Repository: heiyeluren/xds
Branch: main
Commit: 37a98a7f7bfa
Files: 22
Total size: 103.8 KB
Directory structure:
gitextract_26nmso4x/
├── .gitignore
├── LICENSE
├── README.md
├── common.go
├── docs/
│ ├── README.md
│ ├── Xmap-Implement.md
│ └── img/
│ └── README
├── example/
│ ├── README.md
│ ├── xmap_test0.go
│ ├── xmap_test1.go
│ └── xslice_test0.go
├── go.mod
├── go.sum
├── xmap/
│ ├── README
│ ├── concurrent_hash_map_benchmark_test.go
│ ├── concurrent_hash_map_test.go
│ ├── concurrent_raw_hash_map.go
│ ├── entry/
│ │ └── rbtree.go
│ ├── map_test.go
│ └── xmap.go
└── xslice/
├── xslice.go
└── xslice_test.go
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Binaries for programs and plugins
*.exe
*.exe~
*.dll
*.so
*.dylib
# Test binary, built with `go test -c`
*.test
# Output of the go coverage tool, specifically when used with LiteIDE
*.out
# Dependency directories (remove the comment below to include it)
# vendor/
.idea
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================




## XDS - eXtensible Data Structure Sets
(第三方可扩展的 Golang 高性能数据结构和数据类型合集)
A third-party extensible collection of high-performance data structures and data types in Go
- [XDS - eXtensible Data Structure
(第三方可扩展的 Go 语言中高性能数据结构和数据类型合集)](#xds---extensible-data-structure-第三方可扩展的-go-语言中高性能数据结构和数据类型合集)
- [XDS 介绍:(什么是 Xds)](#xds-介绍什么是-xds)
- [XDS - XMap 概要介绍](#xds---xmap-概要介绍)
- [为什么要设计 XMap?](#为什么要设计-xmap)
- [XMap 设计目标是什么?](#xmap-设计目标是什么)
- [XMap 的技术特点](#xmap-的技术特点)
- [XMap 性能数据和实现对比](#xmap-性能数据和实现对比)
- [XMap 与 Go 官方数据结构特点对比:(20% 写入,80% 读场景)](#xmap-与-go-官方数据结构特点对比20-写入80-读场景)
- [如何使用 XMap?](#如何使用-xmap)
- [XMap 各类 API 使用案例](#xmap-各类-api-使用案例)
- [- XMap 使用示例](#--xmap-使用示例)
- [XMap 内部是如何实现的?](#xmap-内部是如何实现的)
- [XDS 项目开发者](#xds-项目开发者)
- [XDS 技术交流](#xds-技术交流)
## XDS 介绍:(什么是 Xds)
XDS - eXtensible Data Structure(第三方可扩展的 Go 语言中高性能数据结构和数据类型合集)
XDS 主要是为了解决现有 Go 语言官方内置的各类数据结构性能在高并发场景中不尽如人意的情况而开发,核心主要是依赖于 [XMM](https://github.com/heiyeluren/xmm) 内存管理库基础之上开发,保证了高性能和内存可控。
XDS 集合目前主要包含:
- XMap - 高性能的类似 map/sync.map 的 Map 型数据结构类型(已开源)
- XSlice - 高性能类似 slice 的数组型数据结构类型(开发中)
- XChannel - 高性能的 channel 管道类型结构(调研中)
- 更多...
## XDS - XMap 概要介绍
XMap 是属于高性能开源 Go 数据结构 Xds 中的 map 数据结构类型的实现,主要是基于高性能内存管理库 [XMM](https://github.com/heiyeluren/xmm) 基础之上进行的开发,主要弥补了 Go 内置 map 的无法并发读写,并且总体读写性能比较差的问题而开发。
### 为什么要设计 XMap?
现有 Golang 中的 map 数据结构无法解决并发读写问题,Sync.map 并发性能偏差,针对这个情况,各种高性能底层服务需要一个高性能、大容量、高并发、无 GC 的 Map,所以开发实现 XMap。
针对我们需求调研了市场上主要的 hashmap 结构,不能满足我们性能和功能要求。
### XMap 设计目标是什么?
要求设计一个可以并发读写不会出现 panic,要求并发读写 200w+ OPS/s 的并发 map 结构。
(写 20%,读 80% 场景;说明:go 自带 map 读写性能在 80w ops/s,大量并发读写下可能 panic;sync.map 写入性能在 100w OPS/s)
### XMap 的技术特点
- 绝对高性能的 map 数据结构(map 的 3 倍,sync.map 的 2 倍并发性能)
- 内部实现机制对比 Go 原生 map/sync.map 技术设计上要更细致,更考虑性能,使用包括开地址法,红黑树等等结构提升性能;
- 为了节约内存,初始的值比较低,但是依赖于 XMM 高性能内存扩容方式,能够快速进行内存扩容,保证并发写入性能
- 底层采用 XMM 内存管理,不会受到 Go 系统本身 GC 机制的卡顿影响,保证高性能;
- 提供 API 更具备扩展性,在一些高性能场景提供更多调用定制设置,并且能够同时支持 map 类型操作和底层 hash 表类型操作,适用场景更多;
- 其他特性
### XMap 性能数据和实现对比
XMap 目前并发读写场景下性能可以达到 200 万 op/s,对比原生 map 单机性能 80 万 op/s,提升了 3 倍 +,对比 Go 官方扩展库 sync.Map 性能有 2 倍的提升。
#### XMap 与 Go 官方数据结构特点对比:(20% 写入,80% 读场景)
| map 模块 | 性能数据
| 加锁机制 | 底层数据结构 | 内存机制 |
|------|------|------|------|------|
|map | 80w+ read/s
并发读写会 panic | 无 | Hashtable + Array | Go gc |
|sync.Map | 100w+ op/s | RWMutex | map | Go gc |
| Xds.XMap | 200w+ op/s | CAS + RWMutex | Hashtable + Array + RBTree | XMM |
## 如何使用 XMap?
快速使用:
1. 下载对应包
```shell
go get -u github.com/heiyeluren/xds
go get -u github.com/heiyeluren/xmm
```
2. 快速包含调用库:
```go
//注意:本代码只是伪代码,大家最好看这个使用测试案例更充分一些
//详细使用案例:https://github.com/heiyeluren/xds/blob/main/example/xmap_test0.go
//快速使用入门:https://github.com/heiyeluren/xds/blob/main/example/xmap_test1.go
import (
xmm "github.com/heiyeluren/xmm"
xds "github.com/heiyeluren/xds"
xmap "github.com/heiyeluren/xds/xmap"
)
// 创建一个 XMM 内存块
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
// 构建一个 map[string]string 的 xmap
m, err := xmap.NewMap(mm, xds.String, xds.String)
// 写入、读取、删除一个元素
err = m.Set("name", "heiyeluren")
ret, key_exists, err := m.Get("name")
err = m.Remove("name")
// 遍历整个map
m.Each(func(key, val interface{}) error {
fmt.Printf("For each XMap all key:[%s] value:[%s] \n", key, val)
return nil
})
//...
```
3. 执行对应代码
```shell
go run map-test.go
```
### XMap 各类 API 使用案例
#### - [Xmap 快速使用入门](https://github.com/heiyeluren/xds/blob/main/example/xmap_test1.go)
#### - [XMap 详细使用示例](https://github.com/heiyeluren/xds/blob/main/example/xmap_test0.go) -
- 更多案例(期待)
以上代码案例执行输出:
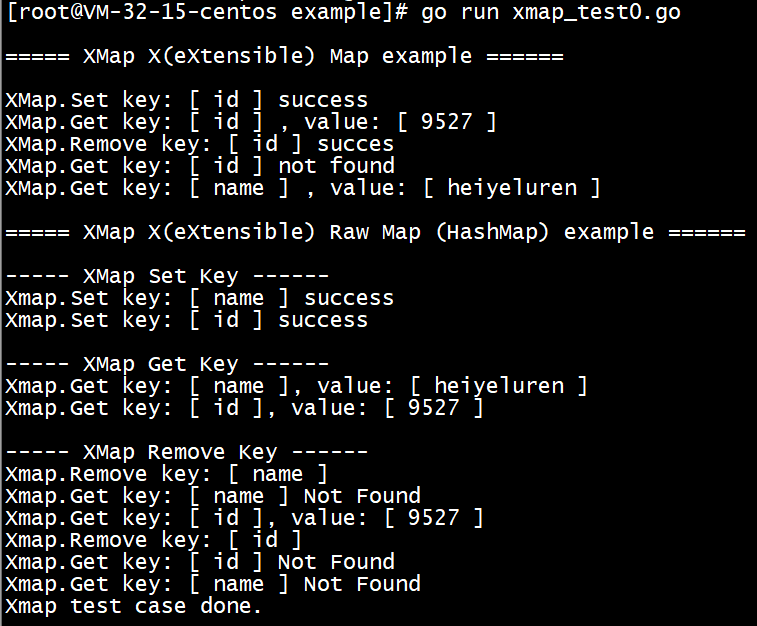
## XMap 内部是如何实现的?
#### - [《Xds-XMap技术设计与实现》](https://github.com/heiyeluren/xds/blob/main/docs/Xmap-Implement.md) -
- 参考:[《Go map 内部实现机制一》](https://www.jianshu.com/p/aa0d4808cbb8) | [《Go map 内部实现二》](https://zhuanlan.zhihu.com/p/406751292) | [《Golang sync.Map 性能及原理分析》](https://blog.csdn.net/u010853261/article/details/103848666)
- 其他
## XDS 项目开发者
| 项目角色 | 项目成员 |
| ----------- | ----------- |
| 项目发起人/负责人 | 黑夜路人 ( @heiyeluren )
老张 ( @Zhang-Jun-tao ) |
| 项目开发者 | 老张 ( @Zhang-Jun-tao )
黑夜路人 ( @heiyeluren )
Viktor ( @guojun1992 ) |
## XDS 技术交流
XDS 还在早期,当然也少不了一些问题和 bug,欢迎大家一起共创,或者直接提交 PR 等等。
欢迎加入 XDS 技术交流微信群,要加群,可以先关注添加如下公众号:
(如无法看到图片,请直接微信里搜索公众号“黑夜路人技术”,关注发送“加群”字样信息即可 )

================================================
FILE: common.go
================================================
// Copyright (c) 2022 XDS project Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// XDS Project Site: https://github.com/heiyeluren
// XDS URL: https://github.com/heiyeluren/xds
//
package xds
import (
"errors"
"reflect"
"unsafe"
// "github.com/heiyeluren/xmm"
)
// 定义XDS共用的常量和一些基础函数
//调用方法:
/*
//包含
import(
"github.com/heiyeluren/xds"
)
//结构体中使用
type ConcurrentHashMap struct {
keyKind xds.Kind
valKind xds.Kind
data *ConcurrentRawHashMap
}
//一般数据结构中使用
m, err := xds.NewMap(mm, xds.String, xds.Int)
//序列化处理 (其他类型到 []byte,两个函数效果一样)
data, err := xds.Marshal(xds.String, "heiyeluren")
data, err := xds.RawToByte(xds.String, "heiyeluren")
// 反序列化处理 (从 []byte到原始类型)
str, err := xds.UnMarshal(xds.String, data)
data, err := xds.ByteToRaw(xds.String, "heiyeluren")
*/
//========================================================
//
// XDS 常量和数据结构定义区
// XDS constant and data structure definition
//
//========================================================
// XDS 中数据类型的定义
// map[keyKind]valKind == xds.NewMap(mm, xds.keyKind, xds.valKind)
// make([]typeKind, len) == xds.NewSlice(mm, xds.dataKind)
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
ByteSlice
String
Struct
UnsafePointer
)
// 类型错误
// type error
var InvalidType = errors.New("Kind type Error")
// type ConcurrentHashMap struct {
// keyKind Kind
// valKind Kind
// data *ConcurrentRawHashMap
// }
//========================================================
//
// XDS 常用函数定义区
// XDS common function definition area
//
//========================================================
// 针对一些Kind数据类型的序列化
// Serialization for some kind data types
func Marshal(kind Kind, content interface{}) (data []byte, err error) {
switch kind {
case String:
data, ok := content.(string)
if !ok {
return nil, InvalidType
}
sh := (*reflect.StringHeader)(unsafe.Pointer(&data))
return *(*[]byte)(unsafe.Pointer(&reflect.SliceHeader{Data: sh.Data, Len: sh.Len, Cap: sh.Len})), nil
case ByteSlice:
data, ok := content.([]byte)
if !ok {
return nil, InvalidType
}
return data, nil
case Int:
h, ok := content.(int)
if !ok {
return nil, InvalidType
}
return (*[8]byte)(unsafe.Pointer(&h))[:], nil
case Uintptr:
h, ok := content.(uintptr)
if !ok {
return nil, InvalidType
}
return (*[8]byte)(unsafe.Pointer(&h))[:], nil
}
return
}
// 针对一些Kind数据类型的反序列化
// Deserialization for some kind data types
func UnMarshal(kind Kind, data []byte) (content interface{}, err error) {
switch kind {
case String:
return *(*string)(unsafe.Pointer(&data)), nil
case Uintptr:
sh := (*reflect.SliceHeader)(unsafe.Pointer(&data))
return *(*uintptr)(unsafe.Pointer(sh.Data)), nil
case Int:
sh := (*reflect.SliceHeader)(unsafe.Pointer(&data))
return *(*int)(unsafe.Pointer(sh.Data)), nil
case ByteSlice:
return data, nil
}
return
}
// Marshal 函数的别名
// Marshal function link name
func RawToByte(kind Kind, content interface{}) (data []byte, err error) {
return Marshal(kind, content)
}
// UnMarshal 函数的别名
// UnMarshal function link name
func ByteToRaw(kind Kind, data []byte) (content interface{}, err error) {
return UnMarshal(kind, data)
}
================================================
FILE: docs/README.md
================================================
================================================
FILE: docs/Xmap-Implement.md
================================================
# Xds - XMap技术设计与实现
## 一、XMap 背景目标
- 名词解释:
```
XMap - eXtensible Map Struct(高性能的第三方Map数据结构)
Map - Golang原生map数据结构
sync.Map - Golang原生并发map结构
```
#### XMap设计背景:
现有Golang中的map数据结构无法解决并发读写问题,Sync.map 并发性能偏差,针对这个情况,为XCache服务需要一个高性能、大容量、高并发、无GC的Map,所以开发实现 XMap。
针对我们需求调研了市场上主要的 hashmap 结构,不能满足我们性能和功能要求。
#### XMap设计目标:
要求设计一个可以并发读写不会出现panic,要求并发读写 200w+ OPS/s 的并发map结构。
(写20%,读80%场景;说明:go自带map读写性能在80w ops/s,大量并发读写下可能panic;sync.map 写入性能在 100w OPS/s)
## 二、XMap数据结构设计
为了保证读写性能的要求,同时保证内存的友好。我们采用了开链法方式来做为存储结构,如图为基本数据结构:
```go
type ConcurrentHashMap struct {
size uint64 //当前key的数量
threshold uint64 // 扩容阈值
initCap uint64 //初始化bulks大小
//off-heap
bulks *[]uintptr // 保存链表头结点指针的数组
mm xmm.XMemory // 非堆的对象初始化器
lock sync.RWMutex
treeSize uint64 // 由链表转为红黑树的阈值
//resize
sizeCtl int64 // 状态: -1 正在扩容
nextBulks *[]uintptr //正在扩容的目标Bulks
transferIndex uint64 //扩容的索引
}
```
核心数据结构示例图:
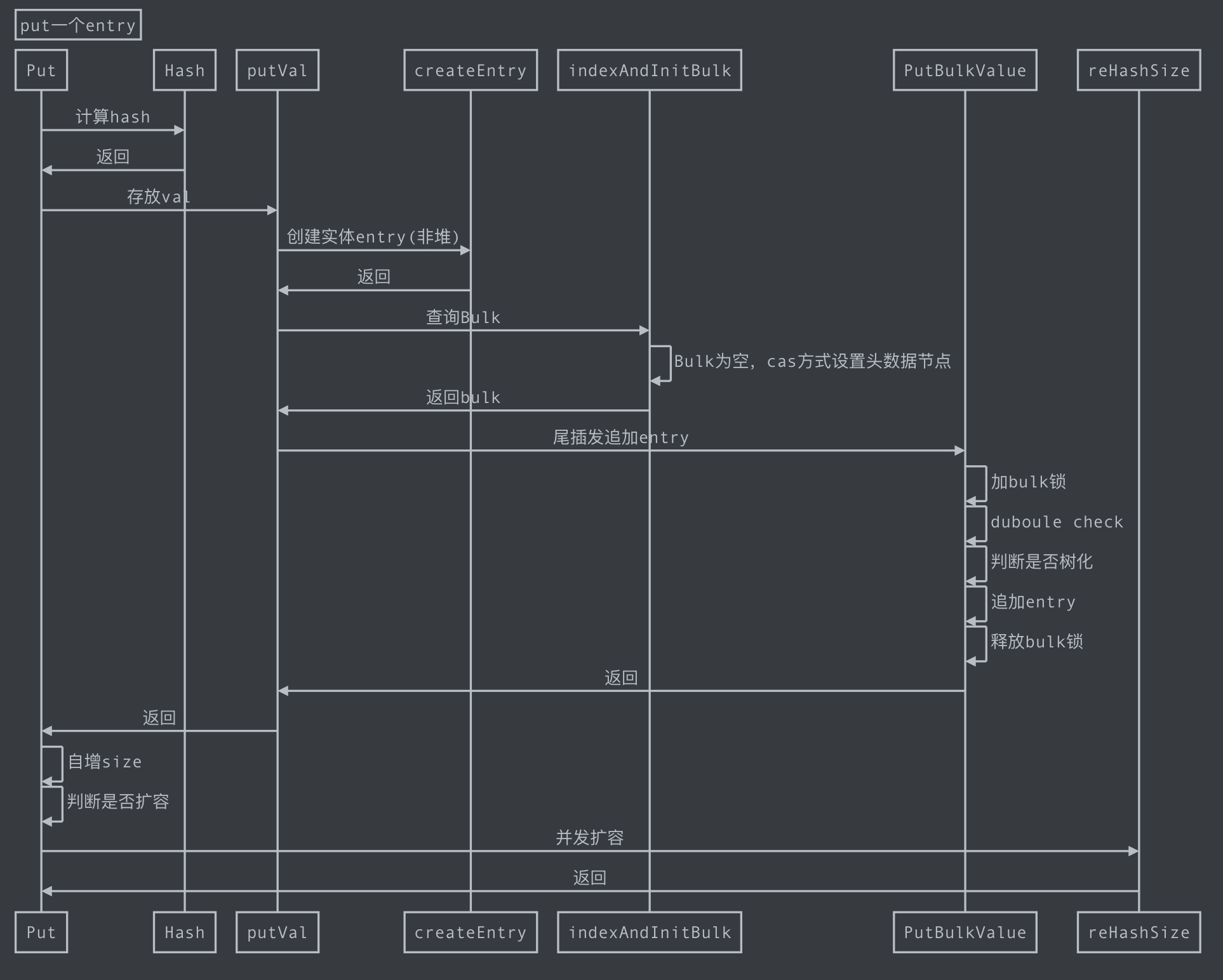
 - 核心说明:使用key的hash值计算出数组索引,每个数组中保存一个链表或者红黑树头结点,找到所处的索引,利用尾插发追加节点。每个节点中有key、value等数据。
- 核心说明:使用key的hash值计算出数组索引,每个数组中保存一个链表或者红黑树头结点,找到所处的索引,利用尾插发追加节点。每个节点中有key、value等数据。
## 三、XMap内部实现流程图
#### 3.1、Set 存储
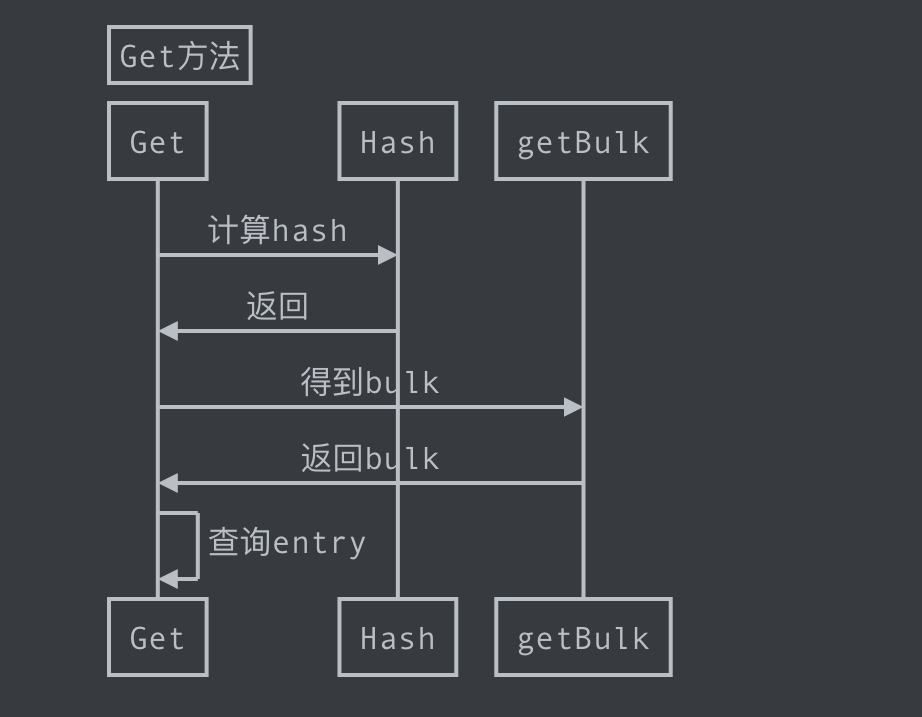
#### 3.2、Get 查询
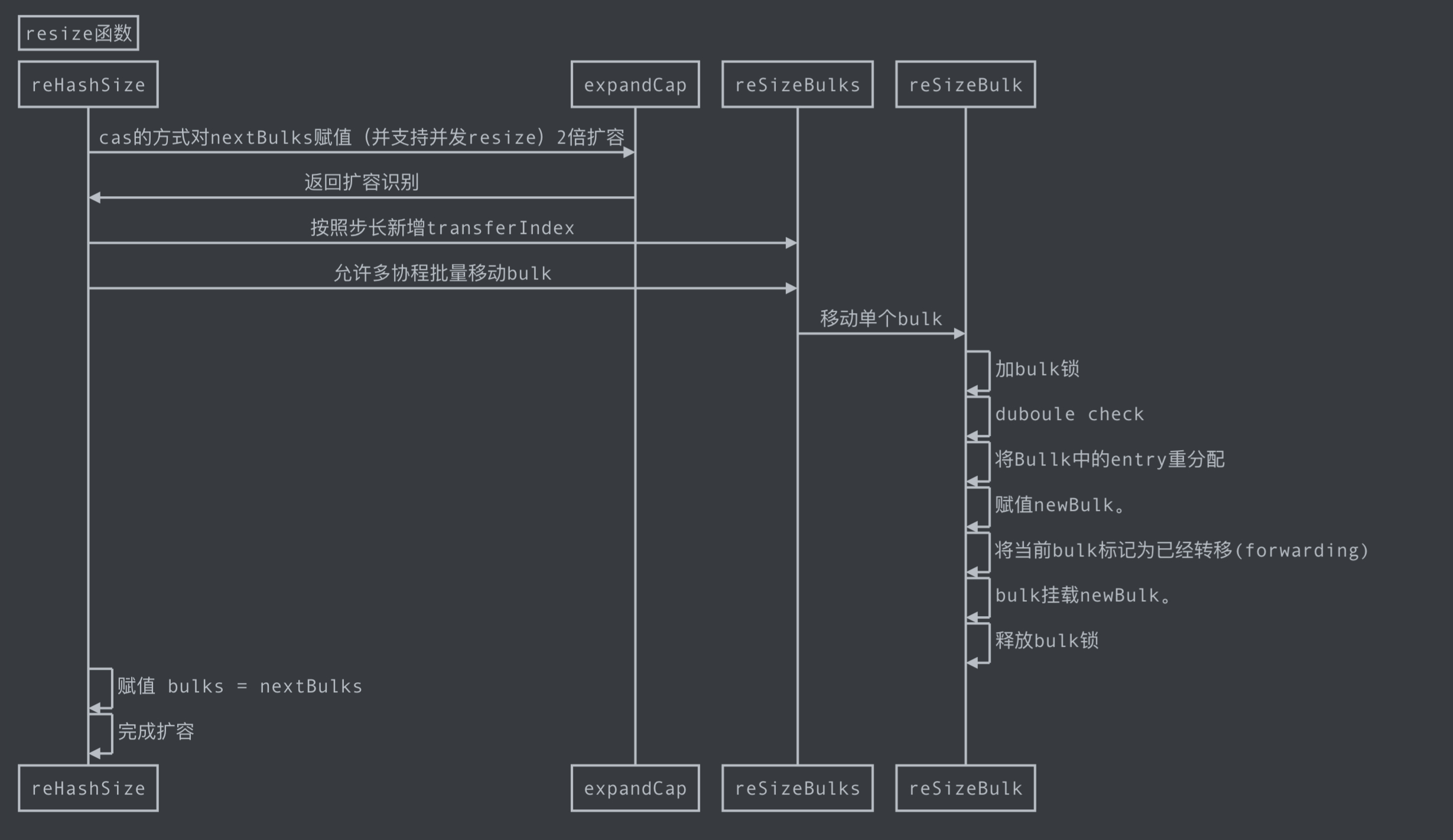
#### 3.3、Resize 扩容
================================================
FILE: docs/img/README
================================================
================================================
FILE: example/README.md
================================================
================================================
FILE: example/xmap_test0.go
================================================
package main
import (
"fmt"
"github.com/spf13/cast"
"github.com/heiyeluren/xmm"
"github.com/heiyeluren/xds"
"github.com/heiyeluren/xds/xmap"
)
// TestMap testing
// -----------------------------------
// 把Xmap当做普通map来使用
// 说明:类型不限制,初始化必须设定好数据类型,写入数据必须与这个数据类型一致,类似于 map[KeyType]ValType 必须相互符合
// -----------------------------------
/*
目前支持的类似于 map[keyType][valType] key value 类型如下:
就是调用:m, err := xds.NewMap(mm, xmap.String, xmap.Int) 后面的两个 keyType 和 valType 类型定义如下:
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
ByteSlice
String
Struct
UnsafePointer
)
*/
func TestMap(mm xmm.XMemory) {
// -------------------
// 常规的map操作
// -------------------
fmt.Println("\n--[ XMap NewMap() API example]--")
// 初始化xmap的时候必须制定key和val的数据类型,数据类型是在xmap中定义的
// 构建一个 map[string]int 的xmap
m, err := xmap.NewMap(mm, xds.String, xds.Int)
if err != nil {
panic("call NewMap() fail")
}
var (
k11 string = "id"
v11 int = 9527
)
// set的时候需要关注类型是否跟初始化对象的时候一致
err = m.Set(k11, v11)
if err != nil {
panic("XMap.Set fail")
}
fmt.Println("XMap.Set key: [", k11, "] success")
// get数据不用关心类型,也不用做类型转换
ret, exists, err := m.Get(k11)
if err != nil {
panic("XMap.Get fail")
}
fmt.Println("XMap.Get key: [", k11, "] , value: [", ret, "]")
// Remove数据
err = m.Remove(k11)
if err != nil {
panic("XMap.Remove fail")
}
fmt.Println("XMap.Remove key: [", k11, "] succes")
ret, exists, err = m.Get(k11)
if !exists {
fmt.Println("XMap.Get key: [", k11, "] not found")
}
// -------------------
// 调用扩展的Map函数使用方法(可以获得更多定制性和更高性能)
// -------------------
fmt.Println("\n--[ XMap NewMapEx() API example]--")
// 生成KV数据
var (
k22 = "name"
v22 = "heiyeluren"
)
// 生成一个 map[string]string 数据结构,默认大小256个元素,占用了75%后进行map扩容(这个初始化函数可以获得更好性能,看个人使用场景)
m1, err := xmap.NewMapEx(mm, xds.String, xds.String, uintptr(256), 0.75)
// set数据
m1.Set(k22, v22)
// get数据
ret, exists, err = m1.Get(k22)
fmt.Println("XMap.Get key: [", k22, "] , value: [", ret, "]")
// -------------------
// 遍历所有map数据
// -------------------
fmt.Println("\n--[ XMap ForEach all Key ]--")
// 写入数据
err = m.Set("k1", 1)
err = m.Set("k2", 2)
err = m.Set("k3", 3)
err = m.Set("k4", 4)
err = m.Set("k5", 5)
//全局变量可以在匿名函数中访问(如果需要使用外部变量,可以像这样)
gi := 1
fmt.Printf("for each itam start, gi: [%s] \n", gi)
// 遍历xmap中所有元素
m.Each(func(key, val interface{}) error {
//针对每个KV进行操作,比如打印出来
fmt.Printf("for each XMap all key:[%s] value:[%s] \n", key, val)
//外部变量使用操作
gi++
return nil
})
fmt.Printf("for each itam done, gi: [%s] \n", gi)
//读取map长度
len := m.Len()
fmt.Printf("\nMap length(size): [%s] \n", len)
}
// TestHashMap testing
// -----------------------------------
// 把Xmap当做普通hashmap来使用
// 说明:Key/Value 都必须是 []byte
// -----------------------------------
func TestHashMap(mm xmm.XMemory) {
fmt.Println("\n\n===== XMap X(eXtensible) Raw Map (HashMap) example ======\n")
hm, err := xmap.NewHashMap(mm)
if err != nil {
panic("call NewHashMap() fail")
}
var (
k1 string = "name"
v1 string = "heiyeluren"
k2 string = "id"
v2 uint32 = 9527
)
// 新增Key
fmt.Println("\n--[ Raw Map Set Key ]--")
err = hm.Set([]byte(k1), []byte(v1))
if err != nil {
panic("xmap.Set fail")
}
fmt.Println("Xmap.Set key: [", k1, "] success")
err = hm.Set([]byte(k2), []byte(cast.ToString(v2)))
if err != nil {
panic("xmap.Set fail")
}
fmt.Println("Xmap.Set key: [", k2, "] success")
// 读取Key
fmt.Println("\n--[ Raw Map Get Key ]--")
s1, exists, err := hm.Get([]byte(k1))
if err != nil {
panic("xmap.Get fail")
}
fmt.Println("Xmap.Get key: [", k1, "], value: [", cast.ToString(s1), "]")
s2, exists, err := hm.Get([]byte(k2))
if err != nil {
panic("xmap.Get fail")
}
fmt.Println("Xmap.Get key: [", k2, "], value: [", cast.ToString(s2), "]")
// 删除Key
fmt.Println("\n--[ Raw Map Remove Key ]--")
err = hm.Remove([]byte(k1))
if err != nil {
panic("xmap.Remove fail")
}
fmt.Println("Xmap.Remove key: [", k1, "]")
s1, exists, err = hm.Get([]byte(k1))
// fmt.Println(s1, exists, err)
if !exists {
fmt.Println("Xmap.Get key: [", k1, "] Not Found")
}
s2, exists, err = hm.Get([]byte(k2))
if err != nil {
panic("xmap.Get fail")
}
fmt.Println("Xmap.Get key: [", k2, "], value: [", cast.ToString(s2), "]")
err = hm.Remove([]byte(k2))
if err != nil {
panic("xmap.Remove fail")
}
fmt.Println("Xmap.Remove key: [", k2, "]")
s2, exists, err = hm.Get([]byte(k2))
// fmt.Println(s1, exists, err)
if !exists {
fmt.Println("Xmap.Get key: [", k2, "] Not Found")
}
s1, exists, err = hm.Get([]byte(k1))
// fmt.Println(s1, exists, err)
if !exists {
fmt.Println("Xmap.Get key: [", k1, "] Not Found")
}
//--------------------
// 遍历RawMap
//--------------------
fmt.Println("\n--[ Raw Map for each all Key ]--")
hm1, err := xmap.NewHashMap(mm)
// 写入数据
hm1.Set([]byte("K1"), []byte("V1"))
hm1.Set([]byte("K2"), []byte("V2"))
hm1.Set([]byte("K3"), []byte("V3"))
hm1.Set([]byte("K4"), []byte("V4"))
//hm1.Each(func(key, val []byte)(error) {
// fmt.Println("for each raw map key:[", key, "], val[", val, "]")
//})
//全局变量可以在匿名函数中访问(如果需要使用外部变量,可以像这样)
gi := 1
fmt.Printf("for each itam start, gi: [%s] \n", gi)
// 遍历xmap中所有元素
hm1.Each(func(key, val []byte) error {
//针对每个KV进行操作,比如打印出来
fmt.Printf("for each XMap all key:[%s] value:[%s] \n", key, val)
//外部变量使用操作
gi++
return nil
})
//读取map长度
len := hm1.Len()
fmt.Printf("\nMap length(size): [%s] \n", len)
}
// xmap测试代码
func main() {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
panic("xmm.CreateConcurrentHashMapMemory fail")
}
fmt.Println("\n===== XMap X(eXtensible) Map example ======\n")
// var NotFound = errors.New("not found")
// 把Xmap当做普通map来使用
TestMap(mm)
// 把Xmap当做普通hashmap来使用
TestHashMap(mm)
fmt.Println("\nXmap test case done.\n\n")
}
================================================
FILE: example/xmap_test1.go
================================================
package main
import (
"fmt"
"github.com/heiyeluren/xmm"
"github.com/heiyeluren/xds"
"github.com/heiyeluren/xds/xmap"
)
//------------------
// xmap快速使用案例
//------------------
func main() {
//创建XMM内存块
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
panic("error")
}
//用xmap创建一个map,结构类似于 map[string]uint,操作类似于 m: = make(map[string]uint)
m, err := xmap.NewMap(mm, xds.String, xds.Int)
if err != nil {
panic("error")
}
// 调用Set()给xmap写入数据
err = m.Set("k1", 1)
err = m.Set("k2", 2)
err = m.Set("k3", 3)
err = m.Set("k4", 4)
err = m.Set("k5", 5)
// 调用Get()读取单个数据
ret, exists, err := m.Get("k1")
if exists == false {
panic("key not found")
}
fmt.Printf("Get data key:[%s] value:[%s] \n", "k1", ret)
// 使用Each()访问所有xmap元素
// 在遍历操作中,让全局变量可以在匿名函数中访问(如果需要使用外部变量,可以像这样)
gi := 1
//调用 Each 遍历函数
m.Each(func(key, val interface{}) error {
//针对每个KV进行操作,比如打印出来
fmt.Printf("For each XMap all key:[%s] value:[%s] \n", key, val)
//外部变量使用操作
gi++
return nil
})
fmt.Printf("For each success, var[gi], val[%s]\n", gi);
//使用Len()获取xmap元素总数量
len := m.Len()
fmt.Printf("Xmap item size:[%s]\n", len);
}
================================================
FILE: example/xslice_test0.go
================================================
package main
import (
"fmt"
// "github.com/heiyeluren/xmm"
"github.com/heiyeluren/xds"
"github.com/heiyeluren/xds/xslice"
)
//---------------------
// xslice快速使用案例
//---------------------
func main() {
fmt.Println("\n--[ Xslice API example]--\n")
//创建XSlice对象, 类似于 s0 []Int64 = make([]Int64, 1)
s0 := xslice.NewXslice(xds.Int,1)
fmt.Println("\n### Xslice - Set/Get OP ###\n")
//Set压入数据, 类似于 s0 :=[] int { 11, 22, 33 }
s0.Set(1, 11)
s0.Set(2, 22)
s0.Set(3, 33)
//Get读取一个数据
vi,nil := s0.Get(1)
fmt.Println("XSlice get data 1: ", vi)
vi,nil = s0.Get(2)
fmt.Println("XSlice get data 2: ", vi)
vi,nil = s0.Get(3)
fmt.Println("XSlice get data 3: ", vi)
//读取整个slice长度, 类似于 len()
fmt.Println("XSlice data size: ", s0.Len(), "\n")
//释放资源
s0.Free()
fmt.Println("\n### Xslice - Append/ForEach OP ###\n")
//批量压入Int ( 类似于 s1 []Int64 = make([]Int64, 1) )
s1 := xslice.NewXslice(xds.Int, 1)
for i:=50; i<=55; i++ {
s1.Append(i)
}
//fmt.Println(s1.Get(2))
//使用ForEach读取所有数据
s1.ForEach(func(i int, v interface{}) error {
fmt.Println("XSlice foreach data i: ",i, " v: ", v)
return nil
})
fmt.Println("\n### Xslice - Append/ForEach Data struct ###\n")
fmt.Println(s1, "\n")
////读取整个slice长度, 类似于 len()
fmt.Println("XSlice data size: ", s1.Len(), "\n")
}
================================================
FILE: go.mod
================================================
module github.com/heiyeluren/xds
go 1.12
require (
github.com/heiyeluren/xmm v0.2.7
github.com/spf13/cast v1.4.1
)
================================================
FILE: go.sum
================================================
github.com/creack/pty v1.1.9/go.mod h1:oKZEueFk5CKHvIhNR5MUki03XCEU+Q6VDXinZuGJ33E=
github.com/davecgh/go-spew v1.1.1 h1:vj9j/u1bqnvCEfJOwUhtlOARqs3+rkHYY13jYWTU97c=
github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38=
github.com/frankban/quicktest v1.14.3/go.mod h1:mgiwOwqx65TmIk1wJ6Q7wvnVMocbUorkibMOrVTHZps=
github.com/google/go-cmp v0.5.7/go.mod h1:n+brtR0CgQNWTVd5ZUFpTBC8YFBDLK/h/bpaJ8/DtOE=
github.com/heiyeluren/xmm v0.2.7 h1:jC3LX4bd7VezczzCJwDLHFQTUAfW9uVNzQZL0jNQNKk=
github.com/heiyeluren/xmm v0.2.7/go.mod h1:l/H95AVDlcr0eGIbyGb7T7RVUPTKrGGK5knl75nsWk8=
github.com/kr/pretty v0.1.0/go.mod h1:dAy3ld7l9f0ibDNOQOHHMYYIIbhfbHSm3C4ZsoJORNo=
github.com/kr/pretty v0.3.0/go.mod h1:640gp4NfQd8pI5XOwp5fnNeVWj67G7CFk/SaSQn7NBk=
github.com/kr/pty v1.1.1/go.mod h1:pFQYn66WHrOpPYNljwOMqo10TkYh1fy3cYio2l3bCsQ=
github.com/kr/text v0.1.0/go.mod h1:4Jbv+DJW3UT/LiOwJeYQe1efqtUx/iVham/4vfdArNI=
github.com/kr/text v0.2.0/go.mod h1:eLer722TekiGuMkidMxC/pM04lWEeraHUUmBw8l2grE=
github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4=
github.com/rogpeppe/go-internal v1.6.1/go.mod h1:xXDCJY+GAPziupqXw64V24skbSoqbTEfhy4qGm1nDQc=
github.com/spf13/cast v1.4.1 h1:s0hze+J0196ZfEMTs80N7UlFt0BDuQ7Q+JDnHiMWKdA=
github.com/spf13/cast v1.4.1/go.mod h1:Qx5cxh0v+4UWYiBimWS+eyWzqEqokIECu5etghLkUJE=
github.com/spf13/cast v1.5.0/go.mod h1:SpXXQ5YoyJw6s3/6cMTQuxvgRl3PCJiyaX9p6b155UU=
github.com/stretchr/testify v1.2.2 h1:bSDNvY7ZPG5RlJ8otE/7V6gMiyenm9RtJ7IUVIAoJ1w=
github.com/stretchr/testify v1.2.2/go.mod h1:a8OnRcib4nhh0OaRAV+Yts87kKdq0PP7pXfy6kDkUVs=
golang.org/x/xerrors v0.0.0-20191204190536-9bdfabe68543/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
gopkg.in/errgo.v2 v2.1.0/go.mod h1:hNsd1EY+bozCKY1Ytp96fpM3vjJbqLJn88ws8XvfDNI=
================================================
FILE: xmap/README
================================================
================================================
FILE: xmap/concurrent_hash_map_benchmark_test.go
================================================
// Copyright (c) 2022 XDS project Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// XDS Project Site: https://github.com/heiyeluren
// XDS URL: https://github.com/heiyeluren/xds
//
package xmap
import (
"fmt"
"math/rand"
"reflect"
"strconv"
"sync"
"testing"
"time"
"unsafe"
// "xds/xmap/entry"
// "github.com/spf13/cast"
"github.com/heiyeluren/xmm"
"github.com/heiyeluren/xds/xmap/entry"
)
// 1000000000
func BenchmarkCHM_Put(b *testing.B) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
b.Fatal(err)
}
chm, err := NewConcurrentRawHashMap(mm, 16, 2, 8)
if err != nil {
b.Fatal(err)
}
keys := make([]string, 10000000)
for i := 0; i < 10000000; i++ {
keys[i] = strconv.Itoa(rand.Int())
}
length := len(keys)
b.ResetTimer()
for i := 0; i < b.N; i++ {
key := []byte(keys[rand.Int()%length])
if err := chm.Put(key, key); err != nil {
b.Error(err)
}
}
}
func BenchmarkCHM_Get(b *testing.B) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
b.Fatal(err)
}
chm, err := NewConcurrentRawHashMap(mm, 16, 2, 8)
if err != nil {
b.Fatal(err)
}
keys := make([]string, 8000000)
for i := 0; i < 8000000; i++ {
keys[i] = strconv.Itoa(rand.Int())
}
length := len(keys)
for _, key := range keys {
if err := chm.Put([]byte(key), []byte(key)); err != nil {
b.Error(err)
}
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
key := keys[rand.Int()%length]
if _, exist, err := chm.Get([]byte(key)); err != nil || !exist {
b.Error(err)
}
}
}
func Test_CHM_Concurrent_Get(t *testing.T) {
// Init()
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
chm, err := NewConcurrentRawHashMap(mm, 16, 2, 8)
if err != nil {
t.Fatal(err)
}
keys := make([]string, 8000000)
for i := 0; i < 8000000; i++ {
keys[i] = strconv.Itoa(rand.Int() % 800000)
}
for _, key := range keys {
if err := chm.Put([]byte(key), []byte(key)); err != nil {
t.Error(err)
}
}
var wait sync.WaitGroup
wait.Add(10)
fmt.Println("开始")
t1 := time.Now()
for j := 0; j < 10; j++ {
go func(z int) {
defer wait.Done()
start, end := z*800000, (z+1)*800000
for _, s := range keys[start:end] {
if err := chm.Put([]byte(s), []byte(s)); err != nil {
t.Error(err)
}
}
}(j)
}
wait.Wait()
fmt.Println(len(keys), time.Now().Sub(t1), len(keys))
<-time.After(time.Minute)
}
func TestGoCreateEntry(t *testing.T) {
var wait sync.WaitGroup
wait.Add(10)
node := &entry.NodeEntry{}
// nodes := make([]*entry.NodeEntry, 8000000)
tt := time.Now()
for j := 0; j < 10; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 800000; i++ {
node.Key = []byte("keyPtr")
node.Value = []byte("valPtr")
node.Hash = 12121
// nodes[z*800000+i] = node
}
}(j)
}
wait.Wait()
fmt.Println(time.Now().Sub(tt))
}
func TestCreateEntry(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
entryPtr, err := mm.Alloc(_NodeEntrySize)
if err != nil {
t.Fatal(err)
}
/* 80445440 \ 283598848 \ 228630528 \ 267530240 \97157120 \ 129908736
keyPtr, valPtr, err := mm.From2("hjjhj", "jjjshjfhsdf")
if err != nil {
t.Fatal(err)
}*/
pageNum := float64(uintptr(entryPtr)) / 4096.0
fmt.Println(uintptr(entryPtr), pageNum, (pageNum+1)*4096 > float64(uintptr(entryPtr)+_NodeEntrySize))
node := (*entry.NodeEntry)(entryPtr)
tt := time.Now()
var wait sync.WaitGroup
wait.Add(10)
for j := 0; j < 10; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 8000000; i++ {
node.Key = []byte("keyPtr")
node.Value = []byte("valPtr")
node.Hash = 12121
}
}(j)
}
wait.Wait()
fmt.Println(time.Now().Sub(tt))
}
// todo 优秀一些,使用这种方式
func TestFieldCopy(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
var wait sync.WaitGroup
wait.Add(10)
for j := 0; j < 10; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 800000; i++ {
entryPtr, err := mm.Alloc(_NodeEntrySize)
if err != nil {
t.Fatal(err)
}
keyPtr, valPtr, err := mm.Copy2([]byte("hjjhj"), []byte("jjjshjfhsdf"))
if err != nil {
t.Fatal(err)
}
source := entry.NodeEntry{Value: keyPtr, Key: valPtr, Hash: 12312}
offset := unsafe.Offsetof(source.Next) // 40
srcData := (*[]byte)(unsafe.Pointer(&reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&source)), Len: int(offset), Cap: int(offset)}))
dstData := (*[]byte)(unsafe.Pointer(&reflect.SliceHeader{Data: uintptr(entryPtr), Len: int(offset), Cap: int(offset)}))
copy(*dstData, *srcData)
}
}(j)
}
wait.Wait()
}
================================================
FILE: xmap/concurrent_hash_map_test.go
================================================
// Copyright (c) 2022 XDS project Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// XDS Project Site: https://github.com/heiyeluren
// XDS URL: https://github.com/heiyeluren/xds
//
package xmap
import (
"bytes"
"fmt"
"io/ioutil"
"math/rand"
"os"
"path/filepath"
"strings"
"sync"
"testing"
"time"
"unsafe"
// "xds/xmap/entry"
"github.com/heiyeluren/xds/xmap/entry"
"github.com/heiyeluren/xmm"
"github.com/spf13/cast"
)
func TestMap(t *testing.T) {
t1 := time.Now()
var data sync.Map
var wait sync.WaitGroup
wait.Add(10)
for h := 0; h < 10; h++ {
go func() {
defer wait.Done()
for i := 0; i < 1000000; i++ {
key := cast.ToString(i)
data.Store(key, key)
}
}()
}
wait.Wait()
fmt.Println(time.Now().Sub(t1))
}
func TestConcurrentRawHashMap_Performance(t *testing.T) {
Init()
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.6)
if err != nil {
t.Fatal(err)
}
chm, err := NewConcurrentRawHashMap(mm, 16, 0.75, 8)
if err != nil {
t.Fatal(err)
}
fmt.Println("http://localhost:6060/debug/pprof/profile")
// http://localhost:6060/debug/pprof/profile
for i := 0; i < 1000000000; i++ {
key := cast.ToString(i)
if err := chm.Put([]byte(key), []byte(key)); err != nil {
t.Error(err)
}
}
}
func TestConcurrentRawHashMap_Function_Second(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
chm, err := NewConcurrentRawHashMap(mm, 16, 4, 8)
if err != nil {
t.Fatal(err)
}
var wait sync.WaitGroup
wait.Add(10)
keys := make(chan string, 1000000)
quit := make(chan bool, 1)
go func() {
<-time.After(time.Second * 22)
t2 := time.Now()
for {
key, ok := <-keys
if !ok {
fmt.Println("read time:", time.Now().Sub(t2))
quit <- true
return
}
val, exist, err := chm.Get([]byte(cast.ToString(key)))
if bytes.Compare(val, []byte(cast.ToString(key))) != 0 || !exist {
t.Error(err, key)
}
}
}()
t1 := time.Now()
for j := 0; j < 10; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 100000; i++ {
key := cast.ToString(i + (z * 10000))
if err := chm.Put([]byte(key), []byte(key)); err != nil {
t.Error(err)
} else {
keys <- key
}
}
}(j)
}
wait.Wait()
fmt.Println(len(keys), time.Now().Sub(t1), len(keys))
close(keys)
f.PrintStatus()
<-quit
<-time.After(time.Second * 10)
}
func TestConcurrentRawHashMap_Function1(t *testing.T) {
Init()
// runtime.GOMAXPROCS(16)
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
chm, err := NewConcurrentRawHashMap(mm, 16, 4, 8)
if err != nil {
t.Fatal(err)
}
var wait sync.WaitGroup
wait.Add(10)
keys := make(chan string, 8000000)
quit := make(chan bool, 1)
go func() {
<-time.After(time.Second * 10)
t2 := time.Now()
for {
key, ok := <-keys
if !ok {
fmt.Println("read time:", time.Now().Sub(t2))
quit <- true
return
}
val, exist, err := chm.Get([]byte(key))
if bytes.Compare(val, []byte(key)) != 0 || !exist {
t.Fatal(err, key)
}
}
}()
t1 := time.Now()
for j := 0; j < 10; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 800000; i++ {
key := cast.ToString(i + (z * 10000))
if err := chm.Put([]byte(key), []byte(key)); err != nil {
t.Error(err)
} else {
keys <- key
}
}
}(j)
}
wait.Wait()
fmt.Println(len(keys), time.Now().Sub(t1), len(keys))
close(keys)
<-quit
}
func TestMMM(t *testing.T) {
// /usr/local/go/src/runtime
filepath.Walk("/usr/local/go/src/runtime", func(path string, info os.FileInfo, err error) error {
if info.IsDir() {
return nil
}
if path[len(path)-3:] != ".go" {
return nil
}
bytes, err := ioutil.ReadFile(path)
if err != nil {
return err
}
for _, s1 := range strings.Split(string(bytes), "\n") {
s1 = strings.TrimSpace(s1)
if len(s1) < 3 || s1[:len("//")] == "//" || strings.Contains(s1, " = ") || strings.Contains(info.Name(), "_test.go") {
continue
}
for _, s2 := range strings.Split(s1, " ") {
s := strings.TrimSpace(s2)
if len(s) < 1 {
continue
}
if int(s[0]) <= 64 || int(s[0]) >= 91 {
continue
}
fmt.Println( /*path, info.Name(),*/ s, s1)
}
}
return nil
})
}
type A struct {
lock sync.RWMutex
age int
}
func TestSizeOf(t *testing.T) {
fmt.Println(unsafe.Sizeof(sync.RWMutex{}), unsafe.Sizeof(A{}))
fmt.Println(unsafe.Sizeof(Bucket2{}))
}
type Bucket2 struct {
forwarding bool // 已经迁移完成
rwlock sync.RWMutex
index uint64
newBuckets *[]uintptr
Head *entry.NodeEntry
/*
Tree *entry.Tree
isTree bool
size uint64
*/
}
func TestMMCopyString(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
var item1, item2 string
for i := 0; i < 10000000; i++ {
item1, item2, err = mm.From2("sdsddsds", "sdsddsdssdsds")
if err != nil {
t.Error(err)
}
}
fmt.Println(item1, item2)
}
func TestGoCopyString(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.75)
if err != nil {
t.Fatal(err)
}
var item1, item2 string
for i := 0; i < 10000000; i++ {
item1, item2, err = mm.From2("sdsddsds", "sdsddsdssdsds")
if err != nil {
t.Error(err)
}
}
fmt.Println(item1, item2)
}
type KV struct {
K string
V string
}
func TestDataSet(t *testing.T) {
fmt.Println(string(make([]byte, 100)))
num, maxLen := 10000000, 1000
kvs := make([]*KV, num)
for i := 0; i < num; i++ {
r := rand.New(rand.NewSource(time.Now().UnixNano())).Int()
k := RandString(r % maxLen)
kvs[i] = &KV{
K: cast.ToString(r % num),
V: k,
}
}
fmt.Println(RandString(1000))
}
func RandString(len int) string {
r := rand.New(rand.NewSource(time.Now().UnixNano()))
bytes := make([]byte, len)
for i := 0; i < len; i++ {
b := r.Intn(26) + 65
bytes[i] = byte(b)
}
return string(bytes)
}
/*func TestDecode(t *testing.T) {
node := entry.NodeEntry{}
sss := node.Int64Encode(212121)
fmt.Println(node.Int64Decode(sss))
}*/
================================================
FILE: xmap/concurrent_raw_hash_map.go
================================================
// Copyright (c) 2022 XDS project Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// XDS Project Site: https://github.com/heiyeluren
// XDS URL: https://github.com/heiyeluren/xds
//
package xmap
import (
"bytes"
"errors"
"github.com/heiyeluren/xds/xmap/entry"
"github.com/heiyeluren/xmm"
"log"
"reflect"
"runtime"
"sync"
"sync/atomic"
"unsafe"
)
// MinTransferStride is the minimum number of entries to transfer between
// 1、步长resize
// 2、sizeCtl增加cap的cas,不允许提前resize。
// 考虑 数组+ 链表方式
const MinTransferStride = 16
const maximumCapacity = 1 << 30
// KeyExists 标识key已经存在
const KeyExists = true
// KeyNotExists 标识key不存在
const KeyNotExists = false
var NotFound = errors.New("not found")
var _BucketSize = unsafe.Sizeof(Bucket{})
var _ForwardingBucketSize = unsafe.Sizeof(ForwardingBucket{})
var _NodeEntrySize = unsafe.Sizeof(entry.NodeEntry{})
var _TreeSize = unsafe.Sizeof(entry.Tree{})
var uintPtrSize = uintptr(8)
// ConcurrentRawHashMap is a concurrent hash map with a fixed number of buckets.
// 清理方式:1、del清除entry(简单)
// 2、buckets清除旧的(resize结束,并无get读引用【引入重试来解决该问题】)
// 3、Bucket清除
// 4、ForwardingBucket清除
// 5、Tree 清除(spliceEntry2时候)
type ConcurrentRawHashMap struct {
size uint64
threshold uint64
initCap uint64
// off-heap
buckets *[]uintptr
mm xmm.XMemory
lock sync.RWMutex
treeSize uint64
// resize
sizeCtl int64 // -1 正在扩容
reSizeGen uint64
nextBuckets *[]uintptr
transferIndex uint64
destroyed uint32 // 0:未销毁 1:已经销毁
destroyLock sync.RWMutex
}
// Bucket is a hash bucket.
type Bucket struct {
forwarding bool // 已经迁移完成
rwLock sync.RWMutex
index uint64
newBuckets *[]uintptr
Head *entry.NodeEntry
Tree *entry.Tree
isTree bool
size uint64
}
// ForwardingBucket is a hash bucket that has been forwarded to a new table.
type ForwardingBucket struct {
forwarding bool // 已经迁移完成
rwLock sync.RWMutex
index uint64
newBuckets *[]uintptr
}
// Snapshot 利用快照比对产生
type Snapshot struct {
buckets *[]uintptr
sizeCtl int64 // -1 正在扩容
nextBuckets *[]uintptr
}
// NewDefaultConcurrentRawHashMap returns a new ConcurrentRawHashMap with the default
// mm: xmm
func NewDefaultConcurrentRawHashMap(mm xmm.XMemory) (*ConcurrentRawHashMap, error) {
return NewConcurrentRawHashMap(mm, 16, 0.75, 8)
}
// NewConcurrentRawHashMap will create a new ConcurrentRawHashMap with the given
// mm: xmm 内存对象
// cap:初始化bucket长度 (可以理解为 map 元素预计最大个数~,如果知道这个值可以提前传递)
// fact:负责因子,当存放的元素超过该百分比,就会触发扩容。
// treeSize:bucket中的链表长度达到该值后,会转换为红黑树。
func NewConcurrentRawHashMap(mm xmm.XMemory, cap uintptr, fact float64, treeSize uint64) (*ConcurrentRawHashMap, error) {
if cap < 1 {
return nil, errors.New("cap < 1")
}
var alignCap uintptr
for i := 1; i < 64 && cap > alignCap; i++ {
alignCap = 1 << uint(i)
}
cap = alignCap
bucketsPtr, err := mm.AllocSlice(uintPtrSize, cap, cap)
if err != nil {
return nil, err
}
buckets := (*[]uintptr)(bucketsPtr)
return &ConcurrentRawHashMap{buckets: buckets, initCap: uint64(cap), threshold: uint64(float64(cap) * fact),
mm: mm, treeSize: treeSize}, nil
}
func (chm *ConcurrentRawHashMap) getBucket(h uint64, tab *[]uintptr) *Bucket {
mask := uint64(cap(*tab) - 1)
idx := h & mask
_, _, bucket := chm.tabAt(tab, idx)
if bucket != nil && bucket.forwarding && chm.transferIndex >= 0 {
return chm.getBucket(h, bucket.newBuckets)
}
return bucket
}
// Get Fetch key from hashmap
func (chm *ConcurrentRawHashMap) Get(key []byte) (val []byte, keyExists bool, err error) {
h := BKDRHashWithSpread(key)
bucket := chm.getBucket(h, chm.buckets)
if bucket == nil {
return nil, KeyNotExists, NotFound
}
if bucket.isTree {
exist, value := bucket.Tree.Get(key)
if !exist {
return nil, KeyNotExists, NotFound
}
return value, KeyExists, nil
}
keySize := len(key)
for cNode := bucket.Head; cNode != nil; cNode = cNode.Next {
if keySize == len(cNode.Key) && bytes.Compare(key, cNode.Key) == 0 {
return cNode.Value, KeyExists, nil
}
}
return nil, KeyNotExists, NotFound
}
func (chm *ConcurrentRawHashMap) initForwardingEntries(newBuckets *[]uintptr, index uint64) (*ForwardingBucket, error) {
entriesPtr, err := chm.mm.Alloc(_ForwardingBucketSize)
if err != nil {
return nil, err
}
entries := (*ForwardingBucket)(entriesPtr)
chm.assignmentForwardingEntries(newBuckets, entries, index)
return entries, nil
}
func (chm *ConcurrentRawHashMap) assignmentForwardingEntries(newBuckets *[]uintptr, entries *ForwardingBucket, index uint64) {
entries.newBuckets = newBuckets
entries.index = index
entries.forwarding = true
}
func (chm *ConcurrentRawHashMap) initEntries(entry *entry.NodeEntry, idx uint64) (*Bucket, error) {
ptr, err := chm.mm.Alloc(_BucketSize)
if err != nil {
return nil, err
}
entries := (*Bucket)(ptr)
chm.assignmentEntries(entries, entry, idx)
return entries, nil
}
func (chm *ConcurrentRawHashMap) assignmentEntries(entries *Bucket, entry *entry.NodeEntry, index uint64) {
entries.index = index
entries.Head = entry
}
func (chm *ConcurrentRawHashMap) getStride(length uint64) (stride uint64) {
cpuNum := uint64(runtime.NumCPU())
if cpuNum > 1 {
stride = (length >> 3) / cpuNum
} else {
stride = length
}
if stride < MinTransferStride {
stride = MinTransferStride
}
return stride
}
func (chm *ConcurrentRawHashMap) resizeStamp(length uint64) (stride int64) {
return -10000 - int64(length)
}
func (chm *ConcurrentRawHashMap) helpTransform(entry *entry.NodeEntry, bucket *Bucket, tab *[]uintptr) (currentBucket *Bucket, init bool, currentTab *[]uintptr, err error) {
if bucket != nil && bucket.forwarding {
if err := chm.reHashSize(tab); err != nil {
return nil, init, nil, err
}
tabPtr := bucket.newBuckets
bucket, swapped, err := chm.getAndInitBucket(entry, tabPtr)
if err != nil {
return nil, init, nil, err
}
if swapped {
return nil, true, nil, err
}
return bucket, init, tabPtr, nil
}
return bucket, init, tab, nil
}
func (chm *ConcurrentRawHashMap) indexAndInitBucket(entry *entry.NodeEntry) (entries *Bucket, init bool, tabPtr *[]uintptr, err error) {
tabPtr = chm.buckets
bucket, swapped, err := chm.getAndInitBucket(entry, tabPtr)
if err != nil {
return nil, init, nil, err
}
if swapped {
return bucket, true, tabPtr, nil
}
if bucket != nil && bucket.forwarding && chm.transferIndex >= 0 {
bucket, swapped, tabPtr, err = chm.helpTransform(entry, bucket, tabPtr)
if err != nil {
return nil, init, nil, err
}
if swapped {
return bucket, true, tabPtr, nil
}
}
return bucket, init, tabPtr, nil
}
func (chm *ConcurrentRawHashMap) index(h uint64, length int) uint64 {
idx := h & uint64(length-1)
return idx
}
func (chm *ConcurrentRawHashMap) tabAt(buckets *[]uintptr, idx uint64) (*uintptr, uintptr, *Bucket) {
addr := &((*buckets)[idx])
ptr := atomic.LoadUintptr(addr)
if ptr == 0 {
return addr, ptr, nil
}
bucket := (*Bucket)(unsafe.Pointer(ptr))
return addr, ptr, bucket
}
// cas 设置bucket
func (chm *ConcurrentRawHashMap) getAndInitBucket(entry *entry.NodeEntry, tabPtr *[]uintptr) (bucket *Bucket, swapped bool, err error) {
h := entry.Hash
idx := chm.index(h, cap(*tabPtr))
// retry := 10改小后,出现该问题。
addr, _, bucket := chm.tabAt(tabPtr, idx)
if bucket != nil {
return bucket, false, nil
}
entity, err := chm.initEntries(entry, idx)
if err != nil {
return nil, false, err
}
ptr := uintptr(unsafe.Pointer(entity))
atomic.CompareAndSwapUintptr(addr, 0, ptr)
bucket = (*Bucket)(unsafe.Pointer(atomic.LoadUintptr(addr)))
return bucket, swapped, nil
}
func (chm *ConcurrentRawHashMap) increaseSize() (newSize uint64) {
retry := 30
var swapped bool
for !swapped && retry > 0 {
retry--
oldVal := atomic.LoadUint64(&chm.size)
newVal := oldVal + 1
swapped = atomic.CompareAndSwapUint64(&chm.size, oldVal, newVal)
if swapped {
return newVal
}
}
chm.lock.Lock()
defer chm.lock.Unlock()
size := chm.size + 1
chm.size = size
return size
}
func (chm *ConcurrentRawHashMap) createEntry(key []byte, val []byte, hash uint64) (*entry.NodeEntry, error) {
entryPtr, err := chm.mm.Alloc(_NodeEntrySize)
if err != nil {
return nil, err
}
node := (*entry.NodeEntry)(entryPtr)
keyPtr, valPtr, err := chm.mm.Copy2(key, val)
if err != nil {
return nil, err
}
chm.entryAssignment(keyPtr, valPtr, hash, node)
return node, nil
}
func (chm *ConcurrentRawHashMap) entryAssignment(keyPtr []byte, valPtr []byte, hash uint64, entry *entry.NodeEntry) {
entry.Key = keyPtr
entry.Value = valPtr
entry.Hash = hash
}
func (chm *ConcurrentRawHashMap) entryAssignmentCpy(keyPtr []byte, valPtr []byte, hash uint64, nodePtr unsafe.Pointer) error {
source := entry.NodeEntry{Value: keyPtr, Key: valPtr, Hash: hash}
offset := 40 // unsafe.Offsetof(source.Next) //40
srcData := (*[]byte)(unsafe.Pointer(&reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&source)), Len: offset, Cap: offset}))
dstData := (*[]byte)(unsafe.Pointer(&reflect.SliceHeader{Data: uintptr(nodePtr), Len: offset, Cap: offset}))
if offset != copy(*dstData, *srcData) {
return errors.New("incorrect copy length") // 拷贝长度不正确
}
return nil
}
func (chm *ConcurrentRawHashMap) putVal(key []byte, val []byte, h uint64) (*[]uintptr, error) {
node, err := chm.createEntry(key, val, h)
if err != nil {
return nil, err
}
loop := true
var tabPtr *[]uintptr
for loop {
bucket, init, newTabPtr, err := chm.indexAndInitBucket(node)
if err != nil {
return nil, err
}
tabPtr = newTabPtr
if init {
break
}
if loop, err = chm.PutBucketValue(bucket, node, tabPtr); err != nil {
return nil, err
}
}
return tabPtr, nil
}
// Put 将键值对添加到map中
func (chm *ConcurrentRawHashMap) Put(key []byte, val []byte) error {
h := BKDRHashWithSpread(key)
tabPtr, err := chm.putVal(key, val, h)
if err != nil {
return err
}
size := chm.increaseSize()
threshold := atomic.LoadUint64(&chm.threshold)
if size >= threshold && size < maximumCapacity {
return chm.reHashSize(tabPtr)
}
return nil
}
// Del 删除键值对
func (chm *ConcurrentRawHashMap) Del(key []byte) error {
h := BKDRHashWithSpread(key)
return chm.delVal(key, h)
}
func (chm *ConcurrentRawHashMap) delVal(key []byte, h uint64) error {
loop := true
var tabPtr *[]uintptr
tabPtr = chm.buckets
for loop {
idx := chm.index(h, cap(*tabPtr))
_, _, bucket := chm.tabAt(tabPtr, idx)
if bucket == nil {
return nil
}
if bucket != nil && bucket.forwarding {
if err := chm.reHashSize(tabPtr); err != nil {
return err
}
tabPtr = bucket.newBuckets
idx = chm.index(h, cap(*tabPtr))
_, _, bucket = chm.tabAt(tabPtr, idx)
continue
}
var removeNode *entry.NodeEntry
func() {
// 删除bucket中的数目
bucket.rwLock.Lock()
defer bucket.rwLock.Unlock()
_, _, newBucket := chm.tabAt(tabPtr, chm.index(h, cap(*tabPtr)))
if newBucket != bucket || (bucket != nil && bucket.forwarding) {
return
}
if bucket.isTree {
if node := bucket.Tree.Delete(key); node != nil {
removeNode = node
}
} else {
keySize := len(key)
var pre *entry.NodeEntry
for cNode := bucket.Head; cNode != nil; cNode = cNode.Next {
if keySize == len(cNode.Key) && bytes.Compare(key, cNode.Key) == 0 {
removeNode = cNode
if pre == nil {
bucket.Head = cNode.Next
} else {
pre.Next = cNode.Next
}
break
}
pre = cNode
}
}
loop = false
return
}()
if err := chm.freeEntry(removeNode); err != nil {
return err
}
}
return nil
}
// freeEntry todo 异步free
func (chm *ConcurrentRawHashMap) freeEntry(removeNode *entry.NodeEntry) error {
if removeNode == nil {
return nil
}
if err := chm.mm.Free(uintptr(unsafe.Pointer(removeNode))); err != nil {
return err
}
keySlice, valSlice := (*reflect.SliceHeader)(unsafe.Pointer(&removeNode.Key)), (*reflect.SliceHeader)(unsafe.Pointer(&removeNode.Value))
if err := chm.mm.Free(keySlice.Data); err != nil {
return err
}
if err := chm.mm.Free(valSlice.Data); err != nil {
return err
}
return nil
}
func (chm *ConcurrentRawHashMap) growTree(bucket *Bucket) error {
if bucket.isTree || bucket.size < chm.treeSize {
return nil
}
treePtr, err := chm.mm.Alloc(_TreeSize)
if err != nil {
return err
}
bucket.Tree = (*entry.Tree)(treePtr)
bucket.Tree.SetComparator(entry.BytesAscSort)
for node := bucket.Head; node != nil; {
next := node.Next
if err := bucket.Tree.Put(node); err != nil {
return err
}
node = next
}
bucket.Head = nil
bucket.isTree = true
return nil
}
// PutBucketValue table的可见性问题,并发问题。
func (chm *ConcurrentRawHashMap) PutBucketValue(bucket *Bucket, node *entry.NodeEntry, tab *[]uintptr) (loop bool, err error) {
bucket.rwLock.Lock()
defer bucket.rwLock.Unlock()
idx := chm.index(node.Hash, cap(*tab))
_, _, newBucket := chm.tabAt(tab, idx)
if newBucket != bucket || newBucket.forwarding {
return true, nil
}
bucket = newBucket
// 树化
if err := chm.growTree(bucket); err != nil {
return false, err
}
if bucket.isTree {
if err := bucket.Tree.Put(node); err != nil {
return false, err
}
return false, nil
}
key, val := node.Key, node.Value
var last *entry.NodeEntry
for node := bucket.Head; node != nil; node = node.Next {
if len(key) == len(node.Key) && bytes.Compare(node.Key, key) == 0 {
node.Value = val
return false, nil
}
if node.Next == nil {
last = node
}
}
bucket.size += 1
// 加入
if last == nil {
bucket.Head = node
return false, nil
}
last.Next = node
return false, nil
}
func (chm *ConcurrentRawHashMap) expandCap(tab *[]uintptr) (s *Snapshot, need bool) {
old, size, transferIndex, threshold := uint64(cap(*chm.buckets)), atomic.LoadUint64(&chm.size),
atomic.LoadUint64(&chm.transferIndex), atomic.LoadUint64(&chm.threshold)
if size < threshold || transferIndex >= old {
return nil, false
}
nextBuckets, buckets, sizeCtl := chm.nextBuckets, chm.buckets, atomic.LoadInt64(&chm.sizeCtl)
// 正在扩容
if sizeCtl < 0 && nextBuckets != nil && cap(*nextBuckets) == int(old)*2 {
if sizeCtl >= 0 {
return nil, false
}
// 当前扩容状态正确,开始扩容
if unsafe.Pointer(tab) == unsafe.Pointer(buckets) && nextBuckets != nil {
if atomic.CompareAndSwapInt64(&chm.sizeCtl, sizeCtl, sizeCtl+1) {
return &Snapshot{buckets: buckets, sizeCtl: sizeCtl, nextBuckets: nextBuckets}, true
}
}
return nil, false
}
// 未开始扩容的判断
if sizeCtl >= 0 && (old<<1) > uint64(sizeCtl) && unsafe.Pointer(tab) == unsafe.Pointer(buckets) {
newSizeCtl := chm.resizeStamp(old) + 2
swapped := atomic.CompareAndSwapInt64(&chm.sizeCtl, sizeCtl, newSizeCtl)
// 开始扩容
if swapped {
newCap := old << 1
bucketsPtr, err := chm.mm.AllocSlice(uintPtrSize, uintptr(newCap), uintptr(newCap))
if err != nil {
log.Printf("ConcurrentRawHashMap chm.mm.Alloc newCap:%d err:%s \n", newCap, err)
return nil, false
}
nextBuckets = (*[]uintptr)(bucketsPtr)
chm.nextBuckets = nextBuckets
chm.transferIndex = 0
return &Snapshot{buckets: buckets, sizeCtl: sizeCtl, nextBuckets: nextBuckets}, true
}
return nil, false
}
return nil, false
}
func (chm *ConcurrentRawHashMap) reHashSize(tab *[]uintptr) error {
// cas锁
snapshot, need := chm.expandCap(tab)
if !need {
return nil
}
currentCap := uint64(cap(*snapshot.buckets))
buckets := snapshot.nextBuckets
// 取当前内容oldBuckets,在oldBuckets中利用bucket的lock来避免同时操作。
err := chm.reSizeBuckets(snapshot)
if err != nil {
return err
}
for {
sizeCtl := atomic.LoadInt64(&chm.sizeCtl)
if sizeCtl >= 0 {
return nil
}
if atomic.CompareAndSwapInt64(&chm.sizeCtl, sizeCtl, sizeCtl-1) {
if sizeCtl != chm.resizeStamp(currentCap)+2 {
return nil
}
break
}
}
return func() error {
oldBuckets, tabPtr := chm.buckets, unsafe.Pointer(&chm.buckets)
bucketsAddr := (*unsafe.Pointer)(tabPtr)
old := (*reflect.SliceHeader)(atomic.LoadPointer(bucketsAddr))
if old.Cap != int(currentCap) {
return nil
}
if atomic.CompareAndSwapPointer(bucketsAddr, unsafe.Pointer(old), unsafe.Pointer(buckets)) {
// 更换内容赋值
chm.nextBuckets = nil
newCap := currentCap << 1
atomic.StoreInt64(&chm.sizeCtl, int64(newCap))
chm.threshold = chm.threshold << 1
chm.reSizeGen += 1
if err := chm.freeBuckets(oldBuckets); err != nil {
log.Printf("freeBuckets err:%s\n", err)
}
return err
}
return nil
}()
}
/*
todo 异步free 清除内存
buckets清除旧的(resize结束,并无get读引用【引入重试来解决该问题】)
3、Bucket清除
4、元素清除*/
func (chm *ConcurrentRawHashMap) freeBuckets(buckets *[]uintptr) error {
for _, ptr := range *buckets {
if ptr < 1 {
continue
}
if err := chm.mm.Free(ptr); err != nil {
log.Printf("freeBuckets Free element(%d) err:%s\n", ptr, err)
}
}
if err := chm.mm.Free(uintptr(unsafe.Pointer(buckets))); err != nil {
return err
}
return nil
}
func (chm *ConcurrentRawHashMap) increaseTransferIndex(cap uint64, stride uint64) (offset uint64, over bool) {
for {
transferIndex := atomic.LoadUint64(&chm.transferIndex)
if transferIndex >= cap {
return 0, true
}
swapped := atomic.CompareAndSwapUint64(&chm.transferIndex, transferIndex, transferIndex+stride)
if swapped {
return transferIndex, false
}
}
}
func (chm *ConcurrentRawHashMap) reSizeBuckets(s *Snapshot) error {
newBuckets, oldBuckets, currentCap := s.nextBuckets, s.buckets, uint64(cap(*s.buckets))
for {
stride := chm.getStride(currentCap)
offset, over := chm.increaseTransferIndex(currentCap, stride)
if over {
return nil
}
maxIndex := offset + stride
if maxIndex > currentCap {
maxIndex = currentCap
}
for index := offset; index < maxIndex; index++ {
var err error
loop := true
for loop {
addr := &((*oldBuckets)[index])
entries := (*Bucket)(unsafe.Pointer(atomic.LoadUintptr(addr)))
if entries == nil {
forwardingEntries, err := chm.initForwardingEntries(newBuckets, index)
if err != nil {
log.Printf("ERROR reSizeBucket initForwardingEntries err:%s\n", err)
return err
}
ptr := uintptr(unsafe.Pointer(forwardingEntries))
if atomic.CompareAndSwapUintptr(addr, 0, ptr) {
break
} else {
entries = (*Bucket)(unsafe.Pointer(atomic.LoadUintptr(addr)))
}
}
if loop, err = chm.reSizeBucket(entries, s); err != nil {
log.Printf("ERROR reSizeBucket oldEntries err:%s\n", err)
}
}
}
}
}
// Chain .链接
type Chain struct {
Head *entry.NodeEntry
Tail *entry.NodeEntry
}
// Add 添加节点
func (c *Chain) Add(node *entry.NodeEntry) {
if c.Head == nil {
c.Head = node
}
if c.Tail != nil {
c.Tail.Next = node
}
c.Tail = node
}
// GetHead 获取head节点
func (c *Chain) GetHead() *entry.NodeEntry {
if c.Tail != nil {
c.Tail.Next = nil
}
return c.Head
}
func (chm *ConcurrentRawHashMap) reSizeBucket(entries *Bucket, s *Snapshot) (loop bool, err error) {
entries.rwLock.Lock()
defer entries.rwLock.Unlock()
oldBuckets, newBuckets := s.buckets, s.nextBuckets
currentCap := uint64(cap(*s.buckets))
tabPtr, nextTabPtr := unsafe.Pointer(s.buckets), unsafe.Pointer(s.nextBuckets)
_, _, currentEntries := chm.tabAt(oldBuckets, entries.index)
// 判断newBuckets为chm.newBuckets,判断newBuckets为chm.newBuckets
if entries.forwarding || tabPtr != unsafe.Pointer(chm.buckets) ||
nextTabPtr != unsafe.Pointer(chm.nextBuckets) || entries != currentEntries {
return false, nil
}
if entries != nil && ((!entries.isTree && entries.Head == nil) || (entries.isTree && entries.Tree == nil)) {
entries.newBuckets = newBuckets
entries.forwarding = true
return false, nil
}
mask := (currentCap << 1) - 1
index := entries.index
var oldIndex, newIndex = index, currentCap + index
oldChains, newChains, err := chm.spliceEntry2(entries, mask)
if err != nil {
return true, err
}
oldBucket, newBucket, err := chm.spliceBucket2(oldChains, newChains)
if err != nil {
return false, err
}
if oldBucket != nil {
oldBucket.index = oldIndex
(*newBuckets)[oldIndex] = uintptr(unsafe.Pointer(oldBucket))
}
if newBucket != nil {
newBucket.index = newIndex
(*newBuckets)[newIndex] = uintptr(unsafe.Pointer(newBucket))
}
entries.newBuckets = newBuckets
entries.forwarding = true
entries.Head = nil
return false, nil
}
// TreeSplice .
func (chm *ConcurrentRawHashMap) TreeSplice(node *entry.NodeEntry, index uint64, mask uint64, oldChains, newChains *Chain) {
if node == nil {
return
}
if node.Hash&mask == index {
oldChains.Add(node)
} else {
newChains.Add(node)
}
chm.TreeSplice(node.Left(), index, mask, oldChains, newChains)
chm.TreeSplice(node.Right(), index, mask, oldChains, newChains)
}
// spliceEntry2 将Entry拆分为两个列表
func (chm *ConcurrentRawHashMap) spliceEntry2(entries *Bucket, mask uint64) (old *entry.NodeEntry, new *entry.NodeEntry, err error) {
var oldHead, oldTail, newHead, newTail *entry.NodeEntry
index := entries.index
if entries.isTree {
var oldChains, newChains Chain
chm.TreeSplice(entries.Tree.GetRoot(), index, mask, &oldChains, &newChains)
oldHead, newHead = oldChains.GetHead(), newChains.GetHead()
// 删除现在的tree内容
if err := chm.mm.Free(uintptr(unsafe.Pointer(entries.Tree))); err != nil {
return nil, nil, err
}
} else {
for nodeEntry := entries.Head; nodeEntry != nil; nodeEntry = nodeEntry.Next {
idx := nodeEntry.Hash & mask
if idx == index {
if oldHead == nil {
oldHead = nodeEntry
} else if oldTail != nil {
oldTail.Next = nodeEntry
}
oldTail = nodeEntry
} else {
if newHead == nil {
newHead = nodeEntry
} else if newTail != nil {
newTail.Next = nodeEntry
}
newTail = nodeEntry
}
}
}
if newTail != nil {
newTail.Next = nil
}
if oldTail != nil {
oldTail.Next = nil
}
return oldHead, newHead, nil
}
// 性能更好
func (chm *ConcurrentRawHashMap) spliceBucket2(old *entry.NodeEntry, new *entry.NodeEntry) (oldBucket *Bucket, newBucket *Bucket, err error) {
if old != nil {
head, index := old, uint64(0)
item, err := chm.initEntries(head, index)
if err != nil {
return nil, nil, err
}
oldBucket = item
}
if new != nil {
head, index := new, uint64(0)
item, err := chm.initEntries(head, index)
if err != nil {
return nil, nil, err
}
newBucket = item
}
return
}
func (chm *ConcurrentRawHashMap) indexBucket(idx int, tab *[]uintptr) (bucket *Bucket, outIndex bool) {
if idx >= cap(*tab) {
return nil, false
}
_, _, bucket = chm.tabAt(tab, uint64(idx))
if bucket != nil && bucket.forwarding && chm.transferIndex >= 0 {
return chm.indexBucket(idx, bucket.newBuckets)
}
return bucket, true
}
func (chm *ConcurrentRawHashMap) ForEach(fun func(key, val []byte) error) error {
bucket, exist := chm.indexBucket(0, chm.buckets)
for i := 1; exist; i++ {
if bucket != nil {
if tree := bucket.Tree; bucket.isTree && tree != nil {
if err := chm.TreeForEach(fun, tree.GetRoot()); err != nil {
return err
}
} else {
for cNode := bucket.Head; cNode != nil; cNode = cNode.Next {
if err := fun(cNode.Key, cNode.Value); err != nil {
return err
}
}
}
}
bucket, exist = chm.indexBucket(i, chm.buckets)
}
return nil
}
func (chm *ConcurrentRawHashMap) TreeForEach(fun func(key, val []byte) error, node *entry.NodeEntry) error {
if node == nil {
return nil
}
if err := fun(node.Key, node.Value); err != nil {
return err
}
chm.TreeForEach(fun, node.Left())
chm.TreeForEach(fun, node.Right())
return nil
}
// BKDRHashWithSpread . 31 131 1313 13131 131313 etc..
func BKDRHashWithSpread(str []byte) uint64 {
seed := uint64(131)
hash := uint64(0)
for i := 0; i < len(str); i++ {
hash = (hash * seed) + uint64(str[i])
}
return hash ^ (hash>>16)&0x7FFFFFFF
}
================================================
FILE: xmap/entry/rbtree.go
================================================
/*
Copyright 2014 Gavin Bong.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,
either express or implied. See the License for the specific
language governing permissions and limitations under the
License.
*/
// Package entry Package redblacktree provides a pure Golang implementation
// of a red-black tree as described by Thomas H. Cormen's et al.
// in their seminal Algorithms book (3rd ed). This data structure
// is not multi-goroutine safe.
package entry
import (
"bytes"
"errors"
"fmt"
"io"
"io/ioutil"
"log"
"os"
"reflect"
"strings"
"sync"
)
// NodeEntry interface defines the methods that a node must implement.
type NodeEntry struct {
Key []byte
Value []byte
Hash uint64
Next *NodeEntry
right *NodeEntry
left *NodeEntry
parent *NodeEntry
color Color // 比二叉查找树要多出一个颜色属性
}
func round(n, a uint64) uint64 {
return (n + a - 1) &^ (a - 1)
}
type encodedNodeEntry struct {
TotalLen uint64
KeyLen uint64
ValueLen uint64
Hash uint64
Next *NodeEntry
right *NodeEntry
left *NodeEntry
parent *NodeEntry
color Color // 比二叉查找树要多出一个颜色属性
// 追加string key、value 要不然就内存泄露了
}
/*// total'len(64) + key'len(64) + key'content +
func (n *NodeEntry) encode() []byte {
var keyLen, valLen = round(uint64(len(n.Key)), 8), round(uint64(len(n.Value)), 8)
total := keyLen + valLen + 8*8
encoded := encodedNodeEntry{
TotalLen: total,
KeyLen: keyLen,
ValueLen: valLen,
Hash: 0,
Next: nil,
right: nil,
left: nil,
parent: nil,
color: false,
}
}*/
// BytesAscSort is a helper function that sorts a slice of byte slices
var BytesAscSort Comparator = func(o1, o2 interface{}) int {
key1, key2 := o1.([]byte), o2.([]byte)
return bytes.Compare(key1, key2)
}
// Color of a redblack tree node is either
// `Black` (true) & `Red` (false)
type Color bool
// Direction points to either the Left or Right subtree
type Direction byte
func (c Color) String() string {
switch c {
case true:
return "Black"
default:
return "Red"
}
}
func (d Direction) String() string {
switch d {
case LEFT:
return "left"
case RIGHT:
return "right"
case NODIR:
return "center"
default:
return "not recognized"
}
}
const (
BLACK, RED Color = true, false
)
const (
LEFT Direction = iota
RIGHT
NODIR
)
// A node needs to be able to answer the query:
// (i) Who is my parent node ?
// (ii) Who is my grandparent node ?
// The zero value for Node has color Red.
func (n *NodeEntry) String() string {
if n == nil {
return ""
}
return fmt.Sprintf("(%#v : %s)", n.Key, n.Color())
}
// Parent node will be nil if the node is the root node.
func (n *NodeEntry) Parent() *NodeEntry {
return n.parent
}
// SetColor nodes color to the given color.
func (n *NodeEntry) SetColor(color Color) {
n.color = color
}
// Color returns the color of the node.
func (n *NodeEntry) Color() Color {
return n.color
}
// Left indicates the left child of the node.
func (n *NodeEntry) Left() *NodeEntry {
return n.left
}
// Right indicates the right child of the node.
func (n *NodeEntry) Right() *NodeEntry {
return n.right
}
// Visitor is a function that is called on each node of the tree.
type Visitor interface {
Visit(*NodeEntry)
}
// Visitable A redblack tree is `Visitable` by a `Visitor`.
type Visitable interface {
Walk(Visitor)
}
// Comparator is a function that compares two objects.
// Keys must be comparable. It's mandatory to provide a Comparator,
// which returns zero if o1 == o2, -1 if o1 < o2, 1 if o1 > o2
type Comparator func(o1, o2 interface{}) int
// IntComparator is a Comparator that compares ints.
// Default comparator expects keys to be of type `int`.
// Warning: if either one of `o1` or `o2` cannot be asserted to `int`, it panics.
func IntComparator(o1, o2 interface{}) int {
i1 := o1.(int)
i2 := o2.(int)
switch {
case i1 > i2:
return 1
case i1 < i2:
return -1
default:
return 0
}
}
// StringComparator ...
// Keys of type `string`.
// Warning: if either one of `o1` or `o2` cannot be asserted to `string`, it panics.
func StringComparator(o1, o2 interface{}) int {
s1 := o1.(string)
s2 := o2.(string)
return bytes.Compare([]byte(s1), []byte(s2))
}
// Tree encapsulates the data structure.
type Tree struct {
root *NodeEntry // tip of the tree
cmp Comparator // required function to order keys
lock sync.RWMutex
}
// `lock` protects `logger`
var loggerlock sync.Mutex
var logger *log.Logger
func init() {
logger = log.New(ioutil.Discard, "", log.LstdFlags)
}
// TraceOn turns on logging output to Stderr
func TraceOn() {
SetOutput(os.Stderr)
}
// TraceOff turns off logging.
// By default logging is turned off.
func TraceOff() {
SetOutput(ioutil.Discard)
}
// SetOutput redirects log output
func SetOutput(w io.Writer) {
loggerlock.Lock()
defer loggerlock.Unlock()
logger = log.New(w, "", log.LstdFlags)
}
// NewTree returns an empty Tree with default comparator `IntComparator`.
// `IntComparator` expects keys to be type-assertable to `int`.
func NewTree() *Tree {
return &Tree{root: nil, cmp: IntComparator}
}
// NewTreeWith returns an empty Tree with a supplied `Comparator`.
func NewTreeWith(c Comparator) *Tree {
return &Tree{root: nil, cmp: c}
}
// SetComparator in the Tree of the supplied `Comparator`.
func (t *Tree) SetComparator(c Comparator) {
t.cmp = c
}
// Get looks for the node with supplied key and returns its mapped payload.
// Return value in 1st position indicates whether any payload was found.
func (t *Tree) Get(key []byte) (bool, []byte) {
if err := mustBeValidKey(key); err != nil {
// logger.Printf("Get was prematurely aborted: %s\n", err.Error())
return false, nil
}
ok, node := t.getNode(key)
if ok {
return true, node.Value
}
return false, nil
}
func (t *Tree) getNode(key interface{}) (bool, *NodeEntry) {
found, parent, dir := t.GetParent(key)
if found {
if parent == nil {
return true, t.root
}
var node *NodeEntry
switch dir {
case LEFT:
node = parent.left
case RIGHT:
node = parent.right
}
if node != nil {
return true, node
}
}
return false, nil
}
// getMinimum returns the node with minimum key starting
// at the subtree rooted at node x. Assume x is not nil.
func (t *Tree) getMinimum(x *NodeEntry) *NodeEntry {
for {
if x.left != nil {
x = x.left
} else {
return x
}
}
}
// GetParent looks for the node with supplied key and returns the parent node.
func (t *Tree) GetParent(key interface{}) (found bool, parent *NodeEntry, dir Direction) {
if err := mustBeValidKey(key); err != nil {
// logger.Printf("GetParent was prematurely aborted: %s\n", err.Error())
return false, nil, NODIR
}
if t.root == nil {
return false, nil, NODIR
}
t.lock.RLock()
defer t.lock.RUnlock()
return t.internalLookup(nil, t.root, key, NODIR)
}
func (t *Tree) internalLookup(parent *NodeEntry, this *NodeEntry, key interface{}, dir Direction) (bool, *NodeEntry, Direction) {
switch {
case this == nil:
return false, parent, dir
case t.cmp(key, this.Key) == 0:
return true, parent, dir
case t.cmp(key, this.Key) < 0:
return t.internalLookup(this, this.left, key, LEFT)
case t.cmp(key, this.Key) > 0:
return t.internalLookup(this, this.right, key, RIGHT)
default:
return false, parent, NODIR
}
}
// RotateRight Reverses actions of RotateLeft
func (t *Tree) RotateRight(y *NodeEntry) {
if y == nil {
// logger.Printf("RotateRight: nil arg cannot be rotated. Noop\n")
return
}
if y.left == nil {
// logger.Printf("RotateRight: y has nil left subtree. Noop\n")
return
}
// logger.Printf("\t\t\trotate right of %s\n", y)
x := y.left
y.left = x.right
if x.right != nil {
x.right.parent = y
}
x.parent = y.parent
if y.parent == nil {
t.root = x
} else {
if y == y.parent.left {
y.parent.left = x
} else {
y.parent.right = x
}
}
x.right = y
y.parent = x
}
// RotateLeft Reverses actions of RotateRight
// Side-effect: red-black tree properties is maintained.
func (t *Tree) RotateLeft(x *NodeEntry) {
if x == nil {
// logger.Printf("RotateLeft: nil arg cannot be rotated. Noop\n")
return
}
if x.right == nil {
// logger.Printf("RotateLeft: x has nil right subtree. Noop\n")
return
}
// logger.Printf("\t\t\trotate left of %s\n", x)
y := x.right
x.right = y.left
if y.left != nil {
y.left.parent = x
}
y.parent = x.parent
if x.parent == nil {
t.root = y
} else {
if x == x.parent.left {
x.parent.left = y
} else {
x.parent.right = y
}
}
y.left = x
x.parent = y
}
// Put saves the mapping (key, data) into the tree.
// If a mapping identified by `key` already exists, it is overwritten.
// Constraint: Not everything can be a key.
func (t *Tree) Put(node *NodeEntry) error {
node.parent, node.left, node.Next, node.right = nil, nil, nil, nil
key, data := node.Key, node.Value
if err := mustBeValidKey(key); err != nil {
// logger.Printf("Put was prematurely aborted: %s\n", err.Error())
return err
}
t.lock.Lock()
defer t.lock.Unlock()
if t.root == nil {
node.color = BLACK
t.root = node
// logger.Printf("Added %s as root node\n", t.root.String())
return nil
}
found, parent, dir := t.internalLookup(nil, t.root, key, NODIR)
if found {
if parent == nil {
// logger.Printf("Put: parent=nil & found. Overwrite ROOT node\n")
t.root.Value = data
} else {
// logger.Printf("Put: parent!=nil & found. Overwriting\n")
switch dir {
case LEFT:
parent.left.Value = data
case RIGHT:
parent.right.Value = data
}
}
} else {
if parent != nil {
node.parent = parent
newNode := node
switch dir {
case LEFT:
parent.left = newNode
case RIGHT:
parent.right = newNode
}
// logger.Printf("Added %s to %s node of parent %s\n", newNode.String(), dir, parent.String())
t.fixupPut(newNode)
}
}
return nil
}
func isRed(n *NodeEntry) bool {
key := reflect.ValueOf(n)
if key.IsNil() {
return false
}
return n.color == RED
}
// fix possible violations of red-black-tree properties
// with combinations of:
// 1. recoloring
// 2. rotations
//
// Preconditions:
// P1) z is not nil
//
// @param z - the newly added Node to the tree.
func (t *Tree) fixupPut(z *NodeEntry) {
// logger.Printf("\tfixup new node z %s\n", z.String())
loop:
for {
// logger.Printf("\tcurrent z %s\n", z.String())
switch {
case z.parent == nil:
fallthrough
case z.parent.color == BLACK:
fallthrough
default:
// When the loop terminates, it does so because p[z] is black.
// logger.Printf("\t\t=> bye\n")
break loop
case z.parent.color == RED:
grandparent := z.parent.parent
// logger.Printf("\t\tgrandparent is nil %t addr:%d\n", grandparent == nil, unsafe.Pointer(t))
if z.parent == grandparent.left {
// logger.Printf("\t\t%s is the left child of %s\n", z.parent, grandparent)
y := grandparent.right
// //logger.Printf("\t\ty (right) %s\n", y)
if isRed(y) {
// case 1 - y is RED
// logger.Printf("\t\t(*) case 1\n")
z.parent.color = BLACK
y.color = BLACK
grandparent.color = RED
z = grandparent
} else {
if z == z.parent.right {
// case 2
// logger.Printf("\t\t(*) case 2\n")
z = z.parent
t.RotateLeft(z)
}
// case 3
// logger.Printf("\t\t(*) case 3\n")
z.parent.color = BLACK
grandparent.color = RED
t.RotateRight(grandparent)
}
} else {
// logger.Printf("\t\t%s is the right child of %s\n", z.parent, grandparent)
y := grandparent.left
// logger.Printf("\t\ty (left) %s\n", y)
if isRed(y) {
// case 1 - y is RED
// logger.Printf("\t\t..(*) case 1\n")
z.parent.color = BLACK
y.color = BLACK
grandparent.color = RED
z = grandparent
} else {
// logger.Printf("\t\t## %s\n", z.parent.left)
if z == z.parent.left {
// case 2
// logger.Printf("\t\t..(*) case 2\n")
z = z.parent
t.RotateRight(z)
}
// case 3
// logger.Printf("\t\t..(*) case 3\n")
z.parent.color = BLACK
grandparent.color = RED
t.RotateLeft(grandparent)
}
}
}
}
t.root.color = BLACK
}
// Size returns the number of items in the tree.
func (t *Tree) Size() uint64 {
visitor := &countingVisitor{}
t.Walk(visitor)
return visitor.Count
}
// Has checks for existence of a item identified by supplied key.
func (t *Tree) Has(key interface{}) bool {
if err := mustBeValidKey(key); err != nil {
// logger.Printf("Has was prematurely aborted: %s\n", err.Error())
return false
}
found, _, _ := t.internalLookup(nil, t.root, key, NODIR)
return found
}
func (t *Tree) transplant(u *NodeEntry, v *NodeEntry) {
if u.parent == nil {
t.root = v
} else if u == u.parent.left {
u.parent.left = v
} else {
u.parent.right = v
}
if v != nil && u != nil {
v.parent = u.parent
}
}
// Delete removes the item identified by the supplied key.
// Delete is a noop if the supplied key doesn't exist.
func (t *Tree) Delete(key []byte) *NodeEntry {
if !t.Has(key) {
// logger.Printf("Delete: bail as no node exists for key %d\n", key)
return nil
}
_, z := t.getNode(key)
y := z
yOriginalColor := y.color
var x *NodeEntry
if z.left == nil {
// one child (RIGHT)
// logger.Printf("\t\tDelete: case (a)\n")
x = z.right
// logger.Printf("\t\t\t--- x is right of z")
t.transplant(z, z.right)
} else if z.right == nil {
// one child (LEFT)
// logger.Printf("\t\tDelete: case (b)\n")
x = z.left
// logger.Printf("\t\t\t--- x is left of z")
t.transplant(z, z.left)
} else {
// two children
// logger.Printf("\t\tDelete: case (c) & (d)\n")
y = t.getMinimum(z.right)
// logger.Printf("\t\t\tminimum of z.right is %s (color=%s)\n", y, y.color)
yOriginalColor = y.color
x = y.right
// logger.Printf("\t\t\t--- x is right of minimum")
if y.parent == z {
if x != nil {
x.parent = y
}
} else {
t.transplant(y, y.right)
y.right = z.right
y.right.parent = y
}
t.transplant(z, y)
y.left = z.left
y.left.parent = y
y.color = z.color
}
if yOriginalColor == BLACK {
t.fixupDelete(x)
}
return z
}
func (t *Tree) fixupDelete(x *NodeEntry) {
// logger.Printf("\t\t\tfixupDelete of node %s\n", x)
if x == nil {
return
}
loop:
for {
switch {
case x == t.root:
// logger.Printf("\t\t\t=> bye .. is root\n")
break loop
case x.color == RED:
// logger.Printf("\t\t\t=> bye .. RED\n")
break loop
case x == x.parent.right:
// logger.Printf("\t\tBRANCH: x is right child of parent\n")
w := x.parent.left // is nillable
if isRed(w) {
// Convert case 1 into case 2, 3, or 4
// logger.Printf("\t\t\tR> case 1\n")
w.color = BLACK
x.parent.color = RED
t.RotateRight(x.parent)
w = x.parent.left
}
if w != nil {
switch {
case !isRed(w.left) && !isRed(w.right):
// case 2 - both children of w are BLACK
// logger.Printf("\t\t\tR> case 2\n")
w.color = RED
x = x.parent // recurse up tree
case isRed(w.right) && !isRed(w.left):
// case 3 - right child RED & left child BLACK
// convert to case 4
// logger.Printf("\t\t\tR> case 3\n")
w.right.color = BLACK
w.color = RED
t.RotateLeft(w)
w = x.parent.left
}
if isRed(w.left) {
// case 4 - left child is RED
// logger.Printf("\t\t\tR> case 4\n")
w.color = x.parent.color
x.parent.color = BLACK
w.left.color = BLACK
t.RotateRight(x.parent)
x = t.root
}
}
case x == x.parent.left:
// logger.Printf("\t\tBRANCH: x is left child of parent\n")
w := x.parent.right // is nillable
if isRed(w) {
// Convert case 1 into case 2, 3, or 4
// logger.Printf("\t\t\tL> case 1\n")
w.color = BLACK
x.parent.color = RED
t.RotateLeft(x.parent)
w = x.parent.right
}
if w != nil {
switch {
case !isRed(w.left) && !isRed(w.right):
// case 2 - both children of w are BLACK
// logger.Printf("\t\t\tL> case 2\n")
w.color = RED
x = x.parent // recurse up tree
case isRed(w.left) && !isRed(w.right):
// case 3 - left child RED & right child BLACK
// convert to case 4
// logger.Printf("\t\t\tL> case 3\n")
w.left.color = BLACK
w.color = RED
t.RotateRight(w)
w = x.parent.right
}
if isRed(w.right) {
// case 4 - right child is RED
// logger.Printf("\t\t\tL> case 4\n")
w.color = x.parent.color
x.parent.color = BLACK
w.right.color = BLACK
t.RotateLeft(x.parent)
x = t.root
}
}
}
}
x.color = BLACK
}
// Walk accepts a Visitor
func (t *Tree) Walk(visitor Visitor) {
visitor.Visit(t.root)
}
// GetRoot get root node
func (t *Tree) GetRoot() *NodeEntry {
return t.root
}
// countingVisitor counts the number
// of nodes in the tree.
type countingVisitor struct {
Count uint64
}
// Visit .
func (v *countingVisitor) Visit(node *NodeEntry) {
if node == nil {
return
}
v.Visit(node.left)
v.Count = v.Count + 1
v.Visit(node.right)
}
// InorderVisitor walks the tree in inorder fashion.
// This visitor maintains internal state; thus do not
// reuse after the completion of a walk.
type InorderVisitor struct {
buffer bytes.Buffer
}
// Eq 比较
func (v *InorderVisitor) Eq(other *InorderVisitor) bool {
if other == nil {
return false
}
return v.String() == other.String()
}
func (v *InorderVisitor) trim(s string) string {
return strings.TrimRight(strings.TrimRight(s, "ed"), "lack")
}
// String returns string
func (v *InorderVisitor) String() string {
return v.buffer.String()
}
// Visit .
func (v *InorderVisitor) Visit(node *NodeEntry) {
if node == nil {
v.buffer.Write([]byte("."))
return
}
v.buffer.Write([]byte("("))
v.Visit(node.left)
v.buffer.Write([]byte(fmt.Sprintf("%s", node.Key))) // @TODO
// v.buffer.Write([]byte(fmt.Sprintf("%d{%s}", node.Key, v.trim(node.color.String()))))
v.Visit(node.right)
v.buffer.Write([]byte(")"))
}
// HookVisitor .
type HookVisitor struct {
Hook func(node *NodeEntry)
}
// Visit .
func (v *HookVisitor) Visit(node *NodeEntry) {
if node == nil {
return
}
v.Hook(node)
v.Visit(node.left)
v.Visit(node.right)
}
var (
// ErrorKeyIsNil the literal nil not allowed as keys
ErrorKeyIsNil = errors.New("the literal nil not allowed as keys")
// ErrorKeyDisallowed disallowed key type
ErrorKeyDisallowed = errors.New("disallowed key type")
)
// Allowed key types are: Boolean, Integer, Floating point, Complex, String values
// And structs containing these.
// @TODO Should pointer type be allowed ?
func mustBeValidKey(key interface{}) error {
if key == nil {
return ErrorKeyIsNil
}
/*keyValue := reflect.ValueOf(key)
switch keyValue.Kind() {
case reflect.Chan:
fallthrough
case reflect.Func:
fallthrough
case reflect.Interface:
fallthrough
case reflect.Map:
fallthrough
case reflect.Ptr:
return ErrorKeyDisallowed
default:
return nil
}*/
return nil
}
================================================
FILE: xmap/map_test.go
================================================
// Copyright (c) 2022 XDS project Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// XDS Project Site: https://github.com/heiyeluren
// XDS URL: https://github.com/heiyeluren/xds
//
package xmap
import (
"bytes"
"fmt"
"github.com/heiyeluren/xds"
"github.com/heiyeluren/xds/xmap/entry"
"github.com/heiyeluren/xmm"
"log"
"math/rand"
"net/http"
_ "net/http/pprof"
"os"
"reflect"
"runtime"
"strconv"
"strings"
"sync"
"sync/atomic"
"testing"
"time"
"unsafe"
// "xds/xmap/entry"
"github.com/spf13/cast"
)
type User struct {
Name int
Age int
Addr string
}
// mudi : 1001 -> 10000
// 1001 << 1 -> 10010
// 10010 & (1001 & 0)
func round(n uintptr) uintptr {
return (n << 1) & (0 & (n))
}
type mmanClass uint8
func makemmanClass(sizeclass uint8, noscan bool) mmanClass {
return mmanClass(sizeclass<<1) | mmanClass(bool2int(noscan))
}
func (sc mmanClass) sizeclass() int8 {
return int8(sc >> 1)
}
func (sc mmanClass) noscan() bool {
return sc&1 != 0
}
func bool2int(x bool) int {
// Avoid branches. In the SSA compiler, this compiles to
// exactly what you would want it to.
return int(uint8(*(*uint8)(unsafe.Pointer(&x))))
}
func Init() {
// 略
runtime.GOMAXPROCS(6) // 限制 CPU 使用数,避免过载
runtime.SetMutexProfileFraction(1) // 开启对锁调用的跟踪
runtime.SetBlockProfileRate(1) // 开启对阻塞操作的跟踪
go func() {
// 启动一个 http server,注意 pprof 相关的 handler 已经自动注册过了
if err := http.ListenAndServe(":6060", nil); err != nil {
log.Fatal(err)
}
os.Exit(0)
}()
<-time.After(time.Second * 10)
}
func Test_xmmanPool222(t *testing.T) {
// 同步扩容 680 异步扩容 551
fmt.Println(100000 / (4096 / 48))
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.6)
if err != nil {
t.Fatal(err)
}
var s unsafe.Pointer
sl, err := mm.AllocSlice(unsafe.Sizeof(s), 100000+1, 0)
if err != nil {
t.Fatal(err)
}
ssss := *(*[]unsafe.Pointer)(sl)
var start unsafe.Pointer
data := (*reflect.SliceHeader)(unsafe.Pointer(&ssss)).Data
var us []unsafe.Pointer
for i := 0; i < 100000; i++ {
p, err := mm.Alloc(unsafe.Sizeof(User{}))
if err != nil {
t.Fatal(err)
}
user := (*User)(p)
user.Age = i
user.Name = rand.Int()
us = append(us, p)
ssss = append(ssss, p)
if start == nil {
start = ssss[0]
}
}
if (*reflect.SliceHeader)(unsafe.Pointer(&ssss)).Data != data {
t.Fatal("扩容了")
}
fmt.Printf("sssssss %d %d\n ", start, ssss[0])
if ssss[0] != start {
t.Fatal("-")
}
for i, pointer := range us {
tep := (*User)(ssss[i])
if sss := (*User)(pointer); sss.Age != i || tep.Age != sss.Age {
t.Fatalf("%+v\n", pointer)
}
}
}
func TestPointer2(t *testing.T) {
tmp := make([]*User, 10000000)
us := &tmp
var wait sync.WaitGroup
wait.Add(80)
var sm sync.Map
for j := 0; j < 80; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 10000000; i++ {
key := cast.ToString(i + (z * 1000))
addr := (*unsafe.Pointer)(unsafe.Pointer(&(*us)[i]))
user := atomic.LoadPointer(addr)
if user == nil {
ut := &User{
Name: i,
Age: i,
Addr: key,
}
ptr := unsafe.Pointer(ut)
if atomic.CompareAndSwapPointer(addr, nil, ptr) {
sm.Store(i, uintptr(ptr))
}
}
}
}(j)
}
wait.Wait()
for i := 0; i < 10000000; i++ {
addr := (*unsafe.Pointer)(unsafe.Pointer(&(*us)[i]))
user := atomic.LoadPointer(addr)
u := (*User)(user)
if val, ok := sm.Load(i); !ok || val != uintptr(unsafe.Pointer(u)) {
t.Fatal(val, user, i, u)
}
}
}
func TestPointer(t *testing.T) {
tmp := make([]uintptr, 1000000)
var users []*User
us := &tmp
var wait sync.WaitGroup
wait.Add(80)
var sm sync.Map
for j := 0; j < 80; j++ {
go func(z int) {
defer wait.Done()
for i := 0; i < 100000; i++ {
key := cast.ToString(i + (z * 1000))
addr := &((*us)[i])
user := atomic.LoadUintptr(addr)
if user == 0 {
ut := &User{
Name: i,
Age: i,
Addr: key,
}
ptr := uintptr(unsafe.Pointer(ut))
if atomic.CompareAndSwapUintptr(addr, 0, ptr) {
users = append(users, ut)
sm.Store(i, ptr)
// fmt.Printf("i:%d ptr:%d\n", i, ptr)
}
}
}
}(j)
}
wait.Wait()
for i := 0; i < 100000; i++ {
addr := &((*us)[i])
user := atomic.LoadUintptr(addr)
u := (*User)(unsafe.Pointer(user))
if val, ok := sm.Load(i); !ok || val != user {
t.Fatal(val, user, i, u)
}
}
}
// todo CompareAndSwapPointer xuexi
func TestRBTree(t *testing.T) {
rbt := new(entry.Tree)
rbt.SetComparator(func(o1, o2 interface{}) int {
key1, key2 := o1.(string), o2.(string)
return strings.Compare(key1, key2)
})
num := 10000000
st := time.Now()
for i := 0; i < num/10; i++ {
key := cast.ToString(i)
ce := &entry.NodeEntry{
Value: []byte(key),
Key: []byte(key),
Hash: uint64(rand.Int()),
}
rbt.Put(ce)
}
for i := 0; i < num/10; i++ {
exist, node := rbt.Get([]byte(strconv.Itoa(i)))
if !exist || bytes.Compare(node, []byte(strconv.Itoa(i))) != 0 {
panic(i)
}
}
fmt.Println(rbt.Get([]byte(strconv.Itoa(5))))
fmt.Println(time.Now().Sub(st).Seconds())
rbt.Walk(&entry.HookVisitor{Hook: func(node *entry.NodeEntry) {
fmt.Println(node)
}})
}
func Test_NewDefaultConcurrentHashMap(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.6)
if err != nil {
t.Fatal(err)
}
chmp, err := NewDefaultConcurrentHashMap(mm, xds.Uintptr, xds.Uintptr)
if err != nil {
t.Fatal(err)
}
for i := 0; i < 10000000; i++ {
s := uintptr(i)
if err := chmp.Put(s, s); err != nil {
t.Error(err)
}
}
for i := 0; i < 10000000; i++ {
s := uintptr(i)
if val, exist, err := chmp.Get(s); err != nil || val != s || !exist {
t.Error("sss", err)
}
}
}
func TestXmap_ForEach(t *testing.T) {
f := &xmm.Factory{}
mm, err := f.CreateMemory(0.6)
if err != nil {
t.Fatal(err)
}
chmp, err := NewDefaultConcurrentHashMap(mm, xds.Uintptr, xds.Uintptr)
if err != nil {
t.Fatal(err)
}
for i := 0; i < 10000; i++ {
s := uintptr(i)
if err := chmp.Put(s, s); err != nil {
t.Error(err)
}
}
for i := 0; i < 10000; i++ {
s := uintptr(i)
if val, exist, err := chmp.Get(s); err != nil || val != s || !exist {
t.Error("sss", err)
}
}
i := 0
err = chmp.ForEach(func(key, val interface{}) error {
//fmt.Printf("ForEach key:%s value:%s \n", key, val)
i++
return nil
})
fmt.Println(i, chmp.Len())
if err != nil {
t.Error("sss", err)
}
}
================================================
FILE: xmap/xmap.go
================================================
// Copyright (c) 2022 XDS project Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// XDS Project Site: https://github.com/heiyeluren
// XDS URL: https://github.com/heiyeluren/xds
//
package xmap
import (
"github.com/heiyeluren/xds"
// "xds"
"github.com/heiyeluren/xmm"
)
// XMap is a map of maps.
// ------------------------------------------------
// 当做map[]来使用的场景
// 本套API主要是提供给把Xmap当做map来使用的场景
// ------------------------------------------------
// Xmap struct
type XMap struct {
chm *ConcurrentHashMap
}
// NewMap returns a new XMap.
// 初始化调用xmap生成对象
// mm 是XMM的内存池对象
// keyKind 是要生成 map[keyType]valType 中的 keyType
// valKind 是要生成 map[keyType]valType 中的 valType
// 说明:keyKind / valKind 都是直接调用xmap中对应的kind类型,必须提前初始化写入
//
// 本函数调用参考:
// 生成一个 map[int]string 数据结构,默认大小16个元素,占用了75%后进行map扩容
// m, err := xds.NewMapEx(mm, xmap.Int, xmap.String)
func NewMap(mm xmm.XMemory, keyKind xds.Kind, valKind xds.Kind) (*XMap, error) {
chm, err := NewDefaultConcurrentHashMap(mm, keyKind, valKind)
if err != nil {
return nil, err
}
return &XMap{chm: chm}, nil
}
// NewMapEx returns a new XMap.
// 初始化调用xmap生成对象 - 可扩展方法
// mm 是XMM的内存池对象
// keyKind 是要生成 map[keyType]valType 中的 keyType
// valKind 是要生成 map[keyType]valType 中的 valType
// 说明:keyKind / valKind 都是直接调用xmap中对应的kind类型,必须提前初始化写入
// capSize 是默认初始化整个map的大小,本值最好是 2^N 的数字比较合适(2的N次方);
// 这个值主要提升性能,比如如果你预估到最终会有128个元素,可以初始化时候设置好,这样Xmap不会随意的动态扩容(默认值是16),提升性能
// factSize 负载因子,当存放的元素超过该百分比,就会触发扩容;建议值是0.75 (75%),这就是当存储数据容量达到75%会触发扩容机制;
//
// 本函数调用参考:
// //生成一个 map[int]string 数据结构,默认大小256个元素,占用了75%后进行map扩容
// m, err := xds.NewMapEx(mm, xmap.Int, xmap.String, (uintptr)256, 0.75)
func NewMapEx(mm xmm.XMemory, keyKind xds.Kind, valKind xds.Kind, capSize uintptr, factSize float64) (*XMap, error) {
chm, err := NewConcurrentHashMap(mm, capSize, factSize, 8, keyKind, valKind)
if err != nil {
return nil, err
}
return &XMap{chm: chm}, nil
}
// Set 写入数据
func (xm *XMap) Set(key interface{}, val interface{}) (err error) {
return xm.chm.Put(key, val)
}
// Remove 删除数据
func (xm *XMap) Remove(key interface{}) (err error) {
return xm.chm.Del(key)
}
// Get 数据
func (xm *XMap) Get(key interface{}) (val interface{}, keyExists bool, err error) {
return xm.chm.Get(key)
}
// Each 遍历所有数据
func (xm *XMap) Each(f func(key, val interface{}) error) error {
return xm.chm.ForEach(f)
}
// Len 获取整个map的元素数量
func (xm *XMap) Len() uint64 {
return xm.chm.Len()
}
// RawMap - Hashmap
// ------------------------------------------------
// 当做原生Hash Map来使用场景
// 本套API主要是提供给把Xmap当做Hash表来使用的场景
// ------------------------------------------------
// 定义xmap的入口主结构
type RawMap struct {
chm *ConcurrentRawHashMap
}
// NewHashMap returns a new RawMap.
// 初始化调用xmap - hashmap 生成对象 mm 是XMM的内存池对象
func NewHashMap(mm xmm.XMemory) (*RawMap, error) {
chm, err := NewDefaultConcurrentRawHashMap(mm)
if err != nil {
return nil, err
}
return &RawMap{chm: chm}, nil
}
// Set 写入数据
func (xm *RawMap) Set(key []byte, val []byte) error {
return xm.chm.Put(key, val)
}
// Remove 删除数据
func (xm *RawMap) Remove(key []byte) error {
return xm.chm.Del(key)
}
// Get 数据
func (xm *RawMap) Get(key []byte) ([]byte, bool, error) {
return xm.chm.Get(key)
}
// Each 遍历所有数据
func (xm *RawMap) Each(f func(key, val []byte) error) error {
return xm.chm.ForEach(f)
}
// Len 获取整个map的元素数量
func (xm *RawMap) Len() uint64 {
return xm.chm.size
}
// The data structure and interface between xMAP and the bottom layer
// ------------------------------------------------
// xmap与底层交互的数据结构和接口
//
// 主要提供给上层xmap api调用,完成一些转换工作
// ------------------------------------------------
//底层交互数据结构(带有传入数据类型保存)
type ConcurrentHashMap struct {
keyKind xds.Kind
valKind xds.Kind
data *ConcurrentRawHashMap
}
// NewDefaultConcurrentHashMap 类似于make(map[keyKind]valKind)
// mm 内存分配模块
// keyKind: map中key的类型
// valKind: map中value的类型
func NewDefaultConcurrentHashMap(mm xmm.XMemory, keyKind, valKind xds.Kind) (*ConcurrentHashMap, error) {
return NewConcurrentHashMap(mm, 16, 0.75, 8, keyKind, valKind)
}
// NewConcurrentHashMap 类似于make(map[keyKind]valKind)
// mm 内存分配模块
// keyKind: map中key的类型
// cap:初始化bucket长度
// fact:负载因子,当存放的元素超过该百分比,就会触发扩容。
// treeSize:bucket中的链表长度达到该值后,会转换为红黑树。
// valKind: map中value的类型
func NewConcurrentHashMap(mm xmm.XMemory, cap uintptr, fact float64, treeSize uint64, keyKind, valKind xds.Kind) (*ConcurrentHashMap, error) {
chm, err := NewConcurrentRawHashMap(mm, cap, fact, treeSize)
if err != nil {
return nil, err
}
return &ConcurrentHashMap{keyKind: keyKind, valKind: valKind, data: chm}, nil
}
//Get
func (chm *ConcurrentHashMap) Get(key interface{}) (val interface{}, keyExists bool, err error) {
// k, err := chm.Marshal(chm.keyKind, key)
k, err := xds.RawToByte(chm.keyKind, key)
if err != nil {
return nil, false, err
}
valBytes, exists, err := chm.data.Get(k)
if err != nil {
return nil, exists, err
}
// ret, err := chm.UnMarshal(chm.valKind, valBytes)
ret, err := xds.ByteToRaw(chm.valKind, valBytes)
if err != nil {
return nil, false, err
}
return ret, true, nil
}
//Put
func (chm *ConcurrentHashMap) Put(key interface{}, val interface{}) (err error) {
// k, err := chm.Marshal(chm.keyKind, key)
k, err := xds.RawToByte(chm.keyKind, key)
if err != nil {
return err
}
// v, err := chm.Marshal(chm.valKind, val)
v, err := xds.RawToByte(chm.valKind, val)
return chm.data.Put(k, v)
}
//Del
func (chm *ConcurrentHashMap) Del(key interface{}) (err error) {
// k, err := chm.Marshal(chm.keyKind, key)
k, err := xds.RawToByte(chm.keyKind, key)
if err != nil {
return err
}
return chm.data.Del(k)
}
// ForEach 遍历所有key-vel对
func (chm *ConcurrentHashMap) ForEach(fun func(key, val interface{}) error) error {
return chm.data.ForEach(func(keyRaw, valRaw []byte) error {
key, err := xds.ByteToRaw(chm.keyKind, keyRaw)
if err != nil {
return err
}
val, err := xds.ByteToRaw(chm.valKind, valRaw)
if err != nil {
return err
}
return fun(key, val)
})
}
// Len 存储元素个数
func (chm *ConcurrentHashMap) Len() uint64 {
if chm.data == nil {
return 0
}
return chm.data.size
}
================================================
FILE: xslice/xslice.go
================================================
package xslice
import (
"errors"
"math"
"sync"
"github.com/heiyeluren/xds"
)
var InvalidType = errors.New("type Error") // 类型错误
type _gap []byte
const _blockSize int = 8
type Xslice struct{
s [][_blockSize]_gap //[]*uintptr 改为[]数组。数组内存放基本类型结构体和指针。string的话,存放指针。
//s []uintptr uintptr地址指向一个连续内存(数组)的头。
// s 的创建和扩容,通过xmm的alloc(元素个数*8)。迁移完后销毁。
// s 中的元素创建:通过xmm的alloc(元素个数*元素单位长度)。append到s中。
// 基本类型存放:int、uint、直接放入到s的元素中。
// 非基本类型存放:string、[]byte,先拷贝内存到xmm中,然后,将指针append到s的元素中。
lock *sync.RWMutex
sizeCtl int64 // -1 正在扩容
//游标位置
curRPos int //读光标
curWGapPos int //写gap光标
curWSlotPos int //写slot光标
_sizeof int //每个元素大小
_stype xds.Kind //类型
_len int //元素个数计数
_scap int //容量
}
//func NewXslice(mm xmm.XMemory,_type Kind,_cap int) * Xslice {
func NewXslice(_type xds.Kind,_cap int) *Xslice {
//计算分配slot数量,有余数会多分配一个
slotCap := float64(_cap % _blockSize)
var slotNum int64 = int64(math.Ceil(slotCap))
if slotNum <= 0{
slotNum = 1
}
slot := make([][8]_gap,slotNum,slotNum)
return &Xslice{
s: slot,
lock: new(sync.RWMutex),
_scap: _cap,
_stype: _type,
}
}
func(xs *Xslice) Append(v interface{}) (*Xslice,error) {
xs.lock.Lock()
defer xs.lock.Unlock()
//判断类型:基本copy进去。
// s中将要存放的uintptr拿到,uintptr为一个起始地址,加上一个index偏移量为写入地址。
var gapPos int64 = 0
slotCap := float64(xs.curWGapPos % _blockSize)
gapPos = int64(slotCap)
// 没有空位,扩容
if slotCap == 0 && xs.curWGapPos >= _blockSize{
newSlot := [_blockSize]_gap{}
xs.s = append(xs.s,newSlot)
xs.curWSlotPos += 1
}
b,err := xds.Marshal(xs._stype,v)
if err != nil{
return xs,err
}
xs.s[xs.curWSlotPos][gapPos] = b
xs.curWGapPos += 1
xs._len += 1
return xs,nil
}
func (xs *Xslice) Set(n int,v interface{}) error {
xs.lock.Lock()
defer xs.lock.Unlock()
var gapPos int64 = 0
slotCap := float64(n % _blockSize)
gapPos = int64(slotCap)
// 没有空位,扩容
if slotCap == 0 && xs.curWGapPos >= _blockSize{
newSlot := [_blockSize]_gap{}
xs.s = append(xs.s,newSlot)
xs.curWSlotPos += 1
}
b,err := xds.Marshal(xs._stype,v)
if err != nil{
return err
}
xs.s[xs.curWSlotPos][gapPos] = b
xs.curWGapPos += 1
xs._len += 1
return nil
}
func (xs *Xslice) Get(n int) (interface{}, error) {
xs.lock.Lock()
defer xs.lock.Unlock()
var gapPos int64 = 0
slotCap := float64(n % _blockSize)
gapPos = int64(slotCap)
b := xs.s[xs.curWSlotPos][gapPos]
v,err := xds.UnMarshal(xs._stype,b)
if err != nil{
return nil,err
}
return v,nil
}
func (xs *Xslice) Free () {
xs.lock.Lock()
xs.curWGapPos = 0
xs.curRPos = 0
xs._scap = 0
xs._sizeof = 0
xs._len = 0
xs.curWSlotPos = 0
xs.s = nil
xs.lock.Unlock()
}
func(xs *Xslice) ForEach(f func(i int, v interface{}) error) error{
xs.lock.Lock()
defer xs.lock.Unlock()
var c int = 0
for i,gaps := range xs.s {
for _, b := range gaps {
//判断坐标是否到头
if xs.curWSlotPos == i && xs.curWGapPos == c{
return nil
}
c = c + 1
v,err := xds.UnMarshal(xs._stype,b)
if err != nil{
return nil
}
if err := f(c,v);err != nil{
return err
}
}
}
return nil
}
//返回xslice长度
func (xs *Xslice) Len() int {
xs.lock.Lock()
defer xs.lock.Unlock()
return xs._len
}
//@todo 把扩容逻辑封装起来
func (xs *Xslice) increase() *Xslice {
return nil
}
================================================
FILE: xslice/xslice_test.go
================================================
package xslice
import (
"log"
"testing"
"github.com/heiyeluren/xds"
)
func TestNewXslice(t *testing.T) {
xs := NewXslice(xds.String,10)
log.Println(xs.s)
}
func TestXslice_Append(t *testing.T) {
xs2 := NewXslice(xds.Int,1)
log.Println(xs2.s)
for i:=0;i<=30;i++ {
xs2.Append(i)
}
log.Println(xs2.s)
}
func TestXslice_Set(t *testing.T) {
xs3 := NewXslice(xds.Int,1)
log.Println(xs3.s)
err := xs3.Set(1,123)
if err != nil{
panic(err)
}
log.Println(xs3.s)
}
func TestXslice_Get(t *testing.T) {
xs4 := NewXslice(xds.Int,1)
err := xs4.Set(1,123)
if err != nil{
panic(err)
}
v,err := xs4.Get(1)
if err !=nil{
panic(err)
}
log.Println(v)
}
func TestXslice_Free(t *testing.T) {
xs5 := NewXslice(xds.Int,1)
err := xs5.Set(1,123)
if err != nil{
panic(err)
}
log.Println(xs5)
xs5.Free()
log.Println(xs5)
}
func TestXslice_ForEach(t *testing.T) {
xs6 := NewXslice(xds.String,1)
xs6.Append("aaaa")
xs6.Append("bbb")
xs6.Append("cccc")
xs6.Append("cccc")
xs6.Append("cccc")
xs6.Append("cccc")
xs6.Append("cccc")
xs6.Append("cccc")
xs6.Append("cccc")
xs6.Append("eee")
xs6.ForEach(func(i int, v []byte) error {
log.Println("i: ",i, "v: ", string(v))
return nil
})
}
func TestXslice_Len(t *testing.T) {
xs8 := NewXslice(xds.Int,1)
log.Println(xs8.s)
err := xs8.Set(1,123)
if err != nil{
panic(err)
}
log.Println(xs8.s)
xs8.Set(2,123)
xs8.Set(3,123)
log.Println("len: ",xs8.Len())
}