{{ data.heroText || $title || 'Hello' }}
{{ data.tagline || $description || 'Welcome to your VuePress site' }}
{{ feature.title }}
{{ feature.details }}
{{ data.tagline || $description || 'Welcome to your VuePress site' }}
{{ feature.details }}
←
{{ prev.title || prev.path }}
{{ getMsg() }}
Hello World!
``` `DOM`像原子包含着亚原子微粒那样,也有很多类型的`DOM`节点包含着其他类型的节点。接下来我们先看看其中的三种: ```htmlcontent
...
var p = document.getElementById('p'); // 设置文本为abc: p.innerHTML = 'ABC'; //ABC
// 设置HTML: p.innerHTML = 'ABC RED XYZ'; //...
的内部结构已修改 ``` #### innerText、textContent 自动对字符串进行`HTML`编码,保证无法设置任何`HTML`标签 ``` // 获取...
var p = document.getElementById('p-id'); // 设置文本: p.innerText = ''; // HTML被自动编码,无法设置一个`,拼接到 HTML 中返回给浏览器。形成了如下的 HTML: ```html ">








{this.props.name}
{props.name}
xx
< a href=" ">xxxYou clicked {count} times
You clicked {this.state.count} times
You clicked {this.state.count} times
You clicked {count} times
Current URL: {pathname}
count: {count}
Hello, React
} // React内部 const result = SayHi(props) // »Hello, React
``` 如果是一个类组件,则需要将组件进行实例化,然后调用实例对象的`render`方法: ```jsx // 你的代码 class SayHi extends React.Component { render() { returnHello, React
} } // React内部 const instance = new SayHi(props) // » SayHi {} const result = instance.render() // »Hello, React
``` ### 获取渲染的值 首先给出一个示例 函数组件对应如下: ```jsx function ProfilePage(props) { const showMessage = () => { alert('Followed ' + props.user); } const handleClick = () => { setTimeout(showMessage, 3000); } return ( ) } ``` 类组件对应如下: ```jsx class ProfilePage extends React.Component { showMessage() { alert('Followed ' + this.props.user); } handleClick() { setTimeout(this.showMessage.bind(this), 3000); } render() { return } } ``` 两者看起来实现功能是一致的,但是在类组件中,输出`this.props.user`,`Props `在 `React `中是不可变的所以它永远不会改变,但是 `this` 总是可变的,以便您可以在 `render` 和生命周期函数中读取新版本 因此,如果我们的组件在请求运行时更新。`this.props` 将会改变。`showMessage `方法从“最新”的 `props` 中读取 `user` 而函数组件,本身就不存在`this`,`props`并不发生改变,因此同样是点击,`alert`的内容仍旧是之前的内容 ### 小结 两种组件都有各自的优缺点 函数组件语法更短、更简单,这使得它更容易开发、理解和测试 而类组件也会因大量使用 `this `而让人感到困惑 ## 参考文献 - https://zh-hans.reactjs.org/docs/components-and-props.html#function-and-class-components - https://juejin.cn/post/6844903806140973069 ================================================ FILE: docs/React/communication.md ================================================ # 面试官:React中组件之间如何通信?  ## 一、是什么 我们将组件间通信可以拆分为两个词: - 组件 - 通信 回顾[Vue系列](https://mp.weixin.qq.com/s/uFjMz6BByA5eknBgkvgdeQ)的文章,组件是`vue`中最强大的功能之一,同样组件化是`React`的核心思想 相比`vue`,`React`的组件更加灵活和多样,按照不同的方式可以分成很多类型的组件 而通信指的是发送者通过某种媒体以某种格式来传递信息到收信者以达到某个目的,广义上,任何信息的交通都是通信 组件间通信即指组件通过某种方式来传递信息以达到某个目的 ## 二、如何通信 组件传递的方式有很多种,根据传送者和接收者可以分为如下: - 父组件向子组件传递 - 子组件向父组件传递 - 兄弟组件之间的通信 - 父组件向后代组件传递 - 非关系组件传递 ### 父组件向子组件传递 由于`React`的数据流动为单向的,父组件向子组件传递是最常见的方式 父组件在调用子组件的时候,只需要在子组件标签内传递参数,子组件通过`props`属性就能接收父组件传递过来的参数 ```jsx function EmailInput(props) { return ( ); } const element =我是App中的一段文字描述
我是App中的一段文字描述
Haha
Hehe
``` 页面显示如下:  两个`p`元素之间的距离为`100px`,发生了`margin`重叠(塌陷),以最大的为准,如果第一个P的`margin`为80的话,两个P之间的距离还是100,以最大的为准。 前面讲到,同一个`BFC`的俩个相邻的盒子的`margin`会发生重叠 可以在`p`外面包裹一层容器,并触发这个容器生成一个`BFC`,那么两个`p`就不属于同一个`BFC`,则不会出现`margin`重叠 ```htmlHaha
Hehe
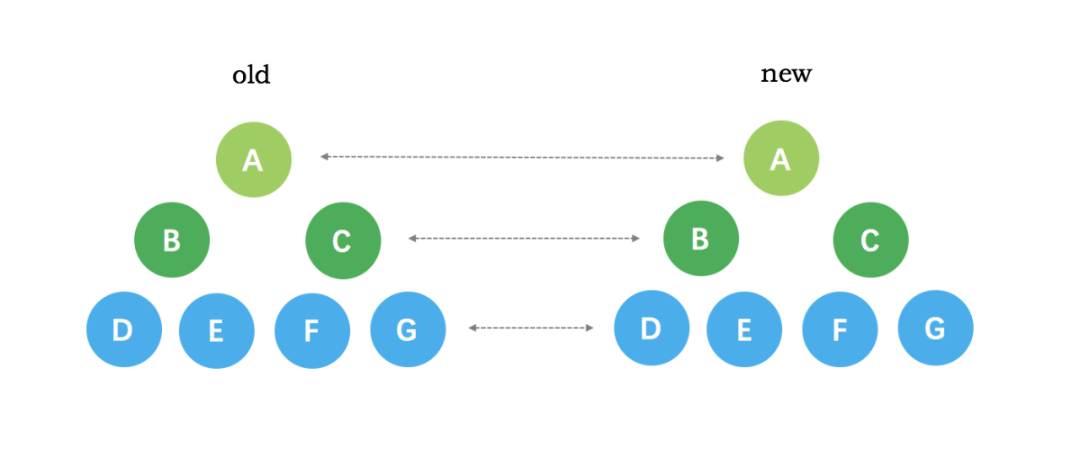 2. 比较的过程中,循环从两边向中间收拢
2. 比较的过程中,循环从两边向中间收拢
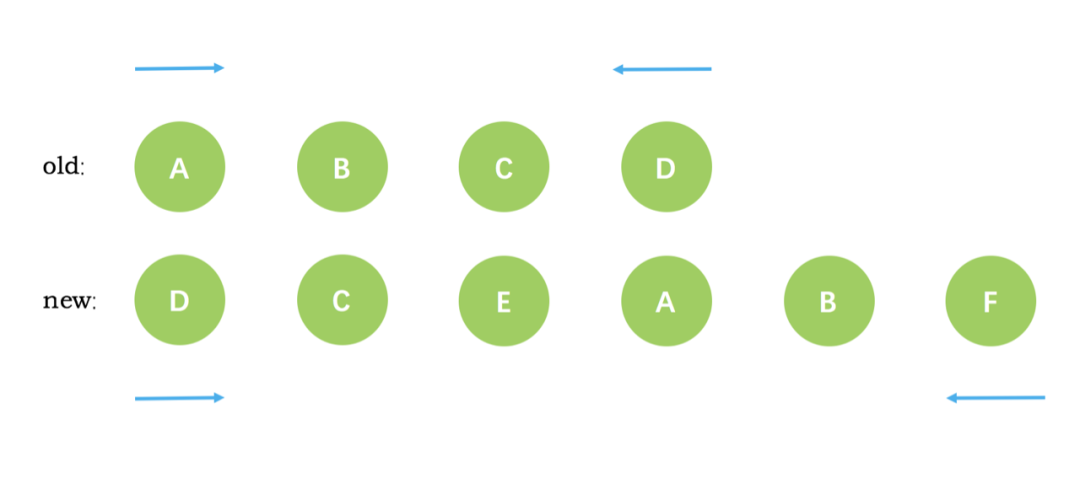 下面举个`vue`通过`diff`算法更新的例子:
新旧`VNode`节点如下图所示:
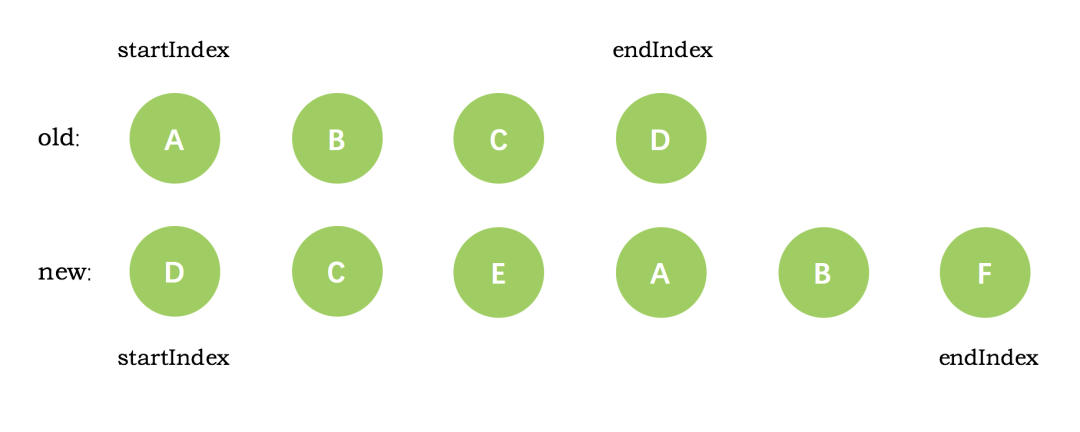
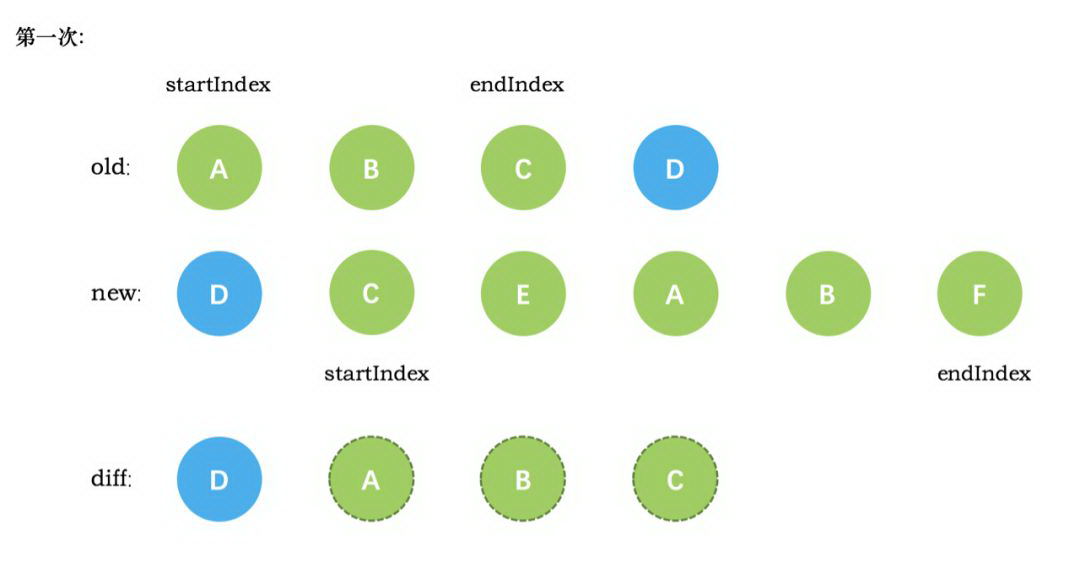
第一次循环后,发现旧节点D与新节点D相同,直接复用旧节点D作为`diff`后的第一个真实节点,同时旧节点`endIndex`移动到C,新节点的 `startIndex` 移动到了 C
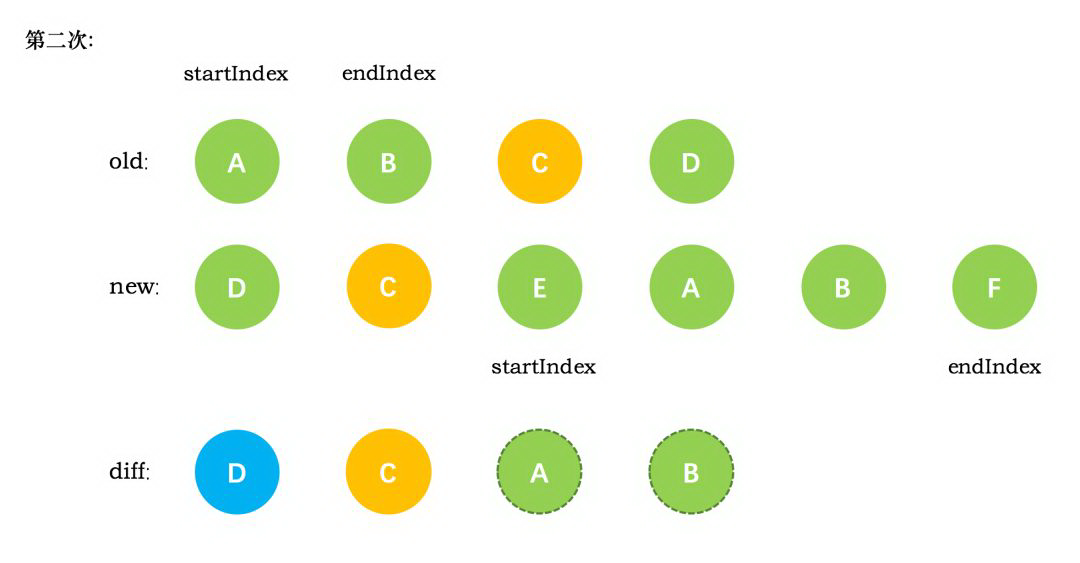
第二次循环后,同样是旧节点的末尾和新节点的开头(都是 C)相同,同理,`diff` 后创建了 C 的真实节点插入到第一次创建的 D 节点后面。同时旧节点的 `endIndex` 移动到了 B,新节点的 `startIndex` 移动到了 E
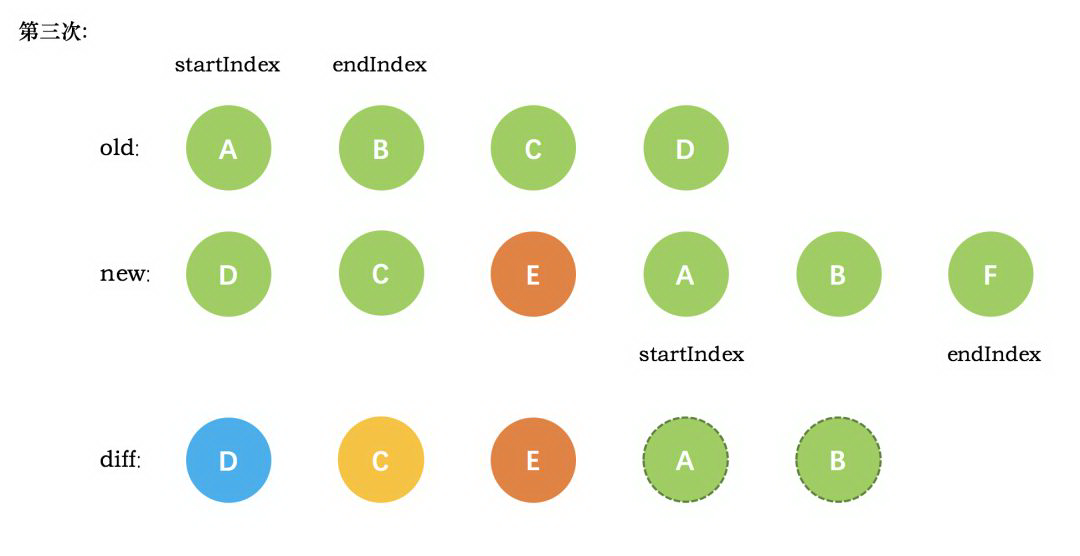
第三次循环中,发现E没有找到,这时候只能直接创建新的真实节点 E,插入到第二次创建的 C 节点之后。同时新节点的 `startIndex` 移动到了 A。旧节点的 `startIndex` 和 `endIndex` 都保持不动
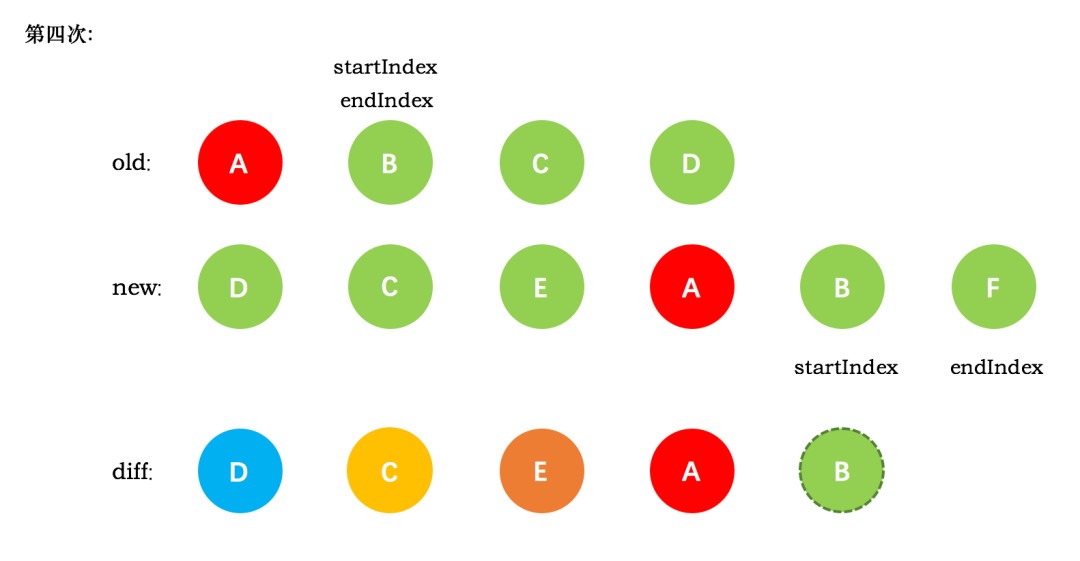
第四次循环中,发现了新旧节点的开头(都是 A)相同,于是 `diff` 后创建了 A 的真实节点,插入到前一次创建的 E 节点后面。同时旧节点的 `startIndex` 移动到了 B,新节点的` startIndex` 移动到了 B
第五次循环中,情形同第四次循环一样,因此 `diff` 后创建了 B 真实节点 插入到前一次创建的 A 节点后面。同时旧节点的 `startIndex `移动到了 C,新节点的 startIndex 移动到了 F
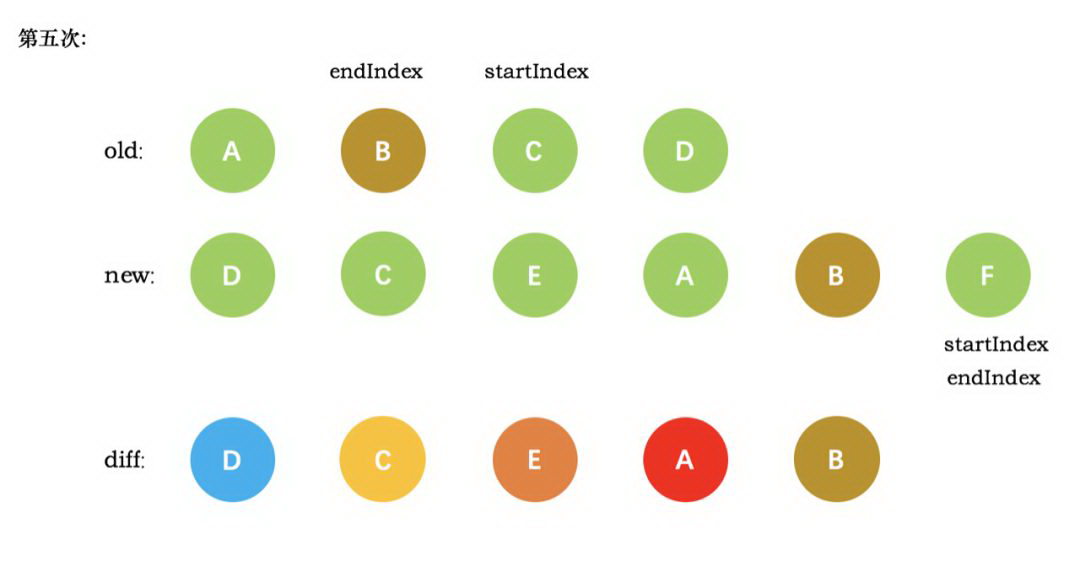
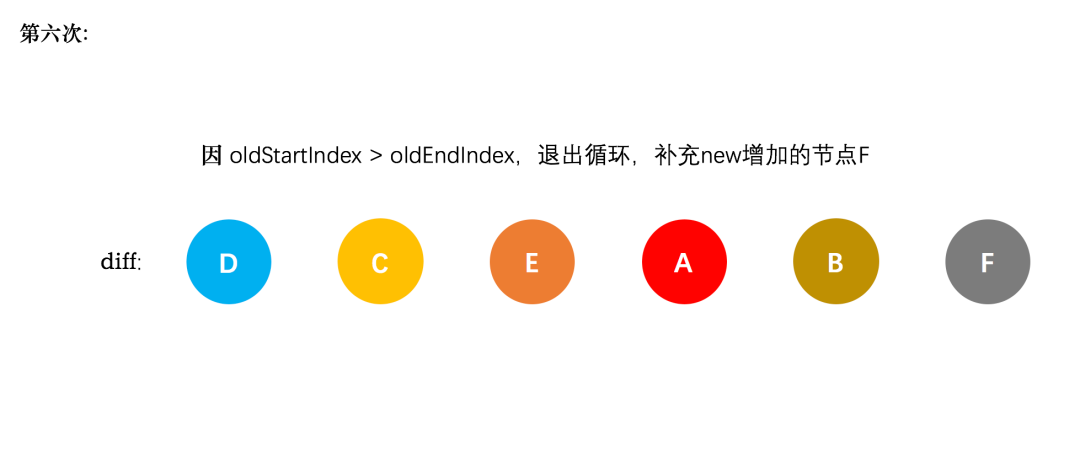
新节点的 `startIndex` 已经大于 `endIndex` 了,需要创建 `newStartIdx` 和 `newEndIdx` 之间的所有节点,也就是节点F,直接创建 F 节点对应的真实节点放到 B 节点后面
## 三、原理分析
当数据发生改变时,`set`方法会调用`Dep.notify`通知所有订阅者`Watcher`,订阅者就会调用`patch`给真实的`DOM`打补丁,更新相应的视图
源码位置:src/core/vdom/patch.js
```js
function patch(oldVnode, vnode, hydrating, removeOnly) {
if (isUndef(vnode)) { // 没有新节点,直接执行destory钩子函数
if (isDef(oldVnode)) invokeDestroyHook(oldVnode)
return
}
let isInitialPatch = false
const insertedVnodeQueue = []
if (isUndef(oldVnode)) {
isInitialPatch = true
createElm(vnode, insertedVnodeQueue) // 没有旧节点,直接用新节点生成dom元素
} else {
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// 判断旧节点和新节点自身一样,一致执行patchVnode
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
} else {
// 否则直接销毁及旧节点,根据新节点生成dom元素
if (isRealElement) {
if (oldVnode.nodeType === 1 && oldVnode.hasAttribute(SSR_ATTR)) {
oldVnode.removeAttribute(SSR_ATTR)
hydrating = true
}
if (isTrue(hydrating)) {
if (hydrate(oldVnode, vnode, insertedVnodeQueue)) {
invokeInsertHook(vnode, insertedVnodeQueue, true)
return oldVnode
}
}
oldVnode = emptyNodeAt(oldVnode)
}
return vnode.elm
}
}
}
```
`patch`函数前两个参数位为`oldVnode` 和 `Vnode` ,分别代表新的节点和之前的旧节点,主要做了四个判断:
- 没有新节点,直接触发旧节点的`destory`钩子
- 没有旧节点,说明是页面刚开始初始化的时候,此时,根本不需要比较了,直接全是新建,所以只调用 `createElm`
- 旧节点和新节点自身一样,通过 `sameVnode` 判断节点是否一样,一样时,直接调用 `patchVnode `去处理这两个节点
- 旧节点和新节点自身不一样,当两个节点不一样的时候,直接创建新节点,删除旧节点
下面主要讲的是`patchVnode`部分
```js
function patchVnode (oldVnode, vnode, insertedVnodeQueue, removeOnly) {
// 如果新旧节点一致,什么都不做
if (oldVnode === vnode) {
return
}
// 让vnode.el引用到现在的真实dom,当el修改时,vnode.el会同步变化
const elm = vnode.elm = oldVnode.elm
// 异步占位符
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue)
} else {
vnode.isAsyncPlaceholder = true
}
return
}
// 如果新旧都是静态节点,并且具有相同的key
// 当vnode是克隆节点或是v-once指令控制的节点时,只需要把oldVnode.elm和oldVnode.child都复制到vnode上
// 也不用再有其他操作
if (isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance
return
}
let i
const data = vnode.data
if (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) {
i(oldVnode, vnode)
}
const oldCh = oldVnode.children
const ch = vnode.children
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode)
}
// 如果vnode不是文本节点或者注释节点
if (isUndef(vnode.text)) {
// 并且都有子节点
if (isDef(oldCh) && isDef(ch)) {
// 并且子节点不完全一致,则调用updateChildren
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
// 如果只有新的vnode有子节点
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
// elm已经引用了老的dom节点,在老的dom节点上添加子节点
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
// 如果新vnode没有子节点,而vnode有子节点,直接删除老的oldCh
} else if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
// 如果老节点是文本节点
} else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
// 如果新vnode和老vnode是文本节点或注释节点
// 但是vnode.text != oldVnode.text时,只需要更新vnode.elm的文本内容就可以
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text)
}
if (isDef(data)) {
if (isDef(i = data.hook) && isDef(i = i.postpatch)) i(oldVnode, vnode)
}
}
```
`patchVnode`主要做了几个判断:
- 新节点是否是文本节点,如果是,则直接更新`dom`的文本内容为新节点的文本内容
- 新节点和旧节点如果都有子节点,则处理比较更新子节点
- 只有新节点有子节点,旧节点没有,那么不用比较了,所有节点都是全新的,所以直接全部新建就好了,新建是指创建出所有新`DOM`,并且添加进父节点
- 只有旧节点有子节点而新节点没有,说明更新后的页面,旧节点全部都不见了,那么要做的,就是把所有的旧节点删除,也就是直接把`DOM` 删除
子节点不完全一致,则调用`updateChildren`
```js
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
let oldStartIdx = 0 // 旧头索引
let newStartIdx = 0 // 新头索引
let oldEndIdx = oldCh.length - 1 // 旧尾索引
let newEndIdx = newCh.length - 1 // 新尾索引
let oldStartVnode = oldCh[0] // oldVnode的第一个child
let oldEndVnode = oldCh[oldEndIdx] // oldVnode的最后一个child
let newStartVnode = newCh[0] // newVnode的第一个child
let newEndVnode = newCh[newEndIdx] // newVnode的最后一个child
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// removeOnly is a special flag used only by
下面举个`vue`通过`diff`算法更新的例子:
新旧`VNode`节点如下图所示:

第一次循环后,发现旧节点D与新节点D相同,直接复用旧节点D作为`diff`后的第一个真实节点,同时旧节点`endIndex`移动到C,新节点的 `startIndex` 移动到了 C

第二次循环后,同样是旧节点的末尾和新节点的开头(都是 C)相同,同理,`diff` 后创建了 C 的真实节点插入到第一次创建的 D 节点后面。同时旧节点的 `endIndex` 移动到了 B,新节点的 `startIndex` 移动到了 E

第三次循环中,发现E没有找到,这时候只能直接创建新的真实节点 E,插入到第二次创建的 C 节点之后。同时新节点的 `startIndex` 移动到了 A。旧节点的 `startIndex` 和 `endIndex` 都保持不动

第四次循环中,发现了新旧节点的开头(都是 A)相同,于是 `diff` 后创建了 A 的真实节点,插入到前一次创建的 E 节点后面。同时旧节点的 `startIndex` 移动到了 B,新节点的` startIndex` 移动到了 B

第五次循环中,情形同第四次循环一样,因此 `diff` 后创建了 B 真实节点 插入到前一次创建的 A 节点后面。同时旧节点的 `startIndex `移动到了 C,新节点的 startIndex 移动到了 F

新节点的 `startIndex` 已经大于 `endIndex` 了,需要创建 `newStartIdx` 和 `newEndIdx` 之间的所有节点,也就是节点F,直接创建 F 节点对应的真实节点放到 B 节点后面

## 三、原理分析
当数据发生改变时,`set`方法会调用`Dep.notify`通知所有订阅者`Watcher`,订阅者就会调用`patch`给真实的`DOM`打补丁,更新相应的视图
源码位置:src/core/vdom/patch.js
```js
function patch(oldVnode, vnode, hydrating, removeOnly) {
if (isUndef(vnode)) { // 没有新节点,直接执行destory钩子函数
if (isDef(oldVnode)) invokeDestroyHook(oldVnode)
return
}
let isInitialPatch = false
const insertedVnodeQueue = []
if (isUndef(oldVnode)) {
isInitialPatch = true
createElm(vnode, insertedVnodeQueue) // 没有旧节点,直接用新节点生成dom元素
} else {
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// 判断旧节点和新节点自身一样,一致执行patchVnode
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
} else {
// 否则直接销毁及旧节点,根据新节点生成dom元素
if (isRealElement) {
if (oldVnode.nodeType === 1 && oldVnode.hasAttribute(SSR_ATTR)) {
oldVnode.removeAttribute(SSR_ATTR)
hydrating = true
}
if (isTrue(hydrating)) {
if (hydrate(oldVnode, vnode, insertedVnodeQueue)) {
invokeInsertHook(vnode, insertedVnodeQueue, true)
return oldVnode
}
}
oldVnode = emptyNodeAt(oldVnode)
}
return vnode.elm
}
}
}
```
`patch`函数前两个参数位为`oldVnode` 和 `Vnode` ,分别代表新的节点和之前的旧节点,主要做了四个判断:
- 没有新节点,直接触发旧节点的`destory`钩子
- 没有旧节点,说明是页面刚开始初始化的时候,此时,根本不需要比较了,直接全是新建,所以只调用 `createElm`
- 旧节点和新节点自身一样,通过 `sameVnode` 判断节点是否一样,一样时,直接调用 `patchVnode `去处理这两个节点
- 旧节点和新节点自身不一样,当两个节点不一样的时候,直接创建新节点,删除旧节点
下面主要讲的是`patchVnode`部分
```js
function patchVnode (oldVnode, vnode, insertedVnodeQueue, removeOnly) {
// 如果新旧节点一致,什么都不做
if (oldVnode === vnode) {
return
}
// 让vnode.el引用到现在的真实dom,当el修改时,vnode.el会同步变化
const elm = vnode.elm = oldVnode.elm
// 异步占位符
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue)
} else {
vnode.isAsyncPlaceholder = true
}
return
}
// 如果新旧都是静态节点,并且具有相同的key
// 当vnode是克隆节点或是v-once指令控制的节点时,只需要把oldVnode.elm和oldVnode.child都复制到vnode上
// 也不用再有其他操作
if (isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
vnode.componentInstance = oldVnode.componentInstance
return
}
let i
const data = vnode.data
if (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) {
i(oldVnode, vnode)
}
const oldCh = oldVnode.children
const ch = vnode.children
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode)
}
// 如果vnode不是文本节点或者注释节点
if (isUndef(vnode.text)) {
// 并且都有子节点
if (isDef(oldCh) && isDef(ch)) {
// 并且子节点不完全一致,则调用updateChildren
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
// 如果只有新的vnode有子节点
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
// elm已经引用了老的dom节点,在老的dom节点上添加子节点
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
// 如果新vnode没有子节点,而vnode有子节点,直接删除老的oldCh
} else if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
// 如果老节点是文本节点
} else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
// 如果新vnode和老vnode是文本节点或注释节点
// 但是vnode.text != oldVnode.text时,只需要更新vnode.elm的文本内容就可以
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text)
}
if (isDef(data)) {
if (isDef(i = data.hook) && isDef(i = i.postpatch)) i(oldVnode, vnode)
}
}
```
`patchVnode`主要做了几个判断:
- 新节点是否是文本节点,如果是,则直接更新`dom`的文本内容为新节点的文本内容
- 新节点和旧节点如果都有子节点,则处理比较更新子节点
- 只有新节点有子节点,旧节点没有,那么不用比较了,所有节点都是全新的,所以直接全部新建就好了,新建是指创建出所有新`DOM`,并且添加进父节点
- 只有旧节点有子节点而新节点没有,说明更新后的页面,旧节点全部都不见了,那么要做的,就是把所有的旧节点删除,也就是直接把`DOM` 删除
子节点不完全一致,则调用`updateChildren`
```js
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
let oldStartIdx = 0 // 旧头索引
let newStartIdx = 0 // 新头索引
let oldEndIdx = oldCh.length - 1 // 旧尾索引
let newEndIdx = newCh.length - 1 // 新尾索引
let oldStartVnode = oldCh[0] // oldVnode的第一个child
let oldEndVnode = oldCh[oldEndIdx] // oldVnode的最后一个child
let newStartVnode = newCh[0] // newVnode的第一个child
let newEndVnode = newCh[newEndIdx] // newVnode的最后一个child
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// removeOnly is a special flag used only by