| Model Name | Performance Sentence Embeddings (14 Datasets) | Performance Semantic Search (6 Datasets) | Avg. Performance | Speed | Model Size | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| {{ item.name }} | {{ item.sentence_performance > 0 ? item.sentence_performance.toFixed(2) : "" }} | {{ item.semantic_search > 0 ? item.semantic_search.toFixed(2) : "" }} | {{ (item.sentence_performance > 0 && item.semantic_search > 0) ? item.avg_performance.toFixed(2) : "" }} | {{ item.speed }} | {{ item.size }} MB | ||||||||||||||||||||||
|
|||||||||||||||||||||||||||
BinaryCrossEntropyLoss is a traditional option that remains very challenging to outperform.
- `(anchor, positive) pairs` without any labels: combined with mine_hard_negatives
- with output_format="labeled-list", then LambdaLoss is frequently used for learning-to-rank tasks.
- with output_format="labeled-pair", then BinaryCrossEntropyLoss remains a strong option.
## Custom Loss Functions
```{eval-rst}
Advanced users can create and train with their own loss functions. Custom loss functions only have a few requirements:
- They must be a subclass of :class:`torch.nn.Module`.
- They must have ``model`` as the first argument in the constructor.
- They must implement a ``forward`` method that accepts ``inputs`` and ``labels``. The former is a nested list of texts in the batch, with each element in the outer list representing a column in the training dataset. You have to combine these texts into pairs that can be 1) tokenized and 2) fed to the model. The latter is an optional (list of) tensor(s) of labels from a ``label``, ``labels``, ``score``, or ``scores`` column in the dataset. The method must return a single loss value or a dictionary of loss components (component names to loss values) that will be summed to produce the final loss value. When returning a dictionary, the individual components will be logged separately in addition to the summed loss, allowing you to monitor the individual components of the loss.
To get full support with the automatic model card generation, you may also wish to implement:
- a ``get_config_dict`` method that returns a dictionary of loss parameters.
- a ``citation`` property so your work gets cited in all models that train with the loss.
Consider inspecting existing loss functions to get a feel for how loss functions are commonly implemented.
```
================================================
FILE: docs/cross_encoder/pretrained_models.md
================================================
# Pretrained Models
```{eval-rst}
We have released various pre-trained Cross Encoder models via our Cross Encoder Hugging Face organization. Additionally, numerous community Cross Encoder models have been publicly released on the Hugging Face Hub.
* **Original models**: `Cross Encoder Hugging Face organization learning_rate
lr_scheduler_type
warmup_ratio
num_train_epochs
max_steps
per_device_train_batch_size
per_device_eval_batch_size
auto_find_batch_size
fp16
bf16
load_best_model_at_end
metric_for_best_model
gradient_accumulation_steps
gradient_checkpointing
eval_accumulation_steps
optim
dataloader_num_workers
dataloader_prefetch_factor
batch_sampler
multi_dataset_batch_sampler
learning_rate_mapping
model_kwargs will be passed on to OVBaseModel.from_pretrained(). Some notable arguments include:
* ``file_name``: The name of the ONNX file to load. If not specified, will default to ``"openvino_model.xml"`` or otherwise ``"openvino/openvino_model.xml"``. This argument is useful for specifying optimized or quantized models.
* ``export``: A boolean flag specifying whether the model will be exported. If not provided, ``export`` will be set to ``True`` if the model repository or directory does not already contain an OpenVINO model.
.. tip::
It's heavily recommended to save the exported model to prevent having to re-export it every time you run your code. You can do this by calling :meth:`model.save_pretrained() sentence1 and sentence2 columns as pairs, with 38.94 ± 13.97 and 38.96 ± 14.05 characters on average, respectively.
query and answer columns as pairs, with 46.99 ± 10.98 and 619.63 ± 345.30 characters on average, respectively.
text column: first 100 characters (100.00 ± 0.00 characters) and each sample repeated 4 times (16804.25 ± 10178.26 characters).
torch-fp32: PyTorch with float32 precision (default).
torch-fp16: PyTorch with float16 precision, via model_kwargs={"torch_dtype": "float16"}.
torch-bf16: PyTorch with bfloat16 precision, via model_kwargs={"torch_dtype": "bfloat16"}.
onnx: ONNX with float32 precision, via backend="onnx".
onnx-O1: ONNX with float32 precision and O1 optimization, via export_optimized_onnx_model(..., optimization_config="O1", ...) and backend="onnx".
onnx-O2: ONNX with float32 precision and O2 optimization, via export_optimized_onnx_model(..., optimization_config="O2", ...) and backend="onnx".
onnx-O3: ONNX with float32 precision and O3 optimization, via export_optimized_onnx_model(..., optimization_config="O3", ...) and backend="onnx".
onnx-O4: ONNX with float16 precision and O4 optimization, via export_optimized_onnx_model(..., optimization_config="O4", ...) and backend="onnx".
onnx-qint8: ONNX quantized to int8 with "avx512_vnni", via export_dynamic_quantized_onnx_model(..., quantization_config="avx512_vnni", ...) and backend="onnx". The different quantization configurations resulted in roughly equivalent speedups.
openvino: OpenVINO, via backend="openvino".
openvino-qint8: OpenVINO quantized to int8 via export_static_quantized_openvino_model(..., quantization_config=OVQuantizationConfig(), ...) and backend="openvino".
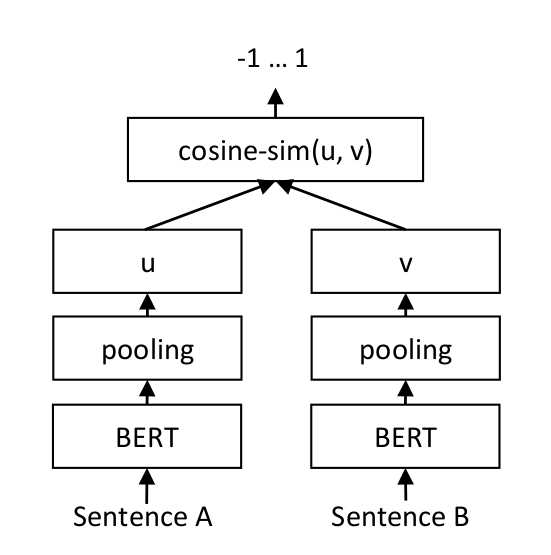 For each sentence pair, we pass sentence A and sentence B through our network which yields the embeddings *u* und *v*. The similarity of these embeddings is computed using cosine similarity and the result is compared to the gold similarity score.
This allows our network to be fine-tuned to recognize the similarity of sentences.
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CosineSimilarityLoss
```
## DenoisingAutoEncoderLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.DenoisingAutoEncoderLoss
```
## GISTEmbedLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.GISTEmbedLoss
```
## CachedGISTEmbedLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CachedGISTEmbedLoss
```
## GlobalOrthogonalRegularizationLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.GlobalOrthogonalRegularizationLoss
```
## MSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MSELoss
```
## MarginMSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MarginMSELoss
```
## MatryoshkaLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MatryoshkaLoss
```
## Matryoshka2dLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.Matryoshka2dLoss
```
## AdaptiveLayerLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.AdaptiveLayerLoss
```
## MegaBatchMarginLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MegaBatchMarginLoss
```
## MultipleNegativesRankingLoss
*MultipleNegativesRankingLoss* is a great loss function if you only have positive pairs, for example, only pairs of similar texts like pairs of paraphrases, pairs of duplicate questions, pairs of (query, response), or pairs of (source_language, target_language).
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MultipleNegativesRankingLoss
```
## CachedMultipleNegativesRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CachedMultipleNegativesRankingLoss
```
## MultipleNegativesSymmetricRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MultipleNegativesSymmetricRankingLoss
```
## CachedMultipleNegativesSymmetricRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CachedMultipleNegativesSymmetricRankingLoss
```
## SoftmaxLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.SoftmaxLoss
```
## TripletLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.TripletLoss
```
## DistillKLDivLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.DistillKLDivLoss
```
================================================
FILE: docs/package_reference/sentence_transformer/models.md
================================================
# Modules
`sentence_transformers.models` defines different building blocks, a.k.a. Modules, that can be used to create SentenceTransformer models from scratch. For more details, see [Creating Custom Models](../../sentence_transformer/usage/custom_models.rst).
## Main Modules
```{eval-rst}
.. autoclass:: sentence_transformers.models.Transformer
.. autoclass:: sentence_transformers.models.Pooling
.. autoclass:: sentence_transformers.models.Dense
.. autoclass:: sentence_transformers.models.Normalize
.. autoclass:: sentence_transformers.models.Router
:members: for_query_document
.. autoclass:: sentence_transformers.models.StaticEmbedding
:members: from_model2vec, from_distillation
```
## Further Modules
```{eval-rst}
.. autoclass:: sentence_transformers.models.BoW
.. autoclass:: sentence_transformers.models.CNN
.. autoclass:: sentence_transformers.models.LSTM
.. autoclass:: sentence_transformers.models.WeightedLayerPooling
.. autoclass:: sentence_transformers.models.WordEmbeddings
.. autoclass:: sentence_transformers.models.WordWeights
```
## Base Modules
```{eval-rst}
.. autoclass:: sentence_transformers.models.Module
:members: config_file_name, config_keys, save_in_root, forward, get_config_dict, load, load_config, load_file_path, load_dir_path, load_torch_weights, save, save_config, save_torch_weights
.. autoclass:: sentence_transformers.models.InputModule
:members: save_in_root, tokenizer, tokenize, save_tokenizer
```
================================================
FILE: docs/package_reference/sentence_transformer/quantization.md
================================================
# quantization
`sentence_transformers.quantization` defines different helpful functions to perform embedding quantization.
```{eval-rst}
.. note::
`Embedding Quantization <../../../examples/sentence_transformer/applications/embedding-quantization/README.html>`_ differs from model quantization. The former shrinks the size of embeddings such that semantic search/retrieval is faster and requires less memory and disk space. The latter refers to lowering the precision of the model weights to speed up inference. This page only shows documentation for the former.
```
```{eval-rst}
.. automodule:: sentence_transformers.quantization
:members: quantize_embeddings, semantic_search_faiss, semantic_search_usearch
```
================================================
FILE: docs/package_reference/sentence_transformer/sampler.md
================================================
# Samplers
## BatchSamplers
```{eval-rst}
.. autoclass:: sentence_transformers.training_args.BatchSamplers
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.DefaultBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.NoDuplicatesBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.GroupByLabelBatchSampler
:members:
```
## MultiDatasetBatchSamplers
```{eval-rst}
.. autoclass:: sentence_transformers.training_args.MultiDatasetBatchSamplers
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.MultiDatasetDefaultBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.RoundRobinBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.ProportionalBatchSampler
:members:
```
================================================
FILE: docs/package_reference/sentence_transformer/trainer.md
================================================
# Trainer
## SentenceTransformerTrainer
```{eval-rst}
.. autoclass:: sentence_transformers.trainer.SentenceTransformerTrainer
:members:
:inherited-members:
:exclude-members: autocast_smart_context_manager, collect_features, compute_loss_context_manager, evaluation_loop, floating_point_ops, get_decay_parameter_names, get_optimizer_cls_and_kwargs, init_hf_repo, log_metrics, metrics_format, num_examples, num_tokens, predict, prediction_loop, prediction_step, save_metrics, save_state, training_step
```
================================================
FILE: docs/package_reference/sentence_transformer/training_args.md
================================================
# Training Arguments
## SentenceTransformerTrainingArguments
```{eval-rst}
.. autoclass:: sentence_transformers.training_args.SentenceTransformerTrainingArguments
:members:
:inherited-members:
```
================================================
FILE: docs/package_reference/sparse_encoder/SparseEncoder.md
================================================
# SparseEncoder
## SparseEncoder
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.SparseEncoder
:members:
:inherited-members:
:exclude-members: fit, old_fit, save, save_to_hub, add_module, append, apply, buffers, children, extra_repr, forward, get_buffer, get_extra_state, get_parameter, get_submodule, ipu, load_state_dict, modules, named_buffers, named_children, named_modules, named_parameters, parameters, register_backward_hook, register_buffer, register_forward_hook, register_forward_pre_hook, register_full_backward_hook, register_full_backward_pre_hook, register_load_state_dict_post_hook, register_module, register_parameter, register_state_dict_pre_hook, requires_grad_, set_extra_state, share_memory, state_dict, to_empty, type, xpu, zero_grad, truncate_sentence_embeddings, encode_multi_process
```
## SparseEncoderModelCardData
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.model_card.SparseEncoderModelCardData
:members:
```
## SimilarityFunction
```{eval-rst}
.. autoclass:: sentence_transformers.SimilarityFunction
:members:
```
================================================
FILE: docs/package_reference/sparse_encoder/callbacks.md
================================================
# Callbacks
## SpladeRegularizerWeightSchedulerCallback
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.callbacks.splade_callbacks.SpladeRegularizerWeightSchedulerCallback
```
================================================
FILE: docs/package_reference/sparse_encoder/evaluation.md
================================================
# Evaluation
`sentence_transformers.sparse_encoder.evaluation` defines different classes, that can be used to evaluate the SparseEncoder model during training.
## SparseInformationRetrievalEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator
```
## SparseNanoBEIREvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator
```
## SparseEmbeddingSimilarityEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseEmbeddingSimilarityEvaluator
```
## SparseBinaryClassificationEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseBinaryClassificationEvaluator
```
## SparseTripletEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseTripletEvaluator
```
## SparseRerankingEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseRerankingEvaluator
```
## SparseTranslationEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseTranslationEvaluator
```
## SparseMSEEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseMSEEvaluator
```
## ReciprocalRankFusionEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.ReciprocalRankFusionEvaluator
================================================
FILE: docs/package_reference/sparse_encoder/index.rst
================================================
Sparse Encoder
=============
.. toctree::
SparseEncoder
trainer
training_args
losses
../sentence_transformer/sampler
evaluation
models
callbacks
search_engines
================================================
FILE: docs/package_reference/sparse_encoder/losses.md
================================================
# Losses
`sentence_transformers.sparse_encoder.losses` defines different loss functions that can be used to fine-tune saprse embedding models on training data. The choice of loss function plays a critical role when fine-tuning the model. It determines how well our embedding model will work for the specific downstream task.
Sadly, there is no "one size fits all" loss function. Which loss function is suitable depends on the available training data and on the target task. Consider checking out the [Loss Overview](../../sparse_encoder/loss_overview.md) to help narrow down your choice of loss function(s).
```{eval-rst}
.. warning::
To train a :class:`~sentence_transformers.sparse_encoder.SparseEncoder`, you need either :class:`~sentence_transformers.sparse_encoder.losses.SpladeLoss` or :class:`~sentence_transformers.sparse_encoder.losses.CSRLoss`, depending on the architecture. These are wrapper losses that add sparsity regularization on top of a main loss function, which must be provided as a parameter. The only loss that can be used independently is :class:`~sentence_transformers.sparse_encoder.losses.SparseMSELoss`, as it performs embedding-level distillation, ensuring sparsity by directly copying the teacher's sparse embedding.
```
## SpladeLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SpladeLoss
```
## CachedSpladeLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.CachedSpladeLoss
```
## FlopsLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.FlopsLoss
```
## CSRLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.CSRLoss
```
## CSRReconstructionLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.CSRReconstructionLoss
```
## SparseMultipleNegativesRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseMultipleNegativesRankingLoss
```
## SparseMarginMSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseMarginMSELoss
```
## SparseDistillKLDivLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseDistillKLDivLoss
```
## SparseTripletLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseTripletLoss
```
## SparseCosineSimilarityLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseCosineSimilarityLoss
```
## SparseCoSENTLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseCoSENTLoss
```
## SparseAnglELoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseAnglELoss
```
## SparseMSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseMSELoss
```
================================================
FILE: docs/package_reference/sparse_encoder/models.md
================================================
# Modules
`sentence_transformers.sparse_encoder.models` defines different building blocks, that can be used to create SparseEncoder networks from scratch. For more details, see [Training Overview](../../sparse_encoder/training_overview.md).
Note that modules from `sentence_transformers.models` can also be used for Sparse models, such as `sentence_transformers.models.Transformer` from [SentenceTransformer > Modules](../sentence_transformer/models.md)
## SPLADE Pooling
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.SpladePooling
```
## MLM Transformer
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.MLMTransformer
```
## SparseAutoEncoder
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.SparseAutoEncoder
```
## SparseStaticEmbedding
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.SparseStaticEmbedding
```
================================================
FILE: docs/package_reference/sparse_encoder/search_engines.md
================================================
# Search Engines
`sentence_transformers.sparse_encoder.search_engines` defines different helpful functions to integrate with vector databases and search engines the sparse embeddings produced.
```{eval-rst}
.. automodule:: sentence_transformers.sparse_encoder.search_engines
:members: semantic_search_qdrant, semantic_search_elasticsearch, semantic_search_seismic, semantic_search_opensearch
```
================================================
FILE: docs/package_reference/sparse_encoder/trainer.md
================================================
# Trainer
## SparseEncoderTrainer
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.SparseEncoderTrainer
:members:
:inherited-members:
:exclude-members: autocast_smart_context_manager, collect_features, compute_loss_context_manager, evaluation_loop, floating_point_ops, get_decay_parameter_names, get_optimizer_cls_and_kwargs, init_hf_repo, log_metrics, metrics_format, num_examples, num_tokens, predict, prediction_loop, prediction_step, save_metrics, save_state, training_step
```
================================================
FILE: docs/package_reference/sparse_encoder/training_args.md
================================================
# Training Arguments
## SparseEncoderTrainingArguments
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.training_args.SparseEncoderTrainingArguments
:members:
:inherited-members:
```
================================================
FILE: docs/package_reference/util.md
================================================
# util
`sentence_transformers.util` defines different helpful functions to work with text embeddings.
## Helper Functions
```{eval-rst}
.. automodule:: sentence_transformers.util
:members: paraphrase_mining, semantic_search, community_detection, http_get, truncate_embeddings, normalize_embeddings, is_training_available, mine_hard_negatives
```
## Model Optimization
```{eval-rst}
.. automodule:: sentence_transformers.backend
:members: export_optimized_onnx_model, export_dynamic_quantized_onnx_model, export_static_quantized_openvino_model
```
## Similarity Metrics
```{eval-rst}
.. automodule:: sentence_transformers.util
:members: cos_sim, pairwise_cos_sim, dot_score, pairwise_dot_score, manhattan_sim, pairwise_manhattan_sim, euclidean_sim, pairwise_euclidean_sim
```
================================================
FILE: docs/pretrained-models/ce-msmarco.md
================================================
# MS MARCO Cross-Encoders
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consists of over 8.8 million passages.
## Usage with SentenceTransformers
Pre-trained models can be used like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder("model_name", max_length=512)
scores = model.predict(
[("Query", "Paragraph1"), ("Query", "Paragraph2"), ("Query", "Paragraph3")]
)
```
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained("model_name")
tokenizer = AutoTokenizer.from_pretrained("model_name")
features = tokenizer(["Query", "Query"], ["Paragraph1", "Paragraph2"], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
## Models & Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- | :-------------: | :-----: | ---: |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L2 | 67.43 | 30.15 | 9000 |
| cross-encoder/ms-marco-TinyBERT-L4 | 68.09 | 34.50 | 2900 |
| cross-encoder/ms-marco-TinyBERT-L6 | 69.57 | 36.13 | 680 |
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340 |
| **Other models** | | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900 |
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340 |
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100 |
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340 |
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330 |
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU with Hugging Face Transformers v4.
================================================
FILE: docs/pretrained-models/dpr.md
================================================
# DPR-Models
In [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) Karpukhin et al. trained models based on [Google's Natural Questions dataset](https://ai.google.com/research/NaturalQuestions):
- **facebook-dpr-ctx_encoder-single-nq-base**
- **facebook-dpr-question_encoder-single-nq-base**
They also trained models on the combination of Natural Questions, TriviaQA, WebQuestions, and CuratedTREC.
- **facebook-dpr-ctx_encoder-multiset-base**
- **facebook-dpr-question_encoder-multiset-base**
There is one model to encode passages and one model to encode question / queries.
## Usage
To encode paragraphs, you need to provide a title (e.g. the Wikipedia article title) and the text passage. These must be separated with a `[SEP]` token. For encoding paragraphs, we use the **ctx_encoder**.
Queries are encoded with **question_encoder**:
```python
from sentence_transformers import SentenceTransformer, util
passage_encoder = SentenceTransformer("facebook-dpr-ctx_encoder-single-nq-base")
passages = [
"London [SEP] London is the capital and largest city of England and the United Kingdom.",
"Paris [SEP] Paris is the capital and most populous city of France.",
"Berlin [SEP] Berlin is the capital and largest city of Germany by both area and population.",
]
passage_embeddings = passage_encoder.encode(passages)
query_encoder = SentenceTransformer("facebook-dpr-question_encoder-single-nq-base")
query = "What is the capital of England?"
query_embedding = query_encoder.encode(query)
# Important: You must use dot-product, not cosine_similarity
scores = util.dot_score(query_embedding, passage_embeddings)
print("Scores:", scores)
```
**Important note:** When you use these models, you have to use them with dot-product (e.g. as implemented in `util.dot_score`) and not with cosine similarity.
================================================
FILE: docs/pretrained-models/msmarco-v1.md
================================================
# MSMARCO Models
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Version History
### v1
Version 1 models were trained on the training set of MS Marco Passage retrieval task. The models were trained using in-batch negative sampling via the MultipleNegativesRankingLoss with a scaling factor of 20 and a batch size of 128.
They can be used like this:
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("distilroberta-base-msmarco-v1")
query_embedding = model.encode("[QRY] " + "How big is London")
passage_embedding = model.encode("[DOC] " + "London has 9,787,426 inhabitants at the 2011 census")
print("Similarity:", util.pytorch_cos_sim(query_embedding, passage_embedding))
```
**Models**:
- **distilroberta-base-msmarco-v1** - Performance MSMARCO dev dataset (queries.dev.small.tsv) MRR@10: 23.28
================================================
FILE: docs/pretrained-models/msmarco-v2.md
================================================
# MSMARCO Models (Version 2)
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("msmarco-distilroberta-base-v2")
query_embedding = model.encode("How big is London")
passage_embedding = model.encode("London has 9,787,426 inhabitants at the 2011 census")
print("Similarity:", util.pytorch_cos_sim(query_embedding, passage_embedding))
```
For more details on the usage, see [Applications - Information Retrieval](../../examples/sentence_transformer/applications/retrieve_rerank/README.md)
## Performance
Performance is evaluated on [TREC-DL 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/), which is a query-passage retrieval task where multiple queries have been annotated as with their relevance with respect to the given query. Further, we evaluate on the [MS Marco Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
As baseline we show the results for lexical search with BM25 using Elasticsearch.
| Approach | NDCG@10 (TREC DL 19 Reranking) | MRR@10 (MS Marco Dev) |
| ------------- |:-------------: | :---: |
| BM25 (Elasticsearch) | 45.46 | 17.29 |
| msmarco-distilroberta-base-v2 | 65.65 | 28.55 |
| msmarco-roberta-base-v2 | 67.18 | 29.17 |
| msmarco-distilbert-base-v2 | 68.35 | 30.77 |
## Version History
- [Version 1](msmarco-v1.md)
================================================
FILE: docs/pretrained-models/msmarco-v3.md
================================================
# MSMARCO Models
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("msmarco-distilbert-base-v3")
query_embedding = model.encode("How big is London")
passage_embedding = model.encode("London has 9,787,426 inhabitants at the 2011 census")
print("Similarity:", util.cos_sim(query_embedding, passage_embedding))
```
For more details on the usage, see [Applications - Information Retrieval](../../examples/sentence_transformer/applications/retrieve_rerank/README.md)
## Performance
Performance is evaluated on [TREC-DL 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/), which is a query-passage retrieval task where multiple queries have been annotated as with their relevance with respect to the given query. Further, we evaluate on the [MS Marco Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
As baseline we show the results for lexical search with BM25 using Elasticsearch.
| Approach | NDCG@10 (TREC DL 19 Reranking) | MRR@10 (MS Marco Dev) | Queries (GPU / CPU) | Docs (GPU / CPU)
| ------------- |:-------------: | :---: | :---: | :---: |
| **Models tuned for cosine-similarity** | |
| msmarco-MiniLM-L6-v3 | 67.46 | 32.27 | 18,000 / 750 | 2,800 / 180
| msmarco-MiniLM-L12-v3 | 65.14 | 32.75 | 11,000 / 400 | 1,500 / 90
| msmarco-distilbert-base-v3| 69.02 | 33.13 | 7,000 / 350 | 1,100 / 70
| msmarco-distilbert-base-v4 | **70.24** | **33.79**| 7,000 / 350 | 1,100 / 70
| msmarco-roberta-base-v3 | 69.08 | 33.01 | 4,000 / 170 | 540 / 30
| **Models tuned for dot-product** | |
| msmarco-distilbert-base-dot-prod-v3 | 68.42 | 33.04 | 7,000 / 350 | 1100 / 70
| [msmarco-roberta-base-ance-firstp](https://github.com/microsoft/ANCE) | 67.84 | 33.01 | 4,000 / 170 | 540 / 30
| [msmarco-distilbert-base-tas-b](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco) | **71.04** | **34.43** | 7,000 / 350 | 1100 / 70
| **Previous approaches** | | |
| BM25 (Elasticsearch) | 45.46 | 17.29 |
| msmarco-distilroberta-base-v2 | 65.65 | 28.55 |
| msmarco-roberta-base-v2 | 67.18 | 29.17 |
| msmarco-distilbert-base-v2 | 68.35 | 30.77 |
**Notes:**
- We provide two type of models, one tuned for **cosine-similarity**, the other for **dot-product**. Make sure to use the right method to compute the similarity between query and passages.
- Models tuned for **cosine-similarity** will prefer the retrieval of shorter passages, while models for **dot-product** will prefer the retrieval of longer passages. Depending on your task, you might prefer the one or the other type of model.
- **msmarco-roberta-base-ance-firstp** is the MSMARCO Dev Passage Retrieval ANCE(FirstP) 600K model from [ANCE](https://github.com/microsoft/ANCE). This model should be used with dot-product instead of cosine similarity.
- **msmarco-distilbert-base-tas-b** uses the model from [sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco). See the linked documentation / paper for more details.
- Encoding speeds are per second and were measured on a V100 GPU and an 8 core Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
## Changes in v3
The models from v2 have been used for find for all training queries similar passages. An [MS MARCO Cross-Encoder](ce-msmarco.md) based on the electra-base-model has been then used to classify if these retrieved passages answer the question.
If they received a low score by the cross-encoder, we saved them as hard negatives: They got a high score from the bi-encoder, but a low-score from the (better) cross-encoder.
We then trained the v2 models with these new hard negatives.
## Version History
- [Version 2](msmarco-v2.md)
- [Version 1](msmarco-v1.md)
================================================
FILE: docs/pretrained-models/msmarco-v5.md
================================================
# MSMARCO Models
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("msmarco-distilbert-dot-v5")
query_embedding = model.encode("How big is London")
passage_embedding = model.encode([
"London has 9,787,426 inhabitants at the 2011 census",
"London is known for its financial district",
])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))
```
For more details on the usage, see [Applications - Information Retrieval](../../examples/sentence_transformer/applications/retrieve_rerank/README.md)
## Performance
Performance is evaluated on [TREC-DL 2019](https://microsoft.github.io/msmarco/TREC-Deep-Learning-2019) and [TREC-DL 2020](https://microsoft.github.io/msmarco/TREC-Deep-Learning-2020), which are a query-passage retrieval task where multiple queries have been annotated as with their relevance with respect to the given query. Further, we evaluate on the [MS Marco Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Approach | MRR@10 (MS Marco Dev) | NDCG@10 (TREC DL 19 Reranking) | NDCG@10 (TREC DL 20 Reranking) | Queries (GPU / CPU) | Docs (GPU / CPU)
| ------------- | :-------------: | :-------------: | :---: | :---: | :---: |
| **Models tuned with normalized embeddings** | |
| [msmarco-MiniLM-L6-cos-v5](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L6-cos-v5) | 32.27 | 67.46 | 64.73 | 18,000 / 750 | 2,800 / 180
| [msmarco-MiniLM-L12-cos-v5](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L12-cos-v5) | 32.75 | 65.14 | 67.48 | 11,000 / 400 | 1,500 / 90
| [msmarco-distilbert-cos-v5](https://huggingface.co/sentence-transformers/msmarco-distilbert-cos-v5) | 33.79 | 70.24 | 66.24 | 7,000 / 350 | 1,100 / 70
| [multi-qa-MiniLM-L6-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1) | | 65.55 | 64.66 | 18,000 / 750 | 2,800 / 180
| [multi-qa-distilbert-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-distilbert-cos-v1) | | 67.59 | 66.46 | 7,000 / 350 | 1,100 / 70
| [multi-qa-mpnet-base-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-cos-v1) | | 67.78 | 69.87 | 4,000 / 170 | 540 / 30
| **Models tuned for dot-product** | |
| [msmarco-distilbert-base-tas-b](https://huggingface.co/sentence-transformers/msmarco-distilbert-base-tas-b) | 34.43 | 71.04 | 69.78 | 7,000 / 350 | 1100 / 70
| [msmarco-distilbert-dot-v5](https://huggingface.co/sentence-transformers/msmarco-distilbert-dot-v5) | 37.25 | 70.14 | 71.08 | 7,000 / 350 | 1100 / 70
| [msmarco-bert-base-dot-v5](https://huggingface.co/sentence-transformers/msmarco-bert-base-dot-v5) | 38.08 | 70.51 | 73.45 | 4,000 / 170 | 540 / 30
| [multi-qa-MiniLM-L6-dot-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-dot-v1) | | 66.70 | 65.98 | 18,000 / 750 | 2,800 / 180
| [multi-qa-distilbert-dot-v1](https://huggingface.co/sentence-transformers/multi-qa-distilbert-dot-v1) | | 68.05 | 70.49 | 7,000 / 350 | 1,100 / 70
| [multi-qa-mpnet-base-dot-v1](https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-dot-v1) | | 70.66 | 71.18 | 4,000 / 170 | 540 / 30
**Notes:**
- We provide two type of models: One that produces **normalized embedding** and can be used with dot-product, cosine-similarity or euclidean distance (all three scoring function will produce the same results). The models tuned for **dot-product** will produce embeddings of different lengths and must be used with dot-product to find close items in a vector space.
- Models with normalized embeddings will prefer the retrieval of shorter passages, while models tuned for **dot-product** will prefer the retrieval of longer passages. Depending on your task, you might prefer the one or the other type of model.
- Encoding speeds are per second and were measured on a V100 GPU and an 8 core Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
## Changes in v5
- Models with normalized embeddings were added: These are the v3 cosine-similarity models, but with an additional normalize layer on-top.
- New models trained with MarginMSE loss trained: msmarco-distilbert-dot-v5 and msmarco-bert-base-dot-v5
## Changes in v4
- Just one new model was trained with better hard negatives, leading to a small improvement compared to v3
## Changes in v3
The models from v2 have been used for find for all training queries similar passages. An [MS MARCO Cross-Encoder](ce-msmarco.md) based on the electra-base-model has been then used to classify if these retrieved passages answer the question.
If they received a low score by the cross-encoder, we saved them as hard negatives: They got a high score from the bi-encoder, but a low-score from the (better) cross-encoder.
We then trained the v2 models with these new hard negatives.
## Version History
- [Version 3](msmarco-v3.md)
- [Version 2](msmarco-v2.md)
- [Version 1](msmarco-v1.md)
================================================
FILE: docs/pretrained-models/nli-models.md
================================================
# NLI Models
Conneau et al., 2017, show in the InferSent-Paper ([Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://huggingface.co/papers/1705.02364)) that training on Natural Language Inference (NLI) data can produce universal sentence embeddings.
The datasets labeled sentence pairs with the labels *entail*, *contradict*, and *neutral*. For both sentences, we compute a sentence embedding. These two embeddings are concatenated and passed to softmax classifier to derive the final label.
As shown, this produces sentence embeddings that can be used for various use cases like clustering or semantic search.
# Datasets
We train the models on the [SNLI](https://nlp.stanford.edu/projects/snli/) and on the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) dataset. We call the combination of the two datasets AllNLI.
For a training example, see [examples/sentence_transformer/training/nli/training_nli.py](../../examples/sentence_transformer/training/nli/training_nli.py).
# Pretrained models
We provide the various pre-trained models. The performance was evaluated on the test set of the STS benchmark dataset ([docs](https://web.archive.org/web/20231128064114/http://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark), [dataset](https://huggingface.co/datasets/sentence-transformers/stsb)) using Spearman rank correlation.
[» Full List of NLI & STS Models](https://docs.google.com/spreadsheets/d/14QplCdTCDwEmTqrn1LH4yrbKvdogK4oQvYO1K1aPR5M/edit#gid=0)
# Performance Comparison
Here are the performances on the STS benchmark for other sentence embeddings methods. They were also computed by using cosine-similarity and Spearman rank correlation:
- Avg. GloVe embeddings: 58.02
- BERT-as-a-service avg. embeddings: 46.35
- BERT-as-a-service CLS-vector: 16.50
- InferSent - GloVe: 68.03
- Universal Sentence Encoder: 74.92
# Applications
This model works well in accessing the coarse-grained similarity between sentences. For application examples, see [semantic_textual_similarity](../sentence_transformer/usage/semantic_textual_similarity.rst) and [semantic search](../../examples/sentence_transformer/applications/semantic-search/README.md).
================================================
FILE: docs/pretrained-models/nq-v1.md
================================================
# Natural Questions Models
[Google's Natural Questions dataset](https://ai.google.com/research/NaturalQuestions) consists of about 100k real search queries from Google with the respective, relevant passage from Wikipedia. Models trained on this dataset work well for question-answer retrieval.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("nq-distilbert-base-v1")
query_embedding = model.encode("How many people live in London?")
# The passages are encoded as [ [title1, text1], [title2, text2], ...]
passage_embedding = model.encode(
[["London", "London has 9,787,426 inhabitants at the 2011 census."]]
)
print("Similarity:", util.cos_sim(query_embedding, passage_embedding))
```
Note: For the passage, we have to encode the Wikipedia article title together with a text paragraph from that article.
## Performance
The models are evaluated on the Natural Questions development dataset using MRR@10.
| Approach | MRR@10 (NQ dev set small) |
| ------------- |:-------------: |
| nq-distilbert-base-v1 | 72.36 |
| *Other models* | |
| [DPR](https://huggingface.co/transformers/model_doc/dpr.html) | 58.96 |
================================================
FILE: docs/pretrained-models/sts-models.md
================================================
# STS Models
The models were first trained on [NLI data](nli-models.md), then we fine-tuned them on the STS benchmark dataset ([docs](https://web.archive.org/web/20231128064114/http://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark), [dataset](https://huggingface.co/datasets/sentence-transformers/stsb)). This generate sentence embeddings that are especially suitable to measure the semantic similarity between sentence pairs.
# Datasets
We use the training file from the [STS benchmark dataset](https://huggingface.co/datasets/sentence-transformers/stsb).
For a training example, see:
- [examples/sentence_transformer/training_stsbenchmark.py](https://github.com/huggingface/sentence-transformers/blob/main/examples/sentence_transformer/training/sts/training_stsbenchmark.py) - Train directly on STS data
- [examples/sentence_transformer/training_stsbenchmark_continue_training.py ](https://github.com/huggingface/sentence-transformers/blob/main/examples/sentence_transformer/training/sts/training_stsbenchmark_continue_training.py) - First train on NLI, than train on STS data.
# Pre-trained models
We provide the following pre-trained models:
[» Full List of STS Models](https://docs.google.com/spreadsheets/d/14QplCdTCDwEmTqrn1LH4yrbKvdogK4oQvYO1K1aPR5M/edit#gid=0)
# Performance Comparison
Here are the performances on the STS benchmark for other sentence embeddings methods. They were also computed by using cosine-similarity and Spearman rank correlation. Note, these models were not-fined on the STS benchmark.
- Avg. GloVe embeddings: 58.02
- BERT-as-a-service avg. embeddings: 46.35
- BERT-as-a-service CLS-vector: 16.50
- InferSent - GloVe: 68.03
- Universal Sentence Encoder: 74.92
================================================
FILE: docs/pretrained-models/wikipedia-sections-models.md
================================================
# Wikipedia Sections Models
The `wikipedia-sections-models` implement the idea from Ein Dor et al., 2018, [Learning Thematic Similarity Metric Using Triplet Networks](https://aclweb.org/anthology/P18-2009).
It was trained with a triplet-loss: The anchor and the positive example were sentences from the same section from an wikipedia article, for example, from the History section of the London article. The negative example came from a different section from the same article, for example, from the Education section of the London article.
# Dataset
We use dataset from Ein Dor et al., 2018, [Learning Thematic Similarity Metric Using Triplet Networks](https://aclweb.org/anthology/P18-2009).
See [examples/sentence_transformer/training/other/training_wikipedia_sections.py](../../examples/sentence_transformer/training/other/training_wikipedia_sections.py) for how to train on this dataset.
# Pre-trained models
We provide the following pre-trained models:
- **bert-base-wikipedia-sections-mean-tokens**: 80.42% accuracy on test set.
You can use them in the following way:
```
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("bert-base-wikipedia-sections-mean-tokens")
```
# Performance Comparison
Performance (accuracy) reported by Dor et al.:
- mean-vectors: 0.65
- skip-thoughts-CS: 0.615
- skip-thoughts-SICK: 0.547
- triplet-sen: 0.74
# Applications
The models achieve a rather low performance on the STS benchmark dataset. The reason for this is the training objective: An anchor, a positive and a negative example are presented. The network must only learn to differentiate what the positive and what the negative example is by ensuring that the negative example is further away from the anchor than the positive example.
However, it does not matter how far the negative example is away, it can be little or really far away. This makes this model rather bad for deciding if a pair is somewhat similar. It learns only to recognize similar pairs (high scores) and dissimilar pairs (low scores).
However, this model works well for **fine-grained clustering**.
================================================
FILE: docs/publications.md
================================================
# Publications
If you find this repository helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://huggingface.co/papers/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
If you use one of the multilingual models, feel free to cite our publication [Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation](https://huggingface.co/papers/2004.09813):
```bibtex
@inproceedings{reimers-2020-multilingual-sentence-bert,
title = "Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2020",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.09813",
}
```
If you use the code for [data augmentation](https://github.com/huggingface/sentence-transformers/tree/main/examples/sentence_transformer/training/data_augmentation), feel free to cite our publication [Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks](https://huggingface.co/papers/2010.08240):
```bibtex
@inproceedings{thakur-2020-AugSBERT,
title = "Augmented {SBERT}: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks",
author = "Thakur, Nandan and Reimers, Nils and Daxenberger, Johannes and Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = "6",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2010.08240",
pages = "296--310",
}
```
If you use the models for [MS MARCO](pretrained-models/msmarco-v2.md), feel free to cite the paper: [The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes](https://huggingface.co/papers/2012.14210)
```bibtex
@inproceedings{reimers-2020-Curse_Dense_Retrieval,
title = "The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = "8",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2012.14210",
pages = "605--611",
}
```
When you use the unsupervised learning example, please have a look at: [TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning](https://huggingface.co/papers/2104.06979):
```bibtex
@inproceedings{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
pages = "671--688",
url = "https://arxiv.org/abs/2104.06979",
}
```
When you use the GenQ learning example, please have a look at: [BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models](https://huggingface.co/papers/2104.08663):
```bibtex
@inproceedings{thakur-2021-BEIR,
title = "BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models",
author = {Thakur, Nandan and Reimers, Nils and R{\"{u}}ckl{\'{e}}, Andreas and Srivastava, Abhishek and Gurevych, Iryna},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021) - Datasets and Benchmarks Track (Round 2)},
month = "4",
year = "2021",
url = "https://arxiv.org/abs/2104.08663",
}
```
When you use GPL, please have a look at: [GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval](https://huggingface.co/papers/2112.07577):
```bibtex
@inproceedings{wang-2021-GPL,
title = "GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval",
author = "Wang, Kexin and Thakur, Nandan and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2112.07577",
month = "12",
year = "2021",
url = "https://arxiv.org/abs/2112.07577",
}
```
**Repositories using SentenceTransformers**
- **[haystack](https://github.com/deepset-ai/haystack)** - Neural Search / Q&A
- **[Top2Vec](https://github.com/ddangelov/Top2Vec)** - Topic modeling
- **[txtai](https://github.com/neuml/txtai)** - AI-powered search engine
- **[BERTTopic](https://github.com/MaartenGr/BERTopic)** - Topic model using SBERT embeddings
- **[KeyBERT](https://github.com/MaartenGr/KeyBERT)** - Key phrase extraction using SBERT
- **[contextualized-topic-models](https://github.com/MilaNLProc/contextualized-topic-models)** - Cross-Lingual Topic Modeling
- **[covid-papers-browser](https://github.com/gsarti/covid-papers-browser)** - Semantic Search for Covid-19 papers
- **[backprop](https://github.com/backprop-ai/backprop)** - Natural Language Engine that makes using state-of-the-art language models easy, accessible and scalable.
**SentenceTransformers in Articles**
In the following you find a (selective) list of articles / applications using SentenceTransformers to do amazing stuff. Feel free to contact me (info@nils-reimers.de) to add you application here.
- **December 2021 - [Sentence Transformer Fine-Tuning (SetFit): Outperforming GPT-3 on few-shot Text-Classification while being 1600 times smaller](https://towardsdatascience.com/sentence-transformer-fine-tuning-setfit-outperforms-gpt-3-on-few-shot-text-classification-while-d9a3788f0b4e?gi=4bdbaff416e3)**
- **October 2021: [Natural Language Processing (NLP) for Semantic Search](https://www.pinecone.io/learn/nlp)**
- **January 2021 - [Advance BERT model via transferring knowledge from Cross-Encoders to Bi-Encoders](https://resources.experfy.com/ai-ml/bert-model-transferring-knowledge-cross-encoders-bi-encoders/)**
- **November 2020 - [How to Build a Semantic Search Engine With Transformers and Faiss](https://towardsdatascience.com/how-to-build-a-semantic-search-engine-with-transformers-and-faiss-dcbea307a0e8)**
- **October 2020 - [Topic Modeling with BERT](https://medium.com/data-science/topic-modeling-with-bert-779f7db187e6)**
- **September 2020 - [Elastic Transformers -
Making BERT stretchy - Scalable Semantic Search on a Jupyter Notebook](https://medium.com/@mihail.dungarov/elastic-transformers-ae011e8f5b88)**
- **July 2020 - [Simple Sentence Similarity Search with SentenceBERT](https://laptrinhx.com/simple-sentence-similarity-search-with-sentencebert-800684405/?fbclid=IwAR0rxdYS2DBGuHhijIRO_lsXqGc9BbjtDA-dDQM5Ng_StahT9xrHdRZuP9M)**
- **May 2020 - [HN Time Machine: finally some Hacker News history!](https://peltarion.com/blog/applied-ai/hacker-news-time-machine)**
- **May 2020 - [A complete guide to transfer learning from English to other Languages using Sentence Embeddings BERT Models](https://medium.com/data-science/a-complete-guide-to-transfer-learning-from-english-to-other-languages-using-sentence-embeddings-8c427f8804a9)**
- **March 2020 - [Building a k-NN Similarity Search Engine using Amazon Elasticsearch and SageMaker](https://medium.com/data-science/building-a-k-nn-similarity-search-engine-using-amazon-elasticsearch-and-sagemaker-98df18d883bd)**
- **February 2020 - [Semantic Search Engine with Sentence BERT](https://medium.com/@evergreenllc2020/semantic-search-engine-with-s-abbfb3cd9377)**
**SentenceTransformers used in Research**
SentenceTransformers is used in hundreds of research projects. For a list of publications, see [Google Scholar](https://scholar.google.com/scholar?oi=bibs&hl=de&cites=12599223809118664426) or [Semantic Scholar](https://www.semanticscholar.org/paper/Sentence-BERT%3A-Sentence-Embeddings-using-Siamese-Reimers-Gurevych/93d63ec754f29fa22572615320afe0521f7ec66d).
================================================
FILE: docs/quickstart.rst
================================================
Quickstart
==========
Sentence Transformer
--------------------
Characteristics of Sentence Transformer (a.k.a bi-encoder) models:
1. Calculates a **fixed-size vector representation (embedding)** given **texts or images**.
2. Embedding calculation is often **efficient**, embedding similarity calculation is **very fast**.
3. Applicable for a **wide range of tasks**, such as semantic textual similarity, semantic search, clustering, classification, paraphrase mining, and more.
4. Often used as a **first step in a two-step retrieval process**, where a Cross-Encoder (a.k.a. reranker) model is used to re-rank the top-k results from the bi-encoder.
Once you have `installed
For each sentence pair, we pass sentence A and sentence B through our network which yields the embeddings *u* und *v*. The similarity of these embeddings is computed using cosine similarity and the result is compared to the gold similarity score.
This allows our network to be fine-tuned to recognize the similarity of sentences.
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CosineSimilarityLoss
```
## DenoisingAutoEncoderLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.DenoisingAutoEncoderLoss
```
## GISTEmbedLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.GISTEmbedLoss
```
## CachedGISTEmbedLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CachedGISTEmbedLoss
```
## GlobalOrthogonalRegularizationLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.GlobalOrthogonalRegularizationLoss
```
## MSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MSELoss
```
## MarginMSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MarginMSELoss
```
## MatryoshkaLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MatryoshkaLoss
```
## Matryoshka2dLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.Matryoshka2dLoss
```
## AdaptiveLayerLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.AdaptiveLayerLoss
```
## MegaBatchMarginLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MegaBatchMarginLoss
```
## MultipleNegativesRankingLoss
*MultipleNegativesRankingLoss* is a great loss function if you only have positive pairs, for example, only pairs of similar texts like pairs of paraphrases, pairs of duplicate questions, pairs of (query, response), or pairs of (source_language, target_language).
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MultipleNegativesRankingLoss
```
## CachedMultipleNegativesRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CachedMultipleNegativesRankingLoss
```
## MultipleNegativesSymmetricRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.MultipleNegativesSymmetricRankingLoss
```
## CachedMultipleNegativesSymmetricRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.CachedMultipleNegativesSymmetricRankingLoss
```
## SoftmaxLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.SoftmaxLoss
```
## TripletLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.TripletLoss
```
## DistillKLDivLoss
```{eval-rst}
.. autoclass:: sentence_transformers.losses.DistillKLDivLoss
```
================================================
FILE: docs/package_reference/sentence_transformer/models.md
================================================
# Modules
`sentence_transformers.models` defines different building blocks, a.k.a. Modules, that can be used to create SentenceTransformer models from scratch. For more details, see [Creating Custom Models](../../sentence_transformer/usage/custom_models.rst).
## Main Modules
```{eval-rst}
.. autoclass:: sentence_transformers.models.Transformer
.. autoclass:: sentence_transformers.models.Pooling
.. autoclass:: sentence_transformers.models.Dense
.. autoclass:: sentence_transformers.models.Normalize
.. autoclass:: sentence_transformers.models.Router
:members: for_query_document
.. autoclass:: sentence_transformers.models.StaticEmbedding
:members: from_model2vec, from_distillation
```
## Further Modules
```{eval-rst}
.. autoclass:: sentence_transformers.models.BoW
.. autoclass:: sentence_transformers.models.CNN
.. autoclass:: sentence_transformers.models.LSTM
.. autoclass:: sentence_transformers.models.WeightedLayerPooling
.. autoclass:: sentence_transformers.models.WordEmbeddings
.. autoclass:: sentence_transformers.models.WordWeights
```
## Base Modules
```{eval-rst}
.. autoclass:: sentence_transformers.models.Module
:members: config_file_name, config_keys, save_in_root, forward, get_config_dict, load, load_config, load_file_path, load_dir_path, load_torch_weights, save, save_config, save_torch_weights
.. autoclass:: sentence_transformers.models.InputModule
:members: save_in_root, tokenizer, tokenize, save_tokenizer
```
================================================
FILE: docs/package_reference/sentence_transformer/quantization.md
================================================
# quantization
`sentence_transformers.quantization` defines different helpful functions to perform embedding quantization.
```{eval-rst}
.. note::
`Embedding Quantization <../../../examples/sentence_transformer/applications/embedding-quantization/README.html>`_ differs from model quantization. The former shrinks the size of embeddings such that semantic search/retrieval is faster and requires less memory and disk space. The latter refers to lowering the precision of the model weights to speed up inference. This page only shows documentation for the former.
```
```{eval-rst}
.. automodule:: sentence_transformers.quantization
:members: quantize_embeddings, semantic_search_faiss, semantic_search_usearch
```
================================================
FILE: docs/package_reference/sentence_transformer/sampler.md
================================================
# Samplers
## BatchSamplers
```{eval-rst}
.. autoclass:: sentence_transformers.training_args.BatchSamplers
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.DefaultBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.NoDuplicatesBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.GroupByLabelBatchSampler
:members:
```
## MultiDatasetBatchSamplers
```{eval-rst}
.. autoclass:: sentence_transformers.training_args.MultiDatasetBatchSamplers
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.MultiDatasetDefaultBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.RoundRobinBatchSampler
:members:
```
```{eval-rst}
.. autoclass:: sentence_transformers.sampler.ProportionalBatchSampler
:members:
```
================================================
FILE: docs/package_reference/sentence_transformer/trainer.md
================================================
# Trainer
## SentenceTransformerTrainer
```{eval-rst}
.. autoclass:: sentence_transformers.trainer.SentenceTransformerTrainer
:members:
:inherited-members:
:exclude-members: autocast_smart_context_manager, collect_features, compute_loss_context_manager, evaluation_loop, floating_point_ops, get_decay_parameter_names, get_optimizer_cls_and_kwargs, init_hf_repo, log_metrics, metrics_format, num_examples, num_tokens, predict, prediction_loop, prediction_step, save_metrics, save_state, training_step
```
================================================
FILE: docs/package_reference/sentence_transformer/training_args.md
================================================
# Training Arguments
## SentenceTransformerTrainingArguments
```{eval-rst}
.. autoclass:: sentence_transformers.training_args.SentenceTransformerTrainingArguments
:members:
:inherited-members:
```
================================================
FILE: docs/package_reference/sparse_encoder/SparseEncoder.md
================================================
# SparseEncoder
## SparseEncoder
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.SparseEncoder
:members:
:inherited-members:
:exclude-members: fit, old_fit, save, save_to_hub, add_module, append, apply, buffers, children, extra_repr, forward, get_buffer, get_extra_state, get_parameter, get_submodule, ipu, load_state_dict, modules, named_buffers, named_children, named_modules, named_parameters, parameters, register_backward_hook, register_buffer, register_forward_hook, register_forward_pre_hook, register_full_backward_hook, register_full_backward_pre_hook, register_load_state_dict_post_hook, register_module, register_parameter, register_state_dict_pre_hook, requires_grad_, set_extra_state, share_memory, state_dict, to_empty, type, xpu, zero_grad, truncate_sentence_embeddings, encode_multi_process
```
## SparseEncoderModelCardData
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.model_card.SparseEncoderModelCardData
:members:
```
## SimilarityFunction
```{eval-rst}
.. autoclass:: sentence_transformers.SimilarityFunction
:members:
```
================================================
FILE: docs/package_reference/sparse_encoder/callbacks.md
================================================
# Callbacks
## SpladeRegularizerWeightSchedulerCallback
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.callbacks.splade_callbacks.SpladeRegularizerWeightSchedulerCallback
```
================================================
FILE: docs/package_reference/sparse_encoder/evaluation.md
================================================
# Evaluation
`sentence_transformers.sparse_encoder.evaluation` defines different classes, that can be used to evaluate the SparseEncoder model during training.
## SparseInformationRetrievalEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator
```
## SparseNanoBEIREvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator
```
## SparseEmbeddingSimilarityEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseEmbeddingSimilarityEvaluator
```
## SparseBinaryClassificationEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseBinaryClassificationEvaluator
```
## SparseTripletEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseTripletEvaluator
```
## SparseRerankingEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseRerankingEvaluator
```
## SparseTranslationEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseTranslationEvaluator
```
## SparseMSEEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.SparseMSEEvaluator
```
## ReciprocalRankFusionEvaluator
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.evaluation.ReciprocalRankFusionEvaluator
================================================
FILE: docs/package_reference/sparse_encoder/index.rst
================================================
Sparse Encoder
=============
.. toctree::
SparseEncoder
trainer
training_args
losses
../sentence_transformer/sampler
evaluation
models
callbacks
search_engines
================================================
FILE: docs/package_reference/sparse_encoder/losses.md
================================================
# Losses
`sentence_transformers.sparse_encoder.losses` defines different loss functions that can be used to fine-tune saprse embedding models on training data. The choice of loss function plays a critical role when fine-tuning the model. It determines how well our embedding model will work for the specific downstream task.
Sadly, there is no "one size fits all" loss function. Which loss function is suitable depends on the available training data and on the target task. Consider checking out the [Loss Overview](../../sparse_encoder/loss_overview.md) to help narrow down your choice of loss function(s).
```{eval-rst}
.. warning::
To train a :class:`~sentence_transformers.sparse_encoder.SparseEncoder`, you need either :class:`~sentence_transformers.sparse_encoder.losses.SpladeLoss` or :class:`~sentence_transformers.sparse_encoder.losses.CSRLoss`, depending on the architecture. These are wrapper losses that add sparsity regularization on top of a main loss function, which must be provided as a parameter. The only loss that can be used independently is :class:`~sentence_transformers.sparse_encoder.losses.SparseMSELoss`, as it performs embedding-level distillation, ensuring sparsity by directly copying the teacher's sparse embedding.
```
## SpladeLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SpladeLoss
```
## CachedSpladeLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.CachedSpladeLoss
```
## FlopsLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.FlopsLoss
```
## CSRLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.CSRLoss
```
## CSRReconstructionLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.CSRReconstructionLoss
```
## SparseMultipleNegativesRankingLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseMultipleNegativesRankingLoss
```
## SparseMarginMSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseMarginMSELoss
```
## SparseDistillKLDivLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseDistillKLDivLoss
```
## SparseTripletLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseTripletLoss
```
## SparseCosineSimilarityLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseCosineSimilarityLoss
```
## SparseCoSENTLoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseCoSENTLoss
```
## SparseAnglELoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseAnglELoss
```
## SparseMSELoss
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.losses.SparseMSELoss
```
================================================
FILE: docs/package_reference/sparse_encoder/models.md
================================================
# Modules
`sentence_transformers.sparse_encoder.models` defines different building blocks, that can be used to create SparseEncoder networks from scratch. For more details, see [Training Overview](../../sparse_encoder/training_overview.md).
Note that modules from `sentence_transformers.models` can also be used for Sparse models, such as `sentence_transformers.models.Transformer` from [SentenceTransformer > Modules](../sentence_transformer/models.md)
## SPLADE Pooling
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.SpladePooling
```
## MLM Transformer
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.MLMTransformer
```
## SparseAutoEncoder
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.SparseAutoEncoder
```
## SparseStaticEmbedding
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.models.SparseStaticEmbedding
```
================================================
FILE: docs/package_reference/sparse_encoder/search_engines.md
================================================
# Search Engines
`sentence_transformers.sparse_encoder.search_engines` defines different helpful functions to integrate with vector databases and search engines the sparse embeddings produced.
```{eval-rst}
.. automodule:: sentence_transformers.sparse_encoder.search_engines
:members: semantic_search_qdrant, semantic_search_elasticsearch, semantic_search_seismic, semantic_search_opensearch
```
================================================
FILE: docs/package_reference/sparse_encoder/trainer.md
================================================
# Trainer
## SparseEncoderTrainer
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.SparseEncoderTrainer
:members:
:inherited-members:
:exclude-members: autocast_smart_context_manager, collect_features, compute_loss_context_manager, evaluation_loop, floating_point_ops, get_decay_parameter_names, get_optimizer_cls_and_kwargs, init_hf_repo, log_metrics, metrics_format, num_examples, num_tokens, predict, prediction_loop, prediction_step, save_metrics, save_state, training_step
```
================================================
FILE: docs/package_reference/sparse_encoder/training_args.md
================================================
# Training Arguments
## SparseEncoderTrainingArguments
```{eval-rst}
.. autoclass:: sentence_transformers.sparse_encoder.training_args.SparseEncoderTrainingArguments
:members:
:inherited-members:
```
================================================
FILE: docs/package_reference/util.md
================================================
# util
`sentence_transformers.util` defines different helpful functions to work with text embeddings.
## Helper Functions
```{eval-rst}
.. automodule:: sentence_transformers.util
:members: paraphrase_mining, semantic_search, community_detection, http_get, truncate_embeddings, normalize_embeddings, is_training_available, mine_hard_negatives
```
## Model Optimization
```{eval-rst}
.. automodule:: sentence_transformers.backend
:members: export_optimized_onnx_model, export_dynamic_quantized_onnx_model, export_static_quantized_openvino_model
```
## Similarity Metrics
```{eval-rst}
.. automodule:: sentence_transformers.util
:members: cos_sim, pairwise_cos_sim, dot_score, pairwise_dot_score, manhattan_sim, pairwise_manhattan_sim, euclidean_sim, pairwise_euclidean_sim
```
================================================
FILE: docs/pretrained-models/ce-msmarco.md
================================================
# MS MARCO Cross-Encoders
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consists of over 8.8 million passages.
## Usage with SentenceTransformers
Pre-trained models can be used like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder("model_name", max_length=512)
scores = model.predict(
[("Query", "Paragraph1"), ("Query", "Paragraph2"), ("Query", "Paragraph3")]
)
```
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained("model_name")
tokenizer = AutoTokenizer.from_pretrained("model_name")
features = tokenizer(["Query", "Query"], ["Paragraph1", "Paragraph2"], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
## Models & Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- | :-------------: | :-----: | ---: |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L2 | 67.43 | 30.15 | 9000 |
| cross-encoder/ms-marco-TinyBERT-L4 | 68.09 | 34.50 | 2900 |
| cross-encoder/ms-marco-TinyBERT-L6 | 69.57 | 36.13 | 680 |
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340 |
| **Other models** | | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900 |
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340 |
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100 |
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340 |
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330 |
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU with Hugging Face Transformers v4.
================================================
FILE: docs/pretrained-models/dpr.md
================================================
# DPR-Models
In [Dense Passage Retrieval for Open-Domain Question Answering](https://huggingface.co/papers/2004.04906) Karpukhin et al. trained models based on [Google's Natural Questions dataset](https://ai.google.com/research/NaturalQuestions):
- **facebook-dpr-ctx_encoder-single-nq-base**
- **facebook-dpr-question_encoder-single-nq-base**
They also trained models on the combination of Natural Questions, TriviaQA, WebQuestions, and CuratedTREC.
- **facebook-dpr-ctx_encoder-multiset-base**
- **facebook-dpr-question_encoder-multiset-base**
There is one model to encode passages and one model to encode question / queries.
## Usage
To encode paragraphs, you need to provide a title (e.g. the Wikipedia article title) and the text passage. These must be separated with a `[SEP]` token. For encoding paragraphs, we use the **ctx_encoder**.
Queries are encoded with **question_encoder**:
```python
from sentence_transformers import SentenceTransformer, util
passage_encoder = SentenceTransformer("facebook-dpr-ctx_encoder-single-nq-base")
passages = [
"London [SEP] London is the capital and largest city of England and the United Kingdom.",
"Paris [SEP] Paris is the capital and most populous city of France.",
"Berlin [SEP] Berlin is the capital and largest city of Germany by both area and population.",
]
passage_embeddings = passage_encoder.encode(passages)
query_encoder = SentenceTransformer("facebook-dpr-question_encoder-single-nq-base")
query = "What is the capital of England?"
query_embedding = query_encoder.encode(query)
# Important: You must use dot-product, not cosine_similarity
scores = util.dot_score(query_embedding, passage_embeddings)
print("Scores:", scores)
```
**Important note:** When you use these models, you have to use them with dot-product (e.g. as implemented in `util.dot_score`) and not with cosine similarity.
================================================
FILE: docs/pretrained-models/msmarco-v1.md
================================================
# MSMARCO Models
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Version History
### v1
Version 1 models were trained on the training set of MS Marco Passage retrieval task. The models were trained using in-batch negative sampling via the MultipleNegativesRankingLoss with a scaling factor of 20 and a batch size of 128.
They can be used like this:
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("distilroberta-base-msmarco-v1")
query_embedding = model.encode("[QRY] " + "How big is London")
passage_embedding = model.encode("[DOC] " + "London has 9,787,426 inhabitants at the 2011 census")
print("Similarity:", util.pytorch_cos_sim(query_embedding, passage_embedding))
```
**Models**:
- **distilroberta-base-msmarco-v1** - Performance MSMARCO dev dataset (queries.dev.small.tsv) MRR@10: 23.28
================================================
FILE: docs/pretrained-models/msmarco-v2.md
================================================
# MSMARCO Models (Version 2)
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("msmarco-distilroberta-base-v2")
query_embedding = model.encode("How big is London")
passage_embedding = model.encode("London has 9,787,426 inhabitants at the 2011 census")
print("Similarity:", util.pytorch_cos_sim(query_embedding, passage_embedding))
```
For more details on the usage, see [Applications - Information Retrieval](../../examples/sentence_transformer/applications/retrieve_rerank/README.md)
## Performance
Performance is evaluated on [TREC-DL 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/), which is a query-passage retrieval task where multiple queries have been annotated as with their relevance with respect to the given query. Further, we evaluate on the [MS Marco Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
As baseline we show the results for lexical search with BM25 using Elasticsearch.
| Approach | NDCG@10 (TREC DL 19 Reranking) | MRR@10 (MS Marco Dev) |
| ------------- |:-------------: | :---: |
| BM25 (Elasticsearch) | 45.46 | 17.29 |
| msmarco-distilroberta-base-v2 | 65.65 | 28.55 |
| msmarco-roberta-base-v2 | 67.18 | 29.17 |
| msmarco-distilbert-base-v2 | 68.35 | 30.77 |
## Version History
- [Version 1](msmarco-v1.md)
================================================
FILE: docs/pretrained-models/msmarco-v3.md
================================================
# MSMARCO Models
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("msmarco-distilbert-base-v3")
query_embedding = model.encode("How big is London")
passage_embedding = model.encode("London has 9,787,426 inhabitants at the 2011 census")
print("Similarity:", util.cos_sim(query_embedding, passage_embedding))
```
For more details on the usage, see [Applications - Information Retrieval](../../examples/sentence_transformer/applications/retrieve_rerank/README.md)
## Performance
Performance is evaluated on [TREC-DL 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/), which is a query-passage retrieval task where multiple queries have been annotated as with their relevance with respect to the given query. Further, we evaluate on the [MS Marco Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
As baseline we show the results for lexical search with BM25 using Elasticsearch.
| Approach | NDCG@10 (TREC DL 19 Reranking) | MRR@10 (MS Marco Dev) | Queries (GPU / CPU) | Docs (GPU / CPU)
| ------------- |:-------------: | :---: | :---: | :---: |
| **Models tuned for cosine-similarity** | |
| msmarco-MiniLM-L6-v3 | 67.46 | 32.27 | 18,000 / 750 | 2,800 / 180
| msmarco-MiniLM-L12-v3 | 65.14 | 32.75 | 11,000 / 400 | 1,500 / 90
| msmarco-distilbert-base-v3| 69.02 | 33.13 | 7,000 / 350 | 1,100 / 70
| msmarco-distilbert-base-v4 | **70.24** | **33.79**| 7,000 / 350 | 1,100 / 70
| msmarco-roberta-base-v3 | 69.08 | 33.01 | 4,000 / 170 | 540 / 30
| **Models tuned for dot-product** | |
| msmarco-distilbert-base-dot-prod-v3 | 68.42 | 33.04 | 7,000 / 350 | 1100 / 70
| [msmarco-roberta-base-ance-firstp](https://github.com/microsoft/ANCE) | 67.84 | 33.01 | 4,000 / 170 | 540 / 30
| [msmarco-distilbert-base-tas-b](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco) | **71.04** | **34.43** | 7,000 / 350 | 1100 / 70
| **Previous approaches** | | |
| BM25 (Elasticsearch) | 45.46 | 17.29 |
| msmarco-distilroberta-base-v2 | 65.65 | 28.55 |
| msmarco-roberta-base-v2 | 67.18 | 29.17 |
| msmarco-distilbert-base-v2 | 68.35 | 30.77 |
**Notes:**
- We provide two type of models, one tuned for **cosine-similarity**, the other for **dot-product**. Make sure to use the right method to compute the similarity between query and passages.
- Models tuned for **cosine-similarity** will prefer the retrieval of shorter passages, while models for **dot-product** will prefer the retrieval of longer passages. Depending on your task, you might prefer the one or the other type of model.
- **msmarco-roberta-base-ance-firstp** is the MSMARCO Dev Passage Retrieval ANCE(FirstP) 600K model from [ANCE](https://github.com/microsoft/ANCE). This model should be used with dot-product instead of cosine similarity.
- **msmarco-distilbert-base-tas-b** uses the model from [sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco). See the linked documentation / paper for more details.
- Encoding speeds are per second and were measured on a V100 GPU and an 8 core Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
## Changes in v3
The models from v2 have been used for find for all training queries similar passages. An [MS MARCO Cross-Encoder](ce-msmarco.md) based on the electra-base-model has been then used to classify if these retrieved passages answer the question.
If they received a low score by the cross-encoder, we saved them as hard negatives: They got a high score from the bi-encoder, but a low-score from the (better) cross-encoder.
We then trained the v2 models with these new hard negatives.
## Version History
- [Version 2](msmarco-v2.md)
- [Version 1](msmarco-v1.md)
================================================
FILE: docs/pretrained-models/msmarco-v5.md
================================================
# MSMARCO Models
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine. The provided models can be used for semantic search, i.e., given keywords / a search phrase / a question, the model will find passages that are relevant for the search query.
The training data consists of over 500k examples, while the complete corpus consist of over 8.8 Million passages.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("msmarco-distilbert-dot-v5")
query_embedding = model.encode("How big is London")
passage_embedding = model.encode([
"London has 9,787,426 inhabitants at the 2011 census",
"London is known for its financial district",
])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))
```
For more details on the usage, see [Applications - Information Retrieval](../../examples/sentence_transformer/applications/retrieve_rerank/README.md)
## Performance
Performance is evaluated on [TREC-DL 2019](https://microsoft.github.io/msmarco/TREC-Deep-Learning-2019) and [TREC-DL 2020](https://microsoft.github.io/msmarco/TREC-Deep-Learning-2020), which are a query-passage retrieval task where multiple queries have been annotated as with their relevance with respect to the given query. Further, we evaluate on the [MS Marco Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Approach | MRR@10 (MS Marco Dev) | NDCG@10 (TREC DL 19 Reranking) | NDCG@10 (TREC DL 20 Reranking) | Queries (GPU / CPU) | Docs (GPU / CPU)
| ------------- | :-------------: | :-------------: | :---: | :---: | :---: |
| **Models tuned with normalized embeddings** | |
| [msmarco-MiniLM-L6-cos-v5](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L6-cos-v5) | 32.27 | 67.46 | 64.73 | 18,000 / 750 | 2,800 / 180
| [msmarco-MiniLM-L12-cos-v5](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L12-cos-v5) | 32.75 | 65.14 | 67.48 | 11,000 / 400 | 1,500 / 90
| [msmarco-distilbert-cos-v5](https://huggingface.co/sentence-transformers/msmarco-distilbert-cos-v5) | 33.79 | 70.24 | 66.24 | 7,000 / 350 | 1,100 / 70
| [multi-qa-MiniLM-L6-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1) | | 65.55 | 64.66 | 18,000 / 750 | 2,800 / 180
| [multi-qa-distilbert-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-distilbert-cos-v1) | | 67.59 | 66.46 | 7,000 / 350 | 1,100 / 70
| [multi-qa-mpnet-base-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-cos-v1) | | 67.78 | 69.87 | 4,000 / 170 | 540 / 30
| **Models tuned for dot-product** | |
| [msmarco-distilbert-base-tas-b](https://huggingface.co/sentence-transformers/msmarco-distilbert-base-tas-b) | 34.43 | 71.04 | 69.78 | 7,000 / 350 | 1100 / 70
| [msmarco-distilbert-dot-v5](https://huggingface.co/sentence-transformers/msmarco-distilbert-dot-v5) | 37.25 | 70.14 | 71.08 | 7,000 / 350 | 1100 / 70
| [msmarco-bert-base-dot-v5](https://huggingface.co/sentence-transformers/msmarco-bert-base-dot-v5) | 38.08 | 70.51 | 73.45 | 4,000 / 170 | 540 / 30
| [multi-qa-MiniLM-L6-dot-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-dot-v1) | | 66.70 | 65.98 | 18,000 / 750 | 2,800 / 180
| [multi-qa-distilbert-dot-v1](https://huggingface.co/sentence-transformers/multi-qa-distilbert-dot-v1) | | 68.05 | 70.49 | 7,000 / 350 | 1,100 / 70
| [multi-qa-mpnet-base-dot-v1](https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-dot-v1) | | 70.66 | 71.18 | 4,000 / 170 | 540 / 30
**Notes:**
- We provide two type of models: One that produces **normalized embedding** and can be used with dot-product, cosine-similarity or euclidean distance (all three scoring function will produce the same results). The models tuned for **dot-product** will produce embeddings of different lengths and must be used with dot-product to find close items in a vector space.
- Models with normalized embeddings will prefer the retrieval of shorter passages, while models tuned for **dot-product** will prefer the retrieval of longer passages. Depending on your task, you might prefer the one or the other type of model.
- Encoding speeds are per second and were measured on a V100 GPU and an 8 core Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
## Changes in v5
- Models with normalized embeddings were added: These are the v3 cosine-similarity models, but with an additional normalize layer on-top.
- New models trained with MarginMSE loss trained: msmarco-distilbert-dot-v5 and msmarco-bert-base-dot-v5
## Changes in v4
- Just one new model was trained with better hard negatives, leading to a small improvement compared to v3
## Changes in v3
The models from v2 have been used for find for all training queries similar passages. An [MS MARCO Cross-Encoder](ce-msmarco.md) based on the electra-base-model has been then used to classify if these retrieved passages answer the question.
If they received a low score by the cross-encoder, we saved them as hard negatives: They got a high score from the bi-encoder, but a low-score from the (better) cross-encoder.
We then trained the v2 models with these new hard negatives.
## Version History
- [Version 3](msmarco-v3.md)
- [Version 2](msmarco-v2.md)
- [Version 1](msmarco-v1.md)
================================================
FILE: docs/pretrained-models/nli-models.md
================================================
# NLI Models
Conneau et al., 2017, show in the InferSent-Paper ([Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://huggingface.co/papers/1705.02364)) that training on Natural Language Inference (NLI) data can produce universal sentence embeddings.
The datasets labeled sentence pairs with the labels *entail*, *contradict*, and *neutral*. For both sentences, we compute a sentence embedding. These two embeddings are concatenated and passed to softmax classifier to derive the final label.
As shown, this produces sentence embeddings that can be used for various use cases like clustering or semantic search.
# Datasets
We train the models on the [SNLI](https://nlp.stanford.edu/projects/snli/) and on the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) dataset. We call the combination of the two datasets AllNLI.
For a training example, see [examples/sentence_transformer/training/nli/training_nli.py](../../examples/sentence_transformer/training/nli/training_nli.py).
# Pretrained models
We provide the various pre-trained models. The performance was evaluated on the test set of the STS benchmark dataset ([docs](https://web.archive.org/web/20231128064114/http://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark), [dataset](https://huggingface.co/datasets/sentence-transformers/stsb)) using Spearman rank correlation.
[» Full List of NLI & STS Models](https://docs.google.com/spreadsheets/d/14QplCdTCDwEmTqrn1LH4yrbKvdogK4oQvYO1K1aPR5M/edit#gid=0)
# Performance Comparison
Here are the performances on the STS benchmark for other sentence embeddings methods. They were also computed by using cosine-similarity and Spearman rank correlation:
- Avg. GloVe embeddings: 58.02
- BERT-as-a-service avg. embeddings: 46.35
- BERT-as-a-service CLS-vector: 16.50
- InferSent - GloVe: 68.03
- Universal Sentence Encoder: 74.92
# Applications
This model works well in accessing the coarse-grained similarity between sentences. For application examples, see [semantic_textual_similarity](../sentence_transformer/usage/semantic_textual_similarity.rst) and [semantic search](../../examples/sentence_transformer/applications/semantic-search/README.md).
================================================
FILE: docs/pretrained-models/nq-v1.md
================================================
# Natural Questions Models
[Google's Natural Questions dataset](https://ai.google.com/research/NaturalQuestions) consists of about 100k real search queries from Google with the respective, relevant passage from Wikipedia. Models trained on this dataset work well for question-answer retrieval.
## Usage
```python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("nq-distilbert-base-v1")
query_embedding = model.encode("How many people live in London?")
# The passages are encoded as [ [title1, text1], [title2, text2], ...]
passage_embedding = model.encode(
[["London", "London has 9,787,426 inhabitants at the 2011 census."]]
)
print("Similarity:", util.cos_sim(query_embedding, passage_embedding))
```
Note: For the passage, we have to encode the Wikipedia article title together with a text paragraph from that article.
## Performance
The models are evaluated on the Natural Questions development dataset using MRR@10.
| Approach | MRR@10 (NQ dev set small) |
| ------------- |:-------------: |
| nq-distilbert-base-v1 | 72.36 |
| *Other models* | |
| [DPR](https://huggingface.co/transformers/model_doc/dpr.html) | 58.96 |
================================================
FILE: docs/pretrained-models/sts-models.md
================================================
# STS Models
The models were first trained on [NLI data](nli-models.md), then we fine-tuned them on the STS benchmark dataset ([docs](https://web.archive.org/web/20231128064114/http://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark), [dataset](https://huggingface.co/datasets/sentence-transformers/stsb)). This generate sentence embeddings that are especially suitable to measure the semantic similarity between sentence pairs.
# Datasets
We use the training file from the [STS benchmark dataset](https://huggingface.co/datasets/sentence-transformers/stsb).
For a training example, see:
- [examples/sentence_transformer/training_stsbenchmark.py](https://github.com/huggingface/sentence-transformers/blob/main/examples/sentence_transformer/training/sts/training_stsbenchmark.py) - Train directly on STS data
- [examples/sentence_transformer/training_stsbenchmark_continue_training.py ](https://github.com/huggingface/sentence-transformers/blob/main/examples/sentence_transformer/training/sts/training_stsbenchmark_continue_training.py) - First train on NLI, than train on STS data.
# Pre-trained models
We provide the following pre-trained models:
[» Full List of STS Models](https://docs.google.com/spreadsheets/d/14QplCdTCDwEmTqrn1LH4yrbKvdogK4oQvYO1K1aPR5M/edit#gid=0)
# Performance Comparison
Here are the performances on the STS benchmark for other sentence embeddings methods. They were also computed by using cosine-similarity and Spearman rank correlation. Note, these models were not-fined on the STS benchmark.
- Avg. GloVe embeddings: 58.02
- BERT-as-a-service avg. embeddings: 46.35
- BERT-as-a-service CLS-vector: 16.50
- InferSent - GloVe: 68.03
- Universal Sentence Encoder: 74.92
================================================
FILE: docs/pretrained-models/wikipedia-sections-models.md
================================================
# Wikipedia Sections Models
The `wikipedia-sections-models` implement the idea from Ein Dor et al., 2018, [Learning Thematic Similarity Metric Using Triplet Networks](https://aclweb.org/anthology/P18-2009).
It was trained with a triplet-loss: The anchor and the positive example were sentences from the same section from an wikipedia article, for example, from the History section of the London article. The negative example came from a different section from the same article, for example, from the Education section of the London article.
# Dataset
We use dataset from Ein Dor et al., 2018, [Learning Thematic Similarity Metric Using Triplet Networks](https://aclweb.org/anthology/P18-2009).
See [examples/sentence_transformer/training/other/training_wikipedia_sections.py](../../examples/sentence_transformer/training/other/training_wikipedia_sections.py) for how to train on this dataset.
# Pre-trained models
We provide the following pre-trained models:
- **bert-base-wikipedia-sections-mean-tokens**: 80.42% accuracy on test set.
You can use them in the following way:
```
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("bert-base-wikipedia-sections-mean-tokens")
```
# Performance Comparison
Performance (accuracy) reported by Dor et al.:
- mean-vectors: 0.65
- skip-thoughts-CS: 0.615
- skip-thoughts-SICK: 0.547
- triplet-sen: 0.74
# Applications
The models achieve a rather low performance on the STS benchmark dataset. The reason for this is the training objective: An anchor, a positive and a negative example are presented. The network must only learn to differentiate what the positive and what the negative example is by ensuring that the negative example is further away from the anchor than the positive example.
However, it does not matter how far the negative example is away, it can be little or really far away. This makes this model rather bad for deciding if a pair is somewhat similar. It learns only to recognize similar pairs (high scores) and dissimilar pairs (low scores).
However, this model works well for **fine-grained clustering**.
================================================
FILE: docs/publications.md
================================================
# Publications
If you find this repository helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://huggingface.co/papers/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
If you use one of the multilingual models, feel free to cite our publication [Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation](https://huggingface.co/papers/2004.09813):
```bibtex
@inproceedings{reimers-2020-multilingual-sentence-bert,
title = "Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2020",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.09813",
}
```
If you use the code for [data augmentation](https://github.com/huggingface/sentence-transformers/tree/main/examples/sentence_transformer/training/data_augmentation), feel free to cite our publication [Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks](https://huggingface.co/papers/2010.08240):
```bibtex
@inproceedings{thakur-2020-AugSBERT,
title = "Augmented {SBERT}: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks",
author = "Thakur, Nandan and Reimers, Nils and Daxenberger, Johannes and Gurevych, Iryna",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = "6",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2010.08240",
pages = "296--310",
}
```
If you use the models for [MS MARCO](pretrained-models/msmarco-v2.md), feel free to cite the paper: [The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes](https://huggingface.co/papers/2012.14210)
```bibtex
@inproceedings{reimers-2020-Curse_Dense_Retrieval,
title = "The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = "8",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2012.14210",
pages = "605--611",
}
```
When you use the unsupervised learning example, please have a look at: [TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning](https://huggingface.co/papers/2104.06979):
```bibtex
@inproceedings{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
pages = "671--688",
url = "https://arxiv.org/abs/2104.06979",
}
```
When you use the GenQ learning example, please have a look at: [BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models](https://huggingface.co/papers/2104.08663):
```bibtex
@inproceedings{thakur-2021-BEIR,
title = "BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models",
author = {Thakur, Nandan and Reimers, Nils and R{\"{u}}ckl{\'{e}}, Andreas and Srivastava, Abhishek and Gurevych, Iryna},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021) - Datasets and Benchmarks Track (Round 2)},
month = "4",
year = "2021",
url = "https://arxiv.org/abs/2104.08663",
}
```
When you use GPL, please have a look at: [GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval](https://huggingface.co/papers/2112.07577):
```bibtex
@inproceedings{wang-2021-GPL,
title = "GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval",
author = "Wang, Kexin and Thakur, Nandan and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2112.07577",
month = "12",
year = "2021",
url = "https://arxiv.org/abs/2112.07577",
}
```
**Repositories using SentenceTransformers**
- **[haystack](https://github.com/deepset-ai/haystack)** - Neural Search / Q&A
- **[Top2Vec](https://github.com/ddangelov/Top2Vec)** - Topic modeling
- **[txtai](https://github.com/neuml/txtai)** - AI-powered search engine
- **[BERTTopic](https://github.com/MaartenGr/BERTopic)** - Topic model using SBERT embeddings
- **[KeyBERT](https://github.com/MaartenGr/KeyBERT)** - Key phrase extraction using SBERT
- **[contextualized-topic-models](https://github.com/MilaNLProc/contextualized-topic-models)** - Cross-Lingual Topic Modeling
- **[covid-papers-browser](https://github.com/gsarti/covid-papers-browser)** - Semantic Search for Covid-19 papers
- **[backprop](https://github.com/backprop-ai/backprop)** - Natural Language Engine that makes using state-of-the-art language models easy, accessible and scalable.
**SentenceTransformers in Articles**
In the following you find a (selective) list of articles / applications using SentenceTransformers to do amazing stuff. Feel free to contact me (info@nils-reimers.de) to add you application here.
- **December 2021 - [Sentence Transformer Fine-Tuning (SetFit): Outperforming GPT-3 on few-shot Text-Classification while being 1600 times smaller](https://towardsdatascience.com/sentence-transformer-fine-tuning-setfit-outperforms-gpt-3-on-few-shot-text-classification-while-d9a3788f0b4e?gi=4bdbaff416e3)**
- **October 2021: [Natural Language Processing (NLP) for Semantic Search](https://www.pinecone.io/learn/nlp)**
- **January 2021 - [Advance BERT model via transferring knowledge from Cross-Encoders to Bi-Encoders](https://resources.experfy.com/ai-ml/bert-model-transferring-knowledge-cross-encoders-bi-encoders/)**
- **November 2020 - [How to Build a Semantic Search Engine With Transformers and Faiss](https://towardsdatascience.com/how-to-build-a-semantic-search-engine-with-transformers-and-faiss-dcbea307a0e8)**
- **October 2020 - [Topic Modeling with BERT](https://medium.com/data-science/topic-modeling-with-bert-779f7db187e6)**
- **September 2020 - [Elastic Transformers -
Making BERT stretchy - Scalable Semantic Search on a Jupyter Notebook](https://medium.com/@mihail.dungarov/elastic-transformers-ae011e8f5b88)**
- **July 2020 - [Simple Sentence Similarity Search with SentenceBERT](https://laptrinhx.com/simple-sentence-similarity-search-with-sentencebert-800684405/?fbclid=IwAR0rxdYS2DBGuHhijIRO_lsXqGc9BbjtDA-dDQM5Ng_StahT9xrHdRZuP9M)**
- **May 2020 - [HN Time Machine: finally some Hacker News history!](https://peltarion.com/blog/applied-ai/hacker-news-time-machine)**
- **May 2020 - [A complete guide to transfer learning from English to other Languages using Sentence Embeddings BERT Models](https://medium.com/data-science/a-complete-guide-to-transfer-learning-from-english-to-other-languages-using-sentence-embeddings-8c427f8804a9)**
- **March 2020 - [Building a k-NN Similarity Search Engine using Amazon Elasticsearch and SageMaker](https://medium.com/data-science/building-a-k-nn-similarity-search-engine-using-amazon-elasticsearch-and-sagemaker-98df18d883bd)**
- **February 2020 - [Semantic Search Engine with Sentence BERT](https://medium.com/@evergreenllc2020/semantic-search-engine-with-s-abbfb3cd9377)**
**SentenceTransformers used in Research**
SentenceTransformers is used in hundreds of research projects. For a list of publications, see [Google Scholar](https://scholar.google.com/scholar?oi=bibs&hl=de&cites=12599223809118664426) or [Semantic Scholar](https://www.semanticscholar.org/paper/Sentence-BERT%3A-Sentence-Embeddings-using-Siamese-Reimers-Gurevych/93d63ec754f29fa22572615320afe0521f7ec66d).
================================================
FILE: docs/quickstart.rst
================================================
Quickstart
==========
Sentence Transformer
--------------------
Characteristics of Sentence Transformer (a.k.a bi-encoder) models:
1. Calculates a **fixed-size vector representation (embedding)** given **texts or images**.
2. Embedding calculation is often **efficient**, embedding similarity calculation is **very fast**.
3. Applicable for a **wide range of tasks**, such as semantic textual similarity, semantic search, clustering, classification, paraphrase mining, and more.
4. Often used as a **first step in a two-step retrieval process**, where a Cross-Encoder (a.k.a. reranker) model is used to re-rank the top-k results from the bi-encoder.
Once you have `installed MultipleNegativesRankingLoss (a.k.a. InfoNCE or in-batch negatives loss) is commonly used to train the top performing embedding models. This data is often relatively cheap to obtain, and the models are generally very performant. CachedMultipleNegativesRankingLoss is often used to increase the batch size, resulting in superior performance.
* `(sentence_A, sentence_B) pairs` with a `float similarity score`: CosineSimilarityLoss is traditionally used a lot, though more recently CoSENTLoss and AnglELoss are used as drop-in replacements with superior performance.
## Custom Loss Functions
```{eval-rst}
Advanced users can create and train with their own loss functions. Custom loss functions only have a few requirements:
- They must be a subclass of :class:`torch.nn.Module`.
- They must have ``model`` as the first argument in the constructor.
- They must implement a ``forward`` method that accepts ``sentence_features`` and ``labels``. The former is a list of tokenized batches, one element for each column. These tokenized batches can be fed directly to the ``model`` being trained to produce embeddings. The latter is an optional tensor of labels. The method must return a single loss value or a dictionary of loss components (component names to loss values) that will be summed to produce the final loss value. When returning a dictionary, the individual components will be logged separately in addition to the summed loss, allowing you to monitor the individual components of the loss.
To get full support with the automatic model card generation, you may also wish to implement:
- a ``get_config_dict`` method that returns a dictionary of loss parameters.
- a ``citation`` property so your work gets cited in all models that train with the loss.
Consider inspecting existing loss functions to get a feel for how loss functions are commonly implemented.
```
================================================
FILE: docs/sentence_transformer/pretrained_models.md
================================================
# Pretrained Models
```{eval-rst}
We provide various pre-trained Sentence Transformers models via our Sentence Transformers Hugging Face organization. Additionally, over 6,000 community Sentence Transformers models have been publicly released on the Hugging Face Hub. All models can be found here:
* **Original models**: `Sentence Transformers Hugging Face organization learning_rate
lr_scheduler_type
warmup_ratio
num_train_epochs
max_steps
per_device_train_batch_size
per_device_eval_batch_size
auto_find_batch_size
fp16
bf16
load_best_model_at_end
metric_for_best_model
gradient_accumulation_steps
gradient_checkpointing
eval_accumulation_steps
optim
batch_sampler
multi_dataset_batch_sampler
prompts
router_mapping
learning_rate_mapping
model_kwargs will be passed on to OVBaseModel.from_pretrained(). Some notable arguments include:
* ``file_name``: The name of the ONNX file to load. If not specified, will default to ``"openvino_model.xml"`` or otherwise ``"openvino/openvino_model.xml"``. This argument is useful for specifying optimized or quantized models.
* ``export``: A boolean flag specifying whether the model will be exported. If not provided, ``export`` will be set to ``True`` if the model repository or directory does not already contain an OpenVINO model.
.. tip::
It's heavily recommended to save the exported model to prevent having to re-export it every time you run your code. You can do this by calling :meth:`model.save_pretrained() torch-fp32: PyTorch with float32 precision (default).
torch-fp16: PyTorch with float16 precision, via model_kwargs={"torch_dtype": "float16"}.
torch-bf16: PyTorch with bfloat16 precision, via model_kwargs={"torch_dtype": "bfloat16"}.
onnx: ONNX with float32 precision, via backend="onnx".
onnx-O1: ONNX with float32 precision and O1 optimization, via export_optimized_onnx_model(..., optimization_config="O1", ...) and backend="onnx".
onnx-O2: ONNX with float32 precision and O2 optimization, via export_optimized_onnx_model(..., optimization_config="O2", ...) and backend="onnx".
onnx-O3: ONNX with float32 precision and O3 optimization, via export_optimized_onnx_model(..., optimization_config="O3", ...) and backend="onnx".
onnx-O4: ONNX with float16 precision and O4 optimization, via export_optimized_onnx_model(..., optimization_config="O4", ...) and backend="onnx".
onnx-qint8: ONNX quantized to int8 with "avx512_vnni", via export_dynamic_quantized_onnx_model(..., quantization_config="avx512_vnni", ...) and backend="onnx". The different quantization configurations resulted in roughly equivalent speedups.
openvino: OpenVINO, via backend="openvino".
openvino-qint8: OpenVINO quantized to int8 via export_static_quantized_openvino_model(..., quantization_config=OVQuantizationConfig(), ...) and backend="openvino".
SpladeLoss implements a specialized loss function for SPLADE (Sparse Lexical and Expansion) models. It combines a main loss function with regularization terms to balance effectiveness and efficiency:
1. Main loss: Supports all the losses from the Loss Table and Distillation, with SparseMultipleNegativesRankingLoss, SparseMarginMSELoss and SparseDistillKLDivLoss commonly used.
2. Regularization loss: FlopsLoss is used to control sparsity, but supports custom regularizers.
- `query_regularizer` and `document_regularizer` can be set to any custom regularization loss.
- `query_regularizer_threshold` and `document_regularizer_threshold` can be set to control the sparsity strictness for queries and documents separately, setting the regularization loss to zero if an embedding has less than the threshold number of active (non-zero) dimensions.
#### Cached SPLADE Loss
The CachedSpladeLoss is a variant of the SPLADE loss adopting GradCache, which allows for much larger batch sizes without additional GPU memory usage. It achieves this by computing and caching loss gradients in mini-batches.
Main losses that use in-batch negatives, primarily SparseMultipleNegativesRankingLoss, benefit heavily from larger batch sizes, as it results in more negatives and a stronger training signal.
### CSR Loss
If you are using the SparseAutoEncoder module, then you have to use the CSRLoss (Contrastive Sparse Representation Loss). It combines two components:
1. Main loss: Supports all the losses from the Loss Table and Distillation, with SparseMultipleNegativesRankingLoss used in the CSR Paper.
2. Reconstruction loss: CSRReconstructionLoss is used to ensure that sparse representation can faithfully reconstruct the original dense embeddings.
## Loss Table
Loss functions play a critical role in the performance of your fine-tuned model. Sadly, there is no "one size fits all" loss function. Ideally, this table should help narrow down your choice of loss function(s) by matching them to your data formats.
```{eval-rst}
.. note::
You can often convert one training data format into another, allowing more loss functions to be viable for your scenario. For example, ``(sentence_A, sentence_B) pairs`` with ``class`` labels can be converted into ``(anchor, positive, negative) triplets`` by sampling sentences with the same or different classes.
```
**Legend:** Loss functions marked with `★` are commonly recommended default choices.
| Inputs | Labels | Appropriate Loss Functions |
|---------------------------------------------------|------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `(anchor, positive) pairs` | `none` | `SparseMultipleNegativesRankingLoss` ★ |
| `(sentence_A, sentence_B) pairs` | `float similarity score between 0 and 1` | `SparseCoSENTLoss`SparseMultipleNegativesRankingLoss (a.k.a. InfoNCE or in-batch negatives loss) is commonly used to train the top performing embedding models. This data is often relatively cheap to obtain, and the models are generally very performant. Here for our sparse retrieval tasks, this format works well with SpladeLoss, CachedSpladeLoss, or CSRLoss, all typically using InfoNCE as their underlying loss function.
* `(query, positive, negative_1, ..., negative_n)` format: This structure with multiple negatives is particularly effective with SpladeLoss configured with SparseMarginMSELoss, especially in knowledge distillation scenarios where a teacher model provides similarity scores. The strongest models are trained with distillation losses like SparseDistillKLDivLoss or SparseMarginMSELoss.
## Custom Loss Functions
```{eval-rst}
Advanced users can create and train with their own loss functions. Custom loss functions only have a few requirements:
- They must be a subclass of :class:`torch.nn.Module`.
- They must have ``model`` as the first argument in the constructor.
- They must implement a ``forward`` method that accepts ``sentence_features`` and ``labels``. The former is a list of tokenized batches, one element for each column. These tokenized batches can be fed directly to the ``model`` being trained to produce embeddings. The latter is an optional tensor of labels. The method must return a single loss value or a dictionary of loss components (component names to loss values) that will be summed to produce the final loss value. When returning a dictionary, the individual components will be logged separately in addition to the summed loss, allowing you to monitor the individual components of the loss.
To get full support with the automatic model card generation, you may also wish to implement:
- a ``get_config_dict`` method that returns a dictionary of loss parameters.
- a ``citation`` property so your work gets cited in all models that train with the loss.
Consider inspecting existing loss functions to get a feel for how loss functions are commonly implemented.
```
================================================
FILE: docs/sparse_encoder/pretrained_models.md
================================================
# Pretrained Models
```{eval-rst}
Several Sparse Encoder models have been publicly released on the Hugging Face Hub:
* **Community models**: `All Sparse Encoder models on Hugging Face learning_rate
lr_scheduler_type
warmup_ratio
num_train_epochs
max_steps
per_device_train_batch_size
per_device_eval_batch_size
auto_find_batch_size
fp16
bf16
load_best_model_at_end
metric_for_best_model
gradient_accumulation_steps
gradient_checkpointing
eval_accumulation_steps
optim
batch_sampler
multi_dataset_batch_sampler
prompts
router_mapping
learning_rate_mapping
model_kwargs will be passed on to OVBaseModel.from_pretrained(). Some notable arguments include:
* ``file_name``: The name of the ONNX file to load. If not specified, will default to ``"openvino_model.xml"`` or otherwise ``"openvino/openvino_model.xml"``. This argument is useful for specifying optimized or quantized models.
* ``export``: A boolean flag specifying whether the model will be exported. If not provided, ``export`` will be set to ``True`` if the model repository or directory does not already contain an OpenVINO model.
.. tip::
It's heavily recommended to save the exported model to prevent having to re-export it every time you run your code. You can do this by calling :meth:`model.save_pretrained() torch-fp32: PyTorch with float32 precision (default).
torch-fp16: PyTorch with float16 precision, via model_kwargs={"torch_dtype": "float16"}.
torch-bf16: PyTorch with bfloat16 precision, via model_kwargs={"torch_dtype": "bfloat16"}.
onnx: ONNX with float32 precision, via backend="onnx".
onnx-O1: ONNX with float32 precision and O1 optimization, via export_optimized_onnx_model(..., optimization_config="O1", ...) and backend="onnx".
onnx-O2: ONNX with float32 precision and O2 optimization, via export_optimized_onnx_model(..., optimization_config="O2", ...) and backend="onnx".
onnx-O3: ONNX with float32 precision and O3 optimization, via export_optimized_onnx_model(..., optimization_config="O3", ...) and backend="onnx".
onnx-O4: ONNX with float16 precision and O4 optimization, via export_optimized_onnx_model(..., optimization_config="O4", ...) and backend="onnx".
onnx-qint8: ONNX quantized to int8 with "avx512_vnni", via export_dynamic_quantized_onnx_model(..., quantization_config="avx512_vnni", ...) and backend="onnx". The different quantization configurations resulted in roughly equivalent speedups.
openvino: OpenVINO, via backend="openvino".
openvino-qint8: OpenVINO quantized to int8 via export_static_quantized_openvino_model(..., quantization_config=OVQuantizationConfig(), ...) and backend="openvino".
 ```{eval-rst}
For each question pair, we pass question A and question B through the BERT-based model, after which a classifier head converts the intermediary representation from the BERT-based model into a similarity score. With this loss, we apply :class:`torch.nn.BCEWithLogitsLoss` which accepts logits (a.k.a. outputs, raw predictions) and gold similarity scores (1 if duplicate, 0 if not duplicate) to compute a loss denoting how well the model has done. This loss is then minimized to improve the performance of the model.
```
## Inference
You can perform inference using any of the [pre-trained CrossEncoder models for Duplicate Question detection](../../../../docs/cross_encoder/pretrained_models.md#quora-duplicate-questions) like so:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/quora-distilroberta-base')
scores = model.predict([
('What do apples consist of?', 'What are in Apple devices?'),
('How do I get good at programming?', 'How to become a good programmer?')
])
print(scores)
# [0.00056, 0.97536]
```
================================================
FILE: examples/cross_encoder/training/quora_duplicate_questions/training_quora_duplicate_questions.py
================================================
"""
This examples trains a CrossEncoder for the Quora Duplicate Questions Detection task. A CrossEncoder takes a sentence pair
as input and outputs a label. Here, it output a continuous labels 0...1 to indicate the similarity between the input pair.
It does NOT produce a sentence embedding and does NOT work for individual sentences.
Usage:
python training_quora_duplicate_questions.py
"""
import logging
import traceback
from datetime import datetime
from datasets import load_dataset
from sentence_transformers.cross_encoder import CrossEncoder, CrossEncoderTrainingArguments
from sentence_transformers.cross_encoder.evaluation import CrossEncoderClassificationEvaluator
from sentence_transformers.cross_encoder.losses import BinaryCrossEntropyLoss
from sentence_transformers.cross_encoder.trainer import CrossEncoderTrainer
# Set the log level to INFO to get more information
logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
train_batch_size = 64
num_epochs = 1
output_dir = "output/training_ce_quora-" + datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# 1. Define our CrossEncoder model. We use distilroberta-base as the base model and set it up to predict 1 label
# You can also use other base models, like bert-base-uncased, microsoft/mpnet-base, or rerankers like Alibaba-NLP/gte-reranker-modernbert-base
model_name = "distilroberta-base"
model = CrossEncoder(model_name, num_labels=1)
# 2. Load the Quora duplicates dataset: https://huggingface.co/datasets/sentence-transformers/quora-duplicates
logging.info("Read quora-duplicates train dataset")
dataset = load_dataset("sentence-transformers/quora-duplicates", "pair-class", split="train")
eval_dataset = dataset.select(range(10_000))
test_dataset = dataset.select(range(10_000, 20_000))
train_dataset = dataset.select(range(20_000, len(dataset)))
logging.info(train_dataset)
logging.info(eval_dataset)
logging.info(test_dataset)
# 3. Define our training loss, we use one that accepts pairs with a binary label
loss = BinaryCrossEntropyLoss(model)
# 4. Before and during training, we use CrossEncoderClassificationEvaluator to measure the performance on the dev set
dev_cls_evaluator = CrossEncoderClassificationEvaluator(
sentence_pairs=list(zip(eval_dataset["sentence1"], eval_dataset["sentence2"])),
labels=eval_dataset["label"],
name="quora-duplicates-dev",
)
dev_cls_evaluator(model)
# 5. Define the training arguments
short_model_name = model_name if "/" not in model_name else model_name.split("/")[-1]
run_name = f"reranker-{short_model_name}-quora-duplicates"
args = CrossEncoderTrainingArguments(
# Required parameter:
output_dir=output_dir,
# Optional training parameters:
num_train_epochs=num_epochs,
per_device_train_batch_size=train_batch_size,
per_device_eval_batch_size=train_batch_size,
warmup_ratio=0.1,
fp16=False, # Set to False if you get an error that your GPU can't run on FP16
bf16=True, # Set to True if you have a GPU that supports BF16
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=500,
save_total_limit=2,
logging_steps=100,
run_name=run_name, # Will be used in W&B if `wandb` is installed
)
# 6. Create the trainer & start training
trainer = CrossEncoderTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=dev_cls_evaluator,
)
trainer.train()
# 7. Evaluate the final model on test dataset
test_cls_evaluator = CrossEncoderClassificationEvaluator(
sentence_pairs=list(zip(eval_dataset["sentence1"], eval_dataset["sentence2"])),
labels=eval_dataset["label"],
name="quora-duplicates-test",
)
test_cls_evaluator(model)
# 8. Save the final model
final_output_dir = f"{output_dir}/final"
model.save_pretrained(final_output_dir)
# 9. (Optional) save the model to the Hugging Face Hub!
# It is recommended to run `huggingface-cli login` to log into your Hugging Face account first
try:
model.push_to_hub(run_name)
except Exception:
logging.error(
f"Error uploading model to the Hugging Face Hub:\n{traceback.format_exc()}To upload it manually, you can run "
f"`huggingface-cli login`, followed by loading the model using `model = CrossEncoder({final_output_dir!r})` "
f"and saving it using `model.push_to_hub('{run_name}')`."
)
================================================
FILE: examples/cross_encoder/training/rerankers/README.md
================================================
# Rerankers
```{eval-rst}
Reranker models are often :class:`~sentence_transformers.cross_encoder.CrossEncoder` models with 1 output class, i.e. given a pair of texts (query, answer), the model outputs one score. This score, either a float score that reasonably ranges between -10.0 and 10.0, or a score that's bound to 0...1, denotes to what extent the answer can help answer the query.
Many reranker models are trained on MS MARCO:
- `MS MARCO Pre-trained Cross Encoders <../../../../docs/cross_encoder/pretrained_models.html#ms-marco>`_
- `Cross Encoder > Training Examples > MS MARCO <../ms_marco/README.html>`_
```
But most likely, you will get the best results when training on your dataset. Because of this, this page includes some examples training scripts that you can adopt for your own data:
- **[training_gooaq_bce.py](training_gooaq_bce.py)**:
```{eval-rst}
This example uses :class:`~sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss` on labeled pair data that was mined from the `GooAQ
```{eval-rst}
For each sentence pair, we pass sentence A and sentence B through the BERT-based model, after which a classifier head converts the intermediary representation from the BERT-based model into a similarity score. With this loss, we apply :class:`torch.nn.BCEWithLogitsLoss` which accepts logits (a.k.a. outputs, raw predictions) and gold similarity scores to compute a loss denoting how well the model has done on this batch. This loss can be minimized to improve the performance of the model.
```
## Inference
You can perform inference using any of the [pre-trained CrossEncoder models for STS](../../../../docs/cross_encoder/pretrained_models.md#stsbenchmark) like so:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/stsb-roberta-base")
scores = model.predict([("It's a wonderful day outside.", "It's so sunny today!"), ("It's a wonderful day outside.", "He drove to work earlier.")])
# => array([0.60443085, 0.00240758], dtype=float32)
```
================================================
FILE: examples/cross_encoder/training/sts/training_stsbenchmark.py
================================================
"""
This examples trains a CrossEncoder for the STSbenchmark task. A CrossEncoder takes a sentence pair
as input and outputs a label. Here, it output a continuous labels 0...1 to indicate the similarity between the input pair.
It does NOT produce a sentence embedding and does NOT work for individual sentences.
Usage:
python training_stsbenchmark.py
"""
import logging
import traceback
from datetime import datetime
from datasets import load_dataset
from sentence_transformers.cross_encoder import CrossEncoder
from sentence_transformers.cross_encoder.evaluation import CrossEncoderCorrelationEvaluator
from sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss import BinaryCrossEntropyLoss
from sentence_transformers.cross_encoder.trainer import CrossEncoderTrainer
from sentence_transformers.cross_encoder.training_args import CrossEncoderTrainingArguments
# Set the log level to INFO to get more information
logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
train_batch_size = 64
num_epochs = 4
output_dir = "output/training_ce_stsbenchmark-" + datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# 1. Define our CrossEncoder model. We use distilroberta-base as the base model and set it up to predict 1 label
# You can also use other base models, like bert-base-uncased, microsoft/mpnet-base, or rerankers like Alibaba-NLP/gte-reranker-modernbert-base
model_name = "distilroberta-base"
model = CrossEncoder(model_name, num_labels=1)
# 2. Load the STSB dataset: https://huggingface.co/datasets/sentence-transformers/stsb
train_dataset = load_dataset("sentence-transformers/stsb", split="train")
eval_dataset = load_dataset("sentence-transformers/stsb", split="validation")
test_dataset = load_dataset("sentence-transformers/stsb", split="test")
logging.info(train_dataset)
# 3. Define our training loss, we use one that accepts pairs with a binary label
loss = BinaryCrossEntropyLoss(model)
# 4. Before and during training, we use CrossEncoderClassificationEvaluator to measure the performance on the dev set
eval_evaluator = CrossEncoderCorrelationEvaluator(
sentence_pairs=list(zip(eval_dataset["sentence1"], eval_dataset["sentence2"])),
scores=eval_dataset["score"],
name="stsb-validation",
)
eval_evaluator(model)
# 5. Define the training arguments
short_model_name = model_name if "/" not in model_name else model_name.split("/")[-1]
run_name = f"reranker-{short_model_name}-stsb"
args = CrossEncoderTrainingArguments(
# Required parameter:
output_dir=output_dir,
# Optional training parameters:
num_train_epochs=num_epochs,
per_device_train_batch_size=train_batch_size,
per_device_eval_batch_size=train_batch_size,
warmup_ratio=0.1,
fp16=False, # Set to False if you get an error that your GPU can't run on FP16
bf16=True, # Set to True if you have a GPU that supports BF16
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=80,
save_strategy="steps",
save_steps=80,
save_total_limit=2,
logging_steps=20,
run_name=run_name, # Will be used in W&B if `wandb` is installed
)
# 6. Create the trainer & start training
trainer = CrossEncoderTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=eval_evaluator,
)
trainer.train()
# 7. Evaluate the final model on test dataset
test_evaluator = CrossEncoderCorrelationEvaluator(
sentence_pairs=list(zip(test_dataset["sentence1"], test_dataset["sentence2"])),
scores=test_dataset["score"],
name="stsb-test",
)
test_evaluator(model)
# 8. Save the final model
final_output_dir = f"{output_dir}/final"
model.save_pretrained(final_output_dir)
# 9. (Optional) save the model to the Hugging Face Hub!
# It is recommended to run `huggingface-cli login` to log into your Hugging Face account first
try:
model.push_to_hub(run_name)
except Exception:
logging.error(
f"Error uploading model to the Hugging Face Hub:\n{traceback.format_exc()}To upload it manually, you can run "
f"`huggingface-cli login`, followed by loading the model using `model = CrossEncoder({final_output_dir!r})` "
f"and saving it using `model.push_to_hub('{run_name}')`."
)
================================================
FILE: examples/sentence_transformer/README.md
================================================
# Examples
This folder contains various examples how to use SentenceTransformers.
## Applications
The [applications](applications/) folder contains examples how to use SentenceTransformers for tasks like clustering or semantic search.
## Evaluation
The [evaluation](evaluation/) folder contains some examples how to evaluate SentenceTransformer models for common tasks.
## Training
The [training](training/) folder contains examples how to fine-tune transformer models like BERT, RoBERTa, or XLM-RoBERTa for generating sentence embedding. For the documentation how to train your own models, see [Training Overview](http://www.sbert.net/docs/sentence_transformer/training_overview.html).
## Unsupervised Learning
The [unsupervised_learning](unsupervised_learning/) folder contains examples how to train sentence embedding models without labeled data.
================================================
FILE: examples/sentence_transformer/applications/README.md
================================================
# Applications
SentenceTransformers can be used for various use-cases. In these folders, you find several example scripts that show case how SentenceTransformers can be used
## Computing Embeddings
The [computing-embeddings](computing-embeddings/) folder contains examples how to compute sentence embeddings using SentenceTransformers.
## Clustering
The [clustering](clustering/) folder shows how SentenceTransformers can be used for text clustering, i.e., grouping sentences together based on their similarity.
## Cross-Encoder
SentenceTransformers also support training and inference of [Cross-Encoders](cross-encoder/). There, two sentences are presented simultaneously to the transformer network and a score (0...1) is derived indicating the similarity or a label.
## Parallel Sentence Mining
The [parallel-sentence-mining](parallel-sentence-mining/) folder contains examples of how parallel (translated) sentences can be found in two corpora of different languages. For example, you take the English and the Spanish Wikipedia and the script finds and returns all translated English-Spanish sentence pairs.
## Paraphrase Mining
The [paraphrase-mining](paraphrase-mining/) folder contains examples to find all paraphrase sentences in a large set of sentences. The example can be used to find e.g. duplicate questions or duplicate sentences in a set of Millions of questions / sentences.
## Semantic Search
The [semantic-search](semantic-search/) folder shows examples for semantic search: Given a sentence, find in a large collection semantically similar sentences.
## Retrieve & Rerank
The [retrieve_rerank](retrieve_rerank/) folder shows how to combine a bi-encoder for semantic search retrieval and a more powerful re-ranking stage with a cross-encoder.
## Image Search
The [image-search](image-search/) folder shows how to use the image&text-models, which can map images and text to the same vector space. This allows for an image search given a user query.
## Text Summarization
The [text-summarization](text-summarization/) folder shows how SentenceTransformers can be used for extractive summarization: Give a long document, find the k sentences that give a good and short summary of the content.
================================================
FILE: examples/sentence_transformer/applications/clustering/README.md
================================================
# Clustering
Sentence-Transformers can be used in different ways to perform clustering of small or large set of sentences.
## k-Means
[kmeans.py](kmeans.py) contains an example of using [K-means Clustering Algorithm](https://scikit-learn.org/stable/modules/clustering.html#k-means). K-Means requires that the number of clusters is specified beforehand. The sentences are clustered in groups of about equal size.
## Agglomerative Clustering
[agglomerative.py](agglomerative.py) shows an example of using [Hierarchical clustering](https://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering) using the [Agglomerative Clustering Algorithm](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html#sklearn.cluster.AgglomerativeClustering). In contrast to k-means, we can specify a threshold for the clustering: Clusters below that threshold are merged. This algorithm can be useful if the number of clusters is unknown. By the threshold, we can control if we want to have many small and fine-grained clusters or few coarse-grained clusters.
## Fast Clustering
Agglomerative Clustering for larger datasets is quite slow, so it is only applicable for maybe a few thousand sentences.
In [fast_clustering.py](fast_clustering.py) we present a clustering algorithm that is tuned for large datasets (50k sentences in less than 5 seconds). In a large list of sentences it searches for local communities: A local community is a set of highly similar sentences.
You can configure the threshold of cosine-similarity for which we consider two sentences as similar. Also, you can specify the minimal size for a local community. This allows you to get either large coarse-grained clusters or small fine-grained clusters.
We apply it on the [Quora Duplicate Questions](https://huggingface.co/datasets/sentence-transformers/quora-duplicates) dataset and the output looks something like this:
```
Cluster 1, #83 Elements
What should I do to improve my English ?
What should I do to improve my spoken English?
Can I improve my English?
...
Cluster 2, #79 Elements
How can I earn money online?
How do I earn money online?
Can I earn money online?
...
...
Cluster 47, #25 Elements
What are some mind-blowing Mobile gadgets that exist that most people don't know about?
What are some mind-blowing gadgets and technologies that exist that most people don't know about?
What are some mind-blowing mobile technology tools that exist that most people don't know about?
...
```
## Topic Modeling
Topic modeling is the process of discovering topics in a collection of documents.
An example is shown in the following picture, which shows the identified topics in the 20 newsgroup dataset:
For each topic, you want to extract the words that describe this topic:

Sentence-Transformers can be used to identify these topics in a collection of sentences, paragraphs or short documents. For an excellent tutorial, see [Topic Modeling with BERT](https://medium.com/data-science/topic-modeling-with-bert-779f7db187e6) as well as the [BERTopic](https://github.com/MaartenGr/BERTopic) and [Top2Vec](https://github.com/ddangelov/Top2Vec) repositories.
Image source: [Top2Vec: Distributed Representations of Topics](https://huggingface.co/papers/2008.09470)
================================================
FILE: examples/sentence_transformer/applications/clustering/agglomerative.py
================================================
"""
This is a simple application for sentence embeddings: clustering
Sentences are mapped to sentence embeddings and then agglomerative clustering with a threshold is applied.
"""
from sklearn.cluster import AgglomerativeClustering
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example sentences
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"The baby is carried by the woman",
"A man is riding a horse.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah is running behind its prey.",
"A cheetah chases prey on across a field.",
]
corpus_embeddings = embedder.encode(corpus)
# Some models don't automatically normalize the embeddings, in which case you should normalize the embeddings:
# corpus_embeddings = corpus_embeddings / np.linalg.norm(corpus_embeddings, axis=1, keepdims=True)
# Perform agglomerative clustering
clustering_model = AgglomerativeClustering(
n_clusters=None, distance_threshold=1.5
) # , affinity='cosine', linkage='average', distance_threshold=0.4)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = {}
for sentence_id, cluster_id in enumerate(cluster_assignment):
if cluster_id not in clustered_sentences:
clustered_sentences[cluster_id] = []
clustered_sentences[cluster_id].append(corpus[sentence_id])
for i, cluster in clustered_sentences.items():
print("Cluster ", i + 1)
print(cluster)
print("")
================================================
FILE: examples/sentence_transformer/applications/clustering/fast_clustering.py
================================================
"""
This is a more complex example on performing clustering on large scale dataset.
This examples find in a large set of sentences local communities, i.e., groups of sentences that are highly
similar. You can freely configure the threshold what is considered as similar. A high threshold will
only find extremely similar sentences, a lower threshold will find more sentence that are less similar.
A second parameter is 'min_community_size': Only communities with at least a certain number of sentences will be returned.
The method for finding the communities is extremely fast, for clustering 50k sentences it requires only 5 seconds (plus embedding computation).
In this example, we download a large set of questions from Quora and then find similar questions in this set.
"""
import csv
import os
import time
from sentence_transformers import SentenceTransformer, util
# Model for computing sentence embeddings. We use one trained for similar questions detection
model = SentenceTransformer("all-MiniLM-L6-v2")
# We download the Quora Duplicate Questions Dataset (https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs)
# and find similar question in it
url = "http://qim.fs.quoracdn.net/quora_duplicate_questions.tsv"
dataset_path = "quora_duplicate_questions.tsv"
max_corpus_size = 50000 # We limit our corpus to only the first 50k questions
# Check if the dataset exists. If not, download and extract
# Download dataset if needed
if not os.path.exists(dataset_path):
print("Download dataset")
util.http_get(url, dataset_path)
# Get all unique sentences from the file
corpus_sentences = set()
with open(dataset_path, encoding="utf8") as fIn:
reader = csv.DictReader(fIn, delimiter="\t", quoting=csv.QUOTE_MINIMAL)
for row in reader:
corpus_sentences.add(row["question1"])
corpus_sentences.add(row["question2"])
if len(corpus_sentences) >= max_corpus_size:
break
corpus_sentences = list(corpus_sentences)
print("Encode the corpus. This might take a while")
corpus_embeddings = model.encode(corpus_sentences, batch_size=64, show_progress_bar=True, convert_to_tensor=True)
print("Start clustering")
start_time = time.time()
# Two parameters to tune:
# min_cluster_size: Only consider cluster that have at least 25 elements
# threshold: Consider sentence pairs with a cosine-similarity larger than threshold as similar
clusters = util.community_detection(corpus_embeddings, min_community_size=25, threshold=0.75)
print(f"Clustering done after {time.time() - start_time:.2f} sec")
# Print for all clusters the top 3 and bottom 3 elements
for i, cluster in enumerate(clusters):
print(f"\nCluster {i + 1}, #{len(cluster)} Elements ")
for sentence_id in cluster[0:3]:
print("\t", corpus_sentences[sentence_id])
print("\t", "...")
for sentence_id in cluster[-3:]:
print("\t", corpus_sentences[sentence_id])
================================================
FILE: examples/sentence_transformer/applications/clustering/kmeans.py
================================================
"""
This is a simple application for sentence embeddings: clustering
Sentences are mapped to sentence embeddings and then k-mean clustering is applied.
"""
from sklearn.cluster import KMeans
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example sentences
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"The baby is carried by the woman",
"A man is riding a horse.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah is running behind its prey.",
"A cheetah chases prey on across a field.",
]
corpus_embeddings = embedder.encode(corpus)
# Perform kmean clustering
num_clusters = 5
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(corpus[sentence_id])
for i, cluster in enumerate(clustered_sentences):
print("Cluster ", i + 1)
print(cluster)
print("")
================================================
FILE: examples/sentence_transformer/applications/computing-embeddings/README.rst
================================================
Computing Embeddings
====================
Once you have `installed <../../../../docs/installation.html>`_ Sentence Transformers, you can easily use Sentence Transformer models:
.. sidebar:: Documentation
1. :class:`SentenceTransformer
```{eval-rst}
For each question pair, we pass question A and question B through the BERT-based model, after which a classifier head converts the intermediary representation from the BERT-based model into a similarity score. With this loss, we apply :class:`torch.nn.BCEWithLogitsLoss` which accepts logits (a.k.a. outputs, raw predictions) and gold similarity scores (1 if duplicate, 0 if not duplicate) to compute a loss denoting how well the model has done. This loss is then minimized to improve the performance of the model.
```
## Inference
You can perform inference using any of the [pre-trained CrossEncoder models for Duplicate Question detection](../../../../docs/cross_encoder/pretrained_models.md#quora-duplicate-questions) like so:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/quora-distilroberta-base')
scores = model.predict([
('What do apples consist of?', 'What are in Apple devices?'),
('How do I get good at programming?', 'How to become a good programmer?')
])
print(scores)
# [0.00056, 0.97536]
```
================================================
FILE: examples/cross_encoder/training/quora_duplicate_questions/training_quora_duplicate_questions.py
================================================
"""
This examples trains a CrossEncoder for the Quora Duplicate Questions Detection task. A CrossEncoder takes a sentence pair
as input and outputs a label. Here, it output a continuous labels 0...1 to indicate the similarity between the input pair.
It does NOT produce a sentence embedding and does NOT work for individual sentences.
Usage:
python training_quora_duplicate_questions.py
"""
import logging
import traceback
from datetime import datetime
from datasets import load_dataset
from sentence_transformers.cross_encoder import CrossEncoder, CrossEncoderTrainingArguments
from sentence_transformers.cross_encoder.evaluation import CrossEncoderClassificationEvaluator
from sentence_transformers.cross_encoder.losses import BinaryCrossEntropyLoss
from sentence_transformers.cross_encoder.trainer import CrossEncoderTrainer
# Set the log level to INFO to get more information
logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
train_batch_size = 64
num_epochs = 1
output_dir = "output/training_ce_quora-" + datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# 1. Define our CrossEncoder model. We use distilroberta-base as the base model and set it up to predict 1 label
# You can also use other base models, like bert-base-uncased, microsoft/mpnet-base, or rerankers like Alibaba-NLP/gte-reranker-modernbert-base
model_name = "distilroberta-base"
model = CrossEncoder(model_name, num_labels=1)
# 2. Load the Quora duplicates dataset: https://huggingface.co/datasets/sentence-transformers/quora-duplicates
logging.info("Read quora-duplicates train dataset")
dataset = load_dataset("sentence-transformers/quora-duplicates", "pair-class", split="train")
eval_dataset = dataset.select(range(10_000))
test_dataset = dataset.select(range(10_000, 20_000))
train_dataset = dataset.select(range(20_000, len(dataset)))
logging.info(train_dataset)
logging.info(eval_dataset)
logging.info(test_dataset)
# 3. Define our training loss, we use one that accepts pairs with a binary label
loss = BinaryCrossEntropyLoss(model)
# 4. Before and during training, we use CrossEncoderClassificationEvaluator to measure the performance on the dev set
dev_cls_evaluator = CrossEncoderClassificationEvaluator(
sentence_pairs=list(zip(eval_dataset["sentence1"], eval_dataset["sentence2"])),
labels=eval_dataset["label"],
name="quora-duplicates-dev",
)
dev_cls_evaluator(model)
# 5. Define the training arguments
short_model_name = model_name if "/" not in model_name else model_name.split("/")[-1]
run_name = f"reranker-{short_model_name}-quora-duplicates"
args = CrossEncoderTrainingArguments(
# Required parameter:
output_dir=output_dir,
# Optional training parameters:
num_train_epochs=num_epochs,
per_device_train_batch_size=train_batch_size,
per_device_eval_batch_size=train_batch_size,
warmup_ratio=0.1,
fp16=False, # Set to False if you get an error that your GPU can't run on FP16
bf16=True, # Set to True if you have a GPU that supports BF16
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=500,
save_total_limit=2,
logging_steps=100,
run_name=run_name, # Will be used in W&B if `wandb` is installed
)
# 6. Create the trainer & start training
trainer = CrossEncoderTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=dev_cls_evaluator,
)
trainer.train()
# 7. Evaluate the final model on test dataset
test_cls_evaluator = CrossEncoderClassificationEvaluator(
sentence_pairs=list(zip(eval_dataset["sentence1"], eval_dataset["sentence2"])),
labels=eval_dataset["label"],
name="quora-duplicates-test",
)
test_cls_evaluator(model)
# 8. Save the final model
final_output_dir = f"{output_dir}/final"
model.save_pretrained(final_output_dir)
# 9. (Optional) save the model to the Hugging Face Hub!
# It is recommended to run `huggingface-cli login` to log into your Hugging Face account first
try:
model.push_to_hub(run_name)
except Exception:
logging.error(
f"Error uploading model to the Hugging Face Hub:\n{traceback.format_exc()}To upload it manually, you can run "
f"`huggingface-cli login`, followed by loading the model using `model = CrossEncoder({final_output_dir!r})` "
f"and saving it using `model.push_to_hub('{run_name}')`."
)
================================================
FILE: examples/cross_encoder/training/rerankers/README.md
================================================
# Rerankers
```{eval-rst}
Reranker models are often :class:`~sentence_transformers.cross_encoder.CrossEncoder` models with 1 output class, i.e. given a pair of texts (query, answer), the model outputs one score. This score, either a float score that reasonably ranges between -10.0 and 10.0, or a score that's bound to 0...1, denotes to what extent the answer can help answer the query.
Many reranker models are trained on MS MARCO:
- `MS MARCO Pre-trained Cross Encoders <../../../../docs/cross_encoder/pretrained_models.html#ms-marco>`_
- `Cross Encoder > Training Examples > MS MARCO <../ms_marco/README.html>`_
```
But most likely, you will get the best results when training on your dataset. Because of this, this page includes some examples training scripts that you can adopt for your own data:
- **[training_gooaq_bce.py](training_gooaq_bce.py)**:
```{eval-rst}
This example uses :class:`~sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss` on labeled pair data that was mined from the `GooAQ
```{eval-rst}
For each sentence pair, we pass sentence A and sentence B through the BERT-based model, after which a classifier head converts the intermediary representation from the BERT-based model into a similarity score. With this loss, we apply :class:`torch.nn.BCEWithLogitsLoss` which accepts logits (a.k.a. outputs, raw predictions) and gold similarity scores to compute a loss denoting how well the model has done on this batch. This loss can be minimized to improve the performance of the model.
```
## Inference
You can perform inference using any of the [pre-trained CrossEncoder models for STS](../../../../docs/cross_encoder/pretrained_models.md#stsbenchmark) like so:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder("cross-encoder/stsb-roberta-base")
scores = model.predict([("It's a wonderful day outside.", "It's so sunny today!"), ("It's a wonderful day outside.", "He drove to work earlier.")])
# => array([0.60443085, 0.00240758], dtype=float32)
```
================================================
FILE: examples/cross_encoder/training/sts/training_stsbenchmark.py
================================================
"""
This examples trains a CrossEncoder for the STSbenchmark task. A CrossEncoder takes a sentence pair
as input and outputs a label. Here, it output a continuous labels 0...1 to indicate the similarity between the input pair.
It does NOT produce a sentence embedding and does NOT work for individual sentences.
Usage:
python training_stsbenchmark.py
"""
import logging
import traceback
from datetime import datetime
from datasets import load_dataset
from sentence_transformers.cross_encoder import CrossEncoder
from sentence_transformers.cross_encoder.evaluation import CrossEncoderCorrelationEvaluator
from sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss import BinaryCrossEntropyLoss
from sentence_transformers.cross_encoder.trainer import CrossEncoderTrainer
from sentence_transformers.cross_encoder.training_args import CrossEncoderTrainingArguments
# Set the log level to INFO to get more information
logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
train_batch_size = 64
num_epochs = 4
output_dir = "output/training_ce_stsbenchmark-" + datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# 1. Define our CrossEncoder model. We use distilroberta-base as the base model and set it up to predict 1 label
# You can also use other base models, like bert-base-uncased, microsoft/mpnet-base, or rerankers like Alibaba-NLP/gte-reranker-modernbert-base
model_name = "distilroberta-base"
model = CrossEncoder(model_name, num_labels=1)
# 2. Load the STSB dataset: https://huggingface.co/datasets/sentence-transformers/stsb
train_dataset = load_dataset("sentence-transformers/stsb", split="train")
eval_dataset = load_dataset("sentence-transformers/stsb", split="validation")
test_dataset = load_dataset("sentence-transformers/stsb", split="test")
logging.info(train_dataset)
# 3. Define our training loss, we use one that accepts pairs with a binary label
loss = BinaryCrossEntropyLoss(model)
# 4. Before and during training, we use CrossEncoderClassificationEvaluator to measure the performance on the dev set
eval_evaluator = CrossEncoderCorrelationEvaluator(
sentence_pairs=list(zip(eval_dataset["sentence1"], eval_dataset["sentence2"])),
scores=eval_dataset["score"],
name="stsb-validation",
)
eval_evaluator(model)
# 5. Define the training arguments
short_model_name = model_name if "/" not in model_name else model_name.split("/")[-1]
run_name = f"reranker-{short_model_name}-stsb"
args = CrossEncoderTrainingArguments(
# Required parameter:
output_dir=output_dir,
# Optional training parameters:
num_train_epochs=num_epochs,
per_device_train_batch_size=train_batch_size,
per_device_eval_batch_size=train_batch_size,
warmup_ratio=0.1,
fp16=False, # Set to False if you get an error that your GPU can't run on FP16
bf16=True, # Set to True if you have a GPU that supports BF16
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=80,
save_strategy="steps",
save_steps=80,
save_total_limit=2,
logging_steps=20,
run_name=run_name, # Will be used in W&B if `wandb` is installed
)
# 6. Create the trainer & start training
trainer = CrossEncoderTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=eval_evaluator,
)
trainer.train()
# 7. Evaluate the final model on test dataset
test_evaluator = CrossEncoderCorrelationEvaluator(
sentence_pairs=list(zip(test_dataset["sentence1"], test_dataset["sentence2"])),
scores=test_dataset["score"],
name="stsb-test",
)
test_evaluator(model)
# 8. Save the final model
final_output_dir = f"{output_dir}/final"
model.save_pretrained(final_output_dir)
# 9. (Optional) save the model to the Hugging Face Hub!
# It is recommended to run `huggingface-cli login` to log into your Hugging Face account first
try:
model.push_to_hub(run_name)
except Exception:
logging.error(
f"Error uploading model to the Hugging Face Hub:\n{traceback.format_exc()}To upload it manually, you can run "
f"`huggingface-cli login`, followed by loading the model using `model = CrossEncoder({final_output_dir!r})` "
f"and saving it using `model.push_to_hub('{run_name}')`."
)
================================================
FILE: examples/sentence_transformer/README.md
================================================
# Examples
This folder contains various examples how to use SentenceTransformers.
## Applications
The [applications](applications/) folder contains examples how to use SentenceTransformers for tasks like clustering or semantic search.
## Evaluation
The [evaluation](evaluation/) folder contains some examples how to evaluate SentenceTransformer models for common tasks.
## Training
The [training](training/) folder contains examples how to fine-tune transformer models like BERT, RoBERTa, or XLM-RoBERTa for generating sentence embedding. For the documentation how to train your own models, see [Training Overview](http://www.sbert.net/docs/sentence_transformer/training_overview.html).
## Unsupervised Learning
The [unsupervised_learning](unsupervised_learning/) folder contains examples how to train sentence embedding models without labeled data.
================================================
FILE: examples/sentence_transformer/applications/README.md
================================================
# Applications
SentenceTransformers can be used for various use-cases. In these folders, you find several example scripts that show case how SentenceTransformers can be used
## Computing Embeddings
The [computing-embeddings](computing-embeddings/) folder contains examples how to compute sentence embeddings using SentenceTransformers.
## Clustering
The [clustering](clustering/) folder shows how SentenceTransformers can be used for text clustering, i.e., grouping sentences together based on their similarity.
## Cross-Encoder
SentenceTransformers also support training and inference of [Cross-Encoders](cross-encoder/). There, two sentences are presented simultaneously to the transformer network and a score (0...1) is derived indicating the similarity or a label.
## Parallel Sentence Mining
The [parallel-sentence-mining](parallel-sentence-mining/) folder contains examples of how parallel (translated) sentences can be found in two corpora of different languages. For example, you take the English and the Spanish Wikipedia and the script finds and returns all translated English-Spanish sentence pairs.
## Paraphrase Mining
The [paraphrase-mining](paraphrase-mining/) folder contains examples to find all paraphrase sentences in a large set of sentences. The example can be used to find e.g. duplicate questions or duplicate sentences in a set of Millions of questions / sentences.
## Semantic Search
The [semantic-search](semantic-search/) folder shows examples for semantic search: Given a sentence, find in a large collection semantically similar sentences.
## Retrieve & Rerank
The [retrieve_rerank](retrieve_rerank/) folder shows how to combine a bi-encoder for semantic search retrieval and a more powerful re-ranking stage with a cross-encoder.
## Image Search
The [image-search](image-search/) folder shows how to use the image&text-models, which can map images and text to the same vector space. This allows for an image search given a user query.
## Text Summarization
The [text-summarization](text-summarization/) folder shows how SentenceTransformers can be used for extractive summarization: Give a long document, find the k sentences that give a good and short summary of the content.
================================================
FILE: examples/sentence_transformer/applications/clustering/README.md
================================================
# Clustering
Sentence-Transformers can be used in different ways to perform clustering of small or large set of sentences.
## k-Means
[kmeans.py](kmeans.py) contains an example of using [K-means Clustering Algorithm](https://scikit-learn.org/stable/modules/clustering.html#k-means). K-Means requires that the number of clusters is specified beforehand. The sentences are clustered in groups of about equal size.
## Agglomerative Clustering
[agglomerative.py](agglomerative.py) shows an example of using [Hierarchical clustering](https://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering) using the [Agglomerative Clustering Algorithm](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html#sklearn.cluster.AgglomerativeClustering). In contrast to k-means, we can specify a threshold for the clustering: Clusters below that threshold are merged. This algorithm can be useful if the number of clusters is unknown. By the threshold, we can control if we want to have many small and fine-grained clusters or few coarse-grained clusters.
## Fast Clustering
Agglomerative Clustering for larger datasets is quite slow, so it is only applicable for maybe a few thousand sentences.
In [fast_clustering.py](fast_clustering.py) we present a clustering algorithm that is tuned for large datasets (50k sentences in less than 5 seconds). In a large list of sentences it searches for local communities: A local community is a set of highly similar sentences.
You can configure the threshold of cosine-similarity for which we consider two sentences as similar. Also, you can specify the minimal size for a local community. This allows you to get either large coarse-grained clusters or small fine-grained clusters.
We apply it on the [Quora Duplicate Questions](https://huggingface.co/datasets/sentence-transformers/quora-duplicates) dataset and the output looks something like this:
```
Cluster 1, #83 Elements
What should I do to improve my English ?
What should I do to improve my spoken English?
Can I improve my English?
...
Cluster 2, #79 Elements
How can I earn money online?
How do I earn money online?
Can I earn money online?
...
...
Cluster 47, #25 Elements
What are some mind-blowing Mobile gadgets that exist that most people don't know about?
What are some mind-blowing gadgets and technologies that exist that most people don't know about?
What are some mind-blowing mobile technology tools that exist that most people don't know about?
...
```
## Topic Modeling
Topic modeling is the process of discovering topics in a collection of documents.
An example is shown in the following picture, which shows the identified topics in the 20 newsgroup dataset:

For each topic, you want to extract the words that describe this topic:

Sentence-Transformers can be used to identify these topics in a collection of sentences, paragraphs or short documents. For an excellent tutorial, see [Topic Modeling with BERT](https://medium.com/data-science/topic-modeling-with-bert-779f7db187e6) as well as the [BERTopic](https://github.com/MaartenGr/BERTopic) and [Top2Vec](https://github.com/ddangelov/Top2Vec) repositories.
Image source: [Top2Vec: Distributed Representations of Topics](https://huggingface.co/papers/2008.09470)
================================================
FILE: examples/sentence_transformer/applications/clustering/agglomerative.py
================================================
"""
This is a simple application for sentence embeddings: clustering
Sentences are mapped to sentence embeddings and then agglomerative clustering with a threshold is applied.
"""
from sklearn.cluster import AgglomerativeClustering
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example sentences
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"The baby is carried by the woman",
"A man is riding a horse.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah is running behind its prey.",
"A cheetah chases prey on across a field.",
]
corpus_embeddings = embedder.encode(corpus)
# Some models don't automatically normalize the embeddings, in which case you should normalize the embeddings:
# corpus_embeddings = corpus_embeddings / np.linalg.norm(corpus_embeddings, axis=1, keepdims=True)
# Perform agglomerative clustering
clustering_model = AgglomerativeClustering(
n_clusters=None, distance_threshold=1.5
) # , affinity='cosine', linkage='average', distance_threshold=0.4)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = {}
for sentence_id, cluster_id in enumerate(cluster_assignment):
if cluster_id not in clustered_sentences:
clustered_sentences[cluster_id] = []
clustered_sentences[cluster_id].append(corpus[sentence_id])
for i, cluster in clustered_sentences.items():
print("Cluster ", i + 1)
print(cluster)
print("")
================================================
FILE: examples/sentence_transformer/applications/clustering/fast_clustering.py
================================================
"""
This is a more complex example on performing clustering on large scale dataset.
This examples find in a large set of sentences local communities, i.e., groups of sentences that are highly
similar. You can freely configure the threshold what is considered as similar. A high threshold will
only find extremely similar sentences, a lower threshold will find more sentence that are less similar.
A second parameter is 'min_community_size': Only communities with at least a certain number of sentences will be returned.
The method for finding the communities is extremely fast, for clustering 50k sentences it requires only 5 seconds (plus embedding computation).
In this example, we download a large set of questions from Quora and then find similar questions in this set.
"""
import csv
import os
import time
from sentence_transformers import SentenceTransformer, util
# Model for computing sentence embeddings. We use one trained for similar questions detection
model = SentenceTransformer("all-MiniLM-L6-v2")
# We download the Quora Duplicate Questions Dataset (https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs)
# and find similar question in it
url = "http://qim.fs.quoracdn.net/quora_duplicate_questions.tsv"
dataset_path = "quora_duplicate_questions.tsv"
max_corpus_size = 50000 # We limit our corpus to only the first 50k questions
# Check if the dataset exists. If not, download and extract
# Download dataset if needed
if not os.path.exists(dataset_path):
print("Download dataset")
util.http_get(url, dataset_path)
# Get all unique sentences from the file
corpus_sentences = set()
with open(dataset_path, encoding="utf8") as fIn:
reader = csv.DictReader(fIn, delimiter="\t", quoting=csv.QUOTE_MINIMAL)
for row in reader:
corpus_sentences.add(row["question1"])
corpus_sentences.add(row["question2"])
if len(corpus_sentences) >= max_corpus_size:
break
corpus_sentences = list(corpus_sentences)
print("Encode the corpus. This might take a while")
corpus_embeddings = model.encode(corpus_sentences, batch_size=64, show_progress_bar=True, convert_to_tensor=True)
print("Start clustering")
start_time = time.time()
# Two parameters to tune:
# min_cluster_size: Only consider cluster that have at least 25 elements
# threshold: Consider sentence pairs with a cosine-similarity larger than threshold as similar
clusters = util.community_detection(corpus_embeddings, min_community_size=25, threshold=0.75)
print(f"Clustering done after {time.time() - start_time:.2f} sec")
# Print for all clusters the top 3 and bottom 3 elements
for i, cluster in enumerate(clusters):
print(f"\nCluster {i + 1}, #{len(cluster)} Elements ")
for sentence_id in cluster[0:3]:
print("\t", corpus_sentences[sentence_id])
print("\t", "...")
for sentence_id in cluster[-3:]:
print("\t", corpus_sentences[sentence_id])
================================================
FILE: examples/sentence_transformer/applications/clustering/kmeans.py
================================================
"""
This is a simple application for sentence embeddings: clustering
Sentences are mapped to sentence embeddings and then k-mean clustering is applied.
"""
from sklearn.cluster import KMeans
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example sentences
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"The baby is carried by the woman",
"A man is riding a horse.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah is running behind its prey.",
"A cheetah chases prey on across a field.",
]
corpus_embeddings = embedder.encode(corpus)
# Perform kmean clustering
num_clusters = 5
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(corpus[sentence_id])
for i, cluster in enumerate(clustered_sentences):
print("Cluster ", i + 1)
print(cluster)
print("")
================================================
FILE: examples/sentence_transformer/applications/computing-embeddings/README.rst
================================================
Computing Embeddings
====================
Once you have `installed <../../../../docs/installation.html>`_ Sentence Transformers, you can easily use Sentence Transformer models:
.. sidebar:: Documentation
1. :class:`SentenceTransformer