Showing preview only (598K chars total). Download the full file or copy to clipboard to get everything.
Repository: hollischuang/toBeTopJavaer
Branch: master
Commit: 4173f8a806c1
Files: 203
Total size: 547.0 KB
Directory structure:
gitextract_5tnf3xan/
├── .gitattributes
├── .gitignore
├── README.md
├── docs/
│ ├── .nojekyll
│ ├── README.md
│ ├── _coverpage.md
│ ├── _sidebar.md
│ ├── advance/
│ │ └── design-patterns/
│ │ ├── abstract-factory-pattern.md
│ │ ├── adapter-pattern.md
│ │ ├── builder-pattern.md
│ │ ├── factory-method-pattern.md
│ │ ├── iterator-pattern.md
│ │ ├── singleton-pattern.md
│ │ └── strategy-pattern.md
│ ├── basement/
│ │ └── jvm/
│ │ ├── break-parants-delegate.md
│ │ ├── define-class-loader.md
│ │ ├── exclusive-in-runtime-area.md
│ │ ├── implements-of-parents-delegate.md
│ │ ├── java-memory-model.md
│ │ ├── moduler.md
│ │ ├── parents-delegate.md
│ │ ├── relation-with-parents-delegate.md
│ │ ├── runtime-area.md
│ │ ├── sample-of-break-parents-delegate.md
│ │ ├── spi-parents-delegate.md
│ │ ├── stack-alloc.md
│ │ ├── tomcat-parents-delegate.md
│ │ └── why-parents-delegate.md
│ ├── basics/
│ │ ├── concurrent-coding/
│ │ │ ├── concurrent-vs-parallel.md
│ │ │ ├── concurrent.md
│ │ │ ├── create-thread-with-Implement.md
│ │ │ ├── create-thread-with-callback-future-task.md
│ │ │ ├── create-thread-with-extends.md
│ │ │ ├── create-thread-with-thead-pool.md
│ │ │ ├── deadlock-java-level.md
│ │ │ ├── deamon-thread.md
│ │ │ ├── debug-in-multithread.md
│ │ │ ├── implement-of-thread.md
│ │ │ ├── parallel.md
│ │ │ ├── priority-of-thread.md
│ │ │ ├── progress-vs-thread.md
│ │ │ ├── state-of-thread.md
│ │ │ ├── synchronized.md
│ │ │ ├── thread-safe.md
│ │ │ ├── thread-scheduling.md
│ │ │ ├── thread.md
│ │ │ ├── volatile.md
│ │ │ └── why-not-executors.md
│ │ ├── java-basic/
│ │ │ ├── ASCII.md
│ │ │ ├── Arrays-asList.md
│ │ │ ├── CET-UTC-GMT-CST.md
│ │ │ ├── Class.md
│ │ │ ├── Collection-vs-Collections.md
│ │ │ ├── ConcurrentSkipListMap.md
│ │ │ ├── CopyOnWriteArrayList.md
│ │ │ ├── Enumeration-vs-Iterator.md
│ │ │ ├── GMT.md
│ │ │ ├── HashMap-HashTable-ConcurrentHashMap.md
│ │ │ ├── README.md
│ │ │ ├── Runtime-Constant-Pool.md
│ │ │ ├── StandardTime-vs-daylightSavingTime.md
│ │ │ ├── UNICODE.md
│ │ │ ├── UTF8-UTF16-UTF32.md
│ │ │ ├── Wildcard-Character.md
│ │ │ ├── YYYY-vs-yyyy.md
│ │ │ ├── annotation-in-java.md
│ │ │ ├── annotation-in-spring.md
│ │ │ ├── annotion-and-reflect.md
│ │ │ ├── aop-vs-proxy.md
│ │ │ ├── apache-collections.md
│ │ │ ├── api-vs-spi.md
│ │ │ ├── arraylist-vs-linkedlist-vs-vector.md
│ │ │ ├── basic-data-types.md
│ │ │ ├── big-endian-vs-little-endian.md
│ │ │ ├── bio-vs-nio-vs-aio.md
│ │ │ ├── block-vs-non-blocking.md
│ │ │ ├── boxing-unboxing.md
│ │ │ ├── bug-in-apache-commons-collections.md
│ │ │ ├── bug-in-fastjson.md
│ │ │ ├── byte-stream-vs-character-stream.md
│ │ │ ├── class-contant-pool.md
│ │ │ ├── const-in-java.md
│ │ │ ├── convert-bytestream-characterstream.md
│ │ │ ├── create-annotation.md
│ │ │ ├── create-spi.md
│ │ │ ├── custom-annotation.md
│ │ │ ├── define-exception.md
│ │ │ ├── delete-while-iterator.md
│ │ │ ├── diff-serializable-vs-externalizable.md
│ │ │ ├── dynamic-proxy-implementation.md
│ │ │ ├── dynamic-proxy-vs-reflection.md
│ │ │ ├── dynamic-proxy.md
│ │ │ ├── enum-class.md
│ │ │ ├── enum-compare.md
│ │ │ ├── enum-impl.md
│ │ │ ├── enum-serializable.md
│ │ │ ├── enum-singleton.md
│ │ │ ├── enum-switch.md
│ │ │ ├── enum-thread-safe.md
│ │ │ ├── enum-usage.md
│ │ │ ├── error-vs-exception.md
│ │ │ ├── exception-chain.md
│ │ │ ├── exception-type.md
│ │ │ ├── extends-vs-super.md
│ │ │ ├── fail-fast-vs-fail-safe.md
│ │ │ ├── final-in-java.md
│ │ │ ├── final-string.md
│ │ │ ├── float-amount.md
│ │ │ ├── float.md
│ │ │ ├── gbk-gb2312-gb18030.md
│ │ │ ├── genericity-list-wildcard.md
│ │ │ ├── genericity-list.md
│ │ │ ├── generics-problem.md
│ │ │ ├── generics.md
│ │ │ ├── get-los_angeles-time.md
│ │ │ ├── h2-db.md
│ │ │ ├── handle-exception.md
│ │ │ ├── hash-in-hashmap.md
│ │ │ ├── hashmap-capacity.md
│ │ │ ├── hashmap-default-capacity.md
│ │ │ ├── hashmap-default-loadfactor.md
│ │ │ ├── hashmap-init-capacity.md
│ │ │ ├── input-stream-vs-output-stream.md
│ │ │ ├── instanceof-in-java.md
│ │ │ ├── integer-cache.md
│ │ │ ├── integer-scope.md
│ │ │ ├── intern.md
│ │ │ ├── ioc-implement-with-factory-and-reflection.md
│ │ │ ├── iteration-of-collection.md
│ │ │ ├── jms.md
│ │ │ ├── junit.md
│ │ │ ├── k-t-v-e.md
│ │ │ ├── keyword-about-exception.md
│ │ │ ├── lambda.md
│ │ │ ├── length-of-string.md
│ │ │ ├── linux-io.md
│ │ │ ├── meta-annotation.md
│ │ │ ├── mock.md
│ │ │ ├── netty.md
│ │ │ ├── order-about-finllly-return.md
│ │ │ ├── protobuf.md
│ │ │ ├── reflection.md
│ │ │ ├── replace-in-string.md
│ │ │ ├── serialVersionUID-modify.md
│ │ │ ├── serialVersionUID.md
│ │ │ ├── serialize-in-java.md
│ │ │ ├── serialize-principle.md
│ │ │ ├── serialize-singleton.md
│ │ │ ├── serialize.md
│ │ │ ├── set-repetition.md
│ │ │ ├── set-vs-list.md
│ │ │ ├── simpledateformat-thread-safe.md
│ │ │ ├── single-double-float.md
│ │ │ ├── spi-principle.md
│ │ │ ├── stack-alloc.md
│ │ │ ├── static-in-java.md
│ │ │ ├── static-proxy.md
│ │ │ ├── stop-create-bigdecimal-with-double.md
│ │ │ ├── stop-use-enum-in-api.md
│ │ │ ├── stop-using-equlas-in-bigdecimal.md
│ │ │ ├── stream.md
│ │ │ ├── string-append.md
│ │ │ ├── string-concat.md
│ │ │ ├── string-pool.md
│ │ │ ├── stringjoiner-in-java8.md
│ │ │ ├── substring.md
│ │ │ ├── success-isSuccess-and-boolean-Boolean.md
│ │ │ ├── switch-string.md
│ │ │ ├── synchronized-vs-asynchronization.md
│ │ │ ├── synchronizedlist-vector.md
│ │ │ ├── syntactic-sugar.md
│ │ │ ├── time-in-java8.md
│ │ │ ├── time-zone.md
│ │ │ ├── timestamp.md
│ │ │ ├── transient-in-java.md
│ │ │ ├── try-with-resources.md
│ │ │ ├── type-erasure.md
│ │ │ ├── url-encode.md
│ │ │ ├── usage-of-reflection.md
│ │ │ ├── ut-with-jmockit.md
│ │ │ ├── value-of-vs-to-string.md
│ │ │ ├── why-gbk.md
│ │ │ ├── why-transient-in-arraylist.md
│ │ │ └── why-utf8.md
│ │ └── object-oriented/
│ │ ├── characteristics.md
│ │ ├── constructor.md
│ │ ├── extends-implement.md
│ │ ├── inheritance-composition.md
│ │ ├── java-pass-by.md
│ │ ├── jvm-language.md
│ │ ├── multiple-inheritance.md
│ │ ├── object-oriented-vs-procedure-oriented.md
│ │ ├── overloading-vs-overriding.md
│ │ ├── platform-independent.md
│ │ ├── polymorphism.md
│ │ ├── principle.md
│ │ ├── scope.md
│ │ ├── variable.md
│ │ └── why-pass-by-reference.md
│ ├── css/
│ │ └── my.css
│ ├── index.html
│ └── menu.md
└── mind-map.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
* text=auto
*.js linguist-language=java
*.css linguist-language=java
*.html linguist-language=java
*.md linguist-language=java
================================================
FILE: .gitignore
================================================
# Created by .ignore support plugin (hsz.mobi)
### JetBrains template
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
# User-specific stuff
.idea/**/workspace.xml
.idea/**/tasks.xml
.idea/**/dictionaries
.idea/**/shelf
.idea/**/common_info.xml
.idea/**
# Sensitive or high-churn files
.idea/**/dataSources/
.idea/**/dataSources.ids
.idea/**/dataSources.local.xml
.idea/**/sqlDataSources.xml
.idea/**/dynamic.xml
.idea/**/uiDesigner.xml
.idea/**/dbnavigator.xml
# Gradle
.idea/**/gradle.xml
.idea/**/libraries
# CMake
cmake-build-debug/
cmake-build-release/
# Mongo Explorer plugin
.idea/**/mongoSettings.xml
# File-based project format
*.iws
# IntelliJ
out/
# mpeltonen/sbt-idea plugin
.idea_modules/
# JIRA plugin
atlassian-ide-plugin.xml
# Cursive Clojure plugin
.idea/replstate.xml
# Crashlytics plugin (for Android Studio and IntelliJ)
com_crashlytics_export_strings.xml
crashlytics.properties
crashlytics-build.properties
fabric.properties
# Editor-based Rest Client
.idea/httpRequests
.DS_Store
================================================
FILE: README.md
================================================
## To Be Top Javaer - Java工程师成神之路
  
| 主要版本 | 更新时间 | 备注 |
| ---- | ---------- | -------------- |
| v4.0 | 2022-05-20 | 知识体系完善,知识点补充|
| v3.0 | 2020-03-31 | 知识体系完善,在v2.0的基础上,新增20%左右的知识点<br>调整部分知识的顺序及结构,方便阅读和理解<br>通过GitHub Page搭建,便于阅读|
| v2.0 | 2019-02-19 | 结构调整,更适合从入门到精通;<br>进一步完善知识体系; <br>新技术补充;|
| v1.1 | 2018-03-12 | 增加新技术知识、完善知识体系 |
| v1.0 | 2015-08-01 | 首次发布 |
Java成神之路全套面试题——围绕成神之路,500多道题,60多万字>>>

扫码下单后,按照短信提示操作即可。
目前正在更新中...
欢迎大家参与共建~
### 联系我们
欢迎关注作者的公众号,可以直接后台留言。

*公众号后台回复:"成神导图",即可获取《Java工程师成神之路最新版思维导图》*
### 在线阅读地址
GitHub Pages 完整阅读:[进入](https://hollischuang.github.io/toBeTopJavaer/)
Gitee Pages 完整阅读:[进入](http://hollischuang.gitee.io/tobetopjavaer) (国内访问速度较快)
### 关于作者
Hollis,阿里巴巴技术专家,51CTO专栏作家,CSDN博客专家,掘金优秀作者,《深入理解Java核心技术》作者,《程序员的三门课》联合作者,《Java工程师成神之路》系列文章作者;热衷于分享计算机编程相关技术,博文全网阅读量上千万。
### 开源协议
本着互联网的开放精神,本项目采用开放的[GPL]协议进行许可。
### 参与共建
如果您对本项目中的内容有建议或者意见
如果你对本项目中未完成的章节感兴趣
欢迎提出专业方面的修改建议及供稿,供稿只接受原创
请直接在[GitHub](https://github.com/hollischuang/toBeTopJavaer)上以issue或者PR的形式提出
如果本项目中的内容侵犯了您的任何权益,欢迎通过邮箱(hollischuang@gmail)与我联系
================================================
FILE: docs/.nojekyll
================================================
================================================
FILE: docs/README.md
================================================
## To Be Top Javaer - Java工程师成神之路
  
成神之路系列丛书的第一本《深入理解Java核心技术(基础篇)》已经正式出版了,这本书囊括了<Java工程师成神之路>中基础篇的几乎全部内容,欢迎大家购买品鉴。

| 主要版本 | 更新时间 | 备注 |
| ---- | ---------- | -------------- |
| v4.0 | 2022-05-20 | 知识体系完善,知识点补充|
| v3.0 | 2020-03-31 | 知识体系完善,在v2.0的基础上,新增20%左右的知识点<br>调整部分知识的顺序及结构,方便阅读和理解<br>通过GitHub Page搭建,便于阅读|
| v2.0 | 2019-02-19 | 结构调整,更适合从入门到精通;<br>进一步完善知识体系; <br>新技术补充;|
| v1.1 | 2018-03-12 | 增加新技术知识、完善知识体系 |
| v1.0 | 2015-08-01 | 首次发布 |
目前正在更新中...
欢迎大家参与共建~
### 联系我们
欢迎关注作者的公众号,可以直接后台留言。

*公众号后台回复:"成神导图",即可获取《Java工程师成神之路最新版思维导图》*
### 关于作者
Hollis,阿里巴巴技术专家,51CTO专栏作家,CSDN博客专家,掘金优秀作者,《程序员的三门课》联合作者,《Java工程师成神之路》系列文章作者;热衷于分享计算机编程相关技术,博文全网阅读量上千万。
### 开源协议
本着互联网的开放精神,本项目采用开放的[GPL]协议进行许可。
### 参与共建
如果您对本项目中的内容有建议或者意见
如果你对本项目中未完成的章节感兴趣
欢迎提出专业方面的修改建议及供稿,供稿只接受原创
请直接在[GitHub](https://github.com/hollischuang/toBeTopJavaer)上以issue或者PR的形式提出
如果本项目中的内容侵犯了您的任何权益,欢迎通过邮箱(hollischuang@gmail)与我联系
### 在线阅读地址
GitHub Pages 完整阅读:[进入](https://hollischuang.github.io/toBeTopJavaer/)
Gitee Pages 完整阅读:[进入](http://hollischuang.gitee.io/tobetopjavaer) (国内访问速度较快)
### <a href="#/menu?id=目录">开始阅读</a></p></div><div class="mask"></div></section>
================================================
FILE: docs/_coverpage.md
================================================
<div class="cover-main"><img width="180px" src="icon/icon.JPG">
<h1 id="toBeTopJavaer">
<a><span>To Be Top Javaer - Java工程师成神之路</span></a></h1>
  
<span id="busuanzi_container_site_pv" style="display: inline;">
👁️本页总访问次数:<span id="busuanzi_value_site_pv"></span>
</span>
<span id="busuanzi_container_site_uv" style="display: inline;">
| 🧑总访客数: <span id="busuanzi_value_site_uv"></span>
</span>
<a href="#/menu">开始阅读</a></p></div><div class="mask"></div></section>
================================================
FILE: docs/_sidebar.md
================================================
* 基础篇
* 面向对象
* 什么是面向对象
* [面向对象与面向过程](/basics/object-oriented/object-oriented-vs-procedure-oriented.md)
* [面向对象的三大基本特征](/basics/object-oriented/characteristics.md)
* [面向对象的五大基本原则](/basics/object-oriented/principle.md)
* 封装、继承、多态
* [什么是多态](/basics/object-oriented/polymorphism.md)
* [方法重写与重载](/basics/object-oriented/overloading-vs-overriding.md)
* [Java的继承与实现](/basics/object-oriented/extends-implement.md)
* [Java为什么不支持多继承](/basics/object-oriented/multiple-inheritance.md)
* [Java的继承与组合](/basics/object-oriented/inheritance-composition.md)
* [构造函数与默认构造函数](/basics/object-oriented/constructor.md)
* [类变量、成员变量和局部变量](/basics/object-oriented/variable.md)
* [成员变量和方法作用域](/basics/object-oriented/scope.md)
* 平台无关性
* [Java如何实现的平台无关性的](/basics/object-oriented/platform-independent.md)
* [JVM还支持哪些语言](/basics/object-oriented/jvm-language.md)
* 值传递
* [值传递、引用传递](/basics/object-oriented/java-pass-by.md)
* [为什么说Java中只有值传递](/basics/object-oriented/why-pass-by-reference.md)
* Java基础知识
* 基本数据类型
* [8种基本数据类型](/basics/java-basic/basic-data-types.md)
* [整型中byte、short、int、long的取值范围](/basics/java-basic/integer-scope.md)
* [什么是浮点型?](/basics/java-basic/float.md)
* [什么是单精度和双精度?](/basics/java-basic/single-double-float.md)
* [为什么不能用浮点型表示金额?](/basics/java-basic/float-amount.md)
* 自动拆装箱
* [自动拆装箱](/basics/java-basic/boxing-unboxing.md)
* [Integer的缓存机制](/basics/java-basic/integer-cache.md)
* [如何正确定义接口的返回值(boolean/Boolean)类型及命名(success/isSuccess)](/basics/java-basic/success-isSuccess-and-boolean-Boolean.md)
* String
* [字符串的不可变性](/basics/java-basic/final-string.md)
* [JDK 6和JDK 7中substring的原理及区别](/basics/java-basic/substring.md)
* [replaceFirst、replaceAll、replace区别](/basics/java-basic/replace-in-string.md)
* [String对“+”的重载](/basics/java-basic/string-append.md)
* [字符串拼接的几种方式和区别](/basics/java-basic/string-concat.md)
* [Java 8中的StringJoiner](/basics/java-basic/stringjoiner-in-java8.md)
* [String.valueOf和Integer.toString的区别](/basics/java-basic/value-of-vs-to-string.md)
* [switch对String的支持](/basics/java-basic/switch-string.md)
* [字符串池](/basics/java-basic/string-pool.md)
* [Class常量池](/basics/java-basic/class-contant-pool.md)
* [运行时常量池](/basics/java-basic/Runtime-Constant-Pool.md)
* [intern](/basics/java-basic/intern.md)
* [String有没有长度限制?](/basics/java-basic/length-of-string.md)
* Java中各种关键字
* [transient](basics/java-basic/transient-in-java.md)
* [instanceof](basics/java-basic/instanceof-in-java.md)
* [volatile](basics/concurrent-coding/volatile.md)
* [synchronized](basics/concurrent-coding/synchronized.md)
* [final](basics/java-basic/final-in-java.md)
* [static](basics/java-basic/static-in-java.md)
* [const](basics/java-basic/const-in-java.md)
* 集合类
* [Collection和Collections区别](/basics/java-basic/Collection-vs-Collections.md)
* 常用集合类的使用
* [Set和List区别?](/basics/java-basic/set-vs-list.md)
* [ArrayList和LinkedList和Vector的区别](/basics/java-basic/arraylist-vs-linkedlist-vs-vector.md)
* [ArrayList使用了transient关键字进行存储优化,而Vector没有,为什么?](/basics/java-basic/why-transient-in-arraylist.md)
* [SynchronizedList和Vector的区别](/basics/java-basic/synchronizedlist-vector.md)
* [Set如何保证元素不重复?](/basics/java-basic/set-repetition.md)
* [HashMap、HashTable、ConcurrentHashMap区别](/basics/java-basic/HashMap-HashTable-ConcurrentHashMap.md)
* Java 8中Map相关的红黑树的引用背景、原理等
* [HashMap的容量、扩容](/basics/java-basic/hashmap-capacity.md)
* [HashMap中hash方法的原理](/basics/java-basic/hash-in-hashmap.md)
* [为什么HashMap的默认容量设置成16](/basics/java-basic/hashmap-default-capacity.md)
* [为什么HashMap的默认负载因子设置成0.75](/basics/java-basic/hashmap-default-loadfactor.md)
* [为什么建议设置HashMap的初始容量,设置多少合适](/basics/java-basic/hashmap-init-capacity.md)
* [Java 8中stream相关用法](/basics/java-basic/stream.md)
* [Apache集合处理工具类的使用](/basics/java-basic/apache-collections.md)
* 不同版本的JDK中HashMap的实现的区别以及原因
* [Arrays.asList获得的List使用时需要注意什么](/basics/java-basic/Arrays-asList.md)
* [Collection如何迭代](/basics/java-basic/iteration-of-collection.md)
* [Enumeration和Iterator区别](/basics/java-basic/Enumeration-vs-Iterator.md)
* [fail-fast 和 fail-safe](/basics/java-basic/fail-fast-vs-fail-safe.md)
* [如何在遍历的同时删除ArrayList中的元素](/basics/java-basic/delete-while-iterator.md)
* [CopyOnWriteArrayList](/basics/java-basic/CopyOnWriteArrayList.md)
* [ConcurrentSkipListMap](/basics/java-basic/ConcurrentSkipListMap.md)
* 枚举
* [枚举的用法](/basics/java-basic/enum-usage.md)
* [枚举的实现](/basics/java-basic/enum-impl.md)
* [枚举与单例](/basics/java-basic/enum-singleton.md)
* [Enum类](/basics/java-basic/enum-class.md)
* [Java枚举如何比较](/basics/java-basic/enum-compare.md)
* [switch对枚举的支持](/basics/java-basic/enum-switch.md)
* [枚举的序列化如何实现](/basics/java-basic/enum-serializable.md)
* [枚举的线程安全性问题](/basics/java-basic/enum-thread-safe.md)
* [为什么不建议在对外接口中使用枚举](/basics/java-basic/stop-use-enum-in-api.md)
* IO
* [字符流、字节流](/basics/java-basic/byte-stream-vs-character-stream.md)
* [输入流、输出流](/basics/java-basic/input-stream-vs-output-stream.md)
* [字节流和字符流之间的相互转换](/basics/java-basic/convert-bytestream-characterstream.md)
* [同步、异步](/basics/java-basic/synchronized-vs-asynchronization.md)
* [阻塞、非阻塞](/basics/java-basic/block-vs-non-blocking.md)
* [Linux 5种IO模型](/basics/java-basic/linux-io.md)
* [BIO、NIO和AIO的区别、三种IO的用法与原理](/basics/java-basic/bio-vs-nio-vs-aio.md)
* [netty](/basics/java-basic/netty.md)
* 反射
* [反射](/basics/java-basic/reflection.md)
* [反射有什么作用](/basics/java-basic/usage-of-reflection.md)
* [Class类](/basics/java-basic/Class.md)
* [反射与工厂模式实现Spring IOC](/basics/java-basic/ioc-implement-with-factory-and-reflection.md)
* `java.lang.reflect.*`
* 动态代理
* [静态代理](/basics/java-basic/static-proxy.md)
* [动态代理](/basics/java-basic/dynamic-proxy.md)
* [动态代理和反射的关系](/basics/java-basic/dynamic-proxy-vs-reflection.md)
* [动态代理的几种实现方式](/basics/java-basic/dynamic-proxy-implementation.md)
* [AOP](/basics/java-basic/aop-vs-proxy.md)
* 序列化
* [什么是序列化与反序列化](basics/java-basic/serialize.md)
* [Java如何实现序列化与反序列化](basics/java-basic/serialize-in-java.md)
* [Serializable 和 Externalizable 有何不同](basics/java-basic/diff-serializable-vs-externalizable.md)
* 为什么序列化
* [serialVersionUID](basics/java-basic/serialVersionUID.md)
* [为什么serialVersionUID不能随便改](basics/java-basic/serialVersionUID-modify.md)
* [transient](basics/java-basic/transient-in-java.md)
* [序列化底层原理](basics/java-basic/serialize-principle.md)
* [序列化如何破坏单例模式](basics/java-basic/serialize-singleton.md)
* [protobuf](basics/java-basic/protobuf.md)
* [Apache-Commons-Collections的反序列化漏洞](basics/java-basic/bug-in-apache-commons-collections.md)
* [fastjson的反序列化漏洞](basics/java-basic/bug-in-fastjson.md)
* 注解
* [元注解](/basics/java-basic/meta-annotation.md)
* [自定义注解](/basics/java-basic/custom-annotation.md)
* [Java中常用注解使用](/basics/java-basic/annotation-in-java.md)
* [注解与反射的结合](/basics/java-basic/annotion-and-reflect.md)
* [如何自定义一个注解?](/basics/java-basic/create-annotation.md)
* [Spring常用注解](/basics/java-basic/annotation-in-spring.md)
* 泛型
* [什么是泛型](/basics/java-basic/generics.md)
* [类型擦除](/basics/java-basic/type-erasure.md)
* [泛型带来的问题](/basics/java-basic/generics-problem.md)
* [泛型中K T V E ? object等的含义](/basics/java-basic/k-t-v-e.md)
* 泛型各种用法
* [限定通配符和非限定通配符](/basics/java-basic/Wildcard-Character.md)
* [上下界限定符extends 和 super](/basics/java-basic/extends-vs-super.md)
* [`List<Object>`和原始类型`List`之间的区别?](/basics/java-basic/genericity-list.md)
* [`List<?>`和`List<Object>`之间的区别是什么?](/basics/java-basic/genericity-list-wildcard.md)
* 单元测试
* [junit](/basics/java-basic/junit.md)
* junit 和Spring 的结合
* [mock](/basics/java-basic/mock.md)
* [JMockit](/basics/java-basic/ut-with-jmockit.md)
* [内存数据库(h2)](/basics/java-basic/h2-db.md)
* 正则表达式
* `java.lang.util.regex.*`
* 常用的Java工具库
* `commons.lang`
* `commons.*...`
* `guava-libraries`
* `netty`
* API&SPI
* API
* [API和SPI的关系和区别](/basics/java-basic/api-vs-spi.md)
* [如何定义SPI](/basics/java-basic/create-spi.md)
* [SPI的实现原理](/basics/java-basic/spi-principle.md)
* 异常
* [Error和Exception](/basics/java-basic/error-vs-exception.md)
* [异常类型](/basics/java-basic/exception-type.md)
* [异常相关关键字](/basics/java-basic/keyword-about-exception.md)
* [正确处理异常](/basics/java-basic/handle-exception.md)
* [自定义异常](/basics/java-basic/define-exception.md)
* [异常链](/basics/java-basic/exception-chain.md)
* [try-with-resources](/basics/java-basic/try-with-resources.md)
* [finally和return的执行顺序](/basics/java-basic/order-about-finllly-return.md)
* 时间处理
* [时区](/basics/java-basic/time-zone.md)
* [冬令时和夏令时](/basics/java-basic/StandardTime-vs-daylightSavingTime.md)
* [时间戳](/basics/java-basic/timestamp.md)
* Java中时间API
* [格林威治时间](/basics/java-basic/GMT.md)
* [CET,UTC,GMT,CST几种常见时间的含义和关系](/basics/java-basic/CET-UTC-GMT-CST.md)
* [SimpleDateFormat的线程安全性问题](/basics/java-basic/simpledateformat-thread-safe.md)
* [Java 8中的时间处理](/basics/java-basic/time-in-java8.md)
* [如何在东八区的计算机上获取美国时间](/basics/java-basic/get-los_angeles-time.md)
* [yyyy和YYYY有什么区别?](/basics/java-basic/YYYY-vs-yyyy.md)
* 为什么日期格式化时必须有使用y表示年,而不能用Y?
* 编码方式
* [什么是ASCII?](/basics/java-basic/ASCII.md)
* [Unicode](/basics/java-basic/UNICODE.md)
* [有了Unicode为啥还需要UTF-8](/basics/java-basic/why-utf8.md)
* [UTF8、UTF16、UTF32区别](/basics/java-basic/UTF8-UTF16-UTF32.md)
* [有了UTF8为什么还需要GBK?](/basics/java-basic/why-gbk.md)
* [GBK、GB2312、GB18030之间的区别](/basics/java-basic/gbk-gb2312-gb18030.md)
* [URL编解码](/basics/java-basic/url-encode.md)
* [Big Endian和Little Endian](/basics/java-basic/big-endian-vs-little-endian.md)
* 如何解决乱码问题
* 语法糖
* [Java中语法糖原理、解语法糖](/basics/java-basic/syntactic-sugar.md)
* [语法糖介绍](/basics/java-basic/syntactic-sugar.md)
* JMS
* 什么是Java消息服务
* JMS消息传送模型
* JMX
* java.lang.management.*
* javax.management.*
* BigDecimal
* 为什么0.1+0.2不等于0.3
* [为什么不能使用BigDecimal的equals比较大小](/basics/java-basic/stop-using-equlas-in-bigdecimal.md)
* [为什么不能直接使用double创建一个BigDecimal](/basics/java-basic/stop-create-bigdecimal-with-double.md)
* Java 8
* [lambda表达式](/basics/java-basic/lambda.md)
* [Stream API](/basics/java-basic/stream.md)
* [时间API](/basics/java-basic/time-in-java8.md)
* 阅读源代码
* String
* Integer
* Long
* Enum
* BigDecimal
* ThreadLocal
* ClassLoader & URLClassLoader
* ArrayList & LinkedList
* HashMap & LinkedHashMap & TreeMap & CouncurrentHashMap
* HashSet & LinkedHashSet & TreeSet
* Java并发编程
* 并发与并行
* [什么是并发](/basics/concurrent-coding/concurrent.md)
* [什么是并行](/basics/concurrent-coding/parallel.md)
* [并发与并行的区别](/basics/concurrent-coding/concurrent-vs-parallel.md)
* 线程
* [线程与进程的区别](/basics/concurrent-coding/progress-vs-thread.md)
* [线程的特点](/basics/concurrent-coding/thread.md)
* [线程的实现](/basics/concurrent-coding/implement-of-thread.md)
* [线程的状态](/basics/concurrent-coding/state-of-thread.md)
* [线程优先级](/basics/concurrent-coding/priority-of-thread.md)
* [线程调度](/basics/concurrent-coding/thread-scheduling.md)
* [多线程如何Debug](/basics/concurrent-coding/debug-in-multithread.md)
* [守护线程](/basics/concurrent-coding/deamon-thread.md)
* 创建线程的多种方式
* [继承Thread类创建线程](/basics/concurrent-coding/create-thread-with-extends.md)
* [实现Runnable接口创建线程](/basics/concurrent-coding/create-thread-with-Implement.md)
* [通过Callable和FutureTask创建线程](/basics/concurrent-coding/create-thread-with-callback-future-task.md)
* [通过线程池创建线程](/basics/concurrent-coding/create-thread-with-thead-pool.md)
* 线程池
* 自己设计线程池
* submit() 和 execute()
* 线程池原理
* [为什么不允许使用Executors创建线程池](/basics/concurrent-coding/why-not-executors.md)
* 线程安全
* [什么是线程安全](/basics/concurrent-coding/thread-safe.md)
* 多级缓存和一致性问题
* CPU时间片和原子性问题
* 指令重排和有序性问题
* 线程安全和内存模型的关系
* happens-before
* as-if-serial
* 锁
* 可重入锁
* 阻塞锁
* 乐观锁与悲观锁
* 数据库相关锁机制
* 分布式锁
* 无锁
* CAS
* CAS的ABA问题
* 锁优化
* 偏向锁
* 轻量级锁
* 重量级锁
* 锁消除
* 锁粗化
* 自旋锁
* 死锁
* [什么是死锁](/basics/concurrent-coding/deadlock-java-level.md)
* 死锁的原因
* 如何避免死锁
* 写一个死锁的程序
* 死锁问题如何排查
* synchronized
* [synchronized是如何实现的?](/basics/concurrent-coding/synchronized.md)
* synchronized和lock之间关系
* 不使用synchronized如何实现一个线程安全的单例
* synchronized和原子性
* synchronized和可见性
* synchronized和有序性
* volatile
* 编译器指令重排和CPU指令重排
* volatile的实现原理
* 内存屏障
* volatile和原子性
* volatile和可见性
* volatile和有序性
* 有了synchronized为什么还需要volatile
* 线程相关方法
* start & run
* sleep 和 wait
* notify & notifyAll
* ThreadLocal
* ThreadLocal 原理
* ThreadLocal 底层的数据结构
* 写代码来解决生产者消费者问题
* 并发包
* 同步容器与并发容器
* Thread
* Runnable
* Callable
* ReentrantLock
* ReentrantReadWriteLock
* Atomic*
* Semaphore
* CountDownLatch
* ConcurrentHashMap
* Executors
* 底层篇
* JVM
* JVM内存结构
* 运行时数据区
* [运行时数据区哪些是线程独享](/basement/jvm/exclusive-in-runtime-area.md)
* 堆和栈区别
* 方法区在不同版本JDK中的位置
* [运行时常量池](/basics/java-basic/Runtime-Constant-Pool.md)
* 堆外内存
* TLAB
* [Java中的对象一定在堆上分配吗?](/basement/jvm/stack-alloc.md)
* 垃圾回收
* GC算法:标记清除、引用计数、复制、标记压缩、分代回收、增量式回收
* GC参数
* 对象存活的判定
* 垃圾收集器(CMS、G1、ZGC、Epsilon)
* JVM参数及调优
* -Xmx
* -Xmn
* -Xms
* -Xss
* -XX:SurvivorRatio
* -XX:PermSize
* -XX:MaxPermSize
* -XX:MaxTenuringThreshold
* Java对象模型
* oop-klass
* 对象头
* HotSpot
* 即时编译器
* 编译优化
* Java内存模型
* 计算机内存模型
* 缓存一致性
* MESI协议
* 可见性
* 原子性
* 顺序性
* happens-before
* as-if-serial
* 内存屏障
* synchronized
* volatile
* final
* 锁
* 虚拟机性能监控与故障处理工具
* jps
* jstack
* jmap
* jstat
* jconsole
* jinfo
* jhat
* javap
* btrace
* TProfiler
* jlink
* Arthas
* 类加载机制
* classLoader
* 类加载过程是线程安全的吗?
* 类加载过程
* 如何判断JVM中类和其他类是不是同一个类
* [双亲委派原则](/basement/jvm/parents-delegate.md)
* [为什么需要双亲委派?](/basement/jvm/why-parents-delegate.md)
* [“父子加载器”之间的关系是继承吗?](/basement/jvm/relation-with-parents-delegate.md)
* [双亲委派是如何实现的?](/basement/jvm/implements-of-parents-delegate.md)
* [如何打破双亲委派](/basement/jvm/ibreak-parants-delegate.md)
* [如何自定义类加载器](/basement/jvm/define-class-loader.md)
* [双亲委派被破坏的例子](/basement/jvm/sample-of-break-parents-delegate.md)
* [为什么JNDI,JDBC等需要破坏双亲委派?](/basement/jvm/spi-parents-delegate.md)
* [为什么Tomcat要破坏双亲委派](/basement/jvm/tomcat-parents-delegate.md)
* [模块化(jboss modules、osgi、jigsaw)](/basement/jvm/moduler.md)
* 打包工具
* jar
* jlink
* jpackage
* 编译与反编译
* 什么是编译
* 什么是反编译
* [Class常量池](/basics/java-basic/class-contant-pool.md)
* 编译工具:javac
* 反编译工具:javap 、jad 、CRF
* JIT
* JIT优化(逃逸分析、栈上分配、标量替换、锁优化)
* 进阶篇
* Java底层知识
* 字节码
* class文件格式
* CAFEBABE
* 位运算
* 用位运算实现加、减、乘、除、取余
* 设计模式
* 设计模式的六大原则
* 开闭原则(Open Close Principle)
* 里氏代换原则(Liskov Substitution Principle)
* 依赖倒转原则(Dependence Inversion Principle)
* 接口隔离原则(Interface Segregation Principle)
* 迪米特法则(最少知道原则)(Demeter Principle)
* 合成复用原则(Composite Reuse Principle)
* 创建型设计模式
* [单例模式](/advance/design-patterns/singleton-pattern.md)
* [抽象工厂模式](/advance/design-patterns/abstract-factory-pattern.md)
* [建造者模式](/advance/design-patterns/builder-pattern.md)
* [工厂模式](/advance/design-patterns/factory-method-pattern.md)
* 原型模式
* 结构型设计模式
* [适配器模式](/advance/design-patterns/adapter-pattern.md)
* 桥接模式
* 装饰模式
* 组合模式
* 外观模式
* 享元模式
* 代理模式
* 行为型设计模式
* 模版方法模式
* 命令模式
* [迭代器模式](/advance/design-patterns/iterator-pattern.md)
* 观察者模式
* 中介者模式
* 备忘录模式
* 解释器模式
* 状态模式
* [策略模式](/advance/design-patterns/strategy-pattern.md)
* 责任链模式
* 访问者模式
* 单例的七种写法
* 懒汉——线程不安全
* 懒汉——线程安全
* 饿汉
* 饿汉——变种
* 静态内部类
* 枚举
* 双重校验锁
* 为什么推荐使用枚举实现单例?
* 三种工厂模式的区别及联系
* 简单工厂、工厂方法、模板工厂
* 会使用常用设计模式
* 工厂模式
* 适配器模式
* 策略模式
* 模板方法模式
* 观察者模式
* 外观模式
* 代理模式
* 不用synchronized和lock,实现线程安全的单例模式
* nio和reactor设计模式
* Spring中用到了哪些设计模式
* 网络编程知识
* 常用协议
* tcp、udp、http、https
* 用Java实现FTP、SMTP协议
* OSI七层模型
* 每一层的主要协议
* TCP/UDP
* 三次握手与四次关闭
* 流量控制和拥塞控制
* tcp粘包与拆包
* TCP/IP
* IPV4
* IPV6
* HTTP
* http/1.0 http/1.1 http/2之间的区别
* http和https的区别
* http中 get和post区别
* 常见的web请求返回的状态码
* 404、302、301、500分别代表什么
* 用Java写一个简单的静态文件的HTTP服务器
* HTTP/2
* HTTP/2 存在哪些问题?
* HTTP/3
* Java RMI,Socket,HttpClient
* cookie 与 session
* cookie被禁用,如何实现session
* 了解nginx和apache服务器的特性并搭建一个对应的服务器
* 进程间通讯的方式
* 什么是CDN?如果实现?
* DNS?
* 什么是DNS
* 记录类型:A记录、CNAME记录、AAAA记录等
* 域名解析
* 根域名服务器
* DNS污染
* DNS劫持
* 公共DNS:114 DNS、Google DNS、OpenDNS
* 反向代理
* 正向代理
* 反向代理
* 反向代理服务器
* 框架知识
* Servlet
* 生命周期
* 线程安全问题
* filter和listener
* web.xml中常用配置及作用
* Hibernate
* 什么是OR Mapping
* Hibernate的缓存机制
* Hibernate的懒加载
* Hibernate/Ibatis/MyBatis之间的区别
* MyBatis
* Mybatis缓存机制
* `#{}`和`${}`的区别
* mapper中传递多个参数
* Mybatis动态sql
* Mybatis的延迟加载
* Spring
* Bean的初始化
* AOP原理
* Spring AOP不支持方法自调用的问题
* 实现Spring的IOC
* spring四种依赖注入方式
* 为什么我不建议使用@Transactional声明事务
* Spring MVC
* 什么是MVC
* Spring mvc与Struts mvc的区别
* Spring Boot
* Spring Boot 2.0
* 起步依赖
* 自动配置
* Spring Boot的starter原理
* 自己实现一个starter
* 为什么Spring Boot可以通过main启动web项目
* Spring Security
* Spring Cloud
* 服务发现与注册:Eureka、Zookeeper、Consul
* 负载均衡:Feign、Spring Cloud Loadbalance
* 服务配置:Spring Cloud Config
* 服务限流与熔断:Hystrix
* 服务链路追踪:Dapper
* 服务网关、安全、消息
* 应用服务器知识
* JBoss
* tomcat
* jetty
* Weblogic
* 工具
* git & svn
* maven & gradle
* git技巧
* 分支合并
* 冲突解决
* 提交回滚
* maven技巧
* 依赖树
* 依赖仲裁
* Intellij IDEA
* 常用插件:Maven Helper、FindBugs-IDEA、阿里巴巴代码规约检测、GsonFormat、Lombok plugin、.ignore、Mybatis plugin
* 高级篇
* 新技术
* Java 9
* Jigsaw
* Jshell
* Reactive Streams
* Java 10
* 局部变量类型推断
* G1的并行Full GC
* ThreadLocal握手机制
* Java 11
* ZGC
* Epsilon
* 增强var
* Java 12
* Switch 表达式
* Java 13
* Text Blocks
* Dynamic CDS Archives
* Java 14
* Java打包工具
* 更有价值的NullPointerException
* record类型
* Spring 5
* 响应式编程
* Spring Boot 2.0
* http/2
* http/3
* 性能优化
* 使用单例
* 使用Future模式
* 使用线程池
* 选择就绪
* 减少上下文切换
* 减少锁粒度
* 数据压缩
* 结果缓存
* Stream并行流
* GC调优
* JVM内存分配调优
* SQL调优
* 线上问题分析
* dump
* 线程Dump
* 内存Dump
* gc情况
* dump获取及分析工具
* jstack
* jstat
* jmap
* jhat
* Arthas
* dump分析死锁
* dump分析内存泄露
* 自己编写各种outofmemory,stackoverflow程序
* HeapOutOfMemory
* Young OutOfMemory
* MethodArea OutOfMemory
* ConstantPool OutOfMemory
* DirectMemory OutOfMemory
* Stack OutOfMemory Stack OverFlow
* Arthas
* jvm相关
* class/classloader相关
* monitor/watch/trace相关
* options
* 管道
* 后台异步任务
* 常见问题解决思路
* 内存溢出
* 线程死锁
* 类加载冲突
* load飙高
* CPU利用率飙高
* 慢SQL
* 使用工具尝试解决以下问题,并写下总结
* 当一个Java程序响应很慢时如何查找问题
* 当一个Java程序频繁FullGC时如何解决问题
* 如何查看垃圾回收日志
* 当一个Java应用发生OutOfMemory时该如何解决
* 如何判断是否出现死锁
* 如何判断是否存在内存泄露
* 使用Arthas快速排查Spring Boot应用404/401问题
* 使用Arthas排查线上应用日志打满问题
* 利用Arthas排查Spring Boot应用NoSuchMethodError
* 编译原理知识
* 编译与反编译
* Java代码的编译与反编译
* Java的反编译工具
* javap
* jad
* CRF
* 即时编译器
* 编译器优化
* 操作系统知识
* Linux的常用命令
* find、grep、ps、cp、move、tar、head、tail、netstat、lsof、tree、wget、curl、ping、ssh、echo、free、top
* 为什么kill -9 不能随便执行
* rm一个被打开的文件会发生什么
* rm一个被打开的文件会发生什么
* 进程间通信
* 服务器性能指标
* load
* CPU利用率
* 内存使用情况
* qps
* rt
* 进程同步
* 生产者消费者问题
* 哲学家就餐问题
* 读者写者问题
* 缓冲区溢出
* 分段和分页
* 虚拟内存与主存
* 虚拟内存管理
* 换页算法
* 数据库知识
* MySql 执行引擎
* MySQL 执行计划
* 如何查看执行计划
* 如何根据执行计划进行SQL优化
* 索引
* Hash索引&B树索引
* 普通索引&唯一索引
* 聚集索引&非聚集索引
* 覆盖索引
* 最左前缀原则
* 索引下推
* 索引失效
* 回表
* SQL优化
* 数据库事务和隔离级别
* 事务的ACID
* 事务的隔离级别与读现象
* 事务能不能实现锁的功能
* 编码方式
* utf8
* utf8mb4
* 为什么不要在数据库中使用utf8编码
* 行数统计
* count(1)、count(*)、count(字段)的区别
* 为什么建议使用count(*)
* 数据库锁
* 共享锁、排它锁
* 行锁、表锁
* 乐观锁、悲观锁
* 使用数据库锁实现乐观锁
* Gap Lock、Next-Key Lock
* 连接
* 内连接
* 左连接
* 右连接
* 数据库主备搭建
* log
* binlog
* redolog
* 内存数据库
* h2
* 分库分表
* 读写分离
* 常用的nosql数据库
* redis
* memcached
* Redis
* Redis多线程
* 分别使用数据库锁、NoSql实现分布式锁
* 性能调优
* 数据库连接池
* 数据结构与算法知识
* 简单的数据结构
* 栈
* 队列
* 链表
* 数组
* 哈希表
* 栈和队列的相同和不同之处
* 栈通常采用的两种存储结构
* 两个栈实现队列,和两个队列实现栈
* 树
* 二叉树
* 字典树
* 平衡树
* 排序树
* B树
* B+树
* R树
* 多路树
* 红黑树
* 堆
* 大根堆
* 小根堆
* 图
* 有向图
* 无向图
* 拓扑
* 稳定的排序算法
* 冒泡排序
* 插入排序
* 鸡尾酒排序
* 桶排序
* 计数排序
* 归并排序
* 原地归并排序
* 二叉排序树排序
* 鸽巢排序
* 基数排序
* 侏儒排序
* 图书馆排序
* 块排序
* 不稳定的排序算法
* 选择排序
* 希尔排序
* Clover排序算法
* 梳排序
* 堆排序
* 平滑排序
* 快速排序
* 内省排序
* 耐心排序
* 各种排序算法和时间复杂度
* 深度优先和广度优先搜索
* 全排列
* 贪心算法
* KMP算法
* hash算法
* 海量数据处理
* 分治
* hash映射
* 堆排序
* 双层桶划分
* Bloom Filter
* bitmap
* 数据库索引
* mapreduce等。
* 大数据知识
* 搜索
* Solr
* Lucene
* ElasticSearch
* 流式计算
* Storm
* Spark
* Flink
* Hadoop,离线计算
* HDFS
* MapReduce
* 分布式日志收集
* flume
* kafka
* logstash
* 数据挖掘
* mahout
* 网络安全知识
* XSS
* XSS的防御
* CSRF
* 注入攻击
* SQL注入
* XML注入
* CRLF注入
* 文件上传漏洞
* 加密与解密
* 对称加密
* 非对称加密
* 哈希算法
* 加盐哈希算法
* 加密算法
* MD5,SHA1、DES、AES、RSA、DSA
* 彩虹表
* DDOS攻击
* DOS攻击
* DDOS攻击
* memcached为什么可以导致DDos攻击
* 什么是反射型DDoS
* 如何通过Hash碰撞进行DOS攻击
* SSL、TLS,HTTPS
* 脱库、洗库、撞库
* 架构篇
* 架构设计原则
* 单一职责原则
* 开放封闭原则
* 里氏替代原则
* 依赖倒置原则
* 接口分离原则
* 分布式
* 分布式理论
* 2PC
* 3PC
* CAP
* BASE
* 分布式协调 Zookeeper
* 基本概念
* 常见用法
* ZAB算法
* 脑裂
* 分布式事务
* 本地事务&分布式事务
* 可靠消息最终一致性
* 最大努力通知
* TCC
* Dubbo
* 服务注册
* 服务发现
* 服务治理
* 分布式数据库
* 怎样打造一个分布式数据库
* 什么时候需要分布式数据库
* mycat
* otter
* HBase
* 分布式文件系统
* mfs
* fastdfs
* 分布式缓存
* 缓存一致性
* 缓存命中率
* 缓存冗余
* 限流降级
* 熔断器模式
* Hystrix
* Sentinal
* resilience4j
* 分布式算法
* 拜占庭问题与算法
* 2PC
* 3PC
* 共识算法
* Paxos 算法与 Raft 算法
* ZAB算法
* 领域驱动设计
* 实体、值对象
* 聚合、聚合根
* 限界上下文
* DDD如何分层
* 充血模型和贫血模型
* DDD和微服务有什么关系
* 微服务
* SOA
* 康威定律
* ServiceMesh
* sidecar
* Docker & Kubernets
* Spring Boot
* Spring Cloud
* 高并发
* 分库分表
* 横向拆分与水平拆分
* 分库分表后的分布式事务问题
* CDN技术
* 消息队列
* RabbitMQ、RocketMQ、ActiveMQ、Kafka
* 各个消息队列的对比
* 高可用
* 双机架构
* 主备复制
* 主从复制
* 主主复制
* 异地多活
* 预案
* 预热
* 限流
* 高性能
* 高性能数据库
* 读写分离
* 分库分表
* 高性能缓存
* 缓存穿透
* 缓存雪崩
* 缓存热点
* 负载均衡
* PPC、TPC
* 监控
* 监控什么
* CPU
* 内存
* 磁盘I/O
* 网络I/O
* 监控手段
* 进程监控
* 语义监控
* 机器资源监控
* 数据波动
* 监控数据采集
* 日志
* 埋点
* Dapper
* 负载均衡
* 负载均衡分类
* 二层负载均衡
* 三层负载均衡
* 四层负载均衡
* 七层负载均衡
* 负载均衡工具
* LVS
* Nginx
* HAProxy
* 负载均衡算法
* 静态负载均衡算法:轮询,比率,优先权
* 动态负载均衡算法: 最少连接数,最快响应速度,观察方法,预测法,动态性能分配,动态服务器补充,服务质量,服务类型,规则模式。
* DNS
* DNS原理
* DNS的设计
* CDN
* 数据一致性
* 扩展篇
* 云计算
* IaaS
* SaaS
* PaaS
* 虚拟化技术
* openstack
* Serverlsess
* 搜索引擎
* Solr
* Lucene
* Nutch
* Elasticsearch
* 权限管理
* Shiro
* 区块链
* 哈希算法
* Merkle树
* 公钥密码算法
* 共识算法
* Raft协议
* Paxos 算法与 Raft 算法
* 拜占庭问题与算法
* 消息认证码与数字签名
* 比特币
* 挖矿
* 共识机制
* 闪电网络
* 侧链
* 热点问题
* 分叉
* 以太坊
* 超级账本
* 人工智能
* 数学基础
* 机器学习
* 人工神经网络
* 深度学习
* 应用场景
* 常用框架
* TensorFlow
* DeepLearning4J
* IoT
* 量子计算
* AR & VR
* 其他语言
* Groovy
* Kotlin
* Python
* Go
* NodeJs
* Swift
* Rust
================================================
FILE: docs/advance/design-patterns/abstract-factory-pattern.md
================================================
## 概念
抽象工厂模式(Abstract Factory Pattern):提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,属于对象创建型模式。
抽象工厂模式提供了一种方式,可以将同一产品族的单独的工厂封装起来。在正常使用中,客户端程序需要创建抽象工厂的具体实现,然后使用抽象工厂作为接口来创建这一主题的具体对象。客户端程序不需要知道(或关心)它从这些内部的工厂方法中获得对象的具体类型,因为客户端程序仅使用这些对象的通用接口。抽象工厂模式将一组对象的实现细节与他们的一般使用分离开来。
### 产品族
来认识下什么是产品族: 位于不同产品等级结构中,功能相关的产品组成的家族。如下面的例子,就有两个产品族:跑车族和商务车族。
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160419-0.png" alt="QQ20160419-0" width="637" height="408" class="alignnone size-full wp-image-1421" />][5]
## 用途
抽象工厂模式和工厂方法模式一样,都符合开放-封闭原则。但是不同的是,工厂方法模式在增加一个具体产品的时候,都要增加对应的工厂。但是抽象工厂模式只有在新增一个类型的具体产品时才需要新增工厂。也就是说,工厂方法模式的一个工厂只能创建一个具体产品。而抽象工厂模式的一个工厂可以创建属于一类类型的多种具体产品。工厂创建产品的个数介于简单工厂模式和工厂方法模式之间。
在以下情况下可以使用抽象工厂模式:
> 一个系统不应当依赖于产品类实例如何被创建、组合和表达的细节,这对于所有类型的工厂模式都是重要的。
>
> 系统中有多于一个的产品族,而每次只使用其中某一产品族。
>
> 属于同一个产品族的产品将在一起使用,这一约束必须在系统的设计中体现出来。
>
> 系统提供一个产品类的库,所有的产品以同样的接口出现,从而使客户端不依赖于具体实现。
## 实现方式
抽象工厂模式包含如下角色:
> AbstractFactory(抽象工厂):用于声明生成抽象产品的方法
>
> ConcreteFactory(具体工厂):实现了抽象工厂声明的生成抽象产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中;
>
> AbstractProduct(抽象产品):为每种产品声明接口,在抽象产品中定义了产品的抽象业务方法;
>
> Product(具体产品):定义具体工厂生产的具体产品对象,实现抽象产品接口中定义的业务方法。
本文的例子采用一个汽车代工厂造汽车的例子。假设我们是一家汽车代工厂商,我们负责给奔驰和特斯拉两家公司制造车子。我们简单的把奔驰车理解为需要加油的车,特斯拉为需要充电的车。其中奔驰车中包含跑车和商务车两种,特斯拉同样也包含跑车和商务车。
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160419-1.png" alt="QQ20160419-1" width="657" height="554" class="alignnone size-full wp-image-1422" />][6]
以上场景,我们就可以把跑车和商务车分别对待,对于跑车有单独的工厂创建,商务车也有单独的工厂。这样,以后无论是再帮任何其他厂商造车,只要是跑车或者商务车我们都不需要再引入工厂。同样,如果我们要增加一种其他类型的车,比如越野车,我们也不需要对跑车或者商务车的任何东西做修改。
下面是抽象产品,奔驰车和特斯拉车:
public interface BenzCar {
//加汽油
public void gasUp();
}
public interface TeslaCar {
//充电
public void charge();
}
下面是具体产品,奔驰跑车、奔驰商务车、特斯拉跑车、特斯拉商务车:
public class BenzSportCar implements BenzCar {
public void gasUp() {
System.out.println("给我的奔驰跑车加最好的汽油");
}
}
public class BenzBusinessCar implements BenzCar{
public void gasUp() {
System.out.println("给我的奔驰商务车加一般的汽油");
}
}
public class TeslaSportCar implements TeslaCar {
public void charge() {
System.out.println("给我特斯拉跑车冲满电");
}
}
public class TeslaBusinessCar implements TeslaCar {
public void charge() {
System.out.println("不用给我特斯拉商务车冲满电");
}
}
下面是抽象工厂:
public interface CarFactory {
public BenzCar getBenzCar();
public TeslaCar getTeslaCar();
}
下面是具体工厂:
public class SportCarFactory implements CarFactory {
public BenzCar getBenzCar() {
return new BenzSportCar();
}
public TeslaCar getTeslaCar() {
return new TeslaSportCar();
}
}
public class BusinessCarFactory implements CarFactory {
public BenzCar getBenzCar() {
return new BenzBusinessCar();
}
public TeslaCar getTeslaCar() {
return new TeslaBusinessCar();
}
}
## “开闭原则”的倾斜性
“开闭原则”要求系统对扩展开放,对修改封闭,通过扩展达到增强其功能的目的。对于涉及到多个产品族与多个产品等级结构的系统,其功能增强包括两方面:
> 增加产品族:对于增加新的产品族,工厂方法模式很好的支持了“开闭原则”,对于新增加的产品族,只需要对应增加一个新的具体工厂即可,对已有代码无须做任何修改。
>
> 增加新的产品等级结构:对于增加新的产品等级结构,需要修改所有的工厂角色,包括抽象工厂类,在所有的工厂类中都需要增加生产新产品的方法,不能很好地支持“开闭原则”。
抽象工厂模式的这种性质称为“开闭原则”的倾斜性,抽象工厂模式以一种倾斜的方式支持增加新的产品,它为新产品族的增加提供方便,但不能为新的产品等级结构的增加提供这样的方便。
## 三种工厂模式之间的关系
当抽象工厂模式中每一个具体工厂类只创建一个产品对象,也就是只存在一个产品等级结构时,抽象工厂模式退化成工厂方法模式;
抽象工厂模式与工厂方法模式最大的区别在于,工厂方法模式针对的是一个产品等级结构,而抽象工厂模式则需要面对多个产品等级结构。
当工厂方法模式中抽象工厂与具体工厂合并,提供一个统一的工厂来创建产品对象,并将创建对象的工厂方法设计为静态方法时,工厂方法模式退化成简单工厂模式。
## 总结
抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,属于对象创建型模式。
抽象工厂模式是所有形式的工厂模式中最为抽象和最具一般性的一种形态。
抽象工厂模式的主要优点是隔离了具体类的生成,使得客户并不需要知道什么被创建,而且每次可以通过具体工厂类创建一个产品族中的多个对象,增加或者替换产品族比较方便,增加新的具体工厂和产品族很方便;主要缺点在于增加新的产品等级结构很复杂,需要修改抽象工厂和所有的具体工厂类,对“开闭原则”的支持呈现倾斜性。
文中所有代码见[GitHub][7]
## 参考资料
[大话设计模式][8]
[深入浅出设计模式][9]
[抽象工厂模式(Factory Method Pattern)][10]
[1]: http://www.hollischuang.com/archives/category/%E7%BB%BC%E5%90%88%E5%BA%94%E7%94%A8/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F
[2]: http://www.hollischuang.com/archives/1401
[3]: http://www.hollischuang.com/archives/1408
[4]: http://www.hollischuang.com/archives/1391
[5]: http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160419-0.png
[6]: http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160419-1.png
[7]: https://github.com/hollischuang/DesignPattern
[8]: http://s.click.taobao.com/t?e=m=2&s=R5B/xd29JVMcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67jN2wQzI0ZBVHBMajAjK1gBpS4hLH/P02ckKYNRBWOBBey11vvWwHXSniyi5vWXIZkKWZZq7zWpCC8X3k5aQlui0qVGgqDL2o8YMXU3NNCg/&pvid=10_42.120.73.203_224_1460382841310
[9]: http://s.click.taobao.com/t?e=m%3D2%26s%3DObpq8Qxse2EcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67utJaEGcptl2kfkm8XrrgBtpS4hLH%2FP02ckKYNRBWOBBey11vvWwHXTpkOAWGyim%2Bw2PNKvM2u52N5aP5%2Bgx7zgh4LxdBQDQSXEqY%2Bakgpmw&pvid=10_121.0.29.199_322_1460465025379
[10]: http://design-patterns.readthedocs.org/zh_CN/latest/creational_patterns/abstract_factory.html#id14
================================================
FILE: docs/advance/design-patterns/adapter-pattern.md
================================================
## 概念
GOF是这样给适配器模式(`Adapter`)定义的:将一个类的接口转化成用户需要的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
GOF中将适配器模式分为类适配器模式和对象适配器模式。区别仅在于适配器角色对于被适配角色的适配是通过继承还是组合来实现的。由于在Java 中不支持多重继承,而且有破坏封装之嫌。而且我们也提倡[多用组合少用继承][2]。所以本文主要介绍对象适配器。
## 用途
相信大家都有这样的生活常识:就是目前我们使用的电子设备充电器的型号是不一样的。现在主流的手机充电器口主要包含Mini Usb、Micro Usb和Lightning三种。其中Mini Usb广泛出现在读卡器、MP3、数码相机以及移动硬盘上。由于Micro Usb比Mini Usb更薄,所有广泛应用于手机上,常见于安卓手机。还有一个比较常见的充电器口就是苹果手机常用的Lightning。
当然,特定型号的手机只能使用特定型号的充电器充电。比如Iphone6手机只能使用Lightning接口的充电器进行充电。但是,如果我们身边只有一条安卓的Micro Usb充电器线的话,我们能不能为苹果手机充电呢?答案是肯定的,只要有一个适配器就可以了。
<img src="http://www.hollischuang.com/wp-content/uploads/2016/05/adapter-300x300.jpg" alt="adapter" width="300" height="300" class="aligncenter size-medium wp-image-1501" />
适配器,在我们日常生活中随处可见。适配器模式也正是解决了类似的问题。
在程序设计过程中我们可能也遇到类似的场景:
> 1、系统需要使用现有的类,而此类的接口不符合系统的需要。
>
> 2、想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作,这些源类不一定有一致的接口。
>
> 3、通过接口转换,将一个类插入另一个类系中。(比如老虎和飞禽,现在多了一个飞虎,在不增加实体的需求下,增加一个适配器,在里面包容一个虎对象,实现飞的接口。)
以上场景都适合使用适配器模式。
## 实现方式
适配器模式包含如下角色:
> Target:目标抽象类
>
> Adapter:适配器类
>
> Adaptee:适配者类
>
> Client:客户类
<img src="http://www.hollischuang.com/wp-content/uploads/2016/05/Adapter-pattern.jpg" alt="Adapter-pattern" width="724" height="313" class="aligncenter size-full wp-image-1520" />
这里采用文章开头介绍的手机充电口的例子,我们定义一个适配器,该适配器的功能就是使用安卓充电器给苹果设备充电。
先定义接口:
/**
* MicroUsb充电器接口
*/
public interface MicroUsbInterface {
public void chargeWithMicroUsb();
}
/**
* Lightning充电器接口
*/
public interface LightningInterface {
public void chargeWithLightning();
}
定义具体的实现类
/**
* 安卓设备的充电器
*/
public class AndroidCharger implements MicroUsbInterface {
@Override
public void chargeWithMicroUsb() {
System.out.println("使用MicroUsb型号的充电器充电...");
}
}
/**
* 苹果设备的充电器
*/
public class AppleCharger implements LightningInterface {
@Override
public void chargeWithLightning() {
System.out.println("使用Lightning型号的充电器充电...");
}
}
> 因为我们要使用适配器模式将MicroUsb转成Lightning,所以这里的AppleCharger是本来不需要定义的。因为我们使用适配器的目的就是代替新建一个他。这里定义出来是为了使例子更加完整。
定义两个手机
public class Iphone6Plus {
private LightningInterface lightningInterface;
public Iphone6Plus() {
}
public Iphone6Plus(LightningInterface lightningInterface) {
this.lightningInterface = lightningInterface;
}
public void charge() {
System.out.println("开始给我的Iphone6Plus手机充电...");
lightningInterface.chargeWithLightning();
System.out.println("结束给我的Iphone6Plus手机充电...");
}
public LightningInterface getLightningInterface() {
return lightningInterface;
}
public void setLightningInterface(LightningInterface lightningInterface) {
this.lightningInterface = lightningInterface;
}
}
public class GalaxyS7 {
private MicroUsbInterface microUsbInterface;
public GalaxyS7() {
}
public GalaxyS7(MicroUsbInterface microUsbInterface) {
this.microUsbInterface = microUsbInterface;
}
public void charge(){
System.out.println("开始给我的GalaxyS7手机充电...");
microUsbInterface.chargeWithMicroUsb();
System.out.println("结束给我的GalaxyS7手机充电...");
}
public MicroUsbInterface getMicroUsbInterface() {
return microUsbInterface;
}
public void setMicroUsbInterface(MicroUsbInterface microUsbInterface) {
this.microUsbInterface = microUsbInterface;
}
}
这里定义手机的作用是为了更方便的理解适配器模式,在该模式中他不扮演任何角色。
定义适配器
/**
* 适配器,将MicroUsb接口转成Lightning接口
*/
public class Adapter implements LightningInterface {
private MicroUsbInterface microUsbInterface;
public Adapter() {
}
public Adapter(MicroUsbInterface microUsbInterface) {
this.microUsbInterface = microUsbInterface;
}
@Override
public void chargeWithLightning() {
microUsbInterface.chargeWithMicroUsb();
}
public MicroUsbInterface getMicroUsbInterface() {
return microUsbInterface;
}
public void setMicroUsbInterface(MicroUsbInterface microUsbInterface) {
this.microUsbInterface = microUsbInterface;
}
}
该适配器的功能是把一个MicroUsb转换成Lightning。实现方式是实现目标类的接口(`LightningInterface`),然后使用组合的方式,在该适配器中定义microUsb。然后在重写的`chargeWithLightning()`方法中,采用microUsb的方法来实现具体细节。
定义客户端
public class Main {
public static void main(String[] args) {
Iphone6Plus iphone6Plus = new Iphone6Plus(new AppleCharger());
iphone6Plus.charge();
System.out.println("==============================");
GalaxyS7 galaxyS7 = new GalaxyS7(new AndroidCharger());
galaxyS7.charge();
System.out.println("==============================");
Adapter adapter = new Adapter(new AndroidCharger());
Iphone6Plus newIphone = new Iphone6Plus();
newIphone.setLightningInterface(adapter);
newIphone.charge();
}
}
输出结果:
开始给我的Iphone6Plus手机充电...
使用Lightning型号的充电器充电...
结束给我的Iphone6Plus手机充电...
==============================
开始给我的GalaxyS7手机充电...
使用MicroUsb型号的充电器充电...
结束给我的GalaxyS7手机充电...
==============================
开始给我的Iphone6Plus手机充电...
使用MicroUsb型号的充电器充电...
结束给我的Iphone6Plus手机充电...
上面的例子通过适配器,把一个MicroUsb型号的充电器用来给Iphone充电。从代码层面,就是通过适配器复用了MicroUsb接口及其实现类。在很大程度上复用了已有的代码。
## 优缺点
### 优点
将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,而无须修改原有代码。
增加了类的透明性和复用性,将具体的实现封装在适配者类中,对于客户端类来说是透明的,而且提高了适配者的复用性。
灵活性和扩展性都非常好,通过使用配置文件,可以很方便地更换适配器,也可以在不修改原有代码的基础上增加新的适配器类,完全符合“开闭原则”。
### 缺点
过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
对于类适配器而言,由于 JAVA 至多继承一个类,所以至多只能适配一个适配者类,而且目标类必须是抽象类
## 总结
结构型模式描述如何将类或者对象结合在一起形成更大的结构。
适配器模式用于将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。
适配器模式包含四个角色:
> 目标抽象类定义客户要用的特定领域的接口;
>
> 适配器类可以调用另一个接口,作为一个转换器,对适配者和抽象目标类进行适配,它是适配器模式的核心;
>
> 适配者类是被适配的角色,它定义了一个已经存在的接口,这个接口需要适配;
>
> 在客户类中针对目标抽象类进行编程,调用在目标抽象类中定义的业务方法。
在对象适配器模式中,适配器类继承了目标抽象类(或实现接口)并定义了一个适配者类的对象实例,在所继承的目标抽象类方法中调用适配者类的相应业务方法。
适配器模式的主要优点是将目标类和适配者类解耦,增加了类的透明性和复用性,同时系统的灵活性和扩展性都非常好,更换适配器或者增加新的适配器都非常方便,符合“[开闭原则][3]”;类适配器模式的缺点是适配器类在很多编程语言中不能同时适配多个适配者类,对象适配器模式的缺点是很难置换适配者类的方法。
适配器模式适用情况包括:系统需要使用现有的类,而这些类的接口不符合系统的需要;想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类一起工作。
## 参考资料
[适配器模式][4]
[适配器模式][5]
文中所有代码见[GitHub][6]
[1]: http://www.hollischuang.com/archives/category/%E7%BB%BC%E5%90%88%E5%BA%94%E7%94%A8/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F
[2]: http://www.hollischuang.com/archives/1319
[3]: http://www.hollischuang.com/archives/220
[4]: http://www.runoob.com/design-pattern/adapter-pattern.html
[5]: http://design-patterns.readthedocs.io/zh_CN/latest/structural_patterns/adapter.html
[6]: https://github.com/hollischuang/DesignPattern
================================================
FILE: docs/advance/design-patterns/builder-pattern.md
================================================
## 概念
建造者模式(英:Builder Pattern)是一种创建型设计模式,又名:生成器模式。GOF 给建造者模式的定义为:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。这句话说的比较抽象,其实解释一下就是:将建造复杂对象的过程和组成对象的部件解耦。
## 用途
假设现在我们是一家网游设计公司,现在我们要"抄袭"梦幻西游这款游戏,你是该公司的游戏角色设计人员。你怎么设计出该游戏中的各种角色呢? 在梦幻西游来中包括人、仙、魔等种族的角色,而每种不同的种族的角色中又包含龙太子、逍遥生等具体的角色。
作为一个出色的开发人员,我们设计的角色生成系统应该包含以下功能和特性:
> 为了保证游戏平衡,所有角色的基本属性应该一致
>
> 因为角色的创建过程可能很复杂,所以角色的生成细节不应该对外暴露
>
> 随时可以新增角色
>
> 对某个具体角色的修改应该不影响其他角色
其实,对于角色的设计,我们可以使用抽象工厂模式,将同一种族的角色看成是一个产品族。但是,这样做可能存在一个问题,那就是我们可能要在每个角色的创建过程中都要从头到尾的构建一遍该角色。比如一个角色包含头部、身体。其中头部又包括脸部、和其他部位。其中脸部又包含眉毛、嘴巴、鼻子等部位。整个角色的创建过程是极其复杂的。很容易遗漏其中的某个步骤。
那么,我们可以将这些具体部位的创建工作和对象的创建进行解耦。这就是建造者模式。
## 实现方式
建造者模式包含如下角色:
> Builder:抽象建造者(`Builder`)
>
> ConcreteBuilder:具体建造者(`CommonBuilder`、`SuperBuilder`)
>
> Director:指挥者(`Director`)
>
> Product:产品角色(`Role`)
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/05/Builder.jpg" alt="Builder" width="713" height="338" class="alignnone size-full wp-image-1478" />][2]
这里采用设计角色的例子,为了便于理解,我们只创建两个角色,分别是普通角色和超级角色。他们都有设置头部、脸部、身体、气血值、魔法值、能量值等方法。值得注意的是设置脸部是依赖于设置头部的,要有先后顺序。
产品角色:Role
public class Role {
private String head; //头部
private String face; //脸部(脸部依赖于头部)
private String body; //身体
private Double hp; //生命值
private Double sp; //能量值
private Double mp; //魔法值
//setter and getter
// toString
}
抽象建造者:Builder
public abstract class Builder {
protected Role role = new Role();
public abstract void buildHead();
public abstract void buildFace();
public abstract void buildBody();
public abstract void buildHp();
public abstract void buildSp();
public abstract void buildMp();
public Role getResult() {
return role;
}
}
具体建造者:
public class CommonRoleBuilder extends Builder {
private Role role = new Role();
@Override
public void buildHead() {
role.setBody("common head");
}
@Override
public void buildFace() {
role.setFace("common face");
}
@Override
public void buildBody() {
role.setBody("common body");
}
@Override
public void buildHp() {
role.setHp(100d);
}
@Override
public void buildSp() {
role.setSp(100d);
}
@Override
public void buildMp() {
role.setMp(100d);
}
@Override
public Role getResult() {
return role;
}
}
public class SuperRoleBuilder extends Builder {
private Role role = new Role();
@Override
public void buildHead() {
role.setBody("suoer head");
}
@Override
public void buildFace() {
role.setFace("super face");
}
@Override
public void buildBody() {
role.setBody("super body");
}
@Override
public void buildHp() {
role.setHp(120d);
}
@Override
public void buildSp() {
role.setSp(120d);
}
@Override
public void buildMp() {
role.setMp(120d);
}
@Override
public Role getResult() {
return role;
}
}
指挥者:
public class Director {
public void construct(Builder builder){
builder.buildBody();
builder.buildHead();
builder.buildFace();
builder.buildHp();
builder.buildMp();
builder.buildSp();
}
}
测试类:
public class Main {
public static void main(String[] args) {
Director director = new Director();
Builder commonBuilder = new CommonRoleBuilder();
director.construct(commonBuilder);
Role commonRole = commonBuilder.getResult();
System.out.println(commonRole);
}
}
到这里,一个建造者模式已经完成了,是不是很简单?
* * *
再回到之前的需求,看看我们是否都满足?
由于建造角色的过程比较复杂,其中还有相互依赖关系(如脸部依赖于头部),所以我们使用建造者模式将将建造复杂对象的过程和组成对象的部件解耦。这样既保证了基本属性全都一致(这里的一致指的是该包含的应该全都包含)也封装了其中的具体实现细节。
同时,在修改某个具体角色的时候我们只需要修改对应的具体角色就可以了,不会影响到其他角色。
如果需要新增角色,只要再增加一个具体建造者,并在该建造者中写好具体细节的建造部分代码就OK了。
## 建造者模式的优缺点
### 优点
建造者模式的**封装性很好。使用建造者模式可以有效的封装变化**,在使用建造者模式的场景中,一般产品类和建造者类是比较稳定的,因此,将主要的业务逻辑封装在导演类中对整体而言可以取得比较好的稳定性。
在建造者模式中,**客户端不必知道产品内部组成的细节**,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
**可以更加精细地控制产品的创建过程** 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
其次,**建造者模式很容易进行扩展**。如果有新的需求,通过实现一个新的建造者类就可以完成,基本上不用修改之前已经测试通过的代码,因此也就不会对原有功能引入风险。符合开闭原则。
### 缺点
建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大。
## 适用环境
在以下情况下可以使用建造者模式:
> 需要生成的产品对象有复杂的内部结构,这些产品对象通常包含多个成员属性。
>
> 需要生成的产品对象的属性相互依赖,需要指定其生成顺序。
>
> 对象的创建过程独立于创建该对象的类。在建造者模式中引入了指挥者类,将创建过程封装在指挥者类中,而不在建造者类中。
>
> 隔离复杂对象的创建和使用,并使得相同的创建过程可以创建不同的产品。
## 建造者模式与工厂模式的区别
我们可以看到,建造者模式与工厂模式是极为相似的,总体上,建造者模式仅仅只比工厂模式多了一个"指挥者"的角色。在建造者模式的类图中,假如把这个导演类看做是最终调用的客户端,那么图中剩余的部分就可以看作是一个简单的工厂模式了。
与工厂模式相比,建造者模式一般用来创建更为复杂的对象,因为对象的创建过程更为复杂,因此将对象的创建过程独立出来组成一个新的类——导演类。
也就是说,工厂模式是将对象的全部创建过程封装在工厂类中,由工厂类向客户端提供最终的产品;而建造者模式中,建造者类一般只提供产品类中各个组件的建造,而将具体建造过程交付给导演类。由导演类负责将各个组件按照特定的规则组建为产品,然后将组建好的产品交付给客户端。
建造者模式与工厂模式类似,适用的场景也很相似。一般来说,如果产品的建造很复杂,那么请用工厂模式;如果产品的建造更复杂,那么请用建造者模式。哈哈哈。。。
## 总结
建造者模式将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
在建造者模式的结构中引入了一个指挥者类,该类的作用主要有两个:一方面它隔离了客户与生产过程;另一方面它负责控制产品的生成过程。指挥者针对抽象建造者编程,客户端只需要知道具体建造者的类型,即可通过指挥者类调用建造者的相关方法,返回一个完整的产品对象。
## 参考资料
[大话设计模式][3]
[深入浅出设计模式][4]
[建造者模式][5]
[1]: http://www.hollischuang.com/archives/category/%E7%BB%BC%E5%90%88%E5%BA%94%E7%94%A8/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F
[2]: http://www.hollischuang.com/wp-content/uploads/2016/05/Builder.jpg
[3]: http://s.click.taobao.com/t?e=m=2&s=R5B/xd29JVMcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67jN2wQzI0ZBVHBMajAjK1gBpS4hLH/P02ckKYNRBWOBBey11vvWwHXSniyi5vWXIZkKWZZq7zWpCC8X3k5aQlui0qVGgqDL2o8YMXU3NNCg/&pvid=10_42.120.73.203_224_1460382841310
[4]: http://s.click.taobao.com/t?e=m=2&s=Obpq8Qxse2EcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67utJaEGcptl2kfkm8XrrgBtpS4hLH/P02ckKYNRBWOBBey11vvWwHXTpkOAWGyim%2bw2PNKvM2u52N5aP5%2bgx7zgh4LxdBQDQSXEqY%2bakgpmw&pvid=10_121.0.29.199_322_1460465025379
[5]: http://design-patterns.readthedocs.io/zh_CN/latest/creational_patterns/builder.html
================================================
FILE: docs/advance/design-patterns/factory-method-pattern.md
================================================
## 概念
工厂方法模式(Factory Method Pattern)又称为工厂模式,也叫虚拟构造器(Virtual Constructor)模式或者多态工厂(Polymorphic Factory)模式,它属于类创建型模式。
工厂方法模式是一种实现了“工厂”概念的面向对象设计模式。就像其他创建型模式一样,它也是处理在不指定对象具体类型的情况下创建对象的问题。
> 工厂方法模式的实质是“定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类。工厂方法让类的实例化推迟到子类中进行。”
## 用途
工厂方法模式和[简单工厂模式][2]虽然都是通过工厂来创建对象,他们之间最大的不同是——**工厂方法模式在设计上完全完全符合“[开闭原则][3]”。**
在以下情况下可以使用工厂方法模式:
> 一个类不知道它所需要的对象的类:在工厂方法模式中,客户端不需要知道具体产品类的类名,只需要知道所对应的工厂即可,具体的产品对象由具体工厂类创建;客户端需要知道创建具体产品的工厂类。
>
> 一个类通过其子类来指定创建哪个对象:在工厂方法模式中,对于抽象工厂类只需要提供一个创建产品的接口,而由其子类来确定具体要创建的对象,利用面向对象的多态性和[里氏代换原则][3],在程序运行时,子类对象将覆盖父类对象,从而使得系统更容易扩展。
>
> 将创建对象的任务委托给多个工厂子类中的某一个,客户端在使用时可以无须关心是哪一个工厂子类创建产品子类,需要时再动态指定,可将具体工厂类的类名存储在配置文件或数据库中。
## 实现方式
工厂方法模式包含如下角色:
> Product:抽象产品(`Operation`)
>
> ConcreteProduct:具体产品(`OperationAdd`)
>
> Factory:抽象工厂(`IFactory`)
>
> ConcreteFactory:具体工厂(`AddFactory`)
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160412-0.png" alt="QQ20160412-0" width="798" height="518" class="alignnone size-full wp-image-1402" />][4]
这里还用计算器的例子。在保持`Operation`,`OperationAdd`,`OperationDiv`,`OperationSub`,`OperationMul`等几个方法不变的情况下,修改简单工厂模式中的工厂类(`OperationFactory`)。替代原有的那个"万能"的大工厂类,这里使用工厂方法来代替:
//工厂接口
public interface IFactory {
Operation CreateOption();
}
//加法类工厂
public class AddFactory implements IFactory {
public Operation CreateOption() {
return new OperationAdd();
}
}
//除法类工厂
public class DivFactory implements IFactory {
public Operation CreateOption() {
return new OperationDiv();
}
}
//除法类工厂
public class MulFactory implements IFactory {
public Operation CreateOption() {
return new OperationMul();
}
}
//减法类工厂
public class SubFactory implements IFactory {
public Operation CreateOption() {
return new OperationSub();
}
}
这样,在客户端中想要执行加法运算时,需要以下方式:
public class Main {
public static void main(String[] args) {
IFactory factory = new AddFactory();
Operation operationAdd = factory.CreateOption();
operationAdd.setValue1(10);
operationAdd.setValue2(5);
System.out.println(operationAdd.getResult());
}
}
到这里,一个工厂方法模式就已经写好了。
* * *
从代码量上看,这种工厂方法模式比简单工厂方法模式更加复杂。针对不同的操作(Operation)类都有对应的工厂。很多人会有以下疑问:
> 貌似工厂方法模式比简单工厂模式要复杂的多?
>
> 工厂方法模式和我自己创建对象没什么区别?为什么要多搞出一些工厂来?
下面就针对以上两个问题来深入理解一下工厂方法模式。
## 工厂方法模式的利与弊
### 为什么要使用工厂来创建对象?
> 封装对象的创建过程
在工厂方法模式中,工厂方法用来创建客户所需要的产品,同时还向客户**隐藏了哪种具体产品类将被实例化这一细节,用户只需要关心所需产品对应的工厂,无须关心创建细节,甚至无须知道具体产品类的类名。**
基于工厂角色和产品角色的多态性设计是工厂方法模式的关键。**它能够使工厂可以自主确定创建何种产品对象,而如何创建这个对象的细节则完全封装在具体工厂内部。**工厂方法模式之所以又被称为多态工厂模式,是因为所有的具体工厂类都具有同一抽象父类。
### 为什么每种对象要单独有一个工厂?
> 符合『[开放-封闭原则][5]』
主要目的是为了解耦。在系统中加入新产品时,无须修改抽象工厂和抽象产品提供的接口,无须修改客户端,也无须修改其他的具体工厂和具体产品,而只要添加一个具体工厂和具体产品就可以了。这样,系统的可扩展性也就变得非常好,完全符合“[开闭原则][3]”。
以上就是工厂方法模式的优点。但是,工厂模式也有一些不尽如人意的地方:
> 在添加新产品时,需要编写新的具体产品类,而且还要提供与之对应的具体工厂类,系统中类的个数将成对增加,在一定程度上增加了系统的复杂度,有更多的类需要编译和运行,会给系统带来一些额外的开销。
>
> 由于考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度,且在实现时可能需要用到DOM、反射等技术,增加了系统的实现难度。
## 工厂方法与简单工厂的区别
工厂模式克服了简单工厂模式违背[开放-封闭原则][3]的缺点,又保持了封装对象创建过程的优点。
他们都是集中封装了对象的创建,使得要更换对象时,不需要做大的改动就可实现,降低了客户端与产品对象的耦合。
## 总结
工厂方法模式是简单工厂模式的进一步抽象和推广。
由于使用了面向对象的多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
在工厂方法模式中,核心的工厂类不再负责所有产品的创建,而是将具体创建工作交给子类去做。这个核心类仅仅负责给出具体工厂必须实现的接口,而不负责产品类被实例化这种细节,这使得工厂方法模式可以允许系统在不修改工厂角色的情况下引进新产品。
工厂方法模式的主要优点是增加新的产品类时无须修改现有系统,并封装了产品对象的创建细节,系统具有良好的灵活性和可扩展性;其缺点在于增加新产品的同时需要增加新的工厂,导致系统类的个数成对增加,在一定程度上增加了系统的复杂性。
文中所有代码见[GitHub][6]
## 参考资料
[大话设计模式][7]
[深入浅出设计模式][8]
[工厂方法模式(Factory Method Pattern)][9]
[1]: http://www.hollischuang.com/archives/category/%E7%BB%BC%E5%90%88%E5%BA%94%E7%94%A8/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F
[2]: http://www.hollischuang.com/archives/1391
[3]: http://www.hollischuang.com/archives/220
[4]: http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160412-0.png
[5]: http://www.hollischuang.com/archives/220http://
[6]: https://github.com/hollischuang/DesignPattern
[7]: http://s.click.taobao.com/t?e=m=2&s=R5B/xd29JVMcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67jN2wQzI0ZBVHBMajAjK1gBpS4hLH/P02ckKYNRBWOBBey11vvWwHXSniyi5vWXIZkKWZZq7zWpCC8X3k5aQlui0qVGgqDL2o8YMXU3NNCg/&pvid=10_42.120.73.203_224_1460382841310
[8]: http://s.click.taobao.com/t?e=m%3D2%26s%3DObpq8Qxse2EcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67utJaEGcptl2kfkm8XrrgBtpS4hLH%2FP02ckKYNRBWOBBey11vvWwHXTpkOAWGyim%2Bw2PNKvM2u52N5aP5%2Bgx7zgh4LxdBQDQSXEqY%2Bakgpmw&pvid=10_121.0.29.199_322_1460465025379
[9]: http://design-patterns.readthedocs.org/zh_CN/latest/creational_patterns/factory_method.html#id11
================================================
FILE: docs/advance/design-patterns/iterator-pattern.md
================================================
## 概念
一提到迭代器模式很多人可能感觉很陌生,但是实际上,迭代器模式是所有设计模式中最简单也是最常用的设计模式,正是因为他太常用了,所以很多人忽略了他的存在。
> 迭代器模式提供一种方法访问一个容器中各个元素,而又不需要暴露该对象的内部细节。
那么,这里提到的容器是什么呢?其实就是可以包含一组对象的数据结构,如Java中的`Collection`和`Set`。
## 用途
从迭代器模式的概念中我们也看的出来,迭代器模式的重要用途就是帮助我们遍历容器。拿List来举例。如果我们想要遍历他的话,通常有以下几种方式:
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + ",");
}
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + ",");
}
for (Integer i : list) {
System.out.print(i + ",");
}
其实,第二种和[第三种][2]都是基于迭代器模式实现的。本文重点是介绍迭代器模式,那么先暂不介绍Java中内置的迭代器,我们尝试自己实现一下迭代器模式,这样更有助于我们彻底理解迭代器模式。
## 实现方式
迭代器模式包含如下角色:
> Iterator 抽象迭代器
>
> ConcreteIterator 具体迭代器
>
> Aggregate 抽象容器
>
> Concrete Aggregate 具体容器
[<img src="http://www.hollischuang.com/wp-content/uploads/2017/02/iterator.jpg" alt="iterator" width="542" height="287" class="aligncenter size-full wp-image-1767" />][3]
这里我们举一个菜单的例子,我们有一个菜单,我们想要展示出菜单中所有菜品的名字和报价信息等。
先定义抽象迭代器:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
}
这里的迭代器提供了三个方法,分别包括hasNext方法、next方法和remove方法。
> hasNext 返回该迭代器中是否还有未遍历过的元素
>
> next 返回迭代器中的下一个元素
在定义一个具体的迭代器:
public class MenuIterator implements Iterator {
String[] foods;
int position = 0;
public MenuIterator(String[] foods){
this.foods = foods;
}
@Override
public boolean hasNext() {
return position != foods.length;
}
@Override
public Object next() {
String food = foods[position];
position += 1;
return food;
}
}
这个具体的类实现了Iterator接口,并实现了其中的方法。具体实现就不详细写了,相信都能看得懂(请忽略线程安全问题)。
接下来定义一个抽象容器:
/**
* Created by hollis on 17/2/18.
* /
public interface Menu {
void add(String name);
Iterator getIterator();
}
这里定义一个菜单接口,只提供两个方法,一个add方法和一个getIterator方法,用于返回一个迭代器。
然后定义一个具体的容器,用于实现Menu接口:
public class ChineseFoodMenu implements Menu {
private String[] foods = new String[4];
private int position = 0;
@Override
public void add(String name) {
foods[position] = name;
position += 1;
}
@Override
public Iterator getIterator() {
return new MenuIterator(this.foods);
}
}
该类的实现也相对简单。至此,我们已经具备了一个迭代器模式需要的所有角色。接下来写一个测试类看看具体使用:
public class Main {
public static void main(String[] args) {
ChineseFoodMenu chineseFoodMenu = new ChineseFoodMenu();
chineseFoodMenu.add("宫保鸡丁");
chineseFoodMenu.add("孜然羊肉");
chineseFoodMenu.add("水煮鱼");
chineseFoodMenu.add("北京烤鸭");
Iterator iterator = chineseFoodMenu.getIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
//output:
//宫保鸡丁
//孜然羊肉
//水煮鱼
//北京烤鸭
我们通过迭代器的方式实现了对一个容器(Menu)的遍历。迭代器的好处就是我们在Main类中使用Menu的时候根本不知道他底层的实现,只需要通过迭代器来遍历就可以了。
## 总结
迭代器的使用现在非常广泛,因为Java中提供了java.util.Iterator。而且Java中的很多容器(Collection、Set)也都提供了对迭代器的支持。
迭代器甚至可以从23种设计模式中移除,因为他已经普遍的可以称之为工具了。
最后最后,迭代器模式很好用,本文中介绍了如何写迭代器模式,但是,如果你要做Java开发,请直接用Java提供的Iterator。
文中所有代码见[GitHub][4]
[1]: http://www.hollischuang.com/archives/1691
[2]: http://www.hollischuang.com/archives/1776
[3]: http://www.hollischuang.com/wp-content/uploads/2017/02/iterator.jpg
[4]: https://github.com/hollischuang/DesignPattern
================================================
FILE: docs/advance/design-patterns/singleton-pattern.md
================================================
## 概念
单例模式(`Singleton Pattern`)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式。在 [GOF 书][3]中给出的定义为:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
单例模式一般体现在类声明中,单例的类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
## 用途
单例模式有以下两个优点:
> 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如网站首页页面缓存)。
>
> 避免对资源的多重占用(比如写文件操作)。
有时候,我们在选择使用单例模式的时候,不仅仅考虑到其带来的优点,还有可能是有些场景就必须要单例。比如类似"一个党只能有一个主席"的情况。
## 实现方式
我们知道,一个类的对象的产生是由类构造函数来完成的。如果一个类对外提供了`public`的构造方法,那么外界就可以任意创建该类的对象。所以,如果想限制对象的产生,一个办法就是将构造函数变为私有的(至少是受保护的),使外面的类不能通过引用来产生对象。同时为了保证类的可用性,就必须提供一个自己的对象以及访问这个对象的静态方法。
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160406-0.png" alt="QQ20160406-0" width="325" height="232" class="alignnone size-full wp-image-1388" />][4]
### 饿汉式
下面是一个简单的单例的实现:
//code 1
public class Singleton {
//在类内部实例化一个实例
private static Singleton instance = new Singleton();
//私有的构造函数,外部无法访问
private Singleton() {
}
//对外提供获取实例的静态方法
public static Singleton getInstance() {
return instance;
}
}
使用以下代码测试:
//code2
public class SingletonClient {
public static void main(String[] args) {
SimpleSingleton simpleSingleton1 = SimpleSingleton.getInstance();
SimpleSingleton simpleSingleton2 = SimpleSingleton.getInstance();
System.out.println(simpleSingleton1==simpleSingleton2);
}
}
输出结果:
true
code 1就是一个简单的单例的实现,这种实现方式我们称之为饿汉式。所谓饿汉。这是个比较形象的比喻。对于一个饿汉来说,他希望他想要用到这个实例的时候就能够立即拿到,而不需要任何等待时间。所以,通过`static`的静态初始化方式,在该类第一次被加载的时候,就有一个`SimpleSingleton`的实例被创建出来了。这样就保证在第一次想要使用该对象时,他已经被初始化好了。
同时,由于该实例在类被加载的时候就创建出来了,所以也避免了线程安全问题。(原因见:[在深度分析Java的ClassLoader机制(源码级别)][5]、[Java类的加载、链接和初始化][6])
还有一种饿汉模式的变种:
//code 3
public class Singleton2 {
//在类内部定义
private static Singleton2 instance;
static {
//实例化该实例
instance = new Singleton2();
}
//私有的构造函数,外部无法访问
private Singleton2() {
}
//对外提供获取实例的静态方法
public static Singleton2 getInstance() {
return instance;
}
}
code 3和code 1其实是一样的,都是在类被加载的时候实例化一个对象。
**饿汉式单例,在类被加载的时候对象就会实例化。这也许会造成不必要的消耗,因为有可能这个实例根本就不会被用到。而且,如果这个类被多次加载的话也会造成多次实例化。其实解决这个问题的方式有很多,下面提供两种解决方式,第一种是使用静态内部类的形式。第二种是使用懒汉式。**
### 静态内部类式
先来看通过静态内部类的方式解决上面的问题:
//code 4
public class StaticInnerClassSingleton {
//在静态内部类中初始化实例对象
private static class SingletonHolder {
private static final StaticInnerClassSingleton INSTANCE = new StaticInnerClassSingleton();
}
//私有的构造方法
private StaticInnerClassSingleton() {
}
//对外提供获取实例的静态方法
public static final StaticInnerClassSingleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
这种方式同样利用了classloder的机制来保证初始化`instance`时只有一个线程,它跟饿汉式不同的是(很细微的差别):饿汉式是只要`Singleton`类被装载了,那么`instance`就会被实例化(没有达到lazy loading效果),而这种方式是`Singleton`类被装载了,`instance`不一定被初始化。因为`SingletonHolder`类没有被主动使用,只有显示通过调用`getInstance`方法时,才会显示装载`SingletonHolder`类,从而实例化`instance`。想象一下,如果实例化`instance`很消耗资源,我想让他延迟加载,另外一方面,我不希望在`Singleton`类加载时就实例化,因为我不能确保`Singleton`类还可能在其他的地方被主动使用从而被加载,那么这个时候实例化`instance`显然是不合适的。这个时候,这种方式相比饿汉式更加合理。
### 懒汉式
下面看另外一种在该对象真正被使用的时候才会实例化的单例模式——懒汉模式。
//code 5
public class Singleton {
//定义实例
private static Singleton instance;
//私有构造方法
private Singleton(){}
//对外提供获取实例的静态方法
public static Singleton getInstance() {
//在对象被使用的时候才实例化
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
上面这种单例叫做懒汉式单例。懒汉,就是不会提前把实例创建出来,将类对自己的实例化延迟到第一次被引用的时候。`getInstance`方法的作用是希望该对象在第一次被使用的时候被`new`出来。
有没有发现,其实code 5这种懒汉式单例其实还存在一个问题,那就是线程安全问题。在多线程情况下,有可能两个线程同时进入`if`语句中,这样,在两个线程都从if中退出的时候就创建了两个不一样的对象。(这里就不详细讲解了,不理解的请恶补多线程知识)。
### 线程安全的懒汉式
针对线程不安全的懒汉式的单例,其实解决方式很简单,就是给创建对象的步骤加锁:
//code 6
public class SynchronizedSingleton {
//定义实例
private static SynchronizedSingleton instance;
//私有构造方法
private SynchronizedSingleton(){}
//对外提供获取实例的静态方法,对该方法加锁
public static synchronized SynchronizedSingleton getInstance() {
//在对象被使用的时候才实例化
if (instance == null) {
instance = new SynchronizedSingleton();
}
return instance;
}
}
这种写法能够在多线程中很好的工作,而且看起来它也具备很好的延迟加载,但是,遗憾的是,他效率很低,因为99%情况下不需要同步。(因为上面的`synchronized`的加锁范围是整个方法,该方法的所有操作都是同步进行的,但是对于非第一次创建对象的情况,也就是没有进入`if`语句中的情况,根本不需要同步操作,可以直接返回`instance`。)
### 双重校验锁
针对上面code 6存在的问题,相信对并发编程了解的同学都知道如何解决。其实上面的代码存在的问题主要是锁的范围太大了。只要缩小锁的范围就可以了。那么如何缩小锁的范围呢?相比于同步方法,同步代码块的加锁范围更小。code 6可以改造成:
//code 7
public class Singleton {
private static Singleton singleton;
private Singleton() {
}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
code 7是对于code 6的一种改进写法,通过使用同步代码块的方式减小了锁的范围。这样可以大大提高效率。(对于已经存在`singleton`的情况,无须同步,直接return)。
但是,事情这的有这么容易吗?上面的代码看上去好像是没有任何问题。实现了惰性初始化,解决了同步问题,还减小了锁的范围,提高了效率。但是,该代码还存在隐患。隐患的原因主要和[Java内存模型(JMM][7])有关。考虑下面的事件序列:
> 线程A发现变量没有被初始化, 然后它获取锁并开始变量的初始化。
>
> 由于某些编程语言的语义,编译器生成的代码允许在线程A执行完变量的初始化之前,更新变量并将其指向部分初始化的对象。
>
> 线程B发现共享变量已经被初始化,并返回变量。由于线程B确信变量已被初始化,它没有获取锁。如果在A完成初始化之前共享变量对B可见(这是由于A没有完成初始化或者因为一些初始化的值还没有穿过B使用的内存(缓存一致性)),程序很可能会崩溃。
(上面的例子不太能理解的同学,请恶补JAVA内存模型相关知识)
在[J2SE 1.4][8]或更早的版本中使用双重检查锁有潜在的危险,有时会正常工作(区分正确实现和有小问题的实现是很困难的。取决于编译器,线程的调度和其他并发系统活动,不正确的实现双重检查锁导致的异常结果可能会间歇性出现。重现异常是十分困难的。) 在[J2SE 5.0][8]中,这一问题被修正了。[volatile][9]关键字保证多个线程可以正确处理单件实例
所以,针对code 7 ,可以有code 8 和code 9两种替代方案:
使用`volatile`
//code 8
public class VolatileSingleton {
private static volatile VolatileSingleton singleton;
private VolatileSingleton() {
}
public static VolatileSingleton getSingleton() {
if (singleton == null) {
synchronized (VolatileSingleton.class) {
if (singleton == null) {
singleton = new VolatileSingleton();
}
}
}
return singleton;
}
}
**上面这种双重校验锁的方式用的比较广泛,他解决了前面提到的所有问题。**但是,即使是这种看上去完美无缺的方式也可能存在问题,那就是遇到序列化的时候。详细内容后文介绍。
使用`final`
//code 9
class FinalWrapper<T> {
public final T value;
public FinalWrapper(T value) {
this.value = value;
}
}
public class FinalSingleton {
private FinalWrapper<FinalSingleton> helperWrapper = null;
public FinalSingleton getHelper() {
FinalWrapper<FinalSingleton> wrapper = helperWrapper;
if (wrapper == null) {
synchronized (this) {
if (helperWrapper == null) {
helperWrapper = new FinalWrapper<FinalSingleton>(new FinalSingleton());
}
wrapper = helperWrapper;
}
}
return wrapper.value;
}
}
### 枚举式
在1.5之前,实现单例一般只有以上几种办法,在1.5之后,还有另外一种实现单例的方式,那就是使用枚举:
// code 10
public enum Singleton {
INSTANCE;
Singleton() {
}
}
这种方式是[Effective Java][10]作者`Josh Bloch` 提倡的方式,它不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象(下面会介绍),可谓是很坚强的壁垒啊,在深度分析Java的枚举类型—-枚举的线程安全性及序列化问题中有详细介绍枚举的线程安全问题和序列化问题,不过,个人认为由于1.5中才加入`enum`特性,用这种方式写不免让人感觉生疏,在实际工作中,我也很少看见有人这么写过,但是不代表他不好。
## 单例与序列化
在[单例与序列化的那些事儿][11]一文中,[Hollis][12]就分析过单例和序列化之前的关系——序列化可以破坏单例。要想防止序列化对单例的破坏,只要在`Singleton`类中定义`readResolve`就可以解决该问题:
//code 11
package com.hollis;
import java.io.Serializable;
/**
* Created by hollis on 16/2/5.
* 使用双重校验锁方式实现单例
*/
public class Singleton implements Serializable{
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
private Object readResolve() {
return singleton;
}
}
## 总结
本文中介绍了几种实现单例的方法,主要包括饿汉、懒汉、使用静态内部类、双重校验锁、枚举等。还介绍了如何防止序列化破坏类的单例性。
从单例的实现中,我们可以发现,一个简单的单例模式就能涉及到这么多知识。在不断完善的过程中可以了解并运用到更多的知识。所谓学无止境。
**文中所有代码见[GitHub][13]**
## 参考资料
[单例模式的七种写法][14]
[双重检查锁定模式][15]
[深入浅出设计模式][16]
[单例模式][17]
[1]: http://www.hollischuang.com/archives/category/%E7%BB%BC%E5%90%88%E5%BA%94%E7%94%A8/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F
[2]: http://www.hollischuang.com/archives/1368
[3]: http://s.click.taobao.com/t?e=m%3D2%26s%3DT5l23XuxzMIcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67sqCcISrC8hOF%2FSaKyaJTUZpS4hLH%2FP02ckKYNRBWOBBey11vvWwHXSniyi5vWXIZhtlrJbLMDAQihpQCXu2JnMU7C4KV%2Fo0CcYMXU3NNCg%2F&pvid=10_42.120.73.203_2589754_1459955095482
[4]: http://www.hollischuang.com/wp-content/uploads/2016/04/QQ20160406-0.png
[5]: http://www.hollischuang.com/archives/197
[6]: http://www.hollischuang.com/archives/201
[7]: http://www.hollischuang.com/archives/1003
[8]: https://zh.wikipedia.org/wiki/Java_SE
[9]: https://zh.wikipedia.org/wiki/Volatile%E5%8F%98%E9%87%8F
[10]: http://s.click.taobao.com/t?e=m=2&s=ix/dAcrx42AcQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67vbkYfk%2bHavVTHm2guh0YLtpS4hLH/P02ckKYNRBWOBBey11vvWwHXSniyi5vWXIZtVr9sOV2MxmP1RxEmSieVPs8Gq%2bZDw%2bWcYMXU3NNCg/&pvid=10_42.120.73.203_425_1459957079215
[11]: http://www.hollischuang.com/archives/1144
[12]: http://www.hollischuang.com
[13]: https://github.com/hollischuang/DesignPattern
[14]: http://www.hollischuang.com/archives/205
[15]: https://zh.wikipedia.org/wiki/%E5%8F%8C%E9%87%8D%E6%A3%80%E6%9F%A5%E9%94%81%E5%AE%9A%E6%A8%A1%E5%BC%8F
[16]: http://s.click.taobao.com/t?e=m%3D2%26s%3Detkt7EP2O5scQipKwQzePOeEDrYVVa64K7Vc7tFgwiHjf2vlNIV67nWAf3rZA5A%2FrumJQoe%2FxcNpS4hLH%2FP02ckKYNRBWOBBey11vvWwHXTpkOAWGyim%2Bw2PNKvM2u52N5aP5%2Bgx7zgh4LxdBQDQSXEqY%2Bakgpmw&pvid=10_42.120.73.203_1238_1459955035603
[17]: http://www.runoob.com/design-pattern/singleton-pattern.html
================================================
FILE: docs/advance/design-patterns/strategy-pattern.md
================================================
## 概念
学习过设计模式的人大概都知道[Head First设计模式][2]这本书,这本书中介绍的第一个模式就是策略模式。把策略模式放在第一个,笔者认为主要有两个原因:1、这的确是一个比较简单的模式。2、这个模式可以充分的体现面向对象设计原则中的`封装变化`、`多用组合,少用继承`、`针对接口编程,不针对实现编程`等原则。
> 策略模式(Strategy Pattern):定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化,也称为政策模式(Policy)。
## 用途
结合策略模式的概念,我们找一个实际的场景来理解一下。
假设我们是一家新开的书店,为了招揽顾客,我们推出会员服务,我们把店里的会员分为三种,分别是初级会员、中级会员和高级会员。针对不同级别的会员我们给予不同的优惠。初级会员买书我们不打折、中级会员买书我们打九折、高级会员买书我们打八折。
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/09/bookstore-300x300.jpg" alt="bookstore" width="300" height="300" class="alignright size-medium wp-image-1694" />][3] 我们希望用户在付款的时候,只要刷一下书的条形码,会员再刷一下他的会员卡,收银台的工组人员就能直接知道应该向顾客收取多少钱。
在不使用模式的情况下,我们可以在结算的方法中使用`if/else`语句来区别出不同的会员来计算价格。
但是,如果我们有一天想要把初级会员的折扣改成9.8折怎么办?有一天我要推出超级会员怎么办?有一天我要针对中级会员可打折的书的数量做限制怎么办?
使用`if\else`设计出来的系统,所有的算法都写在了一起,只要有改动我就要修改整个类。我们都知道,只要是修改代码就有可能引入问题。为了避免这个问题,我们可以使用策略模式。。。
> 对于收银台系统,计算应收款的时候,一个客户只可能是初级、中级、高级会员中的一种。不同的会员使用不同的算法来计算价格。收银台系统其实不关心具体的会员类型和折扣之间的关系。也不希望会员和折扣之间的任何改动会影响到收银台系统。
在介绍策略模式的具体实现方式之前,再来巩固一下几个面向对象设计原则:`封装变化`、`多用组合,少用继承`、`针对接口编程,不针对实现编程`。想一想如何运用到策略模式中,并且有什么好处。
## 实现方式
策略模式包含如下角色:
> Context: 环境类
>
> Strategy: 抽象策略类
>
> ConcreteStrategy: 具体策略类
[<img src="http://www.hollischuang.com/wp-content/uploads/2016/09/Strategy.jpg" alt="strategy" width="764" height="329" class="aligncenter size-full wp-image-1692" />][4]
我们运用策略模式来实现一下书店的收银台系统。我们可以把会员抽象成一个策略类,不同的会员类型是具体的策略类。不同策略类里面实现了计算价格这一算法。然后通过组合的方式把会员集成到收银台中。
先定义一个接口,这个接口就是抽象策略类,该接口定义了计算价格方法,具体实现方式由具体的策略类来定义。
/**
* Created by hollis on 16/9/19. 会员接口
*/
public interface Member {
/**
* 计算应付价格
* @param bookPrice 书籍原价(针对金额,建议使用BigDecimal,double会损失精度)
* @return 应付金额
*/
public double calPrice(double bookPrice);
}
针对不同的会员,定义三种具体的策略类,每个类中都分别实现计算价格方法。
/**
* Created by hollis on 16/9/19. 初级会员
*/
public class PrimaryMember implements Member {
@Override
public double calPrice(double bookPrice) {
System.out.println("对于初级会员的没有折扣");
return bookPrice;
}
}
/**
* Created by hollis on 16/9/19. 中级会员,买书打九折
*/
public class IntermediateMember implements Member {
@Override
public double calPrice(double bookPrice) {
System.out.println("对于中级会员的折扣为10%");
return bookPrice * 0.9;
}
}
/**
* Created by hollis on 16/9/19. 高级会员,买书打八折
*/
public class AdvancedMember implements Member {
@Override
public double calPrice(double bookPrice) {
System.out.println("对于高级会员的折扣为20%");
return bookPrice * 0.8;
}
}
上面几个类的定义体现了`封装变化`的设计原则,不同会员的具体折扣方式改变不会影响到其他的会员。
定义好了抽象策略类和具体策略类之后,我们再来定义环境类,所谓环境类,就是集成算法的类。这个例子中就是收银台系统。采用组合的方式把会员集成进来。
/**
* Created by hollis on 16/9/19. 书籍价格类
*/
public class Cashier {
/**
* 会员,策略对象
*/
private Member member;
public Cashier(Member member){
this.member = member;
}
/**
* 计算应付价格
* @param booksPrice
* @return
*/
public double quote(double booksPrice) {
return this.member.calPrice(booksPrice);
}
}
这个Cashier类就是一个环境类,该类的定义体现了`多用组合,少用继承`、`针对接口编程,不针对实现编程`两个设计原则。由于这里采用了组合+接口的方式,后面我们在推出超级会员的时候无须修改Cashier类。只要再定义一个`SuperMember implements Member` 就可以了。
下面定义一个客户端来测试一下:
/**
* Created by hollis on 16/9/19.
*/
public class BookStore {
public static void main(String[] args) {
//选择并创建需要使用的策略对象
Member strategy = new AdvancedMember();
//创建环境
Cashier cashier = new Cashier(strategy);
//计算价格
double quote = cashier.quote(300);
System.out.println("高级会员图书的最终价格为:" + quote);
strategy = new IntermediateMember();
cashier = new Cashier(strategy);
quote = cashier.quote(300);
System.out.println("中级会员图书的最终价格为:" + quote);
}
}
//对于高级会员的折扣为20%
//高级会员图书的最终价格为:240.0
//对于中级会员的折扣为10%
//中级会员图书的最终价格为:270.0
从上面的示例可以看出,策略模式仅仅封装算法,提供新的算法插入到已有系统中,策略模式并不决定在何时使用何种算法。在什么情况下使用什么算法是由客户端决定的。
* 策略模式的重心
* 策略模式的重心不是如何实现算法,而是如何组织、调用这些算法,从而让程序结构更灵活,具有更好的维护性和扩展性。
* 算法的平等性
* 策略模式一个很大的特点就是各个策略算法的平等性。对于一系列具体的策略算法,大家的地位是完全一样的,正因为这个平等性,才能实现算法之间可以相互替换。所有的策略算法在实现上也是相互独立的,相互之间是没有依赖的。
* 所以可以这样描述这一系列策略算法:策略算法是相同行为的不同实现。
* 运行时策略的唯一性
* 运行期间,策略模式在每一个时刻只能使用一个具体的策略实现对象,虽然可以动态地在不同的策略实现中切换,但是同时只能使用一个。
* 公有的行为
* 经常见到的是,所有的具体策略类都有一些公有的行为。这时候,就应当把这些公有的行为放到共同的抽象策略角色Strategy类里面。当然这时候抽象策略角色必须要用Java抽象类实现,而不能使用接口。([《JAVA与模式》之策略模式][5])
## 策略模式的优缺点
### 优点
* 策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
* 策略模式提供了管理相关的算法族的办法。策略类的等级结构定义了一个算法或行为族。恰当使用继承可以把公共的代码移到父类里面,从而避免代码重复。
* 使用策略模式可以避免使用多重条件(if-else)语句。多重条件语句不易维护,它把采取哪一种算法或采取哪一种行为的逻辑与算法或行为的逻辑混合在一起,统统列在一个多重条件语句里面,比使用继承的办法还要原始和落后。
### 缺点
* 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法类。
* 由于策略模式把每个具体的策略实现都单独封装成为类,如果备选的策略很多的话,那么对象的数目就会很可观。可以通过使用享元模式在一定程度上减少对象的数量。
文中所有代码见[GitHub][6]
## 参考资料
[《JAVA与模式》之策略模式][5]
[1]: http://www.hollischuang.com/archives/category/%E7%BB%BC%E5%90%88%E5%BA%94%E7%94%A8/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F
[2]: http://s.click.taobao.com/DxA2xSx
[3]: http://www.hollischuang.com/wp-content/uploads/2016/09/bookstore.jpg
[4]: http://www.hollischuang.com/wp-content/uploads/2016/09/Strategy.jpg
[5]: http://www.cnblogs.com/java-my-life/archive/2012/05/10/2491891.html
[6]: https://github.com/hollischuang/DesignPattern
================================================
FILE: docs/basement/jvm/break-parants-delegate.md
================================================
知道了双亲委派模型的实现,那么想要破坏双亲委派机制就很简单了。
因为他的双亲委派过程都是在loadClass方法中实现的,那么想要破坏这种机制,那么就自定义一个类加载器,重写其中的loadClass方法,使其不进行双亲委派即可。
================================================
FILE: docs/basement/jvm/define-class-loader.md
================================================
ClassLoader中和类加载有关的方法有很多,前面提到了loadClass,除此之外,还有findClass和defineClass等,那么这几个方法有什么区别呢?
* loadClass()
* 就是主要进行类加载的方法,默认的双亲委派机制就实现在这个方法中。
* findClass()
* 根据名称或位置加载.class字节码
* definclass()
* 把字节码转化为Class
这里面需要展开讲一下loadClass和findClass,我们前面说过,当我们想要自定义一个类加载器的时候,并且像破坏双亲委派原则时,我们会重写loadClass方法。
那么,如果我们想定义一个类加载器,但是不想破坏双亲委派模型的时候呢?
这时候,就可以继承ClassLoader,并且重写findClass方法。findClass()方法是JDK1.2之后的ClassLoader新添加的一个方法。
/**
* @since 1.2
*/
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
这个方法只抛出了一个异常,没有默认实现。
JDK1.2之后已不再提倡用户直接覆盖loadClass()方法,而是建议把自己的类加载逻辑实现到findClass()方法中。
因为在loadClass()方法的逻辑里,如果父类加载器加载失败,则会调用自己的findClass()方法来完成加载。
所以,如果你想定义一个自己的类加载器,并且要遵守双亲委派模型,那么可以继承ClassLoader,并且在findClass中实现你自己的加载逻辑即可。
================================================
FILE: docs/basement/jvm/exclusive-in-runtime-area.md
================================================
在JVM运行时内存区域中,PC寄存器、虚拟机栈和本地方法栈是线程独享的。
而Java堆、方法区是线程共享的。但是值得注意的是,Java堆其实还未每一个线程单独分配了一块TLAB空间,这部分空间在分配时是线程独享的,在使用时是线程共享的。
================================================
FILE: docs/basement/jvm/implements-of-parents-delegate.md
================================================
双亲委派模型对于保证Java程序的稳定运作很重要,但它的实现并不复杂。
实现双亲委派的代码都集中在java.lang.ClassLoader的loadClass()方法之中:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
代码不难理解,主要就是以下几个步骤:
1、先检查类是否已经被加载过
2、若没有加载则调用父加载器的loadClass()方法进行加载
3、若父加载器为空则默认使用启动类加载器作为父加载器。
4、如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
================================================
FILE: docs/basement/jvm/java-memory-model.md
================================================
## Java内存模型
> 本文是[《成神之路系列文章》](/catalog/catalog.md)中的一篇,主要是关于JVM的一些介绍。
>
> 持续更新中
### Java内存模型
[JVM内存结构 VS Java内存模型 VS Java对象模型][2](Hollis原创)
[再有人问你Java内存模型是什么,就把这篇文章发给他。][3](Hollis原创)
[内存模型是怎么解决缓存一致性问题的?][4](Hollis原创)
[细说Java多线程之内存可见性][5](视频)(`推荐`)(如果嫌视频讲的慢,建议使用1.5倍速度观看)
[JSR 133: JavaTM Memory Model and Thread Specification Revision][6](JMM英文官方文档)
[Java内存模型FAQ][7]
[深入理解Java内存模型(一)——基础][8]
[深入理解Java内存模型(二)——重排序][9]
[深入理解Java内存模型(三)——顺序一致性][10]
[深入理解Java内存模型(四)——volatile][11]
[深入理解Java内存模型(五)——锁][12]
[深入理解Java内存模型(六)——final][13]
[深入理解Java内存模型(七)——总结][14]
[Java 理论与实践: 修复 Java 内存模型,第 2 部分][15](拓展阅读)
[1]: http://www.hollischuang.com/archives/1001
[2]: http://www.hollischuang.com/archives/2509
[3]: http://www.hollischuang.com/archives/2550
[4]: http://www.hollischuang.com/archives/2662
[5]: http://www.imooc.com/learn/352
[6]: https://www.jcp.org/en/jsr/detail?id=133
[7]: http://ifeve.com/jmm-faq/
[8]: http://www.infoq.com/cn/articles/java-memory-model-1
[9]: http://www.infoq.com/cn/articles/java-memory-model-2
[10]: http://www.infoq.com/cn/articles/java-memory-model-3
[11]: http://www.infoq.com/cn/articles/java-memory-model-4
[12]: http://www.infoq.com/cn/articles/java-memory-model-5
[13]: http://www.infoq.com/cn/articles/java-memory-model-6
[14]: http://www.infoq.com/cn/articles/java-memory-model-7
[15]: https://www.ibm.com/developerworks/cn/java/j-jtp03304/
================================================
FILE: docs/basement/jvm/moduler.md
================================================
近几年模块化技术已经很成熟了,在JDK 9中已经应用了模块化的技术。
其实早在JDK 9之前,OSGI这种框架已经是模块化的了,**而OSGI之所以能够实现模块热插拔和模块内部可见性的精准控制都归结于其特殊的类加载机制,加载器之间的关系不再是双亲委派模型的树状结构,而是发展成复杂的网状结构。**
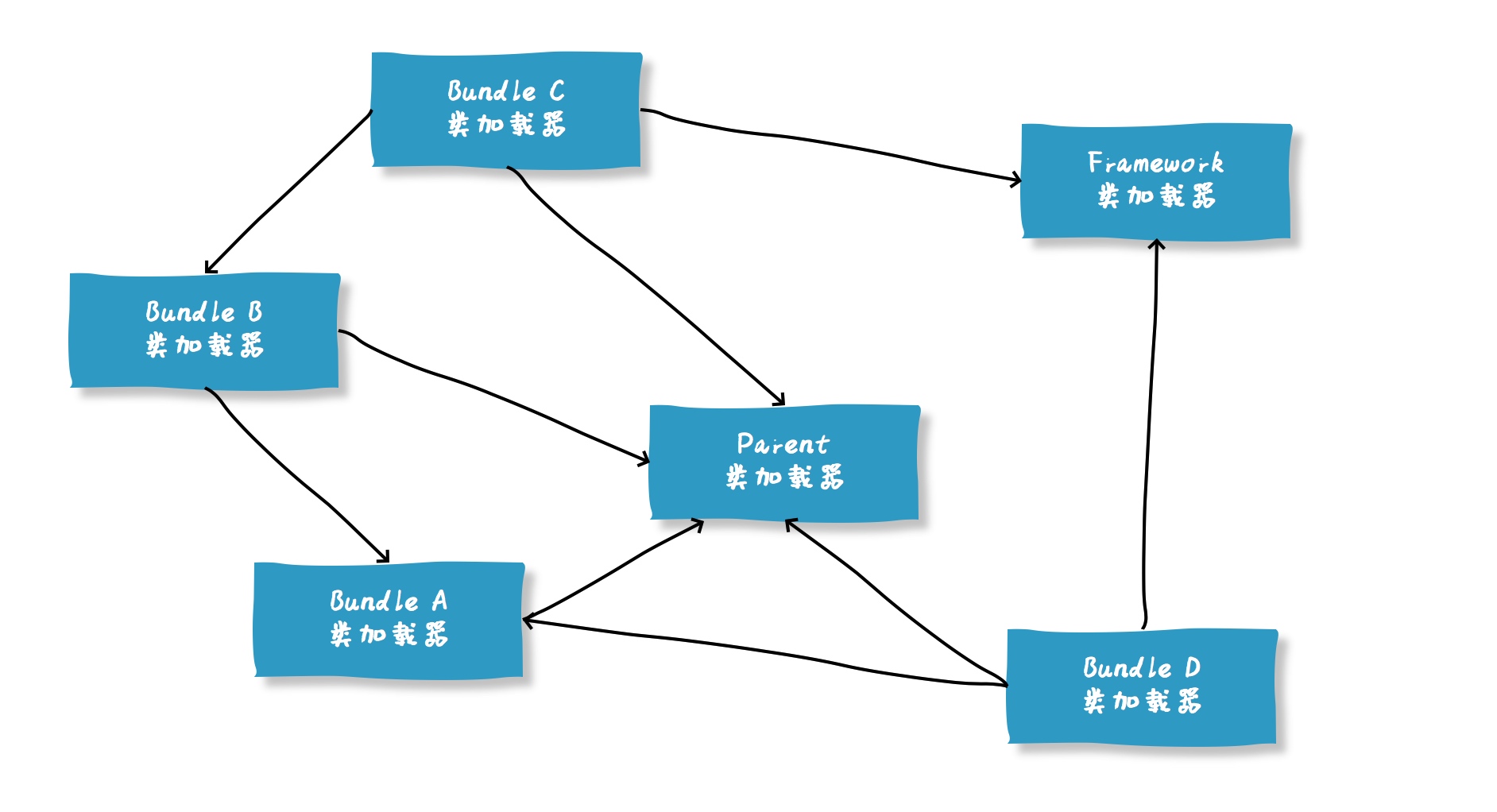
**在JDK中,双亲委派也不是绝对的了。**
在JDK9之前,JVM的基础类以前都是在rt.jar这个包里,这个包也是JRE运行的基石。
这不仅是违反了单一职责原则,同样程序在编译的时候会将很多无用的类也一并打包,造成臃肿。
**在JDK9中,整个JDK都基于模块化进行构建,以前的rt.jar, tool.jar被拆分成数十个模块,编译的时候只编译实际用到的模块,同时各个类加载器各司其职,只加载自己负责的模块。**
Class<?> c = findLoadedClass(cn);
if (c == null) {
// 找到当前类属于哪个模块
LoadedModule loadedModule = findLoadedModule(cn);
if (loadedModule != null) {
//获取当前模块的类加载器
BuiltinClassLoader loader = loadedModule.loader();
//进行类加载
c = findClassInModuleOrNull(loadedModule, cn);
} else {
// 找不到模块信息才会进行双亲委派
if (parent != null) {
c = parent.loadClassOrNull(cn);
}
}
}
### 总结
以上,从什么是双亲委派,到如何实现与破坏双亲委派,又从破坏双亲委派的示例等多个方面全面介绍了关于双亲委派的知识。
相信通过学习本文,你一定对双亲委派机制有了更加深刻的了解。
阅读过本文之后,反手在简历上写下:熟悉Java的类加载机制,不服来问!
================================================
FILE: docs/basement/jvm/parents-delegate.md
================================================
虚拟机在加载类的过程中需要使用类加载器进行加载,而在Java中,类加载器有很多,那么当JVM想要加载一个.class文件的时候,到底应该由哪个类加载器加载呢?
这就不得不提到”双亲委派机制”。
首先,我们需要知道的是,Java语言系统中支持以下4种类加载器:
* Bootstrap ClassLoader 启动类加载器
* Extention ClassLoader 标准扩展类加载器
* Application ClassLoader 应用类加载器
* User ClassLoader 用户自定义类加载器
这四种类加载器之间,是存在着一种层次关系的,如下图
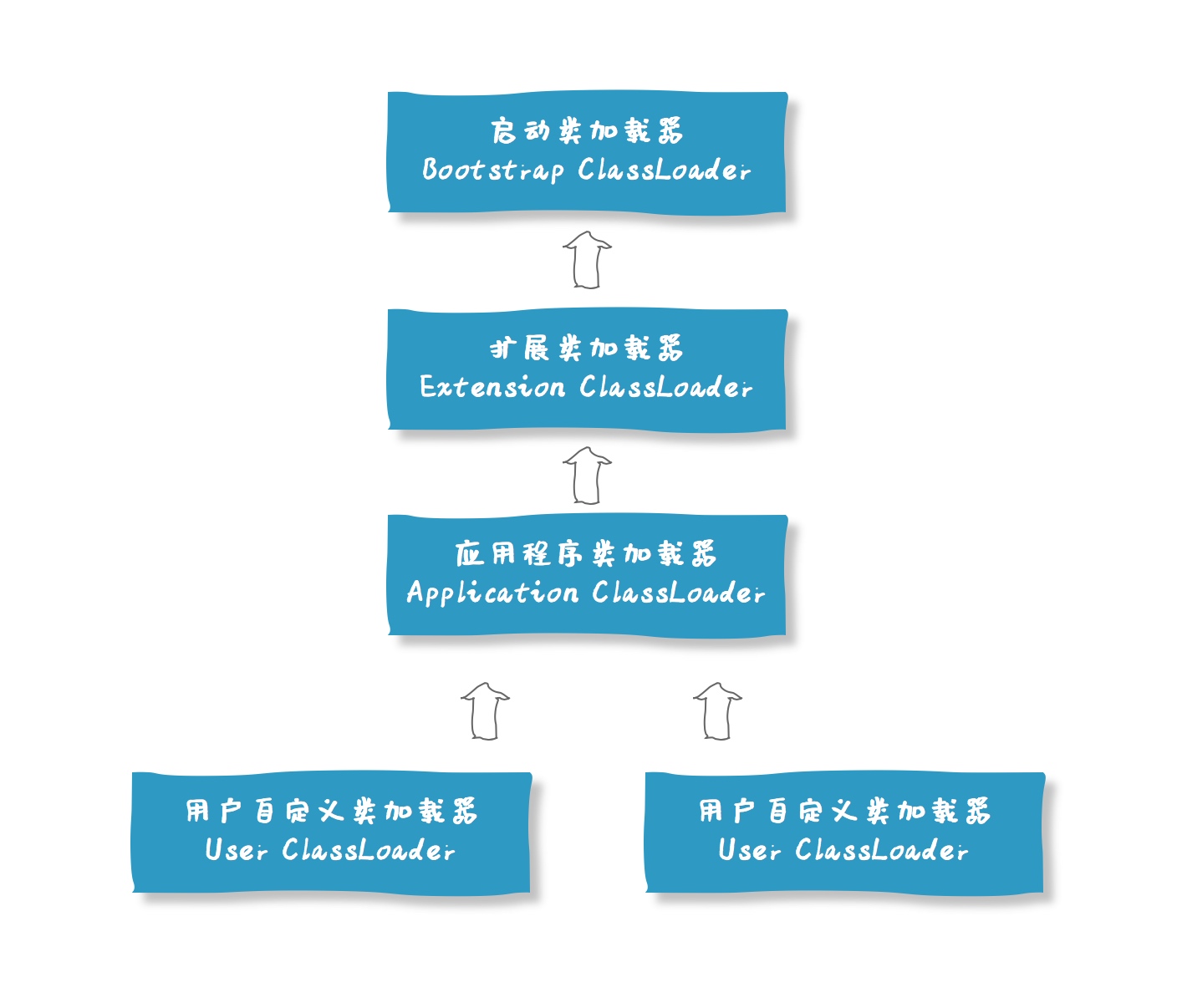
一般认为上一层加载器是下一层加载器的父加载器,那么,除了BootstrapClassLoader之外,所有的加载器都是有父加载器的。
那么,所谓的双亲委派机制,指的就是:当一个类加载器收到了类加载的请求的时候,他不会直接去加载指定的类,而是把这个请求委托给自己的父加载器去加载。只有父加载器无法加载这个类的时候,才会由当前这个加载器来负责类的加载。
那么,什么情况下父加载器会无法加载某一个类呢?
其实,Java中提供的这四种类型的加载器,是有各自的职责的:
* Bootstrap ClassLoader ,主要负责加载Java核心类库,%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等。
* Extention ClassLoader,主要负责加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件。
* Application ClassLoader ,主要负责加载当前应用的classpath下的所有类
* User ClassLoader , 用户自定义的类加载器,可加载指定路径的class文件
那么也就是说,一个用户自定义的类,如com.hollis.ClassHollis 是无论如何也不会被Bootstrap和Extention加载器加载的。
================================================
FILE: docs/basement/jvm/relation-with-parents-delegate.md
================================================
很多人看到父加载器、子加载器这样的名字,就会认为Java中的类加载器之间存在着继承关系。
甚至网上很多文章也会有类似的错误观点。
这里需要明确一下,双亲委派模型中,类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是都使用组合(Composition)关系来复用父加载器的代码的。
如下为ClassLoader中父加载器的定义:
public abstract class ClassLoader {
// The parent class loader for delegation
private final ClassLoader parent;
}
================================================
FILE: docs/basement/jvm/runtime-area.md
================================================
Java虚拟机在执行Java程序的过程中会把他所管理的内存划分为若干个不同的数据区域。《Java虚拟机规范》中规定了JVM所管理的内存需要包括一下几个运行时区域:

主要包含了PC寄存器(程序计数器)、Java虚拟机栈、本地方法栈、Java堆、方法区以及运行时常量池。
1、以上是Java虚拟机规范,不同的虚拟机实现会各有不同,但是一般会遵守规范。
2、规范中定义的方法区,只是一种概念上的区域,并说明了其应该具有什么功能。但是并没有规定这个区域到底应该处于何处。所以,对于不同的虚拟机实现来说,是由一定的自由度的。
3、不同版本的方法区所处位置不同,上图中划分的是逻辑区域,并不是绝对意义上的物理区域。因为某些版本的JDK中方法区其实是在堆中实现的。
4、运行时常量池用于存放编译期生成的各种字面量和符号应用。但是,Java语言并不要求常量只有在编译期才能产生。比如在运行期,String.intern也会把新的常量放入池中。
5、除了以上介绍的JVM运行时内存外,还有一块内存区域可供使用,那就是直接内存。Java虚拟机规范并没有定义这块内存区域,所以他并不由JVM管理,是利用本地方法库直接在堆外申请的内存区域。
6、堆和栈的数据划分也不是绝对的,如HotSpot的JIT会针对对象分配做相应的优化。
如上,做个总结,JVM内存结构,由Java虚拟机规范定义。描述的是Java程序执行过程中,由JVM管理的不同数据区域。各个区域有其特定的功能。
但是,需要注意的是,上面的区域划分只是逻辑区域,对于有些区域的限制是比较松的,所以不同的虚拟机厂商在实现上,甚至是同一款虚拟机的不同版本也是不尽相同的。
================================================
FILE: docs/basement/jvm/sample-of-break-parents-delegate.md
================================================
双亲委派机制的破坏不是什么稀奇的事情,很多框架、容器等都会破坏这种机制来实现某些功能。
*第一种被破坏的情况是在双亲委派出现之前。*
由于双亲委派模型是在JDK1.2之后才被引入的,而在这之前已经有用户自定义类加载器在用了。所以,这些是没有遵守双亲委派原则的。
*第二种,是JNDI、JDBC等需要加载SPI接口实现类的情况。*
*第三种是为了实现热插拔热部署工具。*为了让代码动态生效而无需重启,实现方式时把模块连同类加载器一起换掉就实现了代码的热替换。
*第四种时tomcat等web容器的出现。*
*第五种时OSGI、Jigsaw等模块化技术的应用。*
================================================
FILE: docs/basement/jvm/spi-parents-delegate.md
================================================
我们日常开发中,大多数时候会通过API的方式调用Java提供的那些基础类,这些基础类时被Bootstrap加载的。
但是,调用方式除了API之外,还有一种SPI的方式。
如典型的JDBC服务,我们通常通过以下方式创建数据库连接:
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mysql", "root", "1234");
在以上代码执行之前,DriverManager会先被类加载器加载,因为java.sql.DriverManager类是位于rt.jar下面的 ,所以他会被根加载器加载。
类加载时,会执行该类的静态方法。其中有一段关键的代码是:
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
这段代码,会尝试加载classpath下面的所有实现了Driver接口的实现类。
那么,问题就来了。
**DriverManager是被根加载器加载的,那么在加载时遇到以上代码,会尝试加载所有Driver的实现类,但是这些实现类基本都是第三方提供的,根据双亲委派原则,第三方的类不能被根加载器加载。**
那么,怎么解决这个问题呢?
于是,就**在JDBC中通过引入ThreadContextClassLoader(线程上下文加载器,默认情况下是AppClassLoader)的方式破坏了双亲委派原则。**
我们深入到ServiceLoader.load方法就可以看到:
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
第一行,获取当前线程的线程上下⽂类加载器 AppClassLoader,⽤于加载 classpath 中的具体实现类。
================================================
FILE: docs/basement/jvm/stack-alloc.md
================================================
### JVM内存分配策略
关于JVM的内存结构及内存分配方式,不是本文的重点,这里只做简单回顾。以下是我们知道的一些常识:
1、根据Java虚拟机规范,Java虚拟机所管理的内存包括方法区、虚拟机栈、本地方法栈、堆、程序计数器等。
2、我们通常认为JVM中运行时数据存储包括堆和栈。这里所提到的栈其实指的是虚拟机栈,或者说是虚拟栈中的局部变量表。
3、栈中存放一些基本类型的变量数据(int/short/long/byte/float/double/Boolean/char)和对象引用。
4、堆中主要存放对象,即通过new关键字创建的对象。
5、数组引用变量是存放在栈内存中,数组元素是存放在堆内存中。
在《深入理解Java虚拟机中》关于Java堆内存有这样一段描述:
但是,随着JIT编译期的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。
这里只是简单提了一句,并没有深入分析,很多人看到这里由于对JIT、逃逸分析等技术不了解,所以也无法真正理解上面这段话的含义。
**PS:这里默认大家都了解什么是JIT,不了解的朋友可以先自行Google了解下,或者加入我的知识星球,阅读那篇球友专享文章。**
其实,在编译期间,JIT会对代码做很多优化。其中有一部分优化的目的就是减少内存堆分配压力,其中一种重要的技术叫做**逃逸分析**。
### 逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。这是一种可以有效减少Java 程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
例如:
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
上述代码如果想要StringBuffer sb不逃出方法,可以这样写:
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
使用逃逸分析,编译器可以对代码做如下优化:
一、同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
二、将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配。
三、分离对象或标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。
上面的关于同步省略的内容,我在《[深入理解多线程(五)—— Java虚拟机的锁优化技术][1]》中有介绍过,即锁优化中的锁消除技术,依赖的也是逃逸分析技术。
本文,主要来介绍逃逸分析的第二个用途:将堆分配转化为栈分配。
> 其实,以上三种优化中,栈上内存分配其实是依靠标量替换来实现的。由于不是本文重点,这里就不展开介绍了。如果大家感兴趣,我后面专门出一篇文章,全面介绍下逃逸分析。
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析, `-XX:+DoEscapeAnalysis` : 表示开启逃逸分析 `-XX:-DoEscapeAnalysis` : 表示关闭逃逸分析 从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定`-XX:-DoEscapeAnalysis`
### 对象的栈上内存分配
我们知道,在一般情况下,对象和数组元素的内存分配是在堆内存上进行的。但是随着JIT编译器的日渐成熟,很多优化使这种分配策略并不绝对。JIT编译器就可以在编译期间根据逃逸分析的结果,来决定是否可以将对象的内存分配从堆转化为栈。
我们来看以下代码:
public static void main(String[] args) {
long a1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
alloc();
}
// 查看执行时间
long a2 = System.currentTimeMillis();
System.out.println("cost " + (a2 - a1) + " ms");
// 为了方便查看堆内存中对象个数,线程sleep
try {
Thread.sleep(100000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
private static void alloc() {
User user = new User();
}
static class User {
}
其实代码内容很简单,就是使用for循环,在代码中创建100万个User对象。
**我们在alloc方法中定义了User对象,但是并没有在方法外部引用他。也就是说,这个对象并不会逃逸到alloc外部。经过JIT的逃逸分析之后,就可以对其内存分配进行优化。**
我们指定以下JVM参数并运行:
-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
在程序打印出 `cost XX ms` 后,代码运行结束之前,我们使用`[jmap][1]`命令,来查看下当前堆内存中有多少个User对象:
➜ ~ jps
2809 StackAllocTest
2810 Jps
➜ ~ jmap -histo 2809
num #instances #bytes class name
----------------------------------------------
1: 524 87282184 [I
2: 1000000 16000000 StackAllocTest$User
3: 6806 2093136 [B
4: 8006 1320872 [C
5: 4188 100512 java.lang.String
6: 581 66304 java.lang.Class
从上面的jmap执行结果中我们可以看到,堆中共创建了100万个`StackAllocTest$User`实例。
在关闭逃避分析的情况下(-XX:-DoEscapeAnalysis),虽然在alloc方法中创建的User对象并没有逃逸到方法外部,但是还是被分配在堆内存中。也就说,如果没有JIT编译器优化,没有逃逸分析技术,正常情况下就应该是这样的。即所有对象都分配到堆内存中。
接下来,我们开启逃逸分析,再来执行下以上代码。
-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
在程序打印出 `cost XX ms` 后,代码运行结束之前,我们使用`jmap`命令,来查看下当前堆内存中有多少个User对象:
➜ ~ jps
709
2858 Launcher
2859 StackAllocTest
2860 Jps
➜ ~ jmap -histo 2859
num #instances #bytes class name
----------------------------------------------
1: 524 101944280 [I
2: 6806 2093136 [B
3: 83619 1337904 StackAllocTest$User
4: 8006 1320872 [C
5: 4188 100512 java.lang.String
6: 581 66304 java.lang.Class
从以上打印结果中可以发现,开启了逃逸分析之后(-XX:+DoEscapeAnalysis),在堆内存中只有8万多个`StackAllocTest$User`对象。也就是说在经过JIT优化之后,堆内存中分配的对象数量,从100万降到了8万。
> 除了以上通过jmap验证对象个数的方法以外,读者还可以尝试将堆内存调小,然后执行以上代码,根据GC的次数来分析,也能发现,开启了逃逸分析之后,在运行期间,GC次数会明显减少。正是因为很多堆上分配被优化成了栈上分配,所以GC次数有了明显的减少。
### 总结
所以,如果以后再有人问你:是不是所有的对象和数组都会在堆内存分配空间?
那么你可以告诉他:不一定,随着JIT编译器的发展,在编译期间,如果JIT经过逃逸分析,发现有些对象没有逃逸出方法,那么有可能堆内存分配会被优化成栈内存分配。但是这也并不是绝对的。就像我们前面看到的一样,在开启逃逸分析之后,也并不是所有User对象都没有在堆上分配。
[1]: http://www.hollischuang.com/archives/2344
================================================
FILE: docs/basement/jvm/tomcat-parents-delegate.md
================================================
我们知道,Tomcat是web容器,那么一个web容器可能需要部署多个应用程序。
不同的应用程序可能会依赖同一个第三方类库的不同版本,但是不同版本的类库中某一个类的全路径名可能是一样的。
如多个应用都要依赖hollis.jar,但是A应用需要依赖1.0.0版本,但是B应用需要依赖1.0.1版本。这两个版本中都有一个类是com.hollis.Test.class。
**如果采用默认的双亲委派类加载机制,那么是无法加载多个相同的类。**
所以,**Tomcat破坏双亲委派原则,提供隔离的机制,为每个web容器单独提供一个WebAppClassLoader加载器。**
Tomcat的类加载机制:为了实现隔离性,优先加载 Web 应用自己定义的类,所以没有遵照双亲委派的约定,每一个应用自己的类加载器——WebAppClassLoader负责加载本身的目录下的class文件,加载不到时再交给CommonClassLoader加载,这和双亲委派刚好相反。
================================================
FILE: docs/basement/jvm/why-parents-delegate.md
================================================
如前文我们提到的,因为类加载器之间有严格的层次关系,那么也就使得Java类也随之具备了层次关系。
或者说这种层次关系是优先级。
比如一个定义在java.lang包下的类,因为它被存放在rt.jar之中,所以在被加载过程汇总,会被一直委托到Bootstrap ClassLoader,最终由Bootstrap ClassLoader所加载。
而一个用户自定义的com.hollis.ClassHollis类,他也会被一直委托到Bootstrap ClassLoader,但是因为Bootstrap ClassLoader不负责加载该类,那么会在由Extention ClassLoader尝试加载,而Extention ClassLoader也不负责这个类的加载,最终才会被Application ClassLoader加载。
这种机制有几个好处。
首先,通过委派的方式,可以避免类的重复加载,当父加载器已经加载过某一个类时,子加载器就不会再重新加载这个类。
另外,通过双亲委派的方式,还保证了安全性。因为Bootstrap ClassLoader在加载的时候,只会加载JAVA_HOME中的jar包里面的类,如java.lang.Integer,那么这个类是不会被随意替换的,除非有人跑到你的机器上, 破坏你的JDK。
那么,就可以避免有人自定义一个有破坏功能的java.lang.Integer被加载。这样可以有效的防止核心Java API被篡改。
================================================
FILE: docs/basics/concurrent-coding/concurrent-vs-parallel.md
================================================
Erlang 之父 Joe Armstrong 用一张比较形象的图解释了并发与并行的区别:

并发是两个队伍交替使用一台咖啡机。并行是两个队伍同时使用两台咖啡机。
映射到计算机系统中,上图中的咖啡机就是CPU,两个队伍指的就是两个进程。
================================================
FILE: docs/basics/concurrent-coding/concurrent.md
================================================
并发(Concurrent),在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。
那么,操作系统是如何实现这种并发的呢?
现在我们用到操作系统,无论是Windows、Linux还是MacOS等其实都是**多用户多任务分时操作系统**。使用这些操作系统的用户是可以“同时”干多件事的。
但是实际上,对于单CPU的计算机来说,在CPU中,同一时间是只能干一件事儿的。为了看起来像是“同时干多件事”,分时操作系统是把CPU的时间划分成长短基本相同的时间区间,即”时间片”,通过操作系统的管理,把这些时间片依次轮流地分配给各个用户使用。
如果某个作业在时间片结束之前,整个任务还没有完成,那么该作业就被暂停下来,放弃CPU,等待下一轮循环再继续做.此时CPU又分配给另一个作业去使用。
由于计算机的处理速度很快,只要时间片的间隔取得适当,那么一个用户作业从用完分配给它的一个时间片到获得下一个CPU时间片,中间有所”停顿”,但用户察觉不出来,好像整个系统全由它”独占”似的。
所以,在单CPU的计算机中,我们看起来“同时干多件事”,其实是通过CPU时间片技术,并发完成的。
================================================
FILE: docs/basics/concurrent-coding/create-thread-with-Implement.md
================================================
public class MultiThreads {
public static void main(String[] args) throws InterruptedException {
System.out.println(Thread.currentThread().getName());
System.out.println("实现Runnable接口创建线程");
RunnableThread runnableThread = new RunnableThread();
new Thread(runnableThread).start();
}
}
class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
}
输出结果:
main
实现Runnable接口创建线程
Thread-1
通过实现接口,同样覆盖`run()`就可以创建一个新的线程了。
我们都知道,Java是不支持多继承的,所以,使用Runnbale接口的形式,就可以避免要多继承 。比如有一个类A,已经继承了类B,就无法再继承Thread类了,这时候要想实现多线程,就需要使用Runnable接口了。
除此之外,两者之间几乎无差别。
但是,这两种创建线程的方式,其实是有一个缺点的,那就是:在执行完任务之后无法获取执行结果。
如果我们希望再主线程中得到子线程的执行结果的话,就需要用到Callable和FutureTask
================================================
FILE: docs/basics/concurrent-coding/create-thread-with-callback-future-task.md
================================================
自从Java 1.5开始,提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果。
public class MultiThreads {
public static void main(String[] args) throws InterruptedException {
CallableThread callableThread = new CallableThread();
FutureTask futureTask = new FutureTask<>(callableThread);
new Thread(futureTask).start();
System.out.println(futureTask.get());
}
class CallableThread implements Callable {
@Override
public Object call() throws Exception {
System.out.println(Thread.currentThread().getName());
return "Hollis";
}
}
输出结果:
main
通过Callable和FutureTask创建线程
Thread-2
Hollis
Callable位于java.util.concurrent包下,它也是一个接口,在它里面也只声明了一个方法,只不过这个方法call(),和Runnable接口中的run()方法不同的是,call()方法有返回值。
以上代码中,我们在CallableThread的call方法中返回字符串"Hollis",在主线程是可以获取到的。
FutureTask可用于异步获取执行结果或取消执行任务的场景。通过传入Callable的任务给FutureTask,直接调用其run方法或者放入线程池执行,之后可以在外部通过FutureTask的get方法异步获取执行结果,因此,FutureTask非常适合用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。
另外,FutureTask还可以确保即使调用了多次run方法,它都只会执行一次Runnable或者Callable任务,或者通过cancel取消FutureTask的执行等。
值得注意的是,`futureTask.get()`会阻塞主线程,一直等子线程执行完并返回后才能继续执行主线程后面的代码。
一般,在Callable执行完之前的这段时间,主线程可以先去做一些其他的事情,事情都做完之后,再获取Callable的返回结果。可以通过`isDone()`来判断子线程是否执行完。
以上代码改造下就是如下内容:
public class MultiThreads {
public static void main(String[] args) throws InterruptedException {
CallableThread callableThread = new CallableThread();
FutureTask futureTask = new FutureTask<>(callableThread);
new Thread(futureTask).start();
System.out.println("主线程先做其他重要的事情");
if(!futureTask.isDone()){
// 继续做其他事儿
}
System.out.println(future.get()); // 可能会阻塞等待结果
}
一般,我们会把Callable放到线程池中,然后让线程池去执行Callable中的代码。关于线程池前面介绍过了,是一种避免重复创建线程的开销的技术手段,线程池也可以用来创建线程。
================================================
FILE: docs/basics/concurrent-coding/create-thread-with-extends.md
================================================
/**
* @author Hollis
*/
public class MultiThreads {
public static void main(String[] args) throws InterruptedException {
System.out.println(Thread.currentThread().getName());
System.out.println("继承Thread类创建线程");
SubClassThread subClassThread = new SubClassThread();
subClassThread.start();
}
}
class SubClassThread extends Thread {
@Override
public void run() {
System.out.println(getName());
}
}
输出结果:
main
继承Thread类创建线程
Thread-0
SubClassThread是一个继承了Thread类的子类,继承Thread类,并重写其中的run方法。然后new 一个SubClassThread的对象,并调用其start方法,即可启动一个线程。之后就会运行run中的代码。
每个线程都是通过某个特定Thread对象所对应的方法`run()`来完成其操作的,方法`run()`称为线程体。通过调用Thread类的`start()`方法来启动一个线程。
在主线程中,调用了子线程的`start()`方法后,主线程无需等待子线程的执行,即可执行后续的代码。而子线程便会开始执行其`run()`方法。
当然,`run()`方法也是一个公有方法,在main函数中也可以直接调用这个方法,但是直接调用`run()`的话,主线程就需要等待其执行完,这种情况下,`run()`就是一个普通方法。
如果读者感兴趣的话,查看一下前面介绍的Thread的源码,就可以发现,他继承了一个接口,那就是`java.lang.Runnable`,其实,开发者在代码中也可以直接通过这个接口创建一个新的线程。
================================================
FILE: docs/basics/concurrent-coding/create-thread-with-thead-pool.md
================================================
Java中提供了对线程池的支持,有很多种方式。Jdk提供给外部的接口也很简单。直接调用ThreadPoolExecutor构造一个就可以了:
public class MultiThreads {
public static void main(String[] args) throws InterruptedException, ExecutionException {
System.out.println(Thread.currentThread().getName());
System.out.println("通过线程池创建线程");
ExecutorService executorService = new ThreadPoolExecutor(1, 1, 60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(10));
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
}
}
输出结果:
main
通过线程池创建线程
pool-1-thread-1
所谓线程池本质是一个hashSet。多余的任务会放在阻塞队列中。
线程池的创建方式其实也有很多,也可以通过Executors静态工厂构建,但一般不建议。建议使用线程池来创建线程,并且建议使用带有ThreadFactory参数的ThreadPoolExecutor(需要依赖guava)构造方法设置线程名字,具体原因我们在后面的章节中在详细介绍。
================================================
FILE: docs/basics/concurrent-coding/deadlock-java-level.md
================================================
java级别死锁
## 一、什么是死锁
死锁不仅在个人学习中,甚至在开发中也并不常见。但是一旦出现死锁,后果将非常严重。
首先什么是死锁呢?打个比方,就好像有两个人打架,互相限制住了(锁住,抱住)彼此一样,互相动弹不得,而且互相欧气,你不松手我就不松手。好了谁也动弹不得。
在多线程的环境下,势必会对资源进行抢夺。当两个线程锁住了当前资源,但都需要对方的资源才能进行下一步操作,这个时候两方就会一直等待对方的资源释放。这就形成了死锁。这些永远在互相等待的进程称为死锁进程。
那么我们来总结一下死锁产生的条件:
1. 互斥:资源的锁是排他性的,加锁期间只能有一个线程拥有该资源。其他线程只能等待锁释放才能尝试获取该资源。
2. 请求和保持:当前线程已经拥有至少一个资源,但其同时又发出新的资源请求,而被请求的资源被其他线程拥有。此时进入保持当前资源并等待下个资源的状态。
3. 不剥夺:线程已拥有的资源,只能由自己释放,不能被其他线程剥夺。
4. 循环等待:是指有多个线程互相的请求对方的资源,但同时拥有对方下一步所需的资源。形成一种循环,类似2)请求和保持。但此处指多个线程的关系。并不是指单个线程一直在循环中等待。
什么?还是不理解?那我们直接上代码,动手写一个死锁。
## 二、动手写死锁
根据条件,我们让两个线程互相请求保持。
```java
public class DeadLockDemo implements Runnable{
public static int flag = 1;
//static 变量是 类对象共享的
static Object o1 = new Object();
static Object o2 = new Object();
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ":此时 flag = " + flag);
if(flag == 1){
synchronized (o1){
try {
System.out.println("我是" + Thread.currentThread().getName() + "锁住 o1");
Thread.sleep(3000);
System.out.println(Thread.currentThread().getName() + "醒来->准备获取 o2");
}catch (Exception e){
e.printStackTrace();
}
synchronized (o2){
System.out.println(Thread.currentThread().getName() + "拿到 o2");//第24行
}
}
}
if(flag == 0){
synchronized (o2){
try {
System.out.println("我是" + Thread.currentThread().getName() + "锁住 o2");
Thread.sleep(3000);
System.out.println(Thread.currentThread().getName() + "醒来->准备获取 o2");
}catch (Exception e){
e.printStackTrace();
}
synchronized (o1){
System.out.println(Thread.currentThread().getName() + "拿到 o1");//第38行
}
}
}
}
public static void main(String args[]){
DeadLockDemo t1 = new DeadLockDemo();
DeadLockDemo t2 = new DeadLockDemo();
t1.flag = 1;
new Thread(t1).start();
//让main线程休眠1秒钟,保证t2开启锁住o2.进入死锁
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.flag = 0;
new Thread(t2).start();
}
}
```
代码中,
t1创建,t1先拿到o1的锁,开始休眠3秒。然后
t2线程创建,t2拿到o2的锁,开始休眠3秒。然后
t1先醒来,准备拿o2的锁,发现o2已经加锁,只能等待o2的锁释放。
t2后醒来,准备拿o1的锁,发现o1已经加锁,只能等待o1的锁释放。
t1,t2形成死锁。
我们查看运行状态,

## 三、发现排查死锁情况
我们利用jdk提供的工具定位死锁问题:
1. jps显示所有当前Java虚拟机进程名及pid.
2. jstack打印进程堆栈信息。
列出所有java进程。
我们检查一下DeadLockDemo,为什么这个线程不退栈。
```shell
jstack 11170
```

我们直接翻到最后:已经检测出了一个java级别死锁。其中两个线程分别卡在了代码第38行和第24行。检查我们代码的对应位置,即可排查错误。此处我们是第二个锁始终拿不到,所以死锁了。

## 四、解决办法
死锁一旦发生,我们就无法解决了。所以我们只能避免死锁的发生。
既然死锁需要满足四种条件,那我们就从条件下手,只要打破任意规则即可。
1. (互斥)尽量少用互斥锁,能加读锁,不加写锁。当然这条无法避免。
2. (请求和保持)采用资源静态分配策略(进程资源静态分配方式是指一个进程在建立时就分配了它需要的全部资源).我们尽量不让线程同时去请求多个锁,或者在拥有一个锁又请求不到下个锁时,不保持等待,先释放资源等待一段时间在重新请求。
3. (不剥夺)允许进程剥夺使用其他进程占有的资源。优先级。
4. (循环等待)尽量调整获得锁的顺序,不发生嵌套资源请求。加入超时。
================================================
FILE: docs/basics/concurrent-coding/deamon-thread.md
================================================
在Java中有两类线程:User Thread(用户线程)、Daemon Thread(守护线程) 。用户线程一般用户执行用户级任务,而守护线程也就是“后台线程”,一般用来执行后台任务,守护线程最典型的应用就是GC(垃圾回收器)。
这两种线程其实是没有什么区别的,唯一的区别就是Java虚拟机在所有“用户线程”都结束后就会退出。
我们可以通过使用`setDaemon()`方法通过传递true作为参数,使线程成为一个守护线程。我们必须在启动线程之前调用一个线程的`setDaemon()`方法。否则,就会抛出一个`java.lang.IllegalThreadStateException`。
可以使用`isDaemon()`方法来检查线程是否是守护线程。
/**
* @author Hollis
*/
public class Main {
public static void main(String[] args) {
Thread t1 = new Thread();
System.out.println(t1.isDaemon());
t1.setDaemon(true);
System.out.println(t1.isDaemon());
t1.start();
t1.setDaemon(false);
}
}
以上代码输出结果:
false
true
Exception in thread "main" java.lang.IllegalThreadStateException
at java.lang.Thread.setDaemon(Thread.java:1359)
at com.hollis.Main.main(Main.java:16)
我们提到,当JVM中只剩下守护线程的时候,JVM就会退出,那么写一段代码测试下:
/**
* @author Hollis
*/
public class Main {
public static void main(String[] args) {
Thread childThread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println("I'm child thread..");
try {
TimeUnit.MILLISECONDS.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
childThread.start();
System.out.println("I'm main thread...");
}
}
以上代码中,我们在Main线程中开启了一个子线程,在并没有显示将其设置为守护线程的情况下,他是一个用户线程,代码比较好理解,就是子线程处于一个while(true)循环中,每隔一秒打印一次`I'm child thread..`
输出结果为:
I'm main thread...
I'm child thread..
I'm child thread..
.....
I'm child thread..
I'm child thread..
我们再把子线程设置成守护线程,重新运行以上代码。
/**
* @author Hollis
*/
public class Main {
public static void main(String[] args) {
Thread childThread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println("I'm child thread..");
try {
TimeUnit.MILLISECONDS.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
childThread.setDaemon(true);
childThread.start();
System.out.println("I'm main thread...");
}
}
以上代码,我们通过`childThread.setDaemon(true);`把子线程设置成守护线程,然后运行,得到以下结果:
I'm main thread...
I'm child thread..
子线程只打印了一次,也就是,在main线程执行结束后,由于子线程是一个守护线程,JVM就会直接退出了。
**值得注意的是,在Daemon线程中产生的新线程也是Daemon的。**
提到线程,有一个很重要的东西我们需要介绍一下,那就是ThreadLocal。
================================================
FILE: docs/basics/concurrent-coding/debug-in-multithread.md
================================================
在学习过了前面几篇文章之后,相信很多人对于Java中的多线程都有了一定的了解,相信很多读者已经尝试过中写一些多线程的代码了。
但是我之前面试过很多人,很多人都知道多线程怎么实现,但是却不知道如何调试多线程的代码,这篇文章我们来介绍下如何调试多线程的代码。
首先我们写一个多线程的例子,使用实现Runnable接口的方式定义多个线程,并启动执行。
/**
* @author Hollis
*/
public class MultiThreadDebug {
public static void main(String[] args) {
MyThread myThread = new MyThread();
Thread thread1 = new Thread(myThread, "thread 1");
Thread thread2 = new Thread(myThread, "thread 2");
Thread thread3 = new Thread(myThread, "thread 3");
thread1.start();
thread2.start();
thread3.start();
}
}
class MyThread implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " running");
}
}
我们尝试在代码中设置断点,并使用debug模式启动。
![][1]
如题,程序启动后,会进入一个线程的断点中,我们尝试看一下当前是哪个线程:
![][2]
发现是thread 1进入了断点。接着,我们尝试让代码继续执行,代码就直接结束运行,并且控制台打印如下:
Connected to the target VM, address: '127.0.0.1:55768', transport: 'socket'
thread 3 running
Disconnected from the target VM, address: '127.0.0.1:55768', transport: 'socket'
thread 2 running
thread 1 running
Process finished with exit code 0
如果我们多次执行这个代码,就会发现,每一次打印的结果都不一样,三个线程的输出顺序是随机的,并且每一次debug只会进入到一个线程的执行。
每次执行结果随即是因为不一定哪个线程可以先获得CPU时间片。
那么,我们怎么才能让每一个线程的执行都能被debug呢?如何在多线程中进行debug排查问题呢?
其实,在IDEA中有一个设置,那就是当我们在断点处单击鼠标右键就会弹出一个设置对话框,当我们把其中的All 修改为 Thread之后,尝试重新执行debug代码。
![][3]
重新执行之后,就可以发现,每一个线程都会进入到断点当中了。
[1]: https://www.hollischuang.com/wp-content/uploads/2020/11/16065562943648.jpg
[2]: https://www.hollischuang.com/wp-content/uploads/2020/11/16065563249582.jpg
[3]: https://www.hollischuang.com/wp-content/uploads/2020/11/16065565440571.jpg
================================================
FILE: docs/basics/concurrent-coding/implement-of-thread.md
================================================
主流的操作系统都提供了线程实现,实现线程主要有3种方式:使用内核线程实现、使用用户线程实现和使用用户线程加轻量级进程混合实现。
## 使用内核线程实现
内核线程(Kernel-Level Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核(Multi-Threads Kernel)。
程序一般不会直接去使用内核线程,而是去使用内核线程的一种高级接口——轻量级进程(Light Weight Process,LWP),轻量级进程就是我们通常意义上所讲的线程,由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。这种轻量级进程与内核线程之间1:1的关系称为一对一的线程模型,如图所示。
![][1]
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使有一个轻量级进程在系统调用中阻塞了,也不会影响整个进程继续工作,但是轻量级进程具有它的局限性:首先,由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。其次,每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
## 使用用户线程实现
从广义上来讲,一个线程只要不是内核线程,就可以认为是用户线程(User Thread,UT),因此,从这个定义上来讲,轻量级进程也属于用户线程,但轻量级进程的实现始终是建立在内核之上的,许多操作都要进行系统调用,效率会受到限制。
而狭义上的用户线程指的是完全建立在用户空间的线程库上,系统内核不能感知线程存在的实现。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。如果程序实现得当,这种线程不需要切换到内核态,因此操作可以是非常快速且低消耗的,也可以支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。这种进程与用户线程之间1:N的关系称为一对多的线程模型,如图所示。
![][2]
使用用户线程的优势在于不需要系统内核支援,劣势也在于没有系统内核的支援,所有的线程操作都需要用户程序自己处理。线程的创建、切换和调度都是需要考虑的问题,而且由于操作系统只把处理器资源分配到进程,那诸如“阻塞如何处理”、“多处理器系统中如何将线程映射到其他处理器上”这类问题解决起来将会异常困难,甚至不可能完成。因而使用用户线程实现的程序一般都比较复杂 ,除了以前在不支持多线程的操作系统中(如DOS)的多线程程序与少数有特殊需求的程序外,现在使用用户线程的程序越来越少了,Java、Ruby等语言都曾经使用过用户线程,最终又都放弃使用它。
## 使用用户线程加轻量级进程混合实现
线程除了依赖内核线程实现和完全由用户程序自己实现之外,还有一种将内核线程与用户线程一起使用的实现方式。在这种混合实现下,既存在用户线程,也存在轻量级进程。用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并且可以支持大规模的用户线程并发。而操作系统提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级线程来完成,大大降低了整个进程被完全阻塞的风险。在这种混合模式中,用户线程与轻量级进程的数量比是不定的,即为N:M的关系,如图12-5所示,这种就是多对多的线程模型。
许多UNIX系列的操作系统,如Solaris、HP-UX等都提供了N:M的线程模型实现。
![][3]
## Java线程的实现
Java线程在JDK 1.2之前,是基于称为“绿色线程”(Green Threads)的用户线程实现的,而在JDK 1.2中,线程模型替换为基于操作系统原生线程模型来实现。因此,在目前的JDK版本中,操作系统支持怎样的线程模型,在很大程度上决定了Java虚拟机的线程是怎样映射的,这点在不同的平台上没有办法达成一致,虚拟机规范中也并未限定Java线程需要使用哪种线程模型来实现。线程模型只对线程的并发规模和操作成本产生影响,对Java程序的编码和运行过程来说,这些差异都是透明的。
对于Sun JDK来说,它的Windows版与Linux版都是使用一对一的线程模型实现的,一条Java线程就映射到一条轻量级进程之中,因为Windows和Linux系统提供的线程模型就是一对一的。
而在Solaris平台中,由于操作系统的线程特性可以同时支持一对一(通过Bound Threads或Alternate Libthread实现)及多对多(通过LWP/Thread Based Synchronization实现)的线程模型,因此在Solaris版的JDK中也对应提供了两个平台专有的虚拟机参数:-XX:+UseLWPSynchronization(默认值)和-XX:+UseBoundThreads来明确指定虚拟机使用哪种线程模型。 Java语言则提供了在不同硬件和操作系统平台下对线程操作的统一处理,每个已经执行start()且还未结束的java.lang.Thread类的实例就代表了一个线程。我们注意到Thread类与大部分的Java API有显著的差别,它的所有关键方法都是声明为Native的。在Java API中,一个Native方法往往意味着这个方法没有使用或无法使用平台无关的手段来实现(当然也可能是为了执行效率而使用Native方法,不过,通常最高效率的手段也就是平台相关的手段)。
(参考:深入理解Java虚拟机)
[1]: http://www.hollischuang.com/wp-content/uploads/2018/12/15442554190788.jpg
[2]: http://www.hollischuang.com/wp-content/uploads/2018/12/15442554407298.jpg
[3]: http://www.hollischuang.com/wp-content/uploads/2018/12/15442554705166.jpg
================================================
FILE: docs/basics/concurrent-coding/parallel.md
================================================
并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
================================================
FILE: docs/basics/concurrent-coding/priority-of-thread.md
================================================
我们学习过,Java虚拟机采用抢占式调度模型。也就是说他会给优先级更高的线程优先分配CPU。
虽然Java线程调度是系统自动完成的,但是我们还是可以“建议”系统给某些线程多分配一点执行时间,另外的一些线程则可以少分配一点——这项操作可以通过设置线程优先级来完成。
Java语言一共设置了10个级别的线程优先级(Thread.MIN_PRIORITY至Thread.MAX_PRIORITY),在两个线程同时处于Ready状态时,优先级越高的线程越容易被系统选择执行。
Java 线程优先级使用 1 ~ 10 的整数表示。默认的优先级是5。
最低优先级 1:Thread.MIN_PRIORITY
最高优先级 10:Thread.MAX_PRIORITY
普通优先级 5:Thread.NORM_PRIORITY
在Java中,可以使用Thread类的`setPriority()`方法为线程设置了新的优先级。`getPriority()`方法返回线程的当前优先级。当创建一个线程时,其默认优先级是创建该线程的线程的优先级。
以下代码演示如何设置和获取线程的优先:
/**
* @author Hollis
*/
public class Main {
public static void main(String[] args) {
Thread t = Thread.currentThread();
System.out.println("Main Thread Priority:" + t.getPriority());
Thread t1 = new Thread();
System.out.println("Thread(t1) Priority:" + t1.getPriority());
t1.setPriority(Thread.MAX_PRIORITY - 1);
System.out.println("Thread(t1) Priority:" + t1.getPriority());
t.setPriority(Thread.NORM_PRIORITY);
System.out.println("Main Thread Priority:" + t.getPriority());
Thread t2 = new Thread();
System.out.println("Thread(t2) Priority:" + t2.getPriority());
// Change thread t2 priority to minimum
t2.setPriority(Thread.MIN_PRIORITY);
System.out.println("Thread(t2) Priority:" + t2.getPriority());
}
}
输出结果为:
Main Thread Priority:5
Thread(t1) Priority:5
Thread(t1) Priority:9
Main Thread Priority:5
Thread(t2) Priority:5
Thread(t2) Priority:1
在上面的代码中,Java虚拟机启动时,就会通过main方法启动一个线程,JVM就会一直运行下去,直到以下任意一个条件发生:
* 调用了exit()方法,并且exit()有权限被正常执行。
* 所有的“非守护线程”都死了(即JVM中仅仅只有“守护线程”)。
================================================
FILE: docs/basics/concurrent-coding/progress-vs-thread.md
================================================
为了看起来像是“同时干多件事”,分时操作系统是把CPU的时间划分成长短基本相同的”时间片”,通过操作系统的管理,把这些时间片依次轮流地分配给各个用户的各个任务使用。
在多任务处理系统中,CPU需要处理所有程序的操作,当用户来回切换它们时,需要记录这些程序执行到哪里。在操作系统中,CPU切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态:当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。**上下文切换**就是这样一个过程,他允许CPU记录并恢复各种正在运行程序的状态,使它能够完成切换操作。
> 在上下文切换过程中,CPU会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。从这个角度来看,上下文切换有点像我们同时阅读几本书,在来回切换书本的同时我们需要记住每本书当前读到的页码。在程序中,上下文切换过程中的“页码”信息是保存在进程控制块(PCB)中的。PCB还经常被称作“切换帧”(switchframe)。“页码”信息会一直保存到CPU的内存中,直到他们被再次使用。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
而在多个进程之间切换的时候,需要进行上下文切换。但是上下文切换势必会耗费一些资源。于是人们考虑,能不能在一个进程中增加一些“子任务”,这样减少上下文切换的成本。比如我们使用Word的时候,它可以同时进行打字、拼写检查、字数统计等,这些子任务之间共用同一个进程资源,但是他们之间的切换不需要进行上下文切换。
在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
随着时间的慢慢发展,人们进一步的切分了进程和线程之间的职责。**把进程当做资源分配的基本单元,把线程当做执行的基本单元,同一个进程的多个线程之间共享资源**
拿我们比较熟悉的Java语言来说,Java程序是运行在JVM上面的,每一个JVM其实就是一个进程。所有的资源分配都是基于JVM进程来的。而在这个JVM进程中,又可以创建出很多线程,多个线程之间共享JVM资源,并且多个线程可以并发执行。
================================================
FILE: docs/basics/concurrent-coding/state-of-thread.md
================================================
线程是有状态的,并且这些状态之间也是可以互相流转的。Java中线程的状态分为6种:
* 1\.初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
* 1\.运行(RUNNABLE):Java线程中将就绪(READY)和运行中(RUNNING)两种状态笼统的称为“运行”。
* 就绪(READY):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中并分配cpu使用权 。
* 运行中(RUNNING):就绪(READY)的线程获得了cpu 时间片,开始执行程序代码。
* 3\.阻塞(BLOCKED):表示线程阻塞于锁(关于锁,在后面章节会介绍)。
* 4\.等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
* 5\.超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
* 6\. 终止(TERMINATED):表示该线程已经执行完毕。
下图是一张线程状态的流转图:
<img src="https://www.hollischuang.com/wp-content/uploads/2018/12/167019dc85aaaf5a.jpg" alt="" width="1155" height="771" class="aligncenter size-full wp-image-5859" />
可以看到,图中的各个状态之间的流转路径上都有标注对应的Java中的方法。这些就是Java中进行线程调度的一些api。
================================================
FILE: docs/basics/concurrent-coding/synchronized.md
================================================
在[再有人问你Java内存模型是什么,就把这篇文章发给他。][1]中我们曾经介绍过,Java语言为了解决并发编程中存在的原子性、可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如`synchronized`、`volatile`、`final`、`concurren包`等。
在《深入理解Java虚拟机》中,有这样一段话:
> `synchronized`关键字在需要原子性、可见性和有序性这三种特性的时候都可以作为其中一种解决方案,看起来是“万能”的。的确,大部分并发控制操作都能使用synchronized来完成。
海明威在他的《午后之死》说过的:“冰山运动之雄伟壮观,是因为他只有八分之一在水面上。”对于程序员来说,`synchronized`只是个关键字而已,用起来很简单。之所以我们可以在处理多线程问题时可以不用考虑太多,就是因为这个关键字帮我们屏蔽了很多细节。
那么,本文就围绕`synchronized`展开,主要介绍`synchronized`的用法、`synchronized`的原理,以及`synchronized`是如何提供原子性、可见性和有序性保障的等。
### synchronized的用法
`synchronized`是Java提供的一个并发控制的关键字。主要有两种用法,分别是同步方法和同步代码块。也就是说,`synchronized`既可以修饰方法也可以修饰代码块。
/**
* @author Hollis 18/08/04.
*/
public class SynchronizedDemo {
//同步方法
public synchronized void doSth(){
System.out.println("Hello World");
}
//同步代码块
public void doSth1(){
synchronized (SynchronizedDemo.class){
System.out.println("Hello World");
}
}
}
被`synchronized`修饰的代码块及方法,在同一时间,只能被单个线程访问。
### synchronized的实现原理
`synchronized`,是Java中用于解决并发情况下数据同步访问的一个很重要的关键字。当我们想要保证一个共享资源在同一时间只会被一个线程访问到时,我们可以在代码中使用`synchronized`关键字对类或者对象加锁。
在[深入理解多线程(一)——Synchronized的实现原理][2]中我曾经介绍过其实现原理,为了保证知识的完整性,这里再简单介绍一下,详细的内容请去原文阅读。
我们对上面的代码进行反编译,可以得到如下代码:
public synchronized void doSth();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello World
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
public void doSth1();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: ldc #5 // class com/hollis/SynchronizedTest
2: dup
3: astore_1
4: monitorenter
5: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
8: ldc #3 // String Hello World
10: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
13: aload_1
14: monitorexit
15: goto 23
18: astore_2
19: aload_1
20: monitorexit
21: aload_2
22: athrow
23: return
通过反编译后代码可以看出:对于同步方法,JVM采用`ACC_SYNCHRONIZED`标记符来实现同步。 对于同步代码块。JVM采用`monitorenter`、`monitorexit`两个指令来实现同步。
在[The Java® Virtual Machine Specification][3]中有关于同步方法和同步代码块的实现原理的介绍,我翻译成中文如下:
> 方法级的同步是隐式的。同步方法的常量池中会有一个`ACC_SYNCHRONIZED`标志。当某个线程要访问某个方法的时候,会检查是否有`ACC_SYNCHRONIZED`,如果有设置,则需要先获得监视器锁,然后开始执行方法,方法执行之后再释放监视器锁。这时如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。值得注意的是,如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,那么在异常被抛到方法外面之前监视器锁会被自动释放。
>
> 同步代码块使用`monitorenter`和`monitorexit`两个指令实现。可以把执行`monitorenter`指令理解为加锁,执行`monitorexit`理解为释放锁。 每个对象维护着一个记录着被锁次数的计数器。未被锁定的对象的该计数器为0,当一个线程获得锁(执行`monitorenter`)后,该计数器自增变为 1 ,当同一个线程再次获得该对象的锁的时候,计数器再次自增。当同一个线程释放锁(执行`monitorexit`指令)的时候,计数器再自减。当计数器为0的时候。锁将被释放,其他线程便可以获得锁。
无论是`ACC_SYNCHRONIZED`还是`monitorenter`、`monitorexit`都是基于Monitor实现的,在Java虚拟机(HotSpot)中,Monitor是基于C++实现的,由ObjectMonitor实现。
ObjectMonitor类中提供了几个方法,如`enter`、`exit`、`wait`、`notify`、`notifyAll`等。`sychronized`加锁的时候,会调用objectMonitor的enter方法,解锁的时候会调用exit方法。(关于Monitor详见[深入理解多线程(四)—— Moniter的实现原理][4])
### synchronized与原子性
原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行。
我们在[Java的并发编程中的多线程问题到底是怎么回事儿?][5]中分析过:线程是CPU调度的基本单位。CPU有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去CPU使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。
在Java中,为了保证原子性,提供了两个高级的字节码指令`monitorenter`和`monitorexit`。前面中,介绍过,这两个字节码指令,在Java中对应的关键字就是`synchronized`。
通过`monitorenter`和`monitorexit`指令,可以保证被`synchronized`修饰的代码在同一时间只能被一个线程访问,在锁未释放之前,无法被其他线程访问到。因此,在Java中可以使用`synchronized`来保证方法和代码块内的操作是原子性的。
> 线程1在执行`monitorenter`指令的时候,会对Monitor进行加锁,加锁后其他线程无法获得锁,除非线程1主动解锁。即使在执行过程中,由于某种原因,比如CPU时间片用完,线程1放弃了CPU,但是,他并没有进行解锁。而由于`synchronized`的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码。直到所有代码执行完。这就保证了原子性。
### synchronized与可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
我们在[再有人问你Java内存模型是什么,就把这篇文章发给他。][1]中分析过:Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。所以,就可能出现线程1改了某个变量的值,但是线程2不可见的情况。
前面我们介绍过,被`synchronized`修饰的代码,在开始执行时会加锁,执行完成后会进行解锁。而为了保证可见性,有一条规则是这样的:对一个变量解锁之前,必须先把此变量同步回主存中。这样解锁后,后续线程就可以访问到被修改后的值。
所以,synchronized关键字锁住的对象,其值是具有可见性的。
### synchronized与有序性
有序性即程序执行的顺序按照代码的先后顺序执行。
我们在[再有人问你Java内存模型是什么,就把这篇文章发给他。][1]中分析过:除了引入了时间片以外,由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如load->add->save 有可能被优化成load->save->add 。这就是可能存在有序性问题。
这里需要注意的是,`synchronized`是无法禁止指令重排和处理器优化的。也就是说,`synchronized`无法避免上述提到的问题。
那么,为什么还说`synchronized`也提供了有序性保证呢?
这就要再把有序性的概念扩展一下了。Java程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有操作都是天然有序的。如果在一个线程中观察另一个线程,所有操作都是无序的。
以上这句话也是《深入理解Java虚拟机》中的原句,但是怎么理解呢?周志明并没有详细的解释。这里我简单扩展一下,这其实和`as-if-serial语义`有关。
`as-if-serial`语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果都不能被改变。编译器和处理器无论如何优化,都必须遵守`as-if-serial`语义。
这里不对`as-if-serial语义`详细展开了,简单说就是,`as-if-serial语义`保证了单线程中,指令重排是有一定的限制的,而只要编译器和处理器都遵守了这个语义,那么就可以认为单线程程序是按照顺序执行的。当然,实际上还是有重排的,只不过我们无须关心这种重排的干扰。
所以呢,由于`synchronized`修饰的代码,同一时间只能被同一线程访问。那么也就是单线程执行的。所以,可以保证其有序性。
### synchronized与锁优化
前面介绍了`synchronized`的用法、原理以及对并发编程的作用。是一个很好用的关键字。
`synchronized`其实是借助Monitor实现的,在加锁时会调用objectMonitor的`enter`方法,解锁的时候会调用`exit`方法。事实上,只有在JDK1.6之前,synchronized的实现才会直接调用ObjectMonitor的`enter`和`exit`,这种锁被称之为重量级锁。
所以,在JDK1.6中出现对锁进行了很多的优化,进而出现轻量级锁,偏向锁,锁消除,适应性自旋锁,锁粗化(自旋锁在1.4就有,只不过默认的是关闭的,jdk1.6是默认开启的),这些操作都是为了在线程之间更高效的共享数据 ,解决竞争问题。
关于自旋锁、锁粗化和锁消除可以参考[深入理解多线程(五)—— Java虚拟机的锁优化技术][6],关于轻量级锁和偏向锁,已经在排期规划中,我后面会有文章单独介绍,将独家发布在我的博客(http://www.hollischuang.com)和公众号(Hollis)中,敬请期待。
好啦,关于`synchronized`关键字,我们介绍了其用法、原理、以及如何保证的原子性、顺序性和可见性,同时也扩展的留下了锁优化相关的资料及思考。后面我们会继续介绍`volatile`关键字以及他和`synchronized`的区别等。敬请期待。
[1]: http://www.hollischuang.com/archives/2550
[2]: http://www.hollischuang.com/archives/1883
[3]: https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.11.10
[4]: http://www.hollischuang.com/archives/2030
[5]: http://www.hollischuang.com/archives/2618
[6]: http://www.hollischuang.com/archives/2344
================================================
FILE: docs/basics/concurrent-coding/thread-safe.md
================================================
# 什么是线程安全
线程安全,维基百科中的解释是:
> 线程安全是编程中的术语,指某个函数、函数库在**并发**环境中被调用时,能够正确地处理**多个线程**之间的**共享变量**,使程序功能正确完成。
我们把这个定义拆解一下,我们需要弄清楚这么几点: 1、并发 2、多线程 3、共享变量
# 并发
提到线程安全,必须要提及的一个词那就是并发,如果没有并发的话,那么也就不存在线程安全问题了。
## 什么是并发
并发(Concurrent),在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。
那么,操作系统视如何实现这种并发的呢?
现在我们用到操作系统,无论是Windows、Linux还是MacOS等其实都是**多用户多任务分时操作系统**。使用这些操作系统的用户是可以“同时”干多件事的。
但是实际上,对于单CPU的计算机来说,在CPU中,同一时间是只能干一件事儿的。为了看起来像是“同时干多件事”,分时操作系统是把CPU的时间划分成长短基本相同的时间区间,即”时间片”,通过操作系统的管理,把这些时间片依次轮流地分配给各个用户使用。
如果某个作业在时间片结束之前,整个任务还没有完成,那么该作业就被暂停下来,放弃CPU,等待下一轮循环再继续做.此时CPU又分配给另一个作业去使用。
由于计算机的处理速度很快,只要时间片的间隔取得适当,那么一个用户作业从用完分配给它的一个时间片到获得下一个CPU时间片,中间有所”停顿”,但用户察觉不出来,好像整个系统全由它”独占”似的。
所以,在单CPU的计算机中,我们看起来“同时干多件事”,其实是通过CPU时间片技术,并发完成的。
提到并发,还有另外一个词容易和他混淆,那就是并行。
## 并发与并行之间的关系
并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
Erlang 之父 Joe Armstrong 用一张比较形象的图解释了并发与并行的区别:
<img src="http://www.hollischuang.com/wp-content/uploads/2018/12/166719746fa11df4.jpg" alt="" width="600" height="451" class="aligncenter size-full wp-image-5857" />
并发是两个队伍交替使用一台咖啡机。并行是两个队伍同时使用两台咖啡机。
映射到计算机系统中,上图中的咖啡机就是CPU,两个队伍指的就是两个进程。
# 多线程
## 进程和线程
理解了并发和并行之间的关系和区别后,我们再回到前面介绍的多任务分时操作系统,看看CPU是如何进行进程调度的。
为了看起来像是“同时干多件事”,分时操作系统是把CPU的时间划分成长短基本相同的”时间片”,通过操作系统的管理,把这些时间片依次轮流地分配给各个用户的各个任务使用。
在多任务处理系统中,CPU需要处理所有程序的操作,当用户来回切换它们时,需要记录这些程序执行到哪里。在操作系统中,CPU切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态:当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。**上下文切换**就是这样一个过程,他允许CPU记录并恢复各种正在运行程序的状态,使它能够完成切换操作。
> 在上下文切换过程中,CPU会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。从这个角度来看,上下文切换有点像我们同时阅读几本书,在来回切换书本的同时我们需要记住每本书当前读到的页码。在程序中,上下文切换过程中的“页码”信息是保存在进程控制块(PCB)中的。PCB还经常被称作“切换帧”(switchframe)。“页码”信息会一直保存到CPU的内存中,直到他们被再次使用。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
而在多个进程之间切换的时候,需要进行上下文切换。但是上下文切换势必会耗费一些资源。于是人们考虑,能不能在一个进程中增加一些“子任务”,这样减少上下文切换的成本。比如我们使用Word的时候,它可以同时进行打字、拼写检查、字数统计等,这些子任务之间共用同一个进程资源,但是他们之间的切换不需要进行上下文切换。
在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
随着时间的慢慢发展,人们进一步的切分了进程和线程之间的职责。**把进程当做资源分配的基本单元,把线程当做执行的基本单元,同一个进程的多个线程之间共享资源**
拿我们比较熟悉的Java语言来说,Java程序是运行在JVM上面的,每一个JVM其实就是一个进程。所有的资源分配都是基于JVM进程来的。而在这个JVM进程中,又可以创建出很多线程,多个线程之间共享JVM资源,并且多个线程可以并发执行。
# 共享变量
所谓共享变量,指的是多个线程都可以操作的变量。
前面我们提到过,进程视分配资源的基本单位,线程是执行的基本单位。所以,多个线程之间是可以共享一部分进程中的数据的。在JVM中,Java堆和方法区的区域是多个线程共享的数据区域。也就是说,多个线程可以操作保存在堆或者方法区中的同一个数据。那么,换句话说,保存在堆和方法区中的变量就是Java中的共享变量。
那么,Java中哪些变量是存放在堆中,哪些变量是存放在方法区中,又有哪些变量是存放在栈中的呢?
## 类变量、成员变量和局部变量
Java中共有三种变量,分别是类变量、成员变量和局部变量。他们分别存放在JVM的方法区、堆内存和栈内存中。
/**
* @author Hollis
*/
public class Variables {
/**
* 类变量
*/
private static int a;
/**
* 成员变量
*/
private int b;
/**
* 局部变量
* @param c
*/
public void test(int c){
int d;
}
}
上面定义的三个变量中,变量a就是类变量,变量b就是成员变量,而变量c和d是局部变量。
所以,变量a和b是共享变量,变量c和d是非共享变量。所以如果遇到多线程场景,对于变量a和b的操作是需要考虑线程安全的,而对于线程c和d的操作是不需要考虑线程安全的。
# 小结
在了解了一些基础知识以后,我们再来回过头看看线程安全的定义:
> 线程安全是编程中的术语,指某个函数、函数库在**并发**环境中被调用时,能够正确地处理**多个线程**之间的**共享变量**,使程序功能正确完成。
现在我们知道了什么是并发环境,什么是多个线程以及什么是共享变量。那么只要我们在编写多线程的代码的时候注意一下,保证程序功能可以正确的执行就行了。
那么问题来了,定义中说线程安全能够**正确地处理**多个线程之间的共享变量,使程序功能**正确完成**。
多线程场景中存在哪些问题会导致无法正确的处理共享变量? 多线程场景中存在哪些问题会导致程序无法正确完成? 如何解决多线程场景中影响『正确』的这些问题? 解决这些问题的各个手段的实现原理又是什么?
[1]: http://www.hollischuang.com/archives/3029
[2]: http://www.hollischuang.com/archives/tag/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3java%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B
================================================
FILE: docs/basics/concurrent-coding/thread-scheduling.md
================================================
在关于线程安全的文章中,我们提到过,对于单CPU的计算机来说,在任意时刻只能执行一条机器指令,每个线程只有获得CPU的使用权才能执行指令。
所谓多线程的并发运行,其实是指从宏观上看,各个线程轮流获得CPU的使用权,分别执行各自的任务。
前面关于线程状态的介绍中,我们知道,线程的运行状态中包含两种子状态,即就绪(READY)和运行中(RUNNING)。
而一个线程想要从就绪状态变成运行中状态,这个过程需要系统调度,即给线程分配CPU的使用权,获得CPU使用权的线程才会从就绪状态变成运行状态。
**给多个线程按照特定的机制分配CPU的使用权的过程就叫做线程调度。**
还记得在介绍进程和线程的区别的时候,我们提到过的一句话吗:进程是分配资源的基本单元,线程是CPU调度的基本单元。这里所说的调度指的就是给其分配CPU时间片,让其执行任务。
## Linux线程调度
在Linux中,线程是由进程来实现,线程就是轻量级进程( lightweight process ),因此在Linux中,线程的调度是按照进程的调度方式来进行调度的,也就是说线程是调度单元。
Linux这样实现的线程的好处的之一是:线程调度直接使用进程调度就可以了,没必要再搞一个进程内的线程调度器。在Linux中,调度器是基于线程的调度策略(scheduling policy)和静态调度优先级(static scheduling priority)来决定那个线程来运行。
在Linux中,主要有三种调度策略。分别是:
* SCHED_OTHER 分时调度策略,(默认的)
* SCHED_FIFO 实时调度策略,先到先服务
* SCHED_RR 实时调度策略,时间片轮转
## Windows线程调度
Windows 采用基于优先级的、抢占调度算法来调度线程。
用于处理调度的 Windows 内核部分称为调度程序,Windows 调度程序确保具有最高优先级的线程总是在运行的。由于调度程序选择运行的线程会一直运行,直到被更高优先级的线程所抢占,或终止,或时间片已到,或调用阻塞系统调用(如 I/O)。如果在低优先级线程运行时,更高优先级的实时线程变成就绪,那么低优先级线程就被抢占。这种抢占使得实时线程在需要使用 CPU 时优先得到使用。
# Java线程调度
可以看到,不同的操作系统,有不同的线程调度策略。但是,作为一个Java开发人员来说,我们日常开发过程中一般很少关注操作系统层面的东西。
主要是因为Java程序都是运行在Java虚拟机上面的,而虚拟机帮我们屏蔽了操作系统的差异,所以我们说Java是一个跨平台语言。
**在操作系统中,一个Java程序其实就是一个进程。所以,我们说Java是单进程、多线程的!**
前面关于线程的实现也介绍过,Thread类与大部分的Java API有显著的差别,它的所有关键方法都是声明为Native的,也就是说,他需要根据不同的操作系统有不同的实现。
在Java的多线程程序中,为保证所有线程的执行能按照一定的规则执行,JVM实现了一个线程调度器,它定义了线程调度模型,对于CPU运算的分配都进行了规定,按照这些特定的机制为多个线程分配CPU的使用权。
主要有两种调度模型:**协同式线程调度**和**抢占式调度模型**。
## 协同式线程调度
协同式调度的多线程系统,线程的执行时间由线程本身来控制,线程把自己的工作执行完了之后,要主动通知系统切换到另外一个线程上。协同式多线程的最大好处是实现简单,而且由于线程要把自己的事情干完后才会进行线程切换,切换操作对线程自己是可知的,所以没有什么线程同步的问题。
## 抢占式调度模型
抢占式调度的多线程系统,那么每个线程将由系统来分配执行时间,线程的切换不由线程本身来决定。在这种实现线程调度的方式下,线程的执行时间是系统可控的,也不会有一个线程导致整个进程阻塞的问题。
系统会让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃CPU。
**Java虚拟机采用抢占式调度模型。**
虽然Java线程调度是系统自动完成的,但是我们还是可以“建议”系统给某些线程多分配一点执行时间,另外的一些线程则可以少分配一点——这项操作可以通过设置线程优先级来完成。Java语言一共设置了10个级别的线程优先级(Thread.MIN_PRIORITY至Thread.MAX_PRIORITY),在两个线程同时处于Ready状态时,优先级越高的线程越容易被系统选择执行。
不过,线程优先级并不是太靠谱,原因是Java的线程是通过映射到系统的原生线程上来实现的,所以线程调度最终还是取决于操作系统,虽然现在很多操作系统都提供线程优先级的概念,但是并不见得能与Java线程的优先级一一对应。
================================================
FILE: docs/basics/concurrent-coding/thread.md
================================================
在多线程操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。
## 轻型实体
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。 线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。TCB包括以下信息: (1)线程状态。 (2)当线程不运行时,被保存的现场资源。 (3)一组执行堆栈。 (4)存放每个线程的局部变量主存区。 (5)访问同一个进程中的主存和其它资源。 用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
## 独立调度和分派的基本单位。
在多线程操作系统中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。
## 可并发执行。
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
## 共享进程资源。
在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:所有线程都具有相同的地址空间(进程的地址空间),这意味着,线程可以访问该地址空间的每一个虚地址;此外,还可以访问进程所拥有的已打开文件、定时器、信号量机构等。由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。
================================================
FILE: docs/basics/concurrent-coding/volatile.md
================================================
在[再有人问你Java内存模型是什么,就把这篇文章发给他][1]中我们曾经介绍过,Java语言为了解决并发编程中存在的原子性、可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如`synchronized`、`volatile`、`final`、`concurren包`等。在[前一篇][2]文章中,我们也介绍了`synchronized`的用法及原理。本文,来分析一下另外一个关键字——`volatile`。
本文就围绕`volatile`展开,主要介绍`volatile`的用法、`volatile`的原理,以及`volatile`是如何提供可见性和有序性保障的等。
`volatile`这个关键字,不仅仅在Java语言中有,在很多语言中都有的,而且其用法和语义也都是不尽相同的。尤其在C语言、C++以及Java中,都有`volatile`关键字。都可以用来声明变量或者对象。下面简单来介绍一下Java语言中的`volatile`关键字。
### volatile的用法
`volatile`通常被比喻成"轻量级的`synchronized`",也是Java并发编程中比较重要的一个关键字。和`synchronized`不同,`volatile`是一个变量修饰符,只能用来修饰变量。无法修饰方法及代码块等。
`volatile`的用法比较简单,只需要在声明一个可能被多线程同时访问的变量时,使用`volatile`修饰就可以了。
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
如以上代码,是一个比较典型的使用双重锁校验的形式实现单例的,其中使用`volatile`关键字修饰可能被多个线程同时访问到的singleton。
### volatile的原理
在[再有人问你Java内存模型是什么,就把这篇文章发给他][1]中我们曾经介绍过,为了提高处理器的执行速度,在处理器和内存之间增加了多级缓存来提升。但是由于引入了多级缓存,就存在缓存数据不一致问题。
但是,对于`volatile`变量,当对`volatile`变量进行写操作的时候,JVM会向处理器发送一条lock前缀的指令,将这个缓存中的变量回写到系统主存中。
但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现`缓存一致性协议`
**缓存一致性协议**:每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
所以,如果一个变量被`volatile`所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个`volatile`在并发编程中,其值在多个缓存中是可见的。
### volatile与可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
我们在[再有人问你Java内存模型是什么,就把这篇文章发给他][1]中分析过:Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中使用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。所以,就可能出现线程1改了某个变量的值,但是线程2不可见的情况。
前面的关于`volatile`的原理中介绍过了,Java中的`volatile`关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次使用之前都从主内存刷新。因此,可以使用`volatile`来保证多线程操作时变量的可见性。
### volatile与有序性
有序性即程序执行的顺序按照代码的先后顺序执行。
我们在[再有人问你Java内存模型是什么,就把这篇文章发给他][1]中分析过:除了引入了时间片以外,由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如`load->add->save` 有可能被优化成`load->save->add` 。这就是可能存在有序性问题。
而`volatile`除了可以保证数据的可见性之外,还有一个强大的功能,那就是他可以禁止指令重排优化等。
普通的变量仅仅会保证在该方法的执行过程中所依赖的赋值结果的地方都能获得正确的结果,而不能保证变量的赋值操作的顺序与程序代码中的执行顺序一致。
volatile可以禁止指令重排,这就保证了代码的程序会严格按照代码的先后顺序执行。这就保证了有序性。被`volatile`修饰的变量的操作,会严格按照代码顺序执行,`load->add->save` 的执行顺序就是:load、add、save。
### volatile与原子性
原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行。
我们在[Java的并发编程中的多线程问题到底是怎么回事儿?][3]中分析过:线程是CPU调度的基本单位。CPU有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去CPU使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。
在上一篇文章中,我们介绍`synchronized`的时候,提到过,为了保证原子性,需要通过字节码指令`monitorenter`和`monitorexit`,但是`volatile`和这两个指令之间是没有任何关系的。
**所以,`volatile`是不能保证原子性的。**
在以下两个场景中可以使用`volatile`来代替`synchronized`:
> 1、运算结果并不依赖变量的当前值,或者能够确保只有单一的线程会修改变量的值。
>
> 2、变量不需要与其他状态变量共同参与不变约束。
除以上场景外,都需要使用其他方式来保证原子性,如`synchronized`或者`concurrent包`。
我们来看一下volatile和原子性的例子:
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}
以上代码比较简单,就是创建10个线程,然后分别执行1000次`i++`操作。正常情况下,程序的输出结果应该是10000,但是,多次执行的结果都小于10000。这其实就是`volatile`无法满足原子性的原因。
为什么会出现这种情况呢,那就是因为虽然volatile可以保证`inc`在多个线程之间的可见性。但是无法`inc++`的原子性。
### 总结与思考
我们介绍过了`volatile`关键字和`synchronized`关键字。现在我们知道,`synchronized`可以保证原子性、有序性和可见性。而`volatile`却只能保证有序性和可见性。
那么,我们再来看一下双重校验锁实现的单例,已经使用了`synchronized`,为什么还需要`volatile`?
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
答案,我们在下一篇文章:既生synchronized,何生亮volatile中介绍,敬请关注我的博客(http://47.103.216.138)和公众号(Hollis)。
[1]: http://47.103.216.138/archives/2550
[2]: http://47.103.216.138/archives/2637
[3]: http://47.103.216.138/archives/2618
================================================
FILE: docs/basics/concurrent-coding/why-not-executors.md
================================================
在《[深入源码分析Java线程池的实现原理][1]》这篇文章中,我们介绍过了Java中线程池的常见用法以及基本原理。
在文中有这样一段描述:
> 可以通过Executors静态工厂构建线程池,但一般不建议这样使用。
关于这个问题,在那篇文章中并没有深入的展开。作者之所以这么说,是因为这种创建线程池的方式有很大的隐患,稍有不慎就有可能导致线上故障,如:一次Java线程池误用引发的血案和总结( <https://zhuanlan.zhihu.com/p/32867181> )
本文我们就来围绕这个问题来分析一下为什么JDK自身提供的构建线程池的方式并不建议使用?到底应该如何创建一个线程池呢?
### Executors
Executors 是一个Java中的工具类。提供工厂方法来创建不同类型的线程池。
![][2]
从上图中也可以看出,Executors的创建线程池的方法,创建出来的线程池都实现了ExecutorService接口。常用方法有以下几个:
`newFiexedThreadPool(int Threads)`:创建固定数目线程的线程池。
`newCachedThreadPool()`:创建一个可缓存的线程池,调用execute 将重用以前构造的线程(如果线程可用)。如果没有可用的线程,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
`newSingleThreadExecutor()`创建一个单线程化的Executor。
`newScheduledThreadPool(int corePoolSize)`创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
类看起来功能还是比较强大的,又用到了工厂模式、又有比较强的扩展性,重要的是用起来还比较方便,如:
<pre><code class="language-text">ExecutorService executor = Executors.newFixedThreadPool(nThreads) ;
</code></pre>
即可创建一个固定大小的线程池。
但是为什么我说不建议大家使用这个类来创建线程池呢?
我提到的是『不建议』,但是在阿里巴巴Java开发手册中也明确指出,而且用的词是『不允许』使用Executors创建线程池。
<img src="http://www.hollischuang.com/wp-content/uploads/2018/10/15406254121131.jpg" alt="" style="width:1177px" />
### Executors存在什么问题
在阿里巴巴Java开发手册中提到,使用Executors创建线程池可能会导致OOM(OutOfMemory ,内存溢出),但是并没有说明为什么,那么接下来我们就来看一下到底为什么不允许使用Executors?
我们先来一个简单的例子,模拟一下使用Executors导致OOM的情况。
<pre><code class="language-text">/**
* @author Hollis
*/
public class ExecutorsDemo {
private static ExecutorService executor = Executors.newFixedThreadPool(15);
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(new SubThread());
}
}
}
class SubThread implements Runnable {
@Override
public void run() {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
}
}
</code></pre>
通过指定JVM参数:`-Xmx8m -Xms8m` 运行以上代码,会抛出OOM:
<pre><code class="language-text">Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371)
at com.hollis.ExecutorsDemo.main(ExecutorsDemo.java:16)
</code></pre>
以上代码指出,`ExecutorsDemo.java`的第16行,就是代码中的`executor.execute(new SubThread());`。
### Executors为什么存在缺陷
通过上面的例子,我们知道了`Executors`创建的线程池存在OOM的风险,那么到底是什么原因导致的呢?我们需要深入`Executors`的源码来分析一下。
其实,在上面的报错信息中,我们是可以看出蛛丝马迹的,在以上的代码中其实已经说了,真正的导致OOM的其实是`LinkedBlockingQueue.offer`方法。
<pre><code class="language-text">Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371)
at com.hollis.ExecutorsDemo.main(ExecutorsDemo.java:16)
</code></pre>
如果读者翻看代码的话,也可以发现,其实底层确实是通过`LinkedBlockingQueue`实现的:
<pre><code class="language-text">public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
</code></pre>
如果读者对Java中的阻塞队列有所了解的话,看到这里或许就能够明白原因了。
Java中的`BlockingQueue`主要有两种实现,分别是`ArrayBlockingQueue` 和 `LinkedBlockingQueue`。
`ArrayBlockingQueue`是一个用数组实现的有界阻塞队列,必须设置容量。
`LinkedBlockingQueue`是一个用链表实现的有界阻塞队列,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为`Integer.MAX_VALUE`。
这里的问题就出在:**不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE。**也就是说,如果我们不设置`LinkedBlockingQueue`的容量的话,其默认容量将会是`Integer.MAX_VALUE`。
而`newFixedThreadPool`中创建`LinkedBlockingQueue`时,并未指定容量。此时,`LinkedBlockingQueue`就是一个无边界队列,对于一个无边界队列来说,是可以不断的向队列中加入任务的,这种情况下就有可能因为任务过多而导致内存溢出问题。
上面提到的问题主要体现在`newFixedThreadPool`和`newSingleThreadExecutor`两个工厂方法上,并不是说`newCachedThreadPool`和`newScheduledThreadPool`这两个方法就安全了,这两种方式创建的最大线程数可能是`Integer.MAX_VALUE`,而创建这么多线程,必然就有可能导致OOM。
### 创建线程池的正确姿势
避免使用Executors创建线程池,主要是避免使用其中的默认实现,那么我们可以自己直接调用`ThreadPoolExecutor`的构造函数来自己创建线程池。在创建的同时,给`BlockQueue`指定容量就可以了。
<pre><code class="language-text">private static ExecutorService executor = new ThreadPoolExecutor(10, 10,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(10));
</code></pre>
这种情况下,一旦提交的线程数超过当前可用线程数时,就会抛出`java.util.concurrent.RejectedExecutionException`,这是因为当前线程池使用的队列是有边界队列,队列已经满了便无法继续处理新的请求。但是异常(Exception)总比发生错误(Error)要好。
除了自己定义`ThreadPoolExecutor`外。还有其他方法。这个时候第一时间就应该想到开源类库,如apache和guava等。
作者推荐使用guava提供的ThreadFactoryBuilder来创建线程池。
<pre><code class="language-text">public class ExecutorsDemo {
private static ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("demo-pool-%d").build();
private static ExecutorService pool = new ThreadPoolExecutor(5, 200,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
pool.execute(new SubThread());
}
}
}
</code></pre>
通过上述方式创建线程时,不仅可以避免OOM的问题,还可以自定义线程名称,更加方便的出错的时候溯源。
思考题,文中作者说:发生异常(Exception)要比发生错误(Error)好,为什么这么说?
文中提到的《阿里巴巴Java开发手册》,请关注公众号Hollis,回复:手册。即可获得完整版PDF。
[1]: https://mp.weixin.qq.com/s/-89-CcDnSLBYy3THmcLEdQ
[2]: http://www.hollischuang.com/wp-content/uploads/2018/10/15406248096737.jpg
================================================
FILE: docs/basics/java-basic/ASCII.md
================================================
ASCII( American Standard Code for InformationInterchange, 美国信息交换标准代码) 是基于拉丁字母的⼀套电脑编码系统, 主要⽤于显⽰现代英语和其他西欧语⾔。
它是现今最通⽤的单字节编码系统, 并等同于国际标准ISO/IEC646。
标准ASCII 码也叫基础ASCII码, 使⽤7 位⼆进制数( 剩下的1位⼆进制为0) 来表⽰所有的⼤写和⼩写字母, 数字0 到9、 标点符号, 以及在美式英语中使⽤的特殊控制字符。
其中:
0~31及127(共33个)是控制字符或通信专⽤字符( 其余为可显⽰字符) , 如控制符: LF( 换⾏) 、 CR( 回车) 、 FF( 换页) 、 DEL( 删除) 、 BS( 退格)、 BEL( 响铃) 等; 通信专⽤字符: SOH( ⽂头) 、 EOT( ⽂尾) 、 ACK( 确认) 等;
ASCII值为8、 9、 10 和13 分别转换为退格、 制表、 换⾏和回车字符。 它们并没有特定的图形显⽰, 但会依不同的应⽤程序,⽽对⽂本显⽰有不同的影响
32~126(共95个)是字符(32是空格) , 其中48~57为0到9⼗个阿拉伯数字。
65~90为26个⼤写英⽂字母, 97~122号为26个⼩写英⽂字母, 其余为⼀些标点符号、 运算符号等。
================================================
FILE: docs/basics/java-basic/Arrays-asList.md
================================================
1. asList 得到的只是一个 Arrays 的内部类,一个原来数组的视图 List,因此如果对它进行增删操作会报错
2. 用 ArrayList 的构造器可以将其转变成真正的 ArrayList
================================================
FILE: docs/basics/java-basic/CET-UTC-GMT-CST.md
================================================
### CET
欧洲中部时间(英語:Central European Time,CET)是比世界标准时间(UTC)早一个小时的时区名称之一。它被大部分欧洲国家和部分北非国家采用。冬季时间为UTC+1,夏季欧洲夏令时为UTC+2。
### UTC
协调世界时,又称世界标准时间或世界协调时间,简称UTC,从英文“Coordinated Universal Time”/法文“Temps Universel Cordonné”而来。台湾采用CNS 7648的《资料元及交换格式–资讯交换–日期及时间的表示法》(与ISO 8601类似)称之为世界统一时间。中国大陆采用ISO 8601-1988的国标《数据元和交换格式信息交换日期和时间表示法》(GB/T 7408)中称之为国际协调时间。协调世界时是以原子时秒长为基础,在时刻上尽量接近于世界时的一种时间计量系统。
### GMT
格林尼治标准时间(旧译格林尼治平均时间或格林威治标准时间;英语:Greenwich Mean Time,GMT)是指位于英国伦敦郊区的皇家格林尼治天文台的标准时间,因为本初子午线被定义在通过那里的经线。
### CST
北京时间,China Standard Time,又名中国标准时间,是中国的标准时间。在时区划分上,属东八区,比协调世界时早8小时,记为UTC+8,与中华民国国家标准时间(旧称“中原标准时间”)、香港时间和澳门时间和相同。當格林威治時間為凌晨0:00時,中國標準時間剛好為上午8:00。
### 关系
CET=UTC/GMT + 1小时
CST=UTC/GMT +8 小时
CST=CET + 7 小时
================================================
FILE: docs/basics/java-basic/Class.md
================================================
Java的Class类是java反射机制的基础,通过Class类我们可以获得关于一个类的相关信息
Java.lang.Class是一个比较特殊的类,它用于封装被装入到JVM中的类(包括类和接口)的信息。当一个类或接口被装入的JVM时便会产生一个与之关联的java.lang.Class对象,可以通过这个Class对象对被装入类的详细信息进行访问。
虚拟机为每种类型管理一个独一无二的Class对象。也就是说,每个类(型)都有一个Class对象。运行程序时,Java虚拟机(JVM)首先检查是否所要加载的类对应的Class对象是否已经加载。如果没有加载,JVM就会根据类名查找.class文件,并将其Class对象载入。
================================================
FILE: docs/basics/java-basic/Collection-vs-Collections.md
================================================
Collection 是一个集合接口。
它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。是list,set等的父接口。
Collections 是一个包装类。
它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
日常开发中,不仅要了解Java中的Collection及其子类的用法,还要了解Collections用法。可以提升很多处理集合类的效率。
================================================
FILE: docs/basics/java-basic/ConcurrentSkipListMap.md
================================================
ConcurrentSkipListMap是一个内部使用跳表,并且支持排序和并发的一个Map,是线程安全的。一般很少会被用到,也是一个比较偏门的数据结构。
简单介绍下跳表
跳表是一种允许在一个有顺序的序列中进行快速查询的数据结构。
在普通的顺序链表中查询一个元素,需要从链表头部开始一个一个节点进行遍历,然后找到节点。如图1。
跳表可以解决这种查询时间过长,其元素遍历的图示如图2,跳表是一种使用”空间换时间”的概念用来提高查询效率的链表。
ConcurrentSkipListMap 和 ConcurrentHashMap 的主要区别:
a.底层实现方式不同。ConcurrentSkipListMap底层基于跳表。ConcurrentHashMap底层基于Hash桶和红黑树。
b.ConcurrentHashMap不支持排序。ConcurrentSkipListMap支持排序。
================================================
FILE: docs/basics/java-basic/CopyOnWriteArrayList.md
================================================
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
CopyOnWriteArrayList相当于线程安全的ArrayList,CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素add到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
注意:CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。也就是说add方法是线程安全的。
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景。
和ArrayList不同的是,它具有以下特性:
支持高效率并发且是线程安全的
因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大
迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作
使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照
================================================
FILE: docs/basics/java-basic/Enumeration-vs-Iterator.md
================================================
函数接口不同
Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。
Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,也能数据进行删除操作。
Iterator支持fail-fast机制,而Enumeration不支持。
Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK 1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。
而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
注意:Enumeration迭代器只能遍历Vector、Hashtable这种古老的集合,因此通常不要使用它,除非在某些极端情况下,不得不使用Enumeration,否则都应该选择Iterator迭代器。
================================================
FILE: docs/basics/java-basic/GMT.md
================================================
格林尼治平时(英语:Greenwich Mean Time,GMT)是指位于英国伦敦郊区的皇家格林尼治天文台当地的平太阳时,因为本初子午线被定义为通过那里的经线。
自1924年2月5日开始,格林尼治天文台负责每隔一小时向全世界发放调时信息。
格林尼治平时的正午是指当平太阳横穿格林尼治子午线时(也就是在格林尼治上空最高点时)的时间。由于地球每天的自转是有些不规则的,而且正在缓慢减速,因此格林尼治平时基于天文观测本身的缺陷,已经被原子钟报时的协调世界时(UTC)所取代。
一般使用GMT+8表示中国的时间,是因为中国位于东八区,时间上比格林威治时间快8个小时。
================================================
FILE: docs/basics/java-basic/HashMap-HashTable-ConcurrentHashMap.md
================================================
### HashMap和HashTable有何不同?
线程安全:
HashTable 中的方法是同步的,而HashMap中的方法在默认情况下是非同步的。在多线程并发的环境下,可以直接使用HashTable,但是要使用HashMap的话就要自己增加同步处理了。
继承关系:
HashTable是基于陈旧的Dictionary类继承来的。
HashMap继承的抽象类AbstractMap实现了Map接口。
允不允许null值:
HashTable中,key和value都不允许出现null值,否则会抛出NullPointerException异常。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
默认初始容量和扩容机制:
HashTable中的hash数组初始大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。原因参考全网把Map中的hash()分析的最透彻的文章,别无二家。-HollisChuang's Blog
哈希值的使用不同 :
HashTable直接使用对象的hashCode。
HashMap重新计算hash值。
遍历方式的内部实现上不同 :
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
HashMap 实现 Iterator,支持fast-fail,Hashtable的 Iterator 遍历支持fast-fail,用 Enumeration 不支持 fast-fail
### HashMap 和 ConcurrentHashMap 的区别?
ConcurrentHashMap和HashMap的实现方式不一样,虽然都是使用桶数组实现的,但是还是有区别,ConcurrentHashMap对桶数组进行了分段,而HashMap并没有。
ConcurrentHashMap在每一个分段上都用锁进行了保护。HashMap没有锁机制。所以,前者线程安全的,后者不是线程安全的。
PS:以上区别基于jdk1.8以前的版本。
================================================
FILE: docs/basics/java-basic/README.md
================================================
## To Be Top Javaer - Java工程师成神之路
  
| 主要版本 | 更新时间 | 备注 |
| ---- | ---------- | -------------- |
| v1.0 | 2015-08-01 | 首次发布 |
| v1.1 | 2018-03-12 | 增加新技术知识、完善知识体系 |
| v2.0 | 2019-02-19 | 结构调整,更适合从入门到精通;<br>进一步完善知识体系; <br>新技术补充;|
Java 基础
================================================
FILE: docs/basics/java-basic/Runtime-Constant-Pool.md
================================================
运行时常量池( Runtime Constant Pool)是每一个类或接口的常量池( Constant_Pool)的运行时表示形式。
它包括了若干种不同的常量:从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。运行时常量池扮演了类似传统语言中符号表( SymbolTable)的角色,不过它存储数据范围比通常意义上的符号表要更为广泛。
每一个运行时常量池都分配在 Java 虚拟机的方法区之中,在类和接口被加载到虚拟机后,对应的运行时常量池就被创建出来。
以上,是Java虚拟机规范中关于运行时常量池的定义。
### 运行时常量池在JDK各个版本中的实现
根据Java虚拟机规范约定:每一个运行时常量池都在Java虚拟机的方法区中分配,在加载类和接口到虚拟机后,就创建对应的运行时常量池。
在不同版本的JDK中,运行时常量池所处的位置也不一样。以HotSpot为例:
在JDK 1.7之前,方法区位于堆内存的永久代中,运行时常量池作为方法区的一部分,也处于永久代中。
因为使用永久代实现方法区可能导致内存泄露问题,所以,从JDK1.7开始,JVM尝试解决这一问题,在1.7中,将原本位于永久代中的运行时常量池移动到堆内存中。(永久代在JDK 1.7并没有完全移除,只是原来方法区中的运行时常量池、类的静态变量等移动到了堆内存中。)
在JDK 1.8中,彻底移除了永久代,方法区通过元空间的方式实现。随之,运行时常量池也在元空间中实现。
### 运行时常量池中常量的来源
运行时常量池中包含了若干种不同的常量:
编译期可知的字面量和符号引用(来自Class常量池)
运行期解析后可获得的常量(如String的intern方法)
所以,运行时常量池中的内容包含:Class常量池中的常量、字符串常量池中的内容
### 运行时常量池、Class常量池、字符串常量池的区别与联系
虚拟机启动过程中,会将各个Class文件中的常量池载入到运行时常量池中。
所以, Class常量池只是一个媒介场所。在JVM真的运行时,需要把常量池中的常量加载到内存中,进入到运行时常量池。
字符串常量池可以理解为运行时常量池分出来的部分。加载时,对于class的静态常量池,如果字符串会被装到字符串常量池中。
================================================
FILE: docs/basics/java-basic/StandardTime-vs-daylightSavingTime.md
================================================
夏令时、冬令时的出现,是为了充分利用夏天的日照,所以时钟要往前拨快一小时,冬天再把表往回拨一小时。其中夏令时从3月第二个周日持续到11月第一个周日。
冬令时:
北京和洛杉矶时差:16
北京和纽约时差:13
夏令时:
北京和洛杉矶时差:15
北京和纽约时差:12
================================================
FILE: docs/basics/java-basic/UNICODE.md
================================================
ASCII码,只有256个字符,美国人倒是没啥问题了,他们用到的字符几乎都包括了,但是世界上不只有美国程序员啊,所以需要一种更加全面的字符集。
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2018年6月5日公布的11.0.0,已经收录超过13万个字符(第十万个字符在2005年获采纳)。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
Unicode发展由非营利机构统一码联盟负责,该机构致力于让Unicode方案取代既有的字符编码方案。因为既有的方案往往空间非常有限,亦不适用于多语环境。
Unicode备受认可,并广泛地应用于计算机软件的国际化与本地化过程。有很多新科技,如可扩展置标语言(Extensible Markup Language,简称:XML)、Java编程语言以及现代的操作系统,都采用Unicode编码。
Unicode可以表示中文。
================================================
FILE: docs/basics/java-basic/UTF8-UTF16-UTF32.md
================================================
Unicode 是容纳世界所有文字符号的国际标准编码,使用四个字节为每个字符编码。
UTF 是英文 Unicode Transformation Format 的缩写,意为把 Unicode 字符转换为某种格式。UTF 系列编码方案(UTF-8、UTF-16、UTF-32)均是由 Unicode 编码方案衍变而来,以适应不同的数据存储或传递,它们都可以完全表示 Unicode 标准中的所有字符。目前,这些衍变方案中 UTF-8 被广泛使用,而 UTF-16 和 UTF-32 则很少被使用。
UTF-8 使用一至四个字节为每个字符编码,其中大部分汉字采用三个字节编码,少量不常用汉字采用四个字节编码。因为 UTF-8 是可变长度的编码方式,相对于 Unicode 编码可以减少存储占用的空间,所以被广泛使用。
UTF-16 使用二或四个字节为每个字符编码,其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。UTF-16 编码有大尾序和小尾序之别,即 UTF-16BE 和 UTF-16LE,在编码前会放置一个 U+FEFF 或 U+FFFE(UTF-16BE 以 FEFF 代表,UTF-16LE 以 FFFE 代表),其中 U+FEFF 字符在 Unicode 中代表的意义是 ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。
UTF-32 使用四个字节为每个字符编码,使得 UTF-32 占用空间通常会是其它编码的二到四倍。UTF-32 与 UTF-16 一样有大尾序和小尾序之别,编码前会放置 U+0000FEFF 或 U+0000FFFE 以区分。
================================================
FILE: docs/basics/java-basic/Wildcard-Character.md
================================================
`限定通配符`对类型进⾏限制, 泛型中有两种限定通配符:
表示类型的上界,格式为:`<? extends T>`,即类型必须为T类型或者T子类
表示类型的下界,格式为:`<? super T>`,即类型必须为T类型或者T的父类
泛型类型必须⽤限定内的类型来进⾏初始化,否则会导致编译错误。
`⾮限定通配符`表⽰可以⽤任意泛型类型来替代,类型为`<T>`
================================================
FILE: docs/basics/java-basic/YYYY-vs-yyyy.md
================================================
在使用SimpleDateFormat的时候,需要通过字母来描述时间元素,并组装成想要的日期和时间模式。常用的时间元素和字母的对应表(JDK 1.8)如下:

可以看到,*y表示Year ,而Y表示Week Year*
### 什么是Week Year
我们知道,不同的国家对于一周的开始和结束的定义是不同的。如在中国,我们把星期一作为一周的第一天,而在美国,他们把星期日作为一周的第一天。
同样,如何定义哪一周是一年当中的第一周?这也是一个问题,有很多种方式。
比如下图是2019年12月-2020年1月的一份日历。

到底哪一周才算2020年的第一周呢?不同的地区和国家,甚至不同的人,都有不同的理解。
* 1、1月1日是周三,到下周三(1月8日),这7天算作这一年的第一周。
* 2、因为周日(周一)才是一周的第一天,所以,要从2020年的第一个周日(周一)开始往后推7天才算这一年的第一周。
* 3、因为12.29、12.30、12.31是2019年,而1.1、1.2、1.3才是2020年,而1.4周日是下一周的开始,所以,第一周应该只有1.1、1.2、1.3这三天。
#### ISO 8601
因为不同人对于日期和时间的表示方法有不同的理解,于是,大家就共同制定了了一个国际规范:ISO 8601 。
国际标准化组织的国际标准ISO 8601是日期和时间的表示方法,全称为《数据存储和交换形式·信息交换·日期和时间的表示方法》。
在 ISO 8601中。对于一年的第一个日历星期有以下四种等效说法:
* 1,本年度第一个星期四所在的星期;
* 2,1月4日所在的星期;
* 3,本年度第一个至少有4天在同一星期内的星期;
* 4,星期一在去年12月29日至今年1月4日以内的星期;
根据这个标准,我们可以推算出:
2020年第一周:2019.12.29-2020.1.4
所以,根据ISO 8601标准,2019年12月29日、2019年12月30日、2019年12月31日这两天,其实不属于2019年的最后一周,而是属于2020年的第一周。
#### JDK针对ISO 8601提供的支持
根据ISO 8601中关于日历星期和日表示法的定义,2019.12.29-2020.1.4是2020年的第一周。
我们希望输入一个日期,然后程序告诉我们,根据ISO 8601中关于日历日期的定义,这个日期到底属于哪一年。
比如我输入2019-12-20,他告诉我是2019;而我输入2019-12-30的时候,他告诉我是2020。
为了提供这样的数据,Java 7引入了「YYYY」作为一个新的日期模式来作为标识。使用「YYYY」作为标识,。再通过SimpleDateFormat就可以得到一个日期所属的周属于哪一年了
所以,当我们要表示日期的时候,一定要使用 yyyy-MM-dd 而不是 YYYY-MM-dd ,这两者的返回结果大多数情况下都一样,但是极端情况就会有问题了。
================================================
FILE: docs/basics/java-basic/annotation-in-java.md
================================================
@Override 表示当前方法覆盖了父类的方法
@Deprecated 表示方法已经过时,方法上有横线,使用时会有警告。
@SuppressWarnings 表示关闭一些警告信息(通知java编译器忽略特定的编译警告)
@SafeVarargs (jdk1.7更新) 表示:专门为抑制“堆污染”警告提供的。
@FunctionalInterface (jdk1.8更新) 表示:用来指定某个接口必须是函数式接口,否则就会编译出错。
### Spring常用注解
@Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了@Bean,就会作为这个Spring容器中的Bean。
@Scope注解 作用域
@Lazy(true) 表示延迟初始化
@Service用于标注业务层组件
@Controller用于标注控制层组件@Repository用于标注数据访问组件,即DAO组件。
@Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
@Scope用于指定scope作用域的(用在类上)
@PostConstruct用于指定初始化方法(用在方法上)
@PreDestory用于指定销毁方法(用在方法上)
@DependsOn:定义Bean初始化及销毁时的顺序
@Primary:自动装配时当出现多个Bean候选者时,被注解为@Primary的Bean将作为首选者,否则将抛出异常
@Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。如下:
@Autowired @Qualifier("personDaoBean") 存在多个实例配合使用
@Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
@PostConstruct 初始化注解
@PreDestroy 摧毁注解 默认 单例 启动就加载
================================================
FILE: docs/basics/java-basic/annotation-in-spring.md
================================================
@Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了@Bean,就会作为这个Spring容器中的Bean。
@Scope注解 作用域
@Lazy(true) 表示延迟初始化
@Service用于标注业务层组件、
@Controller用于标注控制层组件@Repository用于标注数据访问组件,即DAO组件。
@Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
@Scope用于指定scope作用域的(用在类上)
@PostConstruct用于指定初始化方法(用在方法上)
@PreDestory用于指定销毁方法(用在方法上)
@DependsOn:定义Bean初始化及销毁时的顺序
@Primary:自动装配时当出现多个Bean候选者时,被注解为@Primary的Bean将作为首选者,否则将抛出异常
@Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。如下:
@Autowired @Qualifier("personDaoBean") 存在多个实例配合使用
@Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
### Spring中的这几个注解有什么区别:@Component 、@Repository、@Service、@Controller
1. @Component指的是组件,
@Controller,@Repository和@Service 注解都被@Component修饰,用于代码中区分表现层,持久层和业务层的组件,代码中组件不好归类时可以使用@Component来标注
2. 当前版本只有区分的作用,未来版本可能会添加更丰富的功能
================================================
FILE: docs/basics/java-basic/annotion-and-reflect.md
================================================
注解和反射经常结合在一起使用,在很多框架的代码中都能看到他们结合使用的影子
可以通过反射来判断类,方法,字段上是否有某个注解以及获取注解中的值, 获取某个类中方法上的注解代码示例如下:
```
Class<?> clz = bean.getClass();
Method[] methods = clz.getMethods();
for (Method method : methods) {
if (method.isAnnotationPresent(EnableAuth.class)) {
String name = method.getAnnotation(EnableAuth.class).name();
}
}
```
通过isAnnotationPresent判断是否存在某个注解,通过getAnnotation获取注解对象,然后获取值。
### 示例
示例参考:https://blog.csdn.net/KKALL1314/article/details/96481557
自己写了一个例子,实现功能如下:
一个类的某些字段上被注解标识,在读取该属性时,将注解中的默认值赋给这些属性,没有标记的属性不赋值
```
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Documented
@Inherited
public @interface MyAnno {
String value() default "有注解";
}
```
定义一个类
```
@Data
@ToString
public class Person {
@MyAnno
private String stra;
private String strb;
private String strc;
public Person(String str1,String str2,String str3){
super();
this.stra = str1;
this.strb = str2;
this.strc = str3;
}
}
```
这里给str1加了注解,并利用反射解析并赋值:
```
public class MyTest {
public static void main(String[] args) {
//初始化全都赋值无注解
Person person = new Person("无注解","无注解","无注解");
//解析注解
doAnnoTest(person);
System.out.println(person.toString());
}
private static void doAnnoTest(Object obj) {
Class clazz = obj.getClass();
Field[] declareFields = clazz.getDeclaredFields();
for (Field field:declareFields) {
//检查该字段是否使用了某个注解
if(field.isAnnotationPresent(MyAnno.class)){
MyAnno anno = field.getAnnotation(MyAnno.class);
if(anno!=null){
String fieldName = field.getName();
try {
Method setMethod = clazz.getDeclaredMethod("set" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1),String.class);
//获取注解的属性
String annoValue = anno.value();
//将注解的属性值赋给对应的属性
setMethod.invoke(obj,annoValue);
}catch (NoSuchMethodException e){
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
}
}
}
```
运行结果:
```
Person(stra=有注解, strb=无注解, strc=无注解)
``
当开发者使用了Annotation 修饰了类、方法、Field 等成员之后,这些 Annotation 不会自己生效,必须由开发者提供相应的代码来提取并处理 Annotation 信息。这些处理提取和处理 Annotation 的代码统称为 APT(Annotation Processing Tool)。
注解的提取需要借助于 Java 的反射技术,反射比较慢,所以注解使用时也需要谨慎计较时间成本。
================================================
FILE: docs/basics/java-basic/aop-vs-proxy.md
================================================
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。
JDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。
如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。
CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
================================================
FILE: docs/basics/java-basic/apache-collections.md
================================================
Commons Collections增强了Java Collections Framework。 它提供了几个功能,使收集处理变得容易。 它提供了许多新的接口,实现和实用程序。 Commons Collections的主要功能如下
* Bag - Bag界面简化了每个对象具有多个副本的集合。
* BidiMap - BidiMap接口提供双向映射,可用于使用值使用键或键查找值。
* MapIterator - MapIterator接口提供简单而容易的迭代迭代。
* Transforming Decorators - 转换装饰器可以在将集合添加到集合时更改集合的每个对象。
* Composite Collections - 在需要统一处理多个集合的情况下使用复合集合。
* Ordered Map - 有序地图保留添加元素的顺序。
* Ordered Set - 有序集保留了添加元素的顺序。
* Reference map - 参考图允许在密切控制下对键/值进行垃圾收集。
* Comparator implementations - 可以使用许多Comparator实现。
* Iterator implementations - 许多Iterator实现都可用。
* Adapter Classes - 适配器类可用于将数组和枚举转换为集合。
* Utilities - 实用程序可用于测试测试或创建集合的典型集合论属性,例如union,intersection。 支持关闭。
### Commons Collections - Bag
Bag定义了一个集合,用于计算对象在集合中出现的次数。 例如,如果Bag包含{a,a,b,c},则getCount(“a”)将返回2,而uniqueSet()将返回唯一值。
```java
import org.apache.commons.collections4.Bag;
import org.apache.commons.collections4.bag.HashBag;
public class BagTester {
public static void main(String[] args) {
Bag<String> bag = new HashBag<>();
//add "a" two times to the bag.
bag.add("a" , 2);
//add "b" one time to the bag.
bag.add("b");
//add "c" one time to the bag.
bag.add("c");
//add "d" three times to the bag.
bag.add("d",3);
//get the count of "d" present in bag.
System.out.println("d is present " + bag.getCount("d") + " times.");
System.out.println("bag: " +bag);
//get the set of unique values from the bag
System.out.println("Unique Set: " +bag.uniqueSet());
//remove 2 occurrences of "d" from the bag
bag.remove("d",2);
System.out.println("2 occurences of d removed from bag: " +bag);
System.out.println("d is present " + bag.getCount("d") + " times.");
System.out.println("bag: " +bag);
System.out.println("Unique Set: " +bag.uniqueSet());
}
}
```
它将打印以下结果:
```
d is present 3 times.
bag: [2:a,1:b,1:c,3:d]
Unique Set: [a, b, c, d]
2 occurences of d removed from bag: [2:a,1:b,1:c,1:d]
d is present 1 times.
bag: [2:a,1:b,1:c,1:d]
Unique Set: [a, b, c, d]
```
### Commons Collections - BidiMap
使用双向映射,可以使用值查找键,并且可以使用键轻松查找值。
```java
import org.apache.commons.collections4.BidiMap;
import org.apache.commons.collections4.bidimap.TreeBidiMap;
public class BidiMapTester {
public static void main(String[] args) {
BidiMap<String, String> bidi = new TreeBidiMap<>();
bidi.put("One", "1");
bidi.put("Two", "2");
bidi.put("Three", "3");
System.out.println(bidi.get("One"));
System.out.println(bidi.getKey("1"));
System.out.println("Original Map: " + bidi);
bidi.removeValue("1");
System.out.println("Modified Map: " + bidi);
BidiMap<String, String> inversedMap = bidi.inverseBidiMap();
System.out.println("Inversed Map: " + inversedMap);
}
}
```
它将打印以下结果。
```
1
One
Original Map: {One=1, Three=3, Two=2}
Modified Map: {Three=3, Two=2}
Inversed Map: {2=Two, 3=Three}
```
### Commons Collections - MapIterator
JDK Map接口很难迭代,因为迭代要在EntrySet或KeySet对象上完成。 MapIterator提供了对Map的简单迭代。
```java
import org.apache.commons.collections4.IterableMap;
import org.apache.commons.collections4.MapIterator;
import org.apache.commons.collections4.map.HashedMap;
public class MapIteratorTester {
public static void main(String[] args) {
IterableMap<String, String> map = new HashedMap<>();
map.put("1", "One");
map.put("2", "Two");
map.put("3", "Three");
map.put("4", "Four");
map.put("5", "Five");
MapIterator<String, String> iterator = map.mapIterator();
while (iterator.hasNext()) {
Object key = iterator.next();
Object value = iterator.getValue();
System.out.println("key: " + key);
System.out.println("Value: " + value);
iterator.setValue(value + "_");
}
System.out.println(map);
}
}
```
它将打印以下结果。
```
key: 3
Value: Three
key: 5
Value: Five
key: 2
Value: Two
key: 4
Value: Four
key: 1
Value: One
{3=Three_, 5=Five_, 2=Two_, 4=Four_, 1=One_}
```
### Commons Collections - OrderedMap
OrderedMap是地图的新接口,用于保留添加元素的顺序。 LinkedMap和ListOrderedMap是两个可用的实现。 此接口支持Map的迭代器,并允许在Map中向前或向后迭代两个方向。
```java
import org.apache.commons.collections4.OrderedMap;
import org.apache.commons.collections4.map.LinkedMap;
public class OrderedMapTester {
public static void main(String[] args) {
OrderedMap<String, String> map = new LinkedMap<String, String>();
map.put("One", "1");
map.put("Two", "2");
map.put("Three", "3");
System.out.println(map.firstKey());
System.out.println(map.nextKey("One"));
System.out.println(map.nextKey("Two"));
}
}
```
它将打印以下结果。
```
One
Two
Three
```
### Commons Collections - Ignore NULL
Apache Commons Collections库的CollectionUtils类为常见操作提供了各种实用方法,涵盖了广泛的用例。 它有助于避免编写样板代码。 这个库在jdk 8之前非常有用,因为Java 8的Stream API现在提供了类似的功能。
```java
import java.util.LinkedList;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
List<String> list = new LinkedList<String>();
CollectionUtils.addIgnoreNull(list, null);
CollectionUtils.addIgnoreNull(list, "a");
System.out.println(list);
if(list.contains(null)) {
System.out.println("Null value is present");
} else {
System.out.println("Null value is not present");
}
}
}
```
它将打印以下结果。
```
[a]
Null value is not present
```
### Merge & Sort
Apache Commons Collections库的CollectionUtils类为常见操作提供了各种实用方法,涵盖了广泛的用例。 它有助于避免编写样板代码。 这个库在jdk 8之前非常有用,因为Java 8的Stream API现在提供了类似的功能。
```java
import java.util.Arrays;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
List<String> sortedList1 = Arrays.asList("A","C","E");
List<String> sortedList2 = Arrays.asList("B","D","F");
List<String> mergedList = CollectionUtils.collate(sortedList1, sortedList2);
System.out.println(mergedList);
}
}
```
它将打印以下结果。
```
[A, B, C, D, E, F]
```
### 安全空检查(Safe Empty Checks)
Apache Commons Collections库的CollectionUtils类为常见操作提供了各种实用方法,涵盖了广泛的用例。 它有助于避免编写样板代码。 这个库在jdk 8之前非常有用,因为Java 8的Stream API现在提供了类似的功能。
```java
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
List<String> list = getList();
System.out.println("Non-Empty List Check: " + checkNotEmpty1(list));
System.out.println("Non-Empty List Check: " + checkNotEmpty1(list));
}
static List<String> getList() {
return null;
}
static boolean checkNotEmpty1(List<String> list) {
return !(list == null || list.isEmpty());
}
static boolean checkNotEmpty2(List<String> list) {
return CollectionUtils.isNotEmpty(list);
}
}
```
它将打印以下结果。
```
Non-Empty List Check: false
Non-Empty List Check: false
```
### Commons Collections - Inclusion
检查列表是否是另一个列表的一部分
```java
import java.util.Arrays;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
//checking inclusion
List<String> list1 = Arrays.asList("A","A","A","C","B","B");
List<String> list2 = Arrays.asList("A","A","B","B");
System.out.println("List 1: " + list1);
System.out.println("List 2: " + list2);
System.out.println("Is List 2 contained in List 1: "
+ CollectionUtils.isSubCollection(list2, list1));
}
}
```
它将打印以下结果。
```
List 1: [A, A, A, C, B, B]
List 2: [A, A, B, B]
Is List 2 contained in List 1: true
```
### Commons Collections - Intersection
用于获取两个集合(交集)之间的公共对象
```java
import java.util.Arrays;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
//checking inclusion
List<String> list1 = Arrays.asList("A","A","A","C","B","B");
List<String> list2 = Arrays.asList("A","A","B","B");
System.out.println("List 1: " + list1);
System.out.println("List 2: " + list2);
System.out.println("Commons Objects of List 1 and List 2: "
+ CollectionUtils.intersection(list1, list2));
}
}
```
它将打印以下结果。
```
List 1: [A, A, A, C, B, B]
List 2: [A, A, B, B]
Commons Objects of List 1 and List 2: [A, A, B, B]
```
### Commons Collections - Subtraction
通过从其他集合中减去一个集合的对象来获取新集合
```java
import java.util.Arrays;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
//checking inclusion
List<String> list1 = Arrays.asList("A","A","A","C","B","B");
List<String> list2 = Arrays.asList("A","A","B","B");
System.out.println("List 1: " + list1);
System.out.println("List 2: " + list2);
System.out.println("List 1 - List 2: "
+ CollectionUtils.subtract(list1, list2));
}
}
```
它将打印以下结果。
```
List 1: [A, A, A, C, B, B]
List 2: [A, A, B, B]
List 1 - List 2: [A, C]
```
### Commons Collections - Union
用于获取两个集合的并集
```java
import java.util.Arrays;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class CollectionUtilsTester {
public static void main(String[] args) {
//checking inclusion
List<String> list1 = Arrays.asList("A","A","A","C","B","B");
List<String> list2 = Arrays.asList("A","A","B","B");
System.out.println("List 1: " + list1);
System.out.println("List 2: " + list2);
System.out.println("Union of List 1 and List 2: "
+ CollectionUtils.union(list1, list2));
}
}
```
它将打印以下结果。
```
List 1: [A, A, A, C, B, B]
List 2: [A, A, B, B]
Union of List 1 and List 2: [A, A, A, B, B, C]
```
原文地址:https://iowiki.com/commons_collections/commons_collections_index.html
================================================
FILE: docs/basics/java-basic/api-vs-spi.md
================================================
Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,API 直接被应用开发人员使用,SPI 被框架扩展人员使用
API Application Programming Interface
大多数情况下,都是实现方来制定接口并完成对接口的不同实现,调用方仅仅依赖却无权选择不同实现。
SPI Service Provider Interface
而如果是调用方来制定接口,实现方来针对接口来实现不同的实现。调用方来选择自己需要的实现方。
================================================
FILE: docs/basics/java-basic/arraylist-vs-linkedlist-vs-vector.md
================================================
List主要有ArrayList、LinkedList与Vector几种实现。
这三者都实现了List 接口,使用方式也很相似,主要区别在于因为实现方式的不同,所以对不同的操作具有不同的效率。
ArrayList 是一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组.
LinkedList 是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList.
当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义.
Vector 和ArrayList类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个集合/对象),那么使用ArrayList是更好的选择。
Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%.
而 LinkedList 还实现了 Queue 接口,该接口比List提供了更多的方法,包括 offer(),peek(),poll()等.
注意: 默认情况下ArrayList的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销。
================================================
FILE: docs/basics/java-basic/basic-data-types.md
================================================
Java中有8种基本数据类型分为三大类。
### 字符型
char
### 布尔型
boolean
### 数值型
1.整型:byte、short、int、long
2.浮点型:float、double
*String不是基本数据类型,是引用类型。*
================================================
FILE: docs/basics/java-basic/big-endian-vs-little-endian.md
================================================
字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如:如果C/C++中的一个int型变量 a 的起始地址是&a = 0x100,那么 a 的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103位置。
根据整数 a 在连续的 4 byte 内存中的存储顺序,字节序被分为大端序(Big Endian) 与 小端序(Little Endian)两类。
Big Endian 是指低地址端 存放 高位字节。
Little Endian 是指低地址端 存放 低位字节。
比如数字0x12345678在两种不同字节序CPU中的存储顺序:
Big Endian:12345678
Little Endian : 78563412
Java采用Big Endian来存储数据、C\C++采用Little Endian。在网络传输一般采用的网络字节序是BIG-ENDIAN。和Java是一致的。
所以在用C/C++写通信程序时,在发送数据前务必把整型和短整型的数据进行从主机字节序到网络字节序的转换,而接收数据后对于整型和短整型数据则必须实现从网络字节序到主机字节序的转换。如果通信的一方是JAVA程序、一方是C/C++程序时,则需要在C/C++一侧使用以上几个方法进行字节序的转换,而JAVA一侧,则不需要做任何处理,因为JAVA字节序与网络字节序都是BIG-ENDIAN,只要C/C++一侧能正确进行转换即可(发送前从主机序到网络序,接收时反变换)。如果通信的双方都是JAVA,则根本不用考虑字节序的问题了。
================================================
FILE: docs/basics/java-basic/bio-vs-nio-vs-aio.md
================================================
### IO
什么是IO? 它是指计算机与外部世界或者一个程序与计算机的其余部分之间的接口。它对于任何计算机系统都非常关键,因而所有 I/O 的主体实际上是内置在操作系统中的。单独的程序一般是让系统为它们完成大部分的工作。
在 Java 编程中,直到最近一直使用 流 的方式完成 I/O。所有 I/O 都被视为单个的字节的移动,通过一个称为 Stream 的对象一次移动一个字节。流 I/O 用于与外部世界接触。它也在内部使用,用于将对象转换为字节,然后再转换回对象。
### BIO
Java BIO即Block I/O , 同步并阻塞的IO。
BIO就是传统的java.io包下面的代码实现。
### NIO
什么是NIO? NIO 与原来的 I/O 有同样的作用和目的, 他们之间最重要的区别是数据打包和传输的方式。原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
一个 面向块 的 I/O 系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
### AIO
Java AIO即Async非阻塞,是异步非阻塞的IO。
### 区别及联系
BIO (Blocking I/O):同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。
NIO (New I/O):同时支持阻塞与非阻塞模式,但这里我们以其同步非阻塞I/O模式来说明,那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO的做法是叫一个线程不断地轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。
AIO ( Asynchronous I/O):异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。
### 各自适用场景
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
### 使用方式
#### 使用BIO实现文件的读取和写入。
```
//Initializes The Object
User1 user = new User1();
user.setName("hollis");
user.setAge(23);
System.out.println(user);
//Write Obj to File
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
oos.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeQuietly(oos);
}
//Read Obj from File
File file = new File("tempFile");
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream(file));
User1 newUser = (User1) ois.readObject();
System.out.println(newUser);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
IOUtils.closeQuietly(ois);
try {
FileUtils.forceDelete(file);
} catch (IOException e) {
e.printStackTrace();
}
}
```
#### 使用NIO实现文件的读取和写入。
```
static void readNIO() {
String pathname = "C:\\Users\\adew\\Desktop\\jd-gui.cfg";
FileInputStream fin = null;
try {
fin = new FileInputStream(new File(pathname));
FileChannel channel = fin.getChannel();
int capacity = 100;// 字节
ByteBuffer bf = ByteBuffer.allocate(capacity);
System.out.println("限制是:" + bf.limit() + "容量是:" + bf.capacity()
+ "位置是:" + bf.position());
int length = -1;
while ((length = channel.read(bf)) != -1) {
/*
* 注意,读取后,将位置置为0,将limit置为容量, 以备下次读入到字节缓冲中,从0开始存储
*/
bf.clear();
byte[] bytes = bf.array();
System.out.write(bytes, 0, length);
System.out.println();
System.out.println("限制是:" + bf.limit() + "容量是:" + bf.capacity()
+ "位置是:" + bf.position());
}
channel.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fin != null) {
try {
fin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
static void writeNIO() {
String filename = "out.txt";
FileOutputStream fos = null;
try {
fos = new FileOutputStream(new File(filename));
FileChannel channel = fos.getChannel();
ByteBuffer src = Charset.forName("utf8").encode("你好你好你好你好你好");
// 字节缓冲的容量和limit会随着数据长度变化,不是固定不变的
System.out.println("初始化容量和limit:" + src.capacity() + ","
+ src.limit());
int length = 0;
while ((length = channel.write(src)) != 0) {
/*
* 注意,这里不需要clear,将缓冲中的数据写入到通道中后 第二次接着上一次的顺序往下读
*/
System.out.println("写入长度:" + length);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
```
#### 使用AIO实现文件的读取和写入
```
public class ReadFromFile {
public static void main(String[] args) throws Exception {
Path file = Paths.get("/usr/a.txt");
AsynchronousFileChannel channel = AsynchronousFileChannel.open(file);
ByteBuffer buffer = ByteBuffer.allocate(100_000);
Future<Integer> result = channel.read(buffer, 0);
while (!result.isDone()) {
ProfitCalculator.calculateTax();
}
Integer bytesRead = result.get();
System.out.println("Bytes read [" + bytesRead + "]");
}
}
class ProfitCalculator {
public ProfitCalculator() {
}
public static void calculateTax() {
}
}
public class WriteToFile {
public static void main(String[] args) throws Exception {
AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(
Paths.get("/asynchronous.txt"), StandardOpenOption.READ,
StandardOpenOption.WRITE, StandardOpenOption.CREATE);
CompletionHandler<Integer, Object> handler = new CompletionHandler<Integer, Object>() {
@Override
public void completed(Integer result, Object attachment) {
System.out.println("Attachment: " + attachment + " " + result
+ " bytes written");
System.out.println("CompletionHandler Thread ID: "
+ Thread.currentThread().getId());
}
@Override
public void failed(Throwable e, Object attachment) {
System.err.println("Attachment: " + attachment + " failed with:");
e.printStackTrace();
}
};
System.out.println("Main Thread ID: " + Thread.currentThread().getId());
fileChannel.write(ByteBuffer.wrap("Sample".getBytes()), 0, "First Write",
handler);
fileChannel.write(ByteBuffer.wrap("Box".getBytes()), 0, "Second Write",
handler);
}
}
```
================================================
FILE: docs/basics/java-basic/block-vs-non-blocking.md
================================================
阻塞与非阻塞描述的是调用者的
如A调用B:
如果是阻塞,A在发出调用后,要一直等待,等着B返回结果。
如果是非阻塞,A在发出调用后,不需要等待,可以去做自己的事情。
### 同步,异步 和 阻塞,非阻塞之间的区别
[同步、异步](/basics/java-basic/synchronized-vs-asynchronization.md),是描述被调用方的。
阻塞,非阻塞,是描述调用方的。
同步不一定阻塞,异步也不一定非阻塞。没有必然关系。
举个简单的例子,老张烧水。
1 老张把水壶放到火上,一直在水壶旁等着水开。(同步阻塞)
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
3 老张把响水壶放到火上,一直在水壶旁等着水开。(异步阻塞)
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
1和2的区别是,调用方在得到返回之前所做的事情不一行。
1和3的区别是,被调用方对于烧水的处理不一样。
================================================
FILE: docs/basics/java-basic/boxing-unboxing.md
================================================
本文主要介绍 Java 中的自动拆箱与自动装箱的有关知识。
## 基本数据类型
基本类型,或者叫做内置类型,是 Java 中不同于类(Class)的特殊类型。它们是我们编程中使用最频繁的类型。
Java 是一种强类型语言,第一次申明变量必须说明数据类型,第一次变量赋值称为变量的初始化。
Java 基本类型共有八种,基本类型可以分为三类:
> 字符类型 `char`
>
> 布尔类型 `boolean`
>
> 数值类型 `byte`、`short`、`int`、`long`、`float`、`double`。
数值类型又可以分为整数类型 `byte`、`short`、`int`、`long` 和浮点数类型 `float`、`double`。
Java 中的数值类型不存在无符号的,它们的取值范围是固定的,不会随着机器硬件环境或者操作系统的改变而改变。
实际上,Java 中还存在另外一种基本类型 `void`,它也有对应的包装类 `java.lang.Void`,不过我们无法直接对它们进行操作。
### 基本数据类型有什么好处
我们都知道在 Java 语言中,`new` 一个对象是存储在堆里的,我们通过栈中的引用来使用这些对象;所以,对象本身来说是比较消耗资源的。
对于经常用到的类型,如 int 等,如果我们每次使用这种变量的时候都需要 new 一个 Java 对象的话,就会比较笨重。所以,和 C++ 一样,Java 提供了基本数据类型,这种数据的变量不需要使用 new 创建,他们不会在堆上创建,而是直接在栈内存中存储,因此会更加高效。
### 整型的取值范围
Java 中的整型主要包含`byte`、`short`、`int`和`long`这四种,表示的数字范围也是从小到大的,之所以表示范围不同主要和他们存储数据时所占的字节数有关。
先来个简答的科普,1 字节= 8 位(bit)。Java 中的整型属于有符号数。
先来看计算中 8 bit 可以表示的数字:
最小值:10000000 (-128)(-2^7)
最大值:01111111(127)(2^7-1)
整型的这几个类型中,
* byte:byte 用 1 个字节来存储,范围为 -128(-2^7) 到 127(2^7-1),在变量初始化的时候,byte 类型的默认值为 0。
* short:short 用 2 个字节存储,范围为 -32,768(-2^15) 到 32,767(2^15-1),在变量初始化的时候,short 类型的默认值为 0,一般情况下,因为 Java 本身转型的原因,可以直接写为 0。
* int:int 用 4 个字节存储,范围为 -2,147,483,648(-2^31) 到 2,147,483,647(2^31-1),在变量初始化的时候,int 类型的默认值为 0。
* long:long 用 8 个字节存储,范围为 -9,223,372,036,854,775,808(-2^63) 到 9,223,372,036, 854,775,807(2^63-1),在变量初始化的时候,long 类型的默认值为 0L 或 0l,也可直接写为 0。
### 超出范围怎么办
上面说过了,整型中,每个类型都有一定的表示范围,但是,在程序中有些计算会导致超出表示范围,即溢出。如以下代码:
```java
int i = Integer.MAX_VALUE;
int j = Integer.MAX_VALUE;
int k = i + j;
System.out.println("i (" + i + ") + j (" + j + ") = k (" + k + ")");
```
输出结果:i (2147483647) + j (2147483647) = k (-2)
**这就是发生了溢出,溢出的时候并不会抛异常,也没有任何提示。** 所以,在程序中,使用同类型的数据进行运算的时候,**一定要注意数据溢出的问题。**
## 包装类型
Java 语言是一个面向对象的语言,但是 Java 中的基本数据类型却是不面向对象的,这在实际使用时存在很多的不便,为了解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,这样八个和基本数据类型对应的类统称为包装类(Wrapper Class)。
包装类均位于 `java.lang` 包,包装类和基本数据类型的对应关系如下表所示
| 基本数据类型 | 包装类 |
| ------- | --------- |
| byte | Byte |
| boolean | Boolean |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
在这八个类名中,除了 Integer 和 Character 类以后,其它六个类的类名和基本数据类型一致,只是类名的第一个字母大写即可。
### 为什么需要包装类
很多人会有疑问,既然 Java 中为了提高效率,提供了八种基本数据类型,为什么还要提供包装类呢?
这个问题,其实前面已经有了答案,因为 Java 是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。比如,在集合类中,我们是无法将 int 、double 等类型放进去的。因为集合的容器要求元素是 Object 类型。
为了让基本类型也具有对象的特征,就出现了包装类型,它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
## 拆箱与装箱
那么,有了基本数据类型和包装类,肯定有些时候要在他们之间进行转换。比如把一个基本数据类型的 int 转换成一个包装类型的 Integer 对象。
我们认为包装类是对基本类型的包装,所以,把基本数据类型转换成包装类的过程就是打包装,英文对应于 boxing,中文翻译为装箱。
反之,把包装类转换成基本数据类型的过程就是拆包装,英文对应于 unboxing,中文翻译为拆箱。
在 Java SE5 之前,要进行装箱,可以通过以下代码:
```java
Integer i = new Integer(10);
```
## 自动拆箱与自动装箱
在 Java SE5 中,为了减少开发人员的工作,Java 提供了自动拆箱与自动装箱功能。
自动装箱: 就是将基本数据类型自动转换成对应的包装类。
自动拆箱:就是将包装类自动转换成对应的基本数据类型。
```java
Integer i = 10; //自动装箱
int b = i; //自动拆箱
```
`Integer i=10` 可以替代 `Integer i = new Integer(10);`,这就是因为 Java 帮我们提供了自动装箱的功能,不需要开发者手动去 new 一个 Integer 对象。
## 自动装箱与自动拆箱的实现原理
既然 Java 提供了自动拆装箱的能力,那么,我们就来看一下,到底是什么原理,Java 是如何实现的自动拆装箱功能。
我们有以下自动拆装箱的代码:
```java
public static void main(String[]args){
Integer integer=1; //装箱
int i=integer; //拆箱
}
```
对以上代码进行反编译后可以得到以下代码:
```java
public static void main(String[]args){
Integer integer=Integer.valueOf(1);
int i=integer.intValue();
}
```
从上面反编译后的代码可以看出,int 的自动装箱都是通过 `Integer.valueOf()` 方法来实现的,Integer 的自动拆箱都是通过 `integer.intValue` 来实现的。如果读者感兴趣,可以试着将八种类型都反编译一遍 ,你会发现以下规律:
> 自动装箱都是通过包装类的 `valueOf()` 方法来实现的.自动拆箱都是通过包装类对象的 `xxxValue()` 来实现的。
## 哪些地方会自动拆装箱
我们了解过原理之后,在来看一下,什么情况下,Java 会帮我们进行自动拆装箱。前面提到的变量的初始化和赋值的场景就不介绍了,那是最简单的也最容易理解的。
我们主要来看一下,那些可能被忽略的场景。
### 场景一、将基本数据类型放入集合类
我们知道,Java 中的集合类只能接收对象类型,那么以下代码为什么会不报错呢?
```java
List<Integer> li = new ArrayList<>();
for (int i = 1; i < 50; i ++){
li.add(i);
}
```
将上面代码进行反编译,可以得到以下代码:
```java
List<Integer> li = new ArrayList<>();
for (int i = 1; i < 50; i += 2){
li.add(Integer.valueOf(i));
}
```
以上,我们可以得出结论,当我们把基本数据类型放入集合类中的时候,会进行自动装箱。
### 场景二、包装类型和基本类型的大小比较
有没有人想过,当我们对 Integer 对象与基本类型进行大小比较的时候,实际上比较的是什么内容呢?看以下代码:
```java
Integer a = 1;
System.out.println(a == 1 ? "等于" : "不等于");
Boolean bool = false;
System.out.println(bool ? "真" : "假");
```
对以上代码进行反编译,得到以下代码:
```java
Integer a = 1;
System.out.println(a.intValue() == 1 ? "等于" : "不等于");
Boolean bool = false;
System.out.println(bool.booleanValue ? "真" : "假");
```
可以看到,包装类与基本数据类型进行比较运算,是先将包装类进行拆箱成基本数据类型,然后进行比较的。
### 场景三、包装类型的运算
有没有人想过,当我们对 Integer 对象进行四则运算的时候,是如何进行的呢?看以下代码:
```java
Integer i = 10;
Integer j = 20;
System.out.println(i+j);
```
反编译后代码如下:
```java
Integer i = Integer.valueOf(10);
Integer j = Integer.valueOf(20);
System.out.println(i.intValue() + j.intValue());
```
我们发现,两个包装类型之间的运算,会被自动拆箱成基本类型进行。
### 场景四、三目运算符的使用
这是很多人不知道的一个场景,作者也是一次线上的血淋淋的 Bug 发生后才了解到的一种案例。看一个简单的三目运算符的代码:
```java
boolean flag = true;
Integer i = 0;
int j = 1;
int k = flag ? i : j;
```
很多人不知道,其实在 `int k = flag ? i : j;` 这一行,会发生自动拆箱( JDK1.8 之前,详见:[《阿里巴巴Java开发手册-泰山版》提到的三目运算符的空指针问题到底是个怎么回事?](https://www.hollischuang.com/archives/4749) )。
反编译后代码如下:
```java
boolean flag = true;
Integer i = Integer.valueOf(0);
int j = 1;
int k = flag ? i.intValue() : j;
System.out.println(k);
```
这其实是三目运算符的语法规范。当第二,第三位操作数分别为基本类型和对象时,其中的对象就会拆箱为基本类型进行操作。
因为例子中,`flag ? i : j;` 片段中,第二段的 i 是一个包装类型的对象,而第三段的 j 是一个基本类型,所以会对包装类进行自动拆箱。如果这个时候 i 的值为 `null`,那么就会发生 NPE。([自动拆箱导致空指针异常][1])
### 场景五、函数参数与返回值
这个比较容易理解,直接上代码了:
```java
//自动拆箱
public int getNum1(Integer num) {
return num;
}
//自动装箱
public Integer getNum2(int num) {
return num;
}
```
## 自动拆装箱与缓存
Java SE 的自动拆装箱还提供了一个和缓存有关的功能,我们先来看以下代码,猜测一下输出结果:
```java
public static void main(String... strings) {
Integer integer1 = 3;
Integer integer2 = 3;
if (integer1 == integer2)
System.out.println("integer1 == integer2");
else
System.out.println("integer1 != integer2");
Integer integer3 = 300;
Integer integer4 = 300;
if (integer3 == integer4)
System.out.println("integer3 == integer4");
else
System.out.println("integer3 != integer4");
}
```
我们普遍认为上面的两个判断的结果都是 false。虽然比较的值是相等的,但是由于比较的是对象,而对象的引用不一样,所以会认为两个 if 判断都是 false 的。在 Java 中,`==` 比较的是对象引用,而 `equals` 比较的是值。所以,在这个例子中,不同的对象有不同的引用,所以在进行比较的时候都将返回 false。奇怪的是,这里两个类似的 if 条件判断返回不同的布尔值。
上面这段代码真正的输出结果:
integer1 == integer2
integer3 != integer4
原因就和 Integer 中的缓存机制有关。在 Java 5 中,在 Integer 的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
> 适用于整数值区间 -128 至 +127。
>
> 只适用于自动装箱。使用构造函数创建对象不适用。
具体的代码实现可以阅读[Java中整型的缓存机制][2]一文,这里不再阐述。
我们只需要知道,当需要进行自动装箱时,如果数字在 -128 至 127 之间时,会直接使用缓存中的对象,而不是重新创建一个对象。
其中的 Javadoc 详细的说明了缓存支持 -128 到 127 之间的自动装箱过程。最大值 127 可以通过 `-XX:AutoBoxCacheMax=size` 修改。
实际上这个功能在 Java 5 中引入的时候,范围是固定的 -128 至 +127。后来在 Java 6 中,可以通过 `java.lang.Integer.IntegerCache.high` 设置最大值。
这使我们可以根据应用程序的实际情况灵活地调整来提高性能。到底是什么原因选择这个 -128 到 127 范围呢?因为这个范围的数字是最被广泛使用的。 在程序中,第一次使用 Integer 的时候也需要一定的额外时间来初始化这个缓存。
在 Boxing Conversion 部分的 Java 语言规范(JLS)规定如下:
如果一个变量 p 的值是:
- -128 至 127 之间的整数 (§3.10.1)
- true 和 false 的布尔值 (§3.10.3)
- `\u0000` 至 `\u007f` 之间的字符 (§3.10.4)
范围内的时,将 p 包装成 a 和 b 两个对象时,可以直接使用 a == b 判断 a 和 b 的值是否相等。
## 自动拆装箱带来的问题
当然,自动拆装箱是一个很好的功能,大大节省了开发人员的精力,不再需要关心到底什么时候需要拆装箱。但是,他也会引入一些问题。
> 包装对象的数值比较,不能简单的使用 `==`,虽然 -128 到 127 之间的数字可以,但是这个范围之外还是需要使用 `equals` 比较。
>
> 前面提到,有些场景会进行自动拆装箱,同时也说过,由于自动拆箱,如果包装类对象为 null ,那么自动拆箱时就有可能抛出 NPE。
>
> 如果一个 for 循环中有大量拆装箱操作,会浪费很多资源。
gitextract_5tnf3xan/ ├── .gitattributes ├── .gitignore ├── README.md ├── docs/ │ ├── .nojekyll │ ├── README.md │ ├── _coverpage.md │ ├── _sidebar.md │ ├── advance/ │ │ └── design-patterns/ │ │ ├── abstract-factory-pattern.md │ │ ├── adapter-pattern.md │ │ ├── builder-pattern.md │ │ ├── factory-method-pattern.md │ │ ├── iterator-pattern.md │ │ ├── singleton-pattern.md │ │ └── strategy-pattern.md │ ├── basement/ │ │ └── jvm/ │ │ ├── break-parants-delegate.md │ │ ├── define-class-loader.md │ │ ├── exclusive-in-runtime-area.md │ │ ├── implements-of-parents-delegate.md │ │ ├── java-memory-model.md │ │ ├── moduler.md │ │ ├── parents-delegate.md │ │ ├── relation-with-parents-delegate.md │ │ ├── runtime-area.md │ │ ├── sample-of-break-parents-delegate.md │ │ ├── spi-parents-delegate.md │ │ ├── stack-alloc.md │ │ ├── tomcat-parents-delegate.md │ │ └── why-parents-delegate.md │ ├── basics/ │ │ ├── concurrent-coding/ │ │ │ ├── concurrent-vs-parallel.md │ │ │ ├── concurrent.md │ │ │ ├── create-thread-with-Implement.md │ │ │ ├── create-thread-with-callback-future-task.md │ │ │ ├── create-thread-with-extends.md │ │ │ ├── create-thread-with-thead-pool.md │ │ │ ├── deadlock-java-level.md │ │ │ ├── deamon-thread.md │ │ │ ├── debug-in-multithread.md │ │ │ ├── implement-of-thread.md │ │ │ ├── parallel.md │ │ │ ├── priority-of-thread.md │ │ │ ├── progress-vs-thread.md │ │ │ ├── state-of-thread.md │ │ │ ├── synchronized.md │ │ │ ├── thread-safe.md │ │ │ ├── thread-scheduling.md │ │ │ ├── thread.md │ │ │ ├── volatile.md │ │ │ └── why-not-executors.md │ │ ├── java-basic/ │ │ │ ├── ASCII.md │ │ │ ├── Arrays-asList.md │ │ │ ├── CET-UTC-GMT-CST.md │ │ │ ├── Class.md │ │ │ ├── Collection-vs-Collections.md │ │ │ ├── ConcurrentSkipListMap.md │ │ │ ├── CopyOnWriteArrayList.md │ │ │ ├── Enumeration-vs-Iterator.md │ │ │ ├── GMT.md │ │ │ ├── HashMap-HashTable-ConcurrentHashMap.md │ │ │ ├── README.md │ │ │ ├── Runtime-Constant-Pool.md │ │ │ ├── StandardTime-vs-daylightSavingTime.md │ │ │ ├── UNICODE.md │ │ │ ├── UTF8-UTF16-UTF32.md │ │ │ ├── Wildcard-Character.md │ │ │ ├── YYYY-vs-yyyy.md │ │ │ ├── annotation-in-java.md │ │ │ ├── annotation-in-spring.md │ │ │ ├── annotion-and-reflect.md │ │ │ ├── aop-vs-proxy.md │ │ │ ├── apache-collections.md │ │ │ ├── api-vs-spi.md │ │ │ ├── arraylist-vs-linkedlist-vs-vector.md │ │ │ ├── basic-data-types.md │ │ │ ├── big-endian-vs-little-endian.md │ │ │ ├── bio-vs-nio-vs-aio.md │ │ │ ├── block-vs-non-blocking.md │ │ │ ├── boxing-unboxing.md │ │ │ ├── bug-in-apache-commons-collections.md │ │ │ ├── bug-in-fastjson.md │ │ │ ├── byte-stream-vs-character-stream.md │ │ │ ├── class-contant-pool.md │ │ │ ├── const-in-java.md │ │ │ ├── convert-bytestream-characterstream.md │ │ │ ├── create-annotation.md │ │ │ ├── create-spi.md │ │ │ ├── custom-annotation.md │ │ │ ├── define-exception.md │ │ │ ├── delete-while-iterator.md │ │ │ ├── diff-serializable-vs-externalizable.md │ │ │ ├── dynamic-proxy-implementation.md │ │ │ ├── dynamic-proxy-vs-reflection.md │ │ │ ├── dynamic-proxy.md │ │ │ ├── enum-class.md │ │ │ ├── enum-compare.md │ │ │ ├── enum-impl.md │ │ │ ├── enum-serializable.md │ │ │ ├── enum-singleton.md │ │ │ ├── enum-switch.md │ │ │ ├── enum-thread-safe.md │ │ │ ├── enum-usage.md │ │ │ ├── error-vs-exception.md │ │ │ ├── exception-chain.md │ │ │ ├── exception-type.md │ │ │ ├── extends-vs-super.md │ │ │ ├── fail-fast-vs-fail-safe.md │ │ │ ├── final-in-java.md │ │ │ ├── final-string.md │ │ │ ├── float-amount.md │ │ │ ├── float.md │ │ │ ├── gbk-gb2312-gb18030.md │ │ │ ├── genericity-list-wildcard.md │ │ │ ├── genericity-list.md │ │ │ ├── generics-problem.md │ │ │ ├── generics.md │ │ │ ├── get-los_angeles-time.md │ │ │ ├── h2-db.md │ │ │ ├── handle-exception.md │ │ │ ├── hash-in-hashmap.md │ │ │ ├── hashmap-capacity.md │ │ │ ├── hashmap-default-capacity.md │ │ │ ├── hashmap-default-loadfactor.md │ │ │ ├── hashmap-init-capacity.md │ │ │ ├── input-stream-vs-output-stream.md │ │ │ ├── instanceof-in-java.md │ │ │ ├── integer-cache.md │ │ │ ├── integer-scope.md │ │ │ ├── intern.md │ │ │ ├── ioc-implement-with-factory-and-reflection.md │ │ │ ├── iteration-of-collection.md │ │ │ ├── jms.md │ │ │ ├── junit.md │ │ │ ├── k-t-v-e.md │ │ │ ├── keyword-about-exception.md │ │ │ ├── lambda.md │ │ │ ├── length-of-string.md │ │ │ ├── linux-io.md │ │ │ ├── meta-annotation.md │ │ │ ├── mock.md │ │ │ ├── netty.md │ │ │ ├── order-about-finllly-return.md │ │ │ ├── protobuf.md │ │ │ ├── reflection.md │ │ │ ├── replace-in-string.md │ │ │ ├── serialVersionUID-modify.md │ │ │ ├── serialVersionUID.md │ │ │ ├── serialize-in-java.md │ │ │ ├── serialize-principle.md │ │ │ ├── serialize-singleton.md │ │ │ ├── serialize.md │ │ │ ├── set-repetition.md │ │ │ ├── set-vs-list.md │ │ │ ├── simpledateformat-thread-safe.md │ │ │ ├── single-double-float.md │ │ │ ├── spi-principle.md │ │ │ ├── stack-alloc.md │ │ │ ├── static-in-java.md │ │ │ ├── static-proxy.md │ │ │ ├── stop-create-bigdecimal-with-double.md │ │ │ ├── stop-use-enum-in-api.md │ │ │ ├── stop-using-equlas-in-bigdecimal.md │ │ │ ├── stream.md │ │ │ ├── string-append.md │ │ │ ├── string-concat.md │ │ │ ├── string-pool.md │ │ │ ├── stringjoiner-in-java8.md │ │ │ ├── substring.md │ │ │ ├── success-isSuccess-and-boolean-Boolean.md │ │ │ ├── switch-string.md │ │ │ ├── synchronized-vs-asynchronization.md │ │ │ ├── synchronizedlist-vector.md │ │ │ ├── syntactic-sugar.md │ │ │ ├── time-in-java8.md │ │ │ ├── time-zone.md │ │ │ ├── timestamp.md │ │ │ ├── transient-in-java.md │ │ │ ├── try-with-resources.md │ │ │ ├── type-erasure.md │ │ │ ├── url-encode.md │ │ │ ├── usage-of-reflection.md │ │ │ ├── ut-with-jmockit.md │ │ │ ├── value-of-vs-to-string.md │ │ │ ├── why-gbk.md │ │ │ ├── why-transient-in-arraylist.md │ │ │ └── why-utf8.md │ │ └── object-oriented/ │ │ ├── characteristics.md │ │ ├── constructor.md │ │ ├── extends-implement.md │ │ ├── inheritance-composition.md │ │ ├── java-pass-by.md │ │ ├── jvm-language.md │ │ ├── multiple-inheritance.md │ │ ├── object-oriented-vs-procedure-oriented.md │ │ ├── overloading-vs-overriding.md │ │ ├── platform-independent.md │ │ ├── polymorphism.md │ │ ├── principle.md │ │ ├── scope.md │ │ ├── variable.md │ │ └── why-pass-by-reference.md │ ├── css/ │ │ └── my.css │ ├── index.html │ └── menu.md └── mind-map.md
Condensed preview — 203 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (597K chars).
[
{
"path": ".gitattributes",
"chars": 127,
"preview": "* text=auto\n*.js linguist-language=java\n*.css linguist-language=java\n*.html linguist-language=java\n*.md linguist-languag"
},
{
"path": ".gitignore",
"chars": 1155,
"preview": "# Created by .ignore support plugin (hsz.mobi)\n### JetBrains template\n# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpSt"
},
{
"path": "README.md",
"chars": 1383,
"preview": "## To Be Top Javaer - Java工程师成神之路\n\n  :提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,属于对象创建型模式。\n\n抽象工厂模式提供了一种方式,可以将同一"
},
{
"path": "docs/advance/design-patterns/adapter-pattern.md",
"chars": 7181,
"preview": "\n## 概念\n\nGOF是这样给适配器模式(`Adapter`)定义的:将一个类的接口转化成用户需要的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。\n\nGOF中将适配器模式分为类适配器模式和对象适配"
},
{
"path": "docs/advance/design-patterns/builder-pattern.md",
"chars": 6506,
"preview": "\n## 概念\n\n建造者模式(英:Builder Pattern)是一种创建型设计模式,又名:生成器模式。GOF 给建造者模式的定义为:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。这句话说的比较抽象,其实解释一下"
},
{
"path": "docs/advance/design-patterns/factory-method-pattern.md",
"chars": 4682,
"preview": "## 概念\n\n工厂方法模式(Factory Method Pattern)又称为工厂模式,也叫虚拟构造器(Virtual Constructor)模式或者多态工厂(Polymorphic Factory)模式,它属于类创建型模式。\n\n工厂方"
},
{
"path": "docs/advance/design-patterns/iterator-pattern.md",
"chars": 3758,
"preview": "\n## 概念\n\n一提到迭代器模式很多人可能感觉很陌生,但是实际上,迭代器模式是所有设计模式中最简单也是最常用的设计模式,正是因为他太常用了,所以很多人忽略了他的存在。\n\n> 迭代器模式提供一种方法访问一个容器中各个元素,而又不需要暴露该对象"
},
{
"path": "docs/advance/design-patterns/singleton-pattern.md",
"chars": 10379,
"preview": "## 概念\n\n单例模式(`Singleton Pattern`)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式。在 [GOF 书][3]中给出的定义为:保证一个类仅有一个实例,并提供一个访问它的全局访问点。\n\n单例模"
},
{
"path": "docs/advance/design-patterns/strategy-pattern.md",
"chars": 5671,
"preview": "\n## 概念\n\n学习过设计模式的人大概都知道[Head First设计模式][2]这本书,这本书中介绍的第一个模式就是策略模式。把策略模式放在第一个,笔者认为主要有两个原因:1、这的确是一个比较简单的模式。2、这个模式可以充分的体现面向对象"
},
{
"path": "docs/basement/jvm/break-parants-delegate.md",
"chars": 115,
"preview": "知道了双亲委派模型的实现,那么想要破坏双亲委派机制就很简单了。\n\n因为他的双亲委派过程都是在loadClass方法中实现的,那么想要破坏这种机制,那么就自定义一个类加载器,重写其中的loadClass方法,使其不进行双亲委派即可。"
},
{
"path": "docs/basement/jvm/define-class-loader.md",
"chars": 819,
"preview": "ClassLoader中和类加载有关的方法有很多,前面提到了loadClass,除此之外,还有findClass和defineClass等,那么这几个方法有什么区别呢?\n\n* loadClass()\n * 就是主要进行类加载的方法,默"
},
{
"path": "docs/basement/jvm/exclusive-in-runtime-area.md",
"chars": 119,
"preview": "在JVM运行时内存区域中,PC寄存器、虚拟机栈和本地方法栈是线程独享的。\n\n而Java堆、方法区是线程共享的。但是值得注意的是,Java堆其实还未每一个线程单独分配了一块TLAB空间,这部分空间在分配时是线程独享的,在使用时是线程共享的。"
},
{
"path": "docs/basement/jvm/implements-of-parents-delegate.md",
"chars": 1891,
"preview": "双亲委派模型对于保证Java程序的稳定运作很重要,但它的实现并不复杂。\n\n实现双亲委派的代码都集中在java.lang.ClassLoader的loadClass()方法之中:\n\n protected Class<?> loadCla"
},
{
"path": "docs/basement/jvm/java-memory-model.md",
"chars": 1408,
"preview": "## Java内存模型\n\n> 本文是[《成神之路系列文章》](/catalog/catalog.md)中的一篇,主要是关于JVM的一些介绍。\n> \n> 持续更新中\n\n### Java内存模型\n\n[JVM内存结构 VS Java内存模型 VS"
},
{
"path": "docs/basement/jvm/moduler.md",
"chars": 1107,
"preview": "近几年模块化技术已经很成熟了,在JDK 9中已经应用了模块化的技术。\n\n其实早在JDK 9之前,OSGI这种框架已经是模块化的了,**而OSGI之所以能够实现模块热插拔和模块内部可见性的精准控制都归结于其特殊的类加载机制,加载器之间的关系不"
},
{
"path": "docs/basement/jvm/parents-delegate.md",
"chars": 947,
"preview": "虚拟机在加载类的过程中需要使用类加载器进行加载,而在Java中,类加载器有很多,那么当JVM想要加载一个.class文件的时候,到底应该由哪个类加载器加载呢?\n\n这就不得不提到”双亲委派机制”。\n\n首先,我们需要知道的是,Java语言系统中"
},
{
"path": "docs/basement/jvm/relation-with-parents-delegate.md",
"chars": 320,
"preview": "很多人看到父加载器、子加载器这样的名字,就会认为Java中的类加载器之间存在着继承关系。\n\n甚至网上很多文章也会有类似的错误观点。\n\n这里需要明确一下,双亲委派模型中,类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实"
},
{
"path": "docs/basement/jvm/runtime-area.md",
"chars": 795,
"preview": "Java虚拟机在执行Java程序的过程中会把他所管理的内存划分为若干个不同的数据区域。《Java虚拟机规范》中规定了JVM所管理的内存需要包括一下几个运行时区域:\n\n\n\n并发是两"
},
{
"path": "docs/basics/concurrent-coding/concurrent.md",
"chars": 519,
"preview": "并发(Concurrent),在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。\n\n那么,操作系统是如何实现这种并发的呢?\n\n现在我们用到操作系统,无论是Windows、Linux"
},
{
"path": "docs/basics/concurrent-coding/create-thread-with-Implement.md",
"chars": 879,
"preview": "\n\n public class MultiThreads {\n public static void main(String[] args) throws InterruptedException {\n "
},
{
"path": "docs/basics/concurrent-coding/create-thread-with-callback-future-task.md",
"chars": 1889,
"preview": "自从Java 1.5开始,提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果。\n\n public class MultiThreads {\n public static void mai"
},
{
"path": "docs/basics/concurrent-coding/create-thread-with-extends.md",
"chars": 1080,
"preview": "\n\n /**\n * @author Hollis\n */\n public class MultiThreads {\n \n public static void main(String[] ar"
},
{
"path": "docs/basics/concurrent-coding/create-thread-with-thead-pool.md",
"chars": 939,
"preview": "Java中提供了对线程池的支持,有很多种方式。Jdk提供给外部的接口也很简单。直接调用ThreadPoolExecutor构造一个就可以了:\n\n public class MultiThreads {\n public s"
},
{
"path": "docs/basics/concurrent-coding/deadlock-java-level.md",
"chars": 3848,
"preview": "java级别死锁\n\n## 一、什么是死锁\n死锁不仅在个人学习中,甚至在开发中也并不常见。但是一旦出现死锁,后果将非常严重。\n首先什么是死锁呢?打个比方,就好像有两个人打架,互相限制住了(锁住,抱住)彼此一样,互相动弹不得,而且互相欧气,你不"
},
{
"path": "docs/basics/concurrent-coding/deamon-thread.md",
"chars": 2974,
"preview": "在Java中有两类线程:User Thread(用户线程)、Daemon Thread(守护线程) 。用户线程一般用户执行用户级任务,而守护线程也就是“后台线程”,一般用来执行后台任务,守护线程最典型的应用就是GC(垃圾回收器)。\n\n这两种"
},
{
"path": "docs/basics/concurrent-coding/debug-in-multithread.md",
"chars": 1802,
"preview": "在学习过了前面几篇文章之后,相信很多人对于Java中的多线程都有了一定的了解,相信很多读者已经尝试过中写一些多线程的代码了。\n\n但是我之前面试过很多人,很多人都知道多线程怎么实现,但是却不知道如何调试多线程的代码,这篇文章我们来介绍下如何调"
},
{
"path": "docs/basics/concurrent-coding/implement-of-thread.md",
"chars": 2771,
"preview": "主流的操作系统都提供了线程实现,实现线程主要有3种方式:使用内核线程实现、使用用户线程实现和使用用户线程加轻量级进程混合实现。\n\n## 使用内核线程实现\n\n内核线程(Kernel-Level Thread,KLT)就是直接由操作系统内核(K"
},
{
"path": "docs/basics/concurrent-coding/parallel.md",
"chars": 100,
"preview": "\n并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。"
},
{
"path": "docs/basics/concurrent-coding/priority-of-thread.md",
"chars": 1763,
"preview": "我们学习过,Java虚拟机采用抢占式调度模型。也就是说他会给优先级更高的线程优先分配CPU。\n\n虽然Java线程调度是系统自动完成的,但是我们还是可以“建议”系统给某些线程多分配一点执行时间,另外的一些线程则可以少分配一点——这项操作可以通"
},
{
"path": "docs/basics/concurrent-coding/progress-vs-thread.md",
"chars": 992,
"preview": "为了看起来像是“同时干多件事”,分时操作系统是把CPU的时间划分成长短基本相同的”时间片”,通过操作系统的管理,把这些时间片依次轮流地分配给各个用户的各个任务使用。\n\n在多任务处理系统中,CPU需要处理所有程序的操作,当用户来回切换它们时,"
},
{
"path": "docs/basics/concurrent-coding/state-of-thread.md",
"chars": 735,
"preview": "线程是有状态的,并且这些状态之间也是可以互相流转的。Java中线程的状态分为6种:\n\n* 1\\.初始(NEW):新创建了一个线程对象,但还没有调用start()方法。\n* 1\\.运行(RUNNABLE):Java线程中将就绪(REA"
},
{
"path": "docs/basics/concurrent-coding/synchronized.md",
"chars": 6358,
"preview": "在[再有人问你Java内存模型是什么,就把这篇文章发给他。][1]中我们曾经介绍过,Java语言为了解决并发编程中存在的原子性、可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如`synchronized`、`volatile`、"
},
{
"path": "docs/basics/concurrent-coding/thread-safe.md",
"chars": 3528,
"preview": "# 什么是线程安全\n\n线程安全,维基百科中的解释是:\n\n> 线程安全是编程中的术语,指某个函数、函数库在**并发**环境中被调用时,能够正确地处理**多个线程**之间的**共享变量**,使程序功能正确完成。\n\n我们把这个定义拆解一下,我们需"
},
{
"path": "docs/basics/concurrent-coding/thread-scheduling.md",
"chars": 2056,
"preview": "在关于线程安全的文章中,我们提到过,对于单CPU的计算机来说,在任意时刻只能执行一条机器指令,每个线程只有获得CPU的使用权才能执行指令。\n\n所谓多线程的并发运行,其实是指从宏观上看,各个线程轮流获得CPU的使用权,分别执行各自的任务。\n\n"
},
{
"path": "docs/basics/concurrent-coding/thread.md",
"chars": 675,
"preview": "在多线程操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。\n\n## 轻型实体\n\n线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。 线程的实"
},
{
"path": "docs/basics/concurrent-coding/volatile.md",
"chars": 4713,
"preview": "在[再有人问你Java内存模型是什么,就把这篇文章发给他][1]中我们曾经介绍过,Java语言为了解决并发编程中存在的原子性、可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如`synchronized`、`volatile`、`"
},
{
"path": "docs/basics/concurrent-coding/why-not-executors.md",
"chars": 5422,
"preview": "在《[深入源码分析Java线程池的实现原理][1]》这篇文章中,我们介绍过了Java中线程池的常见用法以及基本原理。\n\n在文中有这样一段描述:\n\n> 可以通过Executors静态工厂构建线程池,但一般不建议这样使用。\n\n关于这个问题,在那"
},
{
"path": "docs/basics/java-basic/ASCII.md",
"chars": 577,
"preview": "ASCII( American Standard Code for InformationInterchange, 美国信息交换标准代码) 是基于拉丁字母的⼀套电脑编码系统, 主要⽤于显⽰现代英语和其他西欧语⾔。 \n\n它是现今最通⽤的单字节"
},
{
"path": "docs/basics/java-basic/Arrays-asList.md",
"chars": 101,
"preview": "1. asList 得到的只是一个 Arrays 的内部类,一个原来数组的视图 List,因此如果对它进行增删操作会报错\n\n2. 用 ArrayList 的构造器可以将其转变成真正的 ArrayList"
},
{
"path": "docs/basics/java-basic/CET-UTC-GMT-CST.md",
"chars": 710,
"preview": "### CET\n欧洲中部时间(英語:Central European Time,CET)是比世界标准时间(UTC)早一个小时的时区名称之一。它被大部分欧洲国家和部分北非国家采用。冬季时间为UTC+1,夏季欧洲夏令时为UTC+2。\n\n\n###"
},
{
"path": "docs/basics/java-basic/Class.md",
"chars": 311,
"preview": "Java的Class类是java反射机制的基础,通过Class类我们可以获得关于一个类的相关信息\n\nJava.lang.Class是一个比较特殊的类,它用于封装被装入到JVM中的类(包括类和接口)的信息。当一个类或接口被装入的JVM时便会产"
},
{
"path": "docs/basics/java-basic/Collection-vs-Collections.md",
"chars": 239,
"preview": "Collection 是一个集合接口。 \n它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。是list,set等的父接口。\n\nCollections 是一个包装类。 \n它包含有各种有关"
},
{
"path": "docs/basics/java-basic/ConcurrentSkipListMap.md",
"chars": 412,
"preview": "ConcurrentSkipListMap是一个内部使用跳表,并且支持排序和并发的一个Map,是线程安全的。一般很少会被用到,也是一个比较偏门的数据结构。\n\n简单介绍下跳表\n\n 跳表是一种允许在一个有顺序的序列中进行快速查询的数据结构"
},
{
"path": "docs/basics/java-basic/CopyOnWriteArrayList.md",
"chars": 789,
"preview": "Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始"
},
{
"path": "docs/basics/java-basic/Enumeration-vs-Iterator.md",
"chars": 572,
"preview": "函数接口不同\n\n Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。\n Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,"
},
{
"path": "docs/basics/java-basic/GMT.md",
"chars": 283,
"preview": "格林尼治平时(英语:Greenwich Mean Time,GMT)是指位于英国伦敦郊区的皇家格林尼治天文台当地的平太阳时,因为本初子午线被定义为通过那里的经线。\n\n自1924年2月5日开始,格林尼治天文台负责每隔一小时向全世界发放调时信息"
},
{
"path": "docs/basics/java-basic/HashMap-HashTable-ConcurrentHashMap.md",
"chars": 933,
"preview": "### HashMap和HashTable有何不同?\n\n\n线程安全:\n\nHashTable 中的方法是同步的,而HashMap中的方法在默认情况下是非同步的。在多线程并发的环境下,可以直接使用HashTable,但是要使用HashMap的话"
},
{
"path": "docs/basics/java-basic/README.md",
"chars": 440,
"preview": "## To Be Top Javaer - Java工程师成神之路\n\n 是每一个类或接口的常量池( Constant_Pool)的运行时表示形式。\n\n它包括了若干种不同的常量:从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。运行时常"
},
{
"path": "docs/basics/java-basic/StandardTime-vs-daylightSavingTime.md",
"chars": 133,
"preview": "夏令时、冬令时的出现,是为了充分利用夏天的日照,所以时钟要往前拨快一小时,冬天再把表往回拨一小时。其中夏令时从3月第二个周日持续到11月第一个周日。\n\n冬令时:\n北京和洛杉矶时差:16\n北京和纽约时差:13\n\n夏令时:\n北京和洛杉矶时差:1"
},
{
"path": "docs/basics/java-basic/UNICODE.md",
"chars": 554,
"preview": "ASCII码,只有256个字符,美国人倒是没啥问题了,他们用到的字符几乎都包括了,但是世界上不只有美国程序员啊,所以需要一种更加全面的字符集。\n\nUnicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世"
},
{
"path": "docs/basics/java-basic/UTF8-UTF16-UTF32.md",
"chars": 714,
"preview": "Unicode 是容纳世界所有文字符号的国际标准编码,使用四个字节为每个字符编码。\n\nUTF 是英文 Unicode Transformation Format 的缩写,意为把 Unicode 字符转换为某种格式。UTF 系列编码方案(UT"
},
{
"path": "docs/basics/java-basic/Wildcard-Character.md",
"chars": 182,
"preview": "`限定通配符`对类型进⾏限制, 泛型中有两种限定通配符:\n\n表示类型的上界,格式为:`<? extends T>`,即类型必须为T类型或者T子类\n表示类型的下界,格式为:`<? super T>`,即类型必须为T类型或者T的父类\n\n泛型类型"
},
{
"path": "docs/basics/java-basic/YYYY-vs-yyyy.md",
"chars": 1430,
"preview": "在使用SimpleDateFormat的时候,需要通过字母来描述时间元素,并组装成想要的日期和时间模式。常用的时间元素和字母的对应表(JDK 1.8)如下:\n\n\n\n@Saf"
},
{
"path": "docs/basics/java-basic/annotation-in-spring.md",
"chars": 772,
"preview": "@Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了@Bean,就会作为这个Spring容器中的Bean。\n\n@Scope注解 作用域\n\n@Lazy(true) 表示延迟初始化\n\n@Service用于标注业务层"
},
{
"path": "docs/basics/java-basic/annotion-and-reflect.md",
"chars": 2725,
"preview": "注解和反射经常结合在一起使用,在很多框架的代码中都能看到他们结合使用的影子\n\n\n可以通过反射来判断类,方法,字段上是否有某个注解以及获取注解中的值, 获取某个类中方法上的注解代码示例如下:\n\n``` \nClass<?> clz = bean"
},
{
"path": "docs/basics/java-basic/aop-vs-proxy.md",
"chars": 287,
"preview": "Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。\n\nJDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。"
},
{
"path": "docs/basics/java-basic/apache-collections.md",
"chars": 9943,
"preview": "Commons Collections增强了Java Collections Framework。 它提供了几个功能,使收集处理变得容易。 它提供了许多新的接口,实现和实用程序。 Commons Collections的主要功能如下\n\n* "
},
{
"path": "docs/basics/java-basic/api-vs-spi.md",
"chars": 250,
"preview": "Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,API 直接被应用开发人员使用,SPI 被框架扩展人员使用\n\n\nAPI Application Programming Interf"
},
{
"path": "docs/basics/java-basic/arraylist-vs-linkedlist-vs-vector.md",
"chars": 645,
"preview": "List主要有ArrayList、LinkedList与Vector几种实现。\n\n这三者都实现了List 接口,使用方式也很相似,主要区别在于因为实现方式的不同,所以对不同的操作具有不同的效率。\n\nArrayList 是一个可改变大小的数组"
},
{
"path": "docs/basics/java-basic/basic-data-types.md",
"chars": 134,
"preview": "Java中有8种基本数据类型分为三大类。\n\n### 字符型\n\nchar\n\n### 布尔型\n\nboolean\n\n### 数值型\n\n1.整型:byte、short、int、long \n\n2.浮点型:float、double\n\n*String不是"
},
{
"path": "docs/basics/java-basic/big-endian-vs-little-endian.md",
"chars": 705,
"preview": "字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。\n\n在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如:如果C/C++中的一个int型变量 a 的起始地址是&a = 0x100,那么 a 的四个字节将被存储在存储器"
},
{
"path": "docs/basics/java-basic/bio-vs-nio-vs-aio.md",
"chars": 6159,
"preview": "### IO\n什么是IO? 它是指计算机与外部世界或者一个程序与计算机的其余部分之间的接口。它对于任何计算机系统都非常关键,因而所有 I/O 的主体实际上是内置在操作系统中的。单独的程序一般是让系统为它们完成大部分的工作。\n\n在 Java "
},
{
"path": "docs/basics/java-basic/block-vs-non-blocking.md",
"chars": 446,
"preview": "阻塞与非阻塞描述的是调用者的\n\n如A调用B:\n\n如果是阻塞,A在发出调用后,要一直等待,等着B返回结果。\n\n如果是非阻塞,A在发出调用后,不需要等待,可以去做自己的事情。\n\n\n### 同步,异步 和 阻塞,非阻塞之间的区别\n\n[同步、异步]"
},
{
"path": "docs/basics/java-basic/boxing-unboxing.md",
"chars": 7837,
"preview": "本文主要介绍 Java 中的自动拆箱与自动装箱的有关知识。\n\n## 基本数据类型\n\n基本类型,或者叫做内置类型,是 Java 中不同于类(Class)的特殊类型。它们是我们编程中使用最频繁的类型。\n\nJava 是一种强类型语言,第一次申明变"
},
{
"path": "docs/basics/java-basic/bug-in-apache-commons-collections.md",
"chars": 8556,
"preview": "Apache-Commons-Collections这个框架,相信每一个Java程序员都不陌生,这是一个非常著名的开源框架。\n\n但是,他其实也曾经被爆出过序列化安全漏洞,可以被远程执行命令。\n\n### 背景\n\nApache Commons是"
},
{
"path": "docs/basics/java-basic/bug-in-fastjson.md",
"chars": 10379,
"preview": "fastjson大家一定都不陌生,这是阿里巴巴的开源一个JSON解析库,通常被用于将Java Bean和JSON 字符串之间进行转换。\n\n前段时间,fastjson被爆出过多次存在漏洞,很多文章报道了这件事儿,并且给出了升级建议。\n\n但是作"
},
{
"path": "docs/basics/java-basic/byte-stream-vs-character-stream.md",
"chars": 465,
"preview": "### 字节与字符\n\nBit最小的二进制单位 ,是计算机的操作部分。取值0或者1\n\nByte(字节)是计算机操作数据的最小单位由8位bit组成 取值(-128-127)\n\nChar(字符)是用户的可读写的最小单位,在Java里面由16位bi"
},
{
"path": "docs/basics/java-basic/class-contant-pool.md",
"chars": 4105,
"preview": "在Java中,常量池的概念想必很多人都听说过。这也是面试中比较常考的题目之一。在Java有关的面试题中,一般习惯通过String的有关问题来考察面试者对于常量池的知识的理解,几道简单的String面试题难倒了无数的开发者。所以说,常量池是J"
},
{
"path": "docs/basics/java-basic/const-in-java.md",
"chars": 39,
"preview": " const是Java预留关键字,用于后期扩展用,用法跟final相似,不常用"
},
{
"path": "docs/basics/java-basic/convert-bytestream-characterstream.md",
"chars": 823,
"preview": "\n想要实现字符流和字节流之间的相互转换需要用到两个类:\n\nOutputStreamWriter 是字符流通向字节流的桥梁\n\nInputStreamReader 是字节流通向字符流的桥梁\n\n### 字符流转成字节流\n\n```\n\npublic "
},
{
"path": "docs/basics/java-basic/create-annotation.md",
"chars": 825,
"preview": "在Java中,类使用class定义,接口使用interface定义,注解和接口的定义差不多,增加了一个@符号,即@interface,代码如下:\n\n public @interface EnableAuth {\n \n }\n"
},
{
"path": "docs/basics/java-basic/create-spi.md",
"chars": 1002,
"preview": "步骤1、定义一组接口 (假设是org.foo.demo.IShout),并写出接口的一个或多个实现,(假设是org.foo.demo.animal.Dog、org.foo.demo.animal.Cat)。\n\n public inte"
},
{
"path": "docs/basics/java-basic/custom-annotation.md",
"chars": 81,
"preview": "除了元注解,都是自定义注解。通过元注解定义出来的注解。\n如我们常用的Override 、Autowire等。\n日常开发中也可以自定义一个注解,这些都是自定义注解。"
},
{
"path": "docs/basics/java-basic/define-exception.md",
"chars": 170,
"preview": "⾃定义异常就是开发⼈员⾃⼰定义的异常, ⼀般通过继承`Exception`的⼦类的⽅式实现。\n\n\n编写⾃定义异常类实际上是继承⼀个API标准异常类, ⽤新定义的异常处理信息覆盖原有信息的过程。\n\n这种⽤法在Web开发中也⽐较常见, ⼀般可以"
},
{
"path": "docs/basics/java-basic/delete-while-iterator.md",
"chars": 2812,
"preview": "**1、直接使用普通for循环进行操作**\n\n我们说不能在foreach中进行,但是使用普通的for循环还是可以的,因为普通for循环并没有用到Iterator的遍历,所以压根就没有进行fail-fast的检验。\n\n List"
},
{
"path": "docs/basics/java-basic/diff-serializable-vs-externalizable.md",
"chars": 614,
"preview": "Java中的类通过实现 `java.io.Serializable` 接口以启⽤其序列化功能。 未实现此接口的类将⽆法使其任何状态序列化或反序列化。 \n\n可序列化类的所有⼦类型本⾝都是可序列化的。 \n\n序列化接口没有⽅法或字段, 仅⽤于标识"
},
{
"path": "docs/basics/java-basic/dynamic-proxy-implementation.md",
"chars": 3382,
"preview": "Java中,实现动态代理有两种方式:\n\n1、JDK动态代理:java.lang.reflect 包中的Proxy类和InvocationHandler接口提供了生成动态代理类的能力。\n\n2、Cglib动态代理:Cglib (Code Gen"
},
{
"path": "docs/basics/java-basic/dynamic-proxy-vs-reflection.md",
"chars": 15,
"preview": "反射是动态代理的一种实现方式。"
},
{
"path": "docs/basics/java-basic/dynamic-proxy.md",
"chars": 263,
"preview": "前面介绍了[静态代理](/basics/java-basic/static-proxy.md),虽然静态代理模式很好用,但是静态代理还是存在一些局限性的,比如使用静态代理模式需要程序员手写很多代码,这个过程是比较浪费时间和精力的。一旦需要代"
},
{
"path": "docs/basics/java-basic/enum-class.md",
"chars": 394,
"preview": "Java中定义枚举是使用enum关键字的,但是Java中其实还有一个java.lang.Enum类。这是一个抽象类,定义如下:\n\n\n package java.lang;\n\n public abstract class Enum"
},
{
"path": "docs/basics/java-basic/enum-compare.md",
"chars": 192,
"preview": "java 枚举值比较用 == 和 equals 方法没啥区别,两个随便用都是一样的效果。\n\n因为枚举 Enum 类的 equals 方法默认实现就是通过 == 来比较的;\n\n类似的 Enum 的 compareTo 方法比较的是 Enum "
},
{
"path": "docs/basics/java-basic/enum-impl.md",
"chars": 1241,
"preview": "Java SE5提供了一种新的类型-Java的枚举类型,关键字enum可以将一组具名的值的有限集合创建为一种新的类型,而这些具名的值可以作为常规的程序组件使用,这是一种非常有用的功能。\n\n要想看源码,首先得有一个类吧,那么枚举类型到底是什么"
},
{
"path": "docs/basics/java-basic/enum-serializable.md",
"chars": 5624,
"preview": "> 写在前面:Java SE5提供了一种新的类型-<a href=\"/archives/195\" target=\"_blank\">Java的枚举类型</a>,关键字enum可以将一组具名的值的有限集合创建为一种新的类型,而这些具名的值可以作"
},
{
"path": "docs/basics/java-basic/enum-singleton.md",
"chars": 4966,
"preview": "关于单例模式,我的博客中有很多文章介绍过。作为23种设计模式中最为常用的设计模式,单例模式并没有想象的那么简单。因为在设计单例的时候要考虑很多问题,比如线程安全问题、序列化对单例的破坏等。\n\n单例相关文章一览:\n\n[设计模式(二)——单例模"
},
{
"path": "docs/basics/java-basic/enum-switch.md",
"chars": 233,
"preview": "Java 1.7 之前 switch 参数可用类型为 short、byte、int、char,枚举类型之所以能使用其实是编译器层面实现的\n\n编译器会将枚举 switch 转换为类似 \n\n```\nswitch(s.ordinal()) { \n"
},
{
"path": "docs/basics/java-basic/enum-thread-safe.md",
"chars": 2266,
"preview": "### 枚举是如何保证线程安全的\n\n要想看源码,首先得有一个类吧,那么枚举类型到底是什么类呢?是enum吗?答案很明显不是,enum就和class一样,只是一个关键字,他并不是一个类,那么枚举是由什么类维护的呢,我们简单的写一个枚举:\n\n "
},
{
"path": "docs/basics/java-basic/enum-usage.md",
"chars": 7488,
"preview": "\n### 1 背景\n\n在`java`语言中还没有引入枚举类型之前,表示枚举类型的常用模式是声明一组具有`int`常量。之前我们通常利用`public final static` 方法定义的代码如下,分别用1 表示春天,2表示夏天,3表示秋天"
},
{
"path": "docs/basics/java-basic/error-vs-exception.md",
"chars": 203,
"preview": "Exception和 Error, ⼆者都是 Java异常处理的重要⼦类, 各⾃都包含⼤量⼦类。均继承自Throwable类。\n\n\nError表⽰系统级的错误, 是java运⾏环境内部错误或者硬件问题, 不能指望程序来处理这样的问题, 除了"
},
{
"path": "docs/basics/java-basic/exception-chain.md",
"chars": 731,
"preview": "“异常链”是Java中⾮常流⾏的异常处理概念, 是指在进⾏⼀个异常处理时抛出了另外⼀个异常, 由此产⽣了⼀个异常链条。 \n\n该技术⼤多⽤于将“ 受检查异常” ( checked exception) 封装成为“⾮受检查异常”( unchec"
},
{
"path": "docs/basics/java-basic/exception-type.md",
"chars": 708,
"preview": "Java中的异常, 主要可以分为两⼤类, 即受检异常( checked exception) 和 ⾮受检异常( unchecked exception)\n\n### 受检异常\n对于受检异常来说, 如果⼀个⽅法在声明的过程中证明了其要有受检异常"
},
{
"path": "docs/basics/java-basic/extends-vs-super.md",
"chars": 1487,
"preview": "`<? extends T>`和`<? super T>`是Java泛型中的“通配符(Wildcards)”和“边界(Bounds)”的概念。\n\n`<? extends T>`:是指 “上界通配符(Upper Bounds Wildcard"
},
{
"path": "docs/basics/java-basic/fail-fast-vs-fail-safe.md",
"chars": 7630,
"preview": "### 什么是fail-fast\n\n首先我们看下维基百科中关于fail-fast的解释:\n\n> In systems design, a fail-fast system is one which immediately reports a"
},
{
"path": "docs/basics/java-basic/final-in-java.md",
"chars": 490,
"preview": "final是Java中的一个关键字,它所表示的是“这部分是无法修改的”。\n\n使用 final 可以定义 :变量、方法、类。\n\n### final变量\n\n如果将变量设置为final,则不能更改final变量的值(它将是常量)。\n\n\n c"
},
{
"path": "docs/basics/java-basic/final-string.md",
"chars": 2335,
"preview": "String在Java中特别常用,而且我们经常要在代码中对字符串进行赋值和改变他的值,但是,为什么我们说字符串是不可变的呢?\n\n首先,我们需要知道什么是不可变对象?\n\n不可变对象是在完全创建后其内部状态保持不变的对象。这意味着,一旦对象被赋"
},
{
"path": "docs/basics/java-basic/float-amount.md",
"chars": 94,
"preview": "由于计算机中保存的小数其实是十进制的小数的近似值,并不是准确值,所以,千万不要在代码中使用浮点数来表示金额等重要的指标。\n\n建议使用BigDecimal或者Long(单位为分)来表示金额。"
},
{
"path": "docs/basics/java-basic/float.md",
"chars": 1366,
"preview": "我们知道,计算机的数字的存储和运算都是通过二进制进行的,对于,十进制整数转换为二进制整数采用\"除2取余,逆序排列\"法\n\n具体做法是:\n\n* 用2整除十进制整数,可以得到一个商和余数;\n* 再用2去除商,又会得到一个商和余数,如此进行"
},
{
"path": "docs/basics/java-basic/gbk-gb2312-gb18030.md",
"chars": 468,
"preview": "三者都是支持中文字符的编码方式,最常用的是GBK。\n\n以下内容来自CSDN,介绍的比较详细。\n\nGB2312(1980年):16位字符集,收录有6763个简体汉字,682个符号,共7445个字符; \n优点:适用于简体中文环境,属于中国国家标"
},
{
"path": "docs/basics/java-basic/genericity-list-wildcard.md",
"chars": 138,
"preview": "`List<?>` 是一个未知类型的List,而`List<Object>` 其实是任意类型的List。你可以把`List<String>`, L`ist<Integer>`赋值给`List<?>`,却不能把`List<String>`赋值"
},
{
"path": "docs/basics/java-basic/genericity-list.md",
"chars": 222,
"preview": "原始类型List和带参数类型`List<Object>`之间的主要区别是,在编译时编译器不会对原始类型进行类型安全检查,却会对带参数的类型进行检查。\n\n通过使用Object作为类型,可以告知编译器该方法可以接受任何类型的对象,比如Strin"
},
{
"path": "docs/basics/java-basic/generics-problem.md",
"chars": 1151,
"preview": "\n\n### 一、当泛型遇到重载\n\n public class GenericTypes { \n \n public static void method(List<String> list) { \n "
},
{
"path": "docs/basics/java-basic/generics.md",
"chars": 252,
"preview": "Java泛型( generics) 是JDK 5中引⼊的⼀个新特性, 允许在定义类和接⼜的时候使⽤类型参数( type parameter) 。 \n\n声明的类型参数在使⽤时⽤具体的类型来替换。 泛型最主要的应⽤是在JDK 5中的新集合类框架"
},
{
"path": "docs/basics/java-basic/get-los_angeles-time.md",
"chars": 1666,
"preview": "了解Java8 的朋友可能都知道,Java8提供了一套新的时间处理API,这套API比以前的时间处理API要友好的多。\n\nJava8 中加入了对时区的支持,带时区的时间为分别为:`ZonedDate`、`ZonedTime`、`ZonedD"
},
{
"path": "docs/basics/java-basic/h2-db.md",
"chars": 4362,
"preview": "H2是一个开源的嵌入式(非嵌入式设备)数据库引擎,它是一个用Java开发的类库,可直接嵌入到应用程序中,与应用程序一起打包发布,不受平台限制。\n\nH2与Derby、HSQLDB、MySQL、PostgreSQL等开源数据库相比,H2的优势为"
},
{
"path": "docs/basics/java-basic/handle-exception.md",
"chars": 148,
"preview": "异常的处理⽅式有两种。 1、 ⾃⼰处理。 2、 向上抛, 交给调⽤者处理。\n\n\n异常, 千万不能捕获了之后什么也不做。 或者只是使⽤`e.printStacktrace`。\n\n具体的处理⽅式的选择其实原则⽐较简明: ⾃⼰明确的知道如何处理的"
},
{
"path": "docs/basics/java-basic/hash-in-hashmap.md",
"chars": 10488,
"preview": "你知道HashMap中hash方法的具体实现吗?你知道HashTable、ConcurrentHashMap中hash方法的实现以及原因吗?你知道为什么要这么实现吗?你知道为什么JDK 7和JDK 8中hash方法实现的不同以及区别吗?如果"
},
{
"path": "docs/basics/java-basic/hashmap-capacity.md",
"chars": 6202,
"preview": "很多人在通过阅读源码的方式学习Java,这是个很好的方式。而JDK的源码自然是首选。在JDK的众多类中,我觉得HashMap及其相关的类是设计的比较好的。很多人读过HashMap的代码,不知道你们有没有和我一样,觉得HashMap中关于容量"
},
{
"path": "docs/basics/java-basic/hashmap-default-capacity.md",
"chars": 6646,
"preview": "集合是Java开发日常开发中经常会使用到的,而作为一种典型的K-V结构的数据结构,HashMap对于Java开发者一定不陌生。\n\n在日常开发中,我们经常会像如下方式以下创建一个HashMap:\n\n Map<String, String"
},
{
"path": "docs/basics/java-basic/hashmap-default-loadfactor.md",
"chars": 5789,
"preview": "在Java基础中,集合类是很关键的一块知识点,也是日常开发的时候经常会用到的。比如List、Map这些在代码中也是很常见的。\n\n个人认为,关于HashMap的实现,JDK的工程师其实是做了很多优化的,要说所有的JDK源码中,哪个类埋的彩蛋最"
},
{
"path": "docs/basics/java-basic/hashmap-init-capacity.md",
"chars": 2915,
"preview": "集合是Java开发日常开发中经常会使用到的,而作为一种典型的K-V结构的数据结构,HashMap对于Java开发者一定不陌生。\n\n关于HashMap,很多人都对他有一些基本的了解,比如他和hashtable之间的区别、他和concurren"
},
{
"path": "docs/basics/java-basic/input-stream-vs-output-stream.md",
"chars": 100,
"preview": "输入、输出,有一个参照物,参照物就是存储数据的介质。如果是把对象读入到介质中,这就是输入。从介质中向外读数据,这就是输出。\n\n所以,输入流是把数据写入存储介质的。输出流是从存储介质中把数据读取出来。\n"
},
{
"path": "docs/basics/java-basic/instanceof-in-java.md",
"chars": 492,
"preview": "instanceof 是 Java 的一个二元操作符,类似于 ==,>,< 等操作符。\n\ninstanceof 是 Java 的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。\n\n以下实例创建"
},
{
"path": "docs/basics/java-basic/integer-cache.md",
"chars": 5645,
"preview": "英文原文:[Java Integer Cache][1] 翻译地址:[Java中整型的缓存机制][2] 原文作者:[Java Papers][3] 翻译作者:[Hollis][4] 转载请注明出处。\n\n本文将介绍Java中Integer的缓"
},
{
"path": "docs/basics/java-basic/integer-scope.md",
"chars": 949,
"preview": "Java中的整型主要包含byte、short、int和long这四种,表示的数字范围也是从小到大的,之所以表示范围不同主要和他们存储数据时所占的字节数有关。\n\n先来个简单的科普,1字节=8位(bit)。java中的整型属于有符号数。\n\n先来"
},
{
"path": "docs/basics/java-basic/intern.md",
"chars": 317,
"preview": " \n在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。\n \n\n当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果"
},
{
"path": "docs/basics/java-basic/ioc-implement-with-factory-and-reflection.md",
"chars": 5946,
"preview": "本文系转载,原文地址:https://blog.csdn.net/fuzhongmin05/article/details/61614873\n\n### 反射机制概念\n\n我们考虑一个场景,如果我们在程序运行时,一个对象想要检视自己所拥有的成员"
},
{
"path": "docs/basics/java-basic/iteration-of-collection.md",
"chars": 513,
"preview": "Collection的迭代有很多种方式:\n\n1、通过普通for循环迭代\n\n2、通过增强for循环迭代\n\n3、使用Iterator迭代\n\n4、使用Stream迭代\n\n\n```\nList<String> list = ImmutableList"
},
{
"path": "docs/basics/java-basic/jms.md",
"chars": 0,
"preview": ""
},
{
"path": "docs/basics/java-basic/junit.md",
"chars": 665,
"preview": "JUnit是一个Java语言的单元测试框架。它由肯特·贝克和埃里希·伽玛(Erich Gamma)建立,逐渐成为源于Kent Beck的sUnit的xUnit家族中为最成功的一个。 JUnit有它自己的JUnit扩展生态圈。\n\nJUnit "
},
{
"path": "docs/basics/java-basic/k-t-v-e.md",
"chars": 255,
"preview": "E - Element (在集合中使用,因为集合中存放的是元素)\n\nT - Type(Java 类)\n\nK - Key(键)\n\nV - Value(值)\n\nN - Number(数值类型)\n\n? - 表示不确定的java类型(无限制通配符类"
},
{
"path": "docs/basics/java-basic/keyword-about-exception.md",
"chars": 170,
"preview": "throws、 throw、 try、 catch、 finally\n\ntry⽤来指定⼀块预防所有异常的程序;\n\ncatch⼦句紧跟在try块后⾯, ⽤来指定你想要捕获的异常的类型;\n\nfinally为确保⼀段代码不管发⽣什么异常状况都要被"
},
{
"path": "docs/basics/java-basic/lambda.md",
"chars": 1130,
"preview": "Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。\n\nLambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。\n\n使用 Lambda 表达式可以使代码变的更加简洁紧凑。\n\n### 语法\nlamb"
},
{
"path": "docs/basics/java-basic/length-of-string.md",
"chars": 3776,
"preview": "关于String有没有长度限制的问题,我之前单独写过一篇文章分析过,最近我又抽空回顾了一下这个问题,发现又有了一些新的认识。于是准备重新整理下这个内容。\n\n这次在之前那篇文章的基础上除了增加了一些验证过程外,还有些错误内容的修正。我这次在分"
},
{
"path": "docs/basics/java-basic/linux-io.md",
"chars": 2200,
"preview": "### 阻塞式IO模型\n\n最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。\n\n\n\n当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内"
},
{
"path": "docs/basics/java-basic/meta-annotation.md",
"chars": 402,
"preview": "说简单点,就是 定义其他注解的注解 。\n比如Override这个注解,就不是一个元注解。而是通过元注解定义出来的。\n\n @Target(ElementType.METHOD)\n @Retention(RetentionPoli"
},
{
"path": "docs/basics/java-basic/mock.md",
"chars": 1660,
"preview": "碰撞测试是汽车开发活动中的重要组成部分。所有汽车在上市之前都要经过碰撞测试,并公布测试结果。碰撞测试的目的用于评定运输包装件在运输过程中承受多次重复性机械碰撞的耐冲击强度及包装对内装物的保护能力。说简单点就是为了测试汽车在碰撞的时候锁所产生"
},
{
"path": "docs/basics/java-basic/netty.md",
"chars": 445,
"preview": "Netty是一个非阻塞I/O客户端-服务器框架,主要用于开发Java网络应用程序,如协议服务器和客户端。异步事件驱动的网络应用程序框架和工具用于简化网络编程,例如TCP和UDP套接字服务器。Netty包括了反应器编程模式的实现。Netty最"
},
{
"path": "docs/basics/java-basic/order-about-finllly-return.md",
"chars": 566,
"preview": "\n\n `try()` ⾥⾯有⼀个`return`语句, 那么后⾯的`finally{}`⾥⾯的code会不会被执⾏, 什么时候执⾏, 是在`return`前还是`return`后?\n\n\n如果try中有return语句, 那么finally中"
},
{
"path": "docs/basics/java-basic/protobuf.md",
"chars": 331,
"preview": "\nProtocol Buffer (简称Protobuf) 是Google出品的性能优异、跨语言、跨平台的序列化库。\n\n2001年初,Protobuf首先在Google内部创建, 我们把它称之为 proto1,一直以来在Google的内部使"
},
{
"path": "docs/basics/java-basic/reflection.md",
"chars": 63,
"preview": "反射机制指的是程序在运行时能够获取自身的信息。在java中,只要给定类的名字,那么就可以通过反射机制来获得类的所有属性和方法。"
},
{
"path": "docs/basics/java-basic/replace-in-string.md",
"chars": 1072,
"preview": "replace、replaceAll和replaceFirst是Java中常用的替换字符的方法,它们的方法定义是:\n\nreplace(CharSequence target, CharSequence replacement) ,用repl"
},
{
"path": "docs/basics/java-basic/serialVersionUID-modify.md",
"chars": 8819,
"preview": "关于`serialVersionUID` 。这个字段到底有什么用?如果不设置会怎么样?为什么《阿里巴巴Java开发手册》中有以下规定:\n\n![-w934][4]\n\n### 背景知识\n\n**Serializable 和 Externaliz"
},
{
"path": "docs/basics/java-basic/serialVersionUID.md",
"chars": 858,
"preview": "序列化是将对象的状态信息转换为可存储或传输的形式的过程。 \n\n我们都知道, Java对象是保存在JVM的堆内存中的, 也就是说, 如果JVM堆不存在了, 那么对象也就跟着消失了。 \n\n⽽序列化提供了⼀种⽅案, 可以让你在即使JVM停机的情况"
},
{
"path": "docs/basics/java-basic/serialize-in-java.md",
"chars": 9414,
"preview": "\n## Java对象的序列化与反序列化\n\n在Java中,我们可以通过多种方式来创建对象,并且只要对象没有被回收我们都可以复用该对象。但是,我们创建出来的这些Java对象都是存在于JVM的堆内存中的。只有JVM处于运行状态的时候,这些对象才可"
},
{
"path": "docs/basics/java-basic/serialize-principle.md",
"chars": 12260,
"preview": "序列化是一种对象持久化的手段。普遍应用在网络传输、RMI等场景中。本文通过分析ArrayList的序列化来介绍Java序列化的相关内容。主要涉及到以下几个问题:\n\n> 怎么实现Java的序列化\n> \n> 为什么实现了java.io.Seri"
},
{
"path": "docs/basics/java-basic/serialize-singleton.md",
"chars": 6597,
"preview": "本文将通过实例+阅读Java源码的方式介绍序列化是如何破坏单例模式的,以及如何避免序列化对单例的破坏。\n\n> 单例模式,是设计模式中最简单的一种。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并"
},
{
"path": "docs/basics/java-basic/serialize.md",
"chars": 156,
"preview": "序列化是将对象转换为可传输格式的过程。 是一种数据的持久化手段。一般广泛应用于网络传输,RMI和RPC等场景中。\n\n反序列化是序列化的逆操作。\n\n序列化是将对象的状态信息转换为可存储或传输的形式的过程。一般是以字节码或XML格式传输。而字节"
},
{
"path": "docs/basics/java-basic/set-repetition.md",
"chars": 587,
"preview": "在Java的Set体系中,根据实现方式不同主要分为两大类。HashSet和TreeSet。\n\n1、TreeSet 是二叉树实现的,TreeSet中的数据是自动排好序的,不允许放入 null值 \n2、HashSet 是哈希表实现的,Hash"
},
{
"path": "docs/basics/java-basic/set-vs-list.md",
"chars": 233,
"preview": "List,Set都是继承自Collection接口。都是用来存储一组相同类型的元素的。\n\nList特点:元素有放入顺序,元素可重复 。\n\n有顺序,即先放入的元素排在前面。\n\nSet特点:元素无放入顺序,元素不可重复。\n\n无顺序,即先放入的元"
},
{
"path": "docs/basics/java-basic/simpledateformat-thread-safe.md",
"chars": 9265,
"preview": "在日常开发中,我们经常会用到时间,我们有很多办法在Java代码中获取时间。但是不同的方法获取到的时间的格式都不尽相同,这时候就需要一种格式化工具,把时间显示成我们需要的格式。\n\n最常用的方法就是使用SimpleDateFormat类。这是一"
},
{
"path": "docs/basics/java-basic/single-double-float.md",
"chars": 109,
"preview": "单精度浮点数在计算机存储器中占用4个字节(32 bits),利用“浮点”(浮动小数点)的方法,可以表示一个范围很大的数值。\n\n比起单精度浮点数,双精度浮点数(double)使用 64 位(8字节) 来存储一个浮点数。 "
},
{
"path": "docs/basics/java-basic/spi-principle.md",
"chars": 1098,
"preview": "看ServiceLoader类的签名类的成员变量:\n\n public final class ServiceLoader<S> implements Iterable<S>{\n private static final Stri"
},
{
"path": "docs/basics/java-basic/stack-alloc.md",
"chars": 4965,
"preview": "### JVM内存分配策略\n\n关于JVM的内存结构及内存分配方式,不是本文的重点,这里只做简单回顾。以下是我们知道的一些常识:\n\n1、根据Java虚拟机规范,Java虚拟机所管理的内存包括方法区、虚拟机栈、本地方法栈、堆、程序计数器等。\n\n"
},
{
"path": "docs/basics/java-basic/static-in-java.md",
"chars": 1318,
"preview": "static表示“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块\n\n### 静态变量\n\n我们用static表示变量的级别,一个类中的静态变量,不属于类的对象或者实例。因为静态变量与所有的对象实例共享,因此他们不具"
},
{
"path": "docs/basics/java-basic/static-proxy.md",
"chars": 1189,
"preview": "所谓静态代理,就是代理类是由程序员自己编写的,在编译期就确定好了的。来看下下面的例子:\n```\npublic interface HelloSerivice {\n public void say();\n}\n\npublic class "
},
{
"path": "docs/basics/java-basic/stop-create-bigdecimal-with-double.md",
"chars": 4578,
"preview": "很多人都知道,在进行金额表示、金额计算等场景,不能使用double、float等类型,而是要使用对精度支持的更好的BigDecimal。\n\n所以,很多支付、电商、金融等业务中,BigDecimal的使用非常频繁。**但是,如果误以为只要使用"
},
{
"path": "docs/basics/java-basic/stop-use-enum-in-api.md",
"chars": 4268,
"preview": "最近,我们的线上环境出现了一个问题,线上代码在执行过程中抛出了一个IllegalArgumentException,分析堆栈后,发现最根本的的异常是以下内容:\n\n java.lang.IllegalArgumentException:"
},
{
"path": "docs/basics/java-basic/stop-using-equlas-in-bigdecimal.md",
"chars": 4662,
"preview": "BigDecimal,相信对于很多人来说都不陌生,很多人都知道他的用法,这是一种java.math包中提供的一种可以用来进行精确运算的类型。\n\n很多人都知道,在进行金额表示、金额计算等场景,不能使用double、float等类型,而是要使用"
},
{
"path": "docs/basics/java-basic/stream.md",
"chars": 5085,
"preview": "在Java中,集合和数组是我们经常会用到的数据结构,需要经常对他们做增、删、改、查、聚合、统计、过滤等操作。相比之下,关系型数据库中也同样有这些操作,但是在Java 8之前,集合和数组的处理并不是很便捷。\n\n不过,这一问题在Java 8中得"
},
{
"path": "docs/basics/java-basic/string-append.md",
"chars": 1089,
"preview": "Java中,想要拼接字符串,最简单的方式就是通过\"+\"连接两个字符串。\n\n有人把Java中使用+拼接字符串的功能理解为运算符重载。其实并不是,Java是不支持运算符重载的。这其实只是Java提供的一个语法糖。\n\n>运算符重载:在计算机程序设"
},
{
"path": "docs/basics/java-basic/string-concat.md",
"chars": 7310,
"preview": "字符串,是Java中最常用的一个数据类型了。\n\n本文,也是对于Java中字符串相关知识的一个补充,主要来介绍一下字符串拼接相关的知识。本文基于jdk1.8.0_181。\n\n### 字符串拼接 \n\n字符串拼接是我们在Java代码中比较经常要做"
},
{
"path": "docs/basics/java-basic/string-pool.md",
"chars": 548,
"preview": "字符串大家一定都不陌生,他是我们非常常用的一个类。\n \nString作为一个Java类,可以通过以下两种方式创建一个字符串:\n \n \n String str = \"Hollis\";\n \n String str = new "
},
{
"path": "docs/basics/java-basic/stringjoiner-in-java8.md",
"chars": 4380,
"preview": "在上一节中,我们介绍了几种Java中字符串拼接的方式,以及优缺点。其中还有一个重要的拼接方式我没有介绍,那就是Java 8中提供的StringJoiner ,本文就来介绍一下这个字符串拼接的新兵。\n\n如果你想知道一共有多少种方法可以进行字符"
},
{
"path": "docs/basics/java-basic/substring.md",
"chars": 2796,
"preview": "String是Java中一个比较基础的类,每一个开发人员都会经常接触到。而且,String也是面试中经常会考的知识点。\n\nString有很多方法,有些方法比较常用,有些方法不太常用。今天要介绍的substring就是一个比较常用的方法,而且"
},
{
"path": "docs/basics/java-basic/success-isSuccess-and-boolean-Boolean.md",
"chars": 9441,
"preview": "在日常开发中,我们会经常要在类中定义布尔类型的变量,比如在给外部系统提供一个RPC接口的时候,我们一般会定义一个字段表示本次请求是否成功的。\n\n关于这个\"本次请求是否成功\"的字段的定义,其实是有很多种讲究和坑的,稍有不慎就会掉入坑里,作者在"
},
{
"path": "docs/basics/java-basic/switch-string.md",
"chars": 3879,
"preview": "Java 7中,switch的参数可以是String类型了,这对我们来说是一个很方便的改进。到目前为止switch支持这样几种数据类型:`byte` `short` `int` `char` `String` 。但是,作为一个程序员我们不仅"
},
{
"path": "docs/basics/java-basic/synchronized-vs-asynchronization.md",
"chars": 490,
"preview": "同步与异步描述的是被调用者的。\n\n如A调用B:\n\n如果是同步,B在接到A的调用后,会立即执行要做的事。A的本次调用可以得到结果。\n\n如果是异步,B在接到A的调用后,不保证会立即执行要做的事,但是保证会去做,B在做好了之后会通知A。A的本次调"
},
{
"path": "docs/basics/java-basic/synchronizedlist-vector.md",
"chars": 5029,
"preview": "Vector是java.util包中的一个类。 SynchronizedList是java.util.Collections中的一个静态内部类。\n\n在多线程的场景中可以直接使用Vector类,也可以使用Collections.synchro"
},
{
"path": "docs/basics/java-basic/syntactic-sugar.md",
"chars": 21796,
"preview": "\n\n语法糖(Syntactic Sugar),也称糖衣语法,是由英国计算机学家 Peter.J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。\n\n本 Chat 从 Jav"
},
{
"path": "docs/basics/java-basic/time-in-java8.md",
"chars": 1522,
"preview": "Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。\n\n在旧版的 Java 中,日期时间 API 存在诸多问题,其中有:\n\n* 非线程安全 − java.util.Date 是非线程安全的,"
},
{
"path": "docs/basics/java-basic/time-zone.md",
"chars": 566,
"preview": "时区是地球上的区域使用同一个时间定义。以前,人们通过观察太阳的位置(时角)决定时间,这就使得不同经度的地方的时间有所不同(地方时)。1863年,首次使用时区的概念。时区通过设立一个区域的标准时间部分地解决了这个问题。\n\n世界各个国家位于地球"
},
{
"path": "docs/basics/java-basic/timestamp.md",
"chars": 185,
"preview": "时间戳(timestamp),一个能表示一份数据在某个特定时间之前已经存在的、 完整的、 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间。\n\n时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月"
},
{
"path": "docs/basics/java-basic/transient-in-java.md",
"chars": 625,
"preview": "在关于java的集合类的学习中,我们发现`ArrayList`类和`Vector`类都是使用数组实现的,但是在定义数组`elementData`这个属性时稍有不同,那就是`ArrayList`使用`transient`关键字\n\n pr"
},
{
"path": "docs/basics/java-basic/try-with-resources.md",
"chars": 2908,
"preview": "Java里,对于文件操作IO流、数据库连接等开销非常昂贵的资源,用完之后必须及时通过close方法将其关闭,否则资源会一直处于打开状态,可能会导致内存泄露等问题。\n\n关闭资源的常用方式就是在finally块里是释放,即调用close方法。比"
},
{
"path": "docs/basics/java-basic/type-erasure.md",
"chars": 6243,
"preview": "\n\n### 一、各种语言中的编译器是如何处理泛型的\n\n通常情况下,一个编译器处理泛型有两种方式:\n\n1\\.`Code specialization`。在实例化一个泛型类或泛型方法时都产生一份新的目标代码(字节码or二进制代码)。例如,针对一"
},
{
"path": "docs/basics/java-basic/url-encode.md",
"chars": 236,
"preview": "网络标准RFC 1738做了硬性规定 :只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL;\n\n除此以外的字符是无法在URL中展示的,所以,遇到这种字"
},
{
"path": "docs/basics/java-basic/usage-of-reflection.md",
"chars": 77,
"preview": "在运行时判断任意一个对象所属的类。\n\n在运行时判断任意一个类所具有的成员变量和方法。\n\n在运行时任意调用一个对象的方法\n\n在运行时构造任意一个类的对象\n\n"
},
{
"path": "docs/basics/java-basic/ut-with-jmockit.md",
"chars": 7313,
"preview": "JMockit是基于JavaSE5中的java.lang.instrument包开发,内部使用ASM库来动态修改java的字节码,使得java这种静态语言可以想动态脚本语言一样动态设置被Mock对象私有属性,模拟静态、私有方法行为等等,对于"
},
{
"path": "docs/basics/java-basic/value-of-vs-to-string.md",
"chars": 341,
"preview": "我们有三种方式将一个int类型的变量变成一个String类型,那么他们有什么区别?\n\n 1.int i = 5;\n 2.String i1 = \"\" + i;\n 3.String i2 = String.valueOf(i"
},
{
"path": "docs/basics/java-basic/why-gbk.md",
"chars": 78,
"preview": "其实UTF8确实已经是国际通用的字符编码了,但是这种字符标准毕竟是外国定的,而国内也有类似的标准指定组织,也需要制定一套国内通用的标准,于是GBK就诞生了。"
},
{
"path": "docs/basics/java-basic/why-transient-in-arraylist.md",
"chars": 2906,
"preview": "\n\n`ArrayList`使用了`transient`关键字进行存储优化,而`Vector`没有这样做,为什么?\n\n### ArrayList\n\n /** \n * Save the state of the <tt>A"
},
{
"path": "docs/basics/java-basic/why-utf8.md",
"chars": 584,
"preview": "广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unicode 字符集和 UTF-8、UTF-16、UTF-32 等等编码规则。\n\nUnicode 是字符集。UTF-8 是编码规则。\n\nunicode虽然统一了"
},
{
"path": "docs/basics/object-oriented/characteristics.md",
"chars": 1894,
"preview": "我们说面向对象的开发范式,其实是对现实世界的理解和抽象的方法,那么,具体如何将现实世界抽象成代码呢?这就需要运用到面向对象的三大特性,分别是封装性、继承性和多态性。\n\n### 封装(Encapsulation)\n\n所谓封装,也就是把客观事物"
},
{
"path": "docs/basics/object-oriented/constructor.md",
"chars": 1229,
"preview": "构造函数,是一种特殊的方法。主要用来在创建对象时初始化对象,即为对象成员变量赋初始值,总与new运算符一起使用在创建对象的语句中。 \n\n /**\n * 矩形\n */\n class Rectangle {\n \n "
},
{
"path": "docs/basics/object-oriented/extends-implement.md",
"chars": 892,
"preview": "前面的章节我们提到过面向对象有三个特征:封装、继承、多态。前面我们分别介绍过了这三个特性。\n\n我们知道,继承可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。这种派生方式体现了*传递性*。\n\n在Java中,除了继"
},
{
"path": "docs/basics/object-oriented/inheritance-composition.md",
"chars": 2857,
"preview": "在前面几篇文章中,我们了解了封装、继承、多态是面向对象的三个特征。并且通过对继承和实现的学习,了解到继承可以帮助我实现类的复用。\n\n所以,很多开发人员在需要复用一些代码的时候会很自然的使用类的继承的方式。\n\n但是,遇到想要复用的场景就直接使"
},
{
"path": "docs/basics/object-oriented/java-pass-by.md",
"chars": 2812,
"preview": "关于Java中方法间的参数传递到底是怎样的、为什么很多人说Java只有值传递等问题,一直困惑着很多人,甚至我在面试的时候问过很多有丰富经验的开发者,他们也很难解释的很清楚。\n\n我很久也写过一篇文章,我当时认为我把这件事说清楚了,但是,最近在"
},
{
"path": "docs/basics/object-oriented/jvm-language.md",
"chars": 3246,
"preview": "我们在《[深入分析Java的编译原理][1]》中提到过,为了让Java语言具有良好的跨平台能力,Java独具匠心的提供了一种可以在所有平台上都能使用的一种中间代码——字节码(ByteCode)。\n\n有了字节码,无论是哪种平台(如Window"
},
{
"path": "docs/basics/object-oriented/multiple-inheritance.md",
"chars": 1277,
"preview": "前面我们提到过:\"Java中支持一个类同时实现多个接口,但是不支持同时继承多个类。但是这个问题在Java 8之后也不绝对了。\"\n\n那么,是不是又很很想知道,为什么Java中不支持同时继承多个类呢?\n### 多继承\n\n一个类,只有一个父类的情"
},
{
"path": "docs/basics/object-oriented/object-oriented-vs-procedure-oriented.md",
"chars": 1178,
"preview": "相信很多Java开发者,在最初接触Java的时候就听说过,Java是一种面向对象的开发语言,那么什么是面向对象呢?\n\n首先,所谓面向对象,其实是指软件工程中的一类编程风格,很多人称呼他们为开发范式、编程泛型(Programming Para"
},
{
"path": "docs/basics/object-oriented/overloading-vs-overriding.md",
"chars": 1915,
"preview": "重载(Overloading)和重写(Overriding)是Java中两个比较重要的概念。但是对于新手来说也比较容易混淆,本文就举两个实际的例子,来说明下到底是什么是重写和重载。\n\n## 定义\n\n首先我们分别来看一下重载和重写的定义:\n\n"
},
{
"path": "docs/basics/object-oriented/platform-independent.md",
"chars": 3670,
"preview": "相信对于很多Java开发来说,在刚刚接触Java语言的时候,就听说过Java是一门跨平台的语言,Java是平台无关性的,这也是Java语言可以迅速崛起并风光无限的一个重要原因。那么,到底什么是平台无关性?Java又是如何实现平台无关性的呢?"
},
{
"path": "docs/basics/object-oriented/polymorphism.md",
"chars": 2214,
"preview": "在第1.2章节中,我们介绍了面向对象的封装、继承和多态这三个基本特性,并且分别对封装和继承简单的举例做了说明。\n\n这一章节中,我们针对上一章节遗留的多态性进行展开介绍。\n\n\n## 什么是多态\n\n我们先基于所有的编程语言介绍了什么是多态以及多"
},
{
"path": "docs/basics/object-oriented/principle.md",
"chars": 2400,
"preview": "面向对象开发范式的最大的好处就是易用、易扩展、易维护,但是,什么样的代码是易用、易扩展、易维护的呢?如何衡量他们呢?\n\n罗伯特·C·马丁在21世纪早期提出了SOLID原则,这是五个原则的缩写的组合,这五个原则沿用至今。\n\n### 单一职责原"
},
{
"path": "docs/basics/object-oriented/scope.md",
"chars": 462,
"preview": "我们通过封装的手段,将成员变量、方法等包装在一个类中,那么,被封装在类中的这些成员变量和方法,能不能被外部访问呢?能被谁访问呢?\n\n这种能不能被访问、能被谁访问的特性,Java是通过访问控制修饰符来实现的。Java中,可以使用访问控制符来保"
},
{
"path": "docs/basics/object-oriented/variable.md",
"chars": 755,
"preview": "Java中共有三种变量,分别是类变量、成员变量和局部变量。他们分别存放在JVM的方法区、堆内存和栈内存中。\n```java\n /**\n * @author Hollis\n */\n public class Var"
},
{
"path": "docs/basics/object-oriented/why-pass-by-reference.md",
"chars": 4508,
"preview": "### Java的求值策略\n\n前面我们介绍过了传值调用、传引用调用以及传值调用的特例传共享对象调用,那么,Java中是采用的哪种求值策略呢?\n\n很多人说Java中的基本数据类型是值传递的,这个基本没有什么可以讨论的,普遍都是这样认为的。\n\n"
},
{
"path": "docs/css/my.css",
"chars": 39,
"preview": "body {\n overflow: auto !important;\n}"
}
]
// ... and 3 more files (download for full content)
About this extraction
This page contains the full source code of the hollischuang/toBeTopJavaer GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 203 files (547.0 KB), approximately 224.5k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.