Showing preview only (1,164K chars total). Download the full file or copy to clipboard to get everything.
Repository: google/langextract
Branch: main
Commit: f48cdb27c7f5
Files: 124
Total size: 1.1 MB
Directory structure:
gitextract_s1tifoud/
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── 1-bug.md
│ │ ├── 2-feature-request.md
│ │ └── config.yml
│ ├── PULL_REQUEST_TEMPLATE/
│ │ └── pull_request_template.md
│ ├── scripts/
│ │ ├── add-new-checks.sh
│ │ ├── add-size-labels.sh
│ │ ├── revalidate-all-prs.sh
│ │ └── zenodo_publish.py
│ └── workflows/
│ ├── auto-update-pr.yaml
│ ├── check-infrastructure-changes.yml
│ ├── check-linked-issue.yml
│ ├── check-pr-size.yml
│ ├── check-pr-up-to-date.yaml
│ ├── ci.yaml
│ ├── publish.yml
│ ├── revalidate-pr.yml
│ ├── validate-community-providers.yaml
│ ├── validate_pr_template.yaml
│ └── zenodo-publish.yml
├── .gitignore
├── .pre-commit-config.yaml
├── .pylintrc
├── CITATION.cff
├── COMMUNITY_PROVIDERS.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── README.md
├── autoformat.sh
├── benchmarks/
│ ├── benchmark.py
│ ├── config.py
│ ├── plotting.py
│ └── utils.py
├── docs/
│ └── examples/
│ ├── batch_api_example.md
│ ├── japanese_extraction.md
│ ├── longer_text_example.md
│ └── medication_examples.md
├── examples/
│ ├── custom_provider_plugin/
│ │ ├── README.md
│ │ ├── langextract_provider_example/
│ │ │ ├── __init__.py
│ │ │ ├── provider.py
│ │ │ └── schema.py
│ │ ├── pyproject.toml
│ │ └── test_example_provider.py
│ ├── notebooks/
│ │ └── romeo_juliet_extraction.ipynb
│ └── ollama/
│ ├── .dockerignore
│ ├── Dockerfile
│ ├── README.md
│ ├── demo_ollama.py
│ └── docker-compose.yml
├── langextract/
│ ├── __init__.py
│ ├── _compat/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── exceptions.py
│ │ ├── inference.py
│ │ ├── registry.py
│ │ └── schema.py
│ ├── annotation.py
│ ├── chunking.py
│ ├── core/
│ │ ├── __init__.py
│ │ ├── base_model.py
│ │ ├── data.py
│ │ ├── debug_utils.py
│ │ ├── exceptions.py
│ │ ├── format_handler.py
│ │ ├── schema.py
│ │ ├── tokenizer.py
│ │ └── types.py
│ ├── data.py
│ ├── data_lib.py
│ ├── exceptions.py
│ ├── extraction.py
│ ├── factory.py
│ ├── inference.py
│ ├── io.py
│ ├── plugins.py
│ ├── progress.py
│ ├── prompt_validation.py
│ ├── prompting.py
│ ├── providers/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── builtin_registry.py
│ │ ├── gemini.py
│ │ ├── gemini_batch.py
│ │ ├── ollama.py
│ │ ├── openai.py
│ │ ├── patterns.py
│ │ ├── router.py
│ │ └── schemas/
│ │ ├── __init__.py
│ │ └── gemini.py
│ ├── py.typed
│ ├── registry.py
│ ├── resolver.py
│ ├── schema.py
│ ├── tokenizer.py
│ └── visualization.py
├── pyproject.toml
├── scripts/
│ ├── create_provider_plugin.py
│ └── validate_community_providers.py
├── tests/
│ ├── .pylintrc
│ ├── annotation_test.py
│ ├── chunking_test.py
│ ├── data_lib_test.py
│ ├── extract_precedence_test.py
│ ├── extract_schema_integration_test.py
│ ├── factory_schema_test.py
│ ├── factory_test.py
│ ├── format_handler_test.py
│ ├── inference_test.py
│ ├── init_test.py
│ ├── progress_test.py
│ ├── prompt_validation_test.py
│ ├── prompting_test.py
│ ├── provider_plugin_test.py
│ ├── provider_schema_test.py
│ ├── registry_test.py
│ ├── resolver_test.py
│ ├── schema_test.py
│ ├── test_gemini_batch_api.py
│ ├── test_kwargs_passthrough.py
│ ├── test_live_api.py
│ ├── test_ollama_integration.py
│ ├── tokenizer_test.py
│ └── visualization_test.py
└── tox.ini
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/ISSUE_TEMPLATE/1-bug.md
================================================
---
name: Bug Report
about: Create a bug report to help us improve
title: 'Bug: <brief title of your issue>'
labels: 'bug', 'needs triage'
assignees: ''
---
## Describe the overall issue and situation
Provide a clear summary of what the issue is about, the area of the project you
found it in, and what you were trying to do.
## Expected behavior
Provide a clear and concise description of what you expected to happen
## Actual behavior
Provide a clear and concise description of what actually happened.
## Steps to reproduce the issue
Provide a sequence of steps we can use to reproduce the issue.
1. <First step...>
2. <Second step...>
3. <Third step...>
## Any additional content
Describe your environment or any other set up details that might help us
reproduce the issue.
================================================
FILE: .github/ISSUE_TEMPLATE/2-feature-request.md
================================================
---
name: Feature Request
about: Suggest an idea or improvement
title: 'Request: <brief title of your feature request>'
labels: 'enhancement', 'needs triage'
assignees: ''
---
## Describe the overall idea and motivation
Provide a clear summary of the idea and what use cases it's addressing.
## Related to an issue?
Is this addressing a known / documented issue? If so, which one?
## Possible solutions and alternatives
Do you already have an idea of how the solution should work? If so, document
that here.
Also, if there are alternatives, please document those as well.
## Priority and timeline considerations
Is this time sensitive? Is it a nice to have? Please describe what priority you
feel this should have and why. We'll take this into advisement as we go through
our internal prioritization process.
## Additional context
Is there anything else to consider that wasn't covered by the above?
Would you like to contribute to the project and work on this request?
================================================
FILE: .github/ISSUE_TEMPLATE/config.yml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Allow users to create issues that don't follow the templates since they don't cover all use cases
blank_issues_enabled: true
# Redirect users to other channels for general support or security issues
contact_links:
- name: Community Support
url: https://github.com/google/langextract/discussions
about: Please ask and answer questions here.
- name: Security Bug Reporting
url: https://g.co/vulnz
about: >
To report a security issue, please use https://g.co/vulnz. The Google Security Team will
respond within 5 working days of your report on https://g.co/vulnz.
================================================
FILE: .github/PULL_REQUEST_TEMPLATE/pull_request_template.md
================================================
# Description
Replace this with a clear and concise change description
<!--- Important: All PRs must be linked to at least one issue (except for
extremely trivial and straightforward changes). --->
<!--- This issue (or issues) should document the motivation, context,
alternatives considered, risks (such as breaking backwards compatibility), and
any new dependencies. --->
<!--- Use "Fixes #123" to auto-close the issue when merged (for bug fixes/implementations) -->
<!--- Use "Related to #123" or "Addresses #123" for documentation updates or partial solutions -->
Fixes/Related to #[issue number]
Choose one: (Bug fix | Feature | Documentation | Testing | Code health | Other)
# How Has This Been Tested?
Replace this with a description of the tests that you ran to verify your
changes. If executing the existing test suite without customization, simply
paste the command line used.
```
$ python -m unittest discover ...
```
# Checklist:
<!--- Put an `x` in the box if you did the task -->
<!--- If you forgot a task please follow the instructions below -->
- [ ] I have read and acknowledged Google's Open Source
[Code of conduct](https://opensource.google/conduct).
- [ ] I have read the
[Contributing](https://github.com/google-health/langextract/blob/master/CONTRIBUTING.md)
page, and I either signed the Google
[Individual CLA](https://cla.developers.google.com/about/google-individual)
or am covered by my company's
[Corporate CLA](https://cla.developers.google.com/about/google-corporate).
- [ ] I have discussed my proposed solution with code owners in the linked
issue(s) and we have agreed upon the general approach.
- [ ] I have made any needed documentation changes, or noted in the linked
issue(s) that documentation elsewhere needs updating.
- [ ] I have added tests, or I have ensured existing tests cover the changes
- [ ] I have followed
[Google's Python Style Guide](https://google.github.io/styleguide/pyguide.html)
and ran `pylint` over the affected code.
================================================
FILE: .github/scripts/add-new-checks.sh
================================================
#!/bin/bash
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Script to add new required status checks to an existing branch protection rule.
# This preserves all your current settings and just adds the new checks
echo "Adding new PR validation checks to existing branch protection..."
# Add the new checks to existing ones
echo "Adding new checks: enforce, size, and protect-infrastructure..."
gh api repos/:owner/:repo/branches/main/protection/required_status_checks/contexts \
--method POST \
--input - <<< '["enforce", "size", "protect-infrastructure"]'
echo ""
echo "✓ New checks added!"
echo ""
echo "Updated required status checks will include:"
echo "- test (3.10) [existing]"
echo "- test (3.11) [existing]"
echo "- test (3.12) [existing]"
echo "- Validate PR Template [existing]"
echo "- live-api-tests [existing]"
echo "- ollama-integration-test [existing]"
echo "- enforce [NEW - linked issue validation]"
echo "- size [NEW - PR size limit]"
echo "- protect-infrastructure [NEW - infrastructure file protection]"
================================================
FILE: .github/scripts/add-size-labels.sh
================================================
#!/bin/bash
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Add size labels to PRs based on their change count
echo "Adding size labels to PRs..."
# Get all open PRs with their additions and deletions
gh pr list --limit 50 --json number,additions,deletions --jq '.[]' | while read -r pr_data; do
pr_number=$(echo "$pr_data" | jq -r '.number')
additions=$(echo "$pr_data" | jq -r '.additions')
deletions=$(echo "$pr_data" | jq -r '.deletions')
total_changes=$((additions + deletions))
# Determine size label
if [ $total_changes -lt 50 ]; then
size_label="size/XS"
elif [ $total_changes -lt 150 ]; then
size_label="size/S"
elif [ $total_changes -lt 600 ]; then
size_label="size/M"
elif [ $total_changes -lt 1000 ]; then
size_label="size/L"
else
size_label="size/XL"
fi
echo "PR #$pr_number: $total_changes lines -> $size_label"
# Remove any existing size labels first
existing_labels=$(gh pr view $pr_number --json labels --jq '.labels[].name' | grep "^size/" || true)
if [ ! -z "$existing_labels" ]; then
echo " Removing existing label: $existing_labels"
gh pr edit $pr_number --remove-label "$existing_labels"
fi
# Add the new size label
gh pr edit $pr_number --add-label "$size_label"
sleep 1 # Avoid rate limiting
done
echo "Done adding size labels!"
================================================
FILE: .github/scripts/revalidate-all-prs.sh
================================================
#!/bin/bash
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Revalidate all open PRs
echo "Fetching all open PRs..."
PR_NUMBERS=$(gh pr list --limit 50 --json number --jq '.[].number')
TOTAL=$(echo "$PR_NUMBERS" | wc -w | tr -d ' ')
echo "Found $TOTAL open PRs"
echo "Starting revalidation..."
echo ""
COUNT=0
for pr in $PR_NUMBERS; do
COUNT=$((COUNT + 1))
echo "[$COUNT/$TOTAL] Triggering revalidation for PR #$pr..."
gh workflow run revalidate-pr.yml -f pr_number=$pr
# Small delay to avoid rate limiting
sleep 2
done
echo ""
echo "All workflows triggered!"
echo ""
echo "To monitor progress:"
echo " gh run list --workflow=revalidate-pr.yml --limit=$TOTAL"
echo ""
echo "To see results, check comments on each PR"
================================================
FILE: .github/scripts/zenodo_publish.py
================================================
#!/usr/bin/env python3
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Publish a new version to Zenodo via REST API.
This script reads project metadata from pyproject.toml to avoid duplication.
For subsequent releases, it creates new versions from the existing Zenodo record,
inheriting most metadata automatically.
"""
import glob
import os
import sys
import tomllib
import urllib.request
import requests
API = "https://zenodo.org/api"
TOKEN = os.environ["ZENODO_TOKEN"]
RECORD_ID = os.environ["ZENODO_RECORD_ID"]
VERSION = os.environ["RELEASE_TAG"].lstrip("v")
REPO = os.environ["GITHUB_REPOSITORY"]
SERVER = os.environ.get("GITHUB_SERVER_URL", "https://github.com")
HEADERS = {
"Authorization": f"Bearer {TOKEN}",
"Content-Type": "application/json",
}
try:
with open("pyproject.toml", "rb") as f:
pyproject = tomllib.load(f)
PROJECT_META = pyproject["project"]
PROJECT = PROJECT_META["name"]
except (KeyError, FileNotFoundError) as e:
print(f"❌ Error loading project metadata: {e}", file=sys.stderr)
sys.exit(1)
def new_version_from_record(record_id: str):
"""Create a new draft that inherits metadata from the latest published record."""
r = requests.post(
f"{API}/deposit/depositions/{record_id}/actions/newversion",
headers=HEADERS,
timeout=30,
)
r.raise_for_status()
# Zenodo returns a link to the draft, not the draft itself
latest_draft_url = r.json()["links"]["latest_draft"]
return requests.get(latest_draft_url, headers=HEADERS, timeout=30).json()
def upload_file(bucket_url: str, path: str, dest_name: str = None):
"""Upload a file to the deposition bucket."""
dest = dest_name or os.path.basename(path)
with open(path, "rb") as fp:
r = requests.put(
f"{bucket_url}/{dest}",
data=fp,
headers={"Authorization": f"Bearer {TOKEN}"},
timeout=60,
)
r.raise_for_status()
def main():
"""Main workflow."""
try:
draft = new_version_from_record(RECORD_ID)
bucket = draft["links"]["bucket"]
dep_id = draft["id"]
# GitHub auto-generates source archives for tags
tarball = f"/tmp/{PROJECT}-v{VERSION}.tar.gz"
src_url = f"{SERVER}/{REPO}/archive/refs/tags/v{VERSION}.tar.gz"
urllib.request.urlretrieve(src_url, tarball)
upload_file(bucket, tarball, f"{PROJECT}-{VERSION}.tar.gz")
for path in glob.glob("dist/*"):
upload_file(bucket, path)
# Update only version-specific metadata; rest is inherited
meta = {
"metadata": {
"title": f"{PROJECT.replace('-', ' ').title()} v{VERSION}",
"version": VERSION,
"upload_type": "software",
}
}
r = requests.put(
f"{API}/deposit/depositions/{dep_id}",
headers=HEADERS,
json=meta,
timeout=30,
)
r.raise_for_status()
# Publish to mint DOI
r = requests.post(
f"{API}/deposit/depositions/{dep_id}/actions/publish",
headers=HEADERS,
timeout=30,
)
r.raise_for_status()
record = r.json()
doi = record.get("doi")
record_id = record.get("record_id")
print(f"✅ Published to Zenodo: https://doi.org/{doi}")
if "GITHUB_OUTPUT" in os.environ:
with open(os.environ["GITHUB_OUTPUT"], "a") as f:
f.write(f"doi={doi}\n")
f.write(f"record_id={record_id}\n")
f.write(f"zenodo_url=https://zenodo.org/records/{record_id}\n")
return 0
except Exception as e:
print(f"❌ Error: {e}", file=sys.stderr)
return 1
if __name__ == "__main__":
sys.exit(main())
================================================
FILE: .github/workflows/auto-update-pr.yaml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
name: Auto Update PR
on:
push:
branches: [main]
schedule:
# Run daily at 2 AM UTC to catch stale PRs
- cron: '0 2 * * *'
workflow_dispatch:
inputs:
pr_number:
description: 'PR number to update (optional, updates all if not specified)'
required: false
type: string
permissions:
contents: write # Required for updateBranch API
pull-requests: write
issues: write
jobs:
update-prs:
runs-on: ubuntu-latest
concurrency:
group: auto-update-pr-${{ github.event_name }}
cancel-in-progress: true
steps:
- name: Update PRs that are behind main
uses: actions/github-script@v7
with:
script: |
const prNumber = context.payload.inputs?.pr_number;
// Get list of open PRs
const prs = prNumber
? [(await github.rest.pulls.get({
owner: context.repo.owner,
repo: context.repo.repo,
pull_number: parseInt(prNumber)
})).data]
: await github.paginate(github.rest.pulls.list, {
owner: context.repo.owner,
repo: context.repo.repo,
state: 'open',
sort: 'updated',
direction: 'desc'
});
console.log(`Found ${prs.length} open PRs to check`);
// Constants for comment flood control
const UPDATE_COMMENT_COOLDOWN_DAYS = 7;
const COOLDOWN_MS = UPDATE_COMMENT_COOLDOWN_DAYS * 24 * 60 * 60 * 1000;
for (const pr of prs) {
// Skip bot PRs and drafts
if (pr.user.login.includes('[bot]')) {
console.log(`Skipping bot PR #${pr.number} from ${pr.user.login}`);
continue;
}
if (pr.draft) {
console.log(`Skipping draft PR #${pr.number}`);
continue;
}
try {
// Check if PR is behind main (base...head comparison)
const { data: comparison } = await github.rest.repos.compareCommits({
owner: context.repo.owner,
repo: context.repo.repo,
base: pr.base.ref, // main branch
head: `${pr.head.repo.owner.login}:${pr.head.ref}` // Fully qualified ref for forks
});
if (comparison.behind_by > 0) {
console.log(`PR #${pr.number} is ${comparison.behind_by} commits behind ${pr.base.ref}`);
// Check if the PR allows maintainer edits
if (pr.maintainer_can_modify) {
// Try to update the branch
try {
await github.rest.pulls.updateBranch({
owner: context.repo.owner,
repo: context.repo.repo,
pull_number: pr.number
});
console.log(`✅ Updated PR #${pr.number}`);
// Add a comment
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: pr.number,
body: `🔄 **Branch Updated**\n\nYour branch was ${comparison.behind_by} commits behind \`${pr.base.ref}\` and has been automatically updated. CI checks will re-run shortly.`
});
} catch (updateError) {
console.log(`Could not auto-update PR #${pr.number}: ${updateError.message}`);
// Determine the reason for failure
let failureReason = '';
if (updateError.status === 409 || updateError.message.includes('merge conflict')) {
failureReason = '\n\n**Note:** Automatic update failed due to merge conflicts. Please resolve them manually.';
} else if (updateError.status === 422) {
failureReason = '\n\n**Note:** Cannot push to fork. Please update manually.';
}
// Notify the contributor to update manually
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: pr.number,
body: `⚠️ **Branch Update Required**\n\nYour branch is ${comparison.behind_by} commits behind \`${pr.base.ref}\`.${failureReason}\n\nPlease update your branch:\n\n\`\`\`bash\ngit fetch origin ${pr.base.ref}\ngit merge origin/${pr.base.ref}\ngit push\n\`\`\`\n\nOr use GitHub's "Update branch" button if available.`
});
}
} else {
// Can't modify, just notify
console.log(`PR #${pr.number} doesn't allow maintainer edits`);
// Check if we already commented recently (within last 7 days)
const { data: comments } = await github.rest.issues.listComments({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: pr.number,
since: new Date(Date.now() - COOLDOWN_MS).toISOString()
});
const hasRecentUpdateComment = comments.some(c =>
c.body?.includes('Branch Update Required') &&
c.user?.login === 'github-actions[bot]'
);
if (!hasRecentUpdateComment) {
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: pr.number,
body: `⚠️ **Branch Update Required**\n\nYour branch is ${comparison.behind_by} commits behind \`${pr.base.ref}\`. Please update your branch to ensure CI checks run with the latest code:\n\n\`\`\`bash\ngit fetch origin ${pr.base.ref}\ngit merge origin/${pr.base.ref}\ngit push\n\`\`\`\n\nNote: Enable "Allow edits by maintainers" to allow automatic updates.`
});
}
}
} else {
console.log(`PR #${pr.number} is up to date`);
}
} catch (error) {
console.error(`Error processing PR #${pr.number}:`, error.message);
}
}
// Log rate limit status
const { data: rateLimit } = await github.rest.rateLimit.get();
console.log(`API rate limit remaining: ${rateLimit.rate.remaining}/${rateLimit.rate.limit}`);
================================================
FILE: .github/workflows/check-infrastructure-changes.yml
================================================
name: Protect Infrastructure Files
on:
pull_request_target:
types: [opened, synchronize, reopened]
workflow_dispatch:
permissions:
contents: read
pull-requests: write
jobs:
protect-infrastructure:
if: github.event_name == 'workflow_dispatch' || github.event.pull_request.draft == false
runs-on: ubuntu-latest
steps:
- name: Check for infrastructure file changes
if: github.event_name == 'pull_request_target'
uses: actions/github-script@v7
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
// Get the PR author and check if they're a maintainer
const prAuthor = context.payload.pull_request.user.login;
const { data: authorPermission } = await github.rest.repos.getCollaboratorPermissionLevel({
owner: context.repo.owner,
repo: context.repo.repo,
username: prAuthor
});
const isMaintainer = ['admin', 'maintain'].includes(authorPermission.permission);
// Get list of files changed in the PR
const { data: files } = await github.rest.pulls.listFiles({
owner: context.repo.owner,
repo: context.repo.repo,
pull_number: context.payload.pull_request.number
});
// Check for infrastructure file changes
const infrastructureFiles = files.filter(file =>
file.filename.startsWith('.github/') ||
file.filename === 'pyproject.toml' ||
file.filename === 'tox.ini' ||
file.filename === '.pre-commit-config.yaml' ||
file.filename === '.pylintrc' ||
file.filename === 'Dockerfile' ||
file.filename === 'autoformat.sh' ||
file.filename === '.gitignore' ||
file.filename === 'CONTRIBUTING.md' ||
file.filename === 'LICENSE' ||
file.filename === 'CITATION.cff'
);
if (infrastructureFiles.length > 0 && !isMaintainer) {
// Check if changes are only formatting/whitespace
let hasStructuralChanges = false;
for (const file of infrastructureFiles) {
const additions = file.additions || 0;
const deletions = file.deletions || 0;
const changes = file.changes || 0;
// If file has significant changes (not just whitespace), consider it structural
if (additions > 5 || deletions > 5 || changes > 10) {
hasStructuralChanges = true;
break;
}
}
const fileList = infrastructureFiles.map(f => ` - ${f.filename} (${f.changes} changes)`).join('\n');
// Post a comment explaining the issue
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.payload.pull_request.number,
body: `❌ **Infrastructure File Protection**\n\n` +
`This PR modifies protected infrastructure files:\n\n${fileList}\n\n` +
`Only repository maintainers are allowed to modify infrastructure files (including \`.github/\`, build configuration, and repository documentation).\n\n` +
`**Note**: If these are only formatting changes, please:\n` +
`1. Revert changes to \`.github/\` files\n` +
`2. Use \`./autoformat.sh\` to format only source code directories\n` +
`3. Avoid running formatters on infrastructure files\n\n` +
`If structural changes are necessary:\n` +
`1. Open an issue describing the needed infrastructure changes\n` +
`2. A maintainer will review and implement the changes if approved\n\n` +
`For more information, see our [Contributing Guidelines](https://github.com/google/langextract/blob/main/CONTRIBUTING.md).`
});
core.setFailed(
`This PR modifies ${infrastructureFiles.length} protected infrastructure file(s). ` +
`Only maintainers can modify these files. ` +
`Use ./autoformat.sh to format code without touching infrastructure.`
);
} else if (infrastructureFiles.length > 0 && isMaintainer) {
core.info(`PR modifies ${infrastructureFiles.length} infrastructure file(s) - allowed for maintainer ${prAuthor}`);
} else {
core.info('No infrastructure files modified');
}
================================================
FILE: .github/workflows/check-linked-issue.yml
================================================
name: Require linked issue with community support
on:
pull_request_target:
types: [opened, edited, synchronize, reopened, ready_for_review]
permissions:
contents: read
issues: write
pull-requests: write
concurrency:
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}
cancel-in-progress: true
jobs:
enforce:
if: github.event_name == 'pull_request_target' && !github.event.pull_request.draft
runs-on: ubuntu-latest
steps:
- name: Check linked issue and community support
uses: actions/github-script@v7
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
// Strip code blocks and inline code to avoid false matches
const stripCode = txt =>
txt.replace(/```[\s\S]*?```/g, '').replace(/`[^`]*`/g, '');
// Combine title + body for comprehensive search
const prText = stripCode(`${context.payload.pull_request.title || ''}\n${context.payload.pull_request.body || ''}`);
// Issue reference pattern: #123, org/repo#123, or full URL (with http/https and optional www)
const issueRef = String.raw`(?:#(?<num>\d+)|(?<o1>[\w.-]+)\/(?<r1>[\w.-]+)#(?<n1>\d+)|https?:\/\/(?:www\.)?github\.com\/(?<o2>[\w.-]+)\/(?<r2>[\w.-]+)\/issues\/(?<n2>\d+))`;
// Keywords - supporting common variants
const closingRe = new RegExp(String.raw`\b(?:close[sd]?|fix(?:e[sd])?|resolve[sd]?)\b\s*:?\s+${issueRef}`, 'gi');
const referenceRe = new RegExp(String.raw`\b(?:related\s+to|relates\s+to|refs?|part\s+of|addresses|see(?:\s+also)?|depends\s+on|blocked\s+by|supersedes)\b\s*:?\s+${issueRef}`, 'gi');
// Gather all matches
const closings = [...prText.matchAll(closingRe)];
const references = [...prText.matchAll(referenceRe)];
const first = closings[0] || references[0];
// Check for draft PRs and bots
const pr = context.payload.pull_request;
const isDraft = !!pr.draft;
const login = pr.user.login;
const isBot = pr.user.type === 'Bot' || /\[bot\]$/.test(login);
if (isDraft || isBot) {
core.info('Draft or bot PR – skipping enforcement');
return;
}
// Check if PR author is a maintainer
let authorPerm = 'none';
try {
const { data } = await github.rest.repos.getCollaboratorPermissionLevel({
owner: context.repo.owner,
repo: context.repo.repo,
username: pr.user.login,
});
authorPerm = data.permission || 'none';
} catch (_) {
// User might not have any permissions
}
core.info(`Author permission: ${authorPerm}`);
const isMaintainer = ['admin', 'maintain'].includes(authorPerm); // Removed 'write' for stricter maintainer definition
// Maintainers bypass entirely
if (isMaintainer) {
core.info(`Maintainer ${pr.user.login} - bypassing linked issue requirement`);
return;
}
if (!first) {
// Check for existing comment to avoid duplicates
const MARKER = '<!-- linkcheck:missing-issue -->';
const existing = await github.paginate(github.rest.issues.listComments, {
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.payload.pull_request.number,
per_page: 100,
});
const alreadyLeft = existing.some(c => c.body && c.body.includes(MARKER));
if (!alreadyLeft) {
const contribUrl = `https://github.com/${context.repo.owner}/${context.repo.repo}/blob/main/CONTRIBUTING.md#pull-request-guidelines`;
const commentBody = [
'No linked issues found. Please link an issue in your pull request description or title.',
'',
`Per our [Contributing Guidelines](${contribUrl}), all PRs must:`,
'- Reference an issue with one of:',
' - **Closing keywords**: `Fixes #123`, `Closes #123`, `Resolves #123` (auto-closes on merge in the same repository)',
' - **Reference keywords**: `Related to #123`, `Refs #123`, `Part of #123`, `See #123` (links without closing)',
'- The linked issue should have 5+ 👍 reactions from unique users (excluding bots and the PR author)',
'- Include discussion demonstrating the importance of the change',
'',
'You can also use cross-repo references like `owner/repo#123` or full URLs.',
'',
MARKER
].join('\n');
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.payload.pull_request.number,
body: commentBody
});
}
core.setFailed('No linked issue found. Use "Fixes #123" to close an issue or "Related to #123" to reference it.');
return;
}
// Resolve owner/repo/number, defaulting to the current repo
const groups = first.groups || {};
const owner = groups.o1 || groups.o2 || context.repo.owner;
const repo = groups.r1 || groups.r2 || context.repo.repo;
const issue_number = Number(groups.num || groups.n1 || groups.n2);
// Validate issue number
if (!Number.isInteger(issue_number) || issue_number <= 0) {
core.setFailed(
'Found a potential issue link but no valid number. ' +
'Use "Fixes #123" or "Related to owner/repo#123".'
);
return;
}
core.info(`Found linked issue: ${owner}/${repo}#${issue_number}`);
// Count unique users who reacted with 👍 on the linked issue (excluding bots and PR author)
try {
const reactions = await github.paginate(github.rest.reactions.listForIssue, {
owner,
repo,
issue_number,
per_page: 100,
});
const prAuthorId = pr.user.id;
const uniqueThumbs = new Set(
reactions
.filter(r =>
r.content === '+1' &&
r.user &&
r.user.id !== prAuthorId &&
r.user.type !== 'Bot' &&
!String(r.user.login || '').endsWith('[bot]')
)
.map(r => r.user.id)
).size;
core.info(`Issue ${owner}/${repo}#${issue_number} has ${uniqueThumbs} unique 👍 reactions`);
const REQUIRED_THUMBS_UP = 5;
if (uniqueThumbs < REQUIRED_THUMBS_UP) {
core.setFailed(`Linked issue ${owner}/${repo}#${issue_number} has only ${uniqueThumbs} 👍 (need ${REQUIRED_THUMBS_UP}).`);
return;
}
} catch (error) {
const isSameRepo = owner === context.repo.owner && repo === context.repo.repo;
if (error.status === 404 || error.status === 403) {
if (!isSameRepo) {
core.setFailed(
`Linked issue ${owner}/${repo}#${issue_number} is not accessible. ` +
`Please link to an issue in ${context.repo.owner}/${context.repo.repo} or a public repo.`
);
} else {
core.info(`Cannot access reactions for ${owner}/${repo}#${issue_number}; skipping enforcement for same-repo issue.`);
}
return;
}
// Any other error should fail to prevent accidental bypass
const msg = (error && error.message) ? String(error.message).toLowerCase() : '';
const isRateLimit = msg.includes('rate limit') || error?.headers?.['x-ratelimit-remaining'] === '0';
if (isRateLimit) {
core.setFailed(`Rate limit while checking reactions for ${owner}/${repo}#${issue_number}. Please retry the workflow.`);
} else {
core.setFailed(`Unexpected error checking reactions for ${owner}/${repo}#${issue_number}: ${error?.message || error}`);
}
}
================================================
FILE: .github/workflows/check-pr-size.yml
================================================
name: Check PR size
on:
pull_request_target:
types: [opened, synchronize, reopened]
workflow_dispatch:
inputs:
pr_number:
description: 'PR number to check (optional)'
required: false
type: string
permissions:
contents: read
pull-requests: write
issues: write
concurrency:
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.run_id }}
cancel-in-progress: true
jobs:
size:
runs-on: ubuntu-latest
steps:
- name: Get PR data for manual trigger
if: github.event_name == 'workflow_dispatch' && github.event.inputs.pr_number
id: get_pr
uses: actions/github-script@v7
with:
result-encoding: string
script: |
const { data } = await github.rest.pulls.get({
owner: context.repo.owner,
repo: context.repo.repo,
pull_number: ${{ github.event.inputs.pr_number }}
});
return JSON.stringify(data);
- name: Evaluate PR size
if: github.event_name == 'pull_request_target' || (github.event_name == 'workflow_dispatch' && github.event.inputs.pr_number)
uses: actions/github-script@v7
env:
PR_JSON: ${{ steps.get_pr.outputs.result }}
with:
script: |
const pr = context.payload.pull_request || JSON.parse(process.env.PR_JSON || '{}');
if (!pr || !pr.number) {
core.setFailed('Unable to resolve PR data. For workflow_dispatch, pass a valid pr_number.');
return;
}
// Check for draft PRs and bots
const isDraft = !!pr.draft;
const login = pr.user.login;
const isBot = pr.user.type === 'Bot' || /\[bot\]$/.test(login);
if (isDraft || isBot) {
core.info('Draft or bot PR – skipping size enforcement');
return;
}
const totalChanges = pr.additions + pr.deletions;
core.info(`PR contains ${pr.additions} additions and ${pr.deletions} deletions (${totalChanges} total)`);
const sizeLabel =
totalChanges < 50 ? 'size/XS' :
totalChanges < 150 ? 'size/S' :
totalChanges < 600 ? 'size/M' :
totalChanges < 1000 ? 'size/L' : 'size/XL';
// Re-fetch labels to avoid acting on stale payload data
const { data: freshIssue } = await github.rest.issues.get({
...context.repo,
issue_number: pr.number
});
const currentLabels = (freshIssue.labels || []).map(l => l.name);
// Remove old size labels before adding new one
const allSizeLabels = ['size/XS', 'size/S', 'size/M', 'size/L', 'size/XL'];
const toRemove = currentLabels.filter(name => allSizeLabels.includes(name) && name !== sizeLabel);
for (const name of toRemove) {
try {
await github.rest.issues.removeLabel({
...context.repo,
issue_number: pr.number,
name
});
} catch (_) {
// Ignore if already removed
}
}
await github.rest.issues.addLabels({
...context.repo,
issue_number: pr.number,
labels: [sizeLabel]
});
// Check if PR author is a maintainer
let authorPerm = 'none';
try {
const { data } = await github.rest.repos.getCollaboratorPermissionLevel({
owner: context.repo.owner,
repo: context.repo.repo,
username: pr.user.login,
});
authorPerm = data.permission || 'none';
} catch (_) {
// User might not have any permissions
}
core.info(`Author permission: ${authorPerm}`);
const isMaintainer = ['admin', 'maintain'].includes(authorPerm); // Stricter maintainer definition
// Check for bypass label (using fresh labels)
const hasBypass = currentLabels.includes('bypass:size-limit');
const MAX_LINES = 1000;
if (totalChanges > MAX_LINES) {
if (isMaintainer || hasBypass) {
core.info(`${isMaintainer ? 'Maintainer' : 'Bypass label'} - allowing large PR with ${totalChanges} lines`);
} else {
core.setFailed(
`This PR contains ${totalChanges} lines of changes, which exceeds the maximum of ${MAX_LINES} lines. ` +
`Please split this into smaller, focused pull requests.`
);
}
}
================================================
FILE: .github/workflows/check-pr-up-to-date.yaml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
name: Check PR Up-to-Date
on:
pull_request:
types: [opened, synchronize]
permissions:
contents: read
pull-requests: write
jobs:
check-up-to-date:
runs-on: ubuntu-latest
# Skip for bot PRs
if: ${{ !contains(github.actor, '[bot]') }}
concurrency:
group: check-pr-${{ github.event.pull_request.number }}
cancel-in-progress: true
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 2 # Sufficient for rev-list comparison
- name: Check if PR is up-to-date with main
id: check
run: |
# Fetch the latest main branch
git fetch origin main
# Check how many commits behind main
BEHIND=$(git rev-list --count HEAD..origin/main)
echo "commits_behind=$BEHIND" >> $GITHUB_OUTPUT
if [ "$BEHIND" -gt 0 ]; then
echo "::warning::PR is $BEHIND commits behind main"
exit 0 # Don't fail the check, just warn
else
echo "PR is up-to-date with main"
fi
- name: Comment if PR needs update
if: ${{ steps.check.outputs.commits_behind != '0' }}
uses: actions/github-script@v7
with:
script: |
const behind = ${{ steps.check.outputs.commits_behind }};
const COMMENT_COOLDOWN_HOURS = 24;
const COOLDOWN_MS = COMMENT_COOLDOWN_HOURS * 60 * 60 * 1000;
// Check for recent similar comments
const { data: comments } = await github.rest.issues.listComments({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.payload.pull_request.number,
per_page: 10
});
const hasRecentComment = comments.some(c =>
c.body?.includes('commits behind `main`') &&
c.user?.login === 'github-actions[bot]' &&
new Date(c.created_at) > new Date(Date.now() - COOLDOWN_MS)
);
if (!hasRecentComment) {
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.payload.pull_request.number,
body: `📊 **PR Status**: ${behind} commits behind \`main\`\n\nConsider updating your branch for the most accurate CI results:\n\n**Option 1**: Use GitHub's "Update branch" button (if available)\n\n**Option 2**: Update locally:\n\`\`\`bash\ngit fetch origin main\ngit merge origin/main\ngit push\n\`\`\`\n\n*Note: If you use a different remote name (e.g., upstream), adjust the commands accordingly.*\n\nThis ensures your changes are tested against the latest code.`
});
}
================================================
FILE: .github/workflows/ci.yaml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
name: CI
on:
workflow_dispatch:
push:
branches: ["main"]
pull_request:
branches: ["main"]
pull_request_target:
types: [labeled]
concurrency:
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}
cancel-in-progress: true
permissions:
contents: read
jobs:
format-check:
runs-on: ubuntu-latest
if: github.event_name == 'pull_request'
permissions:
contents: read
issues: write
steps:
- name: Checkout PR branch
uses: actions/checkout@v4
with:
repository: ${{ github.event.pull_request.head.repo.full_name }}
ref: ${{ github.event.pull_request.head.ref }}
persist-credentials: false
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install format tools
run: |
python -m pip install --upgrade pip
pip install -e ".[dev]"
- name: Check formatting
id: format-check
env:
GITHUB_TOKEN: ""
run: |
set -euo pipefail
pyink --check --diff .
isort --check-only --diff .
- name: Check import structure
id: import-check
env:
GITHUB_TOKEN: ""
run: |
set -euo pipefail
lint-imports --config pyproject.toml
- name: Comment on PR if formatting fails
if: failure() && steps.format-check.outcome == 'failure'
uses: actions/github-script@v7
continue-on-error: true
with:
script: |
github.rest.issues.createComment({
issue_number: context.payload.pull_request.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: '❌ **Formatting Check Failed**\n\nYour PR has formatting issues. Please run the following command locally and push the changes:\n\n```bash\n./autoformat.sh\n```\n\nThis will automatically fix all formatting issues using pyink (Google\'s Python formatter) and isort.'
}).catch(err => {
console.log('Comment posting failed:', err.message);
});
test:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12"]
steps:
- uses: actions/checkout@v4
with:
persist-credentials: false
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v5
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install tox
pip install -e ".[dev,test]"
- name: Run unit tests and linting
run: |
PY_VERSION=$(echo "${{ matrix.python-version }}" | tr -d '.')
# Format check is handled by separate job for better isolation
tox -e py${PY_VERSION},lint-src,lint-tests
live-api-tests:
needs: test
runs-on: ubuntu-latest
if: |
github.event_name == 'push' ||
(github.event_name == 'pull_request' &&
github.event.pull_request.head.repo.full_name == github.repository)
steps:
- uses: actions/checkout@v4
with:
persist-credentials: false
- name: Set up Python 3.11
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install tox
pip install -e ".[dev,test]"
- name: Run live API tests
env:
GITHUB_TOKEN: ""
run: |
set -euo pipefail
if [[ -z '${{ secrets.GEMINI_API_KEY }}' && -z '${{ secrets.OPENAI_API_KEY }}' ]]; then
echo "::notice::Live API tests skipped - API keys not configured"
exit 0
fi
GEMINI_API_KEY="${{ secrets.GEMINI_API_KEY }}" \
LANGEXTRACT_API_KEY="${{ secrets.GEMINI_API_KEY }}" \
OPENAI_API_KEY="${{ secrets.OPENAI_API_KEY }}" \
tox -e live-api
plugin-integration-test:
needs: test
runs-on: ubuntu-latest
if: github.event_name == 'pull_request'
permissions:
contents: read
pull-requests: read
steps:
- uses: actions/checkout@v4
with:
persist-credentials: false
fetch-depth: 0
- name: Detect provider-related changes
id: provider-changes
uses: tj-actions/changed-files@v46
with:
files: |
langextract/providers/**
langextract/factory.py
langextract/inference.py
tests/provider_plugin_test.py
pyproject.toml
.github/workflows/ci.yaml
- name: Skip if no provider changes
if: steps.provider-changes.outputs.any_changed == 'false'
run: |
echo "No provider-related changes detected – skipping plugin integration test."
exit 0
- name: Set up Python 3.11
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install tox
- name: Run plugin smoke test
run: tox -e plugin-smoke
- name: Run plugin integration test
run: tox -e plugin-integration
ollama-integration-test:
needs: test
runs-on: ubuntu-latest
if: github.event_name == 'pull_request'
permissions:
contents: read
pull-requests: read
steps:
- uses: actions/checkout@v4
with:
persist-credentials: false
fetch-depth: 0
- name: Detect file changes
id: changes
uses: tj-actions/changed-files@v46
with:
files: |
langextract/inference.py
examples/ollama/**
tests/test_ollama_integration.py
.github/workflows/ci.yaml
- name: Skip if no Ollama changes
if: steps.changes.outputs.any_changed == 'false'
run: |
echo "No Ollama-related changes detected – skipping job."
exit 0
- name: Set up Python 3.11
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Launch Ollama container
run: |
docker run -d --name ollama \
-p 127.0.0.1:11434:11434 \
-v ollama:/root/.ollama \
ollama/ollama:0.5.4
for i in {1..20}; do
curl -fs http://localhost:11434/api/version && break
sleep 3
done
- name: Pull gemma2 model
run: docker exec ollama ollama pull gemma2:2b || true
- name: Install tox
run: |
python -m pip install --upgrade pip
pip install tox
- name: Run Ollama integration tests
run: tox -e ollama-integration
test-fork-pr:
runs-on: ubuntu-latest
timeout-minutes: 30
environment:
name: live-keys
# Triggered when a maintainer adds 'ready-to-merge' label to fork PRs only
if: |
github.event_name == 'pull_request_target' &&
github.event.action == 'labeled' &&
github.event.label.name == 'ready-to-merge' &&
github.event.pull_request.head.repo.full_name != github.repository
permissions:
contents: read
issues: write
steps:
- name: Check if user is maintainer
uses: actions/github-script@v7
with:
script: |
const { data: permission } = await github.rest.repos.getCollaboratorPermissionLevel({
owner: context.repo.owner,
repo: context.repo.repo,
username: context.actor
});
const isMaintainer = ['admin', 'maintain'].includes(permission.permission);
if (!isMaintainer) {
throw new Error(`User ${context.actor} does not have maintainer permissions.`);
}
- name: Pin commit SHA for security
id: sha-pin
run: |
SHA_TO_TEST="${{ github.event.pull_request.head.sha }}"
echo "SHA_TO_TEST=${SHA_TO_TEST}" >> $GITHUB_OUTPUT
echo "::notice title=Security::Pinned commit SHA for testing: ${SHA_TO_TEST}"
- name: Checkout base repo
uses: actions/checkout@v4
with:
ref: main
fetch-depth: 0
persist-credentials: false
- name: Fetch and verify exact PR commit
run: |
set -euo pipefail
EXPECTED_SHA="${STEPS_SHA_PIN_OUTPUTS_SHA_TO_TEST}"
echo "Fetching exact commit: $EXPECTED_SHA"
# Fetch the specific commit SHA
git fetch --no-tags --prune --no-recurse-submodules origin "$EXPECTED_SHA" || {
echo "::error::Failed to fetch PR commit $EXPECTED_SHA. The commit may have been deleted."
exit 1
}
git checkout -b pr-to-test "$EXPECTED_SHA"
# Verify checkout
ACTUAL_SHA="$(git rev-parse HEAD)"
if [ "$ACTUAL_SHA" != "$EXPECTED_SHA" ]; then
echo "::error::SHA verification failed! Expected $EXPECTED_SHA but got $ACTUAL_SHA"
exit 1
fi
echo "::notice title=Security::Successfully verified commit SHA: $ACTUAL_SHA"
env:
STEPS_SHA_PIN_OUTPUTS_SHA_TO_TEST: ${{ steps.sha-pin.outputs.SHA_TO_TEST }}
- name: Set up Python 3.11
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install format tools
run: |
python -m pip install --upgrade pip
# Install formatter tools with pinned versions
pip install pyink==24.3.0 isort==5.13.2 lint-imports==0.3.1
- name: Validate PR formatting
run: |
set -euo pipefail
echo "Validating code formatting..."
pyink --check --diff . || {
echo "::error::Code formatting (pyink) does not meet project standards. Please run ./autoformat.sh locally and push the changes."
exit 1
}
isort --check-only --diff . || {
echo "::error::Import sorting (isort) does not meet project standards. Please run ./autoformat.sh locally and push the changes."
exit 1
}
- name: Checkout main branch
uses: actions/checkout@v4
with:
ref: main
fetch-depth: 0
persist-credentials: false
- name: Merge verified PR commit
run: |
set -euo pipefail
git config user.name "github-actions[bot]"
git config user.email "github-actions[bot]@users.noreply.github.com"
SHA_TO_MERGE="${STEPS_SHA_PIN_OUTPUTS_SHA_TO_TEST}"
echo "Merging verified commit: $SHA_TO_MERGE"
git fetch --no-tags --prune --no-recurse-submodules origin "$SHA_TO_MERGE"
git merge --no-ff --no-edit "$SHA_TO_MERGE" || {
echo "::error::Failed to merge commit $SHA_TO_MERGE"
exit 1
}
echo "::notice title=Security::Successfully merged verified commit"
env:
STEPS_SHA_PIN_OUTPUTS_SHA_TO_TEST: ${{ steps.sha-pin.outputs.SHA_TO_TEST }}
- name: Add status comment
uses: actions/github-script@v7
with:
script: |
github.rest.issues.createComment({
issue_number: context.payload.pull_request.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: 'Preparing to run live API tests (pending environment approval and API key availability)...'
});
- name: Run live API tests
env:
GITHUB_TOKEN: ""
run: |
set -euo pipefail
if [[ -z '${{ secrets.GEMINI_API_KEY }}' && -z '${{ secrets.OPENAI_API_KEY }}' ]]; then
echo "::notice::Live API tests skipped - API keys not configured"
exit 0
fi
python -m pip install --upgrade pip
pip install tox
pip install -e ".[dev,test]"
GEMINI_API_KEY="${{ secrets.GEMINI_API_KEY }}" \
LANGEXTRACT_API_KEY="${{ secrets.GEMINI_API_KEY }}" \
OPENAI_API_KEY="${{ secrets.OPENAI_API_KEY }}" \
tox -e live-api
- name: Report success
if: success()
uses: actions/github-script@v7
with:
script: |
github.rest.issues.createComment({
issue_number: context.payload.pull_request.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: '✅ Live API tests passed! All endpoints are working correctly.'
});
- name: Report failure
if: failure()
uses: actions/github-script@v7
with:
script: |
github.rest.issues.createComment({
issue_number: context.payload.pull_request.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: '❌ Live API tests failed. Please check the workflow logs for details.'
});
================================================
FILE: .github/workflows/publish.yml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
name: Publish to PyPI
on:
release:
types: [published]
permissions:
contents: read
id-token: write
jobs:
pypi-publish:
name: Publish to PyPI
runs-on: ubuntu-latest
environment: pypi
permissions:
id-token: write
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install build dependencies
run: |
python -m pip install --upgrade pip
pip install build
- name: Build package
run: python -m build
- name: Verify build artifacts
run: |
ls -la dist/
pip install twine
twine check dist/*
- name: Publish to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
================================================
FILE: .github/workflows/revalidate-pr.yml
================================================
name: Revalidate PR
on:
workflow_dispatch:
inputs:
pr_number:
description: 'PR number to validate'
required: true
type: string
permissions:
contents: read
pull-requests: write
issues: write
checks: write
statuses: write
jobs:
revalidate:
runs-on: ubuntu-latest
steps:
- name: Get PR data
id: pr_data
uses: actions/github-script@v7
with:
script: |
const { data: pr } = await github.rest.pulls.get({
owner: context.repo.owner,
repo: context.repo.repo,
pull_number: ${{ inputs.pr_number }}
});
core.info(`Validating PR #${pr.number}: ${pr.title}`);
core.info(`Author: ${pr.user.login}`);
core.info(`Changes: +${pr.additions} -${pr.deletions}`);
// Store head SHA for creating status
core.setOutput('head_sha', pr.head.sha);
return pr;
- name: Create pending status
uses: actions/github-script@v7
with:
script: |
await github.rest.repos.createCommitStatus({
owner: context.repo.owner,
repo: context.repo.repo,
sha: '${{ steps.pr_data.outputs.head_sha }}',
state: 'pending',
context: 'Manual Validation',
description: 'Running validation checks...'
});
- name: Validate PR
id: validate
uses: actions/github-script@v7
with:
script: |
const pr = ${{ steps.pr_data.outputs.result }};
const errors = [];
let passed = true;
// Check size
const totalChanges = pr.additions + pr.deletions;
const MAX_LINES = 1000;
if (totalChanges > MAX_LINES) {
errors.push(`PR size (${totalChanges} lines) exceeds ${MAX_LINES} line limit`);
passed = false;
}
// Check template
const body = pr.body || '';
const requiredSections = ["# Description", "Fixes #", "# How Has This Been Tested?", "# Checklist"];
const missingSections = requiredSections.filter(section => !body.includes(section));
if (missingSections.length > 0) {
errors.push(`Missing PR template sections: ${missingSections.join(', ')}`);
passed = false;
}
if (body.match(/Replace this with|Choose one:|Fixes #\[issue number\]/i)) {
errors.push('PR template contains unmodified placeholders');
passed = false;
}
// Check linked issue
const issueMatch = body.match(/(?:Fixes|Closes|Resolves)\s+#(\d+)/i);
if (!issueMatch) {
errors.push('No linked issue found');
passed = false;
}
// Store results
core.setOutput('passed', passed);
core.setOutput('errors', errors.join('; '));
core.setOutput('totalChanges', totalChanges);
core.setOutput('hasTemplate', missingSections.length === 0);
core.setOutput('hasIssue', !!issueMatch);
if (!passed) {
core.setFailed(errors.join('; '));
}
- name: Update commit status
if: always()
uses: actions/github-script@v7
with:
script: |
const passed = ${{ steps.validate.outputs.passed }};
const errors = '${{ steps.validate.outputs.errors }}';
await github.rest.repos.createCommitStatus({
owner: context.repo.owner,
repo: context.repo.repo,
sha: '${{ steps.pr_data.outputs.head_sha }}',
state: passed ? 'success' : 'failure',
context: 'Manual Validation',
description: passed ? 'All validation checks passed' : errors.substring(0, 140),
target_url: `https://github.com/${context.repo.owner}/${context.repo.repo}/actions/runs/${context.runId}`
});
- name: Add validation comment
if: always()
uses: actions/github-script@v7
with:
script: |
const pr = ${{ steps.pr_data.outputs.result }};
const passed = ${{ steps.validate.outputs.passed }};
const totalChanges = ${{ steps.validate.outputs.totalChanges }};
const hasTemplate = ${{ steps.validate.outputs.hasTemplate }};
const hasIssue = ${{ steps.validate.outputs.hasIssue }};
const errors = '${{ steps.validate.outputs.errors }}'.split('; ').filter(e => e);
let body = `### Manual Validation Results\n\n`;
body += `**Status**: ${passed ? '✅ Passed' : '❌ Failed'}\n\n`;
body += `| Check | Status | Details |\n`;
body += `|-------|--------|----------|\n`;
body += `| PR Size | ${totalChanges <= 1000 ? '✅' : '❌'} | ${totalChanges} lines ${totalChanges > 1000 ? '(exceeds 1000 limit)' : ''} |\n`;
body += `| Template | ${hasTemplate ? '✅' : '❌'} | ${hasTemplate ? 'Complete' : 'Missing required sections'} |\n`;
body += `| Linked Issue | ${hasIssue ? '✅' : '❌'} | ${hasIssue ? 'Found' : 'Missing Fixes/Closes #XXX'} |\n`;
if (errors.length > 0) {
body += `\n**Errors:**\n`;
errors.forEach(error => {
body += `- ❌ ${error}\n`;
});
}
body += `\n[View workflow run](https://github.com/${context.repo.owner}/${context.repo.repo}/actions/runs/${context.runId})`;
await github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: pr.number,
body: body
});
================================================
FILE: .github/workflows/validate-community-providers.yaml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
name: Validate Community Providers
on:
pull_request:
paths:
- 'COMMUNITY_PROVIDERS.md'
- 'scripts/validate_community_providers.py'
permissions:
contents: read
pull-requests: read
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Validate table format
run: |
python scripts/validate_community_providers.py COMMUNITY_PROVIDERS.md
================================================
FILE: .github/workflows/validate_pr_template.yaml
================================================
name: Validate PR template
on:
pull_request_target:
types: [opened, edited, synchronize, reopened]
workflow_dispatch:
permissions:
contents: read
pull-requests: read
jobs:
check:
runs-on: ubuntu-latest
steps:
- name: Check PR author permissions
id: check
if: github.event_name == 'pull_request_target' && github.event.pull_request.draft == false
uses: actions/github-script@v7
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
const pr = context.payload.pull_request;
const {owner, repo} = context.repo;
const actor = pr.user.login;
const authorType = pr.user.type;
// Check if PR author is a bot (e.g., Dependabot)
if (authorType === 'Bot') {
core.setOutput('skip_validation', 'true');
console.log(`Skipping validation for bot-authored PR: ${actor}`);
return;
}
// Check if this is a community provider PR (only modifies COMMUNITY_PROVIDERS.md)
const { data: files } = await github.rest.pulls.listFiles({
owner, repo,
pull_number: pr.number
});
const isCommunityProviderPR = files.length === 1 &&
files[0].filename === 'COMMUNITY_PROVIDERS.md';
if (isCommunityProviderPR) {
core.setOutput('is_community_provider', 'true');
console.log('Community provider PR detected - relaxed validation will apply');
} else {
core.setOutput('is_community_provider', 'false');
}
// Get permission level
try {
const { data } = await github.rest.repos.getCollaboratorPermissionLevel({
owner, repo, username: actor
});
const permission = data.permission; // admin|maintain|write|triage|read|none
console.log(`Actor ${actor} has permission level: ${permission}`);
// Check if user has write+ permissions
if (['admin', 'maintain', 'write'].includes(permission)) {
core.setOutput('skip_validation', 'true');
console.log(`Skipping validation for maintainer: ${actor} (${permission})`);
} else {
core.setOutput('skip_validation', 'false');
console.log(`Validation required for: ${actor} (${permission})`);
}
} catch (e) {
// If we can't determine permissions, require validation
core.setOutput('skip_validation', 'false');
core.warning(`Permission lookup failed: ${e.message}`);
}
- name: Validate PR template
if: |
github.event_name == 'pull_request_target' &&
github.event.pull_request.draft == false &&
steps.check.outputs.skip_validation != 'true'
env:
PR_BODY: ${{ github.event.pull_request.body }}
IS_COMMUNITY_PROVIDER: ${{ steps.check.outputs.is_community_provider }}
run: |
printf '%s\n' "$PR_BODY" | tr -d '\r' > body.txt
# Required sections from the template
required=( "# Description" "# How Has This Been Tested?" "# Checklist" )
err=0
# Check for required sections
for h in "${required[@]}"; do
grep -Fq "$h" body.txt || { echo "::error::$h missing"; err=1; }
done
# Check for issue reference - relaxed for community provider PRs
if [ "$IS_COMMUNITY_PROVIDER" = "true" ]; then
# For community provider PRs, accept either "Fixes #" or "Related to #" (case-insensitive)
if ! grep -Eiq '(Fixes #[0-9]+|Related to #[0-9]+)' body.txt; then
echo "::error::Issue reference missing (need 'Fixes #NNN' or 'Related to #NNN')"
err=1
fi
else
# For other PRs, require "Fixes #" with a number
if ! grep -Eq 'Fixes #[0-9]+' body.txt; then
echo "::error::Missing 'Fixes #NNN' reference"
err=1
fi
fi
# Check for placeholder text that should be replaced
grep -Eiq 'Replace this with|Choose one:' body.txt && {
echo "::error::Template placeholders still present"; err=1;
}
# Also check for the unmodified issue number placeholder
grep -Fq 'Fixes #[issue number]' body.txt && {
echo "::error::Issue number placeholder not updated"; err=1;
}
exit $err
- name: Log skip reason
if: |
github.event_name == 'pull_request_target' &&
(github.event.pull_request.draft == true ||
steps.check.outputs.skip_validation == 'true')
run: |
echo "Skipping PR template validation. Draft: ${{ github.event.pull_request.draft }}; skip_validation: ${{ steps.check.outputs.skip_validation || 'N/A' }}"
================================================
FILE: .github/workflows/zenodo-publish.yml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
name: Publish to Zenodo
on:
release:
types: [published]
concurrency:
group: zenodo-${{ github.ref }}
cancel-in-progress: false
jobs:
zenodo:
# Only run on releases from the main repository, not forks
# Skip pre-releases to avoid creating DOIs for test releases
if: ${{ !github.event.release.prerelease && github.repository == 'google/langextract' }}
runs-on: ubuntu-latest
timeout-minutes: 15
permissions:
contents: read
env:
ZENODO_TOKEN: ${{ secrets.ZENODO_TOKEN }}
ZENODO_RECORD_ID: ${{ secrets.ZENODO_RECORD_ID }}
RELEASE_TAG: ${{ github.ref_name }}
GITHUB_REPOSITORY: ${{ github.repository }}
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Build distributions
run: |
python -m pip install --upgrade pip build
python -m build
- name: Install dependencies
run: python -m pip install requests
- name: Publish new Zenodo version
run: python .github/scripts/zenodo_publish.py
================================================
FILE: .gitignore
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Byte-compiled / Cache files
__pycache__/
*.py[cod]
*$py.class
# Distribution / Packaging
build/
dist/
*.egg-info/
.eggs/
eggs/
# Virtual Environments
.env
.venv
env/
venv/
ENV/
*_env/
# Test & Coverage Reports
.pytest_cache/
.tox/
htmlcov/
.coverage
.coverage.*
# Generated Output & Data
# LangExtract outputs are defaulted to test_output/
/test_output/
# Sphinx documentation build output
docs/_build/
# IDE / Editor specific
.idea/
.vscode/
*.swp
*.swo
*~
.*.swp
.*.swo
# OS-specific
.DS_Store
Thumbs.db
ehthumbs.db
Desktop.ini
$RECYCLE.BIN/
*.cab
*.msi
*.msm
*.msp
*.lnk
# Development tools & environments
.python-version
.pytype/
.mypy_cache/
.dmypy.json
dmypy.json
.pyre/
.ruff_cache/
*.sage.py
.hypothesis/
.scrapy
# Jupyter Notebooks
.ipynb_checkpoints
*/.ipynb_checkpoints/*
profile_default/
ipython_config.py
# Logs and databases
*.log
*.sql
*.sqlite
*.sqlite3
db.sqlite3
db.sqlite3-journal
logs/
*.pid
# Security and secrets
*.key
*.pem
*.crt
*.csr
.env.local
.env.production
.env.*.local
secrets/
credentials/
# AI tooling
CLAUDE.md
.claude/settings.local.json
.aider.chat.history.*
.aider.input.history
.gemini/
GEMINI.md
# Package managers
pip-log.txt
pip-delete-this-directory.txt
node_modules/
npm-debug.log*
yarn-debug.log*
yarn-error.log*
.pnpm-debug.log*
package-lock.json
yarn.lock
pnpm-lock.yaml
# Local development
local_settings.py
instance/
.webassets-cache
.sass-cache/
*.css.map
*.js.map
.dev/
# Temporary files
tmp/
temp/
cache/
*.tmp
*.bak
*.backup
*.orig
.~lock.*#
# Archives
*.tar
*.tar.gz
*.zip
*.rar
*.7z
*.dmg
*.iso
*.jar
# Media files
*.mp4
*.avi
*.mov
*.wmv
*.flv
*.mp3
*.wav
*.ogg
# Benchmark results and local environment
langextract_env/
benchmarks/benchmark_results
# Benchmark results in root
benchmark_results/**/*.json
benchmark_results/**/*.jsonl
benchmark_results/**/*.html
================================================
FILE: .pre-commit-config.yaml
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Pre-commit hooks for LangExtract
# Install with: pre-commit install
# Run manually: pre-commit run --all-files
repos:
- repo: https://github.com/PyCQA/isort
rev: 6.0.0
hooks:
- id: isort
name: isort (import sorting)
# Configuration is in pyproject.toml
- repo: https://github.com/google/pyink
rev: 24.3.0
hooks:
- id: pyink
name: pyink (Google's Black fork)
args: ["--config", "pyproject.toml"]
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.5.0
hooks:
- id: end-of-file-fixer
exclude: \.gif$|\.svg$
- id: trailing-whitespace
- id: check-yaml
- id: check-added-large-files
args: ['--maxkb=1000']
- id: check-merge-conflict
- id: check-case-conflict
- id: mixed-line-ending
args: ['--fix=lf']
================================================
FILE: .pylintrc
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
[MASTER]
# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
# number of processors available to use.
jobs=0
# Pickle collected data for later comparisons.
persistent=yes
# List of plugins (as comma separated values of python modules names) to load,
# usually to register additional checkers.
# Note: These plugins require Pylint >= 3.0
load-plugins=
pylint.extensions.docparams,
pylint.extensions.typing
# Allow loading of arbitrary C extensions. Extensions are imported into the
# active Python interpreter and may run arbitrary code.
unsafe-load-any-extension=no
[MESSAGES CONTROL]
# Enable the message, report, category or checker with the given id(s). You can
# either give multiple identifier separated by comma (,) or put this option
# multiple time.
enable=
useless-suppression
# Disable the message, report, category or checker with the given id(s). You
# can either give multiple identifier separated by comma (,) or put this option
# multiple time (only on the command line, not in the configuration file where
# it should appear only once).
disable=
abstract-method, # Protocol/ABC classes often have abstract methods
too-few-public-methods, # Valid for data classes with minimal interface
fixme, # TODO/FIXME comments are useful for tracking work
# --- Code style and formatting ---
line-too-long, # Handled by pyink formatter
bad-indentation, # Pyink uses 2-space indentation
# --- Design complexity ---
too-many-positional-arguments,
too-many-locals,
too-many-arguments,
too-many-branches,
too-many-statements,
too-many-nested-blocks,
# --- Style preferences ---
no-else-return,
no-else-raise,
# --- Documentation ---
missing-function-docstring,
missing-class-docstring,
missing-raises-doc,
# --- Gradual improvements ---
deprecated-typing-alias, # For typing.Type etc.
unspecified-encoding
[REPORTS]
# Set the output format. Available formats are text, parseable, colorized, msvs
# (visual studio) and html.
output-format=text
# Tells whether to display a full report or only the messages
reports=no
# Activate the evaluation score.
score=no
[REFACTORING]
# Maximum number of nested blocks for function / method body
max-nested-blocks=5
# Complete name of functions that never returns. When checking for
# inconsistent-return-statements if a never returning function is called then
# it will be considered as an explicit return statement and no message will be
# printed.
never-returning-functions=sys.exit
[BASIC]
# Naming style matching correct argument names.
argument-naming-style=snake_case
# Naming style matching correct attribute names.
attr-naming-style=snake_case
# Bad variable names which should always be refused, separated by a comma.
bad-names=foo,bar,baz,toto,tutu,tata
# Naming style matching correct class attribute names.
class-attribute-naming-style=any
# Naming style matching correct class names.
class-naming-style=PascalCase
# Naming style matching correct constant names.
const-naming-style=UPPER_CASE
# Minimum line length for functions/classes that require docstrings, shorter
# ones are exempt.
docstring-min-length=-1
# Naming style matching correct function names.
function-naming-style=snake_case
# Good variable names which should always be accepted, separated by a comma.
good-names=i,j,k,ex,Run,_,id,ok
# Good variable names regexes, separated by a comma. If names match any regex,
# they will always be accepted
good-names-rgxs=^T[A-Z][a-zA-Z]*$
# Include a hint for the correct naming format with invalid-name.
include-naming-hint=no
# Naming style matching correct inline iteration names.
inlinevar-naming-style=any
# Naming style matching correct method names.
method-naming-style=snake_case
# Naming style matching correct module names.
module-naming-style=snake_case
# Colon-delimited sets of names that determine each other's naming style when
# the name regexes allow several styles.
name-group=
# Regular expression which should only match function or class names that do
# not require a docstring.
no-docstring-rgx=^_
# List of decorators that produce properties, such as abc.abstractproperty. Add
# to this list to register other decorators that produce valid properties.
# These decorators are taken in consideration only for invalid-name.
property-classes=abc.abstractproperty
# Naming style matching correct variable names.
variable-naming-style=snake_case
[FORMAT]
# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
expected-line-ending-format=LF
# Regexp for a line that is allowed to be longer than the limit.
ignore-long-lines=^\s*(# )?<?https?://\S+>?$
# Number of spaces of indent required inside a hanging or continued line.
indent-after-paren=2
# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
# tab).
indent-string=" "
# Maximum number of characters on a single line.
max-line-length=80
# Maximum number of lines in a module.
max-module-lines=2000
# Allow the body of a class to be on the same line as the declaration if body
# contains single statement.
single-line-class-stmt=no
# Allow the body of an if to be on the same line as the test if there is no
# else.
single-line-if-stmt=no
[LOGGING]
# The type of string formatting that logging methods do. `old` means using %
# formatting, `new` is for `{}` formatting.
logging-format-style=old
# Logging modules to check that the string format arguments are in logging
# function parameter format.
logging-modules=logging
[MISCELLANEOUS]
# List of note tags to take in consideration, separated by a comma.
notes=FIXME,XXX,TODO
[SIMILARITIES]
# Ignore comments when computing similarities.
ignore-comments=yes
# Ignore docstrings when computing similarities.
ignore-docstrings=yes
# Ignore imports when computing similarities.
ignore-imports=no
# Minimum lines number of a similarity.
min-similarity-lines=6
[SPELLING]
# Limits count of emitted suggestions for spelling mistakes.
max-spelling-suggestions=4
# Spelling dictionary name. Available dictionaries: none. To make it working
# install python-enchant package..
spelling-dict=
# List of comma separated words that should not be checked.
spelling-ignore-words=
# A path to a file that contains private dictionary; one word per line.
spelling-private-dict-file=
# Tells whether to store unknown words to indicated private dictionary in
# --spelling-private-dict-file option instead of raising a message.
spelling-store-unknown-words=no
[TYPECHECK]
# List of decorators that produce context managers, such as
# contextlib.contextmanager. Add to this list to register other decorators that
# produce valid context managers.
contextmanager-decorators=contextlib.contextmanager
# List of members which are set dynamically and missed by pylint inference
# system, and so shouldn't trigger E1101 when accessed. Python regular
# expressions are accepted.
generated-members=
# Tells whether missing members accessed in mixin class should be ignored. A
# mixin class is detected if its name ends with "mixin" (case insensitive).
ignore-mixin-members=yes
# Tells whether to warn about missing members when the owner of the attribute
# is inferred to be None.
ignore-none=yes
# This flag controls whether pylint should warn about no-member and similar
# checks whenever an opaque object is returned when inferring. The inference
# can return multiple potential results while evaluating a Python object, but
# some branches might not be evaluated, which results in partial inference. In
# that case, it might be useful to still emit no-member and other checks for
# the rest of the inferred objects.
ignore-on-opaque-inference=yes
# List of class names for which member attributes should not be checked (useful
# for classes with dynamically set attributes). This supports the use of
# qualified names.
ignored-classes=optparse.Values,thread._local,_thread._local,dataclasses.InitVar,typing.Any
# List of module names for which member attributes should not be checked
# (useful for modules/projects where namespaces are manipulated during runtime
# and thus existing member attributes cannot be deduced by static analysis. It
# supports qualified module names, as well as Unix pattern matching.
ignored-modules=dotenv,absl,more_itertools,pandas,requests,pydantic,yaml,IPython.display,
tqdm,numpy,google,langfun,typing_extensions
# Show a hint with possible names when a member name was not found. The aspect
# of finding the hint is based on edit distance.
missing-member-hint=yes
# The minimum edit distance a name should have in order to be considered a
# similar match for a missing member name.
missing-member-hint-distance=1
# The total number of similar names that should be taken in consideration when
# showing a hint for a missing member.
missing-member-max-choices=1
# List of decorators that change the signature of a decorated function.
signature-mutators=
[VARIABLES]
# List of additional names supposed to be defined in builtins. Remember that
# you should avoid defining new builtins when possible.
additional-builtins=
# Tells whether unused global variables should be treated as a violation.
allow-global-unused-variables=yes
# List of strings which can identify a callback function by name. A callback
# name must start or end with one of those strings.
callbacks=cb_,_cb
# A regular expression matching the name of dummy variables (i.e. expected to
# not be used).
dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
# Argument names that match this expression will be ignored. Default to name
# with leading underscore.
ignored-argument-names=_.*|^ignored_|^unused_
# Tells whether we should check for unused import in __init__ files.
init-import=no
# List of qualified module names which can have objects that can redefine
# builtins.
redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
[CLASSES]
# List of method names used to declare (i.e. assign) instance attributes.
defining-attr-methods=__init__,
__new__,
setUp,
__post_init__
# List of member names, which should be excluded from the protected access
# warning.
exclude-protected=_asdict,
_fields,
_replace,
_source,
_make
# List of valid names for the first argument in a class method.
valid-classmethod-first-arg=cls
# List of valid names for the first argument in a metaclass class method.
valid-metaclass-classmethod-first-arg=cls
[DESIGN]
# Maximum number of arguments for function / method.
max-args=7
# Maximum number of attributes for a class (see R0902).
max-attributes=10
# Maximum number of boolean expressions in an if statement.
max-bool-expr=5
# Maximum number of branch for function / method body.
max-branches=12
# Maximum number of locals for function / method body.
max-locals=15
# Maximum number of parents for a class (see R0901).
max-parents=7
# Maximum number of public methods for a class (see R0904).
max-public-methods=20
# Maximum number of return / yield for function / method body.
max-returns=6
# Maximum number of statements in function / method body.
max-statements=50
# Minimum number of public methods for a class (see R0903).
min-public-methods=0
[IMPORTS]
# Allow wildcard imports from modules that define __all__.
allow-wildcard-with-all=yes
# Analyse import fallback blocks. This can be used to support both Python 2 and
# 3 compatible code, which means that the block might have code that exists
# only in one or another interpreter, leading to false positives when analysed.
analyse-fallback-blocks=no
# Deprecated modules which should not be used, separated by a comma.
deprecated-modules=optparse,tkinter.tix
# Create a graph of external dependencies in the given file (report RP0402 must
# not be disabled).
ext-import-graph=
# Create a graph of every (i.e. internal and external) dependencies in the
# given file (report RP0402 must not be disabled).
import-graph=
# Create a graph of internal dependencies in the given file (report RP0402 must
# not be disabled).
int-import-graph=
# Force import order to recognize a module as part of the standard
# compatibility libraries.
known-standard-library=
# Force import order to recognize a module as part of a third party library.
known-third-party=enchant,numpy,pandas,torch,langfun,pyglove
# Couples of modules and preferred modules, separated by a comma.
preferred-modules=
[EXCEPTIONS]
# Exceptions that will emit a warning when being caught. Defaults to
# "BaseException, Exception".
overgeneral-exceptions=BaseException,
Exception
================================================
FILE: CITATION.cff
================================================
# SPDX-FileCopyrightText: 2025 Google LLC
# SPDX-License-Identifier: Apache-2.0
#
# This file contains citation metadata for LangExtract.
# For more information visit: https://citation-file-format.github.io/
cff-version: 1.2.0
title: "LangExtract"
message: "If you use this software, please cite it as below."
type: software
authors:
- given-names: Akshay
family-names: Goel
email: goelak@google.com
affiliation: Google LLC
repository-code: "https://github.com/google/langextract"
url: "https://github.com/google/langextract"
repository: "https://github.com/google/langextract"
abstract: "LangExtract: LLM-powered structured information extraction from text with source grounding"
keywords:
- language-models
- structured-data-extraction
- nlp
- machine-learning
- python
license: Apache-2.0
version: 1.1.1
date-released: 2025-11-27
doi: "10.5281/zenodo.17015089"
identifiers:
- type: doi
value: "10.5281/zenodo.17015089"
description: "Concept DOI for LangExtract"
================================================
FILE: COMMUNITY_PROVIDERS.md
================================================
# Community Provider Plugins
Community-developed provider plugins that extend LangExtract with additional model backends.
**Supporting the Community:** Star plugin repositories you find useful and add 👍 reactions to their tracking issues to support maintainers' efforts.
**⚠️ Important:** These are community-maintained packages. Please review the [safety guidelines](#safety-disclaimer) before use.
## Plugin Registry
| Plugin Name | PyPI Package | Maintainer | GitHub Repo | Description | Issue Link |
|-------------|--------------|------------|-------------|-------------|------------|
| AWS Bedrock | `langextract-bedrock` | [@andyxhadji](https://github.com/andyxhadji) | [andyxhadji/langextract-bedrock](https://github.com/andyxhadji/langextract-bedrock) | AWS Bedrock provider for LangExtract, supports all models & inference profiles | [#148](https://github.com/google/langextract/issues/148) |
| LiteLLM | `langextract-litellm` | [@JustStas](https://github.com/JustStas) | [JustStas/langextract-litellm](https://github.com/JustStas/langextract-litellm) | LiteLLM provider for LangExtract, supports all models covered in LiteLLM, including OpenAI, Azure, Anthropic, etc., See [LiteLLM's supported models](https://docs.litellm.ai/docs/providers) | [#187](https://github.com/google/langextract/issues/187) |
| Llama.cpp | `langextract-llamacpp` | [@fgarnadi](https://github.com/fgarnadi) | [fgarnadi/langextract-llamacpp](https://github.com/fgarnadi/langextract-llamacpp) | Llama.cpp provider for LangExtract, supports GGUF models from HuggingFace and local files | [#199](https://github.com/google/langextract/issues/199) |
| Outlines | `langextract-outlines` | [@RobinPicard](https://github.com/RobinPicard) | [dottxt-ai/langextract-outlines](https://github.com/dottxt-ai/langextract-outlines) | Outlines provider for LangExtract, supports structured generation for various local and API-based models | [#101](https://github.com/google/langextract/issues/101) |
| vLLM | `langextract-vllm` | [@wuli666](https://github.com/wuli666) | [wuli666/langextract-vllm](https://github.com/wuli666/langextract-vllm) | vLLM provider for LangExtract, supports local and distributed model serving | [#236](https://github.com/google/langextract/issues/236) |
<!-- ADD NEW PLUGINS ABOVE THIS LINE -->
## How to Add Your Plugin (PR Checklist)
Copy this row template, replace placeholders, and insert **above** the marker line:
```markdown
| Your Plugin | `langextract-provider-yourname` | [@yourhandle](https://github.com/yourhandle) | [yourorg/yourrepo](https://github.com/yourorg/yourrepo) | Brief description (min 10 chars) | [#456](https://github.com/google/langextract/issues/456) |
```
**Before submitting your PR:**
- [ ] PyPI package name starts with `langextract-` (recommended: `langextract-provider-<name>`)
- [ ] PyPI package is published (or will be soon) and listed in backticks
- [ ] Maintainer(s) listed as GitHub profile links (comma-separated if multiple)
- [ ] Repository link points to public GitHub repo
- [ ] Description clearly explains what your provider does
- [ ] Issue Link points to a tracking issue in the LangExtract repository for integration and usage feedback (plugin-specific features and discussions can optionally happen in the plugin's repository)
- [ ] Entries are sorted alphabetically by Plugin Name
## Documentation
For detailed plugin development instructions, see the [Custom Provider Plugin Example](examples/custom_provider_plugin/README.md).
## Safety Disclaimer
Community plugins are independently developed and maintained. While we encourage community contributions, the LangExtract team cannot guarantee the safety, security, or functionality of third-party packages.
**Before installing any plugin, we recommend:**
- **Review the code** - Examine the source code and dependencies on GitHub
- **Check community feedback** - Read issues and discussions for user experiences
- **Verify the maintainer** - Look for active maintenance and responsive support
- **Test safely** - Try plugins in isolated environments before production use
- **Assess security needs** - Consider your specific security requirements
Community plugins are used at your own discretion. When in doubt, reach out to the community through the plugin's issue tracker or the main LangExtract discussions.
================================================
FILE: CONTRIBUTING.md
================================================
# How to Contribute
We would love to accept your patches and contributions to this project.
## Before you begin
### Sign our Contributor License Agreement
Contributions to this project must be accompanied by a
[Contributor License Agreement](https://cla.developers.google.com/about) (CLA).
You (or your employer) retain the copyright to your contribution; this simply
gives us permission to use and redistribute your contributions as part of the
project.
If you or your current employer have already signed the Google CLA (even if it
was for a different project), you probably don't need to do it again.
Visit <https://cla.developers.google.com/> to see your current agreements or to
sign a new one.
### Review our Community Guidelines
This project follows HAI-DEF's
[Community guidelines](https://developers.google.com/health-ai-developer-foundations/community-guidelines)
## Reporting Issues
If you encounter a bug or have a feature request, please open an issue on GitHub.
We have templates to help guide you:
- **[Bug Report](.github/ISSUE_TEMPLATE/1-bug.md)**: For reporting bugs or unexpected behavior
- **[Feature Request](.github/ISSUE_TEMPLATE/2-feature-request.md)**: For suggesting new features or improvements
When creating an issue, GitHub will prompt you to choose the appropriate template.
Please provide as much detail as possible to help us understand and address your concern.
## Contribution Process
### 1. Development Setup
To get started, clone the repository and install the necessary dependencies for development and testing. Detailed instructions can be found in the [Installation from Source](https://github.com/google/langextract#from-source) section of the `README.md`.
**Windows Users**: The formatting scripts use bash. Please use one of:
- Git Bash (comes with Git for Windows)
- WSL (Windows Subsystem for Linux)
- PowerShell with bash-compatible commands
### 2. Code Style and Formatting
This project uses automated tools to maintain a consistent code style. Before submitting a pull request, please format your code:
```bash
# Run the auto-formatter
./autoformat.sh
```
This script uses:
- `isort` to organize imports with Google style (single-line imports)
- `pyink` (Google's fork of Black) to format code according to Google's Python Style Guide
You can also run the formatters manually:
```bash
isort langextract tests
pyink langextract tests --config pyproject.toml
```
Note: The formatters target only `langextract` and `tests` directories by default to avoid
formatting virtual environments or other non-source directories.
### 3. Pre-commit Hooks (Recommended)
For automatic formatting checks before each commit:
```bash
# Install pre-commit
pip install pre-commit
# Install the git hooks
pre-commit install
# Run manually on all files
pre-commit run --all-files
```
### 4. Linting and Testing
All contributions must pass linting checks and unit tests. Please run these locally before submitting your changes:
```bash
# Run linting with Pylint 3.x
pylint --rcfile=.pylintrc langextract tests
# Run tests
pytest tests
```
**Note on Pylint Configuration**: We use a modern, minimal configuration that:
- Only disables truly noisy checks (not entire categories)
- Keeps critical error detection enabled
- Uses plugins for enhanced docstring and type checking
- Aligns with our pyink formatter (80-char lines, 2-space indents)
For full testing across Python versions:
```bash
tox # runs pylint + pytest on Python 3.10 and 3.11
```
### 5. Adding Custom Model Providers
If you want to add support for a new LLM provider, please refer to the [Provider System Documentation](langextract/providers/README.md). The recommended approach is to create an external plugin package rather than modifying the core library. This allows for:
- Independent versioning and releases
- Faster iteration without core review cycles
- Custom dependencies without affecting core users
### 6. Submit Your Pull Request
All submissions, including submissions by project members, require review. We
use [GitHub pull requests](https://docs.github.com/articles/about-pull-requests)
for this purpose.
When you create a pull request, GitHub will automatically populate it with our
[pull request template](.github/PULL_REQUEST_TEMPLATE/pull_request_template.md).
Please fill out all sections of the template to help reviewers understand your changes.
#### Pull Request Guidelines
- **Keep PRs focused and small**: Each PR should address a single issue and contain one cohesive change. PRs are automatically labeled by size to help reviewers:
- **size/XS**: < 50 lines — Small fixes and documentation updates
- **size/S**: 50-150 lines — Typical features or bug fixes
- **size/M**: 150-600 lines — Larger features that remain well-scoped
- **size/L**: 600-1000 lines — Consider splitting into smaller PRs if possible
- **size/XL**: > 1000 lines — Requires strong justification and may need special review
- **Reference related issues**: All PRs must include "Fixes #123" or "Closes #123" in the description. The linked issue should have at least 5 👍 reactions from the community and include discussion that demonstrates the importance and need for the change.
- **No infrastructure changes**: Contributors cannot modify infrastructure files, build configuration, and core documentation. These files are protected and can only be changed by maintainers. Use `./autoformat.sh` to format code without affecting infrastructure files. In special circumstances, build configuration updates may be considered if they include discussion and evidence of robust testing, ideally with community support.
- **Single-change commits**: A PR should typically comprise a single git commit. Squash multiple commits before submitting.
- **Clear description**: Explain what your change does and why it's needed.
- **Ensure all tests pass**: Check that both formatting and tests are green before requesting review.
- **Respond to feedback promptly**: Address reviewer comments in a timely manner.
If your change is large or complex, consider:
- Opening an issue first to discuss the approach
- Breaking it into multiple smaller PRs
- Clearly explaining in the PR description why a larger change is necessary
For more details, read HAI-DEF's
[Contributing guidelines](https://developers.google.com/health-ai-developer-foundations/community-guidelines#contributing)
================================================
FILE: Dockerfile
================================================
# Production Dockerfile for LangExtract
FROM python:3.10-slim
# Set working directory
WORKDIR /app
# Install LangExtract from PyPI
RUN pip install --no-cache-dir langextract
# Set default command
CMD ["python"]
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
<p align="center">
<a href="https://github.com/google/langextract">
<img src="https://raw.githubusercontent.com/google/langextract/main/docs/_static/logo.svg" alt="LangExtract Logo" width="128" />
</a>
</p>
# LangExtract
[](https://pypi.org/project/langextract/)
[](https://github.com/google/langextract)

[](https://doi.org/10.5281/zenodo.17015089)
## Table of Contents
- [Introduction](#introduction)
- [Why LangExtract?](#why-langextract)
- [Quick Start](#quick-start)
- [Installation](#installation)
- [API Key Setup for Cloud Models](#api-key-setup-for-cloud-models)
- [Adding Custom Model Providers](#adding-custom-model-providers)
- [Using OpenAI Models](#using-openai-models)
- [Using Local LLMs with Ollama](#using-local-llms-with-ollama)
- [More Examples](#more-examples)
- [*Romeo and Juliet* Full Text Extraction](#romeo-and-juliet-full-text-extraction)
- [Medication Extraction](#medication-extraction)
- [Radiology Report Structuring: RadExtract](#radiology-report-structuring-radextract)
- [Community Providers](#community-providers)
- [Contributing](#contributing)
- [Testing](#testing)
- [Disclaimer](#disclaimer)
## Introduction
LangExtract is a Python library that uses LLMs to extract structured information from unstructured text documents based on user-defined instructions. It processes materials such as clinical notes or reports, identifying and organizing key details while ensuring the extracted data corresponds to the source text.
## Why LangExtract?
1. **Precise Source Grounding:** Maps every extraction to its exact location in the source text, enabling visual highlighting for easy traceability and verification.
2. **Reliable Structured Outputs:** Enforces a consistent output schema based on your few-shot examples, leveraging controlled generation in supported models like Gemini to guarantee robust, structured results.
3. **Optimized for Long Documents:** Overcomes the "needle-in-a-haystack" challenge of large document extraction by using an optimized strategy of text chunking, parallel processing, and multiple passes for higher recall.
4. **Interactive Visualization:** Instantly generates a self-contained, interactive HTML file to visualize and review thousands of extracted entities in their original context.
5. **Flexible LLM Support:** Supports your preferred models, from cloud-based LLMs like the Google Gemini family to local open-source models via the built-in Ollama interface.
6. **Adaptable to Any Domain:** Define extraction tasks for any domain using just a few examples. LangExtract adapts to your needs without requiring any model fine-tuning.
7. **Leverages LLM World Knowledge:** Utilize precise prompt wording and few-shot examples to influence how the extraction task may utilize LLM knowledge. The accuracy of any inferred information and its adherence to the task specification are contingent upon the selected LLM, the complexity of the task, the clarity of the prompt instructions, and the nature of the prompt examples.
## Quick Start
> **Note:** Using cloud-hosted models like Gemini requires an API key. See the [API Key Setup](#api-key-setup-for-cloud-models) section for instructions on how to get and configure your key.
Extract structured information with just a few lines of code.
### 1. Define Your Extraction Task
First, create a prompt that clearly describes what you want to extract. Then, provide a high-quality example to guide the model.
```python
import langextract as lx
import textwrap
# 1. Define the prompt and extraction rules
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
# 2. Provide a high-quality example to guide the model
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
),
]
)
]
```
> **Note:** Examples drive model behavior. Each `extraction_text` should ideally be verbatim from the example's `text` (no paraphrasing), listed in order of appearance. LangExtract raises `Prompt alignment` warnings by default if examples don't follow this pattern—resolve these for best results.
### 2. Run the Extraction
Provide your input text and the prompt materials to the `lx.extract` function.
```python
# The input text to be processed
input_text = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
# Run the extraction
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
```
> **Model Selection**: `gemini-2.5-flash` is the recommended default, offering an excellent balance of speed, cost, and quality. For highly complex tasks requiring deeper reasoning, `gemini-2.5-pro` may provide superior results. For large-scale or production use, a Tier 2 Gemini quota is suggested to increase throughput and avoid rate limits. See the [rate-limit documentation](https://ai.google.dev/gemini-api/docs/rate-limits#tier-2) for details.
>
> **Model Lifecycle**: Note that Gemini models have a lifecycle with defined retirement dates. Users should consult the [official model version documentation](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/model-versions) to stay informed about the latest stable and legacy versions.
### 3. Visualize the Results
The extractions can be saved to a `.jsonl` file, a popular format for working with language model data. LangExtract can then generate an interactive HTML visualization from this file to review the entities in context.
```python
# Save the results to a JSONL file
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")
# Generate the visualization from the file
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data) # For Jupyter/Colab
else:
f.write(html_content)
```
This creates an animated and interactive HTML file:
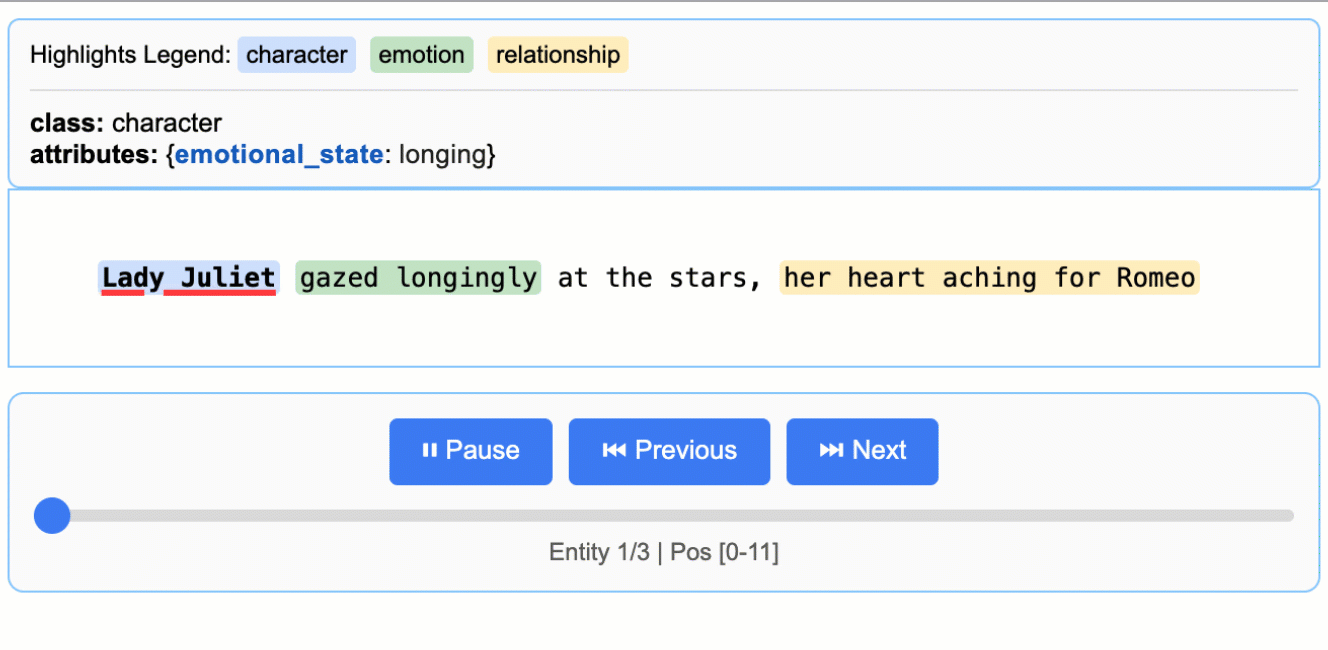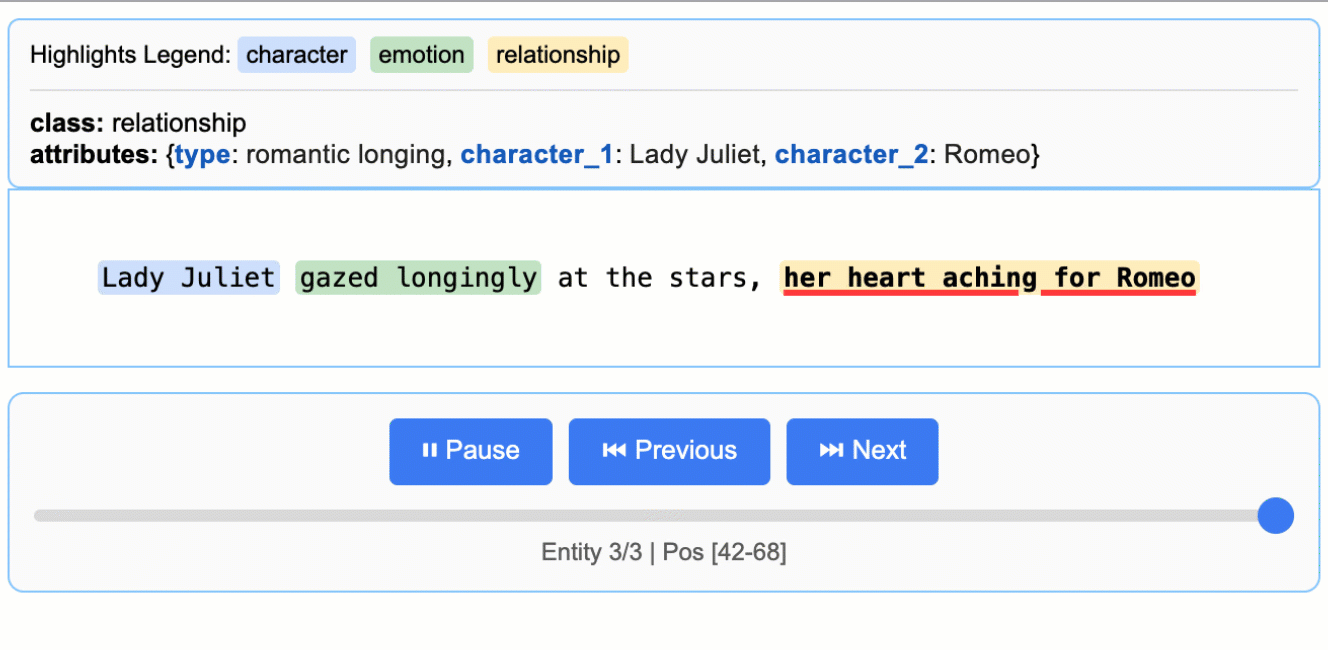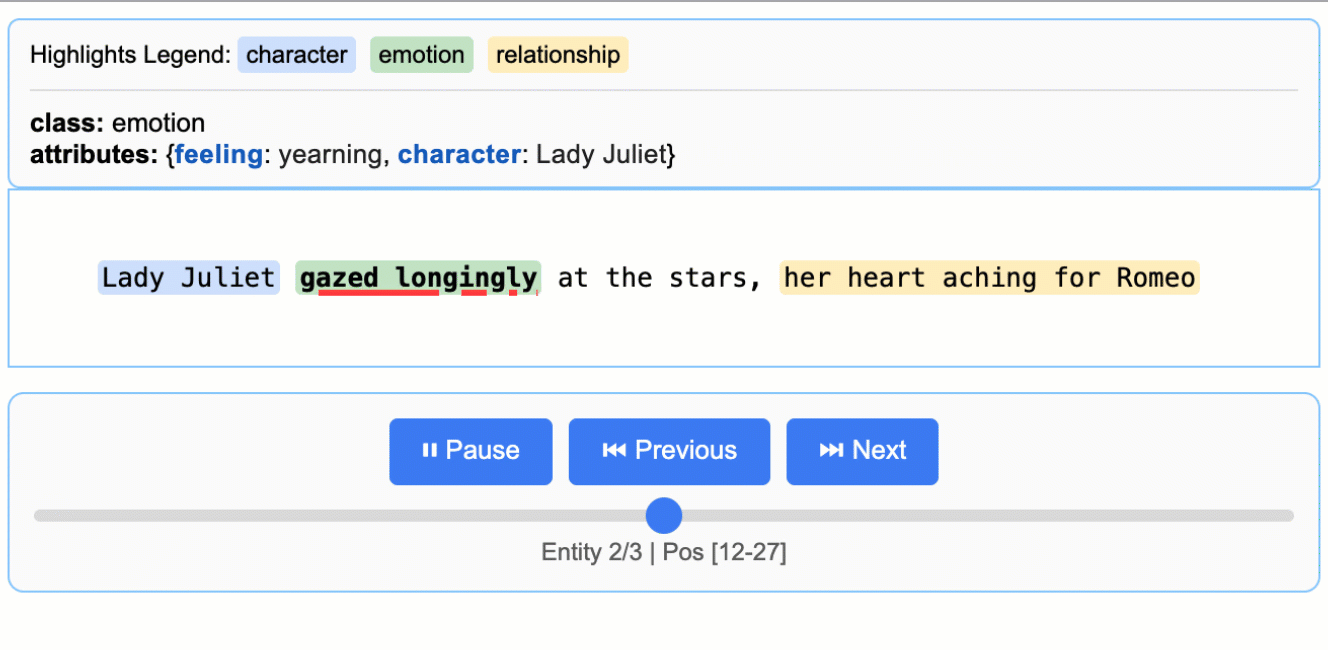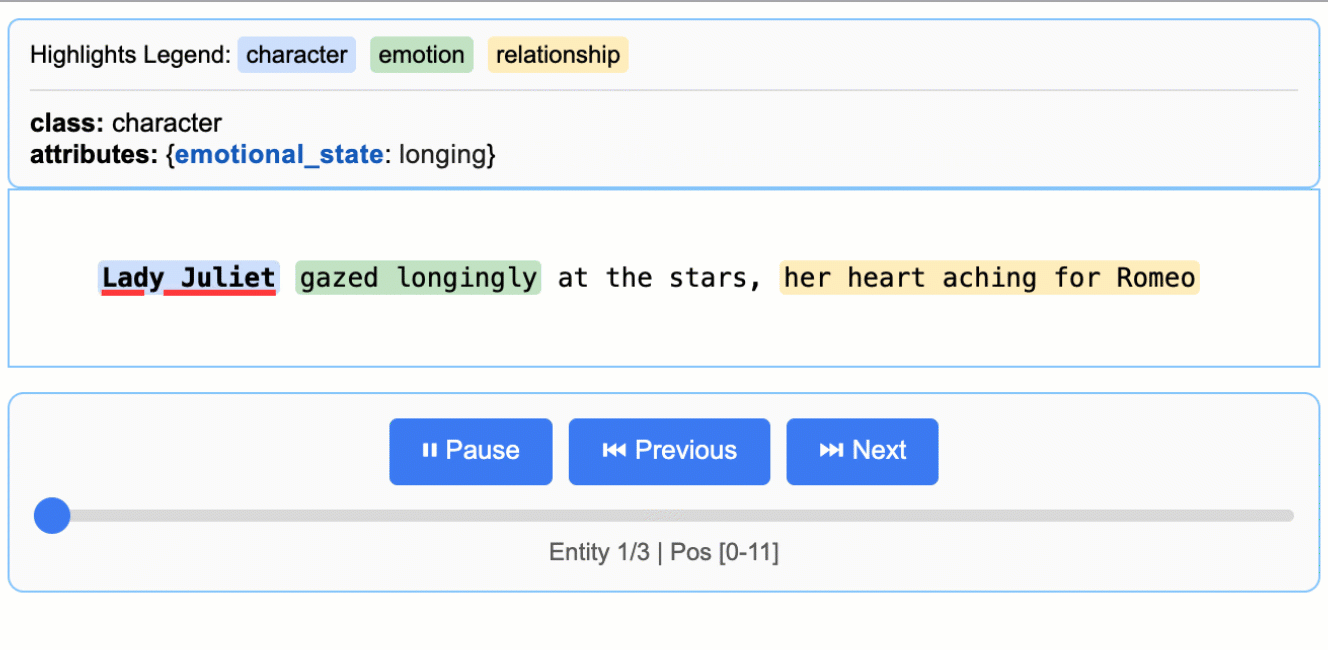
> **Note on LLM Knowledge Utilization:** This example demonstrates extractions that stay close to the text evidence - extracting "longing" for Lady Juliet's emotional state and identifying "yearning" from "gazed longingly at the stars." The task could be modified to generate attributes that draw more heavily from the LLM's world knowledge (e.g., adding `"identity": "Capulet family daughter"` or `"literary_context": "tragic heroine"`). The balance between text-evidence and knowledge-inference is controlled by your prompt instructions and example attributes.
### Scaling to Longer Documents
For larger texts, you can process entire documents directly from URLs with parallel processing and enhanced sensitivity:
```python
# Process Romeo & Juliet directly from Project Gutenberg
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # Improves recall through multiple passes
max_workers=20, # Parallel processing for speed
max_char_buffer=1000 # Smaller contexts for better accuracy
)
```
This approach can extract hundreds of entities from full novels while maintaining high accuracy. The interactive visualization seamlessly handles large result sets, making it easy to explore hundreds of entities from the output JSONL file. **[See the full *Romeo and Juliet* extraction example →](https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md)** for detailed results and performance insights.
### Vertex AI Batch Processing
Save costs on large-scale tasks by enabling Vertex AI Batch API: `language_model_params={"vertexai": True, "batch": {"enabled": True}}`.
See an example of the Vertex AI Batch API usage in [this example](docs/examples/batch_api_example.md).
## Installation
### From PyPI
```bash
pip install langextract
```
*Recommended for most users. For isolated environments, consider using a virtual environment:*
```bash
python -m venv langextract_env
source langextract_env/bin/activate # On Windows: langextract_env\Scripts\activate
pip install langextract
```
### From Source
LangExtract uses modern Python packaging with `pyproject.toml` for dependency management:
*Installing with `-e` puts the package in development mode, allowing you to modify the code without reinstalling.*
```bash
git clone https://github.com/google/langextract.git
cd langextract
# For basic installation:
pip install -e .
# For development (includes linting tools):
pip install -e ".[dev]"
# For testing (includes pytest):
pip install -e ".[test]"
```
### Docker
```bash
docker build -t langextract .
docker run --rm -e LANGEXTRACT_API_KEY="your-api-key" langextract python your_script.py
```
## API Key Setup for Cloud Models
When using LangExtract with cloud-hosted models (like Gemini or OpenAI), you'll need to
set up an API key. On-device models don't require an API key. For developers
using local LLMs, LangExtract offers built-in support for Ollama and can be
extended to other third-party APIs by updating the inference endpoints.
### API Key Sources
Get API keys from:
* [AI Studio](https://aistudio.google.com/app/apikey) for Gemini models
* [Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/sdks/overview) for enterprise use
* [OpenAI Platform](https://platform.openai.com/api-keys) for OpenAI models
### Setting up API key in your environment
**Option 1: Environment Variable**
```bash
export LANGEXTRACT_API_KEY="your-api-key-here"
```
**Option 2: .env File (Recommended)**
Add your API key to a `.env` file:
```bash
# Add API key to .env file
cat >> .env << 'EOF'
LANGEXTRACT_API_KEY=your-api-key-here
EOF
# Keep your API key secure
echo '.env' >> .gitignore
```
In your Python code:
```python
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash"
)
```
**Option 3: Direct API Key (Not Recommended for Production)**
You can also provide the API key directly in your code, though this is not recommended for production use:
```python
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash",
api_key="your-api-key-here" # Only use this for testing/development
)
```
**Option 4: Vertex AI (Service Accounts)**
Use [Vertex AI](https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform) for authentication with service accounts:
```python
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract information...",
examples=[...],
model_id="gemini-2.5-flash",
language_model_params={
"vertexai": True,
"project": "your-project-id",
"location": "global" # or regional endpoint
}
)
```
## Adding Custom Model Providers
LangExtract supports custom LLM providers via a lightweight plugin system. You can add support for new models without changing core code.
- Add new model support independently of the core library
- Distribute your provider as a separate Python package
- Keep custom dependencies isolated
- Override or extend built-in providers via priority-based resolution
See the detailed guide in [Provider System Documentation](langextract/providers/README.md) to learn how to:
- Register a provider with `@registry.register(...)`
- Publish an entry point for discovery
- Optionally provide a schema with `get_schema_class()` for structured output
- Integrate with the factory via `create_model(...)`
## Using OpenAI Models
LangExtract supports OpenAI models (requires optional dependency: `pip install langextract[openai]`):
```python
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o", # Automatically selects OpenAI provider
api_key=os.environ.get('OPENAI_API_KEY'),
fence_output=True,
use_schema_constraints=False
)
```
Note: OpenAI models require `fence_output=True` and `use_schema_constraints=False` because LangExtract doesn't implement schema constraints for OpenAI yet.
## Using Local LLMs with Ollama
LangExtract supports local inference using Ollama, allowing you to run models without API keys:
```python
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b", # Automatically selects Ollama provider
model_url="http://localhost:11434",
fence_output=False,
use_schema_constraints=False
)
```
**Quick setup:** Install Ollama from [ollama.com](https://ollama.com/), run `ollama pull gemma2:2b`, then `ollama serve`.
For detailed installation, Docker setup, and examples, see [`examples/ollama/`](examples/ollama/).
## More Examples
Additional examples of LangExtract in action:
### *Romeo and Juliet* Full Text Extraction
LangExtract can process complete documents directly from URLs. This example demonstrates extraction from the full text of *Romeo and Juliet* from Project Gutenberg (147,843 characters), showing parallel processing, sequential extraction passes, and performance optimization for long document processing.
**[View *Romeo and Juliet* Full Text Example →](https://github.com/google/langextract/blob/main/docs/examples/longer_text_example.md)**
### Medication Extraction
> **Disclaimer:** This demonstration is for illustrative purposes of LangExtract's baseline capability only. It does not represent a finished or approved product, is not intended to diagnose or suggest treatment of any disease or condition, and should not be used for medical advice.
LangExtract excels at extracting structured medical information from clinical text. These examples demonstrate both basic entity recognition (medication names, dosages, routes) and relationship extraction (connecting medications to their attributes), showing LangExtract's effectiveness for healthcare applications.
**[View Medication Examples →](https://github.com/google/langextract/blob/main/docs/examples/medication_examples.md)**
### Radiology Report Structuring: RadExtract
Explore RadExtract, a live interactive demo on HuggingFace Spaces that shows how LangExtract can automatically structure radiology reports. Try it directly in your browser with no setup required.
**[View RadExtract Demo →](https://huggingface.co/spaces/google/radextract)**
## Community Providers
Extend LangExtract with custom model providers! Check out our [Community Provider Plugins](COMMUNITY_PROVIDERS.md) registry to discover providers created by the community or add your own.
For detailed instructions on creating a provider plugin, see the [Custom Provider Plugin Example](examples/custom_provider_plugin/).
## Contributing
Contributions are welcome! See [CONTRIBUTING.md](https://github.com/google/langextract/blob/main/CONTRIBUTING.md) to get started
with development, testing, and pull requests. You must sign a
[Contributor License Agreement](https://cla.developers.google.com/about)
before submitting patches.
## Testing
To run tests locally from the source:
```bash
# Clone the repository
git clone https://github.com/google/langextract.git
cd langextract
# Install with test dependencies
pip install -e ".[test]"
# Run all tests
pytest tests
```
Or reproduce the full CI matrix locally with tox:
```bash
tox # runs pylint + pytest on Python 3.10 and 3.11
```
### Ollama Integration Testing
If you have Ollama installed locally, you can run integration tests:
```bash
# Test Ollama integration (requires Ollama running with gemma2:2b model)
tox -e ollama-integration
```
This test will automatically detect if Ollama is available and run real inference tests.
## Development
### Code Formatting
This project uses automated formatting tools to maintain consistent code style:
```bash
# Auto-format all code
./autoformat.sh
# Or run formatters separately
isort langextract tests --profile google --line-length 80
pyink langextract tests --config pyproject.toml
```
### Pre-commit Hooks
For automatic formatting checks:
```bash
pre-commit install # One-time setup
pre-commit run --all-files # Manual run
```
### Linting
Run linting before submitting PRs:
```bash
pylint --rcfile=.pylintrc langextract tests
```
See [CONTRIBUTING.md](CONTRIBUTING.md) for full development guidelines.
## Disclaimer
This is not an officially supported Google product. If you use
LangExtract in production or publications, please cite accordingly and
acknowledge usage. Use is subject to the [Apache 2.0 License](https://github.com/google/langextract/blob/main/LICENSE).
For health-related applications, use of LangExtract is also subject to the
[Health AI Developer Foundations Terms of Use](https://developers.google.com/health-ai-developer-foundations/terms).
---
**Happy Extracting!**
================================================
FILE: autoformat.sh
================================================
#!/bin/bash
# Copyright 2025 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Autoformat LangExtract codebase
#
# Usage: ./autoformat.sh [target_directory ...]
# If no target is specified, formats the current directory
#
# This script runs:
# 1. isort for import sorting
# 2. pyink (Google's Black fork) for code formatting
# 3. pre-commit hooks for additional formatting (trailing whitespace, end-of-file, etc.)
set -e
echo "LangExtract Auto-formatter"
echo "=========================="
echo
# Check for required tools
check_tool() {
if ! command -v "$1" &> /dev/null; then
echo "Error: $1 not found. Please install with: pip install $1"
exit 1
fi
}
check_tool "isort"
check_tool "pyink"
check_tool "pre-commit"
# Parse command line arguments
show_usage() {
echo "Usage: $0 [target_directory ...]"
echo
echo "Formats Python code using isort and pyink according to Google style."
echo
echo "Arguments:"
echo " target_directory One or more directories to format (default: langextract tests)"
echo
echo "Examples:"
echo " $0 # Format langextract and tests directories"
echo " $0 langextract # Format only langextract directory"
echo " $0 src tests # Format multiple specific directories"
}
# Check for help flag
if [ "$1" = "-h" ] || [ "$1" = "--help" ]; then
show_usage
exit 0
fi
# Determine target directories
if [ $# -eq 0 ]; then
TARGETS="langextract tests"
echo "No target specified. Formatting default directories: langextract tests"
else
TARGETS="$@"
echo "Formatting targets: $TARGETS"
fi
# Find pyproject.toml relative to script location
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
CONFIG_FILE="${SCRIPT_DIR}/pyproject.toml"
if [ ! -f "$CONFIG_FILE" ]; then
echo "Warning: pyproject.toml not found at ${CONFIG_FILE}"
echo "Using default configuration."
CONFIG_ARG=""
else
CONFIG_ARG="--config $CONFIG_FILE"
fi
echo
# Run isort
echo "Running isort to organize imports..."
if isort $TARGETS; then
echo "Import sorting complete"
else
echo "Import sorting failed"
exit 1
fi
echo
# Run pyink
echo "Running pyink to format code (Google style, 80 chars)..."
if pyink $TARGETS $CONFIG_ARG; then
echo "Code formatting complete"
else
echo "Code formatting failed"
exit 1
fi
echo
# Run pre-commit hooks for additional formatting
echo "Running pre-commit hooks for additional formatting..."
if pre-commit run --all-files; then
echo "Pre-commit hooks passed"
else
echo "Pre-commit hooks made changes - please review"
# Exit with success since formatting was applied
exit 0
fi
echo
echo "All formatting complete!"
echo
echo "Next steps:"
echo " - Run: pylint --rcfile=${SCRIPT_DIR}/.pylintrc $TARGETS"
echo " - Commit your changes"
================================================
FILE: benchmarks/benchmark.py
================================================
#!/usr/bin/env python3
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""LangExtract benchmark suite for performance and quality testing.
Measures tokenization speed and extraction quality across multiple languages
and text types. Automatically downloads test texts from Project Gutenberg
and generates comparative visualizations.
Usage:
# Run diverse text type benchmark (default)
python benchmarks/benchmark.py
# Test with specific model
python benchmarks/benchmark.py --model gemini-2.5-flash
python benchmarks/benchmark.py --model gemma2:2b # Local model via Ollama
# Generate comparison plots from existing results
python benchmarks/benchmark.py --compare
Requirements:
- Set GEMINI_API_KEY for cloud models
- Install Ollama for local model testing
- Results saved to benchmark_results/
"""
import argparse
from datetime import datetime
import json
import os
from pathlib import Path
import time
from typing import Any
import urllib.error
import dotenv
from benchmarks import config
from benchmarks import plotting
from benchmarks import utils
import langextract
from langextract import core
from langextract import data
from langextract import visualize
import langextract.io as lio
# Load API key from environment
dotenv.load_dotenv(override=True)
GEMINI_API_KEY = os.environ.get(
"GEMINI_API_KEY", os.environ.get("LANGEXTRACT_API_KEY")
)
class BenchmarkRunner:
"""Orchestrates benchmark execution and result collection."""
def __init__(self):
"""Initialize runner with timestamp and git metadata."""
self.timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
self.git_info = utils.get_git_info()
self.tokenizer = core.tokenizer.RegexTokenizer()
def set_tokenizer(self, tokenizer_type: str):
"""Set the tokenizer to use."""
if tokenizer_type.lower() == "unicode":
self.tokenizer = core.tokenizer.UnicodeTokenizer()
print("Using UnicodeTokenizer")
else:
self.tokenizer = core.tokenizer.RegexTokenizer()
print("Using RegexTokenizer (default)")
def print_header(self):
"""Print benchmark header."""
print("=" * config.DISPLAY.separator_width)
print("LANGEXTRACT BENCHMARK")
print("=" * config.DISPLAY.separator_width)
print(
f"Branch: {self.git_info['branch']} | Commit: {self.git_info['commit']}"
)
print("-" * config.DISPLAY.separator_width)
def benchmark_tokenization(self) -> list[dict[str, Any]]:
"""Measure tokenization throughput at different text sizes.
Returns:
List of dicts with words, tokens, timing, and throughput metrics.
"""
print("\nTokenization Performance")
print("-" * config.DISPLAY.subseparator_width)
results = []
for word_count in config.TOKENIZATION.default_text_sizes:
text = " ".join(["word"] * word_count)
_ = self.tokenizer.tokenize(text)
times = []
for _ in range(config.TOKENIZATION.benchmark_iterations):
start = time.perf_counter()
tokenized = self.tokenizer.tokenize(text)
elapsed = time.perf_counter() - start
times.append(elapsed)
avg_time = sum(times) / len(times)
avg_ms = avg_time * 1000
num_tokens = len(tokenized.tokens)
tokens_per_sec = num_tokens / avg_time if avg_time > 0 else 0
word_str = (
f"{word_count//1000:,}k" if word_count >= 1000 else f"{word_count:,}"
)
print(
f"{word_str:>6} words: {avg_ms:7.2f}ms "
f"({tokens_per_sec/1e6:.1f}M tokens/sec)"
)
results.append({
"words": word_count,
"tokens": num_tokens,
"avg_ms": avg_ms,
"tokens_per_sec": tokens_per_sec,
})
return results
def test_single_extraction(
self,
model_id: str = config.MODELS.default_model,
text_type: config.TextTypes = config.TextTypes.ENGLISH,
) -> dict[str, Any]:
"""Execute extraction test.
Args:
model_id: Model identifier (e.g., 'gemini-2.5-flash', 'gemma2:2b').
text_type: Language/text type to test.
Returns:
Dict with success status, timing, entity counts, and metrics.
"""
print("\nExtraction Test")
print("-" * config.DISPLAY.subseparator_width)
try:
# Get test text
test_text = utils.get_text_from_gutenberg(text_type)
test_text = utils.get_optimal_text_size(test_text, model_id)
print(f" Text: {len(test_text):,} characters ({text_type.value})")
print(f" Model: {model_id}")
# Analyze tokenization
tokenization_analysis = utils.analyze_tokenization(
test_text, self.tokenizer
)
print(
" Tokenization:"
f" {utils.format_tokenization_summary(tokenization_analysis)}"
)
# Get extraction config for text type
extraction_config = utils.get_extraction_example(text_type)
example = data.ExampleData(
text="MACBETH speaks to LADY MACBETH about Duncan.",
extractions=[
data.Extraction(
extraction_text="Macbeth", extraction_class="Character"
),
data.Extraction(
extraction_text="Lady Macbeth", extraction_class="Character"
),
data.Extraction(
extraction_text="Duncan", extraction_class="Character"
),
],
)
max_retries = 5
retry_delay = 3.0
# Retry logic for transient network/API failures
for attempt in range(max_retries):
try:
start_time = time.time()
result = langextract.extract(
text_or_documents=test_text,
model_id=model_id,
api_key=GEMINI_API_KEY,
prompt_description=extraction_config["prompt"],
examples=[example],
max_workers=config.MODELS.default_max_workers,
temperature=config.MODELS.default_temperature,
extraction_passes=config.MODELS.default_extraction_passes,
tokenizer=self.tokenizer,
)
elapsed = time.time() - start_time
break
except (ConnectionError, TimeoutError):
if attempt < max_retries - 1:
print(f" Retrying in {retry_delay}s...")
time.sleep(retry_delay)
retry_delay *= 1.5
continue
raise
print(f"Extraction completed in {elapsed:.1f}s")
grounded_entities = []
ungrounded_entities = []
if result.extractions:
for extraction in result.extractions:
is_grounded = (
extraction.char_interval
and extraction.char_interval.start_pos is not None
and extraction.char_interval.end_pos is not None
)
entity_text = extraction.extraction_text
if entity_text:
if is_grounded:
grounded_entities.append(entity_text)
else:
ungrounded_entities.append(entity_text)
unique_grounded = list(set(grounded_entities))
unique_ungrounded = list(set(ungrounded_entities))
print(f"Found {len(unique_grounded)} grounded entities")
if unique_ungrounded:
print(f" ({len(unique_ungrounded)} ungrounded entities ignored)")
if unique_grounded:
sample = unique_grounded[:5]
sample_str = ", ".join(sample) + (
"..." if len(unique_grounded) > 5 else ""
)
print(f" Sample: {sample_str}")
return {
"success": True,
"model": model_id,
"text_type": text_type.value,
"time_seconds": elapsed,
"entity_count": len(unique_grounded),
"ungrounded_count": len(unique_ungrounded),
"sample_entities": unique_grounded[:10],
"tokenization": tokenization_analysis,
config.EXTRACTION_RESULT_KEY: result,
}
except (urllib.error.URLError, RuntimeError) as e:
# Handle expected text download failures.
print(f"Failed: {e}")
return {
"success": False,
"model": model_id,
"text_type": text_type.value,
"error": str(e),
}
def test_diverse_text_types(
self, models: list[str] | None = None
) -> list[dict[str, Any]]:
"""Test extraction with diverse text types."""
print("\n" + "=" * config.DISPLAY.separator_width)
print("DIVERSE TEXT TYPE MODE")
print("=" * config.DISPLAY.separator_width)
if models is None:
models = [config.MODELS.default_model]
results = []
test_count = 0
for model_id in models:
print(f"\nTesting {model_id}")
print("-" * 30)
for text_type in config.TextTypes:
print(f"\n Testing {text_type.value} text...")
result = self.test_single_extraction(model_id, text_type)
results.append(result)
if result.get("success"):
test_count += 1
if test_count % 3 == 0:
print(
" Rate limit delay"
f" ({config.MODELS.gemini_rate_limit_delay}s)..."
)
time.sleep(config.MODELS.gemini_rate_limit_delay)
print(f"\nCompleted {test_count} successful tests")
return results
def save_results(self, results: dict[str, Any]):
"""Save results and create plots."""
results["timestamp"] = self.timestamp
results["git"] = self.git_info
json_path = config.PATHS.get_result_path(self.timestamp, "").with_suffix(
".json"
)
viz_dir = json_path.parent / "visualizations" / self.timestamp
viz_dir.mkdir(parents=True, exist_ok=True)
if config.RESULTS_KEY in results:
print(f"\nGenerating visualizations in: {viz_dir}")
for result in results[config.RESULTS_KEY]:
if result.get("success") and config.EXTRACTION_RESULT_KEY in result:
model_name = result["model"].replace("/", "_").replace(":", "_")
text_type = result["text_type"]
viz_name = f"{model_name}_{text_type}"
jsonl_path = viz_dir / f"{viz_name}.jsonl"
lio.save_annotated_documents(
[result[config.EXTRACTION_RESULT_KEY]],
output_name=jsonl_path.name,
output_dir=str(viz_dir),
)
html_content = visualize(str(jsonl_path))
html_path = viz_dir / f"{viz_name}.html"
with open(html_path, "w") as f:
f.write(getattr(html_content, "data", html_content))
# Remove extraction result objects before saving JSON
for result in results.get(config.RESULTS_KEY, []):
result.pop(config.EXTRACTION_RESULT_KEY, None)
with open(json_path, "w") as f:
json.dump(results, f, indent=2, default=str)
print(f"\nResults saved to: {json_path}")
plot_created = plotting.create_diverse_plots(results, json_path)
if plot_created:
print(f"Plot saved to: {json_path.with_suffix('.png')}")
else:
print(f"Warning: Failed to create plot for {json_path.name}")
def run_diverse_benchmark(self, models: list[str] | None = None):
"""Run benchmark."""
self.print_header()
tokenization_results = self.benchmark_tokenization()
diverse_results = self.test_diverse_text_types(models)
results = {
"tokenization": tokenization_results,
config.RESULTS_KEY: diverse_results,
}
self.save_results(results)
def main():
"""Main entry point."""
parser = argparse.ArgumentParser(description="LangExtract Benchmark Suite")
parser.add_argument(
"--model",
type=str,
default=None,
help=f"Model to use (default: {config.MODELS.default_model})",
)
parser.add_argument(
"--tokenizer",
type=str,
choices=["regex", "unicode"],
default="regex",
help="Tokenizer to use (default: regex)",
)
parser.add_argument(
"--compare",
action="store_true",
help="Generate comparison plots from existing benchmark results",
)
args = parser.parse_args()
# Handle comparison mode
if args.compare:
results_dir = Path("benchmark_results")
json_files = sorted(results_dir.glob("benchmark_*.json"))
if len(json_files) < 2:
print(
"Need at least 2 benchmark results for comparison, found"
f" {len(json_files)}"
)
return
print(f"Found {len(json_files)} benchmark results to compare")
# Use last 10 results or all if less than 10
files_to_compare = json_files[-10:]
comparison_path = (
results_dir
/ f"comparison_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png"
)
plotting.create_comparison_plots(files_to_compare, comparison_path)
print(f"\nComparison plot saved to: {comparison_path}")
return
model_to_test = args.model or config.MODELS.default_model
if "gemini" in model_to_test.lower() and not GEMINI_API_KEY:
print(
f"Error: {model_to_test} requires GEMINI_API_KEY or LANGEXTRACT_API_KEY"
)
return
runner = BenchmarkRunner()
runner.set_tokenizer(args.tokenizer)
runner.run_diverse_benchmark([args.model] if args.model else None)
if __name__ == "__main__":
main()
================================================
FILE: benchmarks/config.py
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Benchmark configuration settings and constants.
Centralized configuration for tokenization tests, model parameters,
display formatting, and test text sources.
"""
from dataclasses import dataclass
import enum
from pathlib import Path
# Result dictionary keys
RESULTS_KEY = "results"
EXTRACTION_KEY = "extraction"
EXTRACTION_RESULT_KEY = "extraction_result"
TOKENIZATION_KEY = "tokenization"
@dataclass(frozen=True)
class TokenizationConfig:
"""Settings for tokenization performance tests."""
default_text_sizes: tuple[int, ...] = (100, 1000, 10000) # Word counts
benchmark_iterations: int = 10 # Iterations per size for averaging
@dataclass(frozen=True)
class ModelConfig:
"""Model and API configuration."""
default_model: str = "gemini-2.5-flash" # Cloud model default
local_model: str = "gemma2:9b" # Ollama model default
default_temperature: float = 0.0 # Deterministic output
default_max_workers: int = 10 # Parallel processing threads
default_extraction_passes: int = 1 # Single pass extraction
gemini_rate_limit_delay: float = 8.0 # Seconds between batches
class TextTypes(str, enum.Enum):
"""Supported languages for extraction testing."""
ENGLISH = "english"
JAPANESE = "japanese"
FRENCH = "french"
SPANISH = "spanish"
# Test texts from Project Gutenberg (similar genres for fair comparison)
GUTENBERG_TEXTS = {
TextTypes.ENGLISH: (
"https://www.gutenberg.org/files/11/11-0.txt"
), # Alice's Adventures
TextTypes.JAPANESE: (
"https://www.gutenberg.org/files/1982/1982-0.txt"
), # Rashomon
TextTypes.FRENCH: (
"https://www.gutenberg.org/files/55456/55456-0.txt"
), # Alice (French)
TextTypes.SPANISH: (
"https://www.gutenberg.org/files/67248/67248-0.txt"
), # El clavo
}
@dataclass(frozen=True)
class DisplayConfig:
"""Display configuration."""
separator_width: int = 50
subseparator_width: int = 40
figure_size_single: tuple[int, int] = (12, 5)
figure_size_multi: tuple[int, int] = (14, 10)
plot_style: str = "seaborn-v0_8-darkgrid"
@dataclass(frozen=True)
class PathConfig:
"""Path configuration."""
results_dir: Path = Path("benchmark_results")
def get_result_path(self, timestamp: str, suffix: str = "") -> Path:
"""Get result file path."""
if not self.results_dir.exists():
self.results_dir.mkdir(parents=True)
filename = f"benchmark{suffix}_{timestamp}"
return self.results_dir / filename
# Global config instances
TOKENIZATION = TokenizationConfig()
MODELS = ModelConfig()
DISPLAY = DisplayConfig()
PATHS = PathConfig()
================================================
FILE: benchmarks/plotting.py
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Visualization generation for benchmark results.
Creates multi-panel plots showing tokenization performance, extraction metrics,
and cross-language comparisons.
"""
from datetime import datetime
import json
from pathlib import Path
from typing import Any
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from benchmarks import config
matplotlib.use("Agg")
plt.style.use(config.DISPLAY.plot_style)
def create_diverse_plots(results: dict[str, Any], filepath: Path) -> bool:
"""Generate comprehensive benchmark visualization.
Args:
results: Benchmark results dictionary with tokenization and extraction data.
filepath: Output path for PNG file.
Returns:
True if plot created successfully, False on error.
"""
try:
fig = plt.figure(figsize=(15, 10))
# Create 2x3 grid: tokenization metrics (top), extraction metrics (bottom)
gs = fig.add_gridspec(2, 3, hspace=0.25, wspace=0.25)
ax1 = fig.add_subplot(gs[0, 0]) # Tokenization throughput
ax2 = fig.add_subplot(gs[0, 1]) # Token density by language
ax3 = fig.add_subplot(gs[0, 2]) # Entity extraction counts
ax4 = fig.add_subplot(gs[1, 0]) # Processing speed
ax5 = fig.add_subplot(gs[1, 1]) # Summary metrics
ax6 = fig.add_subplot(gs[1, 2]) # Unused
fig.suptitle(
f"LangExtract Benchmark - {results['timestamp']}", fontsize=14, y=0.98
)
_plot_tokenization_throughput(ax1, results)
_plot_tokenization_rate(ax2, results)
_plot_extraction_density(ax3, results)
_plot_processing_speed(ax4, results)
_plot_summary_table(ax5, results)
ax6.axis("off")
plt.tight_layout(rect=[0, 0.02, 1, 0.96])
plot_path = filepath.with_suffix(".png")
plt.savefig(plot_path, dpi=100, bbox_inches="tight")
plt.close()
print(f"Plot saved to: {plot_path}")
return True
except (IOError, OSError) as e:
print(f"Warning: Could not create benchmark plot: {e}")
return False
def _plot_tokenization_throughput(ax, results):
"""Plot tokenization throughput (tokens per second) on log scale."""
if (
config.TOKENIZATION_KEY not in results
or not results[config.TOKENIZATION_KEY]
):
ax.text(0.5, 0.5, "No tokenization data", ha="center", va="center")
ax.set_title("Tokenization Throughput")
return
sizes = [r["words"] for r in results[config.TOKENIZATION_KEY]]
speeds = [r["tokens_per_sec"] for r in results[config.TOKENIZATION_KEY]]
ax.semilogx(sizes, speeds, "b-o", linewidth=2, markersize=8)
ax.set_xlabel("Number of Words (log scale)")
ax.set_ylabel("Tokens per Second")
ax.set_title("Tokenization Throughput")
ax.grid(True, alpha=0.3)
max_speed = max(speeds)
ax.set_ylim(0, max_speed * 1.15)
y_ticks = [0, 100000, 200000, 300000, 400000]
ax.set_yticks(y_ticks)
ax.set_yticklabels([f"{int(y/1000)}K" if y > 0 else "0" for y in y_ticks])
for x, y in zip(sizes, speeds):
label = f"{y/1000:.0f}K"
ax.annotate(
label,
xy=(x, y),
xytext=(0, 5),
textcoords="offset points",
ha="center",
fontsize=9,
)
ax.set_xticks([100, 1000, 10000])
ax.set_xticklabels(["10²", "10³", "10⁴"])
def _plot_tokenization_rate(ax, results):
"""Plot tokenization rate by text type."""
if config.RESULTS_KEY not in results:
ax.text(0.5, 0.5, "No data", ha="center", va="center")
ax.set_title("Tokenization Rate")
return
text_types = []
tok_per_char = []
for result in results[config.RESULTS_KEY]:
if config.TOKENIZATION_KEY in result and result.get("success", False):
text_type = result.get("text_type", "unknown")
if text_type not in text_types:
text_types.append(text_type)
tpc = result[config.TOKENIZATION_KEY]["tokens_per_char"]
tok_per_char.append(tpc)
if not text_types:
ax.text(0.5, 0.5, "No tokenization data", ha="center", va="center")
ax.set_title("Tokenization Rate")
return
x = np.arange(len(text_types))
bars = ax.bar(x, tok_per_char, color="#2196f3", alpha=0.7)
for bar_rect, val in zip(bars, tok_per_char):
ax.text(
bar_rect.get_x() + bar_rect.get_width() / 2,
val + 0.005,
f"{val:.3f}",
ha="center",
va="bottom",
fontsize=9,
)
ax.set_xlabel("Text Type")
ax.set_ylabel("Tokens per Character")
ax.set_title("Tokenization Rate")
ax.set_xticks(x)
ax.set_xticklabels([t.capitalize() for t in text_types])
ax.grid(True, alpha=0.3, axis="y")
ax.set_ylim(0, max(0.30, max(tok_per_char) * 1.2) if tok_per_char else 0.30)
def _plot_extraction_density(ax, results):
"""Plot entity extraction density."""
if config.RESULTS_KEY not in results:
ax.text(0.5, 0.5, "No data", ha="center", va="center")
ax.set_title("Extraction Density")
return
text_types = []
densities = []
for result in results[config.RESULTS_KEY]:
if result.get("success", False):
text_type = result.get("text_type", "unknown")
if text_type not in text_types:
text_types.append(text_type)
char_count = 1000
if config.TOKENIZATION_KEY in result:
char_count = result[config.TOKENIZATION_KEY].get("num_chars", 1000)
entity_count = result.get("entity_count", 0)
density = (entity_count * 1000) / char_count
densities.append(density)
if not text_types:
ax.text(0.5, 0.5, "No successful extractions", ha="center", va="center")
ax.set_title("Extraction Density")
return
x = np.arange(len(text_types))
bars = ax.bar(x, densities, color="#4caf50", alpha=0.7)
for bar_rect, val in zip(bars, densities):
ax.text(
bar_rect.get_x() + bar_rect.get_width() / 2,
val,
f"{val:.1f}",
ha="center",
va="bottom",
fontsize=9,
)
ax.set_xlabel("Text Type")
ax.set_ylabel("Entities per 1K Characters")
ax.set_title("Extraction Density")
ax.set_xticks(x)
ax.set_xticklabels([t.capitalize() for t in text_types])
ax.grid(True, alpha=0.3, axis="y")
def _plot_processing_speed(ax, results):
"""Plot processing speed normalized by text size."""
if config.RESULTS_KEY not in results:
ax.text(0.5, 0.5, "No data", ha="center", va="center")
ax.set_title("Processing Speed")
return
text_types = []
speeds = []
for result in results[config.RESULTS_KEY]:
if result.get("success", False):
text_type = result.get("text_type", "unknown")
if text_type not in text_types:
text_types.append(text_type)
char_count = 1000
if config.TOKENIZATION_KEY in result:
char_count = result[config.TOKENIZATION_KEY].get("num_chars", 1000)
time_seconds = result.get("time_seconds", 0)
speed = (time_seconds * 1000) / char_count
speeds.append(speed)
if not text_types:
ax.text(0.5, 0.5, "No timing data", ha="center", va="center")
ax.set_title("Processing Speed")
return
x = np.arange(len(text_types))
bars = ax.bar(x, speeds, color="#ff9800", alpha=0.7)
for bar_rect, val in zip(bars, speeds):
ax.text(
bar_rect.get_x() + bar_rect.get_width() / 2,
val,
f"{val:.1f}s",
ha="center",
va="bottom",
fontsize=9,
)
ax.set_xlabel("Text Type")
ax.set_ylabel("Seconds per 1K Characters")
ax.set_title("Processing Speed")
ax.set_xticks(x)
ax.set_xticklabels([t.capitalize() for t in text_types])
ax.grid(True, alpha=0.3, axis="y")
def _plot_summary_table(ax, results):
"""Create a summary of key findings."""
ax.axis("off")
if config.RESULTS_KEY not in results:
ax.text(0.5, 0.5, "No data", ha="center", va="center")
ax.set_title("Key Metrics")
return
summary_lines = []
summary_lines.append("Key Metrics")
summary_lines.append("-" * 20)
summary_lines.append("")
success_count = sum(
1 for r in results.get(config.RESULTS_KEY, []) if r.get("success")
)
total_count = len(results.get(config.RESULTS_KEY, []))
if total_count > 0:
summary_lines.append("Tests Run:")
summary_lines.append(f" {success_count} successful")
summary_lines.append(f" {total_count - success_count} failed")
summary_lines.append("")
if success_count > 0:
avg_time = (
sum(
r.get("time_seconds", 0)
for r in results.get(config.RESULTS_KEY, [])
if r.get("success")
)
/ success_count
)
summary_lines.append(f"Avg Time: {avg_time:.1f}s")
summary_text = "\n".join(summary_lines)
ax.text(
0.5,
0.5,
summary_text,
ha="center",
va="center",
fontsize=10,
family="monospace",
)
ax.set_title("Key Metrics", fontweight="bold", y=0.9)
def create_comparison_plots(json_files: list[Path], output_path: Path) -> None:
"""Create comparison plots from multiple benchmark JSON files.
Args:
json_files: List of paths to benchmark JSON files to compare.
output_path: Path where the comparison plot should be saved.
"""
if len(json_files) < 2:
print("Need at least 2 JSON files for comparison")
return
all_results = []
for json_file in json_files:
try:
with open(json_file, "r") as f:
data = json.load(f)
data["filename"] = json_file.stem
all_results.append(data)
except (IOError, OSError, json.JSONDecodeError) as e:
print(f"Error loading {json_file}: {e}")
continue
if len(all_results) < 2:
print("Could not load enough valid JSON files for comparison")
return
plt.figure(figsize=(18, 12))
ax1 = plt.subplot(2, 3, (1, 2))
_plot_tokenization_comparison(ax1, all_results)
ax2 = plt.subplot(2, 3, 3)
_plot_entity_comparison(ax2, all_results)
ax3 = plt.subplot(2, 3, 4)
_plot_time_comparison(ax3, all_results)
ax4 = plt.subplot(2, 3, 5)
_plot_success_rate_comparison(ax4, all_results)
ax5 = plt.subplot(2, 3, 6)
_plot_timeline(ax5, all_results)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
plt.suptitle(
f"LangExtract Benchmark Comparison - {timestamp}",
fontsize=14,
fontweight="bold",
)
plt.tight_layout(rect=[0, 0.01, 1, 0.95])
plt.subplots_adjust(hspace=0.45, wspace=0.35, top=0.93)
plt.savefig(output_path, dpi=100, bbox_inches="tight")
plt.close()
print(f"Comparison plot saved to: {output_path}")
def _plot_entity_comparison(ax, all_results):
"""Plot entity count comparison across runs."""
runs = []
languages = ["english", "french", "spanish", "japanese"]
language_data = []
for result in all_results:
run_name = result["filename"].replace("benchmark_", "")[:10]
runs.append(run_name)
run_counts = {lang: 0 for lang in languages}
if config.RESULTS_KEY in result:
for res in result[config.RESULTS_KEY]:
lang = res.get("text_type", "")
if lang in languages and res.get("success"):
run_counts[lang] = res.get("entity_count", 0)
language_data.append(run_counts)
x = np.arange(len(runs))
width = 0.2
for i, lang in enumerate(languages):
counts = [data[lang] for data in language_data]
bars = ax.bar(x + i * width, counts, width, label=lang.capitalize())
for bar_rect, count in zip(bars, counts):
if count > 0:
ax.text(
bar_rect.get_x() + bar_rect.get_width() / 2,
bar_rect.get_height() + 0.5,
str(count),
ha="center",
fontsize=7,
)
ax.set_xlabel("Run")
ax.set_ylabel("Entity Count")
title = "Entities Extracted by Language\n"
subtitle = "Number of unique character names found per language"
ax.set_title(title, fontweight="bold", fontsize=10)
ax.text(
0.5,
1.01,
subtitle,
transform=ax.transAxes,
ha="center",
fontsize=7,
style="italic",
color="#666666",
va="bottom",
)
ax.set_xticks(x + width * 1.5)
ax.set_xticklabels(runs, rotation=45, ha="right")
ax.legend(loc="upper left", fontsize=8)
ax.grid(True, alpha=0.3)
ax.set_ylim(0, ax.get_ylim()[1] * 1.1)
def _plot_time_comparison(ax, all_results):
"""Plot processing time comparison."""
runs = []
avg_times = []
for result in all_results:
run_name = result["filename"].replace("benchmark_", "")[:10]
runs.append(run_name)
if config.RESULTS_KEY in result:
times = [
r.get("time_seconds", 0)
for r in result[config.RESULTS_KEY]
if r.get("success")
]
avg_time = sum(times) / len(times) if times else 0
avg_times.append(avg_time)
else:
avg_times.append(0)
x_pos = np.arange(len(runs))
bars = ax.bar(x_pos, avg_times, color="skyblue", edgecolor="navy", alpha=0.7)
ax.set_xlabel("Run")
ax.set_ylabel("Average Time (seconds)")
title = "Average Processing Time\n"
subtitle = "Mean extraction time across all language tests"
ax.set_title(title, fontweight="bold", fontsize=10)
ax.text(
0.5,
1.01,
subtitle,
transform=ax.transAxes,
ha="center",
fontsize=7,
style="italic",
color="#666666",
va="bottom",
)
ax.set_xticks(x_pos)
ax.set_xticklabels(runs, rotation=45, ha="right")
ax.grid(True, alpha=0.3)
for bar_rect, time in zip(bars, avg_times):
if time > 0:
ax.text(
bar_rect.get_x() + bar_rect.get_width() / 2,
bar_rect.get_height() + 0.1,
f"{time:.1f}s",
ha="center",
fontsize=8,
)
if max(avg_times) > 0:
ax.set_ylim(0, max(avg_times) * 1.2)
def _plot_tokenization_comparison(ax, all_results):
"""Plot tokenization throughput comparison as line graphs."""
for i, result in enumerate(all_results):
run_name = result["filename"].replace("benchmark_", "")[:10]
if config.TOKENIZATION_KEY in result and result[config.TOKENIZATION_KEY]:
sizes = [r["words"] for r in result[config.TOKENIZATION_KEY]]
speeds = [r["tokens_per_sec"] for r in result[config.TOKENIZATION_KEY]]
ax.semilogx(
sizes,
speeds,
"o-",
linewidth=2,
markersize=6,
label=run_name,
alpha=0.8,
)
for x, y in zip(sizes, speeds):
if i == 0: # Only label first run to avoid overlap
label = f"{y/1000:.0f}K"
ax.annotate(
label,
xy=(x, y),
xytext=(0, 5),
textcoords="offset points",
ha="center",
fontsize=7,
)
ax.set_xlabel("Number of Words (log scale)")
ax.set_ylabel("Tokens per Second")
title = "Tokenization Throughput Comparison\n"
subtitle = "Speed of text tokenization at different document sizes"
ax.set_title(title, fontweight="bold", fontsize=10)
ax.text(
0.5,
1.01,
subtitle,
transform=ax.transAxes,
ha="center",
fontsize=7,
style="italic",
color="#666666",
va="bottom",
)
ax.grid(True, alpha=0.3)
ax.legend(loc="best", fontsize=8)
ax.set_xticks([100, 1000, 10000])
ax.set_xticklabels(["10²", "10³", "10⁴"])
_, ymax = ax.get_ylim()
ax.set_ylim(0, ymax * 1.1)
def _plot_success_rate_comparison(ax, all_results):
"""Plot success rate comparison."""
runs = []
success_rates = []
for result in all_results:
run_name = result["filename"].replace("benchmark_", "")[:10]
runs.append(run_name)
if config.RESULTS_KEY in result:
total = len(result[config.RESULTS_KEY])
success = sum(1 for r in result[config.RESULTS_KEY] if r.get("success"))
rate = (success / total * 100) if total > 0 else 0
success_rates.append(rate)
else:
success_rates.append(0)
x_pos = np.arange(len(runs))
colors = [
"green" if rate == 100 else "orange" if rate >= 75 else "red"
for rate in success_rates
]
bars = ax.bar(x_pos, success_rates, color=colors, alpha=0.7)
ax.set_xlabel("Run")
ax.set_ylabel("Success Rate (%)")
title = "Extraction Success Rate\n"
subtitle = "Percentage of language tests completed without errors"
ax.set_title(title, fontweight="bold", fontsize=10)
ax.text(
0.5,
1.01,
subtitle,
transform=ax.transAxes,
ha="center",
fontsize=7,
style="italic",
color="#666666",
va="bottom",
)
ax.set_ylim(0, 105)
ax.set_xticks(x_pos)
ax.set_xticklabels(runs, rotation=45, ha="right")
ax.axhline(y=100, color="green", linestyle="--", alpha=0.3)
ax.grid(True, alpha=0.3)
for bar_rect, rate in zip(bars, success_rates):
ax.text(
bar_rect.get_x() + bar_rect.get_width() / 2,
bar_rect.get_height() + 1,
f"{rate:.0f}%",
ha="center",
fontsize=8,
)
def _plot_token_rate_by_language(ax, all_results):
"""Plot tokenization rates by language."""
languages = ["english", "french", "spanish", "japanese"]
latest_result = all_results[-1]
token_rates = []
colors = []
if config.RESULTS_KEY in latest_result:
for lang in languages:
lang_results = [
r
for r in latest_result[config.RESULTS_KEY]
if r.get("text_type") == lang and r.get("success")
]
if lang_results and config.TOKENIZATION_KEY in lang_results[0]:
rate = lang_results[0][config.TOKENIZATION_KEY].get(
"tokens_per_char", 0
)
token_rates.append(rate)
colors.append(
"red" if rate < 0.1 else "orange" if rate < 0.2 else "green"
)
else:
token_rates.append(0)
colors.append("gray")
ax.bar(languages, token_rates, color=colors, alpha=0.7)
ax.set_xlabel("Language")
ax.set_ylabel("Tokens per Character")
ax.set_title("Tokenization Density (Latest Run)")
ax.set_xticks(range(len(languages)))
ax.set_xticklabels([l.capitalize() for l in languages])
ax.grid(True, alpha=0.3)
for i, (lang, rate) in enumerate(zip(languages, token_rates)):
ax.text(i, rate + 0.01, f"{rate:.3f}", ha="center", fontsize=8)
def _plot_timeline(ax, all_results):
"""Plot metrics over time if timestamps available."""
timestamps = []
entity_totals = []
for result in all_results:
filename = result["filename"]
if "timestamp" in result:
timestamps.append(result["timestamp"])
else:
# Try to parse from filename (format: benchmark_YYYYMMDD_HHMMSS)
parts = filename.split("_")
if len(parts) >= 3:
timestamps.append(f"{parts[-2]}_{parts[-1]}")
else:
timestamps.append(filename[:10])
if config.RESULTS_KEY in result:
total_entities = sum(
r.get("entity_count", 0)
for r in result[config.RESULTS_KEY]
if r.get("success")
)
entity_totals.append(total_entities)
else:
entity_totals.append(0)
x_pos = np.arange(len(timestamps))
ax.plot(x_pos, entity_totals, "o-", color="blue", linewidth=2, markersize=8)
ax.set_xlabel("Run")
ax.set_ylabel("Total Entities")
title = "Total Entities Over Time\n"
subtitle = "Sum of all entities extracted across all languages"
ax.set_title(title, fontweight="bold", fontsize=10)
ax.text(
0.5,
1.01,
subtitle,
transform=ax.transAxes,
ha="center",
fontsize=7,
style="italic",
color="#666666",
va="bottom",
)
ax.set_xticks(x_pos)
ax.set_xticklabels([t[-6:] for t in timestamps], rotation=45, ha="right")
ax.grid(True, alpha=0.3)
for i, total in enumerate(entity_totals):
ax.text(i, total + 1, str(total), ha="center", fontsize=8)
if entity_totals:
min_val = min(0, min(entity_totals) - 5)
max_val = max(entity_totals) + 5
ax.set_ylim(min_val, max_val)
================================================
FILE: benchmarks/utils.py
================================================
# Copyright 2025 Google LLC.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Helper functions for benchmark text retrieval and analysis."""
import subprocess
from typing import Any
import urllib.error
import urllib.request
from benchmarks import config
from langextract.core import tokenizer
def download_text(url: str) -> str:
"""Download text from URL.
Args:
url: URL to download from.
Returns:
Downloaded text content.
"""
try:
with urllib.request.urlopen(url) as response:
return response.read().decode("utf-8")
except (urllib.error.URLError, urllib.error.HTTPError) as e:
raise RuntimeError(f"Could not download from {url}: {e}") from e
def extract_text_content(full_text: str) -> str:
"""Extract main content from Gutenberg text.
Skips headers and footers by taking middle 60% of text.
Args:
full_text: Full text including Gutenberg headers.
Returns:
Extracted main content.
"""
start_marker = "*** START OF"
end_marker = "*** END OF"
start_idx = full_text.upper().find(start_marker)
end_idx = full_text.upper().find(end_marker)
if start_idx != -1 and end_idx != -1:
content_start = full_text.find("\n", start_idx) + 1
# Handle markers with trailing asterisks (e.g., "*** START ... ***").
line_end = full_text.find("***", start_idx + 3)
if (
line_end != -1 and line_end < content_start + 100
): # Ensure marker is on same line.
content_start = full_text.find("\n", line_end) + 1
return full_text[content_start:end_idx].strip()
text_length = len(full_text)
start = int(text_length * 0.2)
end = int(text_length * 0.8)
return full_text[start:end].strip()
def get_text_from_gutenberg(text_type: config.TextTypes) -> str:
"""Get text from Project Gutenberg for given language.
Args:
text_type: Type of text (language).
Returns:
Text sample from Gutenberg.
"""
url = config.GUTENBERG_TEXTS[text_type]
full_text = download_text(url)
content = extract_text_content(full_text)
mid_point = len(content) // 2
start_chunk = max(0, mid_point - 2500)
return content[start_chunk : start_chunk + 5000].strip()
def get_optimal_text_size(text: str, model_id: str) -> str:
"""Get optimal text size for model.
Args:
text: Original text.
model_id: Model identifier.
Returns:
Text truncated to optimal size.
"""
if (
":" in model_id
or "gemma" in model_id.lower()
or "llama" in model_id.lower()
):
max_chars = 500 # Smaller context for local models.
else:
max_chars = 5000
return text[:max_chars]
def get_extraction_example(text_type: config.TextTypes) -> dict[str, str]: # pylint: disable=unused-argument
"""Get extraction example configuration.
Args:
text_type: Type of text.
Returns:
Dictionary with prompt configuration.
"""
return {
"prompt": "Extract all character names from this text",
}
def get_git_info() -> dict[str, str]:
"""Get current git branch and commit info.
Returns:
Dictionary with branch and commit info.
"""
try:
branch = subprocess.run(
["git", "branch", "--show-current"],
capture_output=True,
text=True,
check=True,
).stdout.strip()
commit = subprocess.run(
["git", "rev-parse", "--short", "HEAD"],
capture_output=True,
text=True,
check=True,
).stdout.strip()
status = subprocess.run(
["git", "status", "--porcelain"],
capture_output=True,
text=True,
check=True,
).stdout.strip()
if status:
commit += "-dirty"
return {"branch": branch, "commit": commit}
except subprocess.CalledProcessError:
return {"branch": "unknown", "commit": "unknown"}
def analyze_tokenization(
text: str, tokenizer_inst: tokenizer.Tokenizer | None = None
) -> dict[str, Any]:
"""Analyze tokenization of given text.
Args:
text: Text to analyze.
tokenizer_inst: Tokenizer instance to use (default: RegexTokenizer).
Returns:
Dictionary with tokenization metrics.
"""
if tokenizer_inst:
tokenized = tokenizer_inst.tokenize(text)
else:
tokenized = tokenizer.tokenize(text)
num_tokens = len(tokenized.tokens)
num_chars = len(text)
tokens_per_char = num_tokens / num_chars if num_chars > 0 else 0
return {
"num_tokens": num_tokens,
"num_chars": num_chars,
"tokens_per_char": tokens_per_char,
}
def format_tokenization_summary(analysis: dict[str, Any]) -> str:
"""Format tokenization analysis as summary string.
Args:
analysis: Tokenization analysis dict.
Returns:
Formatted summary string.
"""
return (
f"{analysis['num_tokens']} tokens, "
f"{analysis['tokens_per_char']:.3f} tok/char"
)
================================================
FILE: docs/examples/batch_api_example.md
================================================
# Vertex AI Batch Processing Guide
The Vertex AI Batch API offers significant cost savings (~50%) for large, non-time-critical workloads. `langextract` seamlessly integrates this with automatic routing, caching, and fault tolerance.
**[Vertex AI Batch Prediction Documentation →](https://docs.cloud.google.com/vertex-ai/generative-ai/docs/multimodal/batch-prediction-gemini)**
**[Quotas & Limits →](https://docs.cloud.google.com/vertex-ai/generative-ai/docs/quotas#batch-prediction-quotas)**
## Real-World Example: Processing Shakespeare
This example demonstrates how to process a large text (the first ~20 pages of *Romeo and Juliet*) using the Batch API. We use a small chunk size (`max_char_buffer=500`) to generate enough chunks to trigger batch processing.
```python
import requests
import textwrap
import langextract as lx
import logging
# Configure logging to see progress (both in console and file)
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("batch_process.log"),
logging.StreamHandler()
]
)
# 1. Download Text (Shakespeare's Romeo and Juliet)
url = "https://www.gutenberg.org/files/1513/1513-0.txt"
print(f"Downloading {url}...")
text = requests.get(url).text
# Process first ~20 pages (approx. 60k characters).
text_subset = text[:60000]
print(f"Processing first {len(text_subset)} characters...")
# 2. Define Prompt & Examples
prompt = textwrap.dedent("""\
Extract characters and emotions from the text.
Use exact text from the input for extraction_text.""")
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
lx.data.Extraction(extraction_class="character", extraction_text="ROMEO"),
lx.data.Extraction(extraction_class="emotion", extraction_text="But soft!"),
]
)
]
# 3. Configure Batch Settings
batch_config = {
"enabled": True,
"threshold": 10,
"poll_interval": 30,
"timeout": 3600,
# Set to True to cache results in GCS. Add timestamp to prompt to force re-run.
"enable_caching": True,
# Retention policy for GCS bucket (days). None for permanent.
"retention_days": 30,
}
# 4. Run Extraction
# langextract will automatically chunk the text and submit a batch job.
results = lx.extract(
text_or_documents=text_subset,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
max_char_buffer=500,
batch_length=1000,
language_model_params={
"vertexai": True,
"project": "your-gcp-project", # TODO: Replace with your Project ID.
"location": "us-central1",
"batch": batch_config
}
)
## GCS File Structure
The library automatically creates and manages a GCS bucket for you, named:
`langextract-{project}-{location}-batch`
Inside this bucket, data is organized as follows:
- **Input**: `batch-input/{job_name}.jsonl`
- **Output**: `batch-input/{job_name}/dest/prediction-model-{timestamp}/predictions.jsonl`
- **Cache**: `cache/{hash}.json` (Individual cached results)
## Cost Optimization & Caching
LangExtract's batch processing is designed to minimize costs:
1. **Cost Efficiency**: Vertex AI Batch predictions are typically ~50% cheaper than online predictions.
2. **Smart Caching**:
- Results are cached in your GCS bucket (`cache/` directory).
- **Instant Retrieval**: Re-running identical prompts fetches results directly from storage, bypassing model inference.
- **Reduced Inference**: You avoid paying for redundant model calls on previously processed data.
- **Lifecycle Management**: Use `retention_days` (e.g., 30) to automatically clean up old data and manage storage usage.
## Analyze Results
print(f"Extracted {len(results.extractions)} entities.")
print("First 5 extractions:")
for extraction in results.extractions[:5]:
print(f"- {extraction.extraction_class}: {extraction.extraction_text}")
```
## Sample Output
```text
Extracted 767 entities.
First 5 extractions:
- character: ESCALUS
- character: MERCUTIO
- character: PARIS
- character: Page to Paris
- character: MONTAGUE
```
> **Note on `batch_length`**: The `batch_length` parameter controls how many chunks are submitted in a single batch job. For optimal performance with the Batch API, set this to a high value (e.g., `1000`) to process all chunks in a single job rather than multiple sequential jobs.
## Key Features
### 1. Automatic Routing
`langextract` automatically switches between real-time and batch APIs based on your `threshold`.
- **< Threshold**: Uses real-time API for immediate results.
- **>= Threshold**: Uses Batch API for cost savings.
### 2. Fault Tolerance & Caching
Built-in GCS caching (`enable_caching=True`) allows you to resume interrupted jobs without re-processing completed items, saving time and cost.
### 3. Automated Storage
`langextract` handles all GCS operations automatically using a dedicated bucket (`gs://langextract-{project}-{location}-batch`). Note that input/output files are retained for debugging.
## Tracking Job Status
To monitor progress, you can watch the log file from a separate terminal:
```bash
tail -f batch_process.log
```
When running a batch job, `langextract` provides clear log feedback with a direct link to the Google Cloud Console:
```text
INFO - Batch job created successfully: projects/123456789/locations/us-central1/batchPredictionJobs/987654321
INFO - Job State: JobState.JOB_STATE_PENDING
INFO - Job Console URL: https://console.cloud.google.com/vertex-ai/jobs/batch-predictions/987654321?project=123456789
INFO - Batch job is running... (State: JOB_STATE_PENDING)
INFO - Batch job is running... (State: JOB_STATE_RUNNING)
```
- **Completion**: Once the job succeeds, `langextract` automatically downloads, parses, and aligns the results.
================================================
FILE: docs/examples/japanese_extraction.md
================================================
# Japanese Information Extraction
This example demonstrates how to use LangExtract to extract structured information from Japanese text.
> **Note:** For non-spaced languages like Japanese, use `UnicodeTokenizer` to ensure correct character-based segmentation and alignment.
## Full Pipeline Example
```python
import langextract as lx
from langextract.core import tokenizer
# Japanese text with entities (Person, Location, Organization)
# "Mr. Tanaka from Tokyo works at Google."
input_text = "東京出身の田中さんはGoogleで働いています。"
# Define extraction prompt
prompt_description = "Extract named entities including Person, Location, and Organization."
# Define example data (few-shot examples help the model understand the task)
examples = [
lx.data.ExampleData(
text="大阪の山田さんはソニーに入社しました。", # Mr. Yamada from Osaka joined Sony.
extractions=[
lx.data.Extraction(extraction_class="Location", extraction_text="大阪"),
lx.data.Extraction(extraction_class="Person", extraction_text="山田"),
lx.data.Extraction(extraction_class="Organization", extraction_text="ソニー"),
]
)
]
# 1. Initialize the UnicodeTokenizer
# Essential for Japanese to ensure correct grapheme segmentation.
unicode_tokenizer = tokenizer.UnicodeTokenizer()
# 2. Run Extraction with the Custom Tokenizer
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt_description,
examples=examples,
model_id="gemini-2.5-flash",
tokenizer=unicode_tokenizer, # <--- Pass the tokenizer here
api_key="your-api-key-here" # Optional if env var is set
)
# 3. Display Results
print(f"Input: {input_text}\n")
print("Extracted Entities:")
for entity in result.extractions:
position_info = ""
if entity.char_interval:
start, end = entity.char_interval.start_pos, entity.char_interval.end_pos
position_info = f" (pos: {start}-{end})"
print(f"• {entity.extraction_class}: {entity.extraction_text}{position_info}")
# Expected Output:
# Input: 東京出身の田中さんはGoogleで働いています。
#
# Extracted Entities:
# • Location: 東京 (pos: 0-2)
# • Person: 田中 (pos: 5-7)
# • Organization: Google (pos: 10-16)
```
================================================
FILE: docs/examples/longer_text_example.md
================================================
# *Romeo and Juliet* Full Text Extraction
LangExtract can process entire documents directly from URLs, handling large texts with high accuracy through parallel processing and enhanced sensitivity features. This example demonstrates extraction from the complete text of *Romeo and Juliet* from Project Gutenberg.
## Example code
The following code uses a comprehensive prompt and examples optimized for large, complex literary texts. For large complex inputs, using more detailed examples is suggested to increase extraction robustness.
> **Warning:** Running this example processes a large document (~44 000 tokens) and will incur costs. For large-scale use, a Tier 2 Gemini quota is suggested to avoid rate-limit issues ([details](https://ai.google.dev/gemini-api/docs/rate-limits#tier-2)). Please review the [Gemini API pricing](https://ai.google.dev/gemini-api/docs/pricing) before proceeding.
```python
import langextract as lx
import textwrap
from collections import Counter, defaultdict
# Define comprehensive prompt and examples for complex literary text
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships from the given text.
Provide meaningful attributes for every entity to add context and depth.
Important: Use exact text from the input for extraction_text. Do not paraphrase.
Extract entities in order of appearance with no overlapping text spans.
Note: In play scripts, speaker names appear in ALL-CAPS followed by a period.""")
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
ROMEO. But soft! What light through yonder window breaks?
It is the east, and Juliet is the sun.
JULIET. O Romeo, Romeo! Wherefore art thou Romeo?"""),
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe", "character": "Romeo"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor", "character_1": "Romeo", "character_2": "Juliet"}
),
lx.data.Extraction(
extraction_class="character",
extraction_text="JULIET",
attributes={"emotional_state": "yearning"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="Wherefore art thou Romeo?",
attributes={"feeling": "longing question", "character": "Juliet"}
),
]
)
]
# Process Romeo & Juliet directly from Project Gutenberg
print("Downloading and processing Romeo and Juliet from Project Gutenberg...")
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # Multiple passes for improved recall
max_workers=20, # Parallel processing for speed
max_char_buffer=1000 # Smaller contexts for better accuracy
)
print(f"Extracted {len(result.extractions)} entities from {len(result.text):,} characters")
# Save and visualize the results
lx.io.save_annotated_documents([result], output_name="romeo_juliet_extractions.jsonl", output_dir=".")
# Generate the interactive visualization
html_content = lx.visualize("romeo_juliet_extractions.jsonl")
with open("romeo_juliet_visualization.html", "w") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data) # For Jupyter/Colab
else:
f.write(html_content)
print("Interactive visualization saved to romeo_juliet_visualization.html")
```
This creates an interactive HTML visualization for exploring the extracted entities:

```python
# Analyze character mentions
characters = {}
for e in result.extractions:
if e.extraction_class == "character":
char_name = e.extraction_text
if char_name not in characters:
characters[char_name] = {"count": 0, "attributes": set()}
characters[char_name]["count"] += 1
if e.attributes:
for attr_key, attr_val in e.attributes.items():
characters[char_name]["attributes"].add(f"{attr_key}: {attr_val}")
# Print character summary
print(f"\nCHARACTER SUMMARY ({len(characters)} unique characters)")
print("=" * 60)
sorted_chars = sorted(characters.items(), key=lambda x: x[1]["count"], reverse=True)
for char_name, char_data in sorted_chars[:10]: # Top 10 characters
attrs_preview = list(char_data["attributes"])[:3]
attrs_str = f" ({', '.join(attrs_preview)})" if attrs_preview else ""
print(f"{char_name}: {char_data['count']} mentions{attrs_str}")
# Entity type breakdown
entity_counts = Counter(e.extraction_class for e in result.extractions)
print(f"\nENTITY TYPE BREAKDOWN")
print("=" * 60)
for entity_type, count in entity_counts.most_common():
percentage = (count / len(result.extractions)) * 100
print(f"{entity_type}: {count} ({percentage:.1f}%)")
```
## Sample output
```
Downloading and processing Romeo and Juliet from Project Gutenberg...
Downloaded 147,843 characters (25,976 words) from 1513-0.txt
Extracted 4,088 entities from 147,843 characters
Interactive visualization saved to romeo_juliet_visualization.html
CHARACTER SUMMARY (153 unique characters)
============================================================
ROMEO: 287 mentions (emotional_state: excitement, emotional_state: eager to please)
JULIET: 204 mentions (emotional_state: fond, emotional_state: resilient)
NURSE: 168 mentions (emotional_state: reporting, emotional_state: teasing and evasive)
MERCUTIO: 107 mentions (emotional_state: approving, emotional_state: responsive)
BENVOLIO: 82 mentions (emotional_state: cautious, emotional_state: teasing)
ENTITY TYPE BREAKDOWN
============================================================
character: 1,685 (41.2%)
emotion: 1,524 (37.3%)
relationship: 879 (21.5%)
```
## Key benefits for long documents
### Sequential extraction passes
Multiple extraction passes improve recall by performing independent extractions and merging non-overlapping results. Each pass uses identical parameters and processing—they are independent runs of the same extraction task. The number of passes is controlled by the `extraction_passes` parameter (e.g., `extraction_passes=3`).
**How it works**: Each pass processes the full text independently using the same prompt and examples. Results are then merged using a "first-pass wins" strategy for overlapping entities, while adding unique non-overlapping entities from later passes. This approach captures entities that might be missed in any single run due to the stochastic nature of language model generation.
### Portable and Interoperable Data with JSONL
LangExtract uses JSONL, a human-readable format ideal for language model data. Each line is a self-contained JSON object, making outputs easy to parse, share, and integrate with other tools. You can save results with `lx.io.save_annotated_documents` and reload them for later analysis, ensuring your data is both portable and persistent.
### Optimal long context management
While single-inference approaches can be powerful, their accuracy may be affected by distant context. LangExtract uses smart chunking strategies that respect text delimiters (such as paragraph breaks) to keep context intact and well-formed for the model. Users can configure context sizes (`max_char_buffer`) combined with parallel processing (`max_workers`) to maintain extraction quality across large documents. Multiple sequential extraction passes further enhance sensitivity by capturing entities that might be missed in any single run due to the stochastic nature of language model generation.
### Enhanced accuracy through chunking
The chunked processing approach can improve extraction quality over a single inference pass on a large document because each chunk uses a smaller, more manageable context size. This helps the model focus on the most relevant information and prevents interference from distant context. While the overall latency and time required remain similar due to parallelization, the extraction quality can be substantially higher with better entity coverage and more accurate attribute assignment across the entire document.¹
### Interactive visualization at scale
Seamlessly explore hundreds or thousands of entities through interactive HTML visualizations generated directly from JSONL output files. The generated visualizations handle large result sets efficiently, providing navigation and detailed entity inspection capabilities for comprehensive analysis of complex documents.
### Schema-guided knowledge extraction
LangExtract combines precise text positioning with world knowledge enrichment, enabling extraction of information not explicitly stated in the text (like character identities and traits). Under the hood, the library implements [Controlled Generation](https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/control-generated-output) with supported models to ensure extracted data adheres to your specified schema while maintaining robust extractions across large inputs.
---
¹ Models like Gemini 1.5 Pro show strong performance on many benchmarks, but [needle-in-a-haystack tests](https://cloud.google.com/blog/products/ai-machine-learning/the-needle-in-the-haystack-test-and-how-gemini-pro-solves-it) across million-token contexts indicate that performance can vary in multi-fact retrieval scenarios. This demonstrates how LangExtract's smaller context windows approach ensures consistently high quality across entire documents by avoiding the complexity and potential degradation of massive single-context processing.
================================================
FILE: docs/examples/medication_examples.md
================================================
# Medication Extraction Examples
LangExtract excels at extracting structured medical information from clinical text, making it particularly useful for healthcare applications. The methodology originated from research in medical information extraction, where early versi
gitextract_s1tifoud/ ├── .github/ │ ├── ISSUE_TEMPLATE/ │ │ ├── 1-bug.md │ │ ├── 2-feature-request.md │ │ └── config.yml │ ├── PULL_REQUEST_TEMPLATE/ │ │ └── pull_request_template.md │ ├── scripts/ │ │ ├── add-new-checks.sh │ │ ├── add-size-labels.sh │ │ ├── revalidate-all-prs.sh │ │ └── zenodo_publish.py │ └── workflows/ │ ├── auto-update-pr.yaml │ ├── check-infrastructure-changes.yml │ ├── check-linked-issue.yml │ ├── check-pr-size.yml │ ├── check-pr-up-to-date.yaml │ ├── ci.yaml │ ├── publish.yml │ ├── revalidate-pr.yml │ ├── validate-community-providers.yaml │ ├── validate_pr_template.yaml │ └── zenodo-publish.yml ├── .gitignore ├── .pre-commit-config.yaml ├── .pylintrc ├── CITATION.cff ├── COMMUNITY_PROVIDERS.md ├── CONTRIBUTING.md ├── Dockerfile ├── LICENSE ├── README.md ├── autoformat.sh ├── benchmarks/ │ ├── benchmark.py │ ├── config.py │ ├── plotting.py │ └── utils.py ├── docs/ │ └── examples/ │ ├── batch_api_example.md │ ├── japanese_extraction.md │ ├── longer_text_example.md │ └── medication_examples.md ├── examples/ │ ├── custom_provider_plugin/ │ │ ├── README.md │ │ ├── langextract_provider_example/ │ │ │ ├── __init__.py │ │ │ ├── provider.py │ │ │ └── schema.py │ │ ├── pyproject.toml │ │ └── test_example_provider.py │ ├── notebooks/ │ │ └── romeo_juliet_extraction.ipynb │ └── ollama/ │ ├── .dockerignore │ ├── Dockerfile │ ├── README.md │ ├── demo_ollama.py │ └── docker-compose.yml ├── langextract/ │ ├── __init__.py │ ├── _compat/ │ │ ├── README.md │ │ ├── __init__.py │ │ ├── exceptions.py │ │ ├── inference.py │ │ ├── registry.py │ │ └── schema.py │ ├── annotation.py │ ├── chunking.py │ ├── core/ │ │ ├── __init__.py │ │ ├── base_model.py │ │ ├── data.py │ │ ├── debug_utils.py │ │ ├── exceptions.py │ │ ├── format_handler.py │ │ ├── schema.py │ │ ├── tokenizer.py │ │ └── types.py │ ├── data.py │ ├── data_lib.py │ ├── exceptions.py │ ├── extraction.py │ ├── factory.py │ ├── inference.py │ ├── io.py │ ├── plugins.py │ ├── progress.py │ ├── prompt_validation.py │ ├── prompting.py │ ├── providers/ │ │ ├── README.md │ │ ├── __init__.py │ │ ├── builtin_registry.py │ │ ├── gemini.py │ │ ├── gemini_batch.py │ │ ├── ollama.py │ │ ├── openai.py │ │ ├── patterns.py │ │ ├── router.py │ │ └── schemas/ │ │ ├── __init__.py │ │ └── gemini.py │ ├── py.typed │ ├── registry.py │ ├── resolver.py │ ├── schema.py │ ├── tokenizer.py │ └── visualization.py ├── pyproject.toml ├── scripts/ │ ├── create_provider_plugin.py │ └── validate_community_providers.py ├── tests/ │ ├── .pylintrc │ ├── annotation_test.py │ ├── chunking_test.py │ ├── data_lib_test.py │ ├── extract_precedence_test.py │ ├── extract_schema_integration_test.py │ ├── factory_schema_test.py │ ├── factory_test.py │ ├── format_handler_test.py │ ├── inference_test.py │ ├── init_test.py │ ├── progress_test.py │ ├── prompt_validation_test.py │ ├── prompting_test.py │ ├── provider_plugin_test.py │ ├── provider_schema_test.py │ ├── registry_test.py │ ├── resolver_test.py │ ├── schema_test.py │ ├── test_gemini_batch_api.py │ ├── test_kwargs_passthrough.py │ ├── test_live_api.py │ ├── test_ollama_integration.py │ ├── tokenizer_test.py │ └── visualization_test.py └── tox.ini
SYMBOL INDEX (834 symbols across 71 files)
FILE: .github/scripts/zenodo_publish.py
function new_version_from_record (line 52) | def new_version_from_record(record_id: str):
function upload_file (line 65) | def upload_file(bucket_url: str, path: str, dest_name: str = None):
function main (line 78) | def main():
FILE: benchmarks/benchmark.py
class BenchmarkRunner (line 66) | class BenchmarkRunner:
method __init__ (line 69) | def __init__(self):
method set_tokenizer (line 75) | def set_tokenizer(self, tokenizer_type: str):
method print_header (line 84) | def print_header(self):
method benchmark_tokenization (line 94) | def benchmark_tokenization(self) -> list[dict[str, Any]]:
method test_single_extraction (line 140) | def test_single_extraction(
method test_diverse_text_types (line 276) | def test_diverse_text_types(
method save_results (line 311) | def save_results(self, results: dict[str, Any]):
method run_diverse_benchmark (line 358) | def run_diverse_benchmark(self, models: list[str] | None = None):
function main (line 373) | def main():
FILE: benchmarks/config.py
class TokenizationConfig (line 33) | class TokenizationConfig:
class ModelConfig (line 41) | class ModelConfig:
class TextTypes (line 52) | class TextTypes(str, enum.Enum):
class DisplayConfig (line 79) | class DisplayConfig:
class PathConfig (line 90) | class PathConfig:
method get_result_path (line 95) | def get_result_path(self, timestamp: str, suffix: str = "") -> Path:
FILE: benchmarks/plotting.py
function create_diverse_plots (line 36) | def create_diverse_plots(results: dict[str, Any], filepath: Path) -> bool:
function _plot_tokenization_throughput (line 84) | def _plot_tokenization_throughput(ax, results):
function _plot_tokenization_rate (line 125) | def _plot_tokenization_rate(ax, results):
function _plot_extraction_density (line 170) | def _plot_extraction_density(ax, results):
function _plot_processing_speed (line 220) | def _plot_processing_speed(ax, results):
function _plot_summary_table (line 270) | def _plot_summary_table(ax, results):
function create_comparison_plots (line 320) | def create_comparison_plots(json_files: list[Path], output_path: Path) -...
function _plot_entity_comparison (line 376) | def _plot_entity_comparison(ax, all_results):
function _plot_time_comparison (line 435) | def _plot_time_comparison(ax, all_results):
function _plot_tokenization_comparison (line 492) | def _plot_tokenization_comparison(ax, all_results):
function _plot_success_rate_comparison (line 550) | def _plot_success_rate_comparison(ax, all_results):
function _plot_token_rate_by_language (line 606) | def _plot_token_rate_by_language(ax, all_results):
function _plot_timeline (line 645) | def _plot_timeline(ax, all_results):
FILE: benchmarks/utils.py
function download_text (line 26) | def download_text(url: str) -> str:
function extract_text_content (line 42) | def extract_text_content(full_text: str) -> str:
function get_text_from_gutenberg (line 77) | def get_text_from_gutenberg(text_type: config.TextTypes) -> str:
function get_optimal_text_size (line 95) | def get_optimal_text_size(text: str, model_id: str) -> str:
function get_extraction_example (line 117) | def get_extraction_example(text_type: config.TextTypes) -> dict[str, str...
function get_git_info (line 131) | def get_git_info() -> dict[str, str]:
function analyze_tokenization (line 167) | def analyze_tokenization(
function format_tokenization_summary (line 194) | def format_tokenization_summary(analysis: dict[str, Any]) -> str:
FILE: examples/custom_provider_plugin/langextract_provider_example/provider.py
class CustomGeminiProvider (line 31) | class CustomGeminiProvider(lx.inference.BaseLanguageModel):
method __init__ (line 56) | def __init__(
method get_schema_class (line 103) | def get_schema_class(cls) -> type[lx.schema.BaseSchema] | None:
method apply_schema (line 114) | def apply_schema(self, schema_instance: lx.schema.BaseSchema | None) -...
method infer (line 138) | def infer(
FILE: examples/custom_provider_plugin/langextract_provider_example/schema.py
class CustomProviderSchema (line 24) | class CustomProviderSchema(lx.schema.BaseSchema):
method __init__ (line 39) | def __init__(self, schema_dict: dict[str, Any], strict_mode: bool = Tr...
method from_examples (line 50) | def from_examples(
method to_provider_config (line 122) | def to_provider_config(self) -> dict[str, Any]:
method supports_strict_mode (line 145) | def supports_strict_mode(self) -> bool:
method schema_dict (line 155) | def schema_dict(self) -> dict[str, Any]:
FILE: examples/custom_provider_plugin/test_example_provider.py
function main (line 29) | def main():
FILE: examples/ollama/demo_ollama.py
function check_ollama_available (line 67) | def check_ollama_available(url: str = DEFAULT_OLLAMA_URL) -> bool:
function ensure_output_directory (line 76) | def ensure_output_directory() -> Path:
function print_header (line 83) | def print_header(title: str, width: int = 80) -> None:
function print_section (line 90) | def print_section(title: str, width: int = 60) -> None:
function print_results_summary (line 96) | def print_results_summary(extractions: list[lx.data.Extraction]) -> None:
function example_romeo_juliet (line 114) | def example_romeo_juliet(
function example_medication_ner (line 175) | def example_medication_ner(
function example_medication_relationships (line 231) | def example_medication_relationships(
function example_shakespeare_dialogue (line 328) | def example_shakespeare_dialogue(
function save_results (line 418) | def save_results(
function main (line 458) | def main():
FILE: langextract/__init__.py
function extract (line 53) | def extract(*args: Any, **kwargs: Any):
function visualize (line 58) | def visualize(*args: Any, **kwargs: Any):
function __getattr__ (line 87) | def __getattr__(name: str) -> Any:
function __dir__ (line 101) | def __dir__():
FILE: langextract/_compat/exceptions.py
function __getattr__ (line 26) | def __getattr__(name: str):
FILE: langextract/_compat/inference.py
class InferenceType (line 23) | class InferenceType(enum.Enum):
function __getattr__ (line 30) | def __getattr__(name: str):
FILE: langextract/_compat/registry.py
function __getattr__ (line 25) | def __getattr__(name: str):
FILE: langextract/_compat/schema.py
function __getattr__ (line 23) | def __getattr__(name: str):
FILE: langextract/annotation.py
function _merge_non_overlapping_extractions (line 46) | def _merge_non_overlapping_extractions(
function _extractions_overlap (line 87) | def _extractions_overlap(
function _document_chunk_iterator (line 118) | def _document_chunk_iterator(
class Annotator (line 163) | class Annotator:
method __init__ (line 166) | def __init__(
method annotate_documents (line 209) | def annotate_documents(
method _annotate_documents_single_pass (line 284) | def _annotate_documents_single_pass(
method _annotate_documents_sequential_passes (line 442) | def _annotate_documents_sequential_passes(
method annotate_text (line 527) | def annotate_text(
FILE: langextract/chunking.py
class TokenUtilError (line 35) | class TokenUtilError(exceptions.LangExtractError):
class TextChunk (line 40) | class TextChunk:
method __str__ (line 60) | def __str__(self):
method document_id (line 86) | def document_id(self) -> str | None:
method document_text (line 93) | def document_text(self) -> tokenizer_lib.TokenizedText | None:
method chunk_text (line 100) | def chunk_text(self) -> str:
method sanitized_chunk_text (line 111) | def sanitized_chunk_text(self) -> str:
method additional_context (line 118) | def additional_context(self) -> str | None:
method char_interval (line 125) | def char_interval(self) -> data.CharInterval:
function create_token_interval (line 143) | def create_token_interval(
function get_token_interval_text (line 169) | def get_token_interval_text(
function get_char_interval (line 216) | def get_char_interval(
function _sanitize (line 246) | def _sanitize(text: str) -> str:
function make_batches_of_textchunk (line 265) | def make_batches_of_textchunk(
class SentenceIterator (line 282) | class SentenceIterator:
method __init__ (line 285) | def __init__(
method __iter__ (line 312) | def __iter__(self) -> Iterator[tokenizer_lib.TokenInterval]:
method __next__ (line 315) | def __next__(self) -> tokenizer_lib.TokenInterval:
class ChunkIterator (line 343) | class ChunkIterator:
method __init__ (line 385) | def __init__(
method __iter__ (line 422) | def __iter__(self) -> Iterator[TextChunk]:
method _tokens_exceed_buffer (line 425) | def _tokens_exceed_buffer(
method __next__ (line 441) | def __next__(self) -> TextChunk:
FILE: langextract/core/base_model.py
class BaseLanguageModel (line 31) | class BaseLanguageModel(abc.ABC):
method __init__ (line 38) | def __init__(self, constraint: types.Constraint | None = None, **kwarg...
method get_schema_class (line 52) | def get_schema_class(cls) -> type[Any] | None:
method apply_schema (line 56) | def apply_schema(self, schema_instance: schema.BaseSchema | None) -> N...
method schema (line 68) | def schema(self) -> schema.BaseSchema | None:
method set_fence_output (line 76) | def set_fence_output(self, fence_output: bool | None) -> None:
method requires_fence_output (line 87) | def requires_fence_output(self) -> bool:
method merge_kwargs (line 104) | def merge_kwargs(
method infer (line 122) | def infer(
method infer_batch (line 137) | def infer_batch(
method parse_output (line 156) | def parse_output(self, output: str) -> Any:
FILE: langextract/core/data.py
class AlignmentStatus (line 43) | class AlignmentStatus(enum.Enum):
class CharInterval (line 51) | class CharInterval:
class Extraction (line 64) | class Extraction:
method __init__ (line 96) | def __init__(
method token_interval (line 120) | def token_interval(self) -> tokenizer.TokenInterval | None:
method token_interval (line 124) | def token_interval(self, value: tokenizer.TokenInterval | None) -> None:
class Document (line 129) | class Document:
method __init__ (line 149) | def __init__(
method document_id (line 161) | def document_id(self) -> str:
method document_id (line 168) | def document_id(self, value: str | None) -> None:
method tokenized_text (line 173) | def tokenized_text(self) -> tokenizer.TokenizedText:
method tokenized_text (line 179) | def tokenized_text(self, value: tokenizer.TokenizedText) -> None:
class AnnotatedDocument (line 184) | class AnnotatedDocument:
method __init__ (line 204) | def __init__(
method document_id (line 216) | def document_id(self) -> str:
method document_id (line 223) | def document_id(self, value: str | None) -> None:
method tokenized_text (line 228) | def tokenized_text(self) -> tokenizer.TokenizedText | None:
method tokenized_text (line 234) | def tokenized_text(self, value: tokenizer.TokenizedText) -> None:
class ExampleData (line 239) | class ExampleData:
FILE: langextract/core/debug_utils.py
function _safe_repr (line 49) | def _safe_repr(obj: Any) -> str:
function _redact_value (line 57) | def _redact_value(name: str, value: Any) -> str:
function _redact_mapping (line 73) | def _redact_mapping(mapping: Mapping[str, Any]) -> dict[str, str]:
function _format_bound_args (line 81) | def _format_bound_args(
function debug_log_calls (line 106) | def debug_log_calls(fn: Callable) -> Callable:
function configure_debug_logging (line 151) | def configure_debug_logging() -> None:
FILE: langextract/core/exceptions.py
class LangExtractError (line 38) | class LangExtractError(Exception):
class InferenceError (line 47) | class InferenceError(LangExtractError):
class InferenceConfigError (line 51) | class InferenceConfigError(InferenceError):
class InferenceRuntimeError (line 59) | class InferenceRuntimeError(InferenceError):
method __init__ (line 66) | def __init__(
class InferenceOutputError (line 85) | class InferenceOutputError(LangExtractError):
method __init__ (line 88) | def __init__(self, message: str):
class InvalidDocumentError (line 93) | class InvalidDocumentError(LangExtractError):
class InternalError (line 100) | class InternalError(LangExtractError):
class ProviderError (line 107) | class ProviderError(LangExtractError):
class SchemaError (line 111) | class SchemaError(LangExtractError):
class FormatError (line 115) | class FormatError(LangExtractError):
class FormatParseError (line 119) | class FormatParseError(FormatError):
FILE: langextract/core/format_handler.py
class FormatHandler (line 49) | class FormatHandler:
method __init__ (line 66) | def __init__(
method __repr__ (line 106) | def __repr__(self) -> str:
method format_extraction_example (line 116) | def format_extraction_example(
method parse_output (line 151) | def parse_output(
method _add_fences (line 247) | def _add_fences(self, content: str) -> str:
method _is_valid_language_tag (line 252) | def _is_valid_language_tag(
method _parse_with_fallback (line 261) | def _parse_with_fallback(self, content: str, strict: bool):
method _extract_content (line 278) | def _extract_content(self, text: str) -> str:
method from_resolver_params (line 348) | def from_resolver_params(
method from_kwargs (line 425) | def from_kwargs(cls, **kwargs) -> FormatHandler:
FILE: langextract/core/schema.py
class BaseSchema (line 38) | class BaseSchema(abc.ABC):
method from_examples (line 43) | def from_examples(
method to_provider_config (line 51) | def to_provider_config(self) -> dict[str, Any]:
method requires_raw_output (line 61) | def requires_raw_output(self) -> bool:
method validate_format (line 68) | def validate_format(self, format_handler: fh.FormatHandler) -> None:
method sync_with_provider_kwargs (line 78) | def sync_with_provider_kwargs(self, kwargs: dict[str, Any]) -> None:
class FormatModeSchema (line 93) | class FormatModeSchema(BaseSchema):
method __init__ (line 101) | def __init__(self, format_type: types.FormatType = types.FormatType.JS...
method from_examples (line 108) | def from_examples(
method to_provider_config (line 117) | def to_provider_config(self) -> dict[str, Any]:
method requires_raw_output (line 122) | def requires_raw_output(self) -> bool:
method sync_with_provider_kwargs (line 126) | def sync_with_provider_kwargs(self, kwargs: dict[str, Any]) -> None:
FILE: langextract/core/tokenizer.py
class BaseTokenizerError (line 53) | class BaseTokenizerError(exceptions.LangExtractError):
class InvalidTokenIntervalError (line 57) | class InvalidTokenIntervalError(BaseTokenizerError):
class SentenceRangeError (line 61) | class SentenceRangeError(BaseTokenizerError):
class CharInterval (line 66) | class CharInterval:
class TokenInterval (line 79) | class TokenInterval:
class TokenType (line 94) | class TokenType(enum.IntEnum):
class Token (line 109) | class Token:
class TokenizedText (line 135) | class TokenizedText:
class Tokenizer (line 165) | class Tokenizer(abc.ABC):
method tokenize (line 169) | def tokenize(self, text: str) -> TokenizedText:
class RegexTokenizer (line 180) | class RegexTokenizer(Tokenizer):
method tokenize (line 188) | def tokenize(self, text: str) -> TokenizedText:
function tokenize (line 234) | def tokenize(
class Sentinel (line 257) | class Sentinel:
method __init__ (line 260) | def __init__(self, name: str):
method __repr__ (line 263) | def __repr__(self) -> str:
function _get_script_fast (line 273) | def _get_script_fast(char: str) -> str | Sentinel:
function _classify_grapheme (line 282) | def _classify_grapheme(g: str) -> TokenType:
function _get_common_script_cached (line 313) | def _get_common_script_cached(c: str) -> str | Sentinel:
class UnicodeTokenizer (line 321) | class UnicodeTokenizer(Tokenizer):
method tokenize (line 336) | def tokenize(self, text: str) -> TokenizedText:
method _emit_token (line 444) | def _emit_token(
function tokens_text (line 470) | def tokens_text(
function _is_end_of_sentence_token (line 510) | def _is_end_of_sentence_token(
function _is_sentence_break_after_newline (line 549) | def _is_sentence_break_after_newline(
function find_sentence_range (line 580) | def find_sentence_range(
FILE: langextract/core/types.py
class FormatType (line 30) | class FormatType(enum.Enum):
class ConstraintType (line 37) | class ConstraintType(enum.Enum):
class Constraint (line 44) | class Constraint:
class ScoredOutput (line 55) | class ScoredOutput:
method __str__ (line 61) | def __str__(self) -> str:
FILE: langextract/data_lib.py
function enum_asdict_factory (line 27) | def enum_asdict_factory(items: Iterable[tuple[str, Any]]) -> dict[str, A...
function annotated_document_to_dict (line 57) | def annotated_document_to_dict(
function dict_to_annotated_document (line 85) | def dict_to_annotated_document(
FILE: langextract/extraction.py
function extract (line 36) | def extract(
FILE: langextract/factory.py
class ModelConfig (line 36) | class ModelConfig:
function _kwargs_with_environment_defaults (line 53) | def _kwargs_with_environment_defaults(
function create_model (line 103) | def create_model(
function create_model_from_id (line 179) | def create_model_from_id(
function _create_model_with_schema (line 200) | def _create_model_with_schema(
FILE: langextract/inference.py
function __getattr__ (line 26) | def __getattr__(name: str):
FILE: langextract/io.py
class InvalidDatasetError (line 38) | class InvalidDatasetError(exceptions.LangExtractError):
class Dataset (line 43) | class Dataset(abc.ABC):
method load (line 50) | def load(self, delimiter: str = ',') -> Iterator[data.Document]:
function save_annotated_documents (line 85) | def save_annotated_documents(
function load_annotated_documents_jsonl (line 140) | def load_annotated_documents_jsonl(
function _read_csv (line 191) | def _read_csv(
function is_url (line 222) | def is_url(text: str) -> bool:
function download_text_from_url (line 261) | def download_text_from_url(
FILE: langextract/plugins.py
function _safe_entry_points (line 44) | def _safe_entry_points(group: str) -> list:
function _discovered (line 63) | def _discovered() -> dict[str, str]:
function available_providers (line 88) | def available_providers(
function _load_class (line 124) | def _load_class(spec: str) -> type[base_model.BaseLanguageModel]:
function get_provider_class (line 183) | def get_provider_class(
FILE: langextract/progress.py
function create_download_progress_bar (line 34) | def create_download_progress_bar(
function create_extraction_progress_bar (line 81) | def create_extraction_progress_bar(
function print_download_complete (line 105) | def print_download_complete(
function print_extraction_complete (line 122) | def print_extraction_complete() -> None:
function print_extraction_summary (line 127) | def print_extraction_summary(
function create_save_progress_bar (line 167) | def create_save_progress_bar(
function create_load_progress_bar (line 189) | def create_load_progress_bar(
function print_save_complete (line 223) | def print_save_complete(num_docs: int, file_path: str) -> None:
function print_load_complete (line 238) | def print_load_complete(num_docs: int, file_path: str) -> None:
function get_model_info (line 253) | def get_model_info(language_model: Any) -> str | None:
function format_extraction_stats (line 271) | def format_extraction_stats(current_chars: int, processed_chars: int) ->...
function create_extraction_postfix (line 286) | def create_extraction_postfix(current_chars: int, processed_chars: int) ...
function format_extraction_progress (line 301) | def format_extraction_progress(
function create_pass_progress_bar (line 331) | def create_pass_progress_bar(
FILE: langextract/prompt_validation.py
class PromptValidationLevel (line 44) | class PromptValidationLevel(enum.Enum):
class _IssueKind (line 52) | class _IssueKind(enum.Enum):
class ValidationIssue (line 60) | class ValidationIssue:
method short_msg (line 72) | def short_msg(self) -> str:
class ValidationReport (line 87) | class ValidationReport:
method has_failed (line 93) | def has_failed(self) -> bool:
method has_non_exact (line 98) | def has_non_exact(self) -> bool:
class PromptAlignmentError (line 103) | class PromptAlignmentError(RuntimeError):
class AlignmentPolicy (line 108) | class AlignmentPolicy:
function _preview (line 116) | def _preview(s: str, n: int = 120) -> str:
function validate_prompt_alignment (line 122) | def validate_prompt_alignment(
function handle_alignment_report (line 212) | def handle_alignment_report(
FILE: langextract/prompting.py
class PromptBuilderError (line 31) | class PromptBuilderError(exceptions.LangExtractError):
class ParseError (line 35) | class ParseError(PromptBuilderError):
class PromptTemplateStructured (line 40) | class PromptTemplateStructured:
function read_prompt_template_structured_from_file (line 52) | def read_prompt_template_structured_from_file(
class QAPromptGenerator (line 85) | class QAPromptGenerator:
method __str__ (line 94) | def __str__(self) -> str:
method format_example_as_text (line 98) | def format_example_as_text(self, example: data.ExampleData) -> str:
method render (line 115) | def render(self, question: str, additional_context: str | None = None)...
class PromptBuilder (line 141) | class PromptBuilder:
method __init__ (line 148) | def __init__(self, generator: QAPromptGenerator):
method build_prompt (line 156) | def build_prompt(
class ContextAwarePromptBuilder (line 179) | class ContextAwarePromptBuilder(PromptBuilder):
method __init__ (line 193) | def __init__(
method context_window_chars (line 210) | def context_window_chars(self) -> int | None:
method build_prompt (line 215) | def build_prompt(
method _build_effective_context (line 242) | def _build_effective_context(
method _update_state (line 268) | def _update_state(self, document_id: str, chunk_text: str) -> None:
FILE: langextract/providers/__init__.py
function load_builtins_once (line 49) | def load_builtins_once() -> None:
function load_plugins_once (line 74) | def load_plugins_once() -> None:
function _reset_for_testing (line 145) | def _reset_for_testing() -> None:
function __getattr__ (line 152) | def __getattr__(name: str):
FILE: langextract/providers/builtin_registry.py
class ProviderConfig (line 26) | class ProviderConfig(TypedDict):
FILE: langextract/providers/gemini.py
class GeminiLanguageModel (line 56) | class GeminiLanguageModel(base_model.BaseLanguageModel): # pylint: disa...
method get_schema_class (line 76) | def get_schema_class(cls) -> type[schema.BaseSchema] | None:
method apply_schema (line 84) | def apply_schema(self, schema_instance: schema.BaseSchema | None) -> N...
method __init__ (line 94) | def __init__(
method _validate_schema_config (line 190) | def _validate_schema_config(self) -> None:
method _process_single_prompt (line 202) | def _process_single_prompt(
method infer (line 228) | def infer(
FILE: langextract/providers/gemini_batch.py
class BatchConfig (line 58) | class BatchConfig:
method __post_init__ (line 82) | def __post_init__(self):
method from_dict (line 113) | def from_dict(cls, d: dict | None) -> BatchConfig:
function _default_job_create_callback (line 142) | def _default_job_create_callback(job: Any) -> None:
function _snake_to_camel (line 165) | def _snake_to_camel(key: str) -> str:
function _is_vertexai_client (line 171) | def _is_vertexai_client(client) -> bool:
function _get_project_location (line 183) | def _get_project_location(
function _get_bucket_name (line 203) | def _get_bucket_name(project: str | None, location: str) -> str:
function _ensure_bucket_lifecycle (line 209) | def _ensure_bucket_lifecycle(
function _build_request (line 248) | def _build_request(
function _submit_file (line 297) | def _submit_file(
class GCSBatchCache (line 378) | class GCSBatchCache:
method __init__ (line 381) | def __init__(self, bucket_name: str, project: str | None = None):
method _compute_hash (line 387) | def _compute_hash(self, key_data: dict) -> str:
method _get_single (line 392) | def _get_single(self, key_hash: str) -> str | None:
method get_multi (line 404) | def get_multi(self, key_data_list: Sequence[dict]) -> dict[int, str]:
method set_multi (line 426) | def set_multi(self, items: Sequence[tuple[dict, str]]) -> None:
method iter_items (line 465) | def iter_items(self) -> Iterator[tuple[str, str]]:
class _TextResponse (line 485) | class _TextResponse(Protocol):
function _safe_get_nested (line 491) | def _safe_get_nested(data: dict, *keys) -> Any:
function _extract_text (line 516) | def _extract_text(resp: _TextResponse | dict[str, Any] | None) -> str | ...
function _poll_completion (line 540) | def _poll_completion(
function _parse_batch_line (line 587) | def _parse_batch_line(
function _extract_from_file (line 614) | def _extract_from_file(
function infer_batch (line 688) | def infer_batch(
FILE: langextract/providers/ollama.py
class OllamaLanguageModel (line 128) | class OllamaLanguageModel(base_model.BaseLanguageModel):
method get_schema_class (line 153) | def get_schema_class(cls) -> type[schema.BaseSchema] | None:
method __repr__ (line 161) | def __repr__(self) -> str:
method __init__ (line 172) | def __init__(
method infer (line 247) | def infer(
method _ollama_query (line 278) | def _ollama_query(
FILE: langextract/providers/openai.py
class OpenAILanguageModel (line 38) | class OpenAILanguageModel(base_model.BaseLanguageModel):
method requires_fence_output (line 54) | def requires_fence_output(self) -> bool:
method __init__ (line 60) | def __init__(
method _normalize_reasoning_params (line 117) | def _normalize_reasoning_params(self, config: dict) -> dict:
method _process_single_prompt (line 133) | def _process_single_prompt(
method infer (line 196) | def infer(
FILE: langextract/providers/router.py
class _Entry (line 41) | class _Entry:
function _add_entry (line 55) | def _add_entry(
function register_lazy (line 83) | def register_lazy(
function register (line 108) | def register(
function resolve (line 139) | def resolve(model_id: str) -> type[base_model.BaseLanguageModel]:
function resolve_provider (line 170) | def resolve_provider(provider_name: str) -> type[base_model.BaseLanguage...
function clear (line 217) | def clear() -> None:
function list_providers (line 226) | def list_providers() -> list[tuple[tuple[str, ...], int]]:
function list_entries (line 238) | def list_entries() -> list[tuple[list[str], int]]:
FILE: langextract/providers/schemas/gemini.py
class GeminiSchema (line 31) | class GeminiSchema(schema.BaseSchema):
method schema_dict (line 41) | def schema_dict(self) -> dict[str, Any]:
method schema_dict (line 46) | def schema_dict(self, schema_dict: dict[str, Any]) -> None:
method to_provider_config (line 50) | def to_provider_config(self) -> dict[str, Any]:
method requires_raw_output (line 62) | def requires_raw_output(self) -> bool:
method validate_format (line 66) | def validate_format(self, format_handler: fh.FormatHandler) -> None:
method from_examples (line 98) | def from_examples(
FILE: langextract/registry.py
function __getattr__ (line 28) | def __getattr__(name: str):
FILE: langextract/resolver.py
class AbstractResolver (line 53) | class AbstractResolver(abc.ABC):
method __init__ (line 57) | def __init__(
method fence_output (line 83) | def fence_output(self) -> bool:
method fence_output (line 88) | def fence_output(self, fence_output: bool) -> None:
method format_type (line 97) | def format_type(self) -> data.FormatType:
method format_type (line 102) | def format_type(self, new_format_type: data.FormatType) -> None:
method resolve (line 107) | def resolve(
method align (line 123) | def align(
class ResolverParsingError (line 166) | class ResolverParsingError(exceptions.LangExtractError):
class Resolver (line 170) | class Resolver(AbstractResolver):
method __init__ (line 181) | def __init__(
method resolve (line 234) | def resolve(
method align (line 279) | def align(
method string_to_extraction_data (line 348) | def string_to_extraction_data(
method extract_ordered_extractions (line 383) | def extract_ordered_extractions(
class WordAligner (line 485) | class WordAligner:
method __init__ (line 488) | def __init__(self):
method _set_seqs (line 494) | def _set_seqs(
method _get_matching_blocks (line 520) | def _get_matching_blocks(self) -> Sequence[tuple[int, int, int]]:
method _fuzzy_align_extraction (line 537) | def _fuzzy_align_extraction(
method align_extractions (line 663) | def align_extractions(
function _tokenize_with_lowercase (line 874) | def _tokenize_with_lowercase(
function _normalize_token (line 904) | def _normalize_token(token: str) -> str:
FILE: langextract/schema.py
function __getattr__ (line 29) | def __getattr__(name: str):
FILE: langextract/visualization.py
function get_ipython (line 43) | def get_ipython(): # type: ignore[no-redef]
function _is_jupyter (line 49) | def _is_jupyter() -> bool:
function _assign_colors (line 179) | def _assign_colors(extractions: list[data.Extraction]) -> dict[str, str]:
function _filter_valid_extractions (line 196) | def _filter_valid_extractions(
class TagType (line 211) | class TagType(enum.Enum):
class SpanPoint (line 219) | class SpanPoint:
function _build_highlighted_text (line 235) | def _build_highlighted_text(
function _build_legend_html (line 314) | def _build_legend_html(color_map: dict[str, str]) -> str:
function _format_attributes (line 331) | def _format_attributes(attributes: dict | None) -> str:
function _prepare_extraction_data (line 359) | def _prepare_extraction_data(
function _build_visualization_html (line 417) | def _build_visualization_html(
function visualize (line 554) | def visualize(
FILE: scripts/create_provider_plugin.py
function create_directory_structure (line 44) | def create_directory_structure(package_name: str, force: bool = False) -...
function create_pyproject_toml (line 68) | def create_pyproject_toml(
function create_provider (line 106) | def create_provider(
function create_schema (line 230) | def create_schema(
function create_test_script (line 318) | def create_test_script(
function create_readme (line 456) | def create_readme(
function create_gitignore (line 522) | def create_gitignore(base_dir: Path) -> None:
function create_license (line 581) | def create_license(base_dir: Path) -> None:
function install_and_test (line 604) | def install_and_test(base_dir: Path) -> bool:
function parse_arguments (line 638) | def parse_arguments():
function validate_patterns (line 693) | def validate_patterns(patterns: list[str]) -> None:
function print_summary (line 710) | def print_summary(
function create_plugin (line 737) | def create_plugin(
function print_completion_summary (line 769) | def print_completion_summary(with_schema: bool) -> None:
function main (line 787) | def main():
FILE: scripts/validate_community_providers.py
function normalize_pypi (line 48) | def normalize_pypi(name: str) -> str:
function find_table_bounds (line 53) | def find_table_bounds(lines: List[str]) -> Tuple[int, int]:
function parse_row (line 64) | def parse_row(line: str) -> List[str]:
function validate (line 70) | def validate(filepath: Path) -> bool:
function print_report (line 188) | def print_report(errors: List[str], warnings: List[str]) -> None:
FILE: tests/annotation_test.py
class AnnotatorTest (line 35) | class AnnotatorTest(absltest.TestCase):
method setUp (line 37) | def setUp(self):
method assert_char_interval_match_source (line 47) | def assert_char_interval_match_source(
method test_annotate_text_single_chunk (line 80) | def test_annotate_text_single_chunk(self):
method test_annotate_text_without_index_suffix (line 206) | def test_annotate_text_without_index_suffix(self):
method test_annotate_text_with_attributes_suffix (line 325) | def test_annotate_text_with_attributes_suffix(self):
method test_annotate_text_multiple_chunks (line 469) | def test_annotate_text_multiple_chunks(self):
method test_annotate_text_no_extractions (line 569) | def test_annotate_text_no_extractions(self):
class AnnotatorMultipleDocumentTest (line 595) | class AnnotatorMultipleDocumentTest(parameterized.TestCase):
method test_annotate_documents (line 691) | def test_annotate_documents(
method test_annotate_documents_exceptions (line 766) | def test_annotate_documents_exceptions(
class AnnotatorMultiPassTest (line 804) | class AnnotatorMultiPassTest(absltest.TestCase):
method setUp (line 807) | def setUp(self):
method test_multipass_extraction_non_overlapping (line 817) | def test_multipass_extraction_non_overlapping(self):
method test_multipass_extraction_overlapping (line 867) | def test_multipass_extraction_overlapping(self):
method test_multipass_extraction_single_pass (line 918) | def test_multipass_extraction_single_pass(self):
method test_multipass_extraction_empty_passes (line 948) | def test_multipass_extraction_empty_passes(self):
class MultiPassHelperFunctionsTest (line 988) | class MultiPassHelperFunctionsTest(parameterized.TestCase):
method test_merge_non_overlapping_extractions (line 1052) | def test_merge_non_overlapping_extractions(
method test_extractions_overlap (line 1117) | def test_extractions_overlap(self, ext1, ext2, expected):
class AnnotateDocumentsGeneratorTest (line 1123) | class AnnotateDocumentsGeneratorTest(absltest.TestCase):
method setUp (line 1126) | def setUp(self):
method test_yields_documents_not_generators (line 1160) | def test_yields_documents_not_generators(self):
class CrossChunkContextTest (line 1207) | class CrossChunkContextTest(absltest.TestCase):
method setUp (line 1210) | def setUp(self):
method test_context_window_includes_previous_chunk_text (line 1220) | def test_context_window_includes_previous_chunk_text(self):
method test_no_context_included_when_disabled (line 1271) | def test_no_context_included_when_disabled(self):
method test_context_window_per_document_isolation (line 1309) | def test_context_window_per_document_isolation(self):
FILE: tests/chunking_test.py
class SentenceIterTest (line 26) | class SentenceIterTest(absltest.TestCase):
method test_basic (line 28) | def test_basic(self):
method test_empty (line 59) | def test_empty(self):
class ChunkIteratorTest (line 67) | class ChunkIteratorTest(absltest.TestCase):
method test_multi_sentence_chunk (line 69) | def test_multi_sentence_chunk(self):
method test_sentence_with_multiple_newlines_and_right_interval (line 96) | def test_sentence_with_multiple_newlines_and_right_interval(self):
method test_break_sentence (line 111) | def test_break_sentence(self):
method test_long_token_gets_own_chunk (line 164) | def test_long_token_gets_own_chunk(self):
method test_newline_at_chunk_boundary_does_not_create_empty_interval (line 207) | def test_newline_at_chunk_boundary_does_not_create_empty_interval(self):
method test_chunk_unicode_text (line 238) | def test_chunk_unicode_text(self):
method test_newlines_is_secondary_sentence_break (line 261) | def test_newlines_is_secondary_sentence_break(self):
method test_tokenizer_propagation (line 312) | def test_tokenizer_propagation(self):
class BatchingTest (line 345) | class BatchingTest(parameterized.TestCase):
method test_make_batches_of_textchunk (line 425) | def test_make_batches_of_textchunk(
class TextChunkTest (line 447) | class TextChunkTest(absltest.TestCase):
method test_string_output (line 449) | def test_string_output(self):
class TextAdditionalContextTest (line 469) | class TextAdditionalContextTest(absltest.TestCase):
method test_text_chunk_additional_context (line 473) | def test_text_chunk_additional_context(self):
method test_chunk_iterator_without_additional_context (line 486) | def test_chunk_iterator_without_additional_context(self):
method test_multiple_chunks_with_additional_context (line 497) | def test_multiple_chunks_with_additional_context(self):
class TextChunkPropertyTest (line 517) | class TextChunkPropertyTest(parameterized.TestCase):
method test_text_chunk_properties (line 549) | def test_text_chunk_properties(
FILE: tests/data_lib_test.py
class DataLibToDictParameterizedTest (line 27) | class DataLibToDictParameterizedTest(parameterized.TestCase):
method test_annotated_document_to_dict (line 180) | def test_annotated_document_to_dict(self, annotated_doc, expected_dict):
method test_annotated_document_to_dict_with_int64 (line 188) | def test_annotated_document_to_dict_with_int64(self):
class IsUrlTest (line 207) | class IsUrlTest(absltest.TestCase):
method test_valid_urls (line 210) | def test_valid_urls(self):
method test_invalid_urls_with_text (line 219) | def test_invalid_urls_with_text(self):
method test_invalid_urls_no_scheme (line 225) | def test_invalid_urls_no_scheme(self):
FILE: tests/extract_precedence_test.py
class ExtractParameterPrecedenceTest (line 27) | class ExtractParameterPrecedenceTest(absltest.TestCase):
method setUp (line 30) | def setUp(self):
method test_model_overrides_all_other_parameters (line 47) | def test_model_overrides_all_other_parameters(
method test_config_overrides_model_id_and_language_model_type (line 76) | def test_config_overrides_model_id_and_language_model_type(
method test_model_id_and_base_kwargs_override_language_model_type (line 115) | def test_model_id_and_base_kwargs_override_language_model_type(
method test_language_model_type_only_emits_warning_and_works (line 154) | def test_language_model_type_only_emits_warning_and_works(
method test_use_schema_constraints_warns_with_config (line 184) | def test_use_schema_constraints_warns_with_config(
method test_use_schema_constraints_warns_with_model (line 216) | def test_use_schema_constraints_warns_with_model(
FILE: tests/extract_schema_integration_test.py
class ExtractSchemaIntegrationTest (line 26) | class ExtractSchemaIntegrationTest(absltest.TestCase):
method setUp (line 29) | def setUp(self):
method test_extract_with_gemini_uses_schema (line 47) | def test_extract_with_gemini_uses_schema(self):
method test_extract_with_ollama_uses_json_mode (line 80) | def test_extract_with_ollama_uses_json_mode(self):
method test_extract_explicit_fence_respected (line 113) | def test_extract_explicit_fence_respected(self):
method test_extract_gemini_schema_deprecation_warning (line 147) | def test_extract_gemini_schema_deprecation_warning(self):
method test_extract_no_schema_when_disabled (line 186) | def test_extract_no_schema_when_disabled(self):
method test_validation_triggers_warning_for_gemini (line 229) | def test_validation_triggers_warning_for_gemini(self, mock_create_model):
method test_no_validation_without_schema (line 280) | def test_no_validation_without_schema(self, mock_create_model):
FILE: tests/factory_schema_test.py
class FactorySchemaIntegrationTest (line 27) | class FactorySchemaIntegrationTest(absltest.TestCase):
method setUp (line 30) | def setUp(self):
method test_gemini_with_schema_returns_false_fence (line 46) | def test_gemini_with_schema_returns_false_fence(self):
method test_ollama_with_schema_returns_false_fence (line 70) | def test_ollama_with_schema_returns_false_fence(self):
method test_explicit_fence_output_respected (line 92) | def test_explicit_fence_output_respected(self):
method test_no_schema_defaults_to_true_fence (line 111) | def test_no_schema_defaults_to_true_fence(self):
method test_schema_disabled_returns_true_fence (line 134) | def test_schema_disabled_returns_true_fence(self):
method test_caller_overrides_schema_config (line 156) | def test_caller_overrides_schema_config(self):
method test_no_examples_no_schema (line 179) | def test_no_examples_no_schema(self):
class SchemaApplicationTest (line 202) | class SchemaApplicationTest(absltest.TestCase):
method test_apply_schema_called_when_supported (line 205) | def test_apply_schema_called_when_supported(self):
FILE: tests/factory_test.py
class FakeGeminiProvider (line 34) | class FakeGeminiProvider(base_model.BaseLanguageModel):
method __init__ (line 37) | def __init__(self, model_id, api_key=None, **kwargs):
method infer (line 43) | def infer(self, batch_prompts, **kwargs):
method infer_batch (line 46) | def infer_batch(self, prompts, batch_size=32):
class FakeOpenAIProvider (line 50) | class FakeOpenAIProvider(base_model.BaseLanguageModel):
method __init__ (line 53) | def __init__(self, model_id, api_key=None, **kwargs):
method infer (line 61) | def infer(self, batch_prompts, **kwargs):
method infer_batch (line 64) | def infer_batch(self, prompts, batch_size=32):
class FactoryTest (line 68) | class FactoryTest(absltest.TestCase): # pylint: disable=too-many-public...
method setUp (line 70) | def setUp(self):
method tearDown (line 80) | def tearDown(self):
method test_create_model_basic (line 87) | def test_create_model_basic(self):
method test_create_model_from_id (line 98) | def test_create_model_from_id(self):
method test_uses_gemini_api_key_from_environment (line 107) | def test_uses_gemini_api_key_from_environment(self):
method test_uses_openai_api_key_from_environment (line 115) | def test_uses_openai_api_key_from_environment(self):
method test_falls_back_to_langextract_api_key_when_provider_key_missing (line 125) | def test_falls_back_to_langextract_api_key_when_provider_key_missing(s...
method test_provider_specific_key_takes_priority_over_langextract_key (line 139) | def test_provider_specific_key_takes_priority_over_langextract_key(self):
method test_explicit_kwargs_override_env (line 146) | def test_explicit_kwargs_override_env(self):
method test_wraps_provider_initialization_error_in_inference_config_error (line 157) | def test_wraps_provider_initialization_error_in_inference_config_error...
method test_raises_error_when_no_provider_matches_model_id (line 167) | def test_raises_error_when_no_provider_matches_model_id(self):
method test_additional_kwargs_passed_through (line 176) | def test_additional_kwargs_passed_through(self):
method test_ollama_uses_base_url_from_environment (line 194) | def test_ollama_uses_base_url_from_environment(self):
method test_ollama_models_select_without_api_keys (line 216) | def test_ollama_models_select_without_api_keys(self):
method test_model_config_fields_are_immutable (line 242) | def test_model_config_fields_are_immutable(self):
method test_model_config_allows_dict_contents_modification (line 251) | def test_model_config_allows_dict_contents_modification(self):
method test_uses_highest_priority_provider_when_multiple_match (line 261) | def test_uses_highest_priority_provider_when_multiple_match(self):
method test_explicit_provider_overrides_pattern_matching (line 283) | def test_explicit_provider_overrides_pattern_matching(self):
method test_provider_without_model_id_uses_provider_default (line 308) | def test_provider_without_model_id_uses_provider_default(self):
method test_raises_error_when_neither_model_id_nor_provider_specified (line 331) | def test_raises_error_when_neither_model_id_nor_provider_specified(self):
method test_gemini_vertexai_parameters_accepted (line 342) | def test_gemini_vertexai_parameters_accepted(self):
method test_gemini_vertexai_with_credentials (line 391) | def test_gemini_vertexai_with_credentials(self):
FILE: tests/format_handler_test.py
class FormatHandlerTest (line 28) | class FormatHandlerTest(parameterized.TestCase):
method test_format_and_parse (line 96) | def test_format_and_parse( # pylint: disable=too-many-arguments
method test_end_to_end_integration_with_prompt_and_resolver (line 147) | def test_end_to_end_integration_with_prompt_and_resolver(self):
method test_format_parse_roundtrip (line 232) | def test_format_parse_roundtrip(
class NonGeminiModelParsingTest (line 257) | class NonGeminiModelParsingTest(parameterized.TestCase):
method test_think_tags_stripped_before_parsing (line 260) | def test_think_tags_stripped_before_parsing(self):
method test_top_level_list_accepted_as_fallback (line 276) | def test_top_level_list_accepted_as_fallback(self):
method test_deepseek_r1_real_output (line 290) | def test_deepseek_r1_real_output(self):
FILE: tests/inference_test.py
class TestBaseLanguageModel (line 37) | class TestBaseLanguageModel(absltest.TestCase):
method test_merge_kwargs_with_none (line 39) | def test_merge_kwargs_with_none(self):
method test_merge_kwargs_without_extra_kwargs (line 71) | def test_merge_kwargs_without_extra_kwargs(self):
class TestOllamaLanguageModel (line 90) | class TestOllamaLanguageModel(absltest.TestCase):
method test_ollama_infer (line 93) | def test_ollama_infer(self, mock_ollama_query):
method test_ollama_extra_kwargs_passed_to_api (line 164) | def test_ollama_extra_kwargs_passed_to_api(self, mock_post):
method test_ollama_stop_and_top_p_passthrough (line 194) | def test_ollama_stop_and_top_p_passthrough(self, mock_post):
method test_ollama_defaults_when_unspecified (line 222) | def test_ollama_defaults_when_unspecified(self, mock_post):
method test_ollama_runtime_kwargs_override_stored (line 247) | def test_ollama_runtime_kwargs_override_stored(self, mock_post):
method test_ollama_temperature_zero (line 274) | def test_ollama_temperature_zero(self, mock_post):
method test_ollama_default_timeout (line 297) | def test_ollama_default_timeout(self):
method test_ollama_timeout_through_infer (line 321) | def test_ollama_timeout_through_infer(self):
class TestGeminiLanguageModel (line 347) | class TestGeminiLanguageModel(absltest.TestCase):
method test_gemini_allowlist_filtering (line 350) | def test_gemini_allowlist_filtering(self, mock_client_class):
method test_gemini_runtime_kwargs_filtered (line 398) | def test_gemini_runtime_kwargs_filtered(self, mock_client_class):
method test_gemini_requires_auth_config (line 439) | def test_gemini_requires_auth_config(self):
method test_gemini_vertexai_requires_project_and_location (line 448) | def test_gemini_vertexai_requires_project_and_location(self):
method test_gemini_vertexai_initialization (line 456) | def test_gemini_vertexai_initialization(self, mock_client_class):
method test_gemini_warns_when_both_auth_provided (line 480) | def test_gemini_warns_when_both_auth_provided(
method test_gemini_vertexai_with_http_options (line 500) | def test_gemini_vertexai_with_http_options(self, mock_client_class):
class TestOpenAILanguageModelInference (line 524) | class TestOpenAILanguageModelInference(parameterized.TestCase):
method test_openai_infer_with_parameters (line 531) | def test_openai_infer_with_parameters(
class TestOpenAILanguageModel (line 569) | class TestOpenAILanguageModel(absltest.TestCase):
method test_openai_parse_output_json (line 571) | def test_openai_parse_output_json(self):
method test_openai_parse_output_yaml (line 584) | def test_openai_parse_output_yaml(self):
method test_openai_no_api_key_raises_error (line 597) | def test_openai_no_api_key_raises_error(self):
method test_openai_extra_kwargs_passed (line 603) | def test_openai_extra_kwargs_passed(self, mock_openai_class):
method test_openai_runtime_kwargs_override (line 629) | def test_openai_runtime_kwargs_override(self, mock_openai_class):
method test_openai_json_response_format (line 652) | def test_openai_json_response_format(self, mock_openai_class):
method test_openai_temperature_zero (line 676) | def test_openai_temperature_zero(self, mock_openai_class):
method test_openai_temperature_none_not_sent (line 698) | def test_openai_temperature_none_not_sent(self, mock_openai_class):
method test_openai_none_values_filtered (line 721) | def test_openai_none_values_filtered(self, mock_openai_class):
method test_openai_no_system_message_when_not_json_yaml (line 744) | def test_openai_no_system_message_when_not_json_yaml(self, mock_openai...
method test_gemini_none_values_filtered (line 770) | def test_gemini_none_values_filtered(self, mock_client_class):
FILE: tests/init_test.py
class InitTest (line 34) | class InitTest(parameterized.TestCase):
method test_lang_extract_as_lx_extract (line 41) | def test_lang_extract_as_lx_extract(
method test_extract_resolver_params_alignment_passthrough (line 160) | def test_extract_resolver_params_alignment_passthrough(
method test_extract_resolver_params_suppress_parse_errors (line 207) | def test_extract_resolver_params_suppress_parse_errors(
method test_extract_resolver_params_none_handling (line 252) | def test_extract_resolver_params_none_handling(
method test_extract_resolver_params_typo_error (line 305) | def test_extract_resolver_params_typo_error(self, mock_create_model):
method test_extract_resolver_params_docs_path_passthrough (line 337) | def test_extract_resolver_params_docs_path_passthrough(
method test_extract_resolver_params_none_threshold (line 381) | def test_extract_resolver_params_none_threshold(
method test_extract_custom_params_reach_inference (line 423) | def test_extract_custom_params_reach_inference(
method test_extract_with_custom_tokenizer (line 468) | def test_extract_with_custom_tokenizer(self, mock_create_model):
method test_data_module_exports_via_compatibility_shim (line 530) | def test_data_module_exports_via_compatibility_shim(self):
method test_tokenizer_module_exports_via_compatibility_shim (line 549) | def test_tokenizer_module_exports_via_compatibility_shim(self):
method test_show_progress_controls_progress_bar (line 600) | def test_show_progress_controls_progress_bar(
method test_schema_validation_warning_issued (line 651) | def test_schema_validation_warning_issued(self, mock_create_model):
method test_gemini_schema_deprecation_warning (line 702) | def test_gemini_schema_deprecation_warning(self):
FILE: tests/progress_test.py
class ProgressTest (line 25) | class ProgressTest(unittest.TestCase):
method test_download_progress_bar (line 27) | def test_download_progress_bar(self):
method test_extraction_progress_bar (line 37) | def test_extraction_progress_bar(self):
method test_save_load_progress_bars (line 47) | def test_save_load_progress_bars(self):
method test_model_info_extraction (line 57) | def test_model_info_extraction(self):
method test_formatting_functions (line 68) | def test_formatting_functions(self):
FILE: tests/prompt_validation_test.py
class PromptAlignmentValidationTest (line 25) | class PromptAlignmentValidationTest(parameterized.TestCase):
method test_alignment_detection (line 59) | def test_alignment_detection(
method test_multiple_extractions_per_example (line 124) | def test_multiple_extractions_per_example(
method test_validation_levels_that_dont_raise (line 173) | def test_validation_levels_that_dont_raise(
method test_error_mode_raises_appropriately (line 213) | def test_error_mode_raises_appropriately(
method test_empty_examples_produces_empty_report (line 244) | def test_empty_examples_produces_empty_report(self):
method test_multiple_examples_preserve_indices (line 251) | def test_multiple_examples_preserve_indices(self):
method test_validation_does_not_mutate_input (line 305) | def test_validation_does_not_mutate_input(self):
method test_alignment_policies (line 353) | def test_alignment_policies(
class ExtractIntegrationTest (line 394) | class ExtractIntegrationTest(absltest.TestCase):
method test_extract_validates_in_error_mode (line 397) | def test_extract_validates_in_error_mode(self):
FILE: tests/prompting_test.py
class QAPromptGeneratorTest (line 25) | class QAPromptGeneratorTest(parameterized.TestCase):
method test_generate_prompt (line 27) | def test_generate_prompt(self):
method test_format_example (line 361) | def test_format_example(
class PromptBuilderTest (line 402) | class PromptBuilderTest(absltest.TestCase):
method _create_generator (line 405) | def _create_generator(self):
method test_build_prompt_renders_chunk_text (line 432) | def test_build_prompt_renders_chunk_text(self):
method test_build_prompt_includes_additional_context (line 445) | def test_build_prompt_includes_additional_context(self):
class ContextAwarePromptBuilderTest (line 459) | class ContextAwarePromptBuilderTest(absltest.TestCase):
method _create_generator (line 462) | def _create_generator(self):
method test_context_window_chars_property (line 489) | def test_context_window_chars_property(self):
method test_first_chunk_has_no_previous_context (line 501) | def test_first_chunk_has_no_previous_context(self):
method test_second_chunk_includes_previous_context (line 517) | def test_second_chunk_includes_previous_context(self):
method test_context_disabled_when_none (line 534) | def test_context_disabled_when_none(self):
method test_context_isolated_per_document (line 550) | def test_context_isolated_per_document(self):
method test_combines_previous_context_with_additional_context (line 574) | def test_combines_previous_context_with_additional_context(self):
FILE: tests/provider_plugin_test.py
function _create_mock_entry_points (line 40) | def _create_mock_entry_points(entry_points_list):
class PluginSmokeTest (line 61) | class PluginSmokeTest(absltest.TestCase):
method setUp (line 64) | def setUp(self):
method test_plugin_discovery_and_usage (line 73) | def test_plugin_discovery_and_usage(self):
method test_plugin_disabled_by_env_var (line 118) | def test_plugin_disabled_by_env_var(self):
method test_handles_import_errors_gracefully (line 126) | def test_handles_import_errors_gracefully(self):
method test_load_plugins_once_is_idempotent (line 159) | def test_load_plugins_once_is_idempotent(self):
method test_non_subclass_entry_point_does_not_crash (line 185) | def test_non_subclass_entry_point_does_not_crash(self):
method test_plugin_priority_override_core_provider (line 217) | def test_plugin_priority_override_core_provider(self):
method test_resolve_provider_for_plugin (line 249) | def test_resolve_provider_for_plugin(self):
method test_plugin_with_custom_schema (line 282) | def test_plugin_with_custom_schema(self):
class PluginE2ETest (line 378) | class PluginE2ETest(absltest.TestCase):
method test_plugin_with_schema_e2e (line 385) | def test_plugin_with_schema_e2e(self):
method test_pip_install_discovery_and_cleanup (line 485) | def test_pip_install_discovery_and_cleanup(self):
FILE: tests/provider_schema_test.py
class ProviderSchemaDiscoveryTest (line 32) | class ProviderSchemaDiscoveryTest(absltest.TestCase):
method test_gemini_returns_gemini_schema (line 35) | def test_gemini_returns_gemini_schema(self):
method test_ollama_returns_format_mode_schema (line 44) | def test_ollama_returns_format_mode_schema(self):
method test_openai_returns_none (line 53) | def test_openai_returns_none(self):
class FormatModeSchemaTest (line 63) | class FormatModeSchemaTest(absltest.TestCase):
method test_from_examples_ignores_examples (line 66) | def test_from_examples_ignores_examples(self):
method test_to_provider_config_returns_format (line 88) | def test_to_provider_config_returns_format(self):
method test_requires_raw_output_returns_true (line 101) | def test_requires_raw_output_returns_true(self):
method test_different_examples_same_output (line 111) | def test_different_examples_same_output(self):
class OllamaFormatParameterTest (line 148) | class OllamaFormatParameterTest(absltest.TestCase):
method test_ollama_json_format_in_request_payload (line 151) | def test_ollama_json_format_in_request_payload(self):
method test_ollama_default_format_is_json (line 179) | def test_ollama_default_format_is_json(self):
method test_extract_with_ollama_passes_json_format (line 199) | def test_extract_with_ollama_passes_json_format(self):
class OllamaYAMLOverrideTest (line 256) | class OllamaYAMLOverrideTest(absltest.TestCase):
method test_ollama_yaml_format_in_request_payload (line 259) | def test_ollama_yaml_format_in_request_payload(self):
method test_yaml_override_sets_fence_output_true (line 280) | def test_yaml_override_sets_fence_output_true(self):
method test_json_format_keeps_fence_output_false (line 320) | def test_json_format_keeps_fence_output_false(self):
class GeminiSchemaProviderIntegrationTest (line 362) | class GeminiSchemaProviderIntegrationTest(absltest.TestCase):
method test_gemini_schema_to_provider_config (line 365) | def test_gemini_schema_to_provider_config(self):
method test_gemini_requires_raw_output (line 410) | def test_gemini_requires_raw_output(self):
method test_gemini_rejects_yaml_with_schema (line 419) | def test_gemini_rejects_yaml_with_schema(self):
method test_gemini_forwards_schema_to_genai_client (line 454) | def test_gemini_forwards_schema_to_genai_client(self):
method test_gemini_doesnt_forward_non_api_kwargs (line 509) | def test_gemini_doesnt_forward_non_api_kwargs(self):
class SchemaShimTest (line 544) | class SchemaShimTest(absltest.TestCase):
method test_constraint_types_import (line 547) | def test_constraint_types_import(self):
method test_provider_schema_imports (line 564) | def test_provider_schema_imports(self):
FILE: tests/registry_test.py
class FakeProvider (line 33) | class FakeProvider(base_model.BaseLanguageModel):
method infer (line 36) | def infer(self, batch_prompts, **kwargs):
method infer_batch (line 39) | def infer_batch(self, prompts, batch_size=32):
class AnotherFakeProvider (line 43) | class AnotherFakeProvider(base_model.BaseLanguageModel):
method infer (line 46) | def infer(self, batch_prompts, **kwargs):
method infer_batch (line 49) | def infer_batch(self, prompts, batch_size=32):
class RegistryTest (line 53) | class RegistryTest(absltest.TestCase):
method setUp (line 55) | def setUp(self):
method tearDown (line 59) | def tearDown(self):
method test_register_decorator (line 63) | def test_register_decorator(self):
method test_register_lazy (line 73) | def test_register_lazy(self):
method test_multiple_patterns (line 81) | def test_multiple_patterns(self):
method test_priority_resolution (line 89) | def test_priority_resolution(self):
method test_no_provider_registered (line 98) | def test_no_provider_registered(self):
method test_caching (line 106) | def test_caching(self):
method test_clear_registry (line 118) | def test_clear_registry(self):
method test_list_entries (line 134) | def test_list_entries(self):
method test_lazy_loading_defers_import (line 152) | def test_lazy_loading_defers_import(self):
method test_regex_pattern_objects (line 165) | def test_regex_pattern_objects(self):
method test_resolve_provider_by_name (line 179) | def test_resolve_provider_by_name(self):
method test_resolve_provider_not_found (line 194) | def test_resolve_provider_not_found(self):
method test_hf_style_model_id_patterns (line 200) | def test_hf_style_model_id_patterns(self):
FILE: tests/resolver_test.py
function assert_char_interval_match_source (line 27) | def assert_char_interval_match_source(
class ParserTest (line 59) | class ParserTest(parameterized.TestCase):
method test_parser_error_cases (line 141) | def test_parser_error_cases(
class ExtractOrderedEntitiesTest (line 148) | class ExtractOrderedEntitiesTest(parameterized.TestCase):
method test_extract_ordered_extractions_success (line 521) | def test_extract_ordered_extractions_success(
method test_extract_ordered_extractions_exceptions (line 561) | def test_extract_ordered_extractions_exceptions(
class AlignEntitiesTest (line 568) | class AlignEntitiesTest(parameterized.TestCase):
method setUp (line 581) | def setUp(self):
method test_extraction_alignment (line 1648) | def test_extraction_alignment(
class ResolverTest (line 1677) | class ResolverTest(parameterized.TestCase):
method setUp (line 1746) | def setUp(self):
method test_resolve_valid_inputs (line 1829) | def test_resolve_valid_inputs(self, resolver, input_text, expected_out...
method test_handle_integer_extraction (line 1834) | def test_handle_integer_extraction(self):
method test_resolve_empty_yaml (line 1858) | def test_resolve_empty_yaml(self):
method test_resolve_empty_yaml_without_suppress_parse_errors (line 1865) | def test_resolve_empty_yaml_without_suppress_parse_errors(self):
method test_align_with_valid_chunk (line 1870) | def test_align_with_valid_chunk(self):
method test_align_with_chunk_starting_in_middle (line 1917) | def test_align_with_chunk_starting_in_middle(self):
method test_align_with_no_extractions_in_chunk (line 1969) | def test_align_with_no_extractions_in_chunk(self):
method test_align_successful (line 1992) | def test_align_successful(self):
method test_align_with_discontinuous_tokenized_text (line 2038) | def test_align_with_discontinuous_tokenized_text(self):
method test_align_with_discontinuous_tokenized_text_but_right_chunk (line 2079) | def test_align_with_discontinuous_tokenized_text_but_right_chunk(self):
method test_align_with_empty_annotated_extractions (line 2124) | def test_align_with_empty_annotated_extractions(self):
class FenceFallbackTest (line 2149) | class FenceFallbackTest(parameterized.TestCase):
method test_parsing_scenarios (line 2195) | def test_parsing_scenarios(
method test_fallback_preserves_content_integrity (line 2213) | def test_fallback_preserves_content_integrity(self):
method test_malformed_json_still_raises_error (line 2262) | def test_malformed_json_still_raises_error(self):
method test_strict_fences_raises_on_missing_markers (line 2276) | def test_strict_fences_raises_on_missing_markers(self):
method test_default_allows_fallback (line 2290) | def test_default_allows_fallback(self):
method test_rejects_multiple_fenced_blocks (line 2302) | def test_rejects_multiple_fenced_blocks(self):
class FlexibleSchemaTest (line 2323) | class FlexibleSchemaTest(parameterized.TestCase):
method test_direct_list_format (line 2326) | def test_direct_list_format(self):
method test_single_dict_as_extraction (line 2342) | def test_single_dict_as_extraction(self):
method test_traditional_format_still_works (line 2354) | def test_traditional_format_still_works(self):
method test_lenient_mode_accepts_list (line 2370) | def test_lenient_mode_accepts_list(self):
method test_flexible_with_attributes (line 2382) | def test_flexible_with_attributes(self):
FILE: tests/schema_test.py
class BaseSchemaTest (line 34) | class BaseSchemaTest(absltest.TestCase):
method test_abstract_methods_required (line 37) | def test_abstract_methods_required(self):
method test_subclass_must_implement_all_methods (line 42) | def test_subclass_must_implement_all_methods(self):
class BaseLanguageModelSchemaTest (line 55) | class BaseLanguageModelSchemaTest(absltest.TestCase):
method test_get_schema_class_returns_none_by_default (line 58) | def test_get_schema_class_returns_none_by_default(self):
method test_apply_schema_stores_instance (line 68) | def test_apply_schema_stores_instance(self):
class GeminiSchemaTest (line 88) | class GeminiSchemaTest(parameterized.TestCase):
method test_from_examples_constructs_expected_schema (line 237) | def test_from_examples_constructs_expected_schema(
method test_to_provider_config_returns_response_schema (line 244) | def test_to_provider_config_returns_response_schema(self):
method test_requires_raw_output_returns_true (line 266) | def test_requires_raw_output_returns_true(self):
class SchemaValidationTest (line 284) | class SchemaValidationTest(parameterized.TestCase):
method _create_test_schema (line 287) | def _create_test_schema(self):
method test_gemini_validation (line 325) | def test_gemini_validation(
method test_base_schema_no_validation (line 355) | def test_base_schema_no_validation(self):
FILE: tests/test_gemini_batch_api.py
function create_mock_batch_job (line 31) | def create_mock_batch_job(
function _create_batch_response (line 46) | def _create_batch_response(idx, text_content):
function _create_batch_error (line 58) | def _create_batch_error(idx, code, message):
class TestGeminiBatchAPI (line 66) | class TestGeminiBatchAPI(absltest.TestCase):
method setUp (line 69) | def setUp(self):
method test_batch_routing_vertex (line 79) | def test_batch_routing_vertex(self, mock_client_cls):
method test_realtime_when_disabled (line 125) | def test_realtime_when_disabled(self, mock_client_cls):
method test_realtime_when_below_threshold (line 150) | def test_realtime_when_below_threshold(self, mock_client_cls):
method test_batch_with_schema (line 180) | def test_batch_with_schema(self, mock_client_cls):
method test_batch_error_handling (line 249) | def test_batch_error_handling(self, mock_client_cls):
method test_file_based_ordering (line 272) | def test_file_based_ordering(self, mock_client_cls):
method test_max_prompts_per_job (line 317) | def test_max_prompts_per_job(self, mock_client_cls):
method test_batch_item_error (line 399) | def test_batch_item_error(self, mock_client_cls):
class BatchConfigValidationTest (line 432) | class BatchConfigValidationTest(parameterized.TestCase):
method test_validation_errors (line 441) | def test_validation_errors(self, **overrides):
class EmptyAndPaddingTest (line 447) | class EmptyAndPaddingTest(absltest.TestCase):
method test_empty_prompts_fast_path (line 451) | def test_empty_prompts_fast_path(self, mock_client_cls):
method test_file_pad_to_expected_count (line 469) | def test_file_pad_to_expected_count(self, mock_client_cls):
class GCSBatchCachingTest (line 505) | class GCSBatchCachingTest(absltest.TestCase):
method setUp (line 508) | def setUp(self):
method test_cache_hit_skips_inference (line 518) | def test_cache_hit_skips_inference(self, mock_client_cls):
method test_partial_cache_hit (line 550) | def test_partial_cache_hit(self, mock_client_cls):
method test_project_passed_to_storage_client (line 620) | def test_project_passed_to_storage_client(self, mock_client_cls):
method test_cache_hashing_stability (line 675) | def test_cache_hashing_stability(self):
FILE: tests/test_kwargs_passthrough.py
class TestOpenAIKwargsPassthrough (line 27) | class TestOpenAIKwargsPassthrough(unittest.TestCase):
method test_reasoning_effort_alias_normalization (line 31) | def test_reasoning_effort_alias_normalization(self, mock_openai_class):
method test_reasoning_parameter_normalized (line 54) | def test_reasoning_parameter_normalized(self, mock_openai_class):
method test_runtime_kwargs_override_stored (line 76) | def test_runtime_kwargs_override_stored(self, mock_openai_class):
method test_falsy_values_preserved (line 102) | def test_falsy_values_preserved(self, mock_openai_class):
method test_both_reasoning_forms_merge (line 127) | def test_both_reasoning_forms_merge(self, mock_openai_class):
method test_custom_response_format (line 154) | def test_custom_response_format(self, mock_openai_class):
method test_direct_reasoning_parameter (line 185) | def test_direct_reasoning_parameter(self, mock_openai_class):
class TestOllamaAuthSupport (line 207) | class TestOllamaAuthSupport(parameterized.TestCase):
method test_api_key_in_authorization_header (line 211) | def test_api_key_in_authorization_header(self, mock_post):
method test_custom_auth_header_name (line 233) | def test_custom_auth_header_name(self, mock_post):
method test_pass_through_kwargs (line 255) | def test_pass_through_kwargs(self, mock_post):
method test_api_key_redacted_in_repr (line 281) | def test_api_key_redacted_in_repr(self):
method test_localhost_auth_warning_but_still_works (line 295) | def test_localhost_auth_warning_but_still_works(self, mock_post):
method test_runtime_kwargs_override (line 321) | def test_runtime_kwargs_override(self, mock_post):
method test_localhost_detection (line 350) | def test_localhost_detection(self, url, should_warn, mock_post):
method test_format_none_not_in_payload (line 377) | def test_format_none_not_in_payload(self, mock_post):
method test_reserved_kwargs_not_in_options (line 402) | def test_reserved_kwargs_not_in_options(self, mock_post):
method test_api_key_without_localhost_warning (line 430) | def test_api_key_without_localhost_warning(self, mock_post):
FILE: tests/test_live_api.py
function has_vertex_ai_credentials (line 59) | def has_vertex_ai_credentials():
function retry_on_transient_errors (line 113) | def retry_on_transient_errors(max_retries=3, backoff_factor=2.0):
function add_delay_between_tests (line 158) | def add_delay_between_tests():
function get_basic_medication_examples (line 164) | def get_basic_medication_examples():
function get_relationship_examples (line 193) | def get_relationship_examples():
function extract_by_class (line 244) | def extract_by_class(result, extraction_class):
function assert_extractions_contain (line 256) | def assert_extractions_contain(test_case, result, expected_classes):
function assert_valid_char_intervals (line 270) | def assert_valid_char_intervals(test_case, result):
class TestLiveAPIGemini (line 296) | class TestLiveAPIGemini(unittest.TestCase):
method _check_cached_result (line 299) | def _check_cached_result(self, result_json: dict[str, Any]) -> bool:
method _verify_gcs_cache_content (line 347) | def _verify_gcs_cache_content(self, bucket_name):
method test_medication_extraction (line 373) | def test_medication_extraction(self):
method test_multilingual_medication_extraction (line 436) | def test_multilingual_medication_extraction(self):
method test_explicit_provider_gemini (line 487) | def test_explicit_provider_gemini(self):
method test_medication_relationship_extraction (line 516) | def test_medication_relationship_extraction(self):
method test_batch_extraction_vertex_gcs (line 579) | def test_batch_extraction_vertex_gcs(self, mock_infer_batch):
method test_batch_caching_live (line 698) | def test_batch_caching_live(self):
class TestCrossChunkContext (line 773) | class TestCrossChunkContext(unittest.TestCase):
method test_context_window_extracts_from_both_chunks (line 779) | def test_context_window_extracts_from_both_chunks(self):
class TestLiveAPIOpenAI (line 848) | class TestLiveAPIOpenAI(unittest.TestCase):
method test_medication_extraction (line 854) | def test_medication_extraction(self):
method test_explicit_provider_selection (line 918) | def test_explicit_provider_selection(self):
method test_medication_relationship_extraction (line 951) | def test_medication_relationship_extraction(self):
FILE: tests/test_ollama_integration.py
function _ollama_available (line 24) | def _ollama_available():
function test_ollama_extraction (line 32) | def test_ollama_extraction():
function test_ollama_extraction_with_fence_fallback (line 76) | def test_ollama_extraction_with_fence_fallback():
function _model_available (line 115) | def _model_available(model_name):
function test_deepseek_r1_extraction (line 131) | def test_deepseek_r1_extraction():
FILE: tests/tokenizer_test.py
class TokenizerTest (line 23) | class TokenizerTest(parameterized.TestCase):
method assertTokenListEqual (line 26) | def assertTokenListEqual(self, actual_tokens, expected_tokens, msg=None):
method test_tokenize_various_inputs (line 150) | def test_tokenize_various_inputs(self, input_text, expected_tokens):
method test_first_token_after_newline_flag (line 158) | def test_first_token_after_newline_flag(self):
method test_performance_optimization_no_crash (line 197) | def test_performance_optimization_no_crash(self):
method test_underscore_handling (line 213) | def test_underscore_handling(self):
class UnicodeTokenizerTest (line 228) | class UnicodeTokenizerTest(parameterized.TestCase):
method assertTokenListEqual (line 231) | def assertTokenListEqual(self, actual_tokens, expected_tokens, msg=None):
method test_tokenize_various_inputs (line 295) | def test_tokenize_various_inputs(self, input_text, expected_tokens):
method test_special_unicode_and_punctuation_handling (line 338) | def test_special_unicode_and_punctuation_handling(
method test_first_token_after_newline_parity (line 377) | def test_first_token_after_newline_parity(self):
method test_expanded_cjk_detection (line 391) | def test_expanded_cjk_detection(self):
method test_mixed_script_and_emoji (line 401) | def test_mixed_script_and_emoji(self):
method test_script_boundary_grouping (line 427) | def test_script_boundary_grouping(self):
method test_non_spaced_scripts_no_grouping (line 451) | def test_non_spaced_scripts_no_grouping(self):
method test_cjk_detection_regex (line 462) | def test_cjk_detection_regex(self):
method test_newline_simplification (line 472) | def test_newline_simplification(self):
method test_newline_simplification_start (line 482) | def test_newline_simplification_start(self):
method test_mixed_line_endings (line 491) | def test_mixed_line_endings(self):
method test_mixed_uncommon_scripts_no_grouping (line 501) | def test_mixed_uncommon_scripts_no_grouping(self):
method test_unknown_script_merging_edge_case (line 518) | def test_unknown_script_merging_edge_case(self):
method test_find_sentence_range_empty_input (line 528) | def test_find_sentence_range_empty_input(self):
method test_normalization_indices_match_input (line 533) | def test_normalization_indices_match_input(self):
method test_acronym_inconsistency (line 546) | def test_acronym_inconsistency(self):
method test_consecutive_punctuation_grouping (line 559) | def test_consecutive_punctuation_grouping(self):
method test_punctuation_merging_identical_only (line 572) | def test_punctuation_merging_identical_only(self):
method test_distinct_unknown_scripts_do_not_merge (line 600) | def test_distinct_unknown_scripts_do_not_merge(self):
method test_identical_unknown_scripts_merge (line 614) | def test_identical_unknown_scripts_merge(self):
class ExceptionTest (line 629) | class ExceptionTest(absltest.TestCase):
method test_invalid_token_interval_errors (line 632) | def test_invalid_token_interval_errors(self):
method test_sentence_range_errors (line 662) | def test_sentence_range_errors(self):
class NegativeTestCases (line 684) | class NegativeTestCases(parameterized.TestCase):
method test_invalid_and_edge_case_unicode (line 745) | def test_invalid_and_edge_case_unicode(self, input_text, expected_toke...
method test_empty_string_edge_case (line 777) | def test_empty_string_edge_case(self):
method test_whitespace_only_string (line 785) | def test_whitespace_only_string(self):
class TokensTextTest (line 802) | class TokensTextTest(parameterized.TestCase):
method test_valid_intervals (line 829) | def test_valid_intervals(
method test_invalid_intervals (line 863) | def test_invalid_intervals(self, input_text, start_index, end_index):
class SentenceRangeTest (line 872) | class SentenceRangeTest(parameterized.TestCase):
method test_partial_sentence_range (line 898) | def test_partial_sentence_range(
method test_full_sentence_range (line 916) | def test_full_sentence_range(self, input_text, start_pos):
method test_invalid_start_pos (line 936) | def test_invalid_start_pos(self, input_text, start_pos):
method test_sentence_boundary_with_quote (line 942) | def test_sentence_boundary_with_quote(self):
method test_sentence_splitting_permissive (line 949) | def test_sentence_splitting_permissive(self):
method test_unicode_sentence_boundaries (line 969) | def test_unicode_sentence_boundaries(self):
method test_configurable_sentence_splitting (line 985) | def test_configurable_sentence_splitting(self):
FILE: tests/visualization_test.py
class VisualizationTest (line 28) | class VisualizationTest(absltest.TestCase):
method test_assign_colors_basic_assignment (line 30) | def test_assign_colors_basic_assignment(self):
method test_build_highlighted_text_single_span_correct_html (line 54) | def test_build_highlighted_text_single_span_correct_html(self):
method test_build_highlighted_text_escapes_html_in_text_and_tooltip (line 75) | def test_build_highlighted_text_escapes_html_in_text_and_tooltip(self):
method test_visualize_basic_document_renders_correctly (line 103) | def test_visualize_basic_document_renders_correctly(self):
method test_visualize_no_extractions_renders_text_and_empty_legend (line 144) | def test_visualize_no_extractions_renders_text_and_empty_legend(self):
Condensed preview — 124 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,206K chars).
[
{
"path": ".github/ISSUE_TEMPLATE/1-bug.md",
"chars": 791,
"preview": "---\nname: Bug Report\nabout: Create a bug report to help us improve\ntitle: 'Bug: <brief title of your issue>'\nlabels: 'bu"
},
{
"path": ".github/ISSUE_TEMPLATE/2-feature-request.md",
"chars": 982,
"preview": "---\nname: Feature Request\nabout: Suggest an idea or improvement\ntitle: 'Request: <brief title of your feature request>'\n"
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"chars": 1172,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".github/PULL_REQUEST_TEMPLATE/pull_request_template.md",
"chars": 2050,
"preview": "# Description\n\nReplace this with a clear and concise change description\n\n<!--- Important: All PRs must be linked to at l"
},
{
"path": ".github/scripts/add-new-checks.sh",
"chars": 1707,
"preview": "#!/bin/bash\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may n"
},
{
"path": ".github/scripts/add-size-labels.sh",
"chars": 1925,
"preview": "#!/bin/bash\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may n"
},
{
"path": ".github/scripts/revalidate-all-prs.sh",
"chars": 1272,
"preview": "#!/bin/bash\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may n"
},
{
"path": ".github/scripts/zenodo_publish.py",
"chars": 4087,
"preview": "#!/usr/bin/env python3\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n"
},
{
"path": ".github/workflows/auto-update-pr.yaml",
"chars": 7440,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".github/workflows/check-infrastructure-changes.yml",
"chars": 4735,
"preview": "name: Protect Infrastructure Files\n\non:\n pull_request_target:\n types: [opened, synchronize, reopened]\n workflow_dis"
},
{
"path": ".github/workflows/check-linked-issue.yml",
"chars": 8634,
"preview": "name: Require linked issue with community support\n\non:\n pull_request_target:\n types: [opened, edited, synchronize, r"
},
{
"path": ".github/workflows/check-pr-size.yml",
"chars": 4776,
"preview": "name: Check PR size\n\non:\n pull_request_target:\n types: [opened, synchronize, reopened]\n workflow_dispatch:\n inpu"
},
{
"path": ".github/workflows/check-pr-up-to-date.yaml",
"chars": 3358,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".github/workflows/ci.yaml",
"chars": 13733,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".github/workflows/publish.yml",
"chars": 1388,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".github/workflows/revalidate-pr.yml",
"chars": 5854,
"preview": "name: Revalidate PR\n\non:\n workflow_dispatch:\n inputs:\n pr_number:\n description: 'PR number to validate'\n"
},
{
"path": ".github/workflows/validate-community-providers.yaml",
"chars": 1207,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".github/workflows/validate_pr_template.yaml",
"chars": 5050,
"preview": "name: Validate PR template\n\non:\n pull_request_target:\n types: [opened, edited, synchronize, reopened]\n workflow_dis"
},
{
"path": ".github/workflows/zenodo-publish.yml",
"chars": 1709,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".gitignore",
"chars": 2414,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".pre-commit-config.yaml",
"chars": 1429,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": ".pylintrc",
"chars": 13440,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "CITATION.cff",
"chars": 1001,
"preview": "# SPDX-FileCopyrightText: 2025 Google LLC\n# SPDX-License-Identifier: Apache-2.0\n#\n# This file contains citation metadata"
},
{
"path": "COMMUNITY_PROVIDERS.md",
"chars": 4328,
"preview": "# Community Provider Plugins\n\nCommunity-developed provider plugins that extend LangExtract with additional model backend"
},
{
"path": "CONTRIBUTING.md",
"chars": 6401,
"preview": "# How to Contribute\n\nWe would love to accept your patches and contributions to this project.\n\n## Before you begin\n\n### S"
},
{
"path": "Dockerfile",
"chars": 214,
"preview": "# Production Dockerfile for LangExtract\nFROM python:3.10-slim\n\n# Set working directory\nWORKDIR /app\n\n# Install LangExtra"
},
{
"path": "LICENSE",
"chars": 11358,
"preview": "\n Apache License\n Version 2.0, January 2004\n "
},
{
"path": "README.md",
"chars": 18297,
"preview": "<p align=\"center\">\n <a href=\"https://github.com/google/langextract\">\n <img src=\"https://raw.githubusercontent.com/go"
},
{
"path": "autoformat.sh",
"chars": 3364,
"preview": "#!/bin/bash\n# Copyright 2025 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may no"
},
{
"path": "benchmarks/benchmark.py",
"chars": 13661,
"preview": "#!/usr/bin/env python3\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n"
},
{
"path": "benchmarks/config.py",
"chars": 3181,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "benchmarks/plotting.py",
"chars": 20223,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "benchmarks/utils.py",
"chars": 5279,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "docs/examples/batch_api_example.md",
"chars": 5910,
"preview": "# Vertex AI Batch Processing Guide\n\nThe Vertex AI Batch API offers significant cost savings (~50%) for large, non-time-c"
},
{
"path": "docs/examples/japanese_extraction.md",
"chars": 2174,
"preview": "# Japanese Information Extraction\n\nThis example demonstrates how to use LangExtract to extract structured information fr"
},
{
"path": "docs/examples/longer_text_example.md",
"chars": 10152,
"preview": "# *Romeo and Juliet* Full Text Extraction\n\nLangExtract can process entire documents directly from URLs, handling large t"
},
{
"path": "docs/examples/medication_examples.md",
"chars": 10482,
"preview": "# Medication Extraction Examples\n\nLangExtract excels at extracting structured medical information from clinical text, ma"
},
{
"path": "examples/custom_provider_plugin/README.md",
"chars": 6859,
"preview": "# Custom Provider Plugin Example\n\nThis example demonstrates how to create a custom provider plugin that extends LangExtr"
},
{
"path": "examples/custom_provider_plugin/langextract_provider_example/__init__.py",
"chars": 760,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "examples/custom_provider_plugin/langextract_provider_example/provider.py",
"chars": 5955,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "examples/custom_provider_plugin/langextract_provider_example/schema.py",
"chars": 5369,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "examples/custom_provider_plugin/pyproject.toml",
"chars": 1391,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "examples/custom_provider_plugin/test_example_provider.py",
"chars": 1752,
"preview": "#!/usr/bin/env python3\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n"
},
{
"path": "examples/notebooks/romeo_juliet_extraction.ipynb",
"chars": 24559,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"header\"\n },\n \"source\": "
},
{
"path": "examples/ollama/.dockerignore",
"chars": 350,
"preview": "# Ignore Python cache\n__pycache__/\n*.pyc\n*.pyo\n*.pyd\n.Python\n\n# Ignore version control\n.git/\n.gitignore\n\n# Ignore OS fil"
},
{
"path": "examples/ollama/Dockerfile",
"chars": 707,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "examples/ollama/README.md",
"chars": 1706,
"preview": "# Ollama Examples\n\nThis directory contains examples for using LangExtract with Ollama for local LLM inference.\n\nFor setu"
},
{
"path": "examples/ollama/demo_ollama.py",
"chars": 17516,
"preview": "#!/usr/bin/env python3\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n"
},
{
"path": "examples/ollama/docker-compose.yml",
"chars": 1207,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/__init__.py",
"chars": 2977,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/_compat/README.md",
"chars": 2022,
"preview": "# Backward Compatibility Layer\n\nThis directory contains backward compatibility shims for deprecated imports.\n\n## Depreca"
},
{
"path": "langextract/_compat/__init__.py",
"chars": 847,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/_compat/exceptions.py",
"chars": 1335,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/_compat/inference.py",
"chars": 1870,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/_compat/registry.py",
"chars": 1059,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/_compat/schema.py",
"chars": 1466,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/annotation.py",
"chars": 21343,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/chunking.py",
"chars": 16352,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/__init__.py",
"chars": 951,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/base_model.py",
"chars": 5651,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/data.py",
"chars": 7616,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/debug_utils.py",
"chars": 5205,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/exceptions.py",
"chars": 3428,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/format_handler.py",
"chars": 15519,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/schema.py",
"chars": 4593,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/tokenizer.py",
"chars": 19228,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/core/types.py",
"chars": 1691,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/data.py",
"chars": 955,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/data_lib.py",
"chars": 3830,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/exceptions.py",
"chars": 1491,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/extraction.py",
"chars": 15646,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/factory.py",
"chars": 8467,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/inference.py",
"chars": 1107,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/io.py",
"chars": 10024,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/plugins.py",
"chars": 6483,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/progress.py",
"chars": 9894,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/prompt_validation.py",
"chars": 8141,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/prompting.py",
"chars": 8645,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/README.md",
"chars": 20187,
"preview": "# LangExtract Provider System\n\nThis directory contains the provider system for LangExtract, which enables support for di"
},
{
"path": "langextract/providers/__init__.py",
"chars": 4865,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/builtin_registry.py",
"chars": 1610,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/gemini.py",
"chars": 12209,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/gemini_batch.py",
"chars": 28680,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/ollama.py",
"chars": 15449,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/openai.py",
"chars": 8790,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/patterns.py",
"chars": 2049,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/router.py",
"chars": 7256,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/schemas/__init__.py",
"chars": 792,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/providers/schemas/gemini.py",
"chars": 5747,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/py.typed",
"chars": 0,
"preview": ""
},
{
"path": "langextract/registry.py",
"chars": 1129,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/resolver.py",
"chars": 32684,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/schema.py",
"chars": 1934,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/tokenizer.py",
"chars": 980,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "langextract/visualization.py",
"chars": 20300,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "pyproject.toml",
"chars": 4344,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "scripts/create_provider_plugin.py",
"chars": 25679,
"preview": "#!/usr/bin/env python3\n# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n"
},
{
"path": "scripts/validate_community_providers.py",
"chars": 6468,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/.pylintrc",
"chars": 2244,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/annotation_test.py",
"chars": 47217,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/chunking_test.py",
"chars": 18995,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/data_lib_test.py",
"chars": 8894,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/extract_precedence_test.py",
"chars": 8871,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/extract_schema_integration_test.py",
"chars": 11360,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/factory_schema_test.py",
"chars": 7812,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/factory_test.py",
"chars": 15311,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/format_handler_test.py",
"chars": 9561,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/inference_test.py",
"chars": 25850,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/init_test.py",
"chars": 23520,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/progress_test.py",
"chars": 2726,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/prompt_validation_test.py",
"chars": 13964,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/prompting_test.py",
"chars": 20219,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/provider_plugin_test.py",
"chars": 22074,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/provider_schema_test.py",
"chars": 19343,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/registry_test.py",
"chars": 7676,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/resolver_test.py",
"chars": 83606,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/schema_test.py",
"chars": 12435,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/test_gemini_batch_api.py",
"chars": 22997,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/test_kwargs_passthrough.py",
"chars": 15367,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/test_live_api.py",
"chars": 32743,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/test_ollama_integration.py",
"chars": 5102,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/tokenizer_test.py",
"chars": 36172,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tests/visualization_test.py",
"chars": 5139,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
},
{
"path": "tox.ini",
"chars": 2044,
"preview": "# Copyright 2025 Google LLC.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this "
}
]
About this extraction
This page contains the full source code of the google/langextract GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 124 files (1.1 MB), approximately 255.2k tokens, and a symbol index with 834 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.