│ ├── change_color/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── weekend_adventure_planner/
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── playwright/
│ ├── easy/
│ │ └── .gitkeep
│ └── standard/
│ ├── eval_web/
│ │ ├── cloudflare_turnstile_challenge/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── extraction_table/
│ │ ├── data.csv
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── web_search/
│ ├── birth_of_arvinxu/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── r1_arxiv/
│ ├── content.txt
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── playwright_webarena/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── reddit/
│ │ │ ├── ai_data_analyst/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── llm_research_summary/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── movie_reviewer_analysis/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── nba_statistics_analysis/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── routine_tracker_forum/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── shopping_admin/
│ │ ├── fitness_promotion_strategy/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── ny_expansion_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── products_sales_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── sales_inventory_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── search_filtering_operations/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── reddit/
│ │ ├── ai_data_analyst/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── budget_europe_travel/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── buyitforlife_research/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── llm_research_summary/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── movie_reviewer_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── nba_statistics_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── routine_tracker_forum/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── shopping/
│ │ ├── advanced_product_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── gaming_accessories_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── health_routine_optimization/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── holiday_baking_competition/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── multi_category_budget_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── printer_keyboard_search/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── running_shoes_purchase/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ └── shopping_admin/
│ ├── customer_segmentation_setup/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── fitness_promotion_strategy/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── marketing_customer_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── ny_expansion_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── products_sales_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── sales_inventory_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ └── search_filtering_operations/
│ ├── description.md
│ ├── label.txt
│ ├── meta.json
│ └── verify.py
├── postgres/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── chinook/
│ │ │ ├── customer_data_migration_basic/
│ │ │ │ ├── customer_data.pkl
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── update_employee_info/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── dvdrental/
│ │ │ └── create_payment_index/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employees/
│ │ │ ├── department_summary_view/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── employee_gender_statistics/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── employee_projects_basic/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── hiring_year_summary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── lego/
│ │ │ ├── basic_security_setup/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── fix_data_inconsistencies/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── sports/
│ │ └── create_performance_indexes/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── chinook/
│ │ ├── customer_data_migration/
│ │ │ ├── customer_data.pkl
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_hierarchy_management/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── sales_and_music_charts/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── dvdrental/
│ │ ├── customer_analysis_fix/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── customer_analytics_optimization/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── film_inventory_management/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── employees/
│ │ ├── employee_demographics_report/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_performance_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_project_tracking/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_retention_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── executive_dashboard_automation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── management_structure_analysis/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── lego/
│ │ ├── consistency_enforcement/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── database_security_policies/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── transactional_inventory_transfer/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── security/
│ │ ├── rls_business_access/
│ │ │ ├── description.md
│ │ │ ├── ground_truth.sql
│ │ │ ├── meta.json
│ │ │ ├── prepare_environment.py
│ │ │ └── verify.py
│ │ └── user_permission_audit/
│ │ ├── description.md
│ │ ├── ground_truth.sql
│ │ ├── meta.json
│ │ ├── prepare_environment.py
│ │ └── verify.py
│ ├── sports/
│ │ ├── baseball_player_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── participant_report_optimization/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── team_roster_management/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── vectors/
│ ├── dba_vector_analysis/
│ │ ├── description.md
│ │ ├── ground_truth.sql
│ │ ├── meta.json
│ │ ├── prepare_environment.py
│ │ └── verify.py
│ └── vectors_setup.py
└── utils/
├── __init__.py
├── notion_utils.py
└── postgres_utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
# Git
.git
.gitignore
# Python
__pycache__
*.pyc
*.pyo
*.pyd
.Python
*.egg
*.egg-info/
dist/
build/
.eggs/
*.so
# Virtual environments
venv/
env/
ENV/
.venv/
# IDE
.vscode/
.idea/
*.swp
*.swo
*~
.DS_Store
# Environment files (contain secrets)
.env
.mcp_env
notion_state.json
# Test and development files
.pytest_cache/
.coverage
htmlcov/
.tox/
.mypy_cache/
.ruff_cache/
tests/
test_environments/
# Results and logs
results/
*.log
logs/
# PostgreSQL data
.postgres/
# Playwright
playwright-report/
test-results/
# Documentation images
asset/
# Temporary files
*.tmp
tmp/
temp/
# Docker
Dockerfile
docker-compose.yml
.dockerignore
# Node modules (if any locally installed)
node_modules/
# Pixi lock file
pixi.lock
.pixi/
# GitHub state files
github_state/
github_template_repo/
# Backup directories
.mcpbench_backups/
================================================
FILE: .editorconfig
================================================
root = true
; Always use Unix style new lines with new line ending on every file and trim whitespace
[*]
end_of_line = lf
insert_final_newline = true
trim_trailing_whitespace = true
; Python: PEP8 defines 4 spaces for indentation
[*.py]
indent_style = space
indent_size = 4
================================================
FILE: .gitattributes
================================================
# SCM syntax highlighting & preventing 3-way merges
pixi.lock merge=binary linguist-language=YAML linguist-generated=true
================================================
FILE: .github/ISSUE_TEMPLATE/1_bug_report.yml
================================================
name: '🐛 Bug Report'
description: 'Report an bug'
labels: ['unconfirm']
type: Bug
body:
- type: textarea
attributes:
label: '🐛 Bug Description'
description: A clear and concise description of the bug, if the above option is `Other`, please also explain in detail.
validations:
required: true
- type: textarea
attributes:
label: '📷 Recurrence Steps'
description: A clear and concise description of how to recurrence.
- type: textarea
attributes:
label: '🚦 Expected Behavior'
description: A clear and concise description of what you expected to happen.
- type: textarea
attributes:
label: '📝 Additional Information'
description: If your problem needs further explanation, or if the issue you're seeing cannot be reproduced in a gist, please add more information here.
================================================
FILE: .github/ISSUE_TEMPLATE/2_feature_request.yml
================================================
name: '🌠 Feature Request'
description: 'Suggest an idea'
title: '[Request] '
type: Feature
body:
- type: textarea
attributes:
label: '🥰 Feature Description'
description: Please add a clear and concise description of the problem you are seeking to solve with this feature request.
validations:
required: true
- type: textarea
attributes:
label: '🧐 Proposed Solution'
description: Describe the solution you'd like in a clear and concise manner.
validations:
required: true
- type: textarea
attributes:
label: '📝 Additional Information'
description: Add any other context about the problem here.
================================================
FILE: .github/ISSUE_TEMPLATE/config.yml
================================================
contact_links:
- name: Questions and ideas
url: https://github.com/eval-sys/mcpmark/discussions/new/choose
about: Please post questions, and ideas in discussions.
================================================
FILE: .github/PULL_REQUEST_TEMPLATE.md
================================================
#### Change Type
<!-- For change type, change [ ] to [x]. -->
- [ ] ✨ feat
- [ ] 🐛 fix
- [ ] ♻️ refactor
- [ ] 💄 style
- [ ] 👷 build
- [ ] ⚡️ perf
- [ ] 📝 docs
- [ ] 🔨 chore
#### Description of Change
<!-- Thank you for your Pull Request. Please provide a description above. -->
#### Additional Information
<!-- Add any other context about the Pull Request here. -->
================================================
FILE: .github/scripts/pr-comment.js
================================================
/**
* Generate or update PR comment with Docker build info
*/
module.exports = async ({ github, context, dockerMetaJson, image, version, dockerhubUrl, platforms }) => {
const COMMENT_IDENTIFIER = '<!-- DOCKER-BUILD-COMMENT -->';
const parseTags = () => {
try {
if (dockerMetaJson) {
const parsed = JSON.parse(dockerMetaJson);
if (Array.isArray(parsed.tags) && parsed.tags.length > 0) {
return parsed.tags;
}
}
} catch (e) {
// ignore parsing error, fallback below
}
if (image && version) {
return [`${image}:${version}`];
}
return [];
};
const generateCommentBody = () => {
const tags = parseTags();
const buildTime = new Date().toISOString();
// Use the first tag as the main version
const mainTag = tags.length > 0 ? tags[0] : `${image}:${version}`;
const tagVersion = mainTag.includes(':') ? mainTag.split(':')[1] : version;
return [
COMMENT_IDENTIFIER,
'',
'### 🐳 Docker Build Completed!',
`**Version**: \`${tagVersion || 'N/A'}\``,
`**Build Time**: \`${buildTime}\``,
'',
dockerhubUrl ? `🔗 View all tags on Docker Hub: ${dockerhubUrl}` : '',
'',
'### Pull Image',
'Download the Docker image to your local machine:',
'',
'```bash',
`docker pull ${mainTag}`,
'```',
'',
'### Run Eval',
'Execute evaluation tasks using the built image:',
'',
'```bash',
`DOCKER_IMAGE_VERSION=${tagVersion} ./run-task.sh --models gpt-4.1-mini --tasks file_context/uppercase`,
'```',
'',
'> [!IMPORTANT]',
'> This build is for testing and validation purposes.',
]
.filter(Boolean)
.join('\n');
};
const body = generateCommentBody();
// List comments on the PR
const { data: comments } = await github.rest.issues.listComments({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
});
const existing = comments.find((c) => c.body && c.body.includes(COMMENT_IDENTIFIER));
if (existing) {
await github.rest.issues.updateComment({
comment_id: existing.id,
owner: context.repo.owner,
repo: context.repo.repo,
body,
});
return { updated: true, id: existing.id };
}
const result = await github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body,
});
return { updated: false, id: result.data.id };
};
================================================
FILE: .github/workflows/publish-docker-image.yml
================================================
name: Publish Docker Image
on:
workflow_dispatch:
release:
types: [ published ]
pull_request:
types: [ synchronize, labeled, unlabeled ]
permissions:
contents: read
pull-requests: write
concurrency:
group: ${{ github.ref }}-${{ github.workflow }}
cancel-in-progress: true
env:
REGISTRY_IMAGE: evalsysorg/mcpmark
PR_TAG_PREFIX: pr-
jobs:
build:
if: |
(github.event_name == 'pull_request' &&
contains(github.event.pull_request.labels.*.name, 'Build Docker')) ||
github.event_name != 'pull_request'
strategy:
matrix:
include:
- platform: linux/amd64
os: ubuntu-latest
- platform: linux/arm64
os: ubuntu-24.04-arm
runs-on: ${{ matrix.os }}
name: Build ${{ matrix.platform }} Image
steps:
- name: Prepare
run: |
platform=${{ matrix.platform }}
echo "PLATFORM_PAIR=${platform//\//-}" >> $GITHUB_ENV
- name: Checkout base
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Generate PR metadata
if: github.event_name == 'pull_request'
id: pr_meta
run: |
branch_name="${{ github.head_ref }}"
sanitized_branch=$(echo "${branch_name}" | sed -E 's/[^a-zA-Z0-9_.-]+/-/g')
echo "pr_tag=${sanitized_branch}-$(git rev-parse --short HEAD)" >> $GITHUB_OUTPUT
- name: Docker meta
id: meta
uses: docker/metadata-action@v5
with:
images: ${{ env.REGISTRY_IMAGE }}
tags: |
type=raw,value=${{ env.PR_TAG_PREFIX }}${{ steps.pr_meta.outputs.pr_tag }},enable=${{ github.event_name == 'pull_request' }}
type=semver,pattern={{version}},enable=${{ github.event_name != 'pull_request' }}
type=raw,value=latest,enable=${{ github.event_name != 'pull_request' }}
- name: Docker login
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKER_REGISTRY_USER }}
password: ${{ secrets.DOCKER_REGISTRY_PASSWORD }}
- name: Get commit SHA
if: github.ref == 'refs/heads/main'
id: vars
run: echo "sha_short=$(git rev-parse --short HEAD)" >> $GITHUB_OUTPUT
- name: Build and export
id: build
uses: docker/build-push-action@v6
with:
platforms: ${{ matrix.platform }}
context: .
file: ./Dockerfile
labels: ${{ steps.meta.outputs.labels }}
build-args: |
SHA=${{ steps.vars.outputs.sha_short }}
outputs: type=image,name=${{ env.REGISTRY_IMAGE }},push-by-digest=true,name-canonical=true,push=true
- name: Export digest
run: |
rm -rf /tmp/digests
mkdir -p /tmp/digests
digest="${{ steps.build.outputs.digest }}"
touch "/tmp/digests/${digest#sha256:}"
- name: Upload artifact
uses: actions/upload-artifact@v4
with:
name: digest-${{ env.PLATFORM_PAIR }}
path: /tmp/digests/*
if-no-files-found: error
retention-days: 1
merge:
name: Merge
needs: build
runs-on: ubuntu-latest
steps:
- name: Checkout base
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Download digests
uses: actions/download-artifact@v5
with:
path: /tmp/digests
pattern: digest-*
merge-multiple: true
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Generate PR metadata
if: github.event_name == 'pull_request'
id: pr_meta
run: |
branch_name="${{ github.head_ref }}"
sanitized_branch=$(echo "${branch_name}" | sed -E 's/[^a-zA-Z0-9_.-]+/-/g')
echo "pr_tag=${sanitized_branch}-$(git rev-parse --short HEAD)" >> $GITHUB_OUTPUT
- name: Docker meta
id: meta
uses: docker/metadata-action@v5
with:
images: ${{ env.REGISTRY_IMAGE }}
tags: |
type=raw,value=${{ env.PR_TAG_PREFIX }}${{ steps.pr_meta.outputs.pr_tag }},enable=${{ github.event_name == 'pull_request' }}
type=semver,pattern={{version}},enable=${{ github.event_name != 'pull_request' }}
type=raw,value=latest,enable=${{ github.event_name != 'pull_request' }}
- name: Docker login
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKER_REGISTRY_USER }}
password: ${{ secrets.DOCKER_REGISTRY_PASSWORD }}
- name: Create manifest list and push
working-directory: /tmp/digests
run: |
docker buildx imagetools create $(jq -cr '.tags | map("-t " + .) | join(" ")' <<< "$DOCKER_METADATA_OUTPUT_JSON") \
$(printf '${{ env.REGISTRY_IMAGE }}@sha256:%s ' *)
- name: Inspect image
run: |
docker buildx imagetools inspect ${{ env.REGISTRY_IMAGE }}:${{ steps.meta.outputs.version }}
- name: Comment on PR with Docker build info
if: github.event_name == 'pull_request'
uses: actions/github-script@v7
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
const prComment = require('${{ github.workspace }}/.github/scripts/pr-comment.js');
const result = await prComment({
github,
context,
dockerMetaJson: ${{ toJSON(steps.meta.outputs.json) }},
image: "${{ env.REGISTRY_IMAGE }}",
version: "${{ steps.meta.outputs.version }}",
dockerhubUrl: "https://hub.docker.com/r/${{ env.REGISTRY_IMAGE }}/tags",
platforms: "linux/amd64, linux/arm64",
});
core.info(`Status: ${result.updated ? 'Updated' : 'Created'}, ID: ${result.id}`);
================================================
FILE: .gitignore
================================================
logs
.claude
CLAUDE.md
.gemini
results
materials
scripts
!.github/scripts
.nfs*
.mcp_env
.idea
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[codz]
*$py.class
logs
logs/*
.DS_Store
notion-sdk-py/
github_state/*
# for playwright cookies
notion_state.json
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py.cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# UV
# Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
#uv.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
#poetry.toml
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
# pdm recommends including project-wide configuration in pdm.toml, but excluding .pdm-python.
# https://pdm-project.org/en/latest/usage/project/#working-with-version-control
#pdm.lock
#pdm.toml
.pdm-python
.pdm-build/
# pixi
# Similar to Pipfile.lock, it is generally recommended to include pixi.lock in version control.
#pixi.lock
# Pixi creates a virtual environment in the .pixi directory, just like venv module creates one
# in the .venv directory. It is recommended not to include this directory in version control.
.pixi
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.envrc
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
# Abstra
# Abstra is an AI-powered process automation framework.
# Ignore directories containing user credentials, local state, and settings.
# Learn more at https://abstra.io/docs
.abstra/
# Visual Studio Code
# Visual Studio Code specific template is maintained in a separate VisualStudioCode.gitignore
# that can be found at https://github.com/github/gitignore/blob/main/Global/VisualStudioCode.gitignore
# and can be added to the global gitignore or merged into this file. However, if you prefer,
# you could uncomment the following to ignore the entire vscode folder
# .vscode/
# Ruff stuff:
.ruff_cache/
# PyPI configuration file
.pypirc
# Cursor
# Cursor is an AI-powered code editor. `.cursorignore` specifies files/directories to
# exclude from AI features like autocomplete and code analysis. Recommended for sensitive data
# refer to https://docs.cursor.com/context/ignore-files
.cursorignore
.cursorindexingignore
# Marimo
marimo/_static/
marimo/_lsp/
__marimo__/
# pixi environments
.pixi
*.egg-info
.postgres
# MCPMark backup directories
.mcpmark_backups/*
test_environments/
postgres_state
================================================
FILE: CHANGELOG.md
================================================
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## v1.2.0 - 2025-09-20
This version includes multiple important feature enhancements, particularly improvements in cost calculation, error handling, and Notion integration. Added per-model cost calculation, comprehensive aggregator functionality, and more robust error recovery mechanisms.
### ✨ Features
- **Add 1m parameter & improve log** (#198) - Added claude-1m-context option and enhanced logging functionality
- **Refine Notion parent resolution and duplicate recovery** (#197) - Improved Notion parent page resolution and duplicate content recovery mechanism
- **Comprehensive aggregator, enable push to new branch** (#185) - Implemented comprehensive aggregator functionality with support for pushing to new branches
- **Support price cost calculating per model** (#186) - Added per-model price cost calculation functionality
- **Improve agent end log** (#183) - Enhanced agent end logging
- **Improve litellm error handling** (#181) - Enhanced LiteLLM error handling mechanism
### ♻️ Refactoring
- **Use notion child block list to locate page** (#196) - Refactored page location logic to use Notion child block list approach
### 🐛 Bug Fixes
- **Fix verification in Notion task company_in_a_box/goals_restructure** (#194) - Fixed verification logic for specific Notion tasks
- **Improve claude error handling** (#195) - Improved error handling for Claude API interactions
- **Fix tailing slash issue for find_legacy_name** - Resolved trailing slash issues in find_legacy_name path handling
- **Recover when duplication lands on parent** (#189) - Fixed recovery mechanism when duplicate content affects parent pages
- **Correctly handle playwright parser** (#184) - Properly handle Playwright parser
- **Handle timeout error, add timeout error for resuming** (#182) - Handle timeout errors and add timeout error handling for resume operations
### 📝 Documentation
- **Better readme, notion language guide** (#190) - Improved README documentation and added comprehensive Notion language guide
### 🔨 Maintenance
- **Update price info** (#188) - Updated pricing information
- **Update desktop_template/file_arrangement/verify.py** (#187) - Maintenance updates to verification scripts
================================================
FILE: Dockerfile
================================================
# MCPMark Docker image with optimized layer caching
# Stage 1: Builder for Python dependencies only
FROM python:3.12-slim AS builder
RUN apt-get update && apt-get install -y --no-install-recommends \
gcc \
g++ \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /build
# Copy project files needed for pip install
COPY pyproject.toml ./
COPY src/ ./src/
COPY tasks/ ./tasks/
# Install dependencies
RUN pip install --no-cache-dir --user .
# Stage 2: Final image with all runtime dependencies
FROM python:3.12-slim
# Layer 1: Core system dependencies (very stable, rarely changes)
RUN apt-get update && apt-get install -y --no-install-recommends \
ca-certificates \
&& rm -rf /var/lib/apt/lists/*
# Layer 2: PostgreSQL runtime and client tools (stable, only changes with postgres version)
RUN apt-get update && apt-get install -y --no-install-recommends \
libpq5 \
postgresql-client \
&& rm -rf /var/lib/apt/lists/*
# Layer 3: Git (stable)
RUN apt-get update && apt-get install -y --no-install-recommends \
git \
&& rm -rf /var/lib/apt/lists/*
# Layer 4: Playwright system dependencies (changes with browser requirements)
RUN apt-get update && apt-get install -y --no-install-recommends \
libnss3 \
libnspr4 \
libatk1.0-0 \
libatk-bridge2.0-0 \
libcups2 \
libdrm2 \
libxkbcommon0 \
libatspi2.0-0 \
libx11-6 \
libxcomposite1 \
libxdamage1 \
libxfixes3 \
libxrandr2 \
libgbm1 \
libxcb1 \
libpango-1.0-0 \
libcairo2 \
libasound2 \
&& rm -rf /var/lib/apt/lists/*
# Layer 5: Download tools and Node.js (changes with Node version)
RUN apt-get update && \
apt-get install -y --no-install-recommends curl wget unzip && \
curl -fsSL https://deb.nodesource.com/setup_20.x | bash - && \
apt-get install -y --no-install-recommends nodejs && \
apt-get autoremove -y && \
rm -rf /var/lib/apt/lists/*
# Layer 6: pipx (rarely changes)
RUN pip install --no-cache-dir pipx && \
pipx ensurepath
# Layer 7: Copy Python packages from builder (changes with dependencies)
COPY --from=builder /root/.local /root/.local
# Layer 8: Playwright browsers (changes with browser versions)
RUN python3 -m playwright install chromium && \
npx -y playwright install chromium
# Layer 9: Install PostgreSQL MCP server (Python, used via `pipx run postgres-mcp`)
RUN pipx install postgres-mcp
# Set working directory
WORKDIR /app
# Layer 9: Create directory structure (rarely changes)
RUN mkdir -p /app/results
# Layer 10: Application code (changes frequently)
COPY . .
# Set environment
ENV PATH="/root/.local/bin:/root/.local/pipx/venvs/*/bin:${PATH}"
ENV PYTHONPATH="/app"
ENV PLAYWRIGHT_BROWSERS_PATH=/root/.cache/ms-playwright
ENV PIPX_HOME=/root/.local/pipx
ENV PIPX_BIN_DIR=/root/.local/bin
# Default command
CMD ["python3", "-m", "pipeline", "--help"]
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
<div align="center">
# MCPMark: Stress-Testing Comprehensive MCP Use
[](https://mcpmark.ai)
[](https://arxiv.org/abs/2509.24002)
[](https://discord.gg/HrKkJAxDnA)
[](https://mcpmark.ai/docs)
[](https://huggingface.co/datasets/Jakumetsu/mcpmark-trajectory-log)
</div>
An evaluation suite for agentic models in real MCP tool environments (Notion / GitHub / Filesystem / Postgres / Playwright).
MCPMark provides a reproducible, extensible benchmark for researchers and engineers: one-command tasks, isolated sandboxes, auto-resume for failures, unified metrics, and aggregated reports.
[](https://mcpmark.ai)
## News
- 📌 **21 Jan** — Pinned MCP server versions for reproducible benchmarks: GitHub MCP Server `v0.15.0` (switched to Docker for version control), Notion MCP Server `@1.9.1` (Notion released 2.0 but it has many bugs, not recommended). See [#246](https://github.com/eval-sys/mcpmark/pull/246).
- 🔥 **13 Dec** — Added auto-compaction support (`--compaction-token`) to summarize long conversations and avoid context overflow during evaluation ([#236](https://github.com/eval-sys/mcpmark/pull/236])).
- 🏅 **02 Dec** — Evaluated `gemini-3-pro-preview` (thinking: low): **Pass@1 50.6%** ± 2.3% — so close to `gpt-5-high` (51.6%)! Also `deepseek-v3.2-thinking` 36.8% and `deepseek-v3.2-chat` 29.7%
- 🔥 **02 Dec** — Obfuscate GitHub @mentions to prevent notification spam during evaluation ([#229](https://github.com/eval-sys/mcpmark/pull/229))
- 🏅 **01 Dec** — DeepSeek v3.2 uses MCPMark! Kudos on securing the best open-source model. [X Post](https://x.com/deepseek_ai/status/1995452650557763728) | [Technical Report](https://huggingface.co/deepseek-ai/DeepSeek-V3.2/resolve/main/assets/paper.pdf)
- 🔥 **17 Nov** — Added 50 easy tasks (10 per MCP server) for smaller open-source models ([#225](https://github.com/eval-sys/mcpmark/pull/225))
- 🤝 **31 Oct** — Community PR from insforge: better MCP servers achieve better results with fewer tokens! ([#214](https://github.com/eval-sys/mcpmark/pull/214))
- 🔥 **13 Oct** — Added ReAct agent support. PRs for new agent scaffolds welcome! ([#209](https://github.com/eval-sys/mcpmark/pull/209))
- 🏅 **10 Sep** — `qwen-3-coder-plus` is the best open-source model! Kudos to Qwen team. [X Post](https://x.com/Alibaba_Qwen/status/1965457023438651532)
---
## What you can do with MCPMark
- **Evaluate real tool usage** across multiple MCP services: `Notion`, `GitHub`, `Filesystem`, `Postgres`, `Playwright`.
- **Use ready-to-run tasks** covering practical workflows, each with strict automated verification.
- **Reliable and reproducible**: isolated environments that do not pollute your accounts/data; failed tasks auto-retry and resume.
- **Unified metrics and aggregation**: single/multi-run (pass@k, avg@k, etc.) with automated results aggregation.
- **Flexible deployment**: local or Docker; fully validated on macOS and Linux.
---
## Quickstart (5 minutes)
### 1) Clone the repository
```bash
git clone https://github.com/eval-sys/mcpmark.git
cd mcpmark
```
### 2) Set environment variables (create `.mcp_env` at repo root)
Only set what you need. Add service credentials when running tasks for that service.
```env
# Example: OpenAI
OPENAI_BASE_URL="https://api.openai.com/v1"
OPENAI_API_KEY="sk-..."
# Optional: Notion (only for Notion tasks)
SOURCE_NOTION_API_KEY="your-source-notion-api-key"
EVAL_NOTION_API_KEY="your-eval-notion-api-key"
EVAL_PARENT_PAGE_TITLE="MCPMark Eval Hub"
PLAYWRIGHT_BROWSER="chromium" # chromium | firefox
PLAYWRIGHT_HEADLESS="True"
# Optional: GitHub (only for GitHub tasks)
GITHUB_TOKENS="token1,token2" # token pooling for rate limits
GITHUB_EVAL_ORG="your-eval-org"
# Optional: Postgres (only for Postgres tasks)
POSTGRES_HOST="localhost"
POSTGRES_PORT="5432"
POSTGRES_USERNAME="postgres"
POSTGRES_PASSWORD="password"
```
See `docs/introduction.md` and the service guides below for more details.
### 3) Install and run a minimal example
Local (Recommended)
```bash
pip install -e .
# If you'll use browser-based tasks, install Playwright browsers first
playwright install
```
MCPMark defaults to the built-in orchestration agent (`MCPMarkAgent`). To experiment with the ReAct-style agent, pass `--agent react` to `pipeline.py` (other settings stay the same).
Docker
```bash
./build-docker.sh
```
Run a filesystem task (no external accounts required):
```bash
python -m pipeline \
--mcp filesystem \
--k 1 \ # run once to quick start
--models gpt-5 \ # or any model you configured
--tasks file_property/size_classification
# Add --task-suite easy to run the lightweight dataset (where available)
```
Results are saved to `./results/{exp_name}/{model}__{mcp}/run-*/...` for the standard suite and `./results/{exp_name}/{model}__{mcp}-easy/run-*/...` when you run `--task-suite easy` (e.g., `./results/test-run/gpt-5__filesystem/run-1/...` or `./results/test-run/gpt-5__github-easy/run-1/...`).
---
## Run your evaluations
### Task suites (standard vs easy)
- Each MCP service now stores tasks under `tasks/<mcp>/<task_suite>/<category>/<task>/`.
- `standard` (default) covers the full benchmark (127 tasks today).
- `easy` hosts 10 lightweight tasks per MCP, ideal for smoke tests and CI (GitHub’s are already available under `tasks/github/easy`).
- Switch suites with `--task-suite easy` (defaults to `--task-suite standard`).
### Single run (k=1)
```bash
# Run ALL tasks for a service
python -m pipeline --exp-name exp --mcp notion --tasks all --models MODEL --k 1
# Run a task group
python -m pipeline --exp-name exp --mcp notion --tasks online_resume --models MODEL --k 1
# Run a specific task
python -m pipeline --exp-name exp --mcp notion --tasks online_resume/daily_itinerary_overview --models MODEL --k 1
# Evaluate multiple models
python -m pipeline --exp-name exp --mcp notion --tasks all --models MODEL1,MODEL2,MODEL3 --k 1
```
### Multiple runs (k>1) for pass@k
```bash
# Run k=4 to compute stability metrics (requires --exp-name to aggregate final results)
python -m pipeline --exp-name exp --mcp notion --tasks all --models MODEL
# Aggregate results (pass@1 / pass@k / pass^k / avg@k)
python -m src.aggregators.aggregate_results --exp-name exp
```
### Run with Docker
```bash
# Run all tasks for a service
./run-task.sh --mcp notion --models MODEL --exp-name exp --tasks all
# Cross-service benchmark
./run-benchmark.sh --models MODEL --exp-name exp --docker
```
Please visit `docs/introduction.md` for choices of *MODEL*.
Tip: MCPMark supports **auto-resume**. When re-running, only unfinished tasks will execute. Failures matching our retryable patterns (see [RETRYABLE_PATTERNS](src/errors.py)) are retried automatically. Models may emit different error strings—if you encounter a new resumable error, please open a PR or issue.
Tip: MCPMark supports **auto-compaction**; pass `--compaction-token N` to enable automatic context summarization when prompt tokens reach `N` (use `999999999` to disable).
---
## Service setup and authentication
| Service | Setup summary | Docs |
|-------------|-----------------------------------------------------------------------------------------------------------------|---------------------------------------|
| Notion | Environment isolation (Source Hub / Eval Hub), integration creation and grants, browser login verification. | [Guide](docs/mcp/notion.md) |
| GitHub | Multi-account token pooling recommended; import pre-exported repo state if needed. | [Guide](docs/mcp/github.md) |
| Postgres | Start via Docker and import sample databases. | [Setup](docs/mcp/postgres.md) |
| Playwright | Install browsers before first run; defaults to `chromium`. | [Setup](docs/mcp/playwright.md) |
| Filesystem | Zero-configuration, run directly. | [Config](docs/mcp/filesystem.md) |
You can also follow [Quickstart](docs/quickstart.md) for the shortest end-to-end path.
### Important Notice: GitHub Repository Privacy
> **Please ensure your evaluation repositories are set to PRIVATE.**
GitHub state templates are now automatically downloaded from our CDN during evaluation — no manual download is required. However, because these templates contain issues and pull requests from real open-source repositories, the recreation process includes `@username` mentions of the original authors.
**We have received feedback from original GitHub authors who were inadvertently notified** when evaluation repositories were created as public. To be a responsible member of the open-source community, we urge all users to:
1. **Always keep evaluation repositories private** during the evaluation process.
2. **In the latest version**, we have added random suffixes to all `@username` mentions (e.g., `@user` becomes `@user_x7k2`) and implemented a safety check that prevents importing templates to public repositories.
3. **If you are using an older version of MCPMark**, please either:
- Pull the latest code immediately, or
- Manually ensure all GitHub evaluation repositories are set to private.
Thank you for helping us maintain a respectful relationship with the open-source community.
---
## Results and metrics
- Results are organized under `./results/{exp_name}/{model}__{mcp}/run-*/` (JSON + CSV per task).
- Generate a summary with:
```bash
# Basic usage
python -m src.aggregators.aggregate_results --exp-name exp
# For k-run experiments with single-run models
python -m src.aggregators.aggregate_results --exp-name exp --k 4 --single-run-models claude-opus-4-1
```
- Only models with complete results across all tasks and runs are included in the final summary.
- Includes multi-run metrics (pass@k, pass^k) for stability comparisons when k > 1.
---
## Model and Tasks
- **Model support**: MCPMark calls models via LiteLLM — see the LiteLLM docs: [`LiteLLM Doc`](https://docs.litellm.ai/docs/). For Anthropic (Claude) extended thinking mode (enabled via `--reasoning-effort`), we use Anthropic’s native API.
- See `docs/introduction.md` for details and configuration of supported models in MCPMark.
- To add a new model, edit `src/model_config.py`. Before adding, check LiteLLM supported models/providers. See [`LiteLLM Doc`](https://docs.litellm.ai/docs/).
- Task design principles in `docs/datasets/task.md`. Each task ships with an automated `verify.py` for objective, reproducible evaluation, see `docs/task.md` for details.
---
## Contributing
Contributions are welcome:
1. Add a new task under `tasks/<mcp>/<task_suite>/<category_id>/<task_id>/` with `meta.json`, `description.md` and `verify.py`.
2. Ensure local checks pass and open a PR.
3. See `docs/contributing/make-contribution.md`.
---
## Citation
If you find our works useful for your research, please consider citing:
```bibtex
@misc{wu2025mcpmark,
title={MCPMark: A Benchmark for Stress-Testing Realistic and Comprehensive MCP Use},
author={Zijian Wu and Xiangyan Liu and Xinyuan Zhang and Lingjun Chen and Fanqing Meng and Lingxiao Du and Yiran Zhao and Fanshi Zhang and Yaoqi Ye and Jiawei Wang and Zirui Wang and Jinjie Ni and Yufan Yang and Arvin Xu and Michael Qizhe Shieh},
year={2025},
eprint={2509.24002},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.24002},
}
```
## License
This project is licensed under the Apache License 2.0 — see `LICENSE`.
================================================
FILE: build-docker.sh
================================================
#!/bin/bash
# Build Docker image for MCPMark
set -e
# Color codes for output
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
echo -e "${YELLOW}Building MCPMark Docker image locally...${NC}"
# Build the Docker image with the same tag as Docker Hub for local testing
docker build -t evalsysorg/mcpmark:latest . "$@"
# Check if build was successful
if [ $? -eq 0 ]; then
echo -e "${GREEN}✓ Docker image built successfully${NC}"
echo " Tag: evalsysorg/mcpmark:latest"
# Show image info
echo ""
echo "Image details:"
docker images evalsysorg/mcpmark:latest --format "table {{.Repository}}\t{{.Tag}}\t{{.Size}}\t{{.CreatedAt}}"
echo ""
echo "You can now run tasks using:"
echo " ./run-task.sh --mcp notion --models o3 --exp-name test --tasks all"
else
echo "Docker build failed!"
exit 1
fi
================================================
FILE: cspell.config.yaml
================================================
version: "0.2"
ignorePaths: []
dictionaryDefinitions: []
dictionaries: []
words:
- datname
- domcontentloaded
- modelcontextprotocol
- pgdumplib
- pixi
- pypi
- topbar
- usename
ignoreWords: []
import: []
================================================
FILE: docs/contributing/make-contribution.md
================================================
# Contributing
1. Fork the repository and create a feature branch.
2. Add new tasks under `tasks/<mcp>/<task_suite>/<category>/<task_id>/` with the files of `meta.json`, `description.md` and `verify.py`. Please refer to [Task Page](../datasets/task.md) for detailed instructions.
3. Ensure all tests pass.
4. Submit a pull request — contributions are welcome!
================================================
FILE: docs/datasets/task.md
================================================
# Task
The tasks in MCPMark follows two major principles
- The tasks are based on realistic digital environments that are also used by human programmers.
- The task outcome can be robustly verified in python scripts.
Therefore, each MCPMark task consists of three files
- `meta.json`
- `description.md`
- `verify.py`
Here, `metadata.json` includes the meta information of the task, `description.md` describes the purpose and setting of the task, as well as the instruction to complete the task. `verify.py` checks whether the task is completed successfully.
For example, you can ask the model agent to create a file with specific name and write specific content to the file, which belongs to the category of operating the file context. The structure looks like
```
tasks
│
└───filesystem
│
└───standard # task_suite (also supports `easy`)
│
└───file_context # category_id
│
└───create_file_write
│ meta.json
│ description.md
│ verify.py
```
All tasks live under `tasks/<mcp>/<task_suite>/<category>/<task_id>/`. `filesystem` refers to the MCP service and `task_suite` captures the difficulty slice (`standard` benchmark vs `easy` smoke tests).
`meta.json` includes the meta information about the task, including the following key
- task_id: the id of the task.
- task_name: full name of the task.
- description: task description.
- category_id: the id of task category.
- category_name: the full name of task categeory.
- author: the author of the task.
- difficulty: the task difficulty level.
- created_at: the timestamp of task creation.
- tags: a list of tags that describe the task.
- mcp: a list of MCP services it belongs to.
- metadata: other meta information.
Here `category_name` describes the shared feature or the environment across different tasks (e.g. the github repository or notion page the task is built on). In this running example, `category_name` refers to `file_context`.
`description.md` could include the following information
- Task name
- Create and Write File.
- Task description
- Use the filesystem MCP tools to create a new file and write content to it.
- Task Objectives
- Create a new file named `hello_world.txt` in the test directory.
- Write the following content to the file: ``` Hello, World```
- Verify the file was created successfully
- Verification Criteria
- File `hello_world.txt` exists in the test directory
- File contains the expected content structure
- File includes "Hello, World!" on the first line
- Tips
- Use the `write_file` tool to create and write content to the file
- The test directory path will be provided in the task context
The entire content of `description.md` will be read by the model agent for completing the task.
Accordingly, the `verify.py` contains the following functionalities
- Check whether the target directory exists. [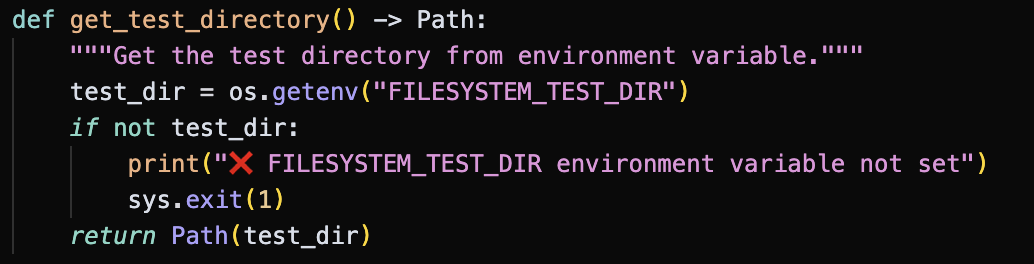](https://postimg.cc/4nnLrw3M)
- Check whether the target directory contains the file with target file name. [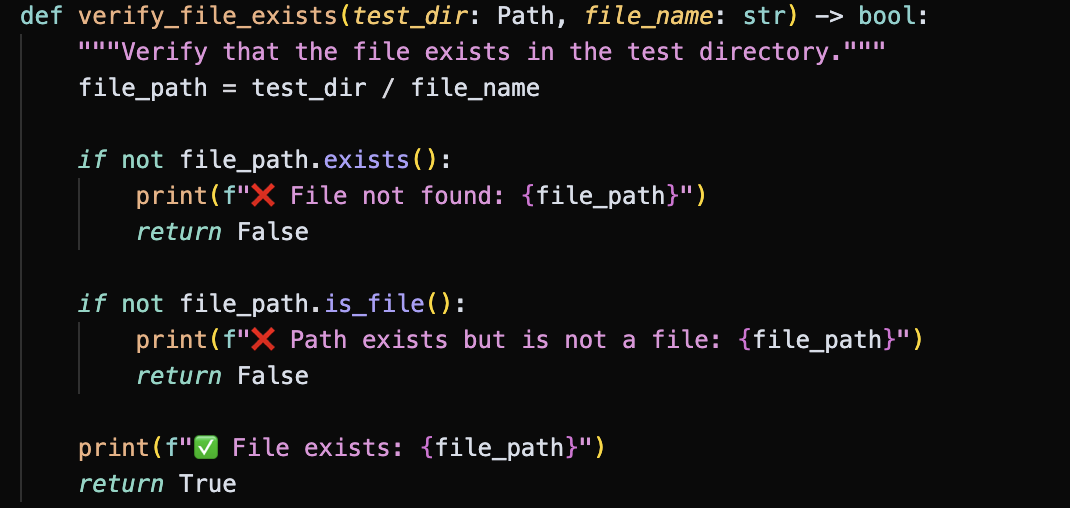](https://postimg.cc/7fGRTX87)
- Check whether the target file contains the desired content `EXPECTED_PATTERNS = ["Hello Wolrd"]`. [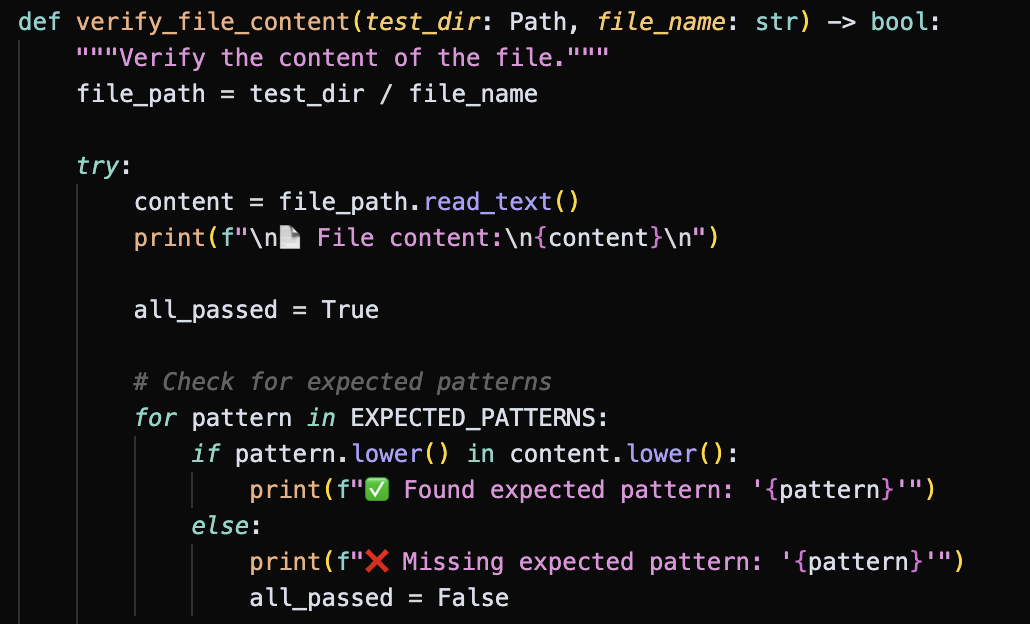](https://postimg.cc/w7ZSWZc0)
- If the outcome passes **all the above verification functionalities**, the task would be marked as successfully completed.
================================================
FILE: docs/installation_and_docker_usage.md
================================================
# Installation and Docker Task Usage Guideline
## Overview
The MCPMark setup supports installation through either pip or MCPMark Docker (recommended) after cloning the code repository.
### Pip Installtion
```bash
pip install -e .
```
The MCPMark Docker setup provides a simple way to run evaluation tasks in isolated containers. PostgreSQL is automatically handled when needed.
## 1. Quick Start
### 1.1 Docker Image
The official Docker image is automatically pulled from Docker Hub on first use.
The image is hosted at: https://hub.docker.com/r/evalsysorg/mcpmark
**Image Management:**
- The scripts automatically download the image when it's not found locally
- To manually update to the latest version:
```bash
docker pull evalsysorg/mcpmark:latest
```
- For local development/testing, you can build your own docker:
```bash
# Creates evalsysorg/mcpmark:latest locally
./build-docker.sh
```
## 2. Running MCP Experiments
### 2.1 Running Individual MCP Experiment
The `run-task.sh` script provides simplified Docker usage:
```bash
# Run filesystem tasks (filesystem is the default mcp service)
./run-task.sh --models MODEL_NAME --k K
# Run github/notion/postgres/playwright/playwright_webarena with specific task
./run-task.sh --mcp MCPSERVICE --models MODEL_NAME --exp-name EXPNAME --tasks TASK --k K
```
where *MODEL_NAME* refers to the model choice from the supported models (see [Introduction Page](./introduction.md) for more information), *EXPNAME* refers to customized experiment name, *TASK* refers to specific task or task group (see `tasks/<mcp>/<task_suite>/...` for more information), *K* refers to the time of independent experiments.
Additionally, the `run-benchmark.sh` script evaluates models across all MCP services:
```bash
# Run all services with Docker (recommended)
./run-benchmark.sh --models MODEL --exp-name EXPNAME --docker
# Run specific services
./run-benchmark.sh --models MODEL --exp-name EXPNAME --mcps MCPSERVICES --docker
# Run with parallel execution for faster results
./run-benchmark.sh --models MODEL --exp-name EXPNAME --docker --parallel
# Run locally without Docker
./run-benchmark.sh --models MODEL --exp-name EXPNAME --mcps MCPSERVICES
```
Here *MCPSERVICES* refers to group of MCP services, separated by comma (e.g. *filesystem,postgres*)
The benchmark script:
- Runs all or selected MCP services automatically
- Supports progress tracking and timing
- Generates summary reports and logs
- Supports parallel service execution
- Continues running even if some services fail
- Automatically generates performance dashboards
### Manual Docker Commands
#### For Non-Postgres Services
Suppose Notion is the service:
```bash
# Build the image first
./build-docker.sh
# Run a task
docker run --rm \
-v $(pwd)/results:/app/results \
-v $(pwd)/.mcp_env:/app/.mcp_env:ro \
-v $(pwd)/notion_state.json:/app/notion_state.json:ro \
evalsysorg/mcpmark:latest \
python3 -m pipeline --mcp notion --models MODEL --exp-name EXPNAME --tasks TASK --k K
```
#### For Postgres Service
```bash
# The run-task.sh script handles postgres automatically, but if doing manually:
# Start postgres container
docker run -d \
--name mcp-postgres \
--network mcp-network \
-e POSTGRES_DATABASE=postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=123456 \
ghcr.io/cloudnative-pg/postgresql:17-bookworm
# Run postgres task
docker run --rm \
--network mcp-network \
-e POSTGRES_HOST=mcp-postgres \
-v $(pwd)/results:/app/results \
-v $(pwd)/.mcp_env:/app/.mcp_env:ro \
evalsysorg/mcpmark:latest \
python3 -m pipeline --mcp postgres --models MODEL --exp-name EXPNAME --tasks TASK --k K
# Stop and remove postgres when done
docker stop mcp-postgres && docker rm mcp-postgres
```
## Script Usage
### Benchmark Runner (`run-benchmark.sh`)
```
./run-benchmark.sh --models MODELS --exp-name NAME [OPTIONS]
Required Options:
--models MODELS Comma-separated list of models to evaluate
--exp-name NAME Experiment name for organizing results
Optional Options:
--docker Run tasks in Docker containers (recommended)
--mcps SERVICES Comma-separated list of services to test
Default: filesystem,notion,github,postgres,playwright
--parallel Run services in parallel (experimental)
--timeout SECONDS Timeout per task in seconds (default: 300)
```
### Individual Task Runner (`run-task.sh`)
```
./run-task.sh [--mcp SERVICE] [PIPELINE_ARGS]
Options:
--mcp SERVICE MCP service (notion|github|filesystem|playwright|postgres)
Default: filesystem
Environment Variables:
DOCKER_MEMORY_LIMIT Memory limit for container (default: 4g)
DOCKER_CPU_LIMIT CPU limit for container (default: 2)
DOCKER_IMAGE_VERSION Docker image tag to use (default: latest)
All other arguments are passed directly to the pipeline command.
Pipeline arguments (see python3 -m pipeline --help):
--mcp {notion,github,filesystem,playwright,postgres,playwright_webarena}
MCP service to use (default: filesystem)
--models MODELS Comma-separated list of models to evaluate (e.g., 'o3,k2,gpt-4.1')
--tasks TASKS Tasks to run: "all", a category name, or "category/task_name"
--exp-name EXP_NAME Experiment name; results are saved under results/<exp-name>/ (default: YYYY-MM-DD-HH-MM-SS)
--k K Number of evaluation runs for pass@k metrics (default: 1)
--timeout TIMEOUT Timeout in seconds for each task
--output-dir OUTPUT_DIR
Directory to save results
```
## Docker Benefits
1. **Efficiency**: Only starts necessary containers
2. **Isolation**: Each task runs in a fresh container
3. **Resource Management**: Automatic cleanup of containers and networks
4. **Smart Dependencies**: PostgreSQL only starts for postgres service
5. **Parallel Support**: Can run multiple services simultaneously for faster benchmarks
6. **Comprehensive Testing**: Benchmark script runs all services with one command
7. **Progress Tracking**: Colored output with timing and status information
8. **Automatic Reporting**: Generates summary reports and performance dashboards
## Common Troubleshooting
### Permission Issues
```bash
chmod +x run-task.sh
```
### Docker Build Issues
```bash
# Force rebuild with no cache
./run-task.sh --build --mcp MCPSERVICE --models MODEL_NAME --exp-name EXPNAME --tasks TASK
```
### PostgreSQL Connection Issues
```bash
# Check if postgres is running
docker ps | grep postgres
# View postgres logs
docker logs mcp-postgres-task
```
### Cleanup Stuck Resources
```bash
# Stop all containers
docker stop $(docker ps -q)
# Remove task network
docker network rm mcp-task-network
# Remove postgres data volume (careful!)
docker volume rm mcp-postgres-data
```
## Environment Variables
Create `.mcp_env` file with your credentials:
```env
# Service credentials
SOURCE_NOTION_API_KEY=your-key
EVAL_NOTION_API_KEY=your-key
GITHUB_TOKEN=your-token
POSTGRES_PASSWORD=your-password
# Model API keys
OPENAI_API_KEY=your-key
ANTHROPIC_API_KEY=your-key
# ... etc
```
Please refer to [Quick Start](./quickstart.md) for setting up API key for specific model.
## Docker Compose Files
- `docker-compose.yml` - Full stack with postgres (for development/testing)
## Notes
- Results are saved under `./results/<exp-name>/`.
- Each task runs in an ephemeral container.
- Docker image is shared across all tasks.
- PostgreSQL data persists in Docker volume.
================================================
FILE: docs/introduction.md
================================================
# MCPMark
MCPMark is a comprehensive evaluation suite for evaluating the agentic ability of frontier models.
MCPMark includes Model Context Protocol (MCP) service in following environments
- Notion
- Github
- Filesystem
- Postgres
- Playwright
- Playwright-WebArena
### General Procedure
MCPMark is designed to run agentic tasks in complex environment **safely**. Specifically, it sets up an isolated environment for the experiment, completing the task, and then destroy the environment without affecting existing user profile or information.
### How to Use MCPMark
1. MCPMark Installation.
2. Authorize service (for Github and Notion).
3. Configure the environment variables in `.mcp_env`.
4. Run MCPMark experiment.
Please refer to [Quick Start](./quickstart.md) for details regarding how to start a sample filesystem experiment in properly, and [Task Page](./datasets/task.md) for task details. Please visit [Installation and Docker Uusage](./installation_and_docker_usage.md) information of full MCPMark setup.
### Running MCPMark
MCPMark supports the following mode to run experiments (suppose the experiment is named as new_exp, and the model used are o3 and gpt-4.1 and the environment is notion), with K repetive experiments.
#### MCPMark in Pip Installation
```bash
# Evaluate ALL tasks
python -m pipeline --exp-name new_exp --mcp notion --tasks all --models o3 --k K
# Evaluate a single task group (online_resume)
python -m pipeline --exp-name new_exp --mcp notion --tasks online_resume --models o3 --k K
# Evaluate one specific task (task_1 in online_resume)
python -m pipeline --exp-name new_exp --mcp notion --tasks online_resume/task_1 --models o3 --k K
# Evaluate multiple models
python -m pipeline --exp-name new_exp --mcp notion --tasks all --models o3,gpt-4.1 --k K
```
#### MCPMark in Docker Installation
```bash
# Run all tasks for one service
./run-task.sh --mcp notion --models o3 --exp-name new_exp --tasks all
# Run comprehensive benchmark across all services
./run-benchmark.sh --models o3,gpt-4.1 --exp-name new_exp --docker
```
#### Experiment Auto-Resume
For re-run experiments, only unfinished tasks will be executed. Tasks that previously failed due to pipeline errors (such as State Duplication Error or MCP Network Error) will also be retried automatically.
### Results
The experiment results are written to `./results/` (JSON + CSV).
#### Reult Aggregation (for K > 1)
MCP supports aggreated metrics of pass@1, pass@K, pass^K, avg@K.
```bash
python -m src.aggregators.aggregate_results --exp-name new_exp
```
### Model Support
MCPMark supports the following models with according providers (model codes in the brackets).
#### OpenAI
- GPT-5 (gpt-5)
- o3 (o3)
#### Anthropic
- Claude-4.1-Opus (claude-4.1-opus)
- Claude-4-Sonnet (claude-4-sonnet)
#### Google
- Gemini-2.5-Pro (gemini-2.5-pro)
#### Grok
- Grok-4 (grok-4)
#### Deepseek
- DeepSeek-Chat (deepseek-chat)
#### Alibaba
- Qwen3-Coder (qwen-3-coder)
#### Kimi
- Kimi-K2 (k2)
### Want to contribute?
Visit [Contributing Page](./contributing) to learn how to make contribution to MCPMark.
================================================
FILE: docs/mcp/filesystem.md
================================================
# Filesystem
This guide walks you through preparing your filesystem environment for MCPMark.
## 1 · Configure Environment Variables
Set the `FILESYSTEM_TEST_ROOT` environment variable in your `.mcp_env` file:
```env
## Filesystem
FILESYSTEM_TEST_ROOT=./test_environments
```
**Recommended**: Use `FILESYSTEM_TEST_ROOT=./test_environments` (relative to project root)
---
## 2 · Automatic Test Environment Download
Our code automatically downloads test folders to your specified `FILESYSTEM_TEST_ROOT` directory when the pipeline starts running.
**Downloaded Structure**:
```
./test_environments/
├── desktop/ # Desktop environment
├── desktop_template/ # Template files for desktop
├── file_context/ # File content understanding tasks
├── file_property/ # File metadata and properties related tasks
├── folder_structure/ # Directory organization tasks
├── legal_document/ # Legal document processing
├── papers/ # Academic paper tasks
├── student_database/ # Database management tasks
├── threestudio/ # 3D Generation codebase
└── votenet/ # 3D Object Detection codebase
```
---
## 3 · Running Filesystem Tasks
**Basic Command**:
```bash
python -m pipeline --exp-name EXPNAME --mcp filesystem --tasks FILESYSTEMTASK --models MODEL --k K
```
**Docker Usage (Recommended)**
Docker is recommended to avoid library version conflicts:
```bash
# Build Docker image
./build-docker.sh
# Run with Docker
./run-task.sh --mcp filesystem --models MODEL --exp-name EXPNAME --tasks FILESYSTEMTASK --k K
```
Here *EXPNAME* refers to customized experiment name, *FILESYSTEMTASK* refers to the github task or task group selected (see [Task Page](../datasets/task.md) for specific task information), *MODEL* refers to the selected model (see [Introduction Page](../introduction.md) for model supported), *K* refers to the time of independent experiments.
---
## 5 · Troubleshooting
**Common Issues**:
- **Test Environment Not Found**: Ensure `FILESYSTEM_TEST_ROOT` is set correctly
- **Prerequisites**: Make sure your terminal has `wget` and `unzip` commands available
- **Recommended**: Use Docker to prevent library version conflicts
================================================
FILE: docs/mcp/github.md
================================================
# GitHub
This guide walks you through preparing your GitHub environment for MCPMark and authenticating the CLI tools with support for **token pooling** to mitigate rate limits.
## 1 · Prepare An Evaluation Organization in Github
1. **Create a free GitHub Organization**
- In GitHub, click your avatar → **Your organizations** → **New organization**.
- We recommend a name like `mcpmark-eval-xxx`. (Check if there is a conflict with other organization names.)
- This keeps all benchmark repositories isolated from your personal and work code.
- [](https://postimg.cc/k27xdXc4)
2. **Create Multiple GitHub Accounts (Recommended for Rate Limit Relief)**
To effectively distribute API load and avoid rate limiting, we recommend creating **2-4 additional GitHub accounts**:
- Create new GitHub accounts (e.g., `your-name-eval-1`, `your-name-eval-2`, etc.)
- **Important**: Add all these accounts as **Owners** to your evaluation organization
- This allows the token pooling system to distribute requests across multiple accounts
3. **Generate Fine-Grained Personal Access Tokens (PATs) for Each Account**
**Repeat the following process for each GitHub account (including your main account):**
- Navigate to *Settings → Developer settings → Personal access tokens → Fine-grained tokens*
- Click **Generate new token**, select the evaluation organization you created
- [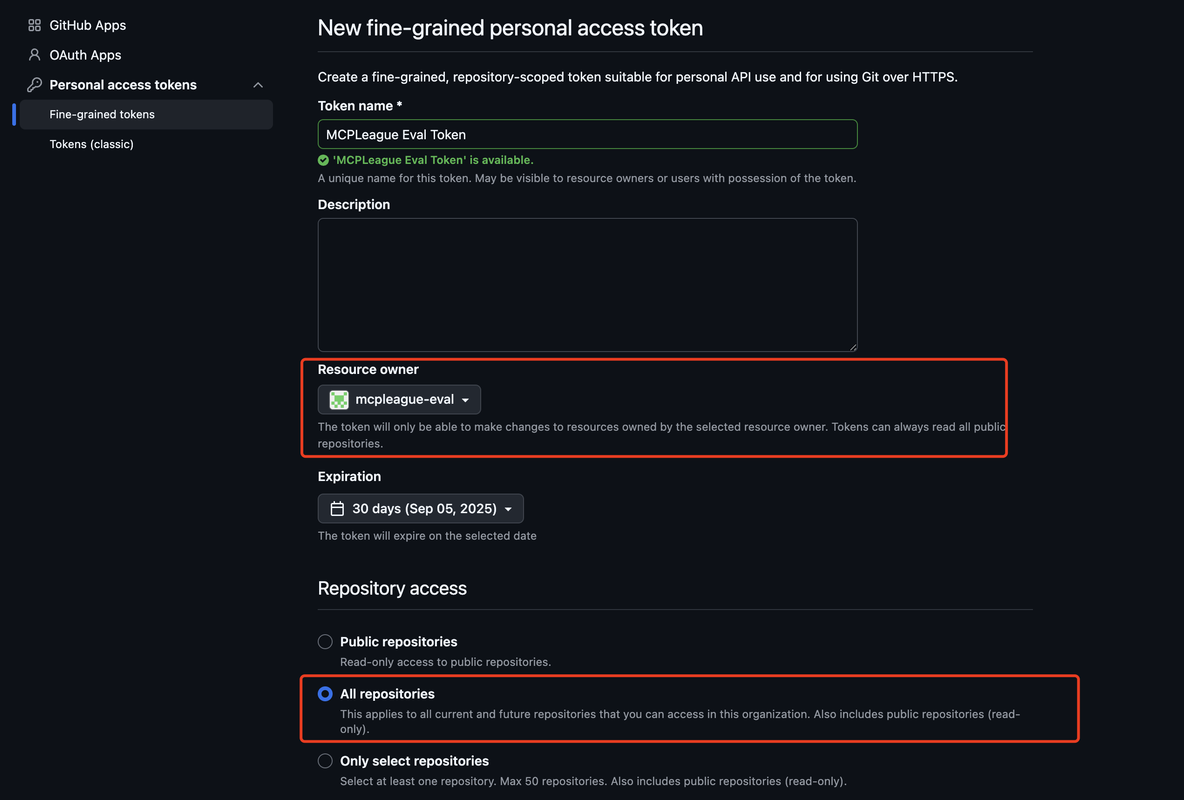](https://postimg.cc/Mv9yqJrm)
- Give the token a descriptive name (e.g., *MCPMark Eval Token - Account 1*)
- Under **Repository permissions** and **Organization permissions**, enable **All permissions** (read and write if applicable)
- [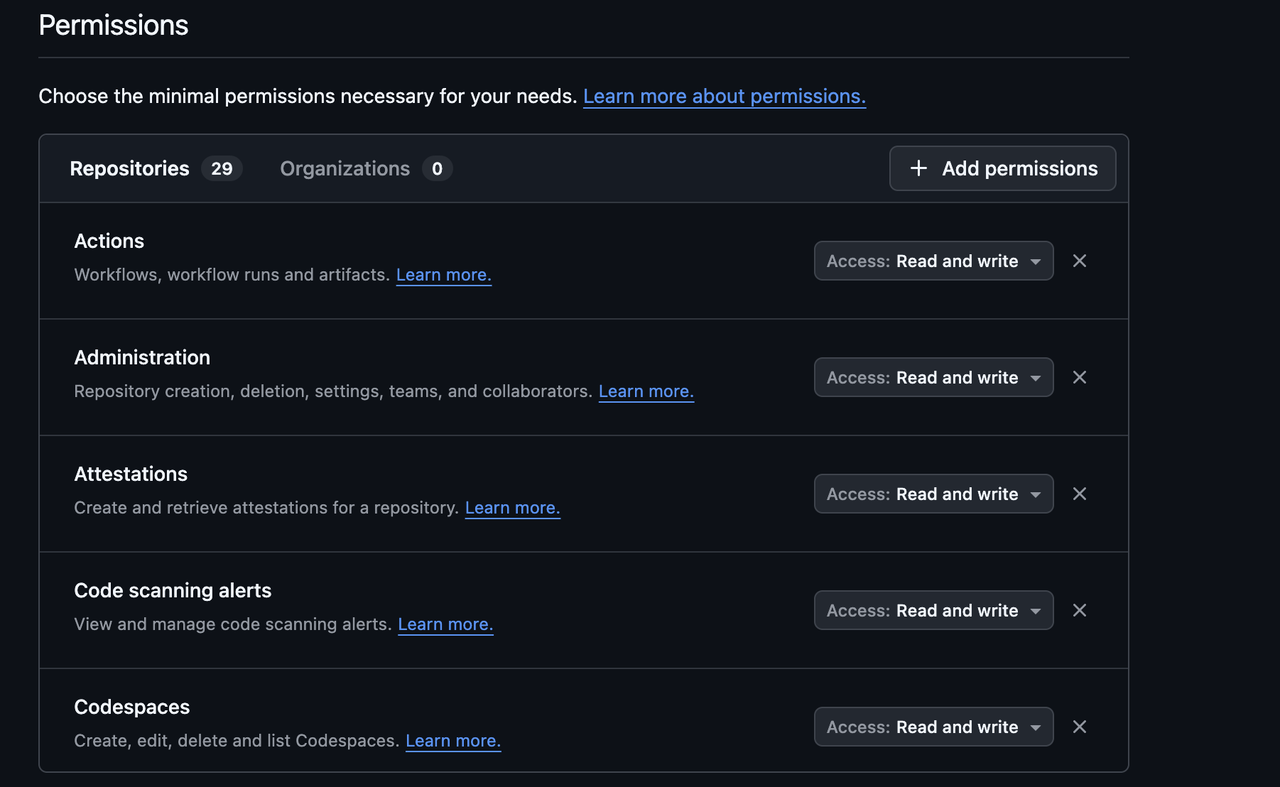](https://postimg.cc/14HFrZP1)
- Copy the generated token and save it safely — you'll need all tokens for the next step
4. **Configure Token Pooling in `.mcp_env`**
In your project root, edit (or create) the `.mcp_env` file and add your tokens:
**For single token (Basic setup):**
```env
## GitHub - Single Token Configuration
GITHUB_TOKENS="your-single-token-here"
GITHUB_EVAL_ORG="your-eval-org-name"
```
**For multiple tokens (Recommended for handling rate limits):**
```env
## GitHub - Token Pooling Configuration
GITHUB_TOKENS="token1,token2,token3,token4"
GITHUB_EVAL_ORG="your-eval-org-name"
```
**Important Notes:**
- Replace `token1,token2,token3,token4` with your actual tokens (comma-separated, no spaces)
- **2-4 tokens** is recommended for optimal rate limit distribution
- All tokens must have **the same permissions** on the evaluation organization
- The system automatically rotates between tokens to distribute API load
---
## 2 · Download the Sample Repository State
We have pre-exported several popular open-source repositories along with curated Issues and PRs.
1. Download the archive from [Google Drive](https://drive.google.com/drive/folders/16bFDjdtqJYzYJlqKcjKBGomo8DwOhWcN?usp=drive_link).
2. Extract it so that the directory `./github_state/` appears in the project root:
```bash
mkdir -p github_state
unzip github_state.zip -d ./github_state
```
---
## 3 · Add New Repositories (Optional)
If you want to benchmark additional repositories:
1. Export the desired repository state:
```bash
python -m src.mcp_services.github.repo_exporter --source_repo_url owner/name --max-issues 20 --max-pulls 5
```
2. Open `src/mcp_services/github/state_manager.py` and add a new entry to `self.initial_state_mapping` pointing to the exported folder.
---
## 4 · GitHub Rate Limits & Token Pooling Benefits
### Understanding Rate Limits
Fine-grained tokens are subject to GitHub API rate limits:
- **Read operations**: 5,000 requests per hour per token
- **General write operations**: 80 writes per minute and 500 writes per hour per token
- **Content creation (Issues, PRs, Comments)**: **500 requests per hour per token** (Secondary Rate Limit)
### How Token Pooling Helps
With **token pooling**, MCPMark automatically:
- **Distributes requests** across multiple tokens to multiply your rate limits
- **Rotates tokens** for each task execution to balance load
- **Handles rate limit failures** by trying the next available token
- **Ensures consistency** between agent execution and verification
### Example: Rate Limit Multiplication
**Read Operations:**
- **Single token**: 5,000 requests/hour
- **4 tokens**: ~20,000 requests/hour total capacity
**Content Creation (Critical for MCPMark):**
- **Single token**: 500 content creation requests/hour
- **4 tokens**: ~2,000 content creation requests/hour total capacity
- **Automatic failover**: If one token hits limits, others continue working
This dramatically improves evaluation performance, especially for large task batches or frequent testing cycles. **The content creation limit is often the bottleneck**, making token pooling essential for efficient evaluations.
### Repository Limits
MCPMark places a cap on the number of PRs and issues (≤ 50 in total) per repository to ensure reasonable evaluation times and to stay within rate limits.
## 2. Running Github Tasks
1. Configure environment variables: make sure `GITHUB_TOKENS` and `GITHUB_EVAL_ORG` are properly set in `.mcp_env`.
2. For single task or task group, run
```bash
python -m pipeline --exp-name EXPNAME --mcp github --tasks GITHUBTASK --models MODEL --k K
```
Here *EXPNAME* refers to customized experiment name, *GITHUBTASK* refers to the github task or task group selected (see [Task Page](../datasets/task.md) for specific task information), *MODEL* refers to the selected model (see [Introduction Page](../introduction.md) for model supported), *K* refers to the time of independent experiments.
================================================
FILE: docs/mcp/notion.md
================================================
# Notion
This guide walks you through preparing your Notion environment for MCPMark and authenticating the CLI tools.
> Note: Set your Notion app and workspace interface language to English. We use Playwright for browser automation and our locator logic relies on raw English text in the UI. Non-English interfaces can cause element selection to fail.
## 1 · Set up Notion Environment
1. **Duplicate the MCPMark Source Pages**
Copy the template database and pages into your workspace from the public template following this tutorial:
[Duplicate MCPMark Source](https://painted-tennis-ebc.notion.site/MCPBench-Source-Hub-23181626b6d7805fb3a7d59c63033819).
2. **Set up the Source and Eval Hub for Environment Isolation**
- Prepare **two separate Notion pages**:
- **Source Hub**: Stores all the template databases/pages. Managed by `SOURCE_NOTION_API_KEY`.
- **Eval Hub**: Only contains the duplicated templates for the current evaluation. Managed by `EVAL_NOTION_API_KEY`.
- In Notion, create an **empty page** in your Eval Hub. The page name **must exactly match** the value you set for `EVAL_PARENT_PAGE_TITLE` in your environment variables (e.g., `MCPMark Eval Hub`).
- Name your **Source Hub** page to match `SOURCE_PARENT_PAGE_TITLE` (default: `MCPMark Source Hub`). This is where all initial-state templates live; we enumerate this page’s first-level children by exact title.
- In Notion's **Connections** settings:
- Bind the integration corresponding to `EVAL_NOTION_API_KEY` to the Eval Hub parent page you just created.
- Bind the integration corresponding to `SOURCE_NOTION_API_KEY` to your Source Hub (where the templates are stored).
3. **Create Notion Integrations & Grant Access**
a. Visit [Notion Integrations](https://www.notion.so/profile/integrations) and create **two internal integrations** (one for Source Hub, one for Eval Hub).
b. Copy the generated **Internal Integration Tokens** (these will be your `SOURCE_NOTION_API_KEY` and `EVAL_NOTION_API_KEY`).
c. Share the **Source Hub** with the Source integration, and the **Eval Hub parent page** with the Eval integration (*Full Access*).
[](https://postimg.cc/XXVGJD5H)
[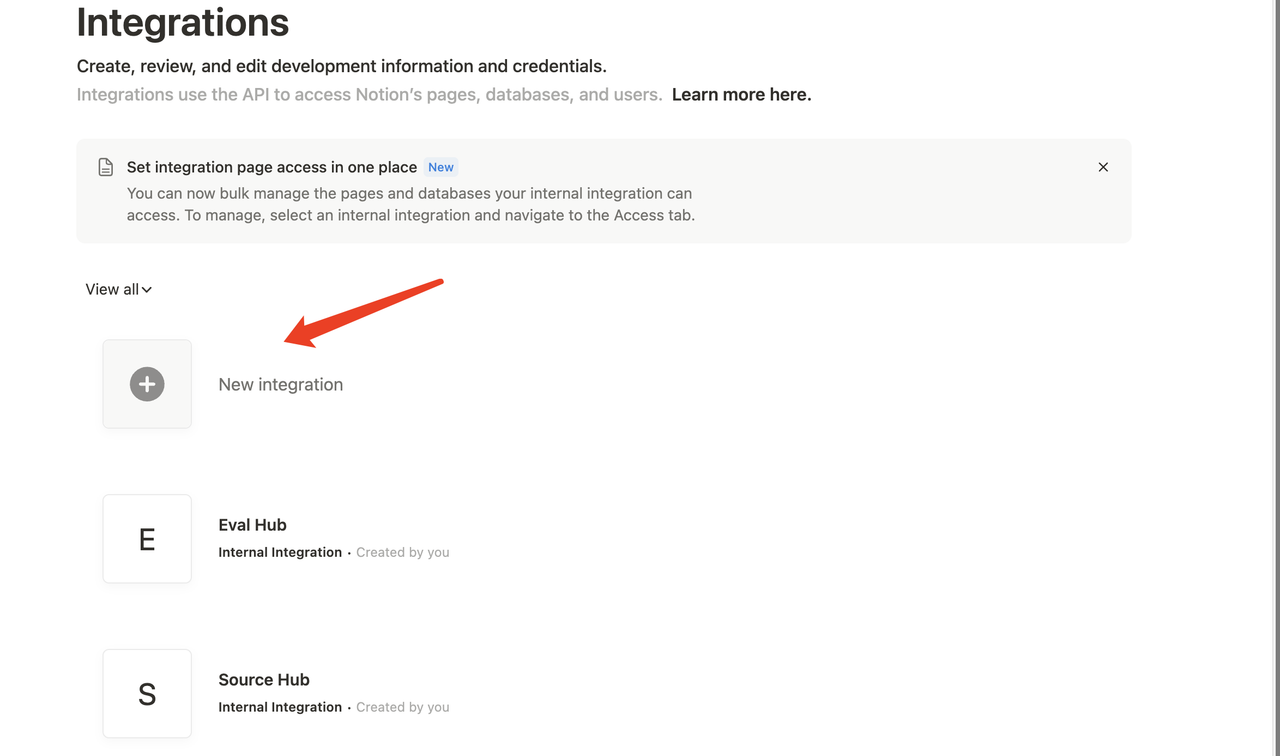](https://postimg.cc/NKrLShhM)
[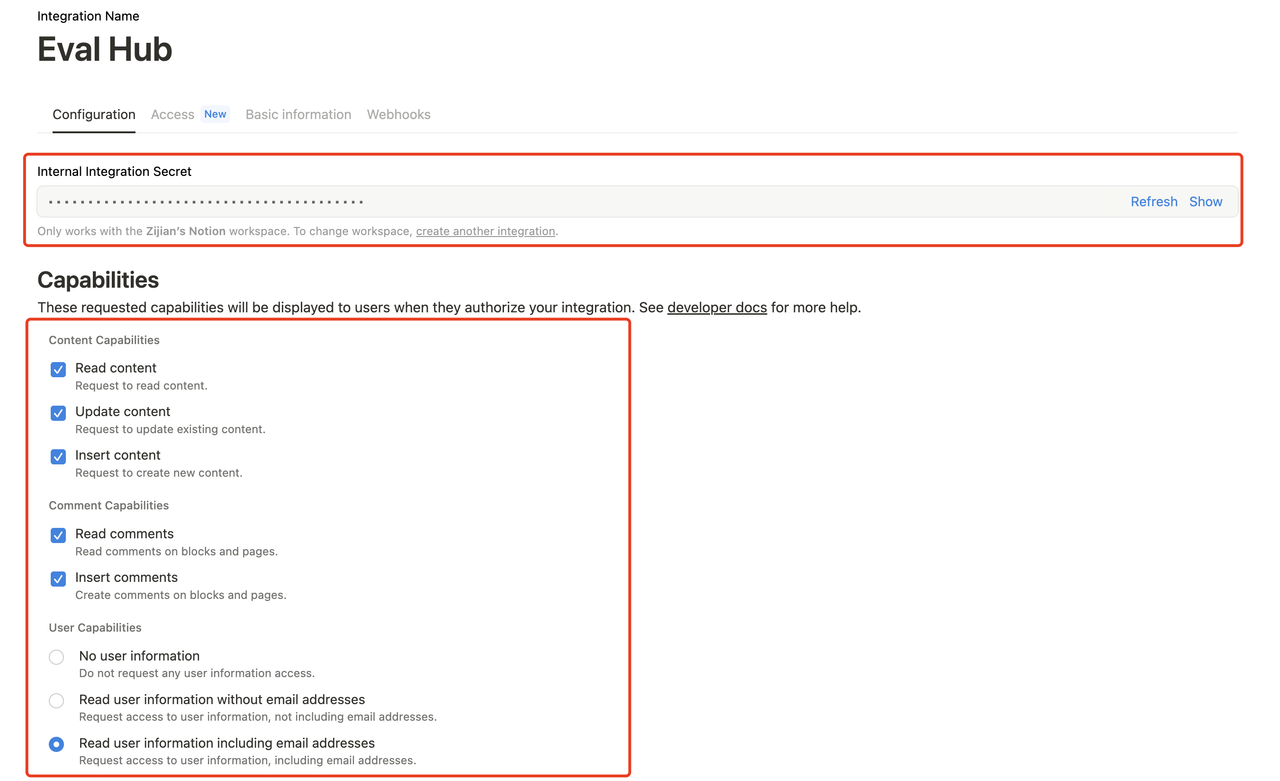](https://postimg.cc/CRDLJjDn)
[](https://postimg.cc/n9Cnm7pz)
[](https://postimg.cc/s1QFp35v)
---
## 2 · Authenticate with Notion
```bash
# First, install Playwright and the browser binaries
playwright install
# Then, run the Notion login helper with your preferred browser
python -m src.mcp_services.notion.notion_login_helper --browser {firefox|chromium}
```
The verification script will tell you which browser is working properly. The pipeline defaults to using **chromium**. Our pipeline has been **fully tested on macOS and Linux**.
## 3. Running Notion Tasks
1. Configure environment variables: make sure the following service credentials are added in `.mcp_env`.
```env
## Notion
SOURCE_NOTION_API_KEY="your-source-notion-api-key" # For Source Hub (templates)
EVAL_NOTION_API_KEY="your-eval-notion-api-key" # For Eval Hub (active evaluation)
SOURCE_PARENT_PAGE_TITLE="MCPMark Source Hub" # Source hub page name (exact match)
EVAL_PARENT_PAGE_TITLE="MCPMark Eval Hub" # Must match the name of the empty page you created in Eval Hub
PLAYWRIGHT_BROWSER="chromium" # default to chromium, you can also choose firefox
PLAYWRIGHT_HEADLESS="True"
```
2. For single task or task group, run
```bash
python -m pipeline --exp-name EXPNAME --mcp notion --tasks NOTIONTASK --models MODEL --k K
```
Here *EXPNAME* refers to customized experiment name, *NOTIONTASK* refers to the notion task or task group selected (see [Task Page](../datasets/task.md) for specific task information), *MODEL* refers to the selected model (see [Introduction Page](../introduction.md) for model supported), *K* refers to the time of independent experiments.
================================================
FILE: docs/mcp/playwright.md
================================================
# Playwright
This guide walks you through setting up WebArena environments for Playwright MCP automated testing, including Shopping, Shopping Admin, and Reddit instances.
Section 1 is designed mainly for completing the Playwright-WebArena tasks.
## 1. Setup WebArena Environment (For Playwright-WebArena Tasks)
### 1.1 Download Docker Images
[WebArena](https://github.com/web-arena-x/webarena/tree/main/environment_docker) provides Docker images from multiple sources. Choose the fastest one for your network:
### Shopping Environment (Port 7770)
```bash
# Option 1: Google Drive (Recommended)
pip install gdown
gdown 1gxXalk9O0p9eu1YkIJcmZta1nvvyAJpA
# Option 2: Archive.org
wget https://archive.org/download/webarena-env-shopping-image/shopping_final_0712.tar
# Option 3: CMU Server
wget http://metis.lti.cs.cmu.edu/webarena-images/shopping_final_0712.tar
```
### Shopping Admin Environment (Port 7780)
```bash
# Option 1: Google Drive (Recommended)
gdown 1See0ZhJRw0WTTL9y8hFlgaduwPZ_nGfd
# Option 2: Archive.org
wget https://archive.org/download/webarena-env-shopping-admin-image/shopping_admin_final_0719.tar
# Option 3: CMU Server
wget http://metis.lti.cs.cmu.edu/webarena-images/shopping_admin_final_0719.tar
```
### Reddit Environment (Port 9999)
```bash
# Option 1: Google Drive (Recommended)
gdown 17Qpp1iu_mPqzgO_73Z9BnFjHrzmX9DGf
# Option 2: Archive.org
wget https://archive.org/download/webarena-env-forum-image/postmill-populated-exposed-withimg.tar
# Option 3: CMU Server
wget http://metis.lti.cs.cmu.edu/webarena-images/postmill-populated-exposed-withimg.tar
```
### 1.2 Deploy Environments
#### Shopping (E-commerce Site)
```bash
docker load --input shopping_final_0712.tar
# Start container
docker run --name shopping -p 7770:80 -d shopping_final_0712
# Wait for service initialization (2-3 minutes)
sleep 180
# Configure for local access
docker exec shopping /var/www/magento2/bin/magento setup:store-config:set --base-url="http://localhost:7770"
docker exec shopping mysql -u magentouser -pMyPassword magentodb -e "UPDATE core_config_data SET value='http://localhost:7770/' WHERE path IN ('web/secure/base_url', 'web/unsecure/base_url');"
docker exec shopping /var/www/magento2/bin/magento cache:flush
```
**Access**: `http://localhost:7770`
#### Shopping Admin (Management Panel)
```bash
docker load --input shopping_admin_final_0719.tar
# Start container
docker run --name shopping_admin -p 7780:80 -d shopping_admin_final_0719
# Wait for service initialization
sleep 120
# Configure for local access
docker exec shopping_admin /var/www/magento2/bin/magento setup:store-config:set --base-url="http://localhost:7780"
docker exec shopping_admin mysql -u magentouser -pMyPassword magentodb -e "UPDATE core_config_data SET value='http://localhost:7780/' WHERE path IN ('web/secure/base_url', 'web/unsecure/base_url');"
docker exec shopping_admin php /var/www/magento2/bin/magento config:set admin/security/password_is_forced 0
docker exec shopping_admin php /var/www/magento2/bin/magento config:set admin/security/password_lifetime 0
docker exec shopping_admin /var/www/magento2/bin/magento cache:flush
```
**Access**: `http://localhost:7780/admin`
**Admin Credentials**: `admin / admin1234`
#### Reddit (Forum)
```bash
docker load --input postmill-populated-exposed-withimg.tar
# Start container
docker run --name forum -p 9999:80 -d postmill-populated-exposed-withimg
# Wait for PostgreSQL initialization
sleep 120
# Verify service status
docker logs forum | grep "database system is ready"
curl -I http://localhost:9999
```
**Access**: `http://localhost:9999`
### 1.3 External Access Configuration
For cloud deployments (GCP, AWS, etc.), configure external access:
#### Configure Firewall (GCP Example)
```bash
# Shopping environment
gcloud compute firewall-rules create allow-shopping-7770 \
--allow tcp:7770 --source-ranges 0.0.0.0/0
# Shopping Admin
gcloud compute firewall-rules create allow-shopping-admin-7780 \
--allow tcp:7780 --source-ranges 0.0.0.0/0
# Reddit
gcloud compute firewall-rules create allow-reddit-9999 \
--allow tcp:9999 --source-ranges 0.0.0.0/0
```
#### Update Base URLs for External Access
```bash
# Get external IP
EXTERNAL_IP=$(curl -s ifconfig.me)
# Shopping
docker exec shopping /var/www/magento2/bin/magento setup:store-config:set --base-url="http://${EXTERNAL_IP}:7770"
docker exec shopping mysql -u magentouser -pMyPassword magentodb -e "UPDATE core_config_data SET value='http://${EXTERNAL_IP}:7770/' WHERE path IN ('web/secure/base_url', 'web/unsecure/base_url');"
docker exec shopping /var/www/magento2/bin/magento cache:flush
# Shopping Admin
docker exec shopping_admin /var/www/magento2/bin/magento setup:store-config:set --base-url="http://${EXTERNAL_IP}:7780"
docker exec shopping_admin mysql -u magentouser -pMyPassword magentodb -e "UPDATE core_config_data SET value='http://${EXTERNAL_IP}:7780/' WHERE path IN ('web/secure/base_url', 'web/unsecure/base_url');"
docker exec shopping_admin /var/www/magento2/bin/magento cache:flush
```
### 1.4 Alternative Access Methods (Not Verified)
#### Cloudflared Tunnel (Free & Persistent)
```bash
# Install cloudflared
wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64
sudo mv cloudflared-linux-amd64 /usr/local/bin/cloudflared
sudo chmod +x /usr/local/bin/cloudflared
# Create tunnels
cloudflared tunnel --url http://localhost:7770 # Shopping
cloudflared tunnel --url http://localhost:7780 # Admin
cloudflared tunnel --url http://localhost:9999 # Reddit
```
#### ngrok (Quick Sharing)
```bash
# Install ngrok
wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz
tar xvzf ngrok-v3-stable-linux-amd64.tgz
sudo mv ngrok /usr/local/bin
# Create tunnel (choose port)
ngrok http 7770 # For Shopping
```
## 2. Running Playwright Tasks
1. Configure environment variables: make sure the following service credentials are added in `.mcp_env`.
```env
PLAYWRIGHT_BROWSER="chromium" # default to chromium, you can also choose firefox
PLAYWRIGHT_HEADLESS="True"
```
2. For single task or task group, run
```bash
python -m pipeline --exp-name EXPNAME --mcp MCP --tasks PLAYWRIGHTTASK --models MODEL
```
Here *EXPNAME* refers to customized experiment name, *MCP* refers to playwright or playwright_webarena denpending on the task, *PLAYWRIGHTTASK* refers to the task or task group selected (see [Task Page](../datasets/task.md) for specific task information), *MODEL* refers to the selected model (see [Introduction Page](../introduction.md) for model supported), *K* refers to the time of independent experiments.
## 3. Troubleshooting
### Container Issues
```bash
# Check status
docker ps -a | grep -E "shopping|forum"
# View logs
docker logs [container_name] --tail 50
# Restart container
docker restart [container_name]
```
### Access Problems
- **First load is slow** (1-2 minutes for Magento) - this is normal
- **Ensure ports are available**: `netstat -tlnp | grep -E "7770|7780|9999"`
- **Clear cache after URL changes**: Required for Magento environments
### Reset Environment
```bash
# Stop and remove container
docker stop [container_name]
docker rm [container_name]
# Re-deploy (follow steps in Section 3)
```
## 4. Important Notes
- **Service startup time**: Allow 2-3 minutes for Magento, 1-2 minutes for Reddit
- **Memory requirements**: Ensure Docker has at least 4GB RAM allocated per container
- **URL configuration**: Must reconfigure base URLs after container restart for external access
- **Port assignments**:
- 7770: Shopping
- 7780: Shopping Admin
- 9999: Reddit
================================================
FILE: docs/mcp/postgres.md
================================================
# PostgreSQL
This guide walks you through preparing your PostgreSQL environment for MCPMark evaluation.
## 1. Setup PostgreSQL Environment
### 1.1 Start PostgreSQL with Docker
1. **Run PostgreSQL Container**
Start a PostgreSQL instance using Docker:
```bash
docker run -d \
--name mcpmark-postgres \
-e POSTGRES_PASSWORD=password \
-e POSTGRES_USER=postgres \
-p 5432:5432 \
pgvector/pgvector:0.8.0-pg17-bookworm
```
2. **Verify Container is Running**
```bash
docker ps | grep mcpmark-postgres
```
---
### 1.2 Import Sample Databases
1. **Download Database Backups**
Download the backup files and place them in `./postgres_state/` directory:
```bash
mkdir -p ./postgres_state
cd ./postgres_state
# Download all database backups
wget https://storage.mcpmark.ai/postgres/employees.backup
wget https://storage.mcpmark.ai/postgres/chinook.backup
wget https://storage.mcpmark.ai/postgres/dvdrental.backup
wget https://storage.mcpmark.ai/postgres/sports.backup
wget https://storage.mcpmark.ai/postgres/lego.backup
cd ..
```
2. **Create Databases and Restore from Backups**
> Make sure your Postgres client version matches the server's version (e.g., pg17).
```bash
# Set the password environment variable
export PGPASSWORD=password
# Create and restore each database
createdb -h localhost -U postgres employees
pg_restore -h localhost -U postgres -d employees -v ./postgres_state/employees.backup
createdb -h localhost -U postgres chinook
pg_restore -h localhost -U postgres -d chinook -v ./postgres_state/chinook.backup
createdb -h localhost -U postgres dvdrental
pg_restore -h localhost -U postgres -d dvdrental -v ./postgres_state/dvdrental.backup
createdb -h localhost -U postgres sports
pg_restore -h localhost -U postgres -d sports -v ./postgres_state/sports.backup
createdb -h localhost -U postgres lego
pg_restore -h localhost -U postgres -d lego -v ./postgres_state/lego.backup
```
3. **Verify Databases are Imported**
```bash
# List all databases
PGPASSWORD=password psql -h localhost -U postgres -c "\l"
```
---
## 2. Configure Environment Variables
Configure environment variables: make sure the following enservice credentials are added in `.mcp_env`:
```env
## PostgreSQL Configuration
POSTGRES_HOST="localhost"
POSTGRES_PORT="5432"
POSTGRES_USERNAME="postgres"
POSTGRES_PASSWORD="password"
```
## 3. Verify Connection
Verify the PostgreSQL setup is working correctly:
```bash
# Test connection using psql
PGPASSWORD=password psql -h localhost -U postgres -c "SELECT version();"
```
## 4. Common Operations
### Stop PostgreSQL Container
```bash
docker stop mcpmark-postgres
```
### Start PostgreSQL Container
```bash
docker start mcpmark-postgres
```
### Remove PostgreSQL Container (Clean Setup)
```bash
docker stop mcpmark-postgres
docker rm mcpmark-postgres
```
### Access PostgreSQL Shell
```bash
PGPASSWORD=mysecretpassword psql -h localhost -U postgres
```
## 5. Running Postgres Experiment
For single task or task group, run
```bash
python -m pipeline --exp-name EXPNAME --mcp postgres --tasks POSTGRESTASK --models MODEL
```
Here *EXPNAME* refers to customized experiment name, *POSTGRESTASK* refers to the postgres task or task group selected (see `tasks/` for specific task information), *MODEL* refers to the selected model (see [Introduction Page](../introduction.md) for model supported), *K* refers to the time of independent experiments.
## 6. Troubleshooting
### Port Already in Use
If port 5432 is already in use, you can use a different port:
```bash
docker run -d \
```bash
docker run -d \
--name mcpmark-postgres \
-e POSTGRES_PASSWORD=password \
-e POSTGRES_USER=postgres \
-p 5433:5432 \
pgvector/pgvector:0.8.0-pg17-bookworm
```
Remember to update `POSTGRES_PORT="5433"` in your `.mcp_env` file.
### Connection Refused
Ensure the Docker container is running and the port mapping is correct:
```bash
docker ps
docker logs mcpmark-postgres
```
================================================
FILE: docs/quickstart.md
================================================
# Quick Start
To quickly experience MCPMark, we recommend firstly preparing the environment, and then execute the Postgres tasks.
### 1. Clone MCPMark
```bash
git clone https://github.com/eval-sys/mcpmark.git
cd mcpmark
```
### 2. Setup Environment Variables
To setup the model access in environment variable, edit the `.mcp_env` file in `mcpmark/`.
```env
# Model Providers (set only those you need)
## Google Gemini
GEMINI_BASE_URL="https://your-gemini-base-url.com/v1"
GEMINI_API_KEY="your-gemini-api-key"
## DeepSeek
DEEPSEEK_BASE_URL="https://your-deepseek-base-url.com/v1"
DEEPSEEK_API_KEY="your-deepseek-api-key"
## OpenAI
OPENAI_BASE_URL="https://your-openai-base-url.com/v1"
OPENAI_API_KEY="your-openai-api-key"
## Anthropic
ANTHROPIC_BASE_URL="https://your-anthropic-base-url.com/v1"
ANTHROPIC_API_KEY="your-anthropic-api-key"
## Moonshot
MOONSHOT_BASE_URL="https://your-moonshot-base-url.com/v1"
MOONSHOT_API_KEY="your-moonshot-api-key"
## xAI
XAI_BASE_URL="https://your-xai-base-url.com/v1"
XAI_API_KEY="your-xai-api-key"
```
### 3. Run Quick Example in MCPMark
Suppose you are running the employee query task with gemini-2.5-flash, and name your experiment as test-run-1, you can use the following command to test the `size_classification` task in `file_property`, which categorizes files by their sizes.
```bash
python -m pipeline
--exp-name test-run-1
--mcp filesystem
--tasks file_property/size_classification
--models gemini-2.5-flash
```
Here is the expected output (the verification may encounter failure due to model choices).
[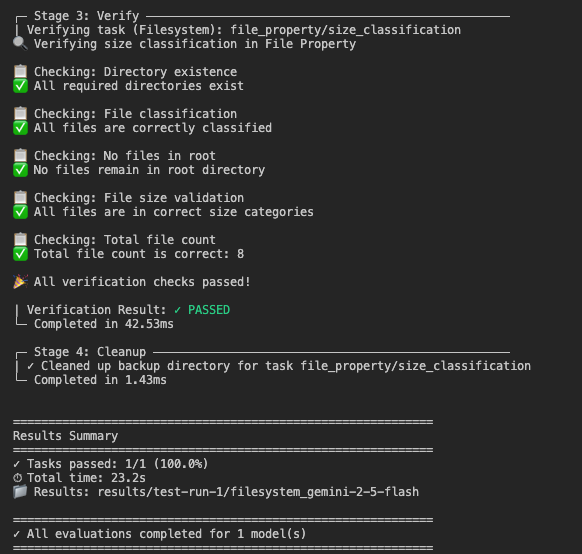](https://postimg.cc/Yj8nPZkQ)
The reuslts are saved under `restuls/{exp_name}/{mcp}_{model}/{tasks}`, if `exp-name` is not specified, the default name would be timestamp of the experiment (but specifying the `exp-name` is useful for resuming experiments).
For other MCP services, please refers to the [Installation and Docker Usage Page](./installation_and_docker_usage.md) for detailed instruction.
================================================
FILE: pipeline.py
================================================
#!/usr/bin/env python3
"""
MCPMark Unified Evaluation Pipeline
===================================
This script provides an automated evaluation pipeline for testing Large Language Models (LLMs)
on various Multi-Step Cognitive Processes (MCP) services like Notion, GitHub, and PostgreSQL.
"""
import argparse
import sys
from datetime import datetime
from pathlib import Path
from dotenv import load_dotenv
from src.logger import get_logger
from src.evaluator import MCPEvaluator
from src.agents import AGENT_REGISTRY
from src.factory import MCPServiceFactory
from src.model_config import ModelConfig
# Suppress httpcore/anyio cleanup exceptions that don't affect functionality.
# These "Exception ignored" messages are caused by MCP library's streamablehttp_client
# timing issues during cleanup, but don't impact actual task execution.
def _suppress_cleanup_exceptions(unraisable):
"""Suppress known cleanup exceptions from httpcore/anyio."""
msg = str(unraisable.exc_value)
if any(
pattern in msg
for pattern in [
"async generator ignored GeneratorExit",
"cancel scope in a different task",
"no running event loop",
]
):
return # Silently ignore
# Use default handler for other exceptions
sys.__unraisablehook__(unraisable)
sys.unraisablehook = _suppress_cleanup_exceptions
# Initialize logger
logger = get_logger(__name__)
def main():
"""Main entry point for the evaluation pipeline."""
parser = argparse.ArgumentParser(description="MCPMark Unified Evaluation Pipeline.")
supported_mcp_services = MCPServiceFactory.get_supported_mcp_services()
supported_models = ModelConfig.get_supported_models()
# Main configuration
parser.add_argument(
"--mcp",
default="filesystem",
choices=supported_mcp_services,
help="MCP service to use (default: filesystem)",
)
parser.add_argument(
"--models",
required=True,
help="Comma-separated list of models to evaluate (e.g., 'o3,k2,gpt-4.1')",
)
parser.add_argument(
"--agent",
default="mcpmark",
choices=sorted(AGENT_REGISTRY.keys()),
help="Agent implementation to use (default: mcpmark)",
)
parser.add_argument(
"--tasks",
default="all",
help='Tasks to run: (1). "all"; (2). "category"; or (3). "category/task".',
)
parser.add_argument(
"--task-suite",
default="standard",
choices=["standard", "easy"],
help="Task suite to run (default: standard). Use 'easy' to run the lightweight dataset.",
)
parser.add_argument(
"--exp-name",
default=None,
help="Experiment name; results are saved under results/<exp-name>/ (default: YYYY-MM-DD-HH-MM-SS)",
)
parser.add_argument(
"--k",
type=int,
default=4,
help="Number of evaluation runs (default: 1)",
)
# Execution configuration
parser.add_argument(
"--timeout",
type=int,
default=3600,
help="Timeout in seconds for agent execution",
)
parser.add_argument(
"--compaction-token",
type=int,
default=999_999_999,
help=(
"Auto-compact conversation when prompt tokens (from API usage) reach this limit. "
"Use 999999999 to disable compaction."
),
)
parser.add_argument(
"--reasoning-effort",
default="default",
choices=["default", "minimal", "low", "medium", "high"],
help="Reasoning effort level for supported models (default: None)",
)
# Output configuration
parser.add_argument(
"--output-dir",
type=Path,
default=Path("./results"),
help="Directory to save results",
)
# Load arguments and environment variables
args = parser.parse_args()
load_dotenv(dotenv_path=".mcp_env", override=False)
# Validate k parameter and exp-name requirement
if args.k > 1 and args.exp_name is None:
parser.error("--exp-name is required when k > 1")
# Generate default exp-name if not provided
if args.exp_name is None:
args.exp_name = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# Parse models (no validation - allow unsupported models)
model_list = [m.strip() for m in args.models.split(",") if m.strip()]
if not model_list:
parser.error("No valid models provided")
# Log warning for unsupported models but don't error
unsupported_models = [m for m in model_list if m not in supported_models]
if unsupported_models:
logger.warning(
f"Using unsupported models: {', '.join(unsupported_models)}. Will use OPENAI_BASE_URL and OPENAI_API_KEY from environment."
)
logger.info("MCPMark Evaluation")
logger.info(
f"Experiment: {args.exp_name} | {len(model_list)} Model(s): {', '.join(model_list)}"
)
logger.info(f"Task suite: {args.task_suite}")
if args.k > 1:
logger.info(f"Running {args.k} evaluation runs for pass@k metrics")
# Run k evaluation runs
for run_idx in range(1, args.k + 1):
if args.k > 1:
logger.info(f"\n{'=' * 80}")
logger.info(f"Starting Run {run_idx}/{args.k}")
logger.info(f"{'=' * 80}\n")
# For k-runs, results/{exp}/{mcp}__{model}/run-N
run_exp_name = f"run-{run_idx}"
run_output_dir = args.output_dir / args.exp_name
else:
# For single run, still use run-1 under service_model
run_exp_name = "run-1"
run_output_dir = args.output_dir / args.exp_name
# Run evaluation for each model
for i, model in enumerate(model_list, 1):
logger.info(f"\n{'=' * 60}")
if args.k > 1:
logger.info(
f"Run {run_idx}/{args.k} | Model {i}/{len(model_list)}: {model}"
)
else:
logger.info(f"Starting evaluation {i}/{len(model_list)}: {model}")
logger.info(f"{'=' * 60}\n")
# Initialize and run the evaluation pipeline for this model
pipeline = MCPEvaluator(
mcp_service=args.mcp,
model=model,
timeout=args.timeout,
exp_name=run_exp_name,
output_dir=run_output_dir,
reasoning_effort=args.reasoning_effort,
agent_name=args.agent,
task_suite=args.task_suite,
compaction_token=args.compaction_token,
)
pipeline.run_evaluation(args.tasks)
logger.info(f"📁 Results: {pipeline.base_experiment_dir}")
logger.info(f"\n{'=' * 60}")
if args.k > 1:
logger.info(f"✓ All {args.k} runs completed for {len(model_list)} model(s)")
logger.info(
f"Run `python -m src.aggregators.aggregate_results --exp-name {args.exp_name}` to compute all metrics"
)
else:
logger.info(f"✓ All evaluations completed for {len(model_list)} model(s)")
logger.info(f"{'=' * 60}")
if __name__ == "__main__":
main()
================================================
FILE: pyproject.toml
================================================
[project]
authors = []
name = "MCPMark"
requires-python = ">= 3.11"
version = "0.0.1"
dependencies = [
"notion-client==2.4.0",
"playwright>=1.43.0",
"seaborn>=0.12.0",
"matplotlib>=3.7.0",
"numpy>=1.23.0",
"openai-agents>=0.2.3,<0.3",
"openai>=1.96.1",
"python-dotenv>=1.1.1,<2",
"ruff>=0.12.4,<0.13",
"psycopg2-binary>=2.9.10,<3",
"pyyaml>=6.0.2,<7",
"nest-asyncio>=1.6.0,<2",
"pixi",
"pipx>=1.7.1,<2",
"pgdumplib>=3.1.0,<4",
"litellm==1.80.0"
]
[build-system]
build-backend = "hatchling.build"
requires = ["hatchling"]
[tool.pixi.workspace]
channels = ["conda-forge"]
platforms = [
"osx-arm64",
"linux-aarch64",
"linux-64",
"win-64",
"osx-64",
]
[tool.pixi.tasks]
fmt = "ruff"
[tool.ruff.format]
indent-style = "space"
line-ending = "auto"
[tool.hatch.build.targets.wheel]
packages = ["src", "tasks"]
================================================
FILE: run-benchmark.sh
================================================
#!/bin/bash
# MCPMark Full Benchmark Runner
# Runs all tasks across all MCP services for comprehensive model evaluation
set -e
# Default values
MODELS=""
EXP_NAME=""
USE_DOCKER=false
SERVICES="filesystem,notion,github,postgres,playwright"
PARALLEL=false
TIMEOUT=3600
K=4
# Color codes for output
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m' # No Color
# Function to print colored output
print_status() {
echo -e "${BLUE}[$(date '+%Y-%m-%d %H:%M:%S')]${NC} $1"
}
print_success() {
echo -e "${GREEN}✓${NC} $1"
}
print_warning() {
echo -e "${YELLOW}⚠${NC} $1"
}
print_error() {
echo -e "${RED}✗${NC} $1"
}
# Parse arguments
while [[ $# -gt 0 ]]; do
case $1 in
--models)
MODELS="$2"
shift 2
;;
--exp-name)
EXP_NAME="$2"
shift 2
;;
--docker)
USE_DOCKER=true
shift
;;
--mcps)
SERVICES="$2"
shift 2
;;
--parallel)
PARALLEL=true
shift
;;
--timeout)
TIMEOUT="$2"
shift 2
;;
--k)
K="$2"
shift 2
;;
--help)
cat << EOF
Usage: $0 --models MODELS --exp-name NAME [OPTIONS]
Run comprehensive benchmark across all MCP services.
Required Options:
--models MODELS Comma-separated list of models to evaluate
(e.g., "o3,gpt-4.1,claude-4-sonnet")
--exp-name NAME Experiment name for organizing results
Optional Options:
--docker Run tasks in Docker containers (recommended)
--mcps SERVICES Comma-separated list of services to test
Default: filesystem,notion,github,postgres,playwright
--parallel Run services in parallel (experimental)
--timeout SECONDS Timeout per task in seconds (default: 300)
--k RUNS Repeat runs per service for pass@k (default: 4)
Examples:
# Run all services with Docker
$0 --models o3,gpt-4.1 --exp-name benchmark-1 --docker
# Run specific services locally
$0 --models o3 --exp-name test-1 --mcps filesystem,postgres
# Run with parallel execution
$0 --models claude-4 --exp-name parallel-test --docker --parallel
EOF
exit 0
;;
*)
print_error "Unknown option: $1"
echo "Use --help for usage information"
exit 1
;;
esac
done
# Validate required arguments
if [ -z "$MODELS" ]; then
print_error "Error: --models is required"
exit 1
fi
if [ -z "$EXP_NAME" ]; then
print_error "Error: --exp-name is required"
exit 1
fi
# Check prerequisites
if [ "$USE_DOCKER" = true ]; then
if ! command -v docker &> /dev/null; then
print_error "Docker is not installed"
exit 1
fi
# Always use Docker Hub image
DOCKER_IMAGE="evalsysorg/mcpmark:latest"
# Check if Docker image exists locally, pull only if not found
if ! docker image inspect "$DOCKER_IMAGE" >/dev/null 2>&1; then
print_status "Docker image not found locally, pulling from Docker Hub..."
docker pull "$DOCKER_IMAGE" || {
print_error "Failed to pull Docker image from Docker Hub"
exit 1
}
else
print_status "Using local Docker image: $DOCKER_IMAGE"
fi
else
# Check Python installation
if ! command -v python3 &> /dev/null; then
print_error "Python 3 is not installed"
exit 1
fi
# Check if dependencies are installed
if ! python3 -c "import src.evaluator" 2>/dev/null; then
print_warning "Python dependencies not installed"
echo "Installing dependencies..."
pip install -e . || {
print_error "Failed to install dependencies"
exit 1
}
fi
fi
# Check .mcp_env file
if [ ! -f .mcp_env ]; then
print_warning ".mcp_env file not found. Some tasks may fail without API credentials."
echo "Create one from .mcp_env.example: cp .mcp_env.example .mcp_env"
fi
# Convert comma-separated services to array
IFS=',' read -ra SERVICE_ARRAY <<< "$SERVICES"
# Summary
echo ""
print_status "MCPMark Benchmark Configuration"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo "Models: $MODELS"
echo "Experiment: $EXP_NAME"
echo "Services: ${SERVICE_ARRAY[*]}"
echo "Docker: $USE_DOCKER"
echo "Parallel: $PARALLEL"
echo "Timeout: ${TIMEOUT}s per task"
echo "K-Runs: $K"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo ""
# Create results directory
RESULTS_DIR="./results/${EXP_NAME}"
mkdir -p "$RESULTS_DIR"
# Log file for this run with timestamp and models
TIMESTAMP=$(date '+%Y%m%d_%H%M%S')
LOG_FILE="${RESULTS_DIR}/benchmark_${TIMESTAMP}.log"
echo "Benchmark started at $(date '+%Y-%m-%d %H:%M:%S')" > "$LOG_FILE"
echo "Models: $MODELS" >> "$LOG_FILE"
echo "Services: ${SERVICE_ARRAY[*]}" >> "$LOG_FILE"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━" >> "$LOG_FILE"
# Function to run a single service
run_service() {
local service=$1
local start_time=$(date +%s)
local start_time_formatted=$(date '+%Y-%m-%d %H:%M:%S')
print_status "[$start_time_formatted] Starting $service tasks..."
if [ "$USE_DOCKER" = true ]; then
# Run with Docker
./run-task.sh --mcp "$service" \
--models "$MODELS" \
--exp-name "$EXP_NAME" \
--tasks all \
--timeout "$TIMEOUT" \
--k "$K" 2>&1 | tee -a "$LOG_FILE"
else
# Run locally
python3 -m pipeline \
--mcp "$service" \
--models "$MODELS" \
--exp-name "$EXP_NAME" \
--tasks all \
--timeout "$TIMEOUT" \
--k "$K" 2>&1 | tee -a "$LOG_FILE"
fi
local exit_code=$?
local end_time=$(date +%s)
local duration=$((end_time - start_time))
if [ $exit_code -eq 0 ]; then
print_success "$service completed in ${duration}s"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $service: SUCCESS (${duration}s)" >> "${RESULTS_DIR}/summary.txt"
else
print_error "$service failed with exit code $exit_code"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $service: FAILED (exit code $exit_code)" >> "${RESULTS_DIR}/summary.txt"
fi
return $exit_code
}
# Track overall results
TOTAL_SERVICES=${#SERVICE_ARRAY[@]}
COMPLETED_SERVICES=0
FAILED_SERVICES=0
# Main execution
BENCHMARK_START=$(date +%s)
if [ "$PARALLEL" = true ]; then
print_status "Running services in parallel..."
# Run all services in background
for service in "${SERVICE_ARRAY[@]}"; do
(
run_service "$service"
) &
pids+=($!)
done
# Wait for all background jobs and collect exit codes
for pid in "${pids[@]}"; do
if wait $pid; then
((COMPLETED_SERVICES++))
else
((FAILED_SERVICES++))
fi
done
else
print_status "Running services sequentially..."
for service in "${SERVICE_ARRAY[@]}"; do
if run_service "$service"; then
((COMPLETED_SERVICES++))
else
((FAILED_SERVICES++))
print_warning "Continuing despite failure in $service"
fi
done
fi
BENCHMARK_END=$(date +%s)
TOTAL_DURATION=$((BENCHMARK_END - BENCHMARK_START))
# Generate final summary
echo ""
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
print_status "Benchmark Summary"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
echo "Completed at: $(date '+%Y-%m-%d %H:%M:%S')"
echo "Total Services: $TOTAL_SERVICES"
echo "Completed: $COMPLETED_SERVICES"
echo "Failed: $FAILED_SERVICES"
echo "Total Duration: ${TOTAL_DURATION}s ($(($TOTAL_DURATION / 60))m $(($TOTAL_DURATION % 60))s)"
echo "Results saved to: $RESULTS_DIR"
echo "Log file: $LOG_FILE"
echo "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━"
# Final status
if [ $FAILED_SERVICES -eq 0 ]; then
print_success "Benchmark completed successfully!"
exit 0
else
print_warning "Benchmark completed with $FAILED_SERVICES failed service(s)"
exit 1
fi
================================================
FILE: run-task.sh
================================================
#!/bin/bash
# MCPMark Task Runner
# Enable strict error handling
set -euo pipefail
# Default values
SERVICE="filesystem"
NETWORK_NAME="mcp-network"
POSTGRES_CONTAINER="mcp-postgres"
# Resource limits (can be overridden by environment variables)
DOCKER_MEMORY_LIMIT="${DOCKER_MEMORY_LIMIT:-4g}"
DOCKER_CPU_LIMIT="${DOCKER_CPU_LIMIT:-2}"
# Cleanup function
cleanup() {
if [ "${SERVICE:-}" = "postgres" ]; then
if docker ps --format '{{.Names}}' | grep -q "^${POSTGRES_CONTAINER}$"; then
echo "Cleaning up PostgreSQL container..."
docker stop "$POSTGRES_CONTAINER" >/dev/null 2>&1 || true
docker rm "$POSTGRES_CONTAINER" >/dev/null 2>&1 || true
fi
fi
}
# Set up cleanup on exit
trap cleanup EXIT
# Parse arguments
while [[ $# -gt 0 ]]; do
case $1 in
--mcp) SERVICE="$2"; shift 2 ;;
--help)
cat << EOF
Usage: $0 [--mcp SERVICE] [PIPELINE_ARGS]
Run MCPMark tasks in Docker containers.
Options:
--mcp SERVICE MCP service (notion|github|filesystem|playwright|postgres)
Default: filesystem
Environment Variables:
DOCKER_MEMORY_LIMIT Memory limit for container (default: 4g)
DOCKER_CPU_LIMIT CPU limit for container (default: 2)
DOCKER_IMAGE_VERSION Docker image tag to use (default: latest)
All other arguments are passed directly to the pipeline.
Examples:
$0 --mcp notion --models o3 --exp-name test-1 --tasks all
$0 --mcp postgres --models gpt-4 --exp-name pg-test --tasks basic_queries
EOF
exit 0
;;
*) break ;; # Stop parsing, rest goes to pipeline
esac
done
# Docker image tag can be overridden by environment variable
DOCKER_IMAGE_REPO="evalsysorg/mcpmark"
DOCKER_IMAGE_VERSION="${DOCKER_IMAGE_VERSION:-latest}"
DOCKER_IMAGE="${DOCKER_IMAGE_REPO}:${DOCKER_IMAGE_VERSION}"
# Check if Docker image exists locally, pull only if not found
if ! docker image inspect "$DOCKER_IMAGE" >/dev/null 2>&1; then
echo "Docker image not found locally, pulling from Docker Hub..."
docker pull "$DOCKER_IMAGE" || {
echo "Error: Failed to pull Docker image from Docker Hub"
echo "Please check your internet connection or Docker Hub access"
exit 1
}
else
echo "Using local Docker image: $DOCKER_IMAGE"
fi
# Check if .mcp_env exists (warn but don't fail)
if [ ! -f .mcp_env ]; then
echo "Warning: .mcp_env file not found. Some tasks may fail without API credentials."
fi
# Create network if doesn't exist
if ! docker network ls --format '{{.Name}}' | grep -q "^${NETWORK_NAME}$"; then
echo "Creating Docker network: $NETWORK_NAME"
docker network create "$NETWORK_NAME" || {
echo "Error: Failed to create Docker network"
exit 1
}
fi
# Service-specific configurations
if [ "$SERVICE" = "postgres" ]; then
# For postgres service, ensure PostgreSQL container is running
if ! docker ps --format '{{.Names}}' | grep -q "^${POSTGRES_CONTAINER}$"; then
echo "Starting PostgreSQL container..."
docker run -d \
--name "$POSTGRES_CONTAINER" \
--network "$NETWORK_NAME" \
-e POSTGRES_DATABASE=postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD="${POSTGRES_PASSWORD:-password}" \
pgvector/pgvector:0.8.0-pg17-bookworm
echo "Waiting for PostgreSQL to be ready..."
for i in {1..10}; do
if docker exec "$POSTGRES_CONTAINER" pg_isready -U postgres >/dev/null 2>&1; then
echo "PostgreSQL is ready!"
break
fi
sleep 1
done
else
echo "PostgreSQL container already running"
fi
# Run task with network connection to postgres
docker run --rm \
--memory="$DOCKER_MEMORY_LIMIT" \
--cpus="$DOCKER_CPU_LIMIT" \
--network "$NETWORK_NAME" \
-e POSTGRES_HOST="$POSTGRES_CONTAINER" \
-e POSTGRES_PORT=5432 \
-e POSTGRES_USERNAME=postgres \
-e POSTGRES_PASSWORD="${POSTGRES_PASSWORD:-password}" \
-e POSTGRES_DATABASE=postgres \
-v "$(pwd)/results:/app/results" \
-v "$(pwd)/postgres_state:/app/postgres_state" \
$([ -f .mcp_env ] && echo "-v $(pwd)/.mcp_env:/app/.mcp_env:ro") \
"$DOCKER_IMAGE" \
python3 -m pipeline --mcp "$SERVICE" --k 1 "$@"
elif [ "$SERVICE" = "filesystem" ]; then
# For filesystem service, mount test_environments
docker run --rm \
--memory="$DOCKER_MEMORY_LIMIT" \
--cpus="$DOCKER_CPU_LIMIT" \
-v "$(pwd)/results:/app/results" \
-v "$(pwd)/test_environments:/app/test_environments" \
$([ -f .mcp_env ] && echo "-v $(pwd)/.mcp_env:/app/.mcp_env:ro") \
"$DOCKER_IMAGE" \
python3 -m pipeline --mcp "$SERVICE" --k 1 "$@"
elif [ "$SERVICE" = "insforge" ]; then
# For Insforge service, use host network to access Insforge backend on host
docker run --rm \
--memory="$DOCKER_MEMORY_LIMIT" \
--cpus="$DOCKER_CPU_LIMIT" \
--add-host=host.docker.internal:host-gateway \
-v "$(pwd)/results:/app/results" \
$([ -f .mcp_env ] && echo "-v $(pwd)/.mcp_env:/app/.mcp_env:ro") \
"$DOCKER_IMAGE" \
python3 -m pipeline --mcp "$SERVICE" --k 1 "$@"
else
# For other services (notion, github, playwright, etc.)
docker run --rm \
--memory="$DOCKER_MEMORY_LIMIT" \
--cpus="$DOCKER_CPU_LIMIT" \
-v "$(pwd)/results:/app/results" \
-v "$(pwd)/test_environments:/app/test_environments" \
$([ -f .mcp_env ] && echo "-v $(pwd)/.mcp_env:/app/.mcp_env:ro") \
$([ -f notion_state.json ] && echo "-v $(pwd)/notion_state.json:/app/notion_state.json") \
"$DOCKER_IMAGE" \
python3 -m pipeline --mcp "$SERVICE" --k 1 "$@"
fi
echo "Task completed!"
================================================
FILE: src/agents/__init__.py
================================================
"""
MCPMark Agent Module
====================
Provides agent implementations and registry for MCPMark.
"""
from .base_agent import BaseMCPAgent
from .mcpmark_agent import MCPMarkAgent
from .react_agent import ReActAgent
AGENT_REGISTRY = {
"mcpmark": MCPMarkAgent,
"react": ReActAgent,
}
__all__ = ["BaseMCPAgent", "MCPMarkAgent", "ReActAgent", "AGENT_REGISTRY"]
================================================
FILE: src/agents/base_agent.py
================================================
"""Shared base agent functionality for MCPMark agents."""
from __future__ import annotations
import asyncio
import copy
import json
import uuid
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Callable
from src.logger import get_logger
from .mcp import MCPStdioServer, MCPHttpServer
from .utils import TokenUsageTracker
logger = get_logger(__name__)
class BaseMCPAgent(ABC):
"""Base class with shared functionality for MCPMark agents."""
STDIO_SERVICES = [
"notion",
"filesystem",
"playwright",
"playwright_webarena",
"postgres",
"insforge",
"github",
]
HTTP_SERVICES = ["supabase"]
DEFAULT_TIMEOUT = 600
COMPACTION_DISABLED_TOKEN = 999_999_999
CLAUDE_THINKING_BUDGETS = {
"low": 1024,
"medium": 2048,
"high": 4096,
}
def __init__(
self,
litellm_input_model_name: str,
api_key: str,
base_url: str,
mcp_service: str,
timeout: int = DEFAULT_TIMEOUT,
service_config: Optional[Dict[str, Any]] = None,
service_config_provider: Optional[Callable[[], Dict[str, Any]]] = None,
reasoning_effort: Optional[str] = "default",
compaction_token: int = COMPACTION_DISABLED_TOKEN,
):
self.litellm_input_model_name = litellm_input_model_name
self.api_key = api_key
self.base_url = base_url
self.mcp_service = mcp_service
self.timeout = timeout
self.service_config = service_config or {}
self._service_config_provider = service_config_provider
self.reasoning_effort = reasoning_effort or "default"
self.compaction_token = int(compaction_token)
self.is_claude = self._is_anthropic_model(litellm_input_model_name)
self.use_claude_thinking = self.is_claude and self.reasoning_effort != "default"
self.usage_tracker = TokenUsageTracker()
self.litellm_run_model_name = None
self._partial_messages: List[Dict[str, Any]] = []
self._partial_token_usage: Dict[str, int] = {}
self._partial_turn_count: int = 0
logger.debug(
"Initialized %s for service '%s' with model '%s'",
self.__class__.__name__,
self.mcp_service,
self.litellm_input_model_name,
)
# Warn if Gemini 3 model uses unsupported reasoning_effort value
if self._is_gemini_3_model() and self.reasoning_effort not in [
"default",
"low",
"high",
]:
logger.warning(
"Gemini 3 models only support reasoning_effort 'low' or 'high', "
"got '%s'. LiteLLM may map this to the nearest supported value.",
self.reasoning_effort,
)
def __repr__(self) -> str: # pragma: no cover - debug helper
return (
f"{self.__class__.__name__}(service='{self.mcp_service}', "
f"model='{self.litellm_input_model_name}')"
)
@abstractmethod
async def execute(
self,
instruction: str,
tool_call_log_file: Optional[str] = None,
) -> Dict[str, Any]:
"""Execute the agent logic and return execution metadata."""
def execute_sync(
self,
instruction: str,
tool_call_log_file: Optional[str] = None,
) -> Dict[str, Any]:
"""Synchronous wrapper for async execution."""
return asyncio.run(self.execute(instruction, tool_call_log_file))
def get_usage_stats(self) -> Dict[str, Any]:
"""Return aggregated usage statistics."""
return self.usage_tracker.get_stats()
def reset_usage_stats(self):
"""Clear usage statistics."""
self.usage_tracker.reset()
# ------------------------------------------------------------------
# Shared helpers
# ------------------------------------------------------------------
def _is_anthropic_model(self, model_name: str) -> bool:
return "claude" in model_name.lower()
def _get_claude_thinking_budget(self) -> Optional[int]:
if not self.use_claude_thinking:
return None
return self.CLAUDE_THINKING_BUDGETS.get(self.reasoning_effort, 2048)
def _refresh_service_config(self):
if not self._service_config_provider:
return
try:
latest_cfg = self._service_config_provider() or {}
self.service_config.update(latest_cfg)
except Exception as exc: # pragma: no cover - best effort refresh
logger.warning("Failed to refresh service config: %s", exc)
def _reset_progress(self):
self._partial_messages = []
self._partial_token_usage = {}
self._partial_turn_count = 0
def _update_progress(
self,
messages: List[Dict[str, Any]],
token_usage: Dict[str, Any],
turn_count: int,
):
try:
self._partial_messages = copy.deepcopy(messages)
self._partial_token_usage = dict(token_usage or {})
self._partial_turn_count = int(turn_count or 0)
except Exception: # pragma: no cover - defensive copy
pass
# ------------------------------------------------------------------
# MCP server management
# ------------------------------------------------------------------
async def _create_mcp_server(self) -> Any:
if self.mcp_service in self.STDIO_SERVICES:
return self._create_stdio_server()
if self.mcp_service in self.HTTP_SERVICES:
return self._create_http_server()
raise ValueError(f"Unsupported MCP service: {self.mcp_service}")
def _create_stdio_server(self) -> MCPStdioServer:
if self.mcp_service == "notion":
notion_key = self.service_config.get("notion_key")
if not notion_key:
raise ValueError("Notion API key required")
return MCPStdioServer(
command="npx",
args=["-y", "@notionhq/notion-mcp-server"],
env={
"OPENAPI_MCP_HEADERS": (
'{"Authorization": "Bearer ' + notion_key + '", '
'"Notion-Version": "2022-06-28"}'
)
},
)
if self.mcp_service == "filesystem":
test_directory = self.service_config.get("test_directory")
if not test_directory:
raise ValueError("Test directory required for filesystem service")
return MCPStdioServer(
command="npx",
args=[
"-y",
"@modelcontextprotocol/server-filesystem",
str(test_directory),
],
)
if self.mcp_service in ("playwright", "playwright_webarena"):
browser = self.service_config.get("browser", "chromium")
headless = self.service_config.get("headless", True)
viewport_width = self.service_config.get("viewport_width", 1280)
viewport_height = self.service_config.get("viewport_height", 720)
args = ["-y", "@playwright/mcp@latest"]
if headless:
args.append("--headless")
args.extend(
[
"--isolated",
"--no-sandbox",
"--browser",
browser,
"--viewport-size",
f"{viewport_width},{viewport_height}",
]
)
return MCPStdioServer(command="npx", args=args)
if self.mcp_service == "postgres":
host = self.service_config.get("host", "localhost")
port = self.service_config.get("port", 5432)
username = self.service_config.get("username")
password = self.service_config.get("password")
database = self.service_config.get(
"current_database"
) or self.service_config.get("database")
if not all([username, password, database]):
raise ValueError("PostgreSQL requires username, password, and database")
database_url = (
f"postgresql://{username}:{password}@{host}:{port}/{database}"
)
return MCPStdioServer(
command="pipx",
args=["run", "postgres-mcp", "--access-mode=unrestricted"],
env={"DATABASE_URI": database_url},
)
if self.mcp_service == "insforge":
api_key = self.service_config.get("api_key")
backend_url = self.service_config.get("backend_url")
if not all([api_key, backend_url]):
raise ValueError("Insforge requires api_key and backend_url")
return MCPStdioServer(
command="npx",
args=["-y", "@insforge/mcp@dev"],
env={
"INSFORGE_API_KEY": api_key,
"INSFORGE_BACKEND_URL": backend_url,
},
)
raise ValueError(f"Unsupported stdio service: {self.mcp_service}")
def _create_http_server(self) -> MCPHttpServer:
if self.mcp_service == "github":
github_token = self.service_config.get("github_token")
if not github_token:
raise ValueError("GitHub token required")
return MCPHttpServer(
url="https://api.githubcopilot.com/mcp/",
headers={
"Authorization": f"Bearer {github_token}",
"User-Agent": "MCPMark/1.0",
},
)
raise ValueError(f"Unsupported HTTP service: {self.mcp_service}")
# ------------------------------------------------------------------
# Message/Tool formatting helpers
# ------------------------------------------------------------------
def _compaction_enabled(self) -> bool:
return 0 < self.compaction_token < self.COMPACTION_DISABLED_TOKEN
def _count_prompt_tokens_litellm(self, messages: List[Dict[str, Any]]) -> int:
try:
from litellm import token_counter
return int(
token_counter(model=self.litellm_input_model_name, messages=messages)
or 0
)
except Exception: # pragma: no cover - best effort
return 0
def _convert_to_sdk_format(
self, messages: List[Dict[str, Any]]
) -> List[Dict[str, Any]]:
sdk_format: List[Dict[str, Any]] = []
function_call_map: Dict[str, str] = {}
for msg in messages:
role = msg.get("role")
if role == "user":
user_content = msg.get("content", "")
if isinstance(user_content, list):
tool_results = [
item
for item in user_content
if isinstance(item, dict) and item.get("type") == "tool_result"
]
if tool_results:
for tr in tool_results:
content_items = tr.get("content", [])
text_content = ""
for ci in content_items:
if isinstance(ci, dict) and ci.get("type") == "text":
text_content = ci.get("text", "")
break
sdk_format.append(
{
"call_id": tr.get("tool_use_id", ""),
"output": json.dumps(
{
"type": "text",
"text": text_content,
"annotations": None,
"meta": None,
}
),
"type": "function_call_output",
}
)
else:
text_parts = []
for item in user_content:
if isinstance(item, dict) and item.get("type") == "text":
text_parts.append(item.get("text", ""))
sdk_format.append(
{"content": "\n".join(text_parts), "role": "user"}
)
else:
sdk_format.append({"content": user_content, "role": "user"})
elif role == "assistant":
tool_calls = msg.get("tool_calls", [])
function_call = msg.get("function_call")
content = msg.get("content")
if isinstance(content, list):
text_parts = []
claude_tool_uses = []
for block in content:
if isinstance(block, dict):
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "thinking":
thinking_text = block.get("thinking", "")
if thinking_text:
text_parts.append(
f"<think>\n{thinking_text}\n</think>"
)
elif block.get("type") == "tool_use":
claude_tool_uses.append(block)
content = "\n".join(text_parts)
if claude_tool_uses and not tool_calls:
tool_calls = []
for tu in claude_tool_uses:
tool_calls.append(
{
"id": tu.get("id"),
"function": {
"name": tu.get("name"),
"arguments": json.dumps(tu.get("input", {})),
},
}
)
if content:
sdk_format.append(
{
"id": "__fake_id__",
"content": [
{
"annotations": [],
"text": content,
"type": "output_text",
}
],
"role": "assistant",
"status": "completed",
"type": "message",
}
)
if tool_calls:
for tool_call in tool_calls:
call_id = tool_call.get("id", f"call_{uuid.uuid4().hex}")
func_name = tool_call.get("function", {}).get("name", "")
sdk_format.append(
{
"arguments": tool_call.get("function", {}).get(
"arguments", "{}"
),
"call_id": call_id,
"name": func_name,
"type": "function_call",
"id": "__fake_id__",
}
)
if function_call:
func_name = function_call.get("name", "")
call_id = f"call_{uuid.uuid4().hex}"
function_call_map[func_name] = call_id
sdk_format.append(
{
"arguments": function_call.get("arguments", "{}"),
"call_id": call_id,
"name": func_name,
"type": "function_call",
"id": "__fake_id__",
}
)
elif role == "tool":
sdk_format.append(
{
"call_id": msg.get("tool_call_id", ""),
"output": json.dumps(
{
"type": "text",
"text": msg.get("content", ""),
"annotations": None,
"meta": None,
}
),
"type": "function_call_output",
}
)
elif role == "function":
func_name = msg.get("name", "")
call_id = function_call_map.get(func_name, f"call_{uuid.uuid4().hex}")
sdk_format.append(
{
"call_id": call_id,
"output": json.dumps(
{
"type": "text",
"text": msg.get("content", ""),
"annotations": None,
"meta": None,
}
),
"type": "function_call_output",
}
)
return sdk_format
def _convert_to_anthropic_format(
self, tools: List[Dict[str, Any]]
) -> List[Dict[str, Any]]:
anthropic_tools = []
for tool in tools:
anthropic_tool = {
"name": tool.get("name"),
"description": tool.get("description", ""),
"input_schema": tool.get(
"inputSchema",
{"type": "object", "properties": {}, "required": []},
),
}
anthropic_tools.append(anthropic_tool)
return anthropic_tools
def _is_gemini_model(self) -> bool:
model_lower = self.litellm_input_model_name.lower()
return "gemini" in model_lower or "bison" in model_lower
def _is_gemini_3_model(self) -> bool:
"""Check if this is a Gemini 3 series model."""
model_lower = self.litellm_input_model_name.lower()
return "gemini-3" in model_lower or "gemini/gemini-3" in model_lower
def _simplify_schema_for_gemini(
self, schema: Optional[Dict[str, Any]]
) -> Dict[str, Any]:
if not isinstance(schema, dict):
return schema or {}
simplified: Dict[str, Any] = {}
for key, value in schema.items():
if key == "type" and isinstance(value, list):
simplified[key] = value[0] if value else "string"
elif key == "items" and isinstance(value, dict):
simplified[key] = self._simplify_schema_for_gemini(value)
elif key == "properties" and isinstance(value, dict):
simplified[key] = {
prop_key: self._simplify_schema_for_gemini(prop_val)
for prop_key, prop_val in value.items()
}
elif isinstance(value, dict):
simplified[key] = self._simplify_schema_for_gemini(value)
elif isinstance(value, list) and key not in ("required", "enum"):
simplified[key] = [
self._simplify_schema_for_gemini(item)
if isinstance(item, dict)
else item
for item in value
]
else:
simplified[key] = value
return simplified
def _convert_to_openai_format(
self, tools: List[Dict[str, Any]]
) -> List[Dict[str, Any]]:
functions = []
is_gemini = self._is_gemini_model()
if is_gemini:
logger.debug(
"Detected Gemini model '%s' – simplifying tool schemas",
self.litellm_input_model_name,
)
for tool in tools:
input_schema = tool.get(
"inputSchema", {"type": "object", "properties": {}, "required": []}
)
if is_gemini:
simplified = self._simplify_schema_for_gemini(input_schema)
if simplified != input_schema:
input_schema = simplified
logger.debug("Simplified schema for tool '%s'", tool.get("name"))
functions.append(
{
"name": tool.get("name"),
"description": tool.get("description", ""),
"parameters": input_schema,
}
)
if is_gemini:
logger.info("Converted %d tools for Gemini compatibility", len(functions))
return functions
================================================
FILE: src/agents/mcp/__init__.py
================================================
"""
MCP (Model Context Protocol) Components
========================================
Minimal MCP server implementations for MCPMark.
"""
from .stdio_server import MCPStdioServer
from .http_server import MCPHttpServer
__all__ = ["MCPStdioServer", "MCPHttpServer"]
================================================
FILE: src/agents/mcp/http_server.py
================================================
"""
Minimal MCP HTTP Server Implementation
=======================================
Provides HTTP-based MCP server communication for services like GitHub.
"""
import asyncio
from contextlib import AsyncExitStack
from typing import Any, Dict, List, Optional
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
class MCPHttpServer:
"""
HTTP-based MCP client using the official MCP Python SDK
(Streamable HTTP transport).
"""
def __init__(
self,
url: str,
headers: Optional[Dict[str, str]] = None,
timeout: int = 30,
):
self.url = url.rstrip("/")
self.headers = headers or {}
self.timeout = timeout
self._stack: Optional[AsyncExitStack] = None
self.session: Optional[ClientSession] = None
self._tools_cache: Optional[List[Dict[str, Any]]] = None
async def __aenter__(self):
await self.start()
return self
async def __aexit__(self, exc_type, exc, tb):
await self.stop()
async def start(self):
"""Open Streamable HTTP transport and initialize MCP session."""
self._stack = AsyncExitStack()
read_stream, write_stream, _ = await self._stack.enter_async_context(
streamablehttp_client(self.url, headers=self.headers)
)
self.session = await self._stack.enter_async_context(ClientSession(read_stream, write_stream))
await asyncio.wait_for(self.session.initialize(), timeout=self.timeout)
async def stop(self):
"""Close the session/transport cleanly."""
if self._stack:
await self._stack.aclose()
self._stack = None
self.session = None
self._tools_cache = None
async def list_tools(self) -> List[Dict[str, Any]]:
"""Return tool definitions (cached)."""
if self._tools_cache is not None:
return self._tools_cache
if not self.session:
raise RuntimeError("MCP HTTP client not started")
resp = await asyncio.wait_for(self.session.list_tools(), timeout=self.timeout)
self._tools_cache = [t.model_dump() for t in resp.tools]
return self._tools_cache
async def call_tool(self, name: str, arguments: Dict[str, Any]) -> Any:
"""Invoke a remote tool and return the structured result."""
if not self.session:
raise RuntimeError("MCP HTTP client not started")
result = await asyncio.wait_for(self.session.call_tool(name, arguments), timeout=self.timeout)
return result.model_dump()
================================================
FILE: src/agents/mcp/stdio_server.py
================================================
"""
Minimal MCP Stdio Server Implementation
========================================
Provides stdio-based MCP server communication for services like
Notion, Filesystem, Playwright, and Postgres.
"""
import asyncio
import os
from contextlib import AsyncExitStack
from typing import Any, Dict, List, Optional
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
class MCPStdioServer:
"""Lightweight wrapper around the official MCP Python SDK."""
def __init__(self, command: str, args: List[str], env: Optional[Dict[str, str]] = None, timeout: int = 120):
self.params = StdioServerParameters(command=command, args=args, env={**os.environ, **(env or {})})
self.timeout = timeout
self._stack: Optional[AsyncExitStack] = None
self._streams = None
self.session: Optional[ClientSession] = None
async def __aenter__(self):
self._stack = AsyncExitStack()
read, write = await self._stack.enter_async_context(stdio_client(self.params))
self.session = await self._stack.enter_async_context(ClientSession(read, write))
await asyncio.wait_for(self.session.initialize(), timeout=self.timeout)
return self
async def __aexit__(self, exc_type, exc, tb):
if self._stack:
await self._stack.aclose()
self._stack = None
self.session = None
async def list_tools(self) -> List[Dict[str, Any]]:
resp = await asyncio.wait_for(self.session.list_tools(), timeout=self.timeout)
return [t.model_dump() for t in resp.tools]
async def call_tool(self, name: str, arguments: Dict[str, Any]) -> Any:
result = await asyncio.wait_for(self.session.call_tool(name, arguments), timeout=self.timeout)
return result.model_dump() # 同上,转成 dict
================================================
FILE: src/agents/mcpmark_agent.py
================================================
"""
MCPMark Agent Implementation
============================
Unified agent using LiteLLM for all model interactions with minimal MCP support.
"""
import asyncio
import json
import time
from typing import Any, Dict, List, Optional, Callable
from pydantic import AnyUrl
import httpx
import litellm
import nest_asyncio
from src.logger import get_logger
from .base_agent import BaseMCPAgent
from .mcp import MCPStdioServer, MCPHttpServer
# Apply nested asyncio support
nest_asyncio.apply()
# Configure LiteLLM
litellm.suppress_debug_info = True
logger = get_logger(__name__)
# To fix the "Object of type AnyUrl is not JSON serializable" error in the find_file_contents function.
class CustomJSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, AnyUrl):
return str(obj)
return super().default(obj)
class MCPMarkAgent(BaseMCPAgent):
"""
Unified agent for LLM and MCP server management using LiteLLM.
- Anthropic models: Native MCP support via extra_body
- Other models: Manual MCP server management with function calling
"""
MAX_TURNS = 100
SYSTEM_PROMPT = (
"You are a helpful agent that uses tools iteratively to complete the user's task, "
'and when finished, provides the final answer or simply states "Task completed" without further tool calls.'
)
COMPACTION_PROMPT = (
"You are performing a CONTEXT CHECKPOINT COMPACTION.\n"
"Summarize the conversation so far for another model to continue.\n\n"
"Include:\n"
"- Current progress and key decisions made\n"
"- Important context, constraints, or user preferences\n"
"- What remains to be done (clear next steps)\n"
"- Any critical data, examples, or references needed to continue\n\n"
"Be concise and structured. Do NOT call tools."
)
DEFAULT_TIMEOUT = BaseMCPAgent.DEFAULT_TIMEOUT
def __init__(
self,
litellm_input_model_name: str,
api_key: str,
base_url: str,
mcp_service: str,
timeout: int = DEFAULT_TIMEOUT,
service_config: Optional[Dict[str, Any]] = None,
service_config_provider: Optional[Callable[[], Dict[str, Any]]] = None,
reasoning_effort: Optional[str] = "default",
compaction_token: int = BaseMCPAgent.COMPACTION_DISABLED_TOKEN,
):
super().__init__(
litellm_input_model_name=litellm_input_model_name,
api_key=api_key,
base_url=base_url,
mcp_service=mcp_service,
timeout=timeout,
service_config=service_config,
service_config_provider=service_config_provider,
reasoning_effort=reasoning_effort,
compaction_token=compaction_token,
)
logger.debug(
"Initialized MCPMarkAgent for '%s' with model '%s' (Claude: %s, Thinking: %s, Reasoning: %s)",
mcp_service,
litellm_input_model_name,
self.is_claude,
self.use_claude_thinking,
reasoning_effort,
)
# ==================== Public Interface Methods ====================
async def execute(
self, instruction: str, tool_call_log_file: Optional[str] = None
) -> Dict[str, Any]:
"""
Execute instruction with the agent.
Args:
instruction: The instruction/prompt to execute
tool_call_log_file: Optional path to log tool calls
Returns:
Dictionary containing execution results
"""
start_time = time.time()
try:
# Reset partial progress for this run
self._reset_progress()
# Refresh service configuration
self._refresh_service_config()
# Execute with timeout control
async def _execute_with_strategy():
if self.use_claude_thinking:
# Claude with thinking -> native Anthropic API with tools
return await self._execute_claude_native_with_tools(
instruction, tool_call_log_file
)
else:
# All other cases -> LiteLLM with tools
return await self._execute_litellm_with_tools(
instruction, tool_call_log_file
)
# Apply timeout to the entire execution
result = await asyncio.wait_for(
_execute_with_strategy(), timeout=self.timeout
)
execution_time = time.time() - start_time
# Update usage statistics
self.usage_tracker.update(
success=result["success"],
token_usage=result.get("token_usage", {}),
turn_count=result.get("turn_count", 0),
execution_time=execution_time,
)
result["execution_time"] = execution_time
return result
except Exception as e:
execution_time = time.time() - start_time
if isinstance(e, asyncio.TimeoutError):
error_msg = f"Execution timed out after {self.timeout} seconds"
logger.error(error_msg)
else:
error_msg = f"Agent execution failed: {e}"
logger.error(error_msg, exc_info=True)
self.usage_tracker.update(
success=False,
token_usage=self._partial_token_usage or {},
turn_count=self._partial_turn_count or 0,
execution_time=execution_time,
)
if self._partial_messages:
if not self.is_claude:
final_msg = self._convert_to_sdk_format(self._partial_messages)
else:
final_msg = self._partial_messages
else:
final_msg = []
return {
"success": False,
"output": final_msg,
"token_usage": self._partial_token_usage or {},
"turn_count": self._partial_turn_count or 0,
"execution_time": execution_time,
"error": error_msg,
"litellm_run_model_name": self.litellm_run_model_name,
}
def execute_sync(
self, instruction: str, tool_call_log_file: Optional[str] = None
) -> Dict[str, Any]:
"""
Synchronous wrapper for execute method.
"""
return asyncio.run(self.execute(instruction, tool_call_log_file))
def get_usage_stats(self) -> Dict[str, Any]:
"""Get usage statistics."""
return self.usage_tracker.get_stats()
def reset_usage_stats(self):
"""Reset usage statistics."""
self.usage_tracker.reset()
# ==================== Claude Native API Execution Path ====================
async def _execute_claude_native_with_tools(
self, instruction: str, tool_call_log_file: Optional[str] = None
) -> Dict[str, Any]:
"""
Execute Claude with thinking using native Anthropic API.
Creates MCP server, gets tools, and executes with thinking.
"""
logger.debug("Using Claude native API with thinking")
thinking_budget = self._get_claude_thinking_budget()
# Create and start MCP server
mcp_server = await self._create_mcp_server()
async with mcp_server:
# Get available tools
tools = await mcp_server.list_tools()
# Convert MCP tools to Anthropic format
anthropic_tools = self._convert_to_anthropic_format(tools)
# Execute with function calling loop
return await self._execute_anthropic_native_tool_loop(
instruction,
anthropic_tools,
mcp_server,
thinking_budget,
tool_call_log_file,
)
async def _call_claude_native_api(
self,
messages: List[Dict],
thinking_budget: int,
tools: Optional[List[Dict]] = None,
mcp_servers: Optional[List[Dict]] = None,
system: Optional[str] = None,
) -> Dict[str, Any]:
"""
Call Claude's native API directly using httpx.
Args:
messages: Conversation messages
thinking_budget: Token budget for thinking
tools: Tool definitions for function calling
mcp_servers: MCP server configurations
system: System prompt
Returns:
API response as dictionary
"""
# Get API base and headers
import os
api_base = os.getenv("ANTHROPIC_API_BASE", "https://api.anthropic.com")
headers = {
"x-api-key": self.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json",
"anthropic-beta": "context-1m-2025-08-07", # by default
}
# Build payload
max_tokens = max(thinking_budget + 4096, 4096)
payload = {
"model": self.litellm_input_model_name.replace("anthropic/", ""),
"max_tokens": max_tokens,
"messages": messages,
}
# Add thinking configuration
if thinking_budget:
payload["thinking"] = {"type": "enabled", "budget_tokens": thinking_budget}
# Add tools if provided
if tools:
payload["tools"] = tools
payload["tool_choice"] = {"type": "auto"}
# Add MCP servers if provided
if mcp_servers:
headers["anthropic-beta"] = "mcp-client-2025-04-04"
payload["mcp_servers"] = mcp_servers
# Add system prompt if provided
if system:
payload["system"] = system
# Make the API call
async with httpx.AsyncClient() as client:
try:
response = await client.post(
f"{api_base}/v1/messages",
headers=headers,
json=payload,
timeout=self.timeout,
)
response.raise_for_status()
return response.json(), None
except httpx.HTTPStatusError as e:
return None, e.response.text
except Exception as e:
return None, e
async def _count_claude_input_tokens(
self,
messages: List[Dict[str, Any]],
tools: Optional[List[Dict]] = None,
system: Optional[str] = None,
) -> int:
import os
api_base = os.getenv("ANTHROPIC_API_BASE", "https://api.anthropic.com")
headers = {
"x-api-key": self.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json",
}
payload: Dict[str, Any] = {
"model": self.litellm_input_model_name.replace("anthropic/", ""),
"messages": messages,
}
if tools:
payload["tools"] = tools
if system:
payload["system"] = system
async with httpx.AsyncClient() as client:
response = await client.post(
f"{api_base}/v1/messages/count_tokens",
headers=headers,
json=payload,
timeout=self.timeout,
)
response.raise_for_status()
data = response.json() or {}
return int(data.get("input_tokens", 0) or 0)
def _extract_litellm_text(self, response: Any) -> str:
try:
choices = getattr(response, "choices", None) or []
if not choices:
return ""
msg = getattr(choices[0], "message", None)
if msg is not None:
return str(getattr(msg, "content", "") or "")
return str(getattr(choices[0], "text", "") or "")
except Exception: # pragma: no cover - best effort
return ""
def _extract_anthropic_text(self, response_json: Dict[str, Any]) -> str:
pieces: List[str] = []
for block in response_json.get("content", []) or []:
if isinstance(block, dict) and block.get("type") == "text":
text = block.get("text")
if text:
pieces.append(str(text))
return "\n".join(pieces).strip()
def _merge_usage(self, total_tokens: Dict[str, int], usage: Dict[str, Any]) -> None:
try:
input_tokens = int(usage.get("input_tokens", 0) or 0)
output_tokens = int(usage.get("output_tokens", 0) or 0)
total_tokens_count = int(
usage.get("total_tokens", 0) or (input_tokens + output_tokens)
)
total_tokens["input_tokens"] += input_tokens
total_tokens["output_tokens"] += output_tokens
total_tokens["total_tokens"] += total_tokens_count
except Exception: # pragma: no cover - best effort
return
async def _maybe_compact_litellm_messages(
self,
messages: List[Dict[str, Any]],
total_tokens: Dict[str, int],
tool_call_log_file: Optional[str],
current_prompt_tokens: int,
) -> List[Dict[str, Any]]:
if not self._compaction_enabled():
return messages
if current_prompt_tokens < self.compaction_token:
return messages
logger.info(
f"| [compaction] Triggered at prompt tokens: {current_prompt_tokens:,}"
)
if tool_call_log_file:
try:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(
f"| [compaction] Triggered at prompt tokens: {current_prompt_tokens:,}\n"
)
except Exception:
pass
compact_messages = [
{"role": "system", "content": self.COMPACTION_PROMPT},
{"role": "user", "content": json.dumps(messages, ensure_ascii=False)},
]
completion_kwargs = {
"model": self.litellm_input_model_name,
"messages": compact_messages,
"api_key": self.api_key,
}
if self.base_url:
completion_kwargs["base_url"] = self.base_url
response = await litellm.acompletion(**completion_kwargs)
usage = getattr(response, "usage", None)
if usage:
input_tokens = (
getattr(usage, "prompt_tokens", None)
or getattr(usage, "input_tokens", None)
or 0
)
output_tokens = (
getattr(usage, "completion_tokens", None)
or getattr(usage, "output_tokens", None)
or 0
)
total_tokens_count = getattr(usage, "total_tokens", None)
if total_tokens_count is None:
total_tokens_count = input_tokens + output_tokens
total_tokens["input_tokens"] += int(input_tokens or 0)
total_tokens["output_tokens"] += int(output_tokens or 0)
total_tokens["total_tokens"] += int(total_tokens_count or 0)
summary = self._extract_litellm_text(response).strip() or "(no summary)"
system_msg = (
messages[0]
if messages
else {"role": "system", "content": self.SYSTEM_PROMPT}
)
first_user = (
messages[1] if len(messages) > 1 else {"role": "user", "content": ""}
)
return [
system_msg,
first_user,
{
"role": "user",
"content": f"Context summary (auto-compacted due to token limit):\n{summary}",
},
]
async def _maybe_compact_anthropic_messages(
self,
messages: List[Dict[str, Any]],
total_tokens: Dict[str, int],
thinking_budget: int,
tool_call_log_file: Optional[str],
current_input_tokens: int,
) -> List[Dict[str, Any]]:
if not self._compaction_enabled():
return messages
if current_input_tokens < self.compaction_token:
return messages
logger.info(
f"| [compaction] Triggered at input tokens: {current_input_tokens:,}"
)
if tool_call_log_file:
try:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(
f"| [compaction] Triggered at input tokens: {current_input_tokens:,}\n"
)
except Exception:
pass
compact_messages = [
{"role": "user", "content": self.COMPACTION_PROMPT},
{"role": "user", "content": json.dumps(messages, ensure_ascii=False)},
]
response, error_msg = await self._call_claude_native_api(
messages=compact_messages,
thinking_budget=thinking_budget,
tools=None,
system=None,
)
if error_msg or not response:
logger.warning(f"| [compaction] Failed: {error_msg}")
return messages
usage = response.get("usage", {}) or {}
input_tokens = usage.get("input_tokens", 0) or 0
output_tokens = usage.get("output_tokens", 0) or 0
total_tokens["input_tokens"] += int(input_tokens)
total_tokens["output_tokens"] += int(output_tokens)
total_tokens["total_tokens"] += int(input_tokens + output_tokens)
summary = self._extract_anthropic_text(response) or "(no summary)"
first_user = messages[0] if messages else {"role": "user", "content": ""}
return [
first_user,
{
"role": "user",
"content": f"Context summary (auto-compacted due to token limit):\n{summary}",
},
]
async def _execute_anthropic_native_tool_loop(
self,
instruction: str,
tools: List[Dict],
mcp_server: Any,
thinking_budget: int,
tool_call_log_file: Optional[str] = None,
) -> Dict[str, Any]:
"""
Execute Claude thinking loop with function calling.
Handles thinking blocks, tool calls, and message formatting.
"""
messages = [{"role": "user", "content": instruction}]
total_tokens = {
"input_tokens": 0,
"output_tokens": 0,
"total_tokens": 0,
"reasoning_tokens": 0,
}
turn_count = 0
max_turns = self.MAX_TURNS
hit_turn_limit = False
ended_normally = False
system_text = self.SYSTEM_PROMPT
# Record initial state
self._update_progress(messages, total_tokens, turn_count)
for _ in range(max_turns):
turn_count += 1
current_input_tokens = 0
if self._compaction_enabled():
try:
current_input_tokens = await self._count_claude_input_tokens(
messages=messages,
tools=tools,
system=system_text,
)
except Exception as exc: # noqa: BLE001
logger.debug("Claude token counting failed: %s", exc)
messages = await self._maybe_compact_anthropic_messages(
messages=messages,
total_tokens=total_tokens,
thinking_budget=thinking_budget,
tool_call_log_file=tool_call_log_file,
current_input_tokens=current_input_tokens,
)
self._update_progress(messages, total_tokens, turn_count)
# Call Claude native API
response, error_msg = await self._call_claude_native_api(
messages=messages,
thinking_budget=thinking_budget,
tools=tools,
system=system_text,
)
if turn_count == 1:
self.litellm_run_model_name = response["model"].split("/")[-1]
if error_msg:
break
# Update token usage
if "usage" in response:
usage = response["usage"]
input_tokens = usage.get("input_tokens", 0)
output_tokens = usage.get("output_tokens", 0)
# Calculate output tokens as total - input for consistency
total_tokens_count = output_tokens + input_tokens
total_tokens["input_tokens"] += input_tokens
total_tokens["output_tokens"] += output_tokens
total_tokens["total_tokens"] += total_tokens_count
## TODO: add reasoning tokens for claude
# Extract blocks from response
blocks = response.get("content", [])
tool_uses = [b for b in blocks if b.get("type") == "tool_use"]
thinking_blocks = [b for b in blocks if b.get("type") == "thinking"]
text_blocks = [b for b in blocks if b.get("type") == "text"]
# Log text output
for tb in text_blocks:
if tb.get("text") and tool_call_log_file:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"{tb['text']}\n")
if tb.get("text"):
for line in tb["text"].splitlines():
logger.info(f"| {line}")
# Build assistant message with all blocks
assistant_content = []
# Add thinking blocks
for tb in thinking_blocks:
assistant_content.append(
{
"type": "thinking",
"thinking": tb.get("thinking", ""),
"signature": tb.get("signature", ""),
}
)
# Add text blocks
for tb in text_blocks:
if tb.get("text"):
assistant_content.append({"type": "text", "text": tb["text"]})
# Add tool_use blocks
for tu in tool_uses:
assistant_content.append(
{
"type": "tool_use",
"id": tu.get("id"),
"name": tu.get("name"),
"input": tu.get("input", {}),
}
)
messages.append({"role": "assistant", "content": assistant_content})
# Update partial progress after assistant response
self._update_progress(messages, total_tokens, turn_count)
# If no tool calls, we're done
if not tool_uses:
ended_normally = True
break
# Execute tools and add results
tool_results = []
for tu in tool_uses:
name = tu.get("name")
inputs = tu.get("input", {})
# Log tool call
args_str = json.dumps(inputs, separators=(",", ": "))
display_args = (
args_str[:140] + "..." if len(args_str) > 140 else args_str
)
logger.info(f"| \033[1m{name}\033[0m \033[2;37m{display_args}\033[0m")
if tool_call_log_file:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"| {name} {args_str}\n")
# Execute tool
try:
result = await asyncio.wait_for(
mcp_server.call_tool(name, inputs), timeout=60
)
tool_results.append(
{
"type": "tool_result",
"tool_use_id": tu["id"],
"content": [
{
"type": "text",
"text": json.dumps(result, cls=CustomJSONEncoder),
}
],
}
)
except Exception as e:
logger.error(f"Tool call failed: {e}")
tool_results.append(
{
"type": "tool_result",
"tool_use_id": tu["id"],
"content": [{"type": "text", "text": f"Error: {str(e)}"}],
}
)
messages.append({"role": "user", "content": tool_results})
# Update partial progress after tool results
self._update_progress(messages, total_tokens, turn_count)
# Detect if we exited due to hitting the turn limit
if not ended_normally:
if turn_count >= max_turns:
hit_turn_limit = True
logger.warning(
f"| Max turns ({max_turns}) exceeded; returning failure with partial output."
)
if tool_call_log_file:
try:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"| Max turns ({max_turns}) exceeded\n")
except Exception:
pass
elif error_msg:
logger.warning(f"| {error_msg}\n")
if tool_call_log_file:
try:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"| {error_msg}\n")
except Exception:
pass
# Display final token usage
if total_tokens["total_tokens"] > 0:
log_msg = (
f"|\n| Token usage: Total: {total_tokens['total_tokens']:,} | "
f"Input: {total_tokens['input_tokens']:,} | "
f"Output: {total_tokens['output_tokens']:,}"
)
if total_tokens.get("reasoning_tokens", 0) > 0:
log_msg += f" | Reasoning: {total_tokens['reasoning_tokens']:,}"
logger.info(log_msg)
logger.info(f"| Turns: {turn_count}")
# Convert messages to SDK format
sdk_format_messages = self._convert_to_sdk_format(messages)
if hit_turn_limit:
return {
"success": False,
"output": sdk_format_messages,
"token_usage": total_tokens,
"turn_count": turn_count,
"error": f"Max turns ({max_turns}) exceeded",
"litellm_run_model_name": self.litellm_run_model_name,
}
if error_msg:
return {
"success": False,
"output": sdk_format_messages,
"token_usage": total_tokens,
"turn_count": turn_count,
"error": error_msg,
"litellm_run_model_name": self.litellm_run_model_name,
}
return {
"success": True,
"output": sdk_format_messages,
"token_usage": total_tokens,
"turn_count": turn_count,
"error": None,
"litellm_run_model_name": self.litellm_run_model_name,
}
# ==================== LiteLLM Execution Path ====================
async def _execute_litellm_with_tools(
self, instruction: str, tool_call_log_file: Optional[str] = None
) -> Dict[str, Any]:
"""
Execute with manual MCP server management.
Used for all non-Anthropic models and Anthropic models with STDIO services.
"""
logger.debug("Using manual MCP execution with function calling loop")
# Create and start MCP server
mcp_server = await self._create_mcp_server()
try:
async with mcp_server:
# Get available tools
tools = await mcp_server.list_tools()
# Convert MCP tools to OpenAI function format
functions = self._convert_to_openai_format(tools)
# Execute with function calling loop
return await self._execute_litellm_tool_loop(
instruction, functions, mcp_server, tool_call_log_file
)
except Exception as e:
logger.error(f"Manual MCP execution failed: {e}")
raise
async def _execute_litellm_tool_loop(
self,
instruction: str,
functions: List[Dict],
mcp_server: Any,
tool_call_log_file: Optional[str] = None,
) -> Dict[str, Any]:
"""Execute function calling loop with LiteLLM."""
messages = [
{"role": "system", "content": self.SYSTEM_PROMPT},
{"role": "user", "content": instruction},
]
total_tokens = {
"input_tokens": 0,
"output_tokens": 0,
"total_tokens": 0,
"reasoning_tokens": 0,
}
turn_count = 0
max_turns = self.MAX_TURNS # Limit turns to prevent infinite loops
consecutive_failures = 0
max_consecutive_failures = 3
hit_turn_limit = False
ended_normally = False
# Convert functions to tools format for newer models
tools = (
[{"type": "function", "function": func} for func in functions]
if functions
else None
)
if tool_call_log_file and tools:
max_name_length = (
max(len(tool.get("function", {}).get("name", "")) for tool in tools)
if tools
else 15
)
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write("===== Available Tools =====\n")
for tool in tools:
function_info = tool.get("function", {})
tool_name = function_info.get("name", "N/A")
description = function_info.get("description", "N/A")
f.write(
f"- ToolName: {tool_name:<{max_name_length}} Description: {description}\n"
)
f.write("\n===== Execution Logs =====\n")
# Record initial state
self._update_progress(messages, total_tokens, turn_count)
try:
while turn_count < max_turns:
current_prompt_tokens = 0
if self._compaction_enabled():
current_prompt_tokens = self._count_prompt_tokens_litellm(messages)
messages = await self._maybe_compact_litellm_messages(
messages=messages,
total_tokens=total_tokens,
tool_call_log_file=tool_call_log_file,
current_prompt_tokens=current_prompt_tokens,
)
self._update_progress(messages, total_tokens, turn_count)
# Build completion kwargs
completion_kwargs = {
"model": self.litellm_input_model_name,
"messages": messages,
"api_key": self.api_key,
}
# Always use tools format if available - LiteLLM will handle conversion
if tools:
completion_kwargs["tools"] = tools
completion_kwargs["tool_choice"] = "auto"
# Add reasoning_effort and base_url if specified
if self.reasoning_effort != "default":
completion_kwargs["reasoning_effort"] = self.reasoning_effort
if self.base_url:
completion_kwargs["base_url"] = self.base_url
try:
# Call LiteLLM with timeout for individual call
response = await asyncio.wait_for(
litellm.acompletion(**completion_kwargs),
timeout=self.timeout / 2, # Use half of total timeout
)
consecutive_failures = 0 # Reset failure counter on success
except asyncio.TimeoutError:
logger.warning(f"| ✗ LLM call timed out on turn {turn_count + 1}")
consecutive_failures += 1
if consecutive_failures >= max_consecutive_failures:
raise Exception(
f"Too many consecutive failures ({consecutive_failures})"
)
await asyncio.sleep(8**consecutive_failures) # Exponential backoff
continue
except Exception as e:
logger.error(f"| ✗ LLM call failed on turn {turn_count + 1}: {e}")
consecutive_failures += 1
if consecutive_failures >= max_consecutive_failures:
raise
if "ContextWindowExceededError" in str(e):
# Best-effort fallback: compact and retry once.
messages = await self._maybe_compact_litellm_messages(
messages=messages,
total_tokens=total_tokens,
tool_call_log_file=tool_call_log_file,
current_prompt_tokens=self.compaction_token,
)
self._update_progress(messages, total_tokens, turn_count)
continue
elif "RateLimitError" in str(e):
await asyncio.sleep(12**consecutive_failures)
else:
await asyncio.sleep(2**consecutive_failures)
continue
# Extract actual model name from response (first turn only)
if turn_count == 0 and hasattr(response, "model") and response.model:
self.litellm_run_model_name = response.model.split("/")[-1]
# Update token usage including reasoning tokens
if hasattr(response, "usage") and response.usage:
input_tokens = response.usage.prompt_tokens or 0
total_tokens_count = response.usage.total_tokens or 0
# Calculate output tokens as total - input for consistency
output_tokens = (
total_tokens_count - input_tokens
if total_tokens_count > 0
else (response.usage.completion_tokens or 0)
)
total_tokens["input_tokens"] += input_tokens
total_tokens["output_tokens"] += output_tokens
total_tokens["total_tokens"] += total_tokens_count
# Extract reasoning tokens if available
if hasattr(response.usage, "completion_tokens_details"):
details = response.usage.completion_tokens_details
if hasattr(details, "reasoning_tokens"):
total_tokens["reasoning_tokens"] += (
details.reasoning_tokens or 0
)
# Get response message
choices = response.choices
if len(choices):
message = choices[0].message
# deeply dump the message to ensure we capture all fields
message_dict = (
message.model_dump()
if hasattr(message, "model_dump")
else dict(message)
)
# Explicitly preserve function_call if present (even if tool_calls exists),
# as it may contain provider-specific metadata (e.g. Gemini thought_signature)
if hasattr(message, "function_call") and message.function_call:
# Ensure it's in the dict if model_dump missed it or it was excluded
if (
"function_call" not in message_dict
or not message_dict["function_call"]
):
fc = message.function_call
message_dict["function_call"] = (
fc.model_dump() if hasattr(fc, "model_dump") else fc
)
# Log assistant's text content if present
if hasattr(message, "content") and message.content:
# Display the content with line prefix
for line in message.content.splitlines():
logger.info(f"| {line}")
# Also log to file if specified
if tool_call_log_file:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"{message.content}\n")
# Check for tool calls (newer format)
if hasattr(message, "tool_calls") and message.tool_calls:
messages.append(message_dict)
turn_count += 1
# Update progress after assistant with tool calls
self._update_progress(messages, total_tokens, turn_count)
# Process tool calls
for tool_call in message.tool_calls:
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
try:
result = await asyncio.wait_for(
mcp_server.call_tool(func_name, func_args), timeout=60
)
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(
result, cls=CustomJSONEncoder
),
}
)
except asyncio.TimeoutError:
error_msg = (
f"Tool call '{func_name}' timed out after 60 seconds"
)
logger.error(error_msg)
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": f"Error: {error_msg}",
}
)
except Exception as e:
logger.error(f"Tool call failed: {e}")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": f"Error: {str(e)}",
}
)
# Format arguments for display (truncate if too long)
args_str = json.dumps(func_args, separators=(",", ": "))
display_arguments = (
args_str[:140] + "..." if len(args_str) > 140 else args_str
)
# Log with ANSI color codes (bold tool name, dim gray arguments)
logger.info(
f"| \033[1m{func_name}\033[0m \033[2;37m{display_arguments}\033[0m"
)
if tool_call_log_file:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"| {func_name} {args_str}\n")
# Update progress after tool results appended
self._update_progress(messages, total_tokens, turn_count)
continue
else:
# Log end reason
if not choices:
logger.info(
"|\n|\n| Task ended with no messages generated by the model."
)
elif choices[0].finish_reason == "stop":
logger.info(
"|\n|\n| Task ended with the finish reason from messages being 'stop'."
)
# No tool/function call, add message and we're done
messages.append(message_dict)
turn_count += 1
# Update progress before exiting
self._update_progress(messages, total_tokens, turn_count)
ended_normally = True
break
except Exception as loop_error:
# On any error, return partial conversation, token usage, and turn count
logger.error(f"Manual MCP loop failed: {loop_error}", exc_info=True)
sdk_format_messages = self._convert_to_sdk_format(messages)
return {
"success": False,
"output": sdk_format_messages,
"token_usage": total_tokens,
"turn_count": turn_count,
"error": str(loop_error),
"litellm_run_model_name": self.litellm_run_model_name,
}
# Detect if we exited due to hitting the turn limit
if (not ended_normally) and (turn_count >= max_turns):
hit_turn_limit = True
logger.warning(
f"| Max turns ({max_turns}) exceeded); returning failure with partial output."
)
if tool_call_log_file:
try:
with open(tool_call_log_file, "a", encoding="utf-8") as f:
f.write(f"| Max turns ({max_turns}) exceeded\n")
except Exception:
pass
# Display final token usage
if total_tokens["total_tokens"] > 0:
log_msg = (
f"| Token usage: Total: {total_tokens['total_tokens']:,} | "
f"Input: {total_tokens['input_tokens']:,} | "
f"Output: {total_tokens['output_tokens']:,}"
)
if total_tokens.get("reasoning_tokens", 0) > 0:
log_msg += f" | Reasoning: {total_tokens['reasoning_tokens']:,}"
logger.info(log_msg)
logger.info(f"| Turns: {turn_count}")
# Convert messages to SDK format for backward compatibility
sdk_format_messages = self._convert_to_sdk_format(messages)
return {
"success": not hit_turn_limit,
"output": sdk_format_messages,
"token_usage": total_tokens,
"turn_count": turn_count,
"error": (f"Max turns ({max_turns}) exceeded" if hit_turn_limit else None),
"litellm_run_model_name": self.litellm_run_model_name,
}
# ==================== MCP Server Management ====================
async def _create_mcp_server(self) -> Any:
"""Create and return an MCP server instance."""
if self.mcp_service in self.STDIO_SERVICES:
return self._create_stdio_server()
elif self.mcp_service in self.HTTP_SERVICES:
return self._create_http_server()
else:
raise ValueError(f"Unsupported MCP service: {self.mcp_service}")
def _create_stdio_server(self) -> MCPStdioServer:
"""Create stdio-based MCP server."""
if self.mcp_service == "notion":
notion_key = self.service_config.get("notion_key")
if not notion_key:
raise ValueError("Notion API key required")
return MCPStdioServer(
command="npx",
args=["-y", "@notionhq/notion-mcp-server@1.9.1"],
env={
"OPENAPI_MCP_HEADERS": (
'{"Authorization": "Bearer ' + notion_key + '", '
'"Notion-Version": "2022-06-28"}'
)
},
)
elif self.mcp_service == "filesystem":
test_directory = self.service_config.get("test_directory")
if not test_directory:
raise ValueError("Test directory required for filesystem service")
return MCPStdioServer(
command="npx",
args=[
"-y",
"@modelcontextprotocol/server-filesystem",
str(test_directory),
],
)
elif self.mcp_service in ["playwright", "playwright_webarena"]:
browser = self.service_config.get("browser", "chromium")
headless = self.service_config.get("headless", True)
viewport_width = self.service_config.get("viewport_width", 1280)
viewport_height = self.service_config.get("viewport_height", 720)
args = ["-y", "@playwright/mcp@latest"]
if headless:
args.append("--headless")
args.extend(
[
"--isolated",
"--no-sandbox",
"--browser",
browser,
"--viewport-size",
f"{viewport_width},{viewport_height}",
]
)
return MCPStdioServer(command="npx", args=args)
elif self.mcp_service == "postgres":
host = self.service_config.get("host", "localhost")
port = self.service_config.get("port", 5432)
username = self.service_config.get("username")
password = self.service_config.get("password")
database = self.service_config.get(
"current_database"
) or self.service_config.get("database")
if not all([username, password, database]):
raise ValueError("PostgreSQL requires username, password, and database")
database_url = (
f"postgresql://{username}:{password}@{host}:{port}/{database}"
)
return MCPStdioServer(
command="pipx",
args=["run", "postgres-mcp", "--access-mode=unrestricted"],
env={"DATABASE_URI": database_url},
)
elif self.mcp_service == "insforge":
api_key = self.service_config.get("api_key")
backend_url = self.service_config.get("backend_url")
if not all([api_key, backend_url]):
raise ValueError("Insforge requires api_key and backend_url")
return MCPStdioServer(
command="npx",
args=["-y", "@insforge/mcp@dev"],
env={
"INSFORGE_API_KEY": api_key,
"INSFORGE_BACKEND_URL": backend_url,
},
)
elif self.mcp_service == "github":
github_token = self.service_config.get("github_token")
if not github_token:
raise ValueError("GitHub token required")
return MCPStdioServer(
command="docker",
args=[
"run", "-i", "--rm",
"-e", "GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server:v0.15.0",
],
env={"GITHUB_PERSONAL_ACCESS_TOKEN": github_token},
)
else:
raise ValueError(f"Unsupported stdio service: {self.mcp_service}")
def _create_http_server(self) -> MCPHttpServer:
"""Create HTTP-based MCP server."""
if self.mcp_service == "supabase":
# Use built-in MCP server from Supabase CLI
api_url = self.service_config.get("api_url", "http://localhost:54321")
api_key = self.service_config.get("api_key", "")
if not api_key:
raise ValueError(
"Supabase requires api_key (use secret key from 'supabase status')"
)
# Supabase CLI exposes MCP at /mcp endpoint
mcp_url = f"{api_url}/mcp"
return MCPHttpServer(
url=mcp_url,
headers={
"apikey": api_key,
"Authorization": f"Bearer {api_key}",
},
)
else:
raise ValueError(f"Unsupported HTTP service: {self.mcp_service}")
================================================
FILE: src/agents/react_agent.py
================================================
"""ReAct agent implementation for the MCPMark pipeline."""
from __future__ import annotations
import asyncio
import json
import time
from typing import Any, Dict, List, Optional, Callable
import litellm
from src.logger import get_logger
from .base_agent import BaseMCPAgent
logger = get_logger(__name__)
class ReActAgent(BaseMCPAgent):
"""ReAct-style agent that reuses MCPMark infrastructure."""
DEFAULT_SYSTEM_PROMPT = (
"You are a careful ReAct (reasoning and acting) agent. "
"At each step you must decide whether to call a tool or provide a final response. "
"Only use the tools that are listed for you. When you finish, respond with either the final answer "
"or the phrase \"Task completed.\" if no further detail is required. "
"Every reply must be valid JSON without code fences."
)
COMPACTION_PROMPT = (
"You are performing a CONTEXT CHECKPOINT COMPACTION.\n"
"Summarize the conversation so far for another model to continue.\n\n"
"Include:\n"
"- Current progress and key decisions made\n"
"- Important context, constraints, or user preferences\n"
"- What remains to be done (clear next steps)\n"
"- Any critical data, examples, or references needed to continue\n\n"
"Be concise and structured. Do NOT call tools."
)
def __init__(
self,
litellm_input_model_name: str,
api_key: str,
base_url: str,
mcp_service: str,
timeout: int = BaseMCPAgent.DEFAULT_TIMEOUT,
service_config: Optional[Dict[str, Any]] = None,
service_config_provider: Optional[Callable[[], Dict[str, Any]]] = None,
reasoning_effort: Optional[str] = "default",
max_iterations: int = 100,
system_prompt: Optional[str] = None,
compaction_token: int = BaseMCPAgent.COMPACTION_DISABLED_TOKEN,
):
super().__init__(
litellm_input_model_name=litellm_input_model_name,
api_key=api_key,
base_url=base_url,
mcp_service=mcp_service,
timeout=timeout,
service_config=service_config,
service_config_provider=service_config_provider,
reasoning_effort=reasoning_effort,
compaction_token=compaction_token,
)
self.max_iterations = max_iterations
self.react_system_prompt = system_prompt or self.DEFAULT_SYSTEM_PROMPT
async def execute(
self,
instruction: str,
tool_call_log_file: Optional[str] = None,
) -> Dict[str, Any]:
start_time = time.time()
try:
self._reset_progress()
self._refresh_service_config()
async def _run_react():
return await self._execute_react_loop(instruction, tool_call_log_file)
result = await asyncio.wait_for(_run_react(), timeout=self.timeout)
execution_time = time.time() - start_time
self.usage_tracker.update(
success=result.get("success", False),
token_usage=result.get("token_usage", {}),
turn_count=result.get("turn_count", 0),
execution_time=execution_time,
)
result["execution_time"] = execution_time
return result
except Exception as exc: # noqa: BLE001
execution_time = time.time() - start_time
if isinstance(exc, asyncio.TimeoutError):
error_msg = f"Execution timed out after {self.timeout} seconds"
logger.error(error_msg)
else:
error_msg = f"ReAct agent execution failed: {exc}"
logger.error(error_msg, exc_info=True)
self.usage_tracker.update(
success=False,
token_usage=self._partial_token_usage or {},
turn_count=self._partial_turn_count or 0,
execution_time=execution_time,
)
if self._partial_messages:
final_msg = self._convert_to_sdk_format(self._partial_messages)
else:
final_msg = []
return {
"success": False,
"output": final_msg,
"token_usage": self._partial_token_usage or {},
"turn_count": self._partial_turn_count or 0,
"execution_time": execution_time,
"error": error_msg,
"litellm_run_model_name": self.litellm_run_model_name,
}
async def _execute_react_loop(
self,
instruction: str,
tool_call_log_file: Optional[str],
) -> Dict[str, Any]:
system_message = {"role": "system", "content": self.react_system_prompt}
total_tokens = {
"input_tokens": 0,
"output_tokens": 0,
"total_tokens": 0,
"reasoning_tokens": 0,
}
turn_count = 0
success = False
final_error: Optional[str] = None
mcp_server = await self._create_mcp_server()
async with mcp_server:
tools = await mcp_server.list_tools()
tool_map = {tool.get("name"): tool for tool in tools}
tools_description = self._render_tools_description(tools)
task_message = {
"role": "user",
"content": self._build_task_prompt(
instruction=instruction,
tools_description=tools_description,
),
}
messages: List[Dict[str, Any]] = [system_message, task_message]
self._update_progress(messages, total_tokens, turn_count)
for step in range(1, self.max_iterations + 1):
current_prompt_tokens = 0
if self._compaction_enabled():
current_prompt_tokens = self._count_prompt_tokens_litellm(messages)
if self._compaction_enabled() and current_prompt_tokens >= self.compaction_token:
logger.info(
f"| [compaction] Triggered at prompt tokens: {current_prompt_tokens:,}"
)
if tool_call_log_file:
try:
with open(tool_call_log_file, "a", encoding="utf-8") as log_file:
log_file.write(
f"| [compaction] Triggered at prompt tokens: {current_prompt_tokens:,}\n"
)
except Exception: # noqa: BLE001
pass
compact_messages = [
{"role": "system", "content": self.COMPACTION_PROMPT},
{"role": "user", "content": json.dumps(messages, ensure_ascii=False)},
]
compact_kwargs = {
"model": self.litellm_input_model_name,
"messages": compact_messages,
"api_key": self.api_key,
}
if self.base_url:
compact_kwargs["base_url"] = self.base_url
compact_response = await litellm.acompletion(**compact_kwargs)
usage = getattr(compact_response, "usage", None)
if usage:
prompt_tokens = (
getattr(usage, "prompt_tokens", None)
or getattr(usage, "input_tokens", None)
or 0
)
completion_tokens = (
getattr(usage, "completion_tokens", None)
or getattr(usage, "output_tokens", None)
or 0
)
total_tokens_count = getattr(usage, "total_tokens", None)
if total_tokens_count is None:
total_tokens_count = prompt_tokens + completion_tokens
total_tokens["input_tokens"] += int(prompt_tokens or 0)
total_tokens["output_tokens"] += int(completion_tokens or 0)
total_tokens["total_tokens"] += int(total_tokens_count or 0)
summary = ""
try:
summary = compact_response.choices[0].message.content or ""
except Exception: # noqa: BLE001
summary = ""
summary = summary.strip() or "(no summary)"
messages = [
system_message,
task_message,
{
"role": "user",
"content": (
"Context summary (auto-compacted due to token limit):\n"
f"{summary}"
),
},
]
self._update_progress(messages, total_tokens, turn_count)
completion_kwargs = {
"model": self.litellm_input_model_name,
"messages": messages,
"api_key": self.api_key,
}
if self.base_url:
completion_kwargs["base_url"] = self.base_url
if self.reasoning_effort != "default":
completion_kwargs["reasoning_effort"] = self.reasoning_effort
try:
response = await asyncio.wait_for(
litellm.acompletion(**completion_kwargs),
timeout=self.timeout / 2,
)
except asyncio.TimeoutError:
final_error = f"LLM call timed out on step {step}"
logger.error(final_error)
break
except Exception as exc: # noqa: BLE001
final_error = f"LLM call failed on step {step}: {exc}"
logger.error(final_
gitextract_5znolca_/
├── .dockerignore
├── .editorconfig
├── .gitattributes
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── 1_bug_report.yml
│ │ ├── 2_feature_request.yml
│ │ └── config.yml
│ ├── PULL_REQUEST_TEMPLATE.md
│ ├── scripts/
│ │ └── pr-comment.js
│ └── workflows/
│ └── publish-docker-image.yml
├── .gitignore
├── CHANGELOG.md
├── Dockerfile
├── LICENSE
├── README.md
├── build-docker.sh
├── cspell.config.yaml
├── docs/
│ ├── contributing/
│ │ └── make-contribution.md
│ ├── datasets/
│ │ └── task.md
│ ├── installation_and_docker_usage.md
│ ├── introduction.md
│ ├── mcp/
│ │ ├── filesystem.md
│ │ ├── github.md
│ │ ├── notion.md
│ │ ├── playwright.md
│ │ └── postgres.md
│ └── quickstart.md
├── pipeline.py
├── pyproject.toml
├── run-benchmark.sh
├── run-task.sh
├── src/
│ ├── agents/
│ │ ├── __init__.py
│ │ ├── base_agent.py
│ │ ├── mcp/
│ │ │ ├── __init__.py
│ │ │ ├── http_server.py
│ │ │ └── stdio_server.py
│ │ ├── mcpmark_agent.py
│ │ ├── react_agent.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ └── token_usage.py
│ ├── aggregators/
│ │ ├── aggregate_results.py
│ │ ├── aggregate_specific_results.py
│ │ ├── aggregate_task_meta.py
│ │ └── pricing.py
│ ├── base/
│ │ ├── __init__.py
│ │ ├── login_helper.py
│ │ ├── state_manager.py
│ │ └── task_manager.py
│ ├── config/
│ │ ├── __init__.py
│ │ └── config_schema.py
│ ├── errors.py
│ ├── evaluator.py
│ ├── factory.py
│ ├── logger.py
│ ├── mcp_services/
│ │ ├── filesystem/
│ │ │ ├── __init__.py
│ │ │ ├── filesystem_login_helper.py
│ │ │ ├── filesystem_state_manager.py
│ │ │ └── filesystem_task_manager.py
│ │ ├── github/
│ │ │ ├── __init__.py
│ │ │ ├── github_login_helper.py
│ │ │ ├── github_state_manager.py
│ │ │ ├── github_task_manager.py
│ │ │ ├── repo_exporter.py
│ │ │ ├── repo_importer.py
│ │ │ └── token_pool.py
│ │ ├── insforge/
│ │ │ ├── __init__.py
│ │ │ ├── insforge_login_helper.py
│ │ │ ├── insforge_state_manager.py
│ │ │ └── insforge_task_manager.py
│ │ ├── notion/
│ │ │ ├── __init__.py
│ │ │ ├── notion_login_helper.py
│ │ │ ├── notion_state_manager.py
│ │ │ └── notion_task_manager.py
│ │ ├── playwright/
│ │ │ ├── __init__.py
│ │ │ ├── playwright_login_helper.py
│ │ │ ├── playwright_state_manager.py
│ │ │ └── playwright_task_manager.py
│ │ ├── playwright_webarena/
│ │ │ ├── playwright_login_helper.py
│ │ │ ├── playwright_state_manager.py
│ │ │ ├── playwright_task_manager.py
│ │ │ └── reddit_env_setup.md
│ │ ├── postgres/
│ │ │ ├── __init__.py
│ │ │ ├── postgres_login_helper.py
│ │ │ ├── postgres_state_manager.py
│ │ │ └── postgres_task_manager.py
│ │ └── supabase/
│ │ ├── __init__.py
│ │ ├── supabase_login_helper.py
│ │ ├── supabase_state_manager.py
│ │ └── supabase_task_manager.py
│ ├── model_config.py
│ ├── results_reporter.py
│ └── services.py
└── tasks/
├── __init__.py
├── filesystem/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── file_context/
│ │ │ ├── file_splitting/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── pattern_matching/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── uppercase/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── file_property/
│ │ │ ├── largest_rename/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── txt_merging/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── folder_structure/
│ │ │ └── structure_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── legal_document/
│ │ │ └── file_reorganize/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── papers/
│ │ │ └── papers_counting/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── student_database/
│ │ ├── duplicate_name/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── recommender_name/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── desktop/
│ │ ├── music_report/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── project_management/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── timeline_extraction/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── desktop_template/
│ │ ├── budget_computation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── contact_information/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── file_arrangement/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── file_context/
│ │ ├── duplicates_searching/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── file_merging/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── file_splitting/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── pattern_matching/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── uppercase/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── file_property/
│ │ ├── size_classification/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── time_classification/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── folder_structure/
│ │ ├── structure_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── structure_mirror/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── legal_document/
│ │ ├── dispute_review/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── individual_comments/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── solution_tracing/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── papers/
│ │ ├── author_folders/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── find_math_paper/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── organize_legacy_papers/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── student_database/
│ │ ├── duplicate_name/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── english_talent/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── gradebased_score/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── threestudio/
│ │ ├── code_locating/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── output_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── requirements_completion/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── votenet/
│ ├── dataset_comparison/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── debugging/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── requirements_writing/
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── github/
│ ├── easy/
│ │ ├── build-your-own-x/
│ │ │ ├── close_commented_issues/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── record_recent_commits/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── claude-code/
│ │ │ ├── add_terminal_shortcuts_doc/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── thank_docker_pr_author/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── triage_missing_tool_result_issue/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── mcpmark-cicd/
│ │ │ ├── basic_ci_checks/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── issue_lint_guard/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── nightly_health_check/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── missing-semester/
│ │ ├── count_translations/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── find_ga_tracking_id/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── build_your_own_x/
│ │ ├── find_commit_date/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── find_rag_commit/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── claude-code/
│ │ ├── automated_changelog_generation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── claude_collaboration_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── critical_issue_hotfix_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── feature_commit_tracking/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── label_color_standardization/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── easyr1/
│ │ ├── advanced_branch_strategy/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── config_parameter_audit/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── performance_regression_investigation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── qwen3_issue_management/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── harmony/
│ │ ├── fix_conflict/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── issue_pr_commit_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── issue_tagging_pr_closure/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── multi_branch_commit_aggregation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── release_management_workflow/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── mcpmark-cicd/
│ │ ├── deployment_status_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── issue_management_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── linting_ci_workflow/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── pr_automation_workflow/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── missing-semester/
│ ├── assign_contributor_labels/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── find_legacy_name/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── find_salient_file/
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── notion/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── computer_science_student_dashboard/
│ │ │ ├── simple__code_snippets_go/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── simple__study_session_tracker/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── it_trouble_shooting_hub/
│ │ │ └── simple__asset_retirement_migration/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── japan_travel_planner/
│ │ │ └── simple__remove_osaka_itinerary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── online_resume/
│ │ │ └── simple__skills_development_tracker/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── python_roadmap/
│ │ │ └── simple__expert_level_lessons/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── self_assessment/
│ │ │ └── simple__faq_column_layout/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── standard_operating_procedure/
│ │ │ └── simple__section_organization/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── team_projects/
│ │ │ └── simple__swap_tasks/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── toronto_guide/
│ │ └── simple__change_color/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── company_in_a_box/
│ │ ├── employee_onboarding/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── goals_restructure/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── quarterly_review_dashboard/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── computer_science_student_dashboard/
│ │ ├── code_snippets_go/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── courses_internships_relation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── study_session_tracker/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── it_trouble_shooting_hub/
│ │ ├── asset_retirement_migration/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── security_audit_ticket/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── verification_expired_update/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── japan_travel_planner/
│ │ ├── daily_itinerary_overview/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── packing_progress_summary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── remove_osaka_itinerary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── restaurant_expenses_sync/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── online_resume/
│ │ ├── layout_adjustment/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── projects_section_update/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── skills_development_tracker/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── work_history_addition/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── python_roadmap/
│ │ ├── expert_level_lessons/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── learning_metrics_dashboard/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── self_assessment/
│ │ ├── faq_column_layout/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── hyperfocus_analysis_report/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── numbered_list_emojis/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── standard_operating_procedure/
│ │ ├── deployment_process_sop/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── section_organization/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── team_projects/
│ │ ├── priority_tasks_table/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── swap_tasks/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── toronto_guide/
│ ├── change_color/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── weekend_adventure_planner/
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── playwright/
│ ├── easy/
│ │ └── .gitkeep
│ └── standard/
│ ├── eval_web/
│ │ ├── cloudflare_turnstile_challenge/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── extraction_table/
│ │ ├── data.csv
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── web_search/
│ ├── birth_of_arvinxu/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── r1_arxiv/
│ ├── content.txt
│ ├── description.md
│ ├── meta.json
│ └── verify.py
├── playwright_webarena/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── reddit/
│ │ │ ├── ai_data_analyst/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── llm_research_summary/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── movie_reviewer_analysis/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── nba_statistics_analysis/
│ │ │ │ ├── description.md
│ │ │ │ ├── label.txt
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── routine_tracker_forum/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── shopping_admin/
│ │ ├── fitness_promotion_strategy/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── ny_expansion_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── products_sales_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── sales_inventory_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── search_filtering_operations/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── reddit/
│ │ ├── ai_data_analyst/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── budget_europe_travel/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── buyitforlife_research/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── llm_research_summary/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── movie_reviewer_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── nba_statistics_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── routine_tracker_forum/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── shopping/
│ │ ├── advanced_product_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── gaming_accessories_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── health_routine_optimization/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── holiday_baking_competition/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── multi_category_budget_analysis/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── printer_keyboard_search/
│ │ │ ├── description.md
│ │ │ ├── label.txt
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── running_shoes_purchase/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ └── shopping_admin/
│ ├── customer_segmentation_setup/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── fitness_promotion_strategy/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── marketing_customer_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── ny_expansion_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── products_sales_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ ├── sales_inventory_analysis/
│ │ ├── description.md
│ │ ├── label.txt
│ │ ├── meta.json
│ │ └── verify.py
│ └── search_filtering_operations/
│ ├── description.md
│ ├── label.txt
│ ├── meta.json
│ └── verify.py
├── postgres/
│ ├── easy/
│ │ ├── .gitkeep
│ │ ├── chinook/
│ │ │ ├── customer_data_migration_basic/
│ │ │ │ ├── customer_data.pkl
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── update_employee_info/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── dvdrental/
│ │ │ └── create_payment_index/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employees/
│ │ │ ├── department_summary_view/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── employee_gender_statistics/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ ├── employee_projects_basic/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── hiring_year_summary/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── lego/
│ │ │ ├── basic_security_setup/
│ │ │ │ ├── description.md
│ │ │ │ ├── meta.json
│ │ │ │ └── verify.py
│ │ │ └── fix_data_inconsistencies/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── sports/
│ │ └── create_performance_indexes/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── standard/
│ ├── chinook/
│ │ ├── customer_data_migration/
│ │ │ ├── customer_data.pkl
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_hierarchy_management/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── sales_and_music_charts/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── dvdrental/
│ │ ├── customer_analysis_fix/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── customer_analytics_optimization/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── film_inventory_management/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── employees/
│ │ ├── employee_demographics_report/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_performance_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_project_tracking/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── employee_retention_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── executive_dashboard_automation/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── management_structure_analysis/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── lego/
│ │ ├── consistency_enforcement/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── database_security_policies/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── transactional_inventory_transfer/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ ├── security/
│ │ ├── rls_business_access/
│ │ │ ├── description.md
│ │ │ ├── ground_truth.sql
│ │ │ ├── meta.json
│ │ │ ├── prepare_environment.py
│ │ │ └── verify.py
│ │ └── user_permission_audit/
│ │ ├── description.md
│ │ ├── ground_truth.sql
│ │ ├── meta.json
│ │ ├── prepare_environment.py
│ │ └── verify.py
│ ├── sports/
│ │ ├── baseball_player_analysis/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ ├── participant_report_optimization/
│ │ │ ├── description.md
│ │ │ ├── meta.json
│ │ │ └── verify.py
│ │ └── team_roster_management/
│ │ ├── description.md
│ │ ├── meta.json
│ │ └── verify.py
│ └── vectors/
│ ├── dba_vector_analysis/
│ │ ├── description.md
│ │ ├── ground_truth.sql
│ │ ├── meta.json
│ │ ├── prepare_environment.py
│ │ └── verify.py
│ └── vectors_setup.py
└── utils/
├── __init__.py
├── notion_utils.py
└── postgres_utils.py
SYMBOL INDEX (1543 symbols across 235 files)
FILE: pipeline.py
function _suppress_cleanup_exceptions (line 26) | def _suppress_cleanup_exceptions(unraisable):
function main (line 48) | def main():
FILE: src/agents/base_agent.py
class BaseMCPAgent (line 19) | class BaseMCPAgent(ABC):
method __init__ (line 41) | def __init__(
method __repr__ (line 92) | def __repr__(self) -> str: # pragma: no cover - debug helper
method execute (line 99) | async def execute(
method execute_sync (line 106) | def execute_sync(
method get_usage_stats (line 114) | def get_usage_stats(self) -> Dict[str, Any]:
method reset_usage_stats (line 118) | def reset_usage_stats(self):
method _is_anthropic_model (line 126) | def _is_anthropic_model(self, model_name: str) -> bool:
method _get_claude_thinking_budget (line 129) | def _get_claude_thinking_budget(self) -> Optional[int]:
method _refresh_service_config (line 134) | def _refresh_service_config(self):
method _reset_progress (line 143) | def _reset_progress(self):
method _update_progress (line 148) | def _update_progress(
method _create_mcp_server (line 165) | async def _create_mcp_server(self) -> Any:
method _create_stdio_server (line 172) | def _create_stdio_server(self) -> MCPStdioServer:
method _create_http_server (line 257) | def _create_http_server(self) -> MCPHttpServer:
method _compaction_enabled (line 275) | def _compaction_enabled(self) -> bool:
method _count_prompt_tokens_litellm (line 278) | def _count_prompt_tokens_litellm(self, messages: List[Dict[str, Any]])...
method _convert_to_sdk_format (line 289) | def _convert_to_sdk_format(
method _convert_to_anthropic_format (line 456) | def _convert_to_anthropic_format(
method _is_gemini_model (line 472) | def _is_gemini_model(self) -> bool:
method _is_gemini_3_model (line 476) | def _is_gemini_3_model(self) -> bool:
method _simplify_schema_for_gemini (line 481) | def _simplify_schema_for_gemini(
method _convert_to_openai_format (line 511) | def _convert_to_openai_format(
FILE: src/agents/mcp/http_server.py
class MCPHttpServer (line 15) | class MCPHttpServer:
method __init__ (line 21) | def __init__(
method __aenter__ (line 35) | async def __aenter__(self):
method __aexit__ (line 39) | async def __aexit__(self, exc_type, exc, tb):
method start (line 42) | async def start(self):
method stop (line 53) | async def stop(self):
method list_tools (line 61) | async def list_tools(self) -> List[Dict[str, Any]]:
method call_tool (line 72) | async def call_tool(self, name: str, arguments: Dict[str, Any]) -> Any:
FILE: src/agents/mcp/stdio_server.py
class MCPStdioServer (line 17) | class MCPStdioServer:
method __init__ (line 20) | def __init__(self, command: str, args: List[str], env: Optional[Dict[s...
method __aenter__ (line 27) | async def __aenter__(self):
method __aexit__ (line 34) | async def __aexit__(self, exc_type, exc, tb):
method list_tools (line 40) | async def list_tools(self) -> List[Dict[str, Any]]:
method call_tool (line 44) | async def call_tool(self, name: str, arguments: Dict[str, Any]) -> Any:
FILE: src/agents/mcpmark_agent.py
class CustomJSONEncoder (line 32) | class CustomJSONEncoder(json.JSONEncoder):
method default (line 33) | def default(self, obj):
class MCPMarkAgent (line 39) | class MCPMarkAgent(BaseMCPAgent):
method __init__ (line 64) | def __init__(
method execute (line 98) | async def execute(
method execute_sync (line 184) | def execute_sync(
method get_usage_stats (line 192) | def get_usage_stats(self) -> Dict[str, Any]:
method reset_usage_stats (line 196) | def reset_usage_stats(self):
method _execute_claude_native_with_tools (line 202) | async def _execute_claude_native_with_tools(
method _call_claude_native_api (line 232) | async def _call_claude_native_api(
method _count_claude_input_tokens (line 306) | async def _count_claude_input_tokens(
method _extract_litellm_text (line 340) | def _extract_litellm_text(self, response: Any) -> str:
method _extract_anthropic_text (line 352) | def _extract_anthropic_text(self, response_json: Dict[str, Any]) -> str:
method _merge_usage (line 361) | def _merge_usage(self, total_tokens: Dict[str, int], usage: Dict[str, ...
method _maybe_compact_litellm_messages (line 374) | async def _maybe_compact_litellm_messages(
method _maybe_compact_anthropic_messages (line 448) | async def _maybe_compact_anthropic_messages(
method _execute_anthropic_native_tool_loop (line 504) | async def _execute_anthropic_native_tool_loop(
method _execute_litellm_with_tools (line 752) | async def _execute_litellm_with_tools(
method _execute_litellm_tool_loop (line 781) | async def _execute_litellm_tool_loop(
method _create_mcp_server (line 1098) | async def _create_mcp_server(self) -> Any:
method _create_stdio_server (line 1107) | def _create_stdio_server(self) -> MCPStdioServer:
method _create_http_server (line 1215) | def _create_http_server(self) -> MCPHttpServer:
FILE: src/agents/react_agent.py
class ReActAgent (line 18) | class ReActAgent(BaseMCPAgent):
method __init__ (line 39) | def __init__(
method execute (line 67) | async def execute(
method _execute_react_loop (line 123) | async def _execute_react_loop(
method _build_task_prompt (line 422) | def _build_task_prompt(
method _render_tools_description (line 449) | def _render_tools_description(self, tools: List[Dict[str, Any]]) -> str:
method _normalize_content (line 475) | def _normalize_content(self, content: Any) -> str:
method _parse_react_response (line 491) | def _parse_react_response(self, payload: str) -> Dict[str, Any]:
method _tool_result_to_text (line 500) | def _tool_result_to_text(self, result: Any) -> str:
FILE: src/agents/utils/token_usage.py
class TokenUsageTracker (line 9) | class TokenUsageTracker:
method __init__ (line 12) | def __init__(self):
method reset (line 16) | def reset(self):
method update (line 28) | def update(self, success: bool, token_usage: Dict[str, int],
method get_stats (line 50) | def get_stats(self) -> Dict[str, Any]:
FILE: src/aggregators/aggregate_results.py
function discover_tasks (line 27) | def discover_tasks(task_set: str = "standard") -> Dict[str, List[str]]:
function collect_results (line 82) | def collect_results(exp_dir: Path, k: int) -> Dict[str, Dict[str, Any]]:
function check_completeness_and_validity (line 131) | def check_completeness_and_validity(
function calculate_metrics (line 193) | def calculate_metrics(complete_models: Dict, all_tasks: Dict, k: int, si...
function generate_model_results (line 483) | def generate_model_results(exp_dir: Path, complete_models: Dict, all_tas...
function generate_task_results (line 525) | def generate_task_results(exp_dir: Path, complete_models: Dict, all_task...
function generate_readme (line 619) | def generate_readme(exp_name: str, summary: Dict, k: int) -> str:
function push_to_github (line 715) | def push_to_github(exp_dir: Path, exp_name: str, branch: Optional[str] =...
function print_validation_report (line 799) | def print_validation_report(complete: Dict, incomplete: Dict, invalid: D...
function main (line 899) | def main():
FILE: src/aggregators/aggregate_specific_results.py
function collect_results_from_dir (line 18) | def collect_results_from_dir(result_dir: Path, k: int) -> Dict[str, Any]:
function get_token_counts (line 44) | def get_token_counts(meta: Dict[str, Any]) -> Tuple[int, int, int]:
function calculate_metrics (line 53) | def calculate_metrics(results: Dict, k: int, model_name: str) -> Dict:
function main (line 184) | def main():
FILE: src/aggregators/aggregate_task_meta.py
function find_all_meta_files (line 16) | def find_all_meta_files(tasks_root: Path = Path("tasks")) -> List[Path]:
function parse_meta_file (line 25) | def parse_meta_file(meta_path: Path) -> Dict[str, Any]:
function aggregate_task_meta (line 35) | def aggregate_task_meta(meta_files: List[Path]) -> Dict[str, Any]:
function create_individual_task_files (line 76) | def create_individual_task_files(meta_files: List[Path]) -> List[Dict[st...
function push_to_file (line 120) | def push_to_file(
function push_to_experiments_repo (line 151) | def push_to_experiments_repo(
function main (line 234) | def main():
FILE: src/aggregators/pricing.py
function normalize_model_name (line 64) | def normalize_model_name(model_name: str) -> str:
function get_price_per_m (line 72) | def get_price_per_m(model_name: str) -> Optional[Dict[str, float]]:
function compute_cost_usd (line 78) | def compute_cost_usd(model_name: str, input_tokens: float, output_tokens...
FILE: src/base/login_helper.py
class BaseLoginHelper (line 4) | class BaseLoginHelper(ABC):
method __init__ (line 7) | def __init__(self):
method login (line 11) | def login(self, **kwargs):
FILE: src/base/state_manager.py
class InitialStateInfo (line 14) | class InitialStateInfo:
class BaseStateManager (line 22) | class BaseStateManager(ABC):
method __init__ (line 30) | def __init__(self, service_name: str):
method set_up (line 37) | def set_up(self, task: BaseTask) -> bool:
method clean_up (line 67) | def clean_up(self, task: BaseTask = None) -> bool:
method track_resource (line 104) | def track_resource(
method get_service_config_for_agent (line 126) | def get_service_config_for_agent(self) -> dict:
method set_verification_environment (line 138) | def set_verification_environment(self, messages_path: str = None) -> N...
method _cleanup_tracked_resources (line 153) | def _cleanup_tracked_resources(self) -> bool:
method _create_initial_state (line 176) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 188) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 200) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 212) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
FILE: src/base/task_manager.py
class BaseTask (line 25) | class BaseTask:
method name (line 35) | def name(self) -> str:
method get_task_instruction (line 39) | def get_task_instruction(self) -> str:
class BaseTaskManager (line 49) | class BaseTaskManager(ABC):
method __init__ (line 52) | def __init__(
method discover_all_tasks (line 82) | def discover_all_tasks(self) -> List[BaseTask]:
method get_categories (line 127) | def get_categories(self) -> List[str]:
method filter_tasks (line 132) | def filter_tasks(self, task_filter: str) -> List[BaseTask]:
method get_task_instruction (line 174) | def get_task_instruction(self, task: BaseTask) -> str:
method execute_task (line 179) | def execute_task(self, task: BaseTask, agent_result: Dict[str, Any]) -...
method run_verification (line 251) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method _get_service_directory_name (line 268) | def _get_service_directory_name(self) -> str:
method _get_task_organization (line 279) | def _get_task_organization(self) -> str:
method _is_valid_category_dir (line 299) | def _is_valid_category_dir(self, category_dir: Path) -> bool:
method _find_task_files (line 308) | def _find_task_files(self, category_dir: Path) -> List[Dict[str, Any]]:
method _create_task_from_files (line 340) | def _create_task_from_files(
method _read_task_instruction (line 368) | def _read_task_instruction(self, task: BaseTask) -> str:
method _format_task_instruction (line 372) | def _format_task_instruction(self, base_instruction: str) -> str:
method _get_verification_command (line 379) | def _get_verification_command(self, task: BaseTask) -> List[str]:
method _standardize_error_message (line 383) | def _standardize_error_message(self, error_message: str) -> str:
FILE: src/config/config_schema.py
function get_service_definition (line 25) | def get_service_definition(service_name: str) -> dict:
class ConfigValue (line 32) | class ConfigValue:
method validate (line 42) | def validate(self) -> bool:
class ConfigSchema (line 54) | class ConfigSchema(ABC):
method __init__ (line 57) | def __init__(self, service_name: str):
method _define_schema (line 66) | def _define_schema(self) -> None:
method _load_dotenv (line 70) | def _load_dotenv(self) -> None:
method _add_config (line 74) | def _add_config(
method _load_values (line 109) | def _load_values(self) -> None:
method _validate (line 121) | def _validate(self) -> None:
method get (line 126) | def get(self, key: str, default: Any = None) -> Any:
method get_all (line 132) | def get_all(self) -> Dict[str, Any]:
method get_debug_info (line 136) | def get_debug_info(self) -> Dict[str, Dict[str, Any]]:
class GenericConfigSchema (line 149) | class GenericConfigSchema(ConfigSchema):
method __init__ (line 152) | def __init__(self, service_name: str):
method _define_schema (line 157) | def _define_schema(self) -> None:
class ConfigRegistry (line 197) | class ConfigRegistry:
method get_config (line 203) | def get_config(cls, service_name: str) -> ConfigSchema:
method validate_all (line 210) | def validate_all(cls) -> Dict[str, bool]:
method export_template (line 225) | def export_template(cls, service_name: str, output_path: Path) -> None:
function get_service_config (line 248) | def get_service_config(service_name: str) -> Dict[str, Any]:
FILE: src/errors.py
function is_retryable_error (line 34) | def is_retryable_error(error: str) -> bool:
function standardize_error_message (line 40) | def standardize_error_message(error: str, mcp_service: Optional[str] = N...
FILE: src/evaluator.py
class MCPEvaluator (line 20) | class MCPEvaluator:
method __init__ (line 21) | def __init__(
method _format_duration (line 94) | def _format_duration(self, seconds: float) -> str:
method _get_task_output_dir (line 98) | def _get_task_output_dir(self, task) -> Path:
method _load_latest_task_result (line 110) | def _load_latest_task_result(self, task) -> Optional[TaskResult]:
method _gather_all_task_results (line 142) | def _gather_all_task_results(self) -> List[TaskResult]:
method _run_single_task (line 181) | def _run_single_task(self, task) -> TaskResult:
method run_evaluation (line 296) | def run_evaluation(self, task_filter: str) -> EvaluationReport:
FILE: src/factory.py
class ServiceComponents (line 27) | class ServiceComponents:
function import_class (line 36) | def import_class(module_path: str):
function apply_config_mapping (line 45) | def apply_config_mapping(config: dict, mapping: dict) -> dict:
class ServiceRegistry (line 57) | class ServiceRegistry:
method get_components (line 64) | def get_components(cls, service_name: str) -> ServiceComponents:
class GenericServiceFactory (line 83) | class GenericServiceFactory:
method __init__ (line 86) | def __init__(self, components: ServiceComponents, service_name: str):
method create_task_manager (line 90) | def create_task_manager(self, **kwargs) -> BaseTaskManager:
method create_state_manager (line 94) | def create_state_manager(self, config) -> BaseStateManager:
method create_login_helper (line 102) | def create_login_helper(self, config) -> BaseLoginHelper:
class MCPServiceFactory (line 118) | class MCPServiceFactory:
method create_service_config (line 122) | def create_service_config(cls, service_name: str):
method create_task_manager (line 136) | def create_task_manager(cls, service_name: str, **kwargs) -> BaseTaskM...
method create_state_manager (line 142) | def create_state_manager(cls, service_name: str, **kwargs) -> BaseStat...
method create_login_helper (line 155) | def create_login_helper(cls, service_name: str, **kwargs) -> BaseLogin...
method get_supported_mcp_services (line 174) | def get_supported_mcp_services(cls) -> list:
method get_config_info (line 179) | def get_config_info(cls, service_name: str) -> dict:
method export_config_template (line 185) | def export_config_template(cls, service_name: str, output_path: str) -...
FILE: src/logger.py
function get_logger (line 8) | def get_logger(name: str) -> logging.Logger:
FILE: src/mcp_services/filesystem/filesystem_login_helper.py
class FilesystemLoginHelper (line 19) | class FilesystemLoginHelper(BaseLoginHelper):
method __init__ (line 27) | def __init__(self, state_path: Optional[Path] = None):
method login (line 40) | def login(self, **kwargs) -> bool:
method is_authenticated (line 52) | def is_authenticated(self) -> bool:
method get_credentials (line 61) | def get_credentials(self) -> dict:
FILE: src/mcp_services/filesystem/filesystem_state_manager.py
class FilesystemStateManager (line 22) | class FilesystemStateManager(BaseStateManager):
method _get_project_root (line 30) | def _get_project_root(self) -> Path:
method __init__ (line 42) | def __init__(self, test_root: Optional[Path] = None, cleanup_on_exit: ...
method initialize (line 74) | def initialize(self, **kwargs) -> bool:
method set_up (line 105) | def set_up(self, task: BaseTask) -> bool:
method _set_dynamic_test_root (line 150) | def _set_dynamic_test_root(self, task: BaseTask) -> None:
method clean_up (line 188) | def clean_up(self, task: Optional[BaseTask] = None, **kwargs) -> bool:
method get_test_directory (line 227) | def get_test_directory(self) -> Optional[Path]:
method get_service_config_for_agent (line 236) | def get_service_config_for_agent(self) -> dict:
method track_resource (line 251) | def track_resource(self, resource_path: Path):
method reset_test_environment (line 262) | def reset_test_environment(self) -> bool:
method _create_backup (line 299) | def _create_backup(self, task: BaseTask) -> bool:
method _restore_from_backup (line 332) | def _restore_from_backup(self, task: Optional[BaseTask] = None) -> bool:
method _create_initial_state (line 373) | def _create_initial_state(self, task: BaseTask) -> Optional[Dict[str, ...
method _store_initial_state_info (line 383) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 394) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 411) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method _download_and_extract_test_environment (line 431) | def _download_and_extract_test_environment(self) -> bool:
FILE: src/mcp_services/filesystem/filesystem_task_manager.py
class FilesystemTask (line 22) | class FilesystemTask(BaseTask):
class FilesystemTaskManager (line 30) | class FilesystemTaskManager(BaseTaskManager):
method __init__ (line 33) | def __init__(self, tasks_root: Path = None, task_suite: str = "standar...
method _create_task_from_files (line 47) | def _create_task_from_files(
method run_verification (line 81) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method filter_tasks (line 105) | def filter_tasks(self, task_filter: str) -> List[BaseTask]:
FILE: src/mcp_services/github/github_login_helper.py
class GitHubLoginHelper (line 20) | class GitHubLoginHelper(BaseLoginHelper):
method __init__ (line 25) | def __init__(
method login_and_save_state (line 43) | def login_and_save_state(self, **kwargs) -> bool:
method _get_token_scopes (line 102) | def _get_token_scopes(self, session: requests.Session) -> list:
method _verify_required_permissions (line 116) | def _verify_required_permissions(self, scopes: list) -> bool:
method _save_auth_state (line 142) | def _save_auth_state(self, auth_state: Dict[str, Any]):
method _get_current_timestamp (line 155) | def _get_current_timestamp(self) -> str:
method get_saved_auth_state (line 161) | def get_saved_auth_state(self) -> Optional[Dict[str, Any]]:
method is_token_valid (line 171) | def is_token_valid(self) -> bool:
method get_rate_limit_info (line 191) | def get_rate_limit_info(self) -> Dict[str, Any]:
method test_repository_access (line 214) | def test_repository_access(self, owner: str, repo: str) -> bool:
FILE: src/mcp_services/github/github_state_manager.py
class GitHubStateManager (line 21) | class GitHubStateManager(BaseStateManager):
method __init__ (line 26) | def __init__(
method _import_template_repo (line 137) | def _import_template_repo(
method _create_initial_state (line 438) | def _create_initial_state(self, task: "BaseTask") -> Optional[InitialS...
method _store_initial_state_info (line 501) | def _store_initial_state_info(self, task, state_info: InitialStateInfo...
method _cleanup_task_initial_state (line 505) | def _cleanup_task_initial_state(self, task) -> bool: # type: ignore[o...
method _cleanup_single_resource (line 509) | def _cleanup_single_resource(self, resource) -> bool: # type: ignore[...
method clean_up (line 514) | def clean_up(self, task=None, **kwargs) -> bool:
method _delete_repository (line 534) | def _delete_repository(self, owner: str, repo_name: str):
method _obfuscate_mentions (line 549) | def _obfuscate_mentions(self, text: str) -> str:
method _get_authenticated_user (line 589) | def _get_authenticated_user(self) -> str:
method _update_session_token (line 603) | def _update_session_token(self):
method _rotate_token (line 610) | def _rotate_token(self):
method _request_with_retry (line 621) | def _request_with_retry(
method select_initial_state_for_task (line 687) | def select_initial_state_for_task(self, task_category: str) -> Optiona...
method extract_repo_info_from_url (line 718) | def extract_repo_info_from_url(self, repo_url: str) -> tuple[str, str]:
method get_service_config_for_agent (line 736) | def get_service_config_for_agent(self) -> dict:
method set_verification_environment (line 754) | def set_verification_environment(self, messages_path: str = None) -> N...
method _enable_github_actions (line 775) | def _enable_github_actions(self, owner: str, repo_name: str):
method _disable_github_actions (line 800) | def _disable_github_actions(self, owner: str, repo_name: str):
method _disable_repository_notifications (line 823) | def _disable_repository_notifications(self, owner: str, repo_name: str):
method _download_and_extract_github_template (line 853) | def _download_and_extract_github_template(self, template_name: str) ->...
FILE: src/mcp_services/github/github_task_manager.py
class GitHubTask (line 26) | class GitHubTask(BaseTask):
class GitHubTaskManager (line 42) | class GitHubTaskManager(BaseTaskManager):
method __init__ (line 45) | def __init__(self, tasks_root: Path = None, task_suite: str = "standar...
method _create_task_from_files (line 68) | def _create_task_from_files(
method _get_verification_command (line 98) | def _get_verification_command(self, task: GitHubTask) -> List[str]:
method get_task_instruction (line 102) | def get_task_instruction(self, task: GitHubTask) -> str:
FILE: src/mcp_services/github/repo_exporter.py
function _make_session (line 54) | def _make_session(token: Optional[str] = None) -> requests.Session:
function _parse_repo (line 62) | def _parse_repo(url: str) -> tuple[str, str]:
function export_repository (line 75) | def export_repository(
FILE: src/mcp_services/github/repo_importer.py
function _make_session (line 48) | def _make_session(token: str) -> requests.Session:
function _create_target_repo (line 54) | def _create_target_repo(
function _get_authenticated_user (line 89) | def _get_authenticated_user(sess: requests.Session) -> str:
function _delete_repo (line 95) | def _delete_repo(sess: requests.Session, owner: str, repo: str):
function _list_refs (line 99) | def _list_refs(repo_dir: str) -> list[str]:
function _push_repo (line 109) | def _push_repo(
function _create_comment (line 162) | def _create_comment(
function _create_issue (line 176) | def _create_issue(
function _create_pull (line 207) | def _create_pull(
function _enable_github_actions (line 232) | def _enable_github_actions(sess: requests.Session, owner: str, repo_name...
function _disable_repository_notifications (line 253) | def _disable_repository_notifications(
function _set_default_branch (line 283) | def _set_default_branch(
function _remove_github_directory (line 304) | def _remove_github_directory(repo_path: Path, owner: str, repo_name: str...
function import_repository (line 334) | def import_repository(
FILE: src/mcp_services/github/token_pool.py
class GitHubTokenPool (line 15) | class GitHubTokenPool:
method __init__ (line 20) | def __init__(self, tokens: List[str]):
method get_next_token (line 34) | def get_next_token(self) -> str:
method get_current_token (line 45) | def get_current_token(self) -> str:
method pool_size (line 55) | def pool_size(self) -> int:
FILE: src/mcp_services/insforge/insforge_login_helper.py
class InsforgeLoginHelper (line 19) | class InsforgeLoginHelper(BaseLoginHelper):
method __init__ (line 22) | def __init__(
method login (line 43) | def login(self, **kwargs) -> bool:
method _save_connection_state (line 129) | def _save_connection_state(self, state: Dict[str, Any]):
method _get_current_timestamp (line 145) | def _get_current_timestamp(self) -> str:
method is_connected (line 151) | def is_connected(self) -> bool:
method get_connection_params (line 155) | def get_connection_params(self) -> Dict[str, Any]:
FILE: src/mcp_services/insforge/insforge_state_manager.py
class InsforgeStateManager (line 23) | class InsforgeStateManager(BaseStateManager):
method __init__ (line 26) | def __init__(
method _test_connection (line 64) | def _test_connection(self):
method _create_initial_state (line 86) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 157) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 169) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 225) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method _run_prepare_environment (line 243) | def _run_prepare_environment(self, task: BaseTask) -> bool:
method _get_timestamp (line 298) | def _get_timestamp(self) -> str:
method _drop_schema (line 304) | def _drop_schema(self, schema_name: str) -> None:
method _create_schema (line 330) | def _create_schema(self, schema_name: str) -> None:
method _get_all_tables (line 354) | def _get_all_tables(self) -> List[Dict[str, str]]:
method _drop_table (line 387) | def _drop_table(self, schema_name: str, table_name: str) -> None:
method _restore_from_backup (line 422) | def _restore_from_backup(self, category_name: str) -> bool:
method get_service_config_for_agent (line 483) | def get_service_config_for_agent(self) -> dict:
method set_verification_environment (line 503) | def set_verification_environment(self, messages_path: str = None) -> N...
FILE: src/mcp_services/insforge/insforge_task_manager.py
class InsforgeTask (line 22) | class InsforgeTask(BaseTask):
class InsforgeTaskManager (line 30) | class InsforgeTaskManager(BaseTaskManager):
method __init__ (line 33) | def __init__(self, tasks_root: Path = None):
method _create_task_from_files (line 49) | def _create_task_from_files(
method _get_verification_command (line 79) | def _get_verification_command(self, task: InsforgeTask) -> List[str]:
method run_verification (line 84) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method _format_task_instruction (line 103) | def _format_task_instruction(self, base_instruction: str) -> str:
FILE: src/mcp_services/notion/notion_login_helper.py
class NotionLoginHelper (line 28) | class NotionLoginHelper(BaseLoginHelper):
method __init__ (line 35) | def __init__(
method login (line 68) | def login(self) -> BrowserContext:
method close (line 116) | def close(self) -> None:
method _handle_headless_login (line 132) | def _handle_headless_login(self, context: BrowserContext) -> None:
method __enter__ (line 172) | def __enter__(self) -> "NotionLoginHelper":
method __exit__ (line 176) | def __exit__(self, exc_type, exc_val, exc_tb):
function main (line 180) | def main():
FILE: src/mcp_services/notion/notion_state_manager.py
class NotionStateManager (line 45) | class NotionStateManager(BaseStateManager):
method __init__ (line 50) | def __init__(
method _cleanup_eval_hub_orphans (line 120) | def _cleanup_eval_hub_orphans(self) -> None:
method _cleanup_source_hub_orphans (line 159) | def _cleanup_source_hub_orphans(self, exclude_page_ids: Optional[Set[s...
method _ensure_eval_parent_page_id (line 217) | def _ensure_eval_parent_page_id(self) -> Optional[str]:
method _ensure_source_hub_page_id (line 255) | def _ensure_source_hub_page_id(self) -> Optional[str]:
method _wait_for_database_ready (line 292) | def _wait_for_database_ready(
method _create_initial_state (line 345) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 411) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 423) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 455) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method _rename_initial_state_via_api (line 475) | def _rename_initial_state_via_api(
method _ensure_browser (line 491) | def _ensure_browser(self) -> Tuple[Browser, BrowserContext]:
method close (line 512) | def close(self) -> None:
method _recover_duplicate_via_ui (line 537) | def _recover_duplicate_via_ui(
method _move_current_page_to_env (line 630) | def _move_current_page_to_env(
method _category_to_initial_state_title (line 701) | def _category_to_initial_state_title(self, category: str) -> str:
method _extract_initial_state_id_from_url (line 705) | def _extract_initial_state_id_from_url(self, url: str) -> str:
method _get_slug_base (line 718) | def _get_slug_base(self, url: str) -> str:
method _is_valid_duplicate_url (line 726) | def _is_valid_duplicate_url(self, original_url: str, duplicated_url: s...
method _find_initial_state_by_title (line 735) | def _find_initial_state_by_title(self, title: str) -> Optional[Tuple[s...
method _duplicate_current_initial_state (line 801) | def _duplicate_current_initial_state(
method _cleanup_orphan_duplicate (line 1008) | def _cleanup_orphan_duplicate(
method _duplicate_initial_state_for_task (line 1072) | def _duplicate_initial_state_for_task(
method get_service_config_for_agent (line 1150) | def get_service_config_for_agent(self) -> dict:
FILE: src/mcp_services/notion/notion_task_manager.py
class NotionTask (line 26) | class NotionTask(BaseTask):
method __post_init__ (line 36) | def __post_init__(self):
method description_path (line 50) | def description_path(self) -> Path:
method verify_path (line 55) | def verify_path(self) -> Path:
method get_description (line 60) | def get_description(self) -> str:
class NotionTaskManager (line 67) | class NotionTaskManager(BaseTaskManager):
method __init__ (line 70) | def __init__(self, tasks_root: Path = None, task_suite: str = "standar...
method _get_service_directory_name (line 88) | def _get_service_directory_name(self) -> str:
method _create_task_from_files (line 92) | def _create_task_from_files(
method _get_verification_command (line 122) | def _get_verification_command(self, task: NotionTask) -> List[str]:
FILE: src/mcp_services/playwright/playwright_login_helper.py
class PlaywrightLoginHelper (line 24) | class PlaywrightLoginHelper(BaseLoginHelper):
method __init__ (line 34) | def __init__(
method login (line 71) | def login(self, **kwargs) -> bool:
method get_browser_context (line 115) | def get_browser_context(self) -> Optional[BrowserContext]:
method is_authenticated (line 124) | def is_authenticated(self) -> bool:
method get_credentials (line 133) | def get_credentials(self) -> dict:
method _save_browser_state (line 146) | def _save_browser_state(self) -> None:
method close (line 155) | def close(self) -> None:
FILE: src/mcp_services/playwright/playwright_state_manager.py
class PlaywrightStateManager (line 26) | class PlaywrightStateManager(BaseStateManager):
method __init__ (line 34) | def __init__(
method _create_initial_state (line 85) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 136) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 145) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 177) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method _get_context_options (line 192) | def _get_context_options(self, task: BaseTask) -> Dict[str, Any]:
method _setup_test_environment (line 215) | def _setup_test_environment(self, task: BaseTask) -> Optional[str]:
method get_current_context (line 250) | def get_current_context(self) -> Optional[BrowserContext]:
method get_test_page (line 254) | def get_test_page(self) -> Optional[Page]:
method navigate_to_test_url (line 265) | def navigate_to_test_url(self, task: BaseTask) -> Optional[Page]:
method get_service_config_for_agent (line 283) | def get_service_config_for_agent(self) -> dict:
method close_all (line 304) | def close_all(self) -> None:
method set_verification_environment (line 335) | def set_verification_environment(self, messages_path: str = None) -> N...
method __del__ (line 353) | def __del__(self):
FILE: src/mcp_services/playwright/playwright_task_manager.py
class PlaywrightTask (line 21) | class PlaywrightTask(BaseTask):
class PlaywrightTaskManager (line 26) | class PlaywrightTaskManager(BaseTaskManager):
method __init__ (line 29) | def __init__(self, tasks_root: Path = None, task_suite: str = "standar...
method _create_task_from_files (line 42) | def _create_task_from_files(
method _get_verification_command (line 71) | def _get_verification_command(self, task: BaseTask) -> List[str]:
method run_verification (line 75) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method _format_task_instruction (line 99) | def _format_task_instruction(self, base_instruction: str) -> str:
FILE: src/mcp_services/playwright_webarena/playwright_login_helper.py
class PlaywrightLoginHelper (line 21) | class PlaywrightLoginHelper(BaseLoginHelper):
method __init__ (line 28) | def __init__(
method login (line 51) | def login(self, **kwargs) -> bool:
method is_authenticated (line 59) | def is_authenticated(self) -> bool:
method get_credentials (line 62) | def get_credentials(self) -> dict:
method close (line 70) | def close(self) -> None:
FILE: src/mcp_services/playwright_webarena/playwright_state_manager.py
class DockerConfig (line 31) | class DockerConfig:
method base_url (line 42) | def base_url(self) -> str:
class PlaywrightStateManager (line 46) | class PlaywrightStateManager(BaseStateManager):
method __init__ (line 77) | def __init__(
method _run_cmd (line 125) | def _run_cmd(
method _image_exists (line 133) | def _image_exists(self, image: str) -> bool:
method _load_image_from_tar_if_needed (line 155) | def _load_image_from_tar_if_needed(self) -> None:
method _stop_and_remove_container (line 168) | def _stop_and_remove_container(self, name: str) -> None:
method _container_is_running (line 174) | def _container_is_running(self, name: str) -> bool:
method _port_open (line 182) | def _port_open(self, host: str, port: int) -> bool:
method _http_ready (line 189) | def _http_ready(self, url: str) -> bool:
method _get_entry_url (line 196) | def _get_entry_url(self) -> str:
method _wait_until_ready (line 203) | def _wait_until_ready(self) -> bool:
method _wait_for_mysql_ready (line 228) | def _wait_for_mysql_ready(self, max_wait_seconds: int = 120) -> bool:
method _wait_for_magento_ready (line 244) | def _wait_for_magento_ready(self, max_wait_seconds: int = 180) -> bool:
method _configure_shopping_post_start (line 260) | def _configure_shopping_post_start(self) -> None:
method _configure_shopping_admin_post_start (line 322) | def _configure_shopping_admin_post_start(self) -> None:
method _create_initial_state (line 403) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 486) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 494) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 512) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method get_service_config_for_agent (line 532) | def get_service_config_for_agent(self) -> dict:
method close_all (line 548) | def close_all(self) -> None:
method __del__ (line 559) | def __del__(self) -> None:
FILE: src/mcp_services/playwright_webarena/playwright_task_manager.py
class PlaywrightTaskManager (line 19) | class PlaywrightTaskManager(BaseTaskManager):
method __init__ (line 22) | def __init__(
method _create_task_from_files (line 38) | def _create_task_from_files(
method get_task_instruction (line 70) | def get_task_instruction(self, task: BaseTask) -> str:
method _get_verification_command (line 77) | def _get_verification_command(self, task: BaseTask) -> List[str]:
method run_verification (line 81) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method _format_task_instruction (line 94) | def _format_task_instruction(self, base_instruction: str) -> str:
FILE: src/mcp_services/postgres/postgres_login_helper.py
class PostgresLoginHelper (line 19) | class PostgresLoginHelper(BaseLoginHelper):
method __init__ (line 22) | def __init__(
method login (line 52) | def login(self, **kwargs) -> bool:
method _save_connection_state (line 111) | def _save_connection_state(self, state: Dict[str, Any]):
method _get_current_timestamp (line 127) | def _get_current_timestamp(self) -> str:
method is_connected (line 133) | def is_connected(self) -> bool:
method get_connection_params (line 137) | def get_connection_params(self) -> Dict[str, Any]:
FILE: src/mcp_services/postgres/postgres_state_manager.py
class PostgresStateManager (line 24) | class PostgresStateManager(BaseStateManager):
method __init__ (line 27) | def __init__(
method _test_connection (line 75) | def _test_connection(self):
method _setup_database (line 80) | def _setup_database(self):
method _setup_database (line 139) | def _setup_database(self):
method _create_initial_state (line 198) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 236) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 246) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 266) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method _database_exists (line 278) | def _database_exists(self, db_name: str) -> bool:
method _create_database_from_template (line 288) | def _create_database_from_template(self, new_db: str, template_db: str):
method _create_empty_database (line 310) | def _create_empty_database(self, db_name: str):
method _drop_database (line 322) | def _drop_database(self, db_name: str):
method _run_prepare_environment (line 347) | def _run_prepare_environment(self, db_name: str, task: BaseTask):
method _setup_task_specific_data (line 396) | def _setup_task_specific_data(self, db_name: str, task: BaseTask):
method _setup_basic_queries_data (line 417) | def _setup_basic_queries_data(self, cursor):
method _setup_data_manipulation_data (line 435) | def _setup_data_manipulation_data(self, cursor):
method _setup_table_operations_data (line 454) | def _setup_table_operations_data(self, cursor):
method _get_timestamp (line 464) | def _get_timestamp(self) -> str:
method get_service_config_for_agent (line 470) | def get_service_config_for_agent(self) -> dict:
FILE: src/mcp_services/postgres/postgres_task_manager.py
class PostgresTask (line 22) | class PostgresTask(BaseTask):
class PostgresTaskManager (line 32) | class PostgresTaskManager(BaseTaskManager):
method __init__ (line 35) | def __init__(self, tasks_root: Path = None, task_suite: str = "standar...
method _create_task_from_files (line 53) | def _create_task_from_files(
method _get_verification_command (line 83) | def _get_verification_command(self, task: PostgresTask) -> List[str]:
method run_verification (line 93) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method _format_task_instruction (line 112) | def _format_task_instruction(self, base_instruction: str) -> str:
FILE: src/mcp_services/supabase/supabase_login_helper.py
class SupabaseLoginHelper (line 17) | class SupabaseLoginHelper(BaseLoginHelper):
method __init__ (line 23) | def __init__(self):
method prepare_credentials (line 26) | def prepare_credentials(self) -> Dict[str, Any]:
method _get_key_from_supabase_status (line 62) | def _get_key_from_supabase_status(self) -> Optional[str]:
method test_credentials (line 92) | def test_credentials(self, credentials: Dict[str, Any]) -> bool:
method format_credentials_info (line 149) | def format_credentials_info(self, credentials: Dict[str, Any]) -> str:
FILE: src/mcp_services/supabase/supabase_state_manager.py
class SupabaseStateManager (line 24) | class SupabaseStateManager(BaseStateManager):
method __init__ (line 31) | def __init__(
method _test_connection (line 80) | def _test_connection(self):
method _create_initial_state (line 96) | def _create_initial_state(self, task: BaseTask) -> Optional[InitialSta...
method _store_initial_state_info (line 167) | def _store_initial_state_info(
method _cleanup_task_initial_state (line 179) | def _cleanup_task_initial_state(self, task: BaseTask) -> bool:
method _cleanup_single_resource (line 235) | def _cleanup_single_resource(self, resource: Dict[str, Any]) -> bool:
method _run_prepare_environment (line 250) | def _run_prepare_environment(self, task: BaseTask) -> bool:
method _get_timestamp (line 310) | def _get_timestamp(self) -> str:
method _drop_schema (line 315) | def _drop_schema(self, schema_name: str) -> None:
method _create_schema (line 338) | def _create_schema(self, schema_name: str) -> None:
method _get_all_tables (line 359) | def _get_all_tables(self) -> List[Dict[str, str]]:
method _drop_table (line 390) | def _drop_table(self, schema_name: str, table_name: str) -> None:
method _restore_from_backup (line 422) | def _restore_from_backup(self, category_name: str) -> bool:
method get_service_config_for_agent (line 482) | def get_service_config_for_agent(self) -> dict:
method set_verification_environment (line 506) | def set_verification_environment(self, messages_path: str = None) -> N...
FILE: src/mcp_services/supabase/supabase_task_manager.py
class SupabaseTask (line 23) | class SupabaseTask(BaseTask):
class SupabaseTaskManager (line 31) | class SupabaseTaskManager(BaseTaskManager):
method __init__ (line 38) | def __init__(self, tasks_root: Path = None):
method _create_task_from_files (line 54) | def _create_task_from_files(
method _get_verification_command (line 84) | def _get_verification_command(self, task: SupabaseTask) -> List[str]:
method run_verification (line 89) | def run_verification(self, task: BaseTask) -> subprocess.CompletedProc...
method _format_task_instruction (line 108) | def _format_task_instruction(self, base_instruction: str) -> str:
FILE: src/model_config.py
class ModelConfig (line 19) | class ModelConfig:
method __init__ (line 187) | def __init__(self, model_name: str):
method _get_model_info (line 214) | def _get_model_info(self, model_name: str) -> Dict[str, str]:
method get_supported_models (line 232) | def get_supported_models(cls) -> List[str]:
function main (line 237) | def main():
FILE: src/results_reporter.py
class TaskResult (line 22) | class TaskResult:
method status (line 55) | def status(self) -> str:
class EvaluationReport (line 61) | class EvaluationReport:
method success_rate (line 73) | def success_rate(self) -> float:
method total_input_tokens (line 80) | def total_input_tokens(self) -> int:
method total_output_tokens (line 89) | def total_output_tokens(self) -> int:
method total_tokens (line 98) | def total_tokens(self) -> int:
method total_reasoning_tokens (line 107) | def total_reasoning_tokens(self) -> int:
method avg_input_tokens (line 116) | def avg_input_tokens(self) -> float:
method avg_output_tokens (line 123) | def avg_output_tokens(self) -> float:
method avg_total_tokens (line 130) | def avg_total_tokens(self) -> float:
method avg_reasoning_tokens (line 137) | def avg_reasoning_tokens(self) -> float:
method total_task_execution_time (line 144) | def total_task_execution_time(self) -> float:
method total_agent_execution_time (line 151) | def total_agent_execution_time(self) -> float:
method get_category_stats (line 155) | def get_category_stats(self) -> Dict[str, Dict[str, Any]]:
class ResultsReporter (line 239) | class ResultsReporter:
method __init__ (line 242) | def __init__(self):
method save_messages_json (line 246) | def save_messages_json(self, messages: Any, output_path: Path) -> Path:
method save_meta_json (line 253) | def save_meta_json(
method save_model_summary (line 288) | def save_model_summary(self, report: EvaluationReport, output_path: Pa...
FILE: src/services.py
function get_service_definition (line 445) | def get_service_definition(service_name: str) -> dict:
function get_supported_mcp_services (line 452) | def get_supported_mcp_services() -> list:
FILE: tasks/filesystem/easy/file_context/file_splitting/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_split_directory_exists (line 17) | def verify_split_directory_exists(test_dir: Path) -> bool:
function verify_all_split_files_exist (line 32) | def verify_all_split_files_exist(test_dir: Path) -> bool:
function verify_similar_file_lengths (line 51) | def verify_similar_file_lengths(test_dir: Path) -> bool:
function verify_content_integrity (line 82) | def verify_content_integrity(test_dir: Path) -> bool:
function verify_no_extra_files (line 117) | def verify_no_extra_files(test_dir: Path) -> bool:
function main (line 132) | def main():
FILE: tasks/filesystem/easy/file_context/pattern_matching/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_answer_file_exists (line 17) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_answer_format (line 28) | def verify_answer_format(test_dir: Path) -> bool:
function find_30_plus_char_matches (line 60) | def find_30_plus_char_matches(test_dir: Path) -> set:
function verify_matches_are_correct (line 96) | def verify_matches_are_correct(test_dir: Path) -> bool:
function verify_files_exist (line 146) | def verify_files_exist(test_dir: Path) -> bool:
function main (line 175) | def main():
FILE: tasks/filesystem/easy/file_context/uppercase/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_uppercase_directory_exists (line 18) | def verify_uppercase_directory_exists(test_dir: Path) -> bool:
function verify_uppercase_files_exist (line 33) | def verify_uppercase_files_exist(test_dir: Path) -> bool:
function verify_uppercase_content (line 48) | def verify_uppercase_content(test_dir: Path) -> bool:
function verify_answer_file_exists (line 79) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_answer_format (line 91) | def verify_answer_format(test_dir: Path) -> bool:
function count_words_in_file (line 152) | def count_words_in_file(file_path: Path) -> int:
function verify_word_counts_are_correct (line 163) | def verify_word_counts_are_correct(test_dir: Path) -> bool:
function verify_all_files_are_included (line 211) | def verify_all_files_are_included(test_dir: Path) -> bool:
function main (line 245) | def main():
FILE: tasks/filesystem/easy/file_property/largest_rename/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_sg_jpg_not_exists (line 17) | def verify_sg_jpg_not_exists(test_dir: Path) -> bool:
function verify_largest_jpg_exists (line 28) | def verify_largest_jpg_exists(test_dir: Path) -> bool:
function main (line 39) | def main():
FILE: tasks/filesystem/easy/file_property/txt_merging/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function get_expected_contents (line 17) | def get_expected_contents():
function verify_merge_file_exists (line 25) | def verify_merge_file_exists(test_dir: Path) -> bool:
function verify_merge_file_contents (line 40) | def verify_merge_file_contents(test_dir: Path) -> bool:
function main (line 67) | def main():
FILE: tasks/filesystem/easy/folder_structure/structure_analysis/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_structure_analysis_file_exists (line 17) | def verify_structure_analysis_file_exists(test_dir: Path) -> bool:
function verify_structure_analysis_content (line 28) | def verify_structure_analysis_content(test_dir: Path) -> bool:
function main (line 54) | def main():
FILE: tasks/filesystem/easy/legal_document/file_reorganize/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_final_version_folder_exists (line 17) | def verify_final_version_folder_exists(test_dir: Path) -> bool:
function verify_target_file_exists (line 32) | def verify_target_file_exists(test_dir: Path) -> bool:
function verify_original_file_preserved (line 47) | def verify_original_file_preserved(test_dir: Path) -> bool:
function verify_only_v10_in_final_version (line 58) | def verify_only_v10_in_final_version(test_dir: Path) -> bool:
function main (line 83) | def main():
FILE: tasks/filesystem/easy/papers/papers_counting/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_count_file_exists (line 17) | def verify_count_file_exists(test_dir: Path) -> bool:
function verify_count_content (line 28) | def verify_count_content(test_dir: Path) -> bool:
function verify_actual_html_count (line 47) | def verify_actual_html_count(test_dir: Path) -> bool:
function main (line 59) | def main():
FILE: tasks/filesystem/easy/student_database/duplicate_name/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_namesake_file_exists (line 18) | def verify_namesake_file_exists(test_dir: Path) -> bool:
function parse_namesake_file (line 29) | def parse_namesake_file(test_dir: Path) -> dict:
function verify_against_expected_results (line 93) | def verify_against_expected_results(namesakes: dict) -> bool:
function main (line 148) | def main():
FILE: tasks/filesystem/easy/student_database/recommender_name/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_recommender_file_exists (line 17) | def verify_recommender_file_exists(test_dir: Path) -> bool:
function verify_recommender_content (line 28) | def verify_recommender_content(test_dir: Path) -> bool:
function main (line 47) | def main():
FILE: tasks/filesystem/standard/desktop/music_report/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_report_file_exists (line 43) | def verify_report_file_exists(test_dir: Path) -> bool:
function verify_file_content_structure (line 58) | def verify_file_content_structure(test_dir: Path) -> bool:
function verify_song_ranking_format (line 77) | def verify_song_ranking_format(test_dir: Path) -> bool:
function verify_song_ranking_order_with_tolerance (line 124) | def verify_song_ranking_order_with_tolerance(test_dir: Path) -> bool:
function verify_song_names_match_expected (line 152) | def verify_song_names_match_expected(test_dir: Path) -> bool:
function verify_popularity_scores_match_expected (line 183) | def verify_popularity_scores_match_expected(test_dir: Path) -> bool:
function verify_top_5_songs (line 221) | def verify_top_5_songs(test_dir: Path) -> bool:
function verify_no_extra_content (line 280) | def verify_no_extra_content(test_dir: Path) -> bool:
function main (line 299) | def main():
FILE: tasks/filesystem/standard/desktop/project_management/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_organized_projects_directory_exists (line 17) | def verify_organized_projects_directory_exists(test_dir: Path) -> bool:
function verify_directory_structure (line 32) | def verify_directory_structure(test_dir: Path) -> bool:
function verify_python_files_in_ml_projects (line 63) | def verify_python_files_in_ml_projects(test_dir: Path) -> bool:
function verify_csv_files_in_data_analysis (line 90) | def verify_csv_files_in_data_analysis(test_dir: Path) -> bool:
function verify_learning_md_files_in_resources (line 118) | def verify_learning_md_files_in_resources(test_dir: Path) -> bool:
function verify_entertainment_md_files_in_entertainment (line 146) | def verify_entertainment_md_files_in_entertainment(test_dir: Path) -> bool:
function verify_music_md_files_in_collections (line 170) | def verify_music_md_files_in_collections(test_dir: Path) -> bool:
function verify_progress_tracking_empty (line 192) | def verify_progress_tracking_empty(test_dir: Path) -> bool:
function verify_project_structure_file_exists (line 205) | def verify_project_structure_file_exists(test_dir: Path) -> bool:
function verify_file_counts (line 221) | def verify_file_counts(test_dir: Path) -> bool:
function main (line 249) | def main():
FILE: tasks/filesystem/standard/desktop/timeline_extraction/verify.py
function get_test_directory (line 13) | def get_test_directory() -> Path:
function verify_timeline_file_exists (line 20) | def verify_timeline_file_exists(test_dir: Path) -> bool:
function verify_timeline_file_readable (line 35) | def verify_timeline_file_readable(test_dir: Path) -> bool:
function verify_line_count (line 52) | def verify_line_count(test_dir: Path) -> bool:
function verify_line_format (line 71) | def verify_line_format(test_dir: Path) -> bool:
function verify_date_format (line 124) | def verify_date_format(test_dir: Path) -> bool:
function verify_chronological_order (line 157) | def verify_chronological_order(test_dir: Path) -> bool:
function verify_expected_entries (line 186) | def verify_expected_entries(test_dir: Path) -> bool:
function verify_no_duplicates (line 306) | def verify_no_duplicates(test_dir: Path) -> bool:
function verify_file_paths_exist (line 325) | def verify_file_paths_exist(test_dir: Path) -> bool:
function main (line 389) | def main():
FILE: tasks/filesystem/standard/desktop_template/budget_computation/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_total_budget_file_exists (line 18) | def verify_total_budget_file_exists(test_dir: Path) -> bool:
function verify_file_format (line 29) | def verify_file_format(test_dir: Path) -> bool:
function verify_expense_entries (line 73) | def verify_expense_entries(test_dir: Path) -> bool:
function verify_file_paths_and_counts (line 100) | def verify_file_paths_and_counts(test_dir: Path) -> bool:
function verify_individual_prices (line 176) | def verify_individual_prices(test_dir: Path) -> bool:
function verify_total_price (line 270) | def verify_total_price(test_dir: Path) -> bool:
function verify_total_calculation (line 300) | def verify_total_calculation(test_dir: Path) -> bool:
function main (line 330) | def main():
FILE: tasks/filesystem/standard/desktop_template/contact_information/verify.py
function get_test_directory (line 12) | def get_test_directory() -> Path:
function verify_contact_info_csv_exists (line 19) | def verify_contact_info_csv_exists(test_dir: Path) -> bool:
function verify_answer_txt_exists (line 30) | def verify_answer_txt_exists(test_dir: Path) -> bool:
function verify_csv_structure (line 41) | def verify_csv_structure(test_dir: Path) -> bool:
function verify_csv_content_accuracy (line 81) | def verify_csv_content_accuracy(test_dir: Path) -> bool:
function verify_csv_data_completeness (line 166) | def verify_csv_data_completeness(test_dir: Path) -> bool:
function verify_answer_content (line 202) | def verify_answer_content(test_dir: Path) -> bool:
function verify_file_locations (line 221) | def verify_file_locations(test_dir: Path) -> bool:
function main (line 238) | def main():
FILE: tasks/filesystem/standard/desktop_template/file_arrangement/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_folder_structure (line 17) | def verify_folder_structure(test_dir: Path) -> bool:
function verify_work_folder_files (line 34) | def verify_work_folder_files(test_dir: Path) -> bool:
function verify_life_folder_files (line 60) | def verify_life_folder_files(test_dir: Path) -> bool:
function verify_archives_folder_files (line 88) | def verify_archives_folder_files(test_dir: Path) -> bool:
function verify_temp_folder_files (line 113) | def verify_temp_folder_files(test_dir: Path) -> bool:
function verify_others_folder_files (line 136) | def verify_others_folder_files(test_dir: Path) -> bool:
function verify_required_files_in_correct_folders (line 149) | def verify_required_files_in_correct_folders(test_dir: Path) -> bool:
function verify_no_duplicate_required_files (line 198) | def verify_no_duplicate_required_files(test_dir: Path) -> bool:
function main (line 229) | def main():
FILE: tasks/filesystem/standard/file_context/duplicates_searching/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function calculate_file_hash (line 18) | def calculate_file_hash(file_path: Path) -> str:
function verify_duplicates_directory_exists (line 27) | def verify_duplicates_directory_exists(test_dir: Path) -> bool:
function get_expected_duplicate_groups (line 42) | def get_expected_duplicate_groups():
function get_expected_unique_files (line 62) | def get_expected_unique_files():
function verify_duplicate_files_moved (line 69) | def verify_duplicate_files_moved(test_dir: Path) -> bool:
function verify_unique_files_remain (line 89) | def verify_unique_files_remain(test_dir: Path) -> bool:
function verify_no_duplicate_files_in_original (line 106) | def verify_no_duplicate_files_in_original(test_dir: Path) -> bool:
function verify_content_integrity (line 124) | def verify_content_integrity(test_dir: Path) -> bool:
function verify_total_file_count (line 162) | def verify_total_file_count(test_dir: Path) -> bool:
function main (line 185) | def main():
FILE: tasks/filesystem/standard/file_context/file_merging/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function get_expected_files (line 17) | def get_expected_files() -> list:
function verify_merged_file_exists (line 34) | def verify_merged_file_exists(test_dir: Path) -> bool:
function verify_correct_files_selected (line 47) | def verify_correct_files_selected(test_dir: Path) -> bool:
function verify_alphabetical_order (line 73) | def verify_alphabetical_order(test_dir: Path) -> bool:
function verify_file_content_integrity (line 106) | def verify_file_content_integrity(test_dir: Path) -> bool:
function verify_filename_headers (line 158) | def verify_filename_headers(test_dir: Path) -> bool:
function main (line 179) | def main():
FILE: tasks/filesystem/standard/file_context/file_splitting/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_split_directory_exists (line 17) | def verify_split_directory_exists(test_dir: Path) -> bool:
function verify_all_split_files_exist (line 32) | def verify_all_split_files_exist(test_dir: Path) -> bool:
function verify_equal_file_lengths (line 51) | def verify_equal_file_lengths(test_dir: Path) -> bool:
function verify_content_integrity (line 75) | def verify_content_integrity(test_dir: Path) -> bool:
function verify_no_extra_files (line 110) | def verify_no_extra_files(test_dir: Path) -> bool:
function main (line 125) | def main():
FILE: tasks/filesystem/standard/file_context/pattern_matching/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_answer_file_exists (line 18) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_answer_format (line 29) | def verify_answer_format(test_dir: Path) -> bool:
function find_30_plus_char_matches (line 79) | def find_30_plus_char_matches(test_dir: Path) -> dict:
function verify_matches_are_correct (line 122) | def verify_matches_are_correct(test_dir: Path) -> bool:
function verify_match_length_is_30_plus (line 180) | def verify_match_length_is_30_plus(test_dir: Path) -> bool:
function verify_files_exist (line 227) | def verify_files_exist(test_dir: Path) -> bool:
function main (line 257) | def main():
FILE: tasks/filesystem/standard/file_context/uppercase/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_uppercase_directory_exists (line 18) | def verify_uppercase_directory_exists(test_dir: Path) -> bool:
function verify_uppercase_files_exist (line 33) | def verify_uppercase_files_exist(test_dir: Path) -> bool:
function verify_uppercase_content (line 48) | def verify_uppercase_content(test_dir: Path) -> bool:
function verify_answer_file_exists (line 79) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_answer_format (line 91) | def verify_answer_format(test_dir: Path) -> bool:
function count_words_in_file (line 152) | def count_words_in_file(file_path: Path) -> int:
function verify_word_counts_are_correct (line 163) | def verify_word_counts_are_correct(test_dir: Path) -> bool:
function verify_all_files_are_included (line 211) | def verify_all_files_are_included(test_dir: Path) -> bool:
function main (line 245) | def main():
FILE: tasks/filesystem/standard/file_property/size_classification/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function get_expected_classification (line 17) | def get_expected_classification():
function verify_directories_exist (line 25) | def verify_directories_exist(test_dir: Path) -> bool:
function verify_file_classification (line 41) | def verify_file_classification(test_dir: Path) -> bool:
function verify_no_files_in_root (line 72) | def verify_no_files_in_root(test_dir: Path) -> bool:
function verify_file_sizes (line 87) | def verify_file_sizes(test_dir: Path) -> bool:
function verify_total_file_count (line 115) | def verify_total_file_count(test_dir: Path) -> bool:
function main (line 136) | def main():
FILE: tasks/filesystem/standard/file_property/time_classification/verify.py
function get_test_directory (line 12) | def get_test_directory() -> Path:
function get_month_mapping (line 19) | def get_month_mapping():
function get_day_mapping (line 26) | def get_day_mapping():
function get_expected_directory_structure (line 35) | def get_expected_directory_structure():
function find_month_directory (line 48) | def find_month_directory(test_dir: Path, expected_month: str) -> Path:
function find_day_directory (line 60) | def find_day_directory(month_dir: Path, expected_day: str) -> Path:
function verify_directory_structure (line 72) | def verify_directory_structure(test_dir: Path) -> bool:
function verify_files_in_directories (line 96) | def verify_files_in_directories(test_dir: Path) -> bool:
function verify_metadata_analysis_files (line 133) | def verify_metadata_analysis_files(test_dir: Path) -> bool:
function verify_no_files_in_root (line 218) | def verify_no_files_in_root(test_dir: Path) -> bool:
function verify_total_file_count (line 233) | def verify_total_file_count(test_dir: Path) -> bool:
function main (line 258) | def main():
FILE: tasks/filesystem/standard/folder_structure/structure_analysis/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_structure_analysis_file_exists (line 18) | def verify_structure_analysis_file_exists(test_dir: Path) -> bool:
function verify_structure_analysis_file_readable (line 29) | def verify_structure_analysis_file_readable(test_dir: Path) -> bool:
function verify_subtask1_file_statistics (line 46) | def verify_subtask1_file_statistics(test_dir: Path) -> bool:
function verify_subtask2_depth_analysis (line 92) | def verify_subtask2_depth_analysis(test_dir: Path) -> bool:
function verify_subtask3_file_type_classification (line 160) | def verify_subtask3_file_type_classification(test_dir: Path) -> bool:
function verify_file_format (line 197) | def verify_file_format(test_dir: Path) -> bool:
function main (line 222) | def main():
FILE: tasks/filesystem/standard/folder_structure/structure_mirror/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_mirror_directory_exists (line 17) | def verify_mirror_directory_exists(test_dir: Path, mirror_path: Path) ->...
function verify_placeholder_file_exists (line 30) | def verify_placeholder_file_exists(mirror_path: Path, test_dir: Path) ->...
function verify_placeholder_content (line 45) | def verify_placeholder_content(mirror_path: Path, test_dir: Path) -> bool:
function verify_no_files_copied (line 72) | def verify_no_files_copied(test_dir: Path) -> bool:
function verify_mirror_structure_completeness (line 99) | def verify_mirror_structure_completeness(test_dir: Path) -> bool:
function main (line 164) | def main():
FILE: tasks/filesystem/standard/legal_document/dispute_review/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_output_file_exists (line 18) | def verify_output_file_exists(test_dir: Path) -> bool:
function verify_output_format (line 29) | def verify_output_format(test_dir: Path) -> bool:
function verify_expected_entries (line 61) | def verify_expected_entries(test_dir: Path) -> bool:
function verify_comment_count_accuracy (line 128) | def verify_comment_count_accuracy(test_dir: Path) -> bool:
function main (line 137) | def main():
FILE: tasks/filesystem/standard/legal_document/individual_comments/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_output_file_exists (line 18) | def verify_output_file_exists(test_dir: Path) -> bool:
function verify_csv_format (line 29) | def verify_csv_format(test_dir: Path) -> bool:
function verify_csv_content (line 66) | def verify_csv_content(test_dir: Path) -> bool:
function verify_data_accuracy (line 169) | def verify_data_accuracy(test_dir: Path) -> bool:
function verify_file_location (line 201) | def verify_file_location(test_dir: Path) -> bool:
function main (line 212) | def main():
FILE: tasks/filesystem/standard/legal_document/solution_tracing/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_output_file_exists (line 18) | def verify_output_file_exists(test_dir: Path) -> bool:
function verify_csv_format (line 29) | def verify_csv_format(test_dir: Path) -> bool:
function verify_csv_content (line 66) | def verify_csv_content(test_dir: Path) -> bool:
function verify_data_accuracy (line 167) | def verify_data_accuracy(test_dir: Path) -> bool:
function verify_file_location (line 209) | def verify_file_location(test_dir: Path) -> bool:
function main (line 220) | def main():
FILE: tasks/filesystem/standard/papers/author_folders/verify.py
function get_test_directory (line 14) | def get_test_directory() -> Path:
class ArxivHTMLParser (line 21) | class ArxivHTMLParser(HTMLParser):
method __init__ (line 24) | def __init__(self):
method handle_starttag (line 29) | def handle_starttag(self, tag, attrs):
function extract_paper_info (line 42) | def extract_paper_info(html_file: Path) -> tuple[List[str], str]:
function normalize_author_name (line 65) | def normalize_author_name(author: str) -> str:
function verify_directories_exist (line 95) | def verify_directories_exist(test_dir: Path) -> bool:
function analyze_papers (line 119) | def analyze_papers(test_dir: Path) -> tuple[Dict[str, List[Path]], Dict[...
function verify_frequent_authors (line 151) | def verify_frequent_authors(test_dir: Path, author_papers: Dict[str, Lis...
function verify_2025_authors (line 197) | def verify_2025_authors(test_dir: Path, author_2025_papers: Dict[str, Li...
function verify_original_files_intact (line 243) | def verify_original_files_intact(test_dir: Path) -> bool:
function verify_naming_convention (line 254) | def verify_naming_convention(test_dir: Path) -> bool:
function main (line 284) | def main():
FILE: tasks/filesystem/standard/papers/find_math_paper/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_answer_file_exists (line 17) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_original_file_removed (line 28) | def verify_original_file_removed(test_dir: Path) -> bool:
function main (line 39) | def main():
FILE: tasks/filesystem/standard/papers/organize_legacy_papers/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_papers_remain (line 18) | def verify_papers_remain(test_dir: Path) -> bool:
function verify_directory_structure (line 64) | def verify_directory_structure(test_dir: Path) -> bool:
function verify_papers_moved (line 89) | def verify_papers_moved(test_dir: Path) -> bool:
function verify_index_files (line 121) | def verify_index_files(test_dir: Path) -> bool:
function verify_author_extraction (line 154) | def verify_author_extraction(test_dir: Path) -> bool:
function verify_summary_file (line 271) | def verify_summary_file(test_dir: Path) -> bool:
function verify_sorting (line 323) | def verify_sorting(test_dir: Path) -> bool:
function main (line 367) | def main():
FILE: tasks/filesystem/standard/student_database/duplicate_name/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_namesake_file_exists (line 18) | def verify_namesake_file_exists(test_dir: Path) -> bool:
function parse_namesake_file (line 29) | def parse_namesake_file(test_dir: Path) -> dict:
function verify_against_expected_results (line 93) | def verify_against_expected_results(namesakes: dict) -> bool:
function main (line 152) | def main():
FILE: tasks/filesystem/standard/student_database/english_talent/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_qualified_students_file_exists (line 18) | def verify_qualified_students_file_exists(test_dir: Path) -> bool:
function verify_file_format (line 29) | def verify_file_format(test_dir: Path) -> bool:
function parse_qualified_students_file (line 94) | def parse_qualified_students_file(test_dir: Path) -> list:
function verify_student_count (line 139) | def verify_student_count(students: list) -> bool:
function verify_expected_students (line 151) | def verify_expected_students(students: list) -> bool:
function main (line 205) | def main():
FILE: tasks/filesystem/standard/student_database/gradebased_score/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_grade_summary_exists (line 18) | def verify_grade_summary_exists(test_dir: Path) -> bool:
function verify_grade_summary_readable (line 29) | def verify_grade_summary_readable(test_dir: Path) -> bool:
function extract_numbers_from_text (line 46) | def extract_numbers_from_text(text: str) -> list:
function verify_three_subjects_present (line 51) | def verify_three_subjects_present(test_dir: Path) -> bool:
function verify_grade_summary_content (line 77) | def verify_grade_summary_content(test_dir: Path) -> bool:
function main (line 132) | def main():
FILE: tasks/filesystem/standard/threestudio/code_locating/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_answer_file_exists (line 18) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_answer_format (line 29) | def verify_answer_format(test_dir: Path) -> bool:
function verify_file_path_structure (line 63) | def verify_file_path_structure(test_dir: Path) -> bool:
function verify_file_exists (line 88) | def verify_file_exists(test_dir: Path) -> bool:
function verify_zero123_guidance_content (line 121) | def verify_zero123_guidance_content(test_dir: Path) -> bool:
function main (line 176) | def main():
FILE: tasks/filesystem/standard/threestudio/output_analysis/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_answer_file_exists (line 18) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_required_strings (line 29) | def verify_required_strings(test_dir: Path) -> bool:
function verify_line_numbers (line 55) | def verify_line_numbers(test_dir: Path) -> bool:
function verify_file_path (line 83) | def verify_file_path(test_dir: Path) -> bool:
function main (line 104) | def main():
FILE: tasks/filesystem/standard/threestudio/requirements_completion/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_requirements_file_exists (line 18) | def verify_requirements_file_exists(test_dir: Path) -> bool:
function verify_requirements_file_readable (line 29) | def verify_requirements_file_readable(test_dir: Path) -> bool:
function verify_required_dependencies_present (line 46) | def verify_required_dependencies_present(test_dir: Path) -> bool:
function verify_specific_dependency_entries (line 82) | def verify_specific_dependency_entries(test_dir: Path) -> bool:
function verify_file_format (line 131) | def verify_file_format(test_dir: Path) -> bool:
function verify_no_duplicate_entries (line 151) | def verify_no_duplicate_entries(test_dir: Path) -> bool:
function main (line 170) | def main():
FILE: tasks/filesystem/standard/votenet/dataset_comparison/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_analysis_file_exists (line 18) | def verify_analysis_file_exists(test_dir: Path) -> bool:
function verify_analysis_format (line 29) | def verify_analysis_format(test_dir: Path) -> bool:
function verify_required_categories (line 100) | def verify_required_categories(test_dir: Path) -> bool:
function verify_category_counts (line 154) | def verify_category_counts(test_dir: Path) -> bool:
function verify_file_structure (line 232) | def verify_file_structure(test_dir: Path) -> bool:
function main (line 248) | def main():
FILE: tasks/filesystem/standard/votenet/debugging/verify.py
function get_test_directory (line 11) | def get_test_directory() -> Path:
function verify_answer_file_exists (line 18) | def verify_answer_file_exists(test_dir: Path) -> bool:
function verify_answer_format (line 29) | def verify_answer_format(test_dir: Path) -> bool:
function verify_file_path_structure (line 58) | def verify_file_path_structure(test_dir: Path) -> bool:
function verify_file_exists (line 81) | def verify_file_exists(test_dir: Path) -> bool:
function verify_bug_fix (line 102) | def verify_bug_fix(test_dir: Path) -> bool:
function main (line 169) | def main():
FILE: tasks/filesystem/standard/votenet/requirements_writing/verify.py
function get_test_directory (line 10) | def get_test_directory() -> Path:
function verify_requirements_file_exists (line 17) | def verify_requirements_file_exists(test_dir: Path) -> bool:
function verify_requirements_file_readable (line 28) | def verify_requirements_file_readable(test_dir: Path) -> bool:
function verify_required_dependencies_present (line 45) | def verify_required_dependencies_present(test_dir: Path) -> bool:
function verify_file_format (line 82) | def verify_file_format(test_dir: Path) -> bool:
function verify_no_duplicate_entries (line 108) | def verify_no_duplicate_entries(test_dir: Path) -> bool:
function main (line 128) | def main():
FILE: tasks/github/easy/build-your-own-x/close_commented_issues/verify.py
function _fetch_issue (line 12) | def _fetch_issue(org: str, token: str, number: int) -> Optional[dict]:
function verify (line 39) | def verify() -> bool:
FILE: tasks/github/easy/build-your-own-x/record_recent_commits/verify.py
function _request (line 14) | def _request(url: str, token: str) -> Optional[requests.Response]:
function _fetch_commits (line 35) | def _fetch_commits(org: str, token: str) -> Optional[List[dict]]:
function _find_issue (line 51) | def _find_issue(org: str, token: str) -> Optional[dict]:
function verify (line 87) | def verify() -> bool:
FILE: tasks/github/easy/claude-code/add_terminal_shortcuts_doc/verify.py
function _download_file (line 20) | def _download_file(org: str, token: str) -> Optional[str]:
function verify (line 50) | def verify() -> bool:
FILE: tasks/github/easy/claude-code/thank_docker_pr_author/verify.py
function _github_get (line 13) | def _github_get(org: str, token: str, path: str) -> Optional[Union[list,...
function verify (line 36) | def verify() -> bool:
FILE: tasks/github/easy/claude-code/triage_missing_tool_result_issue/verify.py
function _github_get (line 19) | def _github_get(org: str, token: str, path: str) -> Optional[dict]:
function verify (line 42) | def verify() -> bool:
FILE: tasks/github/easy/mcpmark-cicd/basic_ci_checks/verify.py
function _download_file (line 14) | def _download_file(org: str, token: str, path: str) -> Optional[str]:
function _line_index (line 44) | def _line_index(lines: List[str], needle: str) -> int:
function verify (line 51) | def verify() -> bool:
FILE: tasks/github/easy/mcpmark-cicd/issue_lint_guard/verify.py
function _download_file (line 19) | def _download_file(org: str, token: str, path: str) -> Optional[str]:
function _line_index (line 49) | def _line_index(lines: List[str], needle: str) -> int:
function _list_workflow_runs (line 56) | def _list_workflow_runs(org: str, token: str) -> Optional[List[dict]]:
function _wait_for_tracking_issue_run (line 83) | def _wait_for_tracking_issue_run(org: str, token: str) -> bool:
function verify (line 137) | def verify() -> bool:
FILE: tasks/github/easy/mcpmark-cicd/nightly_health_check/verify.py
function _download_file (line 14) | def _download_file(org: str, token: str, path: str) -> Optional[str]:
function _line_index (line 44) | def _line_index(lines: List[str], needle: str) -> int:
function verify (line 51) | def verify() -> bool:
FILE: tasks/github/easy/missing-semester/count_translations/verify.py
function _download_file (line 16) | def _download_file(org: str, token: str, path: str) -> Optional[str]:
function verify (line 46) | def verify() -> bool:
FILE: tasks/github/easy/missing-semester/find_ga_tracking_id/verify.py
function _download_file (line 19) | def _download_file(org: str, token: str) -> Optional[str]:
function verify (line 49) | def verify() -> bool:
FILE: tasks/github/standard/build_your_own_x/find_commit_date/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _get_file_content (line 28) | def _get_file_content(
function verify_task (line 50) | def verify_task() -> bool:
FILE: tasks/github/standard/build_your_own_x/find_rag_commit/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _get_file_content (line 28) | def _get_file_content(
function verify_task (line 50) | def verify_task() -> bool:
FILE: tasks/github/standard/claude-code/automated_changelog_generation/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _check_branch_exists (line 29) | def _check_branch_exists(
function _get_file_content (line 37) | def _get_file_content(
function _find_pr_by_title_keyword (line 59) | def _find_pr_by_title_keyword(
function _get_pr_merge_commit (line 74) | def _get_pr_merge_commit(
function _check_file_sections (line 90) | def _check_file_sections(content: str, required_sections: List[str]) -> ...
function _check_issue_references (line 97) | def _check_issue_references(text: str, issue_numbers: List[int]) -> int:
function _check_pr_references (line 108) | def _check_pr_references(text: str, pr_numbers: List[int]) -> int:
function verify (line 119) | def verify() -> bool:
FILE: tasks/github/standard/claude-code/claude_collaboration_analysis/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _get_file_content (line 29) | def _get_file_content(
function _parse_summary_statistics (line 51) | def _parse_summary_statistics(content: str) -> Dict:
function _parse_collaborators_table (line 88) | def _parse_collaborators_table(content: str) -> List[Dict]:
function verify_task (line 127) | def verify_task() -> bool:
FILE: tasks/github/standard/claude-code/critical_issue_hotfix_workflow/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _check_branch_exists (line 28) | def _check_branch_exists(
function _get_file_content (line 36) | def _get_file_content(
function _find_issue_by_title_keyword (line 58) | def _find_issue_by_title_keyword(
function _find_pr_by_title_keyword (line 74) | def _find_pr_by_title_keyword(
function _get_pr_by_number (line 90) | def _get_pr_by_number(
function _check_issue_references (line 100) | def _check_issue_references(text: str, reference_numbers: List[str]) -> ...
function _check_addresses_pattern (line 108) | def _check_addresses_pattern(pr_body: str, issue_numbers: List[str]) -> ...
function _get_issue_comments (line 119) | def _get_issue_comments(
function _get_pr_reviews (line 131) | def _get_pr_reviews(
function _check_title_keywords (line 141) | def _check_title_keywords(title: str, required_keywords: List[str]) -> b...
function _check_headings_and_keywords (line 146) | def _check_headings_and_keywords(
function _check_exact_file_content (line 155) | def _check_exact_file_content(content: str, expected_sections: List[str]...
function verify (line 160) | def verify() -> bool:
FILE: tasks/github/standard/claude-code/feature_commit_tracking/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _get_file_content (line 29) | def _get_file_content(
function _verify_commit_exists (line 51) | def _verify_commit_exists(
function _parse_feature_table (line 59) | def _parse_feature_table(content: str) -> List[Dict]:
function verify_task (line 109) | def verify_task() -> bool:
FILE: tasks/github/standard/claude-code/label_color_standardization/verify.py
function _get_github_api (line 8) | def _get_github_api(
function _check_branch_exists (line 28) | def _check_branch_exists(
function _check_file_content (line 36) | def _check_file_content(
function _parse_label_table (line 63) | def _parse_label_table(content: str) -> List[str]:
function _find_issue_by_title_keywords (line 94) | def _find_issue_by_title_keywords(
function _find_pr_by_title_keywords (line 116) | def _find_pr_by_title_keywords(
function _get_issue_comments (line 135) | def _get_issue_comments(
function verify (line 149) | def verify() -> bool:
FILE: tasks/github/standard/easyr1/advanced_branch_strategy/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _check_gitflow_branches (line 30) | def _check_gitflow_branches(headers: Dict[str, str]) -> bool:
function _check_protocol_fixes_file (line 52) | def _check_protocol_fixes_file(headers: Dict[str, str]) -> bool:
function _check_integration_workflow (line 86) | def _check_integration_workflow(headers: Dict[str, str]) -> Optional[Dict]:
function _check_release_branch_updated (line 108) | def _check_release_branch_updated(headers: Dict[str, str]) -> bool:
function _check_process_documentation (line 124) | def _check_process_documentation(headers: Dict[str, str]) -> Optional[Di...
function verify (line 177) | def verify() -> bool:
FILE: tasks/github/standard/easyr1/config_parameter_audit/verify.py
function _get_github_api (line 12) | def _get_github_api(
function _get_analysis_results (line 32) | def _get_analysis_results(headers: Dict[str, str]) -> Optional[Dict]:
function _verify_commit_data (line 52) | def _verify_commit_data(results: Dict, headers: Dict[str, str]) -> bool:
function _verify_parameter_changes (line 89) | def _verify_parameter_changes(results: Dict, headers: Dict[str, str]) ->...
function _get_all_issues_with_keywords (line 132) | def _get_all_issues_with_keywords(headers: Dict[str, str]) -> set:
function _verify_issue_references (line 166) | def _verify_issue_references(results: Dict, headers: Dict[str, str]) -> ...
function verify (line 241) | def verify() -> bool:
FILE: tasks/github/standard/easyr1/performance_regression_investigation/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _find_main_tracking_issue (line 30) | def _find_main_tracking_issue(headers: Dict[str, str]) -> Optional[Dict]:
function _check_branches_exist (line 47) | def _check_branches_exist(branch_names: List[str], headers: Dict[str, st...
function _check_sub_issues (line 57) | def _check_sub_issues(
function _check_issue_comments (line 100) | def _check_issue_comments(issue_number: int, headers: Dict[str, str]) ->...
function _find_analysis_pr (line 130) | def _find_analysis_pr(headers: Dict[str, str]) -> Optional[Dict]:
function verify (line 149) | def verify() -> bool:
FILE: tasks/github/standard/easyr1/qwen3_issue_management/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _search_github_issues (line 30) | def _search_github_issues(
function _check_qwen3_issues_reopened (line 48) | def _check_qwen3_issues_reopened(headers: Dict[str, str]) -> Tuple[bool,...
function _check_summary_issue (line 100) | def _check_summary_issue(
function verify (line 167) | def verify() -> bool:
FILE: tasks/github/standard/harmony/fix_conflict/verify.py
function _get_github_api (line 8) | def _get_github_api(
function _check_ci_file_exists (line 27) | def _check_ci_file_exists(
function _check_pr_comments (line 35) | def _check_pr_comments(
function _find_infrastructure_pr (line 59) | def _find_infrastructure_pr(
function verify (line 90) | def verify() -> bool:
FILE: tasks/github/standard/harmony/issue_pr_commit_workflow/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _check_branch_exists (line 28) | def _check_branch_exists(
function _check_file_content (line 36) | def _check_file_content(
function _find_issue_by_title (line 62) | def _find_issue_by_title(
function _find_pr_by_title (line 78) | def _find_pr_by_title(
function _check_issue_references (line 94) | def _check_issue_references(issue_body: str, reference_numbers: List[str...
function _check_pr_references (line 102) | def _check_pr_references(
function _get_issue_comments (line 120) | def _get_issue_comments(
function _get_pr_reviews (line 132) | def _get_pr_reviews(
function _check_issue_comment_references (line 142) | def _check_issue_comment_references(
function _check_title_keywords (line 159) | def _check_title_keywords(title: str, required_keywords: List[str]) -> b...
function _check_headings_and_content (line 164) | def _check_headings_and_content(
function _check_pr_review_content (line 173) | def _check_pr_review_content(reviews: List[Dict], keywords: List[str]) -...
function verify (line 182) | def verify() -> bool:
FILE: tasks/github/standard/harmony/issue_tagging_pr_closure/verify.py
function _get_github_api (line 8) | def _get_github_api(
function _check_branch_exists (line 27) | def _check_branch_exists(
function _check_file_content (line 35) | def _check_file_content(
function _find_issue_by_title_keywords (line 63) | def _find_issue_by_title_keywords(
function _find_pr_by_title_keywords (line 79) | def _find_pr_by_title_keywords(
function _check_labels (line 95) | def _check_labels(labels: List[Dict], required_labels: List[str]) -> bool:
function _check_headings_and_keywords (line 101) | def _check_headings_and_keywords(
function _check_issue_reference (line 112) | def _check_issue_reference(body: str, issue_number: int) -> bool:
function _get_issue_comments (line 119) | def _get_issue_comments(
function _get_pr_comments (line 131) | def _get_pr_comments(
function _check_pr_technical_comment (line 143) | def _check_pr_technical_comment(comments: List[Dict], keywords: List[str...
function _check_issue_comment_with_pr_ref (line 152) | def _check_issue_comment_with_pr_ref(
function verify (line 169) | def verify() -> bool:
FILE: tasks/github/standard/harmony/multi_branch_commit_aggregation/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _check_branch_exists (line 29) | def _check_branch_exists(branch_name: str, headers: Dict[str, str], org:...
function _get_file_content (line 35) | def _get_file_content(
function _check_branch_commits_json (line 51) | def _check_branch_commits_json(content: str) -> bool:
function _check_cross_branch_analysis (line 180) | def _check_cross_branch_analysis(content: str) -> bool:
function _check_merge_timeline (line 216) | def _check_merge_timeline(content: str) -> bool:
function verify_task (line 241) | def verify_task() -> bool:
FILE: tasks/github/standard/harmony/release_management_workflow/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _check_branch_exists (line 28) | def _check_branch_exists(
function _check_file_content (line 36) | def _check_file_content(
function _check_specific_file_content (line 62) | def _check_specific_file_content(
function _check_pr_merged (line 90) | def _check_pr_merged(
function _check_pr_squash_merged (line 116) | def _check_pr_squash_merged(
function verify (line 150) | def verify() -> bool:
FILE: tasks/github/standard/mcpmark-cicd/deployment_status_workflow/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _search_github_issues (line 28) | def _search_github_issues(
function _wait_for_workflow_completion (line 46) | def _wait_for_workflow_completion(
function _verify_workflow_runs (line 131) | def _verify_workflow_runs(
function _verify_deployment_issue (line 227) | def _verify_deployment_issue(
function verify (line 402) | def verify() -> bool:
FILE: tasks/github/standard/mcpmark-cicd/issue_management_workflow/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _search_github_issues (line 28) | def _search_github_issues(
function _wait_for_workflow_completion (line 46) | def _wait_for_workflow_completion(
function _find_issue_by_title (line 136) | def _find_issue_by_title(
function _check_issue_labels (line 151) | def _check_issue_labels(
function _check_issue_milestone (line 163) | def _check_issue_milestone(
function _check_issue_comments (line 181) | def _check_issue_comments(
function _find_epic_sub_issues (line 206) | def _find_epic_sub_issues(
function _check_epic_checklist (line 253) | def _check_epic_checklist(
function _verify_bug_issue (line 289) | def _verify_bug_issue(
function _verify_epic_issue (line 333) | def _verify_epic_issue(
function _verify_maintenance_issue (line 432) | def _verify_maintenance_issue(
function verify (line 478) | def verify() -> bool:
FILE: tasks/github/standard/mcpmark-cicd/linting_ci_workflow/verify.py
function _get_github_api (line 11) | def _get_github_api(
function _check_branch_exists (line 31) | def _check_branch_exists(
function _get_file_content (line 39) | def _get_file_content(
function _find_pr_by_title_keyword (line 61) | def _find_pr_by_title_keyword(
function _get_workflow_runs_for_pr (line 76) | def _get_workflow_runs_for_pr(
function _get_pr_commits (line 97) | def _get_pr_commits(
function _get_workflow_runs_for_commit (line 107) | def _get_workflow_runs_for_commit(
function verify (line 119) | def verify() -> bool:
FILE: tasks/github/standard/mcpmark-cicd/pr_automation_workflow/verify.py
function _get_github_api (line 10) | def _get_github_api(
function _post_github_api (line 29) | def _post_github_api(
function _patch_github_api (line 49) | def _patch_github_api(
function _get_file_content (line 69) | def _get_file_content(
function _find_pr_by_title (line 91) | def _find_pr_by_title(
function _wait_for_workflow_completion (line 106) | def _wait_for_workflow_completion(
function _verify_workflow_file (line 175) | def _verify_workflow_file(
function _verify_main_pr_merged (line 224) | def _verify_main_pr_merged(
function _verify_workflow_runs (line 263) | def _verify_workflow_runs(
function _verify_pr_comments (line 378) | def _verify_pr_comments(
function _create_test_pr (line 472) | def _create_test_pr(
function _close_pr (line 581) | def _close_pr(pr_number: int, headers: Dict[str, str], owner: str, repo:...
function _run_unit_tests (line 589) | def _run_unit_tests(
function verify (line 716) | def verify() -> bool:
FILE: tasks/github/standard/missing-semester/assign_contributor_labels/verify.py
function _get_github_api (line 8) | def _get_github_api(
function _get_issue_labels (line 28) | def _get_issue_labels(
function verify (line 43) | def verify() -> bool:
FILE: tasks/github/standard/missing-semester/find_legacy_name/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _get_file_content (line 29) | def _get_file_content(
function verify (line 51) | def verify() -> bool:
FILE: tasks/github/standard/missing-semester/find_salient_file/verify.py
function _get_github_api (line 9) | def _get_github_api(
function _get_file_content (line 29) | def _get_file_content(
function verify (line 51) | def verify() -> bool:
FILE: tasks/notion/easy/computer_science_student_dashboard/simple__code_snippets_go/verify.py
function _normalize (line 26) | def _normalize(text: str) -> str:
function _find_page (line 31) | def _find_page(notion: Client, main_id: str | None) -> str | None:
function _has_bold_header_text (line 45) | def _has_bold_header_text(block, text: str) -> bool:
function _collect_code_blocks (line 59) | def _collect_code_blocks(blocks):
function verify (line 78) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 118) | def main():
FILE: tasks/notion/easy/computer_science_student_dashboard/simple__study_session_tracker/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 121) | def main() -> None:
FILE: tasks/notion/easy/it_trouble_shooting_hub/simple__asset_retirement_migration/verify.py
function _get_database (line 7) | def _get_database(root_page_id: str, notion: Client, name: str) -> str |...
function _check_property (line 12) | def _check_property(props: Dict, name: str, expected_type: str) -> bool:
function verify (line 25) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 133) | def main():
FILE: tasks/notion/easy/japan_travel_planner/simple__remove_osaka_itinerary/verify.py
function get_page_title (line 5) | def get_page_title(page_result):
function get_page_time (line 15) | def get_page_time(page_result):
function get_page_group (line 26) | def get_page_group(page_result):
function get_page_day (line 36) | def get_page_day(page_result):
function parse_time_to_minutes (line 46) | def parse_time_to_minutes(time_str):
function verify (line 91) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 273) | def main():
FILE: tasks/notion/easy/online_resume/simple__skills_development_tracker/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 193) | def main():
FILE: tasks/notion/easy/python_roadmap/simple__expert_level_lessons/verify.py
function _get_database_ids (line 28) | def _get_database_ids(notion: Client, page_id: str) -> tuple[str | None,...
function _query_step_by_title (line 46) | def _query_step_by_title(notion: Client, database_id: str, title: str, *...
function verify (line 58) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 225) | def main() -> None:
FILE: tasks/notion/easy/self_assessment/simple__faq_column_layout/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 148) | def main():
FILE: tasks/notion/easy/standard_operating_procedure/simple__section_organization/verify.py
function _find_heading_indices (line 11) | def _find_heading_indices(blocks: list[dict]) -> tuple[int | None, int |...
function verify (line 31) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 67) | def main() -> None:
FILE: tasks/notion/easy/team_projects/simple__swap_tasks/verify.py
function verify (line 5) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 203) | def main():
FILE: tasks/notion/easy/toronto_guide/simple__change_color/verify.py
function _get_food_database_id (line 15) | def _get_food_database_id(notion: Client, page_id: str) -> str | None:
function verify (line 27) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 91) | def main() -> None:
FILE: tasks/notion/standard/company_in_a_box/employee_onboarding/verify.py
function _check_db_schema (line 7) | def _check_db_schema(db_props: Dict[str, Dict], required: Dict[str, str]...
function verify (line 25) | def verify(notion: Client, main_id: str | None = None) -> bool: # noqa:...
function main (line 167) | def main():
FILE: tasks/notion/standard/company_in_a_box/goals_restructure/verify.py
function _plain (line 13) | def _plain(block) -> str:
function _normalize_string (line 20) | def _normalize_string(s: str) -> str:
function _is_heading (line 24) | def _is_heading(block) -> bool:
function _is_toggle (line 28) | def _is_toggle(block) -> bool:
function _get_children (line 40) | def _get_children(notion: Client, block_id: str) -> List[dict]:
function verify (line 48) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 202) | def main():
FILE: tasks/notion/standard/company_in_a_box/quarterly_review_dashboard/verify.py
function _contains_keywords (line 7) | def _contains_keywords(text: str, keywords: List[str]) -> bool:
function verify (line 12) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 192) | def main():
FILE: tasks/notion/standard/computer_science_student_dashboard/code_snippets_go/verify.py
function _normalize (line 26) | def _normalize(text: str) -> str:
function _find_page (line 31) | def _find_page(notion: Client, main_id: str | None) -> str | None:
function _has_bold_header_text (line 45) | def _has_bold_header_text(block, text: str) -> bool:
function _go_column_order_correct (line 59) | def _go_column_order_correct(notion: Client, page_id: str) -> bool:
function _collect_code_blocks (line 97) | def _collect_code_blocks(blocks):
function verify (line 116) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 164) | def main():
FILE: tasks/notion/standard/computer_science_student_dashboard/courses_internships_relation/verify.py
function _locate_main_page (line 23) | def _locate_main_page(notion: Client, main_id: str | None) -> str | None:
function _locate_database (line 35) | def _locate_database(notion: Client, parent_page_id: str, db_title: str)...
function verify (line 45) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 227) | def main() -> None:
FILE: tasks/notion/standard/computer_science_student_dashboard/study_session_tracker/verify.py
function _normalize_string (line 7) | def _normalize_string(s: str) -> str:
function verify (line 12) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 162) | def main() -> None:
FILE: tasks/notion/standard/it_trouble_shooting_hub/asset_retirement_migration/verify.py
function _get_database (line 7) | def _get_database(root_page_id: str, notion: Client, name: str) -> str |...
function _check_property (line 12) | def _check_property(props: Dict, name: str, expected_type: str) -> bool:
function verify (line 25) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 216) | def main():
FILE: tasks/notion/standard/it_trouble_shooting_hub/security_audit_ticket/verify.py
function _get_title_text (line 7) | def _get_title_text(page_properties: dict) -> str:
function verify (line 17) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 166) | def main():
FILE: tasks/notion/standard/it_trouble_shooting_hub/verification_expired_update/verify.py
function _get_main_page_id (line 15) | def _get_main_page_id(notion: Client, main_id: str | None) -> str | None:
function _fetch_database_id (line 25) | def _fetch_database_id(
function _expired_pages (line 32) | def _expired_pages(notion: Client, db_id: str) -> list[dict]:
function _check_callout_present (line 51) | def _check_callout_present(notion: Client, page_id: str) -> bool:
function _find_request_page (line 76) | def _find_request_page(notion: Client, db_id: str) -> dict | None:
function _check_request_properties (line 86) | def _check_request_properties(page: dict) -> bool:
function _request_page_contains_mentions (line 97) | def _request_page_contains_mentions(
function verify (line 117) | def verify(notion: Client, main_id: str | None = None) -> bool:
function main (line 186) | def main():
FILE: tasks/notion/standard/japan_travel_planner/daily_itinerary_overview/verify.py
function verify_todo_database_correspondence (line 7) | def verify_todo_database_correspondence(all_blocks, activities_by_day, _):
function verify (line 106) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 360) | def main():
FILE: tasks/notion/standard/japan_travel_planner/packing_progress_summary/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 266) | def main():
FILE: tasks/notion/standard/japan_travel_planner/remove_osaka_itinerary/verify.py
function get_page_title (line 5) | def get_page_title(page_result):
function get_page_time (line 15) | def get_page_time(page_result):
function get_page_group (line 26) | def get_page_group(page_result):
function get_page_day (line 36) | def get_page_day(page_result):
function parse_time_to_minutes (line 46) | def parse_time_to_minutes(time_str):
function verify (line 91) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 273) | def main():
FILE: tasks/notion/standard/japan_travel_planner/restaurant_expenses_sync/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 184) | def main():
FILE: tasks/notion/standard/online_resume/layout_adjustment/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 318) | def main():
FILE: tasks/notion/standard/online_resume/projects_section_update/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 248) | def main():
FILE: tasks/notion/standard/online_resume/skills_development_tracker/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 252) | def main():
FILE: tasks/notion/standard/online_resume/work_history_addition/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 175) | def main():
FILE: tasks/notion/standard/python_roadmap/expert_level_lessons/verify.py
function verify (line 5) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 517) | def main():
FILE: tasks/notion/standard/python_roadmap/learning_metrics_dashboard/verify.py
function get_page_title_from_result (line 5) | def get_page_title_from_result(page_result):
function verify (line 20) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 345) | def main():
FILE: tasks/notion/standard/self_assessment/faq_column_layout/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 130) | def main():
FILE: tasks/notion/standard/self_assessment/hyperfocus_analysis_report/verify.py
function validate_comma_separated (line 8) | def validate_comma_separated(text: str, expected_items: list) -> bool:
function verify (line 26) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 403) | def main():
FILE: tasks/notion/standard/self_assessment/numbered_list_emojis/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 84) | def main():
FILE: tasks/notion/standard/standard_operating_procedure/deployment_process_sop/verify.py
function verify (line 6) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 463) | def main():
FILE: tasks/notion/standard/standard_operating_procedure/section_organization/verify.py
function verify (line 5) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 255) | def main():
FILE: tasks/notion/standard/team_projects/priority_tasks_table/verify.py
function _plain_text_from_cell (line 57) | def _plain_text_from_cell(cell):
function _parse_progress (line 62) | def _parse_progress(value: str):
function _parse_eng_hours (line 80) | def _parse_eng_hours(value: str):
function _parse_date (line 90) | def _parse_date(value: str):
function verify (line 98) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 210) | def main():
FILE: tasks/notion/standard/team_projects/swap_tasks/verify.py
function verify (line 5) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 203) | def main():
FILE: tasks/notion/standard/toronto_guide/change_color/verify.py
function get_page_title (line 5) | def get_page_title(page_result):
function get_page_tags (line 17) | def get_page_tags(page_result):
function verify (line 26) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 372) | def main():
FILE: tasks/notion/standard/toronto_guide/weekend_adventure_planner/verify.py
function verify (line 9) | def verify(notion: Client, main_id: str = None) -> bool:
function main (line 279) | def main():
FILE: tasks/playwright/standard/eval_web/cloudflare_turnstile_challenge/verify.py
function get_model_response (line 17) | def get_model_response():
function verify (line 53) | def verify():
function main (line 75) | def main():
FILE: tasks/playwright/standard/eval_web/extraction_table/verify.py
function get_model_response (line 23) | def get_model_response():
function extract_csv_from_response (line 59) | def extract_csv_from_response(response):
function validate_csv_data (line 98) | def validate_csv_data(csv_text):
function verify (line 165) | def verify():
function main (line 198) | def main():
FILE: tasks/playwright/standard/web_search/birth_of_arvinxu/verify.py
function get_working_directory (line 27) | def get_working_directory() -> Path:
function parse_ai_results (line 50) | def parse_ai_results(work_dir: Path) -> Dict[str, Any]:
function verify_task (line 96) | def verify_task() -> bool:
function main (line 117) | def main():
FILE: tasks/playwright/standard/web_search/r1_arxiv/verify.py
function get_working_directory (line 27) | def get_working_directory() -> Path:
function load_expected_content (line 50) | def load_expected_content() -> str:
function parse_ai_results (line 70) | def parse_ai_results(work_dir: Path) -> Dict[str, Any]:
function compare_content (line 112) | def compare_content(extracted: str, expected: str) -> Dict[str, Any]:
function verify_task (line 142) | def verify_task(work_dir: Path) -> bool:
function main (line 195) | def main():
FILE: tasks/playwright_webarena/easy/reddit/ai_data_analyst/verify.py
function parse_key_value_format (line 19) | def parse_key_value_format(text: str) -> dict:
function load_expected_values (line 33) | def load_expected_values() -> dict:
function ensure_logged_in (line 39) | async def ensure_logged_in(page) -> bool:
function fetch_submission_content (line 67) | async def fetch_submission_content(page):
function validate_submission (line 101) | def validate_submission(extracted: dict, expected: dict) -> bool:
function verify (line 132) | async def verify() -> bool:
function main (line 169) | def main():
FILE: tasks/playwright_webarena/easy/reddit/llm_research_summary/verify.py
function parse_key_value_format (line 22) | def parse_key_value_format(text: str) -> dict:
function normalize_text (line 36) | def normalize_text(value: str) -> str:
function load_expected_values (line 50) | def load_expected_values() -> dict:
function ensure_logged_in (line 56) | async def ensure_logged_in(page) -> bool:
function fetch_summary_body (line 84) | async def fetch_summary_body(page):
function validate_fields (line 116) | def validate_fields(extracted: dict, expected: dict) -> bool:
function verify (line 148) | async def verify() -> bool:
function main (line 184) | def main():
FILE: tasks/playwright_webarena/easy/reddit/movie_reviewer_analysis/verify.py
function parse_key_value_format (line 27) | def parse_key_value_format(text: str) -> dict:
function normalize_text (line 41) | def normalize_text(value: str) -> str:
function load_expected_values (line 55) | def load_expected_values() -> dict:
function ensure_logged_in (line 61) | async def ensure_logged_in(page) -> bool:
function fetch_summary_body (line 89) | async def fetch_summary_body(page):
function validate_summary (line 121) | def validate_summary(extracted: dict, expected: dict) -> bool:
function verify (line 153) | async def verify() -> bool:
function main (line 189) | def main():
FILE: tasks/playwright_webarena/easy/reddit/nba_statistics_analysis/verify.py
function parse_key_value_format (line 28) | def parse_key_value_format(text: str) -> dict:
function normalize_text (line 42) | def normalize_text(value: str) -> str:
function load_expected_values (line 56) | def load_expected_values() -> dict:
function ensure_logged_in (line 62) | async def ensure_logged_in(page) -> bool:
function fetch_summary_body (line 90) | async def fetch_summary_body(page):
function validate_summary (line 122) | def validate_summary(extracted: dict, expected: dict) -> bool:
function verify (line 154) | async def verify() -> bool:
function main (line 190) | def main():
FILE: tasks/playwright_webarena/easy/reddit/routine_tracker_forum/verify.py
function ensure_logged_in (line 17) | async def ensure_logged_in(page) -> bool:
function verify_post_body (line 45) | async def verify_post_body(page) -> bool:
function verify_listing_presence (line 70) | async def verify_listing_presence(page) -> bool:
function verify (line 82) | async def verify() -> bool:
function main (line 107) | def main():
FILE: tasks/playwright_webarena/easy/shopping_admin/fitness_promotion_strategy/verify.py
function get_model_response (line 8) | def get_model_response():
function parse_answer_format (line 37) | def parse_answer_format(text):
function load_expected_answer (line 68) | def load_expected_answer(label_path):
function compare_answers (line 88) | def compare_answers(model_answer, expected_answer):
function verify (line 215) | async def verify() -> bool:
function main (line 255) | def main():
FILE: tasks/playwright_webarena/easy/shopping_admin/ny_expansion_analysis/verify.py
function get_model_response (line 8) | def get_model_response():
function parse_answer_format (line 65) | def parse_answer_format(text):
function load_expected_answer (line 141) | def load_expected_answer(label_path):
function compare_answers (line 161) | def compare_answers(model_answer, expected_answer):
function verify (line 240) | async def verify() -> bool:
function main (line 296) | def main():
FILE: tasks/playwright_webarena/easy/shopping_admin/products_sales_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 42) | def parse_answer_format(text):
function load_expected_answer (line 105) | def load_expected_answer(label_path):
function compare_answers (line 126) | def compare_answers(model_answer, expected_answer):
function verify (line 189) | async def verify() -> bool:
function main (line 233) | def main():
FILE: tasks/playwright_webarena/easy/shopping_admin/sales_inventory_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 44) | def parse_answer_format(text):
function load_expected_answer (line 107) | def load_expected_answer(label_path):
function compare_answers (line 128) | def compare_answers(model_answer, expected_answer):
function verify (line 274) | async def verify() -> bool:
function main (line 332) | def main():
FILE: tasks/playwright_webarena/easy/shopping_admin/search_filtering_operations/verify.py
function verify (line 7) | def verify(messages):
FILE: tasks/playwright_webarena/standard/reddit/ai_data_analyst/verify.py
function parse_key_value_format (line 15) | def parse_key_value_format(text):
function normalize_text (line 52) | def normalize_text(text):
function verify (line 69) | async def verify() -> bool:
function main (line 320) | def main():
FILE: tasks/playwright_webarena/standard/reddit/budget_europe_travel/verify.py
function normalize_text (line 10) | def normalize_text(text):
function verify (line 27) | async def verify() -> bool:
function main (line 376) | def main():
FILE: tasks/playwright_webarena/standard/reddit/buyitforlife_research/verify.py
function parse_markdown_list_format (line 14) | def parse_markdown_list_format(text):
function normalize_text (line 37) | def normalize_text(text):
function check_account_login (line 54) | async def check_account_login(page):
function check_submission_exists (line 100) | async def check_submission_exists(page):
function verify (line 168) | async def verify() -> bool:
function main (line 303) | def main():
FILE: tasks/playwright_webarena/standard/reddit/llm_research_summary/verify.py
function parse_key_value_format (line 15) | def parse_key_value_format(text):
function normalize_text (line 53) | def normalize_text(text):
function verify (line 70) | async def verify() -> bool:
function main (line 316) | def main():
FILE: tasks/playwright_webarena/standard/reddit/movie_reviewer_analysis/verify.py
function parse_key_value_format (line 15) | def parse_key_value_format(text):
function normalize_text (line 53) | def normalize_text(text):
function verify (line 71) | async def verify() -> bool:
function main (line 307) | def main():
FILE: tasks/playwright_webarena/standard/reddit/nba_statistics_analysis/verify.py
function parse_key_value_format (line 15) | def parse_key_value_format(text):
function normalize_text (line 47) | def normalize_text(text):
function verify (line 67) | async def verify() -> bool:
function main (line 315) | def main():
FILE: tasks/playwright_webarena/standard/reddit/routine_tracker_forum/verify.py
function verify (line 14) | async def verify() -> bool:
function main (line 157) | def main():
FILE: tasks/playwright_webarena/standard/shopping/advanced_product_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 42) | def parse_answer_format(text):
function load_expected_answer (line 73) | def load_expected_answer(label_path):
function compare_answers (line 94) | def compare_answers(model_answer, expected_answer):
function verify (line 170) | async def verify() -> bool:
function main (line 213) | def main():
FILE: tasks/playwright_webarena/standard/shopping/gaming_accessories_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 43) | def parse_answer_format(text):
function load_expected_answer (line 74) | def load_expected_answer(label_path):
function compare_answers (line 95) | def compare_answers(model_answer, expected_answer):
function verify (line 166) | async def verify() -> bool:
function main (line 209) | def main():
FILE: tasks/playwright_webarena/standard/shopping/health_routine_optimization/verify.py
function get_model_response (line 10) | def get_model_response():
function parse_answer_format (line 43) | def parse_answer_format(text):
function load_expected_answer (line 73) | def load_expected_answer(label_path):
function compare_answers (line 103) | def compare_answers(model_answer, expected_answer):
function verify (line 150) | async def verify() -> bool:
function main (line 193) | def main():
FILE: tasks/playwright_webarena/standard/shopping/holiday_baking_competition/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 43) | def parse_answer_format(text):
function load_expected_answer (line 74) | def load_expected_answer(label_path):
function compare_answers (line 95) | def compare_answers(model_answer, expected_answer):
function verify (line 226) | async def verify() -> bool:
function main (line 269) | def main():
FILE: tasks/playwright_webarena/standard/shopping/multi_category_budget_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 43) | def parse_answer_format(text):
function load_expected_answer (line 74) | def load_expected_answer(label_path):
function compare_answers (line 95) | def compare_answers(model_answer, expected_answer):
function verify (line 199) | async def verify() -> bool:
function main (line 238) | def main():
FILE: tasks/playwright_webarena/standard/shopping/printer_keyboard_search/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 43) | def parse_answer_format(text):
function load_expected_answer (line 74) | def load_expected_answer(label_path):
function compare_answers (line 95) | def compare_answers(model_answer, expected_answer):
function verify (line 164) | async def verify() -> bool:
function main (line 207) | def main():
FILE: tasks/playwright_webarena/standard/shopping/running_shoes_purchase/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 43) | def parse_answer_format(text):
function load_expected_answer (line 74) | def load_expected_answer(label_path):
function compare_answers (line 95) | def compare_answers(model_answer, expected_answer):
function verify (line 174) | async def verify() -> bool:
function main (line 217) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/customer_segmentation_setup/verify.py
function get_model_response (line 16) | def get_model_response():
function parse_answer_format (line 49) | def parse_answer_format(text):
function load_expected_answer (line 80) | def load_expected_answer(label_path):
function compare_answers (line 101) | def compare_answers(model_answer, expected_answer):
function verify (line 131) | async def verify() -> bool:
function main (line 427) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/fitness_promotion_strategy/verify.py
function get_model_response (line 8) | def get_model_response():
function parse_answer_format (line 37) | def parse_answer_format(text):
function load_expected_answer (line 68) | def load_expected_answer(label_path):
function compare_answers (line 88) | def compare_answers(model_answer, expected_answer):
function verify (line 215) | async def verify() -> bool:
function main (line 255) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/marketing_customer_analysis/verify.py
function get_model_response (line 16) | def get_model_response():
function parse_answer_format (line 49) | def parse_answer_format(text):
function load_expected_answer (line 80) | def load_expected_answer(label_path):
function compare_answers (line 101) | def compare_answers(model_answer, expected_answer):
function verify (line 169) | async def verify() -> bool:
function main (line 393) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/ny_expansion_analysis/verify.py
function get_model_response (line 8) | def get_model_response():
function parse_answer_format (line 65) | def parse_answer_format(text):
function load_expected_answer (line 143) | def load_expected_answer(label_path):
function compare_answers (line 163) | def compare_answers(model_answer, expected_answer):
function verify (line 242) | async def verify() -> bool:
function main (line 298) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/products_sales_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 42) | def parse_answer_format(text):
function load_expected_answer (line 105) | def load_expected_answer(label_path):
function compare_answers (line 126) | def compare_answers(model_answer, expected_answer):
function verify (line 189) | async def verify() -> bool:
function main (line 233) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/sales_inventory_analysis/verify.py
function get_model_response (line 9) | def get_model_response():
function parse_answer_format (line 44) | def parse_answer_format(text):
function load_expected_answer (line 108) | def load_expected_answer(label_path):
function compare_answers (line 129) | def compare_answers(model_answer, expected_answer):
function verify (line 275) | async def verify() -> bool:
function main (line 333) | def main():
FILE: tasks/playwright_webarena/standard/shopping_admin/search_filtering_operations/verify.py
function verify (line 7) | def verify(messages):
FILE: tasks/postgres/easy/chinook/customer_data_migration_basic/verify.py
function get_connection_params (line 10) | def get_connection_params() -> dict:
function load_expected_customers (line 20) | def load_expected_customers():
function verify_migrated_customers (line 36) | def verify_migrated_customers(conn, expected_customers) -> bool:
function main (line 114) | def main():
FILE: tasks/postgres/easy/chinook/update_employee_info/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_employee_count_and_titles (line 38) | def verify_employee_count_and_titles(conn) -> bool:
function verify_specific_employees (line 68) | def verify_specific_employees(conn) -> bool:
function main (line 106) | def main():
FILE: tasks/postgres/easy/dvdrental/create_payment_index/verify.py
function get_connection_params (line 9) | def get_connection_params() -> dict:
function check_payment_customer_id_index (line 19) | def check_payment_customer_id_index(conn) -> bool:
function main (line 33) | def main():
FILE: tasks/postgres/easy/employees/department_summary_view/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 32) | def get_connection_params() -> dict:
function verify_materialized_views (line 42) | def verify_materialized_views(conn) -> bool:
function main (line 114) | def main():
FILE: tasks/postgres/easy/employees/employee_gender_statistics/verify.py
function rows_match (line 6) | def rows_match(actual_row, expected_row):
function get_connection_params (line 24) | def get_connection_params() -> dict:
function verify_gender_statistics_results (line 34) | def verify_gender_statistics_results(conn) -> bool:
function main (line 88) | def main():
FILE: tasks/postgres/easy/employees/employee_projects_basic/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 32) | def get_connection_params() -> dict:
function verify_project_data (line 43) | def verify_project_data(conn) -> bool:
function main (line 81) | def main():
FILE: tasks/postgres/easy/employees/hiring_year_summary/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_hiring_year_results (line 38) | def verify_hiring_year_results(conn) -> bool:
function main (line 92) | def main():
FILE: tasks/postgres/easy/lego/basic_security_setup/verify.py
function get_connection_params (line 12) | def get_connection_params() -> Dict[str, any]:
function verify_role_creation (line 22) | def verify_role_creation(conn) -> bool:
function verify_rls_enabled (line 71) | def verify_rls_enabled(conn) -> bool:
function main (line 91) | def main():
FILE: tasks/postgres/easy/lego/fix_data_inconsistencies/verify.py
function get_connection_params (line 13) | def get_connection_params() -> dict:
function fetch_candidate_part_row (line 24) | def fetch_candidate_part_row(cur) -> Optional[Tuple[int, str, str, int]]:
function get_mismatch_count (line 52) | def get_mismatch_count(cur) -> int:
function verify_data_consistency (line 82) | def verify_data_consistency(conn) -> bool:
function main (line 99) | def main():
FILE: tasks/postgres/easy/sports/create_performance_indexes/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 31) | def get_connection_params() -> dict:
function verify_performance_optimization (line 42) | def verify_performance_optimization(conn) -> bool:
function main (line 96) | def main():
FILE: tasks/postgres/standard/chinook/customer_data_migration/verify.py
function get_connection_params (line 10) | def get_connection_params() -> dict:
function load_expected_customers (line 20) | def load_expected_customers():
function verify_migrated_customers (line 36) | def verify_migrated_customers(conn, expected_customers) -> bool:
function main (line 114) | def main():
FILE: tasks/postgres/standard/chinook/employee_hierarchy_management/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_employee_count_and_titles (line 38) | def verify_employee_count_and_titles(conn) -> bool:
function verify_specific_employees (line 74) | def verify_specific_employees(conn) -> bool:
function verify_customer_assignments (line 118) | def verify_customer_assignments(conn) -> bool:
function verify_performance_table (line 148) | def verify_performance_table(conn) -> bool:
function verify_employee_deletion_and_promotion (line 191) | def verify_employee_deletion_and_promotion(conn) -> bool:
function verify_salary_column (line 219) | def verify_salary_column(conn) -> bool:
function main (line 245) | def main():
FILE: tasks/postgres/standard/chinook/sales_and_music_charts/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_monthly_sales_results (line 38) | def verify_monthly_sales_results(conn) -> bool:
function verify_music_charts_results (line 102) | def verify_music_charts_results(conn) -> bool:
function main (line 200) | def main():
FILE: tasks/postgres/standard/dvdrental/customer_analysis_fix/verify.py
function get_connection_params (line 10) | def get_connection_params() -> dict:
function rows_match (line 20) | def rows_match(actual_row, expected_row):
function verify_customer_analysis_fixed_table (line 35) | def verify_customer_analysis_fixed_table(conn) -> bool:
function main (line 192) | def main():
FILE: tasks/postgres/standard/dvdrental/customer_analytics_optimization/verify.py
function get_connection_params (line 9) | def get_connection_params() -> dict:
function check_payment_customer_id_index (line 19) | def check_payment_customer_id_index(conn) -> bool:
function main (line 33) | def main():
FILE: tasks/postgres/standard/dvdrental/film_inventory_management/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 25) | def get_connection_params() -> dict:
function check_new_films (line 35) | def check_new_films(conn) -> bool:
function check_inventory_records (line 70) | def check_inventory_records(conn) -> bool:
function check_available_films_table (line 107) | def check_available_films_table(conn) -> bool:
function check_inventory_cleanup (line 148) | def check_inventory_cleanup(conn) -> bool:
function check_summary_table (line 170) | def check_summary_table(conn) -> bool:
function main (line 212) | def main():
FILE: tasks/postgres/standard/employees/employee_demographics_report/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_gender_statistics_results (line 38) | def verify_gender_statistics_results(conn) -> bool:
function verify_age_group_results (line 92) | def verify_age_group_results(conn) -> bool:
function verify_birth_month_results (line 163) | def verify_birth_month_results(conn) -> bool:
function verify_hiring_year_results (line 223) | def verify_hiring_year_results(conn) -> bool:
function main (line 277) | def main():
FILE: tasks/postgres/standard/employees/employee_performance_analysis/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_performance_results (line 38) | def verify_performance_results(conn) -> bool:
function verify_department_results (line 130) | def verify_department_results(conn) -> bool:
function main (line 189) | def main():
FILE: tasks/postgres/standard/employees/employee_project_tracking/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 32) | def get_connection_params() -> dict:
function verify_table_structures (line 42) | def verify_table_structures(conn) -> bool:
function verify_indexes (line 86) | def verify_indexes(conn) -> bool:
function verify_project_data (line 105) | def verify_project_data(conn) -> bool:
function verify_assignment_data (line 143) | def verify_assignment_data(conn) -> bool:
function verify_milestone_data (line 218) | def verify_milestone_data(conn) -> bool:
function main (line 258) | def main():
FILE: tasks/postgres/standard/employees/employee_retention_analysis/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_retention_analysis_results (line 38) | def verify_retention_analysis_results(conn) -> bool:
function verify_high_risk_results (line 86) | def verify_high_risk_results(conn) -> bool:
function verify_turnover_trend_results (line 173) | def verify_turnover_trend_results(conn) -> bool:
function main (line 248) | def main():
FILE: tasks/postgres/standard/employees/executive_dashboard_automation/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 32) | def get_connection_params() -> dict:
function verify_materialized_views (line 42) | def verify_materialized_views(conn) -> bool:
function verify_stored_procedures (line 339) | def verify_stored_procedures(conn) -> bool:
function verify_triggers (line 369) | def verify_triggers(conn) -> bool:
function verify_procedure_execution (line 430) | def verify_procedure_execution(conn) -> bool:
function verify_indexes (line 485) | def verify_indexes(conn) -> bool:
function main (line 506) | def main():
FILE: tasks/postgres/standard/employees/management_structure_analysis/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 28) | def get_connection_params() -> dict:
function verify_manager_profile_results (line 38) | def verify_manager_profile_results(conn) -> bool:
function verify_department_leadership_results (line 115) | def verify_department_leadership_results(conn) -> bool:
function verify_management_transitions_results (line 180) | def verify_management_transitions_results(conn) -> bool:
function verify_span_of_control_results (line 257) | def verify_span_of_control_results(conn) -> bool:
function main (line 324) | def main():
FILE: tasks/postgres/standard/lego/consistency_enforcement/verify.py
function get_connection_params (line 13) | def get_connection_params() -> dict:
function fetch_candidate_part_row (line 24) | def fetch_candidate_part_row(cur) -> Optional[Tuple[int, str, str, int]]:
function get_mismatch_count (line 52) | def get_mismatch_count(cur) -> int:
function verify_data_consistency (line 82) | def verify_data_consistency(conn) -> bool:
function verify_constraint_triggers_exist (line 99) | def verify_constraint_triggers_exist(conn) -> bool:
function verify_violation_is_blocked (line 133) | def verify_violation_is_blocked(conn) -> bool:
function verify_deferred_transaction_is_allowed (line 169) | def verify_deferred_transaction_is_allowed(conn) -> bool:
function main (line 221) | def main():
FILE: tasks/postgres/standard/lego/database_security_policies/verify.py
function get_connection_params (line 12) | def get_connection_params() -> Dict[str, any]:
function verify_role_creation (line 22) | def verify_role_creation(conn) -> bool:
function verify_rls_enabled (line 71) | def verify_rls_enabled(conn) -> bool:
function verify_rls_policies (line 91) | def verify_rls_policies(conn) -> bool:
function verify_theme_function (line 115) | def verify_theme_function(conn) -> bool:
function test_theme_analyst_access (line 148) | def test_theme_analyst_access(conn) -> bool:
function main (line 214) | def main():
FILE: tasks/postgres/standard/lego/transactional_inventory_transfer/verify.py
function get_connection_params (line 19) | def get_connection_params() -> dict:
function get_inventory_part_quantity (line 30) | def get_inventory_part_quantity(conn, inventory_id: int, part_num: str, ...
function verify_system_components (line 44) | def verify_system_components(conn) -> bool:
function verify_successful_transfer_with_audit (line 82) | def verify_successful_transfer_with_audit(conn) -> bool:
function verify_new_part_transfer (line 168) | def verify_new_part_transfer(conn) -> bool:
function verify_business_rule_validation (line 219) | def verify_business_rule_validation(conn) -> bool:
function verify_insufficient_quantity_error (line 299) | def verify_insufficient_quantity_error(conn) -> bool:
function verify_invalid_inventory_error (line 343) | def verify_invalid_inventory_error(conn) -> bool:
function verify_audit_logging (line 381) | def verify_audit_logging(conn) -> bool:
function verify_exact_quantity_transfer (line 461) | def verify_exact_quantity_transfer(conn) -> bool:
function main (line 521) | def main():
FILE: tasks/postgres/standard/security/rls_business_access/ground_truth.sql
type idx_users_is_public (line 10) | CREATE INDEX IF NOT EXISTS idx_users_is_public ON users(is_public)
type idx_channels_owner_id (line 13) | CREATE INDEX IF NOT EXISTS idx_channels_owner_id ON channels(owner_id)
type idx_channels_is_public (line 14) | CREATE INDEX IF NOT EXISTS idx_channels_is_public ON channels(is_public)
type idx_channel_moderators_channel_user (line 17) | CREATE INDEX IF NOT EXISTS idx_channel_moderators_channel_user ON channe...
type idx_channel_moderators_user (line 18) | CREATE INDEX IF NOT EXISTS idx_channel_moderators_user ON channel_modera...
type idx_posts_channel_id (line 21) | CREATE INDEX IF NOT EXISTS idx_posts_channel_id ON posts(channel_id)
type idx_posts_author_id (line 22) | CREATE INDEX IF NOT EXISTS idx_posts_author_id ON posts(author_id)
type idx_posts_created_at (line 23) | CREATE INDEX IF NOT EXISTS idx_posts_created_at ON posts(created_at)
type idx_comments_post_id (line 26) | CREATE INDEX IF NOT EXISTS idx_comments_post_id ON comments(post_id)
type idx_comments_author_id (line 27) | CREATE INDEX IF NOT EXISTS idx_comments_author_id ON comments(author_id)
type idx_comments_created_at (line 28) | CREATE INDEX IF NOT EXISTS idx_comments_created_at ON comments(created_at)
FILE: tasks/postgres/standard/security/rls_business_access/prepare_environment.py
function setup_rls_environment (line 8) | def setup_rls_environment():
FILE: tasks/postgres/standard/security/rls_business_access/verify.py
function verify_rls_implementation (line 8) | def verify_rls_implementation():
FILE: tasks/postgres/standard/security/user_permission_audit/ground_truth.sql
type security_audit_results (line 106) | CREATE TABLE security_audit_results (
type security_audit_details (line 114) | CREATE TABLE security_audit_details (
type temp_user_discovery (line 127) | CREATE TEMP TABLE temp_user_discovery AS
type temp_role_memberships (line 155) | CREATE TEMP TABLE temp_role_memberships AS
type temp_current_permissions (line 172) | CREATE TEMP TABLE temp_current_permissions AS
FILE: tasks/postgres/standard/security/user_permission_audit/prepare_environment.py
function create_business_tables (line 164) | def create_business_tables(cur):
function create_users (line 314) | def create_users(cur):
function grant_expected_permissions (line 319) | def grant_expected_permissions(cur):
function grant_excessive_permissions (line 328) | def grant_excessive_permissions(cur):
function revoke_permissions (line 333) | def revoke_permissions(cur):
function grant_sequence_permissions (line 338) | def grant_sequence_permissions(cur):
function setup_security_environment (line 344) | def setup_security_environment():
FILE: tasks/postgres/standard/security/user_permission_audit/verify.py
function verify_security_audit (line 6) | def verify_security_audit():
FILE: tasks/postgres/standard/sports/baseball_player_analysis/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 25) | def get_connection_params() -> dict:
function verify_baseball_player_analysis_table (line 35) | def verify_baseball_player_analysis_table(conn) -> bool:
function main (line 144) | def main():
FILE: tasks/postgres/standard/sports/participant_report_optimization/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 31) | def get_connection_params() -> dict:
function verify_report_data (line 41) | def verify_report_data(conn) -> bool:
function verify_performance_optimization (line 89) | def verify_performance_optimization(conn) -> bool:
function main (line 143) | def main():
FILE: tasks/postgres/standard/sports/team_roster_management/verify.py
function rows_match (line 10) | def rows_match(actual_row, expected_row):
function get_connection_params (line 31) | def get_connection_params() -> dict:
function verify_player_evaluation_table (line 41) | def verify_player_evaluation_table(conn) -> bool:
function verify_injury_status_table (line 156) | def verify_injury_status_table(conn) -> bool:
function verify_summary_table (line 215) | def verify_summary_table(conn) -> bool:
function main (line 279) | def main():
FILE: tasks/postgres/standard/vectors/dba_vector_analysis/ground_truth.sql
type expected_vector_column_inventory (line 35) | CREATE TABLE IF NOT EXISTS expected_vector_column_inventory (
type expected_vector_storage_analysis (line 52) | CREATE TABLE IF NOT EXISTS expected_vector_storage_analysis (
type expected_vector_index_analysis (line 70) | CREATE TABLE IF NOT EXISTS expected_vector_index_analysis (
type vector_storage_analysis (line 85) | CREATE TABLE vector_storage_analysis (
type vector_index_analysis (line 123) | CREATE TABLE vector_index_analysis (
type vector_data_quality (line 152) | CREATE TABLE vector_data_quality (
type vector_analysis_columns (line 203) | CREATE TABLE vector_analysis_columns (
type vector_analysis_storage_consumption (line 235) | CREATE TABLE vector_analysis_storage_consumption (
type vector_analysis_indices (line 282) | CREATE TABLE vector_analysis_indices (
FILE: tasks/postgres/standard/vectors/dba_vector_analysis/prepare_environment.py
function prepare_environment (line 19) | def prepare_environment():
FILE: tasks/postgres/standard/vectors/dba_vector_analysis/verify.py
function get_connection_params (line 17) | def get_connection_params():
function verify_vector_analysis_columns (line 28) | def verify_vector_analysis_columns(conn) -> Dict[str, Any]:
function verify_vector_analysis_storage_consumption (line 105) | def verify_vector_analysis_storage_consumption(conn) -> Dict[str, Any]:
function verify_vector_analysis_indices (line 180) | def verify_vector_analysis_indices(conn) -> Dict[str, Any]:
function verify_no_extra_analysis_tables (line 253) | def verify_no_extra_analysis_tables(conn) -> Dict[str, Any]:
function main (line 285) | def main():
FILE: tasks/postgres/standard/vectors/vectors_setup.py
function get_connection_params (line 19) | def get_connection_params():
function generate_mock_embedding (line 30) | def generate_mock_embedding(dimensions: int = 1536) -> List[float]:
function create_vector_extension (line 41) | def create_vector_extension():
function create_vector_tables (line 61) | def create_vector_tables():
function create_vector_indexes (line 168) | def create_vector_indexes():
function insert_sample_data (line 241) | def insert_sample_data():
function verify_vector_setup (line 382) | def verify_vector_setup():
function prepare_vector_environment (line 461) | def prepare_vector_environment():
FILE: tasks/utils/notion_utils.py
function get_notion_client (line 7) | def get_notion_client():
function _find_object (line 20) | def _find_object(notion: Client, title: str, object_type: str):
function find_page (line 63) | def find_page(notion: Client, page_title: str):
function get_page_by_id (line 68) | def get_page_by_id(notion: Client, page_id: str):
function find_page_by_id (line 76) | def find_page_by_id(notion: Client, page_id: str):
function find_database_by_id (line 85) | def find_database_by_id(notion: Client, database_id: str):
function find_page_or_database_by_id (line 94) | def find_page_or_database_by_id(notion: Client, object_id: str):
function find_database (line 116) | def find_database(notion: Client, db_title: str):
function find_database_in_block (line 121) | def find_database_in_block(notion: Client, block_id: str, db_title: str):
function get_all_blocks_recursively (line 139) | def get_all_blocks_recursively(notion: Client, block_id: str):
function get_block_plain_text (line 160) | def get_block_plain_text(block):
FILE: tasks/utils/postgres_utils.py
function get_connection_params (line 19) | def get_connection_params() -> dict:
function execute_schema_sql (line 30) | def execute_schema_sql(conn, schema_sql: str):
function load_csv_to_table (line 38) | def load_csv_to_table(
function insert_data_from_dict (line 83) | def insert_data_from_dict(conn, table_name: str, data: List[Dict[str, An...
function create_table_with_data (line 111) | def create_table_with_data(
function setup_database_with_config (line 140) | def setup_database_with_config(setup_config: Dict[str, Any]):
Condensed preview — 670 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (3,543K chars).
[
{
"path": ".dockerignore",
"chars": 830,
"preview": "# Git\n.git\n.gitignore\n\n# Python\n__pycache__\n*.pyc\n*.pyo\n*.pyd\n.Python\n*.egg\n*.egg-info/\ndist/\nbuild/\n.eggs/\n*.so\n\n# Virt"
},
{
"path": ".editorconfig",
"chars": 276,
"preview": "root = true\n\n; Always use Unix style new lines with new line ending on every file and trim whitespace\n[*]\nend_of_line = "
},
{
"path": ".gitattributes",
"chars": 122,
"preview": "# SCM syntax highlighting & preventing 3-way merges\npixi.lock merge=binary linguist-language=YAML linguist-generated=tru"
},
{
"path": ".github/ISSUE_TEMPLATE/1_bug_report.yml",
"chars": 848,
"preview": "name: '🐛 Bug Report'\ndescription: 'Report an bug'\nlabels: ['unconfirm']\ntype: Bug\nbody:\n - type: textarea\n attribute"
},
{
"path": ".github/ISSUE_TEMPLATE/2_feature_request.yml",
"chars": 667,
"preview": "name: '🌠 Feature Request'\ndescription: 'Suggest an idea'\ntitle: '[Request] '\ntype: Feature\nbody:\n - type: textarea\n "
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"chars": 173,
"preview": "contact_links:\n - name: Questions and ideas\n url: https://github.com/eval-sys/mcpmark/discussions/new/choose\n abo"
},
{
"path": ".github/PULL_REQUEST_TEMPLATE.md",
"chars": 373,
"preview": "#### Change Type\n\n<!-- For change type, change [ ] to [x]. -->\n\n- [ ] ✨ feat\n- [ ] 🐛 fix\n- [ ] ♻️ refactor\n- [ ] 💄 style"
},
{
"path": ".github/scripts/pr-comment.js",
"chars": 2554,
"preview": "/**\n * Generate or update PR comment with Docker build info\n */\nmodule.exports = async ({ github, context, dockerMetaJso"
},
{
"path": ".github/workflows/publish-docker-image.yml",
"chars": 5929,
"preview": "name: Publish Docker Image\n\non:\n workflow_dispatch:\n release:\n types: [ published ]\n pull_request:\n types: [ sy"
},
{
"path": ".gitignore",
"chars": 5009,
"preview": "logs\n.claude\nCLAUDE.md\n.gemini\nresults\nmaterials\nscripts\n!.github/scripts\n.nfs*\n.mcp_env\n.idea\n# Byte-compiled / optimiz"
},
{
"path": "CHANGELOG.md",
"chars": 2446,
"preview": "# Changelog\n\nAll notable changes to this project will be documented in this file.\n\nThe format is based on [Keep a Change"
},
{
"path": "Dockerfile",
"chars": 2886,
"preview": "# MCPMark Docker image with optimized layer caching\n# Stage 1: Builder for Python dependencies only\nFROM python:3.12-sli"
},
{
"path": "LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "README.md",
"chars": 12376,
"preview": "<div align=\"center\">\n\n# MCPMark: Stress-Testing Comprehensive MCP Use\n\n[ Components\n========================================\n\nMinimal MCP server implementations"
},
{
"path": "src/agents/mcp/http_server.py",
"chars": 2595,
"preview": "\"\"\"\nMinimal MCP HTTP Server Implementation \n=======================================\n\nProvides HTTP-based MCP server com"
},
{
"path": "src/agents/mcp/stdio_server.py",
"chars": 1823,
"preview": "\"\"\"\nMinimal MCP Stdio Server Implementation\n========================================\n\nProvides stdio-based MCP server co"
},
{
"path": "src/agents/mcpmark_agent.py",
"chars": 48835,
"preview": "\"\"\"\nMCPMark Agent Implementation\n============================\n\nUnified agent using LiteLLM for all model interactions wi"
},
{
"path": "src/agents/react_agent.py",
"chars": 21747,
"preview": "\"\"\"ReAct agent implementation for the MCPMark pipeline.\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport js"
},
{
"path": "src/agents/utils/__init__.py",
"chars": 157,
"preview": "\"\"\"\nUtility functions for MCPMark Agent\n====================================\n\"\"\"\n\nfrom .token_usage import TokenUsageTra"
},
{
"path": "src/agents/utils/token_usage.py",
"chars": 2818,
"preview": "\"\"\"\nToken Usage Tracking Utilities\n===============================\n\"\"\"\n\nfrom typing import Dict, Any\n\n\nclass TokenUsageT"
},
{
"path": "src/aggregators/aggregate_results.py",
"chars": 42589,
"preview": "#!/usr/bin/env python3\n\"\"\"\nSimplified MCPMark Results Aggregator\nAggregates evaluation results and generates summary wit"
},
{
"path": "src/aggregators/aggregate_specific_results.py",
"chars": 8846,
"preview": "#!/usr/bin/env python3\n\"\"\"\nSimple Results Aggregator - Aggregate specific result directories\nUsage: python -m src.aggreg"
},
{
"path": "src/aggregators/aggregate_task_meta.py",
"chars": 9475,
"preview": "#!/usr/bin/env python3\n\"\"\"\nTask Meta Aggregator for MCPBench\nAggregates all meta.json files from the tasks directory int"
},
{
"path": "src/aggregators/pricing.py",
"chars": 3267,
"preview": "\"\"\"\nPricing utilities for computing per-run cost from token usage.\n\nAll prices are specified per 1,000,000 tokens (M tok"
},
{
"path": "src/base/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "src/base/login_helper.py",
"chars": 218,
"preview": "from abc import ABC, abstractmethod\n\n\nclass BaseLoginHelper(ABC):\n \"\"\"Abstract base class for login helpers.\"\"\"\n\n "
},
{
"path": "src/base/state_manager.py",
"chars": 7144,
"preview": "import time\nfrom abc import ABC, abstractmethod\nfrom dataclasses import dataclass\nfrom typing import Any, Dict, List, Op"
},
{
"path": "src/base/task_manager.py",
"chars": 15690,
"preview": "#!/usr/bin/env python3\n\"\"\"\nEnhanced Base Task Manager with Common Task Discovery Logic\n================================="
},
{
"path": "src/config/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "src/config/config_schema.py",
"chars": 8352,
"preview": "#!/usr/bin/env python3\n\"\"\"\nCentralized Configuration Schema for MCPMark\n=============================================\n\nT"
},
{
"path": "src/errors.py",
"chars": 2067,
"preview": "#!/usr/bin/env python3\n\"\"\"\nSimple Error Handling for MCPMark\n==================================\n\nProvides basic error st"
},
{
"path": "src/evaluator.py",
"chars": 18420,
"preview": "import time\nimport json\nimport shutil\n\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import List, O"
},
{
"path": "src/factory.py",
"chars": 7385,
"preview": "#!/usr/bin/env python3\n\"\"\"\nMCP Service Factory for MCPMark\n=================================\n\nThis module provides a sim"
},
{
"path": "src/logger.py",
"chars": 484,
"preview": "#!/usr/bin/env python3\n\"\"\"Logger configuration for MCPMark.\"\"\"\n\nimport logging\nimport sys\n\n\ndef get_logger(name: str) ->"
},
{
"path": "src/mcp_services/filesystem/__init__.py",
"chars": 556,
"preview": "\"\"\"\nFilesystem MCP Service for MCPMark\n===================================\n\nThis module provides filesystem-specific MCP"
},
{
"path": "src/mcp_services/filesystem/filesystem_login_helper.py",
"chars": 1885,
"preview": "\"\"\"\nFilesystem Login Helper for MCPMark\n====================================\n\nThis module provides a minimal login helpe"
},
{
"path": "src/mcp_services/filesystem/filesystem_state_manager.py",
"chars": 22145,
"preview": "\"\"\"\nFilesystem State Manager for MCPMark\n=====================================\n\nThis module handles filesystem state man"
},
{
"path": "src/mcp_services/filesystem/filesystem_task_manager.py",
"chars": 4969,
"preview": "\"\"\"\nSimplified Filesystem Task Manager using Enhanced Base Class\n======================================================="
},
{
"path": "src/mcp_services/github/__init__.py",
"chars": 569,
"preview": "\"\"\"\nGitHub MCP Service for MCPMark\n===============================\n\nThis module provides GitHub-specific MCP server inte"
},
{
"path": "src/mcp_services/github/github_login_helper.py",
"chars": 7668,
"preview": "\"\"\"\nGitHub Login Helper for MCPMark\n================================\n\nThis module provides GitHub token authentication a"
},
{
"path": "src/mcp_services/github/github_state_manager.py",
"chars": 40208,
"preview": "\"\"\"\nGitHub State Manager for MCPMark\n=================================\n\nThis module handles GitHub repository state mana"
},
{
"path": "src/mcp_services/github/github_task_manager.py",
"chars": 5239,
"preview": "\"\"\"\nGitHub Task Manager for MCPMark Evaluation Pipeline\n====================================================\n\nThis modul"
},
{
"path": "src/mcp_services/github/repo_exporter.py",
"chars": 16568,
"preview": "\"\"\"\nrepo_exporter.py – Export public GitHub repository *and* open Issues/PRs\n==========================================="
},
{
"path": "src/mcp_services/github/repo_importer.py",
"chars": 17247,
"preview": "\"\"\"\nrepo_importer.py – Restore previously exported GitHub repository into an org/user\n=================================="
},
{
"path": "src/mcp_services/github/token_pool.py",
"chars": 1502,
"preview": "\"\"\"\nGitHub Token Pool Manager\n=========================\n\nSimple round-robin token pool for distributing API requests acr"
},
{
"path": "src/mcp_services/insforge/__init__.py",
"chars": 55,
"preview": "\"\"\"Insforge MCP Service Implementation for MCPMark.\"\"\"\n"
},
{
"path": "src/mcp_services/insforge/insforge_login_helper.py",
"chars": 6186,
"preview": "\"\"\"\nInsforge Login Helper for MCPMark\n==================================\n\nHandles Insforge backend authentication and co"
},
{
"path": "src/mcp_services/insforge/insforge_state_manager.py",
"chars": 19242,
"preview": "\"\"\"\nInsforge State Manager for MCPMark\n===================================\n\nManages backend state for Insforge tasks inc"
},
{
"path": "src/mcp_services/insforge/insforge_task_manager.py",
"chars": 3611,
"preview": "\"\"\"\nInsforge Task Manager for MCPMark\n===================================\n\nManages Insforge task discovery, execution, a"
},
{
"path": "src/mcp_services/notion/__init__.py",
"chars": 231,
"preview": "\"\"\"\nNotion-specific modules for MCPMark.\n\"\"\"\n\nfrom .notion_task_manager import NotionTaskManager, NotionTask\nfrom .notio"
},
{
"path": "src/mcp_services/notion/notion_login_helper.py",
"chars": 6896,
"preview": "\"\"\"\nNotion Login Helper for MCPMark\n=================================\n\nThis module provides a utility class and CLI scri"
},
{
"path": "src/mcp_services/notion/notion_state_manager.py",
"chars": 49341,
"preview": "\"\"\"\nNotion State Manager for MCPMark\n=================================\n\nThis module handles the duplication and manageme"
},
{
"path": "src/mcp_services/notion/notion_task_manager.py",
"chars": 4753,
"preview": "\"\"\"\nNotion Task Manager for MCPMark Evaluation Pipeline\n====================================================\n\nThis modul"
},
{
"path": "src/mcp_services/playwright/__init__.py",
"chars": 177,
"preview": "#!/usr/bin/env python3\n\"\"\"\nPlaywright MCP Service for MCPMark\n==================================\n\nThis package provides "
},
{
"path": "src/mcp_services/playwright/playwright_login_helper.py",
"chars": 5608,
"preview": "\"\"\"\nPlaywright Login Helper for MCPMark\n====================================\n\nThis module provides browser session manag"
},
{
"path": "src/mcp_services/playwright/playwright_state_manager.py",
"chars": 12610,
"preview": "\"\"\"\nPlaywright State Manager for MCPMark\n======================================\n\nThis module manages browser contexts an"
},
{
"path": "src/mcp_services/playwright/playwright_task_manager.py",
"chars": 3639,
"preview": "\"\"\"\nPlaywright Task Manager for MCPMark\n====================================\n\nSimple task manager for Playwright MCP tas"
},
{
"path": "src/mcp_services/playwright_webarena/playwright_login_helper.py",
"chars": 2068,
"preview": "\"\"\"\nWebArena (Docker) Login Helper for MCPMark\n==========================================\n\nThis helper exposes basic bro"
},
{
"path": "src/mcp_services/playwright_webarena/playwright_state_manager.py",
"chars": 20737,
"preview": "\"\"\"\nWebArena (Docker) State Manager for MCPMark\n===========================================\n\nThis module manages a WebAr"
},
{
"path": "src/mcp_services/playwright_webarena/playwright_task_manager.py",
"chars": 3526,
"preview": "\"\"\"\nWebArena Playwright Task Manager for MCPMark\n============================================\n\nSimple task manager for W"
},
{
"path": "src/mcp_services/playwright_webarena/reddit_env_setup.md",
"chars": 3950,
"preview": "# WebArena Reddit环境搭建指南\n\n本指南介绍如何搭建WebArena Reddit环境,用于Playwright MCP自动化测试。\n\n## 系统要求\n\n- Ubuntu 22.04+ 或其他Linux发行版\n- Docke"
},
{
"path": "src/mcp_services/postgres/__init__.py",
"chars": 456,
"preview": "\"\"\"\nPostgreSQL MCP Service for MCPMark\n===================================\n\nThis module provides PostgreSQL database int"
},
{
"path": "src/mcp_services/postgres/postgres_login_helper.py",
"chars": 4465,
"preview": "\"\"\"\nPostgreSQL Login Helper for MCPMark\n====================================\n\nHandles PostgreSQL authentication and conn"
},
{
"path": "src/mcp_services/postgres/postgres_state_manager.py",
"chars": 19328,
"preview": "\"\"\"\nPostgreSQL State Manager for MCPMark\n=====================================\n\nManages database state for PostgreSQL ta"
},
{
"path": "src/mcp_services/postgres/postgres_task_manager.py",
"chars": 4022,
"preview": "\"\"\"\nPostgreSQL Task Manager for MCPMark\n====================================\n\nManages PostgreSQL task discovery, executi"
},
{
"path": "src/mcp_services/supabase/__init__.py",
"chars": 317,
"preview": "\"\"\"Supabase MCP service integration for MCPMark.\"\"\"\n\nfrom .supabase_login_helper import SupabaseLoginHelper\nfrom .supaba"
},
{
"path": "src/mcp_services/supabase/supabase_login_helper.py",
"chars": 5981,
"preview": "\"\"\"\nSupabase Login Helper for MCPMark\n===================================\n\nHandles configuration and validation for Supa"
},
{
"path": "src/mcp_services/supabase/supabase_state_manager.py",
"chars": 20083,
"preview": "\"\"\"\nSupabase State Manager for MCPMark\n====================================\n\nManages database state for Supabase tasks u"
},
{
"path": "src/mcp_services/supabase/supabase_task_manager.py",
"chars": 3783,
"preview": "\"\"\"\nSupabase Task Manager for MCPMark\n===================================\n\nManages Supabase task discovery, execution, a"
},
{
"path": "src/model_config.py",
"chars": 8829,
"preview": "#!/usr/bin/env python3\n\"\"\"\nModel Configuration for MCPMark\n================================\n\nThis module provides config"
},
{
"path": "src/results_reporter.py",
"chars": 14566,
"preview": "#!/usr/bin/env python3\n\"\"\"\nResults Reporter for MCPMark Evaluation Pipeline\n============================================"
},
{
"path": "src/services.py",
"chars": 18105,
"preview": "\"\"\"\nService Definitions for MCPMark\n================================\n\nSingle source of truth for all MCP service configu"
},
{
"path": "tasks/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tasks/filesystem/easy/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "tasks/filesystem/easy/file_context/file_splitting/description.md",
"chars": 570,
"preview": "# File Splitting Task\n\n## 📋 Task Description\n\nYou need to split a large text file into multiple smaller files with equal"
},
{
"path": "tasks/filesystem/easy/file_context/file_splitting/meta.json",
"chars": 1401,
"preview": "{\n \"task_id\": \"file_splitting\",\n \"task_name\": \"File Splitting\",\n \"category_id\": \"file_context\",\n \"category_name\": \"F"
},
{
"path": "tasks/filesystem/easy/file_context/file_splitting/verify.py",
"chars": 5347,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Splitting Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimport o"
},
{
"path": "tasks/filesystem/easy/file_context/pattern_matching/description.md",
"chars": 719,
"preview": "# File Filtering Task: Find Files with Common Substring\n\n## 📋 Task Description\n\nYour task is to find all files that cont"
},
{
"path": "tasks/filesystem/easy/file_context/pattern_matching/meta.json",
"chars": 1438,
"preview": "{\n \"task_id\": \"pattern_matching\",\n \"task_name\": \"Pattern Matching\",\n \"category_id\": \"file_context\",\n \"category_name\""
},
{
"path": "tasks/filesystem/easy/file_context/pattern_matching/verify.py",
"chars": 6673,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Filtering Task: Find Files with Common Substring\n\"\"\"\n\nimport sys"
},
{
"path": "tasks/filesystem/easy/file_context/uppercase/description.md",
"chars": 416,
"preview": "# File Context Task: Convert Files to Uppercase\n\n## 📋 Task Description\n\nYou need to process 5 text files (file_01.txt to"
},
{
"path": "tasks/filesystem/easy/file_context/uppercase/meta.json",
"chars": 1387,
"preview": "{\n \"task_id\": \"uppercase\",\n \"task_name\": \"Uppercase\",\n \"category_id\": \"file_context\",\n \"category_name\": \"File Contex"
},
{
"path": "tasks/filesystem/easy/file_context/uppercase/verify.py",
"chars": 9514,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Context Task: Convert Files to Uppercase\n\"\"\"\n\nimport sys\nfrom pa"
},
{
"path": "tasks/filesystem/easy/file_property/largest_rename/description.md",
"chars": 333,
"preview": "# Largest File Rename Task\n\n## 📋 Task Description\n\nRename the largest `.jpg` file in the test directory to `largest.jpg`"
},
{
"path": "tasks/filesystem/easy/file_property/largest_rename/meta.json",
"chars": 936,
"preview": "{\n \"task_id\": \"largest_rename\",\n \"task_name\": \"Largest File Rename\",\n \"category_id\": \"file_property\",\n \"category_nam"
},
{
"path": "tasks/filesystem/easy/file_property/largest_rename/verify.py",
"chars": 1955,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Largest File Rename Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimp"
},
{
"path": "tasks/filesystem/easy/file_property/txt_merging/description.md",
"chars": 519,
"preview": "# Text File Merging Task\n\n## 📋 Task Description\n\nMerge all `.txt` files in the test directory into a single file called "
},
{
"path": "tasks/filesystem/easy/file_property/txt_merging/meta.json",
"chars": 928,
"preview": "{\n \"task_id\": \"txt_merging\",\n \"task_name\": \"Text File Merging\",\n \"category_id\": \"file_property\",\n \"category_name\": \""
},
{
"path": "tasks/filesystem/easy/file_property/txt_merging/verify.py",
"chars": 3710,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Text File Merging Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimpor"
},
{
"path": "tasks/filesystem/easy/folder_structure/structure_analysis/description.md",
"chars": 464,
"preview": "# Directory Structure Analysis Task\n\nYou need to recursively traverse the entire folder structure under the main directo"
},
{
"path": "tasks/filesystem/easy/folder_structure/structure_analysis/meta.json",
"chars": 12703,
"preview": "{\n \"task_id\": \"structure_analysis\",\n \"task_name\": \"Structure Analysis\",\n \"category_id\": \"folder_structure\",\n \"catego"
},
{
"path": "tasks/filesystem/easy/folder_structure/structure_analysis/verify.py",
"chars": 2761,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Directory Structure Analysis Task\n\"\"\"\n\nimport sys\nfrom pathlib import"
},
{
"path": "tasks/filesystem/easy/legal_document/file_reorganize/description.md",
"chars": 748,
"preview": "# Legal Document File Reorganization Task\n\n**Overview**\n\nThe folder \"legal_files/\" contains multiple versions of the Sto"
},
{
"path": "tasks/filesystem/easy/legal_document/file_reorganize/meta.json",
"chars": 1571,
"preview": "{\n \"task_id\": \"file_reorganize\",\n \"task_name\": \"File Reorganize\",\n \"category_id\": \"legal_document\",\n \"category_name\""
},
{
"path": "tasks/filesystem/easy/legal_document/file_reorganize/verify.py",
"chars": 4212,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Legal Document File Reorganization Task\n\"\"\"\n\nimport sys\nfrom pathlib "
},
{
"path": "tasks/filesystem/easy/papers/papers_counting/description.md",
"chars": 435,
"preview": "# File Context Task: Count HTML Files\n\n## 📋 Task Description\n\nYou need to count the number of HTML files in the given di"
},
{
"path": "tasks/filesystem/easy/papers/papers_counting/meta.json",
"chars": 3941,
"preview": "{\n \"task_id\": \"papers_counting\",\n \"task_name\": \"Papers Counting\",\n \"category_id\": \"papers\",\n \"category_name\": \"Paper"
},
{
"path": "tasks/filesystem/easy/papers/papers_counting/verify.py",
"chars": 2898,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Paper Counting Task: Count HTML Files\n\"\"\"\n\nimport sys\nfrom pathlib im"
},
{
"path": "tasks/filesystem/easy/student_database/duplicate_name/description.md",
"chars": 366,
"preview": "Please help me identify any duplicate name from the list of all the 150 students. Do not use python code. You only need "
},
{
"path": "tasks/filesystem/easy/student_database/duplicate_name/meta.json",
"chars": 25178,
"preview": "{\n \"task_id\": \"duplicate_name\",\n \"task_name\": \"Duplicate Name\",\n \"category_id\": \"student_database\",\n \"category_name\""
},
{
"path": "tasks/filesystem/easy/student_database/duplicate_name/verify.py",
"chars": 6563,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Student Database Task: Find Duplicate Names\nSimplified version that o"
},
{
"path": "tasks/filesystem/easy/student_database/recommender_name/description.md",
"chars": 147,
"preview": "Please find the recommendation letter for Patricia Jones and identify who wrote it. Generate a `recommender.txt` file wi"
},
{
"path": "tasks/filesystem/easy/student_database/recommender_name/meta.json",
"chars": 25182,
"preview": "{\n \"task_id\": \"recommender_name\",\n \"task_name\": \"Recommender Name\",\n \"category_id\": \"student_database\",\n \"category_n"
},
{
"path": "tasks/filesystem/easy/student_database/recommender_name/verify.py",
"chars": 2212,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Student Database Task: Find Recommender Name\n\"\"\"\n\nimport sys\nfrom pat"
},
{
"path": "tasks/filesystem/standard/desktop/music_report/description.md",
"chars": 1213,
"preview": "Please use FileSystem tools to finish the following task:\n\n### 1. Data Loading\n\n- Read and extract song information from"
},
{
"path": "tasks/filesystem/standard/desktop/music_report/meta.json",
"chars": 2417,
"preview": "{\n \"task_id\": \"music_report\",\n \"task_name\": \"Music Report\",\n \"category_id\": \"desktop\",\n \"category_name\": \"Desktop\",\n"
},
{
"path": "tasks/filesystem/standard/desktop/music_report/verify.py",
"chars": 12322,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Desktop 2 Music Report Task: Music Collection Analysis\n\"\"\"\n\nimport sy"
},
{
"path": "tasks/filesystem/standard/desktop/project_management/description.md",
"chars": 1263,
"preview": "Please use FileSystem tools to finish the following task:\n\n1. **Create the main directory structure** in `desktop_2`:\n\n "
},
{
"path": "tasks/filesystem/standard/desktop/project_management/meta.json",
"chars": 2415,
"preview": "{\n \"task_id\": \"project_management\",\n \"task_name\": \"Project Management\",\n \"category_id\": \"desktop\",\n \"category_name\":"
},
{
"path": "tasks/filesystem/standard/desktop/project_management/verify.py",
"chars": 10102,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Desktop 2 Project Management Task: File Reorganization\n\"\"\"\n\nimport sy"
},
{
"path": "tasks/filesystem/standard/desktop/timeline_extraction/description.md",
"chars": 830,
"preview": "Please use FileSystem tools to finish the following task:\n\nRead all the files under current path, extract every time/pla"
},
{
"path": "tasks/filesystem/standard/desktop/timeline_extraction/meta.json",
"chars": 2446,
"preview": "{\n \"task_id\": \"timeline_extraction\",\n \"task_name\": \"Timeline Extraction\",\n \"category_id\": \"desktop\",\n \"category_name"
},
{
"path": "tasks/filesystem/standard/desktop/timeline_extraction/verify.py",
"chars": 17114,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Desktop 2 Timeline Extraction Task\n\"\"\"\n\nimport sys\nfrom pathlib impor"
},
{
"path": "tasks/filesystem/standard/desktop_template/budget_computation/description.md",
"chars": 1310,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou need to analyze all the files in th"
},
{
"path": "tasks/filesystem/standard/desktop_template/budget_computation/meta.json",
"chars": 1530,
"preview": "{\n \"task_id\": \"budget_computation\",\n \"task_name\": \"Budget Computation\",\n \"category_id\": \"desktop_template\",\n \"catego"
},
{
"path": "tasks/filesystem/standard/desktop_template/budget_computation/verify.py",
"chars": 15272,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Budget Computation Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimpo"
},
{
"path": "tasks/filesystem/standard/desktop_template/contact_information/description.md",
"chars": 1505,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYour task is to compile all contact inf"
},
{
"path": "tasks/filesystem/standard/desktop_template/contact_information/meta.json",
"chars": 1537,
"preview": "{\n \"task_id\": \"contact_information\",\n \"task_name\": \"Contact Information\",\n \"category_id\": \"desktop_template\",\n \"cate"
},
{
"path": "tasks/filesystem/standard/desktop_template/contact_information/verify.py",
"chars": 10888,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Contact Information Compilation Task\n\"\"\"\n\nimport sys\nfrom pathlib imp"
},
{
"path": "tasks/filesystem/standard/desktop_template/file_arrangement/description.md",
"chars": 1109,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou are tasked with organizing files on"
},
{
"path": "tasks/filesystem/standard/desktop_template/file_arrangement/meta.json",
"chars": 1518,
"preview": "{\n \"task_id\": \"file_arrangement\",\n \"task_name\": \"File Arrangement\",\n \"category_id\": \"desktop_template\",\n \"category_n"
},
{
"path": "tasks/filesystem/standard/desktop_template/file_arrangement/verify.py",
"chars": 9786,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Desktop File Organization Task\n\"\"\"\n\nimport sys\nfrom pathlib import Pa"
},
{
"path": "tasks/filesystem/standard/file_context/duplicates_searching/description.md",
"chars": 828,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou are given a directory containing mu"
},
{
"path": "tasks/filesystem/standard/file_context/duplicates_searching/meta.json",
"chars": 1115,
"preview": "{\n \"task_id\": \"duplicates_searching\",\n \"task_name\": \"Duplicates Searching\",\n \"category_id\": \"file_context\",\n \"catego"
},
{
"path": "tasks/filesystem/standard/file_context/duplicates_searching/verify.py",
"chars": 8162,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Duplicates Detection and Organization Task\n\"\"\"\n\nimport sys\nfrom "
},
{
"path": "tasks/filesystem/standard/file_context/file_merging/description.md",
"chars": 602,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou are given a directory containing mu"
},
{
"path": "tasks/filesystem/standard/file_context/file_merging/meta.json",
"chars": 1099,
"preview": "{\n \"task_id\": \"file_merging\",\n \"task_name\": \"File Merging\",\n \"category_id\": \"file_context\",\n \"category_name\": \"File "
},
{
"path": "tasks/filesystem/standard/file_context/file_merging/verify.py",
"chars": 7451,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Merging Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimport os\n"
},
{
"path": "tasks/filesystem/standard/file_context/file_splitting/description.md",
"chars": 545,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou need to split a large text file int"
},
{
"path": "tasks/filesystem/standard/file_context/file_splitting/meta.json",
"chars": 1075,
"preview": "{\n \"task_id\": \"file_splitting\",\n \"task_name\": \"File Splitting\",\n \"category_id\": \"file_context\",\n \"category_name\": \"F"
},
{
"path": "tasks/filesystem/standard/file_context/file_splitting/verify.py",
"chars": 4945,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Splitting Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimport o"
},
{
"path": "tasks/filesystem/standard/file_context/pattern_matching/description.md",
"chars": 859,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYour task is to find all files that con"
},
{
"path": "tasks/filesystem/standard/file_context/pattern_matching/meta.json",
"chars": 1099,
"preview": "{\n \"task_id\": \"pattern_matching\",\n \"task_name\": \"Pattern Matching\",\n \"category_id\": \"file_context\",\n \"category_name\""
},
{
"path": "tasks/filesystem/standard/file_context/pattern_matching/verify.py",
"chars": 10188,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Filtering Task: Find Files with Common Substring\n\"\"\"\n\nimport sys"
},
{
"path": "tasks/filesystem/standard/file_context/uppercase/description.md",
"chars": 883,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou need to process 10 text files (file"
},
{
"path": "tasks/filesystem/standard/file_context/uppercase/meta.json",
"chars": 1082,
"preview": "{\n \"task_id\": \"uppercase\",\n \"task_name\": \"Uppercase\",\n \"category_id\": \"file_context\",\n \"category_name\": \"File Contex"
},
{
"path": "tasks/filesystem/standard/file_context/uppercase/verify.py",
"chars": 9552,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Context Task: Convert Files to Uppercase\n\"\"\"\n\nimport sys\nfrom pa"
},
{
"path": "tasks/filesystem/standard/file_property/size_classification/description.md",
"chars": 685,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nClassify all files in the test director"
},
{
"path": "tasks/filesystem/standard/file_property/size_classification/meta.json",
"chars": 851,
"preview": "{\n \"task_id\": \"size_classification\",\n \"task_name\": \"Size Classification\",\n \"category_id\": \"file_property\",\n \"categor"
},
{
"path": "tasks/filesystem/standard/file_property/size_classification/verify.py",
"chars": 6593,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Classification Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimp"
},
{
"path": "tasks/filesystem/standard/file_property/time_classification/description.md",
"chars": 1032,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nAnalyze the creation time (ctime) of al"
},
{
"path": "tasks/filesystem/standard/file_property/time_classification/meta.json",
"chars": 870,
"preview": "{\n \"task_id\": \"time_classification\",\n \"task_name\": \"Time Classification\",\n \"category_id\": \"file_property\",\n \"categor"
},
{
"path": "tasks/filesystem/standard/file_property/time_classification/verify.py",
"chars": 12580,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for File Organization by Creation Time Task\n\"\"\"\n\nimport sys\nfrom pathlib "
},
{
"path": "tasks/filesystem/standard/folder_structure/structure_analysis/description.md",
"chars": 1484,
"preview": "Please use FileSystem tools to finish the following task:\n\nYou need to recursively traverse the entire folder structure "
},
{
"path": "tasks/filesystem/standard/folder_structure/structure_analysis/meta.json",
"chars": 8560,
"preview": "{\n \"task_id\": \"structure_analysis\",\n \"task_name\": \"Structure Analysis\",\n \"category_id\": \"folder_structure\",\n \"catego"
},
{
"path": "tasks/filesystem/standard/folder_structure/structure_analysis/verify.py",
"chars": 9481,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Directory Structure Analysis Task\n\"\"\"\n\nimport sys\nfrom pathlib import"
},
{
"path": "tasks/filesystem/standard/folder_structure/structure_mirror/description.md",
"chars": 754,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task\n\nCopy the entire directory structure of `complex_str"
},
{
"path": "tasks/filesystem/standard/folder_structure/structure_mirror/meta.json",
"chars": 8545,
"preview": "{\n \"task_id\": \"structure_mirror\",\n \"task_name\": \"Structure Mirror\",\n \"category_id\": \"folder_structure\",\n \"category_n"
},
{
"path": "tasks/filesystem/standard/folder_structure/structure_mirror/verify.py",
"chars": 7547,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Directory Structure Mirroring with Smart Placeholders Task\n\"\"\"\n\nimpor"
},
{
"path": "tasks/filesystem/standard/legal_document/dispute_review/description.md",
"chars": 1257,
"preview": "Please use FileSystem tools to finish the following task:\n\n**Overview**\n\nThe folder \"legal_files/\" contains all versions"
},
{
"path": "tasks/filesystem/standard/legal_document/dispute_review/meta.json",
"chars": 1414,
"preview": "{\n \"task_id\": \"dispute_review\",\n \"task_name\": \"Dispute Review\",\n \"category_id\": \"legal_document\",\n \"category_name\": "
},
{
"path": "tasks/filesystem/standard/legal_document/dispute_review/verify.py",
"chars": 5650,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Legal Document Dispute Review Task\n\"\"\"\n\nimport sys\nfrom pathlib impor"
},
{
"path": "tasks/filesystem/standard/legal_document/individual_comments/description.md",
"chars": 1459,
"preview": "Please use FileSystem tools to finish the following task:\n\n**Overview**\n\nThe folder \"legal_files/\" contains all versions"
},
{
"path": "tasks/filesystem/standard/legal_document/individual_comments/meta.json",
"chars": 1426,
"preview": "{\n \"task_id\": \"individual_comments\",\n \"task_name\": \"Individual Comments\",\n \"category_id\": \"legal_document\",\n \"catego"
},
{
"path": "tasks/filesystem/standard/legal_document/individual_comments/verify.py",
"chars": 9393,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Legal Document Individual Comments Task\n\"\"\"\n\nimport sys\nfrom pathlib "
},
{
"path": "tasks/filesystem/standard/legal_document/solution_tracing/description.md",
"chars": 1860,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Overview\n\nThe folder \"legal_files/\" contains all versions"
},
{
"path": "tasks/filesystem/standard/legal_document/solution_tracing/meta.json",
"chars": 1388,
"preview": "{\n \"task_id\": \"solution_tracing\",\n \"task_name\": \"Solution Tracing\",\n \"category_id\": \"legal_document\",\n \"category_nam"
},
{
"path": "tasks/filesystem/standard/legal_document/solution_tracing/verify.py",
"chars": 9840,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Legal Document Solution Tracing Task\n\"\"\"\n\nimport sys\nfrom pathlib imp"
},
{
"path": "tasks/filesystem/standard/papers/author_folders/description.md",
"chars": 1958,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou are given a directory containing mu"
},
{
"path": "tasks/filesystem/standard/papers/author_folders/meta.json",
"chars": 2775,
"preview": "{\n \"task_id\": \"author_folders\",\n \"task_name\": \"Author Folders\",\n \"category_id\": \"papers\",\n \"category_name\": \"Papers\""
},
{
"path": "tasks/filesystem/standard/papers/author_folders/verify.py",
"chars": 12215,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Paper Organization Task: Author-Based Paper Categorization\n\"\"\"\n\nimpor"
},
{
"path": "tasks/filesystem/standard/papers/find_math_paper/description.md",
"chars": 475,
"preview": "Please use FileSystem tools to finish the following task:\n\nYou are given a directory containing multiple paper files. Pl"
},
{
"path": "tasks/filesystem/standard/papers/find_math_paper/meta.json",
"chars": 2749,
"preview": "{\n \"task_id\": \"find_math_paper\",\n \"task_name\": \"Find Math Paper\",\n \"category_id\": \"papers\",\n \"category_name\": \"Paper"
},
{
"path": "tasks/filesystem/standard/papers/find_math_paper/verify.py",
"chars": 1961,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Find Math Paper Task\n\"\"\"\n\nimport sys\nfrom pathlib import Path\nimport "
},
{
"path": "tasks/filesystem/standard/papers/organize_legacy_papers/description.md",
"chars": 2518,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nYou are given a directory containing mu"
},
{
"path": "tasks/filesystem/standard/papers/organize_legacy_papers/meta.json",
"chars": 2776,
"preview": "{\n \"task_id\": \"organize_legacy_papers\",\n \"task_name\": \"Organize Legacy Papers\",\n \"category_id\": \"papers\",\n \"category"
},
{
"path": "tasks/filesystem/standard/papers/organize_legacy_papers/verify.py",
"chars": 14704,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Papers Collection Cleanup and Organization Task\n\"\"\"\n\nimport sys\nfrom "
},
{
"path": "tasks/filesystem/standard/student_database/duplicate_name/description.md",
"chars": 459,
"preview": "Please use FileSystem tools to finish the following task:\n\nPlease help me identify duplicate names from the list of all "
},
{
"path": "tasks/filesystem/standard/student_database/duplicate_name/meta.json",
"chars": 16947,
"preview": "{\n \"task_id\": \"duplicate_name\",\n \"task_name\": \"Duplicate Name\",\n \"category_id\": \"student_database\",\n \"category_name\""
},
{
"path": "tasks/filesystem/standard/student_database/duplicate_name/verify.py",
"chars": 6800,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Student Database Task: Find Duplicate Names\nSimplified version that o"
},
{
"path": "tasks/filesystem/standard/student_database/english_talent/description.md",
"chars": 690,
"preview": "Please use FileSystem tools to finish the following task:\n\nWe are now recruiting students proficient in English to be re"
},
{
"path": "tasks/filesystem/standard/student_database/english_talent/meta.json",
"chars": 16984,
"preview": "{\n \"task_id\": \"english_talent\",\n \"task_name\": \"English Talent\",\n \"category_id\": \"student_database\",\n \"category_name\""
},
{
"path": "tasks/filesystem/standard/student_database/english_talent/verify.py",
"chars": 9826,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Student Database Task: English Talent Recruitment\n\"\"\"\n\nimport sys\nfro"
},
{
"path": "tasks/filesystem/standard/student_database/gradebased_score/description.md",
"chars": 832,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Simple Grade Calculation\n\n1. Read Student Data:\n\n* Proces"
},
{
"path": "tasks/filesystem/standard/student_database/gradebased_score/meta.json",
"chars": 16997,
"preview": "{\n \"task_id\": \"gradebased_score\",\n \"task_name\": \"Gradebased Score\",\n \"category_id\": \"student_database\",\n \"category_n"
},
{
"path": "tasks/filesystem/standard/student_database/gradebased_score/verify.py",
"chars": 6158,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for Student Database Grade-Based Score Analysis Task\n\"\"\"\n\nimport sys\nfrom"
},
{
"path": "tasks/filesystem/standard/threestudio/code_locating/description.md",
"chars": 1021,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nThreeStudio is a comprehensive codebase"
},
{
"path": "tasks/filesystem/standard/threestudio/code_locating/meta.json",
"chars": 15394,
"preview": "{\n \"task_id\": \"code_locating\",\n \"task_name\": \"Code Locating\",\n \"category_id\": \"threestudio\",\n \"category_name\": \"Thre"
},
{
"path": "tasks/filesystem/standard/threestudio/code_locating/verify.py",
"chars": 7756,
"preview": "#!/usr/bin/env python3\n\"\"\"\nVerification script for ThreeStudio Task 1: Find Zero123 Guidance Implementation\n\"\"\"\n\nimport "
},
{
"path": "tasks/filesystem/standard/threestudio/output_analysis/description.md",
"chars": 741,
"preview": "Please use FileSystem tools to finish the following task:\n\n### Task Description\n\nThreeStudio is a comprehensive codebase"
},
{
"path": "tasks/filesystem/standard/threestudio/output_analysis/meta.json",
"chars": 15426,
"preview": "{\n \"task_id\": \"output_analysis\",\n \"task_name\": \"Output Analysis\",\n \"category_id\": \"threestudio\",\n \"category_name\": \""
}
]
// ... and 470 more files (download for full content)
About this extraction
This page contains the full source code of the eval-sys/mcpmark GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 670 files (3.1 MB), approximately 855.5k tokens, and a symbol index with 1543 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.