Repository: hzxie/Pix2Vox
Branch: master
Commit: 792f459632a2
Files: 24
Total size: 99.0 KB
Directory structure:
gitextract_816on345/
├── .gitignore
├── .style.yapf
├── .yapfignore
├── LICENSE
├── README.md
├── config.py
├── core/
│ ├── __init__.py
│ ├── test.py
│ └── train.py
├── models/
│ ├── __init__.py
│ ├── decoder.py
│ ├── encoder.py
│ ├── merger.py
│ └── refiner.py
├── requirements.txt
├── runner.py
└── utils/
├── __init__.py
├── binvox_converter.py
├── binvox_rw.py
├── binvox_visualization.py
├── data_loaders.py
├── data_transforms.py
├── dataset_analyzer.py
└── network_utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
env/
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# dotenv
.env
# virtualenv
.venv
venv/
ENV/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
# macOS
.DS_Store
# Datasets
datasets/
# Output
output/
================================================
FILE: .style.yapf
================================================
[style]
based_on_style = pep8
column_limit = 119
spaces_before_comment = 4
split_before_logical_operator = True
use_tabs = False
================================================
FILE: .yapfignore
================================================
config.py
models/decoder.py
models/encoder.py
models/merger.py
models/refiner.py
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2018 Haozhe Xie
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# Pix2Vox
[](https://sonarcloud.io/summary/new_code?id=hzxie_Pix2Vox)
[](https://www.codefactor.io/repository/github/hzxie/Pix2Vox)
This repository contains the source code for the paper [Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images](https://arxiv.org/abs/1901.11153). The follow-up work [Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images](https://arxiv.org/abs/2006.12250) has been published in *International Journal of Computer Vision (IJCV)*.
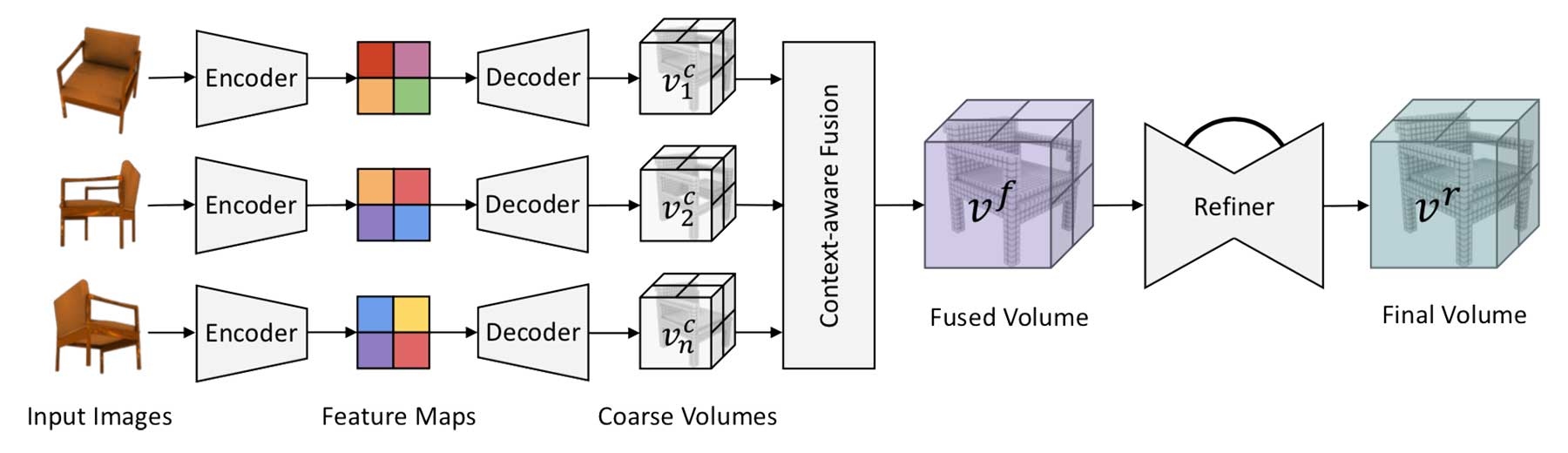
## Cite this work
```
@inproceedings{xie2019pix2vox,
title={Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images},
author={Xie, Haozhe and
Yao, Hongxun and
Sun, Xiaoshuai and
Zhou, Shangchen and
Zhang, Shengping},
booktitle={ICCV},
year={2019}
}
```
## Datasets
We use the [ShapeNet](https://www.shapenet.org/) and [Pix3D](http://pix3d.csail.mit.edu/) datasets in our experiments, which are available below:
- ShapeNet rendering images: http://cvgl.stanford.edu/data2/ShapeNetRendering.tgz
- ShapeNet voxelized models: http://cvgl.stanford.edu/data2/ShapeNetVox32.tgz
- Pix3D images & voxelized models: http://pix3d.csail.mit.edu/data/pix3d.zip
## Pretrained Models
The pretrained models on ShapeNet are available as follows:
- [Pix2Vox-A](https://gateway.infinitescript.com/?fileName=Pix2Vox-A-ShapeNet.pth) (457.0 MB)
- [Pix2Vox-F](https://gateway.infinitescript.com/?fileName=Pix2Vox-F-ShapeNet.pth) (29.8 MB)
## Prerequisites
#### Clone the Code Repository
```
git clone https://github.com/hzxie/Pix2Vox.git
```
#### Install Python Denpendencies
```
cd Pix2Vox
pip install -r requirements.txt
```
#### Update Settings in `config.py`
You need to update the file path of the datasets:
```
__C.DATASETS.SHAPENET.RENDERING_PATH = '/path/to/Datasets/ShapeNet/ShapeNetRendering/%s/%s/rendering/%02d.png'
__C.DATASETS.SHAPENET.VOXEL_PATH = '/path/to/Datasets/ShapeNet/ShapeNetVox32/%s/%s/model.binvox'
__C.DATASETS.PASCAL3D.ANNOTATION_PATH = '/path/to/Datasets/PASCAL3D/Annotations/%s_imagenet/%s.mat'
__C.DATASETS.PASCAL3D.RENDERING_PATH = '/path/to/Datasets/PASCAL3D/Images/%s_imagenet/%s.JPEG'
__C.DATASETS.PASCAL3D.VOXEL_PATH = '/path/to/Datasets/PASCAL3D/CAD/%s/%02d.binvox'
__C.DATASETS.PIX3D.ANNOTATION_PATH = '/path/to/Datasets/Pix3D/pix3d.json'
__C.DATASETS.PIX3D.RENDERING_PATH = '/path/to/Datasets/Pix3D/img/%s/%s.%s'
__C.DATASETS.PIX3D.VOXEL_PATH = '/path/to/Datasets/Pix3D/model/%s/%s/%s.binvox'
```
## Get Started
To train Pix2Vox, you can simply use the following command:
```
python3 runner.py
```
To test Pix2Vox, you can use the following command:
```
python3 runner.py --test --weights=/path/to/pretrained/model.pth
```
If you want to train/test Pix2Vox-F, you need to checkout to `Pix2Vox-F` branch first.
```
git checkout -b Pix2Vox-F origin/Pix2Vox-F
```
## License
This project is open sourced under MIT license.
================================================
FILE: config.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
from easydict import EasyDict as edict
__C = edict()
cfg = __C
#
# Dataset Config
#
__C.DATASETS = edict()
__C.DATASETS.SHAPENET = edict()
__C.DATASETS.SHAPENET.TAXONOMY_FILE_PATH = './datasets/ShapeNet.json'
# __C.DATASETS.SHAPENET.TAXONOMY_FILE_PATH = './datasets/PascalShapeNet.json'
__C.DATASETS.SHAPENET.RENDERING_PATH = '/home/hzxie/Datasets/ShapeNet/ShapeNetRendering/%s/%s/rendering/%02d.png'
# __C.DATASETS.SHAPENET.RENDERING_PATH = '/home/hzxie/Datasets/ShapeNet/PascalShapeNetRendering/%s/%s/render_%04d.jpg'
__C.DATASETS.SHAPENET.VOXEL_PATH = '/home/hzxie/Datasets/ShapeNet/ShapeNetVox32/%s/%s/model.binvox'
__C.DATASETS.PASCAL3D = edict()
__C.DATASETS.PASCAL3D.TAXONOMY_FILE_PATH = './datasets/Pascal3D.json'
__C.DATASETS.PASCAL3D.ANNOTATION_PATH = '/home/hzxie/Datasets/PASCAL3D/Annotations/%s_imagenet/%s.mat'
__C.DATASETS.PASCAL3D.RENDERING_PATH = '/home/hzxie/Datasets/PASCAL3D/Images/%s_imagenet/%s.JPEG'
__C.DATASETS.PASCAL3D.VOXEL_PATH = '/home/hzxie/Datasets/PASCAL3D/CAD/%s/%02d.binvox'
__C.DATASETS.PIX3D = edict()
__C.DATASETS.PIX3D.TAXONOMY_FILE_PATH = './datasets/Pix3D.json'
__C.DATASETS.PIX3D.ANNOTATION_PATH = '/home/hzxie/Datasets/Pix3D/pix3d.json'
__C.DATASETS.PIX3D.RENDERING_PATH = '/home/hzxie/Datasets/Pix3D/img/%s/%s.%s'
__C.DATASETS.PIX3D.VOXEL_PATH = '/home/hzxie/Datasets/Pix3D/model/%s/%s/%s.binvox'
#
# Dataset
#
__C.DATASET = edict()
__C.DATASET.MEAN = [0.5, 0.5, 0.5]
__C.DATASET.STD = [0.5, 0.5, 0.5]
__C.DATASET.TRAIN_DATASET = 'ShapeNet'
__C.DATASET.TEST_DATASET = 'ShapeNet'
# __C.DATASET.TEST_DATASET = 'Pascal3D'
# __C.DATASET.TEST_DATASET = 'Pix3D'
#
# Common
#
__C.CONST = edict()
__C.CONST.DEVICE = '0'
__C.CONST.RNG_SEED = 0
__C.CONST.IMG_W = 224 # Image width for input
__C.CONST.IMG_H = 224 # Image height for input
__C.CONST.N_VOX = 32
__C.CONST.BATCH_SIZE = 64
__C.CONST.N_VIEWS_RENDERING = 1 # Dummy property for Pascal 3D
__C.CONST.CROP_IMG_W = 128 # Dummy property for Pascal 3D
__C.CONST.CROP_IMG_H = 128 # Dummy property for Pascal 3D
#
# Directories
#
__C.DIR = edict()
__C.DIR.OUT_PATH = './output'
__C.DIR.RANDOM_BG_PATH = '/home/hzxie/Datasets/SUN2012/JPEGImages'
#
# Network
#
__C.NETWORK = edict()
__C.NETWORK.LEAKY_VALUE = .2
__C.NETWORK.TCONV_USE_BIAS = False
__C.NETWORK.USE_REFINER = True
__C.NETWORK.USE_MERGER = True
#
# Training
#
__C.TRAIN = edict()
__C.TRAIN.RESUME_TRAIN = False
__C.TRAIN.NUM_WORKER = 4 # number of data workers
__C.TRAIN.NUM_EPOCHES = 250
__C.TRAIN.BRIGHTNESS = .4
__C.TRAIN.CONTRAST = .4
__C.TRAIN.SATURATION = .4
__C.TRAIN.NOISE_STD = .1
__C.TRAIN.RANDOM_BG_COLOR_RANGE = [[225, 255], [225, 255], [225, 255]]
__C.TRAIN.POLICY = 'adam' # available options: sgd, adam
__C.TRAIN.EPOCH_START_USE_REFINER = 0
__C.TRAIN.EPOCH_START_USE_MERGER = 0
__C.TRAIN.ENCODER_LEARNING_RATE = 1e-3
__C.TRAIN.DECODER_LEARNING_RATE = 1e-3
__C.TRAIN.REFINER_LEARNING_RATE = 1e-3
__C.TRAIN.MERGER_LEARNING_RATE = 1e-4
__C.TRAIN.ENCODER_LR_MILESTONES = [150]
__C.TRAIN.DECODER_LR_MILESTONES = [150]
__C.TRAIN.REFINER_LR_MILESTONES = [150]
__C.TRAIN.MERGER_LR_MILESTONES = [150]
__C.TRAIN.BETAS = (.9, .999)
__C.TRAIN.MOMENTUM = .9
__C.TRAIN.GAMMA = .5
__C.TRAIN.SAVE_FREQ = 10 # weights will be overwritten every save_freq epoch
__C.TRAIN.UPDATE_N_VIEWS_RENDERING = False
#
# Testing options
#
__C.TEST = edict()
__C.TEST.RANDOM_BG_COLOR_RANGE = [[240, 240], [240, 240], [240, 240]]
__C.TEST.VOXEL_THRESH = [.2, .3, .4, .5]
================================================
FILE: core/__init__.py
================================================
================================================
FILE: core/test.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import json
import numpy as np
import os
import torch
import torch.backends.cudnn
import torch.utils.data
import utils.binvox_visualization
import utils.data_loaders
import utils.data_transforms
import utils.network_utils
from datetime import datetime as dt
from models.encoder import Encoder
from models.decoder import Decoder
from models.refiner import Refiner
from models.merger import Merger
def test_net(cfg,
epoch_idx=-1,
output_dir=None,
test_data_loader=None,
test_writer=None,
encoder=None,
decoder=None,
refiner=None,
merger=None):
# Enable the inbuilt cudnn auto-tuner to find the best algorithm to use
torch.backends.cudnn.benchmark = True
# Load taxonomies of dataset
taxonomies = []
with open(cfg.DATASETS[cfg.DATASET.TEST_DATASET.upper()].TAXONOMY_FILE_PATH, encoding='utf-8') as file:
taxonomies = json.loads(file.read())
taxonomies = {t['taxonomy_id']: t for t in taxonomies}
# Set up data loader
if test_data_loader is None:
# Set up data augmentation
IMG_SIZE = cfg.CONST.IMG_H, cfg.CONST.IMG_W
CROP_SIZE = cfg.CONST.CROP_IMG_H, cfg.CONST.CROP_IMG_W
test_transforms = utils.data_transforms.Compose([
utils.data_transforms.CenterCrop(IMG_SIZE, CROP_SIZE),
utils.data_transforms.RandomBackground(cfg.TEST.RANDOM_BG_COLOR_RANGE),
utils.data_transforms.Normalize(mean=cfg.DATASET.MEAN, std=cfg.DATASET.STD),
utils.data_transforms.ToTensor(),
])
dataset_loader = utils.data_loaders.DATASET_LOADER_MAPPING[cfg.DATASET.TEST_DATASET](cfg)
test_data_loader = torch.utils.data.DataLoader(dataset=dataset_loader.get_dataset(
utils.data_loaders.DatasetType.TEST, cfg.CONST.N_VIEWS_RENDERING, test_transforms),
batch_size=1,
num_workers=1,
pin_memory=True,
shuffle=False)
# Set up networks
if decoder is None or encoder is None:
encoder = Encoder(cfg)
decoder = Decoder(cfg)
refiner = Refiner(cfg)
merger = Merger(cfg)
if torch.cuda.is_available():
encoder = torch.nn.DataParallel(encoder).cuda()
decoder = torch.nn.DataParallel(decoder).cuda()
refiner = torch.nn.DataParallel(refiner).cuda()
merger = torch.nn.DataParallel(merger).cuda()
print('[INFO] %s Loading weights from %s ...' % (dt.now(), cfg.CONST.WEIGHTS))
checkpoint = torch.load(cfg.CONST.WEIGHTS)
epoch_idx = checkpoint['epoch_idx']
encoder.load_state_dict(checkpoint['encoder_state_dict'])
decoder.load_state_dict(checkpoint['decoder_state_dict'])
if cfg.NETWORK.USE_REFINER:
refiner.load_state_dict(checkpoint['refiner_state_dict'])
if cfg.NETWORK.USE_MERGER:
merger.load_state_dict(checkpoint['merger_state_dict'])
# Set up loss functions
bce_loss = torch.nn.BCELoss()
# Testing loop
n_samples = len(test_data_loader)
test_iou = dict()
encoder_losses = utils.network_utils.AverageMeter()
refiner_losses = utils.network_utils.AverageMeter()
# Switch models to evaluation mode
encoder.eval()
decoder.eval()
refiner.eval()
merger.eval()
for sample_idx, (taxonomy_id, sample_name, rendering_images, ground_truth_volume) in enumerate(test_data_loader):
taxonomy_id = taxonomy_id[0] if isinstance(taxonomy_id[0], str) else taxonomy_id[0].item()
sample_name = sample_name[0]
with torch.no_grad():
# Get data from data loader
rendering_images = utils.network_utils.var_or_cuda(rendering_images)
ground_truth_volume = utils.network_utils.var_or_cuda(ground_truth_volume)
# Test the encoder, decoder, refiner and merger
image_features = encoder(rendering_images)
raw_features, generated_volume = decoder(image_features)
if cfg.NETWORK.USE_MERGER and epoch_idx >= cfg.TRAIN.EPOCH_START_USE_MERGER:
generated_volume = merger(raw_features, generated_volume)
else:
generated_volume = torch.mean(generated_volume, dim=1)
encoder_loss = bce_loss(generated_volume, ground_truth_volume) * 10
if cfg.NETWORK.USE_REFINER and epoch_idx >= cfg.TRAIN.EPOCH_START_USE_REFINER:
generated_volume = refiner(generated_volume)
refiner_loss = bce_loss(generated_volume, ground_truth_volume) * 10
else:
refiner_loss = encoder_loss
# Append loss and accuracy to average metrics
encoder_losses.update(encoder_loss.item())
refiner_losses.update(refiner_loss.item())
# IoU per sample
sample_iou = []
for th in cfg.TEST.VOXEL_THRESH:
_volume = torch.ge(generated_volume, th).float()
intersection = torch.sum(_volume.mul(ground_truth_volume)).float()
union = torch.sum(torch.ge(_volume.add(ground_truth_volume), 1)).float()
sample_iou.append((intersection / union).item())
# IoU per taxonomy
if taxonomy_id not in test_iou:
test_iou[taxonomy_id] = {'n_samples': 0, 'iou': []}
test_iou[taxonomy_id]['n_samples'] += 1
test_iou[taxonomy_id]['iou'].append(sample_iou)
# Append generated volumes to TensorBoard
if output_dir and sample_idx < 3:
img_dir = output_dir % 'images'
# Volume Visualization
gv = generated_volume.cpu().numpy()
rendering_views = utils.binvox_visualization.get_volume_views(gv, os.path.join(img_dir, 'test'),
epoch_idx)
test_writer.add_image('Test Sample#%02d/Volume Reconstructed' % sample_idx, rendering_views, epoch_idx)
gtv = ground_truth_volume.cpu().numpy()
rendering_views = utils.binvox_visualization.get_volume_views(gtv, os.path.join(img_dir, 'test'),
epoch_idx)
test_writer.add_image('Test Sample#%02d/Volume GroundTruth' % sample_idx, rendering_views, epoch_idx)
# Print sample loss and IoU
print('[INFO] %s Test[%d/%d] Taxonomy = %s Sample = %s EDLoss = %.4f RLoss = %.4f IoU = %s' %
(dt.now(), sample_idx + 1, n_samples, taxonomy_id, sample_name, encoder_loss.item(),
refiner_loss.item(), ['%.4f' % si for si in sample_iou]))
# Output testing results
mean_iou = []
for taxonomy_id in test_iou:
test_iou[taxonomy_id]['iou'] = np.mean(test_iou[taxonomy_id]['iou'], axis=0)
mean_iou.append(test_iou[taxonomy_id]['iou'] * test_iou[taxonomy_id]['n_samples'])
mean_iou = np.sum(mean_iou, axis=0) / n_samples
# Print header
print('============================ TEST RESULTS ============================')
print('Taxonomy', end='\t')
print('#Sample', end='\t')
print('Baseline', end='\t')
for th in cfg.TEST.VOXEL_THRESH:
print('t=%.2f' % th, end='\t')
print()
# Print body
for taxonomy_id in test_iou:
print('%s' % taxonomies[taxonomy_id]['taxonomy_name'].ljust(8), end='\t')
print('%d' % test_iou[taxonomy_id]['n_samples'], end='\t')
if 'baseline' in taxonomies[taxonomy_id]:
print('%.4f' % taxonomies[taxonomy_id]['baseline']['%d-view' % cfg.CONST.N_VIEWS_RENDERING], end='\t\t')
else:
print('N/a', end='\t\t')
for ti in test_iou[taxonomy_id]['iou']:
print('%.4f' % ti, end='\t')
print()
# Print mean IoU for each threshold
print('Overall ', end='\t\t\t\t')
for mi in mean_iou:
print('%.4f' % mi, end='\t')
print('\n')
# Add testing results to TensorBoard
max_iou = np.max(mean_iou)
if test_writer is not None:
test_writer.add_scalar('EncoderDecoder/EpochLoss', encoder_losses.avg, epoch_idx)
test_writer.add_scalar('Refiner/EpochLoss', refiner_losses.avg, epoch_idx)
test_writer.add_scalar('Refiner/IoU', max_iou, epoch_idx)
return max_iou
================================================
FILE: core/train.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import os
import random
import torch
import torch.backends.cudnn
import torch.utils.data
import utils.binvox_visualization
import utils.data_loaders
import utils.data_transforms
import utils.network_utils
from datetime import datetime as dt
from tensorboardX import SummaryWriter
from time import time
from core.test import test_net
from models.encoder import Encoder
from models.decoder import Decoder
from models.refiner import Refiner
from models.merger import Merger
def train_net(cfg):
# Enable the inbuilt cudnn auto-tuner to find the best algorithm to use
torch.backends.cudnn.benchmark = True
# Set up data augmentation
IMG_SIZE = cfg.CONST.IMG_H, cfg.CONST.IMG_W
CROP_SIZE = cfg.CONST.CROP_IMG_H, cfg.CONST.CROP_IMG_W
train_transforms = utils.data_transforms.Compose([
utils.data_transforms.RandomCrop(IMG_SIZE, CROP_SIZE),
utils.data_transforms.RandomBackground(cfg.TRAIN.RANDOM_BG_COLOR_RANGE),
utils.data_transforms.ColorJitter(cfg.TRAIN.BRIGHTNESS, cfg.TRAIN.CONTRAST, cfg.TRAIN.SATURATION),
utils.data_transforms.RandomNoise(cfg.TRAIN.NOISE_STD),
utils.data_transforms.Normalize(mean=cfg.DATASET.MEAN, std=cfg.DATASET.STD),
utils.data_transforms.RandomFlip(),
utils.data_transforms.RandomPermuteRGB(),
utils.data_transforms.ToTensor(),
])
val_transforms = utils.data_transforms.Compose([
utils.data_transforms.CenterCrop(IMG_SIZE, CROP_SIZE),
utils.data_transforms.RandomBackground(cfg.TEST.RANDOM_BG_COLOR_RANGE),
utils.data_transforms.Normalize(mean=cfg.DATASET.MEAN, std=cfg.DATASET.STD),
utils.data_transforms.ToTensor(),
])
# Set up data loader
train_dataset_loader = utils.data_loaders.DATASET_LOADER_MAPPING[cfg.DATASET.TRAIN_DATASET](cfg)
val_dataset_loader = utils.data_loaders.DATASET_LOADER_MAPPING[cfg.DATASET.TEST_DATASET](cfg)
train_data_loader = torch.utils.data.DataLoader(dataset=train_dataset_loader.get_dataset(
utils.data_loaders.DatasetType.TRAIN, cfg.CONST.N_VIEWS_RENDERING, train_transforms),
batch_size=cfg.CONST.BATCH_SIZE,
num_workers=cfg.TRAIN.NUM_WORKER,
pin_memory=True,
shuffle=True,
drop_last=True)
val_data_loader = torch.utils.data.DataLoader(dataset=val_dataset_loader.get_dataset(
utils.data_loaders.DatasetType.VAL, cfg.CONST.N_VIEWS_RENDERING, val_transforms),
batch_size=1,
num_workers=1,
pin_memory=True,
shuffle=False)
# Set up networks
encoder = Encoder(cfg)
decoder = Decoder(cfg)
refiner = Refiner(cfg)
merger = Merger(cfg)
print('[DEBUG] %s Parameters in Encoder: %d.' % (dt.now(), utils.network_utils.count_parameters(encoder)))
print('[DEBUG] %s Parameters in Decoder: %d.' % (dt.now(), utils.network_utils.count_parameters(decoder)))
print('[DEBUG] %s Parameters in Refiner: %d.' % (dt.now(), utils.network_utils.count_parameters(refiner)))
print('[DEBUG] %s Parameters in Merger: %d.' % (dt.now(), utils.network_utils.count_parameters(merger)))
# Initialize weights of networks
encoder.apply(utils.network_utils.init_weights)
decoder.apply(utils.network_utils.init_weights)
refiner.apply(utils.network_utils.init_weights)
merger.apply(utils.network_utils.init_weights)
# Set up solver
if cfg.TRAIN.POLICY == 'adam':
encoder_solver = torch.optim.Adam(filter(lambda p: p.requires_grad, encoder.parameters()),
lr=cfg.TRAIN.ENCODER_LEARNING_RATE,
betas=cfg.TRAIN.BETAS)
decoder_solver = torch.optim.Adam(decoder.parameters(),
lr=cfg.TRAIN.DECODER_LEARNING_RATE,
betas=cfg.TRAIN.BETAS)
refiner_solver = torch.optim.Adam(refiner.parameters(),
lr=cfg.TRAIN.REFINER_LEARNING_RATE,
betas=cfg.TRAIN.BETAS)
merger_solver = torch.optim.Adam(merger.parameters(), lr=cfg.TRAIN.MERGER_LEARNING_RATE, betas=cfg.TRAIN.BETAS)
elif cfg.TRAIN.POLICY == 'sgd':
encoder_solver = torch.optim.SGD(filter(lambda p: p.requires_grad, encoder.parameters()),
lr=cfg.TRAIN.ENCODER_LEARNING_RATE,
momentum=cfg.TRAIN.MOMENTUM)
decoder_solver = torch.optim.SGD(decoder.parameters(),
lr=cfg.TRAIN.DECODER_LEARNING_RATE,
momentum=cfg.TRAIN.MOMENTUM)
refiner_solver = torch.optim.SGD(refiner.parameters(),
lr=cfg.TRAIN.REFINER_LEARNING_RATE,
momentum=cfg.TRAIN.MOMENTUM)
merger_solver = torch.optim.SGD(merger.parameters(),
lr=cfg.TRAIN.MERGER_LEARNING_RATE,
momentum=cfg.TRAIN.MOMENTUM)
else:
raise Exception('[FATAL] %s Unknown optimizer %s.' % (dt.now(), cfg.TRAIN.POLICY))
# Set up learning rate scheduler to decay learning rates dynamically
encoder_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(encoder_solver,
milestones=cfg.TRAIN.ENCODER_LR_MILESTONES,
gamma=cfg.TRAIN.GAMMA)
decoder_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(decoder_solver,
milestones=cfg.TRAIN.DECODER_LR_MILESTONES,
gamma=cfg.TRAIN.GAMMA)
refiner_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(refiner_solver,
milestones=cfg.TRAIN.REFINER_LR_MILESTONES,
gamma=cfg.TRAIN.GAMMA)
merger_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(merger_solver,
milestones=cfg.TRAIN.MERGER_LR_MILESTONES,
gamma=cfg.TRAIN.GAMMA)
if torch.cuda.is_available():
encoder = torch.nn.DataParallel(encoder).cuda()
decoder = torch.nn.DataParallel(decoder).cuda()
refiner = torch.nn.DataParallel(refiner).cuda()
merger = torch.nn.DataParallel(merger).cuda()
# Set up loss functions
bce_loss = torch.nn.BCELoss()
# Load pretrained model if exists
init_epoch = 0
best_iou = -1
best_epoch = -1
if 'WEIGHTS' in cfg.CONST and cfg.TRAIN.RESUME_TRAIN:
print('[INFO] %s Recovering from %s ...' % (dt.now(), cfg.CONST.WEIGHTS))
checkpoint = torch.load(cfg.CONST.WEIGHTS)
init_epoch = checkpoint['epoch_idx']
best_iou = checkpoint['best_iou']
best_epoch = checkpoint['best_epoch']
encoder.load_state_dict(checkpoint['encoder_state_dict'])
decoder.load_state_dict(checkpoint['decoder_state_dict'])
if cfg.NETWORK.USE_REFINER:
refiner.load_state_dict(checkpoint['refiner_state_dict'])
if cfg.NETWORK.USE_MERGER:
merger.load_state_dict(checkpoint['merger_state_dict'])
print('[INFO] %s Recover complete. Current epoch #%d, Best IoU = %.4f at epoch #%d.' %
(dt.now(), init_epoch, best_iou, best_epoch))
# Summary writer for TensorBoard
output_dir = os.path.join(cfg.DIR.OUT_PATH, '%s', dt.now().isoformat())
log_dir = output_dir % 'logs'
ckpt_dir = output_dir % 'checkpoints'
train_writer = SummaryWriter(os.path.join(log_dir, 'train'))
val_writer = SummaryWriter(os.path.join(log_dir, 'test'))
# Training loop
for epoch_idx in range(init_epoch, cfg.TRAIN.NUM_EPOCHES):
# Tick / tock
epoch_start_time = time()
# Batch average meterics
batch_time = utils.network_utils.AverageMeter()
data_time = utils.network_utils.AverageMeter()
encoder_losses = utils.network_utils.AverageMeter()
refiner_losses = utils.network_utils.AverageMeter()
# switch models to training mode
encoder.train()
decoder.train()
merger.train()
refiner.train()
batch_end_time = time()
n_batches = len(train_data_loader)
for batch_idx, (taxonomy_names, sample_names, rendering_images,
ground_truth_volumes) in enumerate(train_data_loader):
# Measure data time
data_time.update(time() - batch_end_time)
# Get data from data loader
rendering_images = utils.network_utils.var_or_cuda(rendering_images)
ground_truth_volumes = utils.network_utils.var_or_cuda(ground_truth_volumes)
# Train the encoder, decoder, refiner, and merger
image_features = encoder(rendering_images)
raw_features, generated_volumes = decoder(image_features)
if cfg.NETWORK.USE_MERGER and epoch_idx >= cfg.TRAIN.EPOCH_START_USE_MERGER:
generated_volumes = merger(raw_features, generated_volumes)
else:
generated_volumes = torch.mean(generated_volumes, dim=1)
encoder_loss = bce_loss(generated_volumes, ground_truth_volumes) * 10
if cfg.NETWORK.USE_REFINER and epoch_idx >= cfg.TRAIN.EPOCH_START_USE_REFINER:
generated_volumes = refiner(generated_volumes)
refiner_loss = bce_loss(generated_volumes, ground_truth_volumes) * 10
else:
refiner_loss = encoder_loss
# Gradient decent
encoder.zero_grad()
decoder.zero_grad()
refiner.zero_grad()
merger.zero_grad()
if cfg.NETWORK.USE_REFINER and epoch_idx >= cfg.TRAIN.EPOCH_START_USE_REFINER:
encoder_loss.backward(retain_graph=True)
refiner_loss.backward()
else:
encoder_loss.backward()
encoder_solver.step()
decoder_solver.step()
refiner_solver.step()
merger_solver.step()
# Append loss to average metrics
encoder_losses.update(encoder_loss.item())
refiner_losses.update(refiner_loss.item())
# Append loss to TensorBoard
n_itr = epoch_idx * n_batches + batch_idx
train_writer.add_scalar('EncoderDecoder/BatchLoss', encoder_loss.item(), n_itr)
train_writer.add_scalar('Refiner/BatchLoss', refiner_loss.item(), n_itr)
# Tick / tock
batch_time.update(time() - batch_end_time)
batch_end_time = time()
print(
'[INFO] %s [Epoch %d/%d][Batch %d/%d] BatchTime = %.3f (s) DataTime = %.3f (s) EDLoss = %.4f RLoss = %.4f'
% (dt.now(), epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time.val,
data_time.val, encoder_loss.item(), refiner_loss.item()))
# Append epoch loss to TensorBoard
train_writer.add_scalar('EncoderDecoder/EpochLoss', encoder_losses.avg, epoch_idx + 1)
train_writer.add_scalar('Refiner/EpochLoss', refiner_losses.avg, epoch_idx + 1)
# Adjust learning rate
encoder_lr_scheduler.step()
decoder_lr_scheduler.step()
refiner_lr_scheduler.step()
merger_lr_scheduler.step()
# Tick / tock
epoch_end_time = time()
print('[INFO] %s Epoch [%d/%d] EpochTime = %.3f (s) EDLoss = %.4f RLoss = %.4f' %
(dt.now(), epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, epoch_end_time - epoch_start_time, encoder_losses.avg,
refiner_losses.avg))
# Update Rendering Views
if cfg.TRAIN.UPDATE_N_VIEWS_RENDERING:
n_views_rendering = random.randint(1, cfg.CONST.N_VIEWS_RENDERING)
train_data_loader.dataset.set_n_views_rendering(n_views_rendering)
print('[INFO] %s Epoch [%d/%d] Update #RenderingViews to %d' %
(dt.now(), epoch_idx + 2, cfg.TRAIN.NUM_EPOCHES, n_views_rendering))
# Validate the training models
iou = test_net(cfg, epoch_idx + 1, output_dir, val_data_loader, val_writer, encoder, decoder, refiner, merger)
# Save weights to file
if (epoch_idx + 1) % cfg.TRAIN.SAVE_FREQ == 0:
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
utils.network_utils.save_checkpoints(cfg, os.path.join(ckpt_dir, 'ckpt-epoch-%04d.pth' % (epoch_idx + 1)),
epoch_idx + 1, encoder, encoder_solver, decoder, decoder_solver,
refiner, refiner_solver, merger, merger_solver, best_iou, best_epoch)
if iou > best_iou:
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
best_iou = iou
best_epoch = epoch_idx + 1
utils.network_utils.save_checkpoints(cfg, os.path.join(ckpt_dir, 'best-ckpt.pth'), epoch_idx + 1, encoder,
encoder_solver, decoder, decoder_solver, refiner, refiner_solver,
merger, merger_solver, best_iou, best_epoch)
# Close SummaryWriter for TensorBoard
train_writer.close()
val_writer.close()
================================================
FILE: models/__init__.py
================================================
================================================
FILE: models/decoder.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import torch
class Decoder(torch.nn.Module):
def __init__(self, cfg):
super(Decoder, self).__init__()
self.cfg = cfg
# Layer Definition
self.layer1 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(2048, 512, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(512),
torch.nn.ReLU()
)
self.layer2 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(512, 128, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(128),
torch.nn.ReLU()
)
self.layer3 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(128, 32, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(32),
torch.nn.ReLU()
)
self.layer4 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(32, 8, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(8),
torch.nn.ReLU()
)
self.layer5 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(8, 1, kernel_size=1, bias=cfg.NETWORK.TCONV_USE_BIAS),
torch.nn.Sigmoid()
)
def forward(self, image_features):
image_features = image_features.permute(1, 0, 2, 3, 4).contiguous()
image_features = torch.split(image_features, 1, dim=0)
gen_volumes = []
raw_features = []
for features in image_features:
gen_volume = features.view(-1, 2048, 2, 2, 2)
# print(gen_volume.size()) # torch.Size([batch_size, 2048, 2, 2, 2])
gen_volume = self.layer1(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 512, 4, 4, 4])
gen_volume = self.layer2(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 128, 8, 8, 8])
gen_volume = self.layer3(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 32, 16, 16, 16])
gen_volume = self.layer4(gen_volume)
raw_feature = gen_volume
# print(gen_volume.size()) # torch.Size([batch_size, 8, 32, 32, 32])
gen_volume = self.layer5(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 1, 32, 32, 32])
raw_feature = torch.cat((raw_feature, gen_volume), dim=1)
# print(raw_feature.size()) # torch.Size([batch_size, 9, 32, 32, 32])
gen_volumes.append(torch.squeeze(gen_volume, dim=1))
raw_features.append(raw_feature)
gen_volumes = torch.stack(gen_volumes).permute(1, 0, 2, 3, 4).contiguous()
raw_features = torch.stack(raw_features).permute(1, 0, 2, 3, 4, 5).contiguous()
# print(gen_volumes.size()) # torch.Size([batch_size, n_views, 32, 32, 32])
# print(raw_features.size()) # torch.Size([batch_size, n_views, 9, 32, 32, 32])
return raw_features, gen_volumes
================================================
FILE: models/encoder.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
#
# References:
# - https://github.com/shawnxu1318/MVCNN-Multi-View-Convolutional-Neural-Networks/blob/master/mvcnn.py
import torch
import torchvision.models
class Encoder(torch.nn.Module):
def __init__(self, cfg):
super(Encoder, self).__init__()
self.cfg = cfg
# Layer Definition
vgg16_bn = torchvision.models.vgg16_bn(pretrained=True)
self.vgg = torch.nn.Sequential(*list(vgg16_bn.features.children()))[:27]
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(512, 512, kernel_size=3),
torch.nn.BatchNorm2d(512),
torch.nn.ELU(),
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(512, 512, kernel_size=3),
torch.nn.BatchNorm2d(512),
torch.nn.ELU(),
torch.nn.MaxPool2d(kernel_size=3)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(512, 256, kernel_size=1),
torch.nn.BatchNorm2d(256),
torch.nn.ELU()
)
# Don't update params in VGG16
for param in vgg16_bn.parameters():
param.requires_grad = False
def forward(self, rendering_images):
# print(rendering_images.size()) # torch.Size([batch_size, n_views, img_c, img_h, img_w])
rendering_images = rendering_images.permute(1, 0, 2, 3, 4).contiguous()
rendering_images = torch.split(rendering_images, 1, dim=0)
image_features = []
for img in rendering_images:
features = self.vgg(img.squeeze(dim=0))
# print(features.size()) # torch.Size([batch_size, 512, 28, 28])
features = self.layer1(features)
# print(features.size()) # torch.Size([batch_size, 512, 26, 26])
features = self.layer2(features)
# print(features.size()) # torch.Size([batch_size, 512, 24, 24])
features = self.layer3(features)
# print(features.size()) # torch.Size([batch_size, 256, 8, 8])
image_features.append(features)
image_features = torch.stack(image_features).permute(1, 0, 2, 3, 4).contiguous()
# print(image_features.size()) # torch.Size([batch_size, n_views, 256, 8, 8])
return image_features
================================================
FILE: models/merger.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import torch
class Merger(torch.nn.Module):
def __init__(self, cfg):
super(Merger, self).__init__()
self.cfg = cfg
# Layer Definition
self.layer1 = torch.nn.Sequential(
torch.nn.Conv3d(9, 16, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(16),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv3d(16, 8, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(8),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv3d(8, 4, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(4),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer4 = torch.nn.Sequential(
torch.nn.Conv3d(4, 2, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(2),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer5 = torch.nn.Sequential(
torch.nn.Conv3d(2, 1, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(1),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
def forward(self, raw_features, coarse_volumes):
n_views_rendering = coarse_volumes.size(1)
raw_features = torch.split(raw_features, 1, dim=1)
volume_weights = []
for i in range(n_views_rendering):
raw_feature = torch.squeeze(raw_features[i], dim=1)
# print(raw_feature.size()) # torch.Size([batch_size, 9, 32, 32, 32])
volume_weight = self.layer1(raw_feature)
# print(volume_weight.size()) # torch.Size([batch_size, 16, 32, 32, 32])
volume_weight = self.layer2(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 8, 32, 32, 32])
volume_weight = self.layer3(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 4, 32, 32, 32])
volume_weight = self.layer4(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 2, 32, 32, 32])
volume_weight = self.layer5(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 1, 32, 32, 32])
volume_weight = torch.squeeze(volume_weight, dim=1)
# print(volume_weight.size()) # torch.Size([batch_size, 32, 32, 32])
volume_weights.append(volume_weight)
volume_weights = torch.stack(volume_weights).permute(1, 0, 2, 3, 4).contiguous()
volume_weights = torch.softmax(volume_weights, dim=1)
# print(volume_weights.size()) # torch.Size([batch_size, n_views, 32, 32, 32])
# print(coarse_volumes.size()) # torch.Size([batch_size, n_views, 32, 32, 32])
coarse_volumes = coarse_volumes * volume_weights
coarse_volumes = torch.sum(coarse_volumes, dim=1)
return torch.clamp(coarse_volumes, min=0, max=1)
================================================
FILE: models/refiner.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import torch
class Refiner(torch.nn.Module):
def __init__(self, cfg):
super(Refiner, self).__init__()
self.cfg = cfg
# Layer Definition
self.layer1 = torch.nn.Sequential(
torch.nn.Conv3d(1, 32, kernel_size=4, padding=2),
torch.nn.BatchNorm3d(32),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE),
torch.nn.MaxPool3d(kernel_size=2)
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv3d(32, 64, kernel_size=4, padding=2),
torch.nn.BatchNorm3d(64),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE),
torch.nn.MaxPool3d(kernel_size=2)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv3d(64, 128, kernel_size=4, padding=2),
torch.nn.BatchNorm3d(128),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE),
torch.nn.MaxPool3d(kernel_size=2)
)
self.layer4 = torch.nn.Sequential(
torch.nn.Linear(8192, 2048),
torch.nn.ReLU()
)
self.layer5 = torch.nn.Sequential(
torch.nn.Linear(2048, 8192),
torch.nn.ReLU()
)
self.layer6 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(128, 64, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(64),
torch.nn.ReLU()
)
self.layer7 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(64, 32, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(32),
torch.nn.ReLU()
)
self.layer8 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(32, 1, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.Sigmoid()
)
def forward(self, coarse_volumes):
volumes_32_l = coarse_volumes.view((-1, 1, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX))
# print(volumes_32_l.size()) # torch.Size([batch_size, 1, 32, 32, 32])
volumes_16_l = self.layer1(volumes_32_l)
# print(volumes_16_l.size()) # torch.Size([batch_size, 32, 16, 16, 16])
volumes_8_l = self.layer2(volumes_16_l)
# print(volumes_8_l.size()) # torch.Size([batch_size, 64, 8, 8, 8])
volumes_4_l = self.layer3(volumes_8_l)
# print(volumes_4_l.size()) # torch.Size([batch_size, 128, 4, 4, 4])
flatten_features = self.layer4(volumes_4_l.view(-1, 8192))
# print(flatten_features.size()) # torch.Size([batch_size, 2048])
flatten_features = self.layer5(flatten_features)
# print(flatten_features.size()) # torch.Size([batch_size, 8192])
volumes_4_r = volumes_4_l + flatten_features.view(-1, 128, 4, 4, 4)
# print(volumes_4_r.size()) # torch.Size([batch_size, 128, 4, 4, 4])
volumes_8_r = volumes_8_l + self.layer6(volumes_4_r)
# print(volumes_8_r.size()) # torch.Size([batch_size, 64, 8, 8, 8])
volumes_16_r = volumes_16_l + self.layer7(volumes_8_r)
# print(volumes_16_r.size()) # torch.Size([batch_size, 32, 16, 16, 16])
volumes_32_r = (volumes_32_l + self.layer8(volumes_16_r)) * 0.5
# print(volumes_32_r.size()) # torch.Size([batch_size, 1, 32, 32, 32])
return volumes_32_r.view((-1, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX))
================================================
FILE: requirements.txt
================================================
argparse
easydict
matplotlib
numpy
opencv-python
scipy
torchvision
tensorboardX
================================================
FILE: runner.py
================================================
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import logging
import matplotlib
import multiprocessing as mp
import numpy as np
import os
import sys
# Fix problem: no $DISPLAY environment variable
matplotlib.use('Agg')
from argparse import ArgumentParser
from datetime import datetime as dt
from pprint import pprint
from config import cfg
from core.train import train_net
from core.test import test_net
def get_args_from_command_line():
parser = ArgumentParser(description='Parser of Runner of Pix2Vox')
parser.add_argument('--gpu',
dest='gpu_id',
help='GPU device id to use [cuda0]',
default=cfg.CONST.DEVICE,
type=str)
parser.add_argument('--rand', dest='randomize', help='Randomize (do not use a fixed seed)', action='store_true')
parser.add_argument('--test', dest='test', help='Test neural networks', action='store_true')
parser.add_argument('--batch-size',
dest='batch_size',
help='name of the net',
default=cfg.CONST.BATCH_SIZE,
type=int)
parser.add_argument('--epoch', dest='epoch', help='number of epoches', default=cfg.TRAIN.NUM_EPOCHES, type=int)
parser.add_argument('--weights', dest='weights', help='Initialize network from the weights file', default=None)
parser.add_argument('--out', dest='out_path', help='Set output path', default=cfg.DIR.OUT_PATH)
args = parser.parse_args()
return args
def main():
# Get args from command line
args = get_args_from_command_line()
if args.gpu_id is not None:
cfg.CONST.DEVICE = args.gpu_id
if not args.randomize:
np.random.seed(cfg.CONST.RNG_SEED)
if args.batch_size is not None:
cfg.CONST.BATCH_SIZE = args.batch_size
if args.epoch is not None:
cfg.TRAIN.NUM_EPOCHES = args.epoch
if args.out_path is not None:
cfg.DIR.OUT_PATH = args.out_path
if args.weights is not None:
cfg.CONST.WEIGHTS = args.weights
if not args.test:
cfg.TRAIN.RESUME_TRAIN = True
# Print config
print('Use config:')
pprint(cfg)
# Set GPU to use
if type(cfg.CONST.DEVICE) == str:
os.environ["CUDA_VISIBLE_DEVICES"] = cfg.CONST.DEVICE
# Start train/test process
if not args.test:
train_net(cfg)
else:
if 'WEIGHTS' in cfg.CONST and os.path.exists(cfg.CONST.WEIGHTS):
test_net(cfg)
else:
print('[FATAL] %s Please specify the file path of checkpoint.' % (dt.now()))
sys.exit(2)
if __name__ == '__main__':
# Check python version
if sys.version_info < (3, 0):
raise Exception("Please follow the installation instruction on 'https://github.com/hzxie/Pix2Vox'")
# Setup logger
mp.log_to_stderr()
logger = mp.get_logger()
logger.setLevel(logging.INFO)
main()
================================================
FILE: utils/__init__.py
================================================
================================================
FILE: utils/binvox_converter.py
================================================
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
#
# This script is used to convert OFF format to binvox.
# Please make sure that you have `binvox` installed.
# You can get it in http://www.patrickmin.com/binvox/
import numpy as np
import os
import subprocess
import sys
from datetime import datetime as dt
from glob import glob
import binvox_rw
def main():
if not len(sys.argv) == 2:
print('python binvox_converter.py input_file_folder')
sys.exit(1)
input_file_folder = sys.argv[1]
if not os.path.exists(input_file_folder) or not os.path.isdir(input_file_folder):
print('[ERROR] Input folder not exists!')
sys.exit(2)
N_VOX = 32
MESH_EXTENSION = '*.off'
folder_path = os.path.join(input_file_folder, MESH_EXTENSION)
mesh_files = glob(folder_path)
for m_file in mesh_files:
file_path = os.path.join(input_file_folder, m_file)
file_name, ext = os.path.splitext(m_file)
binvox_file_path = os.path.join(input_file_folder, '%s.binvox' % file_name)
if os.path.exists(binvox_file_path):
print('[WARN] %s File: %s exists. It will be overwritten.' % (dt.now(), binvox_file_path))
os.remove(binvox_file_path)
print('[INFO] %s Processing file: %s' % (dt.now(), file_path))
rc = subprocess.call(['binvox', '-d', str(N_VOX), '-e', '-cb', '-rotx', '-rotx', '-rotx', '-rotz', m_file])
if not rc == 0:
print('[WARN] %s Failed to convert file: %s' % (dt.now(), m_file))
continue
with open(binvox_file_path, 'rb') as file:
v = binvox_rw.read_as_3d_array(file)
v.data = np.transpose(v.data, (2, 0, 1))
with open(binvox_file_path, 'wb') as file:
binvox_rw.write(v, file)
if __name__ == '__main__':
return_code = subprocess.call(['which', 'binvox'], stdout=subprocess.PIPE)
if return_code == 0:
main()
else:
print('[FATAL] %s Please make sure you have binvox installed.' % dt.now())
================================================
FILE: utils/binvox_rw.py
================================================
# Copyright (C) 2012 Daniel Maturana
# This file is part of binvox-rw-py.
#
# binvox-rw-py is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# binvox-rw-py is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with binvox-rw-py. If not, see <http://www.gnu.org/licenses/>.
#
"""
Binvox to Numpy and back.
>>> import numpy as np
>>> import binvox_rw
>>> with open('chair.binvox', 'rb') as f:
... m1 = binvox_rw.read_as_3d_array(f)
...
>>> m1.dims
[32, 32, 32]
>>> m1.scale
41.133000000000003
>>> m1.translate
[0.0, 0.0, 0.0]
>>> with open('chair_out.binvox', 'wb') as f:
... m1.write(f)
...
>>> with open('chair_out.binvox', 'rb') as f:
... m2 = binvox_rw.read_as_3d_array(f)
...
>>> m1.dims == m2.dims
True
>>> m1.scale == m2.scale
True
>>> m1.translate == m2.translate
True
>>> np.all(m1.data == m2.data)
True
>>> with open('chair.binvox', 'rb') as f:
... md = binvox_rw.read_as_3d_array(f)
...
>>> with open('chair.binvox', 'rb') as f:
... ms = binvox_rw.read_as_coord_array(f)
...
>>> data_ds = binvox_rw.dense_to_sparse(md.data)
>>> data_sd = binvox_rw.sparse_to_dense(ms.data, 32)
>>> np.all(data_sd == md.data)
True
>>> # the ordering of elements returned by numpy.nonzero changes with axis
>>> # ordering, so to compare for equality we first lexically sort the voxels.
>>> np.all(ms.data[:, np.lexsort(ms.data)] == data_ds[:, np.lexsort(data_ds)])
True
"""
import numpy as np
class Voxels(object):
""" Holds a binvox model.
data is either a three-dimensional numpy boolean array (dense representation)
or a two-dimensional numpy float array (coordinate representation).
dims, translate and scale are the model metadata.
dims are the voxel dimensions, e.g. [32, 32, 32] for a 32x32x32 model.
scale and translate relate the voxels to the original model coordinates.
To translate voxel coordinates i, j, k to original coordinates x, y, z:
x_n = (i+.5)/dims[0]
y_n = (j+.5)/dims[1]
z_n = (k+.5)/dims[2]
x = scale*x_n + translate[0]
y = scale*y_n + translate[1]
z = scale*z_n + translate[2]
"""
def __init__(self, data, dims, translate, scale, axis_order):
self.data = data
self.dims = dims
self.translate = translate
self.scale = scale
assert (axis_order in ('xzy', 'xyz'))
self.axis_order = axis_order
def clone(self):
data = self.data.copy()
dims = self.dims[:]
translate = self.translate[:]
return Voxels(data, dims, translate, self.scale, self.axis_order)
def write(self, fp):
write(self, fp)
def read_header(fp):
""" Read binvox header. Mostly meant for internal use.
"""
line = fp.readline().strip()
if not line.startswith(b'#binvox'):
raise IOError('[ERROR] Not a binvox file')
dims = list(map(int, fp.readline().strip().split(b' ')[1:]))
translate = list(map(float, fp.readline().strip().split(b' ')[1:]))
scale = list(map(float, fp.readline().strip().split(b' ')[1:]))[0]
fp.readline()
return dims, translate, scale
def read_as_3d_array(fp, fix_coords=True):
""" Read binary binvox format as array.
Returns the model with accompanying metadata.
Voxels are stored in a three-dimensional numpy array, which is simple and
direct, but may use a lot of memory for large models. (Storage requirements
are 8*(d^3) bytes, where d is the dimensions of the binvox model. Numpy
boolean arrays use a byte per element).
Doesn't do any checks on input except for the '#binvox' line.
"""
dims, translate, scale = read_header(fp)
raw_data = np.frombuffer(fp.read(), dtype=np.uint8)
# if just using reshape() on the raw data:
# indexing the array as array[i,j,k], the indices map into the
# coords as:
# i -> x
# j -> z
# k -> y
# if fix_coords is true, then data is rearranged so that
# mapping is
# i -> x
# j -> y
# k -> z
values, counts = raw_data[::2], raw_data[1::2]
data = np.repeat(values, counts).astype(np.int32)
data = data.reshape(dims)
if fix_coords:
# xzy to xyz TODO the right thing
data = np.transpose(data, (0, 2, 1))
axis_order = 'xyz'
else:
axis_order = 'xzy'
return Voxels(data, dims, translate, scale, axis_order)
def read_as_coord_array(fp, fix_coords=True):
""" Read binary binvox format as coordinates.
Returns binvox model with voxels in a "coordinate" representation, i.e. an
3 x N array where N is the number of nonzero voxels. Each column
corresponds to a nonzero voxel and the 3 rows are the (x, z, y) coordinates
of the voxel. (The odd ordering is due to the way binvox format lays out
data). Note that coordinates refer to the binvox voxels, without any
scaling or translation.
Use this to save memory if your model is very sparse (mostly empty).
Doesn't do any checks on input except for the '#binvox' line.
"""
dims, translate, scale = read_header(fp)
raw_data = np.frombuffer(fp.read(), dtype=np.uint8)
values, counts = raw_data[::2], raw_data[1::2]
# sz = np.prod(dims)
# index, end_index = 0, 0
end_indices = np.cumsum(counts)
indices = np.concatenate(([0], end_indices[:-1])).astype(end_indices.dtype)
values = values.astype(np.bool)
indices = indices[values]
end_indices = end_indices[values]
nz_voxels = []
for index, end_index in zip(indices, end_indices):
nz_voxels.extend(range(index, end_index))
nz_voxels = np.array(nz_voxels)
# TODO are these dims correct?
# according to docs,
# index = x * wxh + z * width + y; // wxh = width * height = d * d
x = nz_voxels / (dims[0] * dims[1])
zwpy = nz_voxels % (dims[0] * dims[1]) # z*w + y
z = zwpy / dims[0]
y = zwpy % dims[0]
if fix_coords:
data = np.vstack((x, y, z))
axis_order = 'xyz'
else:
data = np.vstack((x, z, y))
axis_order = 'xzy'
#return Voxels(data, dims, translate, scale, axis_order)
return Voxels(np.ascontiguousarray(data), dims, translate, scale, axis_order)
def dense_to_sparse(voxel_data, dtype=np.int):
""" From dense representation to sparse (coordinate) representation.
No coordinate reordering.
"""
if voxel_data.ndim != 3:
raise ValueError('[ERROR] voxel_data is wrong shape; should be 3D array.')
return np.asarray(np.nonzero(voxel_data), dtype)
def sparse_to_dense(voxel_data, dims, dtype=np.bool):
if voxel_data.ndim != 2 or voxel_data.shape[0] != 3:
raise ValueError('[ERROR] voxel_data is wrong shape; should be 3xN array.')
if np.isscalar(dims):
dims = [dims] * 3
dims = np.atleast_2d(dims).T
# truncate to integers
xyz = voxel_data.astype(np.int)
# discard voxels that fall outside dims
valid_ix = ~np.any((xyz < 0) | (xyz >= dims), 0)
xyz = xyz[:, valid_ix]
out = np.zeros(dims.flatten(), dtype=dtype)
out[tuple(xyz)] = True
return out
#def get_linear_index(x, y, z, dims):
#""" Assuming xzy order. (y increasing fastest.
#TODO ensure this is right when dims are not all same
#"""
#return x*(dims[1]*dims[2]) + z*dims[1] + y
def write(voxel_model, fp):
""" Write binary binvox format.
Note that when saving a model in sparse (coordinate) format, it is first
converted to dense format.
Doesn't check if the model is 'sane'.
"""
if voxel_model.data.ndim == 2:
# TODO avoid conversion to dense
dense_voxel_data = sparse_to_dense(voxel_model.data, voxel_model.dims).astype(int)
else:
dense_voxel_data = voxel_model.data.astype(int)
file_header = [
'#binvox 1\n',
'dim %s\n' % ' '.join(map(str, voxel_model.dims)),
'translate %s\n' % ' '.join(map(str, voxel_model.translate)),
'scale %s\n' % str(voxel_model.scale), 'data\n'
]
for fh in file_header:
fp.write(fh.encode('latin-1'))
if voxel_model.axis_order not in ('xzy', 'xyz'):
raise ValueError('[ERROR] Unsupported voxel model axis order')
if voxel_model.axis_order == 'xzy':
voxels_flat = dense_voxel_data.flatten()
elif voxel_model.axis_order == 'xyz':
voxels_flat = np.transpose(dense_voxel_data, (0, 2, 1)).flatten()
# keep a sort of state machine for writing run length encoding
state = voxels_flat[0]
ctr = 0
for c in voxels_flat:
if c == state:
ctr += 1
# if ctr hits max, dump
if ctr == 255:
fp.write(chr(state).encode('latin-1'))
fp.write(chr(ctr).encode('latin-1'))
ctr = 0
else:
# if switch state, dump
fp.write(chr(state).encode('latin-1'))
fp.write(chr(ctr).encode('latin-1'))
state = c
ctr = 1
# flush out remainders
if ctr > 0:
fp.write(chr(state).encode('latin-1'))
fp.write(chr(ctr).encode('latin-1'))
if __name__ == '__main__':
import doctest
doctest.testmod()
================================================
FILE: utils/binvox_visualization.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import cv2
import matplotlib.pyplot as plt
import os
from mpl_toolkits.mplot3d import Axes3D
def get_volume_views(volume, save_dir, n_itr):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
volume = volume.squeeze().__ge__(0.5)
fig = plt.figure()
ax = fig.gca(projection=Axes3D.name)
ax.set_aspect('equal')
ax.voxels(volume, edgecolor="k")
save_path = os.path.join(save_dir, 'voxels-%06d.png' % n_itr)
plt.savefig(save_path, bbox_inches='tight')
plt.close()
return cv2.imread(save_path)
================================================
FILE: utils/data_loaders.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import cv2
import json
import numpy as np
import os
import random
import scipy.io
import scipy.ndimage
import sys
import torch.utils.data.dataset
from datetime import datetime as dt
from enum import Enum, unique
import utils.binvox_rw
@unique
class DatasetType(Enum):
TRAIN = 0
TEST = 1
VAL = 2
# //////////////////////////////// = End of DatasetType Class Definition = ///////////////////////////////// #
class ShapeNetDataset(torch.utils.data.dataset.Dataset):
"""ShapeNetDataset class used for PyTorch DataLoader"""
def __init__(self, dataset_type, file_list, n_views_rendering, transforms=None):
self.dataset_type = dataset_type
self.file_list = file_list
self.transforms = transforms
self.n_views_rendering = n_views_rendering
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
taxonomy_name, sample_name, rendering_images, volume = self.get_datum(idx)
if self.transforms:
rendering_images = self.transforms(rendering_images)
return taxonomy_name, sample_name, rendering_images, volume
def set_n_views_rendering(self, n_views_rendering):
self.n_views_rendering = n_views_rendering
def get_datum(self, idx):
taxonomy_name = self.file_list[idx]['taxonomy_name']
sample_name = self.file_list[idx]['sample_name']
rendering_image_paths = self.file_list[idx]['rendering_images']
volume_path = self.file_list[idx]['volume']
# Get data of rendering images
if self.dataset_type == DatasetType.TRAIN:
selected_rendering_image_paths = [
rendering_image_paths[i]
for i in random.sample(range(len(rendering_image_paths)), self.n_views_rendering)
]
else:
selected_rendering_image_paths = [rendering_image_paths[i] for i in range(self.n_views_rendering)]
rendering_images = []
for image_path in selected_rendering_image_paths:
rendering_image = cv2.imread(image_path, cv2.IMREAD_UNCHANGED).astype(np.float32) / 255.
if len(rendering_image.shape) < 3:
print('[FATAL] %s It seems that there is something wrong with the image file %s' %
(dt.now(), image_path))
sys.exit(2)
rendering_images.append(rendering_image)
# Get data of volume
_, suffix = os.path.splitext(volume_path)
if suffix == '.mat':
volume = scipy.io.loadmat(volume_path)
volume = volume['Volume'].astype(np.float32)
elif suffix == '.binvox':
with open(volume_path, 'rb') as f:
volume = utils.binvox_rw.read_as_3d_array(f)
volume = volume.data.astype(np.float32)
return taxonomy_name, sample_name, np.asarray(rendering_images), volume
# //////////////////////////////// = End of ShapeNetDataset Class Definition = ///////////////////////////////// #
class ShapeNetDataLoader:
def __init__(self, cfg):
self.dataset_taxonomy = None
self.rendering_image_path_template = cfg.DATASETS.SHAPENET.RENDERING_PATH
self.volume_path_template = cfg.DATASETS.SHAPENET.VOXEL_PATH
# Load all taxonomies of the dataset
with open(cfg.DATASETS.SHAPENET.TAXONOMY_FILE_PATH, encoding='utf-8') as file:
self.dataset_taxonomy = json.loads(file.read())
def get_dataset(self, dataset_type, n_views_rendering, transforms=None):
files = []
# Load data for each category
for taxonomy in self.dataset_taxonomy:
taxonomy_folder_name = taxonomy['taxonomy_id']
print('[INFO] %s Collecting files of Taxonomy[ID=%s, Name=%s]' %
(dt.now(), taxonomy['taxonomy_id'], taxonomy['taxonomy_name']))
samples = []
if dataset_type == DatasetType.TRAIN:
samples = taxonomy['train']
elif dataset_type == DatasetType.TEST:
samples = taxonomy['test']
elif dataset_type == DatasetType.VAL:
samples = taxonomy['val']
files.extend(self.get_files_of_taxonomy(taxonomy_folder_name, samples))
print('[INFO] %s Complete collecting files of the dataset. Total files: %d.' % (dt.now(), len(files)))
return ShapeNetDataset(dataset_type, files, n_views_rendering, transforms)
def get_files_of_taxonomy(self, taxonomy_folder_name, samples):
files_of_taxonomy = []
for sample_idx, sample_name in enumerate(samples):
# Get file path of volumes
volume_file_path = self.volume_path_template % (taxonomy_folder_name, sample_name)
if not os.path.exists(volume_file_path):
print('[WARN] %s Ignore sample %s/%s since volume file not exists.' %
(dt.now(), taxonomy_folder_name, sample_name))
continue
# Get file list of rendering images
img_file_path = self.rendering_image_path_template % (taxonomy_folder_name, sample_name, 0)
img_folder = os.path.dirname(img_file_path)
total_views = len(os.listdir(img_folder))
rendering_image_indexes = range(total_views)
rendering_images_file_path = []
for image_idx in rendering_image_indexes:
img_file_path = self.rendering_image_path_template % (taxonomy_folder_name, sample_name, image_idx)
if not os.path.exists(img_file_path):
continue
rendering_images_file_path.append(img_file_path)
if len(rendering_images_file_path) == 0:
print('[WARN] %s Ignore sample %s/%s since image files not exists.' %
(dt.now(), taxonomy_folder_name, sample_name))
continue
# Append to the list of rendering images
files_of_taxonomy.append({
'taxonomy_name': taxonomy_folder_name,
'sample_name': sample_name,
'rendering_images': rendering_images_file_path,
'volume': volume_file_path,
})
# Report the progress of reading dataset
# if sample_idx % 500 == 499 or sample_idx == n_samples - 1:
# print('[INFO] %s Collecting %d of %d' % (dt.now(), sample_idx + 1, n_samples))
return files_of_taxonomy
# /////////////////////////////// = End of ShapeNetDataLoader Class Definition = /////////////////////////////// #
class Pascal3dDataset(torch.utils.data.dataset.Dataset):
"""Pascal3D class used for PyTorch DataLoader"""
def __init__(self, file_list, transforms=None):
self.file_list = file_list
self.transforms = transforms
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
taxonomy_name, sample_name, rendering_images, volume, bounding_box = self.get_datum(idx)
if self.transforms:
rendering_images = self.transforms(rendering_images, bounding_box)
return taxonomy_name, sample_name, rendering_images, volume
def get_datum(self, idx):
taxonomy_name = self.file_list[idx]['taxonomy_name']
sample_name = self.file_list[idx]['sample_name']
rendering_image_path = self.file_list[idx]['rendering_image']
bounding_box = self.file_list[idx]['bounding_box']
volume_path = self.file_list[idx]['volume']
# Get data of rendering images
rendering_image = cv2.imread(rendering_image_path, cv2.IMREAD_UNCHANGED).astype(np.float32) / 255.
if len(rendering_image.shape) < 3:
print('[WARN] %s It seems the image file %s is grayscale.' % (dt.now(), rendering_image_path))
rendering_image = np.stack((rendering_image, ) * 3, -1)
# Get data of volume
with open(volume_path, 'rb') as f:
volume = utils.binvox_rw.read_as_3d_array(f)
volume = volume.data.astype(np.float32)
return taxonomy_name, sample_name, np.asarray([rendering_image]), volume, bounding_box
# //////////////////////////////// = End of Pascal3dDataset Class Definition = ///////////////////////////////// #
class Pascal3dDataLoader:
def __init__(self, cfg):
self.dataset_taxonomy = None
self.volume_path_template = cfg.DATASETS.PASCAL3D.VOXEL_PATH
self.annotation_path_template = cfg.DATASETS.PASCAL3D.ANNOTATION_PATH
self.rendering_image_path_template = cfg.DATASETS.PASCAL3D.RENDERING_PATH
# Load all taxonomies of the dataset
with open(cfg.DATASETS.PASCAL3D.TAXONOMY_FILE_PATH, encoding='utf-8') as file:
self.dataset_taxonomy = json.loads(file.read())
def get_dataset(self, dataset_type, n_views_rendering, transforms=None):
files = []
# Load data for each category
for taxonomy in self.dataset_taxonomy:
taxonomy_name = taxonomy['taxonomy_name']
print('[INFO] %s Collecting files of Taxonomy[Name=%s]' % (dt.now(), taxonomy_name))
samples = []
if dataset_type == DatasetType.TRAIN:
samples = taxonomy['train']
elif dataset_type == DatasetType.TEST:
samples = taxonomy['test']
elif dataset_type == DatasetType.VAL:
samples = taxonomy['test']
files.extend(self.get_files_of_taxonomy(taxonomy_name, samples))
print('[INFO] %s Complete collecting files of the dataset. Total files: %d.' % (dt.now(), len(files)))
return Pascal3dDataset(files, transforms)
def get_files_of_taxonomy(self, taxonomy_name, samples):
files_of_taxonomy = []
for sample_idx, sample_name in enumerate(samples):
# Get file list of rendering images
rendering_image_file_path = self.rendering_image_path_template % (taxonomy_name, sample_name)
# if not os.path.exists(rendering_image_file_path):
# continue
# Get image annotations
annotations_file_path = self.annotation_path_template % (taxonomy_name, sample_name)
annotations_mat = scipy.io.loadmat(annotations_file_path, squeeze_me=True, struct_as_record=False)
img_width, img_height, _ = annotations_mat['record'].imgsize
annotations = annotations_mat['record'].objects
cad_index = -1
bbox = None
if (type(annotations) == np.ndarray):
max_bbox_aera = -1
for i in range(len(annotations)):
_cad_index = annotations[i].cad_index
_bbox = annotations[i].__dict__['bbox']
bbox_xmin = _bbox[0]
bbox_ymin = _bbox[1]
bbox_xmax = _bbox[2]
bbox_ymax = _bbox[3]
_bbox_area = (bbox_xmax - bbox_xmin) * (bbox_ymax - bbox_ymin)
if _bbox_area > max_bbox_aera:
bbox = _bbox
cad_index = _cad_index
max_bbox_aera = _bbox_area
else:
cad_index = annotations.cad_index
bbox = annotations.bbox
# Convert the coordinates of bounding boxes to percentages
bbox = [bbox[0] / img_width, bbox[1] / img_height, bbox[2] / img_width, bbox[3] / img_height]
# Get file path of volumes
volume_file_path = self.volume_path_template % (taxonomy_name, cad_index)
if not os.path.exists(volume_file_path):
print('[WARN] %s Ignore sample %s/%s since volume file not exists.' %
(dt.now(), taxonomy_name, sample_name))
continue
# Append to the list of rendering images
files_of_taxonomy.append({
'taxonomy_name': taxonomy_name,
'sample_name': sample_name,
'rendering_image': rendering_image_file_path,
'bounding_box': bbox,
'volume': volume_file_path,
})
return files_of_taxonomy
# /////////////////////////////// = End of Pascal3dDataLoader Class Definition = /////////////////////////////// #
class Pix3dDataset(torch.utils.data.dataset.Dataset):
"""Pix3D class used for PyTorch DataLoader"""
def __init__(self, file_list, transforms=None):
self.file_list = file_list
self.transforms = transforms
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
taxonomy_name, sample_name, rendering_images, volume, bounding_box = self.get_datum(idx)
if self.transforms:
rendering_images = self.transforms(rendering_images, bounding_box)
return taxonomy_name, sample_name, rendering_images, volume
def get_datum(self, idx):
taxonomy_name = self.file_list[idx]['taxonomy_name']
sample_name = self.file_list[idx]['sample_name']
rendering_image_path = self.file_list[idx]['rendering_image']
bounding_box = self.file_list[idx]['bounding_box']
volume_path = self.file_list[idx]['volume']
# Get data of rendering images
rendering_image = cv2.imread(rendering_image_path, cv2.IMREAD_UNCHANGED).astype(np.float32) / 255.
if len(rendering_image.shape) < 3:
print('[WARN] %s It seems the image file %s is grayscale.' % (dt.now(), rendering_image_path))
rendering_image = np.stack((rendering_image, ) * 3, -1)
# Get data of volume
with open(volume_path, 'rb') as f:
volume = utils.binvox_rw.read_as_3d_array(f)
volume = volume.data.astype(np.float32)
return taxonomy_name, sample_name, np.asarray([rendering_image]), volume, bounding_box
# //////////////////////////////// = End of Pascal3dDataset Class Definition = ///////////////////////////////// #
class Pix3dDataLoader:
def __init__(self, cfg):
self.dataset_taxonomy = None
self.annotations = dict()
self.volume_path_template = cfg.DATASETS.PIX3D.VOXEL_PATH
self.rendering_image_path_template = cfg.DATASETS.PIX3D.RENDERING_PATH
# Load all taxonomies of the dataset
with open(cfg.DATASETS.PIX3D.TAXONOMY_FILE_PATH, encoding='utf-8') as file:
self.dataset_taxonomy = json.loads(file.read())
# Load all annotations of the dataset
_annotations = None
with open(cfg.DATASETS.PIX3D.ANNOTATION_PATH, encoding='utf-8') as file:
_annotations = json.loads(file.read())
for anno in _annotations:
filename, _ = os.path.splitext(anno['img'])
anno_key = filename[4:]
self.annotations[anno_key] = anno
def get_dataset(self, dataset_type, n_views_rendering, transforms=None):
files = []
# Load data for each category
for taxonomy in self.dataset_taxonomy:
taxonomy_name = taxonomy['taxonomy_name']
print('[INFO] %s Collecting files of Taxonomy[Name=%s]' % (dt.now(), taxonomy_name))
samples = []
if dataset_type == DatasetType.TRAIN:
samples = taxonomy['train']
elif dataset_type == DatasetType.TEST:
samples = taxonomy['test']
elif dataset_type == DatasetType.VAL:
samples = taxonomy['test']
files.extend(self.get_files_of_taxonomy(taxonomy_name, samples))
print('[INFO] %s Complete collecting files of the dataset. Total files: %d.' % (dt.now(), len(files)))
return Pix3dDataset(files, transforms)
def get_files_of_taxonomy(self, taxonomy_name, samples):
files_of_taxonomy = []
for sample_idx, sample_name in enumerate(samples):
# Get image annotations
anno_key = '%s/%s' % (taxonomy_name, sample_name)
annotations = self.annotations[anno_key]
# Get file list of rendering images
_, img_file_suffix = os.path.splitext(annotations['img'])
rendering_image_file_path = self.rendering_image_path_template % (taxonomy_name, sample_name,
img_file_suffix[1:])
# Get the bounding box of the image
img_width, img_height = annotations['img_size']
bbox = [
annotations['bbox'][0] / img_width,
annotations['bbox'][1] / img_height,
annotations['bbox'][2] / img_width,
annotations['bbox'][3] / img_height
] # yapf: disable
model_name_parts = annotations['voxel'].split('/')
model_name = model_name_parts[2]
volume_file_name = model_name_parts[3][:-4].replace('voxel', 'model')
# Get file path of volumes
volume_file_path = self.volume_path_template % (taxonomy_name, model_name, volume_file_name)
if not os.path.exists(volume_file_path):
print('[WARN] %s Ignore sample %s/%s since volume file not exists.' %
(dt.now(), taxonomy_name, sample_name))
continue
# Append to the list of rendering images
files_of_taxonomy.append({
'taxonomy_name': taxonomy_name,
'sample_name': sample_name,
'rendering_image': rendering_image_file_path,
'bounding_box': bbox,
'volume': volume_file_path,
})
return files_of_taxonomy
# /////////////////////////////// = End of Pascal3dDataLoader Class Definition = /////////////////////////////// #
DATASET_LOADER_MAPPING = {
'ShapeNet': ShapeNetDataLoader,
'Pascal3D': Pascal3dDataLoader,
'Pix3D': Pix3dDataLoader
} # yapf: disable
================================================
FILE: utils/data_transforms.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
# References:
# - https://github.com/xiumingzhang/GenRe-ShapeHD
import cv2
# import matplotlib.pyplot as plt
# import matplotlib.patches as patches
import numpy as np
import os
import random
import torch
class Compose(object):
""" Composes several transforms together.
For example:
>>> transforms.Compose([
>>> transforms.RandomBackground(),
>>> transforms.CenterCrop(127, 127, 3),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, rendering_images, bounding_box=None):
for t in self.transforms:
if t.__class__.__name__ == 'RandomCrop' or t.__class__.__name__ == 'CenterCrop':
rendering_images = t(rendering_images, bounding_box)
else:
rendering_images = t(rendering_images)
return rendering_images
class ToTensor(object):
"""
Convert a PIL Image or numpy.ndarray to tensor.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0].
"""
def __call__(self, rendering_images):
assert (isinstance(rendering_images, np.ndarray))
array = np.transpose(rendering_images, (0, 3, 1, 2))
# handle numpy array
tensor = torch.from_numpy(array)
# put it from HWC to CHW format
return tensor.float()
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, rendering_images):
assert (isinstance(rendering_images, np.ndarray))
rendering_images -= self.mean
rendering_images /= self.std
return rendering_images
class RandomPermuteRGB(object):
def __call__(self, rendering_images):
assert (isinstance(rendering_images, np.ndarray))
random_permutation = np.random.permutation(3)
for img_idx, img in enumerate(rendering_images):
rendering_images[img_idx] = img[..., random_permutation]
return rendering_images
class CenterCrop(object):
def __init__(self, img_size, crop_size):
"""Set the height and weight before and after cropping"""
self.img_size_h = img_size[0]
self.img_size_w = img_size[1]
self.crop_size_h = crop_size[0]
self.crop_size_w = crop_size[1]
def __call__(self, rendering_images, bounding_box=None):
if len(rendering_images) == 0:
return rendering_images
crop_size_c = rendering_images[0].shape[2]
processed_images = np.empty(shape=(0, self.img_size_h, self.img_size_w, crop_size_c))
for img_idx, img in enumerate(rendering_images):
img_height, img_width, _ = img.shape
if bounding_box is not None:
bounding_box = [
bounding_box[0] * img_width,
bounding_box[1] * img_height,
bounding_box[2] * img_width,
bounding_box[3] * img_height
] # yapf: disable
# Calculate the size of bounding boxes
bbox_width = bounding_box[2] - bounding_box[0]
bbox_height = bounding_box[3] - bounding_box[1]
bbox_x_mid = (bounding_box[2] + bounding_box[0]) * .5
bbox_y_mid = (bounding_box[3] + bounding_box[1]) * .5
# Make the crop area as a square
square_object_size = max(bbox_width, bbox_height)
x_left = int(bbox_x_mid - square_object_size * .5)
x_right = int(bbox_x_mid + square_object_size * .5)
y_top = int(bbox_y_mid - square_object_size * .5)
y_bottom = int(bbox_y_mid + square_object_size * .5)
# If the crop position is out of the image, fix it with padding
pad_x_left = 0
if x_left < 0:
pad_x_left = -x_left
x_left = 0
pad_x_right = 0
if x_right >= img_width:
pad_x_right = x_right - img_width + 1
x_right = img_width - 1
pad_y_top = 0
if y_top < 0:
pad_y_top = -y_top
y_top = 0
pad_y_bottom = 0
if y_bottom >= img_height:
pad_y_bottom = y_bottom - img_height + 1
y_bottom = img_height - 1
# Padding the image and resize the image
processed_image = np.pad(img[y_top:y_bottom + 1, x_left:x_right + 1],
((pad_y_top, pad_y_bottom), (pad_x_left, pad_x_right), (0, 0)),
mode='edge')
processed_image = cv2.resize(processed_image, (self.img_size_w, self.img_size_h))
else:
if img_height > self.crop_size_h and img_width > self.crop_size_w:
x_left = int(img_width - self.crop_size_w) // 2
x_right = int(x_left + self.crop_size_w)
y_top = int(img_height - self.crop_size_h) // 2
y_bottom = int(y_top + self.crop_size_h)
else:
x_left = 0
x_right = img_width
y_top = 0
y_bottom = img_height
processed_image = cv2.resize(img[y_top:y_bottom, x_left:x_right], (self.img_size_w, self.img_size_h))
processed_images = np.append(processed_images, [processed_image], axis=0)
# Debug
# fig = plt.figure()
# ax1 = fig.add_subplot(1, 2, 1)
# ax1.imshow(img)
# if not bounding_box is None:
# rect = patches.Rectangle((bounding_box[0], bounding_box[1]),
# bbox_width,
# bbox_height,
# linewidth=1,
# edgecolor='r',
# facecolor='none')
# ax1.add_patch(rect)
# ax2 = fig.add_subplot(1, 2, 2)
# ax2.imshow(processed_image)
# plt.show()
return processed_images
class RandomCrop(object):
def __init__(self, img_size, crop_size):
"""Set the height and weight before and after cropping"""
self.img_size_h = img_size[0]
self.img_size_w = img_size[1]
self.crop_size_h = crop_size[0]
self.crop_size_w = crop_size[1]
def __call__(self, rendering_images, bounding_box=None):
if len(rendering_images) == 0:
return rendering_images
crop_size_c = rendering_images[0].shape[2]
processed_images = np.empty(shape=(0, self.img_size_h, self.img_size_w, crop_size_c))
for img_idx, img in enumerate(rendering_images):
img_height, img_width, _ = img.shape
if bounding_box is not None:
bounding_box = [
bounding_box[0] * img_width,
bounding_box[1] * img_height,
bounding_box[2] * img_width,
bounding_box[3] * img_height
] # yapf: disable
# Calculate the size of bounding boxes
bbox_width = bounding_box[2] - bounding_box[0]
bbox_height = bounding_box[3] - bounding_box[1]
bbox_x_mid = (bounding_box[2] + bounding_box[0]) * .5
bbox_y_mid = (bounding_box[3] + bounding_box[1]) * .5
# Make the crop area as a square
square_object_size = max(bbox_width, bbox_height)
square_object_size = square_object_size * random.uniform(0.8, 1.2)
x_left = int(bbox_x_mid - square_object_size * random.uniform(.4, .6))
x_right = int(bbox_x_mid + square_object_size * random.uniform(.4, .6))
y_top = int(bbox_y_mid - square_object_size * random.uniform(.4, .6))
y_bottom = int(bbox_y_mid + square_object_size * random.uniform(.4, .6))
# If the crop position is out of the image, fix it with padding
pad_x_left = 0
if x_left < 0:
pad_x_left = -x_left
x_left = 0
pad_x_right = 0
if x_right >= img_width:
pad_x_right = x_right - img_width + 1
x_right = img_width - 1
pad_y_top = 0
if y_top < 0:
pad_y_top = -y_top
y_top = 0
pad_y_bottom = 0
if y_bottom >= img_height:
pad_y_bottom = y_bottom - img_height + 1
y_bottom = img_height - 1
# Padding the image and resize the image
processed_image = np.pad(img[y_top:y_bottom + 1, x_left:x_right + 1],
((pad_y_top, pad_y_bottom), (pad_x_left, pad_x_right), (0, 0)),
mode='edge')
processed_image = cv2.resize(processed_image, (self.img_size_w, self.img_size_h))
else:
if img_height > self.crop_size_h and img_width > self.crop_size_w:
x_left = int(img_width - self.crop_size_w) // 2
x_right = int(x_left + self.crop_size_w)
y_top = int(img_height - self.crop_size_h) // 2
y_bottom = int(y_top + self.crop_size_h)
else:
x_left = 0
x_right = img_width
y_top = 0
y_bottom = img_height
processed_image = cv2.resize(img[y_top:y_bottom, x_left:x_right], (self.img_size_w, self.img_size_h))
processed_images = np.append(processed_images, [processed_image], axis=0)
return processed_images
class RandomFlip(object):
def __call__(self, rendering_images):
assert (isinstance(rendering_images, np.ndarray))
for img_idx, img in enumerate(rendering_images):
if random.randint(0, 1):
rendering_images[img_idx] = np.fliplr(img)
return rendering_images
class ColorJitter(object):
def __init__(self, brightness, contrast, saturation):
self.brightness = brightness
self.contrast = contrast
self.saturation = saturation
def __call__(self, rendering_images):
if len(rendering_images) == 0:
return rendering_images
# Allocate new space for storing processed images
img_height, img_width, img_channels = rendering_images[0].shape
processed_images = np.empty(shape=(0, img_height, img_width, img_channels))
# Randomize the value of changing brightness, contrast, and saturation
brightness = 1 + np.random.uniform(low=-self.brightness, high=self.brightness)
contrast = 1 + np.random.uniform(low=-self.contrast, high=self.contrast)
saturation = 1 + np.random.uniform(low=-self.saturation, high=self.saturation)
# Randomize the order of changing brightness, contrast, and saturation
attr_names = ['brightness', 'contrast', 'saturation']
attr_values = [brightness, contrast, saturation] # The value of changing attrs
attr_indexes = np.array(range(len(attr_names))) # The order of changing attrs
np.random.shuffle(attr_indexes)
for img_idx, img in enumerate(rendering_images):
processed_image = img
for idx in attr_indexes:
processed_image = self._adjust_image_attr(processed_image, attr_names[idx], attr_values[idx])
processed_images = np.append(processed_images, [processed_image], axis=0)
# print('ColorJitter', np.mean(ori_img), np.mean(processed_image))
# fig = plt.figure(figsize=(8, 4))
# ax1 = fig.add_subplot(1, 2, 1)
# ax1.imshow(ori_img)
# ax2 = fig.add_subplot(1, 2, 2)
# ax2.imshow(processed_image)
# plt.show()
return processed_images
def _adjust_image_attr(self, img, attr_name, attr_value):
"""
Adjust or randomize the specified attribute of the image
Args:
img: Image in BGR format
Numpy array of shape (h, w, 3)
attr_name: Image attribute to adjust or randomize
'brightness', 'saturation', or 'contrast'
attr_value: the alpha for blending is randomly drawn from [1 - d, 1 + d]
Returns:
Output image in BGR format
Numpy array of the same shape as input
"""
gs = self._bgr_to_gray(img)
if attr_name == 'contrast':
img = self._alpha_blend(img, np.mean(gs[:, :, 0]), attr_value)
elif attr_name == 'saturation':
img = self._alpha_blend(img, gs, attr_value)
elif attr_name == 'brightness':
img = self._alpha_blend(img, 0, attr_value)
else:
raise NotImplementedError(attr_name)
return img
def _bgr_to_gray(self, bgr):
"""
Convert a RGB image to a grayscale image
Differences from cv2.cvtColor():
1. Input image can be float
2. Output image has three repeated channels, other than a single channel
Args:
bgr: Image in BGR format
Numpy array of shape (h, w, 3)
Returns:
gs: Grayscale image
Numpy array of the same shape as input; the three channels are the same
"""
ch = 0.114 * bgr[:, :, 0] + 0.587 * bgr[:, :, 1] + 0.299 * bgr[:, :, 2]
gs = np.dstack((ch, ch, ch))
return gs
def _alpha_blend(self, im1, im2, alpha):
"""
Alpha blending of two images or one image and a scalar
Args:
im1, im2: Image or scalar
Numpy array and a scalar or two numpy arrays of the same shape
alpha: Weight of im1
Float ranging usually from 0 to 1
Returns:
im_blend: Blended image -- alpha * im1 + (1 - alpha) * im2
Numpy array of the same shape as input image
"""
im_blend = alpha * im1 + (1 - alpha) * im2
return im_blend
class RandomNoise(object):
def __init__(self,
noise_std,
eigvals=(0.2175, 0.0188, 0.0045),
eigvecs=((-0.5675, 0.7192, 0.4009), (-0.5808, -0.0045, -0.8140), (-0.5836, -0.6948, 0.4203))):
self.noise_std = noise_std
self.eigvals = np.array(eigvals)
self.eigvecs = np.array(eigvecs)
def __call__(self, rendering_images):
alpha = np.random.normal(loc=0, scale=self.noise_std, size=3)
noise_rgb = \
np.sum(
np.multiply(
np.multiply(
self.eigvecs,
np.tile(alpha, (3, 1))
),
np.tile(self.eigvals, (3, 1))
),
axis=1
)
# Allocate new space for storing processed images
img_height, img_width, img_channels = rendering_images[0].shape
assert (img_channels == 3), "Please use RandomBackground to normalize image channels"
processed_images = np.empty(shape=(0, img_height, img_width, img_channels))
for img_idx, img in enumerate(rendering_images):
processed_image = img[:, :, ::-1] # BGR -> RGB
for i in range(img_channels):
processed_image[:, :, i] += noise_rgb[i]
processed_image = processed_image[:, :, ::-1] # RGB -> BGR
processed_images = np.append(processed_images, [processed_image], axis=0)
# from copy import deepcopy
# ori_img = deepcopy(img)
# print(noise_rgb, np.mean(processed_image), np.mean(ori_img))
# print('RandomNoise', np.mean(ori_img), np.mean(processed_image))
# fig = plt.figure(figsize=(8, 4))
# ax1 = fig.add_subplot(1, 2, 1)
# ax1.imshow(ori_img)
# ax2 = fig.add_subplot(1, 2, 2)
# ax2.imshow(processed_image)
# plt.show()
return processed_images
class RandomBackground(object):
def __init__(self, random_bg_color_range, random_bg_folder_path=None):
self.random_bg_color_range = random_bg_color_range
self.random_bg_files = []
if random_bg_folder_path is not None:
self.random_bg_files = os.listdir(random_bg_folder_path)
self.random_bg_files = [os.path.join(random_bg_folder_path, rbf) for rbf in self.random_bg_files]
def __call__(self, rendering_images):
if len(rendering_images) == 0:
return rendering_images
img_height, img_width, img_channels = rendering_images[0].shape
# If the image has the alpha channel, add the background
if not img_channels == 4:
return rendering_images
# Generate random background
r, g, b = np.array([
np.random.randint(self.random_bg_color_range[i][0], self.random_bg_color_range[i][1] + 1) for i in range(3)
]) / 255.
random_bg = None
if len(self.random_bg_files) > 0:
random_bg_file_path = random.choice(self.random_bg_files)
random_bg = cv2.imread(random_bg_file_path).astype(np.float32) / 255.
# Apply random background
processed_images = np.empty(shape=(0, img_height, img_width, img_channels - 1))
for img_idx, img in enumerate(rendering_images):
alpha = (np.expand_dims(img[:, :, 3], axis=2) == 0).astype(np.float32)
img = img[:, :, :3]
bg_color = random_bg if random.randint(0, 1) and random_bg is not None else np.array([[[r, g, b]]])
img = alpha * bg_color + (1 - alpha) * img
processed_images = np.append(processed_images, [img], axis=0)
return processed_images
================================================
FILE: utils/dataset_analyzer.py
================================================
#!/usr/bin/python3
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import numpy as np
import os
import scipy.ndimage
import sys
from datetime import datetime as dt
from fnmatch import fnmatch
from queue import Queue
def main():
if not len(sys.argv) == 2:
print('python dataset_analyzer.py input_file_folder')
sys.exit(1)
input_file_folder = sys.argv[1]
if not os.path.exists(input_file_folder) or not os.path.isdir(input_file_folder):
print('[ERROR] Input folder not exists!')
sys.exit(2)
FILE_NAME_PATTERN = '*.JPEG'
folders_to_explore = Queue()
folders_to_explore.put(input_file_folder)
total_files = 0
mean = np.asarray([0., 0., 0.])
std = np.asarray([0., 0., 0.])
while not folders_to_explore.empty():
current_folder = folders_to_explore.get()
if not os.path.exists(current_folder) or not os.path.isdir(current_folder):
print('[WARN] %s Ignore folder: %s' % (dt.now(), current_folder))
continue
print('[INFO] %s Listing files in folder: %s' % (dt.now(), current_folder))
n_folders = 0
n_files = 0
files = os.listdir(current_folder)
for file_name in files:
file_path = os.path.join(current_folder, file_name)
if os.path.isdir(file_path):
n_folders += 1
folders_to_explore.put(file_path)
elif os.path.isfile(file_path) and fnmatch(file_name, FILE_NAME_PATTERN):
n_files += 1
total_files += 1
img = scipy.ndimage.imread(file_path)
img_mean = np.mean(img, axis=(0, 1))
img_std = np.var(img, axis=(0, 1))
mean += img_mean
std += img_std
# print('[INFO] %s %d folders found, %d files found.' % (dt.now(), n_folders, n_files))
print('[INFO] %s Mean = %s, Std = %s' % (dt.now(), mean / total_files, np.sqrt(std) / total_files))
if __name__ == '__main__':
main()
================================================
FILE: utils/network_utils.py
================================================
# -*- coding: utf-8 -*-
#
# Developed by Haozhe Xie <cshzxie@gmail.com>
import torch
from datetime import datetime as dt
def var_or_cuda(x):
if torch.cuda.is_available():
x = x.cuda(non_blocking=True)
return x
def init_weights(m):
if type(m) == torch.nn.Conv2d or type(m) == torch.nn.Conv3d or type(m) == torch.nn.ConvTranspose3d:
torch.nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
torch.nn.init.constant_(m.bias, 0)
elif type(m) == torch.nn.BatchNorm2d or type(m) == torch.nn.BatchNorm3d:
torch.nn.init.constant_(m.weight, 1)
torch.nn.init.constant_(m.bias, 0)
elif type(m) == torch.nn.Linear:
torch.nn.init.normal_(m.weight, 0, 0.01)
torch.nn.init.constant_(m.bias, 0)
def save_checkpoints(cfg, file_path, epoch_idx, encoder, encoder_solver, decoder, decoder_solver, refiner,
refiner_solver, merger, merger_solver, best_iou, best_epoch):
print('[INFO] %s Saving checkpoint to %s ...' % (dt.now(), file_path))
checkpoint = {
'epoch_idx': epoch_idx,
'best_iou': best_iou,
'best_epoch': best_epoch,
'encoder_state_dict': encoder.state_dict(),
'encoder_solver_state_dict': encoder_solver.state_dict(),
'decoder_state_dict': decoder.state_dict(),
'decoder_solver_state_dict': decoder_solver.state_dict()
}
if cfg.NETWORK.USE_REFINER:
checkpoint['refiner_state_dict'] = refiner.state_dict()
checkpoint['refiner_solver_state_dict'] = refiner_solver.state_dict()
if cfg.NETWORK.USE_MERGER:
checkpoint['merger_state_dict'] = merger.state_dict()
checkpoint['merger_solver_state_dict'] = merger_solver.state_dict()
torch.save(checkpoint, file_path)
def count_parameters(model):
return sum(p.numel() for p in model.parameters())
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
gitextract_816on345/
├── .gitignore
├── .style.yapf
├── .yapfignore
├── LICENSE
├── README.md
├── config.py
├── core/
│ ├── __init__.py
│ ├── test.py
│ └── train.py
├── models/
│ ├── __init__.py
│ ├── decoder.py
│ ├── encoder.py
│ ├── merger.py
│ └── refiner.py
├── requirements.txt
├── runner.py
└── utils/
├── __init__.py
├── binvox_converter.py
├── binvox_rw.py
├── binvox_visualization.py
├── data_loaders.py
├── data_transforms.py
├── dataset_analyzer.py
└── network_utils.py
SYMBOL INDEX (96 symbols across 14 files)
FILE: core/test.py
function test_net (line 25) | def test_net(cfg,
FILE: core/train.py
function train_net (line 27) | def train_net(cfg):
FILE: models/decoder.py
class Decoder (line 8) | class Decoder(torch.nn.Module):
method __init__ (line 9) | def __init__(self, cfg):
method forward (line 39) | def forward(self, image_features):
FILE: models/encoder.py
class Encoder (line 12) | class Encoder(torch.nn.Module):
method __init__ (line 13) | def __init__(self, cfg):
method forward (line 41) | def forward(self, rendering_images):
FILE: models/merger.py
class Merger (line 8) | class Merger(torch.nn.Module):
method __init__ (line 9) | def __init__(self, cfg):
method forward (line 40) | def forward(self, raw_features, coarse_volumes):
FILE: models/refiner.py
class Refiner (line 8) | class Refiner(torch.nn.Module):
method __init__ (line 9) | def __init__(self, cfg):
method forward (line 55) | def forward(self, coarse_volumes):
FILE: runner.py
function get_args_from_command_line (line 24) | def get_args_from_command_line():
function main (line 45) | def main():
FILE: utils/binvox_converter.py
function main (line 21) | def main():
FILE: utils/binvox_rw.py
class Voxels (line 66) | class Voxels(object):
method __init__ (line 87) | def __init__(self, data, dims, translate, scale, axis_order):
method clone (line 95) | def clone(self):
method write (line 101) | def write(self, fp):
function read_header (line 105) | def read_header(fp):
function read_as_3d_array (line 118) | def read_as_3d_array(fp, fix_coords=True):
function read_as_coord_array (line 155) | def read_as_coord_array(fp, fix_coords=True):
function dense_to_sparse (line 206) | def dense_to_sparse(voxel_data, dtype=np.int):
function sparse_to_dense (line 215) | def sparse_to_dense(voxel_data, dims, dtype=np.bool):
function write (line 238) | def write(voxel_model, fp):
FILE: utils/binvox_visualization.py
function get_volume_views (line 12) | def get_volume_views(volume, save_dir, n_itr):
FILE: utils/data_loaders.py
class DatasetType (line 22) | class DatasetType(Enum):
class ShapeNetDataset (line 31) | class ShapeNetDataset(torch.utils.data.dataset.Dataset):
method __init__ (line 33) | def __init__(self, dataset_type, file_list, n_views_rendering, transfo...
method __len__ (line 39) | def __len__(self):
method __getitem__ (line 42) | def __getitem__(self, idx):
method set_n_views_rendering (line 50) | def set_n_views_rendering(self, n_views_rendering):
method get_datum (line 53) | def get_datum(self, idx):
class ShapeNetDataLoader (line 95) | class ShapeNetDataLoader:
method __init__ (line 96) | def __init__(self, cfg):
method get_dataset (line 105) | def get_dataset(self, dataset_type, n_views_rendering, transforms=None):
method get_files_of_taxonomy (line 126) | def get_files_of_taxonomy(self, taxonomy_folder_name, samples):
class Pascal3dDataset (line 173) | class Pascal3dDataset(torch.utils.data.dataset.Dataset):
method __init__ (line 175) | def __init__(self, file_list, transforms=None):
method __len__ (line 179) | def __len__(self):
method __getitem__ (line 182) | def __getitem__(self, idx):
method get_datum (line 190) | def get_datum(self, idx):
class Pascal3dDataLoader (line 215) | class Pascal3dDataLoader:
method __init__ (line 216) | def __init__(self, cfg):
method get_dataset (line 226) | def get_dataset(self, dataset_type, n_views_rendering, transforms=None):
method get_files_of_taxonomy (line 247) | def get_files_of_taxonomy(self, taxonomy_name, samples):
class Pix3dDataset (line 309) | class Pix3dDataset(torch.utils.data.dataset.Dataset):
method __init__ (line 311) | def __init__(self, file_list, transforms=None):
method __len__ (line 315) | def __len__(self):
method __getitem__ (line 318) | def __getitem__(self, idx):
method get_datum (line 326) | def get_datum(self, idx):
class Pix3dDataLoader (line 351) | class Pix3dDataLoader:
method __init__ (line 352) | def __init__(self, cfg):
method get_dataset (line 372) | def get_dataset(self, dataset_type, n_views_rendering, transforms=None):
method get_files_of_taxonomy (line 393) | def get_files_of_taxonomy(self, taxonomy_name, samples):
FILE: utils/data_transforms.py
class Compose (line 16) | class Compose(object):
method __init__ (line 24) | def __init__(self, transforms):
method __call__ (line 27) | def __call__(self, rendering_images, bounding_box=None):
class ToTensor (line 37) | class ToTensor(object):
method __call__ (line 42) | def __call__(self, rendering_images):
class Normalize (line 52) | class Normalize(object):
method __init__ (line 53) | def __init__(self, mean, std):
method __call__ (line 57) | def __call__(self, rendering_images):
class RandomPermuteRGB (line 65) | class RandomPermuteRGB(object):
method __call__ (line 66) | def __call__(self, rendering_images):
class CenterCrop (line 76) | class CenterCrop(object):
method __init__ (line 77) | def __init__(self, img_size, crop_size):
method __call__ (line 84) | def __call__(self, rendering_images, bounding_box=None):
class RandomCrop (line 170) | class RandomCrop(object):
method __init__ (line 171) | def __init__(self, img_size, crop_size):
method __call__ (line 178) | def __call__(self, rendering_images, bounding_box=None):
class RandomFlip (line 252) | class RandomFlip(object):
method __call__ (line 253) | def __call__(self, rendering_images):
class ColorJitter (line 263) | class ColorJitter(object):
method __init__ (line 264) | def __init__(self, brightness, contrast, saturation):
method __call__ (line 269) | def __call__(self, rendering_images):
method _adjust_image_attr (line 303) | def _adjust_image_attr(self, img, attr_name, attr_value):
method _bgr_to_gray (line 330) | def _bgr_to_gray(self, bgr):
method _alpha_blend (line 349) | def _alpha_blend(self, im1, im2, alpha):
class RandomNoise (line 367) | class RandomNoise(object):
method __init__ (line 368) | def __init__(self,
method __call__ (line 376) | def __call__(self, rendering_images):
class RandomBackground (line 415) | class RandomBackground(object):
method __init__ (line 416) | def __init__(self, random_bg_color_range, random_bg_folder_path=None):
method __call__ (line 423) | def __call__(self, rendering_images):
FILE: utils/dataset_analyzer.py
function main (line 16) | def main():
FILE: utils/network_utils.py
function var_or_cuda (line 10) | def var_or_cuda(x):
function init_weights (line 17) | def init_weights(m):
function save_checkpoints (line 30) | def save_checkpoints(cfg, file_path, epoch_idx, encoder, encoder_solver,...
function count_parameters (line 53) | def count_parameters(model):
class AverageMeter (line 57) | class AverageMeter(object):
method __init__ (line 59) | def __init__(self):
method reset (line 62) | def reset(self):
method update (line 68) | def update(self, val, n=1):
Condensed preview — 24 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (105K chars).
[
{
"path": ".gitignore",
"chars": 1215,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": ".style.yapf",
"chars": 128,
"preview": "[style]\nbased_on_style = pep8\ncolumn_limit = 119\nspaces_before_comment = 4\nsplit_before_logical_operator = True\nuse_tabs"
},
{
"path": ".yapfignore",
"chars": 81,
"preview": "config.py\nmodels/decoder.py\nmodels/encoder.py\nmodels/merger.py\nmodels/refiner.py\n"
},
{
"path": "LICENSE",
"chars": 1067,
"preview": "MIT License\n\nCopyright (c) 2018 Haozhe Xie\n\nPermission is hereby granted, free of charge, to any person obtaining a copy"
},
{
"path": "README.md",
"chars": 3311,
"preview": "# Pix2Vox\n\n[:\n"
},
{
"path": "models/encoder.py",
"chars": 2331,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n#\n# References:\n# - https://github.com/shawnxu13"
},
{
"path": "models/merger.py",
"chars": 3091,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport torch\n\n\nclass Merger(torch.nn.Module):\n "
},
{
"path": "models/refiner.py",
"chars": 3555,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport torch\n\n\nclass Refiner(torch.nn.Module):\n"
},
{
"path": "requirements.txt",
"chars": 80,
"preview": "argparse\neasydict\nmatplotlib\nnumpy\nopencv-python\nscipy\ntorchvision\ntensorboardX\n"
},
{
"path": "runner.py",
"chars": 3002,
"preview": "#!/usr/bin/python3\n# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport logging\nimport matplo"
},
{
"path": "utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "utils/binvox_converter.py",
"chars": 2064,
"preview": "#!/usr/bin/python3\n# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n#\n# This script is used to co"
},
{
"path": "utils/binvox_rw.py",
"chars": 9517,
"preview": "# Copyright (C) 2012 Daniel Maturana\n# This file is part of binvox-rw-py.\n#\n# binvox-rw-py is free software: you can "
},
{
"path": "utils/binvox_visualization.py",
"chars": 618,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport cv2\nimport matplotlib.pyplot as plt\nimpo"
},
{
"path": "utils/data_loaders.py",
"chars": 17982,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport cv2\nimport json\nimport numpy as np\nimpor"
},
{
"path": "utils/data_transforms.py",
"chars": 18299,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n# References:\n# - https://github.com/xiumingzhan"
},
{
"path": "utils/dataset_analyzer.py",
"chars": 2042,
"preview": "#!/usr/bin/python3\n# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport numpy as np\nimport os"
},
{
"path": "utils/network_utils.py",
"chars": 2261,
"preview": "# -*- coding: utf-8 -*-\n#\n# Developed by Haozhe Xie <cshzxie@gmail.com>\n\nimport torch\n\nfrom datetime import datetime as "
}
]
About this extraction
This page contains the full source code of the hzxie/Pix2Vox GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 24 files (99.0 KB), approximately 25.1k tokens, and a symbol index with 96 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.