Showing preview only (2,087K chars total). Download the full file or copy to clipboard to get everything.
Repository: im-d-team/Dev-Docs
Branch: master
Commit: 785fb0814164
Files: 248
Total size: 1.4 MB
Directory structure:
gitextract_vbaffuo6/
├── .github/
│ └── workflows/
│ └── action.yml
├── .mergify.yml
├── Android/
│ └── application fundamentals.md
├── Browser/
│ ├── BrowserXY.md
│ ├── Cookie.md
│ ├── Cookie_Store.md
│ ├── FOUC.md
│ ├── HTTP2_Websocket.md
│ ├── IndexedDB_WebSQL.md
│ ├── Layer_Model.md
│ ├── WebWorker.md
│ ├── Worklet.md
│ ├── 웹 브라우저의 작동 원리.md
│ └── 최신_브라우저의_내부_살펴보기.md
├── CS/
│ ├── Binding.md
│ ├── Bomb-Lab(1).md
│ ├── Call-By-Sharing.md
│ ├── Counting-sort.md
│ ├── Graph.md
│ ├── Memory.md
│ ├── Radix-sort.md
│ ├── aspect-oriented-programming.md
│ ├── cohension&coupling.md
│ ├── compression.md
│ ├── dependency-inversion-principle.md
│ ├── grasp.md
│ ├── information_theory.md
│ ├── integer_representation.md
│ ├── interface-segregation-principle.md
│ ├── liskov_substitution_principle.md
│ ├── methods_in_IPC.md
│ ├── non-blocking.md
│ ├── non-linear-search.md
│ ├── open-closed-principle.md
│ ├── soc.md
│ ├── srp.md
│ ├── union-find.md
│ ├── 페이징과 세그먼테이션.md
│ └── 플로이드-와샬-알고리즘.md
├── CSS/
│ ├── CJK.md
│ ├── WebToMobile.md
│ └── safe-area.md
├── Database/
│ ├── DB Connection Pool.md
│ ├── Query Builder ( Knex.js).md
│ └── Types of Databases.md
├── Deprecated/
│ ├── AMD와 CommonJS.md
│ ├── Async-Await.md
│ ├── B_EventLoop.md
│ ├── B_Module.md
│ ├── CORS(Cross-Origin Resource Sharing).md
│ ├── CSS 애니메이션 vs JS 애니메이션.md
│ ├── CallByReference.md
│ ├── EventLoop.md
│ ├── EventLoop_Advanced.md
│ ├── Funtional.md
│ ├── Higher_Order_Functions.md
│ ├── Javascript_BuildTool.md
│ ├── Module.md
│ ├── Promise1.md
│ ├── Promise2.md
│ ├── Reactive.md
│ ├── Repaint와 Reflow.md
│ ├── WebWorker.md
│ ├── animation.md
│ ├── setState.md
│ ├── 기본적인 렌더링 최적화 방법.md
│ ├── 웹 브라우저의 작동 원리.md
│ └── 점진적향상_우아한하향.md
├── Design_Pattern/
│ ├── Composite.md
│ ├── JSP model.md
│ ├── MSA.md
│ ├── MVC1, MVC2.md
│ ├── MVC_MVP_MVVM.md
│ ├── Memoization.md
│ ├── RxJS.md
│ ├── Singleton.md
│ └── Throttle and Debounce.md
├── ECMAScript/
│ ├── ArrowFunction.md
│ ├── Destructuring_Assignment.md
│ ├── ECMA2019.md
│ ├── ES6-module-in-Browser.md
│ ├── Generator와 async-await.md
│ ├── Includes_IndexOf.md
│ ├── Iteration_Protocol.md
│ ├── ModulePattern_class.md
│ ├── Number_isNaN.md
│ ├── Spread_Operator.md
│ └── Tagged_Template_Literals.md
├── Git/
│ └── gitBy_.git.md
├── HTML/
│ ├── ARIA.md
│ ├── DOM API.md
│ ├── DOM.md
│ ├── HTML-Templating.md
│ ├── Head_Meta.md
│ ├── Standard&QuirksMode.md
│ ├── WebM&WebP.md
│ ├── input태그의_value바꾸기(input태그의_dirty flag).md
│ ├── preload&prefetch.md
│ └── 웹 컴포넌트(Web Component).md
├── Java/
│ ├── ArrayList vs LinkedList 그리고 Vector.md
│ ├── Comparable vs Comparator.md
│ ├── Dependency Injection(DI).md
│ ├── JSP와 Servlet처리.md
│ ├── JVM(Java Virtual Machine).md
│ ├── Java Garbage Collection(GC).md
│ ├── Mybatis.md
│ ├── Set.md
│ ├── String, StringBuilder, StringBuffer.md
│ ├── String,StringBuilder, StringBuffer차이.md
│ ├── Upcasting과 Downcasting.md
│ ├── WAS.md
│ ├── copy-object.md
│ ├── date-api-in-java.md
│ └── junit-setup.md
├── Javascript/
│ ├── Ajax.md
│ ├── Animation.md
│ ├── B_Async.md
│ ├── B_Call_Apply_Bind.md
│ ├── B_Callback.md
│ ├── B_Class.md
│ ├── B_Function.md
│ ├── B_Type.md
│ ├── Build Tool.md
│ ├── CallStack.md
│ ├── Closure.md
│ ├── Control_CSSOM.md
│ ├── DocumentFragment.md
│ ├── Event Delegation.md
│ ├── InsertAdjacentHTML.md
│ ├── JavaScript의 this.md
│ ├── Javascript_Engine.md
│ ├── Javascript_메모리관리.md
│ ├── Javascript의_동작원리-변수객체(VariableObject).md
│ ├── Javascript의_동작원리-실행컨텍스트(Execution Contexts).md
│ ├── Jest.md
│ ├── Learning_more_about_this.md
│ ├── Module.md
│ ├── MouseEvent.md
│ ├── Object.create&Object.assign.md
│ ├── Observer.md
│ ├── Optional_Chaining.md
│ ├── PromisePattern.md
│ ├── Prototype_Chain.md
│ ├── Proxy.md
│ ├── Reduce.md
│ ├── Redux State 정규화.md
│ ├── Regular_Expressions.md
│ ├── Scope.md
│ ├── Some_Every.md
│ ├── Storybook.md
│ ├── Sync&Async_Multi&Single_Thread.md
│ ├── TimeInJS.md
│ ├── Variable.md
│ ├── WebRTC.md
│ ├── Web_Storage_API.md
│ ├── ajax(2).md
│ ├── bind.md
│ ├── object.md
│ ├── object_create_pattern-constructor.md
│ ├── object_생성패턴.md
│ ├── prototype(2).md
│ ├── prototype.md
│ ├── scope_this.md
│ ├── throttling과 rAF.md
│ ├── tricks_of_js.md
│ ├── underscore와 lodash그리고 Native.md
│ ├── window.history.md
│ ├── 논리연산자.md
│ ├── 렉시컬_속이기(eval).md
│ ├── 배열 내장함수.md
│ ├── 상태관리 라이브러리.md
│ ├── 이벤트 루프(Event Loop).md
│ ├── 클래스(class).md
│ ├── 클로저.md
│ └── 함수 선언.md
├── LICENSE
├── Language/
│ ├── Currying.md
│ ├── Lamda.md
│ ├── Reactive.md
│ ├── XML_JSON.md
│ ├── 고차함수(High Order Function).md
│ └── 함수형 프로그래밍.md
├── ML/
│ └── 머신러닝이란.md
├── Network/
│ ├── 3-way handshaking & 4-way handshaking.md
│ ├── CORS.md
│ ├── DHCP&DNS.md
│ ├── Flow control.md
│ ├── HTTP3.md
│ ├── IP.md
│ ├── JSend.md
│ ├── OSI7 Layer.md
│ ├── REST API.md
│ ├── REST.md
│ ├── SOAP API.md
│ ├── Subnetmask.md
│ ├── Switch.md
│ ├── TCP & UDP.md
│ ├── TypesOfIP.md
│ ├── comet.md
│ ├── congestion control.md
│ ├── get&post.md
│ ├── http-caching.md
│ ├── 로드밸런싱 & 클러스터링.md
│ └── 사용자 인증 방식(Cookie, Session & oAuth 2.0 & JWT).md
├── Node.js/
│ ├── make_meta_file.md
│ └── nodejs의_특징.md
├── OpenCV/
│ └── 이미지전처리.md
├── Performance/
│ ├── DeadLock(교착상태).md
│ ├── HTTP2.0의 필요성.md
│ ├── Reflow Repaint.md
│ ├── Throttling vs Debouncing.md
│ ├── requestAnimationFram(rAF).md
│ ├── 기본적인 렌더링 최적화 방법.md
│ ├── 서버 사이드 렌더링(SSR).md
│ └── 점진적향상_우아한하향.md
├── README.md
├── React/
│ ├── Component, Props, State.md
│ ├── Composition.md
│ ├── Element와 Component.md
│ ├── ImmutableState.md
│ ├── React Server Components.md
│ ├── React.memo.md
│ ├── React의 Lifecycle Event.md
│ ├── SWR.md
│ ├── Virtual DOM.md
│ └── props와 state.md
├── Rules/
│ ├── Commit.md
│ └── Markdown.md
├── Security/
│ ├── HTTPS와 SSL.md
│ ├── Response_Header_Security.md
│ ├── SQL_Injection.md
│ └── 리만가설과 소수정리.md
├── Tool/
│ ├── Chrome_80_DevTool.md
│ ├── Framework vs Library.md
│ └── Package Manager.md
├── Typescript/
│ ├── 인터페이스(Interface).md
│ ├── 정적 타이핑.md
│ ├── 제네릭(Generic).md
│ └── 클래스(class).md
├── Vue/
│ └── Vue_LifeCycle.md
├── WPF/
│ └── wpf.md
└── assets/
├── IndexDB/
│ ├── TodoList/
│ │ ├── index.html
│ │ ├── js/
│ │ │ ├── indexDB.js
│ │ │ └── todo.js
│ │ └── todoStyle.css
│ └── index2.html
└── TEST/
├── bigfile.html
└── window.history.demo.html
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/action.yml
================================================
name: "Pull Request Action"
on:
pull_request:
types: [opened]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Create link
uses: Im-D/Im-Bot/packages/pr-supporter@master
with:
myToken: ${{ secrets.GITHUB_TOKEN }}
- name: Create reviewRequest
uses: Im-D/Im-Bot/packages/pr-reviewer@master
with:
myToken: ${{ secrets.GITHUB_TOKEN }}
- name: Create Link at README file
uses: Im-D/Im-Bot/packages/update-readme@master
with:
myToken: ${{ secrets.GITHUB_TOKEN}}
linkLocTarget: '### 📅 History'
================================================
FILE: .mergify.yml
================================================
pull_request_rules:
- name: Automatic merge on review
# https://doc.mergify.io/examples.html#require-all-requested-reviews-to-be-approved
conditions:
- "#approved-reviews-by>=4"
- "#changes-requested-reviews-by=0"
- base=master
- label=approval + 3
actions:
merge:
method: merge
delete_head_branch: {}
- name: Add Label needs author response
conditions:
- "#changes-requested-reviews-by>=1"
actions:
label:
add: ["needs author response"]
remove: ["needs review"]
- name: Remove Label needs author response
conditions:
- "#changes-requested-reviews-by=0"
actions:
label:
add: ["needs review"]
remove: ["needs author response"]
- name: Add Label approval + 1
conditions:
- "#approved-reviews-by=1"
actions:
label:
add: ["approval + 1"]
- name: Add Label approval + 2
conditions:
- "#approved-reviews-by=2"
actions:
label:
add: ["approval + 2"]
remove: ["approval + 1"]
- name: Add Label approval + 3
conditions:
- "#approved-reviews-by=3"
actions:
label:
add: ["approval + 3"]
remove: ["approval + 2"]
================================================
FILE: Android/application fundamentals.md
================================================
# 안드로이드 (Android)
Android 앱은 Kotlin, Java, C++ 언어를 사용하여 작성할 수 있습니다. Android SDK(Software Development Kit) 도구는 모든 데이터 및 리소스 파일과 함께 코드를 컴파일하여 하나의 **APK(Android PacKage)** 를 만듭니다. Android Package는 접미사가 .apk인 아카이브 파일입니다. 한 개의 APK 파일에는 Android 앱의 모든 콘텐츠가 들어 있으며, Android로 구동하는 기기가 앱을 설치할 때 바로 이 파일을 사용합니다.
Android 시스템은 **최소 권한의 원리( Principle of least privilege )** 를 구현합니다. 다시 말해, 각 앱은 기본적으로 자신의 작업을 수행하기 위해 **필요한 구성 요소에만 액세스 권한을 가지고 그 이상은 허용되지 않습니다.** 이렇게 하면 대단히 안전한 환경이 구성되어 앱이 시스템에서 권한을 부여받지 못한 부분에는 액세스할 수 없게 됩니다.
앱이 다른 앱과 데이터를 공유하고 시스템 서비스에 액세스하는 방법은 여러 가지가 있습니다. 그 중에서 '권한'을 살펴보도록 하겠습니다. 앱은 사용자의 연락처, SMS 메시지, 마운트 가능한 저장소(SD 카드), 카메라, 블루투스를 비롯한 여러 가지 기기 데이터에 액세스할 '권한'을 요청할 수 있습니다. 사용자는 이러한 **권한(Permission)** 을 명시적으로 부여해야 합니다.
> 권한(Permission) 부여하는 방법
앱은 앱 매니페스트에 <uses-permission> 태그를 포함하여 필요한 권한을 추가해야 합니다. 예를 들어 **SMS 메시지를 보내야 하는 앱** 은 [매니페스트(manifest)](https://developer.android.com/guide/topics/manifest/manifest-intro?hl=ko)에 다음 줄이 있어야 합니다.
```xml
<manifest ... >
<uses-permission android:name="android.permission.SEND_SMS"/> <!-- SMS 메시지 권한 추가 -->
...
</manifest>
```
# 앱 기본요소 (Application Fundamentals)
- **Manifests**: 구성 요소를 선언하고 앱에 필수적인 기기 특징을 선언할 수 있는 매니페스트 파일.
- **App components**: 앱을 정의하는 핵심 프레임워크 구성 요소.
- **Resource**: 앱 코드로부터 별도로 분리되어 있으며 앱이 다양한 기기 구성에 맞게 자신의 동작을 안정적으로 최적화할 수 있도록 하는 리소스.
## 1. Manifests
모든 앱 프로젝트는 프로젝트 소스 세트의 루트에 **AndroidManifest.xml** 파일(정확히 이 이름)이 있어야 합니다. 매니페스트 파일은 Android 앱에서 필요한 모든 구성요소, Android 빌드 도구, Android 운영체제 및 Google Play에 앱에 관한 필수 정보를 설명합니다. 정리하면 다음과 같습니다.
- Package: 앱의 패키지 이름(일반적으로 코드의 네임스페이스와 일치)
- App Components: 앱의 구성 요소(모든 Activity, Service, Broadcast Receiver, Content Provider 포함)
- Permission: 앱이 시스템 또는 다른 앱의 보호된 부분에 액세스하기 위해 필요한 권한
- 앱에 필요한 하드웨어 및 소프트웨어 기능
매니페스트 파일의 추가적인 역할은 다음을 참고해주세요.
- [매니페스트 파일](https://developer.android.com/guide/components/fundamentals?hl=ko#Manifest)
- [앱 매니페스트 개요](https://developer.android.com/guide/topics/manifest/manifest-intro?hl=ko)
## 2. App components
앱 구성 요소(App components)는 Android 앱의 필수적인 기본 구성 요소입니다. 각 구성 요소는 **시스템이나 사용자가 앱에 들어올 수 있는 진입점**입니다. **다른 구성 요소에 종속되는 구성 요소**도 있습니다. 각 유형은 **뚜렷한 목적**을 수행하고 **각자 나름의 수명 주기**가 있어 구성 요소의 생성 및 소멸 방식을 정의합니다.
### 1) Activities
액티비티는 사용자와 상호작용하기 위한 진입점입니다. 이것은 **사용자 인터페이스를 포함한 화면 하나**를 나타냅니다. 여러 액티비티가 함께 작동하여 앱에서 짜임새 있는 사용자 환경을 구성하는 것은 사실이지만, **각자 서로 독립**되어 있습니다. 액티비티 하나를 `Activity` 클래스의 하위 클래스로 구현합니다.
#### Activity Stack 구조
<img src="https://user-images.githubusercontent.com/43839938/82186432-cff4fb80-9925-11ea-9d15-4dba92eea159.png" width="450" height="180">
#### Activity Life Cycle
<img src="https://user-images.githubusercontent.com/43839938/82185881-e3ec2d80-9924-11ea-8de3-c3db8422bc9a.png" width="350" height="450">
### 2) Services
Service는 **백그라운드**에서 오래 실행되는 작업을 수행할 수 있는 애플리케이션 구성 요소이며 **사용자 인터페이스를 제공하지 않습니다.**
- [포그라운드] 사용자가 다른 앱에 있는 동안에 *백그라운드에서 음악을 재생*한다.
- [백그라운드] 사용자와 액티비티 간의 상호작용을 차단하지 않고 *네트워크를 통해 데이터를 가져온다*.
- [바인드] 다른 구성 요소(예: 액티비티)가 서비스를 시작한 다음 실행되도록 두거나 자신에게 *바인딩*하여 상호작용한다. (라이브 배경화면, 알림 리스너, 화면 보호기, 입력 메서드, 접근성 서비스 및 여러 가지 기타 핵심 서비스 기능)
시작된 서비스는 작업이 완료될 때까지 해당 서비스를 계속 실행하라고 **시스템**에 지시합니다.
```xml
<manifest ... >
...
<application ... >
<service android:name=".ExampleService" />
...
</application>
</manifest>
```
##### 서비스는 Service 하위 클래스로 구현됩니다.
##### 참고: Android 5.0(API 레벨 21) 이상을 대상으로 하는 앱의 경우 `JobScheduler` 클래스를 사용하여 작업을 예약하세요.
### 3) Broadcast receivers
Broadcast Receiver는 **시스템이 정기적인 사용자 플로우 밖에서 이벤트를 앱에 전달하도록 지원하는 구성 요소**로, 앱이 시스템 전체의 브로드캐스트 알림에 응답할 수 있게 합니다.
### 4) Content providers
콘텐츠 제공자는 파일 시스템, SQLite 데이터베이스, 웹상이나 앱이 액세스할 수 있는 다른 모든 영구 저장 위치에 저장 가능한 앱 데이터의 공유형 집합을 관리합니다. 다른 앱은 콘텐츠 제공자를 통해 해당 데이터를 쿼리하거나, 콘텐츠 제공자가 허용할 경우에는 수정도 가능합니다.
구성 요소 유형 네 가지 중 세 가지 **(Activities, Services, Broadcast Receiver)** 는 **인텐트라는 비동기식 메시지로 활성화**됩니다. 인텐트는 런타임에서 각 구성 요소를 서로 바인딩합니다. 이것은 일종의 메신저라고 생각하면 됩니다. 즉 구성 요소가 어느 앱에 속하든 관계없이 다른 구성 요소로부터 작업을 요청하는 역할을 합니다.
## 3. Resource
리소스는 코드에서 사용하는 추가 파일과 정적인 콘텐츠입니다. 예를 들어 비트맵, 레이아웃 정의, 사용자 인터페이스 문자열, 애니메이션 지침 등이 있습니다.
이미지나 문자열과 같은 앱 리소스는 항상 코드에서 외부화해야 합니다. 그래야 이들을 독립적으로 유지관리할 수 있습니다. 특정 기기 구성에 대한 대체 리소스도 제공해야 합니다. 이것은 특별하게 명명한 리소스 디렉토리에 그룹화하는 방법을 씁니다. Android는 런타임에 현재 구성을 근거로 적절한 리소스를 사용합니다. 예를 들어 여러 가지 화면 크기에 따라 여러 가지 UI 레이아웃을 제공하거나 언어 설정에 따라 각기 다른 문자열을 제공하고자 할 수 있습니다.
앱 리소스를 외부화하면 프로젝트 R 클래스에서 발생하는 리소스 ID로 액세스할 수 있습니다.
자세한 내용은 다음을 참고해주세요.
- [앱 리소스 개요](https://developer.android.com/guide/topics/resources/providing-resources?hl=ko#top_of_page)
## 4. Intent
Intent는 **메시징 객체**로, **다른 앱 구성 요소로부터 작업을 요청하는 데 사용**할 수 있습니다. 기본적인 사용 사례는 크게 세 가지로 나눌 수 있습니다.
- Starting an activity
- Starting a service
- Delivering a broadcast
### 유형
- **명시적 인텐트**는 인텐트를 충족하는 애플리케이션이 무엇인지 지정합니다. 이를 위해 대상 앱의 패키지 이름 또는 완전히 자격을 갖춘 구성 요소 클래스 이름을 제공합니다. 명시적 인텐트는 일반적으로 앱 안에서 구성 요소를 시작할 때 씁니다. 시작하고자 하는 액티비티 또는 서비스의 클래스 이름을 알고 있기 때문입니다. 예를 들어, 사용자 작업에 응답하여 새로운 액티비티를 시작하거나 백그라운드에서 파일을 다운로드하기 위해 서비스를 시작하는 것 등이 여기에 해당됩니다.
- **암시적 인텐트**는 특정 구성 요소의 이름을 대지 않지만, 그 대신 수행할 일반적인 작업을 선언하여 다른 앱의 구성 요소가 이를 처리할 수 있도록 해줍니다. 예를 들어 사용자에게 지도에 있는 한 위치를 표시하고자 하는 경우, 암시적 인텐트를 사용하여 해당 기능을 갖춘 다른 앱이 지정된 위치를 지도에 표시하도록 요청할 수 있습니다.
<img src="https://user-images.githubusercontent.com/43839938/82185232-de421800-9923-11ea-8086-8b6086c75c14.png" width="450" height="180">
#### 암시적 인텐트 수신하기
앱이 수신할 수 있는 암시적 인텐트가 어느 것인지 알리려면, <intent-filter> 요소를 사용하여 각 앱 구성 요소에 대해 하나 이상의 인텐트 필터를 매니페스트 파일에 선언합니다. 각 인텐트 필터는 인텐트의 작업, 데이터 및 카테고리를 기반으로 어느 유형의 인텐트를 수락하는지 지정합니다. **시스템은 인텐트가 인텐트 필터 중 하나를 통과한 경우에만 암시적 인텐트를 앱 구성 요소에 전달합니다.**
> 예를 들어 데이터 유형이 텍스트인 경우 ACTION_SEND 인텐트를 수신할 인텐트 필터가 있는 액티비티 선언은 다음과 같습니다.
```xml
<activity android:name="ShareActivity">
<intent-filter>
<action android:name="android.intent.action.SEND"/>
<category android:name="android.intent.category.DEFAULT"/>
<data android:mimeType="text/plain"/>
</intent-filter>
</activity>
```
> 소셜 공유 앱의 매니페스트 파일 예시
```xml
<activity android:name="MainActivity">
<!-- This activity is the main entry, should appear in app launcher -->
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<activity android:name="ShareActivity">
<!-- This activity handles "SEND" actions with text data -->
<intent-filter>
<action android:name="android.intent.action.SEND"/>
<category android:name="android.intent.category.DEFAULT"/>
<data android:mimeType="text/plain"/>
</intent-filter>
<!-- This activity also handles "SEND" and "SEND_MULTIPLE" with media data -->
<intent-filter>
<action android:name="android.intent.action.SEND"/>
<action android:name="android.intent.action.SEND_MULTIPLE"/>
<category android:name="android.intent.category.DEFAULT"/>
<data android:mimeType="application/vnd.google.panorama360+jpg"/>
<data android:mimeType="image/*"/>
<data android:mimeType="video/*"/>
</intent-filter>
</activity>
```
### Reference
* [애플리케이션 기본 항목](https://developer.android.com/guide/components/fundamentals?hl=ko)
================================================
FILE: Browser/BrowserXY.md
================================================
# 브라우저의 XY
브라우저에 event가 발생했을 때에 x, y 좌표 값을 얻는 방법에는 크게 4가지가 있다.
- clientX / clientY
- pageX / pageY
- screenX / screenY
- offsetX / offsetY
이렇게 4가지가 존재하는데 어떤 차이가 있는지 알아보았다.
## clientX / clientY
client는 viewport와 매칭된다고 생각하면 쉽다.
브라우저의 화면인 viewport를 기준으로 좌표를 계산한다. 브라우저의 현재 보이는 화면을 기준으로 어느 곳을 선택했는지 반환한다.
스크롤을 하게 되어도 화면의 같은 곳을 클릭하면 같은 값이 반환된다.
브라우저의 크기가 달라져도 화면의 같은 곳에서는 같은 값이 변경된다.
어느 정도 절대값이라고 할 수 있다.
## pageX / pageY
page는 html문서와 매칭된다.
client는 현재 브라우저에 보여지는 부분이다. page는 그것과 상관없이 렌더된 html문서가 기준이다.
스크롤을 하게 되면 값이 달라진다.
브라우저의 크기를 줄여도 값과는 상관없다.
## screenX / screenY
screen은 user device의 모니터를 기준으로 한다.
모니터의 어느 부분을 클릭했는지 물리적인 값을 반환한다.
따라서 브라우저 상단의 tab, bookmark와 같은 정보들의 높이도 포함한다.
스크롤을 해도 달라지지 않는다.
브라우저의 크기가 달라지는 것은 관계가 없다. 다만 브라우저를 작게하여 모니터상의 브라우저 위치를 이동하면 값이 달라질 수 있다.
## offsetX / offsetY
offset은 이벤트가 걸린 DOM기준이다. 예를들어 div를 클릭했다면 div의 왼쪽 상단 모서리가 0, 0이 된다.
스크롤을 해도 달라지지 않는다.
브라우저가 달라져도 값은 달라지지 않는다.
다만 event.target의 크기가 변경된다면 달라질 수 있다.
## 사진으로 보기
글로만 보면 상당히 헷갈린 개념이다. 여러 링크에서 사진들을 모아봤으니 눈으로 확인하자.



마지막 사진은
- yellow : screen
- blue : client
- red : page
로 매칭된다.
사진의 출처는 아래에 링크로 대체한다.
## 예제로 확인하기
헷갈린 개념은 직접 디버깅하는 것이 좋다.
```html
<!DOCTYPE html>
<html>
<head>
<title>Document</title>
<style>
* {
margin: 0;
padding: 0;
}
.container {
overflow-x: scroll;
overflow-y: scroll;
background-color: #fcc2d7;
}
.click {
width: 150%;
height: 120vh;
margin: 0 auto;
padding: 20px;
border: 10px solid #000;
background-color: #74c0fc;
}
</style>
</head>
<body>
<div class="container">
<div class="click">target</div>
</div>
</body>
<script>
const click = document.querySelector('.click');
window.addEventListener('load', () => {
click.addEventListener('click', event => {
console.log(`client: (${event.clientX}, ${event.clientY})`);
console.log(`page: (${event.pageX}, ${event.pageY})`);
console.log(`screen: (${event.screenX}, ${event.screenY})`);
console.log(`offset: (${event.offsetX}, ${event.offsetY})`);
});
});
</script>
</html>
```
---
### 참고자료
- [screen, client, page, offset compare](https://m.blog.naver.com/PostView.nhn?blogId=sung487&logNo=220418825028&proxyReferer=https%3A%2F%2Fwww.google.com%2F)
- [clientX, offsetX, pageX, screenX의 차이](http://megaton111.cafe24.com/2016/11/29/clientx-offsetx-pagex-screenx%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90/)
- [What is the difference between screenX/Y, clientX/Y and pageX/Y?](https://stackoverflow.com/questions/6073505/what-is-the-difference-between-screenx-y-clientx-y-and-pagex-y)
- [What is the difference between pageX/Y clientX/Y screenX/Y in Javascript?](https://stackoverflow.com/questions/9262741/what-is-the-difference-between-pagex-y-clientx-y-screenx-y-in-javascript/17705548)
================================================
FILE: Browser/Cookie.md
================================================
브라우저에는 다양한 저장소가 있다.
<p align="center">
<img src="https://user-images.githubusercontent.com/24274424/58260975-698cda00-7db2-11e9-90d9-1cfabfe6a94a.png" alt="Storage">
</p>
> [참고] Chrome 개발자 도구 - Application Tab
위 사진은 Chrome 개발자 도구에 들어가서 Application Tab을 누르게 되면 왼쪽 메뉴에 보이는 Storage로 총 **5개**가 있다. 그 중 가장 아래에 있는 Cookie에 대해서 알아보자
# Cookie
쿠키는 브라우저에 저장되는 작은 크기의 문자열로, **RFC 6265** 명세에서 정의한 HTTP 프로토콜의 일부이다.
서버가 HTTP 응답 헤더(header)의 `Set-Cookie`에 내용을 넣어 전달하면, 브라우저는 이 내용을 자체적으로 브라우저에 저장하는데 이것이 쿠키이다.
브라우저는 사용자가 쿠키를 생성하도록 동일 서버(사이트)에 접속할 때마다 쿠키 내용을 Cookie 요청 헤더에 넣어서 함께 전달한다.
이를 사용하여 쿠키는 클라이언트 식별 같은 인증에 가장 많이 쓰인다.
1. 사용자가 로그인하면 서버는 HTTP 응답 헤더의 `Set-Cookie`에 담긴 세션 식별자(session identifier) 정보를 사용해 쿠키를 설정한다.
2. 사용자가 동일 도메인에 접속하려고 하면 브라우저는 HTTP Cookie 헤더에 인증 정보가 담긴 고유값(세션 식별자)을 함께 서버에 요청으로 보낸다.
3. 서버는 브라우저가 보낸 요청 헤더의 세션 식별자를 읽어 사용자를 식별한다.
`document.cookie` 프로퍼티를 이용하면 브라우저에서도 쿠키에 접근할 수 있다.
```js
console.log(document.cookie);
```
`document.cookie`는 `name=value` 쌍으로 구성되어 있으며, 쌍은 `;`로 구분된다. 쌍 하나는 하나의 독립된 쿠키이다.
`document.cookie`에 직접 값을 쓸 수 있다. cookie는 데이터 프로퍼티가 아닌 접근자(accessor) 프로퍼티이다.
```js
// getter
document.cookie = "user=SeonHyungJo";
console.log(document.cookie);
```
`document.cookie`에 값을 할당하면, 브라우저는 이 값을 받아 해당 쿠키를 갱신한다. 다른 쿠키의 값은 변경되지 않는다.
```js
document.cookie = "user=SeonHyungJo";
console.log(document.cookie); // user=SeonHyungJo
document.cookie = "newuser=SeonHyungJo";
console.log(document.cookie); // user=SeonHyungJo; newuser=SeonHyungJo
```
쿠키의 이름과 값엔 특별한 제약이 없다. 하지만 형식의 유효성을 일관성 있게 유지하기 위해 반드시 내장 함수 `encodeURIComponent`를 사용하여 이름과 값을 이스케이프 처리를 해주는 것이 좋다.
```js
let name = 'origin';
let value = "github/SeonHyungJo";
document.cookie = encodeURIComponent(name) + '=' + encodeURIComponent(value);
console.log(document.cookie); // origin=github%2FSeonHyungJo
```
## 단점
- 용량 : **4kb**로 매우 작은 용량이다.
- 속도 : 요청 때마다 포함되어서 간다. 작은 용량이라고 하지만 필요 없는 데이터가 전달되는 낭비가 발생한다.
- 보안 : 위험성이 크다.
## 옵션
### path
- `path=/mypath`
URL path(경로)의 접두사로, 경로나 경로의 하위 경로에 있는 페이지만 쿠키에 접근할 수 있다. 절대 경로이어야 하고, 기본값은 현재 경로이다.
`path=/user` 옵션을 사용하여 설정한 쿠키는 `/user`과 `/user/something`에선 볼 수 있지만, `/partner` 이나 `/adminpage`에선 볼 수 없다.
특별한 경우가 아니라면, path 옵션을 `path=/`같이 루트로 설정해 웹사이트의 모든 페이지에서 쿠키에 접근할 수 있도록 한다.
### domain
- `domain=imdev.com`
쿠키에 접근 가능한 domain(도메인)을 지정한다. 다만, 몇 가지 제약이 있어서 아무 도메인이나 지정할 수 없다.
domain 옵션에 아무 값도 넣지 않았다면, 쿠키를 설정한 도메인에서만 쿠키에 접근할 수 있다. `imdev.com`에서 설정한 쿠키는 `other.com`에서 얻을 수 없다. 서브 도메인(subdomain)인 `forum.imdev.com`에서도 쿠키 정보를 얻을 수 없다.
```js
// imdev.com에서 쿠키를 설정함
document.cookie = "user=SeonHyungJo"
// imdev.com의 서브도메인인 forum.imdev.com에서 user 쿠키에 접근하려 함
alert(document.cookie); // 찾을 수 없음
```
서브 도메인이나 다른 도메인에서 쿠키에 접속할 방법은 없다. `imdev.com`에서 생성한 쿠키를 `other.com`에선 절대 전송받을 수 없다.
이런 제약사항은 안정성을 높이기 위해 만들어졌는데, 민감한 데이터가 저장된 쿠키는 관련 페이지에서만 볼 수 있도록 하기 위해서다.
정말 `forum.imdev.com`과 같은 서브 도메인에서 `imdev.com`에서 생성한 쿠키 정보를 얻을 방법이 없는 걸까? `imdev.com`에서 쿠키를 설정할 때 domain 옵션에 루트 도메인인 `domain=imdev.com`을 명시적으로 설정해 주면 된다.
```js
// imdev.com에서
// 서브 도메인(*.imdev.com) 어디서든 쿠키에 접속하게 설정할 수 있다.
document.cookie = "user=SeonHyungJo; domain=imdev.com"
// 이렇게 설정하면
// forum.imdev.com와 같은 서브도메인에서도 쿠키 정보를 얻을 수 있다.
alert(document.cookie); // user=SeonHyungJo 쿠키를 확인할 수 있다.
```
하위 호환성 유지를 위해 (imdev.com 앞에 점을 붙인) `domain=.imdev.com`도 `domain=imdev.com`과 같이 작동한다. 오래된 표기법이긴 하지만 구식 브라우저를 지원하려면 이 표기법을 사용하는 것이 좋다.
이렇게 domain 옵션값을 적절히 사용하면 서브 도메인에서도 쿠키에 접근할 수 있다.
> 테스트 해보기(도메인 설정을 한 경우, 안 한 경우)
### expires와 max-age
expires(유효 일자)나 max-age(만료 기간) 옵션이 지정되어있지 않으면, 브라우저가 닫힐 때 쿠키도 함께 삭제된다. 이런 쿠키를 **세션 쿠키(session cookie)** 라 부른다.
expires 나 max-age 옵션을 설정하면 브라우저를 닫아도 쿠키가 삭제되지 않는다.
- `expires=Tue, 19 Jan 2038 03:14:07 GMT`
브라우저는 설정된 유효 일자까지 쿠키를 유지하다가, 해당 일자가 도달하면 쿠키를 자동으로 삭제한다.
쿠키의 유효 일자는 반드시 GMT(Greenwich Mean Time) 포맷으로 설정해야 한다. `date.toGMTString` (`toUTCString`) 을 사용하면 해당 포맷으로 쉽게 변경할 수 있다.
```js
// 지금으로부터 하루 뒤
let date = new Date(Date.now() + 86400e3);
date = date.toGMTString();
document.cookie = "user=SeonHyungJo; expires=" + date;
```
expires 옵션값을 과거로 설정하면 삭제된다.
- `max-age=3600`
max-age는 expires 옵션의 대안으로, 쿠키 만료 기간을 설정할 수 있다. 현재부터 설정하고자 하는 만료일시까지의 시간을 초로 환산한 값을 설정한다. 0이나 음수값을 설정하면 쿠키는 바로 삭제된다.
```js
// 1시간 뒤에 쿠키가 삭제된다.
document.cookie = "user=SeonHyungJo; max-age=3600";
// 만료 기간을 0으로 지정하여 쿠키를 바로 삭제한다
document.cookie = "user=SeonHyungJo; max-age=0";
```
### secure
- `secure`
이 옵션을 설정하면 HTTPS로 통신하는 경우에만 쿠키가 전송된다.
secure 옵션이 없으면 기본 설정이 적용되어 `http://imdev.com`에서 설정(생성)한 쿠키를 `https://imdev.com`에서 읽을 수 있고, `https://imdev.com`에서 설정(생성)한 쿠키도 `http://imdev.com`에서 읽을 수 있다.
쿠키는 기본적으로 도메인만 확인하지 프로토콜을 확인하지 않는다.
하지만 secure 옵션이 설정된 경우, `https://imdev.com`에서 설정한 쿠키는 `http://imdev.com`에서 접근할 수 없다. 쿠키에 민감한 내용이 저장되어 있어 암호화되지 않은 HTTP 연결을 통해 전달되는 걸 원치 않는다면 이 옵션을 사용하면 된다.
```js
// (https:// 로 통신하고 있다고 가정 중)
// 설정한 쿠키는 HTTPS 통신시에만 접근할 수 있음
document.cookie = "user=SeonHyungJo; secure";
```
## samesite
다른 보안 속성인 samesite 옵션은 크로스 사이트 요청 위조(cross-site request forgery, XSRF) 공격을 막기 위해 만들어진 옵션이다.
아래 XSRF 공격 시나리오를 통해 이 속성의 동작 방식과 언제 이 속성을 유용하게 사용할 수 있는지 알아보자.
### XSRF 공격
현재 bank.com에 로그인되어 있을 때. 해당 사이트에서 사용되는 인증 쿠키가 브라우저에 저장되고, 브라우저는 bank.com에 요청을 보낼 때마다 인증 쿠키를 함께 전송한다. 서버는 전송받은 쿠키를 이용해 사용자를 식별하고, 보안이 필요한 재정 거래를 처리한다.
이제 (로그아웃하지 않고) 다른 창을 띄워서 웹 서핑을 하던 도중에 뜻하지 않게 evil.com이라는 사이트에 접속했다 가정하면, 이 사이트엔 해커에게 송금을 요청하는 폼(form) `<form action="https://bank.com/pay">`이 있고, 이 폼은 자동으로 제출되도록 설정되어 있다.
폼이 evil.com에서 은행 사이트로 바로 전송될 때 인증 쿠키도 함께 전송된다. bank.com에 요청을 보낼 때마다 bank.com에서 설정한 쿠키가 전송되기 때문이다. 은행은 전송받은 쿠키를 읽어 (해커가 아닌) 계정 주인이 접속한 것으로 생각하고 해커에게 돈을 송금한다.
이런 공격을 크로스 사이트 요청 위조라고 부른다.
실제 은행은 당연히 이 공격을 막을 수 있도록 시스템을 설계한다. bank.com에서 사용하는 모든 폼에 **XSRF 보호 토큰(protection token)**이라는 특수 필드를 넣는다. 이 토큰은 악의적인 페이지에서 만들 수 없고, 원격 페이지에서도 훔쳐 올 수 없도록 구현되어 있다. 따라서 악의적인 페이지에서 폼을 전송하더라도 보호 토큰이 없거나 서버에 저장된 값과 일치하지 않기 때문에 요청이 무용지물이 된다.
하지만 이런 절차는 구현에 시간이 걸린다.
> 참고 : [CSRF 공격이란? 그리고 CSRF 방어 방법](https://itstory.tk/entry/CSRF-%EA%B3%B5%EA%B2%A9%EC%9D%B4%EB%9E%80-%EA%B7%B8%EB%A6%AC%EA%B3%A0-CSRF-%EB%B0%A9%EC%96%B4-%EB%B0%A9%EB%B2%95)
### samesite 옵션
쿠키의 samesite 옵션을 이용하면 XSRF 보호 토큰 없이도 크로스 사이트 요청 위조를 막을 수 있다.
이 옵션엔 두 가지 값을 설정할 수 있다.
- `samesite=strict`
사용자가 사이트 외부에서 요청을 보낼 때, `samesite=strict` 옵션이 있는 쿠키는 절대로 전송되지 않는다.
메일에 있는 링크를 따라 접속하거나 evil.com과 같은 사이트에서 폼을 전송하는 경우 등과 같이 제3의 도메인에서 요청이 이뤄질 땐 쿠키가 전송되지 않는다.
인증 쿠키에 samesite 옵션이 있는 경우, XSRF 공격은 절대로 성공하지 못한다. evil.com에서 전송하는 요청엔 쿠키가 없을 것이고, bank.com은 미인식 사용자에게 지급을 허용하지 않을 것이기 때문이다.
만약 사용자가 메모장 등에 bank.com에 요청을 보낼 수 있는 링크를 기록해 놓았다가 이 링크를 클릭해 접속하면 bank.com이 사용자를 인식하지 못하는 상황이 발생하기 때문이다. 실제로 이런 경우 `samesite=strict` 옵션이 설정된 쿠키는 전송되지 않는다.
이런 문제는 쿠키 두 개를 함께 사용해 해결할 수 있다. "Hello, SeonHyungJo"과 같은 환영 메시지를 출력해주는 "일반 인증(general recognition)"용 쿠키, 데이터 교환 시 사용하는 `samesite=strict` 옵션이 있는 쿠키를 따로 두는 것이다.
- `samesite=lax` (Chrome default 값)
> [관련 이슈](https://brocess.tistory.com/263)
`samesite=lax`는 사용자 경험을 해치지 않으면서 XSRF 공격을 막을 수 있는 느슨한 접근법이다.
strict와 마찬가지로 lax도 사이트 외부에서 요청을 보낼 때 브라우저가 쿠키를 보내는 걸 막아준다. 하지만 예외사항이 있다.
아래 두 조건을 동시에 만족할 때는 `samesite=lax` 옵션을 설정한 쿠키가 전송된다.
1. 안전한 HTTP 메서드인 경우(예: GET 방식. POST 방식은 해당하지 않음).
> 또는 `a href`, `link href`
안전한 HTTP 메서드 목록은 RFC7231 명세에서 확인할 수 있다. 안전한 메서드는 읽기 작업만 수행하고 쓰기나 데이터 교환 작업은 수행하지 않는다. 참고로, 링크를 따라가는 행위는 항상 GET 방식이기 때문에 안전한 메서드만 쓰인다.
2. 작업이 최상위 레벨 탐색에서 이루어질 때(브라우저 주소창에서 URL을 변경하는 경우).
대다수의 작업은 이 조건을 충족한다. 하지만 `<iframe>`안에서 탐색이 일어나는 경우는 최상위 레벨 탐색이 아니기 때문에 충족하지 못한다. AJAX 요청 또한 탐색 행위가 아니므로 이 조건이 안된다.
브라우저를 이용해 자주 하는 작업인 "특정 URL로 이동하기"를 실행하는 경우, `samesite=lax` 옵션이 설정되어 있으면 쿠키가 서버로 전송된다. 하지만 외부 사이트에서 AJAX 요청을 보내거나 폼을 전송하는 등의 복잡한 작업을 시도할 때는 쿠키가 전송되지 않는다. 이런 제약사항이 있어도 괜찮다면, `samesite=lax` 옵션은 사용자 경험을 해치지 않으면서 보안을 강화해주는 방법으로 활용할 수 있을 것이다.
samesite는 좋은 옵션이긴 하지만, 한가지 문제점이 있다.
- 오래된 브라우저(2017년 이전 버전)에선 samesite 옵션을 지원하지 않는다.
samesite 옵션으로만 보안 처리를 하게 되면, 구식 브라우저에서 보안 문제가 발생할 수 있다. 구식 브라우저에 대응하지 못한다는 문제가 있긴 하지만, samesite 옵션을 XSRF 토큰 같은 다른 보안 기법과 함께 사용하면 보안을 강화할 수 있다.
구식 브라우저가 사용되지 않는 그날을 위해...
## 함수로 만들어서 사용하기
### getCookie
```js
const getCookie = (name) => {
let matches = document.cookie.match(new RegExp(
"(?:^|; )" + name.replace(/([\.$?*|{}\(\)\[\]\\\/\+^])/g, '\\$1') + "=([^;]*)"
));
return matches ? decodeURIComponent(matches[1]) : undefined;
}
```
### setCookie
```js
const setCookie = (name, data, expire = '', path = '') => {
const date = new Date();
date.setDate(date.getDate() + expire);
date.setHours(0, 0, 0, 0)
document.cookie = `${name}=${data};` + `expires=${date.toGMTString()};` + `path=${path};`;
}
```
### removeCookie
```js
const removeCookie = (name) => {
document.cookie = name + '=; expires=Thu, 01 Jan 1970 00:00:01 GMT;';
}
```
#### Reference
- https://ko.javascript.info/cookie#ref-271
- https://ifuwanna.tistory.com/223
================================================
FILE: Browser/Cookie_Store.md
================================================
# New Cookie Store API(after Chrome 87)
2020년 11월 01일 기준 Chrome의 버전은 `86.0.4240.111`이다.
추후 버전 87에 추가되는 기능 중에서 Cookie관련 API를 알아보자.
# Release
Cookie Store API는 HTTP 쿠키를 서비스 워커에서도 접근이 가능하며, `document.cookie`에서 비동기적으로 사용가능하도록 하는 기능이라고 명세가 되어있다.
> [Chrome Platform Status](https://www.chromestatus.com/feature/5658847691669504)
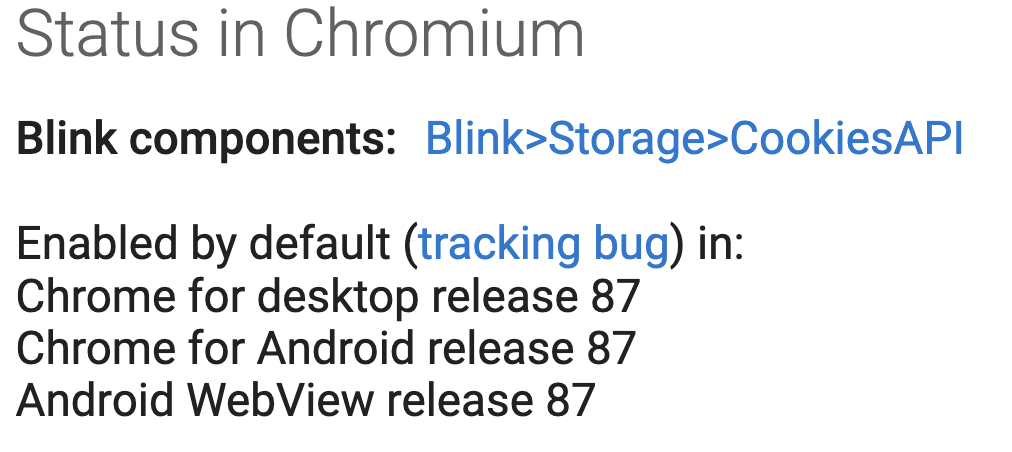
위와 같이 87 버전에 포함된 항목은 추후 업데이트를 하게 되면 확인가능하며, 다른 브라우저들은 아직 적용이 안됨으로 사용하는데 주의가 필요하다.
## 관련 Issue
1. [Add cookie accessor/setter methods? · Issue #707 · w3c/ServiceWorker](https://github.com/w3c/ServiceWorker/issues/707)
2. [Possible API Sketch · Issue #14 · WICG/cookie-store](https://github.com/WICG/cookie-store/issues/14)
# Document
W3C Community Group에서 처음 나온 초안으로 관련 레포인 [WICG/cookie-store](https://github.com/WICG/cookie-store)을 들어가면 설명이 있다.
새로운 API 기존의 cookie의 스펙을 바꾸지 않고 사용하는 방식이며 위에서 언급되었던 바와 같이 Service Worker에서의 접근과 비동기적으로 처리할 수 있게 하는 것을 주 목표로 삼고 있다(Promise 사용).
간단하게 인터페이스를 살펴보자.
```cpp
[Exposed=(ServiceWorker,Window), SecureContext]
interface CookieStore : EventTarget {
Promise<CookieListItem?> get(USVString name);
Promise<CookieListItem?> get(optional CookieStoreGetOptions options = {});
Promise<CookieList> getAll(USVString name);
Promise<CookieList> getAll(optional CookieStoreGetOptions options = {});
Promise<undefined> set(USVString name, USVString value);
Promise<undefined> set(CookieInit options);
Promise<undefined> delete(USVString name);
Promise<undefined> delete(CookieStoreDeleteOptions options);
[Exposed=Window]
attribute EventHandler onchange;
};
dictionary CookieStoreGetOptions {
USVString name;
USVString url;
};
enum CookieSameSite {
"strict",
"lax",
"none"
};
dictionary CookieInit {
required USVString name;
required USVString value;
DOMTimeStamp? expires = null;
USVString? domain = null;
USVString path = "/";
CookieSameSite sameSite = "strict";
};
dictionary CookieStoreDeleteOptions {
required USVString name;
USVString? domain = null;
USVString path = "/";
};
dictionary CookieListItem {
USVString name;
USVString value;
USVString? domain;
USVString path;
DOMTimeStamp? expires;
boolean secure;
CookieSameSite sameSite;
};
typedef sequence<CookieListItem> CookieList;
```
`interface CookieStore`를 살펴보기 전 상단의 코드를 보게 되면, window뿐만 아니라 ServiceWorker가 있는 것을 확인할 수 있다.
`interface CookieStore`에는 우리가 사용할 수 있는 메서드들과 이벤트 핸들러가 있는 것을 볼 수 있는데, 이벤트 핸들러는 window에서만 사용이 가능하다.
`getAll`, `get`, `delete` 메서드를 사용하는 방법은 기본적으로 cookie의 이름만으로 사용할 수 있고, option이라는 것을 통해서 가져오거나 삭제가 가능하다. 자세한 형태는 아래를 살펴보면 된다.
간단하게 `dictionary CookieInit` 부분을 보게 되면 cookie에서 사용하는 설정 중 CookieSameSite의 기본값이 strict라는 것을 알 수 있다.
최근 Chrome 86에서 변경된 Cookie 정책을 알고 있다면, 86 버전 이전 기본값이 `none`이였다면, 86이후에는 기본값이 `lax`로 바뀐 것을 알 것이다. 그런데 해당 API에서는 기본값이 `strict`이다.
이 부분의 차이점을 알고있는 것이 중요하다.
> [Browser Cookie](https://github.com/im-d-team/Dev-Docs/blob/master/Browser/Cookie.md)
# Explainer
[Cookie Store API Explainer](https://wicg.github.io/cookie-store/explainer.html)
## Method
### 일반적인 사용법
```js
document.cookie =
'__Secure-COOKIENAME=cookie-value' +
'; Path=/' +
'; expires=Fri, 12 Aug 2016 23:05:17 GMT' +
'; Secure' +
'; Domain=example.org';
// now we could assume the write succeeded, but since
// failure is silent it is difficult to tell, so we
// read to see whether the write succeeded
var successRegExp =
/(^|; ?)__Secure-COOKIENAME=cookie-value(;|$)/;
if (String(document.cookie).match(successRegExp)) {
console.log('It worked!');
} else {
console.error('It did not work, and we do not know why');
}
```
### set
```js
const one_day_ms = 24 * 60 * 60 * 1000;
cookieStore.set(
{
name: 'imd',
value: '1',
expires: Date.now() + one_day_ms,
}).then(function() {
console.log('It worked!');
}, function(reason) {
console.error(
'It did not work, and this is why:',
reason);
});
```
### get
```js
try {
const cookie = await cookieStore.get('imd');
if (cookie) {
console.log(`Found ${cookie.name} cookie: ${cookie.value}`);
} else {
console.log('Cookie not found');
}
} catch (e) {
console.error(`Cookie store error: ${e}`);
}
```
### getAll
```js
try {
const cookies = await cookieStore.getAll('imd');
for (const cookie of cookies)
console.log(`Result: ${cookie.name} = ${cookie.value}`);
} catch (e) {
console.error(`Cookie store error: ${e}`);
}
```
### delete
```js
try {
await cookieStore.delete('imd');
} catch (e) {
console.error(`Failed to delete cookie: ${e}`);
}
```
### event
```js
cookieStore.addEventListener('change', event => {
console.log(`${event.changed.length} changed cookies`);
for (const cookie of event.changed)
console.log(`Cookie ${cookie.name} changed to ${cookie.value}`);
console.log(`${event.deleted.length} deleted cookies`);
for (const cookie in event.deleted)
console.log(`Cookie ${cookie.name} deleted`);
});
```
### Reference
- [Cookie Store API](https://wicg.github.io/cookie-store/)
- [web-platform-tests/wpt](https://github.com/web-platform-tests/wpt/tree/master/cookie-store)
- [Digital Information World](https://www.digitalinformationworld.com/2020/10/chrome-87-beta-is-aiming-to-become-much.html)
- [web-platform-tests/wpt](https://github.com/web-platform-tests/wpt/tree/master/cookie-store)
- [Asynchronous Access to HTTP Cookies | Web | Google Developers](https://developers.google.com/web/updates/2018/09/asynchronous-access-to-http-cookies)
- [Asynchronous Cookie Access on the Web](https://docs.google.com/document/d/1ak6JzOMMO5q3dXvu4mHFWR-LLvaDc09XDvdeJZLtZd4/edit#heading=h.7nki9mck5t64)
================================================
FILE: Browser/FOUC.md
================================================
# FOUC(Flash of Unstyled Content)
`FOUC(Flash of Unstyled Content)`란 브라우저에서 웹 페이지에 접근했을 때, 미처 스타일이 적용되지 못한 상태로 화면이 나타나는 현상을 말한다.
스타일이 적용되기 전의 상태가 먼저 화면에 렌더링된 후 그 상태에서 스타일이 적용되기 때문에 스타일이 적용되는 과정이 사용자에게 그대로 노출되는 현상이다. 이러한 현상은 사용자의 경험(UX)를 떨어트리게 된다는 문제가 있다.
`FOUC`는 특히 `IE(Internet Explorer)` 브라우저에서 주로 발생되며 `IE11`에서도 여전히 발생되고 있는 문제다.
## FOUC의 발생 원인
`FOUC`의 발생 원인은 다양하지만 몇 가지만 우선적으로 살펴보면 다음과 같다.
### CRP(Critical Rendering Path)

위처럼 브라우저에서 화면이 그려지기까지의 주요한 과정을 `CRP(Critical Rendering Path)`라고 한다.
1. HTML 마크업을 처리하고 DOM 트리를 빌드한다.
2. CSS 마크업을 처리하고 CSSOM 트리를 빌드한다.
3. DOM 및 CSSOM을 결합하여 Rendering 트리를 형성한다.
4. Rendering 트리에서 레이아웃을 실행하여 각 노드의 기하학적 형태(화면의 위치)를 계산한다.
5. 개별 노드를 화면에 paint한다.
`Render Tree`가 노출된 후 CSS와 JS 파일등으로 변경되면 이 변경 사항들이 화면에 노출될 수 있다. 이 현상이 `FOUC`다.
웹 브라우저의 작동 원리에 대해 좀 더 자세히 알고 싶다면 [다음](https://github.com/im-d-team/Dev-Docs/blob/master/Browser/%EC%9B%B9%20%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%EC%9D%98%20%EC%9E%91%EB%8F%99%20%EC%9B%90%EB%A6%AC.md)을 참고하길 바란다.
최근의 웹 페이지들은 여러 개의 CSS 파일을 참조하거나 웹 폰트를 사용함으로써 DOM 구조를 변경하기 때문에 더욱 자주 발생할 수 있는 환경이다.
### `@import`를 사용한 CSS
IE(Internet Explorer)를 제외한 브라우저의 경우, 참조(`@import`)되는 스타일이 적용될때까지 화면에 표시하지 않는다. 하지만, IE의 경우 화면에 노출된 상태로 스타일이 적용되어 FOUC를 유발한다.
### 웹 폰트의 사용
이또한 `@import`를 사용하여 스타일링을 할 때와 같은 원리로 `FOUC`가 발생하게 된다. IE는 웹 폰트를 사용할 경우 기본 폰트를 불러들이고 이를 사용된 웹 폰트로 다시 재변경되게 되는데 이 과정을 그대로 화면에 노출시키게 된다.
## FOUC 해결
### JS import 위치 변경
일반적으로 자바스크립트를 선언할 때는 성능을 위해 `</body>` 태그 바로 위에 위치시키곤 한다.
하지만 이를 `<head>`태그 안으로 위치시킴으로써 `FOUC`를 개선할 수 있다. 하지만 이 방법으로는 웹 폰트나 `@import`를 사용한 CSS로 인한 `FOUC` 발생을 막을 수는 없다.
### FOUC 발생 위치의 컴포넌트 숨기기
`@import` 사용으로 인한, 웹 폰트로 인한 `FOUC`발생을 막기 위해서는 `FOUC`가 발생하는 위치의 컴포넌트를 숨겼다가 웹 폰트 혹은 참조(`@import`) CSS의 로딩이 완료되면 보여주는 방법이 있다. 물론, 숨기는 것은 한 예시일 뿐이고 로딩바를 보여준다거나 스켈레톤 UI를 보여준다거나 할 수 있다.
```html
<html class="no-js">
<head>
<style>
.js #fouc {
display: none
}
</style>
<script>
(function (H) {
H.className = H.className.replace(/\bno-js\b/, 'js')
})(document.documentElement)
</script>
</head>
<body>
<div id="fouc">
FOUC 발생 지점
</div> <!-- /#fouc -->
<script>
document.getElementById("fouc").style.display = "block";
</script>
</body>
</html>
```
[소스 출처 - webdir.tistory.com](https://webdir.tistory.com/416)
위 소스에 대해 간단히 설명하면 자바스크립트와 CSS 스타일이 모두 로딩되었을 경우, `fouc` ID를 가진 컴포넌트를 렌더링시켜준다.
`FOUC`의 발생은 최근에는 대부분 `IE`에서 발생하기 때문에 `IE`에 대해서만 분기 처리를 한 후 `FOUC`에 대한 처리를 하는 것도 좋은 방법이 될 수 있다.
---
#### Reference
- [화면 깜빡임(FOUC) 문제해결](https://webdir.tistory.com/416)
- [UZULAB - #3 FOUC, 화면 깜박임 문제](https://uzulab.tistory.com/4)
================================================
FILE: Browser/HTTP2_Websocket.md
================================================
# HTTP2.0과 Web Socket
## HTTP란
HTTP는 HyperText Transfer Protocol의 약자다. Request와 Response로 이루어진 통신 규약이다.
이 HTTP의 단점 중 하나는 Request가 있어야만 Response가 존재한다는 점이다. 이 요청은 URL로 이루어져 새로운 요청을 보내려면 새로운 페이지가 필요하다. 예를들어 회원가입시 ID 중복확인을 하려면 새 페이지로 넘어가야 한다.
또한 페이스북처럼 정보를 거의 실시간으로 확인 할 수 있는 SNS의 경우, 정보의 갱신이 매우 빠르게 일어나는데 이를 업데이트 하려면 항상 클라이언트의 Request가 필요하다. 만약 이 경우 서버의 정보가 갱신되지 않았다면 통신의 낭비가 일어나기도 한다.
HTTP의 대표적인 단점으로는
- 1개의 커넥션에 1개의 리퀘스트만 가능하다.
- Request는 클라이언트 사이드에서만 시작할 수 있다.
- 헤더가 압축되지 않는다.
- 우선순위가 없다.
등 다양하다.
## 문제해결
이러한 문제들중 몇가지를 해결하기 위해 등장한 것이 AJAX와 COMET방식이다.
### AJAX
---
구글의 AJAX는 HTTP 통신을 사용은 하지만 HttpRequst가 아닌 XMLHttpRequest를 사용하여 새로운 HTML을 사용하지 않고 페이지의 일부만 수정할 수 있게 된다.
### COMET
---
Comet은 서버측의 데이터 갱신이 있을때 Request를 기다리지 않고 Response를 보내기 위한 방법이다. Comet의 경우 Request에 따른 Response를 반환하지 않고 보류해둔다. 그 뒤 서버의 데이터가 갱신되면 Response를 반환하는 방식이다. 롱폴링(long polling)방식이라고도 한다.
위의 두가지 방법은 모두 프로토콜 레벨의 방법은 아니며 HTTP가 가진 근본적인 단점을 해결해 줄 수는 없다.
## SPDY
느린 HTTP를 해결하기 위해 나온 것이 SPDY다. 구글이 시도했던 실험 프로토콜이다. Page Load Time을 50%로 줄이기 위함이 목표였다.
핵심적인 변화는 이러하다. 기존의 데이터는 플레인 텍스트로 통신을 하였는데 이를 바이너리로 인코딩하여 **프레임** 이라는 단위로 변경하여 전송한다. 즉 하나의 chunk에서 frame이라는 단위로 쪼개기가 가능해진다. 이를 통해 요청/응답 다중화, 우선순위 지정 및 헤더 압축이 목표였다.
이게 2012년의 이야기이며 이를 본 HTTP-WG(HTTP Working Group)이 HTTP2.0을 만든다.
이 HTTP2.0은 SPDY의 사양을 채택해 출발하게 되고 2015년 SPDY는 지원을 중단하며 HTTP2.0으로 사실상 통합되게 된다.
## Web Socket
2014년 HTML5의 등장과 함께 Web Socket이 등장한다.
HTTP와 같이 Web Socket은 프로토콜이며 양방향 소통을 지원하는 프로토콜이다. HTTP가 가진 근본적인 문제 중 하나인 **Request는 클라이언트 사이드에서만 시작할 수 있다.** 를 완전히 해결할 수 있는 프로토콜이다.
시작점은 클라이언트에게 있지만 처음 HTTP로 연결한 뒤 그 뒤로는 WebSocket 프로토콜을 이용하여 양쪽 모두 송신이 가능하게 된다.
또한 처음 HTTP 통신 이후에는 헤더의 사이즈를 감소시켜 통신량을 줄이게 된다.
## HTTP 2.0
HTTP 2.0의 도입배경은 SPDY를 통해 소개를 했다.
핵심적인 변화로는 Binary Framing부터 시작한다. 새로운 메커니즘으로 아래와 같은 구조를 가진다.
- 스트림(바이트의 흐름)
- 메시지(전체 시퀀스며 Request / Response의 단위다.)
- 프레임(통신의 최소단위)
프레임이 모여 메시지가 되고 메시지가 모여 스트림이 된다.
장점을 알아보자
### 요청 및 응답 다중화
---
프레임은 헤더나 메시지 페이로드 등을 전송하며 **인터리빙**이 가능하다. 즉 데이터를 읽을 때 순서대로가 아니게 읽는 것이 가능하며 대역폭 증가의 효과를 가진다.
인터리빙으로 병렬처리가 가능해지면서 통신 단위의 변경이 가능해집니다.
HTTP 1.0은 기존의 메시지가 단위였다면 2.0부터는 스트림이 단위가 된다. 따라서 동시에 여러 메시지를 처리할 수 있게 되고 Request의 순서와 상관없이 Response를 보낼 수 있게 되었다.
HTML 파싱 시 여러 Request가 필요한데 이것의 순서가 없어져 Response를 기다려야하는 통신의 낭비가 사라진다.
### 우선순위 지정
---
인터리빙에 따른 병렬처리로 서버와 클라이언트측에 각각 요청이 전달되는 순서가 성능 이슈로 떠오릅니다. 따라서 가중치를 통해 우선순위를 줄 수 있게 됩니다.
### 서버푸쉬
---
서버푸쉬는 웹소켓과는 다른 개념이다.
예를들어 초기 페이지에 index.html만이 아니라 많은 css, js, image파일과 같은 추가적인 리소스가 필요하다면 이를 클라이언트가 요청하지 않아도 서버가 푸쉬할 수 있는 방식이다.
### 헤더압축
---
기존의 HTTP는 헤더를 항상 일반텍스트로 보냈다.
이를 HTTP 2.0에서는 HPACK 압축방식을 이용하여 보내게끔 되어있다.
================================================
FILE: Browser/IndexedDB_WebSQL.md
================================================
# IndexDB WebSQL
데이터 저장소는 서버 DB를 사용해서 데이터를 저장하고 꺼내서 보여줄 수 있도록 데이터를 저장하는 공간이다. 이러한 데이터를 저장할 수 있는 공간이 브라우저에도 존재하는데 이것을 통틀어서 스토리지라고 부른다.
스토리지에는 여러 종류가 존재하는데 로컬 스토리지, 세션 스토리지, 쿠키, indexedDB, Web SQL 이렇게 5가지가 존재한다. 그중에서 오늘 살펴볼 내용은 **indexedDB와 Web SQL이다.**
나머지 3가지에 대해 알아보길 원하면 아래의 링크를 확인하면 됩니다.
> [Cookie, Local Storage](https://github.com/SeonHyungJo/FrontEnd-Dev/blob/master/Browser/Cookie_Storage_Local.md)
<br/>
## IndexedDB
먼저 어디서 볼 수 있나?
개발자들이 많이 사용하는 브라우저 중 하나인 크롬을 열어서 Dev Tool을 열고 Application 탭에 들어가면 좌측에 좀 전에 말했던 5가지의 저장소가 있는 것을 볼 수 있다.
그중에서 우리가 보려는 **IndexedDB**도 있다.
IndexedDB는 새로 등장했다고 하기에는 오래되었는데 2009년 말경 Web SQL의 대안으로 탄생했다. 즉 현재 Web SQL은 사양 책정이 중지된 상태이다. IndexedDB는 자바스크립트 객체 단위의 데이터 저장이 용이하고 객체를 대상으로 인덱스를 걸 수 있어 간단한 구현과 효율적인 검색을 수행할 수 있다.
> `많은 양의 구조화된 데이터를 클라이언트 측에 저장하기 위한 저수준의 API` - Mozilla
IndexedDB는 SQL언어와 무관하며 단순한 저장구조(Key-Value Storage)를 갖추고 있다. 간단한 자바스크립트 API만으로도 데이터베이스 조작이 가능하며, 브라우저 친화적이고 표준화 작업을 쉽게 이끌 수 있다는 장점이 있다. 결국 모바일 환경에서의 가벼운 로컬 DB 컨셉은 관계형 DB보다는 IndexedDB와 같은 객체기반의 비 관계형 DB가 더 어울린다고 할 수 있다.
흔히 PWA에서, IndexedDB를 사용해서 어떻게 오프라인 기반의 애플리케이션을 만들 수 있는지 자세하게 다루고 있다.
> [Progressive Web App용 오프라인 저장소](https://developers.google.com/web/fundamentals/instant-and-offline/web-storage/offline-for-pwa?hl=ko)
- IndexedDB는 브라우저에 많은 양의 구조화된 데이터를 영구적으로 저장할 수 있으며, 네트워크 상태에 상관없이 여러 기능을 사용할 수 있다. (최대 하드디스크의 50%라고 한다. => 실제로 컴퓨터의 하드디스크 50%를 채울 수 있는지에 대한 테스트를 진행하지 못했습니다.)
- IndexedDB는 서비스 워커를 사용한다면 동기적으로 사용이 가능하나 그렇지 않을 경우는 비동기가 기본이다. 그래서 대부분은 Promise로 만들어진 라이브러리를 사용한다. - [idb](https://www.npmjs.com/package/idb)
<br/>
## 실제로 사용해보기
### 브라우저 지원여부확인
```js
if (!window.indexedDB) {
console.log("Your browser doesn't support a stable version of IndexedDB. Such and such feature will not be available.")
}
```
<br/>
### 데이터베이스 열기
기본적으로 비동기로 작동을 하며, 작동의 결과를 4가지의 콜백 이벤트로 전달받는다.
- success : 데이터베이스 연결 성공
- error : 데이터베이스 연결 실패
- upgradeneeded : 데이터베이스를 처음 만들거나, 데이터베이스 버전이 변경되었을 때 작동하는 함수
- blocked : 이전의 연결을 닫지 않았을 경우 실행됨(이번에 사용하지 않을 예정)
```js
// indexedDB 지원유무
if ("indexedDB" in window) {
idbSupported = true;
}
if (idbSupported) {
// indexedDB 열기
const openRequest = indexedDB.open("test", 1);
openRequest.onupgradeneeded = function (e) {
console.log("Upgrading");
}
openRequest.onsuccess = function (e) {
console.log("Success!");
db = e.target.result;
}
openRequest.onerror = function (e) {
console.log("Error");
console.dir(e);
}
}
```
### 처음 접속시
처음 접속 시 `onupgradeneeded`를 타게 되며 이후 버전업이 이루어지지 않는 한 실행되지 않는다.

### 2번째 접속시

### 에러 발생시
### Object Stores(객체 저장소)
위에서 말했듯이 IndexedDB의 컨셉은 객체 저장소이다.
```js
if ("indexedDB" in window) {
idbSupported = true;
}
if (idbSupported) {
const openRequest = indexedDB.open("test_2", 1);
openRequest.onupgradeneeded = function (e) {
console.log("running onupgradeneeded");
const thisDB = e.target.result;
if (!thisDB.objectStoreNames.contains("testBox")) {
thisDB.createObjectStore("testBox");
}
}
openRequest.onsuccess = function (e) {
console.log("Success!");
db = e.target.result;
}
openRequest.onerror = function (e) {
console.log("Error");
console.dir(e);
}
}
```
<br/>
### 데이터 추가하기
데이터를 조작하기 위해서는 `transaction`을 사용해야한다. transaction는 2개의 인자를 받는데 첫번째는 우리가 조작할 테이블이 `Array`로 들어가며, 두번째 인자는 `readonly`, `readwrite` 둘 중의 1개로 타입을 명시해준다.
`const transaction = db.transaction(["people"], "readwrite");`
`const store = transaction.objectStore("people");`
```html
<!doctype html>
<html>
<head>
</head>
<body>
<input type="text" id="name" placeholder="Name"><br />
<input type="email" id="email" placeholder="Email"><br />
<button id="addButton">Add Data</button>
</body>
<script>
let db;
function indexedDBOk() {
return "indexedDB" in window;
}
document.addEventListener("DOMContentLoaded", function () {
//indexedDB 지원 유무
if (!indexedDBOk) return;
//idarticle_people 네임인 DB생성.
const openRequest = indexedDB.open("idarticle_people", 1);
openRequest.onupgradeneeded = function (e) {
const thisDB = e.target.result;
// people ObjectStore 생성(테이블이라고 생각하면 될것 같음..)
if (!thisDB.objectStoreNames.contains("people")) {
thisDB.createObjectStore("people");
}
}
openRequest.onsuccess = function (e) {
console.log("running onsuccess");
db = e.target.result;
//Listen for add clicks
document.querySelector("#addButton").addEventListener("click", addPerson, false);
}
openRequest.onerror = function (e) {
}
}, false);
function addPerson(e) {
const name = document.querySelector("#name").value;
const email = document.querySelector("#email").value;
console.log("About to add " + name + "/" + email);
//people 테이블에 데이터 add 선언..
const transaction = db.transaction(["people"], "readwrite");
const store = transaction.objectStore("people");
//Define a person
const person = {
name: name,
email: email,
created: new Date()
}
//Perform the add
const request = store.add(person, 1);
request.onerror = function (e) {
console.log("Error", e.target.error.name);
//some type of error handler
}
request.onsuccess = function (e) {
console.log("Woot! Did it");
}
}
</script>
</html>
```
위의 경우는 2번째 추가를 하게 될 경우 키가 같아서 에러가 발생한다.

<br/>
### Keys
키를 지정하는 것은 총 3가지의 방법이 있다.
1. 위에서처럼 직접 명시하는 것이다. 자신이 직접 만든 로직으로 **unique한 키**를 만들 수 있다.
2. **keypath**를 사용하는 것으로, 데이터 자체의 속성을 기반으로 하는 방법이다.
3. 우리가 많이 알고 제일 쉬운 방법으로 키 생성기를 사용하는 것이다. 자동 번호 기본키와 매우 유사하며 키를 지정하는 가장 간단한 방법이다.
```js
// second option : keypath
thisDb.createObjectStore("test1", { keyPath : "email" });
// third option : key generator
thisDb.createObjectStore("test2", { autoIncrement : true });
```
<br/>
### 데이터 읽기
아래의 예제는 개별 데이터를 읽는 방법이다. 테이블로 말하면 하나의 row만 갖고 오는 것이다.
```js
// db에서 test 객체(테이블)을 읽는다고 선언.
const transaction = db.transaction(["test"], "readonly");
const objectStore = transaction.objectStore("test");
//x is some value
const ob = objectStore.get(x);
// 가져오는 것을 성공했을 경우
ob.onsuccess = function(e) {
consoel.log(e.target.result)
}
// 한줄로 만들기
// db.transaction(["test"], "readonly").objectStore("test").get(X).onsuccess = function(e) { }
```
<br/>
### 범위 조회
범위조회를 위해서는 `createIndex`가 선행되어야한다.
```js
const store = thisDB.createObjectStore("people", { autoIncrement: true });
store.createIndex("name","name", {unique:false});
```
```js
//Values over 39
const oldRange = IDBKeyRange.lowerBound(39);
//Values 40a dn over
const oldRange2 = IDBKeyRange.lowerBound(40,true);
//39 and smaller...
const youngRange = IDBKeyRange.upperBound(40);
//39 and smaller...
const youngRange2 = IDBKeyRange.upperBound(39,true);
//not young or old
const okRange = IDBKeyRange.bound(20,40)
```
```js
function getPeople(e) {
const name = document.querySelector("#nameSearch").value;
const endname = document.querySelector("#nameSearchEnd").value;
if(name == "" && endname == "") return;
const transaction = db.transaction(["people"],"readonly");
const store = transaction.objectStore("people");
const index = store.index("name");
let range;
if(name != "" && endname != "") {
range = IDBKeyRange.bound(name, endname);
} else if(name == "") {
range = IDBKeyRange.upperBound(endname);
} else {
range = IDBKeyRange.lowerBound(name);
}
let s = "";
index.openCursor(range).onsuccess = function(e) {
const cursor = e.target.result;
if(cursor) {
s += "<h2>Key "+cursor.key+"</h2><p>";
for(var field in cursor.value) {
s+= field+"="+cursor.value[field]+"<br/>";
}
s+="</p>";
cursor.continue();
}
document.querySelector("#status").innerHTML = s;
}
}
```
### Can I use...
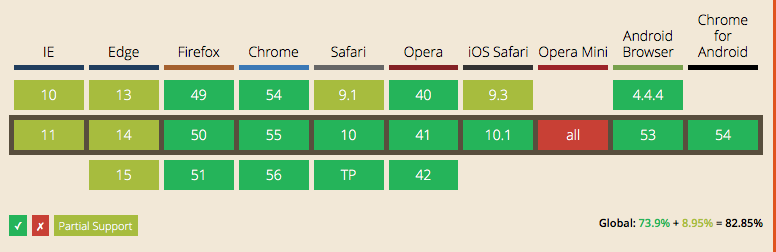
<br/>
## WebSQL
WebSQL은 **클라이언트 측의 관계형 데이터베이스를 위한 API**로, SQLite와 유사하다. 2010년 이후로 W3C 웹 어플리케이션 워킹 그룹은 이 스펙에 대한 작업을 중단했다. WebSQL은 이제 더이상 HTML 스펙이 아니므로, 사용하지 말자
<br/>
#### Reference
- [https://github.com/wonism/TIL/blob/master/front-end/javascript/client-storage.md](https://github.com/wonism/TIL/blob/master/front-end/javascript/client-storage.md)
- [https://iamawebdeveloper.tistory.com/99](https://iamawebdeveloper.tistory.com/99)
- [https://code-examples.net/ko/docs/dom/indexeddb_api](https://code-examples.net/ko/docs/dom/indexeddb_api)
- [https://dongwoo.blog/2016/12/19/클라이언트-측의-저장소-살펴보기/](https://dongwoo.blog/2016/12/19/%ED%81%B4%EB%9D%BC%EC%9D%B4%EC%96%B8%ED%8A%B8-%EC%B8%A1%EC%9D%98-%EC%A0%80%EC%9E%A5%EC%86%8C-%EC%82%B4%ED%8E%B4%EB%B3%B4%EA%B8%B0/)
================================================
FILE: Browser/Layer_Model.md
================================================
# Layer Model
브라우저의 layer model에 대해 알아보자.
## layer란
브라우저는 크게 layer를 두가지로 분류한다.
- RenderLayer
- GraphicsLayer
### RenderLayer
렌더 레이어는 DOM의 subTree에 대응되는 [rendering critical path](https://github.com/Im-D/Dev-Docs/blob/master/Browser/%EC%9B%B9%20%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%EC%9D%98%20%EC%9E%91%EB%8F%99%20%EC%9B%90%EB%A6%AC.md#rendering-engine)의 render tree(frame tree)의 결과를 말한다.
### GraphicsLayer
그래픽스 레이어는 그 외의 레이어를 말한다. 이 글에서 render layer는 크게 중요하지 않으니 그래픽스 레이어만 다루도록 하자.
그래픽스 레이어는 GPU에 텍스쳐로 업로드된다.(GraphicsLayers are what get uploaded to the GPU as textures)
이 GPU의 텍스쳐에 대해 조금 알아보자.
#### GL - GPU
texture는 RAM(주기억장치)에서 GPU의 VRAM(비디오메모리)으로 이동하는 image라고 생각하면 된다.
image가 GPU에 올라가게 되면 mesh geometry라는 것과 매핑된다.
이 mesh는 아래 그림처럼 3차원 모델을 만들 때 다각형의 집합으로 이루어진 모델같은 것이다.

[출처: unity documentation](https://docs.unity3d.com/kr/current/Manual/class-Mesh.html)
#### layer-texture
크롬은 각 그래픽스 레이어를 texture로 취급하여 GPU에 올린다.
즉 한 장의 image 파일처럼 취급하여 GPU에게 위임한다.
GPU에서 texture는 사각형의 메쉬로 만들어진다.
그래서 layer의 position을 수정한다거나 변형(transformation)하는 경우 매우 저렴한 비용으로 매핑될 수 있다.
3D CSS는 이러한 방식으로 작동한다.
## layer 생성 기준
이러한 layer가 생성되는 기준은 다음과 같다.
- 3D나 perspective를 표현하는 CSS transform 속성을 가진 경우
- 하드웨어 가속 디코딩을 사용하는 <video> 엘리먼트
- 3D 컨텍스트(WebGL) 혹은 하드웨어 가속 2D 컨텍스트를 가지는 <canvas> 엘리먼트
- (플래시와 같은) 플러그인 영역
- 투명도(opacity) 속성 혹은 webkit transform의 애니메이션의 사용
- 가속 가능한 CSS 필터를 가진 경우[css filter](https://developer.mozilla.org/en-US/docs/Web/CSS/filter)
- 합성 레이어(Compositing Layer)를 하위 노드로 가진 경우
- 낮은(lower) z-index를 가진 형제 노드(Sibling)가 합성 레이어(Compositing Layer)를 가진 경우
## layer 눈으로 확인하기
layer를 확인하는 가장 좋은 방법은 개발자 도구를 이용하는 것이다.
개발자 도구를 열어서 rendering - layer borders 옵션을 켜면 오렌지색 테두리로 레이어를 보여준다.
### 단일 layer
```html
<!DOCTYPE html>
<html>
<body>
<div>this is single layer</div>
</body>
</html>
```

### transform 사용하여 layer 나누기
css transform 속성을 사용하면 layer가 나뉘게 된다.
```html
<!DOCTYPE html>
<html>
<body>
<div style="transform: rotateY(30deg) rotateX(-30deg); width: 200px;">
this is detached layer
</div>
</body>
</html>
```

transform을 사용하면 div와 body가 구분되어 layer를 가지는 것을 확인 할 수 있다.
### animation
layer를 분리하면 가장 좋은 점은 reflow(relayouting)와 repaint를 하지 않는다는 점이다.
```html
<!DOCTYPE html>
<html>
<head>
<style>
div {
animation-duration: 5s;
animation-name: slide;
animation-iteration-count: infinite;
animation-direction: alternate;
width: 200px;
height: 200px;
margin: 100px;
background-color: gray;
}
@keyframes slide {
from {
transform: rotate(0deg);
}
to {
transform: rotate(120deg);
}
}
</style>
</head>
<body>
<div>this is animation</div>
</body>
</html>
```

위 사진에서는 초록색 부분이 페인트다.
레이어가 분리되어 다르게 동작하기때문에 paint는 처음에만 일어나며 다시 일어나지 않는다.
### reflow repaint
```html
<!DOCTYPE html>
<html>
<head>
<style>
div {
animation-duration: 5s;
animation-name: slide;
animation-iteration-count: infinite;
animation-direction: alternate;
width: 200px;
height: 200px;
margin: 100px;
background-color: gray;
}
@keyframes slide {
from {
transform: rotate(0deg);
}
to {
transform: rotate(120deg);
}
}
</style>
</head>
<body>
<div id="foo">I am a strange root.</div>
<input id="paint" type="button" value="repaint" />
<script>
var w = 200;
document.getElementById('paint').onclick = function() {
document.getElementById('foo').style.width = w++ + 'px';
};
</script>
</body>
</html>
```
다음의 코드는 버튼을 클릭하면 1px씩 증가한다.
따라서 화면을 재 계산해야 하기 때문에 reflow(relayouting) 후 repaint를 하게 된다.
위 코드는 직접 개발자도구를 실행시켜 확인해보자.
## 종합
레이아웃을 중심으로 브라우저가 DOM을 렌더링 하는 과정은 다음과 같다.
1. DOM을 얻고 그것들을 레이어들로 분리합니다.
2. 이 레이어들 각각을 독립적인 소프트웨어 비트맵으로 출력합니다.
3. 그것들을 GPU에 텍스쳐로써 업로드합니다.
4. 다양한 레이어를 최종 스크린 이미지로 함께 합성(composite)합니다.
강제로 레이어를 분리하여 코딩하면 repaint를 일으키지 않고 동작하기 때문에 성능에 매우 유리하다.
좋은 예로는 [네이버 모바일페이지](https://m.naver.com/)에서 화면을 좌/우로 변경하면서 layer를 확인해보자.
처음에만 paint를 하고 그 뒤로는 layer만 변경되는 것을 찾아볼 수 있다.
### 단점
만능은 아니다.
당연히 레이어별로 메모리를 다르게 할당한다.
또한 GPU의 video memory는 RAM과 물리적으로 다른 공간에 위치한다.
따라서 texture를 옮기는 데이터 송수신의 손실도 발생한다.
또한 RAM => VRAM으로 이동하려면 결국 CPU -> RAM에서 texture 로드 -> GPU VRAM으로 전송의 과정이 필요하다.
CPU가 연산하지 않으면 안된다. CPU가 직접 처리하지 않을 뿐 CPU가 작동하지 않는 것은 아니다.
texture 데이터를 다루는 시간도 고려해야 한다.
---
### 참고자료
- [프론트엔드 개발자를 위한 크롬 렌더링 성능 인자 이해하기](https://medium.com/@cwdoh/%ED%94%84%EB%A1%A0%ED%8A%B8%EC%97%94%EB%93%9C-%EA%B0%9C%EB%B0%9C%EC%9E%90%EB%A5%BC-%EC%9C%84%ED%95%9C-%ED%81%AC%EB%A1%AC-%EB%A0%8C%EB%8D%94%EB%A7%81-%EC%84%B1%EB%8A%A5-%EC%9D%B8%EC%9E%90-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-4c9e4d715638)
- [Accelerated Rendering in Chrome](https://www.html5rocks.com/en/tutorials/speed/layers/)
- [Unity documentation](https://docs.unity3d.com/Manual/index.html)
================================================
FILE: Browser/WebWorker.md
================================================
# Web Worker
`WebWorker`는 `script` 실행을 메인 쓰레드가 아니라 백그라운드 쓰레드에서 실행할 수 있도록 해주는 기술이다.
이 기술을 통해 무거운 작업을 분리된 쓰레드에서 처리할 수 있다. 브라우저에서 메인쓰레드라 함은 Rendering을 처리하는 UI쓰레드를 말하는데, 이를 통해 메인 쓰레드가 멈추거나 속도저하 없이 동작할 수 있다.
다음과 같은 작업들을 백그라운드에서 실행하여 더욱 증가한 UX를 제공할 수 있다.
- 매우 복잡한 계산 작업
- 원격리소스에 대한 액세스 작업
- UI 쓰레드에 방해 없이 지속적으로 수행해야 하는 작업(timer, pusher, parser)
## WebWorker의 개념
Worker는 `Worker()` 생성자를 통해 생성되며 지정된 Javascript 파일의 코드를 Worker 쓰레드에서 실행한다. Worker는 현재 `Window` 와 분리된 `DuplicatedWorkerGlobalScope` 라는 별도의 `Global context` 에서 동작한다.
Worker 쓰레드에서 어떠한 코드도 실행할 수 있지만, 몇가지 예외가 있다.
예를들어 Worker 내에서는 `DOM` 을 직접 다룰 수 없다. 또한 `Window` 의 기본 메서드와 속성을 사용할 수 없다. 메인쓰레드와 자원을 공유하기 때문이다.
### 사용예시
Message System을 통해 Worker 와 메인 쓰레드 간에 데이터를 교환할 수 있다.
```html
<div id="result"></div>
<button id="btn">run</button>
<script>
const sleep = (delay) => {
const start = new Date().getTime();
while (new Date().getTime() < start + delay);
};
document.querySelector('#btn').addEventListener('click', function () {
sleep(3000);
const div = document.createElement('div');
div.textContent = Math.random();
document.querySelector('#result').appendChild(div);
});
</script>
```
`sleep()`의 while이 메인 쓰레드의 콜스택을 점유하기 때문에 3000ms 가 되기 전까지는 다른 작업을 진행 할 수 없다.
```html
<div id="result"></div>
<button id="btn">run</button>
<script>
document.querySelector('#btn').addEventListener('click', () => {
const worker = new Worker('./worker.js');
worker.addEventListener('message', (e) => {
const div = document.createElement('div');
div.textContent = e.data;
document.querySelector('#result').appendChild(div);
worker.terminate();
});
worker.postMessage('워커작동 시작');
});
</script>
```
```js
// worker.js
const sleep = (delay) => {
const start = new Date().getTime();
while (new Date().getTime() < start + delay);
};
self.onmessage = (e) => {
console.log(e.data);
sleep(3000);
const random = Math.random();
console.log(random);
self.postMessage(random);
};
```
이렇게 변경하면 3초를 점유하는 작업은 다른 쓰레드에서 진행하기 때문에 메인쓰레드에는 영향을 주지 않게 된다.
`Worker.postMessage()`를 통해 데이터를 전송할 수 있으며, `Worker.onmessage()` 를 통해 응답할 수 있다. 전송되는 데이터는 공유되지 않으며 복제를 통해 전달되게 된다.
부모와 동일한 origin이라면 Worker내에서 새로운 Worker를 생성하는 것도 가능하다. 또한 이렇게 생겨난 Worker들끼리 서로 통신하는 것 역시 가능하다.
### 유형
- Dedicated Worker
- 헌신하는 전용 Worker다. 아래의 Shared Worker와 대비된다.
- Shared worker
- 윈도우 창이나 iframe, Worker등의 다른 브라우징 컨텍스트에서도 공유되는 Worker다.
- 이름 혹은 URL로 식별된다. Socket 통신처럼 Worker들은 port를 할당받고 이를 통해 통신한다.
- `new SharedWorker()`로 생성하며 공유하는 전역 스코프를 가진다.
- [MDN SharedWorker](https://developer.mozilla.org/ko/docs/Web/API/SharedWorker)
- ServiceWorker
- Proxy Server의 역할을 한다.
- 효율적인 오프라인 경험을 구축하고, 네트워크 요청을 가로채어 통신이 가능한지 여부에 따라 적절한 동작을 수행하며, 서버에 존재하는 자원들을 갱신할 수 있다.
- 푸시 알림이나 백그라운드 동기화 API에 접근을 허용한다.
- Audio Workers
- 스크립트를 통해 직접적인 오디오 처리만을 담당하는 Worker다.
- 단순한 오디오 출력만이 아니라 Audio API를 이용하여 오디오에 이펙트를 추가하거나 시각화와 같은 작업으로 오디오 객체를 조작할 수 있다.
- [MDN Web Audio API](https://developer.mozilla.org/ko/docs/Web/API/Web_Audio_API)
현재 브라우저 지원범위는 [여기](http://caniuse.com/#search=webworker)에서 확인 할 수 있는데, 거의 모든 현대 브라우저에서 작동한다.
---
#### Reference
- [MDN-WebWorker](https://developer.mozilla.org/ko/docs/Web/API/Web_Workers_API)
- [MDN 예제](https://github.com/mdn/simple-web-worker)
- [Shared Worker 블로그](https://m.blog.naver.com/sef16/70163116505)
- [google developers - serviceworker](https://developers.google.com/web/fundamentals/primers/service-workers?hl=ko)
- [웹 워커-zerocho](https://www.zerocho.com/category/HTML&DOM/post/5a85672158a199001b42ed9c)
================================================
FILE: Browser/Worklet.md
================================================
# Worklet
## Worklet이란
> Worklet 인터페이스는 Web Workers의 경량 버전이며 개발자가 렌더링 파이프 라인의 하위 수준에 접근할 수 있도록 해준다.
> Worklet을 사용하면 JavaScript 및 WebAssembly 코드를 실행하여 고성능이 필요한 경우 그래픽 렌더링 또는 오디오 처리를 수행 할 수 있다. - MDN
- 기본적으로 Worker는 한 Thread에 하나가 생성이 가능하지만, Worklet은 한 Thread에 여러 개 생성이 가능합니다.
- 메인 Thread에서 만들 수 있습니다.
- 독립적인 GlobalScope와 Event loop를 가집니다.
### Worklet Type
- **PaintWorklet**
- **LayoutWorklet**
- AnimationWorklet
- AudioWorklet
그리고
- Typed OM
## Houdini
- Houdini(후디니)라는 Working Group입니다.
- Houdini 프로젝트는 Mozilla, Apple, Opera, Microsoft, HP, Intel 그리고 Google의 엔지니어들로 구성되어있습니다.
- 이 프로젝트는 공식 W3C 표준으로 채택되기 위한 *표준 초안*들을 작성하고 있습니다..
- "Houdini"라 하면 표준 문서들의 내용을 의미합니다. 표준안 개발 작업이 진행되는 동안 [Houdini 표준안 초안](http://dev.w3.org/houdini/)들은 미완성 단계이며 일부 초안은 다소 가안입니다.
## 들어가기전에
- `Chrome://flag` ⇒ `Experimental Web Platform features` => `Enable`
## CSS Painting API
CSS Painting API를 사용하게 되면 CSS 속성 중 이미지 타입에 사용할 수 있는 모양을 정의할 수 있습니다.
Image Type?
- [background-image](https://googlechromelabs.github.io/houdini-samples/paint-worklet/parameter-checkerboard/)
- [border-image](https://googlechromelabs.github.io/houdini-samples/paint-worklet/border-color/)
- list-style-image
이 중 background-image속성을 사용하면 CSS가 적용된 대상이 그려지는 모양을 정의할 수 있습니다.
```css
.slide-checkbox{
background-image: paint(slide);
}
```
Paint는 대상을 그리는 방법을 다루는 단계입니다.

위의 렌더링 파이프라인은 **Chrome** 기준이며 브라우저에 따라 차이가 있을 수 있습니다.
CSS Painting API는 Worklet의 형태로 개발자가 정의한대로 대상을 그리는 코드를 추가합니다.

위에서 언급했듯이 Worklet은 Worker의 경량 버전이라고도 합니다.
하지만 Worker와는 다르게 한 스레드에 여러개가 생성될 수 있고, 메인 스레드에서 실행될 수 있습니다.

Worklet은 독립적인 GlobalScope와 Event Loop를 가지고 있습니다.

결국, 그려야 할 대상이 많거나, 성능이 필요한 경우에 여러 개의 Thread에서 병렬로 동작할 수 있게 합니다.
## 기본 형태
독립적인 파일을 만들어서 addModule을 하는 형태입니다.
```js
CSS.paintWorklet.addModule("slideWorklet.js")
```
위의 파일을 js class로 작성을 하며 `registerPaint`를 사용하여 해당 paint를 등록합니다.
```js
class Slide {
static get inputArguments() {
return [];
}
static get inputProperties() {
return [];
}
paint(ctx, geom, props, args){
}
}
registerPaint("slide", Slide);
```
paint method에는 기본 4가지의 인자가 있습니다.
- ctx : PaintRenderingContext2D 객체로, 대상이 어떻게 그려질지 표현합니다.
- geom : 대상의 가로, 세로 크기정보입니다.
- props : 대상에게 적용된 스타일 정보입니다.
- args : CSS에서 전달한 값을 입력받습니다.
props와 args는 각각 `inputProperties()`, `inputArguments()`를 사용하여 입력받을 값(속성명)을 지정하여야 합니다.
### 예제
**index.html**
```html
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="index.css">
<script src="index.js"></script>
<title>Document</title>
</head>
<body>
<input type="checkbox" class="switch">
<label class="switch">
<input type="checkbox">
<span class="slider round"></span>
</label>
</body>
```
**index.js**
```js
CSS.registerProperty({
name: '--slide-on',
syntax: '<number>',
inherits: true,
initialValue: "0"
});
CSS.paintWorklet.addModule("slideWorklet.js")
```
**index.css**
```css
/* CSS Paint API */
.slide-checkbox{
background-image: paint(slide);
display: block;
color: green;
width: 60px;
height: 34px;
--slide-on : 0;
-webkit-appearance: none;
transition: --slide-on 200ms
}
.slide-checkbox:checked{
--slide-on : 1;
background-image: paint(slide);
}
/* Custom Checkbox for CSS */
.switch {
position: relative;
display: inline-block;
width: 60px;
height: 34px;
}
.switch input {
opacity: 0;
width: 0;
height: 0;
}
.slider {
position: absolute;
cursor: pointer;
top: 0;
left: 0;
right: 0;
bottom: 0;
background-color: #ccc;
-webkit-transition: .2s;
transition: .2s;
}
.slider:before {
position: absolute;
content: "";
height: 28px;
width: 28px;
left: 3px;
bottom: 3px;
background-color: white;
-webkit-transition: .2s;
transition: .2s;
}
input:checked + .slider {
background-color: #2196F3;
}
input:focus + .slider {
box-shadow: 0 0 1px #2196F3;
}
input:checked + .slider:before {
-webkit-transform: translateX(26px);
-ms-transform: translateX(26px);
transform: translateX(26px);
}
.slider.round {
border-radius: 34px;
}
.slider.round:before {
border-radius: 50%;
}
```
**slideWorklet.js**
```js
const DEG_360 = Math.PI * 2;
const FG_COLOR = "white";
const BG_COLOR = "#E1E1E1";
const BG_COLOR_ON = "#FFCD00";
const CIRCLE_MARGIN = 3;
class Slide {
// static get inputArguments() {
// return ['on|off'];
// }
static get inputProperties() {
return ['--slide-on'];
}
paint(ctx, geom, props, args){
const {width, height} = geom;
const halfOfCircleSize = height / 2;
const innerWidth = width - height;
const on = parseFloat(props.get('--slide-on')).toString();
const x = halfOfCircleSize + innerWidth * on
ctx.fillStyle = on == 1 ? BG_COLOR_ON : BG_COLOR;
ctx.beginPath();
// 양쪽에 원을 그린다.
ctx.arc(halfOfCircleSize, halfOfCircleSize, halfOfCircleSize, 0, DEG_360);
ctx.arc(width - halfOfCircleSize, halfOfCircleSize, halfOfCircleSize, 0, DEG_360);
// 가운데 사각형을 그려준다.
ctx.rect(halfOfCircleSize, 0, innerWidth, height);
ctx.fill();
ctx.fillStyle = FG_COLOR;
ctx.beginPath();
ctx.arc(x, halfOfCircleSize, halfOfCircleSize - CIRCLE_MARGIN, 0, DEG_360);
ctx.fill();
}
}
registerPaint("slide", Slide);
```
### 성능비교
렌더링 파이프라인은 이전 단계의 결과물이 다음 단계의 입력으로 사용됩니다.
따라서 엘리먼트가 많아지게 되면 DOM 객체가 많아지고 이후 모든 과정들의 연산량과 메모리 사용량이 증가하게 됩니다.

위의 슬라이드 체크박스를 약 5,000개를 만들었을 경우,
5000 * 3개의 엘리먼트가 5000개의 엘리먼트로 대체됩니다.
## CSS Layout API
CSS Layout API를 사용하면 CSS가 적용된 대상의 자식 엘리먼트들의 배치를 정의할 수 있습니다.
```css
.cloud{
display: layout(cloud);
}
```
렌더링 파이프라인 중 Layout 단계는 대상을 배치하는 방법을 다룹니다.

CSS Layout API는 Worklet의 형태로 자식 엘리먼트를 개발자가 정의한대로 배치하는 코드를 추가합니다.

기존의 방법은, 렌더링이 끝난 후, JS로 재배치하면 렌더링 파이프라인을 한번 더 수행합니다.

### 기본 형태
```js
class CloudLayout {
static get inputProperties() {
}
*intrinsicSizes(children, edges, styleMap) {
}
*layout(children, edges, constraints, styleMap){
}
}
registerLayout("cloud", CloudLayout);
```
paint method에는 기본 4가지의 인자가 있습니다.
- children : 자식 요소들의 정보입니다.
각각의 layoutNextFragment() 함수를 호출해서 자식요소의 크기를 알 수 있습니다.
layout() 함수는 자식요소들의 비동기 처리를 위해서 제네레이터 함수로 작성해야 합니다.
layoutNextFragment 함수는 LayoutFragment 객체를 반환합니다.
LayoutFragment 객체는 4가지의 정보를 가지고 있습니다.
1. blockSize
2. blockOffset
3. inlineSize
4. inlineOffset
blockSize, inlineSize는 fragment의 크기를 나타냅니다.
blockOffset, inlineOffset은 fragment가 원점으로 부터 떨어진 거리를 나타냅니다.

- edges : 레이아웃이 적용된 요소의 외곽선 정보입니다.
- constraints : 레이아웃이 적용된 요소의 크기 정보입니다.
- styleMap : 레이아웃이 적용된 요소의 Object Model style Map
paint API와 동일하게 대상 엘리먼트에 적용된 스타일 정보를 읽어올 수 있습니다.
마찬가지로 `static inputProperties` 필드로 읽어오려는 속성의 이름을 미리 선언해야합니다.
### 예제
**index.html**
```html
<head>
<link rel="stylesheet" href="index.css">
<script src="index.js"></script>
</head>
<body>
<div class="cloud">
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
<div class="child">Websquare</div>
</div>
</body>
```
**index.js**
```js
CSS.layoutWorklet.addModule('cloudLayout.js');
```
**index.css**
```css
.cloud{
display: layout(cloud);
--random-seed: 30;
width : 500px;
height : 500px;
background: rgba(0,0,0,0.2);
border-radius: 25px;
}
.child{
font-size: 24px;
font-weight: blod;
color: #918EFB;
text-shadow: 0px 2px 2px white;
}
```
**cloudLayout.js**
```js
class CloudLayout {
static get inputProperties() {
return ["--random-seed", "--cloud-level"];
}
*intrinsicSizes(children, edges, styleMap) {
}
*layout(children, edges, constraints, styleMap){
const childFragments = yield children.map(child => {
const level = parseInt(child.styleMap.get("--cloud-level"))
return child.layoutNextFragment({...constraints, level: level})
})
const availableInlineSize = constraints.fixedInlineSize;
const availableBlockSize = constraints.fixedBlockSize;
const randomSeed = parseInt(styleMap.get("--random-seed"));
let seed = randomSeed;
const random = () => {
let x = Math.sin(seed++) * 10000;
return x - Math.floor(x);
}
let nextBlockOffset = 0;
for (const fragment of childFragments) {
let i = 0;
console.log(fragment)
fragment.blockOffset = random() * availableBlockSize;
fragment.inlineOffset = random() * availableInlineSize;
}
return{
childFragments
}
}
}
registerLayout("cloud", CloudLayout);
```
## Typed OM
CSS에는 CSSOM이 있습니다.
> CSSOM은 JavaScript에서 CSS를 조작할 수 있게 해주는 API입니다. CSSOM은 웹 페이지에서 발견되는 CSS 스타일의 기본 '맵'으로, DOM과 결합된 CSSOM은 브라우저에서 웹 페이지를 표현하는데 사용됩니다.
JavaScript에서 .style을 read 또는 set할 때 항상 아래와 같이 사용해왔습니다.
```js
// 요소의 스타일
el.style.opacity = 0.3;
typeof el.style.opacity === 'string' // true??
// 스타일시트 규칙
document.styleSheets[0].cssRules[0].style.opacity = 0.3;
```
### CSS Typed OM이란?
새로 나온 CSS Typed Object Model(Typed OM)은 CSS 값에 타입과 메소드, 적절한 객체모델을 추가함으로써 세계관을 넓혔습니다.
값이 문자열이 아닌 JavaScript 객체로 나타나기 때문에 CSS를 효율적으로(정상적으로) 조작할 수 있습니다.
기존의 사용하던 element.style 대신, `.attributeStyleMap` 속성을 사용하여 스타일에 접근할 수 있습니다.
스타일시트 규칙에는 `.styleMap` 속성을 사용합니다.
두 속성 모두 StylePropertyMap 객체를 반환합니다.
```js
// 요소의 스타일
el.attributeStyleMap.set('opacity', 0.3);
typeof el.attributeStyleMap.get('opacity').value === 'number' // true 숫자값이다!!!!
// 스타일시트 규칙
const stylesheet = document.styleSheets[0];
stylesheet.cssRules[0].styleMap.set('background', 'blue');
```
StylePropertyMap은 Map과 유사한 객체이기 때문에, 일반적인 함수(get/set/keys/values/entries)를 전부 지원합니다. 따라서 아래와 같이 유연하게 작업할 수 있습니다.
```js
// 아래 3가지가 모두 동일하다.
el.attributeStyleMap.set('opacity', 0.3);
el.attributeStyleMap.set('opacity', '0.3');
el.attributeStyleMap.set('opacity', CSS.number(0.3)); // 'Unit values' 파트 참고
// el.attributeStyleMap.get('opacity').value === 0.3
// StylePropertyMaps은 반복 가능하다.
for (const [prop, val] of el.attributeStyleMap) {
console.log(prop, val.value);
} // → opacity, 0.3
el.attributeStyleMap.has('opacity') // true
el.attributeStyleMap.delete('opacity') // opacity 제거
el.attributeStyleMap.clear(); // 모든 스타일 제거
```
두 번째 예에서 opacity를 문자열 '0.3'으로 set 했지만 속성을 read 할 때는 숫자로 읽힌다는 것을 명심하세요.
> 주어진 CSS 속성이 숫자를 지원한다면, Typed OM은 문자열 값을 입력하더라도 항상 숫자값을 반환합니다!
### 장점
CSS Typed OM이 해결하려는 문제가 무엇일까요?
CSS Typed OM이 이전의 Object Model보다 훨씬 장황하다고 주장할 수도 있습니다.
Typed OM을 작성하기 전에 아래의 몇 가지 주요 특징을 고려하세요.
1. 적은 버그 – 예) 숫자 값은 문자열이 아니라 항상 숫자로 반환됩니다.
```JavaScript
el.style.opacity += 0.1;
el.style.opacity === '0.30.1' // CSSOM은 문자열로 붙는다!
el.style.opacity += 0.1;
el.style.opacity === '0.30.1' // CSSOM은 문자열로 붙는다!
```
2. 산술 연산 및 단위 변환 – 절대 길이 단위를 변환하고(px → cm), 기본 수학 연산을 수행할 수 있습니다.
3. 값 클램핑 & 반올림 – Typed OM은 값을 반올림 및 클램핑해서 속성의 허용 범위 내에 있을 수 있습니다. ex) opacity <= 1
> 컴퓨터 그래픽에서 '클램핑'이란, 어떤 위치를 범위 안으로 한정시키는 방법입니다. 위치를 제일 가까운 사용 가능한 값으로 옮깁니다.
4. 성능 향상 – 브라우저는 문자열 값을 직렬화, 병렬화하는 작업을 줄여야 합니다. 이제 엔진은 JS, C++과 비슷한 방식으로 CSS 값을 이해합니다. Tab Akins는 초기 CSS 벤치마크에서 Typed OM이 기존의 CSSOM을 사용할 때보다 초당 작동 속도가 30%까지 빠르다는 것을 입증했습니다. 이는 requestionAnimationFrame()를 사용하여 빠른 CSS 애니메이션을 구현할 때 중요합니다.
5. 오류 처리 – 새로운 파싱 메소드는 CSS 세계에서 오류 처리를 제공합니다.
6. CSSOM은 이름이 camel-case인지 문자열인지 가늠할 수 없었습니다(ex. el.style.backgroundColor vs el.style['background-color']). Typed OM의 CSS 속성 이름은 항상 문자열이며, 실제 CSS에서 작성한 것과 일치시키면 됩니다.
## 그러나...

---
#### Reference
- [houdini-draft](https://drafts.css-houdini.org/)
- [googlechromelabs-sample](https://googlechromelabs.github.io/houdini-samples/)
- [masonry - sample](https://googlechromelabs.github.io/houdini-samples/layout-worklet/masonry/)
- [css-houdini.rocks](https://css-houdini.rocks/)
- [Is houdini ready yet](https://ishoudinireadyyet.com/)
================================================
FILE: Browser/웹 브라우저의 작동 원리.md
================================================
# 웹 브라우저의 작동 원리
## Rendering Engine
현대 브라우저들의 렌더링 엔진은 다양하다. gecko기반의 spider monkey를 사용하는 firefox, webkit - blink기반의 V8을 사용하는 chrome, webkit을 사용하는 safari 등 상당히 종류가 많다.
하지만 모든 브라우저는 크게 비슷한 flow로 동작하며 다음의 그림은 그 뼈대인 main flow다.

1. DOM Tree 구축을 위한 HTML parsing
2. Render Tree 구축
3. Render Tree의 배치
4. paint
모든 브라우저는 위의 과정을 거쳐 화면에 그린다.
모든 작업은 UX를 위해 점진적으로 진행된다.
내용을 최대한 빠르게 paint하기 위해 모든 HTML이 parsing 되기를 기다리지는 않고 layout과 paint 일부를 먼저 처리한다.
중요한 것은 위와 같은 flow로 작동한다는 점이다.
### 예시
HTML5rocks라는 구글이 했던 프로젝트의 [How Browsers Work: Behind the scenes of modern web browsers](https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/)의 유명한 그림이다.
- Webkit Engine 기반

- Gecko Engine 기반

이미 너무 예전 그림이며 현대에는 더욱더 복잡한 과정을 거친다. 고전적인 rendering 과정이지만 두 엔진은 용어가 조금 다를 뿐 main flow는 비슷하게 작동함을 알 수 있다.
## Critical Rendering Path(CRP)
위처럼 브라우저에서 화면이 그려지기까지의 주요한 과정을 Critical Rendering Path라고 한다.
1. HTML 마크업을 처리하고 DOM 트리를 빌드한다.
2. CSS 마크업을 처리하고 CSSOM 트리를 빌드한다.
3. DOM 및 CSSOM을 결합하여 Rendering 트리를 형성한다.
4. Rendering 트리에서 레이아웃을 실행하여 각 노드의 기하학적 형태(화면의 위치)를 계산한다.
5. 개별 노드를 화면에 paint한다.
이 과정을 정리한 유명한 글은 Google Developers의 [주요 렌더링 경로](https://developers.google.com/web/fundamentals/performance/critical-rendering-path/?hl=ko)가 있다.
webkit과 gecko, 다른 모든 렌더링 엔진은 이 Critical Rendering Path를 따른다.
### HTML 파싱 / DOM Tree 빌드
컴파일러는 Source Code를 기계어로 변환한다.

위 그림은 그 변환 과정 중 하나인 parsing 과정이다.
문서는 lexer(tokenizer)와 parser(syntax 분석)가 함께 작업하여 tree를 만든다.
브라우저도 마찬가지다.
브라우저는 HTML 문서를 파싱해 DOM Tree를 만든다.
모든 HTML 태그에는 노드가 있고 각각의 노드는 Tree형태로 구현된다.

### CSSOM Tree 빌드
HTML 파싱 중 CSS 링크를 만나면 리소스를 받아온다.
같은 프로세스로 CSS도 Tree형태로 만들어진다.
이를 CSSOM(CSS Object Model)이라고 부른다.

#### script and css in HTML parsing
HTML parsing과정에서 코드를 읽는 중 script나 css만난 경우 어떻게 처리될까?
- script
script는 기본적으로 parsing을 중단(block)시킨다.
script가 외부에 있다면 네트워크 과정을 기다린다.
이는 HTML4, 5의 spec에도 명시되어 있다.
이러한 중단을 막고자 4에서는 defer, 5에서는 async라는 옵션이 추가되었다.
최근에는 외부 script의 parsing은 main parser가 하지 않으며 별도의 쓰레드에서 작업한다.
- css
이론적으로 css는 dom tree를 수정하지 않기 때문에 block하지 않는다. 하지만 script가 css 정보를 이용해야 하는 경우가 있다. 이 경우 브라우저 엔진이 최적화 작업을 진행하여 문제가 될 경우만 block한다.
### Render Tree 생성
DOM Tree와 CSSOM를 결합하여 Render Tree를 만든다.


위 그림들은 Render Tree를 추상화 한 그림이다.
Render Tree는 DOM Tree에 있는 것 중에 실제 보이는 것들로만 구성한다.
**ex) style='display : none;'은 Render Tree에서 제외된다. Header 역시 제외된다.**
### Layout(Reflow)
Render Tree가 만들어진 뒤 기기의 viewport를 기준으로 노드들의 정확한 위치와 크기를 계산하는 과정이다.
위치와 관련된 속성(position, width, height 등)들을 계산한다.
**ex) width:100%인 상태에서 브라우저를 resize하면, Render Tree는 변경되지 않고 Layout 이후 과정만 다시 거치게 된다.**
### Paint
실제 웹페이지를 화면에 그리는 작업이다.
렌더러의 "paint" 메서드가 호출된다.
**색이 바뀐다거나 노드의 스타일이 바뀌는 것으로는 Layout 과정을 거치지 않고 Paint만 일어난다.**
#### modern browser
최근의 브라우저들은 Critical Rendering Path에 몇 가지 과정이 추가된다.
1. layout 과정 이후 Update Layer Tree라는 단계가 생겼다.
Render Object는 layout 이후 정해진 기준에 따라 layer를 나누게 된다.
여기에서 layer는 포토샵의 layer와 비슷한 개념이다.
[Layer Model](https://github.com/Im-D/Dev-Docs/blob/master/Browser/Layer_Model.md)로 글을 대체한다.
Layer는 Render Layer와 Graphics Layer 두 종류가 있는데 이 두 기준으로 Layer Tree를 만든다.
2. 각각의 layer는 paint 과정을 거친 후 composite layers이라는 새로운 과정을 거친다.
layer들을 합성하여 하나의 bitmap으로 만든 뒤 최종 page를 만든다.
#### Reference
- [How Browsers Work: Behind the scenes of modern web browsers](https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/)
- [Naver D2 - 브라우저의 작동 원리(위 글 번역)](http://d2.naver.com/helloworld/59361)
- [critical rendering path](https://developers.google.com/web/fundamentals/performance/critical-rendering-path/?hl=ko)
- [웹 성능 최적화에 필요한 브라우저의 모든 것](https://tv.naver.com/v/4578425)
================================================
FILE: Browser/최신_브라우저의_내부_살펴보기.md
================================================
# 최신 브라우저의 내부 살펴보기
개인적으로 일을 하다보면 성능(performance)를 올려야하는 일은 당연하게 된다. 성능이 나와야 제품을 사용하는 사람이 생기기 마련이다.
그러다 보면 당연하게 GPU를 사용하는 방법을 택하게 된다. 흔히 우리가 알고 있는 **하드웨어 가속화**를 사용하게 되는 것이다.
> 특정 작업을 CPU가 아닌 다른 특별한 장치를 통해 수행 속도를 높이는 것을
> '**하드웨어 가속(hardware accelerated)**'이라 한다.
>
> 브라우저에서 하드웨어 가속은 주로 GPU를 사용한 그래픽 작업의 가속을 의미한다.
> 간단한 작업을 동시에 수많은 코어가 수행하는 GPU의 특성을 기반으로 그래픽 작업이 훨씬 빠르게 처리될 수 있다.
브라우저에 대해 알아보기 전에 기본적인 내용을 알아보고 가자
## CPU
컴퓨터 부품에서 가장 중요한? **중앙처리장치**이다. 흔히 연산을 담당하는 사람으로 따지면 두뇌라고 한다. 예전 CPU는 단일로 구성되어 있었지만 요즘은 CPU하나 안에 코어가 여러개가 들어가서 성능을 더 높이고 있다.
## GPU
GPU는 그래픽처리장치로 CPU와 다르게 GPU는 간단한 작업에만 특화가 되었는데 여러 GPU 코어를 동시에 사용하여 작업을 할 수 있다.
이름에서 알 수 있듯이 GPU는 **그래픽 작업을 처리하기 위해 개발**되었다. 그래서 빠른 렌더링과 매끄러운 표현을 하는데 관련되어있다. 최근 몇 년 동안 GPU 가속을 통해 GPU가 단독으로 처리할 수 있는 계산이 점점 더 많아졌다.
## 프로세스와 스레드(Process and Thread)
브라우저 아키텍처를 살펴보기 전에 파악해야 할 또 다른 개념은 **프로세스와 스레드**이다.
프로세스는 애플리케이션이 실행하는 **프로그램**이라고 하며, 스레드는 프로세스 내부에 있으며 프로세스로 실행되는 프로그램의 **일부를 실행**한다.
애플리케이션을 시작하면 프로세스가 하나가 만들어진다. 프로세스가 작업을 하기 위해 스레드를 생성할 수도 있지만 **선택 사항**이며, 애플리케이션을 닫으면 프로세스가 사라지고 운영체제가 메모리를 비운다.
프로세스는 여러 작업을 수행하기 위해 운영체제에 다른 프로세스를 실행하라고 요청할 수 있다. 그러면 메모리의 다른 부분이 새 프로세스에 할당된다. 두개 이상의 프로세스가 서로 정보를 공유해야 할 때는 **IPC(inter process communication, 프로세스 간 통신)** 을 사용한다. 대부분의 애플리케이션이 이 방식으로 설계되어 있다. 작업 프로세스가 응답하지 않을 때 애플리케이션의 다른 부분을 실행하는 프로세스를 중지하지 않고 응답하지 않는 프로세스만 다시 시작할 수 있다.
## 브라우저 아키텍처
브라우저는 프로세스와 스레드를 어떻게 사용할까? 크게 방법은 2가지가 있다.
1. 스레드를 많이 사용하는 프로세스 하나만 사용
2. 스레드를 조금만 사용하는 프로세스를 여러 개 만들어 IPC로 통신
### **Chrome의 최근 아키텍처**
상위 브라우저 프로세스는 애플리케이션의 각 부분을 맡고 있는 다른 프로세스를 조정한다. Renderer 프로세스는 여러 개가 만들어져 각 탭마다 할당이 된다.
최근까지 Chrome은 **탭마다 프로세스를 할당**했다. 이제는 사이트(iframe에 있는 사이트 포함)마다 프로세스를 할당한다.
### **어떤 프로세스가 무엇을 담당하나**
- 브라우저 프로세스 : 주소 표시줄, 북마크 막대, 뒤로 가기 버튼, 앞으로 가기 버튼 등 애플리케이션의 "chrome" 부분을 제어한다. 네트워크 요청이나 파일 접근과 같이 눈에 보이지는 않지만 권한이 필요한 부분도 처리한다.
- 렌더러 프로세스 : 탭 안에서 웹 사이트가 표시되는 부분의 모든 것을 제어한다.
- 플러그인 프로세스 : 웹 사이트에서 사용하는 플러그인(예: Flash)을 제어한다.
- GPU 프로세스 : GPU 작업을 다른 프로세스와 격리해서 처리한다. GPU는 여러 애플리케이션의 요청을 처리하고 같은 화면에 요청받은 내용을 그리기 때문에 GPU 프로세스는 별도 프로세스로 분리되어 있다.
이 외에도 확장 프로그램(Extension) 프로세스, 유틸리티 프로세스 등 더 많은 프로세스가 있다.
Chrome에서 실행 중인 프로세스를 확인이 가능하다.(도구 더보기 > 작업 관리자)
### **다중 프로세스 아키텍처가 Chrome에 주는 이점**
Chrome은 렌더러 프로세스를 여러 개 사용한다. 예로 탭마다 렌더러 프로세스를 하나 사용하는 경우를 생각해보면. 3개의 탭이 열려 있고 각 탭은 독립적인 렌더러 프로세스에 의해 실행된다.
이때 한 탭이 응답하지 않으면 그 탭만 닫고 실행 중인 다른 탭으로 이동할 수 있다. 모든 탭이 하나의 프로세스에서 실행 중이었다면 탭이 하나만 응답하지 않아도 모든 탭이 죽는일이 벌어졌을 것이다.
브라우저의 작업을 여러 프로세스에 나눠서 처리하는 방법의 또 다른 장점은 **보안과 격리**이다. 운영체제를 통해 프로세스의 권한을 제한할 수 있어 브라우저는 특정 프로세스가 특정 기능을 사용할 수 없게 제한할 수 있다.
예를 들어 Chrome은 렌더러 프로세스처럼 임의의 사용자 입력을 처리하는 프로세스가 임의의 파일에 접근하지 못하게 제한한다.
프로세스는 전용 메모리 공간을 사용하기 때문에 공통부분(예를 들어 Chrome의 JavaScript 엔진인 V8)을 복사해서 가지고 있는 경우가 많다. 동일한 프로세스의 스레드가 메모리를 공유할 수 있는 데 반해 서로 다른 프로세스는 메모리를 공유할 수 없어 메모리 사용량이 더 많아질 수밖에 없다. Chrome은 메모리를 절약하기 위해서 실행할 수 있는 프로세스의 개수를 제한한다. 정확한 한도는 기기의 메모리 용량과 CPU 성능에 따라 다르지만 프로세스의 개수가 한도에 다다르면 동일한 사이트를 열고 있는 여러 탭을 하나의 프로세스에서 처리한다.
### 더 많은 메모리 절약 - Chrome의 서비스화
Chrome은 브라우저의 각 부분을 서비스로 실행해 여러 프로세스로 쉽게 분할하거나 하나의 프로세스로 통합할 수 있도록 아키텍처를 변경하고 있다.
성능이 좋은 하드웨어에서 Chrome이 실행 중일 때에는 각 서비스를 여러 프로세스로 분할해 안정성을 높이고, 리소스가 제한적인 장치에서 실행 중일 때에는 서비스를 하나의 프로세스에서 실행해서 메모리 사용량을 줄이는 것이 기본 아이디어이다. 메모리 절약을 위해 프로세스를 합치는 이런 방식은 `Android`와 같은 플랫폼에서는 이전부터 사용되었다.
### 프레임별로 실행되는 렌더러 프로세스 - 사이트 격리
`iframe`의 사이트를 별도의 렌더러 프로세스에서 실행하는 것이다. 탭마다 렌더러 프로세스를 할당하는 모델에서는 `iframe`의 사이트가 같은 렌더러 프로세스에서 작동하기 때문에 서로 다른 사이트 간에 메모리가 공유될 수 있다는 문제가 있어 지속적으로 논의가 있었다.
a.com 사이트의 웹 페이지와 b.com 사이트의 웹 페이지를 동일한 렌더러 프로세스에서 실행하는 것이 문제가 없어 보일 수 있다. 하지만 동일 출처 정책(same origin policy)은 웹 보안 모델의 핵심이다. 한 사이트는 동의 없이 다른 사이트의 데이터에 접근할 수 없어야 한다.
이 정책을 우회하는 것이 바로 보안 공격의 주요 목표이다. 프로세스를 격리하는 것이 사이트를 격리하는 가장 효과적인 방법이다. **Meltdown과 Spectre 사태**로 여러 프로세스를 사용해 사이트를 격리해야 한다는 것이 더욱 분명해졌다. Chrome 67부터 데스크톱에서 사이트 격리를 기본으로 사용하도록 설정하면서 탭에서 `iframe` 의 사이트에 별도의 렌더러 프로세스가 적용된다.
사이트 격리를 위해 여러 해에 걸친 노력이 있었다. 사이트 격리는 다른 렌더러 프로세스를 할당하는 것만큼 간단하지 않다. `iframe` 이 서로 통신하는 방식을 근본적으로 바꿔야 하기 때문이다. 다른 프로세스에서 실행되는 `iframe` 이 있는 웹 페이지에서 개발자 도구를 자연스럽게 사용하게 하려면 눈에 보이지 않은 많은 작업이 뒤에서 이루어져야 한다. 또 단순히 `Ctrl + F` 키를 눌러 페이지에서 단어를 찾으려고 해도 서로 다른 렌더러 프로세스를 오가며 찾아야 한다.
#### Reference
- [최신 브라우저의 내부 살펴보기 1 - CPU, GPU, 메모리 그리고 다중 프로세스 아키텍처](https://d2.naver.com/helloworld/2922312)
- [인텔 사태, CPU 보안 이슈 정리, 멜트다운(Meltdown)](https://fillin.tistory.com/259)
================================================
FILE: CS/Binding.md
================================================
# 바인딩(Binding)
**바인딩**은 **이름**을 어떠한 **속성**과 **연결** 시키는 것이다. 더 나아가 바인딩은, 값들을 확정시켜 더 이상 **변경할 수 없는 상태**로 만든다. 또한, **메모리 번지를 연결** 시키는 것도 바인딩이다. 좀 더 정확하게 말하면 바인딩은 식별자(identifiers)를 개체(entity)와 결합(association; 연관)시키는 것이다.
> bind는 묶다, 결속시키다 등의 뜻을 가지고 있는데, 고정, 구속, 속박 등과 같이 틀 안에 가둬 놓는 뉘앙스를 띈다.
> 이름을 연결하는 것이기 때문에 'Name binding' 이라고도 한다.
<br/>
## 바인딩 타임(Binding Time)
바인딩은 프로그램 실행 과정 중 어떤 단계에서 이루어지는지에 따라 역할이 달라진다. 이 때, 특정 단계에서 바인딩이 되는 순간을 바인딩 타임이라 한다.
### 바인딩 타임의 종류
1. 언어 설계(정의) 시간(Language Design/Definition Time)
- 언어의 근본적인 요소를 결정
- 기본 제공 함수, 키워드의 기본 요소 등을 결정
> e.g. int는 정수값을 나타내는 타입명, +는 덧셈 연산자를 나타내는 기호
2. 언어 구현 시간(Language Implementation Time)
- 언어 설계 시간에 정해진 각 유형들의 세부정보를 결정
- 타입의 크기, 파일 표현, 런타임 예외 등을 결정
> e.g. java에서 int의 범위는 -2147483648 ~ 2147483647
3. 컴파일 타임(Compile Time)
- 원시 코드(source code)를 기계어로 매핑(mapping)
- 변수와 변수 타입을 연결(type binding)
4. 링크 타임(Link Time)
- 함수와 외부에서 참조된 객체(e.g. 라이브러리)의 유효성과 주소 검사 및 수정
5. 로드 타임(Load time; 적재 시간)
- 변수를 메모리에 할당(allocation) 하는 단계(주소 결정)
6. 런타임(Run Time/Execution Time; 실행 시간)
- 프로그램을 실행하는 단계
<br/>
## 변수의 바인딩
변수의 바인딩은 바인딩 타임에 따라 달라진다. 런타임 이전에 바인딩 된 것을 정적 바인딩(static binding), 런타임에 바인딩 되는 것을 동적 바인딩(dynamic binding)이라고 한다.
### 정적 바인딩(Static Binding)
정적 바인딩은 이른 바인딩(early binding)이라고 부르기도 한다. **컴파일 타임에 바인딩이 결정**되고, **바인딩이 변하지 않은 상태로 유지**되어야 정적 바인딩이다.
> e.g. 전역(static) 변수
### 동적 바인딩(Dynamic Binding)
동적 바인딩은 늦은 바인딩(late binding)이라고도 한다. 실행 파일을 만들 때에는 바인딩이 되지 않고 보류되었다가, **프로그램이 실행될 때 바인딩** 되는 것이다. 따라서 정적 바인딩에 비해 **유연**하며, 이를 이용해 OOP의 **다형성을 구현**할 수 있다.
하지만, 동적 바인딩은 메모리 위치 및 크기가 정해져있지 않아 정적 바인딩에 비해 비효율적이다. 또한, 바인딩에 필요한 메모리 번지를 저장할 포인터를 가지고 있어야 한다. 따라서 **정적 바인딩에 비해 자원 소모가 크다.**
### 자바(Java)에서...
자바는 동적 바인딩을 사용한다.
```java
class Child extends Parent{
public String parentMethod(){
return "Inheritance Method";
}
public String childMethod() {
return "Child Method";
}
}
class Parent{
public String parentMethod(){
return "Parent Method";
}
}
public class Test01{
public static void main(String[] args) {
// test01 - 타입 체크를 통과하여 컴파일이 되지만, 실제 값의 할당은 런타임에 이루어진다.
try {
String[] arr = new String[1]; // test01 - RuntimeException
arr[2] = "0";
} catch (RuntimeException e) {
System.out.println("test01 - RuntimeException ");
}
// test02 - 마찬가지로 컴파일시 타입 체크를 하지만, 실제 값이 할당되지 않는다.
try {
Child test02 = (Child)new Parent(); // test02 - RuntimeException
// 컴파일시에는 값이 타입에 정의된 내용의 범위 안에 있는지 판단한다.
System.out.println("test02 - " + test02.parentMethod());
System.out.println("test02 - " + test02.childMethod());
} catch (RuntimeException e) {
System.out.println("test02 - RuntimeException");
}
// test03 - 부모 타입을 사용한다면, 부모 타입 내에 정의된 것과 같은 형식의 메소드를 호출 할 수 있다.
try {
Parent childInstance = new Child();
Parent parentInstance = new Parent();
System.out.println("test03 - " + childInstance.parentMethod()); // test03 - Inheritance Method
System.out.println("test03 - " + parentInstance.parentMethod()); // test03 - Parent Method
// childInstance.childMethod() // The method childMethod() is undefined for the type Parent - Compile Error
} catch (RuntimeException e) {
System.out.println("test03 - RuntimeException");
}
}
}
```
<br/>
## 타입 바인딩
**타입 바인딩은 컴파일 타임에 이루어진다.** 타입이 결정 되는 것이기 때문에 타이핑(typing)이라고도 한다. **바인딩 대상(변수)의 타입이 고정적인지 유동적인지에 따라** 정적 타입 바인딩(static type binding)과 동적 타입 바인딩(dynamic type binding)으로 나뉜다.
### 정적 타입 바인딩(Static Type Binding; Static Typing)
정적 타입 바인딩은 'strongly typed' 되었다고 표현하기도 한다. **자료형을 한 번 선언하면 더 이상 변경할 수 없다.**
> e.g.
> 1. 자바나 C 등의 언어에서 선언 한 변수의 타입은 더 이상 변경 불가능하다.(명시적 선언)
> 2. 과거 포트란에서, 문자 i~n으로 시작하는 변수는 정수 이다.(묵시적 선언)
### 동적 타입 바인딩(Dynamic Type Binding; Dynamic Typing)
'weakly typed' 혹은 'loosely typed' 되었다고 표현하기도 한다. 동적 타입 바인딩은 **컴파일러가 데이터의 타입을 추론**한다. 사용하기 쉽다는 장점이 있지만, 타입 바인딩 시 타입 추론으로 인한 비용이 증가하고, 컴파일 중에 타입 에러가 발생하지 않는 단점이 있다.
> e.g. JavaScript나 python 등의 언어에서 변수 선언이 타입에 관계없이 통일되어 있다.
---
#### Reference
- [자바 :: 바인딩(binding)](https://m.blog.naver.com/PostView.nhn?blogId=reeeh&logNo=220716449491&proxyReferer=https%3A%2F%2Fwww.google.co.kr%2F)
- [Binding의 개념](https://twinw.tistory.com/58)
- [Link time - Wikipedia](https://en.wikipedia.org/wiki/Link_time)
- [정적 바인딩과 동적 바인딩](https://wookss-blog.tistory.com/6)
- [Name binding - Wikipedia](https://en.wikipedia.org/wiki/Name_binding)
- [Binding - 정보통신기술용어해설](http://www.ktword.co.kr/word/abbr_view.php?m_temp1=2670&m_search=%EB%B0%94%EC%9D%B8%EB%94%A9)
================================================
FILE: CS/Bomb-Lab(1).md
================================================
# Bomb Lab(1)
Bomb Lab은 Carnegie Mellon University의 시스템 프로그래밍 과제인 Lab 시리즈 중 하나이다. 과제에는 bomb라는 바이너리 파일이 제공된다. 과제의 목적은 gdb(GNU 디버거의 약자로 Unix/Linux 환경에서 C/C++ 디버깅에 사용)를 이용해 해당 파일을 리버스 엔지니링 하여 총 6단계의 문구를 찾아 폭탄을 해체하는 것이다. 과제의 특성상 어셈블리를 분석해야 하기 때문에 문제를 해결하는 과정에서 어셈블리와 친숙해질 수 있다.
해당 문서에서 사용되는 어셈블리는 [AT&T 문법](http://doc.kldp.org/KoreanDoc/html/Assembly_Example-KLDP/Assembly_Example-KLDP.html)을 따른다.
## 사전지식
### 어셈블리의 구성
`[Label]: [operator] [operand1], [operand2] # [comment]`
`L1: mov %eax, %ebx # comment`
`L1:`은 기계어 코드로 번역되지 않고 분기 명령([JMP](https://github.com/im-d-team/Dev-Docs/blob/20201101/dididy/CS/Bomb-Lab(1).md#%EC%96%B4%EC%85%88%EB%B8%94%EB%A6%AC-%EB%AA%85%EB%A0%B9%EC%96%B4) - FLAG 값을 기반으로 조건에 따라 특정 위치로 점프하도록 하는 명령어) 등에서 참조될 때에 번지의 계산에 사용된다. `mov`는 operand2의 값을 operand1에 할당할 때 사용한다.
operand 앞에 붙는 기호 중 `$`는 상수, `%`는 레지스터를 나타낸다.
- AT&T 방식에서는 `[instruction] [src], [dest]` 의 순서로 명렁이 구성된다.(Intel 방식의 경우 이와 반대로 `[instruction] [dest], [src]` 순서)
### 어셈블리 명령어

> 출처: https://aistories.tistory.com/12

> 출처: https://8jz5.tistory.com/50
### 주소지정 방식
- 즉시 지정 방식
- `mov $0x1, %eax`: eax에 1을 할당하는 것처럼 값을 직접 대응시키는 방식이다.
- 레지스터 지정방식
- `mov %esp, %ebp`: 레지스터 ebp에 레지스터 esp의 값을 할당하는 방식이다.
- 직접 주소 지정방식
- `mov &0x127f, %eax `: 주소 0x127f에 있는 값을 eax에 할당하는 것처럼 메모리의 주소를 직접 지정해서 할당하는 방식이다.
- 레지스터 간접 주소 지정방식(괄호 안의 값)
- `mov (%ebx), %eax`: ebx의 값을 주소로 하여 간접적으로 eax 레지스터에 할당하는 방식이다.
- 베이스 상대 주소 지정방식
- `mov 0x4(%esi), %eax`: esi레지스터에서 4 Byte를 더한 주소의 값을 eax 레지스터에 할당하는 방식이다.
### 범용 레지스터
- 레지스터의 첫 글자는 32bit에서 E, 64bit에서 R로 사용된다. 해당 문서에서는 64bit를 기준으로 작성하였다.
- 데이터 레지스터
- RAX(Accumulator): 곱셈, 나눗셈 등 각종 연산에 많이 사용되는 변수이다. 주로 return 값을 저장한다.
- RBX(Base): 목적이 없는 레지스터이다. 공간이 필요할 때 메모리 주소 지정 시 사용한다.
- RCX(Count): for 문에서 i 역할을 한다. ECX는 미리 값을 정해놓고 0이 될 때까지 진행한다. 변수로 사용해도 무방하다.
- RDX(Data): 각종 연산에 쓰이는 변수이다. 나눗셈에서 EAX와 함께 사용한다. 부호 확장 명령 등에 사용한다.
- 인덱스 레지스터
- RSI(Source Index), RDI(Destination Index): 문자열이나 각종 반복 데이터를 처리하거나 메모리를 옮기는 데 사용한다. 각각 Source의 주소와 Destination의 주소를 가리킨다.
- 포인터 레지스터
- RSP(Stack Pointer): Stack의 상위 주소(최종점)를 가리키는 레지스터이다.
- RBP(Base Pointer): Stack의 Base 주소를 가리키는 레지스터이다. ESP를 대신해 스택에 저장된 함수의 파라미터 지역 변수의 주소를 가리키는 용도로 사용된다.
- 상태 레지스터
- RIP(Instruction Pointer): 실행할 명령의 주소를 가리키는 레지스터이다. 각각의 명령이 실행될 때, EIP에 CPU가 현재 실행하고 있는 주소가 저장된다.
## GDB
### 기본 명령어
- `run`: 프로그램을 실행한다. break point가 걸려있다면 break point까지 실행한다.
- `continue`: break point가 걸려있는 경우 다음 break point까지 실행한다.
- `break`: break point를 지정한다. b로 줄여 쓸 수 있다.
- `display $eax`: EAX(accumulator)를 보여주는 역할을 한다.
- `ni`: next instruction의 약자다. 즉 다음 명령어로 넘어간다는 것을 의미한다. 함수 안으로 진입하지 않는다.
- `si`: ni와 동일하게 다음 명령어로 넘어간다는 것을 의미한다. 함수 안으로 들어갈 수 있다.
- `b explode_bomb`: 폭탄 터져서 점수를 잃지 않도록 방지하는 역할을 한다.
- `x/[출력 횟수] [출력 형식] [출력 단위] [출력 위치]`: 메모리 상태와 내용을 확인할 수 있다.
- 출력 형식: t(2), o(8), d, u(10), x(16), c, f, a, s(string), i
- 출력 단위: b(1 Byte), h(2 Byte), w(4 Byte), g(8 Byte)
- `disas [함수명]`: 함수의 어셈블리 코드 출력
- `disas [시작 주소] [끝 주소]`: 주소 범위의 어셈블리 코드 출력
- `p $[레지스터 명]`: 레지스터값 확인
- `i r`: info registers를 줄여 쓴 것이다. 레지스터값 전체를 한 번에 확인할 수 있다.
### TUI(Text User Interface)
- gdb에서 디버깅 정보들을 분리된 창에서 상시로 확인할 수 있게 해준다.
- Source file, Assembly, register info, gdb command 총 4가지 종류의 정보를 띄울 수 있다.
- `tui enable`: TUI를 활성화한다. 혹은 gdb를 실행할 때 `--tui` 옵션을 줘서 실행시킬 수도 있다.
- `layout asm`: Assembly 디버깅 정보를 표시하는 TUI를 활성화 한다.
## bomb 파일 분석
`gdb bomb` 명령어로 bomb 파일을 gdb를 이용해 분석해보도록 하자.
### main
```shell
(gdb) disas main
Dump of assembler code for function main:
0x000000000000116a <+0>: push %rbx
0x000000000000116b <+1>: cmp $0x1,%edi
0x000000000000116e <+4>: je 0x126c <main+258>
0x0000000000001174 <+10>: mov %rsi,%rbx
0x0000000000001177 <+13>: cmp $0x2,%edi
0x000000000000117a <+16>: jne 0x12a1 <main+311>
0x0000000000001180 <+22>: mov 0x8(%rsi),%rdi
0x0000000000001184 <+26>: lea 0x17d9(%rip),%rsi # 0x2964
0x000000000000118b <+33>: callq 0xfc0 <fopen@plt>
0x0000000000001190 <+38>: mov %rax,0x203519(%rip) # 0x2046b0 <infile>
0x0000000000001197 <+45>: test %rax,%rax
0x000000000000119a <+48>: je 0x127f <main+277>
0x00000000000011a0 <+54>: callq 0x17d8 <initialize_bomb>
0x00000000000011a5 <+59>: lea 0x183c(%rip),%rdi # 0x29e8
0x00000000000011ac <+66>: callq 0xee0 <puts@plt>
0x00000000000011b1 <+71>: lea 0x1870(%rip),%rdi # 0x2a28
0x00000000000011b8 <+78>: callq 0xee0 <puts@plt>
0x00000000000011bd <+83>: callq 0x1af2 <read_line>
0x00000000000011c2 <+88>: mov %rax,%rdi
0x00000000000011c5 <+91>: callq 0x12c4 <phase_1>
0x00000000000011ca <+96>: callq 0x1c36 <phase_defused>
0x00000000000011cf <+101>: lea 0x1882(%rip),%rdi # 0x2a58
0x00000000000011d6 <+108>: callq 0xee0 <puts@plt>
0x00000000000011db <+113>: callq 0x1af2 <read_line>
0x00000000000011e0 <+118>: mov %rax,%rdi
0x00000000000011e3 <+121>: callq 0x12e4 <phase_2>
0x00000000000011e8 <+126>: callq 0x1c36 <phase_defused>
0x00000000000011ed <+131>: lea 0x17a9(%rip),%rdi # 0x299d
0x00000000000011f4 <+138>: callq 0xee0 <puts@plt>
0x00000000000011f9 <+143>: callq 0x1af2 <read_line>
0x00000000000011fe <+148>: mov %rax,%rdi
0x0000000000001201 <+151>: callq 0x1353 <phase_3>
0x0000000000001206 <+156>: callq 0x1c36 <phase_defused>
0x000000000000120b <+161>: lea 0x17a9(%rip),%rdi # 0x29bb
0x0000000000001212 <+168>: callq 0xee0 <puts@plt>
0x0000000000001217 <+173>: callq 0x1af2 <read_line>
0x000000000000121c <+178>: mov %rax,%rdi
0x000000000000121f <+181>: callq 0x1440 <phase_4>
0x0000000000001224 <+186>: callq 0x1c36 <phase_defused>
0x0000000000001229 <+191>: lea 0x1858(%rip),%rdi # 0x2a88
0x0000000000001230 <+198>: callq 0xee0 <puts@plt>
0x0000000000001235 <+203>: callq 0x1af2 <read_line>
0x000000000000123a <+208>: mov %rax,%rdi
0x000000000000123d <+211>: callq 0x14af <phase_5>
0x0000000000001242 <+216>: callq 0x1c36 <phase_defused>
0x0000000000001247 <+221>: lea 0x177c(%rip),%rdi # 0x29ca
0x000000000000124e <+228>: callq 0xee0 <puts@plt>
0x0000000000001253 <+233>: callq 0x1af2 <read_line>
0x0000000000001258 <+238>: mov %rax,%rdi
0x000000000000125b <+241>: callq 0x14f5 <phase_6>
0x0000000000001260 <+246>: callq 0x1c36 <phase_defused>
0x0000000000001265 <+251>: mov $0x0,%eax
0x000000000000126a <+256>: pop %rbx
0x000000000000126b <+257>: retq
0x000000000000126c <+258>: mov 0x20341d(%rip),%rax # 0x204690 <stdin@@GLIBC_2.2.5>
0x0000000000001273 <+265>: mov %rax,0x203436(%rip) # 0x2046b0 <infile>
0x000000000000127a <+272>: jmpq 0x11a0 <main+54>
0x000000000000127f <+277>: mov 0x8(%rbx),%rcx
0x0000000000001283 <+281>: mov (%rbx),%rdx
0x0000000000001286 <+284>: lea 0x16d9(%rip),%rsi # 0x2966
0x000000000000128d <+291>: mov $0x1,%edi
0x0000000000001292 <+296>: callq 0xfb0 <__printf_chk@plt>
0x0000000000001297 <+301>: mov $0x8,%edi
0x000000000000129c <+306>: callq 0xfe0 <exit@plt>
0x00000000000012a1 <+311>: mov (%rsi),%rdx
0x00000000000012a4 <+314>: lea 0x16d8(%rip),%rsi # 0x2983
0x00000000000012ab <+321>: mov $0x1,%edi
0x00000000000012b0 <+326>: mov $0x0,%eax
0x00000000000012b5 <+331>: callq 0xfb0 <__printf_chk@plt>
0x00000000000012ba <+336>: mov $0x8,%edi
0x00000000000012bf <+341>: callq 0xfe0 <exit@plt>
End of assembler dump.
```
main 함수를 disassemble 하면 메인 함수는 총 6개 phase로 구성된 것을 확인할 수 있다. break point 없이 run 명령어를 실행하면 문자열을 입력받는 상태가 된다. 여기서 제대로 된 문자열을 입력해야만 폭탄이 터지지 않는다. 이 과정을 6번 거쳐 제대로 된 문자열을 입력하면 폭탄을 해체할 수 있다.
각 phase함수들을 disassemble 하여 어셈블리를 분석하거나 적절하게 break point를 건 뒤 단서를 찾아 폭탄을 해체할 수 있는 입력값들을 발견할 수 있다.
과제는 진행 상황에 따라 웹(score board)을 통해 실시간으로 점수를 확인할 수 있다. 각 phase를 처음 통과할 때 점수를 얻는다. 각 phase에 잘못된 문자열을 입력하여 폭탄이 터지면 터질 때마다 일정 점수를 잃는다.
폭탄이 터져 점수를 잃는 것을 방지하기 위해서는 `b explode_bomb` 명령어를 사용하여 break point를 걸고 시작하면 된다.
### phase_1
`disas phase_1` 명령어로 첫 번째 phase 함수의 어셈블리 코드를 출력할 수 있다. 그 결과는 아래와 같다.
```shell
(gdb) disas phase_1
Dump of assembler code for function phase_1:
0x00000000000012c4 <+0>: sub $0x8,%rsp
0x00000000000012c8 <+4>: lea 0x17dd(%rip),%rsi # 0x2aac
0x00000000000012cf <+11>: callq 0x1771 <strings_not_equal>
0x00000000000012d4 <+16>: test %eax,%eax
0x00000000000012d6 <+18>: jne 0x12dd <phase_1+25>
0x00000000000012d8 <+20>: add $0x8,%rsp
0x00000000000012dc <+24>: retq
0x00000000000012dd <+25>: callq 0x1a75 <explode_bomb>
0x00000000000012e2 <+30>: jmp 0x12d8 <phase_1+20>
End of assembler dump.
```
먼저 `phase_1` 함수는 `+11`에서 ` strings_not_equal` 함수를 호출함을 확인할 수 있다. `+16`의 test 명령은 %eax를 AND 연산한다. 즉 %eax의 값이 0인지, 1인지를 판별하는 것이다. `+18`에서 jne(Jump If Not Equal) 명령은 `+16`이 1(Equal)인 경우 `+20`으로 넘어가고 0(Not Equal)인 경우 `+25`로 넘어가 `explode_bomb` 함수가 호출되어 폭탄이 터지게 된다.
그렇다면 `strings_not_equal` 함수는 어떻게 구성되어 있을까? `disas strings_not_equal`로 확인해보면 아래와 같다.
```shell
(gdb) disas strings_not_equal
Dump of assembler code for function strings_not_equal:
0x0000000000001771 <+0>: push %r12
0x0000000000001773 <+2>: push %rbp
0x0000000000001774 <+3>: push %rbx
0x0000000000001775 <+4>: mov %rdi,%rbx
0x0000000000001778 <+7>: mov %rsi,%rbp
0x000000000000177b <+10>: callq 0x1754 <string_length>
0x0000000000001780 <+15>: mov %eax,%r12d
0x0000000000001783 <+18>: mov %rbp,%rdi
0x0000000000001786 <+21>: callq 0x1754 <string_length>
0x000000000000178b <+26>: mov $0x1,%edx
0x0000000000001790 <+31>: cmp %eax,%r12d
0x0000000000001793 <+34>: je 0x179c <strings_not_equal+43>
0x0000000000001795 <+36>: mov %edx,%eax
0x0000000000001797 <+38>: pop %rbx
0x0000000000001798 <+39>: pop %rbp
0x0000000000001799 <+40>: pop %r12
0x000000000000179b <+42>: retq
0x000000000000179c <+43>: movzbl (%rbx),%eax
0x000000000000179f <+46>: test %al,%al
0x00000000000017a1 <+48>: je 0x17ca <strings_not_equal+89>
0x00000000000017a3 <+50>: cmp 0x0(%rbp),%al
0x00000000000017a6 <+53>: jne 0x17d1 <strings_not_equal+96>
0x00000000000017a8 <+55>: add $0x1,%rbx
0x00000000000017ac <+59>: add $0x1,%rbp
0x00000000000017b0 <+63>: movzbl (%rbx),%eax
0x00000000000017b3 <+66>: test %al,%al
0x00000000000017b5 <+68>: je 0x17c3 <strings_not_equal+82>
0x00000000000017b7 <+70>: cmp %al,0x0(%rbp)
0x00000000000017ba <+73>: je 0x17a8 <strings_not_equal+55>
0x00000000000017bc <+75>: mov $0x1,%edx
0x00000000000017c1 <+80>: jmp 0x1795 <strings_not_equal+36>
0x00000000000017c3 <+82>: mov $0x0,%edx
0x00000000000017c8 <+87>: jmp 0x1795 <strings_not_equal+36>
0x00000000000017ca <+89>: mov $0x0,%edx
0x00000000000017cf <+94>: jmp 0x1795 <strings_not_equal+36>
0x00000000000017d1 <+96>: mov $0x1,%edx
0x00000000000017d6 <+101>: jmp 0x1795 <strings_not_equal+36>
End of assembler dump.
```
비교할 문자열과 입력받은 문자열이 같은지를 확인하는 과정이다. 그렇다면 어셈블리 코드상에서 비교할 문자열이 있는 부분을 찾으면 된다. `b string_not_equal`과 `r`을 실행한 뒤 `layout asm`으로 TUI 환경을 enable 시키고 `ni` 명령어로 한 줄씩 확인해보았다.

`x/s` 명령어로 %rdi와 %rsi의 메모리의 내용을 string 형식으로 출력해보았다. %rdi 레지스터에는 `phase_1` 함수를 실행했을 때 입력했던 값이 들어가 있고 %rsi 레지스터에는 프로그램이 가지고 있는 문자열인 `Wow! Brazil is big`이 들어가 있는 것을 확인 할 수 있었다. bomb 실행 후 `phase_1` 입력값에 해당 문자열을 넣어보았는데 `phase_2`로 넘어가는 것에 성공하였다.
### phase_2
`disas phase_2` 명령어로 두 번째 phase 함수의 어셈블리 코드를 출력해보았다.
```shell
(gdb) disas phase_2
Dump of assembler code for function phase_2:
0x00000000000012e4 <+0>: push %rbp
0x00000000000012e5 <+1>: push %rbx
0x00000000000012e6 <+2>: sub $0x28,%rsp
0x00000000000012ea <+6>: mov %fs:0x28,%rax
0x00000000000012f3 <+15>: mov %rax,0x18(%rsp)
0x00000000000012f8 <+20>: xor %eax,%eax
0x00000000000012fa <+22>: mov %rsp,%rsi
0x00000000000012fd <+25>: callq 0x1ab1 <read_six_numbers>
0x0000000000001302 <+30>: cmpl $0x0,(%rsp)
0x0000000000001306 <+34>: jne 0x130f <phase_2+43>
0x0000000000001308 <+36>: cmpl $0x1,0x4(%rsp)
0x000000000000130d <+41>: je 0x1314 <phase_2+48>
0x000000000000130f <+43>: callq 0x1a75 <explode_bomb>
0x0000000000001314 <+48>: mov %rsp,%rbx
0x0000000000001317 <+51>: lea 0x10(%rbx),%rbp
0x000000000000131b <+55>: jmp 0x1326 <phase_2+66>
0x000000000000131d <+57>: add $0x4,%rbx
0x0000000000001321 <+61>: cmp %rbp,%rbx
0x0000000000001324 <+64>: je 0x1337 <phase_2+83>
0x0000000000001326 <+66>: mov 0x4(%rbx),%eax
0x0000000000001329 <+69>: add (%rbx),%eax
0x000000000000132b <+71>: cmp %eax,0x8(%rbx)
0x000000000000132e <+74>: je 0x131d <phase_2+57>
0x0000000000001330 <+76>: callq 0x1a75 <explode_bomb>
0x0000000000001335 <+81>: jmp 0x131d <phase_2+57>
0x0000000000001337 <+83>: mov 0x18(%rsp),%rax
0x000000000000133c <+88>: xor %fs:0x28,%rax
0x0000000000001345 <+97>: jne 0x134e <phase_2+106>
0x0000000000001347 <+99>: add $0x28,%rsp
0x000000000000134b <+103>: pop %rbx
0x000000000000134c <+104>: pop %rbp
0x000000000000134d <+105>: retq
0x000000000000134e <+106>: callq 0xf00 <__stack_chk_fail@plt>
End of assembler dump.
```
`phase_2` 함수는 `+25`에서 `read_six_numbers` 함수를 호출한다. 이름으로 여섯 개의 숫자를 입력받는다고 유추해볼 수 있다. `b read_six_number`로 해당 함수에 break point를 건 뒤 `r`로 실행해보자. 이때 `b explode_bomb`를 미리 실행해서 폭탄이 터지지 않도록 하는 것을 잊지 않도록 한다.
```shell
(gdb) disas read_six_numbers
Dump of assembler code for function read_six_numbers:
0x0000555555555ab1 <+0>: sub $0x8,%rsp
0x0000555555555ab5 <+4>: mov %rsi,%rdx
0x0000555555555ab8 <+7>: lea 0x4(%rsi),%rcx
0x0000555555555abc <+11>: lea 0x14(%rsi),%rax
0x0000555555555ac0 <+15>: push %rax
0x0000555555555ac1 <+16>: lea 0x10(%rsi),%rax
0x0000555555555ac5 <+20>: push %rax
0x0000555555555ac6 <+21>: lea 0xc(%rsi),%r9
0x0000555555555aca <+25>: lea 0x8(%rsi),%r8
0x0000555555555ace <+29>: lea 0x12b4(%rip),%rsi # 0x555555556d89
0x0000555555555ad5 <+36>: mov $0x0,%eax
0x0000555555555ada <+41>: callq 0x555555554fa0 <__isoc99_sscanf@plt>
0x0000555555555adf <+46>: add $0x10,%rsp
0x0000555555555ae3 <+50>: cmp $0x5,%eax
0x0000555555555ae6 <+53>: jle 0x555555555aed <read_six_numbers+60>
0x0000555555555ae8 <+55>: add $0x8,%rsp
0x0000555555555aec <+59>: retq
0x0000555555555aed <+60>: callq 0x555555555a75 <explode_bomb>
End of assembler dump.
```
`+7`부터 `+29`까지 베이스 상대 주소 지정방식으로 값을 읽어오고 있음을 알 수 있다. 해당 값의 내용을 확인해보기 위해 `ni`와 `x/d $rip+0x12b4`명령어로 무슨 내용인지를 확인해보았다.

그 결과 6개의 숫자를 스페이스로 구분해서 받는다는 것을 확인할 수 있었다. 또한 `+41`을 보면 `<__isoc99_sscanf@plt>`로 무엇인가를 입력받는다는 것을 확인할 수 있다. `+53`은 jle(Jump Less or Equal)이며 `+50`의 cmp명령어에서 비교된 5($0x5)보다 작은 수들임을 알 수 있다. 즉, 5보다 작은 6개의 숫자를 스페이스로 구분하는 형식의 값을 입력해야 하는 것이다.
단서를 얻었으니 `phase_2` 함수를 분석해보자. `+30`의 cmpl명령어는 값이 0($0x0)인지를 판별한다. `+34`의 jne(Jump If Not Equal)는 0인경우 `+43`으로 넘어가 `explode_bomb`를 실행하게 된다. 즉, 첫 번째 값은 0임을 유추할 수 있다.
첫 번째 값을 맞혀 `+36`으로 넘어가면 이번엔 cmpl 명령어로 두 번째 값이 1인지를 검사한다. 따라서 두 번째 값은 1임을 알 수 있다.
`+41`에서 je(Jump If Equal)명령어로 1인 경우 `+48`로 넘어가게 되며 mov명령어로rbx 레지스터에 rsp 레지스터의 값이 복사된다. `+51`에서 rbp 레지스터에 rbx 레지스터의 주소 값이 복사된다. 따라서 세 번째 값은 1이 된다.
jmp 명령어를 통해 `+66`으로 이동 후 eax 레지스터에 rbx 레지스터의 값이 복사된다. 그 후 eax 레지스터의 값과 rbx 레지스터의 값을 더하고 cmp 명령어로 현재 rbx 레지스터의 값과 eax 값이 같은지 확인 후 같으면 `+57`로 보낸다. 즉 네 번째 값은 2가 된다.
여기까지 진행해보면 피보나치 수열의 규칙을 찾을 수 있다. `0 1 1 2 3 5`를 `phase_2` 함수의 입력값으로 넣게 되면 `phase_3`으로 넘어갈 수 있다.
`phase_3` ~ `phase_6` 에 입력될 올바른 문자열을 찾는 방법에 대해서는 다음에 작성하게 될 Bomb Lab(2) 문서에서 설명해보려고 한다.
================================================
FILE: CS/Call-By-Sharing.md
================================================
# Call By Sharing(a.k.a Call By Object, Call By Object-Sharing)
## Call By Value와 Call By Reference
들어가기에 앞서, 메소드의 호출 방식에는 크게 두 가지가 있다. **call by value(값에 의한 호출)** 과 **call by reference(주소에 의한 호출)** 이다. 이 두 가지 방법은 매개 변수로 전달된 값의 유형으로 구분한다. 이처럼 함수 호출 시 전달 값의 종류를 결정하는 방법을 [평가 전략(Evaluation strategy)](https://en.wikipedia.org/wiki/Evaluation_strategy) 이라고 한다.
함수에 전달한 매개변수는 **actual parameter(actual argument; 실질 인자)** 라고 하고, 함수에서 수신받은 매개변수는 **formal parameter(formal argument; 형식인자)** 라고 한다.
```js
void method(formal parameter){}
method(actual paramter)
```
> 하지만 acutal과 formal을 제외하고 parameter와 argument로 나누어 것을 많이볼수있다. 이 경우 parameter는 **formal** parameter(formal argument)를 뜻하고, argument는 **actual** parameter(actual argument)를 뜻한다.
>
>헷갈리면 다음을 참고하자 [Parameter_(computer_programming)](https://en.wikipedia.org/wiki/Parameter_(computer_programming))
### Call By Value
call by value 방식은 actual parameter의 값을 formal parameter에 복사한다. 각각은 서로 다른 메모리 공간에 할당된다. 따라서 call by value 방식에서는 formal parameter가 지역변수 처럼 사용되고, formal parameter의 변경은 actual parameter에 영향을 주지 않는다.
```js
int i = 0;
function changeValue(i){
i = 1;
}
changeValue(i); // i == 0
```
### Call By Reference
call by reference 방식은 formal parameter가 actual parameter를 그대로 사용한다. 따라서 formal parameter가 변경되면 actual parameter도 변경된다.
```js
int i = 0;
function changeValue(i){
i = 1;
}
changeValue(i); // i == 1
```
이러한 방식은 대부분의 고급언어에서는 구현이 불가능하다. 비교적 저급언어에 가까운 c의 pointer를 이용하면 이를 확인할 수 있다.
> call by reference의 예시 c언어의 swap 함수 구현이 많이 사용된다.
> 참고 - [C Program to Swap two Numbers](https://www.geeksforgeeks.org/c-program-swap-two-numbers/)
## 객체 기반 언어의 메소드 호출
java, JS, python 등의 고급 언어는 객체(Object)를 기반으로 구현되어 있다. 원시값(primitive value)을 제외한 모든 것은 객체인데, 객체를 변수에 할당하면 값이 아닌 주소 값이 저장된다. 따라서 객체가 할당된 변수를 사용하는 것은 주소를 참조하는 것과 같다. 이 때문에 다음과 같은 동작이 가능하다.
```js
class Main{
main(){
VO vo = new VO(0);
changeValue(vo); // vo.i == 1;
}
function changeValue(VO vo){
vo.i = 1;
}
}
```
이러한 동작 때문에 call by reference 라고 생각할 수 있지만 그렇지 않다.
> 예시(java)
>
> ```java
> public class Main{
> public static void main(String[] args){
> VO vo = new VO(); // vo.i ==null;
> changeValue(vo); // vo.i == 1;
> changeReference(vo); // vo.i == 1;
> }
>
> private static void changeValue(VO vo){
> vo.i = 1;
> }
>
> private static void changeReference(VO vo){
> vo = new VO();
> vo.i = 2;
> }
> }
>
> class VO{
> Integer i;
> }
> ```
> 예시(JS)
>
> ```js
> var test = { i: 0 }; // test.i === 0
>
> // change value
> ((test) => {
> test.i = 1;
> })(test); // test.i === 1
>
> // change reference
> ((test) => {
> test = { i: 2 };
> })(test); // test.i === 1
> ```
위의 예시처럼 parameter를 바꿔도 argument가 바뀌지 않지만, parameter가 객체인 경우 그 멤버를 변경하면 argument의 멤버도 변경된다. 위의 java 예시는 아래와 같이 동작한다.

이러한 평가 전략을 call by sharing이라고 한다.
## Call By Sharing
> call by sharing은 [CLU](<https://en.wikipedia.org/wiki/CLU_(programming_language)>) 라는 언어에서 처음 사용되었다.
call by sharing은 의 주요 컨셉은 **actual parameter와 formal parameter가 객체만을 주고받는 것**이다.
모든 값을 박스처럼 생각하는 것과 비슷하다. 박스를 주고 받을 때, 박스 자체가 바뀌지 않는다면 그 박스의 내용물은 바뀔 수 있다. 즉 객체 자체가 바뀌지 않는다면 객체의 멤버가 변화하는 것이 actual parameter에 전달된다.
call by value 방식만으로도 이러한 동작을 설명할 수 있기 때문에 call by value라고 설명하기도 하지만 call by sharing이라고 하는 것이 더 정확하다. **call by sharing은 call by value와 달리 actual parameter가 변화한다는 개념을 포함** 하고 있기 때문이다. 또한 **call by sharing은 언어의 값이 객체를 기반으로 한다는 의미를 포함** 한다는 차이가 있다.
---
#### Refereces
- [Difference between Call by Value and Call by Reference](https://www.geeksforgeeks.org/difference-between-call-by-value-and-call-by-reference/)
- [Evaluation strategy](https://en.wikipedia.org/wiki/Evaluation_strategy#Call_by_sharing)
- [[프로그래밍언어] Formal parameter, Actual parameter, 그리고 parameter passing](https://yunmap.tistory.com/entry/프로그래밍언어-Formal-parameter-Actual-parameter-그리고-parameter-passing)
- [Call by Sharing](http://www.pmg.lcs.mit.edu/papers/thetaref/node34.html)
================================================
FILE: CS/Counting-sort.md
================================================
# 계수 정렬(Counting Sort)
비교정렬(comparison sort)의 시간복잡도의 하한은 O(nlogn) 이다.
계수 정렬은 non-comparison sort 기법이며, 정렬에 드는 계산복잡도을 O(n) 으로 낮추기 위한 알고리즘이다.
정확히 말하면, 정렬할 수 중 가장 큰 값을 k라고 했을 때 계수정렬의 계산복잡도는 O(n+k) 이다.
따라서 정렬할 수의 최대값이 낮을때 효과적이며, k의 값이 매우 커지게 되면 다른 정렬 알고리즘에 비해 성능이 떨어진다.
> 가령 k가 n^2보다 커지게 되는 경우 선택, 삽입, 버블 정렬 등의 기본적인 정렬 알고리즘보다도 속도가 느리게 된다.
## 수행 과정
계수 정렬은 정렬하려는 수들의 개수를 세어 누적합을 구한 뒤, 누적합에 따라 수를 정렬하는 것이다.
이 때, 정렬 대상의 원소는 모두 양의 정수여야한다.
1. 정렬 대상에서 중복되는 값의 개수를 구하여 저장한다.
2. 저장한 중복 횟수를 누적합으로 바꾼다.
3. 정렬 대상을 역순으로 순회하며 결과를 출력한다.
### 예시1
```js
// 아래의 배열을 정렬
arr = {2, 0, 2, 0, 4, 1, 5, 5, 2, 0, 2, 4, 0, 4, 0, 3}
```
- 배열 arr 에 들어있는 요소들이 몇 개씩 들어있는지 파악한다.
```js
cnt = {5, 1, 4, 1, 3, 2}
cnt[0] 0의 개수이다. 배열 A에 0이 5개 들어있기 때문에 cnt[0] 의 값은 5가 된다.
```
- 배열 cnt 의 요소값에 이전 요소들의 누적값을 더해준다.
```js
cnt = {5, 6, 10, 11, 14, 16}
cnt[1] = cnt[0] + cnt[1] // 5 + 1
cnt[2] = cnt[0] + cnt[1] + cnt[2] // 5 + 1 + 4
cnt[3] = cnt[0] + cnt[1] + cnt[2] + cnt[3] // 5 + 1 + 4 + 1
...
```
이 과정을 거치지 않고, 순서대로 출력하면 된다고 생각할 수 있다.
이 경우 정렬 대상의 최대값에 큰 영향을 받기 때문에 오히려 비효율적이다.
non-comparison 방식으로 정렬을 하기 위해서는 배열 cnt 의 길이가 정렬 대상의 최대값과 같아야하기 때문이다.
각 요소를 비교하지 않고 누적합을 이용하기 때문에 non-comparison이 된다.
또한, 원본배열을 역순으로 순회하며 정렬하는 방식을 이용하면 stable한 상태를 유지할 수 있다.
> stable하다는 것은 처음 순서대로 정렬이 된다는 것인데, 위의 예시에서는 첫 번째 0과 두 번째 0이 뒤바뀌지 않고 정렬된다. 이는 아래 [예시2](#예시2) 에서 설명할것이다.
- 배열 arr 의 요소값을 역순으로 저장한다.
```c
int[arr.length] result; // 결과값 배열의 크기는 정렬 대상과 같아야 한다.
for(i = arr.length-1; i>=0; i--){
result[cnt[arr[i]] = arr[i];
/* 배열 cnt의 값이 result의 인덱스가 되기 때문에,
* 값을 저장한 수의 누적값을 감소시켜야 한다.
*/
cnt[arr[i]]--;
}
```
### 예시2
계수정렬은 stable한 정렬이고, 이를 위해 카운팅 이후 한 번의 과정을 더 거친다.
숫자의 정렬 예시 만으로는 그 이유가 한 눈에 들어오지 않을 수 있다.
좀 더 쉬운 이해를 위해 이번에는 단어 **banana** 를 정렬해보자.
확인을 위해 순번 `seq` 필드를 추가한 `Alphabet` 타입을 사용할 것이다.
```java
Alphabet{
int seq = 0;
}
Alphabet b, a, n, a, n, a = new Alphabet();
// 아래의 배열을 정렬
Alphabet[] word = {b, a, n, a, n, a};
```
word를 카운팅한 누적합의 인덱스는 쉬운 이해를 위해 영문으로 표기할 것이다.
또한 크기가 a...n 이고 각 요소가 0으로 초기화된 배열 `count` 가 있다고 가정한다.
```java
// 중복 개수 카운팅
for(Alphabet alphabet : word){
count[alphabet] ++;
// 카운팅 순서 저장
alphabet.seq = count[alphabet];
}
// 누적합
for(int i = 1; i < word.length; i ++;){
word[i] += word[i-1];
}
```
누적합이 구해진 `count` 배열은 아래와 같을 것이다.
| a | b | n |
| --- | --- | --- |
| 3 | 4 | 6 |
예시1과 마찬가지로, 배열 `word` 에 저장된 알파벳을 역순으로 꺼내서 결과 배열에 저장하면 stable하게 저장된 결과를 얻을 수 있을 것이다.
역순으로 꺼내는 것과 비교 하기 위해 이번에는 원본 배열을 앞에서 부터 순회해보자.
```java
// word == {b, a, n, a, n, a};
// count == {3, 4, 6}
result[3] = b; // b.seq == 1, count == {3, 3, 6}
result[2] = a; // a.seq == 1, count == {2, 3, 6}
result[5] = n; // n.seq == 1, count == {2, 3, 5}
result[1] = a; // a.seq == 2, count == {1, 3, 5}
result[4] = n; // n.seq == 2, count == {1, 3, 4}
result[0] = a; // a.seq == 3, count == {0, 3, 4}
```
앞에서부터 정렬할 경우도 **a a a b n n** 의 순서로 정렬되는 것은 동일하지만, 원본 배열 `word` 와 순서가 달라진 정렬이 된다.
이는 stable한 정렬이 아니다. `result[0]` 의 `a` 는 `word[5]` 의 `a` 와 같고, `result[1]` 의 `a` 는 `word[3]` 의 `a` 와 같기 때문이다.
stable한 정렬은 `result[0]` 의 `a` 가 `word[1]` 의 `a` 와 같아야 하고 `result[1]` 의 `a` 가 `word[3]` 의 `a` 와 같아야 한다. 즉 원본 배열의 순서를 유지한채로 정렬이 되어야 한다.
---
#### References
- [Counting Sort : 계수 정렬 ](https://bowbowbow.tistory.com/8)
- [카운팅 정렬, 래딕스 정렬 ](https://ratsgo.github.io/data%20structure&algorithm/2017/10/16/countingsort/)
================================================
FILE: CS/Graph.md
================================================
# 그래프
## 쾨니히스베르크 다리 문제

프로이센의 쾨니히스베르크(오늘날 러시아 칼리닌그라드)에 강이 있고 강으로 둘러싸인 섬이 하나 있다. 섬을 잇는 다리가 7개가 있는데 이를 모두 한 번씩만 건너서 출발한 곳으로 다시 돌아오려고 하는 사람들이 있었지만, 아무도 답을 찾지 못했다. 수학자 오일러가 이는 불가능하다는 것을 밝혀냈는데, 여기서 나온 방법론이 방법이 한 번쯤은 들어봤을 법한, 한붓그리기라는 개념이다.
> 참고 - [한붓그리기](https://ko.wikipedia.org/wiki/%ED%95%9C%EB%B6%93%EA%B7%B8%EB%A6%AC%EA%B8%B0)
이처럼 이동할 수 있는 방법을 탐색하는 방법론을 그래프 이론 혹은 그래프 알고리즘이라 한다. 더 정확히는 객체 간의 짝을 이루는 관계를 모델링하기 위한 수학 구조를 그래프라 한다.
<br/>
## 그래프의 구성
그래프는 **꼭짓점(vertex;정점 혹은 교점;node 혹은 점;point)** 으로 구성되며, 이들은 **변(edge; 간선 혹은 link)** 으로 연결된다. 이때 두 꼭짓점 사이에 변이 존재하는 것을 **인접(adjacent)** 이라고 한다. 또한, 어떠한 변을 구성하는 꼭짓점들은 해당 변과 '**근접(incident)하다'** 라고 한다.

<br/>
## 보행(walk)
보행은 꼭짓점과 변이 교대로 나타나는 열(sequence)이면서, 각 변의 앞과 뒤에 위치한 꼭짓점을 그 변의 양 끝점으로 갖는 열을 뜻한다.
> 간단히 말하면, 보행은 그래프상에서 어딘가를 지나가는 것이다.
보행의 종류는 다음과 같다.
- 트레일(trail) : 변이 중복되지 않는 보행
- 경로(path) : 꼭짓점이 중복되지 않는 트레일. 변과 꼭짓점이 모두 중복되지 않는 보행과 같다.
- 닫힌 보행(closed walk) : 시작점과 끝이 같은 보행이다.
- 닫힌 트레일(closed trail) : 변이 겹칠 수 없는 닫힌 보행이다.
- 순환(cycle) : 꼭짓점이 겹치지 않는 닫힌 트레일을 뜻한다. 다른 말로는 회로(circuit) 또는 여행(tour)라고 한다.

위 그래프에서,
AHDGAB는 트레일이다. 중복되는 변이 없지만, 꼭짓점 A가 반복되므로 경로는 아니다.
HAB와 HDG는 경로이다. 변과 꼭짓점이 모두 중복되지 않는 보행이기 때문이다.
BDEFDB는 닫힌 보행이다. 변 BD가 반복되기 때문이다.
BDEFDCB는 닫힌 트레일이다. 꼭짓점 D가 반복되므로 순환이 아니다.
HDGH는 순환이다.
<br/>
## 그래프 크기의 척도
- 거리(distance) : 두 꼭짓점 사이의 경로 가운데 가장 짧은 것의 변의 수이다. 만약 이러한 경로가 존재하지 않는다면, 거리의 길이는 무한대이다.
- 이심률(eccentricity) : 한 꼭짓점에서 다른 모든 꼭짓점 사이의 거리 중 가장 큰 거리
- 지름(diameter) : 그래프의 최대 이심률
- 가중치(weight) : 정점 또는 변에 할당된 비용 또는 거리

> - 무게는 정점 또는 변에 할당된 비용 또는 거리이다.
- 그래프 문제 중 최단 경로 문제는 가중치의 합이 최소가 되는 경로를 구하는 문제이다.
- 가중치 그래프(weighted graph)는 네트워크(network)라고도 한다.
<br/>
## 그래프의 종류
그래프는 크게 유향 그래프와 무향 그래프로 나눌 수 있다. 유향 그래프는 말 그대로 그래프에 방향성이 있는 것이다.
> 모든 보행이 양방향인 유향 그래프는 무향 그래프이다.

### 무향 그래프의 요소
- 차수(degree) : 한 꼭짓점에 이어져 있는 변의 수
<br/>
### 유향 그래프의 요소
- 입력 차수(in-degree) : 한 꼭짓접으로 들어오는 변의 개수
- 출력 차수(out-degree) : 한 꼭짓점에서 나가는 변의 개수
<br/>
## 그래프의 표현
그래프는 크게 인접, 근접, 차수를 이용하여 표현할 수 있다. 그중 인접을 이용한 인접 행렬과 인접 리스트로 표현하는 경우가 많다.
> 그래프를 행렬로 나타낼 경우 직관적이다. 하지만, 2차원 배열로 그래프를 표현하기 때문에 불필요한 정보의 저장이 많아진다. 따라서 알고리즘에는 리스트가 주로 사용된다.
<br/>
### 인접 행렬(Adjacency Matrix)
인접 행렬 그래프는 보행을 1, 보행할 수 없는 꼭짓점의 관계를 0으로 표현한다.

### 인접 리스트 그래프(Adjacency List)
인접 리스트 그래프는 리스트(List)나 벡터(Vector) 등의 자료구조를 이용하여 보행이 가능한 꼭짓점들을 저장한다.


---
#### References
- [쾨니히스베르크 다리 문제 - 수학 이야기](https://suhak.tistory.com/54)
- [그래프 이론 기초 정리 - kwangsik lee's blog](http://www.kwangsiklee.com/2017/11/%EA%B7%B8%EB%9E%98%ED%94%84-%EC%9D%B4%EB%A1%A0-%EA%B8%B0%EC%B4%88-%EC%A0%95%EB%A6%AC/)
- [쉽게 쓴 그래프 알고리즘 기초 - 코딩과 디버깅 사이](https://m.blog.naver.com/occidere/220923695595)
- [그래프 이론 - 위키백과](https://ko.wikipedia.org/wiki/%EA%B7%B8%EB%9E%98%ED%94%84_%EC%9D%B4%EB%A1%A0)
- [가중 그래프 - 위키백과](https://ko.wikipedia.org/wiki/%EA%B0%80%EC%A4%91_%EA%B7%B8%EB%9E%98%ED%94%84)
- [경로(그래프 이론) - 위키백과](<https://ko.wikipedia.org/wiki/%EA%B2%BD%EB%A1%9C_(%EA%B7%B8%EB%9E%98%ED%94%84_%EC%9D%B4%EB%A1%A0)>)
- [IT CookBook, 쉽게 배우는 알고리즘](http://www.hanbit.co.kr/store/books/look.php?p_code=B7707942187)
================================================
FILE: CS/Memory.md
================================================
# Memory
메모리는 말그대로 저장소다. 뭔가를 하려면 어떤 데이터를 어떻게 처리하라고 한다. 즉 데이터와 처리명령 두가지가 필요하다.
그래서 메모리도 두 영역으로 나뉘어 있다. Program / Data 부분이 나뉜다.
## 메모리 계층구조
메모리는 당연히 빠를수록 비싸다. 그래서 빠르고 비싼 메모리는 용량이 작다. 반대로 느리면서도 싼 메모리는 용량이 크다. 아주 쉽게 생각할 것은 HDD와 SSD의 차이를 생각해보면 된다.

그래서 위와 같은 그림이 나온다. 레지스터와 캐시는 CPU 내부에 존재한다. 그만큼 작고 빠르다. Cache는 SRam과 같다. Memory는 Dram이다. 흔히 RAM 이라고 부른다. 8GB DDR4 램 사면 이거다. Disk는 하드디스크 그거다.
보통 레지스터, 캐시, 메모리를 주 기억장치, 디스크를 보조 기억장치라고 부른다. 주 기억장치는 보조보다는 빠르나 전원을 끄면 데이터가 날아간다.(휘발성)
## 메모리 구조
메모리는 다음 그림과 같이 공간을 나누어 관리한다.

그림에 따라 low address와 high address가 반대가 되어 스택이 쌓이는 구조로 보이기도 한다. 그러나 중요한 점은 메모리는 사용용도에 따라 구역을 나누어 관리하고 순서가 있다는 점이다.
### TEXT
프로그램 코드가 저장되는 영역이다. 따라서 코드영역이라고도 불린다. 물론 개발자가 작성한 소스코드는 아니고 기계어로 저장된다.
Read-Only Data다. CPU가 이 영역의 데이터를 fetch해서 실행한다.
### DATA(GVAR + BSS)
전역변수, static 변수가 저장되는 공간이다.
초기화된 데이터는 data 영역에 저장되고, 초기화 되지 않은 데이터는 BSS(Block Stated Symbol)영역에 저장된다.
js의 var let const의 호이스팅 시 선언, 초기화, 할당에 관한 내용 중 초기화와 관련한 내용이지 않을까 싶다.
let과 const는 선언만 되며 초기화가 되지않아 메모리에 없다.
그런데 js는 전역 스코프 역시 객체다. 그럼 참조타입이라 heap에 저장될 것 같다.
실행 컨텍스트와 관련된 내용같은데 자세히 좀 더 알아보자
프로그램이 실행될 때만 생성되고 종료시 반환하는 영역이다.
### HEAP
흔히 참조타입이 저장된다. 이 영역에 저장하기 위해 `new` 키워드를 사용한다.
개발자가 임의로 만들 수 있는 영역이라 동적 할당영역이라고 부른다.
HEAP을 참조하는 영역이 없으면 GC가 돌면서 마킹을 통해 제거하는 영역이다.
### STACK
지역변수, parameter, 리턴 값 등이 임시로 저장되었다가 사라지는 영역입니다.
원시 값 타입이 저장되는 공간입니다.
stack은 함수 호출 시 할당되며 함수 종료(return)시 제거됩니다.
엄격하게 LIFO가 지켜집니다. 이렇게 스택에 저장되는 호출정보를 stack frame이라고 합니다. 흔히 우리가 부르는 call stack은 stack frame과 연관이 있습니다.
### 흐름
1. 개발자가 소스코드를 완성하여 컴파일 => 실행단계가 되면 코드는 TEXT에 올라간다.
2. 프로그램이 실행되면 프로그램은 프로세스가 된다.(프로세스 == 실행중인 프로그램)
3. 프로세스의 흐름에 따라 DATA영역에 전역과 static변수를 만든다.
4. 코드의 흐름에따라 HEAP과 STACK영역을 움직이며 메모리를 사용한다.
5. 프로그램이 종료되면 DATA영역을 반환한다.
### 문제
너무 자주 봐왔고, 참조변수와 포인터에 관한 이야기다.
```js
const arr = [1, 2, 3];
const foo = arr => {
arr[1] = 100;
arr = [4, 5, 6];
console.log(arr);
};
foo(arr);
console.log(arr);
```
어떻게 나올지는 항상 언제 물어봐도 메모리 그림을 그려 대답할 수 있도록 하자.
### 참고자료
- [메모리 저장구조 이해하기](https://m.blog.naver.com/PostView.nhn?blogId=itperson&logNo=220821884483&proxyReferer=https%3A%2F%2Fwww.google.com%2F)
- [TCP school 메모리의 구조](http://tcpschool.com/c/c_memory_structure)
================================================
FILE: CS/Radix-sort.md
================================================
# 기수 정렬(Radix Sort)
비교(comparison) 기반 정렬 알고리즘의 가장 낮은 복합도는 `O(nlogn)` 이다.
반면 계수 정렬(counting sort)은 선형 시간 정렬 알고리즘이다. 검색 대상의 범위가 1부터 k까지라고 할 때 `O(n+k)` 의 복합도를 가진다.
> [선형 시간(lineart time)](https://ko.wikipedia.org/wiki/%EC%84%A0%ED%98%95_%EC%8B%9C%EA%B0%84) : 계산 복잡도 이론에서 입력된 길이 n에 대하여 실행시간이 `O(n)` 이 되는 것
>
> 참고 : [계수 정렬](https://github.com/Im-D/Dev-Docs/blob/master/CS/Counting-sort.md)
하지만 대상의 범위 k가 n^2 보다 커질 경우 `O(n^2)` 이상의 복잡도를 가지게 된다. 이는 비교 기반 정렬 알고리즘보다 성능이 좋지 않다.
이런 경우 기수 정렬을 통해 선형 시간을 갖는 정렬을 할 수 있다.
## 수행과정
기수 정렬은 각 자릿수마다 순차적으로 정렬하는 방식이다.
10진수를 사용한다면 각 자릿수는 최소 0에서 최대 9까지의 값만 나올 수 있다.
따라서 각 자릿수 마다 계수 정렬을 실행한다면, 계수 정렬 대상의 수는 항상 10 이하로 정해진다.
> 계수 정렬을 사용하기 때문에 부동 소수점은 정렬이 불가능하다.
수행과정은 다음과 같다.
```java
// 정렬 대상
int arr[] = {170, 45, 75, 90, 802, 24, 2, 66};
int max = 정렬 대상의 최대값
for (자릿수 = 1; max/자릿수 > 0; 자릿수 *= 10) {
계수정렬 실행
}
```
> 참고 : [수행과정 - Radix Sort | GeeksforGeeks](https://youtu.be/nu4gDuFabIM?t=18)
자릿수의 개수만큼 반복해야하기 때문에 최고 자릿수가 `d` 일 때 기수 정렬의 시간 복잡도는 `O(dn)` 이다. 예를 들어, 가장 큰 수가 10000이라면, 최고 자릿수가 5이기 때문에 `O(5n)` 이 된다.
따라서 특정 조건을 만족하면 아주 빠른 알고리즘이지만, 자릿수 만큼의 저장 공간이 추가로 발생하기 때문에 공간 복잡도가 좋지 않다.
## 기수 정렬의 다른 방법
위에서 알아본 계수 정렬 방법은 일반적인 방법으로 가장 오른쪽 부터 시작하는 LSD radix sort이다. 반대로 가장 왼쪽 부터 시작하는 경우는 MSD라고 한다.
> LSD(Least Significant Digit; 최하위 자릿수)
>
> MSD(Most Significant Digit; 최대 자릿수)
LSD의 경우 stable하지만, MSD는 stable 하지 않다. 따라서 기수 정렬의 서브루틴으로 계수 정렬을 사용하기 위해서는 LSD를 사용해야한다.
LSD는 모든 자릿수를 정렬해야 정렬된 결과를 얻을 수 있지만, MSD의 경우 중간에 정렬이 완료될 수 있다. 하지만 이를 위해 추가적인 연산과정과 메모리가 필요하다. 자세한 사항은 다음을 참고하자.
> 참고 : [In-place MSD radix sort implementations - wikipedia](https://en.wikipedia.org/wiki/Radix_sort#In-place_MSD_radix_sort_implementations)
### 버킷 정렬(bucket sort)
이외에도 큐 혹은 버킷을 이용하여 기수 정렬을 구현하는 경우가 있다. 이는 버킷 정렬을 사용한다.

버킷 정렬은 정렬 대상의 값들이 일정하게 분포되어 있을 때 효과적인 방법이다.
값의 분포에 따라 특정 범위를 지정한다. 이 때, 지정한 범위가 버킷이다.
범위에 해당되는 값들을 각 버킷에 담고 버킷 내의 값들을 정렬하는 방법이다.
이 때, 버킷 내의 값들은 버킷 정렬을 반복하여 적용시키거나, 다른 알고리즘을 사용하여 정렬한다.
이러한 원리를 이용하여 기수 정렬을 병렬 컴퓨팅에 적용하는 경우도 있는데 이는 다음을 참고하자
> 참고
>
> - [Application to parallel computing - wikipedia](https://en.wikipedia.org/wiki/Radix_sort#Application_to_parallel_computing)
> - [Fastest sorting algorithm for distributed systems (Parallel Radix Sort) [Difficulty: Medium]](https://summerofhpc.prace-ri.eu/fastest-sorting-algorithm-for-distributed-systems-parallel-radix-sort-difficulty-medium/)
---
References
- [Bucket Sort - GeeksforGeeks](https://www.geeksforgeeks.org/bucket-sort-2/)
- [What are the differences between radix sort and bucket sort? - Quora](https://www.quora.com/What-are-the-differences-between-radix-sort-and-bucket-sort)
- [Radix Sort - BRILLIANT](https://brilliant.org/wiki/radix-sort/)
- [Radix sort - wikipedia](https://en.wikipedia.org/wiki/Radix_sort)
- [기수 정렬(Radix Sort) - tubuk.tistory.com](https://tubuk.tistory.com/16)
================================================
FILE: CS/aspect-oriented-programming.md
================================================
# 관점(관심) 지향 프로그래밍(Aspect Oriented Programming)
## 관점(Aspect)과 횡단 관심사(Cross-cutting Concern)
관점 지향 프로그래밍은 관점을 기반으로 한 개발 패러다임이다. 여기서 관점이라는 말이 모호한데, 컴퓨팅 용어 **aspect** 를 직역한 표현이라 바로 와 닿지 않는다.
프로그래밍 용어로써 aspect는 프로그램의 다른 부분들과 연결되어있지만, 프로그램의 주요 기능과는 연결되지 않은 부분을 뜻한다. 핵심 관심사(core concerns)를 가로지르는(crosscut) 부분들을 모듈화시킨 것이다. 이때, 핵심 관심사를 가로지르는 부분을 **횡단 관심사(cross-cutting concern)** 라고 한다. 이때 가로지른다는 것은 공통의 관심사를 수직이 아닌 수평적으로 찾아낸다는 것이다. 전통적인 추상화 방식에서는 상위 클래스와 하위 클래스 간의 공통 관심사를 수직적으로 묶지만, 관점 지향 프로그래밍에서는 연관이 없는 클래스들의 공통 관심사를 수평적으로 묶어 캡슐화한다.

가장 쉬운 예시로는 로그를 쌓고자 하는 경우를 들 수 있다. 클래스 혹은 함수단위의 로그를 쌓고자 하는 경우 해당 객체의 핵심 기능과 별개의 코드가 필요하다.
```java
class NonAspectOrientedSample {
private void logging() {
// ...
}
public void doSomething() {
logging();
// ...
}
public void doOtherthing() {
logging();
// ...
}
}
```
하지만 코드는 계속해서 중복되기 때문에 새로운 추상화가 필요한데 전통적인 개발 방식만으로는 추상화가 모호해질 가능성이 크다. 추상화를 하여 함수를 재정의(overriding)하더라도 해당 클래스에는 핵심 기능과 별개의 코드가 포함되는 것이기 때문이다.
```java
class NonAspectOrientedSample implements Logger {
@Override
public void logging() {
// ...
}
public void doSomething() {
logging();
// ...
}
public void doOtherthing() {
logging();
// ...
}
}
```
이처럼 핵심 기능과 별개의 코드가 클래스에 포함되는 것은 엄밀히 따지면 [단일 책임 원칙](https://github.com/im-d-team/Dev-Docs/blob/master/CS/srp.md)을 위반하는 것이다. 이런 경우 횡단 관심사를 분리하여 해결할 수 있다.
## 사용되는 용어들
### Join Point
aspect는 기존 프로그램의 동작과 관계없이 추가, 변경 가능해야 한다. 관점 지향 언어들은 기존 프로그램의 동작과 관계없이 실행 지점을 설정할 수 있도록 지원해주는데 이를 **join point**라고 한다. 메소드 실행(method execution)이나 메소드 콜(method call)과 같은 시스템의 실행을 포인트로 지정하는 것이다.
### Pointcut
join point를 언어 수준에서 표현한 것이다. 언어 구조 내에서 지원하거나, 쿼리와 유사한 표현식을 사용하여 표현할 수 있다.
### Advice
pointcut을 만족하는 join point에 도달했을 때 실행할 코드 모음이다. 이때 advice의 종류에 따라 실행 시점이 달라진다. 실행 시점에 따라 다음과 같은 종류가 있다.
- before advice : 메소드 실행 이전
- after advice
- after returning advice : 메소드가 정상 작동한 이후
- after throwing advice : 예외 발생 시
- after finally advice : 메소드가 실행 된 이후 반드시 실행
- around advice : 모든 시점 실행
### Inter-type Declaration(ITD)
클래스 멤버나 클래스 계층을 임의로 변경하는 것이다. 예를 들어, 클래스 실행 시간을 로깅하고 싶지만 해당 클래스에 관련 멤버가 없다면 aspect 실행 시점에 실행시간 필드를 추가할 수 있다.
### Aspect
aspect는 pointcut과 advice, inter-type declaration이 합쳐진 것이다. 즉 하나의 실행 단위이다.
> spring aop에서는 aspect를 advisor라고 부른다.
### Weaving
Advice를 join point에 합쳐준다. 컴파일 혹은 로드 타임에 바이트 코드를 조작하거나 런타임에 프록시를 생성하여 합치는 방법이 있다.
## AOP는 만능인가?
위에서 본 개념들만 살펴봤을 때는 AOP가 구세주처럼 느껴질 수 있다. 하지만 AOP에도 문제 발생 가능성이 있다. AOP를 사용할 경우 아래 사항들을 인지한 뒤 도입해야 한다.
첫째로 언어 차원에서 타겟 클래스에 표시하지 않도록 되어있다면 해당 코드 작성자 이외에는 해당 코드에 aspect가 적용되는 것인지 알 수 없다. 해당 코드 이외에 전체적인 시스템의 흐름이 파악되어야 정확히 이해할 수 있다. 특히 pointcut이 훼손될 경우 찾아내는 데 큰 어려움을 겪을 수 있다.
둘째로 aspect를 통한 모듈화가 오히려 모듈화를 방해할 수 있다. AOP는 핵심 로직에만 집중할 수 있도록 돕는 도구인데 AOP가 주가 되어버리는 경우이다.
셋째로 동시에 여러 개의 aspect가 적용될 경우 문제가 발생할 수 있으며, aspect가 자기 자신에게 적용된다면 의도하지 않은 결과가 나올 수 있다.
---
#### References
- [Aspect-oriented software development](https://en.wikipedia.org/wiki/Aspect-oriented_software_development#Concepts_and_terminology)
- [Aspect-oriented programming](https://en.wikipedia.org/wiki/Aspect-oriented_programming)
- [Aspect (computer programming)](https://en.wikipedia.org/wiki/Aspect_(computer_programming))
- [Cross-cutting concern](https://en.wikipedia.org/wiki/Cross-cutting_concern)
- [Intertype declarations in AspectJ (member injection)](https://programmer.help/blogs/intertype-declarations-in-aspectj-member-injection.html)
================================================
FILE: CS/cohension&coupling.md
================================================
# 응집도(Cohension)와 결합도(Coupling)
좋은 프로그램은 높은 응집도와 낮은 결합도를 가진다.
## 응집도
응집도는 모듈 내부의 기능적인 응집 정도를 뜻한다. 이상적인 응집도는 모듈 내부의 모든 기능이 단일한 목적을 위해 수행되는 것이다. 응집도는 클 수록 좋다.
* 기능적 응집도(Functional Cohesion)
* 모듈 내부의 모든 기능이 단일한 목적을 위해 수행되는 경우
* 순차적 응집도(Sequential Cohesion)
* 모듈 내에서 한 활동으로 부터 나온 출력값을 다른 활동이 사용할 경우
* 교환적 응집도(Communication Cohesion)
* 동일한 입력과 출력을 사용하여 다른 기능을 수행하는 활동들이 모여있을 경우
* 절차적 응집도(Procedural Cohesion)
* 모듈이 다수의 관련 기능을 가질 때 모듈 안의 구성요소들이 그 기능을 순차적으로 수행할 경우
* 시간적 응집도(Temporal Cohesion)
* 연관된 기능이라기 보단 특정 시간에 처리되어야 하는 활동들을 한 모듈에서 처리할 경우
* 논리적 응집도(Logical Cohesion)
* 유사한 성격을 갖거나 특정 형태로 분류되는 처리 요소들이 한 모듈에서 처리되는 경우
* 우연적 응집도(Coincidental Cohesion)
* 모듈 내부의 각 구성요소들이 연관이 없을 경우
> 우연적 응집도 < 논리적 응집도 < 시간적 응집도 < 절차적 응집도 < 교환적 응집도 < 순차적 응집도 < 기능적 응집도
위에서 아래로 내려올 수록 응집도가 낮아진다(나빠진다)고 할 수 있다. 기능적 응집도가 이상적인 응집정도이다.
## 결합도
결합도는 의존성 정도이다. 이상적인 결합도는 인터페이스의 파라미터를 통해서만 상호 작용이 일어나며, 파라미터는 값으로 이루어져야 한다. 결합도는 낮을 수록 좋다.
* 자료 결합도(Data Coupling)
* 모듈간의 인터페이스 전달되는 파라미터를 통해서만 모듈간의 상호 작용이 일어나는 경우
* 깔끔한 Call by value
* 스탬프 결합도(Stamp Coupling)
* 모듈간의 인터페이스로 배열이나 오브젝트, 스트럭쳐등이 전달되는 경우
* 제어 결합도(Control Coupling)
* 단순히 처리를 해야할 대상인 값만 전달되는게 아니라 어떻게 처리를 해야 한다는 제어 요소(명령어, Flag등)이 전달되는 경우.
* 외부 결합도(External Coupling)
* 어떤 모듈에서 반환한 값을 다른 모듈에서 참조해서 사용하는 경우
* 공통 결합도(Common Coupling)
* 파라미터가 아닌 모듈 밖에 선언되어 있는 전역 변수를 참조하고 전역변수를 갱신하는 식으로 상호작용하는 경우
* 내용 결합도(Content Coupling)
* 다른 모듈 내부에 있는 변수나 기능을 다른 모듈에서 사용 하는 경우
> 자료 결합도 < 스탬프 결합도 < 제어 결합도 < 외부 결합도 < 공통 결합도 < 내용 결합도
위에서 아래로 내려올 수록 결합도가 커진다(나빠진다)고 할 수있다. 자료 결합도가 가장 이상적인 결합정도이다.
---
#### References
- [응집도(Cohension)](http://itwiki.kr/w/%EC%9D%91%EC%A7%91%EB%8F%84)
- [결합도(Coupling)](http://itwiki.kr/w/%EA%B2%B0%ED%95%A9%EB%8F%84)
================================================
FILE: CS/compression.md
================================================
# 압축
압축은 크게 데이터 손실압축과 데이터 비손실압축 두 가지로 나뉜다.
데이터 손실 압축은 우리가 흔히 보는 사진, 영상의 해상도를 낮추는 압축이다. 사진의 픽셀을 일부 제거해 원본데이터가 손상되지만 사진을 보는데는 큰 지장이 없다.
이런 경우 손실 압축을 해도 큰 상관이 없다. 그렇지만 문서의 경우는 다르다.
'내가 A에게 500만원을 보냈다' 라는 정보를 압축했는데 원본 데이터에 손실이 일어나면 큰일이다.
따라서 이 경우 데이터 비손실 압축으로 압축해야 한다.
## 비손실 압축
비손실 압축에는 크게 Run-Length, LZ(lempel-ziv), Huffman 등이 있다. 이 세가지가 가장 대표적이며 보통의 압축 알고리즘은 결국 이 세가지를 조합하거나 조금씩 변형한 것들이다.
### Run-Length
만일 데이터가 `WWWWWWWWWWWWBWWWWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW` 이렇게 생겼다고 가정하자.
이를 `12WB12W3B24WB14W`로 변경한다면 데이터를 손쉽게 압축할 수 있다. 압축을 해제하는 것 역시 직관적이며 쉬울 것이다.
인코딩 이전의 데이터는 67글자였으나 인코딩 이후의 데이터는 16글자다.
이 알고리즘의 단점은 일정한 패턴의 데이터를 압축할 수 없다는 점이다. `BWWBWWBWWBWWBWWBWW` 이 데이터는 Run-Length를 이용해 처리할 수 없다.
### LZ(lempel-ziv)
LZ 알고리즘은 기본적으로는 Run-Length의 방식과 동일하다. Run-Length는 글자 하나를 기준으로 한다면 LZ는 단어를 기준으로 한다. 이를 사전방식(Dictonary methods)이라고 한다.
예를 들어 다음과 같은 문장이 있다고 하자.
`TOBEORNOTTOBETONOT` 이걸 압축해보자.
`TOBEORNOT TOBE TONOT` 저 가운데 TOBE는 사실 앞에서 한번 쓰였다. 그럼 굳이 다시 쓰지 않고 앞에서 쓰였다고 표시만 해주면 되지 않을까? 이 개념이 LZ알고리즘이다.
그래서 아래와 같은 결과를 가진다.
`TOBEORNOT TOBE TO NOT`
`[TOBEORNOT][9,4][4,2][9,3]`
이런식의 블록을 만든다. [9, 4]의 의미는 9번째 떨어진 곳으로부터 4글자가 반복되므로 그걸 사용하라는 의미다.
실제로 완전히 이렇게 생긴것은 아니다. 실제로는 `(0,0)T (0,0)O (0,0)B ... (9,4)T (4,2) N...` 대충 이런식의 형태를 띈다. 참고로 저건 그냥 예시다. 저 TOBEORNOT... 의 인코딩 결과와는 다르다.
그럼 실제 긴 텍스트를 블록 형태의 데이터로 변환할 수 있다.
이러한 LZ 알고리즘은 LZ77, LZ78, LZMA, LZSS 등 엄청 다양한 알고리즘이 있다.
그 차이는 블록(토큰)을 얼마나 길게 나누느냐에 따라 조금씩 다르다. TOBE를 TO BE의 두개의 블록으로 나눌 수 있듯 말이다.
LZSS = winRAR, LZMA = 7zip 등 압축 형식에따라 조금씩 다른 알고리즘을 사용한다.
### Huffman Coding
허프만 코딩은 지난 글에서 설명한 엔트로피와 관련이 깊다. 물론 다른 알고리즘도 엔트로피와 연관이 있지만 이건 더 직관적으로 이해되게 연결된다. 글의 흐름을 따라가보자.
#### ASCII CODE
아스키 코드는 256개의 문자를 7비트 혹은 8비트로 나타내는 규칙이다. 예를들어 abcd라는 글자는 1100001 1100010 1100011 1100100로 나타낼 수 있다. 이런식으로 모든 글자를 치환하는것이 가능하다.
이는 고정 길이 코드(Fixed Length Code)다. 그래서 단점이다.
e와 x가 한 문서에 등장할 확률은 다르다. 정보이론에 따르면 확률이 다른 글자는 e와 x는 같은 한 글자지만 정보량이 다르다.
그런데 7, 8비트로 고정해버리면 다른 각각의 정보량을 같게 표현해버린다.
즉 고정길이코드는 항상 최대 정보량을 사용하게 된다.
#### 가변 길이 코드
그래서 나온 개념이 가변 길이 코드다. 예를들어 문서에는 space, e, s, t, i, a ... 의 순서로 글자가 나온다고 하자.
`space : 0, e : 1, s : 00, t: 01, i: 10, a: 11 ...` 이런식으로 가변길이의 비트를 부여한다. 그럼 문서의 총 비트수는 엄청나게 줄어들 수 있을 것이다.
여기에는 매우 치명적인 단점이 있다. 고정비트의 경우 8비트를 한 문자로 보고 끊어 읽으면 된다. 그런데 가변비트는 그럴 방법이 없다. `0011010010101...`의 코드가 있다고 하자. 그럼 앞에서부터 읽을 때 읽어야할 글자가 0(space)인지 00(s)인지 001인지 모른다.
#### 접두어 코드(prefix code)
가변 길이 코드의 문제는 [0, 1, 01, 010]의 식으로 코드를 부여하면 중복이 발생한다는 점이다. 그럼 중복이 발생하지 않게 부여하면 어떨까??
예를들어 a,b,c,d를 [00, 010, 100, 101]으로 부여한다면 헷갈리지 않을 것이다. 이게 바로 허프만 코딩이다.
#### 허프만 트리
허프만은 빈도가 높은 글자를 작은 코드로 만들면서 동시에 서로 중복이 발생하지 않는 코드를 만들기 위해 이진트리 개념을 사용했다.

[출처](https://spherez.blog.me/60175047026)
이진 트리를 기준으로 왼쪽은 0, 오른쪽은 1을 부여하면 된다.
그림처럼 {D: 00, E: 10, F: 11, C: 011, A: 0100, B: 0101}로 비트를 부여한다면 서로 중복되지 않고 비트를 빈도를 기준으로 부여할 수 있다.
이 경우 어떤 글자는 8비트를 훨씬 넘어선다. 중복을 제거했으니 경우의 수가 늘어난다.
그런데 그래도 괜찮다. 문서에 얼마 안나오기 때문이다.
## Gzip
HTTP 통신 시 자주 사용되는 Gzip은 Deflate 알고리즘을 사용하는 알고리즘이다.
Deflate는 데이터를 우선 LZ77 알고리즘을 사용하여 압축한 결과를 Huffman Coding으로 한번 더 압축하는 방식을 사용한다.
---
참고자료
- 리버싱 핵심원리, 이승원, 인사이트
- [Text Compression for Web Developers](https://www.html5rocks.com/ko/tutorials/speed/txt-compression/)
- [Raul Fraile: How GZIP compression works](https://2014.jsconf.eu/speakers/raul-fraile-how-gzip-compression-works.html)
- [The LZ77 Compression Family (Ep 2, Compressor Head)](https://www.youtube.com/watch?v=Jqc418tQDkg)
- [How Computers Compress Text: Huffman Coding and Huffman Trees](https://www.youtube.com/watch?v=JsTptu56GM8)
- [허프만 코딩을 이용한 데이터 압축](https://softwareji.tistory.com/5)
- [DEFLATE](https://ko.wikipedia.org/wiki/DEFLATE)
================================================
FILE: CS/dependency-inversion-principle.md
================================================
# 의존 역전 원칙(Dependency Inversion Principle)
이름 그대로 의존 관계를 역전시키라는 원칙이다. 의존 역전 원칙은 다음과 같이 정의된다.
1. 고수준 모듈(high level module)은 저수준 모듈(low level module)에 의존하면 안된다. 또한, 두 모듈은 추상화된 것(abstarctions)에 의존해야 한다.
2. 추상화된 것은 상세한 것(details)을 의존하면 안된다. 상세한 것은 추상화된 것을 의존해야 한다.
의존 역전 원칙의 정의 또한 다른 원칙의 정의처럼 많이 추상화되어 있는데, 각 단어들이 낯설게 느껴질 수 있다. 사용되는 용어들 부터 살펴보자면 아래와 같다.
**의존(dependency)**
여기서 의존이란 다른 객체를 포함 또는 사용하고 있다는 것이다.
```java
class A {
private B b
}
class B {
}
```
위의 경우 클래스 `A` 는 클래스 `B` 에 의존한다. uml로 표현하면 다음과 같다.

**모듈의 수준**
- 고수준 모듈이란 실제로 사용하는 것과 근접해있는 것이다. 모듈의 본질적인 기능과 책임이 어떤 것인지 나타내는 것이다.
- 저수준 모듈이란 모듈 내부를 구성하는 각각의 동작들을 의미한다. 고수준 모듈에서 기능을 수행하기 위해 도와주는 역할을 한다.
| 고 수준 모듈 | 저 수준 모듈 |
| :--------------: | :----------------------------------------------------------: |
| 파일을 불러온다. | 불러오기 원하는 파일을 찾는다.<br />찾은 파일을 반환한다. |
| 파일을 저장한다. | 입력값을 이용하여 파일을 생성한다.<br />생성한 파일을 저장한다. |
| 파일을 수정한다. | 기존 파일을 삭제한다.<br />변경된 파일을 저장한다. |
| 파일을 삭제한다. | 삭제 대상 파일을 찾는다.<br />찾은 파일을 삭제한다. |
## 저수준 모듈에 의존하는 고수준 모듈

위 다이어그램에서 고수준 모듈인 `FilePolicy` 클래스는 저수준 모듈에 의존한다.
만약 압축기능이 추가로 필요하다면? 다음과 같이 변경을 해야할 것이다.

이는 [개방 폐쇄 원칙](https://github.com/im-d-team/Dev-Docs/blob/master/CS/open-closed-principle.md)에서 살펴봤던 예시와 비슷한 상황이다. 압축을 하는 것은 모든 파일에서 가능하지만, 압축을 푸는 것은 압축된 파일에서만 동작해야한다. 만약 압축을 풀기위한 클래스를 만든다면 개방 폐쇄 원칙에 위배될 것이기 때문에 인터페이스를 도출하게 될 것이다. 인터페이스를 도출하면 자연스럽게 의존의 역전이 일어난다.
## 의존 역전

`FileHandler`를 인터페이스로 도출한다면 위와 같이 될 것이다. 이것이 의존 역전이 일어난 것인데, 상위 모듈에서 하위 모듈을 사용하기 때문에 의존방향이 상위 모듈에서 하위 모듈을 향해야 한다. 하지만 가운데 추상화 된 인터페이스를 추가시켜 하위 모듈의 방향이 반대로 되었다. 즉 상위 모듈과 하위 모듈의 의존성이 제어의 흐름(flow of control)과 반대 방향이 되었다.

엄밀히 말하면 런타임에 결정되는 의존성은 그대로지만, 컴파일타임에 결정되는 의존성이 변경된다. 이로인해 위에서 얘기했던 저수준 모듈을 의존하는 경우의 단점이 해결 될 수 있다.
> 위의 예시는 인터페이스 분리 원칙에 위배되는데 이에 대한 해결과정은 [CS/interface-segregation-principle](https://github.com/im-d-team/Dev-Docs/blob/master/CS/interface-segregation-principle.md)을 참고하자.
의존 역전을 위해 적용된 인터페이스는 상위 레이어와 같은 레벨이 된다.

즉 경계가 분리 될 때 의존성이 역전되어야 상위 모듈에서 하위 모듈을 사용하는 것이 유연해진다.
## 의존 주입(DI)과 의존 역전 원칙(DIP)
의존성에 대해 다루는 비슷한 용어가 있다. 의존 주입(dependency injection)인데, 이를 잘못 이해하면 의존 역전 원칙과 같은 사항으로 오해할 수 있다.
의존 주입은 말 그대로 의존성을 외부에서 주입하는 것이다. 클래스 `A`가 클래스 `B`를 의존하고 있을 때 다음과 같은 코드를 작성할 수 있을 것이다.
```java
class A {
public void someMethod() {
B b = new B();
}
}
```
위의 예시는 클래스 `B`를 직접 생성하여 사용하는 것이다. 만약 의존성을 주입하려면 클래스 `B`의 생성을 외부에서 하도록 유도하면 된다.
```java
class A {
public void someMethod(B b) {
b.doSomething();
}
}
```
만약 멤버변수를 이용하여 의존성을 주입한다면 우리가 흔히 접하던 코드가 된다.
```java
class A implements Injector<B>{
private B b;
// constructor injection
public A(B b) {
this.b = b;
}
// setter injection
public void setB(B b) {
this.b = b;
}
// interface injection
@Override
public void inject(B b) {
this.b = b;
}
}
```
## 마치며
의존 역전 원칙은 어떻게 보면 앞에서 다뤄봤던 다른 원칙들을 포괄하는 개념일 수 있다. 레이어를 넘나드는 아키텍쳐를 구성하는 근간 원리이기 때문이다. 이를 따르면 변경에 강한 코드 구조가 되는데 추상화된 인터페이스를 바탕으로 상위 모듈과 하위 모듈의 관계를 느슨하게 만들어주기 때문이다.
주의해야 할 점은 위에서 살펴봤듯, 컴파일 타임 의존성을 변경시켜 구조를 유연하게 만드는 것이지 레이어의 순서를 뒤바꾸는 것이 아니다. 상위 모듈은 하위 모듈에 의존하되 런타임 단계에서 의존 관계가 결정될 수 있도록 의존 관계 사이에 추상화된 인터페이스를 둬서 유연성을 최대한 보장하도록 하는 것이 핵심이다.
----
#### References
- [The Dependency Inversion Principle](https://www.labri.fr/perso/clement/enseignements/ao/DIP.pdf)
- [클린 코더스 강의 15.1. DIP(Dependency Inversion Principle)](https://www.youtube.com/watch?v=mI1PsrgogCw&ab_channel=%EB%B0%B1%EB%AA%85%EC%84%9D)
================================================
FILE: CS/grasp.md
================================================
# GRASP - General Responsibility Assignment Software Patterns
직역하자면 일반적으로 책임을 할당할 때 사용할 수 있는 소프트웨어 패턴이다. 말 그대로 책임 할당에 관한 패턴을 이야기한다. 특이한 점은 보통 생각하는 패턴들과는 달리 실체가 없고 추상적인 개념들이다. 따라서 [SOLID 원칙](http://www.nextree.co.kr/p6960/)과 유사하게 어떤 식으로 책임을 부여해야 할지에 대한 원칙과 철학을 담고 있다.
## 책임이란?
객체지향에서 책임은 매우 중요한 개념이다. RDD(Responsibility Driven Design)에서는 책임을 **특정 작업을 수행하거나, 정보를 알아야 할 의무(an obligation to perform a *task* or know *information*)** 라고 정의한다. 즉 행동(behavior; doing)과 아는것(data; knowing)을 명확히 구분한다. 따라서 객체의 책임은 다음과 같이 정의할 수 있다.
### 행동(Behavior; Doing)
- 스스로 하는 것(doing something itself)
- 다른 객체와 협력 하는 것(initiating and coordinating actions with other objects)
```java
public class Customer {
// doing something itself
private Customer() {
//...
}
// doing something itself
public Customer(String email, String name, UniquenessChecker customerUniquenessChecker) {
this.email = email;
this.name = name;
// initiating and coordinating actions with other objects
if (!customerUniquenessChecker.isUnique(id)) {
throw new BusinessRuleValidationException("Customer with this email already exists.");
}
this.addDomainEvent(new CustomerRegisteredEvent(this));
}
// doing something itself
public void addOrder(Order order) {
//...
}
}
```
### 아는 것(Data; Knowing)
- 객체의 데이터를 감추거나 공개하는 것(private and public object data)
- 연관된 객체의 참조를 연결하는 것(related objects references)
- 해당 객체가 도출해낼 수 있는 것(things it can derive)
```JAVA
public class Customer extends Entity/*knowing*/{
@Getter @Setter private Guid id; // knowing
@Getter @Setter private String email; // knowing
@Getter @Setter private String name; // knowing
@Getter private List<Order> orders; // knowing
```
## GRASP
GRASP은 다음의 9가지 패턴으로 이루어져있다. 각 패턴은 특정 객체가 가져야할 책임이 무엇인지에 대한 것이다.
1. Information Expert
2. Creator
3. Controller
4. Low Coupling
5. High Cohesion
6. Indirection
7. Polymorphism
8. Pure Fabrication
9. Protected Variations
### Information Expert
객체에 책임을 할당하는 기본 원칙에 관한 것이다. 동작에 필요한 정보가 있는 객체에 책임을 지정해야 한다. 다르게 말하면 동작에 필요한 정보가 있는 객체는 해당 동작을 할 수있는 책임을 지녀야 한다. 반대로 동작에 필요한 정보가 없는 객체는 관련된 동작을 해서는 안된다.
```java
public class Customer {
private List<Order> orders;
public int getOrdersTotal(Guid orderId) {
return orders.stream()
.map(Order::getValue)
.sum();
}
}
```
위의 예시에서 `Customer` 클래스는 모든 고객의 주문(`List<Orrder>)`을 알고 있다. 따라서 `Customer` 클래스는 주문의 총액을 계산할 수 있는 책임을 지녀야 한다.
### Creator
객체를 생성하는 책임에 관한 것이다. 객체 A와 B가 있다고 가정 했을 때, 객체 B가 다음의 조건 중 하나라도 만족한다면 객체 A를 생성하는 책임을 가져야 한다. 조건을 만족하는 개수는 많을수록 좋다.
- B가 A를 포함하거나 복합적으로 집계
- B가 A를 기록
- B가 A를 밀접하게 사용
- B가 A의 초기화 데이터 보유
```java
public class Customer {
private List<Order> orders;
public void addOrder(List<OrderProduct> orderProducts) {
Order order = new Order(orderProducts); // Creator
if (2 <= orders.stream().filter(Order::isOrderedToday).count()) {
throw new BusinessRuleValidationException("You cannot order more than 2 orders on the same day");
}
orders.add(order);
addDomainEvent(new OrderAddedEvent(order));
}
}
```
`Customer` 클래스는 주문을 집계하고 기록하고 사용한다. 무엇보다도 `Customer` 클래스가 주문(`Order`)을 포함한다.
### Controller
UI 레이어를 넘나들며 시스템 작동의 제어권을 수신하고 조정하는 객체에 관한 것이다. 시스템, 루트객체, 시스템 실행에 필요한 장치, 핵심 서브시스템을 나타내거나 시스템 동작이 발생하는 시나리오(유스케이스)를 표현하는 객체일 경우 컨트롤러의 책임을 가져야 한다.
```java
public class CustomerOrdersController {
private OrderService customerOrderService;
public CustomerOrdersController(OrderService customerOrderService) {
this.customerOrderService = customerOrderService;
}
@PostMapping("/{customerId}/orders")
public String addCustomerOrder(Guid customerId, HttpServletRequest request) {
//...
}
}
```
위는 전형적인 Spring MVC의 컨트롤러인데, 좀 더 엄밀히 말하면 [DispatcherServlet](https://docs.spring.io/spring/docs/3.0.0.M4/spring-framework-reference/html/ch15s02.html)이 Front Controller 역할을 해주는 일종의 GRASP 컨트롤러라고 말할 수 있다.
### Low Coupling
결합도(coupling)가 낮게 유지되도록 책임을 할당 해야 한다. 낮은 결합도는 변화의 영향을 줄이고 낮은 의존성과 재사용성을 증가시키는 방법이다. 위의 Controller 예시는 의존성 주입을 이용해 결합도가 낮다. `OrderService` 인터페이스의 명세가 바뀌지 않으면 이를 구현하는 서비스 객체가 바뀌어도 큰 영향을 받지 않을 것이다.
### High Cohension
좋은 객체는 높은 응집력(cohension)을 가져야 한다. 응집력은 객체 내부의 책임이 얼마나 연관성이 있는지에 관한 것이다. 만약 `Customer` 클래스가 주문 뿐만 아니라 상품의 가격을 관리하는 책임을 가지게 된다면 해당 클래스의 응집력은 크게 떨어진다.
### Indirection
컴포넌트나 서비스가 직접 연결되지 않도록 중재 역할을 해주는 책임을 갖는 객체를 이용하는 것이다. MVC패턴에서 모델과 뷰 사이에 컨트롤러를 구성하는 것을 예시로 들 수 있다. 혹은 [Mediator Pattern](https://springframework.guru/gang-of-four-design-patterns/mediator-pattern/)을 이용할 수 있다. 객체가 직접 연결되어 있지 않다는 것은 시스템을 유연하게 만드는 것을 도와줄 수 있지만, 가독성과 추론을 어렵게 만들 수 있는 trade off가 있기 때문에 직접 구현하게 된다면 이를 잘 고려해야 한다.
### Polymorphism
유형에 따라 서로 다른 케이스를 처리하고 싶을 경우 다형성을 이용할 수 있다.
```java
private Guid id;
public Customer(string email, string name, UniquenessChecker customerUniquenessChecker) {
this.Email = email;
this.Name = name;
if (!customerUniquenessChecker.isUnique(id)) {
throw new BusinessRuleValidationException("Customer with this email already exists.");
}
this.AddDomainEvent(new CustomerRegisteredEvent(this));
}
```
`UniquenessChecker`가 `Customer`에 사용될 경우 `CustomerUniquenessChecker` 다른 곳에 사용될 경우 `OtherUniquenessChecker`를 사용하는 식으로 책임은 같지만 구현에 따라 동작이 달라질 경우 유용하게 쓰일 수 있다.
### Pure Fabrication
다른 원칙들을 적용하여 높은 응집력과 낮은 결합력을 유지하기 힘들 경우(정확한 책임을 할당하기 힘든 경우) 도메인에 독립적인 클래스와 인터페이스를 만드는 것이 좋을 수 있다.
위에서 살펴봤던 예시들을 사용하다 환전 기능을 추가하게 되었다. 이는 `Customer`혹은 `Order`의 책임이라고 명확하게 정의하기 애매한데, 이런 경우 적용할 수 있다. 아래는 이에 따라 작성된 독립적인 인터페이스와 구현 클래스이다.
```java
public interface ForeignExchange {
List<ConversionRate> getConversionRates();
}
public class ForeignExchangeImpl implements ForeignExchange {
private CacheStore cacheStore;
public ForeignExchange(CacheStore cacheStore) {
this.cacheStore = cacheStore;
}
@Override
public List<ConversionRate> getConversionRates() {
//...
}
private static List<ConversionRate> getConversionRatesFromExternalApi() {
// Communication with external API
}
}
```
### Protected Variations
변화가 많거나 변경의 가능성이 높은 불안정한 객체나 서브시스템은 안정적인 인터페이스로 감쌀 수 있다.
```java
public class CustomerOrdersRepository {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// JDBC-backed implementations of the methods...
}
@Configuration
public class SpringJdbcConfig {
@Bean
public DataSource mysqlDataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/springjdbc");
dataSource.setUsername("guest_user");
dataSource.setPassword("guest_password");
return dataSource;
}
}
```
위의 예시는 `DataSource`라는 안정적인 인터페이스 안에서 데이터 베이스 setup에 대한 책임을 담당한다. 데이터 베이스가 교체되더라도 `DataSource` 객체의 명세를 그대로 사용하기 때문에 이를 구현한 클래스를 교체하거나 내부 구현의 내용만 바꿔주면 다른 시스템에 피해 없이 작업을 수행할 수 있다.
## 마치며
객체를 정의할때 가장 중요하지만 그만큼 어려운 것이 책임을 정의하고 그에 따라 설계하는 것이다. SOLID원칙과 마찬가지로 이를 완벽하게 지키기는 힘들다. 하지만 마찬가지로 지키지 않을 수록 절차지향적 코드에 가까워진다. 절차지향적인 프로그램이 나쁜 것은 아니지만, 본인이 객체 지향 프로그래밍을 의도하며 만들었다면 마땅히 따라야할 원칙과도 같은 것이기 때문에 최대한 지키기 위해 노력하는 것이 바람직하다.
---
#### References
- [GRASP – General Responsibility Assignment Software Patterns Explained](http://www.kamilgrzybek.com/design/grasp-explained/)
================================================
FILE: CS/information_theory.md
================================================
# 정보이론
## 소통
소통에는 늘 잡음이 낀다.
이웃이 주식으로 돈을 좀 많이 벌었다라는 사실이 있다면 정보는 왜곡되고 과장이 되기 마련이다.
그 이웃은 돈을 벌어 집도 사고 차도 새로 뽑는다. 친구의 뒷통수를 쳐 돈을 벌었으며 곧 해외로 도망간단다.
꼭 소문만이 아니다. 실제로 정보의 통신에는 잡음이 낀다. 무전기로 통신을 할 때 잡음이 생기는걸 생각해보면 된다.
신호는 전송 도중 에너지를 빼앗겨 그 신호가 약해진다. 봉화에 불을 붙이면 가까이선 잘 보이지만 멀리선 당연히 잘 안 보인다.
0과 1로 이루어진 신호 역시 통신시에는 잡음이 생긴다.
## 통신과 잡음
우리가 컴퓨터로 통신할 때 잡음이 생긴다면 어떨까? 내가 1000만원을 송금했는데 잡음이 생겨 0이 하나 빠져 100만원이 송금된다면? 끔찍하다.
그럼 어떻게 메시지를 온전하게 전달할 수 있을까? 정보를 온전히 전달하는 기술은 정보이론에 기초한다. 정보이론은 1948년 클로드 섀년이 그의 나이 32세에 탄생시킨다.
### 잡음에 대한 다른 시각
통신에는 잡음이 생긴다고 했다. 1948년에는 잡음은 물리적인 현상이며 이를 물리(하드웨어, 아날로그)적인 방식으로 어떻게 극복할 수 있을까 고민했다.
메시지 전달속도를 높이려면 주파수를 높이거나, 잡음이 생긴다면 신호를 강하게 만들면 된다거나 하는 방법으로 말이다.
하지만 섀년은 달랐다. 하드웨어가 아니라 소프트웨어(보내려는 메시지)적인 방법으로 해결하고자 했다.
## 정보량
소프트웨어인 메시지에 주목하고자 먼저 한 일은 정보량에 대해 정리하는 일이었다.
정보의 양은 뭘까? 섀넌은 확률을 기준으로 정보량을 정리했다.
예를들어 '하겠습니' 다음에는 '다'가 나올 확률이 '까'가 나올 확률보다 훨씬 높다. '하겠습니다'는 '하겠습니까'보다 자주 나오므로 예측하기 쉽다. 예측하기 쉬우면 정보의 양이 적다.
왜 예측하기 쉬우면 정보의 양이 적을까? 쉽게 장마철을 생각해보자. 장마철에 비가오는건 당연하다. 확률이 높다. 장마철에 내일도 비가 올 것입니다 라는 정보는 그다지 중요하지 않다.
반대로 가뭄에 비가 올 확률은 매우 적다. 한 달 동안 가뭄인 상태에서 내일은 드디어 비가 올 것 같습니다 라는 정보는 훨씬 더 중요하다. 즉 훨씬 더 중요하며 정보량이 많다.
위의 논리라면 알파고의 78수가 나올 확률은 0.007%이며 이는 매우 중요한 정보라는 것이 증명된다.
### 엔트로피
이는 엔트로피의 개념과 같다. 나는 문과 출신이라 엔트로피에 대해 잘 모른다. 쉽게 무질서의 정도라고 한다.
예를들어 문서에 a, b, c, d만 등장하며, 각각의 문자가 등장할 확률이 모두 25%로 같다고 하자. 그렇다면 이 문서의 정보량은 엔트로피의 공식에 의해 2라고 한다.
확률이 모두 같다면 가장 정돈된 상태다. 가장 정돈된 상태가 네 글자로 만들 수 있는 최대 정보량이다. 확률이 달라진다면 어떤 글자가 나올지 예측하기가 쉬워지며 정보의 양이 줄어든다.
'하겠습니' 뒤에는 '다'가 나올 확률이 높으니 정보가 줄어드는 것처럼 영어에는 e가 제일 많이 나와 정보의 양이 줄어든다.
즉 확률이 서로 다르면 무질서한 상태가 된다. 무질서할수록 정보의 양은 줄어든다.
### 정보량과 잡음
아까도 말했듯 통신에는 잡음이 생긴다. 이를 물리적인 방법으로 해결하는 데에는 한계가 있다. 메시지의 강도를 높이면 잡음도 심해지기 때문이다.
섀넌은 통신의 한계는 물리적인 것에 있다고 보지 않았다. 통신의 한계점은 정보량에 기준한다는 새로운 패러다임을 제시한다.
정보량은 초당 H이며 온전히 전달할 수 있는 채널 용량이 초당 C라고 가정하자.
H <= C 라면 정보에 비해 용량이 크므로 온전하게 전달 할 수 있다.
H > C 라면 잡음은 H-C미만으로 줄일 수 없다.
섀넌은 위와 같은 정의를 내린다.
이에 C를 키우기 위해 신호의 전력을 키우면 잡음도 증가한다를 수식적으로 증명한다.
기존의 개념은 채널의 용량인 C를 키워 통신을 온전하게 만들자는 것이었다. 하지만 섀넌은 잡음을 더 줄일 수 없으니 H를 줄이자라는 길을 제시했다.
H는 정보의 양이며 정보량을 줄이는 방법은 엔트로피를 조정하면 된다. 이 개념에서 시작된 것이 압축이다.
---
참고자료
- [정보이론 1편](https://brunch.co.kr/@chris-song/68)
- 컴퓨터과학이 여는 세계, 이광근, 인사이트
- 성공과 실패를 결정하는 1%의 네트워크 원리, Tsutomu Tone, 이도희 역, BM성안당
================================================
FILE: CS/integer_representation.md
================================================
# 정수 표현(Integer Representation)
전자기기는 신호가 켜졌는지, 꺼졌는지 구분을 하는 것이 효율적이기 때문에 컴퓨터 또한 2진법을 기반으로 발전하였다.

> 그림 출처 : [정보통신기술용어해석](http://ktword.co.kr/abbr_view.php?nav=2&id=122&m_temp1=5048)
컴퓨터는 위와 같이 수를 표현한다. 이때 2진수 자리 한 칸을 비트(bit; binary digit)라 한다.
수의 양 끝에는 MSB(most significant bit; 최상위 비트)와 LSB(least significant bit; 최하위 비트)가 있다. MSB는 주로 부호를 나타내는 데 사용된다.
### 수 표현 단위
#### 비트(Bit; Binary Digit)
위에서 봤듯 가장 기본적인 수 표현 단위는 비트다. 비트 n 개당 2^n 개의 수를 표현할 수 있다. 비트는 0과 1로 이루어진 2진법 체계를 사용하기 때문이다.
> 예를 들어 3비트로 0(000)부터 7(111)까지의 8개(2^3개)의 수를 나타낼 수 있다.
> 하나의 비트를 논릿값(true, false)을 나타내는 데 사용할 수 있다. 논릿값은 두 가지의 경우만 표현하면 되기 때문이다.
#### 바이트(Byte; Octet)
바이트는 8개의 요소를 하나의 그룹으로 묶은 것이다. 때문에 옥텟이라고 부르기도 한다. 즉, 하나의 바이트는 8개의 비트로 이루어져 있다.
> 1kb는 1024byte 이다.
## 음수 표현
비트는 0과 1로만 이루어지기 때문에 컴퓨터는 음수 기호를 사용할 수 없다. 2진수 만으로 음수를 표현하기 위해 첫 번째 자리로 부호를 표기하는 방식을 사용한다. 때문에 가장 왼쪽에 있는 비트인 MSB는 주로 부호 비트(sign bit) 로 사용된다.
> 만약 음수를 사용하지 않고 양의 정수를 더 크게 나타내고 싶을 경우 MSB를 부호 비트로 사용하지 않을 수 있다. 이를 지원하는 언어에서는 부호 비트를 사용하지 않는 정수 표현이라는 의미로 unsigned int 와 같이 표시하기도 한다.
### 부호 크기 체계(Signed Magnitude System; 부호 절대값 형식)
부호 크기 체계는 부호 비트 이외에 나머지 비트를 절댓값 크기로 표현하는 것이다. 예를 들어, 4비트로 정수를 표현할 때 5는 0101이 된다. 부호 크기는 -5를 1101과 같이 표현한다. 1(-부호) + 101(10진수로 5)와 같이 표현하는 것이다. 이처럼 표현하면 -7 부터 7 까지 2^4 - 1개(15개)의 수를 나타낼 수 있다. 이를 수식으로 일반화하면 다음과 같다.
- 표현 범위 : 2^(n-1) + 1 ~ 2^(n-1) - 1
- 표현 가능 개수 : 2^n - 1
### 보수(Complement)
보수는 보충을 해주는 수를 의미한다. 예를 들어 1에 대한 10의 보수는 9(10 - 1), 4에 대한 15의 보수는 11(15 - 4)이 되는 것이다. 2진수에서는 1의 보수와 2의 보수를 사용할 수 있다. 컴퓨터는 이 중 2의 보수를 이용하여 음수를 나타낸다.
#### 1의 보수(One's Complement)
2진수에서 1의 보수는 각 자릿수를 1에서 빼주는 것과 같다. 이는 or(|) 연산을 하는 것과 같이 동작한다. 예를 들어 2진수 0101의 보수는 1010이 되는 것이다. 4비트로 정수를 표현 할 때는 0 부터 7까지는 0000부터 0111까지, -7 부터 0까지는 1000 부터 1111까지로 나타낼 수 있다. 표현 범위와 표현 가능 개수는 부호 크기 체계를 사용할 때와 같지만, 부호 비트가 음수를 나타낼 경우 절댓값으로 표현할 때와 달리 나머지 비트가 작을수록 더 작은 수를 나타낸다.
- 표현 범위 : 2^(n-1) +1 ~ 2^(n-1) -1
- 표현 가능 개수 : 2^n -1
#### 2의 보수(Two's Complement)
2의 보수는 각 자릿수를 2에서 빼주는 것과 같다. 이는 or(|) 연산을 한 뒤 1을 더해주는 것과 같다. 2진수에서 1에 대한 2의 보수는 2 - 1이 될 것인데, 이는 1 - 1을 한 뒤 1을 더해주는 것과 같기 때문이다. 따라서 2진수 0101의 보수는 1011이 된다. 2의 보수를 사용할 경우 -0이 없어진다. 0에 대한 1의 보수에 1을 더하면 다시 0이 되기 때문이다. 따라서 다른 방식보다 하나의 음수를 더 표현할 수 있다.
> 0000의 보수는 1111이다. 여기에 1을 더해주면 10000이 되는데, 지금은 4비트로 정수를 표현하고 있기 때문에 이는 0000으로 표현된다.
- 표현 범위 : 2^(n-1) ~ 2^(n-1) -1
- 표현 가능 개수 : 2^n
### 2의 보수를 사용하는 이유
#### 보수를 사용하는 이유
보수를 사용하면 덧셈만으로 뺄셈 연산을 할 수 있다. 컴퓨터에는 덧셈을 위한 회로만 있기 때문에 만약 부호 이외의 값을 절댓값으로 표현한다면 뺄셈을 위한 회로가 추가되어야 한다. 따라서 뺄셈을 위해서 보수를 구한 뒤 더하는 방식으로 뺄셈 연산을 한다. 2 - 3을 계산해야 한다고 생각해보자. 이는 2 + (-3) 과 같은 수식이다. 따라서 3을 음수로 바꿔주고 덧셈 연산을 하면 뺄셈을 하는 것과 연산이 같아진다.
또한, 부호 이외의 값을 절댓값으로 표현하면 음수 비교 연산 시 모순이 발생한다. 보수를 이용하면 이러한 모순이 해결된다.
#### 2의 보수를 사용하는 이유
2의 보수를 사용하면 1의 보수와 달리 0이 하나로 표현된다. -0에 대한 처리를 따로 하지 않아도 된다. 또한, 뺄셈을 할 경우 캐리(carry; 올림 수) 처리를 해주지 않아도 된다. 이는 다음 예시를 보자.
##### 1의 보수 뺄셈
- 예시 : 1101 - 1010
1. 1010의 1의 보수는 0101이므로 1101에 0101을 더한 값은 10010이 된다.
2. 이 때 범위가 초과된 최상위 비트 1을 없애고 1을 더해준다. 이에 따라 1101 - 0101 = 0011 이라는 결과가 나온다.
> 이러한 캐리를 end aroud carry 라고 한다. MSB에서 발생한 캐리를 뜻한다.
##### 2의 보수 뺄셈
- 예시 : 1101 - 1010
1. 1010의 2의 보수는 0110이다. 1101 + 0110은 10011이 된다.
2. 최상위에 있는 비트는 표현 범위를 넘어갔으니 제외하면 0011 이라는 결과를 얻을 수 있다.
> 2의 보수를 사용하면 end around carry를 무시하고 연산 할 수 있다.
## 오버플로우(Overflow)
계산과정에서 결괏값이 표현 가능한 값의 범위를 넘어갈 경우 오버플로우가 발생하게 된다. 4비트로 부호가 있는 정수를 표현할 때 -4와 -5를 더하면 -9가 되므로 표현 범위를 넘어가게 된다. 따라서 이런 경우가 발생하기 전에 더 큰 범위를 지정해줘야 한다. 오버플로우를 감지하는 방법은 부호 사용 여부에 따라 달라지는데 이는 [오버플로우(Overflow) 조건](https://janggom.tistory.com/328)을 참고하자.
----
#### References
- [정보통신기술용어해석 - 2의 보수, 1의 보수](http://ktword.co.kr/abbr_view.php?nav=2&id=122&m_temp1=4088)
- [정보통신기술용어해석 - 보수(complement)](http://ktword.co.kr/abbr_view.php?nav=2&id=122&m_temp1=4556)
- [dreamincalm의 블로그 - 1의 보수, 2의 보수](https://blog.naver.com/dreamincalm/130081559335)
================================================
FILE: CS/interface-segregation-principle.md
================================================
# 인터페이스 분리 원칙(Interface Segregation Principle)
인터페이스 분리 원칙은 클라이언트는 자신이 사용하지 않는 메서드에 의존하면 안된다는 것이다. 만약 인터페이스가 거대하여 많은 기능을 담고 있다면 해당 인터페이스는 높은 응집도를 갖기 힘들다. 클래스의 인터페이스가 가진 함수들을 그룹화 하여 나눌 수 있다면 해당 인터페이스를 사용하는 클라이언트도 여러 개다.
쉽게 말해, 인터페이스 내부의 함수들의 그룹을 구분할 수 있다면, 해당 인터페이스에 여러 가지 책임이 혼재되어 있는 상태라는 것이다. 이 경우 하나의 인터페이스를 여러 개의 클라이언트에서 사용하지만, 사용하는 기능은 클라이언트별로 한정적일 것이다.
따라서 인터페이스 분리 원칙은 하나의 클래스에 여러 개의 책임을 가진 인터페이스를 사용해야 하는 경우에 관한 이야기이다. 이 때, 클라이언트는 구현된 객체 대신 응집력 있는 인터페이스를 가진 추상 기본 클래스에 의존해야 한다. 이러한 추상 기본 클래스를 '인터페이스', '프로토콜' 또는 '서명(signiture)' 이라고 한다.
## 예시
전역한 한국인은 예비군을 가게 된다.
```java
class Korean {
public void participateReserveForcesTraining() {
// 예비군 훈련 참여
};
}
```
하지만 모든 남자가 예비군 훈련에 가는 것은 아니다. 전역을 한 사람 대상이다. 전역을 했다는 상태값을 나타내도록 간단히 수정해보면 아래와 같을 것이다.
```java
abstract class Korean {
public abstarct boolean isDischarged();
}
class DischargedKoraen extends Korean {
@Override
public boolean isDischarged() {
return true;
}
public void participateReserveForcesTraining() {
// 예비군 훈련 참여
};
}
class ReserveForcesTrainingClient {
public void doReserveForcesTraining(Korean korean) {
if(KoreanPerson.isDischarged()) {
((DischargedKorean) korean).participateReserveForcesTraining();
}
}
}
```
이 경우 상위 클래스와 하위 클래스가 다른 동작을 한다. [리스코프 치환 원칙](https://github.com/im-d-team/Dev-Docs/blob/master/CS/liskov_substitution_principle.md)을 위배한다. 이를 해결해보면 다음과 같을 것이다.
```java
interface Korean {
boolean isDischarged();
void participateReserveForcesTraining(boolean discharged);
}
class DischargedKoraen implements Korean {
@Override
public boolean isDischarged() {
return true;
};
@Override
public void participateReserveForcesTraining(boolean discharged) {
if(discharged) {
// ...
}
};
}
class ReserveForcesTrainingClient {
public void doReserveForcesTraining(Korean korean) {
korean.participateReserveForcesTraining(korean.isDischarged());
}
}
```
이렇게 고칠 경우 `Korean` 의 다른 케이스에서도 반드시 예비군 훈련에 관한 구현이 포함되어야 한다.
```java
class NonDischargedKoraen implements Korean {
@Override
public boolean isDischarged() {
return false;
};
@Override
public void participateReserveForcesTraining(boolean discharged) {
throw new UnsupportedOperationException("전역하지 않은 사람은 예비군 훈련에 참여할 수 없습니다.");
};
}
```
이런 경우, 인터페이스가 오염되었다고 말한다. 또한, 위 예제는 기능이 적기 때문에 인터페이스가 비대해 보이지 않다. 하지만 만약 `Korean` 인터페이스에서 추상화된 모든 기능을 제공할 경우 실제 구현 클래스는 메소드 중 일부분만 사용하지만 거대한 인터페이스의 모든 기능을 재정의해야 할 것이다.
이런 경우 인터페이스 분리를 해주어 해결할 수 있는 것이다.
> 위 경우 [개방-폐쇄 원칙](https://github.com/im-d-team/Dev-Docs/blob/master/CS/open-closed-principle.md)도 위반하였을 가능성이 높다. 예비군에 관한 조건이 변경될 경우 `Korean` 을 구현한 모든 클래스가 변경되어야 할 것이기 때문이다.
```java
class Korean {
// ...
}
interface Discharged {
void participateReserveForcesTraining();
}
class DischargedKoraen extends Korean implements Discharged {
@Override
public void participateReserveForcesTraining() {
// ...
};
}
class ReserveForcesTrainingClient {
public void doReserveForcesTraining(Discharged dischargedPerson) {
dischargedPerson.participateReserveForcesTraining();
}
}
```
`Korean`에 대한 일반화가 이루어졌으며, 전역자에 대한 책임도 분리되었다. 예비군 훈련을 담당하는 클라이언트는 전역에 관한 메세지를 전달할 수 있는 인스턴스만 사용할 수 있도록 강제되었다. 만약, 전역을 한 것과 동시에 여러 개의 책임이 추가된 사람에 대한 객체를 구현하더라도, 전역을 했다는 인터페이스만 구현하게 되면 예비군 훈련에 참가할 수 있게 된다.
```java
class DischaregedKoreanStudent extends Korean implements Discharged, Student {
@Override
public void participateReserveForcesTraining() {
// 학생 예비군으로 참여
}
// ...
}
```
## 마치며
하나의 거대한(일반화된) 인터페이스보다 여러 개의 구체적인 인터페이스가 낫다는 것이 인터페이스 분리 원칙의 핵심이다. [단일 책임 원칙](https://github.com/im-d-team/Dev-Docs/blob/master/CS/srp.md)과 서로 상충하는 개념처럼 보일 수 있다. 단일 책임 원칙에서는 클래스에서 하나의 책임만 담당해야 한다고 하지만, 인터페이스 분리 원칙은 하나의 클래스에서 여러 개의 책임을 갖는 경우가 있음을 인정하는 것이기 때문이다.
하지만 이는 두가지 원칙의 관점이 다르기 때문인데, 단일 책임 원칙은 도메인(실행 대상)의 관점에서 책임을 나누지만, 인터페이스 분리 원칙은 클라이언트(실행하는 곳)의 관점에서 책임을 나누기 때문이다. 예를 들어 단일 책임 원칙은 해당 클래스 내부에서 여러 책임이 발생하는 것이 문제가 되는 것이다. 인터페이스 분리 원칙 또한 해당 클래스 내부에서 사용하지 않는 클래스를 재정의 해야 한다는 점이 문제지만, 이를 다시 생각해보면 클라이언트에 노출되면 안되는 메소드가 노출되는 것이 문제점이다. 이와 같이 생각해보면 큰 혼동 없이 이를 구분할 수 있을 것이다.
---
#### References
- [The Interface Segregation Principle - Robert C. Martin](https://drive.google.com/file/d/0BwhCYaYDn8EgOTViYjJhYzMtMzYxMC00MzFjLWJjMzYtOGJiMDc5N2JkYmJi/view)
- [객체지향 개발 5대 원리: SOLID - NEXTREE](http://www.nextree.co.kr/p6960/)
================================================
FILE: CS/liskov_substitution_principle.md
================================================
# 리스코프 치환 원칙(Liskov Substitution Principle)
> 바바라 리스코프(Barbara Liskov)가 1988년 제시한 파생(상속) 에 관한 원칙.
리스코프 치환 원칙은 하위 타입을 상위 타입으로 치환(substitution)하더라도 같은 동작을 해야 한다는 원칙이다. 상속 시 부모와 자식의 관계가 반드시 IS-A 관계를 맺도록 하면 자식 타입과 부모 타입은 치환 가능하다.
바바라 리스코프는 타입이 `S`인 객체 `o1`과 타입이 `T`인 객체 `o2`가 있을 때, `T`가 정의된 프로그램 `P` 에서 `o2`를 `o1`으로 치환하여도 `P`에서 동작의 변화가 없을 경우 `S`는 `T`의 서브타입이라 할 수 있는 치환 원칙이 필요하다고 했다.
쉽게 얘기하면 호출하는 프로그램 입장에서 부모 타입인지 자식 타입인지 신경써야하는 상황을 없애야 하고, 이를 위해서는 자식 클래스에서 부모 클래스에서 가능한 동작이 보장되어야 한다는 것이다. 그리고 이를 만족하면 자식과 부모클래스가 치환되어도 프로그램의 동작에 문제가 생기지 않는다.
```java
public class Line {
private Point p1;
private Point p2;
public Line(Point p1, Point p2) {
//...
}
public boolean isOn(Point p) {
//...
}
}
public class LineSegment extends Line {
public LineSegment(Point p1, Point p2) {
super(p1, p2);
}
public double getLength() {
//...
}
//Line.isOn()의 참이 아래에서는 거짓이 될 수 있음.
@Override
public boolean isOn(Point p) {
//...
}
}
```
위 코드에서 `LineSegment`는 `Line`의 `isOn()` 메소드를 재정의 하였다.
```java
public class LineClient {
void doSomething(Line line) {
if(line.isOn(point)) {
//...
}
}
}
```
위 코드는 매개변수 `line`의 `isOn()` 메소드가 `true` 를 반환할 것을 기대하고 작성 되었다. 하지만 이 경우 `line`의 인스턴스가 `Line` 이아닌 `LineSegment` 일 경우 제대로 동작하지 않을 수 있다. 버그가 잠재적인 코드인 것이다.
만약 리스코프 치환 원칙을 준수하지 않는다면 부모 클래스에 따라 작성된 클라이언트의 코드가 변경되어야 하는 상황을 피하기 힘들다.
> 이외에 직사각형과 정사각형에 대한 예시가 자주 나오는데, 이 또한 하위 타입의 변경에 의해 상위 타입을 바탕으로 정의한 동작이 제대로 작동하지 않는 경우에 관한 얘기이다. 참고 - [The Liskov Substitution Principle](https://drive.google.com/file/d/0BwhCYaYDn8EgNzAzZjA5ZmItNjU3NS00MzQ5LTkwYjMtMDJhNDU5ZTM0MTlh/view)
## LSP 준수 방법
- [계약에 의한 설계(design by contract; DBC)](https://en.wikipedia.org/wiki/Design_by_contract) : overriding 시 부모 클래스와 같거나 약한 수준에서 동작하는 선행조건을 지정하고, 부모 클래스와 같거나 더 강한 수준에서 동작하는 후행 조건을 정의해야 한다.
> 선행조건(pre-condition) : 모듈을 호출하기 위해 참이어야 하는 조건.
>
> 후행조건(post-condition) : 모듈이 동작한 뒤 반드시 참이어야 하는 조건.
```java
@Override
public boolean isOn(Point p) {
if(isSomthingStartWithBaseClassTrue()) { // 선행조건
// ...
}
if(isEndWithSomthingWrong()) { // 후행조건
throw new SomeException();
}
}
```
- 상속(추출) 대신 공통 인자를 추출한다.
```java
public abstract class LinearObject {
private Point p1;
private Point p2;
public LinearObject(Point p1, Point p2) {
//...
}
public abstract boolean isOn(Point p);
}
public class Line extends LinearObject{
public Line(Point p1, Point p2) {
super(p1, p2);
}
@Override
public boolean isOn(Point p) {
//...
}
}
public class LineSegment extends LinearObject {
public LineSegment(Point p1, Point p2) {
super(p1, p2);
}
public double getLength() {
//...
}
@Override
public boolean isOn(Point p) {
//...
}
}
```
만약 아까와 같이 `Line` 의 `isOn()` 을 이용한 동작이 보장되야 되는경우가 문제 없어진다. 그리고 만약 인스턴스와 무관하거나 인스턴스에 따라 동작이 달라져야 하는 경우라면 추상 클래스(혹은 인터페이스)를 타입으로 사용하면 된다.
```java
public class LineClient {
void doSomething(LinearObject linearObject) {
//...
// 인스턴스에 따라 동작이 달라져야 하는 경우
if(linearObject.isOn(point)) {
//...
}
}
}
```
## 결론
상속을 정의할 때 IS-A 관계만 생각할 경우 가능 범위가 너무 넓어질 수 있다. 이럴 경우 다음 그림을 떠올려보자.

> 유사해 보여도 동작이 달라져야 한다면 이는 잘못된 추상화일 가능성이 높다.
이외에 더 자세한 내용을 원한다면 [리스코프 치환 원칙](https://ko.wikipedia.org/wiki/리스코프_치환_원칙)을 참고해도 좋다. 더 구체적인 조건이 명시되어 있다. 또는 로버트 마틴의 글 [The Liskov Substitution Principle](https://drive.google.com/file/d/0BwhCYaYDn8EgNzAzZjA5ZmItNjU3NS00MzQ5LTkwYjMtMDJhNDU5ZTM0MTlh/view)를 참고해도 좋다. 구체적 예시가 포함되어 있다.
---
#### References
- [LSP : The Liskov Substitution Principle](https://sites.google.com/site/anyflow/software-design/aejail-gaebal-wonchig-agile-development-principle/lsp-the-liskov-substitution-principle)
- [The Liskov Substitution Principle](https://drive.google.com/file/d/0BwhCYaYDn8EgNzAzZjA5ZmItNjU3NS00MzQ5LTkwYjMtMDJhNDU5ZTM0MTlh/view)
================================================
FILE: CS/methods_in_IPC.md
================================================
# IPC(Inter Process Communication) 기법
프로세스는 서로 접근이 불가능하다. 프로세스는 커널만 접근할 수 있기 때문이다. 하지만 병렬처리가 필요하거나 서로 다른 프로세스 간의 상호작용이 필요할 수 있다. 예시를 떠올리기 힘들다면 서버-클라이언트 모델을 생각해보면 이해하기 쉽다. 서버와 클라이언트는 서로 다른 프로세스이지만 정보를 주고받아야 한다. 이걸 해결하는 방법이 IPC(Inter Process Communication; 프로세스 간 커뮤니케이션)이다.
### 들어가기 전에
가장 쉽게 IPC를 구현하는 방법으로 파일을 사용하는 방법이 있다. 하나의 파일에 필요한 자원이나 메세지를 입력하여 공유하는 것이다. 하지만 업데이트 상황을 감지하기 어렵고 저장 매체를 지속적으로 사용해야 하므로 하드웨어 인터럽트가 발생할 것이고 성능이 떨어질 것이다. 때문에 커널 공간을 이용한 기법들이 대부분이다.
모든 프로세스에는 커널 영역이 할당되어 있다. 똑같은 커널 영역을 사용하기 때문에 프로세스에 있는 커널 영역은 물리 메모리에 올라가 있는 하나의 커널 영역을 참조한다. 만약 프로세스 A와 B에서 커널 영역에 접근 하게 된다면 같은 영역에 접근하게 되는 것이다. 즉, 커널 영역을 사용할 수 있도록 [시스템 콜](https://ko.wikipedia.org/wiki/%EC%8B%9C%EC%8A%A4%ED%85%9C_%ED%98%B8%EC%B6%9C)을 제공한다면 IPC를 구현할 수 있다.
## IPC 기법
IPC에 대한 대표적인 접근방식은 아래와 같다.
> 항목은 [Inter-process communication - Wikipedia](https://en.wikipedia.org/wiki/Inter-process_communication#Approaches) 를 바탕으로 linux에서 사용할 수 있는 것들을 기준으로 선정했다.
- 파일(file)
- 공유 메모리(shared memory)
- 메세지 패싱(message passing)
- 파이프(pipe)
- 메세지 큐(message queue)
- 시그널(signal)
- 소켓(socket)
- 세마포어(semaphore)
파일을 이용한 IPC 외에는 크게 두 가지 컨셉이 있다. 프로세스끼리 공유할 수 있는 메모리를 만들어 함께 접근하거나, 메세지를 주고받는 것(메세지 패싱)이다.
> 참고 - https://www.geeksforgeeks.org/inter-process-communication-ipc/
### 공유 메모리(Shared Memory)
물리 메모리 공간에 변수처럼 사용할 수 있도록 공간을 만드는 것이다. key와 접근권한을 부여하여 등록하고 사용할 수 있다.

#### 장점
- 메모리에 있는 것을 그대로 사용할 수 있기 때문에 속도가 빠르다.
- 구현도 간단하다.
- 여러 프로세스가 동시에 접근할 수 있다.
#### 단점
- 동기화(synchronize) 이슈가 생길 수 있다.
- 커널에서 설정된 용량에 종속적이다.
- 데이터를 읽어야 되는 시점을 알 수 없다.
> 사용자(consumer)가 어떤 데이터를 사용할지 직접 명시해야 하기 때문이다. 다른 방식은 메세지를 전달받기 때문에 해당 메세지에 해당하는 데이터를 읽으면 된다.
### 파이프(Pipe)
한 프로세스가 넣으면 다른 프로세스가 읽는 큐 형태의 구조이다. 하지만 방향이 고정되어있어 한 방향으로만 통신할 수 있다. 물탱크에서 관(파이프)을 통해 수도꼭지로 물이 나오는 것을 생각해보면 이해하기 쉽다. 즉, 파이프의 입력부분과 출력 부분이 정해지면 입력 부분이 구현된 프로세스에서는 입력만, 출력 부분이 구현된 프로세스에서는 출력만 가능하다. 또한, 읽기와 쓰기가 block 모드로 이루어지기 때문에 양방향으로 구현하더라도 반이중(half-duplex) 통신으로 동작한다. 반이중 통신의 대표적인 예로 무전기가 있는데 이와 유사하게 동작하는 것이다.
#### 장점
- 매우 간단하게 사용할 수 있다.
#### 단점
- 부모-자식 간에만 사용할 수 있다.
- 단방향(unidirection) 통신이다.
- 양방향(bidirection)으로 구현하여도 반이중 통신이다.
#### Named Pipe(후술 FIFO)
앞에서 살펴본 파이프는 엄밀히 따지면 익명 파이프(anonymous pipe)라고 불린다. 이 방식의 단점 중 부모-자식 프로세스에서만 사용할 수 있다는 것인데, FIFO는 그러한 단점을 해결하기 위한 것이다. 즉 관련 없는 프로세스들에서 파이프를 이용한 IPC를 구현하기 위해 사용할 수 있다.
> 서버-클라이언트 모델에 사용되는 방식이다.
### 메세지 큐(Message Queue)
key를 이용한 큐 방식이다. 선입선출 외에 지정한 key 중 가장 먼저 입력된 자료를 꺼낼 수 있다. 양방향으로 통신할 수 있다.
#### 장점
- 프로세스 간의 비동기(asynchronization) 통신이 가능하다.
- 키를 이용하면 권한이 있는 모든 프로세스에서 접근할 수 있다.
> 하지만 큐이기 때문에 동기화 이슈를 염려할 필요 없다.
#### 단점
- 대기열이 지나치게 길어지면 병목현상이 발생할 수 있다.
### 시그널(Signal)
커널 또는 프로세스에서 다른 프로세스에 어떤 이벤트가 발생했는지 알려주는 기법이다. 프로세스의 실행 종료 등을 알려준다. 프로세스에서 시그널을 재정의하면 시그널의 기본 동작과 다른 동작을 할 수 있다. 이를 이용하기 위해 유저 정의 시그널(리눅스의 경우 SIGUSR1, 2)을 제공한다.
> 시그널 무시, 시그널 블록(block), 핸들러에 정의된 동작 수행(콜백 함수처럼 동작한다)
시그널의 좀 더 자세한 동작 원리는 인터럽트가 종료되어 사용자 모드로 전환하는 시점에 pcb(process control block)에 있는 시그널과 관련된 자료구조의 상태를 확인하는 것이다. 이를 이용하여 다른 IPC 기법과 조합하여 사용할 수 있다. 데이터를 직접 전송할 수 없다는 단점이 있다.
### 소켓(Socket)
기본적으로 네트워크 통신을 위한 기술로 클라이언트와 서버 간의 요청과 응답을 처리하는 기술이다. 앞에서 파이프의 발전된 형태인 FIFO를 잠깐 살펴봤는데 소켓은 FIFO가 양방향으로 구성된 것과 흡사하다. 근본적으로 서로 다른 네트워크의 프로세스를 연결하는 기술이지만, [Unix Domain Socket(IPC socket)](https://en.wikipedia.org/wiki/Unix_domain_socket)을 이용하여 커널 내부의 커뮤니케이션에 사용할 수 있다.
#### 장점
- 양방향으로 많은 데이터가 오고 가야 할때 유리하다.
#### 단점
- 프로그램의 규모가 작다면 오버헤드가 클 수 있다.
### 세마포어(Semaphore)
세마포어는 조금 특이하다. 원래는 동기화 이슈를 해결하기 위한 방법론 중 하나이기 때문이다. 동기화 이슈가 생기는(동시에 접근하면 안 되는) 부분을 임계 영역(critical section)이라고 한다. 여기에 대한 동시 접근을 막는 것을 상호배제(MUTial EXclusion; MUTEX)라고 하는데, 세마포어는 동시 접근 할 수 있는 프로세스의 개수를 정해놓는 기법이다.
```pseudocode
/**
* S : 임계 영역에 동시에 진입할 수 있는 스레드 수
*
* P
* - 임계 영역에 들어가기 전에 실행 가능 여부 판단(S가 0보다 작을 경우 실행 불가)
* - 실행 불가능 시 locking
* - 실행 가능하면 S--
* V : 임계 영역에서 빠져나올 때 완료 체크(완료 시 S++)
*/
P(S) {
while S <=0;
S--;
}
V(S) {
S++;
}
```
> 비효율성을 해결하기 위해 대기 큐를 적용할 수 있다. 주제에서 벗어나기 때문에 다음을 참고 - [세마포어 - 위키백과](https://ko.wikipedia.org/wiki/%EC%84%B8%EB%A7%88%ED%8F%AC%EC%96%B4#%EC%A0%81%EC%9A%A9)
실제 구현 시 특정 임계 영역을 정해놓고 세마포어가 사용 가능할 때까지 기다린다. 따지고 보면 임계 영역이 공유되는 영역이기 때문에 IPC로 이용할 수 있는 것이다.
#### 장점
- 다른 동기화 방법보다 효율적이다.
- 임계 영역에 접근 가능한지 여부를 제공하기때문에 busy waiting을 사용하지 않아도 된다.
> busy waiting : 특정 자원이 사용가능한지 계속 확인하는 것으로 자원 낭비가 일어날 수 있다.
#### 단점
- 동기화에 대한 조건을 다뤄야하기 때문에 오류 없이 구현하기 까다롭다.
## 마치며
이외에도 여러 가지 IPC기법들이 있는데, 잘 생각해봐야 할 것은 위에서도 잠깐 언급되었지만 여러가지 IPC기법을 필요에 따라 조합하여 사용할 수 있다는 것이다. 따라서 구성하려는 시스템의 요구사항이 무엇인지 잘 파악해야 할 것이다.
본문에서는 리눅스를 기반으로 설명하였는데, 윈도우에서 사용되는 IPC가 궁금하다면 [Interprocess Communications - MSDN](https://docs.microsoft.com/ko-kr/windows/win32/ipc/interprocess-communications?redirectedfrom=MSDN)를 참고하자.
이외에 자세한 구현이 궁금하다면 [IPC - joinc](https://www.joinc.co.kr/w/Site/system_programing/Book_LSP/ch08_IPC#s-2.4), [Linux System V and POSIX IPC Examples](http://hildstrom.com/projects/ipc_sysv_posix/index.html)와 [Beej's Guide to Unix IPC](http://beej.us/guide/bgipc/html/single/bgipc.html) 에 잘 정리가 되어있다.
---
#### References
- [POSIX shared-memory API - GeeksforGeeks](https://www.geeksforgeeks.org/posix-shared-memory-api/)
- [Inter-process communication - Wikipedia](https://en.wikipedia.org/wiki/Inter-process_communication#Approaches)
- [Interprocess Communications - MSDN](https://docs.microsoft.com/ko-kr/windows/win32/ipc/interprocess-communications?redirectedfrom=MSDN)
- [Linux System V and POSIX IPC Examples](http://hildstrom.com/projects/ipc_sysv_posix/index.html)
- [IPC - joinc](https://www.joinc.co.kr/w/Site/system_programing/Book_LSP/ch08_IPC#s-2.4)
- [파이프 (유닉스) - 위키백과](https://ko.wikipedia.org/wiki/%ED%8C%8C%EC%9D%B4%ED%94%84_(%EC%9C%A0%EB%8B%89%EC%8A%A4))
- [IPC InterProcess Communication 프로세스 간 통신 - 정보통신기술용어해설](http://www.ktword.co.kr/abbr_view.php?m_temp1=302)
- [Beej's Guide to Unix IPC](http://beej.us/guide/bgipc/html/single/bgipc.html)
================================================
FILE: CS/non-blocking.md
================================================
# non-blocking
Non-blocking은 os와 알고리즘에 대한 것이다. 공유자원을 안전하게 동시 사용할 수 있도록 하는 방법론이다.
Non-blocking은 하나의 작업이 실패하거나 정지하더라도 다른 스레드에 영향을 주지 않도록 한다. 이를 위해 Non-blocking 알고리즘은 [lock-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Lock-freedom) 특성과 [wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) 특성을 포함한다. lock-free는 wait-free를 포함하는 개념이다. 이로인해 non-blocking은 동시성(concurrency)을 갖는다.
> 동시성 : 프로그램을 실행할 때 단 하나의 실행 순서를 갖도록 하는 제약을 없애고 각 부프로그램이 다른 부프로그램과 병렬적으로 동시에 실행되는 것
lock-free 알고리즘이라는 것은 하나의 작업이 시작되어도, 시스템 전체의 진행이 보장되는 것이다.(A non-blocking algorithm is lock-free if there is guaranteed system-wide progress)<br/>
wait-free 알고리즘은 각 스레드의 진행이 각각 보장되는 것(A non-blocking algorithm is wait-free if there is also guaranteed per-thread progress)이다. <br/>

blocking 모델은 요청이 동작 가능할때까지 스레드가 블록된다. 반면, non-blocking 모델은 요청이 동작 불가능하다는 것을 알려주어 블록상태 없이 계속해서 진행가능하다. 즉, 다른 스레드의 작업을 기다리지 않는다. 이를 통해 대기 상태 없이 공유 자원에 접근할 수 있다.
> Java의 멀티 스레드 어플리케이션에서 Synchronized를 시키는 것은 BlockingQueue Interface를 구현하는 것이라고 생각하면 된다. 당연히 non-blocking은 이와 반대다.
<br/>
## Non-blocking I /O
Non-blocking I/O 는 I/O와 관계없이 프로세스가 계속해서 진행되는 것을 뜻한다. 기존 방식(blocking 혹은 synchronous한 I/O모델)에서는 I/O처리를 시작하면 작업이 끝날 때 까지 기다려야한다. 즉 프로그램이 block된다. 반면, Non-blocking I/O 모델에서는 입,출력을 외부에 맡겨 I/O의 진행 상황과 관계없이 프로그램이 진행된다.
<br/>
## Asynchronous Programming과 Non-blocking I/O
프로그램의 주 실행흐름을 멈추거나, 대기 상태 없이 즉시 다음 작업을 수행할 수 있도록 하는 것이 asynchronous 방식이다.
Ansynchronous programming은 언어 차원에서 지원하거나, 함수 전달을 통해 처리하는 방식을 통해 구현한다.<br/>언어차원에서 지원하는 방식은 future, promise와 같이 객체 형태의 결과를 돌려받거나 특정 문법을 이용하여 구현할 수 있다.<br/>함수 전달을 통해 처리하기 위해서는 함수를 값처럼 사용(일급 함수)를 지원하는 언어에서 Callback을 전달하여 결과를 처리할 수 있다.
non-blocking 알고리즘과, non-blocking I/O 모델의 관점이 다른 것 처럼, Asnychronous programming은 Asynchronous I/O 와 다르다. 따라서 Asnychronous programming과 Non-blocking I/O는 서로 바라보는 관점이 다르다. Event-loop를 사용하여 동시성을 확보하였어도 I/O 작업이 blocking될 수 있기 때문이다.
<br/>
만약 I/O 모델들의 조합을 알아보고 싶다면 다음을 참고하길 바란다. - [Asynchronous IO 개념 정리 - Uno's Blog](https://djkeh.github.io/articles/Boost-application-performance-using-asynchronous-IO-kor/)
---
#### Refereces
- [Non-blocking Algorithms - jenkov.com](http://tutorials.jenkov.com/java-concurrency/non-blocking-algorithms.html)
- [Blocking and Non-Blocking Algorithms - modernescpp](https://www.modernescpp.com/index.php/blocking-and-non-blocking)
- [Non-Blocking Algorithms in Java - netjs.blogspot.com](https://netjs.blogspot.com/2016/06/non-blocking-algorithms-in-java.html)
- [Non-blocking algorithm - wikipedia](https://en.wikipedia.org/wiki/Non-blocking_algorithm)
- [멈추지 않고 기다리기(Non-blocking)와 비동기(Asynchronous) 그리고 동시성(Concurrency) - Peoplefund Tech](https://tech.peoplefund.co.kr/2017/08/02/non-blocking-asynchronous-concurrency.html)
================================================
FILE: CS/non-linear-search.md
================================================
# 비선형(Non-Linear) 구조의 탐색
## 선형 구조
선형 구조를 간단히 설명하면, 말 그대로 진행하는 방향이 직선으로(일자로) 되어있는 구조이다. 알고리즘에서는 데이터가 연속적으로 연결되어있는 모양으로 구성이 된 것을 선형 구조라 한다. 선형 구조는 연결리스트, 스택, 큐, 덱 등이 있다.
> 선형 구조를 탐색하는 일반적인 방법론에는 순차검색과 이진검색이 있다.
<br/>
## 비선형 구조
비선형 구조는 선형이 아닌 구조이다. 어떤 원소를 탐색했을 때 다음에 탐색할 수 있는 원소가 여러 개 존재하는 구조가 비선형 구조이다. 비선형 구조는 트리나 그래프 형태로 표현할 수 있다.
> 트리는 순환(cycle)이 없는 그래프이다.
<br/>
## 비선형 구조 탐색
비선형 구조는 탐색해야 할 데이터가 순차적이지 않다. 따라서 단순한 반복만으로 탐색할 수 없다. 이 때문에 스택이나 큐와 같은 자료구조를 활용하여 탐색할 방법과 순서를 만들어 탐색한다. 일반적으로 깊이우선탐색(depth first search; DFS)과 너비우선탐색(breadth first search; BFS)을 이용한다. 만약 탐색 대상이 그래프일 경우 탐색이 완료되면 [신장트리(spanning tree)](http://59.23.150.58/30stair/spanning_tree/spanning_tree.php?pname=spanning_tree#spanning)가 만들어진다.

> DFS와 BFS는 완전 탐색을 위한 방법이며, 가중치가 있는 그래프의 최단 거리를 찾기 위해서는 다익스트라와 플로이드-워셜 알고리즘이 주로 사용된다.
<br/>
### 깊이우선탐색(DFS)
시작점에서 더는 이동할 수 없는 지점까지 탐색한 뒤, 인접한 정점이 있었던 곳으로 돌아가 같은 방법으로 차례로 탐색하는 방법이다. 이때 시작점(부모노드)으로 되돌아오는 과정을 백트래킹이라고 한다.
이러한 탐색 과정은 스택을 이용하는 것과 동일하기 때문에 스택을 사용하거나 재귀호출을 이용하여 구현한다.

현 경로상의 노드만 기억하면 되기 때문에 저장공간이 비교적 적게 필요하다. 또한, 목표 노드가 깊을 경우 유리하다.
반면, 해가 없는 너무 깊은 곳까지 탐색하게 되거나 목표에 이르는 경로가 많을 경우 비효율적이다. 또한, 찾은 경로가 최단 거리가 아닐 수 있다.
> 재귀호출을 하면 스택을 사용하는 것과 같은 효과를 낼 수 있다.
<br/>
### 너비우선탐색(BFS)
시작 정점을 방문한 후 시작정점에 인접한 모든 정점을 방문한 뒤, 해당 정점들과 인접한 정점을 탐색하는 방법이다. 이는 큐와 동일하다.

하나의 레벨에서 보행 가능한 정점을 모두 찾아보기 때문에 목표 노드까지의 최단 길이가 결과로 나오는 것이 보장된다.
반면, 경로가 길 경우(깊을 경우) 많은 기억 공간이 필요하다. 또한, 무한그래프의 경우 탐색이 불가능하다.
> 무한 그래프는 정점이 무한한 그래프를 뜻한다.
> - DFS의 경우 하나의 정점의 결과값을 찾아 들어가기 때문에 무한한 정점 중에서 하나의 해를 구할 수 있으면 된다.
> - 반면 BFS의 경우, 정점이 무한하다면 다음 수준으로 나아가는 것 자체가 불가능해진다.
---
#### References
- [[알고리즘] 비선형구조의 탐색, 그래프의 구현 - https://12bme.tistory.com](https://12bme.tistory.com/123)
- [깊이*우선*탐색 - 위키백과](https://ko.wikipedia.org/wiki/%EA%B9%8A%EC%9D%B4_%EC%9A%B0%EC%84%A0_%ED%83%90%EC%83%89)
- [너비*우선*탐색 - 위키백과](https://ko.wikipedia.org/wiki/%EB%84%88%EB%B9%84_%EC%9A%B0%EC%84%A0_%ED%83%90%EC%83%89)
- [[그래프] DFS와 BFS 구현하기 :: 마이구미 - https://mygumi.tistory.com](https://mygumi.tistory.com/102)
- [[DFS][BFS] DFS 와 BFS - https://cru6548.tistory.com](https://cru6548.tistory.com/10)
================================================
FILE: CS/open-closed-principle.md
================================================
# 개방-폐쇄 원칙(Open-Closed Principle)
개방-폐쇄 원칙은 **확장에 열려있고, 변경에는 닫혀있어야 한다**는 원리이다. 열려있다는 것(개방; open)은 소프트웨어는 확장(기능 추가 등의)할 수 있어야 한다는 것이고, 닫혀있다는 것(폐쇄; closed)은 기존 코드를 수정하지 않고 확장할 수 있어야 한다는 것이다. 즉 소프트웨어는 **수정 없이 확장할 수 있어야 한다**.
열려있다는 것은 비교적 명확하나 닫혀있다는 것의 의미가 애매할 수 있다. 닫혀있다는 것에 대해 좀 더 자세히 말하면, 새로운 기능을 추가할 때 기존 시스템의 수정 없이 변경할 수 있어야 한다는 것이다. 닫혀있는 프로그램은 기존 소스를 새롭게 컴파일하거나 배포할 필요 없이 새롭게 추가된 부분만 배포하면 된다. 이를 위해 폐쇄된 모듈은 잘 은닉되어있고, 사용 혹은 재사용에 반드시 필요한 부분만 인터페이스로 정의되어 있어야 한다.
## 적용 방법
- 변경(확장)이 일어날 수 있는 부분과 변하지 않을 부분을 명확히 정의한다.
- 변경이 일어날 수 있는 모듈과 변하지 않는 모듈의 사이에 인터페이스를 만들어 이를 통하여 메세지를 주고받도록 한다.
- 정의한 인터페이스에 의존하도록 한다(구현에 영향을 받지 않도록).
## 예시1 - 계산기
```java
interface Calculator {
void calculate();
int getResult();
}
class BasicCalculator implements Calculator {
private final static String PLUS = "+";
private final static String MINUS = "-";
private final static String MULTIPLY = "*";
private final static String DIVISION = "/";
private int left;
private int right;
private String operator;
private int result;
public BasicCalculator(int left, int right, String operator) {
this.left = left;
this.right = right;
this.operator = operator;
}
public void calculate() {
if (operator.equals(PLUS)) {
result = left + right;
} else if (operator.equals(MINUS)) {
result = left - right;
} else if (operator.equals(MULTIPLY)) {
result = left * right;
} else if (operator.equals(DIVISION)) {
result = left / right;
}
}
public int getResult() {
return result;
}
}
```
위의 사칙연산 계산기에서 새로운 기능을 추가하려면 기존 소스를 변경해야 한다. 다음과 같을 것이다.
```java
public void calculate() {
if (operator.equals(PLUS)) {
result = left + right;
} else if (operator.equals(MINUS)) {
result = left - right;
} else if (operator.equals(MULTIPLY)) {
result = left * right;
} else if (operator.equals(DIVISION)) {
result = left / right;
} // 추가 할 기능 작성 e.g. 나머지 연산 제곱 연산 제곱근 연산 등등...
}
```
첫째로 상속을 생각해볼 수 있겠지만, 핵심 로직을 변경해야 하는 것은 마찬가지이고 이 경우는 특히나 [캡슐화](https://www.geeksforgeeks.org/encapsulation-in-java/)를 위반할 가능성이 높다. 자식 클래스에서 부모 클래스의 기능을 이용한 변경이 일어날 수 있기 때문이다. 따라서 각 책임을 새롭게 분리해 볼 수 있다.
```java
class PlusCalculator implements Calculator {
private int left;
private int right;
private int result;
public PlusCalculator(int left, int right) {
this.left = left;
this.right = right;
}
@Override
public void calculate() {
result = left + right;
}
@Override
public int getResult() {
return result;
}
}
class MinusCalculator implements Calculator {
// ...
@Override
public void calculate() {
result = left - right;
}
// ...
}
```
각 연산 별로 새로운 클래스를 정의했다. 새로운 기능을 추가할때 새로운 클래스만 작성하면 되는것 처럼 보이지만 클라이언트에 문제가 생긴다.
```java
class CalculatorClient {
private final static String PLUS = "+";
private final static String MINUS = "-";
private final static String MULTIPLY = "*";
private final static String DIVISION = "/";
// +,1,2와 같이 입력이 되었다고 가정
public static void main(String[] args) {
for (String arg : args) {
Calculator calculator;
String[] inputs = arg.split(",");
String operator = inputs[0];
int left = Integer.parseInt(inputs[1]);
int right = Integer.parseInt(inputs[2]);
if (operator.equals(PLUS)) {
calculator = new PlusCalculator(left, right);
} else if (operator.equals(MINUS)) {
calculator = new MinusCalculator(left, right);
} // ... 다른 연산
calculator.calculate();
System.out.println(calculator.getResult());
}
}
}
```
클라이언트에서 또 다른 분기가 이루어져서 추가적인 관리 포인트가 생겼다. 클라이언트와 핵심 로직 사이에 인터페이스를 추가하여 개선해볼 수 있다. 여러가지 방법을 사용해볼 수 있는데, 간단한 팩토리를 이용하여 개선해보겠다.
```java
class CalculatorFactory {
private final static String PLUS = "+";
private final static String MINUS = "-";
private final static String MULTIPLY = "*";
private final static String DIVISION = "/";
private Calculator calculator;
private CalculatorFactory(Calculator calculator) {
this.calculator = calculator;
}
public static Calculator createByOperator(int left, int right, String operator) {
if (operator.equals(PLUS)) {
return new PlusCalculator(left, right);
} else if (operator.equals(MINUS)) {
return new MinusCalculator(left, right);
} // ... 다른 연산
}
}
```
```java
class CalculatorClient {
// +,1,2와 같이 입력이 되었다고 가정
public static void main(String[] args) {
for (String arg : args) {
Calculator calculator;
String[] inputs = arg.split(",");
String operator = inputs[0];
int left = Integer.parseInt(inputs[1]);
int right = Integer.parseInt(inputs[2]);
caluclator = CalculatorFactory.createByOperator(left, right, operator);
calculator.calculate();
System.out.println(calculator.getResult());
}
}
}
```
클라이언트 부분은 해결됐다. 여기까지만 해도 OCP원칙이 어느정도 적용되었다고 볼 수 있지만, 좀 더 완벽한 구현을 위해 enum 객체를 활용해보겠다.
```java
enum Calculator {
PLUS("+") {
public void calculate(int left, int right) {
result = left + right;
}
},
MINUS("-") {
public void calculate(int left, int right) {
result = left - right;
}
},
MULTYPLY("*") {
public void calculate(int left, int right) {
result = left * right;
}
},
DIVISION("/") {
public void calculate(int left, int right) {
result = left / right;
}
};
public final String OPERATOR;
private int result;
Calculator(String operator) {
this.OPERATOR = opeartor;
}
public abstract void calculate(int left, int right);
public int getResult() {
return result;
}
public static Calculator getCalculatorByOperator(String operator) {
// ... 해당하는 enum 객체 반환
}
}
```
## 예시2 - 플러그인 시스템
거시적인 관점으로 생각해보면 플러그인 아키텍쳐를 개방-폐쇄 원칙의 좋은 예시로 볼 수 있다. 플러그인을 사용하게되면 수정이나 재배포 없이 여러가지 도구(tool)들을 쉽게 확장(추가)할 수 있다. 시스템은 플러그인에 대해 모르고, 플러그인은 시스템에 대해서 알고 있기 때문이다. 플러그인은 시스템에 종속성을 가지지만, 시스템은 플러그인에 종속되지 않는다. 플러그인 중 하나가 잘못되면 해당 기능이 제대로 동작하지 않을 뿐이지, 시스템 전체에 영향을 주지 않는다.
우리는 플러그인 시스템을 dependency manager 혹은 package manager와 유사한 이름으로 프레임워크 관리에 사용하고 있다. 이러한 관리 시스템에서 현재 프로젝트에 새로운 기능을 추가하는 것은 특별한 경우를 제외하면 기존의 플러그인과 독립적으로 이루어진다.

소스 레벨까지 가지 않더라도 IDE를 생각해보면 변경이나 재배포 없이 플러그인을 이용하여 손쉽게 확장이 가능하다.

## 결론
위에서 여러가지 방법을 이용하여 개방-폐쇄 원칙에 부합하는 프로그램을 만들었다. 하지만 이는 의미 없게 보일 수 있는데, 우리들이 쓰고 있는 언어들과 설계들은 일반적으로 새로운 기능들이 시스템의 다른 부분들과 분리되어 배포, 컴파일, 작성되는 것을 허용하지 않기 때문이다.
또한 복잡한 시스템이라면 현재의 시스템이 변경에 닫혀있는지, 새로운 기능의 확장에 열려있는지 확인하기 어렵다. 따라서 실제로 새로운 기능을 추가할 때 기존 소스에서 많은 변경이 이루어진다([산탄총수술](https://refactoring.guru/smells/shotgun-surgery)이 바람직하지 않다는 것을 알면서도).
개방-폐쇄 원칙은 실제 개발에서 유용하게 쓰이기 힘들다는 의견이 많다. 하지만 플러그인 아키텍쳐가 그러한 의견이 틀렸다는 반증이다. Robert C. Martin (Uncle Bob)은 플러그인 아키텍쳐가 미래의 소프트웨어 시스템에서 중요한 부분을 차지할 것이라고 했다. 잘 생각해보면 현재 인기가 많은 언어들은 플러그인과 유사하게 의존성을 관리한다. 플러그인 시스템이 모든 것을 해결해주지는 않겠지만, 현재 시점에서 가장 좋은 OCP원칙의 best practice라고 말할 수 있을 것이다.
---
#### References
- [The Open Closed Principle](https://blog.cleancoder.com/uncle-bob/2014/05/12/TheOpenClosedPrinciple.html)
- [객체지향 개발 5대 원리: SOLID](http://www.nextree.co.kr/p6960/)
================================================
FILE: CS/soc.md
================================================
# 관심사 분리(Separation of Concerns; SoC)
관심사 분리는 프로그램의 각 부분이 자신의 관심사만을 다루도록 분리되어야 한다는 것이다. 여기서 `관심사`란 프로그램 코드에 영향을 주는 일련의 정보를 의미한다.
> **예시**
> 자동차 창문을 여는 장치가 망가져 수리를 한다. 간단한 고장이기 때문에 금방 수리를 했다.
> 하지만 창문은 잘 고쳤는데 갑자기 시동이 걸리지 않는다. 원인은 자동차를 자동차를 제어하는 배선이 너무 복잡해 창문을 제어하는 배선을 만지면 차량의 시동을 거는 배선에도 영향을 주기 때문이었다.
> 만약 창문을 제어하는 배선과 시동을 거는 배선이 잘 분리되어 있다면 이런 일은 발생하지 않았을 것이다.
만약 위의 예시를 프로그램화 했다면 창문을 제어하는 기능과 시동을 거는 기능을 분리하는 것으로 생각해볼 수 있다. 이처럼 각 기능들이 서로 얽히지 않고 각각의 역할만 하도록 하는 것을 관심사 분리라고 한다. 각각의 모듈은 각자의 기능만을 해결해야 한다.
관심사 분리는 추상화의 한 형태이다. 때문에 관심사 분리를 위해서 캡슐화가 잘 되어야 한다. 기능의 구현은 내부적으로 숨겨놓고 해당 모듈을 실행시켰을 때 정확한 기능이 동작하도록 보장되어야 한다. 인터페이스 뒤에 모듈의 구현 세부사항을 숨기면 다른 부분의 세부사항을 알 필요 없이 해당 코드를 개선하거나 수정할 수 있다. 이렇게 되면 다른 기능에 영향을 주지 않고 유지 보수가 가능하다.
계층화(layered) 된 설계는 관심사 분리의 좋은 예시이다. 예를들어 MVC패턴의 각 계층(layer)은 각각의 관심사만을 수행하도록 구성된다. 이외에도 객체 지향 언어에서는 관심사를 객체로 분리할 수 있으며 절차 지향 언어에서는 관심사를 메소드 혹은 프로시저로 분리할 수 있다.
웹 프로그램을 개발할 때 JSP 파일 안에 SQL을 작성하지 않는다. 결과를 계산하는 모듈에서 HTML 파일을 생성하지 않는다. 또한 비즈니스 규칙은 데이터베이스 스키마와 독립적으로 이루어져야한다. 만약 그렇게 작성한다면 하나의 기능에 대한 수정때문에 모든 기능이 중단될 수 있다. 이는 관심사 분리를 해야하는 이유이다.
---
#### References
- [The Single Responsibility Principle](https://blog.cleancoder.com/uncle-bob/2014/05/08/SingleReponsibilityPrinciple.html)
================================================
FILE: CS/srp.md
================================================
# 단일 책임 원칙(Single Responsibility Principle; SRP)
단일 책임 원칙은 **클래스(혹은 모듈)는 오직 하나의 책임만을 가져야 한다는 것**이다. 또한 **클래스가 변경되어야 하는 이유는 단 하나여야 한다**는 것이다. 여기서 '책임'과 '이유' 가 무엇인지 모호할 수 있다. 단일 책임 원칙을 이해하기 위해서 먼저 알아 둬야 할 개념들이 있기 때문이다. 단일 책임 원칙은 **관심사 분리**, **응집도와 결합도**에 관한 내용이다. 따라서 이에 대한 이해가 선행되어야 한다.
- [관심사 분리](soc.md)
- [응집도와 결합도](cohension&coupling.md)
클래스는 오직 하나의 책임만을 가져야 한다. 여기서 책임은 각 클래스의 관심사라고 할 수 있다. 즉 단일 책임 원칙은 각 클래스의 관심사가 잘 분리되어 있어야 한다는 것이다. 쉽게 얘기하면 각 클래스는 하나의 기능만을 구현해야 한다. 이를 위해 인터페이스를 사용하여 캡슐화 시키고 노출되어야할 기능에 대한 코드만 응집시켜야 한다.
또한 클래스가 변경되어야 할 이유는 단 하나여야 한다. 즉 같은 이유로 변하는 것은 하나로 모으고, 다른 이유로 변하는 것은 분리해야 한다. 잘 응집된 클래스는 다른 기능을 위한 분기처리가 필요없다. 다른 기능을 실행시키기 위한 상태가 필요없으므로 낮은 결합도를 유지할 수 있게 된다.
## 적용 방법
기본 설계 원칙을 위반하고 설계 품질에 부정적인 영향을 미치는 구조로 코드가 작성된 것을 [code smell](https://en.wikipedia.org/wiki/Code_smell)이라고 한다. code smell은 리팩토링의 징후라고 할 수 있는데, 리팩토링의 근본정신도 객체들의 책임을 최상의 상태로 분배한다는 것이다. 따라서 code smell이 발견 될 경우 단일 책임 원칙을 적용해 볼 수 있는데, code smell 중 '여러 원인에 의한 변경'과 '산탄총 수술'이 단일 책임 원칙과 연관이 깊은 것들이다.
- 여러 원인에 의한 변경(Divergent Change)
- 단일 클래스에 많은 변경이 있는 경우 클래스를 추출하여 책임을 분리해준다.
- 책임만 분리하는 것이 아니라 분리된 두 클래스간의 관계의 복잡도를 줄인다.
> 여러 원인에 의한 변경을 확산적 변경이라고 부르기도 하는데, 여러 원인에 의한 변경이라고 부르는 것이 더욱 직관적이다.
- 산탄총 수술(Shotgun Surgery)
- 변경을 할 때마다 수정해야 할 클래스가 많다면 책임이 분산되어 있는 것이다.
- 이 경우 수술이 잘 끝나면 상관없지만, 수정해야 할 클래스가 너무 많아 빼먹는 경우가 생긴다면 고통이 계속될 것이다.
- 해결을 위해 분산된 책임을 모아 응집도를 높일 수 있다.
## 예시1 - 계산기
```java
class Calculator {
public void calculate(int left, int right, String operator) {
if (operator.equals("+")) {
System.out.println(left + right);
} else if (operator.equals("-")) {
System.out.println(left - right);
} else if (operator.equals("*")) {
System.out.println(left * right);
} else if (operator.equals("/")) {
System.out.println(left / right);
}
}
}
```
위의 클래스는 '계산' 이라는 하나의 책임(기능)만 갖고 있는 것 처럼 보이지만 그렇지 않다. 사칙연산의 기능을 모두 갖고 있고 이를 출력하는 책임까지 갖는다. 여러가지 책임을 갖는 것이다. 클라이언트가 사용하기 편리해 보일지 모르지만, 한 가지 로직만 잘못되어도 이 프로그램은 제대로 동작 하지 않을 것이다. 뿐만 아니라 변경의 이유도 하나가 아니다.
각 기능을 메소드로 분리하여 설계하면 다음과 같은 인터페이스가 작성될 것이다.
```java
interface Calculator {
void calculate();
int getResult();
}
interface Printer {
void print();
}
```
이에 따라 클래스를 작성해보면 다음과 같을 것이다.
```java
class BasicCalculator implements Calculator{ // 연산
private final static String PLUS = "+";
private final static String MINUS = "-";
private final static String MULTIPLY = "*";
private final static String DIVISION = "/";
private int left;
private int right;
private String operator;
private int result;
public BasicCalculator(int left, int right, String operator) {
this.left = left;
this.right = right;
this.operator = operator;
}
public void calculate() {
if (operator.equals(PLUS)) {
result = left + right;
} else if (operator.equals(MINUS)) {
result = left - right;
} else if (operator.equals(MULTIPLY)) {
result = left * right;
} else if (operator.equals(DIVISION)) {
result = left / right;
}
}
public int getResult() {
return result;
}
}
class IntPrinter implements Printer { // 출력
private int i;
public IntPrinter(int i){
this.i = i;
}
public void print() {
System.out.println(i);
};
}
```
각각의 클래스는 하나의 책임만 갖게 되었다. 또한 각각의 기능의 의존성이 사라졌다. 이렇게 책임이 분리 되면 변화에 훨씬 유연하게 대처할 수 있다. 만약 좌항을 최초 한 번만 입력할 수 있다는 비즈니스 로직이 추가되거나, 출력을 하는 방법이 바뀌거나, 연산이 추가되는 등의 변화가 생기더라도 해당되는 클래스만 변경해주면 된다.
## 예시2 - 회사
예시1에서 만들어본 계산기를 통해 단일 책임 원칙의 '책임'은 프로그램의 책임이라는 것을 이해 할 수 있다. 버그 수정이나 리팩토링 같은 작업은 프로그래머의 책임이지 프로그램의 책임이 아니다. 하지만 단일 책임 원칙에 대해 이야기한 로버트 마틴은 단일 책임 원칙은 사람에 대한 것이라고 말한다. 또 다시 미궁에 빠지는 느낌이다.
> "This principle is about people" - Robert C. Martin
변경사항의 이유는 하나여야 한다고 했다. 어떤 것이 변경사항이 발생할 이유를 정의할지 생각을 해봐야 한다. 변경사항이 발생하는 이유는 다르게 말하면 책임이라고 말 할 수 있다. 우리는 책임을 정의하는 것이 무엇인지 생각해봐야 한다. 즉 누가 프로그램의 설계에 책임을 져야 하는지 생각해봐야 한다.
회사의 최상위에 CEO가 있고 그 밑에 CFO, COO, CTO와 같은 C-level 경영진들이 있다고 생각해보자. CFO는 회사의 재무를 관리하는 책임이 있고, COO는 회사 운영 및 관리에 책임이 있다. 그리고 CTO는 회사의 기술 환경 및 개발에 대한 책임이 있다.
우리는 이 회사에 새로 입사하게 되어 다음과 같은 업무를 배정 받았다.
- 직원의 계약, 상태, 근무 시간 등을 기준으로 특정 직원의 지급액을 결정
- 직원 객체가 관리하는 데이터를 데이터베이스에 저장
- 감찰 시 직원이 적절한 시간동안 작업하고, 적절한 보상을 받고있는지 확인하기 위한 보고서 내용 전달
이를 인터페이스로 나타내면 다음과 같이 정의할 수 있다.
```java
public interface Employee {
public Money calculatePay();
public void save();
public String reportHours();
}
```
`calculatePay` 부터 살펴보자. C-level 경영진 중 `calculatePay` 메소드의 동작에 대해 설계해야 하는 사람은 누구일까? 만약 `calculatePay`가 오작동 한다면 누가 그 책임을 져야될까? 바로 CFO다. 너무 명확하다.
직원의 급여를 결정하는 것은 재무의 책임이다. 만약 CFO의 조직의 누군가 급여를 계산하는 규칙을 잘못 정해서 2배의 급여를 받았다면, CEO는 CFO에게 책임을 물을 것이다. 즉 `calculatePay` 메소드의 알고리즘에 변경이 발생한다면 CFO가 이끄는 조직에 의해 변경사항이 요청되어야 한다.
다른 메소드도 마찬가지다. `save` 메소드는 기업의 데이터 베이스에 관한 기능이다. 만약 여기에 문제가 생긴다면 CTO가 책임을 질 것이고, `reportHours` 가 잘못된다면 COO가 책임을 질 것이다. CTO가 요청한 변경사항때문에 COO가 책임을 져서는 안된다. 만약 `save` 메소드를 변경했는데 `reportHours` 메소드가 제대로 동작하지 않는다면, COO는 CTO에게 해당 메소드를 수정하지말라고 압박을 줄 것이다.
## 결론
단일 책임 원칙은 다른 객체지향 원칙들에 비해 단순한 개념이다. 프로그램은 하나의 책임만을 갖도록 하면 된다는 내용이기 때문이다. 만약 여러 원인에 의한 변경 혹은 산탄총 수술이 필요한 경우 단일 책임 원칙에 위배되지 않았는지 점검해볼 필요가 있다.
하지만 이 원리를 적용하여 직접 클래스를 설계하는 것은 매우 힘들다. 예시2 에서 나온 상황들이 단일 책임 원칙을 복잡하게 만들기 때문이다. 만약 비즈니스 프로세스와 관련된 프로그램을 작성하게 된다면 단일 책임 원칙이 사람에 관한 것이라는 구문을 다시 생각해보자.
변경사항의 원인은 변경을 요청하는 사람(혹은 조직)이다. 따라서 소프트웨어를 설계할때 어떤 한 사람 또는 밀접하게 연관된 집단이 단 하나의 비즈니스 기능을 세심하게 정의해서 요청해야 할 것이다. 또한 모듈들이 조직의 복잡성으로부터 독립되어 단 하나의 비즈니스 기능에 대해 대응하고 책임지도록 시스템을 설계해야 한다.
---
#### References
- [The Single Responsibility Principle](https://blog.cleancoder.com/uncle-bob/2014/05/08/SingleReponsibilityPrinciple.html)
- [Code smell](https://en.wikipedia.org/wiki/Code_smell)
- [객체지향 개발 5대 원리 : SOLID](http://www.nextree.co.kr/p6960/)
================================================
FILE: CS/union-find.md
================================================
# 유니온 파인드(Union Find)
상호 배타적집합(disjoint-set) 이라고도 한다. 여러 노드 중 두 개의 노드씩 같은 집합으로 묶어가며 다른 노드가 같은 집합에 있는지 확인하는 그래프 알고리즘이다. 집합을 표현하기 위해 트리를 사용하며, 이를 위해 두 가지 연산을 한다.
노드 x와 y를 찾았다고 가정
- Find : 노드 x가 어떤 집합에 포함되어 있는지 찾는 연산
- Union : 노드 x가 포함된 집합과 노드 y가 포함된 집합을 합치는 연산
> 예시 문제 - [섬 연결하기(프로그래머스)](https://programmers.co.kr/learn/courses/30/lessons/42861)
## Union Find
### 부모 노드
트리를 이용하여 부모와 원소의 인덱스를 매핑한다. `parent[i]` 를 노드 `i` 의 부모 노드로 정의한다. 따라서 `parent[i] = i` 라면 루트 노드이다.
```java
for (int i = 0; i < MAX_SIZE; i++) {
parent[i] = i;
}
```
> 초기 값으로 자기 자신을 부모 노드라고 정의해준다.
### Find
`parent[i] = i` 인 점을 이용해서 부모 노드를 찾을 때 까지 반복하여 탐색한다.
```java
int find(int x) {
if (parent[x] == x) {
return x;
}
return find(parent[x]);
}
```
> 예시
>
> ```text
> [0] : 1, [1] : 2, [2] : 2, [3] : 1
>
> [2]
> |
> [1]
> ┌─┴─┐
> [0] [3]
> ```
>
> 위의 경우 루트 노드는 index와 value가 같은 [2]이다.
### Union
매개변수로 두 개의 노드를 받은 뒤 각 집합을 합쳐준다. `x` 를 `y` 에 합치든 `y` 에 `x` 를 합치든 똑같다.
```java
void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
parent[rootX] = rootY;
}
```
> 예시
>
> ```text
> [0] : 1, [1] : 2, [2] : 2, [3] : 1, [4] : 4
>
> [2] [4]
> |
> [1]
> ┌─┴─┐
> [0] [3]
>
> union(2, 4);
>
> [0] : 1, [1] : 2, [2] : 4, [3] : 1, [4] : 4
>
> [4]
> |
> [2]
> |
> [1]
> ┌─┴─┐
> [0] [3]
> ```
>
> 위의 경우 루트 노드는 index와 value가 같은 [2]이다.
## 시간복잡도 개선
위에서 살펴본 방법의 시간복잡도는 `O(n)` 이다. 위의 예시는 최악의 케이스에 가까운데, `union`의 예시처럼 높이가 낮은 트리에 높은 트리가 자식 노드로 붙게 되면 해당 트리는 끊임없이 길어질 것이다. 이 때, `find` 가 최하위에 있는 자식부터 탐색을 할 경우 트리의 높이만큼 올라가며 탐색해야한다. 이를 해결하기 위해 **path compression** 과 **union by rank** 가 사용된다. 이 기법들을 적용하면 시간복잡도가 `O(log n)` 으로 개선된다.
### Path Compression
말 그대로 경로를 압축해주는 것인데, `find` 를 할 때, 루트 노드를 찾은 경우 루트 노드의 자식 노드로 현재 노드를 붙여준다.
```java
int find(int x) {
if (parent[x] == x) {
return x;
}
parent[x] = find(parent[x]); // 루트 노드를 찾으면 x의 부모를 루트로 바꿔준다.
return parent[x];
}
```
> 예시
>
> ```
> [0] : 1, [1] : 2, [2] : 2, [3] : 1
>
> [2]
> |
> [1]
> ┌─┴─┐
> [0] [3]
>
> find(0);
>
> [0] : 2, [1] : 2, [2] : 2, [3] : 1
>
> [2]
> ┌─┴─┐
> [0] [1]
> |
> [3]
> ```
### Union By Rank
말 그대로 순위에 따라 `union` 을 하는 것이다. 자식 노드의 개수에 따라 우선 순위를 매기고 합치는 것이다. 따라서 `rank` 배열을 따로 만들어준다.
```java
for (int i = 0; i < MAX_SIZE; i++) {
rank[i] = i;
}
```
`rank` 를 이용하여 더 낮은 쪽에 합쳐준다.
```java
void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) {
// rootX와 rootY가 같다는 것은 같은 그룹이라는 뜻이다.
return;
}
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
rank[rootY] += rank[rootX];
return;
}
parent[rootY] = rootX;
rank[rootX] += rank[rootY];
}
```
```text
[0] : 1, [1] : 2, [2] : 2, [3] : 1, [4] : 4
[2] [4]
|
[1]
┌─┴─┐
[0] [3]
union(2, 4);
[0] : 1, [1] : 2, [2] : 4, [3] : 1, [4] : 4
[2]
┌─┴─┐
[1] [4]
┌─┴─┐
[0] [3]
```
## 공간복잡도 개선
하지만 위와 같은 방식은 똑같은 크기의 `parent` 와 `rank` 가 존재하여 메모리를 많이 차지한다. 이를 위해 부모노드와 순위를 함께 표시할 수 있다. `parent` 배열에 음수를 함께 넣어 부모 노드와 rank를 함께 저장하는 것이다.
예를 들어, `parent[2]` 의 값이 `-3` 일 경우 2번 노드를 포함하여 총 3개의 노드로 이루어진 트리라는 뜻이다.
> 자식의 수는 2개
또한 `parent[3]` 의 값이 5일 경우 3번 노드의 부모는 5번 노드라는 것이다.
쉽게 얘기하면 `parent[i] == i` 인 경우를 없애고 해당 경우에 트리의 노드 개수를 저장하는 것이다. 이외의 경우는 자식이 부모 노드를 가리킨다.
### 부모 노드
모두 -1 로 초기화해준다. 만약 `parent[i]` 가 0보다 작을 경우 `i` 는 루트 노드다.
```java
for (int i = 0; i < MAX_SIZE; i++) {
parent[i] = -1;
}
```
### Find
기본적인 동작은 이전과 같고, 매개변수 `x` 가 루트 노드인지 판단할 때 0보다 작은지 판단한다.
```java
int find(int x) {
if (parent[x] < 0) {
return x;
}
parent[x] = find(parent[x]);
return parent[x];
}
```
### Union
주의할 점은 마찬가지로 루트 노드의 값이 음수라는 점이다. 즉, 트리의 높이를 판단할 때 `parent[root]` 의 값이 음수이기 때문에 작을 수록 높은 트리이다. 직관적인 판단을 위해 -1씩 곱해줬다.
> -1을 곱하지 않으면 높이 3인 트리의 루트 노드 `parent[x]` 는 -3, 높이 5인 루트 노드 `parent[y]` 는 -5가 되기 때문에 `parent[y]` 의 값이 더 높지만 판단을 거꾸로 해야 한다.
```java
void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) {
return;
}
if (parent[rootY] * -1 < parent[rootX] * -1 ) {
parent[rootX] += parent[rootY];
parent[rootY] = rootX;
return;
}
parent[rootY] += parent[rootX];
parent[rootX] = rootY;
}
```
## 마치며
단순한 집합 구성이나 사이클 판단 외에도 [최소 신장 트리(Minimum Spanning Tree; MST)](https://ratsgo.github.io/data%20structure&algorithm/2017/11/28/MST/) 를 얻는데 사용할 수 있다. 이 때는 단독으로 사용되지는 않고 [크루스칼 알고리즘](https://ko.wikipedia.org/wiki/%ED%81%AC%EB%9F%AC%EC%8A%A4%EC%BB%AC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)의 사이클 판단에 사용된다.
---
#### References
- [Disjoint Set (Or Union-Find) | Set 1 (Detect Cycle in an Undirected Graph)](https://www.geeksforgeeks.org/union-find/)
- [Union-Find Algorithm | Set 2 (Union By Rank and Path Compression)](https://www.geeksforgeeks.org/union-find-algorithm-set-2-union-by-rank/)
- [Union/Find and the Parent Pointer Implementation](https://opendsa-server.cs.vt.edu/ODSA/Books/Everything/html/UnionFind.html)
- [[Algorithm] 유니온 파인드(Union - Find)](https://ssungkang.tistory.com/entry/Algorithm-%EC%9C%A0%EB%8B%88%EC%98%A8-%ED%8C%8C%EC%9D%B8%EB%93%9CUnion-Find)
================================================
FILE: CS/페이징과 세그먼테이션.md
================================================
# 페이징 기법과 세그먼트 기법
## 가상기억장치
가상기억장치는 **주기억장치의 용량이 부족할 때 하드디스크의 일부 공간을 마치 주기억장치처럼 사용하는 기억장치**를 말한다.
가상기억장치에 프로그램을 저장할 때는 불필요한 메모리 낭비를 줄이기 위해 프로그램을 여러 개의 블록 단위로 나눠 보관한다. 각각의 블록은 **mapping** 과정을 통해 주기억장치에 적재된다.
주기억장치와 가상기억장치 간 프로세스를 무슨 단위로 load하고 store할지 정하는 방법에는 페이징 기법과 세그먼테이션 기법이 있다.
<br/>
## 페이징 기법
### Page와 Page frame, Swapping

우선 페이징 기법은 위 그림과 같이 가상기억장치의 블록을 **고정 크기**로 나눈다. 이 블록을 **Page** 라고 부르며, 프로그램 실행시 요구되는 블록만 주기억장치에 적재된다. 주기억장치의 메모리 역시 Page와 같은 단위의 블록으로 나뉘는데, 이 명칭을 **Page frame** 이라고 한다.
주기억장치에 모든 작업이 상주하지 않기 때문에 프로그램 실행 중 필요한 부분만 교체할 수 있다. 이를 **Swapping** 이라고 한다.
<br/>
### Page mapping - Page fault
Page mapping 과정을 위해서는 주기억장치에 **Page table** 이 생성된다.(때문에 Page의 크기가 작을수록 더 많은 주기억장치의 메모리가 낭비된다.) Page table은 Page의 번호, Page Frame의 시작주소 등이 저장되어있다.
Page frame에 적재되는 Page가 교체되거나 Page fault가 발생할 때마다 Page Table은 갱신된다.
**Page fault** 는 프로그램에서 필요로 하는 Page가 주기억장치에 있지 않는 경우에 발생하는 현상이다. Page fault가 발생하면 Page를 찾아 mapping하고 Page Table이 갱신되는 일이 발생된다. 이러한 현상을 줄이기 위해서 Page frame의 크기를 늘릴 수 있다.
<br/>
### Thrashing
너무 많은 Page fault 현상으로 페이지 교체 시간이 프로세스 수행 시간보다 많은 경우를 말한다. Thrashing이 발생하면 CPU 이용률이 급격히 감소하므로 이를 방지하기 위해 다중 프로그래밍의 정도를 낮추거나 Page frame의 크기를 늘려야 한다.
<br/>
### 내부단편화
프로그램의 크기가 30k이고, 각 page의 고정 크기가 4k라고 한다면 마지막 page의 실질적 크기는 2k가 될 것이다. 따라서 마지막 page가 주기억장치에 적재될 때 2k만큼의 **내부단편화**가 발생된다. 즉 필요한 공간보다 더 큰 메모리가 할당되어 불필요하게 메모리가 낭비되는 현상을 내부단편화라고 한다. 이를 해결하기 위해 page를 작게 만들 수도 있지만 위에서 언급했듯이 page를 무조건 작게 만드는 것이 능사는 아니다.
<br/>
## 세그먼테이션 기법
세그먼테이션 기법은 페이징 기법과 달리 프로그램을 기능별로 분할하는 것을 말한다. 또한 주기억장치는 구분하지 않고, 전체를 비연속적으로 할당받는다. 따라서, 페이징 기법이 프로그램을 물리적으로 분할한 개념이라면 세그먼테이션은 논리적으로 분할한 개념이다.

### Seg fault, 외부 단편화
세그먼테이션 기법에서는 세그먼트 길이에 맞는 주기억장치의 영역을 할당받지 못한 경우 해당 프로그램이 다른 프로그램의 영역을 침범하는 **Seg fault**가 발생할 수 있다.
또한 고질적인 문제로 **외부단편화**가 발생할 수 있다. 위 그림에서 `B-1`의 크기가 6K,남은 공간이 3K라고 가정해보자. `B-1`의 프로세스가 끝나고 메모리를 해제하면 주기억장치에는 `A-1 / 빈공간(6k) / B-3 / 빈공간(3k)`가 있을 것이다. 여기에 7k 크기의 프로세스가 들어오려고 한다면, 총 공간은 9k지만 각 공간이 7k보다 작기 때문에 적재될 수 없다. 이런 현상을 외부 단편화라고 한다. 이를 해결하기 위해 `통합` 또는 `압축`을 할 수 있다.
다음의 그림과 같이, 통합은 빈 공간의 주소가 인접한 경우 하나로 합치는 방법이고 압축은 프로세스의 재배치를 통해 모든 빈 공간을 하나로 합치는 방법이다.


#### Reference
[특수기억장치 및 기억장치의 분류](http://junhojohn.blogspot.com/2018/11/blog-post_12.html)
================================================
FILE: CS/플로이드-와샬-알고리즘.md
================================================
# 플로이드 와샬 알고리즘(Floyd Warshall Algorithm)
플로이드 알고리즘이라고도 많이 부른다. 모든 정점의 쌍에 대한 최단 경로의 길이를 알아야 하는 경우 사용된다. 즉 그래프에서 나올 수 있는 최단 경로를 모두 채워야 하는 경우이다.
한 정점(vertex; 노드)에서 다른 정점으로 가는 최단거리의 합이 가장 적은 곳을 구하여 가장 좋은 입지를 구하는 데 사용할 수 있을 것이다. 또한, 두 개의 임의 지점에서 뭔가(패킷과 같은)를 전달할 때 걸리는 최대 시간을 구할 때 사용할 수도 있다. 또한, 가장 효과적인 출발지점을 찾기 위해 특정 정점에서 도착할 수 있는 모든 정점을 찾아내는 데 사용할 수도 있다.
> 여기서 모든 정점에 대해 각 정점에서 갈 수 있는 정점의 갯수를 계산하는 것을 추이적 폐포(transitive closure)를 찾는 것이라 할 수 있다. 추이적은 원소의 원소를 대상으로한다는 것이고, 폐포는 그 집합을 포함하면서 그 성질을 만족시키는 가장 작은 대상이다. 즉 원소의 원소를 포함하는 가장 작은 집합이라는 것인데, 도착할 수 있는 불필요한 경우의 수를 모두 걷어내고 최단거리만 포함한 최소화 된 집합을 유지할 수 있다.
위에서 나온 예시들은 모든 정점에서 다익스트라 알고리즘을 각각 호출하여 풀이할 수도 있지만, 플로이드 와샬 알고리즘을 사용하면 매우 간단하게 풀이할 수 있다.
모든 칸을 채우는 개념이기 때문에 인접 행렬(adjacency matrix)을 사용하는 것이 좋다. 표현하거나 생각하기도 쉽고, 어차피 모든 칸을 채워야 하기 때문에 공간이 낭비되는 것도 아니다. 아래는 플로이드 와샬의 결과로 나온 인접 행렬이다.
| 1 | 2 | 3 | 4 | 5 |
| ---- | ---- | ---- | ---- | ---- |
| 0 | 2 | 3 | 1 | 4 |
| 12 | 0 | 15 | 2 | 5 |
| 8 | 5 | 0 | 1 | 1 |
| 10 | 7 | 13 | 0 | 3 |
| 7 | 4 | 10 | 6 | 0 |
row가 출발지고 column이 도착지다. 위의 그래프를 참고하여 1번에서 출발하여 4번에 도착하는 최소 거리는 1임을 알 수 있다.
## 구현
### 초기화
```java
int[][] weight = new int[n][n];
// 최댓값으로 초기화
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
int[i][j] = i != j ? MAX : 0;
}
}
```
인접 행렬로 가중치 그래프를 만든다. 정점 사이에 간선(edge)이 없는 경우(이동이 불가능한 경우)는 `MAX`로 초기화한다. 그래프의 지름이 초기화한 `MAX`보다 작을 경우 해당 부분은 무시된다. 예를 들어, int의 최댓값으로 초기화하면 가장 먼 거리(지름), 즉, 나올 수 있는 거리의 최댓값이 int의 최댓값 미만이어야 한다.
> 그래프에서 가장 먼 두 정점 사이의 거리를 지름이라고 한다.
> `MAX`는 최댓값 + 1로 설정해야 한다. 최댓값과 똑같이 설정하면 간선이 있는 것으로 판단하게 된다.
> int를 사용할 경우 `Integer.MAX_VALUE/2` 이하의 값을 최댓값으로 사용할 수 있다. `k`를 거치는 경우 두 값을 더하기 때문에 int 최댓값을 사용하면 안 된다. [그래프 완성하기](#그래프-완성하기)를 보고 다시 보면 이해가 될 것이다.
```java
int[][] edges = ...; // edges[n][0] 은 시작점, [1]은 도착점, [2]는 가중치이며, 충분한 데이터가 들었다고 가정한다.
// 가중치 옮기기
for (int i = 0; i < edges.size(); i++) {
int x = edges[i][0];
int y = edges[i][1];
int curWeight = weight[x][y];
int newWeight = edges[i][2];
weight[x][y] = newWeight < curWeight ? newWeight : curWeight;
}
```
가중치 그래프가 만들어졌으면 가지고 있는 정점이나 간선의 정보를 토대로 가중치를 옮긴다. 이미 가중치 그래프가 있다면 생략한다.
### 그래프 완성하기
우선 n번만큼 반복한다. 0부터 n-1까지 증가하는 변수 `k`를 중간 정점의 후보로 사용한다. k 번째 반복일 경우 `k`를 지나가는 경로의 가중치 합과 기존에 계산해둔 가중치 중 큰 값을 선택한다.
> **예시**
>
> 만약 `k`가 3이고 `i`와 `j`가 각각 1, 5일 경우, 정점3을 거쳐 가는 경로와 바로 가는 경로를 비교한다. 즉, `weight[1][3]`를 거쳐 `weight[3][5]`로 가는 경로의 가중치 합과 `weight[1][5]`의 가중치 합 중 작은 값을 선택한다.
```java
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (weight[i][k] + weight[k][j] < weight[i][j]) {
weight[i][j] = weight[i][k] + weight[k][j];
}
/* 위의 조건문은 아래와 같다
* weight[i][j] = Math.min(weight[i][k] + weight[k][j], weight[i][j]);
*/
}
}
}
```
어떻게 두 개의 경로만 계속 비교하여 모든 그래프를 완성할 수 있는지 의문이 들 수 있는데, 위에서 들었던 예시에서 봤던 `k`가 3인 경우는 `k`가 1과 2였을 때, 그래프를 한 바퀴 순회하며 정점1과 정점2를 거쳐 가는 경우의 최솟값으로 채워져 있는 상태이다. 가령, `k`가 3이고 `i`가 5, `j`가 4인 경우, 정점5에서 정점3을 거쳐 정점4로 가는 경우를 확인한다. 이때, 정점5에서 정점3으로 가는 가중치의 합이 가장 낮은 경로가 정점5에서 정점1, 정점1에서 정점2를 거쳐 가는 것이라면 `k`가 1이었을 때, 그리고 2였을 때 이미 반영되어 있다.
간단히 정리해보면, A에서 B까지의 가장 빠른 경로는 A에서 B로 바로 가는 것 혹은 A에서 k로 가는 가장 빠른 경로와 k에서 B로 가는 가장 빠른 경로를 합친 것이다. 반대로 말하면 A에서 B로 가는 경로보다 빠른, 정점 `k`를 지나는 경로가 있어야 경로가 달라진다.
어려운 문제를 간단하게 나누어 풀기 때문에 동적 프로그래밍(dynamic programming)으로 분류되기도 한다. 그리디(greedy)라 생각할 수도 있는데 각 정점에서 가장 빠른 경로를 찾는 것이 아니라, 전체를 고려하여 최적의 경로를 찾아내는 것이기 때문에 그리디가 아닌 동적 프로그래밍이다.
## [다익스트라 알고리즘(Dijkstra Algorithm)](https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%81%AC%EC%8A%A4%ED%8A%B8%EB%9D%BC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)과 비교
다익스트라 알고리즘 또한 가중치가 있는 그래프에서 최단 거리를 구하는 알고리즘이다. 다익스트라 알고리즘은 모든 간선의 최단 거리가 아닌 한 정점에서 도착점까지의 최단 거리를 구한다. 해당 경우는 다익스트라 알고리즘이 빠르지만, 앞서 말했듯, 한 정점에서 특정 도착점까지의 최단 거리를 구하는 것이다. 따라서 플로이드 와샬을 사용할 때처럼 모든 경로를 채워야 한다면, 각 정점에서 다익스트라를 계속해서 실행해야 하므로 해당 경우는 플로이드 와샬이 효과적이다.
또한, 다익스트라 알고리즘은 그리디 기반이기 때문에 음의 가중치가 있는 그래프의 경우는 판단하지 못한다. 반면, 플로이드 와샬은 음의 가중치가 있는 그래프에서도 사용 가능하며, 음수 사이클도 판단할 수 있다. 음의 사이클이 생기면 `i==j`의 경로가 변하기 때문에 해당 결과가 나오면 음의 사이클이라 판단할 수 있다.
---
#### References
- [플로이드-워셜 알고리즘](https://ko.wikipedia.org/wiki/%ED%94%8C%EB%A1%9C%EC%9D%B4%EB%93%9C-%EC%9B%8C%EC%85%9C_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
- [Programming Challenges: 알고리즘 트레이닝 북](https://www.hanbit.co.kr/store/books/look.php?p_code=B5937184860)
================================================
FILE: CSS/CJK.md
================================================
# CJK
실무에서 은근히 신경 쓰이면서 잘 모르고 있던 것을 발견하여 알아보려고 한다.
대부분의 사이트에서 텍스트가 많은 경우는 드물다. 그렇기 때문에 내가 지정한 영역 안에서 나오는 텍스트의 넘치는 부분을 무심히 구글링하여 CSS로 처리를 하거나 신경 쓰지 않고 있던 부분이다.
그러나 이 부분은 **CJK**라 불리는 것의 차이를 말하는 것과 동일하다.
먼저 생소한 단어인 CJK에 대해서 먼저 알아보자.
W3C 문서에서는 중국어, 일본어, 한글을 통칭하여 CJK(Chinese, Japanes, Korean의 약자)라 지칭하고 있다.
> 왜 중국, 일본, 한국 순인지는 모르지만, K가 앞에 있으면 좋았을 텐데 우리나라의 영향력을 보여주는 부분 같아 아쉽다.
그리고 CJK를 제외한 나머지를 통칭하여 non-CJK(숫자, 영어, 베트남어 등)라 지칭하자.
그렇다면 본론으로 돌아가서 왜 CJK와 non-CJK를 분리하게 된 이유는 두 가지의 따라서 **단어 분리 방법**이 달라지기 때문이다.
## `word-break`와 `overflow-wrap`
두 CSS 속성은 주로 줄 바꿈을 위해서 사용한다. 각각의 속성이 무엇인지 간단하게 살펴보면,
- word-break : 단어의 분리를 어떻게 할 것인지 결정한다.
- (공백/띄어쓰기) 스터디가·좋아요
- (음절) 스·터·디·가·좋·아·요
- overflow-wrap : 박스의 가로 영역을 넘친 단어 내에서 임의의 분리 여부를 결정한다.
<p align="center">
<img width="600" alt="overflow-wrap" src="https://user-images.githubusercontent.com/24274424/80282842-9ed24280-874e-11ea-93a8-713f3243eff1.png">
</p>
위의 두 속성은 역할이 다르지만 줄 바꿈을 위해 필요한 상황에 따라 선언하며, 또한 조합하여 선언한다.
## `word-break` 속성
줄 바꿈은 허용된 중단점에서 수행되는 것이며, 모든 속성이 기본값이라는 전제하에 줄 바꿈은 대부분의 non-CJK의 경우 공백(띄어쓰기), CJK의 경우 음절로 구분된다.
### 속성값
- normal
- break-all
- keep-all(IE에서는 계속 지원하였으나 webkit에서는 15년 6월부터 지원)
> [W3C의 word-break](https://www.w3.org/TR/css-text-3/#word-break)
#### 예제
원본
```txt
스터디가 좋아요 这是一些汉字 and some Latin و کمی نوشتنن عربی และตัวอย่างการเขียนภาษาไทย
```
`word-break: normal`
```txt
스·터·디·가·좋·아·요·这·是·一·些·汉·字,·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย
```
`word-break: break-all`
```txt1212
스·터·디·가·좋·아·요·这·是·一·些·汉·字·a·n·d·s·o·m·e·L·a·t·i·n·و·ﮐ·ﻤ·ﻰ·ﺧ·ﻁ·ﻋ·ﺮ·ﺑ·ﻰ·แ·ล·ะ·ตั·ว·อ·ย่·า·ง·ก·า·ร·เ·ขี·ย·น·ภ·า·ษ·า·ไ·ท·ย
```
`word-break: keep-all`
```txt
스터디가·좋아요·这是一些汉字·and·some·Latin·و·کمی·خط·عربی·และ·ตัวอย่าง·การเขียน·ภาษาไทย
```
### 단어의 분리는 CJK, non-CJK에 따라 다르다.
| |normal(기본값)|break-all|keep-all|
|-|------------|---------|--------|
|non-CJK|공백(띄어쓰기, 하이픈'-')|음절|공백(띄어쓰기, 하이픈'-')|
|CJK|음절|음절|공백(띄어쓰기, 하이픈'-', 그 외 기호|
**하이픈도 공백과 같이 인식을 한다는 것과 `keep-all`에서 CJK에서 기호들이 된다는 것에 주의를 해야 한다.**
## `overflow-wrap` 속성
넘친 단어를 대상으로 줄 바꿈을 하고 싶다면, `overflow-wrap` 속성의 값을 바꾸면 된다. 넘친 단어의 분리는 음절에서 발생하며 `white-space` 속성이 기본값(`normal`)일 때만 적용된다.
> 이전에는 `word-wrap` 속성이라고 불렸으나 CSS3부터는 `overflow-wrap`으로 변경되었다.
### 속성값
- normal
- break-word
#### 예제
normal
<p align="center">
<img width="600" alt="over-flow_normal" src="https://user-images.githubusercontent.com/24274424/80283841-b9f48080-8755-11ea-9dc6-686388bbb693.png">
</p>
break-word
<p align="center">
<img width="600" alt="over-flow_break-word" src="https://user-images.githubusercontent.com/24274424/80283884-f7590e00-8755-11ea-95d5-3fe3b57dba5e.png">
</p>
### 줄바꿈은 CJK, non-CJK에 따라 다르다.
| |normal(기본값)|break-word|
|-------|:----------:|:--------:|
|non-CJK|단어넘침 O|단어넘침 X|
|CJK |단어넘침 X|단어넘침 X|
## 그래서 우리는 어떻게 해야하나?
<p align="center">
<img width="400" alt="CJK-wrap" src="https://user-images.githubusercontent.com/24274424/80282603-48183900-874d-11ea-8c01-a484718dfb67.jpeg">
</p>
참고로 오타가 있는데 `break-all`이 아니라 `break-word`이다.
> [참고 - MDN_overflow-wrap](https://developer.mozilla.org/ko/docs/Web/CSS/overflow-wrap)
#### Reference
- [word-break 속성과 word-wrap 속성 알아보기](https://wit.nts-corp.com/2017/07/25/4675)
- [overflow-wrap | CSS-Tricks](https://css-tricks.com/almanac/properties/o/overflow-wrap/)
- [CSS Text Module Level 3](https://www.w3.org/TR/css-text-3/#word-break)
================================================
FILE: CSS/WebToMobile.md
================================================
# 웹으로 모바일 슬라이드 화면처럼 만들어보기
<div align="center">
<image style="border: 1px solid black" src="../assets/gif/MobileCSS.gif"/>
</div>
오늘은 위와 같이 앱에서 보는 슬라이드 레이아웃을 웹으로 만들어보자.
## 우리가 아는 슬라이드는
우리가 아는 슬라이드는 네이버나 구글에서 검색하고 내리면서 보여주는 위아래 또는 좌우로 움직이는 부드러운 모양새이다.
CSS 속성에 `scroll-snap-type` 이라는 것이 있다.
이 속성은 스크롤에 대한 유형을 지정해줄 수 있는 속성으로 스냅 포인트가 있는 경우 스냅 포인트가 엄격하게 적용되는 정도를 설정할 수 있다.
> [MDN - scroll-snap-type](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-type)
```css
scroll-snap-type: x mandatory;
```
위의 속성을 주게 되면 X축을 기준으로 스냅을 필수적으로 설정하는 것으로 스크롤이 완료된 경우 해당 포인트로 움직이게 된다.
이를 가지고 앱에서 보이는 슬라이드 레이아웃을 구현해볼 수 있다.
### 예제
<div align="center">
<image src="../assets/gif/MobileLayout.gif"/>
</div>
```html
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<style>
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
body {
overflow-y: hidden;
}
.slider {
font-family: sans-serif;
scroll-snap-type: x mandatory;
display: flex;
overflow-x: scroll;
}
section {
height: 100vh;
width: 100vw;
scroll-snap-align: center;
min-width: 100vw;
}
</style>
<body>
<div class="slider">
<section id="slide-1" style="background-color: blueviolet;">
</section>
<section id="slide-2" style="background-color: lightgreen;">
</section>
<section id="slide-3" style="background-color: lightblue;">
</section>
<section id="slide-4" style="background-color: rgb(226, 43, 144);">
</section>
</div>
</body>
</html>
```
## 하단 Dock 내비게이터
앱에서 많이 사용되고 기본이 되는 하단 Dock 내비게이터를 만들기 위해서 CodePen에 있는 오픈 소스를 가져와서 사용하였다.
> [내비게이터 확인하기](https://codepen.io/milanraring/pen/qBEPzKB?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
해당 소스를 가져와서 입맛에 맞게 수정하여 하단에 배치하고 꾸며보았다.
<div align="center">
<image style="border: 1px solid black" src="../assets/gif/MobileDock.gif"/>
</div>
모든 아이콘은 HTML5에서 지원하는 SVG로 만들어졌으며 애니메이션 효과는 CSS의 Transform을 사용해서 구현되어있다.
이 2가지의 방법만 사용하게 되면 사용자 친화적인 인터렉티브하게 구현 가능하다.
이렇게 2가지의 모양을 만들었다면 이제 2개의 다른 화면을 연동하는 작업을 해주어야 한다.
## JS를 사용해서 연결시켜주기
페이지를 이동할 방법은 2가지가 있다.
1. 슬라이드 움직여 Dock 맞추기
2. Dock 메뉴를 눌러 화면 맞추기
### 1. 슬라이드 움직여 Dock 맞추기
슬라이드를 하여 해당 화면이 보이면 하단의 Dock 아이콘이 활성화되도록 구현하였다. 모든 화면을 `IntersectionObserver`을 사용하여 감시하고 있다가 화면의 90%가 보이게 되면 input box을 체크하여 활성화를 시켜주었다.
모든 슬라이드에는 고유의 idx를 넣어주어 하단 Dock과 idx를 맞춰주었다.
```js
const sliders = document.querySelectorAll('section')
let targetIdx = 1
const interselect = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
if (entry.isIntersecting) {
if (targetIdx === parseInt(entry.target.id.split('-')[1], 10)) {
return
}
targetIdx = parseInt(entry.target.id.split('-')[1], 10)
const targetId = 'tab-0' + targetIdx
const targetEl = document.getElementById(targetId)
targetEl.checked = true
}
})
}, {
threshold: 0.9
})
sliders.forEach((slider) => {
interselect.observe(slider)
})
```
### 2. Dock 메뉴를 눌러 화면 맞추기
Dock 아이콘을 눌러서 페이지를 이동하는 기능을 구현하였다.
문제가 있다면 `scroll-snap-type`을 사용하게 되면 원하는 scroll 위치를 이동하는 데 있어 문제가 발생하게 된다. 어떤 값을 주더라도 한 번에 1페이지씩 이동이 되지 않는 것이 문제가 되었다.
그래서 해당 인덱스 간 비교를 하여 해당 수 만큼 반복문을 돌려서 `scrollBy`로 이동하였다.
```js
const sliderC = document.querySelector('.slider')
const tabs = document.querySelector('.tabs')
let targetIdx = 1
tabs.addEventListener('click', function (e) {
if (e.target.tagName === "INPUT") {
const clickedIdx = parseInt(e.target.id.split('-')[1], 10)
const move = clickedIdx - targetIdx
for (let index = 0; index < Math.abs(move); index++) {
sliderC.scrollBy(move, 0)
}
targetIdx = clickedIdx
}
})
```
## 후기
웹에서 모바일 앱과 같은 모양을 만들어서 비슷한 기능까지 넣어보았다.
생각보다 디자인이 이쁘게 나오며 애니메이션이 잘 구현되어있다면, 이번에 구현된 모양보다는 더더욱 좋을 것으로 생각된다.
한가지 문제가 있다면 웹에서 슬라이드를 했을 때 더뎌보이는 문제가 보였으나 모바일로 보게 되면 훨씬 부드워러진 것을 보았다.
모바일용이라고 생각한다면 생각보다 좋았다. 그리고 CSS가 단순한 스타일만 아니라 더욱 멋있고 이쁘고 인터렉티브하고 만들어질 수 있는 요소라는 게 느껴졌으면 한다.
아래의 참고를 보고 이 대단한 CSS를 감상해보자
#### Reference
- [Best Practices To Use Scrolling Effects (With Examples)](https://uxplanet.org/best-practices-to-use-scrolling-effects-with-examples-a448ac761bb9)
- [Snowfall](https://codepen.io/shubniggurath/full/WgJZJo?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
- [Push to Hide](https://codepen.io/eliortabeka/pen/wXwPeb?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
- [CSS Pentagonal Bipryamid Gallery (Hover to navigate)](https://codepen.io/jh3y/pen/PowLmMX?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
- [Card Hover Animation (Cookie Run)](https://codepen.io/richard_w_here/pen/eYmXZMN?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
- [Insta-hearts](https://codepen.io/chrisgannon/details/BaNyWyd?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
- [Cut/Copy/Paste](https://codepen.io/cobra_winfrey/full/abzqxVr?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
- [Animated Night Hill Illustration - Pure CSS](https://codepen.io/aybukeceylan/pen/OJJzXde?utm_campaign=CSS%20Animation%20Weekly&utm_medium=email&utm_source=Revue%20newsletter)
================================================
FILE: CSS/safe-area.md
================================================
# Safe-Area(IOS 11 이상 대응하기)
## 안전영역(Safe-Area)이란?
안전영역(Safe-Area)이라는 말은 TV에서 처음 도입된 개념이라고 한다.
TV 해상도 비율이 다양해지면서 영상에서 타이틀, 자막 등의 필수 콘텐츠 노출을 보장할 수 있는 영역이다.
더욱 자세한 정보는 아래의 링크를 추가하였습니다.
> [Caption/Title Safe Area](http://www.indefilms.net/html/title_safe_area.html)
위에서 언급한 것 같이 원래는 TV에서 쓰이는 개념이었지만 프론트엔드 개발자의 입장에서 찾아보며 이해하는 시간을 가지려고 한다.
처음부터 이 개념을 알고 찾아본 것이 아녔다.
회사에서 웹을 개발하다 보면 다양한 Vendor들의 화면을 그리거나 작동하는 방식의 차이로 인해서 이런저런 일을 많이 겪지만, 이번 일은 처음이라 기록으로 남기려고 한다.
우리나라에서도 아이폰 유저가 많은 비율을 차지하고 있으며 그중에는 많은 버전의 아이폰이 있지만, IOS 11과 함께 출시된 아이폰 X를 기준으로 노치 디자인이 생기고 홈 버튼이 존재하지 않는다.
모든 사건과 사고는 혁신에서 찾아오는 법이다. 애플에서 사건을 만들어 주었다.
<center>
<img src="https://user-images.githubusercontent.com/24274424/82733281-be5c8b00-9d4d-11ea-8855-f1ba7217b72d.png" alt="Iphone 11" width="200">
</center>
> 드디어 시뮬레이터를 써먹은 나의 MAC
정말 이쁘고 탈모탈모한 디자인인데, 문제가 하나 존재한다. 오직 프론트엔드에게만 골칫거리다.
<center>
<img src="https://user-images.githubusercontent.com/24274424/82733424-94f02f00-9d4e-11ea-8fee-7e906740584d.png" alt="not bad" width="400">
</center>
가만히 살펴보고 있으면 잘 나오고 있는 게 아니냐고 생각할 수 있다. 잘 생각해보면 저런 게 되어있으면 `아이텍`이라는 글자와 홈 버튼이 겹치게 되어 글자가 눌리지 않게 될 것이다.
이렇게 겹치는 현상이 발생하게 된다.
단순하게 그럼 아래를 공통으로 높이면 되지 않나? 라고 생각할 수 있다. 그러나 그렇게 되면 아이폰 X 이상의 유저만이 아닌 다른 유저들에게는 좋은 경험을 선사하지 못하게 될 수 있다. 특히 하단 Nav가 있는 디자인이라면 더욱더 그러하다.
예시로 네이버에서는 하단에 29px이 직접 박혀있는 것을 확인하였는데 이처럼 한 것이 아이폰을 노리고 한 것인지는 모르나 저렇게 하면서 모든 Vendor를 위한 공통으로 제작하면 된다.(이 또한 좋은 방법일지도...)
우리는 다른 방법으로 해결해보자.
## Home Indicator
앱 개발을 하시는 분들이 어떻게 부르는지 잘 모르나, 약간 찾아본 결과 하단에 있는 홈 버튼 영역을 저렇게 지칭한다고 한다.
Home Indicator를 신경쓰는 웹 사이트는 많이 않다고 생각한다. 그러나 웹뷰를 가지고 서비스를 하는 기업 또는 하단 Nav를 사용하는 기업이 대상이라고 생각한다.
> 출처 : https://carrotdesign.tistory.com/entry/iPhone-X-iPhone-11의-안전영역Safe-area을-알아보자
어떤 잘 하시는 분이 이쁘게 정리를 하셔서 가져왔다. 위에 사진을 보게 되면 세로 모드 가로 모드에 따라 각각의 영역이 얼마나 되는지 그림과 수치로 보여주고 있다.
여기서 내가 겪었던 부분은 세로 모드일 때 34pt 가로 모드일 때 21pt인 부분이다. 그러나 위에서 언급했듯이 우리는 직접 하드코딩으로 넣지 말고 다르게 넣어보자.
## 해결방안
우리가 해결하려는 화면이 아래와 같다고 하자. 원래는 Home Indicator만 해결해보려고 했으나 추가로 발생할 수 있는 이슈도 같이 해결해보자.
<center>
<img src="https://user-images.githubusercontent.com/24274424/82733747-04ffb480-9d51-11ea-94d1-62ce8ae5b808.png" alt="Test1_Port" width="200">
<img src="https://user-images.githubusercontent.com/24274424/82733751-0b8e2c00-9d51-11ea-9845-5dd1a31bc8e3.png" alt="Test1_Land" width="400">
</center>
위의 사진에서 걸리는 부분이 있다. 가로 모드일 때 이상하게 좌우 흰색영역이 거슬린다. 먼저 없애주자.
```html
<meta name='viewport' content='initial-scale=1, viewport-fit=cover'>
```
간단하게 `viewport-fit=cover`를 주게 되면 해결된다.
<center>
<img src="https://user-images.githubusercontent.com/24274424/82733917-3b89ff00-9d52-11ea-8503-9018251f0de9.png" alt="Test2_Port" width="200">
<img src="https://user-images.githubusercontent.com/24274424/82733922-3e84ef80-9d52-11ea-8a39-df4785d4cad9.png" alt="Test2_Land" width="400">
</center>
위와 같이 메타 태그의 기본값은 `auto`이다. 그러나 cover를 주게 되면 꽉 차는 화면을 가지게 된다. 그러나 여기서 보이는 문제는 header라는 글자와 footer라는 글자가 보이지 않게 된다.
### `constant()`, `env()`
애플이 위와 같은 문제를 해결하기 위해 제공하는 CSS 속성이 있다.
IOS 11 당시 `constant()`라는 속성을 제공하였으나 IOS 11.2로 업데이트가 되면서 `env()` 속성으로 변경이 되었다. 업데이트하지 않은 만약의 경우를 생각해서 둘 다 넣어주면 된다.
```css
header {
position: fixed;
left: 0px;
top: 0px;
width: 100%;
height: 30px;
padding-left: constant(safe-area-inset-left);
padding-right: constant(safe-area-inset-right);
padding-left: env(safe-area-inset-left);
padding-right: env(safe-area-inset-right);
background-color: green;
}
```
```css
footer {
position: fixed;
left: 0px;
bottom: 0px;
width: 100%;
height: 30px;
padding-bottom: constant(safe-area-inset-bottom);
padding-left: constant(safe-area-inset-left);
padding-right: constant(safe-area-inset-right);
padding-bottom: env(safe-area-inset-bottom);
padding-left: env(safe-area-inset-left);
padding-right: env(safe-area-inset-right);
background-color: blue;
}
```
각각 속성 명은 아래와 같이 4개가 된다.
- `safe-area-inset-top`
- `safe-area-inset-bottom`
- `safe-area-inset-left`
- `safe-area-inset-right`
아이폰 X 이상의 폰이 아니라면 해당 CSS 적용되지 않는다.
<center>
<img src="https://user-images.githubusercontent.com/24274424/82734049-29f52700-9d53-11ea-8f6b-a739dedf6ccd.png" alt="Test3_Port" width="200">
<img src="https://user-images.githubusercontent.com/24274424/82734053-2cf01780-9d53-11ea-845c-f102470df08e.png" alt="Test3_Land" width="400">
</center>
## 결과물
비록 제가 적용한 부분이 아니지만, 아래와 같이 결과물이 나옵니다.
<center>
<img src="https://user-images.githubusercontent.com/24274424/82734120-940dcc00-9d53-11ea-9061-d18194a988f0.png" alt="Test3_Port" width="200">
<img src="https://user-images.githubusercontent.com/24274424/82734039-19dd4780-9d53-11ea-87d9-8e20cbefb51e.png" alt="Test3_Land" width="200">
gitextract_vbaffuo6/
├── .github/
│ └── workflows/
│ └── action.yml
├── .mergify.yml
├── Android/
│ └── application fundamentals.md
├── Browser/
│ ├── BrowserXY.md
│ ├── Cookie.md
│ ├── Cookie_Store.md
│ ├── FOUC.md
│ ├── HTTP2_Websocket.md
│ ├── IndexedDB_WebSQL.md
│ ├── Layer_Model.md
│ ├── WebWorker.md
│ ├── Worklet.md
│ ├── 웹 브라우저의 작동 원리.md
│ └── 최신_브라우저의_내부_살펴보기.md
├── CS/
│ ├── Binding.md
│ ├── Bomb-Lab(1).md
│ ├── Call-By-Sharing.md
│ ├── Counting-sort.md
│ ├── Graph.md
│ ├── Memory.md
│ ├── Radix-sort.md
│ ├── aspect-oriented-programming.md
│ ├── cohension&coupling.md
│ ├── compression.md
│ ├── dependency-inversion-principle.md
│ ├── grasp.md
│ ├── information_theory.md
│ ├── integer_representation.md
│ ├── interface-segregation-principle.md
│ ├── liskov_substitution_principle.md
│ ├── methods_in_IPC.md
│ ├── non-blocking.md
│ ├── non-linear-search.md
│ ├── open-closed-principle.md
│ ├── soc.md
│ ├── srp.md
│ ├── union-find.md
│ ├── 페이징과 세그먼테이션.md
│ └── 플로이드-와샬-알고리즘.md
├── CSS/
│ ├── CJK.md
│ ├── WebToMobile.md
│ └── safe-area.md
├── Database/
│ ├── DB Connection Pool.md
│ ├── Query Builder ( Knex.js).md
│ └── Types of Databases.md
├── Deprecated/
│ ├── AMD와 CommonJS.md
│ ├── Async-Await.md
│ ├── B_EventLoop.md
│ ├── B_Module.md
│ ├── CORS(Cross-Origin Resource Sharing).md
│ ├── CSS 애니메이션 vs JS 애니메이션.md
│ ├── CallByReference.md
│ ├── EventLoop.md
│ ├── EventLoop_Advanced.md
│ ├── Funtional.md
│ ├── Higher_Order_Functions.md
│ ├── Javascript_BuildTool.md
│ ├── Module.md
│ ├── Promise1.md
│ ├── Promise2.md
│ ├── Reactive.md
│ ├── Repaint와 Reflow.md
│ ├── WebWorker.md
│ ├── animation.md
│ ├── setState.md
│ ├── 기본적인 렌더링 최적화 방법.md
│ ├── 웹 브라우저의 작동 원리.md
│ └── 점진적향상_우아한하향.md
├── Design_Pattern/
│ ├── Composite.md
│ ├── JSP model.md
│ ├── MSA.md
│ ├── MVC1, MVC2.md
│ ├── MVC_MVP_MVVM.md
│ ├── Memoization.md
│ ├── RxJS.md
│ ├── Singleton.md
│ └── Throttle and Debounce.md
├── ECMAScript/
│ ├── ArrowFunction.md
│ ├── Destructuring_Assignment.md
│ ├── ECMA2019.md
│ ├── ES6-module-in-Browser.md
│ ├── Generator와 async-await.md
│ ├── Includes_IndexOf.md
│ ├── Iteration_Protocol.md
│ ├── ModulePattern_class.md
│ ├── Number_isNaN.md
│ ├── Spread_Operator.md
│ └── Tagged_Template_Literals.md
├── Git/
│ └── gitBy_.git.md
├── HTML/
│ ├── ARIA.md
│ ├── DOM API.md
│ ├── DOM.md
│ ├── HTML-Templating.md
│ ├── Head_Meta.md
│ ├── Standard&QuirksMode.md
│ ├── WebM&WebP.md
│ ├── input태그의_value바꾸기(input태그의_dirty flag).md
│ ├── preload&prefetch.md
│ └── 웹 컴포넌트(Web Component).md
├── Java/
│ ├── ArrayList vs LinkedList 그리고 Vector.md
│ ├── Comparable vs Comparator.md
│ ├── Dependency Injection(DI).md
│ ├── JSP와 Servlet처리.md
│ ├── JVM(Java Virtual Machine).md
│ ├── Java Garbage Collection(GC).md
│ ├── Mybatis.md
│ ├── Set.md
│ ├── String, StringBuilder, StringBuffer.md
│ ├── String,StringBuilder, StringBuffer차이.md
│ ├── Upcasting과 Downcasting.md
│ ├── WAS.md
│ ├── copy-object.md
│ ├── date-api-in-java.md
│ └── junit-setup.md
├── Javascript/
│ ├── Ajax.md
│ ├── Animation.md
│ ├── B_Async.md
│ ├── B_Call_Apply_Bind.md
│ ├── B_Callback.md
│ ├── B_Class.md
│ ├── B_Function.md
│ ├── B_Type.md
│ ├── Build Tool.md
│ ├── CallStack.md
│ ├── Closure.md
│ ├── Control_CSSOM.md
│ ├── DocumentFragment.md
│ ├── Event Delegation.md
│ ├── InsertAdjacentHTML.md
│ ├── JavaScript의 this.md
│ ├── Javascript_Engine.md
│ ├── Javascript_메모리관리.md
│ ├── Javascript의_동작원리-변수객체(VariableObject).md
│ ├── Javascript의_동작원리-실행컨텍스트(Execution Contexts).md
│ ├── Jest.md
│ ├── Learning_more_about_this.md
│ ├── Module.md
│ ├── MouseEvent.md
│ ├── Object.create&Object.assign.md
│ ├── Observer.md
│ ├── Optional_Chaining.md
│ ├── PromisePattern.md
│ ├── Prototype_Chain.md
│ ├── Proxy.md
│ ├── Reduce.md
│ ├── Redux State 정규화.md
│ ├── Regular_Expressions.md
│ ├── Scope.md
│ ├── Some_Every.md
│ ├── Storybook.md
│ ├── Sync&Async_Multi&Single_Thread.md
│ ├── TimeInJS.md
│ ├── Variable.md
│ ├── WebRTC.md
│ ├── Web_Storage_API.md
│ ├── ajax(2).md
│ ├── bind.md
│ ├── object.md
│ ├── object_create_pattern-constructor.md
│ ├── object_생성패턴.md
│ ├── prototype(2).md
│ ├── prototype.md
│ ├── scope_this.md
│ ├── throttling과 rAF.md
│ ├── tricks_of_js.md
│ ├── underscore와 lodash그리고 Native.md
│ ├── window.history.md
│ ├── 논리연산자.md
│ ├── 렉시컬_속이기(eval).md
│ ├── 배열 내장함수.md
│ ├── 상태관리 라이브러리.md
│ ├── 이벤트 루프(Event Loop).md
│ ├── 클래스(class).md
│ ├── 클로저.md
│ └── 함수 선언.md
├── LICENSE
├── Language/
│ ├── Currying.md
│ ├── Lamda.md
│ ├── Reactive.md
│ ├── XML_JSON.md
│ ├── 고차함수(High Order Function).md
│ └── 함수형 프로그래밍.md
├── ML/
│ └── 머신러닝이란.md
├── Network/
│ ├── 3-way handshaking & 4-way handshaking.md
│ ├── CORS.md
│ ├── DHCP&DNS.md
│ ├── Flow control.md
│ ├── HTTP3.md
│ ├── IP.md
│ ├── JSend.md
│ ├── OSI7 Layer.md
│ ├── REST API.md
│ ├── REST.md
│ ├── SOAP API.md
│ ├── Subnetmask.md
│ ├── Switch.md
│ ├── TCP & UDP.md
│ ├── TypesOfIP.md
│ ├── comet.md
│ ├── congestion control.md
│ ├── get&post.md
│ ├── http-caching.md
│ ├── 로드밸런싱 & 클러스터링.md
│ └── 사용자 인증 방식(Cookie, Session & oAuth 2.0 & JWT).md
├── Node.js/
│ ├── make_meta_file.md
│ └── nodejs의_특징.md
├── OpenCV/
│ └── 이미지전처리.md
├── Performance/
│ ├── DeadLock(교착상태).md
│ ├── HTTP2.0의 필요성.md
│ ├── Reflow Repaint.md
│ ├── Throttling vs Debouncing.md
│ ├── requestAnimationFram(rAF).md
│ ├── 기본적인 렌더링 최적화 방법.md
│ ├── 서버 사이드 렌더링(SSR).md
│ └── 점진적향상_우아한하향.md
├── README.md
├── React/
│ ├── Component, Props, State.md
│ ├── Composition.md
│ ├── Element와 Component.md
│ ├── ImmutableState.md
│ ├── React Server Components.md
│ ├── React.memo.md
│ ├── React의 Lifecycle Event.md
│ ├── SWR.md
│ ├── Virtual DOM.md
│ └── props와 state.md
├── Rules/
│ ├── Commit.md
│ └── Markdown.md
├── Security/
│ ├── HTTPS와 SSL.md
│ ├── Response_Header_Security.md
│ ├── SQL_Injection.md
│ └── 리만가설과 소수정리.md
├── Tool/
│ ├── Chrome_80_DevTool.md
│ ├── Framework vs Library.md
│ └── Package Manager.md
├── Typescript/
│ ├── 인터페이스(Interface).md
│ ├── 정적 타이핑.md
│ ├── 제네릭(Generic).md
│ └── 클래스(class).md
├── Vue/
│ └── Vue_LifeCycle.md
├── WPF/
│ └── wpf.md
└── assets/
├── IndexDB/
│ ├── TodoList/
│ │ ├── index.html
│ │ ├── js/
│ │ │ ├── indexDB.js
│ │ │ └── todo.js
│ │ └── todoStyle.css
│ └── index2.html
└── TEST/
├── bigfile.html
└── window.history.demo.html
SYMBOL INDEX (5 symbols across 2 files)
FILE: assets/IndexDB/TodoList/js/indexDB.js
function addToDoPromise (line 57) | function addToDoPromise(todo) {
function addToDoList (line 79) | function addToDoList(e) {
function clearToDoList (line 102) | function clearToDoList(e) {
FILE: assets/IndexDB/TodoList/js/todo.js
constant TODO_LIST (line 1) | const TODO_LIST = {};
constant DOINGDONE_ARR (line 2) | const DOINGDONE_ARR = ["newTodoList", "doneTodoList"];
Condensed preview — 248 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (2,123K chars).
[
{
"path": ".github/workflows/action.yml",
"chars": 585,
"preview": "name: \"Pull Request Action\"\non: \n pull_request:\n types: [opened]\n\njobs:\n test:\n runs-on: ubuntu-latest\n steps"
},
{
"path": ".mergify.yml",
"chars": 1244,
"preview": "pull_request_rules:\n - name: Automatic merge on review\n # https://doc.mergify.io/examples.html#require-all-requested"
},
{
"path": "Android/application fundamentals.md",
"chars": 7068,
"preview": "# 안드로이드 (Android)\n\nAndroid 앱은 Kotlin, Java, C++ 언어를 사용하여 작성할 수 있습니다. Android SDK(Software Development Kit) 도구는 모든 데이터 및 "
},
{
"path": "Browser/BrowserXY.md",
"chars": 3199,
"preview": "# 브라우저의 XY\n\n브라우저에 event가 발생했을 때에 x, y 좌표 값을 얻는 방법에는 크게 4가지가 있다.\n\n- clientX / clientY\n- pageX / pageY\n- screenX / screenY"
},
{
"path": "Browser/Cookie.md",
"chars": 8615,
"preview": "브라우저에는 다양한 저장소가 있다.\n\n<p align=\"center\">\n <img src=\"https://user-images.githubusercontent.com/24274424/58260975-698cda00"
},
{
"path": "Browser/Cookie_Store.md",
"chars": 5811,
"preview": "# New Cookie Store API(after Chrome 87)\n\n2020년 11월 01일 기준 Chrome의 버전은 `86.0.4240.111`이다.\n\n\n\n`FOUC(Flash of Unstyled Content)`란 브라우저에서 웹 페이지에 접근했을 때, 미처 스타일이 적용되지 못한 상태로 화면이 나타나는"
},
{
"path": "Browser/HTTP2_Websocket.md",
"chars": 2557,
"preview": "# HTTP2.0과 Web Socket\n\n## HTTP란\n\nHTTP는 HyperText Transfer Protocol의 약자다. Request와 Response로 이루어진 통신 규약이다.\n\n이 HTTP의 단점 중 "
},
{
"path": "Browser/IndexedDB_WebSQL.md",
"chars": 9238,
"preview": "# IndexDB WebSQL\n\n데이터 저장소는 서버 DB를 사용해서 데이터를 저장하고 꺼내서 보여줄 수 있도록 데이터를 저장하는 공간이다. 이러한 데이터를 저장할 수 있는 공간이 브라우저에도 존재하는데 이것을 통틀"
},
{
"path": "Browser/Layer_Model.md",
"chars": 5369,
"preview": "# Layer Model\n\n브라우저의 layer model에 대해 알아보자.\n\n## layer란\n\n브라우저는 크게 layer를 두가지로 분류한다.\n\n- RenderLayer\n- GraphicsLayer\n\n### Re"
},
{
"path": "Browser/WebWorker.md",
"chars": 3548,
"preview": "# Web Worker\n\n`WebWorker`는 `script` 실행을 메인 쓰레드가 아니라 백그라운드 쓰레드에서 실행할 수 있도록 해주는 기술이다.\n\n이 기술을 통해 무거운 작업을 분리된 쓰레드에서 처리할 수 있다"
},
{
"path": "Browser/Worklet.md",
"chars": 12937,
"preview": "# Worklet\n\n## Worklet이란\n\n> Worklet 인터페이스는 Web Workers의 경량 버전이며 개발자가 렌더링 파이프 라인의 하위 수준에 접근할 수 있도록 해준다. \n> Worklet을 사용하면 J"
},
{
"path": "Browser/웹 브라우저의 작동 원리.md",
"chars": 4483,
"preview": "# 웹 브라우저의 작동 원리\n\n## Rendering Engine\n\n현대 브라우저들의 렌더링 엔진은 다양하다. gecko기반의 spider monkey를 사용하는 firefox, webkit - blink기반의 V8"
},
{
"path": "Browser/최신_브라우저의_내부_살펴보기.md",
"chars": 4251,
"preview": "# 최신 브라우저의 내부 살펴보기\n\n개인적으로 일을 하다보면 성능(performance)를 올려야하는 일은 당연하게 된다. 성능이 나와야 제품을 사용하는 사람이 생기기 마련이다.\n\n그러다 보면 당연하게 GPU를 사용"
},
{
"path": "CS/Binding.md",
"chars": 4539,
"preview": "# 바인딩(Binding)\n**바인딩**은 **이름**을 어떠한 **속성**과 **연결** 시키는 것이다. 더 나아가 바인딩은, 값들을 확정시켜 더 이상 **변경할 수 없는 상태**로 만든다. 또한, **메모리 번지"
},
{
"path": "CS/Bomb-Lab(1).md",
"chars": 15900,
"preview": "# Bomb Lab(1)\n\nBomb Lab은 Carnegie Mellon University의 시스템 프로그래밍 과제인 Lab 시리즈 중 하나이다. 과제에는 bomb라는 바이너리 파일이 제공된다. 과제의 목적은 gd"
},
{
"path": "CS/Call-By-Sharing.md",
"chars": 4035,
"preview": "# Call By Sharing(a.k.a Call By Object, Call By Object-Sharing)\n\n## Call By Value와 Call By Reference\n\n들어가기에 앞서, 메소드의 호출 "
},
{
"path": "CS/Counting-sort.md",
"chars": 3367,
"preview": "# 계수 정렬(Counting Sort)\n\n비교정렬(comparison sort)의 시간복잡도의 하한은 O(nlogn) 이다.\n\n계수 정렬은 non-comparison sort 기법이며, 정렬에 드는 계산복잡도을 O"
},
{
"path": "CS/Graph.md",
"chars": 3303,
"preview": "# 그래프\n\n## 쾨니히스베르크 다리 문제\n\n\n\n프로이센의 쾨니히스베르크(오늘날 러시아 칼리닌그라드)에 강이 있고 강으로 둘러싸인 섬이 하나"
},
{
"path": "CS/Memory.md",
"chars": 2264,
"preview": "# Memory\n\n메모리는 말그대로 저장소다. 뭔가를 하려면 어떤 데이터를 어떻게 처리하라고 한다. 즉 데이터와 처리명령 두가지가 필요하다.\n\n그래서 메모리도 두 영역으로 나뉘어 있다. Program / Data 부"
},
{
"path": "CS/Radix-sort.md",
"chars": 2861,
"preview": "# 기수 정렬(Radix Sort)\n\n비교(comparison) 기반 정렬 알고리즘의 가장 낮은 복합도는 `O(nlogn)` 이다.\n\n반면 계수 정렬(counting sort)은 선형 시간 정렬 알고리즘이다. 검색 "
},
{
"path": "CS/aspect-oriented-programming.md",
"chars": 3600,
"preview": "# 관점(관심) 지향 프로그래밍(Aspect Oriented Programming)\n\n## 관점(Aspect)과 횡단 관심사(Cross-cutting Concern)\n\n관점 지향 프로그래밍은 관점을 기반으로 한 개발"
},
{
"path": "CS/cohension&coupling.md",
"chars": 1700,
"preview": "# 응집도(Cohension)와 결합도(Coupling)\n\n좋은 프로그램은 높은 응집도와 낮은 결합도를 가진다.\n\n## 응집도 \n\n응집도는 모듈 내부의 기능적인 응집 정도를 뜻한다. 이상적인 응집도는 모듈 내부의 모"
},
{
"path": "CS/compression.md",
"chars": 3700,
"preview": "# 압축\n\n압축은 크게 데이터 손실압축과 데이터 비손실압축 두 가지로 나뉜다.\n\n데이터 손실 압축은 우리가 흔히 보는 사진, 영상의 해상도를 낮추는 압축이다. 사진의 픽셀을 일부 제거해 원본데이터가 손상되지만 사진을"
},
{
"path": "CS/dependency-inversion-principle.md",
"chars": 4137,
"preview": "# 의존 역전 원칙(Dependency Inversion Principle)\n\n이름 그대로 의존 관계를 역전시키라는 원칙이다. 의존 역전 원칙은 다음과 같이 정의된다.\n\n1. 고수준 모듈(high level mod"
},
{
"path": "CS/grasp.md",
"chars": 7475,
"preview": "# GRASP - General Responsibility Assignment Software Patterns\n\n직역하자면 일반적으로 책임을 할당할 때 사용할 수 있는 소프트웨어 패턴이다. 말 그대로 책임 할당에 관"
},
{
"path": "CS/information_theory.md",
"chars": 2227,
"preview": "# 정보이론\n\n## 소통\n\n소통에는 늘 잡음이 낀다.\n\n이웃이 주식으로 돈을 좀 많이 벌었다라는 사실이 있다면 정보는 왜곡되고 과장이 되기 마련이다.\n그 이웃은 돈을 벌어 집도 사고 차도 새로 뽑는다. 친구의 뒷통수"
},
{
"path": "CS/integer_representation.md",
"chars": 3875,
"preview": "# 정수 표현(Integer Representation)\n\n전자기기는 신호가 켜졌는지, 꺼졌는지 구분을 하는 것이 효율적이기 때문에 컴퓨터 또한 2진법을 기반으로 발전하였다.\n\n\n\n인터페이스 분리 원칙은 클라이언트는 자신이 사용하지 않는 메서드에 의존하면 안된다는 것이다. 만약 인터페이스가 거대하여 많은 기능"
},
{
"path": "CS/liskov_substitution_principle.md",
"chars": 4088,
"preview": "# 리스코프 치환 원칙(Liskov Substitution Principle)\n\n> 바바라 리스코프(Barbara Liskov)가 1988년 제시한 파생(상속) 에 관한 원칙.\n\n리스코프 치환 원칙은 하위 타입을 상"
},
{
"path": "CS/methods_in_IPC.md",
"chars": 6176,
"preview": "# IPC(Inter Process Communication) 기법\n\n프로세스는 서로 접근이 불가능하다. 프로세스는 커널만 접근할 수 있기 때문이다. 하지만 병렬처리가 필요하거나 서로 다른 프로세스 간의 상호작용이 "
},
{
"path": "CS/non-blocking.md",
"chars": 2769,
"preview": "# non-blocking\n\nNon-blocking은 os와 알고리즘에 대한 것이다. 공유자원을 안전하게 동시 사용할 수 있도록 하는 방법론이다.\n\nNon-blocking은 하나의 작업이 실패하거나 정지하더라도 다른"
},
{
"path": "CS/non-linear-search.md",
"chars": 2230,
"preview": "# 비선형(Non-Linear) 구조의 탐색\n\n## 선형 구조\n\n선형 구조를 간단히 설명하면, 말 그대로 진행하는 방향이 직선으로(일자로) 되어있는 구조이다. 알고리즘에서는 데이터가 연속적으로 연결되어있는 모양으로 "
},
{
"path": "CS/open-closed-principle.md",
"chars": 7304,
"preview": "# 개방-폐쇄 원칙(Open-Closed Principle)\n\n개방-폐쇄 원칙은 **확장에 열려있고, 변경에는 닫혀있어야 한다**는 원리이다. 열려있다는 것(개방; open)은 소프트웨어는 확장(기능 추가 등의)할 "
},
{
"path": "CS/soc.md",
"chars": 1213,
"preview": "# 관심사 분리(Separation of Concerns; SoC)\n\n관심사 분리는 프로그램의 각 부분이 자신의 관심사만을 다루도록 분리되어야 한다는 것이다. 여기서 `관심사`란 프로그램 코드에 영향을 주는 일련의 "
},
{
"path": "CS/srp.md",
"chars": 5798,
"preview": "# 단일 책임 원칙(Single Responsibility Principle; SRP)\n\n단일 책임 원칙은 **클래스(혹은 모듈)는 오직 하나의 책임만을 가져야 한다는 것**이다. 또한 **클래스가 변경되어야 하는 "
},
{
"path": "CS/union-find.md",
"chars": 5282,
"preview": "# 유니온 파인드(Union Find)\n\n상호 배타적집합(disjoint-set) 이라고도 한다. 여러 노드 중 두 개의 노드씩 같은 집합으로 묶어가며 다른 노드가 같은 집합에 있는지 확인하는 그래프 알고리즘이다. "
},
{
"path": "CS/페이징과 세그먼테이션.md",
"chars": 2428,
"preview": "# 페이징 기법과 세그먼트 기법\n\n## 가상기억장치\n\n가상기억장치는 **주기억장치의 용량이 부족할 때 하드디스크의 일부 공간을 마치 주기억장치처럼 사용하는 기억장치**를 말한다. \n가상기억장치에 프로그램을 저장할 "
},
{
"path": "CS/플로이드-와샬-알고리즘.md",
"chars": 4706,
"preview": "# 플로이드 와샬 알고리즘(Floyd Warshall Algorithm)\n\n플로이드 알고리즘이라고도 많이 부른다. 모든 정점의 쌍에 대한 최단 경로의 길이를 알아야 하는 경우 사용된다. 즉 그래프에서 나올 수 있는 "
},
{
"path": "CSS/CJK.md",
"chars": 3349,
"preview": "# CJK\n\n실무에서 은근히 신경 쓰이면서 잘 모르고 있던 것을 발견하여 알아보려고 한다. \n\n대부분의 사이트에서 텍스트가 많은 경우는 드물다. 그렇기 때문에 내가 지정한 영역 안에서 나오는 텍스트의 넘치는 부분을 "
},
{
"path": "CSS/WebToMobile.md",
"chars": 5349,
"preview": "# 웹으로 모바일 슬라이드 화면처럼 만들어보기\n\n<div align=\"center\">\n <image style=\"border: 1px solid black\" src=\"../assets/gif/MobileCSS.gif"
},
{
"path": "CSS/safe-area.md",
"chars": 5330,
"preview": "# Safe-Area(IOS 11 이상 대응하기)\n\n## 안전영역(Safe-Area)이란?\n\n안전영역(Safe-Area)이라는 말은 TV에서 처음 도입된 개념이라고 한다.\n\nTV 해상도 비율이 다양해지면서 영상에서 "
},
{
"path": "Database/DB Connection Pool.md",
"chars": 5409,
"preview": "# DB Connection Pool\n\nAPI 서버를 구동하고 있었는데, 이따금씩 Nginx `502 Bad Gateway` 오류가 났다. \n\n.md",
"chars": 4746,
"preview": "# Query Builder - Knex.js\n\nREST API를 설계 / 구현할 때, 각 API에 해당하는 SQL문을 직접 만들어서 코드에 넣곤 했다. 가령, **회원정보 조회 API** (`GET` `/user"
},
{
"path": "Database/Types of Databases.md",
"chars": 6503,
"preview": "# Types of Databases: The Right Database for the Right Service \n그동안 DB를 사용할 때는 RDB(Relational Database, 관계형 데이터베이스)만 사용했"
},
{
"path": "Deprecated/AMD와 CommonJS.md",
"chars": 2962,
"preview": "# AMD와 CommonJS\n\n## 배경\n\n자바스크립트(ES5 기준)는 파이썬, 루비, 다른 스크립트 언어 계열과 차이점이 존재한다.\n\n바로 **모듈 사용의 표준이 존재하지 않는다는 것**이다.\n\nNode.js를 사"
},
{
"path": "Deprecated/Async-Await.md",
"chars": 8964,
"preview": "# Aync-Await\n\n## Aync-Await에 도달하기 위해서\n\n1. Iterator\n2. Generator\n3. Promise\n4. Aync-Await\n\n<br/>\n\n## 먼저\n\n그전에 가장 먼저 `for-o"
},
{
"path": "Deprecated/B_EventLoop.md",
"chars": 3494,
"preview": "# Event Loop\n\n자바스크립트는 싱글 쓰레드이다. 그래서 비동기를 처리하기 위해서는 다른 누군가의 도움이 필요하다. \n\n우리가 자바스크립트를 기본적으로 브라우저에서 사용을 한다. 그렇다면 당연하게 자바스크립트"
},
{
"path": "Deprecated/B_Module.md",
"chars": 9808,
"preview": "# Module\n\n**Webpack** 및 **SystemJS**와 같은 도구는 무엇일까? 또는 **AMD**, **UMD**, **CommonJS**는 또 무엇인가? 그것들은 어떻게 관련이 있는건가? 그리고 왜 그"
},
{
"path": "Deprecated/CORS(Cross-Origin Resource Sharing).md",
"chars": 4168,
"preview": "# CORS(Cross-Origin Resource Sharing)\n\n## Same Origin Policy\n\n기본적으로 HTTP 요청은 Cross-Site HTTP Requests가 가능하다.\n\n즉, `<img>`"
},
{
"path": "Deprecated/CSS 애니메이션 vs JS 애니메이션.md",
"chars": 3115,
"preview": "# CSS 애니메이션 vs JS 애니메이션\n\n<br/>\n\n## CSS 애니메이션\n\n다음 코드는 W3C tutorial에 있는 코드를 가져와 CSS 애니메이션으로 수정한 코드다.\n\n```html\n<button oncl"
},
{
"path": "Deprecated/CallByReference.md",
"chars": 4143,
"preview": "# Call By Value VS Call By Reference\n\n<div align=center>\n\n\n\n프로미스는 사실 별게 아니다. 콜백을 넘겨주는 위치를 달리했을 뿐이다. foo()에 콜백을 넘기는 것이 아닌 foo()에서 프로미스를 받은 뒤 이 프로미스"
},
{
"path": "Deprecated/Reactive.md",
"chars": 4339,
"preview": "# Reactive\n\n사람들이 흔히 말하는 리액티브의 3가지 의미\n\n- 리액티브 시스템 (구조 및 설계)\n- **리액티브 프로그래밍 (선언적 이벤트 기반)**\n- 함수형 리액티브 프로그래밍 (FRP)\n\n<br/>\n\n"
},
{
"path": "Deprecated/Repaint와 Reflow.md",
"chars": 2819,
"preview": "# Repaint와 Reflow\n\n<br/>\n\n## 브라우저의 rendering 과정\n\n\n\n위의 그림과 같이 브라우저는 화면을 renderi"
},
{
"path": "Deprecated/WebWorker.md",
"chars": 1793,
"preview": "# Web Worker\n\n`WebWorker`는 `script` 실행을 메인 쓰레드가 아니라 백그라운드 쓰레드에서 실행할 수 있도록 해주는 기술이다.\n<br/>\n\n이 기술을 통해 무거운 작업을 분리된 쓰레드에서 처리"
},
{
"path": "Deprecated/animation.md",
"chars": 3283,
"preview": "# CSS Animation\n\n크게 애니메이션을 구현하는 방법은 2가지가 있다. 하나는 자바스크립트로 작성하는 방법이며, 다른 하나는 CSS의 animation 속성을 사용하는 방법이다.\n\n각각의 특성을 살펴보면,\n"
},
{
"path": "Deprecated/setState.md",
"chars": 5999,
"preview": "# Functional setState()\n\n제목을 보고 React를 아는 사람들은 `setState()`를 보고 아~ 했을 것이다.\n흔히 `setState()` 함수(저런 형태는 기본적으로 함수니까)는\n\n```js"
},
{
"path": "Deprecated/기본적인 렌더링 최적화 방법.md",
"chars": 3029,
"preview": "# 기본적인 렌더링 최적화 방법\n\n<br/>\n\n## HTTP 요청의 최소화\n\n대부분의 웹사이트 구성 요소(이미지, 스타일시트, 자바스크립트, 마크업 등)는 웹 서버에 존재한다.\n사용자의 컴퓨터에서 웹 사이트를 띄울 "
},
{
"path": "Deprecated/웹 브라우저의 작동 원리.md",
"chars": 2489,
"preview": "# 웹 브라우저의 작동 원리\n\n<br/>\n\n## Rendering Engine\n\n* Webkit Engine : Chrome, Safari\n<br/>\n\n"
},
{
"path": "Design_Pattern/Composite.md",
"chars": 4932,
"preview": "# Composite 패턴\n\n## Composite 패턴이란?\n\n- 기존 객체를 `재사용`하여 복합 객체를 구성하는 패턴이다\n- 새로운 객체를 구성할 때, 새로운 기능을 모두 작성하는 대신에 이미 존재하는 객체들을 "
},
{
"path": "Design_Pattern/JSP model.md",
"chars": 3773,
"preview": "살짝(?) 늦은 감이 있지만 MVC에 대해 정확히 알아보고자 문서를 새로 작성하기로 하였다.\n\n저번 시간에 MVC1, MVC2 model의 차이점을 알아보았는데 사실 MVC1, MVC2 model은 실제로 존재하지"
},
{
"path": "Design_Pattern/MSA.md",
"chars": 4510,
"preview": "# MicroService Architecture\n\n## Monolithic Architecture\n> Monolithic : 단단히 짜여 하나로 되어 있는\n\nMonolithic Architecture는 전통적인 웹"
},
{
"path": "Design_Pattern/MVC1, MVC2.md",
"chars": 2625,
"preview": "# MVC1 vs MVC2\n주제를 무엇으로 하면 좋을까 생각하다가 MVC model에는 `MVC1`, `MVC2` 이렇게 두 가지 모델이 있다는 것을 발견하였다. \n\n생소한 단어였기 때문에 정리를 해보았다.\n\n##"
},
{
"path": "Design_Pattern/MVC_MVP_MVVM.md",
"chars": 2752,
"preview": "# MVC, MVP, MVVM\n\n간단하게 많이 사용하는 패턴을 정리를 해보자.\n<br/>\n\n웹개발시 쓰이는 패턴들은 다양하게 존재한다.<br/>\n그 중에서 3개를 보게되면 공통점은 모두 화면에 보여주는 로직과 실제 "
},
{
"path": "Design_Pattern/Memoization.md",
"chars": 2089,
"preview": "# Memoization\n\n`React` 10월 말을 기준으로 **새로운 릴리즈**가 올라왔다.\n<br/>\n`React.memo`라는 새로운 기능이 나오게 되었다.\n<br/>\n\n최근 회사에서 사용하는 `vue`의 컴"
},
{
"path": "Design_Pattern/RxJS.md",
"chars": 3318,
"preview": "# [FEConf2017] RxJS\n\n## 주제 : RxJS 써야겠어요? 안써야겠어요?_손창욱\n\nRxJS에 대한 약간의 오해와 본질을 바라보는 시간을 가지려는 시간\n<br/>\n\n## 비동기처리\n\nRxJS 말고도 현재"
},
{
"path": "Design_Pattern/Singleton.md",
"chars": 4532,
"preview": "# Singleton 패턴 \n\n## Singleton 패턴이란? \n\n`Singleton`패턴은 클래스에 객체가 단 하나만 필요한 경우에 사용되는 디자인 패턴이다. \n예를 들어 시스템 안에서 1개밖에 존재하지 "
},
{
"path": "Design_Pattern/Throttle and Debounce.md",
"chars": 1288,
"preview": "# 쓰로틀링과 디바운싱\n\n## 공통점\n\n함수를 호출할 때 호출이 너무 많이 되어 과부화 됨을 방지하기 위한 장치다.\n\n함수 호출이 잦은 예로는 브라우저의 이벤트가 있다. onscroll 이나 onchange 와 같은"
},
{
"path": "ECMAScript/ArrowFunction.md",
"chars": 4533,
"preview": "# 화살표 함수\n\n## 화살표 함수의 선언과 호출\n\n**화살표 함수는 `function` 대신 `=>`를 사용**함으로써 좀 더 간결하게 함수를 선언할 수 있다.\n\n또한 화살표 함수는 익명 함수로만 사용할 수 있기 "
},
{
"path": "ECMAScript/Destructuring_Assignment.md",
"chars": 1437,
"preview": "# 구조 분해 할당\n\n```js\nconst { store } = this.props;\n```\n\n오른쪽의 객체에서 원하는 부분만 뽑아 사용하는 저런 구문을 react에서 처음 접했다. 처음엔 신기해서 그냥 쓰다가 어느"
},
{
"path": "ECMAScript/ECMA2019.md",
"chars": 4731,
"preview": "# ECMAScript 2019\n\n기본적으로 여기에 나오는 내용들은 TC39 committee에서 승인처리가 된 새로 추가가 되는 기능이다.\n\n1. [Array#{flat,flatMap}]\n2. [Object.fro"
},
{
"path": "ECMAScript/ES6-module-in-Browser.md",
"chars": 3597,
"preview": "# ES6 Module in Browser\n\n## module\n\n모듈은 쉽게 생각하면 코드 뭉치다. 코드를 chunk로 만들어 재사용하거나 추상화한다.\n\nJS 모듈에 관한 글은 여기저기 많다. 아래의 링크로 간단한 "
},
{
"path": "ECMAScript/Generator와 async-await.md",
"chars": 4983,
"preview": "# Generator와 async-await\n\n`Generator`는 `ES6`에서 도입되었으며 `Iterable`을 생성하는 함수다. `Generator`를 사용하면 `Iteration Protocol`을 사용하여"
},
{
"path": "ECMAScript/Includes_IndexOf.md",
"chars": 1435,
"preview": "# Includes와 IndexOf\n\n## 소개\n\n두 메서드 모두 배열에 어떤 값이 있는지 찾을 때 비슷하게 사용한다. 정확히는 사용 용도가 조금은 다르지만, 배열에 어느 값이 있는지 확인할 때 사용할 수 있다. i"
},
{
"path": "ECMAScript/Iteration_Protocol.md",
"chars": 3185,
"preview": "# Iteration Protocol\n\n`Iteration Protocol`은 ES6에서 도입되었다. 이는 새로운 구문이 아닌 하나의 프로토콜, 규약이다. 즉, 같은 규칙을 준수하는 객체에 의해 구현될 수 있다. `"
},
{
"path": "ECMAScript/ModulePattern_class.md",
"chars": 7524,
"preview": "# Module Pattern과 class\n\n## Module Pattern\n\n캡슐화는 객체 지향 프로그래밍(OOP; Object Oriented Programming)의 대표적인 특징 중 하나로 **정보 은닉**의"
},
{
"path": "ECMAScript/Number_isNaN.md",
"chars": 1434,
"preview": "# isNaN\n\n## NaN\n\nNaN은 Not a Number이다. 그런데 이건 조금 특이하다. 단순히 숫자가 아닌것이 아니다. 조금 정확히 하자면 Not a Number 보다는 Invaild Number라는 표현이"
},
{
"path": "ECMAScript/Spread_Operator.md",
"chars": 2019,
"preview": "# Spread Operator\n\n## 전개 연산자\n\nES2015인 ES6부터 새롭게 추가된 연산자다. 배열을 각 요소로 확장하는 연산자다. 생긴건 `...` 이렇게 생겼다. 말로 설명하자면 좀 복잡하고 개발자답게 "
},
{
"path": "ECMAScript/Tagged_Template_Literals.md",
"chars": 3483,
"preview": "# Tagged Template Literals\n\n## Template literals\n\nliterals 즉 입력하는 값에 백틱(`)과 치환자(\\${})로 템플릿을 설정할 수 있는 기능이다. ES6에서 추가 된 기능"
},
{
"path": "Git/gitBy_.git.md",
"chars": 2909,
"preview": "# .git으로 이해하는 GIT\n\n깃은 분산된 형상관리 툴(DVCS)이다.\n\n단순하게만 생각하면 별거 없다. 게임 문명을 하다보면... 다른 문명이 내 원더 대신 만들면 돌려서 다른걸 생산해야 한다.\n\n프로젝트도 이"
},
{
"path": "HTML/ARIA.md",
"chars": 9213,
"preview": "# ARIA(Accessible Rich Internet Applications)\n\nARIA란 웹 콘텐츠와 웹 어플리케이션을 제작할 때 누구든 쉽게 접근할수 있도록 하는 접근성 향상 방법 중 하나이다. ARIA를 사"
},
{
"path": "HTML/DOM API.md",
"chars": 4616,
"preview": "# DOM API\n브라우저에서는 W3C DOM, WHATWG DOM 표준에 근거하여 노드의 형태로 DOM을 구현하고, 이를 사용하기 위한 프로퍼티와 메소드를 제공한다. 이 프로퍼티와 메소드의 집합을 **DOM API"
},
{
"path": "HTML/DOM.md",
"chars": 4422,
"preview": "# DOM\n\n\n\n들어가"
},
{
"path": "HTML/HTML-Templating.md",
"chars": 3625,
"preview": "# HTML Templating\n\n서버에서 데이터를 받아온 뒤, DOM 트리에 추가하거나 삭제하거나 교체할 경우가 생길 수 있다. 이러한 작업이 반복적이고(특히 AJAX를 사용할 때) 매번 필요한 태그가 비슷하다면,"
},
{
"path": "HTML/Head_Meta.md",
"chars": 3210,
"preview": "# **Head Meta**\n\n**HTML** `<meta>` 요소는...\n<br/>\n\n`<base>, <link>, <script>, <style>` 또는 `<title>`과 같은 다른 메타관련 요소로 나타낼 수 "
},
{
"path": "HTML/Standard&QuirksMode.md",
"chars": 5611,
"preview": "# 표준모드 :vs: 쿽스모드\n\n## 들어가기에 앞서...\n\n1. **DTD(Document Type Definition)**\n2. 표준모드와 쿽스모드의 차이점은\n\n<br/>\n\n```html\n<!DOCTYPE ..."
},
{
"path": "HTML/WebM&WebP.md",
"chars": 3547,
"preview": "# WebM & WebP\n\n구글에서 만들고 많이 사용되고 최근 많은 사이트에서 최적화의 방안으로 많이 사용되는 WebP에 대해서 정리를 하였다.\n\n구글은 이전에 Media 포맷도 만들었다는 사실을 알게되었다. Web"
},
{
"path": "HTML/input태그의_value바꾸기(input태그의_dirty flag).md",
"chars": 2950,
"preview": "# input태그의 value바꾸기(input태그의 dirty flag)\n\n`<input>`태그의 내용(value)이 변경되면 `setAttribute()`로 값을 변경하여도 브라우저 화면에 반영되지 않는다.\n\n``"
},
{
"path": "HTML/preload&prefetch.md",
"chars": 5746,
"preview": "# Preload, Preconnect, Prefetch\n\n## 브라우저는\n\n인터넷을 통해서 브라우저에 전송되는 모든 자원들이 동일하게 중요한 것은 아니다. \n\n브라우저들은 가장 중요한 리소스를 우선 로드(예: 스크"
},
{
"path": "HTML/웹 컴포넌트(Web Component).md",
"chars": 4945,
"preview": "# 웹 컴포넌트(Web Component)\n\nHTML에서 제공하는 엘리먼트들은 브라우저와 운영체제에 따라 다르게 보이는 경우가 많다. 이를 해결하기 위해서는 외부 JS 라이브러리를 사용하는 것이 일반적인데 이 경우 "
},
{
"path": "Java/ArrayList vs LinkedList 그리고 Vector.md",
"chars": 1434,
"preview": "# ArrayList vs LinkedList 그리고 Vector\n\n`ArrayList`와 `LinkedList`는 `JCF(Java Collection Framework)`의 형태로 제공되며 `List` 인터페이스"
},
{
"path": "Java/Comparable vs Comparator.md",
"chars": 4622,
"preview": "# Comparable vs Comparator\n\n정렬을 위해서 사용하는 인터페이스들이다.<br/>\n`Comparable` 인터페이스는 정렬 기준을 설정할 클래스가 `Comparable` 인터페이스를 직접 상속해 `"
},
{
"path": "Java/Dependency Injection(DI).md",
"chars": 8764,
"preview": "# Dependency Injection(DI)\nDependency Injection는 **Framework에 의해** 객체의 의존성이 주입되는 설계 패턴을 말한다. \n개발자가 class를 만들고 어떤 의존성을 주"
},
{
"path": "Java/JSP와 Servlet처리.md",
"chars": 3973,
"preview": " \n\n# Web Server\n## 기능\n1. Web Server는 클라이언트에서 HTTP 요청을 받은 후, 반환될 페이지의 정적인 "
},
{
"path": "Java/JVM(Java Virtual Machine).md",
"chars": 1772,
"preview": "# JVM(Java Virtual Machine)\n\n<br/>\n\n## JVM이란?\n\n`Java`는 기본적으로 `JVM`위에서 작동된다. `JVM`은 `Java`와 OS(운영체제)사이에 중간 역할을 함으로써, **`J"
},
{
"path": "Java/Java Garbage Collection(GC).md",
"chars": 4120,
"preview": "# Java Garbage Collection(GC)\n\n## Garbage란?\n\n프로그램을 실행하다보면 `Garbage` 즉, 쓰레기가 발생하게 되는데 이는 쉽게 말하자면 **정리되지 않은 메모리**, **유효하지 "
},
{
"path": "Java/Mybatis.md",
"chars": 9514,
"preview": "# Mybatis(마이바티스) Framework\n## 마이바티스란?\n 마이바티스를 설명하기 위해서 JDBC 개념을 알아야한다.\n \n- JDBC(Java Database Connectivity)란 Java에서 데이터"
},
{
"path": "Java/Set.md",
"chars": 5086,
"preview": "# Iterable\n\n\n주요 컬렉션 인터페이스에는 `List<E>`, `Set<E>`, `Qu"
},
{
"path": "Java/String, StringBuilder, StringBuffer.md",
"chars": 1717,
"preview": "# String, StringBuilder, StringBuffer\n\n<br/>\n\n## String\n\n`Java`에서 `String`객체의 특성을 알고 있어야 `StringBuilder`와 `StringBuffer`"
},
{
"path": "Java/String,StringBuilder, StringBuffer차이.md",
"chars": 3822,
"preview": "# String, StringBuilder, StringBuffer의 차이점과 장단점\nString, StringBuilder, StringBuffer는 문자열 클래스들이다. 모두 문자열을 저장하고 관리하는 클래스인데"
},
{
"path": "Java/Upcasting과 Downcasting.md",
"chars": 5801,
"preview": "# Upcasting / Downcasting\n먼저, casting이란 형변환을 말하며 Upcasting과 Downcasting은 참조형을 형변환하는 개념이다. \n참조형이 형변환되는 경우는 다음과 같다.\n1. 클"
},
{
"path": "Java/WAS.md",
"chars": 2882,
"preview": "# WAS(Web Application Server)\n\n## 웹 서버(Web Server)\n\n클라이언트가 요청한 문서나 자원을 전달하는 역할을 한다.\n\n클라이언트는 서버에게 서비스를 요청한다.\n\n서버는 서비스 제공한"
},
{
"path": "Java/copy-object.md",
"chars": 8074,
"preview": "# 객체 복사\n\n객체 지향 프로그래밍에서 객체를 복사하는 방법에 크게 두 가지가 있다.\n\n- 얕은 복사(shallow copy) : 참조(메모리 주소)를 복사\n- 깊은 복사(deep copy) : 참조하는 메모리 안"
},
{
"path": "Java/date-api-in-java.md",
"chars": 11070,
"preview": "# Java의 날짜 API\n\nJDK8 이전의 Java에서는 `java.util.Date` 클래스와 `java.util.Calendar` 클래스를 이용하여 날짜를 다룬다. 하지만 이는 사용하기 불편하기 때문에 대체하는"
},
{
"path": "Java/junit-setup.md",
"chars": 6588,
"preview": "# JUnit 설정해보기\n\n## JUnit\n\n[JUnit](https://junit.org/junit5/)은 Java 언어용 [단위 테스트](https://ko.wikipedia.org/wiki/%EC%9C%A0%E"
},
{
"path": "Javascript/Ajax.md",
"chars": 3426,
"preview": "# AJAX(Asynchronous JavaScript And XML)\n\n## 들어가기 전에...\n\n1990년대까지 웹은 정적 환경이었다. **클라이언트가 서버로 요청**을 보내면, 서버는 **반드시 새로운 웹 페이"
},
{
"path": "Javascript/Animation.md",
"chars": 5295,
"preview": "# CSS 애니메이션 vs JS 애니메이션\n\n웹기술이 발전되면서 좀 더 사용자 친화적으로 개발하려는 노력을 하고 있다.\n이에 방법 중 하나로 애니메이션을 추가함으로써 더욱 이쁘고 완성도가 높은 웹을 만든다.\n\n예전에"
},
{
"path": "Javascript/B_Async.md",
"chars": 4263,
"preview": "# Async\n\n자바스크립트는 기본적으로 싱글 쓰레드이다. 이 말을 쉽게 하면 한번에 1가지의 일을 할 수 밖에 없다. 간단한 예제를 들자면 우리가 요리를 한다고 하면, 야채를 썰면서 물을 끓이는 행위를 동시에 할 "
},
{
"path": "Javascript/B_Call_Apply_Bind.md",
"chars": 3755,
"preview": "# Call Apply Bind \n\n## Function vs Method\n\n한가지 예제를 살펴보고 `console.log()`가 어떻게 출력이 되는지 확인해보자. \n\n```js\n// 함수\nconst greeting"
},
{
"path": "Javascript/B_Callback.md",
"chars": 3721,
"preview": "# Callback Hell\n\n콜백은 단일스레드 환경(이벤트 루프 큐가 단일 쓰레드)인 자바스크립트에서는 필수 불가결이라고 생각한다.\n[이유를 설명하는 EventLoop](./EventLoop.md)\n\n그런데 이 콜"
},
{
"path": "Javascript/B_Class.md",
"chars": 8418,
"preview": "# Class\n \n ES6에 Class 문법이 추가되었다. Class는 특별하게 새로 만들어진 것이 아니다. 기존에 존재하고 있던 상속과 생성자 함수를 기본으로 한 `Proptotype`의 **syntactic su"
},
{
"path": "Javascript/B_Function.md",
"chars": 11824,
"preview": "# **Function**\n\n## **목차**\n\n- [x] Global Scope\n- [x] Local Scope\n- [x] Functional Scope\n- [x] Block Scope\n- [x] Lexical S"
},
{
"path": "Javascript/B_Type.md",
"chars": 13163,
"preview": "# Type\n\n## Primitive Type\n\n한국말로 간단하게 말하면 원시 자료형이라고 하는 자바스크립트의 타입에 대해서 알아보자!\n\n자바스크립트는 자바나 C언어와는 다른게 동적 타입언어라고 불린다. 동적 타입 "
},
{
"path": "Javascript/Build Tool.md",
"chars": 7454,
"preview": "# Build Tool\n\n빌드 작업은 한 번 구성을 하게되면 다시 빌드를 할 때는 단순 반복을 한다. 이에 빌드를 도와주는 도구들이 생겨나게 되었고, 시간이 지남에 따라 종류가 다양해지고 기능도 많아졌다. \n\n현재 "
},
{
"path": "Javascript/CallStack.md",
"chars": 8885,
"preview": "# Basic_CallStack\n\n### 기본 정리 내용들\n\n- [x] Heap\n- [x] Call Stack\n- [x] Web API\n- [x] Queue\n- [x] Event Loop\n- [x] Exe"
},
{
"path": "Javascript/Closure.md",
"chars": 3677,
"preview": "# 클로저\n\n생성된 함수 객체는 `[[Scopes]]` 프로퍼티를 가지게 된다. \n\n`[[Scopes]]` 프로퍼티는 **함수 객체만이 소유하는 내부 프로퍼티(Internal Property)로서 현재 실행 컨텍스트"
},
{
"path": "Javascript/Control_CSSOM.md",
"chars": 2591,
"preview": "# Control CSSOM\n\n`CSSOM(CSS Object Model)` . 즉, 자바스크립트로 `CSS`를 조작할 수 있도록 하는 `API`이다.\n<br/>\n\n위에 관련된 자세한 내용은 웹의 렌더링과정에 대한 "
},
{
"path": "Javascript/DocumentFragment.md",
"chars": 2863,
"preview": "# DocumentFragment\n\n<br/>\n\n## repaint와 reflow\n\n브라우저는 생성된 DOM 노드의 레이아웃이 변경될 때, 모든 노드를 다시 계산하고 렌더 트리를 재생성한다.\n이러한 과정을 `refl"
},
{
"path": "Javascript/Event Delegation.md",
"chars": 3986,
"preview": "# Event Delegation\n\n이벤트 위임의 개념에 앞서, 가장 먼저 이해해야 하는 상황은 다음과 같다.\n\n```html\n<html>\n <body>\n <div id=\"1\">\n <div id=\"2"
},
{
"path": "Javascript/InsertAdjacentHTML.md",
"chars": 3663,
"preview": "# insertAdjacentHTML\n\n## DOM 추가\n\nDocument Object Model이라고 한다. 웹브라우저가 작동하는 원리에 따라 브라우저가 렌더링 될 때 HTML을 파싱한 뒤 DOM Tree를 만든다"
},
{
"path": "Javascript/JavaScript의 this.md",
"chars": 3003,
"preview": "# JavaScript의 this\n\n<br/>\n\n자바스크립트에서 `this`의 바인딩은 함수의 호출 방식에 따라 결정된다.\n\n- **객체의 메서드 호출**\n- **일반 함수 호출**\n- **생성자 함수의 호출**\n-"
},
{
"path": "Javascript/Javascript_Engine.md",
"chars": 3623,
"preview": "# Javascript_Engine\n\n회사에서 `SWT` 에 `CEF` 를 넣어서 통신시키도록 하는 작업을 했다. 그러다 보니 `JS엔진`에 대해서 알고 싶어졌다. \n<br/>\n\n그러다 찾게된 곳을 토대로 엔진들의 "
},
{
"path": "Javascript/Javascript_메모리관리.md",
"chars": 5886,
"preview": "# Javascript_메모리관리\n\n고급 언어 인터프리터는 `가비지 콜렉터` 라는 소프트웨어를 가지고 있다. \n<br/>\n\n## 가비지 콜렉터란 \n\n**메모리 할당을 추적하고 할당된 메모리가 더 이상 필요 없어졌을 "
},
{
"path": "Javascript/Javascript의_동작원리-변수객체(VariableObject).md",
"chars": 9810,
"preview": "# 자바스크립트의 동작 원리 - 변수 객체(Variable Object)\n[자바스크립트의 동작 원리 - 실행 컨텍스트(Execution Contexts)]()에 이어서...\n\n## 변수 객체(Varaiable Obj"
},
{
"path": "Javascript/Javascript의_동작원리-실행컨텍스트(Execution Contexts).md",
"chars": 3703,
"preview": "# 자바스크립트의 동작 원리 - 실행 컨텍스트(Execution Contexts)\n\n> ES3을 기반으로 설명\n\n<br/>\n\n## 실행 컨텍스트(Execution Contexts)\n\nECMA-262-3에서는 \"**실"
},
{
"path": "Javascript/Jest.md",
"chars": 4781,
"preview": "# Jest로 테스트 코드 작성하기\n\n개발자로서 살아가다 보면 테스트 코드의 중요성에 대해 들어본 적 있을 것이다. 과연 테스트 코드는 중요할까?\n\n개발 방법론 중 하나인 TDD는 테스트 주도의 개발을 의미한다. 로"
},
{
"path": "Javascript/Learning_more_about_this.md",
"chars": 6297,
"preview": "# this 더 알아보기\n\n지난 포스팅에서 [scope 관점에서의 this](https://github.com/Im-D/Dev-Docs/blob/master/Javascript/scope_this.md)에 대해 알아"
},
{
"path": "Javascript/Module.md",
"chars": 8443,
"preview": "# Module\n\nJava나 Python 같은 OOP 언어들에서는 Class라는 이름으로 객체지향 프로그래밍을 구현한다. OOP의 특징으로는 *Encapsulation, Inheritance, Polymorphism"
},
{
"path": "Javascript/MouseEvent.md",
"chars": 2831,
"preview": "# Mouse Event\n\n오늘은 약간 심플하면서도 약간 헷갈릴만한 주제로 해보려고한다.\n<br/>\n\n바로 `Mouse Event`\n<br/>\n\n오늘 작업을 하다보니 내가 평소에 알고 있던 마우스 이벤트들인데 왜 이"
},
{
"path": "Javascript/Object.create&Object.assign.md",
"chars": 8421,
"preview": "# Object.create() & Object.assign()\n\n## Object.create()\n\n```js\nObject.create(prototype_object, propertiesObject)\n```\n\n`O"
},
{
"path": "Javascript/Observer.md",
"chars": 3583,
"preview": "# Observer\n\n<br/>\n\n## 옵저버 패턴(Observer Pattern)\n\n옵저버 패턴은 데이터를 기반으로 하는 인터페이스가 데이터의 변화를 감시하는 구조를 말한다. 특정 이벤트가 일어나고 해당 이벤트에 "
},
{
"path": "Javascript/Optional_Chaining.md",
"chars": 2392,
"preview": "# Optional Chaining\n\n## 소개\n\n이 내용은 아직 공식 스펙으로 채택하지 않았다. 다만 추후 추가될만한 소지가 있으며 충분히 매력적이므로 소개해본다.\n\n조건적으로 체이닝을 할 수 있다. 이게 무슨 소"
},
{
"path": "Javascript/PromisePattern.md",
"chars": 1149,
"preview": "# 프로미스 패턴\n\n두개 이상의 프로미스를 사용한 비동기 흐름을 제어할 때 사용한다. 예를들어 a 와 b 라는 비동기 작업이 모두 완료되면 c 라는 비동기 작업을 진행해야 한다고 하면 이 경우 어떻게 해야할까를 정의"
},
{
"path": "Javascript/Prototype_Chain.md",
"chars": 6422,
"preview": "## 프로토타입 체인\n\n특정 객체의 메서드나 프로퍼티에 접근하고자할 때, **해당 객체에 접근하려고 하는 프로퍼티나 객체가 없다면** 프로토타입 링크(`[[Prototype]]` 프로퍼티)를 따라 **자신의 부모 역"
},
{
"path": "Javascript/Proxy.md",
"chars": 7145,
"preview": "# Proxy\n\n사람들이 흔히 생각하는 프록시 패턴이 아닌 프록시 객체에 대해서 알아보는 시간을 가지자\n\n## `Proxy` 객체?\n\nES6는 [Proxy](https://developer.mozilla.org/en"
},
{
"path": "Javascript/Reduce.md",
"chars": 3229,
"preview": "# Reduce\n\nArray.prototype이 가지고 있는 리듀스라는 함수다. 이 리듀스는 흔히 SUM의 기능을 가진다고 생각을 많이 한다. 그러나 생각보다 더 많은 기능을 구현할 수 있다.\n\n## 함수 설명\n\nR"
},
{
"path": "Javascript/Redux State 정규화.md",
"chars": 4719,
"preview": "# Redux State 정규화(Normalization)\n\n<br/>\n\n## 상태 정규화의 필요성\n\n많은 애플리케이션들은 실제로 중복된 데이터들을 많이 처리한다. Facebook의 타임라인을 예로 들어보자.\n\n각각"
},
{
"path": "Javascript/Regular_Expressions.md",
"chars": 7850,
"preview": "# 정규 표현식(Regular Expressions)\n\n## 개념\n\n정규표현식은 줄여서 정규식(영어로 Regular Expression이며, 줄여서 `Regex`, `Regexp` 등으로 불린다.)이라고 한다.\n\n컴"
},
{
"path": "Javascript/Scope.md",
"chars": 4314,
"preview": "# 스코프\n\n## 함수형 스코프\n\n자바스크립트는 기본적으로 **함수형 스코프**를 가진다.(EcmaScript6에서부터는 `let`과 `const`를 이용하여 블록 레벨 스코프를 사용할 수 있다.)\n\n```javas"
},
{
"path": "Javascript/Some_Every.md",
"chars": 1745,
"preview": "# Some과 Every\n\n흔히 javascript의 배열과 관련된 메서드로 map, filter, reduce를 생각한다.\n사실 이 세가지 아니 정확히는 reduce 하나만으로도 모든것을 구현할 수 있다.\n하지만 "
},
{
"path": "Javascript/Storybook.md",
"chars": 4604,
"preview": "# Storybook\n\n프론트엔드에서 컴포넌트 단위로 개발을 진행하는 경우 해당 컴포넌트의 UI를 독립적으로 개발 및 테스트하며 작업하고자 한다면 어떻게 해야 할까? Storybook을 사용하면 원하는 방식으로 작업"
},
{
"path": "Javascript/Sync&Async_Multi&Single_Thread.md",
"chars": 2570,
"preview": "# Sync & Async, Multi & Single Thread\n\n## Sync programming\n\n동기 프로그래밍은 쉽게 설명하자면 순차적인 프로그래밍을 이야기한다. 예를들어 파스타를 만들어보자.\n\n1. 물"
},
{
"path": "Javascript/TimeInJS.md",
"chars": 3240,
"preview": "# Time in JS\n\njs를 사용하여 시간을 측정해야하는 경우가 있다.\n\n예를 들어 내 코드가 얼마만큼의 시간을 사용했는지 알고 싶은 경우다.\n또 [쓰로틀링](https://github.com/Im-D/Dev-D"
},
{
"path": "Javascript/Variable.md",
"chars": 5057,
"preview": "# 자바스크립트의 변수\n\n## 자바스크립트의 실행\n\n자바스크립트가 브라우저에서 해석될 때, 해당 자바스크립트가 실행되기 위한 최소한의 메모리를 확보하는 과정을 거친다.\n이 과정에서 자바스크립트 변수는 [호이스팅](h"
},
{
"path": "Javascript/WebRTC.md",
"chars": 7649,
"preview": "# WebRTC\n\nWebRTC(Web Real-Time Communication)는 Google이 시작한 오픈소스 프로젝트로 별도의 플러그인이나 소프트웨어 없이 Web과 Android, iOS 등에서 p2p 방식으로"
},
{
"path": "Javascript/Web_Storage_API.md",
"chars": 4540,
"preview": "# Web Storage API\n\n개발을 진행하다가 클라이언트에서 특정 값을 저장해야 하는 기능 구현 필요성이 생겼다면 어떻게 해야 할까? 쿠키를 사용할 경우 생성할 수 있는 개수 및 데이터 크기 등의 제약 사항이 "
},
{
"path": "Javascript/ajax(2).md",
"chars": 3728,
"preview": "# Ajax (Asynchronous Javascript And XML)\n- JavaScript 라이브러리인 Jquery의 기능 중 하나이며, Asynchronous Javascript And Xml의 약자이다.\n-"
},
{
"path": "Javascript/bind.md",
"chars": 4470,
"preview": "# bind() 메소드\n\n## 정의\n\n```js\nfunc.bind(thisArg[, arg1[, arg2[, ...]]])\n```\n\n`bind()` 메서드는 새로운 함수를 생성한다. `bind()` 가 호출된 함수의"
},
{
"path": "Javascript/object.md",
"chars": 3042,
"preview": "# 객체\n\n연관된 속성의 집합을 객체라고 한다.\n\n객체지향 프로그래밍에서는 클래스가 반환한 객체 인스턴스를 통해 메서드에 접근하고, 이 메서드를 통해 속성들을 제어한다.\n\n이 경우 복잡한 구조를 모듈화 시켜서 사용할"
},
{
"path": "Javascript/object_create_pattern-constructor.md",
"chars": 2337,
"preview": "# 객체 생성 패턴 - 생성자 패턴\n\n객체를 생성하는 쉽고 단순한 방법에는 `Object` 객체의 인스턴스를 만드는 것과 객체 리터럴을 이용한 방법이 있다.\n\n```js\n// Object의 인스턴스 생성\nvar pe"
},
{
"path": "Javascript/object_생성패턴.md",
"chars": 4825,
"preview": "# 객체 생성 패턴\n\n## 전역 변수 사용\n```js\nfunction Parent() {}\nfunction Child() {}\n\nvar some_var = 1;\nvar module1 = {};\nvar module2 "
},
{
"path": "Javascript/prototype(2).md",
"chars": 7102,
"preview": "# Prototype(2)\n\n일반적으로 객체지향 프로그래밍을 할 경우 클래스를 사용해서 객체를 생성한다. 하지만 자바스크립트는 클래스 기반이 아닌 prototype 기반으로 객체를 생성한다. ES6에 클래스가 추가되"
},
{
"path": "Javascript/prototype.md",
"chars": 4519,
"preview": "# 프로토타입(Prototype)\n\n자바스크립트로 객체지향 프로그래밍을 할 수 있다. 하지만 대부분의 객체지향 언어와 달리 클래스가 아닌, 프로토타입으로 객체지향 프로그래밍을 구현한다. 또한, 클래스라는 개념이 없기"
},
{
"path": "Javascript/scope_this.md",
"chars": 3687,
"preview": "# 스코프와 this, 그리고 화살표 함수\n\nES6에서는 화살표 함수 `() => {}`가 등장했다. 화살표 함수에 없는 것 등을 구글링하면 쉽게 찾아볼 수 있다.\n\n그 중 하나로 this가 있다. 흔히 화살표 함수"
},
{
"path": "Javascript/throttling과 rAF.md",
"chars": 1856,
"preview": "# throttling과 rAF\n\n## throttling(쓰로틀링)\n\n`Throttling`은 스크롤 이벤트에서 주로 사용되는 기술로 지나치게 많은 이벤트가 발생하는 것을 몇 초에 한 번, 또는 몇 밀리초에 한 번"
},
{
"path": "Javascript/tricks_of_js.md",
"chars": 3619,
"preview": "# 자바스크립트 꿀팁\n\njs로 개발하면서 엄청 대단한 것은 아니지만 생각보다 소소한 팁을 정리해봤다.\n\n## Array.length\n\n보통 배열의 길이를 구할 때 사용하는 속성이다. 그런데 이 속성을 이용하면 좀 더"
},
{
"path": "Javascript/underscore와 lodash그리고 Native.md",
"chars": 2296,
"preview": "# underscore와 lodash 그리고 native\n\n`underscore`와 `lodash`는 자바스크립트 개발을 진행하다보면 많이 듣게 되는 라이브러리다.<br/> 이 둘은 모두 자바스크립트의 **유티릴리성"
},
{
"path": "Javascript/window.history.md",
"chars": 8900,
"preview": "# window.history\n\n**SPA(Single Page Application)** 사이트를 만들어 보신 분들은 한 번쯤 생각하게 되는 고민이 있다. 어떻게 앞으로 가기, 뒤로 가기, 새로 고침을 구현해야 할"
},
{
"path": "Javascript/논리연산자.md",
"chars": 3244,
"preview": "# 논리연산자\n\n다른 프로그래밍 언어들과 마찬가지로 자바스크립트도 논리연산자 문법을 사용할 수 있습니다. `||`(OR), `&&`(AND), `!`(NOT) 총 세 종류의 논리 연산자가 존재합니다. 피연산자로 모든"
},
{
"path": "Javascript/렉시컬_속이기(eval).md",
"chars": 2247,
"preview": "# 렉시컬 속이기 - eval()\n\n주변에서 eval은 사용하면 안된다고들 말한다. 왜 그런지 깊숙하게 알아보았다.\n\n자바스크립트에는 렉시컬 스코프라는 개념이 있다. 이를 알기 위해선 scope에 대한 정의가 필요하"
},
{
"path": "Javascript/배열 내장함수.md",
"chars": 7009,
"preview": "# 배열 내장함수\n\n자바스크립트의 배열에서는 기본적으로 많은 종류의 내장 함수를 제공하고 있고 이를 이용하면 보다 간단한 코드로 다양한 기능을 구현할 수 있다.\n\n<br/>\n\n## forEach, map, filte"
},
{
"path": "Javascript/상태관리 라이브러리.md",
"chars": 2120,
"preview": "# 상태관리 라이브러리\n\n<br/>\n\n## 상태관리 라이브러리의 필요성\n\n**'상태관리 라이브러리는 왜 필요할까?'** 라는 것에 초점을 두어야 한다.\n\n**규모가 작은 프로젝트**라면 굳이 상태관리 라이브러리를 사"
},
{
"path": "Javascript/이벤트 루프(Event Loop).md",
"chars": 5632,
"preview": "\n# 이벤트 루프(Event Loop)\n\n<br/>\n\n## 자바스크립트는 싱글쓰레드 기반이다.\n\n자바스크립트를 공부해본 개발자라면 한 번쯤은 `자바스크립트는 싱글 쓰레드 기반의 언어다.`라는 말을 들어봤을 것이다. "
},
{
"path": "Javascript/클래스(class).md",
"chars": 5048,
"preview": "# 클래스(class)\n\n기본적으로 자바스크립트는 프로토타입 기반의 객체지향언어다. `ES6`부터 추가된 `class`문법은 기존의 `ES5`까지 사용하던 객체지향 설계 방식의 **Syntatic Sugar**다.\n"
},
{
"path": "Javascript/클로저.md",
"chars": 2057,
"preview": "# 클로저\n\n<br/> \n\n## 렉시컬 스코프란\n\n\n```js\nfunction outerFunc() {\n var x = 10;\n var innerFunc = function() {console.log(x)"
},
{
"path": "Javascript/함수 선언.md",
"chars": 2741,
"preview": "# 함수 선언식 / 함수 표현식\n연산자 `function`을 이용해 함수를 정의하는 방법에는 함수 선언식과 함수 표현식이 있다. \n\n## 함수 선언식\n```javascript \nfunction fnc()"
},
{
"path": "LICENSE",
"chars": 1066,
"preview": "MIT License\n\nCopyright (c) 2018-2020 Im-D\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\n"
},
{
"path": "Language/Currying.md",
"chars": 2844,
"preview": "# Currying\n\nCurrying은 여러 개의 인자를 가진 함수를 호출할 경우, 파라미터의 수보다 적은 수의 파라미터를 인자로 받으면 누락된 파라미터를 인자로 받는 기법을 말한다.\n부분적으로 인자가 적용된 함수를"
},
{
"path": "Language/Lamda.md",
"chars": 2181,
"preview": "# 람다\n\n## 람다 대수(Lambda calculus)\n\n람다의 근간은 수학에서, 그리고 초기 튜링기계에 사용되었던 *람다 대수 or 람다 계산 (Lambda Calculus)*다. 람다 대수는 수학에서의 함수를 "
},
{
"path": "Language/Reactive.md",
"chars": 4026,
"preview": "# Reactive\n\nReactive Programming의 3가지\n\n- Reactive Programming\n- Functional Reactive Programming\n- Reactive Extensions(Rx"
},
{
"path": "Language/XML_JSON.md",
"chars": 15426,
"preview": "# JSON과 XML\n저번 시간에 [soap api](https://github.com/im-d-team/Dev-Docs/blob/master/Network/SOAP%20API.md)를 정리하면서 데이터 형식에는 `"
},
{
"path": "Language/고차함수(High Order Function).md",
"chars": 4918,
"preview": "# 고차함수(High Order Function)\n\n<br/>\n\n## 코드의 복잡성\n\n큰 프로그램은 복잡성이 올라간다. 그 복잡성은 코드를 이해하기 어렵게 만들고 코드 간의 의존성을 높인다. 이러한 코드는 버그를 유"
},
{
"path": "Language/함수형 프로그래밍.md",
"chars": 7009,
"preview": "# 함수형 프로그래밍\n\n<br/>\n\n## 함수형 프로그래밍이란?\n\n함수형 프로그래밍은 객체지향 프로그래밍과 같은 프로그래밍 패러다임의 한 예다. 함수형 프로그래밍은 몇 가지 기본 규칙을 기반으로 애플리케이션을 구성하"
},
{
"path": "ML/머신러닝이란.md",
"chars": 4604,
"preview": "# 머신 러닝(Machine Learning, ML)이란?\n\n프로그래밍을 간단하게 말하자면, 입력 데이터가 있을 때, 데이터를 집어넣어 원하는 결과 데이터를 출력하는 알고리즘을 만드는 것을 말한다.\n\n머신 러닝은 문"
},
{
"path": "Network/3-way handshaking & 4-way handshaking.md",
"chars": 4872,
"preview": "# 3-way handshaking & 4-way handshaking\n이번 시간에는 TCP 통신에서 쓰이는 `3-way handShaking`과 `4-way handShaking`을 정리해보았다.\n\n# TCP\nTC"
},
{
"path": "Network/CORS.md",
"chars": 3914,
"preview": "# CORS(Cross-Origin Resource Sharing)\n\n## Same Origin Policy\n\n일반적인 HTTP 요청은 다른 도메인의 자원을 요청하는 것이 가능하다 이를 Cross-Site HTTP "
},
{
"path": "Network/DHCP&DNS.md",
"chars": 7217,
"preview": "# DHCP, DNS 프로토콜\n\n### 이전 글 복습하기\n\n1. [네트워크 기초 - IP](https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md)\n2. ["
},
{
"path": "Network/Flow control.md",
"chars": 3637,
"preview": "최근에 네트워크에 관심이 생겨 네트워크에 대해 앞으로 조금씩 정리해볼 예정이다.\n\n# 흐름제어 (Flow control)\n**흐름제어**란 송신 측이 수신 측의 처리 속도보다 더 빨리 데이터를 보내지 못하도록 제어해"
},
{
"path": "Network/HTTP3.md",
"chars": 9294,
"preview": "# HTTP3\n\n### 네트워크 관련 글 보기\n\n1. [네트워크 기초 - IP](https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md)\n2. [네트워크 기"
},
{
"path": "Network/IP.md",
"chars": 5424,
"preview": "# 네트워크 기초 - IP\n\n## 네트워크란\n\n두 대 이상의 컴퓨터가 논리적 또는 물리적으로 연결되어 통신이 가능한 상태를 말한다.\n일반적으로 규모에 따른 네트워크 종류는 아래와 같다.\n\n1. PAN (Persona"
},
{
"path": "Network/JSend.md",
"chars": 2973,
"preview": "# JSend\n\nRESTful하게 개발하는 건 2019년 현재 개발 트렌드다.\n\nbackend - frontend를 완전히 구분하고 자원에 대한 API를 REST하게 설계한다. 이 둘은 JSON 형태로 데이터를 주고"
},
{
"path": "Network/OSI7 Layer.md",
"chars": 5866,
"preview": "# OSI 7 계층과 TCP/IP 계층\n\n### 이전 글 복습하기\n\n[네트워크 기초 - IP](https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md)\n[네"
},
{
"path": "Network/REST API.md",
"chars": 3593,
"preview": "\n\n# REST API란\n문제 정의: Client와 *Web* Server는 어떻게 소통하는가?\n\n<br/>\n\n## REST (REpresentational State Trasfer)\n**HTTP** 기반의 **네트"
},
{
"path": "Network/REST.md",
"chars": 5164,
"preview": "# REST\n\n## REST(REpresentational State Transfer)란\n\n### HTTP에서의 representation \nHTTP GET 요청에 대한 응답으로 다음을 받았다고 가정해보자.\n\n`"
},
{
"path": "Network/SOAP API.md",
"chars": 4342,
"preview": "# SOAP API\nAPI를 사용하면서 여러 종류의 API가 있다는 사실을 알게 되었다. 가장 대표적인 두 가지 방식으로는 SOAP와 REST가 있다. 두 가지 방식은 비슷하지만 본질적으로 다른 기술이다. [SOAP"
},
{
"path": "Network/Subnetmask.md",
"chars": 4376,
"preview": "# 네트워크 기초 - 서브넷마스크(Subnetmask)\n\n### 이전 글 복습하기\n\n[네트워크 기초 - IP](https://github.com/im-d-team/Dev-Docs/blob/master/Network/"
},
{
"path": "Network/Switch.md",
"chars": 3194,
"preview": "네트워크 교육을 듣다가 스위치가 layer 계층별로 각각 존재한다는 것을 알게 되었고 더욱 자세히 알고 싶어 정리를 해보았다.\n\n# 스위치(Switch)\n스위치란 허브의 확장된 개념으로 기본 기능은 허브와 같지만 전"
},
{
"path": "Network/TCP & UDP.md",
"chars": 8489,
"preview": "# TCP와 UDP\n\n### 이전 글 복습하기\n\n1. [네트워크 기초 - IP](https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md)\n2. [네트워크 기"
},
{
"path": "Network/TypesOfIP.md",
"chars": 3586,
"preview": "# 네트워크 기초 - Types of IP\n\n### 이전 글 복습하기\n\n[네트워크 기초 - IP](https://github.com/im-d-team/Dev-Docs/blob/master/Network/IP.md)\n"
},
{
"path": "Network/comet.md",
"chars": 2107,
"preview": "# comet\n \n## Http 통신 방식 \n\nHTTP는 클라이언트의 요청이 있을 때만 서버가 응답하여 처리한 후에 연결을 끊는 **단방향 통신**이다. \n따라서 서버에서 클라이언트로 데이터를 전송하는 **Ser"
},
{
"path": "Network/congestion control.md",
"chars": 5895,
"preview": "# congestion control(혼잡 제어)\n\n저번 시간에는 송신 측과 수신 측의 데이터 처리 속도를 해결하기 위해 쓰이는 `flow control`에 대해 조사를 하였다.\n\n이번 시간에는 `congestion"
}
]
// ... and 48 more files (download for full content)
About this extraction
This page contains the full source code of the im-d-team/Dev-Docs GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 248 files (1.4 MB), approximately 514.5k tokens, and a symbol index with 5 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.