Repository: igorbenav/SQLModel-boilerplate
Branch: main
Commit: de043e2f153d
Files: 72
Total size: 166.3 KB
Directory structure:
gitextract_tl7yp3vy/
├── .github/
│ └── ISSUE_TEMPLATE/
│ ├── PULL_REQUEST_TEMPLATE.md
│ ├── fastapi-boilerplate-feature-request.md
│ └── fastapi-boilerplate-issue.md
├── .gitignore
├── .pre-commit-config.yaml
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE.md
├── README.md
├── default.conf
├── docker-compose.yml
├── mypy.ini
├── pyproject.toml
├── src/
│ ├── __init__.py
│ ├── alembic.ini
│ ├── app/
│ │ ├── __init__.py
│ │ ├── api/
│ │ │ ├── __init__.py
│ │ │ ├── dependencies.py
│ │ │ └── v1/
│ │ │ ├── __init__.py
│ │ │ ├── login.py
│ │ │ ├── logout.py
│ │ │ ├── posts.py
│ │ │ ├── rate_limits.py
│ │ │ ├── tasks.py
│ │ │ ├── tiers.py
│ │ │ └── users.py
│ │ ├── core/
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── db/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── crud_token_blacklist.py
│ │ │ │ ├── database.py
│ │ │ │ ├── models.py
│ │ │ │ └── token_blacklist.py
│ │ │ ├── exceptions/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cache_exceptions.py
│ │ │ │ └── http_exceptions.py
│ │ │ ├── logger.py
│ │ │ ├── schemas.py
│ │ │ ├── security.py
│ │ │ ├── setup.py
│ │ │ ├── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cache.py
│ │ │ │ ├── queue.py
│ │ │ │ └── rate_limit.py
│ │ │ └── worker/
│ │ │ ├── __init__.py
│ │ │ ├── functions.py
│ │ │ └── settings.py
│ │ ├── crud/
│ │ │ ├── __init__.py
│ │ │ ├── crud_posts.py
│ │ │ ├── crud_rate_limit.py
│ │ │ ├── crud_tier.py
│ │ │ └── crud_users.py
│ │ ├── main.py
│ │ ├── middleware/
│ │ │ └── client_cache_middleware.py
│ │ └── models/
│ │ ├── __init__.py
│ │ ├── job.py
│ │ ├── post.py
│ │ ├── rate_limit.py
│ │ ├── tier.py
│ │ └── user.py
│ ├── migrations/
│ │ ├── README
│ │ ├── env.py
│ │ ├── script.py.mako
│ │ └── versions/
│ │ └── README.MD
│ └── scripts/
│ ├── __init__.py
│ ├── create_first_superuser.py
│ └── create_first_tier.py
└── tests/
├── __init__.py
├── conftest.py
├── helper.py
└── test_user.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/ISSUE_TEMPLATE/PULL_REQUEST_TEMPLATE.md
================================================
# Pull Request Template for FastAPI-boilerplate
## Description
Please provide a clear and concise description of what your pull request is about.
## Changes
Briefly list the changes you've made. If applicable, also link any relevant issues or pull requests.
## Tests
Describe the tests you added or modified to cover your changes, if applicable.
## Checklist
- [ ] I have read the [CONTRIBUTING](CONTRIBUTING.md) document.
- [ ] My code follows the code style of this project.
- [ ] I have added necessary documentation (if appropriate).
- [ ] I have added tests that cover my changes (if applicable).
- [ ] All new and existing tests passed.
## Additional Notes
Include any additional information that you think is important for reviewers to know.
================================================
FILE: .github/ISSUE_TEMPLATE/fastapi-boilerplate-feature-request.md
================================================
---
name: FastAPI-boilerplate Feature request
about: Suggest an idea for this project
title: ''
labels: enhancement
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
================================================
FILE: .github/ISSUE_TEMPLATE/fastapi-boilerplate-issue.md
================================================
---
name: FastAPI-boilerplate Issue
about: Create a report to help us improve
title: ''
labels: ''
assignees: ''
---
**Describe the bug or question**
A clear and concise description of what the bug or question is.
**To Reproduce**
Please provide a self-contained, minimal, and reproducible example of your use case
```python
# Your code here
```
**Description**
Describe the problem, question, or error you are facing. Include both the expected output for your input and the actual output you're observing.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Additional context**
Add any other context about the problem here.
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
poetry.lock
src/poetry.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
# Macos
.DS_Store
.ruff_cache
================================================
FILE: .pre-commit-config.yaml
================================================
default_language_version:
python: python3.11
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.1.0
hooks:
- id: end-of-file-fixer
- id: trailing-whitespace
- id: check-yaml
- id: check-docstring-first
- id: check-executables-have-shebangs
- id: check-case-conflict
- id: check-added-large-files
exclude: ^(.*\/dummy.*|.*\.json)$
args: ["--maxkb=750", "--enforce-all"]
- id: detect-private-key
- id: check-merge-conflict
- repo: https://github.com/asottile/pyupgrade
rev: v3.15.0
hooks:
- id: pyupgrade
args: [--py310-plus]
name: Upgrade code to Python 3.10+
- repo: https://github.com/myint/docformatter
rev: v1.7.5
hooks:
- id: docformatter
args: [--in-place, --wrap-summaries=115, --wrap-descriptions=120]
- repo: https://github.com/asottile/yesqa
rev: v1.5.0
hooks:
- id: yesqa
name: Unused noqa
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.1.9
hooks:
- id: ruff
args: [ --fix ]
- id: ruff-format
- repo: https://github.com/asottile/blacken-docs
rev: 1.16.0
hooks:
- id: blacken-docs
args: [--line-length=120]
additional_dependencies: [black==22.1.0]
- repo: https://github.com/executablebooks/mdformat
rev: 0.7.17
hooks:
- id: mdformat
additional_dependencies:
- mdformat-gfm
- mdformat_frontmatter
exclude: CHANGELOG.md
- repo: local
hooks:
- id: unit_test
name: Unit test
language: system
entry: poetry run pytest
pass_filenames: false
always_run: true
types: [python]
stages: [manual]
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
igor.magalhaes.r@gmail.com.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
https://www.contributor-covenant.org/translations.
================================================
FILE: CONTRIBUTING.md
================================================
# Contributing to FastAPI-boilerplate
Thank you for your interest in contributing to FastAPI-boilerplate! This guide is meant to make it easy for you to get started.
Contributions are appreciated, even if just reporting bugs, documenting stuff or answering questions. To contribute with a feature:
## Setting Up Your Development Environment
### Cloning the Repository
Start by forking and cloning the FastAPI-boilerplate repository:
1. **Fork the Repository**: Begin by forking the project repository. You can do this by visiting https://github.com/igormagalhaesr/FastAPI-boilerplate and clicking the "Fork" button.
1. **Create a Feature Branch**: Once you've forked the repo, create a branch for your feature by running `git checkout -b feature/fooBar`.
1. **Testing Changes**: Ensure that your changes do not break existing functionality by running tests. In the root folder, execute poetry run `python -m pytest` to run the tests.
### Using Poetry for Dependency Management
FastAPI-boilerplate uses Poetry for managing dependencies. If you don't have Poetry installed, follow the instructions on the [official Poetry website](https://python-poetry.org/docs/).
Once Poetry is installed, navigate to the cloned repository and install the dependencies:
```sh
cd FastAPI-boilerplate
poetry install
```
### Activating the Virtual Environment
Poetry creates a virtual environment for your project. Activate it using:
```sh
poetry shell
```
## Making Contributions
### Coding Standards
- Follow PEP 8 guidelines.
- Write meaningful tests for new features or bug fixes.
### Testing with Pytest
FastAPI-boilerplate uses pytest for testing. Run tests using:
```sh
poetry run pytest
```
### Linting
Use mypy for type checking:
```sh
mypy src
```
Use ruff for style:
```sh
ruff check --fix
ruff format
```
Ensure your code passes linting before submitting.
### Using pre-commit for Better Code Quality
It helps in identifying simple issues before submission to code review. By running automated checks, pre-commit can ensure code quality and consistency.
1. **Install Pre-commit**:
- **Installation**: Install pre-commit in your development environment. Use the command `pip install pre-commit`.
- **Setting Up Hooks**: After installing pre-commit, set up the hooks with `pre-commit install`. This command will install hooks into your .git/ directory which will automatically check your commits for issues.
1. **Committing Your Changes**:
After making your changes, use `git commit -am 'Add some fooBar'` to commit them. Pre-commit will run automatically on your files when you commit, ensuring that they meet the required standards.
Note: If pre-commit identifies issues, it may block your commit. Fix these issues and commit again. This ensures that all contributions are of high quality.
1. **Pushing Changes and Creating Pull Request**:
Push your changes to the branch using `git push origin feature/fooBar`.
Visit your fork on GitHub and create a new Pull Request to the main repository.
### Additional Notes
**Stay Updated**: Keep your fork updated with the main repository to avoid merge conflicts. Regularly fetch and merge changes from the upstream repository.
**Adhere to Project Conventions**: Follow the coding style, conventions, and commit message guidelines of the project.
**Open Communication**: Feel free to ask questions or discuss your ideas by opening an issue or in discussions.
## Submitting Your Contributions
### Creating a Pull Request
After making your changes:
- Push your changes to your fork.
- Open a pull request with a clear description of your changes.
- Update the README.md if necessary.
### Code Reviews
- Address any feedback from code reviews.
- Once approved, your contributions will be merged into the main branch.
## Code of Conduct
Please adhere to our [Code of Conduct](CODE_OF_CONDUCT.md) to maintain a welcoming and inclusive environment.
Thank you for contributing to FastAPI-boilerplate🚀
================================================
FILE: Dockerfile
================================================
# --------- requirements ---------
FROM python:3.11 as requirements-stage
WORKDIR /tmp
RUN pip install poetry poetry-plugin-export
COPY ./pyproject.toml ./poetry.lock* /tmp/
RUN poetry export -f requirements.txt --output requirements.txt --without-hashes
# --------- final image build ---------
FROM python:3.11
WORKDIR /code
COPY --from=requirements-stage /tmp/requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./src/app /code/app
# -------- replace with comment to run with gunicorn --------
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
# CMD ["gunicorn", "app.main:app", "-w", "4", "-k", "uvicorn.workers.UvicornWorker". "-b", "0.0.0.0:8000"]
================================================
FILE: LICENSE.md
================================================
MIT License
Copyright (c) 2023 Igor Magalhães
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
Fast FastAPI boilerplate (SQLmodel version)
Yet another template to speed your FastAPI development up. This time, using SQLModel.







## 0. About
**FastAPI boilerplate** creates an extendable async API using FastAPI, SQLModel and PostgreSQL:
- [`FastAPI`](https://fastapi.tiangolo.com): modern Python web framework for building APIs
- [`SQLModel`](https://sqlmodel.tiangolo.com): SQL databases in Python, designed for simplicity, compatibility, and robustness.
- [`PostgreSQL`](https://www.postgresql.org): The World's Most Advanced Open Source Relational Database
- [`Redis`](https://redis.io): Source Available, in-memory data store used by millions as a cache, message broker and more.
- [`ARQ`](https://arq-docs.helpmanual.io) Job queues and RPC in python with asyncio and redis.
- [`Docker Compose`](https://docs.docker.com/compose/) With a single command, create and start all the services from your configuration.
- [`NGINX`](https://nginx.org/en/) High-performance low resource consumption web server used for Reverse Proxy and Load Balancing.

## 1. Features
- ⚡️ Fully async
- 🚀 SQLModel with Pydantic V2 and SQLAlchemy 2.0 support
- 🔐 User authentication with JWT
- 🍪 Cookie based refresh token
- 🏬 Easy redis caching
- 👜 Easy client-side caching
- 🚦 ARQ integration for task queue
- ⚙️ Efficient and robust queries with fastcrud
- ⎘ Out of the box offset and cursor pagination support with fastcrud
- 🛑 Rate Limiter dependency
- 👮 FastAPI docs behind authentication and hidden based on the environment
- 🦾 Easily extendable
- 🤸♂️ Flexible
- 🚚 Easy running with docker compose
- ⚖️ NGINX Reverse Proxy and Load Balancing
## 2. Contents
0. [About](#0-about)
1. [Features](#1-features)
1. [Contents](#2-contents)
1. [Prerequisites](#3-prerequisites)
1. [Environment Variables (.env)](#31-environment-variables-env)
1. [Docker Compose](#32-docker-compose-preferred)
1. [From Scratch](#33-from-scratch)
1. [Usage](#4-usage)
1. [Docker Compose](#41-docker-compose)
1. [From Scratch](#42-from-scratch)
1. [Packages](#421-packages)
1. [Running PostgreSQL With Docker](#422-running-postgresql-with-docker)
1. [Running Redis with Docker](#423-running-redis-with-docker)
1. [Running the API](#424-running-the-api)
1. [Creating the first superuser](#43-creating-the-first-superuser)
1. [Database Migrations](#44-database-migrations)
1. [Extending](#5-extending)
1. [Project Structure](#51-project-structure)
1. [Database Model](#52-database-model)
1. [DB Models](#53-db-models)
1. [Validation Models](#54-validation-models)
1. [Alembic Migrations](#55-alembic-migrations)
1. [CRUD](#56-crud)
1. [Routes](#57-routes)
1. [Paginated Responses](#571-paginated-responses)
1. [HTTP Exceptions](#572-http-exceptions)
1. [Caching](#58-caching)
1. [More Advanced Caching](#59-more-advanced-caching)
1. [ARQ Job Queues](#510-arq-job-queues)
1. [Rate Limiting](#511-rate-limiting)
1. [JWT Authentication](#512-jwt-authentication)
1. [Running](#513-running)
1. [Create Application](#514-create-application)
2. [Opting Out of Services](#515-opting-out-of-services)
1. [Running in Production](#6-running-in-production)
1. [Uvicorn Workers with Gunicorn](#61-uvicorn-workers-with-gunicorn)
1. [Running With NGINX](#62-running-with-nginx)
1. [One Server](#621-one-server)
1. [Multiple Servers](#622-multiple-servers)
1. [Testing](#7-testing)
1. [Contributing](#8-contributing)
1. [References](#9-references)
1. [License](#10-license)
1. [Contact](#11-contact)
______________________________________________________________________
## 3. Prerequisites
### 3.0 Start
Start by using the template, and naming the repository to what you want.

Then clone your created repository (I'm using the base for the example)
```sh
git clone https://github.com/igormagalhaesr/SQLModel-boilerplate
```
> \[!TIP\]
> If you are in a hurry, you may use one of the following templates (containing a `.env`, `docker-compose.yml` and `Dockerfile`):
- [Running locally with uvicorn](https://gist.github.com/igorbenav/48ad745120c3f77817e094f3a609111a)
- [Runing in staging with gunicorn managing uvicorn workers](https://gist.github.com/igorbenav/d0518d4f6bdfb426d4036090f74905ee)
- [Running in production with NGINX](https://gist.github.com/igorbenav/232c3b73339d6ca74e2bf179a5ef48a1)
> \[!WARNING\]
> Do not forget to place `docker-compose.yml` and `Dockerfile` in the `root` folder, while `.env` should be in the `src` folder.
### 3.1 Environment Variables (.env)
Then create a `.env` file inside `src` directory:
```sh
touch .env
```
Inside of `.env`, create the following app settings variables:
```
# ------------- app settings -------------
APP_NAME="Your app name here"
APP_DESCRIPTION="Your app description here"
APP_VERSION="0.1"
CONTACT_NAME="Your name"
CONTACT_EMAIL="Your email"
LICENSE_NAME="The license you picked"
```
For the database ([`if you don't have a database yet, click here`](#422-running-postgresql-with-docker)), create:
```
# ------------- database -------------
POSTGRES_USER="your_postgres_user"
POSTGRES_PASSWORD="your_password"
POSTGRES_SERVER="your_server" # default "localhost", if using docker compose you should use "db"
POSTGRES_PORT=5432 # default "5432", if using docker compose you should use "5432"
POSTGRES_DB="your_db"
```
For database administration using PGAdmin create the following variables in the .env file
```
# ------------- pgadmin -------------
PGADMIN_DEFAULT_EMAIL="your_email_address"
PGADMIN_DEFAULT_PASSWORD="your_password"
PGADMIN_LISTEN_PORT=80
```
To connect to the database, log into the PGAdmin console with the values specified in `PGADMIN_DEFAULT_EMAIL` and `PGADMIN_DEFAULT_PASSWORD`.
Once in the main PGAdmin screen, click Add Server:
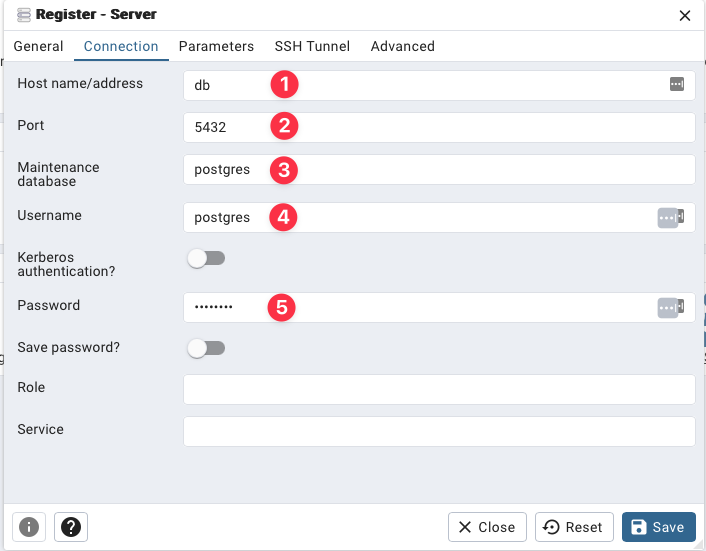
1. Hostname/address is `db` (if using containers)
1. Is the value you specified in `POSTGRES_PORT`
1. Leave this value as `postgres`
1. is the value you specified in `POSTGRES_USER`
1. Is the value you specified in `POSTGRES_PASSWORD`
For crypt:
Start by running
```sh
openssl rand -hex 32
```
And then create in `.env`:
```
# ------------- crypt -------------
SECRET_KEY= # result of openssl rand -hex 32
ALGORITHM= # pick an algorithm, default HS256
ACCESS_TOKEN_EXPIRE_MINUTES= # minutes until token expires, default 30
REFRESH_TOKEN_EXPIRE_DAYS= # days until token expires, default 7
```
Then for the first admin user:
```
# ------------- admin -------------
ADMIN_NAME="your_name"
ADMIN_EMAIL="your_email"
ADMIN_USERNAME="your_username"
ADMIN_PASSWORD="your_password"
```
For redis caching:
```
# ------------- redis cache-------------
REDIS_CACHE_HOST="your_host" # default "localhost", if using docker compose you should use "redis"
REDIS_CACHE_PORT=6379 # default "6379", if using docker compose you should use "6379"
```
And for client-side caching:
```
# ------------- redis client-side cache -------------
CLIENT_CACHE_MAX_AGE=30 # default "30"
```
For ARQ Job Queues:
```
# ------------- redis queue -------------
REDIS_QUEUE_HOST="your_host" # default "localhost", if using docker compose you should use "redis"
REDIS_QUEUE_PORT=6379 # default "6379", if using docker compose you should use "6379"
```
> \[!WARNING\]
> You may use the same redis for both caching and queue while developing, but the recommendation is using two separate containers for production.
To create the first tier:
```
# ------------- first tier -------------
TIER_NAME="free"
```
For the rate limiter:
```
# ------------- redis rate limit -------------
REDIS_RATE_LIMIT_HOST="localhost" # default="localhost", if using docker compose you should use "redis"
REDIS_RATE_LIMIT_PORT=6379 # default=6379, if using docker compose you should use "6379"
# ------------- default rate limit settings -------------
DEFAULT_RATE_LIMIT_LIMIT=10 # default=10
DEFAULT_RATE_LIMIT_PERIOD=3600 # default=3600
```
For tests (optional to run):
```
# ------------- test -------------
TEST_NAME="Tester User"
TEST_EMAIL="test@tester.com"
TEST_USERNAME="testeruser"
TEST_PASSWORD="Str1ng$t"
```
And Finally the environment:
```
# ------------- environment -------------
ENVIRONMENT="local"
```
`ENVIRONMENT` can be one of `local`, `staging` and `production`, defaults to local, and changes the behavior of api `docs` endpoints:
- **local:** `/docs`, `/redoc` and `/openapi.json` available
- **staging:** `/docs`, `/redoc` and `/openapi.json` available for superusers
- **production:** `/docs`, `/redoc` and `/openapi.json` not available
### 3.2 Docker Compose (preferred)
To do it using docker compose, ensure you have docker and docker compose installed, then:
While in the base project directory (FastAPI-boilerplate here), run:
```sh
docker compose up
```
You should have a `web` container, `postgres` container, a `worker` container and a `redis` container running.
Then head to `http://127.0.0.1:8000/docs`.
### 3.3 From Scratch
Install poetry:
```sh
pip install poetry
```
## 4. Usage
### 4.1 Docker Compose
If you used docker compose, your setup is done. You just need to ensure that when you run (while in the base folder):
```sh
docker compose up
```
You get the following outputs (in addition to many other outputs):
```sh
fastapi-boilerplate-worker-1 | ... redis_version=x.x.x mem_usage=999K clients_connected=1 db_keys=0
...
fastapi-boilerplate-db-1 | ... [1] LOG: database system is ready to accept connections
...
fastapi-boilerplate-web-1 | INFO: Application startup complete.
```
So you may skip to [5. Extending](#5-extending).
### 4.2 From Scratch
#### 4.2.1. Packages
In the `root` directory (`FastAPI-boilerplate` if you didn't change anything), run to install required packages:
```sh
poetry install
```
Ensuring it ran without any problem.
#### 4.2.2. Running PostgreSQL With Docker
> \[!NOTE\]
> If you already have a PostgreSQL running, you may skip this step.
Install docker if you don't have it yet, then run:
```sh
docker pull postgres
```
And pick the port, name, user and password, replacing the fields:
```sh
docker run -d \
-p {PORT}:{PORT} \
--name {NAME} \
-e POSTGRES_PASSWORD={PASSWORD} \
-e POSTGRES_USER={USER} \
postgres
```
Such as:
```sh
docker run -d \
-p 5432:5432 \
--name postgres \
-e POSTGRES_PASSWORD=1234 \
-e POSTGRES_USER=postgres \
postgres
```
#### 4.2.3. Running redis With Docker
> \[!NOTE\]
> If you already have a redis running, you may skip this step.
Install docker if you don't have it yet, then run:
```sh
docker pull redis:alpine
```
And pick the name and port, replacing the fields:
```sh
docker run -d \
--name {NAME} \
-p {PORT}:{PORT} \
redis:alpine
```
Such as
```sh
docker run -d \
--name redis \
-p 6379:6379 \
redis:alpine
```
#### 4.2.4. Running the API
While in the `root` folder, run to start the application with uvicorn server:
```sh
poetry run uvicorn src.app.main:app --reload
```
> \[!TIP\]
> The --reload flag enables auto-reload once you change (and save) something in the project
### 4.3 Creating the first superuser
#### 4.3.1 Docker Compose
> \[!WARNING\]
> Make sure DB and tables are created before running create_superuser (db should be running and the api should run at least once before)
If you are using docker compose, you should uncomment this part of the docker-compose.yml:
```
#-------- uncomment to create first superuser --------
# create_superuser:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# command: python -m src.scripts.create_first_superuser
# volumes:
# - ./src:/code/src
```
Getting:
```
#-------- uncomment to create first superuser --------
create_superuser:
build:
context: .
dockerfile: Dockerfile
env_file:
- ./src/.env
depends_on:
- db
command: python -m src.scripts.create_first_superuser
volumes:
- ./src:/code/src
```
While in the base project folder run to start the services:
```sh
docker-compose up -d
```
It will automatically run the create_superuser script as well, but if you want to rerun eventually:
```sh
docker-compose run --rm create_superuser
```
to stop the create_superuser service:
```sh
docker-compose stop create_superuser
```
#### 4.3.2 From Scratch
While in the `root` folder, run (after you started the application at least once to create the tables):
```sh
poetry run python -m src.scripts.create_first_superuser
```
### 4.3.3 Creating the first tier
> \[!WARNING\]
> Make sure DB and tables are created before running create_tier (db should be running and the api should run at least once before)
To create the first tier it's similar, you just replace `create_superuser` for `create_tier` service or `create_first_superuser` to `create_first_tier` for scripts. If using `docker compose`, do not forget to uncomment the `create_tier` service in `docker-compose.yml`.
### 4.4 Database Migrations
> \[!WARNING\]
> To create the tables if you did not create the endpoints, ensure that you import the models in src/app/models/__init__.py. This step is crucial to create the new tables.
If you are using the db in docker, you need to change this in `docker-compose.yml` to run migrations:
```sh
db:
image: postgres:13
env_file:
- ./src/.env
volumes:
- postgres-data:/var/lib/postgresql/data
# -------- replace with comment to run migrations with docker --------
expose:
- "5432"
# ports:
# - 5432:5432
```
Getting:
```sh
db:
...
# expose:
# - "5432"
ports:
- 5432:5432
```
While in the `src` folder, run Alembic migrations:
```sh
poetry run alembic revision --autogenerate
```
And to apply the migration
```sh
poetry run alembic upgrade head
```
> [!NOTE]
> If you do not have poetry, you may run it without poetry after running `pip install alembic`
## 5. Extending
### 5.1 Project Structure
First, you may want to take a look at the project structure and understand what each file is doing.
```sh
.
├── Dockerfile # Dockerfile for building the application container.
├── docker-compose.yml # Docker Compose file for defining multi-container applications.
├── pyproject.toml # Poetry configuration file with project metadata and dependencies.
├── README.md # Project README providing information and instructions.
├── LICENSE.md # License file for the project.
│
├── tests # Unit and integration tests for the application.
│ ├── __init__.py
│ ├── conftest.py # Configuration and fixtures for pytest.
│ ├── helper.py # Helper functions for tests.
│ └── test_user.py # Test cases for user-related functionality.
│
└── src # Source code directory.
├── __init__.py # Initialization file for the src package.
├── alembic.ini # Configuration file for Alembic (database migration tool).
├── poetry.lock # Poetry lock file specifying exact versions of dependencies.
│
├── app # Main application directory.
│ ├── __init__.py # Initialization file for the app package.
│ ├── main.py # Main entry point of the FastAPI application.
│ │
│ │
│ ├── api # Folder containing API-related logic.
│ │ ├── __init__.py
│ │ ├── dependencies.py # Defines dependencies for use across API endpoints.
│ │ │
│ │ └── v1 # Version 1 of the API.
│ │ ├── __init__.py
│ │ ├── login.py # API route for user login.
│ │ ├── logout.py # API route for user logout.
│ │ ├── posts.py # API routes for post operations.
│ │ ├── rate_limits.py # API routes for rate limiting functionalities.
│ │ ├── tasks.py # API routes for task management.
│ │ ├── tiers.py # API routes for user tier functionalities.
│ │ └── users.py # API routes for user management.
│ │
│ ├── core # Core utilities and configurations for the application.
│ │ ├── __init__.py
│ │ ├── config.py # Configuration settings for the application.
│ │ ├── logger.py # Configuration for application logging.
│ │ ├── schemas.py # Pydantic schemas for data validation.
│ │ ├── security.py # Security utilities, such as password hashing.
│ │ ├── setup.py # Setup file for the FastAPI app instance.
│ │ │
│ │ ├── db # Core Database related modules.
│ │ │ ├── __init__.py
│ │ │ ├── crud_token_blacklist.py # CRUD operations for token blacklist.
│ │ │ ├── database.py # Database connectivity and session management.
│ │ │ ├── models.py # Core Database models.
│ │ │ └── token_blacklist.py # Model for token blacklist functionality.
│ │ │
│ │ ├── exceptions # Custom exception classes.
│ │ │ ├── __init__.py
│ │ │ ├── cache_exceptions.py # Exceptions related to cache operations.
│ │ │ └── http_exceptions.py # HTTP-related exceptions.
│ │ │
│ │ ├── utils # Utility functions and helpers.
│ │ │ ├── __init__.py
│ │ │ ├── cache.py # Cache-related utilities.
│ │ │ ├── queue.py # Utilities for task queue management.
│ │ │ └── rate_limit.py # Rate limiting utilities.
│ │ │
│ │ └── worker # Worker script for background tasks.
│ │ ├── __init__.py
│ │ ├── settings.py # Worker configuration and settings.
│ │ └── functions.py # Async task definitions and management.
│ │
│ ├── crud # CRUD operations for the application.
│ │ ├── __init__.py
│ │ ├── crud_base.py # Base class for CRUD operations.
│ │ ├── crud_posts.py # CRUD operations for posts.
│ │ ├── crud_rate_limit.py # CRUD operations for rate limiting.
│ │ ├── crud_tier.py # CRUD operations for user tiers.
│ │ ├── crud_users.py # CRUD operations for users.
│ │ └── helper.py # Helper functions for CRUD operations.
│ │
│ ├── logs # Directory for log files.
│ │ └── app.log # Log file for the application.
│ │
│ ├── middleware # Middleware components for the application.
│ │ └── client_cache_middleware.py # Middleware for client-side caching.
│ │
│ └── models # SQLModel db and validation models for the application.
│ ├── __init__.py
│ ├── post.py # SQLModel models for posts.
│ ├── rate_limit.py # SQLModel models for rate limiting.
│ ├── tier.py # SQLModel models for user tiers.
│ └── user.py # SQLModel models for users.
│
├── migrations # Alembic migration scripts for database changes.
│ ├── README
│ ├── env.py # Environment configuration for Alembic.
│ ├── script.py.mako # Template script for Alembic migrations.
│ │
│ └── versions # Individual migration scripts.
│ └── README.MD
│
└── scripts # Utility scripts for the application.
├── __init__.py
├── create_first_superuser.py # Script to create the first superuser.
└── create_first_tier.py # Script to create the first user tier.
```
### 5.2 Database Model
Create the new entities and relationships and add them to the model

#### 5.2.1 Token Blacklist
Note that this table is used to blacklist the `JWT` tokens (it's how you log a user out)

### 5.3 DB Models
Inside `app/models`, create a new `entity.py` for each new entity (replacing entity with the name) and define the attributes according to [SQLModel standards](https://sqlmodel.tiangolo.com/tutorial/create-db-and-table/):
```python
from sqlmodel import Field, SQLModel
class Entity(SQLModel, table=True):
__tablename__ = "entity"
id: int | None = Field(default=None, primary_key=True)
name: str = Field(max_digits=30)
...
```
### 5.4 Validation Models
Inside each `entity.py` in `app/models`, create your SQLModel data validation models for each new entity, you'll now use `table=False` (or just leave it blank, as it's the default):
```python
from sqlmodel import Field, SQLModel
# this should be here already
class Entity(SQLModel, table=True):
__tablename__ = "entity"
id: int | None = Field(default=None, primary_key=True)
name: str = Field(max_digits=30)
...
# now we'll create the other validation models
class EntityBase(SQLModel):
name: str
...
class EntityRead(EntityBase):
...
class EntityCreate(EntityBase):
...
class EntityCreateInternal(EntityCreate):
...
class EntityUpdate(SQLModel):
...
class EntityUpdateInternal(SQLModel):
...
class EntityDelete(SQLModel):
model_config = {"extra": "forbid"}
is_deleted: bool
deleted_at: datetime
```
### 5.5 Alembic Migrations
> \[!WARNING\]
> To create the tables if you did not create the endpoints, ensure that you import the models in src/app/models/__init__.py. This step is crucial to create the new models.
Then, while in the `src` folder, run Alembic migrations:
```sh
poetry run alembic revision --autogenerate
```
And to apply the migration
```sh
poetry run alembic upgrade head
```
### 5.6 CRUD
Inside `app/crud`, create a new `crud_entities.py` inheriting from `FastCRUD` for each new entity:
```python
from fastcrud import FastCRUD
from app.models.entity import Entity, EntityCreateInternal, EntityUpdate, EntityUpdateInternal, EntityDelete
CRUDEntity = FastCRUD[Entity, EntityCreateInternal, EntityUpdate, EntityUpdateInternal, EntityDelete]
crud_entity = CRUDEntity(Entity)
```
So, for users:
```python
# crud_users.py
from app.model.user import User, UserCreateInternal, UserUpdate, UserUpdateInternal, UserDelete
CRUDUser = FastCRUD[User, UserCreateInternal, UserUpdate, UserUpdateInternal, UserDelete]
crud_users = CRUDUser(User)
```
To understand the methods that `crud_users`, a `FastCRUD` instance provides, head to [FastCRUD's documentation](https://igorbenav.github.io/fastcrud/).
### 5.7 Routes
Inside `app/api/v1`, create a new `entities.py` file and create the desired routes
```python
from typing import Annotated
from fastapi import Depends
from app.models.entity import EntityRead
from app.core.db.database import async_get_db
from app.crud.crud_entity import crud_entity
...
router = fastapi.APIRouter(tags=["entities"])
@router.get("/entities/{id}", response_model=List[EntityRead])
async def read_entities(request: Request, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]):
entity = await crud_entities.get(db=db, id=id)
return entity
...
```
Then in `app/api/v1/__init__.py` add the router such as:
```python
from fastapi import APIRouter
from app.api.v1.entity import router as entity_router
...
router = APIRouter(prefix="/v1") # this should be there already
...
router.include_router(entity_router)
```
#### 5.7.1 Paginated Responses
With the `get_multi` method we get a python `dict` with full suport for pagination:
```javascript
{
"data": [
{
"id": 4,
"name": "User Userson",
"username": "userson4",
"email": "user.userson4@example.com",
"profile_image_url": "https://profileimageurl.com"
},
{
"id": 5,
"name": "User Userson",
"username": "userson5",
"email": "user.userson5@example.com",
"profile_image_url": "https://profileimageurl.com"
}
],
"total_count": 2,
"has_more": false,
"page": 1,
"items_per_page": 10
}
```
And in the endpoint, we can import from `fastcrud.paginated` the following functions and Pydantic Schema:
```python
from fastcrud.paginated import (
PaginatedListResponse, # What you'll use as a response_model to validate
paginated_response, # Creates a paginated response based on the parameters
compute_offset, # Calculate the offset for pagination ((page - 1) * items_per_page)
)
```
Then let's create the endpoint:
```python
import fastapi
from app.models.entity import EntityRead
from app.core.db.database import async_get_db
from app.crud.crud_entity import crud_entity
...
@router.get("/entities", response_model=PaginatedListResponse[EntityRead])
async def read_entities(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], page: int = 1, items_per_page: int = 10
):
entities_data = await crud_entity.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=UserRead,
is_deleted=False,
)
return paginated_response(crud_data=entities_data, page=page, items_per_page=items_per_page)
```
#### 5.7.2 HTTP Exceptions
To add exceptions you may just import from `app/core/exceptions/http_exceptions` and optionally add a detail:
```python
from app.core.exceptions.http_exceptions import NotFoundException
# If you want to specify the detail, just add the message
if not user:
raise NotFoundException("User not found")
# Or you may just use the default message
if not post:
raise NotFoundException()
```
**The predefined possibilities in http_exceptions are the following:**
- `CustomException`: 500 internal error
- `BadRequestException`: 400 bad request
- `NotFoundException`: 404 not found
- `ForbiddenException`: 403 forbidden
- `UnauthorizedException`: 401 unauthorized
- `UnprocessableEntityException`: 422 unprocessable entity
- `DuplicateValueException`: 422 unprocessable entity
- `RateLimitException`: 429 too many requests
### 5.8 Caching
The `cache` decorator allows you to cache the results of FastAPI endpoint functions, enhancing response times and reducing the load on your application by storing and retrieving data in a cache.
Caching the response of an endpoint is really simple, just apply the `cache` decorator to the endpoint function.
> \[!WARNING\]
> Note that you should always pass request as a variable to your endpoint function if you plan to use the cache decorator.
```python
...
from app.core.utils.cache import cache
@app.get("/sample/{my_id}")
@cache(key_prefix="sample_data", expiration=3600, resource_id_name="my_id")
async def sample_endpoint(request: Request, my_id: int):
# Endpoint logic here
return {"data": "my_data"}
```
The way it works is:
- the data is saved in redis with the following cache key: `sample_data:{my_id}`
- then the time to expire is set as 3600 seconds (that's the default)
Another option is not passing the `resource_id_name`, but passing the `resource_id_type` (default int):
```python
...
from app.core.utils.cache import cache
@app.get("/sample/{my_id}")
@cache(key_prefix="sample_data", resource_id_type=int)
async def sample_endpoint(request: Request, my_id: int):
# Endpoint logic here
return {"data": "my_data"}
```
In this case, what will happen is:
- the `resource_id` will be inferred from the keyword arguments (`my_id` in this case)
- the data is saved in redis with the following cache key: `sample_data:{my_id}`
- then the the time to expire is set as 3600 seconds (that's the default)
Passing resource_id_name is usually preferred.
### 5.9 More Advanced Caching
The behaviour of the `cache` decorator changes based on the request method of your endpoint.
It caches the result if you are passing it to a **GET** endpoint, and it invalidates the cache with this key_prefix and id if passed to other endpoints (**PATCH**, **DELETE**).
#### Invalidating Extra Keys
If you also want to invalidate cache with a different key, you can use the decorator with the `to_invalidate_extra` variable.
In the following example, I want to invalidate the cache for a certain `user_id`, since I'm deleting it, but I also want to invalidate the cache for the list of users, so it will not be out of sync.
```python
# The cache here will be saved as "{username}_posts:{username}":
@router.get("/{username}/posts", response_model=List[PostRead])
@cache(key_prefix="{username}_posts", resource_id_name="username")
async def read_posts(request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]):
...
...
# Invalidating cache for the former endpoint by just passing the key_prefix and id as a dictionary:
@router.delete("/{username}/post/{id}")
@cache(
"{username}_post_cache",
resource_id_name="id",
to_invalidate_extra={"{username}_posts": "{username}"}, # also invalidate "{username}_posts:{username}" cache
)
async def erase_post(
request: Request,
username: str,
id: int,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
):
...
# And now I'll also invalidate when I update the user:
@router.patch("/{username}/post/{id}", response_model=PostRead)
@cache("{username}_post_cache", resource_id_name="id", to_invalidate_extra={"{username}_posts": "{username}"})
async def patch_post(
request: Request,
username: str,
id: int,
values: PostUpdate,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
):
...
```
> \[!WARNING\]
> Note that adding `to_invalidate_extra` will not work for **GET** requests.
#### Invalidate Extra By Pattern
Let's assume we have an endpoint with a paginated response, such as:
```python
@router.get("/{username}/posts", response_model=PaginatedListResponse[PostRead])
@cache(
key_prefix="{username}_posts:page_{page}:items_per_page:{items_per_page}",
resource_id_name="username",
expiration=60,
)
async def read_posts(
request: Request,
username: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
page: int = 1,
items_per_page: int = 10,
):
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if not db_user:
raise HTTPException(status_code=404, detail="User not found")
posts_data = await crud_posts.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=PostRead,
created_by_user_id=db_user["id"],
is_deleted=False,
)
return paginated_response(crud_data=posts_data, page=page, items_per_page=items_per_page)
```
Just passing `to_invalidate_extra` will not work to invalidate this cache, since the key will change based on the `page` and `items_per_page` values.
To overcome this we may use the `pattern_to_invalidate_extra` parameter:
```python
@router.patch("/{username}/post/{id}")
@cache("{username}_post_cache", resource_id_name="id", pattern_to_invalidate_extra=["{username}_posts:*"])
async def patch_post(
request: Request,
username: str,
id: int,
values: PostUpdate,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
):
...
```
Now it will invalidate all caches with a key that matches the pattern `"{username}_posts:*`, which will work for the paginated responses.
> \[!CAUTION\]
> Using `pattern_to_invalidate_extra` can be resource-intensive on large datasets. Use it judiciously and consider the potential impact on Redis performance. Be cautious with patterns that could match a large number of keys, as deleting many keys simultaneously may impact the performance of the Redis server.
#### Client-side Caching
For `client-side caching`, all you have to do is let the `Settings` class defined in `app/core/config.py` inherit from the `ClientSideCacheSettings` class. You can set the `CLIENT_CACHE_MAX_AGE` value in `.env,` it defaults to 60 (seconds).
### 5.10 ARQ Job Queues
Depending on the problem your API is solving, you might want to implement a job queue. A job queue allows you to run tasks in the background, and is usually aimed at functions that require longer run times and don't directly impact user response in your frontend. As a rule of thumb, if a task takes more than 2 seconds to run, can be executed asynchronously, and its result is not needed for the next step of the user's interaction, then it is a good candidate for the job queue.
> [!TIP]
> Very common candidates for background functions are calls to and from LLM endpoints (e.g. OpenAI or Openrouter). This is because they span tens of seconds and often need to be further parsed and saved.
#### Background task creation
For simple background tasks, you can just create a function in the `app/core/worker/functions.py` file. For more complex tasks, we recommend you to create a new file in the `app/core/worker` directory.
```python
async def sample_background_task(ctx, name: str) -> str:
await asyncio.sleep(5)
return f"Task {name} is complete!"
```
Then add the function to the `WorkerSettings` class `functions` variable in `app/core/worker/settings.py` to make it available to the worker. If you created a new file in the `app/core/worker` directory, then simply import this function in the `app/core/worker/settings.py` file:
```python
from .functions import sample_background_task
from .your_module import sample_complex_background_task
class WorkerSettings:
functions = [sample_background_task, sample_complex_background_task]
...
```
#### Add the task to an endpoint
Once you have created the background task, you can add it to any endpoint of your choice to be enqueued. The best practice is to enqueue the task in a **POST** endpoint, while having a **GET** endpoint to get more information on the task. For more details on how job results are handled, check the [ARQ docs](https://arq-docs.helpmanual.io/#job-results).
```python
@router.post("/task", response_model=Job, status_code=201)
async def create_task(message: str):
job = await queue.pool.enqueue_job("sample_background_task", message)
return {"id": job.job_id}
@router.get("/task/{task_id}")
async def get_task(task_id: str):
job = ArqJob(task_id, queue.pool)
return await job.info()
```
And finally run the worker in parallel to your fastapi application.
> [!IMPORTANT]
> For any change to the `sample_background_task` to be reflected in the worker, you need to restart the worker (e.g. the docker container).
If you are using `docker compose`, the worker is already running.
If you are doing it from scratch, run while in the `root` folder:
```sh
poetry run arq src.app.core.worker.settings.WorkerSettings
```
#### Database session with background tasks
With time your background functions will become 'workflows' increasing in complexity and requirements. Probably, you will need to use a database session to get, create, update, or delete data as part of this workflow.
To do this, you can add the database session to the `ctx` object in the `startup` and `shutdown` functions in `app/core/worker/functions.py`, like in the example below:
```python
from arq.worker import Worker
from ...core.db.database import async_get_db
async def startup(ctx: Worker) -> None:
ctx["db"] = await anext(async_get_db())
logging.info("Worker Started")
async def shutdown(ctx: Worker) -> None:
await ctx["db"].close()
logging.info("Worker end")
```
This will allow you to have the async database session always available in any background function and automatically close it on worker shutdown. Once you have this database session, you can use it as follows:
```python
from arq.worker import Worker
async def your_background_function(
ctx: Worker,
post_id: int,
...
) -> Any:
db = ctx["db"]
post = crud_posts.get(db=db, schema_to_select=PostRead, id=post_id)
...
```
> [!WARNING]
> When using database sessions, you will want to use Pydantic objects. However, these objects don't mingle well with the seralization required by ARQ tasks and will be retrieved as a dictionary.
### 5.11 Rate Limiting
To limit how many times a user can make a request in a certain interval of time (very useful to create subscription plans or just to protect your API against DDOS), you may just use the `rate_limiter` dependency:
```python
from fastapi import Depends
from app.api.dependencies import rate_limiter
from app.core.utils import queue
from app.models.job import Job
@router.post("/task", response_model=Job, status_code=201, dependencies=[Depends(rate_limiter)])
async def create_task(message: str):
job = await queue.pool.enqueue_job("sample_background_task", message)
return {"id": job.job_id}
```
By default, if no token is passed in the header (that is - the user is not authenticated), the user will be limited by his IP address with the default `limit` (how many times the user can make this request every period) and `period` (time in seconds) defined in `.env`.
Even though this is useful, real power comes from creating `tiers` (categories of users) and standard `rate_limits` (`limits` and `periods` defined for specific `paths` - that is - endpoints) for these tiers.
All of the `tier` and `rate_limit` models and endpoints are already created in the respective folders (and usable only by superusers). You may use the `create_tier` script to create the first tier (it uses the `.env` variable `TIER_NAME`, which is all you need to create a tier) or just use the api:
Here I'll create a `free` tier:

And a `pro` tier:

Then I'll associate a `rate_limit` for the path `api/v1/tasks/task` for each of them, I'll associate a `rate limit` for the path `api/v1/tasks/task`.
> \[!WARNING\]
> Do not forget to add `api/v1/...` or any other prefix to the beggining of your path. For the structure of the boilerplate, `api/v1/`
1 request every hour (3600 seconds) for the free tier:

10 requests every hour for the pro tier:

Now let's read all the tiers available (`GET api/v1/tiers`):
```javascript
{
"data": [
{
"name": "free",
"id": 1,
"created_at": "2023-11-11T05:57:25.420360"
},
{
"name": "pro",
"id": 2,
"created_at": "2023-11-12T00:40:00.759847"
}
],
"total_count": 2,
"has_more": false,
"page": 1,
"items_per_page": 10
}
```
And read the `rate_limits` for the `pro` tier to ensure it's working (`GET api/v1/tier/pro/rate_limits`):
```javascript
{
"data": [
{
"path": "api_v1_tasks_task",
"limit": 10,
"period": 3600,
"id": 1,
"tier_id": 2,
"name": "api_v1_tasks:10:3600"
}
],
"total_count": 1,
"has_more": false,
"page": 1,
"items_per_page": 10
}
```
Now, whenever an authenticated user makes a `POST` request to the `api/v1/tasks/task`, they'll use the quota that is defined by their tier.
You may check this getting the token from the `api/v1/login` endpoint, then passing it in the request header:
```sh
curl -X POST 'http://127.0.0.1:8000/api/v1/tasks/task?message=test' \
-H 'Authorization: Bearer '
```
> \[!TIP\]
> Since the `rate_limiter` dependency uses the `get_optional_user` dependency instead of `get_current_user`, it will not require authentication to be used, but will behave accordingly if the user is authenticated (and token is passed in header). If you want to ensure authentication, also use `get_current_user` if you need.
To change a user's tier, you may just use the `PATCH api/v1/user/{username}/tier` endpoint.
Note that for flexibility (since this is a boilerplate), it's not necessary to previously inform a tier_id to create a user, but you probably should set every user to a certain tier (let's say `free`) once they are created.
> \[!WARNING\]
> If a user does not have a `tier` or the tier does not have a defined `rate limit` for the path and the token is still passed to the request, the default `limit` and `period` will be used, this will be saved in `app/logs`.
### 5.12 JWT Authentication
#### 5.12.1 Details
The JWT in this boilerplate is created in the following way:
1. **JWT Access Tokens:** how you actually access protected resources is passing this token in the request header.
1. **Refresh Tokens:** you use this type of token to get an `access token`, which you'll use to access protected resources.
The `access token` is short lived (default 30 minutes) to reduce the damage of a potential leak. The `refresh token`, on the other hand, is long lived (default 7 days), and you use it to renew your `access token` without the need to provide username and password every time it expires.
Since the `refresh token` lasts for a longer time, it's stored as a cookie in a secure way:
```python
# app/api/v1/login
...
response.set_cookie(
key="refresh_token",
value=refresh_token,
httponly=True, # Prevent access through JavaScript
secure=True, # Ensure cookie is sent over HTTPS only
samesite="Lax", # Default to Lax for reasonable balance between security and usability
max_age=number_of_seconds, # Set a max age for the cookie
)
...
```
You may change it to suit your needs. The possible options for `samesite` are:
- `Lax`: Cookies will be sent in top-level navigations (like clicking on a link to go to another site), but not in API requests or images loaded from other sites.
- `Strict`: Cookies are sent only on top-level navigations from the same site that set the cookie, enhancing privacy but potentially disrupting user sessions.
- `None`: Cookies will be sent with both same-site and cross-site requests.
#### 5.12.2 Usage
What you should do with the client is:
- `Login`: Send credentials to `/api/v1/login`. Store the returned access token in memory for subsequent requests.
- `Accessing Protected Routes`: Include the access token in the Authorization header.
- `Token Renewal`: On access token expiry, the front end should automatically call `/api/v1/refresh` for a new token.
- `Login Again`: If refresh token is expired, credentials should be sent to `/api/v1/login` again, storing the new access token in memory.
- `Logout`: Call /api/v1/logout to end the session securely.
This authentication setup in the provides a robust, secure, and user-friendly way to handle user sessions in your API applications.
### 5.13 Running
If you are using docker compose, just running the following command should ensure everything is working:
```sh
docker compose up
```
If you are doing it from scratch, ensure your postgres and your redis are running, then
while in the `root` folder, run to start the application with uvicorn server:
```sh
poetry run uvicorn src.app.main:app --reload
```
And for the worker:
```sh
poetry run arq src.app.core.worker.settings.WorkerSettings
```
### 5.14 Create Application
If you want to stop tables from being created every time you run the api, you should disable this here:
```python
# app/main.py
from .api import router
from .core.config import settings
from .core.setup import create_application
# create_tables_on_start defaults to True
app = create_application(router=router, settings=settings, create_tables_on_start=False)
```
This `create_application` function is defined in `app/core/setup.py`, and it's a flexible way to configure the behavior of your application.
A few examples:
- Deactivate or password protect /docs
- Add client-side cache middleware
- Add Startup and Shutdown event handlers for cache, queue and rate limit
### 5.15 Opting Out of Services
To opt out of services (like `Redis`, `Queue`, `Rate Limiter`), head to the `Settings` class in `src/app/core/config`:
```python
# src/app/core/config
import os
from enum import Enum
from pydantic_settings import BaseSettings
from starlette.config import Config
current_file_dir = os.path.dirname(os.path.realpath(__file__))
env_path = os.path.join(current_file_dir, "..", "..", ".env")
config = Config(env_path)
...
class Settings(
AppSettings,
PostgresSettings,
CryptSettings,
FirstUserSettings,
TestSettings,
RedisCacheSettings,
ClientSideCacheSettings,
RedisQueueSettings,
RedisRateLimiterSettings,
DefaultRateLimitSettings,
EnvironmentSettings,
):
pass
settings = Settings()
```
And remove the Settings of the services you do not need. For example, without using redis (removed `Cache`, `Queue` and `Rate limit`):
```python
class Settings(
AppSettings,
PostgresSettings,
CryptSettings,
FirstUserSettings,
TestSettings,
ClientSideCacheSettings,
DefaultRateLimitSettings,
EnvironmentSettings,
):
pass
```
Then comment or remove the services you do not want from `docker-compose.yml`. Here, I removed `redis` and `worker` services:
```yml
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
# -------- replace with comment to run with gunicorn --------
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
env_file:
- ./src/.env
# -------- replace with comment if you are using nginx --------
ports:
- "8000:8000"
# expose:
# - "8000"
depends_on:
- db
- redis
volumes:
- ./src/app:/code/app
- ./src/.env:/code/.env
db:
image: postgres:13
env_file:
- ./src/.env
volumes:
- postgres-data:/var/lib/postgresql/data
# -------- replace with comment to run migrations with docker --------
expose:
- "5432"
# ports:
# - 5432:5432
volumes:
postgres-data:
redis-data:
#pgadmin-data:
```
## 6. Running in Production
### 6.1 Uvicorn Workers with Gunicorn
In production you may want to run using gunicorn to manage uvicorn workers:
```sh
command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
```
Here it's running with 4 workers, but you should test it depending on how many cores your machine has.
To do this if you are using docker compose, just replace the comment:
This part in `docker-compose.yml`:
```YAML
# docker-compose.yml
# -------- replace with comment to run with gunicorn --------
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
```
Should be changed to:
```YAML
# docker-compose.yml
# -------- replace with comment to run with uvicorn --------
# command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
```
And the same in `Dockerfile`:
This part:
```Dockerfile
# Dockerfile
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
# CMD ["gunicorn", "app.main:app", "-w", "4", "-k", "uvicorn.workers.UvicornWorker". "-b", "0.0.0.0:8000"]
```
Should be changed to:
```Dockerfile
# Dockerfile
# CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
CMD ["gunicorn", "app.main:app", "-w", "4", "-k", "uvicorn.workers.UvicornWorker". "-b", "0.0.0.0:8000"]
```
> \[!CAUTION\]
> Do not forget to set the `ENVIRONMENT` in `.env` to `production` unless you want the API docs to be public.
### 6.2 Running with NGINX
NGINX is a high-performance web server, known for its stability, rich feature set, simple configuration, and low resource consumption. NGINX acts as a reverse proxy, that is, it receives client requests, forwards them to the FastAPI server (running via Uvicorn or Gunicorn), and then passes the responses back to the clients.
To run with NGINX, you start by uncommenting the following part in your `docker-compose.yml`:
```python
# docker-compose.yml
...
# -------- uncomment to run with nginx --------
# nginx:
# image: nginx:latest
# ports:
# - "80:80"
# volumes:
# - ./default.conf:/etc/nginx/conf.d/default.conf
# depends_on:
# - web
...
```
Which should be changed to:
```YAML
# docker-compose.yml
...
#-------- uncomment to run with nginx --------
nginx:
image: nginx:latest
ports:
- "80:80"
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf
depends_on:
- web
...
```
Then comment the following part:
```YAML
# docker-compose.yml
services:
web:
...
# -------- Both of the following should be commented to run with nginx --------
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
```
Which becomes:
```YAML
# docker-compose.yml
services:
web:
...
# -------- Both of the following should be commented to run with nginx --------
# command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
```
Then pick the way you want to run (uvicorn or gunicorn managing uvicorn workers) in `Dockerfile`.
The one you want should be uncommented, comment the other one.
```Dockerfile
# Dockerfile
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
# CMD ["gunicorn", "app.main:app", "-w", "4", "-k", "uvicorn.workers.UvicornWorker". "-b", "0.0.0.0:8000"]
```
And finally head to `http://localhost/docs`.
#### 6.2.1 One Server
If you want to run with one server only, your setup should be ready. Just make sure the only part that is not a comment in `default.conf` is:
```conf
# default.conf
# ---------------- Running With One Server ----------------
server {
listen 80;
location / {
proxy_pass http://web:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
So just type on your browser: `http://localhost/docs`.
#### 6.2.2 Multiple Servers
NGINX can distribute incoming network traffic across multiple servers, improving the efficiency and capacity utilization of your application.
To run with multiple servers, just comment the `Running With One Server` part in `default.conf` and Uncomment the other one:
```conf
# default.conf
# ---------------- Running With One Server ----------------
...
# ---------------- To Run with Multiple Servers, Uncomment below ----------------
upstream fastapi_app {
server fastapi1:8000; # Replace with actual server names or IP addresses
server fastapi2:8000;
# Add more servers as needed
}
server {
listen 80;
location / {
proxy_pass http://fastapi_app;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
And finally, on your browser: `http://localhost/docs`.
> \[!WARNING\]
> Note that we are using `fastapi1:8000` and `fastapi2:8000` as examples, you should replace it with the actual name of your service and the port it's running on.
## 7. Testing
For tests, ensure you have in `.env`:
```
# ------------- test -------------
TEST_NAME="Tester User"
TEST_EMAIL="test@tester.com"
TEST_USERNAME="testeruser"
TEST_PASSWORD="Str1ng$t"
```
While in the tests folder, create your test file with the name "test\_{entity}.py", replacing entity with what you're testing
```sh
touch test_items.py
```
Finally create your tests (you may want to copy the structure in test_user.py)
Now, to run:
### 7.1 Docker Compose
First you need to uncomment the following part in the `docker-compose.yml` file:
```YAML
#-------- uncomment to run tests --------
# pytest:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - create_superuser
# - redis
# command: python -m pytest ./tests
# volumes:
# - .:/code
```
You'll get:
```YAML
#-------- uncomment to run tests --------
pytest:
build:
context: .
dockerfile: Dockerfile
env_file:
- ./src/.env
depends_on:
- db
- create_superuser
- redis
command: python -m pytest ./tests
volumes:
- .:/code
```
Start the Docker Compose services:
```sh
docker-compose up -d
```
It will automatically run the tests, but if you want to run again later:
```sh
docker-compose run --rm pytest
```
### 7.2 From Scratch
While in the `root` folder, run:
```sh
poetry run python -m pytest
```
## 8. Contributing
Read [contributing](CONTRIBUTING.md).
## 9. References
This project is a SQLModel version of Fastapi-boilerplate:
- [`FastAPI-boilerplate`](https://github.com/igorbenav/FastAPI-boilerplate)
## 10. License
[`MIT`](LICENSE.md)
## 11. Contact
Benav Labs – [benav.io](https://benav.io)
[github.com/benavlabs](https://github.com/benavlabs/)
 ================================================
FILE: default.conf
================================================
# ---------------- Running With One Server ----------------
server {
listen 80;
location / {
proxy_pass http://web:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
# # ---------------- To Run with Multiple Servers, Uncomment below ----------------
# upstream fastapi_app {
# server fastapi1:8000; # Replace with actual server names or IP addresses
# server fastapi2:8000;
# # Add more servers as needed
# }
# server {
# listen 80;
# location / {
# proxy_pass http://fastapi_app;
# proxy_set_header Host $host;
# proxy_set_header X-Real-IP $remote_addr;
# proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# proxy_set_header X-Forwarded-Proto $scheme;
# }
# }
================================================
FILE: docker-compose.yml
================================================
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
# -------- replace with comment to run with gunicorn --------
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
env_file:
- ./src/.env
# -------- replace with comment if you are using nginx --------
ports:
- "8000:8000"
# expose:
# - "8000"
depends_on:
- db
- redis
volumes:
- ./src/app:/code/app
- ./src/.env:/code/.env
worker:
build:
context: .
dockerfile: Dockerfile
command: arq app.core.worker.settings.WorkerSettings
env_file:
- ./src/.env
depends_on:
- db
- redis
volumes:
- ./src/app:/code/app
- ./src/.env:/code/.env
db:
image: postgres:13
env_file:
- ./src/.env
volumes:
- postgres-data:/var/lib/postgresql/data
# -------- replace with comment to run migrations with docker --------
expose:
- "5432"
# ports:
# - 5432:5432
redis:
image: redis:alpine
volumes:
- redis-data:/data
expose:
- "6379"
#-------- uncomment to run with pgadmin --------
# pgadmin:
# container_name: pgadmin4
# image: dpage/pgadmin4:latest
# restart: always
# ports:
# - "5050:80"
# volumes:
# - pgadmin-data:/var/lib/pgadmin
# env_file:
# - ./src/.env
# depends_on:
# - db
#-------- uncomment to run with nginx --------
# nginx:
# image: nginx:latest
# ports:
# - "80:80"
# volumes:
# - ./default.conf:/etc/nginx/conf.d/default.conf
# depends_on:
# - web
#-------- uncomment to create first superuser --------
# create_superuser:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - web
# command: python -m src.scripts.create_first_superuser
# volumes:
# - ./src:/code/src
#-------- uncomment to run tests --------
# pytest:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - create_superuser
# - redis
# command: python -m pytest ./tests
# volumes:
# - .:/code
#-------- uncomment to create first tier --------
# create_tier:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - web
# command: python -m src.scripts.create_first_tier
# volumes:
# - ./src:/code/src
volumes:
postgres-data:
redis-data:
#pgadmin-data:
================================================
FILE: mypy.ini
================================================
[mypy]
python_version = 3.11
warn_return_any = True
warn_unused_configs = True
ignore_missing_imports = True
[mypy-src.app.*]
disallow_untyped_defs = True
================================================
FILE: pyproject.toml
================================================
[tool.poetry]
name = "fastapi-boilerplate"
version = "0.1.0"
description = "A fully Async FastAPI boilerplate using SQLAlchemy and Pydantic 2"
authors = ["Igor Magalhaes "]
license = "MIT"
readme = "README.md"
packages = [{ include = "src" }]
[tool.poetry.requires-plugins]
poetry-plugin-export = ">=1.8"
[tool.poetry.dependencies]
python = "^3.11"
python-dotenv = "^1.0.0"
pydantic = { extras = ["email"], version = "^2.6.1" }
fastapi = "^0.109.1"
uvicorn = "^0.27.0"
uvloop = "^0.19.0"
httptools = "^0.6.1"
uuid = "^1.30"
alembic = "^1.13.1"
asyncpg = "^0.29.0"
SQLAlchemy-Utils = "^0.41.1"
python-jose = "^3.3.0"
SQLAlchemy = "^2.0.25"
pytest = "^7.4.2"
python-multipart = "^0.0.9"
greenlet = "^2.0.2"
httpx = "^0.26.0"
pydantic-settings = "^2.0.3"
redis = "^5.0.1"
arq = "^0.25.0"
gunicorn = "^22.0.0"
bcrypt = "^4.1.1"
fastcrud = "^0.12.0"
sqlmodel = "^0.0.18"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
[tool.ruff]
target-version = "py311"
line-length = 120
fix = true
select = [
# https://docs.astral.sh/ruff/rules/#pyflakes-f
"F", # Pyflakes
# https://docs.astral.sh/ruff/rules/#pycodestyle-e-w
"E", # pycodestyle
"W", # Warning
# https://docs.astral.sh/ruff/rules/#flake8-comprehensions-c4
# https://docs.astral.sh/ruff/rules/#mccabe-c90
"C", # Complexity (mccabe+) & comprehensions
# https://docs.astral.sh/ruff/rules/#pyupgrade-up
"UP", # pyupgrade
# https://docs.astral.sh/ruff/rules/#isort-i
"I", # isort
]
ignore = [
# https://docs.astral.sh/ruff/rules/#pycodestyle-e-w
"E402", # module level import not at top of file
# https://docs.astral.sh/ruff/rules/#pyupgrade-up
"UP006", # use-pep585-annotation
"UP007", # use-pep604-annotation
"E741", # Ambiguous variable name
# "UP035", # deprecated-assertion
]
[tool.ruff.per-file-ignores]
"__init__.py" = [
"F401", # unused import
"F403", # star imports
]
[tool.ruff.mccabe]
max-complexity = 24
[tool.ruff.pydocstyle]
convention = "numpy"
================================================
FILE: src/__init__.py
================================================
================================================
FILE: src/alembic.ini
================================================
# A generic, single database configuration.
[alembic]
# path to migration scripts
script_location = migrations
# template used to generate migration file names; The default value is %%(rev)s_%%(slug)s
# Uncomment the line below if you want the files to be prepended with date and time
# see https://alembic.sqlalchemy.org/en/latest/tutorial.html#editing-the-ini-file
# for all available tokens
# file_template = %%(year)d_%%(month).2d_%%(day).2d_%%(hour).2d%%(minute).2d-%%(rev)s_%%(slug)s
# sys.path path, will be prepended to sys.path if present.
# defaults to the current working directory.
prepend_sys_path = .
# timezone to use when rendering the date within the migration file
# as well as the filename.
# If specified, requires the python-dateutil library that can be
# installed by adding `alembic[tz]` to the pip requirements
# string value is passed to dateutil.tz.gettz()
# leave blank for localtime
# timezone =
# max length of characters to apply to the
# "slug" field
# truncate_slug_length = 40
# set to 'true' to run the environment during
# the 'revision' command, regardless of autogenerate
# revision_environment = false
# set to 'true' to allow .pyc and .pyo files without
# a source .py file to be detected as revisions in the
# versions/ directory
# sourceless = false
# version location specification; This defaults
# to migrations/versions. When using multiple version
# directories, initial revisions must be specified with --version-path.
# The path separator used here should be the separator specified by "version_path_separator" below.
# version_locations = %(here)s/bar:%(here)s/bat:migrations/versions
# version path separator; As mentioned above, this is the character used to split
# version_locations. The default within new alembic.ini files is "os", which uses os.pathsep.
# If this key is omitted entirely, it falls back to the legacy behavior of splitting on spaces and/or commas.
# Valid values for version_path_separator are:
#
# version_path_separator = :
# version_path_separator = ;
# version_path_separator = space
version_path_separator = os # Use os.pathsep. Default configuration used for new projects.
# set to 'true' to search source files recursively
# in each "version_locations" directory
# new in Alembic version 1.10
# recursive_version_locations = false
# the output encoding used when revision files
# are written from script.py.mako
# output_encoding = utf-8
sqlalchemy.url = driver://user:pass@localhost/dbname
[post_write_hooks]
# post_write_hooks defines scripts or Python functions that are run
# on newly generated revision scripts. See the documentation for further
# detail and examples
# format using "black" - use the console_scripts runner, against the "black" entrypoint
# hooks = black
# black.type = console_scripts
# black.entrypoint = black
# black.options = -l 79 REVISION_SCRIPT_FILENAME
# lint with attempts to fix using "ruff" - use the exec runner, execute a binary
# hooks = ruff
# ruff.type = exec
# ruff.executable = %(here)s/.venv/bin/ruff
# ruff.options = --fix REVISION_SCRIPT_FILENAME
# Logging configuration
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = WARN
handlers = console
qualname =
[logger_sqlalchemy]
level = WARN
handlers =
qualname = sqlalchemy.engine
[logger_alembic]
level = INFO
handlers =
qualname = alembic
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
================================================
FILE: src/app/__init__.py
================================================
================================================
FILE: src/app/api/__init__.py
================================================
from fastapi import APIRouter
from ..api.v1 import router as v1_router
router = APIRouter(prefix="/api")
router.include_router(v1_router)
================================================
FILE: src/app/api/dependencies.py
================================================
from typing import Annotated, Any
from fastapi import Depends, HTTPException, Request
from sqlalchemy.ext.asyncio import AsyncSession
from ..core.config import settings
from ..core.db.database import async_get_db
from ..core.exceptions.http_exceptions import ForbiddenException, RateLimitException, UnauthorizedException
from ..core.logger import logging
from ..core.security import oauth2_scheme, verify_token
from ..core.utils.rate_limit import is_rate_limited
from ..crud.crud_rate_limit import crud_rate_limits
from ..crud.crud_tier import crud_tiers
from ..crud.crud_users import crud_users
from ..models.user import User
from ..models.rate_limit import sanitize_path
logger = logging.getLogger(__name__)
DEFAULT_LIMIT = settings.DEFAULT_RATE_LIMIT_LIMIT
DEFAULT_PERIOD = settings.DEFAULT_RATE_LIMIT_PERIOD
async def get_current_user(
token: Annotated[str, Depends(oauth2_scheme)], db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, Any] | None:
token_data = await verify_token(token, db)
if token_data is None:
raise UnauthorizedException("User not authenticated.")
if "@" in token_data.username_or_email:
user: dict | None = await crud_users.get(db=db, email=token_data.username_or_email, is_deleted=False)
else:
user = await crud_users.get(db=db, username=token_data.username_or_email, is_deleted=False)
if user:
return user
raise UnauthorizedException("User not authenticated.")
async def get_optional_user(request: Request, db: AsyncSession = Depends(async_get_db)) -> dict | None:
token = request.headers.get("Authorization")
if not token:
return None
try:
token_type, _, token_value = token.partition(" ")
if token_type.lower() != "bearer" or not token_value:
return None
token_data = await verify_token(token_value, db)
if token_data is None:
return None
return await get_current_user(token_value, db=db)
except HTTPException as http_exc:
if http_exc.status_code != 401:
logger.error(f"Unexpected HTTPException in get_optional_user: {http_exc.detail}")
return None
except Exception as exc:
logger.error(f"Unexpected error in get_optional_user: {exc}")
return None
async def get_current_superuser(current_user: Annotated[dict, Depends(get_current_user)]) -> dict:
if not current_user["is_superuser"]:
raise ForbiddenException("You do not have enough privileges.")
return current_user
async def rate_limiter(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], user: User | None = Depends(get_optional_user)
) -> None:
path = sanitize_path(request.url.path)
if user:
user_id = user["id"]
tier = await crud_tiers.get(db, id=user["tier_id"])
if tier:
rate_limit = await crud_rate_limits.get(db=db, tier_id=tier["id"], path=path)
if rate_limit:
limit, period = rate_limit["limit"], rate_limit["period"]
else:
logger.warning(
f"User {user_id} with tier '{tier['name']}' has no specific rate limit for path '{path}'. \
Applying default rate limit."
)
limit, period = DEFAULT_LIMIT, DEFAULT_PERIOD
else:
logger.warning(f"User {user_id} has no assigned tier. Applying default rate limit.")
limit, period = DEFAULT_LIMIT, DEFAULT_PERIOD
else:
user_id = request.client.host
limit, period = DEFAULT_LIMIT, DEFAULT_PERIOD
is_limited = await is_rate_limited(db=db, user_id=user_id, path=path, limit=limit, period=period)
if is_limited:
raise RateLimitException("Rate limit exceeded.")
================================================
FILE: src/app/api/v1/__init__.py
================================================
from fastapi import APIRouter
from .login import router as login_router
from .logout import router as logout_router
from .posts import router as posts_router
from .rate_limits import router as rate_limits_router
from .tasks import router as tasks_router
from .tiers import router as tiers_router
from .users import router as users_router
router = APIRouter(prefix="/v1")
router.include_router(login_router)
router.include_router(logout_router)
router.include_router(users_router)
router.include_router(posts_router)
router.include_router(tasks_router)
router.include_router(tiers_router)
router.include_router(rate_limits_router)
================================================
FILE: src/app/api/v1/login.py
================================================
from datetime import timedelta
from typing import Annotated
from fastapi import APIRouter, Depends, Request, Response
from fastapi.security import OAuth2PasswordRequestForm
from sqlalchemy.ext.asyncio import AsyncSession
from ...core.config import settings
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import UnauthorizedException
from ...core.schemas import Token
from ...core.security import (
ACCESS_TOKEN_EXPIRE_MINUTES,
authenticate_user,
create_access_token,
create_refresh_token,
verify_token,
)
router = APIRouter(tags=["login"])
@router.post("/login", response_model=Token)
async def login_for_access_token(
response: Response,
form_data: Annotated[OAuth2PasswordRequestForm, Depends()],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
user = await authenticate_user(username_or_email=form_data.username, password=form_data.password, db=db)
if not user:
raise UnauthorizedException("Wrong username, email or password.")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = await create_access_token(data={"sub": user["username"]}, expires_delta=access_token_expires)
refresh_token = await create_refresh_token(data={"sub": user["username"]})
max_age = settings.REFRESH_TOKEN_EXPIRE_DAYS * 24 * 60 * 60
response.set_cookie(
key="refresh_token", value=refresh_token, httponly=True, secure=True, samesite="Lax", max_age=max_age
)
return {"access_token": access_token, "token_type": "bearer"}
@router.post("/refresh")
async def refresh_access_token(request: Request, db: AsyncSession = Depends(async_get_db)) -> dict[str, str]:
refresh_token = request.cookies.get("refresh_token")
if not refresh_token:
raise UnauthorizedException("Refresh token missing.")
user_data = await verify_token(refresh_token, db)
if not user_data:
raise UnauthorizedException("Invalid refresh token.")
new_access_token = await create_access_token(data={"sub": user_data.username_or_email})
return {"access_token": new_access_token, "token_type": "bearer"}
================================================
FILE: src/app/api/v1/logout.py
================================================
from fastapi import APIRouter, Depends, Response
from jose import JWTError
from sqlalchemy.ext.asyncio import AsyncSession
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import UnauthorizedException
from ...core.security import blacklist_token, oauth2_scheme
router = APIRouter(tags=["login"])
@router.post("/logout")
async def logout(
response: Response, access_token: str = Depends(oauth2_scheme), db: AsyncSession = Depends(async_get_db)
) -> dict[str, str]:
try:
await blacklist_token(token=access_token, db=db)
response.delete_cookie(key="refresh_token")
return {"message": "Logged out successfully"}
except JWTError:
raise UnauthorizedException("Invalid token.")
================================================
FILE: src/app/api/v1/posts.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser, get_current_user
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import ForbiddenException, NotFoundException
from ...core.utils.cache import cache
from ...crud.crud_posts import crud_posts
from ...crud.crud_users import crud_users
from ...models.post import PostCreate, PostCreateInternal, PostRead, PostUpdate
from ...models.user import UserRead
router = APIRouter(tags=["posts"])
@router.post("/{username}/post", response_model=PostRead, status_code=201)
async def write_post(
request: Request,
username: str,
post: PostCreate,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> PostRead:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
if current_user["id"] != db_user["id"]:
raise ForbiddenException()
post_internal_dict = post.model_dump()
post_internal_dict["created_by_user_id"] = db_user["id"]
post_internal = PostCreateInternal(**post_internal_dict)
created_post: PostRead = await crud_posts.create(db=db, object=post_internal)
return created_post
@router.get("/{username}/posts", response_model=PaginatedListResponse[PostRead])
@cache(
key_prefix="{username}_posts:page_{page}:items_per_page:{items_per_page}",
resource_id_name="username",
expiration=60,
)
async def read_posts(
request: Request,
username: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
page: int = 1,
items_per_page: int = 10,
) -> dict:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if not db_user:
raise NotFoundException("User not found")
posts_data = await crud_posts.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=PostRead,
created_by_user_id=db_user["id"],
is_deleted=False,
)
response: dict[str, Any] = paginated_response(crud_data=posts_data, page=page, items_per_page=items_per_page)
return response
@router.get("/{username}/post/{id}", response_model=PostRead)
@cache(key_prefix="{username}_post_cache", resource_id_name="id")
async def read_post(
request: Request, username: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
db_post: PostRead | None = await crud_posts.get(
db=db, schema_to_select=PostRead, id=id, created_by_user_id=db_user["id"], is_deleted=False
)
if db_post is None:
raise NotFoundException("Post not found")
return db_post
@router.patch("/{username}/post/{id}")
@cache("{username}_post_cache", resource_id_name="id", pattern_to_invalidate_extra=["{username}_posts:*"])
async def patch_post(
request: Request,
username: str,
id: int,
values: PostUpdate,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
if current_user["id"] != db_user["id"]:
raise ForbiddenException()
db_post = await crud_posts.get(db=db, schema_to_select=PostRead, id=id, is_deleted=False)
if db_post is None:
raise NotFoundException("Post not found")
await crud_posts.update(db=db, object=values, id=id)
return {"message": "Post updated"}
@router.delete("/{username}/post/{id}")
@cache("{username}_post_cache", resource_id_name="id", to_invalidate_extra={"{username}_posts": "{username}"})
async def erase_post(
request: Request,
username: str,
id: int,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
if current_user["id"] != db_user["id"]:
raise ForbiddenException()
db_post = await crud_posts.get(db=db, schema_to_select=PostRead, id=id, is_deleted=False)
if db_post is None:
raise NotFoundException("Post not found")
await crud_posts.delete(db=db, id=id)
return {"message": "Post deleted"}
@router.delete("/{username}/db_post/{id}", dependencies=[Depends(get_current_superuser)])
@cache("{username}_post_cache", resource_id_name="id", to_invalidate_extra={"{username}_posts": "{username}"})
async def erase_db_post(
request: Request, username: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
db_post = await crud_posts.get(db=db, schema_to_select=PostRead, id=id, is_deleted=False)
if db_post is None:
raise NotFoundException("Post not found")
await crud_posts.db_delete(db=db, id=id)
return {"message": "Post deleted from the database"}
================================================
FILE: src/app/api/v1/rate_limits.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import DuplicateValueException, NotFoundException, RateLimitException
from ...crud.crud_rate_limit import crud_rate_limits
from ...crud.crud_tier import crud_tiers
from ...models.rate_limit import RateLimitCreate, RateLimitCreateInternal, RateLimitRead, RateLimitUpdate
router = APIRouter(tags=["rate_limits"])
@router.post("/tier/{tier_name}/rate_limit", dependencies=[Depends(get_current_superuser)], status_code=201)
async def write_rate_limit(
request: Request, tier_name: str, rate_limit: RateLimitCreate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> RateLimitRead:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
rate_limit_internal_dict = rate_limit.model_dump()
rate_limit_internal_dict["tier_id"] = db_tier["id"]
db_rate_limit = await crud_rate_limits.exists(db=db, name=rate_limit_internal_dict["name"])
if db_rate_limit:
raise DuplicateValueException("Rate Limit Name not available")
rate_limit_internal = RateLimitCreateInternal(**rate_limit_internal_dict)
created_rate_limit: RateLimitRead = await crud_rate_limits.create(db=db, object=rate_limit_internal)
return created_rate_limit
@router.get("/tier/{tier_name}/rate_limits", response_model=PaginatedListResponse[RateLimitRead])
async def read_rate_limits(
request: Request,
tier_name: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
page: int = 1,
items_per_page: int = 10,
) -> dict:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
rate_limits_data = await crud_rate_limits.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=RateLimitRead,
tier_id=db_tier["id"],
)
response: dict[str, Any] = paginated_response(crud_data=rate_limits_data, page=page, items_per_page=items_per_page)
return response
@router.get("/tier/{tier_name}/rate_limit/{id}", response_model=RateLimitRead)
async def read_rate_limit(
request: Request, tier_name: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
db_rate_limit: dict | None = await crud_rate_limits.get(
db=db, schema_to_select=RateLimitRead, tier_id=db_tier["id"], id=id
)
if db_rate_limit is None:
raise NotFoundException("Rate Limit not found")
return db_rate_limit
@router.patch("/tier/{tier_name}/rate_limit/{id}", dependencies=[Depends(get_current_superuser)])
async def patch_rate_limit(
request: Request,
tier_name: str,
id: int,
values: RateLimitUpdate,
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if db_tier is None:
raise NotFoundException("Tier not found")
db_rate_limit = await crud_rate_limits.get(db=db, schema_to_select=RateLimitRead, tier_id=db_tier["id"], id=id)
if db_rate_limit is None:
raise NotFoundException("Rate Limit not found")
db_rate_limit_path = await crud_rate_limits.exists(db=db, tier_id=db_tier["id"], path=values.path)
if db_rate_limit_path:
raise DuplicateValueException("There is already a rate limit for this path")
await crud_rate_limits.exists(db=db)
if db_rate_limit_path:
raise DuplicateValueException("There is already a rate limit with this name")
await crud_rate_limits.update(db=db, object=values, id=db_rate_limit["id"])
return {"message": "Rate Limit updated"}
@router.delete("/tier/{tier_name}/rate_limit/{id}", dependencies=[Depends(get_current_superuser)])
async def erase_rate_limit(
request: Request, tier_name: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
db_rate_limit = await crud_rate_limits.get(db=db, schema_to_select=RateLimitRead, tier_id=db_tier["id"], id=id)
if db_rate_limit is None:
raise NotFoundException("Rate Limit not found")
await crud_rate_limits.delete(db=db, id=db_rate_limit["id"])
return {"message": "Rate Limit deleted"}
================================================
FILE: src/app/api/v1/tasks.py
================================================
from typing import Any
from arq.jobs import Job as ArqJob
from fastapi import APIRouter, Depends
from ...api.dependencies import rate_limiter
from ...core.utils import queue
from ...models.job import Job
router = APIRouter(prefix="/tasks", tags=["tasks"])
@router.post("/task", response_model=Job, status_code=201, dependencies=[Depends(rate_limiter)])
async def create_task(message: str) -> dict[str, str]:
"""Create a new background task.
Parameters
----------
message: str
The message or data to be processed by the task.
Returns
-------
dict[str, str]
A dictionary containing the ID of the created task.
"""
job = await queue.pool.enqueue_job("sample_background_task", message) # type: ignore
return {"id": job.job_id}
@router.get("/task/{task_id}")
async def get_task(task_id: str) -> dict[str, Any] | None:
"""Get information about a specific background task.
Parameters
----------
task_id: str
The ID of the task.
Returns
-------
Optional[dict[str, Any]]
A dictionary containing information about the task if found, or None otherwise.
"""
job = ArqJob(task_id, queue.pool)
job_info: dict = await job.info()
return vars(job_info)
================================================
FILE: src/app/api/v1/tiers.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import DuplicateValueException, NotFoundException
from ...crud.crud_tier import crud_tiers
from ...models.tier import TierCreate, TierCreateInternal, TierRead, TierUpdate
router = APIRouter(tags=["tiers"])
@router.post("/tier", dependencies=[Depends(get_current_superuser)], status_code=201)
async def write_tier(
request: Request, tier: TierCreate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> TierRead:
tier_internal_dict = tier.model_dump()
db_tier = await crud_tiers.exists(db=db, name=tier_internal_dict["name"])
if db_tier:
raise DuplicateValueException("Tier Name not available")
tier_internal = TierCreateInternal(**tier_internal_dict)
created_tier: TierRead = await crud_tiers.create(db=db, object=tier_internal)
return created_tier
@router.get("/tiers", response_model=PaginatedListResponse[TierRead])
async def read_tiers(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], page: int = 1, items_per_page: int = 10
) -> dict:
tiers_data = await crud_tiers.get_multi(
db=db, offset=compute_offset(page, items_per_page), limit=items_per_page, schema_to_select=TierRead
)
response: dict[str, Any] = paginated_response(crud_data=tiers_data, page=page, items_per_page=items_per_page)
return response
@router.get("/tier/{name}", response_model=TierRead)
async def read_tier(request: Request, name: str, db: Annotated[AsyncSession, Depends(async_get_db)]) -> dict:
db_tier: TierRead | None = await crud_tiers.get(db=db, schema_to_select=TierRead, name=name)
if db_tier is None:
raise NotFoundException("Tier not found")
return db_tier
@router.patch("/tier/{name}", dependencies=[Depends(get_current_superuser)])
async def patch_tier(
request: Request, values: TierUpdate, name: str, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, schema_to_select=TierRead, name=name)
if db_tier is None:
raise NotFoundException("Tier not found")
await crud_tiers.update(db=db, object=values, name=name)
return {"message": "Tier updated"}
@router.delete("/tier/{name}", dependencies=[Depends(get_current_superuser)])
async def erase_tier(request: Request, name: str, db: Annotated[AsyncSession, Depends(async_get_db)]) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, schema_to_select=TierRead, name=name)
if db_tier is None:
raise NotFoundException("Tier not found")
await crud_tiers.delete(db=db, name=name)
return {"message": "Tier deleted"}
================================================
FILE: src/app/api/v1/users.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser, get_current_user
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import DuplicateValueException, ForbiddenException, NotFoundException
from ...core.security import blacklist_token, get_password_hash, oauth2_scheme
from ...crud.crud_rate_limit import crud_rate_limits
from ...crud.crud_tier import crud_tiers
from ...crud.crud_users import crud_users
from ...models.tier import Tier, TierRead
from ...models.user import UserCreate, UserCreateInternal, UserRead, UserTierUpdate, UserUpdate
router = APIRouter(tags=["users"])
@router.post("/user", response_model=UserRead, status_code=201)
async def write_user(
request: Request, user: UserCreate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> UserRead:
email_row = await crud_users.exists(db=db, email=user.email)
if email_row:
raise DuplicateValueException("Email is already registered")
username_row = await crud_users.exists(db=db, username=user.username)
if username_row:
raise DuplicateValueException("Username not available")
user_internal_dict = user.model_dump()
user_internal_dict["hashed_password"] = get_password_hash(password=user_internal_dict["password"])
del user_internal_dict["password"]
user_internal = UserCreateInternal(**user_internal_dict)
created_user: UserRead = await crud_users.create(db=db, object=user_internal)
return created_user
@router.get("/users", response_model=PaginatedListResponse[UserRead])
async def read_users(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], page: int = 1, items_per_page: int = 10
) -> dict:
users_data = await crud_users.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=UserRead,
is_deleted=False,
)
response: dict[str, Any] = paginated_response(crud_data=users_data, page=page, items_per_page=items_per_page)
return response
@router.get("/user/me/", response_model=UserRead)
async def read_users_me(request: Request, current_user: Annotated[UserRead, Depends(get_current_user)]) -> UserRead:
return current_user
@router.get("/user/{username}", response_model=UserRead)
async def read_user(request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]) -> dict:
db_user: UserRead | None = await crud_users.get(
db=db, schema_to_select=UserRead, username=username, is_deleted=False
)
if db_user is None:
raise NotFoundException("User not found")
return db_user
@router.patch("/user/{username}")
async def patch_user(
request: Request,
values: UserUpdate,
username: str,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username)
if db_user is None:
raise NotFoundException("User not found")
if db_user["username"] != current_user["username"]:
raise ForbiddenException()
if values.username != db_user["username"]:
existing_username = await crud_users.exists(db=db, username=values.username)
if existing_username:
raise DuplicateValueException("Username not available")
if values.email != db_user["email"]:
existing_email = await crud_users.exists(db=db, email=values.email)
if existing_email:
raise DuplicateValueException("Email is already registered")
await crud_users.update(db=db, object=values, username=username)
return {"message": "User updated"}
@router.delete("/user/{username}")
async def erase_user(
request: Request,
username: str,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
token: str = Depends(oauth2_scheme),
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username)
if not db_user:
raise NotFoundException("User not found")
if username != current_user["username"]:
raise ForbiddenException()
await crud_users.delete(db=db, username=username)
await blacklist_token(token=token, db=db)
return {"message": "User deleted"}
@router.delete("/db_user/{username}", dependencies=[Depends(get_current_superuser)])
async def erase_db_user(
request: Request,
username: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
token: str = Depends(oauth2_scheme),
) -> dict[str, str]:
db_user = await crud_users.exists(db=db, username=username)
if not db_user:
raise NotFoundException("User not found")
await crud_users.db_delete(db=db, username=username)
await blacklist_token(token=token, db=db)
return {"message": "User deleted from the database"}
@router.get("/user/{username}/rate_limits", dependencies=[Depends(get_current_superuser)])
async def read_user_rate_limits(
request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, Any]:
db_user: dict | None = await crud_users.get(db=db, username=username, schema_to_select=UserRead)
if db_user is None:
raise NotFoundException("User not found")
if db_user["tier_id"] is None:
db_user["tier_rate_limits"] = []
return db_user
db_tier = await crud_tiers.get(db=db, id=db_user["tier_id"])
if db_tier is None:
raise NotFoundException("Tier not found")
db_rate_limits = await crud_rate_limits.get_multi(db=db, tier_id=db_tier["id"])
db_user["tier_rate_limits"] = db_rate_limits["data"]
return db_user
@router.get("/user/{username}/tier")
async def read_user_tier(
request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict | None:
db_user = await crud_users.get(db=db, username=username, schema_to_select=UserRead)
if db_user is None:
raise NotFoundException("User not found")
db_tier = await crud_tiers.exists(db=db, id=db_user["tier_id"])
if not db_tier:
raise NotFoundException("Tier not found")
joined: dict = await crud_users.get_joined(
db=db,
join_model=Tier,
join_prefix="tier_",
schema_to_select=UserRead,
join_schema_to_select=TierRead,
username=username,
)
return joined
@router.patch("/user/{username}/tier", dependencies=[Depends(get_current_superuser)])
async def patch_user_tier(
request: Request, username: str, values: UserTierUpdate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_user = await crud_users.get(db=db, username=username, schema_to_select=UserRead)
if db_user is None:
raise NotFoundException("User not found")
db_tier = await crud_tiers.get(db=db, id=values.tier_id)
if db_tier is None:
raise NotFoundException("Tier not found")
await crud_users.update(db=db, object=values, username=username)
return {"message": f"User {db_user['name']} Tier updated"}
================================================
FILE: src/app/core/__init__.py
================================================
================================================
FILE: src/app/core/config.py
================================================
import os
from enum import Enum
from pydantic_settings import BaseSettings
from starlette.config import Config
current_file_dir = os.path.dirname(os.path.realpath(__file__))
env_path = os.path.join(current_file_dir, "..", "..", ".env")
config = Config(env_path)
class AppSettings(BaseSettings):
APP_NAME: str = config("APP_NAME", default="FastAPI app")
APP_DESCRIPTION: str | None = config("APP_DESCRIPTION", default=None)
APP_VERSION: str | None = config("APP_VERSION", default=None)
LICENSE_NAME: str | None = config("LICENSE", default=None)
CONTACT_NAME: str | None = config("CONTACT_NAME", default=None)
CONTACT_EMAIL: str | None = config("CONTACT_EMAIL", default=None)
class CryptSettings(BaseSettings):
SECRET_KEY: str = config("SECRET_KEY")
ALGORITHM: str = config("ALGORITHM", default="HS256")
ACCESS_TOKEN_EXPIRE_MINUTES: int = config("ACCESS_TOKEN_EXPIRE_MINUTES", default=30)
REFRESH_TOKEN_EXPIRE_DAYS: int = config("REFRESH_TOKEN_EXPIRE_DAYS", default=7)
class DatabaseSettings(BaseSettings):
pass
class SQLiteSettings(DatabaseSettings):
SQLITE_URI: str = config("SQLITE_URI", default="./sql_app.db")
SQLITE_SYNC_PREFIX: str = config("SQLITE_SYNC_PREFIX", default="sqlite:///")
SQLITE_ASYNC_PREFIX: str = config("SQLITE_ASYNC_PREFIX", default="sqlite+aiosqlite:///")
class PostgresSettings(DatabaseSettings):
POSTGRES_USER: str = config("POSTGRES_USER", default="postgres")
POSTGRES_PASSWORD: str = config("POSTGRES_PASSWORD", default="postgres")
POSTGRES_SERVER: str = config("POSTGRES_SERVER", default="localhost")
POSTGRES_PORT: int = config("POSTGRES_PORT", default=5432)
POSTGRES_DB: str = config("POSTGRES_DB", default="postgres")
POSTGRES_SYNC_PREFIX: str = config("POSTGRES_SYNC_PREFIX", default="postgresql://")
POSTGRES_ASYNC_PREFIX: str = config("POSTGRES_ASYNC_PREFIX", default="postgresql+asyncpg://")
POSTGRES_URI: str = f"{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_SERVER}:{POSTGRES_PORT}/{POSTGRES_DB}"
POSTGRES_URL: str | None = config("POSTGRES_URL", default=None)
class FirstUserSettings(BaseSettings):
ADMIN_NAME: str = config("ADMIN_NAME", default="admin")
ADMIN_EMAIL: str = config("ADMIN_EMAIL", default="admin@admin.com")
ADMIN_USERNAME: str = config("ADMIN_USERNAME", default="admin")
ADMIN_PASSWORD: str = config("ADMIN_PASSWORD", default="!Ch4ng3Th1sP4ssW0rd!")
class TestSettings(BaseSettings):
TEST_NAME: str = config("TEST_NAME", default="Tester User")
TEST_EMAIL: str = config("TEST_EMAIL", default="test@tester.com")
TEST_USERNAME: str = config("TEST_USERNAME", default="testeruser")
TEST_PASSWORD: str = config("TEST_PASSWORD", default="Str1ng$t")
class RedisCacheSettings(BaseSettings):
REDIS_CACHE_HOST: str = config("REDIS_CACHE_HOST", default="localhost")
REDIS_CACHE_PORT: int = config("REDIS_CACHE_PORT", default=6379)
REDIS_CACHE_URL: str = f"redis://{REDIS_CACHE_HOST}:{REDIS_CACHE_PORT}"
class ClientSideCacheSettings(BaseSettings):
CLIENT_CACHE_MAX_AGE: int = config("CLIENT_CACHE_MAX_AGE", default=60)
class RedisQueueSettings(BaseSettings):
REDIS_QUEUE_HOST: str = config("REDIS_QUEUE_HOST", default="localhost")
REDIS_QUEUE_PORT: int = config("REDIS_QUEUE_PORT", default=6379)
class RedisRateLimiterSettings(BaseSettings):
REDIS_RATE_LIMIT_HOST: str = config("REDIS_RATE_LIMIT_HOST", default="localhost")
REDIS_RATE_LIMIT_PORT: int = config("REDIS_RATE_LIMIT_PORT", default=6379)
REDIS_RATE_LIMIT_URL: str = f"redis://{REDIS_RATE_LIMIT_HOST}:{REDIS_RATE_LIMIT_PORT}"
class DefaultRateLimitSettings(BaseSettings):
DEFAULT_RATE_LIMIT_LIMIT: int = config("DEFAULT_RATE_LIMIT_LIMIT", default=10)
DEFAULT_RATE_LIMIT_PERIOD: int = config("DEFAULT_RATE_LIMIT_PERIOD", default=3600)
class EnvironmentOption(Enum):
LOCAL = "local"
STAGING = "staging"
PRODUCTION = "production"
class DBOption(Enum):
POSTGRES = "postgres"
SQLITE = "sqlite"
class EnvironmentSettings(BaseSettings):
ENVIRONMENT: EnvironmentOption = config("ENVIRONMENT", default="local")
DB_ENGINE: DBOption = config("DB_ENGINE", default="sqlite")
db_type = PostgresSettings
if config("DB_ENGINE", default="sqlite") == "sqlite":
db_type = SQLiteSettings
class Settings(
AppSettings,
db_type,
CryptSettings,
FirstUserSettings,
TestSettings,
RedisCacheSettings,
ClientSideCacheSettings,
RedisQueueSettings,
RedisRateLimiterSettings,
DefaultRateLimitSettings,
EnvironmentSettings,
):
pass
settings = Settings()
================================================
FILE: src/app/core/db/__init__.py
================================================
================================================
FILE: src/app/core/db/crud_token_blacklist.py
================================================
from fastcrud import FastCRUD
from ..db.token_blacklist import TokenBlacklist
from ..schemas import TokenBlacklistCreate, TokenBlacklistUpdate
CRUDTokenBlacklist = FastCRUD[TokenBlacklist, TokenBlacklistCreate, TokenBlacklistUpdate, TokenBlacklistUpdate, None]
crud_token_blacklist = CRUDTokenBlacklist(TokenBlacklist)
================================================
FILE: src/app/core/db/database.py
================================================
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.ext.asyncio.session import AsyncSession
from sqlalchemy.orm import sessionmaker
from ..config import settings, DBOption
if settings.DB_ENGINE == DBOption.SQLITE:
DATABASE_URI = settings.SQLITE_URI
DATABASE_PREFIX = settings.SQLITE_ASYNC_PREFIX
DATABASE_URL = f"{DATABASE_PREFIX}{DATABASE_URI}"
if settings.DB_ENGINE == DBOption.POSTGRES:
DATABASE_URI = settings.POSTGRES_URI
DATABASE_PREFIX = settings.POSTGRES_ASYNC_PREFIX
DATABASE_URL = f"{DATABASE_PREFIX}{DATABASE_URI}"
async_engine = create_async_engine(DATABASE_URL, echo=False, future=True)
local_session = sessionmaker(bind=async_engine, class_=AsyncSession, expire_on_commit=False)
async def async_get_db() -> AsyncSession:
async_session = local_session
async with async_session() as db:
yield db
================================================
FILE: src/app/core/db/models.py
================================================
import uuid as uuid_pkg
from datetime import UTC, datetime
from sqlalchemy import Boolean, Column, DateTime, text
from sqlalchemy.dialects.postgresql import UUID
class UUIDMixin:
uuid: uuid_pkg.UUID = Column(
UUID, primary_key=True, default=uuid_pkg.uuid4, server_default=text("gen_random_uuid()")
)
class TimestampMixin:
created_at: datetime = Column(DateTime, default=datetime.now(UTC), server_default=text("current_timestamp(0)"))
updated_at: datetime = Column(
DateTime, nullable=True, onupdate=datetime.now(UTC), server_default=text("current_timestamp(0)")
)
class SoftDeleteMixin:
deleted_at: datetime = Column(DateTime, nullable=True)
is_deleted: bool = Column(Boolean, default=False)
================================================
FILE: src/app/core/db/token_blacklist.py
================================================
from datetime import datetime
from sqlmodel import SQLModel, Field
class TokenBlacklist(SQLModel, table=True):
id: int = Field(default=None, primary_key=True, nullable=False)
token: str = Field(index=True, nullable=False, unique=True)
expires_at: datetime = Field(nullable=False)
================================================
FILE: src/app/core/exceptions/__init__.py
================================================
================================================
FILE: src/app/core/exceptions/cache_exceptions.py
================================================
class CacheIdentificationInferenceError(Exception):
def __init__(self, message: str = "Could not infer id for resource being cached.") -> None:
self.message = message
super().__init__(self.message)
class InvalidRequestError(Exception):
def __init__(self, message: str = "Type of request not supported.") -> None:
self.message = message
super().__init__(self.message)
class MissingClientError(Exception):
def __init__(self, message: str = "Client is None.") -> None:
self.message = message
super().__init__(self.message)
================================================
FILE: src/app/core/exceptions/http_exceptions.py
================================================
# ruff: noqa
from fastcrud.exceptions.http_exceptions import (
CustomException,
BadRequestException,
NotFoundException,
ForbiddenException,
UnauthorizedException,
UnprocessableEntityException,
DuplicateValueException,
RateLimitException,
)
================================================
FILE: src/app/core/logger.py
================================================
import logging
import os
from logging.handlers import RotatingFileHandler
LOG_DIR = os.path.join(os.path.dirname(os.path.dirname(__file__)), "logs")
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
LOG_FILE_PATH = os.path.join(LOG_DIR, "app.log")
LOGGING_LEVEL = logging.INFO
LOGGING_FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
logging.basicConfig(level=LOGGING_LEVEL, format=LOGGING_FORMAT)
file_handler = RotatingFileHandler(LOG_FILE_PATH, maxBytes=10485760, backupCount=5)
file_handler.setLevel(LOGGING_LEVEL)
file_handler.setFormatter(logging.Formatter(LOGGING_FORMAT))
logging.getLogger("").addHandler(file_handler)
================================================
FILE: src/app/core/schemas.py
================================================
import uuid as uuid_pkg
from datetime import UTC, datetime
from typing import Any
from pydantic import BaseModel, Field, field_serializer
class HealthCheck(BaseModel):
name: str
version: str
description: str
# -------------- mixins --------------
class UUIDSchema(BaseModel):
uuid: uuid_pkg.UUID = Field(default_factory=uuid_pkg.uuid4)
class TimestampSchema(BaseModel):
created_at: datetime = Field(default_factory=lambda: datetime.now(UTC).replace(tzinfo=None))
updated_at: datetime = Field(default=None)
@field_serializer("created_at")
def serialize_dt(self, created_at: datetime | None, _info: Any) -> str | None:
if created_at is not None:
return created_at.isoformat()
return None
@field_serializer("updated_at")
def serialize_updated_at(self, updated_at: datetime | None, _info: Any) -> str | None:
if updated_at is not None:
return updated_at.isoformat()
return None
class PersistentDeletion(BaseModel):
deleted_at: datetime | None = Field(default=None)
is_deleted: bool = False
@field_serializer("deleted_at")
def serialize_dates(self, deleted_at: datetime | None, _info: Any) -> str | None:
if deleted_at is not None:
return deleted_at.isoformat()
return None
# -------------- token --------------
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username_or_email: str
class TokenBlacklistBase(BaseModel):
token: str
expires_at: datetime
class TokenBlacklistCreate(TokenBlacklistBase):
pass
class TokenBlacklistUpdate(TokenBlacklistBase):
pass
================================================
FILE: src/app/core/security.py
================================================
from datetime import UTC, datetime, timedelta
from typing import Any, Literal
import bcrypt
from fastapi.security import OAuth2PasswordBearer
from jose import JWTError, jwt
from sqlalchemy.ext.asyncio import AsyncSession
from ..crud.crud_users import crud_users
from .config import settings
from .db.crud_token_blacklist import crud_token_blacklist
from .schemas import TokenBlacklistCreate, TokenData
SECRET_KEY = settings.SECRET_KEY
ALGORITHM = settings.ALGORITHM
ACCESS_TOKEN_EXPIRE_MINUTES = settings.ACCESS_TOKEN_EXPIRE_MINUTES
REFRESH_TOKEN_EXPIRE_DAYS = settings.REFRESH_TOKEN_EXPIRE_DAYS
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="/api/v1/login")
async def verify_password(plain_password: str, hashed_password: str) -> bool:
correct_password: bool = bcrypt.checkpw(plain_password.encode(), hashed_password.encode())
return correct_password
def get_password_hash(password: str) -> str:
hashed_password: str = bcrypt.hashpw(password.encode(), bcrypt.gensalt()).decode()
return hashed_password
async def authenticate_user(username_or_email: str, password: str, db: AsyncSession) -> dict[str, Any] | Literal[False]:
if "@" in username_or_email:
db_user: dict | None = await crud_users.get(db=db, email=username_or_email, is_deleted=False)
else:
db_user = await crud_users.get(db=db, username=username_or_email, is_deleted=False)
if not db_user:
return False
elif not await verify_password(password, db_user["hashed_password"]):
return False
return db_user
async def create_access_token(data: dict[str, Any], expires_delta: timedelta | None = None) -> str:
to_encode = data.copy()
if expires_delta:
expire = datetime.now(UTC).replace(tzinfo=None) + expires_delta
else:
expire = datetime.now(UTC).replace(tzinfo=None) + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt: str = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def create_refresh_token(data: dict[str, Any], expires_delta: timedelta | None = None) -> str:
to_encode = data.copy()
if expires_delta:
expire = datetime.now(UTC).replace(tzinfo=None) + expires_delta
else:
expire = datetime.now(UTC).replace(tzinfo=None) + timedelta(days=REFRESH_TOKEN_EXPIRE_DAYS)
to_encode.update({"exp": expire})
encoded_jwt: str = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def verify_token(token: str, db: AsyncSession) -> TokenData | None:
"""Verify a JWT token and return TokenData if valid.
Parameters
----------
token: str
The JWT token to be verified.
db: AsyncSession
Database session for performing database operations.
Returns
-------
TokenData | None
TokenData instance if the token is valid, None otherwise.
"""
is_blacklisted = await crud_token_blacklist.exists(db, token=token)
if is_blacklisted:
return None
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username_or_email: str = payload.get("sub")
if username_or_email is None:
return None
return TokenData(username_or_email=username_or_email)
except JWTError:
return None
async def blacklist_token(token: str, db: AsyncSession) -> None:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
expires_at = datetime.fromtimestamp(payload.get("exp"))
await crud_token_blacklist.create(db, object=TokenBlacklistCreate(**{"token": token, "expires_at": expires_at}))
================================================
FILE: src/app/core/setup.py
================================================
from collections.abc import AsyncGenerator, Callable
from contextlib import _AsyncGeneratorContextManager, asynccontextmanager
from typing import Any
import anyio
import fastapi
import redis.asyncio as redis
from arq import create_pool
from arq.connections import RedisSettings
from fastapi import APIRouter, Depends, FastAPI
from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html
from fastapi.openapi.utils import get_openapi
from sqlmodel import SQLModel
from ..api.dependencies import get_current_superuser
from ..middleware.client_cache_middleware import ClientCacheMiddleware
from .config import (
AppSettings,
ClientSideCacheSettings,
DatabaseSettings,
EnvironmentOption,
EnvironmentSettings,
RedisCacheSettings,
RedisQueueSettings,
RedisRateLimiterSettings,
settings,
)
from .db.database import async_engine as engine
from .utils import cache, queue, rate_limit
from ..models import *
# -------------- database --------------
async def create_tables() -> None:
async with engine.begin() as conn:
await conn.run_sync(SQLModel.metadata.create_all)
# -------------- cache --------------
async def create_redis_cache_pool() -> None:
cache.pool = redis.ConnectionPool.from_url(settings.REDIS_CACHE_URL)
cache.client = redis.Redis.from_pool(cache.pool) # type: ignore
async def close_redis_cache_pool() -> None:
await cache.client.aclose() # type: ignore
# -------------- queue --------------
async def create_redis_queue_pool() -> None:
queue.pool = await create_pool(RedisSettings(host=settings.REDIS_QUEUE_HOST, port=settings.REDIS_QUEUE_PORT))
async def close_redis_queue_pool() -> None:
await queue.pool.aclose() # type: ignore
# -------------- rate limit --------------
async def create_redis_rate_limit_pool() -> None:
rate_limit.pool = redis.ConnectionPool.from_url(settings.REDIS_RATE_LIMIT_URL)
rate_limit.client = redis.Redis.from_pool(rate_limit.pool) # type: ignore
async def close_redis_rate_limit_pool() -> None:
await rate_limit.client.aclose() # type: ignore
# -------------- application --------------
async def set_threadpool_tokens(number_of_tokens: int = 100) -> None:
limiter = anyio.to_thread.current_default_thread_limiter()
limiter.total_tokens = number_of_tokens
def lifespan_factory(
settings: (
DatabaseSettings
| RedisCacheSettings
| AppSettings
| ClientSideCacheSettings
| RedisQueueSettings
| RedisRateLimiterSettings
| EnvironmentSettings
),
create_tables_on_start: bool = True,
) -> Callable[[FastAPI], _AsyncGeneratorContextManager[Any]]:
"""Factory to create a lifespan async context manager for a FastAPI app."""
@asynccontextmanager
async def lifespan(app: FastAPI) -> AsyncGenerator:
await set_threadpool_tokens()
if isinstance(settings, DatabaseSettings) and create_tables_on_start:
await create_tables()
if settings.ENVIRONMENT != EnvironmentOption.LOCAL:
if isinstance(settings, RedisCacheSettings):
await create_redis_cache_pool()
if isinstance(settings, RedisQueueSettings):
await create_redis_queue_pool()
if isinstance(settings, RedisRateLimiterSettings):
await create_redis_rate_limit_pool()
yield
if isinstance(settings, RedisCacheSettings):
await close_redis_cache_pool()
if isinstance(settings, RedisQueueSettings):
await close_redis_queue_pool()
if isinstance(settings, RedisRateLimiterSettings):
await close_redis_rate_limit_pool()
return lifespan
# -------------- application --------------
def create_application(
router: APIRouter,
settings: (
DatabaseSettings
| RedisCacheSettings
| AppSettings
| ClientSideCacheSettings
| RedisQueueSettings
| RedisRateLimiterSettings
| EnvironmentSettings
),
create_tables_on_start: bool = True,
**kwargs: Any,
) -> FastAPI:
"""Creates and configures a FastAPI application based on the provided settings.
This function initializes a FastAPI application and configures it with various settings
and handlers based on the type of the `settings` object provided.
Parameters
----------
router : APIRouter
The APIRouter object containing the routes to be included in the FastAPI application.
settings
An instance representing the settings for configuring the FastAPI application.
It determines the configuration applied:
- AppSettings: Configures basic app metadata like name, description, contact, and license info.
- DatabaseSettings: Adds event handlers for initializing database tables during startup.
- RedisCacheSettings: Sets up event handlers for creating and closing a Redis cache pool.
- ClientSideCacheSettings: Integrates middleware for client-side caching.
- RedisQueueSettings: Sets up event handlers for creating and closing a Redis queue pool.
- RedisRateLimiterSettings: Sets up event handlers for creating and closing a Redis rate limiter pool.
- EnvironmentSettings: Conditionally sets documentation URLs and integrates custom routes for API documentation
based on the environment type.
create_tables_on_start : bool
A flag to indicate whether to create database tables on application startup.
Defaults to True.
**kwargs
Additional keyword arguments passed directly to the FastAPI constructor.
Returns
-------
FastAPI
A fully configured FastAPI application instance.
The function configures the FastAPI application with different features and behaviors
based on the provided settings. It includes setting up database connections, Redis pools
for caching, queue, and rate limiting, client-side caching, and customizing the API documentation
based on the environment settings.
"""
# --- before creating application ---
if isinstance(settings, AppSettings):
to_update = {
"title": settings.APP_NAME,
"description": settings.APP_DESCRIPTION,
"contact": {"name": settings.CONTACT_NAME, "email": settings.CONTACT_EMAIL},
"license_info": {"name": settings.LICENSE_NAME},
}
kwargs.update(to_update)
if isinstance(settings, EnvironmentSettings):
kwargs.update({"docs_url": None, "redoc_url": None, "openapi_url": None})
lifespan = lifespan_factory(settings, create_tables_on_start=create_tables_on_start)
application = FastAPI(lifespan=lifespan, **kwargs)
application.include_router(router)
if isinstance(settings, ClientSideCacheSettings):
application.add_middleware(ClientCacheMiddleware, max_age=settings.CLIENT_CACHE_MAX_AGE)
if isinstance(settings, EnvironmentSettings):
if settings.ENVIRONMENT != EnvironmentOption.PRODUCTION:
docs_router = APIRouter()
if settings.ENVIRONMENT != EnvironmentOption.LOCAL:
docs_router = APIRouter(dependencies=[Depends(get_current_superuser)])
@docs_router.get("/docs", include_in_schema=False)
async def get_swagger_documentation() -> fastapi.responses.HTMLResponse:
return get_swagger_ui_html(openapi_url="/openapi.json", title="docs")
@docs_router.get("/redoc", include_in_schema=False)
async def get_redoc_documentation() -> fastapi.responses.HTMLResponse:
return get_redoc_html(openapi_url="/openapi.json", title="docs")
@docs_router.get("/openapi.json", include_in_schema=False)
async def openapi() -> dict[str, Any]:
out: dict = get_openapi(title=application.title, version=application.version, routes=application.routes)
return out
application.include_router(docs_router)
return application
================================================
FILE: src/app/core/utils/__init__.py
================================================
================================================
FILE: src/app/core/utils/cache.py
================================================
import functools
import json
import re
from collections.abc import Callable
from typing import Any
from fastapi import Request, Response
from fastapi.encoders import jsonable_encoder
from redis.asyncio import ConnectionPool, Redis
from ..exceptions.cache_exceptions import CacheIdentificationInferenceError, InvalidRequestError, MissingClientError
pool: ConnectionPool | None = None
client: Redis | None = None
def _infer_resource_id(kwargs: dict[str, Any], resource_id_type: type | tuple[type, ...]) -> int | str:
"""Infer the resource ID from a dictionary of keyword arguments.
Parameters
----------
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
resource_id_type: Union[type, Tuple[type, ...]]
The expected type of the resource ID, which can be integer (int) or a string (str).
Returns
-------
Union[None, int, str]
The inferred resource ID. If it cannot be inferred or does not match the expected type, it returns None.
Note
----
- When `resource_id_type` is `int`, the function looks for an argument with the key 'id'.
- When `resource_id_type` is `str`, it attempts to infer the resource ID as a string.
"""
resource_id: int | str | None = None
for arg_name, arg_value in kwargs.items():
if isinstance(arg_value, resource_id_type):
if (resource_id_type is int) and ("id" in arg_name):
resource_id = arg_value
elif (resource_id_type is int) and ("id" not in arg_name):
pass
elif resource_id_type is str:
resource_id = arg_value
if resource_id is None:
raise CacheIdentificationInferenceError
return resource_id
def _extract_data_inside_brackets(input_string: str) -> list[str]:
"""Extract data inside curly brackets from a given string using regular expressions.
Parameters
----------
input_string: str
The input string in which to find data enclosed within curly brackets.
Returns
-------
List[str]
A list of strings containing the data found inside the curly brackets within the input string.
Example
-------
>>> _extract_data_inside_brackets("The {quick} brown {fox} jumps over the {lazy} dog.")
['quick', 'fox', 'lazy']
"""
data_inside_brackets = re.findall(r"{(.*?)}", input_string)
return data_inside_brackets
def _construct_data_dict(data_inside_brackets: list[str], kwargs: dict[str, Any]) -> dict[str, Any]:
"""Construct a dictionary based on data inside brackets and keyword arguments.
Parameters
----------
data_inside_brackets: List[str]
A list of keys inside brackets.
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
Returns
-------
Dict[str, Any]: A dictionary with keys from data_inside_brackets and corresponding values from kwargs.
"""
data_dict = {}
for key in data_inside_brackets:
data_dict[key] = kwargs[key]
return data_dict
def _format_prefix(prefix: str, kwargs: dict[str, Any]) -> str:
"""Format a prefix using keyword arguments.
Parameters
----------
prefix: str
The prefix template to be formatted.
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
Returns
-------
str: The formatted prefix.
"""
data_inside_brackets = _extract_data_inside_brackets(prefix)
data_dict = _construct_data_dict(data_inside_brackets, kwargs)
formatted_prefix = prefix.format(**data_dict)
return formatted_prefix
def _format_extra_data(to_invalidate_extra: dict[str, str], kwargs: dict[str, Any]) -> dict[str, Any]:
"""Format extra data based on provided templates and keyword arguments.
This function takes a dictionary of templates and their associated values and a dictionary of keyword arguments.
It formats the templates with the corresponding values from the keyword arguments and returns a dictionary
where keys are the formatted templates and values are the associated keyword argument values.
Parameters
----------
to_invalidate_extra: Dict[str, str]
A dictionary where keys are templates and values are the associated values.
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
Returns
-------
Dict[str, Any]: A dictionary where keys are formatted templates and values
are associated keyword argument values.
"""
formatted_extra = {}
for prefix, id_template in to_invalidate_extra.items():
formatted_prefix = _format_prefix(prefix, kwargs)
id = _extract_data_inside_brackets(id_template)[0]
formatted_extra[formatted_prefix] = kwargs[id]
return formatted_extra
async def _delete_keys_by_pattern(pattern: str) -> None:
"""Delete keys from Redis that match a given pattern using the SCAN command.
This function iteratively scans the Redis key space for keys that match a specific pattern
and deletes them. It uses the SCAN command to efficiently find keys, which is more
performance-friendly compared to the KEYS command, especially for large datasets.
The function scans the key space in an iterative manner using a cursor-based approach.
It retrieves a batch of keys matching the pattern on each iteration and deletes them
until no matching keys are left.
Parameters
----------
pattern: str
The pattern to match keys against. The pattern can include wildcards,
such as '*' for matching any character sequence. Example: 'user:*'
Notes
-----
- The SCAN command is used with a count of 100 to retrieve keys in batches.
This count can be adjusted based on the size of your dataset and Redis performance.
- The function uses the delete command to remove keys in bulk. If the dataset
is extremely large, consider implementing additional logic to handle bulk deletion
more efficiently.
- Be cautious with patterns that could match a large number of keys, as deleting
many keys simultaneously may impact the performance of the Redis server.
"""
if client is None:
raise MissingClientError
cursor = -1
while cursor != 0:
cursor, keys = await client.scan(cursor, match=pattern, count=100)
if keys:
await client.delete(*keys)
def cache(
key_prefix: str,
resource_id_name: Any = None,
expiration: int = 3600,
resource_id_type: type | tuple[type, ...] = int,
to_invalidate_extra: dict[str, Any] | None = None,
pattern_to_invalidate_extra: list[str] | None = None,
) -> Callable:
"""Cache decorator for FastAPI endpoints.
This decorator enables caching the results of FastAPI endpoint functions to improve response times
and reduce the load on the application by storing and retrieving data in a cache.
Parameters
----------
key_prefix: str
A unique prefix to identify the cache key.
resource_id_name: Any, optional
The name of the resource ID argument in the decorated function. If provided, it is used directly;
otherwise, the resource ID is inferred from the function's arguments.
expiration: int, optional
The expiration time for the cached data in seconds. Defaults to 3600 seconds (1 hour).
resource_id_type: Union[type, Tuple[type, ...]], default int
The expected type of the resource ID.
This can be a single type (e.g., int) or a tuple of types (e.g., (int, str)).
Defaults to int. This is used only if resource_id_name is not provided.
to_invalidate_extra: Dict[str, Any] | None, optional
A dictionary where keys are cache key prefixes and values are templates for cache key suffixes.
These keys are invalidated when the decorated function is called with a method other than GET.
pattern_to_invalidate_extra: List[str] | None, optional
A list of string patterns for cache keys that should be invalidated when the decorated function is called.
This allows for bulk invalidation of cache keys based on a matching pattern.
Returns
-------
Callable
A decorator function that can be applied to FastAPI endpoint functions.
Example usage
-------------
```python
from fastapi import FastAPI, Request
from my_module import cache # Replace with your actual module and imports
app = FastAPI()
# Define a sample endpoint with caching
@app.get("/sample/{resource_id}")
@cache(key_prefix="sample_data", expiration=3600, resource_id_type=int)
async def sample_endpoint(request: Request, resource_id: int):
# Your endpoint logic here
return {"data": "your_data"}
```
This decorator caches the response data of the endpoint function using a unique cache key.
The cached data is retrieved for GET requests, and the cache is invalidated for other types of requests.
Advanced Example Usage
-------------
```python
from fastapi import FastAPI, Request
from my_module import cache
app = FastAPI()
@app.get("/users/{user_id}/items")
@cache(key_prefix="user_items", resource_id_name="user_id", expiration=1200)
async def read_user_items(request: Request, user_id: int):
# Endpoint logic to fetch user's items
return {"items": "user specific items"}
@app.put("/items/{item_id}")
@cache(
key_prefix="item_data",
resource_id_name="item_id",
to_invalidate_extra={"user_items": "{user_id}"},
pattern_to_invalidate_extra=["user_*_items:*"],
)
async def update_item(request: Request, item_id: int, data: dict, user_id: int):
# Update logic for an item
# Invalidate both the specific item cache and all user-specific item lists
return {"status": "updated"}
```
In this example:
- When reading user items, the response is cached under a key formed with 'user_items' prefix and 'user_id'.
- When updating an item, the cache for this specific item (under 'item_data:item_id') and all caches with keys
starting with 'user_{user_id}_items:' are invalidated. The `to_invalidate_extra` parameter specifically targets
the cache for user-specific item lists, while `pattern_to_invalidate_extra` allows bulk invalidation of all keys
matching the pattern 'user_*_items:*', covering all users.
Note
----
- resource_id_type is used only if resource_id is not passed.
- `to_invalidate_extra` and `pattern_to_invalidate_extra` are used for cache invalidation on methods other than GET.
- Using `pattern_to_invalidate_extra` can be resource-intensive on large datasets. Use it judiciously and
consider the potential impact on Redis performance.
"""
def wrapper(func: Callable) -> Callable:
@functools.wraps(func)
async def inner(request: Request, *args: Any, **kwargs: Any) -> Response:
if client is None:
raise MissingClientError
if resource_id_name:
resource_id = kwargs[resource_id_name]
else:
resource_id = _infer_resource_id(kwargs=kwargs, resource_id_type=resource_id_type)
formatted_key_prefix = _format_prefix(key_prefix, kwargs)
cache_key = f"{formatted_key_prefix}:{resource_id}"
if request.method == "GET":
if to_invalidate_extra is not None or pattern_to_invalidate_extra is not None:
raise InvalidRequestError
cached_data = await client.get(cache_key)
if cached_data:
return json.loads(cached_data.decode())
result = await func(request, *args, **kwargs)
if request.method == "GET":
serializable_data = jsonable_encoder(result)
serialized_data = json.dumps(serializable_data)
await client.set(cache_key, serialized_data)
await client.expire(cache_key, expiration)
serialized_data = json.loads(serialized_data)
else:
await client.delete(cache_key)
if to_invalidate_extra is not None:
formatted_extra = _format_extra_data(to_invalidate_extra, kwargs)
for prefix, id in formatted_extra.items():
extra_cache_key = f"{prefix}:{id}"
await client.delete(extra_cache_key)
if pattern_to_invalidate_extra is not None:
for pattern in pattern_to_invalidate_extra:
formatted_pattern = _format_prefix(pattern, kwargs)
await _delete_keys_by_pattern(formatted_pattern + "*")
return result
return inner
return wrapper
================================================
FILE: src/app/core/utils/queue.py
================================================
from arq.connections import ArqRedis
pool: ArqRedis | None = None
================================================
FILE: src/app/core/utils/rate_limit.py
================================================
from datetime import UTC, datetime
from redis.asyncio import ConnectionPool, Redis
from sqlalchemy.ext.asyncio import AsyncSession
from ...core.logger import logging
from ...models.rate_limit import sanitize_path
logger = logging.getLogger(__name__)
pool: ConnectionPool | None = None
client: Redis | None = None
async def is_rate_limited(db: AsyncSession, user_id: int, path: str, limit: int, period: int) -> bool:
if client is None:
logger.error("Redis client is not initialized.")
raise Exception("Redis client is not initialized.")
current_timestamp = int(datetime.now(UTC).timestamp())
window_start = current_timestamp - (current_timestamp % period)
sanitized_path = sanitize_path(path)
key = f"ratelimit:{user_id}:{sanitized_path}:{window_start}"
try:
current_count = await client.incr(key)
if current_count == 1:
await client.expire(key, period)
if current_count > limit:
return True
except Exception as e:
logger.exception(f"Error checking rate limit for user {user_id} on path {path}: {e}")
raise e
return False
================================================
FILE: src/app/core/worker/__init__.py
================================================
================================================
FILE: src/app/core/worker/functions.py
================================================
import asyncio
import logging
import uvloop
from arq.worker import Worker
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
# -------- background tasks --------
async def sample_background_task(ctx: Worker, name: str) -> str:
await asyncio.sleep(5)
return f"Task {name} is complete!"
# -------- base functions --------
async def startup(ctx: Worker) -> None:
logging.info("Worker Started")
async def shutdown(ctx: Worker) -> None:
logging.info("Worker end")
================================================
FILE: src/app/core/worker/settings.py
================================================
from arq.connections import RedisSettings
from ...core.config import settings
from .functions import sample_background_task, shutdown, startup
REDIS_QUEUE_HOST = settings.REDIS_QUEUE_HOST
REDIS_QUEUE_PORT = settings.REDIS_QUEUE_PORT
class WorkerSettings:
functions = [sample_background_task]
redis_settings = RedisSettings(host=REDIS_QUEUE_HOST, port=REDIS_QUEUE_PORT)
on_startup = startup
on_shutdown = shutdown
handle_signals = False
================================================
FILE: src/app/crud/__init__.py
================================================
================================================
FILE: src/app/crud/crud_posts.py
================================================
from fastcrud import FastCRUD
from ..models.post import Post, PostCreateInternal, PostDelete, PostUpdate, PostUpdateInternal
CRUDPost = FastCRUD[Post, PostCreateInternal, PostUpdate, PostUpdateInternal, PostDelete]
crud_posts = CRUDPost(Post)
================================================
FILE: src/app/crud/crud_rate_limit.py
================================================
from fastcrud import FastCRUD
from ..models.rate_limit import RateLimit, RateLimitCreateInternal, RateLimitDelete, RateLimitUpdate, RateLimitUpdateInternal
CRUDRateLimit = FastCRUD[RateLimit, RateLimitCreateInternal, RateLimitUpdate, RateLimitUpdateInternal, RateLimitDelete]
crud_rate_limits = CRUDRateLimit(RateLimit)
================================================
FILE: src/app/crud/crud_tier.py
================================================
from fastcrud import FastCRUD
from ..models.tier import Tier, TierCreateInternal, TierDelete, TierUpdate, TierUpdateInternal
CRUDTier = FastCRUD[Tier, TierCreateInternal, TierUpdate, TierUpdateInternal, TierDelete]
crud_tiers = CRUDTier(Tier)
================================================
FILE: src/app/crud/crud_users.py
================================================
from fastcrud import FastCRUD
from ..models.user import User, UserCreateInternal, UserDelete, UserUpdate, UserUpdateInternal
CRUDUser = FastCRUD[User, UserCreateInternal, UserUpdate, UserUpdateInternal, UserDelete]
crud_users = CRUDUser(User)
================================================
FILE: src/app/main.py
================================================
from .api import router
from .core.config import settings
from .core.setup import create_application
app = create_application(router=router, settings=settings)
================================================
FILE: src/app/middleware/client_cache_middleware.py
================================================
from fastapi import FastAPI, Request, Response
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
class ClientCacheMiddleware(BaseHTTPMiddleware):
"""Middleware to set the `Cache-Control` header for client-side caching on all responses.
Parameters
----------
app: FastAPI
The FastAPI application instance.
max_age: int, optional
Duration (in seconds) for which the response should be cached. Defaults to 60 seconds.
Attributes
----------
max_age: int
Duration (in seconds) for which the response should be cached.
Methods
-------
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
Process the request and set the `Cache-Control` header in the response.
Note
----
- The `Cache-Control` header instructs clients (e.g., browsers)
to cache the response for the specified duration.
"""
def __init__(self, app: FastAPI, max_age: int = 60) -> None:
super().__init__(app)
self.max_age = max_age
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
"""Process the request and set the `Cache-Control` header in the response.
Parameters
----------
request: Request
The incoming request.
call_next: RequestResponseEndpoint
The next middleware or route handler in the processing chain.
Returns
-------
Response
The response object with the `Cache-Control` header set.
Note
----
- This method is automatically called by Starlette for processing the request-response cycle.
"""
response: Response = await call_next(request)
response.headers["Cache-Control"] = f"public, max-age={self.max_age}"
return response
================================================
FILE: src/app/models/__init__.py
================================================
from .post import Post
from .rate_limit import RateLimit
from .tier import Tier
from .user import User
================================================
FILE: src/app/models/job.py
================================================
from sqlmodel import SQLModel
class Job(SQLModel):
id: str
================================================
FILE: src/app/models/post.py
================================================
from datetime import datetime
from typing import Optional
from sqlmodel import SQLModel, Field, Relationship
from uuid import uuid4
class PostBase(SQLModel):
title: str = Field(..., min_length=2, max_length=30, schema_extra={"example": "This is my post"})
text: str = Field(..., min_length=1, max_length=63206, schema_extra={"example": "This is the content of my post."})
class Post(PostBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
created_by_user_id: int = Field(foreign_key="user.id")
media_url: Optional[str] = Field(default=None, regex=r"^(https?|ftp)://[^\s/$.?#].[^\s]*$", schema_extra={"example": "https://www.postimageurl.com"})
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
updated_at: Optional[datetime] = None
deleted_at: Optional[datetime] = None
is_deleted: bool = Field(default=False)
class PostRead(PostBase):
id: int
created_by_user_id: int
media_url: Optional[str]
created_at: datetime
class PostCreate(PostBase):
media_url: Optional[str] = Field(default=None, regex=r"^(https?|ftp)://[^\s/$.?#].[^\s]*$", schema_extra={"example": "https://www.postimageurl.com"})
class PostCreateInternal(PostCreate):
created_by_user_id: int
class PostUpdate(SQLModel):
title: Optional[str] = Field(default=None, min_length=2, max_length=30)
text: Optional[str] = Field(default=None, min_length=1, max_length=63206)
media_url: Optional[str] = Field(default=None, regex=r"^(https?|ftp)://[^\s/$.?#].[^\s]*$")
class PostUpdateInternal(PostUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class PostDelete(SQLModel):
is_deleted: bool
deleted_at: datetime
================================================
FILE: src/app/models/rate_limit.py
================================================
from datetime import datetime
from typing import Optional
from sqlmodel import SQLModel, Field
def sanitize_path(path: str) -> str:
return path.strip("/").replace("/", "_")
class RateLimitBase(SQLModel):
path: str = Field(..., schema_extra={"example": "users"})
limit: int = Field(..., schema_extra={"example": 5})
period: int = Field(..., schema_extra={"example": 60})
@classmethod
def validate_path(cls, v: str) -> str:
return sanitize_path(v)
class RateLimit(RateLimitBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
tier_id: int = Field(foreign_key="tier.id")
name: Optional[str] = Field(default=None, schema_extra={"example": "users:5:60"})
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
updated_at: Optional[datetime] = None
class RateLimitRead(RateLimitBase):
id: int
tier_id: int
name: str
class RateLimitCreate(RateLimitBase):
name: Optional[str] = Field(default=None, schema_extra={"example": "api_v1_users:5:60"})
class RateLimitCreateInternal(RateLimitCreate):
tier_id: int
class RateLimitUpdate(SQLModel):
path: Optional[str] = Field(default=None)
limit: Optional[int] = None
period: Optional[int] = None
name: Optional[str] = None
@classmethod
def validate_path(cls, v: Optional[str]) -> Optional[str]:
return sanitize_path(v) if v is not None else None
class RateLimitUpdateInternal(RateLimitUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class RateLimitDelete(SQLModel):
pass
================================================
FILE: src/app/models/tier.py
================================================
from datetime import datetime
from typing import Optional
from sqlmodel import SQLModel, Field
class TierBase(SQLModel):
name: str = Field(..., schema_extra={"example": "free"})
class Tier(TierBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
updated_at: Optional[datetime] = None
class TierRead(TierBase):
id: int
created_at: datetime
class TierCreate(TierBase):
pass
class TierCreateInternal(TierCreate):
pass
class TierUpdate(SQLModel):
name: Optional[str] = None
class TierUpdateInternal(TierUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class TierDelete(SQLModel):
pass
================================================
FILE: src/app/models/user.py
================================================
from datetime import datetime
from typing import Optional
import uuid as uuid_pkg
from sqlmodel import SQLModel, Field
from pydantic import validator
class UserBase(SQLModel):
name: str = Field(..., min_length=2, max_length=30, schema_extra={"example": "User Userson"})
username: str = Field(..., min_length=2, max_length=20, regex="^[a-z0-9]+$", schema_extra={"example": "userson"})
email: str = Field(..., schema_extra={"example": "user.userson@example.com"})
class User(UserBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
profile_image_url: str = Field("https://www.profileimageurl.com")
hashed_password: str
is_superuser: bool = Field(default=False)
tier_id: Optional[int] = Field(default=None, foreign_key="tier.id")
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
uuid: uuid_pkg.UUID = Field(default_factory=uuid_pkg.uuid4, primary_key=True)
updated_at: Optional[datetime] = None
deleted_at: Optional[datetime] = None
is_deleted: bool = Field(default=False)
class UserRead(SQLModel):
id: int
name: str
username: str
email: str
profile_image_url: str
tier_id: Optional[int]
class UserCreate(UserBase):
password: str = Field(..., regex="^.{8,}|[0-9]+|[A-Z]+|[a-z]+|[^a-zA-Z0-9]+$", schema_extra={"example": "Str1ngst!"})
@validator('password')
def validate_password(cls, value):
if len(value) < 8:
raise ValueError("Password must be at least 8 characters")
return value
class UserCreateInternal(UserBase):
hashed_password: str
class UserUpdate(SQLModel):
name: Optional[str] = Field(None, min_length=2, max_length=30)
username: Optional[str] = Field(None, min_length=2, max_length=20, regex="^[a-z0-9]+$")
email: Optional[str] = None
profile_image_url: Optional[str] = None
class UserUpdateInternal(UserUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class UserTierUpdate(SQLModel):
tier_id: int
class UserDelete(SQLModel):
is_deleted: bool
deleted_at: datetime
class UserRestoreDeleted(SQLModel):
is_deleted: bool
================================================
FILE: src/migrations/README
================================================
Generic single-database configuration.
================================================
FILE: src/migrations/env.py
================================================
import asyncio
from logging.config import fileConfig
from alembic import context
from app.core.config import settings
from app.core.db.database import SQLModel
from sqlalchemy import pool
from sqlalchemy.engine import Connection
from sqlalchemy.ext.asyncio import async_engine_from_config
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
config.set_main_option(
"sqlalchemy.url",
f"{settings.POSTGRES_ASYNC_PREFIX}{settings.POSTGRES_USER}:{settings.POSTGRES_PASSWORD}@localhost/{settings.POSTGRES_DB}",
)
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
target_metadata = SQLModel.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL and not an Engine, though an Engine is acceptable here as well. By
skipping the Engine creation we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def do_run_migrations(connection: Connection) -> None:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
async def run_async_migrations() -> None:
"""In this scenario we need to create an Engine and associate a connection with the context."""
connectable = async_engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
async with connectable.connect() as connection:
await connection.run_sync(do_run_migrations)
await connectable.dispose()
def run_migrations_online() -> None:
"""Run migrations in 'online' mode."""
asyncio.run(run_async_migrations())
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
================================================
FILE: src/migrations/script.py.mako
================================================
"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
Create Date: ${create_date}
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
${imports if imports else ""}
# revision identifiers, used by Alembic.
revision: str = ${repr(up_revision)}
down_revision: Union[str, None] = ${repr(down_revision)}
branch_labels: Union[str, Sequence[str], None] = ${repr(branch_labels)}
depends_on: Union[str, Sequence[str], None] = ${repr(depends_on)}
def upgrade() -> None:
${upgrades if upgrades else "pass"}
def downgrade() -> None:
${downgrades if downgrades else "pass"}
================================================
FILE: src/migrations/versions/README.MD
================================================
================================================
FILE: src/scripts/__init__.py
================================================
================================================
FILE: src/scripts/create_first_superuser.py
================================================
import asyncio
import logging
import uuid
from datetime import UTC, datetime
from sqlalchemy import Boolean, Column, DateTime, ForeignKey, Integer, MetaData, String, Table, insert, select
from sqlalchemy.dialects.postgresql import UUID
from ..app.core.config import settings
from ..app.core.db.database import AsyncSession, async_engine, local_session
from ..app.core.security import get_password_hash
from ..app.models.user import User
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_first_user(session: AsyncSession) -> None:
try:
name = settings.ADMIN_NAME
email = settings.ADMIN_EMAIL
username = settings.ADMIN_USERNAME
hashed_password = get_password_hash(settings.ADMIN_PASSWORD)
query = select(User).filter_by(email=email)
result = await session.execute(query)
user = result.scalar_one_or_none()
if user is None:
metadata = MetaData()
user_table = Table(
"user",
metadata,
Column("id", Integer, primary_key=True, autoincrement=True, nullable=False),
Column("name", String(30), nullable=False),
Column("username", String(20), nullable=False, unique=True, index=True),
Column("email", String(50), nullable=False, unique=True, index=True),
Column("hashed_password", String, nullable=False),
Column("profile_image_url", String, default="https://profileimageurl.com"),
Column("uuid", UUID(as_uuid=True), primary_key=True, default=uuid.uuid4, unique=True),
Column("created_at", DateTime(timezone=True), default=lambda: datetime.now(UTC), nullable=False),
Column("updated_at", DateTime),
Column("deleted_at", DateTime),
Column("is_deleted", Boolean, default=False, index=True),
Column("is_superuser", Boolean, default=False),
Column("tier_id", Integer, ForeignKey("tier.id"), index=True),
)
data = {
"name": name,
"email": email,
"username": username,
"hashed_password": hashed_password,
"is_superuser": True,
}
stmt = insert(user_table).values(data)
async with async_engine.connect() as conn:
await conn.execute(stmt)
await conn.commit()
logger.info(f"Admin user {username} created successfully.")
else:
logger.info(f"Admin user {username} already exists.")
except Exception as e:
logger.error(f"Error creating admin user: {e}")
async def main():
async with local_session() as session:
await create_first_user(session)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
================================================
FILE: src/scripts/create_first_tier.py
================================================
import asyncio
import logging
from sqlalchemy import select
from ..app.core.config import config
from ..app.core.db.database import AsyncSession, local_session
from ..app.models.tier import Tier
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_first_tier(session: AsyncSession) -> None:
try:
tier_name = config("TIER_NAME", default="free")
query = select(Tier).where(Tier.name == tier_name)
result = await session.execute(query)
tier = result.scalar_one_or_none()
if tier is None:
session.add(Tier(name=tier_name))
await session.commit()
logger.info(f"Tier '{tier_name}' created successfully.")
else:
logger.info(f"Tier '{tier_name}' already exists.")
except Exception as e:
logger.error(f"Error creating tier: {e}")
async def main():
async with local_session() as session:
await create_first_tier(session)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
================================================
FILE: tests/__init__.py
================================================
================================================
FILE: tests/conftest.py
================================================
import pytest
from fastapi.testclient import TestClient
from src.app.main import app
@pytest.fixture(scope="session")
def client():
with TestClient(app) as _client:
yield _client
================================================
FILE: tests/helper.py
================================================
from fastapi.testclient import TestClient
def _get_token(username: str, password: str, client: TestClient):
return client.post(
"/api/v1/login",
data={"username": username, "password": password},
headers={"content-type": "application/x-www-form-urlencoded"},
)
================================================
FILE: tests/test_user.py
================================================
from fastapi.testclient import TestClient
from src.app.core.config import settings
from src.app.main import app
from .helper import _get_token
test_name = settings.TEST_NAME
test_username = settings.TEST_USERNAME
test_email = settings.TEST_EMAIL
test_password = settings.TEST_PASSWORD
admin_username = settings.ADMIN_USERNAME
admin_password = settings.ADMIN_PASSWORD
client = TestClient(app)
def test_post_user(client: TestClient) -> None:
response = client.post(
"/api/v1/user",
json={"name": test_name, "username": test_username, "email": test_email, "password": test_password},
)
assert response.status_code == 201
def test_get_user(client: TestClient) -> None:
response = client.get(f"/api/v1/user/{test_username}")
assert response.status_code == 200
def test_get_multiple_users(client: TestClient) -> None:
response = client.get("/api/v1/users")
assert response.status_code == 200
def test_update_user(client: TestClient) -> None:
token = _get_token(username=test_username, password=test_password, client=client)
response = client.patch(
f"/api/v1/user/{test_username}",
json={"name": f"Updated {test_name}"},
headers={"Authorization": f'Bearer {token.json()["access_token"]}'},
)
assert response.status_code == 200
def test_delete_user(client: TestClient) -> None:
token = _get_token(username=test_username, password=test_password, client=client)
response = client.delete(
f"/api/v1/user/{test_username}", headers={"Authorization": f'Bearer {token.json()["access_token"]}'}
)
assert response.status_code == 200
def test_delete_db_user(client: TestClient) -> None:
token = _get_token(username=admin_username, password=admin_password, client=client)
response = client.delete(
f"/api/v1/db_user/{test_username}", headers={"Authorization": f'Bearer {token.json()["access_token"]}'}
)
assert response.status_code == 200
================================================
FILE: default.conf
================================================
# ---------------- Running With One Server ----------------
server {
listen 80;
location / {
proxy_pass http://web:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
# # ---------------- To Run with Multiple Servers, Uncomment below ----------------
# upstream fastapi_app {
# server fastapi1:8000; # Replace with actual server names or IP addresses
# server fastapi2:8000;
# # Add more servers as needed
# }
# server {
# listen 80;
# location / {
# proxy_pass http://fastapi_app;
# proxy_set_header Host $host;
# proxy_set_header X-Real-IP $remote_addr;
# proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# proxy_set_header X-Forwarded-Proto $scheme;
# }
# }
================================================
FILE: docker-compose.yml
================================================
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
# -------- replace with comment to run with gunicorn --------
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
# command: gunicorn app.main:app -w 4 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8000
env_file:
- ./src/.env
# -------- replace with comment if you are using nginx --------
ports:
- "8000:8000"
# expose:
# - "8000"
depends_on:
- db
- redis
volumes:
- ./src/app:/code/app
- ./src/.env:/code/.env
worker:
build:
context: .
dockerfile: Dockerfile
command: arq app.core.worker.settings.WorkerSettings
env_file:
- ./src/.env
depends_on:
- db
- redis
volumes:
- ./src/app:/code/app
- ./src/.env:/code/.env
db:
image: postgres:13
env_file:
- ./src/.env
volumes:
- postgres-data:/var/lib/postgresql/data
# -------- replace with comment to run migrations with docker --------
expose:
- "5432"
# ports:
# - 5432:5432
redis:
image: redis:alpine
volumes:
- redis-data:/data
expose:
- "6379"
#-------- uncomment to run with pgadmin --------
# pgadmin:
# container_name: pgadmin4
# image: dpage/pgadmin4:latest
# restart: always
# ports:
# - "5050:80"
# volumes:
# - pgadmin-data:/var/lib/pgadmin
# env_file:
# - ./src/.env
# depends_on:
# - db
#-------- uncomment to run with nginx --------
# nginx:
# image: nginx:latest
# ports:
# - "80:80"
# volumes:
# - ./default.conf:/etc/nginx/conf.d/default.conf
# depends_on:
# - web
#-------- uncomment to create first superuser --------
# create_superuser:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - web
# command: python -m src.scripts.create_first_superuser
# volumes:
# - ./src:/code/src
#-------- uncomment to run tests --------
# pytest:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - create_superuser
# - redis
# command: python -m pytest ./tests
# volumes:
# - .:/code
#-------- uncomment to create first tier --------
# create_tier:
# build:
# context: .
# dockerfile: Dockerfile
# env_file:
# - ./src/.env
# depends_on:
# - db
# - web
# command: python -m src.scripts.create_first_tier
# volumes:
# - ./src:/code/src
volumes:
postgres-data:
redis-data:
#pgadmin-data:
================================================
FILE: mypy.ini
================================================
[mypy]
python_version = 3.11
warn_return_any = True
warn_unused_configs = True
ignore_missing_imports = True
[mypy-src.app.*]
disallow_untyped_defs = True
================================================
FILE: pyproject.toml
================================================
[tool.poetry]
name = "fastapi-boilerplate"
version = "0.1.0"
description = "A fully Async FastAPI boilerplate using SQLAlchemy and Pydantic 2"
authors = ["Igor Magalhaes "]
license = "MIT"
readme = "README.md"
packages = [{ include = "src" }]
[tool.poetry.requires-plugins]
poetry-plugin-export = ">=1.8"
[tool.poetry.dependencies]
python = "^3.11"
python-dotenv = "^1.0.0"
pydantic = { extras = ["email"], version = "^2.6.1" }
fastapi = "^0.109.1"
uvicorn = "^0.27.0"
uvloop = "^0.19.0"
httptools = "^0.6.1"
uuid = "^1.30"
alembic = "^1.13.1"
asyncpg = "^0.29.0"
SQLAlchemy-Utils = "^0.41.1"
python-jose = "^3.3.0"
SQLAlchemy = "^2.0.25"
pytest = "^7.4.2"
python-multipart = "^0.0.9"
greenlet = "^2.0.2"
httpx = "^0.26.0"
pydantic-settings = "^2.0.3"
redis = "^5.0.1"
arq = "^0.25.0"
gunicorn = "^22.0.0"
bcrypt = "^4.1.1"
fastcrud = "^0.12.0"
sqlmodel = "^0.0.18"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
[tool.ruff]
target-version = "py311"
line-length = 120
fix = true
select = [
# https://docs.astral.sh/ruff/rules/#pyflakes-f
"F", # Pyflakes
# https://docs.astral.sh/ruff/rules/#pycodestyle-e-w
"E", # pycodestyle
"W", # Warning
# https://docs.astral.sh/ruff/rules/#flake8-comprehensions-c4
# https://docs.astral.sh/ruff/rules/#mccabe-c90
"C", # Complexity (mccabe+) & comprehensions
# https://docs.astral.sh/ruff/rules/#pyupgrade-up
"UP", # pyupgrade
# https://docs.astral.sh/ruff/rules/#isort-i
"I", # isort
]
ignore = [
# https://docs.astral.sh/ruff/rules/#pycodestyle-e-w
"E402", # module level import not at top of file
# https://docs.astral.sh/ruff/rules/#pyupgrade-up
"UP006", # use-pep585-annotation
"UP007", # use-pep604-annotation
"E741", # Ambiguous variable name
# "UP035", # deprecated-assertion
]
[tool.ruff.per-file-ignores]
"__init__.py" = [
"F401", # unused import
"F403", # star imports
]
[tool.ruff.mccabe]
max-complexity = 24
[tool.ruff.pydocstyle]
convention = "numpy"
================================================
FILE: src/__init__.py
================================================
================================================
FILE: src/alembic.ini
================================================
# A generic, single database configuration.
[alembic]
# path to migration scripts
script_location = migrations
# template used to generate migration file names; The default value is %%(rev)s_%%(slug)s
# Uncomment the line below if you want the files to be prepended with date and time
# see https://alembic.sqlalchemy.org/en/latest/tutorial.html#editing-the-ini-file
# for all available tokens
# file_template = %%(year)d_%%(month).2d_%%(day).2d_%%(hour).2d%%(minute).2d-%%(rev)s_%%(slug)s
# sys.path path, will be prepended to sys.path if present.
# defaults to the current working directory.
prepend_sys_path = .
# timezone to use when rendering the date within the migration file
# as well as the filename.
# If specified, requires the python-dateutil library that can be
# installed by adding `alembic[tz]` to the pip requirements
# string value is passed to dateutil.tz.gettz()
# leave blank for localtime
# timezone =
# max length of characters to apply to the
# "slug" field
# truncate_slug_length = 40
# set to 'true' to run the environment during
# the 'revision' command, regardless of autogenerate
# revision_environment = false
# set to 'true' to allow .pyc and .pyo files without
# a source .py file to be detected as revisions in the
# versions/ directory
# sourceless = false
# version location specification; This defaults
# to migrations/versions. When using multiple version
# directories, initial revisions must be specified with --version-path.
# The path separator used here should be the separator specified by "version_path_separator" below.
# version_locations = %(here)s/bar:%(here)s/bat:migrations/versions
# version path separator; As mentioned above, this is the character used to split
# version_locations. The default within new alembic.ini files is "os", which uses os.pathsep.
# If this key is omitted entirely, it falls back to the legacy behavior of splitting on spaces and/or commas.
# Valid values for version_path_separator are:
#
# version_path_separator = :
# version_path_separator = ;
# version_path_separator = space
version_path_separator = os # Use os.pathsep. Default configuration used for new projects.
# set to 'true' to search source files recursively
# in each "version_locations" directory
# new in Alembic version 1.10
# recursive_version_locations = false
# the output encoding used when revision files
# are written from script.py.mako
# output_encoding = utf-8
sqlalchemy.url = driver://user:pass@localhost/dbname
[post_write_hooks]
# post_write_hooks defines scripts or Python functions that are run
# on newly generated revision scripts. See the documentation for further
# detail and examples
# format using "black" - use the console_scripts runner, against the "black" entrypoint
# hooks = black
# black.type = console_scripts
# black.entrypoint = black
# black.options = -l 79 REVISION_SCRIPT_FILENAME
# lint with attempts to fix using "ruff" - use the exec runner, execute a binary
# hooks = ruff
# ruff.type = exec
# ruff.executable = %(here)s/.venv/bin/ruff
# ruff.options = --fix REVISION_SCRIPT_FILENAME
# Logging configuration
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = WARN
handlers = console
qualname =
[logger_sqlalchemy]
level = WARN
handlers =
qualname = sqlalchemy.engine
[logger_alembic]
level = INFO
handlers =
qualname = alembic
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
================================================
FILE: src/app/__init__.py
================================================
================================================
FILE: src/app/api/__init__.py
================================================
from fastapi import APIRouter
from ..api.v1 import router as v1_router
router = APIRouter(prefix="/api")
router.include_router(v1_router)
================================================
FILE: src/app/api/dependencies.py
================================================
from typing import Annotated, Any
from fastapi import Depends, HTTPException, Request
from sqlalchemy.ext.asyncio import AsyncSession
from ..core.config import settings
from ..core.db.database import async_get_db
from ..core.exceptions.http_exceptions import ForbiddenException, RateLimitException, UnauthorizedException
from ..core.logger import logging
from ..core.security import oauth2_scheme, verify_token
from ..core.utils.rate_limit import is_rate_limited
from ..crud.crud_rate_limit import crud_rate_limits
from ..crud.crud_tier import crud_tiers
from ..crud.crud_users import crud_users
from ..models.user import User
from ..models.rate_limit import sanitize_path
logger = logging.getLogger(__name__)
DEFAULT_LIMIT = settings.DEFAULT_RATE_LIMIT_LIMIT
DEFAULT_PERIOD = settings.DEFAULT_RATE_LIMIT_PERIOD
async def get_current_user(
token: Annotated[str, Depends(oauth2_scheme)], db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, Any] | None:
token_data = await verify_token(token, db)
if token_data is None:
raise UnauthorizedException("User not authenticated.")
if "@" in token_data.username_or_email:
user: dict | None = await crud_users.get(db=db, email=token_data.username_or_email, is_deleted=False)
else:
user = await crud_users.get(db=db, username=token_data.username_or_email, is_deleted=False)
if user:
return user
raise UnauthorizedException("User not authenticated.")
async def get_optional_user(request: Request, db: AsyncSession = Depends(async_get_db)) -> dict | None:
token = request.headers.get("Authorization")
if not token:
return None
try:
token_type, _, token_value = token.partition(" ")
if token_type.lower() != "bearer" or not token_value:
return None
token_data = await verify_token(token_value, db)
if token_data is None:
return None
return await get_current_user(token_value, db=db)
except HTTPException as http_exc:
if http_exc.status_code != 401:
logger.error(f"Unexpected HTTPException in get_optional_user: {http_exc.detail}")
return None
except Exception as exc:
logger.error(f"Unexpected error in get_optional_user: {exc}")
return None
async def get_current_superuser(current_user: Annotated[dict, Depends(get_current_user)]) -> dict:
if not current_user["is_superuser"]:
raise ForbiddenException("You do not have enough privileges.")
return current_user
async def rate_limiter(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], user: User | None = Depends(get_optional_user)
) -> None:
path = sanitize_path(request.url.path)
if user:
user_id = user["id"]
tier = await crud_tiers.get(db, id=user["tier_id"])
if tier:
rate_limit = await crud_rate_limits.get(db=db, tier_id=tier["id"], path=path)
if rate_limit:
limit, period = rate_limit["limit"], rate_limit["period"]
else:
logger.warning(
f"User {user_id} with tier '{tier['name']}' has no specific rate limit for path '{path}'. \
Applying default rate limit."
)
limit, period = DEFAULT_LIMIT, DEFAULT_PERIOD
else:
logger.warning(f"User {user_id} has no assigned tier. Applying default rate limit.")
limit, period = DEFAULT_LIMIT, DEFAULT_PERIOD
else:
user_id = request.client.host
limit, period = DEFAULT_LIMIT, DEFAULT_PERIOD
is_limited = await is_rate_limited(db=db, user_id=user_id, path=path, limit=limit, period=period)
if is_limited:
raise RateLimitException("Rate limit exceeded.")
================================================
FILE: src/app/api/v1/__init__.py
================================================
from fastapi import APIRouter
from .login import router as login_router
from .logout import router as logout_router
from .posts import router as posts_router
from .rate_limits import router as rate_limits_router
from .tasks import router as tasks_router
from .tiers import router as tiers_router
from .users import router as users_router
router = APIRouter(prefix="/v1")
router.include_router(login_router)
router.include_router(logout_router)
router.include_router(users_router)
router.include_router(posts_router)
router.include_router(tasks_router)
router.include_router(tiers_router)
router.include_router(rate_limits_router)
================================================
FILE: src/app/api/v1/login.py
================================================
from datetime import timedelta
from typing import Annotated
from fastapi import APIRouter, Depends, Request, Response
from fastapi.security import OAuth2PasswordRequestForm
from sqlalchemy.ext.asyncio import AsyncSession
from ...core.config import settings
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import UnauthorizedException
from ...core.schemas import Token
from ...core.security import (
ACCESS_TOKEN_EXPIRE_MINUTES,
authenticate_user,
create_access_token,
create_refresh_token,
verify_token,
)
router = APIRouter(tags=["login"])
@router.post("/login", response_model=Token)
async def login_for_access_token(
response: Response,
form_data: Annotated[OAuth2PasswordRequestForm, Depends()],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
user = await authenticate_user(username_or_email=form_data.username, password=form_data.password, db=db)
if not user:
raise UnauthorizedException("Wrong username, email or password.")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = await create_access_token(data={"sub": user["username"]}, expires_delta=access_token_expires)
refresh_token = await create_refresh_token(data={"sub": user["username"]})
max_age = settings.REFRESH_TOKEN_EXPIRE_DAYS * 24 * 60 * 60
response.set_cookie(
key="refresh_token", value=refresh_token, httponly=True, secure=True, samesite="Lax", max_age=max_age
)
return {"access_token": access_token, "token_type": "bearer"}
@router.post("/refresh")
async def refresh_access_token(request: Request, db: AsyncSession = Depends(async_get_db)) -> dict[str, str]:
refresh_token = request.cookies.get("refresh_token")
if not refresh_token:
raise UnauthorizedException("Refresh token missing.")
user_data = await verify_token(refresh_token, db)
if not user_data:
raise UnauthorizedException("Invalid refresh token.")
new_access_token = await create_access_token(data={"sub": user_data.username_or_email})
return {"access_token": new_access_token, "token_type": "bearer"}
================================================
FILE: src/app/api/v1/logout.py
================================================
from fastapi import APIRouter, Depends, Response
from jose import JWTError
from sqlalchemy.ext.asyncio import AsyncSession
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import UnauthorizedException
from ...core.security import blacklist_token, oauth2_scheme
router = APIRouter(tags=["login"])
@router.post("/logout")
async def logout(
response: Response, access_token: str = Depends(oauth2_scheme), db: AsyncSession = Depends(async_get_db)
) -> dict[str, str]:
try:
await blacklist_token(token=access_token, db=db)
response.delete_cookie(key="refresh_token")
return {"message": "Logged out successfully"}
except JWTError:
raise UnauthorizedException("Invalid token.")
================================================
FILE: src/app/api/v1/posts.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser, get_current_user
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import ForbiddenException, NotFoundException
from ...core.utils.cache import cache
from ...crud.crud_posts import crud_posts
from ...crud.crud_users import crud_users
from ...models.post import PostCreate, PostCreateInternal, PostRead, PostUpdate
from ...models.user import UserRead
router = APIRouter(tags=["posts"])
@router.post("/{username}/post", response_model=PostRead, status_code=201)
async def write_post(
request: Request,
username: str,
post: PostCreate,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> PostRead:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
if current_user["id"] != db_user["id"]:
raise ForbiddenException()
post_internal_dict = post.model_dump()
post_internal_dict["created_by_user_id"] = db_user["id"]
post_internal = PostCreateInternal(**post_internal_dict)
created_post: PostRead = await crud_posts.create(db=db, object=post_internal)
return created_post
@router.get("/{username}/posts", response_model=PaginatedListResponse[PostRead])
@cache(
key_prefix="{username}_posts:page_{page}:items_per_page:{items_per_page}",
resource_id_name="username",
expiration=60,
)
async def read_posts(
request: Request,
username: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
page: int = 1,
items_per_page: int = 10,
) -> dict:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if not db_user:
raise NotFoundException("User not found")
posts_data = await crud_posts.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=PostRead,
created_by_user_id=db_user["id"],
is_deleted=False,
)
response: dict[str, Any] = paginated_response(crud_data=posts_data, page=page, items_per_page=items_per_page)
return response
@router.get("/{username}/post/{id}", response_model=PostRead)
@cache(key_prefix="{username}_post_cache", resource_id_name="id")
async def read_post(
request: Request, username: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
db_post: PostRead | None = await crud_posts.get(
db=db, schema_to_select=PostRead, id=id, created_by_user_id=db_user["id"], is_deleted=False
)
if db_post is None:
raise NotFoundException("Post not found")
return db_post
@router.patch("/{username}/post/{id}")
@cache("{username}_post_cache", resource_id_name="id", pattern_to_invalidate_extra=["{username}_posts:*"])
async def patch_post(
request: Request,
username: str,
id: int,
values: PostUpdate,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
if current_user["id"] != db_user["id"]:
raise ForbiddenException()
db_post = await crud_posts.get(db=db, schema_to_select=PostRead, id=id, is_deleted=False)
if db_post is None:
raise NotFoundException("Post not found")
await crud_posts.update(db=db, object=values, id=id)
return {"message": "Post updated"}
@router.delete("/{username}/post/{id}")
@cache("{username}_post_cache", resource_id_name="id", to_invalidate_extra={"{username}_posts": "{username}"})
async def erase_post(
request: Request,
username: str,
id: int,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
if current_user["id"] != db_user["id"]:
raise ForbiddenException()
db_post = await crud_posts.get(db=db, schema_to_select=PostRead, id=id, is_deleted=False)
if db_post is None:
raise NotFoundException("Post not found")
await crud_posts.delete(db=db, id=id)
return {"message": "Post deleted"}
@router.delete("/{username}/db_post/{id}", dependencies=[Depends(get_current_superuser)])
@cache("{username}_post_cache", resource_id_name="id", to_invalidate_extra={"{username}_posts": "{username}"})
async def erase_db_post(
request: Request, username: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username, is_deleted=False)
if db_user is None:
raise NotFoundException("User not found")
db_post = await crud_posts.get(db=db, schema_to_select=PostRead, id=id, is_deleted=False)
if db_post is None:
raise NotFoundException("Post not found")
await crud_posts.db_delete(db=db, id=id)
return {"message": "Post deleted from the database"}
================================================
FILE: src/app/api/v1/rate_limits.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import DuplicateValueException, NotFoundException, RateLimitException
from ...crud.crud_rate_limit import crud_rate_limits
from ...crud.crud_tier import crud_tiers
from ...models.rate_limit import RateLimitCreate, RateLimitCreateInternal, RateLimitRead, RateLimitUpdate
router = APIRouter(tags=["rate_limits"])
@router.post("/tier/{tier_name}/rate_limit", dependencies=[Depends(get_current_superuser)], status_code=201)
async def write_rate_limit(
request: Request, tier_name: str, rate_limit: RateLimitCreate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> RateLimitRead:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
rate_limit_internal_dict = rate_limit.model_dump()
rate_limit_internal_dict["tier_id"] = db_tier["id"]
db_rate_limit = await crud_rate_limits.exists(db=db, name=rate_limit_internal_dict["name"])
if db_rate_limit:
raise DuplicateValueException("Rate Limit Name not available")
rate_limit_internal = RateLimitCreateInternal(**rate_limit_internal_dict)
created_rate_limit: RateLimitRead = await crud_rate_limits.create(db=db, object=rate_limit_internal)
return created_rate_limit
@router.get("/tier/{tier_name}/rate_limits", response_model=PaginatedListResponse[RateLimitRead])
async def read_rate_limits(
request: Request,
tier_name: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
page: int = 1,
items_per_page: int = 10,
) -> dict:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
rate_limits_data = await crud_rate_limits.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=RateLimitRead,
tier_id=db_tier["id"],
)
response: dict[str, Any] = paginated_response(crud_data=rate_limits_data, page=page, items_per_page=items_per_page)
return response
@router.get("/tier/{tier_name}/rate_limit/{id}", response_model=RateLimitRead)
async def read_rate_limit(
request: Request, tier_name: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
db_rate_limit: dict | None = await crud_rate_limits.get(
db=db, schema_to_select=RateLimitRead, tier_id=db_tier["id"], id=id
)
if db_rate_limit is None:
raise NotFoundException("Rate Limit not found")
return db_rate_limit
@router.patch("/tier/{tier_name}/rate_limit/{id}", dependencies=[Depends(get_current_superuser)])
async def patch_rate_limit(
request: Request,
tier_name: str,
id: int,
values: RateLimitUpdate,
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if db_tier is None:
raise NotFoundException("Tier not found")
db_rate_limit = await crud_rate_limits.get(db=db, schema_to_select=RateLimitRead, tier_id=db_tier["id"], id=id)
if db_rate_limit is None:
raise NotFoundException("Rate Limit not found")
db_rate_limit_path = await crud_rate_limits.exists(db=db, tier_id=db_tier["id"], path=values.path)
if db_rate_limit_path:
raise DuplicateValueException("There is already a rate limit for this path")
await crud_rate_limits.exists(db=db)
if db_rate_limit_path:
raise DuplicateValueException("There is already a rate limit with this name")
await crud_rate_limits.update(db=db, object=values, id=db_rate_limit["id"])
return {"message": "Rate Limit updated"}
@router.delete("/tier/{tier_name}/rate_limit/{id}", dependencies=[Depends(get_current_superuser)])
async def erase_rate_limit(
request: Request, tier_name: str, id: int, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, name=tier_name)
if not db_tier:
raise NotFoundException("Tier not found")
db_rate_limit = await crud_rate_limits.get(db=db, schema_to_select=RateLimitRead, tier_id=db_tier["id"], id=id)
if db_rate_limit is None:
raise NotFoundException("Rate Limit not found")
await crud_rate_limits.delete(db=db, id=db_rate_limit["id"])
return {"message": "Rate Limit deleted"}
================================================
FILE: src/app/api/v1/tasks.py
================================================
from typing import Any
from arq.jobs import Job as ArqJob
from fastapi import APIRouter, Depends
from ...api.dependencies import rate_limiter
from ...core.utils import queue
from ...models.job import Job
router = APIRouter(prefix="/tasks", tags=["tasks"])
@router.post("/task", response_model=Job, status_code=201, dependencies=[Depends(rate_limiter)])
async def create_task(message: str) -> dict[str, str]:
"""Create a new background task.
Parameters
----------
message: str
The message or data to be processed by the task.
Returns
-------
dict[str, str]
A dictionary containing the ID of the created task.
"""
job = await queue.pool.enqueue_job("sample_background_task", message) # type: ignore
return {"id": job.job_id}
@router.get("/task/{task_id}")
async def get_task(task_id: str) -> dict[str, Any] | None:
"""Get information about a specific background task.
Parameters
----------
task_id: str
The ID of the task.
Returns
-------
Optional[dict[str, Any]]
A dictionary containing information about the task if found, or None otherwise.
"""
job = ArqJob(task_id, queue.pool)
job_info: dict = await job.info()
return vars(job_info)
================================================
FILE: src/app/api/v1/tiers.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import DuplicateValueException, NotFoundException
from ...crud.crud_tier import crud_tiers
from ...models.tier import TierCreate, TierCreateInternal, TierRead, TierUpdate
router = APIRouter(tags=["tiers"])
@router.post("/tier", dependencies=[Depends(get_current_superuser)], status_code=201)
async def write_tier(
request: Request, tier: TierCreate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> TierRead:
tier_internal_dict = tier.model_dump()
db_tier = await crud_tiers.exists(db=db, name=tier_internal_dict["name"])
if db_tier:
raise DuplicateValueException("Tier Name not available")
tier_internal = TierCreateInternal(**tier_internal_dict)
created_tier: TierRead = await crud_tiers.create(db=db, object=tier_internal)
return created_tier
@router.get("/tiers", response_model=PaginatedListResponse[TierRead])
async def read_tiers(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], page: int = 1, items_per_page: int = 10
) -> dict:
tiers_data = await crud_tiers.get_multi(
db=db, offset=compute_offset(page, items_per_page), limit=items_per_page, schema_to_select=TierRead
)
response: dict[str, Any] = paginated_response(crud_data=tiers_data, page=page, items_per_page=items_per_page)
return response
@router.get("/tier/{name}", response_model=TierRead)
async def read_tier(request: Request, name: str, db: Annotated[AsyncSession, Depends(async_get_db)]) -> dict:
db_tier: TierRead | None = await crud_tiers.get(db=db, schema_to_select=TierRead, name=name)
if db_tier is None:
raise NotFoundException("Tier not found")
return db_tier
@router.patch("/tier/{name}", dependencies=[Depends(get_current_superuser)])
async def patch_tier(
request: Request, values: TierUpdate, name: str, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, schema_to_select=TierRead, name=name)
if db_tier is None:
raise NotFoundException("Tier not found")
await crud_tiers.update(db=db, object=values, name=name)
return {"message": "Tier updated"}
@router.delete("/tier/{name}", dependencies=[Depends(get_current_superuser)])
async def erase_tier(request: Request, name: str, db: Annotated[AsyncSession, Depends(async_get_db)]) -> dict[str, str]:
db_tier = await crud_tiers.get(db=db, schema_to_select=TierRead, name=name)
if db_tier is None:
raise NotFoundException("Tier not found")
await crud_tiers.delete(db=db, name=name)
return {"message": "Tier deleted"}
================================================
FILE: src/app/api/v1/users.py
================================================
from typing import Annotated, Any
from fastapi import APIRouter, Depends, Request
from fastcrud.paginated import PaginatedListResponse, compute_offset, paginated_response
from sqlalchemy.ext.asyncio import AsyncSession
from ...api.dependencies import get_current_superuser, get_current_user
from ...core.db.database import async_get_db
from ...core.exceptions.http_exceptions import DuplicateValueException, ForbiddenException, NotFoundException
from ...core.security import blacklist_token, get_password_hash, oauth2_scheme
from ...crud.crud_rate_limit import crud_rate_limits
from ...crud.crud_tier import crud_tiers
from ...crud.crud_users import crud_users
from ...models.tier import Tier, TierRead
from ...models.user import UserCreate, UserCreateInternal, UserRead, UserTierUpdate, UserUpdate
router = APIRouter(tags=["users"])
@router.post("/user", response_model=UserRead, status_code=201)
async def write_user(
request: Request, user: UserCreate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> UserRead:
email_row = await crud_users.exists(db=db, email=user.email)
if email_row:
raise DuplicateValueException("Email is already registered")
username_row = await crud_users.exists(db=db, username=user.username)
if username_row:
raise DuplicateValueException("Username not available")
user_internal_dict = user.model_dump()
user_internal_dict["hashed_password"] = get_password_hash(password=user_internal_dict["password"])
del user_internal_dict["password"]
user_internal = UserCreateInternal(**user_internal_dict)
created_user: UserRead = await crud_users.create(db=db, object=user_internal)
return created_user
@router.get("/users", response_model=PaginatedListResponse[UserRead])
async def read_users(
request: Request, db: Annotated[AsyncSession, Depends(async_get_db)], page: int = 1, items_per_page: int = 10
) -> dict:
users_data = await crud_users.get_multi(
db=db,
offset=compute_offset(page, items_per_page),
limit=items_per_page,
schema_to_select=UserRead,
is_deleted=False,
)
response: dict[str, Any] = paginated_response(crud_data=users_data, page=page, items_per_page=items_per_page)
return response
@router.get("/user/me/", response_model=UserRead)
async def read_users_me(request: Request, current_user: Annotated[UserRead, Depends(get_current_user)]) -> UserRead:
return current_user
@router.get("/user/{username}", response_model=UserRead)
async def read_user(request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]) -> dict:
db_user: UserRead | None = await crud_users.get(
db=db, schema_to_select=UserRead, username=username, is_deleted=False
)
if db_user is None:
raise NotFoundException("User not found")
return db_user
@router.patch("/user/{username}")
async def patch_user(
request: Request,
values: UserUpdate,
username: str,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username)
if db_user is None:
raise NotFoundException("User not found")
if db_user["username"] != current_user["username"]:
raise ForbiddenException()
if values.username != db_user["username"]:
existing_username = await crud_users.exists(db=db, username=values.username)
if existing_username:
raise DuplicateValueException("Username not available")
if values.email != db_user["email"]:
existing_email = await crud_users.exists(db=db, email=values.email)
if existing_email:
raise DuplicateValueException("Email is already registered")
await crud_users.update(db=db, object=values, username=username)
return {"message": "User updated"}
@router.delete("/user/{username}")
async def erase_user(
request: Request,
username: str,
current_user: Annotated[UserRead, Depends(get_current_user)],
db: Annotated[AsyncSession, Depends(async_get_db)],
token: str = Depends(oauth2_scheme),
) -> dict[str, str]:
db_user = await crud_users.get(db=db, schema_to_select=UserRead, username=username)
if not db_user:
raise NotFoundException("User not found")
if username != current_user["username"]:
raise ForbiddenException()
await crud_users.delete(db=db, username=username)
await blacklist_token(token=token, db=db)
return {"message": "User deleted"}
@router.delete("/db_user/{username}", dependencies=[Depends(get_current_superuser)])
async def erase_db_user(
request: Request,
username: str,
db: Annotated[AsyncSession, Depends(async_get_db)],
token: str = Depends(oauth2_scheme),
) -> dict[str, str]:
db_user = await crud_users.exists(db=db, username=username)
if not db_user:
raise NotFoundException("User not found")
await crud_users.db_delete(db=db, username=username)
await blacklist_token(token=token, db=db)
return {"message": "User deleted from the database"}
@router.get("/user/{username}/rate_limits", dependencies=[Depends(get_current_superuser)])
async def read_user_rate_limits(
request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, Any]:
db_user: dict | None = await crud_users.get(db=db, username=username, schema_to_select=UserRead)
if db_user is None:
raise NotFoundException("User not found")
if db_user["tier_id"] is None:
db_user["tier_rate_limits"] = []
return db_user
db_tier = await crud_tiers.get(db=db, id=db_user["tier_id"])
if db_tier is None:
raise NotFoundException("Tier not found")
db_rate_limits = await crud_rate_limits.get_multi(db=db, tier_id=db_tier["id"])
db_user["tier_rate_limits"] = db_rate_limits["data"]
return db_user
@router.get("/user/{username}/tier")
async def read_user_tier(
request: Request, username: str, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict | None:
db_user = await crud_users.get(db=db, username=username, schema_to_select=UserRead)
if db_user is None:
raise NotFoundException("User not found")
db_tier = await crud_tiers.exists(db=db, id=db_user["tier_id"])
if not db_tier:
raise NotFoundException("Tier not found")
joined: dict = await crud_users.get_joined(
db=db,
join_model=Tier,
join_prefix="tier_",
schema_to_select=UserRead,
join_schema_to_select=TierRead,
username=username,
)
return joined
@router.patch("/user/{username}/tier", dependencies=[Depends(get_current_superuser)])
async def patch_user_tier(
request: Request, username: str, values: UserTierUpdate, db: Annotated[AsyncSession, Depends(async_get_db)]
) -> dict[str, str]:
db_user = await crud_users.get(db=db, username=username, schema_to_select=UserRead)
if db_user is None:
raise NotFoundException("User not found")
db_tier = await crud_tiers.get(db=db, id=values.tier_id)
if db_tier is None:
raise NotFoundException("Tier not found")
await crud_users.update(db=db, object=values, username=username)
return {"message": f"User {db_user['name']} Tier updated"}
================================================
FILE: src/app/core/__init__.py
================================================
================================================
FILE: src/app/core/config.py
================================================
import os
from enum import Enum
from pydantic_settings import BaseSettings
from starlette.config import Config
current_file_dir = os.path.dirname(os.path.realpath(__file__))
env_path = os.path.join(current_file_dir, "..", "..", ".env")
config = Config(env_path)
class AppSettings(BaseSettings):
APP_NAME: str = config("APP_NAME", default="FastAPI app")
APP_DESCRIPTION: str | None = config("APP_DESCRIPTION", default=None)
APP_VERSION: str | None = config("APP_VERSION", default=None)
LICENSE_NAME: str | None = config("LICENSE", default=None)
CONTACT_NAME: str | None = config("CONTACT_NAME", default=None)
CONTACT_EMAIL: str | None = config("CONTACT_EMAIL", default=None)
class CryptSettings(BaseSettings):
SECRET_KEY: str = config("SECRET_KEY")
ALGORITHM: str = config("ALGORITHM", default="HS256")
ACCESS_TOKEN_EXPIRE_MINUTES: int = config("ACCESS_TOKEN_EXPIRE_MINUTES", default=30)
REFRESH_TOKEN_EXPIRE_DAYS: int = config("REFRESH_TOKEN_EXPIRE_DAYS", default=7)
class DatabaseSettings(BaseSettings):
pass
class SQLiteSettings(DatabaseSettings):
SQLITE_URI: str = config("SQLITE_URI", default="./sql_app.db")
SQLITE_SYNC_PREFIX: str = config("SQLITE_SYNC_PREFIX", default="sqlite:///")
SQLITE_ASYNC_PREFIX: str = config("SQLITE_ASYNC_PREFIX", default="sqlite+aiosqlite:///")
class PostgresSettings(DatabaseSettings):
POSTGRES_USER: str = config("POSTGRES_USER", default="postgres")
POSTGRES_PASSWORD: str = config("POSTGRES_PASSWORD", default="postgres")
POSTGRES_SERVER: str = config("POSTGRES_SERVER", default="localhost")
POSTGRES_PORT: int = config("POSTGRES_PORT", default=5432)
POSTGRES_DB: str = config("POSTGRES_DB", default="postgres")
POSTGRES_SYNC_PREFIX: str = config("POSTGRES_SYNC_PREFIX", default="postgresql://")
POSTGRES_ASYNC_PREFIX: str = config("POSTGRES_ASYNC_PREFIX", default="postgresql+asyncpg://")
POSTGRES_URI: str = f"{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_SERVER}:{POSTGRES_PORT}/{POSTGRES_DB}"
POSTGRES_URL: str | None = config("POSTGRES_URL", default=None)
class FirstUserSettings(BaseSettings):
ADMIN_NAME: str = config("ADMIN_NAME", default="admin")
ADMIN_EMAIL: str = config("ADMIN_EMAIL", default="admin@admin.com")
ADMIN_USERNAME: str = config("ADMIN_USERNAME", default="admin")
ADMIN_PASSWORD: str = config("ADMIN_PASSWORD", default="!Ch4ng3Th1sP4ssW0rd!")
class TestSettings(BaseSettings):
TEST_NAME: str = config("TEST_NAME", default="Tester User")
TEST_EMAIL: str = config("TEST_EMAIL", default="test@tester.com")
TEST_USERNAME: str = config("TEST_USERNAME", default="testeruser")
TEST_PASSWORD: str = config("TEST_PASSWORD", default="Str1ng$t")
class RedisCacheSettings(BaseSettings):
REDIS_CACHE_HOST: str = config("REDIS_CACHE_HOST", default="localhost")
REDIS_CACHE_PORT: int = config("REDIS_CACHE_PORT", default=6379)
REDIS_CACHE_URL: str = f"redis://{REDIS_CACHE_HOST}:{REDIS_CACHE_PORT}"
class ClientSideCacheSettings(BaseSettings):
CLIENT_CACHE_MAX_AGE: int = config("CLIENT_CACHE_MAX_AGE", default=60)
class RedisQueueSettings(BaseSettings):
REDIS_QUEUE_HOST: str = config("REDIS_QUEUE_HOST", default="localhost")
REDIS_QUEUE_PORT: int = config("REDIS_QUEUE_PORT", default=6379)
class RedisRateLimiterSettings(BaseSettings):
REDIS_RATE_LIMIT_HOST: str = config("REDIS_RATE_LIMIT_HOST", default="localhost")
REDIS_RATE_LIMIT_PORT: int = config("REDIS_RATE_LIMIT_PORT", default=6379)
REDIS_RATE_LIMIT_URL: str = f"redis://{REDIS_RATE_LIMIT_HOST}:{REDIS_RATE_LIMIT_PORT}"
class DefaultRateLimitSettings(BaseSettings):
DEFAULT_RATE_LIMIT_LIMIT: int = config("DEFAULT_RATE_LIMIT_LIMIT", default=10)
DEFAULT_RATE_LIMIT_PERIOD: int = config("DEFAULT_RATE_LIMIT_PERIOD", default=3600)
class EnvironmentOption(Enum):
LOCAL = "local"
STAGING = "staging"
PRODUCTION = "production"
class DBOption(Enum):
POSTGRES = "postgres"
SQLITE = "sqlite"
class EnvironmentSettings(BaseSettings):
ENVIRONMENT: EnvironmentOption = config("ENVIRONMENT", default="local")
DB_ENGINE: DBOption = config("DB_ENGINE", default="sqlite")
db_type = PostgresSettings
if config("DB_ENGINE", default="sqlite") == "sqlite":
db_type = SQLiteSettings
class Settings(
AppSettings,
db_type,
CryptSettings,
FirstUserSettings,
TestSettings,
RedisCacheSettings,
ClientSideCacheSettings,
RedisQueueSettings,
RedisRateLimiterSettings,
DefaultRateLimitSettings,
EnvironmentSettings,
):
pass
settings = Settings()
================================================
FILE: src/app/core/db/__init__.py
================================================
================================================
FILE: src/app/core/db/crud_token_blacklist.py
================================================
from fastcrud import FastCRUD
from ..db.token_blacklist import TokenBlacklist
from ..schemas import TokenBlacklistCreate, TokenBlacklistUpdate
CRUDTokenBlacklist = FastCRUD[TokenBlacklist, TokenBlacklistCreate, TokenBlacklistUpdate, TokenBlacklistUpdate, None]
crud_token_blacklist = CRUDTokenBlacklist(TokenBlacklist)
================================================
FILE: src/app/core/db/database.py
================================================
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.ext.asyncio.session import AsyncSession
from sqlalchemy.orm import sessionmaker
from ..config import settings, DBOption
if settings.DB_ENGINE == DBOption.SQLITE:
DATABASE_URI = settings.SQLITE_URI
DATABASE_PREFIX = settings.SQLITE_ASYNC_PREFIX
DATABASE_URL = f"{DATABASE_PREFIX}{DATABASE_URI}"
if settings.DB_ENGINE == DBOption.POSTGRES:
DATABASE_URI = settings.POSTGRES_URI
DATABASE_PREFIX = settings.POSTGRES_ASYNC_PREFIX
DATABASE_URL = f"{DATABASE_PREFIX}{DATABASE_URI}"
async_engine = create_async_engine(DATABASE_URL, echo=False, future=True)
local_session = sessionmaker(bind=async_engine, class_=AsyncSession, expire_on_commit=False)
async def async_get_db() -> AsyncSession:
async_session = local_session
async with async_session() as db:
yield db
================================================
FILE: src/app/core/db/models.py
================================================
import uuid as uuid_pkg
from datetime import UTC, datetime
from sqlalchemy import Boolean, Column, DateTime, text
from sqlalchemy.dialects.postgresql import UUID
class UUIDMixin:
uuid: uuid_pkg.UUID = Column(
UUID, primary_key=True, default=uuid_pkg.uuid4, server_default=text("gen_random_uuid()")
)
class TimestampMixin:
created_at: datetime = Column(DateTime, default=datetime.now(UTC), server_default=text("current_timestamp(0)"))
updated_at: datetime = Column(
DateTime, nullable=True, onupdate=datetime.now(UTC), server_default=text("current_timestamp(0)")
)
class SoftDeleteMixin:
deleted_at: datetime = Column(DateTime, nullable=True)
is_deleted: bool = Column(Boolean, default=False)
================================================
FILE: src/app/core/db/token_blacklist.py
================================================
from datetime import datetime
from sqlmodel import SQLModel, Field
class TokenBlacklist(SQLModel, table=True):
id: int = Field(default=None, primary_key=True, nullable=False)
token: str = Field(index=True, nullable=False, unique=True)
expires_at: datetime = Field(nullable=False)
================================================
FILE: src/app/core/exceptions/__init__.py
================================================
================================================
FILE: src/app/core/exceptions/cache_exceptions.py
================================================
class CacheIdentificationInferenceError(Exception):
def __init__(self, message: str = "Could not infer id for resource being cached.") -> None:
self.message = message
super().__init__(self.message)
class InvalidRequestError(Exception):
def __init__(self, message: str = "Type of request not supported.") -> None:
self.message = message
super().__init__(self.message)
class MissingClientError(Exception):
def __init__(self, message: str = "Client is None.") -> None:
self.message = message
super().__init__(self.message)
================================================
FILE: src/app/core/exceptions/http_exceptions.py
================================================
# ruff: noqa
from fastcrud.exceptions.http_exceptions import (
CustomException,
BadRequestException,
NotFoundException,
ForbiddenException,
UnauthorizedException,
UnprocessableEntityException,
DuplicateValueException,
RateLimitException,
)
================================================
FILE: src/app/core/logger.py
================================================
import logging
import os
from logging.handlers import RotatingFileHandler
LOG_DIR = os.path.join(os.path.dirname(os.path.dirname(__file__)), "logs")
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
LOG_FILE_PATH = os.path.join(LOG_DIR, "app.log")
LOGGING_LEVEL = logging.INFO
LOGGING_FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
logging.basicConfig(level=LOGGING_LEVEL, format=LOGGING_FORMAT)
file_handler = RotatingFileHandler(LOG_FILE_PATH, maxBytes=10485760, backupCount=5)
file_handler.setLevel(LOGGING_LEVEL)
file_handler.setFormatter(logging.Formatter(LOGGING_FORMAT))
logging.getLogger("").addHandler(file_handler)
================================================
FILE: src/app/core/schemas.py
================================================
import uuid as uuid_pkg
from datetime import UTC, datetime
from typing import Any
from pydantic import BaseModel, Field, field_serializer
class HealthCheck(BaseModel):
name: str
version: str
description: str
# -------------- mixins --------------
class UUIDSchema(BaseModel):
uuid: uuid_pkg.UUID = Field(default_factory=uuid_pkg.uuid4)
class TimestampSchema(BaseModel):
created_at: datetime = Field(default_factory=lambda: datetime.now(UTC).replace(tzinfo=None))
updated_at: datetime = Field(default=None)
@field_serializer("created_at")
def serialize_dt(self, created_at: datetime | None, _info: Any) -> str | None:
if created_at is not None:
return created_at.isoformat()
return None
@field_serializer("updated_at")
def serialize_updated_at(self, updated_at: datetime | None, _info: Any) -> str | None:
if updated_at is not None:
return updated_at.isoformat()
return None
class PersistentDeletion(BaseModel):
deleted_at: datetime | None = Field(default=None)
is_deleted: bool = False
@field_serializer("deleted_at")
def serialize_dates(self, deleted_at: datetime | None, _info: Any) -> str | None:
if deleted_at is not None:
return deleted_at.isoformat()
return None
# -------------- token --------------
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username_or_email: str
class TokenBlacklistBase(BaseModel):
token: str
expires_at: datetime
class TokenBlacklistCreate(TokenBlacklistBase):
pass
class TokenBlacklistUpdate(TokenBlacklistBase):
pass
================================================
FILE: src/app/core/security.py
================================================
from datetime import UTC, datetime, timedelta
from typing import Any, Literal
import bcrypt
from fastapi.security import OAuth2PasswordBearer
from jose import JWTError, jwt
from sqlalchemy.ext.asyncio import AsyncSession
from ..crud.crud_users import crud_users
from .config import settings
from .db.crud_token_blacklist import crud_token_blacklist
from .schemas import TokenBlacklistCreate, TokenData
SECRET_KEY = settings.SECRET_KEY
ALGORITHM = settings.ALGORITHM
ACCESS_TOKEN_EXPIRE_MINUTES = settings.ACCESS_TOKEN_EXPIRE_MINUTES
REFRESH_TOKEN_EXPIRE_DAYS = settings.REFRESH_TOKEN_EXPIRE_DAYS
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="/api/v1/login")
async def verify_password(plain_password: str, hashed_password: str) -> bool:
correct_password: bool = bcrypt.checkpw(plain_password.encode(), hashed_password.encode())
return correct_password
def get_password_hash(password: str) -> str:
hashed_password: str = bcrypt.hashpw(password.encode(), bcrypt.gensalt()).decode()
return hashed_password
async def authenticate_user(username_or_email: str, password: str, db: AsyncSession) -> dict[str, Any] | Literal[False]:
if "@" in username_or_email:
db_user: dict | None = await crud_users.get(db=db, email=username_or_email, is_deleted=False)
else:
db_user = await crud_users.get(db=db, username=username_or_email, is_deleted=False)
if not db_user:
return False
elif not await verify_password(password, db_user["hashed_password"]):
return False
return db_user
async def create_access_token(data: dict[str, Any], expires_delta: timedelta | None = None) -> str:
to_encode = data.copy()
if expires_delta:
expire = datetime.now(UTC).replace(tzinfo=None) + expires_delta
else:
expire = datetime.now(UTC).replace(tzinfo=None) + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt: str = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def create_refresh_token(data: dict[str, Any], expires_delta: timedelta | None = None) -> str:
to_encode = data.copy()
if expires_delta:
expire = datetime.now(UTC).replace(tzinfo=None) + expires_delta
else:
expire = datetime.now(UTC).replace(tzinfo=None) + timedelta(days=REFRESH_TOKEN_EXPIRE_DAYS)
to_encode.update({"exp": expire})
encoded_jwt: str = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def verify_token(token: str, db: AsyncSession) -> TokenData | None:
"""Verify a JWT token and return TokenData if valid.
Parameters
----------
token: str
The JWT token to be verified.
db: AsyncSession
Database session for performing database operations.
Returns
-------
TokenData | None
TokenData instance if the token is valid, None otherwise.
"""
is_blacklisted = await crud_token_blacklist.exists(db, token=token)
if is_blacklisted:
return None
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username_or_email: str = payload.get("sub")
if username_or_email is None:
return None
return TokenData(username_or_email=username_or_email)
except JWTError:
return None
async def blacklist_token(token: str, db: AsyncSession) -> None:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
expires_at = datetime.fromtimestamp(payload.get("exp"))
await crud_token_blacklist.create(db, object=TokenBlacklistCreate(**{"token": token, "expires_at": expires_at}))
================================================
FILE: src/app/core/setup.py
================================================
from collections.abc import AsyncGenerator, Callable
from contextlib import _AsyncGeneratorContextManager, asynccontextmanager
from typing import Any
import anyio
import fastapi
import redis.asyncio as redis
from arq import create_pool
from arq.connections import RedisSettings
from fastapi import APIRouter, Depends, FastAPI
from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html
from fastapi.openapi.utils import get_openapi
from sqlmodel import SQLModel
from ..api.dependencies import get_current_superuser
from ..middleware.client_cache_middleware import ClientCacheMiddleware
from .config import (
AppSettings,
ClientSideCacheSettings,
DatabaseSettings,
EnvironmentOption,
EnvironmentSettings,
RedisCacheSettings,
RedisQueueSettings,
RedisRateLimiterSettings,
settings,
)
from .db.database import async_engine as engine
from .utils import cache, queue, rate_limit
from ..models import *
# -------------- database --------------
async def create_tables() -> None:
async with engine.begin() as conn:
await conn.run_sync(SQLModel.metadata.create_all)
# -------------- cache --------------
async def create_redis_cache_pool() -> None:
cache.pool = redis.ConnectionPool.from_url(settings.REDIS_CACHE_URL)
cache.client = redis.Redis.from_pool(cache.pool) # type: ignore
async def close_redis_cache_pool() -> None:
await cache.client.aclose() # type: ignore
# -------------- queue --------------
async def create_redis_queue_pool() -> None:
queue.pool = await create_pool(RedisSettings(host=settings.REDIS_QUEUE_HOST, port=settings.REDIS_QUEUE_PORT))
async def close_redis_queue_pool() -> None:
await queue.pool.aclose() # type: ignore
# -------------- rate limit --------------
async def create_redis_rate_limit_pool() -> None:
rate_limit.pool = redis.ConnectionPool.from_url(settings.REDIS_RATE_LIMIT_URL)
rate_limit.client = redis.Redis.from_pool(rate_limit.pool) # type: ignore
async def close_redis_rate_limit_pool() -> None:
await rate_limit.client.aclose() # type: ignore
# -------------- application --------------
async def set_threadpool_tokens(number_of_tokens: int = 100) -> None:
limiter = anyio.to_thread.current_default_thread_limiter()
limiter.total_tokens = number_of_tokens
def lifespan_factory(
settings: (
DatabaseSettings
| RedisCacheSettings
| AppSettings
| ClientSideCacheSettings
| RedisQueueSettings
| RedisRateLimiterSettings
| EnvironmentSettings
),
create_tables_on_start: bool = True,
) -> Callable[[FastAPI], _AsyncGeneratorContextManager[Any]]:
"""Factory to create a lifespan async context manager for a FastAPI app."""
@asynccontextmanager
async def lifespan(app: FastAPI) -> AsyncGenerator:
await set_threadpool_tokens()
if isinstance(settings, DatabaseSettings) and create_tables_on_start:
await create_tables()
if settings.ENVIRONMENT != EnvironmentOption.LOCAL:
if isinstance(settings, RedisCacheSettings):
await create_redis_cache_pool()
if isinstance(settings, RedisQueueSettings):
await create_redis_queue_pool()
if isinstance(settings, RedisRateLimiterSettings):
await create_redis_rate_limit_pool()
yield
if isinstance(settings, RedisCacheSettings):
await close_redis_cache_pool()
if isinstance(settings, RedisQueueSettings):
await close_redis_queue_pool()
if isinstance(settings, RedisRateLimiterSettings):
await close_redis_rate_limit_pool()
return lifespan
# -------------- application --------------
def create_application(
router: APIRouter,
settings: (
DatabaseSettings
| RedisCacheSettings
| AppSettings
| ClientSideCacheSettings
| RedisQueueSettings
| RedisRateLimiterSettings
| EnvironmentSettings
),
create_tables_on_start: bool = True,
**kwargs: Any,
) -> FastAPI:
"""Creates and configures a FastAPI application based on the provided settings.
This function initializes a FastAPI application and configures it with various settings
and handlers based on the type of the `settings` object provided.
Parameters
----------
router : APIRouter
The APIRouter object containing the routes to be included in the FastAPI application.
settings
An instance representing the settings for configuring the FastAPI application.
It determines the configuration applied:
- AppSettings: Configures basic app metadata like name, description, contact, and license info.
- DatabaseSettings: Adds event handlers for initializing database tables during startup.
- RedisCacheSettings: Sets up event handlers for creating and closing a Redis cache pool.
- ClientSideCacheSettings: Integrates middleware for client-side caching.
- RedisQueueSettings: Sets up event handlers for creating and closing a Redis queue pool.
- RedisRateLimiterSettings: Sets up event handlers for creating and closing a Redis rate limiter pool.
- EnvironmentSettings: Conditionally sets documentation URLs and integrates custom routes for API documentation
based on the environment type.
create_tables_on_start : bool
A flag to indicate whether to create database tables on application startup.
Defaults to True.
**kwargs
Additional keyword arguments passed directly to the FastAPI constructor.
Returns
-------
FastAPI
A fully configured FastAPI application instance.
The function configures the FastAPI application with different features and behaviors
based on the provided settings. It includes setting up database connections, Redis pools
for caching, queue, and rate limiting, client-side caching, and customizing the API documentation
based on the environment settings.
"""
# --- before creating application ---
if isinstance(settings, AppSettings):
to_update = {
"title": settings.APP_NAME,
"description": settings.APP_DESCRIPTION,
"contact": {"name": settings.CONTACT_NAME, "email": settings.CONTACT_EMAIL},
"license_info": {"name": settings.LICENSE_NAME},
}
kwargs.update(to_update)
if isinstance(settings, EnvironmentSettings):
kwargs.update({"docs_url": None, "redoc_url": None, "openapi_url": None})
lifespan = lifespan_factory(settings, create_tables_on_start=create_tables_on_start)
application = FastAPI(lifespan=lifespan, **kwargs)
application.include_router(router)
if isinstance(settings, ClientSideCacheSettings):
application.add_middleware(ClientCacheMiddleware, max_age=settings.CLIENT_CACHE_MAX_AGE)
if isinstance(settings, EnvironmentSettings):
if settings.ENVIRONMENT != EnvironmentOption.PRODUCTION:
docs_router = APIRouter()
if settings.ENVIRONMENT != EnvironmentOption.LOCAL:
docs_router = APIRouter(dependencies=[Depends(get_current_superuser)])
@docs_router.get("/docs", include_in_schema=False)
async def get_swagger_documentation() -> fastapi.responses.HTMLResponse:
return get_swagger_ui_html(openapi_url="/openapi.json", title="docs")
@docs_router.get("/redoc", include_in_schema=False)
async def get_redoc_documentation() -> fastapi.responses.HTMLResponse:
return get_redoc_html(openapi_url="/openapi.json", title="docs")
@docs_router.get("/openapi.json", include_in_schema=False)
async def openapi() -> dict[str, Any]:
out: dict = get_openapi(title=application.title, version=application.version, routes=application.routes)
return out
application.include_router(docs_router)
return application
================================================
FILE: src/app/core/utils/__init__.py
================================================
================================================
FILE: src/app/core/utils/cache.py
================================================
import functools
import json
import re
from collections.abc import Callable
from typing import Any
from fastapi import Request, Response
from fastapi.encoders import jsonable_encoder
from redis.asyncio import ConnectionPool, Redis
from ..exceptions.cache_exceptions import CacheIdentificationInferenceError, InvalidRequestError, MissingClientError
pool: ConnectionPool | None = None
client: Redis | None = None
def _infer_resource_id(kwargs: dict[str, Any], resource_id_type: type | tuple[type, ...]) -> int | str:
"""Infer the resource ID from a dictionary of keyword arguments.
Parameters
----------
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
resource_id_type: Union[type, Tuple[type, ...]]
The expected type of the resource ID, which can be integer (int) or a string (str).
Returns
-------
Union[None, int, str]
The inferred resource ID. If it cannot be inferred or does not match the expected type, it returns None.
Note
----
- When `resource_id_type` is `int`, the function looks for an argument with the key 'id'.
- When `resource_id_type` is `str`, it attempts to infer the resource ID as a string.
"""
resource_id: int | str | None = None
for arg_name, arg_value in kwargs.items():
if isinstance(arg_value, resource_id_type):
if (resource_id_type is int) and ("id" in arg_name):
resource_id = arg_value
elif (resource_id_type is int) and ("id" not in arg_name):
pass
elif resource_id_type is str:
resource_id = arg_value
if resource_id is None:
raise CacheIdentificationInferenceError
return resource_id
def _extract_data_inside_brackets(input_string: str) -> list[str]:
"""Extract data inside curly brackets from a given string using regular expressions.
Parameters
----------
input_string: str
The input string in which to find data enclosed within curly brackets.
Returns
-------
List[str]
A list of strings containing the data found inside the curly brackets within the input string.
Example
-------
>>> _extract_data_inside_brackets("The {quick} brown {fox} jumps over the {lazy} dog.")
['quick', 'fox', 'lazy']
"""
data_inside_brackets = re.findall(r"{(.*?)}", input_string)
return data_inside_brackets
def _construct_data_dict(data_inside_brackets: list[str], kwargs: dict[str, Any]) -> dict[str, Any]:
"""Construct a dictionary based on data inside brackets and keyword arguments.
Parameters
----------
data_inside_brackets: List[str]
A list of keys inside brackets.
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
Returns
-------
Dict[str, Any]: A dictionary with keys from data_inside_brackets and corresponding values from kwargs.
"""
data_dict = {}
for key in data_inside_brackets:
data_dict[key] = kwargs[key]
return data_dict
def _format_prefix(prefix: str, kwargs: dict[str, Any]) -> str:
"""Format a prefix using keyword arguments.
Parameters
----------
prefix: str
The prefix template to be formatted.
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
Returns
-------
str: The formatted prefix.
"""
data_inside_brackets = _extract_data_inside_brackets(prefix)
data_dict = _construct_data_dict(data_inside_brackets, kwargs)
formatted_prefix = prefix.format(**data_dict)
return formatted_prefix
def _format_extra_data(to_invalidate_extra: dict[str, str], kwargs: dict[str, Any]) -> dict[str, Any]:
"""Format extra data based on provided templates and keyword arguments.
This function takes a dictionary of templates and their associated values and a dictionary of keyword arguments.
It formats the templates with the corresponding values from the keyword arguments and returns a dictionary
where keys are the formatted templates and values are the associated keyword argument values.
Parameters
----------
to_invalidate_extra: Dict[str, str]
A dictionary where keys are templates and values are the associated values.
kwargs: Dict[str, Any]
A dictionary of keyword arguments.
Returns
-------
Dict[str, Any]: A dictionary where keys are formatted templates and values
are associated keyword argument values.
"""
formatted_extra = {}
for prefix, id_template in to_invalidate_extra.items():
formatted_prefix = _format_prefix(prefix, kwargs)
id = _extract_data_inside_brackets(id_template)[0]
formatted_extra[formatted_prefix] = kwargs[id]
return formatted_extra
async def _delete_keys_by_pattern(pattern: str) -> None:
"""Delete keys from Redis that match a given pattern using the SCAN command.
This function iteratively scans the Redis key space for keys that match a specific pattern
and deletes them. It uses the SCAN command to efficiently find keys, which is more
performance-friendly compared to the KEYS command, especially for large datasets.
The function scans the key space in an iterative manner using a cursor-based approach.
It retrieves a batch of keys matching the pattern on each iteration and deletes them
until no matching keys are left.
Parameters
----------
pattern: str
The pattern to match keys against. The pattern can include wildcards,
such as '*' for matching any character sequence. Example: 'user:*'
Notes
-----
- The SCAN command is used with a count of 100 to retrieve keys in batches.
This count can be adjusted based on the size of your dataset and Redis performance.
- The function uses the delete command to remove keys in bulk. If the dataset
is extremely large, consider implementing additional logic to handle bulk deletion
more efficiently.
- Be cautious with patterns that could match a large number of keys, as deleting
many keys simultaneously may impact the performance of the Redis server.
"""
if client is None:
raise MissingClientError
cursor = -1
while cursor != 0:
cursor, keys = await client.scan(cursor, match=pattern, count=100)
if keys:
await client.delete(*keys)
def cache(
key_prefix: str,
resource_id_name: Any = None,
expiration: int = 3600,
resource_id_type: type | tuple[type, ...] = int,
to_invalidate_extra: dict[str, Any] | None = None,
pattern_to_invalidate_extra: list[str] | None = None,
) -> Callable:
"""Cache decorator for FastAPI endpoints.
This decorator enables caching the results of FastAPI endpoint functions to improve response times
and reduce the load on the application by storing and retrieving data in a cache.
Parameters
----------
key_prefix: str
A unique prefix to identify the cache key.
resource_id_name: Any, optional
The name of the resource ID argument in the decorated function. If provided, it is used directly;
otherwise, the resource ID is inferred from the function's arguments.
expiration: int, optional
The expiration time for the cached data in seconds. Defaults to 3600 seconds (1 hour).
resource_id_type: Union[type, Tuple[type, ...]], default int
The expected type of the resource ID.
This can be a single type (e.g., int) or a tuple of types (e.g., (int, str)).
Defaults to int. This is used only if resource_id_name is not provided.
to_invalidate_extra: Dict[str, Any] | None, optional
A dictionary where keys are cache key prefixes and values are templates for cache key suffixes.
These keys are invalidated when the decorated function is called with a method other than GET.
pattern_to_invalidate_extra: List[str] | None, optional
A list of string patterns for cache keys that should be invalidated when the decorated function is called.
This allows for bulk invalidation of cache keys based on a matching pattern.
Returns
-------
Callable
A decorator function that can be applied to FastAPI endpoint functions.
Example usage
-------------
```python
from fastapi import FastAPI, Request
from my_module import cache # Replace with your actual module and imports
app = FastAPI()
# Define a sample endpoint with caching
@app.get("/sample/{resource_id}")
@cache(key_prefix="sample_data", expiration=3600, resource_id_type=int)
async def sample_endpoint(request: Request, resource_id: int):
# Your endpoint logic here
return {"data": "your_data"}
```
This decorator caches the response data of the endpoint function using a unique cache key.
The cached data is retrieved for GET requests, and the cache is invalidated for other types of requests.
Advanced Example Usage
-------------
```python
from fastapi import FastAPI, Request
from my_module import cache
app = FastAPI()
@app.get("/users/{user_id}/items")
@cache(key_prefix="user_items", resource_id_name="user_id", expiration=1200)
async def read_user_items(request: Request, user_id: int):
# Endpoint logic to fetch user's items
return {"items": "user specific items"}
@app.put("/items/{item_id}")
@cache(
key_prefix="item_data",
resource_id_name="item_id",
to_invalidate_extra={"user_items": "{user_id}"},
pattern_to_invalidate_extra=["user_*_items:*"],
)
async def update_item(request: Request, item_id: int, data: dict, user_id: int):
# Update logic for an item
# Invalidate both the specific item cache and all user-specific item lists
return {"status": "updated"}
```
In this example:
- When reading user items, the response is cached under a key formed with 'user_items' prefix and 'user_id'.
- When updating an item, the cache for this specific item (under 'item_data:item_id') and all caches with keys
starting with 'user_{user_id}_items:' are invalidated. The `to_invalidate_extra` parameter specifically targets
the cache for user-specific item lists, while `pattern_to_invalidate_extra` allows bulk invalidation of all keys
matching the pattern 'user_*_items:*', covering all users.
Note
----
- resource_id_type is used only if resource_id is not passed.
- `to_invalidate_extra` and `pattern_to_invalidate_extra` are used for cache invalidation on methods other than GET.
- Using `pattern_to_invalidate_extra` can be resource-intensive on large datasets. Use it judiciously and
consider the potential impact on Redis performance.
"""
def wrapper(func: Callable) -> Callable:
@functools.wraps(func)
async def inner(request: Request, *args: Any, **kwargs: Any) -> Response:
if client is None:
raise MissingClientError
if resource_id_name:
resource_id = kwargs[resource_id_name]
else:
resource_id = _infer_resource_id(kwargs=kwargs, resource_id_type=resource_id_type)
formatted_key_prefix = _format_prefix(key_prefix, kwargs)
cache_key = f"{formatted_key_prefix}:{resource_id}"
if request.method == "GET":
if to_invalidate_extra is not None or pattern_to_invalidate_extra is not None:
raise InvalidRequestError
cached_data = await client.get(cache_key)
if cached_data:
return json.loads(cached_data.decode())
result = await func(request, *args, **kwargs)
if request.method == "GET":
serializable_data = jsonable_encoder(result)
serialized_data = json.dumps(serializable_data)
await client.set(cache_key, serialized_data)
await client.expire(cache_key, expiration)
serialized_data = json.loads(serialized_data)
else:
await client.delete(cache_key)
if to_invalidate_extra is not None:
formatted_extra = _format_extra_data(to_invalidate_extra, kwargs)
for prefix, id in formatted_extra.items():
extra_cache_key = f"{prefix}:{id}"
await client.delete(extra_cache_key)
if pattern_to_invalidate_extra is not None:
for pattern in pattern_to_invalidate_extra:
formatted_pattern = _format_prefix(pattern, kwargs)
await _delete_keys_by_pattern(formatted_pattern + "*")
return result
return inner
return wrapper
================================================
FILE: src/app/core/utils/queue.py
================================================
from arq.connections import ArqRedis
pool: ArqRedis | None = None
================================================
FILE: src/app/core/utils/rate_limit.py
================================================
from datetime import UTC, datetime
from redis.asyncio import ConnectionPool, Redis
from sqlalchemy.ext.asyncio import AsyncSession
from ...core.logger import logging
from ...models.rate_limit import sanitize_path
logger = logging.getLogger(__name__)
pool: ConnectionPool | None = None
client: Redis | None = None
async def is_rate_limited(db: AsyncSession, user_id: int, path: str, limit: int, period: int) -> bool:
if client is None:
logger.error("Redis client is not initialized.")
raise Exception("Redis client is not initialized.")
current_timestamp = int(datetime.now(UTC).timestamp())
window_start = current_timestamp - (current_timestamp % period)
sanitized_path = sanitize_path(path)
key = f"ratelimit:{user_id}:{sanitized_path}:{window_start}"
try:
current_count = await client.incr(key)
if current_count == 1:
await client.expire(key, period)
if current_count > limit:
return True
except Exception as e:
logger.exception(f"Error checking rate limit for user {user_id} on path {path}: {e}")
raise e
return False
================================================
FILE: src/app/core/worker/__init__.py
================================================
================================================
FILE: src/app/core/worker/functions.py
================================================
import asyncio
import logging
import uvloop
from arq.worker import Worker
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
# -------- background tasks --------
async def sample_background_task(ctx: Worker, name: str) -> str:
await asyncio.sleep(5)
return f"Task {name} is complete!"
# -------- base functions --------
async def startup(ctx: Worker) -> None:
logging.info("Worker Started")
async def shutdown(ctx: Worker) -> None:
logging.info("Worker end")
================================================
FILE: src/app/core/worker/settings.py
================================================
from arq.connections import RedisSettings
from ...core.config import settings
from .functions import sample_background_task, shutdown, startup
REDIS_QUEUE_HOST = settings.REDIS_QUEUE_HOST
REDIS_QUEUE_PORT = settings.REDIS_QUEUE_PORT
class WorkerSettings:
functions = [sample_background_task]
redis_settings = RedisSettings(host=REDIS_QUEUE_HOST, port=REDIS_QUEUE_PORT)
on_startup = startup
on_shutdown = shutdown
handle_signals = False
================================================
FILE: src/app/crud/__init__.py
================================================
================================================
FILE: src/app/crud/crud_posts.py
================================================
from fastcrud import FastCRUD
from ..models.post import Post, PostCreateInternal, PostDelete, PostUpdate, PostUpdateInternal
CRUDPost = FastCRUD[Post, PostCreateInternal, PostUpdate, PostUpdateInternal, PostDelete]
crud_posts = CRUDPost(Post)
================================================
FILE: src/app/crud/crud_rate_limit.py
================================================
from fastcrud import FastCRUD
from ..models.rate_limit import RateLimit, RateLimitCreateInternal, RateLimitDelete, RateLimitUpdate, RateLimitUpdateInternal
CRUDRateLimit = FastCRUD[RateLimit, RateLimitCreateInternal, RateLimitUpdate, RateLimitUpdateInternal, RateLimitDelete]
crud_rate_limits = CRUDRateLimit(RateLimit)
================================================
FILE: src/app/crud/crud_tier.py
================================================
from fastcrud import FastCRUD
from ..models.tier import Tier, TierCreateInternal, TierDelete, TierUpdate, TierUpdateInternal
CRUDTier = FastCRUD[Tier, TierCreateInternal, TierUpdate, TierUpdateInternal, TierDelete]
crud_tiers = CRUDTier(Tier)
================================================
FILE: src/app/crud/crud_users.py
================================================
from fastcrud import FastCRUD
from ..models.user import User, UserCreateInternal, UserDelete, UserUpdate, UserUpdateInternal
CRUDUser = FastCRUD[User, UserCreateInternal, UserUpdate, UserUpdateInternal, UserDelete]
crud_users = CRUDUser(User)
================================================
FILE: src/app/main.py
================================================
from .api import router
from .core.config import settings
from .core.setup import create_application
app = create_application(router=router, settings=settings)
================================================
FILE: src/app/middleware/client_cache_middleware.py
================================================
from fastapi import FastAPI, Request, Response
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
class ClientCacheMiddleware(BaseHTTPMiddleware):
"""Middleware to set the `Cache-Control` header for client-side caching on all responses.
Parameters
----------
app: FastAPI
The FastAPI application instance.
max_age: int, optional
Duration (in seconds) for which the response should be cached. Defaults to 60 seconds.
Attributes
----------
max_age: int
Duration (in seconds) for which the response should be cached.
Methods
-------
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
Process the request and set the `Cache-Control` header in the response.
Note
----
- The `Cache-Control` header instructs clients (e.g., browsers)
to cache the response for the specified duration.
"""
def __init__(self, app: FastAPI, max_age: int = 60) -> None:
super().__init__(app)
self.max_age = max_age
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
"""Process the request and set the `Cache-Control` header in the response.
Parameters
----------
request: Request
The incoming request.
call_next: RequestResponseEndpoint
The next middleware or route handler in the processing chain.
Returns
-------
Response
The response object with the `Cache-Control` header set.
Note
----
- This method is automatically called by Starlette for processing the request-response cycle.
"""
response: Response = await call_next(request)
response.headers["Cache-Control"] = f"public, max-age={self.max_age}"
return response
================================================
FILE: src/app/models/__init__.py
================================================
from .post import Post
from .rate_limit import RateLimit
from .tier import Tier
from .user import User
================================================
FILE: src/app/models/job.py
================================================
from sqlmodel import SQLModel
class Job(SQLModel):
id: str
================================================
FILE: src/app/models/post.py
================================================
from datetime import datetime
from typing import Optional
from sqlmodel import SQLModel, Field, Relationship
from uuid import uuid4
class PostBase(SQLModel):
title: str = Field(..., min_length=2, max_length=30, schema_extra={"example": "This is my post"})
text: str = Field(..., min_length=1, max_length=63206, schema_extra={"example": "This is the content of my post."})
class Post(PostBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
created_by_user_id: int = Field(foreign_key="user.id")
media_url: Optional[str] = Field(default=None, regex=r"^(https?|ftp)://[^\s/$.?#].[^\s]*$", schema_extra={"example": "https://www.postimageurl.com"})
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
updated_at: Optional[datetime] = None
deleted_at: Optional[datetime] = None
is_deleted: bool = Field(default=False)
class PostRead(PostBase):
id: int
created_by_user_id: int
media_url: Optional[str]
created_at: datetime
class PostCreate(PostBase):
media_url: Optional[str] = Field(default=None, regex=r"^(https?|ftp)://[^\s/$.?#].[^\s]*$", schema_extra={"example": "https://www.postimageurl.com"})
class PostCreateInternal(PostCreate):
created_by_user_id: int
class PostUpdate(SQLModel):
title: Optional[str] = Field(default=None, min_length=2, max_length=30)
text: Optional[str] = Field(default=None, min_length=1, max_length=63206)
media_url: Optional[str] = Field(default=None, regex=r"^(https?|ftp)://[^\s/$.?#].[^\s]*$")
class PostUpdateInternal(PostUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class PostDelete(SQLModel):
is_deleted: bool
deleted_at: datetime
================================================
FILE: src/app/models/rate_limit.py
================================================
from datetime import datetime
from typing import Optional
from sqlmodel import SQLModel, Field
def sanitize_path(path: str) -> str:
return path.strip("/").replace("/", "_")
class RateLimitBase(SQLModel):
path: str = Field(..., schema_extra={"example": "users"})
limit: int = Field(..., schema_extra={"example": 5})
period: int = Field(..., schema_extra={"example": 60})
@classmethod
def validate_path(cls, v: str) -> str:
return sanitize_path(v)
class RateLimit(RateLimitBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
tier_id: int = Field(foreign_key="tier.id")
name: Optional[str] = Field(default=None, schema_extra={"example": "users:5:60"})
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
updated_at: Optional[datetime] = None
class RateLimitRead(RateLimitBase):
id: int
tier_id: int
name: str
class RateLimitCreate(RateLimitBase):
name: Optional[str] = Field(default=None, schema_extra={"example": "api_v1_users:5:60"})
class RateLimitCreateInternal(RateLimitCreate):
tier_id: int
class RateLimitUpdate(SQLModel):
path: Optional[str] = Field(default=None)
limit: Optional[int] = None
period: Optional[int] = None
name: Optional[str] = None
@classmethod
def validate_path(cls, v: Optional[str]) -> Optional[str]:
return sanitize_path(v) if v is not None else None
class RateLimitUpdateInternal(RateLimitUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class RateLimitDelete(SQLModel):
pass
================================================
FILE: src/app/models/tier.py
================================================
from datetime import datetime
from typing import Optional
from sqlmodel import SQLModel, Field
class TierBase(SQLModel):
name: str = Field(..., schema_extra={"example": "free"})
class Tier(TierBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
updated_at: Optional[datetime] = None
class TierRead(TierBase):
id: int
created_at: datetime
class TierCreate(TierBase):
pass
class TierCreateInternal(TierCreate):
pass
class TierUpdate(SQLModel):
name: Optional[str] = None
class TierUpdateInternal(TierUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class TierDelete(SQLModel):
pass
================================================
FILE: src/app/models/user.py
================================================
from datetime import datetime
from typing import Optional
import uuid as uuid_pkg
from sqlmodel import SQLModel, Field
from pydantic import validator
class UserBase(SQLModel):
name: str = Field(..., min_length=2, max_length=30, schema_extra={"example": "User Userson"})
username: str = Field(..., min_length=2, max_length=20, regex="^[a-z0-9]+$", schema_extra={"example": "userson"})
email: str = Field(..., schema_extra={"example": "user.userson@example.com"})
class User(UserBase, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
profile_image_url: str = Field("https://www.profileimageurl.com")
hashed_password: str
is_superuser: bool = Field(default=False)
tier_id: Optional[int] = Field(default=None, foreign_key="tier.id")
created_at: datetime = Field(default_factory=lambda: datetime.now(datetime.timezone.utc))
uuid: uuid_pkg.UUID = Field(default_factory=uuid_pkg.uuid4, primary_key=True)
updated_at: Optional[datetime] = None
deleted_at: Optional[datetime] = None
is_deleted: bool = Field(default=False)
class UserRead(SQLModel):
id: int
name: str
username: str
email: str
profile_image_url: str
tier_id: Optional[int]
class UserCreate(UserBase):
password: str = Field(..., regex="^.{8,}|[0-9]+|[A-Z]+|[a-z]+|[^a-zA-Z0-9]+$", schema_extra={"example": "Str1ngst!"})
@validator('password')
def validate_password(cls, value):
if len(value) < 8:
raise ValueError("Password must be at least 8 characters")
return value
class UserCreateInternal(UserBase):
hashed_password: str
class UserUpdate(SQLModel):
name: Optional[str] = Field(None, min_length=2, max_length=30)
username: Optional[str] = Field(None, min_length=2, max_length=20, regex="^[a-z0-9]+$")
email: Optional[str] = None
profile_image_url: Optional[str] = None
class UserUpdateInternal(UserUpdate):
updated_at: Optional[datetime] = Field(default_factory=datetime.utcnow)
class UserTierUpdate(SQLModel):
tier_id: int
class UserDelete(SQLModel):
is_deleted: bool
deleted_at: datetime
class UserRestoreDeleted(SQLModel):
is_deleted: bool
================================================
FILE: src/migrations/README
================================================
Generic single-database configuration.
================================================
FILE: src/migrations/env.py
================================================
import asyncio
from logging.config import fileConfig
from alembic import context
from app.core.config import settings
from app.core.db.database import SQLModel
from sqlalchemy import pool
from sqlalchemy.engine import Connection
from sqlalchemy.ext.asyncio import async_engine_from_config
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
config.set_main_option(
"sqlalchemy.url",
f"{settings.POSTGRES_ASYNC_PREFIX}{settings.POSTGRES_USER}:{settings.POSTGRES_PASSWORD}@localhost/{settings.POSTGRES_DB}",
)
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
target_metadata = SQLModel.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL and not an Engine, though an Engine is acceptable here as well. By
skipping the Engine creation we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def do_run_migrations(connection: Connection) -> None:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
async def run_async_migrations() -> None:
"""In this scenario we need to create an Engine and associate a connection with the context."""
connectable = async_engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
async with connectable.connect() as connection:
await connection.run_sync(do_run_migrations)
await connectable.dispose()
def run_migrations_online() -> None:
"""Run migrations in 'online' mode."""
asyncio.run(run_async_migrations())
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
================================================
FILE: src/migrations/script.py.mako
================================================
"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
Create Date: ${create_date}
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
${imports if imports else ""}
# revision identifiers, used by Alembic.
revision: str = ${repr(up_revision)}
down_revision: Union[str, None] = ${repr(down_revision)}
branch_labels: Union[str, Sequence[str], None] = ${repr(branch_labels)}
depends_on: Union[str, Sequence[str], None] = ${repr(depends_on)}
def upgrade() -> None:
${upgrades if upgrades else "pass"}
def downgrade() -> None:
${downgrades if downgrades else "pass"}
================================================
FILE: src/migrations/versions/README.MD
================================================
================================================
FILE: src/scripts/__init__.py
================================================
================================================
FILE: src/scripts/create_first_superuser.py
================================================
import asyncio
import logging
import uuid
from datetime import UTC, datetime
from sqlalchemy import Boolean, Column, DateTime, ForeignKey, Integer, MetaData, String, Table, insert, select
from sqlalchemy.dialects.postgresql import UUID
from ..app.core.config import settings
from ..app.core.db.database import AsyncSession, async_engine, local_session
from ..app.core.security import get_password_hash
from ..app.models.user import User
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_first_user(session: AsyncSession) -> None:
try:
name = settings.ADMIN_NAME
email = settings.ADMIN_EMAIL
username = settings.ADMIN_USERNAME
hashed_password = get_password_hash(settings.ADMIN_PASSWORD)
query = select(User).filter_by(email=email)
result = await session.execute(query)
user = result.scalar_one_or_none()
if user is None:
metadata = MetaData()
user_table = Table(
"user",
metadata,
Column("id", Integer, primary_key=True, autoincrement=True, nullable=False),
Column("name", String(30), nullable=False),
Column("username", String(20), nullable=False, unique=True, index=True),
Column("email", String(50), nullable=False, unique=True, index=True),
Column("hashed_password", String, nullable=False),
Column("profile_image_url", String, default="https://profileimageurl.com"),
Column("uuid", UUID(as_uuid=True), primary_key=True, default=uuid.uuid4, unique=True),
Column("created_at", DateTime(timezone=True), default=lambda: datetime.now(UTC), nullable=False),
Column("updated_at", DateTime),
Column("deleted_at", DateTime),
Column("is_deleted", Boolean, default=False, index=True),
Column("is_superuser", Boolean, default=False),
Column("tier_id", Integer, ForeignKey("tier.id"), index=True),
)
data = {
"name": name,
"email": email,
"username": username,
"hashed_password": hashed_password,
"is_superuser": True,
}
stmt = insert(user_table).values(data)
async with async_engine.connect() as conn:
await conn.execute(stmt)
await conn.commit()
logger.info(f"Admin user {username} created successfully.")
else:
logger.info(f"Admin user {username} already exists.")
except Exception as e:
logger.error(f"Error creating admin user: {e}")
async def main():
async with local_session() as session:
await create_first_user(session)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
================================================
FILE: src/scripts/create_first_tier.py
================================================
import asyncio
import logging
from sqlalchemy import select
from ..app.core.config import config
from ..app.core.db.database import AsyncSession, local_session
from ..app.models.tier import Tier
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_first_tier(session: AsyncSession) -> None:
try:
tier_name = config("TIER_NAME", default="free")
query = select(Tier).where(Tier.name == tier_name)
result = await session.execute(query)
tier = result.scalar_one_or_none()
if tier is None:
session.add(Tier(name=tier_name))
await session.commit()
logger.info(f"Tier '{tier_name}' created successfully.")
else:
logger.info(f"Tier '{tier_name}' already exists.")
except Exception as e:
logger.error(f"Error creating tier: {e}")
async def main():
async with local_session() as session:
await create_first_tier(session)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
================================================
FILE: tests/__init__.py
================================================
================================================
FILE: tests/conftest.py
================================================
import pytest
from fastapi.testclient import TestClient
from src.app.main import app
@pytest.fixture(scope="session")
def client():
with TestClient(app) as _client:
yield _client
================================================
FILE: tests/helper.py
================================================
from fastapi.testclient import TestClient
def _get_token(username: str, password: str, client: TestClient):
return client.post(
"/api/v1/login",
data={"username": username, "password": password},
headers={"content-type": "application/x-www-form-urlencoded"},
)
================================================
FILE: tests/test_user.py
================================================
from fastapi.testclient import TestClient
from src.app.core.config import settings
from src.app.main import app
from .helper import _get_token
test_name = settings.TEST_NAME
test_username = settings.TEST_USERNAME
test_email = settings.TEST_EMAIL
test_password = settings.TEST_PASSWORD
admin_username = settings.ADMIN_USERNAME
admin_password = settings.ADMIN_PASSWORD
client = TestClient(app)
def test_post_user(client: TestClient) -> None:
response = client.post(
"/api/v1/user",
json={"name": test_name, "username": test_username, "email": test_email, "password": test_password},
)
assert response.status_code == 201
def test_get_user(client: TestClient) -> None:
response = client.get(f"/api/v1/user/{test_username}")
assert response.status_code == 200
def test_get_multiple_users(client: TestClient) -> None:
response = client.get("/api/v1/users")
assert response.status_code == 200
def test_update_user(client: TestClient) -> None:
token = _get_token(username=test_username, password=test_password, client=client)
response = client.patch(
f"/api/v1/user/{test_username}",
json={"name": f"Updated {test_name}"},
headers={"Authorization": f'Bearer {token.json()["access_token"]}'},
)
assert response.status_code == 200
def test_delete_user(client: TestClient) -> None:
token = _get_token(username=test_username, password=test_password, client=client)
response = client.delete(
f"/api/v1/user/{test_username}", headers={"Authorization": f'Bearer {token.json()["access_token"]}'}
)
assert response.status_code == 200
def test_delete_db_user(client: TestClient) -> None:
token = _get_token(username=admin_username, password=admin_password, client=client)
response = client.delete(
f"/api/v1/db_user/{test_username}", headers={"Authorization": f'Bearer {token.json()["access_token"]}'}
)
assert response.status_code == 200