Repository: greyireland/algorithm-pattern
Branch: master
Commit: 0a8d0cf6644b
Files: 24
Total size: 99.1 KB
Directory structure:
gitextract_3kj3zxap/
├── .gitignore
├── LICENSE
├── README.md
├── SUMMARY.md
├── TODO.md
├── advanced_algorithm/
│ ├── backtrack.md
│ ├── binary_search_tree.md
│ ├── recursion.md
│ └── slide_window.md
├── basic_algorithm/
│ ├── binary_search.md
│ ├── dp.md
│ └── sort.md
├── data_structure/
│ ├── binary_op.md
│ ├── binary_tree.md
│ ├── linked_list.md
│ └── stack_queue.md
├── introduction/
│ ├── golang.md
│ └── quickstart.md
├── practice_algorithm/
│ ├── bplus.md
│ ├── data_index.md
│ └── skiplist.md
└── src/
├── main.go
└── sort/
├── heap_sort.go
└── heap_sort_test.go
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.DS_Store
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2023 greyireland
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# 算法模板

算法模板,最科学的刷题方式,最快速的刷题路径,一个月从入门到 offer,你值得拥有 🐶~
算法模板顾名思义就是刷题的套路模板,掌握了刷题模板之后,刷题也变得好玩起来了~
> 此项目是自己找工作时,从 0 开始刷 LeetCode 的心得记录,通过各种刷题文章、专栏、视频等总结了一套自己的刷题模板。
>
> 这个模板主要是介绍了一些通用的刷题模板,以及一些常见问题,如到底要刷多少题,按什么顺序来刷题,如何提高刷题效率等。
## 在线文档
在线文档 Gitbook:[算法模板 🔥](https://greyireland.gitbook.io/algorithm-pattern/)
## 核心内容
### 入门篇 🐶
- [go 语言入门](./introduction/golang.md)
- [算法快速入门](./introduction/quickstart.md)
### 数据结构篇 🐰
- [二叉树](./data_structure/binary_tree.md)
- [链表](./data_structure/linked_list.md)
- [栈和队列](./data_structure/stack_queue.md)
- [二进制](./data_structure/binary_op.md)
### 基础算法篇 🐮
- [二分搜索](./basic_algorithm/binary_search.md)
- [排序算法](./basic_algorithm/sort.md)
- [动态规划](./basic_algorithm/dp.md)
### 算法思维 🦁
- [递归思维](./advanced_algorithm/recursion.md)
- [滑动窗口思想](./advanced_algorithm/slide_window.md)
- [二叉搜索树](./advanced_algorithm/binary_search_tree.md)
- [回溯法](./advanced_algorithm/backtrack.md)
## 心得体会
文章大部分是对题目的思路介绍,和一些问题的解析,有了思路还是需要自己手动写写的,所以每篇文章最后都有对应的练习题
刷完这些练习题,基本对数据结构和算法有自己的认识体会,基本大部分面试题都能写得出来,国内的 BAT、TMD 应该都不是问题
从 4 月份找工作开始,从 0 开始刷 LeetCode,中间大概花了一个半月(6 周)左右时间刷完 240 题。
开始刷题时,确实是无从下手,因为从序号开始刷,刷到几道题就遇到 hard 的题型,会卡住很久,后面去评论区看别人怎么刷题,也去 Google 搜索最好的刷题方式,发现按题型刷题会舒服很多,基本一个类型的题目,一天能做很多,慢慢刷题也不再枯燥,做起来也很有意思,最后也收到不错的 offer(最后去了宇宙系)。
回到最开始的问题,面试到底要刷多少题,其实这个取决于你想进什么样公司,你定的目标如果是国内一线大厂,个人感觉大概 200 至 300 题基本就满足大部分面试需要了。第二个问题是按什么顺序刷及如何提高效率,这个也是本 repo 的目的,给你指定了一个刷题的顺序,以及刷题的模板,有了方向和技巧后,就去动手吧~ 希望刷完之后,你也能自己总结一套属于自己的刷题模板,有所收获,有所成长~
## 推荐的刷题路径
按此 repo 目录刷一遍,如果中间有题目卡住了先跳过,然后刷题一遍 LeetCode 探索基础卡片,最后快要面试时刷题一遍剑指 offer。
为什么这么要这么刷,因为 repo 里面的题目是按类型归类,都是一些常见的高频题,很有代表性,大部分都是可以用模板加一点变形做出来,刷完后对大部分题目有基本的认识。然后刷一遍探索卡片,巩固一下一些基础知识点,总结这些知识点。最后剑指 offer 是大部分公司的出题源头,刷完面试中基本会遇到现题或者变形题,基本刷完这三部分,大部分国内公司的面试题应该就没什么问题了~
1、 [algorithm-pattern 练习题](https://greyireland.gitbook.io/algorithm-pattern/)
2、 [LeetCode 卡片](https://leetcode-cn.com/explore/)
3、 [剑指 offer](https://leetcode-cn.com/problemset/lcof/)
刷题时间可以合理分配,如果打算准备面试了,建议前面两部分 一个半月 (6 周)时间刷完,最后剑指 offer 半个月刷完,边刷可以边投简历进行面试,遇到不会的不用着急,往模板上套就对了,如果面试管给你提示,那就好好做,不要错过这大好机会~
> 注意点:如果为了找工作刷题,遇到 hard 的题如果有思路就做,没思路先跳过,先把基础打好,再来刷 hard 可能效果会更好~
## 面试资源
分享一些计算机的经典书籍,大部分对面试应该都有帮助,强烈推荐 🌝
[我看过的 100 本书](https://github.com/greyireland/awesome-programming-books-1)
## 更新计划
持续更新中,觉得还可以的话点个 **star** 收藏呀 ⭐️~
【 Github 】[https://github.com/greyireland/algorithm-pattern](https://github.com/greyireland/algorithm-pattern) ⭐️
## 完成打卡
完成计划之后,可以提交 Pull requests,在下面添加自己的项目仓库,完成自己的算法模板打卡呀~
| 完成 | 用户 | 项目地址 |
| ---- | ------------------------------------------------- | ------------------------------------------------------------------- |
| ✅ | [easyui](https://github.com/easyui/) | [algorithm-pattern-swift(Swift 实现)](https://github.com/easyui/algorithm-pattern-swift),[在线文档 Gitbook](https://zyj.gitbook.io/algorithm-pattern-swift/) |
| ✅ | [wardseptember](https://github.com/wardseptember) | [notes(Java 实现)](https://github.com/wardseptember/notes) |
| ✅ | [dashidhy](https://github.com/dashidhy) | [algorithm-pattern-python(Python 实现)](https://github.com/dashidhy/algorithm-pattern-python) |
| ✅ | [binzi56](https://github.com/binzi56) | [algorithm-pattern-c(c++ 实现)](https://github.com/binzi56/algorithm-pattern-c) |
| ✅ | [lvseouren](https://github.com/lvseouren) | [algorithm-study-record(c++ 实现)](https://github.com/lvseouren/algorithm-study-record) |
| ✅ | [chienmy](https://github.com/chienmy) | [algorithm-pattern-java(Java 实现)](https://github.com/chienmy/algorithm-pattern-java), [在线文档 Gitbook](https://chienmy.gitbook.io/algorithm-pattern-java/) |
| ✅ | [ligecarryme](https://github.com/ligecarryme) | [algorithm-pattern-JavaScript(JS+TS实现)](https://github.com/ligecarryme/algorithm-pattern-JavaScript) |
| ✅ | [Esdeath](https://github.com/Esdeath) | [algorithm-pattern-dart(dart实现)](https://github.com/Esdeath/algorithm-pattern-dart),[在线文档 Gitbook](https://ayaseeri.gitbook.io/algorithm-pattern-dart/) |
| ✅ | [longpi1](https://github.com/longpi1) | [algorithm-pattern-golang(golang实现)](https://github.com/longpi1/algorithm-pattern)
| ✅ | [tpxxn](https://github.com/tpxxn) | [algorithm-pattern-CSharp(C# 实现)](https://github.com/tpxxn/algorithm-pattern-CSharp)
================================================
FILE: SUMMARY.md
================================================
# 算法模板
## 入门篇
- [go 语言入门](introduction/golang.md)
- [算法快速入门](introduction/quickstart.md)
## 数据结构篇
- [二叉树](data_structure/binary_tree.md)
- [链表](data_structure/linked_list.md)
- [栈和队列](data_structure/stack_queue.md)
- [二进制](data_structure/binary_op.md)
## 基础算法篇
- [二分搜索](basic_algorithm/binary_search.md)
- [排序算法](basic_algorithm/sort.md)
- [动态规划](basic_algorithm/dp.md)
## 算法思维
- [递归思维](advanced_algorithm/recursion.md)
- [滑动窗口思想](advanced_algorithm/slide_window.md)
- [二叉搜索树](advanced_algorithm/binary_search_tree.md)
- [回溯法](advanced_algorithm/backtrack.md)
================================================
FILE: TODO.md
================================================
# 计划
## v1
- [ ] 完善文档细节
- [ ] 工程实现用到的算法解析
- [ ] 周赛计划
- [ ] 面试体系计划
================================================
FILE: advanced_algorithm/backtrack.md
================================================
# 回溯法
## 背景
回溯法(backtrack)常用于遍历列表所有子集,是 DFS 深度搜索一种,一般用于全排列,穷尽所有可能,遍历的过程实际上是一个决策树的遍历过程。时间复杂度一般 O(N!),它不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
## 模板
```go
result = []
func backtrack(选择列表,路径):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(选择列表,路径)
撤销选择
```
核心就是从选择列表里做一个选择,然后一直递归往下搜索答案,如果遇到路径不通,就返回来撤销这次选择。
## 示例
### [subsets](https://leetcode-cn.com/problems/subsets/)
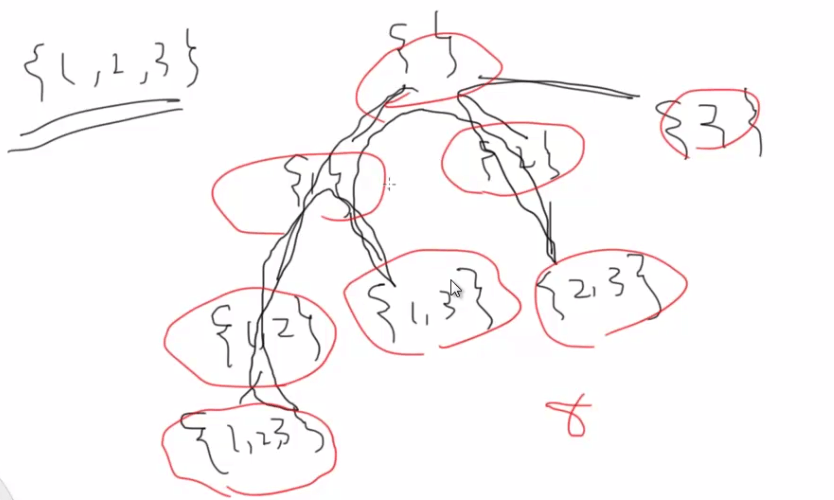
> 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
遍历过程
```go
func subsets(nums []int) [][]int {
// 保存最终结果
result := make([][]int, 0)
// 保存中间结果
list := make([]int, 0)
backtrack(nums, 0, list, &result)
return result
}
// nums 给定的集合
// pos 下次添加到集合中的元素位置索引
// list 临时结果集合(每次需要复制保存)
// result 最终结果
func backtrack(nums []int, pos int, list []int, result *[][]int) {
// 把临时结果复制出来保存到最终结果
ans := make([]int, len(list))
copy(ans, list)
*result = append(*result, ans)
// 选择、处理结果、再撤销选择
for i := pos; i < len(nums); i++ {
list = append(list, nums[i])
backtrack(nums, i+1, list, result)
list = list[0 : len(list)-1]
}
}
```
### [subsets-ii](https://leetcode-cn.com/problems/subsets-ii/)
> 给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。说明:解集不能包含重复的子集。
```go
import (
"sort"
)
func subsetsWithDup(nums []int) [][]int {
// 保存最终结果
result := make([][]int, 0)
// 保存中间结果
list := make([]int, 0)
// 先排序
sort.Ints(nums)
backtrack(nums, 0, list, &result)
return result
}
// nums 给定的集合
// pos 下次添加到集合中的元素位置索引
// list 临时结果集合(每次需要复制保存)
// result 最终结果
func backtrack(nums []int, pos int, list []int, result *[][]int) {
// 把临时结果复制出来保存到最终结果
ans := make([]int, len(list))
copy(ans, list)
*result = append(*result, ans)
// 选择时需要剪枝、处理、撤销选择
for i := pos; i < len(nums); i++ {
// 排序之后,如果再遇到重复元素,则不选择此元素
if i != pos && nums[i] == nums[i-1] {
continue
}
list = append(list, nums[i])
backtrack(nums, i+1, list, result)
list = list[0 : len(list)-1]
}
}
```
### [permutations](https://leetcode-cn.com/problems/permutations/)
> 给定一个 没有重复 数字的序列,返回其所有可能的全排列。
思路:需要记录已经选择过的元素,满足条件的结果才进行返回
```go
func permute(nums []int) [][]int {
result := make([][]int, 0)
list := make([]int, 0)
// 标记这个元素是否已经添加到结果集
visited := make([]bool, len(nums))
backtrack(nums, visited, list, &result)
return result
}
// nums 输入集合
// visited 当前递归标记过的元素
// list 临时结果集(路径)
// result 最终结果
func backtrack(nums []int, visited []bool, list []int, result *[][]int) {
// 返回条件:临时结果和输入集合长度一致 才是全排列
if len(list) == len(nums) {
ans := make([]int, len(list))
copy(ans, list)
*result = append(*result, ans)
return
}
for i := 0; i < len(nums); i++ {
// 已经添加过的元素,直接跳过
if visited[i] {
continue
}
// 添加元素
list = append(list, nums[i])
visited[i] = true
backtrack(nums, visited, list, result)
// 移除元素
visited[i] = false
list = list[0 : len(list)-1]
}
}
```
### [permutations-ii](https://leetcode-cn.com/problems/permutations-ii/)
> 给定一个可包含重复数字的序列,返回所有不重复的全排列。
```go
import (
"sort"
)
func permuteUnique(nums []int) [][]int {
result := make([][]int, 0)
list := make([]int, 0)
// 标记这个元素是否已经添加到结果集
visited := make([]bool, len(nums))
sort.Ints(nums)
backtrack(nums, visited, list, &result)
return result
}
// nums 输入集合
// visited 当前递归标记过的元素
// list 临时结果集
// result 最终结果
func backtrack(nums []int, visited []bool, list []int, result *[][]int) {
// 临时结果和输入集合长度一致 才是全排列
if len(list) == len(nums) {
subResult := make([]int, len(list))
copy(subResult, list)
*result = append(*result, subResult)
}
for i := 0; i < len(nums); i++ {
// 已经添加过的元素,直接跳过
if visited[i] {
continue
}
// 上一个元素和当前相同,并且没有访问过就跳过
if i != 0 && nums[i] == nums[i-1] && !visited[i-1] {
continue
}
list = append(list, nums[i])
visited[i] = true
backtrack(nums, visited, list, result)
visited[i] = false
list = list[0 : len(list)-1]
}
}
```
## 练习
- [ ] [subsets](https://leetcode-cn.com/problems/subsets/)
- [ ] [subsets-ii](https://leetcode-cn.com/problems/subsets-ii/)
- [ ] [permutations](https://leetcode-cn.com/problems/permutations/)
- [ ] [permutations-ii](https://leetcode-cn.com/problems/permutations-ii/)
挑战题目
- [ ] [combination-sum](https://leetcode-cn.com/problems/combination-sum/)
- [ ] [letter-combinations-of-a-phone-number](https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/)
- [ ] [palindrome-partitioning](https://leetcode-cn.com/problems/palindrome-partitioning/)
- [ ] [restore-ip-addresses](https://leetcode-cn.com/problems/restore-ip-addresses/)
- [ ] [permutations](https://leetcode-cn.com/problems/permutations/)
================================================
FILE: advanced_algorithm/binary_search_tree.md
================================================
# 二叉搜索树
## 定义
- 每个节点中的值必须大于(或等于)存储在其左侧子树中的任何值。
- 每个节点中的值必须小于(或等于)存储在其右子树中的任何值。
## 应用
[validate-binary-search-tree](https://leetcode-cn.com/problems/validate-binary-search-tree/)
> 验证二叉搜索树
```go
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func isValidBST(root *TreeNode) bool {
return dfs(root).valid
}
type ResultType struct{
max int
min int
valid bool
}
func dfs(root *TreeNode)(result ResultType){
if root==nil{
result.max=-1<<63
result.min=1<<63-1
result.valid=true
return
}
left:=dfs(root.Left)
right:=dfs(root.Right)
// 1、满足左边最大值<root<右边最小值 && 左右两边valid
if root.Val>left.max && root.Val<right.min && left.valid && right.valid {
result.valid=true
}
// 2、更新当前节点的最大最小值
result.max=Max(Max(left.max,right.max),root.Val)
result.min=Min(Min(left.min,right.min),root.Val)
return
}
func Max(a,b int)int{
if a>b{
return a
}
return b
}
func Min(a,b int)int{
if a>b{
return b
}
return a
}
```
[insert-into-a-binary-search-tree](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/)
> 给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 保证原始二叉搜索树中不存在新值。
```go
func insertIntoBST(root *TreeNode, val int) *TreeNode {
if root==nil{
return &TreeNode{Val:val}
}
if root.Val<val{
root.Right=insertIntoBST(root.Right,val)
}else{
root.Left=insertIntoBST(root.Left,val)
}
return root
}
```
[delete-node-in-a-bst](https://leetcode-cn.com/problems/delete-node-in-a-bst/)
> 给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
```go
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func deleteNode(root *TreeNode, key int) *TreeNode {
// 删除节点分为三种情况:
// 1、只有左节点 替换为右
// 2、只有右节点 替换为左
// 3、有左右子节点 左子节点连接到右边最左节点即可
if root ==nil{
return root
}
if root.Val<key{
root.Right=deleteNode(root.Right,key)
}else if root.Val>key{
root.Left=deleteNode(root.Left,key)
}else if root.Val==key{
if root.Left==nil{
return root.Right
}else if root.Right==nil{
return root.Left
}else{
cur:=root.Right
// 一直向左找到最后一个左节点即可
for cur.Left!=nil{
cur=cur.Left
}
cur.Left=root.Left
return root.Right
}
}
return root
}
```
[balanced-binary-tree](https://leetcode-cn.com/problems/balanced-binary-tree/)
> 给定一个二叉树,判断它是否是高度平衡的二叉树。
```go
type ResultType struct{
height int
valid bool
}
func isBalanced(root *TreeNode) bool {
return dfs(root).valid
}
func dfs(root *TreeNode)(result ResultType){
if root==nil{
result.valid=true
result.height=0
return
}
left:=dfs(root.Left)
right:=dfs(root.Right)
// 满足所有特点:二叉搜索树&&平衡
if left.valid&&right.valid&&abs(left.height,right.height)<=1{
result.valid=true
}
result.height=Max(left.height,right.height)+1
return
}
func abs(a,b int)int{
if a>b{
return a-b
}
return b-a
}
func Max(a,b int)int{
if a>b{
return a
}
return b
}
```
## 练习
- [ ] [validate-binary-search-tree](https://leetcode-cn.com/problems/validate-binary-search-tree/)
- [ ] [insert-into-a-binary-search-tree](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/)
- [ ] [delete-node-in-a-bst](https://leetcode-cn.com/problems/delete-node-in-a-bst/)
- [ ] [balanced-binary-tree](https://leetcode-cn.com/problems/balanced-binary-tree/)
================================================
FILE: advanced_algorithm/recursion.md
================================================
# 递归
## 介绍
将大问题转化为小问题,通过递归依次解决各个小问题
## 示例
[reverse-string](https://leetcode-cn.com/problems/reverse-string/)
> 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 `char[]` 的形式给出。
```go
func reverseString(s []byte) {
res := make([]byte, 0)
reverse(s, 0, &res)
for i := 0; i < len(s); i++ {
s[i] = res[i]
}
}
func reverse(s []byte, i int, res *[]byte) {
if i == len(s) {
return
}
reverse(s, i+1, res)
*res = append(*res, s[i])
}
```
[swap-nodes-in-pairs](https://leetcode-cn.com/problems/swap-nodes-in-pairs/)
> 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
> **你不能只是单纯的改变节点内部的值**,而是需要实际的进行节点交换。
```go
func swapPairs(head *ListNode) *ListNode {
// 思路:将链表翻转转化为一个子问题,然后通过递归方式依次解决
// 先翻转两个,然后将后面的节点继续这样翻转,然后将这些翻转后的节点连接起来
return helper(head)
}
func helper(head *ListNode)*ListNode{
if head==nil||head.Next==nil{
return head
}
// 保存下一阶段的头指针
nextHead:=head.Next.Next
// 翻转当前阶段指针
next:=head.Next
next.Next=head
head.Next=helper(nextHead)
return next
}
```
[unique-binary-search-trees-ii](https://leetcode-cn.com/problems/unique-binary-search-trees-ii/)
> 给定一个整数 n,生成所有由 1 ... n 为节点所组成的二叉搜索树。
```go
func generateTrees(n int) []*TreeNode {
if n==0{
return nil
}
return generate(1,n)
}
func generate(start,end int)[]*TreeNode{
if start>end{
return []*TreeNode{nil}
}
ans:=make([]*TreeNode,0)
for i:=start;i<=end;i++{
// 递归生成所有左右子树
lefts:=generate(start,i-1)
rights:=generate(i+1,end)
// 拼接左右子树后返回
for j:=0;j<len(lefts);j++{
for k:=0;k<len(rights);k++{
root:=&TreeNode{Val:i}
root.Left=lefts[j]
root.Right=rights[k]
ans=append(ans,root)
}
}
}
return ans
}
```
## 递归+备忘录
[fibonacci-number](https://leetcode-cn.com/problems/fibonacci-number/)
> 斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
> F(0) = 0, F(1) = 1
> F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
> 给定 N,计算 F(N)。
```go
func fib(N int) int {
return dfs(N)
}
var m map[int]int=make(map[int]int)
func dfs(n int)int{
if n < 2{
return n
}
// 读取缓存
if m[n]!=0{
return m[n]
}
ans:=dfs(n-2)+dfs(n-1)
// 缓存已经计算过的值
m[n]=ans
return ans
}
```
## 练习
- [ ] [reverse-string](https://leetcode-cn.com/problems/reverse-string/)
- [ ] [swap-nodes-in-pairs](https://leetcode-cn.com/problems/swap-nodes-in-pairs/)
- [ ] [unique-binary-search-trees-ii](https://leetcode-cn.com/problems/unique-binary-search-trees-ii/)
- [ ] [fibonacci-number](https://leetcode-cn.com/problems/fibonacci-number/)
================================================
FILE: advanced_algorithm/slide_window.md
================================================
# 滑动窗口
## 模板
```cpp
/* 滑动窗口算法框架 */
void slidingWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// c 是将移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 进行窗口内数据的一系列更新
...
/*** debug 输出的位置 ***/
printf("window: [%d, %d)\n", left, right);
/********************/
// 判断左侧窗口是否要收缩
while (window needs shrink) {
// d 是将移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 进行窗口内数据的一系列更新
...
}
}
}
```
需要变化的地方
- 1、右指针右移之后窗口数据更新
- 2、判断窗口是否要收缩
- 3、左指针右移之后窗口数据更新
- 4、根据题意计算结果
## 示例
[minimum-window-substring](https://leetcode-cn.com/problems/minimum-window-substring/)
> 给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字母的最小子串
```go
func minWindow(s string, t string) string {
// 保存滑动窗口字符集
win := make(map[byte]int)
// 保存需要的字符集
need := make(map[byte]int)
for i := 0; i < len(t); i++ {
need[t[i]]++
}
// 窗口
left := 0
right := 0
// match匹配次数
match := 0
start := 0
end := 0
min := math.MaxInt64
var c byte
for right < len(s) {
c = s[right]
right++
// 在需要的字符集里面,添加到窗口字符集里面
if need[c] != 0 {
win[c]++
// 如果当前字符的数量匹配需要的字符的数量,则match值+1
if win[c] == need[c] {
match++
}
}
// 当所有字符数量都匹配之后,开始缩紧窗口
for match == len(need) {
// 获取结果
if right-left < min {
min = right - left
start = left
end = right
}
c = s[left]
left++
// 左指针指向不在需要字符集则直接跳过
if need[c] != 0 {
// 左指针指向字符数量和需要的字符相等时,右移之后match值就不匹配则减一
// 因为win里面的字符数可能比较多,如有10个A,但需要的字符数量可能为3
// 所以在压死骆驼的最后一根稻草时,match才减一,这时候才跳出循环
if win[c] == need[c] {
match--
}
win[c]--
}
}
}
if min == math.MaxInt64 {
return ""
}
return s[start:end]
}
```
[permutation-in-string](https://leetcode-cn.com/problems/permutation-in-string/)
> 给定两个字符串 **s1** 和 **s2**,写一个函数来判断 **s2** 是否包含 **s1 **的排列。
```go
func checkInclusion(s1 string, s2 string) bool {
win := make(map[byte]int)
need := make(map[byte]int)
for i := 0; i < len(s1); i++ {
need[s1[i]]++
}
left := 0
right := 0
match := 0
for right < len(s2) {
c := s2[right]
right++
if need[c] != 0 {
win[c]++
if win[c] == need[c] {
match++
}
}
// 当窗口长度大于字符串长度,缩紧窗口
for right-left >= len(s1) {
// 当窗口长度和字符串匹配,并且里面每个字符数量也匹配时,满足条件
if match == len(need) {
return true
}
d := s2[left]
left++
if need[d] != 0 {
if win[d] == need[d] {
match--
}
win[d]--
}
}
}
return false
}
```
[find-all-anagrams-in-a-string](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/)
> 给定一个字符串 **s **和一个非空字符串 **p**,找到 **s **中所有是 **p **的字母异位词的子串,返回这些子串的起始索引。
```go
func findAnagrams(s string, p string) []int {
win := make(map[byte]int)
need := make(map[byte]int)
for i := 0; i < len(p); i++ {
need[p[i]]++
}
left := 0
right := 0
match := 0
ans:=make([]int,0)
for right < len(s) {
c := s[right]
right++
if need[c] != 0 {
win[c]++
if win[c] == need[c] {
match++
}
}
// 当窗口长度大于字符串长度,缩紧窗口
for right-left >= len(p) {
// 当窗口长度和字符串匹配,并且里面每个字符数量也匹配时,满足条件
if right-left == len(p)&& match == len(need) {
ans=append(ans,left)
}
d := s[left]
left++
if need[d] != 0 {
if win[d] == need[d] {
match--
}
win[d]--
}
}
}
return ans
}
```
[longest-substring-without-repeating-characters](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/)
> 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
> 示例 1:
>
> 输入: "abcabcbb"
> 输出: 3
> 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
```go
func lengthOfLongestSubstring(s string) int {
// 滑动窗口核心点:1、右指针右移 2、根据题意收缩窗口 3、左指针右移更新窗口 4、根据题意计算结果
if len(s)==0{
return 0
}
win:=make(map[byte]int)
left:=0
right:=0
ans:=1
for right<len(s){
c:=s[right]
right++
win[c]++
// 缩小窗口
for win[c]>1{
d:=s[left]
left++
win[d]--
}
// 计算结果
ans=max(right-left,ans)
}
return ans
}
func max(a,b int)int{
if a>b{
return a
}
return b
}
```
## 总结
- 和双指针题目类似,更像双指针的升级版,滑动窗口核心点是维护一个窗口集,根据窗口集来进行处理
- 核心步骤
- right 右移
- 收缩
- left 右移
- 求结果
## 练习
- [ ] [minimum-window-substring](https://leetcode-cn.com/problems/minimum-window-substring/)
- [ ] [permutation-in-string](https://leetcode-cn.com/problems/permutation-in-string/)
- [ ] [find-all-anagrams-in-a-string](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/)
- [ ] [longest-substring-without-repeating-characters](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/)
================================================
FILE: basic_algorithm/binary_search.md
================================================
# 二分搜索
## 二分搜索模板
给一个**有序数组**和目标值,找第一次/最后一次/任何一次出现的索引,如果没有出现返回-1
模板四点要素
- 1、初始化:start=0、end=len-1
- 2、循环退出条件:start + 1 < end
- 3、比较中点和目标值:A[mid] ==、 <、> target
- 4、判断最后两个元素是否符合:A[start]、A[end] ? target
时间复杂度 O(logn),使用场景一般是有序数组的查找
典型示例
[binary-search](https://leetcode-cn.com/problems/binary-search/)
> 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
```go
// 二分搜索最常用模板
func search(nums []int, target int) int {
// 1、初始化start、end
start := 0
end := len(nums) - 1
// 2、处理for循环
for start+1 < end {
mid := start + (end-start)/2
// 3、比较a[mid]和target值
if nums[mid] == target {
end = mid
} else if nums[mid] < target {
start = mid
} else if nums[mid] > target {
end = mid
}
}
// 4、最后剩下两个元素,手动判断
if nums[start] == target {
return start
}
if nums[end] == target {
return end
}
return -1
}
```
大部分二分查找类的题目都可以用这个模板,然后做一点特殊逻辑即可
另外二分查找还有一些其他模板如下图,大部分场景模板#3 都能解决问题,而且还能找第一次/最后一次出现的位置,应用更加广泛

所以用模板#3 就对了,详细的对比可以这边文章介绍:[二分搜索模板](https://leetcode-cn.com/explore/learn/card/binary-search/212/template-analysis/847/)
如果是最简单的二分搜索,不需要找第一个、最后一个位置、或者是没有重复元素,可以使用模板#1,代码更简洁
```go
// 无重复元素搜索时,更方便
func search(nums []int, target int) int {
start := 0
end := len(nums) - 1
for start <= end {
mid := start + (end-start)/2
if nums[mid] == target {
return mid
} else if nums[mid] < target {
start = mid+1
} else if nums[mid] > target {
end = mid-1
}
}
// 如果找不到,start 是第一个大于target的索引
// 如果在B+树结构里面二分搜索,可以return start
// 这样可以继续向子节点搜索,如:node:=node.Children[start]
return -1
}
```
## 常见题目
### [search-for-range](https://www.lintcode.com/problem/search-for-a-range/description)
> 给定一个包含 n 个整数的排序数组,找出给定目标值 target 的起始和结束位置。
> 如果目标值不在数组中,则返回`[-1, -1]`
思路:核心点就是找第一个 target 的索引,和最后一个 target 的索引,所以用两次二分搜索分别找第一次和最后一次的位置
```go
func searchRange (A []int, target int) []int {
if len(A) == 0 {
return []int{-1, -1}
}
result := make([]int, 2)
start := 0
end := len(A) - 1
for start+1 < end {
mid := start + (end-start)/2
if A[mid] > target {
end = mid
} else if A[mid] < target {
start = mid
} else {
// 如果相等,应该继续向左找,就能找到第一个目标值的位置
end = mid
}
}
// 搜索左边的索引
if A[start] == target {
result[0] = start
} else if A[end] == target {
result[0] = end
} else {
result[0] = -1
result[1] = -1
return result
}
start = 0
end = len(A) - 1
for start+1 < end {
mid := start + (end-start)/2
if A[mid] > target {
end = mid
} else if A[mid] < target {
start = mid
} else {
// 如果相等,应该继续向右找,就能找到最后一个目标值的位置
start = mid
}
}
// 搜索右边的索引
if A[end] == target {
result[1] = end
} else if A[start] == target {
result[1] = start
} else {
result[0] = -1
result[1] = -1
return result
}
return result
}
```
### [search-insert-position](https://leetcode-cn.com/problems/search-insert-position/)
> 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
```go
func searchInsert(nums []int, target int) int {
// 思路:找到第一个 >= target 的元素位置
start := 0
end := len(nums) - 1
for start+1 < end {
mid := start + (end-start)/2
if nums[mid] == target {
// 标记开始位置
start = mid
} else if nums[mid] > target {
end = mid
} else {
start = mid
}
}
if nums[start] >= target {
return start
} else if nums[end] >= target {
return end
} else if nums[end] < target { // 目标值比所有值都大
return end + 1
}
return 0
}
```
### [search-a-2d-matrix](https://leetcode-cn.com/problems/search-a-2d-matrix/)
> 编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
>
> - 每行中的整数从左到右按升序排列。
> - 每行的第一个整数大于前一行的最后一个整数。
```go
func searchMatrix(matrix [][]int, target int) bool {
// 思路:将2纬数组转为1维数组 进行二分搜索
if len(matrix) == 0 || len(matrix[0]) == 0 {
return false
}
row := len(matrix)
col := len(matrix[0])
start := 0
end := row*col - 1
for start+1 < end {
mid := start + (end-start)/2
// 获取2纬数组对应值
val := matrix[mid/col][mid%col]
if val > target {
end = mid
} else if val < target {
start = mid
} else {
return true
}
}
if matrix[start/col][start%col] == target || matrix[end/col][end%col] == target{
return true
}
return false
}
```
### [first-bad-version](https://leetcode-cn.com/problems/first-bad-version/)
> 假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。
> 你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
```go
func firstBadVersion(n int) int {
// 思路:二分搜索
start := 0
end := n
for start+1 < end {
mid := start + (end - start)/2
if isBadVersion(mid) {
end = mid
} else if isBadVersion(mid) == false {
start = mid
}
}
if isBadVersion(start) {
return start
}
return end
}
```
### [find-minimum-in-rotated-sorted-array](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array/)
> 假设按照升序排序的数组在预先未知的某个点上进行了旋转( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
> 请找出其中最小的元素。
```go
func findMin(nums []int) int {
// 思路:/ / 最后一个值作为target,然后往左移动,最后比较start、end的值
if len(nums) == 0 {
return -1
}
start := 0
end := len(nums) - 1
for start+1 < end {
mid := start + (end-start)/2
// 最后一个元素值为target
if nums[mid] <= nums[end] {
end = mid
} else {
start = mid
}
}
if nums[start] > nums[end] {
return nums[end]
}
return nums[start]
}
```
### [find-minimum-in-rotated-sorted-array-ii](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array-ii/)
> 假设按照升序排序的数组在预先未知的某个点上进行了旋转
> ( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
> 请找出其中最小的元素。(包含重复元素)
```go
func findMin(nums []int) int {
// 思路:跳过重复元素,mid值和end值比较,分为两种情况进行处理
if len(nums) == 0 {
return -1
}
start := 0
end := len(nums) - 1
for start+1 < end {
// 去除重复元素
for start < end && nums[end] == nums[end-1] {
end--
}
for start < end && nums[start] == nums[start+1] {
start++
}
mid := start + (end-start)/2
// 中间元素和最后一个元素比较(判断中间点落在左边上升区,还是右边上升区)
if nums[mid] <= nums[end] {
end = mid
} else {
start = mid
}
}
if nums[start] > nums[end] {
return nums[end]
}
return nums[start]
}
```
### [search-in-rotated-sorted-array](https://leetcode-cn.com/problems/search-in-rotated-sorted-array/)
> 假设按照升序排序的数组在预先未知的某个点上进行了旋转。
> ( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
> 搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
> 你可以假设数组中不存在重复的元素。
```go
func search(nums []int, target int) int {
// 思路:/ / 两条上升直线,四种情况判断
if len(nums) == 0 {
return -1
}
start := 0
end := len(nums) - 1
for start+1 < end {
mid := start + (end-start)/2
// 相等直接返回
if nums[mid] == target {
return mid
}
// 判断在那个区间,可能分为四种情况
if nums[start] < nums[mid] {
if nums[start] <= target && target <= nums[mid] {
end = mid
} else {
start = mid
}
} else if nums[end] > nums[mid] {
if nums[end] >= target && nums[mid] <= target {
start = mid
} else {
end = mid
}
}
}
if nums[start] == target {
return start
} else if nums[end] == target {
return end
}
return -1
}
```
注意点
> 面试时,可以直接画图进行辅助说明,空讲很容易让大家都比较蒙圈
### [search-in-rotated-sorted-array-ii](https://leetcode-cn.com/problems/search-in-rotated-sorted-array-ii/)
> 假设按照升序排序的数组在预先未知的某个点上进行了旋转。
> ( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
> 编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。(包含重复元素)
```go
func search(nums []int, target int) bool {
// 思路:/ / 两条上升直线,四种情况判断,并且处理重复数字
if len(nums) == 0 {
return false
}
start := 0
end := len(nums) - 1
for start+1 < end {
// 处理重复数字
for start < end && nums[start] == nums[start+1] {
start++
}
for start < end && nums[end] == nums[end-1] {
end--
}
mid := start + (end-start)/2
// 相等直接返回
if nums[mid] == target {
return true
}
// 判断在那个区间,可能分为四种情况
if nums[start] < nums[mid] {
if nums[start] <= target && target <= nums[mid] {
end = mid
} else {
start = mid
}
} else if nums[end] > nums[mid] {
if nums[end] >= target && nums[mid] <= target {
start = mid
} else {
end = mid
}
}
}
if nums[start] == target || nums[end] == target {
return true
}
return false
}
```
## 总结
二分搜索核心四点要素(必背&理解)
- 1、初始化:start=0、end=len-1
- 2、循环退出条件:start + 1 < end
- 3、比较中点和目标值:A[mid] ==、 <、> target
- 4、判断最后两个元素是否符合:A[start]、A[end] ? target
## 练习题
- [ ] [search-for-range](https://www.lintcode.com/problem/search-for-a-range/description)
- [ ] [search-insert-position](https://leetcode-cn.com/problems/search-insert-position/)
- [ ] [search-a-2d-matrix](https://leetcode-cn.com/problems/search-a-2d-matrix/)
- [ ] [first-bad-version](https://leetcode-cn.com/problems/first-bad-version/)
- [ ] [find-minimum-in-rotated-sorted-array](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array/)
- [ ] [find-minimum-in-rotated-sorted-array-ii](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array-ii/)
- [ ] [search-in-rotated-sorted-array](https://leetcode-cn.com/problems/search-in-rotated-sorted-array/)
- [ ] [search-in-rotated-sorted-array-ii](https://leetcode-cn.com/problems/search-in-rotated-sorted-array-ii/)
================================================
FILE: basic_algorithm/dp.md
================================================
# 动态规划
## 背景
先从一道题目开始~
如题 [triangle](https://leetcode-cn.com/problems/triangle/)
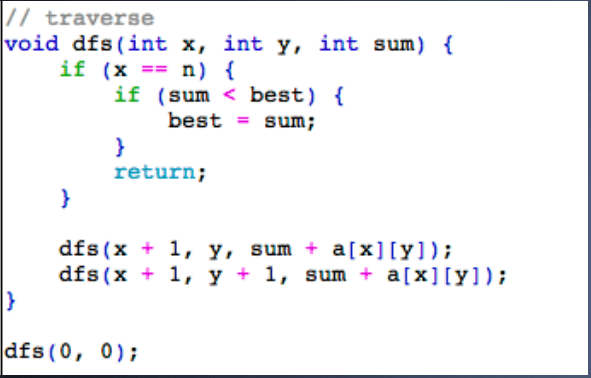
> 给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
例如,给定三角形:
```text
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]
```
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
使用 DFS(遍历 或者 分治法)
遍历
分治法
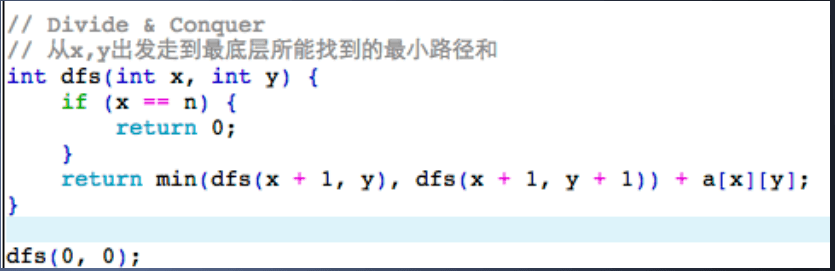
优化 DFS,缓存已经被计算的值(称为:记忆化搜索 本质上:动态规划)
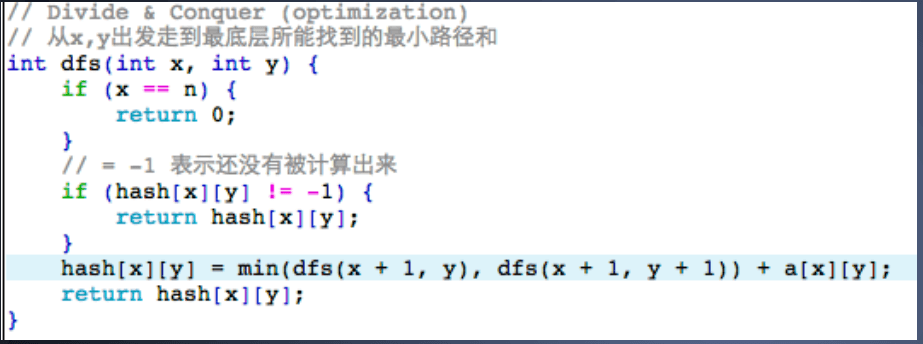
动态规划就是把大问题变成小问题,并解决了小问题重复计算的方法称为动态规划
动态规划和 DFS 区别
- 二叉树 子问题是没有交集,所以大部分二叉树都用递归或者分治法,即 DFS,就可以解决
- 像 triangle 这种是有重复走的情况,**子问题是有交集**,所以可以用动态规划来解决
动态规划,自底向上
```go
func minimumTotal(triangle [][]int) int {
if len(triangle) == 0 || len(triangle[0]) == 0 {
return 0
}
// 1、状态定义:f[i][j] 表示从i,j出发,到达最后一层的最短路径
var l = len(triangle)
var f = make([][]int, l)
// 2、初始化
for i := 0; i < l; i++ {
for j := 0; j < len(triangle[i]); j++ {
if f[i] == nil {
f[i] = make([]int, len(triangle[i]))
}
f[i][j] = triangle[i][j]
}
}
// 3、递推求解
for i := len(triangle) - 2; i >= 0; i-- {
for j := 0; j < len(triangle[i]); j++ {
f[i][j] = min(f[i+1][j], f[i+1][j+1]) + triangle[i][j]
}
}
// 4、答案
return f[0][0]
}
func min(a, b int) int {
if a > b {
return b
}
return a
}
```
动态规划,自顶向下
```go
// 测试用例:
// [
// [2],
// [3,4],
// [6,5,7],
// [4,1,8,3]
// ]
func minimumTotal(triangle [][]int) int {
if len(triangle) == 0 || len(triangle[0]) == 0 {
return 0
}
// 1、状态定义:f[i][j] 表示从0,0出发,到达i,j的最短路径
var l = len(triangle)
var f = make([][]int, l)
// 2、初始化
for i := 0; i < l; i++ {
for j := 0; j < len(triangle[i]); j++ {
if f[i] == nil {
f[i] = make([]int, len(triangle[i]))
}
f[i][j] = triangle[i][j]
}
}
// 递推求解
for i := 1; i < l; i++ {
for j := 0; j < len(triangle[i]); j++ {
// 这里分为两种情况:
// 1、上一层没有左边值
// 2、上一层没有右边值
if j-1 < 0 {
f[i][j] = f[i-1][j] + triangle[i][j]
} else if j >= len(f[i-1]) {
f[i][j] = f[i-1][j-1] + triangle[i][j]
} else {
f[i][j] = min(f[i-1][j], f[i-1][j-1]) + triangle[i][j]
}
}
}
result := f[l-1][0]
for i := 1; i < len(f[l-1]); i++ {
result = min(result, f[l-1][i])
}
return result
}
func min(a, b int) int {
if a > b {
return b
}
return a
}
```
## 递归和动规关系
递归是一种程序的实现方式:函数的自我调用
```go
Function(x) {
...
Funciton(x-1);
...
}
```
动态规划:是一种解决问 题的思想,大规模问题的结果,是由小规模问 题的结果运算得来的。动态规划可用递归来实现(Memorization Search)
## 使用场景
满足两个条件
- 满足以下条件之一
- 求最大/最小值(Maximum/Minimum )
- 求是否可行(Yes/No )
- 求可行个数(Count(\*) )
- 满足不能排序或者交换(Can not sort / swap )
如题:[longest-consecutive-sequence](https://leetcode-cn.com/problems/longest-consecutive-sequence/) 位置可以交换,所以不用动态规划
## 四点要素
1. **状态 State**
- 灵感,创造力,存储小规模问题的结果
2. 方程 Function
- 状态之间的联系,怎么通过小的状态,来算大的状态
3. 初始化 Intialization
- 最极限的小状态是什么, 起点
4. 答案 Answer
- 最大的那个状态是什么,终点
## 常见四种类型
1. Matrix DP (10%)
1. Sequence (40%)
1. Two Sequences DP (40%)
1. Backpack (10%)
> 注意点
>
> - 贪心算法大多题目靠背答案,所以如果能用动态规划就尽量用动规,不用贪心算法
## 1、矩阵类型(10%)
### [minimum-path-sum](https://leetcode-cn.com/problems/minimum-path-sum/)
> 给定一个包含非负整数的 *m* x *n* 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
思路:动态规划
1、state: f[x][y]从起点走到 x,y 的最短路径
2、function: f[x][y] = min(f[x-1][y], f[x][y-1]) + A[x][y]
3、intialize: f[0][0] = A[0][0]、f[i][0] = sum(0,0 -> i,0)、 f[0][i] = sum(0,0 -> 0,i)
4、answer: f[n-1][m-1]
```go
func minPathSum(grid [][]int) int {
// 思路:动态规划
// f[i][j] 表示i,j到0,0的和最小
if len(grid) == 0 || len(grid[0]) == 0 {
return 0
}
// 复用原来的矩阵列表
// 初始化:f[i][0]、f[0][j]
for i := 1; i < len(grid); i++ {
grid[i][0] = grid[i][0] + grid[i-1][0]
}
for j := 1; j < len(grid[0]); j++ {
grid[0][j] = grid[0][j] + grid[0][j-1]
}
for i := 1; i < len(grid); i++ {
for j := 1; j < len(grid[i]); j++ {
grid[i][j] = min(grid[i][j-1], grid[i-1][j]) + grid[i][j]
}
}
return grid[len(grid)-1][len(grid[0])-1]
}
func min(a, b int) int {
if a > b {
return b
}
return a
}
```
### [unique-paths](https://leetcode-cn.com/problems/unique-paths/)
> 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
> 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
> 问总共有多少条不同的路径?
```go
func uniquePaths(m int, n int) int {
// f[i][j] 表示i,j到0,0路径数
f := make([][]int, m)
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
if f[i] == nil {
f[i] = make([]int, n)
}
f[i][j] = 1
}
}
for i := 1; i < m; i++ {
for j := 1; j < n; j++ {
f[i][j] = f[i-1][j] + f[i][j-1]
}
}
return f[m-1][n-1]
}
```
### [unique-paths-ii](https://leetcode-cn.com/problems/unique-paths-ii/)
> 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
> 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
> 问总共有多少条不同的路径?
> 现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
```go
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
// f[i][j] = f[i-1][j] + f[i][j-1] 并检查障碍物
if obstacleGrid[0][0] == 1 {
return 0
}
m := len(obstacleGrid)
n := len(obstacleGrid[0])
f := make([][]int, m)
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
if f[i] == nil {
f[i] = make([]int, n)
}
f[i][j] = 1
}
}
for i := 1; i < m; i++ {
if obstacleGrid[i][0] == 1 || f[i-1][0] == 0 {
f[i][0] = 0
}
}
for j := 1; j < n; j++ {
if obstacleGrid[0][j] == 1 || f[0][j-1] == 0 {
f[0][j] = 0
}
}
for i := 1; i < m; i++ {
for j := 1; j < n; j++ {
if obstacleGrid[i][j] == 1 {
f[i][j] = 0
} else {
f[i][j] = f[i-1][j] + f[i][j-1]
}
}
}
return f[m-1][n-1]
}
```
## 2、序列类型(40%)
### [climbing-stairs](https://leetcode-cn.com/problems/climbing-stairs/)
> 假设你正在爬楼梯。需要 *n* 阶你才能到达楼顶。
```go
func climbStairs(n int) int {
// f[i] = f[i-1] + f[i-2]
if n == 1 || n == 0 {
return n
}
f := make([]int, n+1)
f[1] = 1
f[2] = 2
for i := 3; i <= n; i++ {
f[i] = f[i-1] + f[i-2]
}
return f[n]
}
```
### [jump-game](https://leetcode-cn.com/problems/jump-game/)
> 给定一个非负整数数组,你最初位于数组的第一个位置。
> 数组中的每个元素代表你在该位置可以跳跃的最大长度。
> 判断你是否能够到达最后一个位置。
```go
func canJump(nums []int) bool {
// 思路:看最后一跳
// 状态:f[i] 表示是否能从0跳到i
// 推导:f[i] = OR(f[j],j<i&&j能跳到i) 判断之前所有的点最后一跳是否能跳到当前点
// 初始化:f[0] = 0
// 结果: f[n-1]
if len(nums) == 0 {
return true
}
f := make([]bool, len(nums))
f[0] = true
for i := 1; i < len(nums); i++ {
for j := 0; j < i; j++ {
if f[j] == true && nums[j]+j >= i {
f[i] = true
}
}
}
return f[len(nums)-1]
}
```
### [jump-game-ii](https://leetcode-cn.com/problems/jump-game-ii/)
> 给定一个非负整数数组,你最初位于数组的第一个位置。
> 数组中的每个元素代表你在该位置可以跳跃的最大长度。
> 你的目标是使用最少的跳跃次数到达数组的最后一个位置。
```go
// v1动态规划(其他语言超时参考v2)
func jump(nums []int) int {
// 状态:f[i] 表示从起点到当前位置最小次数
// 推导:f[i] = f[j],a[j]+j >=i,min(f[j]+1)
// 初始化:f[0] = 0
// 结果:f[n-1]
f := make([]int, len(nums))
f[0] = 0
for i := 1; i < len(nums); i++ {
// f[i] 最大值为i
f[i] = i
// 遍历之前结果取一个最小值+1
for j := 0; j < i; j++ {
if nums[j]+j >= i {
f[i] = min(f[j]+1,f[i])
}
}
}
return f[len(nums)-1]
}
func min(a, b int) int {
if a > b {
return b
}
return a
}
```
```go
// v2 动态规划+贪心优化
func jump(nums []int) int {
n:=len(nums)
f := make([]int, n)
f[0] = 0
for i := 1; i < n; i++ {
// 取第一个能跳到当前位置的点即可
// 因为跳跃次数的结果集是单调递增的,所以贪心思路是正确的
idx:=0
for idx<n&&idx+nums[idx]<i{
idx++
}
f[i]=f[idx]+1
}
return f[n-1]
}
```
### [palindrome-partitioning-ii](https://leetcode-cn.com/problems/palindrome-partitioning-ii/)
> 给定一个字符串 _s_,将 _s_ 分割成一些子串,使每个子串都是回文串。
> 返回符合要求的最少分割次数。
```go
func minCut(s string) int {
// state: f[i] "前i"个字符组成的子字符串需要最少几次cut(个数-1为索引)
// function: f[i] = MIN{f[j]+1}, j < i && [j+1 ~ i]这一段是一个回文串
// intialize: f[i] = i - 1 (f[0] = -1)
// answer: f[s.length()]
if len(s) == 0 || len(s) == 1 {
return 0
}
f := make([]int, len(s)+1)
f[0] = -1
f[1] = 0
for i := 1; i <= len(s); i++ {
f[i] = i - 1
for j := 0; j < i; j++ {
if isPalindrome(s, j, i-1) {
f[i] = min(f[i], f[j]+1)
}
}
}
return f[len(s)]
}
func min(a, b int) int {
if a > b {
return b
}
return a
}
func isPalindrome(s string, i, j int) bool {
for i < j {
if s[i] != s[j] {
return false
}
i++
j--
}
return true
}
```
注意点
- 判断回文字符串时,可以提前用动态规划算好,减少时间复杂度
### [longest-increasing-subsequence](https://leetcode-cn.com/problems/longest-increasing-subsequence/)
> 给定一个无序的整数数组,找到其中最长上升子序列的长度。
```go
func lengthOfLIS(nums []int) int {
// f[i] 表示从0开始到i结尾的最长序列长度
// f[i] = max(f[j])+1 ,a[j]<a[i]
// f[0...n-1] = 1
// max(f[0]...f[n-1])
if len(nums) == 0 || len(nums) == 1 {
return len(nums)
}
f := make([]int, len(nums))
f[0] = 1
for i := 1; i < len(nums); i++ {
f[i] = 1
for j := 0; j < i; j++ {
if nums[j] < nums[i] {
f[i] = max(f[i], f[j]+1)
}
}
}
result := f[0]
for i := 1; i < len(nums); i++ {
result = max(result, f[i])
}
return result
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
```
### [word-break](https://leetcode-cn.com/problems/word-break/)
> 给定一个**非空**字符串 *s* 和一个包含**非空**单词列表的字典 *wordDict*,判定 *s* 是否可以被空格拆分为一个或多个在字典中出现的单词。
```go
func wordBreak(s string, wordDict []string) bool {
// f[i] 表示前i个字符是否可以被切分
// f[i] = f[j] && s[j+1~i] in wordDict
// f[0] = true
// return f[len]
if len(s) == 0 {
return true
}
f := make([]bool, len(s)+1)
f[0] = true
max,dict := maxLen(wordDict)
for i := 1; i <= len(s); i++ {
l := 0
if i - max > 0 {
l = i - max
}
for j := l; j < i; j++ {
if f[j] && inDict(s[j:i],dict) {
f[i] = true
break
}
}
}
return f[len(s)]
}
func maxLen(wordDict []string) (int,map[string]bool) {
dict := make(map[string]bool)
max := 0
for _, v := range wordDict {
dict[v] = true
if len(v) > max {
max = len(v)
}
}
return max,dict
}
func inDict(s string,dict map[string]bool) bool {
_, ok := dict[s]
return ok
}
```
小结
常见处理方式是给 0 位置占位,这样处理问题时一视同仁,初始化则在原来基础上 length+1,返回结果 f[n]
- 状态可以为前 i 个
- 初始化 length+1
- 取值 index=i-1
- 返回值:f[n]或者 f[m][n]
## Two Sequences DP(40%)
### [longest-common-subsequence](https://leetcode-cn.com/problems/longest-common-subsequence/)
> 给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列。
> 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
> 例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
```go
func longestCommonSubsequence(a string, b string) int {
// dp[i][j] a前i个和b前j个字符最长公共子序列
// dp[m+1][n+1]
// ' a d c e
// ' 0 0 0 0 0
// a 0 1 1 1 1
// c 0 1 1 2 1
//
dp:=make([][]int,len(a)+1)
for i:=0;i<=len(a);i++ {
dp[i]=make([]int,len(b)+1)
}
for i:=1;i<=len(a);i++ {
for j:=1;j<=len(b);j++ {
// 相等取左上元素+1,否则取左或上的较大值
if a[i-1]==b[j-1] {
dp[i][j]=dp[i-1][j-1]+1
} else {
dp[i][j]=max(dp[i-1][j],dp[i][j-1])
}
}
}
return dp[len(a)][len(b)]
}
func max(a,b int)int {
if a>b{
return a
}
return b
}
```
注意点
- go 切片初始化
```go
dp:=make([][]int,len(a)+1)
for i:=0;i<=len(a);i++ {
dp[i]=make([]int,len(b)+1)
}
```
- 从 1 开始遍历到最大长度
- 索引需要减一
### [edit-distance](https://leetcode-cn.com/problems/edit-distance/)
> 给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数
> 你可以对一个单词进行如下三种操作:
> 插入一个字符
> 删除一个字符
> 替换一个字符
思路:和上题很类似,相等则不需要操作,否则取删除、插入、替换最小操作次数的值+1
```go
func minDistance(word1 string, word2 string) int {
// dp[i][j] 表示a字符串的前i个字符编辑为b字符串的前j个字符最少需要多少次操作
// dp[i][j] = OR(dp[i-1][j-1],a[i]==b[j],min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])+1)
dp:=make([][]int,len(word1)+1)
for i:=0;i<len(dp);i++{
dp[i]=make([]int,len(word2)+1)
}
for i:=0;i<len(dp);i++{
dp[i][0]=i
}
for j:=0;j<len(dp[0]);j++{
dp[0][j]=j
}
for i:=1;i<=len(word1);i++{
for j:=1;j<=len(word2);j++{
// 相等则不需要操作
if word1[i-1]==word2[j-1] {
dp[i][j]=dp[i-1][j-1]
}else{ // 否则取删除、插入、替换最小操作次数的值+1
dp[i][j]=min(min(dp[i-1][j],dp[i][j-1]),dp[i-1][j-1])+1
}
}
}
return dp[len(word1)][len(word2)]
}
func min(a,b int)int{
if a>b{
return b
}
return a
}
```
说明
> 另外一种做法:MAXLEN(a,b)-LCS(a,b)
## 零钱和背包(10%)
### [coin-change](https://leetcode-cn.com/problems/coin-change/)
> 给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
思路:和其他 DP 不太一样,i 表示钱或者容量
```go
func coinChange(coins []int, amount int) int {
// 状态 dp[i]表示金额为i时,组成的最小硬币个数
// 推导 dp[i] = min(dp[i-1], dp[i-2], dp[i-5])+1, 前提 i-coins[j] > 0
// 初始化为最大值 dp[i]=amount+1
// 返回值 dp[n] or dp[n]>amount =>-1
dp:=make([]int,amount+1)
for i:=0;i<=amount;i++{
dp[i]=amount+1
}
dp[0]=0
for i:=1;i<=amount;i++{
for j:=0;j<len(coins);j++{
if i-coins[j]>=0 {
dp[i]=min(dp[i],dp[i-coins[j]]+1)
}
}
}
if dp[amount] > amount {
return -1
}
return dp[amount]
}
func min(a,b int)int{
if a>b{
return b
}
return a
}
```
注意
> dp[i-a[j]] 决策 a[j]是否参与
### [backpack](https://www.lintcode.com/problem/backpack/description)
> 在 n 个物品中挑选若干物品装入背包,最多能装多满?假设背包的大小为 m,每个物品的大小为 A[i]
```go
func backPack (m int, A []int) int {
// write your code here
// f[i][j] 前i个物品,是否能装j
// f[i][j] =f[i-1][j] f[i-1][j-a[i] j>a[i]
// f[0][0]=true f[...][0]=true
// f[n][X]
f:=make([][]bool,len(A)+1)
for i:=0;i<=len(A);i++{
f[i]=make([]bool,m+1)
}
f[0][0]=true
for i:=1;i<=len(A);i++{
for j:=0;j<=m;j++{
f[i][j]=f[i-1][j]
if j-A[i-1]>=0 && f[i-1][j-A[i-1]]{
f[i][j]=true
}
}
}
for i:=m;i>=0;i--{
if f[len(A)][i] {
return i
}
}
return 0
}
```
### [backpack-ii](https://www.lintcode.com/problem/backpack-ii/description)
> 有 `n` 个物品和一个大小为 `m` 的背包. 给定数组 `A` 表示每个物品的大小和数组 `V` 表示每个物品的价值.
> 问最多能装入背包的总价值是多大?
思路:f[i][j] 前 i 个物品,装入 j 背包 最大价值
```go
func backPackII (m int, A []int, V []int) int {
// write your code here
// f[i][j] 前i个物品,装入j背包 最大价值
// f[i][j] =max(f[i-1][j] ,f[i-1][j-A[i]]+V[i]) 是否加入A[i]物品
// f[0][0]=0 f[0][...]=0 f[...][0]=0
f:=make([][]int,len(A)+1)
for i:=0;i<len(A)+1;i++{
f[i]=make([]int,m+1)
}
for i:=1;i<=len(A);i++{
for j:=0;j<=m;j++{
f[i][j]=f[i-1][j]
if j-A[i-1] >= 0{
f[i][j]=max(f[i-1][j],f[i-1][j-A[i-1]]+V[i-1])
}
}
}
return f[len(A)][m]
}
func max(a,b int)int{
if a>b{
return a
}
return b
}
```
## 练习
Matrix DP (10%)
- [ ] [triangle](https://leetcode-cn.com/problems/triangle/)
- [ ] [minimum-path-sum](https://leetcode-cn.com/problems/minimum-path-sum/)
- [ ] [unique-paths](https://leetcode-cn.com/problems/unique-paths/)
- [ ] [unique-paths-ii](https://leetcode-cn.com/problems/unique-paths-ii/)
Sequence (40%)
- [ ] [climbing-stairs](https://leetcode-cn.com/problems/climbing-stairs/)
- [ ] [jump-game](https://leetcode-cn.com/problems/jump-game/)
- [ ] [jump-game-ii](https://leetcode-cn.com/problems/jump-game-ii/)
- [ ] [palindrome-partitioning-ii](https://leetcode-cn.com/problems/palindrome-partitioning-ii/)
- [ ] [longest-increasing-subsequence](https://leetcode-cn.com/problems/longest-increasing-subsequence/)
- [ ] [word-break](https://leetcode-cn.com/problems/word-break/)
Two Sequences DP (40%)
- [ ] [longest-common-subsequence](https://leetcode-cn.com/problems/longest-common-subsequence/)
- [ ] [edit-distance](https://leetcode-cn.com/problems/edit-distance/)
Backpack & Coin Change (10%)
- [ ] [coin-change](https://leetcode-cn.com/problems/coin-change/)
- [ ] [backpack](https://www.lintcode.com/problem/backpack/description)
- [ ] [backpack-ii](https://www.lintcode.com/problem/backpack-ii/description)
================================================
FILE: basic_algorithm/sort.md
================================================
# 排序
## 常考排序
### 快速排序
```go
func QuickSort(nums []int) []int {
// 思路:把一个数组分为左右两段,左段小于右段
quickSort(nums, 0, len(nums)-1)
return nums
}
// 原地交换,所以传入交换索引
func quickSort(nums []int, start, end int) {
if start < end {
// 分治法:divide
pivot := partition(nums, start, end)
quickSort(nums, 0, pivot-1)
quickSort(nums, pivot+1, end)
}
}
// 分区
func partition(nums []int, start, end int) int {
// 选取最后一个元素作为基准pivot
p := nums[end]
i := start
// 最后一个值就是基准所以不用比较
for j := start; j < end; j++ {
if nums[j] < p {
swap(nums, i, j)
i++
}
}
// 把基准值换到中间
swap(nums, i, end)
return i
}
// 交换两个元素
func swap(nums []int, i, j int) {
t := nums[i]
nums[i] = nums[j]
nums[j] = t
}
```
### 归并排序
```go
func MergeSort(nums []int) []int {
return mergeSort(nums)
}
func mergeSort(nums []int) []int {
if len(nums) <= 1 {
return nums
}
// 分治法:divide 分为两段
mid := len(nums) / 2
left := mergeSort(nums[:mid])
right := mergeSort(nums[mid:])
// 合并两段数据
result := merge(left, right)
return result
}
func merge(left, right []int) (result []int) {
// 两边数组合并游标
l := 0
r := 0
// 注意不能越界
for l < len(left) && r < len(right) {
// 谁小合并谁
if left[l] > right[r] {
result = append(result, right[r])
r++
} else {
result = append(result, left[l])
l++
}
}
// 剩余部分合并
result = append(result, left[l:]...)
result = append(result, right[r:]...)
return
}
```
### 堆排序
用数组表示的完美二叉树 complete binary tree
> 完美二叉树 VS 其他二叉树
[动画展示](https://www.bilibili.com/video/av18980178/)
核心代码
```go
package main
func HeapSort(a []int) []int {
// 1、无序数组a
// 2、将无序数组a构建为一个大根堆
for i := len(a)/2 - 1; i >= 0; i-- {
sink(a, i, len(a))
}
// 3、交换a[0]和a[len(a)-1]
// 4、然后把前面这段数组继续下沉保持堆结构,如此循环即可
for i := len(a) - 1; i >= 1; i-- {
// 从后往前填充值
swap(a, 0, i)
// 前面的长度也减一
sink(a, 0, i)
}
return a
}
func sink(a []int, i int, length int) {
for {
// 左节点索引(从0开始,所以左节点为i*2+1)
l := i*2 + 1
// 右节点索引
r := i*2 + 2
// idx保存根、左、右三者之间较大值的索引
idx := i
// 存在左节点,左节点值较大,则取左节点
if l < length && a[l] > a[idx] {
idx = l
}
// 存在右节点,且值较大,取右节点
if r < length && a[r] > a[idx] {
idx = r
}
// 如果根节点较大,则不用下沉
if idx == i {
break
}
// 如果根节点较小,则交换值,并继续下沉
swap(a, i, idx)
// 继续下沉idx节点
i = idx
}
}
func swap(a []int, i, j int) {
a[i], a[j] = a[j], a[i]
}
```
## 参考
[十大经典排序](https://www.cnblogs.com/onepixel/p/7674659.html)
[二叉堆](https://labuladong.gitbook.io/algo/shu-ju-jie-gou-xi-lie/er-cha-dui-xiang-jie-shi-xian-you-xian-ji-dui-lie)
## 练习
- [ ] 手写快排、归并、堆排序
================================================
FILE: data_structure/binary_op.md
================================================
# 二进制
## 常见二进制操作
### 基本操作
a=0^a=a^0
0=a^a
由上面两个推导出:a=a^b^b
### 交换两个数
a=a^b
b=a^b
a=a^b
### 移除最后一个 1
a=n&(n-1)
### 获取最后一个 1
diff=(n&(n-1))^n
## 常见题目
[single-number](https://leetcode-cn.com/problems/single-number/)
> 给定一个**非空**整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
```go
func singleNumber(nums []int) int {
// 10 ^10 == 00
// 两个数异或就变成0
result:=0
for i:=0;i<len(nums);i++{
result=result^nums[i]
}
return result
}
```
[single-number-ii](https://leetcode-cn.com/problems/single-number-ii/)
> 给定一个**非空**整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。
```go
func singleNumber(nums []int) int {
// 统计每位1的个数
var result int
for i := 0; i < 64; i++ {
sum := 0
for j := 0; j < len(nums); j++ {
// 统计1的个数
sum += (nums[j] >> i) & 1
}
// 还原位00^10=10 或者用| 也可以
result ^= (sum % 3) << i
}
return result
}
```
[single-number-iii](https://leetcode-cn.com/problems/single-number-iii/)
> 给定一个整数数组 `nums`,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。
```go
func singleNumber(nums []int) []int {
// a=a^b
// b=a^b
// a=a^b
// 关键点怎么把a^b分成两部分,方案:可以通过diff最后一个1区分
diff:=0
for i:=0;i<len(nums);i++{
diff^=nums[i]
}
result:=[]int{diff,diff}
// 去掉末尾的1后异或diff就得到最后一个1的位置
diff=(diff&(diff-1))^diff
for i:=0;i<len(nums);i++{
if diff&nums[i]==0{
result[0]^=nums[i]
}else{
result[1]^=nums[i]
}
}
return result
}
```
[number-of-1-bits](https://leetcode-cn.com/problems/number-of-1-bits/)
> 编写一个函数,输入是一个无符号整数,返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为[汉明重量](https://baike.baidu.com/item/%E6%B1%89%E6%98%8E%E9%87%8D%E9%87%8F))。
```go
func hammingWeight(num uint32) int {
res:=0
for num!=0{
num=num&(num-1)
res++
}
return res
}
```
[counting-bits](https://leetcode-cn.com/problems/counting-bits/)
> 给定一个非负整数 **num**。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
```go
func countBits(num int) []int {
res:=make([]int,num+1)
for i:=0;i<=num;i++{
res[i]=count1(i)
}
return res
}
func count1(n int)(res int){
for n!=0{
n=n&(n-1)
res++
}
return
}
```
另外一种动态规划解法
```go
func countBits(num int) []int {
res:=make([]int,num+1)
for i:=1;i<=num;i++{
// 上一个缺1的元素+1即可
res[i]=res[i&(i-1)]+1
}
return res
}
```
[reverse-bits](https://leetcode-cn.com/problems/reverse-bits/)
> 颠倒给定的 32 位无符号整数的二进制位。
思路:依次颠倒即可
```go
func reverseBits(num uint32) uint32 {
var res uint32
var pow int=31
for num!=0{
// 把最后一位取出来,左移之后累加到结果中
res+=(num&1)<<pow
num>>=1
pow--
}
return res
}
```
[bitwise-and-of-numbers-range](https://leetcode-cn.com/problems/bitwise-and-of-numbers-range/)
> 给定范围 [m, n],其中 0 <= m <= n <= 2147483647,返回此范围内所有数字的按位与(包含 m, n 两端点)。
```go
func rangeBitwiseAnd(m int, n int) int {
// m 5 1 0 1
// 6 1 1 0
// n 7 1 1 1
// 把可能包含0的全部右移变成
// m 5 1 0 0
// 6 1 0 0
// n 7 1 0 0
// 所以最后结果就是m<<count
var count int
for m!=n{
m>>=1
n>>=1
count++
}
return m<<count
}
```
## 练习
- [ ] [single-number](https://leetcode-cn.com/problems/single-number/)
- [ ] [single-number-ii](https://leetcode-cn.com/problems/single-number-ii/)
- [ ] [single-number-iii](https://leetcode-cn.com/problems/single-number-iii/)
- [ ] [number-of-1-bits](https://leetcode-cn.com/problems/number-of-1-bits/)
- [ ] [counting-bits](https://leetcode-cn.com/problems/counting-bits/)
- [ ] [reverse-bits](https://leetcode-cn.com/problems/reverse-bits/)
================================================
FILE: data_structure/binary_tree.md
================================================
# 二叉树
## 知识点
### 二叉树遍历
**前序遍历**:**先访问根节点**,再前序遍历左子树,再前序遍历右子树
**中序遍历**:先中序遍历左子树,**再访问根节点**,再中序遍历右子树
**后序遍历**:先后序遍历左子树,再后序遍历右子树,**再访问根节点**
注意点
- 以根访问顺序决定是什么遍历
- 左子树都是优先右子树
#### 前序递归
```go
func preorderTraversal(root *TreeNode) {
if root==nil{
return
}
// 先访问根再访问左右
fmt.Println(root.Val)
preorderTraversal(root.Left)
preorderTraversal(root.Right)
}
```
#### 前序非递归
```go
// V3:通过非递归遍历
func preorderTraversal(root *TreeNode) []int {
// 非递归
if root == nil{
return nil
}
result:=make([]int,0)
stack:=make([]*TreeNode,0)
for root!=nil || len(stack)!=0{
for root !=nil{
// 前序遍历,所以先保存结果
result=append(result,root.Val)
stack=append(stack,root)
root=root.Left
}
// pop
node:=stack[len(stack)-1]
stack=stack[:len(stack)-1]
root=node.Right
}
return result
}
```
#### 中序非递归
```go
// 思路:通过stack 保存已经访问的元素,用于原路返回
func inorderTraversal(root *TreeNode) []int {
result := make([]int, 0)
if root == nil {
return result
}
stack := make([]*TreeNode, 0)
for len(stack) > 0 || root != nil {
for root != nil {
stack = append(stack, root)
root = root.Left // 一直向左
}
// 弹出
val := stack[len(stack)-1]
stack = stack[:len(stack)-1]
result = append(result, val.Val)
root = val.Right
}
return result
}
```
#### 后序非递归
```go
func postorderTraversal(root *TreeNode) []int {
// 通过lastVisit标识右子节点是否已经弹出
if root == nil {
return nil
}
result := make([]int, 0)
stack := make([]*TreeNode, 0)
var lastVisit *TreeNode
for root != nil || len(stack) != 0 {
for root != nil {
stack = append(stack, root)
root = root.Left
}
// 这里先看看,先不弹出
node:= stack[len(stack)-1]
// 根节点必须在右节点弹出之后,再弹出
if node.Right == nil || node.Right == lastVisit {
stack = stack[:len(stack)-1] // pop
result = append(result, node.Val)
// 标记当前这个节点已经弹出过
lastVisit = node
} else {
root = node.Right
}
}
return result
}
```
注意点
- 核心就是:根节点必须在右节点弹出之后,再弹出
#### DFS 深度搜索-从上到下
```go
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func preorderTraversal(root *TreeNode) []int {
result := make([]int, 0)
dfs(root, &result)
return result
}
// V1:深度遍历,结果指针作为参数传入到函数内部
func dfs(root *TreeNode, result *[]int) {
if root == nil {
return
}
*result = append(*result, root.Val)
dfs(root.Left, result)
dfs(root.Right, result)
}
```
#### DFS 深度搜索-从下向上(分治法)
```go
// V2:通过分治法遍历
func preorderTraversal(root *TreeNode) []int {
result := divideAndConquer(root)
return result
}
func divideAndConquer(root *TreeNode) []int {
result := make([]int, 0)
// 返回条件(null & leaf)
if root == nil {
return result
}
// 分治(Divide)
left := divideAndConquer(root.Left)
right := divideAndConquer(root.Right)
// 合并结果(Conquer)
result = append(result, root.Val)
result = append(result, left...)
result = append(result, right...)
return result
}
```
注意点:
> DFS 深度搜索(从上到下) 和分治法区别:前者一般将最终结果通过指针参数传入,后者一般递归返回结果最后合并
#### BFS 层次遍历
```go
func levelOrder(root *TreeNode) [][]int {
// 通过上一层的长度确定下一层的元素
result := make([][]int, 0)
if root == nil {
return result
}
queue := make([]*TreeNode, 0)
queue = append(queue, root)
for len(queue) > 0 {
list := make([]int, 0)
// 为什么要取length?
// 记录当前层有多少元素(遍历当前层,再添加下一层)
l := len(queue)
for i := 0; i < l; i++ {
// 出队列
level := queue[0]
queue = queue[1:]
list = append(list, level.Val)
if level.Left != nil {
queue = append(queue, level.Left)
}
if level.Right != nil {
queue = append(queue, level.Right)
}
}
result = append(result, list)
}
return result
}
```
### 分治法应用
先分别处理局部,再合并结果
适用场景
- 快速排序
- 归并排序
- 二叉树相关问题
分治法模板
- 递归返回条件
- 分段处理
- 合并结果
```go
func traversal(root *TreeNode) ResultType {
// nil or leaf
if root == nil {
// do something and return
}
// Divide
ResultType left = traversal(root.Left)
ResultType right = traversal(root.Right)
// Conquer
ResultType result = Merge from left and right
return result
}
```
#### 典型示例
```go
// V2:通过分治法遍历二叉树
func preorderTraversal(root *TreeNode) []int {
result := divideAndConquer(root)
return result
}
func divideAndConquer(root *TreeNode) []int {
result := make([]int, 0)
// 返回条件(null & leaf)
if root == nil {
return result
}
// 分治(Divide)
left := divideAndConquer(root.Left)
right := divideAndConquer(root.Right)
// 合并结果(Conquer)
result = append(result, root.Val)
result = append(result, left...)
result = append(result, right...)
return result
}
```
#### 归并排序
```go
func MergeSort(nums []int) []int {
return mergeSort(nums)
}
func mergeSort(nums []int) []int {
if len(nums) <= 1 {
return nums
}
// 分治法:divide 分为两段
mid := len(nums) / 2
left := mergeSort(nums[:mid])
right := mergeSort(nums[mid:])
// 合并两段数据
result := merge(left, right)
return result
}
func merge(left, right []int) (result []int) {
// 两边数组合并游标
l := 0
r := 0
// 注意不能越界
for l < len(left) && r < len(right) {
// 谁小合并谁
if left[l] > right[r] {
result = append(result, right[r])
r++
} else {
result = append(result, left[l])
l++
}
}
// 剩余部分合并
result = append(result, left[l:]...)
result = append(result, right[r:]...)
return
}
```
注意点
> 递归需要返回结果用于合并
#### 快速排序
```go
func QuickSort(nums []int) []int {
// 思路:把一个数组分为左右两段,左段小于右段,类似分治法没有合并过程
quickSort(nums, 0, len(nums)-1)
return nums
}
// 原地交换,所以传入交换索引
func quickSort(nums []int, start, end int) {
if start < end {
// 分治法:divide
pivot := partition(nums, start, end)
quickSort(nums, 0, pivot-1)
quickSort(nums, pivot+1, end)
}
}
// 分区
func partition(nums []int, start, end int) int {
p := nums[end]
i := start
for j := start; j < end; j++ {
if nums[j] < p {
swap(nums, i, j)
i++
}
}
// 把中间的值换为用于比较的基准值
swap(nums, i, end)
return i
}
func swap(nums []int, i, j int) {
t := nums[i]
nums[i] = nums[j]
nums[j] = t
}
```
注意点:
> 快排由于是原地交换所以没有合并过程
> 传入的索引是存在的索引(如:0、length-1 等),越界可能导致崩溃
常见题目示例
#### maximum-depth-of-binary-tree
[maximum-depth-of-binary-tree](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
> 给定一个二叉树,找出其最大深度。
思路:分治法
```go
func maxDepth(root *TreeNode) int {
// 返回条件处理
if root == nil {
return 0
}
// divide:分左右子树分别计算
left := maxDepth(root.Left)
right := maxDepth(root.Right)
// conquer:合并左右子树结果
if left > right {
return left + 1
}
return right + 1
}
```
#### balanced-binary-tree
[balanced-binary-tree](https://leetcode-cn.com/problems/balanced-binary-tree/)
> 给定一个二叉树,判断它是否是高度平衡的二叉树。
思路:分治法,左边平衡 && 右边平衡 && 左右两边高度 <= 1,
因为需要返回是否平衡及高度,要么返回两个数据,要么合并两个数据,
所以用-1 表示不平衡,>0 表示树高度(二义性:一个变量有两种含义)。
```go
func isBalanced(root *TreeNode) bool {
if maxDepth(root) == -1 {
return false
}
return true
}
func maxDepth(root *TreeNode) int {
// check
if root == nil {
return 0
}
left := maxDepth(root.Left)
right := maxDepth(root.Right)
// 为什么返回-1呢?(变量具有二义性)
if left == -1 || right == -1 || left-right > 1 || right-left > 1 {
return -1
}
if left > right {
return left + 1
}
return right + 1
}
```
注意
> 一般工程中,结果通过两个变量来返回,不建议用一个变量表示两种含义
#### binary-tree-maximum-path-sum
[binary-tree-maximum-path-sum](https://leetcode-cn.com/problems/binary-tree-maximum-path-sum/)
> 给定一个**非空**二叉树,返回其最大路径和。
思路:分治法,分为三种情况:左子树最大路径和最大,右子树最大路径和最大,左右子树最大加根节点最大,需要保存两个变量:一个保存子树最大路径和,一个保存左右加根节点和,然后比较这个两个变量选择最大值即可
```go
type ResultType struct {
SinglePath int // 保存单边最大值
MaxPath int // 保存最大值(单边或者两个单边+根的值)
}
func maxPathSum(root *TreeNode) int {
result := helper(root)
return result.MaxPath
}
func helper(root *TreeNode) ResultType {
// check
if root == nil {
return ResultType{
SinglePath: 0,
MaxPath: -(1 << 31),
}
}
// Divide
left := helper(root.Left)
right := helper(root.Right)
// Conquer
result := ResultType{}
// 求单边最大值
if left.SinglePath > right.SinglePath {
result.SinglePath = max(left.SinglePath + root.Val, 0)
} else {
result.SinglePath = max(right.SinglePath + root.Val, 0)
}
// 求两边加根最大值
maxPath := max(right.MaxPath, left.MaxPath)
result.MaxPath = max(maxPath,left.SinglePath+right.SinglePath+root.Val)
return result
}
func max(a,b int) int {
if a > b {
return a
}
return b
}
```
#### lowest-common-ancestor-of-a-binary-tree
[lowest-common-ancestor-of-a-binary-tree](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
> 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
思路:分治法,有左子树的公共祖先或者有右子树的公共祖先,就返回子树的祖先,否则返回根节点
```go
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
// check
if root == nil {
return root
}
// 相等 直接返回root节点即可
if root == p || root == q {
return root
}
// Divide
left := lowestCommonAncestor(root.Left, p, q)
right := lowestCommonAncestor(root.Right, p, q)
// Conquer
// 左右两边都不为空,则根节点为祖先
if left != nil && right != nil {
return root
}
if left != nil {
return left
}
if right != nil {
return right
}
return nil
}
```
### BFS 层次应用
#### binary-tree-level-order-traversal
[binary-tree-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-level-order-traversal/)
> 给你一个二叉树,请你返回其按 **层序遍历** 得到的节点值。 (即逐层地,从左到右访问所有节点)
思路:用一个队列记录一层的元素,然后扫描这一层元素添加下一层元素到队列(一个数进去出来一次,所以复杂度 O(logN))
```go
func levelOrder(root *TreeNode) [][]int {
result := make([][]int, 0)
if root == nil {
return result
}
queue := make([]*TreeNode, 0)
queue = append(queue, root)
for len(queue) > 0 {
list := make([]int, 0)
// 为什么要取length?
// 记录当前层有多少元素(遍历当前层,再添加下一层)
l := len(queue)
for i := 0; i < l; i++ {
// 出队列
level := queue[0]
queue = queue[1:]
list = append(list, level.Val)
if level.Left != nil {
queue = append(queue, level.Left)
}
if level.Right != nil {
queue = append(queue, level.Right)
}
}
result = append(result, list)
}
return result
}
```
#### binary-tree-level-order-traversal-ii
[binary-tree-level-order-traversal-ii](https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/)
> 给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
思路:在层级遍历的基础上,翻转一下结果即可
```go
func levelOrderBottom(root *TreeNode) [][]int {
result := levelOrder(root)
// 翻转结果
reverse(result)
return result
}
func reverse(nums [][]int) {
for i, j := 0, len(nums)-1; i < j; i, j = i+1, j-1 {
nums[i], nums[j] = nums[j], nums[i]
}
}
func levelOrder(root *TreeNode) [][]int {
result := make([][]int, 0)
if root == nil {
return result
}
queue := make([]*TreeNode, 0)
queue = append(queue, root)
for len(queue) > 0 {
list := make([]int, 0)
// 为什么要取length?
// 记录当前层有多少元素(遍历当前层,再添加下一层)
l := len(queue)
for i := 0; i < l; i++ {
// 出队列
level := queue[0]
queue = queue[1:]
list = append(list, level.Val)
if level.Left != nil {
queue = append(queue, level.Left)
}
if level.Right != nil {
queue = append(queue, level.Right)
}
}
result = append(result, list)
}
return result
}
```
#### binary-tree-zigzag-level-order-traversal
[binary-tree-zigzag-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal/)
> 给定一个二叉树,返回其节点值的锯齿形层次遍历。Z 字形遍历
```go
func zigzagLevelOrder(root *TreeNode) [][]int {
result := make([][]int, 0)
if root == nil {
return result
}
queue := make([]*TreeNode, 0)
queue = append(queue, root)
toggle := false
for len(queue) > 0 {
list := make([]int, 0)
// 记录当前层有多少元素(遍历当前层,再添加下一层)
l := len(queue)
for i := 0; i < l; i++ {
// 出队列
level := queue[0]
queue = queue[1:]
list = append(list, level.Val)
if level.Left != nil {
queue = append(queue, level.Left)
}
if level.Right != nil {
queue = append(queue, level.Right)
}
}
if toggle {
reverse(list)
}
result = append(result, list)
toggle = !toggle
}
return result
}
func reverse(nums []int) {
for i := 0; i < len(nums)/2; i++ {
nums[i], nums[len(nums)-1-i] = nums[len(nums)-1-i], nums[i]
}
}
```
### 二叉搜索树应用
#### validate-binary-search-tree
[validate-binary-search-tree](https://leetcode-cn.com/problems/validate-binary-search-tree/)
> 给定一个二叉树,判断其是否是一个有效的二叉搜索树。
思路 1:中序遍历,检查结果列表是否已经有序
思路 2:分治法,判断左 MAX < 根 < 右 MIN
```go
// v1
func isValidBST(root *TreeNode) bool {
result := make([]int, 0)
inOrder(root, &result)
// check order
for i := 0; i < len(result) - 1; i++{
if result[i] >= result[i+1] {
return false
}
}
return true
}
func inOrder(root *TreeNode, result *[]int) {
if root == nil{
return
}
inOrder(root.Left, result)
*result = append(*result, root.Val)
inOrder(root.Right, result)
}
```
```go
// v2分治法
type ResultType struct {
IsValid bool
// 记录左右两边最大最小值,和根节点进行比较
Max *TreeNode
Min *TreeNode
}
func isValidBST2(root *TreeNode) bool {
result := helper(root)
return result.IsValid
}
func helper(root *TreeNode) ResultType {
result := ResultType{}
// check
if root == nil {
result.IsValid = true
return result
}
left := helper(root.Left)
right := helper(root.Right)
if !left.IsValid || !right.IsValid {
result.IsValid = false
return result
}
if left.Max != nil && left.Max.Val >= root.Val {
result.IsValid = false
return result
}
if right.Min != nil && right.Min.Val <= root.Val {
result.IsValid = false
return result
}
result.IsValid = true
// 如果左边还有更小的3,就用更小的节点,不用4
// 5
// / \
// 1 4
// / \
// 3 6
result.Min = root
if left.Min != nil {
result.Min = left.Min
}
result.Max = root
if right.Max != nil {
result.Max = right.Max
}
return result
}
```
#### insert-into-a-binary-search-tree
[insert-into-a-binary-search-tree](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/)
> 给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。
思路:找到最后一个叶子节点满足插入条件即可
```go
// DFS查找插入位置
func insertIntoBST(root *TreeNode, val int) *TreeNode {
if root == nil {
root = &TreeNode{Val: val}
return root
}
if root.Val > val {
root.Left = insertIntoBST(root.Left, val)
} else {
root.Right = insertIntoBST(root.Right, val)
}
return root
}
```
## 总结
- 掌握二叉树递归与非递归遍历
- 理解 DFS 前序遍历与分治法
- 理解 BFS 层次遍历
## 练习
- [ ] [maximum-depth-of-binary-tree](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
- [ ] [balanced-binary-tree](https://leetcode-cn.com/problems/balanced-binary-tree/)
- [ ] [binary-tree-maximum-path-sum](https://leetcode-cn.com/problems/binary-tree-maximum-path-sum/)
- [ ] [lowest-common-ancestor-of-a-binary-tree](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
- [ ] [binary-tree-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-level-order-traversal/)
- [ ] [binary-tree-level-order-traversal-ii](https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/)
- [ ] [binary-tree-zigzag-level-order-traversal](https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal/)
- [ ] [validate-binary-search-tree](https://leetcode-cn.com/problems/validate-binary-search-tree/)
- [ ] [insert-into-a-binary-search-tree](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/)
================================================
FILE: data_structure/linked_list.md
================================================
# 链表
## 基本技能
链表相关的核心点
- null/nil 异常处理
- dummy node 哑巴节点
- 快慢指针
- 插入一个节点到排序链表
- 从一个链表中移除一个节点
- 翻转链表
- 合并两个链表
- 找到链表的中间节点
## 常见题型
### [remove-duplicates-from-sorted-list](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list/)
> 给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
```go
func deleteDuplicates(head *ListNode) *ListNode {
current := head
for current != nil {
// 全部删除完再移动到下一个元素
for current.Next != nil && current.Val == current.Next.Val {
current.Next = current.Next.Next
}
current = current.Next
}
return head
}
```
### [remove-duplicates-from-sorted-list-ii](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list-ii/)
> 给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现的数字。
思路:链表头结点可能被删除,所以用 dummy node 辅助删除
```go
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil {
return head
}
dummy := &ListNode{Val: 0}
dummy.Next = head
head = dummy
var rmVal int
for head.Next != nil && head.Next.Next != nil {
if head.Next.Val == head.Next.Next.Val {
// 记录已经删除的值,用于后续节点判断
rmVal = head.Next.Val
for head.Next != nil && head.Next.Val == rmVal {
head.Next = head.Next.Next
}
} else {
head = head.Next
}
}
return dummy.Next
}
```
注意点
• A->B->C 删除 B,A.next = C
• 删除用一个 Dummy Node 节点辅助(允许头节点可变)
• 访问 X.next 、X.value 一定要保证 X != nil
### [reverse-linked-list](https://leetcode-cn.com/problems/reverse-linked-list/)
> 反转一个单链表。
思路:用一个 prev 节点保存向前指针,temp 保存向后的临时指针
```go
func reverseList(head *ListNode) *ListNode {
var prev *ListNode
for head != nil {
// 保存当前head.Next节点,防止重新赋值后被覆盖
// 一轮之后状态:nil<-1 2->3->4
// prev head
temp := head.Next
head.Next = prev
// pre 移动
prev = head
// head 移动
head = temp
}
return prev
}
```
### [reverse-linked-list-ii](https://leetcode-cn.com/problems/reverse-linked-list-ii/)
> 反转从位置 *m* 到 *n* 的链表。请使用一趟扫描完成反转。
思路:先遍历到 m 处,翻转,再拼接后续,注意指针处理
```go
func reverseBetween(head *ListNode, m int, n int) *ListNode {
// 思路:先遍历到m处,翻转,再拼接后续,注意指针处理
// 输入: 1->2->3->4->5->NULL, m = 2, n = 4
if head == nil {
return head
}
// 头部变化所以使用dummy node
dummy := &ListNode{Val: 0}
dummy.Next = head
head = dummy
// 最开始:0->1->2->3->4->5->nil
var pre *ListNode
var i = 0
for i < m {
pre = head
head = head.Next
i++
}
// 遍历之后: 1(pre)->2(head)->3->4->5->NULL
// i = 1
var j = i
var next *ListNode
// 用于中间节点连接
var mid = head
for head != nil && j <= n {
// 第一次循环: 1 nil<-2 3->4->5->nil
temp := head.Next
head.Next = next
next = head
head = temp
j++
}
// 循环需要执行四次
// 循环结束:1 nil<-2<-3<-4 5(head)->nil
pre.Next = next
mid.Next = head
return dummy.Next
}
```
### [merge-two-sorted-lists](https://leetcode-cn.com/problems/merge-two-sorted-lists/)
> 将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
思路:通过 dummy node 链表,连接各个元素
```go
func mergeTwoLists(l1 *ListNode, l2 *ListNode) *ListNode {
dummy := &ListNode{Val: 0}
head := dummy
for l1 != nil && l2 != nil {
if l1.Val < l2.Val {
head.Next = l1
l1 = l1.Next
} else {
head.Next = l2
l2 = l2.Next
}
head = head.Next
}
// 连接l1 未处理完节点
for l1 != nil {
head.Next = l1
head = head.Next
l1 = l1.Next
}
// 连接l2 未处理完节点
for l2 != nil {
head.Next = l2
head = head.Next
l2 = l2.Next
}
return dummy.Next
}
```
### [partition-list](https://leetcode-cn.com/problems/partition-list/)
> 给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 *x* 的节点都在大于或等于 *x* 的节点之前。
思路:将大于 x 的节点,放到另外一个链表,最后连接这两个链表
```go
func partition(head *ListNode, x int) *ListNode {
// 思路:将大于x的节点,放到另外一个链表,最后连接这两个链表
// check
if head == nil {
return head
}
headDummy := &ListNode{Val: 0}
tailDummy := &ListNode{Val: 0}
tail := tailDummy
headDummy.Next = head
head = headDummy
for head.Next != nil {
if head.Next.Val < x {
head = head.Next
} else {
// 移除<x节点
t := head.Next
head.Next = head.Next.Next
// 放到另外一个链表
tail.Next = t
tail = tail.Next
}
}
// 拼接两个链表
tail.Next = nil
head.Next = tailDummy.Next
return headDummy.Next
}
```
哑巴节点使用场景
> 当头节点不确定的时候,使用哑巴节点
### [sort-list](https://leetcode-cn.com/problems/sort-list/)
> 在 *O*(*n* log *n*) 时间复杂度和常数级空间复杂度下,对链表进行排序。
思路:归并排序,找中点和合并操作
```go
func sortList(head *ListNode) *ListNode {
// 思路:归并排序,找中点和合并操作
return mergeSort(head)
}
func findMiddle(head *ListNode) *ListNode {
// 1->2->3->4->5
slow := head
fast := head.Next
// 快指针先为nil
for fast !=nil && fast.Next != nil {
fast = fast.Next.Next
slow = slow.Next
}
return slow
}
func mergeTwoLists(l1 *ListNode, l2 *ListNode) *ListNode {
dummy := &ListNode{Val: 0}
head := dummy
for l1 != nil && l2 != nil {
if l1.Val < l2.Val {
head.Next = l1
l1 = l1.Next
} else {
head.Next = l2
l2 = l2.Next
}
head = head.Next
}
// 连接l1 未处理完节点
for l1 != nil {
head.Next = l1
head = head.Next
l1 = l1.Next
}
// 连接l2 未处理完节点
for l2 != nil {
head.Next = l2
head = head.Next
l2 = l2.Next
}
return dummy.Next
}
func mergeSort(head *ListNode) *ListNode {
// 如果只有一个节点 直接就返回这个节点
if head == nil || head.Next == nil{
return head
}
// find middle
middle := findMiddle(head)
// 断开中间节点
tail := middle.Next
middle.Next = nil
left := mergeSort(head)
right := mergeSort(tail)
result := mergeTwoLists(left, right)
return result
}
```
注意点
- 快慢指针 判断 fast 及 fast.Next 是否为 nil 值
- 递归 mergeSort 需要断开中间节点
- 递归返回条件为 head 为 nil 或者 head.Next 为 nil
### [reorder-list](https://leetcode-cn.com/problems/reorder-list/)
> 给定一个单链表 *L*:*L*→*L*→…→*L\_\_n*→*L*
> 将其重新排列后变为: *L*→*L\_\_n*→*L*→*L\_\_n*→*L*→*L\_\_n*→…
思路:找到中点断开,翻转后面部分,然后合并前后两个链表
```go
func reorderList(head *ListNode) {
// 思路:找到中点断开,翻转后面部分,然后合并前后两个链表
if head == nil {
return
}
mid := findMiddle(head)
tail := reverseList(mid.Next)
mid.Next = nil
head = mergeTwoLists(head, tail)
}
func findMiddle(head *ListNode) *ListNode {
fast := head.Next
slow := head
for fast != nil && fast.Next != nil {
fast = fast.Next.Next
slow = slow.Next
}
return slow
}
func mergeTwoLists(l1 *ListNode, l2 *ListNode) *ListNode {
dummy := &ListNode{Val: 0}
head := dummy
toggle := true
for l1 != nil && l2 != nil {
// 节点切换
if toggle {
head.Next = l1
l1 = l1.Next
} else {
head.Next = l2
l2 = l2.Next
}
toggle = !toggle
head = head.Next
}
// 连接l1 未处理完节点
for l1 != nil {
head.Next = l1
head = head.Next
l1 = l1.Next
}
// 连接l2 未处理完节点
for l2 != nil {
head.Next = l2
head = head.Next
l2 = l2.Next
}
return dummy.Next
}
func reverseList(head *ListNode) *ListNode {
var prev *ListNode
for head != nil {
// 保存当前head.Next节点,防止重新赋值后被覆盖
// 一轮之后状态:nil<-1 2->3->4
// prev head
temp := head.Next
head.Next = prev
// pre 移动
prev = head
// head 移动
head = temp
}
return prev
}
```
### [linked-list-cycle](https://leetcode-cn.com/problems/linked-list-cycle/)
> 给定一个链表,判断链表中是否有环。
思路:快慢指针,快慢指针相同则有环,证明:如果有环每走一步快慢指针距离会减 1
```go
func hasCycle(head *ListNode) bool {
// 思路:快慢指针 快慢指针相同则有环,证明:如果有环每走一步快慢指针距离会减1
if head == nil {
return false
}
fast := head.Next
slow := head
for fast != nil && fast.Next != nil {
// 比较指针是否相等(不要使用val比较!)
if fast == slow {
return true
}
fast = fast.Next.Next
slow = slow.Next
}
return false
}
```
### [linked-list-cycle-ii](https://leetcode-cn.com/problems/linked-list-cycle-ii/)
> 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 `null`。
思路:快慢指针,快慢相遇之后,慢指针回到头,快慢指针步调一致一起移动,相遇点即为入环点
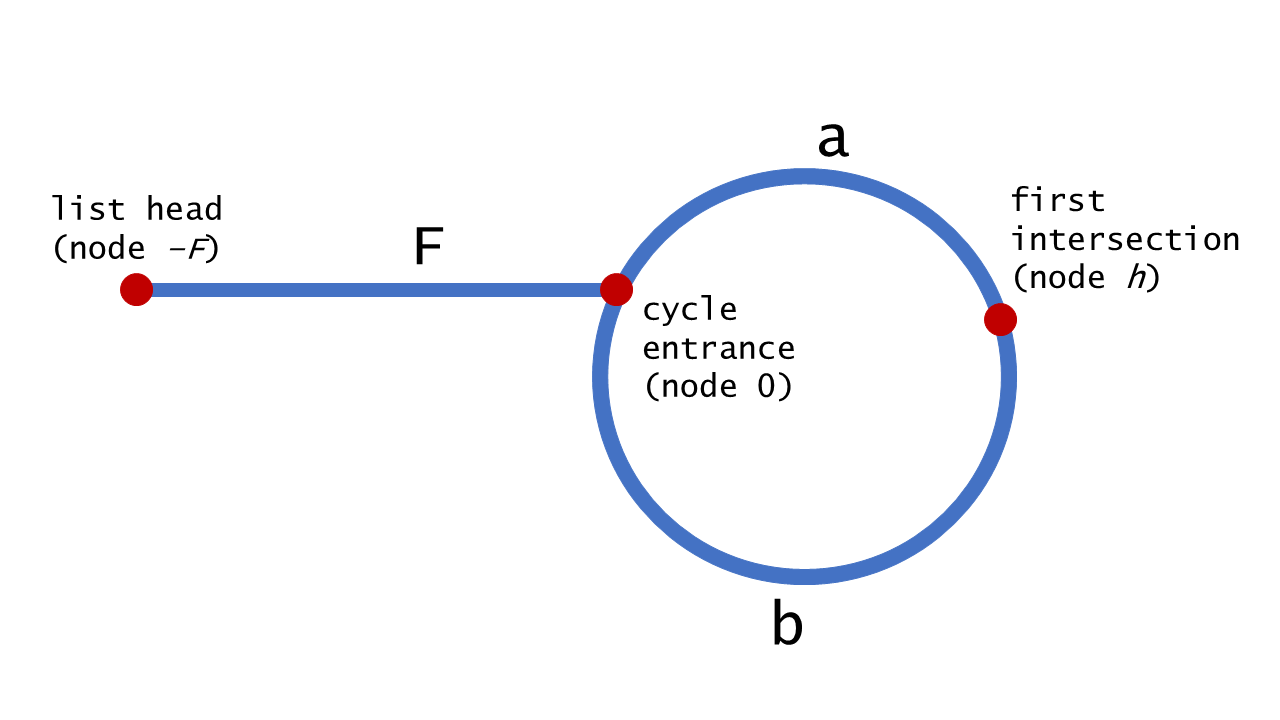
```go
func detectCycle(head *ListNode) *ListNode {
// 思路:快慢指针,快慢相遇之后,慢指针回到头,快慢指针步调一致一起移动,相遇点即为入环点
if head == nil {
return head
}
fast := head.Next
slow := head
for fast != nil && fast.Next != nil {
if fast == slow {
// 慢指针重新从头开始移动,快指针从第一次相交点下一个节点开始移动
fast = head
slow = slow.Next // 注意
// 比较指针对象(不要比对指针Val值)
for fast != slow {
fast = fast.Next
slow = slow.Next
}
return slow
}
fast = fast.Next.Next
slow = slow.Next
}
return nil
}
```
坑点
- 指针比较时直接比较对象,不要用值比较,链表中有可能存在重复值情况
- 第一次相交后,快指针需要从下一个节点开始和头指针一起匀速移动
另外一种方式是 fast=head,slow=head
```go
func detectCycle(head *ListNode) *ListNode {
// 思路:快慢指针,快慢相遇之后,其中一个指针回到头,快慢指针步调一致一起移动,相遇点即为入环点
// nb+a=2nb+a
if head == nil {
return head
}
fast := head
slow := head
for fast != nil && fast.Next != nil {
fast = fast.Next.Next
slow = slow.Next
if fast == slow {
// 指针重新从头开始移动
fast = head
for fast != slow {
fast = fast.Next
slow = slow.Next
}
return slow
}
}
return nil
}
```
这两种方式不同点在于,**一般用 fast=head.Next 较多**,因为这样可以知道中点的上一个节点,可以用来删除等操作。
- fast 如果初始化为 head.Next 则中点在 slow.Next
- fast 初始化为 head,则中点在 slow
### [palindrome-linked-list](https://leetcode-cn.com/problems/palindrome-linked-list/)
> 请判断一个链表是否为回文链表。
```go
func isPalindrome(head *ListNode) bool {
// 1 2 nil
// 1 2 1 nil
// 1 2 2 1 nil
if head==nil{
return true
}
slow:=head
// fast如果初始化为head.Next则中点在slow.Next
// fast初始化为head,则中点在slow
fast:=head.Next
for fast!=nil&&fast.Next!=nil{
fast=fast.Next.Next
slow=slow.Next
}
tail:=reverse(slow.Next)
// 断开两个链表(需要用到中点前一个节点)
slow.Next=nil
for head!=nil&&tail!=nil{
if head.Val!=tail.Val{
return false
}
head=head.Next
tail=tail.Next
}
return true
}
func reverse(head *ListNode)*ListNode{
// 1->2->3
if head==nil{
return head
}
var prev *ListNode
for head!=nil{
t:=head.Next
head.Next=prev
prev=head
head=t
}
return prev
}
```
### [copy-list-with-random-pointer](https://leetcode-cn.com/problems/copy-list-with-random-pointer/)
> 给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
> 要求返回这个链表的 深拷贝。
思路:1、hash 表存储指针,2、复制节点跟在原节点后面
```go
func copyRandomList(head *Node) *Node {
if head == nil {
return head
}
// 复制节点,紧挨到到后面
// 1->2->3 ==> 1->1'->2->2'->3->3'
cur := head
for cur != nil {
clone := &Node{Val: cur.Val, Next: cur.Next}
temp := cur.Next
cur.Next = clone
cur = temp
}
// 处理random指针
cur = head
for cur != nil {
if cur.Random != nil {
cur.Next.Random = cur.Random.Next
}
cur = cur.Next.Next
}
// 分离两个链表
cur = head
cloneHead := cur.Next
for cur != nil && cur.Next != nil {
temp := cur.Next
cur.Next = cur.Next.Next
cur = temp
}
// 原始链表头:head 1->2->3
// 克隆的链表头:cloneHead 1'->2'->3'
return cloneHead
}
```
## 总结
链表必须要掌握的一些点,通过下面练习题,基本大部分的链表类的题目都是手到擒来~
- null/nil 异常处理
- dummy node 哑巴节点
- 快慢指针
- 插入一个节点到排序链表
- 从一个链表中移除一个节点
- 翻转链表
- 合并两个链表
- 找到链表的中间节点
## 练习
- [ ] [remove-duplicates-from-sorted-list](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list/)
- [ ] [remove-duplicates-from-sorted-list-ii](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list-ii/)
- [ ] [reverse-linked-list](https://leetcode-cn.com/problems/reverse-linked-list/)
- [ ] [reverse-linked-list-ii](https://leetcode-cn.com/problems/reverse-linked-list-ii/)
- [ ] [merge-two-sorted-lists](https://leetcode-cn.com/problems/merge-two-sorted-lists/)
- [ ] [partition-list](https://leetcode-cn.com/problems/partition-list/)
- [ ] [sort-list](https://leetcode-cn.com/problems/sort-list/)
- [ ] [reorder-list](https://leetcode-cn.com/problems/reorder-list/)
- [ ] [linked-list-cycle](https://leetcode-cn.com/problems/linked-list-cycle/)
- [ ] [linked-list-cycle-ii](https://leetcode-cn.com/problems/linked-list-cycle-ii/)
- [ ] [palindrome-linked-list](https://leetcode-cn.com/problems/palindrome-linked-list/)
- [ ] [copy-list-with-random-pointer](https://leetcode-cn.com/problems/copy-list-with-random-pointer/)
================================================
FILE: data_structure/stack_queue.md
================================================
# 栈和队列
## 简介
栈的特点是后入先出

根据这个特点可以临时保存一些数据,之后用到依次再弹出来,常用于 DFS 深度搜索
队列一般常用于 BFS 广度搜索,类似一层一层的搜索
## Stack 栈
[min-stack](https://leetcode-cn.com/problems/min-stack/)
> 设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
思路:用两个栈实现,一个最小栈始终保证最小值在顶部
```go
type MinStack struct {
min []int
stack []int
}
/** initialize your data structure here. */
func Constructor() MinStack {
return MinStack{
min: make([]int, 0),
stack: make([]int, 0),
}
}
func (this *MinStack) Push(x int) {
min := this.GetMin()
if x < min {
this.min = append(this.min, x)
} else {
this.min = append(this.min, min)
}
this.stack = append(this.stack, x)
}
func (this *MinStack) Pop() {
if len(this.stack) == 0 {
return
}
this.stack = this.stack[:len(this.stack)-1]
this.min = this.min[:len(this.min)-1]
}
func (this *MinStack) Top() int {
if len(this.stack) == 0 {
return 0
}
return this.stack[len(this.stack)-1]
}
func (this *MinStack) GetMin() int {
if len(this.min) == 0 {
return 1 << 31
}
min := this.min[len(this.min)-1]
return min
}
/**
* Your MinStack object will be instantiated and called as such:
* obj := Constructor();
* obj.Push(x);
* obj.Pop();
* param_3 := obj.Top();
* param_4 := obj.GetMin();
*/
```
[evaluate-reverse-polish-notation](https://leetcode-cn.com/problems/evaluate-reverse-polish-notation/)
> **波兰表达式计算** > **输入:** `["2", "1", "+", "3", "*"]` > **输出:** 9
>
> **解释:** `((2 + 1) * 3) = 9`
思路:通过栈保存原来的元素,遇到表达式弹出运算,再推入结果,重复这个过程
```go
func evalRPN(tokens []string) int {
if len(tokens)==0{
return 0
}
stack:=make([]int,0)
for i:=0;i<len(tokens);i++{
switch tokens[i]{
case "+","-","*","/":
if len(stack)<2{
return -1
}
// 注意:a为被除数,b为除数
b:=stack[len(stack)-1]
a:=stack[len(stack)-2]
stack=stack[:len(stack)-2]
var result int
switch tokens[i]{
case "+":
result=a+b
case "-":
result=a-b
case "*":
result=a*b
case "/":
result=a/b
}
stack=append(stack,result)
default:
// 转为数字
val,_:=strconv.Atoi(tokens[i])
stack=append(stack,val)
}
}
return stack[0]
}
```
[decode-string](https://leetcode-cn.com/problems/decode-string/)
> 给定一个经过编码的字符串,返回它解码后的字符串。
> s = "3[a]2[bc]", 返回 "aaabcbc".
> s = "3[a2[c]]", 返回 "accaccacc".
> s = "2[abc]3[cd]ef", 返回 "abcabccdcdcdef".
思路:通过栈辅助进行操作
```go
func decodeString(s string) string {
if len(s) == 0 {
return ""
}
stack := make([]byte, 0)
for i := 0; i < len(s); i++ {
switch s[i] {
case ']':
temp := make([]byte, 0)
for len(stack) != 0 && stack[len(stack)-1] != '[' {
v := stack[len(stack)-1]
stack = stack[:len(stack)-1]
temp = append(temp, v)
}
// pop '['
stack = stack[:len(stack)-1]
// pop num
idx := 1
for len(stack) >= idx && stack[len(stack)-idx] >= '0' && stack[len(stack)-idx] <= '9' {
idx++
}
// 注意索引边界
num := stack[len(stack)-idx+1:]
stack = stack[:len(stack)-idx+1]
count, _ := strconv.Atoi(string(num))
for j := 0; j < count; j++ {
// 把字符正向放回到栈里面
for j := len(temp) - 1; j >= 0; j-- {
stack = append(stack, temp[j])
}
}
default:
stack = append(stack, s[i])
}
}
return string(stack)
}
```
利用栈进行 DFS 递归搜索模板
```go
boolean DFS(int root, int target) {
Set<Node> visited;
Stack<Node> s;
add root to s;
while (s is not empty) {
Node cur = the top element in s;
return true if cur is target;
for (Node next : the neighbors of cur) {
if (next is not in visited) {
add next to s;
add next to visited;
}
}
remove cur from s;
}
return false;
}
```
[binary-tree-inorder-traversal](https://leetcode-cn.com/problems/binary-tree-inorder-traversal/)
> 给定一个二叉树,返回它的*中序*遍历。
```go
// 思路:通过stack 保存已经访问的元素,用于原路返回
func inorderTraversal(root *TreeNode) []int {
result := make([]int, 0)
if root == nil {
return result
}
stack := make([]*TreeNode, 0)
for len(stack) > 0 || root != nil {
for root != nil {
stack = append(stack, root)
root = root.Left // 一直向左
}
// 弹出
val := stack[len(stack)-1]
stack = stack[:len(stack)-1]
result = append(result, val.Val)
root = val.Right
}
return result
}
```
[clone-graph](https://leetcode-cn.com/problems/clone-graph/)
> 给你无向连通图中一个节点的引用,请你返回该图的深拷贝(克隆)。
```go
func cloneGraph(node *Node) *Node {
visited:=make(map[*Node]*Node)
return clone(node,visited)
}
// 1 2
// 4 3
// 递归克隆,传入已经访问过的元素作为过滤条件
func clone(node *Node,visited map[*Node]*Node)*Node{
if node==nil{
return nil
}
// 已经访问过直接返回
if v,ok:=visited[node];ok{
return v
}
newNode:=&Node{
Val:node.Val,
Neighbors:make([]*Node,len(node.Neighbors)),
}
visited[node]=newNode
for i:=0;i<len(node.Neighbors);i++{
newNode.Neighbors[i]=clone(node.Neighbors[i],visited)
}
return newNode
}
```
[number-of-islands](https://leetcode-cn.com/problems/number-of-islands/)
> 给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
思路:通过深度搜索遍历可能性(注意标记已访问元素)
```go
func numIslands(grid [][]byte) int {
var count int
for i:=0;i<len(grid);i++{
for j:=0;j<len(grid[i]);j++{
if grid[i][j]=='1' && dfs(grid,i,j)>=1{
count++
}
}
}
return count
}
func dfs(grid [][]byte,i,j int)int{
if i<0||i>=len(grid)||j<0||j>=len(grid[0]){
return 0
}
if grid[i][j]=='1'{
// 标记已经访问过(每一个点只需要访问一次)
grid[i][j]=0
return dfs(grid,i-1,j)+dfs(grid,i,j-1)+dfs(grid,i+1,j)+dfs(grid,i,j+1)+1
}
return 0
}
```
[largest-rectangle-in-histogram](https://leetcode-cn.com/problems/largest-rectangle-in-histogram/)
> 给定 _n_ 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
> 求在该柱状图中,能够勾勒出来的矩形的最大面积。
思路:求以当前柱子为高度的面积,即转化为寻找小于当前值的左右两边值
用栈保存小于当前值的左的元素
```go
func largestRectangleArea(heights []int) int {
if len(heights) == 0 {
return 0
}
stack := make([]int, 0)
max := 0
for i := 0; i <= len(heights); i++ {
var cur int
if i == len(heights) {
cur = 0
} else {
cur = heights[i]
}
// 当前高度小于栈,则将栈内元素都弹出计算面积
for len(stack) != 0 && cur <= heights[stack[len(stack)-1]] {
pop := stack[len(stack)-1]
stack = stack[:len(stack)-1]
h := heights[pop]
// 计算宽度
w := i
if len(stack) != 0 {
peek := stack[len(stack)-1]
w = i - peek - 1
}
max = Max(max, h*w)
}
// 记录索引即可获取对应元素
stack = append(stack, i)
}
return max
}
func Max(a, b int) int {
if a > b {
return a
}
return b
}
```
## Queue 队列
常用于 BFS 宽度优先搜索
[implement-queue-using-stacks](https://leetcode-cn.com/problems/implement-queue-using-stacks/)
> 使用栈实现队列
```go
type MyQueue struct {
stack []int
back []int
}
/** Initialize your data structure here. */
func Constructor() MyQueue {
return MyQueue{
stack: make([]int, 0),
back: make([]int, 0),
}
}
// 1
// 3
// 5
/** Push element x to the back of queue. */
func (this *MyQueue) Push(x int) {
for len(this.back) != 0 {
val := this.back[len(this.back)-1]
this.back = this.back[:len(this.back)-1]
this.stack = append(this.stack, val)
}
this.stack = append(this.stack, x)
}
/** Removes the element from in front of queue and returns that element. */
func (this *MyQueue) Pop() int {
for len(this.stack) != 0 {
val := this.stack[len(this.stack)-1]
this.stack = this.stack[:len(this.stack)-1]
this.back = append(this.back, val)
}
if len(this.back) == 0 {
return 0
}
val := this.back[len(this.back)-1]
this.back = this.back[:len(this.back)-1]
return val
}
/** Get the front element. */
func (this *MyQueue) Peek() int {
for len(this.stack) != 0 {
val := this.stack[len(this.stack)-1]
this.stack = this.stack[:len(this.stack)-1]
this.back = append(this.back, val)
}
if len(this.back) == 0 {
return 0
}
val := this.back[len(this.back)-1]
return val
}
/** Returns whether the queue is empty. */
func (this *MyQueue) Empty() bool {
return len(this.stack) == 0 && len(this.back) == 0
}
/**
* Your MyQueue object will be instantiated and called as such:
* obj := Constructor();
* obj.Push(x);
* param_2 := obj.Pop();
* param_3 := obj.Peek();
* param_4 := obj.Empty();
*/
```
二叉树层次遍历
```go
func levelOrder(root *TreeNode) [][]int {
// 通过上一层的长度确定下一层的元素
result := make([][]int, 0)
if root == nil {
return result
}
queue := make([]*TreeNode, 0)
queue = append(queue, root)
for len(queue) > 0 {
list := make([]int, 0)
// 为什么要取length?
// 记录当前层有多少元素(遍历当前层,再添加下一层)
l := len(queue)
for i := 0; i < l; i++ {
// 出队列
level := queue[0]
queue = queue[1:]
list = append(list, level.Val)
if level.Left != nil {
queue = append(queue, level.Left)
}
if level.Right != nil {
queue = append(queue, level.Right)
}
}
result = append(result, list)
}
return result
}
```
[01-matrix](https://leetcode-cn.com/problems/01-matrix/)
> 给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。
> 两个相邻元素间的距离为 1
```go
// BFS 从0进队列,弹出之后计算上下左右的结果,将上下左右重新进队列进行二层操作
// 0 0 0 0
// 0 x 0 0
// x x x 0
// 0 x 0 0
// 0 0 0 0
// 0 1 0 0
// 1 x 1 0
// 0 1 0 0
// 0 0 0 0
// 0 1 0 0
// 1 2 1 0
// 0 1 0 0
func updateMatrix(matrix [][]int) [][]int {
q:=make([][]int,0)
for i:=0;i<len(matrix);i++{
for j:=0;j<len(matrix[0]);j++{
if matrix[i][j]==0{
// 进队列
point:=[]int{i,j}
q=append(q,point)
}else{
matrix[i][j]=-1
}
}
}
directions:=[][]int{{0,1},{0,-1},{-1,0},{1,0}}
for len(q)!=0{
// 出队列
point:=q[0]
q=q[1:]
for _,v:=range directions{
x:=point[0]+v[0]
y:=point[1]+v[1]
if x>=0&&x<len(matrix)&&y>=0&&y<len(matrix[0])&&matrix[x][y]==-1{
matrix[x][y]=matrix[point[0]][point[1]]+1
// 将当前的元素进队列,进行一次BFS
q=append(q,[]int{x,y})
}
}
}
return matrix
}
```
## 总结
- 熟悉栈的使用场景
- 后入先出,保存临时值
- 利用栈 DFS 深度搜索
- 熟悉队列的使用场景
- 利用队列 BFS 广度搜索
## 练习
- [ ] [min-stack](https://leetcode-cn.com/problems/min-stack/)
- [ ] [evaluate-reverse-polish-notation](https://leetcode-cn.com/problems/evaluate-reverse-polish-notation/)
- [ ] [decode-string](https://leetcode-cn.com/problems/decode-string/)
- [ ] [binary-tree-inorder-traversal](https://leetcode-cn.com/problems/binary-tree-inorder-traversal/)
- [ ] [clone-graph](https://leetcode-cn.com/problems/clone-graph/)
- [ ] [number-of-islands](https://leetcode-cn.com/problems/number-of-islands/)
- [ ] [largest-rectangle-in-histogram](https://leetcode-cn.com/problems/largest-rectangle-in-histogram/)
- [ ] [implement-queue-using-stacks](https://leetcode-cn.com/problems/implement-queue-using-stacks/)
- [ ] [01-matrix](https://leetcode-cn.com/problems/01-matrix/)
================================================
FILE: introduction/golang.md
================================================
# GO 快速入门
## 基本语法
[Go 语言圣经](https://books.studygolang.com/gopl-zh/)
## 常用库
### 切片
go 通过切片模拟栈和队列
栈
```go
// 创建栈
stack:=make([]int,0)
// push压入
stack=append(stack,10)
// pop弹出
v:=stack[len(stack)-1]
stack=stack[:len(stack)-1]
// 检查栈空
len(stack)==0
```
队列
```go
// 创建队列
queue:=make([]int,0)
// enqueue入队
queue=append(queue,10)
// dequeue出队
v:=queue[0]
queue=queue[1:]
// 长度0为空
len(queue)==0
```
注意点
- 参数传递,只能修改,不能新增或者删除原始数据
- 默认 s=s[0:len(s)],取下限不取上限,数学表示为:[)
### 字典
基本用法
```go
// 创建
m:=make(map[string]int)
// 设置kv
m["hello"]=1
// 删除k
delete(m,"hello")
// 遍历
for k,v:=range m{
println(k,v)
}
```
注意点
- map 键需要可比较,不能为 slice、map、function
- map 值都有默认值,可以直接操作默认值,如:m[age]++ 值由 0 变为 1
- 比较两个 map 需要遍历,其中的 kv 是否相同,因为有默认值关系,所以需要检查 val 和 ok 两个值
### 标准库
sort
```go
// int排序
sort.Ints([]int{})
// 字符串排序
sort.Strings([]string{})
// 自定义排序
sort.Slice(s,func(i,j int)bool{return s[i]<s[j]})
```
math
```go
// int32 最大最小值
math.MaxInt32 // 实际值:1<<31-1
math.MinInt32 // 实际值:-1<<31
// int64 最大最小值(int默认是int64)
math.MaxInt64
math.MinInt64
```
copy
```go
// 删除a[i],可以用 copy 将i+1到末尾的值覆盖到i,然后末尾-1
copy(a[i:],a[i+1:])
a=a[:len(a)-1]
// make创建长度,则通过索引赋值
a:=make([]int,n)
a[n]=x
// make长度为0,则通过append()赋值
a:=make([]int,0)
a=append(a,x)
```
### 常用技巧
类型转换
```go
// byte转数字
s="12345" // s[0] 类型是byte
num:=int(s[0]-'0') // 1
str:=string(s[0]) // "1"
b:=byte(num+'0') // '1'
fmt.Printf("%d%s%c\n", num, str, b) // 111
// 字符串转数字
num,_:=strconv.Atoi()
str:=strconv.Itoa()
```
## 刷题注意点
- leetcode 中,全局变量不要当做返回值,否则刷题检查器会报错
================================================
FILE: introduction/quickstart.md
================================================
# 快速开始
## 数据结构与算法
数据结构是一种数据的表现形式,如链表、二叉树、栈、队列等都是内存中一段数据表现的形式。
算法是一种通用的解决问题的模板或者思路,大部分数据结构都有一套通用的算法模板,所以掌握这些通用的算法模板即可解决各种算法问题。
后面会分专题讲解各种数据结构、基本的算法模板、和一些高级算法模板,每一个专题都有一些经典练习题,完成所有练习的题后,你对数据结构和算法会有新的收获和体会。
先介绍两个算法题,试试感觉~
示例 1
[strStr](https://leetcode-cn.com/problems/implement-strstr/)
> 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从 0 开始)。如果不存在,则返回 -1。
思路:核心点遍历给定字符串字符,判断以当前字符开头字符串是否等于目标字符串
```go
func strStr(haystack string, needle string) int {
if len(needle) == 0 {
return 0
}
var i, j int
// i不需要到len-1
for i = 0; i < len(haystack)-len(needle)+1; i++ {
for j = 0; j < len(needle); j++ {
if haystack[i+j] != needle[j] {
break
}
}
// 判断字符串长度是否相等
if len(needle) == j {
return i
}
}
return -1
}
```
需要注意点
- 循环时,i 不需要到 len-1
- 如果找到目标字符串,len(needle)==j
示例 2
[subsets](https://leetcode-cn.com/problems/subsets/)
> 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
思路:这是一个典型的应用回溯法的题目,简单来说就是穷尽所有可能性,算法模板如下
```go
result = []
func backtrack(选择列表,路径):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(选择列表,路径)
撤销选择
```
通过不停的选择,撤销选择,来穷尽所有可能性,最后将满足条件的结果返回
答案代码
```go
func subsets(nums []int) [][]int {
// 保存最终结果
result := make([][]int, 0)
// 保存中间结果
list := make([]int, 0)
backtrack(nums, 0, list, &result)
return result
}
// nums 给定的集合
// pos 下次添加到集合中的元素位置索引
// list 临时结果集合(每次需要复制保存)
// result 最终结果
func backtrack(nums []int, pos int, list []int, result *[][]int) {
// 把临时结果复制出来保存到最终结果
ans := make([]int, len(list))
copy(ans, list)
*result = append(*result, ans)
// 选择、处理结果、再撤销选择
for i := pos; i < len(nums); i++ {
list = append(list, nums[i])
backtrack(nums, i+1, list, result)
list = list[0 : len(list)-1]
}
}
```
说明:后面会深入讲解几个典型的回溯算法问题,如果当前不太了解可以暂时先跳过
## 面试注意点
我们大多数时候,刷算法题可能都是为了准备面试,所以面试的时候需要注意一些点
- 快速定位到题目的知识点,找到知识点的**通用模板**,可能需要根据题目**特殊情况做特殊处理**。
- 先去朝一个解决问题的方向!**先抛出可行解**,而不是最优解!先解决,再优化!
- 代码的风格要统一,熟悉各类语言的代码规范。
- 命名尽量简洁明了,尽量不用数字命名如:i1、node1、a1、b2
- 常见错误总结
- 访问下标时,不能访问越界
- 空值 nil 问题 run time error
## 练习
- [ ] [strStr](https://leetcode-cn.com/problems/implement-strstr/)
- [ ] [subsets](https://leetcode-cn.com/problems/subsets/)
================================================
FILE: practice_algorithm/bplus.md
================================================
# b+ tree (MySQL 索引实现)
================================================
FILE: practice_algorithm/data_index.md
================================================
# 数据索引(kafka 稀疏索引)
================================================
FILE: practice_algorithm/skiplist.md
================================================
# skiplist(Redis Zset 实现)
================================================
FILE: src/main.go
================================================
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
================================================
FILE: src/sort/heap_sort.go
================================================
package sort
func HeapSort(a []int) []int {
// 1、无序数组a
// 2、将无序数组a构建为一个大根堆
for i := len(a)/2 - 1; i >= 0; i-- {
sink(a, i, len(a))
}
// 3、交换a[0]和a[len(a)-1]
// 4、然后把前面这段数组继续下沉保持堆结构,如此循环即可
for i := len(a) - 1; i >= 1; i-- {
// 从后往前填充值
swap(a, 0, i)
// 前面的长度也减一
sink(a, 0, i)
}
return a
}
func sink(a []int, i int, length int) {
for {
// 左节点索引(从0开始,所以左节点为i*2+1)
l := i*2 + 1
// 有节点索引
r := i*2 + 2
// idx保存根、左、右三者之间较大值的索引
idx := i
// 存在左节点,左节点值较大,则取左节点
if l < length && a[l] > a[idx] {
idx = l
}
// 存在有节点,且值较大,取右节点
if r < length && a[r] > a[idx] {
idx = r
}
// 如果根节点较大,则不用下沉
if idx == i {
break
}
// 如果根节点较小,则交换值,并继续下沉
swap(a, i, idx)
// 继续下沉idx节点
i = idx
}
}
func swap(a []int, i, j int) {
a[i], a[j] = a[j], a[i]
}
================================================
FILE: src/sort/heap_sort_test.go
================================================
package sort
import (
"reflect"
"testing"
)
func TestHeapSort(t *testing.T) {
type args struct {
a []int
}
tests := []struct {
name string
args args
want []int
}{
{"", args{a: []int{7, 8, 9, 2, 3, 5}}, []int{2, 3, 5, 7, 8, 9}},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := HeapSort(tt.args.a); !reflect.DeepEqual(got, tt.want) {
t.Errorf("HeapSort() = %v, want %v", got, tt.want)
}
})
}
}
gitextract_3kj3zxap/
├── .gitignore
├── LICENSE
├── README.md
├── SUMMARY.md
├── TODO.md
├── advanced_algorithm/
│ ├── backtrack.md
│ ├── binary_search_tree.md
│ ├── recursion.md
│ └── slide_window.md
├── basic_algorithm/
│ ├── binary_search.md
│ ├── dp.md
│ └── sort.md
├── data_structure/
│ ├── binary_op.md
│ ├── binary_tree.md
│ ├── linked_list.md
│ └── stack_queue.md
├── introduction/
│ ├── golang.md
│ └── quickstart.md
├── practice_algorithm/
│ ├── bplus.md
│ ├── data_index.md
│ └── skiplist.md
└── src/
├── main.go
└── sort/
├── heap_sort.go
└── heap_sort_test.go
SYMBOL INDEX (5 symbols across 3 files)
FILE: src/main.go
function main (line 5) | func main() {
FILE: src/sort/heap_sort.go
function HeapSort (line 3) | func HeapSort(a []int) []int {
function sink (line 19) | func sink(a []int, i int, length int) {
function swap (line 45) | func swap(a []int, i, j int) {
FILE: src/sort/heap_sort_test.go
function TestHeapSort (line 8) | func TestHeapSort(t *testing.T) {
Condensed preview — 24 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (109K chars).
[
{
"path": ".gitignore",
"chars": 10,
"preview": ".DS_Store\n"
},
{
"path": "LICENSE",
"chars": 1068,
"preview": "MIT License\n\nCopyright (c) 2023 greyireland\n\nPermission is hereby granted, free of charge, to any person obtaining a cop"
},
{
"path": "README.md",
"chars": 4590,
"preview": "# 算法模板\n\n\n\n算法模板,最科学的刷题方式,最快速的刷题路径,一个月从入门到 offer,你值得拥有 🐶~\n\n算法模板顾名思义就是刷题的套路模板"
},
{
"path": "SUMMARY.md",
"chars": 568,
"preview": "# 算法模板\n\n## 入门篇\n\n- [go 语言入门](introduction/golang.md)\n- [算法快速入门](introduction/quickstart.md)\n\n## 数据结构篇\n\n- [二叉树](data_struc"
},
{
"path": "TODO.md",
"chars": 68,
"preview": "# 计划\n\n## v1\n\n- [ ] 完善文档细节\n- [ ] 工程实现用到的算法解析\n- [ ] 周赛计划\n- [ ] 面试体系计划\n"
},
{
"path": "advanced_algorithm/backtrack.md",
"chars": 4707,
"preview": "# 回溯法\n\n## 背景\n\n回溯法(backtrack)常用于遍历列表所有子集,是 DFS 深度搜索一种,一般用于全排列,穷尽所有可能,遍历的过程实际上是一个决策树的遍历过程。时间复杂度一般 O(N!),它不像动态规划存在重叠子问题可以优化"
},
{
"path": "advanced_algorithm/binary_search_tree.md",
"chars": 3766,
"preview": "# 二叉搜索树\n\n## 定义\n\n- 每个节点中的值必须大于(或等于)存储在其左侧子树中的任何值。\n- 每个节点中的值必须小于(或等于)存储在其右子树中的任何值。\n\n## 应用\n\n[validate-binary-search-tree](h"
},
{
"path": "advanced_algorithm/recursion.md",
"chars": 2641,
"preview": "# 递归\n\n## 介绍\n\n将大问题转化为小问题,通过递归依次解决各个小问题\n\n## 示例\n\n[reverse-string](https://leetcode-cn.com/problems/reverse-string/)\n\n> 编写一个"
},
{
"path": "advanced_algorithm/slide_window.md",
"chars": 4784,
"preview": "# 滑动窗口\n\n## 模板\n\n```cpp\n/* 滑动窗口算法框架 */\nvoid slidingWindow(string s, string t) {\n unordered_map<char, int> need, window;"
},
{
"path": "basic_algorithm/binary_search.md",
"chars": 10459,
"preview": "# 二分搜索\n\n## 二分搜索模板\n\n给一个**有序数组**和目标值,找第一次/最后一次/任何一次出现的索引,如果没有出现返回-1\n\n模板四点要素\n\n- 1、初始化:start=0、end=len-1\n- 2、循环退出条件:start + "
},
{
"path": "basic_algorithm/dp.md",
"chars": 16414,
"preview": "# 动态规划\n\n## 背景\n\n先从一道题目开始~\n\n如题 [triangle](https://leetcode-cn.com/problems/triangle/)\n\n> 给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行"
},
{
"path": "basic_algorithm/sort.md",
"chars": 2843,
"preview": "# 排序\n\n## 常考排序\n\n### 快速排序\n\n```go\nfunc QuickSort(nums []int) []int {\n // 思路:把一个数组分为左右两段,左段小于右段\n quickSort(nums, 0, le"
},
{
"path": "data_structure/binary_op.md",
"chars": 3607,
"preview": "# 二进制\n\n## 常见二进制操作\n\n### 基本操作\n\na=0^a=a^0\n\n0=a^a\n\n由上面两个推导出:a=a^b^b\n\n### 交换两个数\n\na=a^b\n\nb=a^b\n\na=a^b\n\n### 移除最后一个 1\n\na=n&(n-1)"
},
{
"path": "data_structure/binary_tree.md",
"chars": 15947,
"preview": "# 二叉树\n\n## 知识点\n\n### 二叉树遍历\n\n**前序遍历**:**先访问根节点**,再前序遍历左子树,再前序遍历右子树\n**中序遍历**:先中序遍历左子树,**再访问根节点**,再中序遍历右子树\n**后序遍历**:先后序遍历左子树,"
},
{
"path": "data_structure/linked_list.md",
"chars": 13013,
"preview": "# 链表\n\n## 基本技能\n\n链表相关的核心点\n\n- null/nil 异常处理\n- dummy node 哑巴节点\n- 快慢指针\n- 插入一个节点到排序链表\n- 从一个链表中移除一个节点\n- 翻转链表\n- 合并两个链表\n- 找到链表的中间"
},
{
"path": "data_structure/stack_queue.md",
"chars": 11746,
"preview": "# 栈和队列\n\n## 简介\n\n栈的特点是后入先出\n\n\n\n根据这个特点可以临时保存一些数据,之后用到依次再弹出来,常用于 DFS 深度搜索\n"
},
{
"path": "introduction/golang.md",
"chars": 1524,
"preview": "# GO 快速入门\n\n## 基本语法\n\n[Go 语言圣经](https://books.studygolang.com/gopl-zh/)\n\n## 常用库\n\n### 切片\n\ngo 通过切片模拟栈和队列\n\n栈\n\n```go\n// 创建栈\nst"
},
{
"path": "introduction/quickstart.md",
"chars": 2343,
"preview": "# 快速开始\n\n## 数据结构与算法\n\n数据结构是一种数据的表现形式,如链表、二叉树、栈、队列等都是内存中一段数据表现的形式。\n算法是一种通用的解决问题的模板或者思路,大部分数据结构都有一套通用的算法模板,所以掌握这些通用的算法模板即可解决"
},
{
"path": "practice_algorithm/bplus.md",
"chars": 23,
"preview": "# b+ tree (MySQL 索引实现)\n"
},
{
"path": "practice_algorithm/data_index.md",
"chars": 19,
"preview": "# 数据索引(kafka 稀疏索引)\n"
},
{
"path": "practice_algorithm/skiplist.md",
"chars": 26,
"preview": "# skiplist(Redis Zset 实现)\n"
},
{
"path": "src/main.go",
"chars": 72,
"preview": "package main\n\nimport \"fmt\"\n\nfunc main() {\n\tfmt.Println(\"hello world\")\n}\n"
},
{
"path": "src/sort/heap_sort.go",
"chars": 784,
"preview": "package sort\n\nfunc HeapSort(a []int) []int {\n\t// 1、无序数组a\n\t// 2、将无序数组a构建为一个大根堆\n\tfor i := len(a)/2 - 1; i >= 0; i-- {\n\t\tsi"
},
{
"path": "src/sort/heap_sort_test.go",
"chars": 454,
"preview": "package sort\n\nimport (\n\t\"reflect\"\n\t\"testing\"\n)\n\nfunc TestHeapSort(t *testing.T) {\n\ttype args struct {\n\t\ta []int\n\t}\n\ttest"
}
]
About this extraction
This page contains the full source code of the greyireland/algorithm-pattern GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 24 files (99.1 KB), approximately 38.7k tokens, and a symbol index with 5 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.