Showing preview only (1,704K chars total). Download the full file or copy to clipboard to get everything.
Repository: hitzhangjie/golang-debugger-book
Branch: master
Commit: 061471090217
Files: 165
Total size: 1.0 MB
Directory structure:
gitextract_wz0yy6cs/
├── .cursor/
│ ├── commands/
│ │ ├── gg_catalogue.md
│ │ └── gg_commit.md
│ └── rules/
│ ├── rule-heading.mdc
│ ├── rule-summary.mdc
│ └── rule-translate.mdc
├── .github/
│ └── workflows/
│ ├── SETUP_GITHUB_ACTIONS.md
│ └── deploy.yml
├── .gitignore
├── .vscode/
│ ├── bookmarks.json
│ └── settings.json
├── Makefile
├── README.md
├── book/
│ ├── 10-extras/
│ │ ├── 1-development-of-debugger.md
│ │ ├── 2-development-of-logging.md
│ │ ├── 3-development-of-metrics.md
│ │ ├── 4-development-of-tracing.md
│ │ ├── 5-development-of-bisect.md
│ │ ├── 6-development-of-ebpf.md
│ │ ├── 7-development-of-replay.md
│ │ ├── 8-development-of-debug-dsys.md
│ │ ├── 9-ai-assisted-debugging.md
│ │ └── README.md
│ ├── 11-thanks/
│ │ └── README.md
│ ├── 12-appendix/
│ │ ├── 1-go-programme-start.md
│ │ ├── 2-auto-trace-cloned-threads.md
│ │ ├── 3-git-bisect.md
│ │ ├── 4-vscode-extension-bisect.md
│ │ ├── 80-go-tool-compile.md
│ │ ├── 81-go-tool-asm.md
│ │ ├── 82-go-tool-link.md
│ │ ├── 90-why-buildid-loaded.md
│ │ ├── 91-syntax-and-semantic-analysis.md
│ │ ├── 92-why-gdb-uses-symtab.md
│ │ └── README.md
│ ├── 2-preface/
│ │ └── README.md
│ ├── 3-terms/
│ │ └── README.md
│ ├── 4-basics/
│ │ ├── 1-purposes.md
│ │ ├── 2-dependencies.md
│ │ ├── 3-countertactics.md
│ │ └── README.md
│ ├── 5-debugger-skeleton/
│ │ ├── 1-debugger_skeleton.md
│ │ ├── 2-debugger_solution.md
│ │ ├── 3-debugger_solution_final.md
│ │ ├── 4-debugger_demos.md
│ │ └── README.md
│ ├── 6-develop-inst-debugger/
│ │ ├── 1-process_start.md
│ │ ├── 10-clearall-atexit.md
│ │ ├── 11-step.md
│ │ ├── 12-continue.md
│ │ ├── 13-pmem.md
│ │ ├── 14-pregs.md
│ │ ├── 15-set-mem.md
│ │ ├── 16-set-regs.md
│ │ ├── 2-process_attach.md
│ │ ├── 20-multithread/
│ │ │ ├── 1-trace_old_threads.md
│ │ │ ├── 2-trace_new_threads.md
│ │ │ ├── 3-suspend_policy.md
│ │ │ ├── 4-continue.md
│ │ │ ├── 5-breakpoint.md
│ │ │ └── README.md
│ │ ├── 21-multiprocess/
│ │ │ └── README.md
│ │ ├── 3-process_start_attach.md
│ │ ├── 4-debug-session.md
│ │ ├── 5-disassemble.md
│ │ ├── 6-breakpoint.md
│ │ ├── 7-breakpoints.md
│ │ ├── 8-clear.md
│ │ ├── 80-aslr.md
│ │ ├── 9-clearall.md
│ │ ├── 99-more.md
│ │ └── README.md
│ ├── 7-headto-sym-debugger/
│ │ ├── 1-how-go-build-works.md
│ │ ├── 2-elf.md
│ │ ├── 3-syms.md
│ │ ├── 4-syms-resolve-reloc.md
│ │ ├── 5-loading.md
│ │ ├── 6-gopkg-debug/
│ │ │ ├── 1-elf.md
│ │ │ ├── 2-gosym.md
│ │ │ ├── 3-dwarf.md
│ │ │ └── README.md
│ │ ├── 7-headto-dwarf/
│ │ │ ├── 1-gopkgs-about-dwarf.md
│ │ │ ├── 2-delve-into-internals.md
│ │ │ ├── 3-compiler-gen-dwarfdata.md
│ │ │ ├── 4-linker-gen-dwarfdata.md
│ │ │ ├── 5-headto-dwarf.md
│ │ │ └── README.md
│ │ └── README.md
│ ├── 8-dwarf/
│ │ ├── 1-history.md
│ │ ├── 2-overview.md
│ │ ├── 3-dwarfdata.md
│ │ ├── 4-die/
│ │ │ ├── 1-desc-data-type.md
│ │ │ ├── 2-desc-locations.md
│ │ │ ├── 3-desc-code.md
│ │ │ ├── 4-encoding.md
│ │ │ └── README.md
│ │ ├── 5-other/
│ │ │ ├── 1-accelerated-access.md
│ │ │ ├── 2-lineno-table.md
│ │ │ ├── 3-callframe-info.md
│ │ │ ├── 4-macro-info.md
│ │ │ ├── 5-varlen-data.md
│ │ │ ├── 6-shrink-data.md
│ │ │ ├── 7-elf-sections.md
│ │ │ └── README.md
│ │ ├── 6-practices.md
│ │ ├── 7-summary.md
│ │ └── README.md
│ ├── 9-develop-sym-debugger/
│ │ ├── 1-架构设计/
│ │ │ ├── 1-现代调试器架构.md
│ │ │ ├── 2-前端UI层设计.md
│ │ │ ├── 3-Service层设计.md
│ │ │ ├── 4-后端符号层设计.md
│ │ │ ├── 5-后端目标层设计.md
│ │ │ ├── 6-日志系统设计.md
│ │ │ └── README.md
│ │ ├── 2-核心调试逻辑/
│ │ │ ├── 00-cmds.md
│ │ │ ├── 01-debug-session.md
│ │ │ ├── 100-debug_goroutines.md
│ │ │ ├── 100-how_listfunctions_work.md
│ │ │ ├── 100-multi-threads.md
│ │ │ ├── 11-tinydbg_attach.md
│ │ │ ├── 12-tinydbg_attach_waitfor.md
│ │ │ ├── 13-tinydbg_exec.md
│ │ │ ├── 14-tinydbg_debug.md
│ │ │ ├── 15-tinydbg_core1.md
│ │ │ ├── 15-tinydbg_core2.md
│ │ │ ├── 16-tinydbg_connect.md
│ │ │ ├── 17-tinydbg_trace.md
│ │ │ ├── 19-how_evalexpr_works.md
│ │ │ ├── 20-how_locspec_works.md
│ │ │ ├── 21-debug_disassemble.md
│ │ │ ├── 22-debug_breakpoint_part1.md
│ │ │ ├── 23-debug_breakpoint_part2.md
│ │ │ ├── 24-debug_breakpoint_part3.md
│ │ │ ├── 25-debug_breakpoint_part4.md
│ │ │ ├── 26-debug_trace.md
│ │ │ ├── 27-debug_watch.md
│ │ │ ├── 28-debug_continue.md
│ │ │ ├── 29-debug_next.md
│ │ │ ├── 30-debug_step.md
│ │ │ ├── 31-debug_pmem.md
│ │ │ ├── 32-debug_regs.md
│ │ │ ├── 33-debug_funcs.md
│ │ │ ├── 34-debug_vars.md
│ │ │ ├── 35-debug_bt.md
│ │ │ └── README.md
│ │ ├── 3-高级功能扩展/
│ │ │ ├── 100-howto_integrate_starlark.md
│ │ │ ├── 101-howto_tracing_via_ebpf.md
│ │ │ ├── 102-howto_syntax_highlight.md
│ │ │ ├── 103-howto_paging_output.md
│ │ │ ├── 104-howto_read_separate_dwarfdata.md
│ │ │ ├── 105-howto_guess_substitutepath.md
│ │ │ ├── 106-howto_redirect_target_io.md
│ │ │ ├── 107-howto_customize_tinydbg.md
│ │ │ ├── 108-howto_accept_multiclient.md
│ │ │ ├── 109-howto_transcript_debugging.md
│ │ │ ├── 110-howto_debug_deterministically.md
│ │ │ ├── 111-howto-integrate-with-rr.md
│ │ │ └── README.md
│ │ └── README.md
│ ├── README.md
│ ├── SUMMARY.md
│ └── book.json
├── changelog.md
├── contributing.md
├── contributing.zh_CN.md
└── deploy.sh
================================================
FILE CONTENTS
================================================
================================================
FILE: .cursor/commands/gg_catalogue.md
================================================
# gg_catalogue
`/gg_catalogue` 是一个命令,用于更新目录操作(包括目录中的引用的文件路径以及显示的章节名称),需要执行以下步骤:
1. 确定当前有变更的文件列表(比如通过git status)
2. 如果是新增文件,记得在目录文件SUMMARY.md中添加对应的章节
3. 如果是删除文件,记得在目录文件SUMMARY.md中删除对应的章节
4. 如果是重命名文件,需要先确定旧文件的名称及SUMMARY.md中的章节名称,然后更新为新的文件名称及章节名称
## 注意事项
- 确保在更新目录前已经保存了所有文件变更
- 检查SUMMARY.md的格式是否正确
- 保持章节顺序的逻辑性和连贯性
This command will be available in chat with `/gg_catalogue`
================================================
FILE: .cursor/commands/gg_commit.md
================================================
# gg_commit
`/gg_commit [message]` is a command to commit staged changes to the repository.
## Usage
```bash
/gg_commit [message]
```
## Behavior
1. **With message provided**: Commits the staged changes with the provided message.
- Example: `/gg_commit Fix bug in debugger initialization`
2. **Without message**: Automatically generates a commit message by:
- Running `git diff --cached` to analyze staged changes
- Summarizing the changes into an appropriate commit message
- Committing with the generated message
## Workflow
1. Stage your changes using `git add` (if not already staged)
2. Run `/gg_commit` with or without a message
3. The command will create a commit with the appropriate message
## Notes
- Only commits staged changes (files added via `git add`)
- Does not push changes to remote repository
- Automatically generates meaningful commit messages when none provided
- Follows conventional commit message format when possible
This command will be available in chat with `/gg_commit`
================================================
FILE: .cursor/rules/rule-heading.mdc
================================================
---
description: 标题级别设置
globs: *.md
alwaysApply: true
---
文档起始标题统一设置为二级标题,即 `##`。
================================================
FILE: .cursor/rules/rule-summary.mdc
================================================
---
description: 本节小结应该如何写
globs: *.md
alwaysApply: true
---
本节小结是对当前章节核心内容的提炼,需帮助读者回顾重点、理清逻辑,并为后续内容做好铺垫。作用包括强化主要印象、梳理知识逻辑、解答潜在疑惑、预示下文方向、突出创新价值。
以下是个本节小结的示例:
```markdown
### 本节小结
本节主要探讨了{什么内容},核心内容包括:{要点1};{要点2};{要点3}。本节内容为读者学习{后续内容}打下了{基础}。
```
================================================
FILE: .cursor/rules/rule-translate.mdc
================================================
---
description: 文章翻译设置
globs: *.md
alwaysApply: true
---
当要求将文章内容翻译为中文时,或者要求对文章内容进行润色时,要注意:
- 避免生硬,要结合作者文风以及中国人的说话习惯,翻译为地道的中国普通话。
- 分段翻译,如果文章内容过长,可以逐一对段落进行翻译,也方便用户review译文或者润色后的质量。
- 特殊内容,如代码、代码注释、英文论文或者书籍名称、英文作者名称、链接地址等,不进行翻译。
- 专有名词,专业属于,翻译为中文时注意保留原英文,可以采取这样的格式 “译文(英文)”。
================================================
FILE: .github/workflows/SETUP_GITHUB_ACTIONS.md
================================================
# GitHub Actions 设置指南
## 快速开始
### 1. 选择工作流文件
根据你的需求选择合适的工作流文件:
**选项A:基础部署(推荐)**
```bash
# 使用基础版本,只部署到目标仓库
cp .github/workflows/deploy.yml .github/workflows/
```
**选项B:增强部署**
```bash
# 使用增强版本,包含GitHub Pages
cp .github/workflows/deploy-with-pages.yml .github/workflows/deploy.yml
```
### 2. 提交并推送
```bash
git add .github/workflows/
git commit -m "Add GitHub Actions for auto deployment"
git push origin main
```
### 3. 验证配置
1. 进入GitHub仓库页面
2. 点击 "Actions" 标签
3. 你应该能看到 "Auto Deploy GitBook" 工作流
4. 点击工作流查看详情
## 配置说明
### 触发条件
- **自动触发**:每次push到 `main` 或 `master` 分支
- **手动触发**:通过GitHub界面手动运行
### 目标仓库
工作流会将构建结果推送到:`https://github.com/hitzhangjie/debugger101.io`
### Docker镜像
使用你的自定义Docker镜像:`hitzhangjie/gitbook-cli:latest`
## 测试部署
### 方法1:推送测试
```bash
# 修改任意文件
echo "# Test" >> README.md
git add README.md
git commit -m "Test GitHub Actions deployment"
git push origin main
```
### 方法2:手动触发
1. 进入GitHub仓库的Actions页面
2. 选择 "Auto Deploy GitBook" 工作流
3. 点击 "Run workflow"
4. 选择分支并运行
## 监控部署
### 查看日志
1. 进入Actions页面
2. 点击最新的工作流运行
3. 查看每个步骤的详细日志
### 成功标志
- ✅ 所有步骤显示绿色
- 📤 目标仓库收到新的提交
- 🌐 GitHub Pages更新(如果使用增强版本)
## 故障排除
### 常见问题
**1. 权限错误**
```
Error: fatal: Authentication failed
```
**解决方案**:确保目标仓库存在且有推送权限
**2. Docker镜像错误**
```
Error: Unable to find image 'hitzhangjie/gitbook-cli:latest'
```
**解决方案**:确保Docker镜像已发布到Docker Hub
**3. GitBook构建失败**
```
Error: gitbook: command not found
```
**解决方案**:检查 `book/` 目录结构和 `book.json` 配置
### 获取帮助
如果遇到问题:
1. 查看GitHub Actions的详细日志
2. 检查目标仓库的权限设置
3. 验证Docker镜像是否可用
4. 确认GitBook配置正确
## 高级配置
### 自定义触发条件
编辑 `.github/workflows/deploy.yml` 中的 `on` 部分:
```yaml
on:
push:
branches: [ main, master ]
paths: [ 'book/**', '*.md' ] # 只监听特定文件变化
workflow_dispatch:
```
### 环境变量
如果需要使用私有仓库或自定义配置,可以添加环境变量:
```yaml
env:
TARGET_REPO: https://github.com/hitzhangjie/debugger101.io
DOCKER_IMAGE: hitzhangjie/gitbook-cli:latest
```
### 缓存优化
为了加快构建速度,可以添加缓存:
```yaml
- name: Cache node modules
uses: actions/cache@v3
with:
path: ~/.npm
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}
```
================================================
FILE: .github/workflows/deploy.yml
================================================
name: Auto Deploy GitBook
on:
push:
branches: [ main, master ]
workflow_dispatch: # 允许手动触发
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout source code
uses: actions/checkout@v4
- name: Build and Deploy GitBook
run: |
# 创建临时目录
tmpdir=$(mktemp -d)
builddir=$(mktemp -d)
# 清理函数
cleanup() {
rm -rf "$tmpdir" 2>/dev/null || true
rm -rf "$builddir" 2>/dev/null || true
}
trap cleanup EXIT
echo "🚀 Starting GitBook build and deployment..."
# 克隆目标仓库(使用带token的HTTPS URL)
echo "📥 Cloning target repository..."
git clone --depth 1 https://${{ secrets.DEPLOY_TOKEN }}@github.com/hitzhangjie/debugger101.io $tmpdir
# 使用Docker构建GitBook
echo "🔨 Building GitBook with Docker..."
docker run --name gitbook --rm \
-v ${PWD}:/root/gitbook \
-v $builddir:$builddir \
hitzhangjie/gitbook-cli:latest \
bash -c "cd book && gitbook install && cd - && gitbook build book $builddir"
# 复制构建结果到目标目录
echo "📋 Copying build results..."
cp -rf $builddir/* $tmpdir/
# 提交更改
echo "💾 Committing changes..."
cd $tmpdir
git config --local user.name "hitzhangjie"
git config --local user.email "hit.zhangjie@gmail.com"
git add .
git commit -m "Auto-deploy: $(date)"
# 使用 URL 重写方式推送,避免写入凭证文件
git remote set-url origin https://${{ secrets.DEPLOY_TOKEN }}@github.com/hitzhangjie/debugger101.io
git push -f -u origin master
cd -
echo "✅ Deployment completed successfully!"
================================================
FILE: .gitignore
================================================
**/.DS_Store
**/_book/
**/node_modules/
debugger101.io
================================================
FILE: .vscode/bookmarks.json
================================================
{}
================================================
FILE: .vscode/settings.json
================================================
{
"makefile.configureOnOpen": false,
"explorer.sortOrder": "mixed",
"files.exclude": {
"**/book.en": true
},
"explorer.sortOrderReverse": false,
"editor.detectIndentation": false,
"markdown.validate.enabled": true
}
================================================
FILE: Makefile
================================================
chineseWordsCnt := $(shell find book -iname "*.md" -print0 | grep -z -v _book | grep -z -v node_modules | wc -m --files0-from - | tail -n 1 | cut -f1)
#englishWordsCnt := $(shell find book.en -iname "*.md" -print0 | grep -z -v zh_CN | grep -z -v _book | grep -z -v node_modules | wc -m --files0-from - | tail -n 1 | cut -f1)
deploy := https://github.com/hitzhangjie/debugger101.io
tmpdir := /tmp/debugger101.io
book := book
.PHONY: english chinese stat clean deploy
PWD := $(shell pwd -P)
# english:
# rm -rf book.en/_book
# #gitbook install book.en
# #gitbook serve book.en
# docker run --name gitbook --rm -v ${PWD}/book.en:/root/gitbook hitzhangjie/gitbook-cli:latest gitbook install .
# docker run --name gitbook --rm -v ${PWD}/book.en:/root/gitbook -p 4000:4000 -p 35729:35729 hitzhangjie/gitbook-cli:latest gitbook serve .
chinese:
rm -rf book/_book
# #gitbook install book
# #gitbook serve book
docker run --name gitbook --rm -v ${PWD}/book:/root/gitbook hitzhangjie/gitbook-cli:latest gitbook install .
docker run --name gitbook --rm -v ${PWD}/book:/root/gitbook -p 4000:4000 -p 35729:35729 hitzhangjie/gitbook-cli:latest gitbook serve .
# pdfchinese:
# @echo "Warn: must do it mannually so far for lack of proper docker image,"
# @echo "- install 'calibre' first (see https://calibre-ebook.com/download),"
# @echo "- make sure 'ebook-convert' could be found in envvar 'PATH',"
# @echo " take macOS for example:"
# @echo " run 'sudo ln -s /Applications/calibre.app/Contents/MacOS/ebook-convert /usr/bin'."
# @echo "- run 'gitbook pdf <book> <book.pdf>'"
# @echo ""
stat:
@echo "Chinese version, words: ${chineseWordsCnt}"
# @echo "English version, words: ${englishWordsCnt}"
clean:
rm -rf book/_book
# #rm -rf book.en/_book
# #rm -rf ./node_modules
deploy:
./deploy.sh
================================================
FILE: README.md
================================================
# The Art of Debugging: Go Debugger Internals
Ever wondered how to develop a Go debugger? Curious about how debuggers work under the hood? This book provides comprehensive insights into these topics. Read the Chinese version online at: https://www.hitzhangjie.pro/debugger101.io/
> English version available at: https://www.hitzhangjie.pro/debugger101-en.io/
> And the repo: https://github.com/hitzhangjie/golang-debugger-book-en .
<p align="center">
<img alt="" src="./book/bookcover.jpeg" width="360px" />
</p>
## Introduction
This project delves into the development of a Go debugger, exploring various aspects including:
- Operating System support mechanisms
- Coordination between compiler, linker, and debugger
- Debugging information standards
- How to develop an instruction level debugger
- How to develop an symbolic level debugger
- How does the mordern debugger architect looks like
- How do to debug in modern software development
- And much more
Special thanks to [delve](https://github.com/go-delve/delve) and its author [derek parker](https://twitter.com/derkthedaring?lang=en), maintainer [aarzilli](https://github.com/aarzilli), along with all contributors. Their work has been instrumental in my learning journey, and I'm excited to share this knowledge with developers interested in debugging.
Developing a symbolic debugger requires a deep understanding of:
- Operating Systems (e.g., Linux ptrace and OS scheduler)
- CPU semantics, instructions (e.g., instruction patching), hardware breakpoints register, eflags
- Compilers, linkers, and loaders, and the debugger? How do they work together to help debugging
- Executable file formats and debugging information storage
- The description of different languages features, data, types on different OS, Archs
- Programming language-specific features (e.g., goroutines)
This project serves as an excellent opportunity to enhance your understanding of computer systems and their underlying technologies.
## Sample Code
The project includes a companion repository "**[golang-debugger-lessons](https://github.com/hitzhangjie/golang-debugger-lessons)**" containing sample code that corresponds to each chapter. The "[**0-godbg**](https://github.com/hitzhangjie/godbg)" directory provides a complete implementation of a insctruction-level debugger for Go."[**tinydbg**](https://github.com/hitzhangjie/tinydbg/tree/tinydbg_minimal)" repository is a [go-delve/delve](https://github.com/go-delve/delve) fork and simplified version for **Linux/Amd64** to help you quickly understand the core concepts and code.
While established debuggers like GDB and Delve exist for Go, developing a debugger from scratch serves as an excellent learning exercise. It not only helps understand how the debugger works, but also helps integrate knowledge across various domains:
- Go language internals (type system, goroutine scheduling)
- Go commandline utities development, especially uses spf13/cobra
- System level programming, understand how build toolchain works, how kernel works, how CPU works
- Go ebpf tracing utilities programming
- Operating system kernel concepts (virtual memory, task scheduling, system calls, instruction patching)
- etc.
> Perhaps more than understanding how debuggers work, deepening my knowledge of Computer Systems was the fundamental motivation behind writing this book. And, I wish this book could help more readers, too.
## Reading Locally
The book follows GitBook's structure, but since gitbook-cli is deprecated, we offer two methods to read the book locally:
### Using Docker (Recommended)
```bash
# For English version
rm book/_book
docker run --name gitbook --rm -v ${PWD}/book:/root/gitbook hitzhangjie/gitbook-cli:latest gitbook install .
docker run --name gitbook --rm -v ${PWD}/book:/root/gitbook -p 4000:4000 -p 35729:35729 hitzhangjie/gitbook-cli:latest gitbook serve .
```
For convenience, these commands are available in the Makefile - simply run `make english` to start the server.
### Using Legacy gitbook-cli
1. Clone the repository:
```bash
git clone https://github.com/hitzhangjie/golang-debugger-book-en
```
2. Serve the book:
```bash
cd book
gitbook install && gitbook serve
```
> Note: Installing gitbook-cli directly may encounter compatibility issues with recent Node.js and graceful-fs versions. To avoid these issues, we recommend using our Docker image `hitzhangjie/gitbook-cli:latest` instead of npm or homebrew installation.
## Contact
For any questions or feedback, please email me at **hit.zhangjie@gmail.com**. I'll respond as soon as possible.
### License
<a rel="license" href="http://creativecommons.org/licenses/by-nd/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nd/4.0/88x31.png" /></a><br/>
This work is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by-nd/4.0/">Creative Commons Attribution-NoDerivatives 4.0 International License </a>.
================================================
FILE: book/10-extras/1-development-of-debugger.md
================================================
## 软件调试器的发展历程
### 1. 调试器诞生的问题背景
软件开发从诞生之初便伴随着错误和缺陷。早期的程序员在面对程序错误时,往往依靠最原始的方法:通过打印语句输出变量值,或在关键节点插入输出语句来观察程序的执行流程。这种方法不仅效率低下,还常常无法准确定位复杂问题。
20世纪40年代末至50年代初,当第一批电子计算机开始运行时,程序员面临着极大的挑战:
* 编写的程序直接在硬件层面运行,与现代高级语言相比抽象程度极低
* 计算资源极为有限,每一次程序运行都是宝贵的计算时间
* 没有操作系统的辅助,程序错误常常导致整个系统崩溃
* 调试工具几乎不存在,程序员需要通过记忆和纸笔记录程序状态
在这样的背景下,一个能够控制程序执行流程、检查内存和寄存器状态、动态修改变量值的工具变得至关重要。这就是调试器出现的历史必然性。
### 2. 调试器的技术演进
#### 早期的硬件调试手段(1940s-1950s)
最早的"调试"并非软件概念,而是源于硬件故障修复。传说中的"bug"一词起源于1947年,当时计算机先驱Grace Hopper在Harvard Mark II计算机中发现了一只导致系统故障的飞蛾。工程师们实际使用的调试手段包括:
* **控制面板指示灯** :通过观察指示灯的状态来判断程序执行情况
* **打孔纸带** :在纸带上标记执行流程,用于事后分析
* **示波器** :观察信号波形来判断程序行为
#### 早期软件调试器(1960s-1970s)
随着编程语言的发展,真正意义上的软件调试器开始出现:
* **DDT (Dynamic Debugging Technique/Tool)** : 1961年在PDP系列计算机上开发的早期调试工具,允许程序员检查和修改内存
* **断点设置** :首次允许程序员在程序特定位置停止执行,检查内存状态
* **IBM的TSS/360调试器** :引入了更多交互式调试功能
这一时期的重大突破是从"事后分析"转向"交互式调试",程序员首次可以在程序运行过程中观察和控制程序行为。
#### 符号级调试器(1970s-1980s)
这一阶段的主要突破在于调试器开始理解源代码和符号,不再局限于机器码层面:
* **Source-level debugging** :调试器可以显示源代码而非汇编代码
* **UNIX's sdb和dbx** :引入了更强大的符号级调试功能
* **Symbolic debugger** :可以使用变量名而非内存地址
这些进步极大地提高了调试效率,使程序员可以在熟悉的源代码环境中进行调试。
#### 图形界面调试器(1980s-1990s)
个人计算机时代带来了图形界面的普及,调试器也随之进化:
* **Borland的Turbo Debugger** :提供了友好的蓝色界面,成为一代经典
* **Microsoft的Visual Studio Debugger** :集成在IDE中,提供了可视化的调试体验
* **GDB与DDD** :GDB作为命令行调试器的标准,DDD为其提供图形前端
图形界面极大地降低了调试的门槛,使更多程序员能够有效利用调试工具。
#### 分布式和远程调试(1990s-2000s)
随着网络应用的兴起,调试工具开始适应分布式环境:
* **远程调试协议** :允许调试器连接到远程运行的程序
* **JPDA (Java Platform Debugger Architecture)** :为Java引入标准化的调试架构
* **Web开发者工具** :浏览器中的JavaScript调试器的出现
#### 现代调试技术(2000s-2010s)
* **时间旅行调试(Time-Travel Debugging)** :允许开发者"倒回"程序执行过程
* **硬件辅助调试** :现代处理器提供硬件断点和性能计数器
* **自动化调试** :结合静态分析和动态执行信息自动定位错误
### 3. 分布式系统与云原生时代的调试挑战
#### 微服务架构下的调试难点
现代应用从单体架构转向微服务,带来了全新的调试挑战:
* **服务边界问题** :错误可能发生在服务之间的交互中,而非单一服务内部
* **请求跟踪困难** :一个用户请求可能穿越数十个微服务,难以跟踪完整路径
* **环境一致性** :开发、测试和生产环境差异导致"在我这里能运行"的问题
* **异步通信** :基于消息队列的通信使得调试序列难以重现
#### 云原生环境的挑战
* **容器化应用** :容器的短暂性和不可变性使传统调试模式难以应用
* **Kubernetes复杂性** :Pod的调度和生命周期管理增加了调试的复杂度
* **多云部署** :跨云服务提供商的应用调试需要统一的工具和方法
#### 解决方案与发展方向
现代分布式调试正在向以下方向发展:
1. **分布式追踪系统** :
* OpenTelemetry统一标准
* Jaeger、Zipkin等开源工具的普及
* 端到端请求可视化
1. **可观察性三支柱** :
* 日志(Logs):结构化日志和集中式日志分析
* 指标(Metrics):实时系统性能监控
* 追踪(Traces):分布式请求路径跟踪
1. **服务网格** :
* Istio、Linkerd等提供的流量管理和可观察性
* 边车模式(Sidecar)简化了服务间通信的监控
1. **混沌工程** :
* 通过故意引入故障来提前发现系统弱点
* Netflix的Chaos Monkey等工具的应用
### 4. AI时代调试器的发展方向
人工智能正在深刻改变软件开发的各个环节,调试领域也不例外:
#### 智能根因分析
* 利用机器学习模型分析历史故障数据,预测当前错误的可能原因
* 自动关联分布式系统中的异常事件,找出因果关系
* 智能优先级排序,识别最可能导致当前症状的错误
#### 自然语言交互式调试
* 开发者可以用自然语言描述问题:"为什么用户A无法登录?"
* AI助手可以检索相关日志、追踪信息,并给出人类可理解的解释
* 大型语言模型(LLM)辅助生成调试策略和修复建议
#### 预测性调试
* 基于代码变更自动识别潜在风险区域
* 在问题发生前预警可能的性能瓶颈或资源耗尽
* 智能测试生成,针对高风险区域自动构建测试用例
#### 自动化修复
* AI系统提出可能的补丁并验证其正确性
* 对于常见模式的错误,自动应用已知修复方案
* 持续学习系统,从每次修复中改进修复策略
#### 程序合成与调试结合
* 使用程序合成技术自动生成符合规范的代码替代有缺陷的部分
* 通过反向工程理解程序员意图,提供更符合原始设计的修复
### 5. 软件Bug的教训
#### 航天领域的教训
##### 火星气候轨道器失败(1999年)
美国宇航局(NASA)的火星气候轨道器(Mars Climate Orbiter)价值1.25亿美元,在接近火星进入轨道时失去了联系。经调查发现,地面控制软件使用英制单位(磅-力秒),而飞行器的软件期望使用公制单位(牛顿秒)。这个单位换算问题导致轨道器进入大气层的角度错误,最终坠毁。
教训:单元测试和集成测试的重要性,以及明确定义和验证系统接口的必要性。
##### 阿丽亚娜5号爆炸(1996年)
欧洲航天局的阿丽亚娜5号火箭在首次发射40秒后爆炸,损失约5亿美元。故障原因是软件试图将64位浮点数转换为16位有符号整数,导致溢出。令人讽刺的是,涉及错误的代码实际上对阿丽亚娜5号来说是多余的,它是从阿丽亚娜4号火箭复制过来的。
教训:软件重用时必须验证新环境下的适用性,以及硬件限制下的软件边界条件测试的重要性。
#### 金融领域的教训
##### 奈特资本的破产(2012年)
华尔街交易公司Knight Capital因软件部署错误,在45分钟内损失了4.6亿美元,最终导致公司破产。一名工程师忘记将新代码复制到8台服务器中的一台,导致旧系统和新系统混合运行,触发了数百万个错误的交易订单。
教训:自动化部署流程的重要性,以及对关键系统进行全面验证的必要性。
#### 医疗设备的教训
##### Therac-25放射治疗事故(1985-1987年)
Therac-25是一款用于癌症放射治疗的机器,由于软件错误导致至少6名患者接受了过量辐射,其中3人死亡。问题出在竞态条件和操作员界面设计缺陷上,使得致命的高能射线在不应该被激活的情况下被触发。
教训:关键安全系统中的代码审查和严格测试的重要性,以及用户界面设计如何影响系统安全。
#### 通信行业的教训
##### AT&T网络崩溃(1990年)
1990年1月15日,AT&T的长途电话网络崩溃9小时,影响了美国约7,000万电话用户。故障原因是一个软件更新中的小错误:一条switch语句中的break语句被错误地放置,导致在特定条件下系统重启,进而触发连锁反应。
教训:关键基础设施中的变更管理的重要性,以及代码审查流程的严格性。
### 6. 总结
调试技术的发展历程反映了软件工程本身的进化。从最初的硬件调试到现代AI辅助调试,每一次技术变革都在解决特定时代的挑战:
1. **早期阶段** 解决了程序可视化和控制的基本问题
2. **符号调试器** 使调试更加人性化,贴近源代码
3. **图形界面** 降低了调试工具的使用门槛
4. **分布式调试** 适应了网络应用的复杂需求
5. **云原生调试** 应对现代微服务架构的挑战
6. **AI辅助调试** 正在解决规模和复杂度不断增长的软件系统问题
软件调试不仅是一项技术活动,更是软件质量的最后防线。正如历史上许多灾难性的软件故障所示,一个看似微小的bug可能导致巨大的经济损失,甚至危及生命。在AI时代,调试工具将继续演化,但其核心目标始终不变:帮助开发者理解程序行为,及时发现并修复错误,确保软件系统的可靠性和安全性。
随着软件继续渗透到人类生活的各个方面,高效的调试工具和方法将变得比以往任何时候都更加重要。未来的调试技术将更加智能、更加自动化,但也将需要开发者具备更全面的系统思维和更深入的技术理解,才能充分发挥这些工具的潜力。
================================================
FILE: book/10-extras/2-development-of-logging.md
================================================
## 软件日志系统的发展历程
### 1. 打日志诞生的问题背景
软件日志系统的起源可以追溯到计算机系统诞生的早期。在计算机技术发展初期,程序员们面临着一个共同的困境:如何有效地监控和调试程序执行过程。当时的程序调试主要依靠打印语句,程序员手动在代码中插入打印语句,输出变量值和执行流程信息,以此来追踪程序执行路径和定位错误。
这种原始方法存在诸多问题:
* **代码侵入性强** :调试代码与业务逻辑混杂在一起
* **难以管理** :调试完成后需要手动删除或注释这些打印语句
* **缺乏标准化** :不同开发者使用不同的打印格式和方法
* **难以在生产环境中应用** :无法动态控制日志输出级别和目标
随着软件系统规模的不断扩大和复杂性的增加,这些问题变得越来越突出。开发者们迫切需要一种系统化、标准化的方法来记录程序运行信息,以便于问题定位和系统监控。这种需求催生了专门的日志系统。
### 2. 日志系统的发展历程
#### 2.1 早期系统日志
Unix系统的syslog是最早的系统化日志解决方案之一,诞生于1980年代。它提供了一个集中的日志记录机制,允许应用程序将日志信息发送到系统日志守护进程,由该进程统一处理和存储日志信息。syslog引入了日志级别和设施的概念,实现了日志的分类和筛选功能。
#### 2.2 应用级日志框架的出现
1990年代末至2000年代初,随着面向对象编程的普及,专门的应用级日志框架开始出现:
* **Log4j (1999)** : Apache Log4j是Java平台上最早的专业日志框架之一,由Ceki Gülcü开发。它引入了日志级别、日志分类和可配置的日志输出目标等概念,奠定了现代日志框架的基础。
* **SLF4J (2005)** : 简单日志门面(Simple Logging Facade for Java)提供了一个抽象层,使应用程序可以使用各种日志实现,而不需要更改代码。
* **各语言的日志框架** : Python的logging模块、.NET的log4net、C++的log4cpp等,不同编程语言平台都开发了自己的日志框架。
#### 2.3 日志系统的重大教训与突破
##### Log4Shell漏洞事件(2021)
2021年12月,Log4j中的一个严重安全漏洞(CVE-2021-44228)震惊了整个技术界。这个被称为"Log4Shell"的漏洞允许攻击者通过向使用Log4j的应用程序发送特制的消息,执行任意代码。这一事件凸显了日志系统安全性的重要性,并导致了对日志框架安全设计的重新审视。
##### 结构化日志的兴起
随着数据处理技术的发展,传统的纯文本日志逐渐显露出局限性。结构化日志(如JSON格式)的出现使日志信息更易于机器处理和分析,成为现代日志系统的一个重要突破。
### 3. 分布式系统时代的日志挑战与解决方案
#### 3.1 分布式系统的日志挑战
随着互联网规模的扩大,单体应用逐渐演变为分布式系统和微服务架构,日志系统面临的挑战也随之变化:
* **日志收集与聚合** :分散在多个节点的日志需要集中收集和处理
* **分布式跟踪** :单个请求可能跨越多个服务,需要跟踪完整的请求路径
* **海量数据处理** :日志数据量呈爆炸式增长,对存储和处理能力提出挑战
* **实时分析需求** :需要从海量日志中快速提取有价值的信息
#### 3.2 ELK/EFK Stack
为应对这些挑战,一系列专门的日志收集、处理和分析工具应运而生,其中最具代表性的是ELK堆栈:
* **Elasticsearch** :分布式搜索引擎,提供高效的日志存储和查询能力
* **Logstash** :日志收集和处理管道
* **Kibana** :数据可视化和分析平台
* **Beats(后加入)** :轻量级日志收集代理
#### 3.3 分布式追踪系统
为解决分布式系统中的请求跟踪问题,专门的分布式追踪系统被开发出来:
* **Google Dapper (2010)** :Google发表的分布式追踪系统论文,奠定了现代分布式追踪的理论基础
* **Zipkin, Jaeger** :受Dapper启发的开源实现
* **OpenTelemetry** :统一的可观测性框架,整合了分布式追踪、度量和日志
### 4. 云原生时代的日志系统
#### 4.1 云原生环境的特点与挑战
云原生时代的特点包括容器化、动态编排、短暂性实例等,这给日志系统带来了新的挑战:
* **短暂性实例的日志保存** :容器可能随时启动或销毁,其本地日志也会随之消失
* **动态扩缩容** :日志收集系统需要适应动态变化的服务实例数量
* **多租户环境** :需要隔离不同租户的日志数据
* **自动化与可观测性** :需要与自动化运维系统集成,提供全面的可观测性
#### 4.2 云原生日志解决方案
为应对这些挑战,云原生日志解决方案应运而生:
* **Sidecar模式** :在每个应用容器旁边部署专门的日志收集容器
* **Fluentd/Fluent Bit** :轻量级、云原生友好的日志收集器
* **Loki** :Grafana开发的轻量级日志聚合系统,专为Kubernetes设计
* **Vector** :高性能、可扩展的日志处理系统
#### 4.3 可观测性三支柱的融合
在云原生环境中,日志、指标和追踪这三大可观测性支柱开始融合,形成统一的可观测性解决方案:
* **统一的数据模型** :OpenTelemetry提供了统一的数据收集和处理标准
* **关联分析** :将日志、指标和追踪数据关联起来,提供全面的系统视图
* **AIOps的兴起** :利用人工智能技术对可观测性数据进行智能分析
### 5. 人工智能时代的日志系统展望
随着人工智能技术的快速发展,日志系统正在经历新一轮的变革:
#### 5.1 AI增强的日志分析
* **异常检测** :使用机器学习算法自动识别日志中的异常模式
* **根因分析** :AI可以分析各种日志和指标数据,自动推断问题的根本原因
* **预测性维护** :基于历史日志数据预测潜在的系统故障
* **自然语言处理** :允许工程师使用自然语言查询日志数据
#### 5.2 自适应日志系统
* **智能采样** :根据上下文重要性动态调整日志详细程度
* **自优化存储** :智能决定哪些日志需要长期保存,哪些可以压缩或归档
* **上下文感知** :根据系统状态自动调整日志级别和内容
#### 5.3 大型语言模型(LLM)与日志分析
* **日志总结与理解** :LLM可以将复杂的日志数据总结为人类可理解的叙述
* **智能问答** :开发人员可以直接向系统询问有关日志的问题
* **代码与日志关联** :将日志与源代码关联,自动提供修复建议
#### 5.4 隐私与合规的智能处理
* **自动敏感数据识别** :AI可以识别并处理日志中的敏感个人信息
* **智能合规监控** :确保日志处理符合GDPR、CCPA等隐私法规
### 6. 总结与展望
软件日志系统从最初的简单打印语句,发展到今天的复杂分布式可观测性平台,经历了巨大的变革。每个阶段的变化都是为了应对当时软件架构和规模带来的新挑战。
回顾这一发展历程,我们可以看到几个关键趋势:
1. **从简单到复杂** :日志系统已从简单的文本记录发展为完整的可观测性解决方案
2. **从孤立到集成** :日志系统与监控、追踪等其他系统日益融合
3. **从被动到主动** :从被动记录信息到主动分析和预警
4. **从人工到智能** :从人工分析日志到AI辅助和自动化分析
未来,随着人工智能技术的进一步发展和软件系统复杂度的不断提高,日志系统将继续演进。我们可以期待看到更加智能、自适应的日志系统,它们不仅能记录发生了什么,还能理解为什么发生,甚至预测将要发生什么,成为软件系统可靠性和安全性的重要保障。
在这个过程中,日志系统将不再只是一个技术工具,而是成为连接开发、运维和业务的桥梁,为整个软件生命周期提供关键的数据支持和决策依据。
================================================
FILE: book/10-extras/3-development-of-metrics.md
================================================
## 软件监控指标系统的发展历程
### 1. 监控打点诞生的问题背景
在软件系统的早期发展阶段,工程师们面临着一个普遍的困境:当系统出现故障时,往往难以快速定位问题所在。这种情况就像是在黑暗中摸索,没有有效的工具来指引方向。
最初的故障排查方法相当原始:开发人员通过查看日志文件,或者在代码中插入打印语句来观察系统行为。然而,随着系统规模的扩大,这种方法变得越来越低效。特别是当面对生产环境中的问题时,这些方法往往会造成滞后的问题诊断,导致严重的服务中断和业务损失。
监控打点(instrumentation)正是在这样的背景下应运而生。它的核心理念是在系统的关键位置埋入"探针",实时收集系统运行状态的数据,从而使工程师能够:
* 实时了解系统的健康状况
* 在问题发生时快速定位根源
* 通过历史数据分析系统行为模式
* 预测潜在的风险并提前采取措施
监控指标系统的诞生,标志着软件工程从被动响应向主动预防的重要转变,为现代高可用系统奠定了基础。
### 2. 指标系统从诞生到现在的技术演进
#### 早期:简单计数器和日志分析
最初的监控系统非常简单,主要依赖于:
* 基本计数器:记录请求次数、错误次数等简单数值
* 日志分析:通过分析日志文件来推断系统状态
* 系统自带工具:如Unix/Linux的 `top`、`vmstat`等命令
这个阶段的监控主要是针对单机环境,缺乏统一的标准和集中化的视图。
#### 集中式监控系统的兴起
随着系统规模扩大,集中式监控系统开始出现:
* **Nagios** (1999年):作为最早的开源监控系统之一,Nagios提供了基于主机和服务的监控框架。
* **Ganglia** (2000年代初):专为高性能计算集群设计,引入了时间序列数据的概念。
* **Graphite** (2006年):提供了存储时间序列数据和图形化展示的能力,使得指标可视化变得更加直观。
* **Munin** 、**Cacti**等:进一步完善了数据收集和可视化能力。
这个阶段的突破在于实现了多主机的集中监控,但系统架构仍然相对简单,主要关注于基础设施层面。
#### 现代指标系统的形成
2010年后,随着云计算和大规模分布式系统的兴起,监控指标系统迎来了革命性的变化:
* **Prometheus** (2012年):引入了多维度数据模型和强大的查询语言PromQL,成为云原生监控的标准之一。
* **OpenTSDB** (2010年):基于HBase的可扩展时间序列数据库,能够处理大规模指标数据。
* **InfluxDB** (2013年):专为时间序列数据优化的数据库,提供高效的写入和查询性能。
* **Grafana** (2014年):强大的可视化平台,整合了多种数据源,成为监控面板的事实标准。
这个阶段的关键特点是:
* 多维度标签(labels/tags)的广泛采用,使得指标数据更具表达力
* 分布式架构设计,支持大规模部署
* 更丰富的指标类型:计数器(Counter)、仪表盘(Gauge)、直方图(Histogram)、汇总(Summary)等
* 强大的查询语言和告警功能
#### 标准化与生态系统
近年来,监控指标系统在标准化和生态系统构建方面取得了重要进展:
* **OpenMetrics** :源于Prometheus的暴露格式,成为CNCF的孵化项目,旨在建立统一的指标暴露标准。
* **OpenTelemetry** :整合了OpenTracing和OpenCensus,提供了统一的可观测性框架,覆盖指标、追踪和日志。
* **CNCF Observability** :将监控作为云原生生态系统的核心组成部分,推动了行业标准的形成。
### 3. 不同时代的挑战与应对
#### 分布式系统时代的挑战
分布式系统带来了全新的监控挑战:
* **系统规模激增** :节点数量从数十增长到数千甚至数万
* **依赖关系复杂化** :服务之间的调用关系形成复杂网络
* **故障模式多样化** :出现了更多难以预测的故障类型
**惨痛教训** :2010年代初,许多大型互联网公司在向分布式架构迁移过程中,因为监控系统未能跟上架构变化而导致严重事故。如亚马逊在2011年的一次著名宕机事件,持续了近四天,造成了数百万美元的损失,部分原因是现有监控系统无法有效追踪分布式存储系统中的级联故障。
应对措施:
* 采用可扩展的监控架构,如Prometheus的联邦模式
* 引入服务发现机制,自动适应动态变化的环境
* 开发专门针对分布式系统的指标,如延迟分布、错误预算等
#### 微服务时代的挑战
微服务架构进一步分解了系统边界,带来新的挑战:
* **服务数量爆炸式增长** :从数十个服务增加到数百甚至数千个
* **更频繁的部署与变更** :CI/CD流水线使得变更频率大幅提高
* **服务边界模糊** :用户体验往往跨越多个服务
**惨痛教训** :Netflix在早期微服务转型中,曾因为监控系统不到位而导致多次严重故障。2012年,他们的一次重大服务中断就是因为无法及时发现微服务之间的异常调用模式,导致故障快速蔓延。这直接促使他们开发了著名的Chaos Monkey和更完善的监控系统。
应对措施:
* 服务网格(Service Mesh)技术的应用,提供统一的监控埋点
* RED方法论:请求率(Rate)、错误率(Error)和持续时间(Duration)
* 分布式追踪的广泛应用,如Zipkin、Jaeger等
#### 云原生时代的挑战
云原生环境引入了更多动态性和抽象层:
* **基础设施抽象化** :物理资源被多层虚拟化
* **短生命周期组件** :容器可能只存在几分钟甚至几秒
* **异构和多云环境** :需要跨不同环境收集一致的指标
**惨痛教训** :2017年,一家大型金融科技公司在迁移到Kubernetes平台后,经历了一次严重的服务降级事件。他们的监控系统无法适应容器的高动态性,导致无法检测到资源争用问题,影响了数百万用户的交易处理。这个事件直接促使他们重新设计了整个可观测性栈。
应对措施:
* 采用云原生监控解决方案,如Prometheus + Grafana
* 容器化监控代理,实现自动发现和自愈
* SLO(Service Level Objective)和error budget的引入
* eBPF技术的应用,提供内核级的可观测性
### 4. 人工智能时代的发展方向
随着AI技术的成熟,监控指标系统正在朝着以下方向发展:
#### AIOps的崛起
人工智能正在从根本上改变监控范式:
* **异常检测** :基于机器学习的算法自动发现异常模式,不再依赖人为设定的阈值
* **根因分析** :AI可以分析复杂的依赖关系,快速定位故障根源
* **预测性维护** :通过历史数据预测潜在故障,实现提前干预
#### 智能告警与噪音减少
告警疲劳是传统监控系统的痛点之一,AI正在改变这一现状:
* **智能分组** :自动将相关告警归类,减少重复通知
* **动态阈值** :适应系统的自然变化,减少误报
* **上下文感知** :考虑业务周期、维护窗口等因素
#### 自适应监控
监控系统本身正变得更加智能和自主:
* **自动发现** :智能识别需要监控的新服务和端点
* **自调优** :根据系统负载动态调整采样率和精度
* **自恢复** :监控系统具备自我修复能力
#### 大规模指标数据的智能处理
随着监控数据量的爆炸式增长,新的挑战与机遇并存:
* **高效存储和查询** :新型时间序列数据库专为AI时代设计
* **智能采样** :使用统计学方法在保持准确性的同时减少数据量
* **自动数据生命周期管理** :智能确定数据的保留策略
#### 深度分析与业务集成
监控不再局限于技术指标,而是更加贴近业务:
* **业务指标关联** :将技术指标与业务成果直接关联
* **用户体验监控** :从用户视角衡量服务质量
* **行为分析** :结合用户行为数据,提供更全面的系统视图
### 5. 总结与展望
监控指标系统的发展历程反映了软件工程本身的演进:从简单到复杂,从静态到动态,从被动响应到主动预防。我们可以看到几个关键趋势:
1. **整合趋势** :指标、日志和追踪正在融合为统一的可观测性平台
2. **智能化趋势** :AI正在重塑监控的每个环节,从数据收集到分析决策
3. **业务导向** :技术监控与业务目标的对齐日益紧密
4. **自治系统** :监控系统本身正变得更加自适应和自我管理
未来的监控指标系统将不再仅仅是一个工具,而是智能运维的核心神经系统,能够自主感知、分析和调整,实现真正的闭环自动化。在这个AI驱动的新时代,监控将从"观察系统"演变为"理解系统",甚至是"预测系统",为软件工程的下一个飞跃奠定基础。
然而,我们也应该记住,技术的进步不应该让我们忽视监控的本质目的:确保系统可靠地为用户提供价值。无论监控技术如何先进,它始终是一种手段,而非目的本身。真正的挑战在于如何将这些技术进步转化为更可靠的系统和更好的用户体验,这也将是监控指标系统未来发展的核心驱动力。
================================================
FILE: book/10-extras/4-development-of-tracing.md
================================================
## 软件跟踪系统(Tracing)的发展历程
### 1. Tracing诞生的问题背景
软件跟踪系统(Tracing)的出现源于开发者面临的一个永恒挑战:如何有效地理解和排查复杂系统中的问题。在早期计算机系统中,调试主要依靠简单的日志记录和调试器,这些工具在单体应用中表现尚可,但随着系统规模的扩大和复杂度的提升,它们逐渐显露出局限性。
在20世纪90年代末到21世纪初,随着互联网的兴起,分布式系统开始普及。开发者们面临着前所未有的挑战:
* 系统组件分布在不同的物理机器上
* 请求穿越多个服务和网络边界
* 失败可能发生在任何环节,且难以定位
* 性能问题的根源变得更加难以追踪
传统的调试方法在这种环境下捉襟见肘。当一个请求在分布式系统中失败时,开发人员不得不手动关联各个组件的日志,这是一项耗时且容易出错的工作。这种痛点催生了对更先进跟踪技术的需求,促使了专门的分布式跟踪系统的诞生。
### 2. Tracing系统的技术演进
#### 早期基础:从日志到分布式跟踪
分布式跟踪的概念最早可以追溯到2000年代初期。这一时期的重要里程碑包括:
**Magpie (2003)** :微软研究院开发的系统,能够自动提取分布式系统中事件的因果关系,被认为是分布式跟踪的先驱之一。
**X-Trace (2007)** :UC Berkeley开发的框架,首次引入了跨多个协议和系统边界的端到端跟踪能力。X-Trace的创新之处在于它为每个请求分配了唯一标识符,使得追踪请求路径成为可能。
#### Google Dapper:分布式跟踪的奠基石
2010年,Google发表了题为《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》的论文,这被广泛认为是现代分布式跟踪系统的奠基之作。Dapper引入了几个关键概念:
* **Trace** :表示一个分布式事务或请求的完整路径
* **Span** :表示在单个服务中完成的工作单元
* **SpanId和TraceId** :用于唯一标识和关联分布式系统中的操作
Dapper的设计理念影响深远,它平衡了低开销和高可用性,同时保持了对开发者的透明性。这些特性使其成为后来众多开源跟踪系统的灵感来源。
#### 开源生态的繁荣
在Dapper论文发表后,开源社区开始活跃开发各种分布式跟踪解决方案:
**Zipkin (2012)** :由Twitter开源,直接受Dapper启发的分布式跟踪系统,使用简单的库使开发人员能够检测他们的代码。
**Jaeger (2016)** :由Uber开发并开源,兼容OpenTracing API,提供了分布式上下文传播、分布式事务监控等功能。
**OpenTracing (2016)** :一个厂商中立的开放标准,旨在统一分布式跟踪接口。通过OpenTracing,开发者可以使用一致的API,而不必关心底层的具体实现。
**OpenCensus (2018)** :由Google主导的项目,将指标收集和分布式跟踪结合在一个框架中。
#### 标准化:OpenTelemetry的诞生
分布式跟踪生态系统的多样化也带来了碎片化的问题。为解决这一挑战,2019年,OpenTracing和OpenCensus项目合并,形成了 **OpenTelemetry** 。这一里程碑事件标志着分布式观测领域向标准化的重要一步。
OpenTelemetry提供:
* 与厂商无关的APIs和SDKs
* 用于收集和处理遥测数据的规范
* 整合了分布式跟踪、指标和日志
* 广泛的语言和平台支持
到2021年,OpenTelemetry已经成为云原生计算基金会(CNCF)的第二大活跃项目,仅次于Kubernetes,显示了业界对统一可观测性标准的强烈需求。
### 3. 不同时代的挑战与应对
#### 分布式系统时代的挑战
在早期分布式系统中,tracing面临的主要挑战包括:
* **性能开销** :早期跟踪系统对应用性能影响较大
* **兼容性** :不同语言和框架的集成难度高
* **采样策略** :如何在数据量和精确度之间取得平衡
**惨痛教训** :2012年,一家大型电子商务平台在黑色星期五部署了新版跟踪系统,但由于跟踪代理的高CPU占用,导致整个交易系统响应缓慢,损失数百万美元的销售额。这一事件凸显了在设计跟踪系统时必须考虑性能影响。
#### 微服务时代的挑战
随着微服务架构的流行,新的挑战出现:
* **服务激增** :需要追踪穿越数十甚至数百个微服务的请求
* **异构环境** :不同技术栈的服务需要统一的跟踪方案
* **上下文传播** :在异步通信和事件驱动架构中保持跟踪上下文
**应对措施** :
* 轻量级跟踪协议的发展
* 自动化检测技术的提升
* 智能采样算法的应用
**惨痛教训** :2018年,一家金融科技公司的支付系统因为跟踪上下文传播失败,导致无法确定哪些交易成功完成、哪些失败,最终不得不进行长达36小时的系统重建,造成严重的用户信任危机。
#### 云原生时代的挑战
云原生环境为Tracing带来了更复杂的场景:
* **动态基础设施** :容器和Kubernetes环境中服务实例频繁创建和销毁
* **服务网格** :如Istio等技术引入了新的通信层
* **无服务器架构** :函数计算(FaaS)模型下的跟踪复杂性
* **可观测性融合** :需要将跟踪与日志、指标等其他信号整合
**应对策略** :
* 服务网格中的sidecar自动注入跟踪信息
* 云原生跟踪收集器的发展
* 自动关联各种可观测性数据
### 4. 人工智能时代的Tracing发展方向
随着人工智能技术的发展,Tracing系统正在迎来新的变革:
#### AI驱动的异常检测与根因分析
现代系统生成大量跟踪数据,人工分析变得几乎不可能。AI可以帮助:
* 自动识别异常的请求路径和模式
* 预测潜在的系统瓶颈和故障点
* 通过机器学习模型关联根本原因
例如,Facebook的Narya系统利用机器学习预测网络中的潜在故障并自动修复,大幅减少了系统中断。
#### 大规模语言模型的应用
LLM正在改变开发者与跟踪数据的交互方式:
* 自然语言查询跟踪数据("上周星期四的支付失败是什么原因?")
* 自动生成故障排查建议
* 将复杂的跟踪数据转化为人类可理解的叙述
#### 智能采样与压缩
AI可以优化跟踪数据的采集策略:
* 针对特定请求路径的自适应采样率
* 在保留关键信息的同时压缩跟踪数据
* 基于过往模式预测性地调整采样行为
#### 自治修复能力
未来的跟踪系统可能不仅仅是观测工具,还能实现自动修复:
* 实时检测到异常后自动调整系统配置
* 基于历史跟踪数据训练的AI模型提供优化建议
* 在某些场景下实现全自动故障修复
#### 分布式AI系统的跟踪挑战
随着AI系统本身变得更加分布式和复杂,跟踪这些系统也带来了新的挑战:
* 追踪大规模分布式训练和推理过程
* 理解和可视化复杂的神经网络决策路径
* 监控和调试AI模型性能波动的根本原因
### 5. 总结与展望
从最初解决分布式系统调试难题的工具,到如今融合AI技术的智能化系统,软件跟踪技术已经走过了长足的发展历程。这一演进过程清晰地反映了软件系统本身从单体到分布式,再到云原生和AI驱动的技术变革。
关键的发展脉络可以总结为:
1. **问题驱动** :每一次技术突破都来源于实际开发运维痛点
2. **标准化** :从各自为战到OpenTelemetry的统一标准
3. **融合化** :从单一的跟踪向全方位可观测性的转变
4. **智能化** :AI技术为跟踪系统注入智能分析能力
未来,随着系统复杂度的持续提升和AI技术的深入应用,跟踪系统将继续演化,可能会呈现以下趋势:
* **预测性洞察** :从被动观测转向主动预测
* **无代码跟踪** :降低开发者集成成本
* **上下文感知** :更加智能地理解业务语境
* **隐私保护** :在保证可观测性的同时保护敏感数据
无论技术如何变革,跟踪系统的核心价值始终如一:让开发者能够理解、监控和优化他们创建的系统,确保软件能够可靠高效地运行,为用户提供优质的服务体验。
================================================
FILE: book/10-extras/5-development-of-bisect.md
================================================
## Go编译器+运行时DEBUG:基于哈希的二分调试技术
【注】本文翻译自 Russ Cox 于2024-07-18 发表的一篇文章[《Hash-Based Bisect Debugging in Compilers and Runtimes》](https://research.swtch.com/bisect)。为了本章bisect reduce调试技术的内容完整性,特别引用并翻译该文章来介绍bisect reduce的算法逻辑。
### [背景介绍](https://research.swtch.com/bisect#setting_the_stage)
这样的场景是否似曾相识?你对某个库进行修改以优化性能、清理技术债务或修复bug,结果却收到一份错误报告:某个庞大而复杂的测试用例现在失败了。或者你添加了一个新的编译器优化,结果也大同小异。现在你不得不在一个完全陌生的代码库中进行大量的调试工作。
如果我告诉你,存在一种"魔法棒"可以精确定位那个陌生代码库中的相关代码行或调用栈,你会作何感想?这种工具确实存在。这是一个真实可用的工具,我将向你展示它的神奇之处。这个描述可能听起来有些夸张,但每次我使用这个工具时,它确实给我带来魔法般的感觉。这不是普通的魔法,而是最棒的魔法:即使你完全了解它的工作原理,观看它的运行过程仍然令人赏心悦目。[](https://research.swtch.com/bisect#binary_search_and_bisecting_data)
### [二分搜索与数据二分](https://research.swtch.com/bisect#binary_search_and_bisecting_data)
在介绍新技巧之前,让我们先回顾一些更简单、更基础的技术。每个优秀的魔术师都从掌握基本功开始。在我们的场景中,这个基本功就是二分搜索。大多数二分搜索的演示都专注于在有序列表中查找元素,但实际上它有着更加有趣的应用。这是我很久以前为Go的[`sort.Search`](https://go.dev/pkg/sort/#Search)文档编写的一个例子:
```go
func GuessingGame() {
var s string
fmt.Printf("Pick an integer from 0 to 100.\n")
answer := sort.Search(100, func(i int) bool {
fmt.Printf("Is your number <= %d? ", i)
fmt.Scanf("%s", &s)
return s != "" && s[0] == 'y'
})
fmt.Printf("Your number is %d.\n", answer)
}
```
如果我们运行这段代码,它会和我们玩一个猜数字游戏:
```bash
% go run guess.go
Pick an integer from 0 to 100.
Is your number <= 50? y
Is your number <= 25? n
Is your number <= 38? y
Is your number <= 32? y
Is your number <= 29? n
Is your number <= 31? n
Your number is 32.
%
```
同样的猜数字游戏原理也可以应用到调试中。Jon Bentley在他1983年9月发表于《ACM通讯》的《编程珠玑》专栏"Aha! Algorithms"中,将二分搜索称为"寻找问题的解决方案"。这是他给出的一个经典例子:
> Roy Weil在清理大约一千张包含一张坏卡片的穿孔卡片时应用了[二分搜索]技术。不幸的是,坏卡片无法通过视觉识别;只能通过将卡片的某个子集运行程序并观察严重错误的答案来识别——这个过程需要几分钟。他的前任们试图通过一次运行几张卡片来解决这个问题,并朝着解决方案稳步(但缓慢)前进。Weil是如何在仅十次程序运行中找到罪魁祸首的?
显然,Weil使用了二分搜索的猜数字游戏策略。坏卡片在前500张中吗?是的。前250张中吗?不是。以此类推。这是我能够找到的关于通过二分搜索进行调试的最早发表描述。在这种情况下,它是用于调试数据的。[](https://research.swtch.com/bisect#bisecting_version_history)
### [基于提交历史的二分搜索](https://research.swtch.com/bisect#bisecting_version_history)
我们可以将二分搜索应用到程序的版本历史上,而不仅仅是数据上。每当我们发现旧程序中出现新错误时,我们就会玩猜数字游戏:"这个程序最后一次正常工作是什么时候?"
* 50天前它工作正常吗?是的。
* 25天前它工作正常吗?不是。
* 38天前它工作正常吗?是的。
以此类推,直到我们发现程序最后一次正确工作是在32天前,这意味着错误是在31天前引入的。
通过时间进行二分搜索调试是一个非常古老的技巧,被许多人独立发现了很多次。例如,我们可以使用像`cvs checkout -D '31 days ago'`这样的命令或Plan 9的[更音乐化的](https://9fans.github.io/plan9port/man/man1/yesterday.html)`yesterday -n 31`来玩猜数字游戏。对于一些程序员来说,使用二分搜索来调试数据或通过时间调试的技术似乎"[如此基础,以至于没有必要写下来](https://groups.google.com/g/comp.compilers/c/vGh4s3HBQ-s/m/qmrVKmF5AgAJ)"。但记录这些技巧是确保每个人都能掌握的第一步:魔术技巧可以是基础的,但不一定是显而易见的。在软件中,记录技巧也是自动化它和构建优秀工具的第一步。
在1990年代后期,版本历史二分搜索的想法[至少被记录过两次](https://groups.google.com/g/comp.compilers/c/vGh4s3HBQ-s/m/Chvpu7vTAgAJ)。Brian Ness和Viet Ngo在COMPSAC '97(1997年8月)发表了"[通过源代码变更隔离进行回归控制](https://ieeexplore.ieee.org/abstract/document/625082)",描述了他们在Cray Research构建的一个系统,用于交付更频繁的非回归编译器版本。独立地,Larry McVoy在Linux 1.3.73版本(1996年3月)中发布了一个文件"[Documentation/BUG-HUNTING](https://elixir.bootlin.com/linux/1.3.73/source/Documentation/BUG-HUNTING)"。他捕捉到了这个技巧的神奇之处:即使你对被测试的代码没有特别的专业知识,它也能发挥作用:
> 如果你对内核黑客一无所知,这就是如何追踪错误的方法。这是一种蛮力方法,但效果很好。
>
> 你需要:
>
> * 一个可重现的错误 - 它必须可预测地发生(抱歉)
> * 从工作版本到不工作版本的所有内核tar文件
>
> 然后你将:
>
> * 重新构建一个你认为工作的版本,安装并验证它。
> * 在内核上进行二分搜索,找出哪个版本引入了错误。即,假设1.3.28没有错误,但你知道1.3.69有。选择一个中间的内核并构建它,比如1.3.50。构建和测试;如果它工作,选择.50和.69之间的中点,否则选择.28和.50之间的中点。
> * 你将缩小到引入错误的内核。你可能可以做得比这更好,但这变得棘手。
>
> . . .
>
> 我为向Linus和其他内核黑客描述这种蛮力方法而道歉,这几乎不是内核黑客会做的事情。然而,它确实有效,它让非黑客帮助修复错误。这很酷,因为Linux快照让你可以这样做 - 这是你无法用供应商提供的版本做的事情。
后来,Larry McVoy创建了Bitkeeper,Linux将其用作第一个源代码控制系统。Bitkeeper提供了一种通过提交的有向无环图打印最长直线变更的方法,为二分搜索提供了更细粒度的时间线。当Linus Torvalds创建Git时,他将这个想法进一步发展,推出了[`git rev-list --bisect`](https://github.com/git/git/commit/8b3a1e056f2107deedfdada86046971c9ad7bb87),这启用了相同类型的手动二分搜索。在添加该功能几天后,他在Linux内核邮件列表上[解释了如何使用它](https://groups.google.com/g/fa.linux.kernel/c/N4CqlNCvFCY/m/ItQoFhVZyJgJ):
> 嗯..既然你似乎是git用户,也许你可以尝试git的"bisect"功能来帮助缩小确切发生的位置(并帮助测试那个东西;)。
>
> 你基本上可以使用git找到一组"已知良好"点和"已知错误"点之间的中点("二分"提交集),只做几次这些应该给我们一个更好的视图,了解事情开始出错的地方。
>
> 例如,既然你知道2.6.12-rc3是好的,而2.6.12是坏的,你会这样做
>
> git-rev-list --bisect v2.6.12 ^v2.6.12-rc3
>
> 其中"v2.6.12 ^v2.6.12-rc3"基本上意味着"v2.6.12中的所有内容但_不是_v2.6.12-rc3中的内容"(这就是^标记的含义),而"--bisect"标志只是要求git-rev-list列出最中间的提交,而不是那些内核版本之间的所有提交。
这个回应引发了一场[关于简化过程的单独讨论](https://groups.google.com/g/fa.linux.kernel/c/cp6abJnEN5U/m/5Z5s14LkzR4J),最终催生了今天广泛使用的[`git bisect`](https://git-scm.com/docs/git-bisect)工具。
这里有一个实际例子。我们尝试更新到Go的更新版本,发现一个测试失败了。我们可以使用`git bisect`来精确定位导致失败的特定提交:
```bash
% git bisect start master go1.21.0
Previous HEAD position was 3b8b550a35 doc: document run..
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 5 commits.
Bisecting: a merge base must be tested
[2639a17f146cc7df0778298c6039156d7ca68202] doc: run rel...
% git bisect run sh -c '
git clean -df
cd src
./make.bash || exit 125
cd $HOME/src/rsc.io/tmp/timertest/retry
go list || exit 0
go test -count=5
'
```
编写正确的`git bisect`调用需要一些注意,但一旦配置正确,你就可以放手让它自动运行,让`git bisect`施展它的魔法。在这种情况下,我们传递给`git bisect run`的脚本会清理任何过时的文件,然后构建Go工具链(`./make.bash`)。如果那一步失败,它以代码125退出,这是`git bisect`的特殊不确定答案:这个提交有其他问题,我们不能确定我们正在寻找的错误是否存在。否则它切换到失败测试的目录。如果`go list`失败,这在bisect使用太旧的Go版本时会发生,脚本成功退出,表示错误不存在。否则脚本运行`go test`并以该命令的状态退出。`-count=5`在那里是因为这是一个不稳定的失败,不总是发生:运行五次足以确保我们观察到错误(如果它存在的话)。
当我们运行这个命令时,`git bisect`打印大量输出,以及我们测试脚本的输出,以确保我们可以看到进度:
```bash
% git bisect run ...
...
go: download go1.23 for darwin/arm64: toolchain not available
Bisecting: 1360 revisions left to test after this (roughly 10 steps)
[752379113b7c3e2170f790ec8b26d590defc71d1]
runtime/race: update race syso for PPC64LE
...
go: download go1.23 for darwin/arm64: toolchain not available
Bisecting: 680 revisions left to test after this (roughly 9 steps)
[ff8a2c0ad982ed96aeac42f0c825219752e5d2f6]
go/types: generate mono.go from types2 source
...
ok rsc.io/tmp/timertest/retry 10.142s
Bisecting: 340 revisions left to test after this (roughly 8 steps)
[97f1b76b4ba3072ab50d0d248fdce56e73b45baf]
runtime: optimize timers.cleanHead
...
FAIL rsc.io/tmp/timertest/retry 22.136s
Bisecting: 169 revisions left to test after this (roughly 7 steps)
[80157f4cff014abb418004c0892f4fe48ee8db2e]
io: close PipeReader in test
...
ok rsc.io/tmp/timertest/retry 10.145s
Bisecting: 84 revisions left to test after this (roughly 6 steps)
[8f7df2256e271c8d8d170791c6cd90ba9cc69f5e]
internal/asan: match runtime.asan{read,write} len parameter type
...
FAIL rsc.io/tmp/timertest/retry 20.148s
Bisecting: 42 revisions left to test after this (roughly 5 steps)
[c9ed561db438ba413ba8cfac0c292a615bda45a8]
debug/elf: avoid using binary.Read() in NewFile()
...
FAIL rsc.io/tmp/timertest/retry 14.146s
Bisecting: 20 revisions left to test after this (roughly 4 steps)
[2965dc989530e1f52d80408503be24ad2582871b]
runtime: fix lost sleep causing TestZeroTimer flakes
...
FAIL rsc.io/tmp/timertest/retry 18.152s
Bisecting: 10 revisions left to test after this (roughly 3 steps)
[b2e9221089f37400f309637b205f21af7dcb063b]
runtime: fix another lock ordering problem
...
ok rsc.io/tmp/timertest/retry 10.142s
Bisecting: 5 revisions left to test after this (roughly 3 steps)
[418e6d559e80e9d53e4a4c94656e8fb4bf72b343]
os,internal/godebugs: add missing IncNonDefault calls
...
ok rsc.io/tmp/timertest/retry 10.163s
Bisecting: 2 revisions left to test after this (roughly 2 steps)
[6133c1e4e202af2b2a6d4873d5a28ea3438e5554]
internal/trace/v2: support old trace format
...
FAIL rsc.io/tmp/timertest/retry 22.164s
Bisecting: 0 revisions left to test after this (roughly 1 step)
[508bb17edd04479622fad263cd702deac1c49157]
time: garbage collect unstopped Tickers and Timers
...
FAIL rsc.io/tmp/timertest/retry 16.159s
Bisecting: 0 revisions left to test after this (roughly 0 steps)
[74a0e3160d969fac27a65cd79a76214f6d1abbf5]
time: clean up benchmarks
...
ok rsc.io/tmp/timertest/retry 10.147s
508bb17edd04479622fad263cd702deac1c49157 is the first bad commit
commit 508bb17edd04479622fad263cd702deac1c49157
Author: Russ Cox <rsc@golang.org>
AuthorDate: Wed Feb 14 20:36:47 2024 -0500
Commit: Russ Cox <rsc@golang.org>
CommitDate: Wed Mar 13 21:36:04 2024 +0000
time: garbage collect unstopped Tickers and Timers
...
This CL adds an undocumented GODEBUG asynctimerchan=1
that will disable the change. The documentation happens in
the CL 568341.
...
bisect found first bad commit
%
```
这个错误似乎是由我的新的垃圾回收友好的定时器实现引起的,它将在Go 1.23中发布。*变魔术!*[](https://research.swtch.com/bisect#new_trick)
### [基于程序位置的二分搜索](https://research.swtch.com/bisect#new_trick)
#### 寻找更高效的方法
`git bisect`定位到的有问题的提交,正是定时器实现的一次重大变更。考虑到这次改动可能会引发一些隐晦的测试失败,我特意加入了一个[GODEBUG设置](https://go.dev/doc/godebug),以便能够在新旧实现之间灵活切换。实际验证时,切换回旧实现后,相关错误果然消失了:
```bash
% GODEBUG=asynctimerchan=1 go test -count=5 # old
PASS
ok rsc.io/tmp/timertest/retry 10.117s
% GODEBUG=asynctimerchan=0 go test -count=5 # new
--- FAIL: TestDo (4.00s)
...
--- FAIL: TestDo (6.00s)
...
--- FAIL: TestDo (4.00s)
...
FAIL rsc.io/tmp/timertest/retry 18.133s
%
```
知道哪个提交导致了错误,以及关于失败的表现信息,通常足以帮助识别错误了。但如果不是呢?如果测试很大很复杂,完全是你从未见过的代码,它以某种难以理解的方式失败,似乎与你的更改无关怎么办?当你从事编译器或低级库的工作时,这种情况经常发生。为此,我们有一个新的魔法技巧:**基于程序位置的二分搜索**。
换句话说,我们**可以在不同的“维度”上进行二分搜索**:**不仅仅是在代码的版本历史上,还可以直接在程序的代码路径上进行**。我们将这种能力集成到了一个名为 `bisect` 的新工具中。当面对像定时器实现这样影响库函数行为的变更时,`bisect` 能够遍历所有可能触发新代码的调用堆栈,对部分堆栈启用新实现,对其他堆栈保持旧实现。通过多次迭代,工具最终可以将问题定位到只在特定堆栈启用新代码时才会出现失败。
```bash
% go install golang.org/x/tools/cmd/bisect@latest
% bisect -godebug asynctimerchan=1 go test -count=5
...
bisect: FOUND failing change set
--- change set #1 (disabling changes causes failure)
internal/godebug.(*Setting).Value()
/Users/rsc/go/src/internal/godebug/godebug.go:165
time.syncTimer()
/Users/rsc/go/src/time/sleep.go:25
time.NewTimer()
/Users/rsc/go/src/time/sleep.go:145
time.After()
/Users/rsc/go/src/time/sleep.go:203
rsc.io/tmp/timertest/retry.Do()
/Users/rsc/src/rsc.io/tmp/timertest/retry/retry.go:37
rsc.io/tmp/timertest/retry.TestDo()
/Users/rsc/src/rsc.io/tmp/timertest/retry/retry_test.go:63
```
在这里,`bisect` 工具报告,仅需在这个特定调用堆栈上禁用 `asynctimerchan=1`(即启用新实现),就能复现测试失败。
调试时最棘手的问题之一,是逆向追踪程序的执行路径:当你发现某个数据结构出现异常值,或控制流偏离预期,往往很难还原它是如何一步步走到这一步的。而 `bisect` 工具的独特之处在于,它直接展示了问题发生*之前*的完整堆栈信息——也就是决定测试成败的关键分叉点。与其在茫茫代码中盲目向前推测,不如借助 `bisect` 精确定位到那些真正影响结果的几行代码。这样,我们可以聚焦于分析特定调用序列背后的实现逻辑,深入理解为何新定时器实现会引发行为变化。
对于在编译器或运行时等底层系统工作的人来说,若在庞大且陌生的代码库中引入了测试失败,`bisect` 能将原因缩小到几行关键代码,这种体验无疑令人惊叹。
接下来的内容将详细介绍 `bisect` 工具的内部原理。这一工具是 Keith Randall、David Chase 和我在过去十年 Go 语言开发过程中不断完善的成果。虽然类似的二分定位思想也被其他人和项目采用过,但我们在方法论和系统化实现上做了进一步拓展和总结。本文希望将这些经验分享出来,帮助更多人站在我们的基础上继续前进,而无需重复造轮子。[](https://research.swtch.com/bisect#example)
#### [示例:查找函数优化引入的BUG](https://research.swtch.com/bisect#example)
我们先来看一个简单的例子,再回到堆栈跟踪的问题。假设你正在开发一个编译器,并且发现某个测试程序只有在开启优化编译时才会失败。此时,你可以列出程序中所有的函数,然后逐个尝试禁用某个函数的优化,直到找到一个最小的函数集合(有时甚至只有一个函数),只要优化这些函数就会触发错误。显然,二分搜索可以极大地加快这个定位过程:
1. 首先,修改编译器,让它输出所有被考虑优化的函数列表。
2. 然后,调整编译器,使其可以接收一个允许优化的函数列表。传递空列表(即不优化任何函数)时,测试应当通过;传递完整列表(优化所有函数)时,测试应当失败。
3. 利用二分搜索,找出能让测试失败的最短函数列表前缀。这个前缀的最后一个函数,是导致失败的必要优化目标之一(但可能不止一个)。
4. 将该函数始终设为优化,再重复上述过程,继续查找其他必须优化才能引发错误的函数。
举个例子,假设程序里有十个函数,我们依次进行三轮二分搜索实验:

当只优化前5个函数时,测试通过;优化前7个时,测试失败;优化前6个时,测试依然通过。这说明第7个函数`sin`是导致失败的关键之一。更具体地说,优化`sin`后,列表中后面的函数无需优化,但前面的函数是否也必须优化还不确定。为了进一步确认,我们可以在剩下的前六个函数中继续二分搜索,每次都加上`sin`:

这次,优化前两个(加上`sin`)会失败,优化第一个(加上`sin`)则通过,说明`cos`同样是必须优化的函数。最后只剩下`add`函数需要验证,结果发现即使去掉`add`,测试依然失败。
最终,我们得出结论:导致测试失败的一个局部最小函数集是`cos`和`sin`。只要从这个集合中去掉任何一个函数,测试就会通过。当然,这个集合未必是全局最小的,也许只优化`tan`会引发另一种失败(也可能不会)。但至少我们已经掌握了一组能够复现问题的最小优化组合。
#### 误区:可能的二分搜索认识误区
有些人可能会下意识地采用传统二分查找的方式:每次都把列表一分为二,先测试前半部分是否会导致错误。如果前半部分通过,就直接把它排除掉,接着只在后半部分继续查找。用在我们的例子中,这种算法的流程大致如下:

第一次试验通过后,我们可能会以为问题出在列表的后半部分,于是直接舍弃了前半部分。然而,这样做的结果是,像 `cos` 这样的函数被排除在优化之外,后续的所有试验也都顺利通过,反而让我们无法再复现原本的失败。这其实暴露了一个核心问题:只有在确信某一部分对结果没有影响时,才能安全地将其移除。这个前提仅在错误由单一函数的优化引发时才成立,但实际情况往往更复杂——有时只有多个函数同时被优化才会触发问题。如果贸然丢弃一半列表,可能就把导致失败的组合也一并丢掉了。因此,二分搜索在这里应当以列表前缀的长度为基础,而不是简单地将列表一分为二。[](https://research.swtch.com/bisect#bisect-reduce)
### [Bisect-Reduce算法](https://research.swtch.com/bisect#bisect-reduce)
#### 算法核心思想简介
前面提到的“重复二分搜索”虽然能够解决问题,但其实质是对传统二分查找的多次迭代,效率并不理想。为此,我们引入一种更为简洁高效的方案——“bisect-reduce”算法。这是一种以二分为基础、结合归约思想的策略,能够更直接地缩小问题范围,提升定位效率。
为了便于说明,我们假设有一个全局函数 `buggy`,用于判断当在指定的位置列表启用更改时,是否会触发错误:
```go
// buggy reports whether the bug is triggered
// by enabling the change at the listed locations.
func buggy(locations []string) bool
```
`BisectReduce`函数接收一个输入列表`targets`,在`buggy(targets)`为真的前提下,返回一个局部最小的子集`x`,使得`buggy(x)`依然为真。其实现依赖于一个更通用的辅助函数`bisect`,该函数多了一个参数`forced`,用于在归约过程中始终保持启用的目标位置列表。
```go
// BisectReduce returns a locally minimal subset x of targets
// where buggy(x) is true, assuming that buggy(targets) is true.
func BisectReduce(targets []string) []string {
return bisect(targets, []string{})
}
// bisect returns a locally minimal subset x of targets
// where buggy(x+forced) is true, assuming that
// buggy(targets+forced) is true.
//
// Precondition: buggy(targets+forced) = true.
//
// Postcondition: buggy(result+forced) = true,
// and buggy(x+forced) = false for any x ⊂ result.
func bisect(targets []string, forced []string) []string {
if len(targets) == 0 || buggy(forced) {
// Targets are not needed at all.
return []string{}
}
if len(targets) == 1 {
// Reduced list to a single required entry.
return []string{targets[0]}
}
// Split targets in half and reduce each side separately.
m := len(targets)/2
left, right := targets[:m], targets[m:]
leftReduced := bisect(left, slices.Concat(right, forced))
rightReduced := bisect(right, slices.Concat(leftReduced, forced))
return slices.Concat(leftReduced, rightReduced)
}
```
正如优秀的分治算法所展现的那样,这几行代码实际上蕴含了丰富的逻辑:
* 当目标列表被缩减为空,或者`buggy(forced)`(即即使没有任何目标也会触发错误)返回真时,说明目标列表中的元素都不是必需的,此时可以直接返回空列表。反之,则意味着目标列表中至少有部分元素是不可或缺的。
* 若目标列表只剩下一个元素,则该元素必然是必要的,直接返回仅包含该元素的列表即可。
* 其他情况下,算法进入递归阶段:将目标列表一分为二,分别对左右两部分进行归约。这里有一个关键点:归约左半部分(left)时,强制保留的是 right+forced;归约右半部分时,强制保留的是已经归约得到的左半部分(`leftReduced`)加上 forced,而不是原始的 left。这一细节对于算法的正确性至关重要。
应用于函数优化例子,`BisectReduce`最终会调用
```go
bisect([add cos div exp mod mul sin sqr sub tan], [])
```
这将把目标列表分成
```go
left = [add cos div exp mod]
right = [mul sin sqr sub tan]
```
递归调用计算:
```go
bisect([add cos div exp mod], [mul sin sqr sub tan]) = [cos]
bisect([mul sin sqr sub tan], [cos]) = [sin]
```
然后`return`将两半放在一起:`[cos sin]`,这就是一个导致出现BUG的函数优化组合。
我们前面讨论的`BisectReduce`实现,是我见过的最为简洁的版本,可以称为“简单版本”。与之相对,还有一种实现方式更为详细复杂:它会优先处理当错误仅出现在一半目标中的情况,若无法满足,则进入必须组合两半目标的情形。我们可以将这种实现称为“精细版本”。
```go
// BisectReduce returns a locally minimal subset x of targets
// where buggy(x) is true, assuming that buggy(targets) is true.
func BisectReduce(targets []string) []string {
if len(targets) == 0 || buggy(nil) {
return nil
}
return bisect(targets, []string{})
}
// bisect returns a locally minimal subset x of targets
// where buggy(x+forced) is true, assuming that
// buggy(targets+forced) is true.
//
// Precondition: buggy(targets+forced) = true,
// and buggy(forced) = false.
//
// Postcondition: buggy(result+forced) = true,
// and buggy(x+forced) = false for any x ⊂ result.
// Also, if there are any valid single-element results,
// then bisect returns one of them.
func bisect(targets []string, forced []string) []string {
if len(targets) == 1 {
// Reduced list to a single required entry.
return []string{targets[0]}
}
// Split targets in half.
m := len(targets)/2
left, right := targets[:m], targets[m:]
// If either half is sufficient by itself, focus there.
if buggy(slices.Concat(left, forced)) {
return bisect(left, forced)
}
if buggy(slices.Concat(right, forced)) {
return bisect(right, forced)
}
// Otherwise need parts of both halves.
leftReduced := bisect(left, slices.Concat(right, forced))
rightReduced := bisect(right, slices.Concat(leftReduced, forced))
return slices.Concat(leftReduced, rightReduced)
}
```
与简单版本算法相比,这个精细版本算法有两个主要优点:
- 该算法更贴合我们对二分查找的直观理解:先尝试一边,再尝试另一边,如果都不行,再考虑两边的组合。这种分步处理方式让算法逻辑更加清晰易懂,而简洁版则始终依赖于通用情形,理解起来相对抽象。
- 该算法能够在存在单一罪魁祸首时,确保找到该唯一问题点。由于大多数实际错误最终都可以归结为单一原因,这一特性极大提升了调试效率。
例如,如果某次优化`tan`导致测试失败,该版本算法会优先定位到该单一问题点,从而简化调试过程。
```go
buggy([add cos div exp mod]) = false // left
buggy([mul sin sqr sub tan]) = true // right
```
然后会丢弃左侧,专注于右侧,最终找到`[tan]`,而不是`[sin cos]`。
那么缺点是什么呢?缺点就是没有找到`[sin cos]`吧 :)
#### [基于列表的Bisect-Reduce](https://research.swtch.com/bisect#list-based_bisect-reduce)
在算法已经确立的基础上,接下来我们关注如何将其与编译器实际对接。具体来说,就是如何获取源代码中的位置列表,并将这些信息反馈给编译器以控制优化行为。
最直接的实现方式,是为编译器增加调试模式:一方面输出所有相关优化的位置列表,另一方面支持通过调试参数输入一个允许优化的位置列表。例如,Meta的Python Cinder JIT(2021年发布,详见[相关博客](https://bernsteinbear.com/blog/cinder-jit-bisect/))就采用了这种机制来决定哪些函数采用JIT编译。它的[`Tools/scripts/jitlist_bisect.py`](https://github.com/facebookincubator/cinder/blob/cinder/3.10/Tools/scripts/jitlist_bisect.py)脚本,是我所知最早正确实现bisect-reduce算法(精细版本算法)的开源实例。
这种方案的主要局限在于列表可能非常庞大,尤其是在需要对大型程序进行二分调试时,数据量会迅速膨胀。如果能减少每轮迭代需要传递给编译器的数据量,将极大提升效率。在复杂的构建系统中,函数列表可能大到无法通过命令行或环境变量传递,甚至难以为每次编译调用安排新的输入文件。因此,能够通过简短命令行参数指定目标列表的机制,在实际工程中会更加实用。[](https://research.swtch.com/bisect#counter-based_bisect-reduce)
#### [基于计数器的Bisect-Reduce](https://research.swtch.com/bisect#counter-based_bisect-reduce)
Java的HotSpot C2即时(JIT)编译器提供了一套调试机制,用于控制哪些函数会被JIT编译。与Cinder采用显式函数列表不同,HotSpot通过为待编译函数分配编号来实现管理。开发者可以通过编译器参数`-XX:CIStart`和`-XX:CIStop`来指定允许JIT编译的函数编号区间。这些参数[至今仍在调试版本中保留](https://github.com/openjdk/jdk/blob/151ef5d4d261c9fc740d3ccd64a70d3b9ccc1ab5/src/hotspot/share/compiler/compileBroker.cpp#L1569),其用法甚至可以在[2000年初的Java问题报告](https://bugs.java.com/bugdatabase/view_bug?bug_id=4311720)中找到踪迹。
然而,基于函数编号的方案存在至少两个局限:
首先,这种方式只支持对单一连续编号区间进行二分查找,因此仅适用于定位单一罪魁祸首的场景,无法直接支持多个问题点的通用bisect-reduce。如果要实现更通用的bisect-reduce,只需让参数支持多个编号区间即可,例如`-XX:CIAllow=1-5,7-10,12,15`。
其次,更为棘手的问题在于,函数编号在不同运行之间难以保持稳定。比如,采用并行编译时,线程间的调度顺序可能导致函数被赋予不同的编号;在JIT场景下,甚至运行时的线程行为也会影响函数的编号顺序。二十多年前,线程用得较少,这一问题影响有限;但在今天,依赖编号一致性已成为实际应用中的一大障碍。[](https://research.swtch.com/bisect#hash-based_bisect-reduce)
#### [New!!!: 基于哈希的Bisect-Reduce](https://research.swtch.com/bisect#hash-based_bisect-reduce)
在前文中,我们依次介绍了基于列表、计数器的 bisect-reduce 算法及其在实际工程中的应用与局限。可以看到,随着程序规模的扩大和并发编译的普及,传统的列表或编号方式在可扩展性和稳定性上都面临挑战。为此,下一节将聚焦于一种更为通用且健壮的方案——基于哈希的 bisect-reduce 方法。该方法通过哈希映射实现对位置集合的高效、无序管理,极大提升了算法在复杂系统中的适用性。
接下来,我们将详细解析其原理与实现细节,并探讨其在现代编译器和调试工具中的实际价值。
### [基于哈希的Bisect-Reduce详解](https://research.swtch.com/bisect#hash-based_bisect-reduce)
在前述基于列表和编号的 bisect-reduce 方法基础上,我们进一步引入了一种更为灵活和健壮的实现思路——基于哈希的隐式位置表示。具体做法是,将每个目标位置通过哈希函数映射为一个(近似随机的)整数,再利用二进制后缀来描述和筛选一组位置。由于哈希值的生成与源代码遍历顺序无关,这种方式天然适合并行编译、多线程等复杂场景,极大提升了算法的可扩展性和稳定性。
借助哈希映射,所有函数或位置实际上被组织成一棵二叉树,为后续的高效定位和归约操作奠定了基础:

定位单一问题点时,只需沿着这棵树逐步下探即可。而更通用的bisect-reduce算法,也可以很自然地迁移到哈希后缀的框架下。为此,我们需要稍作调整`buggy`的定义:它不仅要判断当前后缀对应的位置集是否会触发bug,还要返回该后缀实际匹配的位置数量,这样才能判断是否已经归约到最小单元:
```go
// buggy reports whether the bug is triggered
// by enabling the change at the locations with
// hashes ending in suffix or any of the extra suffixes.
// It also returns the number of locations found that
// end in suffix (only suffix, ignoring extra).
func buggy(suffix string, extra []string) (fail bool, n int)
```
现在我们可以直译一下精细版本的算法实现,大致是这样:
```go
// BisectReduce returns a locally minimal list of hash suffixes,
// each of which uniquely identifies a single location hash,
// such that buggy(list) is true.
func BisectReduce() []string {
if fail, _ := buggy("none", nil); fail {
return nil
}
return bisect("", []string{})
}
// bisect returns a locally minimal list of hash suffixes,
// each of which uniquely identifies a single location hash,
// and all of which end in suffix,
// such that buggy(result+forced) = true.
//
// Precondition: buggy(suffix, forced) = true, _.
// and buggy("none", forced) = false, 0.
//
// Postcondition: buggy("none", result+forced) = true, 0;
// each suffix in result matches a single location hash;
// and buggy("none", x+forced) = false for any x ⊂ result.
// Also, if there are any valid single-element results,
// then bisect returns one of them.
func bisect(suffix string, forced []string) []string {
if _, n := buggy(suffix, forced); n == 1 {
// Suffix identifies a single location.
return []string{suffix}
}
// If either of 0suffix or 1suffix is sufficient
// by itself, focus there.
if fail, _ := buggy("0"+suffix, forced); fail {
return bisect("0"+suffix, forced)
}
if fail, _ := buggy("1"+suffix, forced); fail {
return bisect("1"+suffix, forced)
}
// Matches from both extensions are needed.
// Otherwise need parts of both halves.
leftReduced := bisect("0"+suffix, slices.Concat([]string{"1"+suffix}, forced))
rightReduced := bisect("1"+suffix, slices.Concat(leftReduced, forced))
return slices.Concat(leftReduce, rightReduce)
}
```
细心的读者可能已经注意到,在简单场景下,`bisect`的递归调用往往会重复执行与调用者相同的`buggy`检测,以统计当前后缀匹配的数量。为了提升效率,理想的做法是将已有的检测结果直接传递给递归调用,避免重复试验。
此外,这个版本的`bisect`并不保证每次递归都能将搜索空间严格对半分。实际上,由于哈希的随机性,平均而言搜索空间会被大致平分。当潜在的罪魁祸首数量较少时,这种方式依然能够实现对数级别的查找效率。如果后缀用于匹配有序编号而非哈希,算法同样适用,唯一的难点在于如何为元素分配编号。
值得一提的是,哈希后缀与函数编号的长度相当,因此非常适合在命令行参数中传递。例如,假设某个Java编译器可以通过`-XX:CIAllowHash=000,10,111`这样的参数来指定。[](https://research.swtch.com/bisect#use_case)
### Go编译器+运行时中的DEBUG实践
本节介绍了 bisect 算法在 Go 编译器及运行时中的实际应用和工程实践。通过前面的分析,我们已经理解了 bisect-reduce 的基本原理及其在定位复杂问题时的高效性。接下来,我们将结合具体的用例,详细剖析 bisect 技术如何在真实项目中帮助开发者快速定位和解决难以复现的 bug,并探讨其在不同场景下的灵活变体与演进过程。
#### [用例:函数选择](https://research.swtch.com/bisect#use_case)
Go中基于哈希的bisect-reduce最早的实际应用场景,就是用于函数选择,这也是我们前文反复讨论的典型例子。2015年,Keith Randall在为Go编译器开发全新的SSA后端时,面临新旧后端并存、可针对任意函数灵活切换的问题。为此,Keith设计了一个[环境变量GOSSAHASH](https://go.googlesource.com/go/+/e3869a6b65bb0f95dac7eca3d86055160b12589f),用于指定哪些函数应采用新后端。具体做法是:GOSSAHASH的值为一串二进制位(如GOSSAHASH=0110),表示“仅对函数名哈希值末4位为0110的函数使用新后端”。当新后端导致测试失败时,调试者可以先尝试GOSSAHASH=0和GOSSAHASH=1,然后通过二分法逐步细化匹配模式,最终定位到唯一一个用新后端编译的函数,从而精准锁定问题根源。这种方法在面对庞大、复杂且并非自己编写的真实世界测试(如库或生产代码测试)时,极大提升了调试效率。需要注意的是,这一策略假设每次失败都能归因于某个特定的函数。
有趣的是,HotSpot、Cinder和Go三大项目都独立采用了二分搜索来定位编译器中的错误编译函数,但各自实现的选择机制却各不相同:HotSpot用计数器,Cinder用函数列表,Go则采用哈希后缀。[](https://research.swtch.com/bisect#use_case)
#### [用例:SSA重写选择](https://research.swtch.com/bisect#use_case)
2016年底,David Chase在调试一条新的优化器重写规则时,遇到了本应正确却引发神秘测试失败的情况。为了解决这个问题,他[沿用了之前的二分定位技术](https://go-review.googlesource.com/29273),但将控制粒度进一步细化:通过位模式来限定哪些函数可以应用该重写规则。
此外,David还开发了[工具`gossahash`的初版](https://github.com/dr2chase/gossahash/tree/e0bba144af8b1cc8325650ea8fbe3a5c946eb138),专门用于自动化二分查找过程。尽管`gossahash`最初只能定位单一的失败点,但它在实际调试中表现出极高的实用价值,并被沿用多年,最终演化为今天的`bisect`工具。[](https://research.swtch.com/bisect#use_case)
#### [用例:融合乘加](https://research.swtch.com/bisect#use_case)
有了自动化的工具,我们无需再手动进行二分查找,能够持续高效地定位各种问题。2022年,团队在为Go编译器引入新架构下的浮点融合乘加(FMA)指令时,遇到了一些测试失败的情况。为此,我们让FMA相关的重写逻辑依赖于当前文件名和行号的哈希后缀,从而借助bisect-reduce方法,精准定位到导致测试失败的具体源代码行。
例如,借助该二分查找工具,最终定位到`b.go:7`这一行是问题根源:

FMA指令并非大多数程序员日常会接触的内容,但一旦因其引发测试失败,能够自动识别出具体出错行的工具就显得尤为宝贵。[](https://research.swtch.com/bisect#use_case)
#### [用例:语言特性变更](https://research.swtch.com/bisect#use_case)
另一个典型应用场景是语言特性的变更。以Go为例,和C#、JavaScript等语言一样,Go在发展过程中逐渐意识到“循环作用域下的循环变量”与闭包、并发等特性结合时容易引发问题。为了解决这一历史遗留问题,Go近期也采用了[迭代作用域循环变量](https://go.dev/blog/loopvar-preview)的方案,从而修正了许多原本存在缺陷的程序。
然而,现实中有些测试用例其实是在无意中依赖了原本的错误行为。当我们在大型代码库中推广循环变量的语义变更时,常常会在陌生且复杂的代码中遇到难以解释的失败。此时,如果将循环变量的行为变更与源文件名和行号的哈希后缀绑定,就可以借助bisect-reduce方法,精准定位到导致测试失败的具体循环或循环组合。实践中我们甚至发现,有些情况下单独更改任意一个循环并不会导致失败,只有特定的循环组合被同时更改时才会触发问题,因此支持定位多个“罪魁祸首”也非常重要。
如果没有自动化诊断工具,类似的循环变量语义变更将变得更加棘手和低效。[](https://research.swtch.com/bisect#use_case)
#### [用例:库更改](https://research.swtch.com/bisect#use_case)
Bisect-reduce 同样非常适合用于库的变更场景:我们可以对调用者,或者更准确地说,对调用堆栈进行哈希,然后根据哈希后缀,在新旧实现之间动态切换。
举个例子,假设你为一个大型程序引入了新的排序实现,结果程序出现了失败。即便新排序算法本身没有问题,失败往往也源于新旧排序在处理相等元素时的顺序差异。当然,也不排除排序实现本身存在缺陷。无论是哪种情况,大型程序中排序函数可能被多处调用。此时,基于调用堆栈哈希运行 bisect-reduce,就能精准定位到因采用新排序而导致失败的具体调用堆栈。这正如本文开头的例子所示,只不过当时是定时器实现的切换,而非排序。
调用堆栈的这种用法只适合哈希,不适合顺序编号。前面提到的其他例子中,我们可以为程序中的所有函数或源代码行分配编号,然后用 bisect-reduce 针对编号的二进制后缀进行筛查。但对于调用堆栈,几乎不可能为所有可能出现的堆栈分配密集的顺序编号,而对程序计数器列表进行哈希却非常简单高效。
我们是在引入 [GODEBUG 机制](https://go.dev/doc/godebug) 时意识到 bisect-reduce 对库变更同样适用的。GODEBUG 提供了一个框架,用于跟踪和切换这些兼容但可能破坏性的更改。我们也让该框架自动为所有 GODEBUG 设置集成了 `bisect` 支持。
以 Go 1.23 为例,我们重写了 [time.Timer](https://go.dev/pkg/time/#Timer) 的实现,并对其语义做了微调,消除了原有 API 中的一些竞争条件,同时让垃圾回收在某些常见场景下能更早发生。新实现的一个显著效果是极短定时器的触发变得更加可靠。以往 0ns 或 1ns 的定时器(常见于测试)可能需要数微秒才能触发,而现在能准时响应。当然,这也暴露出一些原本隐藏的代码缺陷(主要出现在测试中):当定时器按预期时间触发时,反而导致测试失败。我们在 Google 的代码库中调试了十几个类似的问题——这些问题都很复杂且陌生——而 `bisect` 工具让整个定位过程变得轻松甚至有趣。
有一次,我在排查一个失败的测试用例时犯了个错误。这个测试看起来很简单,似乎可以直接通过代码阅读找出原因,于是我花了半小时反复琢磨唯一的定时器——一个硬编码为一分钟的定时器——怎么会受到新实现的影响。最终我选择放弃,转而运行 `bisect`。结果堆栈跟踪立刻揭示,原来有一层测试中间件会把一分钟的超时重写为 1ns,以加快测试速度。工具能发现人眼难以察觉的细节。[](https://research.swtch.com/bisect#interesting_lessons_learned)
### [学到的有趣经验](https://research.swtch.com/bisect#interesting_lessons_learned)
在开发 `bisect` 工具的过程中,我们有两个值得分享的经验体会。
首先,检测测试用例的不稳定性至关重要。早期在调试循环相关的失败时,`bisect` 曾经定位到加密包中一个本应完全正确、毫无问题的循环。最初我们非常紧张,担心编译器出现了严重的隐藏错误。深入分析后才发现,根本原因在于测试本身存在随机性——测试偶尔失败,导致 `bisect` 在代码中“随机游走”,最终指向了无辜的代码。为此,我们为 `bisect` 增加了 `-count=N` 选项,让每次试验自动重复 N 次,若结果不一致则直接终止。默认值设为 `-count=2`,以确保每次都能做基本的不稳定性检测。
```bash
% cat bin/allpass
##!/bin/sh
n=$1
shift
for i in $(seq $n); do
"$@" || exit 1
done
```
然后可以这样调用`bisect`:
```bash
% bisect -godebug=timer allpass 5 ./flakytest
```
现在bisect只看到`./flakytest`连续通过五次作为成功运行。
类似地,如果测试从不可靠地通过变为一直失败,可以使用`anypass`变体:
```bash
% cat bin/anypass
##!/bin/sh
n=$1
shift
for i in $(seq $n); do
"$@" && exit 0
done
exit 1
```
如果更改导致测试一直运行而不是直接失败,此时可以借助 [`timeout` 命令](https://man7.org/linux/man-pages/man1/timeout.1.html)来辅助控制测试超时时间,避免测试陷入无休止的等待。
虽然通过外部工具来应对测试不稳定性在实际中效果不错,但这并非终极方案。如果能在 `bisect` 工具内部引入更系统、更有原则的机制,将会更加理想。我们目前仍在探索更完善的实现方式。
另一个有趣的经验是:在对运行时行为进行二分调试时,哈希决策的频率极高。如果在 bisect-reduce 的每个阶段都输出完整的堆栈跟踪,开销会非常大(尤其是在初始阶段,所有哈希后缀都匹配时)。因此,bisect 的哈希模式默认采用“安静”模式,仅输出每次决策的哈希位,这已经足够支撑 bisect 的搜索和定位过程。当 bisect 最终确定了最小相关堆栈集合后,会切换到“详细”模式重新运行测试,此时 bisect 库会输出哈希位及对应的堆栈跟踪,最终这些信息会被 bisect 工具收集并展示在报告中。[](https://research.swtch.com/bisect#try_bisect)
### [尝试工具Bisect](https://research.swtch.com/bisect#try_bisect)
[`bisect`工具](https://pkg.go.dev/golang.org/x/tools/cmd/bisect),您可以这样安装bisect工具:
```bash
% go install golang.org/x/tools/cmd/bisect@latest
```
如果你正在调试Go 1.22中的[循环变量问题](https://go.dev/wiki/LoopvarExperiment),你可以使用这样的命令:
```bash
% bisect -compile=loopvar go test
```
如果你正在调试[Go 1.23中的定时器问题](https://go.dev/change/966609ad9e82ba173bcc8f57f4bfc35a86a62c8a),你可以使用:
```bash
% bisect -godebug asynctimerchan=1 go test
```
`-compile`和`-godebug`标志是便利功能。命令的一般形式是
```bash
% bisect [KEY=value...] cmd [args...]
```
在命令行中,前置的 `KEY=value` 参数会在执行后续命令前设置相应的环境变量。`bisect` 工具要求在命令行参数中包含字面量字符串 `PATTERN`,每次运行时会将其替换为当前的哈希模式。
你可以利用 `bisect` 来调试自己编写的编译器或库,只需让你的程序支持通过环境变量或命令行参数接收哈希模式,并在标准输出或标准错误中输出特定格式的信息供 `bisect` 解析。最便捷的做法是直接使用 [bisect 包](https://pkg.go.dev/golang.org/x/tools/internal/bisect)。目前该包尚未正式纳入 Go 标准库(参见[相关提案](https://go.dev/issue/67140)),但它本身只是一个[无依赖的单文件实现](https://cs.opensource.google/go/x/tools/+/master:internal/bisect/bisect.go),可以轻松复制到你的项目中,甚至移植到其他语言。包文档中还详细说明了哈希模式的语法及所需的输出格式。
如果你在开发编译器或库时,遇到“明明做了正确修改却导致复杂程序出错”的棘手问题,不妨试试 `bisect`。它的调试体验总能带来意想不到的惊喜。
### 本节小结
本节围绕编译器和运行时中的哈希二分调试技术展开,梳理了二分搜索在调试领域的历史演变,从最初的版本回溯二分到针对程序内部位置的哈希二分。重点解析了 bisect-reduce 算法的核心原理、实现方式及其在定位复杂问题时的高效性。并且通过与基于列表、基于计数器的二分调试技术进行对比,阐明了基于哈希的二分调试技术的优势,并且展示了它如何使用、如何显著提升调试效率,尤其是在大规模代码和难以复现的错误场景下。然后介绍了该方法在 Go 语言编译器、标准库等项目中进行问题定位的真实案例,表明了哈希二分调试方法的价值。
需要特别关注的是,该哈希二分调试技术,已经沉淀为了工具、公共库,如果你也想为你的项目开启哈希二分调试支持,也可以通过集成相关操作来予以实现。感兴趣的话可以了解下下面工具和库的使用:
- 配套的命令行工具,https://github.com/golang/tools/tree/master/cmd/bisect
- 代码添加开关位置,https://github.com/golang/tools/tree/master/internal/bisect
### 参考内容
1. hash-based bisect debugging in compilers and runtimes, https://research.swtch.com/bisect
2. vscode extension bisect, https://code.visualstudio.com/blogs/2021/02/16/extension-bisect
3. git bisect, https://git-scm.com/docs/git-bisect
================================================
FILE: book/10-extras/6-development-of-ebpf.md
================================================
## eBPF技术的发展历程与未来展望
### 1. eBPF诞生的问题背景
操作系统跟踪和监控一直是系统性能分析和故障排查的重要手段。在eBPF诞生之前,Linux系统中存在多种跟踪技术,但它们各自为政,缺乏统一性和灵活性:
#### 传统跟踪技术的局限
* **动态跟踪(kprobe/uprobe)** :允许在内核或用户空间函数入口和返回处插入探针,但使用复杂且需要特殊工具链。
* **静态跟踪(tracepoint)** :内核中预定义的静态检测点,覆盖面有限。
* **硬件性能计数器(PMC)** :提供硬件级事件监控,但难以与软件层面事件关联。
* **定时器抽样** :如perf采样,开销大且可能错过关键事件。
这些工具各自成体系,使用方式不统一,导致学习和使用成本高昂。更重要的是,它们大多数需要特权访问,无法提供细粒度的安全控制。
#### 系统监控的痛点
在云计算兴起的背景下,传统跟踪技术面临几个关键挑战:
1. **性能开销** :许多跟踪工具会引入显著的性能损耗,不适合生产环境。
2. **安全隐患** :部分工具需要root权限,可能导致系统不稳定或安全风险。
3. **可扩展性** :随着系统规模扩大,跟踪点数量激增,分析变得困难。
4. **灵活性不足** :很难根据特定需求定制跟踪行为。
正是在这一背景下,eBPF(extended Berkeley Packet Filter)技术应运而生。
### 2. eBPF系统的发展历程
#### 初期:从BPF到eBPF
1992年,Steven McCanne和Van Jacobson在Lawrence Berkeley National Laboratory开发了原始的BPF(Berkeley Packet Filter),最初用于网络数据包过滤。它允许用户空间程序指定过滤条件,只接收感兴趣的数据包,大大提高了网络监控工具的效率。
2014年,Alexei Starovoitov对BPF进行了重大改进,引入了eBPF(extended BPF)。这一改进扩展了BPF的功能,使其不再局限于网络数据包过滤,而是成为一个通用的内核内虚拟机。
#### 关键里程碑
##### Linux 3.15(2014年):eBPF首次引入
* 增加了eBPF的基础架构,包括JIT(Just-In-Time)编译器
* 扩展了指令集,支持更复杂的操作
##### Linux 3.18(2014年):kprobe支持
* eBPF程序可以附加到kprobe上,实现动态内核跟踪
##### Linux 4.1(2015年):地图(Maps)功能
* 引入了BPF Maps,作为eBPF程序与用户空间通信的数据结构
* 使得数据存储和共享变得可能
##### Linux 4.4(2016年):tracepoint支持
* eBPF可以附加到静态tracepoint
* 提供了更加稳定的跟踪接口
##### Linux 4.7(2016年):perf支持
* 与Linux perf工具集成,提供更强大的性能分析能力
##### Linux 4.8(2016年):XDP(eXpress Data Path)
* 引入高性能网络数据包处理技术
* 数据包在到达常规网络栈之前就可被处理
##### Linux 4.9(2016年):BPF Type Format(BTF)初步支持
* 为eBPF程序提供更丰富的类型信息
* 开始支持CO-RE(Compile Once, Run Everywhere)
##### Linux 4.10(2017年):cgroup支持
* 允许eBPF程序与cgroup结合,实现更细粒度的控制
##### Linux 4.12(2017年):硬件性能计数器(PMC)支持
* 支持硬件事件监控
##### Linux 4.14(2017年):uprobe支持
* 允许eBPF程序附加到用户空间函数
* 扩展了跟踪范围
##### Linux 4.15(2018年):socket支持
* 增强了网络相关功能
##### Linux 4.18(2018年):BPF to BPF函数调用
* 允许eBPF程序之间互相调用,提高了代码复用能力
##### Linux 5.0(2019年):原生结构化日志支持
* 引入BPF_TRACE_PRINTK,简化了日志记录
##### Linux 5.10(2020年):完整的BTF支持
* 完善了BTF元数据,增强了CO-RE能力
##### Linux 5.13(2021年):BPF LSM(Linux Security Module)
* 允许使用eBPF编写安全策略
#### 代表性工具和框架
* **BCC(BPF Compiler Collection)** :2015年推出,提供了一套用于创建eBPF程序的工具和库。
* **bpftrace** :2018年推出,提供了类似DTrace的高级脚本语言,简化了eBPF程序的开发。
* **Cilium** :2017年推出,基于eBPF的网络安全和可观察性解决方案。
* **Falco** :2016年推出,利用eBPF进行云原生应用安全监控。
* **Hubble** :2020年推出,为Kubernetes提供基于eBPF的网络可视化工具。
#### 教训与突破
##### 案例1:Netflix的性能优化之旅
Netflix在2016年采用eBPF进行性能分析,发现了一个长期存在但难以检测的TCP缓冲区问题。传统工具无法发现这一问题,因为它需要同时跟踪网络栈和应用层。eBPF帮助他们找出了系统瓶颈,提高了服务响应时间。
##### 案例2:Google的BPF安全漏洞
2017年,Google发现了一个eBPF验证器中的安全漏洞(CVE-2017-16995),该漏洞可以被利用来实现本地权限提升。这一事件促使了eBPF安全模型的全面审查,最终导致了更加严格的验证机制。
##### 案例3:Facebook的网络优化
Facebook(现为Meta)在2018年利用eBPF的XDP功能构建了DDoS防御系统。之前,他们的网络防御系统需要专用硬件。采用eBPF后,他们能够在标准服务器上实现高效的DDoS防御,显著降低了成本。
### 3. 分布式系统时代的eBPF挑战与机遇
#### 微服务架构的挑战
随着微服务架构的普及,应用程序分解为多个相互通信的小型服务,这为监控和跟踪带来了新的挑战:
1. **服务间通信** :难以追踪跨服务请求的完整路径。
2. **根因分析** :故障可能源于多个服务之间的复杂交互。
3. **性能开销** :传统监控工具可能对轻量级服务造成过大的性能影响。
eBPF在这方面有独特优势:
* **低开销** :eBPF程序直接在内核中执行,减少了上下文切换。
* **细粒度洞察** :可以跟踪网络、系统调用、应用程序等各个层面。
* **安全性** :验证器确保eBPF程序不会崩溃或无限循环。
#### 云原生环境的应用
在Kubernetes等云原生环境中,eBPF正在重塑可观察性和网络安全:
##### 网络策略实施
* **Cilium** :利用eBPF实现Kubernetes网络策略,提供比传统iptables更高效的网络隔离。
* **性能优势** :相比传统的iptables,eBPF可以实现更高的吞吐量和更低的延迟。
##### 服务网格
* **eBPF基础的Service mesh** :替代传统的基于Sidecar的方案,减少了资源开销。
* **例如** :Cilium的Hubble提供了服务网格功能,无需额外的代理。
##### 安全监控
* **系统调用监控** :检测异常行为,如权限升级尝试。
* **运行时安全** :实时监控容器行为,确保符合安全策略。
#### 可能的发展方向
1. **eBPF作为内核可编程性的统一接口** :
* 简化内核扩展开发
* 降低新功能引入的风险
1. **跨平台支持** :
* 扩展到非Linux系统
* 目前已有Windows eBPF项目
1. **硬件加速** :
* 利用SmartNIC等专用硬件加速eBPF程序
* 降低CPU开销
1. **自动问题检测与修复** :
* 利用eBPF构建自动化故障检测系统
* 实现自愈功能
#### 应用潜力
1. **负载均衡** :
* 高性能的L4/L7负载均衡器
* 动态调整流量分配
1. **可观察性** :
* 深入了解应用性能和行为
* 跨服务追踪
1. **安全增强** :
* 实时入侵检测
* 零信任网络实现
1. **网络优化** :
* 智能路由
* 流量整形
### 4. 人工智能时代的eBPF
随着人工智能和机器学习的快速发展,eBPF面临新的机遇和挑战。
#### AI工作负载的监控与优化
AI工作负载与传统应用有很大不同,它们往往:
* 需要大量的计算资源
* 有复杂的内存访问模式
* 依赖专用的硬件加速器(如GPU、TPU)
eBPF可以通过以下方式优化AI工作负载:
1. **资源利用率监控** :
* 实时跟踪GPU/TPU使用情况
* 监控内存带宽消耗
1. **IO优化** :
* 识别数据加载瓶颈
* 优化存储访问模式
1. **智能调度** :
* 根据工作负载特性动态分配资源
* 优化多租户环境中的资源共享
#### AI与eBPF协同优化
另一个有前景的方向是利用AI来优化eBPF程序本身:
1. **自动化程序生成** :
* 使用AI生成特定场景的eBPF程序
* 简化开发流程
1. **异常检测** :
* 利用机器学习模型分析eBPF收集的数据
* 自动发现异常模式
1. **预测性维护** :
* 基于历史数据预测系统问题
* 提前采取措施防止故障
#### 跨领域应用
eBPF与AI的结合将为多个领域带来变革:
1. **自动驾驶系统** :
* 实时监控车载系统性能
* 确保关键组件的可靠性
1. **边缘计算** :
* 在资源受限的设备上优化AI推理
* 减少网络延迟和带宽消耗
1. **医疗设备** :
* 监控关键医疗系统的性能和安全
* 确保医疗AI应用的可靠性
#### 未来发展方向
1. **eBPF加速器** :
* 专用硬件加速eBPF程序执行
* 降低处理开销
1. **统一的可观察性框架** :
* 整合系统、应用和AI模型的监控
* 提供端到端的性能分析
1. **自适应安全** :
* 基于AI和eBPF构建自适应安全系统
* 动态调整安全策略
1. **量子计算准备** :
* 扩展eBPF以支持量子计算环境
* 为量子-经典混合系统提供监控能力
1. **AI工作流优化** :
* 利用eBPF优化AI训练和推理流程
* 提高资源利用率和能效
### 5. 总结与展望(续)
#### 当前价值
* **统一的可观察性** :eBPF提供了一个统一的框架,整合了动态跟踪、静态跟踪和硬件监控等多种技术,使系统可观察性变得更加全面和一致。
* **安全增强** :通过细粒度的访问控制和安全验证,eBPF可以在不牺牲安全性的前提下提供强大的系统可观察性和网络控制能力。
* **性能优化** :eBPF程序直接在内核中执行,避免了频繁的上下文切换,大大降低了监控和网络处理的开销。
* **灵活性** :开发者可以编写自定义的eBPF程序,满足特定场景的需求,而不需要修改内核代码或加载内核模块。
#### 未来展望
随着技术的不断发展,eBPF的应用前景将更加广阔:
1. **全栈可观察性** :
* 从硬件到应用层的全方位监控
* 实时数据分析和问题诊断
1. **网络现代化** :
* 替代传统的网络栈组件
* 更高效的协议实现和路由决策
1. **安全革新** :
* 从被动检测到主动防御
* 细粒度的安全策略执行
1. **云原生生态整合** :
* 与Kubernetes、服务网格等更深入的集成
* 成为云原生基础设施的核心组件
1. **跨平台标准化** :
* 扩展到更多操作系统和平台
* 建立统一的接口标准
#### 面临的挑战
尽管eBPF前景广阔,但仍面临一些挑战:
1. **学习曲线** :
* 复杂的概念和编程模型
* 需要深入理解内核机制
1. **调试困难** :
* 内核级别的调试比用户空间更复杂
* 错误处理机制有限
1. **版本兼容性** :
* 不同内核版本支持的功能差异
* CO-RE机制仍在完善中
1. **生态系统成熟度** :
* 工具链和开发环境尚需改进
* 社区支持和文档体系建设
#### 结语
eBPF代表了Linux系统可编程性的未来方向。通过提供一个安全、高效、灵活的执行环境,eBPF正在重新定义我们与操作系统内核交互的方式。从网络数据包过滤到全面的系统可观察性,从简单的计数器到复杂的安全策略执行,eBPF已经证明了其作为系统扩展机制的强大潜力。
在分布式系统、云原生和人工智能的推动下,eBPF将继续演进,为解决现代计算环境中的挑战提供创新解决方案。随着社区的不断壮大和技术的持续完善,eBPF有望成为未来操作系统设计和实现的核心组成部分,为系统可观察性、网络和安全领域带来更多突破。
无论是系统管理员、开发人员还是安全专家,都应该关注eBPF技术的发展,掌握这一强大工具,以应对日益复杂的IT环境挑战。eBPF不仅是一项技术创新,更是一种全新的系统交互范式,它将继续重塑我们构建、监控和保护计算系统的方式。
================================================
FILE: book/10-extras/7-development-of-replay.md
================================================
## 确定性重放解决方案的发展历程
### 1. 确定性重放解决方案诞生的问题背景
软件开发中,调试(Debugging)一直是开发者面临的最具挑战性的任务之一。传统调试方法如打印日志、设置断点等在处理复杂系统时显得力不从心,特别是面对以下问题:
* **Heisenbugs** : 这类bug在观察时会改变行为或消失,使其难以重现和修复
* **时序相关的并发问题** : 多线程环境中的竞态条件可能仅在特定执行顺序下出现
* **非确定性行为** : 系统可能因随机数生成、线程调度、I/O操作等因素导致每次运行结果不同
* **难以复现的生产环境问题** : 在客户环境中发生的问题在开发环境中可能无法重现
这些挑战导致调试过程耗时且低效,严重影响开发效率和软件质量。为解决这些问题,确定性重放(Deterministic Replay)技术应运而生。
### 2. 确定性重放的思想与发展历程
#### 确定性重放的基本思想
确定性重放的核心思想是: **记录程序执行过程中的非确定性事件,并在重放阶段精确重现这些事件,使程序的执行路径与原始执行完全一致** 。这使开发者能够:
* 多次重放相同的执行路径进行调试
* 向前和向后遍历程序状态
* 分析程序行为而不影响其执行
#### 早期探索 (1990年代-2000年代初)
确定性重放技术的研究始于上世纪90年代的学术界:
* **Instant Replay (1987)** : 由莱斯大学提出的早期概念验证系统,专注于多处理器环境中的共享内存访问记录
* **Amber (1991)** : 一个为分布式系统设计的确定性重放框架,聚焦消息传递的记录和重放
* **DejaVu (1998)** : Java虚拟机级别的确定性重放系统,记录线程调度和I/O操作
这些早期系统主要在学术环境中使用,存在性能开销大、可用性差的问题,未能在实际开发中广泛应用。
#### 商业化尝试与挫折 (2000年代)
* **Reversible Debugger (2003-2005)** : 微软研究院开发的确定性重放原型,后来启发了部分Visual Studio调试功能
* **Green Hills TimeMachine (2004)** : 嵌入式系统领域的商业重放调试器,但仅限于特定硬件平台
* **Replay Solutions (2006-2012)** : 一家尝试将确定性重放商业化的创业公司,最终因技术困难和市场接受度不足而失败
这一时期的惨痛教训在于,全面的确定性重放在通用计算环境中实现成本过高,商业产品难以平衡性能、可用性和兼容性。
#### Mozilla RR: 实用确定性重放的突破 (2011年至今)
Mozilla Research在2011年启动的rr (record and replay)项目标志着确定性重放技术的重要突破:
* **轻量级设计** : 聚焦于Linux平台下的x86处理器,精简了设计目标
* **低开销记录** : 通过创新技术如硬件性能计数器减少记录阶段的性能影响
* **与GDB集成** : 利用开发者熟悉的调试工具界面,降低学习成本
* **开源模式** : 促进社区贡献和技术改进
Mozilla RR成功的关键在于其设计哲学: **不追求解决所有问题,而是聚焦于最常见、最有价值的应用场景** 。它主要关注单进程应用程序,不尝试解决分布式系统的全部挑战。
> ps: GDB内置的record/replay模式,和mozilla rr有关系吗?
>
> **GDB 的内置 record/replay 模式(`record full`等)是一个独立的功能,它**不依赖** Mozilla 的 rr (Record and Replay) 工具。**
>
> 不过,它们之间有密切的关系和区别:
>
> 1. **GDB 内置的 Record/Replay:**
> * 这是 GDB 本身的功能(使用 `record` 命令)。
> * 它的工作原理通常是记录每一条机器指令的执行和状态变化(例如 `record full`),因此通常 **速度较慢** ,且对内存消耗较大,有时被称为“指令级记录/回放”。
> * 它支持多种架构,但它的性能和功能(例如对多线程的支持)在某些情况下不如 rr。
> 2. **Mozilla 的 rr (Record and Replay):**
> * 这是一个 **独立的工具** ,最初由 Mozilla 开发者开发,用于调试 Firefox。
> * 它使用了一种更高效的方法,通过拦截系统调用和记录异步事件(例如使用硬件性能计数器)来确保确定性回放,因此通常 **开销更低** 。
> * rr 在回放时是作为一个 GDB **server** (调试服务端)来运行的,而你可以用标准的 GDB **client** (调试客户端)连接到它,并使用 GDB 的反向调试命令(如 `reverse-continue`, `reverse-next` 等)。
> * rr 主要是针对 **x86_64 架构上的 Linux 用户空间程序**设计的。
>
> **总结来说:** GDB 有自己的内置记录/回放机制,这是一个独立的功能。但由于 GDB 内置的记录/回放性能和扩展性限制(尤其是在面对像 Firefox 这样的大型多线程应用时), **rr 成为了在 Linux/x86_64 上进行高性能记录/回放调试的一个流行且更优的选择** ,它通过 GDB 的远程调试协议来提供服务,让用户能够通过 GDB 的界面使用它。
#### 其他重要进展
* **Chronon (2010-2016)** : 面向Java的"DVR for Java"时间旅行调试器,最终被CA Technologies收购
* **UndoDB (2007至今)** : 商业Linux确定性重放调试器,特别在嵌入式领域有所应用
* **Microsoft TTD (2016至今)** : Windows Time Travel Debugging,集成到WinDbg中的确定性重放功能
* **Pernosco (2018至今)** : 由RR开发者创建的基于云的调试平台,进一步提升了确定性重放的可用性
### 3. 分布式时代的确定性重放挑战
随着软件架构向分布式系统、微服务和云原生应用演进,确定性重放面临更大挑战:
#### 主要难点
* **多节点协同** : 需要捕获和同步分布在多个物理机器上的事件
* **规模问题** : 系统规模扩大导致记录开销和数据量激增
* **异构环境** : 不同服务可能使用不同语言、框架和运行时环境
* **非确定性来源增多** : 网络延迟、负载均衡、服务发现等引入更多不确定性
#### 现有的部分解决方案
尽管全系统确定性重放仍然难以实现,但业界已发展出几种针对性方案:
##### 分布式追踪系统
* **Jaeger、Zipkin、OpenTelemetry** : 这些工具虽不提供完整的确定性重放,但通过分布式追踪提供系统行为的可观测性
* **Chrome DevTools Protocol** : 为前端应用提供时间旅行调试能力
##### 事件溯源与CQRS
* **事件溯源(Event Sourcing)** : 通过记录所有状态变更事件,实现系统状态的重建和回溯
* **命令查询责任分离(CQRS)** : 配合事件溯源,提供对系统状态历史的查询能力
##### 隔离测试与服务虚拟化
* **服务存根(Service Stubbing)** : 模拟依赖服务行为,减少外部因素影响
* **请求记录与回放** : 记录特定服务的请求与响应,用于测试和调试
##### 不完全确定性重放
* **Debugging Microservices (Netflix)** : 记录关键服务间交互而非完整状态
* **Jepsen和TLA+** : 形式化验证和混沌工程工具,帮助发现分布式系统中的问题
### 4. 人工智能时代的确定性重放发展方向
AI时代为确定性重放带来新挑战也带来新机遇:
#### AI增强的调试体验
* **智能根因分析** : 利用机器学习分析执行轨迹,自动识别异常模式和潜在根因
* **自然语言调试界面** : "为什么这个变量在第500步后变成了null?"等自然语言问题直接获得答案
* **异常预测** : 通过学习历史执行模式,预测可能出现的问题
#### 针对AI系统的确定性重放
* **神经网络执行的重放** : 记录大型模型推理过程中的关键决策点
* **训练过程重放** : 捕获模型训练中的关键节点状态,用于调试和理解
* **解释性增强** : 结合可解释AI技术,提供模型决策过程的可视化和重放
#### 混合方法与领域特定解决方案
* **领域特定语言(DSL)** : 为特定应用领域设计的确定性执行环境
* **可验证计算** : 结合形式化方法与确定性重放,提供更强的正确性保证
* **硬件辅助** : 利用新型处理器特性如Intel PT (Processor Trace)降低记录开销
#### 开放挑战与前沿探索
* **跨平台一致性** : 在异构环境中实现一致的重放体验
* **隐私保护下的重放** : 在记录敏感数据的同时保护用户隐私
* **规模化重放** : 为超大规模系统设计高效的记录与重放机制
* **量子计算环境** : 为本质非确定性的量子计算提供调试能力
### 5. 总结与展望
确定性重放技术从学术概念到Mozilla RR等实用工具的发展,展示了软件工程面对复杂性挑战的演进过程。尽管在分布式和云原生环境中面临更多困难,确定性重放的核心思想——通过捕获和重现非确定性事件来实现可预测的调试体验——仍然具有重要价值。
随着AI技术的融入和硬件能力的提升,确定性重放很可能发展为更智能、更高效的调试范式。未来的解决方案将不再追求完美的全系统重放,而是关注特定领域的高价值应用,结合其他技术如可观测性、形式化验证和机器学习,共同提升软件质量和开发效率。
确定性重放技术告诉我们,有时候解决问题的最佳方式不是构建完美的全能工具,而是深入理解问题本质,针对最有价值的场景提供实用的解决方案。这一理念不仅适用于调试工具,也值得整个软件工程领域借鉴。
================================================
FILE: book/10-extras/8-development-of-debug-dsys.md
================================================
## 分布式系统调试的发展历程
### 1. 分布式系统调试诞生的问题背景
随着计算机科学的发展,单机系统逐渐无法满足高并发、高可用、大规模数据处理的需求,分布式系统应运而生。分布式系统将计算任务分散到多台计算机上,通过网络协作完成复杂的业务逻辑,极大地提高了系统的性能和可靠性。然而,分布式系统的复杂性也带来了前所未有的调试挑战:
* **状态分散性** :系统状态分散在多个节点上,难以获得全局一致的视图
* **时序不确定性** :分布式事件的发生顺序难以精确控制和复现
* **异步通信** :组件间的异步消息传递增加了调试复杂度
* **部分故障** :系统可能处于部分失效状态,某些节点故障而其他节点正常运行
* **环境依赖性** :问题可能只在特定环境或配置下出现
这些特性使得传统的调试方法(如单步执行、断点调试)在分布式系统中难以应用。开发者面临着如何理解、分析和修复分布式系统中的错误这一巨大挑战。
#### 传统调试方法的局限性
在单机系统时代,开发者可以依赖诸如GDB、Visual Studio Debugger等工具,通过设置断点、检查变量、单步执行代码等方式直观地跟踪程序执行流程。然而,这些工具在分布式环境中面临严重局限:
1. **无法捕获跨节点交互** :传统调试器无法捕获跨节点的消息传递和状态变化
2. **难以重现问题** :由于时序不确定性,同样的操作可能导致不同的结果
3. **调试过程影响系统行为** :调试器的介入可能改变系统的时序特性,导致"观察者效应"
4. **难以处理大规模数据** :分布式系统产生的日志和状态信息常常过于庞大,难以手动分析
这些挑战催生了专门针对分布式系统的调试解决方案的需求。
### 2. 分布式系统调试方案的发展历程
#### 初期阶段:日志分析与追踪(1990年代-2000年代初)
在分布式系统调试的早期阶段,开发者主要依赖于日志分析。每个节点产生独立的日志文件,开发者通过手动分析和关联这些日志来理解系统行为。
**代表性技术与事件:**
* **集中式日志系统** :如Syslog,允许将多个节点的日志集中到一个位置进行分析
* **日志分析工具** :如Splunk(2003年推出)提供了更强大的日志搜索和分析能力
* **分布式追踪的理论基础** :Google发表了Dapper论文(2010年),为后来的分布式追踪系统奠定了基础
**教训与挑战:**
* **时间同步问题** :不同节点的时钟可能不同步,导致日志时间戳不准确,难以重建事件顺序
* **缺乏关联性** :难以将不同节点上的相关事件联系起来
* **分析效率低** :手动分析大量日志耗时且容易出错
#### 发展阶段:分布式追踪与监控(2000年代中期-2010年代中期)
随着分布式系统规模的扩大,单纯依靠日志分析变得越来越困难。开发者开始寻求更系统化的解决方案。
**代表性技术与事件:**
* **分布式追踪系统** :
* Zipkin(2012年,由Twitter开源)
* Jaeger(2017年,由Uber开源)
* X-Trace(2007年,UC Berkeley)
* **监控系统的演进** :
* Nagios(1999年)
* Prometheus(2012年)
* Grafana(2014年)
* **APM工具** :
* New Relic(2008年)
* AppDynamics(2008年)
* Dynatrace(1993年,但在2000年代后期重新定位为APM工具)
**教训与挑战:**
* **追踪数据爆炸** :随着系统规模增长,追踪数据量呈爆炸式增长,需要抽样或过滤
* **追踪对性能的影响** :全面追踪可能导致系统性能下降
* **缺乏事后调试能力** :这些系统主要用于监控和分析,而非实时调试
#### 突破阶段:交互式分布式调试(2010年代中期-2020年代初)
随着容器化和Kubernetes等技术的普及,出现了真正意义上的交互式分布式调试工具。
**代表性技术与事件:**
* **SquashIO的Squash Debugger** (2017年):这是一个重要的里程碑,它允许开发者在Kubernetes集群中进行实时调试。Squash集成了传统调试器(如GDB、Delve)与Kubernetes环境,使开发者能够在分布式环境中设置断点和检查变量。
* **Telepresence** (2017年):允许开发者将本地开发环境与远程Kubernetes集群连接起来,在本地调试运行在集群中的服务。
* **Rookout** (2018年):提供了非侵入式的调试能力,允许在生产环境中实时收集调试数据,而无需重启应用或修改代码。
**教训与挑战:**
* **平台特定性** :这些工具往往与特定平台(如Kubernetes)紧密耦合
* **语言依赖性** :部分工具只支持特定的编程语言
* **难以扩展到超大规模系统** :在有数千个微服务的环境中,定位问题仍然十分复杂
#### 惨痛教训:真实案例
**案例1:Knight Capital的灾难性部署(2012年)**
Knight Capital是一家金融交易公司,在2012年8月1日,由于一个分布式系统部署错误,公司在45分钟内损失了4.6亿美元。问题的根源是软件部署不一致,导致活跃服务器使用了旧代码,而这些服务器又与使用新代码的服务器交互。由于缺乏有效的分布式调试工具,Knight Capital花了数小时才理解并修复问题,但为时已晚。
**案例2:亚马逊S3宕机事件(2017年)**
2017年2月28日,亚马逊S3服务发生了严重的宕机事件,影响了大量依赖AWS的网站和服务。问题的根源是一个看似简单的命令错误,但在分布式系统中产生了级联故障。尽管亚马逊拥有大量监控和调试工具,但系统的复杂性使得快速识别和解决问题变得极其困难。
### 3. 微服务与云原生时代的分布式调试挑战
随着微服务架构和云原生技术的广泛采用,分布式系统调试面临新的挑战:
* **服务数量激增** :一个企业级应用可能包含数百甚至数千个微服务
* **动态性增强** :容器的自动扩缩容、服务网格等技术使系统更加动态
* **多语言、多框架** :微服务可能使用不同的编程语言和框架实现
* **复杂的依赖关系** :服务之间的复杂依赖关系使得故障定位更加困难
#### 当前解决方案
**服务网格技术** :
* **Istio** (2017年):提供了流量管理、安全性和可观察性功能
* **Linkerd** (2016年):专注于轻量级、简单的服务网格实现
* **Consul** (2014年):提供服务发现和配置管理功能
**可观察性三支柱** :
* **日志(Logs)** :ELK/EFK Stack(Elasticsearch、Logstash/Fluentd、Kibana)
* **指标(Metrics)** :Prometheus、Grafana等
* **追踪(Traces)** :OpenTelemetry(2019年)统一了追踪标准
**混沌工程** :
* **Chaos Monkey** (2011年,Netflix):有意引入故障以测试系统弹性
* **Gremlin** (2016年):提供了更系统化的混沌工程平台
**生产环境调试** :
* **Lightstep** (2015年):提供了深入的分布式追踪和分析能力
* **Honeycomb** (2016年):专注于可观察性和事件驱动的调试
虽然这些工具极大地提高了分布式系统的可观察性,但仍然缺乏真正的交互式调试能力。开发者需要组合使用多种工具,并且需要额外的专业知识来解释和分析获得的数据。
### 4. 人工智能时代的分布式系统调试
随着人工智能技术的飞速发展,分布式系统调试也开始融入AI能力,开启了新的可能性。
#### 当前趋势与探索
**AIOps(人工智能运维)** :
* **异常检测** :使用机器学习算法自动检测系统异常
* **根因分析** :通过因果推理分析故障根源
* **自动修复** :在某些情况下,系统可以自动生成修复方案
**代表性技术与平台** :
* **Datadog的Watchdog** (2018年):使用AI检测系统异常
* **IBM的Watson AIOps** (2020年):应用AI技术进行问题诊断和解决
* **Microsoft的BugLab** (2021年):使用AI辅助bug定位和修复
#### 未来发展方向
**大型语言模型(LLM)辅助调试** :
* **代码理解与分析** :LLM可以理解复杂的分布式系统代码和架构
* **日志分析与解释** :自动分析日志并提供人类可理解的解释
* **自动生成调试计划** :根据系统描述和问题现象,生成调试步骤
**自适应调试系统** :
* **动态调整观察点** :根据系统行为自动调整数据收集点
* **智能采样** :在保证有效性的前提下,减少数据收集量
* **预测性调试** :在问题发生前预测可能的故障点
**数字孪生与模拟** :
* **系统行为模拟** :通过数字孪生技术模拟分布式系统行为
* **假设验证** :在虚拟环境中测试修复方案
* **时间旅行调试** :在模拟环境中实现时间前后移动的调试能力
**自主式调试助手** :
* **调试代理** :自主运行在分布式系统中,收集和分析数据
* **自动化工具链** :集成多种调试工具,形成闭环调试流程
* **持续学习** :通过历史调试数据不断改进调试能力
### 5. 总结与展望
分布式系统调试从最初的简单日志分析,发展到今天的综合性解决方案,经历了多个阶段的演变。每个阶段都伴随着技术的突破和惨痛的教训。
#### 关键发展阶段回顾
1. **初期的日志分析阶段** :依靠简单工具,效率低下
2. **分布式追踪与监控阶段** :提高了系统的可观察性,但缺乏交互能力
3. **交互式调试阶段** :以Squash Debugger为代表,实现了真正的分布式调试
4. **微服务与云原生时代** :服务网格和可观察性工具的广泛应用
5. **人工智能辅助调试** :开始探索AI在分布式调试中的应用
#### 未来展望
分布式系统调试的未来将可能是一个全方位的综合平台,它将包含:
* **AI驱动的根因分析** :自动分析系统行为,定位问题根源
* **自适应调试工具** :根据系统特性和问题类型自动选择合适的调试策略
* **无代码调试接口** :允许开发者通过自然语言描述进行调试
* **实时协作调试** :支持多人协作调试复杂系统
* **预防性调试** :在问题发生前预测并防范潜在问题
随着技术的不断进步,我们有理由相信,未来的分布式系统调试将变得更加智能、高效和用户友好。这将大大降低开发和维护分布式系统的成本,推动分布式计算技术的进一步发展。
### 参考文献
1. [squash debugger](https://squash.solo.io/overview/), https://squash.solo.io/overview/
2. [rookout debugger](https://www.rookout.com/solutions/live-debugger/), https://www.rookout.com/solutions/live-debugger/
3. [telepresence](https://telepresence.io/), https://telepresence.io/
================================================
FILE: book/10-extras/9-ai-assisted-debugging.md
================================================
## Latest: AI Agent自动化调试
### 思考:AI是否可以在调试领域有所作为
在软件开发过程中,调试是一项耗时且重复性高的工作。传统的调试方式通常是开发者手动与调试器交互:设置断点,运行到断点,检查变量状态,决定下一步动作 …… 重复上述过程。这种方式在定位复杂bug时往往需要进行数十次或数百次的交互,是典型的"体力活"。
随着大型语言模型(LLM)的发展,我们有机会将这类重复性工作自动化。AI Agent可以:理解程序逻辑和错误症状,根据当前调试状态推导下一步调试策略,通过ReAct(Reasoning + Acting)模式不断执行并根据结果调整下一步调试命令,从而自动定位问题所在。
这样做的优势包括:
1. **效率提升**:从手动数十次交互降低到自动多轮推理
2. **减少人工成本**:让专家从重复性工作中解放出来
3. **提高诊断准确性**:AI可以系统地遍历可能的状态空间
4. **支持复杂场景**:多线程、并发、分布式系统等复杂场景的调试,AI更能解放人工调试的局限性
### 原理:AI自动化调试是否可以真实落地
#### 人工调试时与调试器的交互模式
通常,我们使用调试器时是通过交互式终端(Interactive Terminal):
```
用户+交互式终端 ←→ 调试器进程 ←→ 被调试程序进程
```
- **输入(stdin)**:用户在终端输入调试命令(break, step, print等)
- **输出(stdout)**:调试器打印执行结果、变量信息、源代码视图等
- **实时反馈**:用户立即看到结果,基于结果调整下一步操作
#### AI自动化调试时与调试器的交互模式
当使用I/O重定向时,流程变为:
```
AI Agent ←→ stdin/stdout/stderr 文件 ←→ 调试器进程 ←→ 被调试程序进程
```
**关键洞察**:
1. **行缓冲执行**:调试器每次从stdin读取一行命令,执行该命令,然后将结果写入stdout
2. **AI驱动**:AI Agent作为外部控制器,根据当前stdout内容决定下一条命令
3. **多轮交互**:通过不断读取stdin反馈、调用LLM推理、写入新命令到stdin,实现自动化调试
#### 具体可行的工作流程
```
[和AI交互阶段]
你好,程序main中有个bug,你帮我定位下。你可以使用tinydbg对其进行调试,tinydbg支持输入输出重定向,具体参数可以查看 `tinydbg help`。
这个阶段,AI会通过工具调用了解tinydbg的使用方法、IO重定向的方法。当LLM确定了如何使用之后,就会推理出下一步要执行的 `tinydbg命令`, 以及接下来大致希望执行的调试动作,blablabla。
[初始化阶段]
1. 将调试命令序列写入stdin.txt
2. 启动调试器:tinydbg exec ./main --allow-non-terminal-interactive < stdin.txt > stdout.txt 2> stderr.txt
3. 调试器以行缓冲模式读取stdin,每次读取一个命令来执行
[执行阶段 - 每次迭代]
1. 调试器读入一条命令(如 "step")
2. 执行该命令,得到结果(源代码位置、变量值等)
3. 将结果写入stdout,如果报错将错误信息写入stderr
4. 调试器尝试读取下一条命令
[AI反馈循环]
1. AI Agent读取stdout的最新输出和stderr的最新错误信息
2. 通过ReAct推理判断:
- 当前程序状态是什么?
- 是否到达预期状态?
- 下一步应该怎么做?
3. 追加新命令到stdin
4. 调试器继续读取命令并执行
5. 返回步骤1
[终止阶段]
1. 当AI判断bug已定位或问题已解决
2. 追加 "exit" 命令
3. 调试器退出,stdin/stdout/stderr保存完整的调试过程
```
#### 为什么这种模式有效
1. **确定性**:每个调试命令的效果完全由当前程序状态决定,方便AI推理
2. **完全可观测**:所有调试输出(stdout/stderr)都被记录,便于事后分析
3. **灵活性**:AI可以在任何时刻基于最新输出调整策略
4. **可复现**:完整的stdin记录了调试过程,可以完全重放
5. **兼容性**:对调试器无特殊要求,只要支持IO重定向即可
### 案例演示:Array Index Out Of Bounds
#### 1. 问题代码
文件:`main.go`
```go
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5}
sum := 0
for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a)
sum += a[i]
}
fmt.Println("Sum:", sum)
}
```
**问题**:循环条件为 `i <= len(a)` 而非 `i < len(a)`,导致当 `i == 5` 时访问 `a[5]`,超出数组边界。
**预期表现**:运行程序会触发panic: `runtime error: index out of range [5] with length 5`
#### 2. 编译与调试准备
```bash
cd /home/zhangjie/debugger101/tinydbg/examples/llm_debug2
# 使用Go 1.24.6编译,禁用优化
go1.24.6 build -gcflags 'all=-N -l' -o main main.go
# 验证编译成功
ls -la main
```
#### 3. AI驱动的调试过程
>这里的AI Agent可选项就很多了,比如cursor、vscode copilot甚至你自己写的AI Agent。这个读者根据自己的喜好进行选择就可以了。
LLM输出工具调用参数,驱动AI Agent执行调试器help命令(`tinydbg help` 和 `tinydbg help redirect`)来了解如何实现重定向。学习到下列命令:`tinydbg exec ./main --allow-non-terminal-interactive < stdin.txt > stdoutxxx.txt 2> stderrxxx.txt` 。接下来LLM就继续推理初步的调试命令,如先停在main.main入口,再一步步尝试其他调试命令及执行结果,来逼近最终问题。那么调试命令LLM如何输出的呢?其实就是调用WriteFile之类的toolcall将对应的调试命令写入stdin.txt。
下面是真实执行过程中的演示,您可以使用常见的AI Agent工具(如cursor、vscode copilot等进行测试)。
##### 第1轮:设置断点,达到初始状态
**AI推理**:程序无法直接看到内部状态,需要使用调试器。首先应在 `main` 函数入口设置断点,然后运行到该断点。
**调试命令** (写入stdin.txt第1-2行):
```
break main.main
continue
```
**执行结果** (stdout片段):
```
(tinydbg) Breakpoint 1 set at 0x4b1af3 for main.main() ./main.go:5
(tinydbg) > [Breakpoint 1] main.main() ./main.go:5 (hits goroutine(1):1 total:1) (PC: 0x4b1af3)
1: package main
2:
3: import "fmt"
4:
=> 5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a)
9: sum += a[i]
10: }
```
**AI观察**:程序已停在function entry point。现在应该检查初始变量。
##### 第2轮:尝试打印变量(失败)
**AI推理**:需要理解程序的初始状态。尝试打印数组 `a` 的当前值。
**调试命令** (第3行):
```
print a
```
**执行结果** (stderr片段):
```
Command failed: could not find symbol value for a
```
**AI学习**:当前执行位置虽然在 `main` 入口,但变量 `a` 尚未初始化。需要向前执行。
##### 第3轮:逐步执行,初始化变量
**AI推理**:使用 `step` 命令逐行执行,让变量完成初始化。
**调试命令** (第4行):
```
step
```
**执行结果** (stdout片段):
```
(tinydbg) > main.main() ./main.go:6 (PC: 0x4b1afa)
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
...
```
**AI观察**:现在停在第6行,即 `a` 的声明处。
##### 第4轮:再次打印变量
**AI推理**:已经到达变量初始化语句。再执行一次 `step` 让赋值完成,然后打印。
**调试命令** (第5-7行):
```
step
print a
```
**执行结果** (stdout片段):
```
(tinydbg) > main.main() ./main.go:7 (PC: 0x4b1b75)
7: sum := 0
...
(tinydbg) []int len: 5, cap: 5, [1,2,3,4,5]
```
**AI确认**:`a = [1,2,3,4,5]`,长度为5。
##### 第5轮:进入循环,检查循环变量
**AI推理**:已理解初始状态:`a` 是长度为5的数组。现在需要进入循环,理解循环如何执行。首先应该到达循环的 `for` 语句。
**调试命令** (第8-10行):
```
step
print i
```
**执行结果** (stdout片段):
```
(tinydbg) > main.main() ./main.go:8 (PC: 0x4b1b7e)
=> 8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a)
9: sum += a[i]
(tinydbg) (tinydbg) > main.main() ./main.go:9 (PC: 0x4b1b9c)
=> 9: sum += a[i]
(tinydbg) 0
```
**AI确认**:`i = 0`,已进入循环体第一次迭代。
##### 第6轮:循环遍历(多次迭代)
**AI推理**:现在需要系统地观察循环如何进行。继续执行 `step` 和 `print i`,观察循环变量的递增。
**调试命令** (第11-28行,重复的 step/print i):
```
step
print i
step
print i
step
print i
step
print i
...(共累计到i=4)
```
**执行结果** (stdout关键片段):
```
(tinydbg) 0
(tinydbg) 1
(tinydbg) 2
(tinydbg) 3
```
**AI观察**:
- 循环变量依次为:0, 1, 2, 3
- 这些值都在数组范围 `[0, 4]` 内(因为数组长度为5)
- 循环条件为 `i <= len(a)`,意味着还会执行 `i = 5` 的情况
##### 第7轮:触发异常
**AI推理**:根据循环条件 `i <= 5`,下一次循环应该会有 `i = 5` 的情况。这会导致访问 `a[5]`,超出数组界限。为了看到异常,应该执行 `continue`(继续执行直到异常或程序结束)。
**调试命令** (第29行):
```
continue
```
**执行结果** (stdout关键片段):
```
(tinydbg) > [unrecovered-panic] runtime.fatalpanic() /home/zhangjie/.goenv/sdk/go1.24.6/src/runtime/panic.go:1301
(hits goroutine(1):1 total:1) (PC: 0x43da84)
Warning: debugging optimized function
runtime.curg._panic.arg: interface {}(string) "runtime error: index out of range [5] with length 5"
1296: // fatalpanic implements an unrecoverable panic. It is like fatalthrow, except
1297: // that if msgs != nil, fatalpanic also prints panic messages and decrements
1298: // runningPanicDefers once main is blocked from exiting.
...
=>1301: func fatalpanic(msgs *_panic) {
```
**AI诊断**:
- 程序已捕获到panic异常
- 异常信息:`runtime error: index out of range [5] with length 5`
- 这正好对应 `i = 5` 时访问 `a[5]` 的情况
- 根本原因:循环条件应该是 `i < len(a)` 而非 `i <= len(a)`
##### 第8轮:退出调试器
**AI结论**:Bug已定位,无需继续调试。
**调试命令** (第30行):
```
exit
```
### 完整的调试文件内容
#### stdin.txt - 调试命令序列
```
break main.main
continue
print a
step
print a
step
print a
step
print i
step
print i
step
print i
step
print i
step
print i
step
print i
step
print i
step
print i
step
print i
continue
print i
exit
```
#### stdout.txt - 调试器输出(完整)
```
Type 'help' for list of commands.
(tinydbg) Breakpoint 1 set at 0x4b1af3 for main.main() ./main.go:5
(tinydbg) > [Breakpoint 1] main.main() ./main.go:5 (hits goroutine(1):1 total:1) (PC: 0x4b1af3)
1: package main
2:
3: import "fmt"
4:
=> 5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
(tinydbg) (tinydbg) > main.main() ./main.go:6 (PC: 0x4b1afa)
1: package main
2:
3: import "fmt"
4:
5: func main() {
=> 6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
(tinydbg) (tinydbg) > main.main() ./main.go:7 (PC: 0x4b1b75)
2:
3: import "fmt"
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
=> 7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) []int len: 5, cap: 5, [1,2,3,4,5]
(tinydbg) > main.main() ./main.go:8 (PC: 0x4b1b7e)
3: import "fmt"
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
=> 8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) (tinydbg) > main.main() ./main.go:9 (PC: 0x4b1b9c)
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
=> 9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) 0
(tinydbg) > main.main() ./main.go:8 (PC: 0x4b1bc8)
3: import "fmt"
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
=> 8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) (tinydbg) > main.main() ./main.go:9 (PC: 0x4b1b9c)
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
=> 9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) 1
(tinydbg) > main.main() ./main.go:8 (PC: 0x4b1bc8)
3: import "fmt"
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
=> 8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) (tinydbg) > main.main() ./main.go:9 (PC: 0x4b1b9c)
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
=> 9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) 2
(tinydbg) > main.main() ./main.go:8 (PC: 0x4b1bc8)
3: import "fmt"
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
=> 8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) (tinydbg) > main.main() ./main.go:9 (PC: 0x4b1b9c)
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
=> 9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) 3
(tinydbg) > main.main() ./main.go:8 (PC: 0x4b1bc8)
3: import "fmt"
4:
5: func main() {
6: a := []int{1, 2, 3, 4, 5}
7: sum := 0
=> 8: for i := 0; i <= len(a); i++ { // Bug: loop condition should be i < len(a) to avoid index out of range
9: sum += a[i]
10: }
11: fmt.Println("Sum:", sum)
12: }
(tinydbg) (tinydbg) > [unrecovered-panic] runtime.fatalpanic() /home/zhangjie/.goenv/sdk/go1.24.6/src/runtime/panic.go:1301 (hits goroutine(1):1 total:1) (PC: 0x43da84)
Warning: debugging optimized function
runtime.curg._panic.arg: interface {}(string) "runtime error: index out of range [5] with length 5"
1296: // fatalpanic implements an unrecoverable panic. It is like fatalthrow, except
1297: // that if msgs != nil, fatalpanic also prints panic messages and decrements
1298: // runningPanicDefers once main is blocked from exiting.
1299: //
1300: //go:nosplit
=>1301: func fatalpanic(msgs *_panic) {
1302: pc := sys.GetCallerPC()
1303: sp := sys.GetCallerSP()
1304: gp := getg()
1305: var docrash bool
1306: // Switch to the system stack to avoid any stack growth, which
(tinydbg) exit
```
#### stderr.txt - 错误输出(关键失败案例)
```
Command failed: could not find symbol value for a
Command failed: could not find symbol value for a
Command failed: could not find symbol value for i
Command failed: could not find symbol value for i
Command failed: could not find symbol value for i
Command failed: could not find symbol value for i
Command failed: could not find symbol value for i
```
**说明**:前两条错误是因为在变量完全初始化前尝试打印。后续的错误是在循环条件判断时尝试打印尚未进入循环体的 `i`。如果读者感兴趣可以手动模拟下上述调试过程,感受下LLM+toolcall+调试器IO重定向基础上的自动化调试的威力。
### 局限性和未来方向
#### 当前局限
1. **上下文窗口是第一瓶颈**:自动化调试依赖“持续观察 + 连续推理”,但真实工程里的调用链、变量快照、日志片段很容易超出模型可处理窗口,导致关键信息被截断或被稀释。
2. **调试轨迹长度持续增长**:随着toolcall轮数增多,历史命令与中间结论会不断堆积。如果没有结构化压缩机制,AI容易出现“记忆漂移”,重复已做过的尝试或忽略早期关键线索。
3. **长期记忆能力仍在演进**:当前很多Agent更多依赖短期上下文,而不是稳定、可检索、可更新的长期memory。跨会话、跨版本、跨故障类型复用经验的能力还有提升空间。
4. **信息组织方式影响推理上限**:不是只有模型参数决定效果,调试证据如何分层(现象、路径、假设、验证)同样关键。若上下文组织混乱,即使模型更强也可能无法稳定收敛。
5. **其他问题可能存在但可工程化处理**:例如工具调用预算、观测信号噪声、环境差异等,在部分场景中可能带来额外挑战,但总体属于可通过工程策略逐步优化的问题。
#### 未来方向
1. **上下文压缩与分层记忆**:将长链路调试信息压缩为结构化摘要(症状、证据、假设、结论),并通过可检索memory实现“短上下文推理 + 长记忆补全”。
2. **更大上下文窗口模型落地**:随着百万级甚至2M上下文窗口模型逐步成熟,AI一次可处理的调试信息规模将显著提升,长链路分析能力有望变得更稳定。
3. **动态记忆更新机制**:让Agent在调试过程中持续写入、修正、淘汰记忆项,避免“旧结论污染新推理”,提高多轮决策一致性。
4. **证据驱动的推理框架**:将日志、变量、调用栈、断点结果统一为证据图,按可信度驱动下一步动作,减少盲目试探和重复探索。
5. **time-travel debugging**: 通过类似 `rr` 的工具,可以逆向调试,某些情景下可以缓解多次重启调试会话对上下文窗口大小的侵蚀。
6. **模型进化与工程系统共振**:未来突破不只来自更强模型,也来自更好的Agent框架、工具协议与可观测性基础设施协同,自动化调试的上限会持续上移。
### 本节小结
本节主要探讨了AI Agent自动化调试的可行性与实践路径,核心内容包括:利用stdin/stdout重定向把调试器交互转化为可编排的自动化流程;通过真实案例演示“推理-执行-反馈”的闭环定位方法;围绕当前AI阶段性瓶颈,重点分析上下文窗口、长链路记忆与信息组织对调试效果的影响。整体上,自动化调试的愿景清晰且可落地,当前问题更多是能力边界与工程细节问题,而非方向性障碍。随着上下文压缩、memory机制和大上下文模型持续演进,AI自动化调试有望从“可用”走向“稳定好用”。
================================================
FILE: book/10-extras/README.md
================================================
## 软件调试技术全景:工具与场景的精准适配
### 引言
软件调试(Debugging)是贯穿软件生命周期的重要活动,其目标可能是一个进程、一个核心转储文件、带有不同优化特性的复杂程序,一个单体服务,也可能是一个分布式系统。**调试的本质是系统性认知与场景化工具的结合**。当开发者抱怨 “某个工具没用” 时,往往是因为他尚未遭遇需要该工具特性的复杂场景。本文将通过核心调试技术及其适用场景的解析,展示现代软件调试的立体图景。
### 核心调试技术矩阵
#### 1. 调试器(Debugger)
调试器设计实现是全书介绍的目标,大家读到这里自然更不陌生了。调试器是通过断点控制、内存分析、堆栈跟踪等机制实现对目标进程状态观测的交互式工具。调试器对于单进程、多进程、多线程应用程序的实时状态分析中,作用非常大。现代调试器如go-delve/delve甚至实现了协程级的调试能力。对于操作系统内核的调试一般需要内核级调试器,如Linux kdb,Windows winDBG。对于编译期优化后的代码,借助DWARF也可以进行调试,比如内联函数。
> 前面提到过调试器也从一个简单的3层架构,演化到前后端分离式架构,以应对不同软硬件架构的差异。一些主流的IDE为了能与不同的调试器backend进行集成,也需要调试协议层面的标准化支持,如DAP(Debugger Adapter Protocol)。
>
> 调试器对单进程、少量进程的程序调试还算比较简单,微服务架构下的分布式系统调试是一个挑战。
#### 2. 日志系统(Logging)
打日志也是一种非常普遍的调试手段,只要有源码,不管是本地运行的命令行程序,还是远程运行的服务,在可疑位置加几行代码,重新部署运行,就可以观察验证。打日志虽然适用面广,但并不总是那么高效。比如可能需要多次修改源码、编译构建、部署测试才能缩小问题范围。在某些代码交付、制品管理比较严格的企业,还需要经过一系列的评审、CI/CD流程检查。对于分布式系统,一般需要借助远程日志系统,并通过TraceID来串联完整的事务处理日志。为了方便检索,还可能需要结构化日志解析、存储、检索能力的支持,比如ELK Stack。
> 日志就是些不断追加的文本,如何从中提取有价值的信息?
>
> 在远程日志系统出现之前, `tail -f <xyz.log> | grep` 或者 `grep <xyz.log>` 就是大家最常用的操作了吧,如果日志很多还需要 `ls -rth` 查看下日志最后修改时间以确定日志落在哪个文件。远程日志系统出现之后,我们需要将日志进行采集、清洗、解析,比如提取出traceid, loglevel, timestamp, event message 以及其他参数信息,上报到远程日志,远程日志基于这些构建一些索引方便我们进行检索。
>
> 除了上述提及的流程方面的问题,远程日志系统有个不便之处,就是日志量大的情况下、等待日志入库、能被检索出来,一般都有分钟级延迟,对于希望高效调试的情景可能非常不便。
#### 3. 指标监控(Metrics)
监控打点,是一个软件工程师的必修课。有些新手只知道在出错的时候加个监控上报,但是老手却会在每个接口的总请求量、成功量、失败量加监控上报,处理逻辑进入一些关键分支、异常分支也会加上报,对于整体逻辑的处理耗时、其中关键步骤的耗时也会加监控。为什么?就是因为老司机们知道解决线上问题的急迫性,以及如何更好地定位问题。监控打点如果加的细致,也可以作为分析代码执行路径的一种根据,至少可以知道大盘的一个情况。再加上对代码的熟悉程度,也能比较容易缩小问题范围。
> 如CPU利用率、内存泄露趋势图会让开发者迅速联想到耗CPU、耗内存的部分代码,再比如事务处理耗时分布可以帮助联想到某些处理步骤。业务侧指标上报一般借助框架提供的操作,平台侧指标监控一般来源于平台可观测性能力的建设,如机器(物理机、虚拟机、容器)的网络、文件系统、任务调度、CPU、内存等情况,最近几年eBPF在这方面非常出彩。
>
> 借助监控指标缩小问题范围后,还是需要再借助源码、其他手段进一步确定根因,在确定根因之前,监控指标也只是现象。
#### 4. 追踪系统(Tracing)
在微服务架构下的分布式系统领域,如何跟踪事务处理的全流程,是一个挑战。[Google dapper](https://static.googleusercontent.com/media/research.google.com/en//archive/papers/dapper-2010-1.pdf) 详细介绍了如何化解这些难题,如事务处理中调用了哪些服务、调用顺序、各自耗时、各自成功与否、请求及响应参数、关联事件信息等。该论文公开后,市面上出现了zipkin、jaeger等众多开源产品。
其实大家Chrome Developer Tools的Timing Tab也能看到类似的网络请求的tracing可视化信息,区别是dapper里的每个span展示的往往是微服务粒度的,而Timing Tab展示的是每个关键步骤的信息,如Queueing、Request Sent、Wait for response、Content Download。go tool trace也借鉴了这里的思路,将整个go runtime的执行情况都纳入了tracing分析之中,而且还提供了API允许开发者创建自己关心的tracing。
> 早期的opentracing往往聚焦在tracing领域,和metrics、logging的结合比较少,这意味着当你看到一个耗时比较久的span时,如果缺少日志系统的支持,你可能还是不知道当时的问题详情是什么,缺少日志嘛。如果没有关联metrics,你也不知道特定的某个请求触发了什么监控打点。
>
> 这就是早期opentracing、opencencus等存在的不足,现在opentelemetry意识到了这点,将logging、metrics、tracing整合到了一起,形成了新的行业的可观测性标准。[opentelemetry](https://opentelemetry.io/) 可以在框架层实现,也可以借助eBPF的强大能力作为平台化能力来实现。
#### 5. 二分定位法
##### 二分搜索
二分查找,特别适用于在有序数组中寻找目标元素,时间复杂度为 O(log n)。通过二分不断缩小搜索范围,直到找到目标或确定目标不存在。大家有算法基础,对此应该不陌生,这里我们想谈谈二分思想在bug定位方面的实践。
##### git bisect
借助git bisect寻找引入bug的commit,`git bisect (good|bad) [<rev>...]`。假定我们发现当前版本存在bug,bad=HEAD,但是并不是当前版本首次引入的,但是我们凭印象记得v1.0是正常的,那么引入bug的commit肯定介于v1.0和当前最新版本之间。git提交历史中的commits都是按照时间顺序有序排列的,意味着可以采用二分查找的方式每次取一个commit,然后测试当前commit是否有bug,然后通过 `git bisect good|bad` 将比较结果反馈给git,辅助git确定下次的查找范围。附录[《Appendix: 使用 git bisect 定位引入bug的commit》](../12-appendix/3-git-bisect.md)提供了一个示例。
`git bisect` 可以在git commit粒度下锁定bug,但是这对于大型项目还不够。思考下面几个问题:1)程序中不止有一个bug;2)程序中的bug是在某几个特性共同开启的情况下才会出现;3)这些特性的代码分散在多个commit、多个源文件位置。这种情况下使用 `git bisect` 确定导致bug的源文件位置的最小集合比较困难,尤其是在具有一定规模的项目中,如何能解决这类问题呢?
##### bisect reduce
Russ Cox等人提出了一种方法,用于快速定位go编译器、go运行时中bug位置的方法,[Hash-Based Bisect Debugging in Compilers and Runtimes](https://research.swtch.com/bisect),在这之前也有其他技术人员提出了类似的技术,比如 List-Based Bisect-Reduce,Counter-Based Bisect-Reduce,Russ Cox等人是在他们基础上提出了 Hash-Based Bisect-Reduce。区别就是使用hash值来唯一标识每个特性相关的代码(Hash("feat1"),或者特定源文件位置(Hash("file:lineno")),而不是使用冗长的locspec列表,或者对应位置的计数器(同一位置计数编号随着代码修改会失效)。
bisect reduce,大致思想就是我们要采用 “特性开关” 的实践方式,当然这里不完全等同于特性开关,也可以是一个简单的优化changelist(如同一个feat对应的多个源文件位置、特定的源码行) …… 我们会给changelist一个名字,比如MyChangeList。假设我们使用 [go bisect](https://github.com/golang/tools/cmd/bisect) 并使用对应的 [golang/tools/internal/bisect库](https://github.com/golang/tools/tree/master/internal/bisect) 来控制changelist开启关闭、上报,然后执行程序 `MyChangeList=y ./a.out` 就等同于打开该changelist所有源码位置,`MyChangeList=n ./a.out` 就等同于关闭该changelist所有源码位置。预期关闭changelist时没有bug、开启时有bug,此时结合上报可以收集到该changelist涉及到的所有源码位置,然后在此基础上进行基于二分的缩减(bisect-based reduction)。
大致思路是:先打开一半位置(记为集合a)检查有没有预期的bug,如果没有就再添加额外一半位置(记为集合b),如果有bug就将刚才添加的b缩减一半(记为c),如果减少后发现没没bug了,那可以确定刚才新添加的一半位置(差集b-c)会导致该预期的bug。将这些可疑位置(b-c)固定下来并在后续搜索过程中带上它们,接下来继续搜索a中可能的位置 …… 最终可以确定一个导致bug出现的源文件位置的局部最小集合,只要这些位置都被打开就会导致该预期的bug。详细的算法可以参考 https://research.swtch.com/bisect。
这里提供了一个demo供大家学习如何在go项目中使用bisect [bisect example](https://github.com/hitzhangjie/golang-debugger-lessons/tree/master/1000_hash_based_bisect_reduce)。
> ps: bisect reduce,和二分搜索都是基于分治或者二分的思想,但也不完全一样,这个场景下核心算法如果使用二分搜索是不正确的。
#### 6. 动态跟踪
eBPF(扩展Berkeley Packet Filter)是一项强大的技术,允许用户在不修改、不重启内核或明显降低系统性能的情况下安全地注入和执行自定义代码。它主要用于网络、性能分析和监控等领域。这里重点强调下eBPF在动态跟踪技术中的应用,Linux kprobe、uprobe、tracepoint 现在已经支持回调eBPF程序,借此可以实现非常强大的动态跟踪功能,比如bpftrace。
对于go语言调试而言,结合eBPF可以实现任意源文件位置的动态跟踪,只要工具实现的足够细致。作者现在维护了一个go程序动态跟踪工具[go-ftrace](https://github.com/hitzhangjie/go-ftrace),基于DWARF调试信息识别特定函数位置,并动态添加uprobe,然后注册eBPF耗时统计程序,这样就实现了强大的函数调用跟踪能力。
```bash
$ sudo ftrace -u 'main.*' -u 'fmt.Print*' ./main 'main.(*Student).String(s.name=(*+0(%ax)):c64, s.name.len=(+8(%ax)):s64, s.age=(+16(%ax)):s64)'
...
23 17:11:00.0890 main.doSomething() { main.main+15 ~/github/go-ftrace/examples/main.go:10
23 17:11:00.0890 main.add() { main.doSomething+37 ~/github/go-ftrace/examples/main.go:15
23 17:11:00.0890 main.add1() { main.add+149 ~/github/go-ftrace/examples/main.go:27
23 17:11:00.0890 main.add3() { main.add1+149 ~/github/go-ftrace/examples/main.go:40
23 17:11:00.0890 000.0000 } main.add3+148 ~/github/go-ftrace/examples/main.go:46
23 17:11:00.0890 000.0000 } main.add1+154 ~/github/go-ftrace/examples/main.go:33
23 17:11:00.0890 000.0001 } main.add+154 ~/github/go-ftrace/examples/main.go:27
23 17:11:00.0890 main.minus() { main.doSomething+52 ~/github/go-ftrace/examples/main.go:16
23 17:11:00.0890 000.0000 } main.minus+3 ~/github/go-ftrace/examples/main.go:51
23 17:11:00.0891 main.(*Student).String(s.name=zhang<ni, s.name.len=5, s.age=100) { fmt.(*pp).handleMethods+690 /opt/go/src/fmt/print.go:673
23 17:11:00.0891 000.0000 } main.(*Student).String+138 ~/github/go-ftrace/examples/main.go:64
23 17:11:01.0895 001.0005 } main.doSomething+180 ~/github/go-ftrace/examples/main.go:22
```
#### 7. 确定性重放
即便我们拥有了上述这些令人拍手叫好的技术,还有一个困扰在开发者头上的问题。“**我们知道有bug,但是如何稳定复现它**”。flaky tests,是开发者调试时最头疼的一个问题。应对这个问题,有几个办法:1)先从准备可复现的测试用例集入手,看能不能将原本不能稳定复现的bug,精心构造测试参数后能够稳定复现;2)使用确定性重放技术,首先通过录制记录下问题出现时的情景,然后便可以无限制重放这个场景。第一种办法,更应该理解成是一种工程素养,我们日常就应该这么做。但是面对棘手的问题时,即便做到了也不一定能奏效,这里我们重点介绍第二种办法。
> You record a failure once, then debug the recording, deterministically, as many times as you want. The same execution is replayed every time.
>
> 你只要能录制一次失败,就能利用这次录制进行无限制地重放,进而进行确定性地调试。
明星项目 **Mozilla RR** 做到了这一点,它记录了程序非确定性执行时的全量上下文信息,以使得后续基于录制文件的调试能够精准重放当时的状态,进而进行确定性地调试。rr 还支持了逆向调试,比如 gdb、dlv 的逆向调试命令,在使用 Mozilla RR 作为调试器backend的情况下就可以实现逆向调试,这是非常有用的,不必因为错过执行语句而重启整个调试过程。
读者可能很好奇,rr 录制全量上下文信息,指的是录制了什么呢?系统调用结果、收到的信号、线程创建和销毁、线程调度顺序、共享内存访问、时钟和计数器、硬件中断、随机性来源、内存分配情况,等等。究竟如何解决这些问题,详见论文:[Engineering Record And Replay For Deployability: Extended Technical Report](https://arxiv.org/pdf/1705.05937)。在记录了这些信息的基础上,我们就可以在调试期间通过tracer做些文章实现状态的精准重放,这样就解决了那些会导致flaky test的可变因素干扰的问题。
> ps: 录制数据如何精准重放呢?读者可以先联想下本书介绍过的ptrace对tracee的一系列控制,具体如控制tracee执行多少条指令停止,读写寄存器信息等,看看有没有什么思路。完整解决方案可以查看 Mozilla RR 的论文。
#### 8. 分布式系统调试
在系统架构设计领域,微服务架构越来越获得大家的青睐,独立部署、技术多样性、可扩展性、故障隔离、团队自治、模块化设计,等等都是它的一些优势。但是它确实也带来一些挑战,所以业界也针对性的出现了微服务治理方面的一些解决方案,比如CNCF中的一系列明星项目。这里我们重点提一下对于软件调试带来的挑战。
微服务架构下,由于一个完整的事务处理会在多个微服务中进行处理,给调试带来了非常多的麻烦:
- 首先,整个系统的运行,依赖所有微服务的正确部署,可能涉及到很多机器,不一定支持混部,不一定能保证每个开发都有自己的自测环境;
- 如果没有专属的自测环境,传统的调试器attach一个进程进行跟踪的方式,还会影响服务正常运行,影响其他人测试;
- 即使有专属的自测环境,如果不能混部,还需要分别登录多台机器attach目标进程进行跟踪;
- 即使有专属的自测环境,也能混部,attach多个进程、加断点的位置和时机也还是很难协调;
- ……
总而言之,如果用调试器的思路去尝试解决这个问题,是真的比较难。我们一般会通过Logging、Metrics、Tracing系统来解决微服务架构下的这类问题,生产环境下实践看来也还不错。但是你要说这种方案完美,那也很不现实,比如开发、测试环境中,我们更希望快速定位问题,但是实际情况是:1)你可能要等待一段时间才能观察到日志、监控上报、链路跟踪信息,有一定延迟。2)而且你可能要反复修改代码(补充下日志、监控、创建新的trace或者span),编译,构建,部署测试 …… 然后才能观察到。
本来调试器可能只需要几秒钟就能搞定的事情,只是因为对多机多个进程attach、添加断点时机这块比较难协调,难道就认为调试器搞不定这种情景了?SquashIO提供了完整的云原生情景下的解决方案:Squash Debugger,支持Kubernetes、Openshift、Istio等容器编排平台,实时注入调试容器,并自动关联对应版本的源码,并且能在RPC调用触发后自动触发对Callee特定接口处理函数的断点设置、UI上也支持自动切换到目标服务,支持常见的VSCode等IDE。
### 调试技术选择哲学
从单体应用到云原生、分布式系统,调试技术已形成多维武器库,形成了针对不同场景的技术矩阵。即将展开的系列文章将深入解析每项技术的实现原理、最佳实践和前沿发展,帮助开发者建立"场景-工具-方法论"的立体化调试思维。调试不仅是解决问题的过程,更是理解系统本质的认知革命。掌握不同场景的调试技术,开发者如同获得了上帝之眼,可以了解系统全貌,也可以拨开迷雾探查一切。
### 参考文献
1. [Hash-Based Bisect Debugging in Compilers and Runtimes](https://research.swtch.com/bisect)
2. [go bisect tool](https://github.com/golang/tools/tree/master/cmd/bisect)
3. [go bisect library](https://github.com/golang/tools/tree/master/internal/bisect)
4. [Engineering Record And Replay For Deployability: Extended Technical Report](https://arxiv.org/pdf/1705.05937)
5. [Squash Debugger Docs](https://squash.solo.io/)
6. [Squash Debugger GitHub](https://github.com/solo-io/squash)
7. [Lightning Talk: Debugging microservices applications with Envoy + Squash - Idit Levine, Solo.io](https://www.youtube.com/watch?v=i5_eacXkw3w)
8. [Dapper, a Large-Scale Distributed System Tracing Infrastructure](https://static.googleusercontent.com/media/research.google.com/en//archive/papers/dapper-2010-1.pdf)
9. [OpenTelemetry](https://opentelemetry.io/)
================================================
FILE: book/11-thanks/README.md
================================================
## 致谢
一路走来,收获过成功,也遭遇过失败,感谢父母一直做我坚强的后盾,即便在未知面前,他们的鼓励也总能给我无穷的信心,让我能够走出迷雾。
感谢我的妻子,容忍我在家庭生活中的偷懒,容忍我无数次放鸽子来写这些东西。没有她的包容、理解、照顾、鼓励,我可能也不会坚持到现在。
也感谢朋友、同事、其他贡献者的支持、鼓励。
最后,我也要感谢自己,感谢自己对价值的探索、追求和坚持。
================================================
FILE: book/12-appendix/1-go-programme-start.md
================================================
# go runtime: go程序启动流程
## go程序启动流程概览
我们使用如下源程序作为示例,来看一看go程序的启动过程:
**file: main.go**
```go
package main
import "fmt"
func main() {
fmt.Println("vim-go")
}
```
运行dlv进行调试,将程序执行到main.main处:
```
$ dlv debug main.go
Type 'help' for list of commands.
(dlv) b main.main
Breakpoint 1 set at 0x10d0faf for main.main() ./main.go:5
(dlv) c
> main.main() ./main.go:5 (hits goroutine(1):1 total:1) (PC: 0x10d0faf)
1: package main
2:
3: import "fmt"
4:
=> 5: func main() {
6: fmt.Println("vim-go")
7: }
(dlv)
```
这个时候看一下调用堆栈:
```bash
(dlv) bt
0 0x00000000010d0faf in main.main
at ./main.go:5
1 0x000000000103aacf in runtime.main
at /usr/local/go/src/runtime/proc.go:204
2 0x000000000106d021 in runtime.goexit
at /usr/local/go/src/runtime/asm_amd64.s:1374
(dlv)
```
由此可知go程序启动是按照如下流程启动的:
1. asm_amd64.s:1374 runtime·goexit:runtime·goexit1(SB)
2. runtime/proc.go:204 runtime.main:fn()
这里的fn就是测试源程序中的main.main
3. 现在PC就停在main.main处,等待我们进行后续调试。
## go程序启动前初始化
这里我们讲的启动前初始化,指的是程序执行到我们的入口函数main.main之前的操作,理解这部分内容,将有助于建立对go的全局认识,也有助于加强对实现go调试器的认识。
### go进程实例化
当我们在shell里面键入`./prog`时,操作系统为我们实例化了一个prog程序的实例,进程启动了,这个过程中发生了什么呢?
- shell中首先fork一个子进程,就称为子shell吧;
- 子shell中再通过执行execvp替换掉进程待执行程序的代码、数据等等;
- 一切准备就绪后,操作系统将准备好的进程状态交给调度器调度执行;
我们就假定当前调度器选中了当前进程,看下go进程从启动开始执行了什么逻辑。
在编译c程序的时候,我们知道一个源程序首先会被编译成*.o文件,然后同系统提供的共享库、系统提供的启动代码结合起来进行链接(link)之后,形成一个最终的可执行程序。链接的时候有internal linkage(静态链接)或者external linkage(动态链接)两种方式。
go程序和c程序类似,也有不同的链接方式,参考`go tool link`中的`-linkmode`选项说明进行了解。通常情况下如果没有cgo,默认go build构建出来的都是internal linkage,所以其体积也稍大,通过系统工具`ldd <prog>`查看依赖的共享库会提示错误`not dynamic executable`也可以证实这点。
### go进程启动代码
go程序对应的进程开始执行之后,其首先要执行的指令就是启动代码,如下所示:
**file: asm_amd64.s**
```asm
// _rt0_amd64 is common startup code for most amd64 systems when using
// internal linking. This is the entry point for the program from the
// kernel for an ordinary -buildmode=exe program. The stack holds the
// number of arguments and the C-style argv.
TEXT _rt0_amd64(SB),NOSPLIT,$-8
MOVQ 0(SP), DI // argc
LEAQ 8(SP), SI // argv
JMP runtime·rt0_go(SB)
// main is common startup code for most amd64 systems when using
// external linking. The C startup code will call the symbol "main"
// passing argc and argv in the usual C ABI registers DI and SI.
TEXT main(SB),NOSPLIT,$-8
JMP runtime·rt0_go(SB)
```
上述是go程序构建时分别采用internal、external linkage时使用的启动代码,go进程启动时将首先执行这段指令。第一种是首先为进程传递参数argc、argv,然后跳到`runtime.rt0_go(SB)`执行,第二种是说c启动代码在调用main之前会负责传递argc、argv,`runtime.rt0_go(SB)`。
就先不在linkmode对启动代码的影响这多做讨论了,直接看`runtime.rt0_go(SB)`。
### `runtime.rt0_go(SB)`
这里汇编代码篇幅过长,我们省去了大部分汇编代码,只保留了比较重要的步骤的说明。
```asm
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// copy arguments forward on an even stack
...
// create istack out of the given (operating system) stack.
...
// find out information about the processor we're on
...
// others
...
ok:
// set the per-goroutine and per-mach "registers"
...
// save m->g0 = g0
...
// save m0 to g0->m
...
// copy argc
...
// copy argv
...
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RET
// Prevent dead-code elimination of debugCallV1, which is
// intended to be called by debuggers.
MOVQ $runtime·debugCallV1(SB), AX
RET
```
我们看到在完成上半部分的一些初始化之后,还做了这些操作:
1. copy argc, copy argv
2. call runtime·args(SB), call runtime·osinit(SB), call runtime·schedinit(SB)
3. create a new goroutine to start program
1. push entry: $runtime·mainPC(SB)
2. push arg size: $0
3. call runtime·newproc(SB)
4. call runtime·mstart(SB)
这些步骤就是我们关心的go程序启动的关键部分了,不妨一一来看下。
> ps:阅读go汇编,需要先阅读下相关的基础知识,可以参考下 [a quick guide to go's assembler](https://golang.org/doc/asm).
>
> - `FP`: Frame pointer: arguments and locals.
> - `PC`: Program counter: jumps and branches.
> - `SB`: Static base pointer: global symbols.
> - `SP`: Stack pointer: top of stack.
>
> All user-defined symbols are written as offsets to the pseudo-registers `FP` (arguments and locals) and `SB` (globals).
>
> The `SB` pseudo-register can be thought of as the origin of memory, so the symbol `foo(SB)` is the name `foo` as an address in memory. This form is used to name global functions and data. Adding `<>` to the name, as in `foo<>(SB)`, makes the name visible only in the current source file, like a top-level `static` declaration in a C file. Adding an offset to the name refers to that offset from the symbol's address, so `foo+4(SB)` is four bytes past the start of `foo`.
#### call runtime·args(SB)
指的是runtime package下的args这个函数,总之就是设置argc、argv这些参数的。
**file: runtime/runtime1.go**
```go
func args(c int32, v **byte) {
argc = c
argv = v
sysargs(c, v)
}
```
#### runtime·osinit(SB)
指的是runtime package下的osinit这个函数,总之就是写系统设置相关的,先不关心。
**file: runtime/os_linux.go**
```go
func osinit() {
ncpu = getproccount()
physHugePageSize = getHugePageSize()
osArchInit()
}
```
#### call runtime·schedinit(SB)
指的是runtime package下的schedinit这个函数,做了一些调度执行前的准备。
```go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
// lockInit Linux下为空操作
...
// raceinit must be the first call to race detector.
// In particular, it must be done before mallocinit below calls racemapshadow.
// @see https://github.com/golang/go/blob/master/src/runtime/HACKING.md
// 参考对getg()的解释:这里应该是在系统栈上运行,返回的_g_应该是当前M的g0
_g_ := getg()
if raceenabled {
_g_.racectx, raceprocctx0 = raceinit()
}
sched.maxmcount = 10000
moduledataverify()
stackinit()
mallocinit()
fastrandinit() // must run before mcommoninit
mcommoninit(_g_.m, -1)
cpuinit() // must run before alginit
alginit() // maps must not be used before this call
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
msigsave(_g_.m)
initSigmask = _g_.m.sigmask
goargs()
goenvs()
parsedebugvars()
gcinit()
lock(&sched.lock)
sched.lastpoll = uint64(nanotime())
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
procresize(procs)
...
unlock(&sched.lock)
...
}
```
#### 启动runtime.main & main.main
好了,上面一大堆都是一些初始化的工作,现在看下runtime.main启动的最直接部分:
```asm
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
PUSHQ $0 // arg size
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
CALL runtime·mstart(SB)
```
这里首先首先获取符号`$runtime.mainPC(SB)`的地址放入AX,这个其实是函数runtime.main的入口地址,然后压函数调用参数argsize 0,因为这个函数没有参数。
```asm
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
GLOBL runtime·mainPC(SB),RODATA,$8
```
runtime·main(SB)对应的就是runtime.main这个函数:
```go
// The main goroutine.
func main() {
g := getg()
// Racectx of m0->g0 is used only as the parent of the main goroutine.
// It must not be used for anything else.
g.m.g0.racectx = 0
// 调整协程栈大小,64位最大1GB,32位最大250M
...
// Allow newproc to start new Ms.
mainStarted = true
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
systemstack(func() {
// 创建新的m,并执行sysmon,-1表示不预先指定m的id
newm(sysmon, nil, -1)
})
}
// 注意,现在执行的是main goroutine,当前线程是主线程,
// 调用该方法将是的main goroutine绑定调度线程到主线程,
// 意味着我们可以断定,main.main这个函数永远运行在主线程之上,除非之后解绑
lockOSThread()
...
// 这里就是执行runtime package下的初始化逻辑:
// - 每个package都有一些import进来的依赖,这些import的package需要做初始化逻辑;
// - 每个package内部的func init()需要在初始化完依赖之后完成调用;
doInit(&runtime_inittask) // must be before defer
...
// Defer unlock so that runtime.Goexit during init does the unlock too.
needUnlock := true
defer func() {
if needUnlock {
unlockOSThread()
}
}()
...
// 在调用用户编写的程序代码之前,开启gc,这里并没有创建独立线程来做gc,可能以后会
gcenable()
main_init_done = make(chan bool)
if iscgo {
...
// Start the template thread in case we enter Go from
// a C-created thread and need to create a new thread.
startTemplateThread()
cgocall(_cgo_notify_runtime_init_done, nil)
}
// 初始化main package,包括其import的依赖,以及main package下的func init()
doInit(&main_inittask)
// main package初始化完成
close(main_init_done)
needUnlock = false
// 注意,此处又将当前goroutine与thread做了分离,看来go的设计者只是想
// 将某些初始化动作放在main thread上完成,并不想事后仍然特殊对待main goroutine,
// main goroutine和其他goroutine一样,可以由scheduler选择其他线程对其进行调度
unlockOSThread()
// 如果编译成的是静态库、动态库,虽然有main函数,但是不能执行
if isarchive || islibrary {
return
}
// 注意,调用main_main,其实就是main.main,请查看前面的go directive定义:
// 就是//go:linkname main_main main.main,对main_main的调用将转入main.main
//
// 因为前面已经解绑了main goroutine和main thread的关系,所以我们唯一可以断定的,
// 是main.main方法是执行在main goroutine上的,但是不一定在main thread上
fn := main_main
fn()
if raceenabled {
racefini()
}
// main.main结束,意味着整个程序准备结束,
// 如果有panic发生,会通知所有协程打印堆栈
if atomic.Load(&runningPanicDefers) != 0 {
// Running deferred functions should not take long.
for c := 0; c < 1000; c++ {
if atomic.Load(&runningPanicDefers) == 0 {
break
}
Gosched()
}
}
if atomic.Load(&panicking) != 0 {
gopark(nil, nil, waitReasonPanicWait, traceEvGoStop, 1)
}
exit(0)
...
}
```
这里我们分析了go程序启动的一个流程,以及我们可以得出的一个非常重要的结论:
> main.main方法是由main goroutine来执行,但是main goroutine不一定由main thread来调度执行。
>
> main goroutine和main thread二者之间没有默认的绑定关系!
明确这点是非常重要的,它将有助于我们理解`godbg attach <pid>`之后为什么main方法没有停下来的问题。
================================================
FILE: book/12-appendix/2-auto-trace-cloned-threads.md
================================================
## Appendix: trace newly cloned threads
### how does tracer automatically trace newly cloned threads
PTRACE_O_TRACECLONE is an option for the ptrace system call that allows a tracer process to receive notifications when a traced process clones new child processes via fork() or clone().
Here is how PTRACE_O_TRACECLONE works:
- A tracer process calls ptrace() on the process to be traced, passing the PTRACE_O_TRACECLONE option.
- This sets up the traced process to notify the tracer when it clones new child processes.
- When the traced process calls fork()/clone(), the kernel will pause the new child process before it starts executing.
- The kernel notifies the tracer process by delivering a PTRACE_EVENT_CLONE event along with information about the new child process (pid, registers, etc).
- The tracer can inspect or modify the child process as desired using regular ptrace commands.
- When the tracer is done, it calls ptrace() with PTRACE_CONT on the child, allowing the child to continue executing.
- The tracer will receive a PTRACE_EVENT_CLONE event for each new child cloned by the traced process going forward.
So in summary, PTRACE_O_TRACECLONE makes ptrace notify the tracer process whenever a new child process is cloned, allowing the tracer to introspect or control the child even before it starts running. This provides deeper process tracing capabilities.
================================================
FILE: book/12-appendix/3-git-bisect.md
================================================
## Appendix: 使用 git bisect 定位引入bug的commit
`git bisect` 是一个非常有用的工具,用于在大型代码库中快速定位引起特定错误或功能变化的具体提交。它通过二分查找算法,将可能包含问题的提交范围逐步缩小,从而帮助开发者更快地找到引入bug的那个commit。
下面是一个使用 `git bisect` 搜索引入bug的commit的示例。这个例子假设你已经知道一个特定版本没有问题(比如标签v1.0),而后续的一个版本有问题(比如最新的master分支):
### 步骤 1: 开始bisect
首先,你需要从有已知错误的状态开始bisect搜索:
```bash
git bisect start
```
### 步骤 2: 指定没有问题的提交点
指定一个你确信没有任何问题的特定版本(这可以是标签、分支或具体的commit hash):
```bash
git bisect good v1.0 # 假设v1.0是一个好的状态,没有bug。
```
### 步骤 3: 指定有问题的提交点
接着指定一个你确信存在问题的版本(这同样可以是标签、分支或具体的commit hash):
```bash
git bisect bad master # 假设master是最新的开发分支,并且包含已知bug。
```
### 步骤 4: 编译并测试
Git会自动切换到两个指定提交之间的某个中间点(通过二分法来选择)。你需要在这个版本上进行编译和测试,以确认当前的代码是否有问题:
```bash
make # 假设你的构建命令是 make。
./test_program # 运行自定义脚本来检查是否存在bug。
```
### 步骤 5: 反馈测试结果给git bisect
在执行了编译和测试之后,你必须告知 `git bisect` 当前的提交是否包含问题:
- 如果当前版本没有问题,则运行:
```bash
git bisect good
```
- 如果当前版本有问题,则运行:
```bash
git bisect bad
```
### 步骤 6: 反复执行直到找到引入bug的commit
根据上述步骤反复进行,直到 `git` 找到引入bug的那个具体提交为止。当bisect结束时,它会打印出“首先被标记为错误”的提交信息。
```bash
# 最终会显示类似这样的内容:
```
bisect run failed:
c94218e7b5d390a6c6eb7f3f7aaf5aa92e0bddd2 is the first bad commit
commit c94218e7b5d390a6c6eb7f3f7aaf5aa92e0bddd2
Author: Your Name <your.email@example.com>
Date: Date of commit
Commit message goes here
:100644 100644 8d9bdc2... a91d6ae... M filename
```
在这个示例中,`c94218e7b5d390a6c6eb7f3f7aaf5aa92e0bddd2` 就是引入bug的commit。
### 步骤 7: 完成bisect
当你找到了引发问题的那个提交后,可以通过以下命令结束 bisect:
```bash
git bisect reset
```
这会将你的工作区恢复到开始 `git bisect` 之前的最后一个分支或标签状态。至此,你就完成了使用 `git bisect` 来定位引入bug的commit的过程。
希望这个示例对你有所帮助!如果你有更多的问题或者需要进一步的帮助,请随时提问。
================================================
FILE: book/12-appendix/4-vscode-extension-bisect.md
================================================
## Appendix: 使用二分查找解决扩展问题
[来源](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect "Permalink to Resolving extension issues with bisect")
2021年2月16日,作者:Johannes Rieken,[@johannesrieken](https://twitter.com/johannesrieken)
> "就像 git-bisect 一样,但适用于 VS Code 扩展。"
Visual Studio Code 的真正威力在于其扩展:主题扩展添加颜色和图标,语言扩展启用智能代码补全(IntelliSense)和导航,调试器扩展让你能够运行代码并轻松找到错误。有些扩展播放音乐,有些显示股票行情,还有一些扩展支持跨地点和时区的协作工作。VS Code [市场](https://marketplace.visualstudio.com/vscode)托管着超过 28,000 个扩展,用户安装 50 个或更多扩展并不罕见。有如此多的扩展,出现错误是不可避免的。与其否认这一点,我们更希望让故障排除变得简单。
### ["问题"扩展](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect#_bad-extensions)
我们热爱扩展,并不认为真的存在"问题"扩展。然而,就像所有软件一样,扩展也有错误和功能缺陷。因此,为了阅读便利和增加戏剧效果,让我们使用"问题扩展"这个术语,指的是可能会崩溃或显示不期望行为的扩展。幸运的是,我们在设计 VS Code 时考虑了"问题"扩展的存在,因此将它们运行在单独的[进程](https://code.visualstudio.com/api/advanced-topics/extension-host)中。这种隔离保证了 VS Code 继续运行,光标始终闪烁,你总是能够保存你的工作。
为了好玩,也为了让扩展二分查找的演示更容易,我们创建并发布了 [Extension Bisect Demo](https://marketplace.visualstudio.com/items?itemName=jrieken.bisectdemo) 扩展。安装后,每当你输入"bisect"这个词时,它会烦人地重置你的光标。你可以使用这个扩展来跟随这篇博客文章。
### [用困难的方式找到"问题"扩展](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect#_finding-a-bad-extension-the-hard-way)
如今,找到"问题"扩展可能很容易,也可能很困难。打开扩展视图(Ctrl+Shift+X),[禁用扩展](https://code.visualstudio.com/docs/configure/extensions/extension-marketplace#_disable-an-extension),重新加载窗口(**开发者:重新加载窗口**),然后检查问题是否仍然存在。如果问题消失了,那个扩展就是"问题"扩展,你就完成了。否则,重新启用该扩展并对下一个扩展重复此过程。
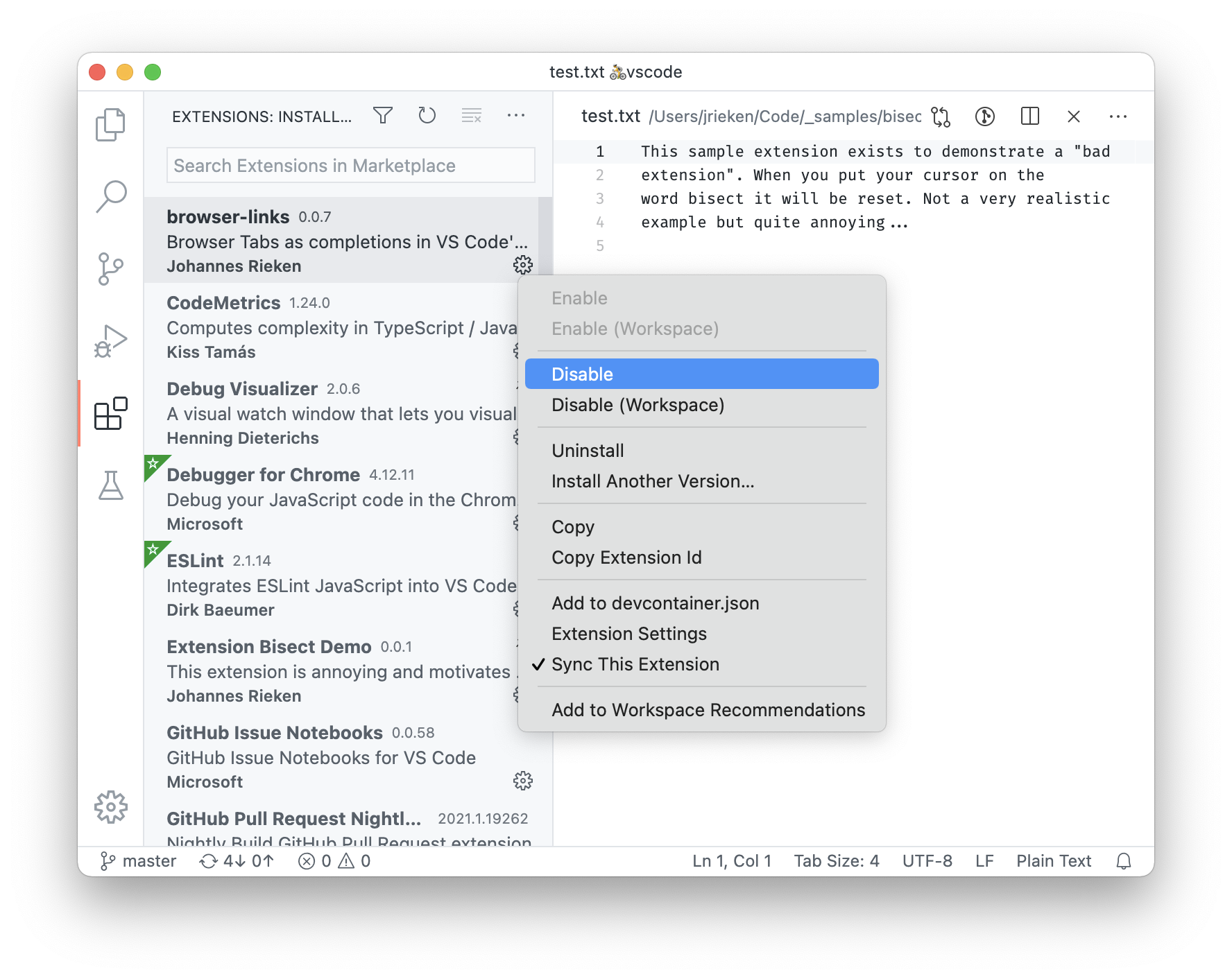
如果你幸运的话,第一个扩展就是"问题"扩展;如果你不幸的话,它就是最后一个扩展。用计算机科学的语言来说,这意味着对于 `N` 个扩展,你在最坏情况下需要重复这个过程 `O(N)` 次(N 阶),平均情况下是 `O(N/2)` 次。因为这个算法是由人类(你)操作的,即使 `N` 值很小也很费力。这就是 **扩展二分查找** 工具派上用场的地方。它在最坏情况和平均情况下都要好得多,因为它按一半一半地禁用扩展。
### [欢迎扩展二分查找](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect#_welcome-extension-bisect)
VS Code 中的扩展二分查找工具受到 [git bisect](https://git-scm.com/docs/git-bisect) 命令的启发。对于熟悉 Git 的人来说,这个命令有助于找出仓库中哪个提交引入了问题。
让我们用一个例子:我安装了 24 个扩展,第 8 个扩展是"问题"扩展。我们知道迭代方法需要 8 步。二分查找怎么样?
下面的视频显示了通过 **帮助:开始扩展二分查找** 命令启动扩展二分查找,然后选择 **现在正常** 或 **这是问题** 直到识别出"问题"扩展。一旦识别出来,你可以选择为该扩展报告问题。
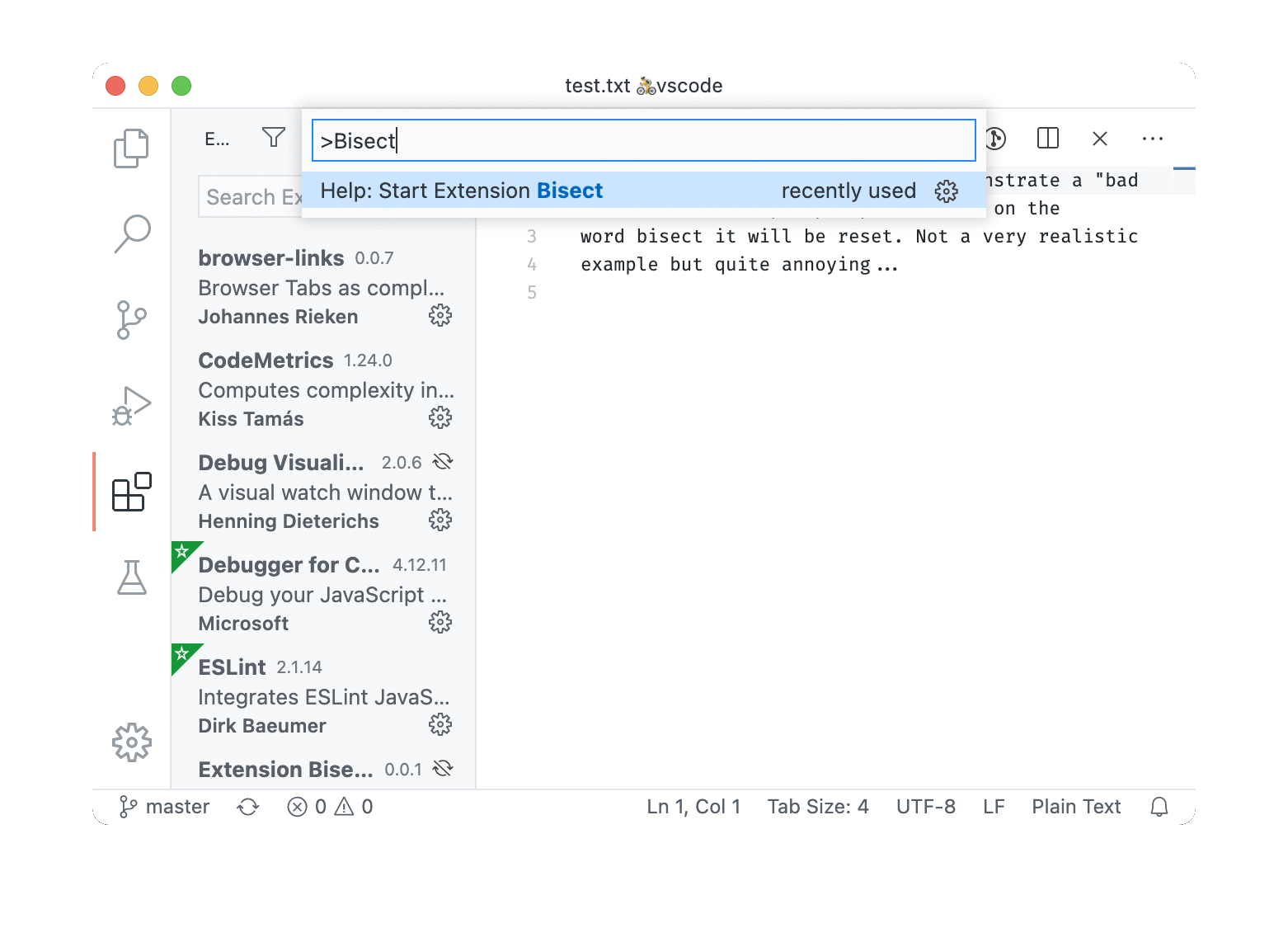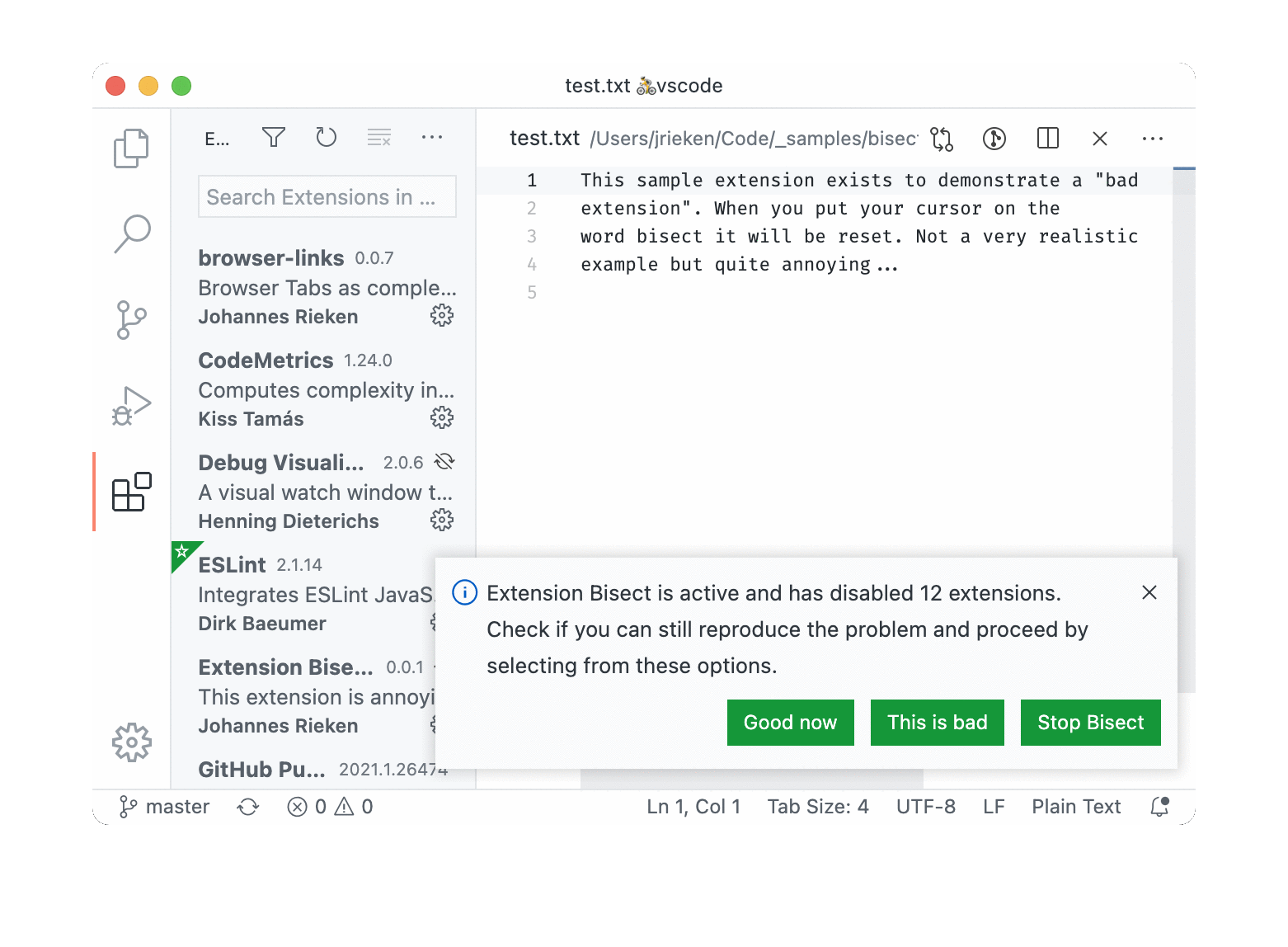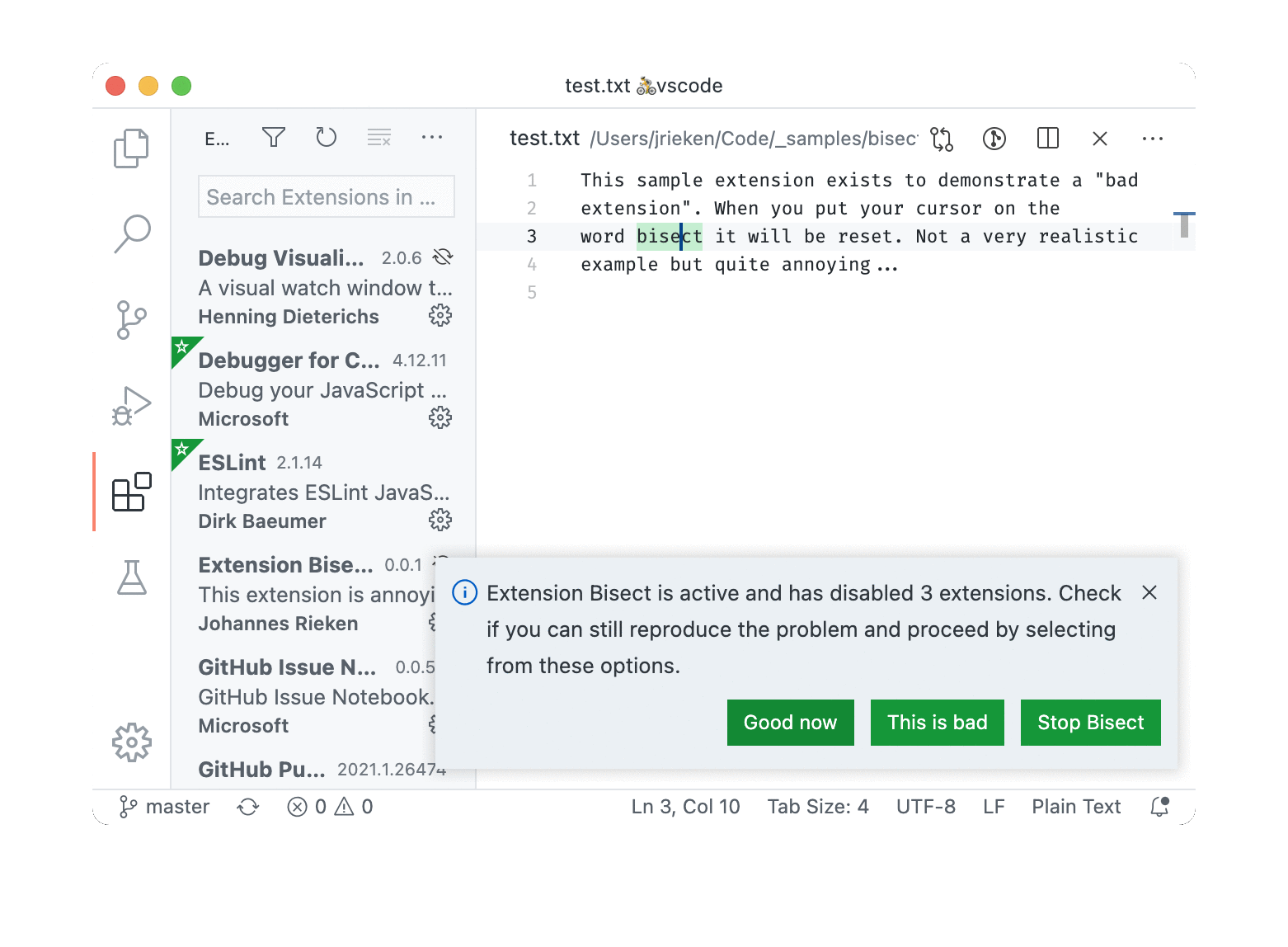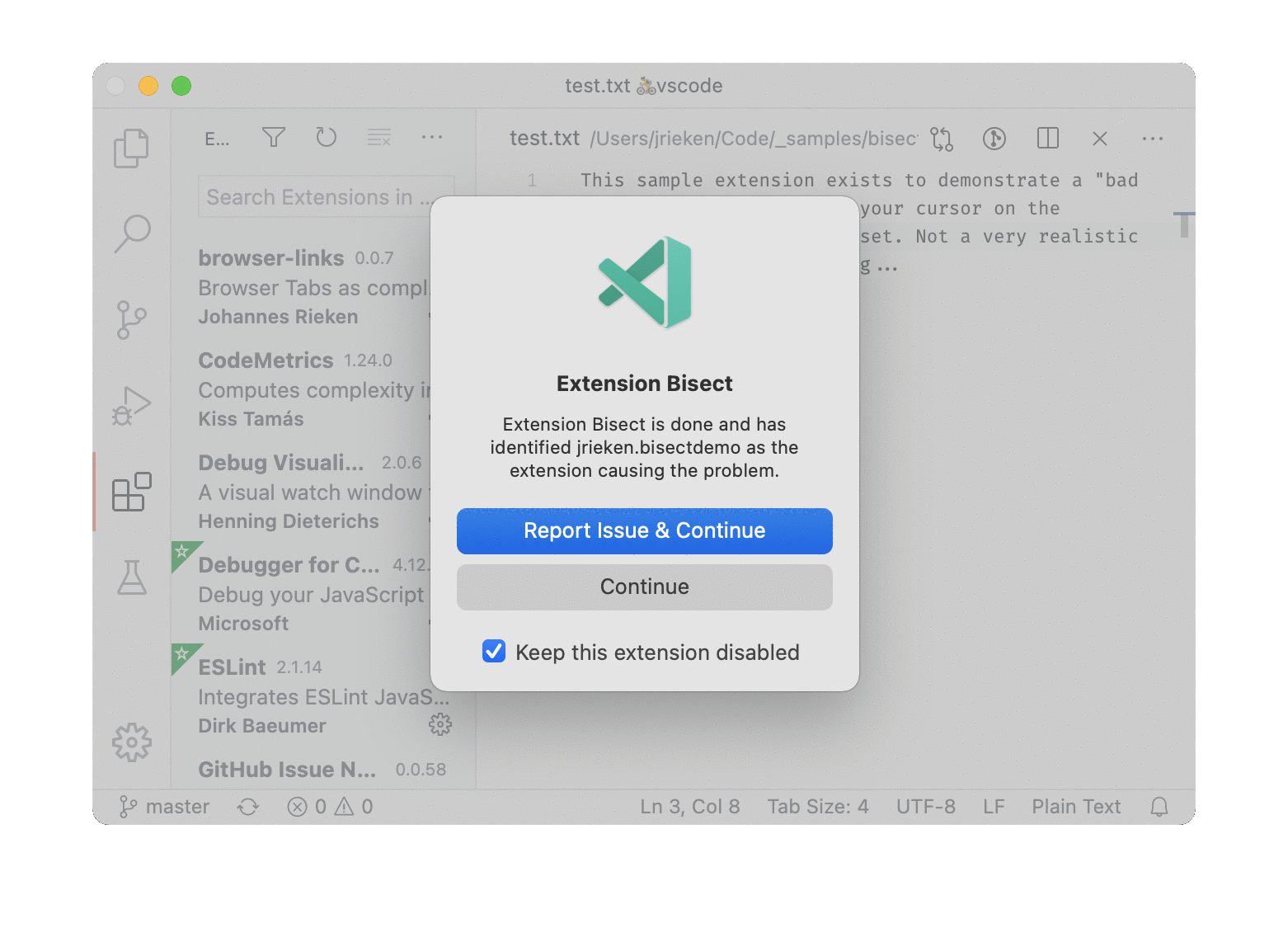
以下是逐步找到"问题"扩展的过程:
1. 二分查找将 24 个扩展分成两半,每半 12 个扩展,并禁用后半部分的所有 12 个扩展。
2. 在这个例子中,第 8 个扩展是"问题"扩展,所以它在前半部分,没有被禁用。事情仍然不像我们期望的那样工作。因为仍然有问题,扩展二分查找重复这个过程,将前 12 个扩展分成两部分:6 个启用,6 个禁用。所有其他扩展也重新启用。
3. 第 8 个扩展现在被禁用了。现在一切正常。这意味着二分查找可以继续处理后半部分(扩展 6-11),并将它们分成 3 个启用和 3 个禁用的扩展。
4. 现在,第 8 个扩展重新启用,问题重新出现。这意味着二分查找继续处理前半部分。它将它们分成 1 个启用和 2 个禁用的扩展。
5. 第 8 个扩展现在被禁用,一切又正常了,二分查找继续处理后半部分,将其分成 1 个启用和 1 个禁用的扩展。
6. 第 8 个扩展是唯一被禁用的扩展,问题消失了。这意味着我们已经找到了"问题"扩展,我们完成了。
### [更快地故障排除](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect#_troubleshoot-faster)
我们看到,在每一步中,二分查找都将搜索空间减半。现在步骤以对数时间运行,导致平均和最坏情况性能为 `O(log N)`。这很好,因为它扩展性很好。对于 24 个扩展,你需要 4 到 5 步来找到"问题"扩展,对于 38 个扩展,只需要多 1 步。然而,最好情况更糟,因为使用迭代方法,你可能很幸运地在第一轮就找到"问题"扩展。
请记住,扩展二分查找依赖于你给出正确的反馈。你可以很容易地欺骗它,也欺骗自己,总是回答 **现在正常**(责怪最后一个扩展)或 **这是问题**(不会找到扩展)。
另一个有用的见解是,扩展二分查找从考虑所有启用的扩展列表开始。这意味着你可以通过在开始前禁用已知的"正常"扩展,然后在之后重新启用它来将其从二分查找中排除。但是,只有当你确定该扩展不是"问题"扩展时才这样做。
最后,你可能会注意到二分查找需要额外的一步(`log2(N) + 1`)。这是因为它通过禁用所有扩展来开始第一轮。这第一步是因为你可能看到的是由 VS Code 本身引起的问题,而不是由扩展引起的,我们不想不必要地让你陷入兔子洞。
就是这样。我们希望您永远不需要使用扩展二分查找。但是,如果您确实遇到可能与扩展相关的问题,那么我们希望能够让故障排除变得更容易、更快、更愉快。
编码愉快,
Johannes Rieken,VS Code 首席软件工程师 [@johannesrieken](https://twitter.com/johannesrieken)
### 参考内容
1. vscode extension bisect, https://code.visualstudio.com/blogs/2021/02/16/extension-bisect
================================================
FILE: book/12-appendix/80-go-tool-compile.md
================================================
## 扩展阅读:Go编译器简介
`cmd/compile` 包含构成Go编译器的主要包。编译器逻辑上可分为四个阶段,我们将简要描述每个阶段,并列出包含其代码的包列表。
您可能听到过"前端(front-end)"和"后端(back-end)"这两个术语。粗略地说,它们对应我们列出的前两个阶段和后两个阶段。第三个术语"中端(middle-end)"通常指第二阶段中进行的大部分工作。
请注意,`go/*` 系列包(如 `go/parser` 和 `go/types`)主要由编译器内部API使用。由于编译器最初是用C语言编写的,`go/*` 包被开发用于编写处理Go代码的工具(如 `gofmt` 和 `vet`)。然而,随着时间推移,编译器的内部API已逐渐演变为更符合 `go/*` 包用户的习惯。
需要澄清的是,"gc"代表"Go编译器",与表示垃圾回收的大写"GC"无关。
### 1. 解析(Parsing)
* `cmd/compile/internal/syntax`(词法分析器、语法分析器、语法树)
编译的第一阶段将源代码进行分词(词法分析)、解析(语法分析),并为每个源文件构建语法树。
每个语法树都是相应源文件的精确表示,节点对应源代码的各种元素(如表达式、声明和语句)。语法树还包含位置信息,用于错误报告和调试信息生成。
### 2. 类型检查(Type checking)
* `cmd/compile/internal/types2`(类型检查)
`types2` 包是将 `go/types` 移植到使用 `syntax` 包的AST而非 `go/ast` 的版本。
### 3. 中间表示构建(IR construction, "noding")
* `cmd/compile/internal/types`(编译器类型)
* `cmd/compile/internal/ir`(编译器AST)
* `cmd/compile/internal/noder`(创建编译器AST)
编译器中端使用自己的AST定义和Go类型表示(源自C语言版本)。类型检查后的下一步是将 `syntax` 和 `types2` 表示转换为 `ir` 和 `types`。此过程称为"noding"。
使用称为统一IR(Unified IR)的技术构建节点表示,该技术基于第2阶段类型检查代码的序列化版本。统一IR还参与包的导入导出和内联优化。
### 4. 中端优化(Middle end)
* `cmd/compile/internal/inline`(函数调用内联)
* `cmd/compile/internal/devirtualize`(已知接口方法调用的虚函数消除)
* `cmd/compile/internal/escape`(逃逸分析)
对IR表示执行多个优化过程:
- 死代码消除
- (早期)虚函数消除
- 函数调用内联
- 逃逸分析
早期死代码消除集成在统一IR写入阶段。
### 5. 遍历(Walk)
* `cmd/compile/internal/walk`(求值顺序、解糖)
对IR表示的最后一步处理是"walk",其作用包括:
1. 将复杂语句分解为简单语句,引入临时变量并保持求值顺序(也称为"order"阶段)
2. 将高级Go构造解糖为原始形式。例如:
- `switch` 语句转换为二分查找或跳转表
- map和channel操作替换为运行时调用
### 6. 通用SSA(Generic SSA)
* `cmd/compile/internal/ssa`(SSA传递和规则)
* `cmd/compile/internal/ssagen`(将IR转换为SSA)
在此阶段,IR被转换为静态单赋值(SSA)形式,这是一种具有特定属性的低级中间表示,便于实现优化和最终生成机器码。
转换过程中应用函数内联(intrinsics)——编译器针对特定情况用高度优化的代码替换的特殊函数。某些节点也会降级为更简单的组件(例如 `copy` 内置函数替换为内存移动,`range` 循环重写为 `for` 循环)。出于历史原因,部分转换目前发生在SSA转换之前,但长期计划是将所有转换集中于此阶段。
随后执行一系列与机器无关的传递和规则,包括:
- 死代码消除
- 删除冗余的空指针检查
- 删除未使用的分支
通用重写规则主要涉及表达式优化,例如用常量替换某些表达式,优化乘法和浮点运算。
### 7. 生成机器码(Generating machine code)
* `cmd/compile/internal/ssa`(SSA降级和架构相关传递)
* `cmd/internal/obj`(机器码生成)
编译器的机器相关阶段从"降级(lower)"传递开始,将通用值重写为其机器特定变体。例如,在amd64架构上允许内存操作数,因此许多加载-存储操作可以合并。
请注意,降级传递运行所有机器特定重写规则,因此当前也执行大量优化。
一旦SSA被"降级"并针对目标架构具体化,将运行最终代码优化传递,包括:
- 另一次死代码消除
- 将值移近使用位置
- 删除从未读取的局部变量
- 寄存器分配
此步骤的其他重要工作包括:
- 栈帧布局(为局部变量分配栈偏移)
- 指针存活分析(计算每个GC安全点上栈上指针的存活状态)
SSA生成阶段结束时,Go函数已转换为一系列 `obj.Prog` 指令。这些指令传递给汇编器(`cmd/internal/obj`),后者将其转换为机器码并输出最终目标文件。目标文件还将包含反射数据、导出数据和调试信息。
### 7a. 导出(Export)
除了为链接器编写目标文件外,编译器还为下游编译单元编写"导出数据"文件。导出数据包含编译包P时计算的以下信息:
- 所有导出声明的类型信息
- 可内联函数的IR
- 可能在其他包实例化的泛型函数的IR
- 函数参数逃逸分析结果的摘要
导出数据格式经历多次迭代,当前版本称为"统一格式"(unified),它是对象图的序列化表示,带有允许延迟解码部分内容的索引(因为大多数导入仅用于提供少数符号)。
GOROOT仓库包含统一格式的读取器和写入器;它从/向编译器的IR进行编码和解码。`golang.org/x/tools` 仓库也为导出数据读者提供公共API(使用 `go/types` 表示),始终支持编译器的当前文件格式和少量历史版本。(`x/tools/go/packages` 在需要类型信息但不需要带类型注释的语法模式中使用它。)
`x/tools` 仓库还为使用旧版"索引格式"的导出类型信息(仅限类型信息)提供公共API。(例如,`gopls` 使用此版本存储工作区信息数据库,其中包括类型信息。)
导出数据通常提供"深度"摘要,因此编译包Q只需读取每个直接导入的导出数据文件,即可确保这些文件提供间接导入(如P的公共API中引用的类型的方法和结构字段)的所有必要信息。深度导出数据简化了构建系统,因为每个直接依赖只需要一个文件。然而,当处于大型仓库的导入图较高层时,这会导致导出数据膨胀:如果有常用类型具有大型API,几乎每个包的导出数据都会包含副本。这一问题推动了"索引"设计的发展,该设计允许按需部分加载。
### 8. 实用技巧
#### 入门指南
* 如果您从未贡献过编译器,简单的方法是在感兴趣的位置添加日志语句或 `panic("here")` 以初步了解问题。
* 编译器本身提供日志、调试和可视化功能:
```bash
$ go build -gcflags=-m=2 # 打印优化信息(包括内联、逃逸分析)
$ go build -gcflags=-d=ssa/check_bce/debug # 打印边界检查信息
$ go build -gcflags=-W # 打印类型检查后的内部解析树
$ GOSSAFUNC=Foo go build # 为函数Foo生成ssa.html文件
$ go build -gcflags=-S # 打印汇编代码
$ go tool compile -bench=out.txt x.go # 打印编译器阶段的计时信息
```
* 部分标志会改变编译器行为,例如:
```bash
$ go tool compile -h file.go # 遇到第一个编译错误时恐慌
$ go build -gcflags=-d=checkptr=2 # 启用额外的unsafe指针检查
```
* 更多标志详情可通过以下方式获取:
```bash
$ go tool compile -h # 查看编译器标志(如 -m=1 -l)
$ go tool compile -d help # 查看调试标志(如 -d=checkptr=2)
$ go tool compile -d ssa/help # 查看SSA标志(如 -d=ssa/prove/debug=2)
```
#### 测试修改
* 请务必阅读 [快速测试修改](https://go.dev/doc/contribute#quick_test) 部分。
* 部分测试位于 `cmd/compile` 包内,可通过 `go test ./...` 运行,但许多测试位于顶级 [test](https://github.com/golang/go/tree/master/test) 目录:
```bash
$ go test cmd/internal/testdir # 运行'test'目录所有测试
$ go test cmd/internal/testdir -run='Test/escape.*.go' # 运行特定模式的测试
```
详情参见 [testdir README](https://github.com/golang/go/tree/master/test#readme)。
`testdir_test.go` 中的 `errorCheck` 方法有助于解析测试中使用的 `ERROR` 注释。
* 新的 [基于应用的覆盖率分析](https://go.dev/testing/coverage/) 可用于编译器:
```bash
$ go install -cover -coverpkg=cmd/compile/... cmd/compile # 构建带覆盖率检测的编译器
$ mkdir /tmp/coverdir # 选择覆盖率数据存放位置
$ GOCOVERDIR=/tmp/coverdir go test [...] # 使用编译器并保存覆盖率数据
$ go tool covdata textfmt -i=/tmp/coverdir -o coverage.out # 转换为传统覆盖率格式
$ go tool cover -html coverage.out # 通过传统工具查看覆盖率
```
#### 处理编译器版本
* 许多编译器测试使用 `$PATH` 中的 `go` 命令及其对应的 `compile` 二进制文件。
* 如果您在分支中且 `$PATH` 包含 `<go-repo>/bin`,执行 `go install cmd/compile` 将使用分支代码构建编译器,并安装到正确位置,以便后续 `go` 命令使用新编译器。
* [toolstash](https://pkg.go.dev/golang.org/x/tools/cmd/toolstash) 提供保存、运行和恢复Go工具链已知良好版本的功能。例如:
```bash
$ go install golang.org/x/tools/cmd/toolstash@latest
$ git clone https://go.googlesource.com/go
$ cd go
$ git checkout -b mybranch
$ ./src/all.bash # 构建并确认良好起点
$ export PATH=$PWD/bin:$PATH
$ toolstash save # 保存当前工具链
```
之后编辑/编译/测试循环类似:
```bash
<... 修改cmd/compile源码 ...>
$ toolstash restore && go install cmd/compile # 恢复已知良好工具链构建编译器
<... 'go build', 'go test', etc. ...> # 使用新编译器进行测试
```
* `toolstash` 还允许比较已安装与存储版本的编译器,例如验证重构后行为一致性:
```bash
$ toolstash restore && go install cmd/compile # 构建最新编译器
$ go build -toolexec "toolstash -cmp" -a -v std # 比较新旧编译器生成的std库
```
* 如果版本不同步(例如出现 `linked object header mismatch` 错误),可执行:
```bash
$ toolstash restore && go install cmd/...
```
#### 其他有用的工具
* [compilebench](https://pkg.go.dev/golang.org/x/tools/cmd/compilebench) 用于基准测试编译器速度。
* [benchstat](https://pkg.go.dev/golang.org/x/perf/cmd/benchstat) 是报告编译器修改性能变化的标准工具:
```bash
$ go test -bench=SomeBenchmarks -count=20 > new.txt # 使用新编译器测试
$ toolstash restore # 恢复旧编译器
$ go test -bench=SomeBenchmarks -count=20 > old.txt # 使用旧编译器测试
$ benchstat old.txt new.txt # 对比结果
```
* [bent](https://pkg.go.dev/golang.org/x/benchmarks/cmd/bent) 可方便地在Docker容器中运行社区Go项目的基准测试集。
* [perflock](https://github.com/aclements/perflock) 通过控制CPU频率等手段提高基准测试一致性。
* [view-annotated-file](https://github.com/loov/view-annotated-file) 可将内联、边界检查和逃逸信息叠加显示在源代码上。
* [godbolt.org](https://go.godbolt.org) 广泛用于查看和分享汇编输出,支持比较不同Go编译器版本的汇编代码。
---
### 进阶阅读
如需深入了解SSA包的工作原理(包括其传递和规则),请参阅 [cmd/compile/internal/ssa/README.md](internal/ssa/README.md)。
如果本文档介绍或SSA README有任何不清楚之处,或您有改进建议,请在 [issue 30074](https://go.dev/issue/30074) 中留言。
================================================
FILE: book/12-appendix/81-go-tool-asm.md
================================================
## 扩展阅读:Go汇编器简介
### 1. Plan9项目和Go语言的关系
Plan9是Bell实验室的一个研究性质的分布式操作系统,Go语言早期核心开发人员多来自这个项目组,他们将设计实现Plan9过程中的一些经验带到了Go语言中来,特别是a.out文件格式、plan9汇编、工具链这块。
see: https://man.cat-v.org/plan_9/6/a.out,比如:
- 汇编器输出后的目标文件格式、运行时会依赖的symtab+pclntab;
- 采用的汇编语言、伪寄存器(fp,sb,sp,pc);
- `FP`: Frame pointer: arguments and locals.
- `PC`: Program counter: jumps and branches.
- `SB`: Static base pointer: global symbols.
- `SP`: Stack pointer: the highest address within the local stack frame.
in Go, all user-defined symbols are written as offsets to the pseudo-registers `FP` (arguments and locals) and `SB` (globals).
### 2. Plan9 和其它OS不一样之处
Plan9本身是一个实验操作系统,它也有些设计实现上不同寻常操作系统的地方:
- 一切皆文件,包括对网络套接字甚至对远程计算机的操作,API都是通过一套编程接口,比Unix、Linux操作系统设计的还要绝;
- 有点奇葩的工具链命名,
- 2c,3c,4c...8c,这些都是编译器,将.c源码编译为plan9汇编文件;
- 2a,3a,4a...8a,这些都是汇编器,将.s源码汇编为目标文件;
ps: object file, 翻译为目标文件好,还是对象文件好,@gemini表示翻译为目标文件好,ok! 目标程序的一部分。
- 2l,3l,4l...8l,这些都是加载器,将可执行文件加载前会完成常规linker要做的符号解析、重定位的操作,然后再加载到内存中;
ps:没有专门的linker,plan9的loader存在一部分常规linker的功能,well,ok!
- 汇编指令是一种semi-abstract instrution set,并不严格对应特定平台上的指令操作,比如MOV操作,指令选择阶段,会选择不同平台特定的机器指令,这点plan9和go都是这样的;
> **Plan9 loaders**: 关于Plan9 loader 2l,3l,..8l的疑问,为什么没有专门的linker?Plan9 loaders是不是具备常规linker的功能?
> 在 Plan 9 操作系统中,“加载器”(例如 Intel 386 的 `8l`)所扮演的角色与传统意义上的“链接器”有很大程度的重叠。
关于Plan9 loaders的功能说明:
* **编译器与加载器:**
* Plan 9 的编译器(如 `8c`)生成目标文件。
* 然后,加载器获取这些目标文件并生成最终的可执行文件。
* **加载器的功能:**
* Plan 9 的加载器不仅仅是执行典型的运行时“加载”操作。它还执行关键的链接任务,包括:
* **符号解析:** 解析不同目标文件和库之间的引用。
* **机器码生成:**在plan9中,加载器才是真正生成最终机器码的程序。
* **指令选择:**选择最有效的机器指令。
* **分支折叠和指令调度:**优化可执行文件。
* **库链接:**自动链接必要的库。
* **关键区别:**
* 一个显著的区别是,Plan 9 加载器处理了大部分最终机器码的生成,而在许多其他系统中,这部分工作是在编译过程的早期完成的。这意味着plan9编译器产生的是一种抽象的汇编,而加载器将其转换为最终的机器码。
* **本质上:**
* Plan 9 加载器的功能不仅仅是加载,它还包含了核心的链接职责。
### 3. Plan9和Go汇编器异同点
要充分掌握Go汇编,就得了解它的前身及它自己的演进,也就是说了解Plan9汇编器,以及Go中特殊的地方。
- [a manual for plan9 assembler, rob pike](https://doc.cat-v.org/plan_9/4th_edition/papers/asm)
- [a quick guide to Go's assembler](https://go.dev/doc/asm)
后续有机会,可以在我的博客里总结下Go汇编器的使用,本电子书中我们就不过多展开了,我们这里只介绍下Go汇编器的主要工作即可,我们不会考虑调试期间对Go汇编进行特殊支持 …… 这不在我们计划中,除非我们有大把时间。
### 参考文献
- plan9 a.out目标文件格式, https://man.cat-v.org/plan_9/6/a.out
- plan9 assemblers, https://man.cat-v.org/plan_9/1/2a
- plan9 compilers, https://man.cat-v.org/plan_9/1/2c
- plan9 loaders, https://man.cat-v.org/plan_9/1/2l
- plan9 used compilers, https://doc.cat-v.org/bell_labs/new_c_compilers/new_c_compiler.pdf
> “ *This paper describes yet another series of C compilers. These compilers were developed over the last several years and are now in use on Plan 9. These compilers are experimental in nature and were developed to try out new ideas. Some of the ideas were good and some not so good.* ”
>
- how to use plan9 c compiler, rob pike, https://doc.cat-v.org/plan_9/4th_edition/papers/comp
- a manual for plan9 assembler, rob pike, https://doc.cat-v.org/plan_9/4th_edition/papers/asm
- a quick guide to Go's assembler, https://go.dev/doc/asm
================================================
FILE: book/12-appendix/82-go-tool-link.md
================================================
## 扩展阅读:Go链接器简介
### 1. Go语言链接器是什么?
Go语言的链接器是Go工具链中的一个关键组成部分,负责将编译生成的目标文件(如.o文件)连接成最终的可执行文件、共享库或静态库。在Go生态系统中,链接器通常被称为`go tool link`,它是Go语言编译过程中的最后一步,确保所有模块和依赖项正确地组合在一起。
### 2. Go语言链接器的工作原理
#### 基本流程
1. **输入文件处理**:链接器接收多个目标文件(`.o`或`.obj`)、静态库(如`.a`文件)以及可能的共享库。
2. **符号解析与重定位**:
- 链接器扫描所有输入文件,解析其中未定义的符号。这些符号可能来自其他目标文件、库或Go语言运行时环境。
- 对于每个符号引用,链接器查找其定义位置,并记录下需要进行重定位的操作(如调整指针以正确指向函数或变量)。
3. **段和节的合并**:
- 将所有输入文件中的相同类型的段(如`text`段用于代码、`data`段用于初始化数据)合并到一起。
- 处理各个段中的重定位信息,确保所有指针和偏移量正确无误。
4. **输出生成**:将处理后的段组合成最终的可执行文件或库。
#### 内部机制
- **符号表管理**:链接器维护一个全局符号表,用于跟踪已解析的符号及其地址。这包括函数、变量以及其他标识符。
- **重定位记录**:在编译阶段生成的目标文件中包含重定位信息,告诉链接器哪些位置需要调整以指向正确的符号或节的位置。
- **依赖处理**:Go语言的模块系统允许项目依赖于多个包,链接器会自动将这些外部库包含进来,确保所有必要的代码和资源都被整合到最终输出中。
### 3. 编译器与链接器的协同工作
#### 相关Sections
在编译过程中,Go编译器生成以下几个关键段:
- **`text`**:存储可执行代码。
- **`data`**:用于初始化的数据(如全局变量)。
- **`rodata`**:只读数据,通常包含常量字符串和编译时常量。
- **`bss`**:未初始化的零初始化数据段。
编译器负责将源代码转换为这些段中的内容,并在生成的目标文件中记录必要的重定位信息。链接器的任务是将所有目标文件中的相应段合并,并解决符号依赖关系,确保最终程序或库能够在运行时正确执行。
#### 协作流程
1. **编译阶段**:每个Go源文件被分割成多个段,并生成包含重定位指令的信息。
2. **链接阶段**:
- 链接器读取所有目标文件和库的段信息。
- 解析未定义符号,可能需要查找标准库或其他依赖库中的实现。
- 合并各个段(如将所有`text`段合并为一个连续的代码段)。
- 应用重定位操作,调整指针地址以反映实际内存布局。
### 4. ELF文件中的Program Header Table
在ELF(Executable and Linkable Format)文件中,`program header table`是由编译器和链接器共同作用的结果。具体来说:
- **编译器**:生成初始的段信息,并创建基本的程序头表结构。
- **链接器**:调整和完善这些段的布局,更新程序头表中的偏移量、大小等信息,以确保最终文件能够被操作系统正确加载。
总结来说,虽然编译器为ELF文件奠定了基础,但链接器负责将其转化为适合执行的形式,包括调整段的位置和属性,使程序能够在目标环境中运行。
### 5. 参考文献
- TODO [Internals of the Go Linker by Jessie Frazelle](https://www.youtube.com/watch?v=NLl5zwl9Hk8)
- [Golang Internals, Part 2: Diving Into the Go Compiler](https://www.altoros.com/blog/golang-internals-part-2-diving-into-the-go-compiler/)
- [Golang Internals, Part 3: The Linker, Object Files, and Relocations](https://www.altoros.com/blog/golang-internals-part-3-the-linker-object-files-and-relocations/)
- [Golang Internals, Part 4: Object Files and Function Metadata](https://www.altoros.com/blog/golang-internals-part-4-object-files-and-function-metadata/)
- TODO [Linkers and Loaders](https://www.amazon.com/Linkers-Kaufmann-Software-Engineering-Programming/dp/1558604960)
通过这些参考资料,可以更全面地理解Go语言链接器的工作机制及其在编译过程中的重要性。
================================================
FILE: book/12-appendix/90-why-buildid-loaded.md
================================================
## 问题探讨:why load buildid sections
### 先说点结论性的
涉及到build id这个概念的sections主要有两个,.note.go.buildid,以及.note.gnu.build-id,前者就是大家熟知的go tool buildid `<binary>` 显示的buildid,后者是更多的Linux生态中的工具使用的。
前面讲解ELF文件段头表的时候发现个问题,.note.go.build, .note.gnu.build-id 为何会被加载到内存中呢?有几个猜测:
- 程序运行时希望不读取ELF文件直接获取这些buildid信息;
- 程序生成内存转储后,希望将这些信息包含在core文件中,方便其他工具从core文件中提取buildid信息与符号
.note.gnu.build-id,这个的作用是用来跟踪构建时的代码版本、代码目录、构建环境是否一致,有些构建系统会记录这个buildid以及关联的上述信息、制品、分离的调试符号、符号表等等,在需要定位问题的时候可以按需加载这些。
.note.go.buildid,这个的作用主要是go工具链内部使用,外部工具不应该使用这个buildid。
### 探索:pprof profile信息中希望记录下GNU build-id
在阅读了go源码以后,初步判断是pprof生成profile信息时希望能在其中记录下buildid,以方便分析时用来跟踪版本、构建环境、符号信息,这些信息可能构建系统会自己通过数据库维护起来。但是仔细查看后这里的buildid是.note.gnu.build-id中的build-id,而非go buildid,前者是一些工具通用的
从/proc/pid/maps获取对应的GNU build-id的源码,大致如下:
```
// newProfileBuilder returns a new profileBuilder.
// CPU profiling data obtained from the runtime can be added
// by calling b.addCPUData, and then the eventual profile
// can be obtained by calling b.finish.
func newProfileBuilder(w io.Writer) *profileBuilder {
zw, _ := gzip.NewWriterLevel(w, gzip.BestSpeed)
b := &profileBuilder{
...
}
b.readMapping()
return b
}
// readMapping reads /proc/self/maps and writes mappings to b.pb.
// It saves the address ranges of the mappings in b.mem for use
// when emitting locations.
func (b *profileBuilder) readMapping() {
data, _ := os.ReadFile("/proc/self/maps")
parseProcSelfMaps(data, b.addMapping)
...
}
func parseProcSelfMaps(data []byte, addMapping func(lo, hi, offset uint64, file, buildID string)) {
// $ cat /proc/self/maps
// 00400000-0040b000 r-xp 00000000 fc:01 787766 /bin/cat
// 0060a000-0060b000 r--p 0000a000 fc:01 787766 /bin/cat
// 0060b000-0060c000 rw-p 0000b000 fc:01 787766 /bin/cat
// 014ab000-014cc000 rw-p 00000000 00:00 0 [heap]
// 7f7d76af8000-7f7d7797c000 r--p 00000000 fc:01 1318064 /usr/lib/locale/locale-archive
// 7f7d7797c000-7f7d77b36000 r-xp 00000000 fc:01 1180226 /lib/x86_64-linux-gnu/libc-2.19.so
// 7f7d77b36000-7f7d77d36000 ---p 001ba000 fc:01 1180226 /lib/x86_64-linux-gnu/libc-2.19.so
...
// 7f7d77f65000-7f7d77f66000 rw-p 00000000 00:00 0
// 7ffc342a2000-7ffc342c3000 rw-p 00000000 00:00 0 [stack]
// 7ffc34343000-7ffc34345000 r-xp 00000000 00:00 0 [vdso]
// ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
...
for len(data) > 0 {
...
buildID, _ := elfBuildID(file)
addMapping(lo, hi, offset, file, buildID)
}
}
// elfBuildID returns the GNU build ID of the named ELF binary,
// without introducing a dependency on debug/elf and its dependencies.
func elfBuildID(file string) (string, error) {
...
}
```
### 探索:测试下pprof profile信息中包含GNU build-id
在这个基础上,我们生成个pprof profile信息,然后查看下是否有记录这个GNU build-id:
```
$ cat main.go
package main
import (
"log"
"os"
"runtime/pprof"
)
func main() {
f, err := os.Create("profile.pb.gz")
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
var i int64
for i = 0; i < (1 << 33); i++ {
}
}
```
```bash
$ go build -ldflags "-B gobuildid" main.go
$ file main
main: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=f4b5d514bc46fad9417898216b23910ae874a85d, with debug_info, not stripped
$ readelf -n main
Displaying notes found in: .note.gnu.build-id
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
Build ID: f4b5d514bc46fad9417898216b23910ae874a85d
Displaying notes found in: .note.go.buildid
Owner Data size Description
Go 0x00000053 GO BUILDID
description data: 45 72 5a 36 6f 30 30 37 79 53 35 48 4c 67 41 7a 51 66 6e 52 2f 42 5a 53 51 58 54 4b 49 35 53 61 61 4f 4d 6e 65 49 36 63 56 2f 52 37 41 42 44 38 68 6c 34 6c 6b 65 79 44 66 7a 35 35 69 4d 2f 73 58 6a 56 4b 38 6d 52 58 79 35 4d 79 41 73 46 46 52 6d 74
$ ./main
$ pprof -raw profile.pb.gz | grep -A10 Mappings
Mappings
1: 0x400000/0x4ac000/0x0 /tmp/main f4b5d514bc46fad9417898216b23910ae874a85d [FN]
```
注意这里的GNU build-id不是默认生成的,需要显示传 -ldflags "-B ..." 来指定,如果不指定的话,就没有这个信息:
```
$ go build main.go
$ file main
main: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, Go BuildID=llrn1go725_F2vCvvETz/OITeRu6kDScHG6FVjdK8/R7ABD8hl4lkeyDfz55iM/uoTostDrfB5kdwhy6UpG, with debug_info, not stripped
$ readelf -n main
Displaying notes found in: .note.go.buildid
Owner Data size Description
Go 0x00000053 GO BUILDID
description data: 6c 6c 72 6e 31 67 6f 37 32 35 5f 46 32 76 43 76 76 45 54 7a 2f 4f 49 54 65 52 75 36 6b 44 53 63 48 47 36 46 56 6a 64 4b 38 2f 52 37 41 42 44 38 68 6c 34 6c 6b 65 79 44 66 7a 35 35 69 4d 2f 75 6f 54 6f 73 74 44 72 66 42 35 6b 64 77 68 79 36 55 70 47
$ ./main
$ pprof -raw profile.pb.gz | grep -A10 Mappings
Mappings
1: 0x400000/0x4ac000/0x0 /tmp/main [FN]
```
### 探索:为什么text segment要包含buildid? coredump?
但是我们想搞清楚的是,这么一个GNU build-id或者go buildid,链接器创建对应的segment的时候为什么非要将其和.text section一起定义为PT_LOAD类型,毕竟没有工具直接从二进制中去读它。实际上如果没有原始ELF信息中的sections、segments信息也不知道进程中该buildid应该位于内存地址的什么位置、占多少字节,还是没法解析。实际上现在看go官方工具链里至少也没有直接这么去读的,都最终还是读的ELF文件中的sections来拿到这个GNU build-id或者go buildid信息的。
我现在能联想到的就是,如果不是一个bug的话,那很可能是希望在生成core文件 或者 内存转储(dump memory)的时候能把这部分信息存下来,好方便确定生成core文件的builid,以和构建系统中维护的信息建立联系。下面举个这样的例子:
启动一个go程序 myapp 并生成 core 文件
1. go build -o main main.go
2. ./main
3. gcore -o main.core $(pidof main)
加载这个core文件,并读取buildid信息
1. gdb main.core main
2. gdb> maintenance info sections
```bash
Exec file:
`/home/zhangjie/test/main', file type elf64-x86-64.
[0] 0x00401000->0x00480c75 at 0x00001000: .text ALLOC LOAD READONLY CODE HAS_CONTENTS
[1] 0x00481000->0x004be35d at 0x00081000: .rodata ALLOC LOAD READONLY DATA HAS_CONTENTS
[2] 0x004be360->0x004be8f0 at 0x000be360: .typelink ALLOC LOAD READONLY DATA HAS_CONTENTS
[3] 0x004be900->0x004be958 at 0x000be900: .itablink ALLOC LOAD READONLY DATA HAS_CONTENTS
[4] 0x004be958->0x004be958 at 0x000be958: .gosymtab ALLOC LOAD READONLY DATA HAS_CONTENTS
[5] 0x004be960->0x00523070 at 0x000be960: .gopclntab ALLOC LOAD READONLY DATA HAS_CONTENTS
[6] 0x00524000->0x00524150 at 0x00124000: .go.buildinfo ALLOC LOAD DATA HAS_CONTENTS
[7] 0x00524160->0x00529600 at 0x00124160: .noptrdata ALLOC LOAD DATA HAS_CONTENTS
[8] 0x00529600->0x0052d850 at 0x00129600: .data ALLOC LOAD DATA HAS_CONTENTS
[9] 0x0052d860->0x0058d390 at 0x0012d860: .bss ALLOC
[10] 0x0058d3a0->0x00590de0 at 0x0018d3a0: .noptrbss ALLOC
[11] 0x00000000->0x00000214 at 0x0012e000: .debug_abbrev READONLY HAS_CONTENTS
[12] 0x00000000->0x00037302 at 0x0012e135: .debug_line READONLY HAS_CONTENTS
[13] 0x00000000->0x00012674 at 0x0014d803: .debug_frame READONLY HAS_CONTENTS
[14] 0x00000000->0x0000002a at 0x00153a70: .debug_gdb_scripts READONLY HAS_CONTENTS
[15] 0x00000000->0x000928ac at 0x00153a9a: .debug_info READONLY HAS_CONTENTS
[16] 0x00000000->0x000a772c at 0x00191567: .debug_loc READONLY HAS_CONTENTS
[17] 0x00000000->0x0003e3a0 at 0x001adaae: .debug_ranges READONLY HAS_CONTENTS
[18] 0x00400fdc->0x00401000 at 0x00000fdc: .note.gnu.build-id ALLOC LOAD READONLY DATA HAS_CONTENTS
[19] 0x00400f78->0x00400fdc at 0x00000f78: .note.go.buildid ALLOC LOAD READONLY DATA HAS_CONTENTS
Core file:
`/home/zhangjie/test/mycore.444388', file type elf64-x86-64.
[0] 0x00000000->0x00002798 at 0x00000548: note0 READONLY HAS_CONTENTS
[1] 0x00000000->0x000000d8 at 0x00000668: .reg/444388 HAS_CONTENTS
[2] 0x00000000->0x000000d8 at 0x00000668: .reg HAS_CONTENTS
...
```
3. 生成转储,包含了go buildid
```bash
gdb$ dump memory dump.go.buildid 0x00400f78 0x00400fdc
```
4. 生成转储,包含了GNU build-id
```bash
gdb$ dump memory dump.gnu.buildid 0x00400fdc 0x00401000
```
对比分析上述内存中转出来的buildid信息与ELF文件中数据是否一致:
- 查看上述内存转储数据可以使用 `strings`、`hexdump`;
- 查看ELF文件中数据 `file`、`readelf -S <main> --string-dump=|--hex-dump=`;
- 对比发现是一致的。
### 探索:似乎除了core没有其他理由要load上述sections?
但是呢?还是那句话,如果我们拿不到原始的executable文件,拿不到对应的ELF sections、segments信息,上面调试器也输出不了各个sections在内存中的地址,我们也不方便内存转储后分析。
思来想去,将这个.note.gnu.build-id和.note.go.builid加载到内存,唯一可能的原因就是为了生成core文件的时候能够包含这个信息了。
> ps: 得有工具帮助跟踪这个core文件的pid对应的二进制文件的映射关系。
Read More:
- [what does go build -ldflags "-B [0x999|gobuildid]" do](https://go-review.googlesource.com/c/go/+/511475#related-content) , 这个其实就是想在ELF里记录一个GNU buildid,但是能从go buildid派生出来,不用外部系统重复做这个计算工作。这个buildid可以用来用来追踪构建有没有发生改变,有些外部系统会维护一个数据库记录构建时代码版本、符号信息以及与buildid的映射关系,方便进行问题定位、制品跟踪等。
- .note.gnu.build-id 可以由外部系统构建好在编译的时候传入(go build -ldflags "-B `<yourbuildid>`"),也可以通过.note.go.buildid生成规则来派生一个出来(go build -ldflags "-B gobuildid")。
- .note.gnu.build-id 是很多通用工具会去读取的,而.note.go.buildid定位上是只给go官方工具链中的内部工具使用。
- 不管怎么样吧,现在pprof profile信息里记录这个GNU build-id的时候也是通过先读取 /proc/`<pid>/maps然后找到可执行权限的mmaped的文件,然后再去读取这个文件找到对应的section .note.gnu.build-id来读取的。这部分代码写的很重复,实际上只是为了避免引入标准库中的东西,不想导入那么多依赖,所以是自己读取后来解析的。`
Well, I'm still a little confused:
- 通过这个来跟踪下讨论进展:https://groups.google.com/g/golang-nuts/c/Pv5gPIUTVyY
================================================
FILE: book/12-appendix/91-syntax-and-semantic-analysis.md
================================================
## 扩展阅读:解释下语法分析和语义分析的区别
### 回顾编译过程
学习过编译原理的话,编译过程包含的主要步骤,我们应该都有这方面认识。Go编译期编译过程主要包含这么几个步骤:
- 词法分析(Lexical Analysis):将源代码转换为单词流(tokens),识别关键字、标识符、运算符等;
- 语法分析(Syntax Analysis):将 token 流解析为抽象语法树(AST);
- 语义分析(Semantic Analysis):检查 AST 的语义,处理变量声明、类型检查、作用域等;
- 中间代码生成(Intermediate Code Generation):将 AST 转换为静态单赋值(SSA)形式,便于优化;
- 目标代码生成(Target Code Generation):将 SSA 中间表示转换为平台特定的汇编代码;
> ps: ELF 符号表和调试信息(DWARF),编译器在处理中间代码时,会收集符号信息并生成 DWARF 调试数据。
### 语法 vs 语义
其中语法分析、语义分析,没有其他几个步骤字面上区分度那么高,如果没有亲自尝试写编译器,只是看这个术语本身的话,很容易混淆它们的不同。其实,**语法分析和语义分析,是有明显不同之处的:**
**1. 目标不同**
- **语法分析**的主要目的是验证源代码是否符合语言的语法规则,并将其转换为抽象语法树(AST)。这一步骤关注的是代码的结构是否正确,确保没有语法错误。
- **语义分析**则侧重于理解代码的意义和逻辑。它在生成的AST基础上进行进一步的处理,如类型检查、作用域分析等,以确保代码在语义上是正确的。
**2. 输入与输出不同**
- **语法分析**的输入是源代码文本,其输出是一个抽象语法树(AST),表示代码的结构。
- **语义分析**的输入是抽象语法树(AST),其输出是对程序进行了一系列语义检查和处理后的中间表示,确保每个元素在类型和逻辑上都是合理的。
**3. 关注点不同**
- 在**语法分析**中,编译器关注的是代码的形式结构,比如词法单元是否正确组合成有效的语句和表达式。
- 而在**语义分析**中,编译器不仅检查结构的正确性,还要确保变量的使用符合其声明类型,函数调用参数与定义一致等。
**4. 错误类型**
- **语法分析**过程中发现的错误通常是词法或语法错误,如拼写错误、括号不匹配等。
- **语义分析**过程中发现的错误是语义错误,如类型不兼容、变量未声明等。
**5. 实现步骤**
- **语法分析**一般包括:
- 扫描源代码生成token流。
- 解析token流生成AST。
- **语义分析**一般包括:
- 建立符号表,管理变量的作用域。
- 进行类型检查,确保操作的合法性。
- 处理表达式和语句的语义信息。
**6. 在Go编译器中的实现**
- **语法分析**主要由 `parser.go`文件中的 `ParseFile()`函数实现,生成AST。
- **语义分析**主要由 `noder.go`文件中的 `NewNoder()`和 `Noder.Emit()`函数实现,处理中间表示并进行类型检查。
**7. 示例**
举个简单的例子:
```go
func main() {
var a int
a = 5
}
```
- **语法分析**会将这段代码转换为一个AST,包含函数定义、变量声明和赋值操作。
- **语义分析**则会在生成的AST基础上检查:
- `a`是否在作用域内被正确声明。
- 赋值操作中5是否与int类型兼容。
- 函数调用等其他可能的操作是否符合语义规则。
通过以上步骤和示例,可以看出语法分析和语义分析虽然都是编译过程中的关键阶段,但它们关注的焦点和处理的内容是不同的。语法分析确保代码的结构正确,而语义分析则确保代码在逻辑上合理且无误。
================================================
FILE: book/12-appendix/92-why-gdb-uses-symtab.md
================================================
## 扩展阅读:GDB为什么同时使用.symtab和DWARF
### **GDB 使用 `.symtab` 吗?**
是的,它使用,而且是作为非常基础的依赖数据在使用。
### 为什么使用 `.symtab`?
`.symtab` (符号表) 是 ELF (可执行和可链接格式) 文件的一个核心组成部分。它包含以下信息:
* **函数名:** 程序中函数的名称。这对于单步调试、设置断点和理解程序执行流程至关重要。
* **变量名:** 全局和静态变量的名称。虽然 GDB *可以* 访问局部变量的信息(稍后会讲到),但 `.symtab` 提供了全局可访问变量的名称。
* **符号地址:** 函数和变量在内存中的地址。这对于 GDB 在调试时定位它们是必需的。
* **节信息:** 链接到包含代码和数据的 ELF 文件节的链接。
从历史上看,`.symtab` 是主要的调试信息来源。早期的调试器,包括最初的 GDB,都是围绕它构建的。它是一个相对简单且紧凑的数据结构。如果没有它,GDB 会受到严重限制——它无法有意义地表示程序的结构。
### 为什么不只用 DWARF 呢?
这是关键问题,答案是:**GDB *确实* 使用 DWARF 信息,但它并没有 *取代* `.symtab`。它们扮演着不同的、互补的角色。**
让我们了解一下 DWARF:
* **什么是 DWARF?** DWARF (Debugging With Attributed Record Format) 是一种标准化的调试信息格式。它比 `.symtab` 更加全面。它包含:
* **局部变量信息:** 这是相对于 `.symtab` 的一个 *主要* 优势。`.symtab` 通常不存储函数内部的局部变量信息。
* **类型信息:** 关于变量和函数参数的数据类型细节。
* **行号信息:** 机器指令和源代码行之间的映射关系。这使得 GDB 能够显示你单步执行时对应的源代码行。
* **参数信息:** 函数参数的信息。
* **内联函数信息:** 关于内联函数的细节。
* **为什么不能 *仅仅* 用 DWARF?**
* **大小和性能:** DWARF 信息会显著增加可执行文件或共享库的大小。这会影响磁盘空间、内存使用以及潜在的加载时间。虽然存在压缩技术,但仍然是一个需要考虑的因素。
* **兼容性:** 虽然 DWARF 是标准化的,但存在不同的版本和扩展。较旧的 GDB 版本可能无法完全支持所有 DWARF 功能。`.symtab` 是一个更通用的基础。
* **符号名称:** 虽然 DWARF *可以* 包含符号名称,但它通常不是存储它们的唯一地方。`.symtab` 仍然是可靠的函数和全局变量名称来源。有时,DWARF 可能会包含混杂或不易读懂的名称。
* **历史原因和兼容性:** GDB 的核心架构是围绕 `.symtab` 构建的。虽然它已经发展到高度依赖 DWARF,但完全放弃 `.symtab` 将是一个巨大的工程,并且会破坏与旧二进制文件的兼容性。
**### GDB如何同时使用二者**
**这里解释下GDB 如何同时使用两者:**
1. **初始加载:** GDB 首先使用 `.symtab` 获取基本的符号信息(函数名、地址)。
2. **使用 DWARF 补充:** 然后,它使用 DWARF 获取更详细的调试信息(局部变量、类型、行号)。
3. **结合使用:** 例如,当你单步执行时,GDB 使用 `.symtab` 找到函数地址,然后使用 DWARF 显示对应的源代码行。
**现代 GDB 和 DWARF:**
现代版本的 GDB(尤其是使用最新编译器编译的版本)高度依赖 DWARF。它提供的更丰富的调试信息显著改善了用户体验。但是,`.symtab` 仍然是一个关键的后备方案和基础元素。 很难想象 GDB 会在不久的将来完全放弃它。
**总结:**
| 特性 | `.symtab` | DWARF |
| ------------------ | ---------------------------- | -------------------------------------- |
| **主要用途** | 基本符号信息(函数名、地址) | 详细的调试信息(局部变量、类型、行号) |
| **大小** | 较小 | 较大 |
| **兼容性** | 非常高 | 取决于版本 |
| **局部变量** | 无 | 有 |
| **类型信息** | 有限 | 丰富 |
希望这个详细的解释能让读者更清楚地了解 GDB、`.symtab` 和 DWARF 之间的关系。
================================================
FILE: book/12-appendix/README.md
================================================
================================================
FILE: book/2-preface/README.md
================================================
# Preface
2018年开始接触golang,在学习阶段通过调试器gdb、delve进行了大量调试分析,这些实践让我在理解go类型系统、标准库、运行时相关设计实现方面事半功倍。
我本人好奇心比较强,喜欢刨根问底,有一天突然产生了疑问:**调试器是如何工作的呢**?
- 如果只是想了解调试器的大致工作原理,阅读几篇高质量博客或许就足够了。
- 但如果想要胜任调试器的开发工作,尤其是从零开始构建一个完整的调试器,那就完全是另外一回事了。
调试器的设计、实现以及调试信息标准构成了一个极其庞杂而精深的工程体系。我渴望深入探索其中的奥秘,但在我的刨根问底之下,发现市面上缺乏系统全面且高质量的技术总结。正是这种技术空白促使我开始了这本书的编写之旅。
在编写过程中,我不仅大大加深了对软件开发工具链的认识,更逐渐意识到开发一款功能全面的现代调试器所具有的深远意义:它不仅具有极高的技术含量和实践价值,更能帮助开发者从多维度巩固和完善软件开发知识体系。因此,我决心在工作之余完成这个工程,与大家分享这些宝贵的技术洞察。
由于作者水平有限,书中难免存在错误或疏漏之处,真诚希望读者能够指出问题,共同完善这份调试器设计开发的技术文档。
================================================
FILE: book/3-terms/README.md
================================================
# Terms
在本书中,我们将介绍编译器、链接器、操作系统、调试器和调试信息标准,以及软件开发等方面的知识,使用到的术语会非常多。在此处列出常见重要术语,以便读者方便地查找。
| **Term** | **Description** |
|:---------------------------|:------------------------|
| Source | 源代码,如go语言编写的源代码 |
| Compiler | 编译器,编译源代码为目标文件 |
| Linker | 链接器,将目标文件、共享库、系统启动代码链接到一起构建可执行程序 |
| Debugger | 调试器,跟踪正在运行的进程或者装载一个core文件,加载程序或core文件调试符号信息,探查、修改、控制进程运行时状态,如暂停执行并查看内存、寄存器 |
| Debugger Frontend | 调试器前端,主要负责与用户进行交互,接收用户输入的调试命令,并将结果以友好的方式展示给用户。前端可以是命令行界面(CLI)、图形界面(GUI)、集成开发环境(IDE)插件等。前端本身不直接与被调试进程交互,而是通过后端完成具体的调试操作 |
| Debugger Backend | 调试器后端,负责与被调试进程(tracee)进行实际的交互,包括进程控制、断点设置、内存和寄存器读写、符号信息加载等。后端通常以服务的形式运行,接收前端发来的调试命令请求,并将执行结果返回给前端。前后端之间可以通过本地调用或远程协议(如RPC)通信,实现分布式或跨平台调试 |
| DWARF | DWARF,是一种调试信息标准,指导编译器将调试信息生成到目标文件中,指导链接器合并存储在多个目标文件中的调试信息,调试器将加载此调试信息。简言之,DWARF用来协调编译器、链接器和调试器之间的工作 |
| Debugger types | 通常,调试器可以分为两种类型:指令级调试器和符号级调试器 |
| Instruction level debugger | 指令级调试器主要面向指令级别的执行控制,如设置指令地址断点、执行到断点或单步操作等。在查看进程内存和寄存器数据时,它提供相对低级的操作,如查看内存区域数据时需要指定以二进制或十进制格式显示。指令级调试器不依赖调试符号信息,因此不支持以源代码符号进行程序控制和数据操作。 指令级调试器对于逆向工程等安全分析领域也是很常见的 |
| Symbol level debugger | 符号级调试器通常具备指令级调试器的所有功能,同时依靠可执行程序中的调试符号信息,建立内存地址、指令地址与源代码之间的映射关系。它支持在源代码位置设置断点、使用源代码符号查看修改变量、通过源代码表达式设置断点条件,还可以查看当前调用堆栈。符号级调试器具备许多指令级调试器所不具备的高级功能,使得使用高级语言开发时的软件调试变得便利 |
| Tracee | 泛指被调试的进程,准确地讲,tracee指的是被调试器跟踪的线程。一个被调试器调试的进程也可能是多线程程序,因此如果需要对其中的多个线程进行调试跟踪,那么就存在多个tracee |
| Tracer | 泛指调试器对应的进程,严格来讲也是线程,以Linux为例tracer指的是通过ptrace_attach系统调用与tracee建立跟踪、被跟踪关系的调试器中的线程。Linux内核要求ptrace attach之后的后续ptrace请求必须来自发起ptrace attach请求的线程,因此Linux下的调试器实现往往会有一个专门线程作为tracer,负责与被调试进程中的多个tracee进行交互 |
================================================
FILE: book/4-basics/1-purposes.md
================================================
## 4.1 调试目的
尽管开发者花费了大量精力来避免自己的代码中引入bug,但是写出bug仍然是一个很平常的事情。开发人员定位代码中的问题时,通常会借助 “**走读代码**” + “**打印日志**” 的方式来理解程序执行路径、关键变量值变化,进而推断程序执行结果是否符合预期。在某些更复杂的场景下,这种方式可能难以胜任,调试器会更好地协助我们定位问题。
调试器可以帮助我们控制tracee(被调试进程、线程)的执行,也可以观察tracee的运行时内存、寄存器状态,借此我们可以实现代码的逐语句执行、控制代码执行流程、检查变量值是否符合预期,等等。
我认为调试器对于刚入门的开发者而言,是一个不可缺少的工具,它还能加深对编程语言、内存模型、操作系统的认识。即便是对于一些从业多年的开发者而言,调试器也会是一个有用的帮手。
本书将指导我们如何开发一个面向go语言的调试器,如果读者之前有使用符号级调试器(如gdb、delve等)的经验,那对于理解本书内容将会非常有帮助。
调试器要支持的重要操作,通常包括:
- 设置断点,在指定内存地址、函数、语句、文件行号处设置断点;
- 单步执行,单步执行一条指令,单步执行一条语句,或运行到下个断点处;
- 获取、设置寄存器信息;
- 获取、设置内存信息;
- 对表达式进行估值计算;
- 调用函数;
- 其他;
本书后续章节会介绍如何实现上述操作,如果对调试器内部工作原理好奇,那就请继续吧。
> ps:go被广泛应用于微服务开发,如何在微服务架构下方便地对微服务进行调试呢?如果是一个单体应用,我们还可以通过跟踪多个线程、协程的状态来了解全貌,那如果当处理过程被分解到了多个不同的微服务上时,又如何通过调试器来完成整个处理过程的调试呢?
>
> 对于线上服务,这种方式可应用的空间会比较小,因为其会对性能影响比较大,且容器平台必须放开调试相关的安全设置,这意味着可能存在更多的安全风险。通过opentelemetry来观测线上服务的metrics、logging、tracing数据应该更有效。
>
> 但是对开发阶段的服务,那调试器这种方式就有比较大的优势了,opentelemetry等解决方案存在较明显的延迟,对于及时调试并不算一种很好的解决方案。如果能在一个单点完成对整个微服务上下游的调试,那就太棒了。能做到吗?solo.io打造了 [**squash**](https://squash.solo.io/) 这款微服务架构下的调试器。
>
> 本书最后,也会简单解释下squash的实现思路,看看别人是怎么做到的 :)
================================================
FILE: book/4-basics/2-dependencies.md
================================================
## 4.2 依赖(支持)
### 4.2.1 调试符号信息
编译器、链接器根据源代码构建可执行程序,可执行程序中的数据是面向机器的,而非面向人类的。调试器如何理解可执行程序中的数据,并在机器表示和人类可读形式之间进行转换呢?这就需要调试信息的支持了。
当编译器将源代码转换成目标文件的时候,编译器会生成一些调试信息并将其存储到可执行程序中特殊的section中。当链接器将多个目标对象文件链接成一个完整的可执行程序的时候,链接器会将分散在不同目标文件中的调试信息进行合并后存储。

这里的调试信息如何生成、编解码、存储等是有相应的调试信息标准(如DWARF)指导的,调试信息标准指导编译器、链接器、调试器之间如何进行协作。编译器、链接器生成这些调试信息并将其存储到可执行程序的sections中,调试器会从中提取、解析与调试相关的信息,然后就可以构建起源码层面的视图。进而,调试器可以完成内存地址、指令地址、源码之间的相互映射。
不同的目标文件格式,调试符号信息可能会存储在不同的地方,一般可能有两种存储方式:
#### 4.2.1.1 存储在目标文件自身
例如,[ELF](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format) 文件格式包含了DWARF调试信息对应的section,一般以".debug”或”.zdebug”开头。.debug前缀开头的section表示数据未压缩,.zdebug前缀开头的section表示数据经过了压缩。
> 这里给个实例,__debug_bin是一个由 `dlv debug`生成的可执行程序,包含了调试符号信息,`readelf`可以用来读取ELF文件中的section header,下面我们看一下ELF文件中包含的调试信息相关的 section。
>
> go build可以通过指定链接器选项“**-ldflags=-compressdwarf=false**”来禁用压缩,提前了解这点,方便以后通过dwarfdump等工具分析理解dwarf调试信息如何组织非常有用。
>
> ```bash
> [root@centos ~]# readelf -a __debug_bin | grep debug
> [12] .zdebug_abbrev PROGBITS 0000000000599000 0017b000
> [13] .zdebug_line PROGBITS 0000000000599114 0017b114
> [14] .zdebug_frame PROGBITS 00000000005a9f37 0018bf37
> [15] .zdebug_pubnames PROGBITS 00000000005b11a8 001931a8
> [16] .zdebug_pubtypes PROGBITS 00000000005b2fa0 00194fa0
> [17] .debug_gdb_script PROGBITS 00000000005b624b 0019824b
> [18] .zdebug_info PROGBITS 00000000005b6273 00198273
> [19] .zdebug_loc PROGBITS 00000000005dcfe2 001befe2
> [20] .zdebug_ranges PROGBITS 00000000005e982d 001cb82d
> ```
>
> ps: 作者开始写这本电子书的时候非常早,当时2018年还是用的1.13,现在这么多年过去,发生了很多变化。
>
> - 首先,go1.13中确实是这样的,zlib压缩后写入.zdebug_ sections (see: https://github.com/golang/go/issues/11799#issuecomment-399564050);
> - 由于没有一次性完成该电子书,后续go1.19中作者再次尝试运行已有代码、校对内容时,发现已经不会写入.zdebug_ sections了 (上述linker flag失效了);
> - 截止到今天2025.2.14再次续写本书内容,继续求证后发现,go1.22中已经明确废弃了 `.zdebug_` sections,而是以 `.debug_` section中内容是否带有 SHM_COMPRESSED flag来确定是否开启了压缩。
> see: https://github.com/golang/go/issues/58254#issuecomment-1421624004
> see: https://sourcegraph.com/github.com/golang/go/-/commit/75136fc14c0d3ec64a2f6728e96fc86066d853c9
>
> 所以,还是要尽快完成,很有可能go后续会从DWARF v4升级到v5,到时候又会引入更多变化。
#### 4.2.1.2 存储在独立的文件中
例如,Microsoft Visual C++ 2.0生成的调试信息存储在独立的**.PDB(Program Database)**文件中,macOS平台上构建的调试符号信息一般存储在独立的**.dSYM/Resources/DWARF/**目录中。
> 这里给个示例,在macOS 10.15上,通过“**gcc -g**”构建一个包含调试符号的可执行程序,我们看下它生成的调试信息是如何存储的:
>
> **file: main.c**
>
> ```cpp
> #include <stdio.h>
> #include <stdlib.h>
>
> int main(int argc, char *argv[])
> {
> return 0;
> }
>
> ```
>
> ```bash
> $ gcc -g -o main main.c
> $ ls
> main main.c main.dSYM/
> $ tree main.dSYM
> main.dSYM/
> └── Contents
> ├── Info.plist
> └── Resources
> └── DWARF
> └── main|
> ```
可以看到,macOS 10.15上,gcc将调试信息也存储到了独立的main.dSYM/目录。可以借助 `dwarfdump or splitdwarf`工具进行分析,可以参考这篇文章:https://blog.golang.org/debug-opt。
#### 4.2.1.3 调试信息有什么用呢
调试器利用调试信息能够将源码中的函数、变量映射为内存中的地址,也就意味着开发者可以直接对源码中函数、变量进行操作而不用关心具体的内存地址,这也是符号级调试器相比于指令级调试器的优势。
借助源码到内存地址的映射,符号级调试器就可以直接显示变量的值,如何做到的呢?因为变量标识符可以映射成程序的内存地址,此外,调试信息中还记录了该变量的数据类型信息,这里的类型信息告诉调试器该变量一共占用多少个字节、实际用了多少比特、应该解读成哪种数据类型,调试器就可正确解析内存数据,进而显示变量值。

这里的映射关系也包含从源代码语句与内存中代码段指令地址范围的映射,这个也是符号级调试器的优势。当希望单步执行一条语句的时候,调试器可以根据该语句对应的地址范围决定应该执行多少条指令后停下来。
### 4.2.2 调试相关支持
除了调试符号信息,调试器还需要其他的一些支持,即调试基础设施,包括:调试中断、系统调用、解释器、调试用户界面(GUI或者命令行)。
#### 4.2.2.1 调试中断
所有的商用操作系统都提供了调试相关的hook机制,这里的hook机制通常是通过内核系统调用的形式实现。为什么要通过系统调用实现呢?调试器调试应用程序的时候,需要读、写程序的数据、指令,就涉及到访问系统内存中一些受保护的特殊数据结构,普通用户进程是无权访问的,只能借助内核提供的系统调用来代表用户进程操作。
相比之下有个例外,DOS操作系统是实模式操作系统,由于没有对内存做保护,你可以直接做任何事情。
#### 4.2.2.2 系统调用
现在,绝大多数操作系统都实现了内存保护模式,内存保护模式是多用户、多任务操作系统的根基。如果没有保护模式,根本就不存在所谓的安全。关于内存保护模式如何实现的,可以参考X86系列处理器的发展史。
与DOS相反,Windows、Linux以及BSD都实现了内存保护模式,这意味着如果你想在这些平台上开发一个调试器,就需要通过平台提供的系统调用来实现。
以Linux系统调用为例,调试器进程(tracer)可以通过 `ptrace(PTRACE_ATTACH…)` attach到一个被调试进程(tracee),然后操作系统内核会给tracee进程发送一个信号SIGSTOP,tracee进程就会停下来,tracer进程就可以通过 `waitpid(pid)`来等待tracee停止事件。当tracer进程感知到tracee进程停止执行之后,tracer进程就可以进一步通过 `ptrace`系统调用、配合其他ptrace参数 `PTRACE_GETREGS、PTRACE_SETREGS、PTRACE_PEEKDATA、PTRACE_POKEDATA等`来读写寄存器、内存数据、设置断点,通过PTRACE_SINGLESTEP、PTRACE_CONT等控制代码的执行等。
简单提下内存 "**保护模式**" 的实现,这样有助于理解为什么现在调试器一般通过操作系统 "**系统调用**" 来实现,比如Linux ptrace。
**实模式大致原理:**
这里以x86处理器发展史来简单说明下,8086处理器是实模式寻址,意味着你可以写个程序通过CS:IP来跳到任意指令地址执行指令,或者DS:Offset读写任意内存地址数据,这样就很不安全。
在Intel后续处理器上为了建立起内存保护模式,首先引入了特权级的概念,ring0~ring3(ring0权限最高),Linux中仅使用ring0、ring3这两个(区分内核态和用户态够用了)。然后又引入了GDT、LDT的概念,这个什么用呢,它们是个表结构,记录了一系列的内存区间以及访问这些内存位置所需要的特权级。在访问真正的内存区域之前,需要先查表检查特权级是否足够。
**阻止执行任意位置指令:**
实模式下的CS:IP直接可以计算后用来寻址,保护模式下不行,CS的含义已经变了,不再是代码段起始地址,它(CS部分位字段)变成了一个指向GDT、LDT中的索引,查GDT、LDT可以知道访问对应的内存区所需要的特权级信息。如果当前特权级(CS部分位字段)低于CS对应的GDT描表项中的特权级,则不能访问对应内存区。这样执行指令的时候,就不能够随意指定个地址去执行该位置的指令了。
**阻止读写任意位置数据:**
对于如何阻止读写任意位置的数据,这个问题可以通过类似的方式来做到,就不进一步展开了,感兴趣读者可以自己查阅资料。
关于80286实现内存保护模式的更多信息,可参考[protected mode basics by Robert Collins](http://www.rcollins.org/articles/pmbasics/tspec_a1_doc.html),我是基于《Linux源码情景分析》中关于保护模式的内容回忆来补充这部分信息的,Robert Collins还额外描述了中断情况下如何保证保护模式。
那保护模式下当我们希望执行tracee的指令、读写tracee的数据时,只能借助于操作系统提供的 "**系统调用**" 来完成这些任务。
> **扩展阅读**:
> - 对与进程、线程的表示,建议了解下操作系统进程控制块PCB的概念以及Linux下taskstruct、GDT、LDT相关的知识。
> - Linux平台对SIGSTOP信号的处理,可以参考:[How does SIGSTOP work in Linux kernel?](https://stackoverflow.com/questions/31946854/how-does-sigstop-work-in-linux-kernel)
#### 4.2.2.3 解释器
如果是调试一门解释型的语言,会简单的多,因为所有的调试基础设施都可以直接内建在解释器中。通过一个解释器,就可以无限制地访问执行引擎。所有的调试操作及其依赖的能力都是运行在用户空间而非内核空间,也就不需要借助系统调用了。没有什么东西是被隐藏的。所要做的就是增加扩展来处理断点、单步执行等操作。
Andreas Zeller在《软件调试》书中提到,解释型语言的调试器通常比编译型语言的调试器简单,因为解释型语言的执行过程是透明的,而编译型语言的执行过程是隐藏的。
>"Building a debugger for an interpreted language is much easier than for a compiled language... Since the interpreter already has full control over the execution, it can easily provide debugging features."
**核心论点如下:**
- **解释型语言(Interpreted Languages)**: 解释器本身就是程序的运行环境。它在执行每一行代码时,都保留了完整的符号表、变量名和源代码映射。调试器只需要向解释器查询当前状态即可。因此,Zeller 认为编写解释型语言的调试器“相对简单”(Much easier),因为执行过程对解释器来说是透明的。
- **编译型语言(Compiled Languages)**: 程序被翻译成了机器码,原本的变量名和结构在执行时已经消失了。调试器必须通过“调试信息”(如 DWARF 或 PDB 格式)这种复杂的辅助手段,强行将二进制状态映射回源代码。这种过程是“非自然的”,因为执行过程在硬件层面是隐藏的(Opaque)。
ps: Andreas Zeller 还维护了 https://debuggingbook.org/ 这个网站,提供了jupyter notebook这种可以交互式阅读的电子书,但是是建立在解释型语言、解释器基础上的。对这部分内容感兴趣的读者可以参考,也会有所收获。
#### 4.2.2.4 内核调试器
操作系统构建起严格的内存保护模式之后,要想调试内核本身,就得通过一种特殊类型的调试器。传统的用户模式下的调试器是不行的,因为内存保护模式(如段、页式管理的相关逻辑)阻止了用户态程序操作内核映像。
你需要一个内核调试器!
内核调试器,能够指挥、控制中央处理器(CPU),这样就可以通过单步执行、断点等操作对内核代码进行调试、检查。这意味着内核调试器必须能够避开内存保护模式机制,通常内核级调试器都是与操作系统内核镜像打包在一起的。有些厂商要实现自己的内核级调试器,也会考虑将调试器作为设备驱动、可加载的内核模块的方式来设计、开发。
**内核调试和用户程序调试有着明显不同,我们以打印一个内存变量为例简单说明下:**
- 当打印这个变量时,不巧这个内存页面被操作系统换出到交换区了,如果我们在用户级调试器里面通过系统调用的形式ptrace(PTRACE_PEEKDATA...)操作系统会自动把这个换出的页面加回来,然后帮把数据读回来,很简单,我们甚至都没有感觉到这背后一连串的缺页处理发生过。
- 但是如果是内核级调试的话,内核级调试器需要调试内核的代码,一步步地,这样缺页处理这些问题也要一步步过,如果我们直接打印变量地址很可能是看不到值的,可能这只会触发一个缺页异常。
**另外,内核级调试场景的复杂性,也决定了适用的调试器或者说调试方式的多样性:**
- kgdb:内核自带的远程源码级调试工具,常用于源码级别定位和单步调试内核。
- kdb:内核自带的交互式调试工具,可直接在内核环境下进行简单调试操作。
- gdb + QEMU:结合QEMU虚拟机使用gdb,可用于内核源码的功能开发与学习。
- JTAG/OpenOCD:硬件级的底层调试工具,适合芯片带板、Bootloader、裸机环境等调试场景。
- Crash/Kdump:用于生产环境异常时的内核崩溃分析(core dump分析)。
- eBPF/Ftrace:用于性能剖析、动态追踪、线上排查复杂问题等动态观测场景。
>**扩展阅读:
>
>- [kernel space debuggers in Linux](https://sysplay.github.io/books/LinuxDrivers/book/Content/Part10.html)
>- [user mode debugging vs kernel mode debugging](https://stackoverflow.com/questions/32998218/is-there-ever-an-advantage-to-user-mode-debug-over-kernel-mode-debug#:~:text=in%20kernel%20mode.-,User%20mode%20debugging,you%20need%20to%20have%20really%20professional%20comprehension%20of%20all%20those%20topics.,-Conclusion)
>- [kernel debugger internals](https://www.kernel.org/doc/html/v4.18/dev-tools/kgdb.html#kernel-debugger-internals)
#### 4.2.2.5 调试器界面
调试关心的是程序的状态,不同的调试器为用户提供了不同的方式来查看程序的运行状态。某些调试器(如gdb)提供简单但一致的命令行界面,其他调试器可能会与GUI环境集成。
GUI调试器能够同时呈现和访问更多的机器状态信息,使用GUI调试器,您可以轻松地同时监视数十个程序元素。
另一方面,如果你正在开发跨平台的应用程序,则可能很难找到在所有平台上都能运行的GUI IDE,这个时候跨平台的命令行调试器相比GUI调试器来说就有优势了。命令行调试器可能没有精美的GUI接口,但在任何平台上其命令行操作和行为都是一样的。命令行调试器相比GUI调试器拥有更陡峭的学习曲线,但一旦掌握了,你就可以在不同平台以一致的方式调试你的应用程序。
### 4.2.3 符号调试器
#### 4.2.3.1 程序断点
程序断点(breakpoint),指的是程序中的一个位置,当程序执行到该位置时能够停下来,以便调试人员观察程序状态。
下面对程序断点进行分类说明:
- 从实现手段而言,程序断点可以分为“**软件断点**”和“**硬件断点**”,前者是通过机器指令来实现,后者是借助处理器提供的调试寄存器来实现。
- 从生成销毁方式、生命周期角度而言,程序断点又可以分为“**静态断点**”和“**动态断点**”,前者是在程序编译时就已经确定,后者是在程序运行时动态创建。
##### 4.2.3.1.1 软件断点 vs. 硬件断点
**软件断点**:
X86平台上创建软件断点可以通过指令 `int 3`来生成**0xCC**这个一字节机器指令来创建,处理器执行完0xCC之后会暂停当前正在执行的进程。
具体是如何执行的呢?int 3表示会触发3号中断,对应机器指令是0xCC,处理器执行完该指令后就会触发3号中断,对应的中断服务程序就在IDT[3]中(IDT,Interrupt Descriptor Table,中断描述表或中断向量表)。BIOS中提供的中断服务程序是16位的,了解过Linux如何构建32位、64位内存保护模式的话,就会明白Linux启动后,IDT[3]指向的其实是Linux内核提供的中断处理程序(Linux初始化会覆盖BIOS提供的16位中断服务程序的中断向量表),这里就是暂停执行当前tracee进程,并通知tracer进程tracee已暂停执行。
> ps: 严格意义上来说,中断更倾向于表示外设产生的事件,而异常则指处理器执行指令时生成的一些事件,比如除零exception、缺页fault、陷阱trap等,详见:https://linux-kernel-labs.github.io/refs/heads/master/lectures/interrupts.html。我们文中将中断作为了一个更宽泛的术语来使用,希望读者能明确这一点。
**硬件断点**:
以x86架构为例,提供了4个调试地址寄存器(DR0-DR3)和2个调试控制寄存器(DR6-DR7)来支持硬件断点。
当设置一个硬件断点时,需要执行如下操作:
1. 将断点地址写入某个未使用的DR0-DR3寄存器。
2. 在DR7寄存器中设置相应的控制位:
- L0-L3位:启用对应的DR0-DR3断点(置1表示启用);
- G0-G3位:全局启用对应断点(置1表示启用);
- R/W0-R/W3位:设置断点类型;
- 00:执行断点
- 01:数据写入断点
- 11:数据读写断点
- LEN0-LEN3位:设置监控的数据长度(1/2/4/8字节)。
那么,程序执行过程中访问了设置为硬件断点的地址时,硬件是如何检测到断点事件发生的?以及是谁来做出判断和响应?
实际执行时,由CPU本身负责检测断点命中。每当CPU执行一条指令涉及内存读写或指令执行时,处理器会自动比较即将访问的地址和已经配置在DR0-DR3中的硬件断点地址。当命中了硬件断点的匹配条件(如执行、读写等类型和监控长度),CPU会自动触发一个调试异常(通常为#DB,Debug Exception,异常向量1)。此时,CPU会将调试状态信息写入DR6寄存器,指明是哪个断点触发。系统内核中的异常处理程序会捕获这个异常,将控制权交给调试器或对应的异常处理流程,从而完成对硬件断点的捕捉和响应工作。
简而言之,是CPU在硬件级别自动不断检测已设置的断点条件,一旦发现断点被触发,就通过产生异常通知操作系统和调试器,无需程序员手动检查。
好,现在理解了如何创建“程序断点”后,我们继续讨论“静态断点”和“动态断点”的区别。
##### 4.2.3.1.2 静态断点 vs. 动态断点
**静态断点**:
静态断点指的是,在程序开发或调试时,由开发者预先在程序的某些位置插入断点语句,比如在代码里嵌入 `int 0x3` 这样的指令用于触发断点(常见于C/C++等支持内联汇编的语言)。此类断点通常需要借助调试器配合使用:程序执行到该位置时会触发中断,调试器捕获到该事件后暂停程序,等待用户在调试器中手动输入命令进行调试。静态断点的生命周期一般与进程一致,如果需要在不同情况下有选择地触发静态断点,可以通过在代码中增加一些条件判断。
静态断点的缺点在于不够灵活,每次需要修改断点位置都要重新编译程序,调试流程相对繁琐。而动态断点则允许调试人员在不修改源代码的情况下,随时在运行的程序任意位置插入或移除断点,使用上更加灵活方便。
**动态断点**:
动态断点是指调试人员在程序运行过程中,根据需要动态插入的断点。借助动态断点,符号级调试器可以在源码层面实现如 gdb 的 next、step、finish、continue 等单步和控制流程操作。
与静态断点不同,静态断点的生命周期通常与进程一致,而动态断点则更加灵活。实际调试时,符号级调试器主要依靠动态断点来控制程序的执行。
以软件断点为例,动态断点的设置与移除大致流程如下:
- 调试器定位到目标语句`statement`的首条机器指令,读取其首字节操作码;
- 保存该操作码的第一个字节,并将其替换为 0xCC(即 int3 指令);
- 被调试进程(tracee)执行到该指令并运行 0xCC 后,会触发断点异常,程序暂停,此时调试器可以检测寄存器、变量等状态;
- 当调试器继续控制tracee执行时,会将 tracee 的 PC(程序计数器)减 1,并将 0xCC 处的字节还原为原先的操作码;
- 最后,通知内核恢复 tracee 的运行,程序会继续执行直到下一个断点或其他调试事件发生;
我们通过下面的C语言语句进行下简单的说明:
> ```c
> total = total +value;
> ```
假定上述语句对应的汇编指令为:

给上述语句设置一个动态断点,调试器首先获取statement对应的第一条指令的操作码的第一个字节0x8B,并将其替换为0xCC。当调试器遇到这个断点的时候,它执行完0xCC后就会停下来。等清除这个断点时,它会将这里的0xCC替换为原来的操作码数据0x8b,并将PC值从00007调整为00006,然后通知tracee恢复执行,tracee就可以执行statement `total = total + value` 对应的完整3条指令。
一旦上述语句对应的指令被执行了之后,调试器可以考虑是否要再次为该语句设置动态断点,如果不可能执行到上述语句了,就可以不设置了,但是如果还是会执行到就会设置动态断点,比如for循环体中语句设置断点,当你调试完一轮之后,还希望下次循环进入时再次让断点生效,调试器这种情况下就应该再次插入断点。
#### 4.2.3.2 单步执行
对指令级调试器(也称机器级调试器)而言,单步执行很简单:处理器只需执行下一条机器指令,然后将程序控制权返回给调试器。 对于符号调试器,此过程并不那么简单,因为高级编程语言中的单个语句通常会转换为多个机器级指令,而且不同源代码语句对应的机器指令数量也不同。
符号调试器如何插入动态断点呢?这将取决于单步执行的动作的类型,可分三种类型。
##### 4.2.3.2.1 单步执行进入 (下一条语句)
当符号调试器单步执行函数调用时,如 `function(value)` ,调试器需要检查接下来的机器指令,确认是否是函数调用(CALL指令):
- 如果不是,下一条指令操作码不是函数调用,则当普通断点处理即可,保存该操作码并将其替换为断点。
- 如果是,需要确定CALL指令实际要执行的函数体在内存中的地址,并在函数体开头指令处设置断点。

>ps: 不一定是在函数体内第一条指令处设置断点,比如Go语言函数调用通常会涉及到栈分裂(stack splitting),会在函数体开头插入一些指令来处理栈空间。在栈分裂相关指令处设置断点就不太好,因为如果涉及到栈分裂这个断点会被命中两次,对于调试来说会有干扰。
##### 4.2.3.2.2 单步执行跳出 (一个函数)
当符号级调试器退出函数(或例程)时,它将在函数的活动记录(调用栈信息)中查找返回地址。 然后,它将返回地址处机器指令的操作码保存,并用断点替换。 当程序恢复执行时,该例程将执行完剩余语句,并跳转到其返回地址。 然后回到返回地址处的下一条指令后,将命中断点,程序控制权将交还给调试器。 这样做的结果是,您可以使调试器从被调函数返回到调用该函数的代码上。
>ps: ABI函数调用约定相关知识,简单提一下的话,就是函数调用时会创建栈帧,并将参数、返回地址、寄存器信息保存入栈,局部变量在栈帧中分配等等,函数返回前销毁栈帧,程序则继续跳转到返回地址对应指令处继续执行。您可以参考相关资料了解更多细节。
##### 4.2.3.2.3 单步执行跳过 (下一条语句)
当符号级调试器单步执行一条语句时,它将查询程序的调试信息以确定该语句在内存中的地址范围,一旦调试器确定了该语句的结束位置,它将保存该语句后的第一条机器指令的操作码,并将其替换为断点。 加断点的语句,tracee执行完该语句对应的所有机器指令之后,调试器才能重新获得程序控制。

>ps: 在一个源代码行中,可能包含了一条语句,也可能是多条语句,甚至可能是一个for循环,那么在执行符号级调试器next时通常是希望跳转到下一行源码处,那就需要知道当前这行源码对应着多少机器指令,才好控制调试器应该在那个指令地址处添加断点。这个如何做到呢?需要依赖调试信息对源代码行对应的指令地址范围进行描述,后面介绍DWARF调试信息时会介绍。
### 4.2.4 本节小结
本节简要介绍了调试信息的生成、存储和解析操作,概要性地讲述了不同类型调试器的特点,以及断点的工作原理。我们还以单步步进一条语句为例,说明了单步执行进入、跳出、跳过时断点设置的大致流程。由于篇幅和层次原因,本节未展开详细讲解,但为后续更深入理解调试器的实现和调试原理打下了基础。
================================================
FILE: book/4-basics/3-countertactics.md
================================================
## 4.3 反调试技术
只要付出足够的时间和精力,可以说任何程序都能被逆向。调试器使得理解程序逻辑更加方便了,对心怀恶意的软件逆向人员也不例外。防人之心不可无,君子也要采取战术给软件逆向增加点难度,使恶意工程师越痛苦越好以阻止或者延缓他们弄清程序的工作逻辑。
鉴于此,可以采取一些步骤,将使恶意工程师很难通过调试器窥视您的程序。
### 4.3.1 系统调用
#### 4.3.1.1 Windows
某些操作系统提供了特殊的系统调用,能指示当前进程是否正在调试器的调试模式下执行。 例如,Windows KERNEL32.DLL导出了一个名为`IsDebuggerPresent()`的函数。 您可以包装一个chk()函数,函数体内使用该系统调用进行检查。


该窍门是程序启动后立即调用chk(),让检查逻辑在逆向人员设置并执行到断点前先执行。

如果观测到调试器正在调试当前进程,则可以强制程序运行异常、做些诡异的逻辑,把正在调试的人绕晕。 调试器是个独特的工具,因为它使用户可以从中立的角度来观察程序。 通过插入类似chk的代码,可以迫使用户进入一个扭曲的量子宇宙,在该宇宙中,精心构造的诡异行为、输出,可以有效保护您的程序,避免或者延缓被逆向。
对调试器使用有经验的读者,很快就可以发现上述方法,并不总是可靠,有经验的调试人员可以通过gdb启动进程并在main、chk位置添加断点,待chk返回前篡改寄存器EAX中的值来绕过该检查。所以这个方法并不总是奏效,有可能将chk()低调行事隐藏在一堆看似正常的代码中,反而有助于戏弄调试人员。有没有更靠谱的做法呢?
我们也可以使用 `NtQueryInformationProcess` 系统调用来判断当前进程是否正在被调试,这是一个内核态的系统调用,可以获取进程的详细信息,包括是否正在被调试。这个检查逻辑可以在整个生命周期内持续进行,不容易被绕过,一旦检测到正在被调试,就可以立即退出程序。
```
__kernel_entry NTSTATUS NtQueryInformationProcess(
[in] HANDLE ProcessHandle,
[in] PROCESSINFOCLASS ProcessInformationClass,
[out] PVOID ProcessInformation,
[in] ULONG ProcessInformationLength,
[out, optional] PULONG ReturnLength
);
```
可以指定PROCESSINFOCLASS ProcessInformationClass = ProcessBasicInformation,此时会返回一个PEB结构来描述当前进程是否正在被调试器调试。
see: https://learn.microsoft.com/en-us/windows/win32/api/winternl/nf-winternl-ntqueryinformationprocess
#### 4.3.1.2 Linux
在Linux下,也有类似Windows的方式,通常可以借助“`/proc/self/status`”中的“`TracePid`”属性来判断是否有调试器正在调试当前进程。
下面是个示例,检查当前进程是否正在被调试。
**被调试程序:**
```go
package main
import "fmt"
import "os"
func main() {
fmt.Println("vim-go, pid: %d", os.Getpid())
}
```
**执行调试操作:**
```bash
$ dlv debug main.go
dlv> b main.main
dlv> c
dlv> n
dlv> n
dlv> vim-go, pid: 746
```
**检查TracePid:**
```bash
cat /proc/746/status | grep TracePid
TracePid: 688
cat /proc/688/cmdline
dlv debug main.go
```
现在我们可以判断出当前进程正在被pid=688的调试器进程调试,并且该调试器是dlv。
如果不希望程序被调试,就可以在检测到 `TracePid != 0` 时直接退出。我们可以将检查逻辑隐藏在一堆看似正常的代码中,并尽量在程序启动后立即执行,或者在整个生命周期内持续进行。这样就不容易被绕过。
#### 4.3.1.3 其他平台
其他平台下,应该也有对应的解决方法,读者感兴趣可以自行查阅相关资料。
### 4.3.2 移除调试信息
使调试更加困难的一种简单方法是从程序中删除调试信息:
- 通过设置集成开发环境、编译构建工具链来生成release版本而非debug版本,比如C/C++ 通过gcc/g++构建时需要显示 `-g` 选项来生成调试信息,生成release版本时可以去掉 `-g` 选项,必要时还可以开 `-O` 优化。
- 对于有些编程语言的编译器默认生成调试信息,比如Go,对于已经包含了调试信息的二进制,也可以通过后期剥离调试信息来达成,比如使用GNU的 `strip` 工具从ELF文件中删除.debug_ sections。
一些商业软件公司更喜欢这种做法,并能接受后续诊断过程中额外加载调试信息以及加载调试信息带来的性能影响,它允许销售工程师执行现场诊断。当售后工程师进行内部咨询时,他们要做的就是插入调试信息并启动调试器。
对于移除了调试信息的程序,如果尝试使用调试器调试它,因为没有源码相关的信息展示,调试人员将很难明白程序的状态、工作方式。往往看到gdb提示找不到调试符号“no debugging symbols found”,此时就会让很多调试人员望而却步、放弃调试。

但是,缺少调试符号并不能阻止所有人,一些反编译器可以将机器指令重铸为高级源代码,好消息是这些工具倾向于生成可读性较差的代码。
>ps: 但是现如今借助于AI的力量,情况可能有所变化。现在AI有能力抽取这些源代码来推断更合适的函数名,让代码更容易被理解。这个方向也值得关注和研究。
### 4.3.3 代码加盐
如果内存占用不是大问题,并且您不介意对性能造成轻微影响,则阻止调试器的一种方法是定期在代码中添加不必要的语句。可以这么说,这使得尝试进行逆向工程的人更容易迷失。
这样,即使您在程序中附带了调试符号,也很难弄清正在发生的事情(尤其是如果您认为每个语句都有合法目的)。扰乱视听,让调试人员摸不着头脑,这样,我们就相对更安全。
>ps: 俗话说“道高一尺魔高一丈”,在真正的高手面前,“茅、盾、机、巧” 你知道、我也知道,经验和高敏感性能让高手察觉这部分代码的意图,排除掉它或者通过其他逐个击破的策略收敛到更少的关键代码。
### 4.3.4 混合内存模型
有一些强大的调试器,例如SoftICE,可以在用户模式和内核模式之间轻松切换。但是,很少有调试器可以在两个不同的内存模型之间进行跳转。比较特殊地,Windows下就允许发生这种行为。在Windows上,这种现象通常称为“thunking”,它允许16位代码和32位代码进行混合。
以下描述了Windows中使用的改进技术:

这种混合内存模型也给调试器调试增加了难度。
### 4.3.5 本节小结
调试器确实是一个定位分析问题的好帮手,但是用在“坏人”手里也可能成为他们攻击正常程序的工具。因此,本节对反调试技术进行了介绍。反调试技术也是一种重要的阻止逆向分析、提高安全性的手段。反调试技术大大增加了逆向分析的难度,降低了逆向分析的成功率。尽管不能100%杜绝攻击者的调试行为,但是增加其难度,也是降低攻击成功率的一种手段。
================================================
FILE: book/4-basics/README.md
================================================
# 调试器基础
先简要介绍下调试器相关的基础知识,包括:
- **目的**, 我们为什么需要一个调试器?
- **支持**, 支持调试操作需要哪些能力的支持?
- **安全**, 调试会带来哪些安全风险,又该如何防范?
================================================
FILE: book/5-debugger-skeleton/1-debugger_skeleton.md
================================================
## 设计一个调试器雏形
调试器需要支持哪些常见操作才能满足调试需求?本节先从功能性需求、非功能性需求分析角度切入,分析下接下来的调试器开发过程中要做什么、注意些什么。
本章还有个任务,要先搭建一个基础的调试器框架,方便扩展调试器命令、命令选项、命令参数、查看帮助信息、命令自动补全等。在此基础上,后续章节实现不同调试命令时,我们只需要添加子命令及对应的处理逻辑即可。
大家在理解了这个调试器雏形之后,后续阅读到相关调试动作的具体实现章节时,会自然联想到如何定位工程中对应的代码,也有益于我们后续章节内容组织、方便读者阅读。
### 功能性需求
调试器需要支持哪些功能?大家联想下常见调试器的使用经历,这个是比较直观的:
- 允许调试可执行程序、调试运行中进程、调试coredump文件;
- 允许对golang代码自动编译构建、调试完成后清理临时构建产物;
- 允许查看源码信息 **list**;
- 允许对二进制文件进行反汇编 **disass**;
- 允许在源码中添加断点 **breakpoint `file:lineno`**;
- 允许在源码中添加条件断点 **breakpoint `file:lineno` if `expr`**;
- 允许逐语句执行 **next**;
- 允许逐指令执行(也能允许进入函数)**step**;
- 允许从function退出 **finish**;
- 允许显示变量信息、寄存器信息 **print、display**;
- 允许更新变量、寄存器信息 **set**;
- 允许打印变量类型 **ptype**;
- 允许对函数进行临时调用 **call**;
- 允许查看调用堆栈信息 **bt**;
- 允许选择调用栈中的特定栈帧 **frame**;
- 允许查看goroutines列表、切换goroutine执行;
- 允许查看threads列表、切换thread执行;
**聪明人写代码时也会思考后续如何更加聪明地debug**,也因此对现代调试器提出了更多能力需求,比如:
- 如何在“充满不确定性的环境”中实现“确定性调试”,`record & replay` 沉淀几十年,通过它我们能在程序中前进、后退并且允许重复地进行调试。
- 如何能够实现自动化调试,比如通过脚本、CI/CD流水线等自动化手段进行调试,现在 go-delve/delve 就支持了通过starlark脚本控制调试器执行自动化调试。
- 更进一步地,现在借助 LLM + 调试器相关的mcp ,也可以借助人工智能的力量进行调试分析。
在后续内容中,我们也会对这些高级调试技术进行介绍。
### 非功能性需求
我们需要注重用户体验,即站在调试人员使用的角度,考虑如何让调试人员用的方便、调试的顺利。
对于一个调试器而言,因为我们会在各种任务间穿插切换,要灵活运行调试命令是必要的。一个基于命令行实现的调试器,要实现快速有效输入并不轻松。
- 首先调试器有很多调试命令,记住这些命令是有学习成本的,基于命令行的调试器会比基于GUI的调试器学习曲线更陡;
- 基于命令行的调试器,其UI基于终端的文本模式进行显示,而非图形模式,这意味着它不能像GUI界面一样非常灵活方便地展示多种信息,如同时显示源码、断点、变量、寄存器、调用栈信息等;
- 基于命令行的调试器需考虑调试命令输入效率的问题,比如输入命令以及对应的参数。GUI调试器在源码某行处添加一个断点通常是很简单的事情,鼠标点一下即可,但基于命令行的调试器则需要用户显示提供一个源码位置,如"break main.go:15",或者"break main.main";
- 调试器诸多调试命令,需要考虑自动补全命令、自动补全参数,如果支持别名,将会是一个不错的选项。调试器还需要记忆上次刚使用过的调试命令,以方便重复使用,例如频繁地逐语句执行命令序列 <next, next, next>,可以通过命令序列 <next, enter, enter> 代替,回车键默认使用上次的命令,这样对用户来说更方便;
- 调试器有多种启动方式,对应多个启动命令,如`godbg exec <prog>`、`godbg debug <module>`、`godbg attach <pid>`、`godbg core <coredump>`,各自有不同的参数。此外调试器也有多种交互式的调试命令,如`break <locspec>`、`break <locspec> if <expression>`等,各自也有不同的参数。如何高效、合理地管理这些命令是一个需要考虑的事情;
- 好的产品塑造用户习惯,但用户更懂用户自己,一个可配置化的调试器是比较合适的,如允许用户自定义命令的别名,等等;
- 调试器本身,可能需要考虑未来的应用情况,其是否具备足够的适应性以在各种应用场景中使用,如能否在GoLand、VSCode等IDE中使用,或者可能的远程调试场景等。这些也对调试器本身的软件架构设计提出了要求;
- 可扩展性,除了使用的便利性,也要考虑其未来的扩展性,如何支持一门新的编程语言,如何支持采用不同调试信息标准的程序调试,如何便利地与其他开发工具集成;
- 健壮性、正确性,如何保证调试器本身的健壮性、正确性,可以借助代码评审、自动化测试、提高测试覆盖率等手段来改进;
### 本节小结
本节我们从调试器的功能性需求和非功能性需求两个维度,梳理了现代调试器应当具备的核心能力。功能性需求方面,调试器需要支持多种调试对象(可执行程序、运行中进程、coredump)、丰富的调试操作(断点、单步、查看变量、调用栈等),以及更高级的特性(如record and replay)。非功能性需求方面,则强调了用户体验、命令管理、自动补全、可配置性、可扩展性、健壮性等对调试器产品化的重要影响。
这些需求的梳理让我们认识到了现代调试器所面临的挑战,也为后续调试器架构设计和实现方案的选择奠定了基础。下一节我们将探讨调试器的架构设计,以及如何通过合理的技术方案满足上述需求,打造一个易用、可扩展的调试器。
================================================
FILE: book/5-debugger-skeleton/2-debugger_solution.md
================================================
## 架构设计和技术方案选择
### 整体架构设计
调试器应该具备良好的扩展性设计,以支持在不同应用场景中的应用,如在命令行中调试,与不同的IDE VsCode、Goland进行集成,支持远程调试。这就要求调试器必须实现 “**frontend**”和“**backend**” 前后端分离式架构。
比如,我们可能在一台macOS机器上调试运行在Linux机器上的进程,此时frontend可以是运行在darwin/amd64机器上的VsCode或者命令行调试器,而backend可以是运行在linux/amd64 or linux/arm64机器上的调试器服务(被调试进程则与backend运行在同一台机器上)。
#### 最基础的三层架构
一个最基础的调试器,通常至少需要包含以下三层:

- **UI层 (UI layer)**:负责与用户交互,接收用户输入、展示调试信息(如变量、堆栈等)。将UI层单独分离,可以让用户交互逻辑与核心调试逻辑解耦,便于后续更换或支持不同的用户界面(如命令行、GUI、IDE插件等)。
- **符号层 (Symbolic Layer)**:负责解析和管理符号信息(如变量名、函数名、源码位置与内存地址的映射等),是调试器的核心桥梁,连接用户操作与底层调试逻辑。分离符号层有助于支持多种编程语言和不同的调试信息格式。
- **目标层 (Target Layer)**:直接与被调试程序(target)交互,负责进程控制、数据读写、断点设置、单步执行、内存和寄存器访问等。目标层的独立,使得调试器可以更容易适配不同的操作系统和硬件架构。
>ps:第6章《指令级调试器开发》将采用这种最基础的三层架构设计,帮助大家掌握这种最基础但也是最核心的设计实现。
#### 前后端分离式架构
上述三层架构设计是调试器不可或缺的核心部分,但是考虑到实际应用场景的多样性和复杂性,三层架构设计还远远不够。比如,如何支持前后端分离、远程调试、服务化、分布式调试等高级需求?还需要引入更细腻的架构层面的设计来满足这些扩展性和灵活性需求。
这里在三层架构的基础上,引入 **服务层(Service Layer)**,以实现调试器的前后端分离架构,如下所示:

- **前端 (frontend)**: 聚焦于与用户的交互逻辑,完成调试动作的触发、结果的展示;
- **后端 (backend)**: 聚焦于目标进程、平台特性相关的底层实现,接收frontend的调试命令,并返回对应的结果,以在frontend进行展示;
- **服务层 (service layer)**: 服务层是frontend和backend之间通信的桥梁,借助 **RPC (Remote Procedure Call)** 进行通信。
通过引入服务层,调试器的前后端可以实现解耦,前端专注于用户交互和命令管理,后端专注于与被调试进程的底层交互。服务层则负责命令的转发、数据的序列化与反序列化、状态同步等工作。这样一来,调试器不仅可以支持本地调试,还可以很容易地扩展为远程调试、分布式调试等场景。例如,前端可以是命令行工具、IDE插件,甚至是Web界面,而后端则可以部署在本地或远程服务器上,二者通过RPC(如gRPC、JSON-RPC等)进行通信。
这种架构设计极大提升了调试器的灵活性和可扩展性。无论是支持多种用户界面,还是适配不同的操作系统和硬件平台,亦或是实现多用户协作调试、云端调试等高级功能,都变得更加容易。同时,前后端分离也有助于团队协作开发,前端和后端可以并行开发、独立演进。
前后端分离式架构是现代调试器实现的主流趋势,也是满足复杂应用场景和未来扩展需求的坚实基础。
>ps:第9章《符号级调试器开发》,我们将采用这里的前后端分离式架构,以帮助读者掌握现代调试器架构设计及实现。
### 调试命令管理
对于一个命令行调试器,涉及到多种启动调试的命令,在调试会话中也需要多种多样的调试命令,这些调试命令驱动着一个高效的调试过程,直到我们定位到问题源头。比如启动调试就可能多种方式,`godbg <exec|attach|core|trace> ...`,在调试会话中也涉及到大量调试命令,如 `break, condition, continue, next, step, stepin, stepout, finish, bt, args, loals` 等等,如何对这些调试命令进行有效地管理和扩展是一个挑战。
#### spf13/cobra
go标准库支持flags,方便对命令行选项进行解析,但是和我们想要的能力比起来,还是差点意思。所以社区里也成长起一些非常优秀的命令行开发支持项目距,比如 [spf13/cobra](https://github.com/spf13/cobra),它是一个基于golang的开源的命令行程序开发框架,它具有如下特点:
- 支持快速添加cmd;
- 支持为指定cmd添加subcmd;
- 支持帮助信息汇总展示;
- 支持POSIX风格的参数解析;
- 支持常见数据类型的参数解析;
- 支持为cmd指定必要参数;
- 支持生成shell自动补全脚本;
- 等等;
可以说,cobra是一个非常优秀的命令行程序开发框架,在诸多大型开源项目中得以应用,如kubernetes、hugo、github-cli gh,等等。在我的个人项目中,也有不少是采用了cobra来对命令、子命令进行管理。
#### 命令分组
使用cobra对调试命令进行管理,将给我们带来很大的便利。对于`godbg exec <proc>`、`godbg attach <pid>`类似的命令及选项管理,cobra绰绰有余,使用默认的设置就可以提供很好的支持。
调试器除了上述“启动调试”相关的命令以外,也有很多“调试会话”中使用的调试命令,如断点相关的,调用栈相关的,查看源码、变量、寄存器等相关的。为了方便调试会话中中查看调试命令的帮助信息,对这些调试命令进行必要的分组是非常有必要的 (调试人员如果不能借助分组快速找到急需的调试命令,就会打断需要高度集中注意力的调试活动)。
比如:
- break、condition、clear、toggle、on,这几个与增删激活断点以及命中后处理强相关,可以将它们归类到分组“**[breakpoint]**”;
- print、display、args、locals、funcs、types、list,这几个与查看变量、参数、函数、类型、源码强相关,可以将它们归类到分组“**[show]**”;
- backtrace、frame,这几个与查看调用栈、切换调用栈强相关,可以将它们归类到分组“**[frames]**”;
- restart、continue、stepin、stepout、finish,这几个与运行强相关,可以将它们归类到分组“**[run]**”。
- ...
- 其他调试命令及分组;
cobra为每个命令提供了一个属性cobra.Command.Annotations,它是一个map类型,可以为每个命令添加一些kv属性信息,然后基于此可以对其进行一些分组等自定义的操作:
```go
breakCmd.Annotation["group"] = "breakpoint"
clearCmd.Annotation["group"] = "breakpoint"
printCmd.Annotation["group"] = "show"
frameCmd.Annotation["group"] = "frames"
```
上面我们对几个命令根据功能进行了分组,假如我们用debugRootCmd表示最顶层的命令,那么我们可以自定义debugRootCmd的Use方法,方法内部我们遍历所有的子命令,并根据它们的属性Annotation["group"]进行分组后,再显示帮助信息。
查看帮助信息时将得到如下分组后的展示样式(而非默认列表样式),更便利、更有条理:
```bash
[breakpoint]
break : break <locspec>,添加断点
clear : clear <n>,清除断点
[show]
print : print <variable>,显示变量信息
[frames]
frame : frame <n>,选择对应的栈帧
```
综上不管是调试器启动时的命令,还是调试会话中需要交互式键入的调试命令,都可以安心地使用cobra来完成,cobra能很好地满足我们的开发需求。
### 其他易用性方案
需求分析阶段列出了一些要支持的调试操作,每个操作基本都需要一个或几个调试命令来支持,而每个调试命令又包含不同的选项。考虑到我们最终交付的是一个命令行调试器,命令行调试器尽管有它的优点,但是缺点也显而易见。
对使用者而言,要记住这么多调试命令、调试选项,还要正确输入它们以及它们的取值,会是一个巨大挑战。为了方便使用者,我们需要考虑一些非常必要的易用性方案设计。
> ps: 读者可能有疑问,既然命令行调试器用起来不方便,那为什么不提供一个GUI界面呢?
> 考虑到在不同软硬件平台的可移植性、操作的一致性、go技术栈以及最终实现的工作量,我们更倾向于提供一个命令行版本的调试器。实际上,当我们掌握了命令行调试器之后,攀登过那陡峭的学习曲线这时候,你也会获得巨大的收益,你可以以一致的调试界面、调试命令、调试习惯在不同软硬件平台上进行调试。
#### 输入补全:启动命令选项
在调试过程中,我们很可能会遗忘命令名和选项名,或者需要高频输入它们,或者很容易输入错误,对于特定类型的选项、参数的值,也可能比较难输入,比如输入一个源文件的位置。此时,就会中断调试会话,这是一个很低效的过程。试想下,我们不得不执行help命令查看帮助信息,帮助信息将污染我们的调试会话,使得我们注意力被分散。所以作为一个调试器产品的设计者、开发者,应该对“查看帮助”信息的需求进行进一步挖掘。
用户是需要查看帮助信息,但是并不一定是通过help的形式,我们可以在他输入命令的同时就给予辅助输入的提示信息,自动补全就是不错的方法。
自动补全大家并不陌生,我们在shell里面使用的很多命令有自动补全的功能,包括 spf13/cobra 开发的命令行应用程序本身也支持生成shell的自动完成脚本(导入即可实现自动补全功能)。
```bash
godbg completion bash > ~/.bash_godbg
source ~/.bash_godbg
```
然后我们可以执行命令并通过TAB来触发自动补全,如 `godbg att<TAB>` 会被自动补全为 `godbg attach`。
#### 输入补全:会话命令选项
这里借助spf13/cobra只可以解决启动调试时的命令和选项的自动补全,但是还解决不了调试器进程启动后调试会话内的自动补全。
- [go-prompt](https://github.com/c-bata/go-prompt)是一个不错的自动补全的库,它能够在程序运行期间根据用户输入自动给出自动补全的候选列表,并且支持多种选项设置,如候选列表的颜色、选中列表项的颜色等等。可以说,go-prompt是一个非常不错的选择。但是它的命令管理不如spf13/cobra方便,实际上它也可以和cobra结合使用。
- [cobra-prompt](https://github.com/stromland/cobra-prompt) 就是来解决这个问题的,它将go-prompt和spf13/cobra进行了一个比较好的集成,既能利用cobra的命令管理,也能发挥go-prompt的自动补全优势。cobra-prompt的实现原理很简单,将go-prompt获得的用户输入适当处理后,转给cobra debugRootCmd进行处理就可以。
- [liner](https://github.com/peterh/liner) 本书第6章提供的指令级调试器实现,最初采用了cobra-prompt进行开发,但是最终使用了liner进行代替,因为cobra-prompt的自动补全功能会经常干扰调试会话信息的连贯性,不一定真的有实质性的帮助,所以最后我们替换为了liner代替。最后,使用liner读取用户键入的调试命令,并通过cobra的命令管理来执行调试动作。简言之,我们仍然具备自动补全能力,只是放弃了go-prompt似的自动补全方式。
ps: 这里我们只对调试会话内的命令进行了输入自动补全,对于命令选项,则没有进行支持。调试器使用者可以通过 `help <command>` 查看相应选项及帮助信息。
#### 输入补全:其他输入信息
输入补全,我们借助spf13/cobra生成的completion脚本可以解决启动调试相关命令选项的输入补全,通过liner可以解决调试会话中命令的输入补全,但是这就够了吗?
对于后续还需要输入的参数值,比如 `break main.<funcName>` ,此时我们想在main中某个函数处添加断点,但是我们此时希望借助TAB来自动补全输入函数名。spf13/cobra是做不到这点的,如果希望支持类似能力,就还需要进一步探索,这点也可以借助liner来完成。
理论上,我们为每个调试命令设置一个专用的completer(类似spf13/cobra那样),每个completer可以负责自动补全该调试命令的命令名、选项名,以及对应的值。比如 `break` 命令对应的completer就可以自动提取不同package里定义的funcs,然后根据用户输入进行过滤,并进行补全。
ps:这部分内容权当一种“愿景”了,我们不一定真的实现,但是这么做可能会让调试活动更加简单高效,读者也可以思考下有没有更好的方式。
### 其他可扩展性支持
除了前后端分离和分层架构,调试器在设计和实现时还应考虑以下可扩展性支持:
- **多语言支持**:调试器不仅要支持Go语言,还应具备扩展到其他语言(如C/C++、Rust等)的能力。这要求符号层和目标层的实现要有良好的抽象,便于适配不同语言的调试信息格式(如DWARF、PDB等)和运行时特性。
- **插件机制**:通过插件机制,调试器可以灵活地扩展新功能。例如,可以为不同的调试命令、表达式求值器、UI组件等提供插件接口,用户或第三方开发者可根据需要动态加载和卸载插件,增强调试器的功能。
- **脚本化与自动化**:支持脚本语言(如Python、Lua等)集成,允许用户编写脚本自动化调试流程、批量设置断点、批量分析变量等。这对于复杂调试场景和大规模问题定位非常有帮助。
- **远程与分布式调试**:除了本地调试,还应支持远程调试和分布式系统的调试。调试器需要具备跨网络通信、认证授权、数据加密等能力,能够安全高效地调试云端、容器、Kubernetes集群等环境中的进程。
- **多用户协作调试**:在某些场景下,多个开发者可能需要协同调试同一个进程。调试器可以设计为支持多用户会话、权限管理、调试状态同步等协作特性,提升团队效率。
- **可配置性与个性化**:调试器应允许用户自定义命令别名、快捷键、UI主题、命令分组等,满足不同用户的使用习惯和偏好。
- **与其他开发工具集成**:调试器应易于与IDE、CI/CD系统、性能分析工具等集成。例如,提供API、命令行接口、事件通知等机制,方便与外部工具协作。
- **健壮性与可测试性**:为保证调试器的健壮性和正确性,应支持单元测试、集成测试、回归测试等自动化测试机制,并具备良好的错误处理和日志记录能力,便于问题定位和维护。
通过上述多维度的可扩展性设计,调试器能够具备持续演进和扩展的能力,更好地适应不断变化的调试场景。在进行到后续章节、介绍完必要前置知识时,我们会继续对这些内容进行展开。
### 本节小结
本节我们围绕调试器的架构设计与技术方案选择进行了系统梳理。首先介绍了调试器的基础三层架构(UI层、符号层、目标层),并进一步探讨了前后端分离式架构如何提升调试器的灵活性和可扩展性。随后,我们分析了调试命令的管理方式,以及命令行和调试会话中的自动补全技术选型与实现思路。最后,列举了其他多维度的可扩展性设计要点。
通过本节内容,读者可以对现代调试器的整体架构、关键技术选型及未来可扩展方向有一个全面的认识。接下来,我们将以具体的实现为例,逐步带领大家开发一个具备基础调试能力的指令级调试器,深入理解调试器各层的实际落地方式与工程细节。
================================================
FILE: book/5-debugger-skeleton/3-debugger_solution_final.md
================================================
## 具体的实现方案选择
### 确定方案
对于业界主流的调试器实现,一般都会将其分为frontend、backend,二者通过service层进行通信,gdb、delve等等,无一例外。
本书提供的调试器实现,是从普及调试器设计实现角度出发,我们实际上提供了两个版本的调试器实现。
- 指令级调试器实现:它是一个基于UI层、符号层、目标层3层架构的简易调试器实现,实现思路已体现在了本节各部分描述中。本书提供的配套的完整版指令级调试器实现的源码地址为: [hitzhangjie/golang-debugger-lessons/0-godbg](https://github.com/hitzhangjie/godbg) or [hitzhangjie/godbg](https://github.com/hitzhangjie/godbg)。为了方便大家按照章节循序渐进地学习,本书也提供了按照章节组织、循序渐进地开发调试器的代码示例,其源码地址为: [hitzhangjie/golang-debugger-lessons](https://github.com/debugger101/golang-debugger-lessons)。
- 符号级调试器实现:最初希望从头编写或者讲指令级调试器版本演变成一个符号级调试器版本作为教学示例,但是开发工作量较大,要想达到一个可用标准的版本工作量就更大。所以最后倾向于裁剪go-delve/delve以用更少的代码、更少的时间来完成符号级调试部分,把最核心的设计实现要点呈现给大家。对应的源码地址为 [hitzhangjie/tinydbg](https://github.com/hitzhangjie/tinydbg)。
ps:也许我们提供的两个版本的调试器,中间可能有点“跳跃”,是的,但是这样也并不是没有好处。一个是指令级调试器,非常精简,适合读者了解底层原理;一个是裁剪后的go-delve/delve,功能相对完整,适合读者了解现代调试器应具备的方方面面。作者最终选择裁剪go-delve/delve,工作量是一方面原因,再一个就是有go-delve/delve背书读者学完后也可以真正建立起调试器开发这个领域的“信心”。
### 工作量评估
读者可能以为裁剪 go-delve/delve 会变得很简单,也对也不对:
- 如果要达到对go语言程序调试完全可用,方便大家系统性学习、测试,从0到1开发工作量本身就会很大。我们搞个极度简化版的,作为教学目的作用也不大,大家学完之后还是会认为自己是个250,只知道点皮毛,而不会建立起那种“我能行”“我可以”的信心。所以要从0到1开发一个符合作者意愿的版本,开发工作量是非常大的。从这点来说,从已经发布的版本中筛选一个版本进行裁剪,和从头开发一个相比,工作量会一点;
- 但是,要知道 go-delve/delve 是一个10多年来不断进行更新的项目,go语言在演进、DWARF调试信息也在演进、delve也在演进,这里的工作量“基数”摆在这,即便是像作者这样先裁剪、再重构优化也是个工作量非常大的工作。在此基础上,还要将过去几十年来调试领域的探索在delve中的实践进行系统性总结,比如 DWARF调试信息如何描述不同程序构造、状态,Mozilla RR 如何实现确定性重放,等等。
简而言之,即便是裁剪go-delve/delve,工作量也非常大。
欢迎读者朋友们下载体验,如您发现有问题,或者有更好的建议,欢迎请在本书项目issues中留言 :) 。
> ps: shit! 这flag都不知立了多少次了,今天2025.2.18,过去1年《三角洲行动》上线攻坚,实在没有时间续更,今年上半年能完成吧!
> ps:本电子书的更新断断停停,这几年中发生了很多事情,2023.8.6开始恢复更新。今年必须完成,:muscle:
> 我准备用AI帮我翻译成英文版,也许可以吸引到一些同样感兴趣的贡献者。
### 本节小结
本节我们对调试器实现方案进行了梳理和分析,介绍了指令级调试器和符号级调试器两种实现路径,并结合实际项目(如 godbg 和裁剪版 delve)讨论了各自的设计思路、适用场景及开发工作量。通过对比可以看出,指令级调试器适合入门和理解底层原理,而符号级调试器则更贴近实际应用需求,能够帮助读者建立起开发现代调试器的信心。
在明确了实现方案和工作量评估后,接下来我们将深入探讨调试器各个核心模块的设计与实现细节,帮助读者逐步掌握调试器开发的关键技术点。
================================================
FILE: book/5-debugger-skeleton/4-debugger_demos.md
================================================
## 功能演示和实现效果
结合前面的思考,我们初步实现了一个调试器的雏形 `godbg`,它大致包含了我们需要的交互能力。后面我们将在此基础上一步步实现指令级调试器、符号级调试器。
先看下godbg的执行效果,然后大致介绍下源码的组织方式,方便读者了解讲解的功能点对应代码的哪一部分,后续新增章节的内容、源码就很容易对应上了。
ps: 最开始作者也是想在此godbg基础上演化成符号级调试器,前几节也提过了,最终的符号级调试器demo是裁剪的go-delve/delve,就不再赘述了,ok!
### 运行效果
#### 调试器帮助信息
`godbg help`用于展示启动调试器时的使用帮助信息。我们可以看到它有几个子命令,attach、core、exec分别对应不同的启动调试器的方式,help用于查看godbg及上述几个调试命令的使用帮助信息。
```bash
$ godbg help
godbg是一个go程序符号级调试器,它是以学习为目的驱动开发的调试器,
希望我们的工作可以为更多人打开一个认识计算机世界的大门,不谢!
Usage:
godbg [flags]
godbg [command]
Available Commands:
attach 调试运行中进程
core 调试内核转储
exec 调试可执行程序
help Help about any command
Flags:
--config string config file (default is $HOME/.godbg.yaml)
-h, --help help for godbg
Use "godbg [command] --help" for more information about a command.
```
#### 调试器调试会话界面
当启动godbg之后,默认会以弹出提示列表的方式来列出调试器支持的命令信息,这个只会在godbg启动时展示一次,期间为了保证调试会话不被污染,在没有用户输入时是不会显示任何提示信息的。
调试器启动成功后,会通过“**godbg>**”来表示当前创建好的调试会话,我们在此调试会话中输入调试命令来完成对应的调试动作。

以清除断点操作为例,clear是清除单个断点,clearall是清除所有的断点,当我们输入 `cl`时,可以匹配到 `clear`、`clearall`两个命令,开发人员可以通过 `tab`按键或者 `arrow-down`来在候选列表中移动,`enter`选中列表项。

再看一个命令参数层面自动补全的例子,以list查看源码命令为例,此时会返回进程中涉及到的源码信息,如此处有main.go helloworld.go,方便用户选择,调试时就更简单了。

这是关于调试会话界面的运行效果展示。
> NOTE: 有必要提及的是,当前小节在撰写时是基于cobra-prompt实现的调试器版本进行描述的,在后续开发中,我们移除了cobra-prompt的自动补全方式,转而采用对用户干扰更小的自动补全方式,文档中的描述暂未来得及更新。
>
> 读者也不用过于担心,这点不一致还不至于给上手学习带来负担。后续,我们会基于最新版实现更新这里的交互界面。
#### 会话中显示帮助信息
调试器调试会话中支持多个调试命令,各调试命令的功能是什么,又如何使用呢?
在调试器内部运行帮助命令“**godbg> help**”,就可以列出调试器已经支持的所有命令及其功能说明,并且对这些命令按照功能进行了归类,如断点相关的命令break、clear、clearall全部放置在了分组“**[breakpoint]**”下面,代码相关的有list、disass全部放置在了“**[code]**”分组下面,控制流相关的有next、step、finish全部放在了“**[ctrlflow]**”下面,还有其他一些调试命令。
```bash
godbg> help
interactive debugging commands
[breakpoint]
break <locspec> : 在源码中添加断点
clear <n> : 清除指定编号的断点
clearall <n> : 清除所有的断点
[code]
disass <locspec>: 反汇编机器指令
list <linespec> : 查看源码信息
[ctrlflow]
finish : 退出当前函数
next : 执行一条语句
step : 执行一条指令
[information]
bt : 打印调用栈信息
display <var|reg>: 始终显示变量或寄存器值
frame : 选择调用栈中栈帧
print <var|reg> : 打印变量或寄存器值
ptypes <variable>: 打印变量类型信息
set <var|reg>=<value>: 设置变量或寄存器值
[other]
exit : 结束调试会话
help [command] : Help about any command
```
如果想详细了解某一个调试命令如何使用,可以运行“**godbg> help `cmd`**”,如想查看break命令的使用运行“**godbg> help break**”。
#### 会话中执行调试命令
这里以显示源码信息为例,来演示如何在调试会话中执行调试动作。调试会话中执行调试命令“**godbg> list main.go**”来显示main.go中的源码信息。
```bash
godbg> list main.go
list codes in file
```
我们试运行命令 `list main.go`发现输出了一行语句,并没有实际打印源代码出来。
别急,这就是我们提到过的,目前这还只是一个调试器的雏形,我们确实已经把该搭的架子搭起来了,接下来的章节,我们将一步步实现这里的各个命令,实现指令级调试器,再实现符号级调试器。
### 代码实现
该调试器代码,详见:[golang-debugger-lessons/0_godbg](https://github.com/debugger101/golang-debugger-lessons/tree/master/0_godbg),现在大致看下实现。
#### 目录结构
godbg的源码目录结构如下所示,为了节省篇幅省略了部分文件条目:
```bash
tree godbg
godbg : 项目根目录
├── LICENSE :版权信息
├── cmd :调试器启动调试的命令
│ ├── root.go : rootCmd绑定了子命令core、exec、attach
│ ├── attach.go
│ ├── core.go
│ ├── exec.go
│ ├── debug :调试会话中可使用的调试命令
│ │ ├── root_debug.go : debugRootCmd绑定了众多调试会话调试命令
│ │ ├── backtrace.go
│ │ ├── break.go
│ │ ├── clear.go
│ │ ├── clearall.go
│ │ ├── disass.go
│ │ ├── display.go
│ │ ├── exit.go
....
├── go.mod
├── go.sum
├── main.go :程序入口main.main
├── syms :符号层,用于实现指令地址和源码的映射、符号查询等等
└── target :target层,用于实现低级操作,如指令patch设置断点等等
├── backtrace.go
├── breakpoint.go
├── call.go
├── continue.go
├── disassemble.go
....
```
可见我们已经将大部分调试需要的命令给纳入进来了,只不过还没有实现,后续我们将一步步实现各个调试命令。命令实现的功能逻辑,可能会涉及到对应的 `${命令}.go`文件,以及符号层syms package、target层target package下的相关代码。
介绍完代码组织,后面讲解一个调试命令或者功能的实现时,读者应该可以方便快速地找到对应的实现代码。
#### 源码解析:命令管理逻辑
熟悉cobra编程的看完main.go就会知道该调试器是基于cobra进行命令管理的。
```go
package main
import "godbg/cmd"
func main() {
cmd.Execute()
}
```
godbg下各个子命令exec、debug、core分别对应cmd/exec.go、cmd/debug.go、cmd/core.go,它们都是cmd/root.go中定义的rootCmd的子命令。
```go
var rootCmd = &cobra.Command{
Use: "godbg",
Short: "godbg是一个面向go语言的符号级调试器",
Long: `
godbg是一个go程序符号级调试器,它是以学习为目的驱动开发的调试器,
希望我们的工作可以为更多人打开一个认识计算机世界的大门,不谢!`,
// Uncomment the following line if your bare application
// has an action associated with it:
Run: func(cmd *cobra.Command, args []string) {
// TODO comment out this, this should be enabled only in debugging phase
debug.NewDebugShell().Run()
},
}
```
当我们执行godbg的时候,执行的 `rootCmd.Run()`逻辑,当我们执行 `godbg exec`的时候执行的则是 `execCmd.Run()`逻辑,这个很好理解,也很容易上手。
```go
var execCmd = &cobra.Command{
Use: "exec <prog>",
Short: "调试可执行程序",
Long: `调试可执行程序`,
Run: func(cmd *cobra.Command, args []string) {
// TODO start process and attach
fmt.Printf("exec %s\n", strings.Join(args, ""))
debug.NewDebugShell().Run()
},
}
func init() {
rootCmd.AddCommand(execCmd)
}
```
以上是 `godbg exec <prog>`时要执行的exec命令,它首先启动进程并attach到进程,准备就绪后,再启动一个调试会话,我们在调试会话中继续输入调试命令来进行调试。
#### 源码解析:调试会话调试命令管理
godbg/cmd/debug/root_debug.go中是使用cobra-prompt构建的一个命令管理器,它结合了cobra命令管理以及go-prompt的自动提示补全能力,非常适合管理命令多、命令选项多、命令候选参数多、命令使用频繁的场景,比如调试器会话中。
只需要执行 `debug.NewDebugShell().Run()`即可快速模拟一个调试会话的用户输入、执行处理、完成调试信息展示的逻辑。
```go
// NewDebugShell 创建一个debug专用的交互管理器
func NewDebugShell() *cobraprompt.CobraPrompt {
fn := func() func(cmd *cobra.Command) error {
return func(cmd *cobra.Command) error {
usage := groupDebugCommands(cmd)
fmt.Println(usage)
return nil
}
}
debugRootCmd.SetUsageFunc(fn())
return &cobraprompt.CobraPrompt{
RootCmd: debugRootCmd,
DynamicSuggestionsFunc: dynamicSuggestions,
ResetFlagsFlag: true,
GoPromptOptions: []prompt.Option{
prompt.OptionTitle(description),
prompt.OptionPrefix(prefix),
prompt.OptionSuggestionBGColor(prompt.DarkBlue),
prompt.OptionDescriptionBGColor(prompt.DarkBlue),
prompt.OptionSelectedSuggestionBGColor(prompt.Red),
prompt.OptionSelectedDescriptionBGColor(prompt.Red),
// here, hide prompt dropdown list
// TODO do we have a better way to show/hide the prompt dropdown list?
prompt.OptionMaxSuggestion(10),
prompt.OptionShowCompletionAtStart(),
},
EnableSilentPrompt: true,
EnableShowAtStart: true,
}
}
```
关于自定义自动提示信息的实现,可以参考函数实现 `dynamicSuggestions(string, prompt.Document)`。
```go
func dynamicSuggestions(annotation string, _ prompt.Document) []prompt.Suggest {
switch annotation {
case suggestionListSourceFiles:
return GetSourceFiles()
default:
return []prompt.Suggest{}
}
}
// list 输入list时返回候选源文件名作为提示补全信息
func GetSourceFiles() []prompt.Suggest {
return []prompt.Suggest{
{Text: "main.go", Description: "main.go"},
{Text: "helloworld.go", Description: "helloworld.go"},
}
}
```
需要注意的是cobra-prompt规定了cobra command只有添加了 `<cobraprompt.CALLBACK_ANNOTATION,"value">`的annotation项之后才会激发命令参数的自动补全逻辑。以list命令将源文件列表作为补全信息为例,list命令在Annotations这个map字段中添加了CALLBACK_ANNOTATION的kvpair。
```go
var listCmd = &cobra.Command{
Use: "list <linespec>",
Short: "查看源码信息",
Aliases: []string{"l"},
Annotations: map[string]string{
cmdGroupKey: cmdGroupSource,
cobraprompt.CALLBACK_ANNOTATION: suggestionListSourceFiles,
},
Run: func(cmd *cobra.Command, args []string) {
fmt.Println("list codes in file")
},
}
```
调试会话中运行 `list main.go`
```bash
godbg> list main.go
list codes in file
```
我们试运行命令 `list main.go`发现输出了一行语句,代表命令已经顺利执行了,我们后面会实现真实的展示源代码的功能。
现在,我们大致介绍了godbg的一个相对完整的骨架,相信读者朋友们已经跃跃欲试想进入下一步的开发了 :) 。
> Note:在该调试器demo的完整版实现中,详见 [hitzhangjie/godbg](https://github.com/hitzhangjie/godbg) 中,我们已经彻底移除了cobraprompt,动态提示对调试会话干扰性有点大,在其他的非高频输入的命令行程序中使用更合适。
### 本节小结
本节我们通过具体的演示和代码片段,展示了调试器雏形 godbg 的基本交互能力,包括命令行帮助信息、调试会话界面、命令及参数的自动补全、分组帮助等功能。我们详细介绍了如何利用 cobra-prompt 实现命令参数的动态补全,并结合实际代码说明了命令注册、补全回调的实现方式。通过这些内容,读者可以直观感受到调试器的基本使用体验和交互流程,为后续深入实现各个调试功能模块(如断点管理、单步执行、源码查看等)打下了坚实的基础。
接下来,我们将以此骨架为基础,逐步实现调试器的核心功能模块,深入剖析调试器各层的设计与实现细节,帮助大家系统掌握调试器开发的关键技术点。
================================================
FILE: book/5-debugger-skeleton/README.md
================================================
## 走进调试器开发
从本章开始,我们正式走进调试器开发的世界。
本章内容分为四个部分:
- **需求分析**:从功能性需求和非功能性需求两个维度,分析现代调试器应该具备的核心能力
- **架构设计**:介绍调试器的分层架构设计,以及如何实现良好的扩展性和命令管理
- **实现方案**:确定具体的实现策略,包括指令级和符号级两个版本的调试器实现
- **功能演示**:通过实际运行效果,展示调试器的各项功能和交互体验
本章我们将从需求分析切入,探讨开发一个调试器时需关注的核心要点,随后逐步梳理调试器的技术架构,甄选合适的实现方案,最终实现一个能够运行的调试器雏形。
我们将在此基础上继续深入,逐步实现指令级调试、符号级调试,带领读者一步步理解调试器的工作原理和设计实现。
>本章结束后,读者也将掌握使用 [spf13/cobra](https://github.com/spf13/cobra) 进行命令行程序开发的一些技巧,如命令管理、选项管理、参数管理、help信息管理、如何实现自动补全等等。go语言经常用来开发一些使用的命令行工具,而spf13/cobra 就是当前最成功的一个项目,很多知名项目的命令行工具是基于它构建,比如 kubernetes、hugo、Github CLI 等等。
================================================
FILE: book/6-develop-inst-debugger/1-process_start.md
================================================
## 启动调试:启动进程
### 实现目标:`godbg exec <prog>` 启动新进程
调试器执行调试,首先得确定要调试的目标。它可能是一个进程实例,或者是一个core文件。为了便利性,调试器也可以代为执行编译操作,如 `dlv debug [main module] | [test package]`,会自动对main module或者test package进行编译构建。
我们先关注如何对一个运行中的进程进行调试,这是本章指令级调试部分的重点。core文件是为进程生成的运行时内核转储文件,包含了进程结束前的内存、硬件上下文信息。调试器可以分析core文件来了解当时的进程执行情况,如程序crash之前的调用栈信息。对运行中的进程可以执行的调试操作,覆盖了对core文件能执行的操作。所以本章优先介绍对运行中的进程进行调试,对core文件的调试支持(包括core文件构成、生成、调试)我们将在符号级调试部分再进行介绍。
调试一个进程,主要有以下几种情况:
- 如果目标程序 `<prog>`已构建好,但是没有运行:我们需要启动程序并跟踪进程,如 `dlv exec <prog>`、`gdb <prog>`;
- 如果目标程序还没有进行构建,要先构建然后运行:我们需要传递相关的编译选项,确保生成必要的调试信息、关闭编译优化,如 `dlv debug`、`dlv test`;
dlv自动构建时会自动传递 `-gcflags="all=-N -l"`选项来禁用编译构建过程中的内联、优化,以保证构建产物满足调试器调试需要。
- 如果目标程序已经运行,且已经确认了进程pid:我们需要通过进程pid来跟踪进程,如 `dlv attach <pid>`、`gdb <pid>`;
OK,我们先介绍第一种情况,启动构建好的程序并执行调试。
本节呢,我们先介绍如何启动一个目标程序,得到一个运行中的进程,等待程序执行结束,并获取运行结果。下一节我们再介绍如何启动并跟踪进程执行。
### 基础知识
我们一步步实现指令级调试器godbg,首先为它添加第一个调试命令 `godbg exec <prog>`:
- exec命令接收参数prog、启动程序prog并获取其执行结果;
- prog参数为可执行程序的文件路径,或者一个可执行程序的名字,这个名字在 `$PATH` 搜索路径中可以搜索到。
在SHELL中只要键入可执行程序路径或者程序名就可以启动程序,在stdout、stderr获取程序运行时输出,并可以通过 `$?` 获取进程返回值。那么在Go编程中应该如何实现这些操作呢?Go标准库提供了 `os/exec` 包,允许指定程序路径、程序名来启动进程,并获取输出信息、执行结果。
通过 `cmd = exec.Command(...)`方法我们可以创建一个 `exec.Cmd` 实例:
- 之后则可以通过 `err := cmd.Start()`方法来启动程序,继续执行 `err := cmd.Wait() 可以`等待进程结束,然后可以再获取结果;
- 如果希望启动程序并一直等待到进程执行结束,也可以通过 `err := cmd.Run()` 来代替上述 `err := cmd.Start() + err := cmd.Wait()`;
- 如果希望获取进程执行期间输出到stdout、stderr的信息,可以在启动前修改 `cmd.Stdout`、`cmd.Stderr` 指向一个bytes.Buffer收集起来;
如果您感觉上述操作比较复杂,想寻求更简化的操作实现,别急真的有:
- 如果希望启动程序并等待执行结束,同时能获取stdout、stderr输出信息,可以通过 `buf, err := Cmd.CombineOutput()` 来完成。
其中err表示进程启动、执行期间是否出错,buf中记录了执行期间输出到stdout、stderr的信息:
```go
package exec // import "os/exec"
// Command 该方法接收可执行程序名称或者路径,arg是传递给可执行程序的参数信息,
// 该函数返回一个Cmd对象,通过它来启动程序、获取程序执行结果等,注意参数name
// 可以是一个可执行程序的路径,也可以是一个PATH中可以搜索到的可执行程序名
func Command(name string, arg ...string) *Cmd
// Cmd 通过Cmd来执行程序、获取程序执行结果等等,Cmd一旦调用Start、Run等方法之
// 后就不能再复用了
type Cmd struct {
...
}
// CombinedOutput 返回程序执行时输出到stdout、stderr的信息
func (c *Cmd) CombinedOutput() ([]byte, error)
// Output 返回程序执行时输出到stdout的信息,返回值列表中的error表示执行中遇到错误
func (c *Cmd) Output() ([]byte, error)
// Run 启动程序并且等待程序执行结束,返回值列表中的error表示执行中遇到错误
func (c *Cmd) Run() error
// Start 启动程序,但是不等待程序执行结束,返回值列表中的error表示执行中遇到错误
func (c *Cmd) Start() error
...
// Wait 等待cmd执行结束,该方法必须与Start()方法配合使用,返回值error表示执行中遇到错误
//
// Wait等待程序执行结束并获得程序的退出码(也就是返回值,os.Exit(?)将值返回给操作系统进而被父进程获取),
// 并释放对应的资源(比如id资源,联想下PCB)
func (c *Cmd) Wait() error
```
### 代码实现
下面基于go标准库 `os/exec` package来演示如何启动程序创建进程实例。示例代码详见:golang-debugger-lessons/1_process_start。
file: main.go
```go
package main
import (
"fmt"
"os"
"os/exec"
)
const (
usage = "Usage: ./godbg exec <path/to/prog>"
cmdExec = "exec"
)
func main() {
if len(os.Args) < 3 {
fmt.Fprintf(os.Stderr, "%s\n\n", usage)
os.Exit(1)
}
cmd := os.Args[1]
switch cmd {
case cmdExec:
prog := os.Args[2]
progCmd := exec.Command(prog)
buf, err := progCmd.CombinedOutput()
if err != nil {
fmt.Fprintf(os.Stderr, "%s exec error: %v, \n\n%s\n\n", err, string(buf))
os.Exit(1)
}
fmt.Fprintf(os.Stdout, "%s\n", string(buf))
default:
fmt.Fprintf(os.Stderr, "%s unknown cmd\n\n", cmd)
os.Exit(1)
}
}
```
这里的程序逻辑比较简单:
- 程序运行时,首先检查命令行参数,
- `godbg exec <prog>`,`os.Args` 至少有3个参数,如果参数数量不对,直接报错退出;
- 接下来校验第2个参数,如果 `os.Args[1]` 不是exec,也直接报错退出;
- 参数正常情况下,第3个参数 `os.Args[2]` 应该是一个程序路径或者程序名,我们准备一个exec.Cmd对象,然后启动并获取运行结果;
### 代码测试
执行以下命令先完成程序构建,然后执行程序进行测试:
```bash
1_start-process $ GO111MODULE=off go build -o godbg main.go
./godbg exec <prog>
```
后续随着功能越来越多,我们会分包分文件管理,此时就需要对整个module进行go build再测试,或者直接go install之后再测试。当前示例代码只有一个简单的源文件,`go run main.go` 就可以快速测试,如在目录golang-debugger-lessons/1_start-process下执行 `GO111MODULE=off go run main.go exec ls` 。
```bash
1_start-process $ GO111MODULE=off go run main.go exec ls
tracee pid: 270
main.go
README.md
```
godbg正常执行了命令ls并显示出了当前目录下的文件 `main.go README.md` ,目标进程ls被正常执行了,并且我们成功获得了ls的执行结果。
### 本节小结
本节我们学习了如何通过 Go 代码启动并执行一个外部进程,掌握了使用 `exec.Command` 创建和运行子进程的方法,并能够捕获其输出和错误信息。通过简单的命令行参数解析,实现了 `godbg exec <prog>` 的基本功能,为后续实现调试器的进程控制和调试功能打下了基础。建议读者动手实践,熟悉进程启动和参数校验的流程,为后续章节的深入学习做好准备。
================================================
FILE: book/6-develop-inst-debugger/10-clearall-atexit.md
================================================
## 软件动态断点:退出前清理机制
### 问题背景:断点残留的危害
在调试器开发过程中,我们通过ptrace系统调用对目标进程的指令进行动态修改来实现动态软件断点。具体来说,断点的添加是通过将目标地址的指令字节替换为0xCC(int3指令)来实现的,同时需要备份原始指令字节以便后续恢复。
调试器与tracee的关系存在多种场景:
- 通过 `debug` 编译构建并启动构建好的程序;
- 通过 `exec` 启动已经构建好的程序;
- 通过 `attach`跟踪正在运行中的进程。
对于前两种情况,调试器退出时通常会主动终止tracee;而对于 `attach`场景,调试器退出后时一般会倾向于恢复tracee的执行。
然而,如果调试器在退出前没有主动清理这些动态添加的断点,将会给被调试进程造成严重的不良影响:
1. **指令不完整**:多字节指令被patch后变成不完整的指令序列
2. **SIGTRAP信号**:当tracee执行到断点位置时,会触发SIGTRAP信号
3. **进程终止**:在没有tracer的情况下,内核的默认行为是杀死该tracee进程
我们必须足够重视这个问题,需要实现一个类似C语言atexit的机制,在调试器退出前自动清理所有断点。
### 实现目标:自动断点清理
为了避免上述问题,我们需要在调试器退出前自动清理所有已添加的断点。这要求我们:
1. **跟踪所有断点**:维护一个全局的断点集合,记录所有已添加的断点信息
2. **自动清理机制**:在调试会话结束时,自动遍历并清理所有断点
3. **优雅退出**:确保tracee进程在调试器退出后能够继续正常运行
### 代码实现
我们通过实现一个类似C语言 `atexit`的机制来实现自动断点清理。具体实现包括:
#### 1. DebugSession结构体扩展
```go
type DebugSession struct {
// ... 其他字段
defers []func() // 退出前需要执行的清理函数
}
// AtExit 注册退出前的清理函数
func (s *DebugSession) AtExit(fn func()) *DebugSession {
s.defers = append(s.defers, fn)
return s
}
```
#### 2. 启动方法中的defer机制
```go
func (s *DebugSession) Start() {
s.liner.SetCompleter(completer)
s.liner.SetTabCompletionStyle(liner.TabPrints)
// 注册退出前的清理逻辑
defer func() {
for idx := len(s.defers) - 1; idx >= 0; idx-- {
s.defers[idx]()
}
}()
// ... 其他启动逻辑
}
```
#### 3. 断点清理函数
```go
// Cleanup 清理所有断点的函数
func Cleanup() {
var (
dbp = target.DBPProcess
err error
)
// 先清理掉之前创建的断点
fmt.Printf("before detached, clearall created breakpoints.")
if err := target.DBPProcess.ClearAll(); err != nil {
fmt.Fprintf(os.Stderr, "clearall failed err: %v\n", err)
}
// 根据被调试进程创建的方式,debug、exec or attach,来决定如何做善后处理
// - debug: kill traced process, delete generated binary
// - exec: kill traced process
// - attach: detach traced process
if err = dbp.Detach(); err != nil {
fmt.Fprintf(os.Stderr, "detach tracee: %d, err: %v\n", dbp.Process.Pid, err)
return
}
switch dbp.Kind {
case target.DEBUG:
fmt.Fprintf(os.Stdout, "tracee is is built and run by tracer, remove binary and kill it: %d\n", dbp.Kind)
if err = os.RemoveAll(dbp.Command); err != nil {
fmt.Fprintf(os.Stderr, "remove built binary %s, err: %v\n", dbp.Command, err)
return
}
if err = syscall.Kill(dbp.Process.Pid, syscall.SIGKILL); err != nil {
fmt.Fprintf(os.Stderr, "kill tracee: %d, err: %v\n", dbp.Process.Pid, err)
return
}
fallthrough
case target.EXEC:
fmt.Fprintf(os.Stdout, "tracee is is run by tracer, kill it: %d\n", dbp.Kind)
if err = syscall.Kill(dbp.Process.Pid, syscall.SIGKILL); err != nil {
fmt.Fprintf(os.Stderr, "kill tracee: %d, err: %v\n", dbp.Process.Pid, err)
return
}
default:
fmt.Fprintf(os.Stdout, "tracee is an attached process, leave it running")
}
}
```
特别注意的是 `target.DBPProcess.ClearAll()` 执行过程中,不光会还原断点处指令数据,还会rewind所有受影响的线程的PC,保证调试器退出后各个线程可以继续正常执行。同时考虑了attach、debug两种方式下对于tracee的不同处理,后者会杀死,前者会询问是否要继续执行。
#### 4. 调试会话的创建和使用
```go
// 创建调试会话并注册清理函数
session := debug.NewDebugSession().AtExit(Cleanup)
session.Start()
```
### 测试用例
#### 测试场景:不清理断点的后果
我们通过一个实际的测试来演示不清理断点会导致的问题:
1. **启动测试进程**:
```bash
$ while [ 1 -eq 1 ]; do t=`date`; echo "$t pid: $$"; sleep 1; done
Sun Sep 7 15:22:23 CST 2025 pid: 416728
Sun Sep 7 15:22:24 CST 2025 pid: 416728
Sun Sep 7 15:22:25 CST 2025 pid: 416728
Sun Sep 7 15:22:26 CST 2025 pid: 416728
```
2. **附加调试器并添加断点**:
```bash
godbg attach 416728
godbg> pregs
Rax <Rax value>
Rbx <Rbx value>
...
Rip <Rip value>
...
godbg> break <Rip value>
godbg> continue
```
3. **观察进程行为**:
执行continue后,tracee开始重新输出信息:
```bash
Sun Sep 7 15:23:19 CST 2025 pid: 416728 <= after we run `continue`, we see the output again.
```
4. **退出调试器(不清理断点)**:
```bash
godbg> exit
```
5. **观察进程终止**:
```bash
Sun Sep 7 15:22:23 CST 2025 pid: 416728
Sun Sep 7 15:22:24 CST 2025 pid: 416728
Sun Sep 7 15:22:25 CST 2025 pid: 416728
Sun Sep 7 15:22:26 CST 2025 pid: 416728
Sun Sep 7 15:22:27 CST 2025 pid: 416728
Sun Sep 7 15:23:19 CST 2025 pid: 416728
[process exited with code 5 (0x00000005)] <= tracee exited with error
You can now close this terminal with Ctrl+D, or press Enter to restart.
```
#### 测试场景:使用AtExit机制的正确行为
1. **启动测试进程**:
```bash
$ while [ 1 -eq 1 ]; do t=`date`; echo "$t pid: $$"; sleep 1; done
```
2. **使用带AtExit的调试器**:
```bash
godbg attach 416728
godbg> break <address>
godbg> exit
正在清理断点...
断点清理完成
```
3. **验证进程继续运行**:
```bash
Sun Sep 7 15:22:23 CST 2025 pid: 416728
Sun Sep 7 15:22:24 CST 2025 pid: 416728
Sun Sep 7 15:22:25 CST 2025 pid: 416728
Sun Sep 7 15:22:26 CST 2025 pid: 416728
Sun Sep 7 15:22:27 CST 2025 pid: 416728
Sun Sep 7 15:23:19 CST 2025 pid: 416728
Sun Sep 7 15:23:20 CST 2025 pid: 416728 <= 进程继续正常运行
Sun Sep 7 15:23:21 CST 2025 pid: 416728
```
### 本节小结
本节主要探讨了调试器退出前断点清理机制的重要性与实现方法,核心内容包括:**断点残留的危害性分析**;**SIGTRAP信号导致的进程终止问题**;**AtExit机制的实现原理**;**自动断点清理的代码实现**。
本节核心要点包括:
- 断点通过ptrace修改指令字节实现,如果不清理会导致多字节指令不完整,执行时触发SIGTRAP信号
- 在没有tracer的情况下,内核默认行为是杀死触发SIGTRAP的进程,导致被调试进程异常终止
- 通过实现类似C语言atexit的机制,在调试会话退出前自动清理所有断点,确保tracee进程能够继续正常运行
- AtExit机制通过defer函数和回调函数注册实现,提供了优雅的资源清理方式
本节内容为调试器的健壮性设计提供了重要保障,确保调试器在各种退出场景下都能正确清理资源,为读者理解调试器的生命周期管理和资源清理机制奠定了实践基础。通过本节的学习,读者可以掌握调试器开发中资源管理的最佳实践,为后续开发更复杂的调试器功能提供了重要的设计参考。
================================================
FILE: book/6-develop-inst-debugger/11-step.md
================================================
## 执行控制:逐指令执行
### 实现目标:`godbg> step` 逐指令执行
在实现了反汇编以及添加移除断点功能后,我们将开始进一步探索如何控制调试进程的执行,如step逐指令执行、continue运行到断点位置,在后面符号级调试器开发章节,我们还会实现next逐语句执行。
本节我们先实现 `step`命令来支持逐指令执行。
### 代码实现
逐指令执行,通过执行 `ptrace(PTRACE_SINGLESTEP,...)` 操作即可由内核代为完成。但是在上述操作执行之前,step命令还有些特殊因素要考虑方能正常执行。
此时的PC值有可能是越过了一个断点之后的地址,比如:
1. 一条经过指令patch后的多字节指令,首字节处修改为了0xCC,当前寄存器PC值实际上是该多字节指令的第二个字节的地址,而非首字节的地址。如果对PC值不做修改,处理器执行的时候从第二字节开始解码会解码失败,无法执行指令;
2. 一条单字节指令,如果我们直接decode下一个地址处的指令,还会漏掉断点处原来的一字节指令;
为了保证step正常执行,在 `ptrace(PTRACE_SINGLESTEP,...) ` 之前,需要首先通过 `ptrace(PTRACE_PEEKTEXT,...)` 去读取 `PC-1` 地址处的数据,如果是0xCC,则表明此处为一个断点,需要将添加断点前的原始数据还原、PC=PC-1,然后再继续执行。
**file:cmd/debug/step.go**
```go
package debug
import (
"fmt"
"syscall"
"github.com/spf13/cobra"
)
var stepCmd = &cobra.Command{
Use: "step",
Short: "执行一条指令",
Annotations: map[string]string{
cmdGroupKey: cmdGroupCtrlFlow,
},
RunE: func(cmd *cobra.Command, args []string) error {
dbp := target.DBPProcess
defer func() {
if err != nil {
return
}
// display current pc
regs, err := dbp.ReadRegister(dbp.Process.Pid)
if err != nil {
fmt.Printf("get regs error: %v", err)
return
}
fmt.Printf("single step ok, current PC: %#x\n", regs.PC())
}()
// 读取PC值
regs, err := dbp.ReadRegister(dbp.Process.Pid)
if err != nil {
return fmt.Errorf("get regs error: %v", err)
}
// isn't a breakpoint
_, ok := dbp.Breakpoint(uintptr(regs.PC() - 1))
if !ok {
if _, err = dbp.SingleStep(dbp.Process.Pid); err != nil {
return fmt.Errorf("single step err: %v", err)
}
return nil
}
// is a breakpoint
brk, err := dbp.RestoreInstruction(uintptr(regs.PC() - 1))
if err == target.ErrBreakpointNotExisted {
// this 0xcc isn't patched by debugger, and this 0xcc is already executed,
// just single step
_, err = dbp.SingleStep(dbp.Process.Pid)
return err
}
if err != nil {
// debugger inner error
return fmt.Errorf("clear breakpoint err: %v", err)
}
defer dbp.AddBreakpoint(brk.Addr)
// rewind pc by 1
regs.SetPC(regs.PC() - 1)
if err = dbp.WriteRegister(dbp.Process.Pid, regs); err != nil {
return err
}
// single step
if _, err = dbp.SingleStep(dbp.Process.Pid); err != nil {
return fmt.Errorf("single step error: %v", err)
}
return nil
},
}
func init() {
debugRootCmd.AddCommand(stepCmd)
}
```
以上就是step命令的实现代码,但这并不是一个十分友好的实现:
- 它确实实现了逐指令执行,完成了本节目标;
- 每逐指令执行之后,它还能打印当前寄存器PC值,方便我们确定下条待执行指令地址;
美中不足的是,没有将当前待执行指令的前后指令打印出来,并通过箭头指示下条待执行指令,一种更好的交互可能是这样:
```
godbg> step
=> 地址1 汇编指令1
地址2 汇编指令2
地址3 汇编指令3
...
```
这里会影响到调试体验,我们将在后续过程中予以完善。
> ps:上述代码是 [hitzhangjie/godbg](https://github.com/hitzhangjie/godbg) 中的实现,我们重点介绍了step的实现。另外在 [hitzhangjie/golang-debuger-lessons](https://github.com/hitzhangjie/golang-debugger-lessons) /11_step 下,我们也提供了一个step执行的示例,只有一个源文件,与其他demo互不影响,您也可以按照你的想法修改测试下,不用担心改坏整个 godbg的问题。
>
> FIXME(demo) 这里的代码实际上也是godbg中的早期实现版本了,后续为了增强维护性,早就进行了大范围的重构。
### 代码测试
启动一个程序,获取其进程pid,然后执行 `godbg attach <pid>`对进程进行调试,等调试会话就绪之后,我们输入 `disass` 反汇编看下当前指令地址之后的汇编指令有哪些。
```bash
godbg> disass
0x40ab47 movb $0x0,0x115(%rdx)
0x40ab4e mov 0x18(%rsp),%rcx
0x40ab53 mov 0x38(%rsp),%rdx
0x40ab58 mov (%rdx),%ebx
0x40ab5a test %ebx,%ebx
0x40ab5c jne 0x4c
0x40ab5e mov 0x30(%rax),%rbx
0x40ab62 movb $0x1,0x115(%rbx)
0x40ab69 mov %rdx,(%rsp)
0x40ab6d movl $0x0,0x8(%rsp)
```
然后尝试执行 `step` 命令,观察输出情况。
```bash
godbg> step
step
single step ok, current PC: 0x40ab4e
godbg> step
step
single step ok, current PC: 0x40ab53
godbg> step
step
single step ok, current PC: 0x40ab58
godbg>
```
我们执行了step指令3次,step每次执行一条指令之后,会输出执行指令后的PC值,依次是0x40ab4e、0x40ab53、0x40ab58,依次是下条指令的首地址。
不禁要问,执行系统调用 `ptrace(PTRACE_SINGLESTEP,...)` 时,内核是如何实现逐指令执行的?只执行一条机器指令后立即停下来,有点奇妙!
### 更多相关内容:SINGLESTEP
内核是如何处理PTRACE_SINGLESTEP请求的呢?SINGLESTEP确实比较特殊,在man(2)手册里面并没有找到太多有价值的信息:
```bash
$ man 2 ptrace
------------------------------------------------------------------
NAME
ptrace - process trace
SYNOPSIS
#include <sys/ptrace.h>
long ptrace(enum __ptrace_request request, pid_t pid,
void *addr, void *data);
Description
...
PTRACE_SINGLESTEP stops
[Details of these kinds of stops are yet to be documented.]
```
man(2)手册里面没有太多有价值的相关信息,查看内核源码以及Intel开发手册之后,可以了解到这方面的细节。
1. SINGLESTEP调试在Intel平台上是借助了处理器自身硬件特性来实现的,参考《Intel® 64 and IA-32 Architectures Software Developer's Manual Volume 1: Basic Architecture》,Intel架构处理器是有一个标识寄存器EFLAGS,当通过内核将标志寄存器的TF标志置为1时,处理器会自动进入单步执行模式,清0退出单步执行模式。
> **System Flags and IOPL Field**
>
> The system flags and IOPL field in the **EFLAGS** register control operating-system or executive operations. **They should not be modified by application programs.** The functions of the system flags are as follows:
>
> **TF (bit 8) Trap flag** — Set to enable single-step mode for debugging; clear to disable single-step mode.
>
2. 我们执行系统调用 `syscall.PtraceSingleStep(...)` 时,实际上是 `ptrace(PTRACE_SINGLESTEP, pid...)` ,此时内核会将被跟踪的tracee的task_struct中的寄存器部分的flags设置为flags |= TRAP,然后调度tracee执行。
3. 调度器执行tracee时会先将其进程控制块task_struct中的硬件上下文信息还原到处理器寄存器中,然后再执行对应tracee的指令。此时处理器发现EFLAGS.TF=1,进入单步执行模式。处理器执行单条指令,执行完成后处理器会自动生成一个陷阱中断,然后重置该标志位。这里的陷阱中断是type-1中断 (中断1是调试异常#DB,中断3是断点异常#BP)。
> **Single-step interrupt**
> When a system is instructed to single-step, it will execute one instruction and then stop.
> ...
> The Intel 8086 trap flag and type-1 interrupt response make it quite easy to implement a single-step feature in an 8086-based system. If the trap flag is set, the 8086 will automatically do a type-1 interrupt after each instruction executes. When the 8086 does a type-1 interrupt, ...
> The trap flag is reset when the 8086 does a type-1 interrupt, so the single-step mode will be disabled during the interrupt-service procedure.
>
4. 内核中断服务程序负责处理这个中断(中断1,#DB异常),会像处理中断3#BP异常时那样,给tracee发送SIGTRAP,信号处理时进而会暂停tracee调度,然后通过SIGCHLD、__wake_up_parent唤醒tracer,以这种方式通知调试器tracer,“嘿,tracee已经单步执行了一条指令,并且已经停下来等待接收后续调试命令了”。
ps:这就是Intel平台下单步执行的一些细节信息,读者如果对其他硬件平台感兴趣,也可以自行了解下它们是如何设计实现来解决单步调试问题的。
### 本节小结
本节主要探讨了调试器中step逐指令执行功能的实现原理与具体实现,核心内容包括:通过ptrace(PTRACE_SINGLESTEP)系统调用实现单步执行;处理断点恢复的特殊情况,确保PC值正确性;理解Intel平台下基于EFLAGS.TF标志位的硬件单步执行机制。
本节内容为读者深入理解调试器执行控制机制以及后续实现continue、next等高级调试命令奠定了重要基础。
================================================
FILE: book/6-develop-inst-debugger/12-continue.md
================================================
## 执行控制:运行到下个断点
### 实现目标:`godbg> continue` 运行到下个断点
假定当前tracee处于被调试跟踪、暂停执行状态,如果要运行到下个断点处,应该如何做呢?detach之后,被跟踪的tracee会自动恢复执行,但我们肯定要继续跟踪。
操作系统提供了 `ptrace(PTRACE_CONT,...)` 操作,允许我们恢复tracee执行,此时的tracee仍然被tracer跟踪。当tracee运行到下个断点处时,执行0xCC触发3号中断#BP,内核生成SIGTRAP给tracee,进入信号处理逻辑,暂停tracee并唤醒tracer。
在执行恢复操作前,需要检查当前 `PC-1` 地址处是否是我们添加的断点,如果是则需要将其替换为原始指令数据,并回退PC (PC=PC-1),确保tracee能够正确执行后续指令。
### 代码实现
continue命令的执行流程如下:
1. 检查当前PC-1处数据是否为0xCC,如果是则说明该处是被patch的断点指令
2. 将断点位置的数据还原为原始指令,并将PC回退1
3. 执行 `ptrace(PTRACE_CONT, ...)` 操作请求操作系统恢复tracee执行
4. 通过 `syscall.Wait4(...)` 等待tracee停下来
5. 当tracee运行到断点处时,会重新触发int3中断,tracer被唤醒后获取寄存器信息
注意:当前PC值是执行了0xCC指令之后的地址值,因此 PC=断点地址+1。
**file: cmd/debug/continue.go**
```go
package debug
import (
"fmt"
"syscall"
"github.com/spf13/cobra"
)
var continueCmd = &cobra.Command{
Use: "continue",
Short: "运行到下个断点",
Annotations: map[string]string{
cmdGroupKey: cmdGroupCtrlFlow,
},
Aliases: []string{"c"},
RunE: func(cmd *cobra.Command, args []string) error {
fmt.Println("continue")
// 读取PC值
regs := syscall.PtraceRegs{}
err := syscall.PtraceGetRegs(TraceePID, ®s)
if err != nil {
return fmt.Errorf("get regs error: %v", err)
}
buf := make([]byte, 1)
n, err := syscall.PtracePeekText(TraceePID, uintptr(regs.PC()-1), buf)
if err != nil || n != 1 {
return fmt.Errorf("peek text error: %v, bytes: %d", err, n)
gitextract_wz0yy6cs/ ├── .cursor/ │ ├── commands/ │ │ ├── gg_catalogue.md │ │ └── gg_commit.md │ └── rules/ │ ├── rule-heading.mdc │ ├── rule-summary.mdc │ └── rule-translate.mdc ├── .github/ │ └── workflows/ │ ├── SETUP_GITHUB_ACTIONS.md │ └── deploy.yml ├── .gitignore ├── .vscode/ │ ├── bookmarks.json │ └── settings.json ├── Makefile ├── README.md ├── book/ │ ├── 10-extras/ │ │ ├── 1-development-of-debugger.md │ │ ├── 2-development-of-logging.md │ │ ├── 3-development-of-metrics.md │ │ ├── 4-development-of-tracing.md │ │ ├── 5-development-of-bisect.md │ │ ├── 6-development-of-ebpf.md │ │ ├── 7-development-of-replay.md │ │ ├── 8-development-of-debug-dsys.md │ │ ├── 9-ai-assisted-debugging.md │ │ └── README.md │ ├── 11-thanks/ │ │ └── README.md │ ├── 12-appendix/ │ │ ├── 1-go-programme-start.md │ │ ├── 2-auto-trace-cloned-threads.md │ │ ├── 3-git-bisect.md │ │ ├── 4-vscode-extension-bisect.md │ │ ├── 80-go-tool-compile.md │ │ ├── 81-go-tool-asm.md │ │ ├── 82-go-tool-link.md │ │ ├── 90-why-buildid-loaded.md │ │ ├── 91-syntax-and-semantic-analysis.md │ │ ├── 92-why-gdb-uses-symtab.md │ │ └── README.md │ ├── 2-preface/ │ │ └── README.md │ ├── 3-terms/ │ │ └── README.md │ ├── 4-basics/ │ │ ├── 1-purposes.md │ │ ├── 2-dependencies.md │ │ ├── 3-countertactics.md │ │ └── README.md │ ├── 5-debugger-skeleton/ │ │ ├── 1-debugger_skeleton.md │ │ ├── 2-debugger_solution.md │ │ ├── 3-debugger_solution_final.md │ │ ├── 4-debugger_demos.md │ │ └── README.md │ ├── 6-develop-inst-debugger/ │ │ ├── 1-process_start.md │ │ ├── 10-clearall-atexit.md │ │ ├── 11-step.md │ │ ├── 12-continue.md │ │ ├── 13-pmem.md │ │ ├── 14-pregs.md │ │ ├── 15-set-mem.md │ │ ├── 16-set-regs.md │ │ ├── 2-process_attach.md │ │ ├── 20-multithread/ │ │ │ ├── 1-trace_old_threads.md │ │ │ ├── 2-trace_new_threads.md │ │ │ ├── 3-suspend_policy.md │ │ │ ├── 4-continue.md │ │ │ ├── 5-breakpoint.md │ │ │ └── README.md │ │ ├── 21-multiprocess/ │ │ │ └── README.md │ │ ├── 3-process_start_attach.md │ │ ├── 4-debug-session.md │ │ ├── 5-disassemble.md │ │ ├── 6-breakpoint.md │ │ ├── 7-breakpoints.md │ │ ├── 8-clear.md │ │ ├── 80-aslr.md │ │ ├── 9-clearall.md │ │ ├── 99-more.md │ │ └── README.md │ ├── 7-headto-sym-debugger/ │ │ ├── 1-how-go-build-works.md │ │ ├── 2-elf.md │ │ ├── 3-syms.md │ │ ├── 4-syms-resolve-reloc.md │ │ ├── 5-loading.md │ │ ├── 6-gopkg-debug/ │ │ │ ├── 1-elf.md │ │ │ ├── 2-gosym.md │ │ │ ├── 3-dwarf.md │ │ │ └── README.md │ │ ├── 7-headto-dwarf/ │ │ │ ├── 1-gopkgs-about-dwarf.md │ │ │ ├── 2-delve-into-internals.md │ │ │ ├── 3-compiler-gen-dwarfdata.md │ │ │ ├── 4-linker-gen-dwarfdata.md │ │ │ ├── 5-headto-dwarf.md │ │ │ └── README.md │ │ └── README.md │ ├── 8-dwarf/ │ │ ├── 1-history.md │ │ ├── 2-overview.md │ │ ├── 3-dwarfdata.md │ │ ├── 4-die/ │ │ │ ├── 1-desc-data-type.md │ │ │ ├── 2-desc-locations.md │ │ │ ├── 3-desc-code.md │ │ │ ├── 4-encoding.md │ │ │ └── README.md │ │ ├── 5-other/ │ │ │ ├── 1-accelerated-access.md │ │ │ ├── 2-lineno-table.md │ │ │ ├── 3-callframe-info.md │ │ │ ├── 4-macro-info.md │ │ │ ├── 5-varlen-data.md │ │ │ ├── 6-shrink-data.md │ │ │ ├── 7-elf-sections.md │ │ │ └── README.md │ │ ├── 6-practices.md │ │ ├── 7-summary.md │ │ └── README.md │ ├── 9-develop-sym-debugger/ │ │ ├── 1-架构设计/ │ │ │ ├── 1-现代调试器架构.md │ │ │ ├── 2-前端UI层设计.md │ │ │ ├── 3-Service层设计.md │ │ │ ├── 4-后端符号层设计.md │ │ │ ├── 5-后端目标层设计.md │ │ │ ├── 6-日志系统设计.md │ │ │ └── README.md │ │ ├── 2-核心调试逻辑/ │ │ │ ├── 00-cmds.md │ │ │ ├── 01-debug-session.md │ │ │ ├── 100-debug_goroutines.md │ │ │ ├── 100-how_listfunctions_work.md │ │ │ ├── 100-multi-threads.md │ │ │ ├── 11-tinydbg_attach.md │ │ │ ├── 12-tinydbg_attach_waitfor.md │ │ │ ├── 13-tinydbg_exec.md │ │ │ ├── 14-tinydbg_debug.md │ │ │ ├── 15-tinydbg_core1.md │ │ │ ├── 15-tinydbg_core2.md │ │ │ ├── 16-tinydbg_connect.md │ │ │ ├── 17-tinydbg_trace.md │ │ │ ├── 19-how_evalexpr_works.md │ │ │ ├── 20-how_locspec_works.md │ │ │ ├── 21-debug_disassemble.md │ │ │ ├── 22-debug_breakpoint_part1.md │ │ │ ├── 23-debug_breakpoint_part2.md │ │ │ ├── 24-debug_breakpoint_part3.md │ │ │ ├── 25-debug_breakpoint_part4.md │ │ │ ├── 26-debug_trace.md │ │ │ ├── 27-debug_watch.md │ │ │ ├── 28-debug_continue.md │ │ │ ├── 29-debug_next.md │ │ │ ├── 30-debug_step.md │ │ │ ├── 31-debug_pmem.md │ │ │ ├── 32-debug_regs.md │ │ │ ├── 33-debug_funcs.md │ │ │ ├── 34-debug_vars.md │ │ │ ├── 35-debug_bt.md │ │ │ └── README.md │ │ ├── 3-高级功能扩展/ │ │ │ ├── 100-howto_integrate_starlark.md │ │ │ ├── 101-howto_tracing_via_ebpf.md │ │ │ ├── 102-howto_syntax_highlight.md │ │ │ ├── 103-howto_paging_output.md │ │ │ ├── 104-howto_read_separate_dwarfdata.md │ │ │ ├── 105-howto_guess_substitutepath.md │ │ │ ├── 106-howto_redirect_target_io.md │ │ │ ├── 107-howto_customize_tinydbg.md │ │ │ ├── 108-howto_accept_multiclient.md │ │ │ ├── 109-howto_transcript_debugging.md │ │ │ ├── 110-howto_debug_deterministically.md │ │ │ ├── 111-howto-integrate-with-rr.md │ │ │ └── README.md │ │ └── README.md │ ├── README.md │ ├── SUMMARY.md │ └── book.json ├── changelog.md ├── contributing.md ├── contributing.zh_CN.md └── deploy.sh
Condensed preview — 165 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,723K chars).
[
{
"path": ".cursor/commands/gg_catalogue.md",
"chars": 378,
"preview": "# gg_catalogue\n\n`/gg_catalogue` 是一个命令,用于更新目录操作(包括目录中的引用的文件路径以及显示的章节名称),需要执行以下步骤:\n\n1. 确定当前有变更的文件列表(比如通过git status)\n2. 如果是"
},
{
"path": ".cursor/commands/gg_commit.md",
"chars": 1023,
"preview": "# gg_commit\n\n`/gg_commit [message]` is a command to commit staged changes to the repository.\n\n## Usage\n\n```bash\n/gg_comm"
},
{
"path": ".cursor/rules/rule-heading.mdc",
"chars": 83,
"preview": "---\ndescription: 标题级别设置\nglobs: *.md\nalwaysApply: true\n---\n\n文档起始标题统一设置为二级标题,即 `##`。\n"
},
{
"path": ".cursor/rules/rule-summary.mdc",
"chars": 250,
"preview": "---\ndescription: 本节小结应该如何写\nglobs: *.md\nalwaysApply: true\n---\n\n本节小结是对当前章节核心内容的提炼,需帮助读者回顾重点、理清逻辑,并为后续内容做好铺垫。作用包括强化主要印象、梳理知"
},
{
"path": ".cursor/rules/rule-translate.mdc",
"chars": 277,
"preview": "---\ndescription: 文章翻译设置\nglobs: *.md\nalwaysApply: true\n---\n\n当要求将文章内容翻译为中文时,或者要求对文章内容进行润色时,要注意:\n\n- 避免生硬,要结合作者文风以及中国人的说话习惯,"
},
{
"path": ".github/workflows/SETUP_GITHUB_ACTIONS.md",
"chars": 2085,
"preview": "# GitHub Actions 设置指南\n\n## 快速开始\n\n### 1. 选择工作流文件\n\n根据你的需求选择合适的工作流文件:\n\n**选项A:基础部署(推荐)**\n```bash\n# 使用基础版本,只部署到目标仓库\ncp .github"
},
{
"path": ".github/workflows/deploy.yml",
"chars": 1742,
"preview": "name: Auto Deploy GitBook\n\non:\n push:\n branches: [ main, master ]\n workflow_dispatch: # 允许手动触发\n\njobs:\n deploy:\n "
},
{
"path": ".gitignore",
"chars": 55,
"preview": "**/.DS_Store\n**/_book/\n**/node_modules/\ndebugger101.io\n"
},
{
"path": ".vscode/bookmarks.json",
"chars": 2,
"preview": "{}"
},
{
"path": ".vscode/settings.json",
"chars": 251,
"preview": "{\n \"makefile.configureOnOpen\": false,\n \"explorer.sortOrder\": \"mixed\",\n \"files.exclude\": {\n \"**/book.en\":"
},
{
"path": "Makefile",
"chars": 1807,
"preview": "chineseWordsCnt := $(shell find book -iname \"*.md\" -print0 | grep -z -v _book | grep -z -v node_modules | wc -m --files"
},
{
"path": "README.md",
"chars": 4975,
"preview": "# The Art of Debugging: Go Debugger Internals\n\nEver wondered how to develop a Go debugger? Curious about how debuggers w"
},
{
"path": "book/10-extras/1-development-of-debugger.md",
"chars": 4340,
"preview": "## 软件调试器的发展历程\n\n### 1. 调试器诞生的问题背景\n\n软件开发从诞生之初便伴随着错误和缺陷。早期的程序员在面对程序错误时,往往依靠最原始的方法:通过打印语句输出变量值,或在关键节点插入输出语句来观察程序的执行流程。这种方法不仅"
},
{
"path": "book/10-extras/2-development-of-logging.md",
"chars": 3462,
"preview": "## 软件日志系统的发展历程\n\n### 1. 打日志诞生的问题背景\n\n软件日志系统的起源可以追溯到计算机系统诞生的早期。在计算机技术发展初期,程序员们面临着一个共同的困境:如何有效地监控和调试程序执行过程。当时的程序调试主要依靠打印语句,程"
},
{
"path": "book/10-extras/3-development-of-metrics.md",
"chars": 3915,
"preview": "## 软件监控指标系统的发展历程\n\n### 1. 监控打点诞生的问题背景\n\n在软件系统的早期发展阶段,工程师们面临着一个普遍的困境:当系统出现故障时,往往难以快速定位问题所在。这种情况就像是在黑暗中摸索,没有有效的工具来指引方向。\n\n最初的"
},
{
"path": "book/10-extras/4-development-of-tracing.md",
"chars": 3550,
"preview": "## 软件跟踪系统(Tracing)的发展历程\n\n### 1. Tracing诞生的问题背景\n\n软件跟踪系统(Tracing)的出现源于开发者面临的一个永恒挑战:如何有效地理解和排查复杂系统中的问题。在早期计算机系统中,调试主要依靠简单的日"
},
{
"path": "book/10-extras/5-development-of-bisect.md",
"chars": 27952,
"preview": "## Go编译器+运行时DEBUG:基于哈希的二分调试技术\n\n【注】本文翻译自 Russ Cox 于2024-07-18 发表的一篇文章[《Hash-Based Bisect Debugging in Compilers and Runti"
},
{
"path": "book/10-extras/6-development-of-ebpf.md",
"chars": 5837,
"preview": "## eBPF技术的发展历程与未来展望\n\n### 1. eBPF诞生的问题背景\n\n操作系统跟踪和监控一直是系统性能分析和故障排查的重要手段。在eBPF诞生之前,Linux系统中存在多种跟踪技术,但它们各自为政,缺乏统一性和灵活性:\n\n###"
},
{
"path": "book/10-extras/7-development-of-replay.md",
"chars": 4419,
"preview": "## 确定性重放解决方案的发展历程\n\n### 1. 确定性重放解决方案诞生的问题背景\n\n软件开发中,调试(Debugging)一直是开发者面临的最具挑战性的任务之一。传统调试方法如打印日志、设置断点等在处理复杂系统时显得力不从心,特别是面对"
},
{
"path": "book/10-extras/8-development-of-debug-dsys.md",
"chars": 4975,
"preview": "## 分布式系统调试的发展历程\n\n### 1. 分布式系统调试诞生的问题背景\n\n随着计算机科学的发展,单机系统逐渐无法满足高并发、高可用、大规模数据处理的需求,分布式系统应运而生。分布式系统将计算任务分散到多台计算机上,通过网络协作完成复杂"
},
{
"path": "book/10-extras/9-ai-assisted-debugging.md",
"chars": 13483,
"preview": "## Latest: AI Agent自动化调试\n\n### 思考:AI是否可以在调试领域有所作为\n\n在软件开发过程中,调试是一项耗时且重复性高的工作。传统的调试方式通常是开发者手动与调试器交互:设置断点,运行到断点,检查变量状态,决定下一步"
},
{
"path": "book/10-extras/README.md",
"chars": 9575,
"preview": "## 软件调试技术全景:工具与场景的精准适配\n\n### 引言\n\n软件调试(Debugging)是贯穿软件生命周期的重要活动,其目标可能是一个进程、一个核心转储文件、带有不同优化特性的复杂程序,一个单体服务,也可能是一个分布式系统。**调试的"
},
{
"path": "book/11-thanks/README.md",
"chars": 191,
"preview": "## 致谢\n\n一路走来,收获过成功,也遭遇过失败,感谢父母一直做我坚强的后盾,即便在未知面前,他们的鼓励也总能给我无穷的信心,让我能够走出迷雾。\n\n感谢我的妻子,容忍我在家庭生活中的偷懒,容忍我无数次放鸽子来写这些东西。没有她的包容、理解、"
},
{
"path": "book/12-appendix/1-go-programme-start.md",
"chars": 9561,
"preview": "# go runtime: go程序启动流程\n\n## go程序启动流程概览\n\n我们使用如下源程序作为示例,来看一看go程序的启动过程:\n\n**file: main.go**\n\n```go\npackage main\n\nimport \"fmt\""
},
{
"path": "book/12-appendix/2-auto-trace-cloned-threads.md",
"chars": 1381,
"preview": "## Appendix: trace newly cloned threads\n\n### how does tracer automatically trace newly cloned threads\n\nPTRACE_O_TRACECLO"
},
{
"path": "book/12-appendix/3-git-bisect.md",
"chars": 1624,
"preview": "## Appendix: 使用 git bisect 定位引入bug的commit\n\n`git bisect` 是一个非常有用的工具,用于在大型代码库中快速定位引起特定错误或功能变化的具体提交。它通过二分查找算法,将可能包含问题的提交范围逐"
},
{
"path": "book/12-appendix/4-vscode-extension-bisect.md",
"chars": 3477,
"preview": "## Appendix: 使用二分查找解决扩展问题\n\n[来源](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect \"Permalink to Resolving "
},
{
"path": "book/12-appendix/80-go-tool-compile.md",
"chars": 6936,
"preview": "## 扩展阅读:Go编译器简介\n\n`cmd/compile` 包含构成Go编译器的主要包。编译器逻辑上可分为四个阶段,我们将简要描述每个阶段,并列出包含其代码的包列表。\n\n您可能听到过\"前端(front-end)\"和\"后端(back-end"
},
{
"path": "book/12-appendix/81-go-tool-asm.md",
"chars": 3004,
"preview": "## 扩展阅读:Go汇编器简介\n\n### 1. Plan9项目和Go语言的关系\n\nPlan9是Bell实验室的一个研究性质的分布式操作系统,Go语言早期核心开发人员多来自这个项目组,他们将设计实现Plan9过程中的一些经验带到了Go语言中来"
},
{
"path": "book/12-appendix/82-go-tool-link.md",
"chars": 2216,
"preview": "## 扩展阅读:Go链接器简介\n\n### 1. Go语言链接器是什么?\n\nGo语言的链接器是Go工具链中的一个关键组成部分,负责将编译生成的目标文件(如.o文件)连接成最终的可执行文件、共享库或静态库。在Go生态系统中,链接器通常被称为`g"
},
{
"path": "book/12-appendix/90-why-buildid-loaded.md",
"chars": 9402,
"preview": "## 问题探讨:why load buildid sections\n\n### 先说点结论性的\n\n涉及到build id这个概念的sections主要有两个,.note.go.buildid,以及.note.gnu.build-id,前者就是"
},
{
"path": "book/12-appendix/91-syntax-and-semantic-analysis.md",
"chars": 1676,
"preview": "## 扩展阅读:解释下语法分析和语义分析的区别\n\n### 回顾编译过程\n\n学习过编译原理的话,编译过程包含的主要步骤,我们应该都有这方面认识。Go编译期编译过程主要包含这么几个步骤:\n\n- 词法分析(Lexical Analysis):将源"
},
{
"path": "book/12-appendix/92-why-gdb-uses-symtab.md",
"chars": 2309,
"preview": "## 扩展阅读:GDB为什么同时使用.symtab和DWARF\n\n### **GDB 使用 `.symtab` 吗?**\n\n是的,它使用,而且是作为非常基础的依赖数据在使用。\n\n### 为什么使用 `.symtab`?\n\n`.symtab`"
},
{
"path": "book/12-appendix/README.md",
"chars": 0,
"preview": ""
},
{
"path": "book/2-preface/README.md",
"chars": 520,
"preview": "# Preface\n\n2018年开始接触golang,在学习阶段通过调试器gdb、delve进行了大量调试分析,这些实践让我在理解go类型系统、标准库、运行时相关设计实现方面事半功倍。\n\n我本人好奇心比较强,喜欢刨根问底,有一天突然产生了疑"
},
{
"path": "book/3-terms/README.md",
"chars": 1738,
"preview": "# Terms\n\n在本书中,我们将介绍编译器、链接器、操作系统、调试器和调试信息标准,以及软件开发等方面的知识,使用到的术语会非常多。在此处列出常见重要术语,以便读者方便地查找。\n\n| **Term** "
},
{
"path": "book/4-basics/1-purposes.md",
"chars": 1096,
"preview": "## 4.1 调试目的\n\n尽管开发者花费了大量精力来避免自己的代码中引入bug,但是写出bug仍然是一个很平常的事情。开发人员定位代码中的问题时,通常会借助 “**走读代码**” + “**打印日志**” 的方式来理解程序执行路径、关键变量"
},
{
"path": "book/4-basics/2-dependencies.md",
"chars": 12416,
"preview": "## 4.2 依赖(支持)\n\n### 4.2.1 调试符号信息\n\n编译器、链接器根据源代码构建可执行程序,可执行程序中的数据是面向机器的,而非面向人类的。调试器如何理解可执行程序中的数据,并在机器表示和人类可读形式之间进行转换呢?这就需要调"
},
{
"path": "book/4-basics/3-countertactics.md",
"chars": 3579,
"preview": "## 4.3 反调试技术\n\n只要付出足够的时间和精力,可以说任何程序都能被逆向。调试器使得理解程序逻辑更加方便了,对心怀恶意的软件逆向人员也不例外。防人之心不可无,君子也要采取战术给软件逆向增加点难度,使恶意工程师越痛苦越好以阻止或者延缓他"
},
{
"path": "book/4-basics/README.md",
"chars": 113,
"preview": "# 调试器基础\n\n先简要介绍下调试器相关的基础知识,包括:\n\n- **目的**, 我们为什么需要一个调试器?\n- **支持**, 支持调试操作需要哪些能力的支持?\n- **安全**, 调试会带来哪些安全风险,又该如何防范?\n\n"
},
{
"path": "book/5-debugger-skeleton/1-debugger_skeleton.md",
"chars": 2554,
"preview": "## 设计一个调试器雏形\n\n调试器需要支持哪些常见操作才能满足调试需求?本节先从功能性需求、非功能性需求分析角度切入,分析下接下来的调试器开发过程中要做什么、注意些什么。\n\n本章还有个任务,要先搭建一个基础的调试器框架,方便扩展调试器命令、"
},
{
"path": "book/5-debugger-skeleton/2-debugger_solution.md",
"chars": 7025,
"preview": "## 架构设计和技术方案选择\n\n### 整体架构设计\n\n调试器应该具备良好的扩展性设计,以支持在不同应用场景中的应用,如在命令行中调试,与不同的IDE VsCode、Goland进行集成,支持远程调试。这就要求调试器必须实现 “**fron"
},
{
"path": "book/5-debugger-skeleton/3-debugger_solution_final.md",
"chars": 1905,
"preview": "## 具体的实现方案选择\n\n### 确定方案\n\n对于业界主流的调试器实现,一般都会将其分为frontend、backend,二者通过service层进行通信,gdb、delve等等,无一例外。\n\n本书提供的调试器实现,是从普及调试器设计实现"
},
{
"path": "book/5-debugger-skeleton/4-debugger_demos.md",
"chars": 8148,
"preview": "## 功能演示和实现效果\n\n结合前面的思考,我们初步实现了一个调试器的雏形 `godbg`,它大致包含了我们需要的交互能力。后面我们将在此基础上一步步实现指令级调试器、符号级调试器。\n\n先看下godbg的执行效果,然后大致介绍下源码的组织方"
},
{
"path": "book/5-debugger-skeleton/README.md",
"chars": 556,
"preview": "## 走进调试器开发\n\n从本章开始,我们正式走进调试器开发的世界。\n\n本章内容分为四个部分:\n\n- **需求分析**:从功能性需求和非功能性需求两个维度,分析现代调试器应该具备的核心能力\n- **架构设计**:介绍调试器的分层架构设计,以及"
},
{
"path": "book/6-develop-inst-debugger/1-process_start.md",
"chars": 4260,
"preview": "## 启动调试:启动进程\n\n### 实现目标:`godbg exec <prog>` 启动新进程\n\n调试器执行调试,首先得确定要调试的目标。它可能是一个进程实例,或者是一个core文件。为了便利性,调试器也可以代为执行编译操作,如 `dlv"
},
{
"path": "book/6-develop-inst-debugger/10-clearall-atexit.md",
"chars": 5320,
"preview": "## 软件动态断点:退出前清理机制\n\n### 问题背景:断点残留的危害\n\n在调试器开发过程中,我们通过ptrace系统调用对目标进程的指令进行动态修改来实现动态软件断点。具体来说,断点的添加是通过将目标地址的指令字节替换为0xCC(int3"
},
{
"path": "book/6-develop-inst-debugger/11-step.md",
"chars": 6230,
"preview": "## 执行控制:逐指令执行\n\n### 实现目标:`godbg> step` 逐指令执行\n\n在实现了反汇编以及添加移除断点功能后,我们将开始进一步探索如何控制调试进程的执行,如step逐指令执行、continue运行到断点位置,在后面符号级调"
},
{
"path": "book/6-develop-inst-debugger/12-continue.md",
"chars": 6509,
"preview": "## 执行控制:运行到下个断点\n\n### 实现目标:`godbg> continue` 运行到下个断点\n\n假定当前tracee处于被调试跟踪、暂停执行状态,如果要运行到下个断点处,应该如何做呢?detach之后,被跟踪的tracee会自动恢"
},
{
"path": "book/6-develop-inst-debugger/13-pmem.md",
"chars": 9421,
"preview": "## 查看进程状态:查看内存数据\n\n### 实现目标:`godbg> pmem` 查看内存数据\n\n这一小节,我们来实现pmem命令,方便调试进程时查看进程内存数据。\n\n### 基础知识\n\n我们知道,内存中的数据按字节编址,1字节包含8bit"
},
{
"path": "book/6-develop-inst-debugger/14-pregs.md",
"chars": 3247,
"preview": "## 查看进程状态: 查看寄存器数据\n\n### 实现目标:`godbg> pregs` 查看寄存器数据\n\n这一小节,我们来实现pregs命令,方便调试进程时查看进程寄存器数据。对于指令级调试而言,我们通过反汇编看到待执行的汇编指令,为了搞清"
},
{
"path": "book/6-develop-inst-debugger/15-set-mem.md",
"chars": 6159,
"preview": "## 修改进程状态: 修改内存数据\n\n### 实现目标: `godbg> setmem <addr> <val>` 修改内存数据\n\n添加、移除断点过程中其实也是对内存数据做修改,只不过断点操作是修改的指令数据,而我们这里强调的是对数据做修改"
},
{
"path": "book/6-develop-inst-debugger/16-set-regs.md",
"chars": 7542,
"preview": "## 修改进程状态:修改寄存器数据\n\n### 实现目标:`godbg> setreg <reg> <val>` 修改寄存器数据\n\n我们已经展示过如何读取并且修改寄存器数据了,比如continue命令执行时,如果当前PC-1处是软件断点0xC"
},
{
"path": "book/6-develop-inst-debugger/2-process_attach.md",
"chars": 20007,
"preview": "## 启动调试:跟踪进程\n\n### 实现目标:`godbg attach <pid>` 跟踪运行中进程\n\n如果进程已经在运行了,要对其进行调试需要先通过attach操作跟踪进程,待其停止执行后,再执行查看修改数据、控制程序执行的操作。常见的"
},
{
"path": "book/6-develop-inst-debugger/20-multithread/1-trace_old_threads.md",
"chars": 12236,
"preview": "## 调试多线程程序 - 跟踪已创建线程\n\n### 实现目标:枚举并跟踪已创建的线程\n\n在我们准备开始调试时,有些线程就已经被创建并在运行了,如何枚举并跟踪进程中已有的线程呢?以dlv为例,`dlv attach <pid>` 之后会立即枚"
},
{
"path": "book/6-develop-inst-debugger/20-multithread/2-trace_new_threads.md",
"chars": 18840,
"preview": "## 调试多线程程序 - 跟踪新创建线程\n\n### 实现目标:感知新线程创建并跟踪\n\n进程执行过程中有可能会创建新线程,尤其是像Go程序这样,为了充分利用多核CPU资源,会自动创建新线程来执行goroutine。当某些goroutine执行"
},
{
"path": "book/6-develop-inst-debugger/20-multithread/3-suspend_policy.md",
"chars": 6456,
"preview": "## 线程执行控制 - 挂起策略\n\n线程执行控制,指的是调试器会通过continue、step、breakpoint等命令来控制进程内线程的执行,前面我们介绍了这些命令的底层原理以及实现方式。但是这些对于多线程程序来说,还远远不够,我们还需"
},
{
"path": "book/6-develop-inst-debugger/20-multithread/4-continue.md",
"chars": 6217,
"preview": "## 线程执行控制 - continue\n\n### 实现目标:多线程环境下的continue命令\n\n前面我们已经介绍了如何跟踪进程中的已有线程,以及后续执行期间会新创建的线程。在对进程内所有已有、未来创建的线程获得了可以全部跟踪的能力之后,"
},
{
"path": "book/6-develop-inst-debugger/20-multithread/5-breakpoint.md",
"chars": 9465,
"preview": "## 线程执行控制 - breakpoint\n\n### 实现目标:多线程环境下的断点命中处理\n\n前面我们已经介绍了多线程调试中的挂起策略(3-suspend_policy.md)和continue命令的实现(4-continue.md),现"
},
{
"path": "book/6-develop-inst-debugger/20-multithread/README.md",
"chars": 872,
"preview": "## 多线程调试的挑战\n\n**前面章节介绍调试器工作原理时,用于演示调试器工作过程的测试代码,有意弱化了多线程情景带来的挑战:**\n\n- 被调试的进程往往倾向于使用单线程程序,如一个简单的单进程单线程shell命令,或者使用C程序编写的单线"
},
{
"path": "book/6-develop-inst-debugger/21-multiprocess/README.md",
"chars": 468,
"preview": "父子进程,在调试器实现过程中,跟踪父子进程和跟踪进程内的线程,实现技术上差别不大。\n\n尽管大多数调试场景中,我们更加侧重于单进程内的多线程调试部分,但是为了系统性介绍调试的方方面面,我们还是希望简单讲一下多进程调试中涉及到的一些内容.\n\n必"
},
{
"path": "book/6-develop-inst-debugger/3-process_start_attach.md",
"chars": 23845,
"preview": "## 启动调试:启动&跟踪进程\n\n### 实现目标:`godbg exec <prog>` 启动并跟踪进程\n\n#### 思考:如何让进程刚启动就停止?\n\n前面小节介绍了通过 `exec.Command(prog, args...)`来启动一"
},
{
"path": "book/6-develop-inst-debugger/4-debug-session.md",
"chars": 15216,
"preview": "## 调试会话: 交互式调试会话\n\n### 实现目标:建立交互式调试会话\n\n为了使调试过程更方便,我们需要建立一个高效便捷的交互式调试会话,在调试会话中可以输入各种调试命令 `godbg> cmd [flags] [args]`。\n\n这里有"
},
{
"path": "book/6-develop-inst-debugger/5-disassemble.md",
"chars": 10308,
"preview": "## 调试命令:`disass` 反汇编\n\n### 实现目标:`godbg> disass [address]` 实现反汇编\n\n反汇编是指令级调试过程中不可缺少的环节,对于符号级调试需要展示源码信息,对于指令级调试而言就是要展示汇编指令了。"
},
{
"path": "book/6-develop-inst-debugger/6-breakpoint.md",
"chars": 5075,
"preview": "## 软件动态断点:添加断点\n\n### 实现目标:`godbg> breakpoint [address]` 添加断点\n\n断点按照其“**生命周期**”进行分类,可以分为“**静态断点**”和“**动态断点**”。\n\n- 静态断点的生命周期"
},
{
"path": "book/6-develop-inst-debugger/7-breakpoints.md",
"chars": 4722,
"preview": "## 软件动态断点:列出断点\n\n### 实现目标:`godbg> breakpoints` 列出断点\n\n前一节中我们实现了动态断点的添加,为了能够支持移除断点,我们必须为断点提供一些描述信息,比如断点编号,这样用户可以借助断点编号来移除断点"
},
{
"path": "book/6-develop-inst-debugger/8-clear.md",
"chars": 5992,
"preview": "## 软件动态断点:移除断点\n\n### 设计目标:`godbg> clear -n [bpNo.]` 移除断点\n\n前面介绍了如何添加断点、显示断点列表,现在我们来看看如何移除断点。\n\n移除断点与新增断点,都是需要借助ptrace来实现。回想"
},
{
"path": "book/6-develop-inst-debugger/80-aslr.md",
"chars": 2794,
"preview": "## 扩展阅读:地址空间布局随机化\n\n### ASLR是什么\n\n\n\nASLR是一种操作系统级别的安全技术,主要作用是通过随机化程序在内存中的加载位置来增加攻击者预测目标地址、利用软件漏洞进行恶"
},
{
"path": "book/6-develop-inst-debugger/9-clearall.md",
"chars": 3930,
"preview": "## 软件动态断点:清空断点\n\n### 实现目标:`godbg> clearall` 清空断点\n\n`clearall`命令的功能是为了快速移除所有断点,而不用通过 `clear -n <breakNo>`逐个删除断点,适合添加了很多断点想快"
},
{
"path": "book/6-develop-inst-debugger/99-more.md",
"chars": 2494,
"preview": "## 更多关于指令级调试的内容\n\n### 简单回顾\n\n本章从零开始基于Go语言构建了一个指令级调试器,并通过详细的说明和示例进行了解释,让读者能够亲手实践并理解其中的每个细节。我们不仅提供了可以直接编译运行的测试代码,还精心设计了每一步测试"
},
{
"path": "book/6-develop-inst-debugger/README.md",
"chars": 7172,
"preview": "## 指令级调试器开发\n\n本章开始进入指令级调试器开发,我们将一步步实现指令级调试相关操作。\n\n### 指令级调试 VS. 符号级调试\n\n指令级调试是相对符号级调试而言的。它只关心机器指令级别的调试,不依赖调试符号、源程序信息。缺少了调试符"
},
{
"path": "book/7-headto-sym-debugger/1-how-go-build-works.md",
"chars": 11123,
"preview": "## How \"go build\" works\n\n### 基础知识\n\n`go build` 这个命令用于完成go程序构建,只要用过go的相信都不陌生,但大家是否有仔细去看过这条命令到底涉及到了哪些操作呢?更甚至有没有仔细看过 `go hel"
},
{
"path": "book/7-headto-sym-debugger/2-elf.md",
"chars": 17248,
"preview": "## 认识ELF文件\n\nELF ([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format)),可执行可链接格"
},
{
"path": "book/7-headto-sym-debugger/3-syms.md",
"chars": 17971,
"preview": "## 符号表和符号\n\n在 \"认识ELF文件\" 一节中,我们有介绍过ELF文件中常见的一些section及其作用,本节我们重点讲述符号表及符号。\n\n### 生成过程\n\n尽管这部分知识是非常有价值的,但是仍然难免感觉有些枯燥。OK,那我们换个讲"
},
{
"path": "book/7-headto-sym-debugger/4-syms-resolve-reloc.md",
"chars": 14064,
"preview": "## 符号解析 & 重定位\n\n前面详细介绍了符号和符号表的基础知识,这里我们继续介绍下符号解析(symbol resolution)和重定位(relocation)相关内容。\n\n### 内容概览\n\n每个可重定位目标模块m都有一个符号表,它包"
},
{
"path": "book/7-headto-sym-debugger/5-loading.md",
"chars": 5111,
"preview": "## 程序加载\n\n从我们最初编写的源程序,经过编译工具链处理后,源文件(ASCII or UTF-8编码文件)现在已经被转换为一个可执行的二进制文件,这个二进制文件包含了加载程序到内存运行所需的必要信息。前面我们提及过有些引用了动态共享库的"
},
{
"path": "book/7-headto-sym-debugger/6-gopkg-debug/1-elf.md",
"chars": 13551,
"preview": "## pkg debug/elf 应用\n\n### 数据类型及关系\n\n标准库提供了package`debug/elf`来读取、解析elf文件数据,相关的数据类型及其之间的依赖关系,如下图所示:\n\n、节头表(section header table)、常见的节(sections)的结构和作用,我们也"
},
{
"path": "book/7-headto-sym-debugger/7-headto-dwarf/1-gopkgs-about-dwarf.md",
"chars": 11388,
"preview": "## Go DWARF Support\n\n### 为什么要探讨这个问题\n\nGo编译工具链在进行编译链接时会生成DWARF调试信息,有哪些Go库可以实现对这些数据的读取呢?读取的话,针对类型、变量、常量、函数(包括参数列表、返回值)等,有没有"
},
{
"path": "book/7-headto-sym-debugger/7-headto-dwarf/2-delve-into-internals.md",
"chars": 7156,
"preview": "## 如何跟踪DWARF生成过程\n\n本章节开头我们介绍了 `go build` 执行期间实际调用的工具列表,DWARF调试信息生成逻辑是由compile、link生成的,本文介绍下编译器compile中生成DWARF调试信息的大致过程。\n\n"
},
{
"path": "book/7-headto-sym-debugger/7-headto-dwarf/3-compiler-gen-dwarfdata.md",
"chars": 15531,
"preview": "## go tool compile: DWARF调试信息生成\n\n### gc.Main()→dwarfgen.RecordFlags()\n\n**记录当前构建信息到dwarf调试信息中去,方便调试器调试时查看tracee的构建细节**\n\n`"
},
{
"path": "book/7-headto-sym-debugger/7-headto-dwarf/4-linker-gen-dwarfdata.md",
"chars": 6967,
"preview": "## go tool link: 调试信息生成\n\n### ld.Main()->dwarfGenerateDebugSyms()\n\n下面是链接器生成所有DWARF调试信息的路径,\n\nfile: cmd/link/internal/ld/ma"
},
{
"path": "book/7-headto-sym-debugger/7-headto-dwarf/5-headto-dwarf.md",
"chars": 444,
"preview": "## 可以了解DWARF了\n\n回头看下,我们的底子已经比较扎实:\n\n- 1~2章,介绍了作者分享本书内容的初衷;\n- 第3章,介绍了调试领域的专业术语;\n- 第4章,一起学习了调试相关的基础知识,目的、依赖的支持、安全为目的的反调试措施;\n"
},
{
"path": "book/7-headto-sym-debugger/7-headto-dwarf/README.md",
"chars": 787,
"preview": "## 挺近DWARF\n\n前面介绍go标准库debug/dwarf时,我们展示了几个读取DWARF中源文件、函数名、函数参数信息的示例,但是我们没有讨论 :\n\n1. 这些DWARF调试信息具体是如何生成的?\n 我们知道是编译器、链接器生成"
},
{
"path": "book/7-headto-sym-debugger/README.md",
"chars": 3222,
"preview": "## 符号级调试基础\n\n### 内容回顾\n\n前面我们介绍了指令级调试过程中对tracee的各种控制,线程跟踪、执行到断点、单步执行、读写内存、读写寄存器等等,这些也是符号级调试必备的控制能力。前面提过一个设计良好的符号级调试器至少要做到3层"
},
{
"path": "book/8-dwarf/1-history.md",
"chars": 2621,
"preview": "## 发展历史\n\nDWARF调试信息标准,主要是面向开发者的,用以指导如何生成、如何消费调试信息,具体就是编译器、链接器开发者需要参考DWARF标准来生成调试信息,而调试器开发者需要参考DWARF来消费调试信息。我们先不妨了解下DWARF调"
},
{
"path": "book/8-dwarf/2-overview.md",
"chars": 1511,
"preview": "## DWARF内容概览\n\n### 内容概览\n\n大多数现代编程语言都采用块结构:每个实体(例如,类定义或函数)都包含在另一个实体中。一个 C 程序中的每个文件可能包含多个数据定义、多个变量定义和多个函数。在每个 C 函数中,可能有几个数据定"
},
{
"path": "book/8-dwarf/3-dwarfdata.md",
"chars": 2609,
"preview": "## DWARF数据分类\n\nDWARF (Debugging With Attributed Record Formats) 使用一系列数据结构来存储调试信息,这些信息允许调试器提供源代码级别的调试体验。核心概念是 **调试信息条目 (DI"
},
{
"path": "book/8-dwarf/4-die/1-desc-data-type.md",
"chars": 10128,
"preview": "## 描述数据和类型\n\n软件调试期间,我们经常打印变量值、查看变量类型、修改变量值,如dlv的print、whatis、set操作,这些操作的实现就离不开DWARF对数据和数据类型的描述。\n\n不同的编程语言都定义了内置的数据类型,也提供了自"
},
{
"path": "book/8-dwarf/4-die/2-desc-locations.md",
"chars": 6140,
"preview": "## 位置数据\n\n调试信息必须为调试器提供一种方法,使其能够查找程序变量的位置、确定动态数组和字符串的范围,以及能找到函数栈帧的基地址或函数返回地址的方法。此外,为了满足最新的计算机体系结构和优化技术的需求,调试信息必须能够描述对象的位置,"
},
{
"path": "book/8-dwarf/4-die/3-desc-code.md",
"chars": 2956,
"preview": "## 描述可执行代码\n\n前面介绍了DIE如何描述数据和类型的,也了解了如何对数据位置进行描述,这个小节继续看下如何描述可执行代码。这部分我们主要介绍下对函数和编译单元的描述。\n\n### 描述函数\n\n不同编程语言、开发者对函数的叫法也不完全一"
},
{
"path": "book/8-dwarf/4-die/4-encoding.md",
"chars": 1315,
"preview": "## DIE数据编码\n\nDWARF中的所有调试信息条目(DIE, Debugging Information Entry),它们可以用来描述程序中的数据、类型、代码,在之前内容中我们已经见识过了描述不同类型程序构造的DIE Tags、Att"
},
{
"path": "book/8-dwarf/4-die/README.md",
"chars": 5221,
"preview": "## DIE详细介绍\n\n跟其他一些标准需要不断演进一样,DWARF也经历了DWARF v1到DWARF v5的发展阶段。随着DWARF调试信息的完善,以及高级语言进一步抽象、进化,为了更好更高效地对高级语言进行描述,DWARF标准中的Tag"
},
{
"path": "book/8-dwarf/5-other/1-accelerated-access.md",
"chars": 2936,
"preview": "## 加速访问(Accelerated Access)\n\n### 更高效地查询\n\n**按名称查找数据对象或函数**:在调试过程中,当tracee暂停执行时,调试器经常需要根据符号名称查找对应的数据对象或函数的调试信息。这些信息可能分布在当前"
},
{
"path": "book/8-dwarf/5-other/2-lineno-table.md",
"chars": 9111,
"preview": "## 行号表(Line Number Table)\n\n### 功能介绍\n\n符号级调试器需要建立源代码位置与机器指令地址之间的映射关系,有了这种映射关系,调试器就可以实现如下操作:\n\n- 将源代码位置(文件名:行号)转换为对应的机器指令地址,"
},
{
"path": "book/8-dwarf/5-other/3-callframe-info.md",
"chars": 17203,
"preview": "## 调用帧信息表(Call Frame Information)\n\n### 功能介绍\n\nDWARF调试信息中的**调用帧信息表(CFI, Call Frame Information)**是一个重要组成部分,它为调试器提供了函数调用相关的"
},
{
"path": "book/8-dwarf/5-other/4-macro-info.md",
"chars": 184,
"preview": "## 宏信息\n\n大多数调试器很难显示和调试具有宏的代码。 用户看到带有宏的原始源文件,而代码则对应于宏展开后的内容。\n\nDWARF调试信息中包含了程序中定义的宏的描述。 这是非常基本的信息,但是调试器可以使用它来显示宏的值或将宏翻译成相应的"
},
{
"path": "book/8-dwarf/5-other/5-varlen-data.md",
"chars": 2128,
"preview": "## 可变长数据\n\n在整个DWARF中有大量信息使用整数值来表示,从数据段偏移量,到数组或结构体的大小,等等。由于大多数整数值是小整数,用几位就可以表示,因此这意味着数据主要由零组成,对应的bits相当于被浪费了。\n\nDWARF定义了一个可"
},
{
"path": "book/8-dwarf/5-other/6-shrink-data.md",
"chars": 2152,
"preview": "## 压缩DWARF数据\n\n与DWARF v1相比,DWARF新版本使用的编码方案大大减少了调试信息的大小。但不幸的是,编译器生成的调试信息仍然很大,通常大于可执行代码和数据的存储占用。DWARF新版本提供了进一步减少调试数据大小的方法,比"
},
{
"path": "book/8-dwarf/5-other/7-elf-sections.md",
"chars": 1939,
"preview": "## ELF Sections\n\n虽然DWARF设计上可以与任何目标文件格式一起使用,但最经常与ELF一起使用,作者提供的示例也主要是基于Linux的。\n\nDWARF调试信息根据描述对象的不同,在最终存储的时候也进行了归类、存储到不同的se"
},
{
"path": "book/8-dwarf/5-other/README.md",
"chars": 3163,
"preview": "## 其他调试数据\n\n我们在8.3节中提到了通过DIE描述变量、数据类型、可执行代码。8.4节要描述的调试信息不是DIE能描述的,这些信息也不出现在.debug_info section中,这些信息对于符号级调试也是至关重要的。\n\n这几种重"
},
{
"path": "book/8-dwarf/6-practices.md",
"chars": 33852,
"preview": "## DWARF解析及应用\n\n前面我们系统性介绍了DWARF调试信息标准的方方面面,它是什么,由谁生成,它如何描述不同的数据、类型、函数,如何描述指令地址与源码位置的映射关系,如何展开调用栈,以及具体的设计实现,等等,可以说我们对DWARF"
},
{
"path": "book/8-dwarf/7-summary.md",
"chars": 908,
"preview": "## 本章总结\n\nDWARF的基本概念非常简单:\n\n- 程序被描述为“**DIE节点构成的树**”,以紧凑的语言和与机器无关的方式表示源码中的各种函数、数据和类型;\n- “**行号表**”提供了可执行指令地址和生成它们的源码之间的映射关系;"
},
{
"path": "book/8-dwarf/README.md",
"chars": 4298,
"preview": "## 软件调试挑战\n\n<img alt=\"dwarf-logo\" src=\"assets/dwarf-logo.svg\"/>\n\n如果能编写出保证正确运行且无需调试的程序,那将是再好不过了。但至少在实现这一目标之前,正常的编程周期仍然包括编写"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/1-现代调试器架构.md",
"chars": 10125,
"preview": "## 软件调试的挑战与现代调试器架构设计\n\n### 软件调试在真实环境中的挑战\n\n在现代软件开发与运维过程中,调试器作为定位和解决问题的核心工具,面临着诸多挑战:\n\n- **多平台兼容性**:应用程序需要在不同操作系统(如Linux、mac"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/2-前端UI层设计.md",
"chars": 11597,
"preview": "## 前端UI层设计\n\n<img alt=\"arch\" src=\"assets/debugger-arch.png\" width=\"700px\" />\n\n联想下调试器的整体架构设计,前后端分离式架构中,前端部分主要包括两部分:\n\n- UI层"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/3-Service层设计.md",
"chars": 15704,
"preview": "## Service层设计\n\n<img alt=\"arch\" src=\"assets/debugger-arch.png\" width=\"700px\" />\n\n调试器前后端分离式架构,调试器的前端和后端需要通过service层进行通信。尽管"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/4-后端符号层设计.md",
"chars": 24521,
"preview": "## 后端符号层设计\n\n<img alt=\"arch\" src=\"assets/debugger-arch.png\" width=\"700px\" />\n\n本节我们来介绍下调试器后端的符号层设计,这里的符号层指的就是利用DWARF调试信息建立"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/5-后端目标层设计.md",
"chars": 2445,
"preview": "## 后端目标层设计\n\n<img alt=\"arch\" src=\"assets/debugger-arch.png\" width=\"700px\" />\n\n调试器后端目标层是调试器架构中最底层的一层,它直接与被调试进程(tracee)交互,负"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/6-日志系统设计.md",
"chars": 1698,
"preview": "## tinydbg 日志系统设计\n\n### 多层次的调试器与日志挑战\n\n现代调试器是一个复杂的系统,通常包含多个层次和组件,如核心调试引擎、RPC通信层、函数调用处理、堆栈跟踪等。在这种复杂的系统中,如果没有一个精心设计的日志系统,将会导"
},
{
"path": "book/9-develop-sym-debugger/1-架构设计/README.md",
"chars": 575,
"preview": "## 架构设计\n\n本章开头,我们介绍了调试器在软件开发全生命周期中的必要性,这一节我们将来分析在真实的开发、测试、线上环境中软件调试面临的诸多挑战,包括多平台兼容性、远程调试、安全隔离、性能影响等等。\n\n为了应对这些挑战,现代调试器普遍采用"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/00-cmds.md",
"chars": 15593,
"preview": "## 核心调试命令\n\n在第5章《调试器概貌》我们分析了下调试器的功能性需求、非功能性需求、大致的实现方案,第6章紧跟着介绍了指令级调试器的设计实现,第7章介绍了与调试器写作紧密相关的ELF文件格式、编译器、链接器、加载器的工作原理以及调试信"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/01-debug-session.md",
"chars": 25027,
"preview": "## Debug Session\n\n### 实现目标\n\n后面的attach、exec、debug、core、connect,这几个命令本质上都是启动一个debugger backend,然后让debugger frontend和debugg"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/100-debug_goroutines.md",
"chars": 564,
"preview": "go语言既然是面向协程的,我们的调试器就应该提供协程级的调试控制能力,比如切换到g1去执行并调试,或者切换到g2去执行并调试。这个功能在多线程调试中是很常见的,比如eclipse里面调试java多线程程序时,我们可以暂停其他线程只调试一个线"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/100-how_listfunctions_work.md",
"chars": 5898,
"preview": "## ListFunctions\n\n### 实现目标\n\n`ListFunctions`是tinydbg中的一个强大功能,它允许用户列出目标进程中定义的函数列表,也允许按照正则表达式的方式查询满足条件的函数列表。\n\n`funcs <expr>"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/100-multi-threads.md",
"chars": 157,
"preview": "多线程调试的问题,前面已经提到过,对go程序而言,我们关注的是:\n\n- 区分go中哪些线程可以trace、哪些不可以trace\n- 可以trace的多个线程,如何自动trace\n- GPM模型中,如果因为ptrace挂起了一个线"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/11-tinydbg_attach.md",
"chars": 18591,
"preview": "## Attach\n\n### 实现目标:`tinydbg attach <pid>`\n\n本节介绍attach这个启动调试的命令:`tinydbg attach <pid> [executable] [flags]`,attach操作将挂住目"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/12-tinydbg_attach_waitfor.md",
"chars": 3948,
"preview": "## Attach WaitFor 工作原理\n\n### 简介\n\n在调试进程时,我们经常需要等待目标进程启动后再附加调试器。`waitfor` 机制提供了一种灵活的方式来等待进程启动,它通过匹配进程名称前缀来实现。本文将详细解释这个功能在调试"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/13-tinydbg_exec.md",
"chars": 6039,
"preview": "## Exec\n\n### 实现目标: `tinydbg exec ./prog`\n\n本节介绍exec这个启动调试的命令:`tinydbg exec [executable] [flags]`,exec操作将执行executable对自动at"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/14-tinydbg_debug.md",
"chars": 5071,
"preview": "## Debug\n\n### 实现目标: `tinydbg debug ./path-to`\n\nattach操作是对一个已经运行的程序进行调试,或者--waitfor等待一个程序运行起来后进行调试。exec是对一个已经编译构建好的go可执行程"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/15-tinydbg_core1.md",
"chars": 18539,
"preview": "## Core (Part1): ELF核心转储文件剖析\n\n可执行与可链接格式(ELF) 🧝 用于编译输出(`.o`文件)、可执行文件、共享库和核心转储文件。前几种用途在[System V ABI规范](http://www.sco.com"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/15-tinydbg_core2.md",
"chars": 22198,
"preview": "## Core (Part2): 生成Core+调试Core\n\n### 实现目标: `tinydbg core [corefile]`\n\n本节我们介绍根据core文件进行调试 `tinydbg core [corefile]`,通常情况下c"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/16-tinydbg_connect.md",
"chars": 4112,
"preview": "## Connect\n\n### 实现目标: `tinydbg connect <addr>`\n\n在远程调试模式下,connect命令用来连接一个调试器后端,完成网络通信层的初始化,然后初始化一个前端调试会话,开发者即可交互式地进行调试了。\n"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/17-tinydbg_trace.md",
"chars": 10367,
"preview": "## Trace\n\n### 实现目标\n\ntrace命令用于对go进程中的特定函数调用进行跟踪,适合性能分析、异常检测和安全审计等场景。\n\n本节介绍 `trace` 命令的实现,它能够对某个package下的函数名匹配regexp的函数进行跟"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/19-how_evalexpr_works.md",
"chars": 25621,
"preview": "## 支持表达式计算\n\n### 实现目标:理解并实现表达式计算 evalexpr\n\n调试器调试过程中,我们经常会输入调试命令,有些调试命令允许输入一些表达式,比如 `print 1+2`, `print a+b`,`break 20`,`b"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/20-how_locspec_works.md",
"chars": 14958,
"preview": "## locspec解析与地址转换\n\n符号级调试器和指令级调试器相比,最明显的不同之一就是我们可以使用字符串来表示位置信息,如添加断点时、反汇编时可以使用\"文件名:行号\"、\"函数名\"来表示目标地址。为了调试时更加便利,我们需要设计一些大家常"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/21-debug_disassemble.md",
"chars": 24667,
"preview": "## Disassemble\n\n这一节我们先介绍这个命令分组中的第一各命令 `disassemble` 的设计及实现。\n\n```bash\n(tinydbg) help\n...\nViewing source and disassembly, "
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/22-debug_breakpoint_part1.md",
"chars": 18464,
"preview": "## Breakpoint part1: 现代调试器断点精细化管理\n\n### 前言\n\n断点是调试器能力的核心功能之一,在介绍指令级调试器时,我们详细介绍过断点的底层工作原理。如果你忘记了指令0xCC的作用,忘记了 `ptrace(PTRAC"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/23-debug_breakpoint_part2.md",
"chars": 28862,
"preview": "## Breakpoint - part2: 添加断点+执行到断点\n\n前一小节我们深入介绍了现代调试器断点精细化管理面临的挑战以及解决办法,本节我们从实现角度出发,来看一看tinydbg是如何实现常用断点操作的,以及执行到断点之后的处理。\n"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/24-debug_breakpoint_part3.md",
"chars": 63,
"preview": "## Condition\n\n### 实现目标\n\n### 基础知识\n\n### 代码实现\n\n### 执行测试\n\n### 本节小结\n"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/25-debug_breakpoint_part4.md",
"chars": 17425,
"preview": "## Breakpoint - part4: 其他调试命令\n\n前一小节我们深入介绍了现代调试器断点精细化管理面临的挑战以及解决办法,本节我们从实现角度出发,来看一看tinydbg是如何实现常用断点操作的。\n\n### 实现目标: `break"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/26-debug_trace.md",
"chars": 62,
"preview": "## trace\n\ntrace,在指定位置设置tracepoint,本质上还是断点,命中后并打印相关位置信息,然后恢复执行;"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/27-debug_watch.md",
"chars": 8494,
"preview": "## watchpoint\n\nwatch,监视对某个变量或者内存地址处的读写操作,是借助硬件断点对特定地址的数据读写、指令执行来实现的;\n\n本文我们介绍下watchpoint的设计及实现,详细解释一下watchpoint的实现原理,以及它与"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/28-debug_continue.md",
"chars": 79,
"preview": "continue,运行到下一个断点处,这个也是无需调整的,其内部实现逻辑都是利用断点0xcc来停下来,没什么需要调整的。\n\n\n\nTODO 任务优先级:无需调整"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/29-debug_next.md",
"chars": 70,
"preview": "step本身是利用了处理器的step步进执行模式,对指令级调试器和符号级调试器都是一样的,无需进行调整。\n\n\n\nTODO 任务:无需进行调整"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/30-debug_step.md",
"chars": 70,
"preview": "step本身是利用了处理器的step步进执行模式,对指令级调试器和符号级调试器都是一样的,无需进行调整。\n\n\n\nTODO 任务:无需进行调整"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/31-debug_pmem.md",
"chars": 70,
"preview": "pmem,是打印内存原始数据用的,无需进行调整\n\n\n\n我们将增加新的调试命令来支持打印变量信息(print|p)。\n\n\n\nTODO 无需调整"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/32-debug_regs.md",
"chars": 33,
"preview": "本身就是查看寄存器数据的,无需进行调整\n\nTODO 任务:无需调整"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/33-debug_funcs.md",
"chars": 2790,
"preview": "## godbg> funcs `<regexp>`\n\n### 实现目标\n\n前面一节介绍了调试器后端ListFunctions的实现,这一小节介绍下在此基础上 `godbg> funcs <expr>` 的实现。\n\n### 基础知识\n\n前面"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/34-debug_vars.md",
"chars": 486,
"preview": "打印变量,以print name为例,这里首先需要检查所有的DIE,找到name对应的DIE,然后找到对应的Type DIE,然后再结合name变量值在内存中的地址,结合这里的Type DIE的描述信息来读取并理解内存中的数据。这样就完成了"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/35-debug_bt.md",
"chars": 251,
"preview": "需要新增加一个调试命令backtrack|bt,这个命令将打印当前函数所处的调用栈信息。前面简单介绍过如何读取.[z]debug_frame信息并用来查看指定pc对应的FDE,以及当下的CFA计算计算规则等,要实现这个bt特性,只需要了解下"
},
{
"path": "book/9-develop-sym-debugger/2-核心调试逻辑/README.md",
"chars": 391,
"preview": "## 核心调试逻辑\n\n接下来,我们将开发一个面向Go语言的符号级调试器,它除了具备前面介绍过的基础的指令级调试能力,也会支持源码级别的调试,同时也会根据Go的语言特性来提供一些更友好易用的调试能力,如支持协程级别(而非线程级别)的断点能力,"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/100-howto_integrate_starlark.md",
"chars": 11793,
"preview": "## 扩展阅读:starlark让你的程序更强大\n\nstarlark是一门配置语言,它是从Python语言中衍生出来的,但是比Python更简单、更安全。它最初是由Google开发的,用于Bazel构建系统。starlark保留了Pytho"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/101-howto_tracing_via_ebpf.md",
"chars": 2758,
"preview": "## 扩展阅读:breakpoint-based vs. eBPF-based tracing\n\n在程序调试和性能分析中,跟踪(tracing)是一项非常重要的技术。目前主要有两种实现方案:基于断点(breakpoint-based)和基于"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/102-howto_syntax_highlight.md",
"chars": 11373,
"preview": "## 语法高亮\n\n软件开发过程中对源代码进行语法高亮是非常有必要的,通过这种方式可以将程序中不同的要素进行有效地区分,如关键字、保留字、标识符、括号匹配、注释、字符串等等。开发人员使用的IDE一般都支持语法高亮,在vscode中通过gopl"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/103-howto_paging_output.md",
"chars": 1770,
"preview": "## 分页输出的设计与实现\n\n### 功能概述\n\n分页输出(Paging Output)是调试器中的一个重要功能,它能够智能地处理大量输出内容,通过分页器(如 less、more 等)来展示输出,提升用户体验。这个功能在查看大量调试信息、堆"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/104-howto_read_separate_dwarfdata.md",
"chars": 2171,
"preview": "# 分离式DWARF数据的工作原理\n\n## 概述\n\nDWARF(Debugging With Attributed Record Formats)是一种广泛使用的调试数据格式,它提供了关于程序结构、变量和执行流程的详细信息。在Linux/A"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/105-howto_guess_substitutepath.md",
"chars": 1829,
"preview": "## Guess SubstitutePath Automatically\n\n在调试过程中,源代码路径映射是一个重要的问题。本文详细解释 Delve 调试器中的 substitutePath 功能是如何工作的。\n\n### 路径映射的挑战\n\n"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/106-howto_redirect_target_io.md",
"chars": 4171,
"preview": "## 进程IO重定向\n\n### 为什么需要支持输入输出重定向?\n\n在调试程序时,控制程序的输入输出流是非常必要的,原因如下:\n\n1. **交互式程序**:许多程序需要用户交互输入。如果没有适当的重定向支持,调试这类程序将会变得困难或不可能。"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/107-howto_customize_tinydbg.md",
"chars": 2922,
"preview": "## tinydbg 配置系统设计实现\n\ntinydbg 提供了一个灵活的配置系统,允许用户根据自己的使用习惯自定义调试器的行为。本文将详细介绍配置系统的设计实现。\n\n### 配置命令使用\n\ntinydbg 提供了以下配置命令:\n\n1. `"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/108-howto_accept_multiclient.md",
"chars": 2361,
"preview": "## acceptMulti 模式的工作原理\n\n### 为什么要支持多客户端调试\n\n在社区讨论如何解决这个问题 [Extend Delve backend RPC API to be able to make a Delve REPL fr"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/109-howto_transcript_debugging.md",
"chars": 2473,
"preview": "## transcript 设计与实现\n\n### 调试记录本\n\n大家在执行Linux命令时,为了记录刚才一系列操作中执行的命令,以及命令的输出,通常我们会使用 `script` 命令来完成这个事情。系统学习过Linux命令行操作的读者,对此"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/110-howto_debug_deterministically.md",
"chars": 2986,
"preview": "## 如何实现确定性调试\n\n### 1. 问题背景\n\n#### 1.1 Bug并不总是可以稳定复现\n\n在软件开发和测试过程中,我们经常遇到一些难以稳定复现的bug。以软件测试中的flaky tests为例,如果我们有沉淀测试用例,团队也有例"
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/111-howto-integrate-with-rr.md",
"chars": 0,
"preview": ""
},
{
"path": "book/9-develop-sym-debugger/3-高级功能扩展/README.md",
"chars": 425,
"preview": "## 高级功能扩展\n\n在前面的章节中,我们详细介绍了调试器的核心功能设计与实现,包括进程控制、断点管理、调用栈分析等基础特性。这些功能构成了一个调试器的核心框架。\n\n然而,要打造一个真正实用的调试器,仅有这些基础功能是不够的。还有许多细节特"
},
{
"path": "book/9-develop-sym-debugger/README.md",
"chars": 817,
"preview": "## 调试器:开发者的得力助手\n\n### 无法避免的bug\n\n从打孔卡片时代开始,到机器指令、汇编语言,再到现在五花八门的高级编程语言,编程语言的表达能力和易用性不断提升,编译器和静态分析工具也日益完善,开发人员对计算机系统的理解也越来越深"
},
{
"path": "book/README.md",
"chars": 5646,
"preview": "# 1 软件调试的艺术:Go语言调试器设计实现内幕\n\n<img alt=\"封面图片\" src=\"bookcover.jpeg\" width=\"320px\" />\n\n## 1.1 作者简介\n\n大家好,我是张杰,目前担任腾讯(深圳)科技有限公司"
},
{
"path": "book/SUMMARY.md",
"chars": 9859,
"preview": "# Summary\n\n* [1 介绍](README.md)\n* [2 前言](2-preface/README.md)\n* [3 常用术语](3-terms/README.md)\n* [4 软件调试基础](4-basics/README."
},
{
"path": "book/book.json",
"chars": 654,
"preview": "{\n \"plugins\": [\n \"numbered-headings\",\n \"github\",\n \"intopic-toc\",\n \"splitter\",\n \"-lunr\",\n "
},
{
"path": "changelog.md",
"chars": 952,
"preview": "## 项目进度\n\n- ~ - 2018.11.30 完成Linux平台调试器开发\n- ~ - 2018.12.31 完成调试器开发文档撰写\n- ~ - 2019.01.31 完成《从0开发go调试器》相关章节\n- ~ - 2019.02.2"
},
{
"path": "contributing.md",
"chars": 1118,
"preview": "# Contributing Guide\n\n# introduction\n\n# golang-debugger\n\nThis project aims at describing how to develop a (symbolic) gol"
},
{
"path": "contributing.zh_CN.md",
"chars": 1477,
"preview": "# Contributing Guide\n\n# 写在开头\n\n# golang-debugger\n\n该项目“**golang debugger**”,是一款面向go语言的调试器,现在业界已经有针对go语言的调试器了,如gdb、dlv等等,那么"
},
{
"path": "deploy.sh",
"chars": 1062,
"preview": "#!/bin/bash -e\n\n# repository to fetch book content\ndeploy=https://github.com/hitzhangjie/debugger101.io\n\n# build the boo"
}
]
About this extraction
This page contains the full source code of the hitzhangjie/golang-debugger-book GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 165 files (1.0 MB), approximately 452.2k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.