Showing preview only (711K chars total). Download the full file or copy to clipboard to get everything.
Repository: gzc/CLRS
Branch: master
Commit: b7d3df5ba834
Files: 231
Total size: 656.5 KB
Directory structure:
gitextract_c2bux98h/
├── .gitignore
├── C01-The-Role-of-Algorithms-in-Computing/
│ ├── 1.1.md
│ ├── 1.2.md
│ └── problem.md
├── C02-Getting-Started/
│ ├── 2.1.md
│ ├── 2.2.md
│ ├── 2.3.md
│ ├── exercise_code/
│ │ ├── Insertion_sort_with_binary_search.py
│ │ ├── binary-search.py
│ │ ├── inversions.cpp
│ │ ├── inversions.py
│ │ └── merge-sort.py
│ └── problem.md
├── C03-Growth-of-Functions/
│ ├── 3.1.md
│ ├── 3.2.md
│ └── problem.md
├── C04-Recurrences/
│ ├── 4.1.md
│ ├── 4.2.md
│ ├── 4.3.md
│ ├── 4.4.md
│ ├── exercise_code/
│ │ ├── findIndex.py
│ │ └── findMissing.py
│ └── problem.md
├── C05-Probabilistic-Analysis-and-Randomized-Algorithms/
│ ├── 5.1.md
│ ├── 5.2.md
│ ├── 5.3.md
│ ├── 5.4.md
│ ├── myrandom.py
│ └── problem.md
├── C06-Heapsort/
│ ├── 6.1.md
│ ├── 6.2.md
│ ├── 6.3.md
│ ├── 6.4.md
│ ├── 6.5.md
│ ├── d-ary-heaps.cpp
│ ├── heap.cpp
│ ├── main.cpp
│ ├── makefile
│ ├── p_queue.cpp
│ ├── p_queue.h
│ ├── problem.md
│ └── young.cpp
├── C07-Quicksort/
│ ├── 7.1.md
│ ├── 7.2.md
│ ├── 7.3.md
│ ├── 7.4.md
│ ├── exercise_code/
│ │ ├── fuzzy_sort.py
│ │ ├── hoare.py
│ │ ├── quickSortWithEqualElements.cpp
│ │ ├── quicksort.py
│ │ └── tailrecursive.py
│ ├── problem.md
│ ├── quicksort.py
│ └── randomized-quicksort.py
├── C08-Sorting-in-Linear-Time/
│ ├── 8.1.md
│ ├── 8.2.md
│ ├── 8.3.md
│ ├── 8.4.md
│ ├── exercise_code/
│ │ ├── in_place_counting_sort.py
│ │ ├── intergerQuery.cpp
│ │ ├── radixSort.cpp
│ │ └── water-jugs.py
│ └── problem.md
├── C09-Medians-and-Order-Statistics/
│ ├── 9.1.md
│ ├── 9.2.md
│ ├── 9.3.md
│ ├── exercise_code/
│ │ ├── k-close2median.py
│ │ ├── k-quantile.py
│ │ ├── randomized-select-iterative.cpp
│ │ └── second-smallest.cpp
│ ├── minmax.c
│ ├── problem.md
│ ├── problems/
│ │ ├── i-largest.cpp
│ │ ├── i-largest.py
│ │ └── weighted_median.py
│ ├── randomized-select.cpp
│ └── worst-case-linear-time.cpp
├── C10-Elementary-Data-Structures/
│ ├── 10.1.md
│ ├── 10.2.md
│ ├── 10.3.md
│ ├── 10.4.md
│ ├── README.md
│ ├── exercise_code/
│ │ ├── af-obj.c
│ │ ├── deque.cpp
│ │ ├── deque.py
│ │ ├── dict.cpp
│ │ └── traversal.cpp
│ └── problem.md
├── C11-Hash-Tables/
│ ├── 11.1.md
│ ├── 11.2.md
│ ├── 11.3.md
│ ├── 11.4.md
│ ├── 11.5.md
│ ├── README.md
│ └── problem.md
├── C12-Binary-Search-Trees/
│ ├── 12.1.md
│ ├── 12.2.md
│ ├── 12.3.md
│ ├── 12.4.md
│ ├── BSTree.h
│ ├── main.cpp
│ └── makefile
├── C13-Red-Black-Trees/
│ ├── 13.1.md
│ ├── 13.2.md
│ ├── 13.3.md
│ ├── 13.4.md
│ ├── problem.md
│ ├── rbtree.c
│ └── rbtree.cpp
├── C14-Augmenting-Data-Structures/
│ ├── 14.1.md
│ ├── 14.2.md
│ ├── 14.3.md
│ ├── exercise_code/
│ │ ├── m-Josephus.cpp
│ │ └── test
│ └── problem.md
├── C15-Dynamic-Programming/
│ ├── 15.1.md
│ ├── 15.2.md
│ ├── 15.3.md
│ ├── 15.4.md
│ ├── 15.5.md
│ ├── Assembly-line-sche.c
│ ├── Matrix-chain-multiplication.c
│ ├── lincrs.cpp
│ ├── optimalBST.cpp
│ └── rodcutting.cpp
├── C16-Greedy-Algorithms/
│ ├── 16.1.md
│ ├── 16.2.md
│ ├── 16.3.md
│ └── huffman/
│ ├── BinaryStdIn.cpp
│ ├── BinaryStdIn.h
│ ├── BinaryStdOut.cpp
│ ├── BinaryStdOut.h
│ ├── HUFFMAN.cpp
│ ├── HUFFMAN.h
│ ├── binary_test/
│ │ ├── main.cpp
│ │ └── makefile
│ ├── binarystdin_test/
│ │ ├── main.cpp
│ │ └── makefile
│ ├── binarystdout_test/
│ │ ├── data
│ │ ├── main.cpp
│ │ └── makefile
│ └── huffman_test/
│ ├── compressed
│ ├── huffman_test_client.cpp
│ └── makefile
├── C17-Amortized-Analysis/
│ ├── 17.1.md
│ ├── 17.2.md
│ ├── 17.3.md
│ └── 17.4.md
├── C18-B-Trees/
│ ├── 18.1.md
│ ├── 18.2.md
│ ├── 18.3.md
│ ├── btree.cpp
│ └── btree.py
├── C19-Binomial-Heaps/
│ ├── 19.1.md
│ ├── 19.2.md
│ ├── BinomialHeap.h
│ └── Main.cpp
├── C21-Data-Structures-for-Disjoint-Sets/
│ ├── 21.1.md
│ ├── 21.2.md
│ ├── 21.3.md
│ ├── problem.md
│ └── uf.cpp
├── C22-Elementary-Graph-Algorithms/
│ ├── 22.1.md
│ ├── 22.2.md
│ ├── 22.3.md
│ ├── 22.4.md
│ ├── 22.5.md
│ ├── README.md
│ ├── elementary_graph_algo.py
│ ├── exercise_code/
│ │ └── EulerTour.cpp
│ └── problem.md
├── C23-Minimum-Spanning-Trees/
│ ├── 23.1.md
│ └── 23.2.md
├── C24-Single-Source-Shortest-Paths/
│ ├── 24.1.md
│ ├── 24.2.md
│ ├── 24.3.md
│ ├── 24.4.md
│ └── README.md
├── C25-All-Pairs-Shortest-Paths/
│ ├── 25.1.md
│ ├── 25.2.md
│ ├── 25.3.md
│ ├── Floyd_Warshall.cpp
│ └── README.md
├── C26-Flow-networks/
│ ├── 26.1.md
│ ├── 26.2.md
│ ├── 26.3.md
│ └── maxflow/
│ ├── FlowEdge.cpp
│ ├── FlowNetwork.cpp
│ ├── FordFulkerson.cpp
│ ├── input.txt
│ ├── makefile
│ ├── readme.md
│ ├── testFlowEdge.cpp
│ └── testFlowNetwork.cpp
├── C31-Number-Theoretic-Algorithms/
│ ├── 31.1.md
│ ├── 31.2.md
│ ├── 31.7.md
│ ├── euclid.py
│ ├── exercise_code/
│ │ ├── binary2decimal.py
│ │ └── lcm.py
│ └── extended_euclid.py
├── C32-String-Matching/
│ ├── 32.1.md
│ ├── 32.2.md
│ ├── 32.3.md
│ ├── 32.4.md
│ ├── BF.c
│ ├── BM.c
│ ├── FA.c
│ ├── KMP.c
│ ├── README.md
│ ├── RK.c
│ └── exercise_code/
│ └── str_spin.c
├── C33-Computational-Geometry/
│ ├── 33.1.md
│ ├── Graham_Scan.py
│ ├── exercise_code/
│ │ ├── area.cpp
│ │ ├── colinear.cpp
│ │ ├── convex_polygon.cpp
│ │ ├── pointpolygon.cpp
│ │ ├── polarCMP.cpp
│ │ └── ray_intersection.cpp
│ └── twoline.cpp
├── C35-Approximation-Algorithms/
│ ├── 35.1.md
│ └── 35.2-5.md
├── LICENSE
├── README.md
└── other/
├── Karatsuba/
│ ├── Karatsuba.cpp
│ ├── main.cpp
│ └── makefile
├── segmentTree.cpp
├── stringSpilit.cpp
└── trie.cpp
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.DS_Store
*.out
*.log
*.gz
*.aux
*.tex
images/
Tools/
================================================
FILE: C01-The-Role-of-Algorithms-in-Computing/1.1.md
================================================
### Exercises 1.1-1
***
Give a real-world example in which one of the following computational problems appears: sorting, determining the best order for multiplying matrices, or finding the convex hull.
### `Answer`
* 用到排序的应用很多,比如电商网站对商品按价格进行排序
* The multiplication process in computers are time consuming than addition process. If we have three or more matrices to multiply, then we should check the order in which to multiply to reduce the number of multiplications.
* [From Wiki]The problem of finding convex hulls finds its practical applications in pattern recognition, image processing, statistics, geographic information system, game theory, construction of phase diagrams, and static code analysis by abstract interpretation. It also serves as a tool, a building block for a number of other computational-geometric algorithms such as the rotating calipers method for computing the width and diameter of a point set. also application in [CV](http://docs.opencv.org/doc/tutorials/imgproc/shapedescriptors/hull/hull.html).
### Exercises 1.1-2
***
Other than speed, what other measures of efficiency might one use in a real-world setting?
### `Answer`
内存使用,资源占用(网络,磁盘等)
Memory requirement, Degree of parallelism, Resource use( cpu or gpu cycles, Disk IO etc), Accessibility(Cloud/local)
### Exercises 1.1-3
***
Select a data structure that you have seen previously, and discuss its strengths and limitations.
### `Answer`
数组,访问速度快,不能动态调整大小.
### Exercises 1.1-4
***
How are the shortest-path and traveling-salesman problems given above similar? How are they different?
### `Answer`
* 相同点:都是在图中找一条路径
* 不同点:最短路径只是求2个点之间的路径,但是旅行商问题要遍历全部点并且回到起点,是一个全排列问题.
* In travelling salesman problem we want to know an order of delivery of stops that yields "lowest overall distance" travelled .
* This "lowest overall distance" is similar to shortest path finding situation .
* Shortest path is polynomially solvable but travelling -salesman is NP-Complete
### Exercises 1.1-5
***
Come up with a real-world problem in which only the best solution will do. Then come up with one in which a solution that is "approximately" the best is good enough.
### `Answer`
这题好抽象 0 0 求根如果是无理数近似就行了找不到最优的.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C01-The-Role-of-Algorithms-in-Computing/1.2.md
================================================
### Exercises 1.2-1
***
Give an example of an application that requires algorithmic content at the application level, and discuss the function of the algorithms involved.
### `Answer`
导航!!!
Fingerprint matching algorithm used by forensics. Storing the fingerprints, and comparing them with the suspects prints
it requires algorithms at application level. Function of algorithm is to have accurate matching and quick response.
Akinator is a web application that tells what was on our mind simply by asking questions. It uses Decision trees to come to conclusion.
http://en.akinator.com/
### Exercises 1.2-2
***
Suppose we are comparing implementations of insertion sort and merge sort on the same machine. For inputs of size n, insertion sort runs in 
steps, while merge sort runs in 
steps. For which values of n does insertion sort beat merge sort?
### `Answer`
解方程 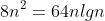
for 2 < n < 43
### Exercises 1.2-3
***
What is the smallest value of n such that an algorithm whose running time is  runs faster
than an algorithm whose running time is 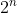 on the same machine?
### `Answer`
还是解方程 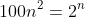
for n = 15
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C01-The-Role-of-Algorithms-in-Computing/problem.md
================================================
### Problems 1 : Comparison of running times
***
For each function **f**(n) and time t in the following table, determine the largest size n of a problem that can be solved in time t, assuming that the algorithm to solve the problem takes **f**(n) microseconds.
### `Answer`
Item | 1 second | 1 miniute | 1 hour | 1 day | 1 month | 1 year | 1 century
:----:|----:|----:|----:|----:|----:|----:|----:
 |  |  |  |  |  |  | 
 |  |  |  |  |  |  | 
 |  |  |  |  |  |  | 
 | 62746 | 2801417 | 133378058 | 2755147513| 71870856404 | 797633893349 | 68654697441062
 | 1000 | 7745 | 60000 | 293938 | 1609968 | 5615692 | 56175382
 | 100 | 391 | 1532 | 4420 | 13736 | 31593 | 146677
 | 19 | 25 | 31 | 36 | 41 | 44 | 51
 | 9 | 11 | 12 | 13 | 15 | 16 | 17
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C02-Getting-Started/2.1.md
================================================
### Exercises 2.1-1
***
Using Figure 2.2 as a model, illustrate the operation of INSERTION-SORT on the array A = [31, 41, 59, 26, 41, 58].
### `Answer`

### Exercises 2.1-2
***
Rewrite the INSERTION-SORT procedure to sort into nonincreasing instead of nondecreasing order.
### `Answer`

### Exercises 2.1-3
***
Consider the searching problem:
* **Input**: A sequence of n numbers A = [a1, a2, . . . , an] and a value v.
* **Output**: An index i such that v = A[i] or the special value NIL if v does not appear in A.
Write pseudocode for **linear search**, which scans through the sequence, looking for v. Using a loop invariant, prove that your algorithm is correct. Make sure that your loop invariant fulfills the three necessary properties.
### `Answer`

### Exercises 2.1-4
***
Consider the problem of adding two n-bit binary integers, stored in two n-element arrays A and B. The sum of the two integers should be stored in binary form in an (n + 1)-element array C. State the problem formally and write pseudocode for adding the two integers.
### `Answer`

```
C = Array[A.length+1]
carry <- 0,
for i <- A.length to 1
C[i+1] <- (A[i] + B[i] + carry) % 2;
carry = (A[i] + B[i] + carry)/2;
C[1] <- carry;
return C
```
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C02-Getting-Started/2.2.md
================================================
### Exercises 2.2-1
***
Express the function 
in terms of Θ-notation.
### `Answer`
Θ(n^3)
### Exercises 2.2-2
***
Consider sorting n numbers stored in array A by first finding the smallest element of A and exchanging it with the element in A[1]. Then find the second smallest element of A, and exchange it with A[2]. Continue in this manner for the first n - 1 elements of A. Write pseudocode for this algorithm, which is known as **selection sort**. What loop invariant does this algorithm maintain? Why does it need to run for only the first n - 1 elements, rather than for all n elements? Give the best-case and worst-case running times of selection sort in Θ- notation.
### `Answer`

Loop invariant: at the start of each iteration of the outer for loop, the subarray A[1..i-1] consists of the i-1 smallest elements in the array A[1..n] and this subarray is in sorted order.
After the first n-1 elements, the subarray A[1..n-1] contains the smallest n-1 elements, sorted, and therefore element A[n] must be the largest element
时间都是Θ(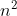)
### Exercises 2.2-3
***
Consider linear search again (see Exercise 2.1-3). How many elements of the input sequence need to be checked on the average, assuming that the element being searched for is equally likely to be any element in the array? How about in the worst case? What are the average-case and worst-case running times of linear search in Θ-notation? Justify your answers.
### `Answer`
* 平均情况应该要查找(n+1)/2个元素
* 最坏情况是n个
* Assuming equal probability of occurrence 1/n, average number of elements which need to be checked is 1/n * (1 + 2 + ... +n) = (n+1)/2. Running time is Θ(n)
* Worst case, the element to search is dead last in the array. In that case n elements need to be searched. Running time is Θ(n)
所以都是Θ(n)
### Exercises 2.2-4
***
How can we modify almost any algorithm to have a good best-case running time?
### `Answer`
算法开始检测输入数据,若符合特殊条件则输出事先计算好的结果
Modify the algorithm so it checks whether the input satisfies some special case condition. If it does, output a pre-computed answer.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C02-Getting-Started/2.3.md
================================================
### Exercises 2.3-1
***
Using Figure 2.4 as a model, illustrate the operation of merge sort on the array A = [3, 41, 52, 26, 38, 57, 9, 49].
### `Answer`

### Exercises 2.3-2
***
Rewrite the MERGE procedure so that it does not use sentinels, instead stopping once either array L or R has had all its elements copied back to A and then copying the remainder of the other array back into A.
### `Answer`
[code](./exercise_code/merge-sort.py)
### Exercises 2.3-3
***
Use mathematical induction to show that when n is an exact power of 2, the solution of the recurrence
 is =n\\lg{n})
1.定义 =T\(2^k\))
2.当k = 1时,=T\(2\)=2=2\lg{2}=2^1\lg{2^1})
3.假设=2^k\\lg{2^k})
4.=T\(2^{k+1}\)=2T\(2^k\)+2^{k+1})
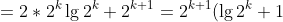)
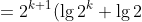=2^{k+1}\lg{2^{k+1}})
### `Answer`
[code](./exercise_code/merge-sort.py)
### Exercises 2.3-4
***
Insertion sort can be expressed as a recursive procedure as follows. In order to sort A[1..n], we recursively sort A[1..n -1] and then insert A[n] into the sorted array A[1..n - 1]. Write a recurrence for the running time of this recursive version of insertion sort.
### `Answer`

### Exercises 2.3-5
***
Referring back to the searching problem (see Exercise 2.1-3), observe that if the sequence A is sorted, we can check the midpoint of the sequence against v and eliminate half of the sequence from further consideration. **Binary search** is an algorithm that repeats this procedure, halving the size of the remaining portion of the sequence each time. Write pseudocode, either iterative or recursive, for binary search. Argue that the worst-case running time of binary search is Θ(lg n).
### `Answer`

[python code](./exercise_code/binary-search.py)
### Exercises 2.3-6
***
Observe that the while loop of lines 5 - 7 of the **INSERTION-SORT** procedure in Section 2.1 uses a linear search to scan (backward) through the sorted subarray A[1..j - 1]. Can we use a binary search (see Exercise 2.3-5) instead to improve the overall worst-case running time of insertion sort to Θ(n lg n)?
### `Answer`
不可以,查找可以达到对数级的,但是依然要移动元素,依然是线性的.
Although we can reduce the number of comparisons by using binary search, we still need to shift all the elements greater than key towards the end of the array to insert key. And this shifting of elements runs at Θ(n) time, even in average case (as we need to shift half of the elements). So, the overall worst-case running time of insertion sort will still be Θ(n^2).
Pseudo-code:
```
A = [1 .. n];
selectionSort(A){
for (i = 2) to (i = n)
// find the correct position of A[i] in array A[1 .. i-1]
pos = binarySearch(1,i-1,A[i]);
// shifting of elements to place A[i] in its correct position pos
for (j = i-1) to (j = pos)
temp = A[j+1];
A[j+1] = A[j];
A[j] = temp;
endfor
endfor
}
binarySearch(low,high,v)
mid = (low + high) / 2;
// we are not looking for the value v explicitly, but for its correct position
if (v >= A[mid] && v < A[mid+1])
return mid
else
if (v < A[mid])
return binarySearch(low,mid,v)
else
return binarySearch(mid,high,v)
endif
endif
```
[python code](./exercise_code/Insertion_sort_with_binary_search.py)
### Exercises 2.3-7
***
Describe a Θ(n lg n)-time algorithm that, given a set S of n integers and another integer x,
determines whether or not there exist two elements in S whose sum is exactly x.
先用mergesort进行排序,然后两根指针分别在集合的头和尾,往中间扫描~
这个题目可以利用哈希表(散列表)达到O(n),[my code](https://github.com/gzc/leetcode/blob/master/cpp/001-010/Two%20Sum.cpp)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C02-Getting-Started/exercise_code/Insertion_sort_with_binary_search.py
================================================
# Exercise 2.3-6 in book
# Standalone Python version 2.7 code
import os
import re
import math
import time
from random import randint
def insertion_sort(array):
for j, v in enumerate(array):
key = v
i = j - 1
while i > -1 and array[i] > key:
array[i+1] = array[i]
i = i - 1
array[i+1] = key
def insertion_sort_v2(array):
for j, v in enumerate(array):
if j > 0:
key = array[j]
a = binary_search(array, key, j)
for i in range(j, a, -1):
array[i] = array[i-1]
array[a] = key
def binary_search(array, searchingelement, arraypart):
array = list(array[:arraypart])
last = array.__len__()
mid = int(last/2)
min = 0
for i in range(int(math.log(last)/math.log(2)) + 1):
if array[mid] == searchingelement:
return mid
elif array[mid] < searchingelement:
min = mid
mid = int((last + mid) / 2)
else:
last = mid
mid = int((mid + min) / 2)
if array[mid] < searchingelement:
return mid+1
elif array[mid] > searchingelement:
if mid-1 > -1:
return mid-1
else:
return mid
else:
return mid
if __name__ == '__main__':
array1 = []
for i in range(10000):
array1.append(randint(0, 1000))
array = list(array1)
t0 = time.clock()
insertion_sort(array)
t1 = time.clock()
print "insertion_sort: " + str(t1-t0)
array = list(array1)
t0 = time.clock()
insertion_sort_v2(array)
t1 = time.clock()
print "insertion_sort_v2: " + str(t1-t0)
# Test results shows that worst case of improved insertion sort is O(n * (n\2) * lg(n))
# Better than insertion sort but still very bad
# Tested for 1000 random elements
# insertion_sort:----0.0390096090178
# insertion_sort_v2:-0.0287921815039
# Tested for 10000 random elements
# insertion_sort:----3.76619711492
# insertion_sort_v2:-2.25984142782
# End of 2.3-6 in book
================================================
FILE: C02-Getting-Started/exercise_code/binary-search.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Standalone python code, version 2.7
# I can provide older version to compare them with each other
import os
import re
import math
import time
def binary_search(array, searchingelement):
last = array.__len__()
mid = int(last/2)
min = 0
for i in range(int(math.log(last)/math.log(2)) + 1):
if array[mid] == searchingelement:
return str(mid) + " th index"
elif array[mid] < searchingelement:
min = mid
mid = int((last + mid) / 2)
else:
last = mid
mid = int((mid + min) / 2)
return null
if __name__ == '__main__':
array = []
for i in range(1000000):
array.append(i)
t0 = time.clock()
print binary_search(array, 345676)
t1 = time.clock()
print "binary_search: " + str(t1-t0)
================================================
FILE: C02-Getting-Started/exercise_code/inversions.cpp
================================================
// Created by wander on 16/5/14.
// Copyright © 2016年 W4anD0eR96. All rights reserved.
// 采用左闭右开的区间描述方式
#include "bits/stdc++.h"
using namespace std;
void MergeWithCountInversions(vector<int>& v, int p, int q, int r, int& cnt) {
int n1 = q - p, n2 = r - q;
vector<int> L, R;
for (int i = 0; i < n1; ++i) L.push_back(v[p + i]);
for (int i = 0; i < n2; ++i) R.push_back(v[q + i]);
L.push_back(INT_MAX); R.push_back(INT_MAX);
int i = 0, j = 0;
for (int k = p; k < r; ++k) {
// i n1 j n2
// | | | |
// |--------)|---------)
// 若此时发生L[i] > R[j],则由于L[0..i) < R[j]且R[0..j) < R[j]
// 故与R[j]构成逆序对的元素是L[i..n1)
if (L[i] <= R[j]) { v[k] = L[i]; i += 1; }
else { v[k] = R[j]; j += 1; cnt += n1 - i;
{ for (int u = i; u < n1; ++u) cout << "(" << L[u] << "," << R[j - 1] << "), "; } // Print Inversions
}
}
}
void MergeSort(vector<int>& v, int p, int r, int& cnt) {
if (p >= r - 1) return;
int q = (p + r) >> 1;
MergeSort(v, p, q, cnt);
MergeSort(v, q, r, cnt);
MergeWithCountInversions(v, p, q, r, cnt);
}
int main(int argc, const char * argv[]) {
vector<int> v = { 31, 41, 59, 26, 41, 58 };
int cntInversions = 0;
cout << "v: ";
for (auto i : v) cout << i << " ";
cout << endl;
cout << "Total inversions are: ";
MergeSort(v, 0, (int)v.size(), cntInversions);
cout << endl;
cout << "Whose amount is: " << cntInversions << "." << endl;
return 0;
}
================================================
FILE: C02-Getting-Started/exercise_code/inversions.py
================================================
#!/usr/bin/env python
# coding=utf-8
def merge(items, p, q, r):
L = items[p:q+1]
R = items[q+1:r+1]
i = j = 0
k = p
inversions = 0
while i < len(L) and j < len(R):
if(L[i] < R[j]):
items[k] = L[i]
i += 1
else:
items[k] = R[j]
j += 1
inversions += (len(L) - i)
k += 1
if(j == len(R)):
items[k:r+1] = L[i:]
return inversions
def mergesort(items, p, r):
inversions = 0
if(p < r):
q = (p+r)/2
inversions += mergesort(items, p, q)
inversions += mergesort(items, q+1, r)
inversions += merge(items, p, q, r)
return inversions
items = [4,3,2,1,17]
inversions = mergesort(items, 0, len(items)-1)
print items,inversions
================================================
FILE: C02-Getting-Started/exercise_code/merge-sort.py
================================================
#!/usr/bin/env python
# coding=utf-8
import math
def merge(items, p, q, r):
L = items[p:q+1]
R = items[q+1:r+1]
i = j = 0
k = p
while i < len(L) and j < len(R):
if(L[i] < R[j]):
items[k] = L[i]
i += 1
else:
items[k] = R[j]
j += 1
k += 1
if(j == len(R)):
items[k:r+1] = L[i:]
def mergesort(items, p, r):
if(p < r):
q = math.floor((p+r)/2)
mergesort(items, p, q)
mergesort(items, q+1, r)
merge(items, p, q, r)
items = [4,3,2,1,17]
mergesort(items, 0, len(items)-1)
print items
================================================
FILE: C02-Getting-Started/problem.md
================================================
### Problems 1 : Insertion sort on small arrays in merge sort
***
Although merge sort runs in Θ(n lg n) worst-case time and insertion sort runs in Θ(n^2) worst- case time, the constant factors in insertion sort make it faster for small n. Thus, it makes sense to use insertion sort within merge sort when subproblems become sufficiently small. Consider a modification to merge sort in which n/k sublists of length k are sorted using insertion sort and then merged using the standard merging mechanism, where k is a value to be determined.
a. Show that the n/k sublists, each of length k, can be sorted by insertion sort in Θ(nk) worst-case time.
b. Show that the sublists can be merged in Θ(n lg (n/k) worst-case time.
c. Given that the modified algorithm runs in Θ(nk + n lg (n/k)) worst-case time, what is
the largest asymptotic (Θnotation) value of k as a function of n for which the modified
algorithm has the same asymptotic running time as standard merge sort?
d. How should k be chosen in practice?
### `Answer`
**(a)** T(n) = (n/k)\*Θ(k<sup>2</sup>) = Θ(nk)
**(b)** If there are n/k sublists, then the height of the tree formed will be lg(n/k). And at each level of the tree, the complexity of
merging is Θ(n). So the worst case to merge the sublists is Θ(n lg(n/k)).
**(c)** Θ(nk + nlg(n/k)) = Θ(nk + nlgn - nlgk)) should be equal to Θ(nlgn)
To satisfy this, `k` cannot grow faster than `lgn`, otherwise `nk` term will run worse than `Θ(nlgn)`. So `k <= Θ(lgn)` to satisfy the above condition.
So largest value of `k = lgn`.
**(d)** Time complexity of insertion sort = c<sub>1</sub>n<sup>2</sup> and the time complexity of merge sort is c<sub>2</sub>nlgn.
To find the value of k
c<sub>1</sub>k<sup>2</sup> <= c<sub>2</sub>klgk
k <= (c<sub>2</sub>/c<sub>1</sub>)lgk
Now we can check manually by putting different values of k.
### Problems 2 : Correctness of bubblesort
***
Bubblesort is a popular sorting algorithm. It works by repeatedly swapping adjacent elements that are out of order.
### `Answer`
a. 我们还需要证明数组里面的元素就是原来的那些元素
b. **每次循环前,子数组A[j..]的最小元素是A[j]** <br />
Initialization:刚开始的时候,子数组只有一个元素,是A的最后一个元素,循环不变式自然成立 <br />
Maintenance:每个迭代,会比较A[j]和A[j-1]的大小,并把小的往前放 <br />
Termination:迭代结束时,j = i,A[i]是子数组A[i..]最小的元素 <br />
c. **每次循环前,A[1,i-1]是一个排序好的数组,且小于等于A[i..]中的元素**
Initialization:刚开始的时候,子数组为空,循环不变式自然成立 <br />
Maintenance:每个迭代,A[i]会变成A[i..]中的最小元素 <br />
Termination:迭代结束时,i = n, 我们获得了一个排序好的数组 <br />
d. **bubblesort**的最坏运行时间与**insertion sort**一样都是Θ(n^2),但是一般来说**bubblesort**会慢点,因为它有许多的**swap**操作.
### Problems 3 : Correctness of Horner's rule
***
### `Answer`
**a.** Θ(n)
**b.**
Naive-Poly-Eval:
y = 0
for i = 0 to n
m = 1
for k = 1 to i
m = m·x
y = y + aᵢ·m
运行时间是Θ(n2),非常慢
**c.**
**Initialization:** 一开始没有项,y = 0
**Maintenance:**根据循环不变式,第i次迭代结束有
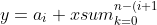}a_{k+i+1}x^k=a_ix^0+\\sum_{k=0}^{n-i-1}a_{k+i+1}x^{k+1}=\\sum_{k=-1}^{n-i-1}a_{k+i+1}x^{k+1}=\\sum_{k=0}^{n-i}a_{k+i}x^k)
**Termination:**循环结束时 i = -1, 将i = 0代入
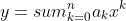
**d.**
前面已经证明了循环不变式,结论自然是成立的.
### Problems 4 : Inversions
***
Let A[1..n] be an array of n distinct numbers. If i < j and A[i] > A[j], then the pair (i, j) is called an inversion of A.
a. List the five inversions of the array 2, 3, 8, 6, 1.
b. What array with elements from the set {1, 2, . . . , n} has the most inversions? How
many does it have?
c. What is the relationship between the running time of insertion sort and the number of
inversions in the input array? Justify your answer.
d. Give an algorithm that determines the number of inversions in any permutation on n
elements in Θ(n lg n) worst-case time. (Hint: Modify merge sort.)
### `Answer`
**a.**
(1, 5), (2, 5), (3, 5), (4, 5), (3, 4)
**b.** The array with decending order arrangement i.e. {n, n-1, n-2, ..., 3, 2, 1} has the most inversions.
Number of inversions = Number of ways to choose two distinct element from the above set = n(n-1)/2.
**c.** we know that the inner while loop of insertion sort shift the elements to left to their right position. So if there is more inversion in an array, then we need to shift more elements. Hence as the number of inversions increases, running time of insertion sort increases.
**d.**
[PythonCode](./exercise_code/inversions.py)
[CppCode](./exercise_code/inversions.cpp)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C03-Growth-of-Functions/3.1.md
================================================
### Exercises 3.1-1
***
Let f(n) and g(n) be asymptotically nonnegative functions. Using the basic definition of Θ-
notation, prove that max(f(n), g(n)) = Θ(f(n) + g(n)).
### `Answer`
我们需要证明 c1(f(n) + g(n)) <= max(f(n), g(n)) <= c2(f(n) + g(n))
因为f和g都是非负函数,只需要令c1 = 0.5, c2 = 1即可.
English:
Use the definition of Θ-notation and set it up with the given values:
0 <= c1(f(n) + g(n)) <= max(f(n), g(n)) <= c2(f(n) + g(n))
---If we can Solve All inequalities, we can then use that as proof for the definition of Θ-notation.
c2 = 1: This holds because the Max must be lower than the sum of the two functions.
c1 = 1/2: This holds because the Max can at its lowest be equal to 1/2 of the Sum of the two functions.
0 <= c1(f(n) + g(n)) is trivial.
Thus, since all inequalities hold, we've proven that: max(f(n), g(n)) = Θ(f(n) + g(n)).
### Exercises 3.1-2
***
Show that for any real constants a and b, where b > 0,
^b=\\Theta\(n^b\))
### `Answer`
Here (n + a) <= 2n, when |a| <= n and (n + a) >= n/2, when |a| <= n/2.
So n >= 2a
So we can write,
0 <= n/2 <= (n + a) <= 2n
Now raising to the power b, we get
0 <= (n/2)<sup>b</sup> <= (n + a)<sup>b</sup> <= (2n)<sup>b</sup>
0 <= (1/2)<sup>b</sup>n<sup>b</sup> <= (n + a)<sup>b</sup> <= 2<sup>b</sup>n<sup>b</sup>
Comparing this with 0 <= c1n<sup>b</sup> <= (n + a)<sup>b</sup> <= c2n<sup>b</sup>, we get
c1 = (1/2)<sup>b</sup> , c2 = 2<sup>b</sup> and n<sub>0</sub> = 2a
Therefore (n + a)<sup>b</sup> = Θ(n<sup>b</sup>).
### Exercises 3.1-3
***
Explain why the statement, "The running time of algorithm A is at least O(n^2)," is meaningless.
### `Answer`
O-notation确定的是一个上界,而at least确定的是一个下界
### Exercises 3.1-4
***
Is 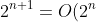?)Is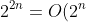?)
### `Answer`
(1)成立,因为当c0=2时,对所有的n>=1有0<=2^(n+1)<=2*2^n。
(2)不成立,假设存在常数c使得2^(2*n)<=c*2^n,则有2*n<=lg c+n,即n<=lg c,并不存在一个常数c使得这个不等式对n成立。
English:
for f(n) = O(g(n)), the definition of O-notation is:
0 <= f(n) <= c(g(n)) for all n > n0.
(1) 2^(n+1) = 2(2^n) <= c*2^n. If c = 2, the inequality holds and we prove 2^(n+1) = O(2^n) to be True! Answer: Yes.
(2) 2^2n = (2^n)^2. There is no possible constant c that can make 2^n into (2^n)^2. Thus, 2^2n =/= O(2^n). Answer: No.
### Exercises 3.1-5
***
Prove Theorem 3.1. *For any two functions f(n) and g(n), we have f(n) = Θ(g(n)) if and only if f(n) = O(g(n)) and
f(n) = Ω(g(n)).*
### `Answer`
充分性:f(n)=Θ(g(n))意味着存在c1、c2和n0(其中n>=n0)使得0<=c1g(n)<=f(n)<=c2g(n)。我们由此可推出以下两个结论:
* 存在c1和n0(其中n>=n0)使得0<=c1g(n)<=f(n),即f(n)=Ω(g(n))
* 存在c2和n0(其中n>=n0)使得0<=f(n)<=c2g(n),即f(n)=O(g(n))
必要性:f(n)=Ω(g(n))意味着“存在c1'和n1(其中n>=n1)使得0<=c1'g(n)<=f(n)”。类似的,f(n)=O(g(n))意味着“存在c2'和n2(其中n>=n2)使得0<=f(n)<=c2'g(n)”。
令c1=c1',c2=c2',n0=max{n1, n2},由Θ的定义我们有:f(n) = Θ(g(n))。
### Exercises 3.1-6
***
Prove that the running time of an algorithm is Θ(g(n)) if and only if its worst-case running
time is O(g(n)) and its best-case running time is Ω(g(n)).
### `Answer`
Theorem 3.1.
### Exercises 3.1-7
***
Prove that o(g(n)) ∩ ω(g(n)) is the empty set.
### `Answer`
假设o(g(n)) ∩ ω(g(n))不是一个空集,则等价于说:对于所有的c1,c2>0有0<=c1g(n)\<f(n)\<c2g(n)其中n>=max(n1, n2)。
我们令c1=c2,可以得出悖论,因此假设不成立,所以o(g(n)) ∩ ω(g(n))是一个空集。
### Exercises 3.1-8
***
We can extend our notation to the case of two parameters n and m that can go to infinity independently at different rates. For a given function g(n, m), we denote by O(g(n, m)) the set of functions
O(g(n, m)) = {f(n, m): there exist positive constants c, n0, and m0 such that 0 ≤ f(n, m) ≤ cg(n, m)for all n≥n0 and m≥m0}.
Give corresponding definitions for Ω(g(n, m)) and Θ(g(n, m)).
### `Answer`
Ω(g(n,m)={f(n,m):there exist positive constants c,n0, and m0 such that 0 ≤ cg(n,m) ≤ f(n,m) for all n≥n0 or m≥m0.
Θ(g(n,m)={f(n,m):there exist positive constants c1,c2,n0, and m0 such that 0 ≤ c1g(n,m) ≤ f(n,m) ≤ c2g(n,m) for all n≥n0 or m≥m0.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C03-Growth-of-Functions/3.2.md
================================================
### Exercises 3.2-1
***
Show that if f(n) and g(n) are monotonically increasing functions, then so are the functions f(n) + g(n) and f (g(n)), and if f(n) and g(n) are in addition nonnegative, then f(n) · g(n) is monotonically increasing.
### `Answer`
Given that f(n) and g(n) are monotonically increasing functions, So
f(n) <= f(n+1) (1)
g(n) <= g(n+1) (2)
Adding eqn. (1) and (2), we get
f(n) + g(n) <= f(n+1) + g(n+1)
Therefore f(n) + g(n) is monotonically increasing function.
Since, g(n) <= g(n+1) and f(n) is a monotonically increasing function.
So, f(g(n)) <= f(g(n+1))
Therefore f(g(n)) is a monotonically increasing function.
Given f(n) >=0 and g(n) >= 0
Then multiplying eqn. (1) and (2) results into
f(n) · g(n) <= f(n+1) · g(n+1)
Therefore f(n) · g(n) is monotonically increasing.
### Exercises 3.2-2
***
Prove equation (3.15).
### `Answer`
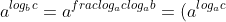^{\\frac{1}{\\log_{a}{b}}}=c^{\\log_{b}{a}})
### Exercises 3.2-3
***
Prove equation (3.18). Also prove that n! = ω(2^n) and n! = o(n^n).
### `Answer`
采用暴力方法,直接证明极限在一个常数区间内
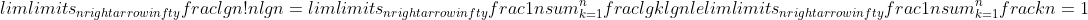
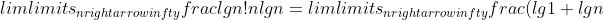+\(\\lg{2}+\\lg{\(n-1\)}\)+...}{n\\lg{n}}\\ge\\lim\\limits_{n\\rightarrow\\infty}\\frac{\\frac{n}{2}*\\lg{n}}{n\\lg{n}}=\\frac{1}{2})
### Exercises 3.2-4
***
Is the function  polynomially bounded? Is the function  polynomially bounded?
### `Answer`
多项式边界也就是函数\\lecn^k)
两边取对数得到}\\le\\lg{c}+k\\lg{n})
所以,如果一个函数f(n)是有多项式边界,就满足}=o\(\\lg{n}\))
令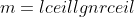
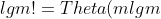=\\Theta\(\\lceil\\lg{n}\\rceil\\lg{\\lceil\\lg{n}\\rceil}\)>\\Theta\(\\lg{n}\))
令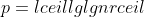
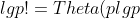=\\Theta\(\\lceil\\lg{{\\lg{n}}}\\rceil\\lg{\\lceil\\lg{{\\lg{n}}}\\rceil}\)=\\Theta\(\\lg{{\\lg{n}}}\\lg{\\lg{{\\lg{n}}}}\)=o\(\\lg{{\\lg{n}}}\\lg{{\\lg{n}}}\)=o\(\\lg{n}\))
### Exercises 3.2-5
***
Which is asymptotically larger: **lg(lg* n)** or **lg*(lg n)**?
### `Answer`
第2个大. Suppose log star of n is k, then the first one is log(k) while the second one is k - 1.
...表示多重对数函数的逆操作
### Exercises 3.2-6
***
Prove by induction that the ith Fibonacci number satisfies the equality
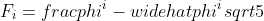
### `Answer`
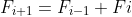\(\\phi^{i-2}\\widehat\\phi^0+\\phi^{i-3}\\widehat\\phi^1+...+\\phi^{0}\\widehat\\phi^{i-2}\)+\(\\phi-\\widehat\\phi\)\(\\phi^{i-1}\\widehat\\phi^0+\\phi^{i-2}\\widehat\\phi^1+...+\\phi^{0}\\widehat\\phi^{i-1}\)}{\\sqrt5}\\\\~\\hspace{14mm}=\\frac{\(\\phi-\\widehat\\phi\)\(\\phi^{i}\\widehat\\phi^0+\\phi^{i-1}\\widehat\\phi^1+...+\\phi^{0}\\widehat\\phi^{i}\)}{\\sqrt5}\\\\~\\hspace{14mm}=\\frac{\\phi^{i+1}-\\widehat\\phi^{i+1}}{\\sqrt5})
### Exercises 3.2-7
***
Prove that for i ≥ 0, the (i + 2)nd Fibonacci number satisfies Fi+2 ≥ φi.
### `Answer`
\\phi^i\\ge\\widehat\\phi^2\\widehat\\phi^i\\\\~\\hspace{14mm}\\iff\\phi^i\\ge\\widehat\\phi^i)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C03-Growth-of-Functions/problem.md
================================================
### Problems 1 : Asymptotic behavior of polynomials
***
### `Answer`
显而易见.
### Problems 2 : Relative asymptotic growths
***
Indicate for each pair of expressions (A,B) in the table below, whether A is O, o, Ω, ω, or Θ of B. Assume that k≥1, ϵ>0, and c>1 are constants. Your answer should be in the form of the table with "yes" or "no" written in each box.
### `Answer`
A | B | O | o | Ω | ω | Θ
:----:|:----:|:----:|:----:|:----:|:----:|:----:
 |  | yes | yes | no | no | no
 |  | yes | yes | no | no | no
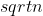 |  | no | no | no | no | no
 |  | no | no | yes | yes | no
 |  | yes | no | yes | no | yes
}) | }) | yes | no | yes | no | yes
For this problem, some people point out that
for 0 < epsilon < 1,
lg^k n > n^epsilon
and for epsilon >= 1,
lg^k n) < n^epsilon
Therefore, the correct answer is
YES YES YES YES YES
[issue 103](https://github.com/gzc/CLRS/issues/103)
### Problems 3 : Ordering by asymptotic growth rates
***
a.
Rank the following functions by order of growth; that is, find an arrangement  of the functions satisfying 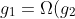,g_2=\Omega\(g_3\),...,g_{29}=\Omega\(g_{30}\)). Partition your list into equivalence classes such that functions ) and ) are in the same class if and only if =\Theta\(g\(n\)\)).
\quad&space;2^{lg^*n}\quad&space;\(\sqrt{2}\)^{lgn}\quad&space;n^2&space;\quad&space;n!\quad&space;\(lgn\)!\newline&space;\(\frac{2}{3}\)^n\quad&space;n^3\quad&space;lg^2n\quad&space;lg\(n!\)\quad&space;2^2^n\quad&space;n^{1/lgn}\newline&space;ln&space;lnn\quad&space;lg^*n\quad&space;n\cdot&space;2^n\quad&space;n^{lg&space;lgn}\quad&space;lnn\quad&space;1\newline&space;2^{lgn}\quad&space;{\(lgn\)}^{lgn}\quad&space;e^n\quad&space;4^{lgn}\quad&space;\(n+1\)!\quad&space;\sqrt{lgn}\newline&space;lg^*\(lgn\)\quad&space;2^{\sqrt{2lgn}}\quad&space;n\quad&space;2^n\quad&space;nlgn\quad&space;2^{2^{n+1}})
b.
Give an example of a single nonnegative function ) such that for all functions ) in part (a), ) is neither \)) nor \)).
### `Answer`
a.
!\quad&space;n!\newline&space;e^n\quad&space;n\cdot&space;2^n\quad&space;2^n\quad&space;\(\frac{3}{2}\)^n\newline&space;\(lgn\)^{lgn}=n^{lglgn}\quad&space;\(lgn\)!\newline&space;n^3\quad&space;n^2=4^{lgn}\quad&space;nlgn=lg\(n!\)\quad&space;2^{lgn}=n\quad&space;\(\sqrt{2}\)^{lgn}=\sqrt{n}\quad&space;2^{\sqrt{2\cdot&space;lgn}}\newline&space;lg^{2}n\quad&space;lnn\quad&space;\sqrt{lgn}\newline&space;lnlnn\quad&space;2^{lg^{*}n}\newline&space;lg^{*}n\quad&space;lg^{*}\(lgn\)\quad&space;lg\(lg^{*}\)n\newline&space;n^{\frac{1}{lgn}}=2\quad&space;1)
^{lgn}=n^{lglgn}\quad&space;because&space;of\quad&space;a^{log_bc}=c^{log_ba}\newline&space;n^{\frac{1}{lgn}}=2\quad&space;because\quad&space;n^{\frac{1}{lgn}}=2^{lgn\cdot&space;\frac{1}{lgn}}=2)
b.

***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C04-Recurrences/4.1.md
================================================
### Exercises 4.1-1
***
Show that the solution of %20=%20T\(\\lceil%20n/2%20\\rceil\)%20+%201) is O(lg n).
### `Answer`
我们猜想 %20\\le%20c\\lg\(n-2\)%20)
%20=%20T\(\\lceil%20n/2%20\\rceil\)%20+%201%20\\le%20T\(n/2+1\)%20+1%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20c\\lg\(n/2-1\)+1%20%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=clg\(n-2\)%20-c\\lg2%20+%201%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20clg\(n-2\)%0d%0a)
### Exercises 4.1-2
***
We saw that the solution of %20=%202T\(\\lfloor%20n/2%20\\rfloor\)%20+%20n)
is O(n lg n). Show that the solution of this recurrence is also Ω(n lg n). Conclude that the solution is Θ(n lg n).
### `Answer`
我们假设%20\\ge%20cn\\lg{n}%20)
%20=%202T\(\\lfloor%20n/2%20\\rfloor\)%20+%20n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\ge%20cn\(\\lg{n}%20-%20\\lg{2}\)+n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=cn\\lg{n}%20+\(1-c\\lg{2}\)n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\ge%20cnlg\(n\)%0d%0a\\\\%20%20~%0d%0a\\hspace{15%20mm}%20for%20~%201-c\\lg{2}%20<%200%0d%0a)
### Exercises 4.1-3
***
Show that by making a different inductive hypothesis, we can overcome the difficulty with the boundary condition T (1) = 1 for the recurrence (4.4) without adjusting the boundary conditions for the inductive proof.
### `Answer`
我们假设 %20\\le%20n\\lg{n}+n)
%20\\le%202\(c\\lfloor%20n/2%20\\rfloor%20\\lg\(\\lfloor%20n/2%20\\rfloor\)%20+%20\\lfloor%20n/2%20\\rfloor\)%20+%20n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%202c\(n/2\)\\lg\(n/2\)%20+%202\(n/2\)%20+%20n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn\\lg\(n/2\)%20+%202n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn\\lg{n}%20-%20\\lg{2}cn%20+%202n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn\\lg{n}%20+%20\(2-c\)n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn\\lg{n}%20+%20n%20~~~~~~~~~~~~%20for%20~%20c%20\\ge%201%0d%0a)
### Exercises 4.1-4
***
Show that Θ(n lg n) is the solution to the "exact" recurrence (4.2) for merge sort.
### `Answer`
我们假设%20\\ge%20cn\\lg{n}%20)
%20\\ge%202T\(n/2\)%20+%20kn%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=cn\\lg{n}%20+\(k-c\\lg{2}\)n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\ge%20cn\\lg{n}%20%20~~~~~~%20if%20~%20k%20\\le%20c\\lg{2}%0d%0a)
我们假设%20\\le%20c\(n-2\)\\lg\(n-2\)%20)
%20\\le%20T\(n/2+1\)%20+%20T\(n/2\)%20+%20kn%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20c\(n-2\)\\lg\(\\frac{n-2}{2}\)%20+%20kn%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=%20c\(n-2\)\\lg\(n-2\)%20+kn%20-%20c\\lg{2}\(n-2\)%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20c\(n-2\)\\lg\(n-2\)%20~~~~~~~~if~~kn%20\\le%20c\\lg{2}\(n-2\)%0d%0a)
### Exercises 4.1-5
***
Show that the solution to %20=%202T\(\\lfloor%20n/2%20\\rfloor%20+%2017\)%20+%20n%20) is O(n lg n).
### `Answer`
我们假设%20\\le%20c\(n-a\)\\lg\(n-a\)%20)
%20\\le%202c\(\\lfloor%20n/2%20\\rfloor%20+%2017%20-%20a\)\\lg\(\\lfloor%20n/2%20\\rfloor%20+%2017-a\)%20+%20n\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20%202c\(n/2%20+1+%2017%20-%20a\)\\lg\(%20n/2%20+1+%2017-a\)%20+%20n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20c\(n+36-2a\)\\lg\(\\frac{n+36-2a}{2}\)+n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20c\(n+36-2a\)\\lg\(n+36-2a\)%20-%20c\(n+36-2a\)+n%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20c\(n+36-2a\)\\lg\(n+36-2a\)%20~~~if%20~~%20c%20>%201%20\\\\%20%20~%20%0d%0a\\hspace{15%20mm}%20\\le%20c\(n-a\)\\lg\(n-a\)%20~~~~if%20~~%20a%20\ge%2036%0d%0a)
### Exercises 4.1-6
***
Solve the recurrence %20=%202T\(\\sqrt{n}\)+1%20)
by making a change of variables. Your solution should be asymptotically tight. Do not worry about whether values are integral.
### `Answer`
设n = lgn,得到新的递归式
%20=%202T\(2^{n/2}\)%20+%201)
再令S(n) = T(2^n)可以得到
%20=%20S2\(m/2\)%20+%201)
按照前面的方法解这个递归式即可
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C04-Recurrences/4.2.md
================================================
### Exercises 4.2-1
***
Use a recursion tree to determine a good asymptotic upper bound on the recurrence
%20=%203T\(\\lceil%20n/2%20\\rceil\)%20+%20n). Use the substitution method to verify your answer.
### `Answer`

树的高度是lgn,有3^lgn个叶子节点.
%20=%20n\\sum_{i%20=%200}^{lg\(n\)-1}\(\\frac{3}{2}\)^i%20+%20\\Theta\(3^{\\lg{n}}\)%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=%20\\Theta\(n^{\\lg{3}}\)%20+%20\\Theta\(3^{\\lg{n}}\)%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=%20\\Theta\(n^{\\lg{3}}\)%20+%20\\Theta\(n^{\\lg{3}}\)%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=%20\\Theta\(n^{\\lg{3}}\)%0d%0a)
我们猜想 %20\\le%20cn^{\\lg{3}}+2n%20)
%20\\le%203c\(n/2\)^{\\lg{3}}%20+%202n%20%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn^{\\lg{3}}+2n%20%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=%20\\Theta\(n^{\\lg{3}}\)%0d%0a)
### Exercises 4.2-2
***
Argue that the solution to the recurrence
%20=%20T\(n/3\)%20+%20T\(2n/3\)%20+%20cn%20)
, where c is a constant, is Ω(nlgn) by appealing to the recurrsion tree.
### `Answer`
最短的叶子高度是lg3n,每一层都要cn.也就是说,只考虑最短叶子的那一层(忽略其他层)已经有cnlg3n.
### Exercises 4.2-3
***
Draw the recursion tree for
%20=%204T\(\\lfloor%20n/2%20\\rfloor\)%20+%20cn)
,where c is a constant, and provide a tight asymptotic bound on its solution. Verify your bound by the substitution method.
### `Answer`

很明显是n^2的级别
我们假设 %20\\le%20n^2+2cn)
%20\\le%20%204c\(n/2\)^2%20+%202cn/2+cn%20\\le%20cn^2+2cn)
我们假设 %20\\ge%20n^2+2cn)
%20\\ge%20%204c\(n/2\)^2%20+%202cn/2+cn%20\\ge%20cn^2+2cn)
### Exercises 4.2-4
***
Use a recursion tree to give an asymptotically tight solution to the recurrence T(n) = T(n - a) + T(a) + cn, where a ≥ 1 and c > 0 are constants.
### `Answer`

%20=%20\\sum_{i=0}^{n/a}c\(n-ia\)%20+%20\(n/a\)ca%0d%0a=%20\\Theta\(n^2\))
我们假设 %20\\le%20cn^2)
%20\\le%20c\(n-a\)^2%20+%20ca%20+%20cn%20%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn^2-2acn+ca+cn%20%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20\\le%20cn^2-c\(2an-a-n\)%20\\\\%20%20~%0d%0a\\hspace{15%20mm}\\le%20cn^2%20-%20cn%20~~~~%20if%20~~%20a%20>%201/2,n%20>%202a%20\\\\%20%20~%0d%0a\\hspace{15%20mm}\\le%20cn^2%20\\\\%20%20~%0d%0a\\hspace{15%20mm}%20=%20O\(n^2\)%0d%0a)
另外一个方向的证明和这个基本一样.
### Exercises 4.2-5
***
Use a recursion tree to give an asymptotically tight solution to the recurrence T(n) = T(αn) +
T((1 - α)n) + cn, where α is a constant in the range 0 <α < 1 and c > 0 is also a constant.
### `Answer`

可以假设α < 1/2,因此树的高度有
%20=%20\\sum_{i%20=%200}^{\\log_{1/%20\\alpha}{n}}cn%20+%20\\Theta\(n\)%20=%20cn\\log_{1/%20\\alpha}{n}%20+%20\\Theta\(n\)%20=%20\\Theta\(n\\lg{n}\)%20)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C04-Recurrences/4.3.md
================================================
### Exercises 4.3-1
***
Use the master method to give tight asymptotic bounds for the following recurrences.
a. %20=%204T\(n/2\)+n%20)
b. %20=%204T\(n/2\)+n^2%20)
c. %20=%204T\(n/2\)+n^3%20)
### `Answer`
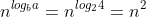
a. %20)
b. %20)
c. %20)
### Exercises 4.3-2
***
The recurrence T(n) = 7T (n/2)+n2 describes the running time of an algorithm A. A competing algorithm A′ has a running time of T′(n) = aT′(n/4) + n2. What is the largest integer value for a such that A′ is asymptotically faster than A?
### `Answer`
根据主定理,算法A的运行时间为%20=%20\\Theta\(\\lg{7}\)\ \\approx%20n^{2.8}%20)
A'的运行时间在a > 16时超过n^2,此时
%20=%20\\Theta\(n^{\\log_{4}{a}}\)%20<%20%20\\lg{7}%20=%20\\log_{4}{49})
所以最大值为48
### Exercises 4.3-3
***
Use the master method to show that the solution to the binary-search recurrence T(n) = T (n/2)
+ Θ(1) is T(n) = Θ(lg n). (See Exercise 2.3-5 for a description of binary search.)
### `Answer`
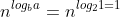
so the solution is Θ(lgn).
### Exercises 4.3-4
***
Can the master method be applied to the recurrence
%20=%204T\(n/2\)%20+%20n^2%20\\lg{n}%20)
Why or why not? Give an asymptotic upper bound for this recurrence.
### `Answer`
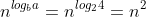
The problem is that it is not polynomially larger. The ratio 
%20/%20n^{\\log_{b}{a}}%20=%20\\lg{n})
is asymptotically less than
 for any positive constant

### Exercises 4.3-5
***
Consider the regularity condition af (n/b) ≤ cf(n) for some constant c < 1, which is part of case 3 of the master theorem. Give an example of constants a ≥ 1 and b > 1 and a function f (n) that satisfies all the conditions in case 3 of the master theorem except the regularity condition.
### `Answer`
let
a = 1
b = 2
f(n) = 2n - n * cos(n)
We are in Case 3, but the regularity condition is violated. (Consider n = 2πk, where k is odd and arbitrarily large. For any such choice of n, you can show that c ≥ 3/2, thereby violating the regularity condition.)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C04-Recurrences/4.4.md
================================================
### Exercises 4.4-1
***
Give a simple and exact expression for nj in equation (4.12) for the case in which b is a positive integer instead of an arbitrary real number.
### `Answer`
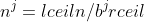
### Exercises 4.4-2
***
Show that if %20=%20\\Theta\(n^{\\log_{b}{a}}\)%20\\lg^k{n}%20) , where k ≥ 0, then the master recurrence has solution
Show that if %20=%20\\Theta\(n^{\\log_{b}{a}}\)%20\\lg^{k+1}{n}%20).
### `Answer`
%20=%20\\sum_{j%20=%200}^{\\log_{b}{n-1}}%20a^jf\(n/b^j\)%20\\\\%20%20~%20f\(n/b^j\)%20=%20\\Theta\\Big\(\(n/b^j\)^{\\log_b{a}}\\lg^k\(n/b^j\)\\Big\)%20\\\\%0d%0ag\(n\)%20=%20\\Theta\\Big\(\\sum_{j=0}^{\\log_b{n}-1}a^j\\big\(\\frac{n}{b^j}\\big\)^{\\log_b{a}}\\lg^k\\big\(\\frac{n}{b^j}\\big\)\\Big\)%20=%20\\Theta\(A\)%20\\\\%0d%0aA%20=%20\\sum_{j=0}^{\\log_b{n}-1}a^j\\big\(\\frac{n}{b^j}\\big\)^{\\log_b{a}}\\lg^k\\frac{n}{b^j}%0d%0a%20%20%20=%20n^{\\log_b{a}}\\sum_{j=0}^{\\log_b{n}-1}\\Big\(\\frac{a}{b^{\\log_b{a}}}\\Big\)^j\\lg^k\\frac{n}{b^j}%0d%0a%20%20%20=%20n^{\\log_b{a}}\\sum_{j=0}^{\\log_b{n}-1}\\lg^k\\frac{n}{b^j}%20%0d%0a%20%20%20=%20n^{\\log_b{a}}B%20\\\\%0d%0a\\lg^k\\frac{n}{d}%20=%20\(\\lg{n}%20-%20\\lg{d}\)^k%20=%20\\lg^k{n}%20+%20o\(\\lg^k{n}\)%20\\\\%0d%0aB%20=%20\\sum_{j=0}^{\\log_b{n}-1}\\lg^k\\frac{n}{b^j}%0d%0a%20%20%20%20%20=%20\\sum_{j=0}^{\\log_b{n}-1}\\Big\(\\lg^k{n}%20-%20o\(\\lg^k{n}\)\\Big\)%0d%0a%20%20%20%20%20=%20\\log_b{n}\\lg^k{n}%20+%20\\log_b{n}%20\\cdot%20o\(\\lg^k{n}\)%0d%0a%20%20%20%20%20=%20\\Theta\(\\log_b{n}\\lg^k{n}\)%0d%0a%20%20%20%20%20=%20\\Theta\(\\lg^{k+1}{n}\)%20\\\\%0d%0ag\(n\)%20=%20\\Theta\(A\)%20=%20\\Theta\(n^{\\log_b{a}}B\)%20=%20\\Theta\(n^{\\log_b{a}}\\lg^{k+1}{n}\)%0d%0a)
### Exercises 4.3-3
***
Show that case 3 of the master theorem is overstated, in the sense that the regularity condition af(n/b) ≤ cf(n) for some constant c < 1 implies that there exists a constant %20=%20\\Omega\(n^{\\log_b{a+\\epsilon}}\)).
### `Answer`
根据case3,我们有%20\\le%20cf\(n\)%20~~~~%20a%20\\ge%201,b%20\\ge%201%20c%20<%201%20)
变形一下
%20\\ge%20kf\(n\)%20~~~where%20~%20k%20=%20a/c%20>%20a%20\\\\%20\\Rightarrow%20f\(b^i\)%20\\ge%20k^i%20f\(1\)%20\\\\%0d%0aif~~%20n%20=%20b^i,%20i%20=%20\\log_b{n},%20then%20f\(n\)%20\\ge%20k^{\\log_b{n}}f\(1\)%20\\\\%0d%0ak^{\\log_b{n}}%20=%20n^{\\log_b{k}}%20~%20and%20~%20\\log_b{k}%20\\ge%20\\log_b{a}%20~so~%20\\log_b{k}%20=%20\\log_b{a}%20+%20\\epsilon%0d%0a)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C04-Recurrences/exercise_code/findIndex.py
================================================
#!/usr/bin/env python
# coding=utf-8
def mergeindex(items, evens):
res = []
l = len(items[0])
for i in range(len(items)):
left = evens[i]
right = -1
if i == len(items)-1 and len(evens) == len(items):
right = l - 1
else:
right = evens[i+1]
minimum = items[i][left]
pos = left
for j in range(left, right+1):
if items[i][j] < minimum:
minimum = items[i][j]
pos = j
res.append(evens[i])
res.append(pos)
if len(evens) > len(items):
res.append(evens[-1])
return res
def findindex(items):
if len(items) == 1:
res = 0
minimum = 2**31-1
for i in range(len(items[0])):
if items[0][i] < minimum:
minimum = items[0][i]
res = i
return [res]
evens = items[::2]
evenres = findindex(evens)
res = mergeindex(items[1::2], evenres)
return res
items=[[37,23,24,32],[21,6,7,10],[53,34,30,31],[32,13,9,6],[43,21,15,8]]
print findindex(items)
================================================
FILE: C04-Recurrences/exercise_code/findMissing.py
================================================
#!/usr/bin/env python
# coding=utf-8
def findmissing(items, i) :
if len(items) == 0:
return 0
numone = numzero = 0
itemone = []
itemzero = []
for e in items:
if (e >> i) & 1 == 0:
numzero += 1
itemzero.append(e)
else:
numone += 1
itemone.append(e)
if numone >= numzero:
#remove 0
return 2 * findmissing(itemzero, i+1)
else:
#remove 1
return 2 * findmissing(itemone, i+1) + 1
items = [0,1,2,3,5,6,7,8]
print findmissing(items, 0)
================================================
FILE: C04-Recurrences/problem.md
================================================
### Problems 1 : Recurrence examples
***
Throughout this book, we assume that parameter passing during procedure calls takes constant time, even if an N-element array is being passed. This assumption is valid in most systems because a pointer to the array is passed, not the array itself. This problem examines the implications of three parameter-passing strategies:
1. An array is passed by pointer. Time = Θ(1).
2. An array is passed by copying. Time = Θ(N), where N is the size of the array.
3. An array is passed by copying only the subrange that might be accessed by the called
procedure. Time = Θ(q - p + 1) if the subarray A[p...q] is passed.
**a.** Consider the recursive binary search algorithm for finding a number in a sorted array (see Exercise 2.3-5). Give recurrences for the worst-case running times of binary search when arrays are passed using each of the three methods above, and give good upper bounds on the solutions of the recurrences. Let N be the size of the original problem and n be the size of a subproblem.
**b.** Redo part (a) for the MERGE-SORT algorithm from Section 2.3.1.
### `Answer`
1. Θ(n^4)
2. Θ(n)
3. Θ(n^2lgn)
4. Θ(n^2)
5. %20)
6. 
7. Θ(n^3)
### Problems 2 : Finding the missing integer
***
An array A[1...n] contains all the integers from 0 to n except one. It would be easy to determine the missing integer in O(n) time by using an auxiliary array B[0...n] to record which numbers appear in A. In this problem, however, we cannot access an entire integer in A with a single operation. The elements of A are represented in binary, and the only operation we can use to access them is "fetch the jth bit of A[i]," which takes constant time.
Show that if we use only this operation, we can still determine the missing integer in O(n) time.
### `Answer`
* 00000
* 00001
* 00010
* 00011
* 00101
* 00110
* 00111
* 01000
[code](./exercise_code/findMissing.py)
我们用上面的8个数字当作例子,[0,8]缺4. <br \>
1.第一次迭代发现最末位1出现4次0出现3次,所以missnum的最后一位是4,排除掉末位为1的数字
2.然后一次次迭代
### Problems 3 : Parameter-passing costs
Throughout this book, we assume that parameter passing during procedure calls takes constant time, even if an N-element array is being passed. This assumption is valid in most systems because a pointer to the array is passed, not the array itself. This problem examines the implications of three parameter-passing strategies:
1. An array is passed by pointer. Time = Θ(1).
2. An array is passed by copying. Time = Θ(N), where N is the size of the array.
3. An array is passed by copying only the subrange that might be accessed by the calledprocedure. Time = Θ(q - p + 1) if the subarray A[p...q] is passed.
**a.** Consider the recursive binary search algorithm for finding a number in a sorted array (see Exercise 2.3-5). Give recurrences for the worst-case running times of binary search when arrays are passed using each of the three methods above, and give good upper bounds on the solutions of the recurrences. Let N be the size of the original problem and n be the size of a subproblem.
**b.** Redo part (a) for the MERGE-SORT algorithm from Section 2.3.1.
### `Answer`
**a.** <br \>
1. T(n) = T(n/2) + 2, O(lgN)
2. T(n) = T(n/2) + N, O(NlgN)
3. T(n) = T(n/2) + n, O(N)
**b.** <br />
1. 
2. 
3. 
### Problems 4 : More recurrence examples
**a.** <br \>
%20=%203T\(n/2\)%20+%20\\lg{n}%20\\\\%20%0d%0aby~applying~master~method~\\Theta\(n^{\\log_3{4}}\))
***
**b.** <br \>
%20=%205T\(n/5\)%20+%20n/\\lg{n}%20\\\\%0d%0aT\(n\)%20=%205T\(n/5\)%20+%20\\frac{n}{\\lg{n}}%20=%2025T\(n/25\)%20+%205\\frac{n/5}{\\lg\(n/5\)}%20+%20\\frac{n}{\\lg{n}}%20=%2025T\(n/25\)%20+%20\\frac{n}{\\lg{n}-\\lg{5}}%20+%20\\frac{n}{\\lg{n}}%20=%20nT\(1\)+\\sum_{i%20=%200}^{\\lg{n}-1}\\frac{n}{\\lg{n}-i\\lg{5}}%20%20=%20nT\(1\)+n\\sum_{i%20=%201}^{\\lg{n}}\\frac{1}{\\lg{n}}%20=%20\\Theta\(n\\lg{\\lg{n}}\))
***
**c.** <br \>
%20=%204T\(n/2\)+n^2\\sqrt{n}%20\\\\%0d%0aby%20~applying~master~method~%20\\Theta\(n^2\\sqrt{n}\)%20)
***
**d.** <br \>
%20=%203T\(n/3+5\)%20+%20n/2%20\\\\%0d%0aby%20~applying~master~method~%20\\Theta\(n\\lg{n}\)%20%0d%0a)
***
**e.** <br \>
The same as b
***
**f.** <br \>
%20=%20T\(n/2\)%20+%20T\(n/4\)%20+%20T\(n/8\)%20+%20n\\\\%0d%0aLet's%20~%20guess%20~%20\\Theta\(n\)%20\\\\%0d%0aT\(n\)%20=%20cn/2%20+%20cn/4%20+%20cn/8%20\\le%20cn%20=%20O\(n\)%20\\\\%0d%0aT\(n\)%20=%20cn/2%20+%20cn/4%20+%20cn/8%20\\ge%20cn%20=%20\\Omega\(n\)%0d%0a)
***
**g.** <br \>
%20=%20T\(n-1\)%20+%201/n%20\\\\%0d%0aT\(n\)%20=%20\\sum_{i%20=%201}^{n}\\frac{1}{i}%20=%20\\Theta\(lg{n}\)%0d%0a)
***
**h.** <br \>
%20=%20T\(n-1\)%20+%20\\lg{n}%20\\\\%0d%0aT\(n\)%20=%20\\sum_{i=1}^{n}\\lg{i}%20=%20\\lg{n!}%20=%20\\Theta\(n\\lg{n}\)%20~%20remember%20~we%20~prove%20~it%20~in%20~section~1%0d%0a)
***
**i.** <br \>
%20=%20T\(n-2\)%20+%202\\lg{n}%20~%20The%20~same%0d%0a)
***
**j.** <br \>
%20=%20\\sqrt{n}T\(\\sqrt{n}\)+n%20\\\\%0d%0aLet's%20~%20guess%20~%20\\Theta\(cn\\lg{\\lg{n}}\)%20\\\\%0d%0aT\(n\)%20\\le%20\\sqrt{n}c\\sqrt{n}\\lg{\\lg{\\sqrt{n}}}+n%20\\\\%0d%0a=%20cn\\lg{\\lg{\\sqrt{n}}}+n%20\\\\%0d%0a=%20cn\\lg{\\frac{\\lg{n}}{2}}+n%20\\\\%0d%0a=%20cn\\lg{\\lg{n}}%20-%20cn\\lg{2}+n%20\\\\%0d%0a=%20cn\\lg{\\lg{n}}%20+%20\(1-c\)n%20%20%20%20\\\\%0d%0a\\le%20cn\\lg{\\lg{n}}%20~~~~~~~~~%20if%20~%20c%20>%201%20\\\\%0d%0a=%20\\Theta\(cn\\lg{\\lg{n}}\)%0d%0a)
### Problems 5 : Fibonacci numbers
***
This problem develops properties of the Fibonacci numbers, which are defined by recurrence (3.21). We shall use the technique of generating functions to solve the Fibonacci recurrence. Define the generating function (or formal power series) F as
%20=%20\\sum_{i=0}^{\\infty}F\_iz^i%20\\\\%0d%0a=%200%20+%20z%20+%20z^2%20+%202z^3%20+%203z^4%20+%205z^5%20+%208z^6%20+%2013z^7%20+%2021z^8%20+%20\\ldots%20\\\\%0d%0awhere~%20F_i%20~is%20~the~%20ith%20~Fibonacci~%20number.)
a. Show that %20=%20z%20+%20z\mathcal{F}\(z\)%20+%20z^2\mathcal{F}\(z\))
b. Show that %20=%20\\frac{z}{1-z-z^2}%20=%20\\frac{z}{\(1-\\phi{z}\)\(1-\\widehat\\phi{z}\)}%20=%20\\frac{1}{\\sqrt{5}}\(\\frac{1}{1-\\phi{z}}-\\frac{1}{1-\\widehat\\phi{z}}\)%0d%0a)
c. Show that Show that %20=%20\\sum_{i=0}^{\\infty}\\frac{1}{\\sqrt{5}}\(\\phi^i%20-%20\\widehat\\phi^i\)z^i%20)
d. Prove that %20=%20\\phi^i/\\sqrt{5}) for i > 0 , rounded to the nearest integer.
e. Prove that  for i ≥ 0.
### `Answer`
**a.**
%20+%20z^2\mathcal{F}\(z\)%20\\\\%0d%0a=%20z%20+%20z\\sum_{i=0}^{\\infty}F\_iz^i%20+%20z^2\\sum_{i=0}^{\\infty}F\_iz^i%20\\\\%0d%0a=%20z%20+%20z\\sum_{i=1}^{\\infty}F\_{i-1}z^i%20+%20z^2\\sum_{i=2}^{\\infty}F\_{i-2}z^i%20\\\\%0d%0a=%20z%20+%20F_1z%20+%20\\sum_{i=2}^{\\infty}\(F_{i-1}+F_{i-2}\)z^i%20\\\\%0d%0a=%20z%20+%20F_1z%20+%20\\sum_{i=2}^{\\infty}F_iz^i%20\\\\%0d%0a=%20\\mathcal{F}\(z\))
**b.**
这个结论的证明还是很straight-forward的,就不写公式啦.
**c.**
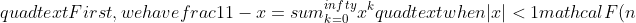%20=%20\\frac{1}{\\sqrt5}\\Big\(\\frac{1}{1%20-%20\\phi%20z}%20-%20\\frac{1}{1%20-%20\\hat\\phi%20z}\\Big\)%20=%20\\frac{1}{\\sqrt5}\\Big\(\\sum_{i=0}^{\\infty}\\phi^i%20z^i%20-%20\\sum_{i=0}^{\\infty}\\hat{\\phi}^i%20z^i\\Big\)=%20\\sum_{i=0}^{\\infty}\\frac{1}{\\sqrt5}\(\\phi^i%20-%20\\hat{\\phi}^i\)%20z^i%0d%0a)
**d.**
%20=%20\\sum_{i=0}^{\\infty}\\alpha_iz^i%20\\quad\\text{%20where%20}%20\\alpha_i%20=%20\\frac{\\phi^i%20-%20\\hat{\\phi}^i}{\\sqrt5}%20\\\\%0d%0a\\quad\\text{%20so%20we%20have%20}%20\\alpha_i%20=%20F_i%20\\\\%0d%0aF_i%20=%20\\frac{\\phi^i%20-%20\\hat{\\phi}^i}{\\sqrt5}%20%20=%20\\frac{\\phi^i}{\\sqrt5}%20-%20\\frac{\\hat{\\phi}^i}{\\sqrt5}%20\\\\%0d%0a\\quad\\text{because%20}%20|\\hat\\phi|%20<%201%20\\quad\\text{,%20so%20}%20\\frac{|\\hat\\phi^i|}{\\sqrt{5}}%20<%200.5%0d%0a)
**e.**
[we had prove it previously](https://github.com/gzc/CLRS/blob/master/C03-Growth-of-Functions/3.2.md#exercises-32-7)
### Problems 6 : VLSI chip testing
***
Professor Diogenes has n supposedly identical VLSI[1] chips that in principle are capable of testing each other. The professor's test jig accommodates two chips at a time. When the jig is loaded, each chip tests the other and reports whether it is good or bad. A good chip always reports accurately whether the other chip is good or bad, but the answer of a bad chip cannot be trusted. Thus, the four possible outcomes of a test are as follows:
Chip A says | Chip B says | Conclusion
:----:|:----:|:----:
B is good | A is good | both are good, or both are bad
B is good | A is bad | at least one is bad
B is bad | A is good | at least one is bad
B is bad | A is bad | at least one is bad
a. Show that if more than n/2 chips are bad, the professor cannot necessarily determine which chips are good using any strategy based on this kind of pairwise test. Assume that the bad chips can conspire to fool the professor.
b. Consider the problem of finding a single good chip from among n chips, assuming that
more than n/2 of the chips are good. Show that ⌊n/2⌋ pairwise tests are sufficient to
reduce the problem to one of nearly half the size.
c. Show that the good chips can be identified with Θ(n) pairwise tests, assuming that
more than n/2 of the chips are good. Give and solve the recurrence that describes the number of tests.
### `Answer`
中文版
a. 如果超过一半是坏的,那么我们可以从这些坏的中取出一组数量和好的一样多的,他们的表现能和好的一样.
b. 将所有的芯片两两配对,如果报告是both are good or bad,那么就从中随机选一个留下来,否则全部扔掉. 一直这样递归下去,最后剩下的是好的.
c. T(n) = T(n/2)+n/2,是Θ(n)的.
English Version
a. consider the situation that at least half chips are bad. Denote good chip number is N.
**We can choice more than N bad chips, and make them act as same as GOOD one.**
In this situation, we cannot distinguish whether is GOOD or BAD.(The BAD chips are always major and perfectly confuse information GOOD chips make)
b. Let make floor(N / 2) pairs arbitrarily. We **focus the pairs that both of it report opponent is GOOD.**
Because at least half chips are GOOD, **the pairs both report opponent is GOOD contains at least half GOOD-GOOD pairs.** Next, **we discard one chip of the GOOD-GOOD pair, per every GOOD-GOOD pairs.** After all, **we operate the remained chips as same as this action.**(make pairs -> focus GOOD-GOOD reported pairs -> discard one chip per pairs)
We can decrease the target chips by half by discarding, and **after discarding we can still assure that target chips contains at least half GOOD chips.** As a conclusion, if we make this actions till the last chip remained, the last must be GOOD.
c. The recurrence is
T(n) = T(n / 2) + n / 2
This is Θ(n) admittedly.
日本語版
a. 過半数のチップがbadの時、**goodのチップより多くのbadチップに、goodチップと同じ挙動をしてもらえばよい。**
そのとき、判別者はどれがgoodでどれがbadチップなのかを判別できない。
b. 任意にfloor(N / 2)ペア組んで、その中で「どちらもGOOD」のペアに着目する。この時、**必ず過半数のペアはGOOD-GOODである(つまり、BAD-BADよりもGOOD-GOODの方が必ず多い)**
次に、その「どちらもGOOD」の各ペアのうち片方のチップを除外する。この操作後でも、着目するチップのうち、GOODチップはBADチップより必ず多くなる。
よって、その半分にする作業を最後の1つになるまで繰り返せば、残ったチップはGOODだと確定する。(常にGOODチップは
BADチップより多いため)
c. T(n)は、n / 2回のペア判別と捨てるを行った後、T(n / 2)の計算に移るので、漸化式は
T(n) = T(n / 2) + n / 2
この漸化式は明らかに、Θ(n)の式となる。
### Problems 7 : Monge arrays
***
An m × n array A of real numbers is a **Monge array** if for all i, j, k, and l such that 1 ≤ i < k ≤ m and 1 ≤ j < l ≤ n, we have
A[i, j] + A[k, l] ≤ A[i, l] + A[k, j].
In other words, whenever we pick two rows and two columns of a Monge array and consider the four elements at the intersections of the rows and the columns, the sum of the upper-left and lower-right elements is less or equal to the sum of the lower-left and upper-right elements. For example, the following array is Monge:

a. Prove that an array is Monge if and only if for all i = 1,2,...,m-1 and j = 1,2,...,n- 1, we have <br \>
A[i, j] + A[i + 1, j + 1] ≤ A[i, j + 1] + A[i + 1, j]. <br \>
Note (For the "only if" part, use induction separately on rows and columns.)
b. The following array is not Monge. Change one element in order to make it Monge.

c. Let f(i) be the index of the column containing the leftmost minimum element of row i. Prove that f(1) ≤ f(2) ≤ ··· ≤ f(m) for any m × n Monge array.
d. Here is a description of a divide-and-conquer algorithm that computes the left-most minimum element in each row of an m × n Monge array A: <br \>
Construct a submatrix A′ of A consisting of the even-numbered rows of A. Recursively determine the leftmost minimum for each row of A′. Then compute the leftmost minimum in the odd-numbered rows of A. <br \>
Explain how to compute the leftmost minimum in the odd-numbered rows of A (given that the leftmost minimum of the even-numbered rows is known) in O(m + n) time.
e. Write the recurrence describing the running time of the algorithm described in part (d). Show that its solution is O(m + n log m).
### `Answer`
**a.**
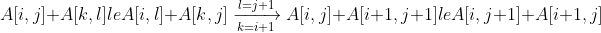
***

**b.**

**c.** **反证法**
如果i < j,f(i) >= f(j)
A[i,f(j)]+A[j,f(i))] <= A[i,f(i)]+A[j,f(j)] 但是A[i,f(i)]和A[j,f(j)]是两行最小的元素,等式不成立.
**d.**根据c可以知道第i行的左端最小值落在f(i-1)和f(i+1)之间. 总共有n/2个奇数行,总共需要比较m次,所以是O(m+n).
**e.**
T(m) = T(m/2) + cn + dm = O(nlgm + m)
[code](./exercise_code/findIndex.py)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.1.md
================================================
### Exercises 5.1-1
***
Show that the assumption that we are always able to determine which candidate is best in line 4 of procedure HIRE-ASSISTANT implies that we know a total order on the ranks of the candidates.
### `Answer`
**always**这个词表示对所有n!种组合,都能够确定,而这n!种组合已经囊括了所有的两两比较.
### Exercises 5.1-2
***
Describe an implementation of the procedure RANDOM(a, b) that only makes calls to RANDOM(0, 1). What is the expected running time of your procedure, as a function of a and b?
### `Answer`
Without loss of generality we may assume that a = 0. Otherwise we can generate a random number between 0 and b − a, then add a to it.
[solution](./myrandom.py)
Each iteration of the while loop takes O(n) time to run. The probability that the while loop stops on a given iteration is (b+1)/(2^n). Thus the expected running time is the expected number of iterations of the while-loop times
n. This is given by:

Since we assume a = 0 in the first, the final running time is: O(lg(b-a))
But this algorithm is non-deterministic.
[Reference1: mathcamp.org](https://www.mathcamp.org/2015/academics/michelle/AlgorithmsHomework3Solutions.pdf)
[Reference2: stackoverflow](https://stackoverflow.com/questions/8692818/how-to-implement-randoma-b-with-only-random0-1)
### Exercises 5.1-3
***
Suppose that you want to output 0 with probability 1/2 and 1 with probability 1/2. At your disposal is a procedure BIASED-RANDOM, that outputs either 0 or 1. It outputs 1 with some probability p and 0 with probability 1 - p, where 0 < p < 1, but you do not know what p is. Give an algorithm that uses BIASED-RANDOM as a subroutine, and returns an unbiased answer, returning 0 with probability 1/2 and 1 with probability 1/2. What is the expected running time of your algorithm as a function of p?
### `Answer`
while true:
x = BIASED-RANDOM()
y = BIASED-RANDOM()
if x != y:
return x
expected running time = 1/(2p(1-p))
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.2.md
================================================
### Exercises 5.2-1
***
In HIRE-ASSISTANT, assuming that the candidates are presented in a random order, what is the probability that you will hire exactly one time? What is the probability that you will hire exactly n times?
### `Answer`
分别是1/n和1/n!
### Exercises 5.2-2
***
In HIRE-ASSISTANT, assuming that the candidates are presented in a random order, what is the probability that you will hire exactly twice?
### `Answer`
如果第一个雇员的质量是k,那么质量高于k的雇员都必须在质量最高的雇员后面.
假设有n个雇员,质量分别是1,2,...,n.当第一个质量为k时,只雇佣2次的概率p = 1/(n-k).因为有n-k个质量比k高的,而且必须要最高的那个在前.而第一个质量为k的概率是1/n.所以
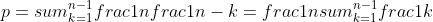
### Exercises 5.2-3
***
Use indicator random variables to compute the expected value of the sum of n dice.
### `Answer`
Expectation of a single die
%20=%20\\frac{1+2+3+4+5+6}{6}%20=%203.5%20%20)
Expectation of N dies
%20=%20\\sum_{i%20=%201}^{n}%20E\(X_i\)%20=%203.5n%20)
### Exercises 5.2-4
***
Use indicator random variables to solve the following problem, which is known as the **hat- check problem**. Each of n customers gives a hat to a hat-check person at a restaurant. The hat- check person gives the hats back to the customers in a random order. What is the expected number of customers that get back their own hat?
### `Answer`

### Exercises 5.2-5
***
Let A[1...n] be an array of n distinct numbers. If i < j and A[i] > A[j], then the pair (i, j) is called an inversion of A. (See Problem 2-4 for more on inversions.) Suppose that each element of A is chosen randomly, independently, and uniformly from the range 1 through n. Use indicator random variables to compute the expected number of inversions.
### `Answer`
最简单的解法如下:
因为概率是一样的,所以出现正序和逆序是等量的,总共有n(n-1)/2对,所以期望是n(n-1)/4对.
Explaination:
Let I{A} be an indicator random variable defined as: 1, if a given pair in array is inversion; 0 if it pair is not inversion.
Then we know that E[I{A}] = P{A} i.e. Execpecation of above randon variable is same as probability of event A.
Now, since the numbers in array are **distinct** (_this is important_) and are **uniform random permutations** then the probability of event A is 1/2.
let X be a random varaible giving us number of inversions in array. Y is random variable that a given pair is inversion. And let there be k such pairs, then
<a href="https://www.codecogs.com/eqnedit.php?latex=X&space;=&space;\sum&space;Y" target="_blank"><img src="https://latex.codecogs.com/gif.latex?X&space;=&space;\sum&space;Y" title="X = \sum Y" /></a>
sum over all k.
And you might have guessed already
<a href="https://www.codecogs.com/eqnedit.php?latex=k&space;=&space;\binom{n}{2}" target="_blank"><img src="https://latex.codecogs.com/gif.latex?k&space;=&space;\binom{n}{2}" title="k = \binom{n}{2}" /></a>
By linearity of expectation:
<a href="https://www.codecogs.com/eqnedit.php?latex=E[X]&space;=&space;k&space;*&space;E[Y]" target="_blank"><img src="https://latex.codecogs.com/gif.latex?E[X]&space;=&space;k&space;*&space;E[Y]" title="E[X] = k * E[Y]" /></a>
Hence
<a href="https://www.codecogs.com/eqnedit.php?latex=E[X]&space;=&space;\binom{n}{2}&space;*&space;1&space;/2&space;=&space;n(n-1)/4" target="_blank"><img src="https://latex.codecogs.com/gif.latex?E[X]&space;=&space;\binom{n}{2}&space;*&space;1&space;/2&space;=&space;n(n-1)/4" title="E[X] = \binom{n}{2} * 1 /2 = n(n-1)/4" /></a>
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.3.md
================================================
### Exercises 5.3-1
***
Professor Marceau objects to the loop invariant used in the proof of Lemma 5.5. He questions whether it is true prior to the first iteration. His reasoning is that one could just as easily declare that an empty subarray contains no 0-permutations. Therefore, the probability that an empty subarray contains a 0-permutation should be 0, thus invalidating the loop invariant prior to the first iteration. Rewrite the procedure RANDOMIZE-IN-PLACE so that its associated loop invariant applies to a nonempty subarray prior to the first iteration, and modify the proof of Lemma 5.5 for your procedure.
### `Answer`
We can redefine the algo in a very simple way that we do not have to deal with 0-permutation of n array at all and then leave
no iota of doubt for professor Marceau.
RANDOMIZE-IN-PLACE(A)
n = A.legth
if n == 1
return
else
swap A[1] with RANDOM(1, n)
for i = 2 to n
swap A[i] with RANDOM(i, n)
And now we can use the same loop invarient that was used earlier.
### Exercises 5.3-2
***
Professor Kelp decides to write a procedure that will produce at random any permutation besides the identity permutation. He proposes the following procedure:
PERMUTE-WITHOUT-IDENTITY(A)
1 n ← length[A]
2 for i ← 1 to n
3 do swap A[i] ↔ A[RANDOM(i + 1, n)]
Does this code do what Professor Kelp intends?
### `Answer`
没有,因为[1,3,2...]这样的序列虽然不是identity permutation但是却不会产生.
### Exercises 5.3-3
***
Suppose that instead of swapping element A[i] with a random element from the subarray A[i .. n], we swapped it with a random element from anywhere in the array:

PERMUTE-WITH-ALL(A)
1 n ← length[A]
2 for i ← 1 to n
3 do swap A[i] ↔ A[RANDOM(1, n)]
Does this code produce a uniform random permutation? Why or why not?
### `Answer`
不可以,因为本来有n!种排列,但是这种做法每个迭代有n种选择,所以有n^n种选择.而n^n不能被n!整除,因此不是uniform的排列.
### Exercises 5.3-4
***
Professor Armstrong suggests the following procedure for generating a uniform random permutation:
PERMUTE-BY-CYCLIC(A)
1 n ← length[A]
2 offset ← RANDOM(1, n)
3 for i <- i to n
4 do dest <- i + offset
5 if dest > n
6 then dest <- dest-n
7 B[dest] -< A[i]
8 return B
Show that each element A[i] has a 1/n probability of winding up in any particular position in B. Then show that Professor Armstrong is mistaken by showing that the resulting permutation is not uniformly random.
### `Answer`
这个算法对于给定的offset,只会产生一种排列...也就是最后只有n种排列而不是n!种. 只会将原数组**平移**,谈不上**随机**.
### Exercises 5.3-5
***
Prove that in the array P in procedure PERMUTE-BY-SORTING, the probability that all
elements are unique is at least 1 - 1/n.
### `Answer`
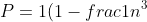\(1-\\frac{2}{n^3}\)%20\(1-\\frac{3}{n^3}\)\\ldots%20\\\\%20~%20\\hspace{10%20mm}%0d%0a\\ge%201\(1-\\frac{n}{n^3}\)\(1-\\frac{n}{n^3}\)%20\(1-\\frac{n}{n^3}\)\\ldots%20\\\\%20~%20\\hspace{10%20mm}%0d%0a\\ge%20\(1-\\frac{1}{n^2}\)^n%20\\\\%20~%20\\hspace{10%20mm}%0d%0a\\ge%201-\\frac{1}{n}%20)
### Exercises 5.3-6
***
Explain how to implement the algorithm PERMUTE-BY-SORTING to handle the case in which two or more priorities are identical. That is, your algorithm should produce a uniform random permutation, even if two or more priorities are identical.
### `Answer`
既然冲突了,那就重新产生嘛...
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.4.md
================================================
### Exercises 5.4-1
***
How many people must there be in a room before the probability that someone has the same birthday as you do is at least 1/2? How many people must there be before the probability that at least two people have a birthday on July 4 is greater than 1/2?
### `Answer`
^n%20\\ge%20\\frac{1}{2}%20\\rightarrow%20n%20\\ge%20253%20)
\(\\frac{364}{365}\)^{n-1}%20-%20C^0_n\(\\frac{364}{365}\)^n%20\\ge%20\\frac{1}{2}%20\\rightarrow%20n%20\\ge%20613%20)
### Exercises 5.4-2
***
Suppose that balls are tossed into b bins. Each toss is independent, and each ball is equally likely to end up in any bin. What is the expected number of ball tosses before at least one of the bins contains two balls?
### `Answer`
This is a rewording of the Birthday Problem. The answer is the following:
%20=%201%20+%20\\sum_{k%20=%201}^{B}%20\\frac{B!}{\(B-k\)!B^k}%20)
check [Quora](http://www.quora.com/What-is-the-expected-number-of-ball-tosses-until-some-bin-contains-two-balls) and [wiki](https://en.wikipedia.org/wiki/Birthday_problem#Average_number_of_people)
### Exercises 5.4-3
***
For the analysis of the birthday paradox, is it important that the birthdays be mutually independent, or is pairwise independence sufficient? Justify your answer.
### `Answer`
Pairwise independence is sufficient.
### Exercises 5.4-4
***
How many people should be invited to a party in order to make it likely that there are three people with the same birthday?
### `Answer`
If n=365 and k is the number of people at the party:
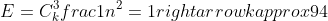
### Exercises 5.4-5
***
What is the probability that a k-string over a set of size n is actually a k-permutation? How does this question relate to the birthday paradox?
### `Answer`
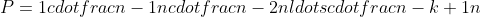
To be a k-permutation, there can be no repeated letters, so this is the birthday problem where k is the number of people and n is the number of days.
### Exercises 5.4-6
***
Suppose that n balls are tossed into n bins, where each toss is independent and the ball is equally likely to end up in any bin. What is the expected number of empty bins? What is the expected number of bins with exactly one ball?
### `Answer`
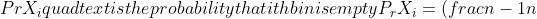^n%20%20=%20\(1-\\frac{1}{n}\)^n%20\\approx%20\\frac{1}{e}%20\\\\%0d%0aE[X]%20=%20\\sum_{1}^{n}E[X_i]%20=%20\\frac{n}{e}%20\\\\%0d%0aPr\\{Y_i\\}%20\\quad\\text{is%20the%20probability%20that%20ith%20has%20one%20ball}%20\\\\%0d%0a%20P_r\\{Y_i\\}%20=%20n%20\\cdot%20\\frac{1}{n}%20\(\\frac{n-1}{n}\)^{n-1}%20\\approx%20\\frac{1}{e}%20\\\\E[Y]%20=%20\\sum_{1}^{n}E[Y_i]%20=%20\\frac{n}{e}%20\\\\)
### Exercises 5.4-7
***
Sharpen the lower bound on streak length by showing that in n flips of a fair coin, the
probability is less than 1/n that no streak longer than lg n-2 lg lg n consecutive heads occurs.
### `Answer`

***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/myrandom.py
================================================
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
from math import log
from random import randint
from collections import Counter
import matplotlib.pyplot as plt
def _m_random(b):
n = int(log(b, 2)) + 1
while True:
r = 0
for i in range(n):
r = 2*r + randint(0, 1)
if r <= b:
return r
def m_random(a, b):
return _m_random(b - a) + a
def main():
result = Counter()
for i in xrange(10000):
temp = m_random(1,7)
result.update('{}'.format(temp))
key, value = zip(*result.items())
indexes = np.arange(len(key))
width = 1
plt.bar(indexes,value,width)
plt.xticks(indexes + 0.5 * width, key)
plt.show()
if __name__ == '__main__':
main()
================================================
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/problem.md
================================================
### Problems 1 : Probabilistic counting
***
With a b-bit counter, we can ordinarily only count up to 2b - 1. With R. Morris's probabilistic counting, we can count up to a much larger value at the expense of some loss of precision.

We let a counter value of i represent a count of ni for i = 0, 1,..., 2b -1, where the ni form an increasing sequence of nonnegative values. We assume that the initial value of the counter is 0, representing a count of n0 = 0. The INCREMENT operation works on a counter containing the value i in a probabilistic manner. If i = 2b - 1, then an overflow error is reported. Otherwise, the counter is increased by 1 with probability 1/(ni+1 - ni), and it remains unchanged with probability 1 - 1/(ni+1 - ni).
If we select ni = i for all i ≥ 0, then the counter is an ordinary one. More interesting situations arise if we select, say, ni = 2i-1 for i > 0 or ni = Fi (the ith Fibonacci number-see Section 3.2).
For this problem, assume that n_(2^b-1) is large enough that the probability of an overflow error is negligible.
a. Show that the expected value represented by the counter after n INCREMENT operations have been performed is exactly n.
b. The analysis of the variance of the count represented by the counter depends on the sequence of the ni. Let us consider a simple case: ni = 100i for all i ≥ 0. Estimate the variance in the value represented by the register after n INCREMENT operations have been performed.
### `Answer`
**a.**
每一次递增操作增加的期望为
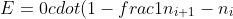%20+%201\\cdot%20\(n_{i+1}-n_i\)%20\\cdot%20\\frac{1}{n_{i+1}-n_i}%20=%201%20)
**b.**
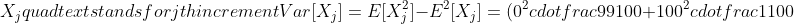%20-%201^2%20=%2099%20\\\\%20%0d%0aVar[X]%20=%20\\sum_{i=%201}^{n}Var[X_i]%20=%2099n)
### Problems 2 : Searching an unsorted array
***
Thus problem examines three algorithms for searching for a value x in an unsorted array A consisting of n elements.
Consider the following randomized strategy: pick a random index i into A. If A[i] = x, then we terminate; otherwise, we continue the search by picking a new random index into A. We continue picking random indices into A until we find an index j such that A[j] = x or until we have checked every element of A. Note that we pick from the whole set of indices each time, so that we may examine a given element more than once.
**a.** Write pseudocode for a procedure RANDOM-SEARCH to implement the strategy above. Be sure that your algorithm terminates when all indices into A have been picked.
**b.** Suppose that there is exactly one index i such that A[i] = x. What is the expected number of indices into A that must be picked before x is found and RANDOM- SEARCH terminates?
**c.** Generalizing your solution to part (b), suppose that there are k ≥ 1 indices i such that A[i] = x. What is the expected number of indices into A that must be picked before x is found and RANDOM-SEARCH terminates? Your answer should be a function of n and k.
**d.** Suppose that there are no indices i such that A[i] = x. What is the expected number of indices into A that must be picked before all elements of A have been checked and RANDOM-SEARCH terminates?
Now consider a deterministic linear search algorithm, which we refer to as DETERMINISTIC-SEARCH. Specifically, the algorithm searches A for x in order,
considering A[1], A[2], A[3],..., A[n] until either A[i] = x is found or the end of the array is reached. Assume that all possible permutations of the input array are equally likely.
**e.** Suppose that there is exactly one index i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH?
**f.** Generalizing your solution to part (e), suppose that there are k ≥ 1 indices i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH? Your answer should be a function of n and k.
**g.** Suppose that there are no indices i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH?
Finally, consider a randomized algorithm SCRAMBLE-SEARCH that works by first randomly permuting the input array and then running the deterministic linear search given above on the resulting permuted array.
**h.** Letting k be the number of indices i such that A[i] = x, give the worst-case and expected running times of SCRAMBLE-SEARCH for the cases in which k = 0 and k = 1. Generalize your solution to handle the case in which k ≥ 1.
**i.** Which of the three searching algorithms would you use? Explain your answer.
### `Answer`
**a.**
RANDOM-SEARCH(A, v):
B = new array[n]
count = 0
while(count < n):
r = RANDOM(1, n)
if A[r] == v:
return r
if B[r] == false:
count += 1
B[r] = true
return false
**b.**
就是几何分布~n
**c.**
还是几何分布~n/k
**d.**
Section5.4.2,在每个盒子里至少有一个球前,要投多少个球.
n(lnn+O(1))
**e.**
平均查找时间是n/2,最坏查找时间是n
**f.**
最坏运行时间是n-k+1.平均运行时间是n/(k+1)
**g.**
都是n
**h.**
跟DETERMINISTIC-SEARCH是一样的,这时候的期望就是平均.
**i.**
自然是**DETERMINISTIC-SEARCH**
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/6.1.md
================================================
### Exercises 6.1-1
***
What are the minimum and maximum numbers of elements in a heap of height h?
### `Answer`
最多就是一颗很完美的二叉树,是2^(h+1) − 1 ; 最少的话最后一层只有一个,是2^h
What it is a perfect complete tree, it is 2^(h+1) - 1; when the last level has only one element, we have 2^h.
### Exercises 6.1-2
***
Show that an n-element heap has height ⌞lg n⌟
### `Answer`
-1%20)
所以h = ⌞lg n⌟
### Exercises 6.1-3
***
Show that in any subtree of a max-heap, the root of the subtree contains the largest value occurring anywhere in that subtree.
### `Answer`
这就是最大堆的性质.
This is the property of maximum heap.
### Exercises 6.1-4
***
Where in a max-heap might the smallest element reside, assuming that all elements are distinct?
### `Answer`
It must be in the leaf node.
### Exercises 6.1-5
***
Is an array that is in sorted order a min-heap?
### `Answer`
没有说明是递增数组还是递减数组,所以不一定.
We don't know whether it's an increasing order or descending order.
### Exercises 6.1-6
***
Is the sequence [23, 17, 14, 6, 13, 10, 1, 5, 7, 12] a max-heap?
### `Answer`
NO, because 7 > 6
### Exercises 6.1-7
***
Show that, with the array representation for storing an n-element heap, the leaves are the nodes indexed by ⌞n/2⌟ + 1, ⌞n/2⌟ + 2, ... , n.
### `Answer`
挺容易推的,因为每增加两个节点,树的叶子节点就会往后推移一位.再注意一下取整的位置就行.
It is easy to conclude, every time we add two nodes, the index of leaf nodes will increase 1.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/6.2.md
================================================
### Exercises 6.2-1
***
Using Figure 6.2 as a model, illustrate the operation of MAX-HEAPIFY(A, 3) on the array A = 27,17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0.
### `Answer`

### Exercises 6.2-2
***
Starting with the procedure MAX-HEAPIFY, write pseudocode for the procedure MIN- HEAPIFY(A, i), which performs the corresponding manipulation on a min-heap. How does the running time of MIN-HEAPIFY compare to that of MAX-HEAPIFY?
### `Answer`
MIN-HEAPIFY(A, i):
l <- LEFT(i)
r <- RIGHT(i)
smallest <- i
if l ≤ heap-size[A] and A[l] < A[i]:
then smallest <- l
if r ≤ heap-size[A] and A[r] < A[smallest]:
then smallest <- r
if smallest ≠ i:
then swap(A[i], A[smallest])
MIN-HEAPIFY(A, smallest)
### Exercises 6.2-3
***
What is the effect of calling MAX-HEAPIFY(A, i) when the element A[i] is larger than its children?
### `Answer`
函数直接返回.
Just return.
### Exercises 6.2-4
***
What is the effect of calling MAX-HEAPIFY(A, i) for i > heap-size[A]/2?
### `Answer`
这种情况下,这个节点是叶子节点.
Under this condition, this node is a leaf node.
### Exercises 6.2-5
***
The code for MAX-HEAPIFY is quite efficient in terms of constant factors, except possibly for the recursive call in line 10, which might cause some compilers to produce inefficient code. Write an efficient MAX-HEAPIFY that uses an iterative control construct (a loop) instead of recursion.
### `Answer`
MIN-HEAPIFY(A, i):
while i ≤ heap-size[A]:
l <- LEFT(i)
r <- RIGHT(i)
largest <- i
if l ≤ heap-size[A] and A[l] > A[i]:
then largest <- l
if r ≤ heap-size[A] and A[r] > A[largest]:
then largest <- r
if largest ≠ i:
then swap(A[i], A[largest])
i = largest
else break
### Exercises 6.2-6
***
Show that the worst-case running time of MAX-HEAPIFY on a heap of size n is Ω(lg n). (Hint: For a heap with n nodes, give node values that cause MAX-HEAPIFY to be called recursively at every node on a path from the root down to a leaf.)
### `Answer`
最坏情况是从root一直递归到leaf,因为heap的高度为⌞lg n⌟,所以最坏运行时间是Ω(lgn).
In the worst case, this function will call until the leaf node.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/6.3.md
================================================
### Exercises 6.3-1
***
Using Figure 6.3 as a model, illustrate the operation of BUILD-MAX-HEAP on the array A = [5, 3, 17, 10, 84, 19, 6, 22, 9].
### `Answer`

### Exercises 6.3-2
***
Why do we want the loop index i in line 2 of BUILD-MAX-HEAP to decrease from ⌞length[A]/2⌟ to 1 rather than increase from 1 to ⌞length[A]/2⌟?
### `Answer`
如果先从1开始,它的子树并不是最大堆,肯定不能这样迭代.
If we start from 1, because its subtree is not a maximum heap, we can't follow this order.
### Exercises 6.3-3
***
Show that there are at most %20\\rceil) nodes of height h in any n-element heap.
### `Answer`
According to [6.1.1](./6.1.md)we have

Mark h0 as the height of tree.
%20\\rceil%20\\le%20\\lceil%20\(2^{h_0+1}-1\)/\(2^{h+1}\)%20\\rceil%20=%202^{h_0-h})
If the current layer is full, then we have equal. If in the leaf node and not full, we have less.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/6.4.md
================================================
### Exercises 6.4-1
***
Using Figure 6.4 as a model, illustrate the operation of HEAPSORT on the array A = [5, 13, 2, 25, 7, 17, 20, 8, 4].
### `Answer`

### Exercises 6.4-2
***
Argue the correctness of HEAPSORT using the following loop invariant:
• At the start of each iteration of the for loop of lines 2-5, the subarray A[1...i] is a max-heap containing the i smallest elements of A[1...n], and the subarray A[i + 1...n] contains the n - i largest elements of A[1...n], sorted.
### `Answer`
It is very obvious.
### Exercises 6.4-3
***
What is the running time of heapsort on an array A of length n that is already sorted in increasing order? What about decreasing order?
### `Answer`
If the array is in descending order, then we have the worst case, we need
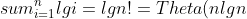%20)
If it is in increasing order, we still need%20),Because the cost of Max_heapify doesn't change.
### Exercises 6.4-4
***
Show that the worst-case running time of heapsort is Ω(n lg n).
### `Answer`
Same as 6.3.3.
### Exercises 6.4-5
***
Show that when all elements are distinct, the best-case running time of heapsort is Ω(n lg n).
### `Answer`
It is actually a hard problem, see [solution](http://stackoverflow.com/questions/4589988/lower-bound-on-heapsort)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/6.5.md
================================================
### Exercises 6.5-1
***
Illustrate the operation of HEAP-EXTRACT-MAX on the heap A = [15, 13, 9, 5, 12, 8, 7, 4, 0, 6, 2, 1].
### `Answer`

### Exercises 6.5-2
***
Illustrate the operation of MAX-HEAP-INSERT(A, 10) on the heap A = [15, 13, 9, 5, 12, 8,
7, 4, 0, 6, 2, 1]. Use the heap of Figure 6.5 as a model for the HEAP-INCREASE-KEY call.
### `Answer`

### Exercises 6.5-3
***
Write pseudocode for the procedures HEAP-MINIMUM, HEAP-EXTRACT-MIN, HEAP- DECREASE-KEY, and MIN-HEAP-INSERT that implement a min-priority queue with a min-heap.
### `Answer`
My implementation on priority queue.
[p_queue.h](./p_queue.h)
[p_queue.cpp](./p_queue.cpp)
### Exercises 6.5-4
***
Why do we bother setting the key of the inserted node to -∞ in line 2 of MAX-HEAP- INSERT when the next thing we do is increase its key to the desired value?
### `Answer`
keey the HEAP-INCREASE-KEY condition still holds.
### Exercises 6.5-5
***
Argue the correctness of HEAP-INCREASE-KEY using the following loop invariant:
• At the start of each iteration of the while loop of lines 4-6, the array A[1...heap- size[A]] satisfies the max-heap property, except that there may be one violation: A[i] may be larger than A[PARENT(i)].
### `Answer`
obvious loop-invariant.
### Exercises 6.5-6
***
Each exchange operation on line 5 of HEAP-INCREASE-KEY typically requires three asignments. Show how to use the idea of the inner loop of INSERTION-SORT to reduce the three assignments down to just one assignment.
### `Answer`
HEAP-INCREASE-KEY(A, i, key):
if key < A[i]
error "New key is smaller than current key"
A[i] = key
while i > 1 and A[PARENT(i)] < key
A[i] = A[PARENT(i)]
i = PARENT(i)
A[i] = key
### Exercises 6.5-7
***
Show how to implement a first-in, first-out queue with a priority queue. Show how to
implement a stack with a priority queue. (Queues and stacks are defined in Section 10.1.)
### `Answer`
* 先进先出队列: 每次都给新插入的元素赋予更低的优先级即可.
* 栈:每次都给新插入的元素赋予更高的优先级.
* First-in, first-out queue: Assign a lower priority to the newly inserted element.
* stack:Assign a higher priority to the newly inserted element.
### Exercises 6.5-8
***
The operation HEAP-DELETE(A, i) deletes the item in node i from heap A. Give an
implementation of HEAP-DELETE that runs in O(lg n) time for an n-element max-heap.
### `Answer`
```c
HEAP-DELETE(A, i):
if A[i] < A[A.heap-size]
HEAP-INCREASE-KEY(A, i, A[A.heap-size])
A.heap-size -= 1
else
A[i] = A[A.heap-size]
A.heap-size -= 1
MAX-HEAPIFY(A,i)
```
**Notice: What's wrong with the implementation bellow?**
```c
HEAP-DELETE(A, i):
A[i] = A[A.heap-size]
A.heap-size -= 1
MAX-HEAPIFY(A, i)
```
You can't assume there always be A[i] > A[A.heap-size].
For example:
```
10
/ \
5 9
/ \ / \
2 3 7 8
```
If you want to delete key 2, the A[A.heap-size] is 8. But 8 should climb up to the position of 5.
### Exercises 6.5-9
***
Give an O(n lg k)-time algorithm to merge k sorted lists into one sorted list, where n is the
total number of elements in all the input lists. (Hint: Use a min-heap for k-way merging.)
### `Answer`
The problem occurs in [leetcode](https://leetcode.com/problems/merge-k-sorted-lists/)
This is my [solution](https://github.com/gzc/leetcode/blob/master/cpp/021-030/Merge%20k%20Sorted%20Lists%20.cpp)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/d-ary-heaps.cpp
================================================
/*************************************************************************
> File Name: d-ary-heaps.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Tue Jun 23 19:22:21 2015
************************************************************************/
#include<iostream>
#include<cstdio>
#include<climits>
using namespace std;
#define PARENT(i,d) ((i - 1) / d)
#define CHILD(i,c,d) (d * i + c + 1)
typedef struct {
int *elements;
int d;
int heap_size;
} heap_t;
void max_heapify(heap_t *heap, int i) {
int largest = i;
int basechild = CHILD(i, 0, heap->d);
for (int k = 0; k < heap->d; k++) {
int child = basechild+k;
if (child < heap->heap_size && heap->elements[child] > heap->elements[largest])
largest = child;
}
if (largest != i) {
swap(heap->elements[i],heap->elements[largest]);
max_heapify(heap, largest);
}
}
int extract_max(heap_t *heap) {
int max = heap->elements[0];
heap->elements[0] = heap->elements[heap->heap_size - 1];
heap->heap_size--;
max_heapify(heap, 0);
return max;
};
void increase_key(heap_t *heap, int i, int key) {
if (key < heap->elements[i]) {
cerr << "new key is smaller than current key" << endl;
exit(-1);
}
while (i > 0 && heap->elements[PARENT(i,heap->d)] < key) {
heap->elements[i] = heap->elements[PARENT(i,heap->d)];
i = PARENT(i,heap->d);
}
heap->elements[i] = key;
}
void insert(heap_t *heap, int key) {
heap->heap_size++;
heap->elements[heap->heap_size - 1] = INT_MIN;
increase_key(heap, heap->heap_size - 1, key);
}
================================================
FILE: C06-Heapsort/heap.cpp
================================================
/*************************************************************************
> File Name: 2.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: 一 12/22 21:47:37 2014
************************************************************************/
#include<iostream>
using namespace std;
/*
* get the parent of this node
*/
int parent(int i)
{
return (i-1)/2;
}
/*
* get the left child
*/
int left(int i)
{
return 2*i+1;
}
/*
* get the right child
*/
int right(int i)
{
return 2*i+2;
}
/*
* construct a sub-tree whose root is node i
*/
void maxHeapify(int A[], int n, int i)
{
int l = left(i);
int r = right(i);
int largest(0);
if (l <= (n-1) && A[l] > A[i])
largest = l;
else
largest = i;
if (r <= (n-1) && A[r] > A[largest])
largest = r;
if(largest != i)
{
swap(A[i], A[largest]);
maxHeapify(A, n, largest);
}
}
/*
* build the heap
*/
void buildMaxHeap(int A[], int n)
{
for(int i = n/2-1;i >= 0;i--)
maxHeapify(A, n, i);
}
/*
* heapsort
*/
void heapsort(int A[], int n)
{
buildMaxHeap(A, n);
for(int i = n-1;i > 0;i--)
{
swap(A[0],A[i]);
maxHeapify(A, --n, 0);
}
}
void print(int A[], int n)
{
for(int i = 0;i < n;i++)
cout << A[i] << " ";
cout << endl;
}
int main()
{
int A[10] = {16,14,10,8,7,9,3,2,4,1};
heapsort(A, 10);
print(A, 10);
return 0;
}
================================================
FILE: C06-Heapsort/main.cpp
================================================
/*************************************************************************
> File Name: main.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Sun Jan 4 19:51:21 2015
************************************************************************/
#include<iostream>
#include<cstdio>
#include<list>
#include<vector>
#include<unordered_map>
#include<climits>
#include<unordered_set>
#include<map>
#include<set>
#include<stack>
#include "p_queue.h"
int main()
{
int A[10] = {10,9,8,7,6,5,4,3,2,1};
p_queue q1(A, 10);
std::cout << q1.maximum() << std::endl;
q1.insert(20);
q1.insert(10);
std::cout << q1.maximum() << std::endl;
q1.extract_max();
std::cout << q1.maximum() << std::endl;
q1.increase_key(0, 5);
std::cout << q1.maximum() << std::endl;
q1.extract_max();
std::cout << q1.maximum() << std::endl;
q1.increase_key(1, 30);
std::cout << q1.maximum() << std::endl;
return 0;
}
================================================
FILE: C06-Heapsort/makefile
================================================
sample : main.o p_queue.o
g++ -o sample main.o p_queue.o
main.o : main.cpp p_queue.h
g++ -c main.cpp
p_queue.o : p_queue.h p_queue.cpp
g++ -c p_queue.cpp
clean :
rm sample main.o p_queue.o
================================================
FILE: C06-Heapsort/p_queue.cpp
================================================
/*************************************************************************
> File Name: p_queue.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Sun Jan 4 19:28:46 2015
************************************************************************/
#include "p_queue.h"
#include <limits>
p_queue::p_queue(int *A, int n)
{
for(int i = 0;i < n;i++)
{
a[i] = A[i];
}
size = n;
buildMaxHeap(a, size);
}
void p_queue::insert(int x)
{
size++;
a[size-1] = x;
int i = size-1;
while(i > 0 && a[parent(i)] < a[i])
{
std::swap(a[i], a[parent(i)]);
i = parent(i);
}
}
int p_queue::maximum()
{
if(size <= 0)
{
std::cerr << "heap overflow" << std::endl;
return -1;
}
return a[0];
}
int p_queue::extract_max()
{
if(size <= 0)
{
std::cerr << "heap overflow" << std::endl;
return -1;
}
int max = a[0];
a[0] = a[size-1];
size--;
maxHeapify(a, size, 0);
return max;
}
void p_queue::increase_key(int i, int x) {
a[i] = std::max(a[i], x);
while (i > 0 && a[parent(i)] < a[i]) {
std::swap(a[parent(i)], a[i]);
i = parent(i);
}
}
int p_queue::parent(int i)
{
return (i-1)/2;
}
int p_queue::left(int i)
{
return 2*i+1;
}
int p_queue::right(int i)
{
return 2*i+2;
}
void p_queue::maxHeapify(int A[], int n, int i)
{
int l = left(i);
int r = right(i);
int largest(0);
if (l <= (n-1) && A[l] > A[i])
largest = l;
else
largest = i;
if (r <= (n-1) && A[r] > A[largest])
largest = r;
if(largest != i)
{
std::swap(A[i], A[largest]);
maxHeapify(A, n, largest);
}
}
void p_queue::buildMaxHeap(int A[], int n)
{
for(int i = n/2-1;i >= 0;i--)
maxHeapify(A, n, i);
}
void p_queue::heapsort(int A[], int n)
{
buildMaxHeap(A, n);
for(int i = n-1;i > 0;i--)
{
std::swap(A[0],A[i]);
maxHeapify(A, --n, 0);
}
}
================================================
FILE: C06-Heapsort/p_queue.h
================================================
/*************************************************************************
> File Name: p_queue.h
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Sun Jan 4 19:16:19 2015
************************************************************************/
#ifndef _P_QUEUE_H
#define _P_QUEUE_H
#endif
#include <iostream>
class p_queue
{
public:
p_queue(int *A, int n);
void insert(int x);
int maximum(void);
int extract_max(void);
void increase_key(int i, int x);
private:
int a[10000];
int size;
int parent(int i);
int left(int i);
int right(int i);
void maxHeapify(int A[], int n, int i);
void buildMaxHeap(int A[], int n);
void heapsort(int A[], int n);
};
================================================
FILE: C06-Heapsort/problem.md
================================================
### Problems 1 : Building a heap using insertion
***
The procedure BUILD-MAX-HEAP in Section 6.3 can be implemented by repeatedly using MAX-HEAP-INSERT to insert the elements into the heap. Consider the following implementation:
BUILD-MAX-HEAP'(A)
heap-size[A] ← 1
for i←2 to length[A]
do MAX-HEAP-INSERT(A, A[i])
a. Do the procedures BUILD-MAX-HEAP and BUILD-MAX-HEAP' always create the same heap when run on the same input array? Prove that they do, or provide a counterexample.
b. Show that in the worst case, BUILD-MAX-HEAP' requires Θ(n lg n) time to build an n-element heap.
### `Answer`
**a.**
不一定.对于数组[1,2,3,4,5,6].有

**b.**
当原数组是递增序列时,需要的时间
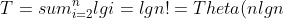%20)
### Problems 2 : Analysis of d-ary heaps
***
A d-ary heap is like a binary heap, but (with one possible exception) non-leaf nodes have d children instead of 2 children.
a. How would you represent a d-ary heap in an array?
b. What is the height of a d-ary heap of n elements in terms of n and d?
c. Give an efficient implementation of EXTRACT-MAX in a d-ary max-heap. Analyze
its running time in terms of d and n.
d. Give an efficient implementation of INSERT in a d-ary max-heap. Analyze its running
time in terms of d and n.
e. Give an efficient implementation of INCREASE-KEY(A, i, k), which first sets A[i] ←
max(A[i], k) and then updates the d-ary max-heap structure appropriately. Analyze its running time in terms of d and n.
### `Answer`
[implementation](./d-ary-heaps.cpp)


### Problems 3 : Young tableaus
***
An m × n Young tableau is an m × n matrix such that the entries of each row are in sorted order from left to right and the entries of each column are in sorted order from top to bottom. Some of the entries of a Young tableau may be ∞, which we treat as nonexistent elements. Thus, a Young tableau can be used to hold r ≤ mn finite numbers.
a. Draw a 4×4 Young tableau containing the elements {9, 16, 3, 2, 4, 8, 5, 14, 12}.
b. Arguethatanm×nYoungtableauYisemptyifY[1,1]=∞.ArguethatYisfull
(contains mn elements) if Y[m, n] < ∞.
c. Give an algorithm to implement EXTRACT-MIN on a nonempty m × n Young
tableau that runs in O(m + n) time. Your algorithm should use a recursive subroutine that solves an m × n problem by recursively solving either an (m - 1) × n or an m × (n - 1) subproblem. (Hint: Think about MAX-HEAPIFY.) Define T(p), where p = m + n, to be the maximum running time of EXTRACT-MIN on any m × n Young tableau. Give and solve a recurrence for T(p) that yields the O(m + n) time bound.
d. Show how to insert a new element into a nonfull m × n Young tableau in O(m + n) time.
e. Using no other sorting method as a subroutine, show how to use an n × n Young tableau to sort n^2 numbers in O(n^3) time.
f. Give an O(m+n)-time algorithm to determine whether a given number is stored in a given m × n Young tableau.
### `Answer`
[implementation](./young.cpp)
**a.**

**b.**
这是显然的~
**c.**
T(p) = T(p-1) + O(1) = O(p)
**d.**
跟c是一个相反的操作,具体见代码.
**e.**
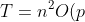%20%20=%20O\(n^3\))
**f.**
实现见代码.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C06-Heapsort/young.cpp
================================================
/*************************************************************************
> File Name: young.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Tue Jun 23 20:05:44 2015
************************************************************************/
#include<iostream>
#include<vector>
#include<climits>
using namespace std;
int EXTRACT_MIN(vector<vector<int> > &young)
{
int minimum = young[0][0];
int i(0),j(0);
while(i < young.size() && j < young[0].size())
{
int cur = young[i][j];
int ori(i),orj(j);
int right(INT_MAX),down(INT_MAX);
if(i < young.size()-1) down = young[i+1][j];
if(j < young[0].size()-1) right = young[i][j+1];
if(right == INT_MAX && down == INT_MAX)
{
young[i][j] = INT_MAX;
break;
}
else if(down <= right)
i++;
else
j++;
swap(young[i][j], young[ori][orj]);
}
return minimum;
}
void INSERT(vector<vector<int> > &young, int v)
{
int i = young.size()-1;
int j = young[0].size()-1;
young[i][j] = v;
while(i >= 0 && j >= 0)
{
int left(INT_MIN),up(INT_MIN);
if(i > 0) up = young[i-1][j];
if(j > 0) left = young[i][j-1];
if(v >= up && v >= left)
break;
else if(v < up)
{
swap(young[i][j], young[i-1][j]);
i--;
} else {
swap(young[i][j], young[i][j-1]);
j--;
}
}
}
bool EXIST(vector<vector<int> > &young, int v)
{
int i(young.size()-1),j(0);
while(i >= 0 && j < young[0].size())
{
cout << i << " " << j << endl;
if(young[i][j] == v)
return true;
if(young[i][j] < v)
j++;
else
i--;
}
return false;
}
void print_young(vector<vector<int> > &young)
{
for(int i = 0;i < young.size();i++)
{
for(int j = 0;j < young[0].size();j++)
{
cout << young[i][j] << " ";
}
cout << endl;
}
}
int main() {
int arr1[4] = {2,3,12,INT_MAX};
int arr2[4] = {4,8,16,INT_MAX};
int arr3[4] = {5,9,INT_MAX,INT_MAX};
int arr4[4] = {14,INT_MAX,INT_MAX,INT_MAX};
vector<int> v1(arr1,arr1+4);
vector<int> v2(arr2,arr2+4);
vector<int> v3(arr3,arr3+4);
vector<int> v4(arr4,arr4+4);
vector<vector<int> > v;
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
v.push_back(v4);
for(int i = 0;i < 9;i++)
cout << EXTRACT_MIN(v) << endl;
for(int i = 0;i < 9;i++)
INSERT(v, i);
print_young(v);
cout << EXIST(v, 8) << endl;
return 0;
}
================================================
FILE: C07-Quicksort/7.1.md
================================================
### Exercises 7.1-1
***
Using Figure 7.1 as a model, illustrate the operation of PARTITION on the array A = [13, 19, 3, 5, 12, 8, 7, 4, 21, 2, 6, 11].
### `Answer`

### Exercises 7.1-2
***
What value of q does PARTITION return when all elements in the array A[p...r] have the same value? Modify PARTITION so that q = (p+r)/2 when all elements in the array A[p...r] have the same value.
### `Answer`
It will return r. So we have to modify the code in case the worst situation.
[code](./exercise_code/quicksort.py)
### Exercises 7.1-3
***
Give a brief argument that the running time of PARTITION on a subarray of size n is Θ(n).
### `Answer`
Because we just iterate the array once.
### Exercises 7.1-4
***
How would you modify QUICKSORT to sort into nonincreasing order?
### `Answer`
Change the condition **A[j] <= x** to **A[j] >= x**
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C07-Quicksort/7.2.md
================================================
### Exercises 7.2-1
***
Use the substitution method to prove that the recurrence T (n) = T (n - 1) + Θ(n) has the
solution T (n) = Θ(n^2), as claimed at the beginning of Section 7.2.
### `Answer`
T(n) = T(n-1) + Θ(n) = Θ(n) + Θ(n-1) + ... + Θ(1) = Θ(n^2)
Here is the substitution method:
```
Let's assume that T(n - 1) <= c(n-1)^2
Then T(n) <= c*(n-1)^2 + Θ(n)
<= c*n^2 -(2cn - Θ(n))
So we can find a c which is large enough to make
2cn > Θ(n),eg. assume Θ(n) = kn, then we make c > k/2
So T(n) <= c*n^2
T(n) = Θ(n^2)
```
### Exercises 7.2-2
***
What is the running time of QUICKSORT when all elements of array A have the same value?
### `Answer`
Θ(n^2)
### Exercises 7.2-3
***
Show that the running time of QUICKSORT is Θ(n^2) when the array A contains distinct elements and is sorted in decreasing order.
### `Answer`
Similar to the above problem,because <code>T(n) = T(n-1) + Θ(n)</code>
The pivot value in quicksort is smaller than all of the other values, and hence can never achieve a balanced array in each recursive step.
### Exercises 7.2-4
***
Banks often record transactions on an account in order of the times of the transactions, but many people like to receive their bank statements with checks listed in order by check number. People usually write checks in order by check number, and merchants usually cash them with reasonable dispatch. The problem of converting time-of-transaction ordering to check-number ordering is therefore the problem of sorting almost-sorted input. Argue that the procedure INSERTION-SORT would tend to beat the procedure QUICKSORT on this problem.
### `Answer`
原数组越有序,逆序对越少,插入排序越快.
The more ordered the original array, the less the inversions and Insertion Sort will run much more quickly.
INSERTION-SORT's while loop which checks for whether or not a new insertion needs to be done would stop after only one iteration, and in addition quicksort would not be able to achieve a balanced split at every recursive step due to the pivot being the largest number in the new array to sort.
### Exercises 7.2-5
***
Suppose that the splits at every level of quicksort are in the proportion 1 - α to α, where 0 < α ≤ 1/2 is a constant. Show that the minimum depth of a leaf in the recursion tree is approximately - lg n/ lg α and the maximum depth is approximately -lg n/ lg(1 - α). (Don't worry about integer round-off.)
### `Answer`
First calculate the minimum height:
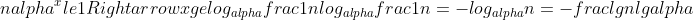
As for the maximum height, replace α with (1 - α)
### Exercises 7.2-6
***
Argue that for any constant 0 < α ≤ 1/2, the probability is approximately 1 - 2α that on a
random input array, PARTITION produces a split more balanced than 1-α to α.
### `Answer`
因为比1-α to α更好的分布的数的在他们之间,有1 - 2α的比例.比他们差的有α+α = 2α
The number better than [1-α,α] among them, and has a propotion 1 - 2α. So number worse than then is 2α
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C07-Quicksort/7.3.md
================================================
### Exercises 7.3-1
***
Why do we analyze the average-case performance of a randomized algorithm and not its worst-case performance?
### `Answer`
因为最坏情况很极端才会发生,我们想要的是期望时间.
Because the worst case happen rarely, we want the average case to be fine.
### Exercises 7.3-2
***
During the running of the procedure RANDOMIZED-QUICKSORT, how many calls are made to the random-number generator RANDOM in the worst case? How about in the best case? Give your answer in terms of Θ-notation.
### `Answer`
The best : <code> T(n) = 2T(n/2) + 1 = Θ(n) </code>
The worst : <code> T(n) = T(n-1) + 1 = Θ(n) </code>
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C07-Quicksort/7.4.md
================================================
### Exercises 7.4-1
***
Show that in the recurrence
%20=%20\\max%20\\limits_{0%20\\le%20q%20\\le%20n-1}%20\(T\(q\)%20+%20T\(n-q-1\)\)+\\Theta\(n\)%20\\\\%0d%0aT\(n\)%20=%20\\Omega%20\(n^2\)%0d%0a)
### `Answer`
%20=%20\\max%20\\limits_{0%20\\le%20q%20\\le%20n-1}%20\(T\(q\)%20+%20T\(n-q-1\)\)+\\Theta\(n\)%20\\\\%20~\\hspace{15%20mm}%0d%0a=%20T\(n-1\)%20+%20\\Theta\(n\)%20\\\\%20~\\hspace{15%20mm}%0d%0a=%20\\Theta\(n^2\)%20\\\\%0d%0a\\quad\\text{because%20it%20is%20}%20\\Theta\(n^2\)%0d%0a\quad\\text{so%20it%20is%20also%20}%20\\Omega\(n^2\)%0d%0a)
### Exercises 7.4-2
***
Show that quicksort's best-case running time is Ω(nlgn).
### `Answer`
%20=%202T\(n/2\)%20+%20\\Theta\(n\)%0d%0a)
According to the master theorem,it is Ω(nlgn)
### Exercises 7.4-3
***
Show that q^2 +(n-q-1)^2 achieves a maximum over q = 0,1,...,n-1 when q=0 or q=n-1.
### `Answer`
抛物线的简单性质~~~~
或者可以用不等式,转化成已知A+B = n - 1,求A^2 + B^2在[0,n-1]的最大值.
Just get by the property parabolic curve.
### Exercises 7.4-4
***
Show that RANDOMIZED-QUICKSORT's expected running time is Ω(n lg n).
### `Answer`
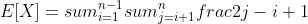%20\\\\%20~%20\\hspace{16%20mm}%0d%0a=%20%20%20\\Omega\(n\\lg{n}\)%0d%0a)
For a monotonically increasing function 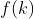, we can approximate it by integrals:

Similarly, for a monotonically decreasing function 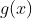, would have:

Similar to the proof in (7.4):
![E[X]=\sum_{i=1}^{n-1}\sum_{j=i+1}^{n}\frac{2}{j-i+1}\\~\hspace{15.5mm}=\sum_{i=1}^{n-1}\sum_{j=i+1}^{n}\frac{2}{j-i+1}\\~\hspace{15.5mm}=\sum_{i=1}^{n-1}\sum_{k=1}^{n-i}\frac{2}{k+1}\\~\hspace{15.5mm}\geqslant \sum_{i=1}^{n-1}2\int_{1}^{n-i}\frac{1}{k+1}\\~\hspace{15.5mm}=\sum_{i=1}^{n-1}2(ln(n-i+2)-O(1))\\~\hspace{15.5mm}\geqslant2\int_{1}^{n}ln(n-i+2)di-O(n)\\~\hspace{15.5mm}=\int_{2}^{n+1}ln(x)dx-O(n)\\~\hspace{15.5mm}=2nln(n+1)-O(n)=\Omega (nlgn)](http://latex.codecogs.com/gif.latex?E%5BX%5D%3D%5Csum_%7Bi%3D1%7D%5E%7Bn-1%7D%5Csum_%7Bj%3Di+1%7D%5E%7Bn%7D%5Cfrac%7B2%7D%7Bj-i+1%7D%20%5C%5C%7E%5Chspace%7B15.5mm%7D%3D%5Csum_%7Bi%3D1%7D%5E%7Bn-1%7D%5Csum_%7Bj%3Di+1%7D%5E%7Bn%7D%5Cfrac%7B2%7D%7Bj-i+1%7D%20%5C%5C%7E%5Chspace%7B15.5mm%7D%3D%5Csum_%7Bi%3D1%7D%5E%7Bn-1%7D%5Csum_%7Bk%3D1%7D%5E%7Bn-i%7D%5Cfrac%7B2%7D%7Bk+1%7D%20%5C%5C%7E%5Chspace%7B15.5mm%7D%5Cgeqslant%20%5Csum_%7Bi%3D1%7D%5E%7Bn-1%7D2%5Cint_%7B1%7D%5E%7Bn-i%7D%5Cfrac%7B1%7D%7Bk+1%7D%20%5C%5C%7E%5Chspace%7B15.5mm%7D%3D%5Csum_%7Bi%3D1%7D%5E%7Bn-1%7D2%28ln%28n-i+2%29-O%281%29%29%20%5C%5C%7E%5Chspace%7B15.5mm%7D%5Cgeqslant2%5Cint_%7B1%7D%5E%7Bn%7Dln%28n-i+2%29di-O%28n%29%20%5C%5C%7E%5Chspace%7B15.5mm%7D%3D%5Cint_%7B2%7D%5E%7Bn+1%7Dln%28x%29dx-O%28n%29%20%5C%5C%7E%5Chspace%7B15.5mm%7D%3D2nln%28n+1%29-O%28n%29%3D%5COmega%20%28nlgn%29)
### Exercises 7.4-5
***
The running time of quicksort can be improved in practice by taking advantage of the fast running time of insertion sort when its input is "nearly" sorted. When quicksort is called on a subarray with fewer than k elements, let it simply return without sorting the subarray. After the top-level call to quicksort returns, run insertion sort on the entire array to finish the sorting process. Argue that this sorting algorithm runs in O(nk + nlg(n/k)) expected time. How should k be picked, both in theory and in practice?
### `Answer`
先看快速排序的那部分,当深度为lg(n/k)便停止了快速排序,所以快速排序的时间为O(nlg(n/k));再看插入排序那部分,现在有n/k个小数组,每个数组的大小为k,需要O(k^2)的时间排序,所以插入排序的时间是n/k * O(k^2) = O(nk).
理论上很难确定k,因为快速排序的渐近函数在数量级上优于插入排序;用实验确定是比较靠谱的方法.
The main idea is to note that the recursion stops when n^2*i = k, that is i = log2(n)(k). The recursion takes in total O(n * lg(n)(k)). The resulting array is composed of k subarrays of size n=k, where the elements in each subarray are all less than all the subarrays following it. Running Insertion-Sort on the entire array is thus equivalent to sorting each of the n/k subarrays of size k, which takes on the average n/k * O(k2) = O(nk) (the expected running time of Insertion-Sort is O(n^2)).
If k is chosen too big, then the O(nk) cost of insertion becomes bigger than (n lg n). Therefore k must be O(lg n). Furthermore it must be that O(nk + n lg (n)(k) ) = O(n lg n). If the constant factors in the big-oh notation are ignored, than it follows that k should be
such that k < lg k which is impossible (unless k = 1) - the error comes from ignoring the constant factors. Let c1 be the constant factor in quicksort, and c2 be the constant factor in insertion sort. Than k must be chosen such that c2k + c1 lg n k < c1 lg n which requires c1k<c2 lg k. In practice these constants cannot be ignored (also there can be lower order terms in O(n lg n)) and k should be chosen experimentally.
English version solution copied from [here](http://s3.alirezaweb.com/91-5/introduction-to-algorithms/solution-manual/CLRS-Exercises-Introduction-to-Algorithms_Borna66/CLRS-Introduction-to-Algorithms/H6-solution[www.alirezaweb.com].pdf)
### Exercises 7.4-6
***
Consider modifying the PARTITION procedure by randomly picking three elements from array A and partitioning about their median (the middle value of the three elements). Approximate the probability of getting at worst an **α**-to-**(1 - α)** split, as a function of α in the range 0 < α < 1.
### `Answer`
假设α < 1/2并且能取相同的元素,这并不影响最后的结果.
先考虑概率小于α的这边,此时中位数落在nα内,也就是说至少选到了两个在nα内的数字.有以下几种组合
1. 1,2,3都在
2. 1,2在,3不在
3. 1,3在,2不在
4. 2,3在,1不在.
概率是1*(α^3)+3*(α^2*(1-α)) = 3α^2-2α^3.
概率大于(1-α)的概率和小于α是一样的.
因此最后的答案是6α^2-4α^3
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C07-Quicksort/exercise_code/fuzzy_sort.py
================================================
#!/usr/bin/env python
# coding=utf-8
import random
import copy
def intersects(a, b):
return a[0] <= b[1] and b[0] <= a[1]
def before(a, b):
return a[1] < b[0]
def partition(items, p, r):
pick = random.randint(p, r)
items[pick], items[r] = items[r], items[pick]
intersection = copy.deepcopy(items[r]);
for i in range(p, r):
if intersects(intersection, items[i]):
if items[i][0] > intersection[0]:
intersection[0] = items[i][0]
if items[i][1] < intersection[1]:
intersection[1] = items[i][1]
s = p
for i in range(p, r):
if before(items[i], intersection):
items[i], items[s] = items[s], items[i]
s += 1
items[r], items[s] = items[s], items[r]
t = s + 1
while t <= i:
if intersects(items[i], intersection):
items[t], items[i] = items[i], items[t]
t += 1
else:
i -= 1
return (s, t)
def fuzzy_sort(items, p, r):
if (p < r):
pivot = partition(items, p, r);
fuzzy_sort(items, p, pivot[0]);
fuzzy_sort(items, pivot[1], r);
items = [[2,4],[0,1],[3,5],[-1,-2],[0,99]]
print items
fuzzy_sort(items, 0, len(items)-1)
print items
================================================
FILE: C07-Quicksort/exercise_code/hoare.py
================================================
#!/usr/bin/env python
# coding=utf-8
def quicksort(items, p, r):
if p < r:
q = partition(items, p, r)
quicksort(items, p, q)
quicksort(items, q+1, r)
def partition(items, p, r):
x = items[p]
i = p - 1
j = r + 1
while True:
while True:
j = j - 1
if items[j] <= x:
break
while True:
i = i + 1
if items[i] >= x:
break
if i < j:
items[i],items[j] = items[j],items[i]
else:
return j
items = [13,19,9,5,12,8,7,4,11,2,6,21]
quicksort(items, 0, len(items)-1)
print items
================================================
FILE: C07-Quicksort/exercise_code/quickSortWithEqualElements.cpp
================================================
#include <vector>
#include <algorithm>
#include <stdlib.h>
#include <time.h>
#include <utility>
#include <cassert>
using namespace std;
class QuickSort{
public:
QuickSort(){}
~QuickSort(){}
void qsort(vector<int> &data);
bool isSorted(int start, int end, vector<int> & data);
private:
void sortHelper(int start, int end, vector<int> & data);
int hoarePartition(int start, int end, vector<int> & data);
void threeSortHelper(int start, int end, vector<int> & data);
pair<int, int> threeWayPartition(int start, int end, vector<int> & data);
pair<int, int> fastThreePartition(int start, int end, vector<int> & data);
int getRandom(int start, int end);
};
void QuickSort::qsort(vector<int> & data){
threeSortHelper(0, data.size() - 1, data);
}
void QuickSort::sortHelper(int start, int end, vector<int> & data){
if(start < end){
int pivot = hoarePartition(start, end, data);
sortHelper(start, pivot - 1, data);
sortHelper(pivot + 1, end, data);
}
}
void QuickSort::threeSortHelper(int start, int end, vector<int> & data){
if(start < end){
int randomIdx = getRandom(start, end);
swap(data[start], data[randomIdx]);
auto bound = fastThreePartition(start, end, data);
threeSortHelper(start,bound.first - 1, data);
threeSortHelper(bound.second + 1, end, data);
}
}
/*/////////////////////////////////////////
*
* Partition Algorithm Block
*
*/////////////////////////////////////////
/*
* Modified Hoare Partition, which stops scanning on equal elements to avoid
* the occurence of worst case O(n^2)
*
* Ref: Programming Perls 2nd Edition, Jon Bentley
*/
int QuickSort::hoarePartition(int start, int end, vector<int> & data){
int pivot = data[start];
int i = start;
int j = end + 1;
while(true){
do{
++i;
} while( i <= end && data[i] < pivot);
do{
--j;
} while (data[j] > pivot);
if(i > j){
break;
}
swap(data[i], data[j]);
}
swap(data[start], data[j]);
return j;
}
/**
* Ref:Algorithms, 4th Edition by Robert S. and Kevin W.
*/
pair<int, int> QuickSort::threeWayPartition(int start, int end, vector<int> & data){
int pivot = data[start];
int low = start;
int high = end;
int i = low + 1;
while(i <= high){
if(data[i] < pivot){
swap(data[i++], data[low++]);
} else if (data[i] > pivot){
swap(data[i], data[high--]);
} else {
++i;
}
}
return make_pair(low, high);
}
/**
* The three way partition above does extra swaps for elements not equal to pivot.
* The fast three way partition below does extra swaps for elements equal to pivot to i.
* This algorithm does fewer swaps when the number of elements equal to pivot is smaller.
*
* Ref:Algorithms, 4th Edition by Robert S. and Kevin W.
*
*/
pair<int, int> QuickSort::fastThreePartition(int start, int end, vector<int> & data){
int i = start, j = end + 1;
int p = start, q = end + 1;
int v = data[start];
while(true){
while(data[++i] < v){
if(i == end){
break;
}
}
while(data[--j] > v){
if(j == start){
break;
}
}
if(i == j && data[i] == v){
swap(data[++p], data[i]);
}
if(i >= j) break;
swap(data[i], data[j]);
if(data[i] == v){
swap(data[++p], data[i]);
}
if(data[j] == v){
swap(data[--q], data[j]);
}
}
i = j + 1;
for(int k = start; k <= p; ++k){
swap(data[k], data[j--]);
}
for(int k = end; k>= q; --k){
swap(data[k], data[i++]);
}
return make_pair(j + 1, i - 1);
}
/*/////////////////////////////////////////
*
* Utility Function Block
*
*/////////////////////////////////////////
int QuickSort::getRandom(int start, int end){
srand(time(NULL));
return rand() % (end - start + 1) + start;
}
bool QuickSort::isSorted(int start, int end, vector<int> & data){
for(int i = start + 1; i <= end; ++i){
if(data[i] < data[i-1]){
return false;
}
}
return true;
}
int main(){
vector<int> test1 {0};
vector<int> test2 {-1, 3, 2, 4,-10, 100};
QuickSort solver;
solver.qsort(test1);
solver.qsort(test2);
assert(solver.isSorted(0, test1.size()-1, test1));
assert(solver.isSorted(0, test2.size()-1, test2));
}
================================================
FILE: C07-Quicksort/exercise_code/quicksort.py
================================================
#!/usr/bin/env python
# coding=utf-8
def quicksort(items, p, r):
if p < r:
q = partition(items, p, r)
quicksort(items, p, q-1)
quicksort(items, q+1, r)
def partition(items, p, r):
x = items[r]
i = p-1
count = 0
for j in range(p, r):
if items[j] == x:
count += 1
if items[j] <= x:
i = i + 1
items[i],items[j] = items[j],items[i]
items[i+1],items[r] = items[r],items[i+1]
return i+1-count/2
items = [2,5,9,3,7,0,-1]
quicksort(items, 0, len(items)-1)
print items
================================================
FILE: C07-Quicksort/exercise_code/tailrecursive.py
================================================
#!/usr/bin/env python
# coding=utf-8
def tail_quicksort(items, p, r):
while p < r:
q = partition(items, p, r)
if r-q >= q-p:
tail_quicksort(items, p, q-1)
p = q+1
else:
tail_quicksort(items, q+1, r)
r = q-1;
def partition(items, p, r):
x = items[r]
i = p-1
for j in range(p, r):
if items[j] <= x:
i = i + 1
items[i],items[j] = items[j],items[i]
items[i+1],items[r] = items[r],items[i+1]
return i+1
items = [2,5,9,3,7,0,-1]
tail_quicksort(items, 0, len(items)-1)
print items
================================================
FILE: C07-Quicksort/problem.md
================================================
### Problems 1 : Hoare partition correctness
***
The version of PARTITION given in this chapter is not the original partitioning algorithm. Here is the original partition algorithm, which is due to T. Hoare:
HOARE-PARTITION(A, p, r):
x <- A[p]
i <- p - 1
j <- r + 1
while TRUE:
do repeat j <- j - 1
until A[j] <= x
repeat i <- i + 1
until A[i] >= x
if i < j:
then exchange A[i] <-> A[j]
else return j
**a.** Demonstrate the operation of HOARE-PARTITION on the array A = [13, 19, 9, 5, 12, 8, 7, 4, 11, 2, 6, 21], showing the values of the array and auxiliary values after each iteration of the for loop in lines 4-11.
The next three questions ask you to give a careful argument that the procedure HOARE- PARTITION is correct. Prove the following:
**b.** The indices i and j are such that we never access an element of A outside the subarray A[p...r].
**c.** When HOARE-PARTITION terminates, it returns a value j such that p ≤ j < r.
**d.** Every element of A[p...j] is less than or equal to every element of A[j+1...r] when
HOARE-PARTITION terminates.
The PARTITION procedure in Section 7.1 separates the pivot value (originally in A[r]) from the two partitions it forms. The HOARE-PARTITION procedure, on the other hand, always places the pivot value (originally in A[p]) into one of the two partitions A[p...j] and A[j + 1...r]. Since p ≤ j < r, this split is always nontrivial.
**e.** Rewrite the QUICKSORT procedure to use HOARE-PARTITION.
### `Answer`
**a.**

**b.**
这是肯定的,因为i,j是往中间靠拢的.
**c.**
j至少会减2次. 若第一次进入while,j只减了1次,那么会做一次swap.然后继续进入while.
**d.**
很显然,小于x的放前面了,大于等于x的在后面.
**e.**
[implementation](./exercise_code/hoare.py)
### Problems 2 : Alternative quicksort analysis
***
An alternative analysis of the running time of randomized quicksort focuses on the expected running time of each individual recursive call to QUICKSORT, rather than on the number of comparisons performed.
**a.** Argue that, given an array of size n, the probability that any particular element is chosen as the pivot is 1/n. Use this to define indicator random variables Xi = I{ith smallest element is chosen as the pivot}. What is E [Xi]?
**b.** Let T (n) be a random variable denoting the running time of quicksort on an array of size n. Argue that
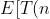]%20=%20E\\bigg[\\sum_{q=1}^nX_q\(T\(q-1\)%20+%20T\(n-q\)%20+%20\\Theta\(n\)\)\\bigg]%20)
**c.**
Show that equation (7.5) simplifies to
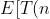]%20=%20\\frac{2}{n}\\sum_{q=2}^{n-1}E[T\(q\)]%20+%20\\Theta\(n\)%20)
**d.**
Show that
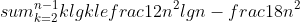
**e.**
Using the bound from equation (7.7), show that the recurrence in equation (7.6) has
the solution E [T (n)] = Θ(n lg n). (Hint: Show, by substitution, that E[T (n)] ≤ an log n - bn for some positive constants a and b.)
### `Answer`
**a.**
E[Xi]=1/n.
**b.**
这个算式的本质和之前分析快速排序的算式是一样的.
**c.**
就是简单的化简
**d.**
%20+%20\\sum_{k=n/2%20+%201}^{n}k\\lg{n}%20\\\\%20~%20\\hspace{22%20mm}%0d%0a%20%20%20=%20%20%20\\lg\(n/2\)\\sum_{k=2}^{n/2}k%20+%20\\lg{n}\\sum_{k=n/2%20+%201}^{n}k%20\\\\%20~%20\\hspace{22%20mm}%0d%0a%20%20%20=%20%20%20\(\\lg{n}%20-%20\\lg{2}\)\\bigg\(\\frac{\(n/2\)\(n/2%20+%201\)}{2}\\bigg\)%20+%20\\lg{n}\\bigg\(\\frac{n\(n+1\)}{2}%20-%20\\frac{\(n/2\)\(n/2%20+%201\)}{2}\\bigg\)%20\\\\%20%20~%20\\hspace{22%20mm}%0d%0a%20%20%20=%20%20%20\\lg{n}\\frac{n\(n+1\)}{2}%20-%20\\frac{\(n/2\)\(n/2%20+%201\)}{2}%20\\\\%20%20~%20\\hspace{22%20mm}%0d%0a%20%20%20=%20%20%20\\frac{1}{2}\\lg{n}\(n^2%20+%202n%20+%201\)%20-%20\\frac{1}{8}\(n^2%20+%202n%20+%201/8\)%20\\\\%20~%20\\hspace{22%20mm}%0d%0a%20%20%20=%20%20%20\\frac{1}{2}n^2\\lg{n}%20-%20\\frac{1}{8}n^2%20-%20\\frac{8n\\lg{n}%20+%204\\lg{n}%20-%202n%20-%201/8}{8}%20\\\\%20~%20\\hspace{22%20mm}%0d%0a%20%20%20\\le%20\\frac{1}{2}n^2\\lg{n}%20-%20\\frac{1}{8}n^2)
**e.**
我们猜想 E[T(n)] ≤ anlgn
]%20=%20%20%20\\frac{2}{n}\\sum_{q=2}^{n-1}E[T\(q\)]%20+%20\\Theta\(n\)%20\\\\%20~%20\\hspace{21%20mm}%0d%0a%20%20%20%20%20%20%20%20%20%20%20%20\\le%20\\frac{2}{n}\\sum_{q=2}^{n-1}an\\lg{n}%20+%20\\Theta\(n\)%20%20%20\\\\%20~%20\\hspace{21%20mm}%0d%0a%20%20%20%20%20%20%20%20%20%20%20%20\\le%20\\frac{2a}{n}\\bigg\(\\frac{1}{2}n^2\\lg{n}%20-%20\\frac{1}{8}n^2\\bigg\)%0d%0a%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20+%20\\Theta\(n\)%20\\\\\ ~%20\\hspace{21%20mm}%0d%0a%20%20%20%20%20%20%20%20%20%20%20%20=%20%20%20an\\lg{n}%20-%20\\frac{a}{4}n%20+%20\\Theta\(n\)%20\\\\%20~%20\\hspace{21%20mm}%0d%0a%20%20%20%20%20%20%20%20%20%20%20%20\\le%20an\\lg{n}%20%20)
### Problems 3 : Stooge sort
***
Professors Howard, Fine, and Howard have proposed the following "elegant" sorting algorithm:
STOOGE-SORT(A, i, j):
if A[i] > A[j]
then exchange A[i] <-> A[j]
if i + 1 >= j
then return
k <- ⌊(j-i+1)/3⌋
STOOGE-SORT(A, i, j-k)
STOOGE-SORT(A, i+k, j)
STOOGE-SORT(A, i, j-k)
a. Argue that, if n = length[A], then STOOGE-SORT(A, 1, length[A]) correctly sorts the input array A[1...n].
b. Give a recurrence for the worst-case running time of STOOGE-SORT and a tight asymptotic (Θ-notation) bound on the worst-case running time.
c. Compare the worst-case running time of STOOGE-SORT with that of insertion sort, merge sort, heapsort, and quicksort. Do the professors deserve tenure?
### `Answer`
**a.**
分三次进行排序,先将前2/3排好,再排后2/3,那么这时候最大的1/3已经在后面了。最后再对前面的2/3进行排序。是正确的。
**b.**
T(n) = 3T(2n/3) + O(1)
根据主定理最坏运行时间是)
**c.**
当然不会!
### Problems 4 : Stack depth for quicksort
***
The QUICKSORT algorithm of Section 7.1 contains two recursive calls to itself. After the call to PARTITION, the left subarray is recursively sorted and then the right subarray is recursively sorted. The second recursive call in QUICKSORT is not really necessary; it can be avoided by using an iterative control structure. This technique, called tail recursion, is provided automatically by good compilers. Consider the following version of quicksort, which simulates tail recursion.
QUICKSORT'(A, p, r):
while p < r:
do Partition and sort left subarray.
q <- PARTITION(A, p, r)
QUICKSORT'(A, p, q-1)
p <- q + 1
**a.** Argue that QUICKSORT'(A, 1, length[A]) correctly sorts the array A.
Compilers usually execute recursive procedures by using a stack that contains pertinent information, including the parameter values, for each recursive call. The information for the most recent call is at the top of the stack, and the information for the initial call is at the bottom. When a procedure is invoked, its information is pushed onto the stack; when it terminates, its information is popped. Since we assume that array parameters are represented by pointers, the information for each procedure call on the stack requires O(1) stack space. The stack depth is the maximum amount of stack space used at any time during a computation.
**b.** Describe a scenario in which the stack depth of QUICKSORT' is Θ(n) on an n-element input array.
**c.**
Modify the code for QUICKSORT' so that the worst-case stack depth is Θ(lg n). Maintain the O(n lg n) expected running time of the algorithm.
### `Answer`
**a.**
这个递推式总是先把左边的排好序,再排右边的. 顺序上和以前的版本是一样的.
**b.**
当运气比较差的时候,每次PARTITION都return r,会产生O(n)的堆栈深度.
**c.**
key idea : 先选range小的那一边迭代
[implementation](./exercise_code/tailrecursive.py)
### Problems 5 : Median-of-3 partition
***
One way to improve the RANDOMIZED-QUICKSORT procedure is to partition around a pivot that is chosen more carefully than by picking a random element from the subarray. One common approach is the **median-of-3** method: choose the pivot as the median (middle element) of a set of 3 elements randomly selected from the subarray. (See Exercise 7.4-6.) For this problem, let us assume that the elements in the input array A[1...n] are distinct and that n ≥ 3. We denote the sorted output array by A'[1...n]. Using the median-of-3 method to choose the pivot element x, define pi = Pr{x = A'[i]}.
**a.** Give an exact formula for pi as a function of n and i for i=2,3,...,n-1.(Note that p1 = pn = 0.)
**b.** By what amount have we increased the likelihood of choosing the pivot as x = A'[⌊(n
+ 1/2⌋], the median of A[1...n], compared to the ordinary implementation? Assume that n → ∞, and give the limiting ratio of these probabilities.
**c.** If we define a "good" split to mean choosing the pivot as x = A'[i], where n/ ≤ i ≤ 2n/3, by what amount have we increased the likelihood of getting a good split compared to the ordinary implementation? (Hint: Approximate the sum by an integral.)
**d.** Argue that in the Ω(n lg n) running time of quicksort, the median-of-3 method affects only the constant factor.
### `Answer`
**a.**
\(n-i\)}{n\(n-1\)\(n-2\)}%20)
**b.**
\(n-i\)}{n\(n-1\)\(n-2\)}/\\frac{1}{n}%0d%0a%20=%20\\lim_{n%20\\to%20\\infty}\\frac{6n\(n/2%20-%201\)\(n/2\)}{\(n-1\)\(n-2\)}%20=%201.5%20)
**c.**
\(n-i\)}{n\(n-1\)\(n-2\)}%20=%20%0d%0a\\lim_{n%20\\to%20\\infty}\\frac{6}{n\(n-1\)\(n-2\)}\\sum_{i=n/3}^{2n/3}\(i-1\)\(n-i\)%20=%20%0d%0a\\frac{13}{27})
**d.**
这种方法无法保证能取最优划分点,依然是概率问题,而且比普通的提升并没有很大.
### Problems 6 : Fuzzy sorting of intervals
Consider a sorting problem in which the numbers are not known exactly. Instead, for each number, we know an interval on the real line to which it belongs. That is, we are given n closed intervals of the form [ai, bi], where ai ≤ bi. The goal is to **fuzzy-sort** these intervals, i.e., produce a permutation [i1, i2,..., in] of the intervals such that there exist
, satisfying c1 ≤c2 ≤···≤cn.
**a.** Design an algorithm for fuzzy-sorting n intervals. Your algorithm should have the general structure of an algorithm that quicksorts the left endpoints (the ai 's), but it should take advantage of overlapping intervals to improve the running time. (As the intervals overlap more and more, the problem of fuzzy-sorting the intervals gets easier and easier. Your algorithm should take advantage of such overlapping, to the extent that it exists.)
### `Answer`
[implementation](./exercise_code/fuzzy_sort.py)
类似于quicksort,只是当重叠区域越多,pivot内的区别就越多~~
### Problems 2 (3rd Edition): Quicksort with equal element values
The analysis of the expected running time of randomized quicksort in Section 7.4.2 assumes that all element values are distinct. In this problem, we examine what happens when they are not.
**a.** Suppose that all element values are equal. What would be randomized quick-sort's running time in this case?
If the algorithm uses Lumuto Partition, then running time is O(n^2)
If the algorithm uses modified Hoare partition that stops scanning at equal case, then the worst case can be avoided.
**b.** Write a 3-way partition algorithm
**c.** Implement randomized-3-way-partition
[implementation](./exercise_code/quickSortWithEqualElements.cpp)
**d.** Using 3-way-partition-qsort, adjust the analysis in Section 7.4.2 to avoid the assumpton that all elements are equal.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C07-Quicksort/quicksort.py
================================================
#!/usr/bin/env python
# coding=utf-8
def quicksort(items, p, r):
if p < r:
q = partition(items, p, r)
quicksort(items, p, q-1)
quicksort(items, q+1, r)
def partition(items, p, r):
x = items[r]
i = p-1
for j in range(p, r):
if items[j] <= x:
i = i + 1
items[i],items[j] = items[j],items[i]
items[i+1],items[r] = items[r],items[i+1]
return i+1
items = [2,5,9,3,7,0,-1]
quicksort(items, 0, len(items)-1)
print items
================================================
FILE: C07-Quicksort/randomized-quicksort.py
================================================
#!/usr/bin/env python
# coding=utf-8
import random
def randomized_quicksort(items, p, r):
if p < r:
q = randomized_partition(items, p, r)
randomized_quicksort(items, p, q-1)
randomized_quicksort(items, q+1, r)
def randomized_partition(items, p, r):
i = random.randint(p, r)
items[i],items[r] = items[r],items[i]
return partition(items, p, r)
def partition(items, p, r):
x = items[r]
i = p-1
for j in range(p, r):
if items[j] <= x:
i = i + 1
items[i],items[j] = items[j],items[i]
items[i+1],items[r] = items[r],items[i+1]
return i+1
items = [2,5,9,3,7,0,-1]
randomized_quicksort(items, 0, len(items)-1)
print items
================================================
FILE: C08-Sorting-in-Linear-Time/8.1.md
================================================
### Exercises 8.1-1
***
What is the smallest possible depth of a leaf in a decision tree for a comparison sort?
### `Answer`
当数组已经排序好,是n-1.
### Exercises 8.1-2
***
Obtain asymptotically tight bounds on lg(n!) without using Stirling's approximation. Instead, evaluate the summation 
using techniques from Section A.2.
### `Answer`
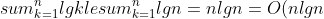%20)
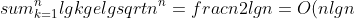%20)
### Exercises 8.1-3
***
Show that there is no comparison sort whose running time is linear for at least half of the n! inputs of length n. What about a fraction of 1/n of the inputs of length n? What about a fraction 1/2^n?
### `Answer`
n!/2, n!/n, n!/(2^n) are smaller than 2^n only when n is small.
### Exercises 8.1-4
***
You are given a sequence of n elements to sort. The input sequence consists of n/k subsequences, each containing k elements. The elements in a given subsequence are all smaller than the elements in the succeeding subsequence and larger than the elements in the preceding subsequence. Thus, all that is needed to sort the whole sequence of length n is to sort the k elements in each of the n/k subsequences. Show an Ω(n lg k) lower bound on the number of comparisons needed to solve this variant of the sorting problem. (Hint: It is not rigorous to simply combine the lower bounds for the individual subsequences.)
### `Answer`
^{n/k}%20\\le%202^h%20\\\\%0d%0a\\Rightarrow%20h%20\\ge%20\\lg\(k!\)^{n/k}%20\\\\%0d%0a%20%20%20%20%20=%20%20%20\(n/k\)\lg\(k!\)%20\\\\%0d%0a%20%20%20%20%20\\ge%20\(n/k\)k\\lg{k}%20\\\\%0d%0a%20%20%20%20%20=%20%20%20\\Omega\(n\\lg{k}\))
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C08-Sorting-in-Linear-Time/8.2.md
================================================
### Exercises 8.2-1
***
Using Figure 8.2 as a model, illustrate the operation of COUNTING-SORT on the array A = [6, 0, 2, 0, 1, 3, 4, 6, 1, 3, 2].
### `Answer`

### Exercises 8.2-2
***
Prove that COUNTING-SORT is stable.
### `Answer`
COUNTING-SORT最后是从后面往前面扫,并且把遇到的每一个item放在同大小(key)的最后面的位子.所以不改变相对顺序.
### Exercises 8.2-3
***
Suppose that the for loop header in line 9 of the COUNTING-SORT procedure is rewritten
as 9 for j ← 1 to length[A]
Show that the algorithm still works properly. Is the modified algorithm stable?
### `Answer`
可以正常工作,只是不stable.
### Exercises 8.2-4
***
Describe an algorithm that, given n integers in the range 0 to k, preprocesses its input and then answers any query about how many of the n integers fall into a range [a...b] in O(1) time. Your algorithm should use Θ(n + k) preprocessing time.
### `Answer`
利用数组C,[a,b]间的个数是C[b]-C[a-1].(C[-1] = 0)
[implementation](./exercise_code/integerQuery.cpp)
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C08-Sorting-in-Linear-Time/8.3.md
================================================
### Exercises 8.3-1
***
Using Figure 8.3 as a model, illustrate the operation of RADIX-SORT on the following list of English words: COW, DOG, SEA, RUG, ROW, MOB, BOX, TAB, BAR, EAR, TAR, DIG, BIG, TEA, NOW, FOX.
### `Answer`
1| 2 |3 | 4
:----:|:----:|:----:|:----:
COW | SE**A** | T**A**B | **B**AR
DOG | TE**A** | B**A**R | **B**IG
SEA | MO**B** | E**A**R | **B**OX
RUG | TA**B** | T**A**R | **C**OW
ROW | DO**G** | S**E**A | **D**IG
MOB | RU**G** | T**E**A | **D**OG
BOX | DI**G** | D**I**G | **E**AR
TAB | BI**G** | B**I**G | **F**OX
BAR | BA**R** | M**O**B | **M**OB
EAR | EA**R** | D**O**G | **N**OW
TAR | TA**R** | C**O**W | **R**OW
DIG | CO**W** | R**O**W | **R**OG
BIG | RO**W** | N**O**W | **S**EA
TEA | NO**W** | B**O**X | **T**AB
NOW | BO**X** | F**O**X | **T**AR
FOX | FO**X** | R**O**G | **T**EA
### Exercises 8.3-2
***
Which of the following sorting algorithms are stable: insertion sort, merge sort, heapsort, and quicksort? Give a simple scheme that makes any sorting algorithm stable. How much additional time and space does your scheme entail?
### `Answer`
* stable: insertion sort, merge sort
* not stable: heapsort, quicksort
给每个item都增加一个原始index属性,最后相同的元素根据index再排一次.需要O(n)的额外空间.
### Exercises 8.3-3
***
Use induction to prove that radix sort works. Where does your proof need the assumption that the intermediate sort is stable?
### `Answer`
循环不变式:每次**for**循环前,最后的**i-1**个数字是排好序的.
Initialization:循环还没开始,0个数字,是排好的.
Maintenance:排第i个数字时,如果数字不相同,那肯定是排号序的,如果相同,因为采用stable的COUNTTING-SORT算法,后面的i-1位是排好序的,所以能保持性质.
Termination:最后是排好序的.
### Exercises 8.3-4
***
Show how to sort n integers in the range 0 to n^2 - 1 in O(n) time.
Note: In 3rd Edition, the number range is 0 to n^3 - 1, the basic idea is same
### `Answer`
将这些数字看成n进制,使用radix-sort.
The running time is O(4n) = O(n)
The radix sort running time is O(d * (n + k)) , where d is the number of digit, n is the number of elements, and k is the number of possible values.
In this case, k equals n. So the total running time is O(2 * (n + n)) = O(4n) = O(n)
Naive Implementation with a lot of copy: [implementation](./exercise_code/radixSort.cpp)
### Exercises 8.3-5
***
In the first card-sorting algorithm in this section, exactly how many sorting passes are needed to sort d-digit decimal numbers in the worst case? How many piles of cards would an operator need to keep track of in the worst case?
### `Answer`
从最高位往后面排序不是一种好办法,需要递归去做. 需要k^d次. 要同时care nk堆数据.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C08-Sorting-in-Linear-Time/8.4.md
================================================
### Exercises 8.4-1
***
Using Figure 8.4 as a model, illustrate the operation of BUCKET-SORT on the array A =[.79, .13, .16, .64, .39, .20, .89, .53, .71, .42]
### `Answer`

### Exercises 8.4-2
***
What is the worst-case running time for the bucket-sort algorithm? What simple change to the algorithm preserves its linear expected running time and makes its worst-case running time O(n lg n)?
### `Answer`
当所有的item都落在一个bucket内,是最坏情况,相当于对所有数据做一次插入排序,是O(n^2)
可以用merge-sort,只是操作链表比较麻烦.
[insertion-sort-list](https://leetcode.com/problems/insertion-sort-list/)
[merge-sort-list](https://leetcode.com/problems/sort-list/)
答案可以在我的[github](https://github.com/gzc/leetcode)上找到
### Exercises 8.4-3
***
Let X be a random variable that is equal to the number of heads in two flips of a fair coin.
What is E [X^2]? What is E^2[X]?
### `Answer`
E[X^2]
= 1^2 * P(head in one flip) + 0^2 * P(tail in one flip)
= 1 * 1/2 + 0 * 1/2
= 1/2
E^2[X]
= E[X] * E[X]
= 1/2 * 1/2
= 1/4
### Exercises 8.4-4
***
We are given n point s in the unit circl e,pi =(xi,yi),such that

for i = 1, 2,...,n. Suppose that the points are uniformly distributed; that is, the probability of finding a point in any region of the circle is proportional to the area of that region. Design a Θ(n) expected-time
algorithm to sort the n points by their distances
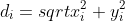
from the origin. (Hint: Design the bucket sizes in BUCKET-SORT to reflect the uniform distribution of the points in the unit circle.)
### `Answer`
初中数学题~
就是划分n个面积相同的圆环.
[More details](http://clrs.skanev.com/08/04/04.html)
### Exercises 8.4-5
***
A probability distribution function P(x) for a random variable X is defined by P(x) = Pr {X ≤ x}. Suppose that a list of n random variables X1, X2, . . .,Xn is drawn from a continuous probability distribution function P that is computable in O(1) time. Show how to sort these numbers in linear expected time.
### `Answer`
共有n个数字,bucket的划分点i1,i2...in为P(i1) = 1/n,p(i2) = 2/n, ..., P(i_n) = (n-1)/n. 因为找出这些划分点需要n*O(1) = O(n)的时间,桶排序也是O(n)的,所以最终是O(n)的.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C08-Sorting-in-Linear-Time/exercise_code/in_place_counting_sort.py
================================================
#!/usr/bin/env python
# coding=utf-8
def in_place_counting_sort(items, k):
C = [0] * k
for e in items:
C[e] += 1
for i in range(1,k):
C[i] += C[i-1]
i = len(items) - 1
while i >= 0:
print items,C
v = items[i]
pos = C[v] - 1
if i > pos:
i -= 1
elif v != items[pos]:
items[i],items[pos] = items[pos],items[i]
C[v] -= 1
else:
C[v] -= 1
items = [2, 5, 3, 0, 2, 3, 0, 3];
print items
print "sorting --------------"
in_place_counting_sort(items, 6)
print "sorting finishing -------------"
print items
================================================
FILE: C08-Sorting-in-Linear-Time/exercise_code/intergerQuery.cpp
================================================
#include <vector>
#include <cassert>
#include <stdexcept>
#include <algorithm>
using namespace std;
class IntegerQuery{
public:
IntegerQuery(vector<int> & data);
int countInRange(int a, int b);
private:
vector<int> countArray;
int k;
bool noData;
};
IntegerQuery::IntegerQuery(vector<int> & data){
noData = data.empty();
if(!noData){
k = *max_element(data.begin(), data.end());
countArray = vector<int> (k + 1);
for(auto & num: data){
++countArray[num];
}
for(int i = 1; i <= k; ++i){
countArray[i] += countArray[i - 1];
}
}
}
int IntegerQuery::countInRange(int a, int b){
if(a > b || b < 0 || a > k || noData){
return 0;
}
int sum = a <= 0 ? countArray[0] : 0;
sum += countArray[min(k, b)] - countArray[max(0, a - 1)];
return sum;
}
int main(){
vector<int> test{0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3};
IntegerQuery query(test);
assert(query.countInRange(-1, 4) == 12);
assert(query.countInRange(-2, -1) == 0);
assert(query.countInRange(-3, 0) == 3);
assert(query.countInRange(0,1) == 6);
}
================================================
FILE: C08-Sorting-in-Linear-Time/exercise_code/radixSort.cpp
================================================
#include <random>
#include <cmath>
#include <iostream>
#include <chrono>
#include <utility>
using namespace std;
/*
* The RandInt class is adapted from the code segments in
* The C++ Programming Language, 4th Edition, Bjarne S., P130
*
*/
class RandInt{
public:
// range [low, high]
RandInt(int low, int high): ge(chrono::system_clock::now().time_since_epoch().count()),dist(low, high) {}
int operator()() {return dist(ge);}
private:
minstd_rand ge;
uniform_int_distribution<int> dist;
};
class RadixSort{
public:
RadixSort(int n, int powValue);
~RadixSort(){}
void printData();
void sort();
private:
int size;
int digitNum;
vector<int> sortData;
vector<pair<int, int>> dataCopy;
void countingSortDigit();
};
RadixSort::RadixSort(int n, int powValue): size(n), digitNum(powValue), sortData(vector<int>(n)), dataCopy(vector<pair<int, int>>(n)){
RandInt rnd{0, (int)pow(n, powValue) - 1};
for(auto & num: sortData){
num = rnd();
}
}
void RadixSort::printData(){
for(auto & num: sortData){
cout << num << " ";
}
cout << endl;
}
void RadixSort::sort(){
for(int i = 0; i < size; ++i){
dataCopy[i] = make_pair(i, sortData[i]);
}
for(int i = 1; i <= digitNum; ++i){
countingSortDigit();
}
vector<int> auxData(sortData.begin(), sortData.end());
for(int i = 0; i < size; ++i){
sortData[i] = auxData[dataCopy[i].first];
}
}
void RadixSort::countingSortDigit(){
vector<pair<int, int>> digitData(size);
for(int i = 0; i < size; ++i){
digitData[i] = make_pair(i, dataCopy[i].second % size);
dataCopy[i].second /= size;
}
vector<int> countArray(size);
for(auto & digit: digitData){
++countArray[digit.second];
}
for(int i = 1; i < size; ++i){
countArray[i] += countArray[i-1];
}
vector<pair<int, int>> auxData(dataCopy.begin(), dataCopy.end());
for(int i = size - 1; i >= 0; --i){
int curIdx = --countArray[digitData[i].second];
dataCopy[curIdx] = auxData[digitData[i].first];
}
}
int main(){
RadixSort rst{25, 3};
rst.printData();
rst.sort();
rst.printData();
}
================================================
FILE: C08-Sorting-in-Linear-Time/exercise_code/water-jugs.py
================================================
#!/usr/bin/env python
# coding=utf-8
import random
def match(reds, blues):
if not reds:
return
r = random.randint(0,len(reds)-1)
v = reds[r]
smaller_red = [item for item in reds if item < v]
larger_red = [item for item in reds if item > v]
smaller_blue = [item for item in blues if item < v]
larger_blue = [item for item in blues if item > v]
print v,v
match(smaller_red,smaller_blue)
match(larger_red,larger_blue)
reds = [3,2,1,5,4]
blues = [2,3,5,1,4]
match(reds, blues)
================================================
FILE: C08-Sorting-in-Linear-Time/problem.md
================================================
### Problems 1 : Average-case lower bounds on comparison sorting
***
In this problem, we prove an Ω(n lg n) lower bound on the expected running time of any deterministic or randomized comparison sort on n distinct input elements. We begin by examining a deterministic comparison sort A with decision tree TA. We assume that every permutation of A's inputs is equally likely.
**a.** Suppose that each leaf of TA is labeled with the probability that it is reached given a random input. Prove that exactly n! leaves are labeled 1/n! and that the rest are labeled 0.
**b.** Let D(T) denote the external path length of a decision tree T ; that is, D(T) is the sum of the depths of all the leaves of T. Let T be a decision tree with k > 1 leaves, and let LT and RT be the left and right subtrees of T. Show that D(T) = D(LT) + D(RT) + k.
**c.** Let d(k) be the minimum value of D(T) over all decision trees T with k > 1 leaves. Show that
%20=%20\\min_{1%20\\le%20i%20\\le%20k-1}\\{d\(i\)%20+%20d\(k-i\)%20+%20k\\}%20)
(Hint: Consider a decision tree T with k leaves that achieves the minimum. Let i0 be the number of leaves in LT and k - i0 the number of leaves in RT.)
**d.** Prove that for a given value of k > 1 and i in the range 1 ≤ i ≤ k-1,the function ilgi+ (k - i)lg(k - i) is minimized at i = k/2. Conclude that d(k) = Θ(klgk).
The PARTITION procedure in Section 7.1 separates the pivot value (originally in A[r]) from the two partitions it forms. The HOARE-PARTITION procedure, on the other hand, always places the pivot value (originally in A[p]) into one of the two partitions A[p...j] and A[j + 1...r]. Since p ≤ j < r, this split is always nontrivial.
**e.** Prove that D(TA) = Θ(n! lg(n!)), and conclude that the expected time to sort n elements is Θ(n lg n).
Now, consider a randomized comparison sort B. We can extend the decision-tree model to handle randomization by incorporating two kinds of nodes: ordinary comparison nodes and "randomization" nodes. A randomization node models a random choice of the form RANDOM(1, r) made by algorithm B; the node has r children, each of which is equally likely to be chosen during an execution of the algorithm.
**f.** Show that for any randomized comparison sort B, there exists a deterministic comparison sort A that makes no more comparisons on the average than B does.
### `Answer`
**a.**
总共有n!个排列,也就是n!种可能,所以概率当然是1/n!.
**b.**
因为T比RT和LT高度少1,所以有多少叶子节点,就需要多加这么多个1.很好思考~
**c.**
由前一小题可知,有k个节点的树有关系式D(T)=D(LT)+D(RT)+k.
那么很自然可以知道,就是左子树的叶子节点从1到k-1这么多可能.
%20=%20D\(T\)%20=%20D\(LT\)%20+%20D\(RT\)%20+%20k%20=%20\\min_{1%20\\le%20i%20\\le%20k-1}\\{d\(i\)%20+%20d\(k-i\)%20+%20k\\}%20)
**d.**
比较简单的求导.
%20=%20i\\lg{i}%20+%20\(k-i\)\\lg\(k-i\)%20\\\\%20~%20\\hspace{6%20mm}%0d%0a%20%20%20%20%20f'\(i\)%20=%20\\lg{i}%20+%201%20-%20\\lg\(k-i\)%20-%201%20=%20\\lg\\frac{i}{k-i}%20\\\\%20~%20\\hspace{6%20mm}%0d%0a%20%20%20%20%20f'\(i\)%20=%200%20%20\\Leftrightarrow%20\\lg\\frac{i}{k-i}%20=%200%20\\Rightarrow%20i/\(k-i\)%20=%201%20\\Rightarrow%20i%20=%20\\frac{k}{2}%20)
**e.**
TA一共有n!个叶子节点,所以有D(T) > d(n!) = Ω(n!lg(n!))
我们已经求出了外路径长度,总共有n!个概率相同的节点,所以最终有
\)}{n!}%20=%20\\Omega\(\\lg\(n!\)\)%20=%20\\Omega\(n\\lg{n}\)%20)
**f.**
非随机化版本有n!种路径,囊括了所有可能. 而任何一种随机化都肯定在这n!里面,而且少了random的操作.
### Problems 2 : Sorting in place in linear time
***
Suppose that we have an array of n data records to sort and that the key of each record has the value 0 or 1. An algorithm for sorting such a set of records might possess some subset of the following three desirable characteristics:
1. The algorithm runs in O(n) time.
2. The algorithm is stable.
3. The algorithm sorts in place, using no more than a constant amount of storage space in addition to the original array.
**a.** Give an algorithm that satisfies criteria 1 and 2 above.
**b.** Give an algorithm that satisfies criteria 1 and 3 above.
**c.** Give an algorithm that satisfies criteria 2 and 3 above.
**d.**
Can any of your sorting algorithms from parts (a)-(c) be used to sort n records with b- bit keys using radix sort in O(bn) time? Explain how or why not.
**e.**
Suppose that the n records have keys in the range from 1 to k. Show how to modify counting sort so that the records can be sorted in place in O(n + k) time. You may use O(k) storage outside the input array. Is your algorithm stable? (Hint: How would you do it for k = 3?)
### `Answer`
**a.**
计数排序就可以.
**b.**
Using HOARE-PARTITION can do it.More details in [Exercise7.1](https://github.com/gzc/CLRS/blob/master/C07-Quicksort/7.1.md)
**c.**
merge-sort就可以
[stable in-place sort](http://www.codeproject.com/Articles/26048/Fastest-In-Place-Stable-Sort)
**d.**
1. The first one can be used.
2. The second is not stable.
3. The third takes `Theta(nlgn)`.
**e.**
[implementation](./exercise_code/in_place_counting_sort.py)
我的实现不是stable的
### Problems 3 : Sorting variable-length items
***
a. You are given an array of integers, where different integers may have different numbers of digits, but the total number of digits over all the integers in the array is n. Show how to sort the array in O(n) time.
b. You are given an array of strings, where different strings may have different numbers of characters, but the total number of characters over all the strings is n. Show how to sort the strings in O(n) time.
(Note that the desired order here is the standard alphabetical order; for example, a < ab < b.)
### `Answer`
**a.**
For the nubers, we can do this:
- Group the nunbers by number of digits and order groups.
- RADIX sort each group.
We let the `Gi` be the group of numbers with i digits and ci = |Gi|, thus: we can multiply the `n*Ci` with `i`, then sum from `i = 1` to `i = highest digit`. We can get the
=%20\\sum_{i%20=%201}nc_i%20\\cdot%20i%20=%20n%20)
**b.**
reverse所有的字符串,用RADIX-SORT.当当遍历到某一个字符串超过其大小时,用空格代替(空格 > 其他字母),并且将该数字放在该组正常有数字的前面,以后不要迭代.排序后reverse回来. 保证了O(n)的时间.
假设我们要排序字符串d,c,b,bcd,bc,bd,bdc.过程如下:
0 | 1 | 2 | 3 | 4 | result | reverse
:----: | :----: | :----: | :----: | :----: | :----: | :----:
d | **b** | b | | | b | b
c | dc**b** | d**c**b | cb | | cb | bc
b | c**b** | **c**b | **d**cb | dcb | dcb | bcd
dcb | d**b** | **d**b | db | | db | bd
cb | cd**b** | c**d**b | **c**db | cdb |cdb | bdc
db | **c** | c | | | c | c
cdb | **d** | d | | | d | d
### Problems 4 : Water jugs
***
Suppose that you are given n red and n blue water jugs, all of different shapes and sizes. All red jugs hold different amounts of water, as do the blue ones. Moreover, for every red jug, there is a blue jug that holds the same amount of water, and vice versa.
It is your task to find a grouping of the jugs into pairs of red and blue jugs that hold the same amount of water. To do so, you may perform the following operation: pick a pair of jugs in which one is red and one is blue, fill the red jug with water, and then pour the water into the blue jug. This operation will tell you whether the red or the blue jug can hold more water, or if they are of the same volume. Assume that such a comparison takes one time unit. Your goal is to find an algorithm that makes a minimum number of comparisons to determine the grouping. Remember that you may not directly compare two red jugs or two blue jugs.
a. Describe a deterministic algorithm that uses Θ(n2) comparisons to group the jugs into pairs.
b. Prove a lower bound of Θ(n lg n) for the number of comparisons an algorithm solving this problem must make.
c. Give a randomized algorithm whose expected number of comparisons is O(n lg n), and prove that this bound is correct. What is the worst-case number of comparisons for your algorithm?
### `Answer`
**a.**
二重循环,比较所有的.
**b.**
决策树的每个node都有3个sub-node(A < B | A = B | A > B).总共有n!个输出.所以有
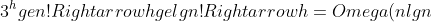)
**c.**
key idea : 跟快速排序是一样的
[implementation](./exercise_code/water-jugs.py)
### Problems 5 : Average sorting
***
Suppose that, instead of sorting an array, we just require that the elements increase on average. More precisely, we call an n-element array A k-sorted if, for all i = 1, 2, . . ., n - k, the following holds:
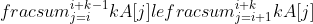
**a.** What does it mean for an array to be 1-sorted?
**b.** Give a permutation of the numbers 1, 2, . . ., 10 that is 2-sorted, but not sorted.
**c.** Provethatann-elementarrayisk-sortedifandonlyifA[i]≤A[i+k]foralli=1,2,..
., n - k.
**d.** Give an algorithm that k-sorts an n-element array in O(n lg(n/k)) time.
**e.** Show that a k-sorted array of length n can be sorted in O(n lg k) time. (Hint: Use the solution to Exercise 6.5-8.)
**f.** Show that when k is a constant, it requires Θ(n lg n) time to k-sort an n-element array. (Hint: Use the solution to the previous part along with the lower bound on comparison sorts.)
### `Answer`
**a.**
该数组完全排好序.
**b.**
[2,1,3,4,5,6,7,8,9,10]
**c.**
这个证明很简单,移项就能得到.
**d.**
把数组分为k组,用heapsort/mergesort.
T = k * O((n/k)log(n/k)) = O(nlg(n/k))
**e.**
确实跟[练习6.5.8](https://github.com/gzc/CLRS/blob/master/C06-Heapsort/6.5.md#exercises-65-8)是一样的
**f.**
我们有d的结果,因为k是常量,所以可以忽略.
### Problems 6 : Lower bound on merging sorted lists
***
The problem of merging two sorted lists arises frequently. It is used as a subroutine of MERGE-SORT, and the procedure to merge two sorted lists is given as MERGE in Section 2.3.1. In this problem, we will show that there is a lower bound of 2n - 1 on the worst-case number of comparisons required to merge two sorted lists, each containing n items.
First we will show a lower bound of 2n - o(n) comparisons by using a decision tree.
**a.** Show that, given 2n numbers, there are  possible ways to divide them into two sorted lists, each with n numbers.
**b.** Using a decision tree, show that any algorithm that correctly merges two sorted lists uses at least 2n - o(n) comparisons.
Now we will show a slightly tighter 2n - 1 bound.
**c.** Show that if two elements are consecutive in the sorted order and from opposite lists, then they must be compared.
**d.** Use your answer to the previous part to show a lower bound of 2n - 1 comparisons for merging two sorted lists.
### `Answer`
这个题目在[leetcode](https://leetcode.com/problems/merge-two-sorted-lists/)出现过
**a.**
很自然,从2n数字中可以选n种.
**b.**
^2}%20%20\\\\%20~%20\\hspace{8%20mm}%0d%0ah%20\\ge%20\\log{2n!}%20-2\\log{n!}%20\\\\%20~%20\\hspace{10%20mm}%0d%0a=%20\\Theta\(2n\\log{2n}\)%20-%202\\Theta\(n\\log{n}\)%20\\\\~%20\\hspace{10%20mm}%0d%0a=%20\\log{2}\\Theta\(2n\)%20\\\\~%20\\hspace{10%20mm}%0d%0a=%20\\Theta\(2n\))
树的高度是2n级别的,因此最少需要2n-o(n)次
**c.**
这不是废话嘛...只有来自同一列表的前后元素才不用比较.
**d.**
根据c,在已排号序的链表中,只有前后元素才有**可能**比较过,因此最多是2n-1次.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C09-Medians-and-Order-Statistics/9.1.md
================================================
### Exercises 9.1-1
***
Show that the second smallest of n elements can be found with 
comparisons in the worst case. (Hint: Also find the smallest element.)
### `Answer`
[code](./exercise_code/second-smallest.cpp) tells everything!
想法大致是这样的:首先由下往上建一颗二叉树,每个节点保存一对的最小值,这样总共需要n-1次比较.这棵树的顶点是最小值.第二小元素肯定在生成顶点的路径上,因为第二小元素只会被最小元素击败,所以两节点肯定交手过一次.因为树的高度不过超过
 所以需要 - 1 次比较.因此总共需要
First we build a BST from bottom to top,each node contains the smaller one of a pair, we need n-1 comparisions to build BST. The top of this BST is minimum, then the second smallest must be in the path to generate the top. Because the second smallest can only be defeated by the smallest one. Because the height of BST does not exceed
 so we need  - 1 comparisions.The total times is
### Exercises 9.1-2
***
Show that  comparisons are necessary in the worst case to find both the maximum and minimum of n numbers. (Hint: Consider how many numbers are potentially either the maximum or minimum, and investigate how a comparison affects these counts.)
### `Answer`
As mentioned before, if n is odd,then we need

If n is even,then we need 3n/2-2
 is the same format.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C09-Medians-and-Order-Statistics/9.2.md
================================================
### Exercises 9.2-1
***
Show that in RANDOMIZED-SELECT, no recursive call is ever made to a 0-length array.
### `Answer`
答案很明显,假如划分的一边数组是空的,那么这个if语句条件是不会成立的,这个调用是不会被call的.
It is obvious, if the array is empty, then the condition of if will not hold, it will definitely not be called.
### Exercises 9.2-2
***
Argue that the indicator random variable  and the value T(max(k - 1, n - k)) are independent.
### `Answer`
不论取0还是1, T(max(k-1,n-k))是不会变的.
No matter  is 0 or 1, T(max(k-1,n-k))will not change.
### Exercises 9.2-3
***
Write an iterative version of RANDOMIZED-SELECT.
### `Answer`
[code](./exercise_code/randomized-select-iterative.cpp) tells everything!
### Exercises 9.2-4
***
Suppose we use RANDOMIZED-SELECT to select the minimum element of the array A = {3, 2, 9, 0, 7, 5, 4, 8, 6, 1}. Describe a sequence of partitions that results in a worst-case performance of RANDOMIZED-SELECT.
### `Answer`
- pivot **9** {3, 2, 0, 7, 5, 4, 8, 6, 1}
- pivot **8** {3, 2, 0, 7, 5, 4, 6, 1}
- pivot **7** {3, 2, 0, 5, 4, 6, 1}
- pivot **6** {3, 2, 0, 5, 4, 1}
- pivot **5** {3, 2, 0, 4, 1}
- pivot **4** {3, 2, 0, 1}
- pivot **3** {2, 0, 1}
- pivot **2** {0, 1}
- pivot **1** {0}
- return 0
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C09-Medians-and-Order-Statistics/9.3.md
================================================
### Exercises 9.3-1
***
In the algorithm SELECT, the input elements are divided into groups of 5. Will the algorithm work in linear time if they are divided into groups of 7? Argue that SELECT does not run in linear time if groups of 3 are used.
### `Answer`
Assuming each group has k elements.
The number that less(or greater) then median of median is at least n/4-k,In the worst case, next call to SELECT will recursive call 3n/4+k elements.
so

Assuming for all n,T(n) <= cn

So according to 1/k+3/4 <= 1 wo get k >= 4
### Exercises 9.3-2
***
Analyze SELECT to show that if n ≥ 140, then at least ⌈n/4⌉ elements are greater than the median-of-medians x and at least ⌈n/4⌉ elements are less than x.
### `Answer`

### Exercises 9.3-3
***
Show how quicksort can be made to run in O() time in the worst case.
### `Answer`
比较直观,我们先利用线性时间去找到中位数,再用这个中位数去做partition.
It is obvious, we first use O(n) time to find median, then use median to do partition.
### Exercises 9.3-4
***
Suppose that an algorithm uses only comparisons to find the ith smallest element in a set of n elements. Show that it can also find the i - 1 smaller elements and the n - i larger elements without performing any additional comparisons.
### `Answer`
只用比较来确定的话,就跟这讲的方法是一样的. 我们既然找到了第i小元素,那么比i大和比i小的都已经被我们分类分好了.
We can find ith element, then the number greater than i and the number less than i have been already partitioned.
### Exercises 9.3-5
***
Suppose that you have a "black-box" worst-case linear-time median subroutine. Give a simple, linear-time algorithm that solves the selection problem for an arbitrary order statistic.
### `Answer`
[code](./exercise_code/black-box.py) tells everything. Thanks original code [here](http://clrs.skanev.com/09/03/05.html).
Find the median, and recursve half of the elements.
### Exercises 9.3-6
***
The *k*th **quantiles** of an n-element set are the *k* - 1 order statistics that divide the sorted set into *k* equal-sized sets (to within 1). Give an O(n lg k)-time algorithm to list the *k*th quantiles of a set.
### `Answer`
[code](./exercise_code/k-quantile.py) tells everything. Thanks original code [here](http://clrs.skanev.com/09/03/06.html).
- 如果k是偶数,那么取中间一个,再对左右两边进行递归.
- 如果k是奇数,取最接近中间的两个数,再对左右两边进行递归.
- If k is even, then choose the middle one, recursive call left part and right part.
- If k is odd,choose two index numbers most close to median,then recursive call the left part and right part.
### Exercises 9.3-7
***
Describe an O(n)-time algorithm that, given a set S of n distinct numbers and a positive
integer k ≤ n, determines the k numbers in S that are closest to the median of S.
### `Answer`
[code](./exercise_code/k-close2median.py)
1. 计算出中位数median
2. 将所有数减去median,再取绝对值
3. 用SELECT计算出第k小数字y
4. 遍历数组,取出所有绝对值小于等于y的
代码的局限性在于只能接收绝对值不含有相同元素的.
1. Find the median
2. For all the numbers, minus median then get the absolute value
3. use SELECT to find the kth smallest number y
4. Iterate the array choose all the absolute value that less than y
### Exercises 9.3-8
***
Let [1 .. n] and Y [1 .. n] be two arrays, each containing n numbers already in sorted order. Give an O(lg n)-time algorithm to find the median of all 2n elements in arrays X and Y.
### `Answer`
Divide and conquer
Here is a cpp code for this question.
First, we compare the mid value of each array
then we can cut down some part of this two arrays.
```cpp
// X[lo1, lo1 + n) Y[lo2, lo2 + n)
int median(int[] X, int[] Y, int lo1, int lo2, int n) {
if (n < 3) return quickMedian(X, Y, lo1, lo2, n);
int mid1 = lo1 + n / 2, mi2 = lo2 + (n - 1) / 2;
if (X[mi1] < Y[mi2])
return median(X, Y, mi1, lo2, n + lo1 - mi1); // use X's right part and Y's left part
else if (X[mi1] > Y[mi2])
return median(X, Y, lo1, mi2, n + lo2 - mi2); // use X's left part and Y's right part
else
return X[mi1];
```
### Exercises 9.3-9
***
Professor Olay is consulting for an oil company, which is planning a large pipeline running east to west through an oil field of n wells. From each well, a spur pipeline is to be connected directly to the main pipeline along a shortest path (either north or south), as shown in [Figure 9.2](#oil). Given x- and y-coordinates of the wells, how should the professor pick the optimal location of the main pipeline (the one that minimizes the total length of the spurs)? Show that the optimal location can be determined in linear time.

Figure 9.2: Professor Olay needs to determine the position of the east-west oil pipeline that minimizes the total length of the north-south spurs.
### `Answer`
Find the median of y.
***
Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
================================================
FILE: C09-Medians-and-Order-Statistics/exercise_code/k-close2median.py
================================================
#!/usr/bin/env python
# coding=utf-8
import math
def k_close2median(items, k):
med = median(items)
abs_items = []
result = []
for element in items:
abs_items.append(abs(element-med))
threshold = select(abs_items, k-1)
for i in range(len(items)):
if abs_items[i] <= threshold:
result.append(items[i])
return result
def select(items, n):
med = median(items)
smaller = [item for item in items if item < med]
larger = [item for item in items if item > med]
if len(smaller) == n:
return med
elif len(smaller) > n:
return select(smaller, n)
else:
return select(list(larger), n - len(smaller) - 1)
def median(items):
def median_index(n):
if n % 2:
return n // 2
else:
return n // 2 - 1
def partition(items, element):
i = 0
for j in range(len(items) - 1):
if items[j] == element:
items[j], items[-1] = items[-1], items[j]
if items[j] < element:
items[i], items[j] = items[j], items[i]
i += 1
items[i], items[-1] = items[-1], items[i]
return i
def select(items, n):
if len(items) <= 1:
return items[0]
medians = []
for i in range(0, len(items), 5):
group = sorted(items[i:i + 5])
items[i:i + 5] = group
median = group[median_index(len(group))]
medians.append(median)
pivot = select(medians, median_index(len(medians)))
index = partition(items, pivot)
if n == index:
return items[index]
elif n < index:
return select(items[:index], n)
else:
return select(items[index + 1:], n - index - 1)
return select(items[:], median_index(len(items)))
array = [1,2,3,4,10,20,30]
print k_close2median(array, 2)
================================================
FILE: C09-Medians-and-Order-Statistics/exercise_code/k-quantile.py
================================================
#!/usr/bin/env python
# coding=utf-8
import math
def k_quantiles(items, k):
index = median_index(len(items))
if k == 1:
return []
elif k % 2:
n = len(items)
left_index = math.ceil((k // 2) * (n / k)) - 1
right_index = n - left_index - 1
left = select(items, left_index)
right = select(items, right_index)
partition(items, left)
lower = k_quantiles(items[:left], k // 2)
partition(items, right)
upper = k_quantiles(items[right + 1:], k // 2)
return lower + [left, right] + upper
else:
index = median_index(len(items))
median = select(items, index)
partition(items, median)
return k_quantiles(items[:index], k // 2) + [median] + k_quantiles(items[index + 1:], k // 2)
def median_index(n):
if n % 2:
return n // 2
else:
return n // 2 - 1
def partition(items, element):
i = 0
for j in range(len(items) - 1):
if items[j] == element:
items[j], items[-1] = items[-1], items[j]
if items[j] < element:
items[i], items[j] = items[j], items[i]
i += 1
items[i], items[-1] = items[-1], items[i]
return i
def select(items, n):
if len(items) <= 1:
return items[0]
medians = []
for i in range(0, len(items), 5):
group = sorted(items[i:i + 5])
items[i:i + 5] = group
median = group[median_index(len(group))]
medians.append(median)
pivot = select(medians, median_index(len(medians)))
index = partition(items, pivot)
if n == index:
return items[index]
elif n < index:
return select(items[:index], n)
else:
return select(items[index + 1:], n - index - 1)
arr = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18]
print k_quantiles(arr, 4)
================================================
FILE: C09-Medians-and-Order-Statistics/exercise_code/randomized-select-iterative.cpp
================================================
/*************************************************************************
> File Name: randomized-select-iterative.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Sun May 24 11:46:39 2015
************************************************************************/
#include<iostream>
#include <cassert>
using namespace std;
class Solution {
int partition(int arr[], int l, int r) {
int x = arr[r], i = l;
for(int j = l; j <= r - 1; j++) {
if (arr[j] <= x) {
swap(arr[i], arr[j]);
i++;
}
}
swap(arr[i], arr[r]);
return i;
}
int randomPartition(int arr[], int l, int r) {
int n = r-l+1;
int pivot = rand() % n;
swap(arr[l + pivot], arr[r]);
return partition(arr, l, r);
}
public:
int kthSmallest(int arr[], int l, int r, int k) {
int originalK = k;
while (k > 0 && k <= r - l + 1) {
int pos = randomPartition(arr, l, r);
if (pos-l == k-1) {
return arr[pos];
} else if(pos-l > k-1) {
r = pos-1;
} else {
l = pos+1;
k = originalK-l;
}
}
return INT_MAX;
}
};
int main() {
int arr[7] = {10, 100, 2, 4, 1, -2, 8};
Solution s;
assert(s.kthSmallest(arr, 0, 6, 1) == -2);
assert(s.kthSmallest(arr, 0, 6, 2) == 1);
assert(s.kthSmallest(arr, 0, 6, 3) == 2);
assert(s.kthSmallest(arr, 0, 6, 4) == 4);
assert(s.kthSmallest(arr, 0, 6, 5) == 8);
assert(s.kthSmallest(arr, 0, 6, 6) == 10);
assert(s.kthSmallest(arr, 0, 6, 7) == 100);
}
================================================
FILE: C09-Medians-and-Order-Statistics/exercise_code/second-smallest.cpp
================================================
/*************************************************************************
> File Name: second-smallest.cpp
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Sun May 24 09:32:14 2015
************************************************************************/
#include<iostream>
#include<queue>
using namespace std;
struct Node
{
int v;
Node *left;
Node *right;
bool dir; // 0 mean left, 1 mean right
Node() : v(-1),left(nullptr),right(nullptr){}
Node(int _v, bool d) : v(_v),left(nullptr),right(nullptr),dir(d){}
};
int second_smallest_element(int arr[], int n)
{
queue<Node*> q;
for(int i = 0;i < n;i++)
{
Node *new_node = new Node(arr[i], 0);
q.push(new_node);
}
Node *root(nullptr);
while(!q.empty())
{
int size = q.size();
if(size == 1)
{
root = q.front();
break;
}
for(int i = 0;i < size;i += 2)
{
if(i == size - 1)
{
Node *n1 = q.front(); q.pop();
q.push(n1);
break;
} else {
Node *n1 = q.front(); q.pop();
Node *n2 = q.front(); q.pop();
int smaller = 0;
bool dir;
if(n1 -> v <= n2 -> v)
{
smaller = n1->v;
dir = false;
} else {
smaller = n2->v;
dir = true;
}
Node *new_node = new Node(smaller,dir);
new_node->left = n1;
new_node->right = n2;
q.push(new_node);
}
}
}
int minium = root->v;
int result(INT_MAX);
while(root)
{
if(root->left && root->right)
{
result = min( (root->left->v ^ root->right->v ^ minium), result);
root = root->dir == true ? root->right : root->left;
} else break;
}
return result;
}
int main() {
int arr[8] = {3,4,1,0,7,-2,-10,100};
int result = second_smallest_element(arr, 8);
cout << result << endl;
return 0;
}
================================================
FILE: C09-Medians-and-Order-Statistics/minmax.c
================================================
/*************************************************************************
> File Name: minmax.c
> Author: Louis1992
> Mail: zhenchaogan@gmail.com
> Blog: http://gzc.github.io
> Created Time: Sat May 23 23:04:35 2015
************************************************************************/
#include<stdio.h>
#define maxf(a,b) ((a) >= (b) ? (a) : (b))
#define minf(a,b) ((a) <= (b) ? (a) : (b))
void minmax(int *arr, int n, int *maximum, int *minium)
{
int i = 0;
if(n % 2 == 1)
{
*maximum = arr[0];
*minium = arr[0];
i = 1;
} else {
if(arr[1] >= arr[0])
{
*maximum = arr[1];
*minium = arr[0];
} else {
*maximum = arr[0];
*minium = arr[1];
}
i = 2;
}
for(;i < n;i += 2)
{
if(arr[i] >= arr[i+1])
{
*maximum = maxf(*maximum, arr[i]);
*minium = minf(*minium, arr[i+1]);
} else {
*maximum = maxf(*maximum, arr[i+1]);
*minium = minf(*minium, arr[i]);
}
}
}
int main()
{
int arr[5] = {3,5,-1,0,2};
int maximum = 0,minium = 0;
minmax(arr, 5, &maximum, &minium);
printf("max=%d min=%d/n", maximum, minium);
}
================================================
FILE: C09-Medians-and-Order-Statistics/problem.md
================================================
### Problems 1 : Largest i numbers in sorted order
***
Given a set of *n* numbers, we wish to find the *i* largest in sorted order using a comparison- based algorithm. Find the algorithm that implements each of the following methods with the best asymptotic worst-case running time, and analyze the running times of the algorithms in terms of *n* and *i*.
a. Sort the numbers, and list the *i* largest.
b. Build a max-priority queue from the numbers, and call EXTRACT-MAX *i* times.
c. Use an order-statistic algorithm to find the *i*th largest number, partition around that number, and sort the *i* largest numbers.
### `Answer`
a和b的代码在这里.[code](./problems/i-largest.py).
如果先排序的话,就需要O(nlgn)+O(i)的时间.
用堆的话,需要O(n)+O(ilogn)的时间.
对于c,[code](./problems/i-largest.cpp)
利用顺序统计量的话,找到这个值需要O(n)的时间,然后需要对i个数排序需要O(ilogi)时间.
### Problems 2 : Weighted median
***
For n distinct elements  with positive weights  such that
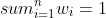
,**the weighted (lower)** median is the element  satisfying

and

a. Argue that the median of x1, x2, ..., xn is the weighted median of the xi with weights wi = 1/n for i = 1,2, ..., n.
b. Show how to compute the weighted median of n elements in O(n lg n) worst-case time using sorting.
c. Show how to compute the weighted median in Θ(n) worst-case time using a linear- time median algorithm such as SELECT from Section 9.3.
The **post-office location problem** is defined as follows. We are given *n* points p1, p2, ..., pn with associated weights w1, w2, ..., wn. We wish to find a point p (not necessarily one of the input points) that minimizes the sum

FILE: C02-Getting-Started/exercise_code/Insertion_sort_with_binary_search.py
function insertion_sort (line 9) | def insertion_sort(array):
function insertion_sort_v2 (line 18) | def insertion_sort_v2(array):
function binary_search (line 27) | def binary_search(array, searchingelement, arraypart):
FILE: C02-Getting-Started/exercise_code/binary-search.py
function binary_search (line 10) | def binary_search(array, searchingelement):
FILE: C02-Getting-Started/exercise_code/inversions.cpp
function MergeWithCountInversions (line 8) | void MergeWithCountInversions(vector<int>& v, int p, int q, int r, int& ...
function MergeSort (line 29) | void MergeSort(vector<int>& v, int p, int r, int& cnt) {
function main (line 37) | int main(int argc, const char * argv[]) {
FILE: C02-Getting-Started/exercise_code/inversions.py
function merge (line 4) | def merge(items, p, q, r):
function mergesort (line 25) | def mergesort(items, p, r):
FILE: C02-Getting-Started/exercise_code/merge-sort.py
function merge (line 5) | def merge(items, p, q, r):
function mergesort (line 23) | def mergesort(items, p, r):
FILE: C04-Recurrences/exercise_code/findIndex.py
function mergeindex (line 5) | def mergeindex(items, evens):
function findindex (line 32) | def findindex(items):
FILE: C04-Recurrences/exercise_code/findMissing.py
function findmissing (line 4) | def findmissing(items, i) :
FILE: C05-Probabilistic-Analysis-and-Randomized-Algorithms/myrandom.py
function _m_random (line 10) | def _m_random(b):
function m_random (line 19) | def m_random(a, b):
function main (line 22) | def main():
FILE: C06-Heapsort/d-ary-heaps.cpp
function max_heapify (line 22) | void max_heapify(heap_t *heap, int i) {
function extract_max (line 38) | int extract_max(heap_t *heap) {
function increase_key (line 46) | void increase_key(heap_t *heap, int i, int key) {
function insert (line 60) | void insert(heap_t *heap, int key) {
FILE: C06-Heapsort/heap.cpp
function parent (line 14) | int parent(int i)
function left (line 22) | int left(int i)
function right (line 30) | int right(int i)
function maxHeapify (line 38) | void maxHeapify(int A[], int n, int i)
function buildMaxHeap (line 59) | void buildMaxHeap(int A[], int n)
function heapsort (line 69) | void heapsort(int A[], int n)
function print (line 79) | void print(int A[], int n)
function main (line 87) | int main()
FILE: C06-Heapsort/main.cpp
function main (line 21) | int main()
FILE: C06-Heapsort/p_queue.h
function class (line 14) | class p_queue
FILE: C06-Heapsort/young.cpp
function EXTRACT_MIN (line 13) | int EXTRACT_MIN(vector<vector<int> > &young)
function INSERT (line 43) | void INSERT(vector<vector<int> > &young, int v)
function EXIST (line 69) | bool EXIST(vector<vector<int> > &young, int v)
function print_young (line 88) | void print_young(vector<vector<int> > &young)
function main (line 101) | int main() {
FILE: C07-Quicksort/exercise_code/fuzzy_sort.py
function intersects (line 6) | def intersects(a, b):
function before (line 9) | def before(a, b):
function partition (line 12) | def partition(items, p, r):
function fuzzy_sort (line 44) | def fuzzy_sort(items, p, r):
FILE: C07-Quicksort/exercise_code/hoare.py
function quicksort (line 4) | def quicksort(items, p, r):
function partition (line 10) | def partition(items, p, r):
FILE: C07-Quicksort/exercise_code/quickSortWithEqualElements.cpp
class QuickSort (line 10) | class QuickSort{
method QuickSort (line 12) | QuickSort(){}
function main (line 177) | int main(){
FILE: C07-Quicksort/exercise_code/quicksort.py
function quicksort (line 4) | def quicksort(items, p, r):
function partition (line 10) | def partition(items, p, r):
FILE: C07-Quicksort/exercise_code/tailrecursive.py
function tail_quicksort (line 4) | def tail_quicksort(items, p, r):
function partition (line 14) | def partition(items, p, r):
FILE: C07-Quicksort/quicksort.py
function quicksort (line 4) | def quicksort(items, p, r):
function partition (line 10) | def partition(items, p, r):
FILE: C07-Quicksort/randomized-quicksort.py
function randomized_quicksort (line 6) | def randomized_quicksort(items, p, r):
function randomized_partition (line 12) | def randomized_partition(items, p, r):
function partition (line 17) | def partition(items, p, r):
FILE: C08-Sorting-in-Linear-Time/exercise_code/in_place_counting_sort.py
function in_place_counting_sort (line 4) | def in_place_counting_sort(items, k):
FILE: C08-Sorting-in-Linear-Time/exercise_code/intergerQuery.cpp
class IntegerQuery (line 8) | class IntegerQuery{
function main (line 43) | int main(){
FILE: C08-Sorting-in-Linear-Time/exercise_code/radixSort.cpp
class RandInt (line 13) | class RandInt{
method RandInt (line 16) | RandInt(int low, int high): ge(chrono::system_clock::now().time_since_...
class RadixSort (line 24) | class RadixSort{
function main (line 91) | int main(){
FILE: C08-Sorting-in-Linear-Time/exercise_code/water-jugs.py
function match (line 5) | def match(reds, blues):
FILE: C09-Medians-and-Order-Statistics/exercise_code/k-close2median.py
function k_close2median (line 5) | def k_close2median(items, k):
function select (line 21) | def select(items, n):
function median (line 33) | def median(items):
FILE: C09-Medians-and-Order-Statistics/exercise_code/k-quantile.py
function k_quantiles (line 6) | def k_quantiles(items, k):
function median_index (line 32) | def median_index(n):
function partition (line 38) | def partition(items, element):
function select (line 53) | def select(items, n):
FILE: C09-Medians-and-Order-Statistics/exercise_code/randomized-select-iterative.cpp
class Solution (line 12) | class Solution {
method partition (line 14) | int partition(int arr[], int l, int r) {
method randomPartition (line 26) | int randomPartition(int arr[], int l, int r) {
method kthSmallest (line 35) | int kthSmallest(int arr[], int l, int r, int k) {
function main (line 53) | int main() {
FILE: C09-Medians-and-Order-Statistics/exercise_code/second-smallest.cpp
type Node (line 12) | struct Node
method Node (line 18) | Node() : v(-1),left(nullptr),right(nullptr){}
method Node (line 19) | Node(int _v, bool d) : v(_v),left(nullptr),right(nullptr),dir(d){}
function second_smallest_element (line 23) | int second_smallest_element(int arr[], int n)
function main (line 84) | int main() {
FILE: C09-Medians-and-Order-Statistics/minmax.c
function minmax (line 13) | void minmax(int *arr, int n, int *maximum, int *minium)
function main (line 46) | int main()
FILE: C09-Medians-and-Order-Statistics/problems/i-largest.cpp
function findMedian (line 20) | int findMedian(int arr[], int n)
function kthSmallest (line 28) | int kthSmallest(int arr[], int l, int r, int k)
function swap (line 64) | void swap(int *a, int *b)
function partition (line 73) | int partition(int arr[], int l, int r, int x)
function main (line 95) | int main()
FILE: C09-Medians-and-Order-Statistics/problems/i-largest.py
function sort1 (line 6) | def sort1(items, i):
function sort2 (line 10) | def sort2(items, i):
FILE: C09-Medians-and-Order-Statistics/problems/weighted_median.py
function select (line 5) | def select(items, n):
function median (line 17) | def median(items):
function weighted_median (line 63) | def weighted_median(items, w_items, start, end):
FILE: C09-Medians-and-Order-Statistics/randomized-select.cpp
function partition (line 5) | int partition(vector<int>& arr, int l, int r) {
function randomPartition (line 17) | int randomPartition(vector<int>& arr, int l, int r) {
function kthSmallest (line 24) | int kthSmallest(vector<int>& arr, int l, int r, int k) {
function kthSmallest (line 35) | int kthSmallest(vector<int>& arr, int k) {
function main (line 40) | int main() {
FILE: C09-Medians-and-Order-Statistics/worst-case-linear-time.cpp
function findMedian (line 20) | int findMedian(int arr[], int n)
function kthSmallest (line 28) | int kthSmallest(int arr[], int l, int r, int k)
function swap (line 64) | void swap(int *a, int *b)
function partition (line 73) | int partition(int arr[], int l, int r, int x)
function main (line 95) | int main()
FILE: C10-Elementary-Data-Structures/exercise_code/af-obj.c
type list_t (line 6) | typedef int list_t;
type obj_t (line 7) | typedef int obj_t;
function init_storage (line 17) | void init_storage() {
function list_t (line 26) | list_t allocate_object() {
function free_object (line 37) | void free_object(list_t list) {
function list_t (line 42) | list_t cons(obj_t key, list_t list) {
function delete (line 56) | void delete(list_t list) {
function obj_t (line 68) | obj_t get(list) {
function list_t (line 73) | list_t next(list) {
function main (line 78) | int main()
FILE: C10-Elementary-Data-Structures/exercise_code/deque.cpp
class Deque (line 8) | class Deque {
method Deque (line 19) | Deque(int size) : size_(0), head_(0), tail_(size-1), capacity_(size), ...
method push_front (line 21) | void push_front(T v) {
method push_back (line 27) | void push_back(T v) {
method pop_front (line 33) | void pop_front() {
method pop_back (line 39) | void pop_back() {
method T (line 45) | T front() const {
method T (line 50) | T back() const {
method size (line 55) | int size() const { return size_; }
method empty (line 57) | int empty() const { return size_ == 0; }
function main (line 63) | int main() {
FILE: C10-Elementary-Data-Structures/exercise_code/deque.py
class Deque (line 4) | class Deque:
method __init__ (line 6) | def __init__(self, size):
method addFirst (line 13) | def addFirst(self, item):
method addLast (line 18) | def addLast(self, item):
method removeFirst (line 23) | def removeFirst(self):
method removeLast (line 29) | def removeLast(self):
method seeAll (line 35) | def seeAll(self):
FILE: C10-Elementary-Data-Structures/exercise_code/dict.cpp
type node_t (line 12) | struct node_t {
type node_t (line 14) | struct node_t
type list_t (line 17) | struct list_t{
type node_t (line 18) | struct node_t
function init_list (line 21) | void init_list(list_t *list) {
function destroy_list (line 26) | void destroy_list(list_t *list) {
function insert (line 37) | void insert(list_t *list, int key) {
function node_t (line 44) | node_t *search(list_t *list, int key) {
type node_t (line 14) | struct node_t
function del (line 59) | void del(list_t *list, int key) {
function main (line 73) | int main()
FILE: C10-Elementary-Data-Structures/exercise_code/traversal.cpp
type tree_t (line 11) | struct tree_t {
type tree_t (line 12) | struct tree_t
type tree_t (line 13) | struct tree_t
type tree_t (line 14) | struct tree_t
method tree_t (line 16) | tree_t() {left = 0; right = 0; parent = 0;}
function print_tree (line 19) | void print_tree(tree_t *tree) {
function main (line 41) | int main() {
FILE: C12-Binary-Search-Trees/BSTree.h
type BSTNode (line 28) | typedef BSTNode* bp;
function insert (line 36) | void insert(const type& a_data) {insertAux(m_root,a_data);}
function inorder (line 38) | void inorder(ostream& out) const {inorderAux(out, m_root);}
function graph (line 39) | void graph(ostream& out) const {graphAux(out, 0, m_root);}
FILE: C12-Binary-Search-Trees/main.cpp
function main (line 15) | int main()
FILE: C13-Red-Black-Trees/rbtree.c
type key_t (line 13) | typedef int key_t;
type data_t (line 14) | typedef int data_t;
type color_t (line 16) | typedef enum color_t {
type rb_node_t (line 20) | typedef struct rb_node_t {
function main (line 37) | int main()
function rb_node_t (line 87) | rb_node_t* rb_new_node(key_t key, data_t data) {
function rb_node_t (line 111) | rb_node_t* rb_rotate_left(rb_node_t* node, rb_node_t* root)
function rb_node_t (line 150) | rb_node_t* rb_rotate_right(rb_node_t* node, rb_node_t* root)
function rb_node_t (line 186) | rb_node_t* rb_search_auxiliary(key_t key, rb_node_t* root, rb_node_t** s...
function rb_node_t (line 218) | rb_node_t* rb_search(key_t key, rb_node_t* root)
function rb_node_t (line 227) | rb_node_t* rb_insert(key_t key, data_t data, rb_node_t* root)
function rb_node_t (line 269) | rb_node_t* rb_insert_rebalance(rb_node_t *node, rb_node_t *root)
function rb_node_t (line 344) | rb_node_t* rb_erase(key_t key, rb_node_t *root)
function rb_node_t (line 471) | rb_node_t* rb_erase_rebalance(rb_node_t *node, rb_node_t *parent, rb_nod...
FILE: C13-Red-Black-Trees/rbtree.cpp
class RedBlackTreeNode (line 17) | class RedBlackTreeNode
method RedBlackTreeNode (line 20) | RedBlackTreeNode():key(T()),parent(NULL),left(NULL),right(NULL),color(...
class RedBlackTree (line 29) | class RedBlackTree
function T (line 227) | T RedBlackTree<T>::get_key(RedBlackTreeNode<T>* pnode) const
function main (line 514) | int main()
FILE: C14-Augmenting-Data-Structures/exercise_code/m-Josephus.cpp
type node (line 11) | struct node
method node (line 15) | node(int i){no = i;}
function main (line 18) | int main()
FILE: C15-Dynamic-Programming/Assembly-line-sche.c
function Fastway (line 4) | int Fastway(int *a1,int *a2,int *t1,int *t2,int *e,int *x,int n,int *l1,...
function PRINT_STATIONS (line 48) | void PRINT_STATIONS(int *l1,int *l2,int way,int n)
function reverse_PRINT_STATIONS (line 64) | void reverse_PRINT_STATIONS(int *l1,int *l2,int way,int n)
function main (line 76) | int main()
FILE: C15-Dynamic-Programming/Matrix-chain-multiplication.c
function MATRIX_CHAIN_ORDER (line 9) | void MATRIX_CHAIN_ORDER(int *p,int n,int **m,int **s)
function PRINT_OPTIMAL_PARRNS (line 43) | void PRINT_OPTIMAL_PARRNS(int **s,int i,int j,int row)
function main (line 55) | int main()
FILE: C15-Dynamic-Programming/lincrs.cpp
function find (line 4) | int find(int *a, int len, int n)
function main (line 17) | int main()
FILE: C15-Dynamic-Programming/optimalBST.cpp
function optimalBST (line 16) | void optimalBST(double *p,double *q,int n)
function printRoot (line 48) | void printRoot()
function printOptimalBST (line 64) | void printOptimalBST(int i,int j,int r)
function main (line 98) | int main()
FILE: C15-Dynamic-Programming/rodcutting.cpp
function CutRod (line 11) | int CutRod(const std::vector<int> &p, const int &n)
function MemoizedCutRodAux (line 29) | int MemoizedCutRodAux(const std::vector<int> &p, const int &n, std::vect...
function MemoizedCutRod (line 53) | int MemoizedCutRod(const std::vector<int> &p, const int &n)
function BottomUpCutRod (line 60) | int BottomUpCutRod(const std::vector<int> &p, const int &n)
function main (line 75) | int main()
FILE: C16-Greedy-Algorithms/huffman/BinaryStdIn.h
function class (line 17) | class BinaryStdIn
FILE: C16-Greedy-Algorithms/huffman/BinaryStdOut.h
function class (line 17) | class BinaryStdOut
FILE: C16-Greedy-Algorithms/huffman/HUFFMAN.cpp
function Htree (line 123) | Htree * HUFFMAN::readTrie() {
function string (line 132) | string HUFFMAN::decode(string filename) {
FILE: C16-Greedy-Algorithms/huffman/HUFFMAN.h
function Htree (line 22) | struct Htree {
function isLeaf (line 33) | static inline bool isLeaf(Htree *node) {
function class (line 38) | class myComparision
function class (line 46) | class HUFFMAN {
FILE: C16-Greedy-Algorithms/huffman/binary_test/main.cpp
function main (line 13) | int main()
FILE: C16-Greedy-Algorithms/huffman/binarystdin_test/main.cpp
function main (line 12) | int main()
FILE: C16-Greedy-Algorithms/huffman/binarystdout_test/main.cpp
function main (line 12) | int main()
FILE: C16-Greedy-Algorithms/huffman/huffman_test/huffman_test_client.cpp
function main (line 12) | int main()
FILE: C18-B-Trees/btree.cpp
class Btree (line 21) | class Btree
type Node (line 26) | struct Node
method Node (line 33) | Node(bool b=true, int _n=0) : isLeaf(b), n(_n){}
method Btree (line 42) | Btree()
method viewStatistics (line 48) | void viewStatistics()
method B_tree_insert (line 55) | void B_tree_insert(T k)
method PrintTree (line 75) | void PrintTree(int kind = 1) const //打印树的关键字
method T (line 109) | T get_minimum() const
method T (line 114) | T get_maximum() const
method search (line 119) | bool search(T k)
method remove (line 136) | bool remove(const T &key) //从B中删除结点key
method clear (line 152) | void clear() //清空B树
method deleteNode (line 159) | void deleteNode(Node *pNode)
method Node (line 170) | Node *allocate_node()
method Node (line 33) | Node(bool b=true, int _n=0) : isLeaf(b), n(_n){}
method disk_write (line 182) | void disk_write(Node *x) const
method disk_read (line 189) | void disk_read(Node *x) const
method B_tree_create (line 196) | void B_tree_create()
method B_tree_split_child (line 202) | void B_tree_split_child(Node *x, int i, Node *y)
method B_tree_insert_nonfull (line 229) | void B_tree_insert_nonfull(Node *x, T k)
method T (line 260) | T B_TREE_FIND_MIN(Node *x) const
method T (line 280) | T B_TREE_FIND_MAX(Node *x) const
method T (line 296) | T B_tree_find_predecessor(Node *x, int i)
method buildPath (line 334) | void buildPath(Node *x, T k, stack<Node*>& mystack)
method Node (line 348) | Node* B_tree_search(Node *x, T k, int *index)
method Node (line 33) | Node(bool b=true, int _n=0) : isLeaf(b), n(_n){}
method recursive_clear (line 367) | void recursive_clear(Node *pNode)
method recursive_remove (line 381) | void recursive_remove(Node *pNode, const T &key)
method mergeChild (line 486) | void mergeChild(Node *pParent, int index)
method T (line 516) | T getPredecessor(Node *pNode)//找到前驱关键字
method T (line 525) | T getSuccessor(Node *pNode)//找到后继关键字
function main (line 537) | int main() {
FILE: C18-B-Trees/btree.py
function main (line 7) | def main():
class BTree (line 181) | class BTree:
method __init__ (line 182) | def __init__(self, t = 2, allocate = None, free = None, read = None, w...
method find (line 203) | def find(self, key):
method create (line 230) | def create(self):
method load (line 240) | def load(self, root):
method insert (line 261) | def insert(self, key, value):
method remove (line 298) | def remove(self, key):
method __find (line 331) | def __find(self, node, key):
method __split_root (line 339) | def __split_root(self):
method __insert_in_nonfull (line 348) | def __insert_in_nonfull(self, node, key, value):
method __split_child (line 369) | def __split_child(self, node, child):
method __remove (line 380) | def __remove(self, node, key):
method __remove_predecessor (line 425) | def __remove_predecessor(self, node):
method __remove_successor (line 442) | def __remove_successor(self, node):
method __extend_child (line 459) | def __extend_child(self, node, child, left = None, right = None):
method __write_page (line 511) | def __write_page(self, node):
method __read_page (line 517) | def __read_page(self, node, root = False):
method __free_page (line 526) | def __free_page(self, node):
method __flush_page (line 530) | def __flush_page(self, node):
class Node (line 536) | class Node:
method __init__ (line 537) | def __init__(self, t, page, leaf = True):
method leaf (line 549) | def leaf(self):
method empty (line 552) | def empty(self):
method full (line 555) | def full(self):
method hasminimum (line 558) | def hasminimum(self):
method page (line 561) | def page(self):
method entries (line 564) | def entries(self):
method children (line 567) | def children(self):
method major (line 570) | def major(self):
method minor (line 574) | def minor(self):
method leftest (line 578) | def leftest(self):
method second_leftest (line 587) | def second_leftest(self):
method rightest (line 597) | def rightest(self):
method second_rightest (line 606) | def second_rightest(self):
method find (line 616) | def find(self, key):
method siblings (line 630) | def siblings(self, key):
method insert (line 641) | def insert(self, key, value, right = None):
method remove_leftest (line 658) | def remove_leftest(self):
method remove_rightest (line 672) | def remove_rightest(self):
method remove (line 686) | def remove(self, key, remove_right = True):
method replace (line 700) | def replace(self, key, newkey, newvalue):
method split (line 710) | def split(self, parent, newnode):
method join (line 725) | def join(self, newkey, newvalue, right = None):
method read (line 735) | def read(self, leaf, root, keyvalues, children):
method free (line 756) | def free(self):
method __position (line 762) | def __position(self, key):
class BTreeNotInitializedError (line 766) | class BTreeNotInitializedError(Exception):
method __init__ (line 767) | def __init__(self):
class BTreeInvalidNodeError (line 771) | class BTreeInvalidNodeError(Exception):
method __init__ (line 772) | def __init__(self, warning, page):
method page (line 776) | def page(self):
FILE: C19-Binomial-Heaps/BinomialHeap.h
function mRoot (line 90) | mRoot(NULL)
FILE: C19-Binomial-Heaps/Main.cpp
function testInsert (line 23) | void testInsert()
function testUnion (line 41) | void testUnion()
function testDelete (line 78) | void testDelete()
function testDecrease (line 102) | void testDecrease()
function testIncrease (line 126) | void testIncrease()
function main (line 149) | int main()
FILE: C21-Data-Structures-for-Disjoint-Sets/uf.cpp
class UF (line 6) | class UF {
method validate (line 14) | bool validate(int p) {
method UF (line 20) | UF(int N) : parent(N), rank(N, 0), N(N), count(N) {
method find (line 26) | int find(int p) {
method getCount (line 35) | int getCount() const {
method connected (line 39) | bool connected(int p, int q) {
method Union (line 43) | void Union(int p, int q) {
function main (line 61) | int main() {
FILE: C22-Elementary-Graph-Algorithms/elementary_graph_algo.py
class Graph (line 6) | class Graph:
method __init__ (line 7) | def __init__(self, adj_list):
method bfs (line 16) | def bfs(self, start):
method bfs_path (line 27) | def bfs_path(self, start, end):
method connected_component (line 42) | def connected_component(self):
method dfs (line 57) | def dfs(self, start, adj_list, visited=None):
method strongly_connected_component (line 70) | def strongly_connected_component(self):
class GraphTest (line 125) | class GraphTest(unittest.TestCase):
method setUp (line 126) | def setUp(self):
method test_bfs (line 135) | def test_bfs(self):
method test_bfs_path (line 139) | def test_bfs_path(self):
method test_connected_component (line 143) | def test_connected_component(self):
method test_dfs (line 154) | def test_dfs(self):
method test_strongly_connected_components (line 163) | def test_strongly_connected_components(self):
FILE: C22-Elementary-Graph-Algorithms/exercise_code/EulerTour.cpp
function input (line 23) | static void input() {
function euler (line 37) | static void euler(int x) {
function main (line 48) | int main() {
FILE: C25-All-Pairs-Shortest-Paths/Floyd_Warshall.cpp
function floydWarshell (line 21) | void floydWarshell (int graph[][V])
function printSolution (line 47) | void printSolution()
function printPre (line 64) | void printPre()
function findPath (line 80) | void findPath(int start, int end) {
function main (line 94) | int main()
FILE: C26-Flow-networks/maxflow/FlowEdge.cpp
class FlowEdge (line 15) | class FlowEdge {
method FlowEdge (line 22) | FlowEdge() {
method FlowEdge (line 29) | FlowEdge(int v, int w, double capacity) {
method FlowEdge (line 36) | FlowEdge(int v, int w, double capacity, double flow) {
method FlowEdge (line 43) | FlowEdge(const FlowEdge &e) {
method from (line 50) | int from() {
method to (line 54) | int to() {
method getCapacity (line 58) | double getCapacity() {
method getFlow (line 62) | double getFlow() {
method other (line 66) | int other(int vertex) {
method residualCapacityTo (line 71) | double residualCapacityTo(int vertex) {
method addResidualFlowTo (line 76) | void addResidualFlowTo(int vertex, double delta) {
method ostream (line 81) | ostream& operator << (ostream& out, FlowEdge& fe)
FILE: C26-Flow-networks/maxflow/FlowNetwork.cpp
class FlowNetwork (line 20) | class FlowNetwork {
method FlowNetwork (line 28) | FlowNetwork(int V) {
method FlowNetwork (line 37) | FlowNetwork(ifstream& in) {
method getV (line 54) | int getV() {
method getE (line 58) | int getE() {
method addEdge (line 62) | void addEdge(FlowEdge e) {
method getadj (line 70) | list<FlowEdge> getadj(int v) {
method addResidualFlowTo (line 74) | void addResidualFlowTo(FlowEdge e, int v, double bottle) {
method edges (line 83) | list<FlowEdge> edges() {
method ostream (line 93) | ostream& operator << (ostream& out, FlowNetwork& fn)
FILE: C26-Flow-networks/maxflow/FordFulkerson.cpp
class FordFulkerson (line 26) | class FordFulkerson {
method excess (line 34) | double excess(FlowNetwork G, int v) {
method check (line 44) | bool check(FlowNetwork G, int s, int t) {
method isFeasible (line 80) | bool isFeasible(FlowNetwork G, int s, int t) {
method hasAugmentingPath (line 117) | bool hasAugmentingPath(FlowNetwork G, int s, int t) {
method FordFulkerson (line 153) | FordFulkerson(FlowNetwork G, int s, int t) {
method getvalue (line 175) | double getvalue() {
method inCut (line 179) | bool inCut(int v) {
function main (line 185) | int main() {
FILE: C26-Flow-networks/maxflow/testFlowEdge.cpp
function main (line 12) | int main() {
FILE: C26-Flow-networks/maxflow/testFlowNetwork.cpp
function main (line 14) | int main() {
FILE: C31-Number-Theoretic-Algorithms/euclid.py
function gcd (line 4) | def gcd(a, b):
FILE: C31-Number-Theoretic-Algorithms/exercise_code/binary2decimal.py
function b2d (line 4) | def b2d(binary, base):
FILE: C31-Number-Theoretic-Algorithms/exercise_code/lcm.py
function gcd (line 4) | def gcd(a, b):
function lcm (line 12) | def lcm(items):
FILE: C31-Number-Theoretic-Algorithms/extended_euclid.py
function ee (line 4) | def ee(a, b):
FILE: C32-String-Matching/BF.c
function BF_match (line 8) | int BF_match(char *text,char *pattern)
function main (line 32) | int main()
FILE: C32-String-Matching/BM.c
function max (line 5) | int max(int a,int b)
function BM_match (line 15) | int BM_match(char* pSrc, int nSrcSize, char* pSubSrc, int nSubSrcSize)
function main (line 86) | int main()
FILE: C32-String-Matching/FA.c
function min (line 8) | int min(int a,int b)
function suffix (line 16) | int suffix(char *pattern,int k,int q,char ch)
function compute_transition_function (line 30) | void compute_transition_function(char *pattern,int *array,int numchars)
function FA_match (line 53) | int FA_match(char *text,int *array,int numchars,int receive)
function main (line 68) | int main()
FILE: C32-String-Matching/KMP.c
function KMP_match (line 27) | int KMP_match(char *text,char *pattern)
function main (line 49) | int main()
FILE: C32-String-Matching/RK.c
function factorial (line 6) | int factorial(int n)
function RK_match (line 21) | int RK_match(char *text,char *pattern,int d,int q)
FILE: C32-String-Matching/exercise_code/str_spin.c
function f (line 8) | int f(char *s1,char *s2)
function main (line 27) | int main()
FILE: C33-Computational-Geometry/Graham_Scan.py
class Point (line 9) | class Point:
method __init__ (line 11) | def __init__(self, x, y):
method __eq__ (line 18) | def __eq__(self, p):
method __sub__ (line 21) | def __sub__(self, p):
method __mul__ (line 27) | def __mul__(self, p):
method __dict__ (line 33) | def __dict__(self):
method dist (line 37) | def dist(cls, P, Q=None):
method dot (line 46) | def dot(cls, P, Q):
method direction (line 53) | def direction(cls, P, Q, R):
method angle (line 61) | def angle(cls, P, Q, R=None):
method polar_sort (line 81) | def polar_sort(cls, p0, *P):
class ConvexHull (line 93) | class ConvexHull:
method __init__ (line 94) | def __init__(self, *P):
method graham_scan (line 97) | def graham_scan(self):
class ConvexHullTest (line 138) | class ConvexHullTest(unittest.TestCase):
method test_graham_scan (line 139) | def test_graham_scan(self):
class PointTest (line 146) | class PointTest(unittest.TestCase):
method test_polar_sort (line 147) | def test_polar_sort(self):
method test_angle (line 154) | def test_angle(self):
FILE: C33-Computational-Geometry/exercise_code/area.cpp
type Point (line 5) | struct Point{
function area (line 10) | float area(Point a, Point b, Point c){
function calculateAreaOfHull (line 15) | float calculateAreaOfHull(Point* hull,int N){
function main (line 22) | int main(){
FILE: C33-Computational-Geometry/exercise_code/colinear.cpp
class Point (line 15) | class Point
method Point (line 20) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 21) | Point():x(0.0),y(0.0){}
method Point (line 23) | Point operator +(const Point &that) const
method Point (line 28) | Point operator -(const Point &that) const
method Point (line 33) | Point& operator =(const Point &that)
method reverse (line 42) | void reverse()
method ostream (line 48) | ostream& operator << (ostream& os, const Point &p)
function myfunc (line 55) | bool myfunc(const Point &p1, const Point &p2)
function crossProduct (line 65) | float crossProduct(const Point &p1, const Point &p2)
function main (line 70) | int main() {
FILE: C33-Computational-Geometry/exercise_code/convex_polygon.cpp
class Point (line 13) | class Point
method Point (line 18) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 20) | Point operator +(const Point &that) const
method Point (line 25) | Point operator -(const Point &that) const
method Point (line 30) | Point& operator =(const Point &that)
function crossProduct (line 40) | float crossProduct(const Point &p1, const Point &p2)
function direction (line 45) | float direction(const Point &pi, const Point &pj, const Point &pk)
function isConvexPolygon (line 50) | bool isConvexPolygon(Point points[], int n)
function main (line 72) | int main() {
FILE: C33-Computational-Geometry/exercise_code/pointpolygon.cpp
class Point (line 13) | class Point
method Point (line 22) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 24) | Point operator +(const Point &that) const
method Point (line 29) | Point operator -(const Point &that) const
method Point (line 34) | Point& operator =(const Point &that)
method inTheLine (line 43) | bool inTheLine(Point p1, Point p2)
class Point (line 17) | class Point
method Point (line 22) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 24) | Point operator +(const Point &that) const
method Point (line 29) | Point operator -(const Point &that) const
method Point (line 34) | Point& operator =(const Point &that)
method inTheLine (line 43) | bool inTheLine(Point p1, Point p2)
function crossProduct (line 51) | float crossProduct(const Point &p1, const Point &p2)
function direction (line 56) | float direction(const Point &pi, const Point &pj, const Point &pk)
function onSegmant (line 61) | bool onSegmant(const Point &pi, const Point &pj, const Point &pk)
function segmentsInterect (line 68) | bool segmentsInterect(const Point &p1, const Point &p2, const Point &p3,...
function point_polygon_pos (line 92) | int point_polygon_pos(Point p0, Point polygon[], int n)
function main (line 116) | int main() {
FILE: C33-Computational-Geometry/exercise_code/polarCMP.cpp
class Point (line 13) | class Point
method Point (line 18) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 20) | Point operator +(const Point &that) const
method Point (line 25) | Point operator -(const Point &that) const
method Point (line 30) | Point& operator =(const Point &that)
method ostream (line 39) | ostream& operator << (ostream& os, const Point &p)
function myfunc (line 46) | bool myfunc(const Point &p1, const Point &p2)
function main (line 56) | int main() {
FILE: C33-Computational-Geometry/exercise_code/ray_intersection.cpp
class Point (line 13) | class Point
method Point (line 18) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 20) | Point operator +(const Point &that) const
method Point (line 25) | Point operator -(const Point &that) const
method Point (line 30) | Point& operator =(const Point &that)
function crossProduct (line 40) | float crossProduct(const Point &p1, const Point &p2)
function direction (line 45) | float direction(const Point &pi, const Point &pj, const Point &pk)
function onSegmant (line 50) | bool onSegmant(const Point &pi, const Point &pj, const Point &pk)
function segmentsInterect (line 57) | bool segmentsInterect(const Point &p1, const Point &p2, const Point &p3,...
function main (line 76) | int main() {
FILE: C33-Computational-Geometry/twoline.cpp
class Point (line 13) | class Point
method Point (line 18) | Point(float _x, float _y):x(_x),y(_y){}
method Point (line 20) | Point operator +(const Point &that) const
method Point (line 25) | Point operator -(const Point &that) const
method Point (line 30) | Point& operator =(const Point &that)
function crossProduct (line 40) | float crossProduct(const Point &p1, const Point &p2)
function direction (line 45) | float direction(const Point &pi, const Point &pj, const Point &pk)
function onSegmant (line 50) | bool onSegmant(const Point &pi, const Point &pj, const Point &pk)
function segmentsInterect (line 57) | bool segmentsInterect(const Point &p1, const Point &p2, const Point &p3,...
function main (line 76) | int main() {
FILE: other/Karatsuba/Karatsuba.cpp
function makeEqualLength (line 6) | int makeEqualLength(string &str1, string &str2)
function string (line 24) | string add(string &first, string &second)
function string (line 45) | string multiplyiSingleBit(string &a, string &b)
function string (line 48) | string sub(string num1, string num2) {
function string (line 73) | string multiply(string &X, string &Y)
function main (line 113) | int main(int argc, char **argv)
FILE: other/Karatsuba/main.cpp
function string (line 6) | string multiply(string &num1, string &num2) {
function main (line 27) | int main(int argc, char **argv) {
FILE: other/segmentTree.cpp
type SegmentTreeNode (line 6) | struct SegmentTreeNode {
method SegmentTreeNode (line 9) | SegmentTreeNode(int start, int end, int sum) {
class NumArray (line 17) | class NumArray {
method SegmentTreeNode (line 21) | SegmentTreeNode* build(int start, int end, const vector<int>& A) {
method modify (line 36) | void modify(SegmentTreeNode *root, int i, int val) {
method query (line 46) | int query(SegmentTreeNode *root, int i, int j) {
method NumArray (line 60) | NumArray(vector<int> &nums) {
method update (line 64) | void update(int i, int val) {
method sumRange (line 68) | int sumRange(int i, int j) {
function main (line 73) | int main() {
FILE: other/stringSpilit.cpp
function split (line 1) | vector<string> split(const string &s, char delim) {
FILE: other/trie.cpp
type TrieNode (line 1) | struct TrieNode {
method TrieNode (line 5) | TrieNode(): word(false) {
class Trie (line 10) | class Trie {
method Trie (line 13) | Trie() {
method insert (line 18) | void insert(const string& s) {
method search (line 31) | bool search(const string& key) const {
method startsWith (line 45) | bool startsWith(const string& prefix) const {
Condensed preview — 231 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (724K chars).
[
{
"path": ".gitignore",
"chars": 55,
"preview": ".DS_Store\n*.out\n*.log\n*.gz\n*.aux\n*.tex\n\nimages/\nTools/\n"
},
{
"path": "C01-The-Role-of-Algorithms-in-Computing/1.1.md",
"chars": 2281,
"preview": "### Exercises 1.1-1\n***\nGive a real-world example in which one of the following computational problems appears: sorting,"
},
{
"path": "C01-The-Role-of-Algorithms-in-Computing/1.2.md",
"chars": 1478,
"preview": "### Exercises 1.2-1\n***\nGive an example of an application that requires algorithmic content at the application level, an"
},
{
"path": "C01-The-Role-of-Algorithms-in-Computing/problem.md",
"chars": 2365,
"preview": "### Problems 1 : Comparison of running times\n***\nFor each function **f**(n) and time t in the following table, determine"
},
{
"path": "C02-Getting-Started/2.1.md",
"chars": 1474,
"preview": "### Exercises 2.1-1\r\n***\r\nUsing Figure 2.2 as a model, illustrate the operation of INSERTION-SORT on the array A = [31, "
},
{
"path": "C02-Getting-Started/2.2.md",
"chars": 2275,
"preview": "### Exercises 2.2-1\n***\nExpress the function \n in terms o"
},
{
"path": "C02-Getting-Started/2.3.md",
"chars": 4039,
"preview": "### Exercises 2.3-1\n***\nUsing Figure 2.4 as a model, illustrate the operation of merge sort on the array A = [3, 41, 52,"
},
{
"path": "C02-Getting-Started/exercise_code/Insertion_sort_with_binary_search.py",
"chars": 1780,
"preview": "# Exercise 2.3-6 in book\n# Standalone Python version 2.7 code\nimport os\nimport re\nimport math\nimport time\nfrom random im"
},
{
"path": "C02-Getting-Started/exercise_code/binary-search.py",
"chars": 750,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n# Standalone python code, version 2.7\n# I can provide older version to compare them"
},
{
"path": "C02-Getting-Started/exercise_code/inversions.cpp",
"chars": 1463,
"preview": "// Created by wander on 16/5/14.\n// Copyright © 2016年 W4anD0eR96. All rights reserved.\n// 采用左闭右开的区间描述方式\n\n#include \"bi"
},
{
"path": "C02-Getting-Started/exercise_code/inversions.py",
"chars": 783,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef merge(items, p, q, r):\n L = items[p:q+1]\n R = items[q+1:r+1]\n i = j ="
},
{
"path": "C02-Getting-Started/exercise_code/merge-sort.py",
"chars": 621,
"preview": "#!/usr/bin/env python\n# coding=utf-8\nimport math\n\ndef merge(items, p, q, r):\n L = items[p:q+1]\n R = items[q+1:r+1]"
},
{
"path": "C02-Getting-Started/problem.md",
"chars": 4630,
"preview": "### Problems 1 : Insertion sort on small arrays in merge sort\r\n***\r\nAlthough merge sort runs in Θ(n lg n) worst-case tim"
},
{
"path": "C03-Growth-of-Functions/3.1.md",
"chars": 4168,
"preview": "### Exercises 3.1-1\r\n***\r\nLet f(n) and g(n) be asymptotically nonnegative functions. Using the basic definition of Θ-\r\nn"
},
{
"path": "C03-Growth-of-Functions/3.2.md",
"chars": 4591,
"preview": "### Exercises 3.2-1\r\n***\r\nShow that if f(n) and g(n) are monotonically increasing functions, then so are the functions f"
},
{
"path": "C03-Growth-of-Functions/problem.md",
"chars": 4237,
"preview": "### Problems 1 : Asymptotic behavior of polynomials\r\n***\r\n\r\n\r\n### `Answer`\r\n显而易见.\r\n\r\n\r\n\r\n### Problems 2 : Relative asymp"
},
{
"path": "C04-Recurrences/4.1.md",
"chars": 4654,
"preview": "### Exercises 4.1-1\n***\nShow that the solution of %20=%20T\\(\\\\lceil%20n"
},
{
"path": "C04-Recurrences/4.2.md",
"chars": 3626,
"preview": "### Exercises 4.2-1\r\n***\r\nUse a recursion tree to determine a good asymptotic upper bound on the recurrence \r\n for the case in which b is a posi"
},
{
"path": "C04-Recurrences/exercise_code/findIndex.py",
"chars": 1116,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\n\ndef mergeindex(items, evens):\n res = []\n l = len(items[0])\n for i in ran"
},
{
"path": "C04-Recurrences/exercise_code/findMissing.py",
"chars": 571,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef findmissing(items, i) :\n if len(items) == 0:\n return 0\n \n numo"
},
{
"path": "C04-Recurrences/problem.md",
"chars": 17012,
"preview": "### Problems 1 : Recurrence examples\r\n***\r\nThroughout this book, we assume that parameter passing during procedure calls"
},
{
"path": "C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.1.md",
"chars": 2012,
"preview": "### Exercises 5.1-1\n***\nShow that the assumption that we are always able to determine which candidate is best in line 4 "
},
{
"path": "C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.2.md",
"chars": 3724,
"preview": "### Exercises 5.2-1\r\n***\r\nIn HIRE-ASSISTANT, assuming that the candidates are presented in a random order, what is the p"
},
{
"path": "C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.3.md",
"chars": 3487,
"preview": "### Exercises 5.3-1\r\n***\r\nProfessor Marceau objects to the loop invariant used in the proof of Lemma 5.5. He questions w"
},
{
"path": "C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.4.md",
"chars": 3574,
"preview": "### Exercises 5.4-1\r\n***\r\nHow many people must there be in a room before the probability that someone has the same birth"
},
{
"path": "C05-Probabilistic-Analysis-and-Randomized-Algorithms/myrandom.py",
"chars": 751,
"preview": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nfrom math import log\nfrom random import randint\nfrom "
},
{
"path": "C05-Probabilistic-Analysis-and-Randomized-Algorithms/problem.md",
"chars": 5585,
"preview": "### Problems 1 : Probabilistic counting\r\n***\r\nWith a b-bit counter, we can ordinarily only count up to 2b - 1. With R. M"
},
{
"path": "C06-Heapsort/6.1.md",
"chars": 1668,
"preview": "### Exercises 6.1-1\r\n***\r\nWhat are the minimum and maximum numbers of elements in a heap of height h?\r\n\r\n### `Answer`\r\n最"
},
{
"path": "C06-Heapsort/6.2.md",
"chars": 2209,
"preview": "### Exercises 6.2-1\n***\nUsing Figure 6.2 as a model, illustrate the operation of MAX-HEAPIFY(A, 3) on the array A = 27,1"
},
{
"path": "C06-Heapsort/6.3.md",
"chars": 1207,
"preview": "### Exercises 6.3-1\r\n***\r\nUsing Figure 6.3 as a model, illustrate the operation of BUILD-MAX-HEAP on the array A = [5, 3"
},
{
"path": "C06-Heapsort/6.4.md",
"chars": 1568,
"preview": "### Exercises 6.4-1\r\n***\r\nUsing Figure 6.4 as a model, illustrate the operation of HEAPSORT on the array A = [5, 13, 2, "
},
{
"path": "C06-Heapsort/6.5.md",
"chars": 3442,
"preview": "### Exercises 6.5-1\n***\nIllustrate the operation of HEAP-EXTRACT-MAX on the heap A = [15, 13, 9, 5, 12, 8, 7, 4, 0, 6, 2"
},
{
"path": "C06-Heapsort/d-ary-heaps.cpp",
"chars": 1698,
"preview": "/*************************************************************************\n\t> File Name: d-ary-heaps.cpp\n\t> Author: Loui"
},
{
"path": "C06-Heapsort/heap.cpp",
"chars": 1509,
"preview": "/*************************************************************************\n\t> File Name: 2.cpp\n\t> Author: Louis1992\n\t> M"
},
{
"path": "C06-Heapsort/main.cpp",
"chars": 994,
"preview": "/*************************************************************************\n\t> File Name: main.cpp\n\t> Author: Louis1992\n\t"
},
{
"path": "C06-Heapsort/makefile",
"chars": 194,
"preview": "sample : main.o p_queue.o\n\tg++ -o sample main.o p_queue.o\nmain.o : main.cpp p_queue.h\n\tg++ -c main.cpp\np_queue.o : p_que"
},
{
"path": "C06-Heapsort/p_queue.cpp",
"chars": 2046,
"preview": "/*************************************************************************\n\t> File Name: p_queue.cpp\n\t> Author: Louis199"
},
{
"path": "C06-Heapsort/p_queue.h",
"chars": 766,
"preview": "/*************************************************************************\n\t> File Name: p_queue.h\n\t> Author: Louis1992\n"
},
{
"path": "C06-Heapsort/problem.md",
"chars": 4035,
"preview": "### Problems 1 : Building a heap using insertion\r\n***\r\nThe procedure BUILD-MAX-HEAP in Section 6.3 can be implemented by"
},
{
"path": "C06-Heapsort/young.cpp",
"chars": 2811,
"preview": "/*************************************************************************\n\t> File Name: young.cpp\n\t> Author: Louis1992\n"
},
{
"path": "C07-Quicksort/7.1.md",
"chars": 985,
"preview": "### Exercises 7.1-1\r\n***\r\nUsing Figure 7.1 as a model, illustrate the operation of PARTITION on the array A = [13, 19, 3"
},
{
"path": "C07-Quicksort/7.2.md",
"chars": 3246,
"preview": "### Exercises 7.2-1\r\n***\r\nUse the substitution method to prove that the recurrence T (n) = T (n - 1) + Θ(n) has the\r\nsol"
},
{
"path": "C07-Quicksort/7.3.md",
"chars": 713,
"preview": "### Exercises 7.3-1\r\n***\r\nWhy do we analyze the average-case performance of a randomized algorithm and not its worst-cas"
},
{
"path": "C07-Quicksort/7.4.md",
"chars": 6772,
"preview": "### Exercises 7.4-1\r\n***\r\nShow that in the recurrence\r\n\r\n%20=%20\\\\max%2"
},
{
"path": "C07-Quicksort/exercise_code/fuzzy_sort.py",
"chars": 1257,
"preview": "#!/usr/bin/env python\n# coding=utf-8\nimport random\nimport copy\n\ndef intersects(a, b):\n return a[0] <= b[1] and b[0] <"
},
{
"path": "C07-Quicksort/exercise_code/hoare.py",
"chars": 656,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef quicksort(items, p, r):\n if p < r:\n q = partition(items, p, r)\n "
},
{
"path": "C07-Quicksort/exercise_code/quickSortWithEqualElements.cpp",
"chars": 4727,
"preview": "#include <vector>\n#include <algorithm>\n#include <stdlib.h>\n#include <time.h>\n#include <utility>\n#include <cassert>\n\nusin"
},
{
"path": "C07-Quicksort/exercise_code/quicksort.py",
"chars": 572,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef quicksort(items, p, r):\n if p < r:\n q = partition(items, p, r)\n "
},
{
"path": "C07-Quicksort/exercise_code/tailrecursive.py",
"chars": 608,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef tail_quicksort(items, p, r):\n while p < r:\n q = partition(items, p, "
},
{
"path": "C07-Quicksort/problem.md",
"chars": 12298,
"preview": "### Problems 1 : Hoare partition correctness\r\n***\r\nThe version of PARTITION given in this chapter is not the original pa"
},
{
"path": "C07-Quicksort/quicksort.py",
"chars": 499,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef quicksort(items, p, r):\n if p < r:\n q = partition(items, p, r)\n "
},
{
"path": "C07-Quicksort/randomized-quicksort.py",
"chars": 714,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\nimport random\n\ndef randomized_quicksort(items, p, r):\n if p < r:\n q = ra"
},
{
"path": "C08-Sorting-in-Linear-Time/8.1.md",
"chars": 2053,
"preview": "### Exercises 8.1-1\r\n***\r\nWhat is the smallest possible depth of a leaf in a decision tree for a comparison sort?\r\n\r\n###"
},
{
"path": "C08-Sorting-in-Linear-Time/8.2.md",
"chars": 1078,
"preview": "### Exercises 8.2-1\r\n***\r\nUsing Figure 8.2 as a model, illustrate the operation of COUNTING-SORT on the array A = [6, 0,"
},
{
"path": "C08-Sorting-in-Linear-Time/8.3.md",
"chars": 2610,
"preview": "### Exercises 8.3-1\r\n***\r\nUsing Figure 8.3 as a model, illustrate the operation of RADIX-SORT on the following list of E"
},
{
"path": "C08-Sorting-in-Linear-Time/8.4.md",
"chars": 2362,
"preview": "### Exercises 8.4-1\r\n***\r\nUsing Figure 8.4 as a model, illustrate the operation of BUCKET-SORT on the array A =[.79, .13"
},
{
"path": "C08-Sorting-in-Linear-Time/exercise_code/in_place_counting_sort.py",
"chars": 630,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef in_place_counting_sort(items, k):\n C = [0] * k\n for e in items:\n "
},
{
"path": "C08-Sorting-in-Linear-Time/exercise_code/intergerQuery.cpp",
"chars": 1150,
"preview": "#include <vector>\n#include <cassert>\n#include <stdexcept>\n#include <algorithm>\n\nusing namespace std;\n\nclass IntegerQuery"
},
{
"path": "C08-Sorting-in-Linear-Time/exercise_code/radixSort.cpp",
"chars": 2233,
"preview": "#include <random>\n#include <cmath>\n#include <iostream>\n#include <chrono>\n#include <utility>\n\nusing namespace std;\n/*\n * "
},
{
"path": "C08-Sorting-in-Linear-Time/exercise_code/water-jugs.py",
"chars": 524,
"preview": "#!/usr/bin/env python\n# coding=utf-8\nimport random\n\ndef match(reds, blues):\n if not reds:\n return\n r = rand"
},
{
"path": "C08-Sorting-in-Linear-Time/problem.md",
"chars": 11672,
"preview": "### Problems 1 : Average-case lower bounds on comparison sorting\r\n***\r\nIn this problem, we prove an Ω(n lg n) lower boun"
},
{
"path": "C09-Medians-and-Order-Statistics/9.1.md",
"chars": 1559,
"preview": "### Exercises 9.1-1\n***\nShow that the second smallest of n elements can be found with :\n med = median(items)\n \n abs_ite"
},
{
"path": "C09-Medians-and-Order-Statistics/exercise_code/k-quantile.py",
"chars": 1921,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\nimport math\n\ndef k_quantiles(items, k):\n index = median_index(len(items))\n \n"
},
{
"path": "C09-Medians-and-Order-Statistics/exercise_code/randomized-select-iterative.cpp",
"chars": 1745,
"preview": "/*************************************************************************\n > File Name: randomized-select-iterative.cpp"
},
{
"path": "C09-Medians-and-Order-Statistics/exercise_code/second-smallest.cpp",
"chars": 2242,
"preview": "/*************************************************************************\n\t> File Name: second-smallest.cpp\n\t> Author: "
},
{
"path": "C09-Medians-and-Order-Statistics/minmax.c",
"chars": 1251,
"preview": "/*************************************************************************\n\t> File Name: minmax.c\n\t> Author: Louis1992\n\t"
},
{
"path": "C09-Medians-and-Order-Statistics/problem.md",
"chars": 5412,
"preview": "### Problems 1 : Largest i numbers in sorted order\r\n***\r\n\r\nGiven a set of *n* numbers, we wish to find the *i* largest i"
},
{
"path": "C09-Medians-and-Order-Statistics/problems/i-largest.cpp",
"chars": 3000,
"preview": "/*************************************************************************\n\t> File Name: worse-case-linear-time.cpp\n\t> A"
},
{
"path": "C09-Medians-and-Order-Statistics/problems/i-largest.py",
"chars": 420,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\nfrom Queue import PriorityQueue\n\ndef sort1(items, i):\n items = sorted(items,rev"
},
{
"path": "C09-Medians-and-Order-Statistics/problems/weighted_median.py",
"chars": 2751,
"preview": "#!/usr/bin/env python\n# coding=utf-8\nimport math\n\ndef select(items, n):\n med = median(items)\n smaller = [item "
},
{
"path": "C09-Medians-and-Order-Statistics/randomized-select.cpp",
"chars": 1178,
"preview": "#include<iostream>\n#include<vector>\nusing namespace std;\n\nint partition(vector<int>& arr, int l, int r) {\n int x = ar"
},
{
"path": "C09-Medians-and-Order-Statistics/worst-case-linear-time.cpp",
"chars": 2856,
"preview": "/*************************************************************************\n\t> File Name: worse-case-linear-time.cpp\n\t> A"
},
{
"path": "C10-Elementary-Data-Structures/10.1.md",
"chars": 3459,
"preview": "### Exercises 10.1-1\r\n***\r\nUsing Figure 10.1 as a model, illustrate the result of each operation in the sequence PUSH(S,"
},
{
"path": "C10-Elementary-Data-Structures/10.2.md",
"chars": 3240,
"preview": "### Exercises 10.2-1\r\n***\r\nCan the dynamic-set operation INSERT be implemented on a singly linked list in O(1) time? How"
},
{
"path": "C10-Elementary-Data-Structures/10.3.md",
"chars": 3556,
"preview": "### Exercises 10.3-1\r\n***\r\nDraw a picture of the sequence[13, 4, 8, 19, 5, 11]stored as a doubly linked list using the m"
},
{
"path": "C10-Elementary-Data-Structures/10.4.md",
"chars": 5120,
"preview": "### Exercises 10.4-1\n***\nDraw the binary tree rooted at index 6 that is represented by the following fields.\n\n<table cla"
},
{
"path": "C10-Elementary-Data-Structures/README.md",
"chars": 27,
"preview": "Problem 10.2 & 10.3 remain\n"
},
{
"path": "C10-Elementary-Data-Structures/exercise_code/af-obj.c",
"chars": 1557,
"preview": "#include <stdio.h>\n#include <stdlib.h>\n\n#define MAX_SIZE 10\n\ntypedef int list_t;\ntypedef int obj_t;\n\nint empty_list = -1"
},
{
"path": "C10-Elementary-Data-Structures/exercise_code/deque.cpp",
"chars": 1243,
"preview": "#include<cassert>\n#include<iostream>\n#include<vector>\n\nusing namespace std;\n\ntemplate <class T>\nclass Deque {\n \npriva"
},
{
"path": "C10-Elementary-Data-Structures/exercise_code/deque.py",
"chars": 1051,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\nclass Deque:\n\n def __init__(self, size):\n self.N = 0\n self.head ="
},
{
"path": "C10-Elementary-Data-Structures/exercise_code/dict.cpp",
"chars": 1752,
"preview": "/*************************************************************************\n\t> File Name: dict.cpp\n\t> Author: Louis1992\n\t"
},
{
"path": "C10-Elementary-Data-Structures/exercise_code/traversal.cpp",
"chars": 1289,
"preview": "/*************************************************************************\n\t> File Name: travelsal.cpp\n\t> Author: Louis1"
},
{
"path": "C10-Elementary-Data-Structures/problem.md",
"chars": 4676,
"preview": "### Problems 1 : Comparisons among lists\r\n***\r\nFor each of the four types of lists in the following table, what is the a"
},
{
"path": "C11-Hash-Tables/11.1.md",
"chars": 2049,
"preview": "### Exercises 11.1-1\n***\nSuppose that a dynamic set S is represented by a direct-address table T of length m. Describe a"
},
{
"path": "C11-Hash-Tables/11.2.md",
"chars": 2084,
"preview": "### Exercises 11.2-1\r\n***\r\nSuppose we use a hash function h to hash n distinct keys into an array T of length m. Assumin"
},
{
"path": "C11-Hash-Tables/11.3.md",
"chars": 7692,
"preview": "### Exercises 11.3-1\r\n***\r\nSuppose we wish to search a linked list of length n, where each element contains a key k alon"
},
{
"path": "C11-Hash-Tables/11.4.md",
"chars": 4180,
"preview": "### Exercises 11.4-1\n***\nConsider inserting the keys 10, 22, 31, 4, 15, 28, 17, 88, 59 into a hash table of length m = 1"
},
{
"path": "C11-Hash-Tables/11.5.md",
"chars": 1123,
"preview": "### Exercises 11.5-1\r\n***\r\nSuppose that we insert n keys into a hash table of size m using open addressing and uniform h"
},
{
"path": "C11-Hash-Tables/README.md",
"chars": 119,
"preview": "UNSOLVED\n\n[11.3.5](./11.3.md#exercises-113-5)\n[11.3.6](./11.3.md#exercises-113-6)\n\n[11.5.1](./11.5.md#exercises-115-1)\n"
},
{
"path": "C11-Hash-Tables/problem.md",
"chars": 2166,
"preview": "### Problems 1 : Longest-probe bound for hashing\r\n***\r\nA hash table of size m is used to store n items, with n ≤ m/2. Op"
},
{
"path": "C12-Binary-Search-Trees/12.1.md",
"chars": 1953,
"preview": "### Exercises 12.1-1\n***\nFor the set of keys {1, 4, 5, 10, 16, 17, 21}, draw binary search trees of height 2, 3, 4, 5, a"
},
{
"path": "C12-Binary-Search-Trees/12.2.md",
"chars": 3574,
"preview": "### Exercises 12.2-1\n***\nSuppose that we have numbers between 1 and 1000 in a binary search tree and want to search for "
},
{
"path": "C12-Binary-Search-Trees/12.3.md",
"chars": 2552,
"preview": "### Exercises 12.3-1\n***\nGive a recursive version of the TREE-INSERT procedure.\n\n### `Answer`\n\n"
},
{
"path": "C12-Binary-Search-Trees/12.4.md",
"chars": 2113,
"preview": "### Exercises 12.4-1\r\n***\r\nProve equation (12.3).\r\n\r\n### `Answer`\r\nThis is basic property of permutations and combinatio"
},
{
"path": "C12-Binary-Search-Trees/BSTree.h",
"chars": 4732,
"preview": "/*************************************************************************\n\t> File Name: BTREE.h\n\t> Author: Louis1992\n\t>"
},
{
"path": "C12-Binary-Search-Trees/main.cpp",
"chars": 1312,
"preview": "\n/*************************************************************************\n\t> File Name: main.cpp\n\t> Author: Louis1992\n"
},
{
"path": "C12-Binary-Search-Trees/makefile",
"chars": 120,
"preview": "sample : main.o \n\tg++ -o sample main.o;rm main.o\nmain.o : main.cpp BSTree.h\n\tg++ -c main.cpp\n\nclean :\n\trm sample main.o\n"
},
{
"path": "C13-Red-Black-Trees/13.1.md",
"chars": 4333,
"preview": "### Exercises 13.1-1\r\n***\r\nIn the style of Figure 13.1(a), draw the complete binary search tree of height 3 on the keys "
},
{
"path": "C13-Red-Black-Trees/13.2.md",
"chars": 2600,
"preview": "### Exercises 13.2-1\n***\nWrite pseudocode for RIGHT-ROTATE.\n\n### `Answer`\n\n就模仿书上的left,right对调一下"
},
{
"path": "C13-Red-Black-Trees/13.3.md",
"chars": 2152,
"preview": "### Exercises 13.3-1\r\n***\r\nIn line 16 of RB-INSERT, we set the color of the newly inserted node z to red. Notice that if"
},
{
"path": "C13-Red-Black-Trees/13.4.md",
"chars": 2351,
"preview": "### Exercises 13.4-1\r\n***\r\nArgue that after executing RB-DELETE-FIXUP, the root of the tree must be black.\r\n\r\n### `Answe"
},
{
"path": "C13-Red-Black-Trees/problem.md",
"chars": 7821,
"preview": "### Problems 1 : Persistent dynamic sets\r\n***\r\n\r\na. For a general persistent binary search tree, identify the nodes that"
},
{
"path": "C13-Red-Black-Trees/rbtree.c",
"chars": 14777,
"preview": "/*************************************************************************\n\t> File Name: rbtree.c\n\t> Author: Louis1992\n\t"
},
{
"path": "C13-Red-Black-Trees/rbtree.cpp",
"chars": 15142,
"preview": "/*************************************************************************\n\t> File Name: rbtree.cpp\n\t> Author: Louis1992"
},
{
"path": "C14-Augmenting-Data-Structures/14.1.md",
"chars": 3107,
"preview": "### Exercises 14.1-1\n***\nShow how OS-SELECT(T, 10) operates on the red-black tree T of Figure 14.1.\n\n### `Answer`\nStraig"
},
{
"path": "C14-Augmenting-Data-Structures/14.2.md",
"chars": 4617,
"preview": "some English answers come from [here](http://ripcrixalis.blog.com/2011/02/08/clrs-14-2-how-to-augment-a-data-structure/)"
},
{
"path": "C14-Augmenting-Data-Structures/14.3.md",
"chars": 4320,
"preview": "### Exercises 14.3-1\n***\nWrite pseudocode for LEFT-ROTATE that operates on nodes in an interval tree and updates the max"
},
{
"path": "C14-Augmenting-Data-Structures/exercise_code/m-Josephus.cpp",
"chars": 1059,
"preview": "/*************************************************************************\n\t> File Name: m-Josephus.cpp\n\t> Author: Louis"
},
{
"path": "C14-Augmenting-Data-Structures/problem.md",
"chars": 4942,
"preview": "### Problems 1 : Point of Maximum Overlap\r\n***\r\nSuppose that we wish to keep track of a **point of maximum overlap** in "
},
{
"path": "C15-Dynamic-Programming/15.1.md",
"chars": 2064,
"preview": "### Exercises 15.1-1\r\n***\r\nShow how to modify the PRINT-STATIONS procedure to print out the stations in increasing order"
},
{
"path": "C15-Dynamic-Programming/15.2.md",
"chars": 2345,
"preview": "### Exercises 15.2-1\r\n***\r\nFind an optimal parenthesization of a matrix-chain product whose sequence of dimensions is [5"
},
{
"path": "C15-Dynamic-Programming/15.3.md",
"chars": 3914,
"preview": "### Exercises 15.3-1\r\n***\r\nWhich is a more efficient way to determine the optimal number of multiplications in a matrix-"
},
{
"path": "C15-Dynamic-Programming/15.4.md",
"chars": 3709,
"preview": "### Exercises 15.4-1\r\n***\r\nDetermine an LCS of <1, 0, 0, 1, 0, 1, 0, 1> and <0, 1, 0, 1, 1, 0, 1, 1, 0>.\r\n\r\n### `Answer`"
},
{
"path": "C15-Dynamic-Programming/15.5.md",
"chars": 1865,
"preview": "### Exercises 15.5-1\r\n***\r\n\r\nWrite pseudocode for the procedure CONSTRUCT-OPTIMAL-BST(root) which, given the table root,"
},
{
"path": "C15-Dynamic-Programming/Assembly-line-sche.c",
"chars": 1795,
"preview": "#include <stdio.h>\n#include <stdlib.h>\n\nint Fastway(int *a1,int *a2,int *t1,int *t2,int *e,int *x,int n,int *l1,int *l2,"
},
{
"path": "C15-Dynamic-Programming/Matrix-chain-multiplication.c",
"chars": 1303,
"preview": "#include <stdlib.h>\n#include <stdio.h>\n\n/*\n * according to introduction to algorithm,\n * we alloc array(n+1)but make use"
},
{
"path": "C15-Dynamic-Programming/lincrs.cpp",
"chars": 675,
"preview": "#include <iostream>\nusing namespace std;\n\nint find(int *a, int len, int n)\n{\n int left(0),right(len),mid = (left+righ"
},
{
"path": "C15-Dynamic-Programming/optimalBST.cpp",
"chars": 2333,
"preview": "#include <iostream>\n\nusing namespace std;\n\nconst int MaxVal = 9999;\n\nconst int n = 5;\n//搜索到根节点和虚拟键的概率\ndouble p[n + 1] = "
},
{
"path": "C15-Dynamic-Programming/rodcutting.cpp",
"chars": 2757,
"preview": "#include <iostream>\r\n#include <vector>\r\n#include <algorithm>\r\n\r\n// #define DEBUG\r\n\r\nusing std::cout;\r\nusing std::endl;\r\n"
},
{
"path": "C16-Greedy-Algorithms/16.1.md",
"chars": 4641,
"preview": "### Exercises 16.1-1\r\n***\r\nGive a dynamic-programming algorithm for the activity-selection problem, based on the recurre"
},
{
"path": "C16-Greedy-Algorithms/16.2.md",
"chars": 4936,
"preview": "### Exercises 16.2-1\n***\nProve that the fractional knapsack problem has the greedy-choice property.\n\n### `Answer`\nThm. T"
},
{
"path": "C16-Greedy-Algorithms/16.3.md",
"chars": 3414,
"preview": "### Exercises 16.3-1\r\n***\r\nProve that a binary tree that is not full cannot correspond to an optimal prefix code.\r\n\r\n###"
},
{
"path": "C16-Greedy-Algorithms/huffman/BinaryStdIn.cpp",
"chars": 1597,
"preview": "/*************************************************************************\n\t> File Name: BinaryStdIn.cpp\n\t> Author: \n\t> "
},
{
"path": "C16-Greedy-Algorithms/huffman/BinaryStdIn.h",
"chars": 653,
"preview": "/*************************************************************************\n\t> File Name: BinaryStdIn.h\n\t> Author: \n\t> Ma"
},
{
"path": "C16-Greedy-Algorithms/huffman/BinaryStdOut.cpp",
"chars": 1597,
"preview": "/*************************************************************************\n\t> File Name: BinaryStdOut.cpp\n\t> Author: \n\t>"
},
{
"path": "C16-Greedy-Algorithms/huffman/BinaryStdOut.h",
"chars": 752,
"preview": "/*************************************************************************\n\t> File Name: BinaryStdOut.h\n\t> Author: \n\t> M"
},
{
"path": "C16-Greedy-Algorithms/huffman/HUFFMAN.cpp",
"chars": 4782,
"preview": "/*************************************************************************\n\t> File Name: HUFFMAN.cpp\n\t> Author: \n\t> Mail"
},
{
"path": "C16-Greedy-Algorithms/huffman/HUFFMAN.h",
"chars": 1591,
"preview": "/*************************************************************************\n\t> File Name: HUFFMAN.h\n\t> Author: \n\t> Mail: "
},
{
"path": "C16-Greedy-Algorithms/huffman/binary_test/main.cpp",
"chars": 1206,
"preview": "/*************************************************************************\n\t> File Name: main.cpp\n\t> Author: \n\t> Mail: \n"
},
{
"path": "C16-Greedy-Algorithms/huffman/binary_test/makefile",
"chars": 385,
"preview": "main : main.o BinaryStdOut.o BinaryStdIn.o\n\t\tg++ -o main main.o BinaryStdOut.o BinaryStdIn.o\nmain.o : main.cpp ../Binary"
},
{
"path": "C16-Greedy-Algorithms/huffman/binarystdin_test/main.cpp",
"chars": 485,
"preview": "/*************************************************************************\n\t> File Name: main.cpp\n\t> Author: \n\t> Mail: \n"
},
{
"path": "C16-Greedy-Algorithms/huffman/binarystdin_test/makefile",
"chars": 283,
"preview": "test_BinaryStdIn : main.o BinaryStdIn.o\n\t\tg++ -o test_BinaryStdIn main.o BinaryStdIn.o \nmain.o : main.cpp ../BinaryStdIn"
},
{
"path": "C16-Greedy-Algorithms/huffman/binarystdout_test/main.cpp",
"chars": 1332,
"preview": "/*************************************************************************\n\t> File Name: main.cpp\n\t> Author: \n\t> Mail: \n"
},
{
"path": "C16-Greedy-Algorithms/huffman/binarystdout_test/makefile",
"chars": 294,
"preview": "test_BinaryStdOut : main.o BinaryStdOut.o\n\t\tg++ -o test_BinaryStdOut main.o BinaryStdOut.o \nmain.o : main.cpp ../BinaryS"
},
{
"path": "C16-Greedy-Algorithms/huffman/huffman_test/huffman_test_client.cpp",
"chars": 592,
"preview": "/*************************************************************************\n\t> File Name: huffman_test_client.cpp\n\t> Auth"
},
{
"path": "C16-Greedy-Algorithms/huffman/huffman_test/makefile",
"chars": 590,
"preview": "main : huffman_test_client.o HUFFMAN.o BinaryStdIn.o BinaryStdOut.o\n\t\tg++ -o main huffman_test_client.o HUFFMAN.o Binary"
},
{
"path": "C17-Amortized-Analysis/17.1.md",
"chars": 1274,
"preview": "### Exercise 17.1-1\n***\nIf the set of stack operations included a MULTIPUSH operation, which pushes k items onto the sta"
},
{
"path": "C17-Amortized-Analysis/17.2.md",
"chars": 2956,
"preview": "### Exercise 17.2-1\n***\nSuppose we perform a sequence of stack operations on a stack whose size never exceeds k. After k"
},
{
"path": "C17-Amortized-Analysis/17.3.md",
"chars": 754,
"preview": "### Exercises 17.3-6\n***\nShow how to implement a queue with two ordinary stacks (Exercise 10.1-6) so that the amortized "
},
{
"path": "C17-Amortized-Analysis/17.4.md",
"chars": 839,
"preview": "### Exercise 17.4-3\n***\nSuppose that instead of contracting a table by halving its size when its load factor drops below"
},
{
"path": "C18-B-Trees/18.1.md",
"chars": 2672,
"preview": "### Exercises 18.1-1\r\n***\r\nWhy don't we allow a minimum degree of t = 1?\r\n\r\n### `Answer`\r\nAccording to the definition, m"
},
{
"path": "C18-B-Trees/18.2.md",
"chars": 6116,
"preview": "### Exercises 18.2-1\r\n***\r\nShow the results of inserting the keys\r\n\r\nF, S, Q, K, C, L, H, T, V, W, M, R, N, P, A, B, X, "
},
{
"path": "C18-B-Trees/18.3.md",
"chars": 505,
"preview": "### Exercises 18.3-1\r\n***\r\nShow the results of deleting C, P, and V , in order, from the tree of Figure 18.8(f).\r\n\r\n### "
},
{
"path": "C18-B-Trees/btree.cpp",
"chars": 15416,
"preview": "#include<iostream>\n#include<stack>\n#include<queue>\nusing namespace std;\n\n//#define DEBUG 1\n\n/***************************"
},
{
"path": "C18-B-Trees/btree.py",
"chars": 32313,
"preview": "import bisect\n\n# See Cormen et al, chapter 18 B-Trees\n# This is an implementation of B-Tree with satellite information s"
},
{
"path": "C19-Binomial-Heaps/19.1.md",
"chars": 1063,
"preview": "### Exercises 19.1-1\r\n***\r\nSuppose that x is a node in a binomial tree within a binomial heap, and assume that sibling[x"
},
{
"path": "C19-Binomial-Heaps/19.2.md",
"chars": 3033,
"preview": "### Exercises 19.2-1\r\n***\r\nWrite pseudocode for BINOMIAL-HEAP-MERGE.\r\n\r\n### `Answer`\r\n[implementation](./BinomialHeap.h)"
},
{
"path": "C19-Binomial-Heaps/BinomialHeap.h",
"chars": 12872,
"preview": "/**\n * C++: 二项堆\n *\n * @author skywang\n * @date 2014/04/02\n * @reference http://www.cnblogs.com/xuqiang/archive/2011/06/0"
},
{
"path": "C19-Binomial-Heaps/Main.cpp",
"chars": 3041,
"preview": "/**\n * C 语言: 二项堆\n *\n * @author skywang\n * @date 2014/04/02\n */\n\n#include <iostream>\n#include \"BinomialHeap.h\"\nusing name"
},
{
"path": "C21-Data-Structures-for-Disjoint-Sets/21.1.md",
"chars": 1769,
"preview": "### Exercises 21.1-1\r\n***\r\nSuppose that CONNECTED-COMPONENTS is run on the undirected graph G = (V, E), where V = {a, b,"
},
{
"path": "C21-Data-Structures-for-Disjoint-Sets/21.2.md",
"chars": 3395,
"preview": "### Exercises 21.2-1\r\n***\r\nWrite pseudocode for MAKE-SET, FIND-SET, and UNION using the linked-list representation and t"
},
{
"path": "C21-Data-Structures-for-Disjoint-Sets/21.3.md",
"chars": 2375,
"preview": "### Exercises 21.3-1\r\n***\r\nDo Exercise 21.2-2 using a disjoint-set forest with union by rank and path compression.\r\n\r\n##"
},
{
"path": "C21-Data-Structures-for-Disjoint-Sets/problem.md",
"chars": 6898,
"preview": "### Problems 1 : Off-line minimum\n***\n\nThe off-line minimum problem asks us to maintain a dynamic set T of elements from"
},
{
"path": "C21-Data-Structures-for-Disjoint-Sets/uf.cpp",
"chars": 1464,
"preview": "#include<iostream>\n#include<vector>\n\nusing namespace std;\n\nclass UF {\n \nprivate:\n vector<int> parent;\n vector<i"
},
{
"path": "C22-Elementary-Graph-Algorithms/22.1.md",
"chars": 7885,
"preview": "### Exercises 22.1-1\r\n***\r\nGiven an adjacency-list representation of a directed graph, how long does it take to compute "
},
{
"path": "C22-Elementary-Graph-Algorithms/22.2.md",
"chars": 5897,
"preview": "### Exercises 22.2-1\r\n***\r\nShow the d and π values that result from running breadth-first search on the directed graph o"
},
{
"path": "C22-Elementary-Graph-Algorithms/22.3.md",
"chars": 7268,
"preview": "### Exercises 22.3-1\r\nMake a 3-by-3 chart with row and column labels WHITE, GRAY, and BLACK. In each cell (i, j), indica"
},
{
"path": "C22-Elementary-Graph-Algorithms/22.4.md",
"chars": 3840,
"preview": "### Exercises 22.4-1\r\nShow the ordering of vertices produced by TOPOLOGICAL-SORT when it is run on the dag\r\nof Figure 22"
},
{
"path": "C22-Elementary-Graph-Algorithms/22.5.md",
"chars": 7039,
"preview": "### Exercises 22.5-1\r\nHow can the number of strongly connected components of a graph change if a new edge is added?\r\n\r\n\r"
},
{
"path": "C22-Elementary-Graph-Algorithms/README.md",
"chars": 10,
"preview": "UNSOLVED\n\n"
},
{
"path": "C22-Elementary-Graph-Algorithms/elementary_graph_algo.py",
"chars": 6226,
"preview": "from collections import defaultdict, deque\nfrom Queue import Queue\nimport unittest\n\n\nclass Graph:\n def __init__(self,"
},
{
"path": "C22-Elementary-Graph-Algorithms/exercise_code/EulerTour.cpp",
"chars": 1109,
"preview": "/*************************************************************************\n\t> File Name: EulerTour.cpp\n\t> Author: Louis1"
},
{
"path": "C22-Elementary-Graph-Algorithms/problem.md",
"chars": 1509,
"preview": "### Problems 3 : Euler tour\r\n***\r\nAn Euler tour of a connected, directed graph G = (V, E) is a cycle that traverses each"
},
{
"path": "C23-Minimum-Spanning-Trees/23.1.md",
"chars": 8455,
"preview": "### Exercises 23.1-1\r\n***\r\nLet (u, v) be a minimum-weight edge in a graph G. Show that (u, v) belongs to some\r\nminimum s"
},
{
"path": "C23-Minimum-Spanning-Trees/23.2.md",
"chars": 6904,
"preview": "### Exercises 23.2-1\r\n***\r\nKruskal's algorithm can return different spanning trees for the same input graph G, depending"
},
{
"path": "C24-Single-Source-Shortest-Paths/24.1.md",
"chars": 4125,
"preview": "### Exercises 24.1-1\r\n***\r\nRun the Bellman-Ford algorithm on the directed graph of Figure 24.4, using vertex z as the so"
},
{
"path": "C24-Single-Source-Shortest-Paths/24.2.md",
"chars": 1834,
"preview": "### Exercises 24.2-1\r\n***\r\nRun DAG-SHORTEST-PATHS on the directed graph of Figure 24.5, using vertex r as the\r\nsource.\r\n"
},
{
"path": "C24-Single-Source-Shortest-Paths/24.3.md",
"chars": 3913,
"preview": "### Exercises 24.3-1\r\n***\r\nRun Dijkstra's algorithm on the directed graph of Figure 24.2, first using vertex s as the so"
},
{
"path": "C24-Single-Source-Shortest-Paths/24.4.md",
"chars": 4937,
"preview": "### Exercises 24.4-1\r\n***\r\nFind a feasible solution or determine that no feasible solution exists for the following syst"
},
{
"path": "C24-Single-Source-Shortest-Paths/README.md",
"chars": 159,
"preview": "UNSOLVED\n\n[24.4.4](./24.4.md#exercises-244-4)\n[24.4.9](./24.4.md#exercises-244-9)\n[24.4.11](./24.4.md#exercises-244-11)\n"
},
{
"path": "C25-All-Pairs-Shortest-Paths/25.1.md",
"chars": 3395,
"preview": "### Exercises 25.1-1\r\n***\r\nRun SLOW-ALL-PAIRS-SHORTEST-PATHS on the weighted, directed graph of Figure 25.2, showing the"
},
{
"path": "C25-All-Pairs-Shortest-Paths/25.2.md",
"chars": 4662,
"preview": "### Exercises 25.2-1\r\n***\r\nRun the Floyd-Warshall algorithm on the weighted, directed graph of Figure 25.2. Show the mat"
},
{
"path": "C25-All-Pairs-Shortest-Paths/25.3.md",
"chars": 3534,
"preview": "### Exercises 25.3-1\n***\nUse Johnson’s algorithm to find the shortest paths between all pairs of vertices in the graph o"
},
{
"path": "C25-All-Pairs-Shortest-Paths/Floyd_Warshall.cpp",
"chars": 2443,
"preview": "/*************************************************************************\n\t> File Name: Floyd_Warshall.cpp\n\t> Author: L"
},
{
"path": "C25-All-Pairs-Shortest-Paths/README.md",
"chars": 157,
"preview": "UNSOLVED\n\n[25.1.4](./25.1.md#exercises-251-4)\n[25.1.5](./25.1.md#exercises-251-5)\n\n[25.2.3](./25.2.md#exercises-252-3)\n["
},
{
"path": "C26-Flow-networks/26.1.md",
"chars": 4027,
"preview": "### Exercises 26.1-1\r\n***\r\n\r\nUsing the definition of a flow, prove that if (u, v) ∉ E and (v, u) ∉ E then f(u, v) = f("
},
{
"path": "C26-Flow-networks/26.2.md",
"chars": 3874,
"preview": "I get some answers from the web but I forgot the link, pretty sorry.\r\n\r\n### Exercises 26.2-1\r\n***\r\n\r\nIn Figure 26.1(b), "
},
{
"path": "C26-Flow-networks/26.3.md",
"chars": 933,
"preview": "### Exercises 26.3-1\r\n***\r\nRun the Ford-Fulkerson algorithm on the flow network in Figure 26.8(b) and show the residual "
},
{
"path": "C26-Flow-networks/maxflow/FlowEdge.cpp",
"chars": 2218,
"preview": "/*************************************************************************\n\t> File Name: FlowEdge.cpp\n\t> Author: Louis19"
},
{
"path": "C26-Flow-networks/maxflow/FlowNetwork.cpp",
"chars": 2447,
"preview": "/*************************************************************************\n\t> File Name: FlowNetwork.cpp\n\t> Author: Loui"
},
{
"path": "C26-Flow-networks/maxflow/FordFulkerson.cpp",
"chars": 6744,
"preview": "/*************************************************************************\n\t> File Name: FordFulkerson.cpp\n\t> Author: Lo"
},
{
"path": "C26-Flow-networks/maxflow/input.txt",
"chars": 71,
"preview": "6\n10\n0 1 16\n0 2 13\n1 2 10\n2 1 4\n1 3 12\n3 2 9\n2 4 14\n4 3 7\n3 5 20\n4 5 4\n"
},
{
"path": "C26-Flow-networks/maxflow/makefile",
"chars": 795,
"preview": "all: testnetwork testflowedge maxflow\n.PHONY:all\n\nmaxflow: FordFulkerson.o\n\tg++ -o maxflow -std=c++11 FordFulkerson.o\n\nF"
},
{
"path": "C26-Flow-networks/maxflow/readme.md",
"chars": 76,
"preview": "[reference](http://algs4.cs.princeton.edu/64maxflow/FordFulkerson.java.html)"
},
{
"path": "C26-Flow-networks/maxflow/testFlowEdge.cpp",
"chars": 443,
"preview": "/*************************************************************************\n\t> File Name: testFlowEdge.cpp\n\t> Author: Lou"
},
{
"path": "C26-Flow-networks/maxflow/testFlowNetwork.cpp",
"chars": 497,
"preview": "/*************************************************************************\n\t> File Name: testFlowNetwork.cpp\n\t> Author: "
},
{
"path": "C31-Number-Theoretic-Algorithms/31.1.md",
"chars": 3802,
"preview": "### Exercises 31.1-1\r\n***\r\nProve that there are infinitely many primes. (Hint: how that none of the primes p1, p2, ..., "
},
{
"path": "C31-Number-Theoretic-Algorithms/31.2.md",
"chars": 4445,
"preview": "### Exercises 31.2-1\r\n***\r\nProve that equations (31.11) and (31.12) imply equation (31.13).\r\n\r\n### `Answer`\r\nstraightfor"
},
{
"path": "C31-Number-Theoretic-Algorithms/31.7.md",
"chars": 626,
"preview": "### Exercises 31.7-1\n***\n\nConsider an RSA key set with `p = 11`, `q = 29`, `n = 319`, and `e = 3`. What\nvalue of `d` sho"
},
{
"path": "C31-Number-Theoretic-Algorithms/euclid.py",
"chars": 153,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef gcd(a, b):\n while b != 0:\n tmp = b\n b = a % b\n a = tmp"
},
{
"path": "C31-Number-Theoretic-Algorithms/exercise_code/binary2decimal.py",
"chars": 281,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef b2d(binary, base):\n l = len(binary)\n if l == 1:\n return int(binar"
},
{
"path": "C31-Number-Theoretic-Algorithms/exercise_code/lcm.py",
"chars": 403,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef gcd(a, b):\n while b != 0:\n tmp = b\n b = a % b\n a = tmp"
},
{
"path": "C31-Number-Theoretic-Algorithms/extended_euclid.py",
"chars": 272,
"preview": "#!/usr/bin/env python\n# coding=utf-8\n\ndef ee(a, b):\n if b == 0:\n return (a, 1, 0)\n res = ee(b, a % b)\n r"
},
{
"path": "C32-String-Matching/32.1.md",
"chars": 2291,
"preview": "### Exercises 32.1-1\r\n***\r\nShow the comparisons the naive string matcher makes for the pattern P = 0001 in the text T = "
},
{
"path": "C32-String-Matching/32.2.md",
"chars": 1870,
"preview": "### Exercises 32.2-1\r\n***\r\nWorking modulo q = 11, how many spurious hits does the Rabin-Karp matcher encounter in\r\nthe t"
}
]
// ... and 31 more files (download for full content)
About this extraction
This page contains the full source code of the gzc/CLRS GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 231 files (656.5 KB), approximately 220.4k tokens, and a symbol index with 487 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.