Repository: huggingface/diffusion-fast
Branch: main
Commit: 7b43ba4a7000
Files: 15
Total size: 52.2 KB
Directory structure:
gitextract_mf9fjc_q/
├── Dockerfile
├── LICENSE
├── Makefile
├── README.md
├── experiment-scripts/
│ ├── run_pixart.sh
│ ├── run_sd.sh
│ └── run_sd_cpu.sh
├── prepare_results.py
├── pyproject.toml
├── run_benchmark.py
├── run_benchmark_pixart.py
├── run_profile.py
└── utils/
├── benchmarking_utils.py
├── pipeline_utils.py
└── pipeline_utils_pixart.py
================================================
FILE CONTENTS
================================================
================================================
FILE: Dockerfile
================================================
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y bash \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
libgl1 \
python3.8 \
python3-pip \
python3.8-venv && \
rm -rf /var/lib/apt/lists
RUN python3 -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
python3 -m pip install --no-cache-dir --pre torch==2.3.0.dev20231218+cu121 --index-url https://download.pytorch.org/whl/nightly/cu121 && \
python3 -m pip install --no-cache-dir \
accelerate \
transformers \
peft
RUN python3 -m pip install --no-cache-dir diffusers==0.25.0
RUN python3 -m pip install --no-cache-dir git+https://github.com/pytorch-labs/ao@54bcd5a10d0abbe7b0c045052029257099f83fd9
CMD ["/bin/bash"]
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright Hugging Face
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: Makefile
================================================
check_dirs := .
quality:
ruff check $(check_dirs)
ruff format --check $(check_dirs)
style:
ruff check $(check_dirs) --fix
ruff format $(check_dirs)
================================================
FILE: README.md
================================================
# Diffusion, fast
Repository for the blog post: [**Accelerating Generative AI Part III: Diffusion, Fast**](https://pytorch.org/blog/accelerating-generative-ai-3/). You can find a run down of the techniques on the [🤗 Diffusers website](https://huggingface.co/docs/diffusers/main/en/optimization/fp16) too.
Check out the Flux edition here: [huggingface/flux-fast](https://github.com/huggingface/flux-fast/).
> [!WARNING]
> This repository relies on the `torchao` package for all things quantization. Since the first version of this repo, the `torchao` package has changed its APIs significantly. More specifically, [this](https://github.com/huggingface/diffusion-fast/blob/f4fa861422d9819226eb2ceac247c85c3547130d/Dockerfile#L30) version was used to obtain the numbers in this repository. For more updated usage of `torchao`, please refer to the [`diffusers-torchao`](https://github.com/sayakpaul/diffusers-torchao) repository.
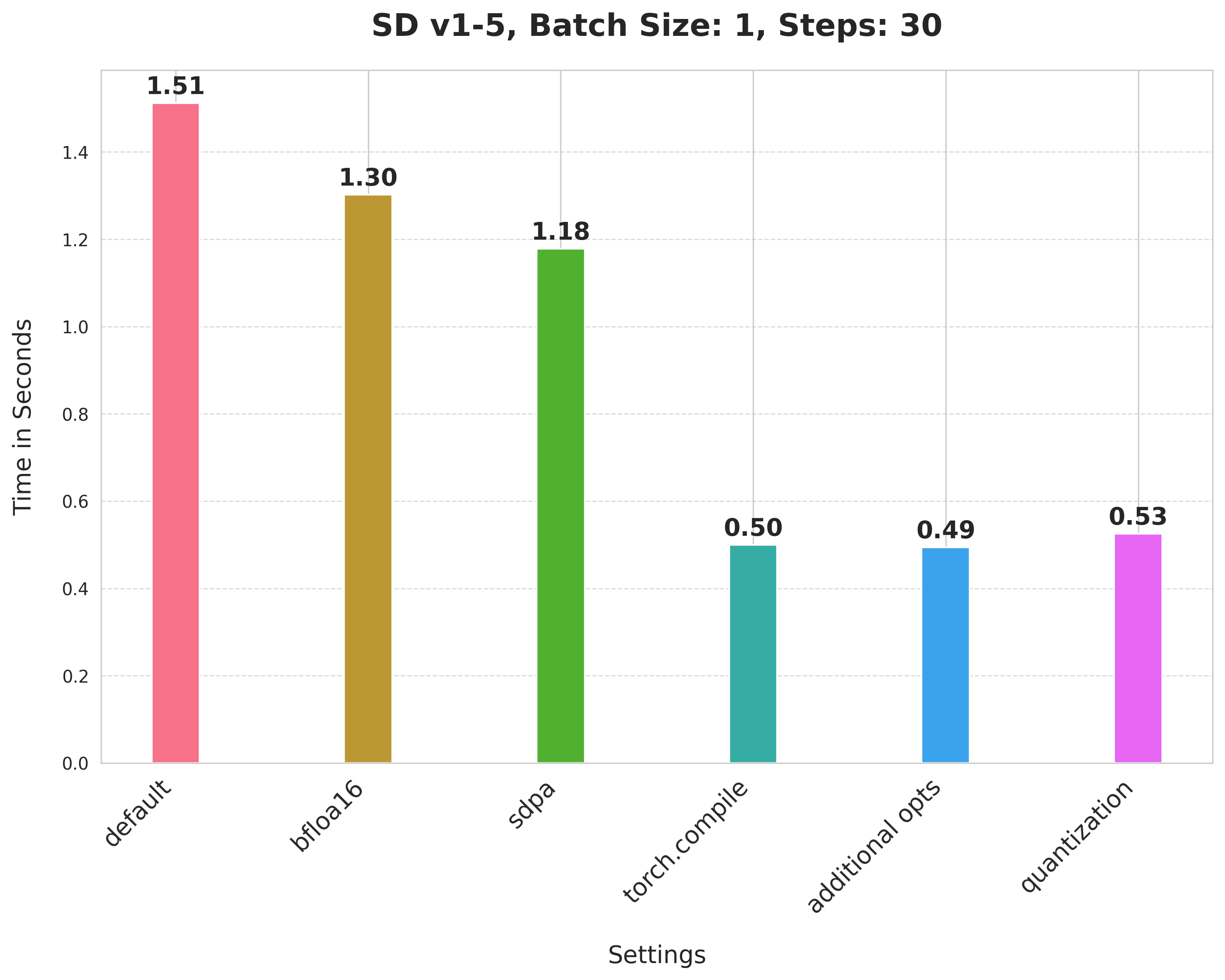
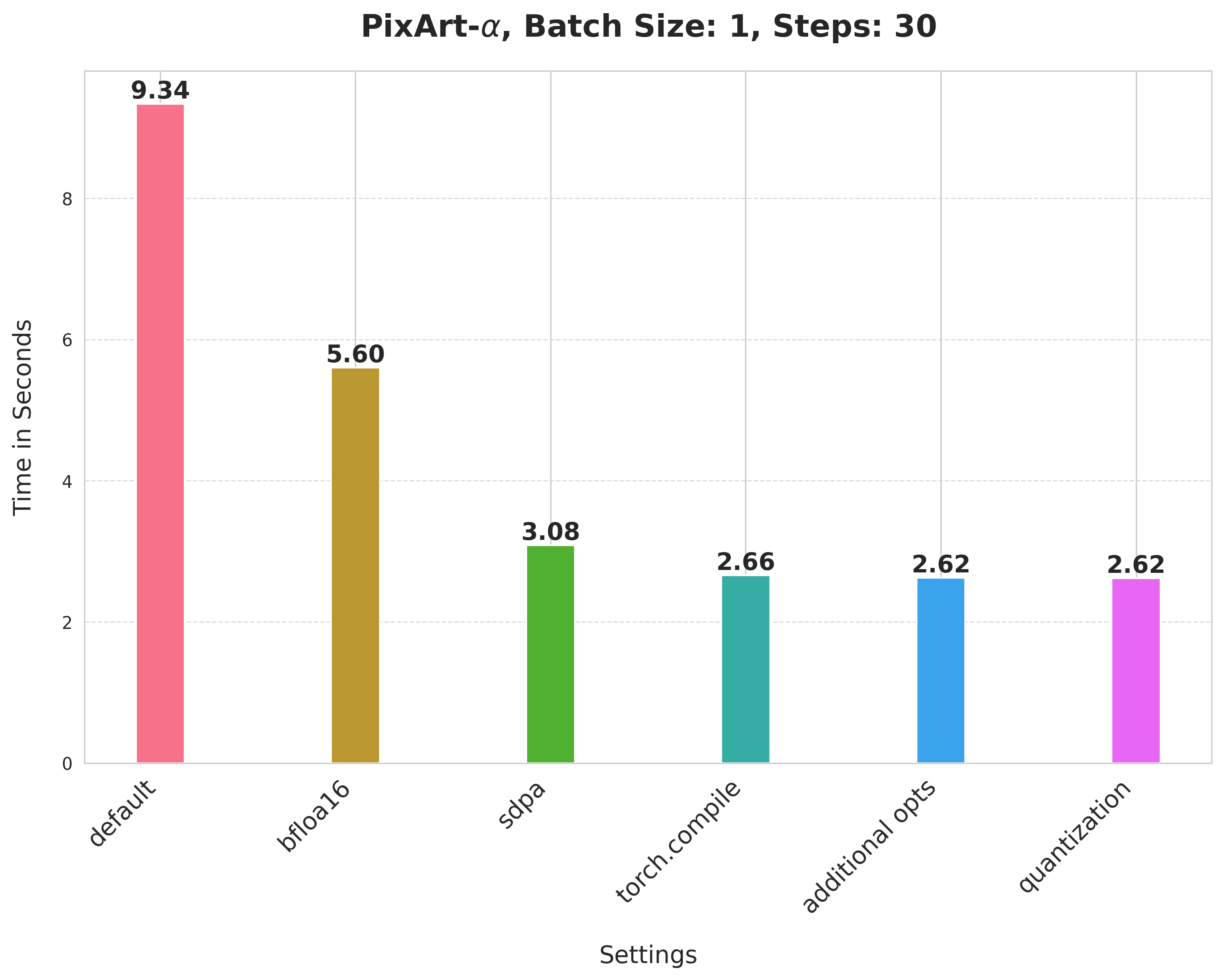
Summary of the optimizations:
* Running with the bfloat16 precision
* `scaled_dot_product_attention` (SDPA)
* `torch.compile`
* Combining q,k,v projections for attention computation
* Dynamic int8 quantization
These techniques are fairly generalizable to other pipelines too, as we show below.
Table of contents:
* [Setup](#setup-🛠️)
* [Running benchmarking experiments](#running-a-benchmarking-experiment-🏎️)
* [Code](#improvements-progressively-📈-📊)
* [Results from other pipelines](#results-from-other-pipelines-🌋)
## Setup 🛠️
We rely on pure PyTorch for the optimizations. You can refer to the [Dockerfile](./Dockerfile) to get the complete development environment setup.
For hardware, we used an 80GB 400W A100 GPU with its memory clock set to the maximum rate (1593 in our case).
Meanwhile, these optimizations (BFloat16, SDPA, torch.compile, Combining q,k,v projections) can run on CPU platforms as well, and bring 4x latency improvement to Stable Diffusion XL (SDXL) on 4th Gen Intel® Xeon® Scalable processors.
## Running a benchmarking experiment 🏎️
[`run_benchmark.py`](./run_benchmark.py) is the main script for benchmarking the different optimization techniques. After an experiment has been done, you should expect to see two files:
* A `.csv` file with all the benchmarking numbers.
* A `.jpeg` image file corresponding to the experiment.
Refer to the [`experiment-scripts/run_sd.sh`](./experiment-scripts/run_sd.sh) for some reference experiment commands.
**Notes on running PixArt-Alpha experiments**:
* Use the [`run_experiment_pixart.py`](./run_benchmark_pixart.py) for this.
* Uninstall the current installation of `diffusers` and re-install it again like so: `pip install git+https://github.com/huggingface/diffusers@fuse-projections-pixart`.
* Refer to the [`experiment-scripts/run_pixart.sh`](./experiment-scripts/run_pixart.sh) script for some reference experiment commands.
_(Support for PixArt-Alpha is experimental.)_
You can use the [`prepare_results.py`](./prepare_results.py) script to generate a consolidated CSV file and a plot to visualize the results from it. This is best used after you have run a couple of benchmarking experiments already and have their corresponding CSV files.
The script also supports CPU platforms, you can refer to the [`experiment-scripts/run_sd_cpu.sh`](./experiment-scripts/run_sd_cpu.sh) for some reference experiment commands.
To run the script, you need the following dependencies:
* pandas
* matplotlib
* seaborn
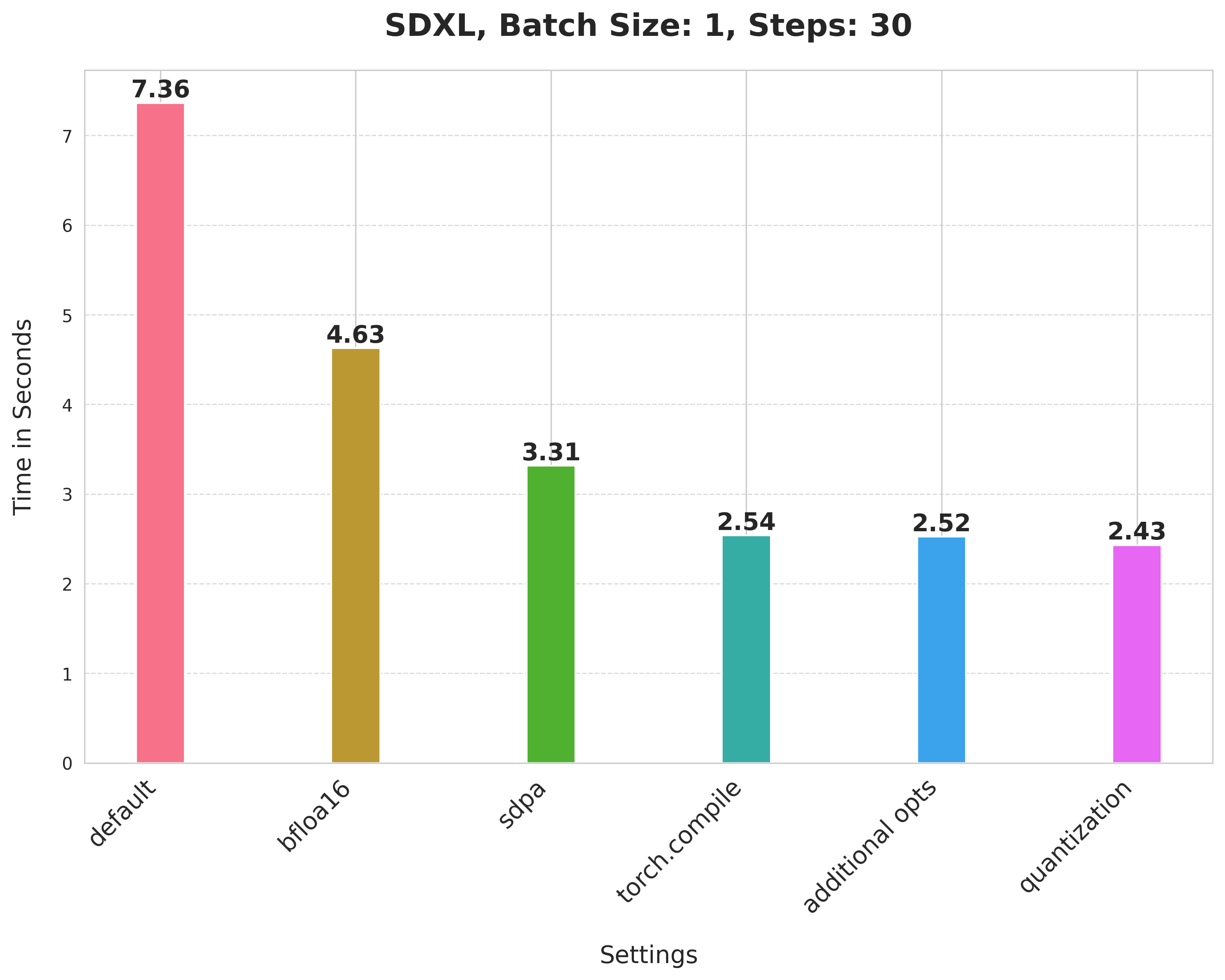
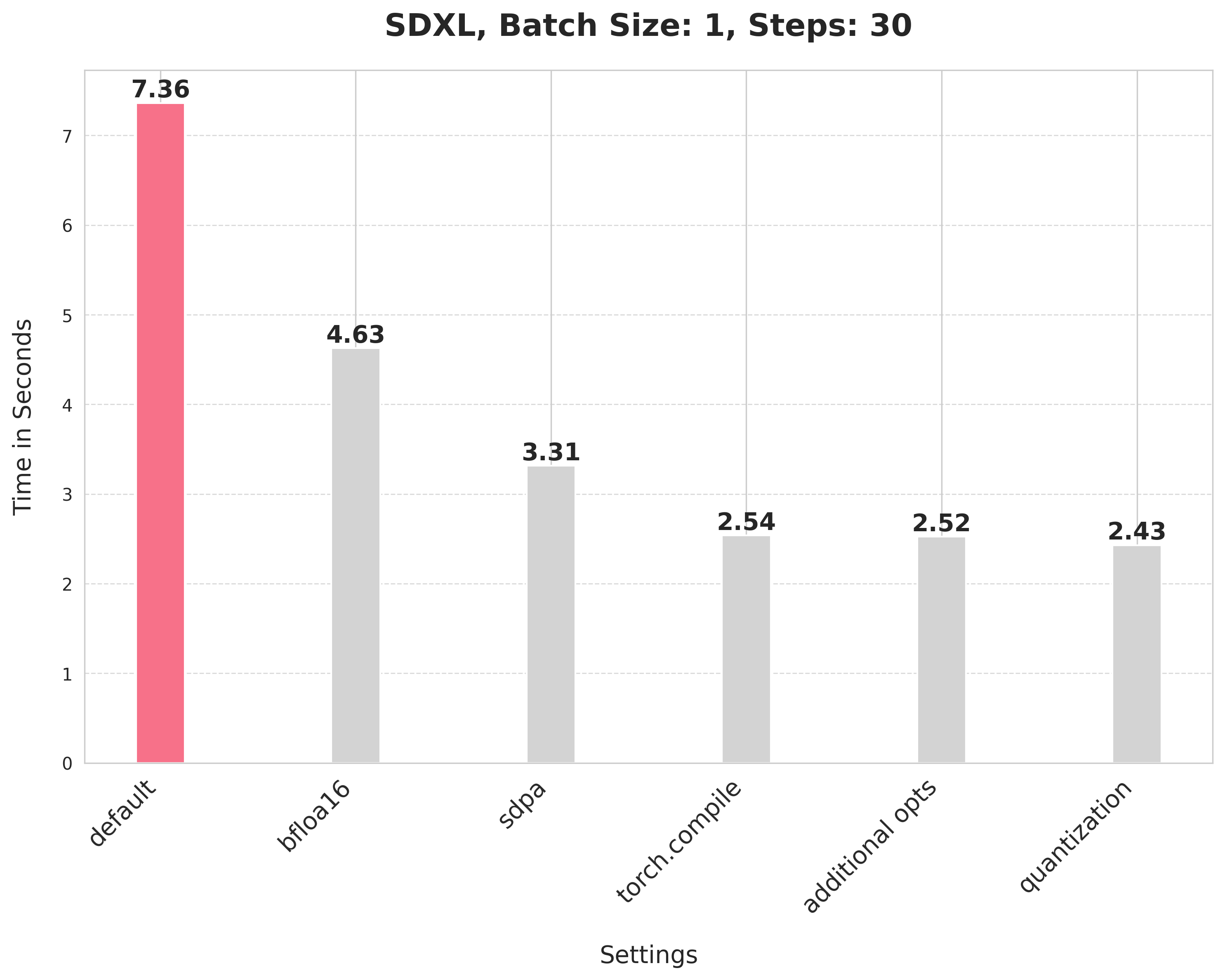
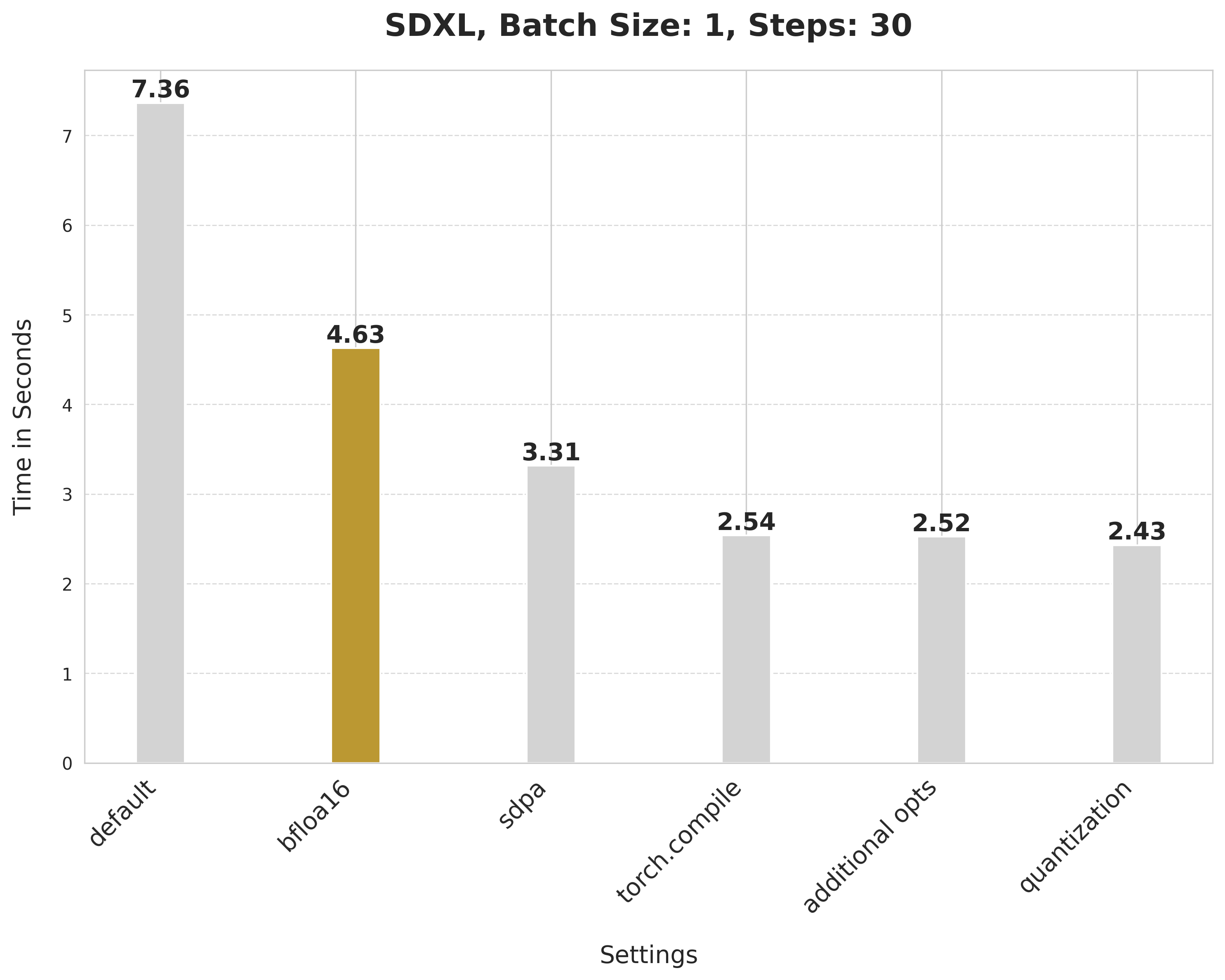
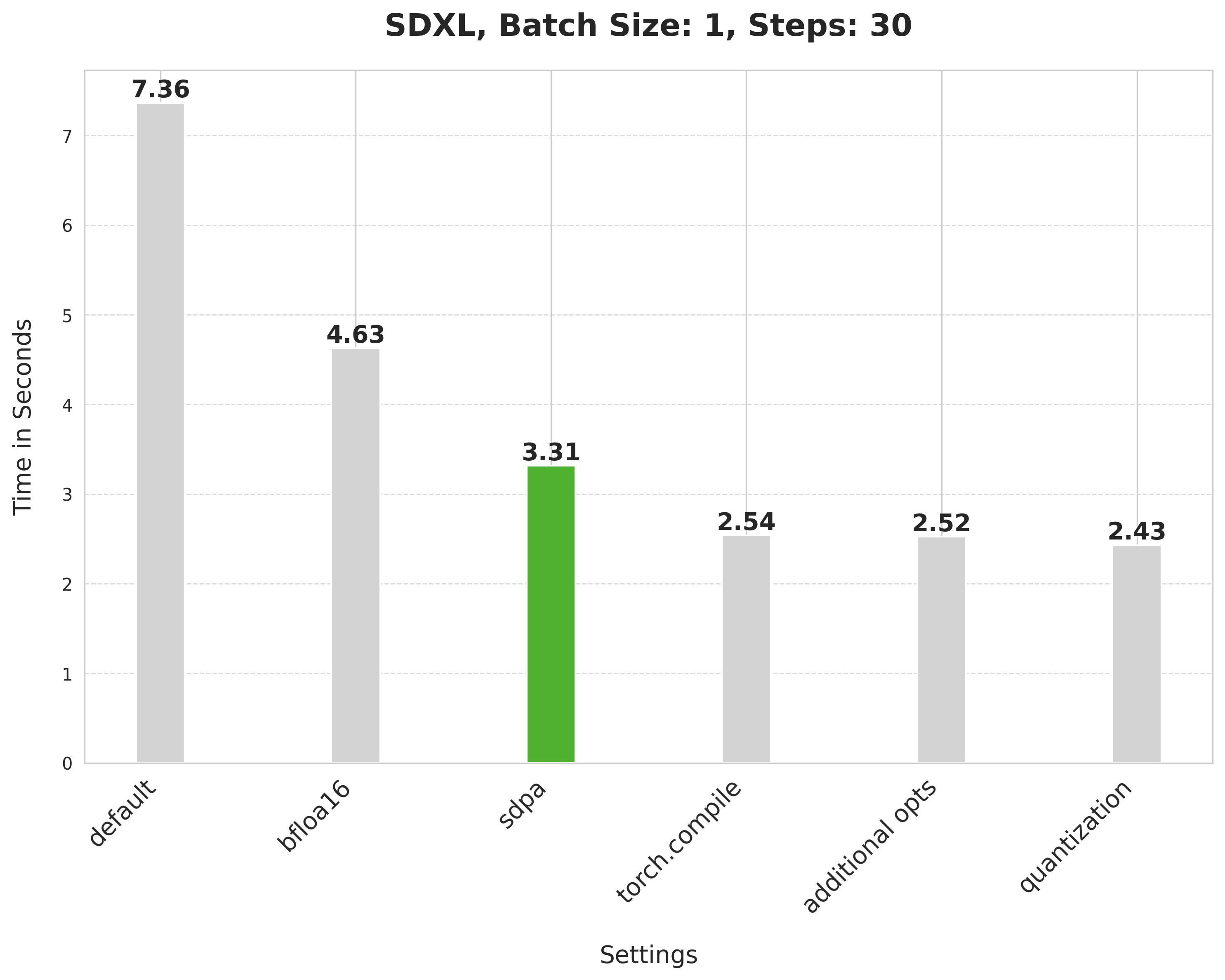
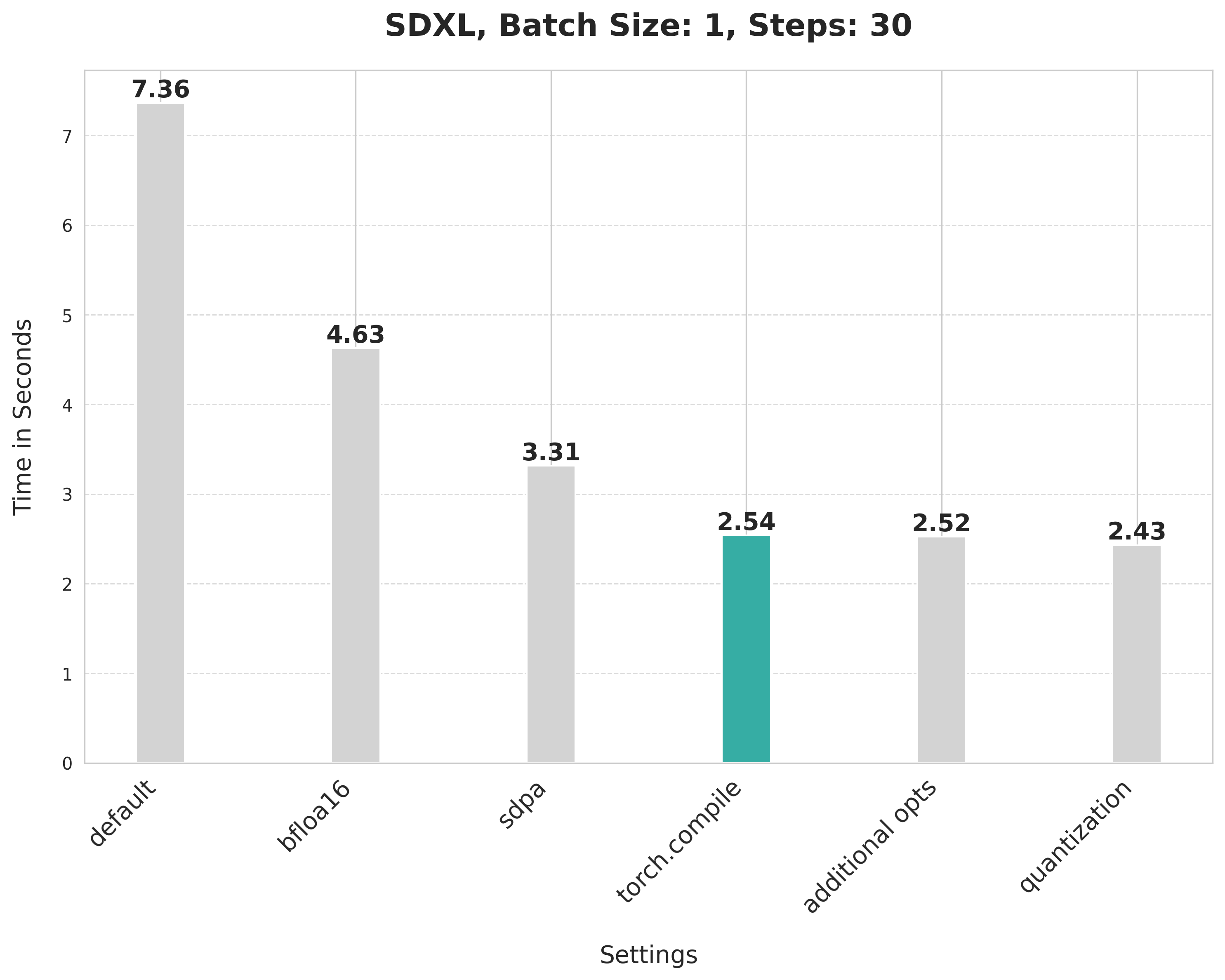
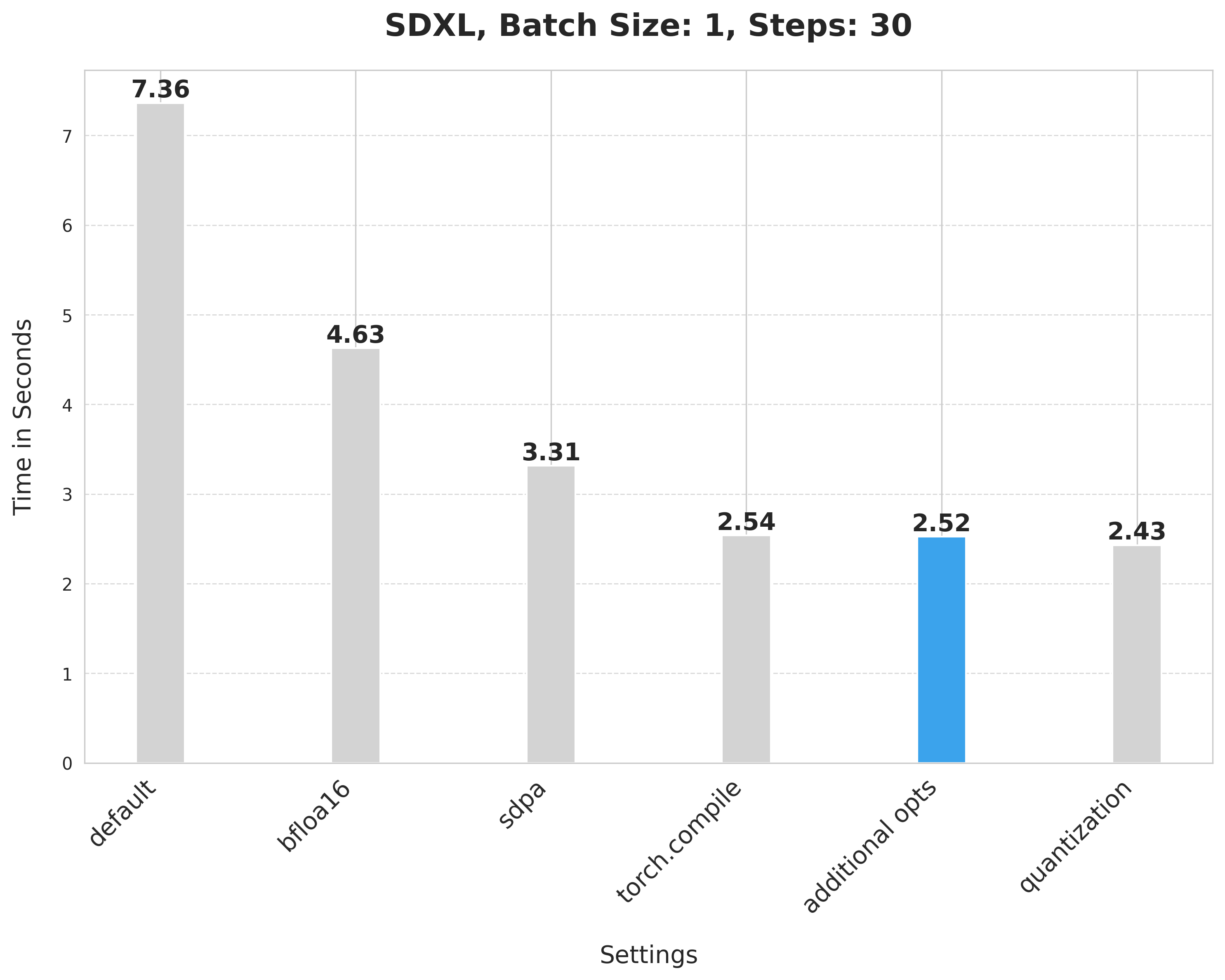
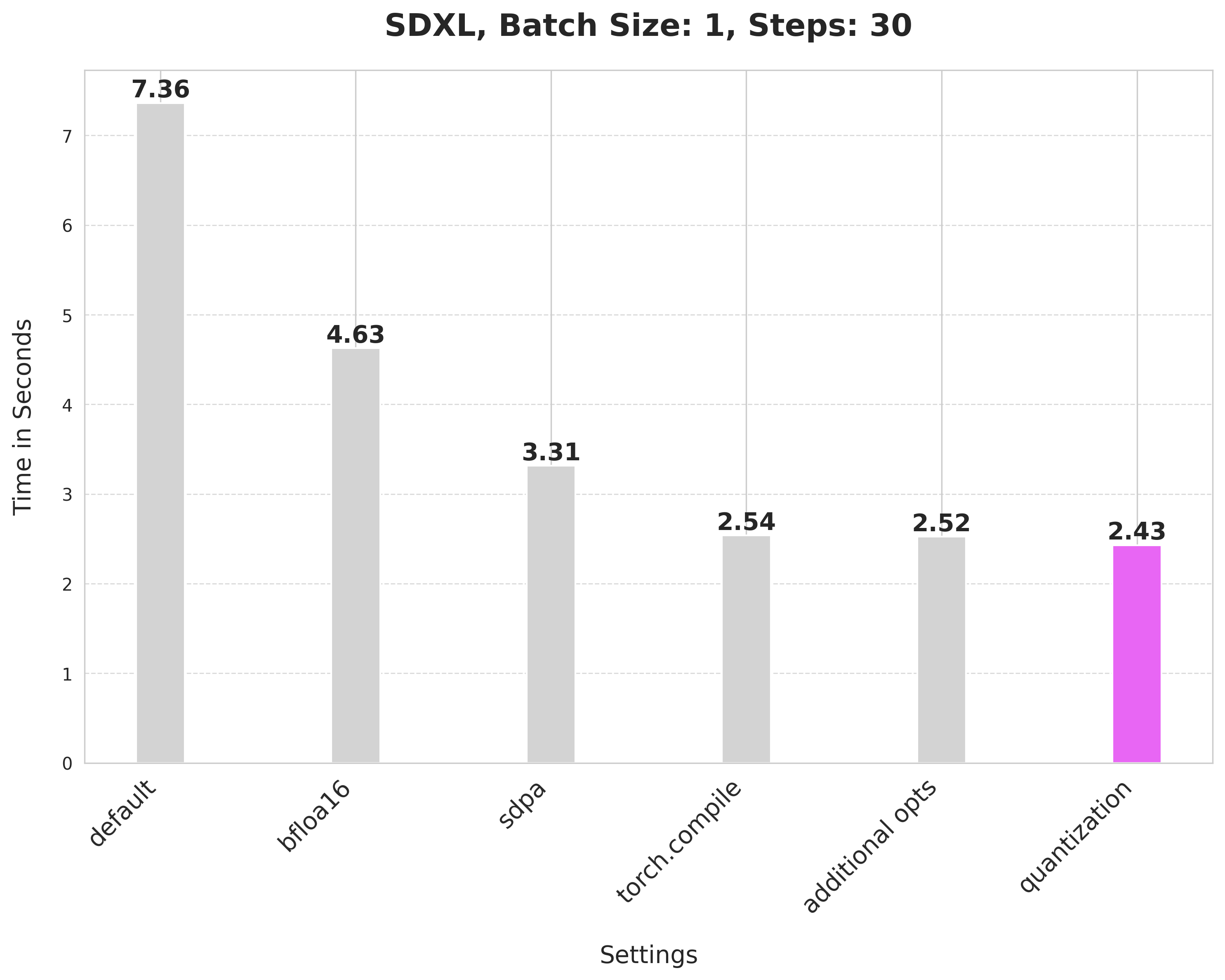
## Improvements, progressively 📈 📊
Baseline
```python
from diffusers import StableDiffusionXLPipeline
# Load the pipeline in full-precision and place its model components on CUDA.
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
With this, we're at:
Bfloat16
```python
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
> 💡 We later ran the experiments in float16 and found out that the recent versions of `torchao` do not incur numerical problems from float16.
scaled_dot_product_attention
```python
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
torch.compile
First, configure some compiler flags:
```python
from diffusers import StableDiffusionXLPipeline
import torch
# Set the following compiler flags to make things go brrr.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
```
Then load the pipeline:
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
```
Compile and perform inference:
```python
# Compile the UNet and VAE.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]
```
Combining attention projection matrices
```python
from diffusers import StableDiffusionXLPipeline
import torch
# Configure the compiler flags.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Compile the UNet and VAE.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]
```
Dynamic quantization
Start by setting the compiler flags (this time, we have two new):
```python
from diffusers import StableDiffusionXLPipeline
import torch
from torchao.quantization import apply_dynamic_quant, swap_conv2d_1x1_to_linear
# Compiler flags. There are two new.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
```
Then write the filtering functions to apply dynamic quantization:
```python
def dynamic_quant_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Linear)
and mod.in_features > 16
and (mod.in_features, mod.out_features)
not in [
(1280, 640),
(1920, 1280),
(1920, 640),
(2048, 1280),
(2048, 2560),
(2560, 1280),
(256, 128),
(2816, 1280),
(320, 640),
(512, 1536),
(512, 256),
(512, 512),
(640, 1280),
(640, 1920),
(640, 320),
(640, 5120),
(640, 640),
(960, 320),
(960, 640),
]
)
def conv_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
)
```
Then we're rwady for inference:
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Change the memory layout.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
# Swap the pointwise convs with linears.
swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
# Apply dynamic quantization.
apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
# Compile.
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
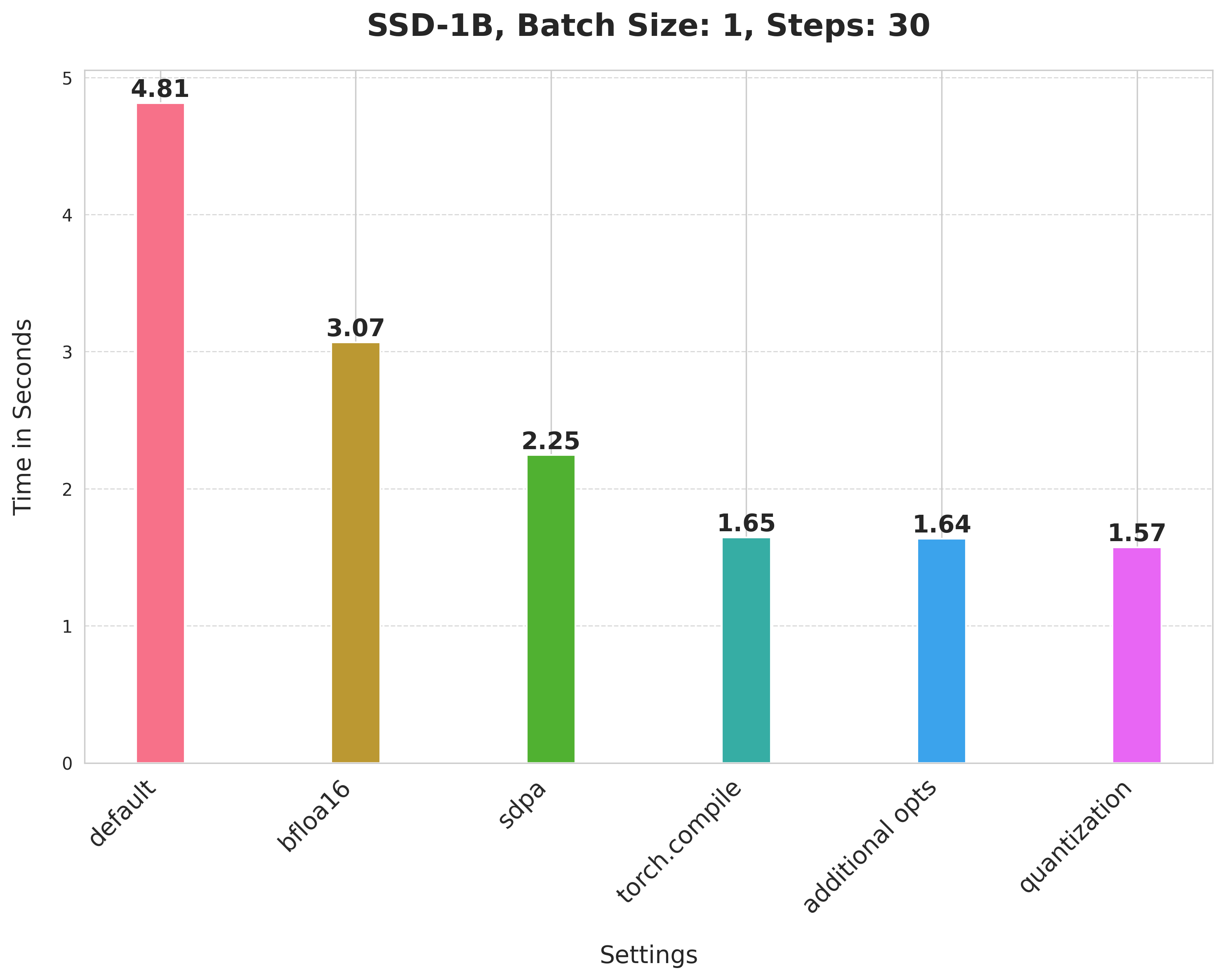
## Results from other pipelines 🌋
SSD-1B
SD v1-5
Pixart-Alpha
================================================
FILE: experiment-scripts/run_pixart.sh
================================================
#!/bin/bash
# From diffusion-fast source directory.
python run_benchmark_pixart.py --ckpt "PixArt-alpha/PixArt-XL-2-1024-MS" --no_sdpa --no_bf16 && \
python run_benchmark_pixart.py --ckpt "PixArt-alpha/PixArt-XL-2-1024-MS" --compile_transformer --compile_mode=max-autotune --compile_vae --change_comp_config && \
python run_benchmark_pixart.py --ckpt "PixArt-alpha/PixArt-XL-2-1024-MS" --compile_transformer --compile_mode=max-autotune --compile_vae --change_comp_config --enable_fused_projections && \
python run_benchmark_pixart.py --ckpt "PixArt-alpha/PixArt-XL-2-1024-MS" --compile_transformer --compile_mode=max-autotune --compile_vae --enable_fused_projections --do_quant "int8dynamic" --change_comp_config && \
python prepare_results.py --plot_title "PixArt-Alpha, Batch Size: 1, Steps: 30" --final_csv_filename "collated_results.csv"
================================================
FILE: experiment-scripts/run_sd.sh
================================================
#!/bin/bash
# From diffusion-fast source directory.
python run_benchmark.py --no_sdpa --no_bf16 && \
python run_benchmark.py --compile_unet --compile_mode=max-autotune --compile_vae --change_comp_config && \
python run_benchmark.py --compile_unet --compile_mode=max-autotune --compile_vae --change_comp_config --enable_fused_projections && \
python run_benchmark.py --compile_unet --compile_mode=max-autotune --compile_vae --enable_fused_projections --do_quant "int8dynamic" --change_comp_config && \
python prepare_results.py --plot_title "SDXL, Batch Size: 1, Steps: 30" --final_csv_filename "collated_results.csv"
================================================
FILE: experiment-scripts/run_sd_cpu.sh
================================================
#!/bin/bash
# From diffusion-fast source directory.
# Run Diffusion benchmark on CPU platforms.
python run_benchmark.py --no_sdpa --no_bf16 --device=cpu
python run_benchmark.py --compile_unet --compile_vae --device=cpu
python run_benchmark.py --compile_unet --compile_vae --enable_fused_projections --device=cpu
================================================
FILE: prepare_results.py
================================================
import argparse
import glob
import os
import sys
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from huggingface_hub import upload_file
sys.path.append(".")
from utils.benchmarking_utils import collate_csv # noqa: E402
REPO_ID = "sayakpaul/sample-datasets"
def prepare_plot(df, args):
# Drop the columns that are not needed
columns_to_drop = [
"batch_size",
"num_inference_steps",
"pipeline_cls",
"ckpt_id",
"upcast_vae",
"memory (gbs)",
"actual_gpu_memory (gbs)",
"tag",
]
df_filtered = df.drop(columns=columns_to_drop)
df_filtered[["quant"]] = df_filtered[["do_quant"]].fillna("None")
df_filtered.drop(columns=["do_quant"], inplace=True)
# Create a new column to consolidate settings into a readable format
df_filtered["settings"] = df_filtered.apply(
lambda row: ", ".join([f"{col}-{row[col]}" for col in df_filtered.columns if col != "time (secs)"]), axis=1
)
df_filtered["formatted_settings"] = df_filtered["settings"].str.replace(", ", "\n", regex=False)
df_filtered.loc[0, "formatted_settings"] = "default"
# Generating the plot with matplotlib directly for better control
plt.figure(figsize=(12, 10))
sns.set_style("whitegrid")
# Calculate the number of unique settings for bar positions
n_settings = len(df_filtered["formatted_settings"].unique())
bar_positions = range(n_settings)
# Choose a color palette
palette = sns.color_palette("husl", n_settings)
# Plot each bar manually
bar_width = 0.25 # Width of the bars
for i, setting in enumerate(df_filtered["formatted_settings"].unique()):
# Filter the dataframe for each setting and get the mean time
mean_time = df_filtered[df_filtered["formatted_settings"] == setting]["time (secs)"].mean()
plt.bar(i, mean_time, width=bar_width, align="center", color=palette[i])
# Add the text above the bars
plt.text(i, mean_time + 0.01, f"{mean_time:.2f}", ha="center", va="bottom", fontsize=14, fontweight="bold")
# Set the x-ticks to correspond to the settings
plt.xticks(bar_positions, df_filtered["formatted_settings"].unique(), rotation=45, ha="right", fontsize=10)
plt.ylabel("Time in Seconds", fontsize=14, labelpad=15)
plt.xlabel("Settings", fontsize=14, labelpad=15)
plt.title(args.plot_title, fontsize=18, fontweight="bold", pad=20)
# Adding horizontal gridlines for better readability
plt.grid(axis="y", linestyle="--", linewidth=0.7, alpha=0.7)
plt.tight_layout()
plt.subplots_adjust(top=0.9, bottom=0.2) # Adjust the top and bottom
plot_path = args.plot_title.replace(" ", "_") + ".png"
plt.savefig(plot_path, bbox_inches="tight", dpi=300)
if args.push_to_hub:
upload_file(repo_id=REPO_ID, path_in_repo=plot_path, path_or_fileobj=plot_path, repo_type="dataset")
print(
f"Plot successfully uploaded. Find it here: https://huggingface.co/datasets/{REPO_ID}/blob/main/{args.plot_file_path}"
)
# Show the plot
plt.show()
def main(args):
all_csvs = sorted(glob.glob(f"{args.base_path}/*.csv"))
all_csvs = [os.path.join(args.base_path, x) for x in all_csvs]
is_pixart = "PixArt-alpha" in all_csvs[0]
collate_csv(all_csvs, args.final_csv_filename, is_pixart=is_pixart)
if args.push_to_hub:
upload_file(
repo_id=REPO_ID,
path_in_repo=args.final_csv_filename,
path_or_fileobj=args.final_csv_filename,
repo_type="dataset",
)
print(
f"CSV successfully uploaded. Find it here: https://huggingface.co/datasets/{REPO_ID}/blob/main/{args.final_csv_filename}"
)
if args.plot_title is not None:
df = pd.read_csv(args.final_csv_filename)
prepare_plot(df, args)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--base_path", type=str, default=".")
parser.add_argument("--final_csv_filename", type=str, default="collated_results.csv")
parser.add_argument("--plot_title", type=str, default=None)
parser.add_argument("--push_to_hub", action="store_true")
args = parser.parse_args()
main(args)
================================================
FILE: pyproject.toml
================================================
[tool.ruff]
# Never enforce `E501` (line length violations).
ignore = ["C901", "E501", "E741", "F402", "F823"]
select = ["C", "E", "F", "I", "W"]
line-length = 119
# Ignore import violations in all `__init__.py` files.
[tool.ruff.per-file-ignores]
"__init__.py" = ["E402", "F401", "F403", "F811"]
"src/diffusers/utils/dummy_*.py" = ["F401"]
[tool.ruff.isort]
lines-after-imports = 2
known-first-party = ["diffusers"]
[tool.ruff.format]
# Like Black, use double quotes for strings.
quote-style = "double"
# Like Black, indent with spaces, rather than tabs.
indent-style = "space"
# Like Black, respect magic trailing commas.
skip-magic-trailing-comma = false
# Like Black, automatically detect the appropriate line ending.
line-ending = "auto"
================================================
FILE: run_benchmark.py
================================================
import torch
torch.set_float32_matmul_precision("high")
import sys # noqa: E402
sys.path.append(".")
from utils.benchmarking_utils import ( # noqa: E402
benchmark_fn,
create_parser,
generate_csv_dict,
write_to_csv,
)
from utils.pipeline_utils import load_pipeline # noqa: E402
def run_inference(pipe, args):
_ = pipe(
prompt=args.prompt,
num_inference_steps=args.num_inference_steps,
num_images_per_prompt=args.batch_size,
)
def main(args) -> dict:
pipeline = load_pipeline(
ckpt=args.ckpt,
compile_unet=args.compile_unet,
compile_vae=args.compile_vae,
no_sdpa=args.no_sdpa,
no_bf16=args.no_bf16,
upcast_vae=args.upcast_vae,
enable_fused_projections=args.enable_fused_projections,
do_quant=args.do_quant,
compile_mode=args.compile_mode,
change_comp_config=args.change_comp_config,
device=args.device,
)
# Warmup.
run_inference(pipeline, args)
run_inference(pipeline, args)
run_inference(pipeline, args)
time = benchmark_fn(run_inference, pipeline, args) # in seconds.
data_dict = generate_csv_dict(
pipeline_cls=str(pipeline.__class__.__name__),
args=args,
time=time,
)
img = pipeline(
prompt=args.prompt,
num_inference_steps=args.num_inference_steps,
num_images_per_prompt=args.batch_size,
).images[0]
return data_dict, img
if __name__ == "__main__":
parser = create_parser()
args = parser.parse_args()
print(args)
data_dict, img = main(args)
name = (
args.ckpt.replace("/", "_")
+ f"bf16@{not args.no_bf16}-sdpa@{not args.no_sdpa}-bs@{args.batch_size}-fuse@{args.enable_fused_projections}-upcast_vae@{args.upcast_vae}-steps@{args.num_inference_steps}-unet@{args.compile_unet}-vae@{args.compile_vae}-mode@{args.compile_mode}-change_comp_config@{args.change_comp_config}-do_quant@{args.do_quant}-tag@{args.tag}-device@{args.device}.csv"
)
img.save(f'{name.replace(".csv", "")}.jpeg')
write_to_csv(name, data_dict)
================================================
FILE: run_benchmark_pixart.py
================================================
import torch
torch.set_float32_matmul_precision("high")
import sys # noqa: E402
sys.path.append(".")
from utils.benchmarking_utils import ( # noqa: E402
benchmark_fn,
create_parser,
generate_csv_dict,
write_to_csv,
)
from utils.pipeline_utils_pixart import load_pipeline # noqa: E402
def run_inference(pipe, args):
_ = pipe(
prompt=args.prompt,
num_inference_steps=args.num_inference_steps,
num_images_per_prompt=args.batch_size,
)
def main(args) -> dict:
pipeline = load_pipeline(
ckpt=args.ckpt,
compile_transformer=args.compile_transformer,
compile_vae=args.compile_vae,
no_sdpa=args.no_sdpa,
no_bf16=args.no_bf16,
enable_fused_projections=args.enable_fused_projections,
do_quant=args.do_quant,
compile_mode=args.compile_mode,
change_comp_config=args.change_comp_config,
device=args.device,
)
# Warmup.
run_inference(pipeline, args)
run_inference(pipeline, args)
run_inference(pipeline, args)
time = benchmark_fn(run_inference, pipeline, args) # in seconds.
data_dict = generate_csv_dict(
pipeline_cls=str(pipeline.__class__.__name__),
args=args,
time=time,
)
img = pipeline(
prompt=args.prompt,
num_inference_steps=args.num_inference_steps,
num_images_per_prompt=args.batch_size,
).images[0]
return data_dict, img
if __name__ == "__main__":
parser = create_parser(is_pixart=True)
args = parser.parse_args()
print(args)
data_dict, img = main(args)
name = (
args.ckpt.replace("/", "_")
+ f"bf16@{not args.no_bf16}-sdpa@{not args.no_sdpa}-bs@{args.batch_size}-fuse@{args.enable_fused_projections}-upcast_vae@NA-steps@{args.num_inference_steps}-transformer@{args.compile_transformer}-vae@{args.compile_vae}-mode@{args.compile_mode}-change_comp_config@{args.change_comp_config}-do_quant@{args.do_quant}-tag@{args.tag}-device@{args.device}.csv"
)
img.save(f"{name}.jpeg")
write_to_csv(name, data_dict, is_pixart=True)
================================================
FILE: run_profile.py
================================================
import torch
torch.set_float32_matmul_precision("high")
from torch._inductor import config as inductorconfig # noqa: E402
inductorconfig.triton.unique_kernel_names = True
import functools # noqa: E402
import sys # noqa: E402
sys.path.append(".")
from utils.benchmarking_utils import create_parser # noqa: E402
from utils.pipeline_utils import load_pipeline # noqa: E402
def profiler_runner(path, fn, *args, **kwargs):
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], record_shapes=True
) as prof:
result = fn(*args, **kwargs)
prof.export_chrome_trace(path)
return result
def run_inference(pipe, args):
_ = pipe(
prompt=args.prompt,
num_inference_steps=args.num_inference_steps,
num_images_per_prompt=args.batch_size,
)
def main(args) -> dict:
pipeline = load_pipeline(
ckpt=args.ckpt,
compile_unet=args.compile_unet,
compile_vae=args.compile_vae,
no_sdpa=args.no_sdpa,
no_bf16=args.no_bf16,
upcast_vae=args.upcast_vae,
enable_fused_projections=args.enable_fused_projections,
do_quant=args.do_quant,
compile_mode=args.compile_mode,
change_comp_config=args.change_comp_config,
device=args.device,
)
# warmup.
run_inference(pipeline, args)
run_inference(pipeline, args)
trace_path = (
args.ckpt.replace("/", "_")
+ f"bf16@{not args.no_bf16}-sdpa@{not args.no_sdpa}-bs@{args.batch_size}-fuse@{args.enable_fused_projections}-upcast_vae@{args.upcast_vae}-steps@{args.num_inference_steps}-unet@{args.compile_unet}-vae@{args.compile_vae}-mode@{args.compile_mode}-change_comp_config@{args.change_comp_config}-do_quant@{args.do_quant}-device@{args.device}.json"
)
runner = functools.partial(profiler_runner, trace_path)
with torch.autograd.profiler.record_function("sdxl-brrr"):
runner(run_inference, pipeline, args)
return trace_path
if __name__ == "__main__":
parser = create_parser()
args = parser.parse_args()
if not args.compile_unet:
args.compile_mode = "NA"
trace_path = main(args)
print(f"Trace generated at: {trace_path}")
================================================
FILE: utils/benchmarking_utils.py
================================================
import argparse
import copy
import csv
import gc
from typing import Dict, List, Union
import torch
import torch.utils.benchmark as benchmark
BENCHMARK_FIELDS = [
"pipeline_cls",
"ckpt_id",
"bf16",
"sdpa",
"fused_qkv_projections",
"upcast_vae",
"batch_size",
"num_inference_steps",
"compile_unet",
"compile_vae",
"compile_mode",
"change_comp_config",
"do_quant",
"time (secs)",
"memory (gbs)",
"actual_gpu_memory (gbs)",
"tag",
]
def create_parser(is_pixart=False):
"""Creates CLI args parser."""
parser = argparse.ArgumentParser()
parser.add_argument("--ckpt", type=str, default="stabilityai/stable-diffusion-xl-base-1.0")
parser.add_argument("--prompt", type=str, default="ghibli style, a fantasy landscape with castles")
parser.add_argument("--no_bf16", action="store_true")
parser.add_argument("--no_sdpa", action="store_true")
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--num_inference_steps", type=int, default=30)
parser.add_argument("--enable_fused_projections", action="store_true")
if not is_pixart:
parser.add_argument("--upcast_vae", action="store_true")
if is_pixart:
parser.add_argument("--compile_transformer", action="store_true")
else:
parser.add_argument("--compile_unet", action="store_true")
parser.add_argument("--compile_vae", action="store_true")
parser.add_argument("--compile_mode", type=str, default=None, choices=["reduce-overhead", "max-autotune"])
parser.add_argument("--change_comp_config", action="store_true")
parser.add_argument("--do_quant", type=str, default=None)
parser.add_argument("--tag", type=str, default="")
parser.add_argument("--device", type=str, choices=["cuda", "cpu"], default="cuda")
return parser
def flush():
"""Wipes off memory."""
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_max_memory_allocated()
torch.cuda.reset_peak_memory_stats()
def bytes_to_giga_bytes(bytes):
return f"{(bytes / 1024 / 1024 / 1024):.3f}"
def benchmark_fn(f, *args, **kwargs):
t0 = benchmark.Timer(
stmt="f(*args, **kwargs)",
globals={"args": args, "kwargs": kwargs, "f": f},
num_threads=torch.get_num_threads(),
)
return f"{(t0.blocked_autorange().mean):.3f}"
def generate_csv_dict(pipeline_cls: str, args, time: float) -> Dict[str, Union[str, bool, float]]:
"""Packs benchmarking data into a dictionary for latter serialization."""
data_dict = {
"pipeline_cls": pipeline_cls,
"ckpt_id": args.ckpt,
"bf16": not args.no_bf16,
"sdpa": not args.no_sdpa,
"fused_qkv_projections": args.enable_fused_projections,
"upcast_vae": "NA" if "PixArt" in pipeline_cls else args.upcast_vae,
"batch_size": args.batch_size,
"num_inference_steps": args.num_inference_steps,
"compile_unet": args.compile_transformer if "PixArt" in pipeline_cls else args.compile_unet,
"compile_vae": args.compile_vae,
"compile_mode": args.compile_mode,
"change_comp_config": args.change_comp_config,
"do_quant": args.do_quant,
"time (secs)": time,
"tag": args.tag,
}
if args.device == "cuda":
memory = bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) # in GBs.
TOTAL_GPU_MEMORY = torch.cuda.get_device_properties(0).total_memory / (1024**3)
data_dict["memory (gbs)"] = memory
data_dict["actual_gpu_memory (gbs)"] = f"{(TOTAL_GPU_MEMORY):.3f}"
if "PixArt" in pipeline_cls:
data_dict["compile_transformer"] = data_dict.pop("compile_unet")
return data_dict
def write_to_csv(file_name: str, data_dict: Dict[str, Union[str, bool, float]], is_pixart=False):
"""Serializes a dictionary into a CSV file."""
fields_copy = copy.deepcopy(BENCHMARK_FIELDS)
fields = BENCHMARK_FIELDS
if is_pixart:
i = BENCHMARK_FIELDS.index("compile_unet")
fields_copy[i] = "compile_transformer"
fields = fields_copy
with open(file_name, mode="w", newline="") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fields)
writer.writeheader()
writer.writerow(data_dict)
def collate_csv(input_files: List[str], output_file: str, is_pixart=False):
"""Collates multiple identically structured CSVs into a single CSV file."""
fields_copy = copy.deepcopy(BENCHMARK_FIELDS)
fields = BENCHMARK_FIELDS
if is_pixart:
i = BENCHMARK_FIELDS.index("compile_unet")
fields_copy[i] = "compile_transformer"
fields = fields_copy
with open(output_file, mode="w", newline="") as outfile:
writer = csv.DictWriter(outfile, fieldnames=fields)
writer.writeheader()
for file in input_files:
with open(file, mode="r") as infile:
reader = csv.DictReader(infile)
for row in reader:
writer.writerow(row)
================================================
FILE: utils/pipeline_utils.py
================================================
import torch
from torchao.quantization import (
apply_dynamic_quant,
change_linear_weights_to_int4_woqtensors,
change_linear_weights_to_int8_woqtensors,
swap_conv2d_1x1_to_linear,
)
from diffusers import AutoencoderKL, DiffusionPipeline, DPMSolverMultistepScheduler
PROMPT = "ghibli style, a fantasy landscape with castles"
def dynamic_quant_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Linear)
and mod.in_features > 16
and (mod.in_features, mod.out_features)
not in [
(1280, 640),
(1920, 1280),
(1920, 640),
(2048, 1280),
(2048, 2560),
(2560, 1280),
(256, 128),
(2816, 1280),
(320, 640),
(512, 1536),
(512, 256),
(512, 512),
(640, 1280),
(640, 1920),
(640, 320),
(640, 5120),
(640, 640),
(960, 320),
(960, 640),
]
)
def conv_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
)
def load_pipeline(
ckpt: str,
compile_unet: bool,
compile_vae: bool,
no_sdpa: bool,
no_bf16: bool,
upcast_vae: bool,
enable_fused_projections: bool,
do_quant: bool,
compile_mode: str,
change_comp_config: bool,
device: str,
):
"""Loads the SDXL pipeline."""
if do_quant and not compile_unet:
raise ValueError("Compilation for UNet must be enabled when quantizing.")
if do_quant and not compile_vae:
raise ValueError("Compilation for VAE must be enabled when quantizing.")
dtype = torch.float32 if no_bf16 else torch.bfloat16
print(f"Using dtype: {dtype}")
if ckpt != "runwayml/stable-diffusion-v1-5":
pipe = DiffusionPipeline.from_pretrained(ckpt, torch_dtype=dtype, use_safetensors=True)
else:
pipe = DiffusionPipeline.from_pretrained(ckpt, torch_dtype=dtype, use_safetensors=True, safety_checker=None)
# As the default scheduler of SD v1-5 doesn't have sigmas device placement
# (https://github.com/huggingface/diffusers/pull/6173)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
if not upcast_vae and ckpt != "runwayml/stable-diffusion-v1-5":
print("Using a more numerically stable VAE.")
pipe.vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=dtype)
if enable_fused_projections:
print("Enabling fused QKV projections for both UNet and VAE.")
pipe.fuse_qkv_projections()
if upcast_vae and ckpt != "runwayml/stable-diffusion-v1-5":
print("Upcasting VAE.")
pipe.upcast_vae()
if no_sdpa:
print("Using vanilla attention.")
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
if device == "cuda":
pipe = pipe.to("cuda")
if compile_unet:
pipe.unet.to(memory_format=torch.channels_last)
print("Compile UNet.")
swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
if compile_mode == "max-autotune" and change_comp_config:
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
if do_quant:
print("Apply quantization to UNet.")
if do_quant == "int4weightonly":
change_linear_weights_to_int4_woqtensors(pipe.unet)
elif do_quant == "int8weightonly":
change_linear_weights_to_int8_woqtensors(pipe.unet)
elif do_quant == "int8dynamic":
apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
else:
raise ValueError(f"Unknown do_quant value: {do_quant}.")
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
pipe.unet = torch.compile(pipe.unet, mode=compile_mode, fullgraph=True)
if compile_vae:
pipe.vae.to(memory_format=torch.channels_last)
print("Compile VAE.")
swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
if compile_mode == "max-autotune" and change_comp_config:
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
if do_quant:
print("Apply quantization to VAE.")
if do_quant == "int4weightonly":
change_linear_weights_to_int4_woqtensors(pipe.vae)
elif do_quant == "int8weightonly":
change_linear_weights_to_int8_woqtensors(pipe.vae)
elif do_quant == "int8dynamic":
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
else:
raise ValueError(f"Unknown do_quant value: {do_quant}.")
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
pipe.vae.decode = torch.compile(pipe.vae.decode, mode=compile_mode, fullgraph=True)
pipe.set_progress_bar_config(disable=True)
return pipe
================================================
FILE: utils/pipeline_utils_pixart.py
================================================
import torch
from torchao.quantization import (
apply_dynamic_quant,
change_linear_weights_to_int4_woqtensors,
change_linear_weights_to_int8_woqtensors,
swap_conv2d_1x1_to_linear,
)
from diffusers import DiffusionPipeline
def dynamic_quant_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Linear)
and mod.in_features > 16
and (mod.in_features, mod.out_features)
not in [
(1280, 640),
(1920, 1280),
(1920, 640),
(2048, 1280),
(2048, 2560),
(2560, 1280),
(256, 128),
(2816, 1280),
(320, 640),
(512, 1536),
(512, 256),
(512, 512),
(640, 1280),
(640, 1920),
(640, 320),
(640, 5120),
(640, 640),
(960, 320),
(960, 640),
]
)
def conv_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
)
def load_pipeline(
ckpt: str,
compile_transformer: bool,
compile_vae: bool,
no_sdpa: bool,
no_bf16: bool,
enable_fused_projections: bool,
do_quant: bool,
compile_mode: str,
change_comp_config: bool,
device: str,
):
"""Loads the PixArt-Alpha pipeline."""
if do_quant and not compile_transformer:
raise ValueError("Compilation for Transformer must be enabled when quantizing.")
if do_quant and not compile_vae:
raise ValueError("Compilation for VAE must be enabled when quantizing.")
dtype = torch.float32 if no_bf16 else torch.bfloat16
print(f"Using dtype: {dtype}")
pipe = DiffusionPipeline.from_pretrained(ckpt, torch_dtype=dtype)
if enable_fused_projections:
print("Enabling fused QKV projections for both Transformer and VAE.")
pipe.fuse_qkv_projections()
if no_sdpa:
print("Using vanilla attention.")
pipe.transformer.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
if device == "cuda":
pipe = pipe.to("cuda")
if compile_transformer:
pipe.transformer.to(memory_format=torch.channels_last)
print("Compile Transformer")
swap_conv2d_1x1_to_linear(pipe.transformer, conv_filter_fn)
if compile_mode == "max-autotune" and change_comp_config:
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
if do_quant:
print("Apply quantization to Transformer")
if do_quant == "int4weightonly":
change_linear_weights_to_int4_woqtensors(pipe.transformer)
elif do_quant == "int8weightonly":
change_linear_weights_to_int8_woqtensors(pipe.transformer)
elif do_quant == "int8dynamic":
apply_dynamic_quant(pipe.transformer, dynamic_quant_filter_fn)
else:
raise ValueError(f"Unknown do_quant value: {do_quant}.")
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
pipe.transformer = torch.compile(pipe.transformer, mode=compile_mode, fullgraph=True)
if compile_vae:
pipe.vae.to(memory_format=torch.channels_last)
print("Compile VAE")
swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
if compile_mode == "max-autotune" and change_comp_config:
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
if do_quant:
print("Apply quantization to VAE")
if do_quant == "int4weightonly":
change_linear_weights_to_int4_woqtensors(pipe.vae)
elif do_quant == "int8weightonly":
change_linear_weights_to_int8_woqtensors(pipe.vae)
elif do_quant == "int8dynamic":
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
else:
raise ValueError(f"Unknown do_quant value: {do_quant}.")
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
pipe.vae.decode = torch.compile(pipe.vae.decode, mode=compile_mode, fullgraph=True)
pipe.set_progress_bar_config(disable=True)
return pipe