Repository: huggingface/instruction-tuned-sd
Branch: main
Commit: 2be8f4900138
Files: 19
Total size: 129.8 KB
Directory structure:
gitextract_ifp0llh4/
├── LICENSE
├── Makefile
├── README.md
├── data_preparation/
│ ├── README.md
│ ├── __init__.py
│ ├── export_to_hub.py
│ ├── generate_dataset.py
│ ├── image_utils.py
│ ├── instructions.txt
│ ├── model_utils.py
│ └── requirements.txt
├── finetune_instruct_pix2pix.py
├── requirements.txt
├── train_instruct_pix2pix.py
└── validation/
├── README.md
├── __init__.py
├── compare_models.py
├── data_utils.py
└── requirements.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
Copyright 2023- The HuggingFace Inc. team and The InstructPix2Pix Authors. All rights reserved.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: Makefile
================================================
check_dirs := .
quality:
black --check $(check_dirs)
ruff $(check_dirs)
style:
black $(check_dirs)
ruff $(check_dirs) --fix
================================================
FILE: README.md
================================================
# Instruction-tuning Stable Diffusion
**TL;DR**: Motivated partly by [FLAN](https://arxiv.org/abs/2109.01652) and partly by [InstructPix2Pix](https://arxiv.org/abs/2211.09800), we explore a way to instruction-tune [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release). This allows us to prompt our model using an input image and an “instruction”, such as - *Apply a cartoon filter to the natural image*.
You can read [our blog post](https://hf.co/blog/instruction-tuning-sd) to know more details.
## Table of contents
🐶 [Motivation](#motivation)
📷 [Data preparation](#data-preparation)
💺 [Training](#training)
🎛 [Models, datasets, demo](#models-datasets-demo)
⭐️ [Inference](#inference)
🧭 [Results](#results)
🤝 [Acknowledgements](#acknowledgements)
## Motivation
Instruction-tuning is a supervised way of teaching language models to follow instructions to solve a task. It was introduced in [Fine-tuned Language Models Are Zero-Shot Learners](https://arxiv.org/abs/2109.01652) (FLAN) by Google. From recent times, you might recall works like [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) and [FLAN V2](https://arxiv.org/abs/2210.11416), which are good examples of how beneficial instruction-tuning can be for various tasks.
On the other hand, the idea of teaching Stable Diffusion to follow user instructions to perform edits on input images was introduced in [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800).
Our motivation behind this work comes partly from the FLAN line of works and partly from InstructPix2Pix. We wanted to explore if it’s possible to prompt Stable Diffusion with specific instructions and input images to process them as per our needs.
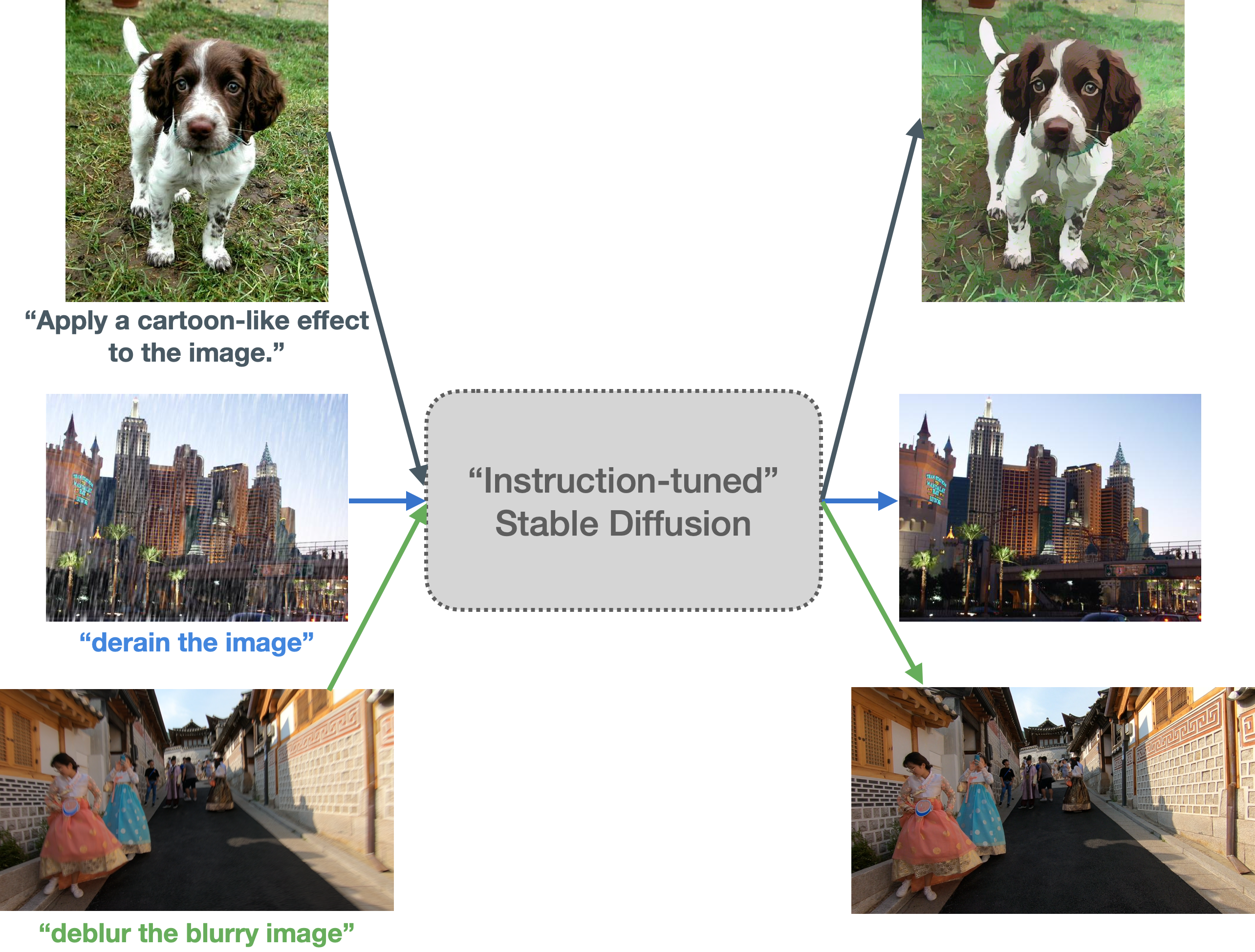
Our main idea is to first create an instruction prompted dataset (as described in [our blog](https://hf.co/blog/instruction-tuning-sd) and then conduct InstructPix2Pix style training. The end objective is to make Stable Diffusion better at following specific instructions that entail image transformation related operations.
## Data preparation
Our data preparation process is inspired by FLAN. Refer to the sections below for more details.
* **Cartoonization**: Refer to the `data_preparation` directory.
* **Low-level image processing**: Refer to the [dataset card](https://huggingface.co/datasets/instruction-tuning-sd/low-level-image-proc).
## Training
> [!TIP]
> In case of using custom datasets, one needs to configure the dataset as per their choice as long as you maintain the format presented here. You might have to configure your dataloader and dataset class in case you don't want to make use of the `datasets` library. If you do so, you might have to adjust the training scripts accordingly.
### Dev env setup
We recommend using a Python virtual environment for this. Feel free to use your favorite one here.
We conducted our experiments with PyTorch 1.13.1 (CUDA 11.6) and a single A100 GPU. Since PyTorch installation can be hardware-dependent, we refer you to the [official docs](https://pytorch.org/) for installing PyTorch.
Once PyTorch is installed, we can install the rest of the dependencies:
```bash
pip install -r requirements.txt
```
Additionally, we recommend installing [xformers](https://github.com/facebookresearch/xformers) as well for enabling memory-efficient training.
> 💡 **Note**: If you're using PyTorch 2.0 then you don't need to additionally install xformers. This is because we default to a memory-efficient attention processor in Diffusers when PyTorch 2.0 is being used.
### Launching training
Our training code leverages [🧨 diffusers](https://github.com/huggingface/diffusers), [🤗 accelerate](https://github.com/huggingface/accelerate), and [🤗 transformers](https://github.com/huggingface/transformers). In particular, we extend [this training example](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py) to fit our needs.
### Cartoonization
#### Training from scratch using the InstructPix2Pix methodology
```bash
export MODEL_ID="runwayml/stable-diffusion-v1-5"
export DATASET_ID="instruction-tuning-sd/cartoonization"
export OUTPUT_DIR="cartoonization-scratch"
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_ID \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=2 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--mixed_precision=fp16 \
--val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
--validation_prompt="Generate a cartoonized version of the natural image" \
--seed=42 \
--output_dir=$OUTPUT_DIR \
--report_to=wandb \
--push_to_hub
```
> 💡 **Note**: Following InstructPix2Pix, we train on the 256x256 resolution and that doesn't seem to affect the end quality too much when we perform inference with the 512x512 resolution.
Once the training successfully launched, the logs will be automatically tracked using Weights and Biases. Depending on how you specified the `checkpointing_steps` and the `max_train_steps`, there will be intermediate checkpoints too. At the end of training, you can expect a directory (namely `OUTPUT_DIR`) that contains the intermediate checkpoints and the final pipeline artifacts.
If `--push_to_hub` is specified, the contents of `OUTPUT_DIR` will be pushed to a repository on the Hugging Face Hub.
[Here](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b) is an example run page on Weights and Biases. [Here](https://huggingface.co/instruction-tuning-sd/scratch-cartoonizer) is an example of how the pipeline repository would look like on the Hugging Face Hub.
#### Fine-tuning from InstructPix2Pix
```bash
export MODEL_ID="timbrooks/instruct-pix2pix"
export DATASET_ID="instruction-tuning-sd/cartoonization"
export OUTPUT_DIR="cartoonization-finetuned"
accelerate launch --mixed_precision="fp16" finetune_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_ID \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=2 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--mixed_precision=fp16 \
--val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
--validation_prompt="Generate a cartoonized version of the natural image" \
--seed=42 \
--output_dir=$OUTPUT_DIR \
--report_to=wandb \
--push_to_hub
```
### Low-level image processing
#### Training from scratch using the InstructPix2Pix methodology
```bash
export MODEL_ID="runwayml/stable-diffusion-v1-5"
export DATASET_ID="instruction-tuning-sd/low-level-image-proc"
export OUTPUT_DIR="low-level-img-proc-scratch"
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_ID \
--dataset_name=$DATASET_ID \
--original_image_column="input_image" \
--edit_prompt_column="instruction" \
--edited_image_column="ground_truth_image" \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=2 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--mixed_precision=fp16 \
--val_image_url="https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/derain_the_image_1.png" \
--validation_prompt="Derain the image" \
--seed=42 \
--output_dir=$OUTPUT_DIR \
--report_to=wandb \
--push_to_hub
```
#### Fine-tuning from InstructPix2Pix
```bash
export MODEL_ID="timbrooks/instruct-pix2pix"
export DATASET_ID="instruction-tuning-sd/low-level-image-proc"
export OUTPUT_DIR="low-level-img-proc-finetuned"
accelerate launch --mixed_precision="fp16" finetune_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_ID \
--dataset_name=$DATASET_ID \
--original_image_column="input_image" \
--edit_prompt_column="instruction" \
--edited_image_column="ground_truth_image" \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=2 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--mixed_precision=fp16 \
--val_image_url="https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/derain_the_image_1.png" \
--validation_prompt="Derain the image" \
--seed=42 \
--output_dir=$OUTPUT_DIR \
--report_to=wandb \
--push_to_hub
```
## Models, datasets, demo
### **Models**:
* [instruction-tuning-sd/scratch-low-level-img-proc](https://huggingface.co/instruction-tuning-sd/scratch-low-level-img-proc)
* [instruction-tuning-sd/scratch-cartoonizer](https://huggingface.co/instruction-tuning-sd/scratch-cartoonizer)
* [instruction-tuning-sd/cartoonizer](https://huggingface.co/instruction-tuning-sd/cartoonizer)
* [instruction-tuning-sd/low-level-img-proc](https://huggingface.co/instruction-tuning-sd/low-level-img-proc)
### **Datasets**:
* [Instruction-prompted cartoonization](https://huggingface.co/datasets/instruction-tuning-sd/cartoonization)
* [Instruction-prompted low-level image processing](https://huggingface.co/datasets/instruction-tuning-sd/low-level-image-proc)
### Demo on 🤗 Spaces
Try out the models interactively WITHOUT any setup: [Demo](https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd)
## Inference
### Cartoonization
```python
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from diffusers.utils import load_image
model_id = "instruction-tuning-sd/cartoonizer"
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
image_path = "https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
image = load_image(image_path)
image = pipeline("Cartoonize the following image", image=image).images[0]
image.save("image.png")
```
### Low-level image processing
```python
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from diffusers.utils import load_image
model_id = "instruction-tuning-sd/low-level-img-proc"
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
image_path = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/derain%20the%20image_1.png"
image = load_image(image_path)
image = pipeline("derain the image", image=image).images[0]
image.save("image.png")
```
> 💡 **Note**: Since the above pipelines are essentially of type `StableDiffusionInstructPix2PixPipeline`, you can customize several arguments that
the pipeline exposes. Refer to the [official docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix) for more details.
## Results
### Cartoonization

---

### Low-level image processing

---

Refer to our [blog post](https://hf.co/blog/instruction-tuning-sd) for more discussions on results and open questions.
## Acknowledgements
Thanks to [Alara Dirik](https://www.linkedin.com/in/alaradirik/) and [Zhengzhong Tu](https://www.linkedin.com/in/zhengzhongtu) for the helpful discussions.
## Citation
```bibtex
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}
```
================================================
FILE: data_preparation/README.md
================================================
This directory provides utilities to create a Cartoonizer dataset for [InstructPix2Pix](https://arxiv.org/abs/2211.09800) like training.
## Steps
We used 5000 randomly sampled images as the original images from the `train` set of [ImageNette](https://www.tensorflow.org/datasets/catalog/imagenette). To derive their
cartoonized renditions, we used the [Whitebox Cartoonizer model](https://huggingface.co/sayakpaul/whitebox-cartoonizer). For deriving the `instructions.txt` file, we used [ChatGPT](https://chat.openai.com/). In particular, we used the following prompt:
> Provide al teast 50 synonymous sentences for the following instruction: "Cartoonize the following image."
Dataset preparation is divided into three steps:
### Step 0: Install dependencies
```bash
pip install -q requirements.txt
```
### Step 1: Obtain the image-cartoon pairs
```bash
python generate_dataset.py
```
If you want to use more than 5000 samples, specify the `--max_num_samples` option. One the image-cartoon pairs are generated, you should see a directory called `cartoonizer-dataset` directory (unless you specified a different one via `--data_root`):

### Step 2: Export the dataset to 🤗 Hub
For this step, you need to be authorized to access your Hugging Face account. Run the following command to do so:
```bash
huggingface-cli login
```
Then run:
```python
python export_to_hub.py
```
> [!WARNING]
> Please ensure that an empty [`DS_NAME` dataset](https://github.com/huggingface/instruction-tuned-sd/blob/0193a90d6932a2eac7a231ef5760fb427e44274d/data_preparation/export_to_hub.py#L26) was created on the Hub first. Instructions on how to do that are [here](https://huggingface.co/docs/datasets/upload_dataset#upload-with-the-hub-ui).
You can find a mini dataset [here](https://huggingface.co/datasets/instruction-tuning-vision/cartoonizer-dataset):

================================================
FILE: data_preparation/__init__.py
================================================
================================================
FILE: data_preparation/export_to_hub.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
from typing import List
import numpy as np
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value
DS_NAME = "cartoonizer-dataset"
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--data_root", type=str, default="cartoonizer-dataset")
parser.add_argument("--instructions_path", type=str, default="instructions.txt")
args = parser.parse_args()
return args
def load_instructions(instructions_path: str) -> List[str]:
with open(instructions_path, "r") as f:
instructions = f.readlines()
instructions = [i.strip() for i in instructions]
return instructions
def generate_examples(data_paths: List[str], instructions: List[str]):
def fn():
for data_path in data_paths:
yield {
"original_image": {"path": data_path[0]},
"edit_prompt": np.random.choice(instructions),
"cartoonized_image": {"path": data_path[1]},
}
return fn
def main(args):
instructions = load_instructions(args.instructions_path)
data_paths = os.listdir(args.data_root)
data_paths = [os.path.join(args.data_root, d) for d in data_paths]
new_data_paths = []
for data_path in data_paths:
original_image = os.path.join(data_path, "original_image.png")
cartoonized_image = os.path.join(data_path, "cartoonized_image.png")
new_data_paths.append((original_image, cartoonized_image))
generation_fn = generate_examples(new_data_paths, instructions)
print("Creating dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
original_image=ImageFeature(),
edit_prompt=Value("string"),
cartoonized_image=ImageFeature(),
),
)
print("Pushing to the Hub...")
ds.push_to_hub(DS_NAME)
if __name__ == "__main__":
args = parse_args()
main(args)
================================================
FILE: data_preparation/generate_dataset.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import hashlib
import os
import model_utils
import tensorflow as tf
import tensorflow_datasets as tfds
from PIL import Image
from tqdm import tqdm
def parse_args():
parser = argparse.ArgumentParser(
description="Prepare a dataset for InstructPix2Pix style training."
)
parser.add_argument(
"--model_id", type=str, default="sayakpaul/whitebox-cartoonizer"
)
parser.add_argument("--dataset_id", type=str, default="imagenette")
parser.add_argument("--max_num_samples", type=int, default=5000)
parser.add_argument("--data_root", type=str, default="cartoonizer-dataset")
args = parser.parse_args()
return args
def load_dataset(dataset_id: str, max_num_samples: int) -> tf.data.Dataset:
dataset = tfds.load(dataset_id, split="train")
dataset = dataset.shuffle(max_num_samples if max_num_samples is not None else 128)
if max_num_samples is not None:
print(f"Dataset will be restricted to {max_num_samples} samples.")
dataset = dataset.take(max_num_samples)
return dataset
def main(args):
print("Loading initial dataset and the Cartoonizer model...")
dataset = load_dataset(args.dataset_id, args.max_num_samples)
concrete_fn = model_utils.load_model(args.model_id)
inference_fn = model_utils.perform_inference(concrete_fn)
print("Preparing the image pairs...")
os.makedirs(args.data_root, exist_ok=True)
for sample in tqdm(dataset.as_numpy_iterator()):
original_image = sample["image"]
cartoonized_image = inference_fn(original_image)
hash_image = hashlib.sha1(original_image.tobytes()).hexdigest()
sample_dir = os.path.join(args.data_root, hash_image)
os.makedirs(sample_dir)
original_image = Image.fromarray(original_image).convert("RGB")
original_image.save(os.path.join(sample_dir, "original_image.png"))
cartoonized_image.save(os.path.join(sample_dir, "cartoonized_image.png"))
print(f"Total generated image-pairs: {len(os.listdir(args.data_root))}.")
if __name__ == "__main__":
args = parse_args()
main(args)
================================================
FILE: data_preparation/image_utils.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import cv2
import numpy as np
import requests
import tensorflow as tf
from PIL import Image
# Taken from
# https://github.com/SystemErrorWang/White-box-Cartoonization/blob/master/test_code/cartoonize.py#L11
def resize_crop(image: np.ndarray) -> np.ndarray:
h, w, c = np.shape(image)
if min(h, w) > 720:
if h > w:
h, w = int(720 * h / w), 720
else:
h, w = 720, int(720 * w / h)
image = cv2.resize(image, (w, h), interpolation=cv2.INTER_AREA)
h, w = (h // 8) * 8, (w // 8) * 8
image = image[:h, :w, :]
return image
def download_image(url: str) -> np.ndarray:
image = Image.open(requests.get(url, stream=True).raw)
image = image.convert("RGB")
image = np.array(image)
return image
def preprocess_image(image: np.ndarray) -> tf.Tensor:
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
image = resize_crop(image)
image = image.astype(np.float32) / 127.5 - 1
image = np.expand_dims(image, axis=0)
image = tf.constant(image)
return image
def postprocess_image(image: tf.Tensor) -> Image.Image:
output = (image[0].numpy() + 1.0) * 127.5
output = np.clip(output, 0, 255).astype(np.uint8)
output = cv2.cvtColor(output, cv2.COLOR_BGR2RGB)
output_image = Image.fromarray(output)
return output_image
================================================
FILE: data_preparation/instructions.txt
================================================
Transform the natural image into a cartoon.
Create a cartoon-style image from the natural image.
Apply a cartoon filter to the natural image.
Turn the natural image into a cartoon-style drawing.
Give the natural image a cartoon effect.
Convert the natural image to a cartoon-like illustration.
Make the natural image look like a cartoon.
Render the natural image in a cartoon style.
Generate a cartoonized version of the natural image.
Apply a cartoon-like effect to the natural image.
Produce a cartoon version of the natural image.
Turn the natural image into a cartoon-style picture.
Use a cartoon filter to create a cartoon-like effect on the natural image.
Transform the natural image into a cartoonish version.
Apply a cartoon effect to the natural image to create a cartoonized version.
Give the natural image a cartoonish look.
Use a cartoon conversion software to turn the natural image into a cartoon.
Use a cartoon-making app to cartoonize the natural image.
Use a digital drawing software to create a cartoon version of the natural image.
Edit the natural image to make it look like a cartoon.
Apply a cartooning effect to the natural image.
Create a cartoon-style illustration from the natural image.
Turn the natural image into a cartoonish drawing.
Use a cartoon filter to give the natural image a cartoon-like appearance.
Use a software to convert the natural image to a cartoon.
Change the natural image to a cartoon-style image.
Use a graphic design software to create a cartoonized version of the natural image.
Use a cartoonizing tool to transform the natural image into a cartoon.
Alter the natural image to give it a cartoonish effect.
Give the natural image a comic book-style look.
Cartoonify the natural image.
Use an image editing tool to turn the natural image into a cartoon.
Use a digital art program to create a cartoonized version of the natural image.
Create a cartoon-style graphic from the natural image.
Give the natural image a hand-drawn, cartoon-like appearance.
Transform the natural image into a sketch-like cartoon.
Change the natural image to a hand-drawn cartoon.
Edit the natural image to give it a toon-like effect.
Use an art software to create a cartoonized version of the natural image.
Apply a cartoon-like filter to the natural image to give it a toon-like appearance.
Apply a filter to the natural image to create a comic book-style effect.
Use a cartoonization program to create a cartoon version of the natural image.
Give the natural image a graphic novel-style look.
Transform the natural image into a caricature.
Use a photo editing software to create a cartoonized version of the natural image.
Turn the natural image into a cartoon character.
Use a cartoon effect to create a cartoon-style illustration of the natural image.
Give the natural image a hand-drawn, animated look.
Use a tool to create a cartoonized version of the natural image.
Change the natural image to a cartoon-like graphic.
================================================
FILE: data_preparation/model_utils.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.dirname(SCRIPT_DIR))
from typing import Callable
import numpy as np
import tensorflow as tf
from huggingface_hub import snapshot_download
from PIL import Image
import image_utils
def load_model(model_id="sayakpaul/whitebox-cartoonizer"):
model_path = snapshot_download(model_id)
loaded_model = tf.saved_model.load(model_path)
concrete_func = loaded_model.signatures["serving_default"]
return concrete_func
def perform_inference(concrete_fn: Callable) -> Callable:
def fn(image: np.ndarray) -> Image.Image:
preprocessed_image = image_utils.preprocess_image(image)
result = concrete_fn(preprocessed_image)["final_output:0"]
output_image = image_utils.postprocess_image(result)
return output_image
return fn
================================================
FILE: data_preparation/requirements.txt
================================================
tensorflow
tensorflow_datasets==4.6.0
datasets
huggingface_hub
numpy
Pillow
opencv-python
protobuf==3.20.*
================================================
FILE: finetune_instruct_pix2pix.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Script to fine-tune InstructPix2Pix."""
import argparse
import logging
import math
import os
from pathlib import Path
from typing import Optional
import accelerate
import datasets
import diffusers
import numpy as np
import PIL
import requests
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from diffusers import (AutoencoderKL, DDPMScheduler,
StableDiffusionInstructPix2PixPipeline,
UNet2DConditionModel)
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel
from diffusers.utils import check_min_version, deprecate, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
from huggingface_hub import HfFolder, Repository, create_repo, whoami
from packaging import version
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.15.0.dev0")
logger = get_logger(__name__, log_level="INFO")
DATASET_NAME_MAPPING = {
"sayakpaul/cartoonizer-dataset": (
"original_image",
"edit_prompt",
"cartoonized_image",
),
}
WANDB_TABLE_COL_NAMES = ["original_image", "edited_image", "edit_prompt"]
def parse_args():
parser = argparse.ArgumentParser(
description="Simple example of a training script for InstructPix2Pix."
)
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--original_image_column",
type=str,
default="original_image",
help="The column of the dataset containing the original image on which edits where made.",
)
parser.add_argument(
"--edited_image_column",
type=str,
default="cartoonized_image",
help="The column of the dataset containing the edited image.",
)
parser.add_argument(
"--edit_prompt_column",
type=str,
default="edit_prompt",
help="The column of the dataset containing the edit instruction.",
)
parser.add_argument(
"--val_image_url",
type=str,
default=None,
help="URL to the original image that you would like to edit (used during inference for debugging purposes).",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
help="A prompt that is sampled during training for inference.",
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=1,
help=(
"Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="instruct-pix2pix-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument(
"--seed", type=int, default=None, help="A seed for reproducible training."
)
parser.add_argument(
"--resolution",
type=int,
default=256,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size",
type=int,
default=16,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps",
type=int,
default=500,
help="Number of steps for the warmup in the lr scheduler.",
)
parser.add_argument(
"--conditioning_dropout_prob",
type=float,
default=None,
help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam",
action="store_true",
help="Whether or not to use 8-bit Adam from bitsandbytes.",
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--use_ema", action="store_true", help="Whether to use EMA model."
)
parser.add_argument(
"--non_ema_revision",
type=str,
default=None,
required=False,
help=(
"Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
" remote repository specified with --pretrained_model_name_or_path."
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument(
"--adam_beta1",
type=float,
default=0.9,
help="The beta1 parameter for the Adam optimizer.",
)
parser.add_argument(
"--adam_beta2",
type=float,
default=0.999,
help="The beta2 parameter for the Adam optimizer.",
)
parser.add_argument(
"--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use."
)
parser.add_argument(
"--adam_epsilon",
type=float,
default=1e-08,
help="Epsilon value for the Adam optimizer",
)
parser.add_argument(
"--max_grad_norm", default=1.0, type=float, help="Max gradient norm."
)
parser.add_argument(
"--push_to_hub",
action="store_true",
help="Whether or not to push the model to the Hub.",
)
parser.add_argument(
"--hub_token",
type=str,
default=None,
help="The token to use to push to the Model Hub.",
)
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--local_rank",
type=int,
default=-1,
help="For distributed training: local_rank",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=(
"Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
" See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
" for more docs"
),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention",
action="store_true",
help="Whether or not to use xformers.",
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
# default to using the same revision for the non-ema model if not specified
if args.non_ema_revision is None:
args.non_ema_revision = args.revision
return args
def get_full_repo_name(
model_id: str, organization: Optional[str] = None, token: Optional[str] = None
):
if token is None:
token = HfFolder.get_token()
if organization is None:
username = whoami(token)["name"]
return f"{username}/{model_id}"
else:
return f"{organization}/{model_id}"
def convert_to_np(image, resolution):
image = image.convert("RGB").resize((resolution, resolution))
return np.array(image).transpose(2, 0, 1)
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
def main():
args = parse_args()
if args.non_ema_revision is not None:
deprecate(
"non_ema_revision!=None",
"0.15.0",
message=(
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
" use `--variant=non_ema` instead."
),
)
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(
total_limit=args.checkpoints_total_limit, logging_dir=logging_dir
)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError(
"Make sure to install wandb if you want to use it for logging during training."
)
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
if args.hub_model_id is None:
repo_name = get_full_repo_name(
Path(args.output_dir).name, token=args.hub_token
)
else:
repo_name = args.hub_model_id
create_repo(repo_name, exist_ok=True, token=args.hub_token)
repo = Repository(
args.output_dir, clone_from=repo_name, token=args.hub_token
)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "checkpoint-*" not in gitignore:
gitignore.write("checkpoint-*\n")
if "checkpoint-*" not in gitignore:
gitignore.write("checkpoint-*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler"
)
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
)
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
revision=args.revision,
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="unet",
revision=args.non_ema_revision,
)
# Freeze vae and text_encoder
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
# Create EMA for the unet.
if args.use_ema:
ema_unet = EMAModel(
unet.parameters(), model_cls=UNet2DConditionModel, model_config=unet.config
)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError(
"xformers is not available. Make sure it is installed correctly"
)
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if args.use_ema:
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(
os.path.join(input_dir, "unet_ema"), UNet2DConditionModel
)
ema_unet.load_state_dict(load_model.state_dict())
ema_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(
input_dir, subfolder="unet"
)
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate
* args.gradient_accumulation_steps
* args.train_batch_size
* accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
use_auth_token=True,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/main/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.original_image_column is None:
original_image_column = (
dataset_columns[0] if dataset_columns is not None else column_names[0]
)
else:
original_image_column = args.original_image_column
if original_image_column not in column_names:
raise ValueError(
f"--original_image_column' value '{args.original_image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edit_prompt_column is None:
edit_prompt_column = (
dataset_columns[1] if dataset_columns is not None else column_names[1]
)
else:
edit_prompt_column = args.edit_prompt_column
if edit_prompt_column not in column_names:
raise ValueError(
f"--edit_prompt_column' value '{args.edit_prompt_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edited_image_column is None:
edited_image_column = (
dataset_columns[2] if dataset_columns is not None else column_names[2]
)
else:
edited_image_column = args.edited_image_column
if edited_image_column not in column_names:
raise ValueError(
f"--edited_image_column' value '{args.edited_image_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(captions):
inputs = tokenizer(
captions,
max_length=tokenizer.model_max_length,
padding="max_length",
truncation=True,
return_tensors="pt",
)
return inputs.input_ids
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.CenterCrop(args.resolution)
if args.center_crop
else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip()
if args.random_flip
else transforms.Lambda(lambda x: x),
]
)
def preprocess_images(examples):
original_images = np.concatenate(
[
convert_to_np(image, args.resolution)
for image in examples[original_image_column]
]
)
edited_images = np.concatenate(
[
convert_to_np(image, args.resolution)
for image in examples[edited_image_column]
]
)
# We need to ensure that the original and the edited images undergo the same
# augmentation transforms.
images = np.concatenate([original_images, edited_images])
images = torch.tensor(images)
images = 2 * (images / 255) - 1
return train_transforms(images)
def preprocess_train(examples):
# Preprocess images.
preprocessed_images = preprocess_images(examples)
# Since the original and edited images were concatenated before
# applying the transformations, we need to separate them and reshape
# them accordingly.
original_images, edited_images = preprocessed_images.chunk(2)
original_images = original_images.reshape(
-1, 3, args.resolution, args.resolution
)
edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
# Collate the preprocessed images into the `examples`.
examples["original_pixel_values"] = original_images
examples["edited_pixel_values"] = edited_images
# Preprocess the captions.
captions = [caption for caption in examples[edit_prompt_column]]
examples["input_ids"] = tokenize_captions(captions)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = (
dataset["train"]
.shuffle(seed=args.seed)
.select(range(args.max_train_samples))
)
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
original_pixel_values = torch.stack(
[example["original_pixel_values"] for example in examples]
)
original_pixel_values = original_pixel_values.to(
memory_format=torch.contiguous_format
).float()
edited_pixel_values = torch.stack(
[example["edited_pixel_values"] for example in examples]
)
edited_pixel_values = edited_pixel_values.to(
memory_format=torch.contiguous_format
).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {
"original_pixel_values": original_pixel_values,
"edited_pixel_values": edited_pixel_values,
"input_ids": input_ids,
}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(
len(train_dataloader) / args.gradient_accumulation_steps
)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
if args.use_ema:
ema_unet.to(accelerator.device)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move text_encode and vae to gpu and cast to weight_dtype
text_encoder.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(
len(train_dataloader) / args.gradient_accumulation_steps
)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("instruct-pix2pix-cartoonizer", config=vars(args))
# Train!
total_batch_size = (
args.train_batch_size
* accelerator.num_processes
* args.gradient_accumulation_steps
)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(
f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}"
)
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
resume_global_step = global_step * args.gradient_accumulation_steps
first_epoch = global_step // num_update_steps_per_epoch
resume_step = resume_global_step % (
num_update_steps_per_epoch * args.gradient_accumulation_steps
)
# Only show the progress bar once on each machine.
progress_bar = tqdm(
range(global_step, args.max_train_steps),
disable=not accelerator.is_local_main_process,
)
progress_bar.set_description("Steps")
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
# Skip steps until we reach the resumed step
if (
args.resume_from_checkpoint
and epoch == first_epoch
and step < resume_step
):
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
continue
with accelerator.accumulate(unet):
# We want to learn the denoising process w.r.t the edited images which
# are conditioned on the original image (which was edited) and the edit instruction.
# So, first, convert images to latent space.
latents = vae.encode(
batch["edited_pixel_values"].to(weight_dtype)
).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0,
noise_scheduler.num_train_timesteps,
(bsz,),
device=latents.device,
)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning.
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Get the additional image embedding for conditioning.
# Instead of getting a diagonal Gaussian here, we simply take the mode.
original_image_embeds = vae.encode(
batch["original_pixel_values"].to(weight_dtype)
).latent_dist.mode()
# Conditioning dropout to support classifier-free guidance during inference. For more details
# check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(
bsz, device=latents.device, generator=generator
)
# Sample masks for the edit prompts.
prompt_mask = random_p < 2 * args.conditioning_dropout_prob
prompt_mask = prompt_mask.reshape(bsz, 1, 1)
# Final text conditioning.
null_conditioning = text_encoder(
tokenize_captions([""]).to(accelerator.device)
)[0]
encoder_hidden_states = torch.where(
prompt_mask, null_conditioning, encoder_hidden_states
)
# Sample masks for the original images.
image_mask_dtype = original_image_embeds.dtype
image_mask = 1 - (
(random_p >= args.conditioning_dropout_prob).to(
image_mask_dtype
)
* (random_p < 3 * args.conditioning_dropout_prob).to(
image_mask_dtype
)
)
image_mask = image_mask.reshape(bsz, 1, 1, 1)
# Final image conditioning.
original_image_embeds = image_mask * original_image_embeds
# Concatenate the `original_image_embeds` with the `noisy_latents`.
concatenated_noisy_latents = torch.cat(
[noisy_latents, original_image_embeds], dim=1
)
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(
f"Unknown prediction type {noise_scheduler.config.prediction_type}"
)
# Predict the noise residual and compute loss
model_pred = unet(
concatenated_noisy_latents, timesteps, encoder_hidden_states
).sample
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_unet.step(unet.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
save_path = os.path.join(
args.output_dir, f"checkpoint-{global_step}"
)
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {
"step_loss": loss.detach().item(),
"lr": lr_scheduler.get_last_lr()[0],
}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if (
(args.val_image_url is not None)
and (args.validation_prompt is not None)
and (epoch % args.validation_epochs == 0)
):
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
if args.use_ema:
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
ema_unet.store(unet.parameters())
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=unet,
revision=args.revision,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
original_image = download_image(args.val_image_url)
edited_images = []
with torch.autocast(
str(accelerator.device),
enabled=accelerator.mixed_precision == "fp16",
):
for _ in range(args.num_validation_images):
edited_images.append(
pipeline(
args.validation_prompt,
image=original_image,
num_inference_steps=20,
image_guidance_scale=1.5,
guidance_scale=7,
generator=generator,
).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "wandb":
wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
for edited_image in edited_images:
wandb_table.add_data(
wandb.Image(original_image),
wandb.Image(edited_image),
args.validation_prompt,
)
tracker.log({"validation": wandb_table})
if args.use_ema:
# Switch back to the original UNet parameters.
ema_unet.restore(unet.parameters())
del pipeline
torch.cuda.empty_cache()
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
if args.use_ema:
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=text_encoder,
vae=vae,
unet=unet,
revision=args.revision,
)
pipeline.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(
commit_message="End of training", blocking=False, auto_lfs_prune=True
)
accelerator.end_training()
if __name__ == "__main__":
main()
================================================
FILE: requirements.txt
================================================
torchvision
accelerate
diffusers
transformers
numpy
datasets
wandb
black~=23.1
isort>=5.5.4
ruff>=0.0.241,<=0.0.259
================================================
FILE: train_instruct_pix2pix.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Script to fine-tune Stable Diffusion for InstructPix2Pix."""
import argparse
import logging
import math
import os
from pathlib import Path
from typing import Optional
import accelerate
import datasets
import numpy as np
import PIL
import requests
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import HfFolder, Repository, create_repo, whoami
from packaging import version
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
import diffusers
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionInstructPix2PixPipeline, UNet2DConditionModel
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel
from diffusers.utils import check_min_version, deprecate, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.15.0.dev0")
logger = get_logger(__name__, log_level="INFO")
DATASET_NAME_MAPPING = {
"fusing/instructpix2pix-1000-samples": ("input_image", "edit_prompt", "edited_image"),
}
WANDB_TABLE_COL_NAMES = ["original_image", "edited_image", "edit_prompt"]
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script for InstructPix2Pix.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--original_image_column",
type=str,
default="input_image",
help="The column of the dataset containing the original image on which edits where made.",
)
parser.add_argument(
"--edited_image_column",
type=str,
default="edited_image",
help="The column of the dataset containing the edited image.",
)
parser.add_argument(
"--edit_prompt_column",
type=str,
default="edit_prompt",
help="The column of the dataset containing the edit instruction.",
)
parser.add_argument(
"--val_image_url",
type=str,
default=None,
help="URL to the original image that you would like to edit (used during inference for debugging purposes).",
)
parser.add_argument(
"--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=1,
help=(
"Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="instruct-pix2pix-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=256,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--conditioning_dropout_prob",
type=float,
default=None,
help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
"--non_ema_revision",
type=str,
default=None,
required=False,
help=(
"Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
" remote repository specified with --pretrained_model_name_or_path."
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=(
"Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
" See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
" for more docs"
),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
# default to using the same revision for the non-ema model if not specified
if args.non_ema_revision is None:
args.non_ema_revision = args.revision
return args
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
if token is None:
token = HfFolder.get_token()
if organization is None:
username = whoami(token)["name"]
return f"{username}/{model_id}"
else:
return f"{organization}/{model_id}"
def convert_to_np(image, resolution):
image = image.convert("RGB").resize((resolution, resolution))
return np.array(image).transpose(2, 0, 1)
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
def main():
args = parse_args()
if args.non_ema_revision is not None:
deprecate(
"non_ema_revision!=None",
"0.15.0",
message=(
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
" use `--variant=non_ema` instead."
),
)
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(
total_limit=args.checkpoints_total_limit, logging_dir=logging_dir
)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
if args.hub_model_id is None:
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
else:
repo_name = args.hub_model_id
create_repo(repo_name, exist_ok=True, token=args.hub_token)
repo = Repository(args.output_dir, clone_from=repo_name, token=args.hub_token)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
)
# InstructPix2Pix uses an additional image for conditioning. To accommodate that,
# it uses 8 channels (instead of 4) in the first (conv) layer of the UNet. This UNet is
# then fine-tuned on the custom InstructPix2Pix dataset. This modified UNet is initialized
# from the pre-trained checkpoints. For the extra channels added to the first layer, they are
# initialized to zero.
if accelerator.is_main_process:
logger.info("Initializing the InstructPix2Pix UNet from the pretrained UNet.")
in_channels = 8
out_channels = unet.conv_in.out_channels
unet.register_to_config(in_channels=in_channels)
with torch.no_grad():
new_conv_in = nn.Conv2d(
in_channels, out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding
)
new_conv_in.weight.zero_()
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
unet.conv_in = new_conv_in
# Freeze vae and text_encoder
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
# Create EMA for the unet.
if args.use_ema:
ema_unet = EMAModel(unet.parameters(), model_cls=UNet2DConditionModel, model_config=unet.config)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if args.use_ema:
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
ema_unet.load_state_dict(load_model.state_dict())
ema_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/main/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.original_image_column is None:
original_image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
original_image_column = args.original_image_column
if original_image_column not in column_names:
raise ValueError(
f"--original_image_column' value '{args.original_image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edit_prompt_column is None:
edit_prompt_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
edit_prompt_column = args.edit_prompt_column
if edit_prompt_column not in column_names:
raise ValueError(
f"--edit_prompt_column' value '{args.edit_prompt_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edited_image_column is None:
edited_image_column = dataset_columns[2] if dataset_columns is not None else column_names[2]
else:
edited_image_column = args.edited_image_column
if edited_image_column not in column_names:
raise ValueError(
f"--edited_image_column' value '{args.edited_image_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(captions):
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
]
)
def preprocess_images(examples):
original_images = np.concatenate(
[convert_to_np(image, args.resolution) for image in examples[original_image_column]]
)
edited_images = np.concatenate(
[convert_to_np(image, args.resolution) for image in examples[edited_image_column]]
)
# We need to ensure that the original and the edited images undergo the same
# augmentation transforms.
images = np.concatenate([original_images, edited_images])
images = torch.tensor(images)
images = 2 * (images / 255) - 1
return train_transforms(images)
def preprocess_train(examples):
# Preprocess images.
preprocessed_images = preprocess_images(examples)
# Since the original and edited images were concatenated before
# applying the transformations, we need to separate them and reshape
# them accordingly.
original_images, edited_images = preprocessed_images.chunk(2)
original_images = original_images.reshape(-1, 3, args.resolution, args.resolution)
edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
# Collate the preprocessed images into the `examples`.
examples["original_pixel_values"] = original_images
examples["edited_pixel_values"] = edited_images
# Preprocess the captions.
captions = [caption for caption in examples[edit_prompt_column]]
examples["input_ids"] = tokenize_captions(captions)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
original_pixel_values = torch.stack([example["original_pixel_values"] for example in examples])
original_pixel_values = original_pixel_values.to(memory_format=torch.contiguous_format).float()
edited_pixel_values = torch.stack([example["edited_pixel_values"] for example in examples])
edited_pixel_values = edited_pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {
"original_pixel_values": original_pixel_values,
"edited_pixel_values": edited_pixel_values,
"input_ids": input_ids,
}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
if args.use_ema:
ema_unet.to(accelerator.device)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move text_encode and vae to gpu and cast to weight_dtype
text_encoder.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("instruct-pix2pix", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
resume_global_step = global_step * args.gradient_accumulation_steps
first_epoch = global_step // num_update_steps_per_epoch
resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
progress_bar.set_description("Steps")
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
# Skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
continue
with accelerator.accumulate(unet):
# We want to learn the denoising process w.r.t the edited images which
# are conditioned on the original image (which was edited) and the edit instruction.
# So, first, convert images to latent space.
latents = vae.encode(batch["edited_pixel_values"].to(weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning.
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Get the additional image embedding for conditioning.
# Instead of getting a diagonal Gaussian here, we simply take the mode.
original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
# Conditioning dropout to support classifier-free guidance during inference. For more details
# check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
# Sample masks for the edit prompts.
prompt_mask = random_p < 2 * args.conditioning_dropout_prob
prompt_mask = prompt_mask.reshape(bsz, 1, 1)
# Final text conditioning.
null_conditioning = text_encoder(tokenize_captions([""]).to(accelerator.device))[0]
encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
# Sample masks for the original images.
image_mask_dtype = original_image_embeds.dtype
image_mask = 1 - (
(random_p >= args.conditioning_dropout_prob).to(image_mask_dtype)
* (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
)
image_mask = image_mask.reshape(bsz, 1, 1, 1)
# Final image conditioning.
original_image_embeds = image_mask * original_image_embeds
# Concatenate the `original_image_embeds` with the `noisy_latents`.
concatenated_noisy_latents = torch.cat([noisy_latents, original_image_embeds], dim=1)
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
# Predict the noise residual and compute loss
model_pred = unet(concatenated_noisy_latents, timesteps, encoder_hidden_states).sample
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_unet.step(unet.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if (
(args.val_image_url is not None)
and (args.validation_prompt is not None)
and (epoch % args.validation_epochs == 0)
):
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
if args.use_ema:
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
ema_unet.store(unet.parameters())
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=unet,
revision=args.revision,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
original_image = download_image(args.val_image_url)
edited_images = []
with torch.autocast(str(accelerator.device), enabled=accelerator.mixed_precision == "fp16"):
for _ in range(args.num_validation_images):
edited_images.append(
pipeline(
args.validation_prompt,
image=original_image,
num_inference_steps=20,
image_guidance_scale=1.5,
guidance_scale=7,
generator=generator,
).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "wandb":
wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
for edited_image in edited_images:
wandb_table.add_data(
wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
)
tracker.log({"validation": wandb_table})
if args.use_ema:
# Switch back to the original UNet parameters.
ema_unet.restore(unet.parameters())
del pipeline
torch.cuda.empty_cache()
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
if args.use_ema:
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=accelerator.unwrap_model(text_encoder),
vae=accelerator.unwrap_model(vae),
unet=unet,
revision=args.revision,
)
pipeline.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message="End of training", blocking=False, auto_lfs_prune=True)
accelerator.end_training()
if __name__ == "__main__":
main()
================================================
FILE: validation/README.md
================================================
This directory provides utilities to visually compare the results of different models:
* [sayakpaul/whitebox-cartoonizer](https://hf.co/sayakpaul/whitebox-cartoonizer) (TensorFlow)
* [instruction-tuning-vision/instruction-tuned-cartoonizer](https://hf.co/sayakpaul/instruction-tuning-vision/instruction-tuned-cartoonizer) (Diffusers)
* [timbrooks/instruct-pix2pix](https://hf.co/sayakpaul/timbrooks/instruct-pix2pix) (Diffusers)
We use the `validation` split of ImageNette for the validation purpose. Launch the following script to cartoonize 10 different samples with a specific model:
```bash
python compare_models.py --model_id sayakpaul/whitebox-cartoonizer --max_num_samples 10
```
For the Diffusers' compatible models, you can additionally specify the following options:
* prompt
* num_inference_steps
* image_guidance_scale
* guidance_scale
After the samples have been generated, they should be serialized in the following structure:
```bash
├── comparison-sayakpaul
│ └── whitebox-cartoonizer
│ ├── 0 -- class label
│ │ └── 55f8f5846192691faa2f603b0c92f27fd8599fc7 -- original image hash
│ │ └── tf_image.png -- cartoonized image
│ ├── 1
│ │ ├── b8bfb2ec1a9af348ade8f467ac99e0af0fa0e937
│ │ │ └── tf_image.png
│ │ └── d23da1e9d9c39b17dacb66ddb52f290049a774a5
│ │ └── tf_image.png
│ ├── 2
│ │ └── 7e25076bd693e10ad04e3c41aa29a3258e3d0ecd
│ │ └── tf_image.png
│ ├── 3
│ │ ├── 1c43c5c5f7350b59d0c0607fd9357ed9e1b55e46
│ │ │ └── tf_image.png
│ │ └── cd4ca63c3d7913b1473937618c157c1919465930
│ │ └── tf_image.png
│ ├── 6
│ │ ├── 220b6c136d47e81b186d337e0bdd064c67532e4e
│ │ │ └── tf_image.png
│ │ └── f80589219ae2b913677ea9417962d4ab75f08c2f
│ │ └── tf_image.png
│ └── 7
│ ├── 4f33183189589bb171ba9489b898e5edbac25dfe
│ │ └── tf_image.png
│ └── 519863ade478d26b467e08dc5fb4353a6316833c
│ └── tf_image.png
```
For you use a Diffusers' compatible model then it would look like so:
```bash
├── comparison-instruction-tuning-vision
│ └── instruction-tuned-cartoonizer
│ ├── 0
│ │ └── 55f8f5846192691faa2f603b0c92f27fd8599fc7
│ │ └── steps@20-igs@1.5-gs@7.0.png
│ ├── 1
│ │ ├── b8bfb2ec1a9af348ade8f467ac99e0af0fa0e937
│ │ │ └── steps@20-igs@1.5-gs@7.0.png
│ │ └── d23da1e9d9c39b17dacb66ddb52f290049a774a5
│ │ └── steps@20-igs@1.5-gs@7.0.png
│ ├── 2
│ │ └── 7e25076bd693e10ad04e3c41aa29a3258e3d0ecd
│ │ └── steps@20-igs@1.5-gs@7.0.png
│ ├── 3
│ │ ├── 1c43c5c5f7350b59d0c0607fd9357ed9e1b55e46
│ │ │ └── steps@20-igs@1.5-gs@7.0.png
│ │ └── cd4ca63c3d7913b1473937618c157c1919465930
│ │ └── steps@20-igs@1.5-gs@7.0.png
│ ├── 6
│ │ ├── 220b6c136d47e81b186d337e0bdd064c67532e4e
│ │ │ └── steps@20-igs@1.5-gs@7.0.png
│ │ └── f80589219ae2b913677ea9417962d4ab75f08c2f
│ │ └── steps@20-igs@1.5-gs@7.0.png
│ └── 7
│ ├── 4f33183189589bb171ba9489b898e5edbac25dfe
│ │ └── steps@20-igs@1.5-gs@7.0.png
│ └── 519863ade478d26b467e08dc5fb4353a6316833c
│ └── steps@20-igs@1.5-gs@7.0.png
```
================================================
FILE: validation/__init__.py
================================================
================================================
FILE: validation/compare_models.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.dirname(SCRIPT_DIR))
import argparse
import hashlib
import os
import data_utils
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from PIL import Image
from data_preparation import model_utils
GEN = torch.manual_seed(0)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_id",
type=str,
default="sayakpaul/whitebox-cartoonizer",
choices=[
"sayakpaul/whitebox-cartoonizer",
"instruction-tuning-vision/instruction-tuned-cartoonizer",
"timbrooks/instruct-pix2pix",
],
)
parser.add_argument("--dataset_id", type=str, default="imagenette")
parser.add_argument("--max_num_samples", type=int, default=10)
parser.add_argument(
"--prompt", type=str, default="Generate a cartoonized version of the image"
)
parser.add_argument("--num_inference_steps", type=int, default=20)
parser.add_argument("--image_guidance_scale", type=float, default=1.5)
parser.add_argument("--guidance_scale", type=float, default=7.0)
args = parser.parse_args()
return args
def load_pipeline(model_id: str):
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
pipeline.enable_xformers_memory_efficient_attention()
pipeline.set_progress_bar_config(disable=True)
return pipeline
def main(args):
data_root = os.path.join(f"comparison-{args.model_id}")
print("Loading validation dataset and inference model...")
dataset = data_utils.load_dataset(args.dataset_id, args.max_num_samples)
using_tf = False
if "sayakpaul" in args.model_id:
inference = model_utils.load_model(args.model_id)
using_tf = True
print(
"TensorFlow model detected for inference, Diffusion-specifc parameters won't be used."
)
else:
inference = load_pipeline(args.model_id)
num_samples_to_generate = (
args.max_num_samples
if args.max_num_samples is not None
else dataset.cardinality()
)
print(f"Generating {num_samples_to_generate} images...")
for sample in dataset.as_numpy_iterator():
# Result dir creation.
concept_path = os.path.join(data_root, str(sample["label"]))
hash_image = hashlib.sha1(sample["image"].tobytes()).hexdigest()
image_path = os.path.join(concept_path, hash_image)
os.makedirs(image_path, exist_ok=True)
# Perform inference and serialize the result.
if using_tf:
image = model_utils.perform_inference(inference)(sample["image"])
Image.fromarray(sample["image"]).save(os.path.join(image_path, "original.png"))
image.save(os.path.join(image_path, "tf_image.png"))
else:
image = inference(
args.prompt,
image=Image.fromarray(sample["image"]).convert("RGB"),
num_inference_steps=args.num_inference_steps,
image_guidance_scale=args.image_guidance_scale,
guidance_scale=args.guidance_scale,
generator=GEN,
).images[0]
image_prefix = f"steps@{args.num_inference_steps}-igs@{args.image_guidance_scale}-gs@{args.guidance_scale}"
Image.fromarray(sample["image"]).save(os.path.join(image_path, "original.png"))
image.save(os.path.join(image_path, f"{image_prefix}.png"))
if __name__ == "__main__":
args = parse_args()
main(args)
================================================
FILE: validation/data_utils.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import tensorflow as tf
import tensorflow_datasets as tfds
tf.keras.utils.set_random_seed(0)
def load_dataset(dataset_id: str, max_num_samples: int) -> tf.data.Dataset:
dataset = tfds.load(dataset_id, split="validation")
dataset = dataset.shuffle(max_num_samples if max_num_samples is not None else 128)
if max_num_samples is not None:
print(f"Dataset will be restricted to {max_num_samples} samples.")
dataset = dataset.take(max_num_samples)
return dataset
================================================
FILE: validation/requirements.txt
================================================
tensorflow
tensorflow_datasets==4.6.0
datasets
huggingface_hub
numpy
Pillow
opencv-python
torch==1.13.1
torchvision==0.14.1