


![]()
![]()

Agents that think in code!


 Writing actions in code rather than JSON-like snippets provides better:
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
- **Generality:** code is built to express simply anything you can have a computer do.
- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!
================================================
FILE: docs/source/en/conceptual_guides/react.md
================================================
# How do multi-step agents work?
The ReAct framework ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) is currently the main approach to building agents.
The name is based on the concatenation of two words, "Reason" and "Act." Indeed, agents following this architecture will solve their task in as many steps as needed, each step consisting of a Reasoning step, then an Action step where it formulates tool calls that will bring it closer to solving the task at hand.
All agents in `smolagents` are based on singular `MultiStepAgent` class, which is an abstraction of ReAct framework.
On a basic level, this class performs actions on a cycle of following steps, where existing variables and knowledge is incorporated into the agent logs like below:
Initialization: the system prompt is stored in a `SystemPromptStep`, and the user query is logged into a `TaskStep` .
While loop (ReAct loop):
- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).
- Execute the action and logs result into memory (an `ActionStep`).
- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .
Optionally, when planning is activated, a plan can be periodically revised and stored in a `PlanningStep` . This includes feeding facts about the task at hand to the memory.
For a `CodeAgent`, it looks like the figure below.
Writing actions in code rather than JSON-like snippets provides better:
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
- **Generality:** code is built to express simply anything you can have a computer do.
- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!
================================================
FILE: docs/source/en/conceptual_guides/react.md
================================================
# How do multi-step agents work?
The ReAct framework ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) is currently the main approach to building agents.
The name is based on the concatenation of two words, "Reason" and "Act." Indeed, agents following this architecture will solve their task in as many steps as needed, each step consisting of a Reasoning step, then an Action step where it formulates tool calls that will bring it closer to solving the task at hand.
All agents in `smolagents` are based on singular `MultiStepAgent` class, which is an abstraction of ReAct framework.
On a basic level, this class performs actions on a cycle of following steps, where existing variables and knowledge is incorporated into the agent logs like below:
Initialization: the system prompt is stored in a `SystemPromptStep`, and the user query is logged into a `TaskStep` .
While loop (ReAct loop):
- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).
- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).
- Execute the action and logs result into memory (an `ActionStep`).
- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .
Optionally, when planning is activated, a plan can be periodically revised and stored in a `PlanningStep` . This includes feeding facts about the task at hand to the memory.
For a `CodeAgent`, it looks like the figure below.


Learn the basics and become familiar with using Agents. Start here if you are using Agents for the first time!
Practical guides to help you achieve a specific goal: create an agent to generate and test SQL queries!
High-level explanations for building a better understanding of important topics.
Horizontal tutorials that cover important aspects of building agents.

 You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
## Setting up telemetry with MLflow
MLflow has one-line autologging for Smolagents: it tracks runs, spans, inputs/outputs, and token usage in the MLflow UI.
Install MLflow, enable autologging, then run your agent with a couple of tools:
```python
%pip install mlflow smolagents
import mlflow
from smolagents import CodeAgent, ToolCallingAgent, WebSearchTool, VisitWebpageTool, InferenceClientModel
mlflow.smolagents.autolog() # start tracing everything below
model = InferenceClientModel()
browser = ToolCallingAgent(
tools=[WebSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="Web search helper",
)
manager = CodeAgent(model=model, managed_agents=[browser])
manager.run("Find the latest US GDP growth rate and estimate when it would double.")
```
Start the UI to inspect traces, then open the Traces view in your browser:
```shell
mlflow server --port 5000
```
## Setting up telemetry with 🪢 Langfuse
This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
### Step 1: Install Dependencies
```python
%pip install langfuse 'smolagents[telemetry]' openinference-instrumentation-smolagents
```
### Step 2: Set Up Environment Variables
Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
```python
import os
# Get keys for your project from the project settings page: https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
# your Hugging Face token
os.environ["HF_TOKEN"] = "hf_..."
```
With the environment variables set, we can now initialize the Langfuse client. `get_client()` initializes the Langfuse client using the credentials provided in the environment variables.
```python
from langfuse import get_client
langfuse = get_client()
# Verify connection
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")
```
### Step 3: Initialize the `SmolagentsInstrumentor`
Initialize the `SmolagentsInstrumentor` before your application code.
```python
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
SmolagentsInstrumentor().instrument()
```
### Step 4: Run your smolagent
```python
from smolagents import (
CodeAgent,
ToolCallingAgent,
WebSearchTool,
VisitWebpageTool,
InferenceClientModel,
)
model = InferenceClientModel(
model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
)
search_agent = ToolCallingAgent(
tools=[WebSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="This is an agent that can do web search.",
)
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent],
)
manager_agent.run(
"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
)
```
### Step 5: View Traces in Langfuse
After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.
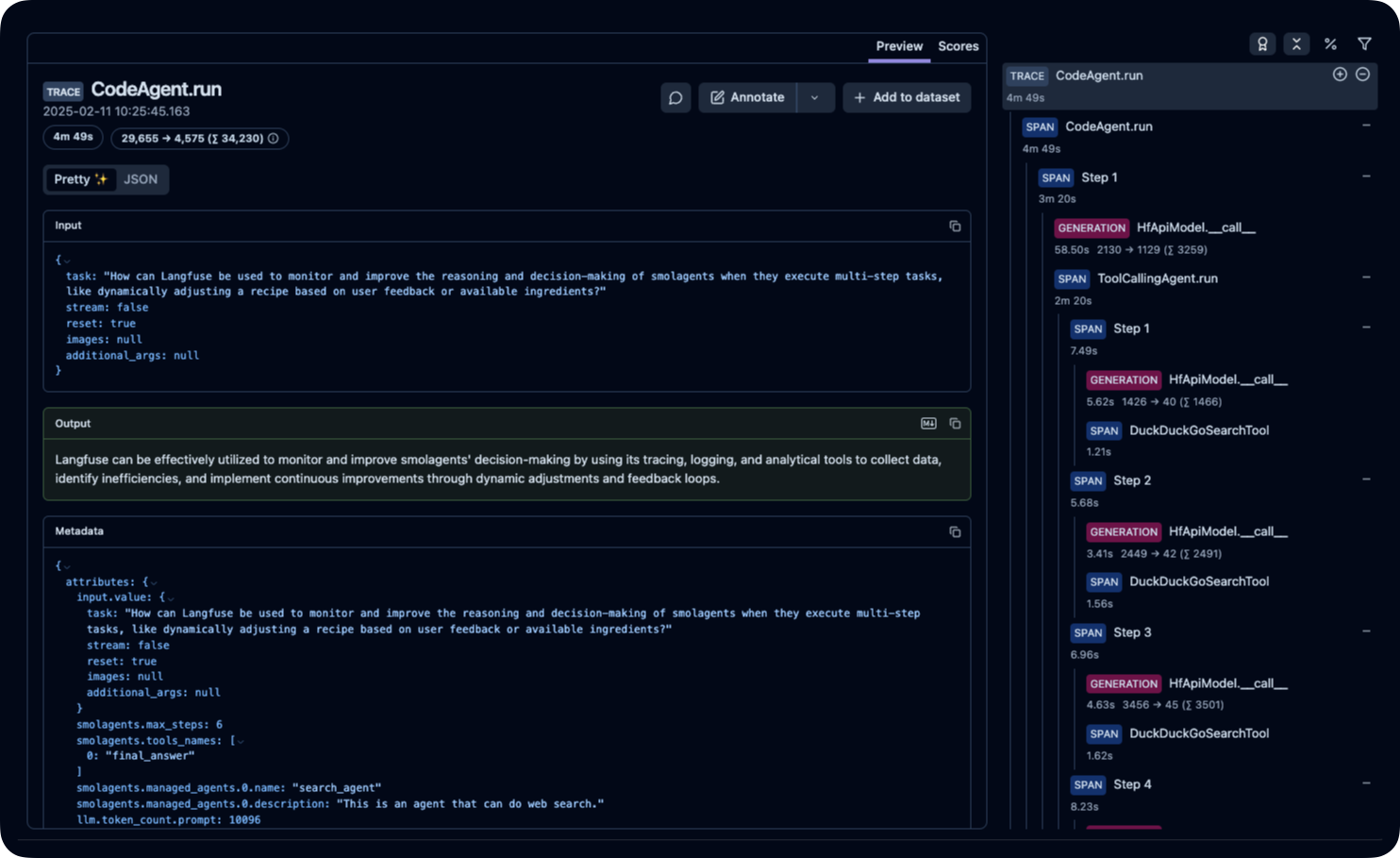
_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
================================================
FILE: docs/source/en/tutorials/memory.md
================================================
# 📚 Manage your agent's memory
[[open-in-colab]]
In the end, an agent can be defined by simple components: it has tools, prompts.
And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
### Replay your agent's memory
We propose several features to inspect a past agent run.
You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
You can also use `agent.replay()`, as follows:
After the agent has run:
```py
from smolagents import InferenceClientModel, CodeAgent
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
result = agent.run("What's the 20th Fibonacci number?")
```
If you want to replay this last run, just use:
```py
agent.replay()
```
### Dynamically change the agent's memory
Many advanced use cases require dynamic modification of the agent's memory.
You can access the agent's memory using:
```py
from smolagents import ActionStep
system_prompt_step = agent.memory.system_prompt
print("The system prompt given to the agent was:")
print(system_prompt_step.system_prompt)
task_step = agent.memory.steps[0]
print("\n\nThe first task step was:")
print(task_step.task)
for step in agent.memory.steps:
if isinstance(step, ActionStep):
if step.error is not None:
print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
else:
print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
```
Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
You can also use step callbacks to dynamically change the agent's memory.
Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
You could run something like the following.
_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
```py
import helium
from PIL import Image
from io import BytesIO
from time import sleep
def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
sleep(1.0) # Let JavaScript animations happen before taking the screenshot
driver = helium.get_driver()
latest_step = memory_step.step_number
for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
previous_memory_step.observations_images = None
png_bytes = driver.get_screenshot_as_png()
image = Image.open(BytesIO(png_bytes))
memory_step.observations_images = [image.copy()]
```
Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
```py
CodeAgent(
tools=[WebSearchTool(), go_back, close_popups, search_item_ctrl_f],
model=model,
additional_authorized_imports=["helium"],
step_callbacks=[update_screenshot],
max_steps=20,
verbosity_level=2,
)
```
Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
### Run agents one step at a time
This can be useful in case you have tool calls that take days: you can just run your agents step by step.
This will also let you update the memory on each step.
```py
from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
agent.python_executor.send_tools({**agent.tools})
print(agent.memory.system_prompt)
task = "What is the 20th Fibonacci number?"
# You could modify the memory as needed here by inputting the memory of another agent.
# agent.memory.steps = previous_agent.memory.steps
# Let's start a new task!
agent.memory.steps.append(TaskStep(task=task, task_images=[]))
final_answer = None
step_number = 1
while final_answer is None and step_number <= 10:
memory_step = ActionStep(
step_number=step_number,
observations_images=[],
)
# Run one step.
final_answer = agent.step(memory_step)
agent.memory.steps.append(memory_step)
step_number += 1
# Change the memory as you please!
# For instance to update the latest step:
# agent.memory.steps[-1] = ...
print("The final answer is:", final_answer)
```
================================================
FILE: docs/source/en/tutorials/secure_code_execution.md
================================================
# Secure code execution
[[open-in-colab]]
> [!TIP]
> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
### Code agents
[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of "writing actions as a JSON of tools names and arguments to use".
Why is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets were a better way, this package would have been written in JSON snippets and the devil would be laughing at us.
Code is just a better way to express actions on a computer. It has better:
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
- **Generality:** code is built to express simply anything you can have a computer do.
- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?
This is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).
This is why we put emphasis on proposing code agents, in this case python agents, which meant putting higher effort on building secure python interpreters.
### Local code execution??
By default, the `CodeAgent` runs LLM-generated code in your environment.
This is inherently risky, LLM-generated code could be harmful to your environment.
Malicious code execution can occur in several ways:
- **Plain LLM error:** LLMs are still far from perfect and may unintentionally generate harmful commands while attempting to be helpful. While this risk is low, instances have been observed where an LLM attempted to execute potentially dangerous code.
- **Supply chain attack:** Running an untrusted or compromised LLM could expose a system to harmful code generation. While this risk is extremely low when using well-known models on secure inference infrastructure, it remains a theoretical possibility.
- **Prompt injection:** an agent browsing the web could arrive on a malicious website that contains harmful instructions, thus injecting an attack into the agent's memory
- **Exploitation of publicly accessible agents:** Agents exposed to the public can be misused by malicious actors to execute harmful code. Attackers may craft adversarial inputs to exploit the agent's execution capabilities, leading to unintended consequences.
Once malicious code is executed, whether accidentally or intentionally, it can damage the file system, exploit local or cloud-based resources, abuse API services, and even compromise network security.
One could argue that on the [spectrum of agency](../conceptual_guides/intro_agents), code agents give much higher agency to the LLM on your system than other less agentic setups: this goes hand-in-hand with higher risk.
So you need to be very mindful of security.
To improve safety, we propose a range of measures that propose elevated levels of security, at a higher setup cost.
We advise you to keep in mind that no solution will be 100% safe.
You can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?
## Setting up telemetry with MLflow
MLflow has one-line autologging for Smolagents: it tracks runs, spans, inputs/outputs, and token usage in the MLflow UI.
Install MLflow, enable autologging, then run your agent with a couple of tools:
```python
%pip install mlflow smolagents
import mlflow
from smolagents import CodeAgent, ToolCallingAgent, WebSearchTool, VisitWebpageTool, InferenceClientModel
mlflow.smolagents.autolog() # start tracing everything below
model = InferenceClientModel()
browser = ToolCallingAgent(
tools=[WebSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="Web search helper",
)
manager = CodeAgent(model=model, managed_agents=[browser])
manager.run("Find the latest US GDP growth rate and estimate when it would double.")
```
Start the UI to inspect traces, then open the Traces view in your browser:
```shell
mlflow server --port 5000
```
## Setting up telemetry with 🪢 Langfuse
This part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.
> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.
### Step 1: Install Dependencies
```python
%pip install langfuse 'smolagents[telemetry]' openinference-instrumentation-smolagents
```
### Step 2: Set Up Environment Variables
Set your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).
Also, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.
```python
import os
# Get keys for your project from the project settings page: https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
# your Hugging Face token
os.environ["HF_TOKEN"] = "hf_..."
```
With the environment variables set, we can now initialize the Langfuse client. `get_client()` initializes the Langfuse client using the credentials provided in the environment variables.
```python
from langfuse import get_client
langfuse = get_client()
# Verify connection
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")
```
### Step 3: Initialize the `SmolagentsInstrumentor`
Initialize the `SmolagentsInstrumentor` before your application code.
```python
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
SmolagentsInstrumentor().instrument()
```
### Step 4: Run your smolagent
```python
from smolagents import (
CodeAgent,
ToolCallingAgent,
WebSearchTool,
VisitWebpageTool,
InferenceClientModel,
)
model = InferenceClientModel(
model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
)
search_agent = ToolCallingAgent(
tools=[WebSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="This is an agent that can do web search.",
)
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent],
)
manager_agent.run(
"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
)
```
### Step 5: View Traces in Langfuse
After running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.

_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
================================================
FILE: docs/source/en/tutorials/memory.md
================================================
# 📚 Manage your agent's memory
[[open-in-colab]]
In the end, an agent can be defined by simple components: it has tools, prompts.
And most importantly, it has a memory of past steps, drawing a history of planning, execution, and errors.
### Replay your agent's memory
We propose several features to inspect a past agent run.
You can instrument the agent's run to display it in a great UI that lets you zoom in/out on specific steps, as highlighted in the [instrumentation guide](./inspect_runs).
You can also use `agent.replay()`, as follows:
After the agent has run:
```py
from smolagents import InferenceClientModel, CodeAgent
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
result = agent.run("What's the 20th Fibonacci number?")
```
If you want to replay this last run, just use:
```py
agent.replay()
```
### Dynamically change the agent's memory
Many advanced use cases require dynamic modification of the agent's memory.
You can access the agent's memory using:
```py
from smolagents import ActionStep
system_prompt_step = agent.memory.system_prompt
print("The system prompt given to the agent was:")
print(system_prompt_step.system_prompt)
task_step = agent.memory.steps[0]
print("\n\nThe first task step was:")
print(task_step.task)
for step in agent.memory.steps:
if isinstance(step, ActionStep):
if step.error is not None:
print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
else:
print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
```
Use `agent.memory.get_full_steps()` to get full steps as dictionaries.
You can also use step callbacks to dynamically change the agent's memory.
Step callbacks can access the `agent` itself in their arguments, so they can access any memory step as highlighted above, and change it if needed. For instance, let's say you are observing screenshots of each step performed by a web browser agent. You want to log the newest screenshot, and remove the images from ancient steps to save on token costs.
You could run something like the following.
_Note: this code is incomplete, some imports and object definitions have been removed for the sake of concision, visit [the original script](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to get the full working code._
```py
import helium
from PIL import Image
from io import BytesIO
from time import sleep
def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
sleep(1.0) # Let JavaScript animations happen before taking the screenshot
driver = helium.get_driver()
latest_step = memory_step.step_number
for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
previous_memory_step.observations_images = None
png_bytes = driver.get_screenshot_as_png()
image = Image.open(BytesIO(png_bytes))
memory_step.observations_images = [image.copy()]
```
Then you should pass this function in the `step_callbacks` argument upon initialization of your agent:
```py
CodeAgent(
tools=[WebSearchTool(), go_back, close_popups, search_item_ctrl_f],
model=model,
additional_authorized_imports=["helium"],
step_callbacks=[update_screenshot],
max_steps=20,
verbosity_level=2,
)
```
Head to our [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) to see the full working example.
### Run agents one step at a time
This can be useful in case you have tool calls that take days: you can just run your agents step by step.
This will also let you update the memory on each step.
```py
from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
agent.python_executor.send_tools({**agent.tools})
print(agent.memory.system_prompt)
task = "What is the 20th Fibonacci number?"
# You could modify the memory as needed here by inputting the memory of another agent.
# agent.memory.steps = previous_agent.memory.steps
# Let's start a new task!
agent.memory.steps.append(TaskStep(task=task, task_images=[]))
final_answer = None
step_number = 1
while final_answer is None and step_number <= 10:
memory_step = ActionStep(
step_number=step_number,
observations_images=[],
)
# Run one step.
final_answer = agent.step(memory_step)
agent.memory.steps.append(memory_step)
step_number += 1
# Change the memory as you please!
# For instance to update the latest step:
# agent.memory.steps[-1] = ...
print("The final answer is:", final_answer)
```
================================================
FILE: docs/source/en/tutorials/secure_code_execution.md
================================================
# Secure code execution
[[open-in-colab]]
> [!TIP]
> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).
### Code agents
[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of "writing actions as a JSON of tools names and arguments to use".
Why is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets were a better way, this package would have been written in JSON snippets and the devil would be laughing at us.
Code is just a better way to express actions on a computer. It has better:
- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?
- **Object management:** how do you store the output of an action like `generate_image` in JSON?
- **Generality:** code is built to express simply anything you can have a computer do.
- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?
This is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).
This is why we put emphasis on proposing code agents, in this case python agents, which meant putting higher effort on building secure python interpreters.
### Local code execution??
By default, the `CodeAgent` runs LLM-generated code in your environment.
This is inherently risky, LLM-generated code could be harmful to your environment.
Malicious code execution can occur in several ways:
- **Plain LLM error:** LLMs are still far from perfect and may unintentionally generate harmful commands while attempting to be helpful. While this risk is low, instances have been observed where an LLM attempted to execute potentially dangerous code.
- **Supply chain attack:** Running an untrusted or compromised LLM could expose a system to harmful code generation. While this risk is extremely low when using well-known models on secure inference infrastructure, it remains a theoretical possibility.
- **Prompt injection:** an agent browsing the web could arrive on a malicious website that contains harmful instructions, thus injecting an attack into the agent's memory
- **Exploitation of publicly accessible agents:** Agents exposed to the public can be misused by malicious actors to execute harmful code. Attackers may craft adversarial inputs to exploit the agent's execution capabilities, leading to unintended consequences.
Once malicious code is executed, whether accidentally or intentionally, it can damage the file system, exploit local or cloud-based resources, abuse API services, and even compromise network security.
One could argue that on the [spectrum of agency](../conceptual_guides/intro_agents), code agents give much higher agency to the LLM on your system than other less agentic setups: this goes hand-in-hand with higher risk.
So you need to be very mindful of security.
To improve safety, we propose a range of measures that propose elevated levels of security, at a higher setup cost.
We advise you to keep in mind that no solution will be 100% safe.
 ### Our local Python executor
To add a first layer of security, code execution in `smolagents` is not performed by the vanilla Python interpreter.
We have re-built a more secure `LocalPythonExecutor` from the ground up.
To be precise, this interpreter works by loading the Abstract Syntax Tree (AST) from your Code and executes it operation by operation, making sure to always follow certain rules:
- By default, imports are disallowed unless they have been explicitly added to an authorization list by the user.
- Furthermore, access to submodules is disabled by default, and each must be explicitly authorized in the import list as well, or you can pass for instance `numpy.*` to allow both `numpy` and all its subpackags, like `numpy.random` or `numpy.a.b`.
- Note that some seemingly innocuous packages like `random` can give access to potentially harmful submodules, as in `random._os`.
- The total count of elementary operations processed is capped to prevent infinite loops and resource bloating.
- Any operation that has not been explicitly defined in our custom interpreter will raise an error.
You could try these safeguards as follows:
```py
from smolagents.local_python_executor import LocalPythonExecutor
# Set up custom executor, authorize package "numpy"
custom_executor = LocalPythonExecutor(["numpy"])
# Utility for pretty printing errors
def run_capture_exception(command: str):
try:
custom_executor(harmful_command)
except Exception as e:
print("ERROR:\n", e)
# Undefined command just do not work
harmful_command="!echo Bad command"
run_capture_exception(harmful_command)
# >>> ERROR: invalid syntax (
### Our local Python executor
To add a first layer of security, code execution in `smolagents` is not performed by the vanilla Python interpreter.
We have re-built a more secure `LocalPythonExecutor` from the ground up.
To be precise, this interpreter works by loading the Abstract Syntax Tree (AST) from your Code and executes it operation by operation, making sure to always follow certain rules:
- By default, imports are disallowed unless they have been explicitly added to an authorization list by the user.
- Furthermore, access to submodules is disabled by default, and each must be explicitly authorized in the import list as well, or you can pass for instance `numpy.*` to allow both `numpy` and all its subpackags, like `numpy.random` or `numpy.a.b`.
- Note that some seemingly innocuous packages like `random` can give access to potentially harmful submodules, as in `random._os`.
- The total count of elementary operations processed is capped to prevent infinite loops and resource bloating.
- Any operation that has not been explicitly defined in our custom interpreter will raise an error.
You could try these safeguards as follows:
```py
from smolagents.local_python_executor import LocalPythonExecutor
# Set up custom executor, authorize package "numpy"
custom_executor = LocalPythonExecutor(["numpy"])
# Utility for pretty printing errors
def run_capture_exception(command: str):
try:
custom_executor(harmful_command)
except Exception as e:
print("ERROR:\n", e)
# Undefined command just do not work
harmful_command="!echo Bad command"
run_capture_exception(harmful_command)
# >>> ERROR: invalid syntax (

 Then you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.
```python
from smolagents import CodeAgent, InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[image_generation_tool], model=model)
agent.run(
"Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
)
```
```text
=== Agent thoughts:
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
>>> Agent is executing the code below:
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
final_answer(image)
```
Then you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.
```python
from smolagents import CodeAgent, InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[image_generation_tool], model=model)
agent.run(
"Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
)
```
```text
=== Agent thoughts:
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
>>> Agent is executing the code below:
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
final_answer(image)
```
 How cool is this? 🤩
### Use LangChain tools
We love Langchain and think it has a very compelling suite of tools.
To import a tool from LangChain, use the `from_langchain()` method.
Here is how you can use it to recreate the intro's search result using a LangChain web search tool.
This tool will need `pip install langchain google-search-results -q` to work properly.
```python
from langchain.agents import load_tools
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
agent = CodeAgent(tools=[search_tool], model=model)
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
```
### Manage your agent's toolbox
You can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.
Let's add the `model_download_tool` to an existing agent initialized with only the default toolbox.
```python
from smolagents import InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
agent.tools[model_download_tool.name] = model_download_tool
```
Now we can leverage the new tool:
```python
agent.run(
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
)
```
> [!TIP]
> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.
### Use a collection of tools
You can leverage tool collections by using [`ToolCollection`]. It supports loading either a collection from the Hub or an MCP server tools.
#### Tool Collection from any MCP server
Leverage tools from the hundreds of MCP servers available on [glama.ai](https://glama.ai/mcp/servers) or [smithery.ai](https://smithery.ai/).
The MCP servers tools can be loaded with [`ToolCollection.from_mcp`].
> [!WARNING]
> **Security Warning:** Always verify the source and integrity of any MCP server before connecting to it, especially for production environments.
> Using MCP servers comes with security risks:
> - **Trust is essential:** Only use MCP servers from trusted sources. Malicious servers can execute harmful code on your machine.
> - **Stdio-based MCP servers** will always execute code on your machine (that's their intended functionality).
> - **Streamable HTTP-based MCP servers:** While remote MCP servers will not execute code on your machine, still proceed with caution.
For stdio-based MCP servers, pass the server parameters as an instance of `mcp.StdioServerParameters`:
```py
from smolagents import ToolCollection, CodeAgent
from mcp import StdioServerParameters
server_parameters = StdioServerParameters(
command="uvx",
args=["--quiet", "pubmedmcp@0.1.3"],
env={"UV_PYTHON": "3.12", **os.environ},
)
with ToolCollection.from_mcp(server_parameters, trust_remote_code=True) as tool_collection:
agent = CodeAgent(tools=[*tool_collection.tools], model=model, add_base_tools=True)
agent.run("Please find a remedy for hangover.")
```
To enable structured output support with ToolCollection, add the `structured_output=True` parameter:
```py
with ToolCollection.from_mcp(server_parameters, trust_remote_code=True, structured_output=True) as tool_collection:
agent = CodeAgent(tools=[*tool_collection.tools], model=model, add_base_tools=True)
agent.run("Please find a remedy for hangover.")
```
For Streamable HTTP-based MCP servers, simply pass a dict with parameters to `mcp.client.streamable_http.streamablehttp_client` and add the key `transport` with the value `"streamable-http"`:
```py
from smolagents import ToolCollection, CodeAgent
with ToolCollection.from_mcp({"url": "http://127.0.0.1:8000/mcp", "transport": "streamable-http"}, trust_remote_code=True) as tool_collection:
agent = CodeAgent(tools=[*tool_collection.tools], add_base_tools=True)
agent.run("Please find a remedy for hangover.")
```
#### Tool Collection from a collection in the Hub
You can leverage it with the slug of the collection you want to use.
Then pass them as a list to initialize your agent, and start using them!
```py
from smolagents import ToolCollection, CodeAgent
image_tool_collection = ToolCollection.from_hub(
collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
token="
How cool is this? 🤩
### Use LangChain tools
We love Langchain and think it has a very compelling suite of tools.
To import a tool from LangChain, use the `from_langchain()` method.
Here is how you can use it to recreate the intro's search result using a LangChain web search tool.
This tool will need `pip install langchain google-search-results -q` to work properly.
```python
from langchain.agents import load_tools
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
agent = CodeAgent(tools=[search_tool], model=model)
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
```
### Manage your agent's toolbox
You can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.
Let's add the `model_download_tool` to an existing agent initialized with only the default toolbox.
```python
from smolagents import InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
agent.tools[model_download_tool.name] = model_download_tool
```
Now we can leverage the new tool:
```python
agent.run(
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
)
```
> [!TIP]
> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.
### Use a collection of tools
You can leverage tool collections by using [`ToolCollection`]. It supports loading either a collection from the Hub or an MCP server tools.
#### Tool Collection from any MCP server
Leverage tools from the hundreds of MCP servers available on [glama.ai](https://glama.ai/mcp/servers) or [smithery.ai](https://smithery.ai/).
The MCP servers tools can be loaded with [`ToolCollection.from_mcp`].
> [!WARNING]
> **Security Warning:** Always verify the source and integrity of any MCP server before connecting to it, especially for production environments.
> Using MCP servers comes with security risks:
> - **Trust is essential:** Only use MCP servers from trusted sources. Malicious servers can execute harmful code on your machine.
> - **Stdio-based MCP servers** will always execute code on your machine (that's their intended functionality).
> - **Streamable HTTP-based MCP servers:** While remote MCP servers will not execute code on your machine, still proceed with caution.
For stdio-based MCP servers, pass the server parameters as an instance of `mcp.StdioServerParameters`:
```py
from smolagents import ToolCollection, CodeAgent
from mcp import StdioServerParameters
server_parameters = StdioServerParameters(
command="uvx",
args=["--quiet", "pubmedmcp@0.1.3"],
env={"UV_PYTHON": "3.12", **os.environ},
)
with ToolCollection.from_mcp(server_parameters, trust_remote_code=True) as tool_collection:
agent = CodeAgent(tools=[*tool_collection.tools], model=model, add_base_tools=True)
agent.run("Please find a remedy for hangover.")
```
To enable structured output support with ToolCollection, add the `structured_output=True` parameter:
```py
with ToolCollection.from_mcp(server_parameters, trust_remote_code=True, structured_output=True) as tool_collection:
agent = CodeAgent(tools=[*tool_collection.tools], model=model, add_base_tools=True)
agent.run("Please find a remedy for hangover.")
```
For Streamable HTTP-based MCP servers, simply pass a dict with parameters to `mcp.client.streamable_http.streamablehttp_client` and add the key `transport` with the value `"streamable-http"`:
```py
from smolagents import ToolCollection, CodeAgent
with ToolCollection.from_mcp({"url": "http://127.0.0.1:8000/mcp", "transport": "streamable-http"}, trust_remote_code=True) as tool_collection:
agent = CodeAgent(tools=[*tool_collection.tools], add_base_tools=True)
agent.run("Please find a remedy for hangover.")
```
#### Tool Collection from a collection in the Hub
You can leverage it with the slug of the collection you want to use.
Then pass them as a list to initialize your agent, and start using them!
```py
from smolagents import ToolCollection, CodeAgent
image_tool_collection = ToolCollection.from_hub(
collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
token="
Domina los conceptos básicos y aprende a manejar agentes. Empieza aquí si nunca los has utilizado.
Ejemplos prácticos para guiarte en diferentes proyectos. ¡Desarrolla un agente que genere y valide consultas SQL!
Conceptos avanzados para profundizar en la comprensión de temas clave.
Tutoriales completos que cubren aspectos clave para el desarrollo de agentes.
JSON जैसे स्निपेट्स की बजाय कोड में क्रियाएं लिखने से बेहतर प्राप्त होता है:
- **कम्पोजेबिलिटी:** क्या आप JSON क्रियाओं को एक-दूसरे के भीतर नेस्ट कर सकते हैं, या बाद में पुन: उपयोग करने के लिए JSON क्रियाओं का एक सेट परिभाषित कर सकते हैं, उसी तरह जैसे आप बस एक पायथन फंक्शन परिभाषित कर सकते हैं?
- **ऑब्जेक्ट प्रबंधन:** आप `generate_image` जैसी क्रिया के आउटपुट को JSON में कैसे स्टोर करते हैं?
- **सामान्यता:** कोड को सरल रूप से कुछ भी व्यक्त करने के लिए बनाया गया है जो आप कंप्यूटर से करवा सकते हैं।
- **LLM प्रशिक्षण डेटा में प्रतिनिधित्व:** बहुत सारी गुणवत्तापूर्ण कोड क्रियाएं पहले से ही LLM के ट्रेनिंग डेटा में शामिल हैं जिसका मतलब है कि वे इसके लिए पहले से ही प्रशिक्षित हैं!
================================================
FILE: docs/source/hi/conceptual_guides/react.md
================================================
# मल्टी-स्टेप एजेंट्स कैसे काम करते हैं?
ReAct फ्रेमवर्क ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) वर्तमान में एजेंट्स बनाने का मुख्य दृष्टिकोण है।
नाम दो शब्दों, "Reason" (तर्क) और "Act" (क्रिया) के संयोजन पर आधारित है। वास्तव में, इस आर्किटेक्चर का पालन करने वाले एजेंट अपने कार्य को उतने चरणों में हल करेंगे जितने आवश्यक हों, प्रत्येक चरण में एक Reasoning कदम होगा, फिर एक Action कदम होगा, जहाँ यह टूल कॉल्स तैयार करेगा जो उसे कार्य को हल करने के करीब ले जाएंगे।
ReAct प्रक्रिया में पिछले चरणों की मेमोरी रखना शामिल है।
> [!TIP]
> मल्टी-स्टेप एजेंट्स के बारे में अधिक जानने के लिए [Open-source LLMs as LangChain Agents](https://huggingface.co/blog/open-source-llms-as-agents) ब्लॉग पोस्ट पढ़ें।
यहाँ एक वीडियो ओवरव्यू है कि यह कैसे काम करता है:
बेसिक्स सीखें और एजेंट्स का उपयोग करने में परिचित हों। यदि आप पहली बार एजेंट्स का उपयोग कर रहे हैं तो यहाँ से शुरू करें!
एक विशिष्ट लक्ष्य प्राप्त करने में मदद के लिए गाइड: SQL क्वेरी जनरेट और टेस्ट करने के लिए एजेंट बनाएं!
महत्वपूर्ण विषयों की बेहतर समझ बनाने के लिए उच्च-स्तरीय व्याख्याएं।
एजेंट्स बनाने के महत्वपूर्ण पहलुओं को कवर करने वाले क्ट्यूटोरियल्स।
आप देख सकते हैं कि CodeAgent ने अपने मैनेज्ड ToolCallingAgent को (वैसे, मैनेज्ड एजेंट एक CodeAgent भी हो सकता था) U.S. 2024 ग्रोथ रेट के लिए वेब सर्च चलाने के लिए कॉल किया। फिर मैनेज्ड एजेंट ने अपनी रिपोर्ट लौटाई और मैनेजर एजेंट ने अर्थव्यवस्था के दोगुना होने का समय गणना करने के लिए उस पर कार्य किया! अच्छा है, है ना?
================================================
FILE: docs/source/hi/tutorials/secure_code_execution.md
================================================
# सुरक्षित कोड एक्जीक्यूशन
[[open-in-colab]]
> [!TIP]
> यदि आप एजेंट्स बनाने में नए हैं, तो सबसे पहले [एजेंट्स का परिचय](../conceptual_guides/intro_agents) और [smolagents की गाइडेड टूर](../guided_tour) पढ़ना सुनिश्चित करें।
### कोड Agents
[कई](https://huggingface.co/papers/2402.01030) [शोध](https://huggingface.co/papers/2411.01747) [पत्रों](https://huggingface.co/papers/2401.00812) ने दिखाया है कि LLM द्वारा अपनी क्रियाओं (टूल कॉल्स) को कोड में लिखना, टूल कॉलिंग के वर्तमान मानक प्रारूप से बहुत बेहतर है, जो industry में "टूल्स नेम्स और आर्ग्यूमेंट्स को JSON के रूप में लिखने" के विभिन्न रूप हैं।
कोड बेहतर क्यों है? क्योंकि हमने अपनी कोड भाषाओं को विशेष रूप से कंप्यूटर द्वारा की जाने वाली क्रियाओं को व्यक्त करने के लिए तैयार किया है। यदि JSON स्निपेट्स एक बेहतर तरीका होता, तो यह पैकेज JSON स्निपेट्स में लिखा गया होता और शैतान हम पर हंस रहा होता।
कोड कंप्यूटर पर क्रियाएँ व्यक्त करने का बेहतर तरीका है। इसमें बेहतर है:
- **कंपोज़ेबिलिटी:** क्या आप JSON क्रियाओं को एक-दूसरे के भीतर नेस्ट कर सकते हैं, या बाद में पुन: उपयोग करने के लिए JSON क्रियाओं का एक सेट परिभाषित कर सकते हैं, जैसे आप बस एक पायथन फ़ंक्शन परिभाषित कर सकते हैं?
- **ऑब्जेक्ट प्रबंधन:** JSON में `generate_image` जैसी क्रिया का आउटपुट कैसे स्टोर करें?
- **सामान्यता:** कोड किसी भी कंप्यूटर कार्य को व्यक्त करने के लिए बनाया गया है।
- **LLM प्रशिक्षण कॉर्पस में प्रतिनिधित्व:** क्यों न इस आशीर्वाद का लाभ उठाएं कि उच्च गुणवत्ता वाले कोड उदाहरण पहले से ही LLM प्रशिक्षण डेटा में शामिल हैं?
यह नीचे दी गई छवि में दर्शाया गया है, जो [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030) से ली गई है।
यही कारण है कि हमने कोड एजेंट्स, इस मामले में पायथन एजेंट्स पर जोर दिया, जिसका मतलब सुरक्षित पायथन इंटरप्रेटर बनाने पर अधिक प्रयास करना था।
### लोकल पायथन इंटरप्रेटर
डिफ़ॉल्ट रूप से, `CodeAgent` LLM-जनरेटेड कोड को आपके एनवायरनमेंट में चलाता है।
यह एक्जीक्यूशन वैनिला पायथन इंटरप्रेटर द्वारा नहीं किया जाता: हमने एक अधिक सुरक्षित `LocalPythonExecutor` को शुरू से फिर से बनाया है।
यह इंटरप्रेटर सुरक्षा के लिए डिज़ाइन किया गया है:
- इम्पोर्ट्स को उपयोगकर्ता द्वारा स्पष्ट रूप से पास की गई सूची तक सीमित करना
- इनफिनिट लूप्स और रिसोर्स ब्लोटिंग को रोकने के लिए ऑपरेशंस की संख्या को कैप करना
- कोई भी ऐसा ऑपरेशन नहीं करेगा जो पूर्व-परिभाषित नहीं है
हमने इसे कई उपयोग मामलों में इस्तेमाल किया है, और कभी भी एनवायरनमेंट को कोई नुकसान नहीं देखा।
हालांकि यह समाधान पूरी तरह से सुरक्षित नहीं है: कोई ऐसे अवसरों की कल्पना कर सकता है जहां दुर्भावनापूर्ण कार्यों के लिए फाइन-ट्यून किए गए LLM अभी भी आपके एनवायरनमेंट को नुकसान पहुंचा सकते हैं। उदाहरण के लिए यदि आपने छवियों को प्रोसेस करने के लिए `Pillow` जैसे मासूम पैकेज की अनुमति दी है, तो LLM आपकी हार्ड ड्राइव को ब्लोट करने के लिए हजारों छवियों को सेव कर सकता है।
यदि आपने खुद LLM इंजन चुना है तो यह निश्चित रूप से संभावित नहीं है, लेकिन यह हो सकता है।
तो यदि आप अतिरिक्त सावधानी बरतना चाहते हैं, तो आप नीचे वर्णित रिमोट कोड एक्जीक्यूशन विकल्प का उपयोग कर सकते हैं।
### E2B कोड एक्जीक्यूटर
अधिकतम सुरक्षा के लिए, आप कोड को सैंडबॉक्स्ड एनवायरनमेंट में चलाने के लिए E2B के साथ हमारे एकीकरण का उपयोग कर सकते हैं। यह एक रिमोट एक्जीक्यूशन सेवा है जो आपके कोड को एक आइसोलेटेड कंटेनर में चलाती है, जिससे कोड का आपके स्थानीय एनवायरनमेंट को प्रभावित करना असंभव हो जाता है।
इसके लिए, आपको अपना E2B अकाउंट सेटअप करने और अपने एनवायरनमेंट वेरिएबल्स में अपना `E2B_API_KEY` सेट करने की आवश्यकता होगी। अधिक जानकारी के लिए [E2B की क्विकस्टार्ट डॉक्यूमेंटेशन](https://e2b.dev/docs/quickstart) पर जाएं।
फिर आप इसे `pip install e2b-code-interpreter python-dotenv` के साथ इंस्टॉल कर सकते हैं।
अब आप तैयार हैं!
कोड एक्जीक्यूटर को E2B पर सेट करने के लिए, बस अपने `CodeAgent` को इनिशियलाइज़ करते समय `executor_type="e2b"` फ्लैग पास करें।
ध्यान दें कि आपको `additional_authorized_imports` में सभी टूल की डिपेंडेंसीज़ जोड़नी चाहिए, ताकि एक्जीक्यूटर उन्हें इंस्टॉल करे।
```py
from smolagents import CodeAgent, VisitWebpageTool, InferenceClientModel
agent = CodeAgent(
tools = [VisitWebpageTool()],
model=InferenceClientModel(),
additional_authorized_imports=["requests", "markdownify"],
executor_type="e2b"
)
agent.run("What was Abraham Lincoln's preferred pet?")
```
E2B कोड एक्जीक्यूशन वर्तमान में मल्टी-एजेंट्स के साथ काम नहीं करता है - क्योंकि कोड ब्लॉब में एक एजेंट कॉल करना जो रिमोटली एक्जीक्यूट किया जाना चाहिए, यह एक गड़बड़ है। लेकिन हम इसे जोड़ने पर काम कर रहे हैं!
================================================
FILE: docs/source/hi/tutorials/tools.md
================================================
# Tools
[[open-in-colab]]
यहाँ, हम एडवांस्ड tools उपयोग देखेंगे।
> [!TIP]
> यदि आप एजेंट्स बनाने में नए हैं, तो सबसे पहले [एजेंट्स का परिचय](../conceptual_guides/intro_agents) और [smolagents की गाइडेड टूर](../guided_tour) पढ़ना सुनिश्चित करें।
- [Tools](#tools)
- [टूल क्या है, और इसे कैसे बनाएं?](#टूल-क्या-है-और-इसे-कैसे-बनाएं)
- [अपना टूल हब पर शेयर करें](#अपना-टूल-हब-पर-शेयर-करें)
- [स्पेस को टूल के रूप में इम्पोर्ट करें](#स्पेस-को-टूल-के-रूप-में-इम्पोर्ट-करें)
- [LangChain टूल्स का उपयोग करें](#LangChain-टूल्स-का-उपयोग-करें)
- [अपने एजेंट के टूलबॉक्स को मैनेज करें](#अपने-एजेंट-के-टूलबॉक्स-को-मैनेज-करें)
- [टूल्स का कलेक्शन उपयोग करें](#टूल्स-का-कलेक्शन-उपयोग-करें)
### टूल क्या है और इसे कैसे बनाएं
टूल मुख्य रूप से एक फ़ंक्शन है जिसे एक LLM एजेंटिक सिस्टम में उपयोग कर सकता है।
लेकिन इसका उपयोग करने के लिए, LLM को एक API दी जाएगी: नाम, टूल विवरण, इनपुट प्रकार और विवरण, आउटपुट प्रकार।
इसलिए यह केवल एक फ़ंक्शन नहीं हो सकता। यह एक क्लास होनी चाहिए।
तो मूल रूप से, टूल एक क्लास है जो एक फ़ंक्शन को मेटाडेटा के साथ रैप करती है जो LLM को समझने में मदद करती है कि इसका उपयोग कैसे करें।
यह कैसा दिखता है:
```python
from smolagents import Tool
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = """
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint."""
inputs = {
"task": {
"type": "string",
"description": "the task category (such as text-classification, depth-estimation, etc)",
}
}
output_type = "string"
def forward(self, task: str):
from huggingface_hub import list_models
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
model_downloads_tool = HFModelDownloadsTool()
```
कस्टम टूल `Tool` को सबक्लास करता है उपयोगी मेथड्स को इनहेरिट करने के लिए। चाइल्ड क्लास भी परिभाषित करती है:
- एक `name` एट्रिब्यूट, जो टूल के नाम से संबंधित है। नाम आमतौर पर बताता है कि टूल क्या करता है। चूंकि कोड एक टास्क के लिए सबसे अधिक डाउनलोड वाले मॉडल को रिटर्न करता है, इसलिए इसे `model_download_counter` नाम दें।
- एक `description` एट्रिब्यूट एजेंट के सिस्टम प्रॉम्प्ट को पॉपुलेट करने के लिए उपयोग किया जाता है।
- एक `inputs` एट्रिब्यूट, जो `"type"` और `"description"` keys वाला डिक्शनरी है। इसमें जानकारी होती है जो पायथन इंटरप्रेटर को इनपुट के बारे में शिक्षित विकल्प चुनने में मदद करती है।
- एक `output_type` एट्रिब्यूट, जो आउटपुट टाइप को निर्दिष्ट करता है। `inputs` और `output_type` दोनों के लिए टाइप [Pydantic formats](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema) होने चाहिए, वे इनमें से कोई भी हो सकते हैं: `["string", "boolean","integer", "number", "image", "audio", "array", "object", "any", "null"]`।
- एक `forward` मेथड जिसमें एक्जीक्यूट किया जाने वाला इन्फरेंस कोड होता है।
एजेंट में उपयोग किए जाने के लिए इतना ही चाहिए!
टूल बनाने का एक और तरीका है। [guided_tour](../guided_tour) में, हमने `@tool` डेकोरेटर का उपयोग करके एक टूल को लागू किया। [`tool`] डेकोरेटर सरल टूल्स को परिभाषित करने का अनुशंसित तरीका है, लेकिन कभी-कभी आपको इससे अधिक की आवश्यकता होती है: अधिक स्पष्टता के लिए एक क्लास में कई मेथड्स का उपयोग करना, या अतिरिक्त क्लास एट्रिब्यूट्स का उपयोग करना।
इस स्थिति में, आप ऊपर बताए अनुसार [`Tool`] को सबक्लास करके अपना टूल बना सकते हैं।
### अपना टूल हब पर शेयर करें
आप टूल पर [`~Tool.push_to_hub`] को कॉल करके अपना कस्टम टूल हब पर शेयर कर सकते हैं। सुनिश्चित करें कि आपने हब पर इसके लिए एक रिपॉजिटरी बनाई है और आप रीड एक्सेस वाला टोकन उपयोग कर रहे हैं।
```python
model_downloads_tool.push_to_hub("{your_username}/hf-model-downloads", token="
फिर आप इस टूल का उपयोग किसी अन्य टूल की तरह कर सकते हैं। उदाहरण के लिए, चलिए प्रॉम्प्ट `a rabbit wearing a space suit` को सुधारें और इसकी एक इमेज जनरेट करें। यह उदाहरण यह भी दिखाता है कि आप एजेंट को अतिरिक्त आर्ग्यूमेंट्स कैसे पास कर सकते हैं।
```python
from smolagents import CodeAgent, InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[image_generation_tool], model=model)
agent.run(
"Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
)
```
```text
=== Agent thoughts:
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
>>> Agent is executing the code below:
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
final_answer(image)
```
यह कितना कूल है? 🤩
### LangChain टूल्स का उपयोग करें
हम LangChain को पसंद करते हैं और मानते हैं कि इसके पास टूल्स का एक बहुत आकर्षक संग्रह है।
LangChain से एक टूल इम्पोर्ट करने के लिए, `from_langchain()` मेथड का उपयोग करें।
यहाँ बताया गया है कि आप LangChain वेब सर्च टूल का उपयोग करके परिचय के सर्च रिजल्ट को कैसे फिर से बना सकते हैं।
इस टूल को काम करने के लिए `pip install langchain google-search-results -q` की आवश्यकता होगी।
```python
from langchain.agents import load_tools
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
agent = CodeAgent(tools=[search_tool], model=model)
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
```
### अपने एजेंट के टूलबॉक्स को मैनेज करें
आप एजेंट के टूलबॉक्स को `agent.tools` एट्रिब्यूट में एक टूल जोड़कर या बदलकर मैनेज कर सकते हैं, क्योंकि यह एक स्टैंडर्ड डिक्शनरी है।
चलिए केवल डिफ़ॉल्ट टूलबॉक्स के साथ इनिशियलाइज़ किए गए मौजूदा एजेंट में `model_download_tool` जोड़ें।
```python
from smolagents import InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
agent.tools[model_download_tool.name] = model_download_tool
```
अब हम नए टूल का लाभ उठा सकते हैं।
```python
agent.run(
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
)
```
> [!TIP]
> एजेंट में बहुत अधिक टूल्स न जोड़ने से सावधान रहें: यह कमजोर LLM इंजन को ओवरव्हेल्म कर सकता है।
### टूल्स का कलेक्शन उपयोग करें
आप `ToolCollection` ऑब्जेक्ट का उपयोग करके टूल कलेक्शंस का लाभ उठा सकते हैं। यह या तो हब से एक कलेक्शन या MCP सर्वर टूल्स को लोड करने का समर्थन करता है।
#### हब में कलेक्शन से टूल कलेक्शन
आप उस कलेक्शन के स्लग के साथ इसका लाभ उठा सकते हैं जिसका आप उपयोग करना चाहते हैं।
फिर उन्हें अपने एजेंट को इनिशियलाइज़ करने के लिए एक लिस्ट के रूप में पास करें, और उनका उपयोग शुरू करें!
```py
from smolagents import ToolCollection, CodeAgent
image_tool_collection = ToolCollection.from_hub(
collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
token="
CodeAgent가 관리하는 ToolCallingAgent를 호출하여(참고로 관리되는 에이전트는 CodeAgent가 될 수도 있습니다) 미국 2024년 성장률을 웹에서 검색하도록 요청한 것을 확인할 수 있습니다. 이후 관리되는 에이전트가 결과를 보고하면, 관리자 에이전트가 이 정보를 활용하여 경제 배증 시간을 계산했습니다! 흥미롭죠?
## 🪢 Langfuse로 텔레메트리 설정[[setting-up-telemetry-with-🪢-langfuse]]
이 부분은 `SmolagentsInstrumentor`를 사용하여 **Langfuse**로 Hugging Face **smolagents**를 모니터링하고 디버깅하는 방법을 보여줍니다.
> **Langfuse란?** [Langfuse](https://langfuse.com)는 LLM 엔지니어링을 위한 오픈소스 플랫폼입니다. AI 에이전트를 위한 추적 및 모니터링 기능을 제공하여 개발자가 제품을 디버깅하고, 분석하고, 최적화할 수 있도록 도와줍니다. Langfuse는 네이티브 통합, OpenTelemetry, SDK를 통해 다양한 도구와 프레임워크와 통합됩니다.
### 1단계: 의존성 설치[[step-1:-install-dependencies]]
```python
%pip install langfuse 'smolagents[telemetry]' openinference-instrumentation-smolagents
```
### 2단계: 환경 변수 설정[[step-2:-set-up-environment-variables]]
Langfuse API 키를 설정하고 Langfuse로 추적을 보내도록 OpenTelemetry 엔드포인트를 구성하세요. [Langfuse Cloud](https://cloud.langfuse.com)에 가입하거나 [Langfuse를 자체 호스팅](https://langfuse.com/self-hosting)하여 Langfuse API 키를 얻으세요.
또한 [Hugging Face 토큰](https://huggingface.co/settings/tokens) (`HF_TOKEN`)을 환경 변수로 추가하세요.
```python
import os
# 프로젝트 설정 페이지(https://cloud.langfuse.com)에서 프로젝트 키를 가져옵니다.
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 유럽 지역
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 미국 지역
# Hugging Face 토큰을 입력합니다.
os.environ["HF_TOKEN"] = "hf_..."
```
환경 변수가 설정되면 이제 Langfuse 클라이언트를 초기화할 수 있습니다. `get_client()`는 환경 변수에 제공된 자격 증명을 사용하여 Langfuse 클라이언트를 초기화합니다.
```python
from langfuse import get_client
langfuse = get_client()
# 연결을 확인합니다.
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")
```
### 3단계: `SmolagentsInstrumentor` 초기화[[step-3:-initialize-the-`smolagentsinstrumentor`]]
애플리케이션 코드를 실행하기 전에 `SmolagentsInstrumentor`를 초기화하세요.
```python
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
SmolagentsInstrumentor().instrument()
```
### 4단계: smolagent 실행[[step-4:-run-your-smolagent]]
```python
from smolagents import (
CodeAgent,
ToolCallingAgent,
WebSearchTool,
VisitWebpageTool,
InferenceClientModel,
)
model = InferenceClientModel(
model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
)
search_agent = ToolCallingAgent(
tools=[WebSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="This is an agent that can do web search.",
)
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent],
)
manager_agent.run(
"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
)
```
### 5단계: Langfuse에서 추적 보기[[step-5:-view-traces-in-langfuse]]
에이전트를 실행한 후, Langfuse의 smolagents 애플리케이션에서 생성된 추적 정보를 확인할 수 있습니다. AI 에이전트의 디버깅과 최적화에 도움이 되는 LLM 상호작용의 상세한 세부 과정을 살펴볼 수 있습니다.

_[Langfuse의 추적 예시](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
================================================
FILE: docs/source/ko/tutorials/memory.md
================================================
# 📚 에이전트 메모리 관리[[-manage-your-agents-memory]]
[[open-in-colab]]
결국 에이전트는 도구와 프롬프트로 이루어진 단순한 구성요소로 정의됩니다.
그리고 무엇보다 중요한 것은 에이전트가 과거 단계의 메모리를 가지고 있어 계획, 실행, 오류의 이력을 추적한다는 점입니다.
### 에이전트 메모리 재생[[replay-your-agents-memory]]
과거 실행된 에이전트를 확인하기 위한 몇 가지 기능을 제공합니다.
[계측 가이드](./inspect_runs)에서 언급한 바와 같이, 에이전트 실행을 계측하여 특정 단계를 확대하거나 축소할 수 있는 우수한 UI로 시각화할 수 있습니다.
또한 다음과 같이 `agent.replay()`를 사용할 수도 있습니다.
에이전트를 실행한 후,
```py
from smolagents import InferenceClientModel, CodeAgent
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
result = agent.run("What's the 20th Fibonacci number?")
```
이 마지막 실행을 다시 재생하고 싶다면, 다음 코드를 사용하면 됩니다.
```py
agent.replay()
```
### 에이전트 메모리 동적 변경[[dynamically-change-the-agents-memory]]
많은 고급 사용 사례에서는 에이전트의 메모리를 동적으로 수정해야 합니다.
에이전트의 메모리는 다음과 같이 접근할 수 있습니다.
```py
from smolagents import ActionStep
system_prompt_step = agent.memory.system_prompt
print("The system prompt given to the agent was:")
print(system_prompt_step.system_prompt)
task_step = agent.memory.steps[0]
print("\n\nThe first task step was:")
print(task_step.task)
for step in agent.memory.steps:
if isinstance(step, ActionStep):
if step.error is not None:
print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
else:
print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
```
`agent.memory.get_full_steps()`를 사용하여 전체 단계를 딕셔너리 형태로 가져올 수 있습니다.
또한 단계 콜백을 사용하여 에이전트의 메모리를 동적으로 변경할 수도 있습니다.
단계 콜백은 인자로 `agent` 객체 자체에 접근할 수 있으므로, 위에서 설명한 것처럼 모든 메모리 단계에 접근하여 필요한 경우 수정할 수 있습니다. 예를 들어, 웹 브라우저 에이전트가 수행하는 각 단계의 스크린샷을 관찰하고 있다고 가정해 보겠습니다. 이 경우 최신 스크린샷은 유지하면서 토큰 비용을 절약하기 위해 이전 단계의 이미지를 메모리에서 제거할 수 있습니다.
이 경우 다음과 같은 코드를 사용할 수 있습니다.
_주의: 이 코드는 간결함을 위해 일부 임포트 및 객체 정의가 생략된 불완전한 예시입니다. 전체 작동 버전의 코드는 [원본 스크립트](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py)에서 확인하세요._
```py
import helium
from PIL import Image
from io import BytesIO
from time import sleep
def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
sleep(1.0) # JavaScript 애니메이션이 완료된 후에 스크린샷을 찍도록 합니다.
driver = helium.get_driver()
latest_step = memory_step.step_number
for previous_memory_step in agent.memory.steps: # 이전 스크린샷을 로그에서 제거하여 처리 과정을 간소화합니다.
if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
previous_memory_step.observations_images = None
png_bytes = driver.get_screenshot_as_png()
image = Image.open(BytesIO(png_bytes))
memory_step.observations_images = [image.copy()]
```
그 다음 에이전트를 초기화할 때 이 함수를 다음과 같이 `step_callbacks` 인수에 전달해야 합니다.
```py
CodeAgent(
tools=[WebSearchTool(), go_back, close_popups, search_item_ctrl_f],
model=model,
additional_authorized_imports=["helium"],
step_callbacks=[update_screenshot],
max_steps=20,
verbosity_level=2,
)
```
전체 작동 예시는 [비전 웹 브라우저 코드](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py)에서 확인할 수 있습니다.
### 에이전트를 단계별로 실행[[run-agents-one-step-at-a-time]]
이 기능은 도구 호출에 오랜 시간이 걸리는 경우에 유용합니다.
에이전트를 한 단계씩 실행하면서 각 단계에서 메모리를 업데이트할 수 있습니다.
```py
from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
agent.python_executor.send_tools({**agent.tools})
print(agent.memory.system_prompt)
task = "What is the 20th Fibonacci number?"
# 필요에 따라 다른 에이전트의 메모리를 불러와 메모리를 수정할 수 있습니다.
# agent.memory.steps = previous_agent.memory.steps
# 새로운 작업을 시작합니다!
agent.memory.steps.append(TaskStep(task=task, task_images=[]))
final_answer = None
step_number = 1
while final_answer is None and step_number <= 10:
memory_step = ActionStep(
step_number=step_number,
observations_images=[],
)
# 한 단계를 실행합니다.
final_answer = agent.step(memory_step)
agent.memory.steps.append(memory_step)
step_number += 1
# 필요한 경우 메모리를 수정할 수도 있습니다
# 예를 들어 최신 단계를 업데이트 하려면 다음과 같이 처리합니다:
# agent.memory.steps[-1] = ...
print("The final answer is:", final_answer)
```
================================================
FILE: docs/source/zh/_config.py
================================================
# docstyle-ignore
INSTALL_CONTENT = """
# Installation
! pip install smolagents
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/smolagents.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
"{object_class}": "FakeObjectClass",
}
================================================
FILE: docs/source/zh/_toctree.yml
================================================
- title: 起步
sections:
- local: index
title: 🤗 Agents
- local: guided_tour
title: 导览
- title: Tutorials
sections:
- local: tutorials/building_good_agents
title: ✨ 构建好用的 agents
- local: tutorials/inspect_runs
title: 📊 监控 Agent 的运行
- local: tutorials/tools
title: 🛠️ 工具 - 深度指南
- local: tutorials/secure_code_execution
title: 🛡️ 使用 E2B 保护你的代码执行
- local: tutorials/memory
title: 📚 管理 Agent 的记忆
- title: Conceptual guides
sections:
- local: conceptual_guides/intro_agents
title: 🤖 Agent 化系统介绍
- local: conceptual_guides/react
title: 🤔 多步骤 Agent 是如何工作的?
- title: Examples
sections:
- local: examples/text_to_sql
title: 自我修正 Text-to-SQL
- local: examples/rag
title: 借助 agentic RAG 掌控知识库
- local: examples/multiagents
title: 编排 multi-agent 系统
- local: examples/web_browser
title: 基于视觉模型构建能够浏览网页的agent
- title: Reference
sections:
- local: reference/agents
title: Agent-related objects
- local: reference/models
title: Model-related objects
- local: reference/tools
title: Tool-related objects
================================================
FILE: docs/source/zh/conceptual_guides/intro_agents.md
================================================
# Agent 简介
> [!TIP]
> 译者注:Agent 的业内术语是“智能体”。本译文将保留 agent,不作翻译,以带来更高效的阅读体验。(在中文为主的文章中,It's easier to 注意到英文。Attention Is All You Need!)
## 🤔 什么是 agent?
任何使用 AI 的高效系统都需要为 LLM 提供某种访问现实世界的方式:例如调用搜索工具获取外部信息,或者操作某些程序以完成任务。换句话说,LLM 应该具有 **_Agent 能力_**。Agent 程序是 LLM 通往外部世界的门户。
> [!TIP]
> AI agent 是 **LLM 输出控制工作流的程序**。
任何利用 LLM 的系统都会将 LLM 输出集成到代码中。LLM 输入对代码工作流的影响程度就是 LLM 在系统中的 agent 能力级别。
请注意,根据这个定义,"Agent" 不是一个离散的、非 0 即 1 的定义:相反,"Agent 能力" 是一个连续谱系,随着你在工作流中给予 LLM 更多或更少的权力而变化。
请参见下表中 agent 能力在不同系统中的变化:
| Agent 能力级别 | 描述 | 名称 | 示例模式 |
| ------------ | ---------------------------------------------- | ---------- | -------------------------------------------------- |
| ☆☆☆ | LLM 输出对程序流程没有影响 | 简单处理器 | `process_llm_output(llm_response)` |
| ★☆☆ | LLM 输出决定 if/else 分支 | 路由 | `if llm_decision(): path_a() else: path_b()` |
| ★★☆ | LLM 输出决定函数执行 | 工具调用者 | `run_function(llm_chosen_tool, llm_chosen_args)` |
| ★★★ | LLM 输出控制迭代和程序继续 | 多步 Agent | `while llm_should_continue(): execute_next_step()` |
| ★★★ | 一个 agent 工作流可以启动另一个 agent 工作流 | 多 Agent | `if llm_trigger(): execute_agent()` |
多步 agent 具有以下代码结构:
```python
memory = [user_defined_task]
while llm_should_continue(memory): # 这个循环是多步部分
action = llm_get_next_action(memory) # 这是工具调用部分
observations = execute_action(action)
memory += [action, observations]
```
这个 agent 系统在一个循环中运行,每一步执行一个新动作(该动作可能涉及调用一些预定义的 *工具*,这些工具只是函数),直到其观察结果表明已达到解决给定任务的满意状态。以下是一个多步 agent 如何解决简单数学问题的示例:
与 JSON 片段相比,用代码编写动作提供了更好的:
- **可组合性:** 你能像定义 python 函数一样,将 JSON 动作嵌套在一起,或定义一组 JSON 动作以供重用吗?
- **对象管理:** 你如何在 JSON 中存储像 `generate_image` 这样的动作的输出?
- **通用性:** 代码被构建为简单地表达任何你可以让计算机做的事情。
- **LLM 训练数据中的表示:** 大量高质量的代码动作已经包含在 LLM 的训练数据中,这意味着它们已经为此进行了训练!
================================================
FILE: docs/source/zh/conceptual_guides/react.md
================================================
# 多步骤 agent 是如何工作的?
ReAct 框架([Yao et al., 2022](https://huggingface.co/papers/2210.03629))是目前构建 agent 的主要方法。
该名称基于两个词的组合:"Reason" (推理)和 "Act" (行动)。实际上,遵循此架构的 agent 将根据需要尽可能多的步骤来解决其任务,每个步骤包括一个推理步骤,然后是一个行动步骤,在该步骤中,它制定工具调用,使其更接近解决手头的任务。
ReAct 过程涉及保留过去步骤的记忆。
> [!TIP]
> 阅读 [Open-source LLMs as LangChain Agents](https://huggingface.co/blog/open-source-llms-as-agents) 博客文章以了解更多关于多步 agent 的信息。
以下是其工作原理的视频概述:
如图所示,CodeAgent 调用了其托管的 ToolCallingAgent(注:托管Agent也可以是另一个 CodeAgent)执行美国2024年经济增长率的网络搜索。托管Agent返回报告后,管理Agent根据结果计算出经济翻倍周期!是不是很智能?
## 使用 🪢 Langfuse 配置遥测
本部分演示如何通过 `SmolagentsInstrumentor` 使用 **Langfuse** 监控和调试 Hugging Face **smolagents**。
> **Langfuse 是什么?** [Langfuse](https://langfuse.com) 是面向LLM工程的开源平台,提供AI Agent的追踪与监控功能,帮助开发者调试、分析和优化产品。该平台通过原生集成、OpenTelemetry 和 SDKs 与各类工具框架对接。
### 步骤 1: 安装依赖
```python
%pip install langfuse 'smolagents[telemetry]' openinference-instrumentation-smolagents
```
### 步骤 2: 配置环境变量
设置 Langfuse API 密钥,并配置 OpenTelemetry 端点将追踪数据发送至 Langfuse。通过注册 [Langfuse Cloud](https://cloud.langfuse.com) 或 [自托管 Langfuse](https://langfuse.com/self-hosting) 获取 API 密钥。
同时需添加 [Hugging Face 令牌](https://huggingface.co/settings/tokens) (`HF_TOKEN`) 作为环境变量:
```python
import os
# Get keys for your project from the project settings page: https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
# your Hugging Face token
os.environ["HF_TOKEN"] = "hf_..."
```
```python
from langfuse import get_client
langfuse = get_client()
# Verify connection
if langfuse.auth_check():
print("Langfuse client is authenticated and ready!")
else:
print("Authentication failed. Please check your credentials and host.")
```
### 步骤 3: 初始化 `SmolagentsInstrumentor`
在应用程序代码执行前初始化 `SmolagentsInstrumentor`。
```python
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
SmolagentsInstrumentor().instrument()
```
### 步骤 4: 运行 smolagent
```python
from smolagents import (
CodeAgent,
ToolCallingAgent,
WebSearchTool,
VisitWebpageTool,
InferenceClientModel,
)
model = InferenceClientModel(
model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
)
search_agent = ToolCallingAgent(
tools=[WebSearchTool(), VisitWebpageTool()],
model=model,
name="search_agent",
description="This is an agent that can do web search.",
)
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent],
)
manager_agent.run(
"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
)
```
### 步骤 5: 在 Langfuse 中查看追踪记录
运行Agent后,您可以在 [Langfuse](https://cloud.langfuse.com) 平台查看 smolagents 应用生成的追踪记录。这些记录会详细展示LLM的交互步骤,帮助您调试和优化AI代理。

_[Langfuse 公开示例追踪](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
================================================
FILE: docs/source/zh/tutorials/memory.md
================================================
# 📚 管理Agent的记忆
[[open-in-colab]]
归根结底,Agent可以定义为由几个简单组件构成:它拥有工具、提示词。最重要的是,它具备对过往步骤的记忆,能够追溯完整的规划、执行和错误历史。
### 回放Agent的记忆
我们提供了多项功能来审查Agent的过往运行记录。
您可以通过插装(instrumentation)在可视化界面中查看Agent的运行过程,该界面支持对特定步骤进行缩放操作,具体方法参见[插装指南](./inspect_runs)。
您也可以使用`agent.replay()`方法实现回放:
当Agent完成运行后:
```py
from smolagents import InferenceClientModel, CodeAgent
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
result = agent.run("What's the 20th Fibonacci number?")
```
若要回放最近一次运行,只需使用:
```py
agent.replay()
```
### 动态修改Agent的记忆
许多高级应用场景需要对Agent的记忆进行动态修改。
您可以通过以下方式访问Agent的记忆:
```py
from smolagents import ActionStep
system_prompt_step = agent.memory.system_prompt
print("The system prompt given to the agent was:")
print(system_prompt_step.system_prompt)
task_step = agent.memory.steps[0]
print("\n\nThe first task step was:")
print(task_step.task)
for step in agent.memory.steps:
if isinstance(step, ActionStep):
if step.error is not None:
print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
else:
print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
```
使用`agent.memory.get_full_steps()`可获取完整步骤字典数据。
您还可以通过步骤回调(step callbacks)实现记忆的动态修改。
步骤回调函数可通过参数直接访问`agent`对象,因此能够访问所有记忆步骤并根据需要进行修改。例如,假设您正在监控网页浏览Agent每个步骤的屏幕截图,希望保留最新截图同时删除旧步骤的图片以节省token消耗。
可参考以下代码示例:
_注:此代码片段不完整,部分导入语句和对象定义已精简,完整代码请访问[原始脚本](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py)_
```py
import helium
from PIL import Image
from io import BytesIO
from time import sleep
def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
sleep(1.0) # Let JavaScript animations happen before taking the screenshot
driver = helium.get_driver()
latest_step = memory_step.step_number
for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
previous_memory_step.observations_images = None
png_bytes = driver.get_screenshot_as_png()
image = Image.open(BytesIO(png_bytes))
memory_step.observations_images = [image.copy()]
```
最后在初始化Agent时,将此函数传入`step_callbacks`参数:
```py
CodeAgent(
tools=[WebSearchTool(), go_back, close_popups, search_item_ctrl_f],
model=model,
additional_authorized_imports=["helium"],
step_callbacks=[update_screenshot],
max_steps=20,
verbosity_level=2,
)
```
请访问我们的 [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) 查看完整可运行示例。
### 分步运行 Agents
当您需要处理耗时数天的工具调用时,这种方式特别有用:您可以逐步执行Agents。这还允许您在每一步更新记忆。
```py
from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
print(agent.memory.system_prompt)
task = "What is the 20th Fibonacci number?"
# You could modify the memory as needed here by inputting the memory of another agent.
# agent.memory.steps = previous_agent.memory.steps
# Let's start a new task!
agent.memory.steps.append(TaskStep(task=task, task_images=[]))
final_answer = None
step_number = 1
while final_answer is None and step_number <= 10:
memory_step = ActionStep(
step_number=step_number,
observations_images=[],
)
# Run one step.
final_answer = agent.step(memory_step)
agent.memory.steps.append(memory_step)
step_number += 1
# Change the memory as you please!
# For instance to update the latest step:
# agent.memory.steps[-1] = ...
print("The final answer is:", final_answer)
```
================================================
FILE: docs/source/zh/tutorials/secure_code_execution.md
================================================
# 安全代码执行
[[open-in-colab]]
> [!TIP]
> 如果你是第一次构建 agent,请先阅读 [agent 介绍](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
### 代码智能体
[多项](https://huggingface.co/papers/2402.01030) [研究](https://huggingface.co/papers/2411.01747) [表明](https://huggingface.co/papers/2401.00812),让大语言模型用代码编写其动作(工具调用)比当前标准的工具调用格式要好得多,目前行业标准是 "将动作写成包含工具名称和参数的 JSON" 的各种变体。
为什么代码更好?因为我们专门为计算机执行的动作而设计编程语言。如果 JSON 片段是更好的方式,那么这个工具包就应该是用 JSON 片段编写的,魔鬼就会嘲笑我们。
代码就是表达计算机动作的更好方式。它具有更好的:
- **组合性**:你能像定义 Python 函数那样,在 JSON 动作中嵌套其他 JSON 动作,或者定义一组 JSON 动作以便以后重用吗?
- **对象管理**:你如何在 JSON 中存储像 `generate_image` 这样的动作的输出?
- **通用性**:代码是为了简单地表达任何可以让计算机做的事情而构建的。
- **在 LLM 训练语料库中的表示**:天赐良机,为什么不利用已经包含在 LLM 训练语料库中的大量高质量动作呢?
下图展示了这一点,取自 [可执行代码动作引出更好的 LLM 智能体](https://huggingface.co/papers/2402.01030)。
这就是为什么我们强调提出代码智能体,在本例中是 Python 智能体,这意味着我们要在构建安全的 Python 解释器上投入更多精力。
### 本地 Python 解释器
默认情况下,`CodeAgent` 会在你的环境中运行 LLM 生成的代码。
这个执行不是由普通的 Python 解释器完成的:我们从零开始重新构建了一个更安全的 `LocalPythonExecutor`。
这个解释器通过以下方式设计以确保安全:
- 将导入限制为用户显式传递的列表
- 限制操作次数以防止无限循环和资源膨胀
- 不会执行任何未预定义的操作
我们已经在许多用例中使用了这个解释器,从未观察到对环境造成任何损害。
然而,这个解决方案并不是万无一失的:可以想象,如果 LLM 被微调用于恶意操作,仍然可能损害你的环境。例如,如果你允许像 `Pillow` 这样无害的包处理图像,LLM 可能会生成数千张图像保存以膨胀你的硬盘。
如果你自己选择了 LLM 引擎,这当然不太可能,但它可能会发生。
所以如果你想格外谨慎,可以使用下面描述的远程代码执行选项。
### E2B 代码执行器
为了最大程度的安全性,你可以使用我们与 E2B 的集成在沙盒环境中运行代码。这是一个远程执行服务,可以在隔离的容器中运行你的代码,使代码无法影响你的本地环境。
为此,你需要设置你的 E2B 账户并在环境变量中设置 `E2B_API_KEY`。请前往 [E2B 快速入门文档](https://e2b.dev/docs/quickstart) 了解更多信息。
然后你可以通过 `pip install e2b-code-interpreter python-dotenv` 安装它。
现在你已经准备好了!
要将代码执行器设置为 E2B,只需在初始化 `CodeAgent` 时传递标志 `executor_type="e2b"`。
请注意,你应该将所有工具的依赖项添加到 `additional_authorized_imports` 中,以便执行器安装它们。
```py
from smolagents import CodeAgent, VisitWebpageTool, InferenceClientModel
agent = CodeAgent(
tools = [VisitWebpageTool()],
model=InferenceClientModel(),
additional_authorized_imports=["requests", "markdownify"],
executor_type="e2b"
)
agent.run("What was Abraham Lincoln's preferred pet?")
```
目前 E2B 代码执行暂不兼容多 agent——因为把 agent 调用放在应该在远程执行的代码块里,是非常混乱的。但我们正在努力做到这件事!
================================================
FILE: docs/source/zh/tutorials/tools.md
================================================
# 工具
[[open-in-colab]]
在这里,我们将学习高级工具的使用。
> [!TIP]
> 如果你是构建 agent 的新手,请确保先阅读 [agent 介绍](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
- [工具](#工具)
- [什么是工具,如何构建一个工具?](#什么是工具如何构建一个工具)
- [将你的工具分享到 Hub](#将你的工具分享到-hub)
- [将 Space 导入为工具](#将-space-导入为工具)
- [使用 LangChain 工具](#使用-langchain-工具)
- [管理你的 agent 工具箱](#管理你的-agent-工具箱)
- [使用工具集合](#使用工具集合)
### 什么是工具,如何构建一个工具?
工具主要是 LLM 可以在 agent 系统中使用的函数。
但要使用它,LLM 需要被提供一个 API:名称、工具描述、输入类型和描述、输出类型。
所以它不能仅仅是一个函数。它应该是一个类。
因此,核心上,工具是一个类,它包装了一个函数,并带有帮助 LLM 理解如何使用它的元数据。
以下是它的结构:
```python
from smolagents import Tool
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = """
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint."""
inputs = {
"task": {
"type": "string",
"description": "the task category (such as text-classification, depth-estimation, etc)",
}
}
output_type = "string"
def forward(self, task: str):
from huggingface_hub import list_models
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
model_downloads_tool = HFModelDownloadsTool()
```
自定义工具继承 [`Tool`] 以继承有用的方法。子类还定义了:
- 一个属性 `name`,对应于工具本身的名称。名称通常描述工具的功能。由于代码返回任务中下载量最多的模型,我们将其命名为 `model_download_counter`。
- 一个属性 `description`,用于填充 agent 的系统提示。
- 一个 `inputs` 属性,它是一个带有键 `"type"` 和 `"description"` 的字典。它包含帮助 Python 解释器对输入做出明智选择的信息。
- 一个 `output_type` 属性,指定输出类型。`inputs` 和 `output_type` 的类型应为 [Pydantic 格式](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema),它们可以是以下之一:`["string", "boolean","integer", "number", "image", "audio", "array", "object", "any", "null"]`。
- 一个 `forward` 方法,包含要执行的推理代码。
这就是它在 agent 中使用所需的全部内容!
还有另一种构建工具的方法。在 [guided_tour](../guided_tour) 中,我们使用 `@tool` 装饰器实现了一个工具。[`tool`] 装饰器是定义简单工具的推荐方式,但有时你需要更多:在类中使用多个方法以获得更清晰的代码,或使用额外的类属性。
在这种情况下,你可以通过如上所述继承 [`Tool`] 来构建你的工具。
### 将你的工具分享到 Hub
你可以通过调用 [`~Tool.push_to_hub`] 将你的自定义工具分享到 Hub。确保你已经在 Hub 上为其创建了一个仓库,并且使用的是具有读取权限的 token。
```python
model_downloads_tool.push_to_hub("{your_username}/hf-model-downloads", token="
然后你可以像使用任何其他工具一样使用这个工具。例如,让我们改进提示 `A rabbit wearing a space suit` 并生成它的图片。
```python
from smolagents import CodeAgent, InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[image_generation_tool], model=model)
agent.run(
"Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
)
```
```text
=== Agent thoughts:
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
>>> Agent is executing the code below:
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
final_answer(image)
```
这得有多酷?🤩
### 使用 LangChain 工具
我们喜欢 Langchain,并认为它有一套非常吸引人的工具。
要从 LangChain 导入工具,请使用 `from_langchain()` 方法。
以下是如何使用它来重现介绍中的搜索结果,使用 LangChain 的 web 搜索工具。
这个工具需要 `pip install langchain google-search-results -q` 才能正常工作。
```python
from langchain.agents import load_tools
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
agent = CodeAgent(tools=[search_tool], model=model)
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
```
### 管理你的 agent 工具箱
你可以通过添加或替换工具来管理 agent 的工具箱。
让我们将 `model_download_tool` 添加到一个仅使用默认工具箱初始化的现有 agent 中。
```python
from smolagents import InferenceClientModel
model = InferenceClientModel(model_id="Qwen/Qwen3-Next-80B-A3B-Thinking")
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
agent.tools[model_download_tool.name] = model_download_tool
```
现在我们可以利用新工具:
```python
agent.run(
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
)
```
> [!TIP]
> 注意不要向 agent 添加太多工具:这可能会让较弱的 LLM 引擎不堪重负。
### 使用工具集合
你可以通过使用 ToolCollection 对象来利用工具集合,使用你想要使用的集合的 slug。
然后将它们作为列表传递给 agent 初始化,并开始使用它们!
```py
from smolagents import ToolCollection, CodeAgent
image_tool_collection = ToolCollection.from_hub(
collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
token="| " + html.escape(cell.text) + " | " else: html_table += "" + html.escape(cell.text) + " | " html_table += "
|---|
", "").
**kwargs: Additional keyword arguments.
"""
def __init__(
self,
tools: list[Tool],
model: Model,
prompt_templates: PromptTemplates | None = None,
additional_authorized_imports: list[str] | None = None,
planning_interval: int | None = None,
executor: PythonExecutor = None,
executor_type: Literal["local", "blaxel", "e2b", "modal", "docker", "wasm"] = "local",
executor_kwargs: dict[str, Any] | None = None,
max_print_outputs_length: int | None = None,
stream_outputs: bool = False,
use_structured_outputs_internally: bool = False,
code_block_tags: str | tuple[str, str] | None = None,
**kwargs,
):
self.additional_authorized_imports = additional_authorized_imports if additional_authorized_imports else []
self.authorized_imports = sorted(set(BASE_BUILTIN_MODULES) | set(self.additional_authorized_imports))
self.max_print_outputs_length = max_print_outputs_length
self._use_structured_outputs_internally = use_structured_outputs_internally
if self._use_structured_outputs_internally:
prompt_templates = prompt_templates or yaml.safe_load(
importlib.resources.files("smolagents.prompts").joinpath("structured_code_agent.yaml").read_text()
)
else:
prompt_templates = prompt_templates or yaml.safe_load(
importlib.resources.files("smolagents.prompts").joinpath("code_agent.yaml").read_text()
)
if isinstance(code_block_tags, str) and not code_block_tags == "markdown":
raise ValueError("Only 'markdown' is supported for a string argument to `code_block_tags`.")
self.code_block_tags = (
code_block_tags
if isinstance(code_block_tags, tuple)
else ("```python", "```")
if code_block_tags == "markdown"
else ("", "")
)
super().__init__(
tools=tools,
model=model,
prompt_templates=prompt_templates,
planning_interval=planning_interval,
**kwargs,
)
self.stream_outputs = stream_outputs
if self.stream_outputs and not hasattr(self.model, "generate_stream"):
raise ValueError(
"`stream_outputs` is set to True, but the model class implements no `generate_stream` method."
)
if "*" in self.additional_authorized_imports:
self.logger.log(
"Caution: you set an authorization for all imports, meaning your agent can decide to import any package it deems necessary. This might raise issues if the package is not installed in your environment.",
level=LogLevel.INFO,
)
self.executor_type = executor_type
self.executor_kwargs: dict[str, Any] = executor_kwargs or {}
self.python_executor = executor or self.create_python_executor()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, traceback):
self.cleanup()
def cleanup(self):
"""Clean up resources used by the agent, such as the remote Python executor."""
if hasattr(self.python_executor, "cleanup"):
self.python_executor.cleanup()
def create_python_executor(self) -> PythonExecutor:
if self.executor_type not in {"local", "blaxel", "e2b", "modal", "docker", "wasm"}:
raise ValueError(f"Unsupported executor type: {self.executor_type}")
if self.executor_type == "local":
return LocalPythonExecutor(
self.additional_authorized_imports,
**{"max_print_outputs_length": self.max_print_outputs_length} | self.executor_kwargs,
)
else:
if self.managed_agents:
raise Exception("Managed agents are not yet supported with remote code execution.")
remote_executors = {
"blaxel": BlaxelExecutor,
"e2b": E2BExecutor,
"docker": DockerExecutor,
"wasm": WasmExecutor,
"modal": ModalExecutor,
}
return remote_executors[self.executor_type](
self.additional_authorized_imports, self.logger, **self.executor_kwargs
)
def initialize_system_prompt(self) -> str:
system_prompt = populate_template(
self.prompt_templates["system_prompt"],
variables={
"tools": self.tools,
"managed_agents": self.managed_agents,
"authorized_imports": (
"You can import from any package you want."
if "*" in self.authorized_imports
else str(self.authorized_imports)
),
"custom_instructions": self.instructions,
"code_block_opening_tag": self.code_block_tags[0],
"code_block_closing_tag": self.code_block_tags[1],
},
)
return system_prompt
def _step_stream(
self, memory_step: ActionStep
) -> Generator[ChatMessageStreamDelta | ToolCall | ToolOutput | ActionOutput]:
"""
Perform one step in the ReAct framework: the agent thinks, acts, and observes the result.
Yields ChatMessageStreamDelta during the run if streaming is enabled.
At the end, yields either None if the step is not final, or the final answer.
"""
memory_messages = self.write_memory_to_messages()
input_messages = memory_messages.copy()
### Generate model output ###
memory_step.model_input_messages = input_messages
stop_sequences = ["Observation:", "Calling tools:"]
if self.code_block_tags[1] not in self.code_block_tags[0]:
# If the closing tag is contained in the opening tag, adding it as a stop sequence would cut short any code generation
stop_sequences.append(self.code_block_tags[1])
try:
additional_args: dict[str, Any] = {}
if self._use_structured_outputs_internally:
additional_args["response_format"] = CODEAGENT_RESPONSE_FORMAT
if self.stream_outputs:
output_stream = self.model.generate_stream(
input_messages,
stop_sequences=stop_sequences,
**additional_args,
)
chat_message_stream_deltas: list[ChatMessageStreamDelta] = []
with Live("", console=self.logger.console, vertical_overflow="visible") as live:
for event in output_stream:
chat_message_stream_deltas.append(event)
live.update(
Markdown(agglomerate_stream_deltas(chat_message_stream_deltas).render_as_markdown())
)
yield event
chat_message = agglomerate_stream_deltas(chat_message_stream_deltas)
memory_step.model_output_message = chat_message
output_text = chat_message.content
else:
chat_message: ChatMessage = self.model.generate(
input_messages,
stop_sequences=stop_sequences,
**additional_args,
)
memory_step.model_output_message = chat_message
output_text = chat_message.content
self.logger.log_markdown(
content=output_text or "",
title="Output message of the LLM:",
level=LogLevel.DEBUG,
)
if not self._use_structured_outputs_internally:
# This adds the end code sequence (i.e. the closing code block tag) to the history.
# This will nudge subsequent LLM calls to finish with this end code sequence, thus efficiently stopping generation.
if output_text and not output_text.strip().endswith(self.code_block_tags[1]):
output_text += self.code_block_tags[1]
memory_step.model_output_message.content = output_text
memory_step.token_usage = chat_message.token_usage
memory_step.model_output = output_text
except Exception as e:
raise AgentGenerationError(f"Error in generating model output:\n{e}", self.logger) from e
### Parse output ###
try:
if self._use_structured_outputs_internally:
code_action = json.loads(output_text)["code"]
code_action = extract_code_from_text(code_action, self.code_block_tags) or code_action
else:
code_action = parse_code_blobs(output_text, self.code_block_tags)
code_action = fix_final_answer_code(code_action)
memory_step.code_action = code_action
except Exception as e:
error_msg = f"Error in code parsing:\n{e}\nMake sure to provide correct code blobs."
raise AgentParsingError(error_msg, self.logger)
tool_call = ToolCall(
name="python_interpreter",
arguments=code_action,
id=f"call_{len(self.memory.steps)}",
)
yield tool_call
memory_step.tool_calls = [tool_call]
### Execute action ###
self.logger.log_code(title="Executing parsed code:", content=code_action, level=LogLevel.INFO)
try:
code_output = self.python_executor(code_action)
execution_outputs_console = []
if len(code_output.logs) > 0:
execution_outputs_console += [
Text("Execution logs:", style="bold"),
Text(code_output.logs),
]
observation = "Execution logs:\n" + code_output.logs
except Exception as e:
if hasattr(self.python_executor, "state") and "_print_outputs" in self.python_executor.state:
execution_logs = str(self.python_executor.state["_print_outputs"])
if len(execution_logs) > 0:
execution_outputs_console = [
Text("Execution logs:", style="bold"),
Text(execution_logs),
]
memory_step.observations = "Execution logs:\n" + execution_logs
self.logger.log(Group(*execution_outputs_console), level=LogLevel.INFO)
error_msg = str(e)
if "Import of " in error_msg and " is not allowed" in error_msg:
self.logger.log(
"[bold red]Warning to user: Code execution failed due to an unauthorized import - Consider passing said import under `additional_authorized_imports` when initializing your CodeAgent.",
level=LogLevel.INFO,
)
raise AgentExecutionError(error_msg, self.logger)
truncated_output = truncate_content(str(code_output.output))
observation += "Last output from code snippet:\n" + truncated_output
memory_step.observations = observation
if not code_output.is_final_answer:
execution_outputs_console += [
Text(
f"Out: {truncated_output}",
),
]
self.logger.log(Group(*execution_outputs_console), level=LogLevel.INFO)
memory_step.action_output = code_output.output
yield ActionOutput(output=code_output.output, is_final_answer=code_output.is_final_answer)
def to_dict(self) -> dict[str, Any]:
"""Convert the agent to a dictionary representation.
Returns:
`dict`: Dictionary representation of the agent.
"""
agent_dict = super().to_dict()
agent_dict["authorized_imports"] = self.authorized_imports
agent_dict["executor_type"] = self.executor_type
agent_dict["executor_kwargs"] = self.executor_kwargs
agent_dict["max_print_outputs_length"] = self.max_print_outputs_length
return agent_dict
@classmethod
def from_dict(cls, agent_dict: dict[str, Any], **kwargs) -> "CodeAgent":
"""Create CodeAgent from a dictionary representation.
Args:
agent_dict (`dict[str, Any]`): Dictionary representation of the agent.
**kwargs: Additional keyword arguments that will override agent_dict values.
Returns:
`CodeAgent`: Instance of the CodeAgent class.
"""
# Add CodeAgent-specific parameters to kwargs
code_agent_kwargs = {
"additional_authorized_imports": agent_dict.get("authorized_imports"),
"executor_type": agent_dict.get("executor_type"),
"executor_kwargs": agent_dict.get("executor_kwargs"),
"max_print_outputs_length": agent_dict.get("max_print_outputs_length"),
"code_block_tags": agent_dict.get("code_block_tags"),
}
# Filter out None values
code_agent_kwargs = {k: v for k, v in code_agent_kwargs.items() if v is not None}
# Update with any additional kwargs
code_agent_kwargs.update(kwargs)
# Call the parent class's from_dict method
return super().from_dict(agent_dict, **code_agent_kwargs)
# Agent Registry for secure deserialization
# This registry maps agent class names to their actual classes.
# Only classes listed here can be instantiated during deserialization (from_dict/from_folder).
# This prevents arbitrary code execution via importlib-based dynamic loading.
AGENT_REGISTRY = {
"ToolCallingAgent": ToolCallingAgent,
"CodeAgent": CodeAgent,
}
================================================
FILE: src/smolagents/cli.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
from dotenv import load_dotenv
from rich.console import Console
from rich.panel import Panel
from rich.prompt import Confirm, Prompt
from rich.rule import Rule
from rich.table import Table
from smolagents import (
CodeAgent,
InferenceClientModel,
LiteLLMModel,
Model,
OpenAIModel,
Tool,
ToolCallingAgent,
TransformersModel,
)
from smolagents.default_tools import TOOL_MAPPING
console = Console()
leopard_prompt = "How many seconds would it take for a leopard at full speed to run through Pont des Arts?"
def parse_arguments():
parser = argparse.ArgumentParser(description="Run a CodeAgent with all specified parameters")
parser.add_argument(
"prompt",
type=str,
nargs="?",
default=None,
help="The prompt to run with the agent. If no prompt is provided, interactive mode will be launched to guide user through agent setup",
)
parser.add_argument(
"--model-type",
type=str,
default="InferenceClientModel",
help="The model type to use (e.g., InferenceClientModel, OpenAIModel, LiteLLMModel, TransformersModel)",
)
parser.add_argument(
"--action-type",
type=str,
default="code",
help="The action type to use (e.g., code, tool_calling)",
)
parser.add_argument(
"--model-id",
type=str,
default="Qwen/Qwen3-Next-80B-A3B-Thinking",
help="The model ID to use for the specified model type",
)
parser.add_argument(
"--imports",
nargs="*", # accepts zero or more arguments
default=[],
help="Space-separated list of imports to authorize (e.g., 'numpy pandas')",
)
parser.add_argument(
"--tools",
nargs="*",
default=["web_search"],
help="Space-separated list of tools that the agent can use (e.g., 'tool1 tool2 tool3')",
)
parser.add_argument(
"--verbosity-level",
type=int,
default=1,
help="The verbosity level, as an int in [0, 1, 2].",
)
group = parser.add_argument_group("api options", "Options for API-based model types")
group.add_argument(
"--provider",
type=str,
default=None,
help="The inference provider to use for the model",
)
group.add_argument(
"--api-base",
type=str,
help="The base URL for the model",
)
group.add_argument(
"--api-key",
type=str,
help="The API key for the model",
)
return parser.parse_args()
def interactive_mode():
"""Run the CLI in interactive mode"""
console.print(
Panel.fit(
"[bold magenta]🤖 SmolaGents CLI[/]\n[dim]Intelligent agents at your service[/]", border_style="magenta"
)
)
console.print("\n[bold yellow]Welcome to smolagents![/] Let's set up your agent step by step.\n")
# Get user input step by step
console.print(Rule("[bold yellow]⚙️ Configuration", style="bold yellow"))
# Get agent action type
action_type = Prompt.ask(
"[bold white]What action type would you like to use? 'code' or 'tool_calling'?[/]",
default="code",
choices=["code", "tool_calling"],
)
# Show available tools
tools_table = Table(title="[bold yellow]🛠️ Available Tools", show_header=True, header_style="bold yellow")
tools_table.add_column("Tool Name", style="bold yellow")
tools_table.add_column("Description", style="white")
for tool_name, tool_class in TOOL_MAPPING.items():
# Get description from the tool class if available
try:
tool_instance = tool_class()
description = getattr(tool_instance, "description", "No description available")
except Exception:
description = "Built-in tool"
tools_table.add_row(tool_name, description)
console.print(tools_table)
console.print(
"\n[dim]You can also use HuggingFace Spaces by providing the full path (e.g., 'username/spacename')[/]"
)
console.print("[dim]Enter tool names separated by spaces (e.g., 'web_search python_interpreter')[/]")
tools_input = Prompt.ask("[bold white]Select tools for your agent[/]", default="web_search")
tools = tools_input.split()
# Get model configuration
console.print("\n[bold yellow]Model Configuration:[/]")
model_type = Prompt.ask(
"[bold]Model type[/]",
default="InferenceClientModel",
choices=["InferenceClientModel", "OpenAIServerModel", "LiteLLMModel", "TransformersModel"],
)
model_id = Prompt.ask("[bold white]Model ID[/]", default="Qwen/Qwen2.5-Coder-32B-Instruct")
# Optional configurations
provider = None
api_base = None
api_key = None
imports = []
action_type = "code"
if Confirm.ask("\n[bold white]Configure advanced options?[/]", default=False):
if model_type in ["InferenceClientModel", "OpenAIServerModel", "LiteLLMModel"]:
provider = Prompt.ask("[bold white]Provider[/]", default="")
api_base = Prompt.ask("[bold white]API Base URL[/]", default="")
api_key = Prompt.ask("[bold white]API Key[/]", default="", password=True)
imports_input = Prompt.ask("[bold white]Additional imports (space-separated)[/]", default="")
if imports_input:
imports = imports_input.split()
# Get prompt
prompt = Prompt.ask(
"[bold white]Now the final step; what task would you like the agent to perform?[/]", default=leopard_prompt
)
return prompt, tools, model_type, model_id, provider, api_base, api_key, imports, action_type
def load_model(
model_type: str,
model_id: str,
api_base: str | None = None,
api_key: str | None = None,
provider: str | None = None,
) -> Model:
if model_type == "OpenAIModel":
return OpenAIModel(
api_key=api_key or os.getenv("FIREWORKS_API_KEY"),
api_base=api_base or "https://api.fireworks.ai/inference/v1",
model_id=model_id,
)
elif model_type == "LiteLLMModel":
return LiteLLMModel(
model_id=model_id,
api_key=api_key,
api_base=api_base,
)
elif model_type == "TransformersModel":
return TransformersModel(model_id=model_id, device_map="auto")
elif model_type == "InferenceClientModel":
return InferenceClientModel(
model_id=model_id,
token=api_key or os.getenv("HF_API_KEY"),
provider=provider,
)
else:
raise ValueError(f"Unsupported model type: {model_type}")
def run_smolagent(
prompt: str,
tools: list[str],
model_type: str,
model_id: str,
api_base: str | None = None,
api_key: str | None = None,
imports: list[str] | None = None,
provider: str | None = None,
action_type: str = "code",
) -> None:
load_dotenv()
model = load_model(model_type, model_id, api_base=api_base, api_key=api_key, provider=provider)
available_tools = []
for tool_name in tools:
if "/" in tool_name:
space_name = tool_name.split("/")[-1].lower().replace("-", "_").replace(".", "_")
description = f"Tool loaded from Hugging Face Space: {tool_name}"
available_tools.append(Tool.from_space(space_id=tool_name, name=space_name, description=description))
else:
if tool_name in TOOL_MAPPING:
available_tools.append(TOOL_MAPPING[tool_name]())
else:
raise ValueError(f"Tool {tool_name} is not recognized either as a default tool or a Space.")
if action_type == "code":
agent = CodeAgent(
tools=available_tools,
model=model,
additional_authorized_imports=imports,
stream_outputs=True,
)
elif action_type == "tool_calling":
agent = ToolCallingAgent(tools=available_tools, model=model, stream_outputs=True)
else:
raise ValueError(f"Unsupported action type: {action_type}")
agent.run(prompt)
def main() -> None:
args = parse_arguments()
# Check if we should run in interactive mode
# Interactive mode is triggered when no prompt is provided
if args.prompt is None:
prompt, tools, model_type, model_id, provider, api_base, api_key, imports, action_type = interactive_mode()
else:
prompt = args.prompt
tools = args.tools
model_type = args.model_type
model_id = args.model_id
provider = args.provider
api_base = args.api_base
api_key = args.api_key
imports = args.imports
action_type = args.action_type
run_smolagent(
prompt,
tools,
model_type,
model_id,
provider=provider,
api_base=api_base,
api_key=api_key,
imports=imports,
action_type=action_type,
)
if __name__ == "__main__":
main()
================================================
FILE: src/smolagents/default_tools.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import Any
from .local_python_executor import (
BASE_BUILTIN_MODULES,
BASE_PYTHON_TOOLS,
MAX_EXECUTION_TIME_SECONDS,
evaluate_python_code,
)
from .tools import PipelineTool, Tool
@dataclass
class PreTool:
name: str
inputs: dict[str, str]
output_type: type
task: str
description: str
repo_id: str
class PythonInterpreterTool(Tool):
name = "python_interpreter"
description = "This is a tool that evaluates python code. It can be used to perform calculations."
inputs = {
"code": {
"type": "string",
"description": "The python code to run in interpreter",
}
}
output_type = "string"
def __init__(self, *args, authorized_imports=None, timeout_seconds=MAX_EXECUTION_TIME_SECONDS, **kwargs):
if authorized_imports is None:
self.authorized_imports = list(set(BASE_BUILTIN_MODULES))
else:
self.authorized_imports = list(set(BASE_BUILTIN_MODULES) | set(authorized_imports))
self.inputs = {
"code": {
"type": "string",
"description": (
"The code snippet to evaluate. All variables used in this snippet must be defined in this same snippet, "
f"else you will get an error. This code can only import the following python libraries: {self.authorized_imports}."
),
}
}
self.base_python_tools = BASE_PYTHON_TOOLS
self.python_evaluator = evaluate_python_code
self.timeout_seconds = timeout_seconds
super().__init__(*args, **kwargs)
def forward(self, code: str) -> str:
state = {}
output = str(
self.python_evaluator(
code,
state=state,
static_tools=self.base_python_tools,
authorized_imports=self.authorized_imports,
timeout_seconds=self.timeout_seconds,
)[0] # The second element is boolean is_final_answer
)
return f"Stdout:\n{str(state['_print_outputs'])}\nOutput: {output}"
class FinalAnswerTool(Tool):
name = "final_answer"
description = "Provides a final answer to the given problem."
inputs = {"answer": {"type": "any", "description": "The final answer to the problem"}}
output_type = "any"
def forward(self, answer: Any) -> Any:
return answer
class UserInputTool(Tool):
name = "user_input"
description = "Asks for user's input on a specific question"
inputs = {"question": {"type": "string", "description": "The question to ask the user"}}
output_type = "string"
def forward(self, question):
user_input = input(f"{question} => Type your answer here:")
return user_input
class DuckDuckGoSearchTool(Tool):
"""Web search tool that performs searches using the DuckDuckGo search engine.
Args:
max_results (`int`, default `10`): Maximum number of search results to return.
rate_limit (`float`, default `1.0`): Maximum queries per second. Set to `None` to disable rate limiting.
**kwargs: Additional keyword arguments for the `DDGS` client.
Examples:
```python
>>> from smolagents import DuckDuckGoSearchTool
>>> web_search_tool = DuckDuckGoSearchTool(max_results=5, rate_limit=2.0)
>>> results = web_search_tool("Hugging Face")
>>> print(results)
```
"""
name = "web_search"
description = """Performs a duckduckgo web search based on your query (think a Google search) then returns the top search results."""
inputs = {"query": {"type": "string", "description": "The search query to perform."}}
output_type = "string"
def __init__(self, max_results: int = 10, rate_limit: float | None = 1.0, **kwargs):
super().__init__()
self.max_results = max_results
self.rate_limit = rate_limit
self._min_interval = 1.0 / rate_limit if rate_limit else 0.0
self._last_request_time = 0.0
try:
from ddgs import DDGS
except ImportError as e:
raise ImportError(
"You must install package `ddgs` to run this tool: for instance run `pip install ddgs`."
) from e
self.ddgs = DDGS(**kwargs)
def forward(self, query: str) -> str:
self._enforce_rate_limit()
results = self.ddgs.text(query, max_results=self.max_results)
if len(results) == 0:
raise Exception("No results found! Try a less restrictive/shorter query.")
postprocessed_results = [f"[{result['title']}]({result['href']})\n{result['body']}" for result in results]
return "## Search Results\n\n" + "\n\n".join(postprocessed_results)
def _enforce_rate_limit(self) -> None:
import time
# No rate limit enforced
if not self.rate_limit:
return
now = time.time()
elapsed = now - self._last_request_time
if elapsed < self._min_interval:
time.sleep(self._min_interval - elapsed)
self._last_request_time = time.time()
class GoogleSearchTool(Tool):
name = "web_search"
description = """Performs a google web search for your query then returns a string of the top search results."""
inputs = {
"query": {"type": "string", "description": "The search query to perform."},
"filter_year": {
"type": "integer",
"description": "Optionally restrict results to a certain year",
"nullable": True,
},
}
output_type = "string"
def __init__(self, provider: str = "serpapi"):
super().__init__()
import os
self.provider = provider
if provider == "serpapi":
self.organic_key = "organic_results"
api_key_env_name = "SERPAPI_API_KEY"
else:
self.organic_key = "organic"
api_key_env_name = "SERPER_API_KEY"
self.api_key = os.getenv(api_key_env_name)
if self.api_key is None:
raise ValueError(f"Missing API key. Make sure you have '{api_key_env_name}' in your env variables.")
def forward(self, query: str, filter_year: int | None = None) -> str:
import requests
if self.provider == "serpapi":
params = {
"q": query,
"api_key": self.api_key,
"engine": "google",
"google_domain": "google.com",
}
base_url = "https://serpapi.com/search.json"
else:
params = {
"q": query,
"api_key": self.api_key,
}
base_url = "https://google.serper.dev/search"
if filter_year is not None:
params["tbs"] = f"cdr:1,cd_min:01/01/{filter_year},cd_max:12/31/{filter_year}"
response = requests.get(base_url, params=params)
if response.status_code == 200:
results = response.json()
else:
raise ValueError(response.json())
if self.organic_key not in results.keys():
if filter_year is not None:
raise Exception(
f"No results found for query: '{query}' with filtering on year={filter_year}. Use a less restrictive query or do not filter on year."
)
else:
raise Exception(f"No results found for query: '{query}'. Use a less restrictive query.")
if len(results[self.organic_key]) == 0:
year_filter_message = f" with filter year={filter_year}" if filter_year is not None else ""
return f"No results found for '{query}'{year_filter_message}. Try with a more general query, or remove the year filter."
web_snippets = []
if self.organic_key in results:
for idx, page in enumerate(results[self.organic_key]):
date_published = ""
if "date" in page:
date_published = "\nDate published: " + page["date"]
source = ""
if "source" in page:
source = "\nSource: " + page["source"]
snippet = ""
if "snippet" in page:
snippet = "\n" + page["snippet"]
redacted_version = f"{idx}. [{page['title']}]({page['link']}){date_published}{source}\n{snippet}"
web_snippets.append(redacted_version)
return "## Search Results\n" + "\n\n".join(web_snippets)
class ApiWebSearchTool(Tool):
"""Web search tool that performs API-based searches.
By default, it uses the Brave Search API.
This tool implements a rate limiting mechanism to ensure compliance with API usage policies.
By default, it limits requests to 1 query per second.
Args:
endpoint (`str`): API endpoint URL. Defaults to Brave Search API.
api_key (`str`): API key for authentication.
api_key_name (`str`): Environment variable name containing the API key. Defaults to "BRAVE_API_KEY".
headers (`dict`, *optional*): Headers for API requests.
params (`dict`, *optional*): Parameters for API requests.
rate_limit (`float`, default `1.0`): Maximum queries per second. Set to `None` to disable rate limiting.
Examples:
```python
>>> from smolagents import ApiWebSearchTool
>>> web_search_tool = ApiWebSearchTool(rate_limit=50.0)
>>> results = web_search_tool("Hugging Face")
>>> print(results)
```
"""
name = "web_search"
description = "Performs a web search for a query and returns a string of the top search results formatted as markdown with titles, URLs, and descriptions."
inputs = {"query": {"type": "string", "description": "The search query to perform."}}
output_type = "string"
def __init__(
self,
endpoint: str = "",
api_key: str = "",
api_key_name: str = "",
headers: dict = None,
params: dict = None,
rate_limit: float | None = 1.0,
):
import os
super().__init__()
self.endpoint = endpoint or "https://api.search.brave.com/res/v1/web/search"
self.api_key_name = api_key_name or "BRAVE_API_KEY"
self.api_key = api_key or os.getenv(self.api_key_name)
self.headers = headers or {"X-Subscription-Token": self.api_key}
self.params = params or {"count": 10}
self.rate_limit = rate_limit
self._min_interval = 1.0 / rate_limit if rate_limit else 0.0
self._last_request_time = 0.0
def _enforce_rate_limit(self) -> None:
import time
# No rate limit enforced
if not self.rate_limit:
return
now = time.time()
elapsed = now - self._last_request_time
if elapsed < self._min_interval:
time.sleep(self._min_interval - elapsed)
self._last_request_time = time.time()
def forward(self, query: str) -> str:
import requests
self._enforce_rate_limit()
params = {**self.params, "q": query}
response = requests.get(self.endpoint, headers=self.headers, params=params)
response.raise_for_status()
data = response.json()
results = self.extract_results(data)
return self.format_markdown(results)
def extract_results(self, data: dict) -> list:
results = []
for result in data.get("web", {}).get("results", []):
results.append(
{"title": result["title"], "url": result["url"], "description": result.get("description", "")}
)
return results
def format_markdown(self, results: list) -> str:
if not results:
return "No results found."
return "## Search Results\n\n" + "\n\n".join(
[
f"{idx}. [{result['title']}]({result['url']})\n{result['description']}"
for idx, result in enumerate(results, start=1)
]
)
class WebSearchTool(Tool):
name = "web_search"
description = "Performs a web search for a query and returns a string of the top search results formatted as markdown with titles, links, and descriptions."
inputs = {"query": {"type": "string", "description": "The search query to perform."}}
output_type = "string"
def __init__(self, max_results: int = 10, engine: str = "duckduckgo"):
super().__init__()
self.max_results = max_results
self.engine = engine
def forward(self, query: str) -> str:
results = self.search(query)
if len(results) == 0:
raise Exception("No results found! Try a less restrictive/shorter query.")
return self.parse_results(results)
def search(self, query: str) -> list:
if self.engine == "duckduckgo":
return self.search_duckduckgo(query)
elif self.engine == "bing":
return self.search_bing(query)
else:
raise ValueError(f"Unsupported engine: {self.engine}")
def parse_results(self, results: list) -> str:
return "## Search Results\n\n" + "\n\n".join(
[f"[{result['title']}]({result['link']})\n{result['description']}" for result in results]
)
def search_duckduckgo(self, query: str) -> list:
import requests
response = requests.get(
"https://lite.duckduckgo.com/lite/",
params={"q": query},
headers={"User-Agent": "Mozilla/5.0"},
)
response.raise_for_status()
parser = self._create_duckduckgo_parser()
parser.feed(response.text)
return parser.results
def _create_duckduckgo_parser(self):
from html.parser import HTMLParser
class SimpleResultParser(HTMLParser):
def __init__(self):
super().__init__()
self.results = []
self.current = {}
self.capture_title = False
self.capture_description = False
self.capture_link = False
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
if tag == "a" and attrs.get("class") == "result-link":
self.capture_title = True
elif tag == "td" and attrs.get("class") == "result-snippet":
self.capture_description = True
elif tag == "span" and attrs.get("class") == "link-text":
self.capture_link = True
def handle_endtag(self, tag):
if tag == "a" and self.capture_title:
self.capture_title = False
elif tag == "td" and self.capture_description:
self.capture_description = False
elif tag == "span" and self.capture_link:
self.capture_link = False
elif tag == "tr":
# Store current result if all parts are present
if {"title", "description", "link"} <= self.current.keys():
self.current["description"] = " ".join(self.current["description"])
self.results.append(self.current)
self.current = {}
def handle_data(self, data):
if self.capture_title:
self.current["title"] = data.strip()
elif self.capture_description:
self.current.setdefault("description", [])
self.current["description"].append(data.strip())
elif self.capture_link:
self.current["link"] = "https://" + data.strip()
return SimpleResultParser()
def search_bing(self, query: str) -> list:
import xml.etree.ElementTree as ET
import requests
response = requests.get(
"https://www.bing.com/search",
params={"q": query, "format": "rss"},
)
response.raise_for_status()
root = ET.fromstring(response.text)
items = root.findall(".//item")
results = [
{
"title": item.findtext("title"),
"link": item.findtext("link"),
"description": item.findtext("description"),
}
for item in items[: self.max_results]
]
return results
class VisitWebpageTool(Tool):
name = "visit_webpage"
description = (
"Visits a webpage at the given url and reads its content as a markdown string. Use this to browse webpages."
)
inputs = {
"url": {
"type": "string",
"description": "The url of the webpage to visit.",
}
}
output_type = "string"
def __init__(self, max_output_length: int = 40000):
super().__init__()
self.max_output_length = max_output_length
def _truncate_content(self, content: str, max_length: int) -> str:
if len(content) <= max_length:
return content
return (
content[:max_length] + f"\n..._This content has been truncated to stay below {max_length} characters_...\n"
)
def forward(self, url: str) -> str:
try:
import re
import requests
from markdownify import markdownify
from requests.exceptions import RequestException
except ImportError as e:
raise ImportError(
"You must install packages `markdownify` and `requests` to run this tool: for instance run `pip install markdownify requests`."
) from e
try:
# Send a GET request to the URL with a 20-second timeout
response = requests.get(url, timeout=20)
response.raise_for_status() # Raise an exception for bad status codes
# Convert the HTML content to Markdown
markdown_content = markdownify(response.text).strip()
# Remove multiple line breaks
markdown_content = re.sub(r"\n{3,}", "\n\n", markdown_content)
return self._truncate_content(markdown_content, self.max_output_length)
except requests.exceptions.Timeout:
return "The request timed out. Please try again later or check the URL."
except RequestException as e:
return f"Error fetching the webpage: {str(e)}"
except Exception as e:
return f"An unexpected error occurred: {str(e)}"
class WikipediaSearchTool(Tool):
"""
Search Wikipedia and return the summary or full text of the requested article, along with the page URL.
Attributes:
user_agent (`str`): Custom user-agent string to identify the project. This is required as per Wikipedia API policies.
See: https://foundation.wikimedia.org/wiki/Policy:Wikimedia_Foundation_User-Agent_Policy
language (`str`, default `"en"`): Language in which to retrieve Wikipedia article.
See: http://meta.wikimedia.org/wiki/List_of_Wikipedias
content_type (`Literal["summary", "text"]`, default `"text"`): Type of content to fetch. Can be "summary" for a short summary or "text" for the full article.
extract_format (`Literal["HTML", "WIKI"]`, default `"WIKI"`): Extraction format of the output. Can be `"WIKI"` or `"HTML"`.
Example:
```python
>>> from smolagents import CodeAgent, InferenceClientModel, WikipediaSearchTool
>>> agent = CodeAgent(
>>> tools=[
>>> WikipediaSearchTool(
>>> user_agent="MyResearchBot (myemail@example.com)",
>>> language="en",
>>> content_type="summary", # or "text"
>>> extract_format="WIKI",
>>> )
>>> ],
>>> model=InferenceClientModel(),
>>> )
>>> agent.run("Python_(programming_language)")
```
"""
name = "wikipedia_search"
description = "Searches Wikipedia and returns a summary or full text of the given topic, along with the page URL."
inputs = {
"query": {
"type": "string",
"description": "The topic to search on Wikipedia.",
}
}
output_type = "string"
def __init__(
self,
user_agent: str = "Smolagents (myemail@example.com)",
language: str = "en",
content_type: str = "text",
extract_format: str = "WIKI",
):
super().__init__()
try:
import wikipediaapi
except ImportError as e:
raise ImportError(
"You must install `wikipedia-api` to run this tool: for instance run `pip install wikipedia-api`"
) from e
if not user_agent:
raise ValueError("User-agent is required. Provide a meaningful identifier for your project.")
self.user_agent = user_agent
self.language = language
self.content_type = content_type
# Map string format to wikipediaapi.ExtractFormat
extract_format_map = {
"WIKI": wikipediaapi.ExtractFormat.WIKI,
"HTML": wikipediaapi.ExtractFormat.HTML,
}
if extract_format not in extract_format_map:
raise ValueError("Invalid extract_format. Choose between 'WIKI' or 'HTML'.")
self.extract_format = extract_format_map[extract_format]
self.wiki = wikipediaapi.Wikipedia(
user_agent=self.user_agent, language=self.language, extract_format=self.extract_format
)
def forward(self, query: str) -> str:
try:
page = self.wiki.page(query)
if not page.exists():
return f"No Wikipedia page found for '{query}'. Try a different query."
title = page.title
url = page.fullurl
if self.content_type == "summary":
text = page.summary
elif self.content_type == "text":
text = page.text
else:
return "⚠️ Invalid `content_type`. Use either 'summary' or 'text'."
return f"✅ **Wikipedia Page:** {title}\n\n**Content:** {text}\n\n🔗 **Read more:** {url}"
except Exception as e:
return f"Error fetching Wikipedia summary: {str(e)}"
class SpeechToTextTool(PipelineTool):
default_checkpoint = "openai/whisper-large-v3-turbo"
description = "This is a tool that transcribes an audio into text. It returns the transcribed text."
name = "transcriber"
inputs = {
"audio": {
"type": "audio",
"description": "The audio to transcribe. Can be a local path, an url, or a tensor.",
}
}
output_type = "string"
def __new__(cls, *args, **kwargs):
from transformers.models.whisper import WhisperForConditionalGeneration, WhisperProcessor
cls.pre_processor_class = WhisperProcessor
cls.model_class = WhisperForConditionalGeneration
return super().__new__(cls)
def encode(self, audio):
from .agent_types import AgentAudio
audio = AgentAudio(audio).to_raw()
return self.pre_processor(audio, return_tensors="pt")
def forward(self, inputs):
return self.model.generate(inputs["input_features"])
def decode(self, outputs):
return self.pre_processor.batch_decode(outputs, skip_special_tokens=True)[0]
TOOL_MAPPING = {
tool_class.name: tool_class
for tool_class in [
PythonInterpreterTool,
DuckDuckGoSearchTool,
VisitWebpageTool,
]
}
__all__ = [
"ApiWebSearchTool",
"PythonInterpreterTool",
"FinalAnswerTool",
"UserInputTool",
"WebSearchTool",
"DuckDuckGoSearchTool",
"GoogleSearchTool",
"VisitWebpageTool",
"WikipediaSearchTool",
"SpeechToTextTool",
]
================================================
FILE: src/smolagents/gradio_ui.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import re
import shutil
from pathlib import Path
from typing import Generator
from smolagents.agent_types import AgentAudio, AgentImage, AgentText
from smolagents.agents import MultiStepAgent, PlanningStep
from smolagents.memory import ActionStep, FinalAnswerStep
from smolagents.models import ChatMessageStreamDelta, MessageRole, agglomerate_stream_deltas
from smolagents.utils import _is_package_available
def get_step_footnote_content(step_log: ActionStep | PlanningStep, step_name: str) -> str:
"""Get a footnote string for a step log with duration and token information"""
step_footnote = f"**{step_name}**"
if step_log.token_usage is not None:
step_footnote += f" | Input tokens: {step_log.token_usage.input_tokens:,} | Output tokens: {step_log.token_usage.output_tokens:,}"
step_footnote += f" | Duration: {round(float(step_log.timing.duration), 2)}s" if step_log.timing.duration else ""
step_footnote_content = f"""{step_footnote} """
return step_footnote_content
def _clean_model_output(model_output: str) -> str:
"""
Clean up model output by removing trailing tags and extra backticks.
Args:
model_output (`str`): Raw model output.
Returns:
`str`: Cleaned model output.
"""
if not model_output:
return ""
model_output = model_output.strip()
# Remove any trailing
go_to('github.com/trending')
You can directly click clickable elements by inputting the text that appears on them.
click("Top products")
If it's a link:
click(Link("Top products"))
If you try to interact with an element and it's not found, you'll get a LookupError.
In general stop your action after each button click to see what happens on your screenshot.
Never try to login in a page.
To scroll up or down, use scroll_down or scroll_up with as an argument the number of pixels to scroll from.
scroll_down(num_pixels=1200) # This will scroll one viewport down
When you have pop-ups with a cross icon to close, don't try to click the close icon by finding its element or targeting an 'X' element (this most often fails).
Just use your built-in tool `close_popups` to close them:
close_popups()
You can use .exists() to check for the existence of an element. For example:
if Text('Accept cookies?').exists():
click('I accept')
Proceed in several steps rather than trying to solve the task in one shot.
And at the end, only when you have your answer, return your final answer.
final_answer("YOUR_ANSWER_HERE")
If pages seem stuck on loading, you might have to wait, for instance `import time` and run `time.sleep(5.0)`. But don't overuse this!
To list elements on page, DO NOT try code-based element searches like 'contributors = find_all(S("ol > li"))': just look at the latest screenshot you have and read it visually, or use your tool search_item_ctrl_f.
Of course, you can act on buttons like a user would do when navigating.
After each code blob you write, you will be automatically provided with an updated screenshot of the browser and the current browser url.
But beware that the screenshot will only be taken at the end of the whole action, it won't see intermediate states.
Don't kill the browser.
When you have modals or cookie banners on screen, you should get rid of them before you can click anything else.
"""
def run_webagent(
prompt: str,
model_type: str,
model_id: str,
provider: str | None = None,
api_base: str | None = None,
api_key: str | None = None,
) -> None:
# Load environment variables
load_dotenv()
# Initialize the model based on the provided arguments
model = load_model(model_type, model_id, provider=provider, api_base=api_base, api_key=api_key)
global driver
driver = initialize_driver()
agent = initialize_agent(model)
# Run the agent with the provided prompt
agent.python_executor("from helium import *")
agent.run(prompt + helium_instructions)
def main() -> None:
# Parse command line arguments
args = parse_arguments()
run_webagent(args.prompt, args.model_type, args.model_id, args.provider, args.api_base, args.api_key)
if __name__ == "__main__":
main()
================================================
FILE: tests/__init__.py
================================================
================================================
FILE: tests/conftest.py
================================================
from unittest.mock import patch
import pytest
from smolagents.agents import MultiStepAgent
from smolagents.monitoring import LogLevel
# Import fixture modules as plugins
pytest_plugins = ["tests.fixtures.agents", "tests.fixtures.tools"]
original_multi_step_agent_init = MultiStepAgent.__init__
@pytest.fixture(autouse=True)
def patch_multi_step_agent_with_suppressed_logging():
with patch.object(MultiStepAgent, "__init__", autospec=True) as mock_init:
def init_with_suppressed_logging(self, *args, verbosity_level=LogLevel.OFF, **kwargs):
original_multi_step_agent_init(self, *args, verbosity_level=verbosity_level, **kwargs)
mock_init.side_effect = init_with_suppressed_logging
yield
================================================
FILE: tests/fixtures/agents.py
================================================
import pytest
AGENT_DICTS = {
"v1.9": {
"tools": [],
"model": {
"class": "InferenceClientModel",
"data": {
"last_input_token_count": None,
"last_output_token_count": None,
"model_id": "Qwen/Qwen2.5-Coder-32B-Instruct",
"provider": None,
},
},
"managed_agents": {},
"prompt_templates": {
"system_prompt": "dummy system prompt",
"planning": {
"initial_facts": "dummy planning initial facts",
"initial_plan": "dummy planning initial plan",
"update_facts_pre_messages": "dummy planning update facts pre messages",
"update_facts_post_messages": "dummy planning update facts post messages",
"update_plan_pre_messages": "dummy planning update plan pre messages",
"update_plan_post_messages": "dummy planning update plan post messages",
},
"managed_agent": {
"task": "dummy managed agent task",
"report": "dummy managed agent report",
},
"final_answer": {
"pre_messages": "dummy final answer pre messages",
"post_messages": "dummy final answer post messages",
},
},
"max_steps": 10,
"verbosity_level": 2,
"grammar": None,
"planning_interval": 2,
"name": "test_agent",
"description": "dummy description",
"requirements": ["smolagents"],
"authorized_imports": ["pandas"],
},
# Added: executor_type, executor_kwargs, max_print_outputs_length
"v1.10": {
"tools": [],
"model": {
"class": "InferenceClientModel",
"data": {
"last_input_token_count": None,
"last_output_token_count": None,
"model_id": "Qwen/Qwen2.5-Coder-32B-Instruct",
"provider": None,
},
},
"managed_agents": {},
"prompt_templates": {
"system_prompt": "dummy system prompt",
"planning": {
"initial_facts": "dummy planning initial facts",
"initial_plan": "dummy planning initial plan",
"update_facts_pre_messages": "dummy planning update facts pre messages",
"update_facts_post_messages": "dummy planning update facts post messages",
"update_plan_pre_messages": "dummy planning update plan pre messages",
"update_plan_post_messages": "dummy planning update plan post messages",
},
"managed_agent": {
"task": "dummy managed agent task",
"report": "dummy managed agent report",
},
"final_answer": {
"pre_messages": "dummy final answer pre messages",
"post_messages": "dummy final answer post messages",
},
},
"max_steps": 10,
"verbosity_level": 2,
"grammar": None,
"planning_interval": 2,
"name": "test_agent",
"description": "dummy description",
"requirements": ["smolagents"],
"authorized_imports": ["pandas"],
"executor_type": "local",
"executor_kwargs": {},
"max_print_outputs_length": None,
},
# Removed: grammar, last_input_token_count, last_output_token_count
"v1.20": {
"tools": [],
"model": {
"class": "InferenceClientModel",
"data": {
"model_id": "Qwen/Qwen2.5-Coder-32B-Instruct",
"provider": None,
},
},
"managed_agents": {},
"prompt_templates": {
"system_prompt": "dummy system prompt",
"planning": {
"initial_facts": "dummy planning initial facts",
"initial_plan": "dummy planning initial plan",
"update_facts_pre_messages": "dummy planning update facts pre messages",
"update_facts_post_messages": "dummy planning update facts post messages",
"update_plan_pre_messages": "dummy planning update plan pre messages",
"update_plan_post_messages": "dummy planning update plan post messages",
},
"managed_agent": {
"task": "dummy managed agent task",
"report": "dummy managed agent report",
},
"final_answer": {
"pre_messages": "dummy final answer pre messages",
"post_messages": "dummy final answer post messages",
},
},
"max_steps": 10,
"verbosity_level": 2,
"planning_interval": 2,
"name": "test_agent",
"description": "dummy description",
"requirements": ["smolagents"],
"authorized_imports": ["pandas"],
"executor_type": "local",
"executor_kwargs": {},
"max_print_outputs_length": None,
},
}
@pytest.fixture
def get_agent_dict():
def _get_agent_dict(agent_dict_key):
return AGENT_DICTS[agent_dict_key]
return _get_agent_dict
================================================
FILE: tests/fixtures/tools.py
================================================
import pytest
from smolagents.tools import Tool, tool
@pytest.fixture
def test_tool():
class TestTool(Tool):
name = "test_tool"
description = "A test tool"
inputs = {"input": {"type": "string", "description": "Input value"}}
output_type = "string"
def forward(self, input):
if input == "error":
raise ValueError("Tool execution error")
return f"Processed: {input}"
return TestTool()
@pytest.fixture
def no_input_tool():
class NoInputTool(Tool):
name = "no_input_tool"
description = "Tool with no inputs"
inputs = {}
output_type = "string"
def forward(self):
return "test"
return NoInputTool()
@pytest.fixture
def single_input_tool():
class SingleInputTool(Tool):
name = "single_input_tool"
description = "Tool with one input"
inputs = {"text": {"type": "string", "description": "Input text"}}
output_type = "string"
def forward(self, text):
return "test"
return SingleInputTool()
@pytest.fixture
def multi_input_tool():
class MultiInputTool(Tool):
name = "multi_input_tool"
description = "Tool with multiple inputs"
inputs = {
"text": {"type": "string", "description": "Text input"},
"count": {"type": "integer", "description": "Number count"},
}
output_type = "object"
def forward(self, text, count):
return "test"
return MultiInputTool()
@pytest.fixture
def multiline_description_tool():
class MultilineDescriptionTool(Tool):
name = "multiline_description_tool"
description = "This is a tool with\nmultiple lines\nin the description"
inputs = {"input": {"type": "string", "description": "Some input"}}
output_type = "string"
def forward(self, input):
return "test"
return MultilineDescriptionTool()
@pytest.fixture
def example_tool():
@tool
def valid_tool_function(input: str) -> str:
"""A valid tool function.
Args:
input (str): Input string.
"""
return input.upper()
return valid_tool_function
@pytest.fixture
def boolean_default_tool_class():
class BooleanDefaultTool(Tool):
name = "boolean_default_tool"
description = "A tool with a boolean default parameter"
inputs = {
"text": {"type": "string", "description": "Input text"},
"flag": {"type": "boolean", "description": "Boolean flag with default value", "nullable": True},
}
output_type = "string"
def forward(self, text: str, flag: bool = False) -> str:
return f"Text: {text}, Flag: {flag}"
return BooleanDefaultTool()
@pytest.fixture
def boolean_default_tool_function():
@tool
def boolean_default_tool(text: str, flag: bool = False) -> str:
"""
A tool with a boolean default parameter.
Args:
text: Input text
flag: Boolean flag with default value
"""
return f"Text: {text}, Flag: {flag}"
return boolean_default_tool
@pytest.fixture
def optional_input_tool_class():
class OptionalInputTool(Tool):
name = "optional_input_tool"
description = "A tool with an optional input parameter"
inputs = {
"required_text": {"type": "string", "description": "Required input text"},
"optional_text": {"type": "string", "description": "Optional input text", "nullable": True},
}
output_type = "string"
def forward(self, required_text: str, optional_text: str | None = None) -> str:
if optional_text:
return f"{required_text} + {optional_text}"
return required_text
return OptionalInputTool()
@pytest.fixture
def optional_input_tool_function():
@tool
def optional_input_tool(required_text: str, optional_text: str | None = None) -> str:
"""
A tool with an optional input parameter.
Args:
required_text: Required input text
optional_text: Optional input text
"""
if optional_text:
return f"{required_text} + {optional_text}"
return required_text
return optional_input_tool
================================================
FILE: tests/test_agents.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import io
import json
import os
import re
import tempfile
import uuid
from collections.abc import Generator
from contextlib import nullcontext as does_not_raise
from dataclasses import dataclass
from pathlib import Path
from textwrap import dedent
from typing import Optional
from unittest.mock import MagicMock, patch
import pytest
from huggingface_hub import (
ChatCompletionOutputFunctionDefinition,
ChatCompletionOutputMessage,
ChatCompletionOutputToolCall,
)
from rich.console import Console
from smolagents import EMPTY_PROMPT_TEMPLATES
from smolagents.agent_types import AgentImage, AgentText
from smolagents.agents import (
AgentError,
AgentMaxStepsError,
AgentToolCallError,
CodeAgent,
MultiStepAgent,
RunResult,
ToolCall,
ToolCallingAgent,
ToolOutput,
populate_template,
)
from smolagents.default_tools import DuckDuckGoSearchTool, FinalAnswerTool, PythonInterpreterTool, VisitWebpageTool
from smolagents.memory import (
ActionStep,
CallbackRegistry,
FinalAnswerStep,
MemoryStep,
PlanningStep,
SystemPromptStep,
TaskStep,
)
from smolagents.models import (
ChatMessage,
ChatMessageToolCall,
ChatMessageToolCallFunction,
InferenceClientModel,
MessageRole,
Model,
TransformersModel,
)
from smolagents.monitoring import AgentLogger, LogLevel, Timing, TokenUsage
from smolagents.tools import Tool, tool
from smolagents.utils import (
BASE_BUILTIN_MODULES,
AgentExecutionError,
AgentGenerationError,
AgentToolExecutionError,
)
@dataclass
class ChoiceDeltaToolCallFunction:
arguments: Optional[str] = None
name: Optional[str] = None
@dataclass
class ChoiceDeltaToolCall:
index: Optional[int] = None
id: Optional[str] = None
function: Optional[ChoiceDeltaToolCallFunction] = None
type: Optional[str] = None
@dataclass
class ChoiceDelta:
content: Optional[str] = None
function_call: Optional[str] = None
refusal: Optional[str] = None
role: Optional[str] = None
tool_calls: Optional[list] = None
def get_new_path(suffix="") -> str:
directory = tempfile.mkdtemp()
return os.path.join(directory, str(uuid.uuid4()) + suffix)
@pytest.fixture
def agent_logger():
return AgentLogger(
LogLevel.DEBUG, console=Console(record=True, no_color=True, force_terminal=False, file=io.StringIO())
)
class FakeToolCallModel(Model):
def generate(self, messages, tools_to_call_from=None, stop_sequences=None):
if len(messages) < 3:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="I will call the python interpreter.",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="python_interpreter", arguments={"code": "2*3.6452"}
),
)
],
)
else:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="I will return the final answer.",
tool_calls=[
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="final_answer", arguments={"answer": "7.2904"}),
)
],
)
class FakeToolCallModelImage(Model):
def generate(self, messages, tools_to_call_from=None, stop_sequences=None):
if len(messages) < 3:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="fake_image_generation_tool",
arguments={"prompt": "An image of a cat"},
),
)
],
)
else:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="final_answer", arguments="image.png"),
)
],
)
class FakeToolCallModelVL(Model):
def generate(self, messages, tools_to_call_from=None, stop_sequences=None):
if len(messages) < 3:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="fake_image_understanding_tool",
arguments={
"prompt": "What is in this image?",
"image": "image.png",
},
),
)
],
)
else:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="final_answer", arguments="The image is a cat."),
)
],
)
class FakeCodeModel(Model):
def generate(self, messages, stop_sequences=None):
prompt = str(messages)
if "special_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should multiply 2 by 3.6452. special_marker
result = 2**3.6452
""",
)
else: # We're at step 2
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I can now answer the initial question
final_answer(7.2904)
""",
)
class FakeCodeModelImageGeneration(Model):
def generate(self, messages, stop_sequences=None):
prompt = str(messages)
if "special_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should generate an image. special_marker
image = image_generation_tool()
""",
)
else: # We're at step 2
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I can now answer the initial question
final_answer(image)
""",
)
class FakeCodeModelPlanning(Model):
def generate(self, messages, stop_sequences=None):
prompt = str(messages)
if "planning_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="llm plan update planning_marker",
token_usage=TokenUsage(input_tokens=10, output_tokens=10),
)
elif "action_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should multiply 2 by 3.6452. action_marker
result = 2**3.6452
""",
token_usage=TokenUsage(input_tokens=10, output_tokens=10),
)
else:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="llm plan again",
token_usage=TokenUsage(input_tokens=10, output_tokens=10),
)
class FakeCodeModelError(Model):
def generate(self, messages, stop_sequences=None):
prompt = str(messages)
if "special_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should multiply 2 by 3.6452. special_marker
print("Flag!")
def error_function():
raise ValueError("error")
error_function()
""",
)
else: # We're at step 2
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I faced an error in the previous step.
final_answer("got an error")
""",
)
class FakeCodeModelSyntaxError(Model):
def generate(self, messages, stop_sequences=None):
prompt = str(messages)
if "special_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should multiply 2 by 3.6452. special_marker
a = 2
b = a * 2
print("Failing due to unexpected indent")
print("Ok, calculation done!")
""",
)
else: # We're at step 2
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I can now answer the initial question
final_answer("got an error")
""",
)
class FakeCodeModelImport(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I can answer the question
import numpy as np
final_answer("got an error")
""",
)
class FakeCodeModelFunctionDef(Model):
def generate(self, messages, stop_sequences=None):
prompt = str(messages)
if "special_marker" not in prompt:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: Let's define the function. special_marker
import numpy as np
def moving_average(x, w):
return np.convolve(x, np.ones(w), 'valid') / w
""",
)
else: # We're at step 2
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I can now answer the initial question
x, w = [0, 1, 2, 3, 4, 5], 2
res = moving_average(x, w)
final_answer(res)
""",
)
class FakeCodeModelSingleStep(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should multiply 2 by 3.6452. special_marker
result = python_interpreter(code="2*3.6452")
final_answer(result)
```
""",
)
class FakeCodeModelNoReturn(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: I should multiply 2 by 3.6452. special_marker
result = python_interpreter(code="2*3.6452")
print(result)
```
""",
)
class TestAgent:
def test_fake_toolcalling_agent(self):
agent = ToolCallingAgent(tools=[PythonInterpreterTool()], model=FakeToolCallModel())
output = agent.run("What is 2 multiplied by 3.6452?")
assert isinstance(output, str)
assert "7.2904" in output
assert agent.memory.steps[0].task == "What is 2 multiplied by 3.6452?"
assert "7.2904" in agent.memory.steps[1].observations
assert agent.memory.steps[2].model_output == "I will return the final answer."
def test_toolcalling_agent_handles_image_tool_outputs(self, shared_datadir):
import PIL.Image
@tool
def fake_image_generation_tool(prompt: str) -> PIL.Image.Image:
"""Tool that generates an image.
Args:
prompt: The prompt
"""
import PIL.Image
return PIL.Image.open(shared_datadir / "000000039769.png")
agent = ToolCallingAgent(tools=[fake_image_generation_tool], model=FakeToolCallModelImage())
output = agent.run("Make me an image.")
assert isinstance(output, AgentImage)
assert isinstance(agent.state["image.png"], PIL.Image.Image)
def test_toolcalling_agent_handles_image_inputs(self, shared_datadir):
import PIL.Image
image = PIL.Image.open(shared_datadir / "000000039769.png") # dummy input
@tool
def fake_image_understanding_tool(prompt: str, image: PIL.Image.Image) -> str:
"""Tool that creates a caption for an image.
Args:
prompt: The prompt
image: The image
"""
return "The image is a cat."
agent = ToolCallingAgent(tools=[fake_image_understanding_tool], model=FakeToolCallModelVL())
output = agent.run("Caption this image.", images=[image])
assert output == "The image is a cat."
def test_fake_code_agent(self):
agent = CodeAgent(tools=[PythonInterpreterTool()], model=FakeCodeModel(), verbosity_level=10)
output = agent.run("What is 2 multiplied by 3.6452?")
assert isinstance(output, float)
assert output == 7.2904
assert agent.memory.steps[0].task == "What is 2 multiplied by 3.6452?"
assert agent.memory.steps[2].tool_calls == [
ToolCall(name="python_interpreter", arguments="final_answer(7.2904)", id="call_2")
]
def test_additional_args_added_to_task(self):
agent = CodeAgent(tools=[], model=FakeCodeModel())
agent.run(
"What is 2 multiplied by 3.6452?",
additional_args={"instruction": "Remember this."},
)
assert "Remember this" in agent.task
def test_reset_conversations(self):
agent = CodeAgent(tools=[PythonInterpreterTool()], model=FakeCodeModel())
output = agent.run("What is 2 multiplied by 3.6452?", reset=True)
assert output == 7.2904
assert len(agent.memory.steps) == 3
output = agent.run("What is 2 multiplied by 3.6452?", reset=False)
assert output == 7.2904
assert len(agent.memory.steps) == 5
output = agent.run("What is 2 multiplied by 3.6452?", reset=True)
assert output == 7.2904
assert len(agent.memory.steps) == 3
def test_setup_agent_with_empty_toolbox(self):
ToolCallingAgent(model=FakeToolCallModel(), tools=[])
def test_fails_max_steps(self):
agent = CodeAgent(
tools=[PythonInterpreterTool()],
model=FakeCodeModelNoReturn(), # use this callable because it never ends
max_steps=5,
)
answer = agent.run("What is 2 multiplied by 3.6452?")
assert len(agent.memory.steps) == 7 # Task step + 5 action steps + Final answer
assert type(agent.memory.steps[-1].error) is AgentMaxStepsError
assert isinstance(answer, str)
agent = CodeAgent(
tools=[PythonInterpreterTool()],
model=FakeCodeModelNoReturn(), # use this callable because it never ends
max_steps=5,
)
answer = agent.run("What is 2 multiplied by 3.6452?", max_steps=3)
assert len(agent.memory.steps) == 5 # Task step + 3 action steps + Final answer
assert type(agent.memory.steps[-1].error) is AgentMaxStepsError
assert isinstance(answer, str)
def test_tool_descriptions_get_baked_in_system_prompt(self):
tool = PythonInterpreterTool()
tool.name = "fake_tool_name"
tool.description = "fake_tool_description"
agent = CodeAgent(tools=[tool], model=FakeCodeModel())
agent.run("Empty task")
assert agent.system_prompt is not None
assert f"def {tool.name}(" in agent.system_prompt
assert f'"""{tool.description}' in agent.system_prompt
def test_module_imports_get_baked_in_system_prompt(self):
agent = CodeAgent(tools=[], model=FakeCodeModel())
agent.run("Empty task")
for module in BASE_BUILTIN_MODULES:
assert module in agent.system_prompt
def test_init_agent_with_different_toolsets(self):
toolset_1 = []
agent = CodeAgent(tools=toolset_1, model=FakeCodeModel())
assert len(agent.tools) == 1 # when no tools are provided, only the final_answer tool is added by default
toolset_2 = [PythonInterpreterTool(), PythonInterpreterTool()]
with pytest.raises(ValueError) as e:
agent = CodeAgent(tools=toolset_2, model=FakeCodeModel())
assert "Each tool or managed_agent should have a unique name!" in str(e)
with pytest.raises(ValueError) as e:
agent.name = "python_interpreter"
agent.description = "empty"
CodeAgent(tools=[PythonInterpreterTool()], model=FakeCodeModel(), managed_agents=[agent])
assert "Each tool or managed_agent should have a unique name!" in str(e)
# check that python_interpreter base tool does not get added to CodeAgent
agent = CodeAgent(tools=[], model=FakeCodeModel(), add_base_tools=True)
assert len(agent.tools) == 3 # added final_answer tool + search + visit_webpage
# check that python_interpreter base tool gets added to ToolCallingAgent
agent = ToolCallingAgent(tools=[], model=FakeCodeModel(), add_base_tools=True)
assert len(agent.tools) == 4 # added final_answer tool + search + visit_webpage
def test_function_persistence_across_steps(self):
agent = CodeAgent(
tools=[],
model=FakeCodeModelFunctionDef(),
max_steps=2,
additional_authorized_imports=["numpy"],
)
res = agent.run("ok")
assert res[0] == 0.5
def test_init_managed_agent(self):
agent = CodeAgent(tools=[], model=FakeCodeModelFunctionDef(), name="managed_agent", description="Empty")
assert agent.name == "managed_agent"
assert agent.description == "Empty"
def test_agent_description_gets_correctly_inserted_in_system_prompt(self):
managed_agent = CodeAgent(
tools=[], model=FakeCodeModelFunctionDef(), name="managed_agent", description="Empty"
)
manager_agent = CodeAgent(
tools=[],
model=FakeCodeModelFunctionDef(),
managed_agents=[managed_agent],
)
assert "You can also give tasks to team members." not in managed_agent.system_prompt
assert "{{managed_agents_descriptions}}" not in managed_agent.system_prompt
assert "You can also give tasks to team members." in manager_agent.system_prompt
def test_replay_shows_logs(self, agent_logger):
agent = CodeAgent(
tools=[],
model=FakeCodeModelImport(),
verbosity_level=0,
additional_authorized_imports=["numpy"],
logger=agent_logger,
)
agent.run("Count to 3")
str_output = agent_logger.console.export_text()
assert "New run" in str_output
assert 'final_answer("got' in str_output
assert "" in str_output
agent = ToolCallingAgent(tools=[PythonInterpreterTool()], model=FakeToolCallModel(), verbosity_level=0)
agent.logger = agent_logger
agent.run("What is 2 multiplied by 3.6452?")
agent.replay()
str_output = agent_logger.console.export_text()
assert "arguments" in str_output
def test_code_nontrivial_final_answer_works(self):
class FakeCodeModelFinalAnswer(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
def nested_answer():
final_answer("Correct!")
nested_answer()
""",
)
agent = CodeAgent(tools=[], model=FakeCodeModelFinalAnswer())
output = agent.run("Count to 3")
assert output == "Correct!"
def test_transformers_toolcalling_agent(self):
@tool
def weather_api(location: str, celsius: str = "") -> str:
"""
Gets the weather in the next days at given location.
Secretly this tool does not care about the location, it hates the weather everywhere.
Args:
location: the location
celsius: the temperature type
"""
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
model = TransformersModel(
model_id="HuggingFaceTB/SmolLM2-360M-Instruct",
max_new_tokens=100,
device_map="auto",
do_sample=False,
)
agent = ToolCallingAgent(model=model, tools=[weather_api], max_steps=1)
task = "What is the weather in Paris? "
agent.run(task)
assert agent.memory.steps[0].task == task
assert agent.memory.steps[1].tool_calls[0].name == "weather_api"
step_memory_dict = agent.memory.get_succinct_steps()[1]
assert step_memory_dict["model_output_message"]["tool_calls"][0]["function"]["name"] == "weather_api"
assert step_memory_dict["model_output_message"]["raw"]["completion_kwargs"]["max_new_tokens"] == 100
assert "model_input_messages" in agent.memory.get_full_steps()[1]
assert step_memory_dict["token_usage"]["total_tokens"] > 100
assert step_memory_dict["timing"]["duration"] > 0.1
def test_final_answer_checks(self):
error_string = "failed with error"
def check_always_fails(final_answer, memory, agent):
assert False, "Error raised in check"
agent = CodeAgent(model=FakeCodeModel(), tools=[], final_answer_checks=[check_always_fails])
agent.run("Dummy task.")
assert error_string in str(agent.write_memory_to_messages())
assert "Error raised in check" in str(agent.write_memory_to_messages())
agent = CodeAgent(
model=FakeCodeModel(),
tools=[],
final_answer_checks=[lambda x, memory, agent: x == 7.2904],
verbosity_level=1000,
)
output = agent.run("Dummy task.")
assert output == 7.2904 # Check that output is correct
assert len([step for step in agent.memory.steps if isinstance(step, ActionStep)]) == 2
assert error_string not in str(agent.write_memory_to_messages())
def test_final_answer_checks_with_agent_access(self):
"""Test that final answer checks can access agent properties."""
def check_uses_agent_properties(final_answer, memory, agent):
# Access agent properties to validate the final answer
assert hasattr(agent, "memory"), "Agent should have memory attribute"
assert hasattr(agent, "state"), "Agent should have state attribute"
assert hasattr(agent, "task"), "Agent should have task attribute"
# Check that the final answer is related to the task
if isinstance(final_answer, str):
return len(final_answer) > 0
return True
def check_uses_agent_state(final_answer, memory, agent):
# Use agent state to validate the answer
if "expected_answer" in agent.state:
return final_answer == agent.state["expected_answer"]
return True
# Test with a check that uses agent properties
agent = CodeAgent(model=FakeCodeModel(), tools=[], final_answer_checks=[check_uses_agent_properties])
output = agent.run("Dummy task.")
assert output == 7.2904 # Should pass the check
# Test with a check that uses agent state
agent = CodeAgent(model=FakeCodeModel(), tools=[], final_answer_checks=[check_uses_agent_state])
agent.state["expected_answer"] = 7.2904
output = agent.run("Dummy task.")
assert output == 7.2904 # Should pass the check
# Test with a check that fails due to state mismatch
agent = CodeAgent(
model=FakeCodeModel(),
tools=[],
final_answer_checks=[check_uses_agent_state],
max_steps=3, # Limit steps to avoid long test run
)
agent.state["expected_answer"] = "wrong answer"
output = agent.run("Dummy task.")
# The agent should have reached max steps and provided a final answer anyway
assert output is not None
# Check that there were failed validation attempts in the memory
failed_steps = [step for step in agent.memory.steps if hasattr(step, "error") and step.error is not None]
assert len(failed_steps) > 0, "Expected some steps to have validation errors"
# Check that at least one error message contains our check function name
error_messages = [str(step.error) for step in failed_steps if step.error is not None]
assert any("check_uses_agent_state failed" in msg for msg in error_messages), (
"Expected to find validation error message"
)
def test_generation_errors_are_raised(self):
class FakeCodeModel(Model):
def generate(self, messages, stop_sequences=None):
assert False, "Generation failed"
agent = CodeAgent(model=FakeCodeModel(), tools=[])
with pytest.raises(AgentGenerationError) as e:
agent.run("Dummy task.")
assert len(agent.memory.steps) == 2
assert "Generation failed" in str(e)
def test_planning_step_with_injected_memory(self):
"""Test that agent properly uses update plan prompts when memory is injected before a run.
This test verifies:
1. Planning steps are created with the correct frequency
2. Injected memory is included in planning context
3. Messages are properly formatted with expected roles and content
"""
planning_interval = 1
max_steps = 4
task = "Continuous task"
previous_task = "Previous user request"
# Create agent with planning capability
agent = CodeAgent(
tools=[],
planning_interval=planning_interval,
model=FakeCodeModelPlanning(),
max_steps=max_steps,
)
# Inject memory before run to simulate existing conversation history
previous_step = TaskStep(task=previous_task)
agent.memory.steps.append(previous_step)
# Run the agent
agent.run(task, reset=False)
# Extract and validate planning steps
planning_steps = [step for step in agent.memory.steps if isinstance(step, PlanningStep)]
assert len(planning_steps) > 2, "Expected multiple planning steps to be generated"
# Verify first planning step incorporates injected memory
first_planning_step = planning_steps[0]
input_messages = first_planning_step.model_input_messages
# Check message structure and content
assert len(input_messages) == 4, (
"First planning step should have 4 messages: system-plan-pre-update + memory + task + user-plan-post-update"
)
# Verify system message contains current task
system_message = input_messages[0]
assert system_message.role == "system", "First message should have system role"
assert task in system_message.content[0]["text"], f"System message should contain the current task: '{task}'"
# Verify memory message contains previous task
memory_message = input_messages[1]
assert previous_task in memory_message.content[0]["text"], (
f"Memory message should contain previous task: '{previous_task}'"
)
# Verify task message contains current task
task_message = input_messages[2]
assert task in task_message.content[0]["text"], f"Task message should contain current task: '{task}'"
# Verify user message for planning
user_message = input_messages[3]
assert user_message.role == "user", "Fourth message should have user role"
# Verify second planning step has more context from first agent actions
second_planning_step = planning_steps[1]
second_messages = second_planning_step.model_input_messages
# Check that conversation history is growing appropriately
assert len(second_messages) == 6, "Second planning step should have 6 messages including tool interactions"
# Verify all conversation elements are present
conversation_text = "".join([msg.content[0]["text"] for msg in second_messages if hasattr(msg, "content")])
assert previous_task in conversation_text, "Previous task should be included in the conversation history"
assert task in conversation_text, "Current task should be included in the conversation history"
assert "tools" in conversation_text, "Tool interactions should be included in the conversation history"
class CustomFinalAnswerTool(FinalAnswerTool):
def forward(self, answer) -> str:
return answer + "CUSTOM"
class MockTool(Tool):
def __init__(self, name):
self.name = name
self.description = "Mock tool description"
self.inputs = {}
self.output_type = "string"
def forward(self):
return "Mock tool output"
class MockAgent:
def __init__(self, name, tools, description="Mock agent description"):
self.name = name
self.tools = {t.name: t for t in tools}
self.description = description
class DummyMultiStepAgent(MultiStepAgent):
def step(self, memory_step: ActionStep) -> Generator[None]:
yield None
def initialize_system_prompt(self):
pass
class FakeLLMModel(Model):
def __init__(self, give_token_usage: bool = True):
self.give_token_usage = give_token_usage
def generate(self, prompt, tools_to_call_from=None, **kwargs):
if tools_to_call_from is not None:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="I will call the final_answer tool.",
tool_calls=[
ChatMessageToolCall(
id="fake_id",
type="function",
function=ChatMessageToolCallFunction(
name="final_answer", arguments={"answer": "This is the final answer."}
),
)
],
token_usage=TokenUsage(input_tokens=10, output_tokens=20) if self.give_token_usage else None,
)
else:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
final_answer('This is the final answer.')
""",
token_usage=TokenUsage(input_tokens=10, output_tokens=20) if self.give_token_usage else None,
)
class TestRunResult:
def test_backward_compatibility(self):
"""Test that RunResult handles deprecated 'messages' parameter correctly."""
# Test 1: Using new 'steps' parameter (should work without warning)
result1 = RunResult(
output="test output",
state="success",
steps=[{"type": "test", "content": "step1"}],
token_usage=None,
timing=Timing(start_time=0.0, end_time=1.0),
)
assert result1.steps == [{"type": "test", "content": "step1"}]
# Test property access warning
with pytest.warns(FutureWarning, match="deprecated"):
messages = result1.messages
assert messages == [{"type": "test", "content": "step1"}]
# Test 2: Using deprecated 'messages' parameter (should show deprecation warning)
with pytest.warns(FutureWarning, match="deprecated"):
result2 = RunResult(
output="test output",
state="success",
messages=[{"type": "test", "content": "message1"}],
token_usage=None,
timing=Timing(start_time=0.0, end_time=1.0),
)
assert result2.steps == [{"type": "test", "content": "message1"}]
# Test 3: Using both 'steps' and 'messages' (should raise ValueError)
with pytest.raises(ValueError, match="Cannot specify both"):
RunResult(
output="test output",
state="success",
steps=[{"type": "test", "content": "step1"}],
messages=[{"type": "test", "content": "message1"}],
token_usage=None,
timing=Timing(start_time=0.0, end_time=1.0),
)
@pytest.mark.parametrize("agent_class", [CodeAgent, ToolCallingAgent])
def test_no_token_usage(self, agent_class):
agent = agent_class(
tools=[],
model=FakeLLMModel(give_token_usage=False),
max_steps=1,
return_full_result=True,
)
result = agent.run("Fake task")
assert isinstance(result, RunResult)
assert result.output == "This is the final answer."
assert result.state == "success"
assert result.token_usage is None
assert isinstance(result.steps, list)
assert result.timing.duration > 0
@pytest.mark.parametrize(
"init_return_full_result,run_return_full_result,expect_runresult",
[
(True, None, True),
(False, None, False),
(True, False, False),
(False, True, True),
],
)
def test_full_result(self, init_return_full_result, run_return_full_result, expect_runresult):
agent = ToolCallingAgent(
tools=[],
model=FakeLLMModel(),
max_steps=1,
return_full_result=init_return_full_result,
)
result = agent.run("Fake task", return_full_result=run_return_full_result)
if expect_runresult:
assert isinstance(result, RunResult)
assert result.output == "This is the final answer."
assert result.state == "success"
assert result.token_usage == TokenUsage(input_tokens=10, output_tokens=20)
assert isinstance(result.steps, list)
assert result.timing.duration > 0
else:
assert isinstance(result, str)
class TestMultiStepAgent:
def test_instantiation_disables_logging_to_terminal(self):
fake_model = MagicMock()
agent = DummyMultiStepAgent(tools=[], model=fake_model)
assert agent.logger.level == -1, "logging to terminal should be disabled for testing using a fixture"
def test_instantiation_with_prompt_templates(self, prompt_templates):
agent = DummyMultiStepAgent(tools=[], model=MagicMock(), prompt_templates=prompt_templates)
assert agent.prompt_templates == prompt_templates
assert agent.prompt_templates["system_prompt"] == "This is a test system prompt."
assert "managed_agent" in agent.prompt_templates
assert agent.prompt_templates["managed_agent"]["task"] == "Task for {{name}}: {{task}}"
assert agent.prompt_templates["managed_agent"]["report"] == "Report for {{name}}: {{final_answer}}"
@pytest.mark.parametrize(
"tools, expected_final_answer_tool",
[([], FinalAnswerTool), ([CustomFinalAnswerTool()], CustomFinalAnswerTool)],
)
def test_instantiation_with_final_answer_tool(self, tools, expected_final_answer_tool):
agent = DummyMultiStepAgent(tools=tools, model=MagicMock())
assert "final_answer" in agent.tools
assert isinstance(agent.tools["final_answer"], expected_final_answer_tool)
def test_system_prompt_property(self):
"""Test that system_prompt property is read-only and calls initialize_system_prompt."""
class SimpleAgent(MultiStepAgent):
def initialize_system_prompt(self) -> str:
return "Test system prompt"
def step(self, memory_step: ActionStep) -> Generator[None]:
yield None
# Create a simple agent with mocked model
model = MagicMock()
agent = SimpleAgent(tools=[], model=model)
# Test reading the property works and calls initialize_system_prompt
assert agent.system_prompt == "Test system prompt"
# Test setting the property raises AttributeError with correct message
with pytest.raises(
AttributeError,
match=re.escape(
"""The 'system_prompt' property is read-only. Use 'self.prompt_templates["system_prompt"]' instead."""
),
):
agent.system_prompt = "New system prompt"
# assert "read-only" in str(exc_info.value)
# assert "Use 'self.prompt_templates[\"system_prompt\"]' instead" in str(exc_info.value)
@pytest.mark.parametrize(
"step_callbacks, expected_registry_state",
[
# Case 0: None as input (initializes empty registry)
(
None,
{
"MemoryStep": 0,
"ActionStep": 1,
"PlanningStep": 0,
"TaskStep": 0,
"SystemPromptStep": 0,
"FinalAnswerStep": 0,
}, # Only monitor.update_metrics is registered for ActionStep
),
# Case 1: List of callbacks (registers only for ActionStep: backward compatibility)
(
[MagicMock(), MagicMock()],
{
"MemoryStep": 0,
"ActionStep": 3,
"PlanningStep": 0,
"TaskStep": 0,
"SystemPromptStep": 0,
"FinalAnswerStep": 0,
},
),
# Case 2: Dict mapping specific step types to callbacks
(
{ActionStep: MagicMock(), PlanningStep: MagicMock()},
{
"MemoryStep": 0,
"ActionStep": 2,
"PlanningStep": 1,
"TaskStep": 0,
"SystemPromptStep": 0,
"FinalAnswerStep": 0,
},
),
# Case 3: Dict with list of callbacks for a step type
(
{ActionStep: [MagicMock(), MagicMock()]},
{
"MemoryStep": 0,
"ActionStep": 3,
"PlanningStep": 0,
"TaskStep": 0,
"SystemPromptStep": 0,
"FinalAnswerStep": 0,
},
),
# Case 4: Dict with mixed single and list callbacks
(
{ActionStep: MagicMock(), MemoryStep: [MagicMock(), MagicMock()]},
{
"MemoryStep": 2,
"ActionStep": 2,
"PlanningStep": 0,
"TaskStep": 0,
"SystemPromptStep": 0,
"FinalAnswerStep": 0,
},
),
],
)
def test_setup_step_callbacks(self, step_callbacks, expected_registry_state):
"""Test that _setup_step_callbacks correctly sets up the callback registry."""
# Create a dummy agent
agent = DummyMultiStepAgent(tools=[], model=MagicMock())
# Mock the monitor
agent.monitor = MagicMock()
# Call the method
agent._setup_step_callbacks(step_callbacks)
# Check that step_callbacks is a CallbackRegistry
assert isinstance(agent.step_callbacks, CallbackRegistry)
# Count callbacks for each step type
actual_registry_state = {}
for step_type in [MemoryStep, ActionStep, PlanningStep, TaskStep, SystemPromptStep, FinalAnswerStep]:
callbacks = agent.step_callbacks._callbacks.get(step_type, [])
actual_registry_state[step_type.__name__] = len(callbacks)
# Verify registry state matches expected
assert actual_registry_state == expected_registry_state
def test_finalize_step_callbacks_with_list(self):
# Create mock callbacks
callback1 = MagicMock()
callback2 = MagicMock()
# Create a test agent with a list of callbacks
agent = DummyMultiStepAgent(tools=[], model=MagicMock(), step_callbacks=[callback1, callback2])
# Create steps of different types
action_step = ActionStep(step_number=1, timing=Timing(start_time=0.0))
planning_step = PlanningStep(
timing=Timing(start_time=1.0),
model_input_messages=[],
model_output_message=ChatMessage(role="assistant", content="Test plan"),
plan="Test planning step",
)
# Test with ActionStep
agent._finalize_step(action_step)
# Verify all callbacks were called
callback1.assert_called_once_with(action_step, agent=agent)
callback2.assert_called_once_with(action_step, agent=agent)
# Reset mocks
callback1.reset_mock()
callback2.reset_mock()
# Test with PlanningStep
agent._finalize_step(planning_step)
# Verify all callbacks were called again with the planning step
callback1.assert_not_called()
callback2.assert_not_called()
def test_finalize_step_callbacks_by_type(self):
# Create mock callbacks for different step types
action_step_callback = MagicMock()
action_step_callback_2 = MagicMock()
planning_step_callback = MagicMock()
step_callback = MagicMock()
final_answer_step_callback = MagicMock()
# Register callbacks for different step types
step_callbacks = {
ActionStep: [action_step_callback, action_step_callback_2],
PlanningStep: planning_step_callback,
MemoryStep: step_callback,
FinalAnswerStep: final_answer_step_callback,
}
agent = DummyMultiStepAgent(tools=[], model=MagicMock(), step_callbacks=step_callbacks)
# Create steps of different types
action_step = ActionStep(step_number=1, timing=Timing(start_time=0.0))
planning_step = PlanningStep(
timing=Timing(start_time=1.0),
model_input_messages=[],
model_output_message=ChatMessage(role="assistant", content="Test plan"),
plan="Test planning step",
)
final_answer_step = FinalAnswerStep(output="Sample output")
# Test with ActionStep
agent._finalize_step(action_step)
# Verify correct callbacks were called
action_step_callback.assert_called_once_with(action_step, agent=agent)
action_step_callback_2.assert_called_once_with(action_step, agent=agent)
step_callback.assert_called_once_with(action_step, agent=agent)
planning_step_callback.assert_not_called()
final_answer_step_callback.assert_not_called()
# Reset mocks
action_step_callback.reset_mock()
action_step_callback_2.reset_mock()
planning_step_callback.reset_mock()
step_callback.reset_mock()
final_answer_step_callback.reset_mock()
# Test with PlanningStep
agent._finalize_step(planning_step)
# Verify correct callbacks were called
planning_step_callback.assert_called_once_with(planning_step, agent=agent)
step_callback.assert_called_once_with(planning_step, agent=agent)
action_step_callback.assert_not_called()
action_step_callback_2.assert_not_called()
final_answer_step_callback.assert_not_called()
# Reset mocks
action_step_callback.reset_mock()
action_step_callback_2.reset_mock()
planning_step_callback.reset_mock()
step_callback.reset_mock()
final_answer_step_callback.reset_mock()
# Test with PlanningStep
agent._finalize_step(final_answer_step)
# Verify correct callbacks were called
planning_step_callback.assert_not_called()
step_callback.assert_called_once_with(final_answer_step, agent=agent)
action_step_callback.assert_not_called()
action_step_callback_2.assert_not_called()
final_answer_step_callback.assert_called_once_with(final_answer_step, agent=agent)
def test_logs_display_thoughts_even_if_error(self):
class FakeJsonModelNoCall(Model):
def generate(self, messages, stop_sequences=None, tools_to_call_from=None):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""I don't want to call tools today""",
tool_calls=None,
raw="""I don't want to call tools today""",
)
agent_toolcalling = ToolCallingAgent(model=FakeJsonModelNoCall(), tools=[], max_steps=1, verbosity_level=10)
with agent_toolcalling.logger.console.capture() as capture:
agent_toolcalling.run("Dummy task")
assert "don't" in capture.get() and "want" in capture.get()
class FakeCodeModelNoCall(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""I don't want to write an action today""",
)
agent_code = CodeAgent(model=FakeCodeModelNoCall(), tools=[], max_steps=1, verbosity_level=10)
with agent_code.logger.console.capture() as capture:
agent_code.run("Dummy task")
assert "don't" in capture.get() and "want" in capture.get()
def test_step_number(self):
fake_model = MagicMock()
fake_model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content="Model output.",
tool_calls=None,
raw="Model output.",
token_usage=None,
)
max_steps = 2
agent = CodeAgent(tools=[], model=fake_model, max_steps=max_steps)
assert hasattr(agent, "step_number"), "step_number attribute should be defined"
assert agent.step_number == 0, "step_number should be initialized to 0"
agent.run("Test task")
assert hasattr(agent, "step_number"), "step_number attribute should be defined"
assert agent.step_number == max_steps + 1, "step_number should be max_steps + 1 after run method is called"
@pytest.mark.parametrize(
"step, expected_messages_list",
[
(
1,
[
[
ChatMessage(
role=MessageRole.USER, content=[{"type": "text", "text": "INITIAL_PLAN_USER_PROMPT"}]
),
],
],
),
(
2,
[
[
ChatMessage(
role=MessageRole.SYSTEM,
content=[{"type": "text", "text": "UPDATE_PLAN_SYSTEM_PROMPT"}],
),
ChatMessage(
role=MessageRole.USER,
content=[{"type": "text", "text": "UPDATE_PLAN_USER_PROMPT"}],
),
],
],
),
],
)
def test_planning_step(self, step, expected_messages_list):
fake_model = MagicMock()
agent = CodeAgent(
tools=[],
model=fake_model,
)
task = "Test task"
planning_step = list(agent._generate_planning_step(task, is_first_step=(step == 1), step=step))[-1]
expected_message_texts = {
"INITIAL_PLAN_USER_PROMPT": populate_template(
agent.prompt_templates["planning"]["initial_plan"],
variables=dict(
task=task,
tools=agent.tools,
managed_agents=agent.managed_agents,
answer_facts=planning_step.model_output_message.content,
),
),
"UPDATE_PLAN_SYSTEM_PROMPT": populate_template(
agent.prompt_templates["planning"]["update_plan_pre_messages"], variables=dict(task=task)
),
"UPDATE_PLAN_USER_PROMPT": populate_template(
agent.prompt_templates["planning"]["update_plan_post_messages"],
variables=dict(
task=task,
tools=agent.tools,
managed_agents=agent.managed_agents,
facts_update=planning_step.model_output_message.content,
remaining_steps=agent.max_steps - step,
),
),
}
for expected_messages in expected_messages_list:
for expected_message in expected_messages:
expected_message.content[0]["text"] = expected_message_texts[expected_message.content[0]["text"]]
assert isinstance(planning_step, PlanningStep)
expected_model_input_messages = expected_messages_list[0]
model_input_messages = planning_step.model_input_messages
assert isinstance(model_input_messages, list)
assert len(model_input_messages) == len(expected_model_input_messages) # 2
for message, expected_message in zip(model_input_messages, expected_model_input_messages):
assert isinstance(message, ChatMessage)
assert message.role in MessageRole.__members__.values()
assert message.role == expected_message.role
assert isinstance(message.content, list)
for content, expected_content in zip(message.content, expected_message.content):
assert content == expected_content
# Test calls to model
assert len(fake_model.generate.call_args_list) == 1
for call_args, expected_messages in zip(fake_model.generate.call_args_list, expected_messages_list):
assert len(call_args.args) == 1
messages = call_args.args[0]
assert isinstance(messages, list)
assert len(messages) == len(expected_messages)
for message, expected_message in zip(messages, expected_messages):
assert isinstance(message, ChatMessage)
assert message.role in MessageRole.__members__.values()
assert message.role == expected_message.role
assert isinstance(message.content, list)
for content, expected_content in zip(message.content, expected_message.content):
assert content == expected_content
@pytest.mark.parametrize(
"expected_messages_list",
[
[
[
ChatMessage(
role=MessageRole.SYSTEM,
content=[{"type": "text", "text": "FINAL_ANSWER_SYSTEM_PROMPT"}],
),
ChatMessage(
role=MessageRole.USER,
content=[{"type": "text", "text": "FINAL_ANSWER_USER_PROMPT"}],
),
]
],
[
[
ChatMessage(
role=MessageRole.SYSTEM,
content=[
{"type": "text", "text": "FINAL_ANSWER_SYSTEM_PROMPT"},
{"type": "image", "image": "image1.png"},
],
),
ChatMessage(
role=MessageRole.USER,
content=[{"type": "text", "text": "FINAL_ANSWER_USER_PROMPT"}],
),
]
],
],
)
def test_provide_final_answer(self, expected_messages_list):
fake_model = MagicMock()
fake_model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content="Final answer.",
tool_calls=None,
raw="Final answer.",
token_usage=None,
)
agent = CodeAgent(
tools=[],
model=fake_model,
)
task = "Test task"
final_answer = agent.provide_final_answer(task).content
expected_message_texts = {
"FINAL_ANSWER_SYSTEM_PROMPT": agent.prompt_templates["final_answer"]["pre_messages"],
"FINAL_ANSWER_USER_PROMPT": populate_template(
agent.prompt_templates["final_answer"]["post_messages"], variables=dict(task=task)
),
}
for expected_messages in expected_messages_list:
for expected_message in expected_messages:
for expected_content in expected_message.content:
if "text" in expected_content:
expected_content["text"] = expected_message_texts[expected_content["text"]]
assert final_answer == "Final answer."
# Test calls to model
assert len(fake_model.generate.call_args_list) == 1
for call_args, expected_messages in zip(fake_model.generate.call_args_list, expected_messages_list):
assert len(call_args.args) == 1
messages = call_args.args[0]
assert isinstance(messages, list)
assert len(messages) == len(expected_messages)
for message, expected_message in zip(messages, expected_messages):
assert isinstance(message, ChatMessage)
assert message.role in MessageRole.__members__.values()
assert message.role == expected_message.role
assert isinstance(message.content, list)
for content, expected_content in zip(message.content, expected_message.content):
assert content == expected_content
def test_interrupt(self):
fake_model = MagicMock()
fake_model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content="Model output.",
tool_calls=None,
raw="Model output.",
token_usage=None,
)
def interrupt_callback(memory_step, agent):
agent.interrupt()
agent = CodeAgent(
tools=[],
model=fake_model,
step_callbacks=[interrupt_callback],
)
with pytest.raises(AgentError) as e:
agent.run("Test task")
assert "Agent interrupted" in str(e)
@pytest.mark.parametrize(
"tools, managed_agents, name, expectation",
[
# Valid case: no duplicates
(
[MockTool("tool1"), MockTool("tool2")],
[MockAgent("agent1", [MockTool("tool3")])],
"test_agent",
does_not_raise(),
),
# Invalid case: duplicate tool names
([MockTool("tool1"), MockTool("tool1")], [], "test_agent", pytest.raises(ValueError)),
# Invalid case: tool name same as managed agent name
(
[MockTool("tool1")],
[MockAgent("tool1", [MockTool("final_answer")])],
"test_agent",
pytest.raises(ValueError),
),
# Valid case: tool name same as managed agent's tool name
([MockTool("tool1")], [MockAgent("agent1", [MockTool("tool1")])], "test_agent", does_not_raise()),
# Invalid case: duplicate managed agent name and managed agent tool name
([MockTool("tool1")], [], "tool1", pytest.raises(ValueError)),
# Valid case: duplicate tool names across managed agents
(
[MockTool("tool1")],
[
MockAgent("agent1", [MockTool("tool2"), MockTool("final_answer")]),
MockAgent("agent2", [MockTool("tool2"), MockTool("final_answer")]),
],
"test_agent",
does_not_raise(),
),
],
)
def test_validate_tools_and_managed_agents(self, tools, managed_agents, name, expectation):
fake_model = MagicMock()
with expectation:
DummyMultiStepAgent(
tools=tools,
model=fake_model,
name=name,
managed_agents=managed_agents,
)
def test_from_dict(self):
# Create a test agent dictionary
agent_dict = {
"model": {"class": "TransformersModel", "data": {"model_id": "test/model"}},
"tools": [
{
"name": "valid_tool_function",
"code": 'from smolagents import Tool\nfrom typing import Any, Optional\n\nclass SimpleTool(Tool):\n name = "valid_tool_function"\n description = "A valid tool function."\n inputs = {"input":{"type":"string","description":"Input string."}}\n output_type = "string"\n\n def forward(self, input: str) -> str:\n """A valid tool function.\n\n Args:\n input (str): Input string.\n """\n return input.upper()',
"requirements": {"smolagents"},
}
],
"managed_agents": {},
"prompt_templates": EMPTY_PROMPT_TEMPLATES,
"max_steps": 15,
"verbosity_level": 2,
"planning_interval": 3,
"name": "test_agent",
"description": "Test agent description",
}
# Call from_dict: mock the MODEL_REGISTRY to return a mock model class
mock_model_class = MagicMock()
mock_model_instance = MagicMock()
mock_model_class.from_dict.return_value = mock_model_instance
with patch.dict("smolagents.models.MODEL_REGISTRY", {"TransformersModel": mock_model_class}):
agent = DummyMultiStepAgent.from_dict(agent_dict)
# Verify the agent was created correctly
assert agent.model == mock_model_instance
assert mock_model_class.from_dict.call_args.args[0] == {"model_id": "test/model"}
assert agent.max_steps == 15
assert agent.logger.level == 2
assert agent.planning_interval == 3
assert agent.name == "test_agent"
assert agent.description == "Test agent description"
# Verify the tool was created correctly
assert sorted(agent.tools.keys()) == ["final_answer", "valid_tool_function"]
assert agent.tools["valid_tool_function"].name == "valid_tool_function"
assert agent.tools["valid_tool_function"].description == "A valid tool function."
assert agent.tools["valid_tool_function"].inputs == {
"input": {"type": "string", "description": "Input string."}
}
assert agent.tools["valid_tool_function"]("test") == "TEST"
# Test overriding with kwargs
with patch.dict("smolagents.models.MODEL_REGISTRY", {"TransformersModel": mock_model_class}):
agent = DummyMultiStepAgent.from_dict(agent_dict, max_steps=30)
assert agent.max_steps == 30
def test_multiagent_to_dict_from_dict_roundtrip(self):
"""Test that to_dict() and from_dict() work correctly for agents with managed agents."""
# Create a managed agent
managed_agent = CodeAgent(
tools=[], model=MagicMock(), name="managed_agent", description="A managed agent for testing", max_steps=5
)
# Create a main agent with the managed agent
main_agent = ToolCallingAgent(
tools=[],
managed_agents=[managed_agent],
model=MagicMock(),
name="main_agent",
description="Main agent with managed agents",
max_steps=10,
)
# Convert to dict
agent_dict = main_agent.to_dict()
# Verify managed_agents structure in dict
assert "managed_agents" in agent_dict
assert isinstance(agent_dict["managed_agents"], list)
assert len(agent_dict["managed_agents"]) == 1
managed_agent_dict = agent_dict["managed_agents"][0]
assert managed_agent_dict["name"] == "managed_agent"
assert managed_agent_dict["class"] == "CodeAgent"
assert managed_agent_dict["description"] == "A managed agent for testing"
assert managed_agent_dict["max_steps"] == 5
# Test round-trip: from_dict should recreate the agent
# Mock the model class for the test
mock_model_class = MagicMock()
mock_model_instance = MagicMock()
mock_model_class.from_dict.return_value = mock_model_instance
with patch.dict("smolagents.models.MODEL_REGISTRY", {"MagicMock": mock_model_class}):
recreated_agent = ToolCallingAgent.from_dict(agent_dict)
# Verify the recreated agent has the same structure
assert recreated_agent.name == "main_agent"
assert recreated_agent.description == "Main agent with managed agents"
assert recreated_agent.max_steps == 10
assert len(recreated_agent.managed_agents) == 1
recreated_managed_agent = list(recreated_agent.managed_agents.values())[0]
assert recreated_managed_agent.name == "managed_agent"
assert recreated_managed_agent.description == "A managed agent for testing"
assert recreated_managed_agent.max_steps == 5
def test_from_dict_invalid_model_class(self):
"""Test that from_dict raises ValueError with helpful message for invalid model class."""
agent_dict = {
"class": "CodeAgent",
"model": {"class": "InvalidModelClass", "data": {}},
"tools": [],
"managed_agents": [],
}
with pytest.raises(ValueError) as exc_info:
CodeAgent.from_dict(agent_dict)
error_message = str(exc_info.value)
assert "InvalidModelClass" in error_message
assert "Unknown model class" in error_message
assert "Supported models:" in error_message
def test_from_dict_invalid_agent_class(self):
"""Test that from_dict raises ValueError with helpful message for invalid agent class."""
# Create a valid agent first
agent = CodeAgent(tools=[], model=MagicMock(), name="test_agent")
agent_dict = agent.to_dict()
# Add a managed agent with invalid class
agent_dict["managed_agents"] = [
{
"class": "InvalidAgentClass",
"model": {"class": "MagicMock", "data": {}},
"tools": [],
"managed_agents": [],
}
]
# Mock the model registry to allow the main agent's model and managed agent's model
mock_model_class = MagicMock()
mock_model_instance = MagicMock()
mock_model_class.from_dict.return_value = mock_model_instance
with patch.dict("smolagents.models.MODEL_REGISTRY", {"MagicMock": mock_model_class}):
with pytest.raises(ValueError) as exc_info:
CodeAgent.from_dict(agent_dict)
error_message = str(exc_info.value)
assert "InvalidAgentClass" in error_message
assert "Unknown agent class" in error_message
assert "Supported agents:" in error_message
class TestToolCallingAgent:
def test_toolcalling_agent_instructions(self):
agent = ToolCallingAgent(tools=[], model=MagicMock(), instructions="Test instructions")
assert agent.instructions == "Test instructions"
assert "Test instructions" in agent.system_prompt
def test_toolcalling_agent_passes_both_tools_and_managed_agents(self, test_tool):
"""Test that both tools and managed agents are passed to the model."""
managed_agent = MagicMock()
managed_agent.name = "managed_agent"
model = MagicMock()
model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"input": "test_value"}),
)
],
)
agent = ToolCallingAgent(tools=[test_tool], managed_agents=[managed_agent], model=model)
# Run the agent one step to trigger the model call
next(agent.run("Test task", stream=True))
# Check that the model was called with both tools and managed agents:
# - Get all tool_to_call_from names passed to the model
tools_to_call_from_names = [tool.name for tool in model.generate.call_args.kwargs["tools_to_call_from"]]
# - Verify both regular tools and managed agents are included
assert "test_tool" in tools_to_call_from_names # The regular tool
assert "managed_agent" in tools_to_call_from_names # The managed agent
assert "final_answer" in tools_to_call_from_names # The final_answer tool (added by default)
@patch("huggingface_hub.InferenceClient")
def test_toolcalling_agent_api(self, mock_inference_client):
mock_client = mock_inference_client.return_value
mock_response = mock_client.chat_completion.return_value
mock_response.choices[0].message = ChatCompletionOutputMessage(
role=MessageRole.ASSISTANT,
content='{"name": "weather_api", "arguments": {"location": "Paris", "date": "today"}}',
)
mock_response.usage.prompt_tokens = 10
mock_response.usage.completion_tokens = 20
model = InferenceClientModel(model_id="test-model")
from smolagents import tool
@tool
def weather_api(location: str, date: str) -> str:
"""
Gets the weather in the next days at given location.
Args:
location: the location
date: the date
"""
return f"The weather in {location} on date:{date} is sunny."
agent = ToolCallingAgent(model=model, tools=[weather_api], max_steps=1)
agent.run("What's the weather in Paris?")
assert agent.memory.steps[0].task == "What's the weather in Paris?"
assert agent.memory.steps[1].tool_calls[0].name == "weather_api"
assert agent.memory.steps[1].tool_calls[0].arguments == {"location": "Paris", "date": "today"}
assert agent.memory.steps[1].observations == "The weather in Paris on date:today is sunny."
mock_response.choices[0].message = ChatCompletionOutputMessage(
role=MessageRole.ASSISTANT,
content=None,
tool_calls=[
ChatCompletionOutputToolCall(
function=ChatCompletionOutputFunctionDefinition(
name="weather_api", arguments='{"location": "Paris", "date": "today"}'
),
id="call_0",
type="function",
)
],
)
agent.run("What's the weather in Paris?")
assert agent.memory.steps[0].task == "What's the weather in Paris?"
assert agent.memory.steps[1].tool_calls[0].name == "weather_api"
assert agent.memory.steps[1].tool_calls[0].arguments == {"location": "Paris", "date": "today"}
assert agent.memory.steps[1].observations == "The weather in Paris on date:today is sunny."
@patch("openai.OpenAI")
def test_toolcalling_agent_stream_logs_multiple_tool_calls_observations(self, mock_openai_client, test_tool):
"""Test that ToolCallingAgent with stream_outputs=True logs the observations of all tool calls when multiple are called."""
mock_client = mock_openai_client.return_value
from smolagents import OpenAIModel
# Mock streaming response with multiple tool calls
mock_deltas = [
ChoiceDelta(role=MessageRole.ASSISTANT),
ChoiceDelta(
tool_calls=[
ChoiceDeltaToolCall(
index=0,
id="call_1",
function=ChoiceDeltaToolCallFunction(name="test_tool"),
type="function",
)
]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=0, function=ChoiceDeltaToolCallFunction(arguments='{"in'))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=0, function=ChoiceDeltaToolCallFunction(arguments='put"'))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=0, function=ChoiceDeltaToolCallFunction(arguments=': "out'))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=0, function=ChoiceDeltaToolCallFunction(arguments="put1"))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=0, function=ChoiceDeltaToolCallFunction(arguments='"}'))]
),
ChoiceDelta(
tool_calls=[
ChoiceDeltaToolCall(
index=1,
id="call_2",
function=ChoiceDeltaToolCallFunction(name="test_tool"),
type="function",
)
]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=1, function=ChoiceDeltaToolCallFunction(arguments='{"in'))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=1, function=ChoiceDeltaToolCallFunction(arguments='put"'))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=1, function=ChoiceDeltaToolCallFunction(arguments=': "out'))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=1, function=ChoiceDeltaToolCallFunction(arguments="put2"))]
),
ChoiceDelta(
tool_calls=[ChoiceDeltaToolCall(index=1, function=ChoiceDeltaToolCallFunction(arguments='"}'))]
),
]
class MockChoice:
def __init__(self, delta):
self.delta = delta
class MockChunk:
def __init__(self, delta):
self.choices = [MockChoice(delta)]
self.usage = None
mock_client.chat.completions.create.return_value = (MockChunk(delta) for delta in mock_deltas)
# Mock usage for non-streaming fallback
mock_usage = MagicMock()
mock_usage.prompt_tokens = 10
mock_usage.completion_tokens = 20
model = OpenAIModel(model_id="fakemodel")
agent = ToolCallingAgent(model=model, tools=[test_tool], max_steps=1, stream_outputs=True)
agent.run("Dummy task")
assert agent.memory.steps[1].model_output_message.tool_calls[0].function.name == "test_tool"
assert agent.memory.steps[1].model_output_message.tool_calls[1].function.name == "test_tool"
assert agent.memory.steps[1].observations == "Processed: output1\nProcessed: output2"
@patch("openai.OpenAI")
def test_toolcalling_agent_final_answer_cannot_be_called_with_parallel_tool_calls(
self, mock_openai_client, test_tool
):
"""Test that ToolCallingAgent with stream_outputs=True returns the all tool calls when multiple are called."""
mock_client = mock_openai_client.return_value
from smolagents import OpenAIModel
class ExtendedChatMessage(ChatMessage):
def __init__(self, *args, usage, **kwargs):
super().__init__(*args, **kwargs)
def model_dump(self, include=None):
return super().model_dump_json()
class MockChoice:
def __init__(self, chat_message):
self.message = chat_message
class MockChatCompletion:
def __init__(self, chat_message):
self.choices = [MockChoice(chat_message)]
self.usage = MockTokenUsage(prompt_tokens=10, completion_tokens=20)
class MockTokenUsage:
def __init__(self, prompt_tokens, completion_tokens):
self.prompt_tokens = prompt_tokens
self.completion_tokens = completion_tokens
from dataclasses import asdict
class ExtendedChatCompletionOutputMessage(ChatCompletionOutputMessage):
def __init__(self, *args, usage, **kwargs):
super().__init__(*args, **kwargs)
self.usage = usage
def model_dump(self, include=None):
print("TOOL CALLS", self.tool_calls)
return {
"role": self.role,
"content": self.content,
"tool_calls": [asdict(tc) for tc in self.tool_calls],
}
mock_client.chat.completions.create.return_value = MockChatCompletion(
ExtendedChatCompletionOutputMessage(
role=MessageRole.ASSISTANT,
content=None,
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"input": "out1"}),
),
ChatMessageToolCall(
id="1",
type="function",
function=ChatMessageToolCallFunction(name="final_answer", arguments={"answer": "out1"}),
),
],
usage=MockTokenUsage(prompt_tokens=10, completion_tokens=20),
)
)
model = OpenAIModel(model_id="fakemodel")
agent = ToolCallingAgent(model=model, tools=[test_tool], max_steps=1)
agent.run("Dummy task")
assert agent.memory.steps[1].error is not None
assert (
"do not perform any other tool calls than the final answer tool call!"
in agent.memory.steps[1].error.message
)
@patch("huggingface_hub.InferenceClient")
def test_toolcalling_agent_api_misformatted_output(self, mock_inference_client):
"""Test that even misformatted json blobs don't interrupt the run for a ToolCallingAgent."""
mock_client = mock_inference_client.return_value
mock_response = mock_client.chat_completion.return_value
mock_response.choices[0].message = ChatCompletionOutputMessage(
role=MessageRole.ASSISTANT,
content='{"name": weather_api", "arguments": {"location": "Paris", "date": "today"}}',
)
mock_response.usage.prompt_tokens = 10
mock_response.usage.completion_tokens = 20
model = InferenceClientModel(model_id="test-model")
logger = AgentLogger(console=Console(markup=False, no_color=True))
agent = ToolCallingAgent(model=model, tools=[], max_steps=2, verbosity_level=1, logger=logger)
with agent.logger.console.capture() as capture:
agent.run("What's the weather in Paris?")
assert agent.memory.steps[0].task == "What's the weather in Paris?"
assert agent.memory.steps[1].tool_calls is None
assert "The JSON blob you used is invalid" in agent.memory.steps[1].error.message
assert "Error while parsing" in capture.get()
assert len(agent.memory.steps) == 4
@pytest.mark.skip(
reason="Test is not properly implemented (GH-1255) because fake_tools should have the same name. "
"Additionally, it uses CodeAgent instead of ToolCallingAgent (GH-1409)"
)
def test_change_tools_after_init(self):
from smolagents import tool
@tool
def fake_tool_1() -> str:
"""Fake tool"""
return "1"
@tool
def fake_tool_2() -> str:
"""Fake tool"""
return "2"
class FakeCodeModel(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(role=MessageRole.ASSISTANT, content="\nfinal_answer(fake_tool_1())\n")
agent = CodeAgent(tools=[fake_tool_1], model=FakeCodeModel())
agent.tools["final_answer"] = CustomFinalAnswerTool()
agent.tools["fake_tool_1"] = fake_tool_2
answer = agent.run("Fake task.")
assert answer == "2CUSTOM"
def test_custom_final_answer_with_custom_inputs(self, test_tool):
class CustomFinalAnswerToolWithCustomInputs(FinalAnswerTool):
inputs = {
"answer1": {"type": "string", "description": "First part of the answer."},
"answer2": {"type": "string", "description": "Second part of the answer."},
}
def forward(self, answer1: str, answer2: str) -> str:
return answer1 + " and " + answer2
model = MagicMock()
model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content=None,
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="final_answer", arguments={"answer1": "1", "answer2": "2"}
),
),
],
)
agent = ToolCallingAgent(tools=[test_tool, CustomFinalAnswerToolWithCustomInputs()], model=model)
answer = agent.run("Fake task.")
assert answer == "1 and 2"
assert agent.memory.steps[-1].model_output_message.tool_calls[0].function.name == "final_answer"
@pytest.mark.parametrize(
"test_case",
[
# Case 0: Single valid tool call
{
"tool_calls": [
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"input": "test_value"}),
)
],
"expected_observations": "Processed: test_value",
"expected_final_outputs": ["Processed: test_value"],
"expected_error": None,
},
# Case 1: Multiple tool calls
{
"tool_calls": [
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"input": "value1"}),
),
ChatMessageToolCall(
id="call_2",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"input": "value2"}),
),
],
"expected_observations": "Processed: value1\nProcessed: value2",
"expected_final_outputs": ["Processed: value1", "Processed: value2"],
"expected_error": None,
},
# Case 2: Invalid tool name
{
"tool_calls": [
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="nonexistent_tool", arguments={"input": "test"}),
)
],
"expected_error": AgentToolExecutionError,
},
# Case 3: Tool execution error
{
"tool_calls": [
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"input": "error"}),
)
],
"expected_error": AgentToolExecutionError,
},
# Case 4: Empty tool calls list
{
"tool_calls": [],
"expected_observations": "",
"expected_final_outputs": [],
"expected_error": None,
},
# Case 5: Final answer call
{
"tool_calls": [
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(
name="final_answer", arguments={"answer": "This is the final answer"}
),
)
],
"expected_observations": "This is the final answer",
"expected_final_outputs": ["This is the final answer"],
"expected_error": None,
},
# Case 6: Invalid arguments
{
"tool_calls": [
ChatMessageToolCall(
id="call_1",
type="function",
function=ChatMessageToolCallFunction(name="test_tool", arguments={"wrong_param": "value"}),
)
],
"expected_error": AgentToolCallError,
},
],
)
def test_process_tool_calls(self, test_case, test_tool):
# Create a ToolCallingAgent instance with the test tool
agent = ToolCallingAgent(tools=[test_tool], model=MagicMock())
# Create chat message with the specified tool calls for process_tool_calls
chat_message = ChatMessage(role=MessageRole.ASSISTANT, content="", tool_calls=test_case["tool_calls"])
# Create a memory step for process_tool_calls
memory_step = ActionStep(step_number=10, timing="mock_timing", model_output="")
# Process tool calls
if test_case["expected_error"]:
with pytest.raises(test_case["expected_error"]):
list(agent.process_tool_calls(chat_message, memory_step))
else:
final_outputs = list(agent.process_tool_calls(chat_message, memory_step))
assert memory_step.model_output == ""
assert memory_step.observations == test_case["expected_observations"]
assert [
final_output.output for final_output in final_outputs if isinstance(final_output, ToolOutput)
] == test_case["expected_final_outputs"]
# Verify memory step tool calls were updated correctly
if test_case["tool_calls"]:
assert memory_step.tool_calls == [
ToolCall(name=tool_call.function.name, arguments=tool_call.function.arguments, id=tool_call.id)
for tool_call in test_case["tool_calls"]
]
class TestCodeAgent:
def test_code_agent_instructions(self):
agent = CodeAgent(tools=[], model=MagicMock(), instructions="Test instructions")
assert agent.instructions == "Test instructions"
assert "Test instructions" in agent.system_prompt
agent = CodeAgent(
tools=[], model=MagicMock(), instructions="Test instructions", use_structured_outputs_internally=True
)
assert agent.instructions == "Test instructions"
assert "Test instructions" in agent.system_prompt
@pytest.mark.parametrize("provide_run_summary", [False, True])
def test_call_with_provide_run_summary(self, provide_run_summary):
agent = CodeAgent(tools=[], model=MagicMock(), provide_run_summary=provide_run_summary)
assert agent.provide_run_summary is provide_run_summary
agent.name = "test_agent"
agent.run = MagicMock(return_value="Test output")
agent.write_memory_to_messages = MagicMock(
return_value=[ChatMessage(role=MessageRole.ASSISTANT, content="Test summary")]
)
result = agent("Test request")
expected_summary = "Here is the final answer from your managed agent 'test_agent':\nTest output"
if provide_run_summary:
expected_summary += (
"\n\nFor more detail, find below a summary of this agent's work:\n"
"\n\nTest summary\n---\n "
)
assert result == expected_summary
def test_code_agent_image_output(self):
from PIL import Image
from smolagents import tool
@tool
def image_generation_tool():
"""Generate an image"""
return Image.new("RGB", (100, 100), color="red")
agent = CodeAgent(tools=[image_generation_tool], model=FakeCodeModelImageGeneration(), verbosity_level=1)
output = agent.run("Make me an image from the latest trend on google trends.")
assert isinstance(output, Image.Image)
def test_errors_logging(self):
class FakeCodeModel(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(role=MessageRole.ASSISTANT, content="\nsecret=3;['1', '2'][secret]\n")
agent = CodeAgent(tools=[], model=FakeCodeModel(), verbosity_level=1)
with agent.logger.console.capture() as capture:
agent.run("Test request")
# Verify [secret] is rendered literally, not interpreted as Rich markup (which would
# inject ANSI reset/re-apply codes like \x1b[0m\x1b[1;31m in place of the brackets).
assert "[secret]" in capture.get()
def test_missing_import_triggers_advice_in_error_log(self):
# Set explicit verbosity level to 1 to override the default verbosity level of -1 set in CI fixture
agent = CodeAgent(tools=[], model=FakeCodeModelImport(), verbosity_level=1)
with agent.logger.console.capture() as capture:
agent.run("Count to 3")
str_output = capture.get()
assert "`additional_authorized_imports`" in str_output.replace("\n", "")
def test_errors_show_offending_line_and_error(self):
agent = CodeAgent(tools=[PythonInterpreterTool()], model=FakeCodeModelError())
output = agent.run("What is 2 multiplied by 3.6452?")
assert isinstance(output, AgentText)
assert output == "got an error"
assert "Code execution failed at line 'error_function()'" in str(agent.memory.steps[1].error)
assert "ValueError" in str(agent.memory.steps)
def test_error_saves_previous_print_outputs(self):
agent = CodeAgent(tools=[PythonInterpreterTool()], model=FakeCodeModelError())
agent.run("What is 2 multiplied by 3.6452?")
assert "Flag!" in str(agent.memory.steps[1].observations)
def test_syntax_error_show_offending_lines(self):
agent = CodeAgent(tools=[PythonInterpreterTool()], model=FakeCodeModelSyntaxError())
output = agent.run("What is 2 multiplied by 3.6452?")
assert isinstance(output, AgentText)
assert output == "got an error"
assert ' print("Failing due to unexpected indent")' in str(agent.memory.steps)
assert isinstance(agent.memory.steps[-2], ActionStep)
assert agent.memory.steps[-2].code_action == dedent("""a = 2
b = a * 2
print("Failing due to unexpected indent")
print("Ok, calculation done!")""")
def test_end_code_appending(self):
# Checking original output message
orig_output = FakeCodeModelNoReturn().generate([])
assert not orig_output.content.endswith("")
# Checking the step output
agent = CodeAgent(
tools=[PythonInterpreterTool()],
model=FakeCodeModelNoReturn(),
max_steps=1,
)
answer = agent.run("What is 2 multiplied by 3.6452?")
assert answer
memory_steps = agent.memory.steps
actions_steps = [s for s in memory_steps if isinstance(s, ActionStep)]
outputs = [s.model_output for s in actions_steps if s.model_output]
assert outputs
assert all(o.endswith(" ") for o in outputs)
messages = [s.model_output_message for s in actions_steps if s.model_output_message]
assert messages
assert all(m.content.endswith("") for m in messages)
@pytest.mark.skip(
reason="Test is not properly implemented (GH-1255) because fake_tools should have the same name. "
)
def test_change_tools_after_init(self):
from smolagents import tool
@tool
def fake_tool_1() -> str:
"""Fake tool"""
return "1"
@tool
def fake_tool_2() -> str:
"""Fake tool"""
return "2"
class FakeCodeModel(Model):
def generate(self, messages, stop_sequences=None):
return ChatMessage(role=MessageRole.ASSISTANT, content="\nfinal_answer(fake_tool_1())\n")
agent = CodeAgent(tools=[fake_tool_1], model=FakeCodeModel())
agent.tools["final_answer"] = CustomFinalAnswerTool()
agent.tools["fake_tool_1"] = fake_tool_2
answer = agent.run("Fake task.")
assert answer == "2CUSTOM"
def test_local_python_executor_with_custom_functions(self):
model = MagicMock()
model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=None,
raw="",
token_usage=None,
)
agent = CodeAgent(tools=[], model=model, executor_kwargs={"additional_functions": {"open": open}})
agent.run("Test run")
assert "open" in agent.python_executor.static_tools
@pytest.mark.parametrize("agent_dict_version", ["v1.9", "v1.10", "v1.20"])
def test_from_folder(self, agent_dict_version, get_agent_dict):
agent_dict = get_agent_dict(agent_dict_version)
mock_model_class = MagicMock()
mock_model_instance = MagicMock()
mock_model_instance.model_id = "Qwen/Qwen2.5-Coder-32B-Instruct"
mock_model_class.from_dict.return_value = mock_model_instance
with (
patch("smolagents.agents.Path") as mock_path,
patch.dict("smolagents.models.MODEL_REGISTRY", {"InferenceClientModel": mock_model_class}),
):
import json
mock_path.return_value.__truediv__.return_value.read_text.return_value = json.dumps(agent_dict)
agent = CodeAgent.from_folder("ignored_dummy_folder")
assert isinstance(agent, CodeAgent)
assert agent.name == "test_agent"
assert agent.description == "dummy description"
assert agent.max_steps == 10
assert agent.planning_interval == 2
assert agent.additional_authorized_imports == ["pandas"]
assert "pandas" in agent.authorized_imports
assert agent.executor_type == "local"
assert agent.executor_kwargs == {}
assert agent.max_print_outputs_length is None
assert agent.managed_agents == {}
assert set(agent.tools.keys()) == {"final_answer"}
assert agent.model == mock_model_instance
assert mock_model_class.from_dict.call_args.args[0]["model_id"] == "Qwen/Qwen2.5-Coder-32B-Instruct"
assert agent.model.model_id == "Qwen/Qwen2.5-Coder-32B-Instruct"
assert agent.logger.level == 2
assert agent.prompt_templates["system_prompt"] == "dummy system prompt"
def test_from_dict(self):
# Create a test agent dictionary
agent_dict = {
"model": {"class": "InferenceClientModel", "data": {"model_id": "Qwen/Qwen2.5-Coder-32B-Instruct"}},
"tools": [
{
"name": "valid_tool_function",
"code": 'from smolagents import Tool\nfrom typing import Any, Optional\n\nclass SimpleTool(Tool):\n name = "valid_tool_function"\n description = "A valid tool function."\n inputs = {"input":{"type":"string","description":"Input string."}}\n output_type = "string"\n\n def forward(self, input: str) -> str:\n """A valid tool function.\n\n Args:\n input (str): Input string.\n """\n return input.upper()',
"requirements": {"smolagents"},
}
],
"managed_agents": {},
"prompt_templates": EMPTY_PROMPT_TEMPLATES,
"max_steps": 15,
"verbosity_level": 2,
"use_structured_output": False,
"planning_interval": 3,
"name": "test_code_agent",
"description": "Test code agent description",
"authorized_imports": ["pandas", "numpy"],
"executor_type": "local",
"executor_kwargs": {"max_print_outputs_length": 10_000},
"max_print_outputs_length": 1000,
}
# Call from_dict
mock_model_class = MagicMock()
mock_model_instance = MagicMock()
mock_model_class.from_dict.return_value = mock_model_instance
with patch.dict("smolagents.models.MODEL_REGISTRY", {"InferenceClientModel": mock_model_class}):
agent = CodeAgent.from_dict(agent_dict)
# Verify the agent was created correctly with CodeAgent-specific parameters
assert agent.model == mock_model_instance
assert agent.additional_authorized_imports == ["pandas", "numpy"]
assert agent.executor_type == "local"
assert agent.executor_kwargs == {"max_print_outputs_length": 10_000}
assert agent.max_print_outputs_length == 1000
# Test with missing optional parameters
minimal_agent_dict = {
"model": {"class": "InferenceClientModel", "data": {"model_id": "Qwen/Qwen2.5-Coder-32B-Instruct"}},
"tools": [],
"managed_agents": {},
}
with patch.dict("smolagents.models.MODEL_REGISTRY", {"InferenceClientModel": mock_model_class}):
agent = CodeAgent.from_dict(minimal_agent_dict)
# Verify defaults are used
assert agent.max_steps == 20 # default from MultiStepAgent.__init__
# Test overriding with kwargs
with patch.dict("smolagents.models.MODEL_REGISTRY", {"InferenceClientModel": mock_model_class}):
agent = CodeAgent.from_dict(
agent_dict,
additional_authorized_imports=["requests"],
executor_kwargs={"max_print_outputs_length": 5_000},
)
assert agent.additional_authorized_imports == ["requests"]
assert agent.executor_kwargs == {"max_print_outputs_length": 5_000}
def test_custom_final_answer_with_custom_inputs(self):
class CustomFinalAnswerToolWithCustomInputs(FinalAnswerTool):
inputs = {
"answer1": {"type": "string", "description": "First part of the answer."},
"answer2": {"type": "string", "description": "Second part of the answer."},
}
def forward(self, answer1: str, answer2: str) -> str:
return answer1 + "CUSTOM" + answer2
model = MagicMock()
model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT, content="\nfinal_answer(answer1='1', answer2='2')\n"
)
agent = CodeAgent(tools=[CustomFinalAnswerToolWithCustomInputs()], model=model)
answer = agent.run("Fake task.")
assert answer == "1CUSTOM2"
def test_use_structured_outputs_internally(self):
expected_code = "print('Hello, world!')"
model = MagicMock()
# mock structured output generation
model.generate.return_value = ChatMessage(
role=MessageRole.ASSISTANT,
content=json.dumps({"thought": "LLM-generated thought", "code": expected_code}),
)
agent = CodeAgent(
tools=[], model=model, use_structured_outputs_internally=True
) # Use structured outputs internally
tool_call: ToolCall = next(
agent._step_stream(ActionStep(step_number=1, timing="mock_timing", model_output=""))
)
assert tool_call.arguments == expected_code
class TestMultiAgents:
def test_multiagents_save(self, tmp_path):
model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct", max_tokens=2096, temperature=0.5)
web_agent = ToolCallingAgent(
model=model,
tools=[DuckDuckGoSearchTool(max_results=2), VisitWebpageTool()],
name="web_agent",
description="does web searches",
)
code_agent = CodeAgent(model=model, tools=[], name="useless", description="does nothing in particular")
agent = CodeAgent(
model=model,
tools=[],
additional_authorized_imports=["pandas", "datetime"],
managed_agents=[web_agent, code_agent],
max_print_outputs_length=1000,
executor_type="local",
executor_kwargs={"max_print_outputs_length": 10_000},
)
agent.save(tmp_path)
expected_structure = {
"managed_agents": {
"useless": {"tools": {"files": ["final_answer.py"]}, "files": ["agent.json", "prompts.yaml"]},
"web_agent": {
"tools": {"files": ["final_answer.py", "visit_webpage.py", "web_search.py"]},
"files": ["agent.json", "prompts.yaml"],
},
},
"tools": {"files": ["final_answer.py"]},
"files": ["app.py", "requirements.txt", "agent.json", "prompts.yaml"],
}
def verify_structure(current_path: Path, structure: dict):
for dir_name, contents in structure.items():
if dir_name != "files":
# For directories, verify they exist and recurse into them
dir_path = current_path / dir_name
assert dir_path.exists(), f"Directory {dir_path} does not exist"
assert dir_path.is_dir(), f"{dir_path} is not a directory"
verify_structure(dir_path, contents)
else:
# For files, verify each exists in the current path
for file_name in contents:
file_path = current_path / file_name
assert file_path.exists(), f"File {file_path} does not exist"
assert file_path.is_file(), f"{file_path} is not a file"
verify_structure(tmp_path, expected_structure)
# Test that re-loaded agents work as expected.
agent2 = CodeAgent.from_folder(tmp_path, planning_interval=5)
assert agent2.planning_interval == 5 # Check that kwargs are used
assert set(agent2.authorized_imports) == set(["pandas", "datetime"] + BASE_BUILTIN_MODULES)
assert agent2.max_print_outputs_length == 1000
assert agent2.executor_type == "local"
assert agent2.executor_kwargs == {"max_print_outputs_length": 10_000}
assert (
agent2.managed_agents["web_agent"].tools["web_search"].max_results == 10
) # For now tool init parameters are forgotten
assert agent2.model.kwargs["temperature"] == pytest.approx(0.5)
def test_multiagents(self):
class FakeModelMultiagentsManagerAgent(Model):
model_id = "fake_model"
def generate(
self,
messages,
stop_sequences=None,
tools_to_call_from=None,
):
if tools_to_call_from is not None:
if len(messages) < 3:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="search_agent",
arguments="Who is the current US president?",
),
)
],
)
else:
assert "Report on the current US president" in str(messages)
return ChatMessage(
role=MessageRole.ASSISTANT,
content="",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="final_answer", arguments="Final report."
),
)
],
)
else:
if len(messages) < 3:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: Let's call our search agent.
result = search_agent("Who is the current US president?")
""",
)
else:
assert "Report on the current US president" in str(messages)
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
Thought: Let's return the report.
final_answer("Final report.")
""",
)
manager_model = FakeModelMultiagentsManagerAgent()
class FakeModelMultiagentsManagedAgent(Model):
model_id = "fake_model"
def generate(
self,
messages,
tools_to_call_from=None,
stop_sequences=None,
):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="Here is the secret content: FLAG1",
tool_calls=[
ChatMessageToolCall(
id="call_0",
type="function",
function=ChatMessageToolCallFunction(
name="final_answer",
arguments="Report on the current US president",
),
)
],
)
managed_model = FakeModelMultiagentsManagedAgent()
web_agent = ToolCallingAgent(
tools=[],
model=managed_model,
max_steps=10,
name="search_agent",
description="Runs web searches for you. Give it your request as an argument. Make the request as detailed as needed, you can ask for thorough reports",
verbosity_level=2,
)
manager_code_agent = CodeAgent(
tools=[],
model=manager_model,
managed_agents=[web_agent],
additional_authorized_imports=["time", "numpy", "pandas"],
)
report = manager_code_agent.run("Fake question.")
assert report == "Final report."
manager_toolcalling_agent = ToolCallingAgent(
tools=[],
model=manager_model,
managed_agents=[web_agent],
)
with web_agent.logger.console.capture() as capture:
report = manager_toolcalling_agent.run("Fake question.")
assert report == "Final report."
assert "FLAG1" in capture.get() # Check that managed agent's output is properly logged
# Test that visualization works
with manager_toolcalling_agent.logger.console.capture() as capture:
manager_toolcalling_agent.visualize()
assert "├──" in capture.get()
@pytest.fixture
def prompt_templates():
return {
"system_prompt": "This is a test system prompt.",
"managed_agent": {"task": "Task for {{name}}: {{task}}", "report": "Report for {{name}}: {{final_answer}}"},
"planning": {
"initial_plan": "The plan.",
"update_plan_pre_messages": "custom",
"update_plan_post_messages": "custom",
},
"final_answer": {"pre_messages": "custom", "post_messages": "custom"},
}
@pytest.mark.parametrize(
"arguments",
[
{},
{"arg": "bar"},
{None: None},
[1, 2, 3],
],
)
def test_tool_calling_agents_raises_tool_call_error_being_invoked_with_wrong_arguments(arguments):
@tool
def _sample_tool(prompt: str) -> str:
"""Tool that returns same string
Args:
prompt: The string to return
Returns:
The same string
"""
return prompt
agent = ToolCallingAgent(model=FakeToolCallModel(), tools=[_sample_tool])
with pytest.raises(AgentToolCallError):
agent.execute_tool_call(_sample_tool.name, arguments)
def test_tool_calling_agents_raises_agent_execution_error_when_tool_raises():
@tool
def _sample_tool(_: str) -> float:
"""Tool that fails
Args:
_: The pointless string
Returns:
Some number
"""
return 1 / 0
agent = ToolCallingAgent(model=FakeToolCallModel(), tools=[_sample_tool])
with pytest.raises(AgentExecutionError):
agent.execute_tool_call(_sample_tool.name, "sample")
================================================
FILE: tests/test_all_docs.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import ast
import os
import re
import shutil
import subprocess
import tempfile
import traceback
from pathlib import Path
import pytest
from dotenv import load_dotenv
from .utils.markers import require_run_all
class SubprocessCallException(Exception):
pass
def run_command(command: list[str], return_stdout=False, env=None):
"""
Runs command with subprocess.check_output and returns stdout if requested.
Properly captures and handles errors during command execution.
"""
for i, c in enumerate(command):
if isinstance(c, Path):
command[i] = str(c)
if env is None:
env = os.environ.copy()
try:
output = subprocess.check_output(command, stderr=subprocess.STDOUT, env=env)
if return_stdout:
if hasattr(output, "decode"):
output = output.decode("utf-8")
return output
except subprocess.CalledProcessError as e:
raise SubprocessCallException(
f"Command `{' '.join(command)}` failed with the following error:\n\n{e.output.decode()}"
) from e
class DocCodeExtractor:
"""Handles extraction and validation of Python code from markdown files."""
@staticmethod
def extract_python_code(content: str) -> list[str]:
"""Extract Python code blocks from markdown content."""
pattern = r"```(?:python|py)\n(.*?)\n```"
matches = re.finditer(pattern, content, re.DOTALL)
return [match.group(1).strip() for match in matches]
@staticmethod
def create_test_script(code_blocks: list[str], tmp_dir: str) -> Path:
"""Create a temporary Python script from code blocks."""
combined_code = "\n\n".join(code_blocks)
assert len(combined_code) > 0, "Code is empty!"
tmp_file = Path(tmp_dir) / "test_script.py"
with open(tmp_file, "w", encoding="utf-8") as f:
f.write(combined_code)
return tmp_file
# Skip: slow tests + require API keys
@require_run_all
class TestDocs:
"""Test case for documentation code testing."""
@classmethod
def setup_class(cls):
cls._tmpdir = tempfile.mkdtemp()
cls.launch_args = ["python3"]
cls.docs_dir = Path(__file__).parent.parent / "docs" / "source" / "en"
cls.extractor = DocCodeExtractor()
if not cls.docs_dir.exists():
raise ValueError(f"Docs directory not found at {cls.docs_dir}")
load_dotenv()
cls.md_files = list(cls.docs_dir.rglob("*.md")) + list(cls.docs_dir.rglob("*.mdx"))
if not cls.md_files:
raise ValueError(f"No markdown files found in {cls.docs_dir}")
@classmethod
def teardown_class(cls):
shutil.rmtree(cls._tmpdir)
@pytest.mark.timeout(100)
def test_single_doc(self, doc_path: Path):
"""Test a single documentation file."""
with open(doc_path, "r", encoding="utf-8") as f:
content = f.read()
code_blocks = self.extractor.extract_python_code(content)
excluded_snippets = [
"ToolCollection",
"image_generation_tool", # We don't want to run this expensive operation
"from_langchain", # Langchain is not a dependency
"while llm_should_continue(memory):", # This is pseudo code
"ollama_chat/llama3.2", # Exclude ollama building in guided tour
"model = TransformersModel(model_id=model_id)", # Exclude testing with transformers model
"SmolagentsInstrumentor", # Exclude telemetry since it needs additional installs
]
code_blocks = [
block
for block in code_blocks
if not any(
[snippet in block for snippet in excluded_snippets]
) # Exclude these tools that take longer to run and add dependencies
]
if len(code_blocks) == 0:
pytest.skip(f"No Python code blocks found in {doc_path.name}")
# Validate syntax of each block individually by parsing it
for i, block in enumerate(code_blocks, 1):
ast.parse(block)
# Create and execute test script
print("\n\nCollected code block:==========\n".join(code_blocks))
try:
code_blocks = [
(
block.replace("world!"
stop_sequences = [""]
removed_content = remove_content_after_stop_sequences(content, stop_sequences)
assert removed_content == "Hello"
def test_remove_content_after_stop_sequences_handles_none():
# Test with None stop sequence
content = "Hello world!"
removed_content = remove_content_after_stop_sequences(content, None)
assert removed_content == content
# Test with None content
removed_content = remove_content_after_stop_sequences(None, [""])
assert removed_content is None
@pytest.mark.parametrize(
"convert_images_to_image_urls, expected_clean_message",
[
(
False,
dict(
role=MessageRole.USER,
content=[
{"type": "image", "image": "encoded_image"},
{"type": "image", "image": "second_encoded_image"},
],
),
),
(
True,
dict(
role=MessageRole.USER,
content=[
{"type": "image_url", "image_url": {"url": "data:image/png;base64,encoded_image"}},
{"type": "image_url", "image_url": {"url": "data:image/png;base64,second_encoded_image"}},
],
),
),
],
)
def test_get_clean_message_list_image_encoding(convert_images_to_image_urls, expected_clean_message):
message = ChatMessage(
role=MessageRole.USER,
content=[{"type": "image", "image": b"image_data"}, {"type": "image", "image": b"second_image_data"}],
)
with patch("smolagents.models.encode_image_base64") as mock_encode:
mock_encode.side_effect = ["encoded_image", "second_encoded_image"]
result = get_clean_message_list([message], convert_images_to_image_urls=convert_images_to_image_urls)
mock_encode.assert_any_call(b"image_data")
mock_encode.assert_any_call(b"second_image_data")
assert len(result) == 1
assert result[0] == expected_clean_message
def test_get_clean_message_list_flatten_messages_as_text():
messages = [
ChatMessage(role=MessageRole.USER, content=[{"type": "text", "text": "Hello!"}]),
ChatMessage(role=MessageRole.USER, content=[{"type": "text", "text": "How are you?"}]),
]
result = get_clean_message_list(messages, flatten_messages_as_text=True)
assert len(result) == 1
assert result[0]["role"] == "user"
assert result[0]["content"] == "Hello!\nHow are you?"
@pytest.mark.parametrize(
"model_class, model_kwargs, patching, expected_flatten_messages_as_text",
[
(AzureOpenAIModel, {}, ("openai.AzureOpenAI", {}), False),
(InferenceClientModel, {}, ("huggingface_hub.InferenceClient", {}), False),
(LiteLLMModel, {}, None, False),
(LiteLLMModel, {"model_id": "ollama"}, None, True),
(LiteLLMModel, {"model_id": "groq"}, None, True),
(LiteLLMModel, {"model_id": "cerebras"}, None, True),
(MLXModel, {}, ("mlx_lm.load", {"return_value": (MagicMock(), MagicMock())}), True),
(OpenAIModel, {}, ("openai.OpenAI", {}), False),
(OpenAIModel, {"flatten_messages_as_text": True}, ("openai.OpenAI", {}), True),
(
TransformersModel,
{},
[
(
"transformers.AutoModelForImageTextToText.from_pretrained",
{"side_effect": ValueError("Unrecognized configuration class")},
),
("transformers.AutoModelForCausalLM.from_pretrained", {}),
("transformers.AutoTokenizer.from_pretrained", {}),
],
True,
),
(
TransformersModel,
{},
[
("transformers.AutoModelForImageTextToText.from_pretrained", {}),
("transformers.AutoProcessor.from_pretrained", {}),
],
False,
),
],
)
def test_flatten_messages_as_text_for_all_models(
model_class, model_kwargs, patching, expected_flatten_messages_as_text
):
with ExitStack() as stack:
if isinstance(patching, list):
for target, kwargs in patching:
stack.enter_context(patch(target, **kwargs))
elif patching:
target, kwargs = patching
stack.enter_context(patch(target, **kwargs))
model = model_class(**{"model_id": "test-model", **model_kwargs})
assert model.flatten_messages_as_text is expected_flatten_messages_as_text, f"{model_class.__name__} failed"
@pytest.mark.parametrize(
"model_id,expected",
[
# Unsupported base models
("o3", False),
("o4-mini", False),
("gpt-5.1", False),
("gpt-5.2", False),
("gpt-5", False),
("gpt-5-mini", False),
("gpt-5-nano", False),
("gpt-5-turbo", False),
("gpt-5.2-mini", False),
("grok-4", False),
("grok-4-latest", False),
("grok-4.1", False),
("grok-3", False),
("grok-3-mini", False),
("grok-code-fast-1", False),
# Unsupported versioned models
("o4-mini-2025-04-16", False),
("gpt-5-2025-01-01", False),
# Unsupported models with path prefixes
("openai/o3", False),
("openai/o4-mini", False),
("openai/o3-2025-04-16", False),
("openai/o4-mini-2025-04-16", False),
("openai/gpt-5.2", False),
("openai/gpt-5.2-mini", False),
("openai/gpt-5.2-2025-01-01", False),
("oci/xai.grok-4", False),
("oci/xai.grok-3-mini", False),
# Supported models
("o3-mini", True),
("gpt-4", True),
("claude-3-5-sonnet", True),
("mistral-large", True),
# Supported models with path prefixes
("openai/gpt-4", True),
("anthropic/claude-3-5-sonnet", True),
("anthropic/claude-opus-4-5", True),
("mistralai/mistral-large", True),
# Edge cases
("", True), # Empty string doesn't match pattern
("o3x", True), # Not exactly o3
("o4x", True), # Not exactly o4
("gpt-5x", False),
("gpt-50", False),
("o3_mini", True), # Not o3-mini format
("prefix-o3", True), # o3 not at start
],
)
def test_supports_stop_parameter(model_id, expected):
"""Test the supports_stop_parameter function with various model IDs"""
assert supports_stop_parameter(model_id) == expected, f"Failed for model_id: {model_id}"
class TestGetToolCallFromText:
@pytest.fixture(autouse=True)
def mock_uuid4(self):
with patch("uuid.uuid4", return_value="test-uuid"):
yield
def test_get_tool_call_from_text_basic(self):
text = '{"name": "weather_tool", "arguments": "New York"}'
result = get_tool_call_from_text(text, "name", "arguments")
assert isinstance(result, ChatMessageToolCall)
assert result.id == "test-uuid"
assert result.type == "function"
assert result.function.name == "weather_tool"
assert result.function.arguments == "New York"
def test_get_tool_call_from_text_name_key_missing(self):
text = '{"action": "weather_tool", "arguments": "New York"}'
with pytest.raises(ValueError) as exc_info:
get_tool_call_from_text(text, "name", "arguments")
error_msg = str(exc_info.value)
assert "Tool call needs to have a key 'name'" in error_msg
assert "'action', 'arguments'" in error_msg
def test_get_tool_call_from_text_json_object_args(self):
text = '{"name": "weather_tool", "arguments": {"city": "New York"}}'
result = get_tool_call_from_text(text, "name", "arguments")
assert result.function.arguments == {"city": "New York"}
def test_get_tool_call_from_text_json_string_args(self):
text = '{"name": "weather_tool", "arguments": "{\\"city\\": \\"New York\\"}"}'
result = get_tool_call_from_text(text, "name", "arguments")
assert result.function.arguments == {"city": "New York"}
def test_get_tool_call_from_text_missing_args(self):
text = '{"name": "weather_tool"}'
result = get_tool_call_from_text(text, "name", "arguments")
assert result.function.arguments is None
def test_get_tool_call_from_text_custom_keys(self):
text = '{"tool": "weather_tool", "params": "New York"}'
result = get_tool_call_from_text(text, "tool", "params")
assert result.function.name == "weather_tool"
assert result.function.arguments == "New York"
def test_get_tool_call_from_text_numeric_args(self):
text = '{"name": "calculator", "arguments": 42}'
result = get_tool_call_from_text(text, "name", "arguments")
assert result.function.name == "calculator"
assert result.function.arguments == 42
@pytest.mark.parametrize(
"model_class,model_id",
[
(LiteLLMModel, "gpt-4o-mini"),
(OpenAIModel, "gpt-4o-mini"),
],
)
def test_tool_calls_json_serialization(model_class, model_id):
"""Test that tool_calls from various API models (Pydantic, dataclass, dict) are properly converted to dataclasses and can be JSON serialized.
This tests the horizontal fix that ensures all models (LiteLLM, OpenAI, InferenceClient, AmazonBedrock)
properly convert tool_calls to dataclasses regardless of the source format (Pydantic models, dataclasses, or dicts).
"""
tool_arguments = "test_result"
messages = [
ChatMessage(
role=MessageRole.USER,
content=[
{
"type": "text",
"text": "Hello! Please return the final answer 'hi there' in a tool call",
}
],
),
]
if model_class == OpenAIModel:
from openai.types.chat.chat_completion import ChatCompletion, Choice
from openai.types.chat.chat_completion_message import ChatCompletionMessage
from openai.types.chat.chat_completion_message_tool_call import ChatCompletionMessageToolCall, Function
from openai.types.completion_usage import CompletionUsage
response = ChatCompletion(
id="chatcmpl-test",
created=0,
model="gpt-4o-mini-2024-07-18",
object="chat.completion",
choices=[
Choice(
finish_reason="tool_calls",
index=0,
logprobs=None,
message=ChatCompletionMessage(
role="assistant",
content=None,
tool_calls=[
ChatCompletionMessageToolCall(
id="call_test",
type="function",
function=Function(name="final_answer", arguments=tool_arguments),
)
],
),
)
],
usage=CompletionUsage(prompt_tokens=69, completion_tokens=15, total_tokens=84),
)
client = MagicMock()
client.chat.completions.create.return_value = response
create_call = client.chat.completions.create
patch_target = "smolagents.models.OpenAIModel.create_client"
elif model_class == LiteLLMModel:
from litellm.types.utils import ChatCompletionMessageToolCall, Choices, Function, Message, ModelResponse, Usage
response = ModelResponse(
id="chatcmpl-test",
created=0,
object="chat.completion",
choices=[
Choices(
finish_reason="tool_calls",
index=0,
message=Message(
role="assistant",
content=None,
tool_calls=[
ChatCompletionMessageToolCall(
id="call_test",
type="function",
function=Function(name="final_answer", arguments=tool_arguments),
)
],
function_call=None,
provider_specific_fields={"refusal": None, "annotations": []},
),
)
],
usage=Usage(prompt_tokens=69, completion_tokens=15, total_tokens=84),
model="gpt-4o-mini-2024-07-18",
)
client = MagicMock()
client.completion.return_value = response
create_call = client.completion
patch_target = "smolagents.models.LiteLLMModel.create_client"
else:
raise ValueError(f"Unexpected model class: {model_class}")
with patch(patch_target, return_value=client):
model = model_class(model_id=model_id)
result = model.generate(messages, tools_to_call_from=[FinalAnswerTool()])
assert create_call.call_count == 1
# Verify tool_calls are converted to dataclasses
assert result.tool_calls is not None
assert len(result.tool_calls) > 0
assert isinstance(result.tool_calls[0], ChatMessageToolCall)
# The critical test: verify JSON serialization works
json_str = result.model_dump_json()
data = json.loads(json_str)
assert "tool_calls" in data
assert len(data["tool_calls"]) > 0
assert data["tool_calls"][0]["function"]["name"] == "final_answer"
assert data["tool_calls"][0]["function"]["arguments"] == "test_result"
================================================
FILE: tests/test_monitoring.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import PIL.Image
import pytest
from rich.console import Console
from smolagents import (
CodeAgent,
ToolCallingAgent,
stream_to_gradio,
)
from smolagents.memory import ActionStep, AgentMemory
from smolagents.models import (
ChatMessage,
ChatMessageToolCall,
ChatMessageToolCallFunction,
MessageRole,
Model,
)
from smolagents.monitoring import AgentLogger, TokenUsage
class FakeLLMModel(Model):
def generate(self, prompt, tools_to_call_from=None, **kwargs):
if tools_to_call_from is not None:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="I will call the final_answer tool.",
tool_calls=[
ChatMessageToolCall(
id="fake_id",
type="function",
function=ChatMessageToolCallFunction(
name="final_answer", arguments={"answer": "This is the final answer."}
),
)
],
token_usage=TokenUsage(input_tokens=10, output_tokens=20),
)
else:
return ChatMessage(
role=MessageRole.ASSISTANT,
content="""
final_answer('This is the final answer.')
""",
token_usage=TokenUsage(input_tokens=10, output_tokens=20),
)
class MonitoringTester(unittest.TestCase):
def test_code_agent_metrics_max_steps(self):
class FakeLLMModelMalformedAnswer(Model):
def generate(self, prompt, **kwargs):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="Malformed answer",
token_usage=TokenUsage(input_tokens=10, output_tokens=20),
)
agent = CodeAgent(
tools=[],
model=FakeLLMModelMalformedAnswer(),
max_steps=1,
)
agent.run("Fake task")
self.assertEqual(agent.monitor.total_input_token_count, 20)
self.assertEqual(agent.monitor.total_output_token_count, 40)
def test_code_agent_metrics_generation_error(self):
class FakeLLMModelGenerationException(Model):
def generate(self, prompt, **kwargs):
raise Exception("Cannot generate")
agent = CodeAgent(
tools=[],
model=FakeLLMModelGenerationException(),
max_steps=1,
)
with pytest.raises(Exception) as e:
agent.run("Fake task")
assert "Cannot generate" in str(e.value)
def test_streaming_agent_text_output(self):
agent = CodeAgent(
tools=[],
model=FakeLLMModel(),
max_steps=1,
planning_interval=2,
)
# Use stream_to_gradio to capture the output
outputs = list(stream_to_gradio(agent, task="Test task"))
self.assertEqual(len(outputs), 11)
plan_message = outputs[1]
self.assertEqual(plan_message.role, "assistant")
self.assertIn("", plan_message.content)
final_message = outputs[-1]
self.assertEqual(final_message.role, "assistant")
self.assertIn("This is the final answer.", final_message.content)
def test_streaming_agent_image_output(self):
class FakeLLMModelImage(Model):
def generate(self, prompt, **kwargs):
return ChatMessage(
role=MessageRole.ASSISTANT,
content="I will call the final_answer tool.",
tool_calls=[
ChatMessageToolCall(
id="fake_id",
type="function",
function=ChatMessageToolCallFunction(name="final_answer", arguments={"answer": "image"}),
)
],
)
agent = ToolCallingAgent(
tools=[],
model=FakeLLMModelImage(),
max_steps=1,
verbosity_level=100,
)
# Use stream_to_gradio to capture the output
outputs = list(
stream_to_gradio(
agent,
task="Test task",
additional_args=dict(image=PIL.Image.new("RGB", (100, 100))),
)
)
self.assertEqual(len(outputs), 7)
final_message = outputs[-1]
self.assertEqual(final_message.role, "assistant")
self.assertIsInstance(final_message.content, dict)
self.assertEqual(final_message.content["mime_type"], "image/png")
def test_streaming_with_agent_error(self):
class DummyModel(Model):
def generate(self, prompt, **kwargs):
return ChatMessage(role=MessageRole.ASSISTANT, content="Malformed call")
agent = CodeAgent(
tools=[],
model=DummyModel(),
max_steps=1,
)
# Use stream_to_gradio to capture the output
outputs = list(stream_to_gradio(agent, task="Test task"))
self.assertEqual(len(outputs), 11)
final_message = outputs[-1]
self.assertEqual(final_message.role, "assistant")
self.assertIn("Malformed call", final_message.content)
@pytest.mark.parametrize("agent_class", [CodeAgent, ToolCallingAgent])
def test_code_agent_metrics(agent_class):
agent = agent_class(
tools=[],
model=FakeLLMModel(),
max_steps=1,
)
agent.run("Fake task")
assert agent.monitor.total_input_token_count == 10
assert agent.monitor.total_output_token_count == 20
class ReplayTester(unittest.TestCase):
def test_replay_with_chatmessage(self):
"""Regression test for dict(message) to message.dict() fix"""
logger = AgentLogger()
memory = AgentMemory(system_prompt="test")
step = ActionStep(step_number=1, timing=0)
step.model_input_messages = [ChatMessage(role=MessageRole.USER, content="Hello")]
memory.steps.append(step)
try:
memory.replay(logger, detailed=True)
except TypeError as e:
self.fail(f"Replay raised an error: {e}")
class AgentLoggerLogTaskTester(unittest.TestCase):
def test_logger_log_task_does_not_crash_on_stray_markup_or_control_chars(self):
"""
Rich Panels parse `title`/`subtitle` as markup when passed as strings.
`AgentLogger.log_task()` must be resilient to arbitrary content/subtitle strings
(e.g. tool logs, binary-ish payloads, or stray bracket sequences).
"""
console = Console(record=True, width=120, highlight=False)
logger = AgentLogger(console=console)
# These inputs would crash Rich markup parsing if passed through as markup strings.
content = b"hello [/bad]\x00\x1b world [bold]bold[/bold]"
subtitle = "sub[/bad]title"
logger.log_task(content=content, subtitle=subtitle, title=None)
rendered = console.export_text()
self.assertIn("hello [/bad]", rendered)
# Control chars are made visible as escape sequences.
self.assertIn("\\x00", rendered)
self.assertIn("\\x1b", rendered)
self.assertIn("sub[/bad]title", rendered)
self.assertIn("bold", rendered)
def test_logger_log_task_accepts_non_string_payloads(self):
console = Console(record=True, width=120, highlight=False)
logger = AgentLogger(console=console)
logger.log_task(content={"k": ["v", 1]}, subtitle={"also": "dict"}, title="Run")
rendered = console.export_text()
self.assertIn("k", rendered)
self.assertIn("also", rendered)
================================================
FILE: tests/test_remote_executors.py
================================================
import importlib
import io
from textwrap import dedent
from unittest.mock import MagicMock, patch
import docker
import PIL.Image
import pytest
from rich.console import Console
from smolagents.default_tools import FinalAnswerTool, WikipediaSearchTool
from smolagents.local_python_executor import CodeOutput
from smolagents.monitoring import AgentLogger, LogLevel
from smolagents.remote_executors import (
BlaxelExecutor,
DockerExecutor,
E2BExecutor,
ModalExecutor,
RemotePythonExecutor,
WasmExecutor,
)
from smolagents.serialization import SerializationError
from smolagents.utils import AgentError
from .utils.markers import require_run_all
class TestRemotePythonExecutor:
def test_send_tools_empty_tools(self):
executor = RemotePythonExecutor(additional_imports=[], logger=MagicMock())
executor.run_code_raise_errors = MagicMock()
executor.send_tools({})
assert executor.run_code_raise_errors.call_count == 1
# No new packages should be installed
assert "!pip install" not in executor.run_code_raise_errors.call_args.args[0]
def test_send_variables_with_empty_dict_is_noop(self):
executor = RemotePythonExecutor(additional_imports=[], logger=MagicMock())
executor.run_code_raise_errors = MagicMock()
executor.send_variables({})
assert executor.run_code_raise_errors.call_count == 0
def test_send_variables_non_empty_generates_executable_deserializer_code(self):
executor = RemotePythonExecutor(additional_imports=[], logger=MagicMock(), allow_pickle=False)
executor.run_code_raise_errors = MagicMock()
variables = {
"counter": 1,
"tags": ("a", "b"),
"blob": b"binary",
}
executor.send_variables(variables)
sent_code = executor.run_code_raise_errors.call_args.args[0]
remote_scope = {}
exec(sent_code, remote_scope, remote_scope)
assert remote_scope["counter"] == 1
assert remote_scope["tags"] == ("a", "b")
assert remote_scope["blob"] == b"binary"
def test_send_variables_allow_pickle_handles_prefixed_payload(self):
executor = RemotePythonExecutor(additional_imports=[], logger=MagicMock(), allow_pickle=True)
executor.run_code_raise_errors = MagicMock()
variables = {"error": ValueError("boom")}
executor.send_variables(variables)
sent_code = executor.run_code_raise_errors.call_args.args[0]
remote_scope = {}
exec(sent_code, remote_scope, remote_scope)
assert isinstance(remote_scope["error"], ValueError)
assert str(remote_scope["error"]) == "boom"
def test_deserialize_final_answer_rejects_unprefixed_payload(self):
with pytest.raises(SerializationError, match="Unknown final answer format"):
RemotePythonExecutor._deserialize_final_answer("legacy-unprefixed-payload", allow_pickle=True)
@require_run_all
def test_send_tools_with_default_wikipedia_search_tool(self):
tool = WikipediaSearchTool()
executor = RemotePythonExecutor(additional_imports=[], logger=MagicMock())
executor.run_code_raise_errors = MagicMock()
executor.send_tools({"wikipedia_search": tool})
assert executor.run_code_raise_errors.call_count == 2
assert "!pip install wikipedia-api" == executor.run_code_raise_errors.call_args_list[0].args[0]
assert "class WikipediaSearchTool(Tool)" in executor.run_code_raise_errors.call_args_list[1].args[0]
class TestE2BExecutorUnit:
def test_e2b_executor_instantiation(self):
logger = MagicMock()
with patch("e2b_code_interpreter.Sandbox") as mock_sandbox:
mock_sandbox.return_value.commands.run.return_value.error = None
mock_sandbox.return_value.run_code.return_value.error = None
# Also set up v2 path in case Sandbox.create is used
mock_sandbox.create.return_value.commands.run.return_value.error = None
mock_sandbox.create.return_value.run_code.return_value.error = None
executor = E2BExecutor(
additional_imports=[], logger=logger, api_key="dummy-api-key", template="dummy-template-id", timeout=60
)
assert isinstance(executor, E2BExecutor)
assert executor.logger == logger
# Support both e2b v1 (Sandbox(...)) and v2 (Sandbox.create(...))
if mock_sandbox.create.called:
sandbox_obj = mock_sandbox.create.return_value
called_ctor = mock_sandbox.create
else:
sandbox_obj = mock_sandbox.return_value
called_ctor = mock_sandbox
assert executor.sandbox == sandbox_obj
assert called_ctor.call_count == 1
assert called_ctor.call_args.kwargs == {
"api_key": "dummy-api-key",
"template": "dummy-template-id",
"timeout": 60,
}
def test_cleanup(self):
"""Test that the cleanup method properly shuts down the sandbox"""
logger = MagicMock()
with patch("e2b_code_interpreter.Sandbox") as mock_sandbox:
# Setup mock
mock_sandbox.return_value.kill = MagicMock()
# Also set up v2 path in case Sandbox.create is used
mock_sandbox.create.return_value.kill = MagicMock()
# Create executor
executor = E2BExecutor(additional_imports=[], logger=logger, api_key="dummy-api-key")
# Call cleanup
executor.cleanup()
# Verify sandbox was killed
if mock_sandbox.create.called:
mock_sandbox.create.return_value.kill.assert_called_once()
else:
mock_sandbox.return_value.kill.assert_called_once()
assert logger.log.call_count >= 2 # Should log start and completion messages
@pytest.fixture
def e2b_executor():
executor = E2BExecutor(
additional_imports=["pillow", "numpy"],
logger=AgentLogger(LogLevel.INFO, Console(force_terminal=False, file=io.StringIO())),
)
yield executor
executor.cleanup()
@require_run_all
class TestE2BExecutorIntegration:
@pytest.fixture(autouse=True)
def set_executor(self, e2b_executor):
self.executor = e2b_executor
@pytest.mark.parametrize(
"code_action, expected_result",
[
(
dedent('''
final_answer("""This is
a multiline
final answer""")
'''),
"This is\na multiline\nfinal answer",
),
(
dedent("""
text = '''Text containing
final_answer(5)
'''
final_answer(text)
"""),
"Text containing\nfinal_answer(5)\n",
),
(
dedent("""
num = 2
if num == 1:
final_answer("One")
elif num == 2:
final_answer("Two")
"""),
"Two",
),
],
)
def test_final_answer_patterns(self, code_action, expected_result):
self.executor.send_tools({"final_answer": FinalAnswerTool()})
code_output = self.executor(code_action)
assert code_output.is_final_answer is True
assert code_output.output == expected_result
def test_custom_final_answer(self):
class CustomFinalAnswerTool(FinalAnswerTool):
def forward(self, answer: str) -> str:
return "CUSTOM" + answer
self.executor.send_tools({"final_answer": CustomFinalAnswerTool()})
code_action = dedent("""
final_answer(answer="_answer")
""")
code_output = self.executor(code_action)
assert code_output.is_final_answer is True
assert code_output.output == "CUSTOM_answer"
def test_custom_final_answer_with_custom_inputs(self):
class CustomFinalAnswerToolWithCustomInputs(FinalAnswerTool):
inputs = {
"answer1": {"type": "string", "description": "First part of the answer."},
"answer2": {"type": "string", "description": "Second part of the answer."},
}
def forward(self, answer1: str, answer2: str) -> str:
return answer1 + "CUSTOM" + answer2
self.executor.send_tools({"final_answer": CustomFinalAnswerToolWithCustomInputs()})
code_action = dedent("""
final_answer(
answer1="answer1_",
answer2="_answer2"
)
""")
code_output = self.executor(code_action)
assert code_output.is_final_answer is True
assert code_output.output == "answer1_CUSTOM_answer2"
class TestDockerExecutorUnit:
def test_cleanup(self):
"""Test that cleanup properly stops and removes the container"""
logger = MagicMock()
with (
patch("docker.from_env") as mock_docker_client,
patch("requests.get") as mock_get,
patch("requests.post") as mock_post,
patch("websocket.create_connection"),
):
# Setup mocks
mock_container = MagicMock()
mock_container.status = "running"
mock_container.short_id = "test123"
mock_docker_client.return_value.containers.run.return_value = mock_container
mock_docker_client.return_value.images.get.return_value = MagicMock()
mock_get.return_value.status_code = 200
mock_post.return_value.status_code = 201
mock_post.return_value.json.return_value = {"id": "test-kernel-id"}
# Create executor
executor = DockerExecutor(additional_imports=[], logger=logger, build_new_image=False)
# Call cleanup
executor.cleanup()
# Verify container was stopped and removed
mock_container.stop.assert_called_once()
mock_container.remove.assert_called_once()
class CommonDockerExecutorIntegration:
@pytest.fixture(autouse=True)
def set_executor(self, custom_executor):
self.executor = custom_executor
def test_state_persistence(self):
"""Test that variables and imports form one snippet persist in the next"""
code_action = "import numpy as np; a = 2"
self.executor(code_action)
code_action = "print(np.sqrt(a))"
code_output = self.executor(code_action)
assert "1.41421" in code_output.logs
def test_execute_output(self):
"""Test execution that returns a string"""
self.executor.send_tools({"final_answer": FinalAnswerTool()})
code_action = 'final_answer("This is the final answer")'
code_output = self.executor(code_action)
assert code_output.output == "This is the final answer", "Result should be 'This is the final answer'"
def test_execute_multiline_output(self):
"""Test execution that returns a string"""
self.executor.send_tools({"final_answer": FinalAnswerTool()})
code_action = 'result = "This is the final answer"\nfinal_answer(result)'
code_output = self.executor(code_action)
assert code_output.output == "This is the final answer", "Result should be 'This is the final answer'"
def test_execute_image_output(self):
"""Test execution that returns a base64 image"""
self.executor.send_tools({"final_answer": FinalAnswerTool()})
code_action = dedent("""
import base64
from PIL import Image
from io import BytesIO
image = Image.new("RGB", (10, 10), (255, 0, 0))
final_answer(image)
""")
code_output = self.executor(code_action)
assert isinstance(code_output.output, PIL.Image.Image), "Result should be a PIL Image"
def test_syntax_error_handling(self):
"""Test handling of syntax errors"""
code_action = 'print("Missing Parenthesis' # Syntax error
with pytest.raises(AgentError) as exception_info:
self.executor(code_action)
assert "SyntaxError" in str(exception_info.value), "Should raise a syntax error"
@pytest.mark.parametrize(
"code_action, expected_result",
[
(
dedent('''
final_answer("""This is
a multiline
final answer""")
'''),
"This is\na multiline\nfinal answer",
),
(
dedent("""
text = '''Text containing
final_answer(5)
'''
final_answer(text)
"""),
"Text containing\nfinal_answer(5)\n",
),
(
dedent("""
num = 2
if num == 1:
final_answer("One")
elif num == 2:
final_answer("Two")
"""),
"Two",
),
],
)
def test_final_answer_patterns(self, code_action, expected_result):
self.executor.send_tools({"final_answer": FinalAnswerTool()})
code_output = self.executor(code_action)
assert code_output.is_final_answer is True
assert code_output.output == expected_result
def test_custom_final_answer(self):
class CustomFinalAnswerTool(FinalAnswerTool):
def forward(self, answer: str) -> str:
return "CUSTOM" + answer
self.executor.send_tools({"final_answer": CustomFinalAnswerTool()})
code_action = dedent("""
final_answer(answer="_answer")
""")
code_output = self.executor(code_action)
assert code_output.is_final_answer is True
assert code_output.output == "CUSTOM_answer"
def test_custom_final_answer_with_custom_inputs(self):
class CustomFinalAnswerToolWithCustomInputs(FinalAnswerTool):
inputs = {
"answer1": {"type": "string", "description": "First part of the answer."},
"answer2": {"type": "string", "description": "Second part of the answer."},
}
def forward(self, answer1: str, answer2: str) -> str:
return answer1 + "CUSTOM" + answer2
self.executor.send_tools({"final_answer": CustomFinalAnswerToolWithCustomInputs()})
code_action = dedent("""
final_answer(
answer1="answer1_",
answer2="_answer2"
)
""")
code_output = self.executor(code_action)
assert code_output.is_final_answer is True
assert code_output.output == "answer1_CUSTOM_answer2"
@require_run_all
class TestDockerExecutorIntegration(CommonDockerExecutorIntegration):
@pytest.fixture
def custom_executor(self):
executor = DockerExecutor(
additional_imports=["pillow", "numpy"],
logger=AgentLogger(LogLevel.INFO, Console(force_terminal=False, file=io.StringIO())),
)
yield executor
executor.delete()
def test_initialization(self):
"""Check if DockerExecutor initializes without errors"""
assert self.executor.container is not None, "Container should be initialized"
def test_cleanup_on_deletion(self):
"""Test if Docker container stops and removes on deletion"""
container_id = self.executor.container.id
self.executor.delete() # Trigger cleanup
client = docker.from_env()
containers = [c.id for c in client.containers.list(all=True)]
assert container_id not in containers, "Container should be removed"
@require_run_all
class TestModalExecutorIntegration(CommonDockerExecutorIntegration):
@pytest.fixture
def custom_executor(self):
executor = ModalExecutor(
additional_imports=["pillow", "numpy"],
logger=AgentLogger(LogLevel.INFO, Console(force_terminal=False, file=io.StringIO())),
)
yield executor
executor.delete()
class TestModalExecutorUnit:
@patch("smolagents.remote_executors._websocket_run_code_raise_errors")
@patch("requests.post")
@patch("requests.get")
@patch("websocket.create_connection")
@patch("modal.App.lookup")
@patch("modal.Sandbox.create")
def test_sandbox_lifecycle(
self, mock_sandbox_create, mock_app_lookup, mock_create_connection, mock_get, mock_post, mock_run_code_raises
):
"""Test that sandbox is created with the correct kwargs and cleaned up correctly."""
modal = pytest.importorskip("modal")
port = 8889
logger = MagicMock()
mock_sandbox = MagicMock()
tunnel_mock = MagicMock()
tunnel_mock.host = "r4234.modal.host"
mock_sandbox.tunnels.return_value = {port: tunnel_mock}
mock_get.return_value.status_code = 200
mock_post.return_value.status_code = 201
mock_post.return_value.json.return_value = {"id": "test-kernel-id"}
mock_run_code_raises.return_value = CodeOutput(output="3", logs="", is_final_answer=False)
mock_sandbox_create.return_value = mock_sandbox
executor = ModalExecutor(
additional_imports=[],
logger=logger,
app_name="my-custom-app-name",
port=port,
create_kwargs={
"secrets": [modal.Secret.from_dict({"MY_SECRET": "ABC"})],
"timeout": 100,
"cpu": 2,
},
)
create_call = mock_sandbox_create.mock_calls[0]
assert create_call.args == (
"jupyter",
"kernelgateway",
"--KernelGatewayApp.ip=0.0.0.0",
f"--KernelGatewayApp.port={port}",
)
assert create_call.kwargs["timeout"] == 100
assert create_call.kwargs["cpu"] == 2
assert len(create_call.kwargs["secrets"]) == 2
mock_app_lookup.assert_called_with("my-custom-app-name", create_if_missing=True)
executor.run_code_raise_errors("1 + 2")
executor.cleanup()
mock_sandbox.terminate.assert_called()
class TestWasmExecutorUnit:
def test_wasm_executor_instantiation(self):
logger = MagicMock()
# Mock subprocess.run to simulate Deno being installed
with (
patch("subprocess.run") as mock_run,
patch("subprocess.Popen") as mock_popen,
patch("smolagents.remote_executors.requests.Session") as mock_session_cls,
patch("time.sleep"),
):
# Configure mocks
mock_run.return_value.returncode = 0
mock_process = MagicMock()
mock_process.poll.return_value = None
mock_popen.return_value = mock_process
mock_session = MagicMock()
mock_session.get.return_value.status_code = 200
mock_session_cls.return_value = mock_session
# Create the executor
executor = WasmExecutor(additional_imports=["numpy", "pandas"], logger=logger, timeout=30)
# Verify the executor was created correctly
assert isinstance(executor, WasmExecutor)
assert executor.logger == logger
assert executor.timeout == 30
assert "numpy" in executor.installed_packages
assert "pandas" in executor.installed_packages
# Verify Deno was checked
assert mock_run.call_count == 1
assert mock_run.call_args.args[0][0] == "deno"
assert mock_run.call_args.args[0][1] == "--version"
# Verify server was started
assert mock_popen.call_count == 1
assert mock_popen.call_args.args[0][0] == "deno"
assert mock_popen.call_args.args[0][1] == "run"
assert (
"--allow-net=127.0.0.1:8000,cdn.jsdelivr.net:443,pypi.org:443,files.pythonhosted.org:443"
in (mock_popen.call_args.args[0])
)
# Clean up
with patch("shutil.rmtree"):
executor.cleanup()
@require_run_all
class TestWasmExecutorIntegration:
"""
Integration tests for WasmExecutor.
These tests require Deno to be installed on the system.
Skip these tests if you don't have Deno installed.
"""
@pytest.fixture(autouse=True)
def setup_and_teardown(self):
"""Setup and teardown for each test."""
try:
# Check if Deno is installed
import subprocess
subprocess.run(["deno", "--version"], capture_output=True, check=True)
# Create the executor
self.executor = WasmExecutor(
additional_imports=["numpy", "pandas"],
logger=AgentLogger(LogLevel.INFO, Console(force_terminal=False, file=io.StringIO())),
timeout=60,
)
yield
# Clean up
self.executor.cleanup()
except (subprocess.SubprocessError, FileNotFoundError):
pytest.skip("Deno is not installed, skipping integration tests")
def test_basic_execution(self):
"""Test basic code execution."""
code = "a = 2 + 2; print(f'Result: {a}')"
code_output = self.executor(code)
assert "Result: 4" in code_output.logs
def test_state_persistence(self):
"""Test that variables persist between executions."""
# Define a variable
self.executor("x = 42")
# Use the variable in a subsequent execution
code_output = self.executor("print(x)")
assert "42" in code_output.logs
def test_final_answer(self):
"""Test returning a final answer."""
self.executor.send_tools({"final_answer": FinalAnswerTool()})
code = 'final_answer("This is the final answer")'
code_output = self.executor(code)
assert code_output.output == "This is the final answer"
assert code_output.is_final_answer is True
def test_numpy_execution(self):
"""Test execution with NumPy."""
code = """
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(f"Mean: {np.mean(arr)}")
"""
code_output = self.executor(code)
assert "Mean: 3.0" in code_output.logs
def test_error_handling(self):
"""Test handling of Python errors."""
code = "1/0" # Division by zero
with pytest.raises(AgentError) as excinfo:
self.executor(code)
assert "ZeroDivisionError" in str(excinfo.value)
def test_syntax_error_handling(self):
"""Test handling of syntax errors."""
code = "print('Missing parenthesis" # Missing closing parenthesis
with pytest.raises(AgentError) as excinfo:
self.executor(code)
assert "SyntaxError" in str(excinfo.value)
class TestBlaxelExecutorUnit:
def test_blaxel_executor_instantiation_without_blaxel_sdk(self):
"""Test that BlaxelExecutor raises appropriate error when blaxel SDK is not installed."""
logger = MagicMock()
with patch.dict("sys.modules", {"blaxel.core": None}):
with pytest.raises(ModuleNotFoundError) as excinfo:
BlaxelExecutor(additional_imports=[], logger=logger)
assert "Please install 'blaxel' extra" in str(excinfo.value)
@patch("smolagents.remote_executors._create_kernel_http")
@patch("blaxel.core.SandboxInstance")
@patch("blaxel.core.settings")
def test_blaxel_executor_instantiation_with_blaxel_sdk(
self, mock_settings, mock_sandbox_instance, mock_create_kernel
):
"""Test BlaxelExecutor instantiation with mocked Blaxel SDK."""
# patch manually for Python 3.10 compatibility
from unittest.mock import patch
mod = importlib.import_module("blaxel.core.client.api.compute")
patcher = patch.object(mod, "create_sandbox")
mock_create_sandbox = patcher.start()
logger = MagicMock()
mock_settings.headers = {}
# Mock sandbox response
mock_response = MagicMock()
mock_create_sandbox.sync.return_value = mock_response
# Mock SandboxInstance
mock_sandbox = MagicMock()
mock_metadata = MagicMock()
mock_metadata.url = "https://test-sandbox.bl.run"
mock_sandbox.metadata = mock_metadata
mock_sandbox_instance.return_value = mock_sandbox
# Mock kernel creation
mock_create_kernel.return_value = "kernel-123"
executor = BlaxelExecutor(additional_imports=[], logger=logger)
patcher.stop()
assert executor.sandbox_name.startswith("smolagent-executor-")
assert executor.image == "blaxel/jupyter-notebook"
assert executor.memory == 4096
assert executor.region is None
@patch("smolagents.remote_executors.BlaxelExecutor.install_packages")
@patch("smolagents.remote_executors._create_kernel_http")
@patch("blaxel.core.SandboxInstance")
@patch("blaxel.core.settings")
def test_blaxel_executor_custom_parameters(
self, mock_settings, mock_sandbox_instance, mock_create_kernel, mock_install_packages
):
"""Test BlaxelExecutor with custom parameters."""
logger = MagicMock()
mock_settings.headers = {}
mock_install_packages.return_value = ["numpy"]
# Mock sandbox response
mock_response = MagicMock()
# patch manually for Python 3.10 compatibility
mod = importlib.import_module("blaxel.core.client.api.compute")
create_sandbox_patcher = patch.object(mod, "create_sandbox")
mock_create_sandbox = create_sandbox_patcher.start()
mock_create_sandbox.sync.return_value = mock_response
# Mock SandboxInstance
mock_sandbox = MagicMock()
mock_metadata = MagicMock()
mock_metadata.url = "https://test-sandbox.us-was-1.bl.run"
mock_sandbox.metadata = mock_metadata
mock_sandbox_instance.return_value = mock_sandbox
# Mock kernel creation
mock_create_kernel.return_value = "kernel-123"
executor = BlaxelExecutor(
additional_imports=["numpy"],
logger=logger,
sandbox_name="test-sandbox",
image="custom-image:latest",
memory=8192,
region="us-was-1",
)
create_sandbox_patcher.stop()
assert executor.sandbox_name == "test-sandbox"
assert executor.image == "custom-image:latest"
assert executor.memory == 8192
assert executor.region == "us-was-1"
assert mock_install_packages.called
@patch("smolagents.remote_executors._create_kernel_http")
@patch("blaxel.core.SandboxInstance")
@patch("blaxel.core.settings")
def test_blaxel_executor_cleanup(self, mock_settings, mock_sandbox_instance, mock_create_kernel):
"""Test BlaxelExecutor cleanup method."""
# patch manually for Python 3.10 compatibility
from unittest.mock import patch
mod = importlib.import_module("blaxel.core.client.api.compute")
create_sandbox_patcher = patch.object(mod, "create_sandbox")
mock_create_sandbox = create_sandbox_patcher.start()
delete_sandbox_patcher = patch.object(mod, "delete_sandbox")
mock_delete_sandbox = delete_sandbox_patcher.start()
logger = MagicMock()
mock_settings.headers = {}
# Mock sandbox response
mock_response = MagicMock()
mock_create_sandbox.sync.return_value = mock_response
# Mock SandboxInstance
mock_sandbox = MagicMock()
mock_metadata = MagicMock()
mock_metadata.url = "https://test-sandbox.bl.run"
mock_sandbox.metadata = mock_metadata
mock_sandbox_instance.return_value = mock_sandbox
# Mock kernel creation
mock_create_kernel.return_value = "kernel-123"
executor = BlaxelExecutor(additional_imports=[], logger=logger)
# Test cleanup
executor.cleanup()
create_sandbox_patcher.stop()
delete_sandbox_patcher.stop()
# Verify that delete_sandbox.sync was called
assert mock_delete_sandbox.sync.called
# Verify sandbox reference was cleaned up
assert not hasattr(executor, "sandbox")
================================================
FILE: tests/test_search.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from smolagents import DuckDuckGoSearchTool
from .test_tools import ToolTesterMixin
from .utils.markers import require_run_all
class TestDuckDuckGoSearchTool(ToolTesterMixin):
def setup_method(self):
self.tool = DuckDuckGoSearchTool()
self.tool.setup()
@require_run_all
def test_exact_match_arg(self):
result = self.tool("Agents")
assert isinstance(result, str)
@require_run_all
def test_agent_type_output(self):
super().test_agent_type_output()
================================================
FILE: tests/test_serialization.py
================================================
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Comprehensive tests for SafeSerializer covering edge cases, error handling,
performance, and integration scenarios.
"""
import base64
import json
import pickle
import warnings
from datetime import datetime, timedelta
from decimal import Decimal
from pathlib import Path
import pytest
from smolagents.serialization import SafeSerializer, SerializationError
# Module-level class for pickle tests (local classes can't be pickled)
class PicklableCustomClass:
"""A simple class that can be pickled."""
def __init__(self):
self.value = 42
class TestSafeSerializationSecurity:
"""Test that safe mode properly blocks pickle."""
def test_safe_mode_blocks_custom_classes(self):
"""Verify custom classes cannot be serialized in safe mode."""
class CustomClass:
def __init__(self):
self.value = 42
obj = CustomClass()
# Should raise SerializationError in safe mode
with pytest.raises(SerializationError, match="Cannot safely serialize"):
SafeSerializer.dumps(obj, allow_pickle=False)
def test_safe_mode_blocks_pickle_deserialization(self):
"""Verify pickle data is rejected in safe mode."""
# Create pickle data (no "safe:" prefix)
pickle_data = base64.b64encode(pickle.dumps({"test": "data"})).decode()
# Should raise error in safe mode
with pytest.raises(SerializationError, match="Pickle data rejected"):
SafeSerializer.loads(pickle_data, allow_pickle=False)
def test_pickle_fallback_with_warning(self):
"""Verify pickle fallback works but warns in legacy mode."""
obj = PicklableCustomClass()
# Should work but emit warning
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
serialized = SafeSerializer.dumps(obj, allow_pickle=True)
# Check warning was raised
assert len(w) == 1
assert issubclass(w[0].category, FutureWarning)
assert "insecure pickle" in str(w[0].message).lower()
# Should deserialize successfully (with warning)
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
result = SafeSerializer.loads(serialized, allow_pickle=True)
assert result.value == 42
assert len(w) == 1
assert "pickle data" in str(w[0].message).lower()
class TestSafeSerializationRoundtrip:
"""Test that safe types serialize and deserialize correctly."""
def test_primitives(self):
"""Test basic Python types."""
test_cases = [
None,
True,
False,
42,
3.14,
"hello",
b"bytes",
complex(1, 2),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
assert serialized.startswith("safe:")
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_collections(self):
"""Test collections."""
test_cases = [
[1, 2, 3],
{"key": "value", "nested": {"a": 1}},
(1, 2, 3),
{1, 2, 3},
frozenset([1, 2, 3]),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_datetime_types(self):
"""Test datetime module types."""
now = datetime.now()
test_cases = [
now,
now.date(),
now.time(),
timedelta(days=1, hours=2, minutes=3),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_special_types(self):
"""Test Decimal and Path."""
test_cases = [
Decimal("3.14159"),
Path("/tmp/test.txt"),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_complex_nested_structure(self):
"""Test deeply nested structures."""
obj = {
"primitives": [1, 2.5, "string", None, True],
"collections": {
"list": [1, 2, 3],
"tuple": (4, 5, 6),
"set": {7, 8, 9},
},
"datetime": datetime.now(),
"path": Path("/tmp"),
"bytes": b"binary data",
}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
assert serialized.startswith("safe:")
result = SafeSerializer.loads(serialized, allow_pickle=False)
# Check structure is preserved
assert result["primitives"] == obj["primitives"]
assert result["collections"]["list"] == obj["collections"]["list"]
assert result["datetime"] == obj["datetime"]
assert result["path"] == obj["path"]
assert result["bytes"] == obj["bytes"]
class TestBackwardCompatibility:
"""Test that legacy pickle data can still be read when explicitly allowed."""
def test_read_legacy_pickle_data(self):
"""Verify we can read old pickle data when allow_insecure=True."""
# Simulate legacy pickle data (no "safe:" prefix)
legacy_data = {"key": "value", "number": 42}
pickle_encoded = base64.b64encode(pickle.dumps(legacy_data)).decode()
# Should work with allow_pickle=True
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
result = SafeSerializer.loads(pickle_encoded, allow_pickle=True)
assert result == legacy_data
assert len(w) == 1 # Warning emitted
assert "pickle data" in str(w[0].message).lower()
def test_safe_data_is_preferred(self):
"""Verify safe serialization is used even when pickle is allowed."""
# Basic dict should use safe serialization
obj = {"key": [1, 2, 3]}
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
serialized = SafeSerializer.dumps(obj, allow_pickle=True)
# Should use safe format (no warning)
assert serialized.startswith("safe:")
assert len(w) == 0 # No warning because safe was used
class TestDefaultBehavior:
"""Test that defaults are secure."""
def test_dumps_defaults_to_safe(self):
"""Verify dumps defaults to safe mode."""
obj = {"key": "value"}
# Call without safe_serialization parameter - should default to True
serialized = SafeSerializer.dumps(obj)
assert serialized.startswith("safe:")
# Should be deserializable in safe mode
result = SafeSerializer.loads(serialized)
assert result == obj
def test_loads_defaults_to_safe(self):
"""Verify loads defaults to safe mode."""
# Create safe data
obj = {"key": "value"}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
# Call without safe_serialization parameter - should default to True
result = SafeSerializer.loads(serialized)
assert result == obj
# Create pickle data
pickle_data = base64.b64encode(pickle.dumps(obj)).decode()
# Should reject pickle data by default
with pytest.raises(SerializationError, match="Pickle data rejected"):
SafeSerializer.loads(pickle_data)
class TestEdgeCases:
"""Test edge cases and boundary conditions."""
def test_empty_data(self):
"""Test serialization of empty collections."""
test_cases = [
[],
{},
(),
set(),
frozenset(),
"",
b"",
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_nested_empty_structures(self):
"""Test deeply nested empty structures."""
obj = {
"empty_list": [],
"empty_dict": {},
"nested": {
"empty_tuple": (),
"empty_set": set(),
"deeply_nested": {"still_empty": []},
},
}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_very_large_numbers(self):
"""Test handling of very large integers and floats."""
test_cases = [
10**100, # Very large int
-(10**100), # Very large negative int
1.7976931348623157e308, # Near max float
2.2250738585072014e-308, # Near min positive float
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_special_float_values(self):
"""Test special float values (infinity, nan)."""
import math
# Note: NaN != NaN, so we handle it specially
test_cases = [
(float("inf"), float("inf")),
(float("-inf"), float("-inf")),
]
for obj, expected in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == expected
# NaN special case
nan_obj = float("nan")
serialized = SafeSerializer.dumps(nan_obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert math.isnan(result)
def test_unicode_strings(self):
"""Test handling of various unicode strings."""
test_cases = [
"Hello 世界", # Mixed ASCII and Chinese
"🚀🎉💎", # Emojis
"Ñoño", # Accented characters
"\u0000", # Null character
"Line1\nLine2\tTabbed", # Escape sequences
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_very_long_strings(self):
"""Test handling of very long strings."""
long_string = "a" * 1_000_000 # 1MB string
serialized = SafeSerializer.dumps(long_string, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == long_string
def test_deeply_nested_structures(self):
"""Test deeply nested data structures."""
# Create nested structure
obj = {"level": 0}
current = obj
for i in range(1, 100): # 100 levels deep
current["nested"] = {"level": i}
current = current["nested"]
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_dict_with_tuple_keys(self):
"""Test dictionaries with tuple keys."""
obj = {
(1, 2): "tuple_key",
(3, 4, 5): "longer_tuple",
("a", "b"): "string_tuple",
}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_dict_with_integer_keys(self):
"""Test dictionaries with non-string keys."""
obj = {
1: "one",
2: "two",
100: "hundred",
}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_mixed_collection_types(self):
"""Test mixed collection types in one structure."""
obj = {
"list": [1, 2, 3],
"tuple": (4, 5, 6),
"set": {7, 8, 9},
"frozenset": frozenset([10, 11, 12]),
"nested_list": [[1, 2], [3, 4]],
"list_of_tuples": [(1, 2), (3, 4)],
}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
# Compare each field
assert result["list"] == obj["list"]
assert result["tuple"] == obj["tuple"]
assert result["set"] == obj["set"]
assert result["frozenset"] == obj["frozenset"]
assert result["nested_list"] == obj["nested_list"]
assert result["list_of_tuples"] == obj["list_of_tuples"]
class TestErrorHandling:
"""Test error handling and malformed data."""
def test_invalid_json_data(self):
"""Test handling of invalid JSON data."""
with pytest.raises((json.JSONDecodeError, SerializationError)):
SafeSerializer.loads("safe:invalid json", allow_pickle=False)
def test_corrupted_safe_prefix(self):
"""Test handling of data with safe prefix but invalid JSON."""
with pytest.raises((json.JSONDecodeError, SerializationError)):
SafeSerializer.loads("safe:{broken", allow_pickle=False)
def test_missing_type_field(self):
"""Test handling of malformed type markers."""
# Valid JSON but missing required fields
malformed = "safe:" + json.dumps({"data": [1, 2, 3]}) # Missing __type__
# Should still work as regular dict
result = SafeSerializer.loads(malformed, allow_pickle=False)
assert result == {"data": [1, 2, 3]}
def test_unknown_type_marker(self):
"""Test handling of unknown type markers."""
unknown_type = "safe:" + json.dumps({"__type__": "unknown_type", "data": "something"})
# Should return as dict with type marker
result = SafeSerializer.loads(unknown_type, allow_pickle=False)
assert "__type__" in result
def test_invalid_base64_in_bytes(self):
"""Test handling of invalid base64 in bytes type."""
invalid_bytes = "safe:" + json.dumps({"__type__": "bytes", "data": "not-valid-base64!!!"})
with pytest.raises(Exception): # Will raise base64 decode error
SafeSerializer.loads(invalid_bytes, allow_pickle=False)
def test_serialization_of_none_type(self):
"""Test that None type is handled correctly."""
obj = None
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result is None
def test_serialization_of_function(self):
"""Test that functions cannot be serialized safely."""
def my_function():
pass
with pytest.raises(SerializationError):
SafeSerializer.dumps(my_function, allow_pickle=False)
def test_serialization_of_class(self):
"""Test that classes cannot be serialized safely."""
class MyClass:
pass
with pytest.raises(SerializationError):
SafeSerializer.dumps(MyClass, allow_pickle=False)
def test_serialization_of_module(self):
"""Test that modules cannot be serialized safely."""
import os
with pytest.raises(SerializationError):
SafeSerializer.dumps(os, allow_pickle=False)
class TestTypeCoverage:
"""Test all supported types comprehensively."""
def test_all_datetime_types(self):
"""Test all datetime module types."""
from datetime import date, datetime, time
test_cases = [
datetime(2024, 1, 1, 12, 30, 45),
date(2024, 1, 1),
time(12, 30, 45),
timedelta(days=5, hours=3, minutes=30, seconds=15),
datetime.min,
datetime.max,
date.min,
date.max,
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_decimal_precision(self):
"""Test Decimal type with various precisions."""
from decimal import getcontext
# Set high precision
getcontext().prec = 50
test_cases = [
Decimal("3.14159265358979323846264338327950288419716939937510"),
Decimal("0.1") + Decimal("0.2"), # Famous float precision issue
Decimal("1e-100"),
Decimal("1e100"),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_pathlib_types(self):
"""Test various Path types."""
test_cases = [
Path("/tmp/test.txt"),
Path("relative/path/file.py"),
Path("/"),
Path("."),
Path(".."),
Path("/path/with spaces/file.txt"),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_complex_numbers(self):
"""Test complex number handling."""
test_cases = [
complex(1, 2),
complex(0, 0),
complex(-5, 10),
complex(3.14, 2.71),
1 + 2j,
-5 + 10j,
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_bytes_types(self):
"""Test various bytes objects."""
test_cases = [
b"hello",
b"\x00\x01\x02\x03",
b"Binary\xff\xfe\xfd",
bytes(range(256)), # All byte values
b"", # Empty bytes
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
class TestNumpySupport:
"""Test numpy array serialization (optional, skip if not installed)."""
def test_numpy_array(self):
"""Test numpy array roundtrip."""
pytest.importorskip("numpy")
import numpy as np
arr = np.array([[1, 2], [3, 4]], dtype=np.float32)
serialized = SafeSerializer.dumps(arr, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
np.testing.assert_array_equal(result, arr)
assert result.dtype == arr.dtype
def test_numpy_scalars(self):
"""Test numpy scalar types."""
pytest.importorskip("numpy")
import numpy as np
test_cases = [
np.int32(42),
np.float64(3.14),
]
for obj in test_cases:
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj.item()
def test_numpy_various_dtypes(self):
"""Test numpy arrays with various dtypes."""
pytest.importorskip("numpy")
import numpy as np
# Test numeric dtypes (non-complex)
dtypes = [
np.int8,
np.int16,
np.int32,
np.int64,
np.uint8,
np.uint16,
np.uint32,
np.uint64,
np.float16,
np.float32,
np.float64,
np.bool_,
]
for dtype in dtypes:
arr = np.array([1, 2, 3], dtype=dtype)
serialized = SafeSerializer.dumps(arr, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
np.testing.assert_array_equal(result, arr)
assert result.dtype == arr.dtype
# Complex dtypes need special handling - test separately
# Note: numpy complex arrays are not fully supported in safe mode
# as they require custom complex number serialization
def test_numpy_multidimensional(self):
"""Test multidimensional numpy arrays."""
pytest.importorskip("numpy")
import numpy as np
test_cases = [
np.array([[1, 2], [3, 4]]), # 2D
np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]), # 3D
np.zeros((10, 10, 10)), # Large 3D
np.ones((5, 5)), # 2D ones
]
for arr in test_cases:
serialized = SafeSerializer.dumps(arr, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
np.testing.assert_array_equal(result, arr)
def test_numpy_empty_array(self):
"""Test empty numpy array."""
pytest.importorskip("numpy")
import numpy as np
arr = np.array([])
serialized = SafeSerializer.dumps(arr, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
np.testing.assert_array_equal(result, arr)
class TestPILSupport:
"""Test PIL Image serialization (optional, skip if not installed)."""
def test_pil_image(self):
"""Test PIL Image roundtrip."""
pytest.importorskip("PIL")
from PIL import Image
# Create a simple test image
img = Image.new("RGB", (10, 10), color="red")
serialized = SafeSerializer.dumps(img, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert isinstance(result, Image.Image)
assert result.size == img.size
assert result.mode == img.mode
def test_pil_various_modes(self):
"""Test PIL images in various modes."""
pytest.importorskip("PIL")
from PIL import Image
modes = ["RGB", "RGBA", "L", "1"] # Color, Alpha, Grayscale, Binary
for mode in modes:
img = Image.new(mode, (10, 10), color="red" if mode != "1" else 1)
serialized = SafeSerializer.dumps(img, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert isinstance(result, Image.Image)
assert result.mode == img.mode
assert result.size == img.size
def test_pil_various_sizes(self):
"""Test PIL images of various sizes."""
pytest.importorskip("PIL")
from PIL import Image
sizes = [(1, 1), (100, 100), (500, 300)]
for size in sizes:
img = Image.new("RGB", size, color="blue")
serialized = SafeSerializer.dumps(img, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result.size == img.size
class TestDataclasses:
"""Test dataclass serialization."""
def test_simple_dataclass(self):
"""Test simple dataclass."""
from dataclasses import dataclass
@dataclass
class Person:
name: str
age: int
person = Person(name="Alice", age=30)
serialized = SafeSerializer.dumps(person, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
# Result is a dict representation
assert result["__dataclass__"] == "Person"
assert result["name"] == "Alice"
assert result["age"] == 30
def test_nested_dataclass(self):
"""Test nested dataclasses."""
from dataclasses import dataclass
@dataclass
class Address:
street: str
city: str
@dataclass
class Person:
name: str
address: Address
person = Person(name="Bob", address=Address(street="123 Main St", city="NYC"))
serialized = SafeSerializer.dumps(person, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result["name"] == "Bob"
assert result["address"]["street"] == "123 Main St"
class TestPerformance:
"""Performance tests for large data."""
def test_large_list(self):
"""Test serialization of large list."""
large_list = list(range(100_000))
serialized = SafeSerializer.dumps(large_list, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == large_list
def test_large_dict(self):
"""Test serialization of large dictionary."""
large_dict = {f"key_{i}": i for i in range(10_000)}
serialized = SafeSerializer.dumps(large_dict, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == large_dict
def test_deeply_nested_performance(self):
"""Test performance with deeply nested structures."""
obj = {"level": 0}
current = obj
for i in range(1, 100): # 100 levels (avoid recursion limit)
current["nested"] = {"level": i}
current = current["nested"]
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
class TestPrefixHandling:
"""Test handling of different prefix formats."""
def test_safe_prefix_detection(self):
"""Test detection of safe: prefix."""
obj = {"test": "data"}
serialized = SafeSerializer.dumps(obj, allow_pickle=False)
assert serialized.startswith("safe:")
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == obj
def test_pickle_prefix_with_allow_pickle(self):
"""Test pickle: prefix when pickle is allowed."""
# Create an object that needs pickle
obj = PicklableCustomClass()
serialized = SafeSerializer.dumps(obj, allow_pickle=True)
# Should have pickle prefix
assert serialized.startswith("pickle:")
result = SafeSerializer.loads(serialized, allow_pickle=True)
assert result.value == 42
def test_legacy_format_detection(self):
"""Test detection and handling of legacy format (no prefix)."""
# Simulate legacy pickle data (no prefix)
legacy_data = {"key": "value"}
legacy_encoded = base64.b64encode(pickle.dumps(legacy_data)).decode()
# Should work with allow_pickle=True
result = SafeSerializer.loads(legacy_encoded, allow_pickle=True)
assert result == legacy_data
class TestRealWorldScenarios:
"""Test real-world usage scenarios."""
def test_agent_variables_scenario(self):
"""Test typical agent variables scenario."""
import numpy as np
from PIL import Image
# Typical variables an agent might use
variables = {
"search_results": ["result1", "result2", "result3"],
"config": {
"temperature": 0.7,
"max_tokens": 100,
"model": "gpt-4",
},
"data_array": np.array([1.0, 2.0, 3.0]),
"image": Image.new("RGB", (50, 50)),
"timestamp": datetime.now(),
"status": "running",
"counter": 42,
}
serialized = SafeSerializer.dumps(variables, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result["search_results"] == variables["search_results"]
assert result["config"] == variables["config"]
assert result["status"] == variables["status"]
assert result["counter"] == variables["counter"]
def test_final_answer_scenario(self):
"""Test typical final answer serialization."""
final_answers = [
"Simple string answer",
{"answer": "structured", "confidence": 0.95},
["multiple", "results", "returned"],
42,
3.14159,
True,
]
for answer in final_answers:
serialized = SafeSerializer.dumps(answer, allow_pickle=False)
result = SafeSerializer.loads(serialized, allow_pickle=False)
assert result == answer
class TestGeneratedDeserializerCode:
"""Regression tests for generated deserializer code used by remote executors."""
def test_generated_deserializer_executes_for_safe_payload(self):
code = SafeSerializer.get_deserializer_code(allow_pickle=False)
namespace = {}
exec(code, namespace, namespace)
payload = SafeSerializer.dumps(
{
"count": 3,
"items": (1, 2, 3),
"raw": b"bytes",
},
allow_pickle=False,
)
result = namespace["_deserialize"](payload)
assert result == {"count": 3, "items": (1, 2, 3), "raw": b"bytes"}
def test_generated_deserializer_handles_pickle_prefix_when_enabled(self):
code = SafeSerializer.get_deserializer_code(allow_pickle=True)
namespace = {}
exec(code, namespace, namespace)
payload = "pickle:" + base64.b64encode(pickle.dumps({"hello": "world"})).decode()
result = namespace["_deserialize"](payload)
assert result == {"hello": "world"}
class TestConcurrency:
"""Test thread safety and concurrent access."""
def test_concurrent_serialization(self):
"""Test concurrent serialization operations."""
import threading
results = []
errors = []
def serialize_data(data, index):
try:
serialized = SafeSerializer.dumps(data, allow_pickle=False)
deserialized = SafeSerializer.loads(serialized, allow_pickle=False)
results.append((index, deserialized == data))
except Exception as e:
errors.append((index, e))
threads = []
test_data = [{"thread": i, "data": list(range(100))} for i in range(10)]
for i, data in enumerate(test_data):
thread = threading.Thread(target=serialize_data, args=(data, i))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
assert len(errors) == 0, f"Errors occurred: {errors}"
assert len(results) == 10
assert all(success for _, success in results)
================================================
FILE: tests/test_telemetry.py
================================================
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Source: https://github.com/Arize-ai/openinference/blob/main/python/instrumentation/openinference-instrumentation-smolagents/tests/openinference/instrumentation/smolagents/test_instrumentor.py
from typing import Generator
import pytest
from .utils.markers import require_run_all
# Add this at the module level to skip all tests if OpenTelemetry is not available
pytest.importorskip("opentelemetry", reason="requires opentelemetry")
pytest.importorskip(
"openinference.instrumentation.smolagents", reason="requires openinference.instrumentation.smolagents"
)
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
from opentelemetry import trace as trace_api
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from opentelemetry.sdk.trace.export.in_memory_span_exporter import InMemorySpanExporter
from smolagents.models import InferenceClientModel
@pytest.fixture
def in_memory_span_exporter() -> InMemorySpanExporter:
return InMemorySpanExporter()
@pytest.fixture
def tracer_provider(in_memory_span_exporter: InMemorySpanExporter) -> trace_api.TracerProvider:
resource = Resource(attributes={})
tracer_provider = trace_sdk.TracerProvider(resource=resource)
span_processor = SimpleSpanProcessor(span_exporter=in_memory_span_exporter)
tracer_provider.add_span_processor(span_processor=span_processor)
return tracer_provider
@pytest.fixture(autouse=True)
def instrument(
tracer_provider: trace_api.TracerProvider,
in_memory_span_exporter: InMemorySpanExporter,
) -> Generator[None, None, None]:
SmolagentsInstrumentor().instrument(tracer_provider=tracer_provider, skip_dep_check=True)
yield
SmolagentsInstrumentor().uninstrument()
in_memory_span_exporter.clear()
@require_run_all
class TestOpenTelemetry:
def test_model(self, in_memory_span_exporter: InMemorySpanExporter):
model = InferenceClientModel()
_ = model(
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Who won the World Cup in 2018? Answer in one word with no punctuation.",
}
],
}
]
)
spans = in_memory_span_exporter.get_finished_spans()
assert len(spans) == 1
span = spans[0]
assert span.name == "InferenceClientModel.generate"
assert span.status.is_ok
assert span.attributes
================================================
FILE: tests/test_tool_validation.py
================================================
import ast
from textwrap import dedent
import pytest
from smolagents.default_tools import (
DuckDuckGoSearchTool,
GoogleSearchTool,
SpeechToTextTool,
VisitWebpageTool,
WebSearchTool,
)
from smolagents.tool_validation import MethodChecker, validate_tool_attributes
from smolagents.tools import Tool, tool
UNDEFINED_VARIABLE = "undefined_variable"
@pytest.mark.parametrize(
"tool_class", [DuckDuckGoSearchTool, GoogleSearchTool, SpeechToTextTool, VisitWebpageTool, WebSearchTool]
)
def test_validate_tool_attributes_with_default_tools(tool_class):
assert validate_tool_attributes(tool_class) is None, f"failed for {tool_class.name} tool"
class ValidTool(Tool):
name = "valid_tool"
description = "A valid tool"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
simple_attr = "string"
dict_attr = {"key": "value"}
def __init__(self, optional_param="default"):
super().__init__()
self.param = optional_param
def forward(self, input: str) -> str:
return input.upper()
@tool
def valid_tool_function(input: str) -> str:
"""A valid tool function.
Args:
input (str): Input string.
"""
return input.upper()
@pytest.mark.parametrize("tool_class", [ValidTool, valid_tool_function.__class__])
def test_validate_tool_attributes_valid(tool_class):
assert validate_tool_attributes(tool_class) is None
class InvalidToolName(Tool):
name = "invalid tool name"
description = "Tool with invalid name"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
def __init__(self):
super().__init__()
def forward(self, input: str) -> str:
return input
class InvalidToolComplexAttrs(Tool):
name = "invalid_tool"
description = "Tool with complex class attributes"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
complex_attr = [x for x in range(3)] # Complex class attribute
def __init__(self):
super().__init__()
def forward(self, input: str) -> str:
return input
class InvalidToolRequiredParams(Tool):
name = "invalid_tool"
description = "Tool with required params"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
def __init__(self, required_param, kwarg1=1): # No default value
super().__init__()
self.param = required_param
def forward(self, input: str) -> str:
return input
class InvalidToolNonLiteralDefaultParam(Tool):
name = "invalid_tool"
description = "Tool with non-literal default parameter value"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
def __init__(self, default_param=UNDEFINED_VARIABLE): # UNDEFINED_VARIABLE as default is non-literal
super().__init__()
self.default_param = default_param
def forward(self, input: str) -> str:
return input
class InvalidToolUndefinedNames(Tool):
name = "invalid_tool"
description = "Tool with undefined names"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
def forward(self, input: str) -> str:
return UNDEFINED_VARIABLE # Undefined name
@pytest.mark.parametrize(
"tool_class, expected_error",
[
(
InvalidToolName,
"Class attribute 'name' must be a valid Python identifier and not a reserved keyword, found 'invalid tool name'",
),
(InvalidToolComplexAttrs, "Complex attributes should be defined in __init__, not as class attributes"),
(InvalidToolRequiredParams, "Parameters in __init__ must have default values, found required parameters"),
(
InvalidToolNonLiteralDefaultParam,
"Parameters in __init__ must have literal default values, found non-literal defaults",
),
(InvalidToolUndefinedNames, "Name 'UNDEFINED_VARIABLE' is undefined"),
],
)
def test_validate_tool_attributes_exceptions(tool_class, expected_error):
with pytest.raises(ValueError, match=expected_error):
validate_tool_attributes(tool_class)
class MultipleAssignmentsTool(Tool):
name = "multiple_assignments_tool"
description = "Tool with multiple assignments"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
def __init__(self):
super().__init__()
def forward(self, input: str) -> str:
a, b = "1", "2"
return a + b
def test_validate_tool_attributes_multiple_assignments():
validate_tool_attributes(MultipleAssignmentsTool)
@tool
def tool_function_with_multiple_assignments(input: str) -> str:
"""A valid tool function.
Args:
input (str): Input string.
"""
a, b = "1", "2"
return input.upper() + a + b
@pytest.mark.parametrize("tool_instance", [MultipleAssignmentsTool(), tool_function_with_multiple_assignments])
def test_tool_to_dict_validation_with_multiple_assignments(tool_instance):
tool_instance.to_dict()
class TestMethodChecker:
def test_multiple_assignments(self):
source_code = dedent(
"""
def forward(self) -> str:
a, b = "1", "2"
return a + b
"""
)
method_checker = MethodChecker(set())
method_checker.visit(ast.parse(source_code))
assert method_checker.errors == []
================================================
FILE: tests/test_tools.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import os
import warnings
from textwrap import dedent
from typing import Any, Literal
from unittest.mock import MagicMock, patch
import mcp
import numpy as np
import PIL.Image
import pytest
from smolagents.agent_types import _AGENT_TYPE_MAPPING
from smolagents.tools import AUTHORIZED_TYPES, Tool, ToolCollection, launch_gradio_demo, tool, validate_tool_arguments
from .utils.markers import require_run_all
class ToolTesterMixin:
def test_inputs_output(self):
assert hasattr(self.tool, "inputs")
assert hasattr(self.tool, "output_type")
inputs = self.tool.inputs
assert isinstance(inputs, dict)
for _, input_spec in inputs.items():
assert "type" in input_spec
assert "description" in input_spec
assert input_spec["type"] in AUTHORIZED_TYPES
assert isinstance(input_spec["description"], str)
output_type = self.tool.output_type
assert output_type in AUTHORIZED_TYPES
def test_common_attributes(self):
assert hasattr(self.tool, "description")
assert hasattr(self.tool, "name")
assert hasattr(self.tool, "inputs")
assert hasattr(self.tool, "output_type")
def test_agent_type_output(self, create_inputs):
inputs = create_inputs(self.tool.inputs)
output = self.tool(**inputs, sanitize_inputs_outputs=True)
if self.tool.output_type != "any":
agent_type = _AGENT_TYPE_MAPPING[self.tool.output_type]
assert isinstance(output, agent_type)
@pytest.fixture
def create_inputs(self, shared_datadir):
def _create_inputs(tool_inputs: dict[str, dict[str | type, str]]) -> dict[str, Any]:
inputs = {}
for input_name, input_desc in tool_inputs.items():
input_type = input_desc["type"]
if input_type == "string":
inputs[input_name] = "Text input"
elif input_type == "image":
inputs[input_name] = PIL.Image.open(shared_datadir / "000000039769.png").resize((512, 512))
elif input_type == "audio":
inputs[input_name] = np.ones(3000)
else:
raise ValueError(f"Invalid type requested: {input_type}")
return inputs
return _create_inputs
class TestTool:
@pytest.mark.parametrize(
"type_value, should_raise_error, error_contains",
[
# Valid cases
("string", False, None),
(["string", "number"], False, None),
# Invalid cases
("invalid_type", ValueError, "must be one of"),
(["string", "invalid_type"], ValueError, "must be one of"),
([123, "string"], TypeError, "when type is a list, all elements must be strings"),
(123, TypeError, "must be a string or list of strings"),
],
)
def test_tool_input_type_validation(self, type_value, should_raise_error, error_contains):
"""Test the validation of the type property in tool inputs."""
# Define a tool class with the test type value
def create_tool():
class TestTool(Tool):
name = "test_tool"
description = "A tool for testing type validation"
inputs = {"text": {"type": type_value, "description": "Some input"}}
output_type = "string"
def forward(self, text) -> str:
return text
return TestTool()
# Check if we expect this to raise an exception
if should_raise_error:
with pytest.raises(should_raise_error) as exc_info:
create_tool()
# Verify the error message contains expected text
assert error_contains in str(exc_info.value)
else:
# Should not raise an exception
tool = create_tool()
assert isinstance(tool, Tool)
@pytest.mark.parametrize(
"tool_fixture, expected_output",
[
("no_input_tool", 'def no_input_tool() -> string:\n """Tool with no inputs\n """'),
(
"single_input_tool",
'def single_input_tool(text: string) -> string:\n """Tool with one input\n\n Args:\n text: Input text\n """',
),
(
"multi_input_tool",
'def multi_input_tool(text: string, count: integer) -> object:\n """Tool with multiple inputs\n\n Args:\n text: Text input\n count: Number count\n """',
),
(
"multiline_description_tool",
'def multiline_description_tool(input: string) -> string:\n """This is a tool with\n multiple lines\n in the description\n\n Args:\n input: Some input\n """',
),
],
)
def test_tool_to_code_prompt_output_format(self, tool_fixture, expected_output, request):
"""Test that to_code_prompt generates properly formatted and indented output."""
tool = request.getfixturevalue(tool_fixture)
code_prompt = tool.to_code_prompt()
assert code_prompt == expected_output
@pytest.mark.parametrize(
"tool_fixture, expected_output",
[
(
"no_input_tool",
"no_input_tool: Tool with no inputs\n Takes inputs: {}\n Returns an output of type: string",
),
(
"single_input_tool",
"single_input_tool: Tool with one input\n Takes inputs: {'text': {'type': 'string', 'description': 'Input text'}}\n Returns an output of type: string",
),
(
"multi_input_tool",
"multi_input_tool: Tool with multiple inputs\n Takes inputs: {'text': {'type': 'string', 'description': 'Text input'}, 'count': {'type': 'integer', 'description': 'Number count'}}\n Returns an output of type: object",
),
(
"multiline_description_tool",
"multiline_description_tool: This is a tool with\nmultiple lines\nin the description\n Takes inputs: {'input': {'type': 'string', 'description': 'Some input'}}\n Returns an output of type: string",
),
],
)
def test_tool_to_tool_calling_prompt_output_format(self, tool_fixture, expected_output, request):
"""Test that to_tool_calling_prompt generates properly formatted output."""
tool = request.getfixturevalue(tool_fixture)
tool_calling_prompt = tool.to_tool_calling_prompt()
assert tool_calling_prompt == expected_output
def test_tool_init_with_decorator(self):
@tool
def coolfunc(a: str, b: int) -> float:
"""Cool function
Args:
a: The first argument
b: The second one
"""
return b + 2, a
assert coolfunc.output_type == "number"
def test_tool_init_vanilla(self):
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = """
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint."""
inputs = {
"task": {
"type": "string",
"description": "the task category (such as text-classification, depth-estimation, etc)",
}
}
output_type = "string"
def forward(self, task: str) -> str:
return "best model"
tool = HFModelDownloadsTool()
assert list(tool.inputs.keys())[0] == "task"
def test_tool_init_decorator_raises_issues(self):
with pytest.raises(Exception) as e:
@tool
def coolfunc(a: str, b: int):
"""Cool function
Args:
a: The first argument
b: The second one
"""
return a + b
assert coolfunc.output_type == "number"
assert "Tool return type not found" in str(e)
with pytest.raises(Exception) as e:
@tool
def coolfunc(a: str, b: int) -> int:
"""Cool function
Args:
a: The first argument
"""
return b + a
assert coolfunc.output_type == "number"
assert "docstring has no description for the argument" in str(e)
def test_saving_tool_raises_error_imports_outside_function(self, tmp_path):
with pytest.raises(Exception) as e:
import numpy as np
@tool
def get_current_time() -> str:
"""
Gets the current time.
"""
return str(np.random.random())
get_current_time.save(tmp_path)
assert "np" in str(e)
# Also test with classic definition
with pytest.raises(Exception) as e:
class GetCurrentTimeTool(Tool):
name = "get_current_time_tool"
description = "Gets the current time"
inputs = {}
output_type = "string"
def forward(self):
return str(np.random.random())
get_current_time = GetCurrentTimeTool()
get_current_time.save(tmp_path)
assert "np" in str(e)
def test_tool_definition_raises_no_error_imports_in_function(self):
@tool
def get_current_time() -> str:
"""
Gets the current time.
"""
from datetime import datetime
return str(datetime.now())
class GetCurrentTimeTool(Tool):
name = "get_current_time_tool"
description = "Gets the current time"
inputs = {}
output_type = "string"
def forward(self):
from datetime import datetime
return str(datetime.now())
def test_tool_to_dict_allows_no_arg_in_init(self):
"""Test that a tool cannot be saved with required args in init"""
class FailTool(Tool):
name = "specific"
description = "test description"
inputs = {"string_input": {"type": "string", "description": "input description"}}
output_type = "string"
def __init__(self, url):
super().__init__(self)
self.url = url
def forward(self, string_input: str) -> str:
return self.url + string_input
fail_tool = FailTool("dummy_url")
with pytest.raises(Exception) as e:
fail_tool.to_dict()
assert "Parameters in __init__ must have default values, found required parameters" in str(e)
class PassTool(Tool):
name = "specific"
description = "test description"
inputs = {"string_input": {"type": "string", "description": "input description"}}
output_type = "string"
def __init__(self, url: str | None = "none"):
super().__init__(self)
self.url = url
def forward(self, string_input: str) -> str:
return self.url + string_input
fail_tool = PassTool()
fail_tool.to_dict()
def test_saving_tool_allows_no_imports_from_outside_methods(self, tmp_path):
# Test that using imports from outside functions fails
import numpy as np
class FailTool(Tool):
name = "specific"
description = "test description"
inputs = {"string_input": {"type": "string", "description": "input description"}}
output_type = "string"
def useless_method(self):
self.client = np.random.random()
return ""
def forward(self, string_input):
return self.useless_method() + string_input
fail_tool = FailTool()
with pytest.raises(Exception) as e:
fail_tool.save(tmp_path)
assert "'np' is undefined" in str(e)
# Test that putting these imports inside functions works
class SuccessTool(Tool):
name = "specific"
description = "test description"
inputs = {"string_input": {"type": "string", "description": "input description"}}
output_type = "string"
def useless_method(self):
import numpy as np
self.client = np.random.random()
return ""
def forward(self, string_input):
return self.useless_method() + string_input
success_tool = SuccessTool()
success_tool.save(tmp_path)
def test_tool_missing_class_attributes_raises_error(self):
with pytest.raises(Exception) as e:
class GetWeatherTool(Tool):
name = "get_weather"
description = "Get weather in the next days at given location."
inputs = {
"location": {"type": "string", "description": "the location"},
"celsius": {
"type": "string",
"description": "the temperature type",
},
}
def forward(self, location: str, celsius: bool | None = False) -> str:
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
GetWeatherTool()
assert "You must set an attribute output_type" in str(e)
def test_tool_from_decorator_optional_args(self):
@tool
def get_weather(location: str, celsius: bool | None = False) -> str:
"""
Get weather in the next days at given location.
Secretly this tool does not care about the location, it hates the weather everywhere.
Args:
location: the location
celsius: the temperature type
"""
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
assert "nullable" in get_weather.inputs["celsius"]
assert get_weather.inputs["celsius"]["nullable"]
assert "nullable" not in get_weather.inputs["location"]
def test_tool_mismatching_nullable_args_raises_error(self):
with pytest.raises(Exception) as e:
class GetWeatherTool(Tool):
name = "get_weather"
description = "Get weather in the next days at given location."
inputs = {
"location": {"type": "string", "description": "the location"},
"celsius": {
"type": "string",
"description": "the temperature type",
},
}
output_type = "string"
def forward(self, location: str, celsius: bool | None = False) -> str:
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
GetWeatherTool()
assert "Nullable" in str(e)
with pytest.raises(Exception) as e:
class GetWeatherTool2(Tool):
name = "get_weather"
description = "Get weather in the next days at given location."
inputs = {
"location": {"type": "string", "description": "the location"},
"celsius": {
"type": "string",
"description": "the temperature type",
},
}
output_type = "string"
def forward(self, location: str, celsius: bool = False) -> str:
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
GetWeatherTool2()
assert "Nullable" in str(e)
with pytest.raises(Exception) as e:
class GetWeatherTool3(Tool):
name = "get_weather"
description = "Get weather in the next days at given location."
inputs = {
"location": {"type": "string", "description": "the location"},
"celsius": {
"type": "string",
"description": "the temperature type",
"nullable": True,
},
}
output_type = "string"
def forward(self, location, celsius: str) -> str:
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
GetWeatherTool3()
assert "Nullable" in str(e)
def test_tool_default_parameters_is_nullable(self):
@tool
def get_weather(location: str, celsius: bool = False) -> str:
"""
Get weather in the next days at given location.
Args:
location: The location to get the weather for.
celsius: is the temperature given in celsius?
"""
return "The weather is UNGODLY with torrential rains and temperatures below -10°C"
assert get_weather.inputs["celsius"]["nullable"]
def test_tool_supports_any_none(self, tmp_path):
@tool
def get_weather(location: Any) -> None:
"""
Get weather in the next days at given location.
Args:
location: The location to get the weather for.
"""
return
get_weather.save(tmp_path)
assert get_weather.inputs["location"]["type"] == "any"
assert get_weather.output_type == "null"
def test_tool_supports_array(self):
@tool
def get_weather(locations: list[str], months: tuple[str, str] | None = None) -> dict[str, float]:
"""
Get weather in the next days at given locations.
Args:
locations: The locations to get the weather for.
months: The months to get the weather for
"""
return
assert get_weather.inputs["locations"]["type"] == "array"
assert get_weather.inputs["months"]["type"] == "array"
def test_tool_supports_string_literal(self):
@tool
def get_weather(unit: Literal["celsius", "fahrenheit"] = "celsius") -> None:
"""
Get weather in the next days at given location.
Args:
unit: The unit of temperature
"""
return
assert get_weather.inputs["unit"]["type"] == "string"
assert get_weather.inputs["unit"]["enum"] == ["celsius", "fahrenheit"]
def test_tool_supports_numeric_literal(self):
@tool
def get_choice(choice: Literal[1, 2, 3]) -> None:
"""
Get choice based on the provided numeric literal.
Args:
choice: The numeric choice to be made.
"""
return
assert get_choice.inputs["choice"]["type"] == "integer"
assert get_choice.inputs["choice"]["enum"] == [1, 2, 3]
def test_tool_supports_nullable_literal(self):
@tool
def get_choice(choice: Literal[1, 2, 3, None]) -> None:
"""
Get choice based on the provided value.
Args:
choice: The numeric choice to be made.
"""
return
assert get_choice.inputs["choice"]["type"] == "integer"
assert get_choice.inputs["choice"]["nullable"] is True
assert get_choice.inputs["choice"]["enum"] == [1, 2, 3]
def test_saving_tool_produces_valid_pyhon_code_with_multiline_description(self, tmp_path):
@tool
def get_weather(location: Any) -> None:
"""
Get weather in the next days at given location.
And works pretty well.
Args:
location: The location to get the weather for.
"""
return
get_weather.save(tmp_path)
with open(os.path.join(tmp_path, "tool.py"), "r", encoding="utf-8") as f:
source_code = f.read()
compile(source_code, f.name, "exec")
@pytest.mark.parametrize("fixture_name", ["boolean_default_tool_class", "boolean_default_tool_function"])
def test_to_dict_boolean_default_input(self, fixture_name, request):
"""Test that boolean input parameter with default value is correctly represented in to_dict output"""
tool = request.getfixturevalue(fixture_name)
result = tool.to_dict()
# Check that the boolean default annotation is preserved
assert "flag: bool = False" in result["code"]
# Check nullable attribute is set for the parameter with default value
assert "'nullable': True" in result["code"]
@pytest.mark.parametrize("fixture_name", ["optional_input_tool_class", "optional_input_tool_function"])
def test_to_dict_optional_input(self, fixture_name, request):
"""Test that Optional/nullable input parameter is correctly represented in to_dict output"""
tool = request.getfixturevalue(fixture_name)
result = tool.to_dict()
# Check the Optional type annotation is preserved
assert "optional_text: str | None = None" in result["code"]
# Check that the input is marked as nullable in the code
assert "'nullable': True" in result["code"]
def test_from_dict_roundtrip(self, example_tool):
# Convert to dict
tool_dict = example_tool.to_dict()
# Create from dict
recreated_tool = Tool.from_dict(tool_dict)
# Verify properties
assert recreated_tool.name == example_tool.name
assert recreated_tool.description == example_tool.description
assert recreated_tool.inputs == example_tool.inputs
assert recreated_tool.output_type == example_tool.output_type
# Verify functionality
test_input = "Hello, world!"
assert recreated_tool(test_input) == test_input.upper()
def test_tool_from_dict_invalid(self):
# Missing code key
with pytest.raises(ValueError) as e:
Tool.from_dict({"name": "invalid_tool"})
assert "must contain 'code' key" in str(e)
def test_tool_decorator_preserves_original_function(self):
# Define a test function with type hints and docstring
def test_function(items: list[str]) -> str:
"""Join a list of strings.
Args:
items: A list of strings to join
Returns:
The joined string
"""
return ", ".join(items)
# Store original function signature, name, and source
original_signature = inspect.signature(test_function)
original_name = test_function.__name__
original_docstring = test_function.__doc__
# Create a tool from the function
test_tool = tool(test_function)
# Check that the original function is unchanged
assert original_signature == inspect.signature(test_function)
assert original_name == test_function.__name__
assert original_docstring == test_function.__doc__
# Verify that the tool's forward method has a different signature (it has 'self')
tool_forward_sig = inspect.signature(test_tool.forward)
assert list(tool_forward_sig.parameters.keys())[0] == "self"
# Original function should not have 'self' parameter
assert "self" not in original_signature.parameters
def test_tool_with_union_type_return(self):
@tool
def union_type_return_tool_function(param: int) -> str | bool:
"""
Tool with output union type.
Args:
param: Input parameter.
"""
return str(param) if param > 0 else False
assert isinstance(union_type_return_tool_function, Tool)
assert union_type_return_tool_function.output_type == "any"
class TestToolDecorator:
def test_tool_decorator_source_extraction_with_multiple_decorators(self):
"""Test that @tool correctly extracts source code with multiple decorators."""
def dummy_decorator(func):
return func
with pytest.warns(UserWarning, match="has decorators other than @tool"):
@tool
@dummy_decorator
def multi_decorator_tool(text: str) -> str:
"""Tool with multiple decorators.
Args:
text: Input text
"""
return text.upper()
# Verify the tool works
assert isinstance(multi_decorator_tool, Tool)
assert multi_decorator_tool.name == "multi_decorator_tool"
assert multi_decorator_tool("hello") == "HELLO"
# Verify the source code extraction is correct
forward_source = multi_decorator_tool.forward.__source__
assert "def forward(self, text: str) -> str:" in forward_source
assert "return text.upper()" in forward_source
# Should not contain decorator lines
assert "@tool" not in forward_source
assert "@dummy_decorator" not in forward_source
# Should not contain definition line
assert "def multi_decorator_tool" not in forward_source
def test_tool_decorator_source_extraction_with_multiline_signature(self):
"""Test that @tool correctly extracts source code with multiline function signatures."""
with warnings.catch_warnings():
warnings.simplefilter("error")
@tool
def multiline_signature_tool(
text: str,
count: int = 1,
uppercase: bool = False,
multiline_parameter_1: int = 1_000,
multiline_parameter_2: int = 2_000,
) -> str:
"""Tool with multiline signature.
Args:
text: Input text
count: Number of repetitions
uppercase: Whether to convert to uppercase
multiline_parameter_1: Dummy parameter
multiline_parameter_2: Dummy parameter
"""
result = text * count
return result.upper() if uppercase else result
# Verify the tool works
assert isinstance(multiline_signature_tool, Tool)
assert multiline_signature_tool.name == "multiline_signature_tool"
assert multiline_signature_tool("hello", 2, True) == "HELLOHELLO"
# Verify the source code extraction is correct
forward_source = multiline_signature_tool.forward.__source__
assert (
"def forward(self, text: str, count: int=1, uppercase: bool=False, multiline_parameter_1: int=1000, multiline_parameter_2: int=2000) -> str:"
in forward_source
or "def forward(self, text: str, count: int = 1, uppercase: bool = False, multiline_parameter_1: int = 1000, multiline_parameter_2: int = 2000) -> str:"
in forward_source
)
assert "result = text * count" in forward_source
assert "return result.upper() if uppercase else result" in forward_source
# Should not contain the original multiline function definition
assert "def multiline_signature_tool(" not in forward_source
# Should not contain leftover lines from the original multiline function definition
assert " count: int = 1," not in forward_source
assert " count: int=1," not in forward_source
def test_tool_decorator_source_extraction_with_multiple_decorators_and_multiline(self):
"""Test that @tool works with both multiple decorators and multiline signatures."""
def dummy_decorator_1(func):
return func
def dummy_decorator_2(func):
return func
with pytest.warns(UserWarning, match="has decorators other than @tool"):
@tool
@dummy_decorator_1
@dummy_decorator_2
def complex_tool(
text: str,
multiplier: int = 2,
separator: str = " ",
multiline_parameter_1: int = 1_000,
multiline_parameter_2: int = 2_000,
) -> str:
"""Complex tool with multiple decorators and multiline signature.
Args:
text: Input text
multiplier: How many times to repeat
separator: What to use between repetitions
multiline_parameter_1: Dummy parameter
multiline_parameter_2: Dummy parameter
"""
parts = [text] * multiplier
return separator.join(parts)
# Verify the tool works
assert isinstance(complex_tool, Tool)
assert complex_tool.name == "complex_tool"
assert complex_tool("hello", 3, "-") == "hello-hello-hello"
# Verify the source code extraction is correct
forward_source = complex_tool.forward.__source__
assert (
"def forward(self, text: str, multiplier: int=2, separator: str=' ', multiline_parameter_1: int=1000, multiline_parameter_2: int=2000) -> str:"
in forward_source
or "def forward(self, text: str, multiplier: int = 2, separator: str = ' ', multiline_parameter_1: int = 1000, multiline_parameter_2: int = 2000) -> str:"
in forward_source
)
assert "parts = [text] * multiplier" in forward_source
assert "return separator.join(parts)" in forward_source
# Should not contain any decorator lines
assert "@tool" not in forward_source
assert "@dummy_decorator_1" not in forward_source
assert "@dummy_decorator_2" not in forward_source
# Should not contain leftover lines from the original multiline function definition
assert " multiplier: int = 2," not in forward_source
assert " multiplier: int=2," not in forward_source
@pytest.fixture
def mock_server_parameters():
return MagicMock()
@pytest.fixture
def mock_mcp_adapt():
with patch("mcpadapt.core.MCPAdapt") as mock:
mock.return_value.__enter__.return_value = ["tool1", "tool2"]
mock.return_value.__exit__.return_value = None
yield mock
@pytest.fixture
def mock_smolagents_adapter():
with patch("mcpadapt.smolagents_adapter.SmolAgentsAdapter") as mock:
yield mock
# Ignore FutureWarning about structured_output default value change: this test intentionally uses default behavior
@pytest.mark.filterwarnings("ignore:.*structured_output:FutureWarning")
class TestToolCollection:
def test_from_mcp(self, mock_server_parameters, mock_mcp_adapt, mock_smolagents_adapter):
with ToolCollection.from_mcp(mock_server_parameters, trust_remote_code=True) as tool_collection:
assert isinstance(tool_collection, ToolCollection)
assert len(tool_collection.tools) == 2
assert "tool1" in tool_collection.tools
assert "tool2" in tool_collection.tools
@require_run_all
def test_integration_from_mcp(self):
# define the most simple mcp server with one tool that echoes the input text
mcp_server_script = dedent("""\
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Echo Server")
@mcp.tool()
def echo_tool(text: str) -> str:
return text
mcp.run()
""").strip()
mcp_server_params = mcp.StdioServerParameters(
command="python",
args=["-c", mcp_server_script],
)
with ToolCollection.from_mcp(mcp_server_params, trust_remote_code=True) as tool_collection:
assert len(tool_collection.tools) == 1, "Expected 1 tool"
assert tool_collection.tools[0].name == "echo_tool", "Expected tool name to be 'echo_tool'"
assert tool_collection.tools[0](text="Hello") == "Hello", "Expected tool to echo the input text"
def test_integration_from_mcp_with_streamable_http(self):
import subprocess
import time
# define the most simple mcp server with one tool that echoes the input text
mcp_server_script = dedent("""\
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Echo Server", host="127.0.0.1", port=8000)
@mcp.tool()
def echo_tool(text: str) -> str:
return text
mcp.run(transport="streamable-http")
""").strip()
# start the SSE mcp server in a subprocess
server_process = subprocess.Popen(
["python", "-c", mcp_server_script],
)
# wait for the server to start
time.sleep(1)
try:
with ToolCollection.from_mcp(
{"url": "http://127.0.0.1:8000/mcp", "transport": "streamable-http"}, trust_remote_code=True
) as tool_collection:
assert len(tool_collection.tools) == 1, "Expected 1 tool"
assert tool_collection.tools[0].name == "echo_tool", "Expected tool name to be 'echo_tool'"
assert tool_collection.tools[0](text="Hello") == "Hello", "Expected tool to echo the input text"
finally:
# clean up the process when test is done
server_process.kill()
server_process.wait()
def test_integration_from_mcp_with_sse(self):
import subprocess
import time
# define the most simple mcp server with one tool that echoes the input text
mcp_server_script = dedent("""\
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Echo Server", host="127.0.0.1", port=8000)
@mcp.tool()
def echo_tool(text: str) -> str:
return text
mcp.run("sse")
""").strip()
# start the SSE mcp server in a subprocess
server_process = subprocess.Popen(
["python", "-c", mcp_server_script],
)
# wait for the server to start
time.sleep(1)
try:
with ToolCollection.from_mcp(
{"url": "http://127.0.0.1:8000/sse", "transport": "sse"}, trust_remote_code=True
) as tool_collection:
assert len(tool_collection.tools) == 1, "Expected 1 tool"
assert tool_collection.tools[0].name == "echo_tool", "Expected tool name to be 'echo_tool'"
assert tool_collection.tools[0](text="Hello") == "Hello", "Expected tool to echo the input text"
finally:
# clean up the process when test is done
server_process.kill()
server_process.wait()
@pytest.mark.parametrize("tool_fixture_name", ["boolean_default_tool_class"])
def test_launch_gradio_demo_does_not_raise(tool_fixture_name, request):
tool = request.getfixturevalue(tool_fixture_name)
with patch("gradio.Interface.launch") as mock_launch:
launch_gradio_demo(tool)
assert mock_launch.call_count == 1
@pytest.mark.parametrize(
"tool_input_type, expected_input, expects_error",
[
(bool, True, False),
(str, "b", False),
(int, 1, False),
(float, 1, False),
(list, ["a", "b"], False),
(list[str], ["a", "b"], False),
(dict[str, str], {"a": "b"}, False),
(dict[str, str], "b", True),
(bool, "b", True),
(str | int, "a", False),
(str | int, 1, False),
(str | int, None, True),
(str | int, True, True),
],
)
def test_validate_tool_arguments(tool_input_type, expected_input, expects_error):
@tool
def test_tool(argument_a: tool_input_type) -> str:
"""Fake tool
Args:
argument_a: The input
"""
return argument_a
if expects_error:
with pytest.raises((ValueError, TypeError)):
validate_tool_arguments(test_tool, {"argument_a": expected_input})
else:
# Should not raise any exception
validate_tool_arguments(test_tool, {"argument_a": expected_input})
@pytest.mark.parametrize(
"scenario, type_hint, default, input_value, expected_error_message",
[
# Required parameters (no default)
# - Valid input
("required_unsupported_none", str, ..., "text", None),
# - None not allowed
("required_unsupported_none", str, ..., None, "Argument param has type 'null' but should be 'string'"),
# - Missing required parameter is not allowed
("required_unsupported_none", str, ..., ..., "Argument param is required"),
#
# Required parameters but supports None
# - Valid input
("required_supported_none", str | None, ..., "text", None),
# - None allowed
("required_supported_none", str | None, ..., None, None),
# - Missing required parameter is not allowed
# TODO: Fix this test case: property is marked as nullable because it can be None, but it can't be missing because it is required
# ("required_supported_none", str | None, ..., ..., "Argument param is required"),
pytest.param(
"required_supported_none",
str | None,
...,
...,
"Argument param is required",
marks=pytest.mark.skip(reason="TODO: Fix this test case"),
),
#
# Optional parameters (has default, doesn't support None)
# - Valid input
("optional_unsupported_none", str, "default", "text", None),
# - None not allowed
# TODO: Fix this test case: property is marked as nullable because it has a default value, but it can't be None
# ("optional_unsupported_none", str, "default", None, "Argument param has type 'null' but should be 'string'"),
pytest.param(
"optional_unsupported_none",
str,
"default",
None,
"Argument param has type 'null' but should be 'string'",
marks=pytest.mark.skip(reason="TODO: Fix this test case"),
),
# - Missing optional parameter is allowed
("optional_unsupported_none", str, "default", ..., None),
#
# Optional and supports None parameters with string default
# - Valid input
("optional_supported_none_str_default", str | None, "default", "text", None),
# - None allowed
("optional_supported_none_str_default", str | None, "default", None, None),
# - Missing optional parameter is allowed
("optional_supported_none_str_default", str | None, "default", ..., None),
#
# Optional and supports None parameters with None default
# - Valid input
("optional_supported_none_none_default", str | None, None, "text", None),
# - None allowed
("optional_supported_none_none_default", str | None, None, None, None),
# - Missing optional parameter is allowed
("optional_supported_none_none_default", str | None, None, ..., None),
],
)
def test_validate_tool_arguments_nullable(scenario, type_hint, default, input_value, expected_error_message):
"""Test validation of tool arguments with focus on nullable properties: optional (with default value) and supporting None value."""
# Create a tool with the appropriate signature
if default is ...: # Using Ellipsis to indicate no default value
@tool
def test_tool(param: type_hint) -> str:
"""Test tool.
Args:
param: Input param
"""
return str(param) if param is not None else "NULL"
else:
@tool
def test_tool(param: type_hint = default) -> str:
"""Test tool.
Args:
param: Input param.
"""
return str(param) if param is not None else "NULL"
# Test with the input dictionary
input_dict = {"param": input_value} if input_value is not ... else {}
if expected_error_message:
with pytest.raises((ValueError, TypeError), match=expected_error_message):
validate_tool_arguments(test_tool, input_dict)
else:
# Should not raise any exception
validate_tool_arguments(test_tool, input_dict)
================================================
FILE: tests/test_types.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import tempfile
import unittest
import uuid
import PIL.Image
from smolagents.agent_types import AgentAudio, AgentImage, AgentText
from .utils.markers import require_soundfile, require_torch
def get_new_path(suffix="") -> str:
directory = tempfile.mkdtemp()
return os.path.join(directory, str(uuid.uuid4()) + suffix)
@require_soundfile
@require_torch
class AgentAudioTests(unittest.TestCase):
def test_from_tensor(self):
import soundfile as sf
import torch
tensor = torch.rand(12, dtype=torch.float64) - 0.5
agent_type = AgentAudio(tensor)
path = str(agent_type.to_string())
# Ensure that the tensor and the agent_type's tensor are the same
self.assertTrue(torch.allclose(tensor, agent_type.to_raw(), atol=1e-4))
del agent_type
# Ensure the path remains even after the object deletion
self.assertTrue(os.path.exists(path))
# Ensure that the file contains the same value as the original tensor
new_tensor, _ = sf.read(path)
self.assertTrue(torch.allclose(tensor, torch.tensor(new_tensor), atol=1e-4))
def test_from_string(self):
import soundfile as sf
import torch
tensor = torch.rand(12, dtype=torch.float64) - 0.5
path = get_new_path(suffix=".wav")
sf.write(path, tensor, 16000)
agent_type = AgentAudio(path)
self.assertTrue(torch.allclose(tensor, agent_type.to_raw(), atol=1e-4))
self.assertEqual(agent_type.to_string(), path)
@require_torch
class TestAgentImage:
def test_from_tensor(self):
import torch
tensor = torch.randint(0, 256, (64, 64, 3))
agent_type = AgentImage(tensor)
path = str(agent_type.to_string())
# Ensure that the tensor and the agent_type's tensor are the same
assert torch.allclose(tensor, agent_type._tensor, atol=1e-4)
assert isinstance(agent_type.to_raw(), PIL.Image.Image)
# Ensure the path remains even after the object deletion
del agent_type
assert os.path.exists(path)
def test_from_string(self, shared_datadir):
path = shared_datadir / "000000039769.png"
image = PIL.Image.open(path)
agent_type = AgentImage(path)
assert path.samefile(agent_type.to_string())
assert image == agent_type.to_raw()
# Ensure the path remains even after the object deletion
del agent_type
assert os.path.exists(path)
def test_from_image(self, shared_datadir):
path = shared_datadir / "000000039769.png"
image = PIL.Image.open(path)
agent_type = AgentImage(image)
assert not path.samefile(agent_type.to_string())
assert image == agent_type.to_raw()
# Ensure the path remains even after the object deletion
del agent_type
assert os.path.exists(path)
class AgentTextTests(unittest.TestCase):
def test_from_string(self):
string = "Hey!"
agent_type = AgentText(string)
self.assertEqual(string, agent_type.to_string())
self.assertEqual(string, agent_type.to_raw())
================================================
FILE: tests/test_utils.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import os
import textwrap
import unittest
import pytest
from IPython.core.interactiveshell import InteractiveShell
from smolagents import Tool
from smolagents.tools import tool
from smolagents.utils import (
create_agent_gradio_app_template,
get_source,
instance_to_source,
is_valid_name,
parse_code_blobs,
parse_json_blob,
)
class ValidTool(Tool):
name = "valid_tool"
description = "A valid tool"
inputs = {"input": {"type": "string", "description": "input"}}
output_type = "string"
simple_attr = "string"
dict_attr = {"key": "value"}
def __init__(self, optional_param="default"):
super().__init__()
self.param = optional_param
def forward(self, input: str) -> str:
return input.upper()
@tool
def valid_tool_function(input: str) -> str:
"""A valid tool function.
Args:
input (str): Input string.
"""
return input.upper()
VALID_TOOL_SOURCE = """\
from smolagents.tools import Tool
class ValidTool(Tool):
name = "valid_tool"
description = "A valid tool"
inputs = {'input': {'type': 'string', 'description': 'input'}}
output_type = "string"
simple_attr = "string"
dict_attr = {'key': 'value'}
def __init__(self, optional_param="default"):
super().__init__()
self.param = optional_param
def forward(self, input: str) -> str:
return input.upper()
"""
VALID_TOOL_FUNCTION_SOURCE = '''\
from smolagents.tools import Tool
class SimpleTool(Tool):
name = "valid_tool_function"
description = "A valid tool function."
inputs = {'input': {'type': 'string', 'description': 'Input string.'}}
output_type = "string"
def __init__(self):
self.is_initialized = True
def forward(self, input: str) -> str:
"""A valid tool function.
Args:
input (str): Input string.
"""
return input.upper()
'''
class AgentTextTests(unittest.TestCase):
def test_parse_code_blobs(self):
with pytest.raises(ValueError):
parse_code_blobs("Wrong blob!", ("", ""))
# Parsing mardkwon with code blobs should work
output = parse_code_blobs(
"""
Here is how to solve the problem:
import numpy as np
""",
("", ""),
)
assert output == "import numpy as np"
# Parsing pure python code blobs should work
code_blob = "import numpy as np"
output = parse_code_blobs(code_blob, ("```python", "```"))
assert output == code_blob
# Allow whitespaces after header
output = parse_code_blobs(" \ncode_a\n", ("", ""))
assert output == "code_a"
# Parsing markdown with code blobs should work
output = parse_code_blobs(
"""
Here is how to solve the problem:
```python
import numpy as np
```
""",
("", ""),
)
assert output == "import numpy as np"
def test_multiple_code_blobs(self):
test_input = "\nFoo\n\n\n\ncode_a\n\n\n\ncode_b\n"
result = parse_code_blobs(test_input, ("", ""))
assert result == "Foo\n\ncode_a\n\ncode_b"
@pytest.fixture(scope="function")
def ipython_shell():
"""Reset IPython shell before and after each test."""
shell = InteractiveShell.instance()
shell.reset() # Clean before test
yield shell
shell.reset() # Clean after test
@pytest.mark.parametrize(
"obj_name, code_blob",
[
("test_func", "def test_func():\n return 42"),
("TestClass", "class TestClass:\n ..."),
],
)
def test_get_source_ipython(ipython_shell, obj_name, code_blob):
ipython_shell.run_cell(code_blob, store_history=True)
obj = ipython_shell.user_ns[obj_name]
assert get_source(obj) == code_blob
def test_get_source_standard_class():
class TestClass: ...
source = get_source(TestClass)
assert source == "class TestClass: ..."
assert source == textwrap.dedent(inspect.getsource(TestClass)).strip()
def test_get_source_standard_function():
def test_func(): ...
source = get_source(test_func)
assert source == "def test_func(): ..."
assert source == textwrap.dedent(inspect.getsource(test_func)).strip()
def test_get_source_ipython_errors_empty_cells(ipython_shell):
test_code = textwrap.dedent("""class TestClass:\n ...""").strip()
ipython_shell.user_ns["In"] = [""]
ipython_shell.run_cell(test_code, store_history=True)
with pytest.raises(ValueError, match="No code cells found in IPython session"):
get_source(ipython_shell.user_ns["TestClass"])
def test_get_source_ipython_errors_definition_not_found(ipython_shell):
test_code = textwrap.dedent("""class TestClass:\n ...""").strip()
ipython_shell.user_ns["In"] = ["", "print('No class definition here')"]
ipython_shell.run_cell(test_code, store_history=True)
with pytest.raises(ValueError, match="Could not find source code for TestClass in IPython history"):
get_source(ipython_shell.user_ns["TestClass"])
def test_get_source_ipython_errors_type_error():
with pytest.raises(TypeError, match="Expected class or callable"):
get_source(None)
@pytest.mark.parametrize(
"tool, expected_tool_source", [(ValidTool(), VALID_TOOL_SOURCE), (valid_tool_function, VALID_TOOL_FUNCTION_SOURCE)]
)
def test_instance_to_source(tool, expected_tool_source):
tool_source = instance_to_source(tool, base_cls=Tool)
assert tool_source == expected_tool_source
def test_e2e_class_tool_save(tmp_path):
class TestTool(Tool):
name = "test_tool"
description = "Test tool description"
inputs = {
"task": {
"type": "string",
"description": "tool input",
}
}
output_type = "string"
def forward(self, task: str):
import IPython # noqa: F401
return task
test_tool = TestTool()
test_tool.save(tmp_path, make_gradio_app=True)
assert set(os.listdir(tmp_path)) == {"requirements.txt", "app.py", "tool.py"}
assert (tmp_path / "tool.py").read_text() == textwrap.dedent(
"""\
from typing import Any, Optional
from smolagents.tools import Tool
import IPython
class TestTool(Tool):
name = "test_tool"
description = "Test tool description"
inputs = {'task': {'type': 'string', 'description': 'tool input'}}
output_type = "string"
def forward(self, task: str):
import IPython # noqa: F401
return task
def __init__(self, *args, **kwargs):
self.is_initialized = False
"""
)
requirements = set((tmp_path / "requirements.txt").read_text().split())
assert requirements == {"IPython", "smolagents"}
assert (tmp_path / "app.py").read_text() == textwrap.dedent(
"""\
from smolagents import launch_gradio_demo
from tool import TestTool
tool = TestTool()
launch_gradio_demo(tool)
"""
)
def test_e2e_ipython_class_tool_save(tmp_path):
shell = InteractiveShell.instance()
code_blob = textwrap.dedent(
f"""\
from smolagents.tools import Tool
class TestTool(Tool):
name = "test_tool"
description = "Test tool description"
inputs = {{"task": {{"type": "string",
"description": "tool input",
}}
}}
output_type = "string"
def forward(self, task: str):
import IPython # noqa: F401
return task
TestTool().save("{tmp_path}", make_gradio_app=True)
"""
)
assert shell.run_cell(code_blob, store_history=True).success
assert set(os.listdir(tmp_path)) == {"requirements.txt", "app.py", "tool.py"}
assert (tmp_path / "tool.py").read_text() == textwrap.dedent(
"""\
from typing import Any, Optional
from smolagents.tools import Tool
import IPython
class TestTool(Tool):
name = "test_tool"
description = "Test tool description"
inputs = {'task': {'type': 'string', 'description': 'tool input'}}
output_type = "string"
def forward(self, task: str):
import IPython # noqa: F401
return task
def __init__(self, *args, **kwargs):
self.is_initialized = False
"""
)
requirements = set((tmp_path / "requirements.txt").read_text().split())
assert requirements == {"IPython", "smolagents"}
assert (tmp_path / "app.py").read_text() == textwrap.dedent(
"""\
from smolagents import launch_gradio_demo
from tool import TestTool
tool = TestTool()
launch_gradio_demo(tool)
"""
)
def test_e2e_function_tool_save(tmp_path):
@tool
def test_tool(task: str) -> str:
"""
Test tool description
Args:
task: tool input
"""
import IPython # noqa: F401
return task
test_tool.save(tmp_path, make_gradio_app=True)
assert set(os.listdir(tmp_path)) == {"requirements.txt", "app.py", "tool.py"}
assert (tmp_path / "tool.py").read_text() == textwrap.dedent(
"""\
from smolagents import Tool
from typing import Any, Optional
class SimpleTool(Tool):
name = "test_tool"
description = "Test tool description"
inputs = {'task': {'type': 'string', 'description': 'tool input'}}
output_type = "string"
def forward(self, task: str) -> str:
\"""
Test tool description
Args:
task: tool input
\"""
import IPython # noqa: F401
return task"""
)
requirements = set((tmp_path / "requirements.txt").read_text().split())
assert requirements == {"smolagents"} # FIXME: IPython should be in the requirements
assert (tmp_path / "app.py").read_text() == textwrap.dedent(
"""\
from smolagents import launch_gradio_demo
from tool import SimpleTool
tool = SimpleTool()
launch_gradio_demo(tool)
"""
)
def test_e2e_ipython_function_tool_save(tmp_path):
shell = InteractiveShell.instance()
code_blob = textwrap.dedent(
f"""
from smolagents import tool
@tool
def test_tool(task: str) -> str:
\"""
Test tool description
Args:
task: tool input
\"""
import IPython # noqa: F401
return task
test_tool.save("{tmp_path}", make_gradio_app=True)
"""
)
assert shell.run_cell(code_blob, store_history=True).success
assert set(os.listdir(tmp_path)) == {"requirements.txt", "app.py", "tool.py"}
assert (tmp_path / "tool.py").read_text() == textwrap.dedent(
"""\
from smolagents import Tool
from typing import Any, Optional
class SimpleTool(Tool):
name = "test_tool"
description = "Test tool description"
inputs = {'task': {'type': 'string', 'description': 'tool input'}}
output_type = "string"
def forward(self, task: str) -> str:
\"""
Test tool description
Args:
task: tool input
\"""
import IPython # noqa: F401
return task"""
)
requirements = set((tmp_path / "requirements.txt").read_text().split())
assert requirements == {"smolagents"} # FIXME: IPython should be in the requirements
assert (tmp_path / "app.py").read_text() == textwrap.dedent(
"""\
from smolagents import launch_gradio_demo
from tool import SimpleTool
tool = SimpleTool()
launch_gradio_demo(tool)
"""
)
@pytest.mark.parametrize(
"raw_json, expected_data, expected_blob",
[
(
"""{}""",
{},
"",
),
(
"""Text{}""",
{},
"Text",
),
(
"""{"simple": "json"}""",
{"simple": "json"},
"",
),
(
"""With text here{"simple": "json"}""",
{"simple": "json"},
"With text here",
),
(
"""{"simple": "json"}With text after""",
{"simple": "json"},
"",
),
(
"""With text before{"simple": "json"}And text after""",
{"simple": "json"},
"With text before",
),
],
)
def test_parse_json_blob_with_valid_json(raw_json, expected_data, expected_blob):
data, blob = parse_json_blob(raw_json)
assert data == expected_data
assert blob == expected_blob
@pytest.mark.parametrize(
"raw_json",
[
"""simple": "json"}""",
"""With text here"simple": "json"}""",
"""{"simple": ""json"}With text after""",
"""{"simple": "json"With text after""",
"}}",
],
)
def test_parse_json_blob_with_invalid_json(raw_json):
with pytest.raises(Exception):
parse_json_blob(raw_json)
@pytest.mark.parametrize(
"name,expected",
[
# Valid identifiers
("valid_name", True),
("ValidName", True),
("valid123", True),
("_private", True),
# Invalid identifiers
("", False),
("123invalid", False),
("invalid-name", False),
("invalid name", False),
("invalid.name", False),
# Python keywords
("if", False),
("for", False),
("class", False),
("return", False),
# Non-string inputs
(123, False),
(None, False),
([], False),
({}, False),
],
)
def test_is_valid_name(name, expected):
"""Test the is_valid_name function with various inputs."""
assert is_valid_name(name) is expected
def test_agent_gradio_app_template_excludes_class_keyword():
"""Test that the AGENT_GRADIO_APP_TEMPLATE excludes 'class' from agent kwargs."""
# Mock agent_dict with 'class' key that should be excluded
agent_dict = {
"model": {"class": "CodeAgent", "data": {}},
"class": "CodeAgent", # This should be excluded to prevent SyntaxError
"some_valid_attr": "value",
"tools": [],
"managed_agents": {},
"requirements": [],
"prompt_templates": {},
}
template = create_agent_gradio_app_template()
result = template.render(
agent_name="test_agent",
class_name="CodeAgent",
agent_dict=agent_dict,
tools={},
managed_agents={},
managed_agent_relative_path="",
)
# Should contain valid attribute but not 'class=' as a keyword argument
assert "some_valid_attr='value'," in result
assert "class=" not in result
# Verify the generated code is syntactically valid Python
import ast
try:
ast.parse(result)
except SyntaxError as e:
pytest.fail(f"Generated app.py contains syntax error: {e}")
================================================
FILE: tests/test_vision_web_browser.py
================================================
"""Test XPath injection vulnerability fix in vision_web_browser.py"""
from unittest.mock import Mock, patch
import pytest
from smolagents.vision_web_browser import _escape_xpath_string, search_item_ctrl_f
@pytest.fixture
def mock_driver():
"""Mock Selenium WebDriver"""
driver = Mock()
driver.find_elements.return_value = [Mock()] # Mock found elements
driver.execute_script.return_value = None
return driver
class TestXPathEscaping:
"""Test XPath string escaping functionality"""
@pytest.mark.parametrize(
"input_text,expected_pattern",
[
("normal text", "'normal text'"),
("text with 'quote'", "\"text with 'quote'\""),
('text with "quote"', "'text with \"quote\"'"),
("text with one single'quote", '"text with one single\'quote"'),
('text with one double"quote', "'text with one double\"quote'"),
(
"text with both 'single' and \"double\" quotes",
"concat('text with both ', \"'\", 'single', \"'\", ' and \"double\" quotes')",
),
("", "''"),
("'", '"\'"'),
('"', "'\"'"),
],
)
def test_escape_xpath_string_basic(self, input_text, expected_pattern):
"""Test basic XPath escaping cases"""
result = _escape_xpath_string(input_text)
assert result == expected_pattern
@pytest.mark.parametrize(
"input_text",
[
"text with both 'single' and \"double\" quotes",
'it\'s a "test" case',
"'mixed\" quotes'",
],
)
def test_escape_xpath_string_mixed_quotes(self, input_text):
"""Test XPath escaping with mixed quotes uses concat()"""
result = _escape_xpath_string(input_text)
assert result.startswith("concat(")
assert result.endswith(")")
@pytest.mark.parametrize(
"malicious_input",
[
"')] | //script[@src='evil.js'] | foo[contains(text(), '",
"') or 1=1 or ('",
"')] | //user[contains(@role,'admin')] | foo[contains(text(), '",
"') and substring(//user[1]/password,1,1)='a",
],
)
def test_escape_prevents_injection(self, malicious_input):
"""Test that malicious XPath injection attempts are safely escaped"""
result = _escape_xpath_string(malicious_input)
# Should either be wrapped in quotes or use concat()
assert (
(result.startswith("'") and result.endswith("'"))
or (result.startswith('"') and result.endswith('"'))
or result.startswith("concat(")
)
class TestSearchItemCtrlF:
"""Test the search_item_ctrl_f function with XPath injection protection"""
@pytest.mark.parametrize(
"search_text",
[
"normal search",
"search with 'quotes'",
'search with "quotes"',
"')] | //script[@src='evil.js'] | foo[contains(text(), '",
"') or 1=1 or ('",
],
)
def test_search_item_prevents_injection(self, search_text, mock_driver):
"""Test that search_item_ctrl_f prevents XPath injection"""
with patch("smolagents.vision_web_browser.driver", mock_driver, create=True):
# Call the function
result = search_item_ctrl_f(search_text)
# Verify driver.find_elements was called
mock_driver.find_elements.assert_called_once()
# Get the actual XPath query that was generated
call_args = mock_driver.find_elements.call_args
xpath_query = call_args[0][1] # Second positional argument
# Verify the query doesn't contain unescaped injection
if "')] | //" in search_text:
# For injection attempts, verify they're properly escaped
# The query should either use concat() or be properly quoted
is_concat = "concat(" in xpath_query
is_properly_quoted = xpath_query.count('"') >= 2 or xpath_query.count("'") >= 2
assert is_concat or is_properly_quoted, f"XPath injection not prevented: {xpath_query}"
# Verify we got a result
assert "Found" in result
def test_search_item_nth_result(self, mock_driver):
"""Test nth_result parameter works correctly"""
mock_driver.find_elements.return_value = [Mock(), Mock(), Mock()] # 3 elements
with patch("smolagents.vision_web_browser.driver", mock_driver, create=True):
result = search_item_ctrl_f("test", nth_result=2)
# Should find 3 matches and focus on element 2
assert "Found 3 matches" in result
assert "Focused on element 2 of 3" in result
def test_search_item_not_found(self, mock_driver):
"""Test exception when nth_result exceeds available matches"""
mock_driver.find_elements.return_value = [Mock()] # Only 1 element
with patch("smolagents.vision_web_browser.driver", mock_driver, create=True):
with pytest.raises(Exception, match="Match n°3 not found"):
search_item_ctrl_f("test", nth_result=3)
================================================
FILE: tests/utils/markers.py
================================================
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Markers for tests ."""
import os
from importlib.util import find_spec
import pytest
require_run_all = pytest.mark.skipif(not os.getenv("RUN_ALL"), reason="requires RUN_ALL environment variable")
require_soundfile = pytest.mark.skipif(find_spec("soundfile") is None, reason="requires soundfile")
require_torch = pytest.mark.skipif(find_spec("torch") is None, reason="requires torch")