Repository: huggingface/olm-datasets
Branch: main
Commit: 246a98a45d1f
Files: 26
Total size: 110.9 KB
Directory structure:
gitextract_wh2bu5g5/
├── .gitmodules
├── LICENSE
├── README.md
├── analysis_scripts/
│ ├── README.md
│ ├── duplicates.py
│ ├── term_counts.py
│ ├── timestamp_dist.py
│ └── url_dist.py
├── pipeline_scripts/
│ ├── common_crawl/
│ │ ├── README.md
│ │ ├── apply_bigscience_filters.py
│ │ ├── combine_last_modified_with_text_dataset.py
│ │ ├── deduplicate.py
│ │ ├── download_common_crawl.py
│ │ ├── download_pipeline_processing_models.sh
│ │ ├── experimental/
│ │ │ ├── add_perplexity.py
│ │ │ ├── filter_for_only_updated_websites.py
│ │ │ └── kenlm/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── model.py
│ │ │ └── wikipedia/
│ │ │ ├── en.sp.model
│ │ │ └── en.sp.vocab
│ │ ├── get_last_modified_dataset_from_wat_downloads.py
│ │ ├── get_text_dataset_from_wet_downloads.py
│ │ └── remove_wikipedia_urls.py
│ └── wikipedia/
│ └── README.md
└── requirements.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitmodules
================================================
[submodule "data-preparation"]
path = pipeline_scripts/common_crawl/data-preparation
url = https://github.com/bigscience-workshop/data-preparation.git
[submodule "deduplicate-text-datasets"]
path = pipeline_scripts/common_crawl/deduplicate-text-datasets
url = https://github.com/TristanThrush/deduplicate-text-datasets.git
================================================
FILE: LICENSE
================================================
Copyright 2022- The Hugging Face team. All rights reserved.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
# Online Language Modelling Dataset Pipeline
This repo enables you to pull a large and up-to-date text corpus from the web. It uses state-of-the-art processing methods to produce a clean text dataset that you can immediately use to pretrain a large language model, like BERT, GPT, or BLOOM. The main use-case for this repo is the Online Language Modelling Project, where we want to keep a language model up-to-date by pretraining it on the latest Common Crawl and Wikipedia dumps every month or so. You can see the models for the OLM project here: https://huggingface.co/olm. They actually get better performance than their original static counterparts.
Specifically, this repo has modular Python commands that enable you to:
* Specify Common Crawl web snapshots, or just Wikipedia snapshots. Then pull the data.
* Filter the data for a particular language, like English or French.
* Run the OSCAR filters used by BigScience for the BLOOM language model. These filters ensure some level of text quality and reduce pornographic content.
* Deduplicate the data.
This code is also fairly parallelized, although it can certianly be improved further. It can process over a terabyte from Common Crawl in a day or two, and all of English Wikipedia in less than an hour if you have:
* A machine with a lot of CPUs and memory.
* A fast internet connection.
## Setup
1. If you want to use this repo to generate a decent amount of data, get a machine with lots of CPUs and memory. We use an `n2d-standard-224` running `Ubuntu 20.04 LTS` on GCP. Add Terabytes of disk space too. You may need an even larger machine if you want to process close to 100% of a Common Crawl snapshot or several snapshots, particularly due to how much memory the deduplication process uses. Alternatively, you can specify in the deduplication arguments that you want to deduplicate the dataset in chunks so your memory doesn't explode.
2. Clone with submodules: `git clone --recursive git@github.com:huggingface/olm-datasets.git`
3. Install cargo (rust package manager) with `curl https://sh.rustup.rs -sSf | sh`. Then install Ungoliant with `cargo install ungoliant@1.2.3`. You may need to install gcc and cmake first.
4. Set up a Python 3.9 environment, and run `pip install -r requirements.txt`
5. Run `huggingface-cli login`. This cli should have been installed from `requirements.txt`. To login, you need to paste a token from your account at [https://huggingface.co](https://huggingface.co). This step is necessary for the pipeline to push the generated datasets to your Hugging Face account.
## Getting a clean and up-to-date Common Crawl corpus
Follow the instructions at [pipeline_scripts/common_crawl](pipeline_scripts/common_crawl).
Here is the output dataset to expect from a 20% random segment sample of the August 2022 Common Crawl Snapshot: [https://huggingface.co/datasets/Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20](https://huggingface.co/datasets/Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20)
## Getting a clean and up-to-date Wikipedia corpus
Follow the instructions at [pipeline_scripts/wikipedia](pipeline_scripts/wikipedia).
Here is the output dataset to expect from a September 2022 snapshot of Wikipedia: [https://huggingface.co/datasets/Tristan/olm-wikipedia-20220920](https://huggingface.co/datasets/Tristan/olm-wikipedia-20220920)
## Analyzing the corpora
Follow the instructions at [analysis_scripts](analysis_scripts).
Here is a tweet thread which utilizes these scripts: [https://twitter.com/TristanThrush/status/1582356055794733057](https://twitter.com/TristanThrush/status/1582356055794733057)
Here is another tweet thread that dives a little deeper:
[https://twitter.com/TristanThrush/status/1588156731909029889](https://twitter.com/TristanThrush/status/1588156731909029889)
And here is a colab where you can quickly run some of the analysis yourself! [https://colab.research.google.com/drive/18Wv7ghW2rRjEe3oWDqh2iz9qqO8O6XcX?usp=sharing](https://colab.research.google.com/drive/18Wv7ghW2rRjEe3oWDqh2iz9qqO8O6XcX?usp=sharing)
## Citation
```
@misc{thrush2022pipeline,
title={Online Language Modelling Data Pipeline},
author={Tristan Thrush and Helen Ngo and Nathan Lambert and Douwe Kiela},
year={2022},
howpublished={\url{https://github.com/huggingface/olm-datasets}}
}
```
================================================
FILE: analysis_scripts/README.md
================================================
# OLM Analysis
## To analyze for term counts accross various datasets
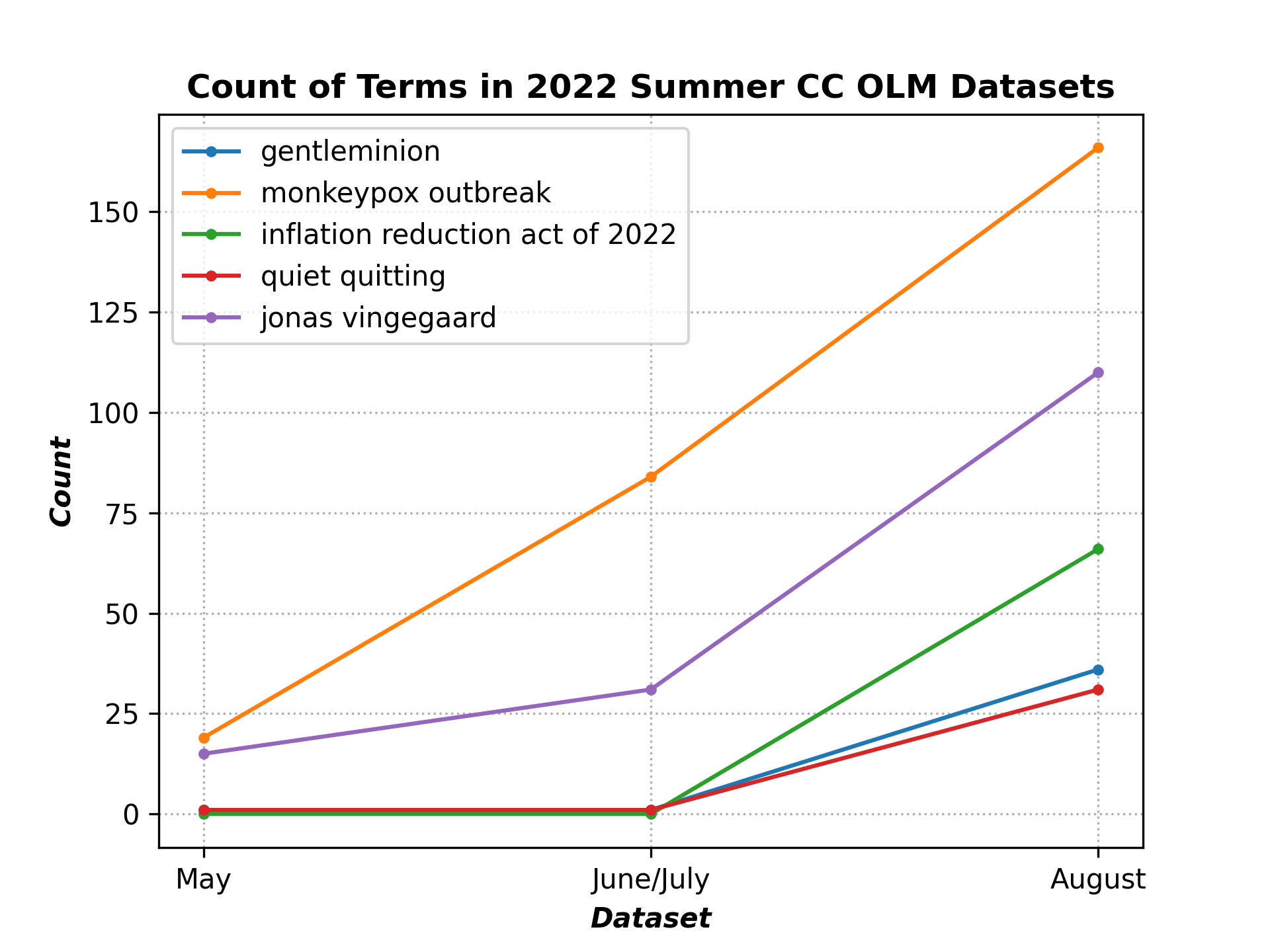
This command reports the count of terms associated with events that happened over summer 2022, accross chronologically ordered summer 2022 OLM datasets. We would expect the counts to go up over the summer:
```
python term_counts.py --input_dataset_names Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 --input_dataset_pretty_names "May" "June/July" "August" --terms "gentleminion" "monkeypox outbreak" "inflation reduction act of 2022" "quiet quitting" "jonas vingegaard" --plot_title="Count of Terms in 2022 Summer CC OLM Datasets" --analysis_column=text --split=train --num_proc=224 --output_filename=summer_2022_term_counts.png --load_from_hub_instead_of_disk --ylabel Count
```
Here is the resulting figure:
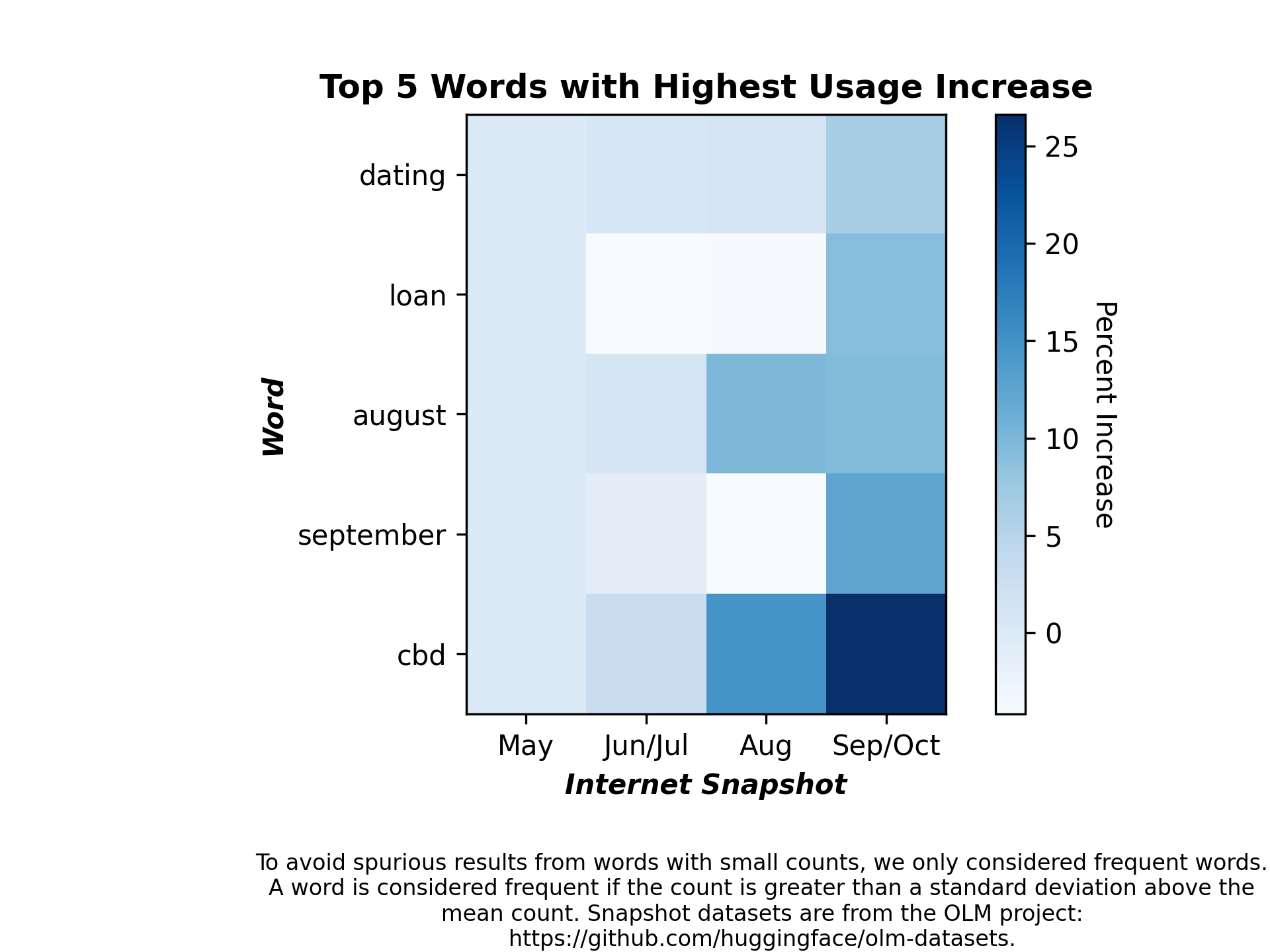
This command reports the count of words with the highest usage increase between the start of summer 2022 and the fall of 2022, out of all of the frequent (> mean + std) words in the dataset with only alphabetic characters, lowercased, and split by spaces:
```
python term_counts.py --input_dataset_names Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 --input_dataset_pretty_names "May" "Jun/Jul" "Aug" "Sep/Oct" --num_terms_to_find 5 --plot_title="Top 5 Words with Highest Usage Increase" --analysis_column=text --split=train --num_proc=224 --output_filename=top_5_term_counts_heatmap.png --load_from_hub_instead_of_disk --ylabel "Word" --as_heatmap --heatmap_bar_label "Percent Increase" --xlabel "Internet Snapshot" --normalize_axis=1 --cache_dir=term_counts_cache_top_5 --percent_increase --annotation "To avoid spurious results from words with small counts, we only considered frequent words. A word is considered frequent if the count is greater than a standard deviation above the mean count. Snapshot datasets are from the OLM project: https://github.com/huggingface/olm-datasets."
```
Here is the resulting figure:
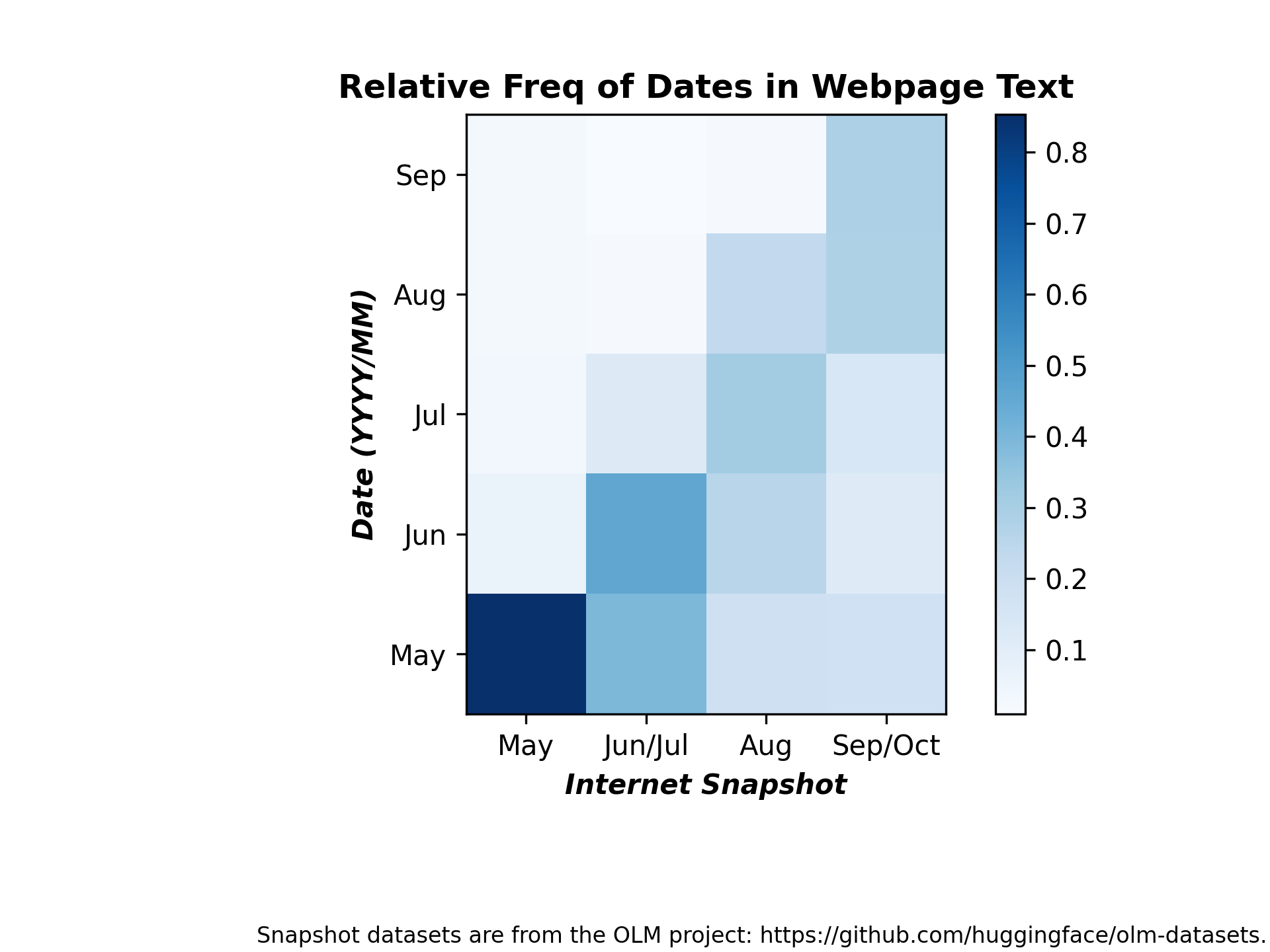
This command reports the count of date mentions in the text between summer 2022 and fall 2022:
```
python term_counts.py --input_dataset_names Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 --input_dataset_pretty_names "May" "Jun/Jul" "Aug" "Sep/Oct" --terms 2022/05 2022/06 2022/07 2022/08 2022/09 --plot_title="Relative Freq of Dates in Webpage Text" --analysis_column=text --split=train --num_proc=224 --output_filename=date_term_counts_heatmap_text.png --load_from_hub_instead_of_disk --as_heatmap --ylabel "Date (YYYY/MM)" --term_pretty_names May Jun Jul Aug Sep --cache_dir term_counts_cache_date_text --xlabel "Internet Snapshot" --annotation "Snapshot datasets are from the OLM project: https://github.com/huggingface/olm-datasets." --normalize
```
Here is the resulting figure:
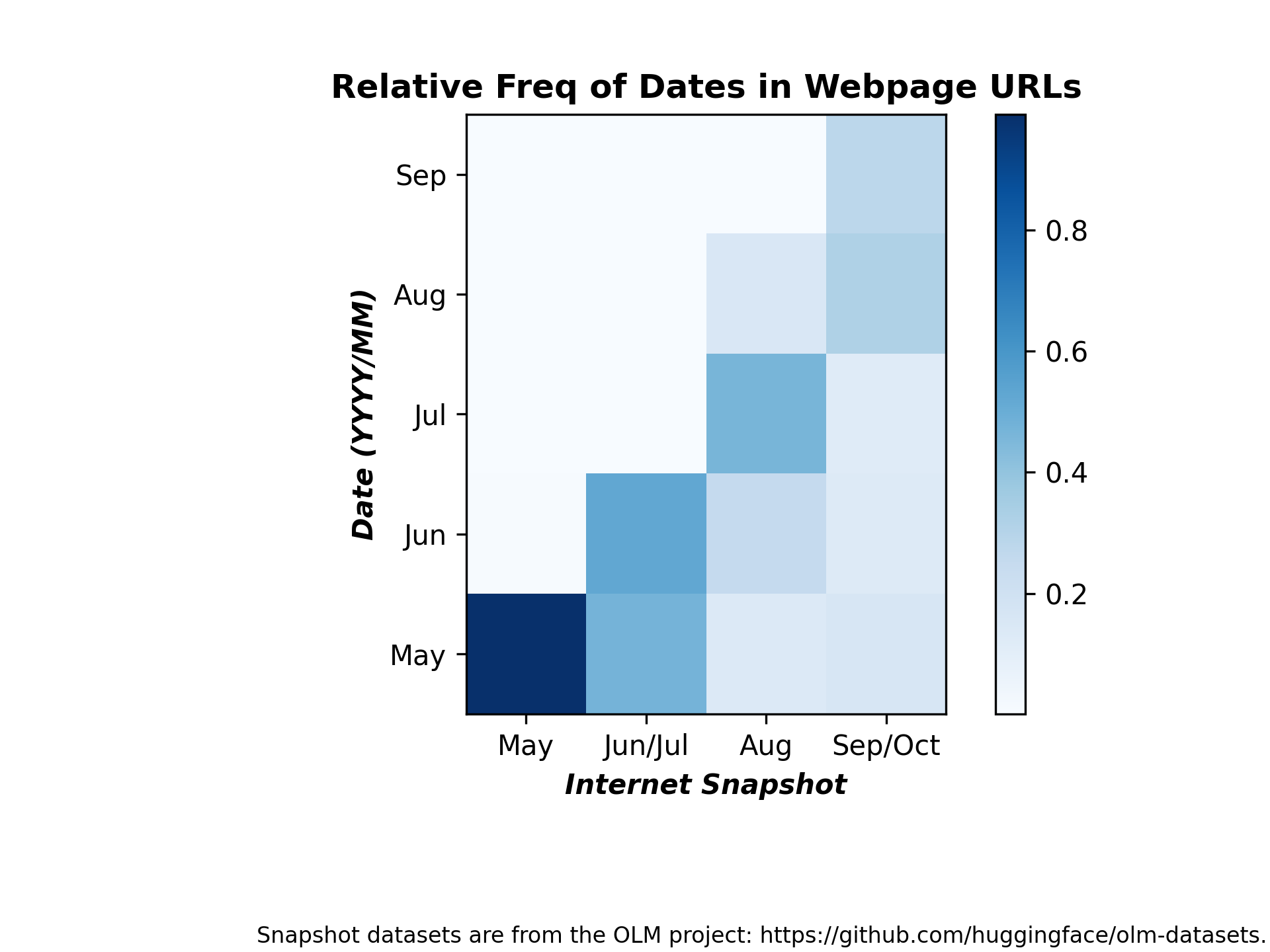
This command reports the count of date mentions in the URLs between summer 2022 and fall 2022:
```
python term_counts.py --input_dataset_names Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 --input_dataset_pretty_names "May" "Jun/Jul" "Aug" "Sep/Oct" --terms 2022/05 2022/06 2022/07 2022/08 2022/09 --plot_title="Relative Freq of Dates in Webpage URLs" --analysis_column=url --split=train --num_proc=224 --output_filename=date_term_counts_heatmap_url.png --load_from_hub_instead_of_disk --as_heatmap --ylabel "Date (YYYY/MM)" --term_pretty_names May Jun Jul Aug Sep --cache_dir term_counts_cache_date_urls --xlabel "Internet Snapshot" --annotation "Snapshot datasets are from the OLM project: https://github.com/huggingface/olm-datasets." --normalize
```
Here is the resulting figure:
## To analyze the timestamp distribution accross and within various datasets
This command reports the last-modified timestamp distribution for the summer 2022 through fall 2022 OLM CC datasets:
```
python timestamp_dist.py --input_dataset_names Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 --input_dataset_pretty_names Sep/Oct Aug Jun/Jul May --timestamp_column last_modified_timestamp --plot_title "Last-Modified Timestamp Distributions from Webpages" --num_proc=224 --output_filename last_modified_dist.png --load_from_hub_instead_of_disk --cache_dir timestamp_dist_cache_last_modified --split=train
```
Here is the resulting figure:
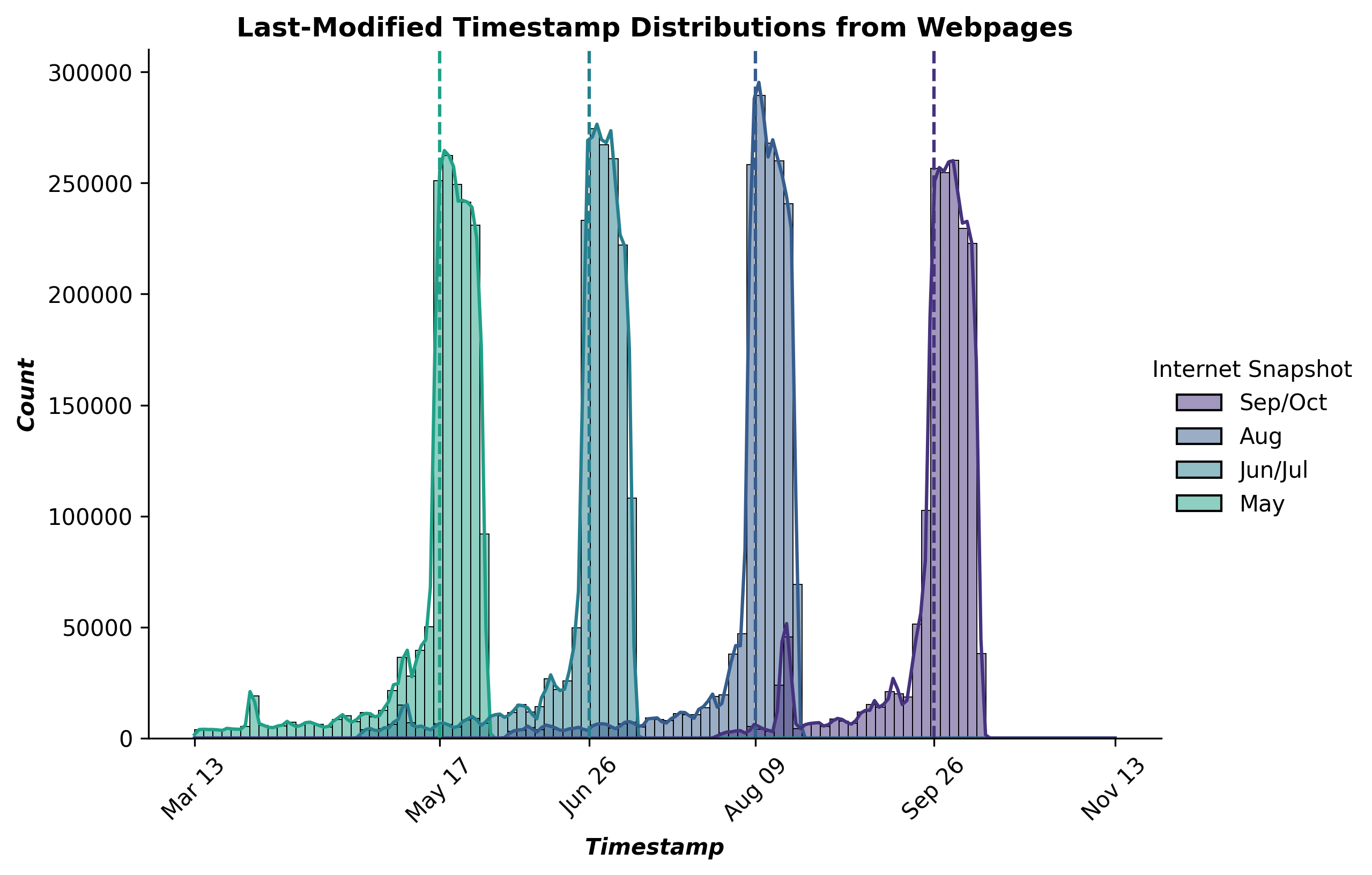
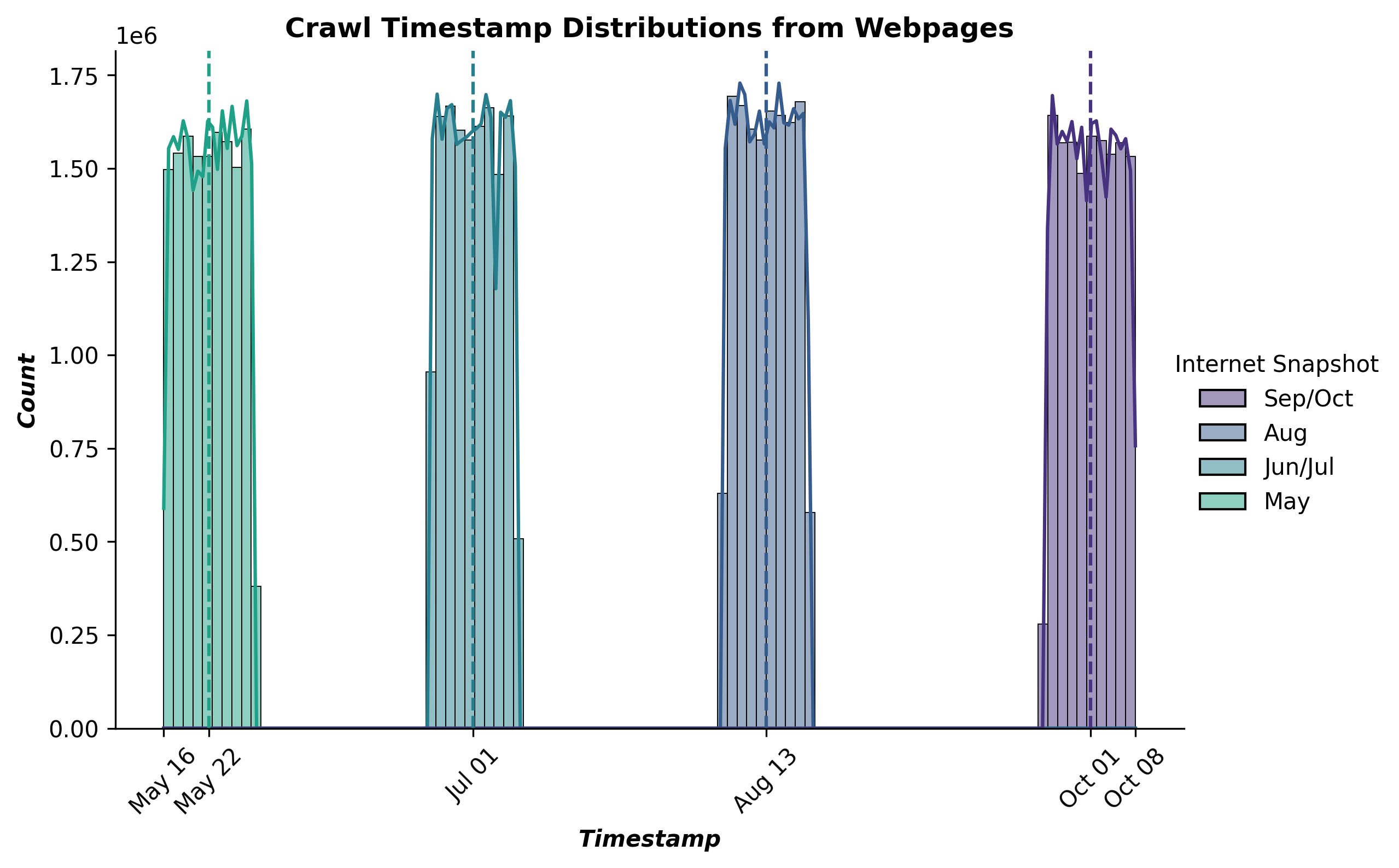
This command reports the crawl timestamp distribution for the summer 2022 through fall 2022 OLM CC datasets:
```
python timestamp_dist.py --input_dataset_names Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 --input_dataset_pretty_names Sep/Oct Aug Jun/Jul May --timestamp_column crawl_timestamp --plot_title "Crawl Timestamp Distributions from Webpages" --num_proc=224 --output_filename crawl_dist.png --load_from_hub_instead_of_disk --cache_dir timestamp_dist_cache_crawl --split=train
```
Here is the resulting figure:
## To analyze the URL domain distribution accross and within various datasets
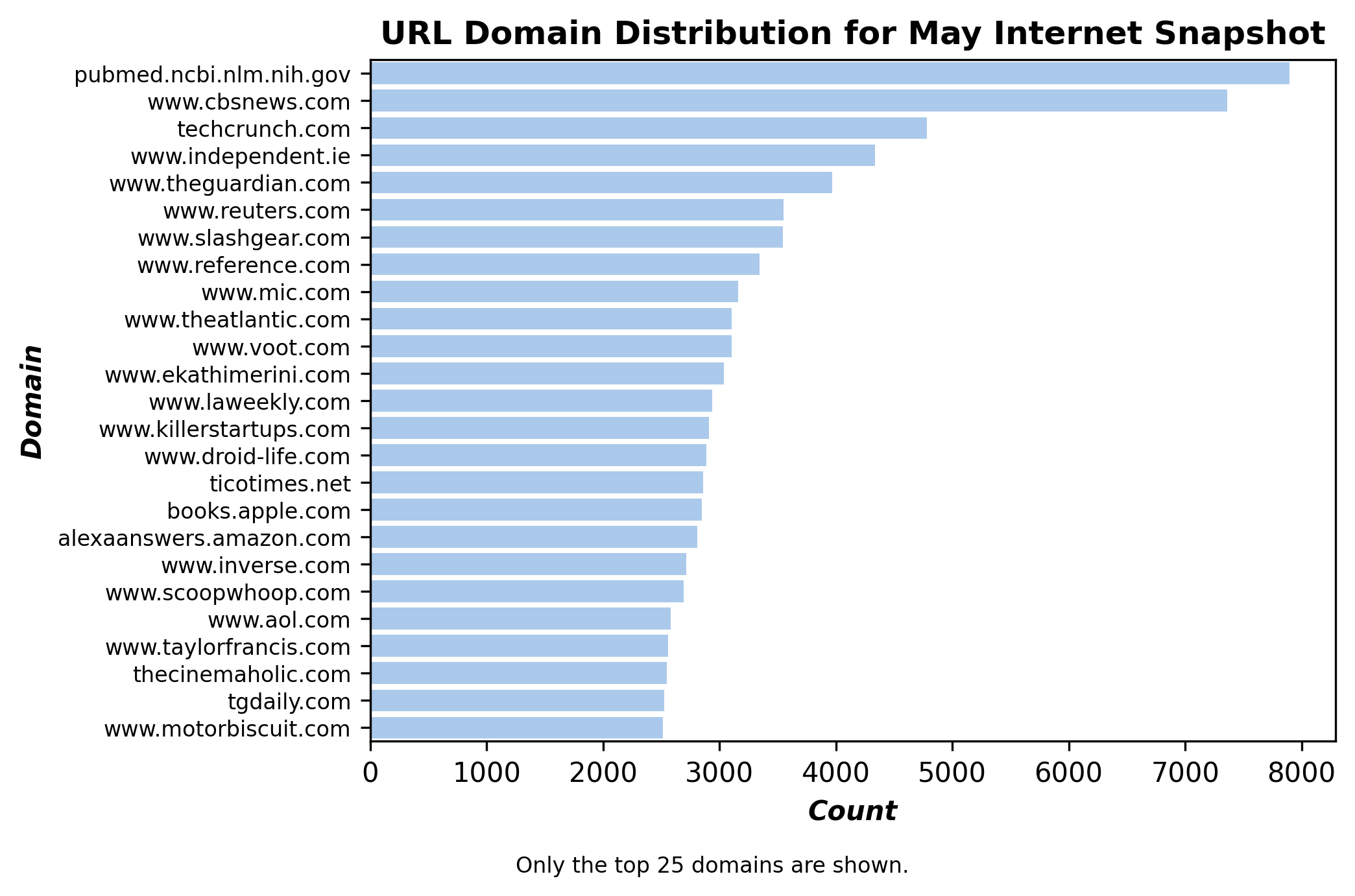
This command reports the domain distribution within the May 2022 OLM CC dataset:
```
python url_dist.py --input_dataset_names Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 --input_dataset_pretty_names May --url_column url --hist_plot_title "URL Domain Distribution for May Internet Snapshot" --corr_plot_title "URL Domain Distribution Corr for May Internet Snapshot" --num_proc=224 --output_corr_filename url_corr_may.png --output_hist_filename url_hist_may.png --load_from_hub_instead_of_disk --cache_dir url_dist_cache_may --no_hist_legend --annotation "Only the top 25 domains are shown."
```
Here is the resulting figure:
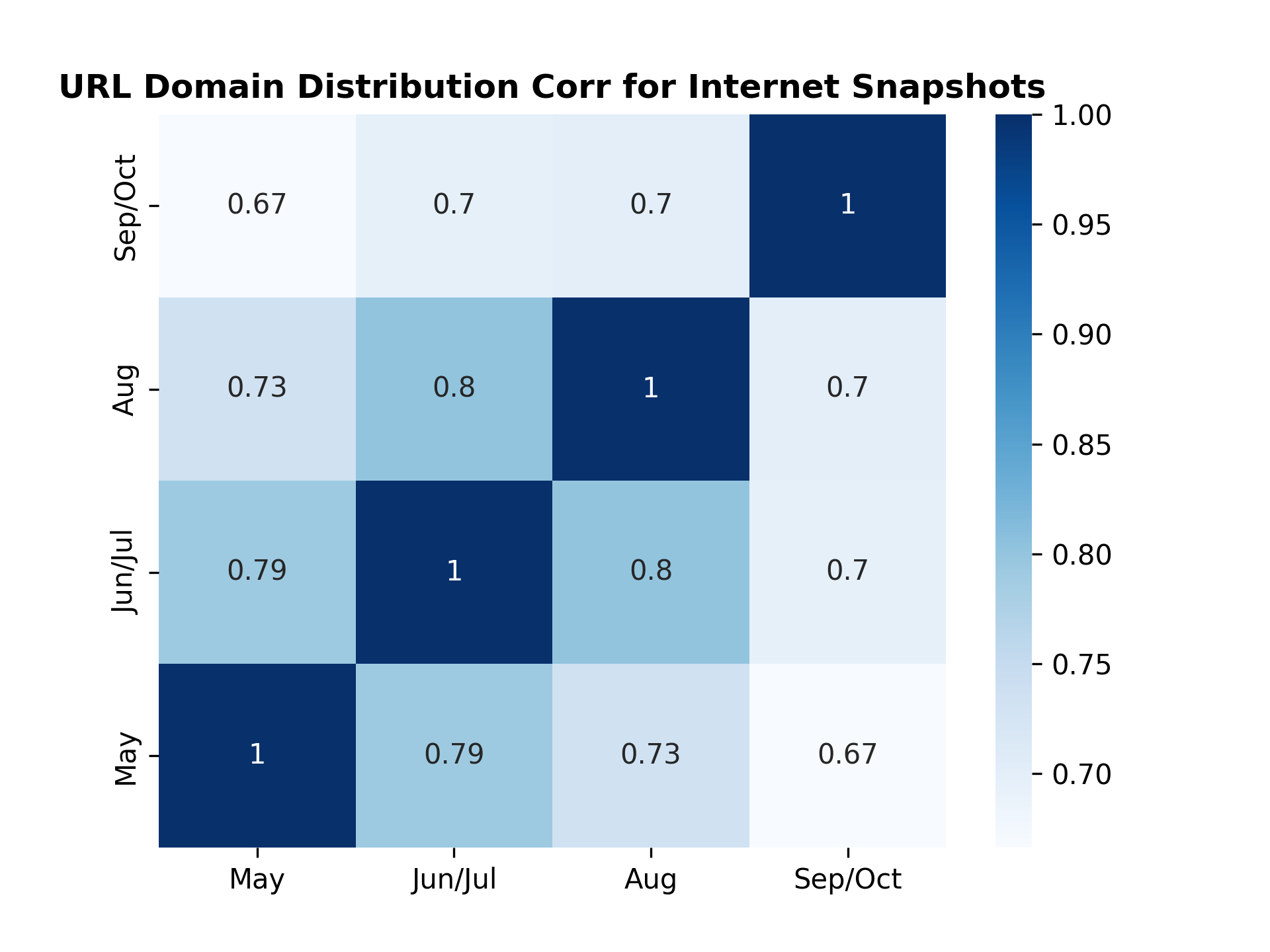
This command reports the domain correlations between the summer 2022 through fall 2022 OLM CC datasets:
```
python url_dist.py --input_dataset_names Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 --input_dataset_pretty_names May Jun/Jul Aug Sep/Oct --url_column url --hist_plot_title "URL Domain Distribution for Internet Snapshots" --corr_plot_title "URL Domain Distribution Corr for Internet Snapshots" --num_proc=224 --output_corr_filename url_corr.png --output_hist_filename url_hist.png --load_from_hub_instead_of_disk --cache_dir url_dist_cache_all
```
Here is the resulting figure:
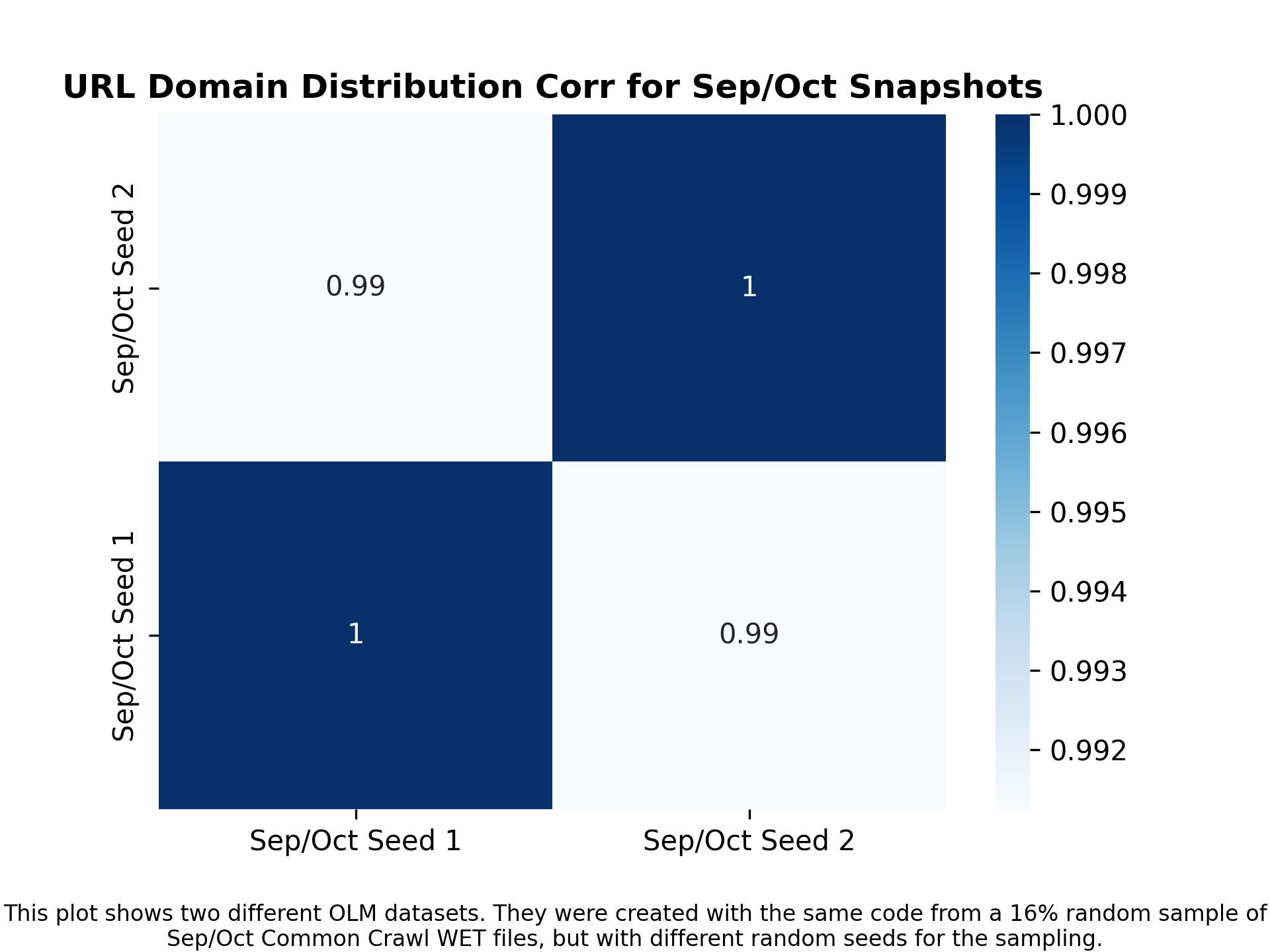
Does sampling about 15-20% of a Common Crawl Snapshot do anything surprising? How much correlation is there between the resulting OLM dataset from a Common Crawl sample from a random seed versus another random seed? This command reports the domain correlation between two Sep/Oct datasets where the only difference is the sampled segments based on different random seeds:
```
python url_dist.py --input_dataset_names Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295-seed-69 --input_dataset_pretty_names "Sep/Oct Seed 1" "Sep/Oct Seed 2" --url_column url --hist_plot_title "URL Domain Distribution for Sep/Oct Snapshots" --corr_plot_title "URL Domain Distribution Corr for Sep/Oct Snapshots" --num_proc=224 --output_corr_filename url_corr_sep_oct_different_seeds.png --output_hist_filename url_hist_sep_oct_different_seeds.png --load_from_hub_instead_of_disk --cache_dir url_dist_cache_all --annotation="This plot shows two different OLM datasets. They were created with the same code from a 16% random sample of Sep/Oct Common Crawl WET files, but with different random seeds for the sampling."
```
Here is the resulting figure:
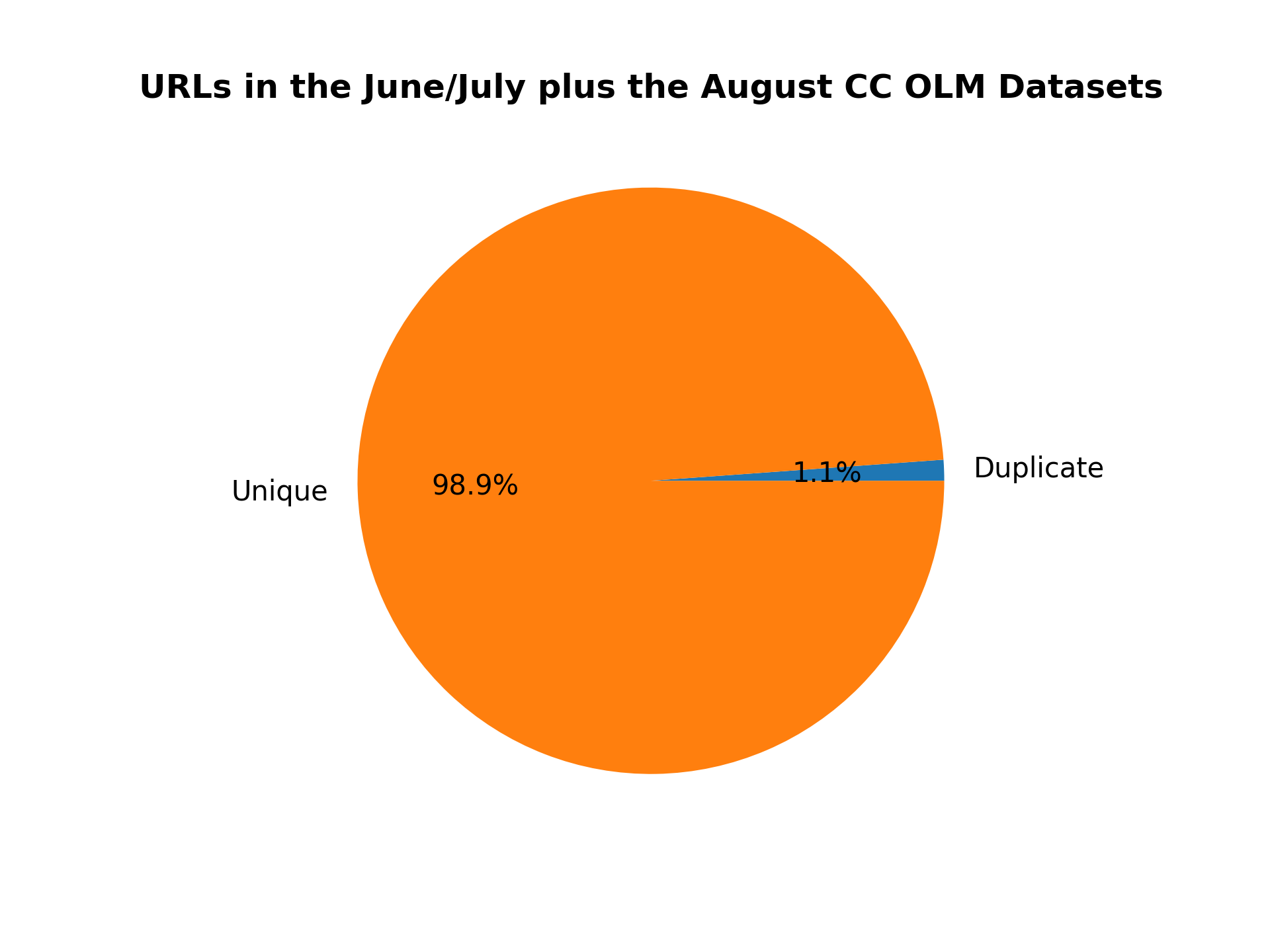
## To analyze for duplicates accross various datasets
This command reports the ratio of shared URLs between the August and June/July Common Crawl OLM Datasets:
```
python duplicates.py --input_dataset_names Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 --analysis_column=url --split=train --num_proc=224 --plot_title="URLs in the June/July plus the August CC OLM Datasets" --output_filename=duplicate_urls_aug_jun_jul.png --load_from_hub_instead_of_disk
```
Here is the resulting figure:
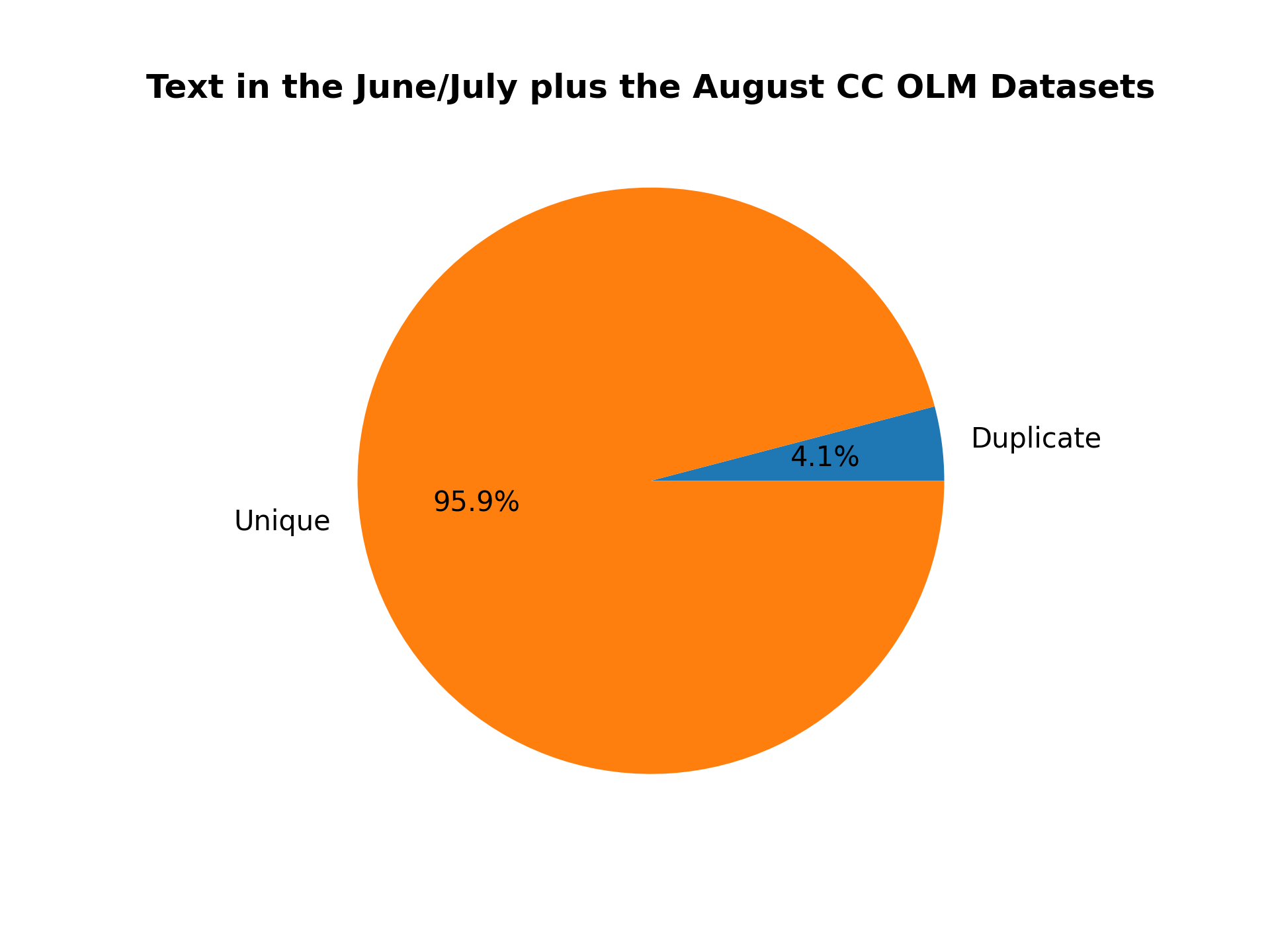
This command reports the ratio of exact text duplicated between the August and June/July Common Crawl OLM Datasets:
```
python duplicates.py --input_dataset_names Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 --analysis_column=text --split=train --num_proc=224 --plot_title="Text in the June/July plus the August CC OLM Datasets" --output_filename=duplicate_text_aug_jun_jul.png --load_from_hub_instead_of_disk
```
Here is the resulting figure:
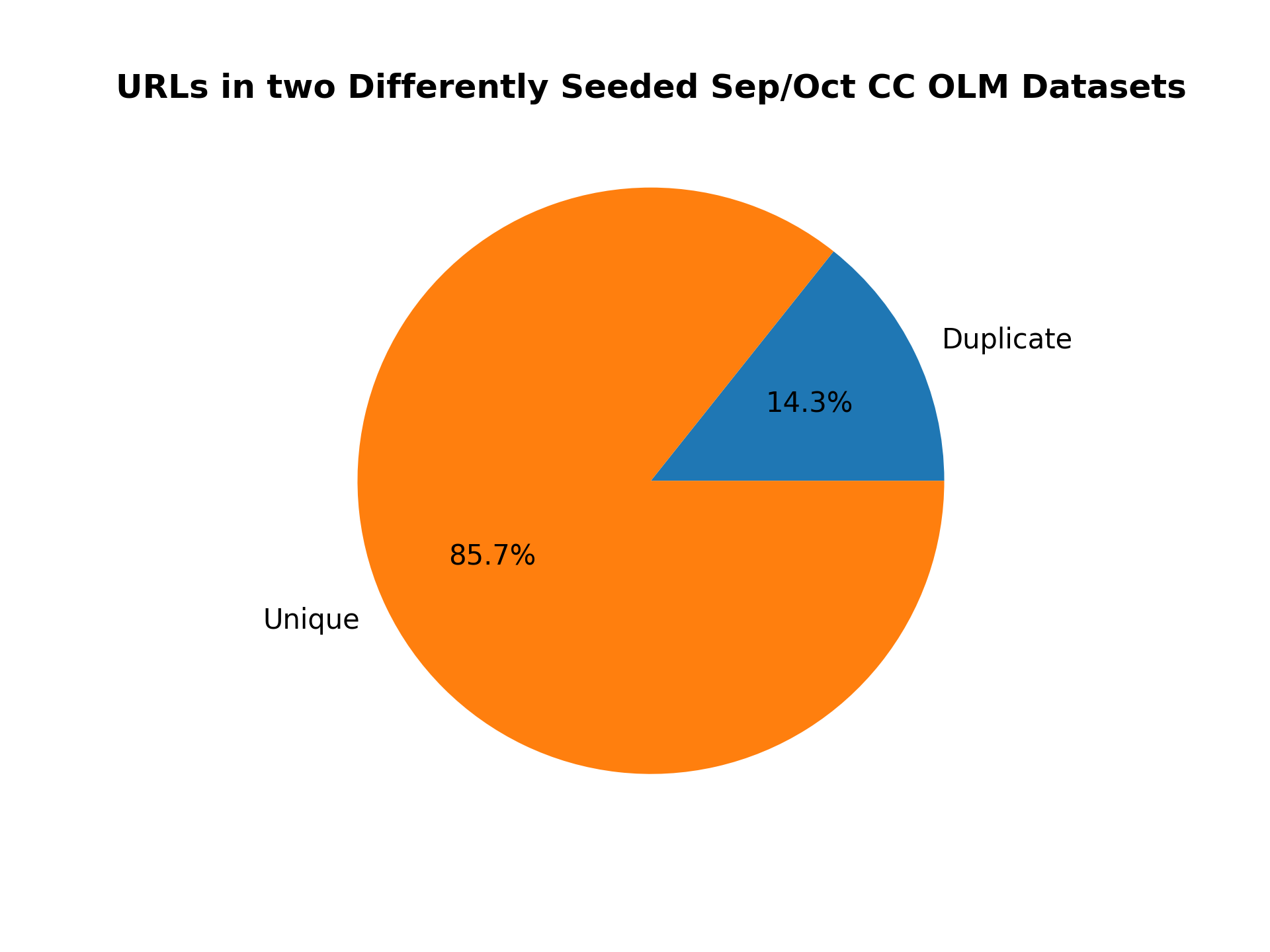
What about the duplicated URLs between two differently seeded OLM datasets from the same month?
```
python duplicates.py --input_dataset_names Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295-seed-69 --analysis_column=url --split=train --num_proc=224 --plot_title="URLs in two Differently Seeded Sep/Oct CC OLM Datasets" --output_filename=duplicate_urls_sep_oct_different_seeds.png --load_from_hub_instead_of_disk
```
Here is the resulting figure:
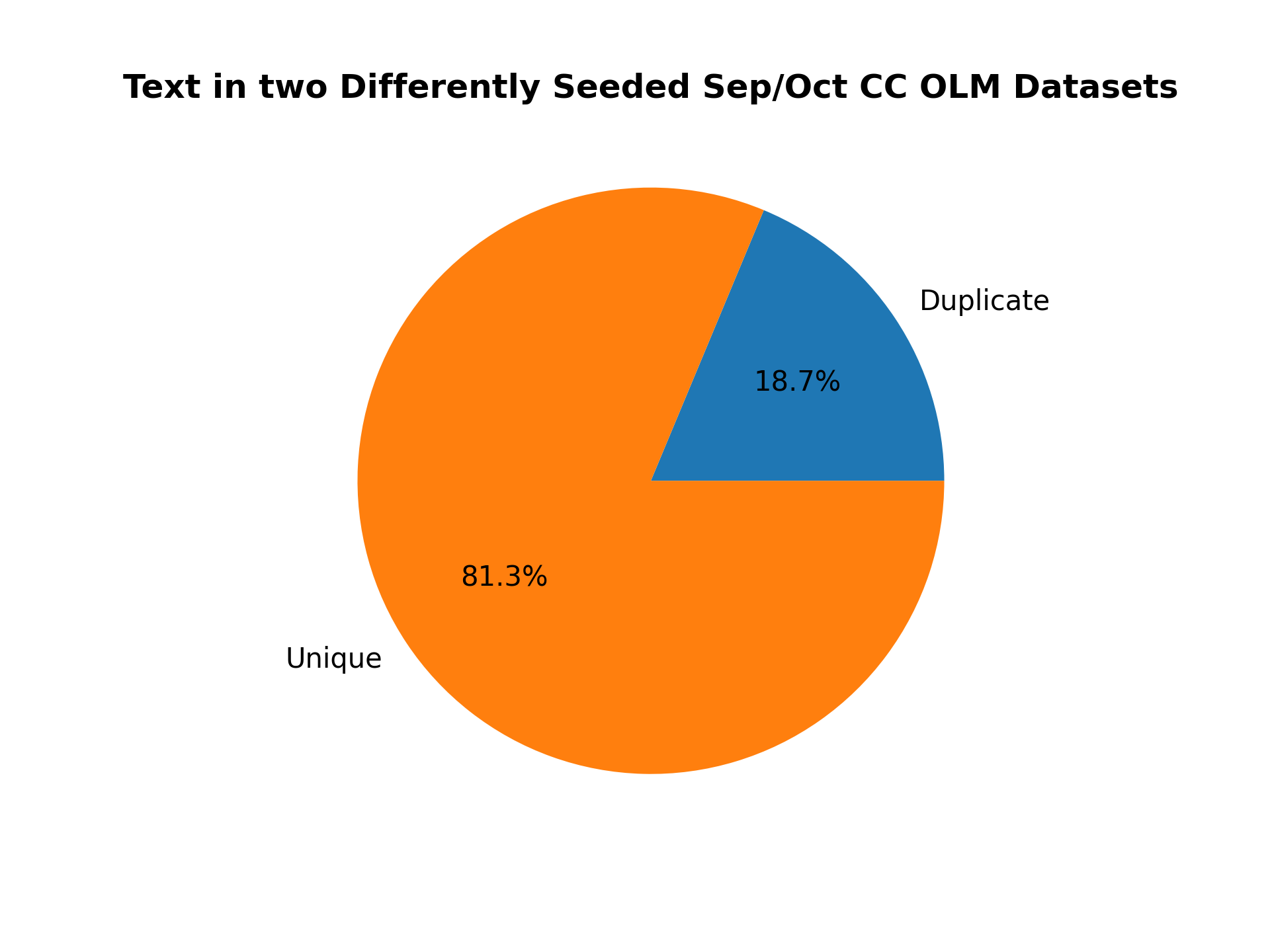
And what about the text?
```
python duplicates.py --input_dataset_names Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295-seed-69 --analysis_column=text --split=train --num_proc=224 --plot_title="Text in two Differently Seeded Sep/Oct CC OLM Datasets" --output_filename=duplicate_text_sep_oct_different_seeds.png --load_from_hub_instead_of_disk
```
## Documentation
```
python term_counts.py --help
```
```
python url_dist.py --help
```
```
python timestamp_dist.py --help
```
```
python duplicates.py --help
```
================================================
FILE: analysis_scripts/duplicates.py
================================================
from datasets import load_dataset, load_from_disk, concatenate_datasets
import argparse
import matplotlib.pyplot as plt
parser = argparse.ArgumentParser(description="This script takes a list of datasets, concatenates them, and saves a pie chart for duplicate versus unique items in the specified column.")
parser.add_argument("--input_dataset_names", nargs="+", required=True)
parser.add_argument("--analysis_column", required=True)
parser.add_argument("--plot_title", required=True)
parser.add_argument("--split", default=None, help="The dataset split to use. Some datasets don't have splits so this argument is optional.")
parser.add_argument("--num_proc", type=int, required=True)
parser.add_argument("--duplicate_label", default="Duplicate")
parser.add_argument("--unique_label", default="Unique")
parser.add_argument("--output_filename", required=True)
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input dataset from the Hugging Face hub instead of the disk (default is the disk).")
args = parser.parse_args()
datasets = []
for input_dataset_name in args.input_dataset_names:
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(input_dataset_name)
else:
ds = load_dataset(input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(input_dataset_name)
else:
ds = load_from_disk(input_dataset_name)[args.split]
datasets.append(ds)
ds = concatenate_datasets(datasets)
ds = ds.sort(args.analysis_column)
max_index = len(ds) - 1
def same_adjacent_entry(entry, index):
if index == max_index:
return ds[index - 1][args.analysis_column] == entry
elif index == 0:
return ds[index + 1][args.analysis_column] == entry
return ds[index - 1][args.analysis_column] == entry or ds[index + 1][args.analysis_column] == entry
num_examples = len(ds)
ds = ds.filter(lambda example, index: same_adjacent_entry(example[args.analysis_column], index), num_proc=args.num_proc, with_indices=True)
num_examples_only_duplicate_entries = len(ds)
labels = [args.duplicate_label, args.unique_label]
sizes = [num_examples_only_duplicate_entries, num_examples - num_examples_only_duplicate_entries]
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title(args.plot_title, fontweight="bold")
plt.rcParams["font.family"] = "Times New Roman"
plt.savefig(args.output_filename, dpi=300)
================================================
FILE: analysis_scripts/term_counts.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
from multiprocessing import Manager
from tqdm import tqdm
from os import path, mkdir
import pickle
import statistics
parser = argparse.ArgumentParser(description="This script takes in an ordered list of datasets and counts terms in each of them, in the specified column. It then plots a graph or a heatmap for how the count changed accross datasets. ")
parser.add_argument("--input_dataset_names", nargs="+", required=True)
parser.add_argument("--input_dataset_pretty_names", nargs="+", required=True, help="The names of the datasets that you want to appear in the saved graph.")
parser.add_argument("--terms", nargs="+", default=None, help="The terms that you want to count. If left as None, then you must specify --num_terms_to_find, and then the script will return the top --num_terms_to_find with the greatest percent change from the first dataset to the last dataset, out of the terms which have count > the mean count plus the standard deviation (so we don't get spurious results from low-count words).")
parser.add_argument("--term_pretty_names", nargs="+", default=None)
parser.add_argument("--analysis_column", required=True)
parser.add_argument("--plot_title", required=True)
parser.add_argument("--split", default=None, help="The dataset split to use. Some datasets don't have splits so this argument is optional.")
parser.add_argument("--num_proc", type=int, required=True)
parser.add_argument("--output_filename", required=True)
parser.add_argument("--as_heatmap", action="store_true")
parser.add_argument("--samples", default=None, type=int)
parser.add_argument("--num_terms_to_find", default=None, type=int)
parser.add_argument("--normalize", action="store_true")
parser.add_argument("--ylabel", required=True)
parser.add_argument("--cache_dir", default="term_count_cache")
parser.add_argument("--load_from_cache_dir", action="store_true")
parser.add_argument("--heatmap_bar_label", default="")
parser.add_argument("--annotation", default=None)
parser.add_argument("--xlabel", default="Dataset")
parser.add_argument("--normalize_axis", default=0, type=int)
parser.add_argument("--percent_increase", action="store_true")
parser.add_argument("--bottom", default=0.25, type=float)
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input dataset from the Hugging Face hub instead of the disk (default is the disk).")
args = parser.parse_args()
datasets = []
term_y_coords = None
count_dicts = []
if args.load_from_cache_dir:
if args.terms is None:
count_dicts = pickle.load(open(path.join(args.cache_dir, "count_dicts.pkl"), "rb"))
else:
term_y_coords = pickle.load(open(path.join(args.cache_dir, "term_y_coords.pkl"), "rb"))
cached_args = pickle.load(open(path.join(args.cache_dir, "args.pkl"), "rb"))
if args != cached_args:
print("Warning: argument mismatch between cached args and current args")
print("Cached args: ", cached_args)
print("Current args: ", args)
if term_y_coords is None:
for input_dataset_name in args.input_dataset_names:
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(input_dataset_name)
else:
ds = load_dataset(input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(input_dataset_name)
else:
ds = load_from_disk(input_dataset_name)[args.split]
if args.samples is not None:
ds = ds.shuffle(seed=42)
ds = ds.select(range(args.samples))
datasets.append(ds)
if args.terms is None and not args.load_from_cache_dir:
with Manager() as manager:
shared_list = manager.list()
def build_count_dict(examples):
counts = None
for text in examples[args.analysis_column]:
if counts is None:
counts = Counter(filter(lambda obj: obj.isalpha(), text.lower().split(" ")))
else:
counts += Counter(filter(lambda obj: obj.isalpha(), text.lower().split(" ")))
shared_list.append(counts)
ds.map(build_count_dict, num_proc=args.num_proc, batched=True, batch_size=len(ds) // args.num_proc, remove_columns=ds.column_names)
count_dict = shared_list[0]
for counts in tqdm(shared_list[1:]):
count_dict += counts
count_dicts.append(count_dict)
if args.terms is None:
if not path.exists(args.cache_dir):
mkdir(args.cache_dir)
pickle.dump(args, open(path.join(args.cache_dir, "args.pkl"), "wb"))
pickle.dump(count_dicts, open(path.join(args.cache_dir, "count_dicts.pkl"), "wb"))
if args.terms is None:
intersection_count_set = set(count_dicts[0].keys())
for count_dict in count_dicts[1:]:
intersection_count_set = intersection_count_set.intersection(set(count_dict.keys()))
words_with_occurence_changes = []
counts = []
for word in intersection_count_set:
count_sum = 0
for count_dict in count_dicts:
count_sum += count_dict[word]
counts.append(count_sum)
mean_count = statistics.mean(counts)
std = statistics.stdev(counts)
for word in intersection_count_set:
count_sum = 0
for count_dict in count_dicts:
count_sum += count_dict[word]
if count_sum > mean_count + std:
change = count_dicts[-1][word]/count_dicts[0][word]
words_with_occurence_changes.append((word, change))
words_with_occurence_changes.sort(key=lambda word_and_change: word_and_change[1], reverse=True)
terms = [word_and_change[0] for word_and_change in words_with_occurence_changes[:args.num_terms_to_find]]
else:
terms = args.terms
if term_y_coords is None:
term_y_coords = {term: [] for term in terms}
for ds in datasets:
def term_counts(text):
return {term + "_count": text.lower().count(term.lower()) for term in terms}
ds = ds.map(lambda example: term_counts(example[args.analysis_column]), num_proc=args.num_proc)
for term in terms:
term_y_coords[term].append(sum(ds[term + "_count"]))
if not path.exists(args.cache_dir):
mkdir(args.cache_dir)
pickle.dump(args, open(path.join(args.cache_dir, "args.pkl"), "wb"))
pickle.dump(term_y_coords, open(path.join(args.cache_dir, "term_y_coords.pkl"), "wb"))
plt.xticks(range(len(args.input_dataset_pretty_names)), args.input_dataset_pretty_names)
if args.as_heatmap:
matrix = []
for term in terms:
matrix.append(term_y_coords[term])
matrix = np.array(matrix)
if args.percent_increase:
matrix = matrix.transpose()
matrix = (matrix - matrix[0])/matrix[0]
matrix = matrix.transpose() * 100
if args.normalize:
column_sums = matrix.sum(axis=args.normalize_axis)
if args.normalize_axis == 0:
normalized_matrix = matrix / column_sums
if args.normalize_axis == 1:
normalized_matrix = matrix.transpose() / column_sums
normalized_matrix = normalized_matrix.transpose()
plt.imshow(np.flipud(normalized_matrix), plt.cm.Blues)
else:
plt.imshow(np.flipud(matrix), plt.cm.Blues)
plt.yticks(range(len(terms)), reversed(terms if args.term_pretty_names is None else args.term_pretty_names))
cbar = plt.colorbar()
cbar.ax.set_ylabel(args.heatmap_bar_label, rotation=-90, va="bottom")
plt.ylabel(args.ylabel, style='italic', fontweight="bold")
else:
for term in terms:
if args.normalize:
term_y_coords[term] = np.array(term_y_coords[term])/sum(term_y_coords[term])
plt.plot(term_y_coords[term], label=term, marker=".")
plt.grid(linestyle=":")
plt.legend(loc="upper left")
plt.ylabel(args.ylabel, style='italic', fontweight="bold")
if args.annotation is not None:
plt.figtext(0.6, 0.01, args.annotation, wrap=True, horizontalalignment='center', fontsize=8)
plt.subplots_adjust(bottom=args.bottom)
plt.xlabel(args.xlabel, style='italic', fontweight="bold")
plt.title(args.plot_title, fontweight="bold")
plt.rcParams["font.family"] = "Times New Roman"
plt.savefig(args.output_filename, dpi=300)
================================================
FILE: analysis_scripts/timestamp_dist.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from datetime import datetime
from os import path, mkdir
import pickle
parser = argparse.ArgumentParser(description="This script takes in an ordered list of datasets. It is assumed that each dataset has a timestamp column. The script plots the timestamp distribution histogram for each dataset.")
parser.add_argument("--input_dataset_names", nargs="+", required=True)
parser.add_argument("--input_dataset_pretty_names", nargs="+", required=True, help="The names of the datasets that you want to appear in the saved graph.")
parser.add_argument("--timestamp_column", required=True)
parser.add_argument("--plot_title", required=True)
parser.add_argument("--split", default=None, help="The dataset split to use. Some datasets don't have splits so this argument is optional.")
parser.add_argument("--num_proc", type=int, required=True)
parser.add_argument("--output_filename", required=True)
parser.add_argument("--samples", default=None, type=int)
parser.add_argument("--bins", default=100, help="The number of histogram bins to plot")
parser.add_argument("--cache_dir", default="timestamp_dist_cache")
parser.add_argument("--load_from_cache_dir", action="store_true")
parser.add_argument("--annotation", default=None)
parser.add_argument("--legend_title", default="Internet Snapshot")
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input dataset from the Hugging Face hub instead of the disk (default is the disk).")
args = parser.parse_args()
if args.load_from_cache_dir:
data_array = np.load(open(path.join(args.cache_dir, "data_array.npy"), "rb"))
cached_args = pickle.load(open(path.join(args.cache_dir, "args.pkl"), "rb"))
if args != cached_args:
print("Warning: argument mismatch between cached args and current args")
print("Cached args: ", cached_args)
print("Current args: ", args)
else:
# Remove timestamp outliers more than 10 median deviations away from the median.
# This is important if the timestamp is the Last-Modified timestamp, which can sometimes be wrong
# because websites can report whatever they want. We don't want one website that says it was created
# a billion years ago to seriously affect the distribution.
def reject_outliers(data, m = 10.):
d = np.abs(data - np.median(data))
mdev = np.median(d)
s = d/mdev if mdev else 0.
return data[s<m]
data_list = []
shortest_len = None
for input_dataset_name in args.input_dataset_names:
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(input_dataset_name)
else:
ds = load_dataset(input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(input_dataset_name)
else:
ds = load_from_disk(input_dataset_name)[args.split]
if args.samples is not None:
ds = ds.shuffle(seed=42)
ds = ds.select(range(args.samples))
ds = ds.filter(lambda example: example[args.timestamp_column] is not None, num_proc=args.num_proc)
data = np.array(ds[args.timestamp_column])
data_no_outliers = reject_outliers(data)
data_list.append(data_no_outliers)
if shortest_len is None:
shortest_len = len(data_no_outliers)
else:
shortest_len = min(shortest_len, len(data_no_outliers))
truncated_data_list = []
for data in data_list:
truncated_data_list.append(data[:shortest_len])
data_array = np.array(truncated_data_list).transpose()
if not path.exists(args.cache_dir):
mkdir(args.cache_dir)
np.save(open(path.join(args.cache_dir, "data_array.npy"), "wb"), data_array)
pickle.dump(args, open(path.join(args.cache_dir, "args.pkl"), "wb"))
df = pd.DataFrame(data=data_array, columns=args.input_dataset_pretty_names)
color_palette = sns.color_palette("viridis")
colors = color_palette[:len(args.input_dataset_names)]
plot = sns.displot(data=df, kde=True, palette=colors, bins=args.bins, height=5, aspect=1.5)
means = np.mean(data_array, axis=0)
xticks = np.concatenate((np.array([np.min(data_array)]), means, np.array([np.max(data_array)])))
for mean, color in zip(means, colors):
plt.axvline(x=mean, linestyle="--", color=color)
plot.set(xticks=xticks)
plot.axes[0,0].set_title(args.plot_title, fontweight="bold")
plot.axes[0,0].set_xlabel("Timestamp", style="italic", fontweight="bold")
plot.axes[0,0].set_ylabel("Count", style="italic", fontweight="bold")
plot.set_xticklabels([datetime.fromtimestamp(timestamp).strftime('%b %d') for timestamp in xticks], rotation=45)
if args.annotation is not None:
plot.figure.text(0.5, 0.01, args.annotation, wrap=True, horizontalalignment='center', fontsize=8)
plot.figure.subplots_adjust(bottom=0.20)
plot._legend.set_title(args.legend_title)
plot.fig.savefig(args.output_filename, dpi=300, bbox_inches='tight')
================================================
FILE: analysis_scripts/url_dist.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
from collections import Counter
from multiprocessing import Manager
from tqdm import tqdm
from urllib.parse import urlparse
import seaborn as sns
import pandas as pd
from os import path, mkdir
import pickle
parser = argparse.ArgumentParser(description="This script takes in an ordered list of datasets which each have a URL column. It extracts domain names from each URL and then plots a histogram of the URL counts per domain and a correlation matrix comparing each dataset's histogram.")
parser.add_argument("--input_dataset_names", nargs="+", required=True)
parser.add_argument("--input_dataset_pretty_names", nargs="+", required=True, help="The names of the datasets that you want to appear in the saved graphs.")
parser.add_argument("--url_column", required=True)
parser.add_argument("--hist_plot_title", required=True)
parser.add_argument("--corr_plot_title", required=True)
parser.add_argument("--split", default=None, help="The dataset split to use. Some datasets don't have splits so this argument is optional.")
parser.add_argument("--num_proc", type=int, required=True)
parser.add_argument("--output_corr_filename", required=True)
parser.add_argument("--output_hist_filename", required=True)
parser.add_argument("--samples", default=None, type=int)
parser.add_argument("--hist_bins", default=25, type=int)
parser.add_argument("--hist_bin_fontsize", default=8, type=int)
parser.add_argument("--cache_dir", default="url_dist")
parser.add_argument("--no_hist_legend", action="store_true")
parser.add_argument("--load_from_cache_dir", action="store_true", help="If you've already run this function and just want to change parameters for the graphs (like --hist_bins, for example), then specify this option to load the cached domain distribution so the computation isn't repeated.")
parser.add_argument("--annotation", default=None)
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input datasets from the Hugging Face hub instead of the disk (default is the disk).")
args = parser.parse_args()
if args.load_from_cache_dir:
count_dicts = pickle.load(open(path.join(args.cache_dir, "count_dicts.pkl"), "rb"))
cached_args = pickle.load(open(path.join(args.cache_dir, "args.pkl"), "rb"))
if args != cached_args:
print("Warning: argument mismatch between cached args and current args")
print("Cached args: ", cached_args)
print("Current args: ", args)
else:
count_dicts = []
for input_dataset_name in args.input_dataset_names:
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(input_dataset_name)
else:
ds = load_dataset(input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(input_dataset_name)
else:
ds = load_from_disk(input_dataset_name)[args.split]
if args.samples is not None:
ds = ds.shuffle(seed=42)
ds = ds.select(range(args.samples))
with Manager() as manager:
shared_list = manager.list()
def build_count_dict(examples):
counts = None
for url in examples[args.url_column]:
domain = urlparse(url).netloc
if counts is None:
counts = Counter([domain])
else:
counts += Counter([domain])
shared_list.append(counts)
ds.map(build_count_dict, num_proc=args.num_proc, batched=True, batch_size=len(ds) // args.num_proc)
count_dict = shared_list[0]
for counts in tqdm(shared_list[1:]):
count_dict += counts
count_dicts.append(count_dict)
if not path.exists(args.cache_dir):
mkdir(args.cache_dir)
pickle.dump(args, open(path.join(args.cache_dir, "args.pkl"), "wb"))
pickle.dump(count_dicts, open(path.join(args.cache_dir, "count_dicts.pkl"), "wb"))
union_count_set = set(count_dicts[0].keys())
for count_dict in tqdm(count_dicts[1:]):
union_count_set = union_count_set.union(set(count_dict.keys()))
dataframe_dict = {dataset_name: [] for dataset_name in args.input_dataset_pretty_names}
dataframe_dict["domain_name"] = []
for domain in tqdm(union_count_set):
for index in range(len(args.input_dataset_pretty_names)):
count_dict = count_dicts[index]
dataset_name = args.input_dataset_pretty_names[index]
dataframe_dict[dataset_name].append(count_dict.get(domain, 0))
dataframe_dict["domain_name"].append(domain)
df = pd.DataFrame(dataframe_dict)
plot = sns.heatmap(df.corr().iloc[::-1], cmap="Blues", annot=True)
plot.set_title(args.corr_plot_title, fontweight="bold")
if args.annotation is not None:
plot.figure.text(0.5, 0.01, args.annotation, wrap=True, horizontalalignment="center", fontsize=8)
plot.figure.subplots_adjust(bottom=0.15)
plot.figure.savefig(args.output_corr_filename, dpi=300)
plot.figure.clf()
df = df.sort_values(by=args.input_dataset_pretty_names, ascending=False)
dataframe_dict = {"samples": [], "dataset": [], "domain": []}
index = 0
for _, datum in df.iterrows():
if index >= args.hist_bins:
break
dataframe_dict["samples"] += [datum[name] for name in args.input_dataset_pretty_names]
dataframe_dict["dataset"] += args.input_dataset_pretty_names
dataframe_dict["domain"] += [datum["domain_name"]]*len(args.input_dataset_pretty_names)
index += 1
df = pd.DataFrame(dataframe_dict)
color_palette = sns.color_palette("pastel")
colors = color_palette[:len(args.input_dataset_names)]
plot = sns.barplot(data=df, palette=colors, hue="dataset", y="domain", x="samples")
if args.annotation is not None:
plot.figure.text(0.4, 0.01, args.annotation, wrap=True, horizontalalignment="center", fontsize=8)
plot.figure.subplots_adjust(bottom=0.15)
plot.legend().set_title("")
if args.no_hist_legend:
plot.legend().remove()
for item in plot.get_yticklabels():
item.set_fontsize(args.hist_bin_fontsize)
plot.set_title(args.hist_plot_title, fontweight="bold")
plot.set_xlabel("Count", style="italic", fontweight="bold")
plot.set_ylabel("Domain", style="italic", fontweight="bold")
plot.figure.savefig(args.output_hist_filename, dpi=300, bbox_inches="tight")
================================================
FILE: pipeline_scripts/common_crawl/README.md
================================================

# Quick start
This section provides all the commands that you need to generate a deduplicated and filtered dataset from Common Crawl, ready for pretraining!
## One time only
`bash download_pipeline_processing_models.sh`
## Every time
Use the following commands to get a dataset. They should take only a few min if you have lots of CPUs. Adjust `--num_proc` to be equal to however many CPUs that you have.
```
python download_common_crawl.py --snapshots CC-MAIN-2022-33 --segment_sampling_ratios 0.0001 --seed=42 --download_dir=common_crawl_wet_downloads --num_proc=224
python get_text_dataset_from_wet_downloads.py --download_dir=common_crawl_wet_downloads --output_dataset_name=cc_raw --num_proc=224
python remove_wikipedia_urls.py --input_dataset_name=cc_raw --output_dataset_name=cc_no_wikipedia --url_column=url --split=en --num_proc=224
python apply_bigscience_filters.py --input_dataset_name=cc_no_wikipedia --output_dataset_name=cc_filtered --lang_id=en --text_column=text --num_proc=224
ulimit -Sn 1000000 && python deduplicate.py --input_dataset_name=cc_filtered --output_dataset_name=cc_olm --text_column=text --remove_whole_example --num_proc=224
# Optionally, get the last-modified headers from the websites and add them to the dataset. --segment_sampling_ratios and --seed must be the same as above for this to work.
python download_common_crawl.py --snapshots CC-MAIN-2022-33 --segment_sampling_ratios 0.0001 --seed=42 --download_dir=common_crawl_wat_downloads --paths_type=wat --num_proc=224
python get_last_modified_dataset_from_wat_downloads.py --download_dir=common_crawl_wat_downloads --output_dataset_name=cc_raw_last_modified --num_proc=224
python combine_last_modified_with_text_dataset.py --text_dataset_name=cc_olm --last_modified_dataset_name=cc_raw_last_modified --output_dataset_name=cc_olm_with_last_modified --url_column=url --crawl_timestamp_column=crawl_timestamp --last_modified_timestamp_column=last_modified_timestamp --num_proc=224
```
You can then upload the final dataset to the Hugging Face Hub from a Python terminal like this:
```
from datasets import load_from_disk
ds = load_from_disk("cc_olm") # Or cc_olm_with_last_modified if you did the optional step above.
ds = ds.shuffle() # Optionally, shuffle the dataset so you can get an idea of what a random sample of the dataset looks like in the Hugging Face Hub dataset preview.
ds.push_to_hub("cc_olm") # Or cc_olm_with_last_modified if you did the optional step above.
```
# Important notes
## Finding the latest Common Crawl snapshots
They are displayed here: [https://commoncrawl.org/the-data/get-started/](https://commoncrawl.org/the-data/get-started/). Just enter the names of the snapshots you want as arguments to the `download_common_crawl.py` script.
## Intermediate dataset checkpoints
Each of the python scripts from the quick start commands saves a Hugging Face dataset to the disk. The dataset is then read by the next python command. These intermediate datasets are not deleted by default, so you can observe what each step of the pipeline does. This also means that you should have a large disk. We use a 15 terabyte disk for the Online Language Modelling Project.
## How to specify the size of the dataset
Increase `--segment_sampling_ratios` to get a larger dataset (it goes up to `1`). In the above quick start code, `0.0001` means that it only uses a sample of `0.01%` of the data from a Common Crawl snapshot. To generate a dataset for the Online Language Modelling Project, we are currently pulling about 1.45 terabytes from each Common Crawl snapshot, which is about 350 gigabytes after going through the BigScience filters and finally 30 gigabytes after going through the deduplication code. For the August 2022 snapshot, 1.45 terabytes is about 20% (i.e. `--segment_sampling_ratios 0.20`). Crawl sizes very though. For May 2022, 1.45 terabytes is about 14%.
If you want to train a larger model than us, then specify a higher value for `--segment_sampling_ratios`, or even use multiple Common Crawl snapshots like this:
```
python download_common_crawl.py --snapshots CC-MAIN-2022-27 CC-MAIN-2022-33 --segment_sampling_ratios 0.5 1 --download_dir=common_crawl_wet_downloads --num_proc=224
```
Keep in mind that, with more data, the deduplication script will need more RAM. Read on for limitations of the deduplication script.
## Limitations of the deduplication code
There are tons of duplicates in Common Crawl data, which means that the deduplication script will need 100's of gigabytes of RAM if you want to generate a 30 gigabyte dataset like us :(. If you want to get around this, there is also the option in the deduplication script for you to chunk the dataset and deduplicate each chunk individually. The main problem is this issue in the Google deduplication code: [https://github.com/google-research/deduplicate-text-datasets/issues/18](https://github.com/google-research/deduplicate-text-datasets/issues/18).
# More documentation
Run any of the python commands with the `--help` flag. For example, `python download_common_crawl.py --help`.
================================================
FILE: pipeline_scripts/common_crawl/apply_bigscience_filters.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
from subprocess import run
from os import path, mkdir
from shutil import rmtree
import sys
import uuid
sys.path.append("data-preparation/preprocessing/training/01b_oscar_cleaning_and_filtering")
from filtering import DatasetFiltering
parser = argparse.ArgumentParser(description="Applies the BigScience BLOOM filters which were used on OSCAR. They are designed to improve text quality and remove pornographic content.")
parser.add_argument("--input_dataset_name", help="The name of the input dataset.", required=True)
parser.add_argument("--output_dataset_name", help="The name of the output dataset.", required=True)
parser.add_argument("--lang_id", help="The language id of your dataset. This is necessary because the BigScience filters use a list of language-specific pornographic words, and also language-specific hyperparameters for text quality improvement.", required=True)
parser.add_argument("--split", default=None, help="The split of the dataset to apply the filters to. Not all datasets have splits, so this is not a required argument.")
parser.add_argument("--text_column", help="The name of the dataset column that contains the text.", required=True)
parser.add_argument("--num_proc", type=int, help="The number of processes to use.", required=True)
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the output dataset to the Hugging Face Hub after saving it to the disk.")
parser.add_argument("--tmp_dir", default=".tmp_apply_bigscience_filters", help="Directory to store temporary files. It will be deleted afterwards. Defaults to .tmp_apply_bigscience_filters.")
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to pull the input dataset by name from the Hugging Face Hub. If this argument is not used, it is assumed that there is a dataset saved to the disk with the input dataset name.")
args = parser.parse_args()
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(args.input_dataset_name)
else:
ds = load_dataset(args.input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(args.input_dataset_name)
else:
ds = load_from_disk(args.input_dataset_name)[args.split]
# We have to do this if the text column is not named "text" in the dataset,
# because DatasetFiltering assumes that the name is "text".
temp_column_name = None
if args.text_column != "text":
if "text" in ds.colum_names:
temp_column_name = str(uuid.uuid4())
ds = ds.rename_column("text", temp_column_name)
ds = ds.rename_column(args.text_column, "text")
if path.exists(args.tmp_dir):
run(f"rm -r {args.tmp_dir}", shell=True)
mkdir(args.tmp_dir)
tmp_dataset_name = path.join(args.tmp_dir, "intermediate_bigscience_filtered_dataset")
dataset_filtering = DatasetFiltering(
dataset=ds,
lang_dataset_id=args.lang_id,
path_fasttext_model="sp_kenlm_ft_models/lid.176.bin",
path_sentencepiece_model=f"sp_kenlm_ft_models/{args.lang_id}.sp.model",
path_kenlm_model=f"sp_kenlm_ft_models/{args.lang_id}.arpa.bin",
num_proc=args.num_proc,
path_dir_save_dataset=tmp_dataset_name,
)
dataset_filtering.modifying_documents()
dataset_filtering.filtering()
dataset_filtering.save_dataset()
ds = load_from_disk(path.join(tmp_dataset_name, args.lang_id))
# We have to do this if the text column is not named "text" in the dataset,
# because DatasetFiltering assumes that the name is "text".
if args.text_column != "text":
ds = ds.rename_column("text", args.text_column)
if temp_column_name is not None:
ds = ds.rename_column(temp_column_name, "text")
ds.save_to_disk(args.output_dataset_name)
rmtree(args.tmp_dir)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/combine_last_modified_with_text_dataset.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
from multiprocessing import Manager
from tqdm import tqdm
import uuid
parser = argparse.ArgumentParser(description="This script takes in a text dataset with crawl timestamps and urls, and then a last-modified dataset with crawl timestamps and urls. It uses the shared urls and crawl timestamps to add last-modified timestamps to the text dataset.")
parser.add_argument("--text_dataset_name", required=True)
parser.add_argument("--last_modified_dataset_name", required=True)
parser.add_argument("--output_dataset_name", required=True)
parser.add_argument("--text_dataset_split", default=None)
parser.add_argument("--last_modified_dataset_split", default=None)
parser.add_argument("--last_modified_timestamp_column", required=True)
parser.add_argument("--crawl_timestamp_column", required=True)
parser.add_argument("--url_column", required=True)
parser.add_argument("--num_proc", type=int, required=True)
parser.add_argument("--load_text_dataset_from_hub_instead_of_disk", action="store_true", help="Whether to load the text dataset from the Hugging Face hub instead of the disk (default is the disk).")
parser.add_argument("--load_last_modified_dataset_from_hub_instead_of_disk", action="store_true", help="Whether to load the last modified dataset from the Hugging Face hub instead of the disk (default is the disk).")
parser.add_argument("--push_to_hub", action="store_true")
args = parser.parse_args()
if args.load_text_dataset_from_hub_instead_of_disk:
if args.text_dataset_split is None:
text_ds = load_dataset(args.text_dataset_name)
else:
text_ds = load_dataset(args.text_dataset_name, split=args.text_dataset_split)
else:
if args.text_dataset_split is None:
text_ds = load_from_disk(args.text_dataset_name)
else:
text_ds = load_from_disk(args.text_dataset_name)[args.text_dataset_split]
if args.load_last_modified_dataset_from_hub_instead_of_disk:
if args.last_modified_dataset_split is None:
last_modified_ds = load_dataset(args.last_modified_dataset_name)
else:
last_modified_ds = load_dataset(args.last_modified_dataset_name, split=args.last_modified_dataset_split)
else:
if args.last_modified_dataset_split is None:
last_modified_ds = load_from_disk(args.last_modified_dataset_name)
else:
last_modified_ds = load_from_disk(args.last_modified_dataset_name)[args.last_modified_dataset_split]
with Manager() as manager:
shared_list = manager.list()
def build_last_modified_dict(examples):
last_modified_dict = {}
for url, crawl_timestamp, last_modified_tag_timestamp in zip(examples[args.url_column], examples[args.crawl_timestamp_column], examples[args.last_modified_timestamp_column]):
last_modified_dict[(url, crawl_timestamp)] = last_modified_tag_timestamp
shared_list.append(last_modified_dict)
last_modified_ds.map(build_last_modified_dict, num_proc=args.num_proc, batched=True, batch_size=len(last_modified_ds) // args.num_proc)
aggregate_last_modified_dict = {}
for last_modified_dict in tqdm(shared_list):
aggregate_last_modified_dict |= last_modified_dict
# Set the new fingerprint manually so the map function doesn't take forever hashing the huge aggregate_last_modified_dict.
text_ds = text_ds.map(lambda example: {args.last_modified_timestamp_column: aggregate_last_modified_dict.get((example[args.url_column], example[args.crawl_timestamp_column]), None)}, new_fingerprint=str(uuid.uuid4()))
text_ds.save_to_disk(args.output_dataset_name)
if args.push_to_hub:
text_ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/deduplicate.py
================================================
from datasets import load_dataset, load_from_disk, concatenate_datasets
from text_dedup.exact_dedup import GoogleSuffixArrayDeduplicator
from shutil import rmtree
from os import path
import argparse
import hashlib
import uuid
parser = argparse.ArgumentParser(description="Applies varying levels of exact deduplication or exact suffix array deduplication to a Hugging Face dataset.")
parser.add_argument("--input_dataset_name", help="Name of the input dataset.", required=True)
parser.add_argument("--output_dataset_name", help="Name of the output dataset.", required=True)
parser.add_argument("--text_column", help="Name of the dataset's text column.", required=True)
parser.add_argument("--split", default=None, help="The split of the dataset to apply deduplication on. Not all datasets have splits, so this argument is optional.")
parser.add_argument("--num_proc", type=int, help="The minimum number of processes to use.", required=True)
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the output dataset to the Hugging Face Hub after saving it to the disk.")
parser.add_argument("--remove_whole_example", action="store_true", help= "If an example in our courpus has a byte string of 100 or longer which is duplicated elsewhere in the corpus, then this option will result in the removal of the whole example. If this option is not specified, then only the substring is removed, not the whole example. In the paper for this deduplication method, they only remove the byte string, not the whole example. Removing the whole example will vastly shrink the size of the dataset, but it will ensure no gaps in text continuity.")
parser.add_argument("--only_exact_duplicates", action="store_true", help="Use this option if you want to forget about the suffix array stuff and just get rid of examples that exactly match other examples in the dataset.")
parser.add_argument("--chunks", type=int, default=1, help="Deduplication can be really memory-intensive. This option allows you to split the dataset up in to n chunks, and perform deduplication independently on each of the chunks. Then the resulting deduplicated datasets are concatenated together at the end.")
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input dataset from the Hugging Face Hub. If this argument is not used, then it is assumed that the input dataset is stored locally on the disk.")
args = parser.parse_args()
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(args.input_dataset_name)
else:
ds = load_dataset(args.input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(args.input_dataset_name)
else:
ds = load_from_disk(args.input_dataset_name)[args.split]
deduplicated_ds_shard_list = []
for ds_shard_index in range(args.chunks):
ds_shard = ds.shard(num_shards=args.chunks, index=ds_shard_index)
if args.remove_whole_example:
def check_for_ending_example_in_cluster(example, index, column, last_index):
if index == last_index:
return True
return ds_shard[index+1][column] != example[column]
# Sort the dataset so examples with the same first 100 bytes of text are grouped together.
print("Sorting by first 100 bytes of text")
temp_column_name = str(uuid.uuid4())
ds_shard = ds_shard.map(lambda example: {temp_column_name: example[args.text_column].encode("u8")[:100]}, num_proc=args.num_proc)
ds_shard = ds_shard.sort(temp_column_name)
# Filter away examples if their first 100 bytes of text exactly matches another example's first 100 bytes of text.
# This gets rid of a subset of the examples that the next step (suffix array deduplication) gets rid of, so we technically
# don't need to do it. But it speeds up the next step quite a bit to do this first.
last_index = len(ds_shard) - 1
len_before = len(ds_shard)
ds_shard = ds_shard.filter(lambda example, index: check_for_ending_example_in_cluster(example, index, temp_column_name, last_index), num_proc=args.num_proc, with_indices=True)
ds_shard = ds_shard.remove_columns(temp_column_name)
print(f"Got rid of all examples sharing first 100 bytes of text, as a speedup step. Removed {len_before - len(ds_shard)} from {len_before} examples.")
# Do the same thing with the ending 100 bytes of text.
print("Sorting by last 100 bytes of text")
temp_column_name = str(uuid.uuid4())
ds_shard = ds_shard.map(lambda example: {temp_column_name: example[args.text_column].encode("u8")[-100:]}, num_proc=args.num_proc)
ds_shard = ds_shard.sort(temp_column_name)
last_index = len(ds_shard) - 1
len_before = len(ds_shard)
ds_shard = ds_shard.filter(lambda example, index: check_for_ending_example_in_cluster(example, index, temp_column_name, last_index), num_proc=args.num_proc, with_indices=True)
ds_shard = ds_shard.remove_columns(temp_column_name)
print(f"Got rid of all examples sharing last 100 bytes of text, as a speedup step. Removed {len_before - len(ds_shard)} from {len_before} examples.")
else:
print("Getting rid of exact duplicates")
def check_for_ending_example_in_cluster(example, index, column, last_index):
if index == last_index:
return True
return ds_shard[index+1][column] != example[column]
temp_column_name = str(uuid.uuid4())
ds_shard = ds_shard.map(lambda example: {temp_column_name: hashlib.md5(example[args.text_column].encode()).hexdigest()}, num_proc=args.num_proc)
ds_shard = ds_shard.sort(temp_column_name)
last_index = len(ds_shard) - 1
ds_shard = ds_shard.filter(lambda example, index: check_for_ending_example_in_cluster(example, index, temp_column_name, last_index), num_proc=args.num_proc, with_indices=True)
ds_shard = ds_shard.remove_columns(temp_column_name)
print("Got rid of exact duplicates")
if path.exists(".cache"):
rmtree(".cache")
if not args.only_exact_duplicates:
# Now, do Suffix Array Substring Exact Deduplication.
deduplicator = GoogleSuffixArrayDeduplicator(k=100)
# We need to create this iterator over the dataset text column
# to ensure that not all of the text entries are loaded into memory at once.
class DatasetColumnIterator():
def __init__(self, dataset, column):
self.iterable_dataset = dataset.__iter__()
self.column = column
def __iter__(self):
return self
def __next__(self):
return self.iterable_dataset.__next__()[self.column]
slices = deduplicator.fit_predict(DatasetColumnIterator(ds_shard, args.text_column))
if args.remove_whole_example:
ds_shard = ds_shard.filter(lambda example, index: slices[index] == [], num_proc=args.num_proc, with_indices=True)
else:
def remove_slice_list(string, slice_list):
for s in slice_list:
string = string.replace(string[s], "")
return string
# It's important to give this map function a uuid as its fingerprint. If we let it compute the fingerprint as a hash of the whole slice_list, then it will take too long.
ds_shard = ds_shard.map(lambda example, index: {args.text_column: remove_slice_list(example[args.text_column], slices[index])}, num_proc=args.num_proc, with_indices=True, new_fingerprint=str(uuid.uuid4()))
ds_shard = ds_shard.filter(lambda example: example[args.text_column] != "", num_proc=args.num_proc)
if path.exists(".cache"):
rmtree(".cache")
deduplicated_ds_shard_list.append(ds_shard)
ds = concatenate_datasets(deduplicated_ds_shard_list)
ds.save_to_disk(args.output_dataset_name)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/download_common_crawl.py
================================================
from os import mkdir, path
from subprocess import run
import argparse
import random
parser = argparse.ArgumentParser(description="Downloads raw Common Crawl WET files, or WAT files if you specify --paths_type=wat.")
parser.add_argument("--snapshots", nargs='+', help="The Common Crawl snapshots to download files from, such as CC-MAIN-2022-33 or CC-MAIN-2022-27. Several can be specified.", required=True)
parser.add_argument("--download_dir", help="The name of the directory to create and download WET files to.", required=True)
parser.add_argument("--segment_sampling_ratios", type=float, nargs="+", help="The ratios of each Common Crawl snapshot to use. The higher the ratio, the larger the generated dataset (but also the longer the time that the OLM pipeline runs). You should specify one for each snapshot. For example, if you specify '--snapshots CC-MAIN-2022-33 CC-MAIN-2022-27', then --segment_sampling_ratios could be '0.15 0.11'. This means that 15 percent of the segments from CC-MAIN-2022-33 will uniformly randomly sampled and used, and 11 percent of the segments from CC-MAIN-2022-27 will be uniformly randomly sampled and used.", required=True)
parser.add_argument("--tmp_dir", default=".tmp_download_common_crawl", help="The directory where temporary files are stored. They are deleted when this script completes. Default is .tmp_download_common_crawl.")
parser.add_argument("--num_proc", type=int, help="The number of processes to use.", required=True)
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--paths_type", default="wet")
args = parser.parse_args()
random.seed(args.seed)
if path.exists(args.download_dir):
run(f"rm -r {args.download_dir}", shell=True)
if path.exists(args.tmp_dir):
run(f"rm -r {args.tmp_dir}", shell=True)
run(f"mkdir {args.download_dir} {args.tmp_dir}", shell=True)
for index in range(len(args.snapshots)):
# Download the data for a certian common crawl snapshot
tmp_download_dir_name = f"{args.tmp_dir}/ungoliant_downloads-{args.snapshots[index]}"
run(f"mkdir {tmp_download_dir_name}", shell=True)
run(f"wget https://data.commoncrawl.org/crawl-data/{args.snapshots[index]}/{args.paths_type}.paths.gz", shell=True)
run(f"gzip -d {args.paths_type}.paths.gz", shell=True)
paths_name = f"{args.paths_type}-{args.snapshots[index]}.paths"
run(f"mv {args.paths_type}.paths {paths_name}", shell=True)
segments = open(paths_name, "r").readlines()
kept_segments = []
for segment in segments:
if random.random() <= args.segment_sampling_ratios[index]:
kept_segments.append(segment)
open(paths_name, "w").writelines(kept_segments)
run(f"ungoliant download -t={args.num_proc} {paths_name} {tmp_download_dir_name}", shell=True)
run(f"rm {paths_name}", shell=True)
# Now, add 0's to the filename for every downloaded file. We want the number of 0's to be different than those from another common crawl snapshot
# because we want every file to have a unique name accross multiple snapshot downloads.
if index > 0:
run(f"cd {tmp_download_dir_name} && for f in * ; do mv \"$f\" {'0'*index}\"$f\" ; done", shell=True)
# Now we can move the downloaded files into the main download dir which has the downloads from the rest of this for loop.
run(f"mv {tmp_download_dir_name}/* {args.download_dir}/", shell=True)
run(f"rm -r {tmp_download_dir_name}", shell=True)
run(f"rm -r {args.tmp_dir}", shell=True)
run("rm -r errors.txt", shell=True)
================================================
FILE: pipeline_scripts/common_crawl/download_pipeline_processing_models.sh
================================================
# exit when any command fails
set -e
python data-preparation/preprocessing/training/01b_oscar_cleaning_and_filtering/download_sentencepiece_kenlm_models.py --output_dir_path=sp_kenlm_ft_models
wget https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin -P sp_kenlm_ft_models/
================================================
FILE: pipeline_scripts/common_crawl/experimental/add_perplexity.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
import sys
sys.path.append("kenlm")
from model import KenlmModel
parser = argparse.ArgumentParser(description="This script simply uses a kenlm trained on English Wikipedia to compute the perplexity of each text example in the dataset. It then sorts the dataset by perplexity so that the user can then select the range of perplexities that they want their data to be in.")
parser.add_argument("--input_dataset_name", help="The name of the input dataset.", required=True)
parser.add_argument("--output_dataset_name", help="The name of the output dataset.", required=True)
parser.add_argument("--split", default=None, help="The split of the dataset to apply the filters to. Not all datasets have splits, so this is not a required argument.")
parser.add_argument("--text_column", help="The name of the dataset column that contains the text.", required=True)
parser.add_argument("--num_proc", type=int, help="The number of processes to use.", required=True)
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the output dataset to the Hugging Face Hub after saving it to the disk.")
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to pull the input dataset by name from the Hugging Face Hub. If this argument is not used, it is assumed that there is a dataset saved to the disk with the input dataset name.")
args = parser.parse_args()
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(args.input_dataset_name)
else:
ds = load_dataset(args.input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(args.input_dataset_name)
else:
ds = load_from_disk(args.input_dataset_name)[args.split]
model = KenlmModel.from_pretrained("kenlm/wikipedia", "en")
ds = ds.map(lambda example: {"kenlm_ppl": model.get_perplexity(example[args.text_column])}, num_proc=args.num_proc)
ds = ds.sort("kenlm_ppl")
ds.save_to_disk(args.output_dataset_name)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/experimental/filter_for_only_updated_websites.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
parser = argparse.ArgumentParser(description="Experimental script to check and filter for a diff between examples with the same URL. It drastically reduces the size of the dataset in many cases, but it helps ensure that the text is up to date. The script only keeps an example if 1) the example shares a URL with other examples 2) the example is the most recent example with that URL 3) there was a diff between the example and an earlier example with the same URL.")
parser.add_argument("--input_dataset_name", required=True)
parser.add_argument("--output_dataset_name", required=True)
parser.add_argument("--text_column", required=True)
parser.add_argument("--timestamp_column", required=True)
parser.add_argument("--split", default=None, help="The split of the datset to apply this filter to. Not all datsets have splits, so this argument is optional.")
parser.add_argument("--url_column", required=True)
parser.add_argument("--num_proc", type=int, required=True)
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the output dataset to the Hugging Face Hub after saving it to the disk.")
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input datset from the Hugging Face Hub. If this argument is not used, it is assumed that the input dataset is stored on the disk.")
args = parser.parse_args()
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(args.input_dataset_name)
else:
ds = load_dataset(args.input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(args.input_dataset_name)
else:
ds = load_from_disk(args.input_dataset_name)[args.split]
# Group so examples with the same URL are next to each other in the dataset.
ds = ds.sort(args.url_column)
# Throw away examples with URLs occuring only once in the dataset.
last_index = len(ds) - 1
def check_for_adjacent_duplicate_url(example, index):
if index == last_index:
return ds[index-1][args.url_column] == example[args.url_column]
if index == 0:
return ds[index+1][args.url_column] == example[args.url_column]
return ds[index-1][args.url_column] == example[args.url_column] or ds[index+1][args.url_column] == example[args.url_column]
ds = ds.filter(lambda example, index: check_for_adjacent_duplicate_url(example, index), num_proc=args.num_proc, with_indices=True)
# Sort the dataset so that examples with the same URL are still grouped together, but also arrange by timestamp from oldest to newest.
ds = ds.sort(args.timestamp_column)
ds = ds.sort(args.url_column, kind="stable")
# Keep only the pair of examples from each URL group with the oldest and newest timestamp.
last_index = len(ds) - 1
def check_for_ending_or_beginning_example_in_url_cluster(example, index):
if index in (last_index, 0):
return True
return ds[index-1][args.url_column] != example[args.url_column] or ds[index+1][args.url_column] != example[args.url_column]
ds = ds.filter(lambda example, index: check_for_ending_or_beginning_example_in_url_cluster(example, index), num_proc=args.num_proc, with_indices=True)
# For each example pair, check to see if the text was modified between the old time and the new time.
# If it was modified, keep the latest example and throw the old example out. We have evidence that this new example is up-to-date :D
# If it wasn't modified, throw both examples out. We have no evidence that this new example is up-to-date :(
last_index = len(ds) - 1
def check_for_updated_example_in_url_pair(example, index):
if index == 0 or ds[index-1][args.url_column] != example[args.url_column]:
return False
if ds[index-1][args.text_column] != example[args.text_column]:
return True
return False
ds = ds.filter(lambda example, index: check_for_updated_example_in_url_pair(example, index), num_proc=args.num_proc, with_indices=True)
ds.save_to_disk(args.output_dataset_name)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/experimental/kenlm/LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2021-2022 Eduardo González Ponferrada
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: pipeline_scripts/common_crawl/experimental/kenlm/README.md
================================================
---
language:
- es
- af
- ar
- arz
- as
- bn
- fr
- sw
- eu
- ca
- zh
- en
- hi
- ur
- id
- pt
- vi
- gu
- kn
- ml
- mr
- ta
- te
- yo
tags:
- kenlm
- perplexity
- n-gram
- kneser-ney
- bigscience
license: "mit"
datasets:
- wikipedia
- oscar
---
Taken from the amazing repo here: [https://huggingface.co/edugp/kenlm](https://huggingface.co/edugp/kenlm)
# KenLM models
This repo contains several KenLM models trained on different tokenized datasets and languages.
KenLM models are probabilistic n-gram languge models that models. One use case of these models consist on fast perplexity estimation for [filtering or sampling large datasets](https://huggingface.co/bertin-project/bertin-roberta-base-spanish). For example, one could use a KenLM model trained on French Wikipedia to run inference on a large dataset and filter out samples that are very unlike to appear on Wikipedia (high perplexity), or very simple non-informative sentences that could appear repeatedly (low perplexity).
At the root of this repo you will find different directories named after the dataset models were trained on (e.g. `wikipedia`, `oscar`). Within each directory, you will find several models trained on different language subsets of the dataset (e.g. `en (English)`, `es (Spanish)`, `fr (French)`). For each language you will find three different files
* `{language}.arpa.bin`: The trained KenLM model binary
* `{language}.sp.model`: The trained SentencePiece model used for tokenization
* `{language}.sp.vocab`: The vocabulary file for the SentencePiece model
The models have been trained using some of the preprocessing steps from [cc_net](https://github.com/facebookresearch/cc_net), in particular replacing numbers with zeros and normalizing punctuation. So, it is important to keep the default values for the parameters: `lower_case`, `remove_accents`, `normalize_numbers` and `punctuation` when using the pre-trained models in order to replicate the same pre-processing steps at inference time.
# Dependencies
* KenLM: `pip install https://github.com/kpu/kenlm/archive/master.zip`
* SentencePiece: `pip install sentencepiece`
# Example:
```
from model import KenlmModel
# Load model trained on English wikipedia
model = KenlmModel.from_pretrained("wikipedia", "en")
# Get perplexity
model.get_perplexity("I am very perplexed")
# 341.3 (low perplexity, since sentence style is formal and with no grammar mistakes)
model.get_perplexity("im hella trippin")
# 46793.5 (high perplexity, since the sentence is colloquial and contains grammar mistakes)
```
In the example above we see that, since Wikipedia is a collection of encyclopedic articles, a KenLM model trained on it will naturally give lower perplexity scores to sentences with formal language and no grammar mistakes than colloquial sentences with grammar mistakes.
================================================
FILE: pipeline_scripts/common_crawl/experimental/kenlm/model.py
================================================
import os
import re
import unicodedata
from typing import Dict
import kenlm
import sentencepiece
from huggingface_hub import cached_download, hf_hub_url
class SentencePiece:
def __init__(
self,
model: str,
):
super().__init__()
self.sp = sentencepiece.SentencePieceProcessor()
self.sp.load(str(model))
def do(self, text: dict) -> dict:
tokenized = self.sp.encode_as_pieces(text)
return " ".join(tokenized)
class KenlmModel:
digit_re: re.Pattern = re.compile(r"\d")
unicode_punct: Dict[str, str] = {
",": ",",
"。": ".",
"、": ",",
"„": '"',
"”": '"',
"“": '"',
"«": '"',
"»": '"',
"1": '"',
"」": '"',
"「": '"',
"《": '"',
"》": '"',
"´": "'",
"∶": ":",
":": ":",
"?": "?",
"!": "!",
"(": "(",
")": ")",
";": ";",
"–": "-",
"—": " - ",
".": ". ",
"~": "~",
"’": "'",
"…": "...",
"━": "-",
"〈": "<",
"〉": ">",
"【": "[",
"】": "]",
"%": "%",
"►": "-",
}
unicode_punct_re = re.compile(f"[{''.join(unicode_punct.keys())}]")
non_printing_chars_re = re.compile(
f"[{''.join(map(chr, list(range(0,32)) + list(range(127,160))))}]"
)
kenlm_model_dir = None
sentence_piece_model_dir = None
def __init__(
self,
model_dataset: str,
language: str,
lower_case: bool = False,
remove_accents: bool = False,
normalize_numbers: bool = True,
punctuation: int = 1,
):
self.model = kenlm.Model(os.path.join(model_dataset, f"{language}.arpa.bin"))
self.tokenizer = SentencePiece(os.path.join(model_dataset, f"{language}.sp.model"))
self.accent = remove_accents
self.case = lower_case
self.numbers = normalize_numbers
self.punct = punctuation
@classmethod
def from_pretrained(
cls,
model_dataset: str,
language: str,
):
return cls(
model_dataset,
language,
False,
False,
True,
1,
)
def pp(self, log_score, length):
return 10.0 ** (-log_score / length)
def get_perplexity(self, doc: str, normalize_cc_net: bool = True):
if normalize_cc_net:
doc = self.normalize(
doc,
accent=self.accent,
case=self.case,
numbers=self.numbers,
punct=self.punct,
)
# Tokenize (after normalizing): See https://github.com/facebookresearch/cc_net/blob/bda555bd1cf1ee2e0b925363e62a61cd46c8b60d/cc_net/mine.py#L352 for full pipeline
doc = self.tokenizer.do(doc)
doc_log_score, doc_length = 0, 0
for line in doc.split("\n"):
log_score = self.model.score(line)
length = len(line.split()) + 1
doc_log_score += log_score
doc_length += length
return round(self.pp(doc_log_score, doc_length), 1)
def normalize(
self,
line: str,
accent: bool = True,
case: bool = True,
numbers: bool = True,
punct: int = 1,
) -> str:
line = line.strip()
if not line:
return line
if case:
line = line.lower()
if accent:
line = self.strip_accents(line)
if numbers:
line = self.digit_re.sub("0", line)
if punct == 1:
line = self.replace_unicode_punct(line)
elif punct == 2:
line = self.remove_unicode_punct(line)
line = self.remove_non_printing_char(line)
return line
def strip_accents(self, line: str) -> str:
"""Strips accents from a piece of text."""
nfd = unicodedata.normalize("NFD", line)
output = [c for c in nfd if unicodedata.category(c) != "Mn"]
if len(output) == line:
return line
return "".join(output)
def replace_unicode_punct(self, text: str) -> str:
return "".join(self.unicode_punct.get(c, c) for c in text)
def remove_unicode_punct(self, text: str) -> str:
"""More aggressive version of replace_unicode_punct but also faster."""
return self.unicode_punct_re.sub("", text)
def remove_non_printing_char(self, text: str) -> str:
return self.non_printing_chars_re.sub("", text)
================================================
FILE: pipeline_scripts/common_crawl/experimental/kenlm/wikipedia/en.sp.model
================================================
version https://git-lfs.github.com/spec/v1
oid sha256:cf8147a573770b4e6c0d4df1dcb75453baa88190706dab406be7711b84f059de
size 931348
================================================
FILE: pipeline_scripts/common_crawl/experimental/kenlm/wikipedia/en.sp.vocab
================================================
version https://git-lfs.github.com/spec/v1
oid sha256:a9c3c51a7736d736cc620cbe9a4c9430533469e57a54bc29546067a252f7d872
size 729017
================================================
FILE: pipeline_scripts/common_crawl/get_last_modified_dataset_from_wat_downloads.py
================================================
from datasets import load_dataset
from tqdm import tqdm
import pandas as pd
import subprocess
from multiprocessing import Process
from os import walk, mkdir, path
from shutil import rmtree
import dateutil
import dateparser
import argparse
import ujson
parser = argparse.ArgumentParser(description="Turns WAT downloads from download_common_crawl.py into a Hugging Face dataset with Last-Modified timestamps, URLs, and crawl timestamps.")
parser.add_argument("--download_dir", help="The directory of the downloaded WAT files.", required=True)
parser.add_argument("--output_dataset_name", help="The name of the Hugging Face dataset which will be saved upon completion of this program.", required=True)
parser.add_argument("--num_proc", type=int, help="The number of processes to use.", required=True)
parser.add_argument("--tmp_dir", default=".tmp_get_last_modified_dataset_from_wat_downloads")
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the Hugging Face dataset to the Hugging Face Hub after saving a copy to the disk.")
args = parser.parse_args()
if path.exists(args.tmp_dir):
rmtree(args.tmp_dir)
mkdir(args.tmp_dir)
filenames = next(walk(args.download_dir), (None, None, []))[2]
def split_a_into_n_parts(a, n):
k, m = divmod(len(a), n)
return [a[i*k+min(i, m):(i+1)*k+min(i+1, m)] for i in range(n)]
filename_per_proc = [names for names in split_a_into_n_parts(filenames, args.num_proc) if len(names) != 0]
processes = []
for filenames in filename_per_proc:
def get_dataset(filenames):
for filename in tqdm(filenames):
dataset_dict = {"last_modified_timestamp": [], "url": [], "crawl_timestamp": []}
file_path = path.join(args.download_dir, filename)
if filename.endswith(".gz"):
subprocess.run(f"gzip -d {file_path}", shell=True)
filename = filename[:-3]
file_path = path.join(args.download_dir, filename)
for line in open(file_path).readlines():
if line.startswith("{"):
parsed_line = ujson.loads(line)
last_modified = parsed_line.get("Envelope", {}).get("Payload-Metadata", {}).get("HTTP-Response-Metadata", {}).get("Headers", {}).get("Last-Modified", None)
url = parsed_line.get("Envelope", {}).get("WARC-Header-Metadata", {}).get("WARC-Target-URI", None)
date = parsed_line.get("Envelope", {}).get("WARC-Header-Metadata", {}).get("WARC-Date", None)
if None not in (last_modified, url, date):
try:
last_modified_timestamp = dateutil.parser.parse(last_modified).timestamp()
except Exception:
try:
last_modified_timestamp = dateparser.parse(last_modified).timestamp()
except Exception:
last_modified_timestamp = None
if last_modified_timestamp is not None:
crawl_timestamp = dateutil.parser.parse(date).timestamp()
dataset_dict["last_modified_timestamp"].append(last_modified_timestamp)
dataset_dict["url"].append(url)
dataset_dict["crawl_timestamp"].append(crawl_timestamp)
# Zip the download file again to save space.
subprocess.run(f"gzip {file_path}", shell=True)
pd.DataFrame(dataset_dict).to_parquet(path.join(args.tmp_dir, filename + ".filtered.parquet"))
p = Process(target=get_dataset, args=(filenames,))
p.start()
processes.append(p)
for p in processes:
p.join()
ds = load_dataset("parquet", data_files=path.join(args.tmp_dir, "*.parquet"))
ds.save_to_disk(args.output_dataset_name)
rmtree(args.tmp_dir)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/get_text_dataset_from_wet_downloads.py
================================================
from datasets import load_dataset
from tqdm import tqdm
import pandas as pd
import subprocess
from multiprocessing import Process
from os import walk, mkdir, path
from shutil import move, rmtree
import dateutil
import argparse
parser = argparse.ArgumentParser(description="Turns downloads from download_common_crawl.py into a Hugging Face dataset, split by language (language is identified using a FastText model). The dataset has a timestamp column for the time it was crawled, along with a url column and, of course, a text column.")
parser.add_argument("--download_dir", help="The directory of the downloaded WET files.", required=True)
parser.add_argument("--output_dataset_name", help="The name of the Hugging Face dataset which will be saved upon completion of this program.", required=True)
parser.add_argument("--num_proc", type=int, help="The number of processes to use, at a minimum.", required=True)
parser.add_argument("--tmp_dir", default=".tmp_get_dataset_from_downloads", help="The directory to store temporary files. The directory will be deleted upon completion of this script. Defaults to .tmp_get_datasets_from_downloads.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the Hugging Face dataset to the Hugging Face Hub after saving a copy to the disk.")
args = parser.parse_args()
if path.exists(args.tmp_dir):
rmtree(args.tmp_dir)
mkdir(args.tmp_dir)
tmp_download_dir = path.join(args.tmp_dir, "downloads")
move(args.download_dir, tmp_download_dir)
filenames = next(walk(tmp_download_dir), (None, None, []))[2]
def split_a_into_n_parts(a, n):
k, m = divmod(len(a), n)
return [a[i*k+min(i, m):(i+1)*k+min(i+1, m)] for i in range(n)]
ungoliant_pipeline_output_dirs = []
filename_per_directory = [names for names in split_a_into_n_parts(filenames, args.num_proc) if len(names) != 0]
num_files_awaiting_processing = 0
dirs_awaiting_processing = []
def do_parallel_pipeline_processing(dirs_awaiting_processing):
processes = []
for obj in dirs_awaiting_processing:
p = subprocess.Popen(f"ungoliant pipeline --lid-path=sp_kenlm_ft_models/lid.176.bin {obj['download_chunk_dir']} {obj['pipeline_output_dir']}", shell=True)
processes.append(p)
for p in processes:
p.wait()
# This loop runs the ungoliant pipeline num_proc number of times to generate num_proc number of output files.
# the ungoliant pipeline is already parallelized, so we don't do this so that the ungoliant pipeline will run faster.
# Instead, we do this so that we will have num_proc number of output files so we can load them in parallel into a
# pandas dataframes, which will eventually be turned into Hugging Face dataset.
ungoliant_pipeline_results = path.join(args.tmp_dir, "ungoliant_pipeline_results")
mkdir(ungoliant_pipeline_results)
for i in range(len(filename_per_directory)):
download_chunk_dir = path.join(tmp_download_dir, "chunk_" + str(i))
mkdir(download_chunk_dir)
for filename in filename_per_directory[i]:
num_files_awaiting_processing += 1
move(path.join(tmp_download_dir, filename), path.join(download_chunk_dir, filename))
pipeline_output_dir = path.join(ungoliant_pipeline_results, "chunk_" + str(i))
mkdir(pipeline_output_dir)
ungoliant_pipeline_output_dirs.append(pipeline_output_dir)
dirs_awaiting_processing.append({"pipeline_output_dir": pipeline_output_dir, "download_chunk_dir": download_chunk_dir})
if num_files_awaiting_processing >= args.num_proc:
do_parallel_pipeline_processing(dirs_awaiting_processing)
num_files_awaiting_processing = 0
dirs_awaiting_processing = []
do_parallel_pipeline_processing(dirs_awaiting_processing)
# For some reason, datasets errors out if we try to load directly from the jsonl, so we need to do this first.
processes = []
for ungoliant_pipeline_output_dir in ungoliant_pipeline_output_dirs:
language_filenames = [name for name in next(walk(ungoliant_pipeline_output_dir), (None, None, []))[2] if name.endswith("_meta.jsonl")]
language_ids = [language_filename.split("_")[0] for language_filename in language_filenames]
def convert_to_parquet_and_reformat(ungoliant_pipeline_output_dir):
for language_filename in language_filenames:
language_id = language_filename.split("_")[0]
i = 0
print("Chunking the ungoliant json into several parquet files and reformatting before loading into huggingface dataset.")
parquet_file_dir = path.join(ungoliant_pipeline_output_dir, language_id + "_parquet")
mkdir(parquet_file_dir)
for chunk in tqdm(pd.read_json(path.join(ungoliant_pipeline_output_dir, language_id + "_meta.jsonl"), lines=True, chunksize=10000)):
parquet_file_path = path.join(parquet_file_dir, str(i) + ".parquet")
chunk["url"] = chunk.apply(lambda row: row["warc_headers"]["warc-target-uri"], axis=1)
chunk["crawl_timestamp"] = chunk.apply(lambda row: dateutil.parser.parse(row["warc_headers"]["warc-date"]).timestamp(), axis=1)
chunk.drop(columns=["warc_headers", "metadata"], inplace=True)
chunk.rename(columns={"content": "text"}, inplace=True)
chunk.to_parquet(parquet_file_path)
i += 1
p = Process(target=convert_to_parquet_and_reformat, args=(ungoliant_pipeline_output_dir,))
p.start()
processes.append(p)
for p in processes:
p.join()
data_files = {language_id: [path.join(ungoliant_pipeline_output_dir, language_id + "_parquet", "*.parquet") for ungoliant_pipeline_output_dir in ungoliant_pipeline_output_dirs] for language_id in language_ids}
ds = load_dataset("parquet", data_files=data_files)
ds.save_to_disk(args.output_dataset_name)
rmtree(args.tmp_dir)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/common_crawl/remove_wikipedia_urls.py
================================================
from datasets import load_dataset, load_from_disk
import argparse
parser = argparse.ArgumentParser(description="Removes all examples from a Hugging Face dataset if they have a Wikipedia URL. This script is intened to be used if you eventually want to merge the dataset with a Wikipedia snapshot. In that case, examples from Wikipedia in this dataset are redundant.")
parser.add_argument("--input_dataset_name", help="Input dataset name.", required=True)
parser.add_argument("--output_dataset_name", help="Output dataset name.", required=True)
parser.add_argument("--url_column", help="Name of the URL column of the dataset.", required=True)
parser.add_argument("--split", default=None, help="The split of the dataset to use. Some datasets don't have splits, so it is optional.")
parser.add_argument("--num_proc", type=int, help="The number of processes to use.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether to push the output dataset to the Hugging Face hub after saving to the disk.")
parser.add_argument("--load_from_hub_instead_of_disk", action="store_true", help="Whether to load the input dataset by name from the Hugging Face hub. If this argument isn't specified then the input dataset will be loaded from a directory of the same name on the disk.")
args = parser.parse_args()
if args.load_from_hub_instead_of_disk:
if args.split is None:
ds = load_dataset(args.input_dataset_name)
else:
ds = load_dataset(args.input_dataset_name, split=args.split)
else:
if args.split is None:
ds = load_from_disk(args.input_dataset_name)
else:
ds = load_from_disk(args.input_dataset_name)[args.split]
ds = ds.filter(lambda example: not example[args.url_column].startswith("https://en.wikipedia.org/wiki/"), num_proc=args.num_proc)
ds.save_to_disk(args.output_dataset_name)
if args.push_to_hub:
ds.push_to_hub(args.output_dataset_name)
================================================
FILE: pipeline_scripts/wikipedia/README.md
================================================
Per the repository [here](https://huggingface.co/datasets/olm/wikipedia), just run this Python code. It uses all CPUs available and should take less than an hour if you have a lot of CPUs (on the order of 100).
```
from datasets import load_dataset
ds = load_dataset("olm/wikipedia", language="en", date="20220920")
ds.save_to_disk("wikipedia_en_20220920")
ds.push_to_hub("wikipedia_en_20220920")
````
The code pulls the Wikipedia snapshot for the given date and language and does all the processing required to turn it into a clean pretraining dataset. You can get the dates for the latest wikipedia snapshots here: [https://dumps.wikimedia.org/enwiki/](https://dumps.wikimedia.org/enwiki/).
================================================
FILE: requirements.txt
================================================
datasets==2.6.1
emoji==1.7.0
fasttext==0.9.2
sentencepiece==0.1.97
pypi-kenlm==0.1.20220713
text-dedup==0.2.1
argparse==1.4.0
dateparser==1.1.1
mwparserfromhell==0.6.4
matplotlib==3.6.2
multiprocess==0.70.13
gitextract_wh2bu5g5/ ├── .gitmodules ├── LICENSE ├── README.md ├── analysis_scripts/ │ ├── README.md │ ├── duplicates.py │ ├── term_counts.py │ ├── timestamp_dist.py │ └── url_dist.py ├── pipeline_scripts/ │ ├── common_crawl/ │ │ ├── README.md │ │ ├── apply_bigscience_filters.py │ │ ├── combine_last_modified_with_text_dataset.py │ │ ├── deduplicate.py │ │ ├── download_common_crawl.py │ │ ├── download_pipeline_processing_models.sh │ │ ├── experimental/ │ │ │ ├── add_perplexity.py │ │ │ ├── filter_for_only_updated_websites.py │ │ │ └── kenlm/ │ │ │ ├── LICENSE │ │ │ ├── README.md │ │ │ ├── model.py │ │ │ └── wikipedia/ │ │ │ ├── en.sp.model │ │ │ └── en.sp.vocab │ │ ├── get_last_modified_dataset_from_wat_downloads.py │ │ ├── get_text_dataset_from_wet_downloads.py │ │ └── remove_wikipedia_urls.py │ └── wikipedia/ │ └── README.md └── requirements.txt
SYMBOL INDEX (34 symbols across 10 files)
FILE: analysis_scripts/duplicates.py
function same_adjacent_entry (line 37) | def same_adjacent_entry(entry, index):
FILE: analysis_scripts/term_counts.py
function build_count_dict (line 75) | def build_count_dict(examples):
function term_counts (line 133) | def term_counts(text):
FILE: analysis_scripts/timestamp_dist.py
function reject_outliers (line 41) | def reject_outliers(data, m = 10.):
FILE: analysis_scripts/url_dist.py
function build_count_dict (line 60) | def build_count_dict(examples):
FILE: pipeline_scripts/common_crawl/combine_last_modified_with_text_dataset.py
function build_last_modified_dict (line 47) | def build_last_modified_dict(examples):
FILE: pipeline_scripts/common_crawl/deduplicate.py
function check_for_ending_example_in_cluster (line 38) | def check_for_ending_example_in_cluster(example, index, column, last_ind...
function check_for_ending_example_in_cluster (line 72) | def check_for_ending_example_in_cluster(example, index, column, last_ind...
class DatasetColumnIterator (line 96) | class DatasetColumnIterator():
method __init__ (line 97) | def __init__(self, dataset, column):
method __iter__ (line 101) | def __iter__(self):
method __next__ (line 104) | def __next__(self):
function remove_slice_list (line 111) | def remove_slice_list(string, slice_list):
FILE: pipeline_scripts/common_crawl/experimental/filter_for_only_updated_websites.py
function check_for_adjacent_duplicate_url (line 32) | def check_for_adjacent_duplicate_url(example, index):
function check_for_ending_or_beginning_example_in_url_cluster (line 47) | def check_for_ending_or_beginning_example_in_url_cluster(example, index):
function check_for_updated_example_in_url_pair (line 58) | def check_for_updated_example_in_url_pair(example, index):
FILE: pipeline_scripts/common_crawl/experimental/kenlm/model.py
class SentencePiece (line 11) | class SentencePiece:
method __init__ (line 12) | def __init__(
method do (line 20) | def do(self, text: dict) -> dict:
class KenlmModel (line 25) | class KenlmModel:
method __init__ (line 70) | def __init__(
method from_pretrained (line 87) | def from_pretrained(
method pp (line 101) | def pp(self, log_score, length):
method get_perplexity (line 104) | def get_perplexity(self, doc: str, normalize_cc_net: bool = True):
method normalize (line 123) | def normalize(
method strip_accents (line 147) | def strip_accents(self, line: str) -> str:
method replace_unicode_punct (line 155) | def replace_unicode_punct(self, text: str) -> str:
method remove_unicode_punct (line 158) | def remove_unicode_punct(self, text: str) -> str:
method remove_non_printing_char (line 162) | def remove_non_printing_char(self, text: str) -> str:
FILE: pipeline_scripts/common_crawl/get_last_modified_dataset_from_wat_downloads.py
function split_a_into_n_parts (line 28) | def split_a_into_n_parts(a, n):
function get_dataset (line 36) | def get_dataset(filenames):
FILE: pipeline_scripts/common_crawl/get_text_dataset_from_wet_downloads.py
function split_a_into_n_parts (line 30) | def split_a_into_n_parts(a, n):
function do_parallel_pipeline_processing (line 38) | def do_parallel_pipeline_processing(dirs_awaiting_processing):
function convert_to_parquet_and_reformat (line 74) | def convert_to_parquet_and_reformat(ungoliant_pipeline_output_dir):
Condensed preview — 26 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (119K chars).
[
{
"path": ".gitmodules",
"chars": 327,
"preview": "[submodule \"data-preparation\"]\n\tpath = pipeline_scripts/common_crawl/data-preparation\n\turl = https://github.com/bigscien"
},
{
"path": "LICENSE",
"chars": 11417,
"preview": "Copyright 2022- The Hugging Face team. All rights reserved.\n\n Apache License\n "
},
{
"path": "README.md",
"chars": 4316,
"preview": "# Online Language Modelling Dataset Pipeline\n\nThis repo enables you to pull a large and up-to-date text corpus from the "
},
{
"path": "analysis_scripts/README.md",
"chars": 12185,
"preview": "# OLM Analysis\n\n## To analyze for term counts accross various datasets\n\nThis command reports the count of terms associat"
},
{
"path": "analysis_scripts/duplicates.py",
"chars": 2504,
"preview": "from datasets import load_dataset, load_from_disk, concatenate_datasets\nimport argparse\nimport matplotlib.pyplot as plt\n"
},
{
"path": "analysis_scripts/term_counts.py",
"chars": 8580,
"preview": "from datasets import load_dataset, load_from_disk\nimport argparse\nimport numpy as np\nimport matplotlib.pyplot as plt\nfro"
},
{
"path": "analysis_scripts/timestamp_dist.py",
"chars": 5163,
"preview": "from datasets import load_dataset, load_from_disk\nimport argparse\nimport numpy as np\nimport matplotlib.pyplot as plt\nimp"
},
{
"path": "analysis_scripts/url_dist.py",
"chars": 6437,
"preview": "from datasets import load_dataset, load_from_disk\nimport argparse\nfrom collections import Counter\nfrom multiprocessing i"
},
{
"path": "pipeline_scripts/common_crawl/README.md",
"chars": 5222,
"preview": "\nfrom model import "
},
{
"path": "pipeline_scripts/common_crawl/experimental/filter_for_only_updated_websites.py",
"chars": 4134,
"preview": "from datasets import load_dataset, load_from_disk\nimport argparse\n\nparser = argparse.ArgumentParser(description=\"Experim"
},
{
"path": "pipeline_scripts/common_crawl/experimental/kenlm/LICENSE",
"chars": 11362,
"preview": "\n Apache License\n Version 2.0, January 2004\n "
},
{
"path": "pipeline_scripts/common_crawl/experimental/kenlm/README.md",
"chars": 2871,
"preview": "---\nlanguage: \n - es\n - af\n - ar\n - arz\n - as\n - bn\n - fr\n - sw\n - eu\n - ca\n - zh\n - en\n - hi\n - ur\n - id"
},
{
"path": "pipeline_scripts/common_crawl/experimental/kenlm/model.py",
"chars": 4558,
"preview": "import os\nimport re\nimport unicodedata\nfrom typing import Dict\n\nimport kenlm\nimport sentencepiece\nfrom huggingface_hub i"
},
{
"path": "pipeline_scripts/common_crawl/experimental/kenlm/wikipedia/en.sp.model",
"chars": 131,
"preview": "version https://git-lfs.github.com/spec/v1\noid sha256:cf8147a573770b4e6c0d4df1dcb75453baa88190706dab406be7711b84f059de\ns"
},
{
"path": "pipeline_scripts/common_crawl/experimental/kenlm/wikipedia/en.sp.vocab",
"chars": 131,
"preview": "version https://git-lfs.github.com/spec/v1\noid sha256:a9c3c51a7736d736cc620cbe9a4c9430533469e57a54bc29546067a252f7d872\ns"
},
{
"path": "pipeline_scripts/common_crawl/get_last_modified_dataset_from_wat_downloads.py",
"chars": 3952,
"preview": "from datasets import load_dataset\nfrom tqdm import tqdm\nimport pandas as pd\nimport subprocess\nfrom multiprocessing impor"
},
{
"path": "pipeline_scripts/common_crawl/get_text_dataset_from_wet_downloads.py",
"chars": 5869,
"preview": "from datasets import load_dataset\nfrom tqdm import tqdm\nimport pandas as pd\nimport subprocess\nfrom multiprocessing impor"
},
{
"path": "pipeline_scripts/common_crawl/remove_wikipedia_urls.py",
"chars": 1912,
"preview": "from datasets import load_dataset, load_from_disk\nimport argparse\n\nparser = argparse.ArgumentParser(description=\"Removes"
},
{
"path": "pipeline_scripts/wikipedia/README.md",
"chars": 697,
"preview": "Per the repository [here](https://huggingface.co/datasets/olm/wikipedia), just run this Python code. It uses all CPUs av"
},
{
"path": "requirements.txt",
"chars": 208,
"preview": "datasets==2.6.1\nemoji==1.7.0\nfasttext==0.9.2\nsentencepiece==0.1.97\npypi-kenlm==0.1.20220713\ntext-dedup==0.2.1\nargparse=="
}
]
About this extraction
This page contains the full source code of the huggingface/olm-datasets GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 26 files (110.9 KB), approximately 26.8k tokens, and a symbol index with 34 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.