[
{
"path": "Part1/Android/AIDL.md",
"content": "#AIDL\n---\n\n1. 创建一个接口,再里面定义方法\n\n```\npackage com.example.taidl; \ninterface ICalcAIDL \n{ \n int add(int x , int y); \n int min(int x , int y ); \n} \n```\n\nbuild一下gen目录下会生成ICalcAIDL.java文件\n\n```\n/*\n * This file is auto-generated. DO NOT MODIFY.\n * Original file: /Users/dream/Downloads/android/androidProject/TAIDL/src/com/example/taidl/ICalcAIDL.aidl\n */\npackage com.example.taidl;\npublic interface ICalcAIDL extends android.os.IInterface\n{\n/** Local-side IPC implementation stub class. */\npublic static abstract class Stub extends android.os.Binder implements com.example.taidl.ICalcAIDL\n{\nprivate static final java.lang.String DESCRIPTOR = \"com.example.taidl.ICalcAIDL\";\n/** Construct the stub at attach it to the interface. */\npublic Stub()\n{\nthis.attachInterface(this, DESCRIPTOR);\n}\n/**\n * Cast an IBinder object into an com.example.taidl.ICalcAIDL interface,\n * generating a proxy if needed.\n */\npublic static com.example.taidl.ICalcAIDL asInterface(android.os.IBinder obj)\n{\nif ((obj==null)) {\nreturn null;\n}\nandroid.os.IInterface iin = obj.queryLocalInterface(DESCRIPTOR);\nif (((iin!=null)&&(iin instanceof com.example.taidl.ICalcAIDL))) {\nreturn ((com.example.taidl.ICalcAIDL)iin);\n}\nreturn new com.example.taidl.ICalcAIDL.Stub.Proxy(obj);\n}\n@Override public android.os.IBinder asBinder()\n{\nreturn this;\n}\n@Override public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply, int flags) throws android.os.RemoteException\n{\nswitch (code)\n{\ncase INTERFACE_TRANSACTION:\n{\nreply.writeString(DESCRIPTOR);\nreturn true;\n}\ncase TRANSACTION_add:\n{\ndata.enforceInterface(DESCRIPTOR);\nint _arg0;\n_arg0 = data.readInt();\nint _arg1;\n_arg1 = data.readInt();\nint _result = this.add(_arg0, _arg1);\nreply.writeNoException();\nreply.writeInt(_result);\nreturn true;\n}\ncase TRANSACTION_min:\n{\ndata.enforceInterface(DESCRIPTOR);\nint _arg0;\n_arg0 = data.readInt();\nint _arg1;\n_arg1 = data.readInt();\nint _result = this.min(_arg0, _arg1);\nreply.writeNoException();\nreply.writeInt(_result);\nreturn true;\n}\n}\nreturn super.onTransact(code, data, reply, flags);\n}\nprivate static class Proxy implements com.example.taidl.ICalcAIDL\n{\nprivate android.os.IBinder mRemote;\nProxy(android.os.IBinder remote)\n{\nmRemote = remote;\n}\n@Override public android.os.IBinder asBinder()\n{\nreturn mRemote;\n}\npublic java.lang.String getInterfaceDescriptor()\n{\nreturn DESCRIPTOR;\n}\n@Override public int add(int x, int y) throws android.os.RemoteException\n{\nandroid.os.Parcel _data = android.os.Parcel.obtain();\nandroid.os.Parcel _reply = android.os.Parcel.obtain();\nint _result;\ntry {\n_data.writeInterfaceToken(DESCRIPTOR);\n_data.writeInt(x);\n_data.writeInt(y);\nmRemote.transact(Stub.TRANSACTION_add, _data, _reply, 0);\n_reply.readException();\n_result = _reply.readInt();\n}\nfinally {\n_reply.recycle();\n_data.recycle();\n}\nreturn _result;\n}\n@Override public int min(int x, int y) throws android.os.RemoteException\n{\nandroid.os.Parcel _data = android.os.Parcel.obtain();\nandroid.os.Parcel _reply = android.os.Parcel.obtain();\nint _result;\ntry {\n_data.writeInterfaceToken(DESCRIPTOR);\n_data.writeInt(x);\n_data.writeInt(y);\nmRemote.transact(Stub.TRANSACTION_min, _data, _reply, 0);\n_reply.readException();\n_result = _reply.readInt();\n}\nfinally {\n_reply.recycle();\n_data.recycle();\n}\nreturn _result;\n}\n}\nstatic final int TRANSACTION_add = (android.os.IBinder.FIRST_CALL_TRANSACTION + 0);\nstatic final int TRANSACTION_min = (android.os.IBinder.FIRST_CALL_TRANSACTION + 1);\n}\npublic int add(int x, int y) throws android.os.RemoteException;\npublic int min(int x, int y) throws android.os.RemoteException;\n}\n\n```\n\n2. 新建一个Service\n\n```\npackage com.example.taidl;\n\nimport android.app.Service;\nimport android.content.Intent;\nimport android.os.IBinder;\nimport android.os.RemoteException;\nimport android.util.Log;\n\npublic class CalcService extends Service{\n\n\tprivate static final String TAG = \"server\"; \n\t\n\tpublic void onCreate() \n { \n Log.e(TAG, \"onCreate\"); \n } \n \n public IBinder onBind(Intent t) \n { \n Log.e(TAG, \"onBind\"); \n return mBinder; \n } \n \n public void onDestroy() \n { \n Log.e(TAG, \"onDestroy\"); \n super.onDestroy(); \n } \n \n public boolean onUnbind(Intent intent) \n { \n Log.e(TAG, \"onUnbind\"); \n return super.onUnbind(intent); \n } \n \n public void onRebind(Intent intent) \n { \n Log.e(TAG, \"onRebind\"); \n super.onRebind(intent); \n } \n\tprivate final ICalcAIDL.Stub mBinder = new ICalcAIDL.Stub() {\n\t\t\n\t\t@Override\n\t\tpublic int min(int x, int y) throws RemoteException {\n\t\t\treturn x + y;\n\t\t}\n\t\t\n\t\t@Override\n\t\tpublic int add(int x, int y) throws RemoteException {\n\t\t\t// TODO Auto-generated method stub\n\t\t\treturn x - y;\n\t\t}\n\t};\n\t\n\t\n\n}\n\n```\n\n创建了一个mBinder对象,并在Service的onBind方法中返回\n\n注册:\n\n```\n \n \n \n \n \n \n \n```\n\n我们一会会在别的应用程序中通过Intent来查找此Service;这个不需要Activity,所以我也就没写Activity,安装完成也看不到安装图标,悄悄在后台运行着。服务端编写完毕。下面开始编写客户端:\n\n```\npackage com.example.tclient;\n\nimport com.example.taidl.ICalcAIDL;\n\nimport android.app.Activity;\nimport android.content.ComponentName;\nimport android.content.Context;\nimport android.content.Intent;\nimport android.content.ServiceConnection;\nimport android.os.Bundle;\nimport android.os.IBinder;\nimport android.util.Log;\nimport android.view.View;\nimport android.widget.Toast;\n\npublic class MainActivity extends Activity {\n\n\tprivate ICalcAIDL mCalcAidl;\n\n\tprivate ServiceConnection mServiceConn = new ServiceConnection()\n\t{\n\t\t@Override\n\t\tpublic void onServiceDisconnected(ComponentName name)\n\t\t{\n\t\t\tLog.e(\"client\", \"onServiceDisconnected\");\n\t\t\tmCalcAidl = null;\n\t\t}\n\n\t\t@Override\n\t\tpublic void onServiceConnected(ComponentName name, IBinder service)\n\t\t{\n\t\t\tLog.e(\"client\", \"onServiceConnected\");\n\t\t\tmCalcAidl = ICalcAIDL.Stub.asInterface(service);\n\t\t}\n\t};\n\n\t@Override\n\tprotected void onCreate(Bundle savedInstanceState)\n\t{\n\t\tsuper.onCreate(savedInstanceState);\n\t\tsetContentView(R.layout.activity_main);\n\n\t}\n\t\n\t/**\n\t * 点击BindService按钮时调用\n\t * @param view\n\t */\n\tpublic void bindService(View view)\n\t{\n\t\tIntent intent = new Intent();\n\t\tintent.setAction(\"com.example.taidl.calc\");\n\t\tbindService(intent, mServiceConn, Context.BIND_AUTO_CREATE);\n\t}\n\t/**\n\t * 点击unBindService按钮时调用\n\t * @param view\n\t */\n\tpublic void unbindService(View view)\n\t{\n\t\tunbindService(mServiceConn);\n\t}\n\t/**\n\t * 点击12+12按钮时调用\n\t * @param view\n\t */\n\tpublic void addInvoked(View view) throws Exception\n\t{\n\n\t\tif (mCalcAidl != null)\n\t\t{\n\t\t\tint addRes = mCalcAidl.add(12, 12);\n\t\t\tToast.makeText(this, addRes + \"\", Toast.LENGTH_SHORT).show();\n\t\t} else\n\t\t{\n\t\t\tToast.makeText(this, \"服务器被异常杀死,请重新绑定服务端\", Toast.LENGTH_SHORT)\n\t\t\t\t\t.show();\n\n\t\t}\n\n\t}\n\t/**\n\t * 点击50-12按钮时调用\n\t * @param view\n\t */\n\tpublic void minInvoked(View view) throws Exception\n\t{\n\n\t\tif (mCalcAidl != null)\n\t\t{\n\t\t\tint addRes = mCalcAidl.min(50, 12);\n\t\t\tToast.makeText(this, addRes + \"\", Toast.LENGTH_SHORT).show();\n\t\t} else\n\t\t{\n\t\t\tToast.makeText(this, \"服务器未绑定或被异常杀死,请重新绑定服务端\", Toast.LENGTH_SHORT)\n\t\t\t\t\t.show();\n\n\t\t}\n\n\t}\n}\n\n```\n\n将服务端的aidl文件完整的复制过来,包名一定要一致。\n\n##分析AIDL生成的代码\n\n1. 服务端\n\n```\nprivate final ICalcAIDL.Stub mBinder = new ICalcAIDL.Stub() \n { \n \n @Override \n public int add(int x, int y) throws RemoteException \n { \n return x + y; \n } \n \n @Override \n public int min(int x, int y) throws RemoteException \n { \n return x - y; \n } \n \n }; \n\n```\n\nICalcAILD.Stub来执行的,让我们来看看Stub这个类的声明:\n\n```\npublic static abstract class Stub extends android.os.Binder implements com.zhy.calc.aidl.ICalcAIDL \n```\n\n清楚的看到这个类是Binder的子类,是不是符合我们文章开通所说的服务端其实是一个Binder类的实例\n接下来看它的onTransact()方法:\n\n```\n@Override public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply, int flags) throws android.os.RemoteException \n{ \nswitch (code) \n{ \ncase INTERFACE_TRANSACTION: \n{ \nreply.writeString(DESCRIPTOR); \nreturn true; \n} \ncase TRANSACTION_add: \n{ \ndata.enforceInterface(DESCRIPTOR); \nint _arg0; \n_arg0 = data.readInt(); \nint _arg1; \n_arg1 = data.readInt(); \nint _result = this.add(_arg0, _arg1); \nreply.writeNoException(); \nreply.writeInt(_result); \nreturn true; \n} \ncase TRANSACTION_min: \n{ \ndata.enforceInterface(DESCRIPTOR); \nint _arg0; \n_arg0 = data.readInt(); \nint _arg1; \n_arg1 = data.readInt(); \nint _result = this.min(_arg0, _arg1); \nreply.writeNoException(); \nreply.writeInt(_result); \nreturn true; \n} \n} \nreturn super.onTransact(code, data, reply, flags); \n} \n```\n\n文章开头也说到服务端的Binder实例会根据客户端依靠Binder驱动发来的消息,执行onTransact方法,然后由其参数决定执行服务端的代码。\n可以看到onTransact有四个参数\ncode , data ,replay , flags\n\n* code 是一个整形的唯一标识,用于区分执行哪个方法,客户端会传递此参数,告诉服务端执行哪个方法\n* data客户端传递过来的参数\n* replay服务器返回回去的值\n* flags标明是否有返回值,0为有(双向),1为没有(单向)\n\n我们仔细看case TRANSACTION_min中的代码\n\ndata.enforceInterface(DESCRIPTOR);\n\n与客户端的writeInterfaceToken对用,标识远程服务的名称\n\n```\nint _arg0;\n_arg0 = data.readInt();\nint _arg1;\n_arg1 = data.readInt();\n```\n\n接下来分别读取了客户端传入的两个参数\n\n```\nint _result = this.min(_arg0, _arg1);\nreply.writeNoException();\nreply.writeInt(_result);\n```\n\n然后执行this.min,即我们实现的min方法;返回result由reply写回。\n\nadd同理,可以看到服务端通过AIDL生成Stub的类,封装了服务端本来需要写的代码。\n\n###客户端\n\n客户端主要通过ServiceConnected与服务端连接\n\n```\nprivate ServiceConnection mServiceConn = new ServiceConnection() \n { \n @Override \n public void onServiceDisconnected(ComponentName name) \n { \n Log.e(\"client\", \"onServiceDisconnected\"); \n mCalcAidl = null; \n } \n \n @Override \n public void onServiceConnected(ComponentName name, IBinder service) \n { \n Log.e(\"client\", \"onServiceConnected\"); \n mCalcAidl = ICalcAIDL.Stub.asInterface(service); \n } \n }; \n```\n\n如果你比较敏锐,应该会猜到这个onServiceConnected中的IBinder实例,其实就是我们文章开通所说的Binder驱动,也是一个Binder实例\n在ICalcAIDL.Stub.asInterface中最终调用了:\n\n```\nreturn new com.zhy.calc.aidl.ICalcAIDL.Stub.Proxy(obj); \n```\n这个Proxy实例传入了我们的Binder驱动,并且封装了我们调用服务端的代码,文章开头说,客户端会通过Binder驱动的transact()方法调用服务端代码\n\n直接看Proxy中的add方法\n\n```\n@Override public int add(int x, int y) throws android.os.RemoteException \n{ \nandroid.os.Parcel _data = android.os.Parcel.obtain(); \nandroid.os.Parcel _reply = android.os.Parcel.obtain(); \nint _result; \ntry { \n_data.writeInterfaceToken(DESCRIPTOR); \n_data.writeInt(x); \n_data.writeInt(y); \nmRemote.transact(Stub.TRANSACTION_add, _data, _reply, 0); \n_reply.readException(); \n_result = _reply.readInt(); \n} \nfinally { \n_reply.recycle(); \n_data.recycle(); \n} \nreturn _result; \n} \n```\n\n首先声明两个Parcel对象,一个用于传递数据,一个用户接收返回的数据\n\n```\n_data.writeInterfaceToken(DESCRIPTOR);与服务器端的enforceInterfac对应\n_data.writeInt(x);\n_data.writeInt(y);写入需要传递的参数\nmRemote.transact(Stub.TRANSACTION_add, _data, _reply, 0);\n```\n\n终于看到了我们的transact方法,第一个对应服务端的code,_data,_repay分别对应服务端的data,reply,0表示是双向的\n\n```\n_reply.readException();\n_result = _reply.readInt();\n```\n\n最后读出我们服务端返回的数据,然后return。可以看到和服务端的onTransact基本是一行一行对应的。\n\n我们已经通过AIDL生成的代码解释了Android Binder框架的工作原理。Service的作用其实就是为我们创建Binder驱动,即服务端与客户端连接的桥梁。\n"
},
{
"path": "Part1/Android/ANR问题.md",
"content": "#ANR\n---\n\n1、ANR排错一般有三种类型\n\n1. KeyDispatchTimeout(5 seconds) --主要是类型按键或触摸事件在特定时间内无响应\n2. BroadcastTimeout(10 seconds) --BroadcastReceiver在特定时间内无法处理完成\n3. ServiceTimeout(20 secends) --小概率事件 Service在特定的时间内无法处理完成\n\n2、哪些操作会导致ANR\n在主线程执行以下操作:\n1. 高耗时的操作,如图像变换\n2. 磁盘读写,数据库读写操作\n3. 大量的创建新对象\n\n\n3、如何避免\n\n1. UI线程尽量只做跟UI相关的工作\n2. 耗时的操作(比如数据库操作,I/O,连接网络或者别的有可能阻塞UI线程的操作)把它放在单独的线程处理\n3. 尽量用Handler来处理UIThread和别的Thread之间的交互\n\n4、解决的逻辑\n1. 使用AsyncTask\n\t1. 在doInBackground()方法中执行耗时操作\n\t2. 在onPostExecuted()更新UI\n2. 使用Handler实现异步任务\n\t1. 在子线程中处理耗时操作\n\t2. 处理完成之后,通过handler.sendMessage()传递处理结果\n\t3. 在handler的handleMessage()方法中更新UI\n\t4. 或者使用handler.post()方法将消息放到Looper中\n\t\n\n5、如何排查\n\n1. 首先分析log\n2. 从trace.txt文件查看调用stack,adb pull data/anr/traces.txt ./mytraces.txt\n3. 看代码\n4. 仔细查看ANR的成因(iowait?block?memoryleak?)\n\n6、监测ANR的Watchdog\n\n最近出来一个叫LeakCanary\n\n#FC(Force Close)\n##什么时候会出现\n1. Error\n2. OOM,内存溢出\n3. StackOverFlowError\n4. Runtime,比如说空指针异常\n\n##解决的办法\n1. 注意内存的使用和管理\n2. 使用Thread.UncaughtExceptionHandler接口\n"
},
{
"path": "Part1/Android/APP启动过程.md",
"content": "#APP启动过程\n---\n\n\n\n* 上图就可以很好的说明App启动的过程\n* ActivityManagerService组织回退栈时以ActivityRecord为基本单位,所有的ActivityRecord放在同一个ArrayList里,可以将mHistory看作一个栈对象,索引0所指的对象位于栈底,索引mHistory.size()-1所指的对象位于栈顶\n* Zygote进程孵化出新的应用进程后,会执行ActivityThread类的main方法.在该方法里会先准备好Looper和消息队列,然后调用attach方法将应用进程绑定到ActivityManagerService,然后进入loop循环,不断地读取消息队列里的消息,并分发消息。\n* ActivityThread的main方法执行后,应用进程接下来通知ActivityManagerService应用进程已启动,ActivityManagerService保存应用进程的一个代理对象,这样ActivityManagerService可以通过这个代理对象控制应用进程,然后ActivityManagerService通知**应用进程**创建入口Activity的实例,并执行它的生命周期方法"
},
{
"path": "Part1/Android/Activity启动过程全解析.md",
"content": "#Activity启动过程\n---\n\n###一些基本的概念\n\n* ActivityManagerServices,简称AMS,服务端对象,负责系统中所有Activity的生命周期\n* ActivityThread,App的真正入口。当开启App之后,会调用main()开始运行,开启消息循环队列,这就是传说中的UI线程或者叫主线程。与ActivityManagerServices配合,一起完成Activity的管理工作\n* ApplicationThread,用来实现ActivityManagerService与ActivityThread之间的交互。在ActivityManagerService需要管理相关Application中的Activity的生命周期时,通过ApplicationThread的代理对象与ActivityThread通讯。\n* ApplicationThreadProxy,是ApplicationThread在服务器端的代理,负责和客户端的ApplicationThread通讯。AMS就是通过该代理与ActivityThread进行通信的。\n* Instrumentation,每一个应用程序只有一个Instrumentation对象,每个Activity内都有一个对该对象的引用。Instrumentation可以理解为应用进程的管家,ActivityThread要创建或暂停某个Activity时,都需要通过Instrumentation来进行具体的操作。\n* ActivityStack,Activity在AMS的栈管理,用来记录已经启动的Activity的先后关系,状态信息等。通过ActivityStack决定是否需要启动新的进程。\n* ActivityRecord,ActivityStack的管理对象,每个Activity在AMS对应一个* ActivityRecord,来记录Activity的状态以及其他的管理信息。其实就是服务器端的Activity对象的映像。\n* TaskRecord,AMS抽象出来的一个“任务”的概念,是记录ActivityRecord的栈,一个“Task”包含若干个ActivityRecord。AMS用TaskRecord确保Activity启动和退出的顺序。如果你清楚Activity的4种launchMode,那么对这个概念应该不陌生。\n\n###回答一些问题\n\n**zygote是什么?有什么作用?**\n\nzygote意为“受精卵“。Android是基于Linux系统的,而在Linux中,所有的进程都是由init进程直接或者是间接fork出来的,zygote进程也不例外。\n\n在Android系统里面,zygote是一个进程的名字。Android是基于Linux System的,当你的手机开机的时候,Linux的内核加载完成之后就会启动一个叫“init“的进程。在Linux System里面,所有的进程都是由init进程fork出来的,我们的zygote进程也不例外。\n\n我们都知道,每一个App其实都是\n\n* 一个单独的dalvik虚拟机\n* 一个单独的进程\n\n所以当系统里面的第一个zygote进程运行之后,在这之后再开启App,就相当于开启一个新的进程。而为了实现资源共用和更快的启动速度,Android系统开启新进程的方式,是通过fork第一个zygote进程实现的。所以说,除了第一个zygote进程,其他应用所在的进程都是zygote的子进程,这下你明白为什么这个进程叫“受精卵”了吧?因为就像是一个受精卵一样,它能快速的分裂,并且产生遗传物质一样的细胞!\n\n**SystemServer是什么?有什么作用?它与zygote的关系是什么?**\n\n首先我要告诉你的是,SystemServer也是一个进程,而且是由zygote进程fork出来的。\n\n知道了SystemServer的本质,我们对它就不算太陌生了,这个进程是Android Framework里面两大非常重要的进程之一——另外一个进程就是上面的zygote进程。\n\n为什么说SystemServer非常重要呢?因为系统里面重要的服务都是在这个进程里面开启的,比如 \nActivityManagerService、PackageManagerService、WindowManagerService等等,看着是不是都挺眼熟的?\n\n那么这些系统服务是怎么开启起来的呢?\n\n在zygote开启的时候,会调用ZygoteInit.main()进行初始化\n\n```\npublic static void main(String argv[]) {\n\n ...ignore some code...\n\n //在加载首个zygote的时候,会传入初始化参数,使得startSystemServer = true\n boolean startSystemServer = false;\n for (int i = 1; i < argv.length; i++) {\n if (\"start-system-server\".equals(argv[i])) {\n startSystemServer = true;\n } else if (argv[i].startsWith(ABI_LIST_ARG)) {\n abiList = argv[i].substring(ABI_LIST_ARG.length());\n } else if (argv[i].startsWith(SOCKET_NAME_ARG)) {\n socketName = argv[i].substring(SOCKET_NAME_ARG.length());\n } else {\n throw new RuntimeException(\"Unknown command line argument: \" + argv[i]);\n }\n }\n\n ...ignore some code...\n\n //开始fork我们的SystemServer进程\n if (startSystemServer) {\n startSystemServer(abiList, socketName);\n }\n\n ...ignore some code...\n\n}\n```\n\n我们看下startSystemServer()做了些什么\n\n```\n /**留着这个注释,就是为了说明SystemServer确实是被fork出来的\n * Prepare the arguments and fork for the system server process.\n */\n private static boolean startSystemServer(String abiList, String socketName)\n throws MethodAndArgsCaller, RuntimeException {\n\n ...ignore some code...\n\n //留着这段注释,就是为了说明上面ZygoteInit.main(String argv[])里面的argv就是通过这种方式传递进来的\n /* Hardcoded command line to start the system server */\n String args[] = {\n \"--setuid=1000\",\n \"--setgid=1000\",\n \"--setgroups=1001,1002,1003,1004,1005,1006,1007,1008,1009,1010,1018,1032,3001,3002,3003,3006,3007\",\n \"--capabilities=\" + capabilities + \",\" + capabilities,\n \"--runtime-init\",\n \"--nice-name=system_server\",\n \"com.android.server.SystemServer\",\n };\n\n int pid;\n try {\n parsedArgs = new ZygoteConnection.Arguments(args);\n ZygoteConnection.applyDebuggerSystemProperty(parsedArgs);\n ZygoteConnection.applyInvokeWithSystemProperty(parsedArgs);\n\n //确实是fuck出来的吧,我没骗你吧~不对,是fork出来的 -_-|||\n /* Request to fork the system server process */\n pid = Zygote.forkSystemServer(\n parsedArgs.uid, parsedArgs.gid,\n parsedArgs.gids,\n parsedArgs.debugFlags,\n null,\n parsedArgs.permittedCapabilities,\n parsedArgs.effectiveCapabilities);\n } catch (IllegalArgumentException ex) {\n throw new RuntimeException(ex);\n }\n\n /* For child process */\n if (pid == 0) {\n if (hasSecondZygote(abiList)) {\n waitForSecondaryZygote(socketName);\n }\n\n handleSystemServerProcess(parsedArgs);\n }\n\n return true;\n }\n```\n\n**ActivityManagerService是什么?什么时候初始化的?有什么作用?**\n\nActivityManagerService,简称AMS,服务端对象,负责系统中所有Activity的生命周期。\n\nActivityManagerService进行初始化的时机很明确,就是在SystemServer进程开启的时候,就会初始化ActivityManagerService。从下面的代码中可以看到\n\n```\npublic final class SystemServer {\n\n //zygote的主入口\n public static void main(String[] args) {\n new SystemServer().run();\n }\n\n public SystemServer() {\n // Check for factory test mode.\n mFactoryTestMode = FactoryTest.getMode();\n }\n\n private void run() {\n\n ...ignore some code...\n\n //加载本地系统服务库,并进行初始化 \n System.loadLibrary(\"android_servers\");\n nativeInit();\n\n // 创建系统上下文\n createSystemContext();\n\n //初始化SystemServiceManager对象,下面的系统服务开启都需要调用SystemServiceManager.startService(Class),这个方法通过反射来启动对应的服务\n mSystemServiceManager = new SystemServiceManager(mSystemContext);\n\n //开启服务\n try {\n startBootstrapServices();\n startCoreServices();\n startOtherServices();\n } catch (Throwable ex) {\n Slog.e(\"System\", \"******************************************\");\n Slog.e(\"System\", \"************ Failure starting system services\", ex);\n throw ex;\n }\n\n ...ignore some code...\n\n }\n\n //初始化系统上下文对象mSystemContext,并设置默认的主题,mSystemContext实际上是一个ContextImpl对象。调用ActivityThread.systemMain()的时候,会调用ActivityThread.attach(true),而在attach()里面,则创建了Application对象,并调用了Application.onCreate()。\n private void createSystemContext() {\n ActivityThread activityThread = ActivityThread.systemMain();\n mSystemContext = activityThread.getSystemContext();\n mSystemContext.setTheme(android.R.style.Theme_DeviceDefault_Light_DarkActionBar);\n }\n\n //在这里开启了几个核心的服务,因为这些服务之间相互依赖,所以都放在了这个方法里面。\n private void startBootstrapServices() {\n\n ...ignore some code...\n\n //初始化ActivityManagerService\n mActivityManagerService = mSystemServiceManager.startService(\n ActivityManagerService.Lifecycle.class).getService();\n mActivityManagerService.setSystemServiceManager(mSystemServiceManager);\n\n //初始化PowerManagerService,因为其他服务需要依赖这个Service,因此需要尽快的初始化\n mPowerManagerService = mSystemServiceManager.startService(PowerManagerService.class);\n\n // 现在电源管理已经开启,ActivityManagerService负责电源管理功能\n mActivityManagerService.initPowerManagement();\n\n // 初始化DisplayManagerService\n mDisplayManagerService = mSystemServiceManager.startService(DisplayManagerService.class);\n\n //初始化PackageManagerService\n mPackageManagerService = PackageManagerService.main(mSystemContext, mInstaller,\n mFactoryTestMode != FactoryTest.FACTORY_TEST_OFF, mOnlyCore);\n\n ...ignore some code...\n\n }\n\n}\n```\n\n经过上面这些步骤,我们的ActivityManagerService对象已经创建好了,并且完成了成员变量初始化。而且在这之前,调用createSystemContext()创建系统上下文的时候,也已经完成了mSystemContext和ActivityThread的创建。注意,这是系统进程开启时的流程,在这之后,会开启系统的Launcher程序,完成系统界面的加载与显示。\n\n你是否会好奇,我为什么说AMS是服务端对象?下面我给你介绍下Android系统里面的服务器和客户端的概念。\n\n其实服务器客户端的概念不仅仅存在于Web开发中,在Android的框架设计中,使用的也是这一种模式。服务器端指的就是所有App共用的系统服务,比如我们这里提到的ActivityManagerService,和前面提到的PackageManagerService、WindowManagerService等等,这些基础的系统服务是被所有的App公用的,当某个App想实现某个操作的时候,要告诉这些系统服务,比如你想打开一个App,那么我们知道了包名和MainActivity类名之后就可以打开\n\n```\nIntent intent = new Intent(Intent.ACTION_MAIN); \nintent.addCategory(Intent.CATEGORY_LAUNCHER); \nComponentName cn = new ComponentName(packageName, className); \nintent.setComponent(cn); \nstartActivity(intent); \n```\n\n但是,我们的App通过调用startActivity()并不能直接打开另外一个App,这个方法会通过一系列的调用,最后还是告诉AMS说:“我要打开这个App,我知道他的住址和名字,你帮我打开吧!”所以是AMS来通知zygote进程来fork一个新进程,来开启我们的目标App的。这就像是浏览器想要打开一个超链接一样,浏览器把网页地址发送给服务器,然后还是服务器把需要的资源文件发送给客户端的。\n\n知道了Android Framework的客户端服务器架构之后,我们还需要了解一件事情,那就是我们的App和AMS(SystemServer进程)还有zygote进程分属于三个独立的进程,他们之间如何通信呢?\n\n知道了Android Framework的客户端服务器架构之后,我们还需要了解一件事情,那就是我们的App和AMS(SystemServer进程)还有zygote进程分属于三个独立的进程,他们之间如何通信呢?\n\nApp与AMS通过Binder进行IPC通信,AMS(SystemServer进程)与zygote通过Socket进行IPC通信。\n\n那么AMS有什么用呢?在前面我们知道了,如果想打开一个App的话,需要AMS去通知zygote进程,除此之外,其实所有的Activity的开启、暂停、关闭都需要AMS来控制,所以我们说,AMS负责系统中所有Activity的生命周期。\n\n在Android系统中,任何一个Activity的启动都是由AMS和应用程序进程(主要是ActivityThread)相互配合来完成的。AMS服务统一调度系统中所有进程的Activity启动,而每个Activity的启动过程则由其所属的进程具体来完成。\n\n这样说你可能还是觉得比较抽象,没关系,下面有一部分是专门来介绍AMS与ActivityThread如何一起合作控制Activity的生命周期的。\n\n**Launcher是什么?什么时候启动的?**\n\n当我们点击手机桌面上的图标的时候,App就由Launcher开始启动了。但是,你有没有思考过Launcher到底是一个什么东西?\n\nLauncher本质上也是一个应用程序,和我们的App一样,也是继承自Activity\n\npackages/apps/Launcher2/src/com/android/launcher2/Launcher.java\n\n```\npublic final class Launcher extends Activity\n implements View.OnClickListener, OnLongClickListener, LauncherModel.Callbacks,\n View.OnTouchListener {\n }\n```\n\nLauncher实现了点击、长按等回调接口,来接收用户的输入。既然是普通的App,那么我们的开发经验在这里就仍然适用,比如,我们点击图标的时候,是怎么开启的应用呢?如果让你,你怎么做这个功能呢?捕捉图标点击事件,然后startActivity()发送对应的Intent请求呗!是的,Launcher也是这么做的,就是这么easy!\n\n那么到底是处理的哪个对象的点击事件呢?既然Launcher是App,并且有界面,那么肯定有布局文件呀,是的,我找到了布局文件launcher.xml\n\n```\n\n\n \n\n \n \n\n \n\n \n \n\n \n \n \n \n \n \n\n ...ignore some code...\n\n \n\n```\n\n为了方便查看,我删除了很多代码,从上面这些我们应该可以看出一些东西来:Launcher大量使用标签来实现界面的复用,而且定义了很多的自定义控件实现界面效果,dock_divider从布局的参数声明上可以猜出,是底部操作栏和上面图标布局的分割线,而paged_view_indicator则是页面指示器,和App首次进入的引导页下面的界面引导是一样的道理。当然,我们最关心的是Workspace这个布局,因为注释里面说在这里面包含了5个屏幕的单元格,想必你也猜到了,这个就是在首页存放我们图标的那五个界面(不同的ROM会做不同的DIY,数量不固定)。\n\n接下来,我们应该打开workspace_screen布局,看看里面有什么东东。\n\nworkspace_screen.xml\n\n```\n\n```\n\n里面就一个CellLayout,也是一个自定义布局,那么我们就可以猜到了,既然可以存放图标,那么这个自定义的布局很有可能是继承自ViewGroup或者是其子类,实际上,CellLayout确实是继承自ViewGroup。在CellLayout里面,只放了一个子View,那就是ShortcutAndWidgetContainer。从名字也可以看出来,ShortcutAndWidgetContainer这个类就是用来存放快捷图标和Widget小部件的,那么里面放的是什么对象呢?\n\n在桌面上的图标,使用的是BubbleTextView对象,这个对象在TextView的基础之上,添加了一些特效,比如你长按移动图标的时候,图标位置会出现一个背景(不同版本的效果不同),所以我们找到BubbleTextView对象的点击事件,就可以找到Launcher如何开启一个App了。\n\n除了在桌面上有图标之外,在程序列表中点击图标,也可以开启对应的程序。这里的图标使用的不是BubbleTextView对象,而是PagedViewIcon对象,我们如果找到它的点击事件,就也可以找到Launcher如何开启一个App。\n\n其实说这么多,和今天的主题隔着十万八千里,上面这些东西,你有兴趣就看,没兴趣就直接跳过,不知道不影响这篇文章阅读。\n\nBubbleTextView的点击事件在哪里呢?我来告诉你:在Launcher.onClick(View v)里面。\n\n```\n/**\n * Launches the intent referred by the clicked shortcut\n */\n public void onClick(View v) {\n\n ...ignore some code...\n\n Object tag = v.getTag();\n if (tag instanceof ShortcutInfo) {\n // Open shortcut\n final Intent intent = ((ShortcutInfo) tag).intent;\n int[] pos = new int[2];\n v.getLocationOnScreen(pos);\n intent.setSourceBounds(new Rect(pos[0], pos[1],\n pos[0] + v.getWidth(), pos[1] + v.getHeight()));\n //开始开启Activity咯~\n boolean success = startActivitySafely(v, intent, tag);\n\n if (success && v instanceof BubbleTextView) {\n mWaitingForResume = (BubbleTextView) v;\n mWaitingForResume.setStayPressed(true);\n }\n } else if (tag instanceof FolderInfo) {\n //如果点击的是图标文件夹,就打开文件夹\n if (v instanceof FolderIcon) {\n FolderIcon fi = (FolderIcon) v;\n handleFolderClick(fi);\n }\n } else if (v == mAllAppsButton) {\n ...ignore some code...\n }\n }\n```\n\n从上面的代码我们可以看到,在桌面上点击快捷图标的时候,会调用\n\n```\nstartActivitySafely(v, intent, tag);\n```\n\n那么从程序列表界面,点击图标的时候会发生什么呢?实际上,程序列表界面使用的是AppsCustomizePagedView对象,所以我在这个类里面找到了onClick(View v)。\n\ncom.android.launcher2.AppsCustomizePagedView.java\n\n```\n/**\n * The Apps/Customize page that displays all the applications, widgets, and shortcuts.\n */\npublic class AppsCustomizePagedView extends PagedViewWithDraggableItems implements\n View.OnClickListener, View.OnKeyListener, DragSource,\n PagedViewIcon.PressedCallback, PagedViewWidget.ShortPressListener,\n LauncherTransitionable {\n\n @Override\n public void onClick(View v) {\n\n ...ignore some code...\n\n if (v instanceof PagedViewIcon) {\n mLauncher.updateWallpaperVisibility(true);\n mLauncher.startActivitySafely(v, appInfo.intent, appInfo);\n } else if (v instanceof PagedViewWidget) {\n ...ignore some code..\n }\n } \n }\n```\n\n可以看到,调用的是\n\n```\nmLauncher.startActivitySafely(v, appInfo.intent, appInfo);\n```\n\n殊途同归\n\n不管从哪里点击图标,调用的都是Launcher.startActivitySafely()。\n\n下面我们就可以一步步的来看一下Launcher.startActivitySafely()到底做了什么事情。\n\n```\n boolean startActivitySafely(View v, Intent intent, Object tag) {\n boolean success = false;\n try {\n success = startActivity(v, intent, tag);\n } catch (ActivityNotFoundException e) {\n Toast.makeText(this, R.string.activity_not_found, Toast.LENGTH_SHORT).show();\n Log.e(TAG, \"Unable to launch. tag=\" + tag + \" intent=\" + intent, e);\n }\n return success;\n }\n```\n\n调用了startActivity(v, intent, tag)\n\n```\n boolean startActivity(View v, Intent intent, Object tag) {\n\n intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);\n try {\n boolean useLaunchAnimation = (v != null) &&\n !intent.hasExtra(INTENT_EXTRA_IGNORE_LAUNCH_ANIMATION);\n\n if (useLaunchAnimation) {\n if (user == null || user.equals(android.os.Process.myUserHandle())) {\n startActivity(intent, opts.toBundle());\n } else {\n launcherApps.startMainActivity(intent.getComponent(), user,\n intent.getSourceBounds(),\n opts.toBundle());\n }\n } else {\n if (user == null || user.equals(android.os.Process.myUserHandle())) {\n startActivity(intent);\n } else {\n launcherApps.startMainActivity(intent.getComponent(), user,\n intent.getSourceBounds(), null);\n }\n }\n return true;\n } catch (SecurityException e) {\n ...\n }\n return false;\n }\n```\n\n这里会调用Activity.startActivity(intent, opts.toBundle()),这个方法熟悉吗?这就是我们经常用到的Activity.startActivity(Intent)的重载函数。而且由于设置了\n\n```\nintent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);\n```\n\n所以这个Activity会添加到一个新的Task栈中,而且,startActivity()调用的其实是startActivityForResult()这个方法。\n\n```\n@Override\n public void startActivity(Intent intent, @Nullable Bundle options) {\n if (options != null) {\n startActivityForResult(intent, -1, options);\n } else {\n // Note we want to go through this call for compatibility with\n // applications that may have overridden the method.\n startActivityForResult(intent, -1);\n }\n }\n```\n\n所以我们现在明确了,Launcher中开启一个App,其实和我们在Activity中直接startActivity()基本一样,都是调用了Activity.startActivityForResult()。\n\n**Instrumentation是什么?和ActivityThread是什么关系?**\n\n还记得前面说过的Instrumentation对象吗?每个Activity都持有Instrumentation对象的一个引用,但是整个进程只会存在一个Instrumentation对象。当startActivityForResult()调用之后,实际上还是调用了mInstrumentation.execStartActivity()\n\n```\npublic void startActivityForResult(Intent intent, int requestCode, @Nullable Bundle options) {\n if (mParent == null) {\n Instrumentation.ActivityResult ar =\n mInstrumentation.execStartActivity(\n this, mMainThread.getApplicationThread(), mToken, this,\n intent, requestCode, options);\n if (ar != null) {\n mMainThread.sendActivityResult(\n mToken, mEmbeddedID, requestCode, ar.getResultCode(),\n ar.getResultData());\n }\n ...ignore some code... \n } else {\n if (options != null) {\n //当现在的Activity有父Activity的时候会调用,但是在startActivityFromChild()内部实际还是调用的mInstrumentation.execStartActivity()\n mParent.startActivityFromChild(this, intent, requestCode, options);\n } else {\n mParent.startActivityFromChild(this, intent, requestCode);\n }\n }\n ...ignore some code... \n }\n```\n\n下面是mInstrumentation.execStartActivity()的实现\n\n```\npublic ActivityResult execStartActivity(\n Context who, IBinder contextThread, IBinder token, Activity target,\n Intent intent, int requestCode, Bundle options) {\n IApplicationThread whoThread = (IApplicationThread) contextThread;\n ...ignore some code...\n try {\n intent.migrateExtraStreamToClipData();\n intent.prepareToLeaveProcess();\n int result = ActivityManagerNative.getDefault()\n .startActivity(whoThread, who.getBasePackageName(), intent,\n intent.resolveTypeIfNeeded(who.getContentResolver()),\n token, target != null ? target.mEmbeddedID : null,\n requestCode, 0, null, options);\n checkStartActivityResult(result, intent);\n } catch (RemoteException e) {\n }\n return null;\n }\n```\n\n所以当我们在程序中调用startActivity()的 时候,实际上调用的是Instrumentation的相关的方法。\n\nInstrumentation意为“仪器”,我们先看一下这个类里面包含哪些方法吧\n\n\n\n我们可以看到,这个类里面的方法大多数和Application和Activity有关,是的,这个类就是完成对Application和Activity初始化和生命周期的工具类。比如说,我单独挑一个callActivityOnCreate()让你看看\n\n```\npublic void callActivityOnCreate(Activity activity, Bundle icicle) {\n prePerformCreate(activity);\n activity.performCreate(icicle);\n postPerformCreate(activity);\n }\n```\n\n对activity.performCreate(icicle);这一行代码熟悉吗?这一行里面就调用了传说中的Activity的入口函数onCreate(),不信?接着往下看\n\nActivity.performCreate()\n\n```\nfinal void performCreate(Bundle icicle) {\n onCreate(icicle);\n mActivityTransitionState.readState(icicle);\n performCreateCommon();\n }\n```\n\n没骗你吧,onCreate在这里调用了吧。但是有一件事情必须说清楚,那就是这个Instrumentation类这么重要,为啥我在开发的过程中,没有发现他的踪迹呢?\n\n是的,Instrumentation这个类很重要,对Activity生命周期方法的调用根本就离不开他,他可以说是一个大管家,但是,这个大管家比较害羞,是一个女的,管内不管外,是老板娘~\n\n那么你可能要问了,老板是谁呀? \n老板当然是大名鼎鼎的ActivityThread了!\n\nActivityThread你都没听说过?那你肯定听说过传说中的UI线程吧?是的,这就是UI线程。我们前面说过,App和AMS是通过Binder传递信息的,那么ActivityThread就是专门与AMS的外交工作的。\n\nAMS说:“ActivityThread,你给我暂停一个Activity!” \nActivityThread就说:“没问题!”然后转身和Instrumentation说:“老婆,AMS让暂停一个Activity,我这里忙着呢,你快去帮我把这事办了把~”\n于是,Instrumentation就去把事儿搞定了。\n\n所以说,AMS是董事会,负责指挥和调度的,ActivityThread是老板,虽然说家里的事自己说了算,但是需要听从AMS的指挥,而Instrumentation则是老板娘,负责家里的大事小事,但是一般不抛头露面,听一家之主ActivityThread的安排。\n\n**如何理解AMS和ActivityThread之间的Binder通信?**\n\n前面我们说到,在调用startActivity()的时候,实际上调用的是\n\n```\nmInstrumentation.execStartActivity()\n```\n\n但是到这里还没完呢!里面又调用了下面的方法\n\n```\nActivityManagerNative.getDefault()\n .startActivity\n```\n\n\n\n\n"
},
{
"path": "Part1/Android/Android关于oom的解决方案.md",
"content": "#Android关于OOM的解决方案\n##OOM\n* 内存溢出(Out Of Memory)\n* 也就是说内存占有量超过了VM所分配的最大\n\n\n##出现OOM的原因\n1. 加载对象过大\n2. 相应资源过多,来不及释放\n\n##如何解决\n1. 在内存引用上做些处理,常用的有软引用、强化引用、弱引用\n2. 在内存中加载图片时直接在内存中作处理,如边界压缩\n3. 动态回收内存\n4. 优化Dalvik虚拟机的堆内存分配\n5. 自定义堆内存大小\n\n\n"
},
{
"path": "Part1/Android/Android内存泄漏总结.md",
"content": "#Android 内存泄漏总结\n\n内存管理的目的就是让我们在开发中怎么有效的避免我们的应用出现内存泄漏的问题。内存泄漏大家都不陌生了,简单粗俗的讲,就是该被释放的对象没有释放,一直被某个或某些实例所持有却不再被使用导致 GC 不能回收。最近自己阅读了大量相关的文档资料,打算做个 总结 沉淀下来跟大家一起分享和学习,也给自己一个警示,以后 coding 时怎么避免这些情况,提高应用的体验和质量。\n\n我会从 java 内存泄漏的基础知识开始,并通过具体例子来说明 Android 引起内存泄漏的各种原因,以及如何利用工具来分析应用内存泄漏,最后再做总结。\n\n\n##Java 内存分配策略\n\nJava 程序运行时的内存分配策略有三种,分别是静态分配,栈式分配,和堆式分配,对应的,三种存储策略使用的内存空间主要分别是静态存储区(也称方法区)、栈区和堆区。\n\n* 静态存储区(方法区):主要存放静态数据、全局 static 数据和常量。这块内存在程序编译时就已经分配好,并且在程序整个运行期间都存在。\n\n* 栈区 :当方法被执行时,方法体内的局部变量(其中包括基础数据类型、对象的引用)都在栈上创建,并在方法执行结束时这些局部变量所持有的内存将会自动被释放。因为栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。\n\n* 堆区 : 又称动态内存分配,通常就是指在程序运行时直接 new 出来的内存,也就是对象的实例。这部分内存在不使用时将会由 Java 垃圾回收器来负责回收。\n\n##栈与堆的区别:\n\n在方法体内定义的(局部变量)一些基本类型的变量和对象的引用变量都是在方法的栈内存中分配的。当在一段方法块中定义一个变量时,Java 就会在栈中为该变量分配内存空间,当超过该变量的作用域后,该变量也就无效了,分配给它的内存空间也将被释放掉,该内存空间可以被重新使用。\n\n堆内存用来存放所有由 new 创建的对象(包括该对象其中的所有成员变量)和数组。在堆中分配的内存,将由 Java 垃圾回收器来自动管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,这个特殊的变量就是我们上面说的引用变量。我们可以通过这个引用变量来访问堆中的对象或者数组。\n\n举个例子:\n\n```\npublic class Sample {\n int s1 = 0;\n Sample mSample1 = new Sample();\n\n public void method() {\n int s2 = 1;\n Sample mSample2 = new Sample();\n }\n}\n\nSample mSample3 = new Sample();\n```\n\nSample 类的局部变量 s2 和引用变量 mSample2 都是存在于栈中,但 mSample2 指向的对象是存在于堆上的。\nmSample3 指向的对象实体存放在堆上,包括这个对象的所有成员变量 s1 和 mSample1,而它自己存在于栈中。\n\n结论:\n\n局部变量的基本数据类型和引用存储于栈中,引用的对象实体存储于堆中。—— 因为它们属于方法中的变量,生命周期随方法而结束。\n\n成员变量全部存储与堆中(包括基本数据类型,引用和引用的对象实体)—— 因为它们属于类,类对象终究是要被new出来使用的。\n\n了解了 Java 的内存分配之后,我们再来看看 Java 是怎么管理内存的。\n\n##Java是如何管理内存\n\nJava的内存管理就是对象的分配和释放问题。在 Java 中,程序员需要通过关键字 new 为每个对象申请内存空间 (基本类型除外),所有的对象都在堆 (Heap)中分配空间。另外,对象的释放是由 GC 决定和执行的。在 Java 中,内存的分配是由程序完成的,而内存的释放是由 GC 完成的,这种收支两条线的方法确实简化了程序员的工作。但同时,它也加重了JVM的工作。这也是 Java 程序运行速度较慢的原因之一。因为,GC 为了能够正确释放对象,GC 必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC 都需要进行监控。\n\n监视对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再被引用。\n\n为了更好理解 GC 的工作原理,我们可以将对象考虑为有向图的顶点,将引用关系考虑为图的有向边,有向边从引用者指向被引对象。另外,每个线程对象可以作为一个图的起始顶点,例如大多程序从 main 进程开始执行,那么该图就是以 main 进程顶点开始的一棵根树。在这个有向图中,根顶点可达的对象都是有效对象,GC将不回收这些对象。如果某个对象 (连通子图)与这个根顶点不可达(注意,该图为有向图),那么我们认为这个(这些)对象不再被引用,可以被 GC 回收。\n以下,我们举一个例子说明如何用有向图表示内存管理。对于程序的每一个时刻,我们都有一个有向图表示JVM的内存分配情况。以下右图,就是左边程序运行到第6行的示意图。\n\n\n\nJava使用有向图的方式进行内存管理,可以消除引用循环的问题,例如有三个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的。这种方式的优点是管理内存的精度很高,但是效率较低。另外一种常用的内存管理技术是使用计数器,例如COM模型采用计数器方式管理构件,它与有向图相比,精度行低(很难处理循环引用的问题),但执行效率很高。\n\n##什么是Java中的内存泄露\n\n在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。\n\n在C++中,内存泄漏的范围更大一些。有些对象被分配了内存空间,然后却不可达,由于C++中没有GC,这些内存将永远收不回来。在Java中,这些不可达的对象都由GC负责回收,因此程序员不需要考虑这部分的内存泄露。\n\n通过分析,我们得知,对于C++,程序员需要自己管理边和顶点,而对于Java程序员只需要管理边就可以了(不需要管理顶点的释放)。通过这种方式,Java提高了编程的效率。\n\n\n\n因此,通过以上分析,我们知道在Java中也有内存泄漏,但范围比C++要小一些。因为Java从语言上保证,任何对象都是可达的,所有的不可达对象都由GC管理。\n\n对于程序员来说,GC基本是透明的,不可见的。虽然,我们只有几个函数可以访问GC,例如运行GC的函数System.gc(),但是根据Java语言规范定义, 该函数不保证JVM的垃圾收集器一定会执行。因为,不同的JVM实现者可能使用不同的算法管理GC。通常,GC的线程的优先级别较低。JVM调用GC的策略也有很多种,有的是内存使用到达一定程度时,GC才开始工作,也有定时执行的,有的是平缓执行GC,有的是中断式执行GC。但通常来说,我们不需要关心这些。除非在一些特定的场合,GC的执行影响应用程序的性能,例如对于基于Web的实时系统,如网络游戏等,用户不希望GC突然中断应用程序执行而进行垃圾回收,那么我们需要调整GC的参数,让GC能够通过平缓的方式释放内存,例如将垃圾回收分解为一系列的小步骤执行,Sun提供的HotSpot JVM就支持这一特性。\n\n同样给出一个 Java 内存泄漏的典型例子,\n\n```\nVector v = new Vector(10);\nfor (int i = 1; i < 100; i++) {\n Object o = new Object();\n v.add(o);\n o = null; \n}\n```\n\n在这个例子中,我们循环申请Object对象,并将所申请的对象放入一个 Vector 中,如果我们仅仅释放引用本身,那么 Vector 仍然引用该对象,所以这个对象对 GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从 Vector 中删除,最简单的方法就是将 Vector 对象设置为 null。\n\n\n**详细Java中的内存泄漏**\n\n1.Java内存回收机制\n\n不论哪种语言的内存分配方式,都需要返回所分配内存的真实地址,也就是返回一个指针到内存块的首地址。Java中对象是采用new或者反射的方法创建的,这些对象的创建都是在堆(Heap)中分配的,所有对象的回收都是由Java虚拟机通过垃圾回收机制完成的。GC为了能够正确释放对象,会监控每个对象的运行状况,对他们的申请、引用、被引用、赋值等状况进行监控,Java会使用有向图的方法进行管理内存,实时监控对象是否可以达到,如果不可到达,则就将其回收,这样也可以消除引用循环的问题。在Java语言中,判断一个内存空间是否符合垃圾收集标准有两个:一个是给对象赋予了空值null,以下再没有调用过,另一个是给对象赋予了新值,这样重新分配了内存空间。 \n\n2.Java内存泄漏引起的原因\n\n内存泄漏是指无用对象(不再使用的对象)持续占有内存或无用对象的内存得不到及时释放,从而造成内存空间的浪费称为内存泄漏。内存泄露有时不严重且不易察觉,这样开发者就不知道存在内存泄露,但有时也会很严重,会提示你Out of memory。j\n\nJava内存泄漏的根本原因是什么呢?长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是Java中内存泄漏的发生场景。具体主要有如下几大类:\n\n1、静态集合类引起内存泄漏:\n\n像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。 \n\n例如\n\n```\nStatic Vector v = new Vector(10);\nfor (int i = 1; i<100; i++)\n{\nObject o = new Object();\nv.add(o);\no = null;\n}\n```\n\n在这个例子中,循环申请Object 对象,并将所申请的对象放入一个Vector 中,如果仅仅释放引用本身(o=null),那么Vector 仍然引用该对象,所以这个对象对GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从Vector 中删除,最简单的方法就是将Vector对象设置为null。\n\n2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。\n\n例如:\n\n```\npublic static void main(String[] args)\n{\nSet set = new HashSet();\nPerson p1 = new Person(\"唐僧\",\"pwd1\",25);\nPerson p2 = new Person(\"孙悟空\",\"pwd2\",26);\nPerson p3 = new Person(\"猪八戒\",\"pwd3\",27);\nset.add(p1);\nset.add(p2);\nset.add(p3);\nSystem.out.println(\"总共有:\"+set.size()+\" 个元素!\"); //结果:总共有:3 个元素!\np3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变\n\nset.remove(p3); //此时remove不掉,造成内存泄漏\n\nset.add(p3); //重新添加,居然添加成功\nSystem.out.println(\"总共有:\"+set.size()+\" 个元素!\"); //结果:总共有:4 个元素!\nfor (Person person : set)\n{\nSystem.out.println(person);\n}\n}\n```\n\n3、监听器\n\n在java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如addXXXListener()等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。\n\n4、各种连接 \n\n比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close()方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。\n\n5、内部类和外部模块的引用\n\n内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。此外程序员还要小心外部模块不经意的引用,例如程序员A 负责A 模块,调用了B 模块的一个方法如:\npublic void registerMsg(Object b);\n这种调用就要非常小心了,传入了一个对象,很可能模块B就保持了对该对象的引用,这时候就需要注意模块B 是否提供相应的操作去除引用。\n\n6、单例模式 \n\n不正确使用单例模式是引起内存泄漏的一个常见问题,单例对象在初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部的引用,那么这个对象将不能被JVM正常回收,导致内存泄漏,考虑下面的例子:\n\n```\nclass A{\npublic A(){\nB.getInstance().setA(this);\n}\n....\n}\n//B类采用单例模式\nclass B{\nprivate A a;\nprivate static B instance=new B();\npublic B(){}\npublic static B getInstance(){\nreturn instance;\n}\npublic void setA(A a){\nthis.a=a;\n}\n//getter...\n} \n```\n\n\n显然B采用singleton模式,它持有一个A对象的引用,而这个A类的对象将不能被回收。想象下如果A是个比较复杂的对象或者集合类型会发生什么情况\n\n##Android中常见的内存泄漏汇总\n---\n\n###集合类泄漏\n\n集合类如果仅仅有添加元素的方法,而没有相应的删除机制,导致内存被占用。如果这个集合类是全局性的变量 (比如类中的静态属性,全局性的 map 等即有静态引用或 final 一直指向它),那么没有相应的删除机制,很可能导致集合所占用的内存只增不减。比如上面的典型例子就是其中一种情况,当然实际上我们在项目中肯定不会写这么 2B 的代码,但稍不注意还是很容易出现这种情况,比如我们都喜欢通过 HashMap 做一些缓存之类的事,这种情况就要多留一些心眼。\n\n###单例造成的内存泄漏\n\n由于单例的静态特性使得其生命周期跟应用的生命周期一样长,所以如果使用不恰当的话,很容易造成内存泄漏。比如下面一个典型的例子,\n\n```\npublic class AppManager {\nprivate static AppManager instance;\nprivate Context context;\nprivate AppManager(Context context) {\nthis.context = context;\n}\npublic static AppManager getInstance(Context context) {\nif (instance == null) {\ninstance = new AppManager(context);\n}\nreturn instance;\n}\n}\n```\n\n这是一个普通的单例模式,当创建这个单例的时候,由于需要传入一个Context,所以这个Context的生命周期的长短至关重要:\n\n1、如果此时传入的是 Application 的 Context,因为 Application 的生命周期就是整个应用的生命周期,所以这将没有任何问题。\n\n2、如果此时传入的是 Activity 的 Context,当这个 Context 所对应的 Activity 退出时,由于该 Context 的引用被单例对象所持有,其生命周期等于整个应用程序的生命周期,所以当前 Activity 退出时它的内存并不会被回收,这就造成泄漏了。\n\n正确的方式应该改为下面这种方式:\n\n```\npublic class AppManager {\nprivate static AppManager instance;\nprivate Context context;\nprivate AppManager(Context context) {\nthis.context = context.getApplicationContext();// 使用Application 的context\n}\npublic static AppManager getInstance(Context context) {\nif (instance == null) {\ninstance = new AppManager(context);\n}\nreturn instance;\n}\n}\n```\n\n或者这样写,连 Context 都不用传进来了:\n\n```\n在你的 Application 中添加一个静态方法,getContext() 返回 Application 的 context,\n\n...\n\ncontext = getApplicationContext();\n\n...\n /**\n * 获取全局的context\n * @return 返回全局context对象\n */\n public static Context getContext(){\n return context;\n }\n\npublic class AppManager {\nprivate static AppManager instance;\nprivate Context context;\nprivate AppManager() {\nthis.context = MyApplication.getContext();// 使用Application 的context\n}\npublic static AppManager getInstance() {\nif (instance == null) {\ninstance = new AppManager();\n}\nreturn instance;\n}\n}\n```\n\n###匿名内部类/非静态内部类和异步线程\n\n非静态内部类创建静态实例造成的内存泄漏\n\n有的时候我们可能会在启动频繁的Activity中,为了避免重复创建相同的数据资源,可能会出现这种写法:\n\n```\n public class MainActivity extends AppCompatActivity {\n private static TestResource mResource = null;\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n if(mManager == null){\n mManager = new TestResource();\n }\n //...\n }\n class TestResource {\n //...\n }\n }\n```\n这样就在Activity内部创建了一个非静态内部类的单例,每次启动Activity时都会使用该单例的数据,这样虽然避免了资源的重复创建,不过这种写法却会造成内存泄漏,因为非静态内部类默认会持有外部类的引用,而该非静态内部类又创建了一个静态的实例,该实例的生命周期和应用的一样长,这就导致了该静态实例一直会持有该Activity的引用,导致Activity的内存资源不能正常回收。正确的做法为:\n\n将该内部类设为静态内部类或将该内部类抽取出来封装成一个单例,如果需要使用Context,请按照上面推荐的使用Application 的 Context。当然,Application 的 context 不是万能的,所以也不能随便乱用,对于有些地方则必须使用 Activity 的 Context,对于Application,Service,Activity三者的Context的应用场景如下:\n\n\n\n其中: NO1表示 Application 和 Service 可以启动一个 Activity,不过需要创建一个新的 task 任务队列。而对于 Dialog 而言,只有在 Activity 中才能创建\n\n###匿名内部类\n\nandroid开发经常会继承实现Activity/Fragment/View,此时如果你使用了匿名类,并被异步线程持有了,那要小心了,如果没有任何措施这样一定会导致泄露\n\n```\n public class MainActivity extends Activity {\n ...\n Runnable ref1 = new MyRunable();\n Runnable ref2 = new Runnable() {\n @Override\n public void run() {\n\n }\n };\n ...\n }\n```\n\nref1和ref2的区别是,ref2使用了匿名内部类。我们来看看运行时这两个引用的内存:\n\n\n\n可以看到,ref1没什么特别的。\n\n但ref2这个匿名类的实现对象里面多了一个引用:\n\nthis$0这个引用指向MainActivity.this,也就是说当前的MainActivity实例会被ref2持有,如果将这个引用再传入一个异步线程,此线程和此Acitivity生命周期不一致的时候,就造成了Activity的泄露。\n\n###Handler 造成的内存泄漏\n\nHandler 的使用造成的内存泄漏问题应该说是最为常见了,很多时候我们为了避免 ANR 而不在主线程进行耗时操作,在处理网络任务或者封装一些请求回调等api都借助Handler来处理,但 Handler 不是万能的,对于 Handler 的使用代码编写一不规范即有可能造成内存泄漏。另外,我们知道 Handler、Message 和 MessageQueue 都是相互关联在一起的,万一 Handler 发送的 Message 尚未被处理,则该 Message 及发送它的 Handler 对象将被线程 MessageQueue 一直持有。\n\n由于 Handler 属于 TLS(Thread Local Storage) 变量, 生命周期和 Activity 是不一致的。因此这种实现方式一般很难保证跟 View 或者 Activity 的生命周期保持一致,故很容易导致无法正确释放。\n\n举个例子:\n\n```\n public class SampleActivity extends Activity {\n\n private final Handler mLeakyHandler = new Handler() {\n @Override\n public void handleMessage(Message msg) {\n // ...\n }\n }\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n // Post a message and delay its execution for 10 minutes.\n mLeakyHandler.postDelayed(new Runnable() {\n @Override\n public void run() { /* ... */ }\n }, 1000 * 60 * 10);\n\n // Go back to the previous Activity.\n finish();\n }\n }\n```\n\n在该 SampleActivity 中声明了一个延迟10分钟执行的消息 Message,mLeakyHandler 将其 push 进了消息队列 MessageQueue 里。当该 Activity 被 finish() 掉时,延迟执行任务的 Message 还会继续存在于主线程中,它持有该 Activity 的 Handler 引用,所以此时 finish() 掉的 Activity 就不会被回收了从而造成内存泄漏(因 Handler 为非静态内部类,它会持有外部类的引用,在这里就是指 SampleActivity)。\n\n修复方法:在 Activity 中避免使用非静态内部类,比如上面我们将 Handler 声明为静态的,则其存活期跟 Activity 的生命周期就无关了。同时通过弱引用的方式引入 Activity,避免直接将 Activity 作为 context 传进去,见下面代码:\n\n```\npublic class SampleActivity extends Activity {\n\n /**\n * Instances of static inner classes do not hold an implicit\n * reference to their outer class.\n */\n private static class MyHandler extends Handler {\n private final WeakReference mActivity;\n\n public MyHandler(SampleActivity activity) {\n mActivity = new WeakReference(activity);\n }\n\n @Override\n public void handleMessage(Message msg) {\n SampleActivity activity = mActivity.get();\n if (activity != null) {\n // ...\n }\n }\n }\n\n private final MyHandler mHandler = new MyHandler(this);\n\n /**\n * Instances of anonymous classes do not hold an implicit\n * reference to their outer class when they are \"static\".\n */\n private static final Runnable sRunnable = new Runnable() {\n @Override\n public void run() { /* ... */ }\n };\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n // Post a message and delay its execution for 10 minutes.\n mHandler.postDelayed(sRunnable, 1000 * 60 * 10);\n\n // Go back to the previous Activity.\n finish();\n }\n}\n```\n\n综述,即推荐使用静态内部类 + WeakReference 这种方式。每次使用前注意判空。\n\n前面提到了 WeakReference,所以这里就简单的说一下 Java 对象的几种引用类型。\n\nJava对引用的分类有 Strong reference, SoftReference, WeakReference, PhatomReference 四种。\n\n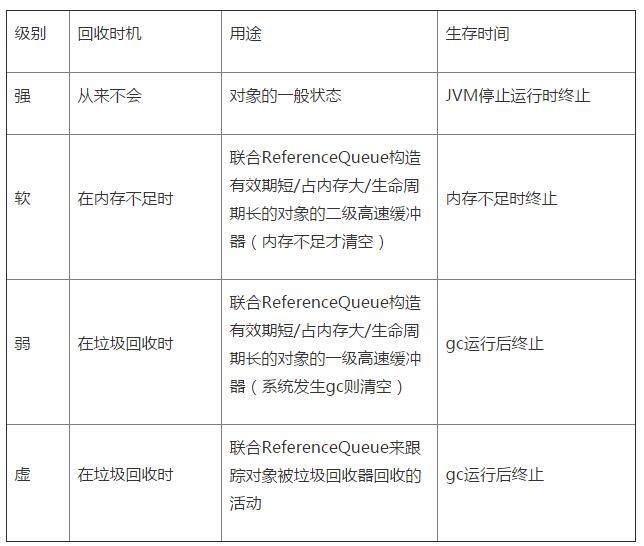\n\n在Android应用的开发中,为了防止内存溢出,在处理一些占用内存大而且声明周期较长的对象时候,可以尽量应用软引用和弱引用技术。\n\n软/弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。利用这个队列可以得知被回收的软/弱引用的对象列表,从而为缓冲器清除已失效的软/弱引用。\n\n假设我们的应用会用到大量的默认图片,比如应用中有默认的头像,默认游戏图标等等,这些图片很多地方会用到。如果每次都去读取图片,由于读取文件需要硬件操作,速度较慢,会导致性能较低。所以我们考虑将图片缓存起来,需要的时候直接从内存中读取。但是,由于图片占用内存空间比较大,缓存很多图片需要很多的内存,就可能比较容易发生OutOfMemory异常。这时,我们可以考虑使用软/弱引用技术来避免这个问题发生。以下就是高速缓冲器的雏形:\n\n首先定义一个HashMap,保存软引用对象。\n\n```\nprivate Map > imageCache = new HashMap > ();\n```\n\n再来定义一个方法,保存Bitmap的软引用到HashMap。\n\n\n\n使用软引用以后,在OutOfMemory异常发生之前,这些缓存的图片资源的内存空间可以被释放掉的,从而避免内存达到上限,避免Crash发生。\n\n如果只是想避免OutOfMemory异常的发生,则可以使用软引用。如果对于应用的性能更在意,想尽快回收一些占用内存比较大的对象,则可以使用弱引用。\n\n另外可以根据对象是否经常使用来判断选择软引用还是弱引用。如果该对象可能会经常使用的,就尽量用软引用。如果该对象不被使用的可能性更大些,就可以用弱引用。\n\nok,继续回到主题。前面所说的,创建一个静态Handler内部类,然后对 Handler 持有的对象使用弱引用,这样在回收时也可以回收 Handler 持有的对象,但是这样做虽然避免了 Activity 泄漏,不过 Looper 线程的消息队列中还是可能会有待处理的消息,所以我们在 Activity 的 Destroy 时或者 Stop 时应该移除消息队列 MessageQueue 中的消息。\n\n下面几个方法都可以移除 Message:\n\n```\npublic final void removeCallbacks(Runnable r);\n\npublic final void removeCallbacks(Runnable r, Object token);\n\npublic final void removeCallbacksAndMessages(Object token);\n\npublic final void removeMessages(int what);\n\npublic final void removeMessages(int what, Object object);\n```\n\n###尽量避免使用 static 成员变量\n\n如果成员变量被声明为 static,那我们都知道其生命周期将与整个app进程生命周期一样。\n\n这会导致一系列问题,如果你的app进程设计上是长驻内存的,那即使app切到后台,这部分内存也不会被释放。按照现在手机app内存管理机制,占内存较大的后台进程将优先回收,yi'wei如果此app做过进程互保保活,那会造成app在后台频繁重启。当手机安装了你参与开发的app以后一夜时间手机被消耗空了电量、流量,你的app不得不被用户卸载或者静默。\n\n这里修复的方法是:\n\n不要在类初始时初始化静态成员。可以考虑lazy初始化。\n架构设计上要思考是否真的有必要这样做,尽量避免。如果架构需要这么设计,那么此对象的生命周期你有责任管理起来。\n\n###避免 override finalize()\n\n1、finalize 方法被执行的时间不确定,不能依赖与它来释放紧缺的资源。时间不确定的原因是:\n 虚拟机调用GC的时间不确定\n Finalize daemon线程被调度到的时间不确定\n\n2、finalize 方法只会被执行一次,即使对象被复活,如果已经执行过了 finalize 方法,再次被 GC 时也不会再执行了,原因是:\n\n含有 finalize 方法的 object 是在 new 的时候由虚拟机生成了一个 finalize reference 在来引用到该Object的,而在 finalize 方法执行的时候,该 object 所对应的 finalize Reference 会被释放掉,即使在这个时候把该 object 复活(即用强引用引用住该 object ),再第二次被 GC 的时候由于没有了 finalize reference 与之对应,所以 finalize 方法不会再执行。\n\n3、含有Finalize方法的object需要至少经过两轮GC才有可能被释放。\n\n\n###资源未关闭造成的内存泄漏\n\n对于使用了BraodcastReceiver,ContentObserver,File,游标 Cursor,Stream,Bitmap等资源的使用,应该在Activity销毁时及时关闭或者注销,否则这些资源将不会被回收,造成内存泄漏。\n\n###一些不良代码造成的内存压力\n\n有些代码并不造成内存泄露,但是它们,或是对没使用的内存没进行有效及时的释放,或是没有有效的利用已有的对象而是频繁的申请新内存。\n\n比如:\n Bitmap 没调用 recycle()方法,对于 Bitmap 对象在不使用时,我们应该先调用 recycle() 释放内存,然后才它设置为 null. 因为加载 Bitmap 对象的内存空间,一部分是 java 的,一部分 C 的(因为 Bitmap 分配的底层是通过 JNI 调用的 )。 而这个 recyle() 就是针对 C 部分的内存释放。\n 构造 Adapter 时,没有使用缓存的 convertView ,每次都在创建新的 converView。这里推荐使用 ViewHolder。\n\n##总结\n\n对 Activity 等组件的引用应该控制在 Activity 的生命周期之内; 如果不能就考虑使用 getApplicationContext 或者 getApplication,以避免 Activity 被外部长生命周期的对象引用而泄露。\n\n尽量不要在静态变量或者静态内部类中使用非静态外部成员变量(包括context ),即使要使用,也要考虑适时把外部成员变量置空;也可以在内部类中使用弱引用来引用外部类的变量。\n\n对于生命周期比Activity长的内部类对象,并且内部类中使用了外部类的成员变量,可以这样做避免内存泄漏:\n\n 将内部类改为静态内部类\n 静态内部类中使用弱引用来引用外部类的成员变量\n\nHandler 的持有的引用对象最好使用弱引用,资源释放时也可以清空 Handler 里面的消息。比如在 Activity onStop 或者 onDestroy 的时候,取消掉该 Handler 对象的 Message和 Runnable.\n\n在 Java 的实现过程中,也要考虑其对象释放,最好的方法是在不使用某对象时,显式地将此对象赋值为 null,比如使用完Bitmap 后先调用 recycle(),再赋为null,清空对图片等资源有直接引用或者间接引用的数组(使用 array.clear() ; array = null)等,最好遵循谁创建谁释放的原则。\n\n正确关闭资源,对于使用了BraodcastReceiver,ContentObserver,File,游标 Cursor,Stream,Bitmap等资源的使用,应该在Activity销毁时及时关闭或者注销。\n\n保持对对象生命周期的敏感,特别注意单例、静态对象、全局性集合等的生命周期。\n\n\n\n"
},
{
"path": "Part1/Android/Android几种进程.md",
"content": "#Android几种进程\n---\n\n1. 前台进程:即与用户正在交互的Activity或者Activity用到的Service等,如果系统内存不足时前台进程是最后被杀死的\n2. 可见进程:可以是处于暂停状态(onPause)的Activity或者绑定在其上的Service,即被用户可见,但由于失去了焦点而不能与用户交互\n3. 服务进程:其中运行着使用startService方法启动的Service,虽然不被用户可见,但是却是用户关心的,例如用户正在非音乐界面听的音乐或者正在非下载页面自己下载的文件等;当系统要空间运行前两者进程时才会被终止\n4. 后台进程:其中运行着执行onStop方法而停止的程序,但是却不是用户当前关心的,例如后台挂着的QQ,这样的进程系统一旦没了有内存就首先被杀死\n5. 空进程:不包含任何应用程序的程序组件的进程,这样的进程系统是一般不会让他存在的\n\n如何避免后台进程被杀死:\n\n1. 调用startForegound,让你的Service所在的线程成为前台进程\n2. Service的onStartCommond返回START_STICKY或START_REDELIVER_INTENT\n3. Service的onDestroy里面重新启动自己"
},
{
"path": "Part1/Android/Android图片中的三级缓存.md",
"content": "#Android图片中的三级缓存\n---\n\n##为什么要使用三级缓存\n\n* 如今的 Android App 经常会需要网络交互,通过网络获取图片是再正常不过的事了\n* 假如每次启动的时候都从网络拉取图片的话,势必会消耗很多流量。在当前的状况下,对于非wifi用户来说,流量还是很贵的,一个很耗流量的应用,其用户数量级肯定要受到影响\n* 特别是,当我们想要重复浏览一些图片时,如果每一次浏览都需要通过网络获取,流量的浪费可想而知\n* 所以提出三级缓存策略,通过网络、本地、内存三级缓存图片,来减少不必要的网络交互,避免浪费流量\n\n##什么是三级缓存\n\n* 网络加载,不优先加载,速度慢,浪费流量\n* 本地缓存,次优先加载,速度快\n* 内存缓存,优先加载,速度最快\n\n\n##三级缓存原理\n\n* 首次加载 Android App 时,肯定要通过网络交互来获取图片,之后我们可以将图片保存至本地SD卡和内存中\n* 之后运行 App 时,优先访问内存中的图片缓存,若内存中没有,则加载本地SD卡中的图片\n* 总之,只在初次访问新内容时,才通过网络获取图片资源\r\n\n\n参考链接\n\n[http://www.jianshu.com/p/2cd59a79ed4a](http://www.jianshu.com/p/2cd59a79ed4a)"
},
{
"path": "Part1/Android/Android基础知识.md",
"content": "#Android:\n---\n**五种布局: FrameLayout 、 LinearLayout 、 AbsoluteLayout 、 RelativeLayout 、 TableLayout 全都继承自ViewGroup,各自特点及绘制效率对比。**\n\n* FrameLayout(框架布局)\n\n 此布局是五种布局中最简单的布局,Android中并没有对child view的摆布进行控制,这个布局中所有的控件都会默认出现在视图的左上角,我们可以使用``android:layout_margin``,``android:layout_gravity``等属性去控制子控件相对布局的位置。\n\n* LinearLayout(线性布局)\n\n 一行(或一列)只控制一个控件的线性布局,所以当有很多控件需要在一个界面中列出时,可以用LinearLayout布局。\n 此布局有一个需要格外注意的属性:``android:orientation=“horizontal|vertical``。\n \n * 当`android:orientation=\"horizontal`时,*说明你希望将水平方向的布局交给**LinearLayout** *,其子元素的`android:layout_gravity=\"right|left\"` 等控制水平方向的gravity值都是被忽略的,*此时**LinearLayout**中的子元素都是默认的按照水平从左向右来排*,我们可以用`android:layout_gravity=\"top|bottom\"`等gravity值来控制垂直展示。\n * 反之,可以知道 当`android:orientation=\"vertical`时,**LinearLayout**对其子元素展示上的的处理方式。\n\n* AbsoluteLayout(绝对布局)\n\n 可以放置多个控件,并且可以自己定义控件的x,y位置\n\n* RelativeLayout(相对布局)\n\n 这个布局也是相对自由的布局,Android 对该布局的child view的 水平layout& 垂直layout做了解析,由此我们可以FrameLayout的基础上使用标签或者Java代码对垂直方向 以及 水平方向 布局中的views进行任意的控制.\n \n * 相关属性:\n \n ```\n \n android:layout_centerInParent=\"true|false\"\n\t android:layout_centerHorizontal=\"true|false\"\n\t android:layout_alignParentRight=\"true|false\"\n\t \n\t```\n\n* TableLayout(表格布局)\n\n 将子元素的位置分配到行或列中,一个TableLayout由许多的TableRow组成\n \n\n---\n\n\n**Activity生命周期。**\n\n* 启动Activity:\n onCreate()—>onStart()—>onResume(),Activity进入运行状态。\n* Activity退居后台:\n 当前Activity转到新的Activity界面或按Home键回到主屏:\n onPause()—>onStop(),进入停滞状态。\n* Activity返回前台:\n onRestart()—>**onStart()**—>onResume(),再次回到运行状态。\n* Activity退居后台,且系统内存不足,\n 系统会杀死这个后台状态的Activity(此时这个Activity引用仍然处在任务栈中,只是这个时候引用指向的对象已经为null),若再次回到这个Activity,则会走onCreate()–>onStart()—>onResume()(将重新走一次Activity的初始化生命周期)\n* 锁屏:`onPause()->onStop()`\n* 解锁:`onStart()->onResume()`\n \n* 更多流程分支,请参照以下生命周期流程图\n\t\n\n\n---\n\n\n**通过Acitivty的xml标签来改变任务栈的默认行为**\n\n* 使用``android:launchMode=\"standard|singleInstance|singleTask|singleTop\"``来控制Acivity任务栈。\n\n **任务栈**是一种后进先出的结构。位于栈顶的Activity处于焦点状态,当按下back按钮的时候,栈内的Activity会一个一个的出栈,并且调用其``onDestory()``方法。如果栈内没有Activity,那么系统就会回收这个栈,每个APP默认只有一个栈,以APP的包名来命名.\n\n * standard : 标准模式,每次启动Activity都会创建一个新的Activity实例,并且将其压入任务栈栈顶,而不管这个Activity是否已经存在。Activity的启动三回调(*onCreate()->onStart()->onResume()*)都会执行。\n - singleTop : 栈顶复用模式.这种模式下,如果新Activity已经位于任务栈的栈顶,那么此Activity不会被重新创建,所以它的启动三回调就不会执行,同时Activity的``onNewIntent()``方法会被回调.如果Activity已经存在但是不在栈顶,那么作用与*standard模式*一样.\n - singleTask: 栈内复用模式.创建这样的Activity的时候,系统会先确认它所需任务栈已经创建,否则先创建任务栈.然后放入Activity,如果栈中已经有一个Activity实例,那么这个Activity就会被调到栈顶,``onNewIntent()``,并且singleTask会清理在当前Activity上面的所有Activity.(clear top)\n - singleInstance : 加强版的singleTask模式,这种模式的Activity只能单独位于一个任务栈内,由于栈内复用的特性,后续请求均不会创建新的Activity,除非这个独特的任务栈被系统销毁了\n\nActivity的堆栈管理以ActivityRecord为单位,所有的ActivityRecord都放在一个List里面.可以认为一个ActivityRecord就是一个Activity栈\n\n---\n\n**Activity缓存方法。**\n\n有a、b两个Activity,当从a进入b之后一段时间,可能系统会把a回收,这时候按back,执行的不是a的onRestart而是onCreate方法,a被重新创建一次,这是a中的临时数据和状态可能就丢失了。\n\n可以用Activity中的onSaveInstanceState()回调方法保存临时数据和状态,这个方法一定会在活动被回收之前调用。方法中有一个Bundle参数,putString()、putInt()等方法需要传入两个参数,一个键一个值。数据保存之后会在onCreate中恢复,onCreate也有一个Bundle类型的参数。\n\n示例代码:\n\n```\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n\n //这里,当Acivity第一次被创建的时候为空\n //所以我们需要判断一下\n if( savedInstanceState != null ){\n savedInstanceState.getString(\"anAnt\");\n }\n }\n\n @Override\n protected void onSaveInstanceState(Bundle outState) {\n super.onSaveInstanceState(outState);\n\n outState.putString(\"anAnt\",\"Android\");\n\n }\n\n```\n\n一、onSaveInstanceState (Bundle outState)\n\n当某个activity变得“容易”被系统销毁时,该activity的onSaveInstanceState就会被执行,除非该activity是被用户主动销毁的,例如当用户按BACK键的时候。\n\n注意上面的双引号,何为“容易”?言下之意就是该activity还没有被销毁,而仅仅是一种可能性。这种可能性有哪些?通过重写一个activity的所有生命周期的onXXX方法,包括onSaveInstanceState和onRestoreInstanceState方法,我们可以清楚地知道当某个activity(假定为activity A)显示在当前task的最上层时,其onSaveInstanceState方法会在什么时候被执行,有这么几种情况:\n\n1、当用户按下HOME键时。\n\n这是显而易见的,系统不知道你按下HOME后要运行多少其他的程序,自然也不知道activity A是否会被销毁,故系统会调用onSaveInstanceState,让用户有机会保存某些非永久性的数据。以下几种情况的分析都遵循该原则\n\n2、长按HOME键,选择运行其他的程序时。\n\n3、按下电源按键(关闭屏幕显示)时。\n\n4、从activity A中启动一个新的activity时。\n\n5、屏幕方向切换时,例如从竖屏切换到横屏时。(如果不指定configchange属性)\n在屏幕切换之前,系统会销毁activity A,在屏幕切换之后系统又会自动地创建activity A,所以onSaveInstanceState一定会被执行\n \n总而言之,onSaveInstanceState的调用遵循一个重要原则,即当系统“未经你许可”时销毁了你的activity,则onSaveInstanceState会被系统调用,这是系统的责任,因为它必须要提供一个机会让你保存你的数据(当然你不保存那就随便你了)。另外,需要注意的几点:\n \n1.布局中的每一个View默认实现了onSaveInstanceState()方法,这样的话,这个UI的任何改变都会自动地存储和在activity重新创建的时候自动地恢复。但是这种情况只有在你为这个UI提供了唯一的ID之后才起作用,如果没有提供ID,app将不会存储它的状态。\n \n2.由于默认的onSaveInstanceState()方法的实现帮助UI存储它的状态,所以如果你需要覆盖这个方法去存储额外的状态信息,你应该在执行任何代码之前都调用父类的onSaveInstanceState()方法(super.onSaveInstanceState())。\n既然有现成的可用,那么我们到底还要不要自己实现onSaveInstanceState()?这得看情况了,如果你自己的派生类中有变量影响到UI,或你程序的行为,当然就要把这个变量也保存了,那么就需要自己实现,否则就不需要。\n\n3.由于onSaveInstanceState()方法调用的不确定性,你应该只使用这个方法去记录activity的瞬间状态(UI的状态)。不应该用这个方法去存储持久化数据。当用户离开这个activity的时候应该在onPause()方法中存储持久化数据(例如应该被存储到数据库中的数据)。\n \n4.onSaveInstanceState()如果被调用,这个方法会在onStop()前被触发,但系统并不保证是否在onPause()之前或者之后触发。\n \n \n二、onRestoreInstanceState (Bundle outState)\n\n至于onRestoreInstanceState方法,需要注意的是,onSaveInstanceState方法和onRestoreInstanceState方法“不一定”是成对的被调用的,(本人注:我昨晚调试时就发现原来不一定成对被调用的!)\n \nonRestoreInstanceState被调用的前提是,activity A“确实”被系统销毁了,而如果仅仅是停留在有这种可能性的情况下,则该方法不会被调用,例如,当正在显示activity A的时候,用户按下HOME键回到主界面,然后用户紧接着又返回到activity A,这种情况下activity A一般不会因为内存的原因被系统销毁,故activity A的onRestoreInstanceState方法不会被执行\n\n另外,onRestoreInstanceState的bundle参数也会传递到onCreate方法中,你也可以选择在onCreate方法中做数据还原。\n还有onRestoreInstanceState在onstart之后执行。\n至于这两个函数的使用,给出示范代码(留意自定义代码在调用super的前或后):\n\n```\n@Override\npublic void onSaveInstanceState(Bundle savedInstanceState) {\n savedInstanceState.putBoolean(\"MyBoolean\", true);\n savedInstanceState.putDouble(\"myDouble\", 1.9);\n savedInstanceState.putInt(\"MyInt\", 1);\n savedInstanceState.putString(\"MyString\", \"Welcome back to Android\");\n // etc.\n super.onSaveInstanceState(savedInstanceState);\n}\n\n@Override\npublic void onRestoreInstanceState(Bundle savedInstanceState) {\n super.onRestoreInstanceState(savedInstanceState);\n\n boolean myBoolean = savedInstanceState.getBoolean(\"MyBoolean\");\n double myDouble = savedInstanceState.getDouble(\"myDouble\");\n int myInt = savedInstanceState.getInt(\"MyInt\");\n String myString = savedInstanceState.getString(\"MyString\");\n}\n\n```\n\n---\n\n\n\n**Fragment的生命周期和activity如何的一个关系**\n\n这我们引用本知识库里的一张图片:\n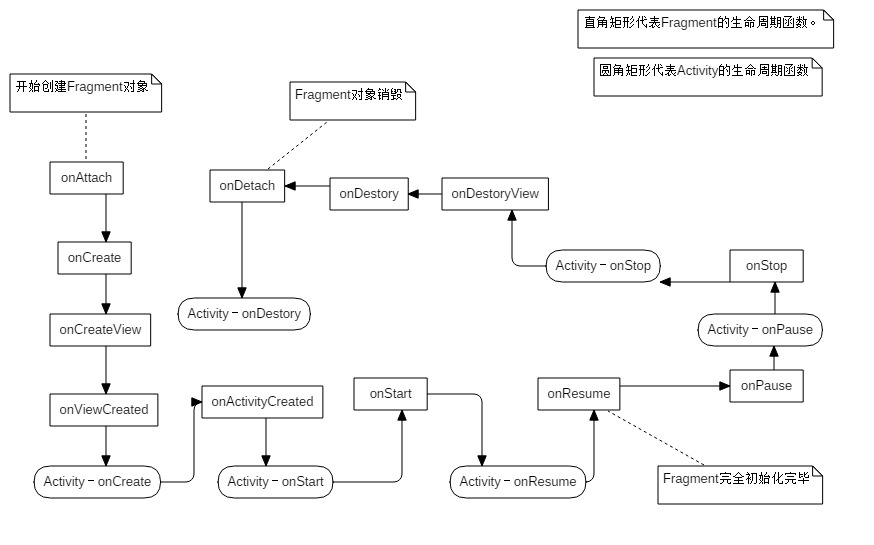\n\n\n**为什么在Service中创建子线程而不是Activity中**\n\n这是因为Activity很难对Thread进行控制,当Activity被销毁之后,就没有任何其它的办法可以再重新获取到之前创建的子线程的实例。而且在一个Activity中创建的子线程,另一个Activity无法对其进行操作。但是Service就不同了,所有的Activity都可以与Service进行关联,然后可以很方便地操作其中的方法,即使Activity被销毁了,之后只要重新与Service建立关联,就又能够获取到原有的Service中Binder的实例。因此,使用Service来处理后台任务,Activity就可以放心地finish,完全不需要担心无法对后台任务进行控制的情况。\n\n\n**Intent的使用方法,可以传递哪些数据类型。**\n\n通过查询Intent/Bundle的API文档,我们可以获知,Intent/Bundle支持传递基本类型的数据和基本类型的数组数据,以及String/CharSequence类型的数据和String/CharSequence类型的数组数据。而对于其它类型的数据貌似无能为力,其实不然,我们可以在Intent/Bundle的API中看到Intent/Bundle还可以传递Parcelable(包裹化,邮包)和Serializable(序列化)类型的数据,以及它们的数组/列表数据。\n\n所以要让非基本类型和非String/CharSequence类型的数据通过Intent/Bundle来进行传输,我们就需要在数据类型中实现Parcelable接口或是Serializable接口。\n\n[http://blog.csdn.net/kkk0526/article/details/7214247](http://blog.csdn.net/kkk0526/article/details/7214247)\n\n**Fragment生命周期**\n\n\n\n注意和Activity的相比的区别,按照执行顺序\n\n* onAttach(),onDetach()\n* onCreateView(),onDestroyView()\n\n---\n\n**Service的两种启动方法,有什么区别**\n1.在Context中通过``public boolean bindService(Intent service,ServiceConnection conn,int flags)`` 方法来进行Service与Context的关联并启动,并且Service的生命周期依附于Context(**不求同时同分同秒生!但求同时同分同秒屎!!**)。\n\n2.通过`` public ComponentName startService(Intent service)``方法去启动一个Service,此时Service的生命周期与启动它的Context无关。\n\n3.要注意的是,whatever,**都需要在xml里注册你的Service**,就像这样:\n```\n\n```\n\n**广播(Broadcast Receiver)的两种动态注册和静态注册有什么区别。**\n\n* 静态注册:在AndroidManifest.xml文件中进行注册,当App退出后,Receiver仍然可以接收到广播并且进行相应的处理\n* 动态注册:在代码中动态注册,当App退出后,也就没办法再接受广播了\n\n---\n\n\n**ContentProvider使用方法**\n\n[http://blog.csdn.net/juetion/article/details/17481039](http://blog.csdn.net/juetion/article/details/17481039)\n\n---\n\n**目前能否保证service不被杀死**\n\n**Service设置成START_STICKY**\n\n* kill 后会被重启(等待5秒左右),重传Intent,保持与重启前一样\n\n**提升service优先级**\n * 在AndroidManifest.xml文件中对于intent-filter可以通过``android:priority = \"1000\"``这个属性设置最高优先级,1000是最高值,如果数字越小则优先级越低,**同时适用于广播**。\n * 【结论】目前看来,priority这个属性貌似只适用于broadcast,对于Service来说可能无效\n\n**提升service进程优先级**\n * Android中的进程是托管的,当系统进程空间紧张的时候,会依照优先级自动进行进程的回收\n * 当service运行在低内存的环境时,将会kill掉一些存在的进程。因此进程的优先级将会很重要,可以在startForeground()使用startForeground()将service放到前台状态。这样在低内存时被kill的几率会低一些。\n * 【结论】如果在极度极度低内存的压力下,该service还是会被kill掉,并且不一定会restart()\n\n**onDestroy方法里重启service**\n * service +broadcast 方式,就是当service走onDestory()的时候,发送一个自定义的广播,当收到广播的时候,重新启动service\n * 也可以直接在onDestroy()里startService\n * 【结论】当使用类似口口管家等第三方应用或是在setting里-应用-强制停止时,APP进程可能就直接被干掉了,onDestroy方法都进不来,所以还是无法保证\n\n**监听系统广播判断Service状态**\n * 通过系统的一些广播,比如:手机重启、界面唤醒、应用状态改变等等监听并捕获到,然后判断我们的Service是否还存活,别忘记加权限\n * 【结论】这也能算是一种措施,不过感觉监听多了会导致Service很混乱,带来诸多不便\n\n**在JNI层,用C代码fork一个进程出来**\n\n* 这样产生的进程,会被系统认为是两个不同的进程.但是Android5.0之后可能不行\n\n**root之后放到system/app变成系统级应用**\n\n**大招: 放一个像素在前台(手机QQ)**\n\n---\n\n\n**动画有哪两类,各有什么特点?三种动画的区别**\n\n* tween 补间动画。通过指定View的初末状态和变化时间、方式,对View的内容完成一系列的图形变换来实现动画效果。\nAlpha\nScale\nTranslate\nRotate。\n\n* frame 帧动画\nAnimationDrawable 控制\nanimation-list xml布局\n\n* PropertyAnimation 属性动画\n \n---\n\n**Android的数据存储形式。**\n\n\n\n* SQLite:SQLite是一个轻量级的数据库,支持基本的SQL语法,是常被采用的一种数据存储方式。\nAndroid为此数据库提供了一个名为SQLiteDatabase的类,封装了一些操作数据库的api\n\n* SharedPreference: 除SQLite数据库外,另一种常用的数据存储方式,其本质就是一个xml文件,常用于存储较简单的参数设置。\n\n* File: 即常说的文件(I/O)存储方法,常用语存储大数量的数据,但是缺点是更新数据将是一件困难的事情。\n\n* ContentProvider: Android系统中能实现所有应用程序共享的一种数据存储方式,由于数据通常在各应用间的是互相私密的,所以此存储方式较少使用,但是其又是必不可少的一种存储方式。例如音频,视频,图片和通讯录,一般都可以采用此种方式进行存储。每个Content Provider都会对外提供一个公共的URI(包装成Uri对象),如果应用程序有数据需要共享时,就需要使用Content Provider为这些数据定义一个URI,然后其他的应用程序就通过Content Provider传入这个URI来对数据进行操作。\n\n---\n\n**Sqlite的基本操作。**\n\n\n[http://blog.csdn.net/zgljl2012/article/details/44769043](http://blog.csdn.net/zgljl2012/article/details/44769043)\n\n---\n\n**如何判断应用被强杀**\n\n在Application中定义一个static常量,赋值为-1,在欢迎界面改为0,如果被强杀,application重新初始化,在父类Activity判断该常量的值。\n\n**应用被强杀如何解决**\n\n如果在每一个Activity的onCreate里判断是否被强杀,冗余了,封装到Activity的父类中,如果被强杀,跳转回主界面,如果没有被强杀,执行Activity的初始化操作,给主界面传递intent参数,主界面会调用onNewIntent方法,在onNewIntent跳转到欢迎页面,重新来一遍流程。\n\n**Json有什么优劣势。**\n\n**怎样退出终止App**\n\n**Asset目录与res目录的区别。**\nres 目录下面有很多文件,例如 drawable,mipmap,raw 等。res 下面除了 raw 文件不会被压缩外,其余文件都会被压缩。同时 res目录下的文件可以通过R 文件访问。Asset 也是用来存储资源,但是 asset 文件内容只能通过路径或者 AssetManager 读取。 [官方文档](https://developer.android.com/studio/projects/index.html)\n\n**Android怎么加速启动Activity。**\n分两种情况,启动应用 和 普通Activity\n启动应用 :Application 的构造方法,onCreate 方法中不要进行耗时操作,数据预读取(例如 init 数据) 放在异步中操作\n启动普通的Activity:A 启动B 时不要在 A 的 onPause 中执行耗时操作。因为 B 的 onResume 方法必须等待 A 的 onPause 执行完成后才能运行\n\n**Android内存优化方法:ListView优化,及时关闭资源,图片缓存等等。**\n\n**Android中弱引用与软引用的应用场景。**\n\n**Bitmap的四种属性,与每种属性队形的大小。**\n\n\n**View与View Group分类。自定义View过程:onMeasure()、onLayout()、onDraw()。**\n\n如何自定义控件:\n\n1. 自定义属性的声明和获取\n\n * 分析需要的自定义属性\n * 在res/values/attrs.xml定义声明\n * 在layout文件中进行使用\n * 在View的构造方法中进行获取 \n2. 测量onMeasure\n3. 布局onLayout(ViewGroup)\n4. 绘制onDraw\n5. onTouchEvent\n6. onInterceptTouchEvent(ViewGroup)\n7. 状态的恢复与保存\n\n\n**Android长连接,怎么处理心跳机制。**\n\n---\n\n**View树绘制流程**\n\n---\n\n**下拉刷新实现原理**\n\n---\n\n**你用过什么框架,是否看过源码,是否知道底层原理。**\n\nRetrofit\n\nEventBus\n\nglide\n\n---\n\n**Android5.0、6.0新特性。**\n\nAndroid5.0新特性:\n\n* MaterialDesign设计风格\n* 支持多种设备\n* 支持64位ART虚拟机\n\nAndroid6.0新特性\n\n* 大量漂亮流畅的动画\n* 支持快速充电的切换\n* 支持文件夹拖拽应用\n* 相机新增专业模式\n\nAndroid7.0新特性\n\n* 分屏多任务\n* 增强的Java8语言模式\n* 夜间模式\n\n---\n\n\n**Context区别**\n\n* Activity和Service以及Application的Context是不一样的,Activity继承自ContextThemeWraper.其他的继承自ContextWrapper\n* 每一个Activity和Service以及Application的Context都是一个新的ContextImpl对象\n* getApplication()用来获取Application实例的,但是这个方法只有在Activity和Service中才能调用的到。那么也许在绝大多数情况下我们都是在Activity或者Service中使用Application的,但是如果在一些其它的场景,比如BroadcastReceiver中也想获得Application的实例,这时就可以借助getApplicationContext()方法,getApplicationContext()比getApplication()方法的作用域会更广一些,任何一个Context的实例,只要调用getApplicationContext()方法都可以拿到我们的Application对象。\n* Activity在创建的时候会new一个ContextImpl对象并在attach方法中关联它,Application和Service也差不多。ContextWrapper的方法内部都是转调ContextImpl的方法\n* 创建对话框传入Application的Context是不可以的\n* 尽管Application、Activity、Service都有自己的ContextImpl,并且每个ContextImpl都有自己的mResources成员,但是由于它们的mResources成员都来自于唯一的ResourcesManager实例,所以它们看似不同的mResources其实都指向的是同一块内存\n* Context的数量等于Activity的个数 + Service的个数 + 1,这个1为Application\n\n---\n\n**IntentService的使用场景与特点。**\n\n>IntentService是Service的子类,是一个异步的,会自动停止的服务,很好解决了传统的Service中处理完耗时操作忘记停止并销毁Service的问题\n\n优点:\n\n* 一方面不需要自己去new Thread\n* 另一方面不需要考虑在什么时候关闭该Service\n\nonStartCommand中回调了onStart,onStart中通过mServiceHandler发送消息到该handler的handleMessage中去。最后handleMessage中回调onHandleIntent(intent)。\n\n---\n\n\n**图片缓存**\n\n查看每个应用程序最高可用内存:\n\n```\n int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024); \n Log.d(\"TAG\", \"Max memory is \" + maxMemory + \"KB\"); \n```\n\n---\n\n**Gradle**\n\n构建工具、Groovy语法、Java\n\nJar包里面只有代码,aar里面不光有代码还包括代码还包括资源文件,比如 drawable 文件,xml 资源文件。对于一些不常变动的 Android Library,我们可以直接引用 aar,加快编译速度\n\n---\n\n**你是如何自学Android**\n\n首先是看书和看视频敲代码,然后看大牛的博客,做一些项目,向github提交代码,觉得自己API掌握的不错之后,开始看进阶的书,以及看源码,看完源码学习到一些思想,开始自己造轮子,开始想代码的提升,比如设计模式,架构,重构等。\n\n---\n\n\n\n"
},
{
"path": "Part1/Android/Android开机过程.md",
"content": "# Android开机过程\n\n* BootLoder引导,然后加载Linux内核.\n* 0号进程init启动.加载init.rc配置文件,配置文件有个命令启动了zygote进程\n* zygote开始fork出SystemServer进程\n* SystemServer加载各种JNI库,然后init1,init2方法,init2方法中开启了新线程ServerThread.\n* 在SystemServer中会创建一个socket客户端,后续AMS(ActivityManagerService)会通过此客户端和zygote通信\n* ServerThread的run方法中开启了AMS,还孵化新进程ServiceManager,加载注册了一溜的服务,最后一句话进入loop 死循环\n* run方法的SystemReady调用resumeTopActivityLocked打开锁屏界面"
},
{
"path": "Part1/Android/Android性能优化.md",
"content": "#Android性能优化\n---\n##合理管理内存\n---\n###节制的使用Service\n如果应用程序需要使用Service来执行后台任务的话,只有当任务正在执行的时候才应该让Service运行起来。当启动一个Service时,系统会倾向于将这个Service所依赖的进程进行保留,系统可以在LRUcache当中缓存的进程数量也会减少,导致切换程序的时候耗费更多性能。我们可以使用IntentService,当后台任务执行结束后会自动停止,避免了Service的内存泄漏。\n\n###当界面不可见时释放内存\n当用户打开了另外一个程序,我们的程序界面已经不可见的时候,我们应当将所有和界面相关的资源进行释放。重写Activity的onTrimMemory()方法,然后在这个方法中监听TRIM_MEMORY_UI_HIDDEN这个级别,一旦触发说明用户离开了程序,此时就可以进行资源释放操作了。\n\n###当内存紧张时释放内存\nonTrimMemory()方法还有很多种其他类型的回调,可以在手机内存降低的时候及时通知我们,我们应该根据回调中传入的级别来去决定如何释放应用程序的资源。\n\n###避免在Bitmap上浪费内存\n读取一个Bitmap图片的时候,千万不要去加载不需要的分辨率。可以压缩图片等操作。\n\n###是有优化过的数据集合\nAndroid提供了一系列优化过后的数据集合工具类,如SparseArray、SparseBooleanArray、LongSparseArray,使用这些API可以让我们的程序更加高效。HashMap工具类会相对比较低效,因为它需要为每一个键值对都提供一个对象入口,而SparseArray就避免掉了基本数据类型转换成对象数据类型的时间。\n\n###知晓内存的开支情况\n* 使用枚举通常会比使用静态常量消耗两倍以上的内存,尽可能不使用枚举\n* 任何一个Java类,包括匿名类、内部类,都要占用大概500字节的内存空间\n* 任何一个类的实例要消耗12-16字节的内存开支,因此频繁创建实例也是会在一定程序上影响内存的\n* 使用HashMap时,即使你只设置了一个基本数据类型的键,比如说int,但是也会按照对象的大小来分配内存,大概是32字节,而不是4字节,因此最好使用优化后的数据集合\n\n###谨慎使用抽象编程\n在Android使用抽象编程会带来额外的内存开支,因为抽象的编程方法需要编写额外的代码,虽然这些代码根本执行不到,但是也要映射到内存中,不仅占用了更多的内存,在执行效率上也会有所降低。所以需要合理的使用抽象编程。\n\n###尽量避免使用依赖注入框架\n使用依赖注入框架貌似看上去把findViewById()这一类的繁琐操作去掉了,但是这些框架为了要搜寻代码中的注解,通常都需要经历较长的初始化过程,并且将一些你用不到的对象也一并加载到内存中。这些用不到的对象会一直站用着内存空间,可能很久之后才会得到释放,所以可能多敲几行代码是更好的选择。\n\n###使用多个进程\n谨慎使用,多数应用程序不该在多个进程中运行的,一旦使用不当,它甚至会增加额外的内存而不是帮我们节省内存。这个技巧比较适用于哪些需要在后台去完成一项独立的任务,和前台是完全可以区分开的场景。比如音乐播放,关闭软件,已经完全由Service来控制音乐播放了,系统仍然会将许多UI方面的内存进行保留。在这种场景下就非常适合使用两个进程,一个用于UI展示,另一个用于在后台持续的播放音乐。关于实现多进程,只需要在Manifast文件的应用程序组件声明一个android:process属性就可以了。进程名可以自定义,但是之前要加个冒号,表示该进程是一个当前应用程序的私有进程。\n\n##分析内存的使用情况\n---\n系统不可能将所有的内存都分配给我们的应用程序,每个程序都会有可使用的内存上限,被称为堆大小。不同的手机堆大小不同,如下代码可以获得堆大小:\n\n```\nActivityManager manager = (ActivityManager)getSystemService(Context.ACTIVITY_SERVICE);\nint heapSize = manager.getMemoryClass();\n```\n结果以MB为单位进行返回,我们开发时应用程序的内存不能超过这个限制,否则会出现OOM。\n\n###Android的GC操作\nAndroid系统会在适当的时机触发GC操作,一旦进行GC操作,就会将一些不再使用的对象进行回收。GC操作会从一个叫做Roots的对象开始检查,所有它可以访问到的对象就说明还在使用当中,应该进行保留,而其他的对系那个就表示已经不再被使用了。\n\n###Android中内存泄漏\nAndroid中的垃圾回收机制并不能防止内存泄漏的出现导致内存泄漏最主要的原因就是某些长存对象持有了一些其它应该被回收的对象的引用,导致垃圾回收器无法去回收掉这些对象,也就是出现内存泄漏了。比如说像Activity这样的系统组件,它又会包含很多的控件甚至是图片,如果它无法被垃圾回收器回收掉的话,那就算是比较严重的内存泄漏情况了。\n举个例子,在MainActivity中定义一个内部类,实例化内部类对象,在内部类新建一个线程执行死循环,会导致内部类资源无法释放,MainActivity的控件和资源无法释放,导致OOM,可借助一系列工具,比如LeakCanary。\n\n##高性能编码优化\n---\n都是一些微优化,在性能方面看不出有什么显著的提升的。使用合适的算法和数据结构是优化程序性能的最主要手段。\n\n###避免创建不必要的对象\n不必要的对象我们应该避免创建:\n\n* 如果有需要拼接的字符串,那么可以优先考虑使用StringBuffer或者StringBuilder来进行拼接,而不是加号连接符,因为使用加号连接符会创建多余的对象,拼接的字符串越长,加号连接符的性能越低。\n* 在没有特殊原因的情况下,尽量使用基本数据类型来代替封装数据类型,int比Integer要更加有效,其它数据类型也是一样。\n* 当一个方法的返回值是String的时候,通常需要去判断一下这个String的作用是什么,如果明确知道调用方会将返回的String再进行拼接操作的话,可以考虑返回一个StringBuffer对象来代替,因为这样可以将一个对象的引用进行返回,而返回String的话就是创建了一个短生命周期的临时对象。\n* 基本数据类型的数组也要优于对象数据类型的数组。另外两个平行的数组要比一个封装好的对象数组更加高效,举个例子,Foo[]和Bar[]这样的数组,使用起来要比Custom(Foo,Bar)[]这样的一个数组高效的多。\n\n尽可能地少创建临时对象,越少的对象意味着越少的GC操作。\n\n###静态优于抽象\n如果你并不需要访问一个对系那个中的某些字段,只是想调用它的某些方法来去完成一项通用的功能,那么可以将这个方法设置成静态方法,调用速度提升15%-20%,同时也不用为了调用这个方法去专门创建对象了,也不用担心调用这个方法后是否会改变对象的状态(静态方法无法访问非静态字段)。\n\n###对常量使用static final修饰符\n```\nstatic int intVal = 42; \nstatic String strVal = \"Hello, world!\"; \n```\n编译器会为上面的代码生成一个初始方法,称为方法,该方法会在定义类第一次被使用的时候调用。这个方法会将42的值赋值到intVal当中,从字符串常量表中提取一个引用赋值到strVal上。当赋值完成后,我们就可以通过字段搜寻的方式去访问具体的值了。\n\nfinal进行优化:\n\n```\nstatic final int intVal = 42; \nstatic final String strVal = \"Hello, world!\"; \n```\n\n这样,定义类就不需要方法了,因为所有的常量都会在dex文件的初始化器当中进行初始化。当我们调用intVal时可以直接指向42的值,而调用strVal会用一种相对轻量级的字符串常量方式,而不是字段搜寻的方式。\n\n这种优化方式只对基本数据类型以及String类型的常量有效,对于其他数据类型的常量是无效的。\n\n###使用增强型for循环语法\n\n```\nstatic class Counter { \n int mCount; \n} \n \nCounter[] mArray = ... \n \npublic void zero() { \n int sum = 0; \n for (int i = 0; i < mArray.length; ++i) { \n sum += mArray[i].mCount; \n } \n} \n \npublic void one() { \n int sum = 0; \n Counter[] localArray = mArray; \n int len = localArray.length; \n for (int i = 0; i < len; ++i) { \n sum += localArray[i].mCount; \n } \n} \n \npublic void two() { \n int sum = 0; \n for (Counter a : mArray) { \n sum += a.mCount; \n } \n} \n```\n\nzero()最慢,每次都要计算mArray的长度,one()相对快得多,two()fangfa在没有JIT(Just In Time Compiler)的设备上是运行最快的,而在有JIT的设备上运行效率和one()方法不相上下,需要注意这种写法需要JDK1.5之后才支持。\n\nTips:ArrayList手写的循环比增强型for循环更快,其他的集合没有这种情况。因此默认情况下使用增强型for循环,而遍历ArrayList使用传统的循环方式。\n\n###多使用系统封装好的API\n\n系统提供不了的Api完成不了我们需要的功能才应该自己去写,因为使用系统的Api很多时候比我们自己写的代码要快得多,它们的很多功能都是通过底层的汇编模式执行的。\n举个例子,实现数组拷贝的功能,使用循环的方式来对数组中的每一个元素一一进行赋值当然可行,但是直接使用系统中提供的System.arraycopy()方法会让执行效率快9倍以上。\n\n###避免在内部调用Getters/Setters方法\n\n面向对象中封装的思想是不要把类内部的字段暴露给外部,而是提供特定的方法来允许外部操作相应类的内部字段。但在Android中,字段搜寻比方法调用效率高得多,我们直接访问某个字段可能要比通过getters方法来去访问这个字段快3到7倍。但是编写代码还是要按照面向对象思维的,我们应该在能优化的地方进行优化,比如避免在内部调用getters/setters方法。\n\n##布局优化技巧\n---\n###重用布局文件\n****\n\n标签可以允许在一个布局当中引入另一个布局,那么比如说我们程序的所有界面都有一个公共的部分,这个时候最好的做法就是将这个公共的部分提取到一个独立的布局中,然后每个界面的布局文件当中来引用这个公共的布局。\n\nTips:如果我们要在标签中覆写layout属性,必须要将layout_width和layout_height这两个属性也进行覆写,否则覆写xiaoguo将不会生效。\n\n****\n\n标签是作为标签的一种辅助扩展来使用的,它的主要作用是为了防止在引用布局文件时引用文件时产生多余的布局嵌套。布局嵌套越多,解析起来就越耗时,性能就越差。因此编写布局文件时应该让嵌套的层数越少越好。\n\n举例:比如在LinearLayout里边使用一个布局。里边又有一个LinearLayout,那么其实就存在了多余的布局嵌套,使用merge可以解决这个问题。\n\n###仅在需要时才加载布局\n\n某个布局当中的元素不是一起显示出来的,普通情况下只显示部分常用的元素,而那些不常用的元素只有在用户进行特定操作时才会显示出来。\n\n举例:填信息时不是需要全部填的,有一个添加更多字段的选项,当用户需要添加其他信息的时候,才将另外的元素显示到界面上。用VISIBLE性能表现一般,可以用ViewStub。ViewStub也是View的一种,但是没有大小,没有绘制功能,也不参与布局,资源消耗非常低,可以认为完全不影响性能。\n\n```\n \n```\n\n```\npublic void onMoreClick() { \n ViewStub viewStub = (ViewStub) findViewById(R.id.view_stub); \n if (viewStub != null) { \n View inflatedView = viewStub.inflate(); \n editExtra1 = (EditText) inflatedView.findViewById(R.id.edit_extra1); \n editExtra2 = (EditText) inflatedView.findViewById(R.id.edit_extra2); \n editExtra3 = (EditText) inflatedView.findViewById(R.id.edit_extra3); \n } \n} \n```\n\ntips:ViewStub所加载的布局是不可以使用标签的,因此这有可能导致加载出来出来的布局存在着多余的嵌套结构。\n\n"
},
{
"path": "Part1/Android/Android系统机制.md",
"content": "#Android系统机制\n---\n###APP启动过程\n\n1. Launcher线程捕获onclick的点击事件,调用Launcher.startActivitySafely,进一步调用Launcher.startActivity,最后调用父类Activity的startActivity。\n2. Activity和ActivityManagerService交互,引入Instrumentation,将启动请求交给Instrumentation,调用Instrumentation.execStartActivity\n3. \n\n###Android内核解读-应用的安装过程\n\n[http://blog.csdn.net/singwhatiwanna/article/details/19578947](http://blog.csdn.net/singwhatiwanna/article/details/19578947)\napk的安装过程分为两步:\n\n1. 将apk文件复制到程序目录下(/data/app/)\n2. 为应用创建数据目录(/data/data/package name/)、提取dex文件到指定目录(/data/delvik-cache/)、修改系统包管理信息。\n\n\n###View的事件体系\n\n\n\n###Handler消息机制\n\n\n###AsyncTask\nAyncTask是一个抽象类。\n\n需要重写的方法有四个:\n1. onPreExecute()\n\t这个方法会在后台任务开始之前调用,用于进行一些界面上的初始化操作,比如显示一个进度条对话框等\n2. doInBackGround(Params...)\n\t在子线程中运行,不可更新UI,返回的是执行结果,第三个参数为Void不返回\n3. onProgressUpdate(Progress...)\n\t利用参数可以进行UI操作。\n4. onPostExecute(Result)\n\t返回的数据会作为参数传递到此方法中,可以利用返回的一些数据来进行一些UI操作。\n\n```\nclass DownloadTask extends AsyncTask { \n \n @Override \n protected void onPreExecute() { \n progressDialog.show(); \n } \n \n @Override \n protected Boolean doInBackground(Void... params) { \n try { \n while (true) { \n int downloadPercent = doDownload(); \n publishProgress(downloadPercent); \n if (downloadPercent >= 100) { \n break; \n } \n } \n } catch (Exception e) { \n return false; \n } \n return true; \n } \n \n @Override \n protected void onProgressUpdate(Integer... values) { \n progressDialog.setMessage(\"当前下载进度:\" + values[0] + \"%\"); \n } \n \n @Override \n protected void onPostExecute(Boolean result) { \n progressDialog.dismiss(); \n if (result) { \n Toast.makeText(context, \"下载成功\", Toast.LENGTH_SHORT).show(); \n } else { \n Toast.makeText(context, \"下载失败\", Toast.LENGTH_SHORT).show(); \n } \n } \n} \n```\n\n启动这个任务:\n\n```\nnew DownloadTask().execute();\n```\n\n\n\n\n\n\n\n###图片缓存机制\n\n\n\n\n"
},
{
"path": "Part1/Android/Art和Dalvik区别.md",
"content": "#ART和Dalvik区别\n---\n\nArt上应用启动快,运行快,但是耗费更多存储空间,安装时间长,总的来说ART的功效就是\"空间换时间\"。\n\nART: Ahead of Time Dalvik: Just in Time\n\n什么是Dalvik:Dalvik是Google公司自己设计用于Android平台的Java虚拟机。Dalvik虚拟机是Google等厂商合作开发的Android移动设备平台的核心组成部分之一,它可以支持已转换为.dex(即Dalvik Executable)格式的Java应用程序的运行,.dex格式是专为Dalvik应用设计的一种压缩格式,适合内存和处理器速度有限的系统。Dalvik经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik应用作为独立的Linux进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。\n\n什么是ART:Android操作系统已经成熟,Google的Android团队开始将注意力转向一些底层组件,其中之一是负责应用程序运行的Dalvik运行时。Google开发者已经花了两年时间开发更快执行效率更高更省电的替代ART运行时。ART代表Android Runtime,其处理应用程序执行的方式完全不同于Dalvik,Dalvik是依靠一个Just-In-Time(JIT)编译器去解释字节码。开发者编译后的应用代码需要通过一个解释器在用户的设备上运行,这一机制并不高效,但让应用能更容易在不同硬件和架构上运行。ART则完全改变了这套做法,在应用安装的时候就预编译字节码到机器语言,这一机制叫Ahead-Of-Time(AOT)编译。在移除解释代码这一过程后,应用程序执行将更有效率,启动更快。\n\nART优点:\n\n1. 系统性能的显著提升\n2. 应用启动更快、运行更快、体验更流畅、触感反馈更及时\n3. 更长的电池续航能力\n4. 支持更低的硬件\n\nART缺点:\n\n1. 更大的存储空间占用,可能会增加10%-20%\n2. 更长的应用安装时间"
},
{
"path": "Part1/Android/Asynctask源码分析.md",
"content": "#AsyncTask\n---\n\n\n首先从Android3.0开始,系统要求网络访问必须在子线程中进行,否则网络访问将会失败并抛出NetworkOnMainThreadException这个异常,这样做是为了避免主线程由于耗时操作所阻塞从而出现ANR现象。AsyncTask封装了线程池和Handler。AsyncTask有两个线程池:SerialExecutor和THREAD_POOL_EXECUTOR。前者是用于任务的排队,默认是串行的线程池:后者用于真正的执行任务。AsyncTask还有一个Handler,叫InternalHandler,用于将执行环境从线程池切换到主线程。AsyncTask内部就是通过InternalHandler来发送任务执行的进度以及执行结束等消息。\n\nAsyncTask排队执行过程:系统先把参数Params封装为FutureTask对象,它相当于Runnable,接着FutureTask交给SerialExcutor的execute方法,它先把FutureTask插入到任务队列tasks中,如果这个时候没有正在活动的AsyncTask任务,那么就会执行下一个AsyncTask任务,同时当一个AsyncTask任务执行完毕之后,AsyncTask会继续执行其他任务直到所有任务都被执行为止。\n\n\n---\n\n关于线程池,AsyncTask对应的线程池ThreadPoolExecutor都是进程范围内共享的,都是static的,所以是AsyncTask控制着进程范围内所有的子类实例。由于这个限制的存在,当使用默认线程池时,如果线程数超过线程池的最大容量,线程池就会爆掉(3.0默认串行执行,不会出现这个问题)。针对这种情况。可以尝试自定义线程池,配合AsyncTask使用。\n\n"
},
{
"path": "Part1/Android/Binder机制.md",
"content": "#Binder机制\n---\n\n首先Binder是Android系统进程间通信(IPC)方式之一。\n\nBinder使用Client-Server通信方式。Binder框架定义了四个角色:Server,Client,ServiceManager以及Binder驱动。其中Server,Client,ServiceManager运行于用户空间,驱动运行于内核空间。Binder驱动程序提供设备文件/dev/binder与用户空间交互,Client、Server和Service Manager通过open和ioctl文件操作函数与Binder驱动程序进行通信。\n\nServer创建了Binder实体,为其取一个字符形式,可读易记的名字,将这个Binder连同名字以数据包的形式通过Binder驱动发送给ServiceManager,通知ServiceManager注册一个名字为XX的Binder,它位于Server中。驱动为这个穿过进程边界的Binder创建位于内核中的实体结点以及ServiceManager对实体的引用,将名字以及新建的引用打包给ServiceManager。ServiceManager收数据包后,从中取出名字和引用填入一张查找表中。但是一个Server若向ServiceManager注册自己Binder就必须通过0这个引用和ServiceManager的Binder通信。Server向ServiceManager注册了Binder实体及其名字后,Client就可以通过名字获得该Binder的引用了。Clent也利用保留的0号引用向ServiceManager请求访问某个Binder:我申请名字叫XX的Binder的引用。ServiceManager收到这个连接请求,从请求数据包里获得Binder的名字,在查找表里找到该名字对应的条目,从条目中取出Binder引用,将该引用作为回复发送给发起请求的Client。\n\n当然,不是所有的Binder都需要注册给ServiceManager广而告之的。Server端可以通过已经建立的Binder连接将创建的Binder实体传给Client,当然这条已经建立的Binder连接必须是通过实名Binder实现。由于这个Binder没有向ServiceManager注册名字,所以是匿名Binder。Client将会收到这个匿名Binder的引用,通过这个引用向位于Server中的实体发送请求。匿名Binder为通信双方建立一条私密通道,只要Server没有把匿名Binder发给别的进程,别的进程就无法通过穷举或猜测等任何方式获得该Binder的引用,向该Binder发送请求。\n\n---\n\n\n###为什么Binder只进行了一次数据拷贝?\n\n\nLinux内核实际上没有从一个用户空间到另一个用户空间直接拷贝的函数,需要先用copy_from_user()拷贝到内核空间,再用copy_to_user()拷贝到另一个用户空间。为了实现用户空间到用户空间的拷贝,mmap()分配的内存除了映射进了接收方进程里,还映射进了内核空间。所以调用copy_from_user()将数据拷贝进内核空间也相当于拷贝进了接收方的用户空间,这就是Binder只需一次拷贝的‘秘密’。\n\n\n最底层的是Android的ashmen(Anonymous shared memory)机制,它负责辅助实现内存的分配,以及跨进程所需要的内存共享。AIDL(android interface definition language)对Binder的使用进行了封装,可以让开发者方便的进行方法的远程调用,后面会详细介绍。Intent是最高一层的抽象,方便开发者进行常用的跨进程调用。\n\n从英文字面上意思看,Binder具有粘结剂的意思那么它是把什么东西粘接在一起呢?在Android系统的Binder机制中,由一系统组件组成,分别是Client、Server、Service Manager和Binder驱动,其中Client、Server、Service Manager运行在用户空间,Binder驱动程序运行内核空间。Binder就是一种把这四个组件粘合在一起的粘连剂了,其中,核心组件便是Binder驱动程序了,ServiceManager提供了辅助管理的功能,Client和Server正是Binder驱动和ServiceManager提供的基础设施上,进行Client-Server之间的通信。\n\n1. Client、Server和ServiceManager实现在用户空间中,Binder驱动实现在内核空间中\n2. Binder驱动程序和ServiceManager在Android平台中已经实现,开发者只需要在用户空间实现自己的Client和Server\n3. Binder驱动程序提供设备文件/dev/binder与用户空间交互,Client、Server和ServiceManager通过open和ioctl文件操作函数与Binder驱动程序进行通信\n4. Client和Server之间的进程间通信通过Binder驱动程序间接实现\n5. ServiceManager是一个守护进程,用来管理Server,并向Client提供查询Server接口的能力\n\n服务器端:一个Binder服务器就是一个Binder类的对象。当创建一个Binder对象后,内部就会开启一个线程,这个线程用户接收binder驱动发送的消息,收到消息后,会执行相关的服务代码。\n\nBinder驱动:当服务端成功创建一个Binder对象后,Binder驱动也会相应创建一个mRemote对象,该对象的类型也是Binder类,客户就可以借助这个mRemote对象来访问远程服务。\n\n客户端:客户端要想访问Binder的远程服务,就必须获取远程服务的Binder对象在binder驱动层对应的binder驱动层对应的mRemote引用。当获取到mRemote对象的引用后,就可以调用相应Binde对象的服务了。\n\n在这里我们可以看到,客户是通过Binder驱动来调用服务端的相关服务。首先,在服务端创建一个Binder对象,接着客户端通过获取Binder驱动中Binder对象的引用来调用服务端的服务。在Binder机制中正是借着Binder驱动将不同进程间的组件bind(粘连)在一起,实现通信。\n\nmmap将一个文件或者其他对象映射进内存。文件被映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会凋零。munmap执行相反的操作,删除特定地址区域的对象映射。\n\n当使用mmap映射文件到进程后,就可以直接操作这段虚拟地址进行文件的读写等操作,不必再调用read,write等系统调用。但需注意,直接对该段内存写时不会写入超过当前文件大小的内容。\n\n使用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次内存数据:一次从输入文件到共享内存区,另一次从共享内存到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域,而是保持共享区域,直到通信完成为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除内存映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。\n\naidl主要就帮助了我们完成了包装数据和解包的过程,并调用了transact过程,而用来传递的数据包我们就称为parcel\n\nAIDL:xxx.aidl -> xxx.java ,注册service\n\n1. 用aidl定义需要被调用方法接口\n2. 实现这些方法\n3. 调用这些方法\n\n"
},
{
"path": "Part1/Android/Bitmap的分析与使用.md",
"content": "## **Bitmap**的分析与使用\n - Bitmap的创建\n - 创建Bitmap的时候,Java不提供`new Bitmap()`的形式去创建,而是通过`BitmapFactory`中的静态方法去创建,如:`BitmapFactory.decodeStream(is);//通过InputStream去解析生成Bitmap`(这里就不贴`BitmapFactory`中创建`Bitmap`的方法了,大家可以自己去看它的源码),我们跟进`BitmapFactory`中创建`Bitmap`的源码,最终都可以追溯到这几个native函数\n ```\n private static native Bitmap nativeDecodeStream(InputStream is, byte[] storage,\n Rect padding, Options opts);\n private static native Bitmap nativeDecodeFileDescriptor(FileDescriptor fd,\n Rect padding, Options opts);\n private static native Bitmap nativeDecodeAsset(long nativeAsset, Rect padding, Options opts);\n private static native Bitmap nativeDecodeByteArray(byte[] data, int offset,\n int length, Options opts);\n ```\n 而`Bitmap`又是Java对象,这个Java对象又是从native,也就是C/C++中产生的,所以,在Android中Bitmap的内存管理涉及到两部分,一部分是*native*,另一部分是*dalvik*,也就是我们常说的java堆(如果对java堆与栈不了解的同学可以戳),到这里基本就已经了解了创建Bitmap的一些内存中的特性(大家可以使用``adb shell dumpsys meminfo``去查看Bitmap实例化之后的内存使用情况)。\n \n - Bitmap的使用\n - 我们已经知道了`BitmapFactory`是如何通过各种资源创建`Bitmap`了,那么我们如何合理的使用它呢?以下是几个我们使用`Bitmap`需要关注的点\n 1. **Size**\n - 这里我们来算一下,在Android中,如果采用`Config.ARGB_8888`的参数去创建一个`Bitmap`,[这是Google推荐的配置色彩参数](https://developer.android.com/reference/android/graphics/Bitmap.Config.html),也是Android4.4及以上版本默认创建Bitmap的Config参数(``Bitmap.Config.inPreferredConfig``的默认值),那么每一个像素将会占用4byte,如果一张手机照片的尺寸为1280×720,那么我们可以很容易的计算出这张图片占用的内存大小为 1280x720x4 = 3686400(byte) = 3.5M,一张未经处理的照片就已经3.5M了! 显而易见,在开发当中,这是我们最需要关注的问题,否则分分钟OOM!\n - *那么,我们一般是如何处理Size这个重要的因素的呢?*,当然是调整`Bitmap`的大小到适合的程度啦!辛亏在`BitmapFactory`中,我们可以很方便的通过`BitmapFactory.Options`中的`options.inSampleSize`去设置`Bitmap`的压缩比,官方给出的说法是 \n > If set to a value > 1, requests the decoder to subsample the original image, returning a smaller image to save memory....For example, inSampleSize == 4 returns\n an image that is 1/4 the width/height of the original, and 1/16 the\n number of pixels. Any value <= 1 is treated the same as 1.\n \n 很简洁明了啊!也就是说,只要按计算方法设置了这个参数,就可以完成我们Bitmap的Size调整了。那么,应该怎么调整姿势才比较舒服呢?下面先介绍其中一种通过``InputStream``的方式去创建``Bitmap``的方法,上一段从Gallery中获取照片并且将图片Size调整到合适手机尺寸的代码:\n ```\n static final int PICK_PICS = 9;\n \n public void startGallery(){\n Intent i = new Intent();\n i.setAction(Intent.ACTION_PICK);\n i.setType(\"image/*\");\n startActivityForResult(i,PICK_PICS);\n }\n \n private int[] getScreenWithAndHeight(){\n WindowManager wm = (WindowManager) getSystemService(Context.WINDOW_SERVICE);\n DisplayMetrics dm = new DisplayMetrics();\n wm.getDefaultDisplay().getMetrics(dm);\n return new int[]{dm.widthPixels,dm.heightPixels};\n }\n \n /**\n *\n * @param actualWidth 图片实际的宽度,也就是options.outWidth\n * @param actualHeight 图片实际的高度,也就是options.outHeight\n * @param desiredWidth 你希望图片压缩成为的目的宽度\n * @param desiredHeight 你希望图片压缩成为的目的高度\n * @return\n */\n private int findBestSampleSize(int actualWidth, int actualHeight, int desiredWidth, int desiredHeight) {\n double wr = (double) actualWidth / desiredWidth;\n double hr = (double) actualHeight / desiredHeight;\n double ratio = Math.min(wr, hr);\n float n = 1.0f;\n //这里我们为什么要寻找 与ratio最接近的2的倍数呢?\n //原因就在于API中对于inSimpleSize的注释:最终的inSimpleSize应该为2的倍数,我们应该向上取与压缩比最接近的2的倍数。\n while ((n * 2) <= ratio) {\n n *= 2;\n }\n \n return (int) n;\n }\n\n @Override\n protected void onActivityResult(int requestCode, int resultCode, Intent data) {\n if(resultCode == RESULT_OK){\n switch (requestCode){\n case PICK_PICS:\n Uri uri = data.getData();\n InputStream is = null;\n try {\n is = getContentResolver().openInputStream(uri);\n } catch (FileNotFoundException e) {\n e.printStackTrace();\n }\n \n BitmapFactory.Options options = new BitmapFactory.Options();\n //当这个参数为true的时候,意味着你可以在解析时候不申请内存的情况下去获取Bitmap的宽和高\n //这是调整Bitmap Size一个很重要的参数设置\n options.inJustDecodeBounds = true;\n BitmapFactory.decodeStream( is,null,options );\n \n int realHeight = options.outHeight;\n int realWidth = options.outWidth;\n \n int screenWidth = getScreenWithAndHeight()[0];\n \n int simpleSize = findBestSampleSize(realWidth,realHeight,screenWidth,300);\n options.inSampleSize = simpleSize;\n //当你希望得到Bitmap实例的时候,不要忘了将这个参数设置为false\n options.inJustDecodeBounds = false;\n \n try {\n is = getContentResolver().openInputStream(uri);\n } catch (FileNotFoundException e) {\n e.printStackTrace();\n }\n \n Bitmap bitmap = BitmapFactory.decodeStream(is,null,options);\n \n iv.setImageBitmap(bitmap);\n \n try {\n is.close();\n is = null;\n } catch (IOException e) {\n e.printStackTrace();\n }\n \n break;\n }\n }\n super.onActivityResult(requestCode, resultCode, data);\n }\n ```\n \n 我们来看看这段代码的功效:\n 压缩前:\n 压缩后:\n **对比条件为:1080P的魅族Note3拍摄的高清无码照片**\n \n 2. **Reuse**\n 上面介绍了``BitmapFactory``通过``InputStream``去创建`Bitmap`的这种方式,以及``BitmapFactory.Options.inSimpleSize`` 和 ``BitmapFactory.Options.inJustDecodeBounds``的使用方法,但将单个Bitmap加载到UI是简单的,但是如果我们需要一次性加载大量的图片,事情就会变得复杂起来。`Bitmap`是吃内存大户,我们不希望多次解析相同的`Bitmap`,也不希望可能不会用到的`Bitmap`一直存在于内存中,所以,这个场景下,`Bitmap`的重用变得异常的重要。\n *在这里只介绍一种``BitmapFactory.Options.inBitmap``的重用方式,下一篇文章会介绍使用三级缓存来实现Bitmap的重用。*\n \n 根据官方文档[在Android 3.0 引进了BitmapFactory.Options.inBitmap](https://developer.android.com/reference/android/graphics/BitmapFactory.Options.html#inBitmap),如果这个值被设置了,decode方法会在加载内容的时候去重用已经存在的bitmap. 这意味着bitmap的内存是被重新利用的,这样可以提升性能, 并且减少了内存的分配与回收。然而,使用inBitmap有一些限制。特别是在Android 4.4 之前,只支持同等大小的位图。\n 我们看来看看这个参数最基本的运用方法。\n \n ```\n new BitmapFactory.Options options = new BitmapFactory.Options();\n //inBitmap只有当inMutable为true的时候是可用的。\n options.inMutable = true;\n Bitmap reusedBitmap = BitmapFactory.decodeResource(getResources(),R.drawable.reused_btimap,options);\n options.inBitmap = reusedBitmap;\n ```\n \n 这样,当你在下一次decodeBitmap的时候,将设置了`options.inMutable=true`以及`options.inBitmap`的`Options`传入,Android就会复用你的Bitmap了,具体实例:\n \n ```\n @Override\n protected void onCreate(@Nullable Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(reuseBitmap());\n }\n \n private LinearLayout reuseBitmap(){\n LinearLayout linearLayout = new LinearLayout(this);\n linearLayout.setLayoutParams(new ViewGroup.LayoutParams(ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT));\n linearLayout.setOrientation(LinearLayout.VERTICAL);\n \n ImageView iv = new ImageView(this);\n iv.setLayoutParams(new ViewGroup.LayoutParams(500,300));\n \n options = new BitmapFactory.Options();\n options.inJustDecodeBounds = true;\n //inBitmap只有当inMutable为true的时候是可用的。\n options.inMutable = true;\n BitmapFactory.decodeResource(getResources(),R.drawable.big_pic,options);\n \n //压缩Bitmap到我们希望的尺寸\n //确保不会OOM\n options.inSampleSize = findBestSampleSize(options.outWidth,options.outHeight,500,300);\n options.inJustDecodeBounds = false;\n \n Bitmap bitmap = BitmapFactory.decodeResource(getResources(),R.drawable.big_pic,options);\n options.inBitmap = bitmap;\n \n iv.setImageBitmap(bitmap);\n \n linearLayout.addView(iv);\n \n ImageView iv1 = new ImageView(this);\n iv1.setLayoutParams(new ViewGroup.LayoutParams(500,300));\n iv1.setImageBitmap( BitmapFactory.decodeResource(getResources(),R.drawable.big_pic,options));\n linearLayout.addView(iv1);\n \n ImageView iv2 = new ImageView(this);\n iv2.setLayoutParams(new ViewGroup.LayoutParams(500,300));\n iv2.setImageBitmap( BitmapFactory.decodeResource(getResources(),R.drawable.big_pic,options));\n linearLayout.addView(iv2);\n \n \n return linearLayout;\n }\n ```\n \n 以上代码中,我们在解析了一次一张1080P分辨率的图片,并且设置在`options.inBitmap`中,然后分别decode了同一张图片,并且传入了相同的`options`。最终只占用一份第一次解析`Bitmap`的内存。\n \n 3. **Recycle**\n 一定要记得及时回收Bitmap,否则如上分析,你的native以及dalvik的内存都会被一直占用着,最终导致OOM\n \n \n ```\n // 先判断是否已经回收\n if(bitmap != null && !bitmap.isRecycled()){\n // 回收并且置为null\n bitmap.recycle();\n bitmap = null;\n }\n System.gc();\n ```\n \n - Enjoy Android :) 如果有误,轻喷,欢迎指正。\n\n"
},
{
"path": "Part1/Android/EventBus用法详解.md",
"content": "#EventBus\n---\n\n###概述\n\nEventBus是一款针对Android优化的发布/订阅(publish/subscribe)事件总线。主要功能是替代Intent,Handler,BroadCast在Fragment,Activity,Service,线程之间传递消息。简化了应用程序内各组件间、组件与后台线程间的通信。优点是开销小,代码更优雅。以及将发送者和接收者解耦。比如请求网络,等网络返回时通过Handler或Broadcast通知UI,两个Fragment之间需要通过Listener通信,这些需求都可以通过EventBus实现。\n\n###EventBus作为一个消息总线,有三个主要的元素:\n\n* Event:事件。可以是任意类型的对象\n* Subscriber:事件订阅者,接收特定的事件。在EventBus中,使用约定来指定事件订阅者以简化使用。即所有事件订阅都都是以onEvent开头的函数,具体来说,函数的名字是onEvent,onEventMainThread,onEventBackgroundThread,onEventAsync这四个,这个和\nThreadMode(下面讲)有关。\n* Publisher:事件发布者,用于通知 Subscriber 有事件发生。可以在任意线程任意位置发送事件,直接调用eventBus.post(Object) 方法,可以自己实例化 EventBus \n对象,但一般使用默认的单例就好了:EventBus.getDefault(), 根据post函数参数的类型,会自动调用订阅相应类型事件的函数。\n\n###关于ThreadMode\n\n前面说了,Subscriber的函数只能是那4个,因为每个事件订阅函数都是和一个ThreadMode相关联的,ThreadMode指定了会调用的函数。有以下四个ThreadMode:\n\n* PostThread:事件的处理在和事件的发送在相同的进程,所以事件处理时间不应太长,不然影响事件的发送线程,而这个线程可能是UI线程。对应的函数名是onEvent。\n* MainThread: 事件的处理会在UI线程中执行。事件处理时间不能太长,这个不用说的,长了会ANR的,对应的函数名是onEventMainThread。\n* BackgroundThread:事件的处理会在一个后台线程中执行,对应的函数名是onEventBackgroundThread,虽然名字是BackgroundThread,事件处理是在后台线程,但事件处理时间还是不应该太长,因为如果发送事件的线程是后台线程,会直接执行事件,如果当前线程是UI线程,事件会被加到一个队列中,由一个线程依次处理这些事件,如果某个事件处理时间太长,会阻塞后面的事件的派发或处理。\n* Async:事件处理会在单独的线程中执行,主要用于在后台线程中执行耗时操作,每个事件会开启一个线程(有线程池),但最好限制线程的数目。\n\n根据事件订阅都函数名称的不同,会使用不同的ThreadMode,比如果在后台线程加载了数据想在UI线程显示,订阅者只需把函数命名onEventMainThread。\n\n对相应的函数名,进一步解释一下:\n\n**onEvent**:如果使用onEvent作为订阅函数,那么该事件在哪个线程发布出来的,onEvent就会在这个线程中运行,也就是说发布事件和接收事件线程在同一个线程。使用这个方法时,在onEvent方法中不能执行耗时操作,如果执行耗时操作容易导致事件分发延迟。\n\n**onEventMainThread**:如果使用onEventMainThread作为订阅函数,那么不论事件是在哪个线程中发布出来的,onEventMainThread都会在UI线程中执行,接收事件就会在UI线程中运行,这个在Android中是非常有用的,因为在Android中只能在UI线程中跟新UI,所以在onEvnetMainThread方法中是不能执行耗时操作的。\n\n**onEventBackground**:如果使用onEventBackgrond作为订阅函数,那么如果事件是在UI线程中发布出来的,那么onEventBackground就会在子线程中运行,如果事件本来就是子线程中发布出来的,那么onEventBackground函数直接在该子线程中执行。\n\n**onEventAsync**:使用这个函数作为订阅函数,那么无论事件在哪个线程发布,都会创建新的子线程在执行onEventAsync。\n\n##基本用法\n\n###引入EventBus:\n\n```\ncompile 'org.greenrobot:eventbus:3.0.0'\n```\n\n定义事件:\n\n```\npublic class MessageEvent { /* Additional fields if needed */ }\n```\n\n注册事件接收者:\n\n```\neventBus.register(this);\n```\n\n发送事件:\n\n```\neventBus.post(event)\n```\n\n接收消息并处理:\n\n```\n// 3.0后不再要求事件以 onEvent 开头,而是采用注解的方式\n@Subscribe(threadMode = ThreadMode.MAIN)\npublic void receive(MessageEvent event){}\n```\n\n注销事件接收:\n\n```\neventBus.unregister(this);\n```\n\n索引加速:\n\n```\n3.0 后引入了索引加速(默认不开启)的功能,即通过 apt 编译插件的方式,在代码编译的时候对注解进行索引,避免了以往通过反射造成的性能损耗。\n如何使用可以参考[官方文档](http://greenrobot.org/eventbus/documentation/subscriber-index/)\n```\n\n最后,proguard 需要做一些额外处理:\n\n```\n#EventBus\n -keepclassmembers class ** {\n public void onEvent*(**);\n void onEvent*(**);\n }\n```\n\n\n\n"
},
{
"path": "Part1/Android/Fragment.md",
"content": "#Fragment\n\n##为何产生\n* 同时适配手机和平板、UI和逻辑的共享。\n\n##介绍\n* Fragment也会被加入回退栈中。\n* Fragment拥有自己的生命周期和接受、处理用户的事件\n* 可以动态的添加、替换和移除某个Fragment\n\n##生命周期\n* 必须依存于Activity\n\n\n\n* Fragment依附于Activity的生命状态\n* \n\n生命周期中那么多方法,懵逼了的话我们就一起来看一下每一个生命周期方法的含义吧。\n\n##Fragment生命周期方法含义:\n* `public void onAttach(Context context)`\n\t* onAttach方法会在Fragment于窗口关联后立刻调用。从该方法开始,就可以通过Fragment.getActivity方法获取与Fragment关联的窗口对象,但因为Fragment的控件未初始化,所以不能够操作控件。\n\t\n* `public void onCreate(Bundle savedInstanceState)`\n\t* 在调用完onAttach执行完之后立刻调用onCreate方法,可以在Bundle对象中获取一些在Activity中传过来的数据。通常会在该方法中读取保存的状态,获取或初始化一些数据。在该方法中不要进行耗时操作,不然窗口不会显示。\n\t\n* `public View onCreateView(LayoutInflater inflater, ViewGroup container,Bundle savedInstanceState)`\n\t* 该方法是Fragment很重要的一个生命周期方法,因为会在该方法中创建在Fragment显示的View,其中inflater是用来装载布局文件的,container是``标签的父标签对应对象,savedInstanceState参数可以获取Fragment保存的状态,如果未保存那么就为null。\n\t\n* `public void onViewCreated(View view,Bundle savedInstanceState)`\n\t* Android在创建完Fragment中的View对象之后,会立刻回调该方法。其种view参数就是onCreateView中返回的view,而bundle对象用于一般用途。\n\t\n* `public void onActivityCreated(Bundle savedInstanceState)`\n\t* 在Activity的onCreate方法执行完之后,Android系统会立刻调用该方法,表示窗口已经初始化完成,从这一个时候开始,就可以在Fragment中使用getActivity().findViewById(Id);来操控Activity中的view了。\n\t\n* `public void onStart()`\n\t* 这个没啥可讲的,但有一个细节需要知道,当系统调用该方法的时候,fragment已经显示在ui上,但还不能进行互动,因为onResume方法还没执行完。\n\t\n* `public void onResume()`\n\t* 该方法为fragment从创建到显示Android系统调用的最后一个生命周期方法,调用完该方法时候,fragment就可以与用户互动了。\n\n* `public void onPause()`\n\t* fragment由活跃状态变成非活跃状态执行的第一个回调方法,通常可以在这个方法中保存一些需要临时暂停的工作。如保存音乐播放进度,然后在onResume中恢复音乐播放进度。\n\n* `public void onStop()`\n\t* 当onStop返回的时候,fragment将从屏幕上消失。\n\n* `public void onDestoryView()`\n\t* 该方法的调用意味着在 `onCreateView` 中创建的视图都将被移除。\n\n* `public void onDestroy()`\n\t* Android在Fragment不再使用时会调用该方法,要注意的是~这时Fragment还和Activity藕断丝连!并且可以获得Fragment对象,但无法对获得的Fragment进行任何操作(呵~呵呵~我已经不听你的了)。\n\n* `public void onDetach()`\n\t* 为Fragment生命周期中的最后一个方法,当该方法执行完后,Fragment与Activity不再有关联(分手!我们分手!!(╯‵□′)╯︵┻━┻)。\n\n##Fragment比Activity多了几个额外的生命周期回调方法:\n* onAttach(Activity):当Fragment和Activity发生关联时使用\n* onCreateView(LayoutInflater, ViewGroup, Bundle):创建该Fragment的视图\n* onActivityCreate(Bundle):当Activity的onCreate方法返回时调用\n* onDestoryView():与onCreateView相对应,当该Fragment的视图被移除时调用\n* onDetach():与onAttach相对应,当Fragment与Activity关联被取消时调用\n\n###注意:除了onCreateView,其他的所有方法如果你重写了,必须调用父类对于该方法的实现\n\n##Fragment与Activity之间的交互\n* Fragment与Activity之间的交互可以通过`Fragment.setArguments(Bundle args)`以及`Fragment.getArguments()`来实现。\n\n##Fragment状态的持久化。\n由于Activity会经常性的发生配置变化,所以依附它的Fragment就有需要将其状态保存起来问题。下面有两个常用的方法去将Fragment的状态持久化。\n\n* 方法一:\n\t* 可以通过`protected void onSaveInstanceState(Bundle outState)`,`protected void onRestoreInstanceState(Bundle savedInstanceState)` 状态保存和恢复的方法将状态持久化。\n* 方法二(更方便,让Android自动帮我们保存Fragment状态):\n\t* 我们只需要将Fragment在Activity中作为一个变量整个保存,只要保存了Fragment,那么Fragment的状态就得到保存了,所以呢.....\n\t\t* `FragmentManager.putFragment(Bundle bundle, String key, Fragment fragment)` 是在Activity中保存Fragment的方法。\n\t\t* `FragmentManager.getFragment(Bundle bundle, String key)` 是在Activity中获取所保存的Frament的方法。\n\t* 很显然,key就传入Fragment的id,fragment就是你要保存状态的fragment,但,我们注意到上面的两个方法,第一个参数都是Bundle,这就意味着*FragmentManager*是通过Bundle去保存Fragment的。但是,这个方法仅仅能够保存Fragment中的控件状态,比如说EditText中用户已经输入的文字(*注意!在这里,控件需要设置一个id,否则Android将不会为我们保存控件的状态*),而Fragment中需要持久化的变量依然会丢失,但依然有解决办法,就是利用方法一!\n\t* 下面给出状态持久化的事例代码:\n\t\t```\t\t\n\t\t\t /** Activity中的代码 **/\n\t\t\t FragmentB fragmentB;\n\n\t\t @Override\n\t\t protected void onCreate(@Nullable Bundle savedInstanceState) {\n\t\t super.onCreate(savedInstanceState);\n\t\t setContentView(R.layout.fragment_activity);\n\t\t if( savedInstanceState != null ){\n\t\t fragmentB = (FragmentB) getSupportFragmentManager().getFragment(savedInstanceState,\"fragmentB\");\n\t\t }\n\t\t init();\n\t\t }\n\n\t\t @Override\n\t\t protected void onSaveInstanceState(Bundle outState) {\n\t\t if( fragmentB != null ){\n\t\t getSupportFragmentManager().putFragment(outState,\"fragmentB\",fragmentB);\n\t\t }\n\n\t\t super.onSaveInstanceState(outState);\n\t\t }\n\n\t\t /** Fragment中保存变量的代码 **/\n\n\t\t @Nullable\n\t\t @Override\n\t\t public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n\t\t AppLog.e(\"onCreateView\");\n\t\t if ( null != savedInstanceState ){\n\t\t String savedString = savedInstanceState.getString(\"string\");\n\t\t //得到保存下来的string\n\t\t }\n\t\t View root = inflater.inflate(R.layout.fragment_a,null);\n\t\t return root;\n\t\t }\n\n\t\t\t@Override\n\t\t public void onSaveInstanceState(Bundle outState) {\n\t\t outState.putString(\"string\",\"anAngryAnt\");\n\t\t super.onSaveInstanceState(outState);\n\t\t }\n\n\t\t```\n\n##静态的使用Fragment\n1. 继承Fragment,重写onCreateView决定Fragment的布局\n2. 在Activity中声明此Fragment,就和普通的View一样\n\n##Fragment常用的API\n* android.support.v4.app.Fragment 主要用于定义Fragment\n* android.support.v4.app.FragmentManager 主要用于在Activity中操作Fragment,可以使用FragmentManager.findFragmenById,FragmentManager.findFragmentByTag等方法去找到一个Fragment\n* android.support.v4.app.FragmentTransaction 保证一些列Fragment操作的原子性,熟悉事务这个词\n* 主要的操作都是FragmentTransaction的方法\n(一般我们为了向下兼容,都使用support.v4包里面的Fragment)\n\n\n\tgetFragmentManager() // Fragment若使用的是support.v4包中的,那就使用getSupportFragmentManager代替\n\t\n\n\n* 主要的操作都是FragmentTransaction的方法\n\n```\n\t\n\tFragmentTransaction transaction = fm.benginTransatcion();//开启一个事务\n\ttransaction.add() \n\t//往Activity中添加一个Fragment\n\n\ttransaction.remove() \n\t//从Activity中移除一个Fragment,如果被移除的Fragment没有添加到回退栈(回退栈后面会详细说),这个Fragment实例将会被销毁。\n\n\ttransaction.replace()\n\t//使用另一个Fragment替换当前的,实际上就是remove()然后add()的合体~\n\n\ttransaction.hide()\n\t//隐藏当前的Fragment,仅仅是设为不可见,并不会销毁\n\n\ttransaction.show()\n\t//显示之前隐藏的Fragment\n\n\tdetach()\n\t//当fragment被加入到回退栈的时候,该方法与*remove()*的作用是相同的,\n\t//反之,该方法只是将fragment从视图中移除,\n\t//之后仍然可以通过*attach()*方法重新使用fragment,\n\t//而调用了*remove()*方法之后,\n\t//不仅将Fragment从视图中移除,fragment还将不再可用。\n\n\tattach()\n\t//重建view视图,附加到UI上并显示。\n\n\ttransatcion.commit()\n\t//提交一个事务\n\n```\n\n##管理Fragment回退栈\n* 跟踪回退栈状态\n\t* 我们通过实现*``OnBackStackChangedListener``*接口来实现回退栈状态跟踪,具体如下\n \t```\n \tpublic class XXX implements FragmentManager.OnBackStackChangedListener \n\n \t/** 实现接口所要实现的方法 **/\n\n\t@Override\n public void onBackStackChanged() {\n //do whatevery you want\n }\n\n /** 设置回退栈监听接口 **/\n getSupportFragmentManager().addOnBackStackChangedListener(this);\n\n\n \t```\n\t\t\n* 管理回退栈\n\t* ``FragmentTransaction.addToBackStack(String)`` *--将一个刚刚添加的Fragment加入到回退栈中*\n\t* ``getSupportFragmentManager().getBackStackEntryCount()`` *-获取回退栈中实体数量*\n\t* ``getSupportFragmentManager().popBackStack(String name, int flags)`` *-根据name立刻弹出栈顶的fragment*\n\t* ``getSupportFragmentManager().popBackStack(int id, int flags)`` *-根据id立刻弹出栈顶的fragment*\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"path": "Part1/Android/Git操作.md",
"content": "# Git 操作\n\n## git 命令\n\n* 创建本地仓库\n\n```\ngit init\n```\n\n* 获取远程仓库\n\n```\ngit clone [url]\n例:git clone https://github.com/you/yourpro.git\n```\n\n* 创建远程仓库\n\n```\n// 添加一个新的 remote 远程仓库\ngit remote add [remote-name] [url]\n例:git remote add origin https://github.com/you/yourpro.git\norigin:相当于该远程仓库的别名\n\n// 列出所有 remote 的别名\ngit remote\n\n// 列出所有 remote 的 url\ngit remote -v\n\n// 删除一个 renote\ngit remote rm [name]\n\n// 重命名 remote\ngit remote rename [old-name] [new-name]\n```\n\n* 从本地仓库中删除\n\n```\ngit rm file.txt // 从版本库中移除,删除文件\ngit rm file.txt -cached // 从版本库中移除,不删除原始文件\ngit rm -r xxx // 从版本库中删除指定文件夹\n```\n\n* 从本地仓库中添加新的文件\n\n```\ngit add . // 添加所有文件\ngit add file.txt // 添加指定文件\n```\n\n* 提交,把缓存内容提交到 HEAD 里\n\n```\ngit commit -m \"注释\"\n```\n\n* 撤销\n\n```\n// 撤销最近的一个提交.\ngit revert HEAD\n\n// 取消 commit + add\ngit reset --mixed\n\n// 取消 commit\ngit reset --soft\n\n// 取消 commit + add + local working\ngit reset --hard\n```\n\n* 把本地提交 push 到远程服务器\n\n```\ngit push [remote-name] [loca-branch]:[remote-branch]\n例:git push origin master:master\n```\n\n* 查看状态\n\n```\ngit status\n```\n\n* 从远程库中下载新的改动\n\n```\ngit fetch [remote-name]/[branch]\n```\n\n* 合并下载的改动到分支\n\n```\ngit merge [remote-name]/[branch]\n```\n\n* 从远程库中下载新的改动\n\n```\npull = fetch + merge\n\ngit pull [remote-name] [branch]\n例:git pull origin master\n```\n\n* 分支\n\n```\n// 列出分支\ngit branch\n\n// 创建一个新的分支\ngit branch (branch-name)\n\n// 删除一个分支\ngit branch -d (branch-nam)\n\n// 删除 remote 的分支\ngit push (remote-name) :(remote-branch)\n```\n\n* 切换分支\n\n```\n// 切换到一个分支\ngit checkout [branch-name]\n\n// 创建并切换到该分支\ngit checkout -b [branch-name]\n```\n\n##与github建立ssh通信,让Git操作免去输入密码的繁琐。\n* 首先呢,我们先建立ssh密匙。\n> ssh key must begin with 'ssh-ed25519', 'ssh-rsa', 'ssh-dss', 'ecdsa-sha2-nistp256', 'ecdsa-sha2-nistp384', or 'ecdsa-sha2-nistp521'. -- from github\n\n 根据以上文段我们可以知道github所支持的ssh密匙类型,这里我们创建ssh-rsa密匙。\n 在command line 中输入以下指令:``ssh-keygen -t rsa``去创建一个ssh-rsa密匙。如果你并不需要为你的密匙创建密码和修改名字,那么就一路回车就OK,如果你需要,请您自行Google翻译,因为只是英文问题。\n>$ ssh-keygen -t rsa\nGenerating public/private rsa key pair.\n//您可以根据括号中的路径来判断你的.ssh文件放在了什么地方\nEnter file in which to save the key (/c/Users/Liang Guan Quan/.ssh/id_rsa):\n\n* 到 https://github.com/settings/keys 这个地址中去添加一个新的SSH key,然后把你的xx.pub文件下的内容文本都复制到Key文本域中,然后就可以提交了。\n* 添加完成之后 我们用``ssh git@github.com`` 命令来连通一下github,如果你在response里面看到了你github账号名,那么就说明配置成功了。 *let's enjoy github ;)*\n\n\n## gitignore\n---\n\n在本地仓库根目录创建 .gitignore 文件。Win7 下不能直接创建,可以创建 \".gitignore.\" 文件,后面的标点自动被忽略;\n\n```\n/.idea // 过滤指定文件夹\n/fd/* // 忽略根目录下的 /fd/ 目录的全部内容;\n*.iml // 过滤指定的所有文件\n!.gitignore // 不忽略该文件\n```\n\n"
},
{
"path": "Part1/Android/Handler内存泄漏分析及解决.md",
"content": "#Handler内存泄漏分析及解决\n---\n\n###一、介绍\n\n首先,请浏览下面这段handler代码:\n\n```\npublic class SampleActivity extends Activity {\n private final Handler mLeakyHandler = new Handler() {\n @Override\n public void handleMessage(Message msg) {\n // ... \n }\n }\n}\n```\n\n在使用handler时,这是一段很常见的代码。但是,它却会造成严重的内存泄漏问题。在实际编写中,我们往往会得到如下警告:\n\n```\n ⚠ In Android, Handler classes should be static or leaks might occur.\n\n```\n\n###二、分析\n\n1、 Android角度\n\n当Android应用程序启动时,framework会为该应用程序的主线程创建一个Looper对象。这个Looper对象包含一个简单的消息队列Message Queue,并且能够循环的处理队列中的消息。这些消息包括大多数应用程序framework事件,例如Activity生命周期方法调用、button点击等,这些消息都会被添加到消息队列中并被逐个处理。\n\n另外,主线程的Looper对象会伴随该应用程序的整个生命周期。\n\n然后,当主线程里,实例化一个Handler对象后,它就会自动与主线程Looper的消息队列关联起来。所有发送到消息队列的消息Message都会拥有一个对Handler的引用,所以当Looper来处理消息时,会据此回调[Handler#handleMessage(Message)]方法来处理消息。\n\n2、 Java角度\n\n在java里,非静态内部类 和 匿名类 都会潜在的引用它们所属的外部类。但是,静态内部类却不会。\n\n###三、泄漏来源\n\n请浏览下面一段代码:\n\n```\npublic class SampleActivity extends Activity {\n\n private final Handler mLeakyHandler = new Handler() {\n @Override\n public void handleMessage(Message msg) {\n // ...\n }\n }\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n // Post a message and delay its execution for 10 minutes.\n mLeakyHandler.postDelayed(new Runnable() {\n @Override\n public void run() { /* ... */ }\n }, 1000 * 60 * 10);\n\n // Go back to the previous Activity.\n finish();\n }\n}\n```\n\n当activity结束(finish)时,里面的延时消息在得到处理前,会一直保存在主线程的消息队列里持续10分钟。而且,由上文可知,这条消息持有对handler的引用,而handler又持有对其外部类(在这里,即SampleActivity)的潜在引用。这条引用关系会一直保持直到消息得到处理,从而,这阻止了SampleActivity被垃圾回收器回收,同时造成应用程序的泄漏。\n\n<<<<<<< HEAD\n注意,上面代码中的Runnable类--非静态匿名类--同样持有对其外部类的引用。从而也导致泄漏。\n\n=======\n注意,上面代码中的Runnable类--非静态匿名类--同样持有对其外部类的引用。从而也导致泄漏。\n\n>>>>>>> c67abfcfd66909095068cb5f0c8632dc5547131b\n###四、泄漏解决方案\n\n首先,上面已经明确了内存泄漏来源:\n\n只要有未处理的消息,那么消息会引用handler,非静态的handler又会引用外部类,即Activity,导致Activity无法被回收,造成泄漏;\n\nRunnable类属于非静态匿名类,同样会引用外部类。\n\n为了解决遇到的问题,我们要明确一点:静态内部类不会持有对外部类的引用。所以,我们可以把handler类放在单独的类文件中,或者使用静态内部类便可以避免泄漏。\n\n另外,如果想要在handler内部去调用所在的外部类Activity,那么可以在handler内部使用弱引用的方式指向所在Activity,这样统一不会导致内存泄漏。\n\n对于匿名类Runnable,同样可以将其设置为静态类。因为静态的匿名类不会持有对外部类的引用。\n\n```\npublic class SampleActivity extends Activity {\n\n /**\n * Instances of static inner classes do not hold an implicit\n * reference to their outer class.\n */\n private static class MyHandler extends Handler {\n private final WeakReference mActivity;\n\n public MyHandler(SampleActivity activity) {\n mActivity = new WeakReference(activity);\n }\n\n @Override\n public void handleMessage(Message msg) {\n SampleActivity activity = mActivity.get();\n if (activity != null) {\n // ...\n }\n }\n }\n\n private final MyHandler mHandler = new MyHandler(this);\n\n /**\n * Instances of anonymous classes do not hold an implicit\n * reference to their outer class when they are \"static\".\n */\n private static final Runnable sRunnable = new Runnable() {\n @Override\n public void run() { /* ... */ }\n };\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n // Post a message and delay its execution for 10 minutes.\n mHandler.postDelayed(sRunnable, 1000 * 60 * 10);\n\n // Go back to the previous Activity.\n finish();\n }\n}\n```\n\n###五、小结\n\n<<<<<<< HEAD\n虽然静态类与非静态类之间的区别并不大,但是对于Android开发者而言却是必须理解的。至少我们要清楚,如果一个内部类实例的生命周期比Activity更长,那么我们千万不要使用非静态的内部类。最好的做法是,使用静态内部类,然后在该类里使用弱引用来指向所在的Activity。\n\n原文链接:\n\n[http://www.jianshu.com/p/cb9b4b71a820](http://www.jianshu.com/p/cb9b4b71a820)\n=======\n虽然静态类与非静态类之间的区别并不大,但是对于Android开发者而言却是必须理解的。至少我们要清楚,如果一个内部类实例的生命周期比Activity更长,那么我们千万不要使用非静态的内部类。最好的做法是,使用静态内部类,然后在该类里使用弱引用来指向所在的Activity。\n\n原文链接:\n\n[http://www.jianshu.com/p/cb9b4b71a820](http://www.jianshu.com/p/cb9b4b71a820)\n>>>>>>> c67abfcfd66909095068cb5f0c8632dc5547131b\n"
},
{
"path": "Part1/Android/Listview详解.md",
"content": "#ListView详解\n---\n直接继承自AbsListView,AbsListView继承自AdapterView,AdapterView又继承自ViewGroup。\n\nAdpater在ListView和数据源之间起到了一个桥梁的作用\n\n###RecycleBin机制\n\nRecycleBin机制是ListView能够实现成百上千条数据都不会OOM最重要的一个原因。RecycleBin是AbsListView的一个内部类。\n\n* RecycleBin当中使用mActiveViews这个数组来存储View,调用这个方法后就会根据传入的参数来将ListView中的指定元素存储到mActiveViews中。\n* mActiveViews当中所存储的View,一旦被获取了之后就会从mActiveViews当中移除,下次获取同样位置的时候将会返回null,所以mActiveViews不能被重复利用。\n* addScrapView()用于将一个废弃的View进行缓存,该方法接收一个View参数,当有某个View确定要废弃掉的时候(比如滚动出了屏幕)就应该调用这个方法来对View进行缓存,RecycleBin当中使用mScrapV\n* iews和mCurrentScrap这两个List来存储废弃View。\n* getScrapView 用于从废弃缓存中取出一个View,这些废弃缓存中的View是没有顺序可言的,因此getScrapView()方法中的算法也非常简单,就是直接从mCurrentScrap当中获取尾部的一个scrap view进行返回。\n* 我们都知道Adapter当中可以重写一个getViewTypeCount()来表示ListView中有几种类型的数据项,而setViewTypeCount()方法的作用就是为每种类型的数据项都单独启用一个RecycleBin缓存机制。\n\nView的流程分三步,onMeasure()用于测量View的大小,onLayout()用于确定View的布局,onDraw()用于将View绘制到界面上。\n"
},
{
"path": "Part1/Android/MVC,MVP,MVVM的区别.md",
"content": "#MVC,MVP,MVVM的区别\n---\n\n\n#MVC\n软件可以分为三部分\n\n* 视图(View):用户界面\n* 控制器(Controller):业务逻辑\n* 模型(Model):数据保存\n\n各部分之间的通信方式如下:\n\n1. View传送指令到Controller\n2. Controller完成业务逻辑后,要求Model改变状态\n3. Model将新的数据发送到View,用户得到反馈\n\nTips:所有的通信都是单向的。\n\n#互动模式\n接受用户指令时,MVC可以分为两种方式。一种是通过View接受指令,传递给Controller。\n\n另一种是直接通过Controller接受指令\n\n\n#MVP\n\nMVP模式将Controller改名为Presenter,同时改变了通信方向。\n\n1. 各部分之间的通信,都是双向的\n2. View和Model不发生联系,都通过Presenter传递\n3. View非常薄,不部署任何业务逻辑,称为\"被动视图\"(Passive View),即没有任何主动性,而Presenter非常厚,所有逻辑都部署在那里。\n\n\n#MVVM\n\nMVVM模式将Presenter改名为ViewModel,基本上与MVP模式完全一致。\n\n唯一的区别是,它采用双向绑定(data-binding):View的变动,自动反映在ViewModel,反之亦然。\n\n\n\n\n\n"
},
{
"path": "Part1/Android/MVP.md",
"content": "#MVP\n---\n###为什么需要MVP\n\n1. 尽量简单\n\t大部分的安卓应用只使用View-Model结构,程序员现在更多的是和复杂的View打交道而不是解决业务逻辑。当你在应用中只使用Model-View时,到最后,你会发现“所有的事物都被连接到一起”。复杂的任务被分成细小的任务,并且很容易解决。越小的东西,bug越少,越容易debug,更好测试。在MVP模式下的View层将会变得简单,所以即便是他请求数据的时候也不需要回调函数。View逻辑变成十分直接。\n2. 后台任务\n\t当你编写一个Actviity、Fragment、自定义View的时候,你会把所有的和后台任务相关的方法写在一个静态类或者外部类中。这样,你的Task不再和Activity联系在一起,这既不会导致内存泄露,也不依赖于Activity的重建。\n\t\n###优缺点\n\n优点:\n\n1. 降低耦合度,实现了Model和View真正的完全分离,可以修改View而不影响Modle\n2. 模块职责划分明显,层次清晰\n3. 隐藏数据\n4. Presenter可以复用,一个Presenter可以用于多个View,而不需要更改Presenter的逻辑(当然是在View的改动不影响业务逻辑的前提下)\n5. 利于测试驱动开发。以前的Android开发是难以进行单元测试的(虽然很多Android开发者都没有写过测试用例,但是随着项目变得越来越复杂,没有测试是很难保证软件质量的;而且近几年来Android上的测试框架已经有了长足的发展——开始写测试用例吧),在使用MVP的项目中Presenter对View是通过接口进行,在对Presenter进行不依赖UI环境的单元测试的时候。可以通过Mock一个View对象,这个对象只需要实现了View的接口即可。然后依赖注入到Presenter中,单元测试的时候就可以完整的测试Presenter应用逻辑的正确性。\n6. View可以进行组件化。在MVP当中,View不依赖Model。这样就可以让View从特定的业务场景中脱离出来,可以说View可以做到对业务完全无知。它只需要提供一系列接口提供给上层操作。这样就可以做到高度可复用的View组件。\n7. 代码灵活性\n\n缺点:\n\n1. Presenter中除了应用逻辑以外,还有大量的View->Model,Model->View的手动同步逻辑,造成Presenter比较笨重,维护起来会比较困难。\n2. 由于对视图的渲染放在了Presenter中,所以视图和Presenter的交互会过于频繁。\n3. 如果Presenter过多地渲染了视图,往往会使得它与特定的视图的联系过于紧密。一旦视图需要变更,那么Presenter也需要变更了。\n4. 额外的代码复杂度及学习成本。\n\n**在MVP模式里通常包含4个要素:**\n\n1. View :负责绘制UI元素、与用户进行交互(在Android中体现为Activity);\n2. View interface :需要View实现的接口,View通过View interface与Presenter进行交互,降低耦合,方便进行单元测试;\n3. Model :负责存储、检索、操纵数据(有时也实现一个Model interface用来降低耦合);\n4. Presenter :作为View与Model交互的中间纽带,处理与用户交互的负责逻辑。"
},
{
"path": "Part1/Android/Recyclerview和Listview的异同.md",
"content": "#RecyclerView和ListView的异同\n---\n\n* ViewHolder是用来保存视图引用的类,无论是ListView亦或是RecyclerView。只不过在ListView中,ViewHolder需要自己来定义,且这只是一种推荐的使用方式,不使用当然也可以,这不是必须的。只不过不使用ViewHolder的话,ListView每次getView的时候都会调用findViewById(int),这将导致ListView性能展示迟缓。而在RecyclerView中使用RecyclerView.ViewHolder则变成了必须,尽管实现起来稍显复杂,但它却解决了ListView面临的上述不使用自定义ViewHolder时所面临的问题。\n* 我们知道ListView只能在垂直方向上滚动,Android API没有提供ListView在水平方向上面滚动的支持。或许有多种方式实现水平滑动,但是请想念我,ListView并不是设计来做这件事情的。但是RecyclerView相较于ListView,在滚动上面的功能扩展了许多。它可以支持多种类型列表的展示要求,主要如下:\n\n\t1. LinearLayoutManager,可以支持水平和竖直方向上滚动的列表。\n\t2. StaggeredGridLayoutManager,可以支持交叉网格风格的列表,类似于瀑布流或者Pinterest。\n\t3. GridLayoutManager,支持网格展示,可以水平或者竖直滚动,如展示图片的画廊。\n\n* 列表动画是一个全新的、拥有无限可能的维度。起初的Android API中,删除或添加item时,item是无法产生动画效果的。后面随着Android的进化,Google的Chat Hasse推荐使用ViewPropertyAnimator属性动画来实现上述需求。\n相比较于ListView,RecyclerView.ItemAnimator则被提供用于在RecyclerView添加、删除或移动item时处理动画效果。同时,如果你比较懒,不想自定义ItemAnimator,你还可以使用DefaultItemAnimator。\n\n* ListView的Adapter中,getView是最重要的方法,它将视图跟position绑定起来,是所有神奇的事情发生的地方。同时我们也能够通过registerDataObserver在Adapter中注册一个观察者。RecyclerView也有这个特性,RecyclerView.AdapterDataObserver就是这个观察者。ListView有三个Adapter的默认实现,分别是ArrayAdapter、CursorAdapter和SimpleCursorAdapter。然而,RecyclerView的Adapter则拥有除了内置的内DB游标和ArrayList的支持之外的所有功能。RecyclerView.Adapter的实现的,我们必须采取措施将数据提供给Adapter,正如BaseAdapter对ListView所做的那样。\n* 在ListView中如果我们想要在item之间添加间隔符,我们只需要在布局文件中对ListView添加如下属性即可:\n\n\t```\n\t android:divider=\"@android:color/transparent\"\n\t android:dividerHeight=\"5dp\"\n\t```\n* ListView通过AdapterView.OnItemClickListener接口来探测点击事件。而RecyclerView则通过RecyclerView.OnItemTouchListener接口来探测触摸事件。它虽然增加了实现的难度,但是却给予开发人员拦截触摸事件更多的控制权限。\n* ListView可以设置选择模式,并添加MultiChoiceModeListener,如下所示:\n\n\t```\n\tlistView.setChoiceMode(ListView.CHOICE_MODE_MULTIPLE_MODAL);\nlistView.setMultiChoiceModeListener(new MultiChoiceModeListener() {\n public boolean onCreateActionMode(ActionMode mode, Menu menu) { ... }\n public void onItemCheckedStateChanged(ActionMode mode, int position,\nlong id, boolean checked) { ... }\n public boolean onActionItemClicked(ActionMode mode, MenuItem item) {\n switch (item.getItemId()) {\n case R.id.menu_item_delete_crime:\n CrimeAdapter adapter = (CrimeAdapter)getListAdapter();\n CrimeLab crimeLab = CrimeLab.get(getActivity());\n for (int i = adapter.getCount() - 1; i >= 0; i--) {\n if (getListView().isItemChecked(i)) {\n crimeLab.deleteCrime(adapter.getItem(i));\n }\n }\n mode.finish();\n adapter.notifyDataSetChanged();\n return true;\n default:\n return false;\n}\n public boolean onPrepareActionMode(ActionMode mode, Menu menu) { ... }\n public void onDestroyActionMode(ActionMode mode) { ... }\n});\n\t```\n\t而RecyclerView则没有此功能。\n\t\n[http://www.cnblogs.com/littlepanpc/p/4497290.html](http://www.cnblogs.com/littlepanpc/p/4497290.html)"
},
{
"path": "Part1/Android/SurfaceView.md",
"content": "##为什么要使用SurfaceView来实现动画?\n###因为View的绘图存在以下缺陷:\n1. View缺乏双缓冲机制\n2. 当程序需要更新View上的图像时,程序必须重绘View上显示的整张图片\n3. 新线程无法直接更新View组件\n\n\n\n##SurfaceView的绘图机制\n* 一般会与SurfaceView结合使用\n* 调用SurfaceView的getHolder()方法即可获得SurfaceView关联的SurfaceHolder\n\n##SurfaceHolder提供了如下方法来获取Canvas对象\n1. Canvas lockCanvas():锁定整个SurfaceView对象,获取该Surface上的Canvas\n2. Canvas lockCanvas(Rect dirty):锁定SurfaceView上Rect划分的区域,获取该Surface上的Canvas\n3. unlockCanvasAndPost(canvas):释放绘图、提交所绘制的图形,需要注意,当调用SurfaceHolder上的unlockCanvasAndPost方法之后,该方法之前所绘制的图形还处于缓冲之中,下一次lockCanvas()方法锁定的区域可能会“遮挡”它\n\n\n```\n\n\tpublic class SurfaceViewTest extends Activity\n{\n\t// SurfaceHolder负责维护SurfaceView上绘制的内容\n\tprivate SurfaceHolder holder;\n\tprivate Paint paint;\n\n\t@Override\n\tpublic void onCreate(Bundle savedInstanceState)\n\t{\n\t\tsuper.onCreate(savedInstanceState);\n\t\tsetContentView(R.layout.main);\n\t\tpaint = new Paint();\n\t\tSurfaceView surface = (SurfaceView) findViewById(R.id.show);\n\t\t// 初始化SurfaceHolder对象\n\t\tholder = surface.getHolder();\n\t\tholder.addCallback(new Callback()\n\t\t{\n\t\t\t@Override\n\t\t\tpublic void surfaceChanged(SurfaceHolder arg0, int arg1, int arg2,\n\t\t\t\t\tint arg3)\n\t\t\t{\n\t\t\t}\n\n\t\t\t@Override\n\t\t\tpublic void surfaceCreated(SurfaceHolder holder)\n\t\t\t{\n\t\t\t\t// 锁定整个SurfaceView\n\t\t\t\tCanvas canvas = holder.lockCanvas();\n\t\t\t\t// 绘制背景\n\t\t\t\tBitmap back = BitmapFactory.decodeResource(\n\t\t\t\t\tSurfaceViewTest.this.getResources()\n\t\t\t\t\t, R.drawable.sun);\n\t\t\t\t// 绘制背景\n\t\t\t\tcanvas.drawBitmap(back, 0, 0, null);\n\t\t\t\t// 绘制完成,释放画布,提交修改\n\t\t\t\tholder.unlockCanvasAndPost(canvas);\n\t\t\t\t// 重新锁一次,\"持久化\"上次所绘制的内容\n\t\t\t\tholder.lockCanvas(new Rect(0, 0, 0, 0));\n\t\t\t\tholder.unlockCanvasAndPost(canvas);\n\t\t\t}\n\n\t\t\t@Override\n\t\t\tpublic void surfaceDestroyed(SurfaceHolder holder)\n\t\t\t{\n\t\t\t}\n\t\t});\n\t\t// 为surface的触摸事件绑定监听器\n\t\tsurface.setOnTouchListener(new OnTouchListener()\n\t\t{\n\t\t\t@Override\n\t\t\tpublic boolean onTouch(View source, MotionEvent event)\n\t\t\t{\n\t\t\t\t// 只处理按下事件\n\t\t\t\tif (event.getAction() == MotionEvent.ACTION_DOWN)\n\t\t\t\t{\n\t\t\t\t\tint cx = (int) event.getX();\n\t\t\t\t\tint cy = (int) event.getY();\n\t\t\t\t\t// 锁定SurfaceView的局部区域,只更新局部内容\n\t\t\t\t\tCanvas canvas = holder.lockCanvas(new Rect(cx - 50,\n\t\t\t\t\t\t\tcy - 50, cx + 50, cy + 50));\n\t\t\t\t\t// 保存canvas的当前状态\n\t\t\t\t\tcanvas.save();\n\t\t\t\t\t// 旋转画布\n\t\t\t\t\tcanvas.rotate(30, cx, cy);\n\t\t\t\t\tpaint.setColor(Color.RED);\n\t\t\t\t\t// 绘制红色方块\n\t\t\t\t\tcanvas.drawRect(cx - 40, cy - 40, cx, cy, paint);\n\t\t\t\t\t// 恢复Canvas之前的保存状态\n\t\t\t\t\tcanvas.restore();\n\t\t\t\t\tpaint.setColor(Color.GREEN);\n\t\t\t\t\t// 绘制绿色方块\n\t\t\t\t\tcanvas.drawRect(cx, cy, cx + 40, cy + 40, paint);\n\t\t\t\t\t// 绘制完成,释放画布,提交修改\n\t\t\t\t\tholder.unlockCanvasAndPost(canvas);\n\t\t\t\t}\n\t\t\t\treturn false;\n\t\t\t}\n\t\t});\n\t}\n\t}\n\t\n ```\n\n上面的程序为SurfaceHolder添加了一个CallBack实例,该Callback中定义了如下三个方法:\n\n* void surfaceChanged(SurfaceHolder holder, int format, int width, int height):当一个surface的格式或大小发生改变时回调该方法。\n* void surfaceCreated(SurfaceHolder holder):当surface被创建时回调该方法\n* void surfaceDestroyed(SurfaceHolder holder):当surface将要被销毁时回调该方法\n\n\n\n\n"
},
{
"path": "Part1/Android/Zygote和System进程的启动过程.md",
"content": "#Zygote和System进程的启动过程\n---\n\n##init脚本的启动\n---\n\n```\n+------------+ +-------+ +-----------+\n|Linux Kernel+--> |init.rc+-> |app_process|\n+------------+ +-------+ +-----------+\n create and public \n server socket\n```\n\nlinux内核加载完成后,运行init.rc脚本\n\n```\nservice zygote /system/bin/app_process -Xzygote /system/bin --zygote --start-system-server socket zygote stream 666\n```\n\n* /system/bin/app_process Zygote服务启动的进程名\n* --start-system-server 表明Zygote启动完成之后,要启动System进程。\n* socket zygote stream 666 在Zygote启动时,创建一个权限为666的socket。此socket用来请求Zygote创建新进程。socket的fd保存在名称为“ANDROID_SOCKET_zygote”的环境变量中。\n\n##Zygote进程的启动过程\n---\n\n```\n create rumtime \n +-----------+ +----------+ \n |app_process+----------> |ZygoteInit| \n +-----------+ +-----+----+ \n | \n | \n | registerZygoteSocket()\n | \n +------+ startSystemServer() | \n |System| <-------+ | \n +------+ fork | runSelectLoopMode() \n | \n v \n```\n\n**app_process进程**\n\n---\n\n/system/bin/app_process 启动时创建了一个AppRuntime对象。通过AppRuntime对象的start方法,通过JNI调用创建了一个虚拟机实例,然后运行com.android.internal.os.ZygoteInit类的静态main方法,传递true(boolean startSystemServer)参数。\n\n**ZygoteInit类**\n\n---\n\nZygoteInit类的main方法运行时,会通过registerZygoteSocket方法创建一个供ActivityManagerService使用的server socket。然后通过调用startSystemServer方法来启动System进程。最后通过runSelectLoopMode来等待AMS的新建进程请求。\n\n1. 在registerZygoteSocket方法中,通过名为ANDROID_SOCKET_zygote的环境获取到zygote启动时创建的socket的fd,然后以此来创建server socket。\n2. 在startSystemServer方法中,通过Zygote.forkSystemServer方法创建了一个子进程,并将其用户和用户组的ID设置为1000。\n3. 在runSelectLoopMode方法中,会将之前建立的server socket保存起来。然后进入一个无限循环,在其中通过selectReadable方法,监听socket是否有数据可读。有数据则说明接收到了一个请求。\nselectReadable方法会返回一个整数值index。如果index为0,则说明这个是AMS发过来的连接请求。这时会与AMS建立一个新的socket连接,并包装成ZygoteConnection对象保存起来。如果index大于0,则说明这是AMS发过来的一个创建新进程的请求。此时会取出之前保存的ZygoteConnection对象,调用其中的runOnce方法创建新进程。调用完成后将connection删除。\n这就是Zygote处理一次AMS请求的过程。\n\n##System进程的启动\n---\n\n```\n + \n | \n | \n v fork() \n +--------------+ \n |System Process| \n +------+-------+ \n | \n | RuntimeInit.zygoteInit() commonInit, zygoteInitNative \n | init1() SurfaceFlinger, SensorServic... \n | \n | \n | init2() +------------+ \n +-------> |ServerThread| \n | +----+-------+ \n | | \n | | AMS, PMS, WMS... \n | | \n | | \n | | \n v v \n```\n\nSystem进程是在ZygoteInit的handleSystemServerProcess中开始启动的。\n\n1. 首先,因为System进程是直接fork Zygote进程的,所以要先通过closeServerSocket方法关掉server socket。\n2. 调用RuntimeInit.zygoteInit方法进一步启动System进程。在zygoteInit中,通过commonInit方法设置时区和键盘布局等通用信息,然后通过zygoteInitNative方法启动了一个Binder线程池。最后通过invokeStaticMain方法调用SystemServer类的静态Main方法。\n3. SystemServer类的main通过JNI调用cpp实现的init1方法。在init1方法中,会启动各种以C++开发的系统服务(例如SurfaceFlinger和SensorService)。然后回调ServerServer类的init2方法来启动以Java开发的系统服务。\n4. 在init2方法中,首先会新建名为\"android.server.ServerThread\"的ServerThread线程,并调用其start方法。然后在该线程中启动各种Service(例如AMS,PMS,WMS等)。启动的方式是调用对应Service类的静态main方法。\n5. 首先,AMS会被创建,但未注册到ServerManager中。然后PMS被创建,AMS这时候才注册到ServerManager中。然后到ContentService、WMS等。\n注册到ServerManager中时会制定Service的名字,其后其他进程可以通过这个名字来获取到Binder Proxy对象,以访问Service提供的服务。\n6. 执行到这里,System就将系统的关键服务启动起来了,这时候其他进程便可利用这些Service提供的基础服务了。\n7. 最后会调用ActivityManagerService的systemReady方法,在该方法里会启动系统界面以及Home程序。\n\n##Android进程启动\n\n---\n\n```\n +----------------------+ +-------+ +----------+ +----------------+ +-----------+ \n |ActivityManagerService| |Process| |ZygoteInit| |ZygoteConnection| |RuntimeInit| \n +--------------+-------+ +---+---+ +-----+----+ +-----------+----+ +------+----+ \n | | | | | \n | | | | | \n startProcessLocked() | | | | \n+---------------> | | | | | \n | start() | | | | \n | \"android.app.ActivityThread\" | | | \n +-----------------> | | | | \n | | | | | \n | | | | | \n | |openZygoteSocketIfNeeded() | | \n | +------+ | | | \n | | | | | | \n | | <----+ | | | \n | | | | | \n | |sZygoteWriter.write(arg) | | \n | +------+ | | | \n | | | | | | \n | | | | | | \n | | <----+ | | | \n | | | | | \n | +--------------> | | | \n | | | | | \n | | |runSelectLoopMode() | | \n | | +-----------------+ | | \n | | | | | | \n | | | <---------------+ | | \n | | | acceptCommandPeer() | \n | | | | | \n | | | | | \n | | | runOnce() | | \n | | +------------------> | | \n | | | |forkAndSpecialize() \n | | | +-------------+ | \n | | | | | | \n | | | | <-----------+ | \n | | | | handleChildProc() \n | | | | | \n | | | | | \n | | | | | \n | | | | zygoteInit() | \n | | | +-------------> | \n | | | | | \n | | | | |in^okeStaticMain() \n | | | | +----------------> \n | | | | |(\"android.app.ActivityThread\")\n | | | | | \n | | | | | \n + + + + + \n```\n\n* AMS向Zygote发起请求(通过之前保存的socket),携带各种参数,包括“android.app.ActivityThread”。\n* Zygote进程fork自己,然后在新Zygote进程中调用RuntimeInit.zygoteInit方法进行一系列的初始化(commonInit、Binder线程池初始化等)。\n* 新Zygote进程中调用ActivityThread的main函数,并启动消息循环。"
},
{
"path": "Part1/Android/事件分发机制.md",
"content": "# 事件分发机制\n---\n\n\n* 对于一个根ViewGroup来说,发生点击事件首先调用dispatchTouchEvent\n* 如果这个ViewGroup的onIterceptTouchEvent返回true就表示它要拦截当前事件,接着这个ViewGroup的onTouchEvent就会被调用.如果onIterceptTouchEvent返回false,那么就会继续向下调用子View的dispatchTouchEvent方法\n* 当一个View需要处理事件的时候,如果它没有设置onTouchListener,那么直接调用onTouchEvent.如果设置了Listenter 那么就要看Listener的onTouch方法返回值.为true就不调,为false就调onTouchEvent\n* View的默认实现会在onTouchEvent里面把touch事件解析成Click之类的事件\n* 点击事件传递顺序 Activity -> Window -> View\n* 一旦一个元素拦截了某事件,那么一个事件序列里面后续的Move,Down事件都会交给它处理.并且它的onInterceptTouchEvent不会再调用\n* View的onTouchEvent默认都会消耗事件,除非它的clickable和longClickable都是false(不可点击),但是enable属性不会影响"
},
{
"path": "Part1/Android/开源框架源码分析.md",
"content": "#框架源码分析\n---\n\n###Retrofit\n---\n\n\n###EventBus\n---\n\n###Glide\n---\n\n"
},
{
"path": "Part1/Android/插件化技术学习.md",
"content": "###Android动态加载dex技术初探\n\n[http://blog.csdn.net/u013478336/article/details/50734108](http://blog.csdn.net/u013478336/article/details/50734108)\n\nAndroid使用Dalvik虚拟机加载可执行程序,所以不能直接加载基于class的jar,而是需要将class转化为dex字节码。\n\nAndroid支持动态加载的两种方式是:DexClassLoader和PathClassLoader,DexClassLoader可加载jar/apk/dex,且支持从SD卡加载;PathClassLoader据说只能加载已经安装在Android系统内APK文件。\n\n###Android插件化基础\n\nAndroid简单来说就是如下操作:\n\n* 开发者将插件代码封装成Jar或者APK\n* 宿主下载或者从本地加载Jar或者APK到宿主中\n* 将宿主调用插件中的算法或者Android特定的Class(如Activity)\n\n###插件化开发—动态加载技术加载已安装和未安装的apk\n\n[http://blog.csdn.net/u010687392/article/details/47121729?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io](http://blog.csdn.net/u010687392/article/details/47121729?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io)\n为什么引入动态加载技术?\n\n* 一个应用程序dex文件的方法数最大不能超过65536个\n* 可以让应用程序实现插件化、插拔式结构,对后期维护有益\n\n什么是动态加载技术\n\n动态加载技术就是使用类加载器加载相应的apk、dex、jar(必须含有dex文件),再通过反射获得该apk、dex、jar内部的资源(class、图片、color等等)进而供宿主app使用。\n\n关于动态加载使用的类加载器\n\n* PathClassLoader - 只能加载已经安装的apk,即/data/app目录下的apk。\n* DexClassLoader - 能加载手机中未安装的apk、jar、dex,只要能在找到对应的路径。\n\n\n\n\n\n\n\n\n\n#插件化技术学习\n---\n原因:\n\n各大厂商都碰到了AndroidNative平台的瓶颈:\n\n1. 从技术上讲,业务逻辑的复杂代码急剧膨胀,各大厂商陆续触到65535方法数的天花板;同时,对模块热更新提出了更高的要求。\n2. 在业务层面上,功能模块的解耦以及维护团队的分离也是大势所趋。\n\n插件化技术主要解决两个问题:\n\n1. 代码加载\n2. 资源加载\n\n###代码加载\n类的加载可以使用Java的ClassLoader机制,还需要组件生命周期管理。\n\n###资源加载\n用AssetManager的隐藏方法addAssetPath。\n\n##Android插件化原理解析——Hook机制之动态代理 \n\n使用代理机制进行API Hook进而达到方法增强。\n\n静态代理\n\n动态代理:可以简单理解为JVM可以在运行时帮我们动态生成一系列的代理类。\n\n###代理Hook\n\n如果我们自己创建代理对象,然后把原始对象替换为我们的代理对象,就可以在这个代理对象中为所欲为了;修改参数,替换返回值,称之为Hook。\n\n整个Hook过程简要总结如下:\n\n1. 寻找Hook点,原则是静态变量或者单例对象,尽量Hook public的对象和方法,非public不保证每个版本都一样,需要适配。\n2. 选择合适的代理方式,如果是接口可以用动态代理;如果是类可以手动写代理也可以使用cglib。\n3. 偷梁换柱-用代理对象替换原始对象\n\n##Android插件化原理解析——Hook机制之Binder Hook \n\n\n\n\n\n"
},
{
"path": "Part1/Android/查漏补缺.md",
"content": "#查漏补缺\n---\n\n请分析一张400*500尺寸的PNG图片加载到程序中占用内存中的大小\n\n[http://m.blog.csdn.net/article/details?id=7856519](http://m.blog.csdn.net/article/details?id=7856519)\n"
},
{
"path": "Part1/Android/热修复技术.md",
"content": "#热修复技术\n---\n\nAPP提早发出去的包,如果出现客户端的问题,实在是干着急,覆水难收。因此线上修复方案迫在眉睫。\n\n###概述\n\n基于Xposed中的思想,通过修改c层的Method实例描述,来实现更改与之对应的java方法的行为,从而达到修复的目的。\n\n###Xposed\n\n诞生于XDA论坛,类似一个应用平台,不同的是其提供诸多系统级的应用。可实现许多神奇的功能。Xposed需要以越狱为前提,像是iOS中的cydia。\n\nXposed可以修改任何程序的任何java方法(需root),github上提供了XposedInstaller,是一个android app。提供很多framework层,应用层级的程序。开发者可以为其开发一些系统或应用方面的插件,自定义android系统,它甚至可以做动态权限管理(XposedMods)。\n\n###Android系统启动与应用启动\n\nZygote进程是Android手机系统启动后,常驻的一个名为‘受精卵’的进程。\n\n* zygote的启动实现脚本在/init.rc文件中\n* 启动过程中执行的二进制文件在/system/bin/app_process\n\n任何应用程序启动时,会从zygote进程fork出一个新的进程。并装载一些必要的class,invoke一些初始化方法。这其中包括像:\n\n* ActivityThread\n* ServiceThread\n* ApplicationPackageManager\n\n等应用启动中必要的类,触发必要的方法,比如:handleBindApplication,将此进程与对应的应用绑定的初始化方法;同时,会将zygote进程中的dalvik虚拟机实例复制一份,因此每个应用程序进程都有自己的dalvik虚拟机实例;会将已有Java运行时加载到进程中;会注册一些android核心类的jni方法到虚拟机中,支撑从c到java的启动过程。\n\n###Xposed做了手脚\n\nXposed在这个过程改写了app_process(源码在Xposed : a modified app_process binary),替换/system/bin/app_process这个二进制文件。然后做了两个事:\n\n1. 通过Xposed的hook技术,在上述过程中,对上面提到的那些加载的类的方法hook。\n2. 加载XposedBridge.jar\n\n这时hook必要的方法是为了方便开发者为它开发插件,加载XposedBridge.jar是为动态hook提供了基础。在这个时候加载它意味着,所有的程序在启动时,都可以加载这个jar(因为上面提到的fork过程)。结合hook技术,从而达到了控制所有程序的所有方法。\n\n为获得/system/bin/目录的读写权限,因而需要以root为前提。\n\n###Xposed的hook思想\n\n那么Xposed是怎么hook java方法的呢?要从XposedBridge看起,重点在\nXposedBridge.hookmethod(原方法的Member对象,含有新方法的XC_MethodHook对象);,这里会调到\n\n```\nprivate native synchronized static void hookMethodNative(Member method, Class declaringClass, int slot, Object additionalInfo);\n```\n\n这个native的方法,通过这个方法,可以让所hook的方法,转向native层的一个c方法。如何做到?\n\n```\nWhen a transmit from java to native occurs, dvm sets up a native stack.\nIn dvmCallJNIMethod(), dvmPlatformInvoke is used to call the native method(signature in Method.insns).\n```\n\n在jni这个中间世界里,类型数据由jni表来沟通java和c的世界;方法由c++指针结合DVM*系(如dvmSlotToMethod,dvmDecodeIndirectRef等方法)的api方法,操作虚拟机,从而实现java方法与c方法的世界。\n\n那么hook的过程是这样:首先通过dexclassload来load所要hook的方法,分析类后,进c层,见代码XposedBridge_hookMethodNative方法,拿到要hook的Method类,然后通过dvmslotTomethod方法获取Method*指针,\n\n```\nMethod* method = dvmSlotToMethod(declaredClass, slot);\n```\n\ndeclaredClass就是所hook方法所在的类,对应的jobject。slot是Method类中,描述此java对象在vm中的索引;那么通过这个方法,我们就获取了c层的Method指针,通过\n\n```\nSET_METHOD_FLAG(method, ACC_NATIVE);\n```\n\n将该方法标记为一个native方法,然后通过\n\n```\nmethod->nativeFunc = &hookedMethodCallback;\n```\n\n定向c层方法到hookedMethodCallback,这样当被hook的java方法执行时,就会调到c层的hookedMethodCallback方法。\n\n通过meth->nativeFunc重定向MethodCallBridge到hookedMethodCallback这个方法上,控制这个c++指针是无视java的private的。\n\n另外,在method结构体中有\n\n```\nmethod->insns = (const u2*) hookInfo;\n```\n\n用insns指向替换成为的方法,以便hookedMethodCallback可以获取真正期望执行的java方法。\n\n现在所有被hook的方法,都指向了hookedMethodCallbackc方法中,然后在此方法中实现调用替换成为的java方法。\n\n###从Xposed提炼精髓\n\n回顾Xposed,以root为必要条件,在app_process加载XposedBidge.jar,从而实现有hook所有应用的所有方法的能力;而后续动态hook应用内的方法,其实只是load了从zypote进程复制出来的运行时的这个XposedBidge.jar,然后hook而已。因此,若在一个应用范围内的hook,root不是必须的,只是单纯的加载hook的实现方法,即可修改本应用的方法。\n\n\n\n业界内也不乏通过「修改BaseDexClassLoader中的pathList,来动态加载dex」方式实现热修复。后者纯java实现,但需要hack类的优化流程,将打CLASS_ISPREVERIFIED标签的类,去除此标签,以解决类与类引用不在一个dex中的异常问题。这会放弃dex optimize对启动运行速度的优化。原则上,这对于方法数没有大到需要multidex的应用,损失更明显。而前者不触犯原有的优化流程,只点杀需要hook的方法,更为纯粹、有效。\n\n\n\n\n"
},
{
"path": "Part1/Android/线程通信基础流程分析.md",
"content": "> 老司机们都知道,Android的线程间通信就靠Handler、Looper、Message、MessageQueue这四个麻瓜兄弟了,那么,他们是怎么运作的呢?下面做一个基于主要源代码的大学生水平的分析。 [原文链接](http://anangryant.leanote.com/post/Handler%E3%80%81Looper%E3%80%81Message%E3%80%81MessageQueue%E5%88%86%E6%9E%90)\n\n##Looper(先分析这个是因为能够引出四者的关系)\n在Looper中,维持一个`Thread`对象以及`MessageQueue`,通过Looper的构造函数我们可以知道:\n```\n private Looper(boolean quitAllowed) {\n mQueue = new MessageQueue(quitAllowed);//传入的参数代表这个Queue是否能够被退出\n mThread = Thread.currentThread();\n }\n```\n`Looper`在构造函数里干了两件事情:\n1. 将线程对象指向了创建`Looper`的线程\n2. 创建了一个新的`MessageQueue`\n\n分析完构造函数之后,接下来我们主要分析两个方法:\n1. `looper.loop()`\n2. `looper.prepare()`\n\n###looper.loop()(在当前线程启动一个Message loop机制,此段代码将直接分析出Looper、Handler、Message、MessageQueue的关系)\n```\n public static void loop() {\n final Looper me = myLooper();//获得当前线程绑定的Looper\n if (me == null) {\n throw new RuntimeException(\"No Looper; Looper.prepare() wasn't called on this thread.\");\n }\n final MessageQueue queue = me.mQueue;//获得与Looper绑定的MessageQueue\n\n // Make sure the identity of this thread is that of the local process,\n // and keep track of what that identity token actually is.\n Binder.clearCallingIdentity();\n final long ident = Binder.clearCallingIdentity();\n \n //进入死循环,不断地去取对象,分发对象到Handler中消费\n for (;;) {\n Message msg = queue.next(); // 不断的取下一个Message对象,在这里可能会造成堵塞。\n if (msg == null) {\n // No message indicates that the message queue is quitting.\n return;\n }\n\n // This must be in a local variable, in case a UI event sets the logger\n Printer logging = me.mLogging;\n if (logging != null) {\n logging.println(\">>>>> Dispatching to \" + msg.target + \" \" +\n msg.callback + \": \" + msg.what);\n }\n \n //在这里,开始分发Message了\n //至于这个target是神马?什么时候被赋值的? \n //我们一会分析Handler的时候就会讲到\n msg.target.dispatchMessage(msg);\n\n if (logging != null) {\n logging.println(\"<<<<< Finished to \" + msg.target + \" \" + msg.callback);\n }\n\n // Make sure that during the course of dispatching the\n // identity of the thread wasn't corrupted.\n final long newIdent = Binder.clearCallingIdentity();\n if (ident != newIdent) {\n Log.wtf(TAG, \"Thread identity changed from 0x\"\n + Long.toHexString(ident) + \" to 0x\"\n + Long.toHexString(newIdent) + \" while dispatching to \"\n + msg.target.getClass().getName() + \" \"\n + msg.callback + \" what=\" + msg.what);\n }\n \n //当分发完Message之后,当然要标记将该Message标记为 *正在使用* 啦\n msg.recycleUnchecked();\n }\n }\n```\n*分析了上面的源代码,我们可以意识到,最重要的方法是:*\n1. `queue.next()`\n2. `msg.target.dispatchMessage(msg)`\n3. `msg.recycleUnchecked()`\n\n其实Looper中最重要的部分都是由`Message`、`MessageQueue`组成的有木有!这段最重要的代码中涉及到了四个对象,他们与彼此的关系如下:\n1. `MessageQueue`:装食物的容器\n2. `Message`:被装的食物\n3. `Handler`(msg.target实际上就是`Handler`):食物的消费者\n4. `Looper`:负责分发食物的人\n\n\n###looper.prepare()(在当前线程关联一个Looper对象)\n```\n private static void prepare(boolean quitAllowed) {\n if (sThreadLocal.get() != null) {\n throw new RuntimeException(\"Only one Looper may be created per thread\");\n }\n //在当前线程绑定一个Looper\n sThreadLocal.set(new Looper(quitAllowed));\n }\n```\n以上代码只做了两件事情:\n1. 判断当前线程有木有`Looper`,如果有则抛出异常(在这里我们就可以知道,Android规定一个线程只能够拥有一个与自己关联的`Looper`)。\n2. 如果没有的话,那么就设置一个新的`Looper`到当前线程。\n\n--------------\n##Handler\n由于我们使用Handler的通常性的第一步是:\n```\n Handler handler = new Handler(){\n //你们有没有很好奇这个方法是在哪里被回调的?\n //我也是!所以接下来会分析到哟!\n @Override\n public void handleMessage(Message msg) {\n //Handler your Message\n }\n };\n```\n所以我们先来分析`Handler`的构造方法\n```\n//空参数的构造方法与之对应,这里只给出主要的代码,具体大家可以到源码中查看\npublic Handler(Callback callback, boolean async) {\n //打印内存泄露提醒log\n ....\n \n //获取与创建Handler线程绑定的Looper\n mLooper = Looper.myLooper();\n if (mLooper == null) {\n throw new RuntimeException(\n \"Can't create handler inside thread that has not called Looper.prepare()\");\n }\n //获取与Looper绑定的MessageQueue\n //因为一个Looper就只有一个MessageQueue,也就是与当前线程绑定的MessageQueue\n mQueue = mLooper.mQueue;\n mCallback = callback;\n mAsynchronous = async;\n \n }\n```\n*带上问题:*\n1. `Looper.loop()`死循环中的`msg.target`是什么时候被赋值的?\n2. `handler.handleMessage(msg)`在什么时候被回调的?\n\n###A1:`Looper.loop()`死循环中的`msg.target`是什么时候被赋值的?\n要分析这个问题,很自然的我们想到从发送消息开始,无论是`handler.sendMessage(msg)`还是`handler.sendEmptyMessage(what)`,我们最终都可以追溯到以下方法\n```\npublic boolean sendMessageAtTime(Message msg, long uptimeMillis) {\n //引用Handler中的MessageQueue\n //这个MessageQueue就是创建Looper时被创建的MessageQueue\n MessageQueue queue = mQueue;\n \n if (queue == null) {\n RuntimeException e = new RuntimeException(\n this + \" sendMessageAtTime() called with no mQueue\");\n Log.w(\"Looper\", e.getMessage(), e);\n return false;\n }\n //将新来的Message加入到MessageQueue中\n return enqueueMessage(queue, msg, uptimeMillis);\n }\n```\n\n我们接下来分析`enqueueMessage(queue, msg, uptimeMillis)`:\n```\nprivate boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {\n //显而易见,大写加粗的赋值啊!\n **msg.target = this;**\n if (mAsynchronous) {\n msg.setAsynchronous(true);\n }\n return queue.enqueueMessage(msg, uptimeMillis);\n }\n```\n\n\n###A2:`handler.handleMessage(msg)`在什么时候被回调的?\n通过以上的分析,我们很明确的知道`Message`中的`target`是在什么时候被赋值的了,我们先来分析在`Looper.loop()`中出现过的过的`dispatchMessage(msg)`方法\n\n```\npublic void dispatchMessage(Message msg) {\n if (msg.callback != null) {\n handleCallback(msg);\n } else {\n if (mCallback != null) {\n if (mCallback.handleMessage(msg)) {\n return;\n }\n }\n //看到这个大写加粗的方法调用没!\n **handleMessage(msg);**\n }\n }\n```\n\n加上以上分析,我们将之前分析结果串起来,就可以知道了某些东西:\n`Looper.loop()`不断地获取`MessageQueue`中的`Message`,然后调用与`Message`绑定的`Handler`对象的`dispatchMessage`方法,最后,我们看到了`handleMessage`就在`dispatchMessage`方法里被调用的。\n\n------------------\n通过以上的分析,我们可以很清晰的知道Handler、Looper、Message、MessageQueue这四者的关系以及如何合作的了。\n\n#总结:\n当我们调用`handler.sendMessage(msg)`方法发送一个`Message`时,实际上这个`Message`是发送到**与当前线程绑定**的一个`MessageQueue`中,然后**与当前线程绑定**的`Looper`将会不断的从`MessageQueue`中取出新的`Message`,调用`msg.target.dispathMessage(msg)`方法将消息分发到与`Message`绑定的`handler.handleMessage()`方法中。\n\n一个`Thread`对应多个`Handler`\n一个`Thread`对应一个`Looper`和`MessageQueue`,`Handler`与`Thread`共享`Looper`和`MessageQueue`。\n`Message`只是消息的载体,将会被发送到**与线程绑定的唯一的**`MessageQueue`中,并且被**与线程绑定的唯一的**`Looper`分发,被与其自身绑定的`Handler`消费。\n\n------\n- Enjoy Android :) 如果有误,轻喷,欢迎指正。\n\n\n\n"
},
{
"path": "Part1/Android/自定义控件.md",
"content": "#自定义控件\n---\n自定义View的步骤:\n\n- 自定义View的属性\n- 在View的构造方法中获得我们自定义View的步骤\n- [3.重写onMeasure](不必须)\n- 重写onDraw"
},
{
"path": "Part1/DesignPattern/Builder模式.md",
"content": "#Builder模式\n---\n\n##模式介绍\n---\n\n###模式的定义\n\n将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。\n\n###模式的使用场景\n\n1. 相同的方法,不同的执行顺序,产生不同的事件结果时;\n2. 多个部件或零件,都可以装配到一个对象中,但是产生的运行结果又不相同时;\n3. 产品类非常复杂,或者产品类中的调用顺序不同产生了不同的效能,这个时候使用建造者模式非常合适;\n\n\n###Android源码中的模式实现\n\n在Android源码中,我们最常用到的Builder模式就是AlertDialog.Builder, 使用该Builder来构建复杂的AlertDialog对象。简单示例如下 :\n\n```\n//显示基本的AlertDialog \n private void showDialog(Context context) { \n AlertDialog.Builder builder = new AlertDialog.Builder(context); \n builder.setIcon(R.drawable.icon); \n builder.setTitle(\"Title\"); \n builder.setMessage(\"Message\"); \n builder.setPositiveButton(\"Button1\", \n new DialogInterface.OnClickListener() { \n public void onClick(DialogInterface dialog, int whichButton) { \n setTitle(\"点击了对话框上的Button1\"); \n } \n }); \n builder.setNeutralButton(\"Button2\", \n new DialogInterface.OnClickListener() { \n public void onClick(DialogInterface dialog, int whichButton) { \n setTitle(\"点击了对话框上的Button2\"); \n } \n }); \n builder.setNegativeButton(\"Button3\", \n new DialogInterface.OnClickListener() { \n public void onClick(DialogInterface dialog, int whichButton) { \n setTitle(\"点击了对话框上的Button3\"); \n } \n }); \n builder.create().show(); // 构建AlertDialog, 并且显示\n } \n```\n\n##优点与缺点\n---\n\n###优点\n\n* 良好的封装性, 使用建造者模式可以使客户端不必知道产品内部组成的细节;\n* 建造者独立,容易扩展;\n* 在对象创建过程中会使用到系统中的一些其它对象,这些对象在产品对象的创建过程中不易得到。\n\n###缺点\n\n* 会产生多余的Builder对象以及Director对象,消耗内存;\n* 对象的构建过程暴露。"
},
{
"path": "Part1/DesignPattern/代理模式.md",
"content": "#代理模式\n---\n\n##模式介绍\n\n代理模式是对象的结构模式。代理模式给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用。\n\n##模式的使用场景\n\n就是一个人或者机构代表另一个人或者机构采取行动。在一些情况下,一个客户不想或者不能够直接引用一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。\n\n##角色介绍\n\n* 抽象对象角色:声明了目标对象和代理对象的共同接口,这样一来在任何可以使用目标对象的地方都可以使用代理对象。\n* 目标对象角色:定义了代理对象所代表的目标对象。\n* 代理对象角色:代理对象内部含有目标对象的引用,从而可以在任何时候操作目标对象;代理对象提供一个与目标对象相同的接口,以便可以在任何时候替代目标对象。代理对象通常在客户端调用传递给目标对象之前或之后,执行某个操作,而不是单纯地将调用传递给目标对象。\n\n##优点与缺点\n---\n\n优点\n\n给对象增加了本地化的扩展性,增加了存取操作控制\n\n缺点\n\n会产生多余的代理类"
},
{
"path": "Part1/DesignPattern/单例模式.md",
"content": "#单例模式\n---\n\n###定义\n>保证一个类仅有一个实例,并提供一个访问它的全局访问点。\n\n>Singleton:负责创建Singleton类自己的唯一实例,并提供一个getInstance的方法,让外部来访问这个类的唯一实例。\n\n\n* 饿汉式:\n\t```\n\tprivate static Singleton uniqueInstance = new Singleton();\n\t```\n* 懒汉式\n\t```\n\tprivate static Singleton uniqueInstance = null;\n\t```\n\n###功能\n单例模式是用来保证这个类在运行期间只会被创建一个类实例,另外,单例模式还提供了一个全局唯一访问这个类实例的访问点,就是getInstance方法。\n\n###范围\nJava里面实现的单例是一个虚拟机的范围。因为装载类的功能是虚拟机的,所以一个虚拟机在通过自己的ClassLoader装载饿汉式实现单例类的时候就会创建一个类的实例。\n\n懒汉式单例有延迟加载和缓存的思想\n\n###优缺点\n* 懒汉式是典型的时间换空间\n* 饿汉式是典型的空间换时间\n\n---\n* 不加同步的懒汉式是线程不安全的。比如,有两个线程,一个是线程A,一个是线程B,它们同时调用getInstance方法,就可能导致并发问题。\n\n* 饿汉式是线程安全的,因为虚拟机保证只会装载一次,在装载类的时候是不会发生并发的。\n\n---\n\n如何实现懒汉式的线程安全?\n\n加上synchronized即可\n\n```\npublic static synchronized Singleton getInstance(){}\n```\n\n但这样会降低整个访问的速度,而且每次都要判断。可以用双重检查加锁。\n\n双重加锁机制,指的是:并不是每次进入getInstance方法都需要同步,而是先不同步,进入方法过后,先检查实例是否存在,如果不存在才进入下面的同步块,这是第一重检查。进入同步块后,再次检查实例是否存在,如果不存在,就在同步的情况下创建一个实例。这是第二重检查。\n\n双重加锁机制的实现会使用一个关键字volatile,它的意思是:被volatile修饰的变量的值,将不会被本地线程缓存,所有对该变量的读写都是直接操作共享内存,从而确保多个线程能正确的处理该变量。\n\n```\n\n/**\n * 双重检查加锁的单例模式\n * @author dream\n *\n */\npublic class Singleton {\n\n\t/**\n\t * 对保存实例的变量添加volitile的修饰\n\t */\n\tprivate volatile static Singleton instance = null;\n\tprivate Singleton(){\n\t\t\n\t}\n\t\n\tpublic static Singleton getInstance(){\n\t\t//先检查实例是否存在,如果不存在才进入下面的同步块\n\t\tif(instance == null){\n\t\t\t//同步块,线程安全的创建实例\n\t\t\tsynchronized (Singleton.class) {\n\t\t\t\t//再次检查实例是否存在,如果不存在才真正的创建实例\n\t\t\t\tinstance = new Singleton();\n\t\t\t}\n\t\t}\n\t\treturn instance;\n\t}\n\t\n}\n\n```\n\n###一种更好的单例实现方式\n\n```\npublic class Singleton {\n\n\t/**\n\t * 类级的内部类,也就是静态类的成员式内部类,该内部类的实例与外部类的实例\n\t * 没有绑定关系,而且只有被调用时才会装载,从而实现了延迟加载\n\t * @author dream\n\t *\n\t */\n\tprivate static class SingletonHolder{\n\t\t/**\n\t\t * 静态初始化器,由JVM来保证线程安全\n\t\t */\n\t\tprivate static final Singleton instance = new Singleton();\n\t}\n\t\n\t/**\n\t * 私有化构造方法\n\t */\n\tprivate Singleton(){\n\t\t\n\t}\n\t\n\tpublic static Singleton getInstance(){\n\t\treturn SingletonHolder.instance;\n\t}\n}\n\n```\n\n根据《高效Java第二版》中的说法,单元素的枚举类型已经成为实现Singleton的最佳方法。\n\n```\npackage example6;\n\n/**\n * 使用枚举来实现单例模式的示例\n * @author dream\n *\n */\npublic class Singleton {\n\n\t/**\n\t * 定义一个枚举的元素,它就代表了Singleton的一个实例\n\t */\n\tuniqueInstance;\n\t\n\t/**\n\t * 示意方法,单例可以有自己的操作\n\t */\n\tpublic void singletonOperation(){\n\t\t//功能树立\n\t}\n}\n\n```\n---\n\n###本质\n控制实例数量\n\n###何时选用单例模式\n当需要控制一个类的实例只能有一个,而且客户只能从一个全局访问点访问它时,可以选用单例模式,这些功能恰好是单例模式要解决的问题。\n\n"
},
{
"path": "Part1/DesignPattern/原型模式.md",
"content": "#原型模式\n---\n\n##模式介绍 \n \n###模式的定义\n\n用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象。\n\n### 模式的使用场景\n\n1. 类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等,通过原型拷贝避免这些消耗;\n2. 通过 new 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式;\n3. 一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用,即保护性拷贝。\n\n##Android源码中的模式实现\n\nIntent中使用了原型模式\n\n```\nUri uri = Uri.parse(\"smsto:0800000123\"); \n Intent shareIntent = new Intent(Intent.ACTION_SENDTO, uri); \n shareIntent.putExtra(\"sms_body\", \"The SMS text\"); \n\n Intent intent = (Intent)shareIntent.clone() ;\n startActivity(intent);\n``` \n\n##优点与缺点\n\n###优点\n原型模式是在内存二进制流的拷贝,要比直接 new 一个对象性能好很多,特别是要在一个循环体内产生大量的对象时,原型模式可以更好地体现其优点。\n\n\n###缺点\n这既是它的优点也是缺点,直接在内存中拷贝,构造函数是不会执行的,在实际开发当中应该注意这个潜在的问题。优点就是减少了约束,缺点也是减少了约束,需要大家在实际应用时考虑。"
},
{
"path": "Part1/DesignPattern/外观模式.md",
"content": "#外观模式\n---\n\n###定义\n为子系统中的一组接口提供一个一致的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。\n\n###外观模式的目的\n\n不是给子系统添加新的功能接口,而是为了让外部减少与子系统内多个模块的交互,松散耦合,从而让外部能够更简单的使用子系统。\n\n###优缺点\n1. 优点\n\t* 松散耦合\n\t* 简单易用\n\t* 更好的划分访问的层次\n2. 缺点\n\t* 过多的或者是不太合理的Facade也容易让人迷惑。到底是调用Facade好还是直接调用模块好。\n\n###本质\n封装交互,简化调用\n\n###何时选用外观模式\n* 如果你希望为复杂的子系统提供一个简单接口的时候,可以考虑使用外观模式。使用外观对象对实现大部分客户需要的功能,从而简化客户的使用。\n* 如果想要让客户程序和抽象类的实现部分松散耦合,可以考虑使用外观模式,使用外观对象来将这个子系统与它的客户分离开来,从而提高子系统的独立性和可移植性。\n* 如果构建多层结构的系统,可以考虑使用外观模式,使用外观对象作为每层的入口,这样就可以简化层间调用,也可以松散层次之间的依赖关系。\n"
},
{
"path": "Part1/DesignPattern/常见的面向对象设计原则.md",
"content": "#常见的面向对象设计原则\n\n1. 单一职责原则 SRP\n一个类应该仅有一个引起它变化的原因。\n2. 开放关闭原则 OCP\n一个类应该对外扩展开放,对修改关闭。\n3. 里氏替换原则 LSP\n子类型能够替换掉它们的父类型。\n4. 依赖倒置原则 DIP\n要依赖于抽象,不要依赖于具体类,要做到依赖倒置,应该做到:\n\t* 高层模块不应该依赖底层模块,二者都应该依赖于抽象。\n\t* 抽象不应该依赖于具体实现,具体实现应该依赖于抽象。\n5. 接口隔离原则 ISP\n不应该强迫客户依赖于他们不用的方法。\n6. 最少知识原则 LKP\n只和你的朋友谈话。\n7. 其他原则\n\t* 面向接口编程\n\t* 优先使用组合,而非继承\n\t* 一个类需要的数据应该隐藏在类的内部\n\t* 类之间应该零耦合,或者只有传导耦合,换句话说,类之间要么没关系,要么只使用另一个类的接口提供的操作\n\t* 在水平方向上尽可能统一地分布系统功能\n\n\n"
},
{
"path": "Part1/DesignPattern/策略模式.md",
"content": "#策略模式\n---\n\n##模式的定义\n\n策略模式定义了一系列的算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变化。\n\n注:针对同一类型操作,将复杂多样的处理方式分别开来,有选择的实现各自特有的操作。\n\n##模式的使用场景\n\n* 针对同一类型问题的多种处理方式,仅仅是具体行为有差别时。\n* 需要安全的封装多种同一类型的操作时。\n* 出现同一抽象多个子类,而又需要使用if-else 或者 switch-case来选择时。\n\n##Android源码中的模式实现\n\n\n\n\n策略模式主要用来分离算法,根据相同的行为抽象来做不同的具体策略实现。\n\n##优缺点\n\n###优点:\n\n* 结构清晰明了、使用简单直观。\n* 耦合度相对而言较低,扩展方便。\n* 操作封装也更为彻底,数据更为安全。\n\n###缺点:\n\n* 随着策略的增加,子类也会变得繁多。"
},
{
"path": "Part1/DesignPattern/简单工厂.md",
"content": "#简单工厂\n---\n###接口\n接口是一种特殊的抽象类,跟一般的抽象类相比,接口里的所有方法都是抽象方法,接口里的所有属性都是常量。也就是说接口里面只有方法定义没有任何方法实现。\n\n接口的思想是\"封装隔离\"\n\n###简单工厂\n示例代码:\n[https://github.com/GeniusVJR/DesignMode_Java/tree/master/SimpleFactory](https://github.com/GeniusVJR/DesignMode_Java/tree/master/SimpleFactory)\n\n客户端在调用的时候,不但知道了接口,同时还知道了具体的实现。接口的思想是\"封装隔离\",而实现类Impl应该是被接口Api封装并同客户端隔离开来的,客户端不应该知道具体的实现类是Impl。\n\n###简单工厂的功能\n不仅可以利用简单工厂来创建接口,也可以用简单工厂来创造抽象类,甚至是一个具体的实例。\n\n###静态工厂\n没有创建工厂实例的必要,把简单工厂实现成一个工具类,直接使用静态方法。\n\n###万能工厂\n 一个简单哪工厂可以包含很多用来构造东西的方法,这些方法可以创建不同的接口、抽象类或者是类实例。\n\n###简单工厂的优缺点\n1. 优点\n* 帮助封装\n* 解耦\n2. 缺点\n* 可能增加客户端的复杂度\n* 不方便扩展子工厂\n\n##思考\n\n简单工厂的本质是选择实现。\n\n"
},
{
"path": "Part1/DesignPattern/观察者模式.md",
"content": "#观察者模式\n---\n\n首先在Android中,我们往ListView添加数据后,都会调用Adapter的notifyDataChanged()方法,其中使用了观察者模式。\n\n当ListView的数据发生变化时,调用Adapter的notifyDataSetChanged函数,这个函数又会调用DataSetObservable的notifyChanged函数,这个函数会调用所有观察者(AdapterDataSetObserver)的onChanged方法,在onChanged函数中又会调用ListView重新布局的函数使得ListView刷新界面。\n\nAndroid中应用程序发送广播的过程:\n\n- 通过sendBroadcast把一个广播通过Binder发送给ActivityManagerService,ActivityManagerService根据这个广播的Action类型找到相应的广播接收器,然后把这个广播放进自己的消息队列中,就完成第一阶段对这个广播的异步分发。\n- ActivityManagerService在消息循环中处理这个广播,并通过Binder机制把这个广播分发给注册的ReceiverDispatcher,ReceiverDispatcher把这个广播放进MainActivity所在线程的消息队列中,就完成第二阶段对这个广播的异步分发:\n- ReceiverDispatcher的内部类Args在MainActivity所在的线程消息循环中处理这个广播,最终是将这个广播分发给所注册的BroadcastReceiver实例的onReceive函数进行处理:"
},
{
"path": "Part1/DesignPattern/责任链模式.md",
"content": "#责任链模式\n---\n\n##模式介绍\n\n###模式的定义\n\n一个请求沿着一条“链”传递,直到该“链”上的某个处理者处理它为止。\n\n###模式的使用场景\n\n一个请求可以被多个处理者处理或处理者未明确指定时。"
},
{
"path": "Part1/DesignPattern/适配器模式.md",
"content": "#适配器模式\n---\n定义:\n>将一个类的接口转换成客户希望的另一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。\n\n功能:\n\n>进行转换匹配,目的是复用已有的功能,而不是来实现新的接口。在适配器里实现功能,这种适配器称为智能适配器。\n\n优点:\n\n* 更好的复用性\n* 更好的扩展性\n\n缺点:\n\n* 过多的使用适配器,会让系统非常零乱,不容易整体进行把握。\n\n本质:\n\n转换匹配,复用功能。\n\n何时选用适配器模式:\n\n* 如果你想要使用一个已经存在的类,但是它的接口不符合你的需求,这种情况可以使用适配器模式,来把已有的实现转换成你需要的接口。\n* 如果你想创建一个可以复用的类,这个类可能和一些不兼容的类一起工作,这种情况可以使用适配器模式,到时候需要什么就适配什么。\n* 如果你想使用一些已经存在的子类,但是不可能对每一个子类都进行适配,这种情况可以选用对象适配器,直接适配这些子类的父类就可以了。\n"
},
{
"path": "Part2/JVM/JVM.md",
"content": "#JVM\n---\n\n**内存模型以及分区,需要详细到每个区放什么。**\n\n[http://blog.csdn.net/ns_code/article/details/17565503](http://blog.csdn.net/ns_code/article/details/17565503)\n\nJVM所管理的内存分为以下几个运行时数据区:程序计数器、Java虚拟机栈、本地方法栈、Java堆、方法区。\n\n\n\n程序计数器(Program Counter Register)\n\n一块较小的内存空间,它是当前线程所执行的字节码的行号指示器,字节码解释器工作时通过改变该计数器的值来选择下一条需要执行的字节码指令,分支、跳转、循环等基础功能都要依赖它来实现。每条线程都有一个独立的的程序计数器,各线程间的计数器互不影响,因此该区域是线程私有的。\n\n当线程在执行一个Java方法时,该计数器记录的是正在执行的虚拟机字节码指令的地址,当线程在执行的是Native方法(调用本地操作系统方法)时,该计数器的值为空。另外,该内存区域是唯一一个在Java虚拟机规范中么有规定任何OOM(内存溢出:OutOfMemoryError)情况的区域。\n\nJava虚拟机栈(Java Virtual Machine Stacks)\n\n该区域也是线程私有的,它的生命周期也与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧,栈它是用于支持续虚拟机进行方法调用和方法执行的数据结构。对于执行引擎来讲,活动线程中,只有栈顶的栈帧是有效的,称为当前栈帧,这个栈帧所关联的方法称为当前方法,执行引擎所运行的所有字节码指令都只针对当前栈帧进行操作。栈帧用于存储局部变量表、操作数栈、动态链接、方法返回地址和一些额外的附加信息。在编译程序代码时,栈帧中需要多大的局部变量表、多深的操作数栈都已经完全确定了,并且写入了方法表的Code属性之中。因此,一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。\n\n本地方法栈(Native Method Stacks)\n\n该区域与虚拟机栈所发挥的作用非常相似,只是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则为使用到的本地操作系统(Native)方法服务。\n\nJava堆(Java Heap)\n\nJava Heap是Java虚拟机所管理的内存中最大的一块,它是所有线程共享的一块内存区域。几乎所有的对象实例和数组都在这类分配内存。Java Heap是垃圾收集器管理的主要区域,因此很多时候也被称为“GC堆”。\n\n根据Java虚拟机规范的规定,Java堆可以处在物理上不连续的内存空间中,只要逻辑上是连续的即可。如果在堆中没有内存可分配时,并且堆也无法扩展时,将会抛出OutOfMemoryError异常。 \n\n方法区(Method Area)\n\n方法区也是各个线程共享的内存区域,它用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。方法区域又被称为“永久代”,但这仅仅对于Sun HotSpot来讲,JRockit和IBM J9虚拟机中并不存在永久代的概念。Java虚拟机规范把方法区描述为Java堆的一个逻辑部分,而且它和Java Heap一样不需要连续的内存,可以选择固定大小或可扩展,另外,虚拟机规范允许该区域可以选择不实现垃圾回收。相对而言,垃圾收集行为在这个区域比较少出现。该区域的内存回收目标主要针是对废弃常量的和无用类的回收。运行时常量池是方法区的一部分,Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Class文件常量池),用于存放编译器生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。运行时常量池相对于Class文件常量池的另一个重要特征是具备动态性,Java语言并不要求常量一定只能在编译期产生,也就是并非预置入Class文件中的常量池的内容才能进入方法区的运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的是String类的intern()方法。\n\n根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。\n\n**内存泄漏和内存溢出的差别**\n\n内存泄露是指分配出去的内存没有被回收回来,由于失去了对该内存区域的控制,因而造成了资源的浪费。Java中一般不会产生内存泄露,因为有垃圾回收器自动回收垃圾,但这也不绝对,当我们new了对象,并保存了其引用,但是后面一直没用它,而垃圾回收器又不会去回收它,这边会造成内存泄露,\n\n内存溢出是指程序所需要的内存超出了系统所能分配的内存(包括动态扩展)的上限。\n\n**类型擦除**\n\n[http://blog.csdn.net/ns_code/article/details/18011009](http://blog.csdn.net/ns_code/article/details/18011009)\n\nJava语言在JDK1.5之后引入的泛型实际上只在程序源码中存在,在编译后的字节码文件中,就已经被替换为了原来的原生类型,并且在相应的地方插入了强制转型代码,因此对于运行期的Java语言来说,`ArrayList`和`ArrayList`就是同一个类。所以泛型技术实际上是Java语言的一颗语法糖,Java语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型被称为伪泛型。\n\n下面是一段简单的Java泛型代码:\n\n```\nMap map = new HashMap(); \nmap.put(1,\"No.1\"); \nmap.put(2,\"No.2\"); \nSystem.out.println(map.get(1)); \nSystem.out.println(map.get(2)); \n````\n\n将这段Java代码编译成Class文件,然后再用字节码反编译工具进行反编译后,将会发现泛型都变回了原生类型,如下面的代码所示:\n\n```\nMap map = new HashMap(); \nmap.put(1,\"No.1\"); \nmap.put(2,\"No.2\"); \nSystem.out.println((String)map.get(1)); \nSystem.out.println((String)map.get(2)); \n```\n\n为了更详细地说明类型擦除,再看如下代码:\n\n```\nimport java.util.List; \npublic class FanxingTest{ \n public void method(List list){ \n System.out.println(\"List String\"); \n } \n public void method(List list){ \n System.out.println(\"List Int\"); \n } \n} \n```\n\n当我用Javac编译器编译这段代码时,报出了如下错误:\n\n\n```\nFanxingTest.java:3: 名称冲突:method(java.util.List) 和 method\n\n(java.util.List) 具有相同疑符\n\npublic void method(List list){\n\n^\n\nFanxingTest.java:6: 名称冲突:method(java.util.List) 和 metho\n\nd(java.util.List) 具有相同疑符\n\npublic void method(List list){\n\n^\n```\n\n2 错误\n\n\n这是因为泛型List和List编译后都被擦除了,变成了一样的原生类型List,擦除动作导致这两个方法的特征签名变得一模一样,在Class类文件结构一文中讲过,Class文件中不能存在特征签名相同的方法。\n\n把以上代码修改如下:\n\n```\nimport java.util.List; \npublic class FanxingTest{ \n public int method(List list){ \n System.out.println(\"List String\"); \n return 1; \n } \n public boolean method(List list){ \n System.out.println(\"List Int\"); \n return true; \n } \n} \n```\n\n发现这时编译可以通过了(注意:Java语言中true和1没有关联,二者属于不同的类型,不能相互转换,不存在C语言中整数值非零即真的情况)。两个不同类型的返回值的加入,使得方法的重载成功了。这是为什么呢?\n\n 我们知道,Java代码中的方法特征签名只包括了方法名称、参数顺序和参数类型,并不包括方法的返回值,因此方法的返回值并不参与重载方法的选择,这样看来为重载方法加入返回值貌似是多余的。对于重载方法的选择来说,这确实是多余的,但我们现在要解决的问题是让上述代码能通过编译,让两个重载方法能够合理地共存于同一个Class文件之中,这就要看字节码的方法特征签名,它不仅包括了Java代码中方法特征签名中所包含的那些信息,还包括方法返回值及受查异常表。为两个重载方法加入不同的返回值后,因为有了不同的字节码特征签名,它们便可以共存于一个Class文件之中。\n\n**堆里面的分区:Eden,survival from to,老年代,各自的特点。**\n\n\n\n**对象创建方法,对象的内存分配,对象的访问定位。**\n\n对内存分配情况分析最常见的示例便是对象实例化:\n\n```\nObject obj = new Object();\n```\n\n这段代码的执行会涉及java栈、Java堆、方法区三个最重要的内存区域。假设该语句出现在方法体中,及时对JVM虚拟机不了解的Java使用这,应该也知道obj会作为引用类型(reference)的数据保存在Java栈的本地变量表中,而会在Java堆中保存该引用的实例化对象,但可能并不知道,Java堆中还必须包含能查找到此对象类型数据的地址信息(如对象类型、父类、实现的接口、方法等),这些类型数据则保存在方法区中。\n\n另外,由于reference类型在Java虚拟机规范里面只规定了一个指向对象的引用,并没有定义这个引用应该通过哪种方式去定位,以及访问到Java堆中的对象的具体位置,因此不同虚拟机实现的对象访问方式会有所不同,主流的访问方式有两种:使用句柄池和直接使用指针。\n\n\n\n**GC的两种判定方法:引用计数与引用链。**\n\n引用计数方式最基本的形态就是让每个被管理的对象与一个引用计数器关联在一起,该计数器记录着该对象当前被引用的次数,每当创建一个新的引用指向该对象时其计数器就加1,每当指向该对象的引用失效时计数器就减1。当该计数器的值降到0就认为对象死亡。\n\nJava的内存回收机制可以形象地理解为在堆空间中引入了重力场,已经加载的类的静态变量和处于活动线程的堆栈空间的变量是这个空间的牵引对象。这里牵引对象是指按照Java语言规范,即便没有其它对象保持对它的引用也不能够被回收的对象,即Java内存空间中的本原对象。当然类可能被去加载,活动线程的堆栈也是不断变化的,牵引对象的集合也是不断变化的。对于堆空间中的任何一个对象,如果存在一条或者多条从某个或者某几个牵引对象到该对象的引用链,则就是可达对象,可以形象地理解为从牵引对象伸出的引用链将其拉住,避免掉到回收池中。\n\n**GC的三种收集方法:标记清除、标记整理、复制算法的原理与特点,分别用在什么地方,如果让你优化收集方法,有什么思路?**\n\n标记清除算法是最基础的收集算法,其他收集算法都是基于这种思想。标记清除算法分为“标记”和“清除”两个阶段:首先标记出需要回收的对象,标记完成之后统一清除对象。它的主要缺点:①.标记和清除过程效率不高 。②.标记清除之后会产生大量不连续的内存碎片。\n\n标记整理,标记操作和“标记-清除”算法一致,后续操作不只是直接清理对象,而是在清理无用对象完成后让所有存活的对象都向一端移动,并更新引用其对象的指针。主要缺点:在标记-清除的基础上还需进行对象的移动,成本相对较高,好处则是不会产生内存碎片。\n\n复制算法,它将可用内存容量划分为大小相等的两块,每次只使用其中的一块。当这一块用完之后,就将还存活的对象复制到另外一块上面,然后在把已使用过的内存空间一次理掉。这样使得每次都是对其中的一块进行内存回收,不会产生碎片等情况,只要移动堆订的指针,按顺序分配内存即可,实现简单,运行高效。主要缺点:内存缩小为原来的一半。\n\n\n**Minor GC与Full GC分别在什么时候发生?**\n\nMinor GC:通常是指对新生代的回收。指发生在新生代的垃圾收集动作,因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快\n\nMajor GC:通常是指对年老代的回收。\n\nFull GC:Major GC除并发gc外均需对整个堆进行扫描和回收。指发生在老年代的 GC,出现了 Major GC,经常会伴随至少一次的 Minor GC(但非绝对的,在 ParallelScavenge 收集器的收集策略里就有直接进行 Major GC 的策略选择过程) 。MajorGC 的速度一般会比 Minor GC 慢 10倍以上。\n\n**几种常用的内存调试工具:jmap、jstack、jconsole。**\n\njmap(linux下特有,也是很常用的一个命令)观察运行中的jvm物理内存的占用情况。\n参数如下:\n-heap:打印jvm heap的情况\n-histo:打印jvm heap的直方图。其输出信息包括类名,对象数量,对象占用大小。\n-histo:live :同上,但是只答应存活对象的情况\n-permstat:打印permanent generation heap情况\njstack(linux下特有)可以观察到jvm中当前所有线程的运行情况和线程当前状态\njconsole一个图形化界面,可以观察到java进程的gc,class,内存等信息\njstat最后要重点介绍下这个命令。这是jdk命令中比较重要,也是相当实用的一个命令,可以观察到classloader,compiler,gc相关信息\n具体参数如下:\n-class:统计class loader行为信息\n-compile:统计编译行为信息\n-gc:统计jdk gc时heap信息\n-gccapacity:统计不同的generations(不知道怎么翻译好,包括新生区,老年区,permanent区)相应的heap容量情况\n-gccause:统计gc的情况,(同-gcutil)和引起gc的事件\n-gcnew:统计gc时,新生代的情况\n-gcnewcapacity:统计gc时,新生代heap容量\n-gcold:统计gc时,老年区的情况\n-gcoldcapacity:统计gc时,老年区heap容量\n-gcpermcapacity:统计gc时,permanent区heap容量\n-gcutil:统计gc时,heap情况\n-printcompilation:不知道干什么的,一直没用过。\n\n**类加载的五个过程:加载、验证、准备、解析、初始化。**\n\n类加载过程\n\n类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括加载、验证、准备、解析、初始化、使用、卸载。\n\n其中类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持Java语言的运行时绑定(也成为动态绑定或晚期绑定)。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。\n\n这里简要说明下Java中的绑定:绑定指的是把一个方法的调用与方法所在的类(方法主体)关联起来,对java来说,绑定分为静态绑定和动态绑定:\n\n* 静态绑定:即前期绑定。在程序执行前方法已经被绑定,此时由编译器或其它连接程序实现。针对java,简单的可以理解为程序编译期的绑定。java当中的方法只有final,static,private和构造方法是前期绑定的。\n* 动态绑定:即晚期绑定,也叫运行时绑定。在运行时根据具体对象的类型进行绑定。在java中,几乎所有的方法都是后期绑定的。\n\n“加载”(Loading)阶段是“类加载”(Class Loading)过程的第一个阶段,在此阶段,虚拟机需要完成以下三件事情:\n\n1. 通过一个类的全限定名来获取定义此类的二进制字节流。\n2. 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。\n3. 在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区这些数据的访问入口。\n\n验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。\n\n准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java堆中。\n\n解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。\n\n类初始化是类加载过程的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。\n\n\n\n**双亲委派模型:Bootstrap ClassLoader、Extension ClassLoader、ApplicationClassLoader。**\n\n1. 启动类加载器,负责将存放在\\lib目录中的,或者被-Xbootclasspath参数所指定的路径中,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即时放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被java程序直接引用。\n2. 扩展类加载器:负责加载\\lib\\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用该类加载器。\n3. 应用程序类加载器:负责加载用户路径上所指定的类库,开发者可以直接使用这个类加载器,也是默认的类加载器。\n三种加载器的关系:启动类加载器->扩展类加载器->应用程序类加载器->自定义类加载器。\n\n这种关系即为类加载器的双亲委派模型。其要求除启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不以继承关系实现,而是用组合的方式来复用父类的代码。\n\n双亲委派模型的工作过程:如果一个类加载器接收到了类加载的请求,它首先把这个请求委托给他的父类加载器去完成,每个层次的类加载器都是如此,因此所有的加载请求都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它在搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。\n\n好处:java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar中,无论哪个类加载器要加载这个类,最终都会委派给启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果用户自己写了一个名为java.lang.Object的类,并放在程序的Classpath中,那系统中将会出现多个不同的Object类,java类型体系中最基础的行为也无法保证,应用程序也会变得一片混乱。\n\n实现:在java.lang.ClassLoader的loadClass()方法中,先检查是否已经被加载过,若没有加载则调用父类加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父加载失败,则抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。\n\n\n**分派:静态分派与动态分派。**\n\n静态分派与重载有关,虚拟机在重载时是通过参数的静态类型,而不是运行时的实际类型作为判定依据的;静态类型在编译期是可知的;\n动态分派与重写(Override)相关,invokevirtual(调用实例方法)指令执行的第一步就是在运行期确定接收者的实际类型,根据实际类型进行方法调用;\n\n**GC收集器有哪些?CMS收集器与G1收集器的特点。**\n\n\n\n**自动内存管理机制,GC算法,运行时数据区结构,可达性分析工作原理,如何分配对象内存**\n\n**反射机制,双亲委派机制,类加载器的种类**\n\n**Jvm内存模型,先行发生原则,violate关键字作用**"
},
{
"path": "Part2/JVM/JVM类加载机制.md",
"content": "#虚拟机类加载机制\n---\n**虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被Java虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。**\n\n类从被加载到虚拟内存中开始,到卸载内存为止,它的整个生命周期包括了:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段。其中,验证,准备和解析三个部分统称为连接(Linking)。\n\n###类加载的过程\n类加载的全过程,加载,验证,准备,解析和初始化这五个阶段。\n\n---\n\n####加载\n在加载阶段,虚拟机需要完成以下三件事情:\n\n* 通过一个类的全限定名来获取定义此类的二进制字节流\n* 将这个字节流所代表的静态存储结构转换为方法区的运行时数据结构\n* 在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区这些数据的访问入口\n\n####验证\n这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。不同的虚拟机对类验证的实现可能有所不同,但大致上都会完成下面四个阶段的检验过程:文件格式验证、元数据验证、字节码验证和符号引用验证。\n\n**文件格式验证**\n\n第一阶段要验证字节流是否符合Class文件格式的规范,并且能被当前版本的虚拟机处理。\n\n**元数据验证**\n\n第二阶段是对字节码描述的信息进行语义分析,以保证其描述的信息符合Java语言规范的要求。\n\n**字节码验证**\n\n第三阶段时整个验证过程中最复杂的一个阶段,主要工作是数据流和控制流的分析。在第二阶段对元数据信息中的数据类型做完校验后,这阶段将对类的方法体进行校验分析。这阶段的任务是保证被校验类的方法在运行时不会做出危害虚拟机安全的行为。\n\n**符号引用验证**\n\n最后一个阶段的校验发生在虚拟机将符号引用直接转化为直接引用的时候,这个转化动作将在连接的第三个阶段-解析阶段产生。符号引用验证可以看作是对类自身以外(常量池中的各种符号引用)的信息进行匹配性的校验。\n\n####准备\n准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区进行分配。\n\n####解析\n解析阶段是虚拟机将常量池的符号引用转换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法四类符号引用进行。\n\n* 类或接口的解析\n* 字段解析\n* 类方法解析\n* 接口方法解析\n\n####初始化\n前面的类加载过程中,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由Java虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码(或者说是字节码)。在准备阶段,变量已经赋过一次系统要求的初始值,而在初始化阶段,则是根据程序员通过程序制定的主观计划去初始化类变量和其他资源,或者说初始化阶段是执行类构造器()方法的过程。\n\n###类加载器\n---\n####类与类加载器\n虚拟机设计团队把类加载阶段中的\"通过一个类的全限定名来获取描述此类的二进制字节流\"这个动作放到Java虚拟机外部去实现,以便让程序自己决定如何去获取所需的类。实现这个动作的代码模块被称为\"类加载器\"。\n\n####双亲委派模型\n站在Java虚拟机的角度讲,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现,是虚拟机自身的一部分;另外一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,并且全部继承自抽象类java.lang.ClassLoader。从Java开发人员的角度来看,类加载器还可以分得更细致一些,绝大部分Java程序都会使用到以下三种系统提供的类加载器:\n\n* 启动类加载器\n* 扩展类加载器\n* 应用程序类加载器\n\n\n\n"
},
{
"path": "Part2/JVM/Java内存区域与内存溢出.md",
"content": "##内存区域\n\nJava虚拟机在执行Java程序的过程中会把他所管理的内存划分为若干个不同的数据区域。Java虚拟机规范将JVM所管理的内存分为以下几个运行时数据区:程序计数器,Java虚拟机栈,本地方法栈,Java堆,方法区。下面详细阐述各数据区所存储的数据类型。\n\n\n\n**程序计数器(Program Counter Register)**\n\n一块较小的内存空间,它是当前线程所执行的子节码的行号指示器,字节码解释器工作时通过改变该计数器的值来选择下一条需要执行的子节码指令,分支、跳转、循环等基础功能都要依赖它来实现。每条线程都有一个独立的程序计数器,各线程间的计数器互不影响,因此该区域是线程私有的。\n\n当线程在执行一个Java方法时,该计数器纪录的是正在执行的虚拟机字节吗指令的地址,当线程在执行的是Native方法(调用本地操作系统方法)时,该计数器的值为空。另外,该内存区域是唯一一个在Java虚拟机规范中没有任何OOM(内存溢出:OutOfMemoryError)情况的区域。\n\n**Java虚拟机栈(Java Virtual Machine Stacks)**\n\n该区域也是线程私有的,它的生命周期也与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会创建一个帧栈,栈它是用于支持虚拟机进行方法调用和方法执行的数据结构。对于执行引擎来讲,活动线程中,只有栈顶的栈帧是有效的,称为当前栈,这个栈帧所关联的方法称为当前方法,执行引擎所运行的所有字节码都只针对当前的栈帧进行操作。栈帧用于存储局部变量表、操作数栈、动态链接、方法返回地址和一些额外的附加信息。在编译程序代码时,栈帧中需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。\n在Java虚拟机规范中,对这个区域规定了两种异常情况:\n\n1. 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。\n2. 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemory异常。\n\n这两种情况存在着一些互相重叠的部分:当栈空间无法继续分配时,到底是内存太小,还是已使用的栈空间太大,其本质只是对同一件事情的两种描述而已。其本质上只是对一件事情的两种描述而已。在单线程的操作中,无论是由于栈帧太大,还是虚拟机栈空间太小,当栈空间无法分配时,虚拟机抛出的都是StackOverflowError异常,而不会得到OutOfMemoryError异常。而在多线程环境下,则会抛出OutOfMemory异常。\n\n下面详细说明栈帧中所存放的各部分信息的作用和数据结构。\n\n局部变量表是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量,其中存放的数据的类型是编译期可知的各种基本数据类型、对象引用(reference)和returnAddress类型(它指向了一条字节码指令的地址)。局部变量表所需的内存空间在编译期间完成分配,即在Java程序被编译成Class文件时,就确定了所需分配的最大局部变量表的容量。当进入一个方法时,这个方法需要在栈中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。\n下面详细说明栈帧中所存放的各部分信息的作用和数据结构。 \n\n1、局部变量表\n局部变量表的容量以变量槽(Slot)为最小单位。在虚拟机规范中并没有明确指明一个Slot应占用的内存空间大小(允许其随着处理器、操作系统或虚拟机的不同而发生变化),一个Slot可以存放一个32位以内的数据类型:boolean、byte、char、short、int、float、reference和returnAddresss。reference是对象的引用类型,returnAddress是为字节指令服务的,它执行了一条字节码指令的地址。对于64位的数据类型(long和double),虚拟机会以高位在前的方式为其分配两个连续的Slot空间。\n\n虚拟机通过索引定位的方式使用局部变量表,索引值的范围是从0开始到局部变量表最大的Slot数量,对于32位数据类型的变量,索引n代表第n个Slot,对于64位的,索引n代表第n和第n+1两个Slot。\n\n在方法执行时,虚拟机是使用局部变量表来完成参数值到参数变量列表的传递过程的,如果是实例方法(非static),则局部变量表中的第0位索引的Slot默认是用于传递方法所属对象实例的引用,在方法中可以通过关键字“this”来访问这个隐含的参数。其余参数则按照参数表的顺序来排列,占用从1开始的局部变量Slot,参数表分配完毕后,再根据方法体内部定义的变量顺序和作用域分配其余的Slot。\n\n局部变量表中的Slot是可重用的,方法体中定义的变量,作用域并不一定会覆盖整个方法体,如果当前字节码PC计数器的值已经超过了某个变量的作用域,那么这个变量对应的Slot就可以交给其他变量使用。这样的设计不仅仅是为了节省空间,在某些情况下Slot的复用会直接影响到系统的而垃圾收集行为。\n\n2、操作数栈\n\n操作数栈又常被称为操作栈,操作数栈的最大深度也是在编译的时候就确定了。32位数据类型所占的栈容量为1,64为数据类型所占的栈容量为2。当一个方法开始执行时,它的操作栈是空的,在方法的执行过程中,会有各种字节码指令(比如:加操作、赋值元算等)向操作栈中写入和提取内容,也就是入栈和出栈操作。\n\nJava虚拟机的解释执行引擎称为“基于栈的执行引擎”,其中所指的“栈”就是操作数栈。因此我们也称Java虚拟机是基于栈的,这点不同于Android虚拟机,Android虚拟机是基于寄存器的。\n\n基于栈的指令集最主要的优点是可移植性强,主要的缺点是执行速度相对会慢些;而由于寄存器由硬件直接提供,所以基于寄存器指令集最主要的优点是执行速度快,主要的缺点是可移植性差。\n\n3、动态连接\n\n每个栈帧都包含一个指向运行时常量池(在方法区中,后面介绍)中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接。Class文件的常量池中存在有大量的符号引用,字节码中的方法调用指令就以常量池中指向方法的符号引用为参数。这些符号引用,一部分会在类加载阶段或第一次使用的时候转化为直接引用(如final、static域等),称为静态解析,另一部分将在每一次的运行期间转化为直接引用,这部分称为动态连接。\n\n4、方法返回地址\n\n当一个方法被执行后,有两种方式退出该方法:执行引擎遇到了任意一个方法返回的字节码指令或遇到了异常,并且该异常没有在方法体内得到处理。无论采用何种退出方式,在方法退出之后,都需要返回到方法被调用的位置,程序才能继续执行。方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层方法的执行状态。一般来说,方法正常退出时,调用者的PC计数器的值就可以作为返回地址,栈帧中很可能保存了这个计数器值,而方法异常退出时,返回地址是要通过异常处理器来确定的,栈帧中一般不会保存这部分信息。\n\n方法退出的过程实际上等同于把当前栈帧出站,因此退出时可能执行的操作有:恢复上层方法的局部变量表和操作数栈,如果有返回值,则把它压入调用者栈帧的操作数栈中,调整PC计数器的值以指向方法调用指令后面的一条指令。\n\n**本地方法栈(Native Method Stacks)**\n\n该区域与虚拟机栈所发挥的作用非常相似,只是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则为使用到的本地操作系统(Native)方法服务。\n\n**Java堆(Java Heap)**\n\nJava Heap是Java虚拟机所管理的内存中的最大的一块,它是所有线程共享的一块内存区域。几乎所有的对象实例和数组都在这类分配内存。Java Heap是垃圾收集器管理的主要区域,因此很多时候也被称为\"GC堆\"。\n\n根据Java虚拟机的规定,Java堆可以处在物理上不连续的内存空间中,只要逻辑上是连续的即可。如果在堆中没有内存可分配时,并且堆也无法扩展时,将会抛出OutOfMemory。\n\n**方法区(Method Area)**\n\n方法区也是各个线程共享的内存区域,它用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。方法区域又被称为\"永久代\"。但着这仅仅对于Sun HotSpot来讲,JRocket和IBMJ9虚拟机中并不存在永久代的概念。Java虚拟机规范把方法区描述为Java堆的一个逻辑部分,而且它和Java Heap一样不需要连续的内存,可以选择固定大小或可扩展,另外,虚拟机规范允许该区域可以选择不实现垃圾回收。相对而言,垃圾收集行为在这个区域比较少出现。该区域的内存回收目标主要针是对废弃常量的和无用类的回收。运行时常量池是方法区的一部分,Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Class文件常量池),用于存放编译器生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。运行时常量池相对于Class文件常量池的另一个重要特征是具备动态性,Java语言并不要求常量一定只能在编译期产生,也就是并非预置入Class文件中的常量池的内容才能进入方法区的运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的是String类的intern()方法。\n\n根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。\n\n直接内存(Direct Memory)\n\n直接内存并不是虚拟机运行内存时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,它直接从操作系统中分配内存,因此不受Java堆的大小的限制,但是会受到本机总内存的大小及处理器寻址空间的限制,因此它也可能导致OutOfMemoryError异常出现。在Java1.4中新引入了NIO机制,它是一种基于通道与缓冲区的新I/O方式,可以直接从操作系统中分配直接内存,可以直接从操作系统中分配直接内存,即在堆外分配内存,这样能在一些场景中提高性能,因为避免了在Java堆和Native堆中来回复制数据。\n\n内存溢出\n\n下面给出个内存区域内存溢出的简单测试方法\n\n\n\n这里有一点要重点说明,在多线程情况下,给每个线程的栈分配的内存越大,反而越容易产生内存产生内存溢出一场。操作系统为每个进程分配的内存是有限制的,虚拟机提供了参数来控制Java堆和方法区这两部分内存的最大值,忽略掉程序计数器消耗的内存(很小),以及进程本身消耗的内存,剩下的内存便给了虚拟机栈和本地方法栈,每个线程分配到的栈容量越大,可以建立的线程数量自然就越少。因此,如果是建立过多的线程导致的内存溢出,在不能减少线程数的情况下,就只能通过减少最大堆和每个线程的栈容量来换取更多的线程。\n另外,由于Java堆内也可能发生内存泄露(Memory Leak),这里简要说明一下内存泄露和内存溢出的区别:\n\n内存泄漏是指分配出去的内存没有被回收回来,由于失去了对该内存区域的控制,因而造成了资源的浪费。Java中一般不会产生内存泄漏,因为有垃圾回收器自动回收垃圾,但这也不绝对,当我们new了对象,并保存了其引用,但是后面一直没用它,而垃圾回收器又不会去回收它,这就会造成内存泄漏。\n\n内存溢出是指程序所需要的内存超过了系统所能分配的内存(包括动态扩展)的上限。\n\n对象实例化分析\n\n对内存分配情况分析最常见的示例便是对象实例化:\n\n```\nObject obj = new Object();\n```\n\n这段代码的执行会涉及java栈、Java堆、方法区三个最重要的内存区域。假设该语句出现在方法体中,及时对JVM虚拟机不了解的Java使用这,应该也知道obj会作为引用类型(reference)的数据保存在Java栈的本地变量表中,而会在Java堆中保存该引用的实例化对象,但可能并不知道,Java堆中还必须包含能查找到此对象类型数据的地址信息(如对象类型、父类、实现的接口、方法等),这些类型数据则保存在方法区中。\n\n另外,由于reference类型在Java虚拟机规范里面只规定了一个指向对象的引用,并没有定义这个引用应该通过哪种方式去定位,以及访问到Java堆中的对象的具体位置,因此不同虚拟机实现的对象访问方式会有所不同,主流的访问方式有两种:使用句柄池和直接使用指针。\n\n通过句柄池访问的方式如下:\n\n\n\n通过直接指针访问的方式如下:\n\n\n\n这两种对象的访问方式各有优势,使用句柄访问方式的最大好处就是reference中存放的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要修改。使用直接指针访问方式的最大好处是速度快,它节省了一次指针定位的时间开销。目前Java默认使用的HotSpot虚拟机采用的便是是第二种方式进行对象访问的。"
},
{
"path": "Part2/JVM/垃圾回收算法.md",
"content": "#垃圾回收算法\n---\n\n1. 引用计数法:缺点是无法处理循环引用问题\n2. 标记-清除法:标记所有从根结点开始的可达对象,缺点是会造成内存空间不连续,不连续的内存空间的工作效率低于连续的内存空间,不容易分配内存\n3. 复制算法:将内存空间分成两块,每次将正在使用的内存中存活对象复制到未使用的内存块中,之后清除正在使用的内存块。算法效率高,但是代价是系统内存折半。适用于新生代(存活对象少,垃圾对象多)\n4. 标记-压缩算法:标记-清除的改进,清除未标记的对象时还将所有的存活对象压缩到内存的一端,之后,清理边界所有空间既避免碎片产生,又不需要两块同样大小的内存快,性价比高。适用于老年代。\n5. 分代\n\n"
},
{
"path": "Part2/JavaConcurrent/Java并发基础知识.md",
"content": "#Java并发\n---\n\n(Executor框架和多线程基础)\n\n**Thread与Runable如何实现多线程**\n\nJava 5以前实现多线程有两种实现方法:一种是继承Thread类;另一种是实现Runnable接口。两种方式都要通过重写run()方法来定义线程的行为,推荐使用后者,因为Java中的继承是单继承,一个类有一个父类,如果继承了Thread类就无法再继承其他类了,显然使用Runnable接口更为灵活。\n\n实现Runnable接口相比继承Thread类有如下优势:\n\n1. 可以避免由于Java的单继承特性而带来的局限\n2. 增强程序的健壮性,代码能够被多个程序共享,代码与数据是独立的\n3. 适合多个相同程序代码的线程区处理同一资源的情况\n\n补充:Java 5以后创建线程还有第三种方式:实现Callable接口,该接口中的call方法可以在线程执行结束时产生一个返回值,代码如下所示:\n\n```\nclass MyTask implements Callable { \n private int upperBounds; \n \n public MyTask(int upperBounds) { \n this.upperBounds = upperBounds; \n } \n \n @Override \n public Integer call() throws Exception { \n int sum = 0; \n for(int i = 1; i <= upperBounds; i++) { \n sum += i; \n } \n return sum; \n } \n \n} \n \npublic class Test { \n \n public static void main(String[] args) throws Exception { \n List> list = new ArrayList<>(); \n ExecutorService service = Executors.newFixedThreadPool(10); \n for(int i = 0; i < 10; i++) { \n list.add(service.submit(new MyTask((int) (Math.random() * 100)))); \n } \n \n int sum = 0; \n for(Future future : list) { \n while(!future.isDone()) ; \n sum += future.get(); \n } \n \n System.out.println(sum); \n } \n} \n```\n\n**线程同步的方法有什么;锁,synchronized块,信号量等**\n\n\n\n**锁的等级:方法锁、对象锁、类锁**\n\n**生产者消费者模式的几种实现,阻塞队列实现,sync关键字实现,lock实现,reentrantLock等**\n\n**ThreadLocal的设计理念与作用,ThreadPool用法与优势(这里在Android SDK原生的AsyncTask底层也有使用)**\n\n**线程池的底层实现和工作原理(建议写一个雏形简版源码实现)**\n\n**几个重要的线程api,interrupt,wait,sleep,stop等等**\n\n**写出生产者消费者模式。**\n\n**ThreadPool用法与优势。**\n\n**Concurrent包里的其他东西:ArrayBlockingQueue、CountDownLatch等等。**\n\n**wait()和sleep()的区别。**\n\nsleep()方法是线程类(Thread)的静态方法,导致此线程暂停执行指定时间,将执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复(线程回到就绪(ready)状态),因为调用sleep 不会释放对象锁。wait()是Object 类的方法,对此对象调用wait()方法导致本线程放弃对象锁(线程暂停执行),进入等待此对象的等待锁定池,只有针对此对象发出notify 方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入就绪状态。\n\n\n\n###3、IO(IO,NIO,目前okio已经被集成Android包)\n\n**IO框架主要用到什么设计模式**\n\nJDK的I/O包中就主要使用到了两种设计模式:Adatper模式和Decorator模式。\n\n\n**NIO包有哪些结构?分别起到的作用?**\n\n\n**NIO针对什么情景会比IO有更好的优化?**\n\n**OKIO底层实现**\n\n"
},
{
"path": "Part2/JavaConcurrent/NIO.md",
"content": "#NIO\n\n---\n\nJava NIO(New IO)是一个可以替代标准Java IO API的IO API(从Java1.4开始),Java NIO提供了与标准IO不同的IO工作方式。\n\n###Java NIO: Channels and Buffers(通道和缓冲区)\n\n标准的俄IO基于字节流和字符流进行操作的,而NIO是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入通道也类似。\n\n###Java NIO: Non-blocking IO(非阻塞IO)\n\nJava NIO可以让你非阻塞的使用IO,例如:当线程从通道读取数据到缓冲区时,线程还是进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。\n\n###Java NIO: Selectors(选择器)\n\nJava NIO引入了选择器的概念,选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。\n\nNIO由以下核心部分组成:\n\n* Channels\n* Buffers\n* Selectors\n\n**Channel和Buffer**\n\n基本上,所有的IO和NIO都从一个Channel开始。Channel有点像流。数据可以从Channel读到Buffer中,也可以从Buffer写到Channel中\n\n\n\nChannel的实现\n\n* FileChannel\n* DatagramChannel\n* SocketChannel\n* ServerSocketChannel\n\n这些通道涵盖了UDP和TCP网络IO,以及文件IO。\n\n以下是Java NIO里关键的Buffer实现\n\n* ByteBuffer\n* CharBuffer\n* DoubleBuffer\n* FloatBuffer\n* IntBuffer\n* LongBuffer\n* ShortBuffer\n\n这些Buffer覆盖了你能通过IO发送的基本数据类型:byte,short,int,long,float,double和char\n\nJava NIO还有个MappedByteBuffer,用于表示内存映射文件。\n\n**Selextor**\n\nSelector允许单线程处理多个Channel。如果你的应用打开了多个连接(通道),但每一个连接的流量都很低,使用Selector就会很方便。\n\n例如,在一个聊天服务器中\n\n这是在一个单线程中使用一个Selector处理3个Channel的图示:\n\n\n\n要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接送等。\n\n\n##Channel\n---\n\nJava NIO的通道类似流,但又有些不同:\n\n* 既可以从通道中读取数据,又可以写数据到通道。但流的读写通常是单向的。\n* 通道可以异步的读写。\n* 通道的数据总是要先读到一个Buffer,或者总要从一个Buffer中写入。\n\n正如上面所说,从通道读取数据到缓冲区,从缓冲区写入数据到通道。\n\n**Channel的实现**\n\n* FileChannel 从文件中读取数据\n* DataChannel 能通过UDP读写网络中的数据\n* SocketChannel 能通过TCP读写网络中的数据\n* ServerSocketChannel 可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel\n\n\n基本的Channel示例\n\n下面是一个使用FileChannel读取数据到Buffer中的示例\n\n```\nRandomAccessFile aFile = new RandomAccessFile(\"data/nio-data.txt\", \"rw\");\nFileChannel inChannel = aFile.getChannel();\nByteBuffer buf = ByteBuffer.allocate(48);\nint bytesRead = inChannel.read(buf);\nwhile (bytesRead != -1) {\nSystem.out.println(\"Read \" + bytesRead);\nbuf.flip();\nwhile(buf.hasRemaining()){\nSystem.out.print((char) buf.get());\n}\nbuf.clear();\nbytesRead = inChannel.read(buf);\n}\naFile.close();\n\n```\n注意 buf.flip() 的调用,首先读取数据到Buffer,然后反转Buffer,接着再从Buffer中读取数据。\n\n\n##Buffer\n\nJava NIO中的Buffer用于和NIO通道进行交互。如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的。\n\n缓冲区本质是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问这块内存。\n\n**Buffer的基本用法**\n\n使用Buffer读写数据一般遵循以下四个步骤:\n\n1. 写入数据到Buffer\n2. 调用flip()方法\n3. 从Buffer中读取数据\n4. 调用clear()方法或者compact()方法\n\n\n\n\n\n"
},
{
"path": "Part2/JavaConcurrent/Synchronized.md",
"content": "#synchronized\n---\n\n在并发编程中,多线程同时并发访问的资源叫做临界资源,当多个线程同时访问对象并要求操作相同资源时,分割了原子操作就有可能出现数据的不一致或数据不完整的情况,为避免这种情况的发生,我们会采取同步机制,以确保在某一时刻,方法内只允许有一个线程。\n\n采用synchronized修饰符实现的同步机制叫做互斥锁机制,它所获得的锁叫做互斥锁。每个对象都有一个monitor(锁标记),当线程拥有这个锁标记时才能访问这个资源,没有锁标记便进入锁池。任何一个对象系统都会为其创建一个互斥锁,这个锁是为了分配给线程的,防止打断原子操作。每个对象的锁只能分配给一个线程,因此叫做互斥锁。\n\n这里就使用同步机制获取互斥锁的情况,进行几点说明:\n\n1. 如果同一个方法内同时有两个或更多线程,则每个线程有自己的局部变量拷贝。\n2. 类的每个实例都有自己的对象级别锁。当一个线程访问实例对象中的synchronized同步代码块或同步方法时,该线程便获取了该实例的对象级别锁,其他线程这时如果要访问synchronized同步代码块或同步方法,便需要阻塞等待,直到前面的线程从同步代码块或方法中退出,释放掉了该对象级别锁。\n3. 访问同一个类的不同实例对象中的同步代码块,不存在阻塞等待获取对象锁的问题,因为它们获取的是各自实例的对象级别锁,相互之间没有影响。\n4. 持有一个对象级别锁不会阻止该线程被交换出来,也不会阻塞其他线程访问同一示例对象中的非synchronized代码。当一个线程A持有一个对象级别锁(即进入了synchronized修饰的代码块或方法中)时,线程也有可能被交换出去,此时线程B有可能获取执行该对象中代码的时间,但它只能执行非同步代码(没有用synchronized修饰),当执行到同步代码时,便会被阻塞,此时可能线程规划器又让A线程运行,A线程继续持有对象级别锁,当A线程退出同步代码时(即释放了对象级别锁),如果B线程此时再运行,便会获得该对象级别锁,从而执行synchronized中的代码。\n5. 持有对象级别锁的线程会让其他线程阻塞在所有的synchronized代码外。例如,在一个类中有三个synchronized方法a,b,c,当线程A正在执行一个实例对象M中的方法a时,它便获得了该对象级别锁,那么其他的线程在执行同一实例对象(即对象M)中的代码时,便会在所有的synchronized方法处阻塞,即在方法a,b,c处都要被阻塞,等线程A释放掉对象级别锁时,其他的线程才可以去执行方法a,b或者c中的代码,从而获得该对象级别锁。\n6. 使用synchronized(obj)同步语句块,可以获取指定对象上的对象级别锁。obj为对象的引用,如果获取了obj对象上的对象级别锁,在并发访问obj对象时时,便会在其synchronized代码处阻塞等待,直到获取到该obj对象的对象级别锁。当obj为this时,便是获取当前对象的对象级别锁。\n7. 类级别锁被特定类的所有示例共享,它用于控制对static成员变量以及static方法的并发访问。具体用法与对象级别锁相似。\n8. 互斥是实现同步的一种手段,临界区、互斥量和信号量都是主要的互斥实现方式。synchronized关键字经过编译后,会在同步块的前后分别形成monitorenter和monitorexit这两个字节码指令。根据虚拟机规范的要求,在执行monitorenter指令时,首先要尝试获取对象的锁,如果获得了锁,把锁的计数器加1,相应地,在执行monitorexit指令时会将锁计数器减1,当计数器为0时,锁便被释放了。由于synchronized同步块对同一个线程是可重入的,因此一个线程可以多次获得同一个对象的互斥锁,同样,要释放相应次数的该互斥锁,才能最终释放掉该锁。\n\n##内存可见性\n\n加锁(synchronized同步)的功能不仅仅局限于互斥行为,同时还存在另外一个重要的方面:内存可见性。我们不仅希望防止某个线程正在使用对象状态而另一个线程在同时修改该状态,而且还希望确保当一个线程修改了对象状态后,其他线程能够看到该变化。而线程的同步恰恰也能够实现这一点。\n\n内置锁可以用于确保某个线程以一种可预测的方式来查看另一个线程的执行结果。为了确保所有的线程都能看到共享变量的最新值,可以在所有执行读操作或写操作的线程上加上同一把锁。下图示例了同步的可见性保证。\n\n\n\n当线程A执行某个同步代码块时,线程B随后进入由同一个锁保护的同步代码块,这种情况下可以保证,当锁被释放前,A看到的所有变量值(锁释放前,A看到的变量包括y和x)在B获得同一个锁后同样可以由B看到。换句话说,当线程B执行由锁保护的同步代码块时,可以看到线程A之前在同一个锁保护的同步代码块中的所有操作结果。如果在线程A unlock M之后,线程B才进入lock M,那么线程B都可以看到线程A unlock M之前的操作,可以得到i=1,j=1。如果在线程B unlock M之后,线程A才进入lock M,那么线程B就不一定能看到线程A中的操作,因此j的值就不一定是1。\n\n现在考虑如下代码:\n\n```\npublic class MutableInteger \n{ \n private int value; \n \n public int get(){ \n return value; \n } \n public void set(int value){ \n this.value = value; \n } \n} \n```\n\n以上代码中,get和set方法都在没有同步的情况下访问value。如果value被多个线程共享,假如某个线程调用了set,那么另一个正在调用get的线程可能会看到更新后的value值,也可能看不到。\n\n通过对set和get方法进行同步,可以使MutableInteger成为一个线程安全的类,如下:\n\n```\npublic class SynchronizedInteger \n{ \n private int value; \n \n public synchronized int get(){ \n return value; \n } \n public synchronized void set(int value){ \n this.value = value; \n } \n} \n```\n\n对set和get方法进行了同步,加上了同一把对象锁,这样get方法可以看到set方法中value值的变化,从而每次通过get方法取得的value的值都是最新的value值。 \n "
},
{
"path": "Part2/JavaConcurrent/Thread和Runnable实现多线程的区别.md",
"content": "#Thread和Runnable实现多线程的区别\n---\n\nJava中实现多线程有两种方法:继承Thread、实现Runnable接口,在程序开发中只要是多线程,肯定永远以实现Runnable接口为主,因为实现Runnable接口相比继承Thread类有如下优势:\n\n1. 可以避免由于Java的单继承特性而带来的局限\n2. 增强程序的健壮性,代码能够被多个线程共享,代码与数据是独立的\n3. 适合多个相同程序的线程区处理同一资源的情况\n\n首先通过Thread类实现\n\n```\nclass MyThread extends Thread{ \n private int ticket = 5; \n public void run(){ \n for (int i=0;i<10;i++) \n { \n if(ticket > 0){ \n System.out.println(\"ticket = \" + ticket--); \n } \n } \n } \n} \n \npublic class ThreadDemo{ \n public static void main(String[] args){ \n new MyThread().start(); \n new MyThread().start(); \n new MyThread().start(); \n } \n} \n```\n\n运行结果:\n\n```\nticket = 5\nticket = 4\nticket = 5\nticket = 5\nticket = 4\nticket = 3\nticket = 2\nticket = 1\nticket = 4\nticket = 3\nticket = 3\nticket = 2\nticket = 1\nticket = 2\nticket = 1\n```\n\n每个线程单独卖了5张票,即独立的完成了买票的任务,但实际应用中,比如火车站售票,需要多个线程去共同完成任务,在本例中,即多个线程共同买5张票。\n\n通过实现Runnable借口实现的多线程程序\n\n```\nclass MyThread implements Runnable{ \n private int ticket = 5; \n public void run(){ \n for (int i=0;i<10;i++) \n { \n if(ticket > 0){ \n System.out.println(\"ticket = \" + ticket--); \n } \n } \n } \n} \n \npublic class RunnableDemo{ \n public static void main(String[] args){ \n MyThread my = new MyThread(); \n new Thread(my).start(); \n new Thread(my).start(); \n new Thread(my).start(); \n } \n} \n```\n\n运行结果\n\n```\nticket = 5\nticket = 2\nticket = 1\nticket = 3\nticket = 4\n```\n\n* 在第二种方法(Runnable)中,ticket输出的顺序并不是54321,这是因为线程执行的时机难以预测。ticket并不是原子操作。\n* 在第一种方法中,我们new了3个Thread对象,即三个线程分别执行三个对象中的代码,因此便是三个线程去独立地完成卖票的任务;而在第二种方法中,我们同样也new了3个Thread对象,但只有一个Runnable对象,3个Thread对象共享这个Runnable对象中的代码,因此,便会出现3个线程共同完成卖票任务的结果。如果我们new出3个Runnable对象,作为参数分别传入3个Thread对象中,那么3个线程便会独立执行各自Runnable对象中的代码,即3个线程各自卖5张票。\n* 在第二种方法中,由于3个Thread对象共同执行一个Runnable对象中的代码,因此可能会造成线程的不安全,比如可能ticket会输出-1(如果我们System.out....语句前加上线程休眠操作,该情况将很有可能出现),这种情况的出现是由于,一个线程在判断ticket为1>0后,还没有来得及减1,另一个线程已经将ticket减1,变为了0,那么接下来之前的线程再将ticket减1,便得到了-1。这就需要加入同步操作(即互斥锁),确保同一时刻只有一个线程在执行每次for循环中的操作。而在第一种方法中,并不需要加入同步操作,因为每个线程执行自己Thread对象中的代码,不存在多个线程共同执行同一个方法的情况。\n"
},
{
"path": "Part2/JavaConcurrent/thread与runable如何实现多线程.md",
"content": "##Thread与Runable如何实现多线程?\n\nJava实现多线程有两种途径:继承Thread类或者实现Runnable接口。Runnable是接口\n\nRunnable是接口,建议用接口的方式生成线程,因为接口可以实现多继承,况且Runnable只有一个run方法,很适合继承。\n\n在使用Thread方法的时候只需继承Thread,并且new一个实例出来,调用start()方法既可以启动一个线程\n\n[ java多线程 Thread 和Runnable](http://blog.csdn.net/luyysea/article/details/7995351)"
},
{
"path": "Part2/JavaConcurrent/volatile变量修饰符.md",
"content": "#volatile变量修饰符\n---\n\n##volatile用处说明\n\n在JDK1.2之前,Java的类型模型实现总是从主存(即共享内存)读取变量,是不需要进行特别的注意的。而随着JVM的成熟和优化,现在在多线程环境下volatile关键字的使用变的非常重要。\n\n在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另一个线程还在继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。\n\n要解决这个问题,就需要把变量声明为volatile,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般来说,多任务环境下,各任务间共享的变量都应该加volatile修饰符。\n\nvolatile修饰de成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。\n\nJava语言规范中指出:为了获得最佳速度,允许线程保存成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才将私有拷贝与共享内存中的原始值进行比较。\n\n这样当多个线程同时与某个对象交互时,就必须注意到要让线程及时的得到共享成员变量的变化。而volatile关键字就是提示JVM:对于这个成员变量,不能保存它的私有拷贝,而应直接与共享成员变量交互。\n\nvolatile是一种稍弱的同步机制,在访问volatile变量时不会执行加锁操作,也就不会执行线程阻塞,因此volatilei变量是一种比synchronized关键字更轻量级的同步机制。\n\n使用建议:在两个或者更多的线程需要访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,或者为常量时,没必要使用volatile。\n\n由于使用volatile屏蔽掉了JVM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。\n\n下面给出一段代码,通过其运行结果来说明使用关键字volatile产生的差异,但实际上遇到了意料之外的问题:\n\n```\n\n```"
},
{
"path": "Part2/JavaConcurrent/使用wait notify notifyall实现线程间通信.md",
"content": "#使用wait/notify/notifyAll实现线程间通信\n---\n\n在Java中,可以通过配合调用Object对象的wait()方法和notify()方法或notifyAll()方法来实现线程间的通信。在线程中调用wait()方法,将阻塞等待其他线程的通知(其他线程调用notify()方法或notifyAll()方法),在线程中调用notify()方法或notifyAll()方法,将通知其他线程从wait()方法处返回。\n\nObject是所有类的超类,它有5个方法组成了等待/通知机制的核心:notify()、notifyAll()、wait()、wait(long)和wait(long,int)。在Java中,所有的类都从Object继承而来,因此,所有的类都拥有这些共有方法可供使用。而且,由于他们都被声明为final,因此在子类中不能覆写任何一个方法。\n\n这里详细说明一下各个方法在使用中需要注意的几点:\n\n1、wait()\n\n```\npublic final void wait() throws InterruptedException,IllegalMonitorStateException\n```\n\n该方法用来将当前线程置入休眠状态,直到接到通知或被中断为止。在调用wait()之前,线程必须要获得该对象的对象级别锁,即只能在同步方法或同步块中调用wait()方法。进入wait()方法后,当前线程释放锁。在从wait()返回前,线程与其他线程竞争重新获得锁。如果调用wait()时,没有持有适当的锁,则抛出IllegalMonitorStateException,它是RuntimeException的一个子类,因此,不需要try-catch结构。\n\n2、notify()\n\n```\npublic final native void notify() throws IllegalMonitorStateException\n```\n\n该方法也要在同步方法或同步块中调用,即在调用前,线程也必须要获得该对象的对象级别锁,的如果调用notify()时没有持有适当的锁,也会抛出IllegalMonitorStateException。\n\n该方法用来通知那些可能等待该对象的对象锁的其他线程。如果有多个线程等待,则线程规划器任意挑选出其中一个wait()状态的线程来发出通知,并使它等待获取该对象的对象锁(notify后,当前线程不会马上释放该对象锁,wait所在的线程并不能马上获取该对象锁,要等到程序退出synchronized代码块后,当前线程才会释放锁,wait所在的线程也才可以获取该对象锁),但不惊动其他同样在等待被该对象notify的线程们。当第一个获得了该对象锁的wait线程运行完毕以后,它会释放掉该对象锁,此时如果该对象没有再次使用notify语句,则即便该对象已经空闲,其他wait状态等待的线程由于没有得到该对象的通知,会继续阻塞在wait状态,直到这个对象发出一个notify或notifyAll。这里需要注意:它们等待的是被notify或notifyAll,而不是锁。这与下面的notifyAll()方法执行后的情况不同。 \n\n3、notifyAll()\n\n```\npublic final native void notifyAll() throws IllegalMonitorStateException\n```\n\n该方法与notify()方法的工作方式相同,重要的一点差异是:\n\nnotifyAll使所有原来在该对象上wait的线程统统退出wait的状态(即全部被唤醒,不再等待notify或notifyAll,但由于此时还没有获取到该对象锁,因此还不能继续往下执行),变成等待获取该对象上的锁,一旦该对象锁被释放(notifyAll线程退出调用了notifyAll的synchronized代码块的时候),他们就会去竞争。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出synchronized代码块,释放锁后,其他的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕。\n\n4、wait(long)和wait(long,int)\n\n显然,这两个方法是设置等待超时时间的,后者在超值时间上加上ns,精度也难以达到,因此,该方法很少使用。对于前者,如果在等待线程接到通知或被中断之前,已经超过了指定的毫秒数,则它通过竞争重新获得锁,并从wait(long)返回。另外,需要知道,如果设置了超时时间,当wait()返回时,我们不能确定它是因为接到了通知还是因为超时而返回的,因为wait()方法不会返回任何相关的信息。但一般可以通过设置标志位来判断,在notify之前改变标志位的值,在wait()方法后读取该标志位的值来判断,当然为了保证notify不被遗漏,我们还需要另外一个标志位来循环判断是否调用wait()方法。\n\n\n深入理解:\n\n* 如果线程调用了对象的wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。\n* 当有线程调用了对象的notifyAll()方法(唤醒所有wait线程)或notify()方法(只随机唤醒一个wait线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。\n* 优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了synchronized代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。\n"
},
{
"path": "Part2/JavaConcurrent/可重入内置锁.md",
"content": "#可重入内置锁\n---\n\n每个Java对象都可以用做一个实现同步的锁,这些锁被称为内置锁或监视器锁。线程在进入同步代码块之前会自动获取锁,并且在退出同步代码块时会自动释放锁。获得内置锁的唯一途径就是进入由这个锁保护的同步代码块或方法。\n\n当某个线程请求一个由其他线程持有的锁时,发出请求的线程就会阻塞。然而,由于内置锁是可重入的,因此如果摸个线程试图获得一个已经由它自己持有的锁,那么这个请求就会成功。“重入”意味着获取锁的操作的粒度是“线程”,而不是调用。重入的一种实现方法是,为每个锁关联一个获取计数值和一个所有者线程。当计数值为0时,这个锁就被认为是没有被任何线程所持有,当线程请求一个未被持有的锁时,JVM将记下锁的持有者,并且将获取计数值置为1,如果同一个线程再次获取这个锁,计数值将递增,而当线程退出同步代码块时,计数器会相应地递减。当计数值为0时,这个锁将被释放。\n\n重入进一步提升了加锁行为的封装性,因此简化了面向对象并发代码的开发。分析如下程序:\n\n```\npublic class Father \n{ \n public synchronized void doSomething(){ \n ...... \n } \n} \n \npublic class Child extends Father \n{ \n public synchronized void doSomething(){ \n ...... \n super.doSomething(); \n } \n} \n```\n\n子类覆写了父类的同步方法,然后调用父类中的方法,此时如果没有可重入的锁,那么这段代码件产生死锁。\n\n由于Fither和Child中的doSomething方法都是synchronized方法,因此每个doSomething方法在执行前都会获取Child对象实例上的锁。如果内置锁不是可重入的,那么在调用super.doSomething时将无法获得该Child对象上的互斥锁,因为这个锁已经被持有,从而线程会永远阻塞下去,一直在等待一个永远也无法获取的锁。重入则避免了这种死锁情况的发生。\n\n同一个线程在调用本类中其他synchronized方法/块或父类中的synchronized方法/块时,都不会阻碍该线程地执行,因为互斥锁时可重入的。"
},
{
"path": "Part2/JavaConcurrent/多线程环境中安全使用集合API.md",
"content": "#多线程环境中安全使用集合API\n---\n\n在集合API中,最初设计的Vector和Hashtable是多线程安全的。例如:对于Vector来说,用来添加和删除元素的方法是同步的。如果只有一个线程与Vector的实例交互,那么,要求获取和释放对象锁便是一种浪费,另外在不必要的时候如果滥用同步化,也有可能会带来死锁。因此,对于更改集合内容的方法,没有一个是同步化的。集合本质上是非多线程安全的,当多个线程与集合交互时,为了使它多线程安全,必须采取额外的措施。\n\n在Collections类 中有多个静态方法,它们可以获取通过同步方法封装非同步集合而得到的集合:\n\n* public static Collection synchronizedCollention(Collection c)\n* public static List synchronizedList(list l)\n* public static Map synchronizedMap(Map m)\n* public static Set synchronizedSet(Set s)\n* public static SortedMap synchronizedSortedMap(SortedMap sm)\n* public static SortedSet synchronizedSortedSet(SortedSet ss)\n\n\n这些方法基本上返回具有同步集合方法版本的新类。比如,为了创建多线程安全且由ArrayList支持的List,可以使用如下代码:\n\n```\nList list = Collection.synchronizedList(new ArrayList());\n```\n\n注意,ArrayList实例马上封装起来,不存在对未同步化ArrayList的直接引用(即直接封装匿名实例)。这是一种最安全的途径。如果另一个线程要直接引用ArrayList实例,它可以执行非同步修改。\n\n下面给出一段多线程中安全遍历集合元素的示例。我们使用Iterator逐个扫描List中的元素,在多线程环境中,当遍历当前集合中的元素时,一般希望阻止其他线程添加或删除元素。安全遍历的实现方法如下:\n\n```\nimport java.util.*; \n \npublic class SafeCollectionIteration extends Object { \n public static void main(String[] args) { \n //为了安全起见,仅使用同步列表的一个引用,这样可以确保控制了所有访问 \n //集合必须同步化,这里是一个List \n List wordList = Collections.synchronizedList(new ArrayList()); \n \n //wordList中的add方法是同步方法,会获取wordList实例的对象锁 \n wordList.add(\"Iterators\"); \n wordList.add(\"require\"); \n wordList.add(\"special\"); \n wordList.add(\"handling\"); \n \n //获取wordList实例的对象锁, \n //迭代时,阻塞其他线程调用add或remove等方法修改元素 \n synchronized ( wordList ) { \n Iterator iter = wordList.iterator(); \n while ( iter.hasNext() ) { \n String s = (String) iter.next(); \n System.out.println(\"found string: \" + s + \", length=\" + s.length()); \n } \n } \n } \n} \n```\n\n这里需要注意的是:在Java语言中,大部分的线程安全类都是相对线程安全的,它能保证对这个对象单独的操作时线程安全的,我们在调用的时候不需要额外的保障措施,但是对于一些特定的连续调用,就可能需要在调用端使用额外的同步手段来保证调用的正确性。例如Vector、HashTable、Collections的synchronizedXxxx()方法包装的集合等。"
},
{
"path": "Part2/JavaConcurrent/守护线程与阻塞线程.md",
"content": "#守护线程与阻塞线程的四种情况\n---\n\nJava中有两类线程:User Thread(用户线程)、Daemon Thread(守护线程)\n\n用户线程即运行在前台的线程,而守护线程是运行在后台的线程。 守护线程作用是为其他前台线程的运行提供便利服务,而且仅在普通、非守护线程仍然运行时才需要,比如垃圾回收线程就是一个守护线程。当VM检测仅剩一个守护线程,而用户线程都已经退出运行时,VM就会退出,因为如果没有了守护者,也就没有继续运行程序的必要了。如果有非守护线程仍然活着,VM就不会退出。\n\n守护线程并非只有虚拟机内部提供,用户在编写程序时也可以自己设置守护线程。用户可以用Thread的setDaemon(true)方法设置当前线程为守护线程。\n\n虽然守护线程可能非常有用,但必须小心确保其它所有非守护线程消亡时,不会由于它的终止而产生任何危害。因为你不可能知道在所有的用户线程退出运行前,守护线程是否已经完成了预期的服务任务。一旦所有的用户线程退出了,虚拟机也就退出运行了。因此,不要再守护线程中执行业务逻辑操作(比如对数据的读写等)。\n\n还有几点:\n\n1. setDaemon(true)必须在调用线程的start()方法之前设置,否则会跑出IllegalThreadStateException异常。\n2. 在守护线程中产生的新线程也是守护线程\n3. 不要认为所有的应用都可以分配给守护线程来进行服务,比如读写操作或者计算逻辑。\n\n\n##线程阻塞\n\n线程可以阻塞于四种状态:\n\n1. 当线程执行Thread.sleep()时,它一直阻塞到指定的毫秒时间之后,或者阻塞被另一个线程打断\n2. 当线程碰到一条wait()语句时,它会一直阻塞到接到通知(notify())、被中断或经过了指定毫秒 时间为止(若指定了超时值的话)\n3. 线程阻塞与不同的I/O的方式有多种。常见的一种方式是InputStream的read()方法,该方法一直阻塞到从流中读取一个字节的数据为止,它可以无限阻塞,因此不能指定超时时间\n4. 线程也可以阻塞等待获取某个对象锁的排它性访问权限(即等待获得synchronized语句必须的锁时阻塞)\n\n并非所有的阻塞状态都是可中断的,以上阻塞状态的前两种可以被中断,后两种不会对中断做出反应。\n"
},
{
"path": "Part2/JavaConcurrent/实现内存可见的两种方法比较:加锁和volatile变量.md",
"content": "#并发编程中实现内存可见的两种方法比较:加锁和volatile变量\n---\n\n 1. volatile变量是一种稍弱的同步机制在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比synchronized关键字更轻量级的同步机制。\n\n2. 从内存可见性的角度看,写入volatile变量相当于退出同步代码块,而读取volatile变量相当于进入同步代码块。\n\n3. 在代码中如果过度依赖volatile变量来控制状态的可见性,通常会比使用锁的代码更脆弱,也更难以理解。仅当volatile变量能简化代码的实现以及对同步策略的验证时,才应该使用它。一般来说,用同步机制会更安全些。\n\n4. 加锁机制(即同步机制)既可以确保可见性又可以确保原子性,而volatile变量只能确保可见性,原因是声明为volatile的简单变量如果当前值与该变量以前的值相关,那么volatile关键字不起作用,也就是说如下的表达式都不是原子操作:“count++”、“count = count+1”。\n\n当且仅当满足以下所有条件时,才应该使用volatile变量:\n\n1. 对变量的写入操作不依赖变量的当前值,或者你能确保只有单个线程更新变量的值。\n2. 该变量没有包含在具有其他变量的不变式中。\n\n\n总结:在需要同步的时候,第一选择应该是synchronized关键字,这是最安全的方式,尝试其他任何方式都是有风险的。尤其在、jdK1.5之后,对synchronized同步机制做了很多优化,如:自适应的自旋锁、锁粗化、锁消除、轻量级锁等,使得它的性能明显有了很大的提升。"
},
{
"path": "Part2/JavaConcurrent/死锁.md",
"content": "#死锁\n---\n\n当线程需要同时持有多个锁时,有可能产生死锁。考虑如下情形:\n\n线程A当前持有互斥所锁lock1,线程B当前持有互斥锁lock2。接下来,当线程A仍然持有lock1时,它试图获取lock2,因为线程B正持有lock2,因此线程A会阻塞等待线程B对lock2的释放。如果此时线程B在持有lock2的时候,也在试图获取lock1,因为线程A正持有lock1,因此线程B会阻塞等待A对lock1的释放。二者都在等待对方所持有锁的释放,而二者却又都没释放自己所持有的锁,这时二者便会一直阻塞下去。这种情形称为死锁。\n\n下面给出一个两个线程间产生死锁的示例,如下:\n\n```\n\npublic class Deadlock {\n\n\tprivate String objID;\n\n\tpublic Deadlock(String id) {\n\t\tobjID = id;\n\t}\n\n\tpublic synchronized void checkOther(Deadlock other) {\n\t\tprint(\"entering checkOther()\"); \n try { Thread.sleep(2000); } \n catch ( InterruptedException x ) { } \n print(\"in checkOther() - about to \" + \"invoke 'other.action()'\"); \n //调用other对象的action方法,由于该方法是同步方法,因此会试图获取other对象的对象锁 \n other.action(); \n print(\"leaving checkOther()\"); \n\t}\n\t\n\tpublic synchronized void action() { \n print(\"entering action()\"); \n try { Thread.sleep(500); } \n catch ( InterruptedException x ) { } \n print(\"leaving action()\"); \n } \n\n\tpublic void print(String msg) {\n\t\tthreadPrint(\"objID=\" + objID + \" - \" + msg);\n\t}\n\t\n\tpublic static void threadPrint(String msg) { \n String threadName = Thread.currentThread().getName(); \n System.out.println(threadName + \": \" + msg); \n } \n\t\n\tpublic static void main(String[] args) {\n\t\tfinal Deadlock obj1 = new Deadlock(\"obj1\"); \n final Deadlock obj2 = new Deadlock(\"obj2\"); \n \n Runnable runA = new Runnable() { \n public void run() { \n obj1.checkOther(obj2); \n } \n }; \n \n Thread threadA = new Thread(runA, \"threadA\"); \n threadA.start(); \n \n try { Thread.sleep(200); } \n catch ( InterruptedException x ) { } \n \n Runnable runB = new Runnable() { \n public void run() { \n obj2.checkOther(obj1); \n } \n }; \n \n Thread threadB = new Thread(runB, \"threadB\"); \n threadB.start(); \n \n try { Thread.sleep(5000); } \n catch ( InterruptedException x ) { } \n \n threadPrint(\"finished sleeping\"); \n \n threadPrint(\"about to interrupt() threadA\"); \n \n threadA.interrupt(); \n \n try { Thread.sleep(1000); } \n catch ( InterruptedException x ) { } \n \n threadPrint(\"about to interrupt() threadB\"); \n threadB.interrupt(); \n \n try { Thread.sleep(1000); } \n catch ( InterruptedException x ) { } \n \n threadPrint(\"did that break the deadlock?\"); \n\t}\n}\n\n```\n\n运行结果:\n\n```\nthreadA: objID=obj1 - entering checkOther()\nthreadB: objID=obj2 - entering checkOther()\nthreadA: objID=obj1 - in checkOther() - about to invoke 'other.action()'\nthreadB: objID=obj2 - in checkOther() - about to invoke 'other.action()'\nmain: finished sleeping\nmain: about to interrupt() threadA\nmain: about to interrupt() threadB\nmain: did that break the deadlock?\n```\n\n从结果中可以看出,在执行到other.action()时,由于两个线程都在试图获取对方的锁,但对方都没有释放自己的锁,因而便产生了死锁,在主线程中试图中断两个线程,但都无果。\n\n大部分代码并不容易产生死锁,死锁可能在代码中隐藏相当长的时间,等待不常见的条件地发生,但即使是很小的概率,一旦发生,便可能造成毁灭性的破坏。避免死锁是一件困难的事,遵循以下原则有助于规避死锁: \n\n1. 只在必要的最短时间内持有锁,考虑使用同步语句块代替整个同步方法;\n2. 尽量编写不在同一时刻需要持有多个锁的代码,如果不可避免,则确保线程持有第二个锁的时间尽量短暂;\n3. 创建和使用一个大锁来代替若干小锁,并把这个锁用于互斥,而不是用作单个对象的对象级别锁;"
},
{
"path": "Part2/JavaConcurrent/生产者和消费者问题.md",
"content": "#生产者和消费者问题\n\n\n```\npackage 生产者消费者;\n\npublic class ProducerConsumerTest {\n\n\tpublic static void main(String[] args) {\n\t\tPublicResource resource = new PublicResource();\n\t\tnew Thread(new ProducerThread(resource)).start();\n new Thread(new ConsumerThread(resource)).start();\n new Thread(new ProducerThread(resource)).start();\n new Thread(new ConsumerThread(resource)).start();\n new Thread(new ProducerThread(resource)).start();\n new Thread(new ConsumerThread(resource)).start();\n\t}\n}\n```\n```\npackage 生产者消费者;\n/**\n * 生产者线程,负责生产公共资源\n * @author dream\n *\n */\npublic class ProducerThread implements Runnable{\n\n\tprivate PublicResource resource;\n\n\t\n\tpublic ProducerThread(PublicResource resource) {\n\t\tthis.resource = resource;\n\t}\n\n\n\t@Override\n\tpublic void run() {\n\t\twhile (true) {\n\t\t\ttry {\n\t\t\t\tThread.sleep((long) (Math.random() * 1000));\n\t\t\t} catch (InterruptedException e) {\n\t\t\t\te.printStackTrace();\n\t\t\t}\n\t\t\tresource.increase();\n\t\t}\n\t}\n\t\n\t\n}\n```\n\n```\npackage 生产者消费者;\n\n/**\n * 消费者线程,负责消费公共资源\n * @author dream\n *\n */\npublic class ConsumerThread implements Runnable{\n\n\tprivate PublicResource resource;\n\t\n\t\n\tpublic ConsumerThread(PublicResource resource) {\n\t\tthis.resource = resource;\n\t}\n\n\n\t@Override\n\tpublic void run() {\n\t\twhile (true) {\n\t\t\ttry {\n\t\t\t\tThread.sleep((long) (Math.random() * 1000));\n\t\t\t} catch (InterruptedException e) {\n\t\t\t\t// TODO Auto-generated catch block\n\t\t\t\te.printStackTrace();\n\t\t\t}\n\t\t\tresource.decrease();\n\t\t}\n\t\t\n\t}\n\t\n\n}\n```\n\n```\npackage 生产者消费者;\n\n/**\n * 公共资源类\n * @author dream\n *\n */\npublic class PublicResource {\n\n\tprivate int number = 0;\n\tprivate int size = 10;\n\t\n\t/**\n\t * 增加公共资源\n\t */\n\tpublic synchronized void increase()\n\t{\n\t\twhile (number >= size) {\n\t\t\ttry {\n\t\t\t\twait();\n\t\t\t} catch (InterruptedException e) {\n\t\t\t\t// TODO Auto-generated catch block\n\t\t\t\te.printStackTrace();\n\t\t\t}\n\t\t}\n\t\tnumber++;\n\t\tSystem.out.println(\"生产了1个,总共有\" + number);\n\t\tnotifyAll();\n\t}\n\t\n\t\n\t/**\n\t * 减少公共资源\n\t */\n\tpublic synchronized void decrease()\n\t{\n\t\twhile (number <= 0) {\n\t\t\ttry {\n\t\t\t\twait();\n\t\t\t} catch (InterruptedException e) {\n\t\t\t\t// TODO Auto-generated catch block\n\t\t\t\te.printStackTrace();\n\t\t\t}\n\t\t}\n\t\tnumber--;\n\t\tSystem.out.println(\"消费了1个,总共有\" + number);\n\t\tnotifyAll();\n\t}\n}\n\n```\n"
},
{
"path": "Part2/JavaConcurrent/线程中断.md",
"content": "#线程中断\n---\n\n##使用interrupt()中断线程\n\n当一个线程运行时,另一个线程可以调用对应的Thread对象的interrupt()方法来中断它,该方法只是在目标线程中设置一个标志,表示它已经被中断,并立即返回。这里需要注意的是,如果只是单纯的调用interrupt()方法,线程并没有实际被中断,会继续往下执行。\n\n演示休眠线程的中断\n\n```\n\npublic class SleepInterrupt extends Object implements Runnable{\n\n\t@Override\n\tpublic void run() {\n\t\t\n\t\ttry {\n\t\t\tSystem.out.println(\"in run() - about to sleep for 20 seconds\");\n\t\t\tThread.sleep(20000);\n\t\t\tSystem.out.println(\"in run() - woke up\");\n\t\t} catch (InterruptedException e) {\n\t\t\tSystem.out.println(\"in run() - interrupted while sleeping\");\n\t\t\t//处理完中断异常后,返回到run()方法入口\n\t\t\t//如果没有return,线程不会实际被中断,它会继续打印下面的信息\n\t\t\treturn;\n\t\t}\n\t\tSystem.out.println(\"in run() - leaving normally\");\n\t}\n\t\n\tpublic static void main(String[] args) {\n\t\tSleepInterrupt si = new SleepInterrupt();\n\t\tThread t = new Thread(si);\n\t\tt.start();\n\t\t//住线程休眠2秒,从而确保刚才启动的线程有机会执行一段时间\n\t\ttry {\n\t\t\tThread.sleep(2000);\n\t\t} catch (InterruptedException e) {\n\t\t\te.printStackTrace();\n\t\t}\n\t\tSystem.out.println(\"in main() - interrupting other thread\"); \n\t\t//中断线程t\n\t\tt.interrupt();\n\t\tSystem.out.println(\"in main() - leaving\");\n\t}\n\n}\n\n```\n\n运行结果如下:\n\n```\nin run() - about to sleep for 20 seconds\nin main() - interrupting other thread\nin main() - leaving\nin run() - interrupted while sleeping\n```\n\n主线程启动新线程后,自身休眠2秒钟,允许新线程获得运行时间。新线程打印信息“about to sleep for 20 seconds”后,继而休眠20秒钟,大约2秒钟后,main线程通知新线程中断,那么新线程的20秒的休眠将被打断,从而抛出InterruptException异常,执行跳转到catch块,打印出“interrupted while sleeping”信息,并立即从run()方法返回,然后消亡,而不会打印出catch块后面的“leaving normally”信息。\n\n请注意:由于不确定的线程规划,上图运行结果的后两行可能顺序相反,这取决于主线程和新线程哪个先消亡。但前两行信息的顺序必定如上图所示。\n\n另外,如果将catch块中的return语句注释掉,则线程在抛出异常后,会继续往下执行,而不会被中断,从而会打印出”leaving normally“信息。\n\n##待决中断\n---\n在上面的例子中,sleep()方法的实现检查到休眠线程被中断,它会相当友好地终止线程,并抛出InterruptedException异常。另外一种情况,如果线程在调用sleep()方法前被中断,那么该中断称为待决中断,它会在刚调用sleep()方法时,立即抛出InterruptedException异常。\n\n```\n\npublic class PendingInterrupt extends Object{\n\n\tpublic static void main(String[] args) {\n\t\t//如果输入了参数,则在main线程中中断当前线程(即main线程)\n\t\tif(args.length > 0){\n\t\t\tThread.currentThread().interrupt();\n\t\t}\n\t\t//获取当前时间\n\t\tlong startTime = System.currentTimeMillis();\n\t\ttry {\n\t\t\tThread.sleep(2000);\n\t\t\tSystem.out.println(\"was NOT interrupted\");\n\t\t} catch (InterruptedException e) {\n\t\t\tSystem.out.println(\"was interrupted\");\n\t\t}\n\t\t//计算中间代码执行的时间\n\t\tSystem.out.println(\"elapsedTime=\" + (System.currentTimeMillis() - startTime));\n\t}\n}\n\n```\n\n如果PendingInterrupt不带任何命令行参数,那么线程不会被中断,最终输出的时间差距应该在2000附近(具体时间由系统决定,不精确),如果PendingInterrupt带有命令行参数,则调用中断当前线程的代码,但main线程仍然运行,最终输出的时间差距应该远小于2000,因为线程尚未休眠,便被中断,因此,一旦调用sleep()方法,会立即打印出catch块中的信息。执行结果如下:\n\n```\nwas NOT interrupted\nelapsedTime=2001\n\n```\n\n这种模式下,main线程中断它自身。除了将中断标志(它是Thread的内部标志)设置为true外,没有其他任何影响。线程被中断了,但main线程仍然运行,main线程继续监视实时时钟,并进入try块,一旦调用sleep()方法,它就会注意到待决中断的存在,并抛出InterruptException。于是执行跳转到catch块,并打印出线程被中断的信息。最后,计算并打印出时间差。\n\n##使用isInterrupted()方法判断中断状态\n---\n\n可以在Thread对象上调用isInterrupted()方法来检查任何线程的中断状态。这里需要注意:线程一旦被中断,isInterrupted()方法便会返回true,而一旦sleep()方法抛出异常,它将清空中断标志,此时isInterrupted()方法将返回false。\n\n下面的代码演示了isInterrupted()方法的使用:\n\n```\n\npublic class InterruptCheck extends Object{\n\t\n\tpublic static void main(String[] args) {\n\t\tThread t = Thread.currentThread();\n\t\tSystem.out.println(\"Point A: t.isInterrupted()=\" + t.isInterrupted()); \n //待决中断,中断自身 \n t.interrupt(); \n System.out.println(\"Point B: t.isInterrupted()=\" + t.isInterrupted()); \n System.out.println(\"Point C: t.isInterrupted()=\" + t.isInterrupted()); \n\t\n try {\n\t\t\tThread.sleep(2000);\n\t\t\tSystem.out.println(\"was NOT interrupted\"); \n\t\t} catch (InterruptedException e) {\n\t\t\tSystem.out.println(\"was interrupted\"); \n\t\t}\n //跑出异常后,会清除中断标志,这里会返回false\n System.out.println(\"Point D: t.isInterrupted()=\" + t.isInterrupted());\n\t}\n\n}\n\n```\n\n运行结果如下:\n\n```\nPoint A: t.isInterrupted()=false\nPoint B: t.isInterrupted()=true\nPoint C: t.isInterrupted()=true\nwas interrupted\nPoint D: t.isInterrupted()=false\n\n```\n\n##使用Thread.interrupted()方法判断中断状态\n---\n\n可以使用Thread.interrupted()方法来检查当前线程的中断状态(并隐式重置为false)。又由于它是静态方法,因此不能在特定的线程上使用,而只能报告调用它的线程的中断状态,如果线程被中断,而且中断状态尚不清楚,那么,这个方法返回true。与isInterrupted()不同,它将自动重置中断状态为false,第二次调用Thread.interrupted()方法,总是返回false,除非中断了线程。\n\n如下代码演示了Thread.interrupted()方法的使用:\n\n```\n\npublic class InterruptReset extends Object{\n\t\n\tpublic static void main(String[] args) {\n\t\tSystem.out.println( \n\t \"Point X: Thread.interrupted()=\" + Thread.interrupted()); \n\t Thread.currentThread().interrupt(); \n\t System.out.println( \n\t \"Point Y: Thread.interrupted()=\" + Thread.interrupted()); \n\t System.out.println( \n\t \"Point Z: Thread.interrupted()=\" + Thread.interrupted()); \n\t}\n\n}\n\n```\n\n运行结果\n\n\n```\nPoint X: Thread.interrupted()=false\nPoint Y: Thread.interrupted()=true\nPoint Z: Thread.interrupted()=false\n\n```\n\n从结果中可以看出,当前线程中断自身后,在Y点,中断状态为true,并由Thread.interrupted()自动重置为false,那么下次调用该方法得到的结果便是false。\n\n##补充\n---\n\nyield和join方法的使用\n\n* join方法用线程对象调用,如果在一个线程A中调用另一个线程B的join方法,线程A将会等待线程B执行完毕后再执行。\n* yield可以直接用Thread类调用,yield让出CPU执行权给同等级的线程,如果没有相同级别的线程在等待CPU的执行权,则该线程继续执行。"
},
{
"path": "Part2/JavaConcurrent/线程挂起、恢复与终止的正确方法.md",
"content": "#线程挂起、恢复与终止的正确方法(含代码)\n---\n\n##挂起和恢复线程\n\nThread 的API中包含两个被淘汰的方法,它们用于临时挂起和重启某个线程,这些方法已经被淘汰,因为它们是不安全的,不稳定的。如果在不合适的时候挂起线程(比如,锁定共享资源时),此时便可能会发生死锁条件——其他线程在等待该线程释放锁,但该线程却被挂起了,便会发生死锁。另外,在长时间计算期间挂起线程也可能导致问题。\n\n下面的代码演示了通过休眠来延缓运行,模拟长时间运行的情况,使线程更可能在不适当的时候被挂起:\n\n```\n\n```"
},
{
"path": "Part2/JavaSE/ArrayList 、 LinkedList 、 Vector 的底层实现和区别.md",
"content": "#Java基础之集合List-ArrayList、LinkedList、Vector的底层实现和区别\n\n\n\n1. ArrayList底层实际是采用数组实现的(并且该数组的类型是Object类型的)\n2. 如果jdk6,采用Array.copyOf()方法来生成一个新的数组,如果是jdk5,采用的是System.arraycopy()方法(当添加的数据量大于数组的长度的时候)\n3. List list = new ArrayList()时,底层会生成一个长度为10的数组来存放对象\n4. ArrayList、Vector底部都是采用数组实现的\n5. 对于ArrayList,方法都不是同步的,对于Vector,大部分public方法都是同步的\n6. LinkedList采用双向循环列表\n7. 对于ArrayList,查询速度很快,增加和删除(非最后一个节点)操作非常慢(本质上由数组的特性决定的)\n8. 对于LinkedList,查询速度非常慢,增加和删除操作非常快(本质上是由双向循环列表决定的)\n\n参考博客:\n\n[http://blog.csdn.net/sundenskyqq/article/details/27630179](http://blog.csdn.net/sundenskyqq/article/details/27630179)\n"
},
{
"path": "Part2/JavaSE/ArrayList源码剖析.md",
"content": "##ArrayList简介\n\nArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存。\n\nArrayList不是线程安全的,只能在单线程环境下,多线程环境下可以考虑用collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的CopyOnWriteArrayList类。\n\n ArrayList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问,实现了Cloneable接口,能被克隆。\n\nArrayList源码剖析\n\nArrayList的源码如下(加入了比较详细的注释):\n\n```\npackage java.util; \n \npublic class ArrayList extends AbstractList \n implements List, RandomAccess, Cloneable, java.io.Serializable \n{ \n // 序列版本号 \n private static final long serialVersionUID = 8683452581122892189L; \n \n // ArrayList基于该数组实现,用该数组保存数据 \n private transient Object[] elementData; \n \n // ArrayList中实际数据的数量 \n private int size; \n \n // ArrayList带容量大小的构造函数。 \n public ArrayList(int initialCapacity) { \n super(); \n if (initialCapacity < 0) \n throw new IllegalArgumentException(\"Illegal Capacity: \"+ \n initialCapacity); \n // 新建一个数组 \n this.elementData = new Object[initialCapacity]; \n } \n \n // ArrayList无参构造函数。默认容量是10。 \n public ArrayList() { \n this(10); \n } \n \n // 创建一个包含collection的ArrayList \n public ArrayList(Collection c) { \n elementData = c.toArray(); \n size = elementData.length; \n if (elementData.getClass() != Object[].class) \n elementData = Arrays.copyOf(elementData, size, Object[].class); \n } \n \n \n // 将当前容量值设为实际元素个数 \n public void trimToSize() { \n modCount++; \n int oldCapacity = elementData.length; \n if (size < oldCapacity) { \n elementData = Arrays.copyOf(elementData, size); \n } \n } \n \n \n // 确定ArrarList的容量。 \n // 若ArrayList的容量不足以容纳当前的全部元素,设置 新的容量=“(原始容量x3)/2 + 1” \n public void ensureCapacity(int minCapacity) { \n // 将“修改统计数”+1,该变量主要是用来实现fail-fast机制的 \n modCount++; \n int oldCapacity = elementData.length; \n // 若当前容量不足以容纳当前的元素个数,设置 新的容量=“(原始容量x3)/2 + 1” \n if (minCapacity > oldCapacity) { \n Object oldData[] = elementData; \n int newCapacity = (oldCapacity * 3)/2 + 1; \n //如果还不够,则直接将minCapacity设置为当前容量 \n if (newCapacity < minCapacity) \n newCapacity = minCapacity; \n elementData = Arrays.copyOf(elementData, newCapacity); \n } \n } \n \n // 添加元素e \n public boolean add(E e) { \n // 确定ArrayList的容量大小 \n ensureCapacity(size + 1); // Increments modCount!! \n // 添加e到ArrayList中 \n elementData[size++] = e; \n return true; \n } \n \n // 返回ArrayList的实际大小 \n public int size() { \n return size; \n } \n \n // ArrayList是否包含Object(o) \n public boolean contains(Object o) { \n return indexOf(o) >= 0; \n } \n \n //返回ArrayList是否为空 \n public boolean isEmpty() { \n return size == 0; \n } \n \n // 正向查找,返回元素的索引值 \n public int indexOf(Object o) { \n if (o == null) { \n for (int i = 0; i < size; i++) \n if (elementData[i]==null) \n return i; \n } else { \n for (int i = 0; i < size; i++) \n if (o.equals(elementData[i])) \n return i; \n } \n return -1; \n } \n \n // 反向查找,返回元素的索引值 \n public int lastIndexOf(Object o) { \n if (o == null) { \n for (int i = size-1; i >= 0; i--) \n if (elementData[i]==null) \n return i; \n } else { \n for (int i = size-1; i >= 0; i--) \n if (o.equals(elementData[i])) \n return i; \n } \n return -1; \n } \n \n // 反向查找(从数组末尾向开始查找),返回元素(o)的索引值 \n public int lastIndexOf(Object o) { \n if (o == null) { \n for (int i = size-1; i >= 0; i--) \n if (elementData[i]==null) \n return i; \n } else { \n for (int i = size-1; i >= 0; i--) \n if (o.equals(elementData[i])) \n return i; \n } \n return -1; \n } \n \n \n // 返回ArrayList的Object数组 \n public Object[] toArray() { \n return Arrays.copyOf(elementData, size); \n } \n \n // 返回ArrayList元素组成的数组 \n public T[] toArray(T[] a) { \n // 若数组a的大小 < ArrayList的元素个数; \n // 则新建一个T[]数组,数组大小是“ArrayList的元素个数”,并将“ArrayList”全部拷贝到新数组中 \n if (a.length < size) \n return (T[]) Arrays.copyOf(elementData, size, a.getClass()); \n \n // 若数组a的大小 >= ArrayList的元素个数; \n // 则将ArrayList的全部元素都拷贝到数组a中。 \n System.arraycopy(elementData, 0, a, 0, size); \n if (a.length > size) \n a[size] = null; \n return a; \n } \n \n // 获取index位置的元素值 \n public E get(int index) { \n RangeCheck(index); \n \n return (E) elementData[index]; \n } \n \n // 设置index位置的值为element \n public E set(int index, E element) { \n RangeCheck(index); \n \n E oldValue = (E) elementData[index]; \n elementData[index] = element; \n return oldValue; \n } \n \n // 将e添加到ArrayList中 \n public boolean add(E e) { \n ensureCapacity(size + 1); // Increments modCount!! \n elementData[size++] = e; \n return true; \n } \n \n // 将e添加到ArrayList的指定位置 \n public void add(int index, E element) { \n if (index > size || index < 0) \n throw new IndexOutOfBoundsException( \n \"Index: \"+index+\", Size: \"+size); \n \n ensureCapacity(size+1); // Increments modCount!! \n System.arraycopy(elementData, index, elementData, index + 1, \n size - index); \n elementData[index] = element; \n size++; \n } \n \n // 删除ArrayList指定位置的元素 \n public E remove(int index) { \n RangeCheck(index); \n \n modCount++; \n E oldValue = (E) elementData[index]; \n \n int numMoved = size - index - 1; \n if (numMoved > 0) \n System.arraycopy(elementData, index+1, elementData, index, \n numMoved); \n elementData[--size] = null; // Let gc do its work \n \n return oldValue; \n } \n \n // 删除ArrayList的指定元素 \n public boolean remove(Object o) { \n if (o == null) { \n for (int index = 0; index < size; index++) \n if (elementData[index] == null) { \n fastRemove(index); \n return true; \n } \n } else { \n for (int index = 0; index < size; index++) \n if (o.equals(elementData[index])) { \n fastRemove(index); \n return true; \n } \n } \n return false; \n } \n \n \n // 快速删除第index个元素 \n private void fastRemove(int index) { \n modCount++; \n int numMoved = size - index - 1; \n // 从\"index+1\"开始,用后面的元素替换前面的元素。 \n if (numMoved > 0) \n System.arraycopy(elementData, index+1, elementData, index, \n numMoved); \n // 将最后一个元素设为null \n elementData[--size] = null; // Let gc do its work \n } \n \n // 删除元素 \n public boolean remove(Object o) { \n if (o == null) { \n for (int index = 0; index < size; index++) \n if (elementData[index] == null) { \n fastRemove(index); \n return true; \n } \n } else { \n // 便利ArrayList,找到“元素o”,则删除,并返回true。 \n for (int index = 0; index < size; index++) \n if (o.equals(elementData[index])) { \n fastRemove(index); \n return true; \n } \n } \n return false; \n } \n \n // 清空ArrayList,将全部的元素设为null \n public void clear() { \n modCount++; \n \n for (int i = 0; i < size; i++) \n elementData[i] = null; \n \n size = 0; \n } \n \n // 将集合c追加到ArrayList中 \n public boolean addAll(Collection c) { \n Object[] a = c.toArray(); \n int numNew = a.length; \n ensureCapacity(size + numNew); // Increments modCount \n System.arraycopy(a, 0, elementData, size, numNew); \n size += numNew; \n return numNew != 0; \n } \n \n // 从index位置开始,将集合c添加到ArrayList \n public boolean addAll(int index, Collection c) { \n if (index > size || index < 0) \n throw new IndexOutOfBoundsException( \n \"Index: \" + index + \", Size: \" + size); \n \n Object[] a = c.toArray(); \n int numNew = a.length; \n ensureCapacity(size + numNew); // Increments modCount \n \n int numMoved = size - index; \n if (numMoved > 0) \n System.arraycopy(elementData, index, elementData, index + numNew, \n numMoved); \n \n System.arraycopy(a, 0, elementData, index, numNew); \n size += numNew; \n return numNew != 0; \n } \n \n // 删除fromIndex到toIndex之间的全部元素。 \n protected void removeRange(int fromIndex, int toIndex) { \n modCount++; \n int numMoved = size - toIndex; \n System.arraycopy(elementData, toIndex, elementData, fromIndex, \n numMoved); \n \n // Let gc do its work \n int newSize = size - (toIndex-fromIndex); \n while (size != newSize) \n elementData[--size] = null; \n } \n \n private void RangeCheck(int index) { \n if (index >= size) \n throw new IndexOutOfBoundsException( \n \"Index: \"+index+\", Size: \"+size); \n } \n \n \n // 克隆函数 \n public Object clone() { \n try { \n ArrayList v = (ArrayList) super.clone(); \n // 将当前ArrayList的全部元素拷贝到v中 \n v.elementData = Arrays.copyOf(elementData, size); \n v.modCount = 0; \n return v; \n } catch (CloneNotSupportedException e) { \n // this shouldn't happen, since we are Cloneable \n throw new InternalError(); \n } \n } \n \n \n // java.io.Serializable的写入函数 \n // 将ArrayList的“容量,所有的元素值”都写入到输出流中 \n private void writeObject(java.io.ObjectOutputStream s) \n throws java.io.IOException{ \n // Write out element count, and any hidden stuff \n int expectedModCount = modCount; \n s.defaultWriteObject(); \n \n // 写入“数组的容量” \n s.writeInt(elementData.length); \n \n // 写入“数组的每一个元素” \n for (int i=0; i T[] copyOf(T[] original, int newLength) { \n return (T[]) copyOf(original, newLength, original.getClass()); \n} \n```\n\n很明显调用了另一个copyof方法,该方法有三个参数,最后一个参数指明要转换的数据的类型,其源码如下:\n\n```\npublic static T[] copyOf(U[] original, int newLength, Class newType) { \n T[] copy = ((Object)newType == (Object)Object[].class) \n ? (T[]) new Object[newLength] \n : (T[]) Array.newInstance(newType.getComponentType(), newLength); \n System.arraycopy(original, 0, copy, 0, \n Math.min(original.length, newLength)); \n return copy; \n} \n```\n\n这里可以很明显地看出,该方法实际上是在其内部又创建了一个长度为newlength的数组,调用System.arraycopy()方法,将原来数组中的元素复制到了新的数组中。\n\n下面来看System.arraycopy()方法。该方法被标记了native,调用了系统的C/C++代码,在JDK中是看不到的,但在openJDK中可以看到其源码。该函数实际上最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时用该方法,以取得更高的效率。\n4. 注意ArrayList的两个转化为静态数组的toArray方法。\n\n第一个,Object[] toArray()方法。该方法有可能会抛出java.lang.ClassCastException异常,如果直接用向下转型的方法,将整个ArrayList集合转变为指定类型的Array数组,便会抛出该异常,而如果转化为Array数组时不向下转型,而是将每个元素向下转型,则不会抛出该异常,显然对数组中的元素一个个进行向下转型,效率不高,且不太方便。\n\n第二个, T[] toArray(T[] a)方法。该方法可以直接将ArrayList转换得到的Array进行整体向下转型(转型其实是在该方法的源码中实现的),且从该方法的源码中可以看出,参数a的大小不足时,内部会调用Arrays.copyOf方法,该方法内部创建一个新的数组返回,因此对该方法的常用形式如下:\n\n```\npublic static Integer[] vectorToArray2(ArrayList v) { \n Integer[] newText = (Integer[])v.toArray(new Integer[0]); \n return newText; \n} \n```\n\n\n5.ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。\n\n6.在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。"
},
{
"path": "Part2/JavaSE/Arraylist.md",
"content": "# ArrarList \n---\n* 是一个类\n* 实现的接口:List、Collectin、Iterable、Serializable、Cloneable、RandomAccess\n* 子类:AttributeList、RoleList、RoleUnresolvedList\n\n##简介\n---\n* 它是顺序表\n* 大小可变\n* 允许null元素\n* 可LinkedList一样,不具备线程同步的安全性、但速度较快\n* 第一次定义的时候没有指定数组的长度则长度是0,在第一次添加的时候判断如果是空则追加10。\n\n##容量是如何变化的\n---\n在源码中:\n\n```\nprivate transient Object[] elementData;\n```\n用于保存对象。它会随着元素的添加而改变大小。在下面的叙述中,容量指的是elementData.length,而不是size。\n\n>size不是容量,ArrayList对象占用的内存不是由size决定的。\n>size的大小在每次调用add(E e)方法时加1。\n>如果是调用ArrayList(Collection c)构造方法,则size的初始值为c\n\n* 如果在初始化时,没有指定大小,则容量大小为0。\n* 当大小为0时,第一次添加元素容量大小变为10。\n* 之后每次添加时,会先确保容量是否够用\n* 如果不够用,每次增加的容量为 newCapacity = oldCapacity + (oldCapacity >> 1);即,每次增加为原来的1.5倍。\n\n##和Vector的区别\n---\n* Vector线程安全\n* ArrayList线程不安全,速度快\n\n##和LinkedList的区别\n---\n* ArrayList是顺序表,LinkedList是链表\n* ArrayList查找,修改方便,LinkedList添加、删除方便\n\n##方法\n---\n**void ensureCapacity(int minCapacity)**\n设置容量能容纳下minCapacity个元素\n\n* 如果"
},
{
"path": "Part2/JavaSE/Arraylist和Hashmap如何扩容等.md",
"content": "#Arraylist和HashMap如何扩容?\n\n\n\n#负载因子有什么作用?\n\n\n\n\n#如何保证读写进程安全?\n"
},
{
"path": "Part2/JavaSE/Collection.md",
"content": "\n####线性表,链表,哈希表是常用的数据结构,在进行Java开发时,JDK已经为我们提供了一系列相应的类来实现基本的数据结构。这些类均在java.util包中。本文试图通过简单的描述,向读者阐述各个类的作用以及如何正确使用这些类。 \n\n# Collection \n***\n* 是最基本的集合接口\n* 继承的接口:Iterable\n* 子接口:List、Set、Queue等\n\n##简介\n* 一个Collection代表一组Object,即Collection的元素(Elements),一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。\n* Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。\n\n##如何遍历Collection中的每一个元素?\n* 不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素,代码如下:\n\n\n\n```\n\n\tIterator it = collection.iterator(); // 获得一个迭代子\n while(it.hasNext()) \n {\n Object obj = it.next(); // 得到下一个元素\n }\n```\n\n## 方法\n\r\n**retainAll(Collection c)**:保留,交运算 \r\n**addAll(Collection c)**:添加,并运算 \r\n**removeAll(Collection c)**:移除,减运算 \n\n\n\n\n"
},
{
"path": "Part2/JavaSE/HashMap源码剖析.md",
"content": "###HashMap简介\n HashMap是基于哈希表实现的,每一个元素都是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阈值)时,同样会自动增长。\n\nHashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。\n\nHashMap实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。\n\n###HashMap源码剖析\n\nHashMap的源码如下(加入了比较详细的注释):\n\n```\npackage java.util; \nimport java.io.*; \n \npublic class HashMap \n extends AbstractMap \n implements Map, Cloneable, Serializable \n{ \n \n // 默认的初始容量(容量为HashMap中槽的数目)是16,且实际容量必须是2的整数次幂。 \n static final int DEFAULT_INITIAL_CAPACITY = 16; \n \n // 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换) \n static final int MAXIMUM_CAPACITY = 1 << 30; \n \n // 默认加载因子为0.75 \n static final float DEFAULT_LOAD_FACTOR = 0.75f; \n \n // 存储数据的Entry数组,长度是2的幂。 \n // HashMap采用链表法解决冲突,每一个Entry本质上是一个单向链表 \n transient Entry[] table; \n \n // HashMap的底层数组中已用槽的数量 \n transient int size; \n \n // HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子) \n int threshold; \n \n // 加载因子实际大小 \n final float loadFactor; \n \n // HashMap被改变的次数 \n transient volatile int modCount; \n \n // 指定“容量大小”和“加载因子”的构造函数 \n public HashMap(int initialCapacity, float loadFactor) { \n if (initialCapacity < 0) \n throw new IllegalArgumentException(\"Illegal initial capacity: \" + \n initialCapacity); \n // HashMap的最大容量只能是MAXIMUM_CAPACITY \n if (initialCapacity > MAXIMUM_CAPACITY) \n initialCapacity = MAXIMUM_CAPACITY; \n //加载因此不能小于0 \n if (loadFactor <= 0 || Float.isNaN(loadFactor)) \n throw new IllegalArgumentException(\"Illegal load factor: \" + \n loadFactor); \n \n // 找出“大于initialCapacity”的最小的2的幂 \n int capacity = 1; \n while (capacity < initialCapacity) \n capacity <<= 1; \n \n // 设置“加载因子” \n this.loadFactor = loadFactor; \n // 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。 \n threshold = (int)(capacity * loadFactor); \n // 创建Entry数组,用来保存数据 \n table = new Entry[capacity]; \n init(); \n } \n \n \n // 指定“容量大小”的构造函数 \n public HashMap(int initialCapacity) { \n this(initialCapacity, DEFAULT_LOAD_FACTOR); \n } \n \n // 默认构造函数。 \n public HashMap() { \n // 设置“加载因子”为默认加载因子0.75 \n this.loadFactor = DEFAULT_LOAD_FACTOR; \n // 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。 \n threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR); \n // 创建Entry数组,用来保存数据 \n table = new Entry[DEFAULT_INITIAL_CAPACITY]; \n init(); \n } \n \n // 包含“子Map”的构造函数 \n public HashMap(Map m) { \n this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, \n DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR); \n // 将m中的全部元素逐个添加到HashMap中 \n putAllForCreate(m); \n } \n \n //求hash值的方法,重新计算hash值 \n static int hash(int h) { \n h ^= (h >>> 20) ^ (h >>> 12); \n return h ^ (h >>> 7) ^ (h >>> 4); \n } \n \n // 返回h在数组中的索引值,这里用&代替取模,旨在提升效率 \n // h & (length-1)保证返回值的小于length \n static int indexFor(int h, int length) { \n return h & (length-1); \n } \n \n public int size() { \n return size; \n } \n \n public boolean isEmpty() { \n return size == 0; \n } \n \n // 获取key对应的value \n public V get(Object key) { \n if (key == null) \n return getForNullKey(); \n // 获取key的hash值 \n int hash = hash(key.hashCode()); \n // 在“该hash值对应的链表”上查找“键值等于key”的元素 \n for (Entry e = table[indexFor(hash, table.length)]; \n e != null; \n e = e.next) { \n Object k; \n //判断key是否相同 \n if (e.hash == hash && ((k = e.key) == key || key.equals(k))) \n return e.value; \n } \n //没找到则返回null \n return null; \n } \n \n // 获取“key为null”的元素的值 \n // HashMap将“key为null”的元素存储在table[0]位置,但不一定是该链表的第一个位置! \n private V getForNullKey() { \n for (Entry e = table[0]; e != null; e = e.next) { \n if (e.key == null) \n return e.value; \n } \n return null; \n } \n \n // HashMap是否包含key \n public boolean containsKey(Object key) { \n return getEntry(key) != null; \n } \n \n // 返回“键为key”的键值对 \n final Entry getEntry(Object key) { \n // 获取哈希值 \n // HashMap将“key为null”的元素存储在table[0]位置,“key不为null”的则调用hash()计算哈希值 \n int hash = (key == null) ? 0 : hash(key.hashCode()); \n // 在“该hash值对应的链表”上查找“键值等于key”的元素 \n for (Entry e = table[indexFor(hash, table.length)]; \n e != null; \n e = e.next) { \n Object k; \n if (e.hash == hash && \n ((k = e.key) == key || (key != null && key.equals(k)))) \n return e; \n } \n return null; \n } \n \n // 将“key-value”添加到HashMap中 \n public V put(K key, V value) { \n // 若“key为null”,则将该键值对添加到table[0]中。 \n if (key == null) \n return putForNullKey(value); \n // 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。 \n int hash = hash(key.hashCode()); \n int i = indexFor(hash, table.length); \n for (Entry e = table[i]; e != null; e = e.next) { \n Object k; \n // 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出! \n if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { \n V oldValue = e.value; \n e.value = value; \n e.recordAccess(this); \n return oldValue; \n } \n } \n \n // 若“该key”对应的键值对不存在,则将“key-value”添加到table中 \n modCount++; \n //将key-value添加到table[i]处 \n addEntry(hash, key, value, i); \n return null; \n } \n \n // putForNullKey()的作用是将“key为null”键值对添加到table[0]位置 \n private V putForNullKey(V value) { \n for (Entry e = table[0]; e != null; e = e.next) { \n if (e.key == null) { \n V oldValue = e.value; \n e.value = value; \n e.recordAccess(this); \n return oldValue; \n } \n } \n // 如果没有存在key为null的键值对,则直接题阿见到table[0]处! \n modCount++; \n addEntry(0, null, value, 0); \n return null; \n } \n \n // 创建HashMap对应的“添加方法”, \n // 它和put()不同。putForCreate()是内部方法,它被构造函数等调用,用来创建HashMap \n // 而put()是对外提供的往HashMap中添加元素的方法。 \n private void putForCreate(K key, V value) { \n int hash = (key == null) ? 0 : hash(key.hashCode()); \n int i = indexFor(hash, table.length); \n \n // 若该HashMap表中存在“键值等于key”的元素,则替换该元素的value值 \n for (Entry e = table[i]; e != null; e = e.next) { \n Object k; \n if (e.hash == hash && \n ((k = e.key) == key || (key != null && key.equals(k)))) { \n e.value = value; \n return; \n } \n } \n \n // 若该HashMap表中不存在“键值等于key”的元素,则将该key-value添加到HashMap中 \n createEntry(hash, key, value, i); \n } \n \n // 将“m”中的全部元素都添加到HashMap中。 \n // 该方法被内部的构造HashMap的方法所调用。 \n private void putAllForCreate(Map m) { \n // 利用迭代器将元素逐个添加到HashMap中 \n for (Iterator> i = m.entrySet().iterator(); i.hasNext(); ) { \n Map.Entry e = i.next(); \n putForCreate(e.getKey(), e.getValue()); \n } \n } \n \n // 重新调整HashMap的大小,newCapacity是调整后的容量 \n void resize(int newCapacity) { \n Entry[] oldTable = table; \n int oldCapacity = oldTable.length; \n //如果就容量已经达到了最大值,则不能再扩容,直接返回 \n if (oldCapacity == MAXIMUM_CAPACITY) { \n threshold = Integer.MAX_VALUE; \n return; \n } \n \n // 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中, \n // 然后,将“新HashMap”赋值给“旧HashMap”。 \n Entry[] newTable = new Entry[newCapacity]; \n transfer(newTable); \n table = newTable; \n threshold = (int)(newCapacity * loadFactor); \n } \n \n // 将HashMap中的全部元素都添加到newTable中 \n void transfer(Entry[] newTable) { \n Entry[] src = table; \n int newCapacity = newTable.length; \n for (int j = 0; j < src.length; j++) { \n Entry e = src[j]; \n if (e != null) { \n src[j] = null; \n do { \n Entry next = e.next; \n int i = indexFor(e.hash, newCapacity); \n e.next = newTable[i]; \n newTable[i] = e; \n e = next; \n } while (e != null); \n } \n } \n } \n \n // 将\"m\"的全部元素都添加到HashMap中 \n public void putAll(Map m) { \n // 有效性判断 \n int numKeysToBeAdded = m.size(); \n if (numKeysToBeAdded == 0) \n return; \n \n // 计算容量是否足够, \n // 若“当前阀值容量 < 需要的容量”,则将容量x2。 \n if (numKeysToBeAdded > threshold) { \n int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1); \n if (targetCapacity > MAXIMUM_CAPACITY) \n targetCapacity = MAXIMUM_CAPACITY; \n int newCapacity = table.length; \n while (newCapacity < targetCapacity) \n newCapacity <<= 1; \n if (newCapacity > table.length) \n resize(newCapacity); \n } \n \n // 通过迭代器,将“m”中的元素逐个添加到HashMap中。 \n for (Iterator> i = m.entrySet().iterator(); i.hasNext(); ) { \n Map.Entry e = i.next(); \n put(e.getKey(), e.getValue()); \n } \n } \n \n // 删除“键为key”元素 \n public V remove(Object key) { \n Entry e = removeEntryForKey(key); \n return (e == null ? null : e.value); \n } \n \n // 删除“键为key”的元素 \n final Entry removeEntryForKey(Object key) { \n // 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算 \n int hash = (key == null) ? 0 : hash(key.hashCode()); \n int i = indexFor(hash, table.length); \n Entry prev = table[i]; \n Entry e = prev; \n \n // 删除链表中“键为key”的元素 \n // 本质是“删除单向链表中的节点” \n while (e != null) { \n Entry next = e.next; \n Object k; \n if (e.hash == hash && \n ((k = e.key) == key || (key != null && key.equals(k)))) { \n modCount++; \n size--; \n if (prev == e) \n table[i] = next; \n else \n prev.next = next; \n e.recordRemoval(this); \n return e; \n } \n prev = e; \n e = next; \n } \n \n return e; \n } \n \n // 删除“键值对” \n final Entry removeMapping(Object o) { \n if (!(o instanceof Map.Entry)) \n return null; \n \n Map.Entry entry = (Map.Entry) o; \n Object key = entry.getKey(); \n int hash = (key == null) ? 0 : hash(key.hashCode()); \n int i = indexFor(hash, table.length); \n Entry prev = table[i]; \n Entry e = prev; \n \n // 删除链表中的“键值对e” \n // 本质是“删除单向链表中的节点” \n while (e != null) { \n Entry next = e.next; \n if (e.hash == hash && e.equals(entry)) { \n modCount++; \n size--; \n if (prev == e) \n table[i] = next; \n else \n prev.next = next; \n e.recordRemoval(this); \n return e; \n } \n prev = e; \n e = next; \n } \n \n return e; \n } \n \n // 清空HashMap,将所有的元素设为null \n public void clear() { \n modCount++; \n Entry[] tab = table; \n for (int i = 0; i < tab.length; i++) \n tab[i] = null; \n size = 0; \n } \n \n // 是否包含“值为value”的元素 \n public boolean containsValue(Object value) { \n // 若“value为null”,则调用containsNullValue()查找 \n if (value == null) \n return containsNullValue(); \n \n // 若“value不为null”,则查找HashMap中是否有值为value的节点。 \n Entry[] tab = table; \n for (int i = 0; i < tab.length ; i++) \n for (Entry e = tab[i] ; e != null ; e = e.next) \n if (value.equals(e.value)) \n return true; \n return false; \n } \n \n // 是否包含null值 \n private boolean containsNullValue() { \n Entry[] tab = table; \n for (int i = 0; i < tab.length ; i++) \n for (Entry e = tab[i] ; e != null ; e = e.next) \n if (e.value == null) \n return true; \n return false; \n } \n \n // 克隆一个HashMap,并返回Object对象 \n public Object clone() { \n HashMap result = null; \n try { \n result = (HashMap)super.clone(); \n } catch (CloneNotSupportedException e) { \n // assert false; \n } \n result.table = new Entry[table.length]; \n result.entrySet = null; \n result.modCount = 0; \n result.size = 0; \n result.init(); \n // 调用putAllForCreate()将全部元素添加到HashMap中 \n result.putAllForCreate(this); \n \n return result; \n } \n \n // Entry是单向链表。 \n // 它是 “HashMap链式存储法”对应的链表。 \n // 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数 \n static class Entry implements Map.Entry { \n final K key; \n V value; \n // 指向下一个节点 \n Entry next; \n final int hash; \n \n // 构造函数。 \n // 输入参数包括\"哈希值(h)\", \"键(k)\", \"值(v)\", \"下一节点(n)\" \n Entry(int h, K k, V v, Entry n) { \n value = v; \n next = n; \n key = k; \n hash = h; \n } \n \n public final K getKey() { \n return key; \n } \n \n public final V getValue() { \n return value; \n } \n \n public final V setValue(V newValue) { \n V oldValue = value; \n value = newValue; \n return oldValue; \n } \n \n // 判断两个Entry是否相等 \n // 若两个Entry的“key”和“value”都相等,则返回true。 \n // 否则,返回false \n public final boolean equals(Object o) { \n if (!(o instanceof Map.Entry)) \n return false; \n Map.Entry e = (Map.Entry)o; \n Object k1 = getKey(); \n Object k2 = e.getKey(); \n if (k1 == k2 || (k1 != null && k1.equals(k2))) { \n Object v1 = getValue(); \n Object v2 = e.getValue(); \n if (v1 == v2 || (v1 != null && v1.equals(v2))) \n return true; \n } \n return false; \n } \n \n // 实现hashCode() \n public final int hashCode() { \n return (key==null ? 0 : key.hashCode()) ^ \n (value==null ? 0 : value.hashCode()); \n } \n \n public final String toString() { \n return getKey() + \"=\" + getValue(); \n } \n \n // 当向HashMap中添加元素时,绘调用recordAccess()。 \n // 这里不做任何处理 \n void recordAccess(HashMap m) { \n } \n \n // 当从HashMap中删除元素时,绘调用recordRemoval()。 \n // 这里不做任何处理 \n void recordRemoval(HashMap m) { \n } \n } \n \n // 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。 \n void addEntry(int hash, K key, V value, int bucketIndex) { \n // 保存“bucketIndex”位置的值到“e”中 \n Entry e = table[bucketIndex]; \n // 设置“bucketIndex”位置的元素为“新Entry”, \n // 设置“e”为“新Entry的下一个节点” \n table[bucketIndex] = new Entry(hash, key, value, e); \n // 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小 \n if (size++ >= threshold) \n resize(2 * table.length); \n } \n \n // 创建Entry。将“key-value”插入指定位置。 \n void createEntry(int hash, K key, V value, int bucketIndex) { \n // 保存“bucketIndex”位置的值到“e”中 \n Entry e = table[bucketIndex]; \n // 设置“bucketIndex”位置的元素为“新Entry”, \n // 设置“e”为“新Entry的下一个节点” \n table[bucketIndex] = new Entry(hash, key, value, e); \n size++; \n } \n \n // HashIterator是HashMap迭代器的抽象出来的父类,实现了公共了函数。 \n // 它包含“key迭代器(KeyIterator)”、“Value迭代器(ValueIterator)”和“Entry迭代器(EntryIterator)”3个子类。 \n private abstract class HashIterator implements Iterator { \n // 下一个元素 \n Entry next; \n // expectedModCount用于实现fast-fail机制。 \n int expectedModCount; \n // 当前索引 \n int index; \n // 当前元素 \n Entry current; \n \n HashIterator() { \n expectedModCount = modCount; \n if (size > 0) { // advance to first entry \n Entry[] t = table; \n // 将next指向table中第一个不为null的元素。 \n // 这里利用了index的初始值为0,从0开始依次向后遍历,直到找到不为null的元素就退出循环。 \n while (index < t.length && (next = t[index++]) == null) \n ; \n } \n } \n \n public final boolean hasNext() { \n return next != null; \n } \n \n // 获取下一个元素 \n final Entry nextEntry() { \n if (modCount != expectedModCount) \n throw new ConcurrentModificationException(); \n Entry e = next; \n if (e == null) \n throw new NoSuchElementException(); \n \n // 注意!!! \n // 一个Entry就是一个单向链表 \n // 若该Entry的下一个节点不为空,就将next指向下一个节点; \n // 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。 \n if ((next = e.next) == null) { \n Entry[] t = table; \n while (index < t.length && (next = t[index++]) == null) \n ; \n } \n current = e; \n return e; \n } \n \n // 删除当前元素 \n public void remove() { \n if (current == null) \n throw new IllegalStateException(); \n if (modCount != expectedModCount) \n throw new ConcurrentModificationException(); \n Object k = current.key; \n current = null; \n HashMap.this.removeEntryForKey(k); \n expectedModCount = modCount; \n } \n \n } \n \n // value的迭代器 \n private final class ValueIterator extends HashIterator { \n public V next() { \n return nextEntry().value; \n } \n } \n \n // key的迭代器 \n private final class KeyIterator extends HashIterator { \n public K next() { \n return nextEntry().getKey(); \n } \n } \n \n // Entry的迭代器 \n private final class EntryIterator extends HashIterator> { \n public Map.Entry next() { \n return nextEntry(); \n } \n } \n \n // 返回一个“key迭代器” \n Iterator newKeyIterator() { \n return new KeyIterator(); \n } \n // 返回一个“value迭代器” \n Iterator newValueIterator() { \n return new ValueIterator(); \n } \n // 返回一个“entry迭代器” \n Iterator> newEntryIterator() { \n return new EntryIterator(); \n } \n \n // HashMap的Entry对应的集合 \n private transient Set> entrySet = null; \n \n // 返回“key的集合”,实际上返回一个“KeySet对象” \n public Set keySet() { \n Set ks = keySet; \n return (ks != null ? ks : (keySet = new KeySet())); \n } \n \n // Key对应的集合 \n // KeySet继承于AbstractSet,说明该集合中没有重复的Key。 \n private final class KeySet extends AbstractSet { \n public Iterator iterator() { \n return newKeyIterator(); \n } \n public int size() { \n return size; \n } \n public boolean contains(Object o) { \n return containsKey(o); \n } \n public boolean remove(Object o) { \n return HashMap.this.removeEntryForKey(o) != null; \n } \n public void clear() { \n HashMap.this.clear(); \n } \n } \n \n // 返回“value集合”,实际上返回的是一个Values对象 \n public Collection values() { \n Collection vs = values; \n return (vs != null ? vs : (values = new Values())); \n } \n \n // “value集合” \n // Values继承于AbstractCollection,不同于“KeySet继承于AbstractSet”, \n // Values中的元素能够重复。因为不同的key可以指向相同的value。 \n private final class Values extends AbstractCollection { \n public Iterator iterator() { \n return newValueIterator(); \n } \n public int size() { \n return size; \n } \n public boolean contains(Object o) { \n return containsValue(o); \n } \n public void clear() { \n HashMap.this.clear(); \n } \n } \n \n // 返回“HashMap的Entry集合” \n public Set> entrySet() { \n return entrySet0(); \n } \n \n // 返回“HashMap的Entry集合”,它实际是返回一个EntrySet对象 \n private Set> entrySet0() { \n Set> es = entrySet; \n return es != null ? es : (entrySet = new EntrySet()); \n } \n \n // EntrySet对应的集合 \n // EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。 \n private final class EntrySet extends AbstractSet> { \n public Iterator> iterator() { \n return newEntryIterator(); \n } \n public boolean contains(Object o) { \n if (!(o instanceof Map.Entry)) \n return false; \n Map.Entry e = (Map.Entry) o; \n Entry candidate = getEntry(e.getKey()); \n return candidate != null && candidate.equals(e); \n } \n public boolean remove(Object o) { \n return removeMapping(o) != null; \n } \n public int size() { \n return size; \n } \n public void clear() { \n HashMap.this.clear(); \n } \n } \n \n // java.io.Serializable的写入函数 \n // 将HashMap的“总的容量,实际容量,所有的Entry”都写入到输出流中 \n private void writeObject(java.io.ObjectOutputStream s) \n throws IOException \n { \n Iterator> i = \n (size > 0) ? entrySet0().iterator() : null; \n \n // Write out the threshold, loadfactor, and any hidden stuff \n s.defaultWriteObject(); \n \n // Write out number of buckets \n s.writeInt(table.length); \n \n // Write out size (number of Mappings) \n s.writeInt(size); \n \n // Write out keys and values (alternating) \n if (i != null) { \n while (i.hasNext()) { \n Map.Entry e = i.next(); \n s.writeObject(e.getKey()); \n s.writeObject(e.getValue()); \n } \n } \n } \n \n \n private static final long serialVersionUID = 362498820763181265L; \n \n // java.io.Serializable的读取函数:根据写入方式读出 \n // 将HashMap的“总的容量,实际容量,所有的Entry”依次读出 \n private void readObject(java.io.ObjectInputStream s) \n throws IOException, ClassNotFoundException \n { \n // Read in the threshold, loadfactor, and any hidden stuff \n s.defaultReadObject(); \n \n // Read in number of buckets and allocate the bucket array; \n int numBuckets = s.readInt(); \n table = new Entry[numBuckets]; \n \n init(); // Give subclass a chance to do its thing. \n \n // Read in size (number of Mappings) \n int size = s.readInt(); \n \n // Read the keys and values, and put the mappings in the HashMap \n for (int i=0; i implements Map.Entry { \n final K key; \n V value; \n // 指向下一个节点 \n Entry next; \n final int hash; \n \n // 构造函数。 \n // 输入参数包括\"哈希值(h)\", \"键(k)\", \"值(v)\", \"下一节点(n)\" \n Entry(int h, K k, V v, Entry n) { \n value = v; \n next = n; \n key = k; \n hash = h; \n } \n \n public final K getKey() { \n return key; \n } \n \n public final V getValue() { \n return value; \n } \n \n public final V setValue(V newValue) { \n V oldValue = value; \n value = newValue; \n return oldValue; \n } \n \n // 判断两个Entry是否相等 \n // 若两个Entry的“key”和“value”都相等,则返回true。 \n // 否则,返回false \n public final boolean equals(Object o) { \n if (!(o instanceof Map.Entry)) \n return false; \n Map.Entry e = (Map.Entry)o; \n Object k1 = getKey(); \n Object k2 = e.getKey(); \n if (k1 == k2 || (k1 != null && k1.equals(k2))) { \n Object v1 = getValue(); \n Object v2 = e.getValue(); \n if (v1 == v2 || (v1 != null && v1.equals(v2))) \n return true; \n } \n return false; \n } \n \n // 实现hashCode() \n public final int hashCode() { \n return (key==null ? 0 : key.hashCode()) ^ \n (value==null ? 0 : value.hashCode()); \n } \n \n public final String toString() { \n return getKey() + \"=\" + getValue(); \n } \n \n // 当向HashMap中添加元素时,绘调用recordAccess()。 \n // 这里不做任何处理 \n void recordAccess(HashMap m) { \n } \n \n // 当从HashMap中删除元素时,绘调用recordRemoval()。 \n // 这里不做任何处理 \n void recordRemoval(HashMap m) { \n } \n} \n```\n\n它的结构元素除了key、value、hash外,还有next,next指向下一个节点。另外,这里覆写了equals和hashCode方法来保证键值对的独一无二。\n\n3、HashMap共有四个构造方法。构造方法中提到了两个很重要的参数:初始容量和加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中槽的数量(即哈希数组的长度),初始容量是创建哈希表时的容量(从构造函数中可以看出,如果不指明,则默认为16),加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize 操作(即扩容)。\n\n下面说下加载因子,如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。\n\n另外,无论我们指定的容量为多少,构造方法都会将实际容量设为不小于指定容量的2的次方的一个数,且最大值不能超过2的30次方\n\n4、HashMap中key和value都允许为null。\n\n5、要重点分析下HashMap中用的最多的两个方法put和get。先从比较简单的get方法着手,源码如下:\n\n```\n// 获取key对应的value \npublic V get(Object key) { \n if (key == null) \n return getForNullKey(); \n // 获取key的hash值 \n int hash = hash(key.hashCode()); \n // 在“该hash值对应的链表”上查找“键值等于key”的元素 \n for (Entry e = table[indexFor(hash, table.length)]; \n e != null; \n e = e.next) { \n Object k; \n/判断key是否相同 \n if (e.hash == hash && ((k = e.key) == key || key.equals(k))) \n return e.value; \n } \n没找到则返回null \n return null; \n} \n \n// 获取“key为null”的元素的值 \n// HashMap将“key为null”的元素存储在table[0]位置,但不一定是该链表的第一个位置! \nprivate V getForNullKey() { \n for (Entry e = table[0]; e != null; e = e.next) { \n if (e.key == null) \n return e.value; \n } \n return null; \n} \n```\n\n首先,如果key为null,则直接从哈希表的第一个位置table[0]对应的链表上查找。记住,key为null的键值对永远都放在以table[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。\n\n如果key不为null,则先求的key的hash值,根据hash值找到在table中的索引,在该索引对应的单链表中查找是否有键值对的key与目标key相等,有就返回对应的value,没有则返回null。\n\nput方法稍微复杂些,代码如下:\n\n```\n // 将“key-value”添加到HashMap中 \n public V put(K key, V value) { \n // 若“key为null”,则将该键值对添加到table[0]中。 \n if (key == null) \n return putForNullKey(value); \n // 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。 \n int hash = hash(key.hashCode()); \n int i = indexFor(hash, table.length); \n for (Entry e = table[i]; e != null; e = e.next) { \n Object k; \n // 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出! \n if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { \n V oldValue = e.value; \n e.value = value; \n e.recordAccess(this); \n return oldValue; \n } \n } \n \n // 若“该key”对应的键值对不存在,则将“key-value”添加到table中 \n modCount++; \n//将key-value添加到table[i]处 \n addEntry(hash, key, value, i); \n return null; \n } \n```\n\n 如果key为null,则将其添加到table[0]对应的链表中,putForNullKey的源码如下:\n\n```\n// putForNullKey()的作用是将“key为null”键值对添加到table[0]位置 \nprivate V putForNullKey(V value) { \n for (Entry e = table[0]; e != null; e = e.next) { \n if (e.key == null) { \n V oldValue = e.value; \n e.value = value; \n e.recordAccess(this); \n return oldValue; \n } \n } \n // 如果没有存在key为null的键值对,则直接题阿见到table[0]处! \n modCount++; \n addEntry(0, null, value, 0); \n return null; \n} \n```\n\n如果key不为null,则同样先求出key的hash值,根据hash值得出在table中的索引,而后遍历对应的单链表,如果单链表中存在与目标key相等的键值对,则将新的value覆盖旧的value,比将旧的value返回,如果找不到与目标key相等的键值对,或者该单链表为空,则将该键值对插入到改单链表的头结点位置(每次新插入的节点都是放在头结点的位置),该操作是有addEntry方法实现的,它的源码如下:\n\n```\n// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。 \nvoid addEntry(int hash, K key, V value, int bucketIndex) { \n // 保存“bucketIndex”位置的值到“e”中 \n Entry e = table[bucketIndex]; \n // 设置“bucketIndex”位置的元素为“新Entry”, \n // 设置“e”为“新Entry的下一个节点” \n table[bucketIndex] = new Entry(hash, key, value, e); \n // 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小 \n if (size++ >= threshold) \n resize(2 * table.length); \n} \n```\n\n注意这里倒数第三行的构造方法,将key-value键值对赋给table[bucketIndex],并将其next指向元素e,这便将key-value放到了头结点中,并将之前的头结点接在了它的后面。该方法也说明,每次put键值对的时候,总是将新的该键值对放在table[bucketIndex]处(即头结点处)。\n\n两外注意最后两行代码,每次加入键值对时,都要判断当前已用的槽的数目是否大于等于阀值(容量*加载因子),如果大于等于,则进行扩容,将容量扩为原来容量的2倍。\n\n6、关于扩容。上面我们看到了扩容的方法,resize方法,它的源码如下:\n\n```\n// 重新调整HashMap的大小,newCapacity是调整后的单位 \nvoid resize(int newCapacity) { \n Entry[] oldTable = table; \n int oldCapacity = oldTable.length; \n if (oldCapacity == MAXIMUM_CAPACITY) { \n threshold = Integer.MAX_VALUE; \n return; \n } \n \n // 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中, \n // 然后,将“新HashMap”赋值给“旧HashMap”。 \n Entry[] newTable = new Entry[newCapacity]; \n transfer(newTable); \n table = newTable; \n threshold = (int)(newCapacity * loadFactor); \n} \n```\n\n 很明显,是新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。transfer方法的源码如下:\n \n```\n// 将HashMap中的全部元素都添加到newTable中 \nvoid transfer(Entry[] newTable) { \n Entry[] src = table; \n int newCapacity = newTable.length; \n for (int j = 0; j < src.length; j++) { \n Entry e = src[j]; \n if (e != null) { \n src[j] = null; \n do { \n Entry next = e.next; \n int i = indexFor(e.hash, newCapacity); \n e.next = newTable[i]; \n newTable[i] = e; \n e = next; \n } while (e != null); \n } \n } \n} \n```\n\n很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。\n\n7、注意containsKey方法和containsValue方法。前者直接可以通过key的哈希值将搜索范围定位到指定索引对应的链表,而后者要对哈希数组的每个链表进行搜索。\n\n8、我们重点来分析下求hash值和索引值的方法,这两个方法便是HashMap设计的最为核心的部分,二者结合能保证哈希表中的元素尽可能均匀地散列。\n\n计算哈希值的方法如下:\n\n```\nstatic int hash(int h) { \n h ^= (h >>> 20) ^ (h >>> 12); \n return h ^ (h >>> 7) ^ (h >>> 4); \n } \n```\n\n它只是一个数学公式,IDK这样设计对hash值的计算,自然有它的好处,至于为什么这样设计,我们这里不去追究,只要明白一点,用的位的操作使hash值的计算效率很高。\n\n由hash值找到对应索引的方法如下:\n```\nstatic int indexFor(int h, int length) { \n return h & (length-1); \n } \n```\n\n这个我们要重点说下,我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。\n\n接下来,我们分析下为什么哈希表的容量一定要是2的整数次幂。首先,length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率;其次,length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。"
},
{
"path": "Part2/JavaSE/HashTable源码剖析.md",
"content": "##Hashtable简介\n\nHashTable同样是基于哈希表实现的,同样每个元素都是key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阈值)时,同样会自动增长。\n\nHashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。\n\nHashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。\n\n##Hashtable源码剖析\nHashtable的源码的很多实现都和HashMap差不多,源码如下(加入了比较详细的注释):\n\n```\npackage java.util; \nimport java.io.*; \n \npublic class Hashtable \n extends Dictionary \n implements Map, Cloneable, java.io.Serializable { \n \n // 保存key-value的数组。 \n // Hashtable同样采用单链表解决冲突,每一个Entry本质上是一个单向链表 \n private transient Entry[] table; \n \n // Hashtable中键值对的数量 \n private transient int count; \n \n // 阈值,用于判断是否需要调整Hashtable的容量(threshold = 容量*加载因子) \n private int threshold; \n \n // 加载因子 \n private float loadFactor; \n \n // Hashtable被改变的次数,用于fail-fast机制的实现 \n private transient int modCount = 0; \n \n // 序列版本号 \n private static final long serialVersionUID = 1421746759512286392L; \n \n // 指定“容量大小”和“加载因子”的构造函数 \n public Hashtable(int initialCapacity, float loadFactor) { \n if (initialCapacity < 0) \n throw new IllegalArgumentException(\"Illegal Capacity: \"+ \n initialCapacity); \n if (loadFactor <= 0 || Float.isNaN(loadFactor)) \n throw new IllegalArgumentException(\"Illegal Load: \"+loadFactor); \n \n if (initialCapacity==0) \n initialCapacity = 1; \n this.loadFactor = loadFactor; \n table = new Entry[initialCapacity]; \n threshold = (int)(initialCapacity * loadFactor); \n } \n \n // 指定“容量大小”的构造函数 \n public Hashtable(int initialCapacity) { \n this(initialCapacity, 0.75f); \n } \n \n // 默认构造函数。 \n public Hashtable() { \n // 默认构造函数,指定的容量大小是11;加载因子是0.75 \n this(11, 0.75f); \n } \n \n // 包含“子Map”的构造函数 \n public Hashtable(Map t) { \n this(Math.max(2*t.size(), 11), 0.75f); \n // 将“子Map”的全部元素都添加到Hashtable中 \n putAll(t); \n } \n \n private int hash(Object k) {\n if (useAltHashing) {\n if (k.getClass() == String.class) {\n return sun.misc.Hashing.stringHash32((String) k);\n } else {\n int h = hashSeed ^ k.hashCode();\n\n // This function ensures that hashCodes that differ only by\n // constant multiples at each bit position have a bounded\n // number of collisions (approximately 8 at default load factor).\n h ^= (h >>> 20) ^ (h >>> 12);\n return h ^ (h >>> 7) ^ (h >>> 4);\n }\n } else {\n return k.hashCode();\n }\n }\n \n public synchronized int size() { \n return count; \n } \n \n public synchronized boolean isEmpty() { \n return count == 0; \n } \n \n // 返回“所有key”的枚举对象 \n public synchronized Enumeration keys() { \n return this.getEnumeration(KEYS); \n } \n \n // 返回“所有value”的枚举对象 \n public synchronized Enumeration elements() { \n return this.getEnumeration(VALUES); \n } \n \n // 判断Hashtable是否包含“值(value)” \n public synchronized boolean contains(Object value) { \n //注意,Hashtable中的value不能是null, \n // 若是null的话,抛出异常! \n if (value == null) { \n throw new NullPointerException(); \n } \n \n // 从后向前遍历table数组中的元素(Entry) \n // 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value \n Entry tab[] = table; \n for (int i = tab.length ; i-- > 0 ;) { \n for (Entry e = tab[i] ; e != null ; e = e.next) { \n if (e.value.equals(value)) { \n return true; \n } \n } \n } \n return false; \n } \n \n public boolean containsValue(Object value) { \n return contains(value); \n } \n \n // 判断Hashtable是否包含key \n public synchronized boolean containsKey(Object key) { \n Entry tab[] = table; \n //计算hash值,直接用key的hashCode代替 \n int hash = key.hashCode(); \n // 计算在数组中的索引值 \n int index = (hash & 0x7FFFFFFF) % tab.length; \n // 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素 \n for (Entry e = tab[index] ; e != null ; e = e.next) { \n if ((e.hash == hash) && e.key.equals(key)) { \n return true; \n } \n } \n return false; \n } \n \n // 返回key对应的value,没有的话返回null \n public synchronized V get(Object key) { \n Entry tab[] = table; \n int hash = hash(key);\n // 计算索引值, \n int index = (hash & 0x7FFFFFFF) % tab.length; \n // 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素 \n for (Entry e = tab[index] ; e != null ; e = e.next) { \n if ((e.hash == hash) && e.key.equals(key)) { \n return e.value; \n } \n } \n return null; \n } \n \n // 调整Hashtable的长度,将长度变成原来的2倍+1 \n protected void rehash() { \n int oldCapacity = table.length; \n Entry[] oldMap = table; \n \n //创建新容量大小的Entry数组 \n int newCapacity = oldCapacity * 2 + 1; \n Entry[] newMap = new Entry[newCapacity]; \n \n modCount++; \n threshold = (int)(newCapacity * loadFactor); \n table = newMap; \n \n //将“旧的Hashtable”中的元素复制到“新的Hashtable”中 \n for (int i = oldCapacity ; i-- > 0 ;) { \n for (Entry old = oldMap[i] ; old != null ; ) { \n Entry e = old; \n old = old.next; \n //重新计算index \n int index = (e.hash & 0x7FFFFFFF) % newCapacity; \n e.next = newMap[index]; \n newMap[index] = e; \n } \n } \n } \n \n // 将“key-value”添加到Hashtable中 \n public synchronized V put(K key, V value) { \n // Hashtable中不能插入value为null的元素!!! \n if (value == null) { \n throw new NullPointerException(); \n } \n \n // 若“Hashtable中已存在键为key的键值对”, \n // 则用“新的value”替换“旧的value” \n Entry tab[] = table; \n int hash = hash(key);\n int index = (hash & 0x7FFFFFFF) % tab.length; \n for (Entry e = tab[index] ; e != null ; e = e.next) { \n if ((e.hash == hash) && e.key.equals(key)) { \n V old = e.value; \n e.value = value; \n return old; \n } \n } \n \n // 若“Hashtable中不存在键为key的键值对”, \n // 将“修改统计数”+1 \n modCount++; \n // 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子) \n // 则调整Hashtable的大小 \n if (count >= threshold) { \n rehash(); \n \n tab = table; \n index = (hash & 0x7FFFFFFF) % tab.length; \n } \n \n //将新的key-value对插入到tab[index]处(即链表的头结点) \n Entry e = tab[index]; \n tab[index] = new Entry(hash, key, value, e); \n count++; \n return null; \n } \n \n // 删除Hashtable中键为key的元素 \n public synchronized V remove(Object key) { \n Entry tab[] = table; \n int hash = hash(key);\n int index = (hash & 0x7FFFFFFF) % tab.length; \n \n //从table[index]链表中找出要删除的节点,并删除该节点。 \n //因为是单链表,因此要保留带删节点的前一个节点,才能有效地删除节点 \n for (Entry e = tab[index], prev = null ; e != null ; prev = e, e = e.next) { \n if ((e.hash == hash) && e.key.equals(key)) { \n modCount++; \n if (prev != null) { \n prev.next = e.next; \n } else { \n tab[index] = e.next; \n } \n count--; \n V oldValue = e.value; \n e.value = null; \n return oldValue; \n } \n } \n return null; \n } \n \n // 将“Map(t)”的中全部元素逐一添加到Hashtable中 \n public synchronized void putAll(Map t) { \n for (Map.Entry e : t.entrySet()) \n put(e.getKey(), e.getValue()); \n } \n \n // 清空Hashtable \n // 将Hashtable的table数组的值全部设为null \n public synchronized void clear() { \n Entry tab[] = table; \n modCount++; \n for (int index = tab.length; --index >= 0; ) \n tab[index] = null; \n count = 0; \n } \n \n // 克隆一个Hashtable,并以Object的形式返回。 \n public synchronized Object clone() { \n try { \n Hashtable t = (Hashtable) super.clone(); \n t.table = new Entry[table.length]; \n for (int i = table.length ; i-- > 0 ; ) { \n t.table[i] = (table[i] != null) \n ? (Entry) table[i].clone() : null; \n } \n t.keySet = null; \n t.entrySet = null; \n t.values = null; \n t.modCount = 0; \n return t; \n } catch (CloneNotSupportedException e) { \n throw new InternalError(); \n } \n } \n \n public synchronized String toString() { \n int max = size() - 1; \n if (max == -1) \n return \"{}\"; \n \n StringBuilder sb = new StringBuilder(); \n Iterator> it = entrySet().iterator(); \n \n sb.append('{'); \n for (int i = 0; ; i++) { \n Map.Entry e = it.next(); \n K key = e.getKey(); \n V value = e.getValue(); \n sb.append(key == this ? \"(this Map)\" : key.toString()); \n sb.append('='); \n sb.append(value == this ? \"(this Map)\" : value.toString()); \n \n if (i == max) \n return sb.append('}').toString(); \n sb.append(\", \"); \n } \n } \n \n // 获取Hashtable的枚举类对象 \n // 若Hashtable的实际大小为0,则返回“空枚举类”对象; \n // 否则,返回正常的Enumerator的对象。 \n private Enumeration getEnumeration(int type) { \n if (count == 0) { \n return (Enumeration)emptyEnumerator; \n } else { \n return new Enumerator(type, false); \n } \n } \n \n // 获取Hashtable的迭代器 \n // 若Hashtable的实际大小为0,则返回“空迭代器”对象; \n // 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口) \n private Iterator getIterator(int type) { \n if (count == 0) { \n return (Iterator) emptyIterator; \n } else { \n return new Enumerator(type, true); \n } \n } \n \n // Hashtable的“key的集合”。它是一个Set,没有重复元素 \n private transient volatile Set keySet = null; \n // Hashtable的“key-value的集合”。它是一个Set,没有重复元素 \n private transient volatile Set> entrySet = null; \n // Hashtable的“key-value的集合”。它是一个Collection,可以有重复元素 \n private transient volatile Collection values = null; \n \n // 返回一个被synchronizedSet封装后的KeySet对象 \n // synchronizedSet封装的目的是对KeySet的所有方法都添加synchronized,实现多线程同步 \n public Set keySet() { \n if (keySet == null) \n keySet = Collections.synchronizedSet(new KeySet(), this); \n return keySet; \n } \n \n // Hashtable的Key的Set集合。 \n // KeySet继承于AbstractSet,所以,KeySet中的元素没有重复的。 \n private class KeySet extends AbstractSet { \n public Iterator iterator() { \n return getIterator(KEYS); \n } \n public int size() { \n return count; \n } \n public boolean contains(Object o) { \n return containsKey(o); \n } \n public boolean remove(Object o) { \n return Hashtable.this.remove(o) != null; \n } \n public void clear() { \n Hashtable.this.clear(); \n } \n } \n \n // 返回一个被synchronizedSet封装后的EntrySet对象 \n // synchronizedSet封装的目的是对EntrySet的所有方法都添加synchronized,实现多线程同步 \n public Set> entrySet() { \n if (entrySet==null) \n entrySet = Collections.synchronizedSet(new EntrySet(), this); \n return entrySet; \n } \n \n // Hashtable的Entry的Set集合。 \n // EntrySet继承于AbstractSet,所以,EntrySet中的元素没有重复的。 \n private class EntrySet extends AbstractSet> { \n public Iterator> iterator() { \n return getIterator(ENTRIES); \n } \n \n public boolean add(Map.Entry o) { \n return super.add(o); \n } \n \n // 查找EntrySet中是否包含Object(0) \n // 首先,在table中找到o对应的Entry链表 \n // 然后,查找Entry链表中是否存在Object \n public boolean contains(Object o) { \n if (!(o instanceof Map.Entry)) \n return false; \n Map.Entry entry = (Map.Entry)o; \n Object key = entry.getKey(); \n Entry[] tab = table; \n int hash = hash(key);\n int index = (hash & 0x7FFFFFFF) % tab.length; \n \n for (Entry e = tab[index]; e != null; e = e.next) \n if (e.hash==hash && e.equals(entry)) \n return true; \n return false; \n } \n \n // 删除元素Object(0) \n // 首先,在table中找到o对应的Entry链表 \n // 然后,删除链表中的元素Object \n public boolean remove(Object o) { \n if (!(o instanceof Map.Entry)) \n return false; \n Map.Entry entry = (Map.Entry) o; \n K key = entry.getKey(); \n Entry[] tab = table; \n int hash = hash(key);\n int index = (hash & 0x7FFFFFFF) % tab.length; \n \n for (Entry e = tab[index], prev = null; e != null; \n prev = e, e = e.next) { \n if (e.hash==hash && e.equals(entry)) { \n modCount++; \n if (prev != null) \n prev.next = e.next; \n else \n tab[index] = e.next; \n \n count--; \n e.value = null; \n return true; \n } \n } \n return false; \n } \n \n public int size() { \n return count; \n } \n \n public void clear() { \n Hashtable.this.clear(); \n } \n } \n \n // 返回一个被synchronizedCollection封装后的ValueCollection对象 \n // synchronizedCollection封装的目的是对ValueCollection的所有方法都添加synchronized,实现多线程同步 \n public Collection values() { \n if (values==null) \n values = Collections.synchronizedCollection(new ValueCollection(), \n this); \n return values; \n } \n \n // Hashtable的value的Collection集合。 \n // ValueCollection继承于AbstractCollection,所以,ValueCollection中的元素可以重复的。 \n private class ValueCollection extends AbstractCollection { \n public Iterator iterator() { \n return getIterator(VALUES); \n } \n public int size() { \n return count; \n } \n public boolean contains(Object o) { \n return containsValue(o); \n } \n public void clear() { \n Hashtable.this.clear(); \n } \n } \n \n // 重新equals()函数 \n // 若两个Hashtable的所有key-value键值对都相等,则判断它们两个相等 \n public synchronized boolean equals(Object o) { \n if (o == this) \n return true; \n \n if (!(o instanceof Map)) \n return false; \n Map t = (Map) o; \n if (t.size() != size()) \n return false; \n \n try { \n // 通过迭代器依次取出当前Hashtable的key-value键值对 \n // 并判断该键值对,存在于Hashtable中。 \n // 若不存在,则立即返回false;否则,遍历完“当前Hashtable”并返回true。 \n Iterator> i = entrySet().iterator(); \n while (i.hasNext()) { \n Map.Entry e = i.next(); \n K key = e.getKey(); \n V value = e.getValue(); \n if (value == null) { \n if (!(t.get(key)==null && t.containsKey(key))) \n return false; \n } else { \n if (!value.equals(t.get(key))) \n return false; \n } \n } \n } catch (ClassCastException unused) { \n return false; \n } catch (NullPointerException unused) { \n return false; \n } \n \n return true; \n } \n \n // 计算Entry的hashCode \n // 若 Hashtable的实际大小为0 或者 加载因子<0,则返回0。 \n // 否则,返回“Hashtable中的每个Entry的key和value的异或值 的总和”。 \n public synchronized int hashCode() { \n int h = 0; \n if (count == 0 || loadFactor < 0) \n return h; // Returns zero \n \n loadFactor = -loadFactor; // Mark hashCode computation in progress \n Entry[] tab = table; \n for (int i = 0; i < tab.length; i++) \n for (Entry e = tab[i]; e != null; e = e.next) \n h += e.key.hashCode() ^ e.value.hashCode(); \n loadFactor = -loadFactor; // Mark hashCode computation complete \n \n return h; \n } \n \n // java.io.Serializable的写入函数 \n // 将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中 \n private synchronized void writeObject(java.io.ObjectOutputStream s) \n throws IOException \n { \n // Write out the length, threshold, loadfactor \n s.defaultWriteObject(); \n \n // Write out length, count of elements and then the key/value objects \n s.writeInt(table.length); \n s.writeInt(count); \n for (int index = table.length-1; index >= 0; index--) { \n Entry entry = table[index]; \n \n while (entry != null) { \n s.writeObject(entry.key); \n s.writeObject(entry.value); \n entry = entry.next; \n } \n } \n } \n \n // java.io.Serializable的读取函数:根据写入方式读出 \n // 将Hashtable的“总的容量,实际容量,所有的Entry”依次读出 \n private void readObject(java.io.ObjectInputStream s) \n throws IOException, ClassNotFoundException \n { \n // Read in the length, threshold, and loadfactor \n s.defaultReadObject(); \n \n // Read the original length of the array and number of elements \n int origlength = s.readInt(); \n int elements = s.readInt(); \n \n // Compute new size with a bit of room 5% to grow but \n // no larger than the original size. Make the length \n // odd if it's large enough, this helps distribute the entries. \n // Guard against the length ending up zero, that's not valid. \n int length = (int)(elements * loadFactor) + (elements / 20) + 3; \n if (length > elements && (length & 1) == 0) \n length--; \n if (origlength > 0 && length > origlength) \n length = origlength; \n \n Entry[] table = new Entry[length]; \n count = 0; \n \n // Read the number of elements and then all the key/value objects \n for (; elements > 0; elements--) { \n K key = (K)s.readObject(); \n V value = (V)s.readObject(); \n // synch could be eliminated for performance \n reconstitutionPut(table, key, value); \n } \n this.table = table; \n } \n \n private void reconstitutionPut(Entry[] tab, K key, V value) \n throws StreamCorruptedException \n { \n if (value == null) { \n throw new java.io.StreamCorruptedException(); \n } \n // Makes sure the key is not already in the hashtable. \n // This should not happen in deserialized version. \n int hash = key.hashCode(); \n int index = (hash & 0x7FFFFFFF) % tab.length; \n for (Entry e = tab[index] ; e != null ; e = e.next) { \n if ((e.hash == hash) && e.key.equals(key)) { \n throw new java.io.StreamCorruptedException(); \n } \n } \n // Creates the new entry. \n Entry e = tab[index]; \n tab[index] = new Entry(hash, key, value, e); \n count++; \n } \n \n // Hashtable的Entry节点,它本质上是一个单向链表。 \n // 也因此,我们才能推断出Hashtable是由拉链法实现的散列表 \n private static class Entry implements Map.Entry { \n // 哈希值 \n int hash; \n K key; \n V value; \n // 指向的下一个Entry,即链表的下一个节点 \n Entry next; \n \n // 构造函数 \n protected Entry(int hash, K key, V value, Entry next) { \n this.hash = hash; \n this.key = key; \n this.value = value; \n this.next = next; \n } \n \n protected Object clone() { \n return new Entry(hash, key, value, \n (next==null ? null : (Entry) next.clone())); \n } \n \n public K getKey() { \n return key; \n } \n \n public V getValue() { \n return value; \n } \n \n // 设置value。若value是null,则抛出异常。 \n public V setValue(V value) { \n if (value == null) \n throw new NullPointerException(); \n \n V oldValue = this.value; \n this.value = value; \n return oldValue; \n } \n \n // 覆盖equals()方法,判断两个Entry是否相等。 \n // 若两个Entry的key和value都相等,则认为它们相等。 \n public boolean equals(Object o) { \n if (!(o instanceof Map.Entry)) \n return false; \n Map.Entry e = (Map.Entry)o; \n \n return (key==null ? e.getKey()==null : key.equals(e.getKey())) && \n (value==null ? e.getValue()==null : value.equals(e.getValue())); \n } \n \n public int hashCode() { \n return hash ^ (value==null ? 0 : value.hashCode()); \n } \n \n public String toString() { \n return key.toString()+\"=\"+value.toString(); \n } \n } \n \n private static final int KEYS = 0; \n private static final int VALUES = 1; \n private static final int ENTRIES = 2; \n \n // Enumerator的作用是提供了“通过elements()遍历Hashtable的接口” 和 “通过entrySet()遍历Hashtable的接口”。 \n private class Enumerator implements Enumeration, Iterator { \n // 指向Hashtable的table \n Entry[] table = Hashtable.this.table; \n // Hashtable的总的大小 \n int index = table.length; \n Entry entry = null; \n Entry lastReturned = null; \n int type; \n \n // Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志 \n // iterator为true,表示它是迭代器;否则,是枚举类。 \n boolean iterator; \n \n // 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。 \n protected int expectedModCount = modCount; \n \n Enumerator(int type, boolean iterator) { \n this.type = type; \n this.iterator = iterator; \n } \n \n // 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。 \n public boolean hasMoreElements() { \n Entry e = entry; \n int i = index; \n Entry[] t = table; \n /* Use locals for faster loop iteration */ \n while (e == null && i > 0) { \n e = t[--i]; \n } \n entry = e; \n index = i; \n return e != null; \n } \n \n // 获取下一个元素 \n // 注意:从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式” \n // 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。 \n // 然后,依次向后遍历单向链表Entry。 \n public T nextElement() { \n Entry et = entry; \n int i = index; \n Entry[] t = table; \n /* Use locals for faster loop iteration */ \n while (et == null && i > 0) { \n et = t[--i]; \n } \n entry = et; \n index = i; \n if (et != null) { \n Entry e = lastReturned = entry; \n entry = e.next; \n return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e); \n } \n throw new NoSuchElementException(\"Hashtable Enumerator\"); \n } \n \n // 迭代器Iterator的判断是否存在下一个元素 \n // 实际上,它是调用的hasMoreElements() \n public boolean hasNext() { \n return hasMoreElements(); \n } \n \n // 迭代器获取下一个元素 \n // 实际上,它是调用的nextElement() \n public T next() { \n if (modCount != expectedModCount) \n throw new ConcurrentModificationException(); \n return nextElement(); \n } \n \n // 迭代器的remove()接口。 \n // 首先,它在table数组中找出要删除元素所在的Entry, \n // 然后,删除单向链表Entry中的元素。 \n public void remove() { \n if (!iterator) \n throw new UnsupportedOperationException(); \n if (lastReturned == null) \n throw new IllegalStateException(\"Hashtable Enumerator\"); \n if (modCount != expectedModCount) \n throw new ConcurrentModificationException(); \n \n synchronized(Hashtable.this) { \n Entry[] tab = Hashtable.this.table; \n int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length; \n \n for (Entry e = tab[index], prev = null; e != null; \n prev = e, e = e.next) { \n if (e == lastReturned) { \n modCount++; \n expectedModCount++; \n if (prev == null) \n tab[index] = e.next; \n else \n prev.next = e.next; \n count--; \n lastReturned = null; \n return; \n } \n } \n throw new ConcurrentModificationException(); \n } \n } \n } \n \n \n private static Enumeration emptyEnumerator = new EmptyEnumerator(); \n private static Iterator emptyIterator = new EmptyIterator(); \n \n // 空枚举类 \n // 当Hashtable的实际大小为0;此时,又要通过Enumeration遍历Hashtable时,返回的是“空枚举类”的对象。 \n private static class EmptyEnumerator implements Enumeration