[
{
"path": ".gitignore",
"content": "# Created by .ignore support plugin (hsz.mobi)\n### Example user template template\n### Example user template\n\n# IntelliJ project files\n.idea\n*.iml\nout\ngen\n/target/\n\n\n\n"
},
{
"path": "ReadMe.md",
"content": "\n\n\n
\n\n\n力求打造最完整最实用的Java工程师学习指南!\n\n这些文章和总结都是我近几年学习Java总结和整理出来的,非常实用,对于学习Java后端的朋友来说应该是最全面最完整的技术仓库。\n我靠着这些内容进行复习,拿到了BAT等大厂的offer,这个仓库也已经帮助了很多的Java学习者,如果对你有用,希望能给个star支持我,谢谢!\n\n为了更好地讲清楚每个知识模块,我们也参考了很多网上的优质博文,力求不漏掉每一个知识点,所有参考博文都将声明转载来源,如有侵权,请联系我。\n\n点击关注[微信公众号](#微信公众号)及时获取笔主最新更新文章,并可免费领取Java工程师必备学习资源\n\n\n\n \n
\n\n\n \n# Java基础\n\n## 基础知识\n* [面向对象基础](docs/Java/basic/面向对象基础.md)\n* [Java基本数据类型](docs/Java/basic/Java基本数据类型.md)\n* [string和包装类](docs/Java/basic/string和包装类.md)\n* [final关键字特性](docs/Java/basic/final关键字特性.md)\n* [Java类和包](docs/Java/basic/Java类和包.md)\n* [抽象类和接口](docs/Java/basic/抽象类和接口.md)\n* [代码块和代码执行顺序](docs/Java/basic/代码块和代码执行顺序.md)\n* [Java自动拆箱装箱里隐藏的秘密](docs/Java/basic/Java自动拆箱装箱里隐藏的秘密.md)\n* [Java中的Class类和Object类](docs/Java/basic/Java中的Class类和Object类.md)\n* [Java异常](docs/Java/basic/Java异常.md)\n* [解读Java中的回调](docs/Java/basic/解读Java中的回调.md)\n* [反射](docs/Java/basic/反射.md)\n* [泛型](docs/Java/basic/泛型.md)\n* [枚举类](docs/Java/basic/枚举类.md)\n* [Java注解和最佳实践](docs/Java/basic/Java注解和最佳实践.md)\n* [JavaIO流](docs/Java/basic/JavaIO流.md)\n* [多线程](docs/Java/basic/多线程.md)\n* [深入理解内部类](docs/Java/basic/深入理解内部类.md)\n* [javac和javap](docs/Java/basic/javac和javap.md)\n* [Java8新特性终极指南](docs/Java/basic/Java8新特性终极指南.md)\n* [序列化和反序列化](docs/Java/basic/序列化和反序列化.md)\n* [继承封装多态的实现原理](docs/Java/basic/继承封装多态的实现原理.md)\n\n## 集合类\n\n* [Java集合类总结](docs/Java/collection/Java集合类总结.md)\n* [Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理](docs/Java/collection/Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理.md) \n* [Java集合详解:Queue和LinkedList](docs/Java/collection/Java集合详解:Queue和LinkedList.md)\n* [Java集合详解:Iterator,fail-fast机制与比较器](docs/Java/collection/Java集合详解:Iterator,fail-fast机制与比较器.md)\n* [Java集合详解:HashMap和HashTable](docs/Java/collection/Java集合详解:HashMap和HashTable.md)\n* [Java集合详解:深入理解LinkedHashMap和LRU缓存](docs/Java/collection/Java集合详解:深入理解LinkedHashMap和LRU缓存.md)\n* [Java集合详解:TreeMap和红黑树](docs/Java/collection/Java集合详解:TreeMap和红黑树.md)\n* [Java集合详解:HashSet,TreeSet与LinkedHashSet](docs/Java/collection/Java集合详解:HashSet,TreeSet与LinkedHashSet.md)\n* [Java集合详解:Java集合类细节精讲](docs/Java/collection/Java集合详解:Java集合类细节精讲.md)\n\n# JavaWeb\n\n* [走进JavaWeb技术世界:JavaWeb的由来和基础知识](docs/JavaWeb/走进JavaWeb技术世界:JavaWeb的由来和基础知识.md)\n* [走进JavaWeb技术世界:JSP与Servlet的曾经与现在](docs/JavaWeb/走进JavaWeb技术世界:JSP与Servlet的曾经与现在.md)\n* [走进JavaWeb技术世界:JDBC的进化与连接池技术](docs/JavaWeb/走进JavaWeb技术世界:JDBC的进化与连接池技术.md)\n* [走进JavaWeb技术世界:Servlet工作原理详解](docs/JavaWeb/走进JavaWeb技术世界:Servlet工作原理详解.md)\n* [走进JavaWeb技术世界:初探Tomcat的HTTP请求过程](docs/JavaWeb/走进JavaWeb技术世界:初探Tomcat的HTTP请求过程.md)\n* [走进JavaWeb技术世界:Tomcat5总体架构剖析](docs/JavaWeb/走进JavaWeb技术世界:Tomcat5总体架构剖析.md)\n* [走进JavaWeb技术世界:Tomcat和其他WEB容器的区别](docs/JavaWeb/走进JavaWeb技术世界:Tomcat和其他WEB容器的区别.md)\n* [走进JavaWeb技术世界:浅析Tomcat9请求处理流程与启动部署过程](docs/JavaWeb/走进JavaWeb技术世界:浅析Tomcat9请求处理流程与启动部署过程.md)\n* [走进JavaWeb技术世界:Java日志系统的诞生与发展](docs/JavaWeb/走进JavaWeb技术世界:Java日志系统的诞生与发展.md)\n* [走进JavaWeb技术世界:从JavaBean讲到Spring](docs/JavaWeb/走进JavaWeb技术世界:从JavaBean讲到Spring.md)\n* [走进JavaWeb技术世界:单元测试框架Junit](docs/JavaWeb/走进JavaWeb技术世界:单元测试框架Junit.md)\n* [走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven](docs/JavaWeb/走进JavaWeb技术世界:从手动编译打包到项目构建工具Maven.md)\n* [走进JavaWeb技术世界:Hibernate入门经典与注解式开发](docs/JavaWeb/走进JavaWeb技术世界:Hibernate入门经典与注解式开发.md)\n* [走进JavaWeb技术世界:Mybatis入门](docs/JavaWeb/走进JavaWeb技术世界:Mybatis入门.md)\n* [走进JavaWeb技术世界:深入浅出Mybatis基本原理](docs/JavaWeb/走进JavaWeb技术世界:深入浅出Mybatis基本原理.md)\n* [走进JavaWeb技术世界:极简配置的SpringBoot](docs/JavaWeb/走进JavaWeb技术世界:极简配置的SpringBoot.md)\n\n# Java进阶\n\n## 并发编程\n\n* [Java并发指南:并发基础与Java多线程](docs/Java/concurrency/Java并发指南:并发基础与Java多线程.md)\n* [Java并发指南:深入理解Java内存模型JMM](docs/Java/concurrency/Java并发指南:深入理解Java内存模型JMM.md)\n* [Java并发指南:并发三大问题与volatile关键字,CAS操作](docs/Java/concurrency/Java并发指南:并发三大问题与volatile关键字,CAS操作.md)\n* [Java并发指南:Java中的锁Lock和synchronized](docs/Java/concurrency/Java并发指南:Java中的锁Lock和synchronized.md)\n* [Java并发指南:JMM中的final关键字解析](docs/Java/concurrency/Java并发指南:JMM中的final关键字解析.md)\n* [Java并发指南:Java内存模型JMM总结](docs/Java/concurrency/Java并发指南:Java内存模型JMM总结.md)\n* [Java并发指南:JUC的核心类AQS详解](docs/Java/concurrency/Java并发指南:JUC的核心类AQS详解.md)\n* [Java并发指南:AQS中的公平锁与非公平锁,Condtion](docs/Java/concurrency/Java并发指南:AQS中的公平锁与非公平锁,Condtion.md)\n* [Java并发指南:AQS共享模式与并发工具类的实现](docs/Java/concurrency/Java并发指南:AQS共享模式与并发工具类的实现.md)\n* [Java并发指南:Java读写锁ReentrantReadWriteLock源码分析](docs/Java/concurrency/Java并发指南:Java读写锁ReentrantReadWriteLock源码分析.md)\n* [Java并发指南:解读Java阻塞队列BlockingQueue](docs/Java/concurrency/Java并发指南:解读Java阻塞队列BlockingQueue.md)\n* [Java并发指南:深度解读java线程池设计思想及源码实现](docs/Java/concurrency/Java并发指南:深度解读Java线程池设计思想及源码实现.md)\n* [Java并发指南:Java中的HashMap和ConcurrentHashMap全解析](docs/Java/concurrency/Java并发指南:Java中的HashMap和ConcurrentHashMap全解析.md)\n* [Java并发指南:JUC中常用的Unsafe和Locksupport](docs/Java/concurrency/Java并发指南:JUC中常用的Unsafe和Locksupport.md)\n* [Java并发指南:ForkJoin并发框架与工作窃取算法剖析](docs/Java/concurrency/Java并发指南:ForkJoin并发框架与工作窃取算法剖析.md)\n* [Java并发编程学习总结](docs/Java/concurrency/Java并发编程学习总结.md)\n\n## JVM\n\n* [JVM总结](docs/Java/JVM/JVM总结.md)\n* [深入理解JVM虚拟机:JVM内存的结构与消失的永久代](docs/Java/JVM/深入理解JVM虚拟机:JVM内存的结构与消失的永久代.md)\n* [深入理解JVM虚拟机:JVM垃圾回收基本原理和算法](docs/Java/JVM/深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md)\n* [深入理解JVM虚拟机:垃圾回收器详解](docs/Java/JVM/深入理解JVM虚拟机:垃圾回收器详解.md)\n* [深入理解JVM虚拟机:Javaclass介绍与解析实践](docs/Java/JVM/深入理解JVM虚拟机:Java字节码介绍与解析实践.md)\n* [深入理解JVM虚拟机:虚拟机字节码执行引擎](docs/Java/JVM/深入理解JVM虚拟机:虚拟机字节码执行引擎.md)\n* [深入理解JVM虚拟机:深入理解JVM类加载机制](docs/Java/JVM/深入理解JVM虚拟机:深入理解JVM类加载机制.md)\n* [深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现](docs/Java/JVM/深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md)\n* [深入了解JVM虚拟机:Java的编译期优化与运行期优化](docs/Java/JVM/深入理解JVM虚拟机:Java的编译期优化与运行期优化.md)\n* [深入理解JVM虚拟机:JVM监控工具与诊断实践](docs/Java/JVM/深入理解JVM虚拟机:JVM监控工具与诊断实践.md)\n* [深入理解JVM虚拟机:JVM常用参数以及调优实践](docs/Java/JVM/深入理解JVM虚拟机:JVM常用参数以及调优实践.md)\n* [深入理解JVM虚拟机:Java内存异常原理与实践](docs/Java/JVM/深入理解JVM虚拟机:Java内存异常原理与实践.md)\n* [深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战](docs/Java/JVM/深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md)\n* [深入理解JVM虚拟机:再谈四种引用及GC实践](docs/Java/JVM/深入理解JVM虚拟机:再谈四种引用及GC实践.md)\n* [深入理解JVM虚拟机:GC调优思路与常用工具](docs/Java/JVM/深入理解JVM虚拟机:GC调优思路与常用工具.md)\n\n## Java网络编程\n\n* [Java网络编程和NIO详解:JAVA 中原生的 socket 通信机制](docs/Java/network/Java网络编程与NIO详解:JAVA中原生的socket通信机制.md)\n* [Java网络编程与NIO详解:JAVA NIO 一步步构建IO多路复用的请求模型](docs/Java/network/Java网络编程与NIO详解:JavaNIO一步步构建IO多路复用的请求模型.md) \n* [Java网络编程和NIO详解:IO模型与Java网络编程模型](docs/Java/network/Java网络编程与NIO详解:IO模型与Java网络编程模型.md) \n* [Java网络编程与NIO详解:浅析NIO包中的BufferChannel和Selector](docs/Java/network/Java网络编程与NIO详解:浅析NIO包中的BufferChannel和Selector.md) \n* [Java网络编程和NIO详解:Java非阻塞IO和异步IO](docs/Java/network/Java网络编程与NIO详解:Java非阻塞IO和异步IO.md)\n* [Java网络编程与NIO详解:LinuxEpoll实现原理详解](docs/Java/network/Java网络编程与NIO详解:LinuxEpoll实现原理详解.md.md) \n* [Java网络编程与NIO详解:浅谈Linux中Selector的实现原理](docs/Java/network/Java网络编程与NIO详解:浅谈Linux中Selector的实现原理.md)\n* [Java网络编程与NIO详解:浅析mmap和DirectBuffer](docs/Java/network/Java网络编程与NIO详解:浅析mmap和DirectBuffer.md)\n* [Java网络编程与NIO详解:基于NIO的网络编程框架Netty](docs/Java/network/Java网络编程与NIO详解:基于NIO的网络编程框架Netty.md)\n* [Java网络编程与NIO详解:Java网络编程与NIO详解](docs/Java/network/Java网络编程与NIO详解:深度解读Tomcat中的NIO模型.md)\n* [Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO)](docs/Java/network/Java网络编程与NIO详解:Tomcat中的Connector源码分析(NIO).md)\n\n# Spring全家桶\n\n## Spring\n\n* [SpringAOP的概念与作用](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [SpringBean的定义与管理(核心)](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring中对于数据库的访问](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring中对于校验功能的支持](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring中的Environment环境变量](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring中的事件处理机制](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring中的资源管理](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring中的配置元数据(管理配置的基本数据)](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring事务基本用法](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring合集](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring容器与IOC](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring常见注解](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [Spring概述](docs/Spring全家桶/Spring/Spring常见注解.md)\n* [第一个Spring应用](docs/Spring全家桶/Spring/Spring常见注解.md)\n\n## Spring源码分析\n\n### 综合\n* [Spring源码剖析:初探SpringIOC核心流程](docs/Spring全家桶/Spring源码分析/Spring源码剖析:初探SpringIOC核心流程.md)\n* [Spring源码剖析:SpringIOC容器的加载过程 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:SpringIOC容器的加载过程.md)\n* [Spring源码剖析:懒加载的单例Bean获取过程分析](docs/Spring全家桶/Spring源码分析/Spring源码剖析:懒加载的单例Bean获取过程分析.md)\n* [Spring源码剖析:JDK和cglib动态代理原理详解 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:JDK和cglib动态代理原理详解.md)\n* [Spring源码剖析:SpringAOP概述](docs/Spring全家桶/Spring源码分析/Spring源码剖析:SpringAOP概述.md)\n* [Spring源码剖析:AOP实现原理详解 ](docs/Spring全家桶/Spring源码分析/Spring源码剖析:AOP实现原理详解.md)\n* [Spring源码剖析:Spring事务概述](docs/Spring全家桶/Spring源码分析/Spring源码剖析:Spring事务概述.md)\n* [Spring源码剖析:Spring事务源码剖析](docs/Spring全家桶/Spring源码分析/Spring源码剖析:Spring事务源码剖析.md)\n\n### AOP\n* [AnnotationAwareAspectJAutoProxyCreator 分析(上)](docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(上).md)\n* [AnnotationAwareAspectJAutoProxyCreator 分析(下)](docs/Spring全家桶/Spring源码分析/SpringAOP/AnnotationAwareAspectJAutoProxyCreator分析(下).md)\n* [AOP示例demo及@EnableAspectJAutoProxy](docs/Spring全家桶/Spring源码分析/SpringAOP/AOP示例demo及@EnableAspectJAutoProxy.md)\n* [SpringAop(四):jdk 动态代理](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(四):jdk动态代理.md)\n* [SpringAop(五):cglib 代理](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(五):cglib代理.md)\n* [SpringAop(六):aop 总结](docs/Spring全家桶/Spring源码分析/SpringAOP/SpringAop(六):aop总结.md)\n\n### 事务\n* [spring 事务(一):认识事务组件](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(一):认识事务组件.md)\n* [spring 事务(二):事务的执行流程](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(二):事务的执行流程.md)\n* [spring 事务(三):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(三):事务的隔离级别与传播方式的处理01.md)\n* [spring 事务(四):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(四):事务的隔离级别与传播方式的处理02.md)\n* [spring 事务(五):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(五):事务的隔离级别与传播方式的处理03.md)\n* [spring 事务(六):事务的隔离级别与传播方式的处理](docs/Spring全家桶/Spring源码分析/Spring事务/Spring事务(六):事务的隔离级别与传播方式的处理04.md)\n\n### 启动流程\n* [spring启动流程(一):启动流程概览](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(一):启动流程概览.md)\n* [spring启动流程(二):ApplicationContext 的创建](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(二):ApplicationContext的创建.md)\n* [spring启动流程(三):包的扫描流程](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(三):包的扫描流程.md)\n* [spring启动流程(四):启动前的准备工作](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(四):启动前的准备工作.md)\n* [spring启动流程(五):执行 BeanFactoryPostProcessor](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(五):执行BeanFactoryPostProcessor.md)\n* [spring启动流程(六):注册 BeanPostProcessor](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(六):注册BeanPostProcessor.md)\n* [spring启动流程(七):国际化与事件处理](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(七):国际化与事件处理.md)\n* [spring启动流程(八):完成 BeanFactory 的初始化](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(八):完成BeanFactory的初始化.md)\n* [spring启动流程(九):单例 bean 的创建](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(九):单例bean的创建.md)\n* [spring启动流程(十):启动完成的处理](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(十):启动完成的处理.md)\n* [spring启动流程(十一):启动流程总结](docs/Spring全家桶/Spring源码分析/Spring启动流程/Spring启动流程(十一):启动流程总结.md)\n\n### 组件分析\n* [spring 组件之 ApplicationContext](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之ApplicationContext.md)\n* [spring 组件之 BeanDefinition](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanDefinition.md)\n* [Spring 组件之 BeanFactory](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanFactory.md)\n* [spring 组件之 BeanFactoryPostProcessor](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanFactoryPostProcessor.md)\n* [spring 组件之 BeanPostProcessor](docs/Spring全家桶/Spring源码分析/Spring组件分析/Spring组件之BeanPostProcessor.md)\n\n### 重要机制探秘\n\n* [ConfigurationClassPostProcessor(一):处理 @ComponentScan 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(一):处理@ComponentScan注解.md)\n* [ConfigurationClassPostProcessor(三):处理 @Import 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(三):处理@Import注解.md)\n* [ConfigurationClassPostProcessor(二):处理 @Bean 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(二):处理@Bean注解.md)\n* [ConfigurationClassPostProcessor(四):处理 @Conditional 注解](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/ConfigurationClassPostProcessor(四):处理@Conditional注解.md)\n* [Spring 探秘之 AOP 的执行顺序](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之AOP的执行顺序.md)\n* [Spring 探秘之 Spring 事件机制](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之Spring事件机制.md)\n* [spring 探秘之循环依赖的解决(一):理论基石](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之循环依赖的解决(一):理论基石.md)\n* [spring 探秘之循环依赖的解决(二):源码分析](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之循环依赖的解决(二):源码分析.md)\n* [spring 探秘之监听器注解 @EventListener](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/spring探秘之监听器注解@EventListener.md)\n* [spring 探秘之组合注解的处理](docs/Spring全家桶/Spring源码分析/Spring重要机制探秘/Spring探秘之组合注解的处理.md)\n\n## SpringMVC\n\n* [SpringMVC中的国际化功能](docs/Spring全家桶/SpringMVC/SpringMVC中的国际化功能.md)\n* [SpringMVC中的异常处理器](docs/Spring全家桶/SpringMVC/SpringMVC中的异常处理器.md)\n* [SpringMVC中的拦截器](docs/Spring全家桶/SpringMVC/SpringMVC中的拦截器.md)\n* [SpringMVC中的视图解析器](docs/Spring全家桶/SpringMVC/SpringMVC中的视图解析器.md)\n* [SpringMVC中的过滤器Filter](docs/Spring全家桶/SpringMVC/SpringMVC中的过滤器Filter.md)\n* [SpringMVC基本介绍与快速入门](docs/Spring全家桶/SpringMVC/SpringMVC基本介绍与快速入门.md)\n* [SpringMVC如何实现文件上传](docs/Spring全家桶/SpringMVC/SpringMVC如何实现文件上传.md)\n* [SpringMVC中的常用功能](docs/Spring全家桶/SpringMVC/SpringMVC中的常用功能.md)\n\n## SpringMVC源码分析\n\n* [SpringMVC源码分析:SpringMVC概述](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC概述.md)\n* [SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:SpringMVC设计理念与DispatcherServlet.md)\n* [SpringMVC源码分析:DispatcherServlet的初始化与请求转发 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet的初始化与请求转发.md)\n* [SpringMVC源码分析:DispatcherServlet如何找到正确的Controller ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC源码分析:DispatcherServlet如何找到正确的Controller.md)\n* [SpringMVC源码剖析:消息转换器HttpMessageConverter与@ResponseBody注解](docs/Spring全家桶/SpringMVC/SpringMVC源码剖析:消息转换器HttpMessageConverter与@ResponseBody注解.md)\n* [DispatcherServlet 初始化流程 ](docs/Spring全家桶/SpringMVC源码分析/DispatcherServlet初始化流程.md)\n* [RequestMapping 初始化流程 ](docs/Spring全家桶/SpringMVC源码分析/RequestMapping初始化流程.md)\n* [Spring 容器启动 Tomcat ](docs/Spring全家桶/SpringMVC源码分析/Spring容器启动Tomcat.md)\n* [SpringMVC demo 与@EnableWebMvc 注解 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC的Demo与@EnableWebMvc注解.md)\n* [SpringMVC 整体源码结构总结 ](docs/Spring全家桶/SpringMVC源码分析/SpringMVC整体源码结构总结.md)\n* [请求执行流程(一)之获取 Handler ](docs/Spring全家桶/SpringMVC源码分析/请求执行流程(一)之获取Handler.md)\n* [请求执行流程(二)之执行 Handler 方法 ](docs/Spring全家桶/SpringMVC源码分析/请求执行流程(二)之执行Handler方法.md)\n\n## SpringBoot\n\n* [SpringBoot系列:SpringBoot的前世今生](docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md)\n* [给你一份SpringBoot知识清单.md](docs/Spring全家桶/SpringBoot/给你一份SpringBoot知识清单.md)\n* [Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot)](docs/Spring全家桶/SpringBoot/Spring常见注解使用指南(包含Spring+SpringMVC+SpringBoot).md)\n* [SpringBoot中的日志管理](docs/Spring全家桶/SpringBoot/SpringBoot中的日志管理.md)\n* [SpringBoot常见注解](docs/Spring全家桶/SpringBoot/SpringBoot常见注解.md)\n* [SpringBoot应用也可以部署到外部Tomcat](docs/Spring全家桶/SpringBoot/SpringBoot应用也可以部署到外部Tomcat.md)\n* [SpringBoot生产环境工具Actuator](docs/Spring全家桶/SpringBoot/SpringBoot生产环境工具Actuator.md)\n* [SpringBoot的Starter机制](docs/Spring全家桶/SpringBoot/SpringBoot的Starter机制.md)\n* [SpringBoot的前世今生](docs/Spring全家桶/SpringBoot/SpringBoot的前世今生.md)\n* [SpringBoot的基本使用](docs/Spring全家桶/SpringBoot/SpringBoot的基本使用.md)\n* [SpringBoot的配置文件管理](docs/Spring全家桶/SpringBoot/SpringBoot的配置文件管理.md)\n* [SpringBoot自带的热部署工具](docs/Spring全家桶/SpringBoot/SpringBoot自带的热部署工具.md)\n* [SpringBoot中的任务调度与@Async](docs/Spring全家桶/SpringBoot/SpringBoot中的任务调度与@Async.md)\n* [基于SpringBoot中的开源监控工具SpringBootAdmin](docs/Spring全家桶/SpringBoot/基于SpringBoot中的开源监控工具SpringBootAdmin.md)\n\n## SpringBoot源码分析\n* [@SpringBootApplication 注解](docs/Spring全家桶/SpringBoot源码解析/@SpringBootApplication注解.md)\n* [springboot web应用(一):servlet 组件的注册流程](docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(一):servlet组件的注册流程.md)\n* [springboot web应用(二):WebMvc 装配过程](docs/Spring全家桶/SpringBoot源码解析/SpringBootWeb应用(二):WebMvc装配过程.md)\n\n* [SpringBoot 启动流程(一):准备 SpringApplication](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(一):准备SpringApplication.md)\n* [SpringBoot 启动流程(二):准备运行环境](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(二):准备运行环境.md)\n* [SpringBoot 启动流程(三):准备IOC容器](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(三):准备IOC容器.md)\n* [springboot 启动流程(四):启动IOC容器](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(四):启动IOC容器.md)\n* [springboot 启动流程(五):完成启动](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(五):完成启动.md)\n* [springboot 启动流程(六):启动流程总结](docs/Spring全家桶/SpringBoot源码解析/SpringBoot启动流程(六):启动流程总结.md)\n\n* [springboot 自动装配(一):加载自动装配类](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(一):加载自动装配类.md)\n* [springboot 自动装配(二):条件注解](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(二):条件注解.md)\n* [springboot 自动装配(三):自动装配顺序](docs/Spring全家桶/SpringBoot源码解析/SpringBoot自动装配(三):自动装配顺序.md)\n\n## SpringCloud\n* [SpringCloud概述](docs/Spring全家桶/SpringCloud/SpringCloud概述.md)\n* [Spring Cloud Config](docs/Spring全家桶/SpringCloud/SpringCloudConfig.md)\n* [Spring Cloud Consul](docs/Spring全家桶/SpringCloud/SpringCloudConsul.md)\n* [Spring Cloud Eureka](docs/Spring全家桶/SpringCloud/SpringCloudEureka.md)\n* [Spring Cloud Gateway](docs/Spring全家桶/SpringCloud/SpringCloudGateway.md)\n* [Spring Cloud Hystrix](docs/Spring全家桶/SpringCloud/SpringCloudHystrix.md)\n* [Spring Cloud LoadBalancer](docs/Spring全家桶/SpringCloud/SpringCloudLoadBalancer.md)\n* [Spring Cloud OpenFeign](docs/Spring全家桶/SpringCloud/SpringCloudOpenFeign.md)\n* [Spring Cloud Ribbon](docs/Spring全家桶/SpringCloud/SpringCloudRibbon.md)\n* [Spring Cloud Sleuth](docs/Spring全家桶/SpringCloud/SpringCloudSleuth.md)\n* [Spring Cloud Zuul](docs/Spring全家桶/SpringCloud/SpringCloudZuul.md)\n\n## SpringCloud 源码分析\n* [Spring Cloud Config源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudConfig源码分析.md)\n* [Spring Cloud Eureka源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudEureka源码分析.md)\n* [Spring Cloud Gateway源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudGateway源码分析.md)\n* [Spring Cloud Hystrix源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudHystrix源码分析.md)\n* [Spring Cloud LoadBalancer源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudLoadBalancer源码分析.md)\n* [Spring Cloud OpenFeign源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudOpenFeign源码分析.md)\n* [Spring Cloud Ribbon源码分析](docs/Spring全家桶/SpringCloud源码分析/SpringCloudRibbon源码分析.md)\n\n## SpringCloud Alibaba\n* [SpringCloud Alibaba概览](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibaba概览.md)\n* [SpringCloud Alibaba nacos](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaNacos.md)\n* [SpringCloud Alibaba RocketMQ](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaRocketMQ.md)\n* [SpringCloud Alibaba sentinel](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSentinel.md)\n* [SpringCloud Alibaba skywalking](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSkywalking.md)\n* [SpringCloud Alibaba seata](docs/Spring全家桶/SpringCloudAlibaba/SpringCloudAlibabaSeata.md)\n\n## SpringCloud Alibaba源码分析\n* [Spring Cloud Seata源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSeata源码分析.md)\n* [Spring Cloud Sentinel源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudSentinel源码分析.md)\n* [SpringCloudAlibaba nacos源码分析:概览](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:概览.md)\n* [SpringCloudAlibaba nacos源码分析:服务发现](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务发现.md)\n* [SpringCloudAlibaba nacos源码分析:服务注册](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:服务注册.md)\n* [SpringCloudAlibaba nacos源码分析:配置中心](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudAlibabaNacos源码分析:配置中心.md)\n* [Spring Cloud RocketMQ源码分析](docs/Spring全家桶/SpringCloudAlibaba源码分析/SpringCloudRocketMQ源码分析.md)\n\n# 设计模式\n\n* [设计模式学习总结](docs/Java/design-parttern/设计模式学习总结.md)\n* [初探Java设计模式:创建型模式(工厂,单例等).md](docs/Java/design-parttern/初探Java设计模式:创建型模式(工厂,单例等).md)\n* [初探Java设计模式:结构型模式(代理模式,适配器模式等).md](docs/Java/design-parttern/初探Java设计模式:结构型模式(代理模式,适配器模式等).md)\n* [初探Java设计模式:行为型模式(策略,观察者等).md](docs/Java/design-parttern/初探Java设计模式:行为型模式(策略,观察者等).md)\n* [初探Java设计模式:JDK中的设计模式.md](docs/Java/design-parttern/初探Java设计模式:JDK中的设计模式.md)\n* [初探Java设计模式:Spring涉及到的种设计模式.md](docs/Java/design-parttern/初探Java设计模式:Spring涉及到的种设计模式.md)\n\n\n# 计算机基础\n\n## 计算机网络\ntodo\n\n\n## 操作系统\ntodo\n\n## Linux相关\ntodo\n\n\n## 数据结构与算法\ntodo\n\n## 数据结构\ntodo\n\n## 算法\ntodo\n\n# 数据库\ntodo\n\n## MySQL\n* [Mysql原理与实践总结](docs/database/Mysql原理与实践总结.md)\n* [重新学习Mysql数据库:无废话MySQL入门](docs/database/重新学习MySQL数据库:无废话MySQL入门.md)\n* [重新学习Mysql数据库:『浅入浅出』MySQL和InnoDB](docs/database/重新学习MySQL数据库:『浅入浅出』MySQL和InnoDB.md)\n* [重新学习Mysql数据库:Mysql存储引擎与数据存储原理](docs/database/重新学习MySQL数据库:Mysql存储引擎与数据存储原理.md)\n* [重新学习Mysql数据库:Mysql索引实现原理和相关数据结构算法](docs/database/重新学习MySQL数据库:Mysql索引实现原理和相关数据结构算法.md)\n* [重新学习Mysql数据库:根据MySQL索引原理进行分析与优化](docs/database/重新学习MySQL数据库:根据MySQL索引原理进行分析与优化.md)\n* [重新学习MySQL数据库:浅谈MySQL的中事务与锁](docs/database/重新学习MySQL数据库:浅谈MySQL的中事务与锁.md) \n* [重新学习Mysql数据库:详解MyIsam与InnoDB引擎的锁实现](docs/database/重新学习MySQL数据库:详解MyIsam与InnoDB引擎的锁实现.md) \n* [重新学习Mysql数据库:MySQL的事务隔离级别实战](docs/database/重新学习MySQL数据库:MySQL的事务隔离级别实战.md)\n* [重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系](docs/database/重新学习MySQL数据库:Innodb中的事务隔离级别和锁的关系.md) \n* [重新学习MySQL数据库:MySQL里的那些日志们](docs/database/重新学习MySQL数据库:MySQL里的那些日志们.md) \n* [重新学习MySQL数据库:以Java的视角来聊聊SQL注入](docs/database/重新学习MySQL数据库:以Java的视角来聊聊SQL注入.md) \n* [重新学习MySQL数据库:从实践sql语句优化开始](docs/database/重新学习MySQL数据库:从实践sql语句优化开始.md) \n* [重新学习Mysql数据库:Mysql主从复制,读写分离,分表分库策略与实践](docs/database/重新学习MySQL数据库:Mysql主从复制,读写分离,分表分库策略与实践.md)\n\n\n# 缓存\n\n## Redis\n* [Redis原理与实践总结](docs/cache/Redis原理与实践总结.md)\n* [探索Redis设计与实现开篇:什么是Redis](docs/cache/探索Redis设计与实现开篇:什么是Redis.md)\n* [探索Redis设计与实现:Redis的基础数据结构概览](docs/cache/探索Redis设计与实现:Redis的基础数据结构概览.md)\n* [探索Redis设计与实现:Redis内部数据结构详解——dict](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——dict.md)\n* [探索Redis设计与实现:Redis内部数据结构详解——sds](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——sds.md)\n* [探索Redis设计与实现:Redis内部数据结构详解——ziplist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——ziplist.md)\n* [探索Redis设计与实现:Redis内部数据结构详解——quicklist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——quicklist.md)\n* [探索Redis设计与实现:Redis内部数据结构详解——skiplist](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——skiplist.md)\n* [探索Redis设计与实现:Redis内部数据结构详解——intset](docs/cache/探索Redis设计与实现:Redis内部数据结构详解——intset.md)\n* [探索Redis设计与实现:连接底层与表面的数据结构robj](docs/cache/探索Redis设计与实现:连接底层与表面的数据结构robj.md)\n* [探索Redis设计与实现:数据库redisDb与键过期删除策略](docs/cache/探索Redis设计与实现:数据库redisDb与键过期删除策略.md)\n* [探索Redis设计与实现:Redis的事件驱动模型与命令执行过程](docs/cache/探索Redis设计与实现:Redis的事件驱动模型与命令执行过程.md)\n* [探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中](docs/cache/探索Redis设计与实现:使用快照和AOF将Redis数据持久化到硬盘中.md)\n* [探索Redis设计与实现:浅析Redis主从复制](docs/cache/探索Redis设计与实现:浅析Redis主从复制.md)\n* [探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例](docs/cache/探索Redis设计与实现:Redis集群机制及一个Redis架构演进实例.md)\n* [探索Redis设计与实现:Redis事务浅析与ACID特性介绍](docs/cache/探索Redis设计与实现:Redis事务浅析与ACID特性介绍.md)\n* [探索Redis设计与实现:Redis分布式锁进化史 ](docs/cache/探索Redis设计与实现:Redis分布式锁进化史.md )\n\n# 消息队列\n\n## Kafka\n* [消息队列kafka详解:Kafka快速上手(Java版)](docs/mq/kafka/消息队列kafka详解:Kafka快速上手(Java版).md)\n* [消息队列kafka详解:Kafka一条消息存到broker的过程](docs/mq/kafka/消息队列kafka详解:Kafka一条消息存到broker的过程.md)\n* [消息队列kafka详解:消息队列kafka详解:Kafka介绍](docs/mq/kafka/消息队列kafka详解:Kafka介绍.md)\n* [消息队列kafka详解:Kafka原理分析总结篇](docs/mq/kafka/消息队列kafka详解:Kafka原理分析总结篇.md)\n* [消息队列kafka详解:Kafka常见命令及配置总结](docs/mq/kafka/消息队列kafka详解:Kafka常见命令及配置总结.md)\n* [消息队列kafka详解:Kafka架构介绍](docs/mq/kafka/消息队列kafka详解:Kafka架构介绍.md)\n* [消息队列kafka详解:Kafka的集群工作原理](docs/mq/kafka/消息队列kafka详解:Kafka的集群工作原理.md)\n* [消息队列kafka详解:Kafka重要知识点+面试题大全](docs/mq/kafka/消息队列kafka详解:Kafka重要知识点+面试题大全.md)\n* [消息队列kafka详解:如何实现延迟队列](docs/mq/kafka/消息队列kafka详解:如何实现延迟队列.md)\n* [消息队列kafka详解:如何实现死信队列](docs/mq/kafka/消息队列kafka详解:如何实现死信队列.md)\n\n## RocketMQ\n* [RocketMQ系列:事务消息(最终一致性)](docs/mq/RocketMQ/RocketMQ系列:事务消息(最终一致性).md)\n* [RocketMQ系列:基本概念](docs/mq/RocketMQ/RocketMQ系列:基本概念.md)\n* [RocketMQ系列:广播与延迟消息](docs/mq/RocketMQ/RocketMQ系列:广播与延迟消息.md)\n* [RocketMQ系列:批量发送与过滤](docs/mq/RocketMQ/RocketMQ系列:批量发送与过滤.md)\n* [RocketMQ系列:消息的生产与消费](docs/mq/RocketMQ/RocketMQ系列:消息的生产与消费.md)\n* [RocketMQ系列:环境搭建](docs/mq/RocketMQ/RocketMQ系列:环境搭建.md)\n* [RocketMQ系列:顺序消费](docs/mq/RocketMQ/RocketMQ系列:顺序消费.md)\n\n# 大后端\n* [后端技术杂谈开篇:云计算,大数据与AI的故事](docs/backend/后端技术杂谈开篇:云计算,大数据与AI的故事.md)\n* [后端技术杂谈:搜索引擎基础倒排索引](docs/backend/后端技术杂谈:搜索引擎基础倒排索引.md)\n* [后端技术杂谈:搜索引擎工作原理](docs/backend/后端技术杂谈:搜索引擎工作原理.md)\n* [后端技术杂谈:Lucene基础原理与实践](docs/backend/后端技术杂谈:Lucene基础原理与实践.md)\n* [后端技术杂谈:Elasticsearch与solr入门实践](docs/backend/后端技术杂谈:Elasticsearch与solr入门实践.md)\n* [后端技术杂谈:云计算的前世今生](docs/backend/后端技术杂谈:云计算的前世今生.md)\n* [后端技术杂谈:白话虚拟化技术](docs/backend/后端技术杂谈:白话虚拟化技术.md )\n* [后端技术杂谈:OpenStack的基石KVM](docs/backend/后端技术杂谈:OpenStack的基石KVM.md)\n* [后端技术杂谈:OpenStack架构设计](docs/backend/后端技术杂谈:OpenStack架构设计.md)\n* [后端技术杂谈:先搞懂Docker核心概念吧](docs/backend/后端技术杂谈:先搞懂Docker核心概念吧.md)\n* [后端技术杂谈:Docker 核心技术与实现原理](docs/backend/后端技术杂谈:Docker%核心技术与实现原理.md)\n* [后端技术杂谈:十分钟理解Kubernetes核心概念](docs/backend/后端技术杂谈:十分钟理解Kubernetes核心概念.md)\n* [后端技术杂谈:捋一捋大数据研发的基本概念](docs/backend/后端技术杂谈:捋一捋大数据研发的基本概念.md)\n\n# 分布式\n## 分布式理论\n* [分布式系统理论基础:一致性PC和PC ](docs/distributed/basic/分布式系统理论基础:一致性PC和PC.md)\n* [分布式系统理论基础:CAP ](docs/distributed/basic/分布式系统理论基础:CAP.md)\n* [分布式系统理论基础:时间时钟和事件顺序](docs/distributed/basic/分布式系统理论基础:时间时钟和事件顺序.md)\n* [分布式系统理论基础:Paxos](docs/distributed/basic/分布式系统理论基础:Paxos.md)\n* [分布式系统理论基础:选举多数派和租约](docs/distributed/basic/分布式系统理论基础:选举多数派和租约.md)\n* [分布式系统理论基础:RaftZab ](docs/distributed/basic/分布式系统理论基础:RaftZab.md)\n* [分布式系统理论进阶:Paxos变种和优化 ](docs/distributed/basic/分布式系统理论进阶:Paxos变种和优化.md)\n* [分布式系统理论基础:zookeeper分布式协调服务 ](docs/distributed/basic/分布式系统理论基础:zookeeper分布式协调服务.md)\n* [分布式理论总结](docs/distributed/分布式技术实践总结.md)\n\n## 分布式技术\n* [搞懂分布式技术:分布式系统的一些基本概念](docs/distributed/practice/搞懂分布式技术:分布式系统的一些基本概念.md )\n* [搞懂分布式技术:分布式一致性协议与Paxos,Raft算法](docs/distributed/practice/搞懂分布式技术:分布式一致性协议与Paxos,Raft算法.md)\n* [搞懂分布式技术:初探分布式协调服务zookeeper](docs/distributed/practice/搞懂分布式技术:初探分布式协调服务zookeeper.md )\n* [搞懂分布式技术:ZAB协议概述与选主流程详解](docs/distributed/practice/搞懂分布式技术:ZAB协议概述与选主流程详解.md )\n* [搞懂分布式技术:Zookeeper的配置与集群管理实战](docs/distributed/practice/搞懂分布式技术:Zookeeper的配置与集群管理实战.md)\n* [搞懂分布式技术:Zookeeper典型应用场景及实践](docs/distributed/practice/搞懂分布式技术:Zookeeper典型应用场景及实践.md )\n* [搞懂分布式技术:LVS实现负载均衡的原理与实践 ](docs/distributed/practice/搞懂分布式技术:LVS实现负载均衡的原理与实践.md )\n* [搞懂分布式技术:分布式session解决方案与一致性hash](docs/distributed/practice/搞懂分布式技术:分布式session解决方案与一致性hash.md)\n* [搞懂分布式技术:分布式ID生成方案 ](docs/distributed/practice/搞懂分布式技术:分布式ID生成方案.md )\n* [搞懂分布式技术:缓存的那些事](docs/distributed/practice/搞懂分布式技术:缓存的那些事.md)\n* [搞懂分布式技术:SpringBoot使用注解集成Redis缓存](docs/distributed/practice/搞懂分布式技术:SpringBoot使用注解集成Redis缓存.md)\n* [搞懂分布式技术:缓存更新的套路 ](docs/distributed/practice/搞懂分布式技术:缓存更新的套路.md )\n* [搞懂分布式技术:浅谈分布式锁的几种方案 ](docs/distributed/practice/搞懂分布式技术:浅谈分布式锁的几种方案.md )\n* [搞懂分布式技术:浅析分布式事务](docs/distributed/practice/搞懂分布式技术:浅析分布式事务.md )\n* [搞懂分布式技术:分布式事务常用解决方案 ](docs/distributed/practice/搞懂分布式技术:分布式事务常用解决方案.md )\n* [搞懂分布式技术:使用RocketMQ事务消息解决分布式事务 ](docs/distributed/practice/搞懂分布式技术:使用RocketMQ事务消息解决分布式事务.md )\n* [搞懂分布式技术:消息队列因何而生](docs/distributed/practice/搞懂分布式技术:消息队列因何而生.md)\n* [搞懂分布式技术:浅谈分布式消息技术Kafka](docs/distributed/practice/搞懂分布式技术:浅谈分布式消息技术Kafka.md )\n* [分布式技术实践总结](docs/distributed/分布式理论总结.md)\n\n# 面试指南\n\ntodo\n## 校招指南\ntodo\n\n## 面经\ntodo\n\n# 工具\ntodo\n\n# 资料\ntodo\n\n## 书单\ntodo\n\n# 待办\nspringboot和springcloud\n\n# 微信公众号\n\n## Java技术江湖\n如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】\n\n"
},
{
"path": "docs/Java/JVM/JVM总结.md",
"content": "# 目录\n\n * [JVM介绍和源码](#jvm介绍和源码)\n * [JVM内存模型](#jvm内存模型)\n * [JVM OOM和内存泄漏](#jvm-oom和内存泄漏)\n * [常见调试工具](#常见调试工具)\n * [class文件结构](#class文件结构)\n * [JVM的类加载机制](#jvm的类加载机制)\n * [defineclass findclass和loadclass](#defineclass-findclass和loadclass)\n * [JVM虚拟机字节码执行引擎](#jvm虚拟机字节码执行引擎)\n * [编译期优化和运行期优化](#编译期优化和运行期优化)\n * [JVM的垃圾回收](#jvm的垃圾回收)\n * [JVM的锁优化](#jvm的锁优化)\n\n\n\n---\ntitle: JVM原理学习总结\ndate: 2018-07-08 22:09:47\ntags:\n\t- JVM\ncategories:\n\t- 后端\n\t- 技术总结\n---\n\n这篇总结主要是基于我之前JVM系列文章而形成的的。主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点。谢谢\n\n更多详细内容可以查看我的专栏文章:深入理解JVM虚拟机\n\nhttps://blog.csdn.net/column/details/21960.html\n\n\n## JVM介绍和源码\n\n首先JVM是一个虚拟机,当你安装了jre,它就包含了jvm环境。JVM有自己的内存结构,字节码执行引擎,因此class字节码才能在jvm上运行,除了Java以外,Scala,groovy等语言也可以编译成字节码而后在jvm中运行。JVM是用c开发的。\n\n## JVM内存模型\n\n内存模型老生常谈了,主要就是线程共享的堆区,方法区,本地方法栈。还有线程私有的虚拟机栈和程序计数器。\n\n堆区存放所有对象,每个对象有一个地址,Java类jvm初始化时加载到方法区,而后会在堆区中生成一个Class对象,来负责这个类所有实例的实例化。\n\n\n\n栈区存放的是栈帧结构,栈帧是一段内存空间,包括参数列表,返回地址,局部变量表等,局部变量表由一堆slot组成,slot的大小固定,根据变量的数据类型决定需要用到几个slot。\n\n方法区存放类的元数据,将原来的字面量转换成引用,当然,方法区也提供常量池,常量池存放-128到127的数字类型的包装类。\n字符串常量池则会存放使用intern的字符串变量。\n## JVM OOM和内存泄漏\n\n这里指的是oom和内存泄漏这类错误。\n\noom一般分为三种,堆区内存溢出,栈区内存溢出以及方法区内存溢出。\n\n堆内存溢出主要原因是创建了太多对象,比如一个集合类死循环添加一个数,此时设置jvm参数使堆内存最大值为10m,一会就会报oom异常。\n\n栈内存溢出主要与栈空间和线程有关,因为栈是线程私有的,如果创建太多线程,内存值超过栈空间上限,也会报oom。\n\n方法区内存溢出主要是由于动态加载类的数量太多,或者是不断创建一个动态代理,用不了多久方法区内存也会溢出,会报oom,这里在1.7之前会报permgem oom,1.8则会报meta space oom,这是因为1.8中删除了堆中的永久代,转而使用元数据区。\n\n内存泄漏一般是因为对象被引用无法回收,比如一个集合中存着很多对象,可能你在外部代码把对象的引用置空了,但是由于对象还被集合给引用着,所以无法被回收,导致内存泄漏。测试也很简单,就在集合里添加对象,添加完以后把引用置空,循环操作,一会就会出现oom异常,原因是内存泄漏太多了,导致没有空间分配新的对象。\n\n## 常见调试工具\n\n命令行工具有jstack jstat jmap 等,jstack可以跟踪线程的调用堆栈,以便追踪错误原因。\n\njstat可以检查jvm的内存使用情况,gc情况以及线程状态等。\n\njmap用于把堆栈快照转储到文件系统,然后可以用其他工具去排查。\n\nvisualvm是一款很不错的gui调试工具,可以远程登录主机以便访问其jvm的状态并进行监控。\n\n## class文件结构\n\nclass文件结构比较复杂,首先jvm定义了一个class文件的规则,并且让jvm按照这个规则去验证与读取。\n\n开头是一串魔数,然后接下来会有各种不同长度的数据,通过class的规则去读取这些数据,jvm就可以识别其内容,最后将其加载到方法区。\n\n## JVM的类加载机制\n\njvm的类加载顺序是bootstrap类加载器,extclassloader加载器,最后是appclassloader用户加载器,分别加载的是jdk/bin ,jdk/ext以及用户定义的类目录下的类(一般通过ide指定),一般核心类都由bootstrap和ext加载器来加载,appclassloader用于加载自己写的类。\n\n双亲委派模型,加载一个类时,首先获取当前类加载器,先找到最高层的类加载器bootstrap让他尝试加载,他如果加载不了再让ext加载器去加载,如果他也加载不了再让appclassloader去加载。这样的话,确保一个类型只会被加载一次,并且以高层类加载器为准,防止某些类与核心类重复,产生错误。\n\n## defineclass findclass和loadclass\n\n类加载classloader中有两个方法loadclass和findclass,loadclass遵从双亲委派模型,先调用父类加载的loadclass,如果父类和自己都无法加载该类,则会去调用findclass方法,而findclass默认实现为空,如果要自定义类加载方式,则可以重写findclass方法。\n\n常见使用defineclass的情况是从网络或者文件读取字节码,然后通过defineclass将其定义成一个类,并且返回一个Class对象,说明此时类已经加载到方法区了。当然1.8以前实现方法区的是永久代,1.8以后则是元空间了。\n\n## JVM虚拟机字节码执行引擎\n\njvm通过字节码执行引擎来执行class代码,他是一个栈式执行引擎。这部分内容比较高深,在这里就不献丑了。\n\n## 编译期优化和运行期优化\n\n编译期优化主要有几种\n\n1 泛型的擦除,使得泛型在编译时变成了实际类型,也叫伪泛型。\n\n2 自动拆箱装箱,foreach循环自动变成迭代器实现的for循环。\n\n3 条件编译,比如if(true)直接可得。\n\n运行期优化主要有几种\n\n1 JIT即时编译\n\nJava既是编译语言也是解释语言,因为需要编译代码生成字节码,而后通过解释器解释执行。\n\n但是,有些代码由于经常被使用而成为热点代码,每次都编译太过费时费力,干脆直接把他编译成本地代码,这种方式叫做JIT即时编译处理,所以这部分代码可以直接在本地运行而不需要通过jvm的执行引擎。\n\n2 公共表达式擦除,就是一个式子在后面如果没有被修改,在后面调用时就会被直接替换成数值。\n\n3 数组边界擦除,方法内联,比较偏,意义不大。\n\n4 逃逸分析,用于分析一个对象的作用范围,如果只局限在方法中被访问,则说明不会逃逸出方法,这样的话他就是线程安全的,不需要进行并发加锁。\n\n1\n\n## JVM的垃圾回收\n\n1 GC算法:停止复制,存活对象少时适用,缺点是需要两倍空间。标记清除,存活对象多时适用,但是容易产生随便。标记整理,存活对象少时适用,需要移动对象较多。\n\n2 GC分区,一般GC发生在堆区,堆区可分为年轻代,老年代,以前有永久代,现在没有了。\n\n年轻代分为eden和survior,新对象分配在eden,当年轻代满时触发minor gc,存活对象移至survivor区,然后两个区互换,等待下一场gc,\n当对象存活的阈值达到设定值时进入老年代,大对象也会直接进入老年代。\n\n老年代空间较大,当老年代空间不足以存放年轻代过来的对象时,开始进行full gc。同时整理年轻代和老年代。\n一般年轻代使用停止复制,老年代使用标记清除。\n\n3 垃圾收集器\n\nserial串行\n\nparallel并行\n\n它们都有年轻代与老年代的不同实现。\n\n然后是scanvage收集器,注重吞吐量,可以自己设置,不过不注重延迟。\n\ncms垃圾收集器,注重延迟的缩短和控制,并且收集线程和系统线程可以并发。\n\ncms收集步骤主要是,初次标记gc root,然后停顿进行并发标记,而后处理改变后的标记,最后停顿进行并发清除。\n\ng1收集器和cms的收集方式类似,但是g1将堆内存划分成了大小相同的小块区域,并且将垃圾集中到一个区域,存活对象集中到另一个区域,然后进行收集,防止产生碎片,同时使分配方式更灵活,它还支持根据对象变化预测停顿时间,从而更好地帮用户解决延迟等问题。\n\n## JVM的锁优化\n\n在Java并发中讲述了synchronized重量级锁以及锁优化的方法,包括轻量级锁,偏向锁,自旋锁等。详细内容可以参考我的专栏:Java并发技术指南\n\n\n"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:GC调优思路与常用工具.md",
"content": "# 目录\n\n* [核心概念(Core Concepts)](#核心概念core-concepts)\n * [Latency(延迟)](#latency延迟)\n * [Throughput(吞吐量)](#throughput吞吐量)\n * [Capacity(系统容量)](#capacity系统容量)\n* [相关示例](#相关示例)\n * [Tuning for Latency(调优延迟指标)](#tuning-for-latency调优延迟指标)\n * [Tuning for Throughput(吞吐量调优)](#tuning-for-throughput吞吐量调优)\n * [Tuning for Capacity(调优系统容量)](#tuning-for-capacity调优系统容量)\n * [6\\. GC 调优(工具篇) - GC参考手册](#6-gc-调优工具篇---gc参考手册)\n * [JMX API](#jmx-api)\n * [JVisualVM](#jvisualvm)\n * [jstat](#jstat)\n * [GC日志(GC logs)](#gc日志gc-logs)\n * [GCViewer](#gcviewer)\n * [分析器(Profilers)](#分析器profilers)\n * [hprof](#hprof)\n * [Java VisualVM](#java-visualvm)\n * [AProf](#aprof)\n * [参考文章](#参考文章)\n\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n> **说明**:\n>\n> **Capacity**: 性能,能力,系统容量; 文中翻译为”**系统容量**“; 意为硬件配置。\n\n您应该已经阅读了前面的章节:\n\n1. 垃圾收集简介 - GC参考手册\n2. Java中的垃圾收集 - GC参考手册\n3. GC 算法(基础篇) - GC参考手册\n4. GC 算法(实现篇) - GC参考手册\n\nGC调优(Tuning Garbage Collection)和其他性能调优是同样的原理。初学者可能会被 200 多个 GC参数弄得一头雾水, 然后随便调整几个来试试结果,又或者修改几行代码来测试。其实只要参照下面的步骤,就能保证你的调优方向正确:\n\n1. 列出性能调优指标(State your performance goals)\n2. 执行测试(Run tests)\n3. 检查结果(Measure the results)\n4. 与目标进行对比(Compare the results with the goals)\n5. 如果达不到指标, 修改配置参数, 然后继续测试(go back to running tests)\n\n第一步, 我们需要做的事情就是: 制定明确的GC性能指标。对所有性能监控和管理来说, 有三个维度是通用的:\n\n* Latency(延迟)\n* Throughput(吞吐量)\n* Capacity(系统容量)\n\n我们先讲解基本概念,然后再演示如何使用这些指标。如果您对 延迟、吞吐量和系统容量等概念很熟悉, 可以跳过这一小节。\n\n### 核心概念(Core Concepts)\n\n我们先来看一家工厂的装配流水线。工人在流水线将现成的组件按顺序拼接,组装成自行车。通过实地观测, 我们发现从组件进入生产线,到另一端组装成自行车需要4小时。\n\n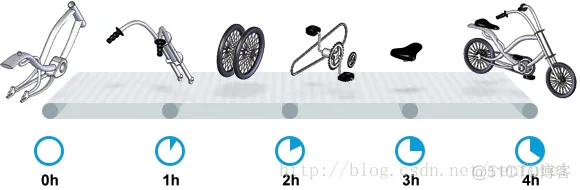\n继续观察,我们还发现,此后每分钟就有1辆自行车完成组装, 每天24小时,一直如此。将这个模型简化, 并忽略维护窗口期后得出结论:**这条流水线每小时可以组装60辆自行车**。\n\n> **说明**: 时间窗口/窗口期,请类比车站卖票的窗口,是一段规定/限定做某件事的时间段。\n\n通过这两种测量方法, 就知道了生产线的相关性能信息:**延迟**与**吞吐量**:\n\n* 生产线的延迟:**4小时**\n* 生产线的吞吐量:**60辆/小时**\n\n请注意, 衡量延迟的时间单位根据具体需要而确定 —— 从纳秒(nanosecond)到几千年(millennia)都有可能。系统的吞吐量是每个单位时间内完成的操作。操作(Operations)一般是特定系统相关的东西。在本例中,选择的时间单位是小时, 操作就是对自行车的组装。\n\n掌握了延迟和吞吐量两个概念之后, 让我们对这个工厂来进行实际的调优。自行车的需求在一段时间内都很稳定, 生产线组装自行车有四个小时延迟, 而吞吐量在几个月以来都很稳定: 60辆/小时。假设某个销售团队突然业绩暴涨, 对自行车的需求增加了1倍。客户每天需要的自行车不再是 60 * 24 = 1440辆, 而是 2*1440 = 2880辆/天。老板对工厂的产能不满意,想要做些调整以提升产能。\n\n看起来总经理很容易得出正确的判断, 系统的延迟没法子进行处理 —— 他关注的是每天的自行车生产总量。得出这个结论以后, 假若工厂资金充足, 那么应该立即采取措施, 改善吞吐量以增加产能。\n\n我们很快会看到, 这家工厂有两条相同的生产线。每条生产线一分钟可以组装一辆成品自行车。 可以想象,每天生产的自行车数量会增加一倍。达到 2880辆/天。要注意的是, 不需要减少自行车的装配时间 —— 从开始到结束依然需要 4 小时。\n\n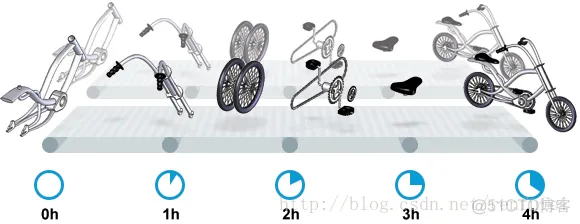\n\n巧合的是,这样进行的性能优化,同时增加了吞吐量和产能。一般来说,我们会先测量当前的系统性能, 再设定新目标, 只优化系统的某个方面来满足性能指标。\n\n在这里做了一个很重要的决定 —— 要增加吞吐量,而不是减小延迟。在增加吞吐量的同时, 也需要增加系统容量。比起原来的情况, 现在需要两条流水线来生产出所需的自行车。在这种情况下, 增加系统的吞吐量并不是免费的, 需要水平扩展, 以满足增加的吞吐量需求。\n\n在处理性能问题时, 应该考虑到还有另一种看似不相关的解决办法。假如生产线的延迟从1分钟降低为30秒,那么吞吐量同样可以增长 1 倍。\n\n或者是降低延迟, 或者是客户非常有钱。软件工程里有一种相似的说法 —— 每个性能问题背后,总有两种不同的解决办法。 可以用更多的机器, 或者是花精力来改善性能低下的代码。\n\n#### Latency(延迟)\n\nGC的延迟指标由一般的延迟需求决定。延迟指标通常如下所述:\n\n* 所有交易必须在10秒内得到响应\n* 90%的订单付款操作必须在3秒以内处理完成\n* 推荐商品必须在 100 ms 内展示到用户面前\n\n面对这类性能指标时, 需要确保在交易过程中, GC暂停不能占用太多时间,否则就满足不了指标。“不能占用太多” 的意思需要视具体情况而定, 还要考虑到其他因素, 比如外部数据源的交互时间(round-trips), 锁竞争(lock contention), 以及其他的安全点等等。\n\n假设性能需求为:`90%`的交易要在`1000ms`以内完成, 每次交易最长不能超过`10秒`。 根据经验, 假设GC暂停时间比例不能超过10%。 也就是说, 90%的GC暂停必须在`100ms`内结束, 也不能有超过`1000ms`的GC暂停。为简单起见, 我们忽略在同一次交易过程中发生多次GC停顿的可能性。\n\n有了正式的需求,下一步就是检查暂停时间。有许多工具可以使用, 在接下来的6\\. GC 调优(工具篇)\n\n\n\n```\n2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)\n [PSYoungGen: 93677K->70109K(254976K)] \n [ParOldGen: 499597K->511230K(761856K)] \n 593275K->581339K(1016832K),\n [Metaspace: 2936K->2936K(1056768K)]\n , 0.0713174 secs]\n [Times: user=0.21 sys=0.02, real=0.07 secs\n```\n\n\n\n这表示一次GC暂停, 在`2015-06-04T13:34:16`这个时刻触发. 对应于JVM启动之后的`2,578 ms`。\n\n此事件将应用线程暂停了`0.0713174`秒。虽然花费的总时间为 210 ms, 但因为是多核CPU机器, 所以最重要的数字是应用线程被暂停的总时间, 这里使用的是并行GC, 所以暂停时间大约为`70ms`。 这次GC的暂停时间小于`100ms`的阈值,满足需求。\n\n继续分析, 从所有GC日志中提取出暂停相关的数据, 汇总之后就可以得知是否满足需求。\n\n#### Throughput(吞吐量)\n\n吞吐量和延迟指标有很大区别。当然两者都是根据一般吞吐量需求而得出的。一般吞吐量需求(Generic requirements for throughput) 类似这样:\n\n* 解决方案每天必须处理 100万个订单\n* 解决方案必须支持1000个登录用户,同时在5-10秒内执行某个操作: A、B或C\n* 每周对所有客户进行统计, 时间不能超过6小时,时间窗口为每周日晚12点到次日6点之间。\n\n可以看出,吞吐量需求不是针对单个操作的, 而是在给定的时间内, 系统必须完成多少个操作。和延迟需求类似, GC调优也需要确定GC行为所消耗的总时间。每个系统能接受的时间不同, 一般来说, GC占用的总时间比不能超过`10%`。\n\n现在假设需求为: 每分钟处理 1000 笔交易。同时, 每分钟GC暂停的总时间不能超过6秒(即10%)。\n\n有了正式的需求, 下一步就是获取相关的信息。依然是从GC日志中提取数据, 可以看到类似这样的信息:\n\n\n\n```\n2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)\n [PSYoungGen: 93677K->70109K(254976K)] \n [ParOldGen: 499597K->511230K(761856K)] \n 593275K->581339K(1016832K), \n [Metaspace: 2936K->2936K(1056768K)], \n 0.0713174 secs] \n [Times: user=0.21 sys=0.02, real=0.07 secs\n```\n\n\n\n此时我们对 用户耗时(user)和系统耗时(sys)感兴趣, 而不关心实际耗时(real)。在这里, 我们关心的时间为`0.23s`(user + sys = 0.21 + 0.02 s), 这段时间内, GC暂停占用了 cpu 资源。 重要的是, 系统运行在多核机器上, 转换为实际的停顿时间(stop-the-world)为`0.0713174秒`, 下面的计算会用到这个数字。\n\n提取出有用的信息后, 剩下要做的就是统计每分钟内GC暂停的总时间。看看是否满足需求: 每分钟内总的暂停时间不得超过6000毫秒(6秒)。\n\n#### Capacity(系统容量)\n\n系统容量(Capacity)需求,是在达成吞吐量和延迟指标的情况下,对硬件环境的额外约束。这类需求大多是来源于计算资源或者预算方面的原因。例如:\n\n* 系统必须能部署到小于512 MB内存的Android设备上\n* 系统必须部署在Amazon**EC2**实例上, 配置不得超过**c3.xlarge(4核8GB)**。\n* 每月的 Amazon EC2 账单不得超过`$12,000`\n\n因此, 在满足延迟和吞吐量需求的基础上必须考虑系统容量。可以说, 假若有无限的计算资源可供挥霍, 那么任何 延迟和吞吐量指标 都不成问题, 但现实情况是, 预算(budget)和其他约束限制了可用的资源。\n\n### 相关示例\n\n介绍完性能调优的三个维度后, 我们来进行实际的操作以达成GC性能指标。\n\n请看下面的代码:\n\n\n\n```\n//imports skipped for brevity\npublic class Producer implements Runnable {\n\n private static ScheduledExecutorService executorService\n = Executors.newScheduledThreadPool(2);\n\n private Deque deque;\n private int objectSize;\n private int queueSize;\n\n public Producer(int objectSize, int ttl) {\n this.deque = new ArrayDeque();\n this.objectSize = objectSize;\n this.queueSize = ttl * 1000;\n }\n\n @Override\n public void run() {\n for (int i = 0; i < 100; i++) { \n deque.add(new byte[objectSize]); \n if (deque.size() > queueSize) {\n deque.poll();\n }\n }\n }\n\n public static void main(String[] args) \n throws InterruptedException {\n executorService.scheduleAtFixedRate(\n new Producer(200 * 1024 * 1024 / 1000, 5), \n 0, 100, TimeUnit.MILLISECONDS\n );\n executorService.scheduleAtFixedRate(\n new Producer(50 * 1024 * 1024 / 1000, 120), \n 0, 100, TimeUnit.MILLISECONDS);\n TimeUnit.MINUTES.sleep(10);\n executorService.shutdownNow();\n }\n}\n```\n\n\n\n这段程序代码, 每 100毫秒 提交两个作业(job)来。每个作业都模拟特定的生命周期: 创建对象, 然后在预定的时间释放, 接着就不管了, 由GC来自动回收占用的内存。\n\n在运行这个示例程序时,通过以下JVM参数打开GC日志记录:\n\n\n\n```\n-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps\n```\n\n\n\n还应该加上JVM参数`-Xloggc`以指定GC日志的存储位置,类似这样:\n\n\n\n```\n-Xloggc:C:\\\\Producer_gc.log\n```\n\n\n\n* 1\n* 2\n\n在日志文件中可以看到GC的行为, 类似下面这样:\n\n\n\n```\n2015-06-04T13:34:16.119-0200: 1.723: [GC (Allocation Failure) \n [PSYoungGen: 114016K->73191K(234496K)] \n 421540K->421269K(745984K), \n 0.0858176 secs] \n [Times: user=0.04 sys=0.06, real=0.09 secs] \n\n2015-06-04T13:34:16.738-0200: 2.342: [GC (Allocation Failure) \n [PSYoungGen: 234462K->93677K(254976K)] \n 582540K->593275K(766464K), \n 0.2357086 secs] \n [Times: user=0.11 sys=0.14, real=0.24 secs] \n\n2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics) \n [PSYoungGen: 93677K->70109K(254976K)] \n [ParOldGen: 499597K->511230K(761856K)] \n 593275K->581339K(1016832K), \n [Metaspace: 2936K->2936K(1056768K)], \n 0.0713174 secs] \n [Times: user=0.21 sys=0.02, real=0.07 secs]\n```\n\n\n\n基于日志中的信息, 可以通过三个优化目标来提升性能:\n\n1. 确保最坏情况下,GC暂停时间不超过预定阀值\n2. 确保线程暂停的总时间不超过预定阀值\n3. 在确保达到延迟和吞吐量指标的情况下, 降低硬件配置以及成本。\n\n为此, 用三种不同的配置, 将代码运行10分钟, 得到了三种不同的结果, 汇总如下:\n\n\n```\n\n\n\n以上参数指示JVM: 将所有GC事件打印到日志文件中, 输出每次GC的日期和时间戳。不同GC算法输出的内容略有不同. ParallelGC 输出的日志类似这样:\n\n\n\n```\n199.879: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1473386 secs] [Times: user=0.43 sys=0.01, real=0.15 secs]\n200.027: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1567794 secs] [Times: user=0.41 sys=0.00, real=0.16 secs]\n200.184: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1621946 secs] [Times: user=0.43 sys=0.00, real=0.16 secs]\n200.346: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1547695 secs] [Times: user=0.41 sys=0.00, real=0.15 secs]\n200.502: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1563071 secs] [Times: user=0.42 sys=0.01, real=0.16 secs]\n200.659: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)], 0.1538778 secs] [Times: user=0.42 sys=0.00, real=0.16 secs]\n```\n\n\n\n在 “04\\. GC算法:实现篇” 中详细介绍了这些格式, 如果对此不了解, 可以先阅读该章节。\n\n分析以上日志内容, 可以得知:\n\n* 这部分日志截取自JVM启动后200秒左右。\n* 日志片段中显示, 在`780毫秒`以内, 因为垃圾回收 导致了5次 Full GC 暂停(去掉第六次暂停,这样更精确一些)。\n* 这些暂停事件的总持续时间是`777毫秒`, 占总运行时间的**99.6%**。\n* 在GC完成之后, 几乎所有的老年代空间(`169,472 KB`)依然被占用(`169,318 KB`)。\n\n通过日志信息可以确定, 该应用的GC情况非常糟糕。JVM几乎完全停滞, 因为GC占用了超过`99%`的CPU时间。 而GC的结果是, 老年代空间仍然被占满, 这进一步肯定了我们的结论。 示例程序和jstat 小节中的是同一个, 几分钟之后系统就挂了, 抛出 “[java.lang.OutOfMemoryError: GC overhead limit exceeded](https://plumbr.eu/outofmemoryerror/gc-overhead-limit-exceeded)” 错误, 不用说, 问题是很严重的.\n\n从此示例可以看出, GC日志对监控GC行为和JVM是否处于健康状态非常有用。一般情况下, 查看 GC 日志就可以快速确定以下症状:\n\n* GC开销太大。如果GC暂停的总时间很长, 就会损害系统的吞吐量。不同的系统允许不同比例的GC开销, 但一般认为, 正常范围在`10%`以内。\n* 极个别的GC事件暂停时间过长。当某次GC暂停时间太长, 就会影响系统的延迟指标. 如果延迟指标规定交易必须在`1,000 ms`内完成, 那就不能容忍任何超过`1000毫秒`的GC暂停。\n* 老年代的使用量超过限制。如果老年代空间在 Full GC 之后仍然接近全满, 那么GC就成为了性能瓶颈, 可能是内存太小, 也可能是存在内存泄漏。这种症状会让GC的开销暴增。\n\n可以看到,GC日志中的信息非常详细。但除了这些简单的小程序, 生产系统一般都会生成大量的GC日志, 纯靠人工是很难阅读和进行解析的。\n\n## GCViewer\n\n我们可以自己编写解析器, 来将庞大的GC日志解析为直观易读的图形信息。 但很多时候自己写程序也不是个好办法, 因为各种GC算法的复杂性, 导致日志信息格式互相之间不太兼容。那么神器来了:[GCViewer](https://github.com/chewiebug/GCViewer)。\n\n[GCViewer](https://github.com/chewiebug/GCViewer)是一款开源的GC日志分析工具。项目的 GitHub 主页对各项指标进行了完整的描述. 下面我们介绍最常用的一些指标。\n\n第一步是获取GC日志文件。这些日志文件要能够反映系统在性能调优时的具体场景. 假若运营部门(operational department)反馈: 每周五下午,系统就运行缓慢, 不管GC是不是主要原因, 分析周一早晨的日志是没有多少意义的。\n\n获取到日志文件之后, 就可以用 GCViewer 进行分析, 大致会看到类似下面的图形界面:\n\n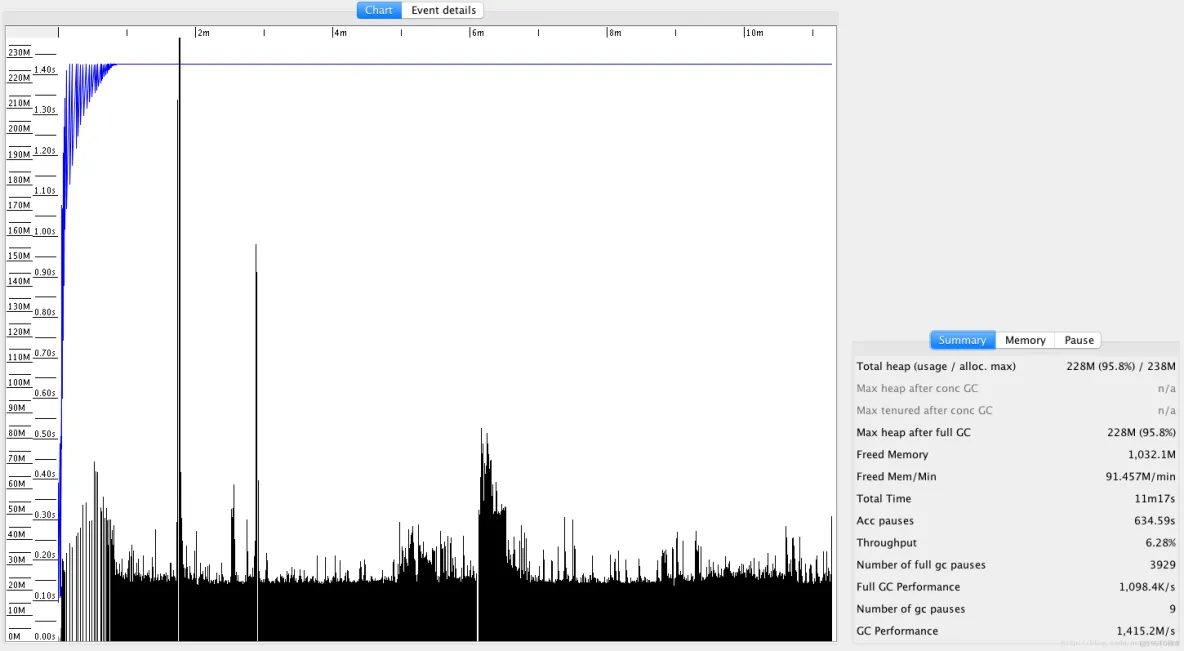\n\n使用的命令行大致如下:\n\n\n\n```\njava -jar gcviewer_1.3.4.jar gc.log\n```\n\n\n\n当然, 如果不想打开程序界面,也可以在后面加上其他参数,直接将分析结果输出到文件。\n\n命令大致如下:\n\n\n\n```\njava -jar gcviewer_1.3.4.jar gc.log summary.csv chart.png\n```\n\n\n\n以上命令将信息汇总到当前目录下的 Excel 文件`summary.csv`之中, 将图形信息保存为`chart.png`文件。\n\n点击下载:gcviewer的jar包及使用示例\n\n上图中, Chart 区域是对GC事件的图形化展示。包括各个内存池的大小和GC事件。上图中, 只有两个可视化指标: 蓝色线条表示堆内存的使用情况, 黑色的Bar则表示每次GC暂停时间的长短。\n\n从图中可以看到, 内存使用量增长很快。一分钟左右就达到了堆内存的最大值. 堆内存几乎全部被消耗, 不能顺利分配新对象, 并引发频繁的 Full GC 事件. 这说明程序可能存在内存泄露, 或者启动时指定的内存空间不足。\n\n从图中还可以看到 GC暂停的频率和持续时间。`30秒`之后, GC几乎不间断地运行,最长的暂停时间超过`1.4秒`。\n\n在右边有三个选项卡。“`**Summary**`(摘要)” 中比较有用的是 “`Throughput`”(吞吐量百分比) 和 “`Number of GC pauses`”(GC暂停的次数), 以及“`Number of full GC pauses`”(Full GC 暂停的次数). 吞吐量显示了有效工作的时间比例, 剩下的部分就是GC的消耗。\n\n以上示例中的吞吐量为`**6.28%**`。这意味着有`**93.72%**`\n\n下一个有意思的地方是“**Pause**”(暂停)选项卡:\n\n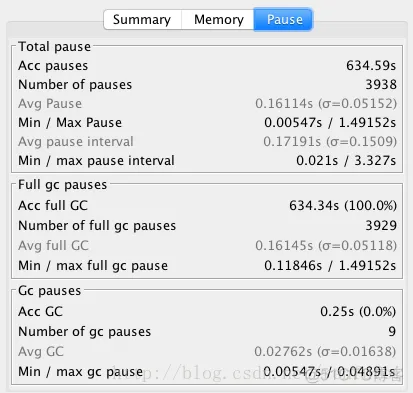\n\n“`Pause`” 展示了GC暂停的总时间,平均值,最小值和最大值, 并且将 total 与minor/major 暂停分开统计。如果要优化程序的延迟指标, 这些统计可以很快判断出暂停时间是否过长。另外, 我们可以得出明确的信息: 累计暂停时间为`634.59 秒`, GC暂停的总次数为`3,938 次`, 这在`11分钟/660秒`的总运行时间里那不是一般的高。\n\n更详细的GC暂停汇总信息, 请查看主界面中的 “**Event details**” 标签:\n\n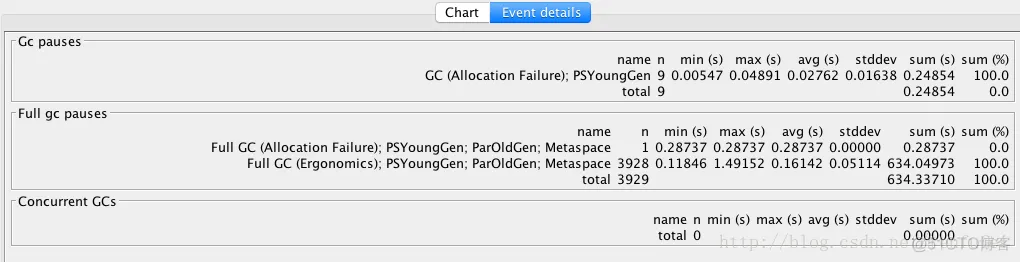\n\n从“**Event details**” 标签中, 可以看到日志中所有重要的GC事件汇总:`普通GC停顿`和`Full GC 停顿次数`, 以及`并发执行数`,`非 stop-the-world 事件`等。此示例中, 可以看到一个明显的地方, Full GC 暂停严重影响了吞吐量和延迟, 依据是:`3,928 次 Full GC`, 暂停了`634秒`。\n\n可以看到, GCViewer 能用图形界面快速展现异常的GC行为。一般来说, 图像化信息能迅速揭示以下症状:\n\n* 低吞吐量。当应用的吞吐量下降到不能容忍的地步时, 有用工作的总时间就大量减少. 具体有多大的 “容忍度”(tolerable) 取决于具体场景。按照经验, 低于 90% 的有效时间就值得警惕了, 可能需要好好优化下GC。\n* 单次GC的暂停时间过长。只要有一次GC停顿时间过长,就会影响程序的延迟指标. 例如, 延迟需求规定必须在 1000 ms以内完成交易, 那就不能容忍任何一次GC暂停超过1000毫秒。\n* 堆内存使用率过高。如果老年代空间在 Full GC 之后仍然接近全满, 程序性能就会大幅降低, 可能是资源不足或者内存泄漏。这种症状会对吞吐量产生严重影响。\n\n业界良心 —— 图形化展示的GC日志信息绝对是我们重磅推荐的。不用去阅读冗长而又复杂的GC日志,通过容易理解的图形, 也可以得到同样的信息。\n\n## 分析器(Profilers)\n\n下面介绍分析器([profilers](http://zeroturnaround.com/rebellabs/developer-productivity-report-2015-java-performance-survey-results/3/), Oracle官方翻译是:`抽样器`)。相对于前面的工具, 分析器只关心GC中的一部分领域. 本节我们也只关注分析器相关的GC功能。\n\n首先警告 —— 不要认为分析器适用于所有的场景。分析器有时确实作用很大, 比如检测代码中的CPU热点时。但某些情况使用分析器不一定是个好方案。\n\n对GC调优来说也是一样的。要检测是否因为GC而引起延迟或吞吐量问题时, 不需要使用分析器. 前面提到的工具(`jstat`或 原生/可视化GC日志)就能更好更快地检测出是否存在GC问题. 特别是从生产环境中收集性能数据时, 最好不要使用分析器, 因为性能开销非常大。\n\n如果确实需要对GC进行优化, 那么分析器就可以派上用场了, 可以对 Object 的创建信息一目了然. 换个角度看, 如果GC暂停的原因不在某个内存池中, 那就只会是因为创建对象太多了。 所有分析器都能够跟踪对象分配(via allocation profiling), 根据内存分配的轨迹, 让你知道**实际驻留在内存中的是哪些对象**。\n\n分配分析能定位到在哪个地方创建了大量的对象. 使用分析器辅助进行GC调优的好处是, 能确定哪种类型的对象最占用内存, 以及哪些线程创建了最多的对象。\n\n下面我们通过实例介绍3种分配分析器:`**hprof**`,`**JVisualV**`**M**和`**AProf**`。实际上还有很多分析器可供选择, 有商业产品,也有免费工具, 但其功能和应用基本上都是类似的。\n\n### hprof\n\n[hprof 分析器](http://docs.oracle.com/javase/8/docs/technotes/samples/hprof.html)内置于JDK之中。 在各种环境下都可以使用, 一般优先使用这款工具。\n\n要让`hprof`和程序一起运行, 需要修改启动脚本, 类似这样:\n\n\n\n```\njava -agentlib:hprof=heap=sites com.yourcompany.YourApplication\n```\n\n\n\n在程序退出时,会将分配信息dump(转储)到工作目录下的`java.hprof.txt`文件中。使用文本编辑器打开, 并搜索 “**SITES BEGIN**” 关键字, 可以看到:\n\n\n\n```\nSITES BEGIN (ordered by live bytes) Tue Dec 8 11:16:15 2015\n percent live alloc'ed stack class\n rank self accum bytes objs bytes objs trace name\n 1 64.43% 4.43% 8370336 20121 27513408 66138 302116 int[]\n 2 3.26% 88.49% 482976 20124 1587696 66154 302104 java.util.ArrayList\n 3 1.76% 88.74% 241704 20121 1587312 66138 302115 eu.plumbr.demo.largeheap.ClonableClass0006\n ... 部分省略 ...\n\nSITES END\n```\n\n\n\n从以上片段可以看到, allocations 是根据每次创建的对象数量来排序的。第一行显示所有对象中有`**64.43%**`的对象是整型数组(`int[]`), 在标识为`302116`的位置创建。搜索 “**TRACE 302116**” 可以看到:\n\n\n\n```\nTRACE 302116: \n eu.plumbr.demo.largeheap.ClonableClass0006.(GeneratorClass.java:11)\n sun.reflect.GeneratedConstructorAccessor7.newInstance(:Unknown line)\n sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)\n java.lang.reflect.Constructor.newInstance(Constructor.java:422)\n```\n\n\n\n现在, 知道有`64.43%`的对象是整数数组, 在`ClonableClass0006`类的构造函数中, 第11行的位置, 接下来就可以优化代码, 以减少GC的压力。\n\n### Java VisualVM\n\n本章前面的第一部分, 在监控 JVM 的GC行为工具时介绍了 JVisualVM , 本节介绍其在分配分析上的应用。\n\nJVisualVM 通过GUI的方式连接到正在运行的JVM。 连接上目标JVM之后 :\n\n1. 打开 “工具” –> “选项” 菜单, 点击**性能分析(Profiler)**标签, 新增配置, 选择 Profiler 内存, 确保勾选了 “Record allocations stack traces”(记录分配栈跟踪)。\n2. 勾选 “Settings”(设置) 复选框, 在内存设置标签下,修改预设配置。\n3. 点击 “Memory”(内存) 按钮开始进行内存分析。\n4. 让程序运行一段时间,以收集关于对象分配的足够信息。\n5. 单击下方的 “Snapshot”(快照) 按钮。可以获取收集到的快照信息。\n\n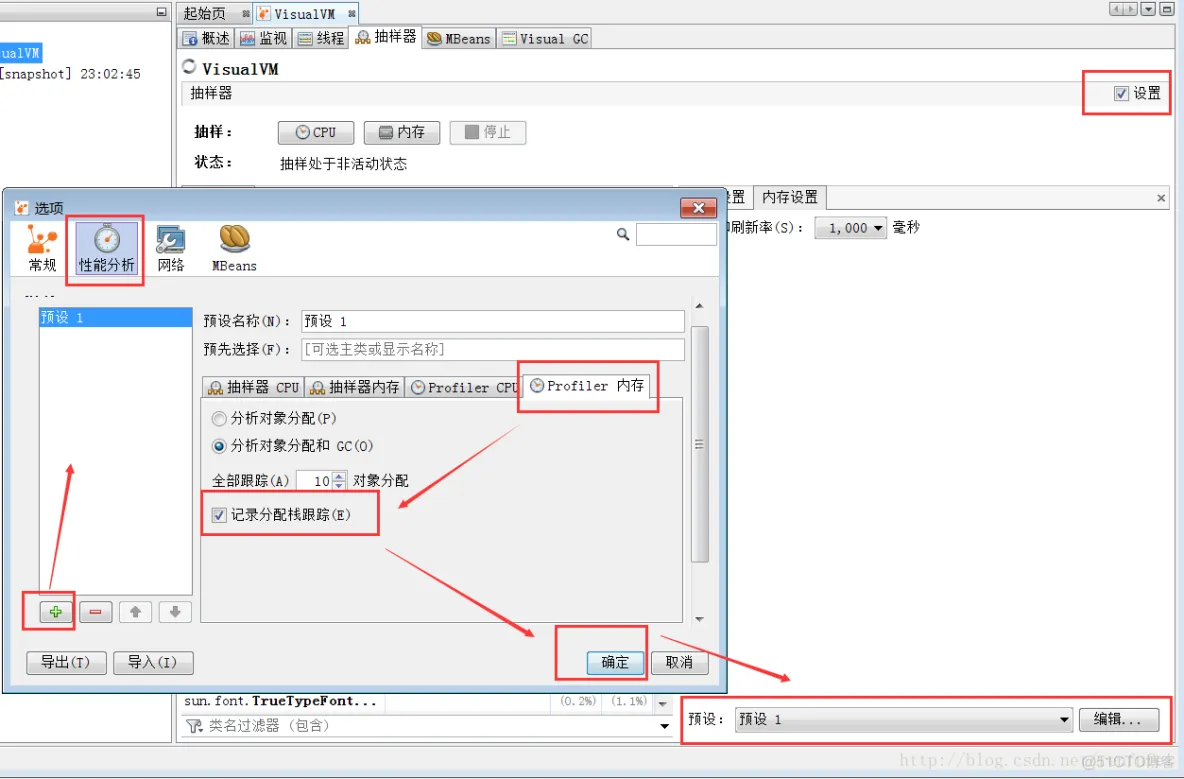\n\n完成上面的步骤后, 可以得到类似这样的信息:\n\n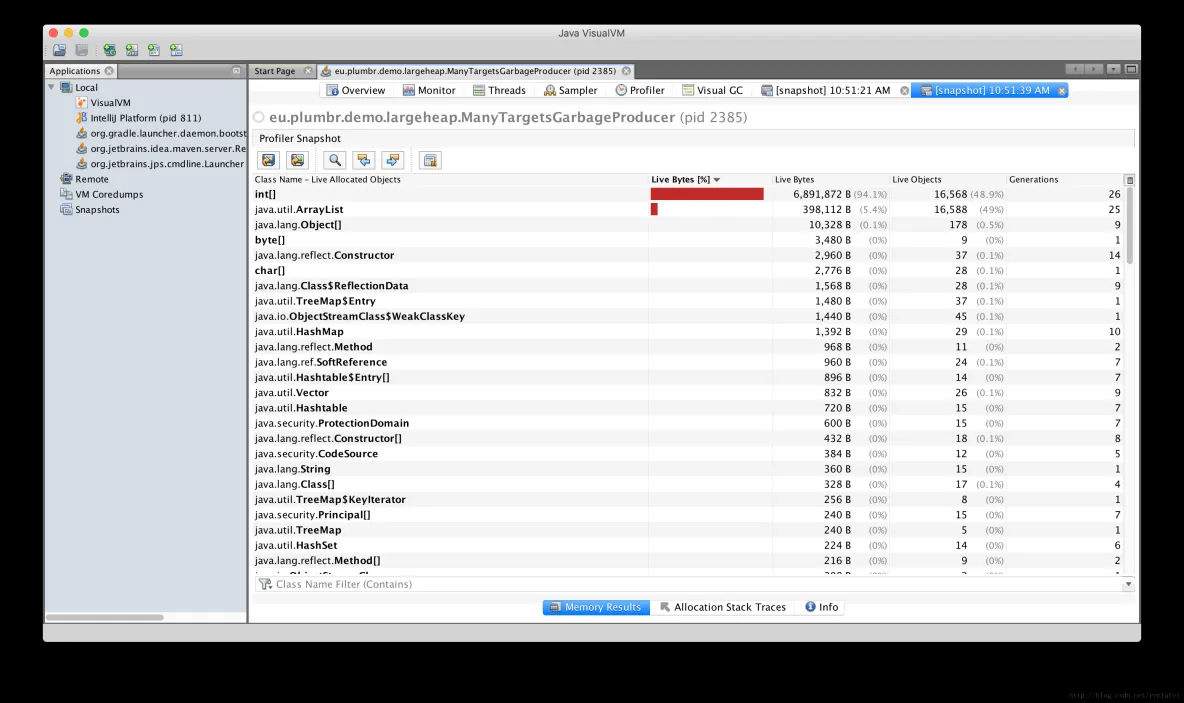\n\n上图按照每个类被创建的对象数量多少来排序。看第一行可以知道, 创建的最多的对象是`int[]`数组. 鼠标右键单击这行, 就可以看到这些对象都在哪些地方创建的:\n\n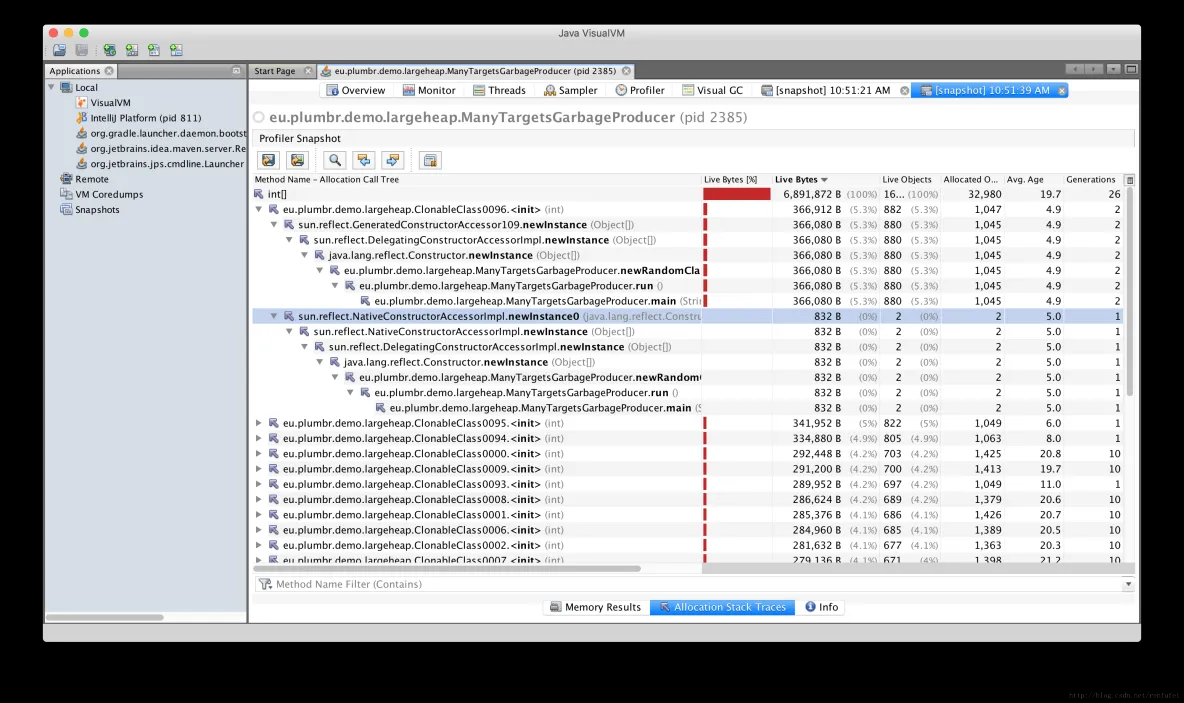\n\n与`hprof`相比, JVisualVM 更加容易使用 —— 比如上面的截图中, 在一个地方就可以看到所有`int[]`的分配信息, 所以多次在同一处代码进行分配的情况就很容易发现。\n\n### AProf\n\n最重要的一款分析器,是由 Devexperts 开发的[**AProf**](https://code.devexperts.com/display/AProf/About+Aprof)。 内存分配分析器 AProf 也被打包为 Java agent 的形式。\n\n用 AProf 分析应用程序, 需要修改 JVM 启动脚本,类似这样:\n\n\n\n```\njava -javaagent:/path-to/aprof.jar com.yourcompany.YourApplication\n```\n\n\n\n重启应用之后, 工作目录下会生成一个`aprof.txt`文件。此文件每分钟更新一次, 包含这样的信息:\n\n\n\n```\n========================================================================================================================\nTOTAL allocation dump for 91,289 ms (0h01m31s)\nAllocated 1,769,670,584 bytes in 24,868,088 objects of 425 classes in 2,127 locations\n========================================================================================================================\n\nTop allocation-inducing locations with the data types allocated from them\n------------------------------------------------------------------------------------------------------------------------\neu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 1,423,675,776 (80.44%) bytes in 17,113,721 (68.81%) objects (avg size 83 bytes)\n int[]: 711,322,976 (40.19%) bytes in 1,709,911 (6.87%) objects (avg size 416 bytes)\n char[]: 369,550,816 (20.88%) bytes in 5,132,759 (20.63%) objects (avg size 72 bytes)\n java.lang.reflect.Constructor: 136,800,000 (7.73%) bytes in 1,710,000 (6.87%) objects (avg size 80 bytes)\n java.lang.Object[]: 41,079,872 (2.32%) bytes in 1,710,712 (6.87%) objects (avg size 24 bytes)\n java.lang.String: 41,063,496 (2.32%) bytes in 1,710,979 (6.88%) objects (avg size 24 bytes)\n java.util.ArrayList: 41,050,680 (2.31%) bytes in 1,710,445 (6.87%) objects (avg size 24 bytes)\n ... cut for brevity ...\n```\n\n\n\n上面的输出是按照`size`进行排序的。可以看出,`80.44%`的 bytes 和`68.81%`的 objects 是在`ManyTargetsGarbageProducer.newRandomClassObject()`方法中分配的。 其中,**int[]**数组占用了`40.19%`的内存, 是最大的一个。\n\n继续往下看, 会发现`allocation traces`(分配痕迹)相关的内容, 也是以 allocation size 排序的:\n\n\n\n```\nTop allocated data types with reverse location traces\n------------------------------------------------------------------------------------------------------------------------\nint[]: 725,306,304 (40.98%) bytes in 1,954,234 (7.85%) objects (avg size 371 bytes)\n eu.plumbr.demo.largeheap.ClonableClass0006.: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)\n java.lang.reflect.Constructor.newInstance: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)\n eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 38,357,280 (2.16%) bytes in 92,205 (0.37%) objects (avg size 416 bytes)\n java.lang.reflect.Constructor.newInstance: 416 (0.00%) bytes in 1 (0.00%) objects (avg size 416 bytes)\n... cut for brevity ...\n```\n\n\n\n可以看到,`int[]`数组的分配, 在`ClonableClass0006`构造函数中继续增大。\n\n和其他工具一样,`AProf`揭露了 分配的大小以及位置信息(`allocation size and locations`), 从而能够快速找到最耗内存的部分。在我们看来,**AProf**是最有用的分配分析器, 因为它只专注于内存分配, 所以做得最好。 当然, 这款工具是开源免费的, 资源开销也最小。\n\n请继续阅读下一章:7\\. GC 调优(实战篇) - GC参考手册\n\n原文链接:[GC Tuning: Tooling](https://plumbr.eu/handbook/gc-tuning-measuring)\n\n翻译时间: 2016年02月06日\n\n## 参考文章\n\n\n\n\n\n\n\n\n\nMySqlDS \njdbc:mysql://localhost:3306/lw \ncom.mysql.jdbc.Driver \nroot \nrootpassword \n\norg.jboss.resource.adapter.jdbc.vendor.MySQLExceptionSorter\n \n\nmySQL \n \n \n \n````\n\n\n这里,定义了一个名为MySqlDS的数据源。其參数包含JDBC的URL。驱动类名,username及密码等。\n\n2、在程序中引用数据源:\n\n```` \n1. Connectionconn=null;\n2. try{\n3. Contextctx=newInitialContext();\n4. ObjectdatasourceRef=ctx.lookup(\"java:MySqlDS\");//引用数据源\n5. DataSourceds=(Datasource)datasourceRef;\n6. conn=ds.getConnection();\n7. ......\n8. c.close();\n9. }catch(Exceptione){\n10. e.printStackTrace();\n11. }finally{\n12. if(conn!=null){\n13. try{\n14. conn.close();\n15. }catch(SQLExceptione){}\n16. }\n17. }\n```` \n\n\n直接使用JDBC或者通过JNDI引用数据源的编程代码量相差无几,可是如今的程序能够不用关心详细JDBC參数了。\n\n//解藕了。可扩展了\n在系统部署后。假设数据库的相关參数变更。仅仅须要又一次配置 mysql-ds.xml 改动当中的JDBC參数,仅仅要保证数据源的名称不变,那么程序源码就无需改动。\n\n由此可见。JNDI避免了程序与数据库之间的紧耦合,使应用更加易于配置、易于部署。\n\nJNDI的扩展:\nJNDI在满足了数据源配置的要求的基础上。还进一步扩充了作用:全部与系统外部的资源的引用,都能够通过JNDI定义和引用。\n\n//注意什么叫资源\n\n所以,在J2EE规范中,J2EE 中的资源并不局限于 JDBC 数据源。\n\n引用的类型有非常多,当中包含资源引用(已经讨论过)、环境实体和 EJB 引用。\n\n特别是 EJB 引用,它暴露了 JNDI 在 J2EE 中的另外一项关键角色:查找其它应用程序组件。\n\nEJB 的 JNDI 引用非常相似于 JDBC 资源的引用。在服务趋于转换的环境中,这是一种非常有效的方法。能够对应用程序架构中所得到的全部组件进行这类配置管理,从 EJB 组件到 JMS 队列和主题。再到简单配置字符串或其它对象。这能够降低随时间的推移服务变更所产生的维护成本,同一时候还能够简化部署,降低集成工作。外部资源”。\n\n总结:\n\nJ2EE 规范要求全部 J2EE 容器都要提供 JNDI 规范的实现。//sun 果然喜欢制定规范JNDI 在 J2EE 中的角色就是“交换机” —— J2EE 组件在执行时间接地查找其它组件、资源或服务的通用机制。在多数情况下,提供 JNDI 供应者的容器能够充当有限的数据存储。这样管理员就能够设置应用程序的执行属性,并让其它应用程序引用这些属性(Java 管理扩展(Java Management Extensions,JMX)也能够用作这个目的)。JNDI 在 J2EE 应用程序中的主要角色就是提供间接层,这样组件就能够发现所须要的资源,而不用了解这些间接性。\n\n在 J2EE 中,JNDI 是把 J2EE 应用程序合在一起的粘合剂。JNDI 提供的间接寻址同意跨企业交付可伸缩的、功能强大且非常灵活的应用程序。\n\n这是 J2EE 的承诺,并且经过一些计划和预先考虑。这个承诺是全然能够实现的。\n\n 从上面的文章中能够看出:\n1、JNDI 提出的目的是为了解藕,是为了开发更加easy维护,easy扩展。easy部署的应用。\n2、JNDI 是一个sun提出的一个规范(相似于jdbc),详细的实现是各个j2ee容器提供商。sun 仅仅是要求,j2ee容器必须有JNDI这种功能。\n\n3、JNDI 在j2ee系统中的角色是“交换机”,是J2EE组件在执行时间接地查找其它组件、资源或服务的通用机制。\n4、JNDI 是通过资源的名字来查找的,资源的名字在整个j2ee应用中(j2ee容器中)是唯一的。\n\n\n 上文提到过双亲委派模型并不是一个强制性的约束模型,而是Java设计者推荐给开发者的类加载器实现方式。在Java的世界中大部分的类加载器都遵循这个模型,但也有例外。\n\n 双亲委派模型的一次“被破坏”是由这个模型自身的缺陷所导致的,双亲委派很好地解决了各个类加载器的基础类的统一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API,但世事往往没有绝对的完美,如果基础类又要调用回用户的代码,那该怎么办?\n\n这并非是不可能的事情,一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK 1.3时放进去的rt.jar),但JNDI的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI,Service Provider Interface)的代码,但启动类加载器不可能“认识”这些代码,因为启动类加载器的搜索范围中找不到用户应用程序类,那该怎么办?\n\n\n为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器(Application ClassLoader)。\n\n 有了线程上下文类加载器,就可以做一些“舞弊”的事情了,JNDI服务使用这个线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。\n\n \n\n## OSGI\n\n \n\n目前,业内关于OSGI技术的学习资源或者技术文档还是很少的。我在某宝网搜索了一下“OSGI”的书籍,结果倒是有,但是种类少的可怜,而且几乎没有人购买。\n因为工作的原因我需要学习OSGI,所以我不得不想尽办法来主动学习OSGI。我将用文字记录学习OSGI的整个过程,通过整理书籍和视频教程,来让我更加了解这门技术,同时也让需要学习这门技术的同志们有一个清晰的学习路线。\n\n我们需要解决一下几问题:\n\n### 1.如何正确的理解和认识OSGI技术?\n\n我们从外文资料上或者从翻译过来的资料上看到OSGi解释和定义,都是直译过来的,但是OSGI的真实意义未必是中文直译过来的意思。OSGI的解释就是Open Service Gateway Initiative,直译过来就是“开放的服务入口(网关)的初始化”,听起来非常费解,什么是服务入口初始化?\n\n所以我们不去直译这个OSGI,我们换一种说法来描述OSGI技术。\n\n我们来回到我们以前的某些开发场景中去,假设我们使用SSH(struts+spring+hibernate)框架来开发我们的Web项目,我们做产品设计和开发的时候都是分模块的,我们分模块的目的就是实现模块之间的“解耦”,更进一步的目的是方便对一个项目的控制和管理。\n我们对一个项目进行模块化分解之后,我们就可以把不同模块交给不同的开发人员来完成开发,然后项目经理把大家完成的模块集中在一起,然后拼装成一个最终的产品。一般我们开发都是这样的基本情况。\n\n那么我们开发的时候预计的是系统的功能,根据系统的功能来进行模块的划分,也就是说,这个产品的功能或客户的需求是划分的重要依据。\n\n但是我们在开发过程中,我们模块之间还要彼此保持联系,比如A模块要从B模块拿到一些数据,而B模块可能要调用C模块中的一些方法(除了公共底层的工具类之外)。所以这些模块只是一种逻辑意义上的划分。\n\n最重要的一点是,我们把最终的项目要去部署到tomcat或者jBoss的服务器中去部署。那么我们启动服务器的时候,能不能关闭项目的某个模块或功能呢?很明显是做不到的,一旦服务器启动,所有模块就要一起启动,都要占用服务器资源,所以关闭不了模块,假设能强制拿掉,就会影响其它的功能。\n\n以上就是我们传统模块式开发的一些局限性。\n\n我们做软件开发一直在追求一个境界,就是模块之间的真正“解耦”、“分离”,这样我们在软件的管理和开发上面就会更加的灵活,甚至包括给客户部署项目的时候都可以做到更加的灵活可控。但是我们以前使用SSH框架等架构模式进行产品开发的时候我们是达不到这种要求的。\n\n所以我们“架构师”或顶尖的技术高手都在为模块化开发努力的摸索和尝试,然后我们的OSGI的技术规范就应运而生。\n\n现在我们的OSGI技术就可以满足我们之前所说的境界:在不同的模块中做到彻底的分离,而不是逻辑意义上的分离,是物理上的分离,也就是说在运行部署之后都可以在不停止服务器的时候直接把某些模块拿下来,其他模块的功能也不受影响。\n\n由此,OSGI技术将来会变得非常的重要,因为它在实现模块化解耦的路上,走得比现在大家经常所用的SSH框架走的更远。这个技术在未来大规模、高访问、高并发的Java模块化开发领域,或者是项目规范化管理中,会大大超过SSH等框架的地位。\n\n现在主流的一些应用服务器,Oracle的weblogic服务器,IBM的WebSphere,JBoss,还有Sun公司的glassfish服务器,都对OSGI提供了强大的支持,都是在OSGI的技术基础上实现的。有那么多的大型厂商支持OSGI这门技术,我们既可以看到OSGI技术的重要性。所以将来OSGI是将来非常重要的技术。 \n\n但是OSGI仍然脱离不了框架的支持,因为OSGI本身也使用了很多spring等框架的基本控件(因为要实现AOP依赖注入等功能),但是哪个项目又不去依赖第三方jar呢?\n\n \n 双亲委派模型的另一次“被破坏”是由于用户对程序动态性的追求而导致的,这里所说的“动态性”指的是当前一些非常“热门”的名词:代码热替换(HotSwap)、模块热部署(HotDeployment)等,说白了就是希望应用程序能像我们的计算机外设那样,接上鼠标、U盘,不用重启机器就能立即使用,鼠标有问题或要升级就换个鼠标,不用停机也不用重启。\n\n 对于个人计算机来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是企业级软件开发者具有很大的吸引力。Sun公司所提出的JSR-294、JSR-277规范在与JCP组织的模块化规范之争中落败给JSR-291(即OSGi R4.2),虽然Sun不甘失去Java模块化的主导权,独立在发展Jigsaw项目,但目前OSGi已经成为了业界“事实上”的Java模块化标准,而OSGi实现模块化热部署的关键则是它自定义的类加载器机制的实现。\n\n 每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。\n\n 在OSGi环境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:\n\n 1)将以java.*开头的类委派给父类加载器加载。\n \n 2)否则,将委派列表名单内的类委派给父类加载器加载。\n \n 3)否则,将Import列表中的类委派给Export这个类的Bundle的类加载器加载。\n \n 4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。\n \n 5)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。\n \n 6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。\n \n 7)否则,类查找失败。\n\n 上面的查找顺序中只有开头两点仍然符合双亲委派规则,其余的类查找都是在平级的类加载器中进行的。\n\n 只要有足够意义和理由,突破已有的原则就可认为是一种创新。正如OSGi中的类加载器并不符合传统的双亲委派的类加载器,并且业界对其为了实现热部署而带来的额外的高复杂度还存在不少争议,但在Java程序员中基本有一个共识:OSGi中对类加载器的使用是很值得学习的,弄懂了OSGi的实现,就可以算是掌握了类加载器的精髓。\n\n\n## Tomcat类加载器以及应用间class隔离与共享\n\n\n\nTomcat的用户一定都使用过其应用部署功能,无论是直接拷贝文件到webapps目录,还是修改server.xml以目录的形式部署,或者是增加虚拟主机,指定新的appBase等等。\n\n但部署应用时,不知道你是否曾注意过这几点:\n\n1. 如果在一个Tomcat内部署多个应用,甚至多个应用内使用了某个类似的几个不同版本,但它们之间却互不影响。这是如何做到的。\n\n2. 如果多个应用都用到了某类似的相同版本,是否可以统一提供,不在各个应用内分别提供,占用内存呢。\n\n3. 还有时候,在开发Web应用时,在pom.xml中添加了servlet-api的依赖,那实际应用的class加载时,会加载你的servlet-api 这个jar吗\n\n以上提到的这几点,在Tomcat以及各类的应用服务器中,都是通过类加载器(ClasssLoader)来实现的。通过本文,你可以了解到Tomcat内部提供的各种类加载器,Web应用的class和资源等加载的方式,以及其内部的实现原理。在遇到类似问题时,更胸有成竹。\n\n### 类加载器\n\nJava语言本身,以及现在其它的一些基于JVM之上的语言(Groovy,Jython, Scala...),都是在将代码编译生成class文件,以实现跨多平台,write once, run anywhere。最终的这些class文件,在应用中,又被加载到JVM虚拟机中,开始工作。而把class文件加载到JVM的组件,就是我们所说的类加载器。而对于类加载器的抽象,能面对更多的class数据提供形式,例如网络、文件系统等。\n\nJava中常见的那个ClassNotFoundException和NoClassDefFoundError就是类加载器告诉我们的。\n\nServlet规范指出,容器用于加载Web应用内Servlet的class loader, 允许加载位于Web应用内的资源。但不允许重写java.*, javax.*以及容器实现的类。同时\n\n每个应用内使用Thread.currentThread.getContextClassLoader()获得的类加载器,都是该应用区别于其它应用的类加载器等等。\n\n根据Servlet规范,各个应用服务器厂商自行实现。所以像其他的一些应用服务器一样, Tomcat也提供了多种的类加载器,以便应用服务器内的class以及部署的Web应用类文件运行在容器中时,可以使用不同的class repositories。\n\n在Java中,类加载器是以一种父子关系树来组织的。除Bootstrap外,都会包含一个parent 类加载器。(这里写parent 类加载器,而不是父类加载器,不是为了装X,是为了避免和Java里的父类混淆)一般以类加载器需要加载一个class或者资源文件的时候,他会先委托给他的parent类加载器,让parent类加载器先来加载,如果没有,才再在自己的路径上加载。这就是人们常说的双亲委托,即把类加载的请求委托给parent。\n\n但是...,这里需要注意一下\n\n> 对于Web应用的类加载,和上面的双亲委托是有区别的。\n\n 主流的Java Web服务器(也就是Web容器),如Tomcat、Jetty、WebLogic、WebSphere或其他笔者没有列举的服务器,都实现了自己定义的类加载器(一般都不止一个)。因为一个功能健全的Web容器,要解决如下几个问题:\n\n 1)部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以实现相互隔离。这是最基本的需求,两个不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求一个类库在一个服务器中只有一份,服务器应当保证两个应用程序的类库可以互相独立使用。\n\n 2)部署在同一个Web容器上的两个Web应用程序所使用的Java类库可以互相共享。这个需求也很常见,例如,用户可能有10个使用[spring](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Fjavaee \"Java EE知识库\")组织的应用程序部署在同一台服务器上,如果把10份Spring分别存放在各个应用程序的隔离目录中,将会是很大的资源浪费——这主要倒不是浪费磁盘空间的问题,而是指类库在使用时都要被加载到Web容器的内存,如果类库不能共享,虚拟机的方法区就会很容易出现过度膨胀的风险。\n\n 3)Web容器需要尽可能地保证自身的安全不受部署的Web应用程序影响。目前,有许多主流的Java Web容器自身也是使用Java语言来实现的。因此,Web容器本身也有类库依赖的问题,一般来说,基于安全考虑,容器所使用的类库应该与应用程序的类库互相独立。\n\n 4)支持JSP应用的Web容器,大多数都需要支持HotSwap功能。我们知道,JSP文件最终要编译成Java Class才能由虚拟机执行,但JSP文件由于其纯文本存储的特性,运行时修改的概率远远大于第三方类库或程序自身的Class文件。而且ASP、[PHP](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Fphp \"PHP知识库\")和JSP这些网页应用也把修改后无须重启作为一个很大的“优势”来看待,因此“主流”的Web容器都会支持JSP生成类的热替换,当然也有“非主流”的,如运行在生产模式(Production Mode)下的WebLogic服务器默认就不会处理JSP文件的变化。\n\n 由于存在上述问题,在部署Web应用时,单独的一个Class Path就无法满足需求了,所以各种Web容都“不约而同”地提供了好几个Class Path路径供用户存放第三方类库,这些路径一般都以“lib”或“classes”命名。被放置到不同路径中的类库,具备不同的访问范围和服务对象,通常,每一个目录都会有一个相应的自定义类加载器去加载放置在里面的Java类库。现在,就以Tomcat容器为例,看一看Tomcat具体是如何规划用户类库结构和类加载器的。\n\n 在Tomcat目录结构中,有3组目录(“/common/*”、“/server/*”和“/shared/*”)可以存放Java类库,另外还可以加上Web应用程序自身的目录“/WEB-INF/*”,一共4组,把Java类库放置在这些目录中的含义分别如下:\n\n ①放置在/common目录中:类库可被Tomcat和所有的Web应用程序共同使用。\n\n ②放置在/server目录中:类库可被Tomcat使用,对所有的Web应用程序都不可见。\n\n ③放置在/shared目录中:类库可被所有的Web应用程序共同使用,但对Tomcat自己不可见。\n\n ④放置在/WebApp/WEB-INF目录中:类库仅仅可以被此Web应用程序使用,对Tomcat和其他Web应用程序都不可见。\n\n 为了支持这套目录结构,并对目录里面的类库进行加载和隔离,Tomcat自定义了多个类加载器,这些类加载器按照经典的双亲委派模型来实现,其关系如下图所示。\n\n\n\n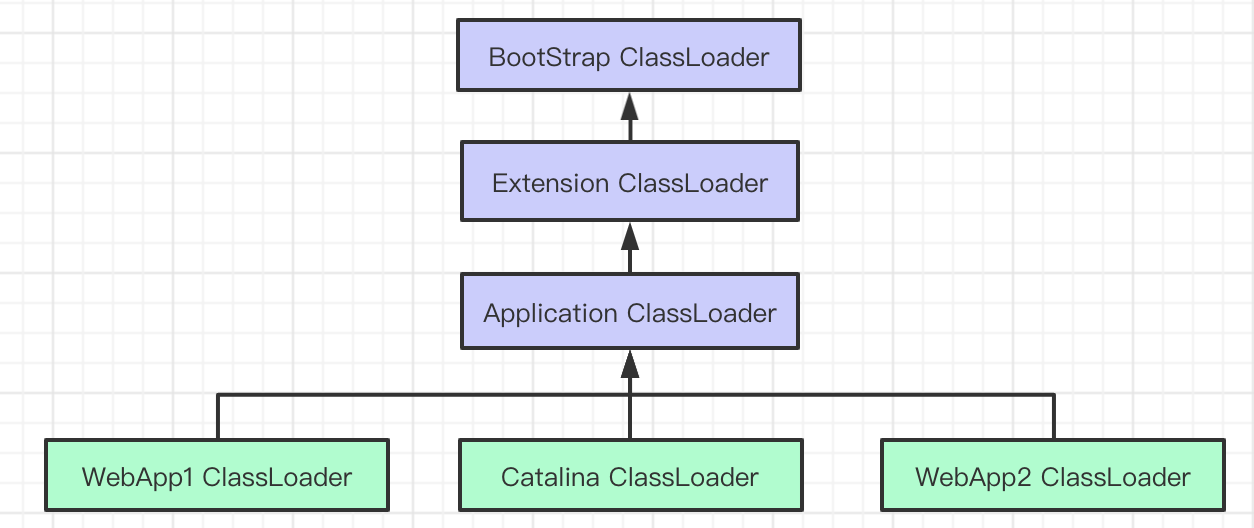\n \n\n \n\n\n\n 上图中灰色背景的3个类加载器是JDK默认提供的类加载器,这3个加载器的作用已经介绍过了。而CommonClassLoader、CatalinaClassLoader、SharedClassLoader和WebappClassLoader则是Tomcat自己定义的类加载器,它们分别加载/common/*、/server/*、/shared/*和/WebApp/WEB-INF/*中的Java类库。其中WebApp类加载器和Jsp类加载器通常会存在多个实例,每一个Web应用程序对应一个WebApp类加载器,每一个JSP文件对应一个Jsp类加载器。\n\n 从图中的委派关系中可以看出,CommonClassLoader能加载的类都可以被CatalinaClassLoader和SharedClassLoader使用,而CatalinaClassLoader和SharedClassLoader自己能加载的类则与对方相互隔离。WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离。\n\n 而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能。\n\n对于Tomcat的6.x版本,只有指定了tomcat/conf/catalina.properties配置文件的server.loader和share.loader项后才会真正建立CatalinaClassLoader和Shared ClassLoader的实例,否则在用到这两个类加载器的地方都会用Common ClassLoader的实例代替,而默认的配置文件中没有设置这两个loader项,所以Tomcat 6.x顺理成章地把/common、/server和/shared三个目录默认合并到一起变成一个/lib目录,这个目录里的类库相当于以前/common目录中类库的作用。\n\n这是Tomcat设计团队为了简化大多数的部署场景所做的一项改进,如果默认设置不能满足需要,用户可以通过修改配置文件指定server.loader和share.loader的方式重新启用Tomcat 5.x的加载器[架构](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Flink.juejin.im%2F%3Ftarget%3Dhttp%253A%252F%252Flib.csdn.net%252Fbase%252Farchitecture \"大型网站架构知识库\")。\n\n Tomcat加载器的实现清晰易懂,并且采用了官方推荐的“正统”的使用类加载器的方式。如果读者阅读完上面的案例后,能完全理解Tomcat设计团队这样布置加载器架构的用意,那说明已经大致掌握了类加载器“主流”的使用方式,那么笔者不妨再提一个问题让读者思考一下:前面曾经提到过一个场景,如果有10个Web应用程序都是用Spring来进行组织和管理的话,可以把Spring放到Common或Shared目录下让这些程序共享。\n\n Spring要对用户程序的类进行管理,自然要能访问到用户程序的类,而用户的程序显然是放在/WebApp/WEB-INF目录中的,那么被CommonClassLoader或SharedClassLoader加载的Spring如何访问并不在其加载范围内的用户程序呢?如果研究过虚拟机类加载器机制中的双亲委派模型,相信读者可以很容易地回答这个问题。\n\n分析:如果按主流的双亲委派机制,显然无法做到让父类加载器加载的类去访问子类加载器加载的类,上面在类加载器一节中提到过通过线程上下文方式传播类加载器。\n\n 答案是使用线程上下文类加载器来实现的,使用线程上下文加载器,可以让父类加载器请求子类加载器去完成类加载的动作。\n\n 看spring源码发现,spring加载类所用的Classloader是通过Thread.currentThread().getContextClassLoader()来获取的,而当线程创建时会默认setContextClassLoader(AppClassLoader),即线程上下文类加载器被设置为AppClassLoader,spring中始终可以获取到这个AppClassLoader(在Tomcat里就是WebAppClassLoader)子类加载器来加载bean,以后任何一个线程都可以通过getContextClassLoader()获取到WebAppClassLoader来getbean了。\n\n \n\n本篇博文内容取材自《深入理解Java虚拟机:JVM高级特性与最佳实践》\n\n## 参考文章\n\n\n\n\n\n\n\n bytes for . Out of swap space?\n\n\n原因:分配本地分配失败。JNI、本地库或者Java虚拟机都会从本地堆中分配内存空间。\n\n\nException in thread “main”: java.lang.OutOfMemoryError: (Native method)\n\n\n原因:同样是本地方法内存分配失败,只不过是JNI或者本地方法或者Java虚拟机发现\n\n关于永久代的废弃可以参考这篇文章\n\nJDK8-废弃永久代(PermGen)迎来元空间(Metaspace)\n(https://www.cnblogs.com/yulei126/p/6777323.html)\n\n\n1.背景\n\n2.为什么废弃永久代(PermGen)\n\n3.深入理解元空间(Metaspace)\n\n4.总结\n\n========正文分割线=====\n\n## 一、背景\n\n### 1.1 永久代(PermGen)在哪里?\n\n根据,hotspot jvm结构如下(虚拟机栈和本地方法栈合一起了):\n\n\n上图引自网络,但有个问题:方法区和heap堆都是线程共享的内存区域。\n\n关于方法区和永久代:\n\n在HotSpot JVM中,这次讨论的永久代,就是上图的方法区(JVM规范中称为方法区)。《Java虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。在其他JVM上不存在永久代。\n\n### 1.2 JDK8永久代的废弃\n\nJDK8 永久代变化如下图:\n\n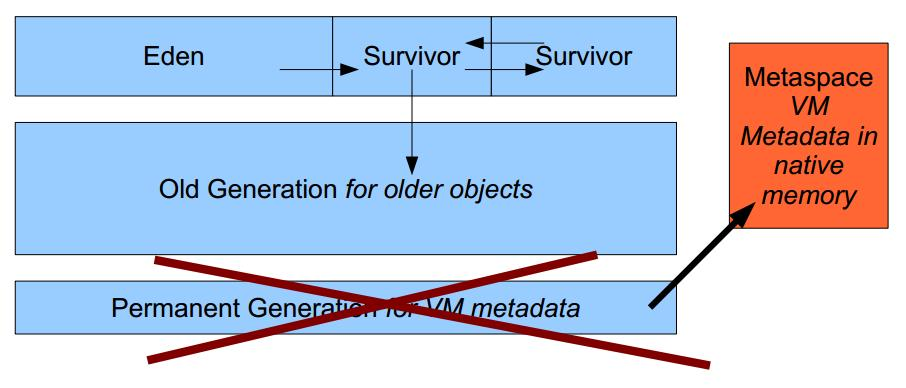\n1.新生代:Eden+From Survivor+To Survivor\n\n2.老年代:OldGen\n\n3.永久代(方法区的实现) : PermGen----->替换为Metaspace(本地内存中)\n\n## 二、为什么废弃永久代(PermGen)\n\n### 2.1 官方说明\n\n参照JEP122:http://openjdk.java.net/jeps/122,原文截取:\n\n## Motivation\n\nThis is part of the JRockit and Hotspot convergence effort. JRockit customers do not need to configure the permanent generation (since JRockit does not have a permanent generation) and are accustomed to not configuring the permanent generation.\n\n即:移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。\n\n### 2.2 现实使用中易出问题\n\n由于永久代内存经常不够用或发生内存泄露,爆出异常java.lang.OutOfMemoryError: PermGen\n\n其实在JDK7时就已经逐步把永久代的内容移动到其他区域了,比如移动到native区,移动到堆区等,而JDK8则是则是废除了永久代,改用元数据。\n\n## 三、深入理解元空间(Metaspace)\n\n### 3.1元空间的内存大小\n\n元空间是方法区的在HotSpot jvm 中的实现,方法区主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。\n\n元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。,理论上取决于32位/64位系统可虚拟的内存大小。可见也不是无限制的,需要配置参数。\n\n### 3.2常用配置参数\n\n1.MetaspaceSize\n\n初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用[Java](http://lib.csdn.net/base/javase \"Java SE知识库\")-XX:+PrintFlagsInitial命令查看本机的初始化参数\n\n2.MaxMetaspaceSize\n\n限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。\n\n3.MinMetaspaceFreeRatio\n\n当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数(即实际非空闲占比过大,内存不够用),那么虚拟机将增长Metaspace的大小。默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。\n\n4.MaxMetasaceFreeRatio\n\n当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。默认值为70,也就是70%。\n\n5.MaxMetaspaceExpansion\n\nMetaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。\n\n6.MinMetaspaceExpansion\n\nMetaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)。\n\n### 3.3测试并追踪元空间大小\n\n#### 3.3.1.测试字符串常量\n\n````\npublic class StringOomMock {\n static String base = \"string\";\n \n public static void main(String[] args) {\n List list = new ArrayList();\n for (int i=0;i< Integer.MAX_VALUE;i++){\n String str = base + base;\n base = str;\n list.add(str.intern());\n }\n }\n}\n````\n\n在eclipse中选中类--》run configuration-->java application--》new 参数如下:\n\n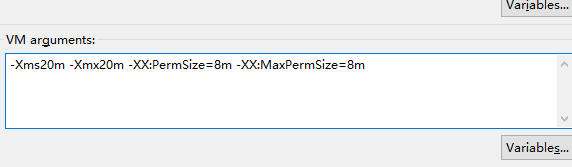\n\n由于设定了最大内存20M,很快就溢出,如下图:\n\n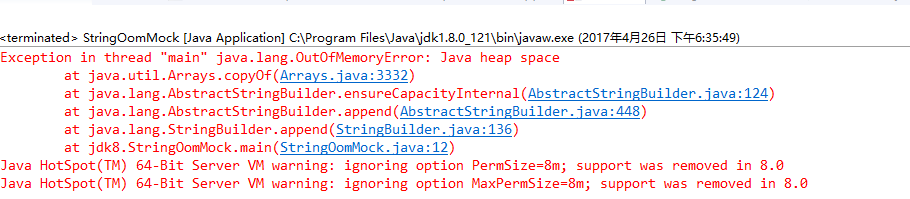\n\n可见在jdk8中:\n\n1.字符串常量由永久代转移到堆中。\n\n2.持久代已不存在,PermSize MaxPermSize参数已移除。(看图中最后两行)\n\n#### 3.3.2.测试元空间溢出\n\n根据定义,我们以加载类来测试元空间溢出,代码如下:\n````\npackage jdk8;\n\nimport java.io.File;\nimport java.lang.management.ClassLoadingMXBean;\nimport java.lang.management.ManagementFactory;\nimport java.net.URL;\nimport java.net.URLClassLoader;\nimport java.util.ArrayList;\nimport java.util.List;\n\n/**\n * \n * @ClassName:OOMTest\n * @Description:模拟类加载溢出(元空间oom)\n * @author diandian.zhang\n * @date 2017年4月27日上午9:45:40\n */\npublic class OOMTest { \n public static void main(String[] args) { \n try { \n //准备url \n URL url = new File(\"D:/58workplace/11study/src/main/java/jdk8\").toURI().toURL(); \n URL[] urls = {url}; \n //获取有关类型加载的JMX接口 \n ClassLoadingMXBean loadingBean = ManagementFactory.getClassLoadingMXBean(); \n //用于缓存类加载器 \n List classLoaders = new ArrayList(); \n while (true) { \n //加载类型并缓存类加载器实例 \n ClassLoader classLoader = new URLClassLoader(urls); \n classLoaders.add(classLoader); \n classLoader.loadClass(\"ClassA\"); \n //显示数量信息(共加载过的类型数目,当前还有效的类型数目,已经被卸载的类型数目) \n System.out.println(\"total: \" + loadingBean.getTotalLoadedClassCount()); \n System.out.println(\"active: \" + loadingBean.getLoadedClassCount()); \n System.out.println(\"unloaded: \" + loadingBean.getUnloadedClassCount()); \n } \n } catch (Exception e) { \n e.printStackTrace(); \n } \n } \n} \n````\n\n为了快速溢出,设置参数:-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=80m,运行结果如下:\n\n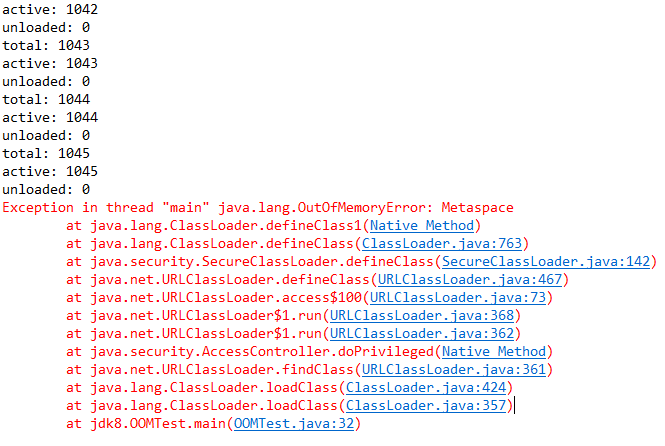\n\n上图证实了,我们的JDK8中类加载(方法区的功能)已经不在永久代PerGem中了,而是Metaspace中。可以配合JVisualVM来看,更直观一些。\n\n## 四、总结\n\n本文讲解了元空间(Metaspace)的由来和本质,常用配置,以及监控测试。元空间的大小是动态变更的,但不是无限大的,最好也时常关注一下大小,以免影响服务器内存。\n\n\n## 参考文章\n\nhttps://segmentfault.com/a/1190000009707894\n\nhttps://www.cnblogs.com/hysum/p/7100874.html\n\nhttp://c.biancheng.net/view/939.html\n\nhttps://www.runoob.com\n\nhttps://blog.csdn.net/android_hl/article/details/53228348\n\n## 微信公众号\n\n### Java技术江湖\n\n如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!\n\n**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。\n\n\n\n### 个人公众号:黄小斜\n\n作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!\n\n**程序员3T技术学习资源:** 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 **“资料”** 即可免费无套路获取。 \n\n\n"
},
{
"path": "docs/Java/JVM/深入理解JVM虚拟机:JVM垃圾回收基本原理和算法.md",
"content": "# 目录\n * [JVM GC基本原理与GC算法](#jvm-gc基本原理与gc算法)\n * [Java关键术语](#java关键术语)\n * [Java HotSpot 虚拟机](#java-hotspot-虚拟机)\n * [Java堆内存](#java堆内存)\n * [启动Java垃圾回收](#启动java垃圾回收)\n * [各种GC的触发时机(When)](#各种gc的触发时机when)\n * [GC类型](#gc类型)\n * [触发时机](#触发时机)\n * [FULL GC触发条件详解](#full-gc触发条件详解)\n * [总结](#总结)\n * [什么是Stop the world](#什么是stop-the-world)\n * [Java垃圾回收过程](#java垃圾回收过程)\n * [垃圾回收中实例的终结](#垃圾回收中实例的终结)\n * [对象什么时候符合垃圾回收的条件?](#对象什么时候符合垃圾回收的条件?)\n * [GC Scope 示例程序](#gc-scope-示例程序)\n * [JVM GC算法](#JVM GC算法)\n * [JVM垃圾判定算法](#jvm垃圾判定算法)\n * [引用计数算法(Reference Counting)](#引用计数算法reference-counting)\n * [可达性分析算法(根搜索算法)](#可达性分析算法(根搜索算法))\n * [四种引用](#四种引用)\n * [JVM垃圾回收算法](#jvm垃圾回收算法)\n * [标记—清除算法(Mark-Sweep)](#标记清除算法(mark-sweep))\n * [复制算法(Copying)](#复制算法(copying))\n * [标记—整理算法(Mark-Compact)](#标记整理算法(mark-compact))\n * [分代收集算法(Generational Collection)](#分代收集算法generational-collection)\n * [参考文章](#参考文章)\n\n\n\n本文转自互联网,侵删\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章将同步到我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n\n该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。\n\n为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n## JVM GC基本原理与GC算法\n\nJava的内存分配与回收全部由JVM垃圾回收进程自动完成。与C语言不同,Java开发者不需要自己编写代码实现垃圾回收。这是Java深受大家欢迎的众多特性之一,能够帮助程序员更好地编写Java程序。\n\n下面四篇教程是了解Java 垃圾回收(GC)的基础:\n\n1. [垃圾回收简介](http://www.importnew.com/13504.html)\n2. [圾回收是如何工作的?](http://www.importnew.com/13493.html)\n3. [垃圾回收的类别](http://www.importnew.com/13827.html)\n\n这篇教程是系列第一部分。首先会解释基本的术语,比如JDK、JVM、JRE和HotSpotVM。接着会介绍JVM结构和Java 堆内存结构。理解这些基础对于理解后面的垃圾回收知识很重要。\n\n## Java关键术语\n\n* JavaAPI:一系列帮助开发者创建Java应用程序的封装好的库。\n* Java 开发工具包 (JDK):一系列工具帮助开发者创建Java应用程序。JDK包含工具编译、运行、打包、分发和监视Java应用程序。\n* Java 虚拟机(JVM):JVM是一个抽象的计算机结构。Java程序根据JVM的特性编写。JVM针对特定于操作系统并且可以将Java指令翻译成底层系统的指令并执行。JVM确保了Java的平台无关性。\n* Java 运行环境(JRE):JRE包含JVM实现和Java API。\n\n## Java HotSpot 虚拟机\n\n每种JVM实现可能采用不同的方法实现垃圾回收机制。在收购SUN之前,Oracle使用的是JRockit JVM,收购之后使用HotSpot JVM。目前Oracle拥有两种JVM实现并且一段时间后两个JVM实现会合二为一。\n\nHotSpot JVM是目前Oracle SE平台标准核心组件的一部分。在这篇垃圾回收教程中,我们将会了解基于HotSpot虚拟机的垃圾回收原则。\n\n## Java堆内存\n\n我们有必要了解堆内存在JVM内存模型的角色。在运行时,Java的实例被存放在堆内存区域。当一个对象不再被引用时,满足条件就会从堆内存移除。在垃圾回收进程中,这些对象将会从堆内存移除并且内存空间被回收。堆内存以下三个主要区域:\n\n1. 新生代(Young Generation)\n * Eden空间(Eden space,任何实例都通过Eden空间进入运行时内存区域)\n * S0 Survivor空间(S0 Survivor space,存在时间长的实例将会从Eden空间移动到S0 Survivor空间)\n * S1 Survivor空间 (存在时间更长的实例将会从S0 Survivor空间移动到S1 Survivor空间)\n2. 老年代(Old Generation)实例将从S1提升到Tenured(终身代)\n3. 永久代(Permanent Generation)包含类、方法等细节的元信息\n\n\n永久代空间[在Java SE8特性](http://javapapers.com/java/java-8-features/)中已经被移除。\n\nJava 垃圾回收是一项自动化的过程,用来管理程序所使用的运行时内存。通过这一自动化过程,JVM 解除了程序员在程序中分配和释放内存资源的开销。\n\n## 启动Java垃圾回收\n\n作为一个自动的过程,程序员不需要在代码中显示地启动垃圾回收过程。`System.gc()`和`Runtime.gc()`用来请求JVM启动垃圾回收。\n\n虽然这个请求机制提供给程序员一个启动 GC 过程的机会,但是启动由 JVM负责。JVM可以拒绝这个请求,所以并不保证这些调用都将执行垃圾回收。启动时机的选择由JVM决定,并且取决于堆内存中Eden区是否可用。JVM将这个选择留给了Java规范的实现,不同实现具体使用的算法不尽相同。\n\n毋庸置疑,我们知道垃圾回收过程是不能被强制执行的。我刚刚发现了一个调用`System.gc()`有意义的场景。通过这篇文章了解一下[适合调用System.gc()](http://javapapers.com/core-java/system-gc-invocation-a-suitable-scenario/)这种极端情况。\n\n## 各种GC的触发时机(When)\n\n### GC类型\n\n说到GC类型,就更有意思了,为什么呢,因为业界没有统一的严格意义上的界限,也没有严格意义上的GC类型,都是左边一个教授一套名字,右边一个作者一套名字。为什么会有这个情况呢,因为GC类型是和收集器有关的,不同的收集器会有自己独特的一些收集类型。所以作者在这里引用**R大**关于GC类型的介绍,作者觉得还是比较妥当准确的。如下:\n\n* Partial GC:并不收集整个GC堆的模式\n * Young GC(Minor GC):只收集young gen的GC\n * Old GC:只收集old gen的GC。只有CMS的concurrent collection是这个模式\n * Mixed GC:收集整个young gen以及部分old gen的GC。只有G1有这个模式\n* Full GC(Major GC):收集整个堆,包括young gen、old gen、perm gen(如果存在的话)等所有部分的模式。\n\n### 触发时机\n\n上面大家也看到了,GC类型分分类是和收集器有关的,那么当然了,对于不同的收集器,GC触发时机也是不一样的,作者就针对默认的serial GC来说:\n\n* young GC:当young gen中的eden区分配满的时候触发。注意young GC中有部分存活对象会晋升到old gen,所以young GC后old gen的占用量通常会有所升高。\n* full GC:当准备要触发一次young GC时,如果发现统计数据说之前young GC的平均晋升大小比目前old gen剩余的空间大,则不会触发young GC而是转为触发full GC(因为HotSpot VM的GC里,除了CMS的concurrent collection之外,其它能收集old gen的GC都会同时收集整个GC堆,包括young gen,所以不需要事先触发一次单独的young GC);或者,如果有perm gen的话,要在perm gen分配空间但已经没有足够空间时,也要触发一次full GC;或者System.gc()、heap dump带GC,默认也是触发full GC。\n\n### FULL GC触发条件详解\n\n除直接调用System.gc外,触发Full GC执行的情况有如下四种。\n\n1.旧生代空间不足\n\n旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:\n\njava.lang.OutOfMemoryError:Javaheapspace\n\n为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。\n\n2\\. Permanet Generation空间满\n\nPermanet Generation中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:\n\njava.lang.OutOfMemoryError:PermGenspace\n\n为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。\n\n3\\. CMS GC时出现promotion failed和concurrent mode failure\n\n对于采用CMS进行旧生代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。\n\npromotion failed是在进行Minor GC时,survivor space放不下、对象只能放入旧生代,而此时旧生代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的。\n\n应对措施为:增大survivor space、旧生代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX: CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。\n\n4.统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间\n\n这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。\n\n例如程序第一次触发Minor GC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。\n\n当新生代采用PS GC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。\n\n除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java -Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。\n\n### 总结\n\n**Minor GC ,Full GC 触发条件**\n\nMinor GC触发条件:当Eden区满时,触发Minor GC。\n\nFull GC触发条件:\n\n(1)调用System.gc时,系统建议执行Full GC,但是不必然执行\n\n(2)老年代空间不足\n\n(3)方法去空间不足\n\n(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存\n\n(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小\n\n### 什么是Stop the world\n\nJava中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(除了垃圾收集帮助器之外)。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于gc引起。\n\nGC时的Stop the World(STW)是大家最大的敌人。但可能很多人还不清楚,除了GC,JVM下还会发生停顿现象。\n\nJVM里有一条特殊的线程--VM Threads,专门用来执行一些特殊的VM Operation,比如分派GC,thread dump等,这些任务,都需要整个Heap,以及所有线程的状态是静止的,一致的才能进行。所以JVM引入了安全点(Safe Point)的概念,想办法在需要进行VM Operation时,通知所有的线程进入一个静止的安全点。\n\n除了GC,其他触发安全点的VM Operation包括:\n\n1\\. JIT相关,比如Code deoptimization, Flushing code cache ;\n\n2\\. Class redefinition (e.g. javaagent,AOP代码植入的产生的instrumentation) ;\n\n3\\. Biased lock revocation 取消偏向锁 ;\n\n4\\. Various debug operation (e.g. thread dump or deadlock check);\n\n## Java垃圾回收过程\n\n垃圾回收是一种回收无用内存空间并使其对未来实例可用的过程。\n\nEden 区:当一个实例被创建了,首先会被存储在堆内存年轻代的 Eden 区中。\n\n注意:如果你不能理解这些词汇,我建议你阅读这篇[垃圾回收介绍](http://javapapers.com/java/java-garbage-collection-introduction/),这篇教程详细地介绍了内存模型、JVM 架构以及这些术语。\n\nSurvivor 区(S0 和 S1):作为年轻代 GC(Minor GC)周期的一部分,存活的对象(仍然被引用的)从 Eden 区被移动到 Survivor 区的 S0 中。类似的,垃圾回收器会扫描 S0 然后将存活的实例移动到 S1 中。\n\n(译注:此处不应该是Eden和S0中存活的都移到S1么,为什么会先移到S0再从S0移到S1?)\n\n死亡的实例(不再被引用)被标记为垃圾回收。根据垃圾回收器(有四种常用的垃圾回收器,将在下一教程中介绍它们)选择的不同,要么被标记的实例都会不停地从内存中移除,要么回收过程会在一个单独的进程中完成。\n\n老年代:老年代(Old or tenured generation)是堆内存中的第二块逻辑区。当垃圾回收器执行 Minor GC 周期时,在 S1 Survivor 区中的存活实例将会被晋升到老年代,而未被引用的对象被标记为回收。\n\n老年代 GC(Major GC):相对于 Java 垃圾回收过程,老年代是实例生命周期的最后阶段。Major GC 扫描老年代的垃圾回收过程。如果实例不再被引用,那么它们会被标记为回收,否则它们会继续留在老年代中。\n\n内存碎片:一旦实例从堆内存中被删除,其位置就会变空并且可用于未来实例的分配。这些空出的空间将会使整个内存区域碎片化。为了实例的快速分配,需要进行碎片整理。基于垃圾回收器的不同选择,回收的内存区域要么被不停地被整理,要么在一个单独的GC进程中完成。\n\n## 垃圾回收中实例的终结\n\n在释放一个实例和回收内存空间之前,Java 垃圾回收器会调用实例各自的`finalize()`方法,从而该实例有机会释放所持有的资源。虽然可以保证`finalize()`会在回收内存空间之前被调用,但是没有指定的顺序和时间。多个实例间的顺序是无法被预知,甚至可能会并行发生。程序不应该预先调整实例之间的顺序并使用`finalize()`方法回收资源。\n\n* 任何在 finalize过程中未被捕获的异常会自动被忽略,然后该实例的 finalize 过程被取消。\n* JVM 规范中并没有讨论关于弱引用的垃圾回收机制,也没有很明确的要求。具体的实现都由实现方决定。\n* 垃圾回收是由一个守护线程完成的。\n\n## 对象什么时候符合垃圾回收的条件?\n\n* 所有实例都没有活动线程访问。\n* 没有被其他任何实例访问的循环引用实例。\n\n[Java 中有不同的引用类型](http://javapapers.com/core-java/java-weak-reference/)。判断实例是否符合垃圾收集的条件都依赖于它的引用类型。\n\n| 引用类型 | 垃圾收集 |\n| --- | --- |\n| 强引用(Strong Reference) | 不符合垃圾收集 |\n| 软引用(Soft Reference) | 垃圾收集可能会执行,但会作为最后的选择 |\n| 弱引用(Weak Reference) | 符合垃圾收集 |\n| 虚引用(Phantom Reference) | 符合垃圾收集 |\n\n在编译过程中作为一种优化技术,Java 编译器能选择给实例赋`null`值,从而标记实例为可回收。\n````\n class Animal {\n \n public static void main(String[] args) {\n \n Animal lion = new Animal();\n \n System.out.println(\"Main is completed.\");\n \n }\n \n \n \n protected void finalize() {\n \n System.out.println(\"Rest in Peace!\");\n \n }\n \n }\n````\n在上面的类中,`lion`对象在实例化行后从未被使用过。因此 Java 编译器作为一种优化措施可以直接在实例化行后赋值`lion = null`。因此,即使在 SOP 输出之前, finalize 函数也能够打印出`'Rest in Peace!'`。我们不能证明这确定会发生,因为它依赖JVM的实现方式和运行时使用的内存。然而,我们还能学习到一点:如果编译器看到该实例在未来再也不会被引用,能够选择并提早释放实例空间。\n\n* 关于对象什么时候符合垃圾回收有一个更好的例子。实例的所有属性能被存储在寄存器中,随后寄存器将被访问并读取内容。无一例外,这些值将被写回到实例中。虽然这些值在将来能被使用,这个实例仍然能被标记为符合垃圾回收。这是一个很经典的例子,不是吗?\n* 当被赋值为null时,这是很简单的一个符合垃圾回收的示例。当然,复杂的情况可以像上面的几点。这是由 JVM 实现者所做的选择。目的是留下尽可能小的内存占用,加快响应速度,提高吞吐量。为了实现这一目标, JVM 的实现者可以选择一个更好的方案或算法在垃圾回收过程中回收内存空间。\n* 当`finalize()`方法被调用时,JVM 会释放该线程上的所有同步锁。\n\n### GC Scope 示例程序\n````\nClass GCScope {\n\n GCScope t;\n\n static int i = 1;\n\n \n\n public static void main(String args[]) {\n\n GCScope t1 = new GCScope();\n\n GCScope t2 = new GCScope();\n\n GCScope t3 = new GCScope();\n\n \n\n // No Object Is Eligible for GC\n\n \n\n t1.t = t2; // No Object Is Eligible for GC\n\n t2.t = t3; // No Object Is Eligible for GC\n\n t3.t = t1; // No Object Is Eligible for GC\n\n \n\n t1 = null;\n\n // No Object Is Eligible for GC (t3.t still has a reference to t1)\n\n \n\n t2 = null;\n\n // No Object Is Eligible for GC (t3.t.t still has a reference to t2)\n\n \n\n t3 = null;\n\n // All the 3 Object Is Eligible for GC (None of them have a reference.\n\n // only the variable t of the objects are referring each other in a\n\n // rounded fashion forming the Island of objects with out any external\n\n // reference)\n\n }\n\n \n\n protected void finalize() {\n\n System.out.println(\"Garbage collected from object\" + i);\n\n i++;\n\n }\n\n \n\nclass GCScope {\n\n GCScope t;\n\n static int i = 1;\n\n \n\n public static void main(String args[]) {\n\n GCScope t1 = new GCScope();\n\n GCScope t2 = new GCScope();\n\n GCScope t3 = new GCScope();\n\n \n\n // 没有对象符合GC\n\n t1.t = t2; // 没有对象符合GC\n\n t2.t = t3; // 没有对象符合GC\n\n t3.t = t1; // 没有对象符合GC\n\n \n\n t1 = null;\n\n // 没有对象符合GC (t3.t 仍然有一个到 t1 的引用)\n\n \n\n t2 = null;\n\n // 没有对象符合GC (t3.t.t 仍然有一个到 t2 的引用)\n\n \n\n t3 = null;\n\n // 所有三个对象都符合GC (它们中没有一个拥有引用。\n\n // 只有各对象的变量 t 还指向了彼此,\n\n // 形成了一个由对象组成的环形的岛,而没有任何外部的引用。)\n\n }\n\n \n\n protected void finalize() {\n\n System.out.println(\"Garbage collected from object\" + i);\n\n i++;\n\n }\n}\n````\n## JVM GC算法\n\n在判断哪些内存需要回收和什么时候回收用到GC 算法,本文主要对GC 算法进行讲解。\n\n## JVM垃圾判定算法\n\n常见的JVM垃圾判定算法包括:引用计数算法、可达性分析算法。\n\n### 引用计数算法(Reference Counting)\n\n引用计数算法是通过判断对象的引用数量来决定对象是否可以被回收。\n\n给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。\n\n优点:简单,高效,现在的objective-c用的就是这种算法。\n\n缺点:很难处理循环引用,相互引用的两个对象则无法释放。因此目前主流的Java虚拟机都摒弃掉了这种算法。\n\n举个简单的例子,对象objA和objB都有字段instance,赋值令objA.instance=objB及objB.instance=objA,除此之外,这两个对象没有任何引用,实际上这两个对象已经不可能再被访问,但是因为互相引用,导致它们的引用计数都不为0,因此引用计数算法无法通知GC收集器回收它们。\n\n```\n\npublic class ReferenceCountingGC {\n public Object instance = null;\n\n public static void main(String[] args) {\n ReferenceCountingGC objA = new ReferenceCountingGC();\n ReferenceCountingGC objB = new ReferenceCountingGC();\n objA.instance = objB;\n objB.instance = objA;\n\n objA = null;\n objB = null;\n\n System.gc();//GC\n }\n}\n```\n\n运行结果\n\n```\n[GC (System.gc()) [PSYoungGen: 3329K->744K(38400K)] 3329K->752K(125952K), 0.0341414 secs] [Times: user=0.00 sys=0.00, real=0.06 secs] \n[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->628K(87552K)] 752K->628K(125952K), [Metaspace: 3450K->3450K(1056768K)], 0.0060728 secs] [Times: user=0.05 sys=0.00, real=0.01 secs] \nHeap\n PSYoungGen total 38400K, used 998K [0x00000000d5c00000, 0x00000000d8680000, 0x0000000100000000)\n eden space 33280K, 3% used [0x00000000d5c00000,0x00000000d5cf9b20,0x00000000d7c80000)\n from space 5120K, 0% used [0x00000000d7c80000,0x00000000d7c80000,0x00000000d8180000)\n to space 5120K, 0% used [0x00000000d8180000,0x00000000d8180000,0x00000000d8680000)\n ParOldGen total 87552K, used 628K [0x0000000081400000, 0x0000000086980000, 0x00000000d5c00000)\n object space 87552K, 0% used [0x0000000081400000,0x000000008149d2c8,0x0000000086980000)\n Metaspace used 3469K, capacity 4496K, committed 4864K, reserved 1056768K\n class space used 381K, capacity 388K, committed 512K, reserved 1048576K\n\nProcess finished with exit code 0\n```\n\n从运行结果看,GC日志中包含“3329K->744K”,意味着虚拟机并没有因为这两个对象互相引用就不回收它们,说明虚拟机不是通过引用技术算法来判断对象是否存活的。\n\n### 可达性分析算法(根搜索算法)\n\n可达性分析算法是通过判断对象的引用链是否可达来决定对象是否可以被回收。\n\n从GC Roots(每种具体实现对GC Roots有不同的定义)作为起点,向下搜索它们引用的对象,可以生成一棵引用树,树的节点视为可达对象,反之视为不可达。\n\n\n\n在Java语言中,可以作为GC Roots的对象包括下面几种:\n\n* 虚拟机栈(栈帧中的本地变量表)中的引用对象。\n* 方法区中的类静态属性引用的对象。\n* 方法区中的常量引用的对象。\n* 本地方法栈中JNI(Native方法)的引用对象\n\n真正标记以为对象为可回收状态至少要标记两次。\n\n## 四种引用\n\n强引用就是指在程序代码之中普遍存在的,类似\"Object obj = new Object()\"这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。\n\n```\n\nObject obj = new Object();\n```\n\n软引用是用来描述一些还有用但并非必需的对象,对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在JDK1.2之后,提供了SoftReference类来实现软引用。\n\n```\n\nObject obj = new Object();\nSoftReference sf = new SoftReference(obj);\n```\n\n弱引用也是用来描述非必需对象的,但是它的强度比软引用更弱一些,被弱引用关联的对象,只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。\n\n```\n\nObject obj = new Object();\nWeakReference wf = new WeakReference(obj);\n```\n\n虚引用也成为幽灵引用或者幻影引用,它是最弱的一中引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。在JDK1.2之后,提供给了PhantomReference类来实现虚引用。\n\n```\n\nObject obj = new Object();\nPhantomReference pf = new PhantomReference(obj);\n```\n\n## JVM垃圾回收算法\n\n常见的垃圾回收算法包括:标记-清除算法,复制算法,标记-整理算法,分代收集算法。\n\n在介绍JVM垃圾回收算法前,先介绍一个概念。\n\nStop-the-World\n\nStop-the-world意味着 JVM由于要执行GC而停止了应用程序的执行,并且这种情形会在任何一种GC算法中发生。当Stop-the-world发生时,除了GC所需的线程以外,所有线程都处于等待状态直到GC任务完成。事实上,GC优化很多时候就是指减少Stop-the-world发生的时间,从而使系统具有高吞吐 、低停顿的特点。\n\n## 标记—清除算法(Mark-Sweep)\n\n之所以说标记/清除算法是几种GC算法中最基础的算法,是因为后续的收集算法都是基于这种思路并对其不足进行改进而得到的。标记/清除算法的基本思想就跟它的名字一样,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。\n\n标记阶段:标记的过程其实就是前面介绍的可达性分析算法的过程,遍历所有的GC Roots对象,对从GC Roots对象可达的对象都打上一个标识,一般是在对象的header中,将其记录为可达对象;\n\n清除阶段:清除的过程是对堆内存进行遍历,如果发现某个对象没有被标记为可达对象(通过读取对象header信息),则将其回收。\n\n不足:\n\n* 标记和清除过程效率都不高\n* 会产生大量碎片,内存碎片过多可能导致无法给大对象分配内存。\n\n\n## 复制算法(Copying)\n\n将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。\n\n现在的商业虚拟机都采用这种收集算法来回收新生代,但是并不是将内存划分为大小相等的两块,而是分为一块较大的 Eden 空间和两块较小的 Survior 空间,每次使用 Eden 空间和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象一次性复制到另一块 Survivor 空间上,最后清理 Eden 和 使用过的那一块 Survivor。HotSpot 虚拟机的 Eden 和 Survivor 的大小比例默认为 8:1,保证了内存的利用率达到 90 %。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 空间就不够用了,此时需要依赖于老年代进行分配担保,也就是借用老年代的空间。\n\n不足:\n\n* 将内存缩小为原来的一半,浪费了一半的内存空间,代价太高;如果不想浪费一半的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。\n* 复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。\n\n\n\n## 标记—整理算法(Mark-Compact)\n\n标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存,因此其不会产生内存碎片。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。\n\n不足:\n\n效率不高,不仅要标记存活对象,还要整理所有存活对象的引用地址,在效率上不如复制算法。\n\n\n\n## 分代收集算法(Generational Collection)\n\n分代回收算法实际上是把复制算法和标记整理法的结合,并不是真正一个新的算法,一般分为:老年代(Old Generation)和新生代(Young Generation),老年代就是很少垃圾需要进行回收的,新生代就是有很多的内存空间需要回收,所以不同代就采用不同的回收算法,以此来达到高效的回收算法。\n\n新生代:由于新生代产生很多临时对象,大量对象需要进行回收,所以采用复制算法是最高效的。\n\n老年代:回收的对象很少,都是经过几次标记后都不是可回收的状态转移到老年代的,所以仅有少量对象需要回收,故采用标记清除或者标记整理算法。\n\n## 参考文章\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件. \n\n-finalizerinfo 打印正等候回收的对象的信息.\n\n-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.\n\n-histo[:live] 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量. \n\n-permstat 打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来. \n\n-F 强迫.在pid没有相应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效. \n\n-h | -help 打印辅助信息 \n\n-J 传递参数给jmap启动的jvm. 复制代码\n```\n\n\n### 5、jhat:jvm堆快照分析工具\n\njhat 命令与jamp搭配使用,用来分析map生产的堆快存储快照。jhat内置了一个微型http/Html服务器,可以在浏览器找那个查看。不过建议尽量不用,既然有dumpt文件,可以从生产环境拉取下来,然后通过本地可视化工具来分析,这样既减轻了线上服务器压力,有可以分析的足够详尽(比如 MAT/jprofile/visualVm)等。\n\n\n### 6、jstack:java堆栈跟踪工具\n\njstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。\n\n命令格式:\n\n\n\n```\njstack [ option ] pid\n\njstack [ option ] executable core\n\njstack [ option ] [server-id@]remote-hostname-or-IP复制代码\n```\n\n\n\n参数:\n\n\n\n```\n-F当’jstack [-l] pid’没有相应的时候强制打印栈信息\n\n-l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.\n\n-m打印java和native c/c++框架的所有栈信息.\n\n-h | -help打印帮助信息\n\npid 需要被打印配置信息的java进程id,可以用jps查询.复制代码\n```\n\n\n\n后续的查找耗费最高cpu例子会用到。\n\n## 二、可视化工具\n\n对jvm监控的常见可视化工具,除了jdk本身提供的Jconsole和visualVm以外,还有第三方提供的jprofilter,perfino,Yourkit,Perf4j,JProbe,MAT等。这些工具都极大的丰富了我们定位以及优化jvm方式。\n\n这些工具的使用,网上有很多教程提供,这里就不再过多介绍了。对于VisualVm来说,比较推荐使用,它除了对jvm的侵入性比较低以外,还是jdk团队自己开发的,相信以后功能会更加丰富和完善。jprofilter对于第三方监控工具,提供的功能和可视化最为完善,目前多数ide都支持其插件,对于上线前的调试以及性能调优可以配合使用。\n\n另外对于线上dump的heap信息,应该尽量拉去到线下用于可视化工具来分析,这样分析更详细。如果对于一些紧急的问题,必须需要通过线上监控,可以采用 VisualVm的远程功能来进行,这需要使用tool.jar下的MAT功能。\n\n## 三、应用\n\n### 1、cpu飙升\n\n在线上有时候某个时刻,可能会出现应用某个时刻突然cpu飙升的问题。对此我们应该熟悉一些指令,快速排查对应代码。\n\n**_1.找到最耗CPU的进程_**\n\n\n\n```\n指令:top复制代码\n```\n\n\n\n\n**_2.找到该进程下最耗费cpu的线程_**\n\n\n\n```\n指令:top -Hp pid复制代码\n```\n\n\n\n\n\n**_3.转换进制_**\n\n\n\n```\nprintf “%x\\n” 15332 // 转换16进制(转换后为0x3be4) 复制代码\n```\n\n\n**_4.过滤指定线程,打印堆栈信息_**\n\n\n\n```\n指令:\njstack pid |grep 'threadPid' -C5 --color \n\njstack 13525 |grep '0x3be4' -C5 --color // 打印进程堆栈 并通过线程id,过滤得到线程堆栈信息。复制代码\n```\n\n可以看到是一个上报程序,占用过多cpu了(以上例子只为示例,本身耗费cpu并不高)\n\n### 2、线程死锁\n\n有时候部署场景会有线程死锁的问题发生,但又不常见。此时我们采用jstack查看下一下。比如说我们现在已经有一个线程死锁的程序,导致某些操作waiting中。\n\n**_1.查找java进程id_**\n\n\n\n```\n指令:top 或者 jps 复制代码\n```\n\n\n### 2.查看java进程的线程快照信息\n\n\n\n```\n指令:jstack -l pid复制代码\n```\n\n从输出信息可以看到,有一个线程死锁发生,并且指出了那行代码出现的。如此可以快速排查问题。\n\n### 3、OOM内存泄露\n\njava堆内的OOM异常是实际应用中常见的内存溢出异常。一般我们都是先通过内存映射分析工具(比如MAT)对dump出来的堆转存快照进行分析,确认内存中对象是否出现问题。\n\n当然了出现OOM的原因有很多,并非是堆中申请资源不足一种情况。还有可能是申请太多资源没有释放,或者是频繁频繁申请,系统资源耗尽。针对这三种情况我需要一一排查。\n\nOOM的三种情况:\n\n> 1.申请资源(内存)过小,不够用。\n> \n> 2.申请资源太多,没有释放。\n> \n> 3.申请资源过多,资源耗尽。比如:线程过多,线程内存过大等。\n\n**1.排查申请申请资源问题。**\n\n\n\n```\n指令:jmap -heap 11869 复制代码\n```\n\n查看新生代,老生代堆内存的分配大小以及使用情况,看是否本身分配过小。\n\n\n从上述排查,发现程序申请的内存没有问题。\n\n**2.排查gc**\n\n特别是fgc情况下,各个分代内存情况。\n\n\n\n```\n指令:jstat -gcutil 11938 1000 每秒输出一次gc的分代内存分配情况,以及gc时间复制代码\n```\n\n\n**3.查找最费内存的对象**\n\n\n\n```\n指令: jmap -histo:live 11869 | more复制代码\n```\n\n上述输出信息中,最大内存对象才161kb,属于正常范围。如果某个对象占用空间很大,比如超过了100Mb,应该着重分析,为何没有释放。\n\n注意,上述指令:\n\n\n\n```\njmap -histo:live 11869 | more\n\n执行之后,会造成jvm强制执行一次fgc,在线上不推荐使用,可以采取dump内存快照,线下采用可视化工具进行分析,更加详尽。\n\njmap -dump:format=b,file=/tmp/dump.dat 11869 \n\n或者采用线上运维工具,自动化处理,方便快速定位,遗失出错时间。复制代码\n```\n\n\n**4.确认资源是否耗尽**\n\n> * pstree 查看进程线程数量\n> * netstat 查看网络连接数量\n\n或者采用:\n\n> * ll /proc/${PID}/fd | wc -l // 打开的句柄数\n> * ll /proc/${PID}/task | wc -l (效果等同pstree -p | wc -l) //打开的线程数\n\n以上就是一些常见的jvm命令应用。\n\n一种工具的应用并非是万能钥匙,包治百病,问题的解决往往是需要多种工具的结合才能更好的定位问题,无论使用何种分析工具,最重要的是熟悉每种工具的优势和劣势。这样才能取长补短,配合使用。\n\n\n\n\n## 参考文章\n\n\n\n\n\n\n\n list = new ArrayList();\n //无限创建对象,在堆中\n while (true) {\n list.add(new OOMObject());\n }\n }\n}\n\n```\n\nRun起来代码后爆出异常如下:\n\njava.lang.OutOfMemoryError: Java heap space\nDumping heap to /Users/zdy/Desktop/dump/java_pid1099.hprof …\n\n可以看到生成了dump文件到指定目录。并且爆出了OutOfMemoryError,还告诉了你是哪一片区域出的问题:heap space\n\n打开VisualVM工具导入对应的heapDump文件(如何使用请读者自行查阅相关资料),相应的说明见图:\n\n\n\n\n分析dump文件后,我们可以知道,OOMObject这个类创建了810326个实例。所以它能不溢出吗?接下来就在代码里找这个类在哪new的。排查问题。(我们的样例代码就不用排查了,While循环太凶猛了)分析dump文件后,我们可以知道,OOMObject这个类创建了810326个实例。所以它能不溢出吗?接下来就在代码里找这个类在哪new的。排查问题。(我们的样例代码就不用排查了,While循环太凶猛了)\n\n### Java栈内存异常\n\n老实说,在栈中出现异常(StackOverFlowError)的概率小到和去苹果专卖店买手机,买回来后发现是Android系统的概率是一样的。因为作者确实没有在生产环境中遇到过,除了自己作死写样例代码测试。先说一下异常出现的情况,前面讲到过,方法调用的过程就是方法帧进虚拟机栈和出虚拟机栈的过程,那么有两种情况可以导致StackOverFlowError,当一个方法帧(比如需要2M内存)进入到虚拟机栈(比如还剩下1M内存)的时候,就会报出StackOverFlow.这里先说一个概念,栈深度:指目前虚拟机栈中没有出栈的方法帧。虚拟机栈容量通过参数-Xss来控制,下面通过一段代码,把栈容量人为的调小一点,然后通过递归调用触发异常。\n\n```\n/**\n * VM Args:\n //设置栈容量为160K,默认1M\n -Xss160k\n */\npublic class JavaVMStackSOF {\n private int stackLength = 1;\n public void stackLeak() {\n stackLength++;\n //递归调用,触发异常\n stackLeak();\n }\n\n public static void main(String[] args) throws Throwable {\n JavaVMStackSOF oom = new JavaVMStackSOF();\n try {\n oom.stackLeak();\n } catch (Throwable e) {\n System.out.println(\"stack length:\" + oom.stackLength);\n throw e;\n }\n }\n}\n\n```\n\n> 结果如下:\n> stack length:751 Exception in thread “main”\n> java.lang.StackOverflowError\n\n可以看到,递归调用了751次,栈容量不够用了。\n默认的栈容量在正常的方法调用时,栈深度可以达到1000-2000深度,所以,一般的递归是可以承受的住的。如果你的代码出现了StackOverflowError,首先检查代码,而不是改参数。\n\n这里顺带提一下,很多人在做多线程开发时,当创建很多线程时,**容易出现OOM(OutOfMemoryError),**这时可以通过具体情况,减少最大堆容量,或者栈容量来解决问题,这是为什么呢。请看下面的公式:\n\n线程数*(最大栈容量)+最大堆值+其他内存(忽略不计或者一般不改动)=机器最大内存 \n\n当线程数比较多时,且无法通过业务上削减线程数,那么再不换机器的情况下,**你只能把最大栈容量设置小一点,或者把最大堆值设置小一点。**\n\n### 方法区内存异常\n\n写到这里时,作者本来想写一个无限创建动态代理对象的例子来演示方法区溢出,避开谈论JDK7与JDK8的内存区域变更的过渡,但细想一想,还是把这一块从始致终的说清楚。在上一篇文章中JVM系列之Java内存结构详解讲到方法区时提到,JDK7环境下方法区包括了(运行时常量池),其实这么说是不准确的。因为从JDK7开始,HotSpot团队就想到开始去\"永久代\",大家首先明确一个概念,**方法区和\"永久代\"(PermGen space)是两个概念,方法区是JVM虚拟机规范,任何虚拟机实现(J9等)都不能少这个区间,而\"永久代\"只是HotSpot对方法区的一个实现。**为了把知识点列清楚,我还是才用列表的形式:\n\n* [ ] JDK7之前(包括JDK7)拥有\"永久代\"(PermGen space),用来实现方法区。但在JDK7中已经逐渐在实现中把永久代中把很多东西移了出来,比如:符号引用(Symbols)转移到了native heap,运行时常量池(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap.\n* [ ] 所以这就是为什么我说上一篇文章中说方法区中包含运行时常量池是不正确的,因为已经移动到了java heap;\n **在JDK7之前(包括7)可以通过-XX:PermSize -XX:MaxPermSize来控制永久代的大小.\n JDK8正式去除\"永久代\",换成Metaspace(元空间)作为JVM虚拟机规范中方法区的实现。**\n 元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但仍可以通过参数控制:-XX:MetaspaceSize与-XX:MaxMetaspaceSize来控制大小。\n\n### 方法区与运行时常量池OOM\n\nJava 永久代是非堆内存的组成部分,用来存放类名、访问修饰符、常量池、字段描述、方法描述等,因运行时常量池是方法区的一部分,所以这里也包含运行时常量池。我们可以通过 jvm 参数 -XX:PermSize=10M -XX:MaxPermSize=10M 来指定该区域的内存大小,-XX:PermSize 默认为物理内存的 1/64 ,-XX:MaxPermSize 默认为物理内存的 1/4 。String.intern() 方法是一个 Native 方法,它的作用是:如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回代表池中这个字符串的 String 对象;否则,将此 String 对象包含的字符串添加到常量池中,并且返回此 String 对象的引用。在 JDK 1.6 及之前的版本中,由于常量池分配在永久代内,我们可以通过 -XX:PermSize 和 -XX:MaxPermSize 限制方法区大小,从而间接限制其中常量池的容量,通过运行 java -XX:PermSize=8M -XX:MaxPermSize=8M RuntimeConstantPoolOom 下面的代码我们可以模仿一个运行时常量池内存溢出的情况:\n\n```\nimport java.util.ArrayList;\nimport java.util.List;\n\npublic class RuntimeConstantPoolOom {\n public static void main(String[] args) {\n List list = new ArrayList();\n int i = 0;\n while (true) {\n list.add(String.valueOf(i++).intern());\n }\n }\n}\n\n```\n\n运行结果如下:\n\n```\n[root@9683817ada51 oom]# ../jdk1.6.0_45/bin/java -XX:PermSize=8m -XX:MaxPermSize=8m RuntimeConstantPoolOom\nException in thread \"main\" java.lang.OutOfMemoryError: PermGen space\n at java.lang.String.intern(Native Method)\n at RuntimeConstantPoolOom.main(RuntimeConstantPoolOom.java:9)\n\n```\n\n还有一种情况就是我们可以通过不停的加载class来模拟方法区内存溢出,《深入理解java虚拟机》中借助 CGLIB 这类字节码技术模拟了这个异常,我们这里使用不同的 classloader 来实现(同一个类在不同的 classloader 中是不同的),代码如下\n\n```\nimport java.io.File;\nimport java.net.MalformedURLException;\nimport java.net.URL;\nimport java.net.URLClassLoader;\nimport java.util.HashSet;\nimport java.util.Set;\n\npublic class MethodAreaOom {\n public static void main(String[] args) throws MalformedURLException, ClassNotFoundException {\n Set> classes = new HashSet>();\n URL url = new File(\"\").toURI().toURL();\n URL[] urls = new URL[]{url};\n while (true) {\n ClassLoader loader = new URLClassLoader(urls);\n Class loadClass = loader.loadClass(Object.class.getName());\n classes.add(loadClass);\n }\n }\n}\n\n```\n\n```\n[root@9683817ada51 oom]# ../jdk1.6.0_45/bin/java -XX:PermSize=2m -XX:MaxPermSize=2m MethodAreaOom\nError occurred during initialization of VM\njava.lang.OutOfMemoryError: PermGen space\n at sun.net.www.ParseUtil.(ParseUtil.java:31)\n at sun.misc.Launcher.getFileURL(Launcher.java:476)\n at sun.misc.Launcher$ExtClassLoader.getExtURLs(Launcher.java:187)\n at sun.misc.Launcher$ExtClassLoader.(Launcher.java:158)\n at sun.misc.Launcher$ExtClassLoader$1.run(Launcher.java:142)\n at java.security.AccessController.doPrivileged(Native Method)\n at sun.misc.Launcher$ExtClassLoader.getExtClassLoader(Launcher.java:135)\n at sun.misc.Launcher.(Launcher.java:55)\n at sun.misc.Launcher.(Launcher.java:43)\n at java.lang.ClassLoader.initSystemClassLoader(ClassLoader.java:1337)\n at java.lang.ClassLoader.getSystemClassLoader(ClassLoader.java:1319)\n\n```\n\n在 jdk1.8 上运行上面的代码将不会出现异常,因为 jdk1.8 已结去掉了永久代,当然 -XX:PermSize=2m -XX:MaxPermSize=2m 也将被忽略,如下\n\n```\n[root@9683817ada51 oom]# java -XX:PermSize=2m -XX:MaxPermSize=2m MethodAreaOom\nJava HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=2m; support was removed in 8.0\nJava HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=2m; support was removed in 8.0\n\n```\n\njdk1.8 使用元空间( Metaspace )替代了永久代( PermSize ),因此我们可以在 1.8 中指定 Metaspace 的大小模拟上述情况\n\n```\n[root@9683817ada51 oom]# java -XX:MetaspaceSize=2m -XX:MaxMetaspaceSize=2m RuntimeConstantPoolOom\nError occurred during initialization of VM\njava.lang.OutOfMemoryError: Metaspace\n <>\n\n```\n\n在JDK8的环境下将报出异常:\nException in thread “main” java.lang.OutOfMemoryError: Metaspace\n这是因为在调用CGLib的创建代理时会生成动态代理类,即Class对象到Metaspace,所以While一下就出异常了。\n**提醒一下:虽然我们日常叫\"堆Dump\",但是dump技术不仅仅是对于\"堆\"区域才有效,而是针对OOM的,也就是说不管什么区域,凡是能够报出OOM错误的,都可以使用dump技术生成dump文件来分析。**\n\n在经常动态生成大量Class的应用中,需要特别注意类的回收状况,这类场景除了例子中的CGLib技术,常见的还有,大量JSP,反射,OSGI等。需要特别注意,当出现此类异常,应该知道是哪里出了问题,然后看是调整参数,还是在代码层面优化。\n\n### 附加-直接内存异常\n\n直接内存异常非常少见,而且机制很特殊,因为直接内存不是直接向操作系统分配内存,而且通过计算得到的内存不够而手动抛出异常,所以当你发现你的dump文件很小,而且没有明显异常,只是告诉你OOM,你就可以考虑下你代码里面是不是直接或者间接使用了NIO而导致直接内存溢出。\n\n## Java内存泄漏\n\nJava的一个重要优点就是通过垃圾收集器(Garbage Collection,GC)自动管理内存的回收,程序员不需要通过调用函数来释放内存。因此,很多程序员认为Java不存在内存泄漏问题,或者认为即使有内存泄漏也不是程序的责任,而是GC或JVM的问题。其实,这种想法是不正确的,因为Java也存在内存泄露,但它的表现与C++不同。\n\n随着越来越多的服务器程序采用Java技术,例如JSP,Servlet, EJB等,服务器程序往往长期运行。另外,在很多嵌入式系统中,内存的总量非常有限。内存泄露问题也就变得十分关键,即使每次运行少量泄漏,长期运行之后,系统也是面临崩溃的危险。\n\n## Java是如何管理内存?\n\n为了判断Java中是否有内存泄露,我们首先必须了解Java是如何管理内存的。Java的内存管理就是对象的分配和释放问题。在Java中,程序员需要通过关键字new为每个对象申请内存空间 (基本类型除外),所有的对象都在堆 (Heap)中分配空间。另外,对象的释放是由GC决定和执行的。在Java中,内存的分配是由程序完成的,而内存的释放是有GC完成的,这种收支两条线的方法确实简化了程序员的工作。但同时,它也加重了JVM的工作。这也是Java程序运行速度较慢的原因之一。因为,GC为了能够正确释放对象,GC必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要进行监控。\n\n监视对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再被引用。\n\n为了更好理解GC的工作原理,我们可以将对象考虑为有向图的顶点,将引用关系考虑为图的有向边,有向边从引用者指向被引对象。另外,每个线程对象可以作为一个图的起始顶点,例如大多程序从main进程开始执行,那么该图就是以main进程顶点开始的一棵根树。在这个有向图中,根顶点可达的对象都是有效对象,GC将不回收这些对象。如果某个对象 (连通子图)与这个根顶点不可达(注意,该图为有向图),那么我们认为这个(这些)对象不再被引用,可以被GC回收。\n\n以下,我们举一个例子说明如何用有向图表示内存管理。对于程序的每一个时刻,我们都有一个有向图表示JVM的内存分配情况。以下右图,就是左边程序运行到第6行的示意图。\n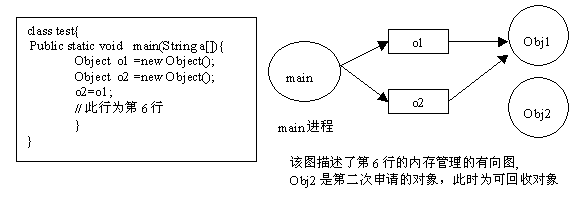\n\nJava使用有向图的方式进行内存管理,可以消除引用循环的问题,例如有三个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的。这种方式的优点是管理内存的精度很高,但是效率较低。另外一种常用的内存管理技术是使用计数器,例如COM模型采用计数器方式管理构件,它与有向图相比,精度行低(很难处理循环引用的问题),但执行效率很高。\n\n## 什么是Java中的内存泄露?\n\n下面,我们就可以描述什么是内存泄漏。在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。\n\n在C++中,内存泄漏的范围更大一些。有些对象被分配了内存空间,然后却不可达,由于C++中没有GC,这些内存将永远收不回来。在Java中,这些不可达的对象都由GC负责回收,因此程序员不需要考虑这部分的内存泄露。\n\n通过分析,我们得知,对于C++,程序员需要自己管理边和顶点,而对于Java程序员只需要管理边就可以了(不需要管理顶点的释放)。通过这种方式,Java提高了编程的效率。\n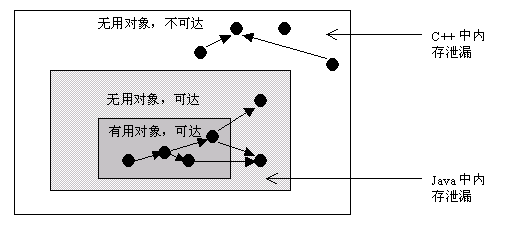\n\n因此,通过以上分析,我们知道在Java中也有内存泄漏,但范围比C++要小一些。因为Java从语言上保证,任何对象都是可达的,所有的不可达对象都由GC管理。\n\n对于程序员来说,GC基本是透明的,不可见的。虽然,我们只有几个函数可以访问GC,例如运行GC的函数System.gc(),但是根据Java语言规范定义, 该函数不保证JVM的垃圾收集器一定会执行。因为,不同的JVM实现者可能使用不同的算法管理GC。通常,GC的线程的优先级别较低。JVM调用GC的策略也有很多种,有的是内存使用到达一定程度时,GC才开始工作,也有定时执行的,有的是平缓执行GC,有的是中断式执行GC。但通常来说,我们不需要关心这些。除非在一些特定的场合,GC的执行影响应用程序的性能,例如对于基于Web的实时系统,如网络游戏等,用户不希望GC突然中断应用程序执行而进行垃圾回收,那么我们需要调整GC的参数,让GC能够通过平缓的方式释放内存,例如将垃圾回收分解为一系列的小步骤执行,Sun提供的HotSpot JVM就支持这一特性。\n\n下面给出了一个简单的内存泄露的例子。在这个例子中,我们循环申请Object对象,并将所申请的对象放入一个Vector中,如果我们仅仅释放引用本身,那么Vector仍然引用该对象,所以这个对象对GC来说是不可回收的。因此,如果对象加入到Vector后,还必须从Vector中删除,最简单的方法就是将Vector对象设置为null。\n\n```\nVector v=new Vector(10);\nfor (int i=1;i<100; i++)\n{\n Object o=new Object();\n v.add(o);\n o=null;\n}\n//此时,所有的Object对象都没有被释放,因为变量v引用这些对象\n\n```\n\n### 其他常见内存泄漏\n\n#### 1、静态集合类引起内存泄露:\n\n像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。\n例:\n\n```\nStatic Vector v = new Vector(10); \nfor (int i = 1; i<100; i++) { \n\tObject o = new Object(); \n\tv.add(o); \n\to = null; \n}// \n在这个例子中,循环申请Object 对象,并将所申请的对象放入一个Vector 中,如果仅仅释放引用本身(o=null),那么Vector 仍然引用该对象,所以这个对象对GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从Vector 中删除,最简单的方法就是将Vector对象设置为null。\n\n```\n\n#### 2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。\n\n例:\n\n```\npublic static void main(String[] args) { \n\tSet set = new HashSet(); \n\tPerson p1 = new Person(\"唐僧\",\"pwd1\",25); \n\tPerson p2 = new Person(\"孙悟空\",\"pwd2\",26); \n\tPerson p3 = new Person(\"猪八戒\",\"pwd3\",27); \n\tset.add(p1); \n\tset.add(p2); \n\tset.add(p3); \n\tSystem.out.println(\"总共有:\"+set.size()+\" 个元素!\"); //结果:总共有:3 个元素! \n\tp3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变 \n\n\tset.remove(p3); //此时remove不掉,造成内存泄漏\n\tset.add(p3); //重新添加,居然添加成功 \n\tSystem.out.println(\"总共有:\"+set.size()+\" 个元素!\"); //结果:总共有:4 个元素! \n\tfor (Person person : set) { \n\t\tSystem.out.println(person); \n\t} \n}\n\n```\n\n#### 3、监听器\n\n在java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如addXXXListener()等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。\n\n#### 4、各种连接\n\n比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close()方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。\n\n#### 5、内部类和外部模块等的引用\n\n内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。此外程序员还要小心外部模块不经意的引用,例如程序员A 负责A 模块,调用了B 模块的一个方法如:\npublic void registerMsg(Object b);\n这种调用就要非常小心了,传入了一个对象,很可能模块B就保持了对该对象的引用,这时候就需要注意模块B 是否提供相应的操作去除引用。\n\n#### 6、单例模式\n\n不正确使用单例模式是引起内存泄露的一个常见问题,单例对象在被初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露,考虑下面的例子:\n\n```\nclass A{ \n\tpublic A(){ \n\t\tB.getInstance().setA(this); \n\t} \n.... \n} \n//B类采用单例模式 \nclass B{ \n\tprivate A a; \n\tprivate static B instance=new B(); \n\tpublic B(){} \n\tpublic static B getInstance(){ \n\t\treturn instance; \n\t} \n\tpublic void setA(A a){ \n\t\tthis.a=a; \n\t} \n\t//getter... \n} \n\n```\n\n**显然B采用singleton模式,它持有一个A对象的引用,而这个A类的对象将不能被回收。想象下如果A是个比较复杂的对象或者集合类型会发生什么情况。**\n\n## 如何检测内存泄漏\n\n最后一个重要的问题,就是如何检测Java的内存泄漏。目前,我们通常使用一些工具来检查Java程序的内存泄漏问题。市场上已有几种专业检查Java内存泄漏的工具,它们的基本工作原理大同小异,都是通过监测Java程序运行时,所有对象的申请、释放等动作,将内存管理的所有信息进行统计、分析、可视化。开发人员将根据这些信息判断程序是否有内存泄漏问题。这些工具包括Optimizeit Profiler,JProbe Profiler,JinSight , Rational 公司的Purify等。\n\n下面,我们将简单介绍Optimizeit的基本功能和工作原理。\n\nOptimizeit Profiler版本4.11支持Application,Applet,Servlet和Romote Application四类应用,并且可以支持大多数类型的JVM,包括SUN JDK系列,IBM的JDK系列,和Jbuilder的JVM等。并且,该软件是由Java编写,因此它支持多种操作系统。Optimizeit系列还包括Thread Debugger和Code Coverage两个工具,分别用于监测运行时的线程状态和代码覆盖面。\n\n当设置好所有的参数了,我们就可以在OptimizeIt环境下运行被测程序,在程序运行过程中,Optimizeit可以监视内存的使用曲线(如下图),包括JVM申请的堆(heap)的大小,和实际使用的内存大小。另外,在运行过程中,我们可以随时暂停程序的运行,甚至强行调用GC,让GC进行内存回收。通过内存使用曲线,我们可以整体了解程序使用内存的情况。这种监测对于长期运行的应用程序非常有必要,也很容易发现内存泄露。\n\n\n## 参考文章\n\n\n\n\n\n\n\n map = new HashMap();\n map.put(\"hello\",\"你好\");\n System.out.println(map.get(\"hello\"));\n}\n \n泛型擦除后的例子 \npublic static void main( String[] args )\n{\n Map map = new HashMap();\n map.put(\"hello\",\"你好\");\n System.out.println((String)map.get(\"hello\"));\n}\n```\n\n##### 自动装箱、拆箱与遍历循环\n\n自动装箱、拆箱在编译之后会被转化成对应的包装和还原方法,如Integer.valueOf()与Integer.intValue(),而遍历循环则把代码还原成了迭代器的实现,变长参数会变成数组类型的参数。\n**然而包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱,以及它们的equals()方法不处理数据转型的关系。**\n\n##### 条件编译\n\nJava语言也可以进行条件编译,方法就是使用条件为常量的if语句,它在编译阶段就会被“运行”:\n\n```\npublic static void main(String[] args) {\n if(true){\n System.out.println(\"block 1\");\n }\n else{\n System.out.println(\"block 2\");\n }\n}\n \n编译后Class文件的反编译结果:\npublic static void main(String[] args) {\n System.out.println(\"block 1\");\n}\n```\n\n**只能是条件为常量的if语句,这也是Java语言的语法糖,根据布尔常量值的真假,编译器会把分支中不成立的代码块消除掉**\n\n### 晚期(运行期)优化\n\n##### 解释器与编译器\n\nJava程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。**同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。\n\nHotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler(C1编译器)和Server Compiler(C2编译器),默认采用解释器与其中一个编译器直接配合的方式工作,使用哪个编译器取决于虚拟机运行的模式,也可以自己去指定。若强制虚拟机运行与“解释模式”,编译器完全不介入工作,若强制虚拟机运行于“编译模式”,则优先采用编译方式执行程序,解释器仍然要在编译无法进行的情况下介入执行过程。\n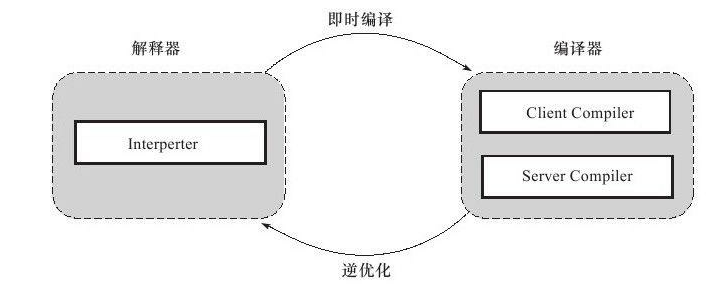\n##### 分层编译策略\n\n```\n分层编译策略作为默认编译策略在JDK1.7的Server模式虚拟机中被开启,其中包括:\n第0层:程序解释执行,解释器不开启性能监控功能,可触发第1层编译;\n第1层:C1编译,将字节码编译成本地代码,进行简单可靠的优化,如有必要将加入性能监控的逻辑;\n第2层:C2编译,也是将字节码编译成本地代码,但是会启动一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。\n实施分层编译后,C1和C2将会同时工作,C1获取更高的编译速度,C2获取更好的编译质量,在解释执行的时候也无须再承担性能监控信息的任务。 \n```\n\n##### 热点代码探测\n\n```\n在运行过程中会被即时编译器编译的“热点代码”有两类:\n1.被多次调用的方法:由方法调用触发的编译,属于JIT编译方式\n2.被多次执行的循环体:也以整个方法作为编译对象,因为编译发生在方法执行过程中,因此成为栈上替换(OSR编译)\n \n热点探测判定方式有两种:\n1.基于采样的热点探测:虚拟机周期性的检查各个线程的栈顶,如果某个方法经常出现在栈顶,则判定为“热点方法”。(简单高效,可以获取方法的调用关系,但容易受线程阻塞或别的外界因素影响扰乱热点探测)\n2.基于计数的热点探测:虚拟机为每个方法建立一个计数器,统计方法的执行次数,超过一定阈值就是“热点方法”。(需要为每个方法维护计数器,不能直接获取方法的调用关系,但是统计结果精确严谨) \n```\n\nHotSpot虚拟机使用的是第二种,它为每个方法准备了两类计数器:方法调用计数器和回边计数器,下图表示方法调用计数器触发即时编译:\n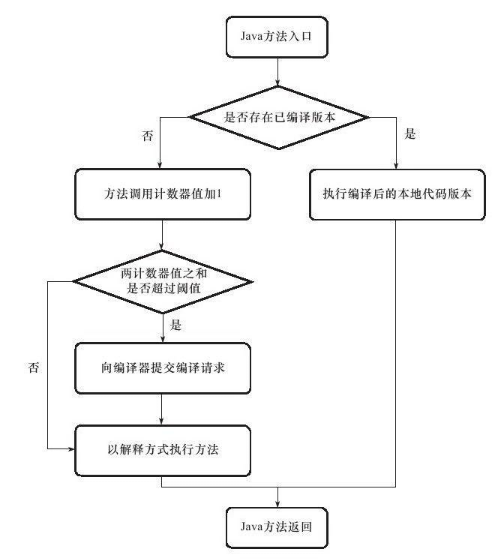\n如果不做任何设置,执行引擎会继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成,下次调用才会使用已编译的版本。另外,方法调用计数器的值也不是一个绝对次数,而是一段时间之内被调用的次数,超过这个时间,次数就减半,这称为计数器热度的衰减。\n\n下图表示回边计数器触发即时编译:\n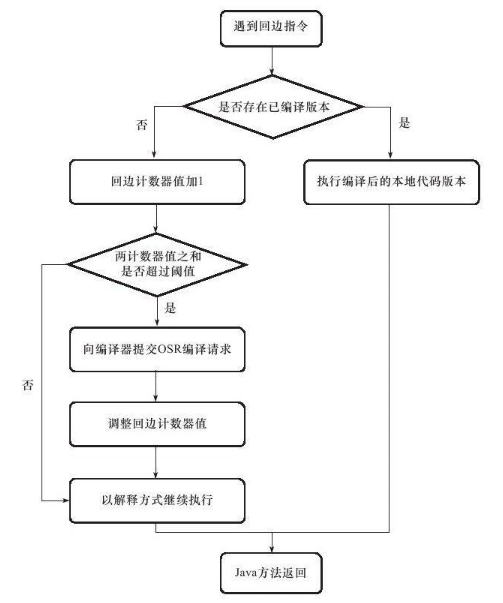\n回边计数器没有计数器热度衰减的过程,因此统计的就是绝对次数,并且当计数器溢出时,它还会把方法计数器的值也调整到溢出状态,这样下次进入该方法的时候就会执行标准编译过程。\n\n##### 编译优化技术\n\n虚拟机设计团队几乎把对代码的所有优化措施都集中在了即时编译器之中,那么在编译器编译的过程中,到底做了些什么事情呢?下面将介绍几种最有代表性的优化技术:\n**公共子表达式消除**\n如果一个表达式E已经计算过了,并且先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就成为了公共表达式,可以直接用之前的结果替换。\n例:int d = (c * b) * 12 + a + (a + b * c) => int d = E * 12 + a + (a + E)\n\n**数组边界检查消除**\nJava语言中访问数组元素都要进行上下界的范围检查,每次读写都有一次条件判定操作,这无疑是一种负担。编译器只要通过数据流分析就可以判定循环变量的取值范围永远在数组长度以内,那么整个循环中就可以把上下界检查消除,这样可以省很多次的条件判断操作。\n\n另一种方法叫做隐式异常处理,Java中空指针的判断和算术运算中除数为0的检查都采用了这个思路:\n\n```\nif(foo != null){\n return foo.value;\n}else{\n throw new NullPointException();\n}\n \n使用隐式异常优化以后:\ntry{\n return foo.value;\n}catch(segment_fault){\n uncommon_trap();\n}\n当foo极少为空时,隐式异常优化是值得的,但是foo经常为空,这样的优化反而会让程序变慢,而HotSpot虚拟机会根据运行期收集到的Profile信息自动选择最优方案。\n```\n\n**方法内联**\n方法内联能去除方法调用的成本,同时也为其他优化建立了良好的基础,因此各种编译器一般会把内联优化放在优化序列的最靠前位置,然而由于Java对象的方法默认都是虚方法,因此方法调用都需要在运行时进行多态选择,为了解决虚方法的内联问题,首先引入了“类型继承关系分析(CHA)”的技术。\n\n```\n1.在内联时,若是非虚方法,则可以直接内联 \n2.遇到虚方法,首先根据CHA判断此方法是否有多个目标版本,若只有一个,可以直接内联,但是需要预留一个“逃生门”,称为守护内联,若在程序的后续执行过程中,加载了导致继承关系发生变化的新类,就需要抛弃已经编译的代码,退回到解释状态执行,或者重新编译。\n3.若CHA判断此方法有多个目标版本,则编译器会使用“内联缓存”,第一次调用缓存记录下方法接收者的版本信息,并且每次调用都比较版本,若一致则可以一直使用,若不一致则取消内联,查找虚方法表进行方法分派。\n```\n\n**逃逸分析**\n逃逸分析的基本行为就是分析对象动态作用域,当一个对象被外部方法所引用,称为方法逃逸;当被外部线程访问,称为线程逃逸。若能证明一个对象不会被外部方法或进程引用,则可以为这个变量进行一些优化:\n\n```\n1.栈上分配:如果确定一个对象不会逃逸,则可以让它分配在栈上,对象所占用的内存空间就可以随栈帧出栈而销毁。这样可以减小垃圾收集系统的压力。 \n2.同步消除:线程同步相对耗时,如果确定一个变量不会逃逸出线程,那这个变量的读写不会有竞争,则对这个变量实施的同步措施也就可以消除掉。 \n3.标量替换:如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆散的话,那么程序真正执行的时候可以不创建这个对象,改为直接创建它的成员变量,这样就可以在栈上分配。\n```\n\n**可是目前还不能保证逃逸分析的性能收益必定高于它的消耗,所以这项技术还不是很成熟。**\n\n### java与C/C++编译器对比\n\n```\nJava虚拟机的即时编译器与C/C++的静态编译器相比,可能会由于下面的原因导致输出的本地代码有一些劣势:\n1.即时编译器运行占用的是用户程序的运行时间,具有很大的时间压力,因此不敢随便引入大规模的优化技术;\n2.Java语言是动态的类型安全语言,虚拟器需要频繁的进行动态检查,如空指针,上下界范围,继承关系等;\n3.Java中使用虚方法频率远高于C++,则需要进行多态选择的频率远高于C++;\n4.Java是可以动态扩展的语言,运行时加载新的类可能改变原有的继承关系,许多全局的优化措施只能以激进优化的方式来完成;\n5.Java语言的对象内存都在堆上分配,垃圾回收的压力比C++大\n \n然而,Java语言这些性能上的劣势换取了开发效率上的优势,并且由于C++编译器所有优化都是在编译期完成的,以运行期性能监控为基础的优化措施都无法进行,这也是Java编译器独有的优势。\n```\n\n\n\n\n\n\n\n\n\n\n\n## 参考文章\n\n\n\n\n\n\n\n weakRerference = new WeakReference(new byte[10*WeakReferenceTest.M]); \n\t\tWeakReferenceTest.printlnMemory(\"2.实例化10M的数组,并建立弱引用\");\n\t\tSystem.out.println(\"weakRerference.get() : \"+weakRerference.get());\n\n\t\tSystem.gc();\n\t\tStrongReferenceTest.printlnMemory(\"3.GC后\");\n\t\tSystem.out.println(\"weakRerference.get() : \"+weakRerference.get());\n\t} \n}\n````\n\n运行结果:\n\n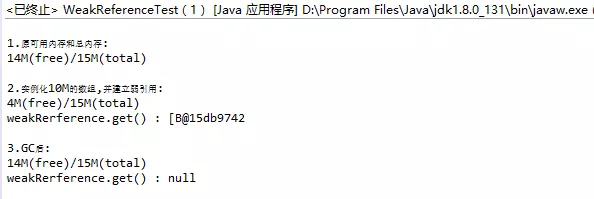\n### 3.软引用 SoftReference\n\n软引用和弱引用的特性基本一致, 主要的区别在于软引用在内存不足时才会被回收。如果一个对象只具有软引用,Java GC在内存充足的时候不会回收它,内存不足时才会被回收。\n````\npublic class SoftReferenceTest {\n\n\tpublic static int M = 1024*1024;\n\n\tpublic static void printlnMemory(String tag){\n\t\tRuntime runtime = Runtime.getRuntime();\n\t\tint M = StrongReferenceTest.M;\n\t\tSystem.out.println(\"\\n\"+tag+\":\");\n\t\tSystem.out.println(runtime.freeMemory()/M+\"M(free)/\" + runtime.totalMemory()/M+\"M(total)\");\n\t}\n\n\tpublic static void main(String[] args){\n\t\tSoftReferenceTest.printlnMemory(\"1.原可用内存和总内存\");\n\n\t\t//建立软引用\n\t\tSoftReference softRerference = new SoftReference(new byte[10*SoftReferenceTest.M]);\n\t\tSoftReferenceTest.printlnMemory(\"2.实例化10M的数组,并建立软引用\");\n\t\tSystem.out.println(\"softRerference.get() : \"+softRerference.get());\n\n\t\tSystem.gc(); \n\t\tSoftReferenceTest.printlnMemory(\"3.内存可用容量充足,GC后\");\n\t\tSystem.out.println(\"softRerference.get() : \"+softRerference.get()); \n\n\t\t//实例化一个4M的数组,使内存不够用,并建立软引用\n\t\t//free=10M=4M+10M-4M,证明内存可用量不足时,GC后byte[10*m]被回收\n\t\tSoftReference softRerference2 = new SoftReference(new byte[4*SoftReferenceTest.M]);\n\t\tSoftReferenceTest.printlnMemory(\"4.实例化一个4M的数组后\");\n\t\tSystem.out.println(\"softRerference.get() : \"+softRerference.get());\n\t\tSystem.out.println(\"softRerference2.get() : \"+softRerference2.get()); \n\t } \n}\n\n````\n运行结果:\n\n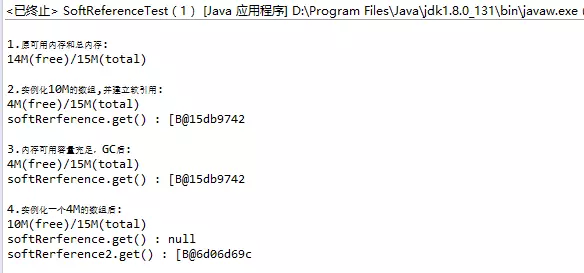\n### 4.虚引用 PhantomReference\n\n从PhantomReference类的源代码可以知道,它的get()方法无论何时返回的都只会是null。所以单独使用虚引用时,没有什么意义,需要和引用队列ReferenceQueue类联合使用。当执行Java GC时如果一个对象只有虚引用,就会把这个对象加入到与之关联的ReferenceQueue中。\n````\npublic class PhantomReferenceTest {\n\n\tpublic static int M = 1024*1024;\n\n\tpublic static void printlnMemory(String tag){\n\t\tRuntime runtime = Runtime.getRuntime();\n\t\tint M = PhantomReferenceTest.M;\n\t\tSystem.out.println(\"\\n\"+tag+\":\");\n\t\tSystem.out.println(runtime.freeMemory()/M+\"M(free)/\" + runtime.totalMemory()/M+\"M(total)\");\n\t}\n\n\tpublic static void main(String[] args) throws InterruptedException {\n\n\t\tPhantomReferenceTest.printlnMemory(\"1.原可用内存和总内存\");\n\t\tbyte[] object = new byte[10*PhantomReferenceTest.M];\t\t\n\t\tPhantomReferenceTest.printlnMemory(\"2.实例化10M的数组后\");\n\n\t //建立虚引用\n\t ReferenceQueue referenceQueue = new ReferenceQueue();\n\t PhantomReference phantomReference = new PhantomReference(object,referenceQueue); \n\n\t PhantomReferenceTest.printlnMemory(\"3.建立虚引用后\");\n\t System.out.println(\"phantomReference : \"+phantomReference); \n\t System.out.println(\"phantomReference.get() : \"+phantomReference.get());\n\t System.out.println(\"referenceQueue.poll() : \"+referenceQueue.poll());\n\n\t //断开byte[10*PhantomReferenceTest.M]的强引用\n\t object = null; \n\t PhantomReferenceTest.printlnMemory(\"4.执行object = null;强引用断开后\");\n\n\t System.gc();\n\t PhantomReferenceTest.printlnMemory(\"5.GC后\");\n\t System.out.println(\"phantomReference : \"+phantomReference); \n\t System.out.println(\"phantomReference.get() : \"+phantomReference.get());\n\t System.out.println(\"referenceQueue.poll() : \"+referenceQueue.poll());\t \n\n\t //断开虚引用\n\t phantomReference = null;\n\t\tSystem.gc(); \n\t\tPhantomReferenceTest.printlnMemory(\"6.断开虚引用后GC\");\n\t System.out.println(\"phantomReference : \"+phantomReference);\n\t System.out.println(\"referenceQueue.poll() : \"+referenceQueue.poll());\t \t\n\t}\n}\n\n````\n运行结果:\n\n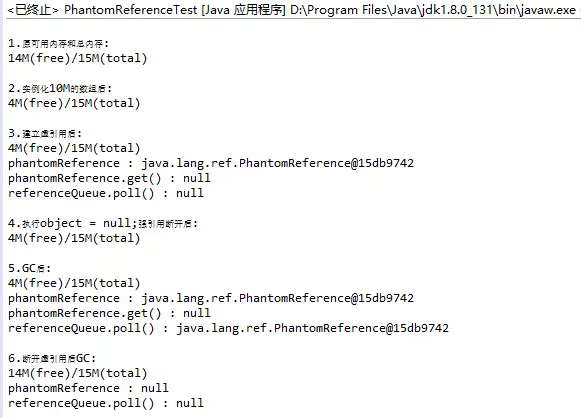\n## 三、小结\n\n强引用是 Java 的默认引用形式,使用时不需要显示定义,是我们平时最常使用到的引用方式。不管系统资源有多紧张,Java GC都不会主动回收具有强引用的对象。 弱引用和软引用一般在引用对象为非必需对象的时候使用。它们的区别是被弱引用关联的对象在垃圾回收时总是会被回收,被软引用关联的对象只有在内存不足时才会被回收。 虚引用的get()方法获取的永远是null,无法获取对象实例。Java GC会把虚引用的对象放到引用队列里面。可用来在对象被回收时做额外的一些资源清理或事物回滚等处理。 由于无法从虚引获取到引用对象的实例。它的使用情况比较特别,所以这里不把虚引用放入表格进行对比。这里对强引用、弱引用、软引用进行对比:\n\n\n\n## 参考文章\n\n\n\n\n\n\n\n方法之中.特例:\n\n```\npublic static final int value = 123;\n\n```\n\n此时value的值在准备阶段过后就是123。\n\n### 解析:\n\n把类型中的符号引用转换为直接引用。\n\n* 符号引用与虚拟机实现的布局无关,引用的目标并不一定要已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。\n* 直接引用可以是指向目标的指针,相对偏移量或是一个能间接定位到目标的句柄。如果有了直接引用,那引用的目标必定已经在内存中存在\n\n主要有以下四种:\n\n1. 类或接口的解析\n2. 字段解析\n3. 类方法解析\n4. 接口方法解析\n\n### 初始化:\n\n初始化阶段是执行类构造器方法的过程。方法是由编译器自动收集类中的类变量的赋值操作和静态语句块中的语句合并而成的。虚拟机会保证方法执行之前,父类的方法已经执行完毕。如果一个类中没有对静态变量赋值也没有静态语句块,那么编译器可以不为这个类生成()方法。\n\njava中,对于初始化阶段,有且只有以下五种情况才会对要求类立刻“初始化”(加载,验证,准备,自然需要在此之前开始):\n\n1. 使用new关键字实例化对象、访问或者设置一个类的静态字段(被final修饰、编译器优化时已经放入常量池的例外)、调用类方法,都会初始化该静态字段或者静态方法所在的类。\n2. 初始化类的时候,如果其父类没有被初始化过,则要先触发其父类初始化。\n3. 使用java.lang.reflect包的方法进行反射调用的时候,如果类没有被初始化,则要先初始化。\n4. 虚拟机启动时,用户会先初始化要执行的主类(含有main)\n5. jdk 1.7后,如果java.lang.invoke.MethodHandle的实例最后对应的解析结果是 REF_getStatic、REF_putStatic、REF_invokeStatic方法句柄,并且这个方法所在类没有初始化,则先初始化。\n\n## 四.类加载器:\n\n把类加载阶段的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作交给虚拟机之外的类加载器来完成。这样的好处在于,我们可以自行实现类加载器来加载其他格式的类,只要是二进制字节流就行,这就大大增强了加载器灵活性。系统自带的类加载器分为三种:\n\n1. 启动类加载器。\n2. 扩展类加载器。\n3. 应用程序类加载器。\n\n## 五.双亲委派机制:\n\n\n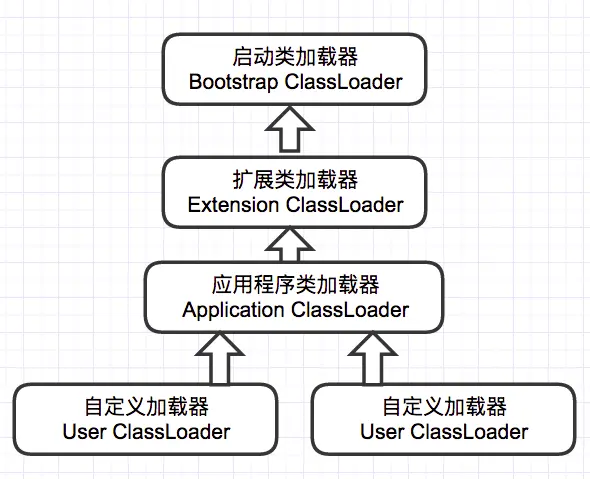\n\n\n双亲委派机制工作过程:\n\n如果一个类加载器收到了类加载器的请求.它首先不会自己去尝试加载这个类.而是把这个请求委派给父加载器去完成.每个层次的类加载器都是如此.因此所有的加载请求最终都会传送到Bootstrap类加载器(启动类加载器)中.只有父类加载反馈自己无法加载这个请求(它的搜索范围中没有找到所需的类)时.子加载器才会尝试自己去加载。\n\n双亲委派模型的优点:java类随着它的加载器一起具备了一种带有优先级的层次关系.\n\n例如类java.lang.Object,它存放在rt.jart之中.无论哪一个类加载器都要加载这个类.最终都是双亲委派模型最顶端的Bootstrap类加载器去加载.因此Object类在程序的各种类加载器环境中都是同一个类.相反.如果没有使用双亲委派模型.由各个类加载器自行去加载的话.如果用户编写了一个称为“java.lang.Object”的类.并存放在程序的ClassPath中.那系统中将会出现多个不同的Object类.java类型体系中最基础的行为也就无法保证.应用程序也将会一片混乱.\n\n\n## 参考文章\n\n\n\n\n\n\n\n() {\n @Override\n public int compare(String a, String b) {\n return b.compareTo(a);\n }\n });\n System.out.println(Arrays.toString(names.toArray()));\n }\n\n @Test\n public void test2() {\n List names = Arrays.asList(\"peter\", \"anna\", \"mike\", \"xenia\");\n\n Collections.sort(names, (String a, String b) -> {\n return b.compareTo(a);\n });\n\n Collections.sort(names, (String a, String b) -> b.compareTo(a));\n\n Collections.sort(names, (a, b) -> b.compareTo(a));\n System.out.println(Arrays.toString(names.toArray()));\n }\n\n}\n\n static void add(double a,String b) {\n System.out.println(a + b);\n }\n @Test\n public void test5() {\n D d = (a,b) -> add(a,b);\n// interface D {\n// void get(int i,String j);\n// }\n //这里要求,add的两个参数和get的两个参数吻合并且返回类型也要相等,否则报错\n// static void add(double a,String b) {\n// System.out.println(a + b);\n// }\n }\n\n @FunctionalInterface\n interface D {\n void get(int i,String j);\n }\n````\n接下来看看Lambda和匿名内部类的区别\n\n匿名内部类仍然是一个类,只是不需要我们显式指定类名,编译器会自动为该类取名。比如有如下形式的代码:\n````\npublic class LambdaTest {\n public static void main(String[] args) {\n new Thread(new Runnable() {\n @Override\n public void run() {\n System.out.println(\"Hello World\");\n }\n }).start();\n }\n}\n````\n编译之后将会产生两个 class 文件:\n\n LambdaTest.class\n LambdaTest$1.class\n\n使用 javap -c LambdaTest.class 进一步分析 LambdaTest.class 的字节码,部分结果如下:\n````\n public static void main(java.lang.String[]);\n Code:\n 0: new #2 // class java/lang/Thread\n 3: dup\n 4: new #3 // class com/example/myapplication/lambda/LambdaTest$1\n 7: dup\n 8: invokespecial #4 // Method com/example/myapplication/lambda/LambdaTest$1.\"\":()V\n 11: invokespecial #5 // Method java/lang/Thread.\"\":(Ljava/lang/Runnable;)V\n 14: invokevirtual #6 // Method java/lang/Thread.start:()V\n 17: return\n````\n可以发现在 4: new #3 这一行创建了匿名内部类的对象。\n\n而对于 Lambda表达式的实现, 接下来我们将上面的示例代码使用 Lambda 表达式实现,代码如下:\n````\npublic class LambdaTest {\n public static void main(String[] args) {\n new Thread(() -> System.out.println(\"Hello World\")).start();\n }\n}\n````\n此时编译后只会产生一个文件 LambdaTest.class,再来看看通过 javap 对该文件反编译后的结果:\n````\npublic static void main(java.lang.String[]);\nCode:\n 0: new #2 // class java/lang/Thread\n 3: dup\n 4: invokedynamic #3, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;\n 9: invokespecial #4 // Method java/lang/Thread.\"\":(Ljava/lang/Runnable;)V\n 12: invokevirtual #5 // Method java/lang/Thread.start:()V\n 15: return\n````\n从上面的结果我们发现 Lambda 表达式被封装成了主类的一个私有方法,并通过 invokedynamic 指令进行调用。\n\n因此,我们可以得出结论:Lambda 表达式是通过 invokedynamic 指令实现的,并且书写 Lambda 表达式不会产生新的类。\n\n既然 Lambda 表达式不会创建匿名内部类,那么在 Lambda 表达式中使用 this 关键字时,其指向的是外部类的引用。\n\n### 函数式接口\n\n所谓的函数式接口就是只有一个抽象方法的接口,注意这里说的是抽象方法,因为Java8中加入了默认方法的特性,但是函数式接口是不关心接口中有没有默认方法的。 一般函数式接口可以使用@FunctionalInterface注解的形式来标注表示这是一个函数式接口,该注解标注与否对函数式接口没有实际的影响, 不过一般还是推荐使用该注解,就像使用@Override注解一样。\n\nlambda表达式是如何符合 Java 类型系统的?每个lambda对应于一个给定的类型,用一个接口来说明。而这个被称为函数式接口(functional interface)的接口必须仅仅包含一个抽象方法声明。每个那个类型的lambda表达式都将会被匹配到这个抽象方法上。因此默认的方法并不是抽象的,你可以给你的函数式接口自由地增加默认的方法。\n\n\n我们可以使用任意的接口作为lambda表达式,只要这个接口只包含一个抽象方法。为了保证你的接口满足需求,你需要增加@FunctionalInterface注解。编译器知道这个注解,一旦你试图给这个接口增加第二个抽象方法声明时,它将抛出一个编译器错误。\n\n下面举几个例子\n```` \npublic class 函数式接口使用 {\n @FunctionalInterface\n interface A {\n void say();\n default void talk() {\n\n }\n }\n @Test\n public void test1() {\n A a = () -> System.out.println(\"hello\");\n a.say();\n }\n\n @FunctionalInterface\n interface B {\n void say(String i);\n }\n public void test2() {\n //下面两个是等价的,都是通过B接口来引用一个方法,而方法可以直接使用::来作为方法引用\n B b = System.out::println;\n B b1 = a -> Integer.parseInt(\"s\");//这里的a其实换成别的也行,只是将方法传给接口作为其方法实现\n B b2 = Integer::valueOf;//i与方法传入参数的变量类型一直时,可以直接替换\n B b3 = String::valueOf;\n //B b4 = Integer::parseInt;类型不符,无法使用\n\n }\n @FunctionalInterface\n interface C {\n int say(String i);\n }\n public void test3() {\n C c = Integer::parseInt;//方法参数和接口方法的参数一样,可以替换。\n int i = c.say(\"1\");\n //当我把C接口的int替换为void时就会报错,因为返回类型不一致。\n System.out.println(i);\n //综上所述,lambda表达式提供了一种简便的表达方式,可以将一个方法传到接口中。\n //函数式接口是只提供一个抽象方法的接口,其方法由lambda表达式注入,不需要写实现类,\n //也不需要写匿名内部类,可以省去很多代码,比如实现runnable接口。\n //函数式编程就是指把方法当做一个参数或引用来进行操作。除了普通方法以外,静态方法,构造方法也是可以这样操作的。\n }\n}\n````\n请记住如果@FunctionalInterface 这个注解被遗漏,此代码依然有效。\n\n### 方法引用\n\nLambda表达式和方法引用\n\n有了函数式接口之后,就可以使用Lambda表达式和方法引用了。其实函数式接口的表中的函数描述符就是Lambda表达式,在函数式接口中Lambda表达式相当于匿名内部类的效果。 举个简单的例子:\n\n````\npublic class TestLambda {\n\n public static void execute(Runnable runnable) {\n runnable.run();\n }\n \n public static void main(String[] args) {\n //Java8之前\n execute(new Runnable() {\n @Override\n public void run() {\n System.out.println(\"run\");\n }\n });\n \n //使用Lambda表达式\n execute(() -> System.out.println(\"run\"));\n }\n}\n````\n可以看到,相比于使用匿名内部类的方式,Lambda表达式可以使用更少的代码但是有更清晰的表述。注意,Lambda表达式也不是完全等价于匿名内部类的, 两者的不同点在于this的指向和本地变量的屏蔽上。\n\n方法引用可以看作Lambda表达式的更简洁的一种表达形式,使用::操作符,方法引用主要有三类:\n\n 指向静态方法的方法引用(例如Integer的parseInt方法,写作Integer::parseInt);\n \n 指向任意类型实例方法的方法引用(例如String的length方法,写作String::length);\n \n 指向现有对象的实例方法的方法引用(例如假设你有一个本地变量localVariable用于存放Variable类型的对象,它支持实例方法getValue,那么可以写成localVariable::getValue)。\n\n举个方法引用的简单的例子:\n\n Function stringToInteger = (String s) -> Integer.parseInt(s);\n\n//使用方法引用\n\n Function stringToInteger = Integer::parseInt;\n\n方法引用中还有一种特殊的形式,构造函数引用,假设一个类有一个默认的构造函数,那么使用方法引用的形式为:\n\n Supplier c1 = SomeClass::new;\n SomeClass s1 = c1.get();\n\n//等价于\n\n Supplier c1 = () -> new SomeClass();\n SomeClass s1 = c1.get();\n如果是构造函数有一个参数的情况:\n\n Function c1 = SomeClass::new;\n SomeClass s1 = c1.apply(100);\n\n//等价于\n \n Function c1 = i -> new SomeClass(i);\n SomeClass s1 = c1.apply(100);\n\n### 接口的默认方法\n\nJava 8 使我们能够使用default 关键字给接口增加非抽象的方法实现。这个特性也被叫做 扩展方法(Extension Methods)。如下例所示:\n````\npublic class 接口的默认方法 {\n class B implements A {\n// void a(){}实现类方法不能重名\n }\n interface A {\n //可以有多个默认方法\n public default void a(){\n System.out.println(\"a\");\n }\n public default void b(){\n System.out.println(\"b\");\n }\n //报错static和default不能同时使用\n// public static default void c(){\n// System.out.println(\"c\");\n// }\n }\n public void test() {\n B b = new B();\n b.a();\n\n }\n}\n````\n默认方法出现的原因是为了对原有接口的扩展,有了默认方法之后就不怕因改动原有的接口而对已经使用这些接口的程序造成的代码不兼容的影响。 在Java8中也对一些接口增加了一些默认方法,比如Map接口等等。一般来说,使用默认方法的场景有两个:可选方法和行为的多继承。\n\n默认方法的使用相对来说比较简单,唯一要注意的点是如何处理默认方法的冲突。关于如何处理默认方法的冲突可以参考以下三条规则:\n\n类中的方法优先级最高。类或父类中声明的方法的优先级高于任何声明为默认方法的优先级。\n\n如果无法依据第一条规则进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口。即如果B继承了A,那么B就比A更具体。\n\n最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现。那么如何显式地指定呢:\n````\n public class C implements B, A {\n \n public void hello() {\n B.super().hello(); \n }\n \n }\n````\n使用X.super.m(..)显式地调用希望调用的方法。\n\nJava 8用默认方法与静态方法这两个新概念来扩展接口的声明。默认方法使接口有点像Traits(Scala中特征(trait)类似于Java中的Interface,但它可以包含实现代码,也就是目前Java8新增的功能),但与传统的接口又有些不一样,它允许在已有的接口中添加新方法,而同时又保持了与旧版本代码的兼容性。\n\n默认方法与抽象方法不同之处在于抽象方法必须要求实现,但是默认方法则没有这个要求。相反,每个接口都必须提供一个所谓的默认实现,这样所有的接口实现者将会默认继承它(如果有必要的话,可以覆盖这个默认实现)。让我们看看下面的例子:\n````\nprivate interface Defaulable {\n // Interfaces now allow default methods, the implementer may or \n // may not implement (override) them.\n default String notRequired() { \n return \"Default implementation\"; \n } \n}\n \nprivate static class DefaultableImpl implements Defaulable {\n}\n \nprivate static class OverridableImpl implements Defaulable {\n @Override\n public String notRequired() {\n return \"Overridden implementation\";\n }\n}\n````\nDefaulable接口用关键字default声明了一个默认方法notRequired(),Defaulable接口的实现者之一DefaultableImpl实现了这个接口,并且让默认方法保持原样。Defaulable接口的另一个实现者OverridableImpl用自己的方法覆盖了默认方法。\n\nJava 8带来的另一个有趣的特性是接口可以声明(并且可以提供实现)静态方法。例如:\n\n````\n private interface DefaulableFactory {\n // Interfaces now allow static methods\n static Defaulable create( Supplier< Defaulable > supplier ) {\n return supplier.get();\n }\n }\n````\n下面的一小段代码片段把上面的默认方法与静态方法黏合到一起。\n\n````\n public static void main( String[] args ) {\n Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new );\n System.out.println( defaulable.notRequired() );\n \n defaulable = DefaulableFactory.create( OverridableImpl::new );\n System.out.println( defaulable.notRequired() );\n }\n````\n这个程序的控制台输出如下:\n\nDefault implementation\nOverridden implementation\n在JVM中,默认方法的实现是非常高效的,并且通过字节码指令为方法调用提供了支持。默认方法允许继续使用现有的Java接口,而同时能够保障正常的编译过程。这方面好的例子是大量的方法被添加到java.util.Collection接口中去:stream(),parallelStream(),forEach(),removeIf(),……\n\n尽管默认方法非常强大,但是在使用默认方法时我们需要小心注意一个地方:在声明一个默认方法前,请仔细思考是不是真的有必要使用默认方法,因为默认方法会带给程序歧义,并且在复杂的继承体系中容易产生编译错误。更多详情请参考官方文档\n \n \n### 重复注解\n自从Java 5引入了注解机制,这一特性就变得非常流行并且广为使用。然而,使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8打破了这条规则,引入了重复注解机制,这样相同的注解可以在同一地方声明多次。\n\n重复注解机制本身必须用@Repeatable注解。事实上,这并不是语言层面上的改变,更多的是编译器的技巧,底层的原理保持不变。让我们看一个快速入门的例子:\n````\npackage com.javacodegeeks.java8.repeatable.annotations;\n \nimport java.lang.annotation.ElementType;\nimport java.lang.annotation.Repeatable;\nimport java.lang.annotation.Retention;\nimport java.lang.annotation.RetentionPolicy;\nimport java.lang.annotation.Target;\n \npublic class RepeatingAnnotations {\n @Target( ElementType.TYPE )\n @Retention( RetentionPolicy.RUNTIME )\n public @interface Filters {\n Filter[] value();\n }\n \n @Target( ElementType.TYPE )\n @Retention( RetentionPolicy.RUNTIME )\n @Repeatable( Filters.class )\n public @interface Filter {\n String value();\n };\n \n @Filter( \"filter1\" )\n @Filter( \"filter2\" )\n public interface Filterable { \n }\n \n public static void main(String[] args) {\n for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) {\n System.out.println( filter.value() );\n }\n }\n}\n````\n正如我们看到的,这里有个使用@Repeatable( Filters.class )注解的注解类Filter,Filters仅仅是Filter注解的数组,但Java编译器并不想让程序员意识到Filters的存在。这样,接口Filterable就拥有了两次Filter(并没有提到Filter)注解。\n\n同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型(请注意Filterable.class.getAnnotation( Filters.class )经编译器处理后将会返回Filters的实例)。\n\n程序输出结果如下:\n\n filter1\n filter2\n更多详情请参考官方文档\n\n## Java编译器的新特性\n\n### 方法参数名字可以反射获取\n\n很长一段时间里,Java程序员一直在发明不同的方式使得方法参数的名字能保留在Java字节码中,并且能够在运行时获取它们(比如,Paranamer类库)。最终,在Java 8中把这个强烈要求的功能添加到语言层面(通过反射API与Parameter.getName()方法)与字节码文件(通过新版的javac的–parameters选项)中。\n````\npackage com.javacodegeeks.java8.parameter.names;\n\nimport java.lang.reflect.Method;\nimport java.lang.reflect.Parameter;\n\npublic class ParameterNames {\n public static void main(String[] args) throws Exception {\n Method method = ParameterNames.class.getMethod( \"main\", String[].class );\n for( final Parameter parameter: method.getParameters() ) {\n System.out.println( \"Parameter: \" + parameter.getName() );\n }\n }\n}\n````\n如果不使用–parameters参数来编译这个类,然后运行这个类,会得到下面的输出:\n\nParameter: arg0\n如果使用–parameters参数来编译这个类,程序的结构会有所不同(参数的真实名字将会显示出来):\n\nParameter: args\n\n## Java 类库的新特性\nJava 8 通过增加大量新类,扩展已有类的功能的方式来改善对并发编程、函数式编程、日期/时间相关操作以及其他更多方面的支持。\n\n### Optional\n到目前为止,臭名昭著的空指针异常是导致Java应用程序失败的最常见原因。以前,为了解决空指针异常,Google公司著名的Guava项目引入了Optional类,Guava通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。受到Google Guava的启发,Optional类已经成为Java 8类库的一部分。\n\nOptional实际上是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。更多详情请参考官方文档。\n\n我们下面用两个小例子来演示如何使用Optional类:一个允许为空值,一个不允许为空值。\n````\n public class 空指针Optional {\n public static void main(String[] args) {\n \n //使用of方法,仍然会报空指针异常\n // Optional optional = Optional.of(null);\n // System.out.println(optional.get());\n \n //抛出没有该元素的异常\n //Exception in thread \"main\" java.util.NoSuchElementException: No value present\n // at java.util.Optional.get(Optional.java:135)\n // at com.javase.Java8.空指针Optional.main(空指针Optional.java:14)\n // Optional optional1 = Optional.ofNullable(null);\n // System.out.println(optional1.get());\n Optional optional = Optional.ofNullable(null);\n System.out.println(optional.isPresent());\n System.out.println(optional.orElse(0));//当值为空时给与初始值\n System.out.println(optional.orElseGet(() -> new String[]{\"a\"}));//使用回调函数设置默认值\n //即使传入Optional容器的元素为空,使用optional.isPresent()方法也不会报空指针异常\n //所以通过optional.orElse这种方式就可以写出避免空指针异常的代码了\n //输出Optional.empty。\n }\n }\n````\n如果Optional类的实例为非空值的话,isPresent()返回true,否从返回false。为了防止Optional为空值,orElseGet()方法通过回调函数来产生一个默认值。map()函数对当前Optional的值进行转化,然后返回一个新的Optional实例。orElse()方法和orElseGet()方法类似,但是orElse接受一个默认值而不是一个回调函数。下面是这个程序的输出:\n\nFull Name is set? false\nFull Name: [none]\nHey Stranger!\n让我们来看看另一个例子:\n\n\n Optional< String > firstName = Optional.of( \"Tom\" );\n System.out.println( \"First Name is set? \" + firstName.isPresent() ); \n System.out.println( \"First Name: \" + firstName.orElseGet( () -> \"[none]\" ) ); \n System.out.println( firstName.map( s -> \"Hey \" + s + \"!\" ).orElse( \"Hey Stranger!\" ) );\n System.out.println();\n\n下面是程序的输出:\n\nFirst Name is set? true\nFirst Name: Tom\nHey Tom!\n\n### Stream\n最新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。\n\nStream API极大简化了集合框架的处理(但它的处理的范围不仅仅限于集合框架的处理,这点后面我们会看到)。让我们以一个简单的Task类为例进行介绍:\n\nTask类有一个分数的概念(或者说是伪复杂度),其次是还有一个值可以为OPEN或CLOSED的状态.让我们引入一个Task的小集合作为演示例子:\n````\n final Collection< Task > tasks = Arrays.asList(\n new Task( Status.OPEN, 5 ),\n new Task( Status.OPEN, 13 ),\n new Task( Status.CLOSED, 8 ) \n );\n````\n我们下面要讨论的第一个问题是所有状态为OPEN的任务一共有多少分数?在Java 8以前,一般的解决方式用foreach循环,但是在Java 8里面我们可以使用stream:一串支持连续、并行聚集操作的元素。\n````\n // Calculate total points of all active tasks using sum()\n final long totalPointsOfOpenTasks = tasks\n .stream()\n .filter( task -> task.getStatus() == Status.OPEN )\n .mapToInt( Task::getPoints )\n .sum();\n \n System.out.println( \"Total points: \" + totalPointsOfOpenTasks );\n````\n程序在控制台上的输出如下:\n\n Total points: 18\n\n这里有几个注意事项。\n\n第一,task集合被转换化为其相应的stream表示。然后,filter操作过滤掉状态为CLOSED的task。\n\n下一步,mapToInt操作通过Task::getPoints这种方式调用每个task实例的getPoints方法把Task的stream转化为Integer的stream。最后,用sum函数把所有的分数加起来,得到最终的结果。\n\n在继续讲解下面的例子之前,关于stream有一些需要注意的地方(详情在这里).stream操作被分成了中间操作与最终操作这两种。\n\n中间操作返回一个新的stream对象。中间操作总是采用惰性求值方式,运行一个像filter这样的中间操作实际上没有进行任何过滤,相反它在遍历元素时会产生了一个新的stream对象,这个新的stream对象包含原始stream\n中符合给定谓词的所有元素。\n\n像forEach、sum这样的最终操作可能直接遍历stream,产生一个结果或副作用。当最终操作执行结束之后,stream管道被认为已经被消耗了,没有可能再被使用了。在大多数情况下,最终操作都是采用及早求值方式,及早完成底层数据源的遍历。\n\nstream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。\n\nstream另一个有价值的地方是能够原生支持并行处理。让我们来看看这个算task分数和的例子。\n````\n // Calculate total points of all tasks\n final double totalPoints = tasks\n .stream()\n .parallel()\n .map( task -> task.getPoints() ) // or map( Task::getPoints ) \n .reduce( 0, Integer::sum );\n \n System.out.println( \"Total points (all tasks): \" + totalPoints );\n````\n这个例子和第一个例子很相似,但这个例子的不同之处在于这个程序是并行运行的,其次使用reduce方法来算最终的结果。\n下面是这个例子在控制台的输出:\n\nTotal points (all tasks): 26.0\n经常会有这个一个需求:我们需要按照某种准则来对集合中的元素进行分组。Stream也可以处理这样的需求,下面是一个例子:\n\n````\n // Group tasks by their status\n final Map< Status, List< Task > > map = tasks\n .stream()\n .collect( Collectors.groupingBy( Task::getStatus ) );\n System.out.println( map );\n````\n\n这个例子的控制台输出如下:\n\n {CLOSED=[[CLOSED, 8]], OPEN=[[OPEN, 5], [OPEN, 13]]}\n\n让我们来计算整个集合中每个task分数(或权重)的平均值来结束task的例子。\n\n````\n // Calculate the weight of each tasks (as percent of total points) \n final Collection< String > result = tasks\n .stream() // Stream< String >\n .mapToInt( Task::getPoints ) // IntStream\n .asLongStream() // LongStream\n .mapToDouble( points -> points / totalPoints ) // DoubleStream\n .boxed() // Stream< Double >\n .mapToLong( weigth -> ( long )( weigth * 100 ) ) // LongStream\n .mapToObj( percentage -> percentage + \"%\" ) // Stream< String> \n .collect( Collectors.toList() ); // List< String > \n \n System.out.println( result );\n````\n\n下面是这个例子的控制台输出:\n\n[19%, 50%, 30%]\n最后,就像前面提到的,Stream API不仅仅处理Java集合框架。像从文本文件中逐行读取数据这样典型的I/O操作也很适合用Stream API来处理。下面用一个例子来应证这一点。\n````\n final Path path = new File( filename ).toPath();\n try( Stream< String > lines = Files.lines( path, StandardCharsets.UTF_8 ) ) {\n lines.onClose( () -> System.out.println(\"Done!\") ).forEach( System.out::println );\n }\n````\n\n对一个stream对象调用onClose方法会返回一个在原有功能基础上新增了关闭功能的stream对象,当对stream对象调用close()方法时,与关闭相关的处理器就会执行。\n\nStream API、Lambda表达式与方法引用在接口默认方法与静态方法的配合下是Java 8对现代软件开发范式的回应。更多详情请参考官方文档。\n\n### Date/Time API (JSR 310)\nJava 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。对日期与时间的操作一直是Java程序员最痛苦的地方之一。标准的 java.util.Date以及后来的java.util.Calendar一点没有改善这种情况(可以这么说,它们一定程度上更加复杂)。\n\n这种情况直接导致了Joda-Time——一个可替换标准日期/时间处理且功能非常强大的Java API的诞生。Java 8新的Date-Time API (JSR 310)在很大程度上受到Joda-Time的影响,并且吸取了其精髓。新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。在设计新版API时,十分注重与旧版API的兼容性:不允许有任何的改变(从java.util.Calendar中得到的深刻教训)。如果需要修改,会返回这个类的一个新实例。\n\n让我们用例子来看一下新版API主要类的使用方法。第一个是Clock类,它通过指定一个时区,然后就可以获取到当前的时刻,日期与时间。Clock可以替换System.currentTimeMillis()与TimeZone.getDefault()。\n````\n // Get the system clock as UTC offset \n final Clock clock = Clock.systemUTC();\n System.out.println( clock.instant() );\n System.out.println( clock.millis() );\n````\n下面是程序在控制台上的输出:\n\n 2014-04-12T15:19:29.282Z\n 1397315969360\n\n我们需要关注的其他类是LocaleDate与LocalTime。LocaleDate只持有ISO-8601格式且无时区信息的日期部分。相应的,LocaleTime只持有ISO-8601格式且无时区信息的时间部分。LocaleDate与LocalTime都可以从Clock中得到。\n````\n // Get the local date and local time\n final LocalDate date = LocalDate.now();\n final LocalDate dateFromClock = LocalDate.now( clock );\n \n System.out.println( date );\n System.out.println( dateFromClock );\n \n // Get the local date and local time\n final LocalTime time = LocalTime.now();\n final LocalTime timeFromClock = LocalTime.now( clock );\n \n System.out.println( time );\n System.out.println( timeFromClock );\n````\n下面是程序在控制台上的输出:\n\n 2014-04-12\n 2014-04-12\n 11:25:54.568\n 15:25:54.568\n\n下面是程序在控制台上的输出:\n\n 2014-04-12T11:47:01.017-04:00[America/New_York]\n 2014-04-12T15:47:01.017Z\n 2014-04-12T08:47:01.017-07:00[America/Los_Angeles]\n\n最后,让我们看一下Duration类:在秒与纳秒级别上的一段时间。Duration使计算两个日期间的不同变的十分简单。下面让我们看一个这方面的例子。\n````\n // Get duration between two dates\n final LocalDateTime from = LocalDateTime.of( 2014, Month.APRIL, 16, 0, 0, 0 );\n final LocalDateTime to = LocalDateTime.of( 2015, Month.APRIL, 16, 23, 59, 59 );\n \n final Duration duration = Duration.between( from, to );\n System.out.println( \"Duration in days: \" + duration.toDays() );\n System.out.println( \"Duration in hours: \" + duration.toHours() );\n````\n上面的例子计算了两个日期2014年4月16号与2014年4月16号之间的过程。下面是程序在控制台上的输出:\n\nDuration in days: 365\nDuration in hours: 8783\n对Java 8在日期/时间API的改进整体印象是非常非常好的。一部分原因是因为它建立在“久战杀场”的Joda-Time基础上,另一方面是因为用来大量的时间来设计它,并且这次程序员的声音得到了认可。更多详情请参考官方文档。\n\n\n### 并行(parallel)数组\nJava 8增加了大量的新方法来对数组进行并行处理。可以说,最重要的是parallelSort()方法,因为它可以在多核机器上极大提高数组排序的速度。下面的例子展示了新方法(parallelXxx)的使用。\n````\n package com.javacodegeeks.java8.parallel.arrays;\n \n import java.util.Arrays;\n import java.util.concurrent.ThreadLocalRandom;\n \n public class ParallelArrays {\n public static void main( String[] args ) {\n long[] arrayOfLong = new long [ 20000 ]; \n \n Arrays.parallelSetAll( arrayOfLong, \n index -> ThreadLocalRandom.current().nextInt( 1000000 ) );\n Arrays.stream( arrayOfLong ).limit( 10 ).forEach( \n i -> System.out.print( i + \" \" ) );\n System.out.println();\n \n Arrays.parallelSort( arrayOfLong ); \n Arrays.stream( arrayOfLong ).limit( 10 ).forEach( \n i -> System.out.print( i + \" \" ) );\n System.out.println();\n }\n }\n````\n上面的代码片段使用了parallelSetAll()方法来对一个有20000个元素的数组进行随机赋值。然后,调用parallelSort方法。这个程序首先打印出前10个元素的值,之后对整个数组排序。这个程序在控制台上的输出如下(请注意数组元素是随机生产的):\n\nUnsorted: 591217 891976 443951 424479 766825 351964 242997 642839 119108 552378 \nSorted: 39 220 263 268 325 607 655 678 723 793\n\n### CompletableFuture\n\n在Java8之前,我们会使用JDK提供的Future接口来进行一些异步的操作,其实CompletableFuture也是实现了Future接口, 并且基于ForkJoinPool来执行任务,因此本质上来讲,CompletableFuture只是对原有API的封装, 而使用CompletableFuture与原来的Future的不同之处在于可以将两个Future组合起来,或者如果两个Future是有依赖关系的,可以等第一个执行完毕后再实行第二个等特性。\n\n**先来看看基本的使用方式:**\n````\n public Future getPriceAsync(final String product) {\n final CompletableFuture futurePrice = new CompletableFuture<>();\n new Thread(() -> {\n double price = calculatePrice(product);\n futurePrice.complete(price); //完成后使用complete方法,设置future的返回值\n }).start();\n return futurePrice;\n }\n````\n得到Future之后就可以使用get方法来获取结果,CompletableFuture提供了一些工厂方法来简化这些API,并且使用函数式编程的方式来使用这些API,例如:\n\nFufure price = CompletableFuture.supplyAsync(() -> calculatePrice(product)); \n代码是不是一下子简洁了许多呢。之前说了,CompletableFuture可以组合多个Future,不管是Future之间有依赖的,还是没有依赖的。 \n\n**如果第二个请求依赖于第一个请求的结果,那么可以使用thenCompose方法来组合两个Future**\n````\n public List findPriceAsync(String product) {\n List> priceFutures = tasks.stream()\n .map(task -> CompletableFuture.supplyAsync(() -> task.getPrice(product),executor))\n .map(future -> future.thenApply(Work::parse))\n .map(future -> future.thenCompose(work -> CompletableFuture.supplyAsync(() -> Count.applyCount(work), executor)))\n .collect(Collectors.toList());\n \n return priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList());\n }\n````\n上面这段代码使用了thenCompose来组合两个CompletableFuture。supplyAsync方法第二个参数接受一个自定义的Executor。 首先使用CompletableFuture执行一个任务,调用getPrice方法,得到一个Future,之后使用thenApply方法,将Future的结果应用parse方法, 之后再使用执行完parse之后的结果作为参数再执行一个applyCount方法,然后收集成一个CompletableFuture的List, 最后再使用一个流,调用CompletableFuture的join方法,这是为了等待所有的异步任务执行完毕,获得最后的结果。\n\n注意,这里必须使用两个流,如果在一个流里调用join方法,那么由于Stream的延迟特性,所有的操作还是会串行的执行,并不是异步的。\n\n**再来看一个两个Future之间没有依赖关系的例子:**\n````\n Future futurePriceInUsd = CompletableFuture.supplyAsync(() -> shop.getPrice(“price1”))\n .thenCombine(CompletableFuture.supplyAsync(() -> shop.getPrice(“price2”)), (s1, s2) -> s1 + s2);\n````\n这里有两个异步的任务,使用thenCombine方法来组合两个Future,thenCombine方法的第二个参数就是用来合并两个Future方法返回值的操作函数。\n\n有时候,我们并不需要等待所有的异步任务结束,只需要其中的一个完成就可以了,CompletableFuture也提供了这样的方法:\n````\n //假设getStream方法返回一个Stream>\n CompletableFuture[] futures = getStream(“listen”).map(f -> f.thenAccept(System.out::println)).toArray(CompletableFuture[]::new);\n //等待其中的一个执行完毕\n CompletableFuture.anyOf(futures).join();\n 使用anyOf方法来响应CompletableFuture的completion事件。\n````\n## Java虚拟机(JVM)的新特性\nPermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。\n\n\n## 总结\n更多展望:Java 8通过发布一些可以增加程序员生产力的特性来推进这个伟大的平台的进步。现在把生产环境迁移到Java 8还为时尚早,但是在接下来的几个月里,它会被大众慢慢的接受。毫无疑问,现在是时候让你的代码与Java 8兼容,并且在Java 8足够安全稳定的时候迁移到Java 8。\n\n## 参考文章\n\nhttps://blog.csdn.net/shuaicihai/article/details/72615495\nhttps://blog.csdn.net/qq_34908167/article/details/79286697\nhttps://www.jianshu.com/p/4df02599aeb2\nhttps://www.cnblogs.com/yangzhilong/p/10973006.html\nhttps://www.cnblogs.com/JackpotHan/p/9701147.html\n\n"
},
{
"path": "docs/Java/basic/JavaIO流.md",
"content": "# 目录\n * [IO概述](#io概述)\n * [什么是Java IO流](#什么是java-io流)\n * [IO文件](#io文件)\n * [字符流和字节流](#字符流和字节流)\n * [IO管道](#io管道)\n * [Java IO:网络](#java-io:网络)\n * [字节和字符数组](#字节和字符数组)\n * [System.in, System.out, System.err](#systemin-systemout-systemerr)\n * [字符流的Buffered和Filter](#字符流的buffered和filter)\n * [JavaIO流面试题](#javaio流面试题)\n * [什么是IO流?](#什么是io流?)\n * [字节流和字符流的区别。](#字节流和字符流的区别。)\n * [Java中流类的超类主要由那些?](#java中流类的超类主要由那些?)\n * [FileInputStream和FileOutputStream是什么?](#fileinputstream和fileoutputstream是什么?)\n * [System.out.println()是什么?](#systemoutprintln是什么?)\n * [什么是Filter流?](#什么是filter流?)\n * [有哪些可用的Filter流?](#有哪些可用的filter流?)\n * [在文件拷贝的时候,那一种流可用提升更多的性能?](#在文件拷贝的时候,那一种流可用提升更多的性能?)\n * [说说管道流(Piped Stream)](#说说管道流piped-stream)\n * [说说File类](#说说file类)\n * [说说RandomAccessFile?](#说说randomaccessfile)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n\n本文参考\n\n并发编程网 – ifeve.com\n\n## IO概述\n\n> 在这一小节,我会试着给出Java IO(java.io)包下所有类的概述。更具体地说,我会根据类的用途对类进行分组。这个分组将会使你在未来的工作中,进行类的用途判定时,或者是为某个特定用途选择类时变得更加容易。\n\n\n**输入和输出**\n\n 术语“输入”和“输出”有时候会有一点让人疑惑。一个应用程序的输入往往是另外一个应用程序的输出\n \n 那么OutputStream流到底是一个输出到目的地的流呢,还是一个产生输出的流?InputStream流到底会不会输出它的数据给读取数据的程序呢?就我个人而言,在第一天学习Java IO的时候我就感觉到了一丝疑惑。\n \n 为了消除这个疑惑,我试着给输入和输出起一些不一样的别名,让它们从概念上与数据的来源和数据的流向相联系。\n\nJava的IO包主要关注的是从原始数据源的读取以及输出原始数据到目标媒介。以下是最典型的数据源和目标媒介:\n \n 文件\n 管道\n 网络连接\n 内存缓存\n System.in, System.out, System.error(注:Java标准输入、输出、错误输出)\n下面这张图描绘了一个程序从数据源读取数据,然后将数据输出到其他媒介的原理:\n\n\n\n**流**\n\n 在Java IO中,流是一个核心的概念。流从概念上来说是一个连续的数据流。你既可以从流中读取数据,也可以往流中写数据。流与数据源或者数据流向的媒介相关联。在Java IO中流既可以是字节流(以字节为单位进行读写),也可以是字符流(以字符为单位进行读写)。\n\n类InputStream, OutputStream, Reader 和Writer\n一个程序需要InputStream或者Reader从数据源读取数据,需要OutputStream或者Writer将数据写入到目标媒介中。以下的图说明了这一点:\n\n\n\nInputStream和Reader与数据源相关联,OutputStream和writer与目标媒介相关联。\n\n**Java IO的用途和特征**\n\nJava IO中包含了许多InputStream、OutputStream、Reader、Writer的子类。这样设计的原因是让每一个类都负责不同的功能。这也就是为什么IO包中有这么多不同的类的缘故。各类用途汇总如下:\n \n 文件访问\n 网络访问\n 内存缓存访问\n 线程内部通信(管道)\n 缓冲\n 过滤\n 解析\n 读写文本 (Readers / Writers)\n 读写基本类型数据 (long, int etc.)\n 读写对象\n\n当通读过Java IO类的源代码之后,我们很容易就能了解这些用途。这些用途或多或少让我们更加容易地理解,不同的类用于针对不同业务场景。\n\nJava IO类概述表\n已经讨论了数据源、目标媒介、输入、输出和各类不同用途的Java IO类,接下来是一张通过输入、输出、基于字节或者字符、以及其他比如缓冲、解析之类的特定用途划分的大部分Java IO类的表格。\n\n\n\nJava IO类图\n\n\n\n### 什么是Java IO流\n\nJava IO流是既可以从中读取,也可以写入到其中的数据流。正如这个系列教程之前提到过的,流通常会与数据源、数据流向目的地相关联,比如文件、网络等等。\n\n流和数组不一样,不能通过索引读写数据。在流中,你也不能像数组那样前后移动读取数据,除非使用RandomAccessFile 处理文件。流仅仅只是一个连续的数据流。\n\n某些类似PushbackInputStream 流的实现允许你将数据重新推回到流中,以便重新读取。然而你只能把有限的数据推回流中,并且你不能像操作数组那样随意读取数据。流中的数据只能够顺序访问。\n>\n> Java IO流通常是基于字节或者基于字符的。字节流通常以“stream”命名,比如InputStream和OutputStream。除了DataInputStream 和DataOutputStream 还能够读写int, long, float和double类型的值以外,其他流在一个操作时间内只能读取或者写入一个原始字节。\n>\n> 字符流通常以“Reader”或者“Writer”命名。字符流能够读写字符(比如Latin1或者Unicode字符)。可以浏览Java Readers and Writers获取更多关于字符流输入输出的信息。\n\n**InputStream**\n\njava.io.InputStream类是所有Java IO输入流的基类。如果你正在开发一个从流中读取数据的组件,请尝试用InputStream替代任何它的子类(比如FileInputStream)进行开发。这么做能够让你的代码兼容任何类型而非某种确定类型的输入流。\n\n**组合流**\n\n你可以将流整合起来以便实现更高级的输入和输出操作。比如,一次读取一个字节是很慢的,所以可以从磁盘中一次读取一大块数据,然后从读到的数据块中获取字节。为了实现缓冲,可以把InputStream包装到BufferedInputStream中。\n\n代码示例\n InputStream input = new BufferedInputStream(new FileInputStream(\"c:\\\\data\\\\input-file.txt\"));\n \n> 缓冲同样可以应用到OutputStream中。你可以实现将大块数据批量地写入到磁盘(或者相应的流)中,这个功能由BufferedOutputStream实现。\n>\n> 缓冲只是通过流整合实现的其中一个效果。你可以把InputStream包装到PushbackInputStream中,之后可以将读取过的数据推回到流中重新读取,在解析过程中有时候这样做很方便。或者,你可以将两个InputStream整合成一个SequenceInputStream。\n>\n> 将不同的流整合到一个链中,可以实现更多种高级操作。通过编写包装了标准流的类,可以实现你想要的效果和过滤器。\n\n### IO文件\n\n在Java应用程序中,文件是一种常用的数据源或者存储数据的媒介。所以这一小节将会对Java中文件的使用做一个简短的概述。这篇文章不会对每一个技术细节都做出解释,而是会针对文件存取的方法提供给你一些必要的知识点。在之后的文章中,将会更加详细地描述这些方法或者类,包括方法示例等等。\n\n\n**通过Java IO读文件**\n\n 如果你需要在不同端之间读取文件,你可以根据该文件是二进制文件还是文本文件来选择使用FileInputStream或者FileReader。\n \n 这两个类允许你从文件开始到文件末尾一次读取一个字节或者字符,或者将读取到的字节写入到字节数组或者字符数组。你不必一次性读取整个文件,相反你可以按顺序地读取文件中的字节和字符。\n\n如果你需要跳跃式地读取文件其中的某些部分,可以使用RandomAccessFile。\n\n**通过Java IO写文件**\n\n 如果你需要在不同端之间进行文件的写入,你可以根据你要写入的数据是二进制型数据还是字符型数据选用FileOutputStream或者FileWriter。\n \n 你可以一次写入一个字节或者字符到文件中,也可以直接写入一个字节数组或者字符数据。数据按照写入的顺序存储在文件当中。\n\n**通过Java IO随机存取文件**\n\n正如我所提到的,你可以通过RandomAccessFile对文件进行随机存取。\n \n 随机存取并不意味着你可以在真正随机的位置进行读写操作,它只是意味着你可以跳过文件中某些部分进行操作,并且支持同时读写,不要求特定的存取顺序。\n \n 这使得RandomAccessFile可以覆盖一个文件的某些部分、或者追加内容到它的末尾、或者删除它的某些内容,当然它也可以从文件的任何位置开始读取文件。\n\n下面是具体例子:\n````\n @Test\n //文件流范例,打开一个文件的输入流,读取到字节数组,再写入另一个文件的输出流\n public void test1() {\n try {\n FileInputStream fileInputStream = new FileInputStream(new File(\"a.txt\"));\n FileOutputStream fileOutputStream = new FileOutputStream(new File(\"b.txt\"));\n byte []buffer = new byte[128];\n while (fileInputStream.read(buffer) != -1) {\n fileOutputStream.write(buffer);\n }\n //随机读写,通过mode参数来决定读或者写\n RandomAccessFile randomAccessFile = new RandomAccessFile(new File(\"c.txt\"), \"rw\");\n } catch (FileNotFoundException e) {\n e.printStackTrace();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n````\n### 字符流和字节流\n\nJava IO的Reader和Writer除了基于字符之外,其他方面都与InputStream和OutputStream非常类似。他们被用于读写文本。InputStream和OutputStream是基于字节的,还记得吗?\n\nReader\nReader类是Java IO中所有Reader的基类。子类包括BufferedReader,PushbackReader,InputStreamReader,StringReader和其他Reader。\n\nWriter\nWriter类是Java IO中所有Writer的基类。子类包括BufferedWriter和PrintWriter等等。\n\n这是一个简单的Java IO Reader的例子:\n````\nReader reader = new FileReader(\"c:\\\\data\\\\myfile.txt\");\n\nint data = reader.read();\n\nwhile(data != -1){\n\n char dataChar = (char) data;\n\n data = reader.read();\n\n}\n````\n你通常会使用Reader的子类,而不会直接使用Reader。Reader的子类包括InputStreamReader,CharArrayReader,FileReader等等。可以查看Java IO概述浏览完整的Reader表格。\n\n**整合Reader与InputStream**\n\n一个Reader可以和一个InputStream相结合。如果你有一个InputStream输入流,并且想从其中读取字符,可以把这个InputStream包装到InputStreamReader中。把InputStream传递到InputStreamReader的构造函数中:\n````\nReader reader = new InputStreamReader(inputStream);\n````\n在构造函数中可以指定解码方式。\n\n**Writer**\n\nWriter类是Java IO中所有Writer的基类。子类包括BufferedWriter和PrintWriter等等。这是一个Java IO Writer的例子:\n````\nWriter writer = new FileWriter(\"c:\\\\data\\\\file-output.txt\"); \n\nwriter.write(\"Hello World Writer\"); \n\nwriter.close();\n````\n同样,你最好使用Writer的子类,不需要直接使用Writer,因为子类的实现更加明确,更能表现你的意图。常用子类包括OutputStreamWriter,CharArrayWriter,FileWriter等。Writer的write(int c)方法,会将传入参数的低16位写入到Writer中,忽略高16位的数据。\n\n**整合Writer和OutputStream**\n\n与Reader和InputStream类似,一个Writer可以和一个OutputStream相结合。把OutputStream包装到OutputStreamWriter中,所有写入到OutputStreamWriter的字符都将会传递给OutputStream。这是一个OutputStreamWriter的例子:\n````\nWriter writer = new OutputStreamWriter(outputStream);\n````\n### IO管道\n\nJava IO中的管道为运行在同一个JVM中的两个线程提供了通信的能力。所以管道也可以作为数据源以及目标媒介。\n\n你不能利用管道与不同的JVM中的线程通信(不同的进程)。在概念上,Java的管道不同于Unix/Linux系统中的管道。在Unix/Linux中,运行在不同地址空间的两个进程可以通过管道通信。在Java中,通信的双方应该是运行在同一进程中的不同线程。\n\n通过Java IO创建管道\n\n 可以通过Java IO中的PipedOutputStream和PipedInputStream创建管道。一个PipedInputStream流应该和一个PipedOutputStream流相关联。\n \n 一个线程通过PipedOutputStream写入的数据可以被另一个线程通过相关联的PipedInputStream读取出来。\n\nJava IO管道示例\n这是一个如何将PipedInputStream和PipedOutputStream关联起来的简单例子:\n````\n//使用管道来完成两个线程间的数据点对点传递\n @Test\n public void test2() throws IOException {\n PipedInputStream pipedInputStream = new PipedInputStream();\n PipedOutputStream pipedOutputStream = new PipedOutputStream(pipedInputStream);\n new Thread(new Runnable() {\n @Override\n public void run() {\n try {\n pipedOutputStream.write(\"hello input\".getBytes());\n pipedOutputStream.close();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n }).start();\n new Thread(new Runnable() {\n @Override\n public void run() {\n try {\n byte []arr = new byte[128];\n while (pipedInputStream.read(arr) != -1) {\n System.out.println(Arrays.toString(arr));\n }\n pipedInputStream.close();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n }).start();\n````\n\n管道和线程\n请记得,当使用两个相关联的管道流时,务必将它们分配给不同的线程。read()方法和write()方法调用时会导致流阻塞,这意味着如果你尝试在一个线程中同时进行读和写,可能会导致线程死锁。\n\n管道的替代\n除了管道之外,一个JVM中不同线程之间还有许多通信的方式。实际上,线程在大多数情况下会传递完整的对象信息而非原始的字节数据。但是,如果你需要在线程之间传递字节数据,Java IO的管道是一个不错的选择。\n\n### Java IO:网络\n\nJava中网络的内容或多或少的超出了Java IO的范畴。关于Java网络更多的是在我的Java网络教程中探讨。但是既然网络是一个常见的数据来源以及数据流目的地,并且因为你使用Java IO的API通过网络连接进行通信,所以本文将简要的涉及网络应用。\n\n\n当两个进程之间建立了网络连接之后,他们通信的方式如同操作文件一样:利用InputStream读取数据,利用OutputStream写入数据。换句话来说,Java网络API用来在不同进程之间建立网络连接,而Java IO则用来在建立了连接之后的进程之间交换数据。\n\n基本上意味着如果你有一份能够对文件进行写入某些数据的代码,那么这些数据也可以很容易地写入到网络连接中去。你所需要做的仅仅只是在代码中利用OutputStream替代FileOutputStream进行数据的写入。因为FileOutputStream是OuputStream的子类,所以这么做并没有什么问题。\n````\n //从网络中读取字节流也可以直接使用OutputStream\n public void test3() {\n //读取网络进程的输出流\n OutputStream outputStream = new OutputStream() {\n @Override\n public void write(int b) throws IOException {\n }\n };\n }\n public void process(OutputStream ouput) throws IOException {\n //处理网络信息\n //do something with the OutputStream\n }\n````\n### 字节和字符数组\n\n\n从InputStream或者Reader中读入数组\n\n从OutputStream或者Writer中写数组\n\n在java中常用字节和字符数组在应用中临时存储数据。而这些数组又是通常的数据读取来源或者写入目的地。如果你需要在程序运行时需要大量读取文件里的内容,那么你也可以把一个文件加载到数组中。\n\n前面的例子中,字符数组或字节数组是用来缓存数据的临时存储空间,不过它们同时也可以作为数据来源或者写入目的地。\n举个例子:\n````\n //字符数组和字节数组在io过程中的作用\n public void test4() {\n //arr和brr分别作为数据源\n char []arr = {'a','c','d'};\n CharArrayReader charArrayReader = new CharArrayReader(arr);\n byte []brr = {1,2,3,4,5};\n ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(brr);\n }\n````\n### System.in, System.out, System.err \n\nSystem.in, System.out, System.err这3个流同样是常见的数据来源和数据流目的地。使用最多的可能是在控制台程序里利用System.out将输出打印到控制台上。\n\nJVM启动的时候通过Java运行时初始化这3个流,所以你不需要初始化它们(尽管你可以在运行时替换掉它们)。\n\n\n System.in\n System.in是一个典型的连接控制台程序和键盘输入的InputStream流。通常当数据通过命令行参数或者配置文件传递给命令行Java程序的时候,System.in并不是很常用。图形界面程序通过界面传递参数给程序,这是一块单独的Java IO输入机制。\n \n System.out\n System.out是一个PrintStream流。System.out一般会把你写到其中的数据输出到控制台上。System.out通常仅用在类似命令行工具的控制台程序上。System.out也经常用于打印程序的调试信息(尽管它可能并不是获取程序调试信息的最佳方式)。\n \n System.err\n System.err是一个PrintStream流。System.err与System.out的运行方式类似,但它更多的是用于打印错误文本。一些类似Eclipse的程序,为了让错误信息更加显眼,会将错误信息以红色文本的形式通过System.err输出到控制台上。\n\nSystem.out和System.err的简单例子:\n这是一个System.out和System.err结合使用的简单示例:\n````\n //测试System.in, System.out, System.err \n public static void main(String[] args) {\n int in = new Scanner(System.in).nextInt();\n System.out.println(in);\n System.out.println(\"out\");\n System.err.println(\"err\");\n //输入10,结果是\n // err(红色)\n // 10\n // out\n }\n````\n\n### 字符流的Buffered和Filter\n\nBufferedReader能为字符输入流提供缓冲区,可以提高许多IO处理的速度。你可以一次读取一大块的数据,而不需要每次从网络或者磁盘中一次读取一个字节。特别是在访问大量磁盘数据时,缓冲通常会让IO快上许多。\n\nBufferedReader和BufferedInputStream的主要区别在于,BufferedReader操作字符,而BufferedInputStream操作原始字节。只需要把Reader包装到BufferedReader中,就可以为Reader添加缓冲区(译者注:默认缓冲区大小为8192字节,即8KB)。代码如下:\n\n Reader input = new BufferedReader(new FileReader(\"c:\\\\data\\\\input-file.txt\"));\n\n你也可以通过传递构造函数的第二个参数,指定缓冲区大小,代码如下:\n\n Reader input = new BufferedReader(new FileReader(\"c:\\\\data\\\\input-file.txt\"), 8 * 1024);\n\n这个例子设置了8KB的缓冲区。最好把缓冲区大小设置成1024字节的整数倍,这样能更高效地利用内置缓冲区的磁盘。\n\n除了能够为输入流提供缓冲区以外,其余方面BufferedReader基本与Reader类似。BufferedReader还有一个额外readLine()方法,可以方便地一次性读取一整行字符。\n\n**BufferedWriter**\n\n与BufferedReader类似,BufferedWriter可以为输出流提供缓冲区。可以构造一个使用默认大小缓冲区的BufferedWriter(译者注:默认缓冲区大小8 * 1024B),代码如下:\n\n Writer writer = new BufferedWriter(new FileWriter(\"c:\\\\data\\\\output-file.txt\"));\n\n也可以手动设置缓冲区大小,代码如下:\n\n Writer writer = new BufferedWriter(new FileWriter(\"c:\\\\data\\\\output-file.txt\"), 8 * 1024);\n\n为了更好地使用内置缓冲区的磁盘,同样建议把缓冲区大小设置成1024的整数倍。除了能够为输出流提供缓冲区以外,其余方面BufferedWriter基本与Writer类似。类似地,BufferedWriter也提供了writeLine()方法,能够把一行字符写入到底层的字符输出流中。\n\n\n**值得注意是,你需要手动flush()方法确保写入到此输出流的数据真正写入到磁盘或者网络中。**\n\n**FilterReader**\n\n与FilterInputStream类似,FilterReader是实现自定义过滤输入字符流的基类,基本上它仅仅只是简单覆盖了Reader中的所有方法。\n\n就我自己而言,我没发现这个类明显的用途。除了构造函数取一个Reader变量作为参数之外,我没看到FilterReader任何对Reader新增或者修改的地方。如果你选择继承FilterReader实现自定义的类,同样也可以直接继承自Reader从而避免额外的类层级结构。\n\n## JavaIO流面试题\n\n### 什么是IO流?\n它是一种数据的流从源头流到目的地。比如文件拷贝,输入流和输出流都包括了。输入流从文件中读取数据存储到进程(process)中,输出流从进程中读取数据然后写入到目标文件。\n\n### 字节流和字符流的区别。\n字节流在JDK1.0中就被引进了,用于操作包含ASCII字符的文件。JAVA也支持其他的字符如Unicode,为了读取包含Unicode字符的文件,JAVA语言设计者在JDK1.1中引入了字符流。ASCII作为Unicode的子集,对于英语字符的文件,可以可以使用字节流也可以使用字符流。\n\n### Java中流类的超类主要由那些?\n\njava.io.InputStream\njava.io.OutputStream\njava.io.Reader\njava.io.Writer\n\n### FileInputStream和FileOutputStream是什么?\n这是在拷贝文件操作的时候,经常用到的两个类。在处理小文件的时候,它们性能表现还不错,在大文件的时候,最好使用BufferedInputStream (或 BufferedReader) 和 BufferedOutputStream (或 BufferedWriter)\n\n### System.out.println()是什么?\nprintln是PrintStream的一个方法。out是一个静态PrintStream类型的成员变量,System是一个java.lang包中的类,用于和底层的操作系统进行交互。\n\n### 什么是Filter流?\nFilter Stream是一种IO流主要作用是用来对存在的流增加一些额外的功能,像给目标文件增加源文件中不存在的行数,或者增加拷贝的性能。\n\n### 有哪些可用的Filter流?\n\n在java.io包中主要由4个可用的filter Stream。两个字节filter stream,两个字符filter stream. 分别是FilterInputStream, FilterOutputStream, FilterReader and FilterWriter.这些类是抽象类,不能被实例化的。\n\n### 在文件拷贝的时候,那一种流可用提升更多的性能?\n在字节流的时候,使用BufferedInputStream和BufferedOutputStream。\n在字符流的时候,使用BufferedReader 和 BufferedWriter\n\n### 说说管道流(Piped Stream)\n有四种管道流, PipedInputStream, PipedOutputStream, PipedReader 和 PipedWriter.在多个线程或进程中传递数据的时候管道流非常有用。\n\n### 说说File类\n它不属于 IO流,也不是用于文件操作的,它主要用于知道一个文件的属性,读写权限,大小等信息。\n\n### 说说RandomAccessFile?\n它在java.io包中是一个特殊的类,既不是输入流也不是输出流,它两者都可以做到。他是Object的直接子类。通常来说,一个流只有一个功能,要么读,要么写。但是RandomAccessFile既可以读文件,也可以写文件。 DataInputStream 和 DataOutStream有的方法,在RandomAccessFile中都存在。\n\n## 参考文章\n\nhttps://www.imooc.com/article/24305\nhttps://www.cnblogs.com/UncleWang001/articles/10454685.html\nhttps://www.cnblogs.com/Jixiangwei/p/Java.html\nhttps://blog.csdn.net/baidu_37107022/article/details/76890019\n\n"
},
{
"path": "docs/Java/basic/Java中的Class类和Object类.md",
"content": "# 目录\n\n * [Java中Class类及用法](#java中class类及用法)\n * [Class类原理](#class类原理)\n * [如何获得一个Class类对象](#如何获得一个class类对象)\n * [使用Class类的对象来生成目标类的实例](#使用class类的对象来生成目标类的实例)\n * [Object类](#object类)\n * [类构造器public Object();](#类构造器public-object)\n * [registerNatives()方法;](#registernatives方法)\n * [Clone()方法实现浅拷贝](#clone方法实现浅拷贝)\n * [getClass()方法](#getclass方法)\n * [equals()方法](#equals方法)\n * [hashCode()方法;](#hashcode方法)\n * [toString()方法](#tostring方法)\n * [wait() notify() notifAll()](#wait-notify-notifall)\n * [finalize()方法](#finalize方法)\n * [CLass类和Object类的关系](#class类和object类的关系)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n## Java中Class类及用法\nJava程序在运行时,Java运行时系统一直对所有的对象进行所谓的运行时类型标识,即所谓的RTTI。\n\n> 这项信息纪录了每个对象所属的类。虚拟机通常使用运行时类型信息选准正确方法去执行,用来保存这些类型信息的类是Class类。Class类封装一个对象和接口运行时的状态,当装载类时,Class类型的对象自动创建。\n\n说白了就是:\n\n> Class类也是类的一种,只是名字和class关键字高度相似。Java是大小写敏感的语言。\n\n> Class类的对象内容是你创建的类的类型信息,比如你创建一个shapes类,那么,Java会生成一个内容是shapes的Class类的对象\n\n> Class类的对象不能像普通类一样,以 new shapes() 的方式创建,它的对象只能由JVM创建,因为这个类没有public构造函数\n````\n/*\n * Private constructor. Only the Java Virtual Machine creates Class objects.\n * This constructor is not used and prevents the default constructor being\n * generated.\n */\n //私有构造方法,只能由jvm进行实例化\nprivate Class(ClassLoader loader) {\n // Initialize final field for classLoader. The initialization value of non-null\n // prevents future JIT optimizations from assuming this final field is null.\n classLoader = loader;\n}\n````\n> Class类的作用是运行时提供或获得某个对象的类型信息,和C++中的typeid()函数类似。这些信息也可用于反射。\n\n### Class类原理\n\n看一下Class类的部分源码\n````\n //Class类中封装了类型的各种信息。在jvm中就是通过Class类的实例来获取每个Java类的所有信息的。\n \n public class Class类 {\n Class aClass = null;\n \n // private EnclosingMethodInfo getEnclosingMethodInfo() {\n // Object[] enclosingInfo = getEnclosingMethod0();\n // if (enclosingInfo == null)\n // return null;\n // else {\n // return new EnclosingMethodInfo(enclosingInfo);\n // }\n // }\n \n /**提供原子类操作\n * Atomic operations support.\n */\n // private static class Atomic {\n // // initialize Unsafe machinery here, since we need to call Class.class instance method\n // // and have to avoid calling it in the static initializer of the Class class...\n // private static final Unsafe unsafe = Unsafe.getUnsafe();\n // // offset of Class.reflectionData instance field\n // private static final long reflectionDataOffset;\n // // offset of Class.annotationType instance field\n // private static final long annotationTypeOffset;\n // // offset of Class.annotationData instance field\n // private static final long annotationDataOffset;\n //\n // static {\n // Field[] fields = Class.class.getDeclaredFields0(false); // bypass caches\n // reflectionDataOffset = objectFieldOffset(fields, \"reflectionData\");\n // annotationTypeOffset = objectFieldOffset(fields, \"annotationType\");\n // annotationDataOffset = objectFieldOffset(fields, \"annotationData\");\n // }\n \n //提供反射信息\n // reflection data that might get invalidated when JVM TI RedefineClasses() is called\n // private static class ReflectionData {\n // volatile Field[] declaredFields;\n // volatile Field[] publicFields;\n // volatile Method[] declaredMethods;\n // volatile Method[] publicMethods;\n // volatile Constructor[] declaredConstructors;\n // volatile Constructor[] publicConstructors;\n // // Intermediate results for getFields and getMethods\n // volatile Field[] declaredPublicFields;\n // volatile Method[] declaredPublicMethods;\n // volatile Class[] interfaces;\n //\n // // Value of classRedefinedCount when we created this ReflectionData instance\n // final int redefinedCount;\n //\n // ReflectionData(int redefinedCount) {\n // this.redefinedCount = redefinedCount;\n // }\n // }\n //方法数组\n // static class MethodArray {\n // // Don't add or remove methods except by add() or remove() calls.\n // private Method[] methods;\n // private int length;\n // private int defaults;\n //\n // MethodArray() {\n // this(20);\n // }\n //\n // MethodArray(int initialSize) {\n // if (initialSize < 2)\n // throw new IllegalArgumentException(\"Size should be 2 or more\");\n //\n // methods = new Method[initialSize];\n // length = 0;\n // defaults = 0;\n // }\n \n //注解信息\n // annotation data that might get invalidated when JVM TI RedefineClasses() is called\n // private static class AnnotationData {\n // final Map, Annotation> annotations;\n // final Map, Annotation> declaredAnnotations;\n //\n // // Value of classRedefinedCount when we created this AnnotationData instance\n // final int redefinedCount;\n //\n // AnnotationData(Map, Annotation> annotations,\n // Map, Annotation> declaredAnnotations,\n // int redefinedCount) {\n // this.annotations = annotations;\n // this.declaredAnnotations = declaredAnnotations;\n // this.redefinedCount = redefinedCount;\n // }\n // }\n }\n````\n\n> 我们都知道所有的java类都是继承了object这个类,在object这个类中有一个方法:getclass().这个方法是用来取得该类已经被实例化了的对象的该类的引用,这个引用指向的是Class类的对象。\n> \n> 我们自己无法生成一个Class对象(构造函数为private),而 这个Class类的对象是在当各类被调入时,由 Java 虚拟机自动创建 Class 对象,或通过类装载器中的 defineClass 方法生成。\n\n //通过该方法可以动态地将字节码转为一个Class类对象\n protected final Class defineClass(String name, byte[] b, int off, int len)\n throws ClassFormatError\n {\n return defineClass(name, b, off, len, null);\n }\n>\n\n### 如何获得一个Class类对象\n\n请注意,以下这些方法都是值、指某个类对应的Class对象已经在堆中生成以后,我们通过不同方式获取对这个Class对象的引用。而上面说的DefineClass才是真正将字节码加载到虚拟机的方法,会在堆中生成新的一个Class对象。\n\n第一种办法,Class类的forName函数\n> \n> public class shapes{} \n> Class obj= Class.forName(\"shapes\");\n> 第二种办法,使用对象的getClass()函数\n\n> public class shapes{}\n> shapes s1=new shapes();\n> Class obj=s1.getClass();\n> Class obj1=s1.getSuperclass();//这个函数作用是获取shapes类的父类的类型\n\n第三种办法,使用类字面常量\n\n> Class obj=String.class;\n> Class obj1=int.class;\n> 注意,使用这种办法生成Class类对象时,不会使JVM自动加载该类(如String类)。==而其他办法会使得JVM初始化该类。==\n\n### 使用Class类的对象来生成目标类的实例\n> \n> 生成不精确的object实例\n> \n\n获取一个Class类的对象后,可以用 newInstance() 函数来生成目标类的一个实例。然而,该函数并不能直接生成目标类的实例,只能生成object类的实例\n\n> Class obj=Class.forName(\"shapes\");\n> Object ShapesInstance=obj.newInstance();\n> 使用泛化Class引用生成带类型的目标实例\n\n> \n> Class obj=shapes.class;\n> shapes newShape=obj.newInstance();\n> 因为有了类型限制,所以使用泛化Class语法的对象引用不能指向别的类。\n \n Class obj1=int.class;\n Class obj2=int.class;\n obj1=double.class;\n //obj2=double.class; 这一行代码是非法的,obj2不能改指向别的类\n \n 然而,有个灵活的用法,使得你可以用Class的对象指向基类的任何子类。\n Class obj=int.class;\n obj=Number.class;\n obj=double.class;\n \n 因此,以下语法生成的Class对象可以指向任何类。\n Class obj=int.class;\n obj=double.class;\n obj=shapes.class;\n 最后一个奇怪的用法是,当你使用这种泛型语法来构建你手头有的一个Class类的对象的基类对象时,必须采用以下的特殊语法\n \n public class shapes{}\n class round extends shapes{}\n Class rclass=round.class;\n Class sclass= rclass.getSuperClass();\n //Class sclass=rclass.getSuperClass();\n\n 我们明知道,round的基类就是shapes,但是却不能直接声明 Class < shapes >,必须使用特殊语法\n \n Class < ? super round >\n \n 这个记住就可以啦。\n\n## Object类\n\n这部分主要参考http://ihenu.iteye.com/blog/2233249\n\nObject类是Java中其他所有类的祖先,没有Object类Java面向对象无从谈起。作为其他所有类的基类,Object具有哪些属性和行为,是Java语言设计背后的思维体现。\n\nObject类位于java.lang包中,java.lang包包含着Java最基础和核心的类,在编译时会自动导入。Object类没有定义属性,一共有13个方法,13个方法之中并不是所有方法都是子类可访问的,一共有9个方法是所有子类都继承了的。\n\n先大概介绍一下这些方法\n\n 1.clone方法\n 保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。\n 2.getClass方法\n final方法,获得运行时类型。\n 3.toString方法\n 该方法用得比较多,一般子类都有覆盖。\n 4.finalize方法\n 该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。\n 5.equals方法\n 该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。\n 6.hashCode方法\n 该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。\n 一般必须满足obj1.equals(obj2)==true。可以推出obj1.hash- Code()==obj2.hashCode(),但是hashCode相等不一定就满足equals。不过为了提高效率,应该尽量使上面两个条件接近等价。\n 7.wait方法\n wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。\n 调用该方法后当前线程进入睡眠状态,直到以下事件发生。\n (1)其他线程调用了该对象的notify方法。\n (2)其他线程调用了该对象的notifyAll方法。\n (3)其他线程调用了interrupt中断该线程。\n (4)时间间隔到了。\n 此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。\n 8.notify方法\n 该方法唤醒在该对象上等待的某个线程。\n 9.notifyAll方法\n 该方法唤醒在该对象上等待的所有线程。\n\n### 类构造器public Object();\n\n> 大部分情况下,Java中通过形如 new A(args..)形式创建一个属于该类型的对象。其中A即是类名,A(args..)即此类定义中相对应的构造函数。通过此种形式创建的对象都是通过类中的构造函数完成。\n\n> 为体现此特性,Java中规定:在类定义过程中,对于未定义构造函数的类,默认会有一个无参数的构造函数,作为所有类的基类,Object类自然要反映出此特性,在源码中,未给出Object类构造函数定义,但实际上,此构造函数是存在的。\n> \n> 当然,并不是所有的类都是通过此种方式去构建,也自然的,并不是所有的类构造函数都是public。\n\n\n### registerNatives()方法;\n````\nprivate static native void registerNatives();\n````\n\n> registerNatives函数前面有native关键字修饰,Java中,用native关键字修饰的函数表明该方法的实现并不是在Java中去完成,而是由C/C++去完成,并被编译成了.dll,由Java去调用。\n> \n> 方法的具体实现体在dll文件中,对于不同平台,其具体实现应该有所不同。用native修饰,即表示操作系统,需要提供此方法,Java本身需要使用。\n> \n> 具体到registerNatives()方法本身,其主要作用是将C/C++中的方法映射到Java中的native方法,实现方法命名的解耦。\n> \n> 既然如此,可能有人会问,registerNatives()修饰符为private,且并没有执行,作用何以达到?其实,在Java源码中,此方法的声明后有紧接着一段静态代码块:\n\n````\nprivate static native void registerNatives(); \nstatic { \n registerNatives(); \n} \n````\n### Clone()方法实现浅拷贝\n````\nprotected native Object clone() throwsCloneNotSupportedException;\n````\n> 看,clode()方法又是一个被声明为native的方法,因此,我们知道了clone()方法并不是Java的原生方法,具体的实现是有C/C++完成的。clone英文翻译为\"克隆\",其目的是创建并返回此对象的一个副本。\n\n> 形象点理解,这有一辆科鲁兹,你看着不错,想要个一模一样的。你调用此方法即可像变魔术一样变出一辆一模一样的科鲁兹出来。配置一样,长相一样。但从此刻起,原来的那辆科鲁兹如果进行了新的装饰,与你克隆出来的这辆科鲁兹没有任何关系了。\n> \n> 你克隆出来的对象变不变完全在于你对克隆出来的科鲁兹有没有进行过什么操作了。Java术语表述为:clone函数返回的是一个引用,指向的是新的clone出来的对象,此对象与原对象分别占用不同的堆空间。\n\n明白了clone的含义后,接下来看看如果调用clone()函数对象进行此克隆操作。\n\n首先看一下下面的这个例子:\n\n````\n package com.corn.objectsummary; \n \n import com.corn.Person; \n \n public class ObjectTest { \n \n public static void main(String[] args) { \n \n Object o1 = new Object(); \n // The method clone() from the type Object is not visible \n Object clone = o1.clone(); \n } \n \n } \n````\n\n> 例子很简单,在main()方法中,new一个Oject对象后,想直接调用此对象的clone方法克隆一个对象,但是出现错误提示:\"The method clone() from the type Object is not visible\"\n> \n> why? 根据提示,第一反应是ObjectTest类中定义的Oject对象无法访问其clone()方法。回到Object类中clone()方法的定义,可以看到其被声明为protected,估计问题就在这上面了,protected修饰的属性或方法表示:在同一个包内或者不同包的子类可以访问。\n> \n> 显然,Object类与ObjectTest类在不同的包中,但是ObjectTest继承自Object,是Object类的子类,于是,现在却出现子类中通过Object引用不能访问protected方法,原因在于对\"不同包中的子类可以访问\"没有正确理解。\n> \n> \"不同包中的子类可以访问\",是指当两个类不在同一个包中的时候,继承自父类的子类内部且主调(调用者)为子类的引用时才能访问父类用protected修饰的成员(属性/方法)。 在子类内部,主调为父类的引用时并不能访问此protected修饰的成员。!(super关键字除外)\n\n于是,上例改成如下形式,我们发现,可以正常编译:\n\n````\npublic class clone方法 {\n public static void main(String[] args) {\n \n }\n public void test1() {\n \n User user = new User();\n //User copy = user.clone();\n }\n public void test2() {\n User user = new User();\n //User copy = (User)user.clone();\n }\n}\n\n````\n是的,因为此时的主调已经是子类的引用了。\n\n> 上述代码在运行过程中会抛出\"java.lang.CloneNotSupportedException\",表明clone()方法并未正确执行完毕,问题的原因在与Java中的语法规定:\n> \n> clone()的正确调用是需要实现Cloneable接口,如果没有实现Cloneable接口,并且子类直接调用Object类的clone()方法,则会抛出CloneNotSupportedException异常。\n> \n> Cloneable接口仅是一个表示接口,接口本身不包含任何方法,用来指示Object.clone()可以合法的被子类引用所调用。\n> \n> 于是,上述代码改成如下形式,即可正确指定clone()方法以实现克隆。\n````\npublic class User implements Cloneable{\n public int id;\n public String name;\n public UserInfo userInfo;\n \n public static void main(String[] args) {\n User user = new User();\n UserInfo userInfo = new UserInfo();\n user.userInfo = userInfo;\n System.out.println(user);\n System.out.println(user.userInfo);\n try {\n User copy = (User) user.clone();\n System.out.println(copy);\n System.out.println(copy.userInfo);\n } catch (CloneNotSupportedException e) {\n e.printStackTrace();\n }\n }\n //拷贝的User实例与原来不一样,是两个对象。\n // com.javase.Class和Object.Object方法.用到的类.User@4dc63996\n // com.javase.Class和Object.Object方法.用到的类.UserInfo@d716361\n //而拷贝后对象的userinfo引用对象是同一个。\n //所以这是浅拷贝\n // com.javase.Class和Object.Object方法.用到的类.User@6ff3c5b5\n // com.javase.Class和Object.Object方法.用到的类.UserInfo@d716361\n }\n````\n\n总结:\nclone方法实现的是浅拷贝,只拷贝当前对象,并且在堆中分配新的空间,放这个复制的对象。但是对象如果里面有其他类的子对象,那么就不会拷贝到新的对象中。\n\n深拷贝和浅拷贝的区别\n\n> 浅拷贝\n> 浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。\n> \n> 深拷贝\n> 深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。\n> 现在为了要在clone对象时进行深拷贝, 那么就要Clonable接口,覆盖并实现clone方法,除了调用父类中的clone方法得到新的对象, 还要将该类中的引用变量也clone出来。如果只是用Object中默认的clone方法,是浅拷贝的。\n\n那么这两种方式有什么相同和不同呢?\n\n> new操作符的本意是分配内存。程序执行到new操作符时, 首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。\n> \n> 分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。\n> \n> 而clone在第一步是和new相似的, 都是分配内存,调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域,\n> \n> 填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。\n\n也就是说,一个对象在浅拷贝以后,只是把对象复制了一份放在堆空间的另一个地方,但是成员变量如果有引用指向其他对象,这个引用指向的对象和被拷贝的对象中引用指向的对象是一样的。当然,基本数据类型还是会重新拷贝一份的。\n\n### getClass()方法\n````\npublic final native Class getClass();\n\n````\n\n> getClass()也是一个native方法,返回的是此Object对象的类对象/运行时类对象Class。效果与Object.class相同。\n> \n> 首先解释下\"类对象\"的概念:在Java中,类是是对具有一组相同特征或行为的实例的抽象并进行描述,对象则是此类所描述的特征或行为的具体实例。\n> \n> 作为概念层次的类,其本身也具有某些共同的特性,如都具有类名称、由类加载器去加载,都具有包,具有父类,属性和方法等。\n> \n> 于是,Java中定义了一个类,Class,去描述其他类所具有的这些特性,因此,从此角度去看,类本身也都是属于Class类的对象。为与经常意义上的对象相区分,在此称之为\"类对象\"。\n````\n public class getClass方法 {\n public static void main(String[] args) {\n User user = new User();\n //getclass方法是native方法,可以取到堆区唯一的Class对象\n Class aClass = user.getClass();\n Class bClass = User.class;\n try {\n Class cClass = Class.forName(\"com.javase.Class和Object.Object方法.用到的类.User\");\n } catch (ClassNotFoundException e) {\n e.printStackTrace();\n }\n System.out.println(aClass);\n System.out.println(bClass);\n // class com.javase.Class和Object.Object方法.用到的类.User\n // class com.javase.Class和Object.Object方法.用到的类.User\n try {\n User a = (User) aClass.newInstance();\n \n } catch (InstantiationException e) {\n e.printStackTrace();\n } catch (IllegalAccessException e) {\n e.printStackTrace();\n }\n }\n } \n````\n\n此处主要大量涉及到Java中的反射知识\n\n### equals()方法\n\n5.public boolean equals(Object obj);\n> \n> 与equals在Java中经常被使用,大家也都知道与equals的区别:\n> \n> ==表示的是变量值完成相同(对于基础类型,地址中存储的是值,引用类型则存储指向实际对象的地址);\n> \n> equals表示的是对象的内容完全相同,此处的内容多指对象的特征/属性。\n\n实际上,上面说法是不严谨的,更多的只是常见于String类中。首先看一下Object类中关于equals()方法的定义:\n\n\n public boolean equals(Object obj) { \n return (this == obj); \n } \n\n> 由此可见,Object原生的equals()方法内部调用的正是==,与==具有相同的含义。既然如此,为什么还要定义此equals()方法?\n> \n> equals()方法的正确理解应该是:判断两个对象是否相等。那么判断对象相等的标尺又是什么?\n> \n> 如上,在object类中,此标尺即为==。当然,这个标尺不是固定的,其他类中可以按照实际的需要对此标尺含义进行重定义。如String类中则是依据字符串内容是否相等来重定义了此标尺含义。如此可以增加类的功能型和实际编码的灵活性。当然了,如果自定义的类没有重写equals()方法来重新定义此标尺,那么默认的将是其父类的equals(),直到object基类。\n> \n> 如下场景的实际业务需求,对于User bean,由实际的业务需求可知当属性uid相同时,表示的是同一个User,即两个User对象相等。则可以重写equals以重定义User对象相等的标尺。\n\n\nObjectTest中打印出true,因为User类定义中重写了equals()方法,这很好理解,很可能张三是一个人小名,张三丰才是其大名,判断这两个人是不是同一个人,这时只用判断uid是否相同即可。\n\n> 如上重写equals方法表面上看上去是可以了,实则不然。因为它破坏了Java中的约定:重写equals()方法必须重写hasCode()方法。\n\n### hashCode()方法;\n````\npublic native int hashCode()\n````\n\nhashCode()方法返回一个整形数值,表示该对象的哈希码值。\n\nhashCode()具有如下约定:\n\n> 1).在Java应用程序程序执行期间,对于同一对象多次调用hashCode()方法时,其返回的哈希码是相同的,前提是将对象进行equals比较时所用的标尺信息未做修改。在Java应用程序的一次执行到另外一次执行,同一对象的hashCode()返回的哈希码无须保持一致;\n> \n> 2).如果两个对象相等(依据:调用equals()方法),那么这两个对象调用hashCode()返回的哈希码也必须相等;\n> \n> 3).反之,两个对象调用hasCode()返回的哈希码相等,这两个对象不一定相等。\n\n 即严格的数学逻辑表示为: 两个对象相等 <=> equals()相等 => hashCode()相等。因此,重写equlas()方法必须重写hashCode()方法,以保证此逻辑严格成立,同时可以推理出:hasCode()不相等 => equals()不相等 <=> 两个对象不相等。\n \n 可能有人在此产生疑问:既然比较两个对象是否相等的唯一条件(也是冲要条件)是equals,那么为什么还要弄出一个hashCode(),并且进行如此约定,弄得这么麻烦?\n \n 其实,这主要体现在hashCode()方法的作用上,其主要用于增强哈希表的性能。\n \n 以集合类中,以Set为例,当新加一个对象时,需要判断现有集合中是否已经存在与此对象相等的对象,如果没有hashCode()方法,需要将Set进行一次遍历,并逐一用equals()方法判断两个对象是否相等,此种算法时间复杂度为o(n)。通过借助于hasCode方法,先计算出即将新加入对象的哈希码,然后根据哈希算法计算出此对象的位置,直接判断此位置上是否已有对象即可。(注:Set的底层用的是Map的原理实现)\n\n> 在此需要纠正一个理解上的误区:对象的hashCode()返回的不是对象所在的物理内存地址。甚至也不一定是对象的逻辑地址,hashCode()相同的两个对象,不一定相等,换言之,不相等的两个对象,hashCode()返回的哈希码可能相同。\n> \n> 因此,在上述代码中,重写了equals()方法后,需要重写hashCode()方法。\n\n public class equals和hashcode方法 {\n @Override\n //修改equals时必须同时修改hashcode方法,否则在作为key时会出问题\n public boolean equals(Object obj) {\n return (this == obj);\n }\n \n @Override\n //相同的对象必须有相同hashcode,不同对象可能有相同hashcode\n public int hashCode() {\n return hashCode() >> 2;\n }\n }\n\n\n### toString()方法\n````\npublic String toString();\n\n toString()方法返回该对象的字符串表示。先看一下Object中的具体方法体:\n \n public String toString() { \n return getClass().getName() + \"@\" + Integer.toHexString(hashCode()); \n } \n \n````\n\n> toString()方法相信大家都经常用到,即使没有显式调用,但当我们使用System.out.println(obj)时,其内部也是通过toString()来实现的。\n> \n> getClass()返回对象的类对象,getClassName()以String形式返回类对象的名称(含包名)。Integer.toHexString(hashCode())则是以对象的哈希码为实参,以16进制无符号整数形式返回此哈希码的字符串表示形式。\n> \n> 如上例中的u1的哈希码是638,则对应的16进制为27e,调用toString()方法返回的结果为:com.corn.objectsummary.User@27e。\n> \n> 因此:toString()是由对象的类型和其哈希码唯一确定,同一类型但不相等的两个对象分别调用toString()方法返回的结果可能相同。\n\n\n### wait() notify() notifAll()\n\n> \n> 一说到wait(...) / notify() | notifyAll()几个方法,首先想到的是线程。确实,这几个方法主要用于java多线程之间的协作。先具体看下这几个方法的主要含义:\n> \n> wait():调用此方法所在的当前线程等待,直到在其他线程上调用此方法的主调(某一对象)的notify()/notifyAll()方法。\n> \n> wait(long timeout)/wait(long timeout, int nanos):调用此方法所在的当前线程等待,直到在其他线程上调用此方法的主调(某一对象)的notisfy()/notisfyAll()方法,或超过指定的超时时间量。\n> \n> notify()/notifyAll():唤醒在此对象监视器上等待的单个线程/所有线程。\n> \n> wait(...) / notify() | notifyAll()一般情况下都是配套使用。下面来看一个简单的例子:\n\n这是一个生产者消费者的模型,只不过这里只用flag来标识哪个线程需要工作\n````\n public class wait和notify {\n //volatile保证线程可见性\n volatile static int flag = 1;\n //object作为锁对象,用于线程使用wait和notify方法\n volatile static Object o = new Object();\n public static void main(String[] args) {\n new Thread(new Runnable() {\n @Override\n public void run() {\n //wait和notify只能在同步代码块内使用\n synchronized (o) {\n while (true) {\n if (flag == 0) {\n try {\n Thread.sleep(2000);\n System.out.println(\"thread1 wait\");\n //释放锁,线程挂起进入object的等待队列,后续代码运行\n o.wait();\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n System.out.println(\"thread1 run\");\n System.out.println(\"notify t2\");\n flag = 0;\n //通知等待队列的一个线程获取锁\n o.notify();\n }\n }\n }\n }).start();\n //解释同上\n new Thread(new Runnable() {\n @Override\n public void run() {\n while (true) {\n synchronized (o) {\n if (flag == 1) {\n try {\n Thread.sleep(2000);\n System.out.println(\"thread2 wait\");\n o.wait();\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n System.out.println(\"thread2 run\");\n System.out.println(\"notify t1\");\n flag = 1;\n o.notify();\n }\n }\n }\n }).start();\n }\n \n //输出结果是\n // thread1 run\n // notify t2\n // thread1 wait\n // thread2 run\n // notify t1\n // thread2 wait\n // thread1 run\n // notify t2\n //不断循环\n }\n````\n\n> 从上述例子的输出结果中可以得出如下结论:\n> \n> 1、wait(...)方法调用后当前线程将立即阻塞,且适当其所持有的同步代码块中的锁,直到被唤醒或超时或打断后且重新获取到锁后才能继续执行;\n> \n> 2、notify()/notifyAll()方法调用后,其所在线程不会立即释放所持有的锁,直到其所在同步代码块中的代码执行完毕,此时释放锁,因此,如果其同步代码块后还有代码,其执行则依赖于JVM的线程调度。\n\n在Java源码中,可以看到wait()具体定义如下:\n\n````\npublic final void wait() throws InterruptedException { \n wait(0); \n} \n````\n\n> 且wait(long timeout, int nanos)方法定义内部实质上也是通过调用wait(long timeout)完成。而wait(long timeout)是一个native方法。因此,wait(...)方法本质上都是native方式实现。\n\nnotify()/notifyAll()方法也都是native方法。\n\nJava中线程具有较多的知识点,是一块比较大且重要的知识点。后期会有博文专门针对Java多线程作出详细总结。此处不再细述。\n\n### finalize()方法\nfinalize方法主要与Java垃圾回收机制有关。首先我们看一下finalized方法在Object中的具体定义:\n\n````\nprotected void finalize() throws Throwable { } \n````\n\n> 我们发现Object类中finalize方法被定义成一个空方法,为什么要如此定义呢?finalize方法的调用时机是怎么样的呢?\n> \n> 首先,Object中定义finalize方法表明Java中每一个对象都将具有finalize这种行为,其具体调用时机在:JVM准备对此对形象所占用的内存空间进行垃圾回收前,将被调用。由此可以看出,此方法并不是由我们主动去调用的(虽然可以主动去调用,此时与其他自定义方法无异)。\n\n## CLass类和Object类的关系\n\n> Object类和Class类没有直接的关系。\n> \n> Object类是一切java类的父类,对于普通的java类,即便不声明,也是默认继承了Object类。典型的,可以使用Object类中的toString()方法。\n> \n> Class类是用于java反射机制的,一切java类,都有一个对应的Class对象,他是一个final类。Class 类的实例表示,正在运行的 Java 应用程序中的类和接口。\n\n转一个知乎很有趣的问题\nhttps://www.zhihu.com/question/30301819\n\n Java的对象模型中:\n 1 所有的类都是Class类的实例,Object是类,那么Object也是Class类的一个实例。\n \n 2 所有的类都最终继承自Object类,Class是类,那么Class也继承自Object。\n \n 3 这就像是先有鸡还是先有蛋的问题,请问实际中JVM是怎么处理的?\n\n\n> 这个问题中,第1个假设是错的:java.lang.Object是一个Java类,但并不是java.lang.Class的一个实例。后者只是一个用于描述Java类与接口的、用于支持反射操作的类型。这点上Java跟其它一些更纯粹的面向对象语言(例如Python和Ruby)不同。\n> \n> 而第2个假设是对的:java.lang.Class是java.lang.Object的派生类,前者继承自后者。虽然第1个假设不对,但“鸡蛋问题”仍然存在:在一个已经启动完毕、可以使用的Java对象系统里,必须要有一个java.lang.Class实例对应java.lang.Object这个类;而java.lang.Class是java.lang.Object的派生类,按“一般思维”前者应该要在后者完成初始化之后才可以初始化…\n> \n> 事实是:这些相互依赖的核心类型完全可以在“混沌”中一口气都初始化好,然后对象系统的状态才叫做完成了“bootstrap”,后面就可以按照Java对象系统的一般规则去运行。JVM、JavaScript、Python、Ruby等的运行时都有这样的bootstrap过程。\n> \n> 在“混沌”(boostrap过程)里,JVM可以为对象系统中最重要的一些核心类型先分配好内存空间,让它们进入[已分配空间]但[尚未完全初始化]状态。此时这些对象虽然已经分配了空间,但因为状态还不完整所以尚不可使用。\n> \n> 然后,通过这些分配好的空间把这些核心类型之间的引用关系串好。到此为止所有动作都由JVM完成,尚未执行任何Java字节码。然后这些核心类型就进入了[完全初始化]状态,对象系统就可以开始自我运行下去,也就是可以开始执行Java字节码来进一步完成Java系统的初始化了。\n\n## 参考文章\n\nhttps://www.cnblogs.com/congsg2016/p/5317362.html\nhttps://www.jb51.net/article/125936.htm\nhttps://blog.csdn.net/dufufd/article/details/80537638\nhttps://blog.csdn.net/farsight1/article/details/80664104\nhttps://blog.csdn.net/xiaomingdetianxia/article/details/77429180\n\n### Java技术江湖\n\n如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!\n\n**Java工程师必备学习资源:** 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 **“Java”** 即可免费无套路获取。\n\n\n\n"
},
{
"path": "docs/Java/basic/Java基本数据类型.md",
"content": "\n# 目录\n\n* [Java 基本数据类型](#java-基本数据类型)\n * [Java 的两大数据类型:](#java-的两大数据类型)\n * [内置数据类型](#内置数据类型)\n * [引用类型](#引用类型)\n * [Java 常量](#java-常量)\n * [自动拆箱和装箱(详解)](#自动拆箱和装箱(详解))\n * [实现](#实现)\n * [自动装箱与拆箱中的“坑”](#自动装箱与拆箱中的坑)\n * [了解基本类型缓存(常量池)的最佳实践](#了解基本类型缓存(常量池)的最佳实践)\n * [总结:](#总结:)\n * [基本数据类型的存储方式](#基本数据类型的存储方式)\n * [存在栈中](#存在栈中)\n * [存在堆里](#存在堆里)\n * [参考文章](#参考文章)\n\n\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n# Java 基本数据类型\n\n变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。\n\n内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。\n\n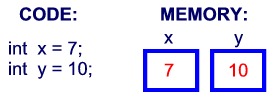\n\n因此,通过定义不同类型的变量,可以在内存中储存整数、小数或者字符。\n\n## Java 的两大数据类型:\n\n- 内置数据类型\n- 引用数据类型\n\n### 内置数据类型\n\nJava语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。\n\n**byte:**\n\n- byte 数据类型是8位、有符号的,以二进制补码表示的整数;\n- 最小值是 -128(-2^7);\n- 最大值是 127(2^7-1);\n- 默认值是 0;\n- byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;\n- 例子:byte a = 100,byte b = -50。\n\n**short:**\n\n- short 数据类型是 16 位、有符号的以二进制补码表示的整数\n- 最小值是 -32768(-2^15);\n- 最大值是 32767(2^15 - 1);\n- Short 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一;\n- 默认值是 0;\n- 例子:short s = 1000,short r = -20000。\n\n**int:**\n\n- int 数据类型是32位、有符号的以二进制补码表示的整数;\n- 最小值是 -2,147,483,648(-2^31);\n- 最大值是 2,147,483,647(2^31 - 1);\n- 一般地整型变量默认为 int 类型;\n- 默认值是 0 ;\n- 例子:int a = 100000, int b = -200000。\n\n**long:**\n\n- long 数据类型是 64 位、有符号的以二进制补码表示的整数;\n- 最小值是 -9,223,372,036,854,775,808(-2^63);\n- 最大值是 9,223,372,036,854,775,807(2^63 -1);\n- 这种类型主要使用在需要比较大整数的系统上;\n- 默认值是 0L;\n- 例子: long a = 100000L,Long b = -200000L。\n \"L\"理论上不分大小写,但是若写成\"l\"容易与数字\"1\"混淆,不容易分辩。所以最好大写。\n\n**float:**\n\n- float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;\n- float 在储存大型浮点数组的时候可节省内存空间;\n- 默认值是 0.0f;\n- 浮点数不能用来表示精确的值,如货币;\n- 例子:float f1 = 234.5f。\n\n**double:**\n\n- double 数据类型是双精度、64 位、符合IEEE 754标准的浮点数;\n- 浮点数的默认类型为double类型;\n- double类型同样不能表示精确的值,如货币;\n- 默认值是 0.0d;\n- 例子:double d1 = 123.4。\n\n**boolean:**\n\n- boolean数据类型表示一位的信息;\n- 只有两个取值:true 和 false;\n- 这种类型只作为一种标志来记录 true/false 情况;\n- 默认值是 false;\n- 例子:boolean one = true。\n\n**char:**\n\n- char类型是一个单一的 16 位 Unicode 字符;\n- 最小值是 \\u0000(即为0);\n- 最大值是 \\uffff(即为65,535);\n- char 数据类型可以储存任何字符;\n- 例子:char letter = 'A';。\n\n### 引用类型\n\n- 在Java中,引用类型的变量非常类似于C/C++的指针。引用类型指向一个对象,指向对象的变量是引用变量。这些变量在声明时被指定为一个特定的类型,比如 Employee、Puppy 等。变量一旦声明后,类型就不能被改变了。\n- 对象、数组都是引用数据类型。\n- 所有引用类型的默认值都是null。\n- 一个引用变量可以用来引用任何与之兼容的类型。\n- 例子:Site site = new Site(\"Runoob\")。\n\n### Java 常量\n\n常量在程序运行时是不能被修改的。\n\n在 Java 中使用 final 关键字来修饰常量,声明方式和变量类似:\n\n```\nfinal double PI = 3.1415927;\n```\n\n虽然常量名也可以用小写,但为了便于识别,通常使用大写字母表示常量。\n\n字面量可以赋给任何内置类型的变量。例如:\n\n```\nbyte a = 68;\nchar a = 'A'\n```\n\n## 自动拆箱和装箱(详解)\n\nJava 5增加了自动装箱与自动拆箱机制,方便基本类型与包装类型的相互转换操作。在Java 5之前,如果要将一个int型的值转换成对应的包装器类型Integer,必须显式的使用new创建一个新的Integer对象,或者调用静态方法Integer.valueOf()。\n````\n//在Java 5之前,只能这样做\nInteger value = new Integer(10);\n//或者这样做\nInteger value = Integer.valueOf(10);\n//直接赋值是错误的\n//Integer value = 10;\n````\n在Java 5中,可以直接将整型赋给Integer对象,由编译器来完成从int型到Integer类型的转换,这就叫自动装箱。\n\n````\n//在Java 5中,直接赋值是合法的,由编译器来完成转换\nInteger value = 10;\n与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。\n//在Java 5 中可以直接这么做\nInteger value = new Integer(10);\nint i = value;\n````\n\n自动装箱与自动拆箱为程序员提供了很大的方便,而在实际的应用中,自动装箱与拆箱也是使用最广泛的特性之一。自动装箱和自动拆箱其实是Java编译器提供的一颗语法糖(语法糖是指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通过可提高开发效率,增加代码可读性,增加代码的安全性)。\n\n### 实现\n\n在八种包装类型中,每一种包装类型都提供了两个方法:\n\n静态方法valueOf(基本类型):将给定的基本类型转换成对应的包装类型;\n\n实例方法xxxValue():将具体的包装类型对象转换成基本类型;\n下面我们以int和Integer为例,说明Java中自动装箱与自动拆箱的实现机制。看如下代码:\n````\n class Auto //code1\n {\n public static void main(String[] args) \n {\n //自动装箱\n Integer inte = 10;\n //自动拆箱\n int i = inte;\n \n //再double和Double来验证一下\n Double doub = 12.40;\n double d = doub;\n \n }\n \n }\n````\n上面的代码先将int型转为Integer对象,再讲Integer对象转换为int型,毫无疑问,这是可以正确运行的。可是,这种转换是怎么进行的呢?使用反编译工具,将生成的Class文件在反编译为Java文件,让我们看看发生了什么:\n\n````\n class Auto//code2\n {\n public static void main(String[] paramArrayOfString)\n {\n Integer localInteger = Integer.valueOf(10);\n \n int i = localInteger.intValue();\n \n Double localDouble = Double.valueOf(12.4D);\n double d = localDouble.doubleValue();\n \n }\n }\n````\n\n我们可以看到经过javac编译之后,code1的代码被转换成了code2,实际运行时,虚拟机运行的就是code2的代码。也就是说,虚拟机根本不知道有自动拆箱和自动装箱这回事;在将Java源文件编译为class文件的过程中,javac编译器在自动装箱的时候,调用了Integer.valueOf()方法,在自动拆箱时,又调用了intValue()方法。我们可以看到,double和Double也是如此。\n实现总结:其实自动装箱和自动封箱是编译器为我们提供的一颗语法糖。在自动装箱时,编译器调用包装类型的valueOf()方法;在自动拆箱时,编译器调用了相应的xxxValue()方法。\n\n### 自动装箱与拆箱中的“坑”\n\n在使用自动装箱与自动拆箱时,要注意一些陷阱,为了避免这些陷阱,我们有必要去看一下各种包装类型的源码。\n\nInteger源码\n\n````\npublic final class Integer extends Number implements Comparable {\n\tprivate final int value;\n\t\n\n/*Integer的构造方法,接受一个整型参数,Integer对象表示的int值,保存在value中*/\n public Integer(int value) {\n this.value = value;\n }\n \n/*equals()方法判断的是:所代表的int型的值是否相等*/\n public boolean equals(Object obj) {\n if (obj instanceof Integer) {\n return value == ((Integer)obj).intValue();\n }\n return false;\n}\n \n/*返回这个Integer对象代表的int值,也就是保存在value中的值*/\n public int intValue() {\n return value;\n }\n \n /**\n * 首先会判断i是否在[IntegerCache.low,Integer.high]之间\n * 如果是,直接返回Integer.cache中相应的元素\n * 否则,调用构造方法,创建一个新的Integer对象\n */\n public static Integer valueOf(int i) {\n assert IntegerCache.high >= 127;\n if (i >= IntegerCache.low && i <= IntegerCache.high)\n return IntegerCache.cache[i + (-IntegerCache.low)];\n return new Integer(i);\n }\n\n/**\n * 静态内部类,缓存了从[low,high]对应的Integer对象\n * low -128这个值不会被改变\n * high 默认是127,可以改变,最大不超过:Integer.MAX_VALUE - (-low) -1\n * cache 保存从[low,high]对象的Integer对象\n */\n private static class IntegerCache {\n static final int low = -128;\n static final int high;\n static final Integer cache[];\n \n static {\n // high value may be configured by property\n int h = 127;\n String integerCacheHighPropValue =\n sun.misc.VM.getSavedProperty(\"java.lang.Integer.IntegerCache.high\");\n if (integerCacheHighPropValue != null) {\n int i = parseInt(integerCacheHighPropValue);\n i = Math.max(i, 127);\n // Maximum array size is Integer.MAX_VALUE\n h = Math.min(i, Integer.MAX_VALUE - (-low) -1);\n }\n high = h;\n \n cache = new Integer[(high - low) + 1];\n int j = low;\n for(int k = 0; k < cache.length; k++)\n cache[k] = new Integer(j++);\n }\n \n private IntegerCache() {}\n}\n````\n\n\n以上是Oracle(Sun)公司JDK 1.7中Integer源码的一部分,通过分析上面的代码,得到:\n\n1)Integer有一个实例域value,它保存了这个Integer所代表的int型的值,且它是final的,也就是说这个Integer对象一经构造完成,它所代表的值就不能再被改变。\n\n2)Integer重写了equals()方法,它通过比较两个Integer对象的value,来判断是否相等。\n\n3)重点是静态内部类IntegerCache,通过类名就可以发现:它是用来缓存数据的。它有一个数组,里面保存的是连续的Integer对象。\n (a) low:代表缓存数据中最小的值,固定是-128。\n\n (b) high:代表缓存数据中最大的值,它可以被该改变,默认是127。high最小是127,最大是Integer.MAX_VALUE-(-low)-1,如果high超过了这个值,那么cache[ ]的长度就超过Integer.MAX_VALUE了,也就溢出了。\n\n (c) cache[]:里面保存着从[low,high]所对应的Integer对象,长度是high-low+1(因为有元素0,所以要加1)。\n\n4)调用valueOf(inti)方法时,首先判断i是否在[low,high]之间,如果是,则复用Integer.cache[i-low]。比如,如果Integer.valueOf(3),直接返回Integer.cache[131];如果i不在这个范围,则调用构造方法,构造出一个新的Integer对象。\n\n5)调用intValue(),直接返回value的值。\n通过3)和4)可以发现,默认情况下,在使用自动装箱时,VM会复用[-128,127]之间的Integer对象。\n````\nInteger a1 = 1;\nInteger a2 = 1;\nInteger a3 = new Integer(1);\n//会打印true,因为a1和a2是同一个对象,都是Integer.cache[129]\nSystem.out.println(a1 == a2);\n//false,a3构造了一个新的对象,不同于a1,a2\nSystem.out.println(a1 == a3);\n````\n### 了解基本类型缓存(常量池)的最佳实践\n\n```\n//基本数据类型的常量池是-128到127之间。\n// 在这个范围中的基本数据类的包装类可以自动拆箱,比较时直接比较数值大小。\npublic static void main(String[] args) {\n\n //int的自动拆箱和装箱只在-128到127范围中进行,超过该范围的两个integer的 == 判断是会返回false的。\n Integer a1 = 128;\n Integer a2 = -128;\n Integer a3 = -128;\n Integer a4 = 128;\n System.out.println(a1 == a4);\n System.out.println(a2 == a3);\n\n Byte b1 = 127;\n Byte b2 = 127;\n Byte b3 = -128;\n Byte b4 = -128;\n //byte都是相等的,因为范围就在-128到127之间\n System.out.println(b1 == b2);\n System.out.println(b3 == b4);\n\n Long c1 = 128L;\n Long c2 = 128L;\n Long c3 = -128L;\n Long c4 = -128L;\n System.out.println(c1 == c2);\n System.out.println(c3 == c4);\n\n //char没有负值\n //发现char也是在0到127之间自动拆箱\n Character d1 = 128;\n Character d2 = 128;\n Character d3 = 127;\n Character d4 = 127;\n System.out.println(d1 == d2);\n System.out.println(d3 == d4);\n\n `结果`\n \n `false`\n `true`\n `true`\n `true`\n `false`\n `true`\n `false`\n `true`\n \n Integer i = 10;\n Byte b = 10;\n //比较Byte和Integer.两个对象无法直接比较,报错\n //System.out.println(i == b);\n System.out.println(\"i == b \" + i.equals(b));\n //答案是false,因为包装类的比较时先比较是否是同一个类,不是的话直接返回false.\n int ii = 128;\n short ss = 128;\n long ll = 128;\n char cc = 128;\n System.out.println(\"ii == bb \" + (ii == ss));\n System.out.println(\"ii == ll \" + (ii == ll));\n System.out.println(\"ii == cc \" + (ii == cc));\n \n 结果\n i == b false\n ii == bb true\n ii == ll true\n ii == cc true\n \n //这时候都是true,因为基本数据类型直接比较值,值一样就可以。\n```\n\n### 总结:\n\n通过上面的代码,我们分析一下自动装箱与拆箱发生的时机:\n\n(1)当需要一个对象的时候会自动装箱,比如Integer a = 10;equals(Object o)方法的参数是Object对象,所以需要装箱。\n\n(2)当需要一个基本类型时会自动拆箱,比如int a = new Integer(10);算术运算是在基本类型间进行的,所以当遇到算术运算时会自动拆箱,比如代码中的 c == (a + b);\n\n(3) 包装类型 == 基本类型时,包装类型自动拆箱;\n\n需要注意的是:“==”在没遇到算术运算时,不会自动拆箱;基本类型只会自动装箱为对应的包装类型,代码中最后一条说明的内容。\n\n在JDK 1.5中提供了自动装箱与自动拆箱,这其实是Java 编译器的语法糖,编译器通过调用包装类型的valueOf()方法实现自动装箱,调用xxxValue()方法自动拆箱。自动装箱和拆箱会有一些陷阱,那就是包装类型复用了某些对象。\n\n(1)Integer默认复用了[-128,127]这些对象,其中高位置可以修改;\n\n(2)Byte复用了全部256个对象[-128,127];\n\n(3)Short复用了[-128,127]这些对象;\n\n(4)Long复用了[-128,127];\n\n(5)Character复用了[0,127],Charater不能表示负数;\n\nDouble和Float是连续不可数的,所以没法复用对象,也就不存在自动装箱复用陷阱。\n\nBoolean没有自动装箱与拆箱,它也复用了Boolean.TRUE和Boolean.FALSE,通过Boolean.valueOf(boolean b)返回的Blooean对象要么是TRUE,要么是FALSE,这点也要注意。\n\n本文介绍了“真实的”自动装箱与拆箱,为了避免写出错误的代码,又从包装类型的源码入手,指出了各种包装类型在自动装箱和拆箱时存在的陷阱,同时指出了自动装箱与拆箱发生的时机。\n\n## 基本数据类型的存储方式\n\n上面自动拆箱和装箱的原理其实与常量池有关。\n\n### 存在栈中\n\npublic void(int a)\n{\nint i = 1;\nint j = 1;\n}\n方法中的i 存在虚拟机栈的局部变量表里,i是一个引用,j也是一个引用,它们都指向局部变量表里的整型值 1.\nint a是传值引用,所以a也会存在局部变量表。\n\n### 存在堆里\n\nclass A{\nint i = 1;\nA a = new A();\n}\ni是类的成员变量。类实例化的对象存在堆中,所以成员变量也存在堆中,引用a存的是对象的地址,引用i存的是值,这个值1也会存在堆中。可以理解为引用i指向了这个值1。也可以理解为i就是1.\n\n3 包装类对象怎么存\n其实我们说的常量池也可以叫对象池。\n比如String a= new String(\"a\").intern()时会先在常量池找是否有“a\"对象如果有的话直接返回“a\"对象在常量池的地址,即让引用a指向常量”a\"对象的内存地址。\npublic native String intern();\nInteger也是同理。\n\n下图是Integer类型在常量池中查找同值对象的方法。\n\n```\npublic static Integer valueOf(int i) {\n if (i >= IntegerCache.low && i <= IntegerCache.high)\n return IntegerCache.cache[i + (-IntegerCache.low)];\n return new Integer(i);\n}\nprivate static class IntegerCache {\n static final int low = -128;\n static final int high;\n static final Integer cache[];\n\n static {\n // high value may be configured by property\n int h = 127;\n String integerCacheHighPropValue =\n sun.misc.VM.getSavedProperty(\"java.lang.Integer.IntegerCache.high\");\n if (integerCacheHighPropValue != null) {\n try {\n int i = parseInt(integerCacheHighPropValue);\n i = Math.max(i, 127);\n // Maximum array size is Integer.MAX_VALUE\n h = Math.min(i, Integer.MAX_VALUE - (-low) -1);\n } catch( NumberFormatException nfe) {\n // If the property cannot be parsed into an int, ignore it.\n }\n }\n high = h;\n\n cache = new Integer[(high - low) + 1];\n int j = low;\n for(int k = 0; k < cache.length; k++)\n cache[k] = new Integer(j++);\n\n // range [-128, 127] must be interned (JLS7 5.1.7)\n assert IntegerCache.high >= 127;\n }\n\n private IntegerCache() {}\n}\n```\n\n所以基本数据类型的包装类型可以在常量池查找对应值的对象,找不到就会自动在常量池创建该值的对象。\n\n而String类型可以通过intern来完成这个操作。\n\nJDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码,这个例子是网上流传较广的一个例子,分析图也是直接粘贴过来的,这里我会用自己的理解去解释这个例子:\n\n```\n[java] view plain copy\nString s = new String(\"1\"); \ns.intern(); \nString s2 = \"1\"; \nSystem.out.println(s == s2); \n \nString s3 = new String(\"1\") + new String(\"1\"); \ns3.intern(); \nString s4 = \"11\"; \nSystem.out.println(s3 == s4); \n输出结果为:\n\n[java] view plain copy\nJDK1.6以及以下:false false \nJDK1.7以及以上:false true\n```\nJDK1.6查找到常量池存在相同值的对象时会直接返回该对象的地址。\n\nJDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。\n\n那么其他字符串在常量池找值时就会返回另一个堆中对象的地址。\n\n下一节详细介绍String以及相关包装类。\n\n具体请见:https://blog.csdn.net/a724888/article/details/80042298\n\n关于Java面向对象三大特性,请参考:\n\nhttps://blog.csdn.net/a724888/article/details/80033043\n\n## 参考文章\n\n\n\n\n\n\n\n\n\n\n"
},
{
"path": "docs/Java/basic/Java异常.md",
"content": "# 目录\n\n * [为什么要使用异常](#为什么要使用异常)\n * [异常基本定义](#异常基本定义)\n * [异常体系](#异常体系)\n * [初识异常](#初识异常)\n * [异常和错误](#异常和错误)\n * [异常的处理方式](#异常的处理方式)\n * [\"不负责任\"的throws](#不负责任的throws)\n * [纠结的finally](#纠结的finally)\n * [throw : JRE也使用的关键字](#throw--jre也使用的关键字)\n * [异常调用链](#异常调用链)\n * [自定义异常](#自定义异常)\n * [异常的注意事项](#异常的注意事项)\n * [当finally遇上return](#当finally遇上return)\n * [JAVA异常常见面试题](#java异常常见面试题)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n## 为什么要使用异常\n\n> 首先我们可以明确一点就是异常的处理机制可以确保我们程序的健壮性,提高系统可用率。虽然我们不是特别喜欢看到它,但是我们不能不承认它的地位,作用。\n\n在没有异常机制的时候我们是这样处理的:通过函数的返回值来判断是否发生了异常(这个返回值通常是已经约定好了的),调用该函数的程序负责检查并且分析返回值。虽然可以解决异常问题,但是这样做存在几个缺陷:\n> \n> 1、 容易混淆。如果约定返回值为-11111时表示出现异常,那么当程序最后的计算结果真的为-1111呢?\n> \n> 2、 代码可读性差。将异常处理代码和程序代码混淆在一起将会降低代码的可读性。\n> \n> 3、 由调用函数来分析异常,这要求程序员对库函数有很深的了解。\n> \n\n在OO中提供的异常处理机制是提供代码健壮的强有力的方式。使用异常机制它能够降低错误处理代码的复杂度,如果不使用异常,那么就必须检查特定的错误,并在程序中的许多地方去处理它。\n\n而如果使用异常,那就不必在方法调用处进行检查,因为异常机制将保证能够捕获这个错误,并且,只需在一个地方处理错误,即所谓的异常处理程序中。\n\n这种方式不仅节约代码,而且把“概述在正常执行过程中做什么事”的代码和“出了问题怎么办”的代码相分离。总之,与以前的错误处理方法相比,异常机制使代码的阅读、编写和调试工作更加井井有条。(摘自《Think in java 》)。\n\n该部分内容选自http://www.cnblogs.com/chenssy/p/3438130.html\n\n## 异常基本定义\n\n> 在《Think in java》中是这样定义异常的:异常情形是指阻止当前方法或者作用域继续执行的问题。在这里一定要明确一点:异常代码某种程度的错误,尽管Java有异常处理机制,但是我们不能以“正常”的眼光来看待异常,异常处理机制的原因就是告诉你:这里可能会或者已经产生了错误,您的程序出现了不正常的情况,可能会导致程序失败!\n\n> 那么什么时候才会出现异常呢?只有在你当前的环境下程序无法正常运行下去,也就是说程序已经无法来正确解决问题了,这时它所就会从当前环境中跳出,并抛出异常。抛出异常后,它首先会做几件事。\n\n> 首先,它会使用new创建一个异常对象,然后在产生异常的位置终止程序,并且从当前环境中弹出对异常对象的引用,这时。异常处理机制就会接管程序,并开始寻找一个恰当的地方来继续执行程序,这个恰当的地方就是异常处理程序。\n\n> 总的来说异常处理机制就是当程序发生异常时,它强制终止程序运行,记录异常信息并将这些信息反馈给我们,由我们来确定是否处理异常。\n\n## 异常体系\n\n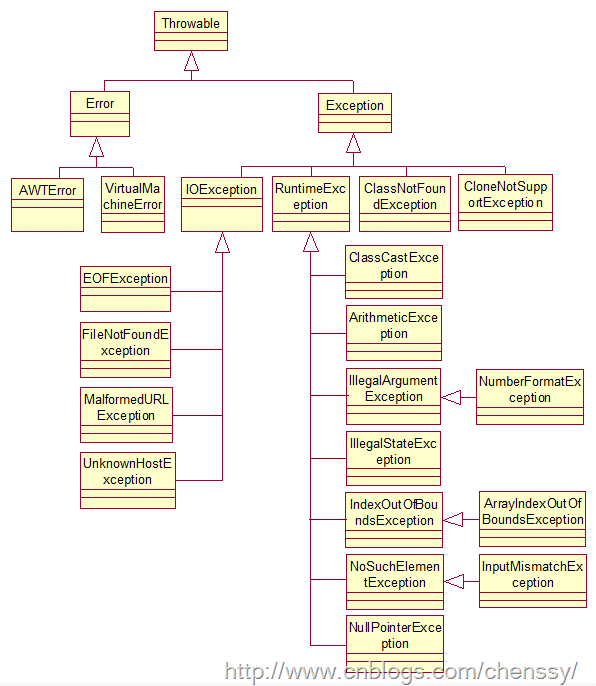\n\n从上面这幅图可以看出,Throwable是java语言中所有错误和异常的超类(万物即可抛)。它有两个子类:Error、Exception。\n\nJava标准库内建了一些通用的异常,这些类以Throwable为顶层父类。\n\nThrowable又派生出Error类和Exception类。\n\n错误:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。\n\n异常:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用,是异常处理的核心。\n\n总体上我们根据Javac对异常的处理要求,将异常类分为2类。\n\n> 非检查异常(unckecked exception):Error 和 RuntimeException 以及他们的子类。javac在编译时,不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用try…catch…finally)这样的异常,也可以不处理。\n\n> 对于这些异常,我们应该修正代码,而不是去通过异常处理器处理 。这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。\n\n> 检查异常(checked exception):除了Error 和 RuntimeException的其它异常。javac强制要求程序员为这样的异常做预备处理工作(使用try…catch…finally或者throws)。在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。\n\n> 这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。\n\n需要明确的是:检查和非检查是对于javac来说的,这样就很好理解和区分了。\n\n这部分内容摘自http://www.importnew.com/26613.html\n\n## 初识异常\n\n异常是在执行某个函数时引发的,而函数又是层级调用,形成调用栈的,因为,只要一个函数发生了异常,那么他的所有的caller都会被异常影响。当这些被影响的函数以异常信息输出时,就形成的了异常追踪栈。\n\n异常最先发生的地方,叫做异常抛出点。\n````\n public class 异常 {\n public static void main (String [] args )\n {\n System . out. println( \"----欢迎使用命令行除法计算器----\" ) ;\n CMDCalculate ();\n }\n public static void CMDCalculate ()\n {\n Scanner scan = new Scanner ( System. in );\n int num1 = scan .nextInt () ;\n int num2 = scan .nextInt () ;\n int result = devide (num1 , num2 ) ;\n System . out. println( \"result:\" + result) ;\n scan .close () ;\n }\n public static int devide (int num1, int num2 ){\n return num1 / num2 ;\n }\n \n // ----欢迎使用命令行除法计算器----\n // 1\n // 0\n // Exception in thread \"main\" java.lang.ArithmeticException: / by zero\n // at com.javase.异常.异常.devide(异常.java:24)\n // at com.javase.异常.异常.CMDCalculate(异常.java:19)\n // at com.javase.异常.异常.main(异常.java:12)\n \n // ----欢迎使用命令行除法计算器----\n // r\n // Exception in thread \"main\" java.util.InputMismatchException\n // at java.util.Scanner.throwFor(Scanner.java:864)\n // at java.util.Scanner.next(Scanner.java:1485)\n // at java.util.Scanner.nextInt(Scanner.java:2117)\n // at java.util.Scanner.nextInt(Scanner.java:2076)\n // at com.javase.异常.异常.CMDCalculate(异常.java:17)\n // at com.javase.异常.异常.main(异常.java:12)\n\n````\n\n从上面的例子可以看出,当devide函数发生除0异常时,devide函数将抛出ArithmeticException异常,因此调用他的CMDCalculate函数也无法正常完成,因此也发送异常,而CMDCalculate的caller——main 因为CMDCalculate抛出异常,也发生了异常,这样一直向调用栈的栈底回溯。\n\n这种行为叫做异常的冒泡,异常的冒泡是为了在当前发生异常的函数或者这个函数的caller中找到最近的异常处理程序。由于这个例子中没有使用任何异常处理机制,因此异常最终由main函数抛给JRE,导致程序终止。\n\n> 上面的代码不使用异常处理机制,也可以顺利编译,因为2个异常都是非检查异常。但是下面的例子就必须使用异常处理机制,因为异常是检查异常。\n\n代码中我选择使用throws声明异常,让函数的调用者去处理可能发生的异常。但是为什么只throws了IOException呢?因为FileNotFoundException是IOException的子类,在处理范围内。\n\n## 异常和错误\n\n下面看一个例子\n```` \n //错误即error一般指jvm无法处理的错误\n //异常是Java定义的用于简化错误处理流程和定位错误的一种工具。\n public class 错误和错误 {\n Error error = new Error();\n \n public static void main(String[] args) {\n throw new Error();\n }\n \n //下面这四个异常或者错误有着不同的处理方法\n public void error1 (){\n //编译期要求必须处理,因为这个异常是最顶层异常,包括了检查异常,必须要处理\n try {\n throw new Throwable();\n } catch (Throwable throwable) {\n throwable.printStackTrace();\n }\n }\n //Exception也必须处理。否则报错,因为检查异常都继承自exception,所以默认需要捕捉。\n public void error2 (){\n try {\n throw new Exception();\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n \n //error可以不处理,编译不报错,原因是虚拟机根本无法处理,所以啥都不用做\n public void error3 (){\n throw new Error();\n }\n \n //runtimeexception众所周知编译不会报错\n public void error4 (){\n throw new RuntimeException();\n }\n // Exception in thread \"main\" java.lang.Error\n // at com.javase.异常.错误.main(错误.java:11)\n \n }\n````\n## 异常的处理方式\n\n在编写代码处理异常时,对于检查异常,有2种不同的处理方式:\n\n> 使用try…catch…finally语句块处理它。\n> \n\n> 或者,在函数签名中使用throws 声明交给函数调用者caller去解决。\n> \n\n下面看几个具体的例子,包括error,exception和throwable\n\n上面的例子是运行时异常,不需要显示捕获。\n下面这个例子是可检查异常需,要显示捕获或者抛出。\n````\n @Test\n public void testException() throws IOException\n {\n //FileInputStream的构造函数会抛出FileNotFoundException\n FileInputStream fileIn = new FileInputStream(\"E:\\\\a.txt\");\n \n int word;\n //read方法会抛出IOException\n while((word = fileIn.read())!=-1)\n {\n System.out.print((char)word);\n }\n //close方法会抛出IOException\n fileIn.close();\n }\n\n一般情况下的处理方式 try catch finally\n\n public class 异常处理方式 {\n \n @Test\n public void main() {\n try{\n //try块中放可能发生异常的代码。\n InputStream inputStream = new FileInputStream(\"a.txt\");\n \n //如果执行完try且不发生异常,则接着去执行finally块和finally后面的代码(如果有的话)。\n int i = 1/0;\n //如果发生异常,则尝试去匹配catch块。\n throw new SQLException();\n //使用1.8jdk同时捕获多个异常,runtimeexception也可以捕获。只是捕获后虚拟机也无法处理,所以不建议捕获。\n }catch(SQLException | IOException | ArrayIndexOutOfBoundsException exception){\n System.out.println(exception.getMessage());\n //每一个catch块用于捕获并处理一个特定的异常,或者这异常类型的子类。Java7中可以将多个异常声明在一个catch中。\n \n //catch后面的括号定义了异常类型和异常参数。如果异常与之匹配且是最先匹配到的,则虚拟机将使用这个catch块来处理异常。\n \n //在catch块中可以使用这个块的异常参数来获取异常的相关信息。异常参数是这个catch块中的局部变量,其它块不能访问。\n \n //如果当前try块中发生的异常在后续的所有catch中都没捕获到,则先去执行finally,然后到这个函数的外部caller中去匹配异常处理器。\n \n //如果try中没有发生异常,则所有的catch块将被忽略。\n \n }catch(Exception exception){\n System.out.println(exception.getMessage());\n //...\n }finally{\n //finally块通常是可选的。\n //无论异常是否发生,异常是否匹配被处理,finally都会执行。\n \n //finally主要做一些清理工作,如流的关闭,数据库连接的关闭等。\n }\n\n一个try至少要跟一个catch或者finally\n\n try {\n int i = 1;\n }finally {\n //一个try至少要有一个catch块,否则, 至少要有1个finally块。但是finally不是用来处理异常的,finally不会捕获异常。\n }\n }\n\n\n异常出现时该方法后面的代码不会运行,即使异常已经被捕获。这里举出一个奇特的例子,在catch里再次使用try catch finally\n\n @Test\n public void test() {\n try {\n throwE();\n System.out.println(\"我前面抛出异常了\");\n System.out.println(\"我不会执行了\");\n } catch (StringIndexOutOfBoundsException e) {\n System.out.println(e.getCause());\n }catch (Exception ex) {\n //在catch块中仍然可以使用try catch finally\n try {\n throw new Exception();\n }catch (Exception ee) {\n \n }finally {\n System.out.println(\"我所在的catch块没有执行,我也不会执行的\");\n }\n }\n }\n //在方法声明中抛出的异常必须由调用方法处理或者继续往上抛,\n // 当抛到jre时由于无法处理终止程序\n public void throwE (){\n // Socket socket = new Socket(\"127.0.0.1\", 80);\n \n //手动抛出异常时,不会报错,但是调用该方法的方法需要处理这个异常,否则会出错。\n // java.lang.StringIndexOutOfBoundsException\n // at com.javase.异常.异常处理方式.throwE(异常处理方式.java:75)\n // at com.javase.异常.异常处理方式.test(异常处理方式.java:62)\n throw new StringIndexOutOfBoundsException();\n }\n````\n\n其实有的语言在遇到异常后仍然可以继续运行\n\n> 有的编程语言当异常被处理后,控制流会恢复到异常抛出点接着执行,这种策略叫做:resumption model of exception handling(恢复式异常处理模式 )\n> \n> 而Java则是让执行流恢复到处理了异常的catch块后接着执行,这种策略叫做:termination model of exception handling(终结式异常处理模式)\n\n## \"不负责任\"的throws\n\nthrows是另一种处理异常的方式,它不同于try…catch…finally,throws仅仅是将函数中可能出现的异常向调用者声明,而自己则不具体处理。\n\n采取这种异常处理的原因可能是:方法本身不知道如何处理这样的异常,或者说让调用者处理更好,调用者需要为可能发生的异常负责。\n````\npublic void foo() throws ExceptionType1 , ExceptionType2 ,ExceptionTypeN\n{ \n //foo内部可以抛出 ExceptionType1 , ExceptionType2 ,ExceptionTypeN 类的异常,或者他们的子类的异常对象。\n}\n````\n\n## 纠结的finally\n\nfinally块不管异常是否发生,只要对应的try执行了,则它一定也执行。只有一种方法让finally块不执行:System.exit()。因此finally块通常用来做资源释放操作:关闭文件,关闭数据库连接等等。\n\n良好的编程习惯是:在try块中打开资源,在finally块中清理释放这些资源。\n\n需要注意的地方:\n\n1、finally块没有处理异常的能力。处理异常的只能是catch块。\n\n2、在同一try…catch…finally块中 ,如果try中抛出异常,且有匹配的catch块,则先执行catch块,再执行finally块。如果没有catch块匹配,则先执行finally,然后去外面的调用者中寻找合适的catch块。\n\n3、在同一try…catch…finally块中 ,try发生异常,且匹配的catch块中处理异常时也抛出异常,那么后面的finally也会执行:首先执行finally块,然后去外围调用者中寻找合适的catch块。\n\n````\n public class finally使用 {\n public static void main(String[] args) {\n try {\n throw new IllegalAccessException();\n }catch (IllegalAccessException e) {\n // throw new Throwable();\n //此时如果再抛异常,finally无法执行,只能报错。\n //finally无论何时都会执行\n //除非我显示调用。此时finally才不会执行\n System.exit(0);\n \n }finally {\n System.out.println(\"算你狠\");\n }\n }\n }\n````\n\n## throw : JRE也使用的关键字\n\nthrow exceptionObject\n\n程序员也可以通过throw语句手动显式的抛出一个异常。throw语句的后面必须是一个异常对象。\n\nthrow 语句必须写在函数中,执行throw 语句的地方就是一个异常抛出点,==它和由JRE自动形成的异常抛出点没有任何差别。==\n````\npublic void save(User user)\n{\n if(user == null) \n throw new IllegalArgumentException(\"User对象为空\");\n //......\n}\n````\n后面开始的大部分内容都摘自http://www.cnblogs.com/lulipro/p/7504267.html\n\n该文章写的十分细致到位,令人钦佩,是我目前为之看到关于异常最详尽的文章,可以说是站在巨人的肩膀上了。\n\n## 异常调用链\n\n异常的链化\n\n在一些大型的,模块化的软件开发中,一旦一个地方发生异常,则如骨牌效应一样,将导致一连串的异常。假设B模块完成自己的逻辑需要调用A模块的方法,如果A模块发生异常,则B也将不能完成而发生异常。\n\n==但是B在抛出异常时,会将A的异常信息掩盖掉,这将使得异常的根源信息丢失。异常的链化可以将多个模块的异常串联起来,使得异常信息不会丢失。==\n\n> 异常链化:以一个异常对象为参数构造新的异常对象。新的异对象将包含先前异常的信息。这项技术主要是异常类的一个带Throwable参数的函数来实现的。这个当做参数的异常,我们叫他根源异常(cause)。\n\n查看Throwable类源码,可以发现里面有一个Throwable字段cause,就是它保存了构造时传递的根源异常参数。这种设计和链表的结点类设计如出一辙,因此形成链也是自然的了。\n````\npublic class Throwable implements Serializable {\n private Throwable cause = this;\n public Throwable(String message, Throwable cause) {\n fillInStackTrace();\n detailMessage = message;\n this.cause = cause;\n }\n public Throwable(Throwable cause) {\n fillInStackTrace();\n detailMessage = (cause==null ? null : cause.toString());\n this.cause = cause;\n }\n //........\n}\n````\n\n下面看一个比较实在的异常链例子哈\n````\npublic class 异常链 {\n @Test\n public void test() {\n C();\n }\n public void A () throws Exception {\n try {\n int i = 1;\n i = i / 0;\n //当我注释掉这行代码并使用B方法抛出一个error时,运行结果如下\n// 四月 27, 2018 10:12:30 下午 org.junit.platform.launcher.core.ServiceLoaderTestEngineRegistry loadTestEngines\n// 信息: Discovered TestEngines with IDs: [junit-jupiter]\n// java.lang.Error: B也犯了个错误\n// at com.javase.异常.异常链.B(异常链.java:33)\n// at com.javase.异常.异常链.C(异常链.java:38)\n// at com.javase.异常.异常链.test(异常链.java:13)\n// at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)\n// Caused by: java.lang.Error\n// at com.javase.异常.异常链.B(异常链.java:29)\n\n }catch (ArithmeticException e) {\n //这里通过throwable类的构造方法将最底层的异常重新包装并抛出,此时注入了A方法的信息。最后打印栈信息时可以看到caused by\n A方法的异常。\n //如果直接抛出,栈信息打印结果只能看到上层方法的错误信息,不能看到其实是A发生了错误。\n //所以需要包装并抛出\n throw new Exception(\"A方法计算错误\", e);\n }\n\n }\n public void B () throws Exception,Error {\n try {\n //接收到A的异常,\n A();\n throw new Error();\n }catch (Exception e) {\n throw e;\n }catch (Error error) {\n throw new Error(\"B也犯了个错误\", error);\n }\n }\n public void C () {\n try {\n B();\n }catch (Exception | Error e) {\n e.printStackTrace();\n }\n\n }\n\n //最后结果\n// java.lang.Exception: A方法计算错误\n// at com.javase.异常.异常链.A(异常链.java:18)\n// at com.javase.异常.异常链.B(异常链.java:24)\n// at com.javase.异常.异常链.C(异常链.java:31)\n// at com.javase.异常.异常链.test(异常链.java:11)\n// 省略\n// Caused by: java.lang.ArithmeticException: / by zero\n// at com.javase.异常.异常链.A(异常链.java:16)\n// ... 31 more\n}\n````\n## 自定义异常\n\n如果要自定义异常类,则扩展Exception类即可,因此这样的自定义异常都属于检查异常(checked exception)。如果要自定义非检查异常,则扩展自RuntimeException。\n\n按照国际惯例,自定义的异常应该总是包含如下的构造函数:\n\n一个无参构造函数\n一个带有String参数的构造函数,并传递给父类的构造函数。\n一个带有String参数和Throwable参数,并都传递给父类构造函数\n一个带有Throwable 参数的构造函数,并传递给父类的构造函数。\n下面是IOException类的完整源代码,可以借鉴。\n````\n public class IOException extends Exception\n {\n static final long serialVersionUID = 7818375828146090155L;\n \n public IOException()\n {\n super();\n }\n \n public IOException(String message)\n {\n super(message);\n }\n \n public IOException(String message, Throwable cause)\n {\n super(message, cause);\n }\n \n public IOException(Throwable cause)\n {\n super(cause);\n }\n }\n````\n## 异常的注意事项\n\n异常的注意事项\n\n> 当子类重写父类的带有 throws声明的函数时,其throws声明的异常必须在父类异常的可控范围内——用于处理父类的throws方法的异常处理器,必须也适用于子类的这个带throws方法 。这是为了支持多态。\n> \n> 例如,父类方法throws 的是2个异常,子类就不能throws 3个及以上的异常。父类throws IOException,子类就必须throws IOException或者IOException的子类。\n\n至于为什么?我想,也许下面的例子可以说明。\n````\nclass Father\n{\n public void start() throws IOException\n {\n throw new IOException();\n }\n}\n \nclass Son extends Father\n{\n public void start() throws Exception\n {\n throw new SQLException();\n }\n}\n/**********************假设上面的代码是允许的(实质是错误的)***********************/\n\nclass Test\n{\n public static void main(String[] args)\n {\n Father[] objs = new Father[2];\n objs[0] = new Father();\n objs[1] = new Son();\n \n for(Father obj:objs)\n {\n //因为Son类抛出的实质是SQLException,而IOException无法处理它。\n //那么这里的try。。catch就不能处理Son中的异常。\n //多态就不能实现了。\n try {\n obj.start();\n }catch(IOException)\n {\n //处理IOException\n }\n }\n }\n}\n````\n==Java的异常执行流程是线程独立的,线程之间没有影响==\n\n> Java程序可以是多线程的。每一个线程都是一个独立的执行流,独立的函数调用栈。如果程序只有一个线程,那么没有被任何代码处理的异常 会导致程序终止。如果是多线程的,那么没有被任何代码处理的异常仅仅会导致异常所在的线程结束。\n> \n> 也就是说,Java中的异常是线程独立的,线程的问题应该由线程自己来解决,而不要委托到外部,也不会直接影响到其它线程的执行。\n\n下面看一个例子\n````\npublic class 多线程的异常 {\n @Test\n public void test() {\n go();\n }\n public void go () {\n ExecutorService executorService = Executors.newFixedThreadPool(3);\n for (int i = 0;i <= 2;i ++) {\n int finalI = i;\n try {\n Thread.sleep(2000);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n executorService.execute(new Runnable() {\n @Override\n //每个线程抛出异常时并不会影响其他线程的继续执行\n public void run() {\n try {\n System.out.println(\"start thread\" + finalI);\n throw new Exception();\n }catch (Exception e) {\n System.out.println(\"thread\" + finalI + \" go wrong\");\n }\n }\n });\n }\n// 结果:\n// start thread0\n// thread0 go wrong\n// start thread1\n// thread1 go wrong\n// start thread2\n// thread2 go wrong\n }\n}\n````\n\n## 当finally遇上return\n\n\n首先一个不容易理解的事实:\n\n在 try块中即便有return,break,continue等改变执行流的语句,finally也会执行。\n````\npublic static void main(String[] args)\n{\n int re = bar();\n System.out.println(re);\n}\nprivate static int bar() \n{\n try{\n return 5;\n } finally{\n System.out.println(\"finally\");\n }\n}\n/*输出:\nfinally\n*/\n````\n\n也就是说:try…catch…finally中的return 只要能执行,就都执行了,他们共同向同一个内存地址(假设地址是0×80)写入返回值,后执行的将覆盖先执行的数据,而真正被调用者取的返回值就是最后一次写入的。那么,按照这个思想,下面的这个例子也就不难理解了。\n\nfinally中的return 会覆盖 try 或者catch中的返回值。\n````\npublic static void main(String[] args)\n {\n int result;\n \n result = foo();\n System.out.println(result); /////////2\n \n result = bar();\n System.out.println(result); /////////2\n }\n \n @SuppressWarnings(\"finally\")\n public static int foo()\n {\n trz{\n int a = 5 / 0;\n } catch (Exception e){\n return 1;\n } finally{\n return 2;\n }\n \n }\n \n @SuppressWarnings(\"finally\")\n public static int bar()\n {\n try {\n return 1;\n }finally {\n return 2;\n }\n }\n````\nfinally中的return会抑制(消灭)前面try或者catch块中的异常\n````\nclass TestException\n{\n public static void main(String[] args)\n {\n int result;\n try{\n result = foo();\n System.out.println(result); //输出100\n } catch (Exception e){\n System.out.println(e.getMessage()); //没有捕获到异常\n }\n \n try{\n result = bar();\n System.out.println(result); //输出100\n } catch (Exception e){\n System.out.println(e.getMessage()); //没有捕获到异常\n }\n }\n \n //catch中的异常被抑制\n @SuppressWarnings(\"finally\")\n public static int foo() throws Exception\n {\n try {\n int a = 5/0;\n return 1;\n }catch(ArithmeticException amExp) {\n throw new Exception(\"我将被忽略,因为下面的finally中使用了return\");\n }finally {\n return 100;\n }\n }\n \n //try中的异常被抑制\n @SuppressWarnings(\"finally\")\n public static int bar() throws Exception\n {\n try {\n int a = 5/0;\n return 1;\n }finally {\n return 100;\n }\n }\n}\n````\nfinally中的异常会覆盖(消灭)前面try或者catch中的异常\n````\nclass TestException\n{\n public static void main(String[] args)\n {\n int result;\n try{\n result = foo();\n } catch (Exception e){\n System.out.println(e.getMessage()); //输出:我是finaly中的Exception\n }\n \n try{\n result = bar();\n } catch (Exception e){\n System.out.println(e.getMessage()); //输出:我是finaly中的Exception\n }\n }\n \n //catch中的异常被抑制\n @SuppressWarnings(\"finally\")\n public static int foo() throws Exception\n {\n try {\n int a = 5/0;\n return 1;\n }catch(ArithmeticException amExp) {\n throw new Exception(\"我将被忽略,因为下面的finally中抛出了新的异常\");\n }finally {\n throw new Exception(\"我是finaly中的Exception\");\n }\n }\n \n //try中的异常被抑制\n @SuppressWarnings(\"finally\")\n public static int bar() throws Exception\n {\n try {\n int a = 5/0;\n return 1;\n }finally {\n throw new Exception(\"我是finaly中的Exception\");\n }\n \n }\n}\n````\n上面的3个例子都异于常人的编码思维,因此我建议:\n\n> 不要在fianlly中使用return。\n\n> 不要在finally中抛出异常。\n\n> 减轻finally的任务,不要在finally中做一些其它的事情,finally块仅仅用来释放资源是最合适的。\n\n> 将尽量将所有的return写在函数的最后面,而不是try … catch … finally中。\n\n## JAVA异常常见面试题\n\n 下面是我个人总结的在Java和J2EE开发者在面试中经常被问到的有关Exception和Error的知识。在分享我的回答的时候,我也给这些问题作了快速修订,并且提供源码以便深入理解。我总结了各种难度的问题,适合新手码农和高级Java码农。如果你遇到了我列表中没有的问题,并且这个问题非常好,请在下面评论中分享出来。你也可以在评论中分享你面试时答错的情况。\n\n**1) Java中什么是Exception?**\n这个问题经常在第一次问有关异常的时候或者是面试菜鸟的时候问。我从来没见过面高级或者资深工程师的时候有人问这玩意,但是对于菜鸟,是很愿意问这个的。简单来说,异常是Java传达给你的系统和程序错误的方式。在java中,异常功能是通过实现比如Throwable,Exception,RuntimeException之类的类,然后还有一些处理异常时候的关键字,比如throw,throws,try,catch,finally之类的。所有的异常都是通过Throwable衍生出来的。Throwable把错误进一步划分为java.lang.Exception\n和 java.lang.Error. \n\njava.lang.Error 用来处理系统错误,例如java.lang.StackOverFlowError 之类的。然后Exception用来处理程序错误,请求的资源不可用等等。\n\n**2) Java中的检查型异常和非检查型异常有什么区别?**\n\n这又是一个非常流行的Java异常面试题,会出现在各种层次的Java面试中。检查型异常和非检查型异常的主要区别在于其处理方式。检查型异常需要使用try, catch和finally关键字在编译期进行处理,否则会出现编译器会报错。对于非检查型异常则不需要这样做。Java中所有继承自java.lang.Exception类的异常都是检查型异常,所有继承自RuntimeException的异常都被称为非检查型异常。\n\n**3) Java中的NullPointerException和ArrayIndexOutOfBoundException之间有什么相同之处?**\n\n在Java异常面试中这并不是一个很流行的问题,但会出现在不同层次的初学者面试中,用来测试应聘者对检查型异常和非检查型异常的概念是否熟悉。顺便说一下,该题的答案是,这两个异常都是非检查型异常,都继承自RuntimeException。该问题可能会引出另一个问题,即Java和C的数组有什么不同之处,因为C里面的数组是没有大小限制的,绝对不会抛出ArrayIndexOutOfBoundException。\n\n**4)在Java异常处理的过程中,你遵循的那些最好的实践是什么?**\n\n这个问题在面试技术经理是非常常见的一个问题。因为异常处理在项目设计中是非常关键的,所以精通异常处理是十分必要的。异常处理有很多最佳实践,下面列举集中,它们提高你代码的健壮性和灵活性:\n\n 1) 调用方法的时候返回布尔值来代替返回null,这样可以NullPointerException。由于空指针是java异常里最恶心的异常\n\n 2) catch块里别不写代码。空catch块是异常处理里的错误事件,因为它只是捕获了异常,却没有任何处理或者提示。通常你起码要打印出异常信息,当然你最好根据需求对异常信息进行处理。\n\n 3)能抛受控异常(checked Exception)就尽量不抛受非控异常(checked Exception)。通过去掉重复的异常处理代码,可以提高代码的可读性。\n\n 4) 绝对不要让你的数据库相关异常显示到客户端。由于绝大多数数据库和SQLException异常都是受控异常,在Java中,你应该在DAO层把异常信息处理,然后返回处理过的能让用户看懂并根据异常提示信息改正操作的异常信息。\n\n 5) 在Java中,一定要在数据库连接,数据库查询,流处理后,在finally块中调用close()方法。\n\n**5) 既然我们可以用RuntimeException来处理错误,那么你认为为什么Java中还存在检查型异常?**\n\n这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比Java更早编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限的系统资源(比如文件描述符)在你使用后尽早得到释放。Joshua\nBloch编写的[Effective Java 一书](http://www.amazon.com/dp/0321356683/?tag=javamysqlanta-20)中多处涉及到了该话题,值得一读。\n\n**6) throw 和 throws这两个关键字在java中有什么不同?**\n\n 一个java初学者应该掌握的面试问题。throw 和 throws乍看起来是很相似的尤其是在你还是一个java初学者的时候。尽管他们看起来相似,都是在处理异常时候使用到的。但在代码里的使用方法和用到的地方是不同的。throws总是出现在一个函数头中,用来标明该成员函数可能抛出的各种异常, 你也可以申明未检查的异常,但这不是编译器强制的。如果方法抛出了异常那么调用这个方法的时候就需要将这个异常处理。另一个关键字 throw 是用来抛出任意异常的,按照语法你可以抛出任意 Throwable(i.e. Throwable\n或任何Throwable的衍生类) , throw可以中断程序运行,因此可以用来代替return . 最常见的例子是用 throw 在一个空方法中需要return的地方抛出 UnSupportedOperationException.\n可以看下这篇[文章](http://javarevisited.blogspot.com/2012/02/difference-between-throw-and-throws-in.html)查看这两个关键字在java中更多的差异 。\n\n**7) 什么是“异常链”?**\n\n “异常链”是Java中非常流行的异常处理概念,是指在进行一个异常处理时抛出了另外一个异常,由此产生了一个异常链条。该技术大多用于将“ 受检查异常” ( checked exception)封装成为“非受检查异常”(unchecked exception)或者RuntimeException。顺便说一下,如果因为因为异常你决定抛出一个新的异常,你一定要包含原有的异常,这样,处理程序才可以通过getCause()和initCause()方法来访问异常最终的根源。\n\n**8) 你曾经自定义实现过异常吗?怎么写的?**\n\n 很显然,我们绝大多数都写过自定义或者业务异常,像AccountNotFoundException。在面试过程中询问这个Java异常问题的主要原因是去发现你如何使用这个特性的。这可以更准确和精致的去处理异常,当然这也跟你选择checked 还是unchecked exception息息相关。通过为每一个特定的情况创建一个特定的异常,你就为调用者更好的处理异常提供了更好的选择。相比通用异常(general exception),我更倾向更为精确的异常。大量的创建自定义异常会增加项目class的个数,因此,在自定义异常和通用异常之间维持一个平衡是成功的关键。\n\n**9) JDK7中对异常处理做了什么改变?**\n\n 这是最近新出的Java异常处理的面试题。JDK7中对错误(Error)和异常(Exception)处理主要新增加了2个特性,一是在一个catch块中可以出来多个异常,就像原来用多个catch块一样。另一个是自动化资源管理(ARM), 也称为try-with-resource块。这2个特性都可以在处理异常时减少代码量,同时提高代码的可读性。对于这些特性了解,不仅帮助开发者写出更好的异常处理的代码,也让你在面试中显的更突出。我推荐大家读一下Java 7攻略,这样可以更深入的了解这2个非常有用的特性。\n\n**10) 你遇到过 OutOfMemoryError 错误嘛?你是怎么搞定的?**\n\n 这个面试题会在面试高级程序员的时候用,面试官想知道你是怎么处理这个危险的OutOfMemoryError错误的。必须承认的是,不管你做什么项目,你都会碰到这个问题。所以你要是说没遇到过,面试官肯定不会买账。要是你对这个问题不熟悉,甚至就是没碰到过,而你又有3、4年的Java经验了,那么准备好处理这个问题吧。在回答这个问题的同时,你也可以借机向面试秀一下你处理内存泄露、调优和调试方面的牛逼技能。我发现掌握这些技术的人都能给面试官留下深刻的印象。\n\n**11) 如果执行finally代码块之前方法返回了结果,或者JVM退出了,finally块中的代码还会执行吗?**\n\n 这个问题也可以换个方式问:“如果在try或者finally的代码块中调用了System.exit(),结果会是怎样”。了解finally块是怎么执行的,即使是try里面已经使用了return返回结果的情况,对了解Java的异常处理都非常有价值。只有在try里面是有System.exit(0)来退出JVM的情况下finally块中的代码才不会执行。\n\n**12)Java中final,finalize,finally关键字的区别**\n\n 这是一个经典的Java面试题了。我的一个朋友为Morgan Stanley招电信方面的核心Java开发人员的时候就问过这个问题。final和finally是Java的关键字,而finalize则是方法。final关键字在创建不可变的类的时候非常有用,只是声明这个类是final的。而finalize()方法则是垃圾回收器在回收一个对象前调用,但也Java规范里面没有保证这个方法一定会被调用。finally关键字是唯一一个和这篇文章讨论到的异常处理相关的关键字。在你的产品代码中,在关闭连接和资源文件的是时候都必须要用到finally块。\n\n## 参考文章\n\nhttps://www.xuebuyuan.com/3248044.html\nhttps://www.jianshu.com/p/49d2c3975c56\nhttp://c.biancheng.net/view/1038.html\nhttps://blog.csdn.net/Lisiluan/article/details/88745820\nhttps://blog.csdn.net/michaelgo/article/details/82790253\n\n\n"
},
{
"path": "docs/Java/basic/Java注解和最佳实践.md",
"content": "# 目录\n * [Java注解简介](#java注解简介)\n * [注解如同标签](#注解如同标签)\n * [Java 注解概述](#java-注解概述)\n * [什么是注解?](#什么是注解?)\n * [注解的用处](#注解的用处)\n * [注解的原理](#注解的原理)\n * [元注解](#元注解)\n * [JDK里的注解](#jdk里的注解)\n * [注解处理器实战](#注解处理器实战)\n * [不同类型的注解](#不同类型的注解)\n * [类注解](#类注解)\n * [方法注解](#方法注解)\n * [参数注解](#参数注解)\n * [变量注解](#变量注解)\n * [Java注解相关面试题](#java注解相关面试题)\n * [什么是注解?他们的典型用例是什么?](#什么是注解?他们的典型用例是什么?)\n * [描述标准库中一些有用的注解。](#描述标准库中一些有用的注解。)\n * [可以从注解方法声明返回哪些对象类型?](#可以从注解方法声明返回哪些对象类型?)\n * [哪些程序元素可以注解?](#哪些程序元素可以注解?)\n * [有没有办法限制可以应用注解的元素?](#有没有办法限制可以应用注解的元素?)\n * [什么是元注解?](#什么是元注解?)\n * [下面的代码会编译吗?](#下面的代码会编译吗?)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。 \n\n\n\n## Java注解简介\n\nAnnotation 中文译过来就是注解、标释的意思,在 Java 中注解是一个很重要的知识点,但经常还是有点让新手不容易理解。\n\n**我个人认为,比较糟糕的技术文档主要特征之一就是:用专业名词来介绍专业名词。**\n比如:\n\n> Java 注解用于为 Java 代码提供元数据。作为元数据,注解不直接影响你的代码执行,但也有一些类型的注解实际上可以用于这一目的。Java 注解是从 Java5 开始添加到 Java 的。\n> 这是大多数网站上对于 Java 注解,解释确实正确,但是说实在话,我第一次学习的时候,头脑一片空白。这什么跟什么啊?听了像没有听一样。因为概念太过于抽象,所以初学者实在是比较吃力才能够理解,然后随着自己开发过程中不断地强化练习,才会慢慢对它形成正确的认识。\n\n我在写这篇文章的时候,我就在思考。如何让自己或者让读者能够比较直观地认识注解这个概念?是要去官方文档上翻译说明吗?我马上否定了这个答案。\n\n后来,我想到了一样东西————墨水,墨水可以挥发、可以有不同的颜色,用来解释注解正好。\n\n不过,我继续发散思维后,想到了一样东西能够更好地代替墨水,那就是印章。印章可以沾上不同的墨水或者印泥,可以定制印章的文字或者图案,如果愿意它也可以被戳到你任何想戳的物体表面。\n\n但是,我再继续发散思维后,又想到一样东西能够更好地代替印章,那就是标签。标签是一张便利纸,标签上的内容可以自由定义。常见的如货架上的商品价格标签、图书馆中的书本编码标签、实验室中化学材料的名称类别标签等等。\n\n并且,往抽象地说,标签并不一定是一张纸,它可以是对人和事物的属性评价。也就是说,标签具备对于抽象事物的解释。\n\n\n\n所以,基于如此,我完成了自我的知识认知升级,我决定用标签来解释注解。\n\n### 注解如同标签\n\n之前某新闻客户端的评论有盖楼的习惯,于是 “乔布斯重新定义了手机、罗永浩重新定义了傻X” 就经常极为工整地出现在了评论楼层中,并且广大网友在相当长的一段时间内对于这种行为乐此不疲。这其实就是等同于贴标签的行为。\n在某些网友眼中,罗永浩就成了傻X的代名词。\n\n广大网友给罗永浩贴了一个名为“傻x”的标签,他们并不真正了解罗永浩,不知道他当教师、砸冰箱、办博客的壮举,但是因为“傻x”这样的标签存在,这有助于他们直接快速地对罗永浩这个人做出评价,然后基于此,罗永浩就可以成为茶余饭后的谈资,这就是标签的力量。\n\n而在网络的另一边,老罗靠他的人格魅力自然收获一大批忠实的拥泵,他们对于老罗贴的又是另一种标签。 \n\n\n\n\n老罗还是老罗,但是由于人们对于它贴上的标签不同,所以造成对于他的看法大相径庭,不喜欢他的人整天在网络上评论抨击嘲讽,而崇拜欣赏他的人则会愿意挣钱购买锤子手机的发布会门票。\n\n我无意于评价这两种行为,我再引个例子。\n\n《奇葩说》是近年网络上非常火热的辩论节目,其中辩手陈铭被另外一个辩手马薇薇攻击说是————“站在宇宙中心呼唤爱”,然后贴上了一个大大的标签————“鸡汤男”,自此以后,观众再看到陈铭的时候,首先映入脑海中便是“鸡汤男”三个大字,其实本身而言陈铭非常优秀,为人师表、作风正派、谈吐举止得体,但是在网络中,因为娱乐至上的环境所致,人们更愿意以娱乐的心态来认知一切,于是“鸡汤男”就如陈铭自己所说成了一个撕不了的标签。\n\n**我们可以抽象概括一下,标签是对事物行为的某些角度的评价与解释。**\n\n到这里,终于可以引出本文的主角注解了。\n\n**初学者可以这样理解注解:想像代码具有生命,注解就是对于代码中某些鲜活个体的贴上去的一张标签。简化来讲,注解如同一张标签。**\n\n在未开始学习任何注解具体语法而言,你可以把注解看成一张标签。这有助于你快速地理解它的大致作用。如果初学者在学习过程有大脑放空的时候,请不要慌张,对自己说:\n\n注解,标签。注解,标签。\n\n## Java 注解概述\n### 什么是注解?\n\n\n> 对于很多初次接触的开发者来说应该都有这个疑问?Annontation是Java5开始引入的新特征,中文名称叫注解。它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata)与程序元素(类、方法、成员变量等)进行关联。为程序的元素(类、方法、成员变量)加上更直观更明了的说明,这些说明信息是与程序的业务逻辑无关,并且供指定的工具或框架使用。Annontation像一种修饰符一样,应用于包、类型、构造方法、方法、成员变量、参数及本地变量的声明语句中。\n\n\n Java注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。包含在 java.lang.annotation 包中。\n\n \n\n### 注解的用处\n\n 1、生成文档。这是最常见的,也是java 最早提供的注解。常用的有@param @return 等\n 2、跟踪代码依赖性,实现替代配置文件功能。比如Dagger 2依赖注入,未来java开发,将大量注解配置,具有很大用处;\n 3、在编译时进行格式检查。如@override 放在方法前,如果你这个方法并不是覆盖了超类方法,则编译时就能检查出。\n\n \n\n### 注解的原理\n 注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。而我们通过反射获取注解时,返回的是Java运行时生成的动态代理对象$Proxy1。通过代理对象调用自定义注解(接口)的方法,会最终调用AnnotationInvocationHandler的invoke方法。该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池。\n\n \n\n### 元注解\njava.lang.annotation提供了四种元注解,专门注解其他的注解(在自定义注解的时候,需要使用到元注解):\n @Documented –注解是否将包含在JavaDoc中\n @Retention –什么时候使用该注解\n @Target –注解用于什么地方\n @Inherited – 是否允许子类继承该注解\n\n 1.)@Retention– 定义该注解的生命周期\n\n ● RetentionPolicy.SOURCE : 在编译阶段丢弃。这些注解在编译结束之后就不再有任何意义,所以它们不会写入字节码。@Override, @SuppressWarnings都属于这类注解。\n \n ● RetentionPolicy.CLASS : 在类加载的时候丢弃。在字节码文件的处理中有用。注解默认使用这种方式\n \n ● RetentionPolicy.RUNTIME : 始终不会丢弃,运行期也保留该注解,因此可以使用反射机制读取该注解的信息。我们自定义的注解通常使用这种方式。\n\n 2.)Target – 表示该注解用于什么地方。默认值为任何元素,表示该注解用于什么地方。可用的ElementType参数包括\n\n ● ElementType.CONSTRUCTOR:用于描述构造器\n ● ElementType.FIELD:成员变量、对象、属性(包括enum实例)\n ● ElementType.LOCAL_VARIABLE:用于描述局部变量\n ● ElementType.METHOD:用于描述方法\n ● ElementType.PACKAGE:用于描述包\n ● ElementType.PARAMETER:用于描述参数\n ● ElementType.TYPE:用于描述类、接口(包括注解类型) 或enum声明\n\n 3.)@Documented–一个简单的Annotations标记注解,表示是否将注解信息添加在java文档中。\n\n 4.)@Inherited – 定义该注释和子类的关系\n @Inherited 元注解是一个标记注解,@Inherited阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited修饰的annotation类型被用于一个class,则这个annotation将被用于该class的子类。\n\n\n### JDK里的注解\nJDK 内置注解\n先来看几个 Java 内置的注解,让大家热热身。\n\n@Override 演示\n````\n class Parent {\n public void run() {\n }\n }\n \n class Son extends Parent {\n /**\n * 这个注解是为了检查此方法是否真的是重写父类的方法\n * 这时候就不用我们用肉眼去观察到底是不是重写了\n */\n @Override\n public void run() {\n }\n }\n````\n@Deprecated 演示\n````\nclass Parent {\n\n /**\n * 此注解代表过时了,但是如果可以调用到,当然也可以正常使用\n * 但是,此方法有可能在以后的版本升级中会被慢慢的淘汰\n * 可以放在类,变量,方法上面都起作用\n */\n @Deprecated\n public void run() {\n }\n }\n \n public class JDKAnnotationDemo {\n public static void main(String[] args) {\n Parent parent = new Parent();\n parent.run(); // 在编译器中此方法会显示过时标志\n }\n }\n````\n@SuppressWarnings 演示\n````\nclass Parent {\n\n // 因为定义的 name 没有使用,那么编译器就会有警告,这时候使用此注解可以屏蔽掉警告\n // 即任意不想看到的编译时期的警告都可以用此注解屏蔽掉,但是不推荐,有警告的代码最好还是处理一下\n @SuppressWarnings(\"all\")\n private String name;\n }\n````\n@FunctionalInterface 演示\n\n````\n/**\n * 此注解是 Java8 提出的函数式接口,接口中只允许有一个抽象方法\n * 加上这个注解之后,类中多一个抽象方法或者少一个抽象方法都会报错\n */\n@FunctionalInterface\ninterface Func {\n void run();\n}\n````\n\n## 注解处理器实战\n\n注解处理器\n注解处理器才是使用注解整个流程中最重要的一步了。所有在代码中出现的注解,它到底起了什么作用,都是在注解处理器中定义好的。\n概念:注解本身并不会对程序的编译方式产生影响,而是注解处理器起的作用;注解处理器能够通过在运行时使用反射获取在程序代码中的使用的注解信息,从而实现一些额外功能。前提是我们自定义的注解使用的是 RetentionPolicy.RUNTIME 修饰的。这也是我们在开发中使用频率很高的一种方式。\n\n我们先来了解下如何通过在运行时使用反射获取在程序中的使用的注解信息。如下类注解和方法注解。\n\n类注解\n\n````\nClass aClass = ApiController.class;\nAnnotation[] annotations = aClass.getAnnotations();\n\nfor(Annotation annotation : annotations) {\n if(annotation instanceof ApiAuthAnnotation) {\n ApiAuthAnnotation apiAuthAnnotation = (ApiAuthAnnotation) annotation;\n System.out.println(\"name: \" + apiAuthAnnotation.name());\n System.out.println(\"age: \" + apiAuthAnnotation.age());\n }\n}\n方法注解\nMethod method = ... //通过反射获取方法对象\nAnnotation[] annotations = method.getDeclaredAnnotations();\n\nfor(Annotation annotation : annotations) {\n if(annotation instanceof ApiAuthAnnotation) {\n ApiAuthAnnotation apiAuthAnnotation = (ApiAuthAnnotation) annotation;\n System.out.println(\"name: \" + apiAuthAnnotation.name());\n System.out.println(\"age: \" + apiAuthAnnotation.age());\n }\n} \n````\n此部分内容可参考: 通过反射获取注解信息\n\n注解处理器实战\n接下来我通过在公司中的一个实战改编来演示一下注解处理器的真实使用场景。\n需求: 网站后台接口只能是年龄大于 18 岁的才能访问,否则不能访问\n前置准备: 定义注解(这里使用上文的完整注解),使用注解(这里使用上文中使用注解的例子)\n接下来要做的事情: 写一个切面,拦截浏览器访问带注解的接口,取出注解信息,判断年龄来确定是否可以继续访问。\n\n在 dispatcher-servlet.xml 文件中定义 aop 切面\n````\n\n \n \n \n \n \n \n \n````\n切面类处理逻辑即注解处理器代码如\n````\n@Component(\"apiAuthAspect\")\npublic class ApiAuthAspect {\n\n public Object auth(ProceedingJoinPoint pjp) throws Throwable {\n Method method = ((MethodSignature) pjp.getSignature()).getMethod();\n ApiAuthAnnotation apiAuthAnnotation = method.getAnnotation(ApiAuthAnnotation.class);\n Integer age = apiAuthAnnotation.age();\n if (age > 18) {\n return pjp.proceed();\n } else {\n throw new RuntimeException(\"你未满18岁,禁止访问\");\n }\n }\n}\n````\n\n## 不同类型的注解\n\n### 类注解\n\n你可以在运行期访问类,方法或者变量的注解信息,下是一个访问类注解的例子:\n\n```\nClass aClass = TheClass.class;\nAnnotation[] annotations = aClass.getAnnotations();\n\nfor(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n}\n```\n\n你还可以像下面这样指定访问一个类的注解:\n\n```\nClass aClass = TheClass.class;\nAnnotation annotation = aClass.getAnnotation(MyAnnotation.class);\n\nif(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n}\n```\n\n### 方法注解\n\n下面是一个方法注解的例子:\n\n```\npublic class TheClass {\n @MyAnnotation(name=\"someName\", value = \"Hello World\")\n public void doSomething(){}\n}\n```\n\n你可以像这样访问方法注解:\n\n```\nMethod method = ... //获取方法对象\nAnnotation[] annotations = method.getDeclaredAnnotations();\n\nfor(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n}\n```\n\n你可以像这样访问指定的方法注解:\n\n```\nMethod method = ... // 获取方法对象\nAnnotation annotation = method.getAnnotation(MyAnnotation.class);\n\nif(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n}\n```\n\n### 参数注解\n\n方法参数也可以添加注解,就像下面这样:\n\n```\npublic class TheClass {\n public static void doSomethingElse(\n @MyAnnotation(name=\"aName\", value=\"aValue\") String parameter){\n }\n}\n```\n\n你可以通过 Method对象来访问方法参数注解:\n\n```\nMethod method = ... //获取方法对象\nAnnotation[][] parameterAnnotations = method.getParameterAnnotations();\nClass[] parameterTypes = method.getParameterTypes();\n\nint i=0;\nfor(Annotation[] annotations : parameterAnnotations){\n Class parameterType = parameterTypes[i++];\n\n for(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"param: \" + parameterType.getName());\n System.out.println(\"name : \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n }\n}\n```\n\n需要注意的是 Method.getParameterAnnotations()方法返回一个注解类型的二维数组,每一个方法的参数包含一个注解数组。\n\n### 变量注解\n\n下面是一个变量注解的例子:\n\n```\npublic class TheClass {\n\n @MyAnnotation(name=\"someName\", value = \"Hello World\")\n public String myField = null;\n}\n```\n\n你可以像这样来访问变量的注解:\n\n```\nField field = ... //获取方法对象目录\nAnnotation[] annotations = field.getDeclaredAnnotations();\n\nfor(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n}\n```\n\n你可以像这样访问指定的变量注解:\n\n```\nField field = ...//获取方法对象目录\n\nAnnotation annotation = field.getAnnotation(MyAnnotation.class);\n\nif(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n}\n```\n\n## Java注解相关面试题\n\n### 什么是注解?他们的典型用例是什么?\n\n注解是绑定到程序源代码元素的元数据,对运行代码的操作没有影响。\n\n他们的典型用例是:\n\n* 编译器的信息 - 使用注解,编译器可以检测错误或抑制警告\n* 编译时和部署时处理 - 软件工具可以处理注解并生成代码,配置文件等。\n* 运行时处理 - 可以在运行时检查注解以自定义程序的行为\n\n### 描述标准库中一些有用的注解。\n\njava.lang和java.lang.annotation包中有几个注解,更常见的包括但不限于此:\n\n* @Override -标记方法是否覆盖超类中声明的元素。如果它无法正确覆盖该方法,编译器将发出错误\n* @Deprecated - 表示该元素已弃用且不应使用。如果程序使用标有此批注的方法,类或字段,编译器将发出警告\n* @SuppressWarnings - 告诉编译器禁止特定警告。在与泛型出现之前编写的遗留代码接口时最常用的\n* @FunctionalInterface - 在Java 8中引入,表明类型声明是一个功能接口,可以使用Lambda Expression提供其实现\n\n\n### 可以从注解方法声明返回哪些对象类型?\n\n返回类型必须是基本类型,String,Class,Enum或数组类型之一。否则,编译器将抛出错误。\n\n这是一个成功遵循此原则的示例代码:\n\n```\nenum Complexity {\n LOW, HIGH\n}\n\npublic @interface ComplexAnnotation {\n Class value();\n\n int[] types();\n\n Complexity complexity();\n}\n\n```\n\n下一个示例将无法编译,因为Object不是有效的返回类型:\n\n```\npublic @interface FailingAnnotation {\n Object complexity();\n}\n\n```\n\n### 哪些程序元素可以注解?\n\n注解可以应用于整个源代码的多个位置。它们可以应用于类,构造函数和字段的声明:\n\n```\n@SimpleAnnotation\npublic class Apply {\n @SimpleAnnotation\n private String aField;\n\n @SimpleAnnotation\n public Apply() {\n // ...\n }\n}\n\n```\n\n方法及其参数:\n\n```\n@SimpleAnnotation\npublic void aMethod(@SimpleAnnotation String param) {\n // ...\n}\n\n```\n\n局部变量,包括循环和资源变量:\n\n```\n@SimpleAnnotation\nint i = 10;\n\nfor (@SimpleAnnotation int j = 0; j < i; j++) {\n // ...\n}\n\ntry (@SimpleAnnotation FileWriter writer = getWriter()) {\n // ...\n} catch (Exception ex) {\n // ...\n}\n\n```\n\n其他注解类型:\n\n```\n@SimpleAnnotation\npublic @interface ComplexAnnotation {\n // ...\n}\n\n```\n\n甚至包,通过package-info.java文件:\n\n```\n@PackageAnnotation\npackage com.baeldung.interview.annotations;\n\n```\n\n从Java 8开始,它们也可以应用于类型的使用。为此,注解必须指定值为ElementType.USE的@Target注解:\n\n```\n@Target(ElementType.TYPE_USE)\npublic @interface SimpleAnnotation {\n // ...\n}\n\n```\n\n现在,注解可以应用于类实例创建:\n\n```\nnew @SimpleAnnotation Apply();\n\n```\n\n类型转换:\n\n```\naString = (@SimpleAnnotation String) something;\n\n```\n\n接口中:\n\n```\npublic class SimpleList\n implements @SimpleAnnotation List<@SimpleAnnotation T> {\n // ...\n}\n\n```\n\n抛出异常上:\n\n```\nvoid aMethod() throws @SimpleAnnotation Exception {\n // ...\n}\n\n```\n\n### 有没有办法限制可以应用注解的元素?\n\n有,@ Target注解可用于此目的。如果我们尝试在不适用的上下文中使用注解,编译器将发出错误。\n\n以下是仅将@SimpleAnnotation批注的用法限制为字段声明的示例:\n\n```\n@Target(ElementType.FIELD)\npublic @interface SimpleAnnotation {\n // ...\n}\n\n```\n\n如果我们想让它适用于更多的上下文,我们可以传递多个常量:\n\n```\n@Target({ ElementType.FIELD, ElementType.METHOD, ElementType.PACKAGE })\n\n```\n\n我们甚至可以制作一个注解,因此它不能用于注解任何东西。当声明的类型仅用作复杂注解中的成员类型时,这可能会派上用场:\n\n```\n@Target({})\npublic @interface NoTargetAnnotation {\n // ...\n}\n\n```\n\n### 什么是元注解?\n\n元注解适用于其他注解的注解。\n\n所有未使用@Target标记或使用它标记但包含ANNOTATION_TYPE常量的注解也是元注解:\n\n```\n@Target(ElementType.ANNOTATION_TYPE)\npublic @interface SimpleAnnotation {\n // ...\n}\n\n```\n\n\n### 下面的代码会编译吗?\n\n```\n@Target({ ElementType.FIELD, ElementType.TYPE, ElementType.FIELD })\npublic @interface TestAnnotation {\n int[] value() default {};\n}\n\n```\n\n不能。如果在@Target注解中多次出现相同的枚举常量,那么这是一个编译时错误。\n\n删除重复常量将使代码成功编译:\n\n```\n@Target({ ElementType.FIELD, ElementType.TYPE})\n\n```\n\n## 参考文章\n\nhttps://blog.fundodoo.com/2018/04/19/130.html\nhttps://blog.csdn.net/qq_37939251/article/details/83215703\nhttps://blog.51cto.com/4247649/2109129\nhttps://www.jianshu.com/p/2f2460e6f8e7\nhttps://blog.csdn.net/yuzongtao/article/details/83306182\n\n\n\n"
},
{
"path": "docs/Java/basic/Java类和包.md",
"content": "# 目录\n\n* [Java中的包概念](#java中的包概念)\n * [包的作用](#包的作用)\n * [package 的目录结构](#package-的目录结构)\n * [设置 CLASSPATH 系统变量](#设置-classpath-系统变量)\n* [常用jar包](#常用jar包)\n * [java软件包的类型](#java软件包的类型)\n * [dt.jar](#dtjar)\n * [rt.jar](#rtjar)\n* [*.java文件的奥秘](#java文件的奥秘)\n * [*.Java文件简介](#java文件简介)\n * [为什么一个java源文件中只能有一个public类?](#为什么一个java源文件中只能有一个public类?)\n * [Main方法](#main方法)\n * [外部类的访问权限](#外部类的访问权限)\n * [Java包的命名规则](#java包的命名规则)\n* [参考文章](#参考文章)\n\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n## Java中的包概念\n\nJava中的包是封装一组类,子包和接口的机制。软件包用于:\n\n防止命名冲突。例如,可以有两个名称分别为Employee的类,college.staff.cse.Employee和college.staff.ee.Employee\n更轻松地搜索/定位和使用类,接口,枚举和注释\n\n提供受控访问:受保护和默认有包级别访问控制。受保护的成员可以通过同一个包及其子类中的类访问。默认成员(没有任何访问说明符)只能由同一个包中的类访问。\n\n包可以被视为数据封装(或数据隐藏)。\n\n我们所需要做的就是将相关类放入包中。之后,我们可以简单地从现有的软件包中编写一个导入类,并将其用于我们的程序中。一个包是一组相关类的容器,其中一些类可以访问,并且其他类被保存用于内部目的。\n我们可以在程序中尽可能多地重用包中的现有类。\n\n为了更好地组织类,Java 提供了包机制,用于区别类名的命名空间。\n\n### 包的作用\n\n* 1、把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。\n\n* 2、如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。\n\n* 3、包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。\n\nJava 使用包(package)这种机制是为了防止命名冲突,访问控制,提供搜索和定位类(class)、接口、枚举(enumerations)和注释(annotation)等。\n\n 包语句的语法格式为:\n \n package pkg1[.pkg2[.pkg3…]];\n \n 例如,一个Something.java 文件它的内容\n \n package net.java.util; public class Something{ ... }\n\n那么它的路径应该是**net/java/util/Something.java**这样保存的。 package(包) 的作用是把不同的 java 程序分类保存,更方便的被其他 java 程序调用。\n\n一个包(package)可以定义为一组相互联系的类型(类、接口、枚举和注释),为这些类型提供访问保护和命名空间管理的功能。\n\n以下是一些 Java 中的包:\n\n* **java.lang**-打包基础的类\n* **java.io**-包含输入输出功能的函数\n\n开发者可以自己把一组类和接口等打包,并定义自己的包。而且在实际开发中这样做是值得提倡的,当你自己完成类的实现之后,将相关的类分组,可以让其他的编程者更容易地确定哪些类、接口、枚举和注释等是相关的。\n\n由于包创建了新的命名空间(namespace),所以不会跟其他包中的任何名字产生命名冲突。使用包这种机制,更容易实现访问控制,并且让定位相关类更加简单。\n\n### package 的目录结构\n\n类放在包中会有两种主要的结果:\n\n* 包名成为类名的一部分,正如我们前面讨论的一样。\n* 包名必须与相应的字节码所在的目录结构相吻合。\n\n下面是管理你自己 java 中文件的一种简单方式:\n\n将类、接口等类型的源码放在一个文本中,这个文件的名字就是这个类型的名字,并以.java作为扩展名。例如:\n\n````\n// 文件名 : Car.java \npackage vehicle; \npublic class Car { \n// 类实现 \n}\n````\n\n接下来,把源文件放在一个目录中,这个目录要对应类所在包的名字。\n\n....\\vehicle\\Car.java\n\n现在,正确的类名和路径将会是如下样子:\n\n* 类名 -> vehicle.Car\n\n* 路径名 -> vehicle\\Car.java (在 windows 系统中)\n\n通常,一个公司使用它互联网域名的颠倒形式来作为它的包名.例如:互联网域名是 runoob.com,所有的包名都以 com.runoob 开头。包名中的每一个部分对应一个子目录。\n\n例如:有一个**com.runoob.test**的包,这个包包含一个叫做 Runoob.java 的源文件,那么相应的,应该有如下面的一连串子目录:\n\n....\\com\\runoob\\test\\Runoob.java\n\n编译的时候,编译器为包中定义的每个类、接口等类型各创建一个不同的输出文件,输出文件的名字就是这个类型的名字,并加上 .class 作为扩展后缀。 例如:\n````\n// 文件名: Runoob.java \npackage com.runoob.test; \npublic class Runoob { } \nclass Google { }\n````\n\n\n现在,我们用-d选项来编译这个文件,如下:\n````\n $javac -d . Runoob.java\n````\n这样会像下面这样放置编译了的文件:\n\n````\n .\\com\\runoob\\test\\Runoob.class \n .\\com\\runoob\\test\\Google.class\n````\n\n你可以像下面这样来导入所有**\\com\\runoob\\test\\**中定义的类、接口等:\n````\n import com.runoob.test.*;\n````\n\n编译之后的 .class 文件应该和 .java 源文件一样,它们放置的目录应该跟包的名字对应起来。但是,并不要求 .class 文件的路径跟相应的 .java 的路径一样。你可以分开来安排源码和类的目录。\n\n````\n \\sources\\com\\runoob\\test\\Runoob.java \n \\classes\\com\\runoob\\test\\Google.class\n````\n\n这样,你可以将你的类目录分享给其他的编程人员,而不用透露自己的源码。用这种方法管理源码和类文件可以让编译器和java 虚拟机(JVM)可以找到你程序中使用的所有类型。\n\n类目录的绝对路径叫做**class path**。设置在系统变量**CLASSPATH**中。编译器和 java 虚拟机通过将 package 名字加到 class path 后来构造 .class 文件的路径。\n\n````\n \\classes 是 class path,package 名字是 com.runoob.test,而编译器和 JVM 会在 \\classes\\com\\runoob\\test 中找 .class 文件。\n````\n\n一个 class path 可能会包含好几个路径,多路径应该用分隔符分开。默认情况下,编译器和 JVM 查找当前目录。JAR 文件按包含 Java 平台相关的类,所以他们的目录默认放在了 class path 中。\n\n### 设置 CLASSPATH 系统变量\n\n用下面的命令显示当前的CLASSPATH变量:\n\n* Windows 平台(DOS 命令行下):C:\\> set CLASSPATH\n* UNIX 平台(Bourne shell 下):# echo $CLASSPATH\n\n删除当前CLASSPATH变量内容:\n\n* Windows 平台(DOS 命令行下):C:\\> set CLASSPATH=\n* UNIX 平台(Bourne shell 下):# unset CLASSPATH; export CLASSPATH\n\n设置CLASSPATH变量:\n\n* Windows 平台(DOS 命令行下): C:\\> set CLASSPATH=C:\\users\\jack\\java\\classes\n* UNIX 平台(Bourne shell 下):# CLASSPATH=/home/jack/java/classes; export CLASSPATH\n\nJava包(package)详解\njava包的作用是为了区别类名的命名空间 \n\n1、把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。、\n\n2、如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,\n\n当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。\n\n3、包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。\n\n创建包\n创建包的时候,你需要为这个包取一个合适的名字。之后,如果其他的一个源文件包含了这个包提供的类、接口、枚举或者注释类型的时候,都必须将这个包的声明放在这个源文件的开头。\n\n包声明应该在源文件的第一行,每个源文件只能有一个包声明,这个文件中的每个类型都应用于它。\n\n如果一个源文件中没有使用包声明,那么其中的类,函数,枚举,注释等将被放在一个无名的包(unnamed package)中。\n\n例子\n让我们来看一个例子,这个例子创建了一个叫做animals的包。通常使用小写的字母来命名避免与类、接口名字的冲突。\n\n在 animals 包中加入一个接口(interface):\n\n````\npackage animals;\ninterface Animal {\n public void eat();\n public void travel();\n}\n````\n\n接下来,在同一个包中加入该接口的实现:\n\n````\npackage animals;\n/* 文件名 : MammalInt.java */\npublic class MammalInt implements Animal{\n public void eat(){\n System.out.println(\"Mammal eats\");\n }\n public void travel(){\n System.out.println(\"Mammal travels\");\n }\n public int noOfLegs(){\n return 0;\n }\n public static void main(String args[]){\n MammalInt m = new MammalInt();\n m.eat();\n m.travel();\n }\n}\n````\n\nimport 关键字\n为了能够使用某一个包的成员,我们需要在 Java 程序中明确导入该包。使用 \"import\" 语句可完成此功能。\n\n在 java 源文件中 import 语句应位于 package 语句之后,所有类的定义之前,可以没有,也可以有多条,其语法格式为:\n\n````\n import package1[.package2…].(classname|*);\n````\n\n如果在一个包中,一个类想要使用本包中的另一个类,那么该包名可以省略。\n\n通常,一个公司使用它互联网域名的颠倒形式来作为它的包名.例如:互联网域名是 runoob.com,所有的包名都以 com.runoob 开头。包名中的每一个部分对应一个子目录。\n\n例如:有一个 com.runoob.test 的包,这个包包含一个叫做 Runoob.java 的源文件,那么相应的,应该有如下面的一连串子目录:\n```\n ....\\com\\runoob\\test\\Runoob.java\n```\n## 常用jar包\n\n### java软件包的类型\n\n软件包的类型有内置的软件包和用户定义的软件包内置软件包\n这些软件包由大量的类组成,这些类是Java API的一部分。一些常用的内置软件包有:\n\n1)java.lang:包含语言支持类(例如分类,用于定义基本数据类型,数学运算)。该软件包会自动导入。\n\n2) java.io:包含分类以支持输入/输出操作。\n\n3) java.util:包含实现像链接列表,字典和支持等数据结构的实用类; 用于日期/时间操作。\n\n4) java.applet:包含用于创建Applets的类。\n\n5) java.awt:包含用于实现图形用户界面组件的类(如按钮,菜单等)。\n\n6) java.net:包含支持网络操作的类。\n\n### dt.jar\n\n> SUN对于dt.jar的定义:Also includesdt.jar, the DesignTime archive of BeanInfo files that tell interactive development environments (IDE's) how to display the Java components and how to let the developer customize them for the application。\n\n中文翻译过来就是:dt.jar是BeanInfo文件的DesignTime归档,BeanInfo文件用来告诉集成开发环境(IDE)如何显示Java组件还有如何让开发人员根据应用程序自定义它们。这段文字中提到了几个关键字:DesignTime,BeanInfo,IDE,Java components。其实dt.jar就是DesignTime Archive的缩写。那么何为DesignTime。\n\n何为DesignTime?翻译过来就是设计时。其实了解JavaBean的人都知道design time和runtime(运行时)这两个术语的含义。设计时(DesignTIme)是指在开发环境中通过添加控件,设置控件或窗体属性等方法,建立应用程序的时间。\n\n与此相对应的运行时(RunTIme)是指可以象用户那样与应用程序交互作用的时间。那么现在再理解一下上面的翻译,其实dt.jar包含了swing控件中的BeanInfo,而IDE的GUI Designer需要这些信息。那让我们看一下dt.jar中到底有什么?\n\ndt.jar中全部是Swing组件的BeanInfo。那么到底什么是BeanInfo呢?\n\n何为BeanInfo?JavaBean和BeanInfo有很大的关系。Sun所制定的JavaBean规范,很大程度上是为IDE准备的——它让IDE能够以可视化的方式设置JavaBean的属性。如果在IDE中开发一个可视化应用程序,我们需要通过属性设置的方式对组成应用的各种组件进行定制,IDE通过属性编辑器让开发人员使用可视化的方式设置组件的属性。\n\ndt.jar里面主要是swing组件的BeanInfo。IDE根据这些BeanInfo显示这些组件以及开发人员如何定制他们。\n\n### rt.jar\nrt.jar是runtime的归档。Java基础类库,也就是Java doc里面看到的所有的类的class文件。\n\n\n\nrt.jar 默认就在Root Classloader的加载路径里面的,而在Claspath配置该变量是不需要的;同时jre/lib目录下的其他jar:jce.jar、jsse.jar、charsets.jar、resources.jar都在Root Classloader中。\n\n## java文件的奥秘\n### Java文件简介\n\n.java文件你可以认为只是一个文本文件, 这个文件即是用java语言写成的程序,或者说任务的代码块。\n\n.class文件本质上是一种二进制文件, 它一般是由.java文件通过 javac这个命令(jdk本身提供的工具)生成的一个文件, 而这个文件可以由jvm(java虚拟机)装载(类装载),然后进java解释执行, 这也就是运行你的程序。\n\n你也可以这样比较一下:\n.java与 .c , .cpp, .asm等等文件,本质 上一样的, 只是用一种 语言来描述你要怎么去完成一件事(一个任务), 而这种语言 计算机本身 是没有办法知道是什么含义的, 它面向的只是程序员本身, 程序员可以通过 语言本身(语法) 来描述或组织这个任务,这也就 是所谓的编程。\n\n最后你当然是需要计算机按照你的意图来运行你的程序, 这时候就先得有一个翻译(编译, 汇编, 链接等等复杂的过程)把它变成机器可理解的指令(这就是大家说的机器语言,机器语言本身也是一种编程语言,只是程序很难写,很难读懂,基本上没有办法维护)。\n\n\n这里的.class文件在计算的体系结构中本质上对应的是一种机器语言(而这里的机器叫作JVM),所以JVM本身是可以直接运行这里的.class文件。所以 你可以进一步地认为,.java与.class与其它的编程语法一样,它们都是程序员用来描述自己的任务的一种语言,只是它们面向的对象不一样,而计算机本身只能识别它自已定义的那些指令什么的(再次强调,这里的计算机本身没有那么严格的定义)\n\n> In short:\n>\n> .java是Java的源文件后缀,里面存放程序员编写的功能代码。\n>\n> .class文件是字节码文件,由.java源文件通过javac命令编译后生成的文件。是可以运行在任何支持Java虚拟机的硬件平台和操作系统上的二进制文件。\n>\n> .class文件并不本地的可执行程序。Java虚拟机就是去运行.class文件从而实现程序的运行。\n\n\n### 为什么一个java源文件中只能有一个public类?\n\n在java编程思想(第四版)一书中有这样3段话(6.4 类的访问权限):\n\n> 1.每个编译单元(文件)都只能有一个public类,这表示,每个编译单元都有单一的公共接口,用public类来表现。该接口可以按要求包含众多的支持包访问权限的类。如果在某个编译单元内有一个以上的public类,编译器就会给出错误信息。\n>\n> 2.public类的名称必须完全与含有该编译单元的文件名相同,包含大小写。如果不匹配,同样将得到编译错误。\n>\n> 3.虽然不是很常用,但编译单元内完全不带public类也是可能的。在这种情况下,可以随意对文件命名。\n\n总结相关的几个问题:\n\n1、一个”.java”源文件中是否可以包括多个类(不是内部类)?有什么限制?\n\n> 答:可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致。\n\n2、为什么一个文件中只能有一个public的类\n\n> 答:编译器在编译时,针对一个java源代码文件(也称为“编译单元”)只会接受一个public类。否则报错。\n\n3、在java文件中是否可以没有public类\n\n> 答:public类不是必须的,java文件中可以没有public类。\n\n4、为什么这个public的类的类名必须和文件名相同\n\n> 答: 是为了方便虚拟机在相应的路径中找到相应的类所对应的字节码文件。\n\n### Main方法\n\n主函数:是一个特殊的函数,作为程序的入口,可以被JVM调用\n\n主函数的定义:\n> public:代表着该函数访问权限是最大的\n\n> static:代表主函数随着类的加载就已经存在了\n\n> void:主函数没有具体的返回值\n\n> main:不是关键字,但是一个特殊的单词,能够被JVM识别\n\n> (String[] args):函数的参数,参数类型是一个数组,该数组中的元素师字符串,字符串数组。main(String[] args) 字符串数组的 此时空数组的长度是0,但也可以在 运行的时候向其中传入参数。\n\n主函数时固定格式的,JVM识别\n\n主函数可以被重载,但是JVM只识别main(String[] args),其他都是作为一般函数。这里面的args知识数组变量可以更改,其他都不能更改。\n\n一个java文件中可以包含很多个类,每个类中有且仅有一个主函数,但是每个java文件中可以包含多个主函数,在运行时,需要指定JVM入口是哪个。例如一个类的主函数可以调用另一个类的主函数。不一定会使用public类的主函数。\n\n### 外部类的访问权限\n\n外部类只能用public和default修饰。\n\n为什么要对外部类或类做修饰呢?\n\n> 1.存在包概念:public 和 default 能区分这个外部类能对不同包作一个划分 (default修饰的类,其他包中引入不了这个类,public修饰的类才能被import)\n>\n> 2.protected是包内可见并且子类可见,但是当一个外部类想要继承一个protected修饰的非同包类时,压根找不到这个类,更别提几层了\n>\n> 3.private修饰的外部类,其他任何外部类都无法导入它。\n\n````\n//Java中的文件名要和public修饰的类名相同,否则会报错\n//如果没有public修饰的类,则文件可以随意命名\npublic class Java中的类文件 {\n}\n//非公共开类的访问权限默认是包访问权限,不能用private和protected\n//一个外部类的访问权限只有两种,一种是包内可见,一种是包外可见。\n//如果用private修饰,其他类根本无法看到这个类,也就没有意义了。\n//如果用protected,虽然也是包内可见,但是如果有子类想要继承该类但是不同包时,\n//压根找不到这个类,也不可能继承它了,所以干脆用default代替。\nclass A{\n}\n````\n\n### Java包的命名规则\n\n> 以 java.* 开头的是Java的核心包,所有程序都会使用这些包中的类;\n\n> 以 javax.* 开头的是扩展包,x 是 extension 的意思,也就是扩展。虽然 javax.* 是对 java.* 的优化和扩展,但是由于 javax.* 使用的越来越多,很多程序都依赖于 javax.*,所以 javax.* 也是核心的一部分了,也随JDK一起发布。\n\n> 以 org.* 开头的是各个机构或组织发布的包,因为这些组织很有影响力,它们的代码质量很高,所以也将它们开发的部分常用的类随JDK一起发布。\n\n> 在包的命名方面,为了防止重名,有一个惯例:大家都以自己域名的倒写形式作为开头来为自己开发的包命名,例如百度发布的包会以 com.baidu.* 开头,w3c组织发布的包会以 org.w3c.* 开头,微学苑发布的包会以 net.weixueyuan.* 开头……\n\n> 组织机构的域名后缀一般为 org,公司的域名后缀一般为 com,可以认为 org.* 开头的包为非盈利组织机构发布的包,它们一般是开源的,可以免费使用在自己的产品中,不用考虑侵权问题,而以 com.* 开头的包往往由盈利性的公司发布,可能会有版权问题,使用时要注意。\n\n\n\n## 参考文章\n\nhttps://www.cnblogs.com/ryanzheng/p/8465701.html\nhttps://blog.csdn.net/fuhanghang/article/details/84102404\nhttps://www.runoob.com/java/java-package.html\nhttps://www.breakyizhan.com/java/4260.html\nhttps://blog.csdn.net/qq_36626914/article/details/80627454\n\n"
},
{
"path": "docs/Java/basic/Java自动拆箱装箱里隐藏的秘密.md",
"content": "# 目录\n\n* [Java 基本数据类型](#java-基本数据类型)\n * [Java 的两大数据类型:](#java-的两大数据类型)\n * [内置数据类型](#内置数据类型)\n * [引用类型](#引用类型)\n * [Java 常量](#java-常量)\n * [自动拆箱和装箱(详解)](#自动拆箱和装箱(详解))\n * [简易实现](#简易实现)\n * [自动装箱与拆箱中的“坑”](#自动装箱与拆箱中的坑)\n * [了解基本类型缓存(常量池)的最佳实践](#了解基本类型缓存(常量池)的最佳实践)\n * [总结:](#总结:)\n * [基本数据类型的存储方式](#基本数据类型的存储方式)\n * [存在栈中:](#存在栈中:)\n * [存在堆里](#存在堆里)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n# Java 基本数据类型\n\n变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。\n\n内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。\n\n\n\n因此,通过定义不同类型的变量,可以在内存中储存整数、小数或者字符。\n\n## Java 的两大数据类型:\n\n* 内置数据类型\n* 引用数据类型\n\n* * *\n\n### 内置数据类型\n\nJava语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。\n\n**byte:**\n\n* byte 数据类型是8位、有符号的,以二进制补码表示的整数;\n* 最小值是 -128(-2^7);\n* 最大值是 127(2^7-1);\n* 默认值是 0;\n* byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;\n* 例子:byte a = 100,byte b = -50。\n\n**short:**\n\n* short 数据类型是 16 位、有符号的以二进制补码表示的整数\n* 最小值是 -32768(-2^15);\n* 最大值是 32767(2^15 - 1);\n* Short 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一;\n* 默认值是 0;\n* 例子:short s = 1000,short r = -20000。\n\n**int:**\n\n* int 数据类型是32位、有符号的以二进制补码表示的整数;\n* 最小值是 -2,147,483,648(-2^31);\n* 最大值是 2,147,483,647(2^31 - 1);\n* 一般地整型变量默认为 int 类型;\n* 默认值是 0 ;\n* 例子:int a = 100000, int b = -200000。\n\n**long:**\n\n* long 数据类型是 64 位、有符号的以二进制补码表示的整数;\n* 最小值是 -9,223,372,036,854,775,808(-2^63);\n* 最大值是 9,223,372,036,854,775,807(2^63 -1);\n* 这种类型主要使用在需要比较大整数的系统上;\n* 默认值是 0L;\n* 例子: long a = 100000L,Long b = -200000L。\n \"L\"理论上不分大小写,但是若写成\"l\"容易与数字\"1\"混淆,不容易分辩。所以最好大写。\n\n**float:**\n\n* float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;\n* float 在储存大型浮点数组的时候可节省内存空间;\n* 默认值是 0.0f;\n* 浮点数不能用来表示精确的值,如货币;\n* 例子:float f1 = 234.5f。\n\n**double:**\n\n* double 数据类型是双精度、64 位、符合IEEE 754标准的浮点数;\n* 浮点数的默认类型为double类型;\n* double类型同样不能表示精确的值,如货币;\n* 默认值是 0.0d;\n* 例子:double d1 = 123.4。\n\n**boolean:**\n\n* boolean数据类型表示一位的信息;\n* 只有两个取值:true 和 false;\n* 这种类型只作为一种标志来记录 true/false 情况;\n* 默认值是 false;\n* 例子:boolean one = true。\n\n**char:**\n\n* char类型是一个单一的 16 位 Unicode 字符;\n* 最小值是 \\u0000(即为0);\n* 最大值是 \\uffff(即为65,535);\n* char 数据类型可以储存任何字符;\n* 例子:char letter = 'A';。\n\n\n```\n//8位\nbyte bx = Byte.MAX_VALUE;\nbyte bn = Byte.MIN_VALUE;\n//16位\nshort sx = Short.MAX_VALUE;\nshort sn = Short.MIN_VALUE;\n//32位\nint ix = Integer.MAX_VALUE;\nint in = Integer.MIN_VALUE;\n//64位\nlong lx = Long.MAX_VALUE;\nlong ln = Long.MIN_VALUE;\n//32位\nfloat fx = Float.MAX_VALUE;\nfloat fn = Float.MIN_VALUE;\n//64位\ndouble dx = Double.MAX_VALUE;\ndouble dn = Double.MIN_VALUE;\n//1位\nboolean bt = Boolean.TRUE;\nboolean bf = Boolean.FALSE;\n```\n\n```\n打印它们的结果可以得到\n\n`127`\n`-128`\n`32767`\n`-32768`\n`2147483647`\n`-2147483648`\n`9223372036854775807`\n`-9223372036854775808`\n`3.4028235E38`\n`1.4E-45`\n`1.7976931348623157E308`\n`4.9E-324`\n`true`\n`false`\n```\n\n### 引用类型\n\n- 在Java中,引用类型的变量非常类似于C/C++的指针。引用类型指向一个对象,指向对象的变量是引用变量。这些变量在声明时被指定为一个特定的类型,比如 Employee、Puppy 等。变量一旦声明后,类型就不能被改变了。\n- 对象、数组都是引用数据类型。\n- 所有引用类型的默认值都是null。\n- 一个引用变量可以用来引用任何与之兼容的类型。\n- 例子:Site site = new Site(\"Runoob\")。\n\n### Java 常量\n\n常量在程序运行时是不能被修改的。\n\n在 Java 中使用 final 关键字来修饰常量,声明方式和变量类似:\n\n```\nfinal double PI = 3.1415927;\n```\n\n虽然常量名也可以用小写,但为了便于识别,通常使用大写字母表示常量。\n\n字面量可以赋给任何内置类型的变量。例如:\n\n```\nbyte a = 68;\nchar a = 'A'\n```\n\n## 自动拆箱和装箱(详解)\n\nJava 5增加了自动装箱与自动拆箱机制,方便基本类型与包装类型的相互转换操作。在Java 5之前,如果要将一个int型的值转换成对应的包装器类型Integer,必须显式的使用new创建一个新的Integer对象,或者调用静态方法Integer.valueOf()。\n````\n//在Java 5之前,只能这样做\nInteger value = new Integer(10);\n//或者这样做\nInteger value = Integer.valueOf(10);\n//直接赋值是错误的\n//Integer value = 10;`\n````\n在Java 5中,可以直接将整型赋给Integer对象,由编译器来完成从int型到Integer类型的转换,这就叫自动装箱。\n````\n//在Java 5中,直接赋值是合法的,由编译器来完成转换\nInteger value = 10;\n与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。\n//在Java 5 中可以直接这么做\nInteger value = new Integer(10);\nint i = value;\n````\n自动装箱与自动拆箱为程序员提供了很大的方便,而在实际的应用中,自动装箱与拆箱也是使用最广泛的特性之一。自动装箱和自动拆箱其实是Java编译器提供的一颗语法糖(语法糖是指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通过可提高开发效率,增加代码可读性,增加代码的安全性)。\n\n### 简易实现\n\n在八种包装类型中,每一种包装类型都提供了两个方法:\n\n静态方法valueOf(基本类型):将给定的基本类型转换成对应的包装类型;\n\n实例方法xxxValue():将具体的包装类型对象转换成基本类型;\n下面我们以int和Integer为例,说明Java中自动装箱与自动拆箱的实现机制。看如下代码:\n\n````\nclass Auto //code1\n{\n\tpublic static void main(String[] args) \n\t{\n\t\t//自动装箱\n\t\tInteger inte = 10;\n\t\t//自动拆箱\n\t\tint i = inte;\n\n\t\t//再double和Double来验证一下\n\t\tDouble doub = 12.40;\n\t\tdouble d = doub;\n\t\t\n\t}\n}\n````\n\n上面的代码先将int型转为Integer对象,再讲Integer对象转换为int型,毫无疑问,这是可以正确运行的。可是,这种转换是怎么进行的呢?使用反编译工具,将生成的Class文件在反编译为Java文件,让我们看看发生了什么:\n````\nclass Auto//code2\n{\n public static void main(String[] paramArrayOfString)\n {\n Integer localInteger = Integer.valueOf(10);\n \n int i = localInteger.intValue();\n Double localDouble = Double.valueOf(12.4D);\n double d = localDouble.doubleValue();\n }\n}\n````\n我们可以看到经过javac编译之后,code1的代码被转换成了code2,实际运行时,虚拟机运行的就是code2的代码。也就是说,虚拟机根本不知道有自动拆箱和自动装箱这回事;在将Java源文件编译为class文件的过程中,javac编译器在自动装箱的时候,调用了Integer.valueOf()方法,在自动拆箱时,又调用了intValue()方法。我们可以看到,double和Double也是如此。\n实现总结:其实自动装箱和自动封箱是编译器为我们提供的一颗语法糖。在自动装箱时,编译器调用包装类型的valueOf()方法;在自动拆箱时,编译器调用了相应的xxxValue()方法。\n\n### 自动装箱与拆箱中的“坑”\n\n在使用自动装箱与自动拆箱时,要注意一些陷阱,为了避免这些陷阱,我们有必要去看一下各种包装类型的源码。\n\nInteger源码\n\n````\npublic final class Integer extends Number implements Comparable {\n private final int value;\n \n /*Integer的构造方法,接受一个整型参数,Integer对象表示的int值,保存在value中*/\n public Integer(int value) {\n this.value = value;\n }\n \n /*equals()方法判断的是:所代表的int型的值是否相等*/\n public boolean equals(Object obj) {\n if (obj instanceof Integer) {\n return value == ((Integer)obj).intValue();\n }\n return false;\n }\n \n /*返回这个Integer对象代表的int值,也就是保存在value中的值*/\n public int intValue() {\n return value;\n }\n \n /**\n * 首先会判断i是否在[IntegerCache.low,Integer.high]之间\n * 如果是,直接返回Integer.cache中相应的元素\n * 否则,调用构造方法,创建一个新的Integer对象\n */\n public static Integer valueOf(int i) {\n assert IntegerCache.high >= 127;\n if (i >= IntegerCache.low && i <= IntegerCache.high)\n return IntegerCache.cache[i + (-IntegerCache.low)];\n return new Integer(i);\n }\n \n /**\n * 静态内部类,缓存了从[low,high]对应的Integer对象\n * low -128这个值不会被改变\n * high 默认是127,可以改变,最大不超过:Integer.MAX_VALUE - (-low) -1\n * cache 保存从[low,high]对象的Integer对象\n */\n private static class IntegerCache {\n static final int low = -128;\n static final int high;\n static final Integer cache[];\n \n static {\n // high value may be configured by property\n int h = 127;\n String integerCacheHighPropValue =\n sun.misc.VM.getSavedProperty(\"java.lang.Integer.IntegerCache.high\");\n if (integerCacheHighPropValue != null) {\n int i = parseInt(integerCacheHighPropValue);\n i = Math.max(i, 127);\n // Maximum array size is Integer.MAX_VALUE\n h = Math.min(i, Integer.MAX_VALUE - (-low) -1);\n }\n high = h;\n \n cache = new Integer[(high - low) + 1];\n int j = low;\n for(int k = 0; k < cache.length; k++)\n cache[k] = new Integer(j++);\n }\n \n private IntegerCache() {}\n }\n}\n````\n\n 以上是Oracle(Sun)公司JDK 1.7中Integer源码的一部分,通过分析上面的代码,得到:\n 1)Integer有一个实例域value,它保存了这个Integer所代表的int型的值,且它是final的,也就是说这个Integer对象一经构造完成,它所代表的值就不能再被改变。\n 2)Integer重写了equals()方法,它通过比较两个Integer对象的value,来判断是否相等。\n 3)重点是静态内部类IntegerCache,通过类名就可以发现:它是用来缓存数据的。它有一个数组,里面保存的是连续的Integer对象。\n (a) low:代表缓存数据中最小的值,固定是-128。\n (b) high:代表缓存数据中最大的值,它可以被该改变,默认是127。high最小是127,最大是Integer.MAX_VALUE-(-low)-1,如果high超过了这个值,那么cache[ ]的长度就超过Integer.MAX_VALUE了,也就溢出了。\n (c) cache[]:里面保存着从[low,high]所对应的Integer对象,长度是high-low+1(因为有元素0,所以要加1)。\n 4)调用valueOf(int i)方法时,首先判断i是否在[low,high]之间,如果是,则复用Integer.cache[i-low]。比如,如果Integer.valueOf(3),直接返回Integer.cache[131];如果i不在这个范围,则调用构造方法,构造出一个新的Integer对象。\n 5)调用intValue(),直接返回value的值。\n 通过3)和4)可以发现,默认情况下,在使用自动装箱时,VM会复用[-128,127]之间的Integer对象。\n \n Integer a1 = 1;\n Integer a2 = 1;\n Integer a3 = new Integer(1);\n //会打印true,因为a1和a2是同一个对象,都是Integer.cache[129]\n System.out.println(a1 == a2);\n //false,a3构造了一个新的对象,不同于a1,a2\n System.out.println(a1 == a3);\n\n### 了解基本类型缓存(常量池)的最佳实践\n\n````\n//基本数据类型的常量池是-128到127之间。\n// 在这个范围中的基本数据类的包装类可以自动拆箱,比较时直接比较数值大小。\npublic static void main(String[] args) {\n\n//int的自动拆箱和装箱只在-128到127范围中进行,超过该范围的两个integer的 == 判断是会返回false的。\nInteger a1 = 128;\nInteger a2 = -128;\nInteger a3 = -128;\nInteger a4 = 128;\nSystem.out.println(a1 == a4);\nSystem.out.println(a2 == a3);\n\nByte b1 = 127;\nByte b2 = 127;\nByte b3 = -128;\nByte b4 = -128;\n//byte都是相等的,因为范围就在-128到127之间\nSystem.out.println(b1 == b2);\nSystem.out.println(b3 == b4);\n\nLong c1 = 128L;\nLong c2 = 128L;\nLong c3 = -128L;\nLong c4 = -128L;\nSystem.out.println(c1 == c2);\nSystem.out.println(c3 == c4);\n\n//char没有负值\n//发现char也是在0到127之间自动拆箱\nCharacter d1 = 128;\nCharacter d2 = 128;\nCharacter d3 = 127;\nCharacter d4 = 127;\nSystem.out.println(d1 == d2);\nSystem.out.println(d3 == d4);\n\n`结果`\n\n`false`\n`true`\n`true`\n`true`\n`false`\n`true`\n`false`\n`true`\n\n\nInteger i = 10;\nByte b = 10;\n//比较Byte和Integer.两个对象无法直接比较,报错\n//System.out.println(i == b);\nSystem.out.println(\"i == b \" + i.equals(b));\n//答案是false,因为包装类的比较时先比较是否是同一个类,不是的话直接返回false.\n\nint ii = 128;\nshort ss = 128;\nlong ll = 128;\nchar cc = 128;\nSystem.out.println(\"ii == bb \" + (ii == ss));\nSystem.out.println(\"ii == ll \" + (ii == ll));\nSystem.out.println(\"ii == cc \" + (ii == cc));\n\n结果\ni == b false\nii == bb true\nii == ll true\nii == cc true\n\n//这时候都是true,因为基本数据类型直接比较值,值一样就可以。\n````\n\n### 总结:\n\n通过上面的代码,我们分析一下自动装箱与拆箱发生的时机:\n\n(1)当需要一个对象的时候会自动装箱,比如Integer a = 10;equals(Object o)方法的参数是Object对象,所以需要装箱。\n\n(2)当需要一个基本类型时会自动拆箱,比如int a = new Integer(10);算术运算是在基本类型间进行的,所以当遇到算术运算时会自动拆箱,比如代码中的 c == (a + b);\n\n(3)包装类型 == 基本类型时,包装类型自动拆箱;\n\n需要注意的是:“==”在没遇到算术运算时,不会自动拆箱;基本类型只会自动装箱为对应的包装类型,代码中最后一条说明的内容。\n\n在JDK 1.5中提供了自动装箱与自动拆箱,这其实是Java 编译器的语法糖,编译器通过调用包装类型的valueOf()方法实现自动装箱,调用xxxValue()方法自动拆箱。自动装箱和拆箱会有一些陷阱,那就是包装类型复用了某些对象。\n\n(1)Integer默认复用了[-128,127]这些对象,其中高位置可以修改;\n\n(2)Byte复用了全部256个对象[-128,127];\n\n(3)Short服用了[-128,127]这些对象;\n\n(4)Long服用了[-128,127];\n\n(5)Character复用了[0,127],Charater不能表示负数;\n\nDouble和Float是连续不可数的,所以没法复用对象,也就不存在自动装箱复用陷阱。\n\nBoolean没有自动装箱与拆箱,它也复用了Boolean.TRUE和Boolean.FALSE,通过Boolean.valueOf(boolean b)返回的Blooean对象要么是TRUE,要么是FALSE,这点也要注意。\n\n本文介绍了“真实的”自动装箱与拆箱,为了避免写出错误的代码,又从包装类型的源码入手,指出了各种包装类型在自动装箱和拆箱时存在的陷阱,同时指出了自动装箱与拆箱发生的时机。\n\n\n## 基本数据类型的存储方式\n上面自动拆箱和装箱的原理其实与常量池有关。\n\n### 存在栈中:\n\n public void(int a)\n {\n int i = 1;\n int j = 1;\n }\n\n方法中的i 存在虚拟机栈的局部变量表里,i是一个引用,j也是一个引用,它们都指向局部变量表里的整型值 1.\nint a是传值引用,所以a也会存在局部变量表。\n\n### 存在堆里\nclass A{\nint i = 1;\nA a = new A();\n}\ni是类的成员变量。类实例化的对象存在堆中,所以成员变量也存在堆中,引用a存的是对象的地址,引用i存的是值,这个值1也会存在堆中。可以理解为引用i指向了这个值1。也可以理解为i就是1.\n\n3 包装类对象怎么存\n其实我们说的常量池也可以叫对象池。\n\n比如String a= new String(\"a\").intern()时会先在常量池找是否有“a\"对象如果有的话直接返回“a\"对象在常量池的地址,即让引用a指向常量”a\"对象的内存地址。\nInteger也是同理。\n\n下图是Integer类型在常量池中查找同值对象的方法。\n\n````\npublic static Integer valueOf(int i) {\n if (i >= IntegerCache.low && i <= IntegerCache.high)\n return IntegerCache.cache[i + (-IntegerCache.low)];\n return new Integer(i);\n}\nprivate static class IntegerCache {\n static final int low = -128;\n static final int high;\n static final Integer cache[];\n\n static {\n // high value may be configured by property\n int h = 127;\n String integerCacheHighPropValue =\n sun.misc.VM.getSavedProperty(\"java.lang.Integer.IntegerCache.high\");\n if (integerCacheHighPropValue != null) {\n try {\n int i = parseInt(integerCacheHighPropValue);\n i = Math.max(i, 127);\n // Maximum array size is Integer.MAX_VALUE\n h = Math.min(i, Integer.MAX_VALUE - (-low) -1);\n } catch( NumberFormatException nfe) {\n // If the property cannot be parsed into an int, ignore it.\n }\n }\n high = h;\n\n cache = new Integer[(high - low) + 1];\n int j = low;\n for(int k = 0; k < cache.length; k++)\n cache[k] = new Integer(j++);\n\n // range [-128, 127] must be interned (JLS7 5.1.7)\n assert IntegerCache.high >= 127;\n }\n\n private IntegerCache() {}\n}\n````\n\n所以基本数据类型的包装类型可以在常量池查找对应值的对象,找不到就会自动在常量池创建该值的对象。\n\n而String类型可以通过intern来完成这个操作。\n\nJDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码,这个例子是网上流传较广的一个例子,分析图也是直接粘贴过来的,这里我会用自己的理解去解释这个例子:\n\n\n```\nString s = new String(\"1\"); \ns.intern(); \nString s2 = \"1\"; \nSystem.out.println(s == s2); \n \nString s3 = new String(\"1\") + new String(\"1\"); \ns3.intern(); \nString s4 = \"11\"; \nSystem.out.println(s3 == s4); \n输出结果为:\n\n[java] view plain copy\nJDK1.6以及以下:false false \nJDK1.7以及以上:false true\n```\n\nJDK1.6查找到常量池存在相同值的对象时会直接返回该对象的地址。\n\nJDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。\n\n那么其他字符串在常量池找值时就会返回另一个堆中对象的地址。\n\n下一节详细介绍String以及相关包装类。\n\n具体请见:https://blog.csdn.net/a724888/article/details/80042298\n\n关于Java面向对象三大特性,请参考:\n\nhttps://blog.csdn.net/a724888/article/details/80033043\n\n## 参考文章\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"path": "docs/Java/basic/Java集合框架梳理.md",
"content": "# 目录\n * [集合类大图](#集合类大图)\n * [Collection接口](#collection接口)\n * [List接口](#list接口)\n * [Set接口](#set接口)\n * [Map接口](#map接口)\n * [Queue](#queue)\n * [关于Java集合的小抄](#关于java集合的小抄)\n * [List](#list)\n * [ArrayList](#arraylist)\n * [LinkedList](#linkedlist)\n * [CopyOnWriteArrayList](#copyonwritearraylist)\n * [遗憾](#遗憾)\n * [Map](#map)\n * [HashMap](#hashmap)\n * [LinkedHashMap](#linkedhashmap)\n * [TreeMap](#treemap)\n * [EnumMap](#enummap)\n * [ConcurrentHashMap](#concurrenthashmap)\n * [ConcurrentSkipListMap](#concurrentskiplistmap)\n * [Set](#set)\n * [Queue](#queue-1)\n * [普通队列](#普通队列)\n * [PriorityQueue](#priorityqueue)\n * [线程安全的队列](#线程安全的队列)\n * [线程安全的阻塞队列](#线程安全的阻塞队列)\n * [同步队列](#同步队列)\n * [参考文章](#参考文章)\n\n---\ntitle: 夯实Java基础系列19:一文搞懂Java集合类框架,以及常见面试题\ndate: 2019-9-19 15:56:26 # 文章生成时间,一般不改\ncategories:\n - Java技术江湖\n - Java基础\ntags:\n - Java集合类\n---\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n本文参考 https://www.cnblogs.com/chenssy/p/3495238.html\n\n## 集合类大图\n\n在编写java程序中,我们最常用的除了八种基本数据类型,String对象外还有一个集合类,在我们的的程序中到处充斥着集合类的身影!\n\n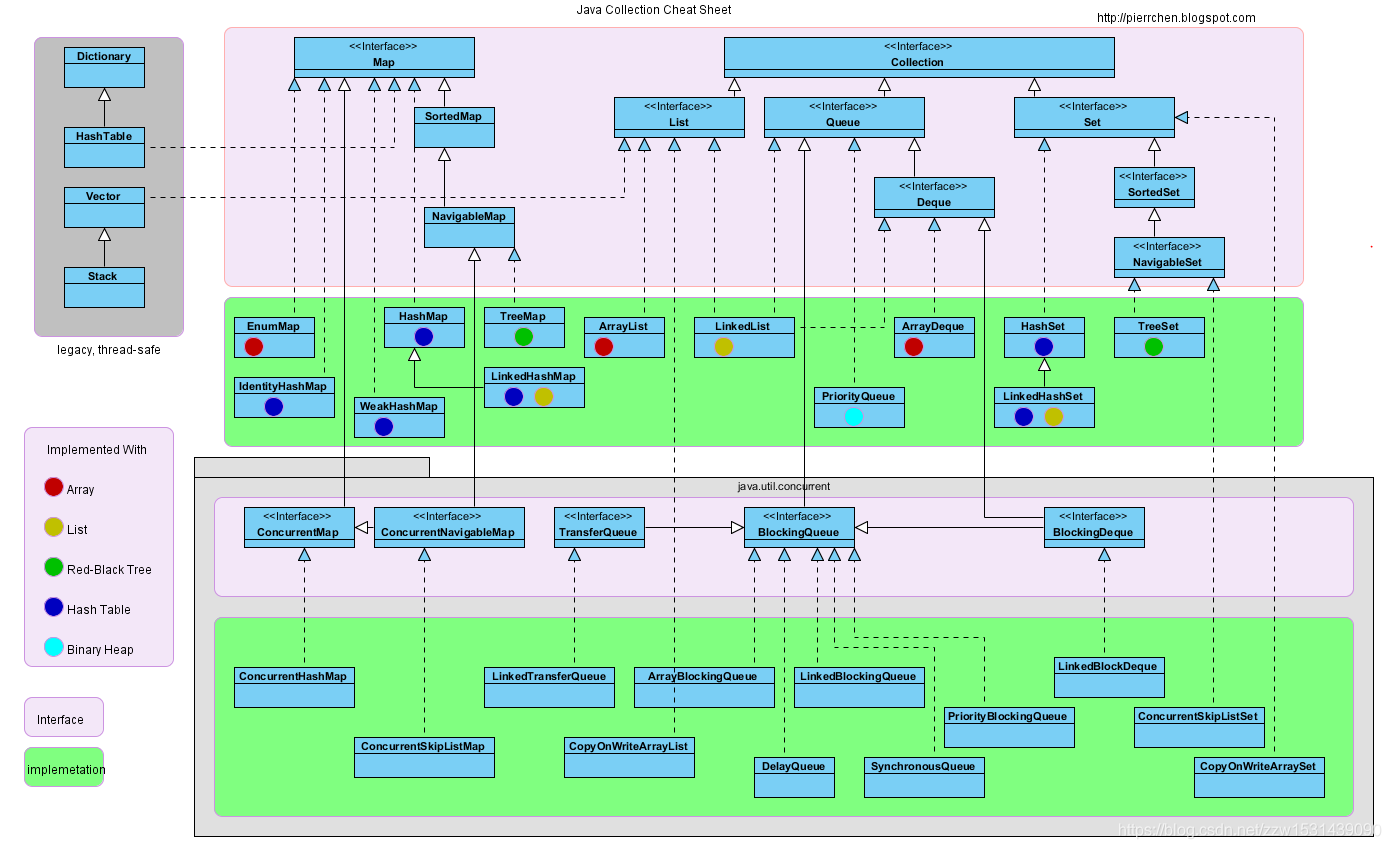\njava中集合大家族的成员实在是太丰富了,有常用的ArrayList、HashMap、HashSet,也有不常用的Stack、Queue,有线程安全的Vector、HashTable,也有线程不安全的LinkedList、TreeMap等等!\n\n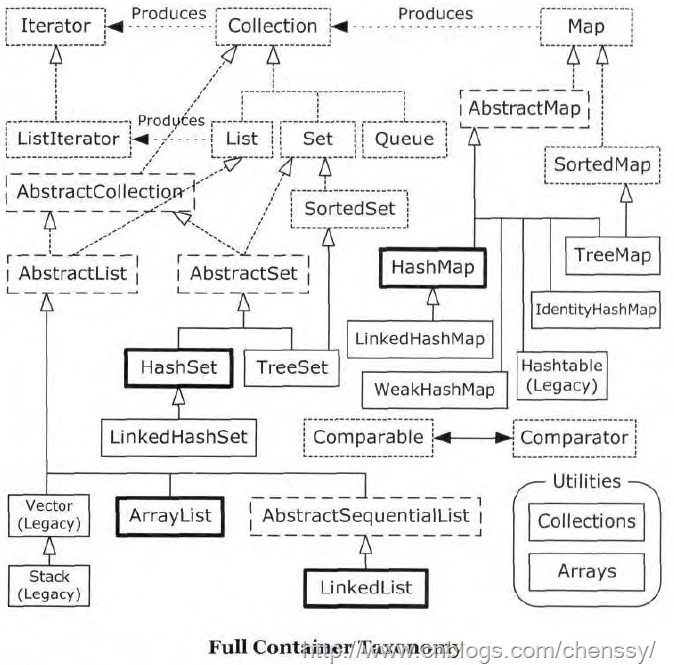\n\n上面的图展示了整个集合大家族的成员以及他们之间的关系。下面就上面的各个接口、基类做一些简单的介绍(主要介绍各个集合的特点。区别)。\n\n下面几张图更清晰地介绍了结合类接口间的关系:\n\n> Collections和Collection。\n> Arrays和Collections。\n>\n> 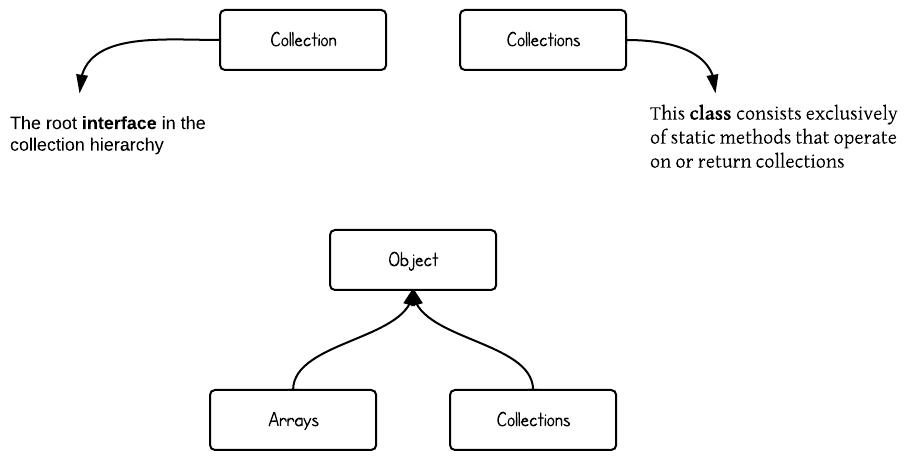\n\n> Collection的子接口\n\n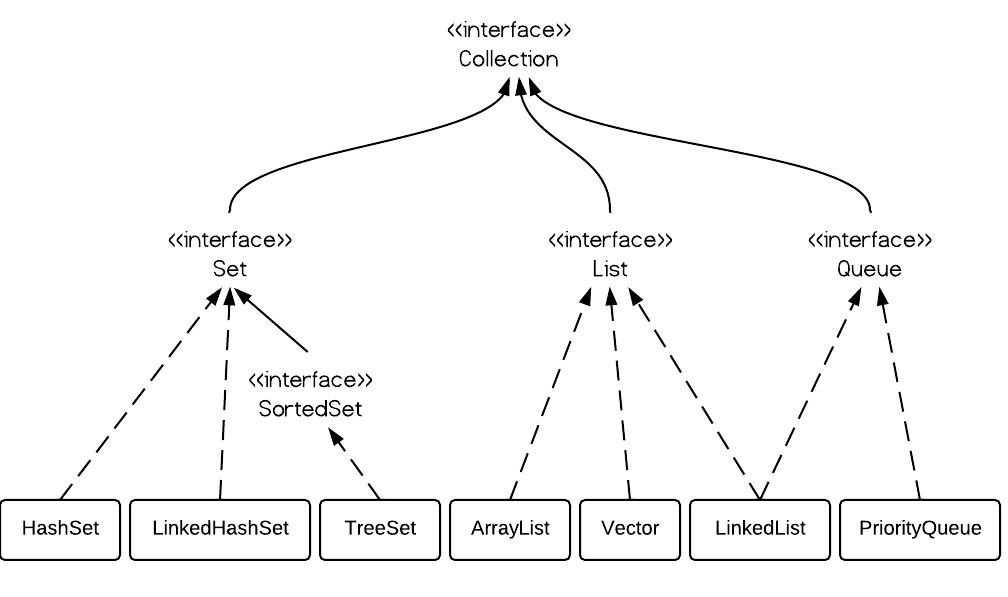\n> map的实现类\n\n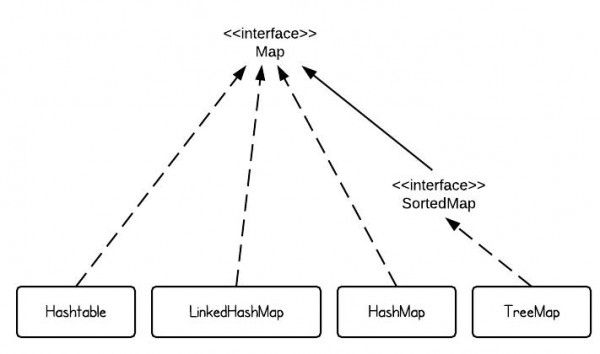\n\n## Collection接口\n\n Collection接口是最基本的集合接口,它不提供直接的实现,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。Collection所代表的是一种规则,它所包含的元素都必须遵循一条或者多条规则。如有些允许重复而有些则不能重复、有些必须要按照顺序插入而有些则是散列,有些支持排序但是有些则不支持。\n\n 在Java中所有实现了Collection接口的类都必须提供两套标准的构造函数,一个是无参,用于创建一个空的Collection,一个是带有Collection参数的有参构造函数,用于创建一个新的Collection,这个新的Collection与传入进来的Collection具备相同的元素。\n//要求实现基本的增删改查方法,并且需要能够转换为数组类型\n\n````\npublic class Collection接口 {\n class collect implements Collection {\n\n @Override\n public int size() {\n return 0;\n }\n\n @Override\n public boolean isEmpty() {\n return false;\n }\n\n @Override\n public boolean contains(Object o) {\n return false;\n }\n\n @Override\n public Iterator iterator() {\n return null;\n }\n\n @Override\n public Object[] toArray() {\n return new Object[0];\n }\n\n @Override\n public boolean add(Object o) {\n return false;\n }\n\n @Override\n public boolean remove(Object o) {\n return false;\n }\n\n @Override\n public boolean addAll(Collection c) {\n return false;\n }\n\n @Override\n public void clear() {\n\n }\n//省略部分代码 \n\n @Override\n public Object[] toArray(Object[] a) {\n return new Object[0];\n }\n }\n}\n````\n## List接口\n\n> List接口为Collection直接接口。List所代表的是有序的Collection,即它用某种特定的插入顺序来维护元素顺序。用户可以对列表中每个元素的插入位置进行精确地控制,同时可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。\n\n2.1、ArrayList\n\n> ArrayList是一个动态数组,也是我们最常用的集合。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。\n>\n> size、isEmpty、get、set、iterator 和 listIterator 操作都以固定时间运行。add 操作以分摊的固定时间运行,也就是说,添加 n 个元素需要 O(n) 时间(由于要考虑到扩容,所以这不只是添加元素会带来分摊固定时间开销那样简单)。\n>\n> ArrayList擅长于随机访问。同时ArrayList是非同步的。\n>\n> 2.2、LinkedList\n\n> 同样实现List接口的LinkedList与ArrayList不同,ArrayList是一个动态数组,而LinkedList是一个双向链表。所以它除了有ArrayList的基本操作方法外还额外提供了get,remove,insert方法在LinkedList的首部或尾部。\n>\n> 由于实现的方式不同,LinkedList不能随机访问,它所有的操作都是要按照双重链表的需要执行。在列表中索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。这样做的好处就是可以通过较低的代价在List中进行插入和删除操作。\n>\n> 与ArrayList一样,LinkedList也是非同步的。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List: \n> List list = Collections.synchronizedList(new LinkedList(...));\n\n> 2.3、Vector\n> 与ArrayList相似,但是Vector是同步的。所以说Vector是线程安全的动态数组。它的操作与ArrayList几乎一样。\n>\n> 2.4、Stack\n> Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。。\n````\npublic class List接口 {\n //下面是List的继承关系,由于List接口规定了包括诸如索引查询,迭代器的实现,所以实现List接口的类都会有这些方法。\n //所以不管是ArrayList和LinkedList底层都可以使用数组操作,但一般不提供这样外部调用方法。\n // public interface Iterable\n// public interface Collection extends Iterable\n// public interface List extends Collection\n class MyList implements List {\n\n @Override\n public int size() {\n return 0;\n }\n\n @Override\n public boolean isEmpty() {\n return false;\n }\n\n @Override\n public boolean contains(Object o) {\n return false;\n }\n\n @Override\n public Iterator iterator() {\n return null;\n }\n\n @Override\n public Object[] toArray() {\n return new Object[0];\n }\n\n @Override\n public boolean add(Object o) {\n return false;\n }\n\n @Override\n public boolean remove(Object o) {\n return false;\n }\n\n @Override\n public void clear() {\n\n }\n\n //省略部分代码\n \n @Override\n public Object get(int index) {\n return null;\n }\n\n @Override\n public ListIterator listIterator() {\n return null;\n }\n\n @Override\n public ListIterator listIterator(int index) {\n return null;\n }\n\n @Override\n public List subList(int fromIndex, int toIndex) {\n return null;\n }\n\n @Override\n public Object[] toArray(Object[] a) {\n return new Object[0];\n }\n }\n}\n````\n## Set接口\n\n> Set是一种不包括重复元素的Collection。它维持它自己的内部排序,所以随机访问没有任何意义。与List一样,它同样运行null的存在但是仅有一个。由于Set接口的特殊性,所有传入Set集合中的元素都必须不同,同时要注意任何可变对象,如果在对集合中元素进行操作时,导致e1.equals(e2)==true,则必定会产生某些问题。实现了Set接口的集合有:EnumSet、HashSet、TreeSet。\n>\n> 3.1、EnumSet\n> 是枚举的专用Set。所有的元素都是枚举类型。\n>\n> 3.2、HashSet\n> HashSet堪称查询速度最快的集合,因为其内部是以HashCode来实现的。它内部元素的顺序是由哈希码来决定的,所以它不保证set 的迭代顺序;特别是它不保证该顺序恒久不变。\n\n````\npublic class Set接口 {\n // Set接口规定将set看成一个集合,并且使用和数组类似的增删改查方式,同时提供iterator迭代器\n // public interface Set extends Collection\n // public interface Collection extends Iterable\n // public interface Iterable\n class MySet implements Set {\n\n @Override\n public int size() {\n return 0;\n }\n\n @Override\n public boolean isEmpty() {\n return false;\n }\n\n @Override\n public boolean contains(Object o) {\n return false;\n }\n\n @Override\n public Iterator iterator() {\n return null;\n }\n\n @Override\n public Object[] toArray() {\n return new Object[0];\n }\n\n @Override\n public boolean add(Object o) {\n return false;\n }\n\n @Override\n public boolean remove(Object o) {\n return false;\n }\n\n @Override\n public boolean addAll(Collection c) {\n return false;\n }\n\n @Override\n public void clear() {\n\n }\n\n @Override\n public boolean removeAll(Collection c) {\n return false;\n }\n\n @Override\n public boolean retainAll(Collection c) {\n return false;\n }\n\n @Override\n public boolean containsAll(Collection c) {\n return false;\n }\n\n @Override\n public Object[] toArray(Object[] a) {\n return new Object[0];\n }\n }\n}\n````\n## Map接口\n\n> Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。实现map的有:HashMap、TreeMap、HashTable、Properties、EnumMap。\n\n> 4.1、HashMap\n> 以哈希表数据结构实现,查找对象时通过哈希函数计算其位置,它是为快速查询而设计的,其内部定义了一个hash表数组(Entry[] table),元素会通过哈希转换函数将元素的哈希地址转换成数组中存放的索引,如果有冲突,则使用散列链表的形式将所有相同哈希地址的元素串起来,可能通过查看HashMap.Entry的源码它是一个单链表结构。\n>\n> 4.2、TreeMap\n> 键以某种排序规则排序,内部以red-black(红-黑)树数据结构实现,实现了SortedMap接口\n>\n> 4.3、HashTable\n> 也是以哈希表数据结构实现的,解决冲突时与HashMap也一样也是采用了散列链表的形式,不过性能比HashMap要低\n````\npublic class Map接口 {\n //Map接口是最上层接口,Map接口实现类必须实现put和get等哈希操作。\n //并且要提供keyset和values,以及entryset等查询结构。\n //public interface Map\n class MyMap implements Map {\n\n @Override\n public int size() {\n return 0;\n }\n\n @Override\n public boolean isEmpty() {\n return false;\n }\n\n @Override\n public boolean containsKey(Object key) {\n return false;\n }\n\n @Override\n public boolean containsValue(Object value) {\n return false;\n }\n\n @Override\n public Object get(Object key) {\n return null;\n }\n\n @Override\n public Object put(Object key, Object value) {\n return null;\n }\n\n @Override\n public Object remove(Object key) {\n return null;\n }\n\n @Override\n public void putAll(Map m) {\n\n }\n\n @Override\n public void clear() {\n\n }\n\n @Override\n public Set keySet() {\n return null;\n }\n\n @Override\n public Collection values() {\n return null;\n }\n\n @Override\n public Set entrySet() {\n return null;\n }\n }\n}\n````\n## Queue\n\n> 队列,它主要分为两大类,一类是阻塞式队列,队列满了以后再插入元素则会抛出异常,主要包括ArrayBlockQueue、PriorityBlockingQueue、LinkedBlockingQueue。另一种队列则是双端队列,支持在头、尾两端插入和移除元素,主要包括:ArrayDeque、LinkedBlockingDeque、LinkedList。\n````\npublic class Queue接口 {\n //queue接口是对队列的一个实现,需要提供队列的进队出队等方法。一般使用linkedlist作为实现类\n class MyQueue implements Queue {\n\n @Override\n public int size() {\n return 0;\n }\n\n @Override\n public boolean isEmpty() {\n return false;\n }\n\n @Override\n public boolean contains(Object o) {\n return false;\n }\n\n @Override\n public Iterator iterator() {\n return null;\n }\n\n @Override\n public Object[] toArray() {\n return new Object[0];\n }\n\n @Override\n public Object[] toArray(Object[] a) {\n return new Object[0];\n }\n\n @Override\n public boolean add(Object o) {\n return false;\n }\n\n @Override\n public boolean remove(Object o) {\n return false;\n }\n\n //省略部分代码\n @Override\n public boolean offer(Object o) {\n return false;\n }\n\n @Override\n public Object remove() {\n return null;\n }\n\n @Override\n public Object poll() {\n return null;\n }\n\n @Override\n public Object element() {\n return null;\n }\n\n @Override\n public Object peek() {\n return null;\n }\n }\n}\n\n````\n## 关于Java集合的小抄\n\n这部分内容转自我偶像 江南白衣 的博客:http://calvin1978.blogcn.com/articles/collection.html\n在尽可能短的篇幅里,将所有集合与并发集合的特征、实现方式、性能捋一遍。适合所有\"精通Java\",其实还不那么自信的人阅读。\n\n期望能不止用于面试时,平时选择数据结构,也能考虑一下其成本与效率,不要看着API合适就用了。\n\n### List\n\n#### ArrayList\n以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组。因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。\n\n按数组下标访问元素-get(i)、set(i,e) 的性能很高,这是数组的基本优势。\n\n如果按下标插入元素、删除元素-add(i,e)、 remove(i)、remove(e),则要用System.arraycopy()来复制移动部分受影响的元素,性能就变差了。\n\n越是前面的元素,修改时要移动的元素越多。直接在数组末尾加入元素-常用的add(e),删除最后一个元素则无影响。\n\n \n\n#### LinkedList\n以双向链表实现。链表无容量限制,但双向链表本身使用了更多空间,每插入一个元素都要构造一个额外的Node对象,也需要额外的链表指针操作。\n\n \n\n按下标访问元素-get(i)、set(i,e) 要悲剧的部分遍历链表将指针移动到位 (如果i>数组大小的一半,会从末尾移起)。\n\n插入、删除元素时修改前后节点的指针即可,不再需要复制移动。但还是要部分遍历链表的指针才能移动到下标所指的位置。\n\n只有在链表两头的操作-add()、addFirst()、removeLast()或用iterator()上的remove()倒能省掉指针的移动。\n\nApache Commons 有个TreeNodeList,里面是棵二叉树,可以快速移动指针到位。\n\n \n\n#### CopyOnWriteArrayList\n并发优化的ArrayList。基于不可变对象策略,在修改时先复制出一个数组快照来修改,改好了,再让内部指针指向新数组。\n\n因为对快照的修改对读操作来说不可见,所以读读之间不互斥,读写之间也不互斥,只有写写之间要加锁互斥。但复制快照的成本昂贵,典型的适合读多写少的场景。\n\n虽然增加了addIfAbsent(e)方法,会遍历数组来检查元素是否已存在,性能可想像的不会太好。\n\n \n\n#### 遗憾\n无论哪种实现,按值返回下标contains(e), indexOf(e), remove(e) 都需遍历所有元素进行比较,性能可想像的不会太好。\n\n没有按元素值排序的SortedList。\n\n除了CopyOnWriteArrayList,再没有其他线程安全又并发优化的实现如ConcurrentLinkedList。凑合着用Set与Queue中的等价类时,会缺少一些List特有的方法如get(i)。如果更新频率较高,或数组较大时,还是得用Collections.synchronizedList(list),对所有操作用同一把锁来保证线程安全。\n\n### Map\n#### HashMap\n\n\n以Entry[]数组实现的哈希桶数组,用Key的哈希值取模桶数组的大小可得到数组下标。\n\n插入元素时,如果两条Key落在同一个桶(比如哈希值1和17取模16后都属于第一个哈希桶),我们称之为哈希冲突。\n\nJDK的做法是链表法,Entry用一个next属性实现多个Entry以单向链表存放。查找哈希值为17的key时,先定位到哈希桶,然后链表遍历桶里所有元素,逐个比较其Hash值然后key值。\n\n在JDK8里,新增默认为8的阈值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。\n\n当然,最好还是桶里只有一个元素,不用去比较。所以默认当Entry数量达到桶数量的75%时,哈希冲突已比较严重,就会成倍扩容桶数组,并重新分配所有原来的Entry。扩容成本不低,所以也最好有个预估值。\n\n取模用与操作(hash & (arrayLength-1))会比较快,所以数组的大小永远是2的N次方, 你随便给一个初始值比如17会转为32。默认第一次放入元素时的初始值是16。\n\niterator()时顺着哈希桶数组来遍历,看起来是个乱序。\n\n \n\n#### LinkedHashMap\n扩展HashMap,每个Entry增加双向链表,号称是最占内存的数据结构。\n\n支持iterator()时按Entry的插入顺序来排序(如果设置accessOrder属性为true,则所有读写访问都排序)。\n\n插入时,Entry把自己加到Header Entry的前面去。如果所有读写访问都要排序,还要把前后Entry的before/after拼接起来以在链表中删除掉自己,所以此时读操作也是线程不安全的了。\n\n \n\n#### TreeMap\n以红黑树实现,红黑树又叫自平衡二叉树:\n\n对于任一节点而言,其到叶节点的每一条路径都包含相同数目的黑结点。\n上面的规定,使得树的层数不会差的太远,使得所有操作的复杂度不超过 O(lgn),但也使得插入,修改时要复杂的左旋右旋来保持树的平衡。\n\n支持iterator()时按Key值排序,可按实现了Comparable接口的Key的升序排序,或由传入的Comparator控制。可想象的,在树上插入/删除元素的代价一定比HashMap的大。\n\n支持SortedMap接口,如firstKey(),lastKey()取得最大最小的key,或sub(fromKey, toKey), tailMap(fromKey)剪取Map的某一段。\n\n \n\n#### EnumMap\nEnumMap的原理是,在构造函数里要传入枚举类,那它就构建一个与枚举的所有值等大的数组,按Enum. ordinal()下标来访问数组。性能与内存占用俱佳。\n\n美中不足的是,因为要实现Map接口,而 V get(Object key)中key是Object而不是泛型K,所以安全起见,EnumMap每次访问都要先对Key进行类型判断,在JMC里录得不低的采样命中频率。\n\n \n\n#### ConcurrentHashMap\n并发优化的HashMap。\n\n在JDK5里的经典设计,默认16把写锁(可以设置更多),有效分散了阻塞的概率。数据结构为Segment[],每个Segment一把锁。Segment里面才是哈希桶数组。Key先算出它在哪个Segment里,再去算它在哪个哈希桶里。\n\n也没有读锁,因为put/remove动作是个原子动作(比如put的整个过程是一个对数组元素/Entry 指针的赋值操作),读操作不会看到一个更新动作的中间状态。\n\n但在JDK8里,Segment[]的设计被抛弃了,改为精心设计的,只在需要锁的时候加锁。\n\n支持ConcurrentMap接口,如putIfAbsent(key,value)与相反的replace(key,value)与以及实现CAS的replace(key, oldValue, newValue)。\n\n \n\n#### ConcurrentSkipListMap\nJDK6新增的并发优化的SortedMap,以SkipList结构实现。Concurrent包选用它是因为它支持基于CAS的无锁算法,而红黑树则没有好的无锁算法。\n\n原理上,可以想象为多个链表组成的N层楼,其中的元素从稀疏到密集,每个元素有往右与往下的指针。从第一层楼开始遍历,如果右端的值比期望的大,那就往下走一层,继续往前走。\n\n \n\n\n\n典型的空间换时间。每次插入,都要决定在哪几层插入,同时,要决定要不要多盖一层楼。\n\n它的size()同样不能随便调,会遍历来统计。\n\n \n\n### Set\n\n\n所有Set几乎都是内部用一个Map来实现, 因为Map里的KeySet就是一个Set,而value是假值,全部使用同一个Object即可。\n\nSet的特征也继承了那些内部的Map实现的特征。\n\nHashSet:内部是HashMap。\n\nLinkedHashSet:内部是LinkedHashMap。\n\nTreeSet:内部是TreeMap的SortedSet。\n\nConcurrentSkipListSet:内部是ConcurrentSkipListMap的并发优化的SortedSet。\n\nCopyOnWriteArraySet:内部是CopyOnWriteArrayList的并发优化的Set,利用其addIfAbsent()方法实现元素去重,如前所述该方法的性能很一般。\n\n好像少了个ConcurrentHashSet,本来也该有一个内部用ConcurrentHashMap的简单实现,但JDK偏偏没提供。Jetty就自己简单封了一个,Guava则直接用java.util.Collections.newSetFromMap(new ConcurrentHashMap()) 实现。\n\n \n\n\n### Queue\nQueue是在两端出入的List,所以也可以用数组或链表来实现。\n\n#### 普通队列\n\nLinkedList\n是的,以双向链表实现的LinkedList既是List,也是Queue。\n\nArrayDeque\n以循环数组实现的双向Queue。大小是2的倍数,默认是16。\n\n为了支持FIFO,即从数组尾压入元素(快),从数组头取出元素(超慢),就不能再使用普通ArrayList的实现了,改为使用循环数组。\n\n有队头队尾两个下标:弹出元素时,队头下标递增;加入元素时,队尾下标递增。如果加入元素时已到数组空间的末尾,则将元素赋值到数组[0],同时队尾下标指向0,再插入下一个元素则赋值到数组[1],队尾下标指向1。如果队尾的下标追上队头,说明数组所有空间已用完,进行双倍的数组扩容。\n\n#### PriorityQueue\n用平衡二叉最小堆实现的优先级队列,不再是FIFO,而是按元素实现的Comparable接口或传入Comparator的比较结果来出队,数值越小,优先级越高,越先出队。但是注意其iterator()的返回不会排序。\n\n平衡最小二叉堆,用一个简单的数组即可表达,可以快速寻址,没有指针什么的。最小的在queue[0] ,比如queue[4]的两个孩子,会在queue[2*4+1] 和 queue[2*(4+1)],即queue[9]和queue[10]。\n\n入队时,插入queue[size],然后二叉地往上比较调整堆。\n\n出队时,弹出queue[0],然后把queque[size]拿出来二叉地往下比较调整堆。\n\n初始大小为11,空间不够时自动50%扩容。\n\n \n\n#### 线程安全的队列\nConcurrentLinkedQueue/Deque\n无界的并发优化的Queue,基于链表,实现了依赖于CAS的无锁算法。\n\nConcurrentLinkedQueue的结构是单向链表和head/tail两个指针,因为入队时需要修改队尾元素的next指针,以及修改tail指向新入队的元素两个CAS动作无法原子,所以需要的特殊的算法。\n\n#### 线程安全的阻塞队列\nBlockingQueue,一来如果队列已空不用重复的查看是否有新数据而会阻塞在那里,二来队列的长度受限,用以保证生产者与消费者的速度不会相差太远。当入队时队列已满,或出队时队列已空,不同函数的效果见下表\n\n\nArrayBlockingQueue\n定长的并发优化的BlockingQueue,也是基于循环数组实现。有一把公共的锁与notFull、notEmpty两个Condition管理队列满或空时的阻塞状态。\n\nLinkedBlockingQueue/Deque\n可选定长的并发优化的BlockingQueue,基于链表实现,所以可以把长度设为Integer.MAX_VALUE成为无界无等待的。\n\n利用链表的特征,分离了takeLock与putLock两把锁,继续用notEmpty、notFull管理队列满或空时的阻塞状态。\n\nPriorityBlockingQueue\n无界的PriorityQueue,也是基于数组存储的二叉堆(见前)。一把公共的锁实现线程安全。因为无界,空间不够时会自动扩容,所以入列时不会锁,出列为空时才会锁。\n\n\nDelayQueue\n内部包含一个PriorityQueue,同样是无界的,同样是出列时才会锁。一把公共的锁实现线程安全。元素需实现Delayed接口,每次调用时需返回当前离触发时间还有多久,小于0表示该触发了。\n\npull()时会用peek()查看队头的元素,检查是否到达触发时间。ScheduledThreadPoolExecutor用了类似的结构。\n\n\n\n#### 同步队列\nSynchronousQueue同步队列本身无容量,放入元素时,比如等待元素被另一条线程的消费者取走再返回。JDK线程池里用它。\n\nJDK7还有个LinkedTransferQueue,在普通线程安全的BlockingQueue的基础上,增加一个transfer(e) 函数,效果与SynchronousQueue一样。\n\n## 参考文章\n\nhttps://blog.csdn.net/zzw1531439090/article/details/87872424\nhttps://blog.csdn.net/weixin_40374341/article/details/86496343\nhttps://www.cnblogs.com/uodut/p/7067162.html\nhttps://www.jb51.net/article/135672.htm\nhttps://www.cnblogs.com/suiyue-/p/6052456.html\n\n"
},
{
"path": "docs/Java/basic/final关键字特性.md",
"content": "# 目录\n\n * [final使用](#final使用)\n * [final变量](#final变量)\n * [final修饰基本数据类型变量和引用](#final修饰基本数据类型变量和引用)\n * [final类](#final类)\n * [final关键字的知识点](#final关键字的知识点)\n * [final关键字的最佳实践](#final关键字的最佳实践)\n * [final的用法](#final的用法)\n * [关于空白final](#关于空白final)\n * [final内存分配](#final内存分配)\n * [使用final修饰方法会提高速度和效率吗](#使用final修饰方法会提高速度和效率吗)\n * [使用final修饰变量会让变量的值不能被改变吗;](#使用final修饰变量会让变量的值不能被改变吗;)\n * [如何保证数组内部不被修改](#如何保证数组内部不被修改)\n * [final方法的三条规则](#final方法的三条规则)\n * [final 和 jvm的关系](#final-和-jvm的关系)\n * [写 final 域的重排序规则](#写-final-域的重排序规则)\n * [读 final 域的重排序规则](#读-final-域的重排序规则)\n * [如果 final 域是引用类型](#如果-final-域是引用类型)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\nfinal关键字在java中使用非常广泛,可以申明成员变量、方法、类、本地变量。一旦将引用声明为final,将无法再改变这个引用。final关键字还能保证内存同步,本博客将会从final关键字的特性到从java内存层面保证同步讲解。这个内容在面试中也有可能会出现。\n\n## final使用\n\n### final变量\n\nfinal变量有成员变量或者是本地变量(方法内的局部变量),在类成员中final经常和static一起使用,作为类常量使用。**其中类常量必须在声明时初始化,final成员常量可以在构造函数初始化。**\n\n```\npublic class Main {\n public static final int i; //报错,必须初始化 因为常量在常量池中就存在了,调用时不需要类的初始化,所以必须在声明时初始化\n public static final int j;\n Main() {\n i = 2;\n j = 3;\n }\n}\n\n```\n\n就如上所说的,对于类常量,JVM会缓存在常量池中,在读取该变量时不会加载这个类。\n\n```\n\npublic class Main {\n public static final int i = 2;\n Main() {\n System.out.println(\"调用构造函数\"); // 该方法不会调用\n }\n public static void main(String[] args) {\n System.out.println(Main.i);\n }\n}\n\n```\n### final修饰基本数据类型变量和引用\n @Test\n public void final修饰基本类型变量和引用() {\n final int a = 1;\n final int[] b = {1};\n final int[] c = {1};\n // b = c;报错\n b[0] = 1;\n final String aa = \"a\";\n final Fi f = new Fi();\n //aa = \"b\";报错\n // f = null;//报错\n f.a = 1;\n }\n\nfinal方法表示该方法不能被子类的方法重写,将方法声明为final,在编译的时候就已经静态绑定了,不需要在运行时动态绑定。final方法调用时使用的是invokespecial指令。\n\n```\nclass PersonalLoan{\n public final String getName(){\n return\"personal loan”;\n }\n}\n\nclass CheapPersonalLoan extends PersonalLoan{\n @Override\n public final String getName(){\n return\"cheap personal loan\";//编译错误,无法被重载\n }\n\n public String test() {\n return getName(); //可以调用,因为是public方法\n }\n}\n\n```\n\n### final类\n\nfinal类不能被继承,final类中的方法默认也会是final类型的,java中的String类和Integer类都是final类型的。\n\n class Si{\n //一般情况下final修饰的变量一定要被初始化。\n //只有下面这种情况例外,要求该变量必须在构造方法中被初始化。\n //并且不能有空参数的构造方法。\n //这样就可以让每个实例都有一个不同的变量,并且这个变量在每个实例中只会被初始化一次\n //于是这个变量在单个实例里就是常量了。\n final int s ;\n Si(int s) {\n this.s = s;\n }\n }\n class Bi {\n final int a = 1;\n final void go() {\n //final修饰方法无法被继承\n }\n }\n class Ci extends Bi {\n final int a = 1;\n // void go() {\n // //final修饰方法无法被继承\n // }\n }\n final char[]a = {'a'};\n final int[]b = {1};\n\n```\nfinal class PersonalLoan{}\n\nclass CheapPersonalLoan extends PersonalLoan { //编译错误,无法被继承 \n}\n\n```\n\n @Test\n public void final修饰类() {\n //引用没有被final修饰,所以是可变的。\n //final只修饰了Fi类型,即Fi实例化的对象在堆中内存地址是不可变的。\n //虽然内存地址不可变,但是可以对内部的数据做改变。\n Fi f = new Fi();\n f.a = 1;\n System.out.println(f);\n f.a = 2;\n System.out.println(f);\n //改变实例中的值并不改变内存地址。\n \n Fi ff = f;\n //让引用指向新的Fi对象,原来的f对象由新的引用ff持有。\n //引用的指向改变也不会改变原来对象的地址\n f = new Fi();\n System.out.println(f);\n System.out.println(ff);\n }\n\n### final关键字的知识点\n\n1. final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。final变量一旦被初始化后不能再次赋值。\n2. 本地变量必须在声明时赋值。 因为没有初始化的过程\n3. 在匿名类中所有变量都必须是final变量。\n4. final方法不能被重写, final类不能被继承\n5. 接口中声明的所有变量本身是final的。类似于匿名类\n6. final和abstract这两个关键字是反相关的,final类就不可能是abstract的。\n7. final方法在编译阶段绑定,称为静态绑定(static binding)。\n8. 将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。\n\nfinal方法的好处:\n\n1. 提高了性能,JVM在常量池中会缓存final变量\n2. final变量在多线程中并发安全,无需额外的同步开销\n3. final方法是静态编译的,提高了调用速度\n4. **final类创建的对象是只可读的,在多线程可以安全共享**\n\n## final关键字的最佳实践\n\n### final的用法 \n1、final 对于常量来说,意味着值不能改变,例如 final int i=100。这个i的值永远都是100。 \n但是对于变量来说又不一样,只是标识这个引用不可被改变,例如 final File f=new File("c:\\\\test.txt");\n\n那么这个f一定是不能被改变的,如果f本身有方法修改其中的成员变量,例如是否可读,是允许修改的。有个形象的比喻:一个女子定义了一个final的老公,这个老公的职业和收入都是允许改变的,只是这个女人不会换老公而已。 \n\n### 关于空白final \nfinal修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。 \n 另外,final变量定义的时候,可以先声明,而不给初值,这中变量也称为final空白,无论什么情况,编译器都确保空白final在使用之前必须被初始化。\n \n但是,final空白在final关键字final的使用上提供了更大的灵活性,为此,一个类中的final数据成员就可以实现依对象而有所不同,却有保持其恒定不变的特征。 \n````\n public class FinalTest { \n final int p; \n final int q=3; \n FinalTest(){ \n p=1; \n } \n FinalTest(int i){ \n p=i;//可以赋值,相当于直接定义p \n q=i;//不能为一个final变量赋值 \n } \n } \n````\n### final内存分配 \n刚提到了内嵌机制,现在详细展开。 \n要知道调用一个函数除了函数本身的执行时间之外,还需要额外的时间去寻找这个函数(类内部有一个函数签名和函数地址的映射表)。所以减少函数调用次数就等于降低了性能消耗。 \n\nfinal修饰的函数会被编译器优化,优化的结果是减少了函数调用的次数。如何实现的,举个例子给你看:\n````\n public class Test{ \n final void func(){System.out.println(\"g\");}; \n public void main(String[] args){ \n for(int j=0;j<1000;j++) \n func(); \n }} \n\n 经过编译器优化之后,这个类变成了相当于这样写: \n public class Test{ \n final void func(){System.out.println(\"g\");}; \n public void main(String[] args){ \n for(int j=0;j<1000;j++) \n {System.out.println(\"g\");} \n }} \n````\n看出来区别了吧?编译器直接将func的函数体内嵌到了调用函数的地方,这样的结果是节省了1000次函数调用,当然编译器处理成字节码,只是我们可以想象成这样,看个明白。 \n\n不过,当函数体太长的话,用final可能适得其反,因为经过编译器内嵌之后代码长度大大增加,于是就增加了jvm解释字节码的时间。\n\n在使用final修饰方法的时候,编译器会将被final修饰过的方法插入到调用者代码处,提高运行速度和效率,但被final修饰的方法体不能过大,编译器可能会放弃内联,但究竟多大的方法会放弃,我还没有做测试来计算过。 \n\n**下面这些内容是通过两个疑问来继续阐述的**\n\n### 使用final修饰方法会提高速度和效率吗\n\n见下面的测试代码,我会执行五次:\n\n````\n public class Test \n { \n public static void getJava() \n { \n String str1 = \"Java \"; \n String str2 = \"final \"; \n for (int i = 0; i < 10000; i++) \n { \n str1 += str2; \n } \n } \n public static final void getJava_Final() \n { \n String str1 = \"Java \"; \n String str2 = \"final \"; \n for (int i = 0; i < 10000; i++) \n { \n str1 += str2; \n } \n } \n public static void main(String[] args) \n { \n long start = System.currentTimeMillis(); \n getJava(); \n System.out.println(\"调用不带final修饰的方法执行时间为:\" + (System.currentTimeMillis() - start) + \"毫秒时间\"); \n start = System.currentTimeMillis(); \n String str1 = \"Java \"; \n String str2 = \"final \"; \n for (int i = 0; i < 10000; i++) \n { \n str1 += str2; \n } \n System.out.println(\"正常的执行时间为:\" + (System.currentTimeMillis() - start) + \"毫秒时间\"); \n start = System.currentTimeMillis(); \n getJava_Final(); \n System.out.println(\"调用final修饰的方法执行时间为:\" + (System.currentTimeMillis() - start) + \"毫秒时间\"); \n } \n } \n\n````\n\n 结果为: \n 第一次: \n 调用不带final修饰的方法执行时间为:1732毫秒时间 \n 正常的执行时间为:1498毫秒时间 \n 调用final修饰的方法执行时间为:1593毫秒时间 \n 第二次: \n 调用不带final修饰的方法执行时间为:1217毫秒时间 \n 正常的执行时间为:1031毫秒时间 \n 调用final修饰的方法执行时间为:1124毫秒时间 \n 第三次: \n 调用不带final修饰的方法执行时间为:1154毫秒时间 \n 正常的执行时间为:1140毫秒时间 \n 调用final修饰的方法执行时间为:1202毫秒时间 \n 第四次: \n 调用不带final修饰的方法执行时间为:1139毫秒时间 \n 正常的执行时间为:999毫秒时间 \n 调用final修饰的方法执行时间为:1092毫秒时间 \n 第五次: \n 调用不带final修饰的方法执行时间为:1186毫秒时间 \n 正常的执行时间为:1030毫秒时间 \n 调用final修饰的方法执行时间为:1109毫秒时间 \n \n 由以上运行结果不难看出,执行最快的是“正常的执行”即代码直接编写,而使用final修饰的方法,不像有些书上或者文章上所说的那样,速度与效率与“正常的执行”无异,而是位于第二位,最差的是调用不加final修饰的方法。 \n\n 观点:加了比不加好一点。 \n\n\n### 使用final修饰变量会让变量的值不能被改变吗; \n见代码:\n\n````\n public class Final \n { \n public static void main(String[] args) \n { \n Color.color[3] = \"white\"; \n for (String color : Color.color) \n System.out.print(color+\" \"); \n } \n } \n \n class Color \n { \n public static final String[] color = { \"red\", \"blue\", \"yellow\", \"black\" }; \n } \n\n\n 执行结果: \n red blue yellow white \n 看!,黑色变成了白色。 \n\n````\n \n 在使用findbugs插件时,就会提示public static String[] color = { \"red\", \"blue\", \"yellow\", \"black\" };这行代码不安全,但加上final修饰,这行代码仍然是不安全的,因为final没有做到保证变量的值不会被修改!\n \n 原因是:final关键字只能保证变量本身不能被赋与新值,而不能保证变量的内部结构不被修改。例如在main方法有如下代码Color.color = new String[]{\"\"};就会报错了。\n\n### 如何保证数组内部不被修改\n\n 那可能有的同学就会问了,加上final关键字不能保证数组不会被外部修改,那有什么方法能够保证呢?答案就是降低访问级别,把数组设为private。这样的话,就解决了数组在外部被修改的不安全性,但也产生了另一个问题,那就是这个数组要被外部使用的。 \n\n解决这个问题见代码:\n````\n import java.util.AbstractList; \n import java.util.List; \n \n public class Final \n { \n public static void main(String[] args) \n { \n for (String color : Color.color) \n System.out.print(color + \" \"); \n Color.color.set(3, \"white\"); \n } \n } \n \n class Color \n { \n private static String[] _color = { \"red\", \"blue\", \"yellow\", \"black\" }; \n public static List color = new AbstractList() \n { \n @Override \n public String get(int index) \n { \n return _color[index]; \n } \n @Override \n public String set(int index, String value) \n { \n throw new RuntimeException(\"为了代码安全,不能修改数组\"); \n } \n @Override \n public int size() \n { \n return _color.length; \n } \n }; \n\n\n }\n````\n这样就OK了,既保证了代码安全,又能让数组中的元素被访问了。\n\n\n### final方法的三条规则\n\n规则1:final修饰的方法不可以被重写。\n\n规则2:final修饰的方法仅仅是不能重写,但它完全可以被重载。\n\n规则3:父类中private final方法,子类可以重新定义,这种情况不是重写。\n\n代码示例\n````\n 规则1代码\n \n public class FinalMethodTest\n {\n \tpublic final void test(){}\n }\n class Sub extends FinalMethodTest\n {\n \t// 下面方法定义将出现编译错误,不能重写final方法\n \tpublic void test(){}\n }\n \n 规则2代码\n \n public class Finaloverload {\n \t//final 修饰的方法只是不能重写,完全可以重载\n \tpublic final void test(){}\n \tpublic final void test(String arg){}\n }\n \n 规则3代码\n \n public class PrivateFinalMethodTest\n {\n \tprivate final void test(){}\n }\n class Sub extends PrivateFinalMethodTest\n {\n \t// 下面方法定义将不会出现问题\n \tpublic void test(){}\n }\n````\n\n## final 和 jvm的关系\n\n与前面介绍的锁和 volatile 相比较,对 final 域的读和写更像是普通的变量访问。对于 final 域,编译器和处理器要遵守两个重排序规则:\n\n1. 在构造函数内对一个 final 域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。\n2. 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。\n\n下面,我们通过一些示例性的代码来分别说明这两个规则:\n````\npublic class FinalExample {\n int i; // 普通变量 \n final int j; //final 变量 \n static FinalExample obj;\n\n public void FinalExample () { // 构造函数 \n i = 1; // 写普通域 \n j = 2; // 写 final 域 \n }\n \n public static void writer () { // 写线程 A 执行 \n obj = new FinalExample ();\n }\n \n public static void reader () { // 读线程 B 执行 \n FinalExample object = obj; // 读对象引用 \n int a = object.i; // 读普通域 \n int b = object.j; // 读 final 域 \n }\n}\n````\n\n这里假设一个线程 A 执行 writer () 方法,随后另一个线程 B 执行 reader () 方法。下面我们通过这两个线程的交互来说明这两个规则。\n\n### 写 final 域的重排序规则\n\n写 final 域的重排序规则禁止把 final 域的写重排序到构造函数之外。这个规则的实现包含下面 2 个方面:\n\n* JMM 禁止编译器把 final 域的写重排序到构造函数之外。\n* 编译器会在 final 域的写之后,构造函数 return 之前,插入一个 StoreStore 屏障。这个屏障禁止处理器把 final 域的写重排序到构造函数之外。\n\n现在让我们分析 writer () 方法。writer () 方法只包含一行代码:finalExample = new FinalExample ()。这行代码包含两个步骤:\n\n1. 构造一个 FinalExample 类型的对象;\n2. 把这个对象的引用赋值给引用变量 obj。\n\n假设线程 B 读对象引用与读对象的成员域之间没有重排序(马上会说明为什么需要这个假设),下图是一种可能的执行时序:\n\n\n\n在上图中,写普通域的操作被编译器重排序到了构造函数之外,读线程 B 错误的读取了普通变量 i 初始化之前的值。而写 final 域的操作,被写 final 域的重排序规则“限定”在了构造函数之内,读线程 B 正确的读取了 final 变量初始化之后的值。\n\n写 final 域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域不具有这个保障。以上图为例,在读线程 B“看到”对象引用 obj 时,很可能 obj 对象还没有构造完成(对普通域 i 的写操作被重排序到构造函数外,此时初始值 1 还没有写入普通域 i)。\n\n### 读 final 域的重排序规则\n\n读 final 域的重排序规则如下:\n\n* 在一个线程中,初次读对象引用与初次读该对象包含的 final 域,JMM 禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读 final 域操作的前面插入一个 LoadLoad 屏障。\n\n初次读对象引用与初次读该对象包含的 final 域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,大多数处理器也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如 alpha 处理器),这个规则就是专门用来针对这种处理器。\n\nreader() 方法包含三个操作:\n\n1. 初次读引用变量 obj;\n2. 初次读引用变量 obj 指向对象的普通域 i。\n3. 初次读引用变量 obj 指向对象的 final 域 j。\n\n现在我们假设写线程 A 没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行,下面是一种可能的执行时序:\n\n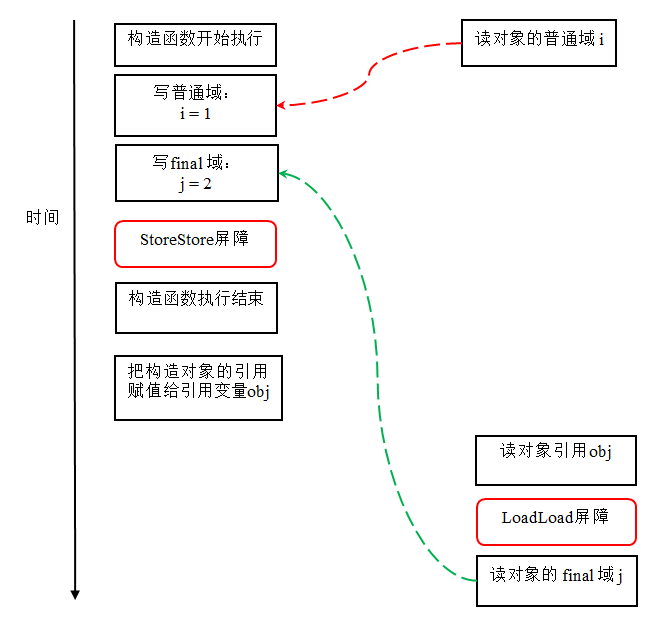\n\n在上图中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程 A 写入,这是一个错误的读取操作。而读 final 域的重排序规则会把读对象 final 域的操作“限定”在读对象引用之后,此时该 final 域已经被 A 线程初始化过了,这是一个正确的读取操作。\n\n读 final 域的重排序规则可以确保:在读一个对象的 final 域之前,一定会先读包含这个 final 域的对象的引用。在这个示例程序中,如果该引用不为 null,那么引用对象的 final 域一定已经被 A 线程初始化过了。\n\n### 如果 final 域是引用类型\n\n上面我们看到的 final 域是基础数据类型,下面让我们看看如果 final 域是引用类型,将会有什么效果?\n\n请看下列示例代码:\n````\npublic class FinalReferenceExample {\nfinal int[] intArray; //final 是引用类型 \nstatic FinalReferenceExample obj;\n\npublic FinalReferenceExample () { // 构造函数 \n intArray = new int[1]; //1\n intArray[0] = 1; //2\n}\n\npublic static void writerOne () { // 写线程 A 执行 \n obj = new FinalReferenceExample (); //3\n}\n\npublic static void writerTwo () { // 写线程 B 执行 \n obj.intArray[0] = 2; //4\n}\n\npublic static void reader () { // 读线程 C 执行 \n if (obj != null) { //5\n int temp1 = obj.intArray[0]; //6\n }\n}\n}\n````\n\n这里 final 域为一个引用类型,它引用一个 int 型的数组对象。对于引用类型,写 final 域的重排序规则对编译器和处理器增加了如下约束:\n\n1. 在构造函数内对一个 final 引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。\n\n对上面的示例程序,我们假设首先线程 A 执行 writerOne() 方法,执行完后线程 B 执行 writerTwo() 方法,执行完后线程 C 执行 reader () 方法。下面是一种可能的线程执行时序:\n\n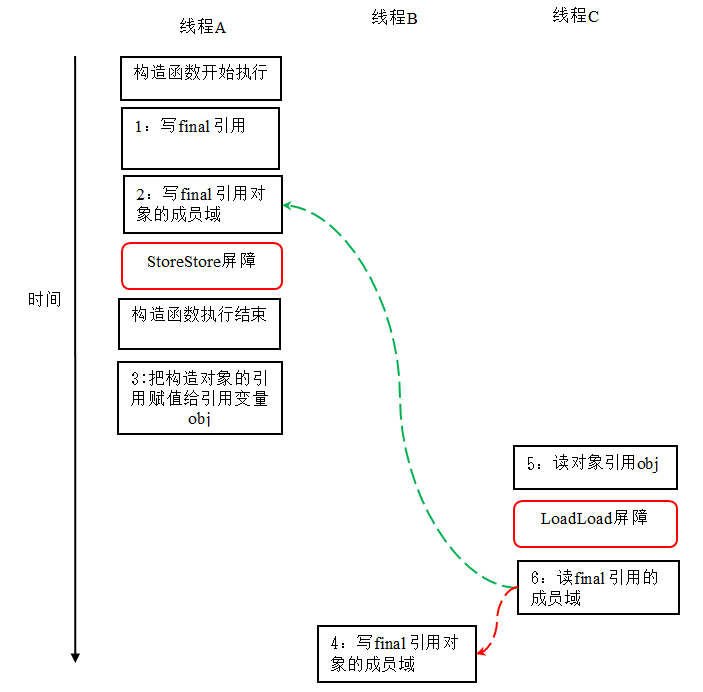\n在上图中,1 是对 final 域的写入,2 是对这个 final 域引用的对象的成员域的写入,3 是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的 1 不能和 3 重排序外,2 和 3 也不能重排序。\n\nJMM 可以确保读线程 C 至少能看到写线程 A 在构造函数中对 final 引用对象的成员域的写入。即 C 至少能看到数组下标 0 的值为 1。而写线程 B 对数组元素的写入,读线程 C 可能看的到,也可能看不到。JMM 不保证线程 B 的写入对读线程 C 可见,因为写线程 B 和读线程 C 之间存在数据竞争,此时的执行结果不可预知。\n\n如果想要确保读线程 C 看到写线程 B 对数组元素的写入,写线程 B 和读线程 C 之间需要使用同步原语(lock 或 volatile)来确保内存可见性。\n\n\n## 参考文章\n\nhttps://www.infoq.cn/article/java-memory-model-6\nhttps://www.jianshu.com/p/067b6c89875a\nhttps://www.jianshu.com/p/f68d6ef2dcf0\nhttps://www.cnblogs.com/xiaoxi/p/6392154.html\nhttps://www.iteye.com/blog/cakin24-2334965\nhttps://blog.csdn.net/chengqiuming/article/details/70139503\nhttps://blog.csdn.net/hupuxiang/article/details/7362267\n\n\n"
},
{
"path": "docs/Java/basic/javac和javap.md",
"content": "# 目录\n * [聊聊IDE的实现原理](#聊聊ide的实现原理)\n * [源代码保存](#源代码保存)\n * [编译为class文件](#编译为class文件)\n * [查找class](#查找class)\n * [生成对象,并调用对象方法](#生成对象,并调用对象方法)\n * [javac命令初窥](#javac命令初窥)\n * [classpath是什么](#classpath是什么)\n * [IDE中的classpath](#ide中的classpath)\n * [Java项目和Java web项目的本质区别](#java项目和java-web项目的本质区别)\n * [javac命令后缀](#javac命令后缀)\n * [-g、-g:none、-g:{lines,vars,source}](#-g、-gnone、-g{linesvarssource})\n * [-bootclasspath、-extdirs](#-bootclasspath、-extdirs)\n * [-sourcepath和-classpath(-cp)](#-sourcepath和-classpath(-cp))\n * [-d](#-d)\n * [-implicit:{none,class}](#-implicit{noneclass})\n * [-source和-target](#-source和-target)\n * [-encoding](#-encoding)\n * [-verbose](#-verbose)\n * [其他命令](#其他命令)\n * [使用javac构建项目](#使用javac构建项目)\n * [javap 的使用](#javap-的使用)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n## 聊聊IDE的实现原理\n\n> IDE是把双刃剑,它可以什么都帮你做了,你只要敲几行代码,点几下鼠标,程序就跑起来了,用起来相当方便。\n>\n> 你不用去关心它后面做了些什么,执行了哪些命令,基于什么原理。然而也是这种过分的依赖往往让人散失了最基本的技能,当到了一个没有IDE的地方,你便觉得无从下手,给你个代码都不知道怎么去跑。好比给你瓶水,你不知道怎么打开去喝,然后活活给渴死。\n>\n> 之前用惯了idea,Java文件编译运行的命令基本忘得一干二净。\n\n那好,不如咱们先来了解一下IDE的实现原理,这样一来,即使离开IDE,我们还是知道如何运行Java程序了。\n\n像Eclipse等java IDE是怎么编译和查找java源代码的呢?\n\n### 源代码保存\n这个无需多说,在编译器写入代码,并保存到文件。这个利用流来实现。\n\n### 编译为class文件\njava提供了JavaCompiler,我们可以通过它来编译java源文件为class文件。\n\n### 查找class\n可以通过Class.forName(fullClassPath)或自定义类加载器来实现。\n\n### 生成对象,并调用对象方法\n通过上面一个查找class,得到Class对象后,可以通过newInstance()或构造器的newInstance()得到对象。然后得到Method,最后调用方法,传入相关参数即可。\n\n示例代码:\n````\npublic class MyIDE {\n\n public static void main(String[] args) throws IOException, ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {\n // 定义java代码,并保存到文件(Test.java)\n StringBuilder sb = new StringBuilder();\n sb.append(\"package com.tommy.core.test.reflect;\\n\");\n sb.append(\"public class Test {\\n\");\n sb.append(\" private String name;\\n\");\n sb.append(\" public Test(String name){\\n\");\n sb.append(\" this.name = name;\\n\");\n sb.append(\" System.out.println(\\\"hello,my name is \\\" + name);\\n\");\n sb.append(\" }\\n\");\n sb.append(\" public String sayHello(String name) {\\n\");\n sb.append(\" return \\\"hello,\\\" + name;\\n\");\n sb.append(\" }\\n\");\n sb.append(\"}\\n\");\n\n System.out.println(sb.toString());\n\n String baseOutputDir = \"F:\\\\output\\\\classes\\\\\";\n String baseDir = baseOutputDir + \"com\\\\tommy\\\\core\\\\test\\\\reflect\\\\\";\n String targetJavaOutputPath = baseDir + \"Test.java\";\n // 保存为java文件\n FileWriter fileWriter = new FileWriter(targetJavaOutputPath);\n fileWriter.write(sb.toString());\n fileWriter.flush();\n fileWriter.close();\n\n // 编译为class文件\n JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();\n StandardJavaFileManager manager = compiler.getStandardFileManager(null,null,null);\n List files = new ArrayList<>();\n files.add(new File(targetJavaOutputPath));\n Iterable compilationUnits = manager.getJavaFileObjectsFromFiles(files);\n\n // 编译\n // 设置编译选项,配置class文件输出路径\n Iterable options = Arrays.asList(\"-d\",baseOutputDir);\n JavaCompiler.CompilationTask task = compiler.getTask(null, manager, null, options, null, compilationUnits);\n // 执行编译任务\n task.call();\n\n\n \n // 通过反射得到对象\n// Class clazz = Class.forName(\"com.tommy.core.test.reflect.Test\");\n // 使用自定义的类加载器加载class\n Class clazz = new MyClassLoader(baseOutputDir).loadClass(\"com.tommy.core.test.reflect.Test\");\n // 得到构造器\n Constructor constructor = clazz.getConstructor(String.class);\n // 通过构造器new一个对象\n Object test = constructor.newInstance(\"jack.tsing\");\n // 得到sayHello方法\n Method method = clazz.getMethod(\"sayHello\", String.class);\n // 调用sayHello方法\n String result = (String) method.invoke(test, \"jack.ma\");\n System.out.println(result);\n }\n}\n````\n自定义类加载器代码:\n\n````\n \npublic class MyClassLoader extends ClassLoader {\n private String baseDir;\n public MyClassLoader(String baseDir) {\n this.baseDir = baseDir;\n }\n @Override\n protected Class findClass(String name) throws ClassNotFoundException {\n String fullClassFilePath = this.baseDir + name.replace(\"\\\\.\",\"/\") + \".class\";\n File classFilePath = new File(fullClassFilePath);\n if (classFilePath.exists()) {\n FileInputStream fileInputStream = null;\n ByteArrayOutputStream byteArrayOutputStream = null;\n try {\n fileInputStream = new FileInputStream(classFilePath);\n byte[] data = new byte[1024];\n int len = -1;\n byteArrayOutputStream = new ByteArrayOutputStream();\n while ((len = fileInputStream.read(data)) != -1) {\n byteArrayOutputStream.write(data,0,len);\n }\n\n return defineClass(name,byteArrayOutputStream.toByteArray(),0,byteArrayOutputStream.size());\n } catch (FileNotFoundException e) {\n e.printStackTrace();\n } catch (IOException e) {\n e.printStackTrace();\n } finally {\n if (null != fileInputStream) {\n try {\n fileInputStream.close();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n\n if (null != byteArrayOutputStream) {\n try {\n byteArrayOutputStream.close();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n }\n }\n return super.findClass(name);\n }\n} \n````\n## javac命令初窥\n\n注:以下红色标记的参数在下文中有所讲解。\n\n本部分参考https://www.cnblogs.com/xiazdong/p/3216220.html\n\n用法: javac \n\n其中, 可能的选项包括:\n\n> -g 生成所有调试信息\n>\n> -g:none 不生成任何调试信息\n>\n> -g:{lines,vars,source} 只生成某些调试信息\n>\n> -nowarn 不生成任何警告\n>\n> -verbose 输出有关编译器正在执行的操作的消息\n>\n> -deprecation 输出使用已过时的 API 的源位置\n>\n> -classpath <路径> 指定查找用户类文件和注释处理程序的位置\n>\n> -cp <路径> 指定查找用户类文件和注释处理程序的位置\n>\n> -sourcepath <路径> 指定查找输入源文件的位置\n>\n> -bootclasspath <路径> 覆盖引导类文件的位置\n>\n> -extdirs <目录> 覆盖所安装扩展的位置\n>\n> -endorseddirs <目录> 覆盖签名的标准路径的位置\n>\n> -proc:{none,only} 控制是否执行注释处理和/或编译。\n>\n> -processor [,,...] 要运行的注释处理程序的名称; 绕过默认的搜索进程\n>\n> -processorpath <路径> 指定查找注释处理程序的位置\n>\n> -d <目录> 指定放置生成的类文件的位置\n>\n> -s <目录> 指定放置生成的源文件的位置\n>\n> -implicit:{none,class} 指定是否为隐式引用文件生成类文件\n>\n> -encoding <编码> 指定源文件使用的字符编码\n>\n> -source <发行版> 提供与指定发行版的源兼容性\n>\n> -target <发行版> 生成特定 VM 版本的类文件\n>\n> -version 版本信息\n>\n> -help 输出标准选项的提要\n>\n> -A关键字[=值] 传递给注释处理程序的选项\n>\n> -X 输出非标准选项的提要\n>\n> -J<标记> 直接将 <标记> 传递给运行时系统\n>\n> -Werror 出现警告时终止编译\n>\n> @<文件名> 从文件读取选项和文件名\n\n\n在详细介绍javac命令之前,先看看这个classpath是什么\n\n\n### classpath是什么\n\n在dos下编译java程序,就要用到classpath这个概念,尤其是在没有设置环境变量的时候。classpath就是存放.class等编译后文件的路径。\n\njavac:如果当前你要编译的java文件中引用了其它的类(比如说:继承),但该引用类的.class文件不在当前目录下,这种情况下就需要在javac命令后面加上-classpath参数,通过使用以下三种类型的方法 来指导编译器在编译的时候去指定的路径下查找引用类。\n\n> (1).绝对路径:javac -classpath c:/junit3.8.1/junit.jar Xxx.java\n>\n> (2).相对路径:javac -classpath ../junit3.8.1/Junit.javr Xxx.java\n>\n> (3).系统变量:javac -classpath %CLASSPATH% Xxx.java (注意:%CLASSPATH%表示使用系统变量CLASSPATH的值进行查找,这里假设Junit.jar的路径就包含在CLASSPATH系统变量中)\n\n\n#### IDE中的classpath\n\n对于一个普通的Javaweb项目,一般有这样的配置:\n\n> 1 WEB-INF/classes,lib才是classpath,WEB-INF/ 是资源目录, 客户端不能直接访问。\n>\n> 2、WEB-INF/classes目录存放src目录java文件编译之后的class文件,xml、properties等资源配置文件,这是一个定位资源的入口。\n>\n> 3、引用classpath路径下的文件,只需在文件名前加classpath:\n>\n> classpath:applicationContext-*.xml \n> \n> classpath:context/conf/controller.xml \n>\n> 4、lib和classes同属classpath,两者的访问优先级为: lib>classes。\n>\n> 5、classpath 和 classpath* 区别:\n>\n> classpath:只会到你的class路径中查找找文件;\n> classpath*:不仅包含class路径,还包括jar文件中(class路径)进行查找。\n\n总结:\n\n(1).何时需要使用-classpath:当你要编译或执行的类引用了其它的类,但被引用类的.class文件不在当前目录下时,就需要通过-classpath来引入类\n\n(2).何时需要指定路径:当你要编译的类所在的目录和你执行javac命令的目录不是同一个目录时,就需要指定源文件的路径(CLASSPATH是用来指定.class路径的,不是用来指定.java文件的路径的) \n#### Java项目和Java web项目的本质区别\n\n(看清IDE及classpath本质)\n\n> 现在只是说说Java Project和Web Project,那么二者有区别么?回答:没有!都是Java语言的应用,只是应用场合不同罢了,那么他们的本质到底是什么?\n\n> 回答:编译后路径!虚拟机执行的是class文件而不是java文件,那么我们不管是何种项目都是写的java文件,怎么就不一样了呢?分成java和web两种了呢?\n\n> 从.classpath文件入手来看,这个文件在每个项目目录下都是存在的,很少有人打开看吧,那么我们就来一起看吧。这是一个XML文件,使用文本编辑器打开即可。\n>\n> 这里展示一个web项目的.classpath\n\nXml代码\n````\n \n \n \n \n \n \n \n \n ……\n \n \n````\n> XML文档包含一个根元素,就是classpath,类路径,那么这里面包含了什么信息呢?子元素是classpathentry,kind属性区别了种 类信息,src源码,con你看看后面的path就知道是JRE容器的信息。lib是项目依赖的第三方类库,output是src编译后的位置。\n\n> 既然是web项目,那么就是WEB-INF/classes目录,可能用MyEclipse的同学会说他们那里是WebRoot或者是WebContext而不是webapp,有区别么?回答:完全没有!\n\n> 既然看到了编译路径的本来面目后,还区分什么java项目和web项目么?回答:不区分!普通的java 项目你这样写就行了:,看看Eclipse是不是这样生成的?这个问题解决了吧。\n\n> 再说说webapp目录命名的问题,这个无所谓啊,web项目是要发布到服务器上的对吧,那么服务器读取的是类文件和页面文件吧,它不管源文件,它也无法去理解源文件。那么webapp目录的命名有何关系呢?只要让服务器找到不就行了。\n\n### javac命令后缀\n\n#### -g、-g:none、-g:{lines,vars,source}\n\n> •-g:在生成的class文件中包含所有调试信息(行号、变量、源文件)\n> •-g:none :在生成的class文件中不包含任何调试信息。\n>\n> 这个参数在javac编译中是看不到什么作用的,因为调试信息都在class文件中,而我们看不懂这个class文件。\n>\n> 为了看出这个参数的作用,我们在eclipse中进行实验。在eclipse中,我们经常做的事就是“debug”,而在debug的时候,我们会\n> •加入“断点”,这个是靠-g:lines起作用,如果不记录行号,则不能加断点。\n> •在“variables”窗口中查看当前的变量,如下图所示,这是靠-g:vars起作用,否则不能查看变量信息。\n> •在多个文件之间来回调用,比如 A.java的main()方法中调用了B.java的fun()函数,而我想看看程序进入fun()后的状态,这是靠-g:source,如果没有这个参数,则不能查看B.java的源代码。\n\n#### -bootclasspath、-extdirs\n\n> -bootclasspath和-extdirs 几乎不需要用的,因为他是用来改变 “引导类”和“扩展类”。\n> •引导类(组成Java平台的类):Java\\jdk1.7.0_25\\jre\\lib\\rt.jar等,用-bootclasspath设置。\n> •扩展类:Java\\jdk1.7.0_25\\jre\\lib\\ext目录中的文件,用-extdirs设置。\n> •用户自定义类:用-classpath设置。\n>\n> 我们用-verbose编译后出现的“类文件的搜索路径”,就是由上面三个路径组成,如下:\n\n\n [类文件的搜索路径: C:\\Java\\jdk1.7.0_25\\jre\\lib\\resources.jar,C:\\Java\\jdk1.7.0_25\n \n \\jre\\lib\\rt.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\sunrsasign.jar,C:\\Java\\jdk1.7.0_25\\j\n \n re\\lib\\jsse.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\jce.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\\n \n charsets.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\jfr.jar,C:\\Java\\jdk1.7.0_25\\jre\\classes\n \n ,C:\\Java\\jdk1.7.0_25\\jre\\lib\\ext\\access-bridge-32.jar,C:\\Java\\jdk1.7.0_25\\jre\\li\n \n b\\ext\\dnsns.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\ext\\jaccess.jar,C:\\Java\\jdk1.7.0_25\\\n \n jre\\lib\\ext\\localedata.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\ext\\sunec.jar,C:\\Java\\jdk\n \n 1.7.0_25\\jre\\lib\\ext\\sunjce_provider.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\ext\\sunmsca\n \n pi.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\\ext\\sunpkcs11.jar,C:\\Java\\jdk1.7.0_25\\jre\\lib\n \\ext\\zipfs.jar,..\\bin] \n\n如果利用 -bootclasspath 重新定义: javac -bootclasspath src Xxx.java,则会出现下面错误:\n\n\n致命错误: 在类路径或引导类路径中找不到程序包 java.lang\n\n#### -sourcepath和-classpath(-cp)\n\n•-classpath(-cp)指定你依赖的类的class文件的查找位置。在Linux中,用“:”分隔classpath,而在windows中,用“;”分隔。\n•-sourcepath指定你依赖的类的java文件的查找位置。\n\n举个例子,\n\n\n````\npublic class A\n{\n public static void main(String[] args) {\n B b = new B();\n b.print();\n }\n}\n\n\n\n\npublic class B\n{\n public void print()\n {\n System.out.println(\"old\");\n }\n}\n````\n\n目录结构如下:\n\n\nsourcepath //此处为当前目录\n\n```\n|-src\n |-com\n |- B.java\n |- A.java\n |-bin\n |- B.class //是 B.java\n```\n 编译后的类文件\n\n如果要编译 A.java,则必须要让编译器找到类B的位置,你可以指定B.class的位置,也可以是B.java的位置,也可以同时都存在。\n\n\n javac -classpath bin src/A.java //查找到B.class\n \n javac -sourcepath src/com src/A.java //查找到B.java\n \n javac -sourcepath src/com -classpath bin src/A.java //同时查找到B.class和B.java\n\n如果同时找到了B.class和B.java,则:\n•如果B.class和B.java内容一致,则遵循B.class。\n•如果B.class和B.java内容不一致,则遵循B.java,并编译B.java。\n\n以上规则可以通过 -verbose选项看出。\n\n#### -d\n\n•d就是 destination,用于指定.class文件的生成目录,在eclipse中,源文件都在src中,编译的class文件都是在bin目录中。\n\n这里我用来实现一下这个功能,假设项目名称为project,此目录为当前目录,且在src/com目录中有一个Main.java文件。‘\n\n\n```` \n package com;\n public class Main\n {\n public static void main(String[] args) {\n System.out.println(\"Hello\");\n }\n }\n\n\n```` \n \njavac -d bin src/com/Main.java\n\n上面的语句将Main.class生成在bin/com目录下。\n\n#### -implicit:{none,class}\n\n•如果有文件为A.java(其中有类A),且在类A中使用了类B,类B在B.java中,则编译A.java时,默认会自动编译B.java,且生成B.class。\n•implicit:none:不自动生成隐式引用的类文件。\n•implicit:class(默认):自动生成隐式引用的类文件。\n````\npublic class A\n{\n public static void main(String[] args) {\n B b = new B();\n }\n}\n\npublic class B\n{\n}\n````\n如果使用:\n\n\n \njavac -implicit:none A.java\n\n则不会生成 B.class。\n\n#### -source和-target\n\n•-source:使用指定版本的JDK编译,比如:-source 1.4表示用JDK1.4的标准编译,如果在源文件中使用了泛型,则用JDK1.4是不能编译通过的。\n•-target:指定生成的class文件要运行在哪个JVM版本,以后实际运行的JVM版本必须要高于这个指定的版本。\n\n\njavac -source 1.4 Xxx.java\n\njavac -target 1.4 Xxx.java\n\n#### -encoding\n\n默认会使用系统环境的编码,比如我们一般用的中文windows就是GBK编码,所以直接javac时会用GBK编码,而Java文件一般要使用utf-8,如果用GBK就会出现乱码。 \n\n•指定源文件的编码格式,如果源文件是UTF-8编码的,而-encoding GBK,则源文件就变成了乱码(特别是有中文时)。\n\n\njavac -encoding UTF-8 Xxx.java\n\n#### -verbose\n\n输出详细的编译信息,包括:classpath、加载的类文件信息。\n\n比如,我写了一个最简单的HelloWorld程序,在命令行中输入:\n\n\nD:\\Java>javac -verbose -encoding UTF-8 HelloWorld01.java\n\n输出:\n\n\n [语法分析开始时间 RegularFileObject[HelloWorld01.java]]\n [语法分析已完成, 用时 21 毫秒]\n [源文件的搜索路径: .,D:\\大三下\\编译原理\\cup\\java-cup-11a.jar,E:\\java\\jflex\\lib\\J //-sourcepath\n Flex.jar]\n [类文件的搜索路径: C:\\Java\\jdk1.7.0_25\\jre\\lib\\resources.jar,C:\\Java\\jdk1.7.0_25 //-classpath、-bootclasspath、-extdirs\n 省略............................................\n [正在加载ZipFileIndexFileObject[C:\\Java\\jdk1.7.0_25\\lib\\ct.sym(META-INF/sym/rt.j\n ar/java/lang/Object.class)]]\n [正在加载ZipFileIndexFileObject[C:\\Java\\jdk1.7.0_25\\lib\\ct.sym(META-INF/sym/rt.j\n ar/java/lang/String.class)]]\n [正在检查Demo]\n 省略............................................\n [已写入RegularFileObject[Demo.class]]\n [共 447 毫秒]\n\n编写一个程序时,比如写了一句:System.out.println(\"hello\"),实际上还需要加载:Object、PrintStream、String等类文件,而上面就显示了加载的全部类文件。\n\n#### 其他命令\n\n-J <标记>\n•传递一些信息给 Java Launcher.\n\n\n javac -J-Xms48m Xxx.java //set the startup memory to 48M.\n\n-@<文件名>\n\n> 如果同时需要编译数量较多的源文件(比如1000个),一个一个编译是不现实的(当然你可以直接 javac *.java ),比较好的方法是:将你想要编译的源文件名都写在一个文件中(比如sourcefiles.txt),其中每行写一个文件名,如下所示:\n>\n>\n> HelloWorld01.java\n> HelloWorld02.java\n> HelloWorld03.java\n\n则使用下面的命令:\n\n\njavac @sourcefiles.txt\n\n编译这三个源文件。\n\n\n\n## 使用javac构建项目\n\n这部分参考:\nhttps://blog.csdn.net/mingover/article/details/57083176\n\n一个简单的javac编译\n\n新建两个文件夹,src和 build \nsrc/com/yp/test/HelloWorld.java \nbuild/\n\n\n````\n├─build\n└─src\n └─com\n └─yp\n └─test\n HelloWorld.java\n````\n\n\njava文件非常简单\n````\n package com.yp.test;\n public class HelloWorld {\n \n public static void main(String[] args) {\n System.out.println(\"helloWorld\");\n }\n }\n````\n\n编译:\njavac src/com/yp/test/HelloWorld.java -d build\n\n-d 表示编译到 build文件夹下\n\n````\n查看build文件夹\n├─build\n│ └─com\n│ └─yp\n│ └─test\n│ HelloWorld.class\n│\n└─src\n └─com\n └─yp\n └─test\n HelloWorld.java\n````\n\n\n运行文件\n\n> E:\\codeplace\\n_learn\\java\\javacmd> java com/yp/test/HelloWorld.class\n> 错误: 找不到或无法加载主类 build.com.yp.test.HelloWorld.class\n>\n> 运行时要指定main\n> E:\\codeplace\\n_learn\\java\\javacmd\\build> java com.yp.test.HelloWorld\n> helloWorld\n\n如果引用到多个其他的类,应该怎么做呢 ?\n\n> 编译\n>\n> E:\\codeplace\\n_learn\\java\\javacmd>javac src/com/yp/test/HelloWorld.java -sourcepath src -d build -g\n> 1\n> -sourcepath 表示 从指定的源文件目录中找到需要的.java文件并进行编译。\n> 也可以用-cp指定编译好的class的路径\n> 运行,注意:运行在build目录下\n>\n> E:\\codeplace\\n_learn\\java\\javacmd\\build>java com.yp.test.HelloWorld\n\n怎么打成jar包?\n\n> 生成:\n> E:\\codeplace\\n_learn\\java\\javacmd\\build>jar cvf h.jar *\n> 运行:\n> E:\\codeplace\\n_learn\\java\\javacmd\\build>java h.jar\n> 错误: 找不到或无法加载主类 h.jar\n\n> 这个错误是没有指定main类,所以类似这样来指定:\n> E:\\codeplace\\n_learn\\java\\javacmd\\build>java -cp h.jar com.yp.test.HelloWorld\n\n\n生成可以运行的jar包\n\n需要指定jar包的应用程序入口点,用-e选项:\n\n E:\\codeplace\\n_learn\\java\\javacmd\\build> jar cvfe h.jar com.yp.test.HelloWorld *\n 已添加清单\n 正在添加: com/(输入 = 0) (输出 = 0)(存储了 0%)\n 正在添加: com/yp/(输入 = 0) (输出 = 0)(存储了 0%)\n 正在添加: com/yp/test/(输入 = 0) (输出 = 0)(存储了 0%)\n 正在添加: com/yp/test/entity/(输入 = 0) (输出 = 0)(存储了 0%)\n 正在添加: com/yp/test/entity/Cat.class(输入 = 545) (输出 = 319)(压缩了 41%)\n 正在添加: com/yp/test/HelloWorld.class(输入 = 844) (输出 = 487)(压缩了 42%)\n\n直接运行\n\n java -jar h.jar\n \n 额外发现 \n 指定了Main类后,jar包里面的 META-INF/MANIFEST.MF 是这样的, 比原来多了一行Main-Class….\n Manifest-Version: 1.0\n Created-By: 1.8.0 (Oracle Corporation)\n Main-Class: com.yp.test.HelloWorld\n\n如果类里有引用jar包呢?\n\n先下一个jar包 这里直接下 log4j \n \n* main函数改成\n\n```` \nimport com.yp.test.entity.Cat;\nimport org.apache.log4j.Logger;\n\npublic class HelloWorld {\n\n static Logger log = Logger.getLogger(HelloWorld.class);\n\n public static void main(String[] args) {\n Cat c = new Cat(\"keyboard\");\n log.info(\"这是log4j\");\n System.out.println(\"hello,\" + c.getName());\n }\n\n}\n````\n现的文件是这样的\n\n\n````\n├─build\n├─lib\n│ log4j-1.2.17.jar\n│\n└─src\n └─com\n └─yp\n └─test\n │ HelloWorld.java\n │\n └─entity\n Cat.java\n````\n\n 这个时候 javac命令要接上 -cp ./lib/*.jar\n E:\\codeplace\\n_learn\\java\\javacmd>javac -encoding \"utf8\" src/com/yp/test/HelloWorld.java -sourcepath src -d build -g -cp ./lib/*.jar\n\n\n 运行要加上-cp, -cp 选项貌似会把工作目录给换了, 所以要加上 ;../build\n E:\\codeplace\\n_learn\\java\\javacmd\\build>java -cp ../lib/log4j-1.2.17.jar;../build com.yp.test.HelloWorld\n\n结果:\n\n log4j:WARN No appenders could be found for logger(com.yp.test.HelloWorld).\n log4j:WARN Please initialize the log4j system properly.\n log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.\n hello,keyboard\n\n由于没有 log4j的配置文件,所以提示上面的问题,往 build 里面加上 log4j.xml\n\n````\n\n\n\n \n \n \n \n\n \n \n \n````\n再运行\n\n E:\\codeplace\\n_learn\\java\\javacmd>java -cp lib/log4j-1.2.17.jar;build com.yp.tes t.HelloWorld\n 15:19:57,359 INFO [HelloWorld] 这是log4j\n hello,keyboard\n\n说明: \n这个log4j配置文件,习惯的做法是放在src目录下, 在编译过程中 copy到build中的,但根据ant的做法,不是用javac的,而是用来处理,我猜测javac是不能copy的,如果想在命令行直接 使用,应该是用cp命令主动去执行 copy操作\n\nok 一个简单的java 工程就运行完了\n但是 貌似有些繁琐, 需要手动键入 java文件 以及相应的jar包 很是麻烦,\nso 可以用 shell 来脚本来简化相关操作 \nshell 文件整理如下:\n````\n #!/bin/bash \n echo \"build start\" \n \n JAR_PATH=libs \n BIN_PATH=bin \n SRC_PATH=src \n \n # java文件列表目录 \n SRC_FILE_LIST_PATH=src/sources.list \n \n #生所有的java文件列表 放入列表文件中 \n rm -f $SRC_PATH/sources \n find $SRC_PATH/ -name *.java > $SRC_FILE_LIST_PATH \n \n #删除旧的编译文件 生成bin目录 \n rm -rf $BIN_PATH/ \n mkdir $BIN_PATH/ \n \n #生成依赖jar包 列表 \n for file in ${JAR_PATH}/*.jar; \n do \n jarfile=${jarfile}:${file} \n done \n echo \"jarfile = \"$jarfile \n \n #编译 通过-cp指定所有的引用jar包,将src下的所有java文件进行编译\n javac -d $BIN_PATH/ -cp $jarfile @$SRC_FILE_LIST_PATH \n \n #运行 通过-cp指定所有的引用jar包,指定入口函数运行\n java -cp $BIN_PATH$jarfile com.zuiapps.danmaku.server.Main \n````\n\n> 有一点需要注意的是, javac -d $BIN_PATH/ -cp $jarfile @$SRC_FILE_LIST_PATH\n> 在要编译的文件很多时候,一个个敲命令会显得很长,也不方便修改,\n\n> 可以把要编译的源文件列在文件中,在文件名前加@,这样就可以对多个文件进行编译,\n\n> 以上就是吧java文件放到 $SRC_FILE_LIST_PATH 中去了\n\n 编译 :\n 1. 需要编译所有的java文件\n 2. 依赖的java 包都需要加入到 classpath 中去\n 3. 最后设置 编译后的 class 文件存放目录 即 -d bin/\n 4. java文件过多是可以使用 @$SRC_FILE_LIST_PATH 把他们放到一个文件中去\n 运行:\n 1.需要吧 编译时设置的bin目录和 所有jar包加入到 classpath 中去\n\n\n \n## javap 的使用\n\n> javap是jdk自带的一个工具,可以对代码反编译,也可以查看java编译器生成的字节码。\n>\n> 情况下,很少有人使用javap对class文件进行反编译,因为有很多成熟的反编译工具可以使用,比如jad。但是,javap还可以查看java编译器为我们生成的字节码。通过它,可以对照源代码和字节码,从而了解很多编译器内部的工作。\n>\n> \n>\n> javap命令分解一个class文件,它根据options来决定到底输出什么。如果没有使用options,那么javap将会输出包,类里的protected和public域以及类里的所有方法。javap将会把它们输出在标准输出上。来看这个例子,先编译(javac)下面这个类。\n````\nimport java.awt.*;\nimport java.applet.*;\n \npublic class DocFooter extends Applet {\n String date;\n String email;\n \n public void init() {\n resize(500,100);\n date = getParameter(\"LAST_UPDATED\");\n email = getParameter(\"EMAIL\");\n }\n}\n````\n在命令行上键入javap DocFooter后,输出结果如下\n\n\nCompiled from \"DocFooter.java\"\n````\npublic class DocFooter extends java.applet.Applet {\n java.lang.String date;\n java.lang.String email;\n public DocFooter();\n public void init();\n}\n````\n如果加入了-c,即javap -c DocFooter,那么输出结果如下\n\nCompiled from \"DocFooter.java\"\n````\n public class DocFooter extends java.applet.Applet {\n java.lang.String date;\n \n java.lang.String email;\n \n public DocFooter();\n Code:\n 0: aload_0 \n 1: invokespecial #1 // Method java/applet/Applet.\"\":()V\n 4: return \n \n public void init();\n Code:\n 0: aload_0 \n 1: sipush 500\n 4: bipush 100\n 6: invokevirtual #2 // Method resize:(II)V\n 9: aload_0 \n 10: aload_0 \n 11: ldc #3 // String LAST_UPDATED\n 13: invokevirtual #4 // Method getParameter:(Ljava/lang/String;)Ljava/lang/String;\n 16: putfield #5 // Field date:Ljava/lang/String;\n 19: aload_0 \n 20: aload_0 \n 21: ldc #6 // String EMAIL\n 23: invokevirtual #4 // Method getParameter:(Ljava/lang/String;)Ljava/lang/String;\n 26: putfield #7 // Field email:Ljava/lang/String;\n 29: return \n \n }\n````\n上面输出的内容就是字节码。\n\n用法摘要\n\n-help 帮助\n-l 输出行和变量的表\n-public 只输出public方法和域\n-protected 只输出public和protected类和成员\n-package 只输出包,public和protected类和成员,这是默认的\n-p -private 输出所有类和成员\n-s 输出内部类型签名\n-c 输出分解后的代码,例如,类中每一个方法内,包含java字节码的指令,\n-verbose 输出栈大小,方法参数的个数\n-constants 输出静态final常量\n总结\n\njavap可以用于反编译和查看编译器编译后的字节码。平时一般用javap -c比较多,该命令用于列出每个方法所执行的JVM指令,并显示每个方法的字节码的实际作用。可以通过字节码和源代码的对比,深入分析java的编译原理,了解和解决各种Java原理级别的问题。\n\n## 参考文章\n\nhttps://blog.csdn.net/Anbernet/article/details/81449390\nhttps://www.cnblogs.com/luobiao320/p/7975442.html\nhttps://www.jianshu.com/p/f7330dbdc051\nhttps://www.jianshu.com/p/6a8997560b05\nhttps://blog.csdn.net/w372426096/article/details/81664431\nhttps://blog.csdn.net/qincidong/article/details/82492140\n\n"
},
{
"path": "docs/Java/basic/string和包装类.md",
"content": "# 目录\n\n * [string基础](#string基础)\n * [Java String 类](#java-string-类)\n * [创建字符串](#创建字符串)\n * [StringDemo.java 文件代码:](#stringdemojava-文件代码:)\n * [String基本用法](#string基本用法)\n * [创建String对象的常用方法](#创建string对象的常用方法)\n * [String中常用的方法,用法如图所示,具体问度娘](#string中常用的方法,用法如图所示,具体问度娘)\n * [三个方法的使用: lenth() substring() charAt()](#三个方法的使用:-lenth---substring---charat)\n * [字符串与byte数组间的相互转换](#字符串与byte数组间的相互转换)\n * [==运算符和equals之间的区别:](#运算符和equals之间的区别:)\n * [字符串的不可变性](#字符串的不可变性)\n * [String的连接](#string的连接)\n * [String、String builder和String buffer的区别](#string、string-builder和string-buffer的区别)\n * [String类的源码分析](#string类的源码分析)\n * [String类型的intern](#string类型的intern)\n * [String类型的equals](#string类型的equals)\n * [StringBuffer和Stringbuilder](#stringbuffer和stringbuilder)\n * [append方法](#append方法)\n * [扩容](#扩容)\n * [](#)\n * [删除](#删除)\n * [system.arraycopy方法](#systemarraycopy方法)\n * [String和JVM的关系](#string和jvm的关系)\n * [String为什么不可变?](#string为什么不可变?)\n * [不可变有什么好处?](#不可变有什么好处?)\n * [String常用工具类](#string常用工具类)\n * [参考文章](#参考文章)\n\n\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n## string基础\n\n### Java String 类\n\n字符串广泛应用 在 Java 编程中,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串。\n\n### 创建字符串\n\n创建字符串最简单的方式如下:\n\nString greeting = \"菜鸟教程\";\n\n在代码中遇到字符串常量时,这里的值是 \"**菜鸟教程**\"\",编译器会使用该值创建一个 String 对象。\n\n和其它对象一样,可以使用关键字和构造方法来创建 String 对象。\n\nString 类有 11 种构造方法,这些方法提供不同的参数来初始化字符串,比如提供一个字符数组参数:\n\n### StringDemo.java 文件代码:\n````\npublic class StringDemo{ \npublic static void main(String args[]){ \nchar[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'}; \nString helloString = new String(helloArray); \nSystem.out.println( helloString ); \n} }\n````\n以上实例编译运行结果如下:\n\n```\nrunoob\n```\n\n**注意:**String 类是不可改变的,所以你一旦创建了 String 对象,那它的值就无法改变了(详看笔记部分解析)。\n\n如果需要对字符串做很多修改,那么应该选择使用 [StringBuffer & StringBuilder 类](https://www.runoob.com/java/java-stringbuffer.html)。\n\n## String基本用法\n\n### 创建String对象的常用方法\n\n(1) String s1 = \"mpptest\"\n\n(2) String s2 = new String();\n\n(3) String s3 = new String(\"mpptest\")\n\n### String中常用的方法,用法如图所示,具体问度娘\n\n\n\n### 三个方法的使用: lenth() substring() charAt()\n````\npackage com.mpp.string; \npublic class StringDemo1 {\n public static void main(String[] args) { //定义一个字符串\"晚来天欲雪 能饮一杯无\"\n String str = \"晚来天欲雪 能饮一杯无\";\n System.out.println(\"字符串的长度是:\"+str.length()); //字符串的雪字打印输出 charAt(int index)\n System.out.println(str.charAt(4)); //取出子串 天欲\n System.out.println(str.substring(2)); //取出从index2开始直到最后的子串,包含2\n System.out.println(str.substring(2,4)); //取出index从2到4的子串,包含2不包含4 顾头不顾尾\n }\n}\n````\n\n\n两个方法的使用,求字符或子串第一次/最后一次在字符串中出现的位置: \nindexOf() lastIndexOf() \n\n````\npackage com.mpp.string; public class StringDemo2 { \n public static void main(String[] args) {\n String str = new String(\"赵客缦胡缨 吴钩胡缨霜雪明\"); //查找胡在字符串中第一次出现的位置\n System.out.println(\"\\\"胡\\\"在字符串中第一次出现的位置:\"+str.indexOf(\"胡\")); //查找子串\"胡缨\"在字符串中第一次出现的位置\n System.out.println(\"\\\"胡缨\\\"在字符串中第一次出现的位置\"+str.indexOf(\"胡缨\")); //查找胡在字符串中最后一次次出现的位置\n System.out.println(str.lastIndexOf(\"胡\")); //查找子串\"胡缨\"在字符串中最后一次出现的位置\n System.out.println(str.lastIndexOf(\"胡缨\")); //从indexof为5的位置,找第一次出现的\"吴\"\n System.out.println(str.indexOf(\"吴\",5));\n }\n}\n````\n\n\n\n### 字符串与byte数组间的相互转换\n\n````\npackage com.mpp.string; import java.io.UnsupportedEncodingException; \npublic class StringDemo3 { \n public static void main(String[] args) throws UnsupportedEncodingException { \n \n //字符串和byte数组之间的相互转换\n String str = new String(\"hhhabc银鞍照白马 飒沓如流星\"); //将字符串转换为byte数组,并打印输出\n byte[] arrs = str.getBytes(\"GBK\"); \n for(int i=0;i){\n System.out.print(arrs[i]);\n } \n \n //将byte数组转换成字符串\n System.out.println();\n String str1 = new String(arrs,\"GBK\"); //保持字符集的一致,否则会出现乱码\n System.out.println(str1);\n }\n}\n````\n\n### ==运算符和equals之间的区别:\n\n引用指向的内容和引用指向的地址\n\n````\npackage com.mpp.string; public class StringDemo5 { \n public static void main(String[] args) {\n String str1 = \"mpp\";\n String str2 = \"mpp\";\n String str3 = new String(\"mpp\");\n\n System.out.println(str1.equals(str2)); //true 内容相同\n System.out.println(str1.equals(str3)); //true 内容相同\n System.out.println(str1==str2); //true 地址相同\n System.out.println(str1==str3); //false 地址不同\n }\n}\n````\n\n### 字符串的不可变性\n\nString的对象一旦被创建,则不能修改,是不可变的\n\n所谓的修改其实是创建了新的对象,所指向的内存空间不变\n\n\n\n上图中,s1不再指向imooc所在的内存空间,而是指向了hello,imooc\n### String的连接\n\n @Test\n public void contact () {\n //1连接方式\n String s1 = \"a\";\n String s2 = \"a\";\n String s3 = \"a\" + s2;\n String s4 = \"a\" + \"a\";\n String s5 = s1 + s2;\n //表达式只有常量时,编译期完成计算\n //表达式有变量时,运行期才计算,所以地址不一样\n System.out.println(s3 == s4); //f\n System.out.println(s3 == s5); //f\n System.out.println(s4 == \"aa\"); //t\n \n }\n### String、String builder和String buffer的区别\nString是Java中基础且重要的类,并且String也是Immutable类的典型实现,被声明为final class,除了hash这个属性其它属性都声明为final,因为它的不可变性,所以例如拼接字符串时候会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响。\n\nStringBuffer就是为了解决大量拼接字符串时产生很多中间对象问题而提供的一个类,提供append和add方法,可以将字符串添加到已有序列的末尾或指定位置,它的本质是一个线程安全的可修改的字符序列,把所有修改数据的方法都加上了synchronized。但是保证了线程安全是需要性能的代价的。\n\n在很多情况下我们的字符串拼接操作不需要线程安全,这时候StringBuilder登场了,StringBuilder是JDK1.5发布的,它和StringBuffer本质上没什么区别,就是去掉了保证线程安全的那部分,减少了开销。\n\nStringBuffer 和 StringBuilder 二者都继承了 AbstractStringBuilder ,底层都是利用可修改的char数组(JDK 9 以后是 byte数组)。\n\n所以如果我们有大量的字符串拼接,如果能预知大小的话最好在new StringBuffer 或者StringBuilder 的时候设置好capacity,避免多次扩容的开销。扩容要抛弃原有数组,还要进行数组拷贝创建新的数组。\n\n我们平日开发通常情况下少量的字符串拼接其实没太必要担心,例如\n\nString str = \"aa\"+\"bb\"+\"cc\";\n\n像这种没有变量的字符串,编译阶段就直接合成\"aabbcc\"了,然后看字符串常量池(下面会说到常量池)里有没有,有也直接引用,没有就在常量池中生成,返回引用。\n\n如果是带变量的,其实影响也不大,JVM会帮我们优化了。\n\n> 1、在字符串不经常发生变化的业务场景优先使用String(代码更清晰简洁)。如常量的声明,少量的字符串操作(拼接,删除等)。\n>\n> 2、在单线程情况下,如有大量的字符串操作情况,应该使用StringBuilder来操作字符串。不能使用String\"+\"来拼接而是使用,避免产生大量无用的中间对象,耗费空间且执行效率低下(新建对象、回收对象花费大量时间)。如JSON的封装等。\n>\n> 3、在多线程情况下,如有大量的字符串操作情况,应该使用StringBuffer。如HTTP参数解析和封装等。\n\n## String类的源码分析\n\n### String类型的intern\n````\npublic void intern () {\n //2:string的intern使用\n //s1是基本类型,比较值。s2是string实例,比较实例地址\n //字符串类型用equals方法比较时只会比较值\n String s1 = \"a\";\n String s2 = new String(\"a\");\n //调用intern时,如果s2中的字符不在常量池,则加入常量池并返回常量的引用\n String s3 = s2.intern();\n System.out.println(s1 == s2);\n System.out.println(s1 == s3);\n}\n````\n### String类型的equals\n````\n//字符串的equals方法\n// public boolean equals(Object anObject) {\n// if (this == anObject) {\n// return true;\n// }\n// if (anObject instanceof String) {\n// String anotherString = (String)anObject;\n// int n = value.length;\n// if (n == anotherString.value.length) {\n// char v1[] = value;\n// char v2[] = anotherString.value;\n// int i = 0;\n// while (n-- != 0) {\n// if (v1[i] != v2[i])\n// return false;\n// i++;\n// }\n// return true;\n// }\n// }\n// return false;\n// }\n````\n### StringBuffer和Stringbuilder\n底层是继承父类的可变字符数组value\n````\n/**\n\n- The value is used for character storage.\n */\n char[] value;\n 初始化容量为16\n\n/**\n\n- Constructs a string builder with no characters in it and an\n- initial capacity of 16 characters.\n */\n public StringBuilder() {\n super(16);\n }\n 这两个类的append方法都是来自父类AbstractStringBuilder的方法\n\npublic AbstractStringBuilder append(String str) {\n if (str == null)\n return appendNull();\n int len = str.length();\n ensureCapacityInternal(count + len);\n str.getChars(0, len, value, count);\n count += len;\n return this;\n}\n@Override\npublic StringBuilder append(String str) {\n super.append(str);\n return this;\n}\n\n@Override\npublic synchronized StringBuffer append(String str) {\n toStringCache = null;\n super.append(str);\n return this;\n}\n````\n\n### append方法\nStringbuffer在大部分涉及字符串修改的操作上加了synchronized关键字来保证线程安全,效率较低。\n\nString类型在使用 + 运算符例如\n\nString a = \"a\"\n\na = a + a;时,实际上先把a封装成stringbuilder,调用append方法后再用tostring返回,所以当大量使用字符串加法时,会大量地生成stringbuilder实例,这是十分浪费的,这种时候应该用stringbuilder来代替string。\n\n### 扩容\n#注意在append方法中调用到了一个函数\n\nensureCapacityInternal(count + len);\n该方法是计算append之后的空间是否足够,不足的话需要进行扩容\n````\npublic void ensureCapacity(int minimumCapacity) {\n if (minimumCapacity > 0)\n ensureCapacityInternal(minimumCapacity);\n}\nprivate void ensureCapacityInternal(int minimumCapacity) {\n // overflow-conscious code\n if (minimumCapacity - value.length > 0) {\n value = Arrays.copyOf(value,\n newCapacity(minimumCapacity));\n }\n}\n````\n如果新字符串长度大于value数组长度则进行扩容\n\n扩容后的长度一般为原来的两倍 + 2;\n\n假如扩容后的长度超过了jvm支持的最大数组长度MAX_ARRAY_SIZE。\n\n考虑两种情况\n\n如果新的字符串长度超过int最大值,则抛出异常,否则直接使用数组最大长度作为新数组的长度。\n````\nprivate int hugeCapacity(int minCapacity) {\n if (Integer.MAX_VALUE - minCapacity < 0) { // overflow\n throw new OutOfMemoryError();\n }\n return (minCapacity > MAX_ARRAY_SIZE)\n ? minCapacity : MAX_ARRAY_SIZE;\n}\n````\n### 删除\n这两个类型的删除操作:\n\n都是调用父类的delete方法进行删除\n````\npublic AbstractStringBuilder delete(int start, int end) {\n if (start < 0)\n throw new StringIndexOutOfBoundsException(start);\n if (end > count)\n end = count;\n if (start > end)\n throw new StringIndexOutOfBoundsException();\n int len = end - start;\n if (len > 0) {\n System.arraycopy(value, start+len, value, start, count-end);\n count -= len;\n }\n return this;\n}\n````\n事实上是将剩余的字符重新拷贝到字符数组value。\n\n这里用到了system.arraycopy来拷贝数组,速度是比较快的\n\n### system.arraycopy方法\n转自知乎:\n\n> 在主流高性能的JVM上(HotSpot VM系、IBM J9 VM系、JRockit系等等),可以认为System.arraycopy()在拷贝数组时是可靠高效的——如果发现不够高效的情况,请报告performance bug,肯定很快就会得到改进。\n>\n> java.lang.System.arraycopy()方法在Java代码里声明为一个native方法。所以最naïve的实现方式就是通过JNI调用JVM里的native代码来实现。\n>\n> String的不可变性\n> 关于String的不可变性,这里转一个不错的回答\n>\n> 什么是不可变?\n> String不可变很简单,如下图,给一个已有字符串\"abcd\"第二次赋值成\"abcedl\",不是在原内存地址上修改数据,而是重新指向一个新对象,新地址。\n>\n\n## String和JVM的关系\n\n下面我们了解下Java栈、Java堆、方法区和常量池:\n\nJava栈(线程私有数据区):\n\n```\n 每个Java虚拟机线程都有自己的Java虚拟机栈,Java虚拟机栈用来存放栈帧,每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。\n```\n\nJava堆(线程共享数据区):\n\n```\n 在虚拟机启动时创建,此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配。\n```\n\n方法区(线程共享数据区):\n\n```\n 方法区在虚拟机启动的时候被创建,它存储了每一个类的结构信息,例如运行时常量池、字段和方法数据、构造函数和普通方法的字节码内容、还包括在类、实例、接口初始化时用到的特殊方法。在JDK8之前永久代是方法区的一种实现,而JDK8元空间替代了永久代,永久代被移除,也可以理解为元空间是方法区的一种实现。\n```\n\n常量池(线程共享数据区):\n\n```\n 常量池常被分为两大类:静态常量池和运行时常量池。\n\n 静态常量池也就是Class文件中的常量池,存在于Class文件中。\n\n 运行时常量池(Runtime Constant Pool)是方法区的一部分,存放一些运行时常量数据。\n```\n\n下面重点了解的是字符串常量池:\n\n```\n 字符串常量池存在运行时常量池之中(在JDK7之前存在运行时常量池之中,在JDK7已经将其转移到堆中)。\n\n 字符串常量池的存在使JVM提高了性能和减少了内存开销。\n\n 使用字符串常量池,每当我们使用字面量(String s=”1”;)创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就将此字符串对象的地址赋值给引用s(引用s在Java栈中)。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,并将此字符串对象的地址赋值给引用s(引用s在Java栈中)。\n```\n\n```\n 使用字符串常量池,每当我们使用关键字new(String s=new String(”1”);)创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么不再在字符串常量池创建该字符串对象,而直接堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s,如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,然后在堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s。\n```\n\n## String为什么不可变?\n翻开JDK源码,java.lang.String类起手前三行,是这样写的:\n````\npublic final class String implements java.io.Serializable, Comparable, CharSequence { \n /** String本质是个char数组. 而且用final关键字修饰.*/ \nprivate final char value[]; ... ...\n } \n````\n首先String类是用final关键字修饰,这说明String不可继承。再看下面,String类的主力成员字段value是个char[]数组,而且是用final修饰的。\n\nfinal修饰的字段创建以后就不可改变。 有的人以为故事就这样完了,其实没有。因为虽然value是不可变,也只是value这个引用地址不可变。挡不住Array数组是可变的事实。\n\nArray的数据结构看下图。\n\n也就是说Array变量只是stack上的一个引用,数组的本体结构在heap堆。\n\nString类里的value用final修饰,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。看下面这个例子,\n````\nfinal int[] value={1,2,3} ;\nint[] another={4,5,6};\n value=another; //编译器报错,final不可变 value用final修饰,编译器不允许我把value指向堆区另一个地址。\n但如果我直接对数组元素动手,分分钟搞定。\n\n final int[] value={1,2,3};\n value[2]=100; //这时候数组里已经是{1,2,100} 所以String是不可变,关键是因为SUN公司的工程师。\n 在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段。private final char value[]这一句里,private的私有访问权限的作用都比final大。而且设计师还很小心地把整个String设成final禁止继承,避免被其他人继承后破坏。所以String是不可变的关键都在底层的实现,而不是一个final。考验的是工程师构造数据类型,封装数据的功力。 \n````\n### 不可变有什么好处?\n这个最简单地原因,就是为了安全。看下面这个场景(有评论反应例子不够清楚,现在完整地写出来),一个函数appendStr( )在不可变的String参数后面加上一段“bbb”后返回。appendSb( )负责在可变的StringBuilder后面加“bbb”。\n\n总结以下String的不可变性。\n\n> 1 首先final修饰的类只保证不能被继承,并且该类的对象在堆内存中的地址不会被改变。\n>\n> 2 但是持有String对象的引用本身是可以改变的,比如他可以指向其他的对象。\n>\n> 3 final修饰的char数组保证了char数组的引用不可变。但是可以通过char[0] = 'a’来修改值。不过String内部并不提供方法来完成这一操作,所以String的不可变也是基于代码封装和访问控制的。\n\n举个例子\n````\nfinal class Fi {\n int a;\n final int b = 0;\n Integer s;\n\n}\nfinal char[]a = {'a'};\nfinal int[]b = {1};\n@Test\npublic void final修饰类() {\n //引用没有被final修饰,所以是可变的。\n //final只修饰了Fi类型,即Fi实例化的对象在堆中内存地址是不可变的。\n //虽然内存地址不可变,但是可以对内部的数据做改变。\n Fi f = new Fi();\n f.a = 1;\n System.out.println(f);\n f.a = 2;\n System.out.println(f);\n //改变实例中的值并不改变内存地址。\n````\n````\nFi ff = f;\n//让引用指向新的Fi对象,原来的f对象由新的引用ff持有。\n//引用的指向改变也不会改变原来对象的地址\nf = new Fi();\nSystem.out.println(f);\nSystem.out.println(ff);\n\n}\n````\n\n这里的对f.a的修改可以理解为char[0] = 'a'这样的操作。只改变数据值,不改变内存值。\n\n## String常用工具类\n问题描述\n很多时候我们需要对字符串进行很多固定的操作,而这些操作在JDK/JRE中又没有预置,于是我们想到了apache-commons组件,但是它也不能完全覆盖我们的业务需求,所以很多时候还是要自己写点代码的,下面就是基于apache-commons组件写的部分常用方法:\n\n\n````\n \n \torg.apache.commons \n \tcommons-lang3 \n \t${commons-lang3.version} \n \n````\n\n代码成果\n\n````\npublic class StringUtils extends org.apache.commons.lang3.StringUtils {\n\n/** 值为\"NULL\"的字符串 */\nprivate static final String NULL_STRING = \"NULL\";\n\nprivate static final char SEPARATOR = '_';\n\n\n/**\n * 满足一下情况返回true list = new ArrayList<>();\n while (i < 1000) {\n list.add(i ++);\n }\n for (Integer j : list) {\n System.out.println(j);\n }\n System.out.println(\"gogogo\");\n }\n System.out.println(\"hello\");\n }\n }\n````\n### 构造代码块\n\n >位置:类成员的位置,就是类中方法之外的位置\n\n >作用:把多个构造方法共同的部分提取出来,共用构造代码块\n\n >调用:每次调用构造方法时,都会优先于构造方法执行,也就是每次new一个对象时自动调用,对 对象的初始化\n````\n class A{\n int i = 1;\n int initValue;//成员变量的初始化交给代码块来完成\n {\n //代码块的作用体现于此:在调用构造方法之前,用某段代码对成员变量进行初始化。\n //而不是在构造方法调用时再进行。一般用于将构造方法的相同部分提取出来。\n //\n for (int i = 0;i < 100;i ++) {\n initValue += i;\n }\n }\n {\n System.out.println(initValue);\n System.out.println(i);//此时会打印1\n int i = 2;//代码块里的变量和成员变量不冲突,但会优先使用代码块的变量\n System.out.println(i);//此时打印2\n //System.out.println(j);//提示非法向后引用,因为此时j的的初始化还没开始。\n //\n }\n {\n System.out.println(\"代码块运行\");\n }\n int j = 2;\n {\n System.out.println(j);\n System.out.println(i);//代码块中的变量运行后自动释放,不会影响代码块之外的代码\n }\n A(){\n System.out.println(\"构造方法运行\");\n }\n }\n public class 构造代码块 {\n @Test\n public void test() {\n A a = new A();\n }\n }\n````\n### 静态代码块\n\n 位置:类成员位置,用static修饰的代码块\n \n 作用:对类进行一些初始化 只加载一次,当new多个对象时,只有第一次会调用静态代码块,因为,静态代码块 是属于类的,所有对象共享一份\n \n 调用: new 一个对象时自动调用\n\n ```` \n public class 静态代码块 {\n \n @Test\n public void test() {\n C c1 = new C();\n C c2 = new C();\n //结果,静态代码块只会调用一次,类的所有对象共享该代码块\n //一般用于类的全局信息初始化\n //静态代码块调用\n //代码块调用\n //构造方法调用\n //代码块调用\n //构造方法调用\n }\n \n }\n class C{\n C(){\n System.out.println(\"构造方法调用\");\n }\n {\n System.out.println(\"代码块调用\");\n }\n static {\n System.out.println(\"静态代码块调用\");\n }\n }\n````\n## Java代码块、构造方法(包含继承关系)的执行顺序\n\n这是一道常见的面试题,要回答这个问题,先看看这个实例吧。\n\n一共3个类:A、B、C \n其中A是B的父类,C无继承仅作为输出\n\nA类:\n````\n public class A {\n \n static {\n Log.i(\"HIDETAG\", \"A静态代码块\");\n }\n \n private static C c = new C(\"A静态成员\");\n private C c1 = new C(\"A成员\");\n \n {\n Log.i(\"HIDETAG\", \"A代码块\");\n }\n \n static {\n Log.i(\"HIDETAG\", \"A静态代码块2\");\n }\n \n public A() {\n Log.i(\"HIDETAG\", \"A构造方法\");\n }\n \n }\n````\nB类:\n````\n public class B extends A {\n \n private static C c1 = new C(\"B静态成员\");\n \n {\n Log.i(\"HIDETAG\", \"B代码块\");\n }\n \n private C c = new C(\"B成员\");\n \n static {\n Log.i(\"HIDETAG\", \"B静态代码块2\");\n }\n \n static {\n Log.i(\"HIDETAG\", \"B静态代码块\");\n }\n \n public B() {\n Log.i(\"HIDETAG\", \"B构造方法\");\n \n }\n \n }\n````\nC类:\n````\n public class C {\n \n public C(String str) {\n Log.i(\"HIDETAG\", str + \"构造方法\");\n }\n }\n````\n执行语句:new B();\n\n输出结果如下:\n\n I/HIDETAG: A静态代码块\n I/HIDETAG: A静态成员构造方法\n I/HIDETAG: A静态代码块2\n I/HIDETAG: B静态成员构造方法\n I/HIDETAG: B静态代码块2\n I/HIDETAG: B静态代码块\n I/HIDETAG: A成员构造方法\n I/HIDETAG: A代码块\n I/HIDETAG: A构造方法\n I/HIDETAG: B代码块\n I/HIDETAG: B成员构造方法\n I/HIDETAG: B构造方法\n得出结论:\n\n 执行顺序依次为:\n 父类的静态成员和代码块\n 子类静态成员和代码块\n 父类成员初始化和代码快\n 父类构造方法\n 子类成员初始化和代码块\n 子类构造方法\n\n注意:可以发现,同一级别的代码块和成员初始化是按照代码顺序从上到下依次执行\n\n**看完上面这个demo,再来看看下面这道题,看看你搞得定吗?**\n\n看下面一段代码,求执行顺序:\n````\n class A {\n public A() {\n System.out.println(\"1A类的构造方法\");\n }\n {\n System.out.println(\"2A类的构造快\");\n }\n static {\n System.out.println(\"3A类的静态块\");\n }\n }\n \n public class B extends A {\n public B() {\n System.out.println(\"4B类的构造方法\");\n }\n {\n System.out.println(\"5B类的构造快\");\n }\n static {\n System.out.println(\"6B类的静态块\");\n }\n public static void main(String[] args) {\n System.out.println(\"7\");\n new B();\n new B();\n System.out.println(\"8\");\n }\n }\n````\n\n执行顺序结果为:367215421548\n\n为什么呢?\n\n首先我们要知道下面这5点:\n\n每次new都会执行构造方法以及构造块。\n构造块的内容会在构造方法之前执行。\n非主类的静态块会在类加载时,构造方法和构造块之前执行,切只执行一次。\n主类(public class)里的静态块会先于main执行。\n继承中,子类实例化,会先执行父类的构造方法,产生父类对象,再调用子类构造方法。\n所以题目里,由于主类B继承A,所以会先加载A,所以第一个执行的是第3句。\n\n从第4点我们知道6会在7之前执行,所以前三句是367。\n\n之后实例化了B两次,每次都会先实例化他的父类A,然后再实例化B,而根据第1、2、5点,知道顺序为2154。\n\n最后执行8\n\n所以顺序是367215421548\n\n## 参考文章\n\nhttps://blog.csdn.net/likunkun__/article/details/83066062\nhttps://www.jianshu.com/p/6877aae403f7\nhttps://www.jianshu.com/p/49e45af288ea\nhttps://blog.csdn.net/du_du1/article/details/91383128\nhttp://c.biancheng.net/view/976.html\nhttps://blog.csdn.net/evilcry2012/article/details/79499786\nhttps://www.jb51.net/article/129990.htm\n\n"
},
{
"path": "docs/Java/basic/反射.md",
"content": "# 目录\n\n * [回顾:什么是反射?](#回顾:什么是反射?)\n * [反射的主要用途](#反射的主要用途)\n * [反射的基础:关于Class类](#反射的基础:关于class类)\n * [Java为什么需要反射?反射要解决什么问题?](#java为什么需要反射?反射要解决什么问题?)\n * [反射的基本运用](#反射的基本运用)\n * [判断是否为某个类的实例](#判断是否为某个类的实例)\n * [创建实例](#创建实例)\n * [获取方法](#获取方法)\n * [获取构造器信息](#获取构造器信息)\n * [获取类的成员变量(字段)信息](#获取类的成员变量(字段)信息)\n * [调用方法](#调用方法)\n * [利用反射创建数组](#利用反射创建数组)\n * [Java反射常见面试题](#java反射常见面试题)\n * [什么是反射?](#什么是反射?)\n * [哪里用到反射机制?](#哪里用到反射机制?)\n * [什么叫对象序列化,什么是反序列化,实现对象序列化需要做哪些工作?](#什么叫对象序列化,什么是反序列化,实现对象序列化需要做哪些工作?)\n * [反射机制的优缺点?](#反射机制的优缺点?)\n * [动态代理是什么?有哪些应用?](#动态代理是什么?有哪些应用?)\n * [怎么实现动态代理?](#怎么实现动态代理?)\n * [Java反射机制的作用](#java反射机制的作用)\n * [如何使用Java的反射?](#如何使用java的反射)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n## 回顾:什么是反射?\n\n反射(Reflection)是Java 程序开发语言的特征之一,它允许运行中的 Java 程序获取自身的信息,并且可以操作类或对象的内部属性。\nOracle官方对反射的解释是\n\n> Reflection enables Java code to discover information about the fields, methods and constructors of loaded classes, and to use reflected fields, methods, and constructors to operate on their underlying counterparts, within security restrictions.\n\n> The API accommodates applications that need access to either the public members of a target object (based on its runtime class) or the members declared by a given class. It also allows programs to suppress default reflective access control.\n> \n> 简而言之,通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。\n>\n> 程序中一般的对象的类型都是在编译期就确定下来的,而Java反射机制可以动态地创建对象并调用其属性,这样的对象的类型在编译期是未知的。所以我们可以通过反射机制直接创建对象,即使这个对象的类型在编译期是未知的。\n> \n> 反射的核心是JVM在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。\n\nJava反射框架主要提供以下功能:\n\n> 1.在运行时判断任意一个对象所属的类;\n\n> 2.在运行时构造任意一个类的对象;\n\n> 3.在运行时判断任意一个类所具有的成员变量和方法(通过反射甚至可以调用private方法);\n\n> 4.在运行时调用任意一个对象的方法\n\n> 重点:是运行时而不是编译时\n\n\n## 反射的主要用途\n\n> 很多人都认为反射在实际的Java开发应用中并不广泛,其实不然。\n\n> 当我们在使用IDE(如Eclipse,IDEA)时,当我们输入一个对象或类并想调用它的属性或方法时,一按点号,编译器就会自动列出它的属性或方法,这里就会用到反射。\n\n> 反射最重要的用途就是开发各种通用框架。\n\n> 很多框架(比如Spring)都是配置化的(比如通过XML文件配置JavaBean,Action之类的),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射——运行时动态加载需要加载的对象。\n\n> 对于框架开发人员来说,反射虽小但作用非常大,它是各种容器实现的核心。而对于一般的开发者来说,不深入框架开发则用反射用的就会少一点,不过了解一下框架的底层机制有助于丰富自己的编程思想,也是很有益的。\n\n## 反射的基础:关于Class类\n\n更多关于Class类和Object类的原理和介绍请见上一节\n\n> 1、Class是一个类,一个描述类的类(也就是描述类本身),封装了描述方法的Method,描述字段的Filed,描述构造器的Constructor等属性\n> \n> 2、对象照镜子后(反射)可以得到的信息:某个类的数据成员名、方法和构造器、某个类到底实现了哪些接口。\n> \n> 3、对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。一个Class对象包含了特定某个类的有关信息。\n> \n> 4、Class 对象只能由系统建立对象\n> \n> 5、一个类在 JVM 中只会有一个Class实例\n> \n````\n//总结一下就是,JDK有一个类叫做Class,这个类用来封装所有Java类型,包括这些类的所有信息,JVM中类信息是放在方法区的。\n\n//所有类在加载后,JVM会为其在堆中创建一个Class<类名称>的对象,并且每个类只会有一个Class对象,这个类的所有对象都要通过Class<类名称>来进行实例化。\n\n//上面说的是JVM进行实例化的原理,当然实际上在Java写代码时只需要用 类名称就可以进行实例化了。\n\npublic final class Class implements java.io.Serializable,\n GenericDeclaration,\n Type,\n AnnotatedElement {\n //通过类名.class获得唯一的Class对象。\n Class cls = UserBean.class;\n //通过integer.TYPEl来获取Class对象\n Class inti = Integer.TYPE;\n //接口本质也是一个类,一样可以通过.class获取\n Class userClass = User.class;\n}\n````\nJAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。\n\n要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象.\n\n以上的总结就是什么是反射\n反射就是把java类中的各种成分映射成一个个的Java对象\n例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象。(其实:一个类中这些成员方法、构造方法、在加入类中都有一个类来描述)\n如图是类的正常加载过程:反射的原理在与class对象。\n熟悉一下加载的时候:Class对象的由来是将class文件读入内存,并为之创建一个Class对象。\n\n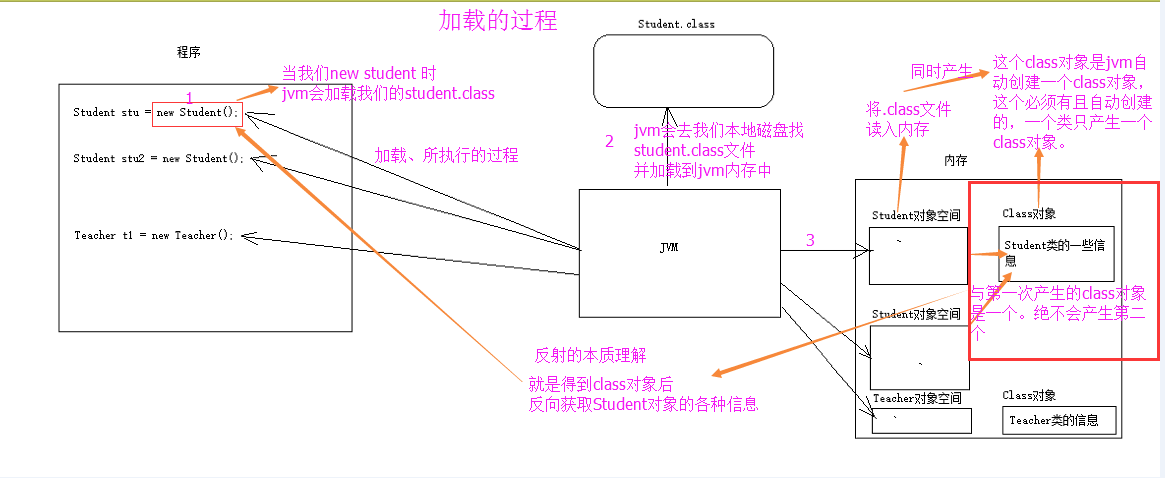\n## Java为什么需要反射?反射要解决什么问题?\nJava中编译类型有两种:\n\n静态编译:在编译时确定类型,绑定对象即通过。\n动态编译:运行时确定类型,绑定对象。动态编译最大限度地发挥了Java的灵活性,体现了多态的应用,可以减低类之间的耦合性。\nJava反射是Java被视为动态(或准动态)语言的一个关键性质。这个机制允许程序在运行时透过Reflection APIs取得任何一个已知名称的class的内部信息,包括其modifiers(诸如public、static等)、superclass(例如Object)、实现之interfaces(例如Cloneable),也包括fields和methods的所有信息,并可于运行时改变fields内容或唤起methods。\n\nReflection可以在运行时加载、探知、使用编译期间完全未知的classes。即Java程序可以加载一个运行时才得知名称的class,获取其完整构造,并生成其对象实体、或对其fields设值、或唤起其methods。\n\n反射(reflection)允许静态语言在运行时(runtime)检查、修改程序的结构与行为。\n在静态语言中,使用一个变量时,必须知道它的类型。在Java中,变量的类型信息在编译时都保存到了class文件中,这样在运行时才能保证准确无误;换句话说,程序在运行时的行为都是固定的。如果想在运行时改变,就需要反射这东西了。\n\n实现Java反射机制的类都位于java.lang.reflect包中:\n\nClass类:代表一个类\nField类:代表类的成员变量(类的属性)\nMethod类:代表类的方法\nConstructor类:代表类的构造方法\nArray类:提供了动态创建数组,以及访问数组的元素的静态方法\n一句话概括就是使用反射可以赋予jvm动态编译的能力,否则类的元数据信息只能用静态编译的方式实现,例如热加载,Tomcat的classloader等等都没法支持。\n\n## 反射的基本运用\n\n上面我们提到了反射可以用于判断任意对象所属的类,获得Class对象,构造任意一个对象以及调用一个对象。这里我们介绍一下基本反射功能的实现(反射相关的类一般都在java.lang.relfect包里)。\n\n1、获得Class对象方法有三种\n\n(1)使用Class类的forName静态方法:\n```` \npublic static Class forName(String className)\n````\n在JDBC开发中常用此方法加载数据库驱动:\n要使用全类名来加载这个类,一般数据库驱动的配置信息会写在配置文件中。加载这个驱动前要先导入jar包\n````\nClass.forName(driver);\n````\n(2)直接获取某一个对象的class,比如:\n````\n//Class是一个泛型表示,用于获取一个类的类型。\nClass klass = int.class;\nClass classInt = Integer.TYPE;\n````\n(3)调用某个对象的getClass()方法,比如:\n```` \nStringBuilder str = new StringBuilder(\"123\");\nClass klass = str.getClass();\n````\n## 判断是否为某个类的实例\n\n一般地,我们用instanceof关键字来判断是否为某个类的实例。同时我们也可以借助反射中Class对象的isInstance()方法来判断是否为某个类的实例,它是一个Native方法:\n````\npublic native boolean isInstance(Object obj);\n````\n## 创建实例\n\n通过反射来生成对象主要有两种方式。\n\n(1)使用Class对象的newInstance()方法来创建Class对象对应类的实例。\n\n注意:利用newInstance创建对象:调用的类必须有无参的构造器\n````\n//Class代表任何类的一个类对象。\n//使用这个类对象可以为其他类进行实例化\n//因为jvm加载类以后自动在堆区生成一个对应的*.Class对象\n//该对象用于让JVM对进行所有*对象实例化。\nClass c = String.class;\n\n//Class 中的 ? 是通配符,其实就是表示任意符合泛类定义条件的类,和直接使用 Class\n//效果基本一致,但是这样写更加规范,在某些类型转换时可以避免不必要的 unchecked 错误。\n\nObject str = c.newInstance();\n````\n(2)先通过Class对象获取指定的Constructor对象,再调用Constructor对象的newInstance()方法来创建实例。这种方法可以用指定的构造器构造类的实例。\n````\n //获取String所对应的Class对象\n Class c = String.class;\n //获取String类带一个String参数的构造器\n Constructor constructor = c.getConstructor(String.class);\n //根据构造器创建实例\n Object obj = constructor.newInstance(\"23333\");\n System.out.println(obj);\n````\n## 获取方法\n获取某个Class对象的方法集合,主要有以下几个方法:\n\ngetDeclaredMethods()方法返回类或接口声明的所有方法,==包括公共、保护、默认(包)访问和私有方法,但不包括继承的方法==。\n````\npublic Method[] getDeclaredMethods() throws SecurityException\n````\ngetMethods()方法返回某个类的所有公用(public)方法,==包括其继承类的公用方法。==\n```` \npublic Method[] getMethods() throws SecurityException\n````\ngetMethod方法返回一个特定的方法,其中第一个参数为方法名称,后面的参数为方法的参数对应Class的对象\n````\npublic Method getMethod(String name, Class... parameterTypes)\n````\n只是这样描述的话可能难以理解,我们用例子来理解这三个方法:\n本文中的例子用到了以下这些类,用于反射的测试。\n\n````\n //注解类,可可用于表示方法,可以通过反射获取注解的内容。\n //Java注解的实现是很多注框架实现注解配置的基础\n @Target(ElementType.METHOD)\n @Retention(RetentionPolicy.RUNTIME)\n public @interface Invoke {\n }\n````\nuserbean的父类personbean\n````\n public class PersonBean {\n private String name;\n \n int id;\n \n public String getName() {\n return name;\n }\n \n public void setName(String name) {\n this.name = name;\n }\n}\n````\n接口user\n````\n public interface User {\n public void login ();\n \n }\n````\nuserBean实现user接口,继承personbean\n````\n public class UserBean extends PersonBean implements User{\n @Override\n public void login() {\n \n }\n \n class B {\n \n }\n \n public String userName;\n protected int i;\n static int j;\n private int l;\n private long userId;\n public UserBean(String userName, long userId) {\n this.userName = userName;\n this.userId = userId;\n }\n public String getName() {\n return userName;\n }\n public long getId() {\n return userId;\n }\n @Invoke\n public static void staticMethod(String devName,int a) {\n System.out.printf(\"Hi %s, I'm a static method\", devName);\n }\n @Invoke\n public void publicMethod() {\n System.out.println(\"I'm a public method\");\n }\n @Invoke\n private void privateMethod() {\n System.out.println(\"I'm a private method\");\n }\n }\n````\n1 getMethods和getDeclaredMethods的区别\n```` \npublic class 动态加载类的反射 {\n public static void main(String[] args) {\n try {\n Class clazz = Class.forName(\"com.javase.反射.UserBean\");\n for (Field field : clazz.getDeclaredFields()) {\n// field.setAccessible(true);\n System.out.println(field);\n }\n //getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。\n System.out.println(\"------共有方法------\");\n// getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。\n// getMethod*()获取的是类的所有共有方法,这就包括自身的所有public方法,和从基类继承的、从接口实现的所有public方法。\n for (Method method : clazz.getMethods()) {\n String name = method.getName();\n System.out.println(name);\n //打印出了UserBean.java的所有方法以及父类的方法\n }\n System.out.println(\"------独占方法------\");\n\n for (Method method : clazz.getDeclaredMethods()) {\n String name = method.getName();\n System.out.println(name);\n }\n } catch (ClassNotFoundException e) {\n e.printStackTrace();\n }\n }\n}\n\n````\n\n2 打印一个类的所有方法及详细信息:\n````\npublic class 打印所有方法 {\n\n public static void main(String[] args) {\n Class userBeanClass = UserBean.class;\n Field[] fields = userBeanClass.getDeclaredFields();\n //注意,打印方法时无法得到局部变量的名称,因为jvm只知道它的类型\n Method[] methods = userBeanClass.getDeclaredMethods();\n for (Method method : methods) {\n //依次获得方法的修饰符,返回类型和名称,外加方法中的参数\n String methodString = Modifier.toString(method.getModifiers()) + \" \" ; // private static\n methodString += method.getReturnType().getSimpleName() + \" \"; // void\n methodString += method.getName() + \"(\"; // staticMethod\n Class[] parameters = method.getParameterTypes();\n Parameter[] p = method.getParameters();\n\n for (Class parameter : parameters) {\n methodString += parameter.getSimpleName() + \" \" ; // String\n }\n methodString += \")\";\n System.out.println(methodString);\n }\n //注意方法只能获取到其类型,拿不到变量名\n/* public String getName()\n public long getId()\n public static void staticMethod(String int )\n public void publicMethod()\n private void privateMethod()*/\n }\n}\n````\n## 获取构造器信息\n\n获取类构造器的用法与上述获取方法的用法类似。主要是通过Class类的getConstructor方法得到Constructor类的一个实例,而Constructor类有一个newInstance方法可以创建一个对象实例:\n````\npublic class 打印构造方法 {\n public static void main(String[] args) {\n // constructors\n Class clazz = UserBean.class;\n\n Class userBeanClass = UserBean.class;\n //获得所有的构造方法\n Constructor[] constructors = userBeanClass.getDeclaredConstructors();\n for (Constructor constructor : constructors) {\n String s = Modifier.toString(constructor.getModifiers()) + \" \";\n s += constructor.getName() + \"(\";\n //构造方法的参数类型\n Class[] parameters = constructor.getParameterTypes();\n for (Class parameter : parameters) {\n s += parameter.getSimpleName() + \", \";\n }\n s += \")\";\n System.out.println(s);\n //打印结果//public com.javase.反射.UserBean(String, long, )\n\n }\n }\n}\n````\n## 获取类的成员变量(字段)信息\n主要是这几个方法,在此不再赘述:\n\ngetFiled: 访问公有的成员变量\ngetDeclaredField:所有已声明的成员变量。但不能得到其父类的成员变量\ngetFileds和getDeclaredFields用法同上(参照Method)\n\n````\npublic class 打印成员变量 {\n public static void main(String[] args) {\n Class userBeanClass = UserBean.class;\n //获得该类的所有成员变量,包括static private\n Field[] fields = userBeanClass.getDeclaredFields();\n\n for(Field field : fields) {\n //private属性即使不用下面这个语句也可以访问\n// field.setAccessible(true);\n\n //因为类的私有域在反射中默认可访问,所以flag默认为true。\n String fieldString = \"\";\n fieldString += Modifier.toString(field.getModifiers()) + \" \"; // `private`\n fieldString += field.getType().getSimpleName() + \" \"; // `String`\n fieldString += field.getName(); // `userName`\n fieldString += \";\";\n System.out.println(fieldString);\n \n //打印结果\n// public String userName;\n// protected int i;\n// static int j;\n// private int l;\n// private long userId;\n }\n\n }\n}\n````\n## 调用方法\n当我们从类中获取了一个方法后,我们就可以用invoke()方法来调用这个方法。invoke方法的原型为:\n````\npublic Object invoke(Object obj, Object... args)\n throws IllegalAccessException, IllegalArgumentException,\n InvocationTargetException\n \npublic class 使用反射调用方法 {\n public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException, NoSuchMethodException {\n Class userBeanClass = UserBean.class;\n //获取该类所有的方法,包括静态方法,实例方法。\n //此处也包括了私有方法,只不过私有方法在用invoke访问之前要设置访问权限\n //也就是使用setAccessible使方法可访问,否则会抛出异常\n// // IllegalAccessException的解释是\n// * An IllegalAccessException is thrown when an application tries\n// * to reflectively create an instance (other than an array),\n// * set or get a field, or invoke a method, but the currently\n// * executing method does not have access to the definition of\n// * the specified class, field, method or constructor.\n\n// getDeclaredMethod*()获取的是类自身声明的所有方法,包含public、protected和private方法。\n// getMethod*()获取的是类的所有共有方法,这就包括自身的所有public方法,和从基类继承的、从接口实现的所有public方法。\n\n //就是说,当这个类,域或者方法被设为私有访问,使用反射调用但是却没有权限时会抛出异常。\n Method[] methods = userBeanClass.getDeclaredMethods(); // 获取所有成员方法\n for (Method method : methods) {\n //反射可以获取方法上的注解,通过注解来进行判断\n if (method.isAnnotationPresent(Invoke.class)) { // 判断是否被 @Invoke 修饰\n //判断方法的修饰符是是static\n if (Modifier.isStatic(method.getModifiers())) { // 如果是 static 方法\n //反射调用该方法\n //类方法可以直接调用,不必先实例化\n method.invoke(null, \"wingjay\",2); // 直接调用,并传入需要的参数 devName\n } else {\n //如果不是类方法,需要先获得一个实例再调用方法\n //传入构造方法需要的变量类型\n Class[] params = {String.class, long.class};\n //获取该类指定类型的构造方法\n //如果没有这种类型的方法会报错\n Constructor constructor = userBeanClass.getDeclaredConstructor(params); // 获取参数格式为 String,long 的构造函数\n //通过构造方法的实例来进行实例化\n Object userBean = constructor.newInstance(\"wingjay\", 11); // 利用构造函数进行实例化,得到 Object\n if (Modifier.isPrivate(method.getModifiers())) {\n method.setAccessible(true); // 如果是 private 的方法,需要获取其调用权限\n// Set the {@code accessible} flag for this object to\n// * the indicated boolean value. A value of {@code true} indicates that\n// * the reflected object should suppress Java language access\n// * checking when it is used. A value of {@code false} indicates\n// * that the reflected object should enforce Java language access checks.\n //通过该方法可以设置其可见或者不可见,不仅可以用于方法\n //后面例子会介绍将其用于成员变量\n //打印结果\n// I'm a public method\n// Hi wingjay, I'm a static methodI'm a private method\n }\n method.invoke(userBean); // 调用 method,无须参数 \n }\n }\n }\n }\n}\n````\n## 利用反射创建数组\n\n数组在Java里是比较特殊的一种类型,它可以赋值给一个Object Reference。下面我们看一看利用反射创建数组的例子:\n````\npublic class 用反射创建数组 {\n public static void main(String[] args) {\n Class cls = null;\n try {\n cls = Class.forName(\"java.lang.String\");\n } catch (ClassNotFoundException e) {\n e.printStackTrace();\n }\n Object array = Array.newInstance(cls,25);\n //往数组里添加内容\n Array.set(array,0,\"hello\");\n Array.set(array,1,\"Java\");\n Array.set(array,2,\"fuck\");\n Array.set(array,3,\"Scala\");\n Array.set(array,4,\"Clojure\");\n //获取某一项的内容\n System.out.println(Array.get(array,3));\n //Scala\n }\n\n}\n````\n其中的Array类为java.lang.reflect.Array类。我们通过Array.newInstance()创建数组对象,它的原型是:\n````\npublic static Object newInstance(Class componentType, int length)\n throws NegativeArraySizeException {\n return newArray(componentType, length);\n }\n````\n而newArray()方法是一个Native方法,它在Hotspot JVM里的具体实现我们后边再研究,这里先把源码贴出来\n````\nprivate static native Object newArray(Class componentType, int length)\n throws NegativeArraySizeException;\n\n````\n \n\n## Java反射常见面试题\n\n### 什么是反射?\n\n反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。\n\n### 哪里用到反射机制?\n\nJDBC中,利用反射动态加载了数据库驱动程序。\nWeb服务器中利用反射调用了Sevlet的服务方法。\nEclispe等开发工具利用反射动态刨析对象的类型与结构,动态提示对象的属性和方法。\n很多框架都用到反射机制,注入属性,调用方法,如Spring。\n\n### 什么叫对象序列化,什么是反序列化,实现对象序列化需要做哪些工作?\n\n对象序列化,将对象中的数据编码为字节序列的过程。\n反序列化;将对象的编码字节重新反向解码为对象的过程。\nJAVA提供了API实现了对象的序列化和反序列化的功能,使用这些API时需要遵守如下约定:\n被序列化的对象类型需要实现序列化接口,此接口是标志接口,没有声明任何的抽象方法,JAVA编译器识别这个接口,自动的为这个类添加序列化和反序列化方法。\n为了保持序列化过程的稳定,建议在类中添加序列化版本号。\n不想让字段放在硬盘上就加transient\n以下情况需要使用 Java 序列化:\n想把的内存中的对象状态保存到一个文件中或者数据库中时候;\n想用套接字在网络上传送对象的时候;\n想通过RMI(远程方法调用)传输对象的时候。\n\n### 反射机制的优缺点?\n\n优点:可以动态执行,在运行期间根据业务功能动态执行方法、访问属性,最大限度发挥了java的灵活性。\n缺点:对性能有影响,这类操作总是慢于直接执行java代码。\n\n### 动态代理是什么?有哪些应用?\n\n动态代理是运行时动态生成代理类。\n动态代理的应用有 Spring AOP数据查询、测试框架的后端 mock、rpc,Java注解对象获取等。\n\n### 怎么实现动态代理?\n\nJDK 原生动态代理和 cglib 动态代理。\nJDK 原生动态代理是基于接口实现的,而 cglib 是基于继承当前类的子类实现的。\n\n### Java反射机制的作用\n\n在运行时判断任意一个对象所属的类\n在运行时构造任意一个类的对象\n在运行时判断任意一个类所具有的成员变量和方法\n在运行时调用任意一个对象的方法\n\n### 如何使用Java的反射?\n\n通过一个全限类名创建一个对象\n\nClass.forName(“全限类名”); 例如:com.mysql.jdbc.Driver Driver类已经被加载到 jvm中,并且完成了类的初始化工作就行了\n类名.class; 获取Class<?> clz 对象\n对象.getClass();\n\n获取构造器对象,通过构造器new出一个对象\n\nClazz.getConstructor([String.class]);\nCon.newInstance([参数]);\n通过class对象创建一个实例对象(就相当与new类名()无参构造器)\nCls.newInstance();\n\n通过class对象获得一个属性对象\n\nField c=cls.getFields():获得某个类的所有的公共(public)的字段,包括父类中的字段。\nField c=cls.getDeclaredFields():获得某个类的所有声明的字段,即包括public、private和proteced,但是不包括父类的声明字段\n\n通过class对象获得一个方法对象\n\nCls.getMethod(“方法名”,class……parameaType);(只能获取公共的)\nCls.getDeclareMethod(“方法名”);(获取任意修饰的方法,不能执行私有)\nM.setAccessible(true);(让私有的方法可以执行)\n让方法执行\n1). Method.invoke(obj实例对象,obj可变参数);-----(是有返回值的)\n\n## 参考文章\nhttp://www.cnblogs.com/peida/archive/2013/04/26/3038503.html\nhttp://www.cnblogs.com/whoislcj/p/5671622.html\nhttps://blog.csdn.net/grandgrandpa/article/details/84832343\nhttp://blog.csdn.net/lylwo317/article/details/52163304\nhttps://blog.csdn.net/qq_37875585/article/details/89340495\n\n"
},
{
"path": "docs/Java/basic/多线程.md",
"content": "# 目录\n * [Java中的线程](#java中的线程)\n * [Java线程状态机](#java线程状态机)\n * [一个线程的生命周期](#一个线程的生命周期)\n * [Java多线程实战](#java多线程实战)\n * [多线程的实现](#多线程的实现)\n * [线程状态转换](#线程状态转换)\n * [Java Thread常用方法](#java-thread常用方法)\n * [Thread#yield():](#threadyield:)\n * [Thread.interrupt():](#threadinterrupt:)\n * [Thread#interrupted(),返回true或者false:](#threadinterrupted,返回true或者false:)\n * [Thread.isInterrupted(),返回true或者false:](#threadisinterrupted,返回true或者false:)\n * [Thread#join(),Thread#join(time):](#threadjoin,threadjointime:)\n * [构造方法和守护线程](#构造方法和守护线程)\n * [启动线程的方式和isAlive方法](#启动线程的方式和isalive方法)\n * [Java多线程优先级](#java多线程优先级)\n * [Java多线程面试题](#java多线程面试题)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n\n\n## Java中的线程\n\nJava之父对线程的定义是:\n> 线程是一个独立执行的调用序列,同一个进程的线程在同一时刻共享一些系统资源(比如文件句柄等)也能访问同一个进程所创建的对象资源(内存资源)。java.lang.Thread对象负责统计和控制这种行为。\n\n> 每个程序都至少拥有一个线程-即作为Java虚拟机(JVM)启动参数运行在主类main方法的线程。在Java虚拟机初始化过程中也可能启动其他的后台线程。这种线程的数目和种类因JVM的实现而异。然而所有用户级线程都是显式被构造并在主线程或者是其他用户线程中被启动。\n\n 本文主要讲了java中多线程的使用方法、线程同步、线程数据传递、线程状态及相应的一些线程函数用法、概述等。在这之前,首先让我们来了解下在操作系统中进程和线程的区别:\n \n 进程:每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1--n个线程。(进程是资源分配的最小单位)\n \n 线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)\n \n 线程和进程一样分为五个阶段:创建、就绪、运行、阻塞、终止。\n \n 多进程是指操作系统能同时运行多个任务(程序)。\n \n 多线程是指在同一程序中有多个顺序流在执行。\n \n 在java中要想实现多线程,有两种手段,一种是继续Thread类,另外一种是实现Runable接口.(其实准确来讲,应该有三种,还有一种是实现Callable接口,并与Future、线程池结合使用\n \n## Java线程状态机\n\n\nJava 给多线程编程提供了内置的支持。 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。\n\n多线程是多任务的一种特别的形式,但多线程使用了更小的资源开销。\n\n这里定义和线程相关的另一个术语 - 进程:一个进程包括由操作系统分配的内存空间,包含一个或多个线程。一个线程不能独立的存在,它必须是进程的一部分。一个进程一直运行,直到所有的非守护线程都结束运行后才能结束。\n\n多线程能满足程序员编写高效率的程序来达到充分利用 CPU 的目的。\n\n* * *\n\n### 一个线程的生命周期\n\n线程是一个动态执行的过程,它也有一个从产生到死亡的过程。\n\n下图显示了一个线程完整的生命周期。\n\n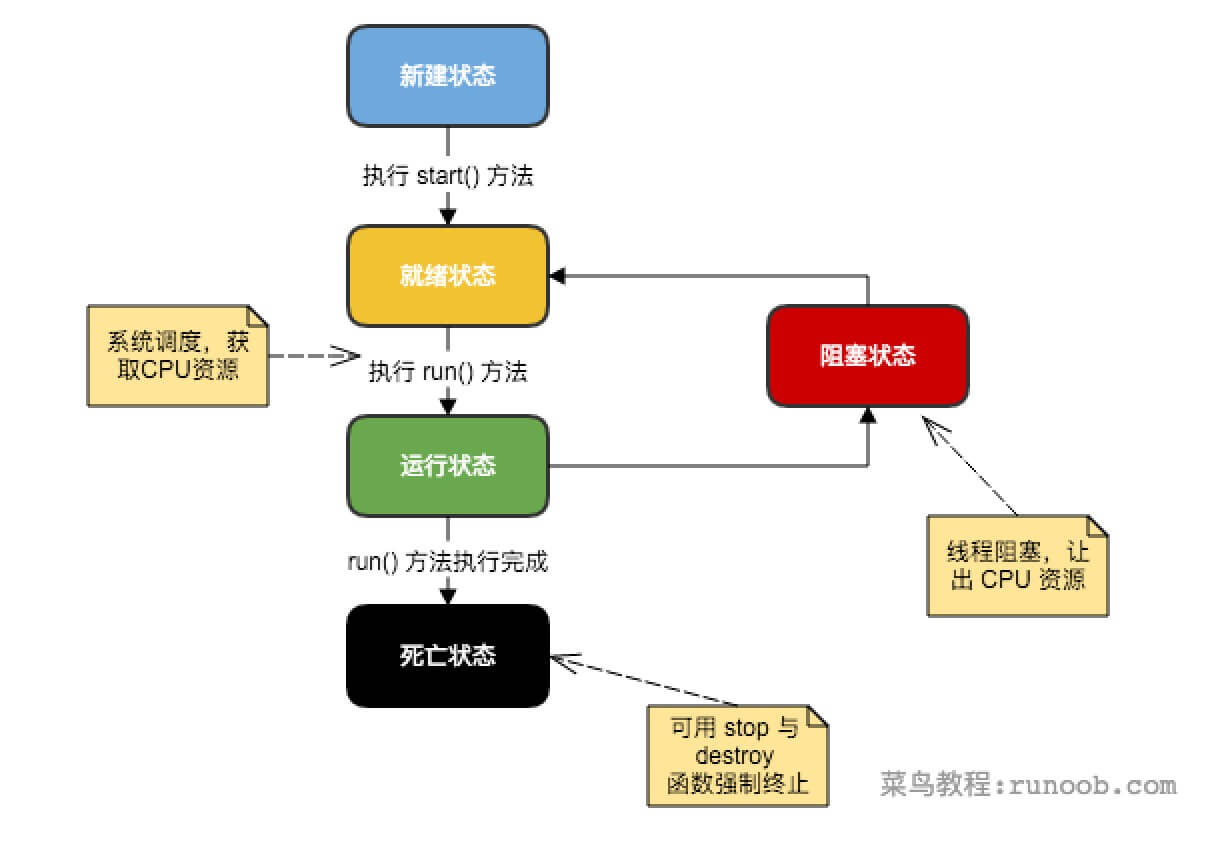\n\n* **新建状态:**\n\n 使用**new**关键字和**Thread**类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序**start()**这个线程。\n\n* **就绪状态:**\n\n 当线程对象调用了start()方法之后,该线程就进入就绪状态。就绪状态的线程处于就绪队列中,要等待JVM里线程调度器的调度。\n\n* **运行状态:**\n\n 如果就绪状态的线程获取 CPU 资源,就可以执行**run()**,此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。\n\n* **阻塞状态:**\n\n 如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。在睡眠时间已到或获得设备资源后可以重新进入就绪状态。可以分为三种:\n\n * 等待阻塞:运行状态中的线程执行 wait() 方法,使线程进入到等待阻塞状态。\n\n * 同步阻塞:线程在获取 synchronized 同步锁失败(因为同步锁被其他线程占用)。\n\n * 其他阻塞:通过调用线程的 sleep() 或 join() 发出了 I/O 请求时,线程就会进入到阻塞状态。当sleep() 状态超时,join() 等待线程终止或超时,或者 I/O 处理完毕,线程重新转入就绪状态。\n\n* **死亡状态:**\n\n 一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态。\n## Java多线程实战\n## 多线程的实现\n\n public class 多线程实例 {\n \n //继承thread\n @Test\n public void test1() {\n class A extends Thread {\n @Override\n public void run() {\n System.out.println(\"A run\");\n }\n }\n A a = new A();\n a.start();\n }\n \n //实现Runnable\n @Test\n public void test2() {\n class B implements Runnable {\n \n @Override\n public void run() {\n System.out.println(\"B run\");\n }\n }\n B b = new B();\n //Runable实现类需要由Thread类包装后才能执行\n new Thread(b).start();\n }\n \n //有返回值的线程\n @Test\n public void test3() {\n Callable callable = new Callable() {\n int sum = 0;\n @Override\n public Object call() throws Exception {\n for (int i = 0;i < 5;i ++) {\n sum += i;\n }\n return sum;\n }\n };\n //这里要用FutureTask,否则不能加入Thread构造方法\n FutureTask futureTask = new FutureTask(callable);\n new Thread(futureTask).start();\n try {\n System.out.println(futureTask.get());\n } catch (InterruptedException e) {\n e.printStackTrace();\n } catch (ExecutionException e) {\n e.printStackTrace();\n }\n }\n \n //线程池实现\n @Test\n public void test4() {\n ExecutorService executorService = Executors.newFixedThreadPool(5);\n //execute直接执行线程\n executorService.execute(new Thread());\n executorService.execute(new Runnable() {\n @Override\n public void run() {\n System.out.println(\"runnable\");\n }\n });\n //submit提交有返回结果的任务,运行完后返回结果。\n Future future = executorService.submit(new Callable() {\n @Override\n public String call() throws Exception {\n return \"a\";\n }\n });\n try {\n System.out.println(future.get());\n } catch (InterruptedException e) {\n e.printStackTrace();\n } catch (ExecutionException e) {\n e.printStackTrace();\n }\n \n ArrayList list = new ArrayList<>();\n //有返回值的线程组将返回值存进集合\n for (int i = 0;i < 5;i ++ ) {\n int finalI = i;\n Future future1 = executorService.submit(new Callable() {\n @Override\n public String call() throws Exception {\n return \"res\" + finalI;\n }\n });\n try {\n list.add((String) future1.get());\n } catch (InterruptedException e) {\n e.printStackTrace();\n } catch (ExecutionException e) {\n e.printStackTrace();\n }\n }\n for (String s : list) {\n System.out.println(s);\n }\n }\n }\n\n## 线程状态转换\n\n public class 线程的状态转换 {\n //一开始线程是init状态,结束时是terminated状态\n class t implements Runnable {\n private String name;\n public t(String name) {\n this.name = name;\n }\n @Override\n public void run() {\n System.out.println(name + \"run\");\n }\n }\n\n //测试join,父线程在子线程运行时进入waiting状态\n @Test\n public void test1() throws InterruptedException {\n Thread dad = new Thread(new Runnable() {\n Thread son = new Thread(new t(\"son\"));\n @Override\n public void run() {\n System.out.println(\"dad init\");\n son.start();\n try {\n //保证子线程运行完再运行父线程\n son.join();\n System.out.println(\"dad run\");\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n });\n //调用start,线程进入runnable状态,等待系统调度\n dad.start();\n //在父线程中对子线程实例使用join,保证子线程在父线程之前执行完\n\n }\n\n //测试sleep\n @Test\n public void test2(){\n Thread t1 = new Thread(new Runnable() {\n @Override\n public void run() {\n System.out.println(\"t1 run\");\n try {\n Thread.sleep(3000);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n });\n\n //主线程休眠。进入time waiting状态\n try {\n Thread.sleep(3000);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n t1.start();\n\n }\n\n //线程2进入blocked状态。\n public static void main(String[] args) {\n test4();\n Thread.yield();//进入runnable状态\n }\n\n //测试blocked状态\n public static void test4() {\n class A {\n //线程1获得实例锁以后线程2无法获得实例锁,所以进入blocked状态\n synchronized void run() {\n while (true) {\n System.out.println(\"run\");\n }\n }\n }\n A a = new A();\n new Thread(new Runnable() {\n @Override\n public void run() {\n System.out.println(\"t1 get lock\");\n a.run();\n }\n }).start();\n new Thread(new Runnable() {\n @Override\n public void run() {\n System.out.println(\"t2 get lock\");\n a.run();\n }\n }).start();\n\n }\n\n //volatile保证线程可见性\n volatile static int flag = 1;\n //object作为锁对象,用于线程使用wait和notify方法\n volatile static Object o = new Object();\n //测试wait和notify\n //wait后进入waiting状态,被notify进入blocked(阻塞等待锁释放)或者runnable状态(获取到锁)\n public void test5() {\n new Thread(new Runnable() {\n @Override\n public void run() {\n //wait和notify只能在同步代码块内使用\n synchronized (o) {\n while (true) {\n if (flag == 0) {\n try {\n Thread.sleep(2000);\n System.out.println(\"thread1 wait\");\n //释放锁,线程挂起进入object的等待队列,后续代码运行\n o.wait();\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n System.out.println(\"thread1 run\");\n System.out.println(\"notify t2\");\n flag = 0;\n //通知等待队列的一个线程获取锁\n o.notify();\n }\n }\n }\n }).start();\n //解释同上\n new Thread(new Runnable() {\n @Override\n public void run() {\n while (true) {\n synchronized (o) {\n if (flag == 1) {\n try {\n Thread.sleep(2000);\n System.out.println(\"thread2 wait\");\n o.wait();\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n System.out.println(\"thread2 run\");\n System.out.println(\"notify t1\");\n flag = 1;\n o.notify();\n }\n }\n }\n }).start();\n }\n\n //输出结果是\n // thread1 run\n // notify t2\n // thread1 wait\n // thread2 run\n // notify t1\n // thread2 wait\n // thread1 run\n // notify t2\n //不断循环\n\n }\n## Java Thread常用方法\n\n### Thread#yield():\n\n执行此方法会向系统线程调度器(Schelduler)发出一个暗示,告诉其当前JAVA线程打算放弃对CPU的使用,但该暗示,有可能被调度器忽略。使用该方法,可以防止线程对CPU的过度使用,提高系统性能。\n\nThread#sleep(time)或Thread.sleep(time, nanos):\n\n使当前线程进入休眠阶段,状态变为:TIME_WAITING\n\n### Thread.interrupt():\n\n中断当前线程的执行,允许当前线程对自身进行中断,否则将会校验调用方线程是否有对该线程的权限。\n\n如果当前线程因被调用Object#wait(),Object#wait(long, int), 或者线程本身的join(), join(long),sleep()处于阻塞状态中,此时调用interrupt方法会使抛出InterruptedException,而且线程的阻塞状态将会被清除。\n\n### Thread#interrupted(),返回true或者false:\n\n查看当前线程是否处于中断状态,这个方法比较特殊之处在于,如果调用成功,会将当前线程的interrupt status清除。所以如果连续2次调用该方法,第二次将返回false。\n\n### Thread.isInterrupted(),返回true或者false:\n\n与上面方法相同的地方在于,该方法返回当前线程的中断状态。不同的地方在于,它不会清除当前线程的interrupt status状态。\n\n### Thread#join(),Thread#join(time):\n\nA线程调用B线程的join()方法,将会使A等待B执行,直到B线程终止。如果传入time参数,将会使A等待B执行time的时间,如果time时间到达,将会切换进A线程,继续执行A线程。\n\n\n## 构造方法和守护线程\n\n 构造方法\n Thread类中不同的构造方法接受如下参数的不同组合:\n \n 一个Runnable对象,这种情况下,Thread.start方法将会调用对应Runnable对象的run方法。如果没有提供Runnable对象,那么就会立即得到一个Thread.run的默认实现。\n \n 一个作为线程标识名的String字符串,该标识在跟踪和调试过程中会非常有用,除此别无它用。\n \n 线程组(ThreadGroup),用来放置新创建的线程,如果提供的ThreadGroup不允许被访问,那么就会抛出一个SecurityException 。\n \n \n \n Thread对象拥有一个守护(daemon)标识属性,这个属性无法在构造方法中被赋值,但是可以在线程启动之前设置该属性(通过setDaemon方法)。\n \n 当程序中所有的非守护线程都已经终止,调用setDaemon方法可能会导致虚拟机粗暴的终止线程并退出。\n \n isDaemon方法能够返回该属性的值。守护状态的作用非常有限,即使是后台线程在程序退出的时候也经常需要做一些清理工作。\n \n (daemon的发音为”day-mon”,这是系统编程传统的遗留,系统守护进程是一个持续运行的进程,比如打印机队列管理,它总是在系统中运行。)\n \n## 启动线程的方式和isAlive方法\n\n启动线程\n调用start方法会触发Thread实例以一个新的线程启动其run方法。新线程不会持有调用线程的任何同步锁。\n\n当一个线程正常地运行结束或者抛出某种未检测的异常(比如,运行时异常(RuntimeException),错误(ERROR) 或者其子类)线程就会终止。\n\n**当线程终止之后,是不能被重新启动的。在同一个Thread上调用多次start方法会抛出InvalidThreadStateException异常。**\n\n如果线程已经启动但是还没有终止,那么调用isAlive方法就会返回true.即使线程由于某些原因处于阻塞(Blocked)状态该方法依然返回true。\n\n如果线程已经被取消(cancelled),那么调用其isAlive在什么时候返回false就因各Java虚拟机的实现而异了。没有方法可以得知一个处于非活动状态的线程是否已经被启动过了。\n\n## Java多线程优先级\n\n**Java的线程实现基本上都是内核级线程的实现,所以Java线程的具体执行还取决于操作系统的特性。**\n\nJava虚拟机为了实现跨平台(不同的硬件平台和各种操作系统)的特性,Java语言在线程调度与调度公平性上未作出任何的承诺,甚至都不会严格保证线程会被执行。但是Java线程却支持优先级的方法,这些方法会影响线程的调度:\n\n每个线程都有一个优先级,分布在Thread.MIN_PRIORITY和Thread.MAX_PRIORITY之间(分别为1和10)\n默认情况下,新创建的线程都拥有和创建它的线程相同的优先级。main方法所关联的初始化线程拥有一个默认的优先级,这个优先级是Thread.NORM_PRIORITY (5).\n\n线程的当前优先级可以通过getPriority方法获得。\n线程的优先级可以通过setPriority方法来动态的修改,一个线程的最高优先级由其所在的线程组限定。\n\n## Java多线程面试题\n\n这篇文章主要是对多线程的问题进行总结的,因此罗列了40个多线程的问题。\n\n这些多线程的问题,有些来源于各大网站、有些来源于自己的思考。可能有些问题网上有、可能有些问题对应的答案也有、也可能有些各位网友也都看过,但是本文写作的重心就是所有的问题都会按照自己的理解回答一遍,不会去看网上的答案,因此可能有些问题讲的不对,能指正的希望大家不吝指教。\n\n> **1、多线程有什么用?**\n\n一个可能在很多人看来很扯淡的一个问题:我会用多线程就好了,还管它有什么用?在我看来,这个回答更扯淡。所谓\"知其然知其所以然\",\"会用\"只是\"知其然\",\"为什么用\"才是\"知其所以然\",只有达到\"知其然知其所以然\"的程度才可以说是把一个知识点运用自如。OK,下面说说我对这个问题的看法:\n\n**1)发挥多核CPU的优势**\n\n随着工业的进步,现在的笔记本、台式机乃至商用的应用服务器至少也都是双核的,4核、8核甚至16核的也都不少见,如果是单线程的程序,那么在双核CPU上就浪费了50%,在4核CPU上就浪费了75%。**单核CPU上所谓的\"多线程\"那是假的多线程,同一时间处理器只会处理一段逻辑,只不过线程之间切换得比较快,看着像多个线程\"同时\"运行罢了**。多核CPU上的多线程才是真正的多线程,它能让你的多段逻辑同时工作,多线程,可以真正发挥出多核CPU的优势来,达到充分利用CPU的目的。\n\n**2)防止阻塞**\n\n从程序运行效率的角度来看,单核CPU不但不会发挥出多线程的优势,反而会因为在单核CPU上运行多线程导致线程上下文的切换,而降低程序整体的效率。但是单核CPU我们还是要应用多线程,就是为了防止阻塞。试想,如果单核CPU使用单线程,那么只要这个线程阻塞了,比方说远程读取某个数据吧,对端迟迟未返回又没有设置超时时间,那么你的整个程序在数据返回回来之前就停止运行了。多线程可以防止这个问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,也不会影响其它任务的执行。\n\n**3)便于建模**\n\n这是另外一个没有这么明显的优点了。假设有一个大的任务A,单线程编程,那么就要考虑很多,建立整个程序模型比较麻烦。但是如果把这个大的任务A分解成几个小任务,任务B、任务C、任务D,分别建立程序模型,并通过多线程分别运行这几个任务,那就简单很多了。\n\n> **2、创建线程的方式**\n\n比较常见的一个问题了,一般就是两种:\n\n1)继承Thread类\n\n2)实现Runnable接口\n\n至于哪个好,不用说肯定是后者好,因为实现接口的方式比继承类的方式更灵活,也能减少程序之间的耦合度,**面向接口编程**也是设计模式6大原则的核心。\n\n\n> **3、start()方法和run()方法的区别**\n\n只有调用了start()方法,才会表现出多线程的特性,不同线程的run()方法里面的代码交替执行。如果只是调用run()方法,那么代码还是同步执行的,必须等待一个线程的run()方法里面的代码全部执行完毕之后,另外一个线程才可以执行其run()方法里面的代码。\n\n> **4、Runnable接口和Callable接口的区别**\n\n有点深的问题了,也看出一个Java程序员学习知识的广度。\n\nRunnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。\n\n这其实是很有用的一个特性,因为**多线程相比单线程更难、更复杂的一个重要原因就是因为多线程充满着未知性**,某条线程是否执行了?某条线程执行了多久?某条线程执行的时候我们期望的数据是否已经赋值完毕?无法得知,我们能做的只是等待这条多线程的任务执行完毕而已。而Callable+Future/FutureTask却可以获取多线程运行的结果,可以在等待时间太长没获取到需要的数据的情况下取消该线程的任务,真的是非常有用。\n\n> **5、CyclicBarrier和CountDownLatch的区别**\n\n两个看上去有点像的类,都在java.util.concurrent下,都可以用来表示代码运行到某个点上,二者的区别在于:\n\n1)CyclicBarrier的某个线程运行到某个点上之后,该线程即停止运行,直到所有的线程都到达了这个点,所有线程才重新运行;CountDownLatch则不是,某线程运行到某个点上之后,只是给某个数值-1而已,该线程继续运行。\n\n2)CyclicBarrier只能唤起一个任务,CountDownLatch可以唤起多个任务。\n\n3) CyclicBarrier可重用,CountDownLatch不可重用,计数值为0该CountDownLatch就不可再用了。\n\n> **6、volatile关键字的作用**\n\n一个非常重要的问题,是每个学习、应用多线程的Java程序员都必须掌握的。理解volatile关键字的作用的前提是要理解Java内存模型,这里就不讲Java内存模型了,可以参见第31点,volatile关键字的作用主要有两个:\n\n1)多线程主要围绕可见性和原子性两个特性而展开,使用volatile关键字修饰的变量,保证了其在多线程之间的可见性,即每次读取到volatile变量,一定是最新的数据。\n\n2)代码底层执行不像我们看到的高级语言----Java程序这么简单,它的执行是**Java代码-->字节码-->根据字节码执行对应的C/C++代码-->C/C++代码被编译成汇编语言-->和硬件电路交互**,现实中,为了获取更好的性能JVM可能会对指令进行重排序,多线程下可能会出现一些意想不到的问题。使用volatile则会对禁止语义重排序,当然这也一定程度上降低了代码执行效率。\n\n从实践角度而言,volatile的一个重要作用就是和CAS结合,保证了原子性,详细的可以参见java.util.concurrent.atomic包下的类,比如AtomicInteger,更多详情请点击[这里](http://mp.weixin.qq.com/s?__biz=MzI3ODcxMzQzMw==&mid=2247483916&idx=1&sn=89daf388da0d6fe40dc54e9a4018baeb&chksm=eb53873adc240e2cf55400f3261228d08fc943c4f196566e995681549c47630b70ac01b75031&scene=21#wechat_redirect)进行学习。\n\n> **7、什么是线程安全**\n\n又是一个理论的问题,各式各样的答案有很多,我给出一个个人认为解释地最好的:**如果你的代码在多线程下执行和在单线程下执行永远都能获得一样的结果,那么你的代码就是线程安全的**。\n\n这个问题有值得一提的地方,就是线程安全也是有几个级别的:\n\n**1)不可变**\n\n像String、Integer、Long这些,都是final类型的类,任何一个线程都改变不了它们的值,要改变除非新创建一个,因此这些不可变对象不需要任何同步手段就可以直接在多线程环境下使用\n\n**2)绝对线程安全**\n\n不管运行时环境如何,调用者都不需要额外的同步措施。要做到这一点通常需要付出许多额外的代价,Java中标注自己是线程安全的类,实际上绝大多数都不是线程安全的,不过绝对线程安全的类,Java中也有,比方说CopyOnWriteArrayList、CopyOnWriteArraySet\n\n**3)相对线程安全**\n\n相对线程安全也就是我们通常意义上所说的线程安全,像Vector这种,add、remove方法都是原子操作,不会被打断,但也仅限于此,如果有个线程在遍历某个Vector、有个线程同时在add这个Vector,99%的情况下都会出现ConcurrentModificationException,也就是**fail-fast机制**。\n\n**4)线程非安全**\n\n这个就没什么好说的了,ArrayList、LinkedList、HashMap等都是线程非安全的类,点击[这里](http://mp.weixin.qq.com/s?__biz=MzI3ODcxMzQzMw==&mid=2247486446&idx=2&sn=cb4f3aff0427c5ac3ffe5b61e150f506&chksm=eb538ed8dc2407ceb91fffe3c3bd559d9b15537446f84eb3bfb1a80e67f5efee176ca468a07b&scene=21#wechat_redirect)了解为什么不安全。\n\n> **8、Java中如何获取到线程dump文件**\n\n死循环、死锁、阻塞、页面打开慢等问题,打线程dump是最好的解决问题的途径。所谓线程dump也就是线程堆栈,获取到线程堆栈有两步:\n\n1)获取到线程的pid,可以通过使用jps命令,在Linux环境下还可以使用ps -ef | grep java\n\n2)打印线程堆栈,可以通过使用jstack pid命令,在Linux环境下还可以使用kill -3 pid\n\n另外提一点,Thread类提供了一个getStackTrace()方法也可以用于获取线程堆栈。这是一个实例方法,因此此方法是和具体线程实例绑定的,每次获取获取到的是具体某个线程当前运行的堆栈。\n\n> **9、一个线程如果出现了运行时异常会怎么样**\n\n如果这个异常没有被捕获的话,这个线程就停止执行了。另外重要的一点是:**如果这个线程持有某个某个对象的监视器,那么这个对象监视器会被立即释放**\n\n> **10、如何在两个线程之间共享数据**\n\n通过在线程之间共享对象就可以了,然后通过wait/notify/notifyAll、await/signal/signalAll进行唤起和等待,比方说阻塞队列BlockingQueue就是为线程之间共享数据而设计的\n\n> **11、sleep方法和wait方法有什么区别**\n\n这个问题常问,sleep方法和wait方法都可以用来放弃CPU一定的时间,不同点在于如果线程持有某个对象的监视器,sleep方法不会放弃这个对象的监视器,wait方法会放弃这个对象的监视器\n\n> **12、生产者消费者模型的作用是什么**\n\n这个问题很理论,但是很重要:\n\n1)**通过平衡生产者的生产能力和消费者的消费能力来提升整个系统的运行效率**,这是生产者消费者模型最重要的作用\n\n2)解耦,这是生产者消费者模型附带的作用,解耦意味着生产者和消费者之间的联系少,联系越少越可以独自发展而不需要收到相互的制约\n\n> **13、ThreadLocal有什么用**\n\n简单说ThreadLocal就是一种以**空间换时间**的做法,在每个Thread里面维护了一个以开地址法实现的ThreadLocal.ThreadLocalMap,把数据进行隔离,数据不共享,自然就没有线程安全方面的问题了\n\n> **14、为什么wait()方法和notify()/notifyAll()方法要在同步块中被调用**\n\n这是JDK强制的,wait()方法和notify()/notifyAll()方法在调用前都必须先获得对象的锁\n\n> **15、wait()方法和notify()/notifyAll()方法在放弃对象监视器时有什么区别**\n\nwait()方法和notify()/notifyAll()方法在放弃对象监视器的时候的区别在于:**wait()方法立即释放对象监视器,notify()/notifyAll()方法则会等待线程剩余代码执行完毕才会放弃对象监视器**。\n\n> **16、为什么要使用线程池**\n\n避免频繁地创建和销毁线程,达到线程对象的重用。另外,使用线程池还可以根据项目灵活地控制并发的数目。点击[这里](https://mp.weixin.qq.com/s?__biz=MzI3ODcxMzQzMw==&mid=2247483824&idx=1&sn=7e34a3944a93d649d78d618cf04e0619&scene=21#wechat_redirect)学习线程池详解。\n\n> **17、怎么唤醒一个阻塞的线程**\n\n如果线程是因为调用了wait()、sleep()或者join()方法而导致的阻塞,可以中断线程,并且通过抛出InterruptedException来唤醒它;如果线程遇到了IO阻塞,无能为力,因为IO是操作系统实现的,Java代码并没有办法直接接触到操作系统。\n\n> **18、不可变对象对多线程有什么帮助**\n\n前面有提到过的一个问题,不可变对象保证了对象的内存可见性,对不可变对象的读取不需要进行额外的同步手段,提升了代码执行效率。\n\n> **19、什么是多线程的上下文切换**\n\n多线程的上下文切换是指CPU控制权由一个已经正在运行的线程切换到另外一个就绪并等待获取CPU执行权的线程的过程。\n\n> **20、线程类的构造方法、静态块是被哪个线程调用的**\n\n这是一个非常刁钻和狡猾的问题。请记住:线程类的构造方法、静态块是被new这个线程类所在的线程所调用的,而run方法里面的代码才是被线程自身所调用的。\n\n如果说上面的说法让你感到困惑,那么我举个例子,假设Thread2中new了Thread1,main函数中new了Thread2,那么:\n\n1)Thread2的构造方法、静态块是main线程调用的,Thread2的run()方法是Thread2自己调用的\n\n2)Thread1的构造方法、静态块是Thread2调用的,Thread1的run()方法是Thread1自己调用的\n\n\n> **21、高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?**\n\n这是我在并发编程网上看到的一个问题,把这个问题放在最后一个,希望每个人都能看到并且思考一下,因为这个问题非常好、非常实际、非常专业。关于这个问题,个人看法是:\n\n1)高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换\n\n2)并发不高、任务执行时间长的业务要区分开看:\n\na)假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以加大线程池中的线程数目,让CPU处理更多的业务\n\nb)假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换\n\nc)并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考其他有关线程池的文章。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。\n\n## 参考文章\nhttps://blog.csdn.net/zl1zl2zl3/article/details/81868173\nhttps://www.runoob.com/java/java-multithreading.html\nhttps://blog.csdn.net/qq_38038480/article/details/80584715\nhttps://blog.csdn.net/tongxuexie/article/details/80145663\nhttps://www.cnblogs.com/snow-flower/p/6114765.html\n\n\n"
},
{
"path": "docs/Java/basic/序列化和反序列化.md",
"content": "# 目录\n * [序列化与反序列化概念](#序列化与反序列化概念)\n * [Java对象的序列化与反序列化](#java对象的序列化与反序列化)\n * [相关接口及类](#相关接口及类)\n * [序列化ID](#序列化id)\n * [静态变量不参与序列化](#静态变量不参与序列化)\n * [探究ArrayList的序列化](#探究arraylist的序列化)\n * [如何自定义的序列化和反序列化策略](#如何自定义的序列化和反序列化策略)\n * [为什么要实现Serializable](#为什么要实现serializable)\n * [序列化知识点总结](#序列化知识点总结)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n本文参考 http://www.importnew.com/17964.html和\nhttps://www.ibm.com/developerworks/cn/java/j-lo-serial/\n\n## 序列化与反序列化概念\n\n序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。一般将一个对象存储至一个储存媒介,例如档案或是记亿体缓冲等。在网络传输过程中,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象。这个相反的过程又称为反序列化。\n\n### Java对象的序列化与反序列化\n\n在Java中,我们可以通过多种方式来创建对象,并且只要对象没有被回收我们都可以复用该对象。但是,我们创建出来的这些Java对象都是存在于JVM的堆内存中的。\n\n只有JVM处于运行状态的时候,这些对象才可能存在。一旦JVM停止运行,这些对象的状态也就随之而丢失了。\n\n但是在真实的应用场景中,我们需要将这些对象持久化下来,并且能够在需要的时候把对象重新读取出来。Java的对象序列化可以帮助我们实现该功能。\n\n> 对象序列化机制(object serialization)是Java语言内建的一种对象持久化方式,通过对象序列化,可以把对象的状态保存为字节数组,并且可以在有需要的时候将这个字节数组通过反序列化的方式再转换成对象。\n\n对象序列化可以很容易的在JVM中的活动对象和字节数组(流)之间进行转换。\n\n在Java中,对象的序列化与反序列化被广泛应用到RMI(远程方法调用)及网络传输中。\n\n### 相关接口及类\n\nJava为了方便开发人员将Java对象进行序列化及反序列化提供了一套方便的API来支持。其中包括以下接口和类:\n\n java.io.Serializable\n \n java.io.Externalizable\n \n ObjectOutput\n \n ObjectInput\n \n ObjectOutputStream\n \n ObjectInputStream\n \n Serializable 接口\n\n**类通过实现 java.io.Serializable 接口以启用其序列化功能。**\n\n未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。 (该接口并没有方法和字段,为什么只有实现了该接口的类的对象才能被序列化呢?)\n\n当试图对一个对象进行序列化的时候,如果遇到不支持 Serializable 接口的对象。在此情况下,将抛出NotSerializableException。\n\n如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该集成java.io.Serializable接口。\n\n下面是一个实现了java.io.Serializable接口的类\n````\npublic class 序列化和反序列化 {\n public static void main(String[] args) {\n\n }\n //注意,内部类不能进行序列化,因为它依赖于外部类\n @Test\n public void test() throws IOException {\n A a = new A();\n a.i = 1;\n a.s = \"a\";\n FileOutputStream fileOutputStream = null;\n FileInputStream fileInputStream = null;\n try {\n //将obj写入文件\n fileOutputStream = new FileOutputStream(\"temp\");\n ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);\n objectOutputStream.writeObject(a);\n fileOutputStream.close();\n //通过文件读取obj\n fileInputStream = new FileInputStream(\"temp\");\n ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);\n A a2 = (A) objectInputStream.readObject();\n fileInputStream.close();\n System.out.println(a2.i);\n System.out.println(a2.s);\n //打印结果和序列化之前相同\n } catch (IOException e) {\n e.printStackTrace();\n } catch (ClassNotFoundException e) {\n e.printStackTrace();\n }\n }\n}\n\nclass A implements Serializable {\n\n int i;\n String s;\n}\n````\n**Externalizable接口**\n\n除了Serializable 之外,java中还提供了另一个序列化接口Externalizable\n\n为了了解Externalizable接口和Serializable接口的区别,先来看代码,我们把上面的代码改成使用Externalizable的形式。\n````\nclass B implements Externalizable {\n //必须要有公开无参构造函数。否则报错\n public B() {\n\n }\n int i;\n String s;\n @Override\n public void writeExternal(ObjectOutput out) throws IOException {\n\n }\n\n @Override\n public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {\n\n }\n}\n\n@Test\n public void test2() throws IOException, ClassNotFoundException {\n B b = new B();\n b.i = 1;\n b.s = \"a\";\n //将obj写入文件\n FileOutputStream fileOutputStream = new FileOutputStream(\"temp\");\n ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);\n objectOutputStream.writeObject(b);\n fileOutputStream.close();\n //通过文件读取obj\n FileInputStream fileInputStream = new FileInputStream(\"temp\");\n ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);\n B b2 = (B) objectInputStream.readObject();\n fileInputStream.close();\n System.out.println(b2.i);\n System.out.println(b2.s);\n //打印结果为0和null,即初始值,没有被赋值\n //0\n //null\n }\n````\n通过上面的实例可以发现,对B类进行序列化及反序列化之后得到的对象的所有属性的值都变成了默认值。也就是说,之前的那个对象的状态并没有被持久化下来。这就是Externalizable接口和Serializable接口的区别:\n\nExternalizable继承了Serializable,该接口中定义了两个抽象方法:writeExternal()与readExternal()。\n\n当使用Externalizable接口来进行序列化与反序列化的时候需要开发人员重写writeExternal()与readExternal()方法。由于上面的代码中,并没有在这两个方法中定义序列化实现细节,所以输出的内容为空。\n\n> 还有一点值得注意:在使用Externalizable进行序列化的时候,在读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。所以,实现Externalizable接口的类必须要提供一个public的无参的构造器。\n\n````\nclass C implements Externalizable {\n int i;\n int j;\n String s;\n public C() {\n\n }\n //实现下面两个方法可以选择序列化中需要被复制的成员。\n //并且,写入顺序和读取顺序要一致,否则报错。\n //可以写入多个同类型变量,顺序保持一致即可。\n @Override\n public void writeExternal(ObjectOutput out) throws IOException {\n out.writeInt(i);\n out.writeInt(j);\n out.writeObject(s);\n }\n\n @Override\n public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {\n i = in.readInt();\n j = in.readInt();\n s = (String) in.readObject();\n }\n}\n\n@Test\npublic void test3() throws IOException, ClassNotFoundException {\n C c = new C();\n c.i = 1;\n c.j = 2;\n c.s = \"a\";\n //将obj写入文件\n FileOutputStream fileOutputStream = new FileOutputStream(\"temp\");\n ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);\n objectOutputStream.writeObject(c);\n fileOutputStream.close();\n //通过文件读取obj\n FileInputStream fileInputStream = new FileInputStream(\"temp\");\n ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);\n C c2 = (C) objectInputStream.readObject();\n fileInputStream.close();\n System.out.println(c2.i);\n System.out.println(c2.j);\n System.out.println(c2.s);\n //打印结果为0和null,即初始值,没有被赋值\n //0\n //null\n}\n````\n\n## 序列化ID\n\n序列化 ID 问题\n情境:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C。\n\n问题:C 对象的全类路径假设为 com.inout.Test,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。\n\n解决:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。\n````\npackage com.inout; \n \nimport java.io.Serializable; \n \npublic class A implements Serializable { \n \n private static final long serialVersionUID = 1L; \n \n private String name; \n \n public String getName() \n { \n return name; \n } \n \n public void setName(String name) \n { \n this.name = name; \n } \n} \n \npackage com.inout; \n \nimport java.io.Serializable; \n \npublic class A implements Serializable { \n \n private static final long serialVersionUID = 2L; \n \n private String name; \n \n public String getName() \n { \n return name; \n } \n \n public void setName(String name) \n { \n this.name = name; \n } \n}\n````\n\n### 静态变量不参与序列化\n\n清单 2 中的 main 方法,将对象序列化后,修改静态变量的数值,再将序列化对象读取出来,然后通过读取出来的对象获得静态变量的数值并打印出来。依照清单 2,这个 System.out.println(t.staticVar) 语句输出的是 10 还是 5 呢?\n````\npublic class Test implements Serializable {\n \n private static final long serialVersionUID = 1L;\n \n public static int staticVar = 5;\n \n public static void main(String[] args) {\n try {\n //初始时staticVar为5\n ObjectOutputStream out = new ObjectOutputStream(\n new FileOutputStream(\"result.obj\"));\n out.writeObject(new Test());\n out.close();\n \n //序列化后修改为10\n Test.staticVar = 10;\n \n ObjectInputStream oin = new ObjectInputStream(new FileInputStream(\n \"result.obj\"));\n Test t = (Test) oin.readObject();\n oin.close();\n \n //再读取,通过t.staticVar打印新的值\n System.out.println(t.staticVar);\n \n } catch (FileNotFoundException e) {\n e.printStackTrace();\n } catch (IOException e) {\n e.printStackTrace();\n } catch (ClassNotFoundException e) {\n e.printStackTrace();\n }\n }\n}\n````\n\n最后的输出是 10,对于无法理解的读者认为,打印的 staticVar 是从读取的对象里获得的,应该是保存时的状态才对。之所以打印 10 的原因在于序列化时,并不保存静态变量,这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量。\n\n## 探究ArrayList的序列化\n\nArrayList的序列化\n在介绍ArrayList序列化之前,先来考虑一个问题:\n\n如何自定义的序列化和反序列化策略\n\n带着这个问题,我们来看java.util.ArrayList的源码\n\n````\n public class ArrayList extends AbstractList\n implements List, RandomAccess, Cloneable, java.io.Serializable\n {\n private static final long serialVersionUID = 8683452581122892189L;\n transient Object[] elementData; // non-private to simplify nested class access\n private int size;\n }\n````\n\n笔者省略了其他成员变量,从上面的代码中可以知道ArrayList实现了java.io.Serializable接口,那么我们就可以对它进行序列化及反序列化。\n\n因为elementData是transient的(1.8好像改掉了这一点),所以我们认为这个成员变量不会被序列化而保留下来。我们写一个Demo,验证一下我们的想法:\n````\npublic class ArrayList的序列化 {\n public static void main(String[] args) throws IOException, ClassNotFoundException {\n ArrayList list = new ArrayList();\n list.add(\"a\");\n list.add(\"b\");\n ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(\"arr\"));\n objectOutputStream.writeObject(list);\n objectOutputStream.close();\n ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(\"arr\"));\n ArrayList list1 = (ArrayList) objectInputStream.readObject();\n objectInputStream.close();\n System.out.println(Arrays.toString(list.toArray()));\n //序列化成功,里面的元素保持不变。\n }\n````\n了解ArrayList的人都知道,ArrayList底层是通过数组实现的。那么数组elementData其实就是用来保存列表中的元素的。通过该属性的声明方式我们知道,他是无法通过序列化持久化下来的。那么为什么code 4的结果却通过序列化和反序列化把List中的元素保留下来了呢?\n\n**writeObject和readObject方法**\n\n在ArrayList中定义了来个方法: writeObject和readObject。\n\n这里先给出结论:\n\n> 在序列化过程中,如果被序列化的类中定义了writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。\n>\n> 如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。\n>\n> 用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。\n\n来看一下这两个方法的具体实现:\n````\nprivate void readObject(java.io.ObjectInputStream s)\n throws java.io.IOException, ClassNotFoundException {\n elementData = EMPTY_ELEMENTDATA;\n\n // Read in size, and any hidden stuff\n s.defaultReadObject();\n\n // Read in capacity\n s.readInt(); // ignored\n\n if (size > 0) {\n // be like clone(), allocate array based upon size not capacity\n ensureCapacityInternal(size);\n\n Object[] a = elementData;\n // Read in all elements in the proper order.\n for (int i=0; i 虽然ArrayList中写了writeObject 和 readObject 方法,但是这两个方法并没有显示的被调用啊。\n>\n> 那么如果一个类中包含writeObject 和 readObject 方法,那么这两个方法是怎么被调用的呢?\n\nObjectOutputStream\n从code 4中,我们可以看出,对象的序列化过程通过ObjectOutputStream和ObjectInputputStream来实现的,那么带着刚刚的问题,我们来分析一下ArrayList中的writeObject 和 readObject 方法到底是如何被调用的呢?\n\n为了节省篇幅,这里给出ObjectOutputStream的writeObject的调用栈:\n\nwriteObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject\n\n这里看一下invokeWriteObject:\n````\nvoid invokeWriteObject(Object obj, ObjectOutputStream out)\n throws IOException, UnsupportedOperationException\n {\n if (writeObjectMethod != null) {\n try {\n writeObjectMethod.invoke(obj, new Object[]{ out });\n } catch (InvocationTargetException ex) {\n Throwable th = ex.getTargetException();\n if (th instanceof IOException) {\n throw (IOException) th;\n } else {\n throwMiscException(th);\n }\n } catch (IllegalAccessException ex) {\n // should not occur, as access checks have been suppressed\n throw new InternalError(ex);\n }\n } else {\n throw new UnsupportedOperationException();\n }\n }\n````\n其中writeObjectMethod.invoke(obj, new Object[]{ out });是关键,通过反射的方式调用writeObjectMethod方法。官方是这么解释这个writeObjectMethod的:\n\nclass-defined writeObject method, or null if none\n\n在我们的例子中,这个方法就是我们在ArrayList中定义的writeObject方法。通过反射的方式被调用了。\n\n至此,我们先试着来回答刚刚提出的问题:\n\n 如果一个类中包含writeObject 和 readObject 方法,那么这两个方法是怎么被调用的?\n \n 答:在使用ObjectOutputStream的writeObject方法和ObjectInputStream的readObject方法时,会通过反射的方式调用。\n \n## 为什么要实现Serializable\n至此,我们已经介绍完了ArrayList的序列化方式。那么,不知道有没有人提出这样的疑问:\n\nSerializable明明就是一个空的接口,它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?\n````\nSerializable接口的定义:\n\npublic interface Serializable {\n}\n````\n\n读者可以尝试把code 1中的继承Serializable的代码去掉,再执行code 2,会抛出java.io.NotSerializableException。\n\n其实这个问题也很好回答,我们再回到刚刚ObjectOutputStream的writeObject的调用栈:\n\n writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject\n\nwriteObject0方法中有这么一段代码:\n````\nif (obj instanceof String) {\n writeString((String) obj, unshared);\n} else if (cl.isArray()) {\n writeArray(obj, desc, unshared);\n} else if (obj instanceof Enum) {\n writeEnum((Enum) obj, desc, unshared);\n} else if (obj instanceof Serializable) {\n writeOrdinaryObject(obj, desc, unshared);\n} else {\n if (extendedDebugInfo) {\n throw new NotSerializableException(\n cl.getName() + \"\\n\" + debugInfoStack.toString());\n } else {\n throw new NotSerializableException(cl.getName());\n }\n}\n````\n在进行序列化操作时,会判断要被序列化的类是否是Enum、Array和Serializable类型,如果不是则直接抛出NotSerializableException。\n\n## 序列化知识点总结\n\n> 1、如果一个类想被序列化,需要实现Serializable接口。否则将抛出NotSerializableException异常,这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。\n>\n> 2、通过ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化\n>\n> 3、虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)\n>\n> 序列化 ID 在 Eclipse 下提供了两种生成策略,一个是固定的 1L,一个是随机生成一个不重复的 long 类型数据(实际上是使用 JDK 工具生成),在这里有一个建议,如果没有特殊需求,就是用默认的 1L 就可以,这样可以确保代码一致时反序列化成功。那么随机生成的序列化 ID 有什么作用呢,有些时候,通过改变序列化 ID 可以用来限制某些用户的使用。\n>\n> 4、序列化并不保存静态变量。\n>\n> 5、要想将父类对象也序列化,就需要让父类也实现Serializable 接口。\n>\n> 6、Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。\n>\n> 7、服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。\n>\n> 8、在类中增加writeObject 和 readObject 方法可以实现自定义序列化策略\n\n\n## 参考文章\n\nhttps://blog.csdn.net/qq_34988624/article/details/86592229\nhttps://www.meiwen.com.cn/subject/slhvhqtx.html\nhttps://blog.csdn.net/qq_34988624/article/details/86592229\nhttps://segmentfault.com/a/1190000012220863\nhttps://my.oschina.net/wuxinshui/blog/1511484\nhttps://blog.csdn.net/hukailee/article/details/81107412\n\n"
},
{
"path": "docs/Java/basic/抽象类和接口.md",
"content": "# 目录\n * [抽象类介绍](#抽象类介绍)\n * [为什么要用抽象类](#为什么要用抽象类)\n * [一个抽象类小故事](#一个抽象类小故事)\n * [一个抽象类小游戏](#一个抽象类小游戏)\n * [接口介绍](#接口介绍)\n * [接口与类相似点:](#接口与类相似点:)\n * [接口与类的区别:](#接口与类的区别:)\n * [接口特性](#接口特性)\n * [抽象类和接口的区别](#抽象类和接口的区别)\n * [接口的使用:](#接口的使用:)\n * [接口最佳实践:设计模式中的工厂模式](#接口最佳实践:设计模式中的工厂模式)\n * [接口与抽象类的本质区别是什么?](#接口与抽象类的本质区别是什么?)\n * [基本语法区别](#基本语法区别)\n * [设计思想区别](#设计思想区别)\n * [如何回答面试题:接口和抽象类的区别?](#如何回答面试题:接口和抽象类的区别)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n## 抽象类介绍\n\n什么是抽象?\n\n百度给出的解释是:从具体事物抽出、概括出它们共同的方面、本质属性与关系等,而将个别的、非本质的方面、属性与关系舍弃,这种思维过程,称为抽象。\n\n这句话概括了抽象的概念,而在Java中,你可以只给出方法的定义不去实现方法的具体事物,由子类去根据具体需求来具体实现。\n\n这种只给出方法定义而不具体实现的方法被称为抽象方法,抽象方法是没有方法体的,在代码的表达上就是没有“{}”。\n\n包含一个或多个抽象方法的类也必须被声明为抽象类。\n\n使用abstract修饰符来表示抽象方法以及抽象类。\n````\n //有抽象方法的类也必须被声明为abstract\n public abstract class Test1 {\n \n \t//抽象方法,不能有“{}”\n \tpublic abstract void f();\n \t\n }\n````\n抽象类除了包含抽象方法外,还可以包含具体的变量和具体的方法。类即使不包含抽象方法,也可以被声明为抽象类,防止被实例化。\n\n抽象类不能被实例化,也就是不能使用new关键字来得到一个抽象类的实例,抽象方法必须在子类中被实现。\n````\n //有抽象方法的类也必须被声明为abstract\n public class Test1 {\n \n \tpublic static void main(String[] args) {\n \t\tTeacher teacher=new Teacher(\"教师\");\n \t\tteacher.work();\n \t\t\n \t\tDriver driver=new Driver(\"驾驶员\");\n \t\tdriver.work();\n \t}\n }\n //一个抽象类\n abstract class People{\n \t//抽象方法\n \tpublic abstract void work();\n }\n class Teacher extends People{\n \tprivate String work;\n \tpublic Teacher(String work) {\n \t\tthis.work=work;\n \t}\n \t@Override\n \tpublic void work() {\n \t\tSystem.out.println(\"我的职业是\"+this.work);\n \t}\t\n }\n class Driver extends People{\n \tprivate String work;\n \tpublic Driver(String work) {\n \t\tthis.work=work;\n \t}\n \t@Override\n \tpublic void work() {\n \t\tSystem.out.println(\"我的职业是\"+this.work);\n \t}\n }\n````\n\n> 运行结果:\n> 我的职业是教师\n> 我的职业是驾驶员\n> 几点说明:\n\n抽象类不能直接使用,需要子类去实现抽象类,然后使用其子类的实例。然而可以创建一个变量,其类型也是一个抽象类,并让他指向具体子类的一个实例,也就是可以使用抽象类来充当形参,实际实现类为实参,也就是多态的应用。\n````\n People people=new Teacher(\"教师\");\n people.work();\n````\n不能有抽象构造方法或抽象静态方法。\n\n如果非要使用new关键在来创建一个抽象类的实例的话,可以这样:\n````\n People people=new People() {\n \t@Override\n \tpublic void work() {\n \t //实现这个方法的具体功能\n \t}\n \t\t};\n````\n个人不推荐这种方法,代码读起来有点累。\n\n在下列情况下,一个类将成为抽象类:\n\n 当一个类的一个或多个方法是抽象方法时。\n 当类是一个抽象类的子类,并且不能实现父类的所有抽象方法时。\n 当一个类实现一个接口,并且不能实现接口的所有抽象方法时。\n 注意:\n 上面说的是这些情况下一个类将称为抽象类,没有说抽象类就一定会是这些情况。\n 抽象类可以不包含抽象方法,包含抽象方法的类就一定是抽象类。\n 事实上,抽象类可以是一个完全正常实现的类。\n\n### 为什么要用抽象类\n\n老是在想为什么要引用抽象类,一般类不就够用了吗。一般类里定义的方法,子类也可以覆盖,没必要定义成抽象的啊。\n\n看了下面的文章,明白了一点。\n\n其实不是说抽象类有什么用,一般类确实也能满足应用,但是现实中确实有些父类中的方法确实没有必要写,因为各个子类中的这个方法肯定会有不同,所以没有必要再父类里写。当然你也可以把抽象类都写成非抽象类,但是这样没有必要。\n\n而写成抽象类,这样别人看到你的代码,或你看到别人的代码,你就会注意抽象方法,而知道这个方法是在子类中实现的,所以,有个提示作用。\n\n### 一个抽象类小故事\n\n下面看一个关于抽象类的小故事\n \n 问你个问题,你知道什么是“东西”吗?什么是“物体”吗? \n “麻烦你,小王。帮我把那个东西拿过来好吗” \n 在生活中,你肯定用过这个词--东西。 \n 小王:“你要让我帮你拿那个水杯吗?” \n 你要的是水杯类的对象。而东西是水杯的父类。通常东西类没有实例对象,但我们有时需要东西的引用指向它的子类实例。 \n \n 你看你的房间乱成什么样子了,以后不要把东西乱放了,知道么? \n\n上面讲的只是子类和父类。而没有说明抽象类的作用。抽象类是据有一个或多个抽象方法的类,必须声明为抽象类。抽象类的特点是,不能创建实例。 \n\n这些该死的抽象类,也不知道它有什么屁用。我非要把它改一改不可。把抽象类中的抽象方法都改为空实现。也就是给抽象方法加上一个方法体,不过这个方法体是空的。这回抽象类就没有抽象方法了。它就可以不在抽象了。 \n\n当你这么尝试之后,你发现,原来的代码没有任何变化。大家都还是和原来一样,工作的很好。你这回可能更加相信,抽象类根本就没有什么用。但总是不死心,它应该有点用吧,不然创造Java的这伙传说中的天才不成了傻子了吗? \n\n### 一个抽象类小游戏\n\n接下来,我们来写一个小游戏。俄罗斯方块!我们来分析一下它需要什么类?\n\n我知道它要在一个矩形的房子里完成。这个房子的上面出现一个方块,慢慢的下落,当它接触到地面或是其它方块的尸体时,它就停止下落了。然后房子的上面又会出现一个新的方块,与前一个方块一样,也会慢慢的下落。在它还没有死亡之前,我可以尽量的移动和翻转它。这样可以使它起到落地时起到一定的作用,如果好的话,还可以减下少几行呢。这看起来好象人生一样,它在为后来人努力着。\n当然,我们不是真的要写一个游戏。所以我们简化它。我抽象出两个必须的类,一个是那个房间,或者就它地图也行。另一个是方块。我发现方块有很多种,数一下,共6种。它们都是四个小矩形构成的。但是它们还有很多不同,例如:它们的翻转方法不同。先把这个问题放到一边去,我们回到房子这个类中。\n\n房子上面总是有方块落下来,房子应该有个属性是方块。当一个方块死掉后,再创建一个方块,让它出现在房子的上面。当玩家要翻转方法时,它翻转的到底是哪个方块呢?当然,房子中只有一个方块可以被翻转,就是当前方块。它是房子的一个属性。那这个属性到底是什么类型的呢?方块有很多不同啊,一共有6种之多,我需要写六个类。一个属性不可能有六种类型吧。当然一个属性只能有一种类型。\n\n我们写一个方块类,用它来派生出6个子类。而房子类的当前方块属性的类型是方块类型。它可以指向任何子类。但是,当我调用当前方块的翻转方法时,它的子类都有吗?如果你把翻转方法写到方块类中,它的子类自然也就有了。可以这六种子类的翻转方法是不同的。我们知道'田'方块,它只有一种状态,无论你怎么翻转它。而长条的方块有两种状态。一种是‘-’,另一种是‘|’。这可怎么办呢?我们知道Java的多态性,你可以让子类来重写父类的方法。也就是说,在父类中定义这个方法,子类在重写这个方法。\n\n那么在父类的这个翻转方法中,我写一些什么代码呢?让它有几种状态呢?因为我们不可能实例化一个方块类的实例,所以它的翻转方法中的代码并不重要。而子类必须去重写它。那么你可以在父类的翻转方法中不写任何代码,也就是空方法。\n\n我们发现,方法类不可能有实例,它的翻转方法的内容可以是任何的代码。而子类必须重写父类的翻转方法。这时,你可以把方块类写成抽象类,而它的抽象方法就是翻转方法。当然,你也可以把方块类写为非抽象的,也可以在方块类的翻转方法中写上几千行的代码。但这样好吗?难道你是微软派来的,非要说Java中的很多东西都是没有用的吗?\n\n当我看到方块类是抽象的,我会很关心它的抽象方法。我知道它的子类一定会重写它,而且,我会去找到抽象类的引用。它一定会有多态性的体现。\n\n但是,如果你没有这样做,我会认为可能会在某个地方,你会实例化一个方块类的实例,但我找了所有的地方都没有找到。最后我会大骂你一句,你是来欺骗我的吗,你这个白痴。\n\n把那些和“东西”差不多的类写成抽象的。而水杯一样的类就可以不是抽象的了。当然水杯也有几千块钱一个的和几块钱一个的。水杯也有子类,例如,我用的水杯都很高档,大多都是一次性的纸水杯。\n\n记住一点,面向对象不是来自于Java,面向对象就在你的生活中。而Java的面向对象是方便你解决复杂的问题。这不是说面向对象很简单,虽然面向对象很复杂,但Java知道,你很了解面向对象,因为它就在你身边。\n\n## 接口介绍\n\n接口(英文:Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。\n\n接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。\n\n除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。\n\n接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在 Java 中,接口类型可用来声明一个变量,他们可以成为一个空指针,或是被绑定在一个以此接口实现的对象。\n\n### 接口与类相似点:\n\n* 一个接口可以有多个方法。\n* 接口文件保存在 .java 结尾的文件中,文件名使用接口名。\n* 接口的字节码文件保存在 .class 结尾的文件中。\n* 接口相应的字节码文件必须在与包名称相匹配的目录结构中。\n\n### 接口与类的区别:\n\n* 接口不能用于实例化对象。\n* 接口没有构造方法。\n* 接口中所有的方法必须是抽象方法。\n* 接口不能包含成员变量,除了 static 和 final 变量。\n* 接口不是被类继承了,而是要被类实现。\n* 接口支持多继承。\n\n### 接口特性\n\n* 接口中每一个方法也是隐式抽象的,接口中的方法会被隐式的指定为 **public abstract**(只能是 public abstract,其他修饰符都会报错)。\n* 接口中可以含有变量,但是接口中的变量会被隐式的指定为 **public static final** 变量(并且只能是 public,用 private 修饰会报编译错误)。\n* 接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法。\n\n### 抽象类和接口的区别\n\n* 1\\. 抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。\n* 2\\. 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 **public static final** 类型的。\n* 3\\. 接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。\n* 4\\. 一个类只能继承一个抽象类,而一个类却可以实现多个接口。\n\n> **注**:JDK 1.8 以后,接口里可以有静态方法和方法体了。\n\n\n### 接口的使用:\n 我们来举个例子,定义一个抽象类People,一个普通子类Student,两个接口。子类Student继承父类People,并实现接口Study,Write\n\n代码演示:\n````\n package demo;\n //构建一个抽象类People\n abstract class People{\n \t//父类属性私有化\n \tprivate String name;\n \tprivate int age;\n \t//提供父类的构造器\n \tpublic People(String name,int age){\n \t\tthis.name = name;\n \t\tthis.age = age;\n \t}\n \t//提供获取和设置属性的getter()/setter()方法\n \tpublic String getName() {\n \t\treturn name;\n \t}\n \n \tpublic int getAge() {\n \t\treturn age;\n \t}\n \n \tpublic void setName(String name) {\n \t\tthis.name = name;\n \t}\n \n \tpublic void setAge(int age) {\n \t\tthis.age = age;\n \t}\n \t\n \t//提供一个抽象方法\n \tpublic abstract void talk();\t\n }\n \n //定义一个接口\n interface Study{\n \t//设置课程数量为3\n \tint COURSENUM = 3;\n \t//构建一个默认方法\n \tdefault void stu(){\n \t\tSystem.out.println(\"学生需要学习\"+COURSENUM+\"门课程\");\n \t}\n }\n \n //再定义一个接口\n interface Write{\n \t//定义一个抽象方法\n \tvoid print();\n }\n \n //子类继承People,实现接口Study,Write\n class Student extends People implements Study,Write{\n \t//通过super关键字调用父类的构造器\n \tpublic Student(String name, int age) {\n \t\tsuper(name, age);\n \t}\n \t//实现父类的抽象方法\n \tpublic void talk() {\n \t\tSystem.out.println(\"我的名字叫\"+this.getName()+\",今年\"+this.getAge()+\"岁\");\n \t}\n \t//实现Write接口的抽象方法\n \tpublic void print() {\n \t\tSystem.out.println(\"学生会写作业\");\n \t}\n }\n \n public class InterfaceDemo{\n \tpublic static void main(String[] args) {\n \t\t//构建student对象\n \t\tStudent student = new Student(\"dodo\", 22);\n \t\t//调用父类的抽象方法\n \t\tstudent.talk();\n \t\t//调用接口Write中的抽象方法\n \t\tstudent.print();\n \t\t//调用接口Study中的默认方法\n \t\tstudent.stu();\n \t}\n }\n````\n代码讲解:上述例子结合了抽象类和接口的知识,内容较多,同学们可以多看多敲一下,学习学习。\n\n接口的实现:类名 implements 接口名,有多个接口名,用“,”隔开即可。\n\n\n\n接口的作用——制定标准\n 接口师表尊,所谓的标准,指的是各方共同遵守一个守则,只有操作标准统一了,所有的参与者才可以按照统一的规则操作。\n\n 如电脑可以和各个设备连接,提供统一的USB接口,其他设备只能通过USB接口和电脑相连\n \n 代码实现:\n```` \n package demo;\n \n interface USB \n {\n public void work() ; // 拿到USB设备就表示要进行工作\n }\n \n class Print implements USB \t\t//实现类(接口类)\t\n { \t\t\t\t\t\t\t// 打印机实现了USB接口标准(对接口的方法实现)\n public void work() \n {\n System.out.println(\"打印机用USB接口,连接,开始工作。\") ;\n }\n }\n class Flash implements USB \t\t//实现类(接口类)\t \t\t \t\n { \t\t\t\t\t\t\t\t// U盘实现了USB接口标准(对接口的方法实现)\n public void work() \n {\n System.out.println(\"U盘使用USB接口,连接,开始工作。\") ;\n }\n }\n \n class Computer \n {\n public void plugin(USB usb) \t\t\t//plugin的意思是插件,参数为接收接口类\n {\n usb.work() ; // 按照固定的方式进行工作\n }\n }\n public class InterfaceStandards { public static void main(String args[]) { Computer computer = new Computer() ; computer.plugin(new Print()) ; //实例化接口类, 在电脑上使用打印机 computer.plugin(new Flash()) ; //实例化接口类, 在电脑上使用U盘 }}\n\n代码讲解:上述例子,就给我们展示了接口制定标准的作用,怎么指定的呢?看下面代码\n \n class Computer \n {\n public void plugin(USB usb) \t\t\t//plugin的意思是插件,参数为接收接口类\n {\n usb.work() ; // 按照固定的方式进行工作\n }\n }\n\n我们可以看到,Computer类里面定义了一个方法plugin(),它的参数内写的是USB usb,即表示plugin()方法里,接收的是一个usb对象,而打印机和U盘对象可以通过向上转型当参数,传入方法里。我们来重新写一个main方法帮助大家理解\n\n代码演示:\n\n public class InterfaceStandards \n {\n public static void main(String args[]) \n { \n Computer computer = new Computer() ;\n \n USB usb = new Print();\n computer.plugin(usb) ; //实例化接口类, 在电脑上使用打印机\n usb = new Flash();\n computer.plugin(usb) ; //实例化接口类, 在电脑上使用U盘\n }\n }\n````\n代码讲解:我们修改了主函数后,发现,使用了两次的向上转型给了USB,虽然使用的都是usb对象,但赋值的子类对象不一样,实现的方法体也不同,这就很像现实生活,无论我使用的是打印机,还是U盘,我都是通过USB接口和电脑连接的,这就是接口的作用之一——制定标准\n\n我们来个图继续帮助大家理解一下:\n\n\n上面的图:我们学习前面的章节多态可以知道对象的多态可以通过动态绑定来实现,即使用向上转型,我们知道类,数组,接口都是引用类型变量,什么是引用类型变量?\n\n引用类型变量都会有一个地址的概念,即指向性的概念,当USB usb = new Print(),此时usb对象是指向new Print()的,当usb = new Flash()后,这时候usb变量就会指向new Flash(),我们会说这是子类对象赋值给了父类对象usb,而在内存中,我们应该说,usb指向了new Flash();\n\n### 接口最佳实践:设计模式中的工厂模式\n\n 首先我们来认识一下什么是工厂模式?工厂模式是为了解耦:把对象的创建和使用的过程分开。就是Class A 想调用 Class B ,那么A只是调用B的方法,而至于B的实例化,就交给工厂类。\n \n 其次,工厂模式可以降低代码重复。如果创建对象B的过程都很复杂,需要一定的代码量,而且很多地方都要用到,那么就会有很多的重复代码。我们可以这些创建对象B的代码放到工厂里统一管理。既减少了重复代码,也方便以后对B的创建过程的修改维护。\n \n 由于创建过程都由工厂统一管理,所以发生业务逻辑变化,不需要找到所有需要创建B的地方去逐个修正,只需要在工厂里修改即可,降低维护成本。同理,想把所有调用B的地方改成B的子类C,只需要在对应生产B的工厂中或者工厂的方法中修改其生产的对象为C即可,而不需要找到所有的new B()改为newC()。\n\n代码演示:\n````\n package demo;\n \n import java.util.Scanner;\n \n interface Fruit\t\t\t\t\t\t//定义一个水果标准\n {\n \tpublic abstract void eat();\n }\n \n class Apple implements Fruit\n {\n \tpublic void eat()\n \t{\n \t\tSystem.out.println(\"吃苹果\");\n \t}\n }\n class Orange implements Fruit\n {\n \tpublic void eat()\n \t{\n \t\tSystem.out.println(\"吃橘子\");\n \t}\n }\n \n class factory\n {\n \tpublic static Fruit getInstance(String className) //返回值是Fruit的子类\n \t{\n \t\tif(\"apple\".equals(className))\n \t\t{\n \t\t\treturn new Apple();\n \t\t}\n \t\telse if(\"orange\".equals(className))\n \t\t{\n \t\t\treturn new Orange();\n \t\t}\n \t\telse\n \t\t{\n \t\t\treturn null;\n \t\t}\n \t}\n }\n \n public class ComplexFactory {\n \tpublic static void main(String[] args)\n \t{\t\n \t\tSystem.out.println(\"请输入水果的英文名:\");\n \t\tScanner sc = new Scanner(System.in);\n \t\tString ans = sc.nextLine();\n \t\tFruit f = factory.getInstance(ans); //初始化参数\n \t\tf.eat();\n \t\tsc.close();\n \t}\n }\n````\n代码讲解:上述代码部分我们讲一下factory这个类,类中有一个getInstance方法,我们用了static关键字修饰,在使用的时候我们就在main中使用类名.方法名调用。\n````\nFruit f = factory.getInstance(ans); //初始化参数\n\n````\n在Factory的getInstance()方法中,我们就可以通过逻辑的实现,将对象的创建和使用的过程分开了。\n\n\n\n 总结点评:在接口的学习中,大家可以理解接口是特殊的抽象类,java中类可以实现多个接口,接口中成员属性默认是public static final修饰,可以省略;成员方法默认是public abstract修饰,同样可以省略,接口中还可定义带方法体的默认方法,需要使用default修饰。利用接口我们还可以制定标准,还能够使用工厂模式,将对象的创建和使用过程分开。\n\n## 接口与抽象类的本质区别是什么?\n\n### 基本语法区别\n\n在 Java 中,接口和抽象类的定义语法是不一样的。这里以动物类为例来说明,其中定义接口的示意代码如下:\n````\npublic interface Animal\n{\n //所有动物都会吃\n public void eat();\n\n //所有动物都会飞\n public void fly();\n}\n````\n\n定义抽象类的示意代码如下:\n\n````\npublic abstract class Animal\n{\n //所有动物都会吃\n public abstract void eat();\n\n //所有动物都会飞\n public void fly(){};\n}\n````\n\n可以看到,在接口内只能是功能的定义,而抽象类中则可以包括功能的定义和功能的实现。在接口中,所有的属性肯定是 public、static 和 final,所有的方法都是 abstract,所以可以默认不写上述标识符;在抽象类中,既可以包含抽象的定义,也可以包含具体的实现方法。\n\n在具体的实现类上,接口和抽象类的实 现类定义方式也是不一样的,其中接口实现类的示意代码如下:\n\n````\npublic class concreteAnimal implements Animal\n{\n //所有动物都会吃\n public void eat(){}\n\n //所有动物都会飞\n public void fly(){}\n}\n````\n\n抽象类的实现类示意代码如下:\n\n````\npublic class concreteAnimal extends Animal\n{\n //所有动物都会吃\n public void eat(){}\n\n //所有动物都会飞\n public void fly(){}\n}\n````\n\n可以看到,在接口的实现类中使用 implements 关键字;而在抽象类的实现类中,则使用 extends 关键字。一个接口的实现类可以实现多个接口,而一个抽象类的实现类则只能实现一个抽象类。\n\n### 设计思想区别\n\n从前面抽象类的具体实现类的实现方式可以看出,其实在 Java 中,抽象类和具体实现类之间是一种继承关系,也就是说如果釆用抽象类的方式,则父类和子类在概念上应该是相同的。接口却不一样,如果采用接口的方式,则父类和子类在概念上不要求相同。\n\n接口只是抽取相互之间没有关系的类的共同特征,而不用关注类之间的关系,它可以使没有层次关系的类具有相同的行为。因此,可以这样说:抽象类是对一组具有相同属性和方法的逻辑上有关系的事物的一种抽象,而接口则是对一组具有相同属性和方法的逻辑上不相关的事物的一种抽象。\n\n仍然以前面动物类的设计为例来说明接口和抽象类关于设计思想的区别,该动物类默认所有的动物都具有吃的功能,其中定义接口的示意代码如下:\n\n````\npublic interface Animal\n{\n //所有动物都会吃\n public void eat();\n}\n````\n\n定义抽象类的示意代码如下:\n\n````\npublic abstract class Animal\n{\n //所有动物都会吃\n public abstract void eat();\n}\n````\n\n不管是实现接口,还是继承抽象类的具体动物,都具有吃的功能,具体的动物类的示意代码如下。\n\n接口实现类的示意代码如下:\n\n````\npublic class concreteAnimal implements Animal\n{\n //所有动物都会吃\n public void eat(){}\n}\n\n抽象类的实现类示意代码如下:\n\npublic class concreteAnimal extends Animal\n{\n //所有动物都会吃\n public void eat(){}\n}\n\n当然,具体的动物类不光具有吃的功能,比如有些动物还会飞,而有些动物却会游泳,那么该如何设计这个抽象的动物类呢?可以别在接口和抽象类中增加飞的功能,其中定义接口的示意代码如下:\n\npublic interface Animal\n{\n //所有动物都会吃\n public void eat();\n\n //所有动物都会飞\n public void fly();\n}\n\n定义抽象类的示意代码如下:\n\n public abstract class Animal\n {\n //所有动物都会吃\n public abstract void eat();\n \n //所有动物都会飞\n public void fly(){};\n }\n\n这样一来,不管是接口还是抽象类的实现类,都具有飞的功能,这显然不能满足要求,因为只有一部分动物会飞,而会飞的却不一定是动物,比如飞机也会飞。那该如何设计呢?有很多种方案,比如再设计一个动物的接口类,该接口具有飞的功能,示意代码如下:\n\npublic interface AnimaiFly\n{\n //所有动物都会飞\n public void fly();\n}\n\n那些具体的动物类,如果有飞的功能的话,除了实现吃的接口外,再实现飞的接口,示意代码如下:\n\npublic class concreteAnimal implements Animal,AnimaiFly\n{\n //所有动物都会吃\n public void eat(){}\n\n //动物会飞\n public void fly();\n}\n\n那些不需要飞的功能的具体动物类只实现具体吃的功能的接口即可。另外一种解决方案是再设计一个动物的抽象类,该抽象类具有飞的功能,示意代码如下:\n\npublic abstract class AnimaiFly\n{\n //动物会飞\n public void fly();\n}\n\n但此时没有办法实现那些既有吃的功能,又有飞的功能的具体动物类。因为在 Java 中具体的实现类只能实现一个抽象类。一个折中的解决办法是,让这个具有飞的功能的抽象类,继承具有吃的功能的抽象类,示意代码如下:\n\npublic abstract class AnimaiFly extends Animal\n{\n //动物会飞\n public void fly();\n}\n\n此时,对那些只需要吃的功能的具体动物类来说,继承 Animal 抽象类即可。对那些既有吃的功能又有飞的功能的具体动物类来说,则需要继承 AnimalFly 抽象类。\n\n但此时对客户端有一个问题,那就是不能针对所有的动物类都使用 Animal 抽象类来进行编程,因为 Animal 抽象类不具有飞的功能,这不符合面向对象的设计原则,因此这种解决方案其实是行不通的。\n\n还有另外一种解决方案,即具有吃的功能的抽象动物类用抽象类来实现,而具有飞的功能的类用接口实现;或者具有吃的功能的抽象动物类用接口来实现,而具有飞的功能的类用抽象类实现。\n\n具有吃的功能的抽象动物类用抽象类来实现,示意代码如下:\n\npublic abstract class Animal\n{\n //所有动物都会吃\n public abstract void eat();\n}\n\n具有飞的功能的类用接口实现,示意代码如下:\n\npublic interface AnimaiFly\n{\n //动物会飞\n public void fly();\n}\n\n既具有吃的功能又具有飞的功能的具体的动物类,则继承 Animal 动物抽象类,实现 AnimalFly 接口,示意代码如下:\n\npublic class concreteAnimal extends Animal implements AnimaiFly\n{\n //所有动物都会吃\n public void eat(){}\n\n //动物会飞\n public void fly();\n}\n\n或者具有吃的功能的抽象动物类用接口来实现,示意代码如下:\n\npublic interface Animal\n{\n //所有动物都会吃\n public abstract void eat();\n}\n\n具有飞的功能的类用抽象类实现,示意代码如下:\n\npublic abstract class AnimaiFly\n{\n //动物会飞\n public void fly(){};\n}\n\n既具有吃的功能又具有飞的功能的具体的动物类,则实现 Animal 动物类接口,继承 AnimaiFly 抽象类,示意代码如下:\n\npublic class concreteAnimal extends AnimaiFly implements Animal\n{\n //所有动物都会吃\n public void eat(){}\n\n //动物会飞\n public void fly();\n}\n````\n\n这些解决方案有什么不同呢?再回过头来看接口和抽象类的区别:抽象类是对一组具有相同属性和方法的逻辑上有关系的事物的一种抽象,而接口则是对一组具有相同属性和方法的逻辑上不相关的事物的一种抽象,因此抽象类表示的是“is a”关系,接口表示的是“like a”关系。\n\n假设现在要研究的系统只是动物系统,如果设计人员认为对既具有吃的功能又具有飞的功能的具体的动物类来说,它和只具有吃的功能的动物一样,都是动物,是一组逻辑上有关系的事物,因此这里应该使用抽象类来抽象具有吃的功能的动物类,即继承 Animal 动物抽象类,实现 AnimalFly 接口。\n\n如果设计人员认为对既具有吃的功能,又具有飞的功能的具体的动物类来说,它和只具有飞的功能的动物一样,都是动物,是一组逻辑上有关系的事物,因此这里应该使用抽象类来抽象具有飞的功能的动物类,即实现 Animal 动物类接口,继承 AnimaiFly 抽象类。\n\n假设现在要研究的系统不只是动物系统,如果设计人员认为不管是吃的功能,还是飞的功能和动物类没有什么关系,因为飞机也会飞,人也会吃,则这里应该实现两个接口来分别抽象吃的功能和飞的功能,即除实现吃的 Animal 接口外,再实现飞的 AnimalFly 接口。\n\n从上面的分析可以看出,对于接口和抽象类的选择,反映出设计人员看待问题的不同角度,即抽象类用于一组相关的事物,表示的是“is a”的关系,而接口用于一组不相关的事物,表示的是“like a”的关系。\n\n\n### 如何回答面试题:接口和抽象类的区别?\n\n接口(interface)和抽象类(abstract class)是支持抽象类定义的两种机制。\n\n接口是公开的,不能有私有的方法或变量,接口中的所有方法都没有方法体,通过关键字interface实现。\n\n抽象类是可以有私有方法或私有变量的,通过把类或者类中的方法声明为abstract来表示一个类是抽象类,被声明为抽象的方法不能包含方法体。子类实现方法必须含有相同的或者更低的访问级别(public->protected->private)。抽象类的子类为父类中所有抽象方法的具体实现,否则也是抽象类。\n\n接口可以被看作是抽象类的变体,接口中所有的方法都是抽象的,可以通过接口来间接的实现多重继承。接口中的成员变量都是static final类型,由于抽象类可以包含部分方法的实现,所以,在一些场合下抽象类比接口更有优势。\n\n **相同点**\n\n(1)都不能被实例化\n(2)接口的实现类或抽象类的子类都只有实现了接口或抽象类中的方法后才能实例化。\n\n **不同点**\n\n(1)接口只有定义,不能有方法的实现,java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。\n\n(2)实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。\n\n(3)接口强调特定功能的实现,而抽象类强调所属关系。\n\n(4)接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。\n\n(5)接口被用于常用的功能,便于日后维护和添加删除,而抽象类更倾向于充当公共类的角色,不适用于日后重新对立面的代码修改。功能需要累积时用抽象类,不需要累积时用接口。\n\n## 参考文章\nhttp://c.biancheng.net/view/1012.html\nhttps://blog.csdn.net/wxw20147854/article/details/88712029\nhttps://blog.csdn.net/zhangquan2015/article/details/82808399\nhttps://blog.csdn.net/qq_38741971/article/details/80099567\nhttps://www.runoob.com/java/java-interfaces.html\nhttps://blog.csdn.net/fengyunjh/article/details/6605085\nhttps://blog.csdn.net/xkfanhua/article/details/80567557\n\n\n"
},
{
"path": "docs/Java/basic/枚举类.md",
"content": "# 目录\n * [初探枚举类](#初探枚举类)\n * [枚举类-语法](#枚举类-语法)\n * [枚举类的具体使用](#枚举类的具体使用)\n * [常量](#常量)\n * [switch](#switch)\n * [向枚举中添加新方法](#向枚举中添加新方法)\n * [覆盖枚举的方法](#覆盖枚举的方法)\n * [实现接口](#实现接口)\n * [使用接口组织枚举](#使用接口组织枚举)\n * [枚举类集合](#枚举类集合)\n * [使用枚举类的注意事项](#使用枚举类的注意事项)\n * [枚举类的实现原理](#枚举类的实现原理)\n * [枚举类实战](#枚举类实战)\n * [实战一无参](#实战一无参)\n * [实战二有一参](#实战二有一参)\n * [实战三有两参](#实战三有两参)\n * [枚举类总结](#枚举类总结)\n * [枚举 API](#枚举-api)\n * [总结](#总结)\n * [参考文章](#参考文章)\n\n\n---\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。\n\n\n\n\n枚举(enum)类型是Java 5新增的特性,它是一种新的类型,允许用常量来表示特定的数据片断,而且全部都以类型安全的形式来表示。\n\n ## 初探枚举类\n\n> 在程序设计中,有时会用到由若干个有限数据元素组成的集合,如一周内的星期一到星期日七个数据元素组成的集合,由三种颜色红、黄、绿组成的集合,一个工作班组内十个职工组成的集合等等,程序中某个变量取值仅限于集合中的元素。此时,可将这些数据集合定义为枚举类型。\n\n> 因此,枚举类型是某类数据可能取值的集合,如一周内星期可能取值的集合为:\n> { Sun,Mon,Tue,Wed,Thu,Fri,Sat}\n> 该集合可定义为描述星期的枚举类型,该枚举类型共有七个元素,因而用枚举类型定义的枚举变量只能取集合中的某一元素值。由于枚举类型是导出数据类型,因此,必须先定义枚举类型,然后再用枚举类型定义枚举型变量。\n> \n\n enum <枚举类型名> \n { <枚举元素表> };\n \n 其中:关键词enum表示定义的是枚举类型,枚举类型名由标识符组成,而枚举元素表由枚举元素或枚举常量组成。例如: \n \n enum weekdays \n { Sun,Mon,Tue,Wed,Thu,Fri,Sat };\n 定义了一个名为 weekdays的枚举类型,它包含七个元素:Sun、Mon、Tue、Wed、Thu、Fri、Sat。\n\n> 在编译器编译程序时,给枚举类型中的每一个元素指定一个整型常量值(也称为序号值)。若枚举类型定义中没有指定元素的整型常量值,则整型常量值从0开始依次递增,因此,weekdays枚举类型的七个元素Sun、Mon、Tue、Wed、Thu、Fri、Sat对应的整型常量值分别为0、1、2、3、4、5、6。\n> 注意:在定义枚举类型时,也可指定元素对应的整型常量值。\n\n 例如,描述逻辑值集合{TRUE、FALSE}的枚举类型boolean可定义如下:\n enum boolean \n { TRUE=1 ,FALSE=0 };\n 该定义规定:TRUE的值为1,而FALSE的值为0。\n \n 而描述颜色集合{red,blue,green,black,white,yellow}的枚举类型colors可定义如下:\n enum colors \n {red=5,blue=1,green,black,white,yellow};\n 该定义规定red为5 ,blue为1,其后元素值从2 开始递增加1。green、black、white、yellow的值依次为2、3、4、5。\n\n 此时,整数5将用于表示二种颜色red与yellow。通常两个不同元素取相同的整数值是没有意义的。枚举类型的定义只是定义了一个新的数据类型,只有用枚举类型定义枚举变量才能使用这种数据类型。 \n\n ### 枚举类-语法\n\n> enum 与 class、interface 具有相同地位;\n> 可以继承多个接口;\n> 可以拥有构造器、成员方法、成员变量;\n> 1.2 枚举类与普通类不同之处\n>\n> 默认继承 java.lang.Enum 类,所以不能继承其他父类;其中 java.lang.Enum 类实现了 java.lang.Serializable 和 java.lang.Comparable 接口;\n\n> 使用 enum 定义,默认使用 final 修饰,因此不能派生子类;\n\n> 构造器默认使用 private 修饰,且只能使用 private 修饰;\n\n> 枚举类所有实例必须在第一行给出,默认添加 public static final 修饰,否则无法产生实例;\n\n### 枚举类的具体使用\n这部分内容参考https://blog.csdn.net/qq_27093465/article/details/52180865\n#### 常量\n````\npublic class 常量 {\n}\nenum Color {\n Red, Green, Blue, Yellow\n}\n````\n#### switch\n\nJDK1.6之前的switch语句只支持int,char,enum类型,使用枚举,能让我们的代码可读性更强。\n````\npublic static void showColor(Color color) {\n switch (color) {\n case Red:\n System.out.println(color);\n break;\n case Blue:\n System.out.println(color);\n break;\n case Yellow:\n System.out.println(color);\n break;\n case Green:\n System.out.println(color);\n break;\n }\n}\n````\n#### 向枚举中添加新方法\n\n如果打算自定义自己的方法,那么必须在enum实例序列的最后添加一个分号。而且 Java 要求必须先定义 enum 实例。\n````\nenum Color {\n //每个颜色都是枚举类的一个实例,并且构造方法要和枚举类的格式相符合。\n //如果实例后面有其他内容,实例序列结束时要加分号。\n Red(\"红色\", 1), Green(\"绿色\", 2), Blue(\"蓝色\", 3), Yellow(\"黄色\", 4);\n String name;\n int index;\n Color(String name, int index) {\n this.name = name;\n this.index = index;\n }\n public void showAllColors() {\n //values是Color实例的数组,在通过index和name可以获取对应的值。\n for (Color color : Color.values()) {\n System.out.println(color.index + \":\" + color.name);\n }\n }\n}\n````\n#### 覆盖枚举的方法\n所有枚举类都继承自Enum类,所以可以重写该类的方法\n下面给出一个toString()方法覆盖的例子。 \n````\n@Override\npublic String toString() {\n return this.index + \":\" + this.name;\n}\n````\n#### 实现接口\n\n所有的枚举都继承自java.lang.Enum类。由于Java 不支持多继承,所以枚举对象不能再继承其他类。\n````\nenum Color implements Print{\n @Override\n public void print() {\n System.out.println(this.name);\n }\n}\n````\n#### 使用接口组织枚举 \n\n 搞个实现接口,来组织枚举,简单讲,就是分类吧。如果大量使用枚举的话,这么干,在写代码的时候,就很方便调用啦。 \n```` \npublic class 用接口组织枚举 {\n public static void main(String[] args) {\n Food cf = chineseFood.dumpling;\n Food jf = Food.JapaneseFood.fishpiece;\n for (Food food : chineseFood.values()) {\n System.out.println(food);\n }\n for (Food food : Food.JapaneseFood.values()) {\n System.out.println(food);\n }\n }\n}\ninterface Food {\n enum JapaneseFood implements Food {\n suse, fishpiece\n }\n}\nenum chineseFood implements Food {\n dumpling, tofu\n}\n````\n#### 枚举类集合\n\njava.util.EnumSet和java.util.EnumMap是两个枚举集合。EnumSet保证集合中的元素不重复;EnumMap中的 key是enum类型,而value则可以是任意类型。\n\nEnumSet在JDK中没有找到实现类,这里写一个EnumMap的例子\n```` \npublic class 枚举类集合 {\n public static void main(String[] args) {\n EnumMap map = new EnumMap(Color.class);\n map.put(Color.Blue, \"Blue\");\n map.put(Color.Yellow, \"Yellow\");\n map.put(Color.Red, \"Red\");\n System.out.println(map.get(Color.Red));\n }\n}\n````\n## 使用枚举类的注意事项\n\n\n枚举类型对象之间的值比较,是可以使用==,直接来比较值,是否相等的,不是必须使用equals方法的哟。\n\n因为枚举类Enum已经重写了equals方法\n````\n/**\n * Returns true if the specified object is equal to this\n * enum constant.\n *\n * @param other the object to be compared for equality with this object.\n * @return true if the specified object is equal to this\n * enum constant.\n */\npublic final boolean equals(Object other) {\n return this==other;\n}\n````\n## 枚举类的实现原理\n\n这部分参考https://blog.csdn.net/mhmyqn/article/details/48087247\n\n> Java从JDK1.5开始支持枚举,也就是说,Java一开始是不支持枚举的,就像泛型一样,都是JDK1.5才加入的新特性。通常一个特性如果在一开始没有提供,在语言发展后期才添加,会遇到一个问题,就是向后兼容性的问题。\n>\n> 像Java在1.5中引入的很多特性,为了向后兼容,编译器会帮我们写的源代码做很多事情,比如泛型为什么会擦除类型,为什么会生成桥接方法,foreach迭代,自动装箱/拆箱等,这有个术语叫“语法糖”,而编译器的特殊处理叫“解语法糖”。那么像枚举也是在JDK1.5中才引入的,又是怎么实现的呢?\n\n> Java在1.5中添加了java.lang.Enum抽象类,它是所有枚举类型基类。提供了一些基础属性和基础方法。同时,对把枚举用作Set和Map也提供了支持,即java.util.EnumSet和java.util.EnumMap。\n\n接下来定义一个简单的枚举类\n````\npublic enum Day {\n MONDAY {\n @Override\n void say() {\n System.out.println(\"MONDAY\");\n }\n }\n , TUESDAY {\n @Override\n void say() {\n System.out.println(\"TUESDAY\");\n }\n }, FRIDAY(\"work\"){\n @Override\n void say() {\n System.out.println(\"FRIDAY\");\n }\n }, SUNDAY(\"free\"){\n @Override\n void say() {\n System.out.println(\"SUNDAY\");\n }\n };\n String work;\n //没有构造参数时,每个实例可以看做常量。\n //使用构造参数时,每个实例都会变得不一样,可以看做不同的类型,所以编译后会生成实例个数对应的class。\n private Day(String work) {\n this.work = work;\n }\n private Day() {\n\n }\n //枚举实例必须实现枚举类中的抽象方法\n abstract void say ();\n\n}\n````\n反编译结果\n````\n D:\\MyTech\\out\\production\\MyTech\\com\\javase\\枚举类>javap Day.class\n Compiled from \"Day.java\"\n \n public abstract class com.javase.枚举类.Day extends java.lang.Enum {\n public static final com.javase.枚举类.Day MONDAY;\n public static final com.javase.枚举类.Day TUESDAY;\n public static final com.javase.枚举类.Day FRIDAY;\n public static final com.javase.枚举类.Day SUNDAY;\n java.lang.String work;\n public static com.javase.枚举类.Day[] values();\n public static com.javase.枚举类.Day valueOf(java.lang.String);\n abstract void say();\n com.javase.枚举类.Day(java.lang.String, int, com.javase.枚举类.Day$1);\n com.javase.枚举类.Day(java.lang.String, int, java.lang.String, com.javase.枚举类.Day$1);\n static {};\n }\n````\n> 可以看到,一个枚举在经过编译器编译过后,变成了一个抽象类,它继承了java.lang.Enum;而枚举中定义的枚举常量,变成了相应的public static final属性,而且其类型就抽象类的类型,名字就是枚举常量的名字.\n>\n> 同时我们可以在Operator.class的相同路径下看到四个内部类的.class文件com/mikan/Day$1.class、com/mikan/Day$2.class、com/mikan/Day$3.class、com/mikan/Day$4.class,也就是说这四个命名字段分别使用了内部类来实现的;同时添加了两个方法values()和valueOf(String);我们定义的构造方法本来只有一个参数,但却变成了三个参数;同时还生成了一个静态代码块。这些具体的内容接下来仔细看看。\n\n下面分析一下字节码中的各部分,其中:\n````\nInnerClasses:\n static #23; //class com/javase/枚举类/Day$4\n static #18; //class com/javase/枚举类/Day$3\n static #14; //class com/javase/枚举类/Day$2\n static #10; //class com/javase/枚举类/Day$1\n````\n从中可以看到它有4个内部类,这四个内部类的详细信息后面会分析。\n````\nstatic {};\n descriptor: ()V\n flags: ACC_STATIC\n Code:\n stack=5, locals=0, args_size=0\n 0: new #10 // class com/javase/枚举类/Day$1\n 3: dup\n 4: ldc #11 // String MONDAY\n 6: iconst_0\n 7: invokespecial #12 // Method com/javase/枚举类/Day$1.\"\":(Ljava/lang/String;I)V\n 10: putstatic #13 // Field MONDAY:Lcom/javase/枚举类/Day;\n 13: new #14 // class com/javase/枚举类/Day$2\n 16: dup\n 17: ldc #15 // String TUESDAY\n 19: iconst_1\n 20: invokespecial #16 // Method com/javase/枚举类/Day$2.\"\":(Ljava/lang/String;I)V\n //后面类似,这里省略\n}\n````\n其实编译器生成的这个静态代码块做了如下工作:分别设置生成的四个公共静态常量字段的值,同时编译器还生成了一个静态字段$VALUES,保存的是枚举类型定义的所有枚举常量\n编译器添加的values方法:\n````\n public static com.javase.Day[] values(); \n flags: ACC_PUBLIC, ACC_STATIC \n Code: \n stack=1, locals=0, args_size=0 \n 0: getstatic #2 // Field $VALUES:[Lcom/javase/Day; \n 3: invokevirtual #3 // Method \"[Lcom/mikan/Day;\".clone:()Ljava/lang/Object; \n 6: checkcast #4 // class \"[Lcom/javase/Day;\" \n 9: areturn \n```` \n这个方法是一个公共的静态方法,所以我们可以直接调用该方法(Day.values()),返回这个枚举值的数组,另外,这个方法的实现是,克隆在静态代码块中初始化的$VALUES字段的值,并把类型强转成Day[]类型返回。\n\n造方法为什么增加了两个参数?\n\n\n有一个问题,构造方法我们明明只定义了一个参数,为什么生成的构造方法是三个参数呢?\n\n从Enum类中我们可以看到,为每个枚举都定义了两个属性,name和ordinal,name表示我们定义的枚举常量的名称,如FRIDAY、TUESDAY,而ordinal是一个顺序号,根据定义的顺序分别赋予一个整形值,从0开始。在枚举常量初始化时,会自动为初始化这两个字段,设置相应的值,所以才在构造方法中添加了两个参数。即:\n\n另外三个枚举常量生成的内部类基本上差不多,这里就不重复说明了。\n\n> 我们可以从Enum类的代码中看到,定义的name和ordinal属性都是final的,而且大部分方法也都是final的,特别是clone、readObject、writeObject这三个方法,这三个方法和枚举通过静态代码块来进行初始化一起。\n\n> 它保证了枚举类型的不可变性,不能通过克隆,不能通过序列化和反序列化来复制枚举,这能保证一个枚举常量只是一个实例,即是单例的,所以在effective java中推荐使用枚举来实现单例。\n\n## 枚举类实战\n\n### 实战一无参\n\n(1)定义一个无参枚举类\n\n```\nenum SeasonType {\n SPRING, SUMMER, AUTUMN, WINTER\n}\n```\n\n(2)实战中的使用\n\n```\n// 根据实际情况选择下面的用法即可\nSeasonType springType = SeasonType.SPRING; // 输出 SPRING \nString springString = SeasonType.SPRING.toString(); // 输出 SPRING\n```\n\n### 实战二有一参\n\n(1)定义只有一个参数的枚举类\n\n```\nenum SeasonType {\n // 通过构造函数传递参数并创建实例\n SPRING(\"spring\"),\n SUMMER(\"summer\"),\n AUTUMN(\"autumn\"),\n WINTER(\"winter\");\n\n // 定义实例对应的参数\n private String msg;\n\n // 必写:通过此构造器给枚举值创建实例\n SeasonType(String msg) {\n this.msg = msg;\n }\n\n // 通过此方法可以获取到对应实例的参数值\n public String getMsg() {\n return msg;\n }\n}\n```\n\n(2)实战中的使用\n\n```\n// 当我们为某个实例类赋值的时候可使用如下方式\nString msg = SeasonType.SPRING.getMsg(); // 输出 spring\n```\n\n### 实战三有两参\n\n(1)定义有两个参数的枚举类\n\n```\npublic enum Season {\n // 通过构造函数传递参数并创建实例\n SPRING(1, \"spring\"),\n SUMMER(2, \"summer\"),\n AUTUMN(3, \"autumn\"),\n WINTER(4, \"winter\");\n\n // 定义实例对应的参数\n private Integer key;\n private String msg;\n\n // 必写:通过此构造器给枚举值创建实例\n Season(Integer key, String msg) {\n this.key = key;\n this.msg = msg;\n }\n\n // 很多情况,我们可能从前端拿到的值是枚举类的 key ,然后就可以通过以下静态方法获取到对应枚举值\n public static Season valueofKey(Integer key) {\n for (Season season : Season.values()) {\n if (season.key.equals(key)) {\n return season;\n }\n }\n throw new IllegalArgumentException(\"No element matches \" + key);\n }\n\n // 通过此方法可以获取到对应实例的 key 值\n public Integer getKey() {\n return key;\n }\n\n // 通过此方法可以获取到对应实例的 msg 值\n public String getMsg() {\n return msg;\n }\n}\n```\n\n(2)实战中的使用\n\n```\n// 输出 key 为 1 的枚举值实例\nSeason season = Season.valueofKey(1);\n// 输出 SPRING 实例对应的 key\nInteger key = Season.SPRING.getKey();\n// 输出 SPRING 实例对应的 msg\nString msg = Season.SPRING.getMsg();\n```\n\n## 枚举类总结\n\n其实枚举类懂了其概念后,枚举就变得相当简单了,随手就可以写一个枚举类出来。所以如上几个实战小例子一定要先搞清楚概念,然后在练习几遍就 ok 了。\n\n重要的概念,我在这里在赘述一遍,帮助老铁们快速掌握这块知识,首先记住,枚举类中的枚举值可以没有参数,也可以有多个参数,每一个枚举值都是一个实例;\n\n并且还有一点很重要,就是如果枚举值有 n 个参数,那么构造函数中的参数值肯定有 n 个,因为声明的每一个枚举值都会调用构造函数去创建实例,所以参数一定是一一对应的;既然明白了这一点,那么我们只需要在枚举类中把这 n 个参数定义为 n 个成员变量,然后提供对应的 get() 方法,之后通过实例就可以随意的获取实例中的任意参数值了。\n\n如果想让枚举类更加的好用,就可以模仿我在实战三中的写法那样,通过某一个参数值,比如 key 参数值,就能获取到其对应的枚举值,然后想要什么值,就 get 什么值就好了。\n\n## 枚举 API\n\n我们使用 enum 定义的枚举类都是继承 java.lang.Enum 类的,那么就会继承其 API ,常用的 API 如下:\n\n* String name()\n\n获取枚举名称\n\n* int ordinal()\n\n获取枚举的位置(下标,初始值为 0 )\n\n* valueof(String msg)\n\n通过 msg 获取其对应的枚举类型。(比如实战二中的枚举类或其它枚举类都行,只要使用得当都可以使用此方法)\n\n* values()\n\n获取枚举类中的所有枚举值(比如在实战三中就使用到了)\n\n## 总结\n\n枚举本质上是通过普通的类来实现的,只是编译器为我们进行了处理。**每个枚举类型都继承自java.lang.Enum,并自动添加了values和valueOf方法。**\n\n而每个枚举常量是一个静态常量字段,**使用内部类实现**,该内部类继承了枚举类。**所有枚举常量都通过静态代码块来进行初始化,即在类加载期间就初始化**。\n\n另外通过把clone、readObject、writeObject这三个方法定义为final的,同时实现是抛出相应的异常。这样保证了每个枚举类型及枚举常量都是不可变的。**可以利用枚举的这两个特性来实现线程安全的单例。**\n\n## 参考文章\n\nhttps://blog.csdn.net/qq_34988624/article/details/86592229\nhttps://www.meiwen.com.cn/subject/slhvhqtx.html\nhttps://blog.csdn.net/qq_34988624/article/details/86592229\nhttps://segmentfault.com/a/1190000012220863\nhttps://my.oschina.net/wuxinshui/blog/1511484\nhttps://blog.csdn.net/hukailee/article/details/81107412\n\n"
},
{
"path": "docs/Java/basic/泛型.md",
"content": "# 目录\n * [泛型概述](#泛型概述)\n * [一个栗子](#一个栗子)\n * [特性](#特性)\n * [泛型的使用方式](#泛型的使用方式)\n * [泛型类](#泛型类)\n * [泛型接口](#泛型接口)\n * [泛型通配符](#泛型通配符)\n * [泛型方法](#泛型方法)\n * [泛型方法的基本用法](#泛型方法的基本用法)\n * [类中的泛型方法](#类中的泛型方法)\n * [泛型方法与可变参数](#泛型方法与可变参数)\n * [静态方法与泛型](#静态方法与泛型)\n * [泛型方法总结](#泛型方法总结)\n * [泛型上下边界](#泛型上下边界)\n * [泛型常见面试题](#泛型常见面试题)\n * [参考文章](#参考文章)\n\n\n本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看\n> https://github.com/h2pl/Java-Tutorial\n\n喜欢的话麻烦点下Star哈\n\n文章首发于我的个人博客:\n> www.how2playlife.com\n\n本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。\n该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。\n\n如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。 \n\n\n\n## 泛型概述\n\n泛型在java中有很重要的地位,在面向对象编程及各种设计模式中有非常广泛的应用。\n\n什么是泛型?为什么要使用泛型?\n\n> 泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。\n> \n> 泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。\n\n### 一个栗子\n\n一个被举了无数次的例子:\n````\nList arrayList = new ArrayList();\narrayList.add(\"aaaa\");\narrayList.add(100);\n\nfor(int i = 0; i< arrayList.size();i++){\n String item = (String)arrayList.get(i);\n Log.d(\"泛型测试\",\"item = \" + item);\n}\n````\n毫无疑问,程序的运行结果会以崩溃结束:\n\n java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String\n\nArrayList可以存放任意类型,例子中添加了一个String类型,添加了一个Integer类型,再使用时都以String的方式使用,因此程序崩溃了。为了解决类似这样的问题(在编译阶段就可以解决),泛型应运而生。\n\n我们将第一行声明初始化list的代码更改一下,编译器会在编译阶段就能够帮我们发现类似这样的问题。\n````\nList arrayList = new ArrayList();\n...\n//arrayList.add(100); 在编译阶段,编译器就会报错\n````\n### 特性\n\n泛型只在编译阶段有效。看下面的代码:\n````\nList stringArrayList = new ArrayList();\nList integerArrayList = new ArrayList();\n\nClass classStringArrayList = stringArrayList.getClass();\nClass classIntegerArrayList = integerArrayList.getClass();\n\nif(classStringArrayList.equals(classIntegerArrayList)){\n Log.d(\"泛型测试\",\"类型相同\");\n}\n````\n> 通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。\n> \n对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。\n\n\n\n## 泛型的使用方式\n\n泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法\n\n### 泛型类\n\n> 泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。\n> \n> 泛型类的最基本写法(这么看可能会有点晕,会在下面的例子中详解):\n````\n class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{\n private 泛型标识 /*(成员变量类型)*/ var; \n .....\n \n }\n````\n一个最普通的泛型类:\n\n//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型\n````\n//在实例化泛型类时,必须指定T的具体类型\npublic class Generic{\n //在类中声明的泛型整个类里面都可以用,除了静态部分,因为泛型是实例化时声明的。\n //静态区域的代码在编译时就已经确定,只与类相关\n class A {\n T t;\n }\n //类里面的方法或类中再次声明同名泛型是允许的,并且该泛型会覆盖掉父类的同名泛型T\n class B {\n T t;\n }\n //静态内部类也可以使用泛型,实例化时赋予泛型实际类型\n static class C {\n T t;\n }\n public static void main(String[] args) {\n //报错,不能使用T泛型,因为泛型T属于实例不属于类\n// T t = null;\n }\n\n //key这个成员变量的类型为T,T的类型由外部指定\n private T key;\n\n public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定\n this.key = key;\n }\n\n public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定\n return key;\n }\n}\n````\n> 12-27 09:20:04.432 13063-13063/? D/泛型测试: key is 123456\n\n> 12-27 09:20:04.432 13063-13063/? D/泛型测试: key is key_vlaue\n\n> 定义的泛型类,就一定要传入泛型类型实参么?并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。\n\n看一个例子:\n````\nGeneric generic = new Generic(\"111111\");\nGeneric generic1 = new Generic(4444);\nGeneric generic2 = new Generic(55.55);\nGeneric generic3 = new Generic(false);\n\nLog.d(\"泛型测试\",\"key is \" + generic.getKey());\nLog.d(\"泛型测试\",\"key is \" + generic1.getKey());\nLog.d(\"泛型测试\",\"key is \" + generic2.getKey());\nLog.d(\"泛型测试\",\"key is \" + generic3.getKey());\n\nD/泛型测试: key is 111111\nD/泛型测试: key is 4444\nD/泛型测试: key is 55.55\nD/泛型测试: key is false\n````\n注意:\n泛型的类型参数只能是类类型,不能是简单类型。\n不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。\n if(ex_num instanceof Generic){ \n } \n\n### 泛型接口\n\n泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:\n````\n//定义一个泛型接口\npublic interface Generator {\n public T next();\n}\n````\n当实现泛型接口的类,未传入泛型实参时:\n````\n/**\n * 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中\n * 即:class FruitGenerator implements Generator{\n * 如果不声明泛型,如:class FruitGenerator implements Generator,编译器会报错:\"Unknown class\"\n */\nclass FruitGenerator implements Generator{\n @Override\n public T next() {\n return null;\n }\n}\n````\n当实现泛型接口的类,传入泛型实参时:\n````\n/**\n * 传入泛型实参时:\n * 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator\n * 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。\n * 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型\n * 即:Generator,public T next();中的的T都要替换成传入的String类型。\n */\npublic class FruitGenerator implements Generator {\n\n private String[] fruits = new String[]{\"Apple\", \"Banana\", \"Pear\"};\n\n @Override\n public String next() {\n Random rand = new Random();\n return fruits[rand.nextInt(3)];\n }\n}\n````\n### 泛型通配符\n\n我们知道Ingeter是Number的一个子类,同时在特性章节中我们也验证过Generic与Generic实际上是相同的一种基本类型。那么问题来了,在使用Generic作为形参的方法中,能否使用Generic的实例传入呢?在逻辑上类似于Generic和Generic是否可以看成具有父子关系的泛型类型呢?\n\n为了弄清楚这个问题,我们使用Generic这个泛型类继续看下面的例子:\n````\npublic void showKeyValue1(Generic obj){\n Log.d(\"泛型测试\",\"key value is \" + obj.getKey());\n}\n\nGeneric gInteger = new Generic(123);\nGeneric gNumber = new Generic(456);\n\nshowKeyValue(gNumber);\n\n// showKeyValue这个方法编译器会为我们报错:Generic \n// cannot be applied to Generic\n// showKeyValue(gInteger);\n````\n通过提示信息我们可以看到Generic不能被看作为`Generic的子类。由此可以看出:同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。\n\n回到上面的例子,如何解决上面的问题?总不能为了定义一个新的方法来处理Generic类型的类,这显然与java中的多台理念相违背。因此我们需要一个在逻辑上可以表示同时是Generic和Generic父类的引用类型。由此类型通配符应运而生。\n\n我们可以将上面的方法改一下:\n````\npublic void showKeyValue1(Generic obj){\n Log.d(\"泛型测试\",\"key value is \" + obj.getKey());\n````\n类型通配符一般是使用?代替具体的类型实参,注意, 此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。\n\n可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型\n````\npublic void showKeyValue(Generic obj){\n System.out.println(obj);\n }\n\n Generic gInteger = new Generic(123);\n Generic gNumber = new Generic(456);\n \n public void test () {\n // showKeyValue(gInteger);该方法会报错\n showKeyValue1(gInteger);\n }\n \n public void showKeyValue1(Generic obj) {\n System.out.println(obj);\n }\n // showKeyValue这个方法编译器会为我们报错:Generic\n // cannot be applied to Generic\n // showKeyValue(gInteger);\n````\n\n### 泛型方法\n\n在java中,泛型类的定义非常简单,但是泛型方法就比较复杂了。\n\n尤其是我们见到的大多数泛型类中的成员方法也都使用了泛型,有的甚至泛型类中也包含着泛型方法,这样在初学者中非常容易将泛型方法理解错了。\n泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。\n````\n/**\n * 泛型方法的基本介绍\n * @param tClass 传入的泛型实参\n * @return T 返回值为T类型\n * 说明:\n * 1)public 与 返回值中间非常重要,可以理解为声明此方法为泛型方法。\n * 2)只有声明了的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。\n * 3)表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。\n * 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。\n */\n public T genericMethod(Class tClass)throws InstantiationException ,\n IllegalAccessException{\n T instance = tClass.newInstance();\n return instance;\n }\n\nObject obj = genericMethod(Class.forName(\"com.test.test\"));\n````\n### 泛型方法的基本用法\n\n光看上面的例子有的同学可能依然会非常迷糊,我们再通过一个例子,把我泛型方法再总结一下。\n````\n/** \n * 这才是一个真正的泛型方法。\n * 首先在public与返回值之间的必不可少,这表明这是一个泛型方法,并且声明了一个泛型T\n * 这个T可以出现在这个泛型方法的任意位置.\n * 泛型的数量也可以为任意多个 \n * 如:public K showKeyName(Generic container){\n * ...\n * }\n */\n\n public class 泛型方法 {\n @Test\n public void test() {\n test1();\n test2(new Integer(2));\n test3(new int[3],new Object());\n\n //打印结果\n //null\n //2\n //[I@3d8c7aca\n //java.lang.Object@5ebec15\n }\n //该方法使用泛型T\n public void test1() {\n T t = null;\n System.out.println(t);\n }\n //该方法使用泛型T\n //并且参数和返回值都是T类型\n public T test2(T t) {\n System.out.println(t);\n return t;\n }\n\n //该方法使用泛型T,E\n //参数包括T,E\n public void test3(T t, E e) {\n System.out.println(t);\n System.out.println(e);\n }\n}\n````\n\n### 类中的泛型方法\n\n当然这并不是泛型方法的全部,泛型方法可以出现杂任何地方和任何场景中使用。但是有一种情况是非常特殊的,当泛型方法出现在泛型类中时,我们再通过一个例子看一下\n````\n//注意泛型类先写类名再写泛型,泛型方法先写泛型再写方法名\n//类中声明的泛型在成员和方法中可用\nclass A {\n {\n T t1 ;\n }\n A (T t){\n this.t = t;\n }\n T t;\n\n public void test1() {\n System.out.println(this.t);\n }\n\n public void test2(T t,E e) {\n System.out.println(t);\n System.out.println(e);\n }\n}\n@Test\npublic void run () {\n A a = new A<>(1);\n a.test1();\n a.test2(2,\"ds\");\n// 1\n// 2\n// ds\n}\n\nstatic class B {\n T t;\n public void go () {\n System.out.println(t);\n }\n}\n````\n### 泛型方法与可变参数\n\n再看一个泛型方法和可变参数的例子:\n````\npublic class 泛型和可变参数 {\n @Test\n public void test () {\n printMsg(\"dasd\",1,\"dasd\",2.0,false);\n print(\"dasdas\",\"dasdas\", \"aa\");\n }\n //普通可变参数只能适配一种类型\n public void print(String ... args) {\n for(String t : args){\n System.out.println(t);\n }\n }\n //泛型的可变参数可以匹配所有类型的参数。。有点无敌\n public void printMsg( T... args){\n for(T t : args){\n System.out.println(t);\n }\n }\n //打印结果:\n //dasd\n //1\n //dasd\n //2.0\n //false\n\n}\n````\n### 静态方法与泛型\n\n静态方法有一种情况需要注意一下,那就是在类中的静态方法使用泛型:静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。\n\n即:如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。\n````\npublic class StaticGenerator {\n ....\n ....\n /**\n * 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)\n * 即使静态方法要使用泛型类中已经声明过的泛型也不可以。\n * 如:public static void show(T t){..},此时编译器会提示错误信息:\n \"StaticGenerator cannot be refrenced from static context\"\n */\n public static void show(T t){\n\n }\n}\n````\n## 泛型方法总结\n\n泛型方法能使方法独立于类而产生变化,以下是一个基本的指导原则:\n\n无论何时,如果你能做到,你就该尽量使用泛型方法。也就是说,如果使用泛型方法将整个类泛型化,那么就应该使用泛型方法。另外对于一个static的方法而已,无法访问泛型类型的参数。所以如果static方法要使用泛型能力,就必须使其成为泛型方法。\n## 泛型上下边界\n\n在使用泛型的时候,我们还可以为传入的泛型类型实参进行上下边界的限制,如:类型实参只准传入某种类型的父类或某种类型的子类。\n\n为泛型添加上边界,即传入的类型实参必须是指定类型的子类型\n````\npublic class 泛型通配符与边界 {\n public void showKeyValue(Generic obj){\n System.out.println(\"key value is \" + obj.getKey());\n }\n @Test\n public void main() {\n Generic gInteger = new Generic(123);\n Generic gNumber = new Generic(456);\n showKeyValue(gNumber);\n //泛型中的子类也无法作为父类引用传入\n// showKeyValue(gInteger);\n }\n //直接使用?通配符可以接受任何类型作为泛型传入\n public void showKeyValueYeah(Generic obj) {\n System.out.println(obj);\n }\n //只能传入number的子类或者number\n public void showKeyValue1(Generic obj){\n System.out.println(obj);\n }\n\n //只能传入Integer的父类或者Integer\n public void showKeyValue2(Generic obj){\n System.out.println(obj);\n }\n\n @Test\n public void testup () {\n //这一行代码编译器会提示错误,因为String类型并不是Number类型的子类\n //showKeyValue1(generic1);\n Generic generic1 = new Generic(\"11111\");\n Generic generic2 = new Generic(2222);\n Generic generic3 = new Generic(2.4f);\n Generic generic4 = new Generic(2.56);\n\n showKeyValue1(generic2);\n showKeyValue1(generic3);\n showKeyValue1(generic4);\n }\n\n @Test\n public void testdown () {\n\n Generic generic1 = new Generic(\"11111\");\n Generic generic2 = new Generic(2222);\n Generic generic3 = new Generic(2);\n// showKeyValue2(generic1);本行报错,因为String并不是Integer的父类\n showKeyValue2(generic2);\n showKeyValue2(generic3);\n }\n}\n````\n== 关于泛型数组要提一下 ==\n\n看到了很多文章中都会提起泛型数组,经过查看sun的说明文档,在java中是”不能创建一个确切的泛型类型的数组”的。\n\n也就是说下面的这个例子是不可以的:\n```` \nList[] ls = new ArrayList
 \n\n
\n\n \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n \n\n
\n\n