"
输出: False
输入: "
unmatched <
"
输出: False
输入: "
closed tags with invalid tag name 123
"
输出: False
输入: "
unmatched tags with invalid tag name and
"
输出: False
输入: "
unmatched start tag and unmatched end tag
"
输出: False
```
## 解题思路
### 思路 1:栈 + 状态机
这是一个复杂的字符串解析问题,需要使用栈来匹配标签,并处理多种特殊情况。
关键点:
1. 使用栈存储标签名,匹配开始和结束标签
2. 处理 CDATA 部分,CDATA 内的内容不需要验证
3. 验证标签名的合法性(1-9 个大写字母)
4. 确保代码被合法的闭合标签包围
5. 处理各种边界情况
步骤:
1. 从左到右扫描字符串
2. 遇到 `<` 时,判断是开始标签、结束标签还是 CDATA
3. 使用栈维护标签的嵌套关系
4. 验证每个标签的合法性
### 思路 1:代码
```python
class Solution:
def isValid(self, code: str) -> bool:
stack = []
i = 0
n = len(code)
while i < n:
if i > 0 and not stack:
# 如果不在标签内且不是开头,无效
return False
if code[i:i+9] == '', i)
if j == -1:
return False
i = j + 3
elif code[i:i+2] == '', i)
if j == -1:
return False
tag_name = code[i+2:j]
if not self.is_valid_tag_name(tag_name):
return False
if not stack or stack[-1] != tag_name:
return False
stack.pop()
i = j + 1
elif code[i] == '<':
# 开始标签
j = code.find('>', i)
if j == -1:
return False
tag_name = code[i+1:j]
if not self.is_valid_tag_name(tag_name):
return False
stack.append(tag_name)
i = j + 1
else:
# 普通字符
if not stack:
return False
i += 1
return len(stack) == 0
def is_valid_tag_name(self, tag_name: str) -> bool:
# 标签名必须是 1-9 个大写字母
if not tag_name or len(tag_name) > 9:
return False
return all(c.isupper() for c in tag_name)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串长度,需要遍历整个字符串。
- **空间复杂度**:$O(n)$,栈的深度最多为 $O(n)$。
================================================
FILE: docs/solutions/0500-0599/the-maze-ii.md
================================================
# [0505. 迷宫 II](https://leetcode.cn/problems/the-maze-ii/)
- 标签:深度优先搜索、广度优先搜索、图、数组、矩阵、最短路、堆(优先队列)
- 难度:中等
## 题目链接
- [0505. 迷宫 II - 力扣](https://leetcode.cn/problems/the-maze-ii/)
## 题目大意
**描述**:
给定一个迷宫(二维数组)$maze$,其中 $0$ 表示空地,$1$ 表示墙壁。球可以向上、下、左、右四个方向滚动,但在碰到墙壁前不会停止滚动。当球停下时,可以选择下一个方向。
给定球的起始位置 $start$ 和目的地 $destination$。
**要求**:
返回球到达目的地的最短距离。如果球无法到达目的地,返回 $-1$。
**说明**:
- 距离 是指球从起始位置(不包括)到终点(包括)经过的空地数量。
- 可以假设迷宫的边界都是墙。
- $m == maze.length$。
- $n == maze[i].length$。
- $1 \le m, n \le 100$。
- $maze[i][j]$ 是 $0$ 或 $1$。
- $start.length == 2$。
- $destination.length == 2$。
- $0 \le start\_row, destination\_row < m$。
- $0 \le start\_col, destination\_col < n$。
- 球和目的地都存在于一个空地中,它们最初不会处于相同的位置。
**示例**:
- 示例 1:
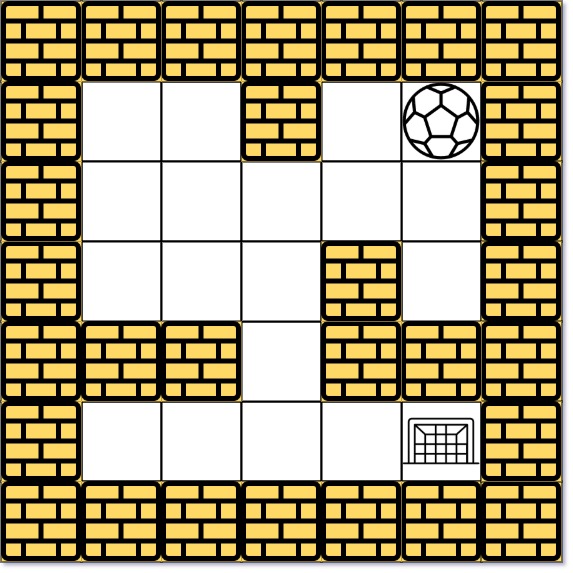
```python
输入: maze = [[0,0,1,0,0],[0,0,0,0,0],[0,0,0,1,0],[1,1,0,1,1],[0,0,0,0,0]], start = [0,4], destination = [4,4]
输出: 12
解析: 一条最短路径 : left -> down -> left -> down -> right -> down -> right。
总距离为 1 + 1 + 3 + 1 + 2 + 2 + 2 = 12。
```
- 示例 2:
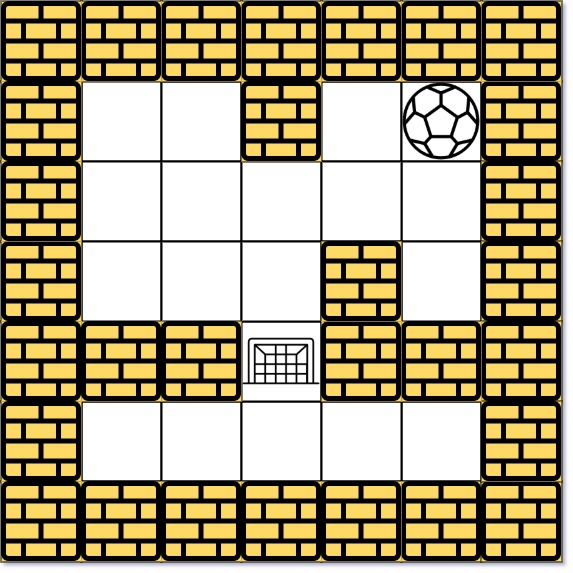
```python
输入: maze = [[0,0,1,0,0],[0,0,0,0,0],[0,0,0,1,0],[1,1,0,1,1],[0,0,0,0,0]], start = [0,4], destination = [3,2]
输出: -1
解析: 球不可能在目的地停下来。注意,你可以经过目的地,但不能在那里停下来。
```
## 解题思路
### 思路 1:Dijkstra 算法(优先队列 + BFS)
这是一个最短路径问题,可以使用 Dijkstra 算法求解。
关键点:
1. 球会一直滚动直到碰到墙壁才停下
2. 需要记录到达每个停止位置的最短距离
3. 使用优先队列(最小堆)保证每次取出距离最小的位置
步骤:
1. 使用优先队列存储 $(distance, row, col)$
2. 使用 $dist$ 数组记录到达每个位置的最短距离
3. 对于每个位置,尝试四个方向滚动,直到碰到墙壁
4. 如果新的距离更短,更新并加入队列
### 思路 1:代码
```python
import heapq
class Solution:
def shortestDistance(self, maze: List[List[int]], start: List[int], destination: List[int]) -> int:
m, n = len(maze), len(maze[0])
# 距离数组,初始化为无穷大
dist = [[float('inf')] * n for _ in range(m)]
dist[start[0]][start[1]] = 0
# 优先队列:(距离, 行, 列)
pq = [(0, start[0], start[1])]
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
while pq:
d, x, y = heapq.heappop(pq)
# 如果到达目的地
if x == destination[0] and y == destination[1]:
return d
# 如果当前距离大于已记录的距离,跳过
if d > dist[x][y]:
continue
# 尝试四个方向
for dx, dy in directions:
nx, ny = x, y
steps = 0
# 一直滚动直到碰到墙壁
while 0 <= nx + dx < m and 0 <= ny + dy < n and maze[nx + dx][ny + dy] == 0:
nx += dx
ny += dy
steps += 1
# 计算新的距离
new_dist = d + steps
# 如果找到更短的路径
if new_dist < dist[nx][ny]:
dist[nx][ny] = new_dist
heapq.heappush(pq, (new_dist, nx, ny))
# 无法到达目的地
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n \times \log(m \times n))$,其中 $m$ 和 $n$ 是迷宫的行数和列数。每个位置最多入队一次,堆操作的时间复杂度为 $O(\log(m \times n))$。
- **空间复杂度**:$O(m \times n)$,需要存储距离数组和优先队列。
================================================
FILE: docs/solutions/0500-0599/valid-square.md
================================================
# [0593. 有效的正方形](https://leetcode.cn/problems/valid-square/)
- 标签:几何、数学
- 难度:中等
## 题目链接
- [0593. 有效的正方形 - 力扣](https://leetcode.cn/problems/valid-square/)
## 题目大意
**描述**:
给定 2D 空间中四个点的坐标 $p1$, $p2$, $p3$ 和 $p4$。
**要求**:
如果这四个点构成一个正方形,则返回 true。
**说明**:
- 点的坐标 $pi$ 表示为 $[xi, yi]$。 输入没有任何顺序。
- 一个有效的正方形有四条等边和四个等角(90 度角)。
- $p1.length == p2.length == p3.length == p4.length == 2$。
- $-10^{4} \le xi, yi \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1]
输出: true
```
- 示例 2:
```python
输入:p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,12]
输出:false
```
## 解题思路
### 思路 1:距离判断
一个有效的正方形需要满足:
1. 四条边长度相等。
2. 两条对角线长度相等。
3. 四个角都是 90 度(可以通过边长的平方和等于对角线平方的一半来判断,即 $a^2 + b^2 = c^2$)。
我们可以计算所有点对之间的距离,对于一个正方形,应该有:
- 4 条边长度相等(设为 $side$)。
- 2 条对角线长度相等(设为 $diagonal$)。
- 满足 $2 \times side^2 = diagonal^2$(勾股定理)。
计算所有 $6$ 个点对之间的距离,排序后应该得到:$4$ 个相等的边长度和 $2$ 个相等的对角线长度,且满足上述关系。同时需要排除所有点重合的情况。
### 思路 1:代码
```python
class Solution:
def validSquare(self, p1: List[int], p2: List[int], p3: List[int], p4: List[int]) -> bool:
def distance(p1: List[int], p2: List[int]) -> int:
# 计算两点间距离的平方(避免浮点数误差)
return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2
# 计算所有点对之间的距离平方
points = [p1, p2, p3, p4]
distances = []
for i in range(4):
for j in range(i + 1, 4):
dist = distance(points[i], points[j])
distances.append(dist)
# 排序距离
distances.sort()
# 检查:应该有 4 条相等的边和 2 条相等的对角线
# 且满足 2 * side^2 = diagonal^2
# 同时排除所有点重合的情况(最小距离不能为 0)
if distances[0] == 0:
return False
# 前 4 个应该是边,后 2 个应该是对角线
return distances[0] == distances[1] == distances[2] == distances[3] and distances[4] == distances[5] and 2 * distances[0] == distances[4]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$,固定计算 $6$ 个点对的距离并排序。
- **空间复杂度**:$O(1)$,只使用了常数额外空间。
================================================
FILE: docs/solutions/0500-0599/word-abbreviation.md
================================================
# [0527. 单词缩写](https://leetcode.cn/problems/word-abbreviation/)
- 标签:贪心、字典树、数组、字符串、排序
- 难度:困难
## 题目链接
- [0527. 单词缩写 - 力扣](https://leetcode.cn/problems/word-abbreviation/)
## 题目大意
**描述**:
给定一个字符串数组 $words$,该数组由 **互不相同** 的若干字符串组成,需要为每个单词生成最短的唯一缩写。
缩写规则如下:
- 初始缩写由起始字母 + 省略字母的数量 + 结尾字母组成。
- 如果多个单词的缩写相同,则使用更长的前缀代替首字母,直到从单词到缩写唯一。换而言之,最终的缩写必须只能映射到一个单词。
- 如果缩写不比原词短,则保持原词。
**要求**:
返回每个单词的最短唯一缩写列表。
**说明**:
- $1 \le words.length \le 400$。
- $2 \le words[i].length \le 400$。
- $words[i]$ 由小写英文字母组成。
- 所有 $words[i]$ 都是唯一的。
**示例**:
- 示例 1:
```python
输入: words = ["like", "god", "internal", "me", "internet", "interval", "intension", "face", "intrusion"]
输出: ["l2e","god","internal","me","i6t","interval","inte4n","f2e","intr4n"]
```
- 示例 2:
```python
输入:words = ["aa","aaa"]
输出:["aa","aaa"]
```
## 解题思路
### 思路 1:分组 + 字典树
每个单词的缩写规则:首字母 + 中间字符数量 + 尾字母。例如 `"like"` 缩写为 `"l2e"`。要求每个缩写唯一,不唯一时需增加前缀长度直到唯一。
**算法步骤**:
1. 将所有单词按 (长度, 首字母, 尾字母) 分组,只有这三个属性相同的单词才可能产生冲突。
2. 对每组单词构建字典树,记录每个前缀路径经过的单词数量。
3. 对于每个单词,在字典树中查找最短的唯一前缀(即路径上 $count = 1$ 的位置)。
4. 生成缩写:如果中间部分长度大于 1,使用 $word[:k] + str(len(word)-k-1) + word[-1]$;否则保持原词。
### 思路 1:代码
```python
class TrieNode:
def __init__(self):
self.children = {}
self.count = 0 # 路径经过多少单词
class Solution:
def wordsAbbreviation(self, words: List[str]) -> List[str]:
from collections import defaultdict
n = len(words)
res = [''] * n
# 按 (长度, 首字母, 尾字母) 分组
groups = defaultdict(list)
for i, word in enumerate(words):
key = (len(word), word[0], word[-1])
groups[key].append((word, i))
# 处理每组
for group in groups.values():
# 构造字典树
root = TrieNode()
for word, _ in group:
node = root
for c in word:
node = node.children.setdefault(c, TrieNode())
node.count += 1
# 查询每个单词的唯一前缀
for word, idx in group:
node = root
prefix_len = 0
for c in word:
node = node.children[c]
prefix_len += 1
if node.count == 1:
break
# 生成缩写
if len(word) - prefix_len - 1 > 1:
res[idx] = word[:prefix_len] + str(len(word) - prefix_len - 1) + word[-1]
else:
res[idx] = word
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times L)$,其中 $n$ 是单词数量,$L$ 是单词的平均长度。需要构建字典树和查询前缀。
- **空间复杂度**:$O(n \times L)$,字典树节点和分组的空间开销。
================================================
FILE: docs/solutions/0600-0699/2-keys-keyboard.md
================================================
# [0650. 两个键的键盘](https://leetcode.cn/problems/2-keys-keyboard/)
- 标签:数学、动态规划
- 难度:中等
## 题目链接
- [0650. 两个键的键盘 - 力扣](https://leetcode.cn/problems/2-keys-keyboard/)
## 题目大意
**描述**:最初记事本上只有一个字符 `'A'`。你每次可以对这个记事本进行两种操作:
- **Copy All(复制全部)**:复制这个记事本中的所有字符(不允许仅复制部分字符)。
- **Paste(粘贴)**:粘贴上一次复制的字符。
现在,给定一个数字 $n$,需要使用最少的操作次数,在记事本上输出恰好 $n$ 个 `'A'` 。
**要求**:返回能够打印出 $n$ 个 `'A'` 的最少操作次数。
**说明**:
- $1 \le n \le 1000$。
**示例**:
- 示例 1:
```python
输入:3
输出:3
解释
最初, 只有一个字符 'A'。
第 1 步, 使用 Copy All 操作。
第 2 步, 使用 Paste 操作来获得 'AA'。
第 3 步, 使用 Paste 操作来获得 'AAA'。
```
- 示例 2:
```python
输入:n = 1
输出:0
```
## 解题思路
### 思路 1:动态规划
###### 1. 阶段划分
按照字符 `'A'` 的个数进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i]$ 表示为:通过「复制」和「粘贴」操作,得到 $i$ 个字符 `'A'`,最少需要的操作数。
###### 3. 状态转移方程
1. 对于 $i$ 个字符 `'A'`,如果 $i$ 可以被一个小于 $i$ 的整数 $j$ 除尽($j$ 是 $i$ 的因子),则说明 $j$ 个字符 `'A'` 可以通过「复制」+「粘贴」总共 $\frac{i}{j}$ 次得到 $i$ 个字符 `'A'`。
2. 而得到 $j$ 个字符 `'A'`,最少需要的操作数可以通过 $dp[j]$ 获取。
则我们可以枚举 $i$ 的因子,从中找到在满足 $j$ 能够整除 $i$ 的条件下,最小的 $dp[j] + \frac{i}{j}$,即为 $dp[i]$,即 $dp[i] = min_{j | i}(dp[i], dp[j] + \frac{i}{j})$。
由于 $j$ 能够整除 $i$,则 $j$ 与 $\frac{i}{j}$ 都是 $i$ 的因子,两者中必有一个因子是小于等于 $\sqrt{i}$ 的,所以在枚举 $i$ 的因子时,我们只需要枚举区间 $[1, \sqrt{i}]$ 即可。
综上所述,状态转移方程为:$dp[i] = min_{j | i}(dp[i], dp[j] + \frac{i}{j}, dp[\frac{i}{j}] + j)$。
###### 4. 初始条件
- 当 $i$ 为 $1$ 时,最少需要的操作数为 $0$。所以 $dp[1] = 0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i]$ 表示为:通过「复制」和「粘贴」操作,得到 $i$ 个字符 `'A'`,最少需要的操作数。 所以最终结果为 $dp[n]$。
### 思路 1:动态规划代码
```python
import math
class Solution:
def minSteps(self, n: int) -> int:
dp = [0 for _ in range(n + 1)]
for i in range(2, n + 1):
dp[i] = float('inf')
for j in range(1, int(math.sqrt(n)) + 1):
if i % j == 0:
dp[i] = min(dp[i], dp[j] + i // j, dp[i // j] + j)
return dp[n]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \sqrt{n})$。外层循环遍历的时间复杂度是 $O(n)$,内层循环遍历的时间复杂度是 $O(\sqrt{n})$,所以总体时间复杂度为 $O(n \sqrt{n})$。
- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。
================================================
FILE: docs/solutions/0600-0699/24-game.md
================================================
# [0679. 24 点游戏](https://leetcode.cn/problems/24-game/)
- 标签:数组、数学、回溯
- 难度:困难
## 题目链接
- [0679. 24 点游戏 - 力扣](https://leetcode.cn/problems/24-game/)
## 题目大意
**描述**:
给定一个长度为4的整数数组 $cards$。你有 $4$ 张卡片,每张卡片上都包含一个范围在 $[1,9]$ 的数字。您应该使用运算符 `['+', '-', '*', '/']` 和括号 `'('` 和 `')'` 将这些卡片上的数字排列成数学表达式,以获得值 $24$。
你须遵守以下规则:
- 除法运算符 `/` 表示实数除法,而不是整数除法。
- 例如, `"4 / (1 - 2 / 3)= 4 / (1 / 3) = 12"`。
- 每个运算都在两个数字之间。特别是,不能使用 `-` 作为一元运算符。
- 例如,如果 $cards =[1,1,1,1]$,则表达式 `"-1 -1 -1 -1"` 是 不允许 的。
- 你不能把数字串在一起
- 例如,如果 $cards =[1,2,1,2]$,则表达式 `"12 + 12"` 无效。
**要求**:
如果可以得到这样的表达式,其计算结果为 24,则返回 true ,否则返回 false。
**说明**:
- $cards.length == 4$。
- $1 \le cards[i] \le 9$。
**示例**:
- 示例 1:
```python
输入: cards = [4, 1, 8, 7]
输出: true
解释: (8-4) * (7-1) = 24
```
- 示例 2:
```python
输入: cards = [1, 2, 1, 2]
输出: false
```
## 解题思路
### 思路 1:回溯算法
#### 思路 1:算法描述
这道题目要求判断是否可以通过四则运算和括号将四个数字组合成 $24$。
我们可以使用回溯算法来枚举所有可能的运算顺序和运算符组合。每次从数组中选择两个数字进行运算,将运算结果放回数组,然后递归处理剩余的数字,直到数组中只剩下一个数字,判断是否等于 $24$。
具体步骤如下:
1. 如果数组中只剩下一个数字,判断是否等于 $24$(考虑浮点数误差,判断是否在 $24$ 的附近)。
2. 枚举数组中的任意两个数字 $a$ 和 $b$,以及四种运算符 $+$、$-$、$\times$、$\div$。
3. 计算 $a$ 和 $b$ 的运算结果,将结果放回数组,递归处理剩余的数字。
4. 如果找到一种方案使得最终结果为 $24$,返回 $True$。
5. 回溯,尝试其他的数字组合和运算符。
注意:除法运算需要判断除数是否为 $0$。
#### 思路 1:代码
```python
class Solution:
def judgePoint24(self, cards: List[int]) -> bool:
TARGET = 24
EPSILON = 1e-6 # 浮点数误差范围
def backtrack(nums):
# 如果只剩下一个数字,判断是否等于 24
if len(nums) == 1:
return abs(nums[0] - TARGET) < EPSILON
# 枚举任意两个数字进行运算
n = len(nums)
for i in range(n):
for j in range(n):
if i == j:
continue
a, b = nums[i], nums[j]
# 剩余的数字
remaining = [nums[k] for k in range(n) if k != i and k != j]
# 枚举四种运算符
# 加法
if backtrack(remaining + [a + b]):
return True
# 减法
if backtrack(remaining + [a - b]):
return True
# 乘法
if backtrack(remaining + [a * b]):
return True
# 除法(需要判断除数是否为 0)
if abs(b) > EPSILON and backtrack(remaining + [a / b]):
return True
return False
# 将整数转换为浮点数
return backtrack([float(card) for card in cards])
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。虽然看起来是指数级别的复杂度,但由于数组长度固定为 $4$,所以时间复杂度是常数级别的。
- **空间复杂度**:$O(1)$。递归调用栈的深度最多为 $4$,空间复杂度是常数级别的。
================================================
FILE: docs/solutions/0600-0699/4-keys-keyboard.md
================================================
# [0651. 四个键的键盘](https://leetcode.cn/problems/4-keys-keyboard/)
- 标签:数学、动态规划
- 难度:中等
## 题目链接
- [0651. 四个键的键盘 - 力扣](https://leetcode.cn/problems/4-keys-keyboard/)
## 题目大意
**描述**:
假设你有一个特殊的键盘包含下面的按键:
- `A`:在屏幕上打印一个 `'A'`。
- `Ctrl-A`:选中整个屏幕。
- `Ctrl-C`:复制选中区域到缓冲区。
- `Ctrl-V`:将缓冲区内容输出到上次输入的结束位置,并显示在屏幕上。
现在,你可以 **最多** 按键 $n$ 次(使用上述四种按键)。
**要求**:
返回屏幕上最多可以显示 `'A'` 的个数。
**说明**:
- $1 \le n \le 50$。
**示例**:
- 示例 1:
```python
输入: n = 3
输出: 3
解释:
我们最多可以在屏幕上显示三个 'A' 通过如下顺序按键:
A, A, A
```
- 示例 2:
```python
输入: n = 7
输出: 9
解释:
我们最多可以在屏幕上显示九个 'A' 通过如下顺序按键:
A, A, A, Ctrl-A, Ctrl-C, Ctrl-V, Ctrl-V
```
## 解题思路
### 思路 1:动态规划
这道题目要求在最多按键 $n$ 次的情况下,屏幕上最多可以显示多少个 `'A'`。
我们可以使用动态规划来解决这个问题。定义 $dp[i]$ 表示按键 $i$ 次后屏幕上最多可以显示的 `'A'` 的个数。
对于每次按键,有两种选择:
1. **按 `A` 键**:屏幕上增加一个 `'A'`,即 $dp[i] = dp[i - 1] + 1$。
2. **使用 `Ctrl-A`、`Ctrl-C`、`Ctrl-V` 组合键进行复制粘贴操作**:假设在第 $j$ 次按键后进行全选复制,然后连续粘贴 $i - j - 2$ 次(需要 $2$ 次按键进行全选和复制),则 $dp[i] = dp[j] \times (i - j - 1)$。
我们需要枚举所有可能的 $j$,取最大值。
**算法步骤**:
1. 初始化 $dp$ 数组,$dp[0] = 0$。
2. 对于 $i$ 从 $1$ 到 $n$:
- 选择 1:按 `A` 键,$dp[i] = dp[i - 1] + 1$。
- 选择 2:枚举在第 $j$ 次按键后进行全选复制($1 \le j \le i - 2$),$dp[i] = \max(dp[i], dp[j] \times (i - j - 1))$。
3. 返回 $dp[n]$。
### 思路 1:代码
```python
class Solution:
def maxA(self, n: int) -> int:
# dp[i] 表示按键 i 次后屏幕上最多可以显示的 'A' 的个数
dp = [0] * (n + 1)
for i in range(1, n + 1):
# 选择 1:按 A 键
dp[i] = dp[i - 1] + 1
# 选择 2:使用复制粘贴操作
# 枚举在第 j 次按键后进行全选复制
for j in range(1, i - 2):
# 需要 2 次按键进行全选和复制,剩余 i - j - 2 次按键进行粘贴
# 粘贴 i - j - 2 次,相当于复制了 i - j - 1 份
dp[i] = max(dp[i], dp[j] * (i - j - 1))
return dp[n]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。需要两层循环,外层循环 $n$ 次,内层循环最多 $n$ 次。
- **空间复杂度**:$O(n)$。需要使用长度为 $n + 1$ 的数组存储动态规划的状态。
================================================
FILE: docs/solutions/0600-0699/add-bold-tag-in-string.md
================================================
# [0616. 给字符串添加加粗标签](https://leetcode.cn/problems/add-bold-tag-in-string/)
- 标签:字典树、数组、哈希表、字符串、字符串匹配
- 难度:中等
## 题目链接
- [0616. 给字符串添加加粗标签 - 力扣](https://leetcode.cn/problems/add-bold-tag-in-string/)
## 题目大意
给定一个字符串 `s` 和一个字符串列表 `words`。
要求:如果 `s` 的子串在字符串列表 `words` 中出现过,则在该子串前后添加加粗闭合标签 `
` 和 ``。如果两个子串有重叠部分,则将它们一起用一对闭合标签包围起来。同理,如果两个子字符串连续被加粗,那么你也需要把它们合起来用一对加粗标签包围。最后返回添加加粗标签后的字符串 `s`。
## 解题思路
构建字典树,将字符串列表 `words` 中所有字符串添加到字典树中。
然后遍历字符串 `s`,从每一个位置开始查询字典树。在第一个符合要求的单词前面添加 `
`。在连续符合要求的单词中的最后一个单词后面添加 ``。
最后返回添加加粗标签后的字符串 `s`。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class Solution:
def addBoldTag(self, s: str, words: List[str]) -> str:
trie_tree = Trie()
for word in words:
trie_tree.insert(word)
size = len(s)
bold_left, bold_right = -1, -1
ans = ""
for i in range(size):
cur = trie_tree
if s[i] in cur.children:
bold_left = i
while bold_left < size and s[bold_left] in cur.children:
cur = cur.children[s[bold_left]]
bold_left += 1
if cur.isEnd:
if bold_right == -1:
ans += "
"
bold_right = max(bold_left, bold_right)
if i == bold_right:
ans += ""
bold_right = -1
ans += s[i]
if bold_right >= 0:
ans += ""
return ans
```
================================================
FILE: docs/solutions/0600-0699/add-one-row-to-tree.md
================================================
# [0623. 在二叉树中增加一行](https://leetcode.cn/problems/add-one-row-to-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0623. 在二叉树中增加一行 - 力扣](https://leetcode.cn/problems/add-one-row-to-tree/)
## 题目大意
**描述**:
给定一个二叉树的根 $root$ 和两个整数 $val$ 和 $depth$。
**要求**:
在给定的深度 $depth$ 处添加一个值为 $val$ 的节点行。
注意,根节点 $root$ 位于深度 1。
**说明**:
- 加法规则如下:
- 给定整数 $depth$,对于深度为 $depth - 1$ 的每个非空树节点 $cur$ ,创建两个值为 $val$ 的树节点作为 $cur$ 的左子树根和右子树根。
- $cur$ 原来的左子树应该是新的左子树根的左子树。
- $cur$ 原来的右子树应该是新的右子树根的右子树。
- 如果 $depth == 1$ 意味着 $depth - 1$ 根本没有深度,那么创建一个树节点,值 $val$ 作为整个原始树的新根,而原始树就是新根的左子树。
- 节点数在 $[1, 10^{4}]$ 范围内。
- 树的深度在 $[1, 10^{4}]$ 范围内。
- $-10^{3} \le Node.val \le 10^{3}$。
- $-10^{5} \le val \le 10^{5}$。
- $1 \le depth \le the depth of tree + 1$。
**示例**:
- 示例 1:
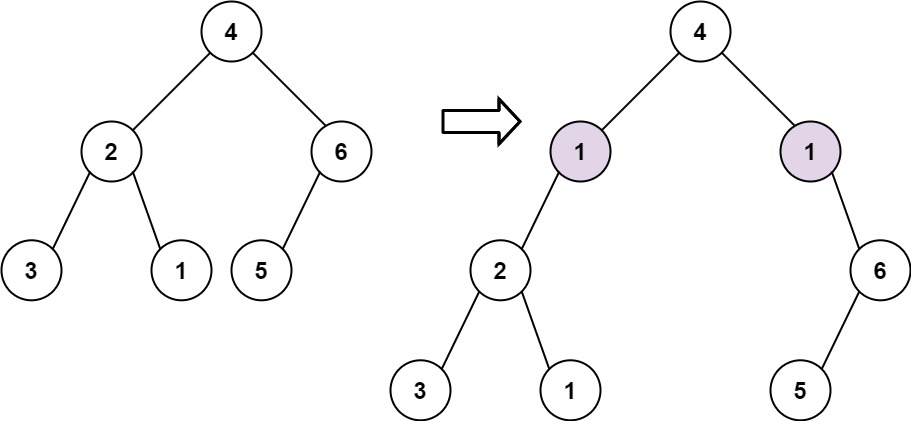
```python
输入: root = [4,2,6,3,1,5], val = 1, depth = 2
输出: [4,1,1,2,null,null,6,3,1,5]
```
- 示例 2:
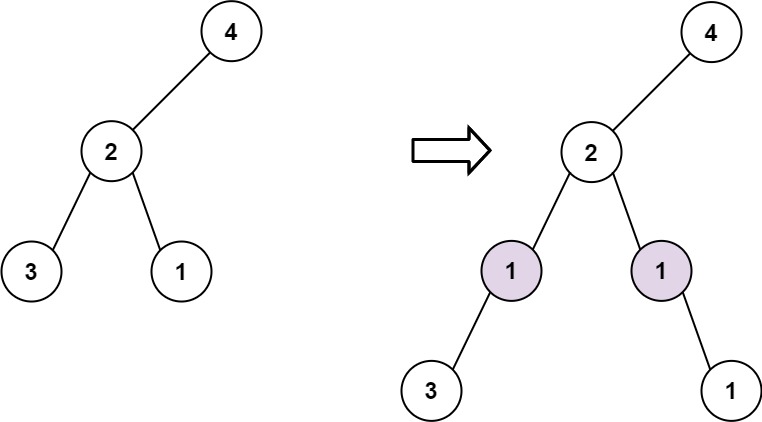
```python
输入: root = [4,2,null,3,1], val = 1, depth = 3
输出: [4,2,null,1,1,3,null,null,1]
```
## 解题思路
### 思路 1:广度优先搜索
#### 思路 1:算法描述
这道题目要求在二叉树的指定深度 $depth$ 处添加一行值为 $val$ 的节点。
我们可以使用广度优先搜索(BFS)来找到深度为 $depth - 1$ 的所有节点,然后为这些节点添加新的左右子节点。
特殊情况:如果 $depth = 1$,则需要创建一个新的根节点,原来的树作为新根节点的左子树。
具体步骤如下:
1. 如果 $depth = 1$,创建一个新的根节点,值为 $val$,原来的根节点作为新根节点的左子节点,返回新根节点。
2. 使用 BFS 遍历二叉树,找到深度为 $depth - 1$ 的所有节点。
3. 对于深度为 $depth - 1$ 的每个节点 $node$:
- 创建两个新节点 $left\_node$ 和 $right\_node$,值都为 $val$。
- 将 $node$ 的原左子节点作为 $left\_node$ 的左子节点。
- 将 $node$ 的原右子节点作为 $right\_node$ 的右子节点。
- 将 $left\_node$ 和 $right\_node$ 分别设置为 $node$ 的左右子节点。
4. 返回根节点。
#### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def addOneRow(self, root: Optional[TreeNode], val: int, depth: int) -> Optional[TreeNode]:
# 特殊情况:在根节点前添加一行
if depth == 1:
new_root = TreeNode(val)
new_root.left = root
return new_root
# 使用 BFS 找到深度为 depth - 1 的所有节点
queue = [root]
current_depth = 1
while queue and current_depth < depth - 1:
size = len(queue)
for _ in range(size):
node = queue.pop(0)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
current_depth += 1
# 为深度为 depth - 1 的所有节点添加新的左右子节点
for node in queue:
# 创建新的左子节点
left_node = TreeNode(val)
left_node.left = node.left
node.left = left_node
# 创建新的右子节点
right_node = TreeNode(val)
right_node.right = node.right
node.right = right_node
return root
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数。最坏情况下需要遍历所有节点。
- **空间复杂度**:$O(n)$。队列中最多存储 $n$ 个节点。
================================================
FILE: docs/solutions/0600-0699/average-of-levels-in-binary-tree.md
================================================
# [0637. 二叉树的层平均值](https://leetcode.cn/problems/average-of-levels-in-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0637. 二叉树的层平均值 - 力扣](https://leetcode.cn/problems/average-of-levels-in-binary-tree/)
## 题目大意
**描述**:
给定一个非空二叉树的根节点 $root$。
**要求**:
以数组的形式返回每一层节点的平均值。与实际答案相差 $10^{-5}$ 以内的答案可以被接受。
**说明**:
- 树中节点数量在 $[1, 10^{4}]$ 范围内。
- $-2^{31} \le Node.val \le 2^{31} - 1$。
**示例**:
- 示例 1:
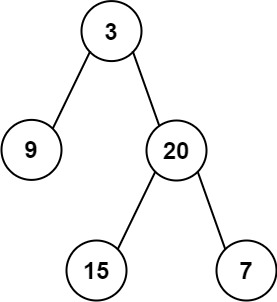
```python
输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。
因此返回 [3, 14.5, 11] 。
```
- 示例 2:
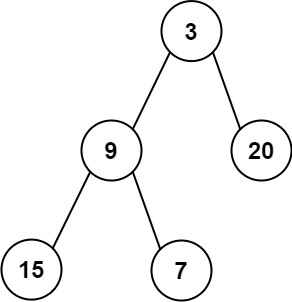
```python
输入:root = [3,9,20,15,7]
输出:[3.00000,14.50000,11.00000]
```
## 解题思路
### 思路 1:广度优先搜索
#### 思路 1:算法描述
这道题目要求返回二叉树每一层节点的平均值。我们可以使用广度优先搜索(BFS)来层序遍历二叉树。
具体步骤如下:
1. 初始化结果数组 $ans$ 和队列 $queue$,将根节点加入队列。
2. 当队列不为空时,执行以下操作:
- 记录当前层的节点数量 $size$。
- 初始化当前层的节点值之和 $level\_sum = 0$。
- 遍历当前层的所有节点:
- 从队列中取出节点,将其值加到 $level\_sum$ 中。
- 如果节点有左子节点,将左子节点加入队列。
- 如果节点有右子节点,将右子节点加入队列。
- 计算当前层的平均值 $level\_sum / size$,加入结果数组 $ans$。
3. 返回结果数组 $ans$。
#### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def averageOfLevels(self, root: Optional[TreeNode]) -> List[float]:
if not root:
return []
ans = []
queue = [root]
while queue:
size = len(queue) # 当前层的节点数量
level_sum = 0 # 当前层的节点值之和
# 遍历当前层的所有节点
for _ in range(size):
node = queue.pop(0)
level_sum += node.val
# 将下一层的节点加入队列
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
# 计算当前层的平均值
ans.append(level_sum / size)
return ans
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数。需要遍历所有节点。
- **空间复杂度**:$O(n)$。队列中最多存储 $n$ 个节点。
================================================
FILE: docs/solutions/0600-0699/baseball-game.md
================================================
# [0682. 棒球比赛](https://leetcode.cn/problems/baseball-game/)
- 标签:栈、数组、模拟
- 难度:简单
## 题目链接
- [0682. 棒球比赛 - 力扣](https://leetcode.cn/problems/baseball-game/)
## 题目大意
**描述**:
你现在是一场采用特殊赛制棒球比赛的记录员。这场比赛由若干回合组成,过去几回合的得分可能会影响以后几回合的得分。
比赛开始时,记录是空白的。你会得到一个记录操作的字符串列表 $ops$,其中 $ops[i]$ 是你需要记录的第 $i$ 项操作,$ops$ 遵循下述规则:
1. 整数 $x$:表示本回合新获得分数 $x$
2. `"+"`:表示本回合新获得的得分是前两次得分的总和。题目数据保证记录此操作时前面总是存在两个有效的分数。
3. `"D"`:表示本回合新获得的得分是前一次得分的两倍。题目数据保证记录此操作时前面总是存在一个有效的分数。
4. `"C"`:表示前一次得分无效,将其从记录中移除。题目数据保证记录此操作时前面总是存在一个有效的分数。
**要求**:
返回记录中所有得分的总和。
**说明**:
- $1 \le ops.length \le 10^{3}$。
- $ops[i]$ 为 `"C"`、`"D"`、`"+"`,或者一个表示整数的字符串。整数范围是 $[-3 \times 10^{4}, 3 \times 10^{4}]$。
- 对于 `"+"` 操作,题目数据保证记录此操作时前面总是存在两个有效的分数。
- 对于 `"C"` 和 `"D"` 操作,题目数据保证记录此操作时前面总是存在一个有效的分数。
**示例**:
- 示例 1:
```python
输入:ops = ["5","2","C","D","+"]
输出:30
解释:
"5" - 记录加 5 ,记录现在是 [5]
"2" - 记录加 2 ,记录现在是 [5, 2]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5].
"D" - 记录加 2 * 5 = 10 ,记录现在是 [5, 10].
"+" - 记录加 5 + 10 = 15 ,记录现在是 [5, 10, 15].
所有得分的总和 5 + 10 + 15 = 30
```
- 示例 2:
```python
输入:ops = ["5","-2","4","C","D","9","+","+"]
输出:27
解释:
"5" - 记录加 5 ,记录现在是 [5]
"-2" - 记录加 -2 ,记录现在是 [5, -2]
"4" - 记录加 4 ,记录现在是 [5, -2, 4]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5, -2]
"D" - 记录加 2 * -2 = -4 ,记录现在是 [5, -2, -4]
"9" - 记录加 9 ,记录现在是 [5, -2, -4, 9]
"+" - 记录加 -4 + 9 = 5 ,记录现在是 [5, -2, -4, 9, 5]
"+" - 记录加 9 + 5 = 14 ,记录现在是 [5, -2, -4, 9, 5, 14]
所有得分的总和 5 + -2 + -4 + 9 + 5 + 14 = 27
```
## 解题思路
### 思路 1:栈
#### 思路 1:算法描述
这道题目需要根据操作记录计算得分总和。我们可以使用栈来模拟这个过程。
具体步骤如下:
1. 初始化一个空栈 $stack$,用于存储有效的得分记录。
2. 遍历操作列表 $ops$,对于每个操作 $op$:
- 如果 $op$ 是 `"+"`,则将栈顶两个元素的和加入栈中。
- 如果 $op$ 是 `"D"`,则将栈顶元素的两倍加入栈中。
- 如果 $op$ 是 `"C"`,则将栈顶元素弹出。
- 否则,$op$ 是一个整数,将其转换为整数后加入栈中。
3. 遍历结束后,返回栈中所有元素的和。
#### 思路 1:代码
```python
class Solution:
def calPoints(self, operations: List[str]) -> int:
stack = [] # 用栈存储有效得分
for op in operations:
if op == "+":
# 前两次得分的总和
stack.append(stack[-1] + stack[-2])
elif op == "D":
# 前一次得分的两倍
stack.append(stack[-1] * 2)
elif op == "C":
# 移除前一次得分
stack.pop()
else:
# 新得分
stack.append(int(op))
# 返回所有得分的总和
return sum(stack)
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是操作列表的长度。需要遍历一次操作列表。
- **空间复杂度**:$O(n)$。栈中最多存储 $n$ 个元素。
================================================
FILE: docs/solutions/0600-0699/beautiful-arrangement-ii.md
================================================
# [0667. 优美的排列 II](https://leetcode.cn/problems/beautiful-arrangement-ii/)
- 标签:数组、数学
- 难度:中等
## 题目链接
- [0667. 优美的排列 II - 力扣](https://leetcode.cn/problems/beautiful-arrangement-ii/)
## 题目大意
**描述**:
给定两个整数 $n$ 和 $k$。
**要求**:
构造一个答案列表 $answer$,该列表应当包含从 1 到 $n$ 的 $n$ 个不同正整数,并同时满足下述条件:
- 假设该列表是 $answer = [a_1, a_2, a_3, ..., a_n]$,那么列表 $[|a_1 - a_2|, |a_2 - a_3|, |a_3 - a_4|, ..., |a_{n-1} - a_n|]$ 中应该有且仅有 $k$ 个不同整数。
返回列表 $answer$ 。如果存在多种答案,只需返回其中任意一种。
**说明**:
- $1 \le k \lt n \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:n = 3, k = 1
输出:[1, 2, 3]
解释:[1, 2, 3] 包含 3 个范围在 1-3 的不同整数,并且 [1, 1] 中有且仅有 1 个不同整数:1
```
- 示例 2:
```python
输入:n = 3, k = 2
输出:[1, 3, 2]
解释:[1, 3, 2] 包含 3 个范围在 1-3 的不同整数,并且 [2, 1] 中有且仅有 2 个不同整数:1 和 2
```
## 解题思路
### 思路 1:构造法
#### 思路 1:算法描述
这道题目要求构造一个包含 $1$ 到 $n$ 的排列,使得相邻元素的差值恰好有 $k$ 个不同的整数。
我们可以使用构造法来解决这个问题。观察发现:
- 如果数组是 $[1, 2, 3, ..., n]$,那么相邻元素的差值都是 $1$,只有 $1$ 个不同的整数。
- 如果数组是 $[1, n, 2, n-1, 3, n-2, ...]$,那么相邻元素的差值是 $n-1, n-2, n-3, ...$,有 $n-1$ 个不同的整数。
因此,我们可以先构造前 $k$ 个元素,使得它们的差值恰好有 $k$ 个不同的整数,然后剩余的元素按顺序排列。
具体步骤如下:
1. 初始化结果数组 $ans$。
2. 使用两个指针 $left = 1$ 和 $right = k + 1$,交替取值,构造前 $k + 1$ 个元素:
- 先取 $left$,然后取 $right$,再取 $left + 1$,再取 $right - 1$,以此类推。
- 这样可以保证前 $k + 1$ 个元素的差值恰好有 $k$ 个不同的整数。
3. 将剩余的元素 $[k + 2, k + 3, ..., n]$ 按顺序加入结果数组。
4. 返回结果数组 $ans$。
#### 思路 1:代码
```python
class Solution:
def constructArray(self, n: int, k: int) -> List[int]:
ans = []
left, right = 1, k + 1
# 构造前 k + 1 个元素,使得差值恰好有 k 个不同的整数
while left <= right:
ans.append(left)
left += 1
if left <= right:
ans.append(right)
right -= 1
# 将剩余的元素按顺序加入结果数组
for i in range(k + 2, n + 1):
ans.append(i)
return ans
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。需要构造长度为 $n$ 的数组。
- **空间复杂度**:$O(1)$。不考虑结果数组的空间,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/binary-number-with-alternating-bits.md
================================================
# [0693. 交替位二进制数](https://leetcode.cn/problems/binary-number-with-alternating-bits/)
- 标签:位运算
- 难度:简单
## 题目链接
- [0693. 交替位二进制数 - 力扣](https://leetcode.cn/problems/binary-number-with-alternating-bits/)
## 题目大意
**描述**:
给定一个正整数 $n$。
**要求**:
检查它的二进制表示是否总是 $0$、$1$ 交替出现:换句话说,就是二进制表示中相邻两位的数字永不相同。
**说明**:
- $1 \le n \le 2^{31} - 1$。
**示例**:
- 示例 1:
```python
输入:n = 5
输出:true
解释:5 的二进制表示是:101
```
- 示例 2:
```python
输入:n = 7
输出:false
解释:7 的二进制表示是:111.
```
## 解题思路
### 思路 1:位运算
#### 思路 1:算法描述
这道题目要求判断一个正整数的二进制表示是否总是 $0$、$1$ 交替出现。
我们可以使用位运算来解决这个问题。如果二进制表示中相邻两位的数字永不相同,那么将 $n$ 右移一位后与 $n$ 进行异或运算,得到的结果应该是所有位都为 $1$ 的数。
具体步骤如下:
1. 计算 $a = n \oplus (n >> 1)$,其中 $\oplus$ 表示异或运算。
2. 如果 $n$ 的二进制表示是交替的,那么 $a$ 的二进制表示应该是所有位都为 $1$。
3. 判断 $a$ 是否满足 $a \& (a + 1) = 0$,如果满足则返回 $True$,否则返回 $False$。
**解释**:如果 $a$ 的所有位都为 $1$,那么 $a + 1$ 会产生进位,使得 $a \& (a + 1) = 0$。
#### 思路 1:代码
```python
class Solution:
def hasAlternatingBits(self, n: int) -> bool:
# 将 n 右移一位后与 n 异或
a = n ^ (n >> 1)
# 判断 a 是否所有位都为 1
return (a & (a + 1)) == 0
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。只需要进行常数次位运算。
- **空间复杂度**:$O(1)$。只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/bulb-switcher-ii.md
================================================
# [0672. 灯泡开关 Ⅱ](https://leetcode.cn/problems/bulb-switcher-ii/)
- 标签:位运算、深度优先搜索、广度优先搜索、数学
- 难度:中等
## 题目链接
- [0672. 灯泡开关 Ⅱ - 力扣](https://leetcode.cn/problems/bulb-switcher-ii/)
## 题目大意
**描述**:
房间中有 $n$ 只已经打开的灯泡,编号从 $1$ 到 $n$。墙上挂着 $4$ 个开关。
这 $4$ 个开关各自都具有不同的功能,其中:
- 开关 1 :反转当前所有灯的状态(即开变为关,关变为开)
- 开关 2 :反转编号为偶数的灯的状态(即 $0, 2, 4, ...$)
- 开关 3 :反转编号为奇数的灯的状态(即 $1, 3, ...$)
- 开关 4 :反转编号为 $j = 3 \times k + 1$ 的灯的状态,其中 $k = 0, 1, 2, ...$(即 $1, 4, 7, 10, ...$)
你必须「恰好」按压开关 $presses$ 次。每次按压,你都需要从 $4$ 个开关中选出一个来执行按压操作。
给定两个整数 $n$ 和 $presses$。
**要求**:
执行完所有按压之后,返回「不同可能状态」的数量。
**说明**:
- $1 \le n \le 10^{3}$。
- $0 \le presses \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:n = 1, presses = 1
输出:2
解释:状态可以是:
- 按压开关 1 ,[关]
- 按压开关 2 ,[开]
```
- 示例 2:
```python
输入:n = 2, presses = 1
输出:3
解释:状态可以是:
- 按压开关 1 ,[关, 关]
- 按压开关 2 ,[开, 关]
- 按压开关 3 ,[关, 开]
```
## 解题思路
### 思路 1:数学 + 枚举
#### 思路 1:算法描述
这道题目要求在恰好按压开关 $presses$ 次后,返回不同可能状态的数量。
我们需要分析四个开关的作用:
- 开关 1:反转所有灯的状态。
- 开关 2:反转编号为偶数的灯的状态。
- 开关 3:反转编号为奇数的灯的状态。
- 开关 4:反转编号为 $3k + 1$ 的灯的状态($k = 0, 1, 2, ...$)。
关键观察:
1. 按压同一个开关两次等于没有按压,所以每个开关最多只需要按压一次。
2. 按压开关的顺序不影响最终结果。
3. 对于前 $3$ 个灯,可以完全确定所有灯的状态(因为灯的状态是周期性的)。
我们可以枚举所有可能的开关组合(最多 $2^4 = 16$ 种),然后判断哪些组合是有效的(按压次数的奇偶性与 $presses$ 相同)。
具体步骤如下:
1. 如果 $presses = 0$,返回 $1$(所有灯都亮着)。
2. 枚举所有可能的开关组合(用二进制表示,$0$ 表示不按压,$1$ 表示按压)。
3. 对于每个组合,计算按压次数,判断是否与 $presses$ 的奇偶性相同,且按压次数不超过 $presses$。
4. 如果有效,计算前 $\min(n, 3)$ 个灯的状态,加入集合中。
5. 返回集合的大小。
#### 思路 1:代码
```python
class Solution:
def flipLights(self, n: int, presses: int) -> int:
if presses == 0:
return 1
# 只需要考虑前 3 个灯的状态
n = min(n, 3)
states = set()
# 枚举所有可能的开关组合(4 个开关,2^4 = 16 种组合)
for mask in range(16):
# 计算按压次数
press_count = bin(mask).count('1')
# 判断按压次数是否有效
if press_count % 2 != presses % 2 or press_count > presses:
continue
# 计算前 n 个灯的状态
lights = [1] * n # 初始状态:所有灯都亮着
# 开关 1:反转所有灯
if mask & 1:
for i in range(n):
lights[i] ^= 1
# 开关 2:反转编号为偶数的灯(索引为 1, 3, 5, ...)
if mask & 2:
for i in range(1, n, 2):
lights[i] ^= 1
# 开关 3:反转编号为奇数的灯(索引为 0, 2, 4, ...)
if mask & 4:
for i in range(0, n, 2):
lights[i] ^= 1
# 开关 4:反转编号为 3k + 1 的灯(索引为 0, 3, 6, ...)
if mask & 8:
for i in range(0, n, 3):
lights[i] ^= 1
# 将状态加入集合
states.add(tuple(lights))
return len(states)
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。枚举的组合数是常数($16$ 种),每种组合的计算时间也是常数。
- **空间复杂度**:$O(1)$。集合中最多存储常数个状态。
================================================
FILE: docs/solutions/0600-0699/can-place-flowers.md
================================================
# [0605. 种花问题](https://leetcode.cn/problems/can-place-flowers/)
- 标签:贪心、数组
- 难度:简单
## 题目链接
- [0605. 种花问题 - 力扣](https://leetcode.cn/problems/can-place-flowers/)
## 题目大意
**描述**:
假设有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给定一个整数数组 $flowerbed$ 表示花坛,由若干 $0$ 和 $1$ 组成,其中 $0$ 表示没种植花,$1$ 表示种植了花。另给定一个数 $n$。
**要求**:
能否在不打破种植规则的情况下种入 $n$ 朵花?能则返回 true,不能则返回 false 。
**说明**:
- $1 \le flowerbed.length \le 2 \times 10^{4}$。
- $flowerbed[i]$ 为 $0$ 或 $1$。
- $flowerbed$ 中不存在相邻的两朵花。
- $0 \le n \le flowerbed.length$。
**示例**:
- 示例 1:
```python
输入:flowerbed = [1,0,0,0,1], n = 1
输出:true
```
- 示例 2:
```python
输入:flowerbed = [1,0,0,0,1], n = 2
输出:false
```
## 解题思路
### 思路 1:贪心算法
#### 思路 1:算法描述
这道题目要求在不违反种植规则的情况下,判断能否种入 $n$ 朵花。种植规则是:花不能种植在相邻的地块上。
我们可以使用贪心算法,从左到右遍历花坛,只要当前位置和相邻位置都没有花,就尽可能地种花。
具体步骤如下:
1. 遍历花坛数组 $flowerbed$,对于每个位置 $i$:
- 如果 $flowerbed[i] = 0$(当前位置没有花)。
- 并且 $i = 0$ 或 $flowerbed[i - 1] = 0$(左边没有花或者是边界)。
- 并且 $i = len(flowerbed) - 1$ 或 $flowerbed[i + 1] = 0$(右边没有花或者是边界)。
- 则在当前位置种花,将 $flowerbed[i]$ 设置为 $1$,并将计数器 $n$ 减 $1$。
2. 如果 $n \le 0$,说明已经种够了 $n$ 朵花,返回 $True$。
3. 遍历结束后,如果 $n > 0$,说明无法种够 $n$ 朵花,返回 $False$。
#### 思路 1:代码
```python
class Solution:
def canPlaceFlowers(self, flowerbed: List[int], n: int) -> bool:
# 遍历花坛
for i in range(len(flowerbed)):
# 当前位置没有花,且左右两边都没有花(或者是边界)
if flowerbed[i] == 0 and (i == 0 or flowerbed[i - 1] == 0) and (i == len(flowerbed) - 1 or flowerbed[i + 1] == 0):
# 在当前位置种花
flowerbed[i] = 1
n -= 1
# 如果已经种够了,直接返回 True
if n <= 0:
return True
# 遍历结束后,判断是否种够了
return n <= 0
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(m)$,其中 $m$ 是花坛的长度。只需要遍历一次花坛数组。
- **空间复杂度**:$O(1)$。只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/coin-path.md
================================================
# [0656. 成本最小路径](https://leetcode.cn/problems/coin-path/)
- 标签:数组、动态规划
- 难度:困难
## 题目链接
- [0656. 成本最小路径 - 力扣](https://leetcode.cn/problems/coin-path/)
## 题目大意
**描述**:
给定一个整数数组 $coins$(下标从 $1$ 开始)长度为 $n$,以及一个整数 $maxJump$。你可以跳到数组 $coins$ 的任意下标 $i$(满足 $coins[i] \ne -1$),访问下标 $i$ 时需要支付 $coins[i]$。此外,如果你当前位于下标 $i$,你只能跳到下标 $i + k$(满足 $i + k \le n$),其中 $k$ 是范围 $[1, maxJump]$ 内的一个值。
初始时你位于下标 $1$($coins[1]$ 不是 $-1$)。
**要求**:
找到一条到达下标 $n$ 的成本最小路径。
返回一个整数数组,包含你访问的下标顺序,以便你以最小成本达到下标 $n$。如果存在多条成本相同的路径,返回 **字典序最小** 的路径。如果无法达到下标 $n$,返回一个空数组。
路径 $p_1 = [Pa_1, Pa_2, ..., Pa_x]$ 的长度为 $x$,路径 $p_2 = [Pb_1, Pb_2, ..., Pb_x]$ 的长度为 $y$,如果在两条路径的第一个不同的下标 $j$ 处,$Pa_j$ 小于 $Pb_j$,则 $p_1$ 在字典序上小于 $p_2$;如果不存在这样的 $j$,则较短的路径字典序较小。
**说明**:
- $1 \le coins.length \le 10^3$。
- $-1 \le coins[i] \le 10^3$。
- $coins[1] \ne -1$。
- $1 \le maxJump \le 10^3$。
**示例**:
- 示例 1:
```python
输入:coins = [1,2,4,-1,2], maxJump = 2
输出:[1,3,5]
```
- 示例 2:
```python
输入:coins = [1,2,4,-1,2], maxJump = 1
输出:[]
```
## 解题思路
### 思路 1:动态规划(反向)
这道题目要求找到一条到达终点的成本最小路径,如果存在多条成本相同的路径,返回字典序最小的路径。
我们可以使用**反向动态规划**来解决这个问题。从终点往前推,定义 $dp[i]$ 表示从位置 $i$ 到达终点的最小成本。
**为什么使用反向DP?**
- 当成本相同时,我们需要选择字典序最小的路径
- 从后往前DP时,如果成本相同,我们选择索引较小的下一个节点,这样可以保证字典序最小
- 如果从前往后DP,即使选择索引较小的前驱节点,也无法保证整个路径的字典序最小
**算法步骤**:
1. 初始化 $dp$ 数组,$dp[n-1] = coins[n-1]$(终点位置)。
2. 从后往前遍历每个位置 $i$,枚举所有可能的下一个位置 $j$(满足 $i < j \le i + maxJump$ 且 $j < n$),更新 $dp[i]$。
3. 使用 $next[i]$ 数组记录从位置 $i$ 出发的下一个节点。如果成本相同,选择索引较小的下一个节点(保证字典序最小)。
4. 从起点开始,沿着 $next$ 数组构造路径。
**注意**:如果某个位置的 $coins[i] = -1$,则该位置不可达。
### 思路 1:代码
```python
class Solution:
def cheapestJump(self, coins: List[int], maxJump: int) -> List[int]:
n = len(coins)
# 如果起点或终点不可达,返回空数组
if coins[0] == -1 or coins[n - 1] == -1:
return []
# dp[i] 表示从位置 i 到达终点的最小成本
dp = [float('inf')] * n
dp[n - 1] = coins[n - 1]
# next[i] 表示从位置 i 出发的下一个节点(用于构造字典序最小的路径)
next_node = [-1] * n
# 从后往前进行动态规划
for i in range(n - 2, -1, -1):
if coins[i] == -1:
continue
# 枚举所有可能的下一个位置
for j in range(i + 1, min(i + maxJump + 1, n)):
if coins[j] == -1:
continue
# 如果从 j 无法到达终点,跳过
if dp[j] == float('inf'):
continue
cost = coins[i] + dp[j]
# 更新最小成本和下一个节点
if cost < dp[i]:
dp[i] = cost
next_node[i] = j
elif cost == dp[i] and (next_node[i] == -1 or j < next_node[i]):
# 成本相同,选择索引较小的下一个节点(保证字典序最小)
next_node[i] = j
# 如果无法从起点到达终点
if dp[0] == float('inf'):
return []
# 从起点开始,沿着 next_node 数组构造路径
path = []
i = 0
# 沿着 next_node 数组遍历,直到到达终点
while i < n and next_node[i] >= 0:
path.append(i + 1) # 题目中位置从 1 开始
i = next_node[i]
# 检查是否成功到达终点
if i == n - 1 and coins[i] >= 0:
path.append(n)
else:
return []
return path
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times maxJump)$,其中 $n$ 是数组的长度。需要两层循环,外层循环 $n$ 次,内层循环最多 $maxJump$ 次。
- **空间复杂度**:$O(n)$。需要使用两个长度为 $n$ 的数组存储动态规划的状态和下一个节点信息。
================================================
FILE: docs/solutions/0600-0699/construct-string-from-binary-tree.md
================================================
# [0606. 根据二叉树创建字符串](https://leetcode.cn/problems/construct-string-from-binary-tree/)
- 标签:树、深度优先搜索、字符串、二叉树
- 难度:中等
## 题目链接
- [0606. 根据二叉树创建字符串 - 力扣](https://leetcode.cn/problems/construct-string-from-binary-tree/)
## 题目大意
**描述**:
给定二叉树的根节点 $root$。
**要求**:
采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
空节点使用一对空括号对 `"()"` 表示,转化后需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
**说明**:
- 树中节点的数目范围是 $[1, 10^{4}]$。
- $-10^{3} \le Node.val \le 10^{3}$。
**示例**:
- 示例 1:
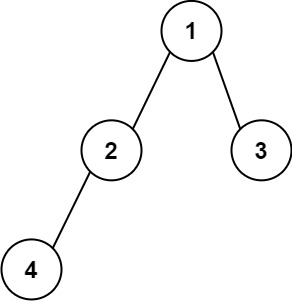
```python
输入:root = [1,2,3,4]
输出:"1(2(4))(3)"
解释:初步转化后得到 "1(2(4)())(3()())" ,但省略所有不必要的空括号对后,字符串应该是"1(2(4))(3)" 。
```
- 示例 2:
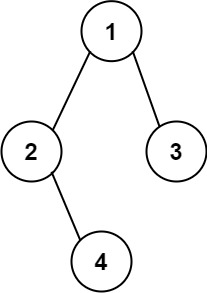
```python
输入:root = [1,2,3,null,4]
输出:"1(2()(4))(3)"
解释:和第一个示例类似,但是无法省略第一个空括号对,否则会破坏输入与输出一一映射的关系。
```
## 解题思路
### 思路 1:深度优先搜索
#### 思路 1:算法描述
这道题目要求将二叉树转化为一个由括号和整数组成的字符串,采用前序遍历的方式。
我们可以使用深度优先搜索(DFS)来递归构造字符串。需要注意的是,要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
具体规则如下:
1. 如果节点有左子树,则需要在左子树的字符串外加上括号。
2. 如果节点有右子树,则需要在右子树的字符串外加上括号。
3. 如果节点没有左子树但有右子树,则需要在左子树的位置加上空括号 `"()"`。
4. 如果节点既没有左子树也没有右子树,则不需要加括号。
#### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def tree2str(self, root: Optional[TreeNode]) -> str:
if not root:
return ""
# 只有根节点
if not root.left and not root.right:
return str(root.val)
# 有左子树,没有右子树
if root.left and not root.right:
return str(root.val) + "(" + self.tree2str(root.left) + ")"
# 有右子树(无论是否有左子树)
return str(root.val) + "(" + self.tree2str(root.left) + ")(" + self.tree2str(root.right) + ")"
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数。需要遍历所有节点。
- **空间复杂度**:$O(n)$。递归调用栈的深度最多为 $n$。
================================================
FILE: docs/solutions/0600-0699/count-binary-substrings.md
================================================
# [0696. 计数二进制子串](https://leetcode.cn/problems/count-binary-substrings/)
- 标签:双指针、字符串
- 难度:简单
## 题目链接
- [0696. 计数二进制子串 - 力扣](https://leetcode.cn/problems/count-binary-substrings/)
## 题目大意
**描述**:
给定一个字符串 $s$。
**要求**:
统计并返回具有相同数量 $0$ 和 $1$ 的非空(连续)子字符串的数量,并且这些子字符串中的所有 $0$ 和所有 $1$ 都是成组连续的。
重复出现(不同位置)的子串也要统计它们出现的次数。
**说明**:
- $1 \le s.length \le 10^{5}$。
- $s[i]$ 为 `'0'` 或 `'1'`。
**示例**:
- 示例 1:
```python
输入:s = "00110011"
输出:6
解释:6 个子串满足具有相同数量的连续 1 和 0 :"0011"、"01"、"1100"、"10"、"0011" 和 "01" 。
注意,一些重复出现的子串(不同位置)要统计它们出现的次数。
另外,"00110011" 不是有效的子串,因为所有的 0(还有 1 )没有组合在一起。
```
- 示例 2:
```python
输入:s = "10101"
输出:4
解释:有 4 个子串:"10"、"01"、"10"、"01" ,具有相同数量的连续 1 和 0 。
```
## 解题思路
### 思路 1:双指针
#### 思路 1:算法描述
这道题目要求统计具有相同数量 $0$ 和 $1$ 的非空连续子字符串的数量,并且这些子字符串中的所有 $0$ 和所有 $1$ 都是成组连续的。
我们可以使用双指针的方法,统计连续的 $0$ 和 $1$ 的个数。
具体步骤如下:
1. 初始化 $prev = 0$(前一组字符的个数)和 $curr = 1$(当前组字符的个数)。
2. 初始化结果 $ans = 0$。
3. 从左到右遍历字符串 $s$,对于每个位置 $i$(从 $1$ 开始):
- 如果 $s[i] = s[i - 1]$,说明当前字符与前一个字符相同,将 $curr$ 加 $1$。
- 否则,说明遇到了新的一组字符,此时可以形成的子字符串数量为 $\min(prev, curr)$,将其加到 $ans$ 中,然后更新 $prev = curr$,$curr = 1$。
4. 遍历结束后,还需要加上最后一组字符可以形成的子字符串数量 $\min(prev, curr)$。
5. 返回 $ans$。
#### 思路 1:代码
```python
class Solution:
def countBinarySubstrings(self, s: str) -> int:
prev = 0 # 前一组字符的个数
curr = 1 # 当前组字符的个数
ans = 0 # 结果
# 遍历字符串
for i in range(1, len(s)):
if s[i] == s[i - 1]:
# 当前字符与前一个字符相同
curr += 1
else:
# 遇到新的一组字符
ans += min(prev, curr)
prev = curr
curr = 1
# 加上最后一组字符可以形成的子字符串数量
ans += min(prev, curr)
return ans
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串的长度。只需要遍历一次字符串。
- **空间复杂度**:$O(1)$。只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/course-schedule-iii.md
================================================
# [0630. 课程表 III](https://leetcode.cn/problems/course-schedule-iii/)
- 标签:贪心、数组、排序、堆(优先队列)
- 难度:困难
## 题目链接
- [0630. 课程表 III - 力扣](https://leetcode.cn/problems/course-schedule-iii/)
## 题目大意
**描述**:
这里有 $n$ 门不同的在线课程,按从 $1$ 到 $n$ 编号。给你一个数组 $courses$ ,其中 $courses[i] = [duration_i, lastDay_i]$ 表示第 $i$ 门课将会持续上 $durationi$ 天课,并且必须在不晚于 $lastDayi$ 的时候完成。
你的学期从第 1 天开始。且不能同时修读两门及两门以上的课程。
**要求**:
返回你最多可以修读的课程数目。
**说明**:
- $1 \le courses.length \le 10^{4}$。
- $1 \le duration_i, lastDay_i \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:courses = [[100, 200], [200, 1300], [1000, 1250], [2000, 3200]]
输出:3
解释:
这里一共有 4 门课程,但是你最多可以修 3 门:
首先,修第 1 门课,耗费 100 天,在第 100 天完成,在第 101 天开始下门课。
第二,修第 3 门课,耗费 1000 天,在第 1100 天完成,在第 1101 天开始下门课程。
第三,修第 2 门课,耗时 200 天,在第 1300 天完成。
第 4 门课现在不能修,因为将会在第 3300 天完成它,这已经超出了关闭日期。
```
- 示例 2:
```python
输入:courses = [[1,2]]
输出:1
```
## 解题思路
### 思路 1:贪心 + 优先队列
#### 思路 1:算法描述
这道题目要求在不晚于截止日期的情况下,最多可以修读多少门课程。
我们可以使用贪心算法结合优先队列(最大堆)来解决这个问题。
基本思路:
1. 按照课程的截止日期从小到大排序。
2. 依次考虑每门课程,如果当前时间加上课程持续时间不超过截止日期,就选择这门课程。
3. 如果超过了截止日期,但当前课程的持续时间比已选课程中持续时间最长的课程短,就替换掉那门课程。
具体步骤如下:
1. 将课程按照截止日期从小到大排序。
2. 初始化当前时间 $time = 0$ 和最大堆 $heap$(存储已选课程的持续时间)。
3. 遍历排序后的课程:
- 如果 $time + duration \le lastDay$,选择这门课程,将持续时间加入堆中,更新 $time$。
- 否则,如果堆不为空且堆顶元素(最大持续时间)大于当前课程的持续时间,就替换掉堆顶课程。
4. 返回堆的大小,即最多可以修读的课程数。
#### 思路 1:代码
```python
class Solution:
def scheduleCourse(self, courses: List[List[int]]) -> int:
import heapq
# 按照截止日期从小到大排序
courses.sort(key=lambda x: x[1])
time = 0 # 当前时间
heap = [] # 最大堆,存储已选课程的持续时间(取负数实现最大堆)
for duration, lastDay in courses:
# 如果可以在截止日期前完成这门课程
if time + duration <= lastDay:
time += duration
heapq.heappush(heap, -duration) # 加入堆中(取负数)
# 如果不能完成,但当前课程的持续时间比已选课程中最长的短
elif heap and -heap[0] > duration:
# 替换掉持续时间最长的课程
time += duration - (-heapq.heappop(heap))
heapq.heappush(heap, -duration)
return len(heap)
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是课程的数量。排序需要 $O(n \log n)$,每门课程最多进出堆一次,堆操作需要 $O(\log n)$。
- **空间复杂度**:$O(n)$。堆中最多存储 $n$ 门课程。
================================================
FILE: docs/solutions/0600-0699/cut-off-trees-for-golf-event.md
================================================
# [0675. 为高尔夫比赛砍树](https://leetcode.cn/problems/cut-off-trees-for-golf-event/)
- 标签:广度优先搜索、数组、矩阵、堆(优先队列)
- 难度:困难
## 题目链接
- [0675. 为高尔夫比赛砍树 - 力扣](https://leetcode.cn/problems/cut-off-trees-for-golf-event/)
## 题目大意
**描述**:
你被请来给一个要举办高尔夫比赛的树林砍树。树林由一个 $m \times n$ 的矩阵表示,在这个矩阵中:
- $0$ 表示障碍,无法触碰
- $1$ 表示地面,可以行走
- 比 $1$ 大的数表示有树的单元格,可以行走,数值表示树的高度
每一步,你都可以向上、下、左、右四个方向之一移动一个单位,如果你站的地方有一棵树,那么你可以决定是否要砍倒它。
你需要按照树的高度从低向高砍掉所有的树,每砍过一颗树,该单元格的值变为 $1$(即变为地面)。
**要求**:
你将从 $(0, 0)$ 点开始工作,返回你砍完所有树需要走的最小步数。 如果你无法砍完所有的树,返回 $-1$。
可以保证的是,没有两棵树的高度是相同的,并且你至少需要砍倒一棵树。
**说明**:
- $m == forest.length$。
- $n == forest[i].length$。
- $1 \le m, n \le 50$。
- $0 \le forest[i][j] \le 10^{9}$。
**示例**:
- 示例 1:
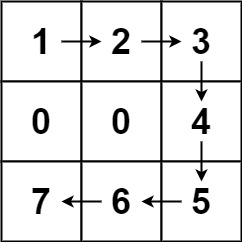
```python
输入:forest = [[1,2,3],[0,0,4],[7,6,5]]
输出:6
解释:沿着上面的路径,你可以用 6 步,按从最矮到最高的顺序砍掉这些树。
```
- 示例 2:
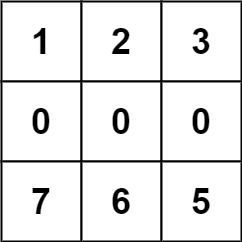
```python
输入:forest = [[1,2,3],[0,0,0],[7,6,5]]
输出:-1
解释:由于中间一行被障碍阻塞,无法访问最下面一行中的树。
```
## 解题思路
### 思路 1:BFS + 排序
#### 思路 1:算法描述
这道题目要求按照树的高度从低到高砍树,返回砍完所有树需要走的最小步数。
我们可以将问题分解为两个子问题:
1. 确定砍树的顺序:按照树的高度从低到高排序。
2. 计算从一个位置到另一个位置的最短路径:使用 BFS。
具体步骤如下:
1. 遍历矩阵,找到所有树的位置和高度,按照高度从低到高排序。
2. 从起点 $(0, 0)$ 开始,依次前往每棵树的位置。
3. 对于每次移动,使用 BFS 计算从当前位置到目标位置的最短路径。
4. 如果无法到达某棵树,返回 $-1$。
5. 累加所有移动的步数,返回总步数。
#### 思路 1:代码
```python
class Solution:
def cutOffTree(self, forest: List[List[int]]) -> int:
from collections import deque
m, n = len(forest), len(forest[0])
# 找到所有树的位置和高度
trees = []
for i in range(m):
for j in range(n):
if forest[i][j] > 1:
trees.append((forest[i][j], i, j))
# 按照高度从低到高排序
trees.sort()
# BFS 计算从 (sr, sc) 到 (tr, tc) 的最短路径
def bfs(sr, sc, tr, tc):
if sr == tr and sc == tc:
return 0
queue = deque([(sr, sc, 0)])
visited = {(sr, sc)}
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
while queue:
r, c, dist = queue.popleft()
for dr, dc in directions:
nr, nc = r + dr, c + dc
# 检查边界和障碍物
if 0 <= nr < m and 0 <= nc < n and (nr, nc) not in visited and forest[nr][nc] != 0:
if nr == tr and nc == tc:
return dist + 1
queue.append((nr, nc, dist + 1))
visited.add((nr, nc))
return -1 # 无法到达
# 从起点开始,依次前往每棵树
total_steps = 0
sr, sc = 0, 0
for _, tr, tc in trees:
steps = bfs(sr, sc, tr, tc)
if steps == -1:
return -1
total_steps += steps
sr, sc = tr, tc
return total_steps
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(m^2 \times n^2 \times t)$,其中 $m$ 和 $n$ 是矩阵的行数和列数,$t$ 是树的数量。每次 BFS 的时间复杂度为 $O(m \times n)$,需要进行 $t$ 次 BFS。
- **空间复杂度**:$O(m \times n)$。BFS 需要使用队列和访问标记。
================================================
FILE: docs/solutions/0600-0699/decode-ways-ii.md
================================================
# [0639. 解码方法 II](https://leetcode.cn/problems/decode-ways-ii/)
- 标签:字符串、动态规划
- 难度:困难
## 题目链接
- [0639. 解码方法 II - 力扣](https://leetcode.cn/problems/decode-ways-ii/)
## 题目大意
**描述**:给定一个包含数字和字符 `'*'` 的字符串 $s$。该字符串已经按照下面的映射关系进行了编码:
- `A` 映射为 $1$。
- `B` 映射为 $2$。
- ...
- `Z` 映射为 $26$。
除了上述映射方法,字符串 $s$ 中可能包含字符 `'*'`,可以表示 $1$ ~ $9$ 的任一数字(不包括 $0$)。例如字符串 `"1*"` 可以表示为 `"11"`、`"12"`、…、`"18"`、`"19"` 中的任何一个编码。
基于上述映射的方法,现在对字符串 `s` 进行「解码」。即从数字到字母进行反向映射。比如 `"11106"` 可以映射为:
- `"AAJF"`,将消息分组为 $(1 1 10 6)$。
- `"KJF"`,将消息分组为 $(11 10 6)$。
**要求**:计算出共有多少种可能的解码方案。
**说明**:
- $1 \le s.length \le 100$。
- $s$ 只包含数字,并且可能包含前导零。
- 题目数据保证答案肯定是一个 $32$ 位的整数。
```python
输入:s = "*"
输出:9
解释:这一条编码消息可以表示 "1"、"2"、"3"、"4"、"5"、"6"、"7"、"8" 或 "9" 中的任意一条。可以分别解码成字符串 "A"、"B"、"C"、"D"、"E"、"F"、"G"、"H" 和 "I" 。因此,"*" 总共有 9 种解码方法。
```
## 解题思路
### 思路 1:动态规划
这道题是「[91. 解码方法 - 力扣](https://leetcode.cn/problems/decode-ways/)」的升级版,其思路是相似的,只不过本题的状态转移方程的条件和公式不太容易想全。
###### 1. 阶段划分
按照字符串的结尾位置进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i]$ 表示为:字符串 $s$ 前 $i$ 个字符构成的字符串可能构成的翻译方案数。
###### 3. 状态转移方程
$dp[i]$ 的来源有两种情况:
1. 使用了一个字符,对 $s[i]$ 进行翻译:
1. 如果 `s[i] == '*'`,则 `s[i]` 可以视作区间 `[1, 9]` 上的任意一个数字,可以被翻译为 `A` ~ `I`。此时当前位置上的方案数为 `9`,即 `dp[i] = dp[i - 1] * 9`。
2. 如果 `s[i] == '0'`,则无法被翻译,此时当前位置上的方案数为 `0`,即 `dp[i] = dp[i - 1] * 0`。
3. 如果是其他情况(即 `s[i]` 是区间 `[1, 9]` 上某一个数字),可以被翻译为 `A` ~ `I` 对应位置上的某个字母。此时当前位置上的方案数为 `1`,即 `dp[i] = dp[i - 1] * 1`。
2. 使用了两个字符,对 `s[i - 1]` 和 `s[i]` 进行翻译:
1. 如果 `s[i - 1] == '*'` 并且 `s[i] == '*'`,则 `s[i]` 可以视作区间 `[11, 19]` 或者 `[21, 26]` 上的任意一个数字。此时当前位置上的方案数为 `15`,即 `dp[i] = dp[i - 2] * 15`。
2. 如果 `s[i - 1] == '*'` 并且 `s[i] != '*'`,则:
1. 如果 `s[i]` 在区间 `[1, 6]` 内,`s[i - 1]` 可以选择 `1` 或 `2`。此时当前位置上的方案数为 `2`,即 `dp[i] = dp[i - 2] * 2`。
2. 如果 `s[i]` 不在区间 `[1, 6]` 内,`s[i - 1]` 只能选择 `1`。此时当前位置上的方案数为 `1`,即 `dp[i] = dp[i - 2] * 1`。
3. 如果 `s[i - 1] == '1'` 并且 `s[i] == '*'`,`s[i]` 可以视作区间 `[1, 9]` 上任意一个数字。此时当前位置上的方案数为 `9`,即 `dp[i] = dp[i - 2] * 9`。
4. 如果 `s[i - 1] == '1'` 并且 `s[i] != '*'`,`s[i]` 可以视作区间 `[1, 9]` 上的某一个数字。此时当前位置上的方案数为 `1`,即 `dp[i] = dp[i - 2] * 1`。
5. 如果 `s[i - 1] == '2'` 并且 `s[i] == '*'`,`s[i]` 可以视作区间 `[1, 6]` 上任意一个数字。此时当前位置上的方案数为 `6`,即 `dp[i] = dp[i - 2] * 6`。
6. 如果 `s[i - 1] == '2'` 并且 `s[i] != '*'`,则:
1. 如果 `s[i]` 在区间 `[1, 6]` 内,此时当前位置上的方案数为 `1`,即 `dp[i] = dp[i - 2] * 1`。
2. 如果 `s[i]` 不在区间 `[1, 6]` 内,此时当前位置上的方案数为 `0`,即 `dp[i] = dp[i - 2] * 0`。
7. 其他情况下(即 `s[i - 1]` 在区间 `[3, 9]` 内),则无法被翻译,此时当前位置上的方案数为 `0`,即 `dp[i] = dp[i - 2] * 0`。
在进行转移的时候,需要将使用一个字符的翻译方案数与使用两个字符的翻译方案数进行相加。同时还要注意对 $10^9 + 7$ 的取余。
这里我们可以单独写两个方法 `,分别来表示「单个字符 `s[i]` 的翻译方案数」和「两个字符 `s[i - 1]` 和 `s[i]` 的翻译方案数」,这样代码逻辑会更加清晰。
###### 4. 初始条件
- 字符串为空时,只有一个翻译方案,翻译为空字符串,即 `dp[0] = 1`。
- 字符串只有一个字符时,单个字符 `s[i]` 的翻译方案数为转移条件的第一种求法,即`dp[1] = self.parse1(s[0])`。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i]` 表示为:字符串 `s` 前 `i` 个字符构成的字符串可能构成的翻译方案数。则最终结果为 `dp[size]`,`size` 为字符串长度。
### 思路 1:动态规划代码
```python
class Solution:
def parse1(self, ch):
if ch == '*':
return 9
if ch == '0':
return 0
return 1
def parse2(self, ch1, ch2):
if ch1 == '*' and ch2 == '*':
return 15
if ch1 == '*' and ch2 != '*':
return 2 if ch2 <= '6' else 1
if ch1 == '1' and ch2 == '*':
return 9
if ch1 == '1' and ch2 != '*':
return 1
if ch1 == '2' and ch2 == '*':
return 6
if ch1 == '2' and ch2 != '*':
return 1 if ch2 <= '6' else 0
return 0
def numDecodings(self, s: str) -> int:
mod = 10 ** 9 + 7
size = len(s)
dp = [0 for _ in range(size + 1)]
dp[0] = 1
dp[1] = self.parse1(s[0])
for i in range(2, size + 1):
dp[i] += dp[i - 1] * self.parse1(s[i - 1])
dp[i] += dp[i - 2] * self.parse2(s[i - 2], s[i - 1])
dp[i] %= mod
return dp[size]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度是 $O(n)$。
- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。
================================================
FILE: docs/solutions/0600-0699/degree-of-an-array.md
================================================
# [0697. 数组的度](https://leetcode.cn/problems/degree-of-an-array/)
- 标签:数组、哈希表
- 难度:简单
## 题目链接
- [0697. 数组的度 - 力扣](https://leetcode.cn/problems/degree-of-an-array/)
## 题目大意
**描述**:
给定一个非空且只包含非负数的整数数组 $nums$,数组的「度」的定义是指数组里任一元素出现频数的最大值。
**要求**:
在 $nums$ 中找到与 $nums$ 拥有相同大小的度的最短连续子数组,返回其长度。
**说明**:
- $nums.length$ 在 $1$ 到 $50,000$ 范围内。
- $nums[i]$ 是一个在 $0$ 到 $49,999$ 范围内的整数。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,2,3,1]
输出:2
解释:
输入数组的度是 2 ,因为元素 1 和 2 的出现频数最大,均为 2 。
连续子数组里面拥有相同度的有如下所示:
[1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2]
最短连续子数组 [2, 2] 的长度为 2 ,所以返回 2 。
```
- 示例 2:
```python
输入:nums = [1,2,2,3,1,4,2]
输出:6
解释:
数组的度是 3 ,因为元素 2 重复出现 3 次。
所以 [2,2,3,1,4,2] 是最短子数组,因此返回 6 。
```
## 解题思路
### 思路 1:哈希表
#### 思路 1:算法描述
这道题目要求找到与原数组拥有相同度的最短连续子数组。数组的度定义为数组里任一元素出现频数的最大值。
我们可以使用哈希表来记录每个元素的出现次数、第一次出现的位置和最后一次出现的位置。
具体步骤如下:
1. 初始化三个哈希表:
- $count$:记录每个元素的出现次数。
- $first$:记录每个元素第一次出现的位置。
- $last$:记录每个元素最后一次出现的位置。
2. 遍历数组 $nums$,更新三个哈希表。
3. 找到数组的度 $degree$,即 $count$ 中的最大值。
4. 遍历 $count$,找到所有出现次数等于 $degree$ 的元素,计算它们对应的子数组长度 $last[num] - first[num] + 1$,取最小值。
5. 返回最小值。
#### 思路 1:代码
```python
class Solution:
def findShortestSubArray(self, nums: List[int]) -> int:
count = {} # 记录每个元素的出现次数
first = {} # 记录每个元素第一次出现的位置
last = {} # 记录每个元素最后一次出现的位置
# 遍历数组,更新哈希表
for i, num in enumerate(nums):
if num not in count:
count[num] = 1
first[num] = i
else:
count[num] += 1
last[num] = i
# 找到数组的度
degree = max(count.values())
# 找到最短子数组长度
min_len = len(nums)
for num, cnt in count.items():
if cnt == degree:
min_len = min(min_len, last[num] - first[num] + 1)
return min_len
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。需要遍历两次数组。
- **空间复杂度**:$O(n)$。需要使用三个哈希表存储信息。
================================================
FILE: docs/solutions/0600-0699/design-circular-deque.md
================================================
# [0641. 设计循环双端队列](https://leetcode.cn/problems/design-circular-deque/)
- 标签:设计、队列、数组、链表
- 难度:中等
## 题目链接
- [0641. 设计循环双端队列 - 力扣](https://leetcode.cn/problems/design-circular-deque/)
## 题目大意
**描述**:
设计实现双端队列。
**要求**:
实现 MyCircularDeque 类:
- `MyCircularDeque(int k)`:构造函数,双端队列最大为 $k$。
- `boolean insertFront()`:将一个元素添加到双端队列头部。 如果操作成功返回 true,否则返回 false。
- `boolean insertLast()`:将一个元素添加到双端队列尾部。如果操作成功返回 true,否则返回 false。
- `boolean deleteFront()`:从双端队列头部删除一个元素。 如果操作成功返回 true,否则返回 false。
- `boolean deleteLast()`:从双端队列尾部删除一个元素。如果操作成功返回 true,否则返回 false。
- `int getFront()`:从双端队列头部获得一个元素。如果双端队列为空,返回 $-1$。
- `int getRear()`:获得双端队列的最后一个元素。 如果双端队列为空,返回 $-1$。
- `boolean isEmpty()`:若双端队列为空,则返回 true,否则返回 false。
- `boolean isFull()`:若双端队列满了,则返回 true,否则返回 false。
**说明**:
- $1 \le k \le 10^{3}$。
- $0 \le value \le 10^{3}$。
- `insertFront`, `insertLast`, `deleteFront`, `deleteLast`, `getFront`, `getRear`, `isEmpty`, `isFull` 调用次数不大于 $2000$ 次。
**示例**:
- 示例 1:
```python
输入
["MyCircularDeque", "insertLast", "insertLast", "insertFront", "insertFront", "getRear", "isFull", "deleteLast", "insertFront", "getFront"]
[[3], [1], [2], [3], [4], [], [], [], [4], []]
输出
[null, true, true, true, false, 2, true, true, true, 4]
解释
MyCircularDeque circularDeque = new MycircularDeque(3); // 设置容量大小为3
circularDeque.insertLast(1); // 返回 true
circularDeque.insertLast(2); // 返回 true
circularDeque.insertFront(3); // 返回 true
circularDeque.insertFront(4); // 已经满了,返回 false
circularDeque.getRear(); // 返回 2
circularDeque.isFull(); // 返回 true
circularDeque.deleteLast(); // 返回 true
circularDeque.insertFront(4); // 返回 true
circularDeque.getFront(); // 返回 4
```
## 解题思路
### 思路 1:数组实现循环双端队列
#### 思路 1:算法描述
这道题目要求设计实现一个循环双端队列。我们可以使用数组来实现。
需要维护以下变量:
- $queue$:存储队列元素的数组,长度为 $k + 1$(多一个空间用于区分队列满和队列空)。
- $front$:队首指针,指向队首元素。
- $rear$:队尾指针,指向队尾元素的下一个位置。
- $capacity$:队列的容量,为 $k + 1$。
各个操作的实现:
1. **insertFront**:在队首插入元素。将 $front$ 向前移动一位(循环),然后在 $front$ 位置插入元素。
2. **insertLast**:在队尾插入元素。在 $rear$ 位置插入元素,然后将 $rear$ 向后移动一位(循环)。
3. **deleteFront**:删除队首元素。将 $front$ 向后移动一位(循环)。
4. **deleteLast**:删除队尾元素。将 $rear$ 向前移动一位(循环)。
5. **getFront**:获取队首元素。返回 $queue[front]$。
6. **getRear**:获取队尾元素。返回 $queue[(rear - 1 + capacity) \% capacity]$。
7. **isEmpty**:判断队列是否为空。当 $front = rear$ 时,队列为空。
8. **isFull**:判断队列是否已满。当 $(rear + 1) \% capacity = front$ 时,队列已满。
#### 思路 1:代码
```python
class MyCircularDeque:
def __init__(self, k: int):
self.capacity = k + 1 # 多一个空间用于区分队列满和队列空
self.queue = [0] * self.capacity
self.front = 0 # 队首指针
self.rear = 0 # 队尾指针
def insertFront(self, value: int) -> bool:
if self.isFull():
return False
# 将 front 向前移动一位(循环)
self.front = (self.front - 1 + self.capacity) % self.capacity
self.queue[self.front] = value
return True
def insertLast(self, value: int) -> bool:
if self.isFull():
return False
self.queue[self.rear] = value
# 将 rear 向后移动一位(循环)
self.rear = (self.rear + 1) % self.capacity
return True
def deleteFront(self) -> bool:
if self.isEmpty():
return False
# 将 front 向后移动一位(循环)
self.front = (self.front + 1) % self.capacity
return True
def deleteLast(self) -> bool:
if self.isEmpty():
return False
# 将 rear 向前移动一位(循环)
self.rear = (self.rear - 1 + self.capacity) % self.capacity
return True
def getFront(self) -> int:
if self.isEmpty():
return -1
return self.queue[self.front]
def getRear(self) -> int:
if self.isEmpty():
return -1
# 队尾元素在 rear 的前一个位置
return self.queue[(self.rear - 1 + self.capacity) % self.capacity]
def isEmpty(self) -> bool:
return self.front == self.rear
def isFull(self) -> bool:
return (self.rear + 1) % self.capacity == self.front
# Your MyCircularDeque object will be instantiated and called as such:
# obj = MyCircularDeque(k)
# param_1 = obj.insertFront(value)
# param_2 = obj.insertLast(value)
# param_3 = obj.deleteFront()
# param_4 = obj.deleteLast()
# param_5 = obj.getFront()
# param_6 = obj.getRear()
# param_7 = obj.isEmpty()
# param_8 = obj.isFull()
```
#### 思路 1:复杂度分析
- **时间复杂度**:所有操作的时间复杂度均为 $O(1)$。
- **空间复杂度**:$O(k)$。需要使用长度为 $k + 1$ 的数组存储队列元素。
================================================
FILE: docs/solutions/0600-0699/design-circular-queue.md
================================================
# [0622. 设计循环队列](https://leetcode.cn/problems/design-circular-queue/)
- 标签:设计、队列、数组、链表
- 难度:中等
## 题目链接
- [0622. 设计循环队列 - 力扣](https://leetcode.cn/problems/design-circular-queue/)
## 题目大意
**要求**:设计实现一个循环队列,支持以下操作:
- `MyCircularQueue(k)`: 构造器,设置队列长度为 `k`。
- `Front`: 从队首获取元素。如果队列为空,返回 `-1`。
- `Rear`: 获取队尾元素。如果队列为空,返回 `-1`。
- `enQueue(value)`: 向循环队列插入一个元素。如果成功插入则返回真。
- `deQueue()`: 从循环队列中删除一个元素。如果成功删除则返回真。
- `isEmpty()`: 检查循环队列是否为空。
- `isFull()`: 检查循环队列是否已满。
**说明**:
- 所有的值都在 `0` 至 `1000` 的范围内。
- 操作数将在 `1` 至 `1000` 的范围内。
- 请不要使用内置的队列库。
**示例**:
- 示例 1:
```python
MyCircularQueue circularQueue = new MyCircularQueue(3); // 设置长度为 3
circularQueue.enQueue(1); // 返回 true
circularQueue.enQueue(2); // 返回 true
circularQueue.enQueue(3); // 返回 true
circularQueue.enQueue(4); // 返回 false,队列已满
circularQueue.Rear(); // 返回 3
circularQueue.isFull(); // 返回 true
circularQueue.deQueue(); // 返回 true
circularQueue.enQueue(4); // 返回 true
circularQueue.Rear(); // 返回 4
```
## 解题思路
这道题可以使用数组,也可以使用链表来实现循环队列。
### 思路 1:使用数组模拟
建立一个容量为 `k + 1` 的数组 `queue`。并保存队头指针 `front`、队尾指针 `rear`,队列容量 `capacity` 为 `k + 1`(这里之所以用了 `k + 1` 的容量,是为了判断空和满,需要空出一个)。
然后实现循环队列的各个接口:
1. `MyCircularQueue(k)`:
1. 将数组 `queue` 初始化大小为 `k + 1` 的数组。
2. `front`、`rear` 初始化为 `0`。
2. `Front`:
1. 先检测队列是否为空。如果队列为空,返回 `-1`。
2. 如果不为空,则返回队头元素。
3. `Rear`:
1. 先检测队列是否为空。如果队列为空,返回 `-1`。
2. 如果不为空,则返回队尾元素。
4. `enQueue(value)`:
1. 如果队列已满,则无法插入,返回 `False`。
2. 如果队列未满,则将队尾指针 `rear` 向右循环移动一位,并进行插入操作。然后返回 `True`。
5. `deQueue()`:
1. 如果队列为空,则无法删除,返回 `False`。
2. 如果队列不空,则将队头指针 `front` 指向元素赋值为 `None`,并将 `front` 向右循环移动一位。然后返回 `True`。
6. `isEmpty()`: 如果 `rear` 等于 `front`,则说明队列为空,返回 `True`。否则,队列不为空,返回 `False`。
7. `isFull()`: 如果 `(rear + 1) % capacity` 等于 `front`,则说明队列已满,返回 `True`。否则,队列未满,返回 `False`。
### 思路 1:代码
```python
class MyCircularQueue:
def __init__(self, k: int):
self.capacity = k + 1
self.queue = [0 for _ in range(k + 1)]
self.front = 0
self.rear = 0
def enQueue(self, value: int) -> bool:
if self.isFull():
return False
self.rear = (self.rear + 1) % self.capacity
self.queue[self.rear] = value
return True
def deQueue(self) -> bool:
if self.isEmpty():
return False
self.front = (self.front + 1) % self.capacity
return True
def Front(self) -> int:
if self.isEmpty():
return -1
return self.queue[(self.front + 1) % self.capacity]
def Rear(self) -> int:
if self.isEmpty():
return -1
return self.queue[self.rear]
def isEmpty(self) -> bool:
return self.front == self.rear
def isFull(self) -> bool:
return (self.rear + 1) % self.capacity == self.front
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。初始化和每项操作的时间复杂度均为 $O(1)$。
- **空间复杂度**:$O(k)$。其中 $k$ 为给定队列的元素数目。
================================================
FILE: docs/solutions/0600-0699/design-compressed-string-iterator.md
================================================
# [0604. 迭代压缩字符串](https://leetcode.cn/problems/design-compressed-string-iterator/)
- 标签:设计、数组、字符串、迭代器
- 难度:简单
## 题目链接
- [0604. 迭代压缩字符串 - 力扣](https://leetcode.cn/problems/design-compressed-string-iterator/)
## 题目大意
**要求**:
设计并实现一个迭代压缩字符串的数据结构。给定的压缩字符串的形式是,每个字母后面紧跟一个正整数,表示该字母在原始未压缩字符串中出现的次数。
设计一个数据结构,它支持如下两种操作: `next` 和 `hasNext`。
- `next()`:如果原始字符串中仍有未压缩字符,则返回下一个字符,否则返回空格。
- `hasNext()`:如果原始字符串中存在未压缩的的字母,则返回 true,否则返回 false。
**说明**:
- $1 \le compressedString.length \le 10^{3}$。
- $compressedString$ 由小写字母、大写字母和数字组成。
- 在 $compressedString$ 中,单个字符的重复次数在 $[1, 10^9]$ 范围内。
- `next` 和 `hasNext` 的操作数最多为 $10^{3}$。
**示例**:
- 示例 1:
```python
输入:
["StringIterator", "next", "next", "next", "next", "next", "next", "hasNext", "next", "hasNext"]
[["L1e2t1C1o1d1e1"], [], [], [], [], [], [], [], [], []]
输出:
[null, "L", "e", "e", "t", "C", "o", true, "d", true]
解释:
StringIterator stringIterator = new StringIterator("L1e2t1C1o1d1e1");
stringIterator.next(); // 返回 "L"
stringIterator.next(); // 返回 "e"
stringIterator.next(); // 返回 "e"
stringIterator.next(); // 返回 "t"
stringIterator.next(); // 返回 "C"
stringIterator.next(); // 返回 "o"
stringIterator.hasNext(); // 返回 True
stringIterator.next(); // 返回 "d"
stringIterator.hasNext(); // 返回 True
```
- 示例 2:
```python
输入:
输出:
```
## 解题思路
### 思路 1:双指针解析
#### 思路 1:算法描述
这道题目要求设计一个迭代压缩字符串的数据结构。压缩字符串的格式是每个字母后面紧跟一个正整数,表示该字母的重复次数。
我们可以在初始化时解析压缩字符串,将字符和对应的重复次数存储起来,然后使用指针来跟踪当前位置。
具体步骤如下:
1. **初始化**:解析压缩字符串,提取每个字符和对应的重复次数,存储在列表中。维护两个变量:
- $idx$:当前字符在列表中的索引。
- $count$:当前字符剩余的重复次数。
2. **next()**:返回下一个字符。
- 如果 $count > 0$,返回当前字符,并将 $count$ 减 $1$。
- 如果 $count = 0$,移动到下一个字符($idx$ 加 $1$),更新 $count$。
- 如果已经没有字符了,返回空格。
3. **hasNext()**:判断是否还有未压缩的字符。
- 如果 $idx < len(chars)$ 或 $count > 0$,返回 $True$。
- 否则返回 $False$。
#### 思路 1:代码
```python
class StringIterator:
def __init__(self, compressedString: str):
self.chars = [] # 存储字符和重复次数的列表
i = 0
n = len(compressedString)
# 解析压缩字符串
while i < n:
char = compressedString[i]
i += 1
num_str = ""
# 提取数字
while i < n and compressedString[i].isdigit():
num_str += compressedString[i]
i += 1
self.chars.append((char, int(num_str)))
self.idx = 0 # 当前字符在列表中的索引
self.count = self.chars[0][1] if self.chars else 0 # 当前字符剩余的重复次数
def next(self) -> str:
if not self.hasNext():
return ' '
# 获取当前字符
char = self.chars[self.idx][0]
self.count -= 1
# 如果当前字符已经用完,移动到下一个字符
if self.count == 0 and self.idx + 1 < len(self.chars):
self.idx += 1
self.count = self.chars[self.idx][1]
return char
def hasNext(self) -> bool:
return self.idx < len(self.chars) and self.count > 0
# Your StringIterator object will be instantiated and called as such:
# obj = StringIterator(compressedString)
# param_1 = obj.next()
# param_2 = obj.hasNext()
```
#### 思路 1:复杂度分析
- **时间复杂度**:
- 初始化:$O(n)$,其中 $n$ 是压缩字符串的长度。
- next():$O(1)$。
- hasNext():$O(1)$。
- **空间复杂度**:$O(m)$,其中 $m$ 是不同字符的数量。
================================================
FILE: docs/solutions/0600-0699/design-excel-sum-formula.md
================================================
# [0631. 设计 Excel 求和公式](https://leetcode.cn/problems/design-excel-sum-formula/)
- 标签:图、设计、拓扑排序、数组、哈希表、字符串、矩阵
- 难度:困难
## 题目链接
- [0631. 设计 Excel 求和公式 - 力扣](https://leetcode.cn/problems/design-excel-sum-formula/)
## 题目大意
**描述**:
请你设计 Excel 中的基本功能,并实现求和公式。
**要求**:
实现 Excel 类:
- `Excel(int height, char width)`:用高度 $height$ 和宽度 $width$ 初始化对象。该表格是一个大小为 $height \times width$ 的整数矩阵 $mat$,其中行下标范围是 $[1, height]$,列下标范围是 $['A', width]$。初始情况下,所有的值都应该为零。
- `void set(int row, char column, int val)`:将 $mat[row][column]$ 的值更改为 $val$。
- `int get(int row, char column)`:返回 $mat[row][column]$ 的值。
- `int sum(int row, char column, List
numbers)`:将 $mat[row][column]$ 的值设为由 $numbers$ 表示的单元格的和,并返回 $mat[row][column]$ 的值。此求和公式应该 **长期作用于** 该单元格,直到该单元格被另一个值或另一个求和公式覆盖。其中,$numbers[i]$ 的格式可以为:
- `"ColRow"`:表示某个单元格。例如,`"F7"` 表示单元格 $mat[7]['F']$。
- `"ColRow1:ColRow2"`:表示一组单元格。该范围将始终为一个矩形,其中 `"ColRow1"` 表示左上角单元格的位置,`"ColRow2"` 表示右下角单元格的位置。例如,`"B3:F7"` 表示 $3 \le i \le 7$ 和 $'B' \le j \le 'F'$ 的单元格 $mat[i][j]$。
**说明**:
- 注意:可以假设不会出现循环求和引用。例如,$mat[1]['A'] == sum(1, "B")$,且 $mat[1]['B'] == sum(1, "A")$。
- $1 \le height \le 26$。
- $'A' \le width \le 'Z'$。
- $1 \le row \le height$。
- $'A' \le column \le width$。
- $-10^3 \le val \le 10^3$。
- $1 \le numbers.length \le 5$。
- $numbers[i]$ 的格式为 `"ColRow"` 或 `"ColRow1:ColRow2"`。
- 最多会对 `set`、`get` 和 `sum` 进行 $10^3$ 次调用。
**示例**:
- 示例 1:
```python
输入:
["Excel", "set", "sum", "set", "get"]
[[3, "C"], [1, "A", 2], [3, "C", ["A1", "A1:B2"]], [2, "B", 2], [3, "C"]]
输出:
[null, null, 4, null, 6]
解释:
执行以下操作:
Excel excel = new Excel(3, "C");
// 构造一个 3 * 3 的二维数组,所有值初始化为零。
// A B C
// 1 0 0 0
// 2 0 0 0
// 3 0 0 0
excel.set(1, "A", 2);
// 将 mat[1]["A"] 设置为 2 。
// A B C
// 1 2 0 0
// 2 0 0 0
// 3 0 0 0
excel.sum(3, "C", ["A1", "A1:B2"]); // 返回 4
// 将 mat[3]["C"] 设置为 mat[1]["A"] 的值与矩形范围的单元格和的和,该范围的左上角单元格位置为 mat[1]["A"],右下角单元格位置为 mat[2]["B"]。
// A B C
// 1 2 0 0
// 2 0 0 0
// 3 0 0 4
excel.set(2, "B", 2);
// 将 mat[2]["B"] 设置为 2 。注意 mat[3]["C"] 也应该更改。
// A B C
// 1 2 0 0
// 2 0 2 0
// 3 0 0 6
excel.get(3, "C"); // 返回 6
```
## 解题思路
### 思路 1:哈希表 + 图
这道题目要求设计一个 Excel 表格,支持设置单元格值、获取单元格值和设置求和公式。关键在于求和公式需要 **长期作用**,即当依赖的单元格值改变时,公式单元格的值也要自动更新。
**核心思路**:
- 使用哈希表存储每个单元格的值。
- 使用图结构记录单元格之间的依赖关系:如果单元格 $A$ 的值依赖于单元格 $B$,则 $B \to A$ 有一条边。
- 当某个单元格的值改变时,需要递归更新所有依赖它的单元格。
**算法步骤**:
1. **初始化**:创建哈希表存储单元格值,创建图存储依赖关系。
2. **set 操作**:设置单元格值,清除该单元格的依赖关系,递归更新依赖它的单元格。
3. **get 操作**:直接返回单元格的值。
4. **sum 操作**:解析 $numbers$,计算和,设置单元格值,建立依赖关系。
### 思路 1:代码
```python
class Excel:
def __init__(self, height: int, width: str):
self.height = height
self.width = ord(width) - ord('A') + 1
# formulas[r][c] = (cells_dict, val)
# cells_dict: 依赖的单元格及其计数,val: 当前值
self.formulas = [[None] * self.width for _ in range(height)]
def get(self, row: int, column: str) -> int:
r, c = row - 1, ord(column) - ord('A')
if self.formulas[r][c] is None:
return 0
return self.formulas[r][c][1]
def set(self, row: int, column: str, val: int) -> None:
r, c = row - 1, ord(column) - ord('A')
# 设置为纯值,清空依赖
self.formulas[r][c] = ({}, val)
# 拓扑排序更新依赖此单元格的所有单元格
stack = []
self._topological_sort(r, c, stack, set())
self._execute_stack(stack)
def sum(self, row: int, column: str, numbers: List[str]) -> int:
r, c = row - 1, ord(column) - ord('A')
cells = self._convert(numbers)
summ = self._calculate_sum(r, c, cells)
self.formulas[r][c] = (cells, summ)
# 拓扑排序更新依赖此单元格的所有单元格
stack = []
self._topological_sort(r, c, stack, set())
self._execute_stack(stack)
return summ
def _convert(self, strs: List[str]) -> dict:
"""将公式字符串转换为单元格计数字典"""
res = {}
for st in strs:
if ':' not in st:
res[st] = res.get(st, 0) + 1
else:
parts = st.split(':')
si, ei = int(parts[0][1:]), int(parts[1][1:])
sj, ej = parts[0][0], parts[1][0]
for i in range(si, ei + 1):
for j in range(ord(sj), ord(ej) + 1):
key = chr(j) + str(i)
res[key] = res.get(key, 0) + 1
return res
def _topological_sort(self, r: int, c: int, stack: list, visited: set) -> None:
"""拓扑排序:找出所有依赖 (r,c) 的单元格"""
key = chr(ord('A') + c) + str(r + 1)
for i in range(len(self.formulas)):
for j in range(len(self.formulas[0])):
if self.formulas[i][j] is not None and key in self.formulas[i][j][0]:
if (i, j) not in visited:
self._topological_sort(i, j, stack, visited)
if (r, c) not in visited:
visited.add((r, c))
stack.append((r, c))
def _execute_stack(self, stack: list) -> None:
"""按拓扑顺序更新单元格"""
while stack:
r, c = stack.pop()
if self.formulas[r][c] is not None and self.formulas[r][c][0]:
self._calculate_sum(r, c, self.formulas[r][c][0])
def _calculate_sum(self, r: int, c: int, cells: dict) -> int:
"""计算单元格的和"""
total = 0
for s, cnt in cells.items():
x, y = int(s[1:]) - 1, ord(s[0]) - ord('A')
val = self.formulas[x][y][1] if self.formulas[x][y] else 0
total += val * cnt
self.formulas[r][c] = (cells, total)
return total
# Your Excel object will be instantiated and called as such:
# obj = Excel(height, width)
# obj.set(row,column,val)
# param_2 = obj.get(row,column)
# param_3 = obj.sum(row,column,numbers)
```
### 思路 1:复杂度分析
- **时间复杂度**:
- $set$ 操作:$O(d)$,其中 $d$ 是依赖此单元格的单元格数量,需要更新所有依赖的单元格。
- $get$ 操作:$O(1)$,直接返回缓存的值。
- $sum$ 操作:$O(k + d)$,其中 $k$ 是公式中依赖的单元格数量,$d$ 是依赖此单元格的单元格数量。需要计算所有依赖的单元格,并更新依赖此单元格的其他单元格。
- **空间复杂度**:$O(n + m)$,其中 $n$ 是单元格的数量,$m$ 是依赖关系的数量。
================================================
FILE: docs/solutions/0600-0699/design-log-storage-system.md
================================================
# [0635. 设计日志存储系统](https://leetcode.cn/problems/design-log-storage-system/)
- 标签:设计、哈希表、字符串、有序集合
- 难度:中等
## 题目链接
- [0635. 设计日志存储系统 - 力扣](https://leetcode.cn/problems/design-log-storage-system/)
## 题目大意
**描述**:
你将获得多条日志,每条日志都有唯一的 $id$ 和 $timestamp$,$timestamp$ 是形如 `Year:Month:Day:Hour:Minute:Second` 的字符串,例如 `2017:01:01:23:59:59`,所有值域都是零填充的十进制数。
**要求**:
实现 LogSystem 类:
- `LogSystem()` 初始化 `LogSystem` 对象
- `void put(int id, string timestamp)` 给定日志的 $id$ 和 $timestamp$,将这个日志存入你的存储系统中。
- `int[] retrieve(string start, string end, string granularity)` 返回在给定时间区间 $[start, end]$(包含两端)内的所有日志的 $id$。$start$、$end$ 和 $timestamp$ 的格式相同,$granularity$ 表示考虑的时间粒度(例如,精确到 `Day`、`Minute` 等)。例如 `start = "2017:01:01:23:59:59"`、`end = "2017:01:02:23:59:59"` 且 `granularity = "Day"` 意味着需要查找从 Jan. 1st 2017 到 Jan. 2nd 2017 范围内的日志,可以忽略日志的 `Hour`、`Minute` 和 `Second`。
**说明**:
- $1 \le id \le 500$。
- $2000 \le Year \le 2017$。
- $1 \le Month \le 12$。
- $1 \le Day \le 31$。
- $0 \le Hour \le 23$。
- $0 \le Minute, Second \le 59$。
- $granularity$ 是这些值 `["Year", "Month", "Day", "Hour", "Minute", "Second"]` 之一。
- 最多调用 $500$ 次 `put` 和 `retrieve`。
**示例**:
- 示例 1:
```python
输入:
["LogSystem", "put", "put", "put", "retrieve", "retrieve"]
[[], [1, "2017:01:01:23:59:59"], [2, "2017:01:01:22:59:59"], [3, "2016:01:01:00:00:00"], ["2016:01:01:01:01:01", "2017:01:01:23:00:00", "Year"], ["2016:01:01:01:01:01", "2017:01:01:23:00:00", "Hour"]]
输出:
[null, null, null, null, [3, 2, 1], [2, 1]]
解释:
LogSystem logSystem = new LogSystem();
logSystem.put(1, "2017:01:01:23:59:59");
logSystem.put(2, "2017:01:01:22:59:59");
logSystem.put(3, "2016:01:01:00:00:00");
// 返回 [3,2,1],返回从 2016 年到 2017 年所有的日志。
logSystem.retrieve("2016:01:01:01:01:01", "2017:01:01:23:00:00", "Year");
// 返回 [2,1],返回从 Jan. 1, 2016 01:XX:XX 到 Jan. 1, 2017 23:XX:XX 之间的所有日志
// 不返回日志 3 因为记录时间 Jan. 1, 2016 00:00:00 超过范围的起始时间
logSystem.retrieve("2016:01:01:01:01:01", "2017:01:01:23:00:00", "Hour");
```
## 解题思路
### 思路 1:哈希表 + 字符串处理
#### 思路 1:算法描述
这道题目要求设计一个日志存储系统,支持存储日志和根据时间粒度检索日志。
我们可以使用哈希表来存储日志,键为日志 ID,值为时间戳。在检索时,根据时间粒度截取时间戳的相应部分进行比较。
**算法步骤**:
1. **初始化**:创建一个哈希表 `logs`,用于存储日志 ID 和时间戳。
2. **put(id, timestamp)**:将日志 ID 和时间戳存入哈希表。
3. **retrieve(start, end, granularity)**:
- 根据时间粒度确定需要比较的时间戳长度。
- 截取 `start` 和 `end` 的相应部分。
- 遍历所有日志,截取时间戳的相应部分,判断是否在 `[start, end]` 范围内。
- 返回符合条件的日志 ID 列表。
时间粒度对应的截取长度:
- Year: 4
- Month: 7
- Day: 10
- Hour: 13
- Minute: 16
- Second: 19
#### 思路 1:代码
```python
class LogSystem:
def __init__(self):
self.logs = {} # 存储日志 ID 和时间戳
# 时间粒度对应的截取长度
self.granularity_map = {
"Year": 4,
"Month": 7,
"Day": 10,
"Hour": 13,
"Minute": 16,
"Second": 19
}
def put(self, id: int, timestamp: str) -> None:
self.logs[id] = timestamp
def retrieve(self, start: str, end: str, granularity: str) -> List[int]:
# 根据时间粒度确定截取长度
length = self.granularity_map[granularity]
# 截取 start 和 end 的相应部分
start_prefix = start[:length]
end_prefix = end[:length]
result = []
# 遍历所有日志
for log_id, timestamp in self.logs.items():
# 截取时间戳的相应部分
timestamp_prefix = timestamp[:length]
# 判断是否在范围内
if start_prefix <= timestamp_prefix <= end_prefix:
result.append(log_id)
return result
# Your LogSystem object will be instantiated and called as such:
# obj = LogSystem()
# obj.put(id,timestamp)
# param_2 = obj.retrieve(start,end,granularity)
```
#### 思路 1:复杂度分析
- **时间复杂度**:
- `put()`:$O(1)$。
- `retrieve()`:$O(n)$,其中 $n$ 是日志的数量。需要遍历所有日志。
- **空间复杂度**:$O(n)$。需要存储 $n$ 条日志。
================================================
FILE: docs/solutions/0600-0699/design-search-autocomplete-system.md
================================================
# [0642. 设计搜索自动补全系统](https://leetcode.cn/problems/design-search-autocomplete-system/)
- 标签:设计、字典树、字符串、数据流
- 难度:困难
## 题目链接
- [0642. 设计搜索自动补全系统 - 力扣](https://leetcode.cn/problems/design-search-autocomplete-system/)
## 题目大意
要求:设计一个搜索自动补全系统。用户会输入一条语句(最少包含一个字母,以特殊字符 `#` 结尾)。除 `#` 以外用户输入的每个字符,返回历史中热度前三并以当前输入部分为前缀的句子。下面是详细规则:
- 一条句子的热度定义为历史上用户输入这个句子的总次数。
- 返回前三的句子需要按照热度从高到低排序(第一个是最热门的)。如果有多条热度相同的句子,请按照 ASCII 码的顺序输出(ASCII 码越小排名越前)。
- 如果满足条件的句子个数少于 3,将它们全部输出。
- 如果输入了特殊字符,意味着句子结束了,请返回一个空集合。
你的工作是实现以下功能:
- 构造函数: `AutocompleteSystem(String[] sentences, int[] times):`
- 输入历史数据。 `sentences` 是之前输入过的所有句子,`times` 是每条句子输入的次数,你的系统需要记录这些历史信息。
- 输入函数(用户输入一条新的句子,下面的函数会提供用户输入的下一个字符):`List input(char c):`
- 其中 `c` 是用户输入的下一个字符。字符只会是小写英文字母(`a` 到 `z` ),空格(` `)和特殊字符(`#`)。输出历史热度前三的具有相同前缀的句子。
## 解题思路
使用字典树来保存输入过的所有句子 `sentences`,并且在字典树中维护每条句子的输入次数 `times`。
构造函数中:
- 将所有句子及对应输入次数插入到字典树中。
输入函数中:
- 使用 `path` 变量保存当前输入句子的前缀。
- 如果遇到 `#`,则将当前句子插入到字典树中。
- 如果遇到其他字符,用 `path` 保存当前字符 `c`。并在字典树中搜索以 `path` 为前缀的节点的所有分支,将每个分支对应的单词 `path` 和它们出现的次数 `times` 存入数组中。然后借助 `heapq` 进行堆排序,根据出现次数和 ASCII 码大小排序,找出 `times` 最多的前三个单词。
## 代码
```python
import heapq
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
self.times = 0
def insert(self, word: str, times=1) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
cur.times += times
def search(self, word: str):
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return []
cur = cur.children[ch]
res = []
path = [word]
cur.dfs(res, path)
return res
def dfs(self, res, path):
cur = self
if cur.isEnd:
res.append((-cur.times, ''.join(path)))
for ch in cur.children:
node = cur.children[ch]
path.append(ch)
node.dfs(res, path)
path.pop()
class AutocompleteSystem:
def __init__(self, sentences: List[str], times: List[int]):
self.path = ''
self.exists = True
self.trie_tree = Trie()
for i in range(len(sentences)):
self.trie_tree.insert(sentences[i], times[i])
def input(self, c: str) -> List[str]:
if c == '#':
self.trie_tree.insert(self.path, 1)
self.path = ''
self.exists = True
return []
else:
self.path += c
if not self.exists:
return []
words = self.trie_tree.search(self.path)
if words:
heapq.heapify(words)
res = []
while words and len(res) < 3:
res.append(heapq.heappop(words)[1])
return res
else:
self.exists = False
return []
```
================================================
FILE: docs/solutions/0600-0699/dota2-senate.md
================================================
# [0649. Dota2 参议院](https://leetcode.cn/problems/dota2-senate/)
- 标签:贪心、队列、字符串
- 难度:中等
## 题目链接
- [0649. Dota2 参议院 - 力扣](https://leetcode.cn/problems/dota2-senate/)
## 题目大意
**描述**:
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
- 禁止一名参议员的权利:参议员可以让另一位参议员在这一轮和随后的几轮中丧失 所有的权利 。
- 宣布胜利:如果参议员发现有权利投票的参议员都是 同一个阵营的 ,他可以宣布胜利并决定在游戏中的有关变化。
给定一个字符串 $senate$ 代表每个参议员的阵营。字母 `'R'` 和 `'D'` 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 $n$ 个参议员,给定字符串的大小将是 $n$。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
**要求**:
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 `"Radiant"` 或 `"Dire"`。
**说明**:
- $n == senate.length$。
- $1 \le n \le 10^{4}$。
- $senate[i]$ 为 `'R'` 或 `'D'`。
**示例**:
- 示例 1:
```python
输入:senate = "RD"
输出:"Radiant"
解释:
第 1 轮时,第一个参议员来自 Radiant 阵营,他可以使用第一项权利让第二个参议员失去所有权利。
这一轮中,第二个参议员将会被跳过,因为他的权利被禁止了。
第 2 轮时,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人。
```
- 示例 2:
```python
输入:senate = "RDD"
输出:"Dire"
解释:
第 1 轮时,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利。
这一轮中,第二个来自 Dire 阵营的参议员会将被跳过,因为他的权利被禁止了。
这一轮中,第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利。
因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利
```
## 解题思路
### 思路 1:贪心 + 队列
#### 思路 1:算法描述
这道题目模拟 Dota2 参议院的投票过程。每个参议员都会采取最优策略,即优先禁止对方阵营中最早投票的参议员。
我们可以使用两个队列分别存储 Radiant 和 Dire 阵营参议员的位置索引,然后模拟投票过程。
具体步骤如下:
1. 初始化两个队列 $radiant$ 和 $dire$,分别存储两个阵营参议员的位置索引。
2. 遍历字符串 $senate$,将每个参议员的位置索引加入对应的队列。
3. 模拟投票过程:
- 当两个队列都不为空时,取出两个队列的队首元素 $r$ 和 $d$。
- 比较 $r$ 和 $d$ 的大小:
- 如果 $r < d$,说明 Radiant 阵营的参议员先投票,他会禁止 Dire 阵营的参议员。将 $r + n$($n$ 是参议员总数)加入 $radiant$ 队列,表示该参议员在下一轮还可以投票。
- 如果 $r > d$,说明 Dire 阵营的参议员先投票,他会禁止 Radiant 阵营的参议员。将 $d + n$ 加入 $dire$ 队列。
4. 最后,哪个队列不为空,哪个阵营获胜。
#### 思路 1:代码
```python
class Solution:
def predictPartyVictory(self, senate: str) -> str:
from collections import deque
n = len(senate)
radiant = deque() # Radiant 阵营参议员的位置索引
dire = deque() # Dire 阵营参议员的位置索引
# 初始化两个队列
for i, s in enumerate(senate):
if s == 'R':
radiant.append(i)
else:
dire.append(i)
# 模拟投票过程
while radiant and dire:
r = radiant.popleft()
d = dire.popleft()
# 位置靠前的参议员先投票,禁止对方阵营的参议员
if r < d:
# Radiant 阵营的参议员先投票
radiant.append(r + n)
else:
# Dire 阵营的参议员先投票
dire.append(d + n)
# 判断哪个阵营获胜
return "Radiant" if radiant else "Dire"
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是参议员的数量。每个参议员最多被处理常数次。
- **空间复杂度**:$O(n)$。需要使用两个队列存储参议员的位置索引。
================================================
FILE: docs/solutions/0600-0699/employee-importance.md
================================================
# [0690. 员工的重要性](https://leetcode.cn/problems/employee-importance/)
- 标签:深度优先搜索、广度优先搜索、哈希表
- 难度:中等
## 题目链接
- [0690. 员工的重要性 - 力扣](https://leetcode.cn/problems/employee-importance/)
## 题目大意
给定一个公司的所有员工信息。其中每个员工信息包含:该员工 id,该员工重要度,以及该员工的所有下属 id。
再给定一个员工 id,要求返回该员工和他所有下属的重要度之和。
## 解题思路
利用哈希表,以「员工 id: 员工数据结构」的形式将员工信息存入哈希表中。然后深度优先搜索该员工以及下属员工。在搜索的同时,计算重要度之和,最终返回结果即可。
## 代码
```python
class Solution:
def getImportance(self, employees: List['Employee'], id: int) -> int:
employee_dict = dict()
for employee in employees:
employee_dict[employee.id] = employee
def dfs(index: int) -> int:
total = employee_dict[index].importance
for sub_index in employee_dict[index].subordinates:
total += dfs(sub_index)
return total
return dfs(id)
```
================================================
FILE: docs/solutions/0600-0699/equal-tree-partition.md
================================================
# [0663. 均匀树划分](https://leetcode.cn/problems/equal-tree-partition/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0663. 均匀树划分 - 力扣](https://leetcode.cn/problems/equal-tree-partition/)
## 题目大意
**描述**:给你一棵二叉树的根节点 $root$,如果你可以通过去掉原始树上的一条边将树分成两棵节点值之和相等的子树,则返回 `true`。
**要求**:判断是否可以通过移除一条边将树分成两个节点值之和相等的子树。
**说明**:
- 树中节点数目在 $[1, 10^4]$ 范围内。
- $-10^5 \le Node.val \le 10^5$。
**示例**:
- 示例 1:
```python
输入:root = [5,10,10,null,null,2,3]
输出:true
```
- 示例 2:
```python
输入:root = [1,2,10,null,null,2,20]
输出:false
解释:在树上移除一条边无法将树分成两棵节点值之和相等的子树。
```
## 解题思路
### 思路 1:DFS + 后序遍历
#### 思路 1:算法描述
判断是否可以通过移除一条边将树分成两个节点值之和相等的子树。
**核心思路**:
- 首先计算整棵树的总和 $total$。
- 如果 $total$ 是奇数,无法平分,返回 `False`。
- 使用 DFS 计算每个子树的和,如果某个子树的和等于 $total / 2$,说明可以分割。
- 注意:不能在根节点处分割(因为需要移除一条边)。
**算法步骤**:
1. 计算整棵树的总和 $total$。
2. 如果 $total$ 是奇数,返回 `False`。
3. 使用 DFS 遍历树,计算每个子树的和:
- 如果某个非根子树的和等于 $total / 2$,返回 `True`。
4. 如果遍历完没有找到,返回 `False`。
#### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def checkEqualTree(self, root: Optional[TreeNode]) -> bool:
# 计算整棵树的总和
def get_sum(node):
if not node:
return 0
return node.val + get_sum(node.left) + get_sum(node.right)
total = get_sum(root)
# 如果总和是奇数,无法平分
if total % 2 != 0:
return False
target = total // 2
self.found = False
# DFS 检查每个子树的和
def dfs(node, is_root):
if not node:
return 0
left_sum = dfs(node.left, False)
right_sum = dfs(node.right, False)
current_sum = node.val + left_sum + right_sum
# 如果不是根节点且子树和等于目标值
if not is_root and current_sum == target:
self.found = True
return current_sum
dfs(root, True)
return self.found
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是树的节点数,需要遍历树两次。
- **空间复杂度**:$O(h)$,其中 $h$ 是树的高度,递归栈的深度。
================================================
FILE: docs/solutions/0600-0699/exclusive-time-of-functions.md
================================================
# [0636. 函数的独占时间](https://leetcode.cn/problems/exclusive-time-of-functions/)
- 标签:栈、数组
- 难度:中等
## 题目链接
- [0636. 函数的独占时间 - 力扣](https://leetcode.cn/problems/exclusive-time-of-functions/)
## 题目大意
**描述**:
有一个单线程 CPU 正在运行一个含有 $n$ 道函数的程序。每道函数都有一个位于 $0$ 和 $n-1$ 之间的唯一标识符。
函数调用存储在一个「调用栈」上:当一个函数调用开始时,它的标识符将会推入栈中。而当一个函数调用结束时,它的标识符将会从栈中弹出。标识符位于栈顶的函数是 当前正在执行的函数。每当一个函数开始或者结束时,将会记录一条日志,包括函数标识符、是开始还是结束、以及相应的时间戳。
给定一个由日志组成的列表 $logs$,其中 $logs[i]$ 表示第 $i$ 条日志消息,该消息是一个按 `"{function_id}:{"start" | "end"}:{timestamp}"` 进行格式化的字符串。例如,`"0:start:3"` 意味着标识符为 $0$ 的函数调用在时间戳 $3$ 的起始开始执行;而 `"1:end:2"` 意味着标识符为 $1$ 的函数调用在时间戳 $2$ 的末尾结束执行。注意,函数可以调用多次,可能存在递归调用。
函数的「独占时间」定义是在这个函数在程序所有函数调用中执行时间的总和,调用其他函数花费的时间不算该函数的独占时间。例如,如果一个函数被调用两次,一次调用执行 $2$ 单位时间,另一次调用执行 $1$ 单位时间,那么该函数的 独占时间 为 $2 + 1 = 3$。
**要求**:
以数组形式返回每个函数的「独占时间」,其中第 $i$ 个下标对应的值表示标识符 $i$ 的函数的独占时间。
**说明**:
- $1 \le n \le 10^{3}$。
- $2 \le logs.length \le 500$。
- $0 \le function_id \lt n$。
- $0 \le timestamp \le 10^{9}$。
- 两个开始事件不会在同一时间戳发生。
- 两个结束事件不会在同一时间戳发生。
- 每道函数都有一个对应 `"start"` 日志的 `"end"` 日志。
**示例**:
- 示例 1:

```python
输入:n = 2, logs = ["0:start:0","1:start:2","1:end:5","0:end:6"]
输出:[3,4]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,于时间戳 1 的末尾结束执行。
函数 1 在时间戳 2 的起始开始执行,执行 4 个单位时间,于时间戳 5 的末尾结束执行。
函数 0 在时间戳 6 的开始恢复执行,执行 1 个单位时间。
所以函数 0 总共执行 2 + 1 = 3 个单位时间,函数 1 总共执行 4 个单位时间。
```
- 示例 2:
```python
输入:n = 1, logs = ["0:start:0","0:start:2","0:end:5","0:start:6","0:end:6","0:end:7"]
输出:[8]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,并递归调用它自身。
函数 0(递归调用)在时间戳 2 的起始开始执行,执行 4 个单位时间。
函数 0(初始调用)恢复执行,并立刻再次调用它自身。
函数 0(第二次递归调用)在时间戳 6 的起始开始执行,执行 1 个单位时间。
函数 0(初始调用)在时间戳 7 的起始恢复执行,执行 1 个单位时间。
所以函数 0 总共执行 2 + 4 + 1 + 1 = 8 个单位时间。
```
## 解题思路
### 思路 1:栈
这道题目需要模拟函数调用栈的执行过程,计算每个函数的独占时间。
1. 使用栈来模拟函数调用过程,栈中存储函数的 ID。
2. 使用数组 $ans$ 记录每个函数的独占时间。
3. 使用变量 $prev\underline{~}time$ 记录上一个时间戳。
4. 遍历日志列表:
- 解析日志,获取函数 ID、操作类型(start/end)和时间戳。
- 如果是 start 操作:
- 如果栈不为空,说明有函数正在执行,将当前时间与上一个时间的差值累加到栈顶函数的独占时间中。
- 将当前函数 ID 入栈。
- 更新 $prev\underline{~}time$ 为当前时间戳。
- 如果是 end 操作:
- 将栈顶函数出栈,并将当前时间与上一个时间的差值加 1(因为 end 时刻也属于该函数)累加到该函数的独占时间中。
- 更新 $prev\underline{~}time$ 为当前时间戳加 1。
5. 返回结果数组 $ans$。
### 思路 1:代码
```python
class Solution:
def exclusiveTime(self, n: int, logs: List[str]) -> List[int]:
ans = [0] * n # 记录每个函数的独占时间
stack = [] # 模拟函数调用栈
prev_time = 0 # 记录上一个时间戳
for log in logs:
parts = log.split(':')
func_id = int(parts[0])
op_type = parts[1]
timestamp = int(parts[2])
if op_type == 'start':
# 如果栈不为空,当前栈顶函数被暂停
if stack:
ans[stack[-1]] += timestamp - prev_time
# 当前函数入栈
stack.append(func_id)
prev_time = timestamp
else: # end
# 当前函数出栈,累加独占时间
func_id = stack.pop()
ans[func_id] += timestamp - prev_time + 1
prev_time = timestamp + 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m)$,其中 $m$ 是日志的数量。需要遍历所有日志。
- **空间复杂度**:$O(n)$,其中 $n$ 是函数的数量。需要使用栈来存储函数调用关系,最坏情况下所有函数都在栈中。
================================================
FILE: docs/solutions/0600-0699/falling-squares.md
================================================
# [0699. 掉落的方块](https://leetcode.cn/problems/falling-squares/)
- 标签:线段树、数组、有序集合
- 难度:困难
## 题目链接
- [0699. 掉落的方块 - 力扣](https://leetcode.cn/problems/falling-squares/)
## 题目大意
**描述**:
在二维平面上的 x 轴上,放置着一些方块。
给定一个二维整数数组 $positions$,其中 $positions[i] = [left\_i, sideLength\_i]$ 表示:第 $i$ 个方块边长为 $sideLength\_i$ ,其左侧边与 x 轴上坐标点 $left\_i$ 对齐。
每个方块都从一个比目前所有的落地方块更高的高度掉落而下。方块沿 y 轴负方向下落,直到着陆到「另一个正方形的顶边」或者是 x 轴上。一个方块仅仅是擦过另一个方块的左侧边或右侧边不算着陆。一旦着陆,它就会固定在原地,无法移动。
在每个方块掉落后,你必须记录目前所有已经落稳的「方块堆叠的最高高度」。
**要求**:
返回一个整数数组 $ans$,其中 $ans[i]$ 表示在第 $i$ 块方块掉落后堆叠的最高高度。
**说明**:
- $1 \le positions.length \le 10^{3}$。
- $1 \le left_i \le 10^{8}$。
- $1 \le sideLength_i \le 10^{6}$。
**示例**:
- 示例 1:
```python
输入:positions = [[1,2],[2,3],[6,1]]
输出:[2,5,5]
解释:
第 1 个方块掉落后,最高的堆叠由方块 1 组成,堆叠的最高高度为 2 。
第 2 个方块掉落后,最高的堆叠由方块 1 和 2 组成,堆叠的最高高度为 5 。
第 3 个方块掉落后,最高的堆叠仍然由方块 1 和 2 组成,堆叠的最高高度为 5 。
因此,返回 [2, 5, 5] 作为答案。
```
- 示例 2:
```python
输入:positions = [[100,100],[200,100]]
输出:[100,100]
解释:
第 1 个方块掉落后,最高的堆叠由方块 1 组成,堆叠的最高高度为 100 。
第 2 个方块掉落后,最高的堆叠可以由方块 1 组成也可以由方块 2 组成,堆叠的最高高度为 100 。
因此,返回 [100, 100] 作为答案。
注意,方块 2 擦过方块 1 的右侧边,但不会算作在方块 1 上着陆。
```
## 解题思路
### 思路 1:线段树 + 坐标压缩
这道题目要求模拟方块掉落的过程,记录每次掉落后的最大高度。由于坐标范围很大,需要使用坐标压缩。
1. 使用字典记录每个区间的当前高度。
2. 对于每个掉落的方块 $[left, sideLength]$:
- 计算方块覆盖的区间 $[left, right]$,其中 $right = left + sideLength - 1$。
- 查询该区间内的最大高度 $max\_height$。
- 方块掉落后的高度为 $max\_height + sideLength$。
- 更新该区间的高度。
- 记录当前的最大高度。
3. 返回每次掉落后的最大高度列表。
### 思路 1:代码
```python
class Solution:
def fallingSquares(self, positions: List[List[int]]) -> List[int]:
# 使用字典记录每个区间的高度
heights = {}
result = []
max_height = 0
for left, side_length in positions:
right = left + side_length - 1
# 查询 [left, right] 区间内的最大高度
base_height = 0
for (l, r), h in list(heights.items()):
# 判断区间是否有重叠
if not (r < left or l > right):
base_height = max(base_height, h)
# 方块掉落后的高度
new_height = base_height + side_length
# 更新区间高度
# 先删除被覆盖的区间
keys_to_remove = []
for (l, r) in list(heights.keys()):
if left <= l and r <= right:
keys_to_remove.append((l, r))
for key in keys_to_remove:
del heights[key]
# 添加新的区间
heights[(left, right)] = new_height
# 更新最大高度
max_height = max(max_height, new_height)
result.append(max_height)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是方块的数量。每次掉落需要遍历所有已有的区间。
- **空间复杂度**:$O(n)$,需要使用字典存储区间高度信息。
================================================
FILE: docs/solutions/0600-0699/find-duplicate-file-in-system.md
================================================
# [0609. 在系统中查找重复文件](https://leetcode.cn/problems/find-duplicate-file-in-system/)
- 标签:数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0609. 在系统中查找重复文件 - 力扣](https://leetcode.cn/problems/find-duplicate-file-in-system/)
## 题目大意
**描述**:
给定一个目录信息列表 $paths$,包括目录路径,以及该目录中的所有文件及其内容。
一组重复的文件至少包括「两个」具有完全相同内容的文件。
「输入」列表中的单个目录信息字符串的格式如下:
- `"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"`
这意味着,在目录 `root/d1/d2/.../dm` 下,有 $n$ 个文件 ($f1.txt, f2.txt ... fn.txt$) 的内容分别是 ($f1\_content$, $f2\_content$ ... $fn\_content$) 。注意:$n \ge 1$ 且 $m \ge 0$ 。如果 $m = 0$,则表示该目录是根目录。
「输出」是由「重复文件路径组」构成的列表。其中每个组由所有具有相同内容文件的文件路径组成。文件路径是具有下列格式的字符串:
- `"directory_path/file_name.txt"`
**要求**:
按路径返回文件系统中的所有重复文件。答案可按任意顺序返回。
**说明**:
- $1 \le paths.length \le 2 \times 10^{4}$。
- $1 \le paths[i].length \le 3000$。
- $1 \le sum(paths[i].length) \le 5 \times 10^{5}$。
- $paths[i]$ 由英文字母、数字、字符 `'/'`、`'.'`、`'('`、`')'` 和 `' '` 组成。
- 你可以假设在同一目录中没有任何文件或目录共享相同的名称。
- 你可以假设每个给定的目录信息代表一个唯一的目录。目录路径和文件信息用单个空格分隔。
- 进阶:
- 假设您有一个真正的文件系统,您将如何搜索文件?广度搜索还是宽度搜索?
- 如果文件内容非常大(GB级别),您将如何修改您的解决方案?
- 如果每次只能读取 1 kb 的文件,您将如何修改解决方案?
- 修改后的解决方案的时间复杂度是多少?其中最耗时的部分和消耗内存的部分是什么?如何优化?
- 如何确保您发现的重复文件不是误报?
**示例**:
- 示例 1:
```python
输入:paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)","root 4.txt(efgh)"]
输出:[["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]]
```
- 示例 2:
```python
输入:paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)"]
输出:[["root/a/2.txt","root/c/d/4.txt"],["root/a/1.txt","root/c/3.txt"]]
```
## 解题思路
### 思路 1:哈希表
这道题目要求找出具有相同内容的文件。使用哈希表,以文件内容为键,文件路径列表为值。
1. 创建哈希表 $content\_map$,键为文件内容,值为文件路径列表。
2. 遍历 $paths$ 中的每个目录信息:
- 解析目录路径和文件信息。
- 对于每个文件,提取文件名和内容。
- 构造完整的文件路径 $directory\_path/file\_name.txt$。
- 将文件路径添加到对应内容的列表中。
3. 遍历哈希表,将包含多个文件路径的列表加入结果。
4. 返回结果。
### 思路 1:代码
```python
class Solution:
def findDuplicate(self, paths: List[str]) -> List[List[str]]:
from collections import defaultdict
content_map = defaultdict(list)
for path in paths:
parts = path.split()
directory = parts[0]
# 遍历该目录下的所有文件
for i in range(1, len(parts)):
file_info = parts[i]
# 找到文件名和内容的分隔位置
idx = file_info.index('(')
file_name = file_info[:idx]
content = file_info[idx + 1:-1] # 去掉括号
# 构造完整路径
full_path = directory + '/' + file_name
content_map[content].append(full_path)
# 筛选出有重复内容的文件组
result = []
for paths_list in content_map.values():
if len(paths_list) > 1:
result.append(paths_list)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是目录信息的数量,$m$ 是每个目录中文件的平均数量。需要遍历所有文件。
- **空间复杂度**:$O(n \times m)$,需要使用哈希表存储所有文件的路径和内容。
================================================
FILE: docs/solutions/0600-0699/find-duplicate-subtrees.md
================================================
# [0652. 寻找重复的子树](https://leetcode.cn/problems/find-duplicate-subtrees/)
- 标签:树、深度优先搜索、哈希表、二叉树
- 难度:中等
## 题目链接
- [0652. 寻找重复的子树 - 力扣](https://leetcode.cn/problems/find-duplicate-subtrees/)
## 题目大意
给定一个二叉树,返回所有重复的子树。对于重复的子树,只需返回其中任意一棵的根节点。
## 解题思路
对二叉树进行先序遍历,对遍历的所有的子树进行序列化处理,将序列化处理后的字符串作为哈希表的键,记录每棵子树出现的次数。
当出现第二次时,则说明该子树是重复的子树,将其加入答案数组。最后返回答案数组即可。
## 代码
```python
class Solution:
def findDuplicateSubtrees(self, root: TreeNode) -> List[TreeNode]:
tree_dict = dict()
res = []
def preorder(node):
if not node:
return '#'
sub_tree = str(node.val) + ',' + preorder(node.left) + ',' + preorder(node.right)
if sub_tree in tree_dict:
tree_dict[sub_tree] += 1
else:
tree_dict[sub_tree] = 1
if tree_dict[sub_tree] == 2:
res.append(node)
return sub_tree
preorder(root)
return res
```
================================================
FILE: docs/solutions/0600-0699/find-k-closest-elements.md
================================================
# [0658. 找到 K 个最接近的元素](https://leetcode.cn/problems/find-k-closest-elements/)
- 标签:数组、双指针、二分查找、排序、滑动窗口、堆(优先队列)
- 难度:中等
## 题目链接
- [0658. 找到 K 个最接近的元素 - 力扣](https://leetcode.cn/problems/find-k-closest-elements/)
## 题目大意
**描述**:给定一个有序数组 $arr$,以及两个整数 $k$、$x$。
**要求**:从数组中找到最靠近 $x$(两数之差最小)的 $k$ 个数。返回包含这 $k$ 个数的有序数组。
**说明**:
- 整数 $a$ 比整数 $b$ 更接近 $x$ 需要满足:
- $|a - x| < |b - x|$ 或者
- $|a - x| == |b - x|$ 且 $a < b$。
- $1 \le k \le arr.length$。
- $1 \le arr.length \le 10^4$。
- $arr$ 按升序排列。
- $-10^4 \le arr[i], x \le 10^4$。
**示例**:
- 示例 1:
```python
输入:arr = [1,2,3,4,5], k = 4, x = 3
输出:[1,2,3,4]
```
- 示例 2:
```python
输入:arr = [1,2,3,4,5], k = 4, x = -1
输出:[1,2,3,4]
```
## 解题思路
### 思路 1:二分查找算法
数组的区间为 $[0, n-1]$,查找的子区间长度为 $k$。我们可以通过查找子区间左端点位置,从而确定子区间。
查找子区间左端点可以通过二分查找来降低复杂度。
因为子区间为 $k$,所以左端点最多取到 $n - k$ 的位置。
设定两个指针 $left$,$right$。$left$ 指向 $0$,$right$ 指向 $n - k$。
每次取 $left$ 和 $right$ 中间位置,判断 $x$ 与左右边界的差值。$x$ 与左边的差值为 $x - arr[mid]$,$x$ 与右边界的差值为 $arr[mid + k] - x$。
- 如果 $x$ 与左边界的差值大于 $x$ 与右边界的差值,即 $x - arr[mid] > arr[mid + k] - x$,将 $left$ 右移,$left = mid + 1$,从右侧继续查找。
- 如果 $x$ 与左边界的差值小于等于 $x$ 与右边界的差值, 即 $x - arr[mid] \le arr[mid + k] - x$,则将 $right$ 向左侧靠拢,$right = mid$,从左侧继续查找。
最后返回 $arr[left, left + k]$ 即可。
### 思路 1:代码
```python
class Solution:
def findClosestElements(self, arr: List[int], k: int, x: int) -> List[int]:
n = len(arr)
left = 0
right = n - k
while left < right:
mid = left + (right - left) // 2
if x - arr[mid] > arr[mid + k] - x:
left = mid + 1
else:
right = mid
return arr[left: left + k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log (n - k) + k)$,其中 $n$ 为数组中的元素个数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0600-0699/find-the-derangement-of-an-array.md
================================================
# [0634. 寻找数组的错位排列](https://leetcode.cn/problems/find-the-derangement-of-an-array/)
- 标签:数学、动态规划、组合数学
- 难度:中等
## 题目链接
- [0634. 寻找数组的错位排列 - 力扣](https://leetcode.cn/problems/find-the-derangement-of-an-array/)
## 题目大意
**描述**:
在组合数学中,如果一个排列中所有元素都不在原先的位置上,那么这个排列就被称为 **错位排列**。
给定一个从 $1$ 到 $n$ 升序排列的数组。
**要求**:
返回 **不同的错位排列** 的数量。
由于答案可能非常大,你只需要将答案对 $10^9 + 7$ 取余输出即可。
**说明**:
- $1 \le n \le 10^6$。
**示例**:
- 示例 1:
```python
输入:n = 3
输出:2
解释:原始的数组为 [1,2,3]。两个错位排列的数组为 [2,3,1] 和 [3,1,2]。
```
- 示例 2:
```python
输入:n = 2
输出:1
```
## 解题思路
### 思路 1:动态规划
#### 思路 1:算法描述
错位排列(Derangement)是组合数学中的经典问题。设 $D(n)$ 表示 $n$ 个元素的错位排列数量。
**递推公式**:
$$D(n) = (n-1) \times [D(n-1) + D(n-2)]$$
**推导思路**:
- 考虑第 $n$ 个元素,它不能放在第 $n$ 个位置。
- 假设第 $n$ 个元素放在第 $k$ 个位置($1 \le k \le n-1$)。
- 情况 1:第 $k$ 个元素放在第 $n$ 个位置,剩余 $n-2$ 个元素错位排列,方案数为 $D(n-2)$。
- 情况 2:第 $k$ 个元素不放在第 $n$ 个位置,相当于 $n-1$ 个元素的错位排列,方案数为 $D(n-1)$。
- 第 $n$ 个元素有 $n-1$ 种选择,所以 $D(n) = (n-1) \times [D(n-1) + D(n-2)]$。
**初始条件**:
- $D(0) = 1$(空排列)
- $D(1) = 0$(1 个元素无法错位)
- $D(2) = 1$(只有 $[2, 1]$ 一种)
#### 思路 1:代码
```python
class Solution:
def findDerangement(self, n: int) -> int:
MOD = 10**9 + 7
# 特殊情况
if n == 1:
return 0
if n == 2:
return 1
# 动态规划
dp_prev2 = 1 # D(0)
dp_prev1 = 0 # D(1)
for i in range(2, n + 1):
dp_curr = ((i - 1) * (dp_prev1 + dp_prev2)) % MOD
dp_prev2 = dp_prev1
dp_prev1 = dp_curr
return dp_prev1
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,需要计算从 $2$ 到 $n$ 的所有错位排列数。
- **空间复杂度**:$O(1)$,只使用了常数额外空间。
================================================
FILE: docs/solutions/0600-0699/image-smoother.md
================================================
# [0661. 图片平滑器](https://leetcode.cn/problems/image-smoother/)
- 标签:数组、矩阵
- 难度:简单
## 题目链接
- [0661. 图片平滑器 - 力扣](https://leetcode.cn/problems/image-smoother/)
## 题目大意
**描述**:
「图像平滑器」是大小为 $3 \times 3$ 的过滤器,用于对图像的每个单元格平滑处理,平滑处理后单元格的值为该单元格的平均灰度。
每个单元格的「平均灰度」定义为:该单元格自身及其周围的 $8$ 个单元格的平均值,结果需向下取整。(即,需要计算蓝色平滑器中 $9$ 个单元格的平均值)。
如果一个单元格周围存在单元格缺失的情况,则计算平均灰度时不考虑缺失的单元格(即,需要计算红色平滑器中 $4$ 个单元格的平均值)。

给定一个表示图像灰度的 $m \times n$ 整数矩阵 $img$。
**要求**:
返回对图像的每个单元格平滑处理后的图像。
**说明**:
- $m == img.length$。
- $n == img[i].length$。
- $1 \le m, n \le 200$。
- $0 \le img[i][j] \le 255$。
**示例**:
- 示例 1:

```python
输入:img = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[0, 0, 0],[0, 0, 0], [0, 0, 0]]
解释:
对于点 (0,0), (0,2), (2,0), (2,2): 平均(3/4) = 平均(0.75) = 0
对于点 (0,1), (1,0), (1,2), (2,1): 平均(5/6) = 平均(0.83333333) = 0
对于点 (1,1): 平均(8/9) = 平均(0.88888889) = 0
```
- 示例 2:

```python
输入: img = [[100,200,100],[200,50,200],[100,200,100]]
输出: [[137,141,137],[141,138,141],[137,141,137]]
解释:
对于点 (0,0), (0,2), (2,0), (2,2): floor((100+200+200+50)/4) = floor(137.5) = 137
对于点 (0,1), (1,0), (1,2), (2,1): floor((200+200+50+200+100+100)/6) = floor(141.666667) = 141
对于点 (1,1): floor((50+200+200+200+200+100+100+100+100)/9) = floor(138.888889) = 138
```
## 解题思路
### 思路 1:矩阵遍历
这道题目要求对图像的每个单元格进行平滑处理,计算该单元格及其周围 8 个单元格的平均值(向下取整)。
1. 创建一个与原图像大小相同的结果矩阵 $result$。
2. 定义 8 个方向的偏移量,用于访问当前单元格周围的 8 个单元格。
3. 遍历图像的每个单元格 $(i, j)$:
- 初始化 $sum$ 为当前单元格的值,$count$ 为 1。
- 遍历 8 个方向,检查相邻单元格是否在边界内。
- 如果在边界内,将该单元格的值累加到 $sum$,并将 $count$ 加 1。
- 计算平均值 $sum // count$(向下取整),存入结果矩阵。
4. 返回结果矩阵。
### 思路 1:代码
```python
class Solution:
def imageSmoother(self, img: List[List[int]]) -> List[List[int]]:
m, n = len(img), len(img[0])
result = [[0] * n for _ in range(m)]
# 8 个方向的偏移量
directions = [(-1, -1), (-1, 0), (-1, 1), (0, -1), (0, 1), (1, -1), (1, 0), (1, 1)]
for i in range(m):
for j in range(n):
total = img[i][j] # 当前单元格的值
count = 1 # 计数器
# 遍历 8 个方向
for dx, dy in directions:
ni, nj = i + dx, j + dy
# 检查是否在边界内
if 0 <= ni < m and 0 <= nj < n:
total += img[ni][nj]
count += 1
# 计算平均值(向下取整)
result[i][j] = total // count
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$ 和 $n$ 分别是图像的行数和列数。需要遍历每个单元格,每个单元格最多检查 8 个相邻单元格。
- **空间复杂度**:$O(m \times n)$,需要创建一个结果矩阵存储平滑后的图像。
================================================
FILE: docs/solutions/0600-0699/implement-magic-dictionary.md
================================================
# [0676. 实现一个魔法字典](https://leetcode.cn/problems/implement-magic-dictionary/)
- 标签:设计、字典树、哈希表、字符串
- 难度:中等
## 题目链接
- [0676. 实现一个魔法字典 - 力扣](https://leetcode.cn/problems/implement-magic-dictionary/)
## 题目大意
**要求**:设计一个使用单词表进行初始化的数据结构。单词表中的单词互不相同。如果给出一个单词,要求判定能否将该单词中的一个字母替换成另一个字母,是的所形成的新单词已经在够构建的单词表中。
实现 MagicDictionary 类:
- `MagicDictionary()` 初始化对象。
- `void buildDict(String[] dictionary)` 使用字符串数组 `dictionary` 设定该数据结构,`dictionary` 中的字符串互不相同。
- `bool search(String searchWord)` 给定一个字符串 `searchWord`,判定能否只将字符串中一个字母换成另一个字母,使得所形成的新字符串能够与字典中的任一字符串匹配。如果可以,返回 `True`;否则,返回 `False`。
**说明**:
- $1 \le dictionary.length \le 100$。
- $1 \le dictionary[i].length \le 100$。
- `dictionary[i]` 仅由小写英文字母组成。
- `dictionary` 中的所有字符串互不相同。
- $1 \le searchWord.length \le 100$。
- `searchWord` 仅由小写英文字母组成。
- `buildDict` 仅在 `search` 之前调用一次。
- 最多调用 $100$ 次 `search`。
**示例**:
- 示例 1:
```python
输入
["MagicDictionary", "buildDict", "search", "search", "search", "search"]
[[], [["hello", "leetcode"]], ["hello"], ["hhllo"], ["hell"], ["leetcoded"]]
输出
[null, null, false, true, false, false]
解释
MagicDictionary magicDictionary = new MagicDictionary();
magicDictionary.buildDict(["hello", "leetcode"]);
magicDictionary.search("hello"); // 返回 False
magicDictionary.search("hhllo"); // 将第二个 'h' 替换为 'e' 可以匹配 "hello" ,所以返回 True
magicDictionary.search("hell"); // 返回 False
magicDictionary.search("leetcoded"); // 返回 False
```
## 解题思路
### 思路 1:字典树
1. 构造一棵字典树。
2. `buildDict` 方法中将所有单词存入字典树中。
3. `search` 方法中替换 `searchWord` 每一个位置上的字符,然后在字典树中查询。
### 思路 1:代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class MagicDictionary:
def __init__(self):
"""
Initialize your data structure here.
"""
self.trie_tree = Trie()
def buildDict(self, dictionary: List[str]) -> None:
for word in dictionary:
self.trie_tree.insert(word)
def search(self, searchWord: str) -> bool:
size = len(searchWord)
for i in range(size):
for j in range(26):
new_ch = chr(ord('a') + j)
if searchWord[i] != new_ch:
new_word = searchWord[:i] + new_ch + searchWord[i + 1:]
if self.trie_tree.search(new_word):
return True
return False
```
### 思路 1:复杂度分析
- **时间复杂度**:初始化操作是 $O(1)$。构建操作是 $O(|dictionary|)$,搜索操作是 $O(|searchWord| \times |\sum|)$。其中 $|dictionary|$ 是字符串数组 `dictionary` 中的字符个数,$|searchWord|$ 是查询操作中字符串的长度,$|\sum|$ 是字符集的大小。
- **空间复杂度**:$O(|dicitonary|)$。
================================================
FILE: docs/solutions/0600-0699/index.md
================================================
## 本章内容
- [0600. 不含连续1的非负整数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/non-negative-integers-without-consecutive-ones.md)
- [0604. 迭代压缩字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/design-compressed-string-iterator.md)
- [0605. 种花问题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/can-place-flowers.md)
- [0606. 根据二叉树创建字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/construct-string-from-binary-tree.md)
- [0609. 在系统中查找重复文件](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/find-duplicate-file-in-system.md)
- [0611. 有效三角形的个数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/valid-triangle-number.md)
- [0616. 给字符串添加加粗标签](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/add-bold-tag-in-string.md)
- [0617. 合并二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/merge-two-binary-trees.md)
- [0621. 任务调度器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/task-scheduler.md)
- [0622. 设计循环队列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/design-circular-queue.md)
- [0623. 在二叉树中增加一行](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/add-one-row-to-tree.md)
- [0624. 数组列表中的最大距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-distance-in-arrays.md)
- [0625. 最小因式分解](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/minimum-factorization.md)
- [0628. 三个数的最大乘积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-product-of-three-numbers.md)
- [0629. K 个逆序对数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/k-inverse-pairs-array.md)
- [0630. 课程表 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/course-schedule-iii.md)
- [0631. 设计 Excel 求和公式](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/design-excel-sum-formula.md)
- [0632. 最小区间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/smallest-range-covering-elements-from-k-lists.md)
- [0633. 平方数之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/sum-of-square-numbers.md)
- [0634. 寻找数组的错位排列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/find-the-derangement-of-an-array.md)
- [0635. 设计日志存储系统](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/design-log-storage-system.md)
- [0636. 函数的独占时间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/exclusive-time-of-functions.md)
- [0637. 二叉树的层平均值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/average-of-levels-in-binary-tree.md)
- [0638. 大礼包](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/shopping-offers.md)
- [0639. 解码方法 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/decode-ways-ii.md)
- [0640. 求解方程](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/solve-the-equation.md)
- [0641. 设计循环双端队列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/design-circular-deque.md)
- [0642. 设计搜索自动补全系统](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/design-search-autocomplete-system.md)
- [0643. 子数组最大平均数 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-average-subarray-i.md)
- [0644. 子数组最大平均数 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-average-subarray-ii.md)
- [0645. 错误的集合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/set-mismatch.md)
- [0646. 最长数对链](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-length-of-pair-chain.md)
- [0647. 回文子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/palindromic-substrings.md)
- [0648. 单词替换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/replace-words.md)
- [0649. Dota2 参议院](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/dota2-senate.md)
- [0650. 两个键的键盘](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/2-keys-keyboard.md)
- [0651. 四个键的键盘](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/4-keys-keyboard.md)
- [0652. 寻找重复的子树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/find-duplicate-subtrees.md)
- [0653. 两数之和 IV - 输入二叉搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/two-sum-iv-input-is-a-bst.md)
- [0654. 最大二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-binary-tree.md)
- [0655. 输出二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/print-binary-tree.md)
- [0656. 成本最小路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/coin-path.md)
- [0657. 机器人能否返回原点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/robot-return-to-origin.md)
- [0658. 找到 K 个最接近的元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/find-k-closest-elements.md)
- [0659. 分割数组为连续子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/split-array-into-consecutive-subsequences.md)
- [0660. 移除 9](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/remove-9.md)
- [0661. 图片平滑器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/image-smoother.md)
- [0662. 二叉树最大宽度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-width-of-binary-tree.md)
- [0663. 均匀树划分](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/equal-tree-partition.md)
- [0664. 奇怪的打印机](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/strange-printer.md)
- [0665. 非递减数列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/non-decreasing-array.md)
- [0666. 路径总和 IV](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/path-sum-iv.md)
- [0667. 优美的排列 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/beautiful-arrangement-ii.md)
- [0669. 修剪二叉搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/trim-a-binary-search-tree.md)
- [0670. 最大交换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-swap.md)
- [0671. 二叉树中第二小的节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/second-minimum-node-in-a-binary-tree.md)
- [0672. 灯泡开关 Ⅱ](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/bulb-switcher-ii.md)
- [0673. 最长递增子序列的个数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/number-of-longest-increasing-subsequence.md)
- [0674. 最长连续递增序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/longest-continuous-increasing-subsequence.md)
- [0675. 为高尔夫比赛砍树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/cut-off-trees-for-golf-event.md)
- [0676. 实现一个魔法字典](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/implement-magic-dictionary.md)
- [0677. 键值映射](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/map-sum-pairs.md)
- [0678. 有效的括号字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/valid-parenthesis-string.md)
- [0679. 24 点游戏](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/24-game.md)
- [0680. 验证回文串 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/valid-palindrome-ii.md)
- [0681. 最近时刻](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/next-closest-time.md)
- [0682. 棒球比赛](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/baseball-game.md)
- [0683. K 个关闭的灯泡](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/k-empty-slots.md)
- [0684. 冗余连接](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/redundant-connection.md)
- [0685. 冗余连接 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/redundant-connection-ii.md)
- [0686. 重复叠加字符串匹配](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/repeated-string-match.md)
- [0687. 最长同值路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/longest-univalue-path.md)
- [0688. 骑士在棋盘上的概率](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/knight-probability-in-chessboard.md)
- [0689. 三个无重叠子数组的最大和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/maximum-sum-of-3-non-overlapping-subarrays.md)
- [0690. 员工的重要性](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/employee-importance.md)
- [0691. 贴纸拼词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/stickers-to-spell-word.md)
- [0692. 前K个高频单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/top-k-frequent-words.md)
- [0693. 交替位二进制数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/binary-number-with-alternating-bits.md)
- [0694. 不同岛屿的数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/number-of-distinct-islands.md)
- [0695. 岛屿的最大面积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/max-area-of-island.md)
- [0696. 计数二进制子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/count-binary-substrings.md)
- [0697. 数组的度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/degree-of-an-array.md)
- [0698. 划分为k个相等的子集](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/partition-to-k-equal-sum-subsets.md)
- [0699. 掉落的方块](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/falling-squares.md)
================================================
FILE: docs/solutions/0600-0699/k-empty-slots.md
================================================
# [0683. K 个关闭的灯泡](https://leetcode.cn/problems/k-empty-slots/)
- 标签:树状数组、数组、有序集合、滑动窗口
- 难度:困难
## 题目链接
- [0683. K 个关闭的灯泡 - 力扣](https://leetcode.cn/problems/k-empty-slots/)
## 题目大意
**描述**:$n$ 个灯泡排成一行,编号从 $1$ 到 $n$。最初,所有灯泡都关闭。每天只打开一个灯泡,直到 $n$ 天后所有灯泡都打开。
给定一个长度为 $n$ 的灯泡数组 $blubs$,其中 `bulls[i] = x` 意味着在第 $i + 1$ 天,我们会把在位置 $x$ 的灯泡打开,其中 $i$ 从 $0$ 开始,$x$ 从 $1$ 开始。
再给定一个整数 $k$。
**要求**:输出在第几天恰好有两个打开的灯泡,使得它们中间正好有 $k$ 个灯泡且这些灯泡全部是关闭的 。如果不存在这种情况,则返回 $-1$。如果有多天都出现这种情况,请返回最小的天数 。
**说明**:
- $n == bulbs.length$。
- $1 \le n \le 2 \times 10^4$。
- $1 \le bulbs[i] \le n$。
- $bulbs$ 是一个由从 $1$ 到 $n$ 的数字构成的排列。
- $0 \le k \le 2 \times 10^4$。
**示例**:
- 示例 1:
```python
输入:
bulbs = [1,3,2],k = 1
输出:2
解释:
第一天 bulbs[0] = 1,打开第一个灯泡 [1,0,0]
第二天 bulbs[1] = 3,打开第三个灯泡 [1,0,1]
第三天 bulbs[2] = 2,打开第二个灯泡 [1,1,1]
返回2,因为在第二天,两个打开的灯泡之间恰好有一个关闭的灯泡。
```
- 示例 2:
```python
输入:bulbs = [1,2,3],k = 1
输出:-1
```
## 解题思路
### 思路 1:滑动窗口
$blubs[i]$ 记录的是第 $i + 1$ 天开灯的位置。我们将其转换一下,使用另一个数组 $days$ 来存储每个灯泡的开灯时间,其中 $days[i]$ 表示第 $i$ 个位置上的灯泡的开灯时间。
- 使用 $ans$ 记录最小满足条件的天数。维护一个窗口 $left$、$right$。其中 `right = left + k + 1`。使得区间 $(left, right)$ 中所有灯泡(总共为 $k$ 个)开灯时间都晚于 $days[left]$ 和 $days[right]$。
- 对于区间 $[left, right]$,$left < i < right$:
- 如果出现 $days[i] < days[left]$ 或者 $days[i] < days[right]$,说明不符合要求。将 $left$、$right$ 移动到 $[i, i + k + 1]$,继续进行判断。
- 如果对于 $left < i < right$ 中所有的 $i$,都满足 $days[i] \ge days[left]$ 并且 $days[i] \ge days[right]$,说明此时满足要求。将当前答案与 $days[left]$ 和 $days[right]$ 中的较大值作比较。如果比当前答案更小,则更新答案。同时将窗口向右移动 $k $位。继续检测新的不相交间隔 $[right, right + k + 1]$。
- 注意:之所以检测新的不相交间隔,是因为如果检测的是相交间隔,原来的 $right$ 位置元素仍在区间中,肯定会出现 $days[right] < days[right_new]$,不满足要求。所以此时相交的区间可以直接跳过,直接检测不相交的间隔。
- 直到 $right \ge len(days)$ 时跳出循环,判断是否有符合要求的答案,并返回答案 $ans$。
### 思路 1:代码
```python
class Solution:
def kEmptySlots(self, bulbs: List[int], k: int) -> int:
size = len(bulbs)
days = [0 for _ in range(size)]
for i in range(size):
days[bulbs[i] - 1] = i + 1
left, right = 0, k + 1
ans = float('inf')
while right < size:
check_flag = True
for i in range(left + 1, right):
if days[i] < days[left] or days[i] < days[right]:
left, right = i, i + k + 1
check_flag = False
break
if check_flag:
ans = min(ans, max(days[left], days[right]))
left, right = right, right + k + 1
if ans != float('inf'):
return ans
else:
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $bulbs$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0600-0699/k-inverse-pairs-array.md
================================================
# [0629. K 个逆序对数组](https://leetcode.cn/problems/k-inverse-pairs-array/)
- 标签:动态规划
- 难度:困难
## 题目链接
- [0629. K 个逆序对数组 - 力扣](https://leetcode.cn/problems/k-inverse-pairs-array/)
## 题目大意
**描述**:
对于一个整数数组 $nums$,逆序对是一对满足 $0 \le i < j < nums$.length$ 且 $nums[i] > nums[j]$ 的整数对 $[i, j]$。
给定两个整数 $n$ 和 $k$。
**要求**:
找出所有包含从 $1$ 到 $n$ 的数字,且恰好拥有 $k$ 个「逆序对」的不同的数组的个数。由于答案可能很大,只需要返回对 $10^9 + 7$ 取余的结果。
**说明**:
- $1 \le n \le 10^{3}$。
- $0 \le k \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:n = 3, k = 0
输出:1
解释:
只有数组 [1,2,3] 包含了从1到3的整数并且正好拥有 0 个逆序对。
```
- 示例 2:
```python
输入:n = 3, k = 1
输出:2
解释:
数组 [1,3,2] 和 [2,1,3] 都有 1 个逆序对。
```
## 解题思路
### 思路 1:动态规划
这道题目要求计算恰好有 $k$ 个逆序对的排列数量。使用动态规划求解。
定义 $dp[i][j]$ 表示使用数字 $1$ 到 $i$ 组成的排列中,恰好有 $j$ 个逆序对的排列数量。
状态转移:
- 当我们在前 $i - 1$ 个数字的排列中插入数字 $i$ 时,可以插入到任意位置。
- 如果插入到最后,不产生新的逆序对。
- 如果插入到倒数第二个位置,产生 1 个新的逆序对。
- 如果插入到第一个位置,产生 $i - 1$ 个新的逆序对。
- 因此:$dp[i][j] = \sum_{t=0}^{\min(j, i-1)} dp[i-1][j-t]$
优化:使用前缀和优化,避免重复计算。
### 思路 1:代码
```python
class Solution:
def kInversePairs(self, n: int, k: int) -> int:
MOD = 10**9 + 7
# dp[i][j] 表示使用 1 到 i 的数字,恰好有 j 个逆序对的排列数
dp = [[0] * (k + 1) for _ in range(n + 1)]
# 初始化:1 个数字,0 个逆序对
dp[0][0] = 1
for i in range(1, n + 1):
dp[i][0] = 1 # 0 个逆序对只有一种排列(升序)
for j in range(1, k + 1):
# dp[i][j] = sum(dp[i-1][j-t]) for t in range(min(j, i-1) + 1)
# 使用前缀和优化
dp[i][j] = (dp[i][j - 1] + dp[i - 1][j]) % MOD
# 减去超出范围的部分
if j >= i:
dp[i][j] = (dp[i][j] - dp[i - 1][j - i]) % MOD
return dp[n][k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times k)$,需要填充 $n \times k$ 的动态规划表。
- **空间复杂度**:$O(n \times k)$,需要使用二维数组存储动态规划状态。可以优化到 $O(k)$。
================================================
FILE: docs/solutions/0600-0699/knight-probability-in-chessboard.md
================================================
# [0688. 骑士在棋盘上的概率](https://leetcode.cn/problems/knight-probability-in-chessboard/)
- 标签:动态规划
- 难度:中等
## 题目链接
- [0688. 骑士在棋盘上的概率 - 力扣](https://leetcode.cn/problems/knight-probability-in-chessboard/)
## 题目大意
**描述**:在一个 `n * n` 的国际象棋棋盘上,一个骑士从单元格 `(row, column)` 开始,尝试进行 `k` 次 移动。行和列是从 `0` 开始的,左上角的单元格是 `(0, 0)`,右下角的单元格是 `(n - 1, n - 1)`。
象棋骑士有 `8` 种可能的走法,如下图所示。每次移动在基本方向上是两个单元格,然后在正交方向上是一个单元格。

每次骑士要移动时,它都会随机从 `8` 种可能的移动中选择一种(即使棋子会离开棋盘),然后移动到那里。骑士继续移动,直到它走了 `k` 步或离开了棋盘。
现在给定代表棋盘大小的整数 `n`、代表骑士移动次数的整数 `k`,以及代表骑士初始位置的坐标 `row` 和 `column`。
**要求**:返回骑士在棋盘停止移动后仍留在棋盘上的概率。
**说明**:
- $1 \le n \le 25$。
- $0 \le k \le 100$。
- $0 \le row, column \le n$。
**示例**:
- 示例 1:
```python
输入:n = 3, k = 2, row = 0, column = 0
输出:0.0625
解释:有两步(到(1,2),(2,1))可以让骑士留在棋盘上。在每一个位置上,也有两种移动可以让骑士留在棋盘上。骑士留在棋盘上的总概率是 0.0625。
```
## 解题思路
### 思路 1:动态规划
###### 1. 阶段划分
按照骑士所在位置和所走步数进行阶段划分。
###### 2. 定义状态
定义状态 `dp[i][j][p]` 表示为:从位置 `(i, j)` 出发,移动不超过 `p` 步的情况下,最后仍留在棋盘内的概率。
###### 3. 状态转移方程
根据象棋骑士的 `8` 种可能的走法,`dp[i][j][p]` 的来源有八个方向(超出棋盘的无需再考虑):
- 假设下一步的落点为 `(new_i, new_j)`。从当前步选择 `8` 个方向其中之一作为下一步方向的概率为 $\frac{1}{8}$。
- 而每个方向上落点仍在棋盘内的概率为 `dp[new_i][new_j][p - 1]`。所以从 `(i, j)` 走到 `(new_i, new_j)` 的可能性为 $dp[new_i][new_j] \times \frac{1}{8}$。
最终 $dp[i][j][p]$ 来源为 `8` 个方向上落点的概率之和,即:$dp[i][j][p] = \sum{ dp[new_i][new_j] \times \frac{1}{8} }$。
###### 4. 初始条件
- 从位置 `(i, j)` 出发,移动不超过 `0` 步的情况下,最后仍留在棋盘内的概率为 `1`。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i][j][p]` 表示为:从位置 `(i, j)` 出发,移动不超过 `p` 步的情况下,最后仍留在棋盘内的概率。则最终结果为 `dp[row][column][k]`。
### 思路 1:动态规划代码
```python
class Solution:
def knightProbability(self, n: int, k: int, row: int, column: int) -> float:
dp = [[[0 for _ in range(k + 1)] for _ in range(n)] for _ in range(n)]
for i in range(n):
for j in range(n):
dp[i][j][0] = 1
directions = {(-1, -2), (-1, 2), (1, -2), (1, 2), (-2, -1), (-2, 1), (2, -1), (2, 1)}
for p in range(1, k + 1):
for i in range(n):
for j in range(n):
for direction in directions:
new_i = i + direction[0]
new_j = j + direction[1]
if 0 <= new_i < n and 0 <= new_j < n:
dp[i][j][p] += dp[new_i][new_j][p - 1] / 8
return dp[row][column][k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 * k)$。外三层循环的时间复杂度为 $O(n^2 * k)$,内层关于 `directions` 的循环每次执行 `8` 次,可以看做是常数级时间复杂度。
- **空间复杂度**:$O(n^2 * k)$。用到了三维数组保存状态。
================================================
FILE: docs/solutions/0600-0699/longest-continuous-increasing-subsequence.md
================================================
# [0674. 最长连续递增序列](https://leetcode.cn/problems/longest-continuous-increasing-subsequence/)
- 标签:数组
- 难度:简单
## 题目链接
- [0674. 最长连续递增序列 - 力扣](https://leetcode.cn/problems/longest-continuous-increasing-subsequence/)
## 题目大意
**描述**:给定一个未经排序的数组 $nums$。
**要求**:找到最长且连续递增的子序列,并返回该序列的长度。
**说明**:
- **连续递增的子序列**:可以由两个下标 $l$ 和 $r$($l < r$)确定,如果对于每个 $l \le i < r$,都有 $nums[i] < nums[i + 1] $,那么子序列 $[nums[l], nums[l + 1], ..., nums[r - 1], nums[r]]$ 就是连续递增子序列。
- $1 \le nums.length \le 10^4$。
- $-10^9 \le nums[i] \le 10^9$。
**示例**:
- 示例 1:
```python
输入:nums = [1,3,5,4,7]
输出:3
解释:最长连续递增序列是 [1,3,5], 长度为 3。尽管 [1,3,5,7] 也是升序的子序列, 但它不是连续的,因为 5 和 7 在原数组里被 4 隔开。
```
- 示例 2:
```python
输入:nums = [2,2,2,2,2]
输出:1
解释:最长连续递增序列是 [2], 长度为 1。
```
## 解题思路
### 思路 1:动态规划
###### 1. 定义状态
定义状态 $dp[i]$ 表示为:以 $nums[i]$ 结尾的最长且连续递增的子序列长度。
###### 2. 状态转移方程
因为求解的是连续子序列,所以只需要考察相邻元素的状态转移方程。
如果一个较小的数右侧相邻元素为一个较大的数,则会形成一个更长的递增子序列。
对于相邻的数组元素 $nums[i - 1]$ 和 $nums[i]$ 来说:
- 如果 $nums[i - 1] < nums[i]$,则 $nums[i]$ 可以接在 $nums[i - 1]$ 后面,此时以 $nums[i]$ 结尾的最长递增子序列长度会在「以 $nums[i - 1]$ 结尾的最长递增子序列长度」的基础上加 $1$,即 $dp[i] = dp[i - 1] + 1$。
- 如果 $nums[i - 1] >= nums[i]$,则 $nums[i]$ 不可以接在 $nums[i - 1]$ 后面,可以直接跳过。
综上,我们的状态转移方程为:$dp[i] = dp[i - 1] + 1$,$nums[i - 1] < nums[i]$。
###### 3. 初始条件
默认状态下,把数组中的每个元素都作为长度为 $1$ 的最长且连续递增的子序列长度。即 $dp[i] = 1$。
###### 4. 最终结果
根据我们之前定义的状态,$dp[i]$ 表示为:以 $nums[i]$ 结尾的最长且连续递增的子序列长度。则为了计算出最大值,则需要再遍历一遍 $dp$ 数组,求出最大值即为最终结果。
### 思路 1:动态规划代码
```python
class Solution:
def findLengthOfLCIS(self, nums: List[int]) -> int:
size = len(nums)
dp = [1 for _ in range(size)]
for i in range(1, size):
if nums[i - 1] < nums[i]:
dp[i] = dp[i - 1] + 1
return max(dp)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度为 $O(n)$,最后求最大值的时间复杂度是 $O(n)$,所以总体时间复杂度为 $O(n)$。
- **空间复杂度**:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为 $O(n)$。
### 思路 2:滑动窗口(不定长度)
1. 设定两个指针:$left$、$right$,分别指向滑动窗口的左右边界,保证窗口内为连续递增序列。使用 $window\_len$ 存储当前窗口大小,使用 $max\_len$ 维护最大窗口长度。
2. 一开始,$left$、$right$ 都指向 $0$。
3. 将最右侧元素 $nums[right]$ 加入当前连续递增序列中,即当前窗口长度加 $1$(`window_len += 1`)。
4. 判断当前元素 $nums[right]$ 是否满足连续递增序列。
5. 如果 $right > 0$ 并且 $nums[right - 1] \ge nums[right]$ ,说明不满足连续递增序列,则将 $left$ 移动到窗口最右侧,重置当前窗口长度为 $1$(`window_len = 1`)。
6. 记录当前连续递增序列的长度,并更新最长连续递增序列的长度。
7. 继续右移 $right$,直到 $right \ge len(nums)$ 结束。
8. 输出最长连续递增序列的长度 $max\_len$。
### 思路 2:代码
```python
class Solution:
def findLengthOfLCIS(self, nums: List[int]) -> int:
size = len(nums)
left, right = 0, 0
window_len = 0
max_len = 0
while right < size:
window_len += 1
if right > 0 and nums[right - 1] >= nums[right]:
left = right
window_len = 1
max_len = max(max_len, window_len)
right += 1
return max_len
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0600-0699/longest-univalue-path.md
================================================
# [0687. 最长同值路径](https://leetcode.cn/problems/longest-univalue-path/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0687. 最长同值路径 - 力扣](https://leetcode.cn/problems/longest-univalue-path/)
## 题目大意
**描述**:给定一个二叉树的根节点 $root$。
**要求**:返回二叉树中最长的路径的长度,该路径中每个节点具有相同值。 这条路径可以经过也可以不经过根节点。
**说明**:
- 树的节点数的范围是 $[0, 10^4]$。
- $-1000 \le Node.val \le 1000$。
- 树的深度将不超过 $1000$。
- 两个节点之间的路径长度:由它们之间的边数表示。
**示例**:
- 示例 1:
```python
输入:root = [5,4,5,1,1,5]
输出:2
```
- 示例 2:
```python
输入:root = [1,4,5,4,4,5]
输出:2
```
## 解题思路
### 思路 1:树形 DP + 深度优先搜索
这道题如果先不考虑「路径中每个节点具有相同值」这个条件,那么这道题就是在求「二叉树的直径长度(最长路径的长度)」。
「二叉树的直径长度」的定义为:二叉树中任意两个节点路径长度中的最大值。并且这条路径可能穿过也可能不穿过根节点。
对于根为 $root$ 的二叉树来说,其直径长度并不简单等于「左子树高度」加上「右子树高度」。
根据路径是否穿过根节点,我们可以将二叉树分为两种:
1. 直径长度所对应的路径穿过根节点,这种情况下:$\text{二叉树的直径} = \text{左子树高度} + \text{右子树高度}$。
2. 直径长度所对应的路径不穿过根节点,这种情况下:$\text{二叉树的直径} = \text{所有子树中最大直径长度}$。
也就是说根为 $root$ 的二叉树的直径长度可能来自于 $\text{左子树高度} + \text{右子树高度}$,也可能来自于 $\text{子树中的最大直径}$,即 $\text{二叉树的直径} = max(\text{左子树高度} + \text{右子树高度}, \quad \text{所有子树中最大直径长度})$。
那么现在问题就变成为如何求「子树的高度」和「子树中的最大直径」。
1. 子树的高度:我们可以利用深度优先搜索方法,递归遍历左右子树,并分别返回左右子树的高度。
2. 子树中的最大直径:我们可以在递归求解子树高度的时候维护一个 $ans$ 变量,用于记录所有 $\text{左子树高度} + \text{右子树高度}$ 中的最大值。
最终 $ans$ 就是我们所求的该二叉树的最大直径。
接下来我们再来加上「路径中每个节点具有相同值」这个限制条件。
1. 「左子树高度」应变为「左子树最长同值路径长度」。
2. 「右子树高度」应变为「右子树最长同值路径长度」。
3. 题目变为求「二叉树的最长同值路径长度」,式子为:$\text{二叉树的最长同值路径长度} = max(\text{左子树最长同值路径长度} + \text{右子树最长同值路径长度}, \quad \text{所有子树中最长同值路径长度})$。
在递归遍历的时候,我们还需要当前节点与左右子节点的值的相同情况,来维护更新「包含当前节点的最长同值路径长度」。
1. 在递归遍历左子树时,如果当前节点与左子树的值相同,则:$\text{包含当前节点向左的最长同值路径长度} = \text{左子树最长同值路径长度} + 1$,否则为 $0$。
2. 在递归遍历左子树时,如果当前节点与左子树的值相同,则:$\text{包含当前节点向右的最长同值路径长度} = \text{右子树最长同值路径长度} + 1$,否则为 $0$。
则:$\text{包含当前节点向左的最长同值路径长度} = max(\text{包含当前节点向左的最长同值路径长度}, \quad \text{包含当前节点向右的最长同值路径长度})$。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def __init__(self):
self.ans = 0
def dfs(self, node):
if not node:
return 0
left_len = self.dfs(node.left) # 左子树高度
right_len = self.dfs(node.right) # 右子树高度
if node.left and node.left.val == node.val:
left_len += 1
else:
left_len = 0
if node.right and node.right.val == node.val:
right_len += 1
else:
right_len = 0
self.ans = max(self.ans, left_len + right_len)
return max(left_len, right_len)
def longestUnivaluePath(self, root: Optional[TreeNode]) -> int:
self.dfs(root)
return self.ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为二叉树的节点个数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0600-0699/map-sum-pairs.md
================================================
# [0677. 键值映射](https://leetcode.cn/problems/map-sum-pairs/)
- 标签:设计、字典树、哈希表、字符串
- 难度:中等
## 题目链接
- [0677. 键值映射 - 力扣](https://leetcode.cn/problems/map-sum-pairs/)
## 题目大意
**要求**:实现一个 MapSum 类,支持两个方法,`insert` 和 `sum`:
- `MapSum()` 初始化 MapSum 对象。
- `void insert(String key, int val)` 插入 `key-val` 键值对,字符串表示键 `key`,整数表示值 `val`。如果键 `key` 已经存在,那么原来的键值对将被替代成新的键值对。
- `int sum(string prefix)` 返回所有以该前缀 `prefix` 开头的键 `key` 的值的总和。
**说明**:
- $1 \le key.length, prefix.length \le 50$。
- `key` 和 `prefix` 仅由小写英文字母组成。
- $1 \le val \le 1000$。
- 最多调用 $50$ 次 `insert` 和 `sum`。
**示例**:
- 示例 1:
```python
输入:
["MapSum", "insert", "sum", "insert", "sum"]
[[], ["apple", 3], ["ap"], ["app", 2], ["ap"]]
输出:
[null, null, 3, null, 5]
解释:
MapSum mapSum = new MapSum();
mapSum.insert("apple", 3);
mapSum.sum("ap"); // 返回 3 (apple = 3)
mapSum.insert("app", 2);
mapSum.sum("ap"); // 返回 5 (apple + app = 3 + 2 = 5)
```
## 解题思路
### 思路 1:字典树
可以构造前缀树(字典树)解题。
- 初始化时,构建一棵前缀树(字典树),并增加 `val` 变量。
- 调用插入方法时,用字典树存储 `key`,并在对应字母节点存储对应的 `val`。
- 在调用查询总和方法时,先查找该前缀 `prefix` 对应的前缀树节点,从该节点开始,递归遍历该节点的子节点,并累积子节点的 `val`,进行求和,并返回求和累加结果。
### 思路 1:代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
self.value = 0
def insert(self, word: str, value: int) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
cur.value = value
def search(self, word: str) -> int:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return 0
cur = cur.children[ch]
return self.dfs(cur)
def dfs(self, root) -> int:
if not root:
return 0
res = root.value
for node in root.children.values():
res += self.dfs(node)
return res
class MapSum:
def __init__(self):
"""
Initialize your data structure here.
"""
self.trie_tree = Trie()
def insert(self, key: str, val: int) -> None:
self.trie_tree.insert(key, val)
def sum(self, prefix: str) -> int:
return self.trie_tree.search(prefix)
```
### 思路 1:复杂度分析
- **时间复杂度**:`insert` 操作的时间复杂度为 $O(|key|)$。其中 $|key|$ 是每次插入字符串 `key` 的长度。`sum` 操作的时间复杂度是 $O(|prefix|)$,其中 $O(| prefix |)$ 是查询字符串 `prefix` 的长度。
- **空间复杂度**:$O(|T| \times m)$。其中 $|T|$ 表示字符串 `key` 的最大长度,$m$ 表示 `key - val` 的键值数目。
================================================
FILE: docs/solutions/0600-0699/max-area-of-island.md
================================================
# [0695. 岛屿的最大面积](https://leetcode.cn/problems/max-area-of-island/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、矩阵
- 难度:中等
## 题目链接
- [0695. 岛屿的最大面积 - 力扣](https://leetcode.cn/problems/max-area-of-island/)
## 题目大意
**描述**:给定一个只包含 $0$、$1$ 元素的二维数组,$1$ 代表岛屿,$0$ 代表水。一座岛的面积就是上下左右相邻的 $1$ 所组成的连通块的数目。
**要求**:计算出最大的岛屿面积。
**说明**:
- $m == grid.length$。
- $n == grid[i].length$。
- $1 \le m, n \le 50$。
- $grid[i][j]$ 为 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
输出:6
解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
```
- 示例 2:
```python
输入:grid = [[0,0,0,0,0,0,0,0]]
输出:0
```
## 解题思路
### 思路 1:深度优先搜索
1. 遍历二维数组的每一个元素,对于每个值为 $1$ 的元素:
1. 将该位置上的值置为 $0$(防止二次重复计算)。
2. 递归搜索该位置上下左右四个位置,并统计搜到值为 $1$ 的元素个数。
3. 返回值为 $1$ 的元素个数(即为该岛的面积)。
2. 维护并更新最大的岛面积。
3. 返回最大的到面积。
### 思路 1:代码
```python
class Solution:
def dfs(self, grid, i, j):
n = len(grid)
m = len(grid[0])
if i < 0 or i >= n or j < 0 or j >= m or grid[i][j] == 0:
return 0
ans = 1
grid[i][j] = 0
ans += self.dfs(grid, i + 1, j)
ans += self.dfs(grid, i, j + 1)
ans += self.dfs(grid, i - 1, j)
ans += self.dfs(grid, i, j - 1)
return ans
def maxAreaOfIsland(self, grid: List[List[int]]) -> int:
ans = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == 1:
ans = max(ans, self.dfs(grid, i, j))
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $m$ 和 $n$ 分别为行数和列数。
- **空间复杂度**:$O(n \times m)$。
### 思路 2:广度优先搜索
1. 使用 $ans$ 记录最大岛屿面积。
2. 遍历二维数组的每一个元素,对于每个值为 $1$ 的元素:
1. 将该元素置为 $0$。并使用队列 $queue$ 存储该节点位置。使用 $temp\_ans$ 记录当前岛屿面积。
2. 然后从队列 $queue$ 中取出第一个节点位置 $(i, j)$。遍历该节点位置上、下、左、右四个方向上的相邻节点。并将其置为 $0$(避免重复搜索)。并将其加入到队列中。并累加当前岛屿面积,即 `temp_ans += 1`。
3. 不断重复上一步骤,直到队列 $queue$ 为空。
4. 更新当前最大岛屿面积,即 `ans = max(ans, temp_ans)`。
3. 将 $ans$ 作为答案返回。
### 思路 2:代码
```python
import collections
class Solution:
def maxAreaOfIsland(self, grid: List[List[int]]) -> int:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
rows, cols = len(grid), len(grid[0])
ans = 0
for i in range(rows):
for j in range(cols):
if grid[i][j] == 1:
grid[i][j] = 0
temp_ans = 1
q = collections.deque([(i, j)])
while q:
i, j = q.popleft()
for direct in directs:
new_i = i + direct[0]
new_j = j + direct[1]
if new_i < 0 or new_i >= rows or new_j < 0 or new_j >= cols or grid[new_i][new_j] == 0:
continue
grid[new_i][new_j] = 0
q.append((new_i, new_j))
temp_ans += 1
ans = max(ans, temp_ans)
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $m$ 和 $n$ 分别为行数和列数。
- **空间复杂度**:$O(n \times m)$。
================================================
FILE: docs/solutions/0600-0699/maximum-average-subarray-i.md
================================================
# [0643. 子数组最大平均数 I](https://leetcode.cn/problems/maximum-average-subarray-i/)
- 标签:数组、滑动窗口
- 难度:简单
## 题目链接
- [0643. 子数组最大平均数 I - 力扣](https://leetcode.cn/problems/maximum-average-subarray-i/)
## 题目大意
**描述**:给定一个由 $n$ 个元素组成的整数数组 $nums$ 和一个整数 $k$。
**要求**:找出平均数最大且长度为 $k$ 的连续子数组,并输出该最大平均数。
**说明**:
- 任何误差小于 $10^{-5}$ 的答案都将被视为正确答案。
- $n == nums.length$。
- $1 \le k \le n \le 10^5$。
- $-10^4 \le nums[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [1,12,-5,-6,50,3], k = 4
输出:12.75
解释:最大平均数 (12-5-6+50)/4 = 51/4 = 12.75
```
- 示例 2:
```python
输入:nums = [5], k = 1
输出:5.00000
```
## 解题思路
### 思路 1:滑动窗口(固定长度)
这道题目是典型的固定窗口大小的滑动窗口题目。窗口大小为 $k$。具体做法如下:
1. $ans$ 用来维护子数组最大平均数,初始值为负无穷,即 `float('-inf')`。$window\_total$ 用来维护窗口中元素的和。
2. $left$ 、$right$ 都指向序列的第一个元素,即:`left = 0`,`right = 0`。
3. 向右移动 $right$,先将 $k$ 个元素填入窗口中。
4. 当窗口元素个数为 $k$ 时,即:$right - left + 1 >= k$ 时,计算窗口内的元素和平均值,并维护子数组最大平均数。
5. 然后向右移动 $left$,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 $k$。
6. 重复 $4 \sim 5$ 步,直到 $right$ 到达数组末尾。
7. 最后输出答案 $ans$。
### 思路 1:代码
```python
class Solution:
def findMaxAverage(self, nums: List[int], k: int) -> float:
left = 0
right = 0
window_total = 0
ans = float('-inf')
while right < len(nums):
window_total += nums[right]
if right - left + 1 >= k:
ans = max(window_total / k, ans)
window_total -= nums[left]
left += 1
# 向右侧增大窗口
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。其中 $n$ 为数组 $nums$ 的元素个数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0600-0699/maximum-average-subarray-ii.md
================================================
# [0644. 子数组最大平均数 II](https://leetcode.cn/problems/maximum-average-subarray-ii/)
- 标签:数组、二分查找、前缀和
- 难度:困难
## 题目链接
- [0644. 子数组最大平均数 II - 力扣](https://leetcode.cn/problems/maximum-average-subarray-ii/)
## 题目大意
**描述**:
给你一个包含 $n$ 个整数的数组 $nums$,和一个整数 $k$。
**要求**:
找出 **长度大于等于** $k$ 且含最大平均值的连续子数组。并输出这个最大平均值。任何计算误差小于 $10^{-5}$ 的结果都将被视为正确答案。
**说明**:
- $n == nums.length$。
- $1 \le k \le n \le 10^4$。
- $-10^4 \le nums[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [1,12,-5,-6,50,3], k = 4
输出:12.75000
解释:
- 当长度为 4 的时候,连续子数组平均值分别为 [0.5, 12.75, 10.5],其中最大平均值是 12.75。
- 当长度为 5 的时候,连续子数组平均值分别为 [10.4, 10.8],其中最大平均值是 10.8。
- 当长度为 6 的时候,连续子数组平均值分别为 [9.16667],其中最大平均值是 9.16667。
当取长度为 4 的子数组(即,子数组 [12, -5, -6, 50])的时候,可以得到最大的连续子数组平均值 12.75,所以返回 12.75。
根据题目要求,无需考虑长度小于 4 的子数组。
```
- 示例 2:
```python
输入:nums = [5], k = 1
输出:5.00000
```
## 解题思路
### 思路 1:二分查找 + 前缀和
这道题目要求找到长度大于等于 $k$ 的子数组的最大平均值。
**核心思路**:
- 使用二分查找来确定最大平均值。
- 对于一个给定的平均值 $mid$,判断是否存在长度大于等于 $k$ 的子数组,其平均值大于等于 $mid$。
- 判断方法:将数组中每个元素减去 $mid$,如果存在长度大于等于 $k$ 的子数组和大于等于 $0$,则说明存在平均值大于等于 $mid$ 的子数组。
**算法步骤**:
1. 二分查找的范围是 $[min(nums), max(nums)]$。
2. 对于每个 $mid$,将数组中每个元素减去 $mid$,得到新数组 $arr$。
3. 使用前缀和 + 滑动窗口,判断是否存在长度大于等于 $k$ 的子数组和大于等于 $0$。
4. 如果存在,说明最大平均值在 $[mid, right]$ 范围内;否则在 $[left, mid]$ 范围内。
5. 重复步骤 2-4,直到 $left$ 和 $right$ 的差值小于 $10^{-5}$。
### 思路 1:代码
```python
class Solution:
def findMaxAverage(self, nums: List[int], k: int) -> float:
def check(mid):
"""判断是否存在长度 >= k 的子数组,平均值 >= mid"""
# 将数组中每个元素减去 mid,计算前缀和
n = len(nums)
prefix_sum = 0
prev_sum = 0 # 前 i-k 个元素的前缀和
min_prev_sum = 0 # 前 i-k 个元素中的最小前缀和
for i in range(n):
prefix_sum += nums[i] - mid
# 长度至少为 k
if i >= k - 1:
# prefix_sum - min_prev_sum 表示某个长度 >= k 的子数组和
if prefix_sum - min_prev_sum >= 0:
return True
# 更新 prev_sum 和 min_prev_sum
# prev_sum 是前 i-k+1 个元素的前缀和
prev_sum += nums[i - k + 1] - mid
min_prev_sum = min(min_prev_sum, prev_sum)
return False
# 二分查找
left, right = min(nums), max(nums)
while right - left > 1e-5:
mid = (left + right) / 2
if check(mid):
left = mid
else:
right = mid
return left
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log(max - min))$,其中 $n$ 是数组长度,$max$ 和 $min$ 分别是数组的最大值和最小值。二分查找的次数为 $O(\log(max - min))$,每次检查需要 $O(n)$ 时间。
- **空间复杂度**:$O(1)$。只使用了常数额外空间。
================================================
FILE: docs/solutions/0600-0699/maximum-binary-tree.md
================================================
# [0654. 最大二叉树](https://leetcode.cn/problems/maximum-binary-tree/)
- 标签:栈、树、数组、分治、二叉树、单调栈
- 难度:中等
## 题目链接
- [0654. 最大二叉树 - 力扣](https://leetcode.cn/problems/maximum-binary-tree/)
## 题目大意
给定一个不含重复元素的整数数组 `nums`。一个以此数组构建的最大二叉树定义如下:
- 二叉树的根是数组中的最大元素。
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。
要求通过给定的数组构建最大二叉树,并且输出这个树的根节点。
## 解题思路
根据题意可知,数组中最大元素位置为根节点,最大元素位置左右部分可分别作为左右子树。则我们可以通过递归的方式构建最大二叉树。
- 定义 left、right 分别表示当前数组的左右边界位置,定义 `max_value_index` 为当前数组中最大值位置。
- 遍历当前数组,找到最大值位置 `max_value_index`,并建立根节点 `root`,将数组 `nums` 分为 `[left, max_value_index]` 和 `[max_value_index, right]` 两部分,并分别递归建树。
- 将其赋值给 `root` 的左右子节点,最后返回 root 节点。
## 代码
```python
class Solution:
def createBinaryTree(self, nums: List[int], left: int, right: int) -> TreeNode:
if left >= right:
return None
max_value_index = left
for i in range(left + 1, right):
if nums[i] > nums[max_value_index]:
max_value_index = i
root = TreeNode(nums[max_value_index])
root.left = self.createBinaryTree(nums, left, max_value_index)
root.right = self.createBinaryTree(nums, max_value_index + 1, right)
return root
def constructMaximumBinaryTree(self, nums: List[int]) -> TreeNode:
return self.createBinaryTree(nums, 0, len(nums))
```
================================================
FILE: docs/solutions/0600-0699/maximum-distance-in-arrays.md
================================================
# [0624. 数组列表中的最大距离](https://leetcode.cn/problems/maximum-distance-in-arrays/)
- 标签:贪心、数组
- 难度:中等
## 题目链接
- [0624. 数组列表中的最大距离 - 力扣](https://leetcode.cn/problems/maximum-distance-in-arrays/)
## 题目大意
**描述**:
给定 $m$ 个数组,每个数组都已经按照升序排好序了。
**要求**:
从两个不同的数组中选择两个整数(每个数组选一个)并且计算它们的距离。两个整数 $a$ 和 $b$ 之间的距离定义为它们差的绝对值 $|a-b|$。
返回最大距离。
**说明**:
- $m == arrays.length$。
- $2 \le m \le 10^{5}$。
- $1 \le arrays[i].length \le 500$。
- $-10^{4} \le arrays[i][j] \le 10^{4}$。
- $arrays[i]$ 以升序排序。
- 所有数组中最多有 $10^{5}$ 个整数。
**示例**:
- 示例 1:
```python
输入:[[1,2,3],[4,5],[1,2,3]]
输出:4
解释:
一种得到答案 4 的方法是从第一个数组或者第三个数组中选择 1,同时从第二个数组中选择 5 。
```
- 示例 2:
```python
输入:arrays = [[1],[1]]
输出:0
```
## 解题思路
### 思路 1:贪心
这道题目要求从不同数组中选择两个数,使得它们的距离最大。由于每个数组都是升序排列的,最大距离一定是某个数组的最大值减去另一个数组的最小值。
1. 初始化 $min\_val$ 为第一个数组的最小值,$max\_val$ 为第一个数组的最大值。
2. 初始化结果 $result = 0$。
3. 从第二个数组开始遍历:
- 计算当前数组的最大值与之前所有数组的最小值的差值。
- 计算之前所有数组的最大值与当前数组的最小值的差值。
- 更新结果为这两个差值的最大值。
- 更新 $min\_val$ 和 $max\_val$。
4. 返回结果。
### 思路 1:代码
```python
class Solution:
def maxDistance(self, arrays: List[List[int]]) -> int:
# 初始化为第一个数组的最小值和最大值
min_val = arrays[0][0]
max_val = arrays[0][-1]
result = 0
# 从第二个数组开始遍历
for i in range(1, len(arrays)):
# 当前数组的最小值和最大值
curr_min = arrays[i][0]
curr_max = arrays[i][-1]
# 计算当前数组与之前数组的最大距离
result = max(result, abs(curr_max - min_val), abs(max_val - curr_min))
# 更新全局最小值和最大值
min_val = min(min_val, curr_min)
max_val = max(max_val, curr_max)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m)$,其中 $m$ 是数组的个数。只需要遍历所有数组一次。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/maximum-length-of-pair-chain.md
================================================
# [0646. 最长数对链](https://leetcode.cn/problems/maximum-length-of-pair-chain/)
- 标签:贪心、数组、动态规划、排序
- 难度:中等
## 题目链接
- [0646. 最长数对链 - 力扣](https://leetcode.cn/problems/maximum-length-of-pair-chain/)
## 题目大意
**描述**:
给定一个由 $n$ 个数对组成的数对数组 $pairs$ ,其中 $pairs[i] = [left_i, right_i]$ 且 $left_i < right_i$ 。
现在,我们定义一种「跟随」关系,当且仅当 $b < c$ 时,数对 $p2 = [c, d]$ 才可以跟在 $p1 = [a, b]$ 后面。我们用这种形式来构造「数对链」。
**要求**:
找出并返回能够形成的 最长数对链的长度 。
你不需要用到所有的数对,你可以以任何顺序选择其中的一些数对来构造。
**说明**:
- $n == pairs.length$。
- $1 \le n \le 10^{3}$。
- $-10^{3} \le left_i \lt right_i \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:pairs = [[1,2], [2,3], [3,4]]
输出:2
解释:最长的数对链是 [1,2] -> [3,4] 。
```
- 示例 2:
```python
输入:pairs = [[1,2],[7,8],[4,5]]
输出:3
解释:最长的数对链是 [1,2] -> [4,5] -> [7,8] 。
```
## 解题思路
### 思路 1:贪心
这道题目要求找到最长的数对链。可以使用贪心策略:按照数对的右端点排序,然后依次选择不冲突的数对。
1. 将数对按照右端点从小到大排序。
2. 初始化链的长度 $count = 1$,当前链的末尾为第一个数对的右端点 $curr\underline{~}end = pairs[0][1]$。
3. 从第二个数对开始遍历:
- 如果当前数对的左端点大于 $curr\underline{~}end$,说明可以将当前数对加入链中。
- 更新 $curr\underline{~}end$ 为当前数对的右端点,$count$ 加 1。
4. 返回 $count$。
### 思路 1:代码
```python
class Solution:
def findLongestChain(self, pairs: List[List[int]]) -> int:
# 按照右端点排序
pairs.sort(key=lambda x: x[1])
count = 1
curr_end = pairs[0][1]
for i in range(1, len(pairs)):
# 如果当前数对的左端点大于链的末尾,可以加入链中
if pairs[i][0] > curr_end:
count += 1
curr_end = pairs[i][1]
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数对的数量。主要时间消耗在排序上。
- **空间复杂度**:$O(\log n)$,排序所需的栈空间。
================================================
FILE: docs/solutions/0600-0699/maximum-product-of-three-numbers.md
================================================
# [0628. 三个数的最大乘积](https://leetcode.cn/problems/maximum-product-of-three-numbers/)
- 标签:数组、数学、排序
- 难度:简单
## 题目链接
- [0628. 三个数的最大乘积 - 力扣](https://leetcode.cn/problems/maximum-product-of-three-numbers/)
## 题目大意
**描述**:
给定一个整型数组 $nums$。
**要求**:
在数组中找出由三个数组成的最大乘积,并输出这个乘积。
**说明**:
- $3 \le nums.length \le 10^{4}$。
- $-10^{3} \le nums[i] \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3]
输出:6
```
- 示例 2:
```python
输入:nums = [1,2,3,4]
输出:24
```
## 解题思路
### 思路 1:排序 + 数学
这道题目要求找出三个数的最大乘积。需要考虑负数的情况。
最大乘积可能有两种情况:
1. 三个最大的正数相乘。
2. 两个最小的负数(绝对值最大)与最大的正数相乘。
因此,对数组排序后,比较这两种情况的结果即可。
### 思路 1:代码
```python
class Solution:
def maximumProduct(self, nums: List[int]) -> int:
nums.sort()
n = len(nums)
# 情况 1:三个最大的数相乘
product1 = nums[n - 1] * nums[n - 2] * nums[n - 3]
# 情况 2:两个最小的数(可能是负数)与最大的数相乘
product2 = nums[0] * nums[1] * nums[n - 1]
return max(product1, product2)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组的长度。主要时间消耗在排序上。
- **空间复杂度**:$O(\log n)$,排序所需的栈空间。
### 思路 2:线性扫描
不需要完整排序,只需要找到最大的三个数和最小的两个数即可。
### 思路 2:代码
```python
class Solution:
def maximumProduct(self, nums: List[int]) -> int:
# 找到最大的三个数
max1 = max2 = max3 = float('-inf')
# 找到最小的两个数
min1 = min2 = float('inf')
for num in nums:
# 更新最大的三个数
if num > max1:
max3 = max2
max2 = max1
max1 = num
elif num > max2:
max3 = max2
max2 = num
elif num > max3:
max3 = num
# 更新最小的两个数
if num < min1:
min2 = min1
min1 = num
elif num < min2:
min2 = num
return max(max1 * max2 * max3, min1 * min2 * max1)
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。只需要遍历数组一次。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/maximum-sum-of-3-non-overlapping-subarrays.md
================================================
# [0689. 三个无重叠子数组的最大和](https://leetcode.cn/problems/maximum-sum-of-3-non-overlapping-subarrays/)
- 标签:数组、动态规划、前缀和、滑动窗口
- 难度:困难
## 题目链接
- [0689. 三个无重叠子数组的最大和 - 力扣](https://leetcode.cn/problems/maximum-sum-of-3-non-overlapping-subarrays/)
## 题目大意
**描述**:
给定一个整数数组 $nums$ 和一个整数 $k$。
**要求**:
找出三个长度为 $k$、互不重叠、且全部数字和最大的子数组,并返回这三个子数组。
以下标的数组形式返回结果,数组中的每一项分别指示每个子数组的起始位置(下标从 $0$ 开始)。如果有多个结果,返回字典序最小的一个。
**说明**:
- $1 \le nums.length \le 2 \times 10^{4}$。
- $1 \le nums[i] \lt 216$。
- $1 \le k \le floor(nums.length / 3)$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,1,2,6,7,5,1], k = 2
输出:[0,3,5]
解释:子数组 [1, 2], [2, 6], [7, 5] 对应的起始下标为 [0, 3, 5]。
也可以取 [2, 1], 但是结果 [1, 3, 5] 在字典序上更大。
```
- 示例 2:
```python
输入:nums = [1,2,1,2,1,2,1,2,1], k = 2
输出:[0,2,4]
```
## 解题思路
### 思路 1:动态规划 + 滑动窗口
这道题目要求找出三个长度为 $k$ 的无重叠子数组,使得它们的和最大。使用动态规划记录最优解。
1. 首先使用滑动窗口计算所有长度为 $k$ 的子数组的和,存储在数组 $sums$ 中。
2. 定义三个数组:
- $left[i]$:表示在 $[0, i]$ 范围内,和最大的子数组的起始索引。
- $right[i]$:表示在 $[i, n-k]$ 范围内,和最大的子数组的起始索引。
- 中间的子数组通过遍历确定。
3. 遍历中间子数组的所有可能位置 $j$(范围 $[k, n-2k]$):
- 左侧子数组的最优位置为 $left[j-k]$。
- 右侧子数组的最优位置为 $right[j+k]$。
- 计算三个子数组的总和,更新最大值和对应的索引。
4. 返回三个子数组的起始索引。
### 思路 1:代码
```python
class Solution:
def maxSumOfThreeSubarrays(self, nums: List[int], k: int) -> List[int]:
n = len(nums)
# 计算所有长度为 k 的子数组的和
sums = []
window_sum = sum(nums[:k])
sums.append(window_sum)
for i in range(k, n):
window_sum += nums[i] - nums[i - k]
sums.append(window_sum)
# left[i] 表示在 [0, i] 范围内和最大的子数组的起始索引
left = [0] * len(sums)
best_idx = 0
for i in range(len(sums)):
if sums[i] > sums[best_idx]:
best_idx = i
left[i] = best_idx
# right[i] 表示在 [i, len(sums)-1] 范围内和最大的子数组的起始索引
right = [0] * len(sums)
best_idx = len(sums) - 1
for i in range(len(sums) - 1, -1, -1):
if sums[i] >= sums[best_idx]:
best_idx = i
right[i] = best_idx
# 遍历中间子数组的位置
max_sum = 0
result = [-1, -1, -1]
for j in range(k, len(sums) - k):
l = left[j - k]
r = right[j + k]
total = sums[l] + sums[j] + sums[r]
if total > max_sum:
max_sum = total
result = [l, j, r]
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。需要遍历数组多次,但每次都是线性时间。
- **空间复杂度**:$O(n)$,需要使用数组存储子数组的和以及左右最优位置。
================================================
FILE: docs/solutions/0600-0699/maximum-swap.md
================================================
# [0670. 最大交换](https://leetcode.cn/problems/maximum-swap/)
- 标签:贪心、数学
- 难度:中等
## 题目链接
- [0670. 最大交换 - 力扣](https://leetcode.cn/problems/maximum-swap/)
## 题目大意
**描述**:
给定一个非负整数,你至多可以交换一次数字中的任意两位。
**要求**:
返回你能得到的最大值。
**说明**:
- 给定数字的范围是 $[0, 10^8]$。
**示例**:
- 示例 1:
```python
输入: 2736
输出: 7236
解释: 交换数字2和数字7。
```
- 示例 2:
```python
输入: 9973
输出: 9973
解释: 不需要交换。
```
## 解题思路
### 思路 1:贪心
这道题目要求交换一次数字中的任意两位,使得结果最大。贪心策略是:从高位到低位找到第一个可以被更大数字替换的位置。
1. 将数字转换为字符数组,方便操作。
2. 从右到左记录每个位置右侧的最大数字及其最右位置。
3. 从左到右遍历,找到第一个可以被右侧更大数字替换的位置:
- 如果当前位置的数字小于右侧的最大数字,交换它们。
- 为了使结果最大,选择最右侧的最大数字进行交换。
4. 返回交换后的数字。
### 思路 1:代码
```python
class Solution:
def maximumSwap(self, num: int) -> int:
# 将数字转换为字符数组
digits = list(str(num))
n = len(digits)
# 记录每个位置右侧(包括自己)的最大数字的最右位置
max_idx = [0] * n
max_idx[n - 1] = n - 1
for i in range(n - 2, -1, -1):
if digits[i] > digits[max_idx[i + 1]]:
max_idx[i] = i
else:
max_idx[i] = max_idx[i + 1]
# 从左到右找到第一个可以交换的位置
for i in range(n):
# 如果当前位置的数字小于右侧的最大数字
if digits[i] < digits[max_idx[i]]:
# 交换
digits[i], digits[max_idx[i]] = digits[max_idx[i]], digits[i]
break
return int(''.join(digits))
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log num)$,其中 $num$ 是输入的数字。需要遍历数字的每一位。
- **空间复杂度**:$O(\log num)$,需要将数字转换为字符数组。
================================================
FILE: docs/solutions/0600-0699/maximum-width-of-binary-tree.md
================================================
# [0662. 二叉树最大宽度](https://leetcode.cn/problems/maximum-width-of-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0662. 二叉树最大宽度 - 力扣](https://leetcode.cn/problems/maximum-width-of-binary-tree/)
## 题目大意
**描述**:给你一棵二叉树的根节点 `root`。
**要求**:返回树的最大宽度。
**说明**:
- **每一层的宽度**:为该层最左和最右的非空节点(即两个端点)之间的长度。将这个二叉树视作与满二叉树结构相同,两端点间会出现一些延伸到这一层的 `null` 节点,这些 `null` 节点也计入长度。
- **树的最大宽度**:是所有层中最大的宽度。
- 题目数据保证答案将会在 32 位带符号整数范围内。
- 树中节点的数目范围是 $[1, 3000]$。
- $-100 \le Node.val \le 100$。
**示例**:
- 示例 1:
```python
输入:root = [1,3,2,5,3,null,9]
输出:4
解释:最大宽度出现在树的第 3 层,宽度为 4 (5,3,null,9)。
```
- 示例 2:
```python
输入:root = [1,3,2,5,null,null,9,6,null,7]
输出:7
解释:最大宽度出现在树的第 4 层,宽度为 7 (6,null,null,null,null,null,7) 。
```
## 解题思路
### 思路 1:广度优先搜索
最直观的做法是,求出每一层的宽度,然后求出所有层高度的最大值。
在计算每一层宽度时,根据题意,两端点之间的 `null` 节点也计入长度,所以我们可以对包括 `null` 节点在内的该二叉树的所有节点进行编号。
也就是满二叉树的编号规则:如果当前节点的编号为 $i$,则左子节点编号记为 $i \times 2 + 1$,则右子节点编号为 $i \times 2 + 2$。
接下来我们使用广度优先搜索方法遍历每一层的节点,在向队列中添加节点时,将该节点与该节点对应的编号一同存入队列中。
这样在计算每一层节点的宽度时,我们可以通过队列中队尾节点的编号与队头节点的编号,快速计算出当前层的宽度。并计算出所有层宽度的最大值。
### 思路 1:代码
```python
class Solution:
def widthOfBinaryTree(self, root: Optional[TreeNode]) -> int:
if not root:
return False
queue = collections.deque([[root, 0]])
ans = 0
while queue:
ans = max(ans, queue[-1][1] - queue[0][1] + 1)
size = len(queue)
for _ in range(size):
cur, index = queue.popleft()
if cur.left:
queue.append([cur.left, index * 2 + 1])
if cur.right:
queue.append([cur.right, index * 2 + 2])
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为二叉树的节点数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0600-0699/merge-two-binary-trees.md
================================================
# [0617. 合并二叉树](https://leetcode.cn/problems/merge-two-binary-trees/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0617. 合并二叉树 - 力扣](https://leetcode.cn/problems/merge-two-binary-trees/)
## 题目大意
给定两个二叉树,将两个二叉树合并成一个新的二叉树。合并规则如下:
- 如果两个二叉树对应节点重叠,则将两个节点的值相加并作为新的二叉树节点。
- 如果两个二叉树对应节点其中一个为空,另一个不为空,则将不为空的节点左心新的二叉树节点。
最终返回新的二叉树的根节点。
## 解题思路
利用前序遍历二叉树,并按照规则递归建立二叉树。将其对应节点值相加或者取其中不为空的节点做为新节点。
## 代码
```python
class Solution:
def mergeTrees(self, root1: TreeNode, root2: TreeNode) -> TreeNode:
if not root1:
return root2
if not root2:
return root1
merged = TreeNode(root1.val + root2.val)
merged.left = self.mergeTrees(root1.left, root2.left)
merged.right = self.mergeTrees(root1.right, root2.right)
return merged
```
================================================
FILE: docs/solutions/0600-0699/minimum-factorization.md
================================================
# [0625. 最小因式分解](https://leetcode.cn/problems/minimum-factorization/)
- 标签:贪心、数学
- 难度:中等
## 题目链接
- [0625. 最小因式分解 - 力扣](https://leetcode.cn/problems/minimum-factorization/)
## 题目大意
**描述**:
给定一个正整数 $num$。
**要求**:
找出最小的正整数 $x$ 使得 $x$ 的所有数位相乘恰好等于 $num$。
如果不存在这样的结果或者结果不是 32 位有符号整数,返回 $0$。
**说明**:
- $1 \le num \le 2^{31} - 1$。
**示例**:
- 示例 1:
```python
输入:num = 48
输出:68
```
- 示例 2:
```python
输入:num = 15
输出:35
```
## 解题思路
### 思路 1:贪心 + 因数分解
#### 思路 1:算法描述
要找到最小的正整数 $x$,使得 $x$ 的所有数位相乘等于 `num`。
**核心思路**:
- 为了让 $x$ 最小,应该让 $x$ 的位数尽可能少,每一位尽可能大。
- 从 $9$ 到 $2$ 依次尝试分解 `num`,将因子从小到大排列(贪心:让结果最小)。
- 特殊情况:如果 $num < 10$,直接返回 `num`。
**算法步骤**:
1. 如果 $num < 10$,直接返回 `num`。
2. 从 $9$ 到 $2$ 依次尝试分解 `num`:
- 如果 `num` 能被 $i$ 整除,将 $i$ 加入结果列表。
- 继续分解 $num / i$。
3. 如果最后 $num > 1$,说明无法分解(存在大于 $9$ 的质因子),返回 $0$。
4. 将结果列表从小到大排列并转换为整数,检查是否超过 32 位整数范围。
#### 思路 1:代码
```python
class Solution:
def smallestFactorization(self, num: int) -> int:
# 特殊情况
if num < 10:
return num
# 从 9 到 2 依次分解
digits = []
for i in range(9, 1, -1):
while num % i == 0:
digits.append(i)
num //= i
# 如果 num > 1,说明存在大于 9 的质因子,无法分解
if num > 1:
return 0
# 将数字从小到大排列(贪心:让结果最小)
digits.sort()
# 转换为整数
result = 0
for digit in digits:
result = result * 10 + digit
# 检查是否超过 32 位整数范围
if result > 2**31 - 1:
return 0
return result
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(\log num)$,需要分解 `num` 的所有因子。
- **空间复杂度**:$O(\log num)$,需要存储分解后的数字。
================================================
FILE: docs/solutions/0600-0699/next-closest-time.md
================================================
# [0681. 最近时刻](https://leetcode.cn/problems/next-closest-time/)
- 标签:哈希表、字符串、回溯、枚举
- 难度:中等
## 题目链接
- [0681. 最近时刻 - 力扣](https://leetcode.cn/problems/next-closest-time/)
## 题目大意
**描述**:
给定一个形如 `"HH:MM"` 表示的时刻 `time`,利用当前出现过的数字构造下一个距离当前时间最近的时刻。每个出现数字都可以被无限次使用。
你可以认为给定的字符串一定是合法的。例如,`"01:34"` 和 `"12:09"` 是合法的,`"1:34"` 和 `"12:9"` 是不合法的。
**要求**:
返回下一个最近的时刻。
**说明**:
- $time.length == 5$。
- $time$ 为有效时间,格式为 `"HH:MM"`。
- $0 \le HH < 24$。
- $0 \le MM < 60$。
**示例**:
- 示例 1:
```python
输入:"19:34"
输出:"19:39"
解释:利用数字 1, 9, 3, 4 构造出来的最近时刻是 19:39,是 5 分钟之后。
结果不是 19:33 因为这个时刻是 23 小时 59 分钟之后。
```
- 示例 2:
```python
输入:"23:59"
输出:"22:22"
解释:利用数字 2, 3, 5, 9 构造出来的最近时刻是 22:22。答案一定是第二天的某一时刻,所以选择可表示的最小时刻。
```
## 解题思路
### 思路 1:枚举 + 模拟
#### 思路 1:算法描述
给定当前时间,需要找到下一个最近的时刻,且只能使用当前时间中出现的数字。
**核心思路**:
- 从当前时间开始,逐分钟递增,检查每个时刻是否只包含当前时间中的数字。
- 最多检查 $24 \times 60 = 1440$ 个时刻(一天的分钟数)。
**算法步骤**:
1. 提取当前时间中出现的所有数字,存入集合。
2. 将时间转换为分钟数。
3. 从下一分钟开始,逐分钟递增:
- 将分钟数转换为时间格式。
- 检查时间中的所有数字是否都在集合中。
- 如果是,返回该时间。
4. 循环最多 $1440$ 次(一天)。
#### 思路 1:代码
```python
class Solution:
def nextClosestTime(self, time: str) -> str:
# 提取当前时间中的数字
digits = set(time.replace(':', ''))
# 将时间转换为分钟数
hour, minute = map(int, time.split(':'))
current_minutes = hour * 60 + minute
# 从下一分钟开始查找
for i in range(1, 24 * 60 + 1):
next_minutes = (current_minutes + i) % (24 * 60)
next_hour = next_minutes // 60
next_minute = next_minutes % 60
# 格式化时间
next_time = f"{next_hour:02d}:{next_minute:02d}"
# 检查是否只包含原有数字
if all(d in digits for d in next_time.replace(':', '')):
return next_time
return time
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$,最多检查 $1440$ 个时刻,每次检查需要常数时间。
- **空间复杂度**:$O(1)$,只使用了常数额外空间。
================================================
FILE: docs/solutions/0600-0699/non-decreasing-array.md
================================================
# [0665. 非递减数列](https://leetcode.cn/problems/non-decreasing-array/)
- 标签:数组
- 难度:中等
## 题目链接
- [0665. 非递减数列 - 力扣](https://leetcode.cn/problems/non-decreasing-array/)
## 题目大意
给定一个整数数组 nums,问能否在最多改变 1 个元素的条件下,使数组变为非递减序列。如果能,返回 True,不能则返回 False。
## 解题思路
循环遍历数组,寻找 nums[i] > nums[i+1] 的情况,一旦这种情况出现超过 2 次,则不可能最多改变 1 个元素,直接返回 False。
遇到 nums[i] > nums[i+1] 的情况,应该手动调节某位置上元素使数组有序。此时,有两种选择:
- 将 nums[i] 调低,与 nums[i-1] 持平
- 将 nums[i+1] 调高,与 nums[i] 持平
如果选择第一种调节方式,如果调节前 nums[i-1] > nums[i+1],那么调节完 nums[i] 之后,nums[i-1] 还是比 nums[i+1] 大,不可取。
所以应选择第二种调节方式,如果调节前 nums[i-1] > nums[i+1],那么调节完 nums[i+1] 之后 nums[i-1] < nums[i] <= nums[i+1],满足非递减要求。
最终如果最多调整过一次,且 nums[i] > nums[i+1] 的情况也最多出现过一次,则返回 True。
## 代码
```python
class Solution:
def checkPossibility(self, nums: List[int]) -> bool:
count = 0
for i in range(len(nums)-1):
if nums[i] > nums[i+1]:
count += 1
if count > 1:
return False
if i > 0 and nums[i-1] > nums[i+1]:
nums[i+1] = nums[i]
return True
```
================================================
FILE: docs/solutions/0600-0699/non-negative-integers-without-consecutive-ones.md
================================================
# [0600. 不含连续1的非负整数](https://leetcode.cn/problems/non-negative-integers-without-consecutive-ones/)
- 标签:动态规划
- 难度:困难
## 题目链接
- [0600. 不含连续1的非负整数 - 力扣](https://leetcode.cn/problems/non-negative-integers-without-consecutive-ones/)
## 题目大意
**描述**:给定一个正整数 $n$。
**要求**:统计在 $[0, n]$ 范围的非负整数中,有多少个整数的二进制表示中不存在连续的 $1$。
**说明**:
- $1 \le n \le 10^9$。
**示例**:
- 示例 1:
```python
输入: n = 5
输出: 5
解释:
下面列出范围在 [0, 5] 的非负整数与其对应的二进制表示:
0 : 0
1 : 1
2 : 10
3 : 11
4 : 100
5 : 101
其中,只有整数 3 违反规则(有两个连续的 1 ),其他 5 个满足规则。
```
- 示例 2:
```python
输入: n = 1
输出: 2
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
将 $n$ 转换为字符串 $s$,定义递归函数 `def dfs(pos, pre, isLimit):` 表示构造第 $pos$ 位及之后所有数位的合法方案数。其中:
1. $pos$ 表示当前枚举的数位位置。
2. $pre$ 表示前一位是否为 $1$,用于过滤连续 $1$ 的不合法方案。
3. $isLimit$ 表示前一位数位是否等于上界,用于限制本次搜索的数位范围。
接下来按照如下步骤进行递归。
1. 从 `dfs(0, False, True)` 开始递归。 `dfs(0, False, True)` 表示:
1. 从位置 $0$ 开始构造。
2. 开始时前一位不为 $1$。
3. 开始时受到数字 $n$ 对应最高位数位的约束。
2. 如果遇到 $pos == len(s)$,表示到达数位末尾,当前为合法方案,此时:直接返回方案数 $1$。
3. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
4. 因为不需要考虑前导 $0$,所以当前所能选择的最小数字 $minX$ 为 $0$。
5. 根据 $isLimit$ 来决定填当前位数位所能选择的最大数字($maxX$)。
6. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
7. 如果前一位为 $1$ 并且当前为 $d$ 也为 $1$,则说明当前方案出现了连续的 $1$,则跳过。
8. 方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, d == 1, isLimit and d == maxX)`。
1. `d == 1` 表示下一位 $pos - 1$ 的前一位 $pos$ 是否为 $1$。
2. `isLimit and d == maxX` 表示 $pos + 1$ 位受到之前位限制和 $pos$ 位限制。
9. 最后的方案数为 `dfs(0, False, True)`,将其返回即可。
### 思路 1:代码
```python
class Solution:
def findIntegers(self, n: int) -> int:
# 将 n 的二进制转换为字符串 s
s = str(bin(n))[2:]
@cache
# pos: 第 pos 个数位
# pre: 第 pos - 1 位是否为 1
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
def dfs(pos, pre, isLimit):
if pos == len(s):
return 1
ans = 0
# 不需要考虑前导 0,则最小可选择数字为 0
minX = 0
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 1。
maxX = int(s[pos]) if isLimit else 1
# 枚举可选择的数字
for d in range(minX, maxX + 1):
if pre and d == 1:
continue
ans += dfs(pos + 1, d == 1, isLimit and d == maxX)
return ans
return dfs(0, False, True)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/0600-0699/number-of-distinct-islands.md
================================================
# [0694. 不同岛屿的数量](https://leetcode.cn/problems/number-of-distinct-islands/)
- 标签:深度优先搜索、广度优先搜索、并查集、哈希表、哈希函数
- 难度:中等
## 题目链接
- [0694. 不同岛屿的数量 - 力扣](https://leetcode.cn/problems/number-of-distinct-islands/)
## 题目大意
**描述**:
给定一个非空 01 二维数组表示的网格,一个岛屿由四连通(上、下、左、右四个方向)的 $1$ 组成,你可以认为网格的四周被海水包围。
**要求**:
计算这个网格中共有多少个形状不同的岛屿。两个岛屿被认为是相同的,当且仅当一个岛屿可以通过平移变换(不可以旋转、翻转)和另一个岛屿重合。
**说明**:
- $m == grid.length$。
- $n == grid[i].length$。
- $1 \le m, n \le 50$。
- $grid[i][j]$ 仅包含 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入: grid = [[1,1,0,0,0],[1,1,0,0,0],[0,0,0,1,1],[0,0,0,1,1]]
输出:1
```
- 示例 2:
```python
输入: grid = [[1,1,0,1,1],[1,0,0,0,0],[0,0,0,0,1],[1,1,0,1,1]]
输出: 3
```
## 解题思路
### 思路 1:深度优先搜索 + 哈希表
这道题目要求计算形状不同的岛屿数量。关键在于如何表示岛屿的形状。
**核心思路**:
- 使用深度优先搜索遍历每个岛屿。
- 记录岛屿的形状:以岛屿的第一个单元格为原点,记录其他单元格相对于原点的坐标。
- 将形状(坐标集合)转换为字符串或元组,存入哈希集合中。
- 最后返回哈希集合的大小。
**算法步骤**:
1. 遍历网格,找到每个岛屿的起点(值为 $1$ 的单元格)。
2. 对每个岛屿进行深度优先搜索,记录岛屿的形状(相对坐标)。
3. 将形状标准化(以第一个单元格为原点),转换为元组。
4. 将形状存入哈希集合。
5. 返回哈希集合的大小。
### 思路 1:代码
```python
class Solution:
def numDistinctIslands(self, grid: List[List[int]]) -> int:
m, n = len(grid), len(grid[0])
visited = [[False] * n for _ in range(m)]
shapes = set()
def dfs(i, j, shape, base_i, base_j):
"""深度优先搜索,记录岛屿形状"""
if i < 0 or i >= m or j < 0 or j >= n or visited[i][j] or grid[i][j] == 0:
return
visited[i][j] = True
# 记录相对坐标
shape.append((i - base_i, j - base_j))
# 四个方向搜索
dfs(i + 1, j, shape, base_i, base_j)
dfs(i - 1, j, shape, base_i, base_j)
dfs(i, j + 1, shape, base_i, base_j)
dfs(i, j - 1, shape, base_i, base_j)
# 遍历网格
for i in range(m):
for j in range(n):
if grid[i][j] == 1 and not visited[i][j]:
shape = []
dfs(i, j, shape, i, j)
# 将形状转换为元组并存入集合
shapes.add(tuple(sorted(shape)))
return len(shapes)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$ 和 $n$ 分别是网格的行数和列数。需要遍历整个网格。
- **空间复杂度**:$O(m \times n)$。需要使用 $visited$ 数组和递归栈空间。
================================================
FILE: docs/solutions/0600-0699/number-of-longest-increasing-subsequence.md
================================================
# [0673. 最长递增子序列的个数](https://leetcode.cn/problems/number-of-longest-increasing-subsequence/)
- 标签:树状数组、线段树、数组、动态规划
- 难度:中等
## 题目链接
- [0673. 最长递增子序列的个数 - 力扣](https://leetcode.cn/problems/number-of-longest-increasing-subsequence/)
## 题目大意
**描述**:给定一个未排序的整数数组 `nums`。
**要求**:返回最长递增子序列的个数。
**说明**:
- 子数列必须是严格递增的。
- $1 \le nums.length \le 2000$。
- $-10^6 \le nums[i] \le 10^6$。
**示例**:
- 示例 1:
```python
输入:[1,3,5,4,7]
输出:2
解释:有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。
```
## 解题思路
### 思路 1:动态规划
可以先做题目 [0300. 最长递增子序列](https://leetcode.cn/problems/longest-increasing-subsequence/)。
动态规划的状态 `dp[i]` 表示为:以第 `i` 个数字结尾的前 `i` 个元素中最长严格递增子序列的长度。
两重循环遍历前 `i` 个数字,对于 $0 \le j \le i$:
- 当 `nums[j] < nums[i]` 时,`nums[i]` 可以接在 `nums[j]` 后面,此时以第 `i` 个数字结尾的最长严格递增子序列长度 + 1,即 `dp[i] = dp[j] + 1`。
- 当 `nums[j] ≥ nums[i]` 时,可以直接跳过。
则状态转移方程为:`dp[i] = max(dp[i], dp[j] + 1)`,`0 ≤ j ≤ i`,`nums[j] < nums[i]`。
最后再遍历一遍 dp 数组,求出最大值即为最长递增子序列的长度。
现在求最长递增子序列的个数。则需要在求解的过程中维护一个 `count` 数组,用来保存以 `nums[i]` 结尾的最长递增子序列的个数。
对于 $0 \le j \le i$:
- 当 `nums[j] < nums[i]`,而且 `dp[j] + 1 > dp[i]` 时,说明第一次找到 `dp[j] + 1`长度且以`nums[i]`结尾的最长递增子序列,则以 `nums[i]` 结尾的最长递增子序列的组合数就等于以 `nums[j]` 结尾的组合数,即 `count[i] = count[j]`。
- 当 `nums[j] < nums[i]`,而且 `dp[j] + 1 == dp[i]` 时,说明以 `nums[i]` 结尾且长度为 `dp[j] + 1` 的递增序列已找到过一次了,则以 `nums[i]` 结尾的最长递增子序列的组合数要加上以 `nums[j]` 结尾的组合数,即 `count[i] += count[j]`。
- 然后根据遍历 dp 数组得到的最长递增子序列的长度 Z,然后再一次遍历 dp 数组,将所有 `dp[i] == max_length` 情况下的组合数 `coun[i]` 累加起来,即为最长递增序列的个数。
### 思路 1:动态规划代码
```python
class Solution:
def findNumberOfLIS(self, nums: List[int]) -> int:
size = len(nums)
dp = [1 for _ in range(size)]
count = [1 for _ in range(size)]
for i in range(size):
for j in range(i):
if nums[j] < nums[i]:
if dp[j] + 1 > dp[i]:
dp[i] = dp[j] + 1
count[i] = count[j]
elif dp[j] + 1 == dp[i]:
count[i] += count[j]
max_length = max(dp)
res = 0
for i in range(size):
if dp[i] == max_length:
res += count[i]
return res
```
### 思路 2:线段树
题目中 `nums` 的长度 为 $[1, 2000]$,值域为 $[-10^6, 10^6]$。
值域范围不是特别大,我们可以直接用线段树保存整个值域区间。但因为数组的长度只有 `2000`,所以算法效率更高的做法是先对数组进行离散化处理。把数组中的元素按照大小依次映射到 `[0, len(nums) - 1]` 这个区间。
1. 构建一棵长度为 `len(nums)` 的线段树,其中每个线段树的节点保存一个二元组。这个二元组 `val = [length, count]` 用来表示:以当前节点为结尾的子序列所能达到的最长递增子序列长度 `length` 和最长递增子序列对应的数量 `count`。
2. 顺序遍历数组 `nums`。对于当前元素 `nums[i]`:
3. 查找 `[0, nums[i - 1]]` 离散化后对应区间节点的二元组,也就是查找以区间 `[0, nums[i - 1]]` 上的点为结尾的子序列所能达到的最长递增子序列长度和其对应的数量,即 `val = [length, count]`。
- 如果所能达到的最长递增子序列长度为 `0`,则加入 `nums[i]` 之后最长递增子序列长度变为 `1`,且数量也变为 `1`。
- 如果所能达到的最长递增子序列长度不为 `0`,则加入 `nums[i]` 之后最长递增子序列长度 +1,但数量不变。
4. 根据上述计算的 `val` 值更新 `nums[i]` 对应节点的 `val` 值。
5. 然后继续向后遍历,重复进行第 `3` ~ `4` 步操作。
6. 最后查询以区间 `[0, nums[len(nums) - 1]]` 上的点为结尾的子序列所能达到的最长递增子序列长度和其对应的数量。返回对应的数量即为答案。
### 思路 2:线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=[0, 1]):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, size):
self.size = size
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.__update_point(i, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = [0, 0]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.tree[index].val = self.merge(self.tree[left_index].val, self.tree[right_index].val) # 向上更新节点的区间值
# 单点更新实现方法:将 nums[i] 更改为 val,节点的存储下标为 index
def __update_point(self, i, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left == i and right == i:
self.tree[index].val = self.merge(self.tree[index].val, val)
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if i <= mid: # 在左子树中更新节点值
self.__update_point(i, val, left_index)
else: # 在右子树中更新节点值
self.__update_point(i, val, right_index)
self.tree[index].val = self.merge(self.tree[left_index].val, self.tree[right_index].val) # 向上更新节点的区间值
# 区间查询实现方法:在线段树中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return [0, 0]
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = [0, 0]
res_right = [0, 0]
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
# 返回合并结果
return self.merge(res_left, res_right)
# 向上合并实现方法
def merge(self, val1, val2):
val = [0, 0]
if val1[0] == val2[0]: # 递增子序列长度一致,则合并后最长递增子序列个数为之前两者之和
val = [val1[0], val1[1] + val2[1]]
elif val1[0] < val2[0]: # 如果递增子序列长度不一致,则合并后最长递增子序列个数取较长一方的个数
val = [val2[0], val2[1]]
else:
val = [val1[0], val1[1]]
return val
class Solution:
def findNumberOfLIS(self, nums: List[int]) -> int:
# 离散化处理
num_dict = dict()
nums_sort = sorted(nums)
for i in range(len(nums_sort)):
num_dict[nums_sort[i]] = i
# 构造线段树
self.STree = SegmentTree(len(nums_sort))
for num in nums:
index = num_dict[num]
# 查询 [0, nums[index - 1]] 区间上以 nums[index - 1] 结尾的子序列所能达到的最长递增子序列长度和对应数量
val = self.STree.query_interval(0, index - 1)
# 如果当前最长递增子序列长度为 0,则加入 num 之后最长递增子序列长度为 1,且数量为 1
# 如果当前最长递增子序列长度不为 0,则加入 num 之后最长递增子序列长度 +1,但数量不变
if val[0] == 0:
val = [1, 1]
else:
val = [val[0] + 1, val[1]]
self.STree.update_point(index, val)
return self.STree.query_interval(0, len(nums_sort) - 1)[1]
```
================================================
FILE: docs/solutions/0600-0699/palindromic-substrings.md
================================================
# [0647. 回文子串](https://leetcode.cn/problems/palindromic-substrings/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [0647. 回文子串 - 力扣](https://leetcode.cn/problems/palindromic-substrings/)
## 题目大意
给定一个字符串 `s`,计算 `s` 中有多少个回文子串。
## 解题思路
动态规划求解。
先定义状态 `dp[i][j]` 表示为区间 `[i, j]` 的子串是否为回文子串,如果是,则 `dp[i][j] = True`,如果不是,则 `dp[i][j] = False`。
接下来确定状态转移共识:
如果 `s[i] == s[j]`,分为以下几种情况:
- `i == j`,单字符肯定是回文子串,`dp[i][j] == True`。
- `j - i == 1`,比如 `aa` 肯定也是回文子串,`dp[i][j] = True`。
- 如果 `j - i > 1`,则需要看 `[i + 1, j - 1]` 区间是不是回文子串,`dp[i][j] = dp[i + 1][j - 1]`。
如果 `s[i] != s[j]`,那肯定不是回文子串,`dp[i][j] = False`。
下一步确定遍历方向。
由于 `dp[i][j]` 依赖于 `dp[i + 1][j - 1]`,所以我们可以从左下角向右上角遍历。
同时,在递推过程中记录下 `dp[i][j] == True` 的个数,即为最后结果。
## 代码
```python
class Solution:
def countSubstrings(self, s: str) -> int:
size = len(s)
dp = [[False for _ in range(size)] for _ in range(size)]
res = 0
for i in range(size - 1, -1, -1):
for j in range(i, size):
if s[i] == s[j]:
if j - i <= 1:
dp[i][j] = True
else:
dp[i][j] = dp[i + 1][j - 1]
else:
dp[i][j] = False
if dp[i][j]:
res += 1
return res
```
================================================
FILE: docs/solutions/0600-0699/partition-to-k-equal-sum-subsets.md
================================================
# [0698. 划分为k个相等的子集](https://leetcode.cn/problems/partition-to-k-equal-sum-subsets/)
- 标签:位运算、记忆化搜索、数组、动态规划、回溯、状态压缩
- 难度:中等
## 题目链接
- [0698. 划分为k个相等的子集 - 力扣](https://leetcode.cn/problems/partition-to-k-equal-sum-subsets/)
## 题目大意
**描述**:给定一个整数数组 $nums$ 和一个正整数 $k$。
**要求**:找出是否有可能把这个数组分成 $k$ 个非空子集,其总和都相等。
**说明**:
- $1 \le k \le len(nums) \le 16$。
- $0 < nums[i] < 10000$。
- 每个元素的频率在 $[1, 4]$ 范围内。
**示例**:
- 示例 1:
```python
输入: nums = [4, 3, 2, 3, 5, 2, 1], k = 4
输出: True
说明: 有可能将其分成 4 个子集(5),(1,4),(2,3),(2,3)等于总和。
```
- 示例 2:
```python
输入: nums = [1,2,3,4], k = 3
输出: False
```
## 解题思路
### 思路 1:状态压缩 DP
根据题目要求,我们可以将几种明显不符合要求的情况过滤掉,比如:元素个数小于 $k$、元素总和不是 $k$ 的倍数、数组 $nums$ 中最大元素超过 $k$ 等分的目标和这几种情况。
然后再来考虑一般情况下,如何判断是否符合要求。
因为题目给定数组 $nums$ 的长度最多为 $16$,所以我们可以使用一个长度为 $16$ 位的二进制数来表示数组子集的选择状态。我们可以定义 $dp[state]$ 表示为当前选择状态下,是否可行。如果 $dp[state] == True$,表示可行;如果 $dp[state] == False$,则表示不可行。
接下来使用动态规划方法,进行求解。具体步骤如下:
###### 1. 阶段划分
按照数组元素选择情况进行阶段划分。
###### 2. 定义状态
定义状态 $dp[state]$ 表示为:当数组元素选择情况为 $state$ 时,是否存在一种方案,使得方案中的数字必定能分割成 $p(0 \le p \le k)$ 组恰好数字和等于目标和 $target$ 的集合和至多 $1$ 组数字和小于目标和 $target$ 的集合。
###### 3. 状态转移方程
对于当前状态 $state$,如果:
1. 当数组元素选择情况为 $state$ 时可行,即 $dp[state] == True$;
2. 第 $i$ 位数字没有被使用;
3. 加上第 $i$ 位元素后的状态为 $next\_state$;
4. 加上第 $i$ 位元素后没有超出目标和。
则:$dp[next\_state] = True$。
###### 4. 初始条件
- 当不选择任何元素时,可按照题目要求
###### 5. 最终结果
根据我们之前定义的状态,$dp[state]$ 表示为:当数组元素选择情况为 $state$ 时,是否存在一种方案,使得方案中的数字必定能分割成 $p(0 \le p \le k)$ 组恰好数字和等于目标和 $target$ 的集合和至多 $1$ 组数字和小于目标和 $target$ 的集合。
所以当 $state == 1 << n - 1$ 时,状态就变为了:当数组元素都选上的情况下,是否存在一种方案,使得方案中的数字必定能分割成 $k$ 组恰好数字和等于目标和 $target$ 的集合。
这里之所以是 $k$ 组恰好数字和等于目标和 $target$ 的集合,是因为一开我们就限定了 $total \mod k == 0$ 这个条件,所以只能是 $k$ 组恰好数字和等于目标和 $target$ 的集合。
所以最终结果为 $dp[states - 1]$,其中 $states = 1 << n$。
### 思路 1:代码
```python
class Solution:
def canPartitionKSubsets(self, nums: List[int], k: int) -> bool:
size = len(nums)
if size < k: # 元素个数小于 k
return False
total = sum(nums)
if total % k != 0: # 元素总和不是 k 的倍数
return False
target = total // k
if nums[-1] > target: # 最大元素超过 k 等分的目标和
return False
nums.sort()
states = 1 << size # 子集选择状态总数
cur_sum = [0 for _ in range(states)]
dp = [False for _ in range(states)]
dp[0] = True
for state in range(states):
if not dp[state]: # 基于 dp[state] == True 前提下进行转移
continue
for i in range(size):
if state & (1 << i) != 0: # 当前数字已被使用
continue
if cur_sum[state] % target + nums[i] > target:
break # 如果加入当前数字超出目标和,则后续不用继续遍历
next_state = state | (1 << i) # 加入当前数字
if dp[next_state]: # 如果新状态能划分,则跳过继续
continue
cur_sum[next_state] = cur_sum[state] + nums[i] # 更新新状态下子集和
dp[next_state] = True # 更新新状态
if dp[states - 1]: # 找到一个符合要求的划分方案,提前返回
return True
return dp[states - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times 2^n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(2^n)$。
## 参考资料
- 【题解】[状态压缩的定义理解 - 划分为k个相等的子集](https://leetcode.cn/problems/partition-to-k-equal-sum-subsets/solution/zhuang-tai-ya-suo-de-ding-yi-li-jie-by-c-fo1b/)
================================================
FILE: docs/solutions/0600-0699/path-sum-iv.md
================================================
# [0666. 路径总和 IV](https://leetcode.cn/problems/path-sum-iv/)
- 标签:树、深度优先搜索、数组、哈希表、二叉树
- 难度:中等
## 题目链接
- [0666. 路径总和 IV - 力扣](https://leetcode.cn/problems/path-sum-iv/)
## 题目大意
**描述**:
对于一棵深度小于 $5$ 的树,可以用一组三位十进制整数来表示。给定一个由三位数组成的 **递增** 的数组 $nums$ 表示一棵深度小于 $5$ 的二叉树,对于每个整数:
- 百位上的数字表示这个节点的深度 $d$,$1 \le d \le 4$。
- 十位上的数字表示这个节点在当前层所在的位置 $p$,$1 \le p \le 8$。位置编号与一棵 **满二叉树** 的位置编号相同。
- 个位上的数字表示这个节点的权值 $v$,$0 \le v \le 9$。
**要求**:
返回从 **根** 到所有 **叶子结点** 的 **路径之和**。
保证 **给定的数组表示一个有效的连接二叉树**。
**说明**:
- $1 \le nums.length \le 15$。
- $110 \le nums[i] \le 489$。
- $nums$ 表示深度小于 $5$ 的有效二叉树。
- $nums$ 以升序排序。
**示例**:
- 示例 1:
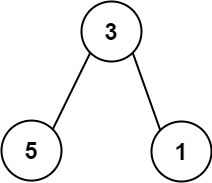
```python
输入:nums = [113, 215, 221]
输出:12
解释:列表所表示的树如上所示。
路径和 = (3 + 5) + (3 + 1) = 12。
```
- 示例 2:
```python
输入:nums = [113, 221]
输出:4
解释:列表所表示的树如上所示。
路径和 = (3 + 1) = 4。
```
## 解题思路
### 思路 1:DFS + 哈希表
#### 思路 1:算法描述
给定一个特殊编码的二叉树,需要计算从根到所有叶子节点的路径和。
**核心思路**:
- 使用哈希表存储节点信息,键为 $(depth, position)$,值为节点的权值。
- 使用 DFS 遍历树,累加路径和。
- 判断叶子节点:左右子节点都不存在。
**算法步骤**:
1. 解析 `nums` 数组,构建哈希表存储节点信息。
2. 使用 DFS 从根节点开始遍历:
- 累加当前路径和。
- 如果是叶子节点,将路径和加入总和。
- 否则递归遍历左右子节点。
3. 返回总和。
**关键点**:
- 对于深度为 $d$、位置为 $p$ 的节点,其左子节点位置为 $2p - 1$,右子节点位置为 $2p$,深度为 $d + 1$。
#### 思路 1:代码
```python
class Solution:
def pathSum(self, nums: List[int]) -> int:
# 构建哈希表,键为 (depth, position),值为节点权值
tree = {}
for num in nums:
depth = num // 100
position = (num % 100) // 10
value = num % 10
tree[(depth, position)] = value
self.total_sum = 0
def dfs(depth, position, current_sum):
# 当前节点的值
if (depth, position) not in tree:
return
current_sum += tree[(depth, position)]
# 计算左右子节点的位置
left_pos = 2 * position - 1
right_pos = 2 * position
# 判断是否为叶子节点
has_left = (depth + 1, left_pos) in tree
has_right = (depth + 1, right_pos) in tree
if not has_left and not has_right:
# 叶子节点,累加路径和
self.total_sum += current_sum
else:
# 递归遍历左右子树
if has_left:
dfs(depth + 1, left_pos, current_sum)
if has_right:
dfs(depth + 1, right_pos, current_sum)
# 从根节点开始 DFS
dfs(1, 1, 0)
return self.total_sum
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是节点数量,每个节点访问一次。
- **空间复杂度**:$O(n)$,哈希表和递归栈的空间开销。
================================================
FILE: docs/solutions/0600-0699/print-binary-tree.md
================================================
# [0655. 输出二叉树](https://leetcode.cn/problems/print-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0655. 输出二叉树 - 力扣](https://leetcode.cn/problems/print-binary-tree/)
## 题目大意
**描述**:
给定一棵二叉树的根节点 $root$。
**要求**:
构造一个下标从 $0$ 开始、大小为 $m \times n$ 的字符串矩阵 $res$,用以表示树的「格式化布局」。
构造此格式化布局矩阵需要遵循以下规则:
- 树的「高度」为 $height$,矩阵的行数 $m$ 应该等于 $height + 1$。
- 矩阵的列数 $n$ 应该等于 $2^{height+1} - 1$。
- 「根节点」需要放置在「顶行」的「正中间」,对应位置为 $res[0][(n-1)/2]$。
- 对于放置在矩阵中的每个节点,设对应位置为 $res[r][c]$,将其左子节点放置在 $res[r+1][c-2^{height-r-1}]$,右子节点放置在 $res[r+1][c+2^{height-r-1}]$。
- 继续这一过程,直到树中的所有节点都妥善放置。
- 任意空单元格都应该包含空字符串 `""`。
返回构造得到的矩阵 $res$。
**说明**:
- 树中节点数在范围 $[1, 2^{10}]$ 内。
- $-99 \le Node.val \le 99$。
- 树的深度在范围 $[1, 10]$ 内。
**示例**:
- 示例 1:
```python
输入:root = [1,2]
输出:
[["","1",""],
["2","",""]]
```
- 示例 2:
```python
输入:root = [1,2,3,null,4]
输出:
[["","","","1","","",""],
["","2","","","","3",""],
["","","4","","","",""]]
```
## 解题思路
### 思路 1:深度优先搜索
这道题目要求将二叉树按照特定格式输出到矩阵中。首先需要计算树的高度,然后根据高度确定矩阵的大小,最后使用 DFS 填充矩阵。
1. 计算树的高度 $height$。
2. 根据题目要求,矩阵的行数 $m = height + 1$,列数 $n = 2^{height + 1} - 1$。
3. 初始化矩阵,所有位置填充空字符串。
4. 使用 DFS 填充矩阵:
- 根节点放在第 0 行的中间位置 $(n - 1) / 2$。
- 对于位置 $(r, c)$ 的节点:
- 左子节点放在 $(r + 1, c - 2^{height - r - 1})$。
- 右子节点放在 $(r + 1, c + 2^{height - r - 1})$。
5. 返回矩阵。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def printTree(self, root: Optional[TreeNode]) -> List[List[str]]:
# 计算树的高度
def get_height(node):
if not node:
return -1
return 1 + max(get_height(node.left), get_height(node.right))
height = get_height(root)
m = height + 1
n = 2 ** (height + 1) - 1
# 初始化矩阵
result = [[""] * n for _ in range(m)]
# DFS 填充矩阵
def dfs(node, row, col):
if not node:
return
result[row][col] = str(node.val)
# 计算左右子节点的列偏移
offset = 2 ** (height - row - 1)
# 递归处理左右子树
dfs(node.left, row + 1, col - offset)
dfs(node.right, row + 1, col + offset)
# 从根节点开始填充
dfs(root, 0, (n - 1) // 2)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(h \times 2^h)$,其中 $h$ 是树的高度。需要遍历所有节点,矩阵的大小为 $(h + 1) \times (2^{h + 1} - 1)$。
- **空间复杂度**:$O(h \times 2^h)$,需要创建矩阵存储结果,递归调用栈的深度为 $O(h)$。
================================================
FILE: docs/solutions/0600-0699/redundant-connection-ii.md
================================================
# [0685. 冗余连接 II](https://leetcode.cn/problems/redundant-connection-ii/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:困难
## 题目链接
- [0685. 冗余连接 II - 力扣](https://leetcode.cn/problems/redundant-connection-ii/)
## 题目大意
**描述**:
在本问题中,有根树指满足以下条件的「有向」图。该树只有一个根节点,所有其他节点都是该根节点的后继。
该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。
输入一个有向图,该图由一个有着 $n$ 个节点(节点值不重复,从 $1$ 到 $n$)的树及一条附加的有向边构成。附加的边包含在 $1$ 到 $n$ 中的两个不同顶点间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组 $edges$。 每个元素是一对 $[ui, vi]$,用以表示「有向」图中连接顶点 $ui$ 和顶点 $vi$ 的边,其中 $ui$ 是 $vi$ 的一个父节点。
**要求**:
返回一条能删除的边,使得剩下的图是有 $n$ 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
**说明**:
- $n == edges.length$。
- $3 \le n \le 10^{3}$。
- $edges[i].length == 2$。
- $1 \le ui, vi \le n$。
**示例**:
- 示例 1:
```python
输入:edges = [[1,2],[1,3],[2,3]]
输出:[2,3]
```
- 示例 2:
```python
输入:edges = [[1,2],[2,3],[3,4],[4,1],[1,5]]
输出:[4,1]
```
## 解题思路
### 思路 1:并查集
这道题目是在有向图中找到一条可以删除的边,使得剩下的图是有根树。有向图中的有根树有以下特点:
1. 只有一个根节点(入度为 0)。
2. 除根节点外,其他节点的入度都为 1。
可能出现的情况:
1. 某个节点的入度为 2(有两个父节点)。
2. 图中存在环。
使用并查集来检测环,并记录入度为 2 的节点。
### 思路 1:代码
```python
class Solution:
def findRedundantDirectedConnection(self, edges: List[List[int]]) -> List[int]:
n = len(edges)
parent = list(range(n + 1))
def find(x):
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def union(x, y):
parent[find(x)] = find(y)
# 记录每个节点的父节点
in_degree = {}
conflict_edge = None
cycle_edge = None
for u, v in edges:
# 如果 v 已经有父节点,说明有冲突
if v in in_degree:
conflict_edge = [u, v]
else:
in_degree[v] = u
# 检查是否形成环
if find(u) == find(v):
cycle_edge = [u, v]
else:
union(u, v)
# 情况 1:没有冲突边,只有环
if not conflict_edge:
return cycle_edge
# 情况 2:有冲突边
# 如果没有环,删除冲突边
if not cycle_edge:
return conflict_edge
# 情况 3:既有冲突边又有环
# 删除导致冲突的第一条边
return [in_degree[conflict_edge[1]], conflict_edge[1]]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \alpha(n))$,其中 $n$ 是边的数量,$\alpha(n)$ 是阿克曼函数的反函数,可以认为是常数。
- **空间复杂度**:$O(n)$,需要使用并查集和哈希表存储节点的父节点信息。
================================================
FILE: docs/solutions/0600-0699/redundant-connection.md
================================================
# [0684. 冗余连接](https://leetcode.cn/problems/redundant-connection/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [0684. 冗余连接 - 力扣](https://leetcode.cn/problems/redundant-connection/)
## 题目大意
**描述**:一个 `n` 个节点的树(节点值为 `1~n`)添加一条边后就形成了图,添加的这条边不属于树中已经存在的边。图的信息记录存储与长度为 `n` 的二维数组 `edges`,`edges[i] = [ai, bi]` 表示图中在 `ai` 和 `bi` 之间存在一条边。
现在给定代表边信息的二维数组 `edges`。
**要求**:找到一条可以山区的边,使得删除后的剩余部分是一个有着 `n` 个节点的树。如果有多个答案,则返回数组 `edges` 中最后出现的边。
**说明**:
- $n == edges.length$。
- $3 \le n \le 1000$。
- $edges[i].length == 2$。
- $1 \le ai < bi \le edges.length$。
- $ai ≠ bi$。
- $edges$ 中无重复元素。
- 给定的图是连通的。
**示例**:
- 示例 1:
```python
输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
```
- 示例 2:
```python
输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
```
## 解题思路
### 思路 1:并查集
树可以看做是无环的图,这道题就是要找出那条添加边之后成环的边。可以考虑用并查集来做。
1. 从前向后遍历每一条边。
2. 如果边的两个节点不在同一个集合,就加入到一个集合(链接到同一个根节点)。
3. 如果边的节点已经出现在同一个集合里,说明边的两个节点已经连在一起了,再加入这条边一定会出现环,则这条边就是所求答案。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
self.parent[root_x] = root_y
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:
size = len(edges)
union_find = UnionFind(size + 1)
for edge in edges:
if union_find.is_connected(edge[0], edge[1]):
return edge
union_find.union(edge[0], edge[1])
return None
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \alpha(n))$。其中 $n$ 是图中的节点个数,$\alpha$ 是反 `Ackerman` 函数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0600-0699/remove-9.md
================================================
# [0660. 移除 9](https://leetcode.cn/problems/remove-9/)
- 标签:数学
- 难度:困难
## 题目链接
- [0660. 移除 9 - 力扣](https://leetcode.cn/problems/remove-9/)
## 题目大意
**描述**:
从 $1$ 开始,移除包含数字 $9$ 的所有整数,例如 $9$,$19$,$29$,……
这样就获得了一个新的整数数列:$1$,$2$,$3$,$4$,$5$,$6$,$7$,$8$,$10$,$11$,……
给定一个整数 $n$。
**要求**:
返回新数列中第 $n$ 个数字(下标从 $1$ 开始)。
**说明**:
- $1 \le n \le 8 \times 10^8$。
**示例**:
- 示例 1:
```python
输入:n = 9
输出:10
```
- 示例 2:
```python
输入:n = 10
输出:11
```
## 解题思路
### 思路 1:进制转换
#### 思路 1:算法描述
移除所有包含数字 $9$ 的整数后,剩余的数字序列实际上是一个九进制数系统。
**核心思路**:
- 原始序列:$1, 2, 3, 4, 5, 6, 7, 8, 10, 11, ...$(跳过所有包含 $9$ 的数字)
- 这相当于九进制:$1, 2, 3, 4, 5, 6, 7, 8, 10, 11, ...$
- 第 $n$ 个数字就是 $n$ 的九进制表示。
**算法步骤**:
1. 将 $n$ 转换为九进制。
2. 返回转换后的结果。
#### 思路 1:代码
```python
class Solution:
def newInteger(self, n: int) -> int:
# 将 n 转换为九进制
result = 0
base = 1
while n > 0:
result += (n % 9) * base
n //= 9
base *= 10
return result
```
#### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$,需要将 $n$ 转换为九进制。
- **空间复杂度**:$O(1)$,只使用了常数额外空间。
================================================
FILE: docs/solutions/0600-0699/repeated-string-match.md
================================================
# [0686. 重复叠加字符串匹配](https://leetcode.cn/problems/repeated-string-match/)
- 标签:字符串、字符串匹配
- 难度:中等
## 题目链接
- [0686. 重复叠加字符串匹配 - 力扣](https://leetcode.cn/problems/repeated-string-match/)
## 题目大意
**描述**:给定两个字符串 `a` 和 `b`。
**要求**:寻找重复叠加字符串 `a` 的最小次数,使得字符串 `b` 成为叠加后的字符串 `a` 的子串,如果不存在则返回 `-1`。
**说明**:
- 字符串 `"abc"` 重复叠加 `0` 次是 `""`,重复叠加 `1` 次是 `"abc"`,重复叠加 `2` 次是 `"abcabc"`。
- $1 \le a.length \le 10^4$。
- $1 \le b.length \le 10^4$。
- `a` 和 `b` 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:a = "abcd", b = "cdabcdab"
输出:3
解释:a 重复叠加三遍后为 "abcdabcdabcd", 此时 b 是其子串。
```
- 示例 2:
```python
输入:a = "a", b = "aa"
输出:2
```
## 解题思路
### 思路 1:KMP 算法
假设字符串 `a` 的长度为 `n`,`b` 的长度为 `m`。
把 `b` 看做是模式串,把字符串 `a` 叠加后的字符串看做是文本串,这道题就变成了单模式串匹配问题。
我们可以模拟叠加字符串 `a` 后进行单模式串匹配问题。模拟叠加字符串可以通过在遍历字符串匹配时对字符串 `a` 的长度 `n` 取余来实现。
那么问题关键点就变为了如何高效的进行单模式串匹配,以及字符串循环匹配的退出条件是什么。
**单模式串匹配问题**:可以用 KMP 算法来做。
**循环匹配退出条件问题**:假设我们用 `i` 遍历 `a` 叠加后字符串,用 `j` 遍历字符串 `b`。如果字符串 `b` 是 `a` 叠加后字符串的子串,那么 `b` 有两种可能:
1. `b` 直接是原字符串 `a` 的子串:这种情况下,最多遍历到 `len(a)`。
2. `b` 是 `a` 叠加后的字符串的子串:
1. 最多遍历到 `len(a) + len(b)`,可以写为 `while i < len(a) + len(b):`,当 `i == len(a) + len(b)` 时跳出循环。
2. 也可以写为 `while i - j < len(a):`,这种写法中 `i - j ` 表示的是字符匹配开始的位置,如果匹配到 `len(a)` 时(即 `i - j == len(a)` 时)最开始位置的字符仍没有匹配,那么 `b` 也不可能是 `a` 叠加后的字符串的子串了,此时跳出循环。
最后我们需要计算一下重复叠加字符串 `a` 的最小次数。假设 `index` 使我们求出的匹配位置。
1. 如果 `index == -1`,则说明 `b` 不可能是 `a` 叠加后的字符串的子串,返回 `False`。
2. 如果 `len(a) - index >= len(b)`,则说明匹配位置未超过字符串 `a` 的长度,叠加 `1` 次(字符串 `a` 本身)就可以匹配。
3. 如果 `len(a) - index < len(b)`,则说明需要叠加才能匹配。此时最小叠加次数为 $\lfloor \frac{index + len(b) - 1}{len(a)} \rfloor + 1$。其中 `index` 代笔匹配开始前的字符串长度,加上 `len(b)` 后就是匹配到字符串 `b` 结束时最少需要的字符数,再 `-1` 是为了向下取整。 除以 `len(a)` 表示至少需要几个 `a`, 因为是向下取整,所以最后要加上 `1`。写成代码就是:`(index + len(b) - 1) // len(a) + 1`。
### 思路 1:代码
```python
class Solution:
# KMP 匹配算法,T 为文本串,p 为模式串
def kmp(self, T: str, p: str) -> int:
n, m = len(T), len(p)
next = self.generateNext(p)
i, j = 0, 0
while i - j < n:
while j > 0 and T[i % n] != p[j]:
j = next[j - 1]
if T[i % n] == p[j]:
j += 1
if j == m:
return i - m + 1
i += 1
return -1
def generateNext(self, p: str):
m = len(p)
next = [0 for _ in range(m)]
left = 0
for right in range(1, m):
while left > 0 and p[left] != p[right]:
left = next[left - 1]
if p[left] == p[right]:
left += 1
next[right] = left
return next
def repeatedStringMatch(self, a: str, b: str) -> int:
len_a = len(a)
len_b = len(b)
index = self.kmp(a, b)
if index == -1:
return -1
if len_a - index >= len_b:
return 1
return (index + len(b) - 1) // len(a) + 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中文本串 $a$ 的长度为 $n$,模式串 $b$ 的长度为 $m$。
- **空间复杂度**:$O(m)$。
================================================
FILE: docs/solutions/0600-0699/replace-words.md
================================================
# [0648. 单词替换](https://leetcode.cn/problems/replace-words/)
- 标签:字典树、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0648. 单词替换 - 力扣](https://leetcode.cn/problems/replace-words/)
## 题目大意
**描述**:给定一个由许多词根组成的字典列表 `dictionary`,以及一个句子字符串 `sentence`。
**要求**:将句子中有词根的单词用词根替换掉。如果单词有很多词根,则用最短的词根替换掉他。最后输出替换之后的句子。
**说明**:
- $1 \le dictionary.length \le 1000$。
- $1 \le dictionary[i].length \le 100$。
- `dictionary[i]` 仅由小写字母组成。
- $1 \le sentence.length \le 10^6$。
- `sentence` 仅由小写字母和空格组成。
- `sentence` 中单词的总量在范围 $[1, 1000]$ 内。
- `sentence` 中每个单词的长度在范围 $[1, 1000]$ 内。
- `sentence` 中单词之间由一个空格隔开。
- `sentence` 没有前导或尾随空格。
**示例**:
- 示例 1:
```python
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
```
- 示例 2:
```python
输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
```
## 解题思路
### 思路 1:字典树
1. 构造一棵字典树。
2. 将所有的词根存入到前缀树(字典树)中。
3. 然后在树上查找每个单词的最短词根。
### 思路 1:代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> str:
"""
Returns if the word is in the trie.
"""
cur = self
index = 0
for ch in word:
if ch not in cur.children:
return word
cur = cur.children[ch]
index += 1
if cur.isEnd:
break
return word[:index]
class Solution:
def replaceWords(self, dictionary: List[str], sentence: str) -> str:
trie_tree = Trie()
for word in dictionary:
trie_tree.insert(word)
words = sentence.split(" ")
size = len(words)
for i in range(size):
word = words[i]
words[i] = trie_tree.search(word)
return ' '.join(words)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(|dictionary| + |sentence|)$。其中 $|dictionary|$ 是字符串数组 `dictionary` 中的字符总数,$|sentence|$ 是字符串 `sentence` 的字符总数。
- **空间复杂度**:$O(|dictionary| + |sentence|)$。
================================================
FILE: docs/solutions/0600-0699/robot-return-to-origin.md
================================================
# [0657. 机器人能否返回原点](https://leetcode.cn/problems/robot-return-to-origin/)
- 标签:字符串、模拟
- 难度:简单
## 题目链接
- [0657. 机器人能否返回原点 - 力扣](https://leetcode.cn/problems/robot-return-to-origin/)
## 题目大意
**描述**:
在二维平面上,有一个机器人从原点 $(0, 0)$ 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 $(0, 0)$ 处结束。
移动顺序由字符串 $moves$ 表示。字符 $move[i]$ 表示其第 $i$ 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。
**要求**:
如果机器人在完成所有动作后返回原点,则返回 true。否则,返回 false。
**说明**:
- 注意:机器人「面朝」的方向无关紧要。 `R` 将始终使机器人向右移动一次,`L` 将始终向左移动等。此外,假设每次移动机器人的移动幅度相同。
- $1 \le moves.length \le 2 \times 10^{4}$。
- moves 只包含字符 `'U'`, `'D'`, `'L'` 和 `'R'`。
**示例**:
- 示例 1:
```python
输入: moves = "UD"
输出: true
解释:机器人向上移动一次,然后向下移动一次。所有动作都具有相同的幅度,因此它最终回到它开始的原点。因此,我们返回 true。
```
- 示例 2:
```python
输入: moves = "LL"
输出: false
解释:机器人向左移动两次。它最终位于原点的左侧,距原点有两次 “移动” 的距离。我们返回 false,因为它在移动结束时没有返回原点。
```
## 解题思路
### 思路 1:模拟
这道题目非常简单,只需要统计上下左右移动的次数,判断是否能回到原点。
1. 初始化坐标 $(x, y) = (0, 0)$。
2. 遍历移动序列中的每个字符:
- 如果是 `'U'`,$y$ 加 1(向上移动)。
- 如果是 `'D'`,$y$ 减 1(向下移动)。
- 如果是 `'L'`,$x$ 减 1(向左移动)。
- 如果是 `'R'`,$x$ 加 1(向右移动)。
3. 判断最终坐标是否为 $(0, 0)$。
### 思路 1:代码
```python
class Solution:
def judgeCircle(self, moves: str) -> bool:
x, y = 0, 0
for move in moves:
if move == 'U':
y += 1
elif move == 'D':
y -= 1
elif move == 'L':
x -= 1
elif move == 'R':
x += 1
return x == 0 and y == 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是移动序列的长度。需要遍历所有移动指令。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/second-minimum-node-in-a-binary-tree copy.md
================================================
# [0671. 二叉树中第二小的节点](https://leetcode.cn/problems/second-minimum-node-in-a-binary-tree/)
- 标签:树、深度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0671. 二叉树中第二小的节点 - 力扣](https://leetcode.cn/problems/second-minimum-node-in-a-binary-tree/)
## 题目大意
**描述**:
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 $2$ 或 $0$。如果一个节点有两个子节点的话,那么该节点的值等于两个子节点中较小的一个。
更正式地说,即 $root.val = min(root.left.val, root.right.val)$ 总成立。
**要求**:
给出这样的一个二叉树,你需要输出所有节点中的「第二小的值」。
如果第二小的值不存在的话,输出 $-1$。
**说明**:
- 树中节点数目在范围 $[1, 25]$ 内。
- $1 \le Node.val \le 2^{31} - 1$。
- 对于树中每个节点 $root.val == min(root.left.val, root.right.val)$。
**示例**:
- 示例 1:
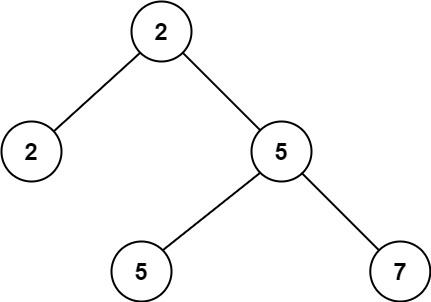
```python
输入:root = [2,2,5,null,null,5,7]
输出:5
解释:最小的值是 2 ,第二小的值是 5 。
```
- 示例 2:
```python
输入:root = [2,2,2]
输出:-1
解释:最小的值是 2, 但是不存在第二小的值。
```
## 解题思路
### 思路 1:深度优先搜索
根据题目描述,二叉树的特性是根节点的值等于两个子节点中较小的值。因此根节点一定是最小值。我们需要找到第二小的值。
1. 根节点的值 $root.val$ 是最小值。
2. 使用深度优先搜索遍历整棵树,寻找第一个大于 $root.val$ 的值。
3. 在遍历过程中:
- 如果当前节点的值大于 $root.val$,说明找到了一个候选值,更新答案。
- 如果当前节点的值等于 $root.val$,继续递归搜索其子树。
4. 如果没有找到第二小的值,返回 $-1$。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def findSecondMinimumValue(self, root: Optional[TreeNode]) -> int:
self.ans = float('inf')
min_val = root.val
def dfs(node):
if not node:
return
# 如果当前节点值大于最小值且小于当前答案,更新答案
if min_val < node.val < self.ans:
self.ans = node.val
# 只有当节点值等于最小值时,才需要继续搜索其子树
elif node.val == min_val:
dfs(node.left)
dfs(node.right)
dfs(root)
return self.ans if self.ans != float('inf') else -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数。最坏情况下需要遍历所有节点。
- **空间复杂度**:$O(h)$,其中 $h$ 是二叉树的高度。递归调用栈的深度最多为树的高度。
================================================
FILE: docs/solutions/0600-0699/second-minimum-node-in-a-binary-tree.md
================================================
# [0671. 二叉树中第二小的节点](https://leetcode.cn/problems/second-minimum-node-in-a-binary-tree/)
- 标签:树、深度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0671. 二叉树中第二小的节点 - 力扣](https://leetcode.cn/problems/second-minimum-node-in-a-binary-tree/)
## 题目大意
**描述**:
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 $2$ 或 $0$。如果一个节点有两个子节点的话,那么该节点的值等于两个子节点中较小的一个。
更正式地说,即 $root.val = min(root.left.val, root.right.val)$ 总成立。
**要求**:
给出这样的一个二叉树,你需要输出所有节点中的「第二小的值」。
如果第二小的值不存在的话,输出 $-1$。
**说明**:
- 树中节点数目在范围 $[1, 25]$ 内。
- $1 \le Node.val \le 2^{31} - 1$。
- 对于树中每个节点 $root.val == min(root.left.val, root.right.val)$。
**示例**:
- 示例 1:

```python
输入:root = [2,2,5,null,null,5,7]
输出:5
解释:最小的值是 2 ,第二小的值是 5 。
```
- 示例 2:

```python
输入:root = [2,2,2]
输出:-1
解释:最小的值是 2, 但是不存在第二小的值。
```
## 解题思路
### 思路 1:深度优先搜索
根据题目描述,二叉树的特性是根节点的值等于两个子节点中较小的值。因此根节点一定是最小值。我们需要找到第二小的值。
1. 根节点的值 $root.val$ 是最小值。
2. 使用深度优先搜索遍历整棵树,寻找第一个大于 $root.val$ 的值。
3. 在遍历过程中:
- 如果当前节点的值大于 $root.val$,说明找到了一个候选值,更新答案。
- 如果当前节点的值等于 $root.val$,继续递归搜索其子树。
4. 如果没有找到第二小的值,返回 $-1$。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def findSecondMinimumValue(self, root: Optional[TreeNode]) -> int:
self.ans = float('inf')
min_val = root.val
def dfs(node):
if not node:
return
# 如果当前节点值大于最小值且小于当前答案,更新答案
if min_val < node.val < self.ans:
self.ans = node.val
# 只有当节点值等于最小值时,才需要继续搜索其子树
elif node.val == min_val:
dfs(node.left)
dfs(node.right)
dfs(root)
return self.ans if self.ans != float('inf') else -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数。最坏情况下需要遍历所有节点。
- **空间复杂度**:$O(h)$,其中 $h$ 是二叉树的高度。递归调用栈的深度最多为树的高度。
================================================
FILE: docs/solutions/0600-0699/set-mismatch.md
================================================
# [0645. 错误的集合](https://leetcode.cn/problems/set-mismatch/)
- 标签:位运算、数组、哈希表、排序
- 难度:简单
## 题目链接
- [0645. 错误的集合 - 力扣](https://leetcode.cn/problems/set-mismatch/)
## 题目大意
**描述**:
集合 $s$ 包含从 $1$ 到 $n$ 的整数。不幸的是,因为数据错误,导致集合里面某一个数字复制了成了集合里面的另外一个数字的值,导致集合「丢失了一个数字」并且「有一个数字重复」。
给定一个数组 $nums$ 代表了集合 $S$ 发生错误后的结果。
**要求**:
找出重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
**说明**:
- $2 \le nums.length \le 10^{4}$。
- $1 \le nums[i] \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,2,4]
输出:[2,3]
```
- 示例 2:
```python
输入:nums = [1,1]
输出:[1,2]
```
## 解题思路
### 思路 1:哈希表
这道题目要求找出重复的数字和丢失的数字。可以使用哈希表记录每个数字出现的次数。
1. 使用哈希表 $freq$ 记录数组中每个数字出现的次数。
2. 遍历 $1$ 到 $n$:
- 如果 $freq[i] = 2$,说明 $i$ 是重复的数字。
- 如果 $freq[i] = 0$,说明 $i$ 是丢失的数字。
3. 返回 `[重复的数字, 丢失的数字]`。
### 思路 1:代码
```python
class Solution:
def findErrorNums(self, nums: List[int]) -> List[int]:
from collections import Counter
n = len(nums)
freq = Counter(nums)
duplicate, missing = 0, 0
for i in range(1, n + 1):
if freq[i] == 2:
duplicate = i
elif freq[i] == 0:
missing = i
return [duplicate, missing]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。需要遍历数组一次统计频率,再遍历 $1$ 到 $n$ 找出重复和丢失的数字。
- **空间复杂度**:$O(n)$,需要使用哈希表存储每个数字的频率。
### 思路 2:数学方法
利用数学方法,通过求和和平方和来找出重复和丢失的数字。
1. 设重复的数字为 $x$,丢失的数字为 $y$。
2. 计算数组的和 $sum\underline{~}nums$ 和 $1$ 到 $n$ 的和 $sum\underline{~}n$,有:$sum\underline{~}nums - sum\underline{~}n = x - y$。
3. 计算数组的平方和 $sum\underline{~}sq\underline{~}nums$ 和 $1$ 到 $n$ 的平方和 $sum\underline{~}sq\underline{~}n$,有:$sum\underline{~}sq\underline{~}nums - sum\underline{~}sq\underline{~}n = x^2 - y^2 = (x + y)(x - y)$。
4. 通过这两个方程可以求出 $x$ 和 $y$。
### 思路 2:代码
```python
class Solution:
def findErrorNums(self, nums: List[int]) -> List[int]:
n = len(nums)
# 计算数组的和与平方和
sum_nums = sum(nums)
sum_sq_nums = sum(x * x for x in nums)
# 计算 1 到 n 的和与平方和
sum_n = n * (n + 1) // 2
sum_sq_n = n * (n + 1) * (2 * n + 1) // 6
# x - y = sum_nums - sum_n
diff = sum_nums - sum_n
# x^2 - y^2 = sum_sq_nums - sum_sq_n
# (x + y)(x - y) = sum_sq_nums - sum_sq_n
# x + y = (sum_sq_nums - sum_sq_n) / (x - y)
sum_xy = (sum_sq_nums - sum_sq_n) // diff
# 求解 x 和 y
duplicate = (diff + sum_xy) // 2
missing = sum_xy - duplicate
return [duplicate, missing]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。需要遍历数组计算和与平方和。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/shopping-offers.md
================================================
# [0638. 大礼包](https://leetcode.cn/problems/shopping-offers/)
- 标签:位运算、记忆化搜索、数组、动态规划、回溯、状态压缩
- 难度:中等
## 题目链接
- [0638. 大礼包 - 力扣](https://leetcode.cn/problems/shopping-offers/)
## 题目大意
**描述**:
在 LeetCode 商店中,有 $n$ 件在售的物品。每件物品都有对应的价格。然而,也有一些大礼包,每个大礼包以优惠的价格捆绑销售一组物品。
给定一个整数数组 $price$ 表示物品价格,其中 $price[i]$ 是第 $i$ 件物品的价格。另有一个整数数组 $needs$ 表示购物清单,其中 $needs[i]$ 是需要购买第 $i$ 件物品的数量。
还有一个数组 $special$ 表示大礼包,$special[i]$ 的长度为 $n + 1$,其中 $special[i][j]$ 表示第 $i$ 个大礼包中内含第 $j$ 件物品的数量,且 $special[i][n]$ (也就是数组中的最后一个整数)为第 $i$ 个大礼包的价格。
**要求**:
返回「确切」满足购物清单所需花费的最低价格,你可以充分利用大礼包的优惠活动。你不能购买超出购物清单指定数量的物品,即使那样会降低整体价格。任意大礼包可无限次购买。
**说明**:
- $n == price.length == needs.length$。
- $1 \le n \le 6$。
- $0 \le price[i], needs[i] \le 10$。
- $1 \le special.length \le 10^{3}$。
- $special[i].length == n + 1$。
- $0 \le special[i][j] \le 50$。
- 生成的输入对于 $0 \le j \le n - 1$ 至少有一个 $special[i][j]$ 非零。
**示例**:
- 示例 1:
```python
输入:price = [2,5], special = [[3,0,5],[1,2,10]], needs = [3,2]
输出:14
解释:有 A 和 B 两种物品,价格分别为 ¥2 和 ¥5 。
大礼包 1 ,你可以以 ¥5 的价格购买 3A 和 0B 。
大礼包 2 ,你可以以 ¥10 的价格购买 1A 和 2B 。
需要购买 3 个 A 和 2 个 B , 所以付 ¥10 购买 1A 和 2B(大礼包 2),以及 ¥4 购买 2A 。
```
- 示例 2:
```python
输入:price = [2,3,4], special = [[1,1,0,4],[2,2,1,9]], needs = [1,2,1]
输出:11
解释:A ,B ,C 的价格分别为 ¥2 ,¥3 ,¥4 。
可以用 ¥4 购买 1A 和 1B ,也可以用 ¥9 购买 2A ,2B 和 1C 。
需要买 1A ,2B 和 1C ,所以付 ¥4 买 1A 和 1B(大礼包 1),以及 ¥3 购买 1B , ¥4 购买 1C 。
不可以购买超出待购清单的物品,尽管购买大礼包 2 更加便宜。
```
## 解题思路
### 思路 1:记忆化搜索
这道题目要求计算满足购物清单的最低价格。可以使用记忆化搜索(动态规划)来避免重复计算。
1. 首先过滤掉不划算的大礼包(大礼包价格大于等于单独购买的价格)。
2. 使用记忆化搜索,状态为当前的购物需求 $needs$。
3. 对于每个状态,有两种选择:
- 不使用大礼包,直接按单价购买所有物品。
- 尝试使用每个大礼包,如果大礼包中的物品数量不超过需求,则使用该大礼包,并递归计算剩余需求的最低价格。
4. 返回所有选择中的最小值。
### 思路 1:代码
```python
class Solution:
def shoppingOffers(self, price: List[int], special: List[List[int]], needs: List[int]) -> int:
from functools import lru_cache
n = len(price)
# 过滤掉不划算的大礼包
filtered_special = []
for offer in special:
# 计算大礼包的原价
original_price = sum(offer[i] * price[i] for i in range(n))
# 如果大礼包价格更优惠,保留
if offer[n] < original_price:
filtered_special.append(offer)
@lru_cache(None)
def dfs(needs_tuple):
needs = list(needs_tuple)
# 不使用大礼包,直接购买
min_cost = sum(needs[i] * price[i] for i in range(n))
# 尝试使用每个大礼包
for offer in filtered_special:
# 检查是否可以使用该大礼包
can_use = True
new_needs = []
for i in range(n):
if needs[i] < offer[i]:
can_use = False
break
new_needs.append(needs[i] - offer[i])
if can_use:
# 使用该大礼包,递归计算剩余需求
min_cost = min(min_cost, offer[n] + dfs(tuple(new_needs)))
return min_cost
return dfs(tuple(needs))
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times k^n)$,其中 $m$ 是大礼包的数量,$n$ 是物品的种类,$k$ 是每种物品的最大需求量。状态数最多为 $k^n$,每个状态需要尝试 $m$ 个大礼包。
- **空间复杂度**:$O(k^n)$,需要使用记忆化存储所有状态的结果。
================================================
FILE: docs/solutions/0600-0699/smallest-range-covering-elements-from-k-lists.md
================================================
# [0632. 最小区间](https://leetcode.cn/problems/smallest-range-covering-elements-from-k-lists/)
- 标签:贪心、数组、哈希表、排序、滑动窗口、堆(优先队列)
- 难度:困难
## 题目链接
- [0632. 最小区间 - 力扣](https://leetcode.cn/problems/smallest-range-covering-elements-from-k-lists/)
## 题目大意
**描述**:
你有 $k$ 个「非递减排列」的整数列表。
**要求**:
找到一个 最小 区间,使得 $k$ 个列表中的每个列表至少有一个数包含在其中。
**说明**:
- 我们定义如果 $b - a < d - c$ 或者在 $b - a == d - c$ 时 $a < c$,则区间 $[a, b]$ 比 $[c, d]$ 小。
- $nums.length == k$。
- $1 \le k \le 3500$。
- $1 \le nums[i].length \le 50$。
- $-10^{5} \le nums[i][j] \le 10^{5}$。
- $nums[i]$ 按非递减顺序排列。
**示例**:
- 示例 1:
```python
输入:nums = [[4,10,15,24,26], [0,9,12,20], [5,18,22,30]]
输出:[20,24]
解释:
列表 1:[4, 10, 15, 24, 26],24 在区间 [20,24] 中。
列表 2:[0, 9, 12, 20],20 在区间 [20,24] 中。
列表 3:[5, 18, 22, 30],22 在区间 [20,24] 中。
```
- 示例 2:
```python
输入:nums = [[1,2,3],[1,2,3],[1,2,3]]
输出:[1,1]
```
## 解题思路
### 思路 1:堆(优先队列)
这道题目要求找到一个最小区间,使得 $k$ 个列表中的每个列表至少有一个数包含在其中。使用最小堆维护当前区间。
1. 初始化最小堆,将每个列表的第一个元素加入堆中,元素格式为 $(value, list\_idx, element\_idx)$。
2. 记录当前堆中的最大值 $max\_val$。
3. 当堆中有 $k$ 个元素时(每个列表都有元素在堆中):
- 取出堆顶元素(最小值)$min\_val$。
- 更新最小区间 $[min\_val, max\_val]$。
- 如果该元素所在列表还有下一个元素,将下一个元素加入堆,并更新 $max\_val$。
- 如果该元素所在列表没有下一个元素,结束循环。
4. 返回最小区间。
### 思路 1:代码
```python
class Solution:
def smallestRange(self, nums: List[List[int]]) -> List[int]:
import heapq
# 初始化堆,加入每个列表的第一个元素
heap = []
max_val = float('-inf')
for i in range(len(nums)):
heapq.heappush(heap, (nums[i][0], i, 0))
max_val = max(max_val, nums[i][0])
# 初始化结果区间
result = [float('-inf'), float('inf')]
while len(heap) == len(nums):
min_val, list_idx, element_idx = heapq.heappop(heap)
# 更新最小区间
if max_val - min_val < result[1] - result[0]:
result = [min_val, max_val]
# 如果当前列表还有下一个元素
if element_idx + 1 < len(nums[list_idx]):
next_val = nums[list_idx][element_idx + 1]
heapq.heappush(heap, (next_val, list_idx, element_idx + 1))
max_val = max(max_val, next_val)
else:
# 当前列表已经遍历完,无法继续
break
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times k \times \log k)$,其中 $n$ 是所有列表的平均长度,$k$ 是列表的数量。需要遍历所有元素,每次堆操作的时间复杂度为 $O(\log k)$。
- **空间复杂度**:$O(k)$,堆中最多存储 $k$ 个元素。
================================================
FILE: docs/solutions/0600-0699/solve-the-equation.md
================================================
# [0640. 求解方程](https://leetcode.cn/problems/solve-the-equation/)
- 标签:数学、字符串、模拟
- 难度:中等
## 题目链接
- [0640. 求解方程 - 力扣](https://leetcode.cn/problems/solve-the-equation/)
## 题目大意
**描述**:
给定一个方程 $equation$。
**要求**:
求解一个给定的方程,将 $x$ 以字符串 `"x=#value"` 的形式返回。该方程仅包含 `'+'`,`'-'` 操作,变量 $x$ 和其对应系数。
如果方程没有解或存在的解不为整数,请返回 `"No $solution$"` 。如果方程有无限解,则返回 `"Infinite solutions"`。
题目保证,如果方程中只有一个解,则 `'x'` 的值是一个整数。
**说明**:
- $3 \le equation.length \le 10^{3}$。
- $equation$ 只有一个 `'='`。
- 方程由绝对值在 $[0, 10^{3}]$ 范围内且无任何前导零的整数和变量 `'x'` 组成。
**示例**:
- 示例 1:
```python
输入: equation = "x+5-3+x=6+x-2"
输出: "x=2"
```
- 示例 2:
```python
输入: equation = "x=x"
输出: "Infinite solutions"
```
## 解题思路
### 思路 1:字符串解析 + 模拟
这道题目要求求解一元一次方程。需要解析方程字符串,分别统计等号左右两边的 $x$ 的系数和常数项。
1. 将方程按 '=' 分割成左右两部分。
2. 对于每一部分,解析出 $x$ 的系数和常数项:
- 遍历字符串,识别数字、符号和变量 $x$。
- 如果是 $x$ 的系数,累加到 $x\_coef$。
- 如果是常数,累加到 $const$。
3. 将右边的系数和常数移到左边(符号取反)。
4. 根据最终的系数和常数判断:
- 如果系数为 0 且常数为 0,返回 "Infinite solutions"。
- 如果系数为 0 且常数不为 0,返回 "No solution"。
- 否则,返回 "x=#value",其中 value = -常数 / 系数。
### 思路 1:代码
```python
class Solution:
def solveEquation(self, equation: str) -> str:
def parse(s):
"""解析表达式,返回 x 的系数和常数项"""
x_coef = 0
const = 0
i = 0
n = len(s)
while i < n:
# 读取符号
sign = 1
if s[i] == '+':
i += 1
elif s[i] == '-':
sign = -1
i += 1
# 读取数字
num = 0
has_num = False
while i < n and s[i].isdigit():
num = num * 10 + int(s[i])
has_num = True
i += 1
# 判断是 x 还是常数
if i < n and s[i] == 'x':
# 如果没有数字,系数为 1
x_coef += sign * (num if has_num else 1)
i += 1
else:
# 常数项
const += sign * num
return x_coef, const
# 分割等号左右两边
left, right = equation.split('=')
# 解析左右两边
left_x, left_const = parse(left)
right_x, right_const = parse(right)
# 移项:左边 - 右边 = 0
x_coef = left_x - right_x
const = left_const - right_const
# 判断解的情况
if x_coef == 0:
if const == 0:
return "Infinite solutions"
else:
return "No solution"
else:
# x = -const / x_coef
return f"x={-const // x_coef}"
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是方程字符串的长度。需要遍历字符串解析表达式。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0600-0699/split-array-into-consecutive-subsequences.md
================================================
# [0659. 分割数组为连续子序列](https://leetcode.cn/problems/split-array-into-consecutive-subsequences/)
- 标签:贪心、数组、哈希表、堆(优先队列)
- 难度:中等
## 题目链接
- [0659. 分割数组为连续子序列 - 力扣](https://leetcode.cn/problems/split-array-into-consecutive-subsequences/)
## 题目大意
**描述**:
给定一个按「非递减顺序」排列的整数数组 $nums$。
**要求**:
判断是否能在将 $nums$ 分割成 一个或多个子序列 的同时满足下述两个条件:
- 每个子序列都是一个「连续递增序列」(即,每个整数「恰好」比前一个整数大 $1$)。
- 所有子序列的长度「至少」为 $3$。
如果可以分割 $nums$ 并满足上述条件,则返回 true ;否则,返回 false。
**说明**:
- $1 \le nums.length \le 10^{4}$。
- $-10^{3} \le nums[i] \le 10^{3}$。
- $nums$ 按非递减顺序排列。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,3,4,5]
输出:true
解释:nums 可以分割成以下子序列:
[1,2,3,3,4,5] --> 1, 2, 3
[1,2,3,3,4,5] --> 3, 4, 5
```
- 示例 2:
```python
输入:nums = [1,2,3,3,4,4,5,5]
输出:true
解释:nums 可以分割成以下子序列:
[1,2,3,3,4,4,5,5] --> 1, 2, 3, 4, 5
[1,2,3,3,4,4,5,5] --> 3, 4, 5
```
## 解题思路
### 思路 1:贪心 + 哈希表
这道题目要求将数组分割成若干个长度至少为 3 的连续递增子序列。使用贪心策略:优先将当前数字接到已有的子序列后面,如果不能接到已有子序列,则尝试创建新的子序列。
1. 使用哈希表 $freq$ 记录每个数字的剩余可用次数。
2. 使用哈希表 $need$ 记录以某个数字结尾的子序列需要的下一个数字的数量。
3. 遍历数组中的每个数字 $num$:
- 如果 $freq[num] = 0$,说明该数字已经被使用完,跳过。
- 如果 $need[num] > 0$,说明存在以 $num - 1$ 结尾的子序列需要 $num$,将 $num$ 接到该子序列后面:
- $need[num]$ 减 1,$freq[num]$ 减 1。
- $need[num + 1]$ 加 1(该子序列现在需要 $num + 1$)。
- 否则,尝试创建新的子序列 $[num, num + 1, num + 2]$:
- 检查 $freq[num + 1]$ 和 $freq[num + 2]$ 是否大于 0。
- 如果可以创建,将这三个数字的频率减 1,并将 $need[num + 3]$ 加 1。
- 如果不能创建,返回 $False$。
4. 如果所有数字都能成功分配,返回 $True$。
### 思路 1:代码
```python
class Solution:
def isPossible(self, nums: List[int]) -> bool:
from collections import defaultdict
freq = defaultdict(int) # 记录每个数字的剩余可用次数
need = defaultdict(int) # 记录以某个数字结尾的子序列需要的下一个数字的数量
# 统计每个数字的频率
for num in nums:
freq[num] += 1
for num in nums:
if freq[num] == 0:
continue
# 优先将 num 接到已有的子序列后面
if need[num] > 0:
need[num] -= 1
freq[num] -= 1
need[num + 1] += 1
# 尝试创建新的子序列 [num, num+1, num+2]
elif freq[num + 1] > 0 and freq[num + 2] > 0:
freq[num] -= 1
freq[num + 1] -= 1
freq[num + 2] -= 1
need[num + 3] += 1
else:
# 无法分配当前数字
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。需要遍历数组两次。
- **空间复杂度**:$O(n)$,需要使用两个哈希表存储频率和需求信息。
================================================
FILE: docs/solutions/0600-0699/stickers-to-spell-word.md
================================================
# [0691. 贴纸拼词](https://leetcode.cn/problems/stickers-to-spell-word/)
- 标签:位运算、数组、字符串、动态规划、回溯、状态压缩
- 难度:困难
## 题目链接
- [0691. 贴纸拼词 - 力扣](https://leetcode.cn/problems/stickers-to-spell-word/)
## 题目大意
**描述**:给定一个字符串数组 $stickers$ 表示不同的贴纸,其中 $stickers[i]$ 表示第 $i$ 张贴纸上的小写英文单词。再给定一个字符串 $target$。为了拼出给定字符串 $target$,我们需要从贴纸中切割单个字母并重新排列它们。贴纸的数量是无限的,可以重复多次使用。
**要求**:返回需要拼出 $target$ 的最小贴纸数量。如果任务不可能,则返回 $-1$。
**说明**:
- 在所有的测试用例中,所有的单词都是从 $1000$ 个最常见的美国英语单词中随机选择的,并且 $target$ 被选择为两个随机单词的连接。
- $n == stickers.length$。
- $1 \le n \le 50$。
- $1 \le stickers[i].length \le 10$。
- $1 \le target.length \le 15$。
- $stickers[i]$ 和 $target$ 由小写英文单词组成。
**示例**:
- 示例 1:
```python
输入:stickers = ["with","example","science"], target = "thehat"
输出:3
解释:
我们可以使用 2 个 "with" 贴纸,和 1 个 "example" 贴纸。
把贴纸上的字母剪下来并重新排列后,就可以形成目标 “thehat“ 了。
此外,这是形成目标字符串所需的最小贴纸数量。
```
- 示例 2:
```python
输入:stickers = ["notice","possible"], target = "basicbasic"
输出:-1
解释:我们不能通过剪切给定贴纸的字母来形成目标“basicbasic”。
```
## 解题思路
### 思路 1:状态压缩 DP + 广度优先搜索
根据题意,$target$ 的长度最大为 $15$,所以我们可以使用一个长度最多为 $15$ 位的二进制数 $state$ 来表示 $target$ 的某个子序列,如果 $state$ 第 $i$ 位二进制值为 $1$,则说明 $target$ 的第 $i$ 个字母被选中。
然后我们从初始状态 $state = 0$(没有选中 $target$ 中的任何字母)开始进行广度优先搜索遍历。
在广度优先搜索过程中,对于当前状态 $cur\_state$,我们遍历所有贴纸的所有字母,如果当前字母可以拼到 $target$ 中的某个位置上,则更新状态 $next\_state$ 为「选中 $target$ 中对应位置上的字母」。
为了得到最小最小贴纸数量,我们可以使用动态规划的方法,定义 $dp[state]$ 表示为到达 $state$ 状态需要的最小贴纸数量。
那么在广度优先搜索中,在更新状态时,同时进行状态转移,即 $dp[next\_state] = dp[cur\_state] + 1$。
> 注意:在进行状态转移时,要跳过 $dp[next\_state]$ 已经有值的情况。
这样在到达状态 $1 \text{ <}\text{< } len(target) - 1$ 时,所得到的 $dp[1 \text{ <}\text{< } len(target) - 1]$ 即为答案。
如果最终到达不了 $dp[1 \text{ <}\text{< } len(target) - 1]$,则说明无法完成任务,返回 $-1$。
### 思路 1:代码
```python
class Solution:
def minStickers(self, stickers: List[str], target: str) -> int:
size = len(target)
states = 1 << size
dp = [0 for _ in range(states)]
queue = collections.deque([0])
while queue:
cur_state = queue.popleft()
for sticker in stickers:
next_state = cur_state
cnts = [0 for _ in range(26)]
for ch in sticker:
cnts[ord(ch) - ord('a')] += 1
for i in range(size):
if cnts[ord(target[i]) - ord('a')] and next_state & (1 << i) == 0:
next_state |= (1 << i)
cnts[ord(target[i]) - ord('a')] -= 1
if dp[next_state] or next_state == 0:
continue
queue.append(next_state)
dp[next_state] = dp[cur_state] + 1
if next_state == states - 1:
return dp[next_state]
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(2^n \times \sum_{i = 0}^{m - 1} len(stickers[i]) \times n$,其中 $n$ 为 $target$ 的长度,$m$ 为 $stickers$ 的元素个数。
- **空间复杂度**:$O(2^n)$。
================================================
FILE: docs/solutions/0600-0699/strange-printer.md
================================================
# [0664. 奇怪的打印机](https://leetcode.cn/problems/strange-printer/)
- 标签:字符串、动态规划
- 难度:困难
## 题目链接
- [0664. 奇怪的打印机 - 力扣](https://leetcode.cn/problems/strange-printer/)
## 题目大意
**描述**:有一台奇怪的打印机,有以下两个功能:
1. 打印机每次只能打印由同一个字符组成的序列,比如:`"aaaa"`、`"bbb"`。
2. 每次可以从起始位置到结束的任意为止打印新字符,并且会覆盖掉原有字符。
现在给定一个字符串 $s$。
**要求**:计算这个打印机打印出字符串 $s$ 需要的最少打印次数。
**说明**:
- $1 \le s.length \le 100$。
- $s$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:s = "aaabbb"
输出:2
解释:首先打印 "aaa" 然后打印 "bbb"。
```
- 示例 2:
```python
输入:s = "aba"
输出:2
解释:首先打印 "aaa" 然后在第二个位置打印 "b" 覆盖掉原来的字符 'a'。
```
## 解题思路
对于字符串 $s$,我们可以先考虑区间 $[i, j]$ 上的子字符串需要的最少打印次数。
1. 如果区间 $[i, j]$ 内只有 $1$ 种字符,则最少打印次数为 $1$,即:$dp[i][i] = 1$。
2. 如果区间 $[i, j]$ 内首尾字符相同,即 $s[i] == s[j]$,则我们在打印 $s[i]$ 的同时我们可以顺便打印 $s[j]$,这样我们可以忽略 $s[j]$,只考虑剩下区间 $[i, j - 1]$ 的打印情况,即:$dp[i][j] = dp[i][j - 1]$。
3. 如果区间 $[i, j]$ 上首尾字符不同,即 $s[i] \ne s[j]$,则枚举分割点 $k$,将区间 $[i, j]$ 分为区间 $[i, k]$ 与区间 $[k + 1, j]$,使得 $dp[i][k] + dp[k + 1][j]$ 的值最小即为 $dp[i][j]$。
### 思路 1:动态规划
###### 1. 阶段划分
按照区间长度进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 表示为:打印第 $i$ 个字符到第 $j$ 个字符需要的最少打印次数。
###### 3. 状态转移方程
1. 如果 $s[i] == s[j]$,则我们在打印 $s[i]$ 的同时我们可以顺便打印 $s[j]$,这样我们可以忽略 $s[j]$,只考虑剩下区间 $[i, j - 1]$ 的打印情况,即:$dp[i][j] = dp[i][j - 1]$。
2. 如果 $s[i] \ne s[j]$,则枚举分割点 $k$,将区间 $[i, j]$ 分为区间 $[i, k]$ 与区间 $[k + 1, j]$,使得 $dp[i][k] + dp[k + 1][j]$ 的值最小即为 $dp[i][j]$,即:$dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j])$。
###### 4. 初始条件
- 初始时,打印单个字符的最少打印次数为 $1$,即 $dp[i][i] = 1$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][j]$ 表示为:打印第 $i$ 个字符到第 $j$ 个字符需要的最少打印次数。 所以最终结果为 $dp[0][size - 1]$。
### 思路 1:代码
```python
class Solution:
def strangePrinter(self, s: str) -> int:
size = len(s)
dp = [[float('inf') for _ in range(size)] for _ in range(size)]
for i in range(size):
dp[i][i] = 1
for l in range(2, size + 1):
for i in range(size):
j = i + l - 1
if j >= size:
break
if s[i] == s[j]:
dp[i][j] = dp[i][j - 1]
else:
for k in range(i, j):
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j])
return dp[0][size - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(n^2)$。
================================================
FILE: docs/solutions/0600-0699/sum-of-square-numbers.md
================================================
# [0633. 平方数之和](https://leetcode.cn/problems/sum-of-square-numbers/)
- 标签:数学、双指针、二分查找
- 难度:中等
## 题目链接
- [0633. 平方数之和 - 力扣](https://leetcode.cn/problems/sum-of-square-numbers/)
## 题目大意
给定一个非负整数 c,判断是否存在两个整数 a 和 b,使得 $a^2 + b^2 = c$,如果存在则返回 True,不存在返回 False。
## 解题思路
最直接的办法就是枚举 a、b 所有可能。这样遍历下来的时间复杂度为 $O(c^2)$。但是没必要进行二重遍历。可以只遍历 a,然后去判断 $\sqrt{c - b^2}$ 是否为整数,并且 a 只需遍历到 $\sqrt{c}$ 即可,时间复杂度为 $O(\sqrt{c})$。
另一种方法是双指针。定义两个指针 left,right 分别指向 0 和 $\sqrt{c}$。判断 $left^2 + right^2$ 与 c 之间的关系。
- 如果 $a^2 + b^2 == c$,则返回 True。
- 如果 $a^2 + b^2 < c$,则将 a 值加一,继续查找。
- 如果 $a^2 + b^2 > c$,则将 b 值减一,继续查找。
- 当 $a == b$ 时,结束查找。如果此时仍没有找到满足 $a^2 + b^2 == c$ 的 a、b 值,则返回 False。
## 代码
```python
class Solution:
def judgeSquareSum(self, c: int) -> bool:
a, b = 0, int(c ** 0.5)
while a <= b:
sum = a*a + b*b
if sum == c:
return True
elif sum < c:
a += 1
else:
b -= 1
return False
```
================================================
FILE: docs/solutions/0600-0699/task-scheduler.md
================================================
# [0621. 任务调度器](https://leetcode.cn/problems/task-scheduler/)
- 标签:贪心、数组、哈希表、计数、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [0621. 任务调度器 - 力扣](https://leetcode.cn/problems/task-scheduler/)
## 题目大意
给定一个字符数组 tasks 表示 CPU 需要执行的任务列表。tasks 中每个字母表示一种不同种类的任务。任务可以按任意顺序执行,并且每个任务执行时间为 1 个单位时间。在任何一个单位时间,CPU 可以完成一个任务,或者也可以处于待命状态。
但是两个相同种类的任务之间需要 n 个单位时间的冷却时间,所以不能在连续的 n 个单位时间内执行相同的任务。
要求计算出完成 tasks 中所有任务所需要的「最短时间」。
## 解题思路
因为相同种类的任务之间最少需要 n 个单位时间间隔,所以为了最短时间,应该优先考虑任务出现此次最多的任务。
先找出出现次数最多的任务,然后中间间隔的单位来安排别的任务,或者处于待命状态。
然后将第二出现次数最多的任务,按照 n 个时间间隔安排起来。如果第二出现次数最多的任务跟第一出现次数最多的任务出现次数相同,则最短时间就会加一。
最后我们会发现:最短时间跟出现次数最多的任务正相关。
假设出现次数最多的任务为 "A"。与 "A" 出现次数相同的任务数为 count。则:
- `最短时间 = (A 出现次数 - 1)* (n + 1)+ count`。
最后还应该比较一下总的任务个数跟计算出的最短时间答案。如果最短时间比总的任务个数还少,说明间隔中放不下所有的任务,会有任务「溢出」。则应该将多余任务插入间隔中,则答案应为总的任务个数。
## 代码
```python
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
# 记录每个任务出现的次数
tasks_counts = [0 for _ in range(26)]
for i in range(len(tasks)):
num = ord(tasks[i]) - ord('A')
tasks_counts[num] += 1
max_task_count = max(tasks_counts)
# 统计多少个出现最多次的任务
count = 0
for task_count in tasks_counts:
if task_count == max_task_count:
count += 1
# 如果结果比任务数量少,则返回总任务数
return max((max_task_count - 1) * (n + 1) + count, len(tasks))
```
================================================
FILE: docs/solutions/0600-0699/top-k-frequent-words copy.md
================================================
# [0692. 前K个高频单词](https://leetcode.cn/problems/top-k-frequent-words/)
- 标签:字典树、数组、哈希表、字符串、桶排序、计数、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [0692. 前K个高频单词 - 力扣](https://leetcode.cn/problems/top-k-frequent-words/)
## 题目大意
**描述**:
给定一个单词列表 $words$ 和一个整数 $k$。
**要求**:
返回前 $k$ 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字典顺序排序。
**说明**:
- $1 \le words.length \le 500$。
- $1 \le words[i].length \le 10$。
- $words[i]$ 由小写英文字母组成。
- $k$ 的取值范围是 $[1, \text{不同 words[i] 的数量}]$
- 进阶:尝试以 $O(n \log k)$ 时间复杂度和 $O(n)$ 空间复杂度解决。
**示例**:
- 示例 1:
```python
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 "i" 在 "love" 之前。
```
- 示例 2:
```python
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
```
## 解题思路
### 思路 1:哈希表 + 排序
这道题目要求找出前 $k$ 个出现频率最高的单词,频率相同时按字典序排序。
1. 使用哈希表统计每个单词的出现频率。
2. 将哈希表中的单词按照以下规则排序:
- 首先按频率从高到低排序。
- 频率相同时按字典序从小到大排序。
3. 返回排序后的前 $k$ 个单词。
### 思路 1:代码
```python
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
from collections import Counter
# 统计单词频率
freq = Counter(words)
# 按照频率从高到低,频率相同时按字典序从小到大排序
result = sorted(freq.keys(), key=lambda x: (-freq[x], x))
# 返回前 k 个单词
return result[:k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是不同单词的数量。统计频率需要 $O(m)$($m$ 是单词总数),排序需要 $O(n \log n)$。
- **空间复杂度**:$O(n)$,需要使用哈希表存储单词频率。
## 解题思路
### 思路 2:堆(优先队列)+ 哈希表
使用最小堆来优化时间复杂度,只维护前 $k$ 个高频单词。
1. 使用哈希表统计每个单词的出现频率。
2. 使用最小堆维护前 $k$ 个高频单词:
- 堆的大小最多为 $k$。
- 堆中元素按照频率从小到大排序,频率相同时按字典序从大到小排序(这样可以保证频率小的或字典序大的在堆顶,会被优先弹出)。
3. 遍历哈希表,将单词加入堆:
- 直接将单词加入堆。
- 如果堆的大小超过 $k$,弹出堆顶元素(频率最小的,或频率相同时字典序最大的)。
4. 将堆中的元素按照频率从高到低、频率相同时按字典序从小到大排序后返回。
**关键点**:使用自定义类来实现堆的比较逻辑,确保频率相同时字典序大的在堆顶。
### 思路 2:代码
```python
from collections import Counter
import heapq
# 自定义类,用于堆的比较
class Word:
def __init__(self, word, freq):
self.word = word
self.freq = freq
def __lt__(self, other):
# 频率不同时,频率小的在堆顶
if self.freq != other.freq:
return self.freq < other.freq
# 频率相同时,字典序大的在堆顶(会被弹出)
return self.word > other.word
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
# 统计单词频率
freq = Counter(words)
# 使用最小堆
heap = []
for word, count in freq.items():
heapq.heappush(heap, Word(word, count))
if len(heap) > k:
heapq.heappop(heap)
# 按照频率从高到低,频率相同时按字典序从小到大排序
heap.sort(key=lambda x: (-x.freq, x.word))
return [x.word for x in heap]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \log k)$,其中 $n$ 是不同单词的数量。统计频率需要 $O(m)$($m$ 是单词总数),维护大小为 $k$ 的堆需要 $O(n \log k)$,最后排序需要 $O(k \log k)$。
- **空间复杂度**:$O(n)$,需要使用哈希表存储单词频率,堆的大小为 $O(k)$。
================================================
FILE: docs/solutions/0600-0699/top-k-frequent-words.md
================================================
# [0692. 前K个高频单词](https://leetcode.cn/problems/top-k-frequent-words/)
- 标签:字典树、数组、哈希表、字符串、桶排序、计数、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [0692. 前K个高频单词 - 力扣](https://leetcode.cn/problems/top-k-frequent-words/)
## 题目大意
**描述**:
给定一个单词列表 $words$ 和一个整数 $k$。
**要求**:
返回前 $k$ 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字典顺序排序。
**说明**:
- $1 \le words.length \le 500$。
- $1 \le words[i].length \le 10$。
- $words[i]$ 由小写英文字母组成。
- $k$ 的取值范围是 $[1, \text{不同 words[i] 的数量}]$
- 进阶:尝试以 $O(n \log k)$ 时间复杂度和 $O(n)$ 空间复杂度解决。
**示例**:
- 示例 1:
```python
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 "i" 在 "love" 之前。
```
- 示例 2:
```python
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
```
## 解题思路
### 思路 1:哈希表 + 排序
这道题目要求找出前 $k$ 个出现频率最高的单词,频率相同时按字典序排序。
1. 使用哈希表统计每个单词的出现频率。
2. 将哈希表中的单词按照以下规则排序:
- 首先按频率从高到低排序。
- 频率相同时按字典序从小到大排序。
3. 返回排序后的前 $k$ 个单词。
### 思路 1:代码
```python
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
from collections import Counter
# 统计单词频率
freq = Counter(words)
# 按照频率从高到低,频率相同时按字典序从小到大排序
result = sorted(freq.keys(), key=lambda x: (-freq[x], x))
# 返回前 k 个单词
return result[:k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是不同单词的数量。统计频率需要 $O(m)$($m$ 是单词总数),排序需要 $O(n \log n)$。
- **空间复杂度**:$O(n)$,需要使用哈希表存储单词频率。
## 解题思路
### 思路 2:堆(优先队列)+ 哈希表
使用最小堆来优化时间复杂度,只维护前 $k$ 个高频单词。
1. 使用哈希表统计每个单词的出现频率。
2. 使用最小堆维护前 $k$ 个高频单词:
- 堆的大小最多为 $k$。
- 堆中元素按照频率从小到大排序,频率相同时按字典序从大到小排序(这样可以保证频率小的或字典序大的在堆顶,会被优先弹出)。
3. 遍历哈希表,将单词加入堆:
- 直接将单词加入堆。
- 如果堆的大小超过 $k$,弹出堆顶元素(频率最小的,或频率相同时字典序最大的)。
4. 将堆中的元素按照频率从高到低、频率相同时按字典序从小到大排序后返回。
**关键点**:使用自定义类来实现堆的比较逻辑,确保频率相同时字典序大的在堆顶。
### 思路 2:代码
```python
from collections import Counter
import heapq
# 自定义类,用于堆的比较
class Word:
def __init__(self, word, freq):
self.word = word
self.freq = freq
def __lt__(self, other):
# 频率不同时,频率小的在堆顶
if self.freq != other.freq:
return self.freq < other.freq
# 频率相同时,字典序大的在堆顶(会被弹出)
return self.word > other.word
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
# 统计单词频率
freq = Counter(words)
# 使用最小堆
heap = []
for word, count in freq.items():
heapq.heappush(heap, Word(word, count))
if len(heap) > k:
heapq.heappop(heap)
# 按照频率从高到低,频率相同时按字典序从小到大排序
heap.sort(key=lambda x: (-x.freq, x.word))
return [x.word for x in heap]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \log k)$,其中 $n$ 是不同单词的数量。统计频率需要 $O(m)$($m$ 是单词总数),维护大小为 $k$ 的堆需要 $O(n \log k)$,最后排序需要 $O(k \log k)$。
- **空间复杂度**:$O(n)$,需要使用哈希表存储单词频率,堆的大小为 $O(k)$。
================================================
FILE: docs/solutions/0600-0699/trim-a-binary-search-tree.md
================================================
# [0669. 修剪二叉搜索树](https://leetcode.cn/problems/trim-a-binary-search-tree/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [0669. 修剪二叉搜索树 - 力扣](https://leetcode.cn/problems/trim-a-binary-search-tree/)
## 题目大意
给定一棵二叉搜索树的根节点 `root`,同时给定最小边界 `low` 和最大边界 `high`。通过修建二叉搜索树,使得所有节点值都在 `[low, high]` 中。修剪树不应该改变保留在树中的元素的相对结构(即如果没有移除节点,则该节点的父节点关系、子节点关系都应当保留)。
现在要求返回修建过后的二叉树的根节点。
## 解题思路
递归修剪,函数返回值为修剪之后的树。
- 如果当前根节点为空,则直接返回 None。
- 如果当前根节点的值小于 `low`,则该节点左子树全部都小于最小边界,则删除左子树,然后递归遍历右子树,在右子树中寻找符合条件的节点。
- 如果当前根节点的值大于 `hight`,则该节点右子树全部都大于最大边界,则删除右子树,然后递归遍历左子树,在左子树中寻找符合条件的节点。
- 如果在最小边界和最大边界的区间内,则分别从左右子树寻找符合条件的节点作为根的左右子树。
## 代码
```python
class Solution:
def trimBST(self, root: TreeNode, low: int, high: int) -> TreeNode:
if not root:
return None
if root.val < low:
right = self.trimBST(root.right, low, high)
return right
if root.val > high:
left = self.trimBST(root.left, low, high)
return left
root.left = self.trimBST(root.left, low, high)
root.right = self.trimBST(root.right, low, high)
return root
```
================================================
FILE: docs/solutions/0600-0699/two-sum-iv-input-is-a-bst.md
================================================
# [0653. 两数之和 IV - 输入二叉搜索树](https://leetcode.cn/problems/two-sum-iv-input-is-a-bst/)
- 标签:树、深度优先搜索、广度优先搜索、二叉搜索树、哈希表、双指针、二叉树
- 难度:简单
## 题目链接
- [0653. 两数之和 IV - 输入二叉搜索树 - 力扣](https://leetcode.cn/problems/two-sum-iv-input-is-a-bst/)
## 题目大意
给定一个二叉搜索树的根节点 `root` 和一个整数 `k`。
要求:判断该二叉搜索树是否存在两个节点值的和等于 `k`。如果存在,则返回 `True`,不存在则返回 `False`。
## 解题思路
二叉搜索树中序遍历的结果是从小到大排序,所以我们可以先对二叉搜索树进行中序遍历,将中序遍历结果存储到列表中。再使用左右指针查找节点值和为 `k` 的两个节点。
## 代码
```python
class Solution:
def inOrder(self, root, nums):
if not root:
return
self.inOrder(root.left, nums)
nums.append(root.val)
self.inOrder(root.right, nums)
def findTarget(self, root: TreeNode, k: int) -> bool:
nums = []
self.inOrder(root, nums)
left, right = 0, len(nums) - 1
while left < right:
sum = nums[left] + nums[right]
if sum == k:
return True
elif sum < k:
left += 1
else:
right -= 1
return False
```
================================================
FILE: docs/solutions/0600-0699/valid-palindrome-ii.md
================================================
# [0680. 验证回文串 II](https://leetcode.cn/problems/valid-palindrome-ii/)
- 标签:贪心、双指针、字符串
- 难度:简单
## 题目链接
- [0680. 验证回文串 II - 力扣](https://leetcode.cn/problems/valid-palindrome-ii/)
## 题目大意
给定一个非空字符串 `s`。
要求:判断如果最多从字符串中删除一个字符能否得到一个回文字符串。
## 解题思路
题目要求在最多删除一个字符的情况下是否能得到一个回文字符串。最直接的思路是遍历各个字符,判断将该字符删除之后,剩余字符串是否是回文串。但是这种思路的时间复杂度是 $O(n^2)$,解答的话会超时。
我们可以通过双指针 + 贪心算法来减少时间复杂度。具体做法如下:
- 使用两个指针变量 `left`、`right` 分别指向字符串的开始和结束位置。
- 判断 `s[left]` 是否等于 `s[right]`。
- 如果等于,则 `left` 右移、`right`左移。
- 如果不等于,则判断 `s[left: right - 1]` 或 `s[left + 1, right]` 是为回文串。
- 如果是则返回 `True`。
- 如果不是则返回 `False`,然后继续判断。
- 如果 `right >= left`,则说明字符串 `s` 本身就是回文串,返回 `True`。
## 代码
```python
class Solution:
def checkPalindrome(self, s: str, left: int, right: int):
i, j = left, right
while i < j:
if s[i] != s[j]:
return False
i += 1
j -= 1
return True
def validPalindrome(self, s: str) -> bool:
left, right = 0, len(s) - 1
while left < right:
if s[left] == s[right]:
left += 1
right -= 1
else:
return self.checkPalindrome(s, left + 1, right) or self.checkPalindrome(s, left, right - 1)
return True
```
================================================
FILE: docs/solutions/0600-0699/valid-parenthesis-string.md
================================================
# [0678. 有效的括号字符串](https://leetcode.cn/problems/valid-parenthesis-string/)
- 标签:栈、贪心、字符串、动态规划
- 难度:中等
## 题目链接
- [0678. 有效的括号字符串 - 力扣](https://leetcode.cn/problems/valid-parenthesis-string/)
## 题目大意
**描述**:给定一个只包含三种字符的字符串:`(` ,`)` 和 `*`。有效的括号字符串具有如下规则:
1. 任何左括号 `(` 必须有相应的右括号 `)`。
2. 任何右括号 `)` 必须有相应的左括号 `(`。
3. 左括号 `(` 必须在对应的右括号之前 `)`。
4. `*` 可以被视为单个右括号 `)`,或单个左括号 `(`,或一个空字符串。
5. 一个空字符串也被视为有效字符串。
**要求**:验证这个字符串是否为有效字符串。如果是,则返回 `True`;否则,则返回 `False`。
**说明**:
- 字符串大小将在 `[1, 100]` 范围内。
**示例**:
- 示例 1:
```python
输入:"(*)"
输出:True
```
## 解题思路
### 思路 1:动态规划(时间复杂度为 $O(n^3)$)
###### 1. 阶段划分
按照子串的起始位置进行阶段划分。
###### 2. 定义状态
定义状态 `dp[i][j]` 表示为:从下标 `i` 到下标 `j` 的子串是否为有效的括号字符串,其中 ($0 \le i < j < size$,$size$ 为字符串长度)。如果是则 `dp[i][j] = True`,否则,`dp[i][j] = False`。
###### 3. 状态转移方程
长度大于 `2` 时,我们需要根据 `s[i]` 和 `s[j]` 的情况,以及子串中间的有效字符串情况来判断 `dp[i][j]`。
- 如果 `s[i]`、`s[j]` 分别表示左括号和右括号,或者为 `'*'`(此时 `s[i]`、`s[j]` 可以分别看做是左括号、右括号)。则如果 `dp[i + 1][j - 1] == True` 时,`dp[i][j] = True`。
- 如果可以将从下标 `i` 到下标 `j` 的子串从中间分开为两个有效字符串,则 `dp[i][j] = True`。即如果存在 $i \le k < j$,使得 `dp[i][k] == True` 并且 `dp[k + 1][j] == True`,则 `dp[i][j] = True`。
###### 4. 初始条件
- 当子串的长度为 `1`,并且该字符串为 `'*'` 时,子串可看做是空字符串,此时子串是有效的括号字符串。
- 当子串的长度为 `2` 时,如果两个字符可以分别看做是左括号和右括号,子串可以看做是 `"()"`,此时子串是有效的括号字符串。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i][j]` 表示为:从下标 `i` 到下标 `j` 的子串是否为有效的括号字符串。则最终结果为 `dp[0][size - 1]`。
### 思路 1:动态规划(时间复杂度为 $O(n^3)$)代码
```python
class Solution:
def checkValidString(self, s: str) -> bool:
size = len(s)
dp = [[False for _ in range(size)] for _ in range(size)]
for i in range(size):
if s[i] == '*':
dp[i][i] = True
for i in range(1, size):
if (s[i - 1] == '(' or s[i - 1] == '*') and (s[i] == ')' or s[i] == '*'):
dp[i - 1][i] = True
for i in range(size - 3, -1, -1):
for j in range(i + 2, size):
if (s[i] == '(' or s[i] == '*') and (s[j] == ')' or s[j] == '*'):
dp[i][j] = dp[i + 1][j - 1]
for k in range(i, j):
if dp[i][j]:
break
dp[i][j] = dp[i][k] and dp[k + 1][j]
return dp[0][size - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$。三重循环遍历的时间复杂度是 $O(n^3)$。
- **空间复杂度**:$O(n^2)$。用到了二维数组保存状态,所以总体空间复杂度为 $O(n^2)$。
### 思路 2:动态规划(时间复杂度为 $O(n^2)$)
###### 1. 阶段划分
按照字符串的结束位置进行阶段划分。
###### 2. 定义状态
定义状态 `dp[i][j]` 表示为:前 `i` 个字符能否通过补齐 `j` 个右括号成为有效的括号字符串。
###### 3. 状态转移方程
1. 如果 `s[i] == '('`,则如果前 `i - 1` 个字符通过补齐 `j - 1` 个右括号成为有效的括号字符串,则前 `i` 个字符就能通过补齐 `j` 个右括号成为有效的括号字符串(比前 `i - 1` 个字符需要多补一个右括号)。也就是说,如果 `s[i] == '('` 并且 `dp[i - 1][j - 1] == True`,则 `dp[i][j] = True`。
2. 如果 `s[i] == ')'`,则如果前 `i - 1` 个字符通过补齐 `j + 1` 个右括号成为有效的括号字符串,则前 `i` 个字符就能通过补齐 `j` 个右括号成为有效的括号字符串(比前 `i - 1` 个字符需要少补一个右括号)。也就是说,如果 `s[i] == ')'` 并且 `dp[i - 1][j + 1] == True`,则 `dp[i][j] = True`。
3. 如果 `s[i] == '*'`,而 `'*'` 可以表示空字符串、左括号或者右括号,则 `dp[i][j]` 取决于这三种情况,只要有一种情况为 `True`,则 `dp[i][j] = True`。也就是说,如果 `s[i] == '*'`,则 `dp[i][j] = dp[i - 1][j] or dp[i - 1][j - 1]`。
###### 4. 初始条件
- `0` 个字符可以通过补齐 `0` 个右括号成为有效的括号字符串(空字符串),即 `dp[0][0] = 0`。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i][j]` 表示为:前 `i` 个字符能否通过补齐 `j` 个右括号成为有效的括号字符串。。则最终结果为 `dp[size][0]`。
### 思路 2:动态规划(时间复杂度为 $O(n^2)$)代码
```python
class Solution:
def checkValidString(self, s: str) -> bool:
size = len(s)
dp = [[False for _ in range(size + 1)] for _ in range(size + 1)]
dp[0][0] = True
for i in range(1, size + 1):
for j in range(i + 1):
if s[i - 1] == '(':
if j > 0:
dp[i][j] = dp[i - 1][j - 1]
elif s[i - 1] == ')':
if j < i:
dp[i][j] = dp[i - 1][j + 1]
else:
dp[i][j] = dp[i - 1][j]
if j > 0:
dp[i][j] = dp[i][j] or dp[i - 1][j - 1]
if j < i:
dp[i][j] = dp[i][j] or dp[i - 1][j + 1]
return dp[size][0]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^2)$。两重循环遍历的时间复杂度是 $O(n^2)$。
- **空间复杂度**:$O(n^2)$。用到了二维数组保存状态,所以总体空间复杂度为 $O(n^2)$。
================================================
FILE: docs/solutions/0600-0699/valid-triangle-number.md
================================================
# [0611. 有效三角形的个数](https://leetcode.cn/problems/valid-triangle-number/)
- 标签:贪心、数组、双指针、二分查找、排序
- 难度:中等
## 题目链接
- [0611. 有效三角形的个数 - 力扣](https://leetcode.cn/problems/valid-triangle-number/)
## 题目大意
**描述**:给定一个包含非负整数的数组 $nums$,其中 $nums[i]$ 表示第 $i$ 条边的边长。
**要求**:统计数组中可以组成三角形三条边的三元组个数。
**说明**:
- $1 \le nums.length \le 1000$。
- $0 \le nums[i] \le 1000$。
**示例**:
- 示例 1:
```python
输入: nums = [2,2,3,4]
输出: 3
解释:有效的组合是:
2,3,4 (使用第一个 2)
2,3,4 (使用第二个 2)
2,2,3
```
- 示例 2:
```python
输入: nums = [4,2,3,4]
输出: 4
```
## 解题思路
### 思路 1:对撞指针
构成三角形的条件为:任意两边和大于第三边,或者任意两边差小于第三边。只要满足这两个条件之一就可以构成三角形。以任意两边和大于第三边为例,如果用 $a$、$b$、$c$ 来表示的话,应该同时满足 $a + b > c$、$a + c > b$、$b + c > a$。如果我们将三条边升序排序,假设 $a \le b \le c$,则如果满足 $a + b > c$,则 $a + c > b$ 和 $b + c > a$ 一定成立。
所以我们可以先对 $nums$ 进行排序。然后固定最大边 $i$,利用对撞指针 $left$、$right$ 查找较小的两条边。然后判断是否构成三角形并统计三元组个数。
为了避免重复计算和漏解,要严格保证三条边的序号关系为:$left < right < i$。具体做法如下:
- 对数组从小到大排序,使用 $ans$ 记录三元组个数。
- 从 $i = 2$ 开始遍历数组的每一条边,$i$ 作为最大边。
- 使用双指针 $left$、$right$。$left$ 指向 $0$,$right$ 指向 $i - 1$。
- 如果 $nums[left] + nums[right] \le nums[i]$,说明第一条边太短了,可以增加第一条边长度,所以将 $left$ 右移,即 `left += 1`。
- 如果 $nums[left] + nums[right] > nums[i]$,说明可以构成三角形,并且第二条边固定为 $right$ 边的话,第一条边可以在 $[left, right - 1]$ 中任意选择。所以三元组个数要加上 $right - left$。即 `ans += (right - left)`。
- 直到 $left == right$ 跳出循环,输出三元组个数 $ans$。
### 思路 1:代码
```python
class Solution:
def triangleNumber(self, nums: List[int]) -> int:
nums.sort()
size = len(nums)
ans = 0
for i in range(2, size):
left = 0
right = i - 1
while left < right:
if nums[left] + nums[right] <= nums[i]:
left += 1
else:
ans += (right - left)
right -= 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为数组中的元素个数。
- **空间复杂度**:$O(\log n)$,排序需要 $\log n$ 的栈空间。
================================================
FILE: docs/solutions/0700-0799/1-bit-and-2-bit-characters.md
================================================
# [0717. 1 比特与 2 比特字符](https://leetcode.cn/problems/1-bit-and-2-bit-characters/)
- 标签:数组
- 难度:简单
## 题目链接
- [0717. 1 比特与 2 比特字符 - 力扣](https://leetcode.cn/problems/1-bit-and-2-bit-characters/)
## 题目大意
**描述**:
有两种特殊字符:
- 第一种字符可以用一比特 $0$ 表示
- 第二种字符可以用两比特($10$ 或 $11$)表示
给定一个以 $0$ 结尾的二进制数组 $bits$。
**要求**:
如果最后一个字符必须是一个一比特字符,则返回 true。
**说明**:
- $1 \le bits.length \le 10^{3}$。
- $bits[i]$ 为 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入: bits = [1, 0, 0]
输出: true
解释: 唯一的解码方式是将其解析为一个两比特字符和一个一比特字符。
所以最后一个字符是一比特字符。
```
- 示例 2:
```python
输入:bits = [1,1,1,0]
输出:false
解释:唯一的解码方式是将其解析为两比特字符和两比特字符。
所以最后一个字符不是一比特字符。
```
## 解题思路
### 思路 1:贪心算法
这道题的关键在于理解字符的编码规则:
- 一比特字符:`0`
- 两比特字符:`10` 或 `11`
由于数组以 `0` 结尾,我们需要判断这个 `0` 是作为一比特字符单独存在,还是作为两比特字符的一部分。
**解题步骤**:
1. 从数组开头开始遍历,使用指针 $i$ 记录当前位置。
2. 如果 $bits[i] = 1$,说明当前是两比特字符,跳过两位($i$ 增加 $2$)。
3. 如果 $bits[i] = 0$,说明当前是一比特字符,跳过一位($i$ 增加 $1$)。
4. 当 $i$ 到达倒数第二个位置时停止遍历。
5. 如果 $i$ 正好等于 $n - 1$(最后一个位置),说明最后一个 `0` 是一比特字符,返回 `True`。
6. 如果 $i$ 超过了 $n - 1$,说明最后一个 `0` 是两比特字符的一部分,返回 `False`。
### 思路 1:代码
```python
class Solution:
def isOneBitCharacter(self, bits: List[int]) -> bool:
n = len(bits)
i = 0
# 遍历到倒数第二个位置
while i < n - 1:
if bits[i] == 1: # 两比特字符
i += 2
else: # 一比特字符
i += 1
# 如果 i 正好等于 n - 1,说明最后一个 0 是一比特字符
return i == n - 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $bits$ 的长度。需要遍历整个数组一次。
- **空间复杂度**:$O(1)$。只使用了常数个额外变量。
================================================
FILE: docs/solutions/0700-0799/accounts-merge.md
================================================
# [0721. 账户合并](https://leetcode.cn/problems/accounts-merge/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [0721. 账户合并 - 力扣](https://leetcode.cn/problems/accounts-merge/)
## 题目大意
**描述**:
给定一个列表 $accounts$,每个元素 $accounts[i]$ 是一个字符串列表,其中第一个元素 $accounts[i][0]$ 是名称($name$),其余元素是 $emails$ 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
**要求**:
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是按字符 ASCII 顺序排列的邮箱地址。账户本身可以以任意顺序返回。
**说明**:
- $1 \le accounts.length \le 10^{3}$。
- $2 \le accounts[i].length \le 10$。
- $1 \le accounts[i][j].length \le 30$。
- $accounts[i][0]$ 由英文字母组成。
- $accounts[i][j] (for j \gt 0)$ 是有效的邮箱地址。
**示例**:
- 示例 1:
```python
输入:accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
输出:[["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','mary@mail.com'],['John','johnnybravo@mail.com'],
['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']] 也是正确的。
```
- 示例 2:
```python
输入:accounts = [["Gabe","Gabe0@m.co","Gabe3@m.co","Gabe1@m.co"],["Kevin","Kevin3@m.co","Kevin5@m.co","Kevin0@m.co"],["Ethan","Ethan5@m.co","Ethan4@m.co","Ethan0@m.co"],["Hanzo","Hanzo3@m.co","Hanzo1@m.co","Hanzo0@m.co"],["Fern","Fern5@m.co","Fern1@m.co","Fern0@m.co"]]
输出:[["Ethan","Ethan0@m.co","Ethan4@m.co","Ethan5@m.co"],["Gabe","Gabe0@m.co","Gabe1@m.co","Gabe3@m.co"],["Hanzo","Hanzo0@m.co","Hanzo1@m.co","Hanzo3@m.co"],["Kevin","Kevin0@m.co","Kevin3@m.co","Kevin5@m.co"],["Fern","Fern0@m.co","Fern1@m.co","Fern5@m.co"]]
```
## 解题思路
### 思路 1:并查集
这道题的核心是将具有相同邮箱的账户合并在一起。可以使用并查集来解决。
**解题步骤**:
1. 将每个邮箱看作一个节点,如果两个邮箱属于同一个账户,就将它们连接起来。
2. 使用哈希表 $email\_to\_id$ 记录每个邮箱对应的账户索引。
3. 使用并查集将属于同一个人的邮箱合并到同一个集合中。
4. 遍历所有账户,对于每个账户中的邮箱:
- 如果邮箱第一次出现,记录其账户索引。
- 如果邮箱已经出现过,将当前账户与之前的账户合并。
5. 最后,将同一集合中的所有邮箱归类到一起,并按字典序排序。
### 思路 1:代码
```python
class Solution:
def accountsMerge(self, accounts: List[List[str]]) -> List[List[str]]:
# 并查集
parent = {}
def find(x):
if x not in parent:
parent[x] = x
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def union(x, y):
root_x = find(x)
root_y = find(y)
if root_x != root_y:
parent[root_x] = root_y
# 邮箱到账户索引的映射
email_to_id = {}
# 邮箱到姓名的映射
email_to_name = {}
# 遍历所有账户,建立邮箱之间的连接
for account in accounts:
name = account[0]
for i in range(1, len(account)):
email = account[i]
email_to_name[email] = name
if email not in email_to_id:
email_to_id[email] = email
# 将当前账户的所有邮箱合并到第一个邮箱的集合中
union(account[1], email)
# 将同一集合的邮箱归类
merged = {}
for email in email_to_id:
root = find(email)
if root not in merged:
merged[root] = []
merged[root].append(email)
# 构建结果
result = []
for emails in merged.values():
name = email_to_name[emails[0]]
result.append([name] + sorted(emails))
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是所有邮箱的总数。并查集操作的时间复杂度接近 $O(1)$,主要时间消耗在排序上。
- **空间复杂度**:$O(n)$。需要存储并查集、哈希表等数据结构。
================================================
FILE: docs/solutions/0700-0799/all-paths-from-source-to-target.md
================================================
# [0797. 所有可能的路径](https://leetcode.cn/problems/all-paths-from-source-to-target/)
- 标签:深度优先搜索、广度优先搜索、图、回溯
- 难度:中等
## 题目链接
- [0797. 所有可能的路径 - 力扣](https://leetcode.cn/problems/all-paths-from-source-to-target/)
## 题目大意
给定一个有 `n` 个节点的有向无环图(DAG),用二维数组 `graph` 表示。
要求:找出所有从节点 `0` 到节点 `n - 1` 的路径并输出(不要求按特定顺序)。
二维数组 `graph` 的第 `i` 个数组 `graph[i]` 中的单元都表示有向图中 `i` 号节点所能到达的下一个节点,如果为空就是没有下一个结点了。
## 解题思路
从第 `0` 个节点开始进行深度优先搜索遍历。在遍历的同时,通过回溯来寻找所有路径。具体做法如下:
- 使用 `ans` 数组存放所有答案路径,使用 `path` 数组记录当前路径。
- 从第 `0` 个节点开始进行深度优先搜索遍历。
- 如果当前开始节点 `start` 等于目标节点 `target`。则将当前路径 `path` 添加到答案数组 `ans` 中,并返回。
- 然后遍历当前节点 `start` 所能达到的下一个节点。
- 将下一个节点加入到当前路径中。
- 从该节点出发进行深度优先搜索遍历。
- 然后将下一个节点从当前路径中移出,进行回退操作。
- 最后返回答案数组 `ans`。
## 代码
```python
class Solution:
def dfs(self, graph, start, target, path, ans):
if start == target:
ans.append(path[:])
return
for end in graph[start]:
path.append(end)
self.dfs(graph, end, target, path, ans)
path.remove(end)
def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
path = [0]
ans = []
self.dfs(graph, 0, len(graph) - 1, path, ans)
return ans
```
================================================
FILE: docs/solutions/0700-0799/asteroid-collision.md
================================================
# [0735. 小行星碰撞](https://leetcode.cn/problems/asteroid-collision/)
- 标签:栈、数组
- 难度:中等
## 题目链接
- [0735. 小行星碰撞 - 力扣](https://leetcode.cn/problems/asteroid-collision/)
## 题目大意
给定一个整数数组 `asteroids`,表示在同一行的小行星。
数组中的每一个元素,其绝对值表示小行星的大小,正负表示小行星的移动方向(正表示向右移动,负表示向左移动)。每一颗小行星以相同的速度移动。小行星按照下面的规则发生碰撞。
- 碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
要求:找出碰撞后剩下的所有小行星,将答案存入数组并返回。
## 解题思路
用栈模拟小行星碰撞,具体步骤如下:
- 遍历数组 `asteroids`。
- 如果栈为空或者当前元素 `asteroid` 为正数,将其压入栈。
- 如果当前栈不为空并且当前元素 `asteroid` 为负数:
- 与栈中元素发生碰撞,判断当前元素和栈顶元素的大小和方向,如果栈顶元素为正数,并且当前元素的绝对值大于栈顶元素,则将栈顶元素弹出,并继续与栈中元素发生碰撞。
- 碰撞完之后,如果栈为空并且栈顶元素为负数,则将当前元素 `asteroid` 压入栈,表示碰撞完剩下了 `asteroid`。
- 如果栈顶元素恰好与当前元素值大小相等、方向相反,则弹出栈顶元素,表示碰撞完两者都爆炸了。
- 最后返回栈作为答案。
## 代码
```python
class Solution:
def asteroidCollision(self, asteroids: List[int]) -> List[int]:
stack = []
for asteroid in asteroids:
if not stack or asteroid > 0:
stack.append(asteroid)
else:
while stack and 0 < stack[-1] < -asteroid:
stack.pop()
if not stack or stack[-1] < 0:
stack.append(asteroid)
elif stack[-1] == -asteroid:
stack.pop()
return stack
```
================================================
FILE: docs/solutions/0700-0799/basic-calculator-iv.md
================================================
# [0770. 基本计算器 IV](https://leetcode.cn/problems/basic-calculator-iv/)
- 标签:栈、递归、哈希表、数学、字符串
- 难度:困难
## 题目链接
- [0770. 基本计算器 IV - 力扣](https://leetcode.cn/problems/basic-calculator-iv/)
## 题目大意
**描述**:
给定一个表达式如 `expression = "e + 8 - a + 5"` 和一个求值映射,如 `{"e": 1}`(给定的形式为 `evalvars = ["e"]` 和 `evalints = [1]`。
**要求**:
返回表示简化表达式的标记列表,例如 `["-1*a","14"]`。
- 表达式交替使用块和符号,每个块和符号之间有一个空格。
- 块要么是括号中的表达式,要么是变量,要么是非负整数。
- 变量是一个由小写字母组成的字符串(不包括数字)。请注意,变量可以是多个字母,并注意变量从不具有像 `"2x"` 或 `"-x"` 这样的前导系数或一元运算符。
表达式按通常顺序进行求值:先是括号,然后求乘法,再计算加法和减法。
- 例如,`expression = "1 + 2 * 3"` 的答案是 ["7"]。
输出格式如下:
- 对于系数非零的每个自变量项,我们按字典排序的顺序将自变量写在一个项中。
- 例如,我们永远不会写像 `"b*a*c"` 这样的项,只写 `"a*b*c"`。
- 项的次数等于被乘的自变量的数目,并计算重复项。我们先写出答案的最大次数项,用字典顺序打破关系,此时忽略词的前导系数。
- 例如,`"a*a*b*c"` 的次数为 $4$。
- 项的前导系数直接放在左边,用星号将它与变量分隔开(如果存在的话)。前导系数 $1$ 仍然要打印出来。
- 格式良好的一个示例答案是 `["-2*a*a*a", "3*a*a*b", "3*b*b", "4*a", "5*c", "-6"]`。
- 系数为 $0$ 的项(包括常数项)不包括在内。
- 例如,`"0"` 的表达式输出为 `[]`。
注意:你可以假设给定的表达式均有效。所有中间结果都在区间 $[-2^{31}, 2^{31} - 1]$ 内。
**说明**:
- $1 \le expression.length \le 250$。
- expression 由小写英文字母,数字 '+', '-', '*', '(', ')', ' ' 组成。
- expression 不包含任何前空格或后空格。
- expression 中的所有符号都用一个空格隔开。
- $0 \le evalvars.length \le 10^{3}$。
- $1 \le evalvars[i].length \le 20$。
- $evalvars[i]$ 由小写英文字母组成。
- $evalints.length == evalvars.length$。
- $-10^{3} \le evalints[i] \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:expression = "e + 8 - a + 5", evalvars = ["e"], evalints = [1]
输出:["-1*a","14"]
```
- 示例 2:
```python
输入:expression = "e - 8 + temperature - pressure",
evalvars = ["e", "temperature"], evalints = [1, 12]
输出:["-1*pressure","5"]
```
## 解题思路
### 思路 1:递归 + 哈希表 + 多项式运算
这道题要求实现一个支持变量的计算器,需要处理加减乘运算、括号和变量替换。
核心思路:
1. 定义多项式类,支持加减乘运算。
2. 多项式用字典表示,键是变量的元组(按字典序排序),值是系数。
3. 使用递归下降解析表达式。
4. 先将给定的变量替换为常数,再进行计算。
算法步骤:
1. 创建多项式类 `Poly`,支持:
- 加法:合并同类项。
- 减法:系数取反后加法。
- 乘法:分配律展开。
2. 解析表达式:
- 使用递归下降解析器处理括号、加减乘运算。
- 遇到变量时,如果在求值映射中,替换为常数;否则保留为变量。
3. 格式化输出:
- 按次数从高到低、字典序排序。
- 格式化每一项。
### 思路 1:代码
```python
class Solution:
def basicCalculatorIV(self, expression: str, evalvars: List[str], evalints: List[int]) -> List[str]:
from collections import Counter
# 创建变量求值映射
eval_map = dict(zip(evalvars, evalints))
# 多项式类
class Poly:
def __init__(self, terms=None):
# terms: {变量元组: 系数}
self.terms = Counter(terms) if terms else Counter()
def __add__(self, other):
result = Poly(self.terms)
for key, val in other.terms.items():
result.terms[key] += val
return result
def __sub__(self, other):
result = Poly(self.terms)
for key, val in other.terms.items():
result.terms[key] -= val
return result
def __mul__(self, other):
result = Poly()
for k1, v1 in self.terms.items():
for k2, v2 in other.terms.items():
# 合并变量(按字典序排序)
key = tuple(sorted(k1 + k2))
result.terms[key] += v1 * v2
return result
def to_list(self):
# 转换为输出格式
# 删除系数为 0 的项
items = [(k, v) for k, v in self.terms.items() if v != 0]
# 排序:先按次数降序,再按字典序
items.sort(key=lambda x: (-len(x[0]), x[0]))
result = []
for vars_tuple, coef in items:
if vars_tuple:
result.append(f"{coef}*{'*'.join(vars_tuple)}")
else:
result.append(str(coef))
return result
# 解析表达式
tokens = expression.replace('(', ' ( ').replace(')', ' ) ').split()
def parse():
"""解析加减表达式"""
nonlocal idx
left = parse_term()
while idx < len(tokens) and tokens[idx] in ['+', '-']:
op = tokens[idx]
idx += 1
right = parse_term()
if op == '+':
left = left + right
else:
left = left - right
return left
def parse_term():
"""解析乘法表达式"""
nonlocal idx
left = parse_factor()
while idx < len(tokens) and tokens[idx] == '*':
idx += 1
right = parse_factor()
left = left * right
return left
def parse_factor():
"""解析因子(数字、变量或括号表达式)"""
nonlocal idx
token = tokens[idx]
idx += 1
if token == '(':
result = parse()
idx += 1 # 跳过 ')'
return result
elif token.lstrip('-').isdigit():
# 数字
return Poly({(): int(token)})
else:
# 变量
if token in eval_map:
return Poly({(): eval_map[token]})
else:
return Poly({(token,): 1})
idx = 0
poly = parse()
return poly.to_list()
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是表达式的长度,$m$ 是多项式项的数量。解析和计算都需要遍历表达式。
- **空间复杂度**:$O(m)$,需要存储多项式的所有项。
================================================
FILE: docs/solutions/0700-0799/best-time-to-buy-and-sell-stock-with-transaction-fee.md
================================================
# [0714. 买卖股票的最佳时机含手续费](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/)
- 标签:贪心、数组、动态规划
- 难度:中等
## 题目链接
- [0714. 买卖股票的最佳时机含手续费 - 力扣](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/)
## 题目大意
给定一个整数数组 `prices`,其中第 `i` 个元素代表了第 `i` 天的股票价格 ;整数 `fee` 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
最后要求返回获得利润的最大值。
## 解题思路
这道题的解题思路和「[0122. 买卖股票的最佳时机 II](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/)」类似,同样可以买卖多次。122 题是在跌入谷底的时候买入,在涨到波峰的时候卖出,这道题多了手续费,则在判断波峰波谷的时候还要考虑手续费。贪心策略如下:
- 当股票价格小于当前最低股价时,更新最低股价,不卖出。
- 当股票价格大于最小价格 + 手续费时,累积股票利润(实质上暂未卖出,等到波峰卖出),同时最低股价减去手续费,以免重复计算。
## 代码
```python
class Solution:
def maxProfit(self, prices: List[int], fee: int) -> int:
res = 0
min_price = prices[0]
for i in range(1, len(prices)):
if prices[i] < min_price:
min_price = prices[i]
elif prices[i] > min_price + fee:
res += prices[i] - min_price - fee
min_price = prices[i] - fee
return res
```
================================================
FILE: docs/solutions/0700-0799/binary-search.md
================================================
# [0704. 二分查找](https://leetcode.cn/problems/binary-search/)
- 标签:数组、二分查找
- 难度:简单
## 题目链接
- [0704. 二分查找 - 力扣](https://leetcode.cn/problems/binary-search/)
## 题目大意
**描述**:给定一个升序的数组 $nums$,和一个目标值 $target$。
**要求**:返回 $target$ 在数组中的位置,如果找不到,则返回 -1。
**说明**:
- 你可以假设 $nums$ 中的所有元素是不重复的。
- $n$ 将在 $[1, 10000]$之间。
- $nums$ 的每个元素都将在 $[-9999, 9999]$之间。
**示例**:
- 示例 1:
```python
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
```
- 示例 2:
```python
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
```
## 解题思路
### 思路 1:二分查找
设定左右节点为数组两端,即 `left = 0`,`right = len(nums) - 1`,代表待查找区间为 $[left, right]$(左闭右闭)。
取两个节点中心位置 $mid$,先比较中心位置值 $nums[mid]$ 与目标值 $target$ 的大小。
- 如果 $target == nums[mid]$,则返回中心位置。
- 如果 $target > nums[mid]$,则将左节点设置为 $mid + 1$,然后继续在右区间 $[mid + 1, right]$ 搜索。
- 如果中心位置值 $target < nums[mid]$,则将右节点设置为 $mid - 1$,然后继续在左区间 $[left, mid - 1]$ 搜索。
### 思路 1:代码
```python
class Solution:
def search(self, nums: List[int], target: int) -> int:
left, right = 0, len(nums) - 1
# 在区间 [left, right] 内查找 target
while left <= right:
# 取区间中间节点
mid = (left + right) // 2
# 如果找到目标值,则直接返回中心位置
if nums[mid] == target:
return mid
# 如果 nums[mid] 小于目标值,则在 [mid + 1, right] 中继续搜索
elif nums[mid] < target:
left = mid + 1
# 如果 nums[mid] 大于目标值,则在 [left, mid - 1] 中继续搜索
else:
right = mid - 1
# 未搜索到元素,返回 -1
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/bold-words-in-string.md
================================================
# [0758. 字符串中的加粗单词](https://leetcode.cn/problems/bold-words-in-string/)
- 标签:字典树、数组、哈希表、字符串、字符串匹配
- 难度:中等
## 题目链接
- [0758. 字符串中的加粗单词 - 力扣](https://leetcode.cn/problems/bold-words-in-string/)
## 题目大意
给定一个关键词集合 `words` 和一个字符串 `s`。
要求:在所有 `s` 中出现的关键词前后位置上添加加粗闭合标签 `` 和 ``。如果两个子串有重叠部分,则将它们一起用一对闭合标签包围起来。同理,如果两个子字符串连续被加粗,那么你也需要把它们合起来用一对加粗标签包围。最后返回添加加粗标签后的字符串 `s`。
## 解题思路
构建字典树,将字符串列表 `words` 中所有字符串添加到字典树中。
然后遍历字符串 `s`,从每一个位置开始查询字典树。在第一个符合要求的单词前面添加 ``。在连续符合要求的单词中的最后一个单词后面添加 ``。
最后返回添加加粗标签后的字符串 `s`。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class Solution:
def boldWords(self, words: List[str], s: str) -> str:
trie_tree = Trie()
for word in words:
trie_tree.insert(word)
size = len(s)
bold_left, bold_right = -1, -1
ans = ""
for i in range(size):
cur = trie_tree
if s[i] in cur.children:
bold_left = i
while bold_left < size and s[bold_left] in cur.children:
cur = cur.children[s[bold_left]]
bold_left += 1
if cur.isEnd:
if bold_right == -1:
ans += ""
bold_right = max(bold_left, bold_right)
if i == bold_right:
ans += ""
bold_right = -1
ans += s[i]
if bold_right >= 0:
ans += ""
return ans
```
================================================
FILE: docs/solutions/0700-0799/champagne-tower.md
================================================
# [0799. 香槟塔](https://leetcode.cn/problems/champagne-tower/)
- 标签:动态规划
- 难度:中等
## 题目链接
- [0799. 香槟塔 - 力扣](https://leetcode.cn/problems/champagne-tower/)
## 题目大意
**描述**:
我们把玻璃杯摆成金字塔的形状,其中第一层有 $1$ 个玻璃杯,第二层有 $2$ 个,依次类推到第 $100$ 层,每个玻璃杯将盛有香槟。
从顶层的第一个玻璃杯开始倾倒一些香槟,当顶层的杯子满了,任何溢出的香槟都会立刻等流量的流向左右两侧的玻璃杯。当左右两边的杯子也满了,就会等流量的流向它们左右两边的杯子,依次类推。(当最底层的玻璃杯满了,香槟会流到地板上)
例如,在倾倒一杯香槟后,最顶层的玻璃杯满了。倾倒了两杯香槟后,第二层的两个玻璃杯各自盛放一半的香槟。在倒三杯香槟后,第二层的香槟满了 - 此时总共有三个满的玻璃杯。在倒第四杯后,第三层中间的玻璃杯盛放了一半的香槟,他两边的玻璃杯各自盛放了四分之一的香槟,如下图所示。
**要求**:
现在当倾倒了非负整数杯香槟后,返回第 $i$ 行 $j$ 个玻璃杯所盛放的香槟占玻璃杯容积的比例( $i$ 和 $j$ 都从 $0$ 开始)。
**说明**:
- $0 \le poured \le 10^{9}$。
- $0 \le query\_glass \le query\_row \lt 10^{3}$。
**示例**:
- 示例 1:
```python
示例 1:
输入: poured(倾倒香槟总杯数) = 1, query_glass(杯子的位置数) = 1, query_row(行数) = 1
输出: 0.00000
解释: 我们在顶层(下标是(0,0))倒了一杯香槟后,没有溢出,因此所有在顶层以下的玻璃杯都是空的。
```
- 示例 2:
```python
输入: poured(倾倒香槟总杯数) = 2, query_glass(杯子的位置数) = 1, query_row(行数) = 1
输出: 0.50000
解释: 我们在顶层(下标是(0,0)倒了两杯香槟后,有一杯量的香槟将从顶层溢出,位于(1,0)的玻璃杯和(1,1)的玻璃杯平分了这一杯香槟,所以每个玻璃杯有一半的香槟。
```
## 解题思路
### 思路 1:动态规划 + 模拟
这道题可以使用动态规划来模拟香槟倾倒的过程。
**解题步骤**:
1. 定义 $dp[i][j]$ 表示第 $i$ 行第 $j$ 个杯子中的香槟量(可能超过 $1$)。
2. 初始时,将所有香槟倒入顶层杯子:$dp[0][0] = poured$。
3. 对于每个杯子 $dp[i][j]$:
- 如果 $dp[i][j] > 1$,说明有香槟溢出。
- 溢出的香槟量为 $overflow = (dp[i][j] - 1) / 2$。
- 将溢出的香槟平均分配给下一层的两个杯子:$dp[i+1][j]$ 和 $dp[i+1][j+1]$。
4. 最后返回 $\min(1, dp[query\_row][query\_glass])$,因为杯子最多只能装 $1$ 杯香槟。
**优化**:由于只需要计算到第 $query\_row$ 行,所以只需要模拟到该行即可。
### 思路 1:代码
```python
class Solution:
def champagneTower(self, poured: int, query_row: int, query_glass: int) -> float:
# dp[i][j] 表示第 i 行第 j 个杯子中的香槟量
dp = [[0.0] * (query_row + 2) for _ in range(query_row + 2)]
dp[0][0] = poured
# 模拟香槟倾倒过程
for i in range(query_row + 1):
for j in range(i + 1):
if dp[i][j] > 1:
# 计算溢出的香槟量
overflow = (dp[i][j] - 1) / 2.0
# 将溢出的香槟平均分配给下一层的两个杯子
dp[i + 1][j] += overflow
dp[i + 1][j + 1] += overflow
# 返回目标杯子中的香槟量,最多为 1
return min(1.0, dp[query_row][query_glass])
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(query\_row^2)$。需要遍历前 $query\_row + 1$ 行的所有杯子。
- **空间复杂度**:$O(query\_row^2)$。需要存储前 $query\_row + 1$ 行的所有杯子的状态。
================================================
FILE: docs/solutions/0700-0799/cheapest-flights-within-k-stops.md
================================================
# [0787. K 站中转内最便宜的航班](https://leetcode.cn/problems/cheapest-flights-within-k-stops/)
- 标签:深度优先搜索、广度优先搜索、图、动态规划、最短路、堆(优先队列)
- 难度:中等
## 题目链接
- [0787. K 站中转内最便宜的航班 - 力扣](https://leetcode.cn/problems/cheapest-flights-within-k-stops/)
## 题目大意
**描述**:
有 $n$ 个城市通过一些航班连接。给你一个数组 $flights$,其中 $flights[i] = [from_i, to_i, price_i]$,表示该航班都从城市 $from_i$ 开始,以价格 $price_i$ 抵达 $to_i$。
现在给定所有的城市和航班,以及出发城市 $src$ 和目的地 $dst$。
**要求**:
找到出一条最多经过 $k$ 站中转的路线,使得从 $src$ 到 $dst$ 的「价格最便宜」,并返回该价格。如果不存在这样的路线,则输出 $-1$。
**说明**:
- $1 \le n \le 10^{3}$。
- $0 \le flights.length \le (n * (n - 1) / 2)$。
- $flights[i].length == 3$。
- $0 \le from_i, to_i \lt n$。
- $from_i \ne to_i$。
- $1 \le price_i \le 10^{4}$。
- 航班没有重复,且不存在自环。
- $0 \le src, dst, k \lt n$。
- $src \ne dst$。
**示例**:
- 示例 1:
```python
输入:
n = 4, flights = [[0,1,100],[1,2,100],[2,0,100],[1,3,600],[2,3,200]], src = 0, dst = 3, k = 1
输出: 700
解释: 城市航班图如上
从城市 0 到城市 3 经过最多 1 站的最佳路径用红色标记,费用为 100 + 600 = 700。
请注意,通过城市 [0, 1, 2, 3] 的路径更便宜,但无效,因为它经过了 2 站。
```
- 示例 2:
```python
输入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 1
输出: 200
解释:
城市航班图如上
从城市 0 到城市 2 经过最多 1 站的最佳路径标记为红色,费用为 100 + 100 = 200。
```
## 解题思路
### 思路 1:动态规划(Bellman-Ford 算法)
这是一个带限制条件的最短路径问题。可以使用动态规划或 Bellman-Ford 算法求解。
**状态定义**:
- $dp[k][i]$ 表示经过最多 $k$ 次中转到达城市 $i$ 的最小花费。
**状态转移**:
- $dp[k][i] = \min(dp[k][i], dp[k-1][j] + price_{j \to i})$,其中 $j$ 是 $i$ 的前驱节点。
**初始化**:
- $dp[0][src] = 0$,其他为无穷大。
### 思路 1:代码
```python
class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]], src: int, dst: int, k: int) -> int:
# 初始化 dp 数组
INF = float('inf')
dp = [INF] * n
dp[src] = 0
# 最多 k+1 次飞行(k 次中转)
for _ in range(k + 1):
# 使用临时数组避免状态覆盖
new_dp = dp[:]
for from_city, to_city, price in flights:
if dp[from_city] != INF:
new_dp[to_city] = min(new_dp[to_city], dp[from_city] + price)
dp = new_dp
return dp[dst] if dp[dst] != INF else -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(k \times m)$,其中 $m$ 是航班数量。
- **空间复杂度**:$O(n)$,$dp$ 数组的空间。
================================================
FILE: docs/solutions/0700-0799/cherry-pickup.md
================================================
# [0741. 摘樱桃](https://leetcode.cn/problems/cherry-pickup/)
- 标签:数组、动态规划、矩阵
- 难度:困难
## 题目链接
- [0741. 摘樱桃 - 力扣](https://leetcode.cn/problems/cherry-pickup/)
## 题目大意
**描述**:
给定一个 $n \times n$ 的网格 $grid$,代表一块樱桃地,每个格子由以下三种数字的一种来表示:
- $0$ 表示这个格子是空的,所以你可以穿过它。
- $1$ 表示这个格子里装着一个樱桃,你可以摘到樱桃然后穿过它。
- $-1$ 表示这个格子里有荆棘,挡着你的路。
**要求**:
请你统计并返回:在遵守下列规则的情况下,能摘到的最多樱桃数:
- 从位置 $(0, 0)$ 出发,最后到达 $(n - 1, n - 1)$,只能向下或向右走,并且只能穿越有效的格子(即只可以穿过值为 $0$ 或者 $1$ 的格子);
- 当到达 $(n - 1, n - 1)$ 后,你要继续走,直到返回到 $(0, 0)$,只能向上或向左走,并且只能穿越有效的格子;
- 当你经过一个格子且这个格子包含一个樱桃时,你将摘到樱桃并且这个格子会变成空的(值变为 0 );
- 如果在 $(0, 0)$ 和 $(n - 1, n - 1)$ 之间不存在一条可经过的路径,则无法摘到任何一个樱桃。
**说明**:
- $n == grid.length$。
- $n == grid[i].length$。
- $1 \le n \le 50$。
- $grid[i][j]$ 为 $-1$、$0$ 或 $1$。
- $grid[0][0] != -1$。
- $grid[n - 1][n - 1] != -1$。
**示例**:
- 示例 1:
```python
输入:grid = [[0,1,-1],[1,0,-1],[1,1,1]]
输出:5
解释:玩家从 (0, 0) 出发:向下、向下、向右、向右移动至 (2, 2) 。
在这一次行程中捡到 4 个樱桃,矩阵变成 [[0,1,-1],[0,0,-1],[0,0,0]] 。
然后,玩家向左、向上、向上、向左返回起点,再捡到 1 个樱桃。
总共捡到 5 个樱桃,这是最大可能值。
```
- 示例 2:
```python
输入:grid = [[1,1,-1],[1,-1,1],[-1,1,1]]
输出:0
```
## 解题思路
### 思路 1:动态规划
这道题的关键在于将「往返两次」转化为"两个人同时从起点出发到终点"。
**问题转化**:
- 一个人从 $(0, 0)$ 走到 $(n-1, n-1)$ 再返回,等价于两个人同时从 $(0, 0)$ 走到 $(n-1, n-1)$。
- 两个人同时走,每次都向右或向下移动一步。
- 如果两个人在同一位置,樱桃只能摘一次。
**状态定义**:
- 定义 $dp[k][i1][i2]$ 表示两个人都走了 $k$ 步,第一个人在第 $i1$ 行,第二个人在第 $i2$ 行时,能摘到的最多樱桃数。
- 由于 $i + j = k$,所以列数可以通过 $j = k - i$ 计算得出。
**状态转移**:
- 两个人可以从四个方向转移过来:$(i1-1, i2-1)$、$(i1-1, i2)$、$(i1, i2-1)$、$(i1, i2)$。
- 如果两个人在同一位置,樱桃只计算一次;否则计算两次。
### 思路 1:代码
```python
class Solution:
def cherryPickup(self, grid: List[List[int]]) -> int:
n = len(grid)
# dp[k][i1][i2] 表示两个人都走了 k 步,第一个人在第 i1 行,第二个人在第 i2 行
dp = [[[-1] * n for _ in range(n)] for _ in range(2 * n - 1)]
dp[0][0][0] = grid[0][0]
for k in range(1, 2 * n - 1):
for i1 in range(max(0, k - n + 1), min(k + 1, n)):
for i2 in range(max(0, k - n + 1), min(k + 1, n)):
j1, j2 = k - i1, k - i2
# 如果当前位置有荆棘,跳过
if grid[i1][j1] == -1 or grid[i2][j2] == -1:
continue
# 从四个方向转移
val = -1
for pi1 in range(i1 - 1, i1 + 1):
for pi2 in range(i2 - 1, i2 + 1):
if pi1 >= 0 and pi2 >= 0 and dp[k - 1][pi1][pi2] >= 0:
val = max(val, dp[k - 1][pi1][pi2])
if val >= 0:
# 如果两个人在同一位置,樱桃只计算一次
if i1 == i2:
val += grid[i1][j1]
else:
val += grid[i1][j1] + grid[i2][j2]
dp[k][i1][i2] = val
return max(0, dp[2 * n - 2][n - 1][n - 1])
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是网格的边长。需要遍历 $O(n)$ 步,每步需要 $O(n^2)$ 的状态转移。
- **空间复杂度**:$O(n^3)$。需要存储 $O(n^3)$ 个状态。
================================================
FILE: docs/solutions/0700-0799/contain-virus.md
================================================
# [0749. 隔离病毒](https://leetcode.cn/problems/contain-virus/)
- 标签:深度优先搜索、广度优先搜索、数组、矩阵、模拟
- 难度:困难
## 题目链接
- [0749. 隔离病毒 - 力扣](https://leetcode.cn/problems/contain-virus/)
## 题目大意
**描述**:
病毒扩散得很快,现在你的任务是尽可能地通过安装防火墙来隔离病毒。
假设世界由 $m \times n$ 的二维矩阵 $isInfected$ 组成,$isInfected[i][j] == 0$ 表示该区域未感染病毒,而 $isInfected[i][j] == 1$ 表示该区域已感染病毒。可以在任意 $2$ 个相邻单元之间的共享边界上安装一个防火墙(并且只有一个防火墙)。
每天晚上,病毒会从被感染区域向相邻未感染区域扩散,除非被防火墙隔离。现由于资源有限,每天你只能安装一系列防火墙来隔离其中一个被病毒感染的区域(一个区域或连续的一片区域),且该感染区域对未感染区域的威胁最大且 保证唯一 。
**要求**:
你需要努力使得最后有部分区域不被病毒感染,如果可以成功,那么返回需要使用的防火墙个数; 如果无法实现,则返回在世界被病毒全部感染时已安装的防火墙个数。
**说明**:
- $m == isInfected.length$。
- $n == isInfected[i].length$。
- $1 \le m, n \le 50$。
- $isInfected[i][j]$ 为 $0$ 或者 $1$。
- 在整个描述的过程中,总有一个相邻的病毒区域,它将在下一轮「严格地感染更多未受污染的方块」。
**示例**:
- 示例 1:
```python
输入: isInfected = [[0,1,0,0,0,0,0,1],[0,1,0,0,0,0,0,1],[0,0,0,0,0,0,0,1],[0,0,0,0,0,0,0,0]]
输出: 10
解释:一共有两块被病毒感染的区域。
在第一天,添加 5 墙隔离病毒区域的左侧。病毒传播后的状态是:
第二天,在右侧添加 5 个墙来隔离病毒区域。此时病毒已经被完全控制住了。
```
- 示例 2:
```python
输入: isInfected = [[1,1,1],[1,0,1],[1,1,1]]
输出: 4
解释: 虽然只保存了一个小区域,但却有四面墙。
注意,防火墙只建立在两个不同区域的共享边界上。
```
## 解题思路
### 思路 1:BFS + 模拟
这道题需要模拟病毒扩散和隔离的过程。
**解题步骤**:
1. 每天找出所有被感染的区域(连通块)。
2. 对于每个区域,计算其威胁值(能感染的未感染区域数量)和需要的防火墙数量。
3. 选择威胁值最大的区域进行隔离,累加防火墙数量。
4. 其他区域的病毒向相邻未感染区域扩散。
5. 重复以上步骤,直到没有区域可以扩散。
**实现细节**:
- 使用 BFS 找出所有连通的感染区域。
- 对于每个区域,记录其能感染的未感染区域(去重)和需要的防火墙数量。
- 隔离后,将该区域标记为特殊值(如 $-1$),表示已隔离。
### 思路 1:代码
```python
class Solution:
def containVirus(self, isInfected: List[List[int]]) -> int:
m, n = len(isInfected), len(isInfected[0])
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
total_walls = 0
while True:
visited = [[False] * n for _ in range(m)]
regions = [] # 存储所有感染区域的信息
# 找出所有感染区域
for i in range(m):
for j in range(n):
if isInfected[i][j] == 1 and not visited[i][j]:
# BFS 找出连通的感染区域
infected_cells = [] # 感染区域的所有单元格
threatened = set() # 能感染的未感染区域
walls = 0 # 需要的防火墙数量
queue = [(i, j)]
visited[i][j] = True
while queue:
x, y = queue.pop(0)
infected_cells.append((x, y))
for dx, dy in directions:
nx, ny = x + dx, y + dy
if 0 <= nx < m and 0 <= ny < n:
if isInfected[nx][ny] == 1 and not visited[nx][ny]:
queue.append((nx, ny))
visited[nx][ny] = True
elif isInfected[nx][ny] == 0:
walls += 1
threatened.add((nx, ny))
regions.append((len(threatened), walls, infected_cells, threatened))
# 如果没有感染区域,结束
if not regions:
break
# 找出威胁值最大的区域
regions.sort(reverse=True)
threat_count, wall_count, infected_cells, threatened = regions[0]
# 如果没有威胁,结束
if threat_count == 0:
break
# 隔离威胁最大的区域
total_walls += wall_count
for x, y in infected_cells:
isInfected[x][y] = -1 # 标记为已隔离
# 其他区域扩散
for i in range(1, len(regions)):
for x, y in regions[i][3]: # threatened
isInfected[x][y] = 1
return total_walls
```
### 思路 1:复杂度分析
- **时间复杂度**:$O((m \times n)^2)$,其中 $m$ 和 $n$ 是矩阵的行数和列数。最坏情况下需要进行 $O(m \times n)$ 轮模拟,每轮需要 $O(m \times n)$ 的时间。
- **空间复杂度**:$O(m \times n)$。需要存储访问标记和区域信息。
================================================
FILE: docs/solutions/0700-0799/count-different-palindromic-subsequences.md
================================================
# [0730. 统计不同回文子序列](https://leetcode.cn/problems/count-different-palindromic-subsequences/)
- 标签:字符串、动态规划
- 难度:困难
## 题目链接
- [0730. 统计不同回文子序列 - 力扣](https://leetcode.cn/problems/count-different-palindromic-subsequences/)
## 题目大意
**描述**:
给定一个字符串 $s$。
**要求**:
返回 $s$ 中不同的非空回文子序列个数 。由于答案可能很大,请返回对 $10^9 + 7$ 取余的结果。
**说明**:
- 字符串的子序列可以经由字符串删除 $0$ 个或多个字符获得。
- 如果一个序列与它反转后的序列一致,那么它是回文序列。
- 如果存在某个 $i$,满足 $ai \ne bi$,则两个序列 $a1, a2, ...$ 和 $b1, b2, ...$ 不同。
- $1 \le s.length \le 10^{3}$。
- $s[i]$ 仅包含 `'a'`, `'b'`, `'c'` 或 `'d'`。
**示例**:
- 示例 1:
```python
输入:s = 'bccb'
输出:6
解释:6 个不同的非空回文子字符序列分别为:'b', 'c', 'bb', 'cc', 'bcb', 'bccb'。
注意:'bcb' 虽然出现两次但仅计数一次。
```
- 示例 2:
```python
输入:s = 'abcdabcdabcdabcdabcdabcdabcdabcddcbadcbadcbadcbadcbadcbadcbadcba'
输出:104860361
解释:共有 3104860382 个不同的非空回文子序列,104860361 是对 109 + 7 取余后的值。
```
## 解题思路
### 思路 1:区间动态规划
这道题要求统计不同的回文子序列个数。可以使用区间动态规划来解决。
**状态定义**:
- 定义 $dp[i][j]$ 表示字符串 $s[i:j+1]$ 中不同回文子序列的个数。
**状态转移**:
- 如果 $s[i] \neq s[j]$,则 $dp[i][j] = dp[i+1][j] + dp[i][j-1] - dp[i+1][j-1]$。
- 减去 $dp[i+1][j-1]$ 是因为它被重复计算了。
- 如果 $s[i] = s[j]$,需要考虑更复杂的情况:
- 在 $s[i+1:j]$ 中找到第一个和最后一个与 $s[i]$ 相同的字符位置 $left$ 和 $right$。
- 如果 $left > right$:说明中间没有相同字符,$dp[i][j] = dp[i+1][j-1] \times 2 + 2$。
- 如果 $left = right$:说明中间只有一个相同字符,$dp[i][j] = dp[i+1][j-1] \times 2 + 1$。
- 如果 $left < right$:说明中间有多个相同字符,$dp[i][j] = dp[i+1][j-1] \times 2 - dp[left+1][right-1]$。
### 思路 1:代码
```python
class Solution:
def countPalindromicSubsequences(self, s: str) -> int:
n = len(s)
MOD = 10**9 + 7
dp = [[0] * n for _ in range(n)]
# 初始化:单个字符是一个回文子序列
for i in range(n):
dp[i][i] = 1
# 按区间长度从小到大遍历
for length in range(2, n + 1):
for i in range(n - length + 1):
j = i + length - 1
if s[i] == s[j]:
# 在 s[i+1:j] 中找第一个和最后一个与 s[i] 相同的字符
left = i + 1
right = j - 1
while left <= right and s[left] != s[i]:
left += 1
while left <= right and s[right] != s[i]:
right -= 1
if left > right:
# 中间没有相同字符
dp[i][j] = (dp[i + 1][j - 1] * 2 + 2) % MOD
elif left == right:
# 中间只有一个相同字符
dp[i][j] = (dp[i + 1][j - 1] * 2 + 1) % MOD
else:
# 中间有多个相同字符
dp[i][j] = (dp[i + 1][j - 1] * 2 - dp[left + 1][right - 1]) % MOD
else:
# s[i] != s[j]
dp[i][j] = (dp[i + 1][j] + dp[i][j - 1] - dp[i + 1][j - 1]) % MOD
return (dp[0][n - 1] + MOD) % MOD
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是字符串 $s$ 的长度。需要填充 $O(n^2)$ 个状态,每个状态的计算时间为 $O(1)$ 到 $O(n)$。
- **空间复杂度**:$O(n^2)$。需要存储 $dp$ 数组。
================================================
FILE: docs/solutions/0700-0799/couples-holding-hands.md
================================================
# [0765. 情侣牵手](https://leetcode.cn/problems/couples-holding-hands/)
- 标签:贪心、深度优先搜索、广度优先搜索、并查集、图
- 难度:困难
## 题目链接
- [0765. 情侣牵手 - 力扣](https://leetcode.cn/problems/couples-holding-hands/)
## 题目大意
**描述**:$n$ 对情侣坐在连续排列的 $2 \times n$ 个座位上,想要牵对方的手。人和座位用 $0 \sim 2 \times n - 1$ 的整数表示。情侣按顺序编号,第一对是 $(0, 1)$,第二对是 $(2, 3)$,以此类推,最后一对是 $(2 \times n - 2, 2 \times n - 1)$。
给定代表情侣初始座位的数组 `row`,`row[i]` 表示第 `i` 个座位上的人的编号。
**要求**:计算最少交换座位的次数,以便每对情侣可以并肩坐在一起。每一次交换可以选择任意两人,让他们互换座位。
**说明**:
- $2 \times n == row.length$。
- $2 \le n \le 30$。
- $n$ 是偶数。
- $0 \le row[i] < 2 \times n$。
- $row$ 中所有元素均无重复。
**示例**:
- 示例 1:
```python
输入: row = [0,2,1,3]
输出: 1
解释: 只需要交换row[1]和row[2]的位置即可。
```
- 示例 2:
```python
输入: row = [3,2,0,1]
输出: 0
解释: 无需交换座位,所有的情侣都已经可以手牵手了。
```
## 解题思路
### 思路 1:并查集
先观察一下可以直接牵手的情侣特点:
- 编号一定相邻。
- 编号为一个奇数一个偶数。
- 偶数 + 1 = 奇数。
将每对情侣的编号 `(0, 1) (2, 3) (4, 5) ...` 除以 `2` 可以得到 `(0, 0) (1, 1) (2, 2) ...`,这样相同编号就代表是一对情侣。
1. 按照 `2` 个一组的顺序,遍历一下所有编号。
1. 如果相邻的两人编号除以 `2` 相同,则两人是情侣,将其合并到一个集合中。
2. 如果相邻的两人编号不同,则将其合并到同一个集合中,而这两个人分别都有各自的对象,所以在后续遍历中两个人各自的对象和他们同组上的另一个人一定都会并到统一集合中,最终形成一个闭环。比如 `(0, 1) (1, 3) (2, 0) (3, 2)`。假设闭环对数为 `k`,最少需要交换 `k - 1` 次才能让情侣牵手。
2. 假设 `n` 对情侣中有 `m` 个闭环,则 `至少交换次数 = (n1 - 1) + (n2 - 1) + ... + (nn - 1) = n - m`。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return False
self.parent[root_x] = root_y
return True
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def minSwapsCouples(self, row: List[int]) -> int:
size = len(row)
n = size // 2
count = n
union_find = UnionFind(n)
for i in range(0, size, 2):
if union_find.union(row[i] // 2, row[i + 1] // 2):
count -= 1
return n - count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \alpha(n))$。其中 $n$ 是数组 $row$ 长度,$\alpha$ 是反 `Ackerman` 函数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0700-0799/cracking-the-safe.md
================================================
# [0753. 破解保险箱](https://leetcode.cn/problems/cracking-the-safe/)
- 标签:深度优先搜索、图、欧拉回路
- 难度:困难
## 题目链接
- [0753. 破解保险箱 - 力扣](https://leetcode.cn/problems/cracking-the-safe/)
## 题目大意
**描述**:
有一个需要密码才能打开的保险箱。密码是 $n$ 位数, 密码的每一位都是范围 $[0, k - 1]$ 中的一个数字。
保险箱有一种特殊的密码校验方法,你可以随意输入密码序列,保险箱会自动记住 最后 $n$ 位输入,如果匹配,则能够打开保险箱。
- 例如,正确的密码是 `"345"`,并且你输入的是 `"012345"`:
- 输入 0 之后,最后 3 位输入是 `"0"`,不正确。
- 输入 1 之后,最后 3 位输入是 `"01"`,不正确。
- 输入 2 之后,最后 3 位输入是 `"012"`,不正确。
- 输入 3 之后,最后 3 位输入是 `"123"`,不正确。
- 输入 4 之后,最后 3 位输入是 `"234"`,不正确。
- 输入 5 之后,最后 3 位输入是 `"345"`,正确,打开保险箱。
**要求**:
在只知道密码位数 $n$ 和范围边界 $k$ 的前提下,请你找出并返回确保在输入的「某个时刻」能够打开保险箱的任一 最短「密码序列」。
**说明**:
- $1 \le n \le 4$。
- $1 \le k \le 10$。
- $1 \le k^n \le 4096$。
**示例**:
- 示例 1:
```python
输入:n = 1, k = 2
输出:"10"
解释:密码只有 1 位,所以输入每一位就可以。"01" 也能够确保打开保险箱。
```
- 示例 2:
```python
输入:n = 2, k = 2
输出:"01100"
解释:对于每种可能的密码:
- "00" 从第 4 位开始输入。
- "01" 从第 1 位开始输入。
- "10" 从第 3 位开始输入。
- "11" 从第 2 位开始输入。
因此 "01100" 可以确保打开保险箱。"01100"、"10011" 和 "11001" 也可以确保打开保险箱。
```
## 解题思路
### 思路 1:欧拉回路(Hierholzer 算法)
这道题本质上是求欧拉回路问题。
**问题转化**:
- 将每个 $n-1$ 位的数字序列看作一个节点。
- 如果在某个 $n-1$ 位序列后面添加一个数字 $d$,可以得到一个 $n$ 位密码,那么就从该节点连一条边到新的 $n-1$ 位序列(去掉第一位,加上 $d$)。
- 例如:$n=2, k=2$ 时,节点有 `0` 和 `1`,边有 `00`、`01`、`10`、`11`。
- 我们需要找到一条路径,经过所有边恰好一次(欧拉回路)。
**Hierholzer 算法**:
1. 从任意节点开始 DFS,每次选择一条未访问的边。
2. 将访问过的边标记,避免重复访问。
3. 当无法继续前进时,将当前节点加入结果(逆序)。
4. 最后将结果反转,得到欧拉回路。
### 思路 1:代码
```python
class Solution:
def crackSafe(self, n: int, k: int) -> str:
if n == 1:
return ''.join(map(str, range(k)))
visited = set()
result = []
start = '0' * (n - 1)
def dfs(node):
for digit in range(k):
edge = node + str(digit)
if edge not in visited:
visited.add(edge)
# 下一个节点是去掉第一位,加上当前数字
next_node = edge[1:]
dfs(next_node)
result.append(str(digit))
dfs(start)
# 结果需要加上起始节点
return ''.join(result[::-1]) + start
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(k^n)$。总共有 $k^n$ 个不同的 $n$ 位密码,需要遍历所有边。
- **空间复杂度**:$O(k^n)$。需要存储访问过的边和递归栈。
================================================
FILE: docs/solutions/0700-0799/custom-sort-string.md
================================================
# [0791. 自定义字符串排序](https://leetcode.cn/problems/custom-sort-string/)
- 标签:哈希表、字符串、排序
- 难度:中等
## 题目链接
- [0791. 自定义字符串排序 - 力扣](https://leetcode.cn/problems/custom-sort-string/)
## 题目大意
**描述**:
给定两个字符串 $order$ 和 $s$。$order$ 的所有字母都是「唯一」的,并且以前按照一些自定义的顺序排序。
对 $s$ 的字符进行置换,使其与排序的 $order$ 相匹配。更具体地说,如果在 $order$ 中的字符 $x$ 出现字符 $y$ 之前,那么在排列后的字符串中,$x$ 也应该出现在 $y$ 之前。
**要求**:
返回满足这个性质的 $s$ 的任意一种排列。
**说明**:
- $1 \le order.length \le 26$。
- $1 \le s.length \le 200$。
- $order$ 和 $s$ 由小写英文字母组成。
- $order$ 中的所有字符都不同。
**示例**:
- 示例 1:
```python
输入: order = "cba", s = "abcd"
输出: "cbad"
解释:
"a"、"b"、"c"是按顺序出现的,所以"a"、"b"、"c"的顺序应该是"c"、"b"、"a"。
因为"d"不是按顺序出现的,所以它可以在返回的字符串中的任何位置。"dcba"、"cdba"、"cbda"也是有效的输出。
```
- 示例 2:
```python
输入: order = "cbafg", s = "abcd"
输出: "cbad"
解释:字符 "b"、"c" 和 "a" 规定了 s 中字符的顺序。s 中的字符 "d" 没有在 order 中出现,所以它的位置是弹性的。
按照出现的顺序,s 中的 "b"、"c"、"a" 应排列为"b"、"c"、"a"。"d" 可以放在任何位置,因为它没有按顺序排列。输出 "bcad" 遵循这一规则。其他排序如 "dbca" 或 "bcda" 也是有效的,只要维持 "b"、"c"、"a" 的顺序。
```
## 解题思路
### 思路 1:自定义排序
这道题要求按照 $order$ 中的顺序对 $s$ 进行排序。
**解题步骤**:
1. 使用哈希表记录 $order$ 中每个字符的优先级(位置索引)。
2. 对于不在 $order$ 中的字符,赋予一个较大的优先级,使其排在后面。
3. 使用自定义排序函数,按照优先级对 $s$ 中的字符进行排序。
**优化方法**:
- 可以先统计 $s$ 中每个字符的出现次数。
- 按照 $order$ 的顺序,依次将字符添加到结果中。
- 最后将不在 $order$ 中的字符添加到结果末尾。
### 思路 1:代码
```python
class Solution:
def customSortString(self, order: str, s: str) -> str:
# 统计 s 中每个字符的出现次数
from collections import Counter
count = Counter(s)
result = []
# 按照 order 的顺序添加字符
for char in order:
if char in count:
result.append(char * count[char])
del count[char]
# 添加不在 order 中的字符
for char, freq in count.items():
result.append(char * freq)
return ''.join(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是字符串 $s$ 的长度,$m$ 是字符串 $order$ 的长度。需要遍历两个字符串各一次。
- **空间复杂度**:$O(|\Sigma|)$,其中 $|\Sigma|$ 是字符集大小(这里是 $26$)。需要存储字符计数。
================================================
FILE: docs/solutions/0700-0799/daily-temperatures.md
================================================
# [0739. 每日温度](https://leetcode.cn/problems/daily-temperatures/)
- 标签:栈、数组、单调栈
- 难度:中等
## 题目链接
- [0739. 每日温度 - 力扣](https://leetcode.cn/problems/daily-temperatures/)
## 题目大意
**描述**:给定一个列表 `temperatures`,`temperatures[i]` 表示第 `i` 天的气温。
**要求**:输出一个列表,列表上每个位置代表「如果要观测到更高的气温,至少需要等待的天数」。如果之后的气温不再升高,则用 `0` 来代替。
**说明**:
- $1 \le temperatures.length \le 10^5$。
- $30 \le temperatures[i] \le 100$。
**示例**:
- 示例 1:
```python
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
```
- 示例 2:
```python
输入: temperatures = [30,40,50,60]
输出: [1,1,1,0]
```
## 解题思路
题目的意思实际上就是给定一个数组,每个位置上有整数值。对于每个位置,在该位置右侧找到第一个比当前元素更大的元素。求「该元素」与「右侧第一个比当前元素更大的元素」之间的距离,将所有距离保存为数组返回结果。
最简单的思路是对于每个温度值,向后依次进行搜索,找到比当前温度更高的值。
更好的方式使用「单调递增栈」,栈中保存元素的下标。
### 思路 1:单调栈
1. 首先,将答案数组 `ans` 全部赋值为 0。然后遍历数组每个位置元素。
2. 如果栈为空,则将当前元素的下标入栈。
3. 如果栈不为空,且当前数字大于栈顶元素对应数字,则栈顶元素出栈,并计算下标差。
4. 此时当前元素就是栈顶元素的下一个更高值,将其下标差存入答案数组 `ans` 中保存起来,判断栈顶元素。
5. 直到当前数字小于或等于栈顶元素,则停止出栈,将当前元素下标入栈。
6. 最后输出答案数组 `ans`。
### 思路 1:代码
```python
class Solution:
def dailyTemperatures(self, T: List[int]) -> List[int]:
n = len(T)
stack = []
ans = [0 for _ in range(n)]
for i in range(n):
while stack and T[i] > T[stack[-1]]:
index = stack.pop()
ans[index] = (i-index)
stack.append(i)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0700-0799/delete-and-earn.md
================================================
# [0740. 删除并获得点数](https://leetcode.cn/problems/delete-and-earn/)
- 标签:数组、哈希表、动态规划
- 难度:中等
## 题目链接
- [0740. 删除并获得点数 - 力扣](https://leetcode.cn/problems/delete-and-earn/)
## 题目大意
**描述**:
给定一个整数数组 $nums$,你可以对它进行一些操作。
每次操作中,选择任意一个 $nums[i]$,删除它并获得 $nums[i]$ 的点数。之后,你必须删除所有等于 $nums[i] - 1$ 和 $nums[i] + 1$ 的元素。
开始你拥有 $0$ 个点数。
**要求**:
返回你能通过这些操作获得的最大点数。
**说明**:
- $1 \le nums.length \le 2 \times 10^{4}$。
- $1 \le nums[i] \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:nums = [3,4,2]
输出:6
解释:
删除 4 获得 4 个点数,因此 3 也被删除。
之后,删除 2 获得 2 个点数。总共获得 6 个点数。
```
- 示例 2:
```python
输入:nums = [2,2,3,3,3,4]
输出:9
解释:
删除 3 获得 3 个点数,接着要删除两个 2 和 4 。
之后,再次删除 3 获得 3 个点数,再次删除 3 获得 3 个点数。
总共获得 9 个点数。
```
## 解题思路
### 思路 1:动态规划
这道题可以转化为「打家劫舍」问题。选择数字 $x$ 后,所有 $x - 1$ 和 $x + 1$ 都会被删除,相当于不能选择相邻的数字。
**实现步骤**:
1. 统计每个数字的总点数:$total[i]$ 表示选择所有数字 $i$ 能获得的总点数。
2. 问题转化为:在数组 $total$ 中选择一些不相邻的元素,使得和最大。
3. 定义 $dp[i]$ 表示考虑前 $i$ 个数字能获得的最大点数:
- $dp[i] = \max(dp[i-1], dp[i-2] + total[i])$
- 不选择 $i$:$dp[i-1]$
- 选择 $i$:$dp[i-2] + total[i]$(不能选择 $i-1$)
### 思路 1:代码
```python
class Solution:
def deleteAndEarn(self, nums: List[int]) -> int:
if not nums:
return 0
# 统计每个数字的总点数
max_num = max(nums)
total = [0] * (max_num + 1)
for num in nums:
total[num] += num
# 动态规划
if max_num == 0:
return total[0]
# dp[i] 表示考虑前 i 个数字能获得的最大点数
prev2 = total[0] # dp[i-2]
prev1 = max(total[0], total[1]) # dp[i-1]
for i in range(2, max_num + 1):
curr = max(prev1, prev2 + total[i])
prev2 = prev1
prev1 = curr
return prev1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是 $nums$ 的长度,$m$ 是 $nums$ 中的最大值。
- **空间复杂度**:$O(m)$,$total$ 数组的空间。
================================================
FILE: docs/solutions/0700-0799/design-hashmap.md
================================================
# [0706. 设计哈希映射](https://leetcode.cn/problems/design-hashmap/)
- 标签:设计、数组、哈希表、链表、哈希函数
- 难度:简单
## 题目链接
- [0706. 设计哈希映射 - 力扣](https://leetcode.cn/problems/design-hashmap/)
## 题目大意
**要求**:不使用任何内建的哈希表库设计一个哈希映射(`HashMap`)。
需要满足以下操作:
- `MyHashMap()` 用空映射初始化对象。
- `void put(int key, int value) 向 HashMap` 插入一个键值对 `(key, value)` 。如果 `key` 已经存在于映射中,则更新其对应的值 `value`。
- `int get(int key)` 返回特定的 `key` 所映射的 `value`;如果映射中不包含 `key` 的映射,返回 `-1`。
- `void remove(key)` 如果映射中存在 key 的映射,则移除 `key` 和它所对应的 `value` 。
**说明**:
- $0 \le key, value \le 10^6$。
- 最多调用 $10^4$ 次 `put`、`get` 和 `remove` 方法。
**示例**:
- 示例 1:
```python
输入:
["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"]
[[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]]
输出:
[null, null, null, 1, -1, null, 1, null, -1]
解释:
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // myHashMap 现在为 [[1,1]]
myHashMap.put(2, 2); // myHashMap 现在为 [[1,1], [2,2]]
myHashMap.get(1); // 返回 1 ,myHashMap 现在为 [[1,1], [2,2]]
myHashMap.get(3); // 返回 -1(未找到),myHashMap 现在为 [[1,1], [2,2]]
myHashMap.put(2, 1); // myHashMap 现在为 [[1,1], [2,1]](更新已有的值)
myHashMap.get(2); // 返回 1 ,myHashMap 现在为 [[1,1], [2,1]]
myHashMap.remove(2); // 删除键为 2 的数据,myHashMap 现在为 [[1,1]]
myHashMap.get(2); // 返回 -1(未找到),myHashMap 现在为 [[1,1]]
```
## 解题思路
### 思路 1:链地址法
和 [0705. 设计哈希集合](https://leetcode.cn/problems/design-hashset/) 类似。这里我们使用「链地址法」来解决哈希冲突。即利用「数组 + 链表」的方式实现哈希集合。
1. 定义哈希表长度 `buckets` 为 `1003`。
2. 定义一个一维长度为 `buckets` 的二维数组 `table`。其中第一维度用于计算哈希函数,为关键字 `key` 分桶。第二个维度用于存放 `key` 和对应的 `value`。第二维度的数组会根据 `key` 值动态增长,用数组模拟真正的链表。
3. 定义一个 `hash(key)` 的方法,将 `key` 转换为对应的地址 `hash_key`。
4. 进行 `put` 操作时,根据 `hash(key)` 方法,获取对应的地址 `hash_key`。然后遍历 `hash_key` 对应的数组元素,查找与 `key` 值一样的元素。
1. 如果找到与 `key` 值相同的元素,则更改该元素对应的 `value` 值。
2. 如果没找到与 `key` 值相同的元素,则在第二维数组 `table[hask_key]` 中增加元素,元素为 `(key, value)` 组成的元组。
5. 进行 `get` 操作跟 `put` 操作差不多。根据 `hash(key)` 方法,获取对应的地址 `hash_key`。然后遍历 `hash_key` 对应的数组元素,查找与 `key` 值一样的元素。
1. 如果找到与 `key` 值相同的元素,则返回该元素对应的 `value`。
2. 如果没找到与 `key` 值相同的元素,则返回 `-1`。
### 思路 1:代码
```python
class MyHashMap:
def __init__(self):
self.buckets = 1003
self.table = [[] for _ in range(self.buckets)]
def hash(self, key):
return key % self.buckets
def put(self, key: int, value: int) -> None:
hash_key = self.hash(key)
for item in self.table[hash_key]:
if key == item[0]:
item[1] = value
return
self.table[hash_key].append([key, value])
def get(self, key: int) -> int:
hash_key = self.hash(key)
for item in self.table[hash_key]:
if key == item[0]:
return item[1]
return -1
def remove(self, key: int) -> None:
hash_key = self.hash(key)
for i, item in enumerate(self.table[hash_key]):
if key == item[0]:
self.table[hash_key].pop(i)
return
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\frac{n}{b})$。其中 $n$ 为哈希表中元素数量,$b$ 为链表的数量。
- **空间复杂度**:$O(n + b)$。
================================================
FILE: docs/solutions/0700-0799/design-hashset.md
================================================
# [0705. 设计哈希集合](https://leetcode.cn/problems/design-hashset/)
- 标签:设计、数组、哈希表、链表、哈希函数
- 难度:简单
## 题目链接
- [0705. 设计哈希集合 - 力扣](https://leetcode.cn/problems/design-hashset/)
## 题目大意
**要求**:不使用内建的哈希表库,自行实现一个哈希集合(HashSet)。
需要满足以下操作:
- `void add(key)` 向哈希集合中插入值 $key$。
- `bool contains(key)` 返回哈希集合中是否存在这个值 $key$。
- `void remove(key)` 将给定值 $key$ 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
**说明**:
- $0 \le key \le 10^6$。
- 最多调用 $10^4$ 次 `add`、`remove` 和 `contains`。
**示例**:
- 示例 1:
```python
输入:
["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]
解释:
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = [1]
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(1); // 返回 True
myHashSet.contains(3); // 返回 False ,(未找到)
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(2); // 返回 True
myHashSet.remove(2); // set = [1]
myHashSet.contains(2); // 返回 False ,(已移除)
```
## 解题思路
### 思路 1:数组 + 链表
定义一个一维长度为 $buckets$ 的二维数组 $table$。
第一维度用于计算哈希函数,为 $key$ 进行分桶。第二个维度用于寻找 $key$ 存放的具体位置。第二维度的数组会根据 $key$ 值动态增长,模拟真正的链表。
### 思路 1:代码
```python
class MyHashSet:
def __init__(self):
self.buckets = 1003
self.table = [[] for _ in range(self.buckets)]
def hash(self, key):
return key % self.buckets
def add(self, key: int) -> None:
hash_key = self.hash(key)
if key in self.table[hash_key]:
return
self.table[hash_key].append(key)
def remove(self, key: int) -> None:
hash_key = self.hash(key)
if key not in self.table[hash_key]:
return
self.table[hash_key].remove(key)
def contains(self, key: int) -> bool:
hash_key = self.hash(key)
return key in self.table[hash_key]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\frac{n}{m})$,其中 $n$ 为哈希表中的元素数量,$b$ 为 $table$ 的元素个数,也就是链表的数量。
- **空间复杂度**:$O(n + m)$。
================================================
FILE: docs/solutions/0700-0799/design-linked-list.md
================================================
# [0707. 设计链表](https://leetcode.cn/problems/design-linked-list/)
- 标签:设计、链表
- 难度:中等
## 题目链接
- [0707. 设计链表 - 力扣](https://leetcode.cn/problems/design-linked-list/)
## 题目大意
**要求**:设计实现一个链表,需要支持以下操作:
- `get(index)`:获取链表中第 `index` 个节点的值。如果索引无效,则返回 `-1`。
- `addAtHead(val)`:在链表的第一个元素之前添加一个值为 `val` 的节点。插入后,新节点将成为链表的第一个节点。
- `addAtTail(val)`:将值为 `val` 的节点追加到链表的最后一个元素。
- `addAtIndex(index, val)`:在链表中的第 `index` 个节点之前添加值为 `val` 的节点。如果 `index` 等于链表的长度,则该节点将附加到链表的末尾。如果 `index` 大于链表长度,则不会插入节点。如果 `index` 小于 `0`,则在头部插入节点。
- `deleteAtIndex(index)`:如果索引 `index` 有效,则删除链表中的第 `index` 个节点。
**说明**:
- 所有`val`值都在 $[1, 1000]$ 之内。
- 操作次数将在 $[1, 1000]$ 之内。
- 请不要使用内置的 `LinkedList` 库。
**示例**:
- 示例 1:
```python
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); // 链表变为 1 -> 2 -> 3
linkedList.get(1); // 返回 2
linkedList.deleteAtIndex(1); // 现在链表是 1-> 3
linkedList.get(1); // 返回 3
```
## 解题思路
### 思路 1:单链表
新建一个带有 `val` 值 和 `next` 指针的链表节点类, 然后按照要求对节点进行操作。
### 思路 1:代码
```python
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class MyLinkedList:
def __init__(self):
"""
Initialize your data structure here.
"""
self.size = 0
self.head = ListNode(0)
def get(self, index: int) -> int:
"""
Get the value of the index-th node in the linked list. If the index is invalid, return -1.
"""
if index < 0 or index >= self.size:
return -1
curr = self.head
for _ in range(index + 1):
curr = curr.next
return curr.val
def addAtHead(self, val: int) -> None:
"""
Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
"""
self.addAtIndex(0, val)
def addAtTail(self, val: int) -> None:
"""
Append a node of value val to the last element of the linked list.
"""
self.addAtIndex(self.size, val)
def addAtIndex(self, index: int, val: int) -> None:
"""
Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted.
"""
if index > self.size:
return
if index < 0:
index = 0
self.size += 1
pre = self.head
for _ in range(index):
pre = pre.next
add_node = ListNode(val)
add_node.next = pre.next
pre.next = add_node
def deleteAtIndex(self, index: int) -> None:
"""
Delete the index-th node in the linked list, if the index is valid.
"""
if index < 0 or index >= self.size:
return
self.size -= 1
pre = self.head
for _ in range(index):
pre = pre.next
pre.next = pre.next.next
```
### 思路 1:复杂度分析
- **时间复杂度**:
- `addAtHead(val)`:$O(1)$。
- `get(index)`、`addAtTail(val)`、`del eteAtIndex(index)`:$O(k)$。$k$ 指的是元素的索引。
- `addAtIndex(index, val)`:$O(n)$。$n$ 指的是链表的元素个数。
- **空间复杂度**:$O(1)$。
### 思路 2:双链表
新建一个带有 `val` 值和 `next` 指针、`prev` 指针的链表节点类,然后按照要求对节点进行操作。
### 思路 2:代码
```python
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
self.prev = None
class MyLinkedList:
def __init__(self):
"""
Initialize your data structure here.
"""
self.size = 0
self.head = ListNode(0)
self.tail = ListNode(0)
self.head.next = self.tail
self.tail.prev = self.head
def get(self, index: int) -> int:
"""
Get the value of the index-th node in the linked list. If the index is invalid, return -1.
"""
if index < 0 or index >= self.size:
return -1
if index + 1 < self.size - index:
curr = self.head
for _ in range(index + 1):
curr = curr.next
else:
curr = self.tail
for _ in range(self.size - index):
curr = curr.prev
return curr.val
def addAtHead(self, val: int) -> None:
"""
Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
"""
self.addAtIndex(0, val)
def addAtTail(self, val: int) -> None:
"""
Append a node of value val to the last element of the linked list.
"""
self.addAtIndex(self.size, val)
def addAtIndex(self, index: int, val: int) -> None:
"""
Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted.
"""
if index > self.size:
return
if index < 0:
index = 0
if index < self.size - index:
prev = self.head
for _ in range(index):
prev = prev.next
next = prev.next
else:
next = self.tail
for _ in range(self.size - index):
next = next.prev
prev = next.prev
self.size += 1
add_node = ListNode(val)
add_node.prev = prev
add_node.next = next
prev.next = add_node
next.prev = add_node
def deleteAtIndex(self, index: int) -> None:
"""
Delete the index-th node in the linked list, if the index is valid.
"""
if index < 0 or index >= self.size:
return
if index < self.size - index:
prev = self.head
for _ in range(index):
prev = prev.next
next = prev.next.next
else:
next = self.tail
for _ in range(self.size - index - 1):
next = next.prev
prev = next.prev.prev
self.size -= 1
prev.next = next
next.prev = prev
```
### 思路 2:复杂度分析
- **时间复杂度**:
- `addAtHead(val)`、`addAtTail(val)`:$O(1)$。
- `get(index)`、`addAtIndex(index, val)`、`del eteAtIndex(index)`:$O(min(k, n - k))$。$n$ 指的是链表的元素个数,$k$ 指的是元素的索引。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/domino-and-tromino-tiling.md
================================================
# [0790. 多米诺和托米诺平铺](https://leetcode.cn/problems/domino-and-tromino-tiling/)
- 标签:动态规划
- 难度:中等
## 题目链接
- [0790. 多米诺和托米诺平铺 - 力扣](https://leetcode.cn/problems/domino-and-tromino-tiling/)
## 题目大意
**描述**:
有两种形状的瓷砖:一种是 $2 \times 1$ 的多米诺形,另一种是形如 `"L"` 的托米诺形。两种形状都可以旋转。
给定整数 $n$。
**要求**:
返回可以平铺 $2 \times n$ 的面板的方法的数量。返回对 $10^9 + 7$ 取模的值。
**说明**:
- 平铺:指的是每个正方形都必须有瓷砖覆盖。两个平铺不同,当且仅当面板上有四个方向上的相邻单元中的两个,使得恰好有一个平铺有一个瓷砖占据两个正方形。
- $1 \le n \le 10^{3}$。
**示例**:
- 示例 1:
```python
示例 1:
输入: n = 3
输出: 5
解释: 五种不同的方法如上所示。
```
- 示例 2:
```python
输入: n = 1
输出: 1
```
## 解题思路
### 思路 1:动态规划
这道题需要计算平铺 $2 \times n$ 面板的方法数。
**状态定义**:
- 定义 $dp[i][0]$ 表示平铺到第 $i$ 列,且第 $i$ 列两行都被填满的方法数。
- 定义 $dp[i][1]$ 表示平铺到第 $i$ 列,且第 $i$ 列只有上行被填满的方法数。
- 定义 $dp[i][2]$ 表示平铺到第 $i$ 列,且第 $i$ 列只有下行被填满的方法数。
**状态转移**:
- $dp[i][0]$ 可以从以下状态转移:
- $dp[i-1][0]$:放置一个竖直的多米诺。
- $dp[i-2][0]$:放置两个水平的多米诺。
- $dp[i-1][1]$ 和 $dp[i-1][2]$:放置托米诺。
- $dp[i][1]$ 可以从 $dp[i-1][0]$ 或 $dp[i-1][2]$ 转移。
- $dp[i][2]$ 可以从 $dp[i-1][0]$ 或 $dp[i-1][1]$ 转移。
**递推公式**:
- $dp[i][0] = (dp[i-1][0] + dp[i-2][0] + dp[i-1][1] + dp[i-1][2]) \mod (10^9 + 7)$
- $dp[i][1] = (dp[i-1][0] + dp[i-1][2]) \mod (10^9 + 7)$
- $dp[i][2] = (dp[i-1][0] + dp[i-1][1]) \mod (10^9 + 7)$
### 思路 1:代码
```python
class Solution:
def numTilings(self, n: int) -> int:
MOD = 10**9 + 7
if n == 1:
return 1
if n == 2:
return 2
# dp[i][0]: 第 i 列两行都填满
# dp[i][1]: 第 i 列只有上行填满
# dp[i][2]: 第 i 列只有下行填满
dp = [[0] * 3 for _ in range(n + 1)]
dp[0][0] = 1
dp[1][0] = 1
for i in range(2, n + 1):
dp[i][0] = (dp[i-1][0] + dp[i-2][0] + dp[i-1][1] + dp[i-1][2]) % MOD
dp[i][1] = (dp[i-2][0] + dp[i-1][2]) % MOD
dp[i][2] = (dp[i-2][0] + dp[i-1][1]) % MOD
return dp[n][0]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。需要遍历 $n$ 列。
- **空间复杂度**:$O(n)$。可以优化到 $O(1)$,只保留最近的几个状态。
================================================
FILE: docs/solutions/0700-0799/escape-the-ghosts.md
================================================
# [0789. 逃脱阻碍者](https://leetcode.cn/problems/escape-the-ghosts/)
- 标签:数组、数学
- 难度:中等
## 题目链接
- [0789. 逃脱阻碍者 - 力扣](https://leetcode.cn/problems/escape-the-ghosts/)
## 题目大意
**描述**:
你在进行一个简化版的吃豆人游戏。你从 $[0, 0]$ 点开始出发,你的目的地是 $target = [xtarget, ytarget]$。地图上有一些阻碍者,以数组 $ghosts$ 给出,第 $i$ 个阻碍者从 $ghosts[i] = [xi, yi]$ 出发。所有输入均为「整数坐标」。
每一回合,你和阻碍者们可以同时向东,西,南,北四个方向移动,每次可以移动到距离原位置 $1$ 个单位 的新位置。当然,也可以选择「不动」。所有动作「同时」发生。
如果你可以在任何阻碍者抓住你「之前」到达目的地(阻碍者可以采取任意行动方式),则被视为逃脱成功。如果你和阻碍者「同时」到达了一个位置(包括目的地)「都不算」是逃脱成功。
**要求**:
如果不管阻碍者怎么移动都可以成功逃脱时,输出 true;否则,输出 false。
**说明**:
- $1 \le ghosts.length \le 10^{3}$。
- $ghosts[i].length == 2$。
- $-10^{4} \le xi, yi \le 10^{4}$。
- 同一位置可能有「多个阻碍者」。
- $target.length == 2$。
- $-10^{4} \le xtarget, ytarget \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:ghosts = [[1,0],[0,3]], target = [0,1]
输出:true
解释:你可以直接一步到达目的地 (0,1) ,在 (1, 0) 或者 (0, 3) 位置的阻碍者都不可能抓住你。
```
- 示例 2:
```python
输入:ghosts = [[1,0]], target = [2,0]
输出:false
解释:你需要走到位于 (2, 0) 的目的地,但是在 (1, 0) 的阻碍者位于你和目的地之间。
```
## 解题思路
### 思路 1:曼哈顿距离
这道题的关键在于理解:如果阻碍者能在你之前或同时到达目的地,你就无法逃脱。
**核心观察**:
- 你和阻碍者都使用曼哈顿距离移动。
- 从 $(x_1, y_1)$ 到 $(x_2, y_2)$ 的曼哈顿距离为 $|x_1 - x_2| + |y_1 - y_2|$。
- 如果存在任何一个阻碍者到目的地的距离 $\leq$ 你到目的地的距离,你就无法逃脱。
- 因为阻碍者可以采取最优策略,直接朝目的地移动。
**解题步骤**:
1. 计算你从起点 $(0, 0)$ 到目的地 $target$ 的曼哈顿距离。
2. 对于每个阻碍者,计算其到目的地的曼哈顿距离。
3. 如果所有阻碍者到目的地的距离都严格大于你的距离,返回 `True`。
4. 否则返回 `False`。
### 思路 1:代码
```python
class Solution:
def escapeGhosts(self, ghosts: List[List[int]], target: List[int]) -> bool:
# 计算你到目的地的曼哈顿距离
my_distance = abs(target[0]) + abs(target[1])
# 检查每个阻碍者到目的地的距离
for ghost in ghosts:
ghost_distance = abs(ghost[0] - target[0]) + abs(ghost[1] - target[1])
# 如果任何阻碍者能在你之前或同时到达,返回 False
if ghost_distance <= my_distance:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是阻碍者的数量。需要遍历所有阻碍者。
- **空间复杂度**:$O(1)$。只使用了常数个额外变量。
================================================
FILE: docs/solutions/0700-0799/find-k-th-smallest-pair-distance.md
================================================
# [0719. 找出第 K 小的距离对](https://leetcode.cn/problems/find-k-th-smallest-pair-distance/)
- 标签:数组、双指针、二分查找、排序
- 难度:困难
## 题目链接
- [0719. 找出第 K 小的距离对 - 力扣](https://leetcode.cn/problems/find-k-th-smallest-pair-distance/)
## 题目大意
**描述**:给定一个整数数组 $nums$,对于数组中不同的数 $nums[i]$、$nums[j]$ 之间的距离定义为 $nums[i]$ 和 $nums[j]$ 的绝对差值,即 $dist(nums[i], nums[j]) = abs(nums[i] - nums[j])$。
**要求**:求所有数对之间第 $k$ 个最小距离。
**说明**:
- $n == nums.length$
- $2 \le n \le 10^4$。
- $0 \le nums[i] \le 10^6$。
- $1 \le k \le n \times (n - 1) / 2$。
**示例**:
- 示例 1:
```python
输入:nums = [1,3,1], k = 1
输出:0
解释:数对和对应的距离如下:
(1,3) -> 2
(1,1) -> 0
(3,1) -> 2
距离第 1 小的数对是 (1,1) ,距离为 0。
```
- 示例 2:
```python
输入:nums = [1,1,1], k = 2
输出:0
```
## 解题思路
### 思路 1:二分查找算法
一般来说 topK 问题都可以用堆排序来解决。但是这道题使用堆排序超时了。所以需要换其他方法。
先来考虑第 $k$ 个最小距离的范围。这个范围一定在 $[0, max(nums) - min(nums)]$ 之间。
我们可以对 $nums$ 先进行排序,然后得到最小距离为 $0$,最大距离为 $nums[-1] - nums[0]$。我们可以在这个区间上进行二分,对于二分的位置 $mid$,统计距离小于等于 $mid$ 的距离对数,并根据它和 $k$ 的关系调整区间上下界。
统计对数可以使用双指针来计算出所有小于等于 $mid$ 的距离对数目。
1. 维护两个指针 $left$、$right$。$left$、$right$ 都指向数组开头位置。
2. 然后不断移动 $right$,计算 $nums[right]$ 和 $nums[left]$ 之间的距离。
3. 如果大于 $mid$,则 $left$ 向右移动,直到距离小于等于 $mid$ 时,统计当前距离对数为 $right - left$。
4. 最终将这些符合要求的距离对数累加,就得到了所有小于等于 $mid$ 的距离对数目。
### 思路 1:代码
```python
class Solution:
def smallestDistancePair(self, nums: List[int], k: int) -> int:
def get_count(dist):
left, count = 0, 0
for right in range(1, len(nums)):
while nums[right] - nums[left] > dist:
left += 1
count += (right - left)
return count
nums.sort()
left, right = 0, nums[-1] - nums[0]
while left < right:
mid = left + (right - left) // 2
if get_count(mid) >= k:
right = mid
else:
left = mid + 1
return left
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组 $nums$ 中的元素个数。
- **空间复杂度**:$O(\log n)$,排序算法所用到的空间复杂度为 $O(\log n)$。
================================================
FILE: docs/solutions/0700-0799/find-pivot-index.md
================================================
# [0724. 寻找数组的中心下标](https://leetcode.cn/problems/find-pivot-index/)
- 标签:数组、前缀和
- 难度:简单
## 题目链接
- [0724. 寻找数组的中心下标 - 力扣](https://leetcode.cn/problems/find-pivot-index/)
## 题目大意
**描述**:给定一个数组 $nums$。
**要求**:找到「左侧元素和」与「右侧元素和相等」的位置,如果找不到,则返回 $-1$。
**说明**:
- $1 \le nums.length \le 10^4$。
- $-1000 \le nums[i] \le 1000$。
**示例**:
- 示例 1:
```python
输入:nums = [1, 7, 3, 6, 5, 6]
输出:3
解释:
中心下标是 3 。
左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11,
右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11,二者相等。
```
- 示例 2:
```python
输入:nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心下标。
```
## 解题思路
### 思路 1:两次遍历
两次遍历,第一次遍历先求出数组全部元素和。第二次遍历找到左侧元素和恰好为全部元素和一半的位置。
### 思路 1:代码
```python
class Solution:
def pivotIndex(self, nums: List[int]) -> int:
sum = 0
for i in range(len(nums)):
sum += nums[i]
curr_sum = 0
for i in range(len(nums)):
if curr_sum * 2 + nums[i] == sum:
return i
curr_sum += nums[i]
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。两次遍历的时间复杂度为 $O(2 \times n)$ ,$O(2 \times n) == O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/find-smallest-letter-greater-than-target.md
================================================
# [0744. 寻找比目标字母大的最小字母](https://leetcode.cn/problems/find-smallest-letter-greater-than-target/)
- 标签:数组、二分查找
- 难度:简单
## 题目链接
- [0744. 寻找比目标字母大的最小字母 - 力扣](https://leetcode.cn/problems/find-smallest-letter-greater-than-target/)
## 题目大意
**描述**:给你一个字符数组 $letters$,该数组按非递减顺序排序,以及一个字符 $target$。$letters$ 里至少有两个不同的字符。
**要求**:找出 $letters$ 中大于 $target$ 的最小的字符。如果不存在这样的字符,则返回 $letters$ 的第一个字符。
**说明**:
- $2 \le letters.length \le 10^4$。
- $letters[i]$$ 是一个小写字母。
- $letters$ 按非递减顺序排序。
- $letters$ 最少包含两个不同的字母。
- $target$ 是一个小写字母。
**示例**:
- 示例 1:
```python
输入: letters = ["c", "f", "j"],target = "a"
输出: "c"
解释:letters 中字典上比 'a' 大的最小字符是 'c'。
```
- 示例 2:
```python
输入: letters = ["c","f","j"], target = "c"
输出: "f"
解释:letters 中字典顺序上大于 'c' 的最小字符是 'f'。
```
## 解题思路
### 思路 1:二分查找
利用二分查找,找到比 $target$ 大的字母。注意 $target$ 可能大于 $letters$ 的所有字符,此时应返回 $letters$ 的第一个字母。
我们可以假定 $target$ 的取值范围为 $[0, len(letters)]$。当 $target$ 取到 $len(letters)$ 时,说明 $target$ 大于 $letters$ 的所有字符,对 $len(letters)$ 取余即可得到 $letters[0]$。
### 思路 1:代码
```python
class Solution:
def nextGreatestLetter(self, letters: List[str], target: str) -> str:
n = len(letters)
left = 0
right = n
while left < right:
mid = left + (right - left) // 2
if letters[mid] <= target:
left = mid + 1
else:
right = mid
return letters[left % n]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。其中 $n$ 为字符数组 $letters$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/flood-fill.md
================================================
# [0733. 图像渲染](https://leetcode.cn/problems/flood-fill/)
- 标签:深度优先搜索、广度优先搜索、数组、矩阵
- 难度:简单
## 题目链接
- [0733. 图像渲染 - 力扣](https://leetcode.cn/problems/flood-fill/)
## 题目大意
给定一个二维数组 image 表示图画,数组的每个元素值表示该位置的像素值大小。再给定一个坐标 (sr, sc) 表示图像渲染开始的位置。然后再给定一个新的颜色值 newColor。现在要求:将坐标 (sr, sc) 以及 (sr, sc) 相连的上下左右区域上与 (sr, sc) 原始颜色相同的区域染色为 newColor。返回染色后的二维数组。
## 解题思路
从起点开始,对上下左右四个方向进行广度优先搜索。每次搜索到一个位置时,如果该位置上的像素值与初始位置像素值相同,则更新该位置像素值,并将该位置加入队列中。最后将二维数组返回。
- 注意:如果起点位置初始颜色和新颜色值 newColor 相同,则不需要染色,直接返回原数组即可。
## 代码
```python
import collections
class Solution:
def floodFill(self, image: List[List[int]], sr: int, sc: int, newColor: int) -> List[List[int]]:
if newColor == image[sr][sc]:
return image
directions = {(1, 0), (-1, 0), (0, 1), (0, -1)}
queue = collections.deque([(sr, sc)])
oriColor = image[sr][sc]
while queue:
point = queue.popleft()
image[point[0]][point[1]] = newColor
for direction in directions:
new_i = point[0] + direction[0]
new_j = point[1] + direction[1]
if 0 <= new_i < len(image) and 0 <= new_j < len(image[0]) and image[new_i][new_j] == oriColor:
queue.append((new_i, new_j))
return image
```
================================================
FILE: docs/solutions/0700-0799/global-and-local-inversions.md
================================================
# [0775. 全局倒置与局部倒置](https://leetcode.cn/problems/global-and-local-inversions/)
- 标签:数组、数学
- 难度:中等
## 题目链接
- [0775. 全局倒置与局部倒置 - 力扣](https://leetcode.cn/problems/global-and-local-inversions/)
## 题目大意
**描述**:
给定一个长度为 $n$ 的整数数组 $nums$ ,表示由范围 $[0, n - 1]$ 内所有整数组成的一个排列。
- 「全局倒置」的数目等于满足下述条件不同下标对 $(i, j)$ 的数目:
- $0 \le i < j < n$
- $nums[i] > nums[j]$
- 「局部倒置」的数目等于满足下述条件的下标 i 的数目:
- $0 <= i < n - 1$
- $nums[i] > nums[i + 1]$
**要求**:
当数组 $nums$ 中「全局倒置」的数量等于「局部倒置」的数量时,返回 true;否则,返回 false。
**说明**:
- $n == nums.length$。
- $1 \le n \le 10^{5}$。
- $0 \le nums[i] \lt n$。
- $nums$ 中的所有整数 互不相同。
- $nums$ 是范围 $[0, n - 1]$ 内所有数字组成的一个排列。
**示例**:
- 示例 1:
```python
输入:nums = [1,0,2]
输出:true
解释:有 1 个全局倒置,和 1 个局部倒置。
```
- 示例 2:
```python
输入:nums = [1,2,0]
输出:false
解释:有 2 个全局倒置,和 1 个局部倒置。
```
## 解题思路
### 思路 1:数学规律
这道题的关键在于观察全局倒置和局部倒置的关系。
**核心观察**:
- 局部倒置是指相邻元素的倒置:$nums[i] > nums[i+1]$。
- 全局倒置是指任意两个元素的倒置:$i < j$ 且 $nums[i] > nums[j]$。
- 显然,所有局部倒置都是全局倒置。
- 要使全局倒置数量等于局部倒置数量,就要保证不存在非局部的全局倒置。
- 即:不存在 $i < j - 1$ 且 $nums[i] > nums[j]$ 的情况。
**等价条件**:
- 对于每个位置 $i$,$nums[i]$ 与其原本应该在的位置 $i$ 的差距不能超过 $1$。
- 即:$|nums[i] - i| \leq 1$。
**解题步骤**:
1. 遍历数组,检查每个元素是否满足 $|nums[i] - i| \leq 1$。
2. 如果所有元素都满足,返回 `True`。
3. 否则返回 `False`。
### 思路 1:代码
```python
class Solution:
def isIdealPermutation(self, nums: List[int]) -> bool:
# 检查每个元素是否与其索引的差距不超过 1
for i in range(len(nums)):
if abs(nums[i] - i) > 1:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $nums$ 的长度。需要遍历数组一次。
- **空间复杂度**:$O(1)$。只使用了常数个额外变量。
================================================
FILE: docs/solutions/0700-0799/index.md
================================================
## 本章内容
- [0700. 二叉搜索树中的搜索](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/search-in-a-binary-search-tree.md)
- [0701. 二叉搜索树中的插入操作](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/insert-into-a-binary-search-tree.md)
- [0702. 搜索长度未知的有序数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/search-in-a-sorted-array-of-unknown-size.md)
- [0703. 数据流中的第 K 大元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/kth-largest-element-in-a-stream.md)
- [0704. 二分查找](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/binary-search.md)
- [0705. 设计哈希集合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/design-hashset.md)
- [0706. 设计哈希映射](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/design-hashmap.md)
- [0707. 设计链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/design-linked-list.md)
- [0708. 循环有序列表的插入](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/insert-into-a-sorted-circular-linked-list.md)
- [0709. 转换成小写字母](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/to-lower-case.md)
- [0710. 黑名单中的随机数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/random-pick-with-blacklist.md)
- [0712. 两个字符串的最小ASCII删除和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/minimum-ascii-delete-sum-for-two-strings.md)
- [0713. 乘积小于 K 的子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/subarray-product-less-than-k.md)
- [0714. 买卖股票的最佳时机含手续费](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/best-time-to-buy-and-sell-stock-with-transaction-fee.md)
- [0715. Range 模块](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/range-module.md)
- [0717. 1 比特与 2 比特字符](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/1-bit-and-2-bit-characters.md)
- [0718. 最长重复子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/maximum-length-of-repeated-subarray.md)
- [0719. 找出第 K 小的数对距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/find-k-th-smallest-pair-distance.md)
- [0720. 词典中最长的单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/longest-word-in-dictionary.md)
- [0721. 账户合并](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/accounts-merge.md)
- [0722. 删除注释](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/remove-comments.md)
- [0724. 寻找数组的中心下标](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/find-pivot-index.md)
- [0725. 分隔链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/split-linked-list-in-parts.md)
- [0726. 原子的数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/number-of-atoms.md)
- [0727. 最小窗口子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/minimum-window-subsequence.md)
- [0728. 自除数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/self-dividing-numbers.md)
- [0729. 我的日程安排表 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/my-calendar-i.md)
- [0730. 统计不同回文子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/count-different-palindromic-subsequences.md)
- [0731. 我的日程安排表 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/my-calendar-ii.md)
- [0732. 我的日程安排表 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/my-calendar-iii.md)
- [0733. 图像渲染](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/flood-fill.md)
- [0735. 小行星碰撞](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/asteroid-collision.md)
- [0736. Lisp 语法解析](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/parse-lisp-expression.md)
- [0738. 单调递增的数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/monotone-increasing-digits.md)
- [0739. 每日温度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/daily-temperatures.md)
- [0740. 删除并获得点数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/delete-and-earn.md)
- [0741. 摘樱桃](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/cherry-pickup.md)
- [0743. 网络延迟时间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/network-delay-time.md)
- [0744. 寻找比目标字母大的最小字母](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/find-smallest-letter-greater-than-target.md)
- [0745. 前缀和后缀搜索](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/prefix-and-suffix-search.md)
- [0746. 使用最小花费爬楼梯](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/min-cost-climbing-stairs.md)
- [0747. 至少是其他数字两倍的最大数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/largest-number-at-least-twice-of-others.md)
- [0748. 最短补全词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/shortest-completing-word.md)
- [0749. 隔离病毒](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/contain-virus.md)
- [0752. 打开转盘锁](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/open-the-lock.md)
- [0753. 破解保险箱](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/cracking-the-safe.md)
- [0754. 到达终点数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/reach-a-number.md)
- [0756. 金字塔转换矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/pyramid-transition-matrix.md)
- [0757. 设置交集大小至少为2](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/set-intersection-size-at-least-two.md)
- [0758. 字符串中的加粗单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/bold-words-in-string.md)
- [0762. 二进制表示中质数个计算置位](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/prime-number-of-set-bits-in-binary-representation.md)
- [0763. 划分字母区间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/partition-labels.md)
- [0764. 最大加号标志](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/largest-plus-sign.md)
- [0765. 情侣牵手](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/couples-holding-hands.md)
- [0766. 托普利茨矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/toeplitz-matrix.md)
- [0767. 重构字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/reorganize-string.md)
- [0768. 最多能完成排序的块 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/max-chunks-to-make-sorted-ii.md)
- [0769. 最多能完成排序的块](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/max-chunks-to-make-sorted.md)
- [0770. 基本计算器 IV](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/basic-calculator-iv.md)
- [0771. 宝石与石头](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/jewels-and-stones.md)
- [0773. 滑动谜题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/sliding-puzzle.md)
- [0775. 全局倒置与局部倒置](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/global-and-local-inversions.md)
- [0777. 在 LR 字符串中交换相邻字符](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/swap-adjacent-in-lr-string.md)
- [0778. 水位上升的泳池中游泳](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/swim-in-rising-water.md)
- [0779. 第K个语法符号](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/k-th-symbol-in-grammar.md)
- [0780. 到达终点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/reaching-points.md)
- [0781. 森林中的兔子](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/rabbits-in-forest.md)
- [0782. 变为棋盘](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/transform-to-chessboard.md)
- [0783. 二叉搜索树节点最小距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/minimum-distance-between-bst-nodes.md)
- [0784. 字母大小写全排列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/letter-case-permutation.md)
- [0785. 判断二分图](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/is-graph-bipartite.md)
- [0786. 第 K 个最小的质数分数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/k-th-smallest-prime-fraction.md)
- [0787. K 站中转内最便宜的航班](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/cheapest-flights-within-k-stops.md)
- [0788. 旋转数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/rotated-digits.md)
- [0789. 逃脱阻碍者](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/escape-the-ghosts.md)
- [0790. 多米诺和托米诺平铺](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/domino-and-tromino-tiling.md)
- [0791. 自定义字符串排序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/custom-sort-string.md)
- [0792. 匹配子序列的单词数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/number-of-matching-subsequences.md)
- [0793. 阶乘函数后 K 个零](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/preimage-size-of-factorial-zeroes-function.md)
- [0794. 有效的井字游戏](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/valid-tic-tac-toe-state.md)
- [0795. 区间子数组个数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/number-of-subarrays-with-bounded-maximum.md)
- [0796. 旋转字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/rotate-string.md)
- [0797. 所有可能的路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/all-paths-from-source-to-target.md)
- [0798. 得分最高的最小轮调](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/smallest-rotation-with-highest-score.md)
- [0799. 香槟塔](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/champagne-tower.md)
================================================
FILE: docs/solutions/0700-0799/insert-into-a-binary-search-tree.md
================================================
# [0701. 二叉搜索树中的插入操作](https://leetcode.cn/problems/insert-into-a-binary-search-tree/)
- 标签:树、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [0701. 二叉搜索树中的插入操作 - 力扣](https://leetcode.cn/problems/insert-into-a-binary-search-tree/)
## 题目大意
**描述**:给定一个二叉搜索树的根节点和要插入树中的值 `val`。
**要求**:将 `val` 插入到二叉搜索树中,返回新的二叉搜索树的根节点。
**说明**:
- 树中的节点数将在 $[0, 10^4]$ 的范围内。
- $-10^8 \le Node.val \le 10^8$
- 所有值 `Node.val` 是独一无二的。
- $-10^8 \le val \le 10^8$。
- **保证** $val$ 在原始 BST 中不存在。
**示例**:
- 示例 1:
```python
输入:root = [4,2,7,1,3], val = 5
输出:[4,2,7,1,3,5]
解释:另一个满足题目要求可以通过的树是:
```
- 示例 2:
```python
输入:root = [40,20,60,10,30,50,70], val = 25
输出:[40,20,60,10,30,50,70,null,null,25]
```
## 解题思路
### 思路 1:递归
已知搜索二叉树的性质:
- 左子树上任意节点值均小于根节点,即 `root.left.val < root.val`。
- 右子树上任意节点值均大于根节点,即 `root.left.val > root.val`。
那么根据 `val` 和当前节点的大小关系,则可以确定将 `val` 插入到当前节点的哪个子树上。具体步骤如下:
1. 从根节点 `root` 开始向下递归遍历。根据 `val` 值和当前子树节点 `cur` 的大小关系:
1. 如果 `val < cur.val`,则应在当前节点的左子树继续遍历判断。
1. 如果左子树为空,则新建节点,赋值为 `val`。链接到该子树的父节点上。并停止遍历。
2. 如果左子树不为空,则继续向左子树移动。
2. 如果 `val >= cur.val`,则应在当前节点的右子树继续遍历判断。
1. 如果右子树为空,则新建节点,赋值为 `val`。链接到该子树的父节点上。并停止遍历。
2. 如果右子树不为空,则继续向左子树移动。
2. 遍历完返回根节点 `root`。
### 思路 1:代码
```python
class Solution:
def insertIntoBST(self, root: TreeNode, val: int) -> TreeNode:
if not root:
return TreeNode(val)
cur = root
while cur:
if val < cur.val:
if not cur.left:
cur.left = TreeNode(val)
break
else:
cur = cur.left
else:
if not cur.right:
cur.right = TreeNode(val)
break
else:
cur = cur.right
return root
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。其中 $n$ 是二叉搜索树的节点数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0700-0799/insert-into-a-sorted-circular-linked-list.md
================================================
# [0708. 循环有序列表的插入](https://leetcode.cn/problems/insert-into-a-sorted-circular-linked-list/)
- 标签:链表
- 难度:中等
## 题目链接
- [0708. 循环有序列表的插入 - 力扣](https://leetcode.cn/problems/insert-into-a-sorted-circular-linked-list/)
## 题目大意
给定循环升序链表中的一个节点 `head` 和一个整数 `insertVal`。
要求:将整数 `insertVal` 插入循环升序链表中,并且满足链表仍为循环升序链表。最终返回原先给定的节点。
## 解题思路
- 先判断所给节点 `head` 是否为空,为空直接创建一个值为 `insertVal` 的新节点,并指向自己,返回即可。
- 如果 `head` 不为空,把 `head` 赋值给 `node` ,方便最后返回原节点 `head`。
- 然后遍历 `node`,判断插入值 `insertVal` 与 `node.val` 和 `node.next.val` 的关系,找到插入位置,具体判断如下:
- 如果新节点值在两个节点值中间, 即 `node.val <= insertVal <= node.next.val`。则说明新节点值在最大值最小值中间,应将新节点插入到当前位置,则应将 `insertVal` 插入到这个位置。
- 如果新节点值比当前节点值和当前节点下一节点值都大,并且当前节点值比当前节点值的下一节点值大,即 `node.next.val < node.val <= insertVal`,则说明 `insertVal` 比链表最大值都大,应插入最大值后边。
- 如果新节点值比当前节点值和当前节点下一节点值都小,并且当前节点值比当前节点值的下一节点值大,即 `insertVal < node.next.val < node.val`,则说明 `insertVal` 比链表中最小值都小,应插入最小值前边。
- 找到插入位置后,跳出循环,在插入位置插入值为 `insertVal` 的新节点。
## 代码
```python
class Solution:
def insert(self, head: 'Node', insertVal: int) -> 'Node':
if not head:
node = Node(insertVal)
node.next = node
return node
node = head
while node.next != head:
if node.val <= insertVal <= node.next.val:
break
elif node.next.val < node.val <= insertVal:
break
elif insertVal < node.next.val < node.val:
break
else:
node = node.next
insert_node = Node(insertVal)
insert_node.next = node.next
node.next = insert_node
return head
```
================================================
FILE: docs/solutions/0700-0799/is-graph-bipartite.md
================================================
# [0785. 判断二分图](https://leetcode.cn/problems/is-graph-bipartite/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [0785. 判断二分图 - 力扣](https://leetcode.cn/problems/is-graph-bipartite/)
## 题目大意
给定一个代表 n 个节点的无向图的二维数组 `graph`,其中 `graph[u]` 是一个节点数组,由节点 `u` 的邻接节点组成。对于 `graph[u]` 中的每个 `v`,都存在一条位于节点 `u` 和节点 `v` 之间的无向边。
该无向图具有以下属性:
- 不存在自环(`graph[u]` 不包含 `u`)。
- 不存在平行边(`graph[u]` 不包含重复值)。
- 如果 `v` 在 `graph[u]` 内,那么 `u` 也应该在 `graph[v]` 内(该图是无向图)。
- 这个图可能不是连通图,也就是说两个节点 `u` 和 `v` 之间可能不存在一条连通彼此的路径。
要求:判断该图是否是二分图,如果是二分图,则返回 `True`;否则返回 `False`。
- 二分图:如果能将一个图的节点集合分割成两个独立的子集 `A` 和 `B`,并使图中的每一条边的两个节点一个来自 `A` 集合,一个来自 `B` 集合,就将这个图称为 二分图 。
## 解题思路
对于图中的任意节点 `u` 和 `v`,如果 `u` 和 `v` 之间有一条无向边,那么 `u` 和 `v` 必然属于不同的集合。
我们可以通过在深度优先搜索中对邻接点染色标记的方式,来识别该图是否是二分图。具体做法如下:
- 找到一个没有染色的节点 `u`,将其染成红色。
- 然后遍历该节点直接相连的节点 `v`,如果该节点没有被染色,则将该节点直接相连的节点染成蓝色,表示两个节点不是同一集合。如果该节点已经被染色并且颜色跟 `u` 一样,则说明该图不是二分图,直接返回 `False`。
- 从上面染成蓝色的节点 `v` 出发,遍历该节点直接相连的节点。。。依次类推的递归下去。
- 如果所有节点都顺利染上色,则说明该图为二分图,返回 `True`。否则,如果在途中不能顺利染色,则返回 `False`。
## 代码
```python
class Solution:
def dfs(self, graph, colors, i, color):
colors[i] = color
for j in graph[i]:
if colors[j] == colors[i]:
return False
if colors[j] == 0 and not self.dfs(graph, colors, j, -color):
return False
return True
def isBipartite(self, graph: List[List[int]]) -> bool:
size = len(graph)
colors = [0 for _ in range(size)]
for i in range(size):
if colors[i] == 0 and not self.dfs(graph, colors, i, 1):
return False
return True
```
================================================
FILE: docs/solutions/0700-0799/jewels-and-stones.md
================================================
# [0771. 宝石与石头](https://leetcode.cn/problems/jewels-and-stones/)
- 标签:哈希表、字符串
- 难度:简单
## 题目链接
- [0771. 宝石与石头 - 力扣](https://leetcode.cn/problems/jewels-and-stones/)
## 题目大意
**描述**:给定一个字符串 $jewels$ 代表石头中宝石的类型,再给定一个字符串 $stones$ 代表你拥有的石头。$stones$ 中每个字符代表了一种你拥有的石头的类型。
**要求**:计算出拥有的石头中有多少是宝石。
**说明**:
- 字母区分大小写,因此 $a$ 和 $A$ 是不同类型的石头。
- $1 \le jewels.length, stones.length \le 50$。
- $jewels$ 和 $stones$ 仅由英文字母组成。
- $jewels$ 中的所有字符都是唯一的。
**示例**:
- 示例 1:
```python
输入:jewels = "aA", stones = "aAAbbbb"
输出:3
```
- 示例 2:
```python
输入:jewels = "z", stones = "ZZ"
输出:0
```
## 解题思路
### 思路 1:哈希表
1. 用 $count$ 来维护石头中的宝石个数。
2. 先使用哈希表或者集合存储宝石。
3. 再遍历数组 $stones$,并统计每块石头是否在哈希表中或集合中。
1. 如果当前石头在哈希表或集合中,则令 $count$ 加 $1$。
2. 如果当前石头不在哈希表或集合中,则不统计。
4. 最后返回 $count$。
### 思路 1:代码
```python
class Solution:
def numJewelsInStones(self, jewels: str, stones: str) -> int:
jewel_dict = dict()
for jewel in jewels:
jewel_dict[jewel] = 1
count = 0
for stone in stones:
if stone in jewel_dict:
count += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m + n)$,其中 $m$ 是字符串 $jewels$ 的长度,$n$ 是 $stones$ 的长度。
- **空间复杂度**:$O(m)$,其中 $m$ 是字符串 $jewels$ 的长度。
================================================
FILE: docs/solutions/0700-0799/k-th-smallest-prime-fraction.md
================================================
# [0786. 第 K 个最小的质数分数](https://leetcode.cn/problems/k-th-smallest-prime-fraction/)
- 标签:数组、双指针、二分查找、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [0786. 第 K 个最小的质数分数 - 力扣](https://leetcode.cn/problems/k-th-smallest-prime-fraction/)
## 题目大意
**描述**:
给定一个按递增顺序排序的数组 $arr$ 和一个整数 $k$。数组 $arr$ 由 $1$ 和若干质数组成,且其中所有整数互不相同。
对于每对满足 $0 \le i < j < arr.length$ 的 $i$ 和 $j$,可以得到分数 $arr[i] / arr[j]$。
**要求**:
计算第 $k$ 个最小的分数。以长度为 $2$ 的整数数组返回你的答案, 这里 $answer[0] == arr[i]$ 且 $answer[1] == arr[j]$。
**说明**:
- $2 \le arr.length \le 10^{3}$。
- $1 \le arr[i] \le 3 * 10^{4}$。
- $arr[0] == 1$。
- $arr[i]$ 是一个「质数」,$i \gt 0$。
- arr 中的所有数字「互不相同」,且按「严格递增」排序。
- $1 \le k \le arr.length \times (arr.length - 1) / 2$。
- 进阶:你可以设计并实现时间复杂度小于 $O(n^2)$ 的算法解决此问题吗?
**示例**:
- 示例 1:
```python
输入:arr = [1,2,3,5], k = 3
输出:[2,5]
解释:已构造好的分数,排序后如下所示:
1/5, 1/3, 2/5, 1/2, 3/5, 2/3
很明显第三个最小的分数是 2/5
```
- 示例 2:
```python
输入:arr = [1,7], k = 1
输出:[1,7]
```
## 解题思路
### 思路 1:优先队列(最小堆)
这道题要求找到第 $k$ 个最小的质数分数。可以使用优先队列来解决。
**解题步骤**:
1. 将所有可能的分数 $\frac{arr[i]}{arr[j]}$($i < j$)加入优先队列。
2. 由于数组是递增的,对于每个分母 $arr[j]$,最小的分数是 $\frac{arr[0]}{arr[j]}$。
3. 使用最小堆,初始时将所有 $\frac{arr[0]}{arr[j]}$($j > 0$)加入堆中。
4. 每次从堆中取出最小的分数,如果这是第 $k$ 个,返回结果。
5. 如果取出的分数是 $\frac{arr[i]}{arr[j]}$ 且 $i + 1 < j$,将 $\frac{arr[i+1]}{arr[j]}$ 加入堆中。
**优化**:使用索引而不是实际的分数值,避免浮点数比较的精度问题。
### 思路 1:代码
```python
class Solution:
def kthSmallestPrimeFraction(self, arr: List[int], k: int) -> List[int]:
import heapq
n = len(arr)
# 最小堆,存储 (分数值, 分子索引, 分母索引)
heap = []
# 初始化:将所有 arr[0]/arr[j] 加入堆
for j in range(1, n):
heapq.heappush(heap, (arr[0] / arr[j], 0, j))
# 取出前 k-1 个最小的分数
for _ in range(k - 1):
_, i, j = heapq.heappop(heap)
# 如果还有更大的分子,加入堆中
if i + 1 < j:
heapq.heappush(heap, (arr[i + 1] / arr[j], i + 1, j))
# 第 k 个最小的分数
_, i, j = heapq.heappop(heap)
return [arr[i], arr[j]]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(k \log n)$,其中 $n$ 是数组 $arr$ 的长度。初始化堆需要 $O(n \log n)$,取出 $k$ 个元素需要 $O(k \log n)$。
- **空间复杂度**:$O(n)$。堆中最多存储 $n$ 个元素。
================================================
FILE: docs/solutions/0700-0799/k-th-symbol-in-grammar.md
================================================
# [0779. 第K个语法符号](https://leetcode.cn/problems/k-th-symbol-in-grammar/)
- 标签:位运算、递归、数学
- 难度:中等
## 题目链接
- [0779. 第K个语法符号 - 力扣](https://leetcode.cn/problems/k-th-symbol-in-grammar/)
## 题目大意
**描述**:给定两个整数 $n$ 和 $k$。我们可以按照下面的规则来生成字符串:
- 第一行写上一个 $0$。
- 从第二行开始,每一行将上一行的 $0$ 替换成 $01$,$1$ 替换为 $10$。
**要求**:输出第 $n$ 行字符串中的第 $k$ 个字符。
**说明**:
- $1 \le n \le 30$。
- $1 \le k \le 2^{n - 1}$。
**示例**:
- 示例 1:
```python
输入: n = 2, k = 1
输出: 0
解释:
第一行: 0
第二行: 01
```
- 示例 2:
```python
输入: n = 4, k = 4
输出: 0
解释:
第一行:0
第二行:01
第三行:0110
第四行:01101001
```
## 解题思路
### 思路 1:递归算法 + 找规律
每一行都是由上一行生成的。我们可以将多行写到一起找下规律。
可以发现:第 $k$ 个数字是由上一位对应位置上的数字生成的。
- $k$ 在奇数位时,由上一行 $(k + 1) / 2$ 位置的值生成。且与上一行 $(k + 1) / 2$ 位置的值相同;
- $k$ 在偶数位时,由上一行 $k / 2$ 位置的值生成。且与上一行 $k / 2$ 位置的值相反。
接下来就是递归求解即可。
### 思路 1:代码
```python
class Solution:
def kthGrammar(self, n: int, k: int) -> int:
if n == 0:
return 0
if k % 2 == 1:
return self.kthGrammar(n - 1, (k + 1) // 2)
else:
return abs(self.kthGrammar(n - 1, k // 2) - 1)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0700-0799/kth-largest-element-in-a-stream.md
================================================
# [0703. 数据流中的第 K 大元素](https://leetcode.cn/problems/kth-largest-element-in-a-stream/)
- 标签:树、设计、二叉搜索树、二叉树、数据流、堆(优先队列)
- 难度:简单
## 题目链接
- [0703. 数据流中的第 K 大元素 - 力扣](https://leetcode.cn/problems/kth-largest-element-in-a-stream/)
## 题目大意
**要求**:设计一个 KthLargest 类,用于找到数据流中第 $k$ 大元素。
实现 KthLargest 类:
- `KthLargest(int k, int[] nums)`:使用整数 $k$ 和整数流 $nums$ 初始化对象。
- `int add(int val)`:将 $val$ 插入数据流 $nums$ 后,返回当前数据流中第 $k$ 大的元素。
**说明**:
- $1 \le k \le 10^4$。
- $0 \le nums.length \le 10^4$。
- $-10^4 \le nums[i] \le 10^4$。
- $-10^4 \le val \le 10^4$。
- 最多调用 `add` 方法 $10^4$ 次。
- 题目数据保证,在查找第 $k$ 大元素时,数组中至少有 $k$ 个元素。
**示例**:
- 示例 1:
```python
输入:
["KthLargest", "add", "add", "add", "add", "add"]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
输出:
[null, 4, 5, 5, 8, 8]
解释:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
```
## 解题思路
### 思路 1:堆
1. 建立大小为 $k$ 的大顶堆,堆中元素保证不超过 $k$ 个。
2. 每次 `add` 操作时,将新元素压入堆中,如果堆中元素超出了 $k$ 个,则将堆中最小元素(堆顶)移除。
- 此时堆中最小元素(堆顶)就是整个数据流中的第 $k$ 大元素。
### 思路 1:代码
```python
import heapq
class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.min_heap = []
self.k = k
for num in nums:
heapq.heappush(self.min_heap, num)
if len(self.min_heap) > k:
heapq.heappop(self.min_heap)
def add(self, val: int) -> int:
heapq.heappush(self.min_heap, val)
if len(self.min_heap) > self.k:
heapq.heappop(self.min_heap)
return self.min_heap[0]
```
### 思路 1:复杂度分析
- **时间复杂度**:
- 初始化时间复杂度:$O(n \times \log k)$,其中 $n$ 为 $nums$ 初始化时的元素个数。
- 单次插入时间复杂度:$O(\log k)$。
- **空间复杂度**:$O(k)$。
================================================
FILE: docs/solutions/0700-0799/largest-number-at-least-twice-of-others.md
================================================
# [0747. 至少是其他数字两倍的最大数](https://leetcode.cn/problems/largest-number-at-least-twice-of-others/)
- 标签:数组、排序
- 难度:简单
## 题目链接
- [0747. 至少是其他数字两倍的最大数 - 力扣](https://leetcode.cn/problems/largest-number-at-least-twice-of-others/)
## 题目大意
**描述**:
给定一个整数数组 $nums$,其中总是存在「唯一的」一个最大整数。
**要求**:
找出数组中的最大元素并检查它是否 至少是数组中每个其他数字的两倍。如果是,则返回「最大元素的下标」,否则返回 $-1$。
**说明**:
- $2 \le nums.length \le 50$。
- $0 \le nums[i] \le 10^{3}$。
- $nums$ 中的最大元素是唯一的。
**示例**:
- 示例 1:
```python
输入:nums = [3,6,1,0]
输出:1
解释:6 是最大的整数,对于数组中的其他整数,6 至少是数组中其他元素的两倍。6 的下标是 1 ,所以返回 1 。
```
- 示例 2:
```python
输入:nums = [1,2,3,4]
输出:-1
解释:4 没有超过 3 的两倍大,所以返回 -1 。
```
## 解题思路
### 思路 1:一次遍历
这道题要求找到数组中的最大元素,并检查它是否至少是其他所有元素的两倍。
**解题步骤**:
1. 遍历数组,找到最大元素及其索引,同时记录第二大元素。
2. 检查最大元素是否至少是第二大元素的两倍。
3. 如果是,返回最大元素的索引;否则返回 $-1$。
**优化**:只需要一次遍历即可完成。
### 思路 1:代码
```python
class Solution:
def dominantIndex(self, nums: List[int]) -> int:
if len(nums) == 1:
return 0
max_val = -1
max_idx = -1
second_max = -1
# 找到最大值和第二大值
for i, num in enumerate(nums):
if num > max_val:
second_max = max_val
max_val = num
max_idx = i
elif num > second_max:
second_max = num
# 检查最大值是否至少是第二大值的两倍
if max_val >= second_max * 2:
return max_idx
else:
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $nums$ 的长度。需要遍历数组一次。
- **空间复杂度**:$O(1)$。只使用了常数个额外变量。
================================================
FILE: docs/solutions/0700-0799/largest-plus-sign.md
================================================
# [0764. 最大加号标志](https://leetcode.cn/problems/largest-plus-sign/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [0764. 最大加号标志 - 力扣](https://leetcode.cn/problems/largest-plus-sign/)
## 题目大意
**描述**:
在一个 $n \times n$ 的矩阵 $grid$ 中,除了在数组 $mines$ 中给出的元素为 $0$,其他每个元素都为 $1$。$mines[i] = [xi, yi]$ 表示 $grid[xi][yi] == 0$。
**要求**:
返回 $grid$ 中包含 $1$ 的最大的「轴对齐」加号标志的阶数。如果未找到加号标志,则返回 $0$。
**说明**:
- 一个 $k$ 阶由 $1$ 组成的「轴对称加号标志」具有中心网格 $grid[r][c] == 1$,以及 $4$ 个从中心向上、向下、向左、向右延伸,长度为 $k - 1$,由 $1$ 组成的臂。注意,只有加号标志的所有网格要求为 $1$,别的网格可能为 $0$ 也可能为 $1$。
- $1 \le n \le 500$。
- $1 \le mines.length \le 5000$。
- $0 \le xi, yi \lt n$。
- 每一对 $(xi, yi)$ 都「不重复」。
**示例**:
- 示例 1:
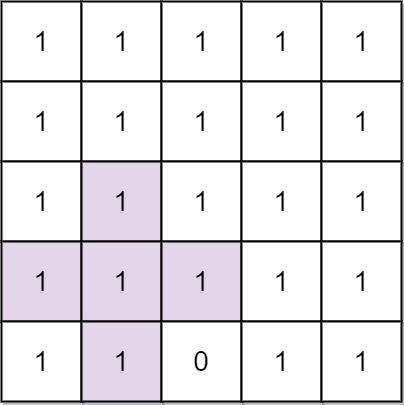
```python
输入: n = 5, mines = [[4, 2]]
输出: 2
解释: 在上面的网格中,最大加号标志的阶只能是2。一个标志已在图中标出。
```
- 示例 2:

```python
输入: n = 1, mines = [[0, 0]]
输出: 0
解释: 没有加号标志,返回 0 。
```
## 解题思路
### 思路 1:动态规划
这道题要求计算每个位置能形成的最大加号标志的阶数。
**解题步骤**:
1. 首先将所有位置初始化为 $1$,将 $mines$ 中的位置标记为 $0$。
2. 对于每个位置 $(i, j)$,计算其四个方向(上、下、左、右)连续 $1$ 的个数。
3. 定义 $dp[i][j]$ 表示位置 $(i, j)$ 能形成的最大加号标志的阶数。
4. $dp[i][j] = \min(\text{上}, \text{下}, \text{左}, \text{右})$,即四个方向中最小的连续 $1$ 的个数。
5. 返回所有 $dp[i][j]$ 中的最大值。
**优化**:可以在一次遍历中同时计算四个方向的连续 $1$ 的个数。
### 思路 1:代码
```python
class Solution:
def orderOfLargestPlusSign(self, n: int, mines: List[List[int]]) -> int:
# 初始化所有位置为 n(表示最多可以延伸 n 个单位)
dp = [[n] * n for _ in range(n)]
# 将 mines 中的位置标记为 0
banned = set(map(tuple, mines))
for x, y in banned:
dp[x][y] = 0
# 计算每个位置四个方向的最小连续 1 的个数
for i in range(n):
# 从左到右
left = 0
# 从右到左
right = 0
# 从上到下
up = 0
# 从下到上
down = 0
for j in range(n):
# 从左到右
left = 0 if (i, j) in banned else left + 1
dp[i][j] = min(dp[i][j], left)
# 从右到左
right = 0 if (i, n - 1 - j) in banned else right + 1
dp[i][n - 1 - j] = min(dp[i][n - 1 - j], right)
# 从上到下
up = 0 if (j, i) in banned else up + 1
dp[j][i] = min(dp[j][i], up)
# 从下到上
down = 0 if (n - 1 - j, i) in banned else down + 1
dp[n - 1 - j][i] = min(dp[n - 1 - j][i], down)
# 返回最大值
return max(max(row) for row in dp)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是矩阵的边长。需要遍历矩阵四次。
- **空间复杂度**:$O(n^2)$。需要存储 $dp$ 数组和 $banned$ 集合。
================================================
FILE: docs/solutions/0700-0799/letter-case-permutation.md
================================================
# [0784. 字母大小写全排列](https://leetcode.cn/problems/letter-case-permutation/)
- 标签:位运算、字符串、回溯
- 难度:中等
## 题目链接
- [0784. 字母大小写全排列 - 力扣](https://leetcode.cn/problems/letter-case-permutation/)
## 题目大意
**描述**:给定一个字符串 $s$,通过将字符串 $s$ 中的每个字母转变大小写,我们可以获得一个新的字符串。
**要求**:返回所有可能得到的字符串集合。
**说明**:
- 答案可以以任意顺序返回输出。
- $1 \le s.length \le 12$。
- $s$ 由小写英文字母、大写英文字母和数字组成。
**示例**:
- 示例 1:
```python
输入:s = "a1b2"
输出:["a1b2", "a1B2", "A1b2", "A1B2"]
```
- 示例 2:
```python
输入: s = "3z4"
输出: ["3z4","3Z4"]
```
## 解题思路
### 思路 1:回溯算法
- $i$ 代表当前要处理的字符在字符串 $s$ 中的下标,$path$ 表示当前路径,$ans$ 表示答案数组。
- 如果处理到 $i == len(s)$ 时,将当前路径存入答案数组中返回,否则进行递归处理。
- 不修改当前字符,直接递归处理第 $i + 1$ 个字符。
- 如果当前字符是小写字符,则变为大写字符之后,递归处理第 $i + 1$ 个字符。
- 如果当前字符是大写字符,则变为小写字符之后,递归处理第 $i + 1$ 个字符。
### 思路 1:代码
```python
class Solution:
def dfs(self, s, path, i, ans):
if i == len(s):
ans.append(path)
return
self.dfs(s, path + s[i], i + 1, ans)
if ord('a') <= ord(s[i]) <= ord('z'):
self.dfs(s, path + s[i].upper(), i + 1, ans)
elif ord('A') <= ord(s[i]) <= ord('Z'):
self.dfs(s, path + s[i].lower(), i + 1, ans)
def letterCasePermutation(self, s: str) -> List[str]:
ans, path = [], ""
self.dfs(s, path, 0, ans)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$n \times 2^n$,其中 $n$ 为字符串的长度。
- **空间复杂度**:$O(1)$,除返回值外不需要额外的空间。
================================================
FILE: docs/solutions/0700-0799/longest-word-in-dictionary.md
================================================
# [0720. 词典中最长的单词](https://leetcode.cn/problems/longest-word-in-dictionary/)
- 标签:字典树、数组、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [0720. 词典中最长的单词 - 力扣](https://leetcode.cn/problems/longest-word-in-dictionary/)
## 题目大意
给出一个字符串数组 `words` 组成的一本英语词典。
要求:从中找出最长的一个单词,该单词是由 `words` 词典中其他单词逐步添加一个字母组成。如果其中有多个可行的答案,则返回答案中字典序最小的单词。如果无答案,则返回空字符串。
## 解题思路
使用字典树存储每一个单词。再在字典树中查找每一个单词,查找的时候判断是否有以当前单词为前缀的单词。如果有,则该单词可以由前缀构成的单词逐步添加字母获得。此时,如果该单词比答案单词更长,则维护更新答案单词。
最后输出答案单词。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children or not cur.children[ch].isEnd:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class Solution:
def longestWord(self, words: List[str]) -> str:
trie_tree = Trie()
for word in words:
trie_tree.insert(word)
ans = ""
for word in words:
if trie_tree.search(word):
if len(word) > len(ans):
ans = word
elif len(word) == len(ans) and word < ans:
ans = word
return ans
```
================================================
FILE: docs/solutions/0700-0799/max-chunks-to-make-sorted-ii.md
================================================
# [0768. 最多能完成排序的块 II](https://leetcode.cn/problems/max-chunks-to-make-sorted-ii/)
- 标签:栈、贪心、数组、排序、单调栈
- 难度:困难
## 题目链接
- [0768. 最多能完成排序的块 II - 力扣](https://leetcode.cn/problems/max-chunks-to-make-sorted-ii/)
## 题目大意
**描述**:
给定一个整数数组 $arr$。将 $arr$ 分割成若干块,并将这些块分别进行排序。之后再连接起来,使得连接的结果和按升序排序后的原数组相同。
**要求**:
返回能将数组分成的最多块数。
**说明**:
- $1 \le arr.length \le 2000$。
- $0 \le arr[i] \le 10^{8}$。
**示例**:
- 示例 1:
```python
输入:arr = [5,4,3,2,1]
输出:1
解释:
将数组分成2块或者更多块,都无法得到所需的结果。
例如,分成 [5, 4], [3, 2, 1] 的结果是 [4, 5, 1, 2, 3],这不是有序的数组。
```
- 示例 2:
```python
输入:arr = [2,1,3,4,4]
输出:4
解释:
可以把它分成两块,例如 [2, 1], [3, 4, 4]。
然而,分成 [2, 1], [3], [4], [4] 可以得到最多的块数。
```
## 解题思路
### 思路 1:单调栈
这道题要求将数组分成若干块,每块单独排序后连接起来,结果与整体排序相同。
**核心观察**:
- 如果可以在位置 $i$ 处分割,那么 $arr[0:i+1]$ 中的最大值必须 $\leq$ $arr[i+1:]$ 中的最小值。
- 等价于:前 $i+1$ 个元素排序后,应该恰好是整体排序后的前 $i+1$ 个元素。
**解题步骤**:
1. 从左到右遍历数组,维护当前的最大值 $max\_left$。
2. 同时预处理从右到左的最小值数组 $min\_right$。
3. 如果在位置 $i$ 处,$max\_left \leq min\_right[i+1]$,说明可以在此处分割。
4. 统计所有可以分割的位置数量。
**优化**:可以使用单调栈来解决,但对于这道题,简单的贪心方法更直观。
### 思路 1:代码
```python
class Solution:
def maxChunksToSorted(self, arr: List[int]) -> int:
n = len(arr)
# 预处理从右到左的最小值
min_right = [0] * (n + 1)
min_right[n] = float('inf')
for i in range(n - 1, -1, -1):
min_right[i] = min(arr[i], min_right[i + 1])
chunks = 0
max_left = 0
# 从左到右遍历
for i in range(n):
max_left = max(max_left, arr[i])
# 如果当前最大值 <= 右侧最小值,可以分割
if max_left <= min_right[i + 1]:
chunks += 1
return chunks
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $arr$ 的长度。需要遍历数组两次。
- **空间复杂度**:$O(n)$。需要存储 $min\_right$ 数组。
================================================
FILE: docs/solutions/0700-0799/max-chunks-to-make-sorted.md
================================================
# [0769. 最多能完成排序的块](https://leetcode.cn/problems/max-chunks-to-make-sorted/)
- 标签:栈、贪心、数组、排序、单调栈
- 难度:中等
## 题目链接
- [0769. 最多能完成排序的块 - 力扣](https://leetcode.cn/problems/max-chunks-to-make-sorted/)
## 题目大意
**描述**:
给定一个长度为 $n$ 的整数数组 $arr$,它表示在 $[0, n - 1]$ 范围内的整数的排列。
我们将 $arr$ 分割成若干块 (即分区),并对每个块单独排序。将它们连接起来后,使得连接的结果和按升序排序后的原数组相同。
**要求**:
返回数组能分成的最多块数量。
**说明**:
- $n == arr.length$。
- $1 \le n \le 10$。
- $0 \le arr[i] \lt n$。
- $arr$ 中每个元素都「不同」。
**示例**:
- 示例 1:
```python
输入: arr = [4,3,2,1,0]
输出: 1
解释:
将数组分成2块或者更多块,都无法得到所需的结果。
例如,分成 [4, 3], [2, 1, 0] 的结果是 [3, 4, 0, 1, 2],这不是有序的数组。
```
- 示例 2:
```python
输入: arr = [1,0,2,3,4]
输出: 4
解释:
我们可以把它分成两块,例如 [1, 0], [2, 3, 4]。
然而,分成 [1, 0], [2], [3], [4] 可以得到最多的块数。
对每个块单独排序后,结果为 [0, 1], [2], [3], [4]
```
## 解题思路
### 思路 1:贪心算法
这道题是 0768 题的简化版本,数组元素是 $[0, n-1]$ 的排列。
**核心观察**:
- 由于数组是 $[0, n-1]$ 的排列,如果前 $i+1$ 个元素的最大值等于 $i$,说明前 $i+1$ 个元素恰好是 $[0, i]$。
- 此时可以在位置 $i$ 处分割,因为前面的元素排序后不会影响后面的元素。
**解题步骤**:
1. 从左到右遍历数组,维护当前的最大值 $max\_val$。
2. 如果在位置 $i$ 处,$max\_val = i$,说明前 $i+1$ 个元素恰好是 $[0, i]$,可以分割。
3. 统计所有可以分割的位置数量。
### 思路 1:代码
```python
class Solution:
def maxChunksToSorted(self, arr: List[int]) -> int:
chunks = 0
max_val = 0
for i in range(len(arr)):
max_val = max(max_val, arr[i])
# 如果当前最大值等于索引,说明前面的元素恰好是 [0, i]
if max_val == i:
chunks += 1
return chunks
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $arr$ 的长度。需要遍历数组一次。
- **空间复杂度**:$O(1)$。只使用了常数个额外变量。
================================================
FILE: docs/solutions/0700-0799/maximum-length-of-repeated-subarray.md
================================================
# [0718. 最长重复子数组](https://leetcode.cn/problems/maximum-length-of-repeated-subarray/)
- 标签:数组、二分查找、动态规划、滑动窗口、哈希函数、滚动哈希
- 难度:中等
## 题目链接
- [0718. 最长重复子数组 - 力扣](https://leetcode.cn/problems/maximum-length-of-repeated-subarray/)
## 题目大意
**描述**:给定两个整数数组 $nums1$、$nums2$。
**要求**:计算两个数组中公共的、长度最长的子数组长度。
**说明**:
- $1 \le nums1.length, nums2.length \le 1000$。
- $0 \le nums1[i], nums2[i] \le 100$。
**示例**:
- 示例 1:
```python
输入:nums1 = [1,2,3,2,1], nums2 = [3,2,1,4,7]
输出:3
解释:长度最长的公共子数组是 [3,2,1] 。
```
- 示例 2:
```python
输入:nums1 = [0,0,0,0,0], nums2 = [0,0,0,0,0]
输出:5
```
## 解题思路
### 思路 1:暴力(超时)
1. 枚举数组 $nums1$ 和 $nums2$ 的子数组开始位置 $i$、$j$。
2. 如果遇到相同项,即 $nums1[i] == nums2[j]$,则以 $nums1[i]$、$nums2[j]$ 为前缀,同时向后遍历,计算当前的公共子数组长度 $subLen$ 最长为多少。
3. 直到遇到超出数组范围或者 $nums1[i + subLen] == nums2[j + subLen]$ 情况时,停止遍历,并更新答案。
4. 继续执行 $1 \sim 3$ 步,直到遍历完,输出答案。
### 思路 1:代码
```python
class Solution:
def findLength(self, nums1: List[int], nums2: List[int]) -> int:
size1, size2 = len(nums1), len(nums2)
ans = 0
for i in range(size1):
for j in range(size2):
if nums1[i] == nums2[j]:
subLen = 1
while i + subLen < size1 and j + subLen < size2 and nums1[i + subLen] == nums2[j + subLen]:
subLen += 1
ans = max(ans, subLen)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m \times min(n, m))$。其中 $n$ 是数组 $nums1$ 的长度,$m$ 是数组 $nums2$ 的长度。
- **空间复杂度**:$O(1)$。
### 思路 2:滑动窗口
暴力方法中,因为子数组在两个数组中的位置不同,所以会导致子数组之间会进行多次比较。
我们可以将两个数组分别看做是两把直尺。然后将数组 $nums1$ 固定, 让 $nums2$ 的尾部与 $nums1$ 的头部对齐,如下所示。
```python
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
```
然后逐渐向右移动直尺 $nums2$,比较 $nums1$ 与 $nums2$ 重叠部分中的公共子数组的长度,直到直尺 $nums2$ 的头部移动到 $nums1$ 的尾部。
```python
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
nums1 = [1, 2, 3, 2, 1]
nums2 = [3, 2, 1, 4, 7]
```
在这个过程中求得的 $nums1$ 与 $nums2$ 重叠部分中的最大的公共子数组的长度就是 $nums1$ 与 $nums2$ 数组中公共的、长度最长的子数组长度。
### 思路 2:代码
```python
class Solution:
def findMaxLength(self, nums1, nums2, i, j):
size1, size2 = len(nums1), len(nums2)
max_len = 0
cur_len = 0
while i < size1 and j < size2:
if nums1[i] == nums2[j]:
cur_len += 1
max_len = max(max_len, cur_len)
else:
cur_len = 0
i += 1
j += 1
return max_len
def findLength(self, nums1: List[int], nums2: List[int]) -> int:
size1, size2 = len(nums1), len(nums2)
res = 0
for i in range(size1):
res = max(res, self.findMaxLength(nums1, nums2, i, 0))
for i in range(size2):
res = max(res, self.findMaxLength(nums1, nums2, 0, i))
return res
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n + m) \times min(n, m)$。其中 $n$ 是数组 $nums1$ 的长度,$m$ 是数组 $nums2$ 的长度。
- **空间复杂度**:$O(1)$。
### 思路 3:动态规划
###### 1. 阶段划分
按照子数组结尾位置进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 为:「以 $nums1$ 中前 $i$ 个元素为子数组($nums1[0]...nums2[i - 1]$)」和「以 $nums2$ 中前 $j$ 个元素为子数组($nums2[0]...nums2[j - 1]$)」的最长公共子数组长度。
###### 3. 状态转移方程
1. 如果 $nums1[i - 1] = nums2[j - 1]$,则当前元素可以构成公共子数组,此时 $dp[i][j] = dp[i - 1][j - 1] + 1$。
2. 如果 $nums1[i - 1] \ne nums2[j - 1]$,则当前元素不能构成公共子数组,此时 $dp[i][j] = 0$。
###### 4. 初始条件
- 当 $i = 0$ 时,$nums1[0]...nums1[i - 1]$ 表示的是空数组,空数组与 $nums2[0]...nums2[j - 1]$ 的最长公共子序列长度为 $0$,即 $dp[0][j] = 0$。
- 当 $j = 0$ 时,$nums2[0]...nums2[j - 1]$ 表示的是空数组,空数组与 $nums1[0]...nums1[i - 1]$ 的最长公共子序列长度为 $0$,即 $dp[i][0] = 0$。
###### 5. 最终结果
- 根据状态定义, $dp[i][j]$ 为:「以 $nums1$ 中前 $i$ 个元素为子数组($nums1[0]...nums2[i - 1]$)」和「以 $nums2$ 中前 $j$ 个元素为子数组($nums2[0]...nums2[j - 1]$)」的最长公共子数组长度。在遍历过程中,我们可以使用 $res$ 记录下所有 $dp[i][j]$ 中最大值即为答案。
### 思路 3:代码
```python
class Solution:
def findLength(self, nums1: List[int], nums2: List[int]) -> int:
size1 = len(nums1)
size2 = len(nums2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
res = 0
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if nums1[i - 1] == nums2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
if dp[i][j] > res:
res = dp[i][j]
return res
```
### 思路 3:复杂度分析
- **时间复杂度**:$O(n \times m)$。其中 $n$ 是数组 $nums1$ 的长度,$m$ 是数组 $nums2$ 的长度。
- **空间复杂度**:$O(n \times m)$。
================================================
FILE: docs/solutions/0700-0799/min-cost-climbing-stairs.md
================================================
# [0746. 使用最小花费爬楼梯](https://leetcode.cn/problems/min-cost-climbing-stairs/)
- 标签:数组、动态规划
- 难度:简单
## 题目链接
- [0746. 使用最小花费爬楼梯 - 力扣](https://leetcode.cn/problems/min-cost-climbing-stairs/)
## 题目大意
给定一个数组 `cost` 代表一段楼梯,`cost[i]` 代表爬上第 `i` 阶楼梯醒酒药花费的体力值(下标从 `0` 开始)。
每爬上一个阶梯都要花费对应的体力值,一旦支付了相应的体力值,你就可以选择向上爬一个阶梯或者爬两个阶梯。
要求:找出达到楼层顶部的最低花费。在开始时,你可以选择从下标为 `0` 或 `1` 的元素作为初始阶梯。
## 解题思路
使用动态规划方法。
状态 `dp[i]` 表示为:到达第 `i` 个台阶所花费的最少体⼒。
则状态转移方程为: `dp[i] = min(dp[i - 1], dp[i - 2]) + cost[i]`。
表示为:到达第 `i` 个台阶所花费的最少体⼒ = 到达第 `i - 1` 个台阶所花费的最小体力 与 到达第 `i - 2` 个台阶所花费的最小体力中的最小值 + 到达第 `i` 个台阶所需要花费的体力值。
## 代码
```python
class Solution:
def minCostClimbingStairs(self, cost: List[int]) -> int:
size = len(cost)
dp = [0 for _ in range(size + 1)]
for i in range(2, size+1):
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2])
return dp[size]
```
================================================
FILE: docs/solutions/0700-0799/minimum-ascii-delete-sum-for-two-strings.md
================================================
# [0712. 两个字符串的最小ASCII删除和](https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [0712. 两个字符串的最小ASCII删除和 - 力扣](https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/)
## 题目大意
**描述**:
给定两个字符串 $s1$ 和 $s2$。
**要求**:
返回使两个字符串相等所需删除字符的 ASCII 值的最小。
**说明**:
- $0 \le s1.length, s2.length \le 10^{3}$。
- $s1$ 和 $s2$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入: s1 = "sea", s2 = "eat"
输出: 231
解释: 在 "sea" 中删除 "s" 并将 "s" 的值(115)加入总和。
在 "eat" 中删除 "t" 并将 116 加入总和。
结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。
```
- 示例 2:
```python
输入: s1 = "delete", s2 = "leet"
输出: 403
解释: 在 "delete" 中删除 "dee" 字符串变成 "let",
将 100[d]+101[e]+101[e] 加入总和。在 "leet" 中删除 "e" 将 101[e] 加入总和。
结束时,两个字符串都等于 "let",结果即为 100+101+101+101 = 403 。
如果改为将两个字符串转换为 "lee" 或 "eet",我们会得到 433 或 417 的结果,比答案更大。
```
## 解题思路
### 思路 1:动态规划
这道题类似于最长公共子序列(LCS)问题,但要求的是删除字符的 ASCII 值之和最小。
**状态定义**:
- 定义 $dp[i][j]$ 表示使 $s1[0:i]$ 和 $s2[0:j]$ 相等所需删除字符的最小 ASCII 值之和。
**状态转移**:
- 如果 $s1[i-1] = s2[j-1]$,不需要删除,$dp[i][j] = dp[i-1][j-1]$。
- 如果 $s1[i-1] \neq s2[j-1]$,有两种选择:
- 删除 $s1[i-1]$:$dp[i][j] = dp[i-1][j] + \text{ord}(s1[i-1])$。
- 删除 $s2[j-1]$:$dp[i][j] = dp[i][j-1] + \text{ord}(s2[j-1])$。
- 取两者的最小值。
**初始化**:
- $dp[0][0] = 0$。
- $dp[i][0] = \sum_{k=0}^{i-1} \text{ord}(s1[k])$,删除 $s1$ 的前 $i$ 个字符。
- $dp[0][j] = \sum_{k=0}^{j-1} \text{ord}(s2[k])$,删除 $s2$ 的前 $j$ 个字符。
### 思路 1:代码
```python
class Solution:
def minimumDeleteSum(self, s1: str, s2: str) -> int:
m, n = len(s1), len(s2)
# dp[i][j] 表示使 s1[0:i] 和 s2[0:j] 相等所需删除字符的最小 ASCII 值之和
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 初始化:删除 s1 的前 i 个字符
for i in range(1, m + 1):
dp[i][0] = dp[i - 1][0] + ord(s1[i - 1])
# 初始化:删除 s2 的前 j 个字符
for j in range(1, n + 1):
dp[0][j] = dp[0][j - 1] + ord(s2[j - 1])
# 状态转移
for i in range(1, m + 1):
for j in range(1, n + 1):
if s1[i - 1] == s2[j - 1]:
# 字符相同,不需要删除
dp[i][j] = dp[i - 1][j - 1]
else:
# 字符不同,选择删除 s1[i-1] 或 s2[j-1]
dp[i][j] = min(
dp[i - 1][j] + ord(s1[i - 1]), # 删除 s1[i-1]
dp[i][j - 1] + ord(s2[j - 1]) # 删除 s2[j-1]
)
return dp[m][n]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$ 和 $n$ 分别是字符串 $s1$ 和 $s2$ 的长度。
- **空间复杂度**:$O(m \times n)$。可以优化到 $O(\min(m, n))$。
================================================
FILE: docs/solutions/0700-0799/minimum-distance-between-bst-nodes.md
================================================
# [0783. 二叉搜索树节点最小距离](https://leetcode.cn/problems/minimum-distance-between-bst-nodes/)
- 标签:树、深度优先搜索、广度优先搜索、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [0783. 二叉搜索树节点最小距离 - 力扣](https://leetcode.cn/problems/minimum-distance-between-bst-nodes/)
## 题目大意
**描述**:给定一个二叉搜索树的根节点 $root$。
**要求**:返回树中任意两不同节点值之间的最小差值。
**说明**:
- **差值**:是一个正数,其数值等于两值之差的绝对值。
- 树中节点的数目范围是 $[2, 100]$。
- $0 \le Node.val \le 10^5$。
**示例**:
- 示例 1:
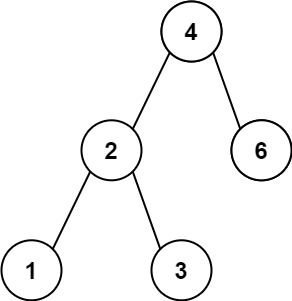
```python
输入:root = [4,2,6,1,3]
输出:1
```
- 示例 2:
```python
输入:root = [1,0,48,null,null,12,49]
输出:1
```
## 解题思路
### 思路 1:中序遍历
先来看二叉搜索树的定义:
- 如果左子树不为空,则左子树上所有节点值均小于它的根节点值;
- 如果右子树不为空,则右子树上所有节点值均大于它的根节点值;
- 任意节点的左、右子树也分别为二叉搜索树。
题目要求二叉搜索树上任意两节点的差的绝对值的最小值。
二叉树的中序遍历顺序是:左 -> 根 -> 右,二叉搜索树的中序遍历最终得到就是一个升序数组。而升序数组中绝对值差的最小值就是比较相邻两节点差值的绝对值,找出其中最小值。
那么我们就可以先对二叉搜索树进行中序遍历,并保存中序遍历的结果。然后再比较相邻节点差值的最小值,从而找出最小值。
### 思路 1:代码
```Python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
res = []
def inorder(root):
if not root:
return
inorder(root.left)
res.append(root.val)
inorder(root.right)
inorder(root)
return res
def minDiffInBST(self, root: Optional[TreeNode]) -> int:
inorder = self.inorderTraversal(root)
ans = float('inf')
for i in range(1, len(inorder)):
ans = min(ans, abs(inorder[i - 1] - inorder[i]))
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为二叉搜索树中的节点数量。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0700-0799/minimum-window-subsequence.md
================================================
# [0727. 最小窗口子序列](https://leetcode.cn/problems/minimum-window-subsequence/)
- 标签:字符串、动态规划、滑动窗口
- 难度:困难
## 题目链接
- [0727. 最小窗口子序列 - 力扣](https://leetcode.cn/problems/minimum-window-subsequence/)
## 题目大意
给定字符串 `s1` 和 `s2`。
要求:找出 `s1` 中最短的(连续)子串 `w`,使得 `s2` 是 `w` 的子序列 。如果 `s1` 中没有窗口可以包含 `s2` 中的所有字符,返回空字符串 `""`。如果有不止一个最短长度的窗口,返回开始位置最靠左的那个。
## 解题思路
这道题跟「[76. 最小覆盖子串](https://leetcode.cn/problems/minimum-window-substring/)」有点类似。但这道题中字符的相对顺序需要保持一致。求解的思路如下:
- 向右扩大窗口,匹配字符,直到匹配完 `s2` 的最后一个字符。
- 当满足条件时,缩小窗口,并更新最小窗口的起始位置和最短长度。
- 缩小窗口到不满足条件为止。
这道题的难点在于第二步中如何缩小窗口。当匹配到一个子序列时,可以采用逆向匹配的方式,从 `s2` 的最后一位字符匹配到 `s2` 的第一位字符。找到符合要求的最大下标,即是窗口的左边界。
整个算法的解题步骤如下:
- 使用两个指针 `left`、`right` 代表窗口的边界,一开始都指向 `0` 。`min_len` 用来记录最小子序列的长度。`i`、`j` 作为索引,用于遍历字符串 `s1` 和 `s2`,一开始都为 `0`。
- 遍历字符串 `s1` 的每一个字符,如果 `s1[i] == s2[j]`,则说明 `s2` 中第 `j` 个字符匹配了,向右移动 `j`,即 `j += 1`,然后继续匹配。
- 如果 `j == len(s2)`,则说明 `s2` 中所有字符都匹配了。
- 此时确定了窗口的右边界 `right = i`,并令 `j` 指向 `s2` 最后一个字符位置。
- 从右至左逆向匹配字符串,找到窗口的左边界。
- 判断当前窗口长度和窗口的最短长度,并更新最小窗口的起始位置和最短长度。
- 令 `j = 0`,重新继续匹配 `s2`。
- 向右移动 `i`,继续匹配。
- 遍历完输出窗口的最短长度(需要判断是否有解)。
## 代码
```python
class Solution:
def minWindow(self, s1: str, s2: str) -> str:
i, j = 0, 0
min_len = float('inf')
left, right = 0, 0
while i < len(s1):
if s1[i] == s2[j]:
j += 1
# 完成了匹配
if j == len(s2):
right = i
j -= 1
while j >= 0:
if s1[i] == s2[j]:
j -= 1
i -= 1
i += 1
if right - i + 1 < min_len:
left = i
min_len = right - left + 1
j = 0
i += 1
if min_len != float('inf'):
return s1[left: left + min_len]
return ""
```
## 参考资料
- 【题解】[c++ 简单好理解的 滑动窗口解法 和 动态规划解法 - 最小窗口子序列 - 力扣](https://leetcode.cn/problems/minimum-window-subsequence/solution/c-jian-dan-hao-li-jie-de-hua-dong-chuang-wguk/)
- 【题解】[727. 最小窗口子序列 C++ 滑动窗口 - 最小窗口子序列 - 力扣](https://leetcode.cn/problems/minimum-window-subsequence/solution/727-zui-xiao-chuang-kou-zi-xu-lie-c-hua-dong-chuan/)
================================================
FILE: docs/solutions/0700-0799/monotone-increasing-digits.md
================================================
# [0738. 单调递增的数字](https://leetcode.cn/problems/monotone-increasing-digits/)
- 标签:贪心、数学
- 难度:中等
## 题目链接
- [0738. 单调递增的数字 - 力扣](https://leetcode.cn/problems/monotone-increasing-digits/)
## 题目大意
给定一个非负整数 n,找出小于等于 n 的最大整数,同时该整数需要满足其各个位数上的数字是单调递增的。
## 解题思路
为了方便操作,我们先将整数 n 转为 list 数组,即 n_list。
题目要求这个整数尽可能的大,那么这个数从高位开始,就应该尽可能的保持不变。那么我们需要从高位到低位,找到第一个满足 `n_list[i - 1] > n_list[i]` 的位置,然后把 `n_list[i] - 1`,再把剩下的低位都变为 9。
## 代码
```python
class Solution:
def monotoneIncreasingDigits(self, n: int) -> int:
n_list = list(str(n))
size = len(n_list)
start_i = size
for i in range(size - 1, 0, -1):
if n_list[i - 1] > n_list[i]:
start_i = i
n_list[i - 1] = chr(ord(n_list[i - 1]) - 1)
for i in range(start_i, size, 1):
n_list[i] = '9'
res = int(''.join(n_list))
return res
```
================================================
FILE: docs/solutions/0700-0799/my-calendar-i.md
================================================
# [0729. 我的日程安排表 I](https://leetcode.cn/problems/my-calendar-i/)
- 标签:设计、线段树、二分查找、有序集合
- 难度:中等
## 题目链接
- [0729. 我的日程安排表 I - 力扣](https://leetcode.cn/problems/my-calendar-i/)
## 题目大意
**要求**:实现一个 `MyCalendar` 类来存放你的日程安排。如果要添加的日程安排不会造成重复预订 ,则可以存储这个新的日程安排。
日程可以用一对整数 $start$ 和 $end$ 表示,这里的时间是半开区间,即 $[start, end)$,实数 $x$ 的范围为 $start \le x < end$。
`MyCalendar` 类:
- `MyCalendar()` 初始化日历对象。
- `boolean book(int start, int end)` 如果可以将日程安排成功添加到日历中而不会导致重复预订,返回 `True` 。否则,返回 `False` 并且不要将该日程安排添加到日历中。
**说明**:
- 重复预订:当两个日程安排有一些时间上的交叉时(例如两个日程安排都在同一时间内),就会产生重复预订 。
- $0 \le start < end \le 10^9$
- 每个测试用例,调用 `book` 方法的次数最多不超过 `1000` 次。
**示例**:
- 示例 1:
```python
输入:
["MyCalendar", "book", "book", "book"]
[[], [10, 20], [15, 25], [20, 30]]
输出:
[null, true, false, true]
解释:
MyCalendar myCalendar = new MyCalendar();
myCalendar.book(10, 20); // return True
myCalendar.book(15, 25); // return False ,这个日程安排不能添加到日历中,因为时间 15 已经被另一个日程安排预订了。
myCalendar.book(20, 30); // return True ,这个日程安排可以添加到日历中,因为第一个日程安排预订的每个时间都小于 20 ,且不包含时间 20 。
```
## 解题思路
### 思路 1:线段树
这道题可以使用线段树来做。
因为区间的范围是 $[0, 10^9]$,普通数组构成的线段树不满足要求。需要用到动态开点线段树。
- 构建一棵线段树。每个线段树的节点类存储当前区间中保存的日程区间个数。
- 在 `book` 方法中,从线段树中查询 `[start, end - 1]` 区间上保存的日程区间个数。
- 如果日程区间个数大于等于 `1`,则说明该日程添加到日历中会导致重复预订,则直接返回 `False`。
- 如果日程区间个数小于 `1`,则说明该日程添加到日历中不会导致重复预定,则在线段树中将区间 `[start, end - 1]` 的日程区间个数 + 1,然后返回 `True`。
### 思路 1:线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, function):
self.tree = SegTreeNode(0, int(1e9))
self.function = function # function 是一个函数,左右区间的聚合方法
# 单点更新,将 nums[i] 更改为 val
def update_point(self, i, val):
self.__update_point(i, val, self.tree)
# 区间更新,将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询,查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self, length):
nums = [0 for _ in range(length)]
for i in range(length):
nums[i] = self.query_interval(i, i)
return nums
# 以下为内部实现方法
# 单点更新,将 nums[i] 更改为 val。node 节点的区间为 [node.left, node.right]
def __update_point(self, i, val, node):
if node.left == node.right:
node.val = val # 叶子节点,节点值修改为 val
return
if i <= node.mid: # 在左子树中更新节点值
self.__update_point(i, val, node.leftNode)
else: # 在右子树中更新节点值
self.__update_point(i, val, node.rightNode)
self.__pushup(node) # 向上更新节点的区间值
# 区间更新
def __update_interval(self, q_left, q_right, val, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if node.lazy_tag is not None:
node.lazy_tag += val # 将当前节点的延迟标记增加 val
else:
node.lazy_tag = val # 将当前节点的延迟标记增加 val
node.val += val # 当前节点所在区间每个元素值增加 val
return
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询,在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, node.rightNode)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新 node 节点区间值,节点的区间值等于该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = self.function(node.leftNode.val, node.rightNode.val)
# 向下更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
lazy_tag = node.lazy_tag
if node.lazy_tag is None:
return
if node.leftNode.lazy_tag is not None:
node.leftNode.lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
node.leftNode.lazy_tag = lazy_tag # 更新左子节点懒惰标记
node.leftNode.val += lazy_tag # 左子节点每个元素值增加 lazy_tag
if node.rightNode.lazy_tag is not None:
node.rightNode.lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
node.rightNode.lazy_tag = lazy_tag # 更新右子节点懒惰标记
node.rightNode.val += lazy_tag # 右子节点每个元素值增加 lazy_tag
node.lazy_tag = None # 更新当前节点的懒惰标记
class MyCalendar:
def __init__(self):
self.STree = SegmentTree(lambda x, y: max(x, y))
def book(self, start: int, end: int) -> bool:
if self.STree.query_interval(start, end - 1) >= 1:
return False
self.STree.update_interval(start, end - 1, 1)
return True
```
================================================
FILE: docs/solutions/0700-0799/my-calendar-ii.md
================================================
# [731. 我的日程安排表 II](https://leetcode.cn/problems/my-calendar-ii/)
- 标签:设计、线段树、二分查找、有序集合
- 难度:中等
## 题目链接
- [731. 我的日程安排表 II - 力扣](https://leetcode.cn/problems/my-calendar-ii/)
## 题目大意
**要求**:实现一个 `MyCalendar` 类来存放你的日程安排。如果要添加的时间内不会导致三重预订时,则可以存储这个新的日程安排。
日程可以用一对整数 $start$ 和 $end$ 表示,这里的时间是半开区间,即 $[start, end)$,实数 $x$ 的范围为 $start \le x < end$。
`MyCalendar` 类:
- `MyCalendar()` 初始化日历对象。
- `boolean book(int start, int end)` 如果可以将日程安排成功添加到日历中而不会导致三重预订,返回 `True` 。否则,返回 `False` 并且不要将该日程安排添加到日历中。
**说明**:
- 三重预定:当三个日程安排有一些时间上的交叉时(例如三个日程安排都在同一时间内),就会产生三重预订 。
- $0 \le start < end \le 10^9$。
- 每个测试用例,调用 `book` 方法的次数最多不超过 `1000` 次。
**示例**:
- 示例 1:
```python
输入:
["MyCalendar", "book", "book", "book"]
[[], [10, 20], [15, 25], [20, 30]]
输出:
[null, true, false, true]
解释:
MyCalendar myCalendar = new MyCalendar();
myCalendar.book(10, 20); // return True
myCalendar.book(15, 25); // return False ,这个日程安排不能添加到日历中,因为时间 15 已经被另一个日程安排预订了。
myCalendar.book(20, 30); // return True ,这个日程安排可以添加到日历中,因为第一个日程安排预订的每个时间都小于 20 ,且不包含时间 20 。
```
## 解题思路
### 思路 1:线段树
这道题可以使用线段树来做。
因为区间的范围是 $[0, 10^9]$,普通数组构成的线段树不满足要求。需要用到动态开点线段树。
- 构建一棵线段树。每个线段树的节点类存储当前区间中保存的日程区间个数。
- 在 `book` 方法中,从线段树中查询 `[start, end - 1]` 区间上保存的日程区间个数。
- 如果日程区间个数大于等于 `2`,则说明该日程添加到日历中会导致三重预订,则直接返回 `False`。
- 如果日程区间个数小于 `2`,则说明该日程添加到日历中不会导致三重预订,则在线段树中将区间 `[start, end - 1]` 的日程区间个数 + 1,然后返回 `True`。
### 思路 1:线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, function):
self.tree = SegTreeNode(0, int(1e9))
self.function = function # function 是一个函数,左右区间的聚合方法
# 单点更新,将 nums[i] 更改为 val
def update_point(self, i, val):
self.__update_point(i, val, self.tree)
# 区间更新,将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询,查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self, length):
nums = [0 for _ in range(length)]
for i in range(length):
nums[i] = self.query_interval(i, i)
return nums
# 以下为内部实现方法
# 单点更新,将 nums[i] 更改为 val。node 节点的区间为 [node.left, node.right]
def __update_point(self, i, val, node):
if node.left == node.right:
node.val = val # 叶子节点,节点值修改为 val
return
if i <= node.mid: # 在左子树中更新节点值
self.__update_point(i, val, node.leftNode)
else: # 在右子树中更新节点值
self.__update_point(i, val, node.rightNode)
self.__pushup(node) # 向上更新节点的区间值
# 区间更新
def __update_interval(self, q_left, q_right, val, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if node.lazy_tag is not None:
node.lazy_tag += val # 将当前节点的延迟标记增加 val
else:
node.lazy_tag = val # 将当前节点的延迟标记增加 val
node.val += val # 当前节点所在区间增加 val
return
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询,在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, node.rightNode)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新 node 节点区间值,节点的区间值等于该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = self.function(node.leftNode.val, node.rightNode.val)
# 向下更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
lazy_tag = node.lazy_tag
if node.lazy_tag is None:
return
if node.leftNode.lazy_tag is not None:
node.leftNode.lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
node.leftNode.lazy_tag = lazy_tag # 更新左子节点懒惰标记
node.leftNode.val += lazy_tag # 左子节点区间增加 lazy_tag
if node.rightNode.lazy_tag is not None:
node.rightNode.lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
node.rightNode.lazy_tag = lazy_tag # 更新右子节点懒惰标记
node.rightNode.val += lazy_tag # 右子节点区间增加 lazy_tag
node.lazy_tag = None # 更新当前节点的懒惰标记
class MyCalendarTwo:
def __init__(self):
self.STree = SegmentTree(lambda x, y: max(x, y))
def book(self, start: int, end: int) -> bool:
if self.STree.query_interval(start, end - 1) >= 2:
return False
self.STree.update_interval(start, end - 1, 1)
return True
```
================================================
FILE: docs/solutions/0700-0799/my-calendar-iii.md
================================================
# [0732. 我的日程安排表 III](https://leetcode.cn/problems/my-calendar-iii/)
- 标签:设计、线段树、二分查找、有序集合
- 难度:困难
## 题目链接
- [0732. 我的日程安排表 III - 力扣](https://leetcode.cn/problems/my-calendar-iii/)
## 题目大意
**要求**:实现一个 `MyCalendarThree` 类来存放你的日程安排,你可以一直添加新的日程安排。
日程可以用一对整数 $start$ 和 $end$ 表示,这里的时间是半开区间,即 $[start, end)$,实数 $x$ 的范围为 $start \le x < end$。
`MyCalendarThree` 类:
- `MyCalendarThree()` 初始化对象。
- `int book(int start, int end)` 返回一个整数 `k`,表示日历中存在的 `k` 次预订的最大值。
**说明**:
- `k` 次预定:当 `k` 个日程安排有一些时间上的交叉时(例如 `k` 个日程安排都在同一时间内),就会产生 `k` 次预订。
- $0 \le start < end \le 10^9$
- 每个测试用例,调用 `book` 函数最多不超过 `400` 次。
**示例**:
- 示例 1:
```python
输入
["MyCalendarThree", "book", "book", "book", "book", "book", "book"]
[[], [10, 20], [50, 60], [10, 40], [5, 15], [5, 10], [25, 55]]
输出
[null, 1, 1, 2, 3, 3, 3]
解释
MyCalendarThree myCalendarThree = new MyCalendarThree();
myCalendarThree.book(10, 20); // 返回 1 ,第一个日程安排可以预订并且不存在相交,所以最大 k 次预订是 1 次预订。
myCalendarThree.book(50, 60); // 返回 1 ,第二个日程安排可以预订并且不存在相交,所以最大 k 次预订是 1 次预订。
myCalendarThree.book(10, 40); // 返回 2 ,第三个日程安排 [10, 40) 与第一个日程安排相交,所以最大 k 次预订是 2 次预订。
myCalendarThree.book(5, 15); // 返回 3 ,剩下的日程安排的最大 k 次预订是 3 次预订。
myCalendarThree.book(5, 10); // 返回 3
myCalendarThree.book(25, 55); // 返回 3
```
## 解题思路
### 思路 1:线段树
这道题可以使用线段树来做。
因为区间的范围是 $[0, 10^9]$,普通数组构成的线段树不满足要求。需要用到动态开点线段树。
- 构建一棵线段树。每个线段树的节点类存储当前区间中保存的日程区间个数。
- 在 `book` 方法中,在线段树中更新 `[start, end - 1]` 的交叉日程区间个数,即令其区间值整体加 `1`。
- 然后从线段树中查询区间 $[0, 10^9]$ 上保存的交叉日程区间个数,并返回。
### 思路 1:代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, function):
self.tree = SegTreeNode(0, int(1e9))
self.function = function # function 是一个函数,左右区间的聚合方法
# 单点更新,将 nums[i] 更改为 val
def update_point(self, i, val):
self.__update_point(i, val, self.tree)
# 区间更新,将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询,查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self, length):
nums = [0 for _ in range(length)]
for i in range(length):
nums[i] = self.query_interval(i, i)
return nums
# 以下为内部实现方法
# 单点更新,将 nums[i] 更改为 val。node 节点的区间为 [node.left, node.right]
def __update_point(self, i, val, node):
if node.left == node.right:
node.val = val # 叶子节点,节点值修改为 val
return
if i <= node.mid: # 在左子树中更新节点值
self.__update_point(i, val, node.leftNode)
else: # 在右子树中更新节点值
self.__update_point(i, val, node.rightNode)
self.__pushup(node) # 向上更新节点的区间值
# 区间更新
def __update_interval(self, q_left, q_right, val, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if node.lazy_tag is not None:
node.lazy_tag += val # 将当前节点的延迟标记增加 val
else:
node.lazy_tag = val # 将当前节点的延迟标记增加 val
node.val += val # 当前节点所在区间增加 val
return
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询,在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, node.rightNode)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新 node 节点区间值,节点的区间值等于该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = self.function(node.leftNode.val, node.rightNode.val)
# 向下更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
lazy_tag = node.lazy_tag
if node.lazy_tag is None:
return
if node.leftNode.lazy_tag is not None:
node.leftNode.lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
node.leftNode.lazy_tag = lazy_tag # 更新左子节点懒惰标记
node.leftNode.val += lazy_tag # 左子节点区间增加 lazy_tag
if node.rightNode.lazy_tag is not None:
node.rightNode.lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
node.rightNode.lazy_tag = lazy_tag # 更新右子节点懒惰标记
node.rightNode.val += lazy_tag # 右子节点区间增加 lazy_tag
node.lazy_tag = None # 更新当前节点的懒惰标记
class MyCalendarThree:
def __init__(self):
self.STree = SegmentTree(lambda x, y: max(x, y))
def book(self, start: int, end: int) -> int:
self.STree.update_interval(start, end - 1, 1)
return self.STree.query_interval(0, int(1e9))
# Your MyCalendarThree object will be instantiated and called as such:
# obj = MyCalendarThree()
# param_1 = obj.book(start,end)
```
================================================
FILE: docs/solutions/0700-0799/network-delay-time.md
================================================
# [0743. 网络延迟时间](https://leetcode.cn/problems/network-delay-time/)
- 标签:深度优先搜索、广度优先搜索、图、最短路、堆(优先队列)
- 难度:中等
## 题目链接
- [0743. 网络延迟时间 - 力扣](https://leetcode.cn/problems/network-delay-time/)
## 题目大意
**描述**:
有 $n$ 个节点组成的网络,节点标记为 $1 \sim n$。
给定一个列表 $times[i] = (u_i, v_i, w_i)$,表示信号经过有向边的传递时间,其中 $u_i$ 是源节点,$v_i$ 是目标节点,$w_i$ 是一个信号从源节点传递到目标节点的时间。
给定一个整数 $n$,表示 $n$ 个节点。
给定一个节点 $k$,表示从节点 $k$ 发出一个信号。
**要求**:
需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 $-1$。
**说明**:
- $1 \le k \le n \le 100$。
- $1 \le times.length \le 6000$。
- $times[i].length == 3$。
- $1 \le u_i, v_i \le n$。
- $u_i \ne v_i$。
- $0 \le w_i \le 100$。
- 所有 $(u_i, v_i)$ 对都互不相同(即不含重复边)。
**示例**:
- 示例 1:

```python
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
输出:2
```
- 示例 2:
```python
输入:times = [[1,2,1]], n = 2, k = 1
输出:1
```
## 解题思路
### 思路 1:Bellman Ford 算法
Bellman Ford 算法核心思想:通过「松弛操作」来逐步更新从源节点 $k$ 到所有其他节点的最短距离。
**算法步骤**:
1. **初始化距离数组**:将源节点 $k$ 的距离 $dist[k]$ 设为 $0$,其他节点的距离设为无穷大。
2. **松弛操作**:进行 $n - 1$ 轮松弛,每轮遍历所有边 $(u_i, v_i, w_i)$,如果 $dist[v_i] > dist[u_i] + w_i$,则更新 $dist[v_i] = dist[u_i] + w_i$。
3. **检测负环**(本题不需要):再次遍历所有边,如果仍然存在 $dist[v_i] > dist[u_i] + w_i$,说明存在负权环。
4. **返回结果**:找出距离数组中的最大值,如果存在无法到达的节点(距离仍为无穷大),则返回 $-1$。
**关键点**:
- 经过 $n - 1$ 轮松弛后,所有可达节点的最短距离已经确定。
- 由于本题没有负权边,不需要检测负环,但保留检测逻辑也无妨。
### 思路 1:代码
```python
from typing import List
class Solution:
def bellmanFord(self, graph, n, source):
"""Bellman Ford 算法实现
Args:
graph: 图的邻接表表示,graph[u][v] 表示边 (u, v) 的权重
n: 节点数量
source: 源节点
Returns:
距离数组,dist[i] 表示从源节点到节点 i 的最短距离
"""
# 初始化距离数组,所有节点距离设为无穷大
dist = [float('inf') for _ in range(n + 1)]
# 源节点距离设为 0
dist[source] = 0
# 进行 n - 1 轮松弛操作
for i in range(n - 1):
# 遍历所有边进行松弛
for u in graph:
for v in graph[u]:
# 如果可以通过 u 更新 v 的距离,则更新
if dist[v] > graph[u][v] + dist[u]:
dist[v] = graph[u][v] + dist[u]
# 检测负权环(本题不需要,但保留检测逻辑)
for u in graph:
for v in graph[u]:
if dist[v] > dist[u] + graph[u][v]:
return None
return dist
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
"""计算网络延迟时间
Args:
times: 边列表,每个元素为 (u, v, w),表示从 u 到 v 的边权重为 w
n: 节点数量
k: 源节点
Returns:
所有节点收到信号的最短时间,如果存在无法到达的节点则返回 -1
"""
# 构建邻接表
graph = dict()
for u, v, w in times:
if u not in graph:
graph[u] = dict()
if v not in graph[u]:
graph[u][v] = w
# 使用 Bellman Ford 算法计算最短距离
dist = self.bellmanFord(graph, n, k)
# 如果返回 None,说明存在负权环(本题不会出现)
if dist is None:
return -1
# 找出最大距离
ans = 0
for i in range(1, len(dist)):
# 如果存在无法到达的节点,返回 -1
if dist[i] >= float('inf'):
return -1
ans = max(ans, dist[i])
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(V \times E)$,其中 $V$ 是节点的数量,$E$ 是边的数量。需要进行 $V - 1$ 轮松弛,每轮遍历所有 $E$ 条边。
- **空间复杂度**:$O(V + E)$,其中 $V$ 是节点的数量,$E$ 是边的数量。需要存储邻接表和距离数组。
### 思路 2:朴素 Dijkstra 算法
朴素 Dijkstra 算法:不使用优先队列,而是每次遍历所有未访问的节点来找到距离最小的节点。虽然时间复杂度较高,但实现更直观。
**算法步骤**:
1. **初始化距离数组**:将源节点 $k$ 的距离 $dist[k]$ 设为 $0$,其他节点的距离设为无穷大。
2. **维护访问数组**:使用 $visited$ 数组记录节点是否已经被访问。
3. **贪心选择**:每次从未访问的节点中找到距离 $dist[u]$ 最小的节点 $u$,标记为已访问。
4. **松弛操作**:更新节点 $u$ 的所有相邻节点 $v$ 的距离,如果 $dist[v] > dist[u] + w(u, v)$,则更新 $dist[v] = dist[u] + w(u, v)$。
5. **重复步骤**:重复步骤 $3 \sim 4$,直到所有节点都被访问。
6. **返回结果**:找出距离数组中的最大值,如果存在无法到达的节点(距离仍为无穷大),则返回 $-1$。
**关键点**:
- Dijkstra 算法适用于非负权图,每次选择距离最小的节点进行松弛。
- 由于题目约束 $0 \le w_i \le 100$,所有边权非负,可以使用 Dijkstra 算法。
### 思路 2:代码
```python
from typing import List
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
"""计算网络延迟时间(朴素 Dijkstra 算法)
Args:
times: 边列表,每个元素为 (u, v, w),表示从 u 到 v 的边权重为 w
n: 节点数量
k: 源节点
Returns:
所有节点收到信号的最短时间,如果存在无法到达的节点则返回 -1
"""
# 使用哈希表构建邻接表
graph = dict()
for u, v, w in times:
if u not in graph:
graph[u] = dict()
graph[u][v] = w
# 初始化距离数组和访问数组
dist = [float('inf')] * (n + 1)
dist[k] = 0 # 源节点距离设为 0
visited = [False] * (n + 1)
# 遍历所有节点,每次选择一个未访问的距离最小的节点
for _ in range(n):
# 找到未访问的距离最小的节点
min_dist = float('inf')
u = -1
for i in range(1, n + 1):
if not visited[i] and dist[i] < min_dist:
min_dist = dist[i]
u = i
# 如果没有找到可达的节点,说明存在无法到达的节点
if u == -1:
return -1
# 标记当前节点为已访问
visited[u] = True
# 更新相邻节点的距离
if u in graph:
for v, w in graph[u].items():
# 如果通过 u 到达 v 的距离更短,则更新
if not visited[v] and dist[v] > dist[u] + w:
dist[v] = dist[u] + w
# 找出最大距离
return max(dist[1:])
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(V^2 + E)$,其中 $V$ 是节点的数量,$E$ 是边的数量。每次需要遍历所有节点找到最小距离节点,总共需要 $V$ 次,每次遍历需要 $O(V)$ 的时间。更新边的操作需要 $O(E)$ 的时间。
- **空间复杂度**:$O(V + E)$,其中 $V$ 是节点的数量,$E$ 是边的数量。需要存储邻接表、距离数组和访问数组。
### 思路 3:Dijkstra 算法(堆优化)
Dijkstra 算法是解决单源最短路径问题的经典算法。在这个问题中,我们可以使用 Dijkstra 算法来找到从节点 $k$ 到所有其他节点的最短路径。
堆优化版本的 Dijkstra 算法:使用优先队列(最小堆)来维护待处理的节点,避免每次遍历所有节点查找最小距离节点,从而降低时间复杂度。
**算法步骤**:
1. **构建邻接表**:使用邻接表存储图结构,方便遍历相邻节点。
2. **初始化距离数组**:将源节点 $k$ 的距离 $dist[k]$ 设为 $0$,其他节点的距离设为无穷大。
3. **初始化优先队列**:将源节点 $k$ 及其距离 $0$ 加入优先队列。
4. **贪心选择**:每次从优先队列中取出距离 $dist[u]$ 最小的节点 $u$。
5. **跳过无效节点**:如果当前距离大于已知最短距离,说明该节点已被更优路径访问过,跳过。
6. **松弛操作**:更新节点 $u$ 的所有相邻节点 $v$ 的距离,如果 $dist[v] > dist[u] + w(u, v)$,则更新 $dist[v] = dist[u] + w(u, v)$ 并将 $(dist[v], v)$ 加入优先队列。
7. **重复步骤**:重复步骤 $4 \sim 6$,直到优先队列为空。
8. **返回结果**:找出距离数组中的最大值,如果存在无法到达的节点(距离仍为无穷大),则返回 $-1$。
**关键点**:
- 使用优先队列可以将查找最小距离节点的时间复杂度从 $O(V)$ 降低到 $O(\log V)$。
- 同一个节点可能被多次加入优先队列,但只有距离更小的才会被处理。
### 思路 3:代码
```python
import heapq
from typing import List
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
"""计算网络延迟时间(Dijkstra 算法堆优化版本)
Args:
times: 边列表,每个元素为 (u, v, w),表示从 u 到 v 的边权重为 w
n: 节点数量
k: 源节点
Returns:
所有节点收到信号的最短时间,如果存在无法到达的节点则返回 -1
"""
# 构建邻接表
graph = [[] for _ in range(n + 1)]
for u, v, w in times:
graph[u].append((v, w))
# 初始化距离数组,所有节点距离设为无穷大
dist = [float('inf')] * (n + 1)
dist[k] = 0 # 源节点距离设为 0
# 使用优先队列(最小堆)存储待处理的节点,格式为 (距离, 节点编号)
pq = [(0, k)]
while pq:
# 取出距离最小的节点
d, u = heapq.heappop(pq)
# 如果当前距离大于已知最短距离,说明该节点已被更优路径访问过,跳过
if d > dist[u]:
continue
# 遍历相邻节点
for v, w in graph[u]:
# 如果通过 u 到达 v 的距离更短,则更新
if dist[v] > dist[u] + w:
dist[v] = dist[u] + w
# 将更新后的节点加入优先队列
heapq.heappush(pq, (dist[v], v))
# 找出最大距离
max_dist = max(dist[1:])
# 如果存在无法到达的节点,返回 -1
return max_dist if max_dist != float('inf') else -1
```
### 思路 3:复杂度分析
- **时间复杂度**:$O(E \log V)$,其中 $E$ 是边的数量,$V$ 是节点的数量。每次从优先队列中取出一个节点需要 $O(\log V)$ 的时间,总共需要处理 $E$ 条边。
- **空间复杂度**:$O(V + E)$,其中 $V$ 是节点的数量,$E$ 是边的数量。需要存储邻接表和优先队列。
### 思路 4:SPFA 算法
SPFA(Shortest Path Faster Algorithm):Bellman-Ford 算法的一个优化版本。它使用队列来维护待更新的节点,只有当节点的距离被更新时,才将其加入队列,从而避免不必要的松弛操作。
**算法步骤**:
1. **初始化距离数组**:将源节点 $k$ 的距离 $dist[k]$ 设为 $0$,其他节点的距离设为无穷大。
2. **初始化队列**:将源节点 $k$ 加入队列,并使用 $in\_queue$ 数组标记节点是否在队列中。
3. **队列处理**:从队列中取出一个节点 $u$,标记其不在队列中。
4. **松弛操作**:遍历节点 $u$ 的所有相邻节点 $v$:
- 如果 $dist[v] > dist[u] + w(u, v)$,则更新 $dist[v] = dist[u] + w(u, v)$。
- 如果节点 $v$ 不在队列中,则将其加入队列并标记。
5. **重复步骤**:重复步骤 $3 \sim 4$,直到队列为空。
6. **返回结果**:找出距离数组中的最大值,如果存在无法到达的节点(距离仍为无穷大),则返回 $-1$。
**关键点**:
- SPFA 算法只对距离发生变化的节点进行松弛,避免了对所有边的重复检查。
- 在非负权图中,SPFA 算法的性能通常优于 Bellman-Ford 算法。
- 由于题目约束 $0 \le w_i \le 100$,所有边权非负,不会出现负权环,SPFA 算法可以正常使用。
### 思路 4:代码
```python
from typing import List
from collections import deque
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
"""计算网络延迟时间(SPFA 算法)
Args:
times: 边列表,每个元素为 (u, v, w),表示从 u 到 v 的边权重为 w
n: 节点数量
k: 源节点
Returns:
所有节点收到信号的最短时间,如果存在无法到达的节点则返回 -1
"""
# 使用哈希表构建邻接表
graph = dict()
for u, v, w in times:
if u not in graph:
graph[u] = dict()
graph[u][v] = w
# 初始化距离数组,所有节点距离设为无穷大
dist = [float('inf')] * (n + 1)
dist[k] = 0 # 源节点距离设为 0
# 使用队列存储待更新的节点
queue = deque([k])
# 记录节点是否在队列中,避免重复入队
in_queue = [False] * (n + 1)
in_queue[k] = True
while queue:
# 取出队头节点
u = queue.popleft()
in_queue[u] = False
# 遍历相邻节点
if u in graph:
for v, w in graph[u].items():
# 如果通过 u 到达 v 的距离更短,则更新
if dist[v] > dist[u] + w:
dist[v] = dist[u] + w
# 如果节点不在队列中,则加入队列
if not in_queue[v]:
queue.append(v)
in_queue[v] = True
# 找出最大距离
max_dist = max(dist[1:])
# 如果存在无法到达的节点,返回 -1
return max_dist if max_dist != float('inf') else -1
```
### 思路 4:复杂度分析
- **时间复杂度**:平均情况下为 $O(kE)$,其中 $E$ 是边的数量,$k$ 是每个节点入队的平均次数。在最坏情况下可能退化为 $O(VE)$。
- **空间复杂度**:$O(V + E)$,其中 $V$ 是节点的数量,$E$ 是边的数量。需要存储邻接表、距离数组和队列。
================================================
FILE: docs/solutions/0700-0799/number-of-atoms.md
================================================
# [0726. 原子的数量](https://leetcode.cn/problems/number-of-atoms/)
- 标签:栈、哈希表、字符串、排序
- 难度:困难
## 题目链接
- [0726. 原子的数量 - 力扣](https://leetcode.cn/problems/number-of-atoms/)
## 题目大意
**描述**:
原子总是以一个大写字母开始,接着跟随 $0$ 个或任意个小写字母,表示原子的名字。
如果数量大于 $1$,原子后会跟着数字表示原子的数量。如果数量等于 $1$ 则不会跟数字。
- 例如,`"H2O"` 和 `"H2O2"` 是可行的,但 `"H1O2"` 这个表达是不可行的。
两个化学式连在一起可以构成新的化学式。
- 例如 `"H2O2He3Mg4"` 也是化学式。
由括号括起的化学式并佐以数字(可选择性添加)也是化学式。
- 例如 `"(H2O2)"` 和 `"(H2O2)3"` 是化学式。
给定一个字符串化学式 $formula$。
**要求**:
返回「每种原子的数量」,格式为:第一个(按字典序)原子的名字,跟着它的数量(如果数量大于 1),然后是第二个原子的名字(按字典序),跟着它的数量(如果数量大于 1),以此类推。
**说明**:
- $1 \le formula.length \le 10^{3}$。
- $formula$ 由英文字母、数字、`'('` 和 `')'` 组成。
- $formula$ 总是有效的化学式。
**示例**:
- 示例 1:
```python
输入:formula = "H2O"
输出:"H2O"
解释:原子的数量是 {'H': 2, 'O': 1}。
```
- 示例 2:
```python
输入:formula = "Mg(OH)2"
输出:"H2MgO2"
解释:原子的数量是 {'H': 2, 'Mg': 1, 'O': 2}。
```
## 解题思路
### 思路 1:栈 + 哈希表
这道题需要解析化学式并统计每种原子的数量。可以使用栈来处理括号嵌套的情况。
**解题步骤**:
1. 使用栈来存储当前层级的原子计数(哈希表)。
2. 遍历化学式字符串:
- 遇到 `(`:将当前哈希表压入栈,创建新的哈希表。
- 遇到 `)`:弹出栈顶哈希表,读取后面的数字,将当前哈希表中的所有原子数量乘以该数字,然后合并到栈顶哈希表。
- 遇到大写字母:读取完整的原子名称和后面的数字,加入当前哈希表。
3. 最后将所有原子按字典序排序,构建结果字符串。
**实现细节**:
- 使用栈存储嵌套的哈希表。
- 解析原子名称:大写字母开头,后面跟若干小写字母。
- 解析数字:连续的数字字符。
### 思路 1:代码
```python
class Solution:
def countOfAtoms(self, formula: str) -> str:
from collections import defaultdict
n = len(formula)
i = 0
stack = [defaultdict(int)]
while i < n:
if formula[i] == '(':
# 遇到左括号,压入新的哈希表
stack.append(defaultdict(int))
i += 1
elif formula[i] == ')':
# 遇到右括号,读取后面的数字
i += 1
start = i
while i < n and formula[i].isdigit():
i += 1
multiplier = int(formula[start:i]) if start < i else 1
# 弹出栈顶哈希表,乘以倍数后合并到新的栈顶
top = stack.pop()
for atom, count in top.items():
stack[-1][atom] += count * multiplier
else:
# 读取原子名称
start = i
i += 1
while i < n and formula[i].islower():
i += 1
atom = formula[start:i]
# 读取数字
start = i
while i < n and formula[i].isdigit():
i += 1
count = int(formula[start:i]) if start < i else 1
# 加入当前哈希表
stack[-1][atom] += count
# 构建结果字符串
result = []
for atom in sorted(stack[-1].keys()):
count = stack[-1][atom]
result.append(atom)
if count > 1:
result.append(str(count))
return ''.join(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + k \log k)$,其中 $n$ 是化学式的长度,$k$ 是不同原子的种类数。需要遍历化学式一次,然后对原子排序。
- **空间复杂度**:$O(n)$。栈的深度最多为括号的嵌套层数,哈希表存储原子计数。
================================================
FILE: docs/solutions/0700-0799/number-of-matching-subsequences.md
================================================
# [0792. 匹配子序列的单词数](https://leetcode.cn/problems/number-of-matching-subsequences/)
- 标签:字典树、数组、哈希表、字符串、二分查找、动态规划、排序
- 难度:中等
## 题目链接
- [0792. 匹配子序列的单词数 - 力扣](https://leetcode.cn/problems/number-of-matching-subsequences/)
## 题目大意
**描述**:
给定字符串 $s$ 和字符串数组 $words$。
**要求**:
返回 $words[i]$ 中是 $s$ 的子序列的单词个数。
**说明**:
- 字符串的「子序列」:是从原始字符串中生成的新字符串,可以从中删去一些字符(可以是 none),而不改变其余字符的相对顺序。
- 例如,`"ace"` 是 `"abcde"` 的子序列。
- $1 \le s.length \le 5 * 10^{4}$。
- $1 \le words.length \le 5000$。
- $1 \le words[i].length \le 50$。
- $words[i]$ 和 $s$ 都只由小写字母组成。
**示例**:
- 示例 1:
```python
输入: s = "abcde", words = ["a","bb","acd","ace"]
输出: 3
解释: 有三个是 s 的子序列的单词: "a", "acd", "ace"。
```
- 示例 2:
```python
输入: s = "dsahjpjauf", words = ["ahjpjau","ja","ahbwzgqnuk","tnmlanowax"]
输出: 2
```
## 解题思路
### 思路 1:哈希表 + 双指针
这道题要求统计有多少个单词是字符串 $s$ 的子序列。
**解题步骤**:
1. **优化方法**:为了避免对每个单词都遍历一次 $s$,可以使用哈希表将单词按首字母分组。
2. 对于 $s$ 中的每个字符 $c$,找到所有以 $c$ 开头的单词,尝试匹配。
3. 使用双指针判断单词是否是 $s$ 的子序列:
- 对于每个单词,维护一个指针指向当前需要匹配的字符。
- 遍历 $s$,如果当前字符与单词的当前字符匹配,移动单词指针。
- 如果单词指针到达末尾,说明该单词是 $s$ 的子序列。
**优化**:将单词按首字母分组,每次只处理首字母匹配的单词。
### 思路 1:代码
```python
class Solution:
def numMatchingSubseq(self, s: str, words: List[str]) -> int:
from collections import defaultdict
# 将单词按首字母分组,存储 (单词, 当前匹配位置)
waiting = defaultdict(list)
for word in words:
waiting[word[0]].append((word, 0))
count = 0
# 遍历 s 中的每个字符
for char in s:
# 获取所有等待匹配当前字符的单词
current_waiting = waiting[char]
waiting[char] = []
for word, index in current_waiting:
index += 1
if index == len(word):
# 单词匹配完成
count += 1
else:
# 继续等待下一个字符
waiting[word[index]].append((word, index))
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是字符串 $s$ 的长度,$m$ 是所有单词的总长度。每个字符最多被访问一次。
- **空间复杂度**:$O(m)$。需要存储所有单词的状态。
================================================
FILE: docs/solutions/0700-0799/number-of-subarrays-with-bounded-maximum.md
================================================
# [0795. 区间子数组个数](https://leetcode.cn/problems/number-of-subarrays-with-bounded-maximum/)
- 标签:数组、双指针
- 难度:中等
## 题目链接
- [0795. 区间子数组个数 - 力扣](https://leetcode.cn/problems/number-of-subarrays-with-bounded-maximum/)
## 题目大意
给定一个元素都是正整数的数组`A` ,正整数 `L` 以及 `R` (`L <= R`)。
求连续、非空且其中最大元素满足大于等于`L` 小于等于`R`的子数组个数。
## 解题思路
最大元素满足大于等于`L` 小于等于`R`的子数组个数 = 最大元素小于等于 `R` 的子数组个数 - 最大元素小于 `L` 的子数组个数。
其中「最大元素小于 `L` 的子数组个数」也可以转变为「最大元素小于等于 `L - 1` 的子数组个数」。那么现在的问题就变为了如何计算最大元素小于等于 `k` 的子数组个数。
我们使用 `count` 记录 小于等于 `k` 的连续元素数量,遍历一遍数组,如果遇到 `nums[i] <= k` 时,`count` 累加,表示在此位置上结束的有效子数组数量为 `count + 1`。如果遇到 `nums[i] > k` 时,`count` 重新开始计算。每次遍历完将有效子数组数量累加到答案中。
## 代码
```python
class Solution:
def numSubarrayMaxK(self, nums, k):
ans = 0
count = 0
for i in range(len(nums)):
if nums[i] <= k:
count += 1
else:
count = 0
ans += count
return ans
def numSubarrayBoundedMax(self, nums: List[int], left: int, right: int) -> int:
return self.numSubarrayMaxK(nums, right) - self.numSubarrayMaxK(nums, left - 1)
```
================================================
FILE: docs/solutions/0700-0799/open-the-lock.md
================================================
# [0752. 打开转盘锁](https://leetcode.cn/problems/open-the-lock/)
- 标签:广度优先搜索、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0752. 打开转盘锁 - 力扣](https://leetcode.cn/problems/open-the-lock/)
## 题目大意
**描述**:有一把带有四个数字的密码锁,每个位置上有 `0` ~ `9` 共 `10` 个数字。每次只能将其中一个位置上的数字转动一下。可以向上转,也可以向下转。比如:`1 -> 2`、`2 -> 1`。
密码锁的初始数字为:`0000`。现在给定一组表示死亡数字的字符串数组 `deadends`,和一个带有四位数字的目标字符串 `target`。
如果密码锁转动到 `deadends` 中任一字符串状态,则锁就会永久锁定,无法再次旋转。
**要求**:给出使得锁的状态由 `0000` 转动到 `target` 的最小的选择次数。如果无论如何不能解锁,返回 `-1` 。
**说明**:
- $1 \le deadends.length \le 500$
$deadends[i].length == 4$
$target.length == 4$
$target$ 不在 $deadends$ 之中
$target$ 和 $deadends[i]$ 仅由若干位数字组成。
**示例**:
- 示例 1:
```python
输入:deadends = ["0201","0101","0102","1212","2002"], target = "0202"
输出:6
解释:
可能的移动序列为 "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202"。
注意 "0000" -> "0001" -> "0002" -> "0102" -> "0202" 这样的序列是不能解锁的,
因为当拨动到 "0102" 时这个锁就会被锁定。
```
- 示例 2:
```python
输入: deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888"
输出:-1
解释:无法旋转到目标数字且不被锁定。
```
## 解题思路
### 思路 1:广度优先搜索
1. 定义 `visited` 为标记访问节点的 set 集合变量,`queue` 为存放节点的队列。
2. 将`0000` 状态标记为访问,并将其加入队列 `queue`。
3. 将当前队列中的所有状态依次出队,判断这些状态是否为死亡字符串。
1. 如果为死亡字符串,则跳过该状态,否则继续执行。
2. 如果为目标字符串,则返回当前路径长度,否则继续执行。
4. 枚举当前状态所有位置所能到达的所有状态(通过向上或者向下旋转),并判断是否访问过该状态。
5. 如果之前出现过该状态,则继续执行,否则将其存入队列,并标记访问。
6. 遍历完步骤 3 中当前队列中的所有状态,令路径长度加 `1`,继续执行 3 ~ 5 步,直到队列为空。
7. 如果队列为空,也未能到达目标状态,则返回 `-1`。
### 思路 1:代码
```python
import collections
class Solution:
def openLock(self, deadends: List[str], target: str) -> int:
queue = collections.deque(['0000'])
visited = set(['0000'])
deadset = set(deadends)
level = 0
while queue:
size = len(queue)
for _ in range(size):
cur = queue.popleft()
if cur in deadset:
continue
if cur == target:
return level
for i in range(len(cur)):
up = self.upward_adjust(cur, i)
if up not in visited:
queue.append(up)
visited.add(up)
down = self.downward_adjust(cur, i)
if down not in visited:
queue.append(down)
visited.add(down)
level += 1
return -1
def upward_adjust(self, s, i):
s_list = list(s)
if s_list[i] == '9':
s_list[i] = '0'
else:
s_list[i] = chr(ord(s_list[i]) + 1)
return "".join(s_list)
def downward_adjust(self, s, i):
s_list = list(s)
if s_list[i] == '0':
s_list[i] = '9'
else:
s_list[i] = chr(ord(s_list[i]) - 1)
return "".join(s_list)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(10^d \times d^2 + m \times d)$。其中 $d$ 是数字的位数,$m$ 是数组 $deadends$ 的长度。
- **空间复杂度**:$O(10^D \times d + m)$。
================================================
FILE: docs/solutions/0700-0799/parse-lisp-expression.md
================================================
# [0736. Lisp 语法解析](https://leetcode.cn/problems/parse-lisp-expression/)
- 标签:栈、递归、哈希表、字符串
- 难度:困难
## 题目链接
- [0736. Lisp 语法解析 - 力扣](https://leetcode.cn/problems/parse-lisp-expression/)
## 题目大意
**描述**:
给定一个类似 Lisp 语句的字符串表达式 $expression$。
表达式语法如下所示:
- 表达式可以为整数,let 表达式,add 表达式,mult 表达式,或赋值的变量。表达式的结果总是一个整数。
- (整数可以是正整数、负整数、0)
- **let** 表达式采用 `"(let v1 e1 v2 e2 ... vn en expr)"` 的形式,其中 let 总是以字符串 `"let"` 来表示,接下来会跟随一对或多对交替的变量和表达式,也就是说,第一个变量 v1 被分配为表达式 e1 的值,第二个变量 v2 被分配为表达式 e2 的值,依次类推;最终 let 表达式的值为 expr 表达式的值。
- **add** 表达式表示为 `"(add e1 e2)"`,其中 add 总是以字符串 `"add"` 来表示,该表达式总是包含两个表达式 e1、e2,最终结果是 e1 表达式的值与 e2 表达式的值之「和」。
- **mult** 表达式表示为 `"(mult e1 e2)"`,其中 mult 总是以字符串 `"mult"` 表示,该表达式总是包含两个表达式 e1、e2,最终结果是 e1 表达式的值与 e2 表达式的值之「积」。
- 在该题目中,变量名以小写字符开始,之后跟随 0 个或多个小写字符或数字。为了方便,`"add"`,`"let"`,`"mult"` 会被定义为 `"关键字"`,不会用作变量名。
- 最后,要说一下作用域的概念。计算变量名所对应的表达式时,在计算上下文中,首先检查最内层作用域(按括号计),然后按顺序依次检查外部作用域。测试用例中每一个表达式都是合法的。有关作用域的更多详细信息,请参阅示例。
**要求**:
求出其计算结果。
**说明**:
- $1 \le expression.length \le 2000$。
- $exprssion$ 中不含前导和尾随空格。
- $expressoin$ 中的不同部分(token)之间用单个空格进行分隔。
- 答案和所有中间计算结果都符合 32-bit 整数范围。
- 测试用例中的表达式均为合法的且最终结果为整数。
**示例**:
- 示例 1:
```python
输入:expression = "(let x 2 (mult x (let x 3 y 4 (add x y))))"
输出:14
解释:
计算表达式 (add x y), 在检查变量 x 值时,
在变量的上下文中由最内层作用域依次向外检查。
首先找到 x = 3, 所以此处的 x 值是 3 。
```
- 示例 2:
```python
输入:expression = "(let x 3 x 2 x)"
输出:2
解释:let 语句中的赋值运算按顺序处理即可。
```
## 解题思路
### 思路 1:递归 + 哈希表
这道题需要解析和计算 Lisp 表达式。可以使用递归来处理嵌套的表达式。
**解题步骤**:
1. 使用递归函数 `evaluate` 来计算表达式的值。
2. 使用哈希表(作用域)来存储变量的值。
3. 根据表达式的类型进行处理:
- 如果是整数,直接返回其值。
- 如果是变量,从作用域中查找其值。
- 如果是 `let` 表达式,依次赋值变量,然后计算最后一个表达式。
- 如果是 `add` 表达式,计算两个子表达式的和。
- 如果是 `mult` 表达式,计算两个子表达式的积。
**实现细节**:
- 使用栈来解析表达式,处理括号嵌套。
- 每个 `let` 表达式创建新的作用域(复制父作用域)。
- 递归计算子表达式的值。
### 思路 1:代码
```python
class Solution:
def evaluate(self, expression: str) -> int:
def parse(expr):
"""解析表达式,返回 token 列表"""
tokens = []
i = 0
while i < len(expr):
if expr[i] in '()':
tokens.append(expr[i])
i += 1
elif expr[i] == ' ':
i += 1
else:
j = i
while j < len(expr) and expr[j] not in '() ':
j += 1
tokens.append(expr[i:j])
i = j
return tokens
def evaluate_helper(tokens, index, scope):
"""递归计算表达式的值"""
token = tokens[index]
if token == '(':
# 处理括号表达式
index += 1
op = tokens[index]
index += 1
if op == 'let':
# 创建新的作用域
new_scope = scope.copy()
# 处理变量赋值
while True:
# 检查是否是最后一个表达式
if tokens[index] == ')':
# 没有最后的表达式,返回 0
return 0, index + 1
# 先保存当前位置
saved_index = index
# 尝试解析下一个表达式
value, next_index = evaluate_helper(tokens, index, new_scope)
# 检查是否还有下一个 token
if tokens[next_index] == ')':
# 这是最后一个表达式
return value, next_index + 1
# 这是一个变量名,读取其值
var_name = tokens[saved_index]
index = next_index
# 计算变量的值
var_value, index = evaluate_helper(tokens, index, new_scope)
new_scope[var_name] = var_value
elif op == 'add':
# 计算两个子表达式的和
val1, index = evaluate_helper(tokens, index, scope)
val2, index = evaluate_helper(tokens, index, scope)
index += 1 # 跳过 ')'
return val1 + val2, index
elif op == 'mult':
# 计算两个子表达式的积
val1, index = evaluate_helper(tokens, index, scope)
val2, index = evaluate_helper(tokens, index, scope)
index += 1 # 跳过 ')'
return val1 * val2, index
elif token.lstrip('-').isdigit():
# 整数
return int(token), index + 1
else:
# 变量
return scope.get(token, 0), index + 1
tokens = parse(expression)
result, _ = evaluate_helper(tokens, 0, {})
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是表达式的长度。需要遍历表达式一次。
- **空间复杂度**:$O(n)$。递归栈和作用域的空间消耗。
================================================
FILE: docs/solutions/0700-0799/partition-labels.md
================================================
# [0763. 划分字母区间](https://leetcode.cn/problems/partition-labels/)
- 标签:贪心、哈希表、双指针、字符串
- 难度:中等
## 题目链接
- [0763. 划分字母区间 - 力扣](https://leetcode.cn/problems/partition-labels/)
## 题目大意
给定一个由小写字母组成的字符串 `s`。要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
要求:返回一个表示每个字符串片段的长度的列表。
## 解题思路
因为同一字母最多出现在一个片段中,则同一字母第一次出现的下标位置和最后一次出现的下标位置肯定在同一个片段中。
我们先遍历一遍字符串,用哈希表 letter_map 存储下每一个字母最后一次出现的下标位置。
为了得到尽可能的片段,我们使用贪心的思想:
- 从头开始遍历字符串,遍历同时维护当前片段的开始位置 start 和结束位置 end。
- 对于字符串中的每个字符 `s[i]`,得到当前字母的最后一次出现的下标位置 `letter_map[s[i]]`,则当前片段的结束位置一定不会早于 `letter_map[s[i]]`,所以更新 end 值为 `end = max(end, letter_map[s[i]])`。
- 当访问到 `i == end` 时,当前片段访问结束,当前片段的下标范围为 `[start, end]`,长度为 `end - start + 1`,将其长度加入答案数组,并更新 start 值为 `i + 1`,继续遍历。
- 最终返回答案数组。
## 代码
```python
class Solution:
def partitionLabels(self, s: str) -> List[int]:
letter_map = dict()
for i in range(len(s)):
letter_map[s[i]] = i
res = []
start, end = 0, 0
for i in range(len(s)):
end = max(end, letter_map[s[i]])
if i == end:
res.append(end - start + 1)
start = i + 1
return res
```
================================================
FILE: docs/solutions/0700-0799/prefix-and-suffix-search.md
================================================
# [0745. 前缀和后缀搜索](https://leetcode.cn/problems/prefix-and-suffix-search/)
- 标签:设计、字典树、数组、哈希表、字符串
- 难度:困难
## 题目链接
- [0745. 前缀和后缀搜索 - 力扣](https://leetcode.cn/problems/prefix-and-suffix-search/)
## 题目大意
**要求**:
设计一个包含一些单词的特殊词典,并能够通过前缀和后缀来检索单词。
实现 WordFilter 类:
- `WordFilter(string[] words)`:使用词典中的单词 $words$ 初始化对象。
- `f(string pref, string suff)`:返回词典中具有前缀 $pref$ 和后缀 $suff$ 的单词的下标。如果存在不止一个满足要求的下标,返回其中「最大的下标」。如果不存在这样的单词,返回 $-1$。
**说明**:
- $1 \le words.length \le 10^{4}$。
- $1 \le words[i].length \le 7$。
- $1 \le pref.length, suff.length \le 7$。
- $words[i]$、$pref$ 和 $suff$ 仅由小写英文字母组成。
- 最多对函数 $f$ 执行 $10^{4}$ 次调用。
**示例**:
- 示例 1:
```python
输入
["WordFilter", "f"]
[[["apple"]], ["a", "e"]]
输出
[null, 0]
解释
WordFilter wordFilter = new WordFilter(["apple"]);
wordFilter.f("a", "e"); // 返回 0 ,因为下标为 0 的单词:前缀 prefix = "a" 且 后缀 suffix = "e" 。
```
## 解题思路
### 思路 1:字典树(Trie)
使用字典树存储所有单词,同时为每个节点存储前缀和后缀的组合。
**实现步骤**:
1. 对于每个单词 $word$,将所有可能的 `{suffix}#{word}` 形式插入字典树。
- 例如,对于单词 `"apple"`,插入 `"e#apple"`, `"le#apple"`, `"ple#apple"`, `"pple#apple"`, `"apple#apple"`, `"#apple"`。
2. 查询时,将 `pref` 和 `suff` 组合成 `{suff}#{pref}`,在字典树中查找。
3. 每个节点存储经过该节点的最大索引。
### 思路 1:代码
```python
class TrieNode:
def __init__(self):
self.children = {}
self.weight = -1 # 存储最大索引
class WordFilter:
def __init__(self, words: List[str]):
self.root = TrieNode()
# 对于每个单词,插入所有可能的 {suffix}#{word} 形式
for index, word in enumerate(words):
word_len = len(word)
# 遍历所有后缀(包括空后缀)
for i in range(word_len + 1):
suffix = word[i:]
# 插入 suffix#word
key = suffix + '#' + word
node = self.root
for char in key:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.weight = index # 更新最大索引
def f(self, pref: str, suff: str) -> int:
# 查找 suff#pref
key = suff + '#' + pref
node = self.root
for char in key:
if char not in node.children:
return -1
node = node.children[char]
return node.weight
# Your WordFilter object will be instantiated and called as such:
# obj = WordFilter(words)
# param_1 = obj.f(pref,suff)
```
### 思路 1:复杂度分析
- **时间复杂度**:
- 初始化:$O(n \times L^2)$,其中 $n$ 是单词数量,$L$ 是单词的平均长度。
- 查询:$O(L)$,$L$ 是前缀和后缀的长度之和。
- **空间复杂度**:$O(n \times L^2)$,字典树的空间。
================================================
FILE: docs/solutions/0700-0799/preimage-size-of-factorial-zeroes-function.md
================================================
# [0793. 阶乘函数后 K 个零](https://leetcode.cn/problems/preimage-size-of-factorial-zeroes-function/)
- 标签:数学、二分查找
- 难度:困难
## 题目链接
- [0793. 阶乘函数后 K 个零 - 力扣](https://leetcode.cn/problems/preimage-size-of-factorial-zeroes-function/)
## 题目大意
**描述**:
$f(x)$ 是 $x!$ 末尾是 $0$ 的数量。回想一下 $x! = 1 \times 2 \times 3 \times ... \times x$,且 $0! = 1$。
- 例如,$f(3) = 0$,因为 $3! = 6$ 的末尾没有 $0$;而 $f(11) = 2$,因为 $11! = 39916800$ 末端有 $2$ 个 $0$。
给定 k。
**要求**:
找出返回能满足 $f(x) = k$ 的非负整数 $x$ 的数量。
**说明**:
- $0 \le k \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:k = 0
输出:5
解释:0!, 1!, 2!, 3!, 和 4! 均符合 k = 0 的条件。
```
- 示例 2:
```python
输入:k = 5
输出:0
解释:没有匹配到这样的 x!,符合 k = 5 的条件。
```
## 解题思路
### 思路 1:二分查找
$n!$ 末尾 $0$ 的个数取决于因子中 $5$ 的个数(因为 $2$ 的个数总是比 $5$ 多)。设 $f(x)$ 表示 $x!$ 末尾 $0$ 的个数,则:
$$f(x) = \lfloor \frac{x}{5} \rfloor + \lfloor \frac{x}{25} \rfloor + \lfloor \frac{x}{125} \rfloor + ...$$
**性质**:
- $f(x)$ 是单调非递减的。
- 对于某个 $k$,要么不存在 $x$ 使得 $f(x) = k$(返回 $0$),要么存在连续的 $5$ 个 $x$ 使得 $f(x) = k$(返回 $5$)。
**原因**:
- 当 $x$ 不是 $5$ 的倍数时,$f(x) = f(x-1)$。
- 当 $x$ 是 $5$ 的倍数但不是 $25$ 的倍数时,$f(x) = f(x-1) + 1$。
- 因此,$f(x)$ 每次增加至少 $1$,且连续 $5$ 个数中至少有一个是 $5$ 的倍数。
### 思路 1:代码
```python
class Solution:
def preimageSizeFZF(self, k: int) -> int:
def count_zeros(x):
"""计算 x! 末尾 0 的个数"""
count = 0
while x > 0:
x //= 5
count += x
return count
def binary_search(k):
"""二分查找最小的 x 使得 f(x) >= k"""
left, right = 0, 5 * (k + 1)
while left < right:
mid = (left + right) // 2
if count_zeros(mid) < k:
left = mid + 1
else:
right = mid
return left
# 找到最小的 x 使得 f(x) = k
x = binary_search(k)
# 如果 f(x) = k,则存在 5 个这样的 x
if count_zeros(x) == k:
return 5
else:
return 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log^2 k)$,二分查找的时间复杂度为 $O(\log k)$,每次计算 $f(x)$ 的时间复杂度为 $O(\log k)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/prime-number-of-set-bits-in-binary-representation.md
================================================
# [0762. 二进制表示中质数个计算置位](https://leetcode.cn/problems/prime-number-of-set-bits-in-binary-representation/)
- 标签:位运算、数学
- 难度:简单
## 题目链接
- [0762. 二进制表示中质数个计算置位 - 力扣](https://leetcode.cn/problems/prime-number-of-set-bits-in-binary-representation/)
## 题目大意
**描述**:
给定两个整数 $left$ 和 $right$。
**要求**:
在闭区间 $[left, right]$ 范围内,统计并返回「计算置位位数为质数」的整数个数。
**说明**:
- 「计算置位位数」就是二进制表示中 $1$ 的个数。
- 例如,$21$ 的二进制表示 $10101$ 有 $3$ 个计算置位。
- $1 \le left \le right \le 10^{6}$。
- $0 \le right - left \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:left = 6, right = 10
输出:4
解释:
6 -> 110 (2 个计算置位,2 是质数)
7 -> 111 (3 个计算置位,3 是质数)
9 -> 1001 (2 个计算置位,2 是质数)
10-> 1010 (2 个计算置位,2 是质数)
共计 4 个计算置位为质数的数字。
```
- 示例 2:
```python
输入:left = 10, right = 15
输出:5
解释:
10 -> 1010 (2 个计算置位, 2 是质数)
11 -> 1011 (3 个计算置位, 3 是质数)
12 -> 1100 (2 个计算置位, 2 是质数)
13 -> 1101 (3 个计算置位, 3 是质数)
14 -> 1110 (3 个计算置位, 3 是质数)
15 -> 1111 (4 个计算置位, 4 不是质数)
共计 5 个计算置位为质数的数字。
```
## 解题思路
### 思路 1:位运算 + 质数判断
计算置位位数就是计算二进制表示中 $1$ 的个数。我们需要统计范围内有多少个数的二进制表示中 $1$ 的个数是质数。
**实现步骤**:
1. 由于 $right \le 10^6 < 2^{20}$,所以二进制表示最多有 $20$ 位,$1$ 的个数最多为 $20$。
2. 预先计算 $20$ 以内的质数:$2, 3, 5, 7, 11, 13, 17, 19$。
3. 遍历 $[left, right]$ 范围内的每个数字:
- 使用 `bin(num).count('1')` 或位运算计算 $1$ 的个数。
- 判断 $1$ 的个数是否是质数。
4. 统计满足条件的数字个数。
### 思路 1:代码
```python
class Solution:
def countPrimeSetBits(self, left: int, right: int) -> int:
# 20 以内的质数集合
primes = {2, 3, 5, 7, 11, 13, 17, 19}
count = 0
for num in range(left, right + 1):
# 计算二进制表示中 1 的个数
set_bits = bin(num).count('1')
# 判断是否是质数
if set_bits in primes:
count += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O((right - left) \times \log(right))$,其中 $\log(right)$ 是计算二进制位数的时间。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/pyramid-transition-matrix.md
================================================
# [0756. 金字塔转换矩阵](https://leetcode.cn/problems/pyramid-transition-matrix/)
- 标签:位运算、深度优先搜索、广度优先搜索、哈希表、字符串
- 难度:中等
## 题目链接
- [0756. 金字塔转换矩阵 - 力扣](https://leetcode.cn/problems/pyramid-transition-matrix/)
## 题目大意
**描述**:
你正在把积木堆成金字塔。每个块都有一个颜色,用一个字母表示。每一行的块比它下面的行 少一个块 ,并且居中。
为了使金字塔美观,只有特定的「三角形图案」是允许的。一个三角形的图案由「两个块」和叠在上面的「单个块」组成。模式是以三个字母字符串的列表形式 $allowed$ 给出的,其中模式的前两个字符分别表示左右底部块,第三个字符表示顶部块。
- 例如,`"ABC"` 表示一个三角形图案,其中一个 `"C"` 块堆叠在一个 `"A"` 块(左)和一个 `"B"` 块(右)之上。请注意,这与 `"BAC"` 不同,`"B"` 在左下角,`"A"` 在右下角。
**要求**:
你从作为单个字符串给出的底部的一排积木 $bottom$ 开始,必须「将其作为金字塔的底部」。
在给定 $bottom$ 和 $allowed$ 的情况下,如果你能一直构建到金字塔顶部,使金字塔中的 每个三角形图案 都是在 $allowed$ 中的,则返回 true,否则返回 false。
**说明**:
- $2 \le bottom.length \le 6$。
- $0 \le allowed.length \le 216$。
- $allowed[i].length == 3$。
- 所有输入字符串中的字母来自集合 `{'A', 'B', 'C', 'D', 'E', 'F'}`。
- $allowed$ 中所有值都是唯一的。
**示例**:
- 示例 1:
```python
输入:bottom = "BCD", allowed = ["BCC","CDE","CEA","FFF"]
输出:true
解释:允许的三角形图案显示在右边。
从最底层(第 3 层)开始,我们可以在第 2 层构建“CE”,然后在第 1 层构建“E”。
金字塔中有三种三角形图案,分别是 “BCC”、“CDE” 和 “CEA”。都是允许的。
```
- 示例 2:
```python
输入:bottom = "AAAA", allowed = ["AAB","AAC","BCD","BBE","DEF"]
输出:false
解释:允许的三角形图案显示在右边。
从最底层(即第 4 层)开始,创造第 3 层有多种方法,但如果尝试所有可能性,你便会在创造第 1 层前陷入困境。
```
## 解题思路
### 思路 1:DFS + 哈希表
使用深度优先搜索(DFS)和哈希表来构建金字塔。
**实现步骤**:
1. 将 $allowed$ 转换为哈希表,键为底部两个字符,值为可能的顶部字符列表。
2. 使用 DFS 递归构建金字塔:
- 如果当前层只有一个字符,返回 `True`。
- 否则,尝试所有可能的下一层组合。
3. 对于当前层的每个相邻字符对,查找可能的顶部字符。
4. 递归检查是否能构建到顶部。
### 思路 1:代码
```python
class Solution:
def pyramidTransition(self, bottom: str, allowed: List[str]) -> bool:
from collections import defaultdict
# 构建哈希表:底部两个字符 -> 可能的顶部字符列表
mapping = defaultdict(list)
for pattern in allowed:
mapping[pattern[:2]].append(pattern[2])
def dfs(current):
"""递归构建金字塔"""
# 如果当前层只有一个字符,成功
if len(current) == 1:
return True
# 尝试构建下一层
return build_next_layer(current, 0, [])
def build_next_layer(current, index, next_layer):
"""构建下一层"""
# 如果已经构建完下一层,递归检查
if index == len(current) - 1:
return dfs(''.join(next_layer))
# 尝试当前位置的所有可能字符
base = current[index:index+2]
for char in mapping[base]:
next_layer.append(char)
if build_next_layer(current, index + 1, next_layer):
return True
next_layer.pop()
return False
return dfs(bottom)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(A^n)$,其中 $A$ 是字母表大小,$n$ 是 $bottom$ 的长度。最坏情况下需要尝试所有可能的组合。
- **空间复杂度**:$O(n^2)$,递归栈的深度为 $O(n)$,每层需要 $O(n)$ 空间。
================================================
FILE: docs/solutions/0700-0799/rabbits-in-forest.md
================================================
# [0781. 森林中的兔子](https://leetcode.cn/problems/rabbits-in-forest/)
- 标签:贪心、数组、哈希表、数学
- 难度:中等
## 题目链接
- [0781. 森林中的兔子 - 力扣](https://leetcode.cn/problems/rabbits-in-forest/)
## 题目大意
**描述**:
森林中有未知数量的兔子。提问其中若干只兔子 `"还有多少只兔子与你(指被提问的兔子)颜色相同?"`,将答案收集到一个整数数组 $answers$ 中,其中 $answers[i]$ 是第 $i$ 只兔子的回答。
给定数组 $answers$。
**要求**:
返回森林中兔子的最少数量。
**说明**:
- $1 \le answers.length \le 10^{3}$。
- $0 \le answers[i] \lt 10^{3}$。
**示例**:
- 示例 1:
```python
输入:answers = [1,1,2]
输出:5
解释:
两只回答了 "1" 的兔子可能有相同的颜色,设为红色。
之后回答了 "2" 的兔子不会是红色,否则他们的回答会相互矛盾。
设回答了 "2" 的兔子为蓝色。
此外,森林中还应有另外 2 只蓝色兔子的回答没有包含在数组中。
因此森林中兔子的最少数量是 5 只:3 只回答的和 2 只没有回答的。
```
- 示例 2:
```python
输入:answers = [10,10,10]
输出:11
```
## 解题思路
### 思路 1:贪心 + 哈希表
如果一只兔子回答 $x$,说明包括它自己在内,有 $x + 1$ 只相同颜色的兔子。为了使兔子总数最少,我们应该让回答相同的兔子尽可能属于同一组。
**实现步骤**:
1. 使用哈希表统计每个回答出现的次数。
2. 对于回答 $x$ 的兔子:
- 每 $x + 1$ 只回答 $x$ 的兔子可以是同一颜色。
- 如果有 $count$ 只兔子回答 $x$,则至少需要 $\lceil \frac{count}{x + 1} \rceil$ 组,每组有 $x + 1$ 只兔子。
- 总数为 $\lceil \frac{count}{x + 1} \rceil \times (x + 1)$。
3. 将所有颜色的兔子数量相加。
### 思路 1:代码
```python
class Solution:
def numRabbits(self, answers: List[int]) -> int:
from collections import Counter
# 统计每个回答出现的次数
count = Counter(answers)
total = 0
for x, cnt in count.items():
# 每组有 x + 1 只兔子
group_size = x + 1
# 需要的组数(向上取整)
groups = (cnt + group_size - 1) // group_size
# 总兔子数
total += groups * group_size
return total
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是 $answers$ 的长度。
- **空间复杂度**:$O(n)$,哈希表的空间。
================================================
FILE: docs/solutions/0700-0799/random-pick-with-blacklist.md
================================================
# [0710. 黑名单中的随机数](https://leetcode.cn/problems/random-pick-with-blacklist/)
- 标签:数组、哈希表、数学、二分查找、排序、随机化
- 难度:困难
## 题目链接
- [0710. 黑名单中的随机数 - 力扣](https://leetcode.cn/problems/random-pick-with-blacklist/)
## 题目大意
**描述**:
给定一个整数 $n$ 和一个「无重复」黑名单整数数组 $blacklist$。设计一种算法,从 $[0, n - 1]$ 范围内的任意整数中选取一个「未加入」黑名单 $blacklist$ 的整数。任何在上述范围内且不在黑名单 $blacklist$ 中的整数都应该有「同等的可能性」被返回。
优化你的算法,使它最小化调用语言「内置」随机函数的次数。
**要求**:
实现 Solution 类:
- `Solution(int n, int[] blacklist)` 初始化整数 $n$ 和被加入黑名单 $blacklist$ 的整数。
- `int pick()` 返回一个范围为 $[0, n - 1]$ 且不在黑名单 $blacklist$ 中的随机整数。
**说明**:
- $1 \le n \le 10^{9}$。
- $0 \le blacklist.length \le min(10^{5}, n - 1)$。
- $0 \le blacklist[i] \lt n$。
- $blacklist$ 中所有值都不同。
- $pick$ 最多被调用 $2 \times 10^{4}$ 次。
**示例**:
- 示例 1:
```python
输入
["Solution", "pick", "pick", "pick", "pick", "pick", "pick", "pick"]
[[7, [2, 3, 5]], [], [], [], [], [], [], []]
输出
[null, 0, 4, 1, 6, 1, 0, 4]
解释
Solution solution = new Solution(7, [2, 3, 5]);
solution.pick(); // 返回0,任何[0,1,4,6]的整数都可以。注意,对于每一个pick的调用,
// 0、1、4和6的返回概率必须相等(即概率为1/4)。
solution.pick(); // 返回 4
solution.pick(); // 返回 1
solution.pick(); // 返回 6
solution.pick(); // 返回 1
solution.pick(); // 返回 0
solution.pick(); // 返回 4
```
## 解题思路
### 思路 1:哈希表 + 随机映射
将黑名单中的数字映射到 $[n - len(blacklist), n)$ 范围内的白名单数字。
**实现步骤**:
1. 计算白名单的大小:$white\_count = n - len(blacklist)$。
2. 将黑名单中 $\ge white\_count$ 的数字放入集合 $black\_set$。
3. 对于黑名单中 $< white\_count$ 的数字,将其映射到 $[white\_count, n)$ 范围内不在黑名单中的数字。
4. 随机生成 $[0, white\_count)$ 范围内的数字:
- 如果在映射表中,返回映射后的值。
- 否则,直接返回该数字。
### 思路 1:代码
```python
class Solution:
def __init__(self, n: int, blacklist: List[int]):
import random
self.random = random
# 白名单的大小
self.white_count = n - len(blacklist)
# 黑名单中 >= white_count 的数字
black_set = set()
for b in blacklist:
if b >= self.white_count:
black_set.add(b)
# 映射表:将黑名单中 < white_count 的数字映射到 [white_count, n) 范围内的白名单数字
self.mapping = {}
white = self.white_count
for b in blacklist:
if b < self.white_count:
# 找到下一个不在黑名单中的数字
while white in black_set or white in blacklist:
white += 1
self.mapping[b] = white
white += 1
def pick(self) -> int:
# 随机生成 [0, white_count) 范围内的数字
rand = self.random.randint(0, self.white_count - 1)
# 如果在映射表中,返回映射后的值
return self.mapping.get(rand, rand)
# Your Solution object will be instantiated and called as such:
# obj = Solution(n, blacklist)
# param_1 = obj.pick()
```
### 思路 1:复杂度分析
- **时间复杂度**:
- 初始化:$O(B)$,其中 $B$ 是黑名单的长度。
- 查询:$O(1)$。
- **空间复杂度**:$O(B)$,映射表的空间。
================================================
FILE: docs/solutions/0700-0799/range-module.md
================================================
# [0715. Range 模块](https://leetcode.cn/problems/range-module/)
- 标签:设计、线段树、有序集合
- 难度:困难
## 题目链接
- [0715. Range 模块 - 力扣](https://leetcode.cn/problems/range-module/)
## 题目大意
**描述**:`Range` 模块是跟踪数字范围的模块。
**要求**:
- 设计一个数据结构来跟踪查询半开区间 `[left, right)` 内的数字是否被跟踪。
- 实现 `RangeModule` 类:
- `RangeModule()` 初始化数据结构的对象。
- `void addRange(int left, int right)` 添加半开区间 `[left, right)`,跟踪该区间中的每个实数。添加与当前跟踪的数字部分重叠的区间时,应当添加在区间 `[left, right)` 中尚未跟踪的任何数字到该区间中。
- `boolean queryRange(int left, int right)` 只有在当前正在跟踪区间 `[left, right)` 中的每一个实数时,才返回 `True` ,否则返回 `False`。
- `void removeRange(int left, int right)` 停止跟踪半开区间 `[left, right)` 中当前正在跟踪的每个实数。
**说明**:
- $1 \le left < right \le 10^9$。
**示例**:
- 示例 1:
```
rangeModule = RangeModule() -> null
rangeModule.addRange(10, 20) -> null
rangeModule.removeRange(14, 16) -> null
rangeModule.queryRange(10, 14) -> True
rangeModule.queryRange(13, 15) -> False
rangeModule.queryRange(16, 17) -> True
```
## 解题思路
### 思路 1:线段树
这道题可以使用线段树来做,但是效率比较差。
区间的范围是 $[0, 10^9]$,普通数组构成的线段树不满足要求。需要用到动态开点线段树。题目要求的是半开区间 `[left, right)` ,而线段树中常用的是闭合区间。但是我们可以将半开区间 `[left, right)` 转为 `[left, right - 1]` 的闭合空间。
这样构建线段树的时间复杂度为 $O(\log n)$,单次区间更新的时间复杂度为 $O(\log n)$,单次区间查询的时间复杂度为 $O(\log n)$。总体时间复杂度为 $O(\log n)$。
## 代码
### 思路 1 代码:
```python
# 线段树的节点类
class TreeNode:
def __init__(self, left, right, val=False, lazy_tag=None, letNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = (left + right) >> 1
self.leftNode = letNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
class RangeModule:
def __init__(self):
self.tree = TreeNode(0, int(1e9))
# 向上更新 node 节点区间值,节点的区间值等于该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = node.leftNode.val and node.rightNode.val
else:
node.val = False
# 向下更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if not node.leftNode:
node.leftNode = TreeNode(node.left, node.mid)
if not node.rightNode:
node.rightNode = TreeNode(node.mid + 1, node.right)
if node.lazy_tag is not None:
node.leftNode.lazy_tag = node.lazy_tag # 更新左子节点懒惰标记
node.leftNode.val = node.lazy_tag # 左子节点每个元素值增加 lazy_tag
node.rightNode.lazy_tag = node.lazy_tag # 更新右子节点懒惰标记
node.rightNode.val = node.lazy_tag # 右子节点每个元素值增加 lazy_tag
node.lazy_tag = None # 更新当前节点的懒惰标记
# 区间更新
def __update_interval(self, q_left, q_right, val, node):
if q_left <= node.left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
node.lazy_tag = val # 将当前节点的延迟标记增加 val
node.val = val # 当前节点所在区间每个元素值增加 val
return
self.__pushdown(node)
if q_left <= node.mid:
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid:
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询,在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if q_left <= node.left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
# 需要向下更新节点所在区间的左右子节点的值和懒惰标记
self.__pushdown(node)
if q_right <= node.mid:
return self.__query_interval(q_left, q_right, node.leftNode)
if q_left > node.mid:
return self.__query_interval(q_left, q_right, node.rightNode)
return self.__query_interval(q_left, q_right, node.leftNode) and self.__query_interval(q_left, q_right, node.rightNode) # 返回左右子树元素值的聚合计算结果
def addRange(self, left: int, right: int) -> None:
self.__update_interval(left, right - 1, True, self.tree)
def queryRange(self, left: int, right: int) -> bool:
return self.__query_interval(left, right - 1, self.tree)
def removeRange(self, left: int, right: int) -> None:
self.__update_interval(left, right - 1, False, self.tree)
```
================================================
FILE: docs/solutions/0700-0799/reach-a-number.md
================================================
# [0754. 到达终点数字](https://leetcode.cn/problems/reach-a-number/)
- 标签:数学、二分查找
- 难度:中等
## 题目链接
- [0754. 到达终点数字 - 力扣](https://leetcode.cn/problems/reach-a-number/)
## 题目大意
**描述**:
在一根无限长的数轴上,你站在 $0$ 的位置。终点在 $target$ 的位置。
你可以做一些数量的移动 $numMoves$:
- 每次你可以选择向左或向右移动。
- 第 $i$ 次移动(从 $i == 1$ 开始,到 $i == numMoves$),在选择的方向上走 $i$ 步。
给定整数 $target$。
**要求**:
返回 到达目标所需的 最小 移动次数(即最小 $numMoves$ ) 。
**说明**:
- $-10^{9} \le target \le 10^{9}$。
- target != 0。
**示例**:
- 示例 1:
```python
示例 1:
输入: target = 2
输出: 3
解释:
第一次移动,从 0 到 1 。
第二次移动,从 1 到 -1 。
第三次移动,从 -1 到 2 。
```
- 示例 2:
```python
输入:
输出:
```
## 解题思路
### 思路 1:数学
在数轴上,从 $0$ 开始,第 $i$ 步可以向左或向右移动 $i$ 步。要到达 $target$,需要找到最小的移动次数。
**分析**:
- 如果一直向右移动,第 $n$ 步后位置为 $1 + 2 + ... + n = \frac{n(n+1)}{2}$。
- 如果某些步向左移动,相当于从总和中减去这些步的两倍。
- 设向右移动的步为正,向左移动的步为负,则:$sum - 2 \times neg = target$。
- 即:$neg = \frac{sum - target}{2}$。
**步骤**:
1. 由于对称性,可以只考虑 $target$ 的绝对值。
2. 找到最小的 $n$,使得 $sum = \frac{n(n+1)}{2} \ge |target|$。
3. 如果 $sum - |target|$ 是偶数,则可以通过翻转某些步到达 $target$,返回 $n$。
4. 否则,继续增加步数,直到差值为偶数。
### 思路 1:代码
```python
class Solution:
def reachNumber(self, target: int) -> int:
# 由于对称性,只考虑绝对值
target = abs(target)
n = 0
sum_n = 0
# 找到最小的 n,使得 sum >= target
while sum_n < target:
n += 1
sum_n += n
# 如果差值是偶数,可以直接到达
diff = sum_n - target
if diff % 2 == 0:
return n
# 否则,继续增加步数
# 如果 n 是奇数,再走 2 步(n+1 和 n+2),差值增加 2n+3(奇数)
# 如果 n 是偶数,再走 1 步(n+1),差值增加 n+1(奇数)
# 总之,最多再走 2 步就能使差值为偶数
while diff % 2 != 0:
n += 1
sum_n += n
diff = sum_n - target
return n
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\sqrt{target})$,需要找到 $n$ 使得 $\frac{n(n+1)}{2} \ge target$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/reaching-points.md
================================================
# [0780. 到达终点](https://leetcode.cn/problems/reaching-points/)
- 标签:数学
- 难度:困难
## 题目链接
- [0780. 到达终点 - 力扣](https://leetcode.cn/problems/reaching-points/)
## 题目大意
**描述**:
给定四个整数 $sx$,$sy$,$tx$ 和 $ty$。
**要求**:
如果通过一系列的转换可以从起点 $(sx, sy)$ 到达终点 $(tx, ty)$,则返回 true,否则返回 false。
从点 $(x, y)$ 可以转换到 $(x, x+y)$ 或者 $(x+y, y)$。
**说明**:
- $1 \le sx, sy, tx, ty \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入: sx = 1, sy = 1, tx = 3, ty = 5
输出: true
解释:
可以通过以下一系列转换从起点转换到终点:
(1, 1) -> (1, 2)
(1, 2) -> (3, 2)
(3, 2) -> (3, 5)
```
- 示例 2:
```python
输入: sx = 1, sy = 1, tx = 2, ty = 2
输出: false
```
## 解题思路
### 思路 1:数学
从起点 $(sx, sy)$ 到终点 $(tx, ty)$,每次可以将 $(x, y)$ 转换为 $(x, x+y)$ 或 $(x+y, y)$。我们可以反向思考:从 $(tx, ty)$ 逆推到 $(sx, sy)$。
**逆向操作**:
- 如果 $tx > ty$,则上一步是 $(tx - ty, ty)$。
- 如果 $ty > tx$,则上一步是 $(tx, ty - tx)$。
**优化**:
- 当 $tx \gg ty$ 时,可以一次性减去多个 $ty$:$tx = tx \% ty$(如果 $ty > sy$)。
- 否则,需要逐步减去,确保不会跳过 $(sx, sy)$。
### 思路 1:代码
```python
class Solution:
def reachingPoints(self, sx: int, sy: int, tx: int, ty: int) -> bool:
# 从终点逆推到起点
while tx >= sx and ty >= sy:
if tx == sx and ty == sy:
return True
if tx > ty:
# 上一步是 (tx - ty, ty)
if ty == sy:
# 检查是否能通过减去若干个 ty 到达 sx
return (tx - sx) % ty == 0
# 一次性减去多个 ty
tx %= ty
else:
# 上一步是 (tx, ty - tx)
if tx == sx:
# 检查是否能通过减去若干个 tx 到达 sy
return (ty - sy) % tx == 0
# 一次性减去多个 tx
ty %= tx
return False
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log(\max(tx, ty)))$,类似辗转相除法。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/remove-comments.md
================================================
# [0722. 删除注释](https://leetcode.cn/problems/remove-comments/)
- 标签:数组、字符串
- 难度:中等
## 题目链接
- [0722. 删除注释 - 力扣](https://leetcode.cn/problems/remove-comments/)
## 题目大意
**描述**:
给一个 C++ 程序,删除程序中的注释。这个程序 $source$ 是一个数组,其中 $source[i]$ 表示第 $i$ 行源码。 这表示每行源码由 `'\n'` 分隔。
在 C++ 中有两种注释风格,行内注释和块注释。
- 字符串 `//` 表示行注释,表示//和其右侧的其余字符应该被忽略。
- 字符串 `/*` 表示一个块注释,它表示直到下一个(非重叠)出现的 `*/` 之间的所有字符都应该被忽略。(阅读顺序为从左到右)非重叠是指,字符串 `/*/` 并没有结束块注释,因为注释的结尾与开头相重叠。
第一个有效注释优先于其他注释。
- 如果字符串 `//` 出现在块注释中会被忽略。
- 同样,如果字符串 `/*` 出现在行或块注释中也会被忽略。
如果一行在删除注释之后变为空字符串,那么不要输出该行。即,答案列表中的每个字符串都是非空的。
样例中没有控制字符,单引号或双引号字符。
- 比如,`source = $string$ $s$ = "/* Not a $comment$. */";" 不会出现在测试样例里。
此外,没有其他内容(如定义或宏)会干扰注释。
我们保证每一个块注释最终都会被闭合, 所以在行或块注释之外的/*总是开始新的注释。
最后,隐式换行符可以通过块注释删除。 有关详细信息,请参阅下面的示例。
从源代码中删除注释后,需要以相同的格式返回源代码。
**要求**:
从源代码中删除注释,以相同的格式返回源代码。
**说明**:
- $1 \le source.length \le 10^{3}$。
- $0 \le source[i].length \le 80$。
- $source[i]$ 由可打印的 ASCII 字符组成。
- 每个块注释都会被闭合。
- 给定的源码中不会有单引号、双引号或其他控制字符。
**示例**:
- 示例 1:
```python
输入: source = ["/*Test program */", "int main()", "{ ", " // variable declaration ", "int a, b, c;", "/* This is a test", " multiline ", " comment for ", " testing */", "a = b + c;", "}"]
输出: ["int main()","{ "," ","int a, b, c;","a = b + c;","}"]
解释: 示例代码可以编排成这样:
/*Test program */
int main()
{
// variable declaration
int a, b, c;
/* This is a test
multiline
comment for
testing */
a = b + c;
}
第 1 行和第 6-9 行的字符串 /* 表示块注释。第 4 行的字符串 // 表示行注释。
编排后:
int main()
{
int a, b, c;
a = b + c;
}
```
- 示例 2:
```python
输入: source = ["a/*comment", "line", "more_comment*/b"]
输出: ["ab"]
解释: 原始的 source 字符串是 "a/*comment\nline\nmore_comment*/b", 其中我们用粗体显示了换行符。删除注释后,隐含的换行符被删除,留下字符串 "ab" 用换行符分隔成数组时就是 ["ab"].
```
## 解题思路
### 思路 1:模拟
删除注释需要处理两种注释:行注释 `//` 和块注释 `/* */`。
**实现步骤**:
1. 使用一个标志 `in_block` 表示当前是否在块注释中。
2. 遍历每一行的每个字符:
- 如果在块注释中,查找 `*/` 结束块注释。
- 如果不在块注释中:
- 遇到 `/*`,进入块注释。
- 遇到 `//`,忽略该行剩余部分。
- 否则,将字符加入当前行。
3. 如果当前行不为空且不在块注释中,将其加入结果。
### 思路 1:代码
```python
class Solution:
def removeComments(self, source: List[str]) -> List[str]:
result = []
in_block = False # 是否在块注释中
current_line = [] # 当前行的内容
for line in source:
i = 0
while i < len(line):
if in_block:
# 在块注释中,查找 */
if i + 1 < len(line) and line[i:i+2] == '*/':
in_block = False
i += 2
else:
i += 1
else:
# 不在块注释中
if i + 1 < len(line) and line[i:i+2] == '/*':
# 进入块注释
in_block = True
i += 2
elif i + 1 < len(line) and line[i:i+2] == '//':
# 行注释,忽略该行剩余部分
break
else:
# 普通字符
current_line.append(line[i])
i += 1
# 如果不在块注释中且当前行不为空,加入结果
if not in_block and current_line:
result.append(''.join(current_line))
current_line = []
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是源代码的行数,$m$ 是每行的平均长度。
- **空间复杂度**:$O(n \times m)$,存储结果的空间。
================================================
FILE: docs/solutions/0700-0799/reorganize-string.md
================================================
# [0767. 重构字符串](https://leetcode.cn/problems/reorganize-string/)
- 标签:贪心、哈希表、字符串、计数、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [0767. 重构字符串 - 力扣](https://leetcode.cn/problems/reorganize-string/)
## 题目大意
**描述**:
给定一个字符串 $s$。
**要求**:
检查是否能重新排布其中的字母,使得两相邻的字符不同。
返回 $s$ 的任意可能的重新排列。若不可行,返回空字符串 `""`。
**说明**:
- $1 \le s.length \le 500$。
- $s$ 只包含小写字母。
**示例**:
- 示例 1:
```python
输入: s = "aab"
输出: "aba"
```
- 示例 2:
```python
输入: s = "aaab"
输出: ""
```
## 解题思路
### 思路 1:贪心 + 堆
要使相邻字符不同,我们应该优先放置出现次数最多的字符。使用最大堆来维护字符的出现次数。
**实现步骤**:
1. 统计每个字符的出现次数。
2. 如果某个字符的出现次数超过 $\lceil \frac{n}{2} \rceil$,则无法重排,返回空字符串。
3. 使用最大堆,每次取出出现次数最多的字符:
- 如果结果字符串为空或最后一个字符与当前字符不同,直接添加。
- 否则,取出次多的字符添加,然后将之前的字符放回堆中。
4. 重复直到所有字符都被添加。
### 思路 1:代码
```python
class Solution:
def reorganizeString(self, s: str) -> str:
from collections import Counter
import heapq
# 统计字符出现次数
count = Counter(s)
n = len(s)
# 如果某个字符出现次数超过 (n + 1) // 2,无法重排
if max(count.values()) > (n + 1) // 2:
return ""
# 使用最大堆(Python 的 heapq 是最小堆,所以用负数)
heap = [(-cnt, char) for char, cnt in count.items()]
heapq.heapify(heap)
result = []
while heap:
# 取出出现次数最多的字符
first_cnt, first_char = heapq.heappop(heap)
# 如果结果为空或最后一个字符与当前字符不同
if not result or result[-1] != first_char:
result.append(first_char)
# 如果还有剩余,放回堆中
if first_cnt + 1 < 0:
heapq.heappush(heap, (first_cnt + 1, first_char))
else:
# 需要取次多的字符
if not heap:
return ""
second_cnt, second_char = heapq.heappop(heap)
result.append(second_char)
# 放回第一个字符
heapq.heappush(heap, (first_cnt, first_char))
# 如果第二个字符还有剩余,放回堆中
if second_cnt + 1 < 0:
heapq.heappush(heap, (second_cnt + 1, second_char))
return ''.join(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log k)$,其中 $n$ 是字符串长度,$k$ 是不同字符的个数(最多 $26$)。
- **空间复杂度**:$O(k)$,堆的空间。
================================================
FILE: docs/solutions/0700-0799/rotate-string.md
================================================
# [0796. 旋转字符串](https://leetcode.cn/problems/rotate-string/)
- 标签:字符串、字符串匹配
- 难度:简单
## 题目链接
- [0796. 旋转字符串 - 力扣](https://leetcode.cn/problems/rotate-string/)
## 题目大意
**描述**:给定两个字符串 `s` 和 `goal`。
**要求**:如果 `s` 在若干次旋转之后,能变为 `goal`,则返回 `True`,否则返回 `False`。
**说明**:
- `s` 的旋转操作:将 `s` 最左侧的字符移动到最右边。
- 比如:`s = "abcde"`,在旋转一次之后结果就是 `s = "bcdea"`。
- $1 \le s.length, goal.length \le 100$。
- `s` 和 `goal` 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入: s = "abcde", goal = "cdeab"
输出: true
```
- 示例 2:
```python
输入: s = "abcde", goal = "abced"
输出: false
```
## 解题思路
### 思路 1:KMP 算法
其实将两个字符串 `s` 拼接在一起,就包含了所有从 `s` 进行旋转后的字符串。那么我们只需要判断一下 `goal` 是否为 `s + s` 的子串即可。可以用 KMP 算法来做。
1. 先排除掉几种不可能的情况,比如 `s` 为空串的情况,`goal` 为空串的情况,`len(s) != len(goal)` 的情况。
2. 然后使用 KMP 算法计算出 `goal` 在 `s + s` 中的下标位置 `index`(`s + s` 可用取余运算模拟)。
3. 如果 `index == -1`,则说明 `s` 在若干次旋转之后,不能能变为 `goal`,则返回 `False`。
4. 如果 `index != -1`,则说明 `s` 在若干次旋转之后,能变为 `goal`,则返回 `True`。
### 思路 1:代码
```python
class Solution:
def kmp(self, T: str, p: str) -> int:
n, m = len(T), len(p)
next = self.generateNext(p)
i, j = 0, 0
while i - j < n:
while j > 0 and T[i % n] != p[j]:
j = next[j - 1]
if T[i % n] == p[j]:
j += 1
if j == m:
return i - m + 1
i += 1
return -1
def generateNext(self, p: str):
m = len(p)
next = [0 for _ in range(m)]
left = 0
for right in range(1, m):
while left > 0 and p[left] != p[right]:
left = next[left - 1]
if p[left] == p[right]:
left += 1
next[right] = left
return next
def rotateString(self, s: str, goal: str) -> bool:
if not s or not goal or len(s) != len(goal):
return False
index = self.kmp(s, goal)
if index == -1:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中文本串 $s$ 的长度为 $n$,模式串 $goal$ 的长度为 $m$。
- **空间复杂度**:$O(m)$。
================================================
FILE: docs/solutions/0700-0799/rotated-digits.md
================================================
# [0788. 旋转数字](https://leetcode.cn/problems/rotated-digits/)
- 标签:数学、动态规划
- 难度:中等
## 题目链接
- [0788. 旋转数字 - 力扣](https://leetcode.cn/problems/rotated-digits/)
## 题目大意
**描述**:给定搞一个正整数 $n$。
**要求**:计算从 $1$ 到 $n$ 中有多少个数 $x$ 是好数。
**说明**:
- **好数**:如果一个数 $x$ 的每位数字逐个被旋转 180 度之后,我们仍可以得到一个有效的,且和 $x$ 不同的数,则成该数为好数。
- 如果一个数的每位数字被旋转以后仍然还是一个数字, 则这个数是有效的。$0$、$1$ 和 $8$ 被旋转后仍然是它们自己;$2$ 和 $5$ 可以互相旋转成对方(在这种情况下,它们以不同的方向旋转,换句话说,$2$ 和 $5$ 互为镜像);$6$ 和 $9$ 同理,除了这些以外其他的数字旋转以后都不再是有效的数字。
- $n$ 的取值范围是 $[1, 10000]$。
**示例**:
- 示例 1:
```python
输入: 10
输出: 4
解释:
在 [1, 10] 中有四个好数: 2, 5, 6, 9。
注意 1 和 10 不是好数, 因为他们在旋转之后不变。
```
## 解题思路
### 思路 1:枚举算法
根据题目描述,一个数满足:数中没有出现 $3$、$4$、$7$,并且至少出现一次 $2$、$5$、$6$ 或 $9$,就是好数。
因此,我们可以枚举 $[1, n]$ 中的每一个正整数 $x$,并判断该正整数 $x$ 的数位中是否满足没有出现 $3$、$4$、$7$,并且至少一次出现了 $2$、$5$、$6$ 或 $9$,如果满足,则该正整数 $x$ 位好数,否则不是好数。
最后统计好数的方案个数并将其返回即可。
### 思路 1:代码
```python
class Solution:
def rotatedDigits(self, n: int) -> int:
check = [0, 0, 1, -1, -1, 1, 1, -1, 0, 1]
ans = 0
for i in range(1, n + 1):
flag = False
num = i
while num:
digit = num % 10
num //= 10
if check[digit] == 1:
flag = True
elif check[digit] == -1:
flag = False
break
if flag:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(\log n)$。
### 思路 2:动态规划 + 数位 DP
将 $n$ 转换为字符串 $s$,定义递归函数 `def dfs(pos, hasDiff, isLimit):` 表示构造第 $pos$ 位及之后所有数位的合法方案数。其中:
1. $pos$ 表示当前枚举的数位位置。
2. $hasDiff$ 表示当前是否用到 $2$、$5$、$6$ 或 $9$ 中任何一个数字。
3. $isLimit$ 表示前一位数位是否等于上界,用于限制本次搜索的数位范围。
接下来按照如下步骤进行递归。
1. 从 `dfs(0, False, True)` 开始递归。 `dfs(0, False, True)` 表示:
1. 从位置 $0$ 开始构造。
2. 初始没有用到 $2$、$5$、$6$ 或 $9$ 中任何一个数字。
3. 开始时受到数字 $n$ 对应最高位数位的约束。
2. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:
1. 如果 $hasDiff == True$,说明当前方案符合要求,则返回方案数 $1$。
2. 如果 $hasDiff == False$,说明当前方案不符合要求,则返回方案数 $0$。
3. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
4. 因为不需要考虑前导 $0$,所以当前所能选择的最小数字 $minX$ 为 $0$。
5. 根据 $isLimit$ 来决定填当前位数位所能选择的最大数字($maxX$)。
6. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
7. 如果当前数位与之前数位没有出现 $3$、$4$、$7$,则方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, hasDiff or check[d], isLimit and d == maxX)`。
1. `hasDiff or check[d]` 表示当前是否用到 $2$、$5$、$6$ 或 $9$ 中任何一个数字或者没有用到 $3$、$4$、$7$。
2. `isLimit and d == maxX` 表示 $pos + 1$ 位受到之前位限制和 $pos$ 位限制。
8. 最后的方案数为 `dfs(0, False, True)`,将其返回即可。
### 思路 2:代码
```python
class Solution:
def rotatedDigits(self, n: int) -> int:
check = [0, 0, 1, -1, -1, 1, 1, -1, 0, 1]
# 将 n 转换为字符串 s
s = str(n)
@cache
# pos: 第 pos 个数位
# hasDiff: 之前选过的数字是否包含 2,5,6,9 中至少一个。
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
def dfs(pos, hasDiff, isLimit):
if pos == len(s):
# isNum 为 True,则表示当前方案符合要求
return int(hasDiff)
ans = 0
# 不需要考虑前导 0,则最小可选择数字为 0
minX = 0
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = int(s[pos]) if isLimit else 9
# 枚举可选择的数字
for d in range(minX, maxX + 1):
# d 不在选择的数字集合中,即之前没有选择过 d
if check[d] != -1:
ans += dfs(pos + 1, hasDiff or check[d], isLimit and d == maxX)
return ans
return dfs(0, False, True)
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/0700-0799/search-in-a-binary-search-tree.md
================================================
# [0700. 二叉搜索树中的搜索](https://leetcode.cn/problems/search-in-a-binary-search-tree/)
- 标签:树、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [0700. 二叉搜索树中的搜索 - 力扣](https://leetcode.cn/problems/search-in-a-binary-search-tree/)
## 题目大意
**描述**:给定一个二叉搜索树和一个值 `val`。
**要求**:在二叉搜索树中查找节点值等于 `val` 的节点,并返回该节点。
**说明**:
- 数中节点数在 $[1, 5000]$ 范围内。
- $1 \le Node.val \le 10^7$。
- `root` 是二叉搜索树。
- $1 \le val \le 10^7$。
**示例**:
- 示例 1:
```python
输入:root = [4,2,7,1,3], val = 2
输出:[2,1,3]
```
- 示例 2:
```python
输入:root = [4,2,7,1,3], val = 5
输出:[]
```
## 解题思路
### 思路 1:递归
1. 从根节点 `root` 开始向下递归遍历。
1. 如果 `val` 等于当前节点的值,即 `val == root.val`,则返回 `root`;
2. 如果 `val` 小于当前节点的值 ,即 `val < root.val`,则递归遍历左子树,继续查找;
3. 如果 `val` 大于当前节点的值 ,即 `val > root.val`,则递归遍历右子树,继续查找。
2. 如果遍历到最后也没有找到,则返回空节点。
### 思路 1:代码
```python
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
if not root or val == root.val:
return root
if val < root.val:
return self.searchBST(root.left, val)
else:
return self.searchBST(root.right, val)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。其中 $n$ 是二叉搜索树的节点数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0700-0799/search-in-a-sorted-array-of-unknown-size.md
================================================
# [0702. 搜索长度未知的有序数组](https://leetcode.cn/problems/search-in-a-sorted-array-of-unknown-size/)
- 标签:数组、二分查找、交互
- 难度:中等
## 题目链接
- [0702. 搜索长度未知的有序数组 - 力扣](https://leetcode.cn/problems/search-in-a-sorted-array-of-unknown-size/)
## 题目大意
**描述**:给定一个升序数组 $secret$,但是数组的大小是未知的。我们无法直接访问数组,智能通过 `ArrayReader` 接口去访问他。我们可以通过接口 `reader.get(k)`:
1. 如果数组访问未越界,则返回数组 $secret$ 中第 $k$ 个下标位置的元素值。
2. 如果数组访问越界,则接口返回 $2^{31} - 1$。
现在再给定一个数字 $target$。
**要求**:从 $secret$ 中找出 $secret[k] == target$ 的下标位置 $k$,如果 $secret$ 中不存在 $target$,则返回 $-1$。
**说明**:
- $1 \le secret.length \le 10^4$。
- $-10^4 \le secret[i], target \le 10^4$。
- $secret$ 严格递增。
**示例**:
- 示例 1:
```python
输入: secret = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 存在在 nums 中,下标为 4
```
- 示例 2:
```python
输入: secret = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不在数组中所以返回 -1
```
## 解题思路
### 思路 1:二分查找算法
这道题的关键点在于找到数组的大小,以便确定查找的右边界位置。右边界可以通过倍增的方式快速查找。在查找右边界的同时,也能将左边界的范围进一步缩小。等确定了左右边界,就可以使用二分查找算法快速查找 $target$。
### 思路 1:代码
```python
class Solution:
def binarySearch(self, reader, left, right, target):
while left < right:
mid = left + (right - left) // 2
if target > reader.get(mid):
left = mid + 1
else:
right = mid
if reader.get(left) == target:
return left
else:
return -1
def search(self, reader, target):
left = 0
right = 1
while reader.get(right) < target:
left = right
right <<= 1
return self.binarySearch(reader, left, right, target)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$,其中 $n$ 为数组长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/self-dividing-numbers.md
================================================
# [0728. 自除数](https://leetcode.cn/problems/self-dividing-numbers/)
- 标签:数学
- 难度:简单
## 题目链接
- [0728. 自除数 - 力扣](https://leetcode.cn/problems/self-dividing-numbers/)
## 题目大意
**描述**:
「自除数」是指可以被它包含的每一位数整除的数。
- 例如,$128$ 是一个自除数,因为 $128 \% 1 == 0, 128 \% 2 == 0, 128 \% 8 == 0$。
「自除数」不允许包含 $0$。
给定两个整数 $left$ 和 $right$。
**要求**:
返回一个列表,列表的元素是范围 $[left, right]$(包括两个端点)内所有的自除数。
**说明**:
- $1 \le left \le right \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:left = 1, right = 22
输出:[1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 15, 22]
```
- 示例 2:
```python
输入:left = 47, right = 85
输出:[48,55,66,77]
```
## 解题思路
### 思路 1:模拟
自除数是指可以被它包含的每一位数整除的数。我们可以遍历范围内的每个数字,检查它是否是自除数。
**实现步骤**:
1. 遍历 $[left, right]$ 范围内的每个数字 $num$。
2. 对于每个数字,检查它的每一位数字:
- 如果某一位是 $0$,则不是自除数。
- 如果 $num$ 不能被某一位整除,则不是自除数。
3. 如果所有位数字都能整除 $num$,则将其加入结果列表。
### 思路 1:代码
```python
class Solution:
def selfDividingNumbers(self, left: int, right: int) -> List[int]:
def isSelfDividing(num):
"""判断一个数是否是自除数"""
temp = num
while temp > 0:
digit = temp % 10
# 如果某一位是 0,或者 num 不能被该位整除
if digit == 0 or num % digit != 0:
return False
temp //= 10
return True
result = []
# 遍历范围内的每个数字
for num in range(left, right + 1):
if isSelfDividing(num):
result.append(num)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O((right - left) \times \log_{10}(right))$,其中 $\log_{10}(right)$ 是数字的位数。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间。
================================================
FILE: docs/solutions/0700-0799/set-intersection-size-at-least-two.md
================================================
# [0757. 设置交集大小至少为2](https://leetcode.cn/problems/set-intersection-size-at-least-two/)
- 标签:贪心、数组、排序
- 难度:困难
## 题目链接
- [0757. 设置交集大小至少为2 - 力扣](https://leetcode.cn/problems/set-intersection-size-at-least-two/)
## 题目大意
**描述**:
给定一个二维整数数组 $intervals$ ,其中 $intervals[i] = [starti, endi]$ 表示从 $starti$ 到 $endi$ 的所有整数,包括 $starti$ 和 $endi$。
「包含集合」是一个名为 $nums$ 的数组,并满足 $intervals$ 中的每个区间都「至少」有「两个」整数在 $nums$ 中。
- 例如,如果 $intervals = [[1,3], [3,7], [8,9]]$,那么 $[1,2,4,7,8,9]$ 和 $[2,3,4,8,9]$ 都符合「包含集合」的定义。
**要求**:
返回包含集合可能的最小大小。
**说明**:
- $1 \le intervals.length \le 3000$。
- $intervals[i].length == 2$。
- $0 \le starti \lt endi \le 10^{8}$。
**示例**:
- 示例 1:
```python
输入:intervals = [[1,3],[3,7],[8,9]]
输出:5
解释:nums = [2, 3, 4, 8, 9].
可以证明不存在元素数量为 4 的包含集合。
```
- 示例 2:
```python
输入:intervals = [[1,3],[1,4],[2,5],[3,5]]
输出:3
解释:nums = [2, 3, 4].
可以证明不存在元素数量为 2 的包含集合。
```
## 解题思路
### 思路 1:贪心 + 排序
贪心策略:按照区间的右端点排序,优先选择右端点较小的区间。
**实现步骤**:
1. 按照区间的右端点升序排序,如果右端点相同,按左端点降序排序。
2. 维护一个集合 $S$,初始为空。
3. 遍历每个区间 $[start, end]$:
- 统计 $S$ 中在该区间内的元素个数 $count$。
- 如果 $count < 2$,需要添加 $2 - count$ 个元素。
- 贪心地选择尽可能靠右的元素($end - 1$ 和 $end$),以便覆盖更多后续区间。
4. 返回集合的大小。
### 思路 1:代码
```python
class Solution:
def intersectionSizeTwo(self, intervals: List[List[int]]) -> int:
# 按右端点升序排序,右端点相同时按左端点降序排序
intervals.sort(key=lambda x: (x[1], -x[0]))
result = []
for start, end in intervals:
# 统计 result 中在 [start, end] 范围内的元素个数
count = sum(1 for x in result if start <= x <= end)
# 需要添加的元素个数
need = 2 - count
if need <= 0:
continue
# 贪心地选择尽可能靠右的元素
if need == 1:
# 添加 end
result.append(end)
else: # need == 2
# 添加 end-1 和 end
result.append(end - 1)
result.append(end)
return len(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是区间的数量。排序需要 $O(n \log n)$,遍历每个区间需要 $O(n)$,每次统计需要 $O(n)$。
- **空间复杂度**:$O(n)$,存储结果的空间。
================================================
FILE: docs/solutions/0700-0799/shortest-completing-word.md
================================================
# [0748. 最短补全词](https://leetcode.cn/problems/shortest-completing-word/)
- 标签:数组、哈希表、字符串
- 难度:简单
## 题目链接
- [0748. 最短补全词 - 力扣](https://leetcode.cn/problems/shortest-completing-word/)
## 题目大意
**描述**:
「补全词」是一个包含 $licensePlate$ 中所有字母的单词。忽略 $licensePlate$ 中的「数字和空格」。不区分大小写。如果某个字母在 $licensePlate$ 中出现不止一次,那么该字母在补全词中的出现次数应当一致或者更多。
例如:`licensePlate = "aBc 12c"`,那么它的补全词应当包含字母 `'a'`、`'b'` (忽略大写)和两个 `'c'`。可能的「补全词」有 `"abccdef"`、`"caaacab"` 以及 `"cbca"`。
给定一个字符串 $licensePlate$ 和一个字符串数组 $words$。
**要求**:
请你找出 $words$ 中的「最短补全词」。
题目数据保证一定存在一个最短补全词。当有多个单词都符合最短补全词的匹配条件时取 $words$ 中 第一个 出现的那个。
**说明**:
- $1 \le licensePlate.length \le 7$。
- $licensePlate$ 由数字、大小写字母或空格 `' '` 组成。
- $1 \le words.length \le 10^{3}$。
- $1 \le words[i].length \le 15$。
- $words[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:licensePlate = "1s3 PSt", words = ["step", "steps", "stripe", "stepple"]
输出:"steps"
解释:最短补全词应该包括 "s"、"p"、"s"(忽略大小写) 以及 "t"。
"step" 包含 "t"、"p",但只包含一个 "s",所以它不符合条件。
"steps" 包含 "t"、"p" 和两个 "s"。
"stripe" 缺一个 "s"。
"stepple" 缺一个 "s"。
因此,"steps" 是唯一一个包含所有字母的单词,也是本例的答案。
```
- 示例 2:
```python
输入:licensePlate = "1s3 456", words = ["looks", "pest", "stew", "show"]
输出:"pest"
解释:licensePlate 只包含字母 "s" 。所有的单词都包含字母 "s" ,其中 "pest"、"stew"、和 "show" 三者最短。答案是 "pest" ,因为它是三个单词中在 words 里最靠前的那个。
```
## 解题思路
### 思路 1:哈希表
补全词是包含 $licensePlate$ 中所有字母的单词(忽略数字、空格和大小写)。我们需要找到最短的补全词。
**实现步骤**:
1. 统计 $licensePlate$ 中每个字母(转为小写)的出现次数,忽略数字和空格。
2. 遍历 $words$ 中的每个单词:
- 统计单词中每个字母的出现次数。
- 检查单词是否包含 $licensePlate$ 中所有字母(次数要足够)。
3. 在所有补全词中,返回长度最短的那个(如果有多个,返回第一个)。
### 思路 1:代码
```python
class Solution:
def shortestCompletingWord(self, licensePlate: str, words: List[str]) -> str:
from collections import Counter
# 统计 licensePlate 中字母的出现次数(忽略数字和空格,转为小写)
plate_count = Counter()
for char in licensePlate:
if char.isalpha():
plate_count[char.lower()] += 1
result = None
min_length = float('inf')
# 遍历每个单词
for word in words:
word_count = Counter(word)
# 检查是否是补全词
is_completing = True
for char, count in plate_count.items():
if word_count[char] < count:
is_completing = False
break
# 更新最短补全词
if is_completing and len(word) < min_length:
result = word
min_length = len(word)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是 $words$ 的长度,$m$ 是单词的平均长度。
- **空间复杂度**:$O(1)$,字母表大小固定为 $26$。
================================================
FILE: docs/solutions/0700-0799/sliding-puzzle.md
================================================
# [0773. 滑动谜题](https://leetcode.cn/problems/sliding-puzzle/)
- 标签:广度优先搜索、记忆化搜索、数组、动态规划、回溯、矩阵
- 难度:困难
## 题目链接
- [0773. 滑动谜题 - 力扣](https://leetcode.cn/problems/sliding-puzzle/)
## 题目大意
**描述**:
在一个 $2 \times 3$ 的板上(board)有 $5$ 块砖瓦,用数字 $1 \sim 5$ 来表示, 以及一块空缺用 $0$ 来表示。一次「移动」定义为选择 $0$ 与一个相邻的数字(上下左右)进行交换.
最终当板 $board$ 的结果是 $[[1,2,3],[4,5,0]]$ 谜板被解开。
给定一个谜板的初始状态 $board$。
**要求**:
返回最少可以通过多少次移动解开谜板,如果不能解开谜板,则返回 $-1$。
**说明**:
- $board.length == 2$。
- $board[i].length == 3$。
- $0 \le board[i][j] \le 5$。
- $board[i][j]$ 中每个值都不同。
**示例**:
- 示例 1:
```python
输入:board = [[1,2,3],[4,0,5]]
输出:1
解释:交换 0 和 5 ,1 步完成
```
- 示例 2:
```python
输入:board = [[1,2,3],[5,4,0]]
输出:-1
解释:没有办法完成谜板
```
## 解题思路
### 思路 1:BFS(广度优先搜索)
将滑动谜题看作状态搜索问题,使用 BFS 找到从初始状态到目标状态的最短路径。
**实现步骤**:
1. 将二维数组转换为字符串表示状态。
2. 目标状态为 `"123450"`。
3. 使用 BFS,每次找到 `0` 的位置,尝试与相邻位置交换:
- 预先定义每个位置可以移动到的相邻位置。
- 位置 $0, 1, 2, 3, 4, 5$ 分别对应二维数组的 $(0,0), (0,1), (0,2), (1,0), (1,1), (1,2)$。
4. 使用集合记录访问过的状态,避免重复。
5. 返回到达目标状态的最小步数。
### 思路 1:代码
```python
class Solution:
def slidingPuzzle(self, board: List[List[int]]) -> int:
from collections import deque
# 将二维数组转换为字符串
start = ''.join(str(board[i][j]) for i in range(2) for j in range(3))
target = "123450"
if start == target:
return 0
# 每个位置可以移动到的相邻位置
neighbors = {
0: [1, 3],
1: [0, 2, 4],
2: [1, 5],
3: [0, 4],
4: [1, 3, 5],
5: [2, 4]
}
# BFS
queue = deque([(start, 0)]) # (状态, 步数)
visited = {start}
while queue:
state, steps = queue.popleft()
# 找到 0 的位置
zero_pos = state.index('0')
# 尝试移动到相邻位置
for next_pos in neighbors[zero_pos]:
# 交换 0 和相邻位置
state_list = list(state)
state_list[zero_pos], state_list[next_pos] = state_list[next_pos], state_list[zero_pos]
next_state = ''.join(state_list)
# 如果到达目标状态
if next_state == target:
return steps + 1
# 如果未访问过,加入队列
if next_state not in visited:
visited.add(next_state)
queue.append((next_state, steps + 1))
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O((m \times n)! \times m \times n)$,状态总数为 $(m \times n)!$,每个状态需要 $O(m \times n)$ 时间处理。对于 $2 \times 3$ 的棋盘,状态数为 $6! = 720$。
- **空间复杂度**:$O((m \times n)!)$,存储访问过的状态。
================================================
FILE: docs/solutions/0700-0799/smallest-rotation-with-highest-score.md
================================================
# [0798. 得分最高的最小轮调](https://leetcode.cn/problems/smallest-rotation-with-highest-score/)
- 标签:数组、前缀和
- 难度:困难
## 题目链接
- [0798. 得分最高的最小轮调 - 力扣](https://leetcode.cn/problems/smallest-rotation-with-highest-score/)
## 题目大意
**描述**:
给定一个数组 $nums$,我们可以将它按一个非负整数 $k$ 进行轮调,这样可以使数组变为 $[nums[k], nums[k + 1], ... nums[nums.length - 1], nums[0], nums[1], ..., nums[k-1]]$ 的形式。此后,任何值小于或等于其索引的项都可以记作一分。
- 例如,数组为 $nums = [2,4,1,3,0]$,我们按 $k = 2$ 进行轮调后,它将变成 $[1,3,0,2,4]$。这将记为 $3$ 分,因为 $1 > 0$ [不计分]、$3 > 1$ [不计分]、$0 \le 2$ [计 $1$ 分]、$2 \le 3$ [计 $1$ 分],$4 \le 4$ [计 $1$ 分]。
**要求**:
在所有可能的轮调中,返回我们所能得到的最高分数对应的轮调下标 $k$。如果有多个答案,返回满足条件的最小的下标 $k$ 。
**说明**:
- $1 \le nums.length \le 10^{5}$。
- $0 \le nums[i] \lt nums.length$。
**示例**:
- 示例 1:
```python
输入:nums = [2,3,1,4,0]
输出:3
解释:
下面列出了每个 k 的得分:
k = 0, nums = [2,3,1,4,0], score 2
k = 1, nums = [3,1,4,0,2], score 3
k = 2, nums = [1,4,0,2,3], score 3
k = 3, nums = [4,0,2,3,1], score 4
k = 4, nums = [0,2,3,1,4], score 3
所以我们应当选择 k = 3,得分最高。
```
- 示例 2:
```python
输入:nums = [1,3,0,2,4]
输出:0
解释:
nums 无论怎么变化总是有 3 分。
所以我们将选择最小的 k,即 0。
```
## 解题思路
### 思路 1:差分数组
对于每次轮调 $k$,计算得分的变化。使用差分数组优化。
**分析**:
- 对于元素 $nums[i]$,在哪些轮调 $k$ 下能得分?
- 轮调 $k$ 后,$nums[i]$ 移动到位置 $(i - k + n) \% n$。
- 要得分,需要 $nums[i] \le (i - k + n) \% n$。
**计算得分区间**:
- 对于 $nums[i]$,它在轮调 $k$ 时能得分的条件是:
- 如果 $i \ge nums[i]$:在 $k \in [0, i - nums[i]]$ 和 $k \in [i + 1, n - 1]$ 时得分。
- 如果 $i < nums[i]$:在 $k \in [i + 1, n - 1 - (nums[i] - i - 1)]$ 时得分(如果该区间有效)。
使用差分数组记录每个 $k$ 的得分变化。
### 思路 1:代码
```python
class Solution:
def bestRotation(self, nums: List[int]) -> int:
n = len(nums)
diff = [0] * n # 差分数组
for i in range(n):
# 计算 nums[i] 不能得分的区间
# nums[i] 在位置 j 时,如果 nums[i] > j,则不能得分
# 轮调 k 后,nums[i] 在位置 (i - k + n) % n
# 不能得分的条件:nums[i] > (i - k + n) % n
# 简化:nums[i] 不能得分的轮调区间为 [(i - nums[i] + 1 + n) % n, i]
# 使用差分数组标记不能得分的区间
left = (i - nums[i] + 1 + n) % n
right = i
if left <= right:
diff[left] -= 1
if right + 1 < n:
diff[right + 1] += 1
else:
# 区间跨越了边界
diff[0] -= 1
if right + 1 < n:
diff[right + 1] += 1
diff[left] -= 1
# 计算每个 k 的得分
max_score = 0
current_score = n # 初始得分为 n(假设所有元素都得分)
result = 0
for k in range(n):
current_score += diff[k]
if current_score > max_score:
max_score = current_score
result = k
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。
- **空间复杂度**:$O(n)$,差分数组的空间。
================================================
FILE: docs/solutions/0700-0799/split-linked-list-in-parts.md
================================================
# [0725. 分隔链表](https://leetcode.cn/problems/split-linked-list-in-parts/)
- 标签:链表
- 难度:中等
## 题目链接
- [0725. 分隔链表 - 力扣](https://leetcode.cn/problems/split-linked-list-in-parts/)
## 题目大意
**描述**:
给定一个头结点为 $head$ 的单链表和一个整数 $k$。
**要求**:
请你设计一个算法将链表分隔为 $k$ 个连续的部分。
每部分的长度应该尽可能的相等:任意两部分的长度差距不能超过 $1$。这可能会导致有些部分为 null。
这 $k$ 个部分应该按照在链表中出现的顺序排列,并且排在前面的部分的长度应该大于或等于排在后面的长度。
返回一个由上述 $k$ 部分组成的数组。
**说明**:
- 链表中节点的数目在范围 $[0, 10^{3}]$。
- $0 \le Node.val \le 10^{3}$。
- $1 \le k \le 50$。
**示例**:
- 示例 1:
```python
输入:head = [1,2,3], k = 5
输出:[[1],[2],[3],[],[]]
解释:
第一个元素 output[0] 为 output[0].val = 1 ,output[0].next = null 。
最后一个元素 output[4] 为 null ,但它作为 ListNode 的字符串表示是 [] 。
```
- 示例 2:

```python
输入:head = [1,2,3,4,5,6,7,8,9,10], k = 3
输出:[[1,2,3,4],[5,6,7],[8,9,10]]
解释:
输入被分成了几个连续的部分,并且每部分的长度相差不超过 1 。前面部分的长度大于等于后面部分的长度。
```
## 解题思路
### 思路 1:链表遍历
将链表分隔为 $k$ 个连续的部分,每部分的长度应该尽可能相等。
**实现步骤**:
1. 先遍历链表,计算链表的总长度 $n$。
2. 计算每部分的基本长度:$size = n // k$。
3. 计算有多少部分需要多一个节点:$extra = n \% k$。
4. 前 $extra$ 个部分的长度为 $size + 1$,其余部分的长度为 $size$。
5. 遍历链表,按照计算的长度分隔链表:
- 对于每一部分,遍历相应数量的节点。
- 断开当前部分与下一部分的连接。
- 将当前部分的头节点加入结果数组。
### 思路 1:代码
```python
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def splitListToParts(self, head: Optional[ListNode], k: int) -> List[Optional[ListNode]]:
# 计算链表长度
length = 0
curr = head
while curr:
length += 1
curr = curr.next
# 计算每部分的长度
size = length // k # 每部分的基本长度
extra = length % k # 前 extra 个部分需要多一个节点
result = []
curr = head
# 分隔链表
for i in range(k):
# 当前部分的头节点
part_head = curr
# 当前部分的长度
part_size = size + (1 if i < extra else 0)
# 遍历当前部分
for j in range(part_size - 1):
if curr:
curr = curr.next
# 断开连接
if curr:
next_part = curr.next
curr.next = None
curr = next_part
result.append(part_head)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + k)$,其中 $n$ 是链表的长度。需要遍历链表两次。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间。
================================================
FILE: docs/solutions/0700-0799/subarray-product-less-than-k.md
================================================
# [0713. 乘积小于 K 的子数组](https://leetcode.cn/problems/subarray-product-less-than-k/)
- 标签:数组、滑动窗口
- 难度:中等
## 题目链接
- [0713. 乘积小于 K 的子数组 - 力扣](https://leetcode.cn/problems/subarray-product-less-than-k/)
## 题目大意
**描述**:给定一个正整数数组 $nums$ 和整数 $k$。
**要求**:找出该数组内乘积小于 $k$ 的连续的子数组的个数。
**说明**:
- $1 \le nums.length \le 3 * 10^4$。
- $1 \le nums[i] \le 1000$。
- $0 \le k \le 10^6$。
**示例**:
- 示例 1:
```python
输入:nums = [10,5,2,6], k = 100
输出:8
解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
```
- 示例 2:
```python
输入:nums = [1,2,3], k = 0
输出:0
```
## 解题思路
### 思路 1:滑动窗口(不定长度)
1. 设定两个指针:$left$、$right$,分别指向滑动窗口的左右边界,保证窗口内所有数的乘积 $window\_product$ 都小于 $k$。使用 $window\_product$ 记录窗口中的乘积值,使用 $count$ 记录符合要求的子数组个数。
2. 一开始,$left$、$right$ 都指向 $0$。
3. 向右移动 $right$,将最右侧元素加入当前子数组乘积 $window\_product$ 中。
4. 如果 $window\_product \ge k$,则不断右移 $left$,缩小滑动窗口长度,并更新当前乘积值 $window\_product$ 直到 $window\_product < k$。
5. 记录累积答案个数加 $1$,继续右移 $right$,直到 $right \ge len(nums)$ 结束。
6. 输出累积答案个数。
### 思路 1:代码
```python
class Solution:
def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:
if k <= 1:
return 0
size = len(nums)
left = 0
right = 0
window_product = 1
count = 0
while right < size:
window_product *= nums[right]
while window_product >= k:
window_product /= nums[left]
left += 1
count += (right - left + 1)
right += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0700-0799/swap-adjacent-in-lr-string.md
================================================
# [0777. 在 LR 字符串中交换相邻字符](https://leetcode.cn/problems/swap-adjacent-in-lr-string/)
- 标签:双指针、字符串
- 难度:中等
## 题目链接
- [0777. 在 LR 字符串中交换相邻字符 - 力扣](https://leetcode.cn/problems/swap-adjacent-in-lr-string/)
## 题目大意
**描述**:
在一个由 `'L'`, `'R'` 和 `'X'` 三个字符组成的字符串(例如 `"RXXLRXRXL"`)中进行移动操作。一次移动操作指用一个 `"LX"` 替换一个 `"XL"`,或者用一个 `"XR"` 替换一个 `"RX"`。
现给定起始字符串 $start$ 和结束字符串 $result$。
**要求**:
请编写代码,当且仅当存在一系列移动操作使得 $start$ 可以转换成 $result$ 时,返回 True。
**说明**:
- $1 \le start.length \le 10^{4}$。
- $start.length == result.length$。
- $start$ 和 $result$ 都只包含 `'L'`, `'R'` 或 `'X'`。
**示例**:
- 示例 1:
```python
输入:start = "RXXLRXRXL", result = "XRLXXRRLX"
输出:true
解释:通过以下步骤我们可以将 start 转化为 result:
RXXLRXRXL ->
XRXLRXRXL ->
XRLXRXRXL ->
XRLXXRRXL ->
XRLXXRRLX
```
- 示例 2:
```python
输入:start = "X", result = "L"
输出:false
```
## 解题思路
### 思路 1:双指针
观察移动规则:
- `XL` → `LX`:`L` 可以向左移动。
- `RX` → `XR`:`R` 可以向右移动。
- `L` 只能向左移动,`R` 只能向右移动,`X` 不影响相对顺序。
**判断条件**:
1. 去掉所有 `X` 后,$start$ 和 $result$ 的字符序列必须相同。
2. 对于每个 `L`,在 $start$ 中的位置必须 $\ge$ 在 $result$ 中的位置(只能向左移)。
3. 对于每个 `R$,在 $start$ 中的位置必须 $\le$ 在 $result$ 中的位置(只能向右移)。
### 思路 1:代码
```python
class Solution:
def canTransform(self, start: str, result: str) -> bool:
# 去掉 X 后的字符序列必须相同
if start.replace('X', '') != result.replace('X', ''):
return False
n = len(start)
i = j = 0
# 使用双指针检查位置关系
while i < n and j < n:
# 跳过 X
while i < n and start[i] == 'X':
i += 1
while j < n and result[j] == 'X':
j += 1
# 如果一个到达末尾,另一个也必须到达末尾
if (i < n) != (j < n):
return False
if i < n and j < n:
# 字符必须相同
if start[i] != result[j]:
return False
# L 只能向左移动,start 中的位置必须 >= result 中的位置
if start[i] == 'L' and i < j:
return False
# R 只能向右移动,start 中的位置必须 <= result 中的位置
if start[i] == 'R' and i > j:
return False
i += 1
j += 1
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串的长度。
- **空间复杂度**:$O(n)$,字符串替换操作的空间。
================================================
FILE: docs/solutions/0700-0799/swim-in-rising-water.md
================================================
# [0778. 水位上升的泳池中游泳](https://leetcode.cn/problems/swim-in-rising-water/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、二分查找、矩阵、堆(优先队列)
- 难度:困难
## 题目链接
- [0778. 水位上升的泳池中游泳 - 力扣](https://leetcode.cn/problems/swim-in-rising-water/)
## 题目大意
**描述**:给定一个 $n \times n$ 大小的二维数组 $grid$,每一个方格的值 $grid[i][j]$ 表示为位置 $(i, j)$ 的高度。
现在要从左上角 $(0, 0)$ 位置出发,经过方格的一些点,到达右下角 $(n - 1, n - 1)$ 位置上。其中所经过路径的花费为这条路径上所有位置的最大高度。
**要求**:计算从 $(0, 0)$ 位置到 $(n - 1, n - 1)$ 的最优路径的花费。
**说明**:
- **最优路径**:路径上最大高度最小的那条路径。
- $n == grid.length$。
- $n == grid[i].length$。
- $1 \le n \le 50$。
- $0 \le grid[i][j] < n^2$。
- $grid[i][j]$ 中每个值均无重复。
**示例**:
- 示例 1:
```python
输入: grid = [[0,2],[1,3]]
输出: 3
解释:
时间为 0 时,你位于坐标方格的位置为 (0, 0)。
此时你不能游向任意方向,因为四个相邻方向平台的高度都大于当前时间为 0 时的水位。
等时间到达 3 时,你才可以游向平台 (1, 1). 因为此时的水位是 3,坐标方格中的平台没有比水位 3 更高的,所以你可以游向坐标方格中的任意位置。
```
- 示例 2:
```python
输入: grid = [[0,1,2,3,4],[24,23,22,21,5],[12,13,14,15,16],[11,17,18,19,20],[10,9,8,7,6]]
输出: 16
解释: 最终的路线用加粗进行了标记。
我们必须等到时间为 16,此时才能保证平台 (0, 0) 和 (4, 4) 是连通的。
```
## 解题思路
### 思路 1:并查集
将整个网络抽象为一个无向图,每个点与相邻的点(上下左右)之间都存在一条无向边,边的权重为两个点之间的最大高度。
我们要找到左上角到右下角的最优路径,可以遍历所有的点,将所有的边存储到数组中,每条边的存储格式为 $[x, y, h]$,意思是编号 $x$ 的点和编号为 $y$ 的点之间的权重为 $h$。
然后按照权重从小到大的顺序,对所有边进行排序。
再按照权重大小遍历所有边,将其依次加入并查集中。并且每次都需要判断 $(0, 0)$ 点和 $(n - 1, n - 1)$ 点是否连通。
如果连通,则该边的权重即为答案。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def swimInWater(self, grid: List[List[int]]) -> int:
row_size = len(grid)
col_size = len(grid[0])
size = row_size * col_size
edges = []
for row in range(row_size):
for col in range(col_size):
if row < row_size - 1:
x = row * col_size + col
y = (row + 1) * col_size + col
h = max(grid[row][col], grid[row + 1][col])
edges.append([x, y, h])
if col < col_size - 1:
x = row * col_size + col
y = row * col_size + col + 1
h = max(grid[row][col], grid[row][col + 1])
edges.append([x, y, h])
edges.sort(key=lambda x: x[2])
union_find = UnionFind(size)
for edge in edges:
x, y, h = edge[0], edge[1], edge[2]
union_find.union(x, y)
if union_find.is_connected(0, size - 1):
return h
return 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \log n)$。其中 $n$ 为网格的边长,$n^2$ 为总格子数。枚举所有相邻格子的边,边数为 $O(n^2)$,排序所有边的时间复杂度为 $O(n^2 \log n^2) = O(n^2 \log n)$。并查集的合并与查找操作均摊 $O(\alpha(n^2))$,$\alpha$ 为反 Ackermann 函数,极慢增长,可视为常数。因此整体复杂度为 $O(n^2 \log n)$。
- **空间复杂度**:$O(n^2)$。主要用于存储并查集的父节点数组和所有边的信息,均为 $O(n^2)$ 级别。
================================================
FILE: docs/solutions/0700-0799/to-lower-case.md
================================================
# [0709. 转换成小写字母](https://leetcode.cn/problems/to-lower-case/)
- 标签:字符串
- 难度:简单
## 题目链接
- [0709. 转换成小写字母 - 力扣](https://leetcode.cn/problems/to-lower-case/)
## 题目大意
**描述**:给定一个字符串 $s$。
**要求**:将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。
**说明**:
- $1 \le s.length \le 100$。
- $s$ 由 ASCII 字符集中的可打印字符组成。
**示例**:
- 示例 1:
```python
输入:s = "Hello"
输出:"hello"
```
- 示例 2:
```python
输入:s = "LOVELY"
输出:"lovely"
```
## 解题思路
### 思路 1:直接模拟
- 大写字母 $A \sim Z$ 的 ASCII 码范围为 $[65, 90]$。
- 小写字母 $a \sim z$ 的 ASCII 码范围为 $[97, 122]$。
将大写字母的 ASCII 码加 $32$,就得到了对应的小写字母,则解决步骤如下:
1. 使用一个字符串变量 $ans$ 存储最终答案字符串。
2. 遍历字符串 $s$,对于当前字符 $ch$:
1. 如果 $ch$ 的 ASCII 码范围在 $[65, 90]$,则说明 $ch$ 为大写字母。将 $ch$ 的 ASCII 码增加 $32$,再转换为对应的字符,存入字符串 $ans$ 的末尾。
2. 如果 $ch$ 的 ASCII 码范围不在 $[65, 90]$,则说明 $ch$ 为小写字母。直接将 $ch$ 存入字符串 $ans$ 的末尾。
3. 遍历完字符串 $s$,返回答案字符串 $ans$。
### 思路 1:代码
```python
class Solution:
def toLowerCase(self, s: str) -> str:
ans = ""
for ch in s:
if ord('A') <= ord(ch) <= ord('Z'):
ans += chr(ord(ch) + 32)
else:
ans += ch
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度为 $O(n)$。
- **空间复杂度**:$O(n)$。如果算上答案数组的空间占用,则空间复杂度为 $O(n)$。不算上则空间复杂度为 $O(1)$。
### 思路 2:使用 API
Python 语言中自带大写字母转小写字母的 API:`lower()`,用 API 转换完成之后,直接返回新的字符串。
### 思路 2:代码
```python
class Solution:
def toLowerCase(self, s: str) -> str:
return s.lower()
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度为 $O(n)$。
- **空间复杂度**:$O(n)$。如果算上答案数组的空间占用,则空间复杂度为 $O(n)$。不算上则空间复杂度为 $O(1)$。
================================================
FILE: docs/solutions/0700-0799/toeplitz-matrix.md
================================================
# [0766. 托普利茨矩阵](https://leetcode.cn/problems/toeplitz-matrix/)
- 标签:数组、矩阵
- 难度:简单
## 题目链接
- [0766. 托普利茨矩阵 - 力扣](https://leetcode.cn/problems/toeplitz-matrix/)
## 题目大意
**描述**:给定一个 $m \times n$ 大小的矩阵 $matrix$。
**要求**:如果 $matrix$ 是托普利茨矩阵,则返回 `True`;否则返回 `False`。
**说明**:
- **托普利茨矩阵**:矩阵上每一条由左上到右下的对角线上的元素都相同。
- $m == matrix.length$。
- $n == matrix[i].length$。
- $1 \le m, n \le 20$。
- $0 \le matrix[i][j] \le 99$。
**示例**:
- 示例 1:
```python
输入:matrix = [[1,2,3,4],[5,1,2,3],[9,5,1,2]]
输出:true
解释:
在上述矩阵中, 其对角线为:
"[9]", "[5, 5]", "[1, 1, 1]", "[2, 2, 2]", "[3, 3]", "[4]"。
各条对角线上的所有元素均相同, 因此答案是 True。
```
- 示例 2:
```python
输入:matrix = [[1,2],[2,2]]
输出:false
解释:
对角线 "[1, 2]" 上的元素不同。
```
## 解题思路
### 思路 1:简单模拟
1. 两层循环遍历矩阵,依次判断矩阵当前位置 $(i, j)$ 上的值 $matrix[i][j]$ 与其左上角位置 $(i - 1, j - 1)$ 位置上的值 $matrix[i - 1][j - 1]$ 是否相等。
2. 如果不相等,则返回 `False`。
3. 遍历完,则返回 `True`。
### 思路 1:代码
```python
class Solution:
def isToeplitzMatrix(self, matrix: List[List[int]]) -> bool:
for i in range(1, len(matrix)):
for j in range(1, len(matrix[0])):
if matrix[i][j] != matrix[i - 1][j - 1]:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$、$n$ 分别是矩阵 $matrix$ 的行数、列数。
- **空间复杂度**:$O(m \times n)$。
================================================
FILE: docs/solutions/0700-0799/transform-to-chessboard.md
================================================
# [0782. 变为棋盘](https://leetcode.cn/problems/transform-to-chessboard/)
- 标签:位运算、数组、数学、矩阵
- 难度:困难
## 题目链接
- [0782. 变为棋盘 - 力扣](https://leetcode.cn/problems/transform-to-chessboard/)
## 题目大意
**描述**:
一个 $n \times n$ 的二维网络 $board$ 仅由 $0$ 和 $1$ 组成。每次移动,你能交换任意两列或是两行的位置。
**要求**:
返回 将这个矩阵变为「棋盘」所需的最小移动次数 。如果不存在可行的变换,输出 $-1$。
**说明**:
- 「棋盘」是指任意一格的上下左右四个方向的值均与本身不同的矩阵。
- $n == board.length$。
- $n == board[i].length$。
- $2 \le n \le 30$。
- $board[i][j]$ 将只包含 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入: board = [[0,1,1,0],[0,1,1,0],[1,0,0,1],[1,0,0,1]]
输出: 2
解释:一种可行的变换方式如下,从左到右:
第一次移动交换了第一列和第二列。
第二次移动交换了第二行和第三行。
```
- 示例 2:
```python
输入: board = [[0, 1], [1, 0]]
输出: 0
解释: 注意左上角的格值为0时也是合法的棋盘,也是合法的棋盘.
```
## 解题思路
### 思路 1:位运算 + 贪心
这道题要求将一个 $n \times n$ 的 01 矩阵通过交换行或列变成棋盘(相邻格子值不同)。
棋盘的性质:
1. 只有两种不同的行(或列)模式,且它们互补(0 和 1 互换)。
2. 这两种行(或列)的数量相差不超过 1。
3. 每一行(或列)中 0 和 1 的数量相差不超过 1。
算法步骤:
1. 检查矩阵是否可以变成棋盘:
- 检查第一行和其他行的关系,只能有两种模式。
- 检查第一列和其他列的关系,只能有两种模式。
- 检查 0 和 1 的数量是否满足条件。
2. 计算最少交换次数:
- 对于行:计算将行变成 `010101...` 或 `101010...` 需要的交换次数,选择较小的。
- 对于列:同样计算。
- 如果 $n$ 是奇数,只有一种合法的目标模式。
3. 返回行和列的最少交换次数之和。
### 思路 1:代码
```python
class Solution:
def movesToChessboard(self, board: List[List[int]]) -> int:
n = len(board)
# 检查第一行和第一列
row_mask = 0
col_mask = 0
for i in range(n):
row_mask = (row_mask << 1) | board[0][i]
col_mask = (col_mask << 1) | board[i][0]
# 检查是否只有两种行模式
row_cnt = {row_mask: 0, row_mask ^ ((1 << n) - 1): 0}
for i in range(n):
mask = 0
for j in range(n):
mask = (mask << 1) | board[i][j]
if mask not in row_cnt:
return -1
row_cnt[mask] += 1
# 检查是否只有两种列模式
col_cnt = {col_mask: 0, col_mask ^ ((1 << n) - 1): 0}
for j in range(n):
mask = 0
for i in range(n):
mask = (mask << 1) | board[i][j]
if mask not in col_cnt:
return -1
col_cnt[mask] += 1
# 检查两种模式的数量是否合法
if abs(row_cnt[row_mask] - row_cnt[row_mask ^ ((1 << n) - 1)]) > 1:
return -1
if abs(col_cnt[col_mask] - col_cnt[col_mask ^ ((1 << n) - 1)]) > 1:
return -1
# 检查第一行和第一列的 0 和 1 数量
row_ones = bin(row_mask).count('1')
col_ones = bin(col_mask).count('1')
if row_ones < n // 2 or row_ones > (n + 1) // 2:
return -1
if col_ones < n // 2 or col_ones > (n + 1) // 2:
return -1
# 计算最少交换次数
def min_swaps(mask, ones):
"""计算将 mask 变成棋盘模式的最少交换次数"""
# 目标模式:010101... 或 101010...
target1 = 0
target2 = 0
for i in range(n):
if i % 2 == 0:
target1 = (target1 << 1) | 1
target2 = (target2 << 1) | 0
else:
target1 = (target1 << 1) | 0
target2 = (target2 << 1) | 1
diff1 = bin(mask ^ target1).count('1')
diff2 = bin(mask ^ target2).count('1')
# 如果 n 是奇数,只有一种合法模式
if n % 2 == 1:
if ones * 2 > n:
return diff1 // 2
else:
return diff2 // 2
else:
return min(diff1, diff2) // 2
row_swaps = min_swaps(row_mask, row_ones)
col_swaps = min_swaps(col_mask, col_ones)
return row_swaps + col_swaps
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,需要遍历整个矩阵检查合法性。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0700-0799/valid-tic-tac-toe-state.md
================================================
# [0794. 有效的井字游戏](https://leetcode.cn/problems/valid-tic-tac-toe-state/)
- 标签:数组、矩阵
- 难度:中等
## 题目链接
- [0794. 有效的井字游戏 - 力扣](https://leetcode.cn/problems/valid-tic-tac-toe-state/)
## 题目大意
**描述**:
井字游戏的棋盘是一个 $3 \times 3$ 数组,由字符 `' '`,`'X'` 和 `'O'` 组成。字符 `' '` 代表一个空位。
以下是井字游戏的规则:
- 玩家轮流将字符放入空位 `' '` 中。
- 玩家 1 总是放字符 `'X'`,而玩家 2 总是放字符 `'O'`。
- `'X'` 和 `'O'` 只允许放置在空位中,不允许对已放有字符的位置进行填充。
- 当有 3 个相同(且非空)的字符填充任何行、列或对角线时,游戏结束。
- 当所有位置非空时,也算为游戏结束。
- 如果游戏结束,玩家不允许再放置字符。
给定一个字符串数组 $board$ 表示井字游戏的棋盘。
**要求**:
当且仅当在井字游戏过程中,棋盘有可能达到 $board$ 所显示的状态时,才返回 true。
**说明**:
- $board.length == 3$。
- $board[i].length == 3$。
- $board[i][j]$ 为 `'X'`、`'O'` 或 `' '`。
**示例**:
- 示例 1:
```python
输入:board = ["O "," "," "]
输出:false
解释:玩家 1 总是放字符 "X" 。
```
- 示例 2:
```python
输入:board = ["XOX"," X "," "]
输出:false
解释:玩家应该轮流放字符。
```
## 解题思路
### 思路 1:模拟
判断井字游戏的状态是否有效,需要检查以下条件:
1. **数量关系**:玩家 1(`X`)先手,所以 `X` 的数量应该等于或比 `O` 多 $1$。
2. **获胜条件**:
- 如果 `X` 获胜,则 `O` 不能获胜,且 `X` 的数量应该比 `O` 多 $1$(因为 `X` 最后一步获胜)。
- 如果 `O` 获胜,则 `X` 不能获胜,且 `X` 的数量应该等于 `O` 的数量(因为 `O` 最后一步获胜)。
### 思路 1:代码
```python
class Solution:
def validTicTacToe(self, board: List[str]) -> bool:
def check_win(player):
"""检查某个玩家是否获胜"""
# 检查行
for i in range(3):
if all(board[i][j] == player for j in range(3)):
return True
# 检查列
for j in range(3):
if all(board[i][j] == player for i in range(3)):
return True
# 检查对角线
if all(board[i][i] == player for i in range(3)):
return True
if all(board[i][2-i] == player for i in range(3)):
return True
return False
# 统计 X 和 O 的数量
x_count = sum(row.count('X') for row in board)
o_count = sum(row.count('O') for row in board)
# X 的数量应该等于或比 O 多 1
if x_count < o_count or x_count > o_count + 1:
return False
# 检查获胜情况
x_win = check_win('X')
o_win = check_win('O')
# X 和 O 不能同时获胜
if x_win and o_win:
return False
# 如果 X 获胜,X 的数量应该比 O 多 1
if x_win and x_count != o_count + 1:
return False
# 如果 O 获胜,X 和 O 的数量应该相等
if o_win and x_count != o_count:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$,棋盘大小固定为 $3 \times 3$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/advantage-shuffle.md
================================================
# [0870. 优势洗牌](https://leetcode.cn/problems/advantage-shuffle/)
- 标签:贪心、数组、双指针、排序
- 难度:中等
## 题目链接
- [0870. 优势洗牌 - 力扣](https://leetcode.cn/problems/advantage-shuffle/)
## 题目大意
**描述**:
给定两个长度相等的数组 $nums1$ 和 $nums2$,$nums1$ 相对于 $nums2$ 的优势可以用满足 $nums1[i] > nums2[i]$ 的索引 $i$ 的数目来描述。
**要求**:
返回 $nums1$ 的 任意 排列,使其相对于 $nums2$ 的优势最大化。
**说明**:
- $1 \le nums1.length \le 10^{5}$。
- $nums2.length == nums1.length$。
- $0 \le nums1[i], nums2[i] \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:nums1 = [2,7,11,15], nums2 = [1,10,4,11]
输出:[2,11,7,15]
```
- 示例 2:
```python
输入:nums1 = [12,24,8,32], nums2 = [13,25,32,11]
输出:[24,32,8,12]
```
## 解题思路
### 思路 1:贪心 + 双指针(田忌赛马)
这道题本质上是经典的"田忌赛马"问题。目标是最大化 $nums1$ 相对于 $nums2$ 的优势。
贪心策略:
1. 将 $nums1$ 排序。
2. 将 $nums2$ 的元素及其索引一起排序。
3. 使用双指针:
- 对于 $nums2$ 中的每个元素(从大到小),尝试用 $nums1$ 中最大的能战胜它的元素。
- 如果 $nums1$ 中最大的元素都无法战胜,则用 $nums1$ 中最小的元素(反正也赢不了,不如浪费最小的)。
具体实现:
1. 对 $nums1$ 排序。
2. 对 $nums2$ 的索引按值从大到小排序。
3. 使用左右指针遍历 $nums1$,对于 $nums2$ 中的每个元素(从大到小):
- 如果 $nums1$ 的右指针元素能战胜,使用它,右指针左移。
- 否则,使用 $nums1$ 的左指针元素(最小的),左指针右移。
### 思路 1:代码
```python
class Solution:
def advantageCount(self, nums1: List[int], nums2: List[int]) -> List[int]:
n = len(nums1)
# 对 nums1 排序
nums1.sort()
# 对 nums2 的索引按值从大到小排序
idx2 = sorted(range(n), key=lambda i: nums2[i], reverse=True)
# 结果数组
result = [0] * n
# 双指针
left, right = 0, n - 1
# 从大到小遍历 nums2
for i in idx2:
# 如果 nums1 的最大值能战胜 nums2[i],使用它
if nums1[right] > nums2[i]:
result[i] = nums1[right]
right -= 1
else:
# 否则用 nums1 的最小值(反正也赢不了)
result[i] = nums1[left]
left += 1
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组的长度。排序需要 $O(n \log n)$。
- **空间复杂度**:$O(n)$,需要存储排序后的索引和结果数组。
================================================
FILE: docs/solutions/0800-0899/all-nodes-distance-k-in-binary-tree.md
================================================
# [0863. 二叉树中所有距离为 K 的结点](https://leetcode.cn/problems/all-nodes-distance-k-in-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、哈希表、二叉树
- 难度:中等
## 题目链接
- [0863. 二叉树中所有距离为 K 的结点 - 力扣](https://leetcode.cn/problems/all-nodes-distance-k-in-binary-tree/)
## 题目大意
**描述**:
给定一个二叉树(具有根结点 $root$), 一个目标结点 $target$,和一个整数值 $k$。
**要求**:
返回到目标结点 $target$ 距离为 $k$ 的所有结点的值的数组。
答案可以以「任何顺序」返回。
**说明**:
- 节点数在 $[1, 500]$ 范围内。
- $0 \le Node.val \le 500$。
- $Node.val$ 中所有值「不同」。
- 目标结点 $target$ 是树上的结点。
- $0 \le k \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, k = 2
输出:[7,4,1]
解释:所求结点为与目标结点(值为 5)距离为 2 的结点,值分别为 7,4,以及 1
```
- 示例 2:
```python
输入: root = [1], target = 1, k = 3
输出: []
```
## 解题思路
### 思路 1:DFS + BFS
这道题要求找到二叉树中距离目标节点 $target$ 为 $k$ 的所有节点。由于二叉树只能从父节点访问子节点,无法直接从子节点访问父节点,因此需要先建立父节点的映射关系。
算法步骤:
1. 使用 DFS 遍历整棵树,建立每个节点到其父节点的映射关系。
2. 从目标节点 $target$ 开始,使用 BFS 向四周扩散(左子节点、右子节点、父节点)。
3. 使用 $visited$ 集合记录已访问的节点,避免重复访问。
4. 当扩散距离达到 $k$ 时,返回当前层的所有节点值。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def distanceK(self, root: TreeNode, target: TreeNode, k: int) -> List[int]:
from collections import deque, defaultdict
# 建立父节点映射
parent = defaultdict(lambda: None)
def dfs(node, par=None):
"""DFS 遍历,建立父节点映射"""
if not node:
return
parent[node] = par
dfs(node.left, node)
dfs(node.right, node)
# 建立父节点映射
dfs(root)
# BFS 从 target 开始扩散
queue = deque([target])
visited = {target}
distance = 0
while queue:
# 如果距离达到 k,返回当前层的所有节点值
if distance == k:
return [node.val for node in queue]
# 遍历当前层
for _ in range(len(queue)):
node = queue.popleft()
# 向左子节点扩散
if node.left and node.left not in visited:
visited.add(node.left)
queue.append(node.left)
# 向右子节点扩散
if node.right and node.right not in visited:
visited.add(node.right)
queue.append(node.right)
# 向父节点扩散
if parent[node] and parent[node] not in visited:
visited.add(parent[node])
queue.append(parent[node])
distance += 1
return []
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数。需要遍历整棵树建立父节点映射,然后进行 BFS。
- **空间复杂度**:$O(n)$,需要存储父节点映射和 BFS 队列。
================================================
FILE: docs/solutions/0800-0899/all-possible-full-binary-trees.md
================================================
# [0894. 所有可能的真二叉树](https://leetcode.cn/problems/all-possible-full-binary-trees/)
- 标签:树、递归、记忆化搜索、动态规划、二叉树
- 难度:中等
## 题目链接
- [0894. 所有可能的真二叉树 - 力扣](https://leetcode.cn/problems/all-possible-full-binary-trees/)
## 题目大意
**描述**:
给定一个整数 $n$。
**要求**:
请你找出所有可能含 $n$ 个节点的 真二叉树 ,并以列表形式返回。
**说明**:
- 答案中每棵树的每个节点都必须符合 $Node$.$val == 0$。
- 答案的每个元素都是一棵真二叉树的根节点。你可以按 任意顺序 返回最终的真二叉树列表。
- 「真二叉树」是一类二叉树,树中每个节点恰好有 0 或 2 个子节点。
- $1 \le n \le 20$。
**示例**:
- 示例 1:
```python
输入:n = 7
输出:[[0,0,0,null,null,0,0,null,null,0,0],[0,0,0,null,null,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,null,null,null,null,0,0],[0,0,0,0,0,null,null,0,0]]
```
- 示例 2:
```python
输入:n = 3
输出:[[0,0,0]]
```
## 解题思路
### 思路 1:递归 + 记忆化搜索
真二叉树的特点是每个节点要么有 0 个子节点(叶子节点),要么有 2 个子节点。因此,真二叉树的节点数必须是奇数。
关键观察:
- 如果 $n$ 是偶数,无法构成真二叉树,返回空列表。
- 如果 $n = 1$,只有一个节点,返回包含单个节点的列表。
- 如果 $n > 1$,根节点占 1 个节点,剩余 $n-1$ 个节点分配给左右子树。
- 左子树可以有 $1, 3, 5, \ldots, n-2$ 个节点,相应地右子树有 $n-2, n-4, \ldots, 1$ 个节点。
算法步骤:
1. 使用记忆化搜索避免重复计算。
2. 递归构建所有可能的左右子树组合。
3. 对于每种组合,创建一个新的根节点,连接左右子树。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def allPossibleFBT(self, n: int) -> List[Optional[TreeNode]]:
# 记忆化字典
memo = {}
def helper(n):
"""返回所有可能的 n 个节点的真二叉树"""
# 如果已经计算过,直接返回
if n in memo:
return memo[n]
# 偶数个节点无法构成真二叉树
if n % 2 == 0:
return []
# 只有一个节点
if n == 1:
return [TreeNode(0)]
result = []
# 枚举左子树的节点数(必须是奇数)
for left_count in range(1, n, 2):
right_count = n - 1 - left_count
# 递归构建所有可能的左右子树
left_trees = helper(left_count)
right_trees = helper(right_count)
# 组合所有可能的左右子树
for left in left_trees:
for right in right_trees:
root = TreeNode(0)
root.left = left
root.right = right
result.append(root)
memo[n] = result
return result
return helper(n)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(2^n)$,生成所有可能的真二叉树需要指数时间。
- **空间复杂度**:$O(2^n)$,需要存储所有可能的树结构。
================================================
FILE: docs/solutions/0800-0899/ambiguous-coordinates.md
================================================
# [0816. 模糊坐标](https://leetcode.cn/problems/ambiguous-coordinates/)
- 标签:字符串、回溯、枚举
- 难度:中等
## 题目链接
- [0816. 模糊坐标 - 力扣](https://leetcode.cn/problems/ambiguous-coordinates/)
## 题目大意
**描述**:
我们有一些二维坐标,如 `"(1, 3)"` 或 `"(2, 0.5)"`,然后我们移除所有逗号,小数点和空格,得到一个字符串 $S$。
**要求**:
返回所有可能的原始字符串到一个列表中。
**说明**:
- 原始的坐标表示法不会存在多余的零,所以不会出现类似于 `"00"`, `"0.0"`, `"0.00"`, `"1.0"`, `"001"`, `"00.01"` 或一些其他更小的数来表示坐标。此外,一个小数点前至少存在一个数,所以也不会出现 `".1"` 形式的数字。
- 最后返回的列表可以是任意顺序的。而且注意返回的两个数字中间(逗号之后)都有一个空格。
- $4 \le S.length \le 12$。
- `S[0] = "(", S[S.length - 1] = ")"`, 且字符串 S$ 中的其他元素都是数字。
**示例**:
- 示例 1:
```python
示例 1:
输入: "(123)"
输出: ["(1, 23)", "(12, 3)", "(1.2, 3)", "(1, 2.3)"]
```
- 示例 2:
```python
输入: "(00011)"
输出: ["(0.001, 1)", "(0, 0.011)"]
解释:
0.0, 00, 0001 或 00.01 是不被允许的。
```
## 解题思路
### 思路 1:枚举 + 字符串处理
这道题要求将去掉括号和逗号的坐标字符串还原为所有可能的原始坐标。
算法步骤:
1. 去掉字符串首尾的括号,得到数字字符串。
2. 枚举逗号的位置,将字符串分为两部分($x$ 坐标和 $y$ 坐标)。
3. 对于每部分,枚举小数点的位置(包括不加小数点的情况)。
4. 检查生成的数字是否合法:
- 不能有前导零(除了 `"0"` 本身)。
- 小数部分不能有后导零。
5. 组合所有合法的 $x$ 和 $y$ 坐标,生成结果。
辅助函数:生成所有可能的合法数字表示。
### 思路 1:代码
```python
class Solution:
def ambiguousCoordinates(self, s: str) -> List[str]:
def get_valid_numbers(num_str):
"""生成字符串的所有合法数字表示"""
n = len(num_str)
result = []
# 不加小数点
if n == 1 or num_str[0] != '0':
result.append(num_str)
# 加小数点
for i in range(1, n):
left = num_str[:i]
right = num_str[i:]
# 检查是否合法:
# 1. 整数部分不能有前导零(除非是 "0")
# 2. 小数部分不能有后导零
if (left == '0' or left[0] != '0') and right[-1] != '0':
result.append(left + '.' + right)
return result
# 去掉首尾括号
s = s[1:-1]
n = len(s)
result = []
# 枚举逗号的位置
for i in range(1, n):
x_str = s[:i]
y_str = s[i:]
# 生成所有可能的 x 和 y 坐标
x_coords = get_valid_numbers(x_str)
y_coords = get_valid_numbers(y_str)
# 组合所有可能的坐标
for x in x_coords:
for y in y_coords:
result.append(f"({x}, {y})")
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是字符串的长度。需要枚举逗号位置 $O(n)$,对于每个位置枚举小数点位置 $O(n)$,生成结果需要 $O(n)$。
- **空间复杂度**:$O(n^2)$,需要存储所有可能的坐标表示。
================================================
FILE: docs/solutions/0800-0899/backspace-string-compare.md
================================================
# [0844. 比较含退格的字符串](https://leetcode.cn/problems/backspace-string-compare/)
- 标签:栈、双指针、字符串、模拟
- 难度:简单
## 题目链接
- [0844. 比较含退格的字符串 - 力扣](https://leetcode.cn/problems/backspace-string-compare/)
## 题目大意
**描述**:给定 $s$ 和 $t$ 两个字符串。字符串中的 `#` 代表退格字符。
**要求**:当它们分别被输入到空白的文本编辑器后,判断二者是否相等。如果相等,返回 $True$;否则,返回 $False$。
**说明**:
- 如果对空文本输入退格字符,文本继续为空。
- $1 \le s.length, t.length \le 200$。
- $s$ 和 $t$ 只含有小写字母以及字符 `#`。
**示例**:
- 示例 1:
```python
输入:s = "ab#c", t = "ad#c"
输出:true
解释:s 和 t 都会变成 "ac"。
```
- 示例 2:
```python
输入:s = "ab##", t = "c#d#"
输出:true
解释:s 和 t 都会变成 ""。
```
## 解题思路
这道题的第一个思路是用栈,第二个思路是使用分离双指针。
### 思路 1:栈
- 定义一个构建方法,用来将含有退格字符串构建为删除退格的字符串。构建方法如下。
- 使用一个栈存放删除退格的字符串。
- 遍历字符串,如果遇到的字符不是 `#`,则将其插入到栈中。
- 如果遇到的字符是 `#`,且当前栈不为空,则将当前栈顶元素弹出。
- 分别使用构建方法处理字符串 $s$ 和 $t$,如果处理完的字符串 $s$ 和 $t$ 相等,则返回 $True$,否则返回 $False$。
### 思路 1:代码
```python
class Solution:
def build(self, s: str):
stack = []
for ch in s:
if ch != '#':
stack.append(ch)
elif stack:
stack.pop()
return stack
def backspaceCompare(self, s: str, t: str) -> bool:
return self.build(s) == self.build(t)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 和 $m$ 分别为字符串 $s$、$t$ 的长度。
- **空间复杂度**:$O(n + m)$。
### 思路 2:分离双指针
由于 `#` 会消除左侧字符,而不会影响右侧字符,所以我们选择从字符串尾端遍历 $s$、$t$ 字符串。具体做法如下:
- 使用分离双指针 $left\_1$、$left\_2$。$left\_1$ 指向字符串 $s$ 末尾,$left\_2$ 指向字符串 $t$ 末尾。使用 $sign\_1$、$sign\_2$ 标记字符串 $s$、$t$ 中当前退格字符个数。
- 从后到前遍历字符串 $s$、$t$。
- 先来循环处理字符串 $s$ 尾端 `#` 的影响,具体如下:
- 如果当前字符是 `#`,则更新 $s$ 当前退格字符个数,即 `sign_1 += 1`。同时将 $left\_1$ 左移。
- 如果 $s$ 当前退格字符个数大于 $0$,则退格数减一,即 `sign_1 -= 1`。同时将 $left\_1$ 左移。
- 如果 $s$ 当前为普通字符,则跳出循环。
- 同理再来处理字符串 $t$ 尾端 `#` 的影响,具体如下:
- 如果当前字符是 `#`,则更新 $t$ 当前退格字符个数,即 `sign_2 += 1`。同时将 $left\_2$ 左移。
- 如果 $t$ 当前退格字符个数大于 $0$,则退格数减一,即 `sign_2 -= 1`。同时将 $left\_2$ 左移。
- 如果 $t$ 当前为普通字符,则跳出循环。
- 处理完,如果两个字符串为空,则说明匹配,直接返回 $True$。
- 再先排除长度不匹配的情况,直接返回 $False$。
- 最后判断 $s[left\_1]$ 是否等于 $s[left\_2]$。不等于则直接返回 $False$,等于则令 $left\_1$、$left\_2$ 左移,继续遍历。
- 遍历完没有出现不匹配的情况,则返回 $True$。
### 思路 2:代码
```python
class Solution:
def backspaceCompare(self, s: str, t: str) -> bool:
left_1, left_2 = len(s) - 1, len(t) - 1
sign_1, sign_2 = 0, 0
while left_1 >= 0 or left_2 >= 0:
while left_1 >= 0:
if s[left_1] == '#':
sign_1 += 1
left_1 -= 1
elif sign_1 > 0:
sign_1 -= 1
left_1 -= 1
else:
break
while left_2 >= 0:
if t[left_2] == '#':
sign_2 += 1
left_2 -= 1
elif sign_2 > 0:
sign_2 -= 1
left_2 -= 1
else:
break
if left_1 < 0 and left_2 < 0:
return True
if left_1 >= 0 and left_2 < 0:
return False
if left_1 < 0 and left_2 >= 0:
return False
if s[left_1] != t[left_2]:
return False
left_1 -= 1
left_2 -= 1
return True
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 和 $m$ 分别为字符串 $s$、$t$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/binary-gap.md
================================================
# [0868. 二进制间距](https://leetcode.cn/problems/binary-gap/)
- 标签:位运算
- 难度:简单
## 题目链接
- [0868. 二进制间距 - 力扣](https://leetcode.cn/problems/binary-gap/)
## 题目大意
**描述**:给定一个正整数 $n$。
**要求**:找到并返回 $n$ 的二进制表示中两个相邻 $1$ 之间的最长距离。如果不存在两个相邻的 $1$,返回 $0$。
**说明**:
- $1 \le n \le 10^9$。
**示例**:
- 示例 1:
```python
输入:n = 22
输出:2
解释:22 的二进制是 "10110"。
在 22 的二进制表示中,有三个 1,组成两对相邻的 1。
第一对相邻的 1 中,两个 1 之间的距离为 2。
第二对相邻的 1 中,两个 1 之间的距离为 1。
答案取两个距离之中最大的,也就是 2。
```
- 示例 2:
```python
输入:n = 8
输出:0
解释:8 的二进制是 "1000"。
在 8 的二进制表示中没有相邻的两个 1,所以返回 0。
```
## 解题思路
### 思路 1:遍历
1. 将正整数 $n$ 转为二进制字符串形式 $bin\_n$。
2. 使用变量 $pre$ 记录二进制字符串中上一个 $1$ 的位置,使用变量 $ans$ 存储两个相邻 $1$ 之间的最长距离。
3. 遍历二进制字符串形式 $bin\_n$ 的每一位,遇到 $1$ 时判断并更新两个相邻 $1$ 之间的最长距离。
4. 遍历完返回两个相邻 $1$ 之间的最长距离,即 $ans$。
### 思路 1:代码
```Python
class Solution:
def binaryGap(self, n: int) -> int:
bin_n = bin(n)
pre, ans = 2, 0
for i in range(2, len(bin_n)):
if bin_n[i] == '1':
ans = max(ans, i - pre)
pre = i
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/binary-tree-pruning.md
================================================
# [0814. 二叉树剪枝](https://leetcode.cn/problems/binary-tree-pruning/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0814. 二叉树剪枝 - 力扣](https://leetcode.cn/problems/binary-tree-pruning/)
## 题目大意
给定一棵二叉树的根节点 `root`,树的每个节点值要么是 `0`,要么是 `1`。
要求:剪除该二叉树中所有节点值为 `0` 的子树。
- 节点 `node` 的子树为: `node` 本身,以及所有 `node` 的后代。
## 解题思路
定义辅助方法 `containsOnlyZero(root)` 递归判断以 `root` 为根的子树中是否只包含 `0`。如果子树中只包含 `0`,则返回 `True`。如果子树中含有 `1`,则返回 `False`。当 `root` 为空时,也返回 `True`。
然后递归遍历二叉树,判断当前节点 `root` 是否只包含 `0`。如果只包含 `0`,则将其置空,返回 `None`。否则递归遍历左右子树,并设置对应的左右指针。
最后返回根节点 `root`。
## 代码
```python
class Solution:
def containsOnlyZero(self, root: TreeNode):
if not root:
return True
if root.val == 1:
return False
return self.containsOnlyZero(root.left) and self.containsOnlyZero(root.right)
def pruneTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
if not root:
return root
if self.containsOnlyZero(root):
return None
root.left = self.pruneTree(root.left)
root.right = self.pruneTree(root.right)
return root
```
================================================
FILE: docs/solutions/0800-0899/binary-trees-with-factors.md
================================================
# [0823. 带因子的二叉树](https://leetcode.cn/problems/binary-trees-with-factors/)
- 标签:数组、哈希表、动态规划、排序
- 难度:中等
## 题目链接
- [0823. 带因子的二叉树 - 力扣](https://leetcode.cn/problems/binary-trees-with-factors/)
## 题目大意
**描述**:
给出一个含有不重复整数元素的数组 $arr$ ,每个整数 $arr[i]$ 均大于 1。
用这些整数来构建二叉树,每个整数可以使用任意次数。其中:每个非叶结点的值应等于它的两个子结点的值的乘积。
**要求**:
计算出满足条件的二叉树的数量。答案可能很大,返回 对 $10^9 + 7$ 取余的结果。
**说明**:
- $1 \le arr.length \le 10^{3}$。
- $2 \le arr[i] \le 10^{9}$。
- $arr$ 中的所有值互不相同。
**示例**:
- 示例 1:
```python
输入: arr = [2, 4]
输出: 3
解释: 可以得到这些二叉树: [2], [4], [4, 2, 2]
```
- 示例 2:
```python
输入: arr = [2, 4, 5, 10]
输出: 7
解释: 可以得到这些二叉树: [2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
```
## 解题思路
### 思路 1:动态规划 + 哈希表
这道题要求计算用数组中的元素构建二叉树的方案数,其中每个非叶节点的值等于其两个子节点值的乘积。
关键观察:
- 对于一个值 $arr[i]$,如果它是非叶节点,那么它的两个子节点值 $left$ 和 $right$ 必须满足 $left \times right = arr[i]$,且 $left$ 和 $right$ 都在数组中。
- 使用动态规划:$dp[x]$ 表示以 $x$ 为根节点的二叉树的方案数。
算法步骤:
1. 将数组排序,方便从小到大处理。
2. 使用哈希表 $dp$,$dp[x]$ 表示以 $x$ 为根节点的二叉树方案数。
3. 初始化:每个元素本身可以作为叶节点,$dp[x] = 1$。
4. 对于每个元素 $x$,枚举所有可能的因子对 $(left, right)$:
- 如果 $left$ 和 $right$ 都在数组中,则 $dp[x] += dp[left] \times dp[right]$。
5. 返回所有 $dp[x]$ 的和。
### 思路 1:代码
```python
class Solution:
def numFactoredBinaryTrees(self, arr: List[int]) -> int:
MOD = 10**9 + 7
# 排序,从小到大处理
arr.sort()
# dp[x] 表示以 x 为根节点的二叉树方案数
dp = {}
# 将数组元素存入集合,方便查找
arr_set = set(arr)
for x in arr:
# 初始化:x 本身可以作为叶节点
dp[x] = 1
# 枚举所有可能的左子节点
for left in arr:
# 如果 left > sqrt(x),后面的 left 更大,right 会更小,会重复计算
if left * left > x:
break
# 检查是否能整除
if x % left == 0:
right = x // left
# 如果 right 在数组中
if right in arr_set:
if left == right:
# 左右子树相同
dp[x] = (dp[x] + dp[left] * dp[right]) % MOD
else:
# 左右子树不同,有两种组合方式
dp[x] = (dp[x] + 2 * dp[left] * dp[right]) % MOD
# 返回所有方案数的和
return sum(dp.values()) % MOD
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是数组的长度。需要对每个元素枚举所有可能的因子。
- **空间复杂度**:$O(n)$,需要使用哈希表存储 DP 状态。
================================================
FILE: docs/solutions/0800-0899/bitwise-ors-of-subarrays.md
================================================
# [0898. 子数组按位或操作](https://leetcode.cn/problems/bitwise-ors-of-subarrays/)
- 标签:位运算、数组、动态规划
- 难度:中等
## 题目链接
- [0898. 子数组按位或操作 - 力扣](https://leetcode.cn/problems/bitwise-ors-of-subarrays/)
## 题目大意
**描述**:
给定一个整数数组 $arr$。
**要求**:
返回所有 $arr$ 的非空子数组的不同按位或的数量。
**说明**:
- 「子数组的按位或」是子数组中每个整数的按位或。含有一个整数的子数组的按位或就是该整数。
- 「子数组」是数组内连续的非空元素序列。
- $1 \le nums.length \le 5 \times 10^{4}$。
- $0 \le nums[i] \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:arr = [0]
输出:1
解释:
只有一个可能的结果 0 。
```
- 示例 2:
```python
输入:arr = [1,1,2]
输出:3
解释:
可能的子数组为 [1],[1],[2],[1, 1],[1, 2],[1, 1, 2]。
产生的结果为 1,1,2,1,3,3 。
有三个唯一值,所以答案是 3 。
```
## 解题思路
### 思路 1:动态规划 + 哈希表
这道题要求计算所有子数组的按位或结果的不同值数量。
关键观察:
- 对于以位置 $i$ 结尾的所有子数组,它们的按位或结果最多只有 $O(\log C)$ 个不同值($C$ 是数组中的最大值)。
- 原因:按位或操作只会增加 1 的位数,而整数最多有 $\log C$ 位。
算法步骤:
1. 使用集合 $result$ 存储所有不同的按位或结果。
2. 使用集合 $cur$ 存储以当前位置结尾的所有子数组的按位或结果。
3. 遍历数组:
- 对于每个元素 $arr[i]$,计算它与 $cur$ 中所有值的按位或结果,加上它本身。
- 更新 $cur$ 为新的按位或结果集合。
- 将 $cur$ 中的所有值加入 $result$。
4. 返回 $result$ 的大小。
### 思路 1:代码
```python
class Solution:
def subarrayBitwiseORs(self, arr: List[int]) -> int:
result = set() # 存储所有不同的按位或结果
cur = set() # 存储以当前位置结尾的所有子数组的按位或结果
for num in arr:
# 计算以当前元素结尾的所有子数组的按位或结果
cur = {num | x for x in cur} | {num}
# 将结果加入总集合
result |= cur
return len(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log C)$,其中 $n$ 是数组的长度,$C$ 是数组中的最大值。对于每个元素,$cur$ 集合的大小最多为 $O(\log C)$。
- **空间复杂度**:$O(n \log C)$,需要存储所有不同的按位或结果。
================================================
FILE: docs/solutions/0800-0899/boats-to-save-people.md
================================================
# [0881. 救生艇](https://leetcode.cn/problems/boats-to-save-people/)
- 标签:贪心、数组、双指针、排序
- 难度:中等
## 题目链接
- [0881. 救生艇 - 力扣](https://leetcode.cn/problems/boats-to-save-people/)
## 题目大意
**描述**:给定一个整数数组 `people` 代表每个人的体重,其中第 `i` 个人的体重为 `people[i]`。再给定一个整数 `limit`,代表每艘船可以承载的最大重量。每艘船最多可同时载两人,但条件是这些人的重量之和最多为 `limit`。
**要求**:返回载到每一个人所需的最小船数(保证每个人都能被船载)。
**说明**:
- $1 \le people.length \le 5 \times 10^4$。
- $1 \le people[i] \le limit \le 3 \times 10^4$。
**示例**:
- 示例 1:
```python
输入:people = [1,2], limit = 3
输出:1
解释:1 艘船载 (1, 2)
```
- 示例 2:
```python
输入:people = [3,2,2,1], limit = 3
输出:3
解释:3 艘船分别载 (1, 2), (2) 和 (3)
```
## 解题思路
### 思路 1:贪心算法 + 双指针
暴力枚举的时间复杂度为 $O(n^2)$。使用双指针可以减少循环内的时间复杂度。
我们可以利用贪心算法的思想,让最重的和最轻的人一起走。这样一只船就可以尽可能的带上两个人。
具体做法如下:
1. 先对数组进行升序排序,使用 `ans` 记录所需最小船数。
2. 使用两个指针 `left`、`right`。`left` 指向数组开始位置,`right` 指向数组结束位置。
3. 判断 `people[left]` 和 `people[right]` 加一起是否超重。
1. 如果 `people[left] + people[right] > limit`,则让重的人上船,船数量 + 1,令 `right` 左移,继续判断。
2. 如果 `people[left] + people[right] <= limit`,则两个人都上船,船数量 + 1,并令 `left` 右移,`right` 左移,继续判断。
4. 如果 `lefft == right`,则让最后一个人上船,船数量 + 1。并返回答案。
### 思路 1:代码
```python
class Solution:
def numRescueBoats(self, people: List[int], limit: int) -> int:
people.sort()
size = len(people)
left, right = 0, size - 1
ans = 0
while left < right:
if people[left] + people[right] > limit:
right -= 1
else:
left += 1
right -= 1
ans += 1
if left == right:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 是数组 `people` 的长度。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/0800-0899/bricks-falling-when-hit.md
================================================
# [0803. 打砖块](https://leetcode.cn/problems/bricks-falling-when-hit/)
- 标签:并查集、数组、矩阵
- 难度:困难
## 题目链接
- [0803. 打砖块 - 力扣](https://leetcode.cn/problems/bricks-falling-when-hit/)
## 题目大意
**描述**:给定一个 $m \times n$ 大小的二元网格,其中 $1$ 表示砖块,$0$ 表示空白。砖块稳定(不会掉落)的前提是:
- 一块砖直接连接到网格的顶部。
- 或者至少有一块相邻(4 个方向之一)砖块稳定不会掉落时。
再给定一个数组 $hits$,这是需要依次消除砖块的位置。每当消除 $hits[i] = (row_i, col_i)$ 位置上的砖块时,对应位置的砖块(如果存在)会消失,然后其他的砖块可能因为这一消除操作而掉落。一旦砖块掉落,它会立即从网格中消失(即,它不会落在其他稳定的砖块上)。
**要求**:返回一个数组 $result$,其中 $result[i]$ 表示第 $i$ 次消除操作对应掉落的砖块数目。
**说明**:
- 消除可能指向是没有砖块的空白位置,如果发生这种情况,则没有砖块掉落。
- $m == grid.length$。
- $n == grid[i].length$。
- $1 \le m, n \le 200$。
- $grid[i][j]$ 为 $0$ 或 $1$。
- $1 \le hits.length \le 4 \times 10^4$。
- $hits[i].length == 2$。
- $0 \le xi \le m - 1$。
- $0 \le yi \le n - 1$。
- 所有 $(xi, yi)$ 互不相同。
**示例**:
- 示例 1:
```python
输入:grid = [[1,0,0,0],[1,1,1,0]], hits = [[1,0]]
输出:[2]
解释:网格开始为:
[[1,0,0,0],
[1,1,1,0]]
消除 (1,0) 处加粗的砖块,得到网格:
[[1,0,0,0]
[0,1,1,0]]
两个加粗的砖不再稳定,因为它们不再与顶部相连,也不再与另一个稳定的砖相邻,因此它们将掉落。得到网格:
[[1,0,0,0],
[0,0,0,0]]
因此,结果为 [2]。
```
- 示例 2:
```python
输入:grid = [[1,0,0,0],[1,1,0,0]], hits = [[1,1],[1,0]]
输出:[0,0]
解释:网格开始为:
[[1,0,0,0],
[1,1,0,0]]
消除 (1,1) 处加粗的砖块,得到网格:
[[1,0,0,0],
[1,0,0,0]]
剩下的砖都很稳定,所以不会掉落。网格保持不变:
[[1,0,0,0],
[1,0,0,0]]
接下来消除 (1,0) 处加粗的砖块,得到网格:
[[1,0,0,0],
[0,0,0,0]]
剩下的砖块仍然是稳定的,所以不会有砖块掉落。
因此,结果为 [0,0]。
```
## 解题思路
### 思路 1:并查集
一个很直观的想法:
- 将所有砖块放入一个集合中。
- 根据 $hits$ 数组的顺序,每敲掉一块砖。则将这块砖与相邻(4 个方向)的砖块断开集合。
- 然后判断哪些砖块会掉落,从集合中删除会掉落的砖块,并统计掉落砖块的数量。
- **掉落砖块的数目 = 击碎砖块之前与屋顶相连的砖块数目 - 击碎砖块之后与屋顶相连的砖块数目 - 1**。
涉及集合问题,很容易想到用并查集来做。但是并查集主要用于合并查找集合,不适合断开集合。我们可以反向思考问题:
- 先将 $hits$ 中的所有位置上的砖块敲掉。
- 将剩下的砖块建立并查集。
- 逆序填回被敲掉的砖块,并与相邻(4 个方向)的砖块合并。这样问题就变为了 **补上砖块会新增多少个砖块粘到屋顶**。
整个算法步骤具体如下:
1. 先将二维数组 $grid$ 复制一份到二维数组 $copy\_gird$ 上。这是因为遍历 $hits$ 元素时需要判断原网格是空白还是被打碎的砖块。
2. 在 $copy\_grid$ 中将 $hits$ 中打碎的砖块赋值为 $0$。
3. 建立并查集,将房顶上的砖块合并到一个集合中。
4. 逆序遍历 $hits$,将 $hits$ 中的砖块补到 $copy\_grid$ 中,并计算每一步中有多少个砖块粘到屋顶上(与屋顶砖块在一个集合中),并存入答案数组对应位置。
5. 最后输出答案数组。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.size = [1 for _ in range(n)]
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return False
self.parent[root_x] = root_y
self.size[root_y] += self.size[root_x]
return True
def is_connected(self, x, y):
return self.find(x) == self.find(y)
def get_size(self, x):
root_x = self.find(x)
return self.size[root_x]
class Solution:
def hitBricks(self, grid: List[List[int]], hits: List[List[int]]) -> List[int]:
directions = {(0, 1), (1, 0), (-1, 0), (0, -1)}
rows, cols = len(grid), len(grid[0])
def is_area(x, y):
return 0 <= x < rows and 0 <= y < cols
def get_index(x, y):
return x * cols + y
copy_grid = [[grid[i][j] for j in range(cols)] for i in range(rows)]
for hit in hits:
copy_grid[hit[0]][hit[1]] = 0
union_find = UnionFind(rows * cols + 1)
for j in range(cols):
if copy_grid[0][j] == 1:
union_find.union(j, rows * cols)
for i in range(1, rows):
for j in range(cols):
if copy_grid[i][j] == 1:
if copy_grid[i - 1][j] == 1:
union_find.union(get_index(i - 1, j), get_index(i, j))
if j > 0 and copy_grid[i][j - 1] == 1:
union_find.union(get_index(i, j - 1), get_index(i, j))
size_hits = len(hits)
res = [0 for _ in range(size_hits)]
for i in range(size_hits - 1, -1, -1):
x, y = hits[i][0], hits[i][1]
if grid[x][y] == 0:
continue
origin = union_find.get_size(rows * cols)
if x == 0:
union_find.union(y, rows * cols)
for direction in directions:
new_x = x + direction[0]
new_y = y + direction[1]
if is_area(new_x, new_y) and copy_grid[new_x][new_y] == 1:
union_find.union(get_index(x, y), get_index(new_x, new_y))
curr = union_find.get_size(rows * cols)
res[i] = max(0, curr - origin - 1)
copy_grid[x][y] = 1
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n \times \alpha(m \times n))$,其中 $\alpha$ 是反 Ackerman 函数。
- **空间复杂度**:$O(m \times n)$。
================================================
FILE: docs/solutions/0800-0899/buddy-strings.md
================================================
# [0859. 亲密字符串](https://leetcode.cn/problems/buddy-strings/)
- 标签:哈希表、字符串
- 难度:简单
## 题目链接
- [0859. 亲密字符串 - 力扣](https://leetcode.cn/problems/buddy-strings/)
## 题目大意
**描述**:
给定两个字符串 $s$ 和 $goal$。
**要求**:
只要我们可以通过交换 $s$ 中的两个字母得到与 $goal$ 相等的结果,就返回 true;否则返回 false。
**说明**:
- 交换字母的定义是:取两个下标 $i$ 和 $j$(下标从 0 开始)且满足 $i \ne j$ ,接着交换 $s[i]$ 和 $s[j]$ 处的字符。
- 例如,在 `"abcd"` 中交换下标 0 和下标 2 的元素可以生成 `"cbad"`。
- $1 \le s.length, goal.length \le 2 \times 10^{4}$。
- $s$ 和 $goal$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:s = "ab", goal = "ba"
输出:true
解释:你可以交换 s[0] = 'a' 和 s[1] = 'b' 生成 "ba",此时 s 和 goal 相等。
```
- 示例 2:
```python
输入:s = "ab", goal = "ab"
输出:false
解释:你只能交换 s[0] = 'a' 和 s[1] = 'b' 生成 "ba",此时 s 和 goal 不相等。
```
## 解题思路
### 思路 1:分情况讨论
这道题要求判断是否可以通过交换 $s$ 中的两个字母得到 $goal$。需要分情况讨论:
1. **长度不同**:如果 $s$ 和 $goal$ 长度不同,直接返回 $False$。
2. **字符串相同**:如果 $s$ 和 $goal$ 完全相同,需要判断 $s$ 中是否有重复字符。如果有重复字符,可以交换这两个相同的字符,返回 $True$;否则返回 $False$。
3. **字符串不同**:找出所有不同的位置,如果不同位置的数量不等于 2,返回 $False$。如果恰好有 2 个不同位置,检查交换后是否能得到 $goal$。
### 思路 1:代码
```python
class Solution:
def buddyStrings(self, s: str, goal: str) -> bool:
# 长度不同,直接返回 False
if len(s) != len(goal):
return False
# 如果两个字符串相同
if s == goal:
# 检查是否有重复字符,有则可以交换
return len(set(s)) < len(s)
# 找出所有不同的位置
diff = []
for i in range(len(s)):
if s[i] != goal[i]:
diff.append(i)
# 不同位置必须恰好为 2 个
if len(diff) != 2:
return False
# 检查交换后是否能得到 goal
i, j = diff[0], diff[1]
return s[i] == goal[j] and s[j] == goal[i]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串的长度。需要遍历字符串一次。
- **空间复杂度**:$O(n)$,使用集合存储字符需要 $O(n)$ 空间。
================================================
FILE: docs/solutions/0800-0899/bus-routes.md
================================================
# [0815. 公交路线](https://leetcode.cn/problems/bus-routes/)
- 标签:广度优先搜索、数组、哈希表
- 难度:困难
## 题目链接
- [0815. 公交路线 - 力扣](https://leetcode.cn/problems/bus-routes/)
## 题目大意
**描述**:
给定一个数组 $routes$ ,表示一系列公交线路,其中每个 $routes[i]$ 表示一条公交线路,第 $i$ 辆公交车将会在上面循环行驶。
- 例如,路线 $routes[0] = [1, 5, 7]$ 表示第 0 辆公交车会一直按序列 $1 \rightarrow 5 \rightarrow 7 \rightarrow 1 \rightarrow 5 \rightarrow 7 \rightarrow 1 \rightarrow ...$ 这样的车站路线行驶。
现在从 $source$ 车站出发(初始时不在公交车上),要前往 $target$ 车站。 期间仅可乘坐公交车。
**要求**:
求出「最少乘坐的公交车数量」。如果不可能到达终点车站,返回 $-1$。
**说明**:
- $1 \le routes.length \le 500.$。
- $1 \le routes[i].length \le 10^{5}$。
- $routes[i]$ 中的所有值互不相同。
- $sum(routes[i].length) \le 10^{5}$。
- $0 \le routes[i][j] \lt 10^{6}$。
- $0 \le source, target \lt 10^{6}$。
**示例**:
- 示例 1:
```python
输入:routes = [[1,2,7],[3,6,7]], source = 1, target = 6
输出:2
解释:最优策略是先乘坐第一辆公交车到达车站 7 , 然后换乘第二辆公交车到车站 6 。
```
- 示例 2:
```python
输入:routes = [[7,12],[4,5,15],[6],[15,19],[9,12,13]], source = 15, target = 12
输出:-1
```
## 解题思路
### 思路 1:BFS(广度优先搜索)
这道题要求找到从起点到终点的最少乘坐公交车数量。可以将问题转化为图的最短路径问题:
- 每个公交站是一个节点。
- 如果两个站在同一条公交线路上,它们之间有边相连。
但直接建图会导致边数过多。更好的方法是:
- 将公交线路作为节点。
- 从起点站开始,找到所有经过该站的公交线路。
- 对于每条线路,找到该线路上的所有站点,再找到这些站点对应的其他线路。
- 使用 BFS 搜索最短路径。
算法步骤:
1. 如果起点等于终点,返回 0。
2. 建立站点到公交线路的映射。
3. 使用 BFS,从起点站开始:
- 找到所有经过该站的公交线路。
- 对于每条线路,遍历该线路上的所有站点。
- 如果到达终点站,返回当前乘坐的公交车数量。
- 否则,将新站点加入队列。
4. 使用 $\text{visited}$ 集合记录已访问的线路和站点,避免重复访问。
### 思路 1:代码
```python
class Solution:
def numBusesToDestination(self, routes: List[List[int]], source: int, target: int) -> int:
from collections import defaultdict, deque
# 如果起点等于终点,直接返回 0
if source == target:
return 0
# 建立站点到公交线路的映射
stop_to_routes = defaultdict(set)
for i, route in enumerate(routes):
for stop in route:
stop_to_routes[stop].add(i)
# BFS
queue = deque([source])
visited_stops = {source}
visited_routes = set()
buses = 0
while queue:
buses += 1
# 遍历当前层的所有站点
for _ in range(len(queue)):
stop = queue.popleft()
# 找到所有经过该站的公交线路
for route_idx in stop_to_routes[stop]:
# 如果该线路已访问,跳过
if route_idx in visited_routes:
continue
visited_routes.add(route_idx)
# 遍历该线路上的所有站点
for next_stop in routes[route_idx]:
# 如果到达终点,返回结果
if next_stop == target:
return buses
# 如果该站点未访问,加入队列
if next_stop not in visited_stops:
visited_stops.add(next_stop)
queue.append(next_stop)
# 无法到达终点
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(N \times S)$,其中 $N$ 是公交线路的数量,$S$ 是每条线路的平均站点数。每条线路最多被访问一次,每次访问需要遍历该线路上的所有站点。
- **空间复杂度**:$O(N \times S)$,需要存储站点到线路的映射和 BFS 队列。
================================================
FILE: docs/solutions/0800-0899/car-fleet.md
================================================
# [0853. 车队](https://leetcode.cn/problems/car-fleet/)
- 标签:栈、数组、排序、单调栈
- 难度:中等
## 题目链接
- [0853. 车队 - 力扣](https://leetcode.cn/problems/car-fleet/)
## 题目大意
**描述**:
在一条单行道上,有 $n$ 辆车开往同一目的地。目的地是几英里以外的 $target$。
给定两个整数数组 $position$ 和 $speed$,长度都是 $n$,其中 $position[i]$ 是第 $i$ 辆车的位置,$speed[i]$ 是第 $i$ 辆车的速度(单位是英里/小时)。
一辆车永远不会超过前面的另一辆车,但它可以追上去,并以较慢车的速度在另一辆车旁边行驶。
车队 是指并排行驶的一辆或几辆汽车。车队的速度是车队中「最慢」的车的速度。
即便一辆车在 $target$ 才赶上了一个车队,它们仍然会被视作是同一个车队。
**要求**:
返回到达目的地的车队数量。
**说明**:
- $n == position.length == speed.length$。
- $1 \le n \le 10^{5}$。
- $0 \lt target \le 10^{6}$。
- $0 \le position[i] \lt target$。
- $position$ 中每个值都「不同」。
- $0 \lt speed[i] \le 10^{6}$。
**示例**:
- 示例 1:
```python
输入:target = 12, position = [10,8,0,5,3], speed = [2,4,1,1,3]
输出:3
解释:
* 从 10(速度为 2)和 8(速度为 4)开始的车会组成一个车队,它们在 12 相遇。车队在 target 形成。
* 从 0(速度为 1)开始的车不会追上其它任何车,所以它自己是一个车队。
* 从 5(速度为 1) 和 3(速度为 3)开始的车组成一个车队,在 6 相遇。车队以速度 1 移动直到它到达 target。
```
- 示例 2:
```python
输入:target = 10, position = [3], speed = [3]
输出:1
解释:只有一辆车,因此只有一个车队。
```
## 解题思路
### 思路 1:排序 + 单调栈
这道题的关键是理解车队的形成:后面的车如果能在到达终点前追上前面的车,它们就会形成车队,以较慢的速度行驶。
算法步骤:
1. 将车按照位置从大到小排序(从离终点近到远)。
2. 计算每辆车到达终点所需的时间。
3. 使用单调栈(或变量)维护车队:
- 从离终点最近的车开始遍历。
- 如果当前车的到达时间大于栈顶车队的到达时间,说明它无法追上前面的车队,形成新的车队。
- 否则,它会追上前面的车队,合并为一个车队。
### 思路 1:代码
```python
class Solution:
def carFleet(self, target: int, position: List[int], speed: List[int]) -> int:
# 将车按位置从大到小排序
cars = sorted(zip(position, speed), reverse=True)
# 单调栈,存储每个车队到达终点的时间
stack = []
for pos, spd in cars:
# 计算当前车到达终点的时间
time = (target - pos) / spd
# 如果栈为空,或当前车无法追上前面的车队,形成新车队
if not stack or time > stack[-1]:
stack.append(time)
# 否则,当前车会追上前面的车队,合并(不需要操作)
# 栈的大小就是车队数量
return len(stack)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是车的数量。排序需要 $O(n \log n)$,遍历需要 $O(n)$。
- **空间复杂度**:$O(n)$,需要存储排序后的车辆信息和栈。
================================================
FILE: docs/solutions/0800-0899/card-flipping-game.md
================================================
# [0822. 翻转卡片游戏](https://leetcode.cn/problems/card-flipping-game/)
- 标签:数组、哈希表
- 难度:中等
## 题目链接
- [0822. 翻转卡片游戏 - 力扣](https://leetcode.cn/problems/card-flipping-game/)
## 题目大意
**描述**:
在桌子上有 $n$ 张卡片,每张卡片的正面和背面都写着一个正数(正面与背面上的数有可能不一样)。
我们可以先翻转任意张卡片,然后选择其中一张卡片。
如果选中的那张卡片背面的数字 $x$ 与任意一张卡片的正面的数字都不同,那么这个数字是我们想要的数字。
如果我们通过翻转卡片来交换正面与背面上的数,那么当初在正面的数就变成背面的数,背面的数就变成正面的数。
给定两个长度为 $n$ 的数组 $fronts[i]$ 和 $backs[i]$,分别代表第 $i$ 张卡片的正面和背面的数字。
**要求**:
计算出哪个数是这些想要的数字中最小的数(找到这些数中的最小值)。如果没有一个数字符合要求的,输出 $0$。
**说明**:
- $n == fronts.length == backs.length$。
- $1 \le n \le 10^{3}$。
- $1 \le fronts[i], backs[i] \le 2000$。
**示例**:
- 示例 1:
```python
输入:fronts = [1,2,4,4,7], backs = [1,3,4,1,3]
输出:2
解释:假设我们翻转第二张卡片,那么在正面的数变成了 [1,3,4,4,7] , 背面的数变成了 [1,2,4,1,3]。
接着我们选择第二张卡片,因为现在该卡片的背面的数是 2,2 与任意卡片上正面的数都不同,所以 2 就是我们想要的数字。
```
- 示例 2:
```python
输入:fronts = [1], backs = [1]
输出:0
解释:
无论如何翻转都无法得到想要的数字,所以返回 0 。
```
## 解题思路
### 思路 1:哈希表
这道题的关键是理解:如果一张卡片的正面和背面数字相同,那么这个数字永远不可能成为答案(因为无论怎么翻转,这个数字都会出现在某张卡片的正面)。
算法步骤:
1. 找出所有正反面数字相同的卡片,将这些数字加入「禁止集合」。
2. 遍历所有卡片的正面和背面,找出不在禁止集合中的最小数字。
### 思路 1:代码
```python
class Solution:
def flipgame(self, fronts: List[int], backs: List[int]) -> int:
n = len(fronts)
# 找出所有正反面相同的数字,这些数字不能作为答案
forbidden = set()
for i in range(n):
if fronts[i] == backs[i]:
forbidden.add(fronts[i])
# 找出所有可能的数字中的最小值
result = float('inf')
# 遍历所有正面和背面的数字
for num in fronts + backs:
if num not in forbidden:
result = min(result, num)
# 如果没有找到合适的数字,返回 0
return result if result != float('inf') else 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是卡片的数量。需要遍历所有卡片两次。
- **空间复杂度**:$O(n)$,需要使用哈希表存储禁止的数字。
================================================
FILE: docs/solutions/0800-0899/chalkboard-xor-game.md
================================================
# [0810. 黑板异或游戏](https://leetcode.cn/problems/chalkboard-xor-game/)
- 标签:位运算、脑筋急转弯、数组、数学、博弈
- 难度:困难
## 题目链接
- [0810. 黑板异或游戏 - 力扣](https://leetcode.cn/problems/chalkboard-xor-game/)
## 题目大意
**描述**:
黑板上写着一个非负整数数组 $nums[i]$。
Alice 和 Bob 轮流从黑板上擦掉一个数字,Alice 先手。如果擦除一个数字后,剩余的所有数字按位异或运算得出的结果等于 0 的话,当前玩家游戏失败。另外,如果只剩一个数字,按位异或运算得到它本身;如果无数字剩余,按位异或运算结果为 0。
并且,轮到某个玩家时,如果当前黑板上所有数字按位异或运算结果等于 0,这个玩家获胜。
**要求**:
假设两个玩家每步都使用最优解,当且仅当 Alice 获胜时返回 true,$Bob$ 获胜时返回 false。
**说明**:
- $1 \le nums.length \le 10^{3}$。
- $0 \le nums[i] \lt 2^{16}$。
**示例**:
- 示例 1:
```python
输入: nums = [1,1,2]
输出: false
解释:
Alice 有两个选择: 擦掉数字 1 或 2。
如果擦掉 1, 数组变成 [1, 2]。剩余数字按位异或得到 1 XOR 2 = 3。那么 Bob 可以擦掉任意数字,因为 Alice 会成为擦掉最后一个数字的人,她总是会输。
如果 Alice 擦掉 2,那么数组变成[1, 1]。剩余数字按位异或得到 1 XOR 1 = 0。Alice 仍然会输掉游戏。
```
- 示例 2:
```python
输入: nums = [0,1]
输出: true
```
## 解题思路
### 思路 1:博弈论 + 数学
这道题是一个博弈问题,需要分析在最优策略下谁会获胜。
关键观察:
1. 如果初始状态所有数字的异或结果为 0,Alice 直接获胜。
2. 如果数组长度为偶数,Alice 必胜。原因如下:
- 假设所有数字的异或结果为 $x \neq 0$。
- 由于异或运算的性质,至少有一个数字 $nums[i]$ 使得 $x \oplus nums[i] \neq 0$(否则所有数字异或结果为 0)。
- 在 Alice 的回合,如果她无法找到一个数字使得擦除后异或结果不为 0,说明擦除任何数字后异或结果都为 0,这意味着所有数字都相同且等于 $x$。
- 但如果所有数字都相同,数组长度为偶数时,异或结果应该为 0,矛盾。
- 因此,Alice 总能找到一个数字擦除,使得游戏继续,最终 Bob 会面临奇数个数字的局面。
3. 如果数组长度为奇数且异或结果不为 0,Bob 必胜。
结论:Alice 获胜的条件是:初始异或结果为 0,或数组长度为偶数。
### 思路 1:代码
```python
class Solution:
def xorGame(self, nums: List[int]) -> bool:
# 计算所有数字的异或结果
xor_sum = 0
for num in nums:
xor_sum ^= num
# Alice 获胜的条件:异或结果为 0,或数组长度为偶数
return xor_sum == 0 or len(nums) % 2 == 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。需要遍历数组计算异或结果。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/consecutive-numbers-sum.md
================================================
# [0829. 连续整数求和](https://leetcode.cn/problems/consecutive-numbers-sum/)
- 标签:数学、枚举
- 难度:困难
## 题目链接
- [0829. 连续整数求和 - 力扣](https://leetcode.cn/problems/consecutive-numbers-sum/)
## 题目大意
**描述**:
给定一个正整数 $n$。
**要求**:
返回连续正整数满足所有数字之和为 $n$ 的组数。
**说明**:
- $1 \le n \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入: n = 5
输出: 2
解释: 5 = 2 + 3,共有两组连续整数([5],[2,3])求和后为 5。
```
- 示例 2:
```python
输入: n = 9
输出: 3
解释: 9 = 4 + 5 = 2 + 3 + 4
```
## 解题思路
### 思路 1:数学 + 枚举
假设有 $k$ 个连续正整数,首项为 $x$,则它们的和为:
$$x + (x+1) + (x+2) + \cdots + (x+k-1) = k \times x + \frac{k \times (k-1)}{2} = n$$
化简得:
$$x = \frac{n - \frac{k \times (k-1)}{2}}{k}$$
要使 $x$ 为正整数,需要满足:
1. $n - \frac{k \times (k-1)}{2} > 0$,即 $k < \sqrt{2n} + 1$。
2. $n - \frac{k \times (k-1)}{2}$ 能被 $k$ 整除。
算法步骤:
1. 枚举 $k$ 从 1 到 $\sqrt{2n}$。
2. 对于每个 $k$,检查是否满足上述两个条件。
3. 如果满足,计数加 1。
### 思路 1:代码
```python
class Solution:
def consecutiveNumbersSum(self, n: int) -> int:
count = 0
# 枚举连续整数的个数 k
# k 的上界为 sqrt(2n)
k = 1
while k * (k - 1) // 2 < n:
# 检查 n - k*(k-1)/2 是否能被 k 整除
if (n - k * (k - 1) // 2) % k == 0:
count += 1
k += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\sqrt{n})$,需要枚举 $k$ 从 1 到 $\sqrt{2n}$。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/construct-binary-tree-from-preorder-and-postorder-traversal.md
================================================
# [0889. 根据前序和后序遍历构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-postorder-traversal/)
- 标签:树、数组、哈希表、分治、二叉树
- 难度:中等
## 题目链接
- [0889. 根据前序和后序遍历构造二叉树 - 力扣](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-postorder-traversal/)
## 题目大意
**描述**:给定一棵无重复值二叉树的前序遍历结果 `preorder` 和后序遍历结果 `postorder`。
**要求**:构造出该二叉树并返回其根节点。如果存在多个答案,则可以返回其中任意一个。
**说明**:
- $1 \le preorder.length \le 30$。
- $1 \le preorder[i] \le preorder.length$。
- `preorder` 中所有值都不同。
- `postorder.length == preorder.length`。
- $1 \le postorder[i] \le postorder.length$。
- `postorder` 中所有值都不同。
- 保证 `preorder` 和 `postorder` 是同一棵二叉树的前序遍历和后序遍历。
**示例**:
- 示例 1:

```python
输入:preorder = [1,2,4,5,3,6,7], postorder = [4,5,2,6,7,3,1]
输出:[1,2,3,4,5,6,7]
```
- 示例 2:
```python
输入: preorder = [1], postorder = [1]
输出: [1]
```
## 解题思路
### 思路 1:递归
如果已知二叉树的前序遍历序列和后序遍历序列,是不能唯一地确定一棵二叉树的。这是因为没有中序遍历序列无法确定左右部分,也就无法进行子序列的分割。
只有二叉树中每个节点度为 `2` 或者 `0` 的时候,已知前序遍历序列和后序遍历序列,才能唯一地确定一颗二叉树,如果二叉树中存在度为 `1` 的节点时是无法唯一地确定一棵二叉树的,这是因为我们无法判断该节点是左子树还是右子树。
而这道题说明了,如果存在多个答案,则可以返回其中任意一个。
我们可以默认指定前序遍历序列的第 `2` 个值为左子树的根节点,由此递归划分左右子序列。具体操作步骤如下:
1. 从前序遍历序列中可知当前根节点的位置在 `preorder[0]`。
2. 前序遍历序列的第 `2` 个值为左子树的根节点,即 `preorder[1]`。通过在后序遍历中查找上一步根节点对应的位置 `postorder[k]`(该节点右侧为右子树序列),从而将二叉树的左右子树分隔开,并得到左右子树节点的个数。
3. 从上一步得到的左右子树个数将后序遍历结果中的左右子树分开。
4. 构建当前节点,并递归建立左右子树,在左右子树对应位置继续递归遍历并执行上述三步,直到节点为空。
### 思路 1:代码
```python
class Solution:
def constructFromPrePost(self, preorder: List[int], postorder: List[int]) -> TreeNode:
def createTree(preorder, postorder, n):
if n == 0:
return None
node = TreeNode(preorder[0])
if n == 1:
return node
k = 0
while postorder[k] != preorder[1]:
k += 1
node.left = createTree(preorder[1: k + 2], postorder[: k + 1], k + 1)
node.right = createTree(preorder[k + 2: ], postorder[k + 1: -1], n - k - 2)
return node
return createTree(preorder, postorder, len(preorder))
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。其中 $n$ 是二叉树的节点数目。
- **空间复杂度**:$O(n^2)$。
================================================
FILE: docs/solutions/0800-0899/count-unique-characters-of-all-substrings-of-a-given-string.md
================================================
# [0828. 统计子串中的唯一字符](https://leetcode.cn/problems/count-unique-characters-of-all-substrings-of-a-given-string/)
- 标签:哈希表、字符串、动态规划
- 难度:困难
## 题目链接
- [0828. 统计子串中的唯一字符 - 力扣](https://leetcode.cn/problems/count-unique-characters-of-all-substrings-of-a-given-string/)
## 题目大意
**描述**:
我们定义了一个函数 `countUniqueChars(s)` 来统计字符串 $s$ 中的唯一字符,并返回唯一字符的个数。
例如:`s = "LEETCODE"`,则其中 `"L"`, `"T"`, `"C"`, "O","D" 都是唯一字符,因为它们只出现一次,所以 `countUniqueChars(s) = 5`。
给定一个字符串 $s$。
**要求**:
返回 `countUniqueChars(t)` 的总和,其中 $t$ 是 $s$ 的子字符串。输入用例保证返回值为 32 位整数。
**说明**:
- 注意:某些子字符串可能是重复的,但你统计时也必须算上这些重复的子字符串(也就是说,你必须统计 $s$ 的所有子字符串中的唯一字符)。
- $1 \le s.length \le 10^{5}$。
- $s$ 只包含大写英文字符。
**示例**:
- 示例 1:
```python
输入: s = "ABC"
输出: 10
解释: 所有可能的子串为:"A","B","C","AB","BC" 和 "ABC"。
其中,每一个子串都由独特字符构成。
所以其长度总和为:1 + 1 + 1 + 2 + 2 + 3 = 10
```
- 示例 2:
```python
输入: s = "ABA"
输出: 8
解释: 除了 countUniqueChars("ABA") = 1 之外,其余与示例 1 相同。
```
## 解题思路
### 思路 1:贡献法
这道题如果暴力枚举所有子串会超时。我们需要换个角度思考:计算每个字符作为唯一字符对答案的贡献。
关键观察:
- 对于字符串中的某个字符 $s[i]$,它在哪些子串中是唯一字符?
- 答案是:子串的左边界在 $s[i]$ 左侧最近的相同字符之后,右边界在 $s[i]$ 右侧最近的相同字符之前。
算法步骤:
1. 对于每个字符,记录它在字符串中所有出现的位置。
2. 对于每个位置 $i$ 的字符 $s[i]$:
- 找到它左侧最近的相同字符位置 $left$(如果没有,则为 $-1$)。
- 找到它右侧最近的相同字符位置 $right$(如果没有,则为 $n$)。
- 该字符作为唯一字符的贡献为:$(i - left) \times (right - i)$。
3. 累加所有字符的贡献。
### 思路 1:代码
```python
class Solution:
def uniqueLetterString(self, s: str) -> int:
from collections import defaultdict
n = len(s)
# 记录每个字符出现的所有位置
pos = defaultdict(list)
for i, ch in enumerate(s):
pos[ch].append(i)
result = 0
# 遍历每个字符
for ch, indices in pos.items():
# 在位置列表前后添加哨兵
indices = [-1] + indices + [n]
# 计算每个位置的贡献
for i in range(1, len(indices) - 1):
left = indices[i - 1] # 左侧最近的相同字符位置
mid = indices[i] # 当前位置
right = indices[i + 1] # 右侧最近的相同字符位置
# 当前字符作为唯一字符的贡献
result += (mid - left) * (right - mid)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串的长度。需要遍历字符串两次。
- **空间复杂度**:$O(n)$,需要存储每个字符的位置列表。
================================================
FILE: docs/solutions/0800-0899/decoded-string-at-index.md
================================================
# [0880. 索引处的解码字符串](https://leetcode.cn/problems/decoded-string-at-index/)
- 标签:栈、字符串
- 难度:中等
## 题目链接
- [0880. 索引处的解码字符串 - 力扣](https://leetcode.cn/problems/decoded-string-at-index/)
## 题目大意
**描述**:
给定一个编码字符串 $s$。请你找出「解码字符串」并将其写入磁带。解码时,从编码字符串中 每次读取一个字符 ,并采取以下步骤:
- 如果所读的字符是字母,则将该字母写在磁带上。
- 如果所读的字符是数字(例如 $d$),则整个当前磁带总共会被重复写 $d-1$ 次。
**要求**:
现在,对于给定的编码字符串 $s$ 和索引 $k$,查找并返回解码字符串中的第 $k$ 个字母。
**说明**:
- $2 \le s.length \le 10^{3}$。
- $s$ 只包含小写字母与数字 2 到 9 。
- $s$ 以字母开头。
- $1 \le k \le 10^{9}$。
- 题目保证 $k$ 小于或等于解码字符串的长度。
- 解码后的字符串保证少于 263 个字母。
**示例**:
- 示例 1:
```python
输入:s = "leet2code3", k = 10
输出:"o"
解释:
解码后的字符串为 "leetleetcodeleetleetcodeleetleetcode"。
字符串中的第 10 个字母是 "o"。
```
- 示例 2:
```python
输入:s = "ha22", k = 5
输出:"h"
解释:
解码后的字符串为 "hahahaha"。第 5 个字母是 "h"。
```
## 解题思路
### 思路 1:逆向思维
这道题如果直接构建解码字符串会超时(解码后的字符串可能非常长)。我们需要逆向思考:
关键观察:
- 如果当前字符是数字 $d$,解码后的长度会变为原来的 $d$ 倍。
- 如果当前字符是字母,解码后的长度加 1。
算法步骤:
1. 先正向遍历,计算解码后的总长度 $size$。
2. 然后逆向遍历:
- 如果遇到数字 $d$,说明当前段是前面内容重复 $d$ 次,将 $size$ 除以 $d$,同时 $k$ 对 $size$ 取模(因为是重复的)。
- 如果遇到字母,$size$ 减 1。如果此时 $k$ 等于 0 或 $k$ 等于 $size$,说明找到了答案。
### 思路 1:代码
```python
class Solution:
def decodeAtIndex(self, s: str, k: int) -> str:
# 计算解码后的总长度
size = 0
for c in s:
if c.isdigit():
size *= int(c)
else:
size += 1
# 逆向遍历
for i in range(len(s) - 1, -1, -1):
c = s[i]
# k 对 size 取模
k %= size
# 如果 k 为 0 且当前是字母,返回该字母
if k == 0 and c.isalpha():
return c
# 更新 size
if c.isdigit():
size //= int(c)
else:
size -= 1
return ""
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。需要遍历字符串两次。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/exam-room.md
================================================
# [0855. 考场就座](https://leetcode.cn/problems/exam-room/)
- 标签:设计、有序集合、堆(优先队列)
- 难度:中等
## 题目链接
- [0855. 考场就座 - 力扣](https://leetcode.cn/problems/exam-room/)
## 题目大意
**描述**:
在考场里,有 $n$ 个座位排成一行,编号为 0 到 $n - 1$。
当学生进入考场后,他必须坐在离最近的人最远的座位上。如果有多个这样的座位,他会坐在编号最小的座位上。(另外,如果考场里没有人,那么学生就坐在 0 号座位上)
**要求**:
设计一个模拟所述考场的类。
实现 ExamRoom 类:
- `ExamRoom(int n)` 用座位的数量 $n$ 初始化考场对象。
- `int seat()` 返回下一个学生将会入座的座位编号。
- `void leave(int p)` 指定坐在座位 $p$ 的学生将离开教室。保证座位 $p$ 上会有一位学生。
**说明**:
- $1 \le n \le 10^{9}$
- 保证有学生正坐在座位 $p$ 上。
- $seat$ 和 $leave$ 最多被调用 $10^{4}$ 次。
**示例**:
- 示例 1:
```python
输入:
["ExamRoom", "seat", "seat", "seat", "seat", "leave", "seat"]
[[10], [], [], [], [], [4], []]
输出:
[null, 0, 9, 4, 2, null, 5]
解释:
ExamRoom examRoom = new ExamRoom(10);
examRoom.seat(); // 返回 0,房间里没有人,学生坐在 0 号座位。
examRoom.seat(); // 返回 9,学生最后坐在 9 号座位。
examRoom.seat(); // 返回 4,学生最后坐在 4 号座位。
examRoom.seat(); // 返回 2,学生最后坐在 2 号座位。
examRoom.leave(4);
examRoom.seat(); // 返回 5,学生最后坐在 5 号座位。
```
## 解题思路
### 思路 1:有序集合 + 贪心
这道题要求设计一个考场座位系统,学生入座时要坐在离最近的人最远的位置。
关键思路:
- 使用有序集合(如 Python 的 `list` 或 `SortedList`)维护已坐学生的位置。
- 入座时,找到最大间隔的中点:
- 检查第一个座位(0 号)到第一个学生的距离。
- 检查相邻两个学生之间的中点到最近学生的距离。
- 检查最后一个学生到最后一个座位($n-1$ 号)的距离。
- 选择距离最大的位置,如果有多个,选择编号最小的。
### 思路 1:代码
```python
class ExamRoom:
def __init__(self, n: int):
self.n = n
self.students = [] # 有序列表,存储已坐学生的位置
def seat(self) -> int:
# 如果没有学生,坐在 0 号位置
if not self.students:
self.students.append(0)
return 0
# 计算最大距离和对应的座位
max_dist = self.students[0] # 第一个座位到第一个学生的距离
seat_pos = 0
# 检查相邻学生之间的中点
for i in range(len(self.students) - 1):
left = self.students[i]
right = self.students[i + 1]
# 中点到最近学生的距离
dist = (right - left) // 2
if dist > max_dist:
max_dist = dist
seat_pos = left + dist
# 检查最后一个学生到最后一个座位的距离
if self.n - 1 - self.students[-1] > max_dist:
seat_pos = self.n - 1
# 将新学生插入有序列表
import bisect
bisect.insort(self.students, seat_pos)
return seat_pos
def leave(self, p: int) -> None:
# 移除学生
self.students.remove(p)
# Your ExamRoom object will be instantiated and called as such:
# obj = ExamRoom(n)
# param_1 = obj.seat()
# obj.leave(p)
```
### 思路 1:复杂度分析
- **时间复杂度**:
- `seat` 操作:$O(n)$,需要遍历所有已坐学生,插入操作需要 $O(n)$。
- `leave` 操作:$O(n)$,需要查找并删除学生。
- **空间复杂度**:$O(n)$,需要存储所有已坐学生的位置。
================================================
FILE: docs/solutions/0800-0899/expressive-words.md
================================================
# [0809. 情感丰富的文字](https://leetcode.cn/problems/expressive-words/)
- 标签:数组、双指针、字符串
- 难度:中等
## 题目链接
- [0809. 情感丰富的文字 - 力扣](https://leetcode.cn/problems/expressive-words/)
## 题目大意
**描述**:
有时候人们会用重复写一些字母来表示额外的感受,比如 `"hello"` -> `"heeellooo"`, `"hi"` -> `"hiii"`。我们将相邻字母都相同的一串字符定义为相同字母组,例如:`"h"`, `"eee"`,` "ll"`, `"ooo"`。
对于一个给定的字符串 $S$ ,如果另一个单词能够通过将一些字母组扩张从而使其和 $S$ 相同,我们将这个单词定义为可扩张的(stretchy)。
扩张操作定义如下:选择一个字母组(包含字母 $c$ ),然后往其中添加相同的字母 $c$ 使其长度达到 3 或以上。
- 例如,以 `"hello"` 为例,我们可以对字母组 `"o"` 扩张得到 `"hellooo"`,但是无法以同样的方法得到 `"helloo"` 因为字母组 `"oo"` 长度小于 3。此外,我们可以进行另一种扩张 `"ll" -> "lllll"` 以获得 `"helllllooo"`。如果 ·,那么查询词 "hello" 是可扩张的,因为可以对它执行这两种扩张操作使得 `query = "hello"` -> `"hellooo"` -> `"helllllooo" = s`。
给定字符串 $S$ 和一组查询单词 $words$。
**要求**:
输出其中可扩张的单词数量。
**说明**:
- $1 \le s.length, words.length \le 10^{3}$。
- $1 \le words[i].length \le 10^{3}$。
- $s$ 和所有在 $words$ 中的单词都只由小写字母组成。
**示例**:
- 示例 1:
```python
输入:
s = "heeellooo"
words = ["hello", "hi", "helo"]
输出:1
解释:
我们能通过扩张 "hello" 的 "e" 和 "o" 来得到 "heeellooo"。
我们不能通过扩张 "helo" 来得到 "heeellooo" 因为 "ll" 的长度小于 3 。
```
## 解题思路
### 思路 1:双指针
这道题要求判断一个单词是否可以通过扩张字母组得到目标字符串 $s$。
关键规则:
- 扩张操作只能将字母组扩张到长度 3 或以上。
- 如果原字母组长度已经是 3 或以上,可以继续扩张。
- 如果原字母组长度小于 3,不能扩张。
算法步骤:
1. 使用双指针分别遍历 $s$ 和 $word$。
2. 对于每个字母组,统计在 $s$ 和 $word$ 中的连续出现次数。
3. 判断是否可以扩张:
- 如果字母不同,返回 $False$。
- 如果 $s$ 中的次数小于 $word$ 中的次数,无法扩张,返回 $False$。
- 如果 $s$ 中的次数大于 $word$ 中的次数,但 $s$ 中的次数小于 3,无法扩张,返回 $False$。
4. 如果所有字母组都满足条件,返回 $True$。
### 思路 1:代码
```python
class Solution:
def expressiveWords(self, s: str, words: List[str]) -> int:
def check(word):
"""检查 word 是否可以扩张得到 s"""
i, j = 0, 0
n, m = len(s), len(word)
while i < n and j < m:
# 如果字母不同,无法扩张
if s[i] != word[j]:
return False
# 统计 s 中当前字母的连续出现次数
ch = s[i]
cnt_s = 0
while i < n and s[i] == ch:
cnt_s += 1
i += 1
# 统计 word 中当前字母的连续出现次数
cnt_word = 0
while j < m and word[j] == ch:
cnt_word += 1
j += 1
# 判断是否可以扩张
if cnt_s < cnt_word:
# s 中的次数少于 word,无法扩张
return False
if cnt_s > cnt_word and cnt_s < 3:
# s 中的次数多于 word,但少于 3,无法扩张
return False
# 检查是否都遍历完
return i == n and j == m
# 统计可扩张的单词数量
count = 0
for word in words:
if check(word):
count += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是 $\text{words}$ 的长度,$m$ 是字符串 $s$ 的长度。需要对每个单词进行检查。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/fair-candy-swap.md
================================================
# [0888. 公平的糖果交换](https://leetcode.cn/problems/fair-candy-swap/)
- 标签:数组、哈希表、二分查找、排序
- 难度:简单
## 题目链接
- [0888. 公平的糖果交换 - 力扣](https://leetcode.cn/problems/fair-candy-swap/)
## 题目大意
**描述**:
爱丽丝和鲍勃拥有不同总数量的糖果。给你两个数组 $aliceSizes$ 和 $bobSizes$,$aliceSizes[i]$ 是爱丽丝拥有的第 $i$ 盒糖果中的糖果数量,$bobSizes[j]$ 是鲍勃拥有的第 $j$ 盒糖果中的糖果数量。
两人想要互相交换一盒糖果,这样在交换之后,他们就可以拥有相同总数量的糖果。一个人拥有的糖果总数量是他们每盒糖果数量的总和。
**要求**:
返回一个整数数组 $answer$,其中 $answer[0]$ 是爱丽丝必须交换的糖果盒中的糖果的数目,$answer[1]$ 是鲍勃必须交换的糖果盒中的糖果的数目。
如果存在多个答案,你可以返回其中「任何一个」。题目测试用例保证存在与输入对应的答案。
**说明**:
- $1 \le aliceSizes.length, bobSizes.length \le 10^{4}$。
- $1 \le aliceSizes[i], bobSizes[j] \le 10^{5}$。
- 爱丽丝和鲍勃的糖果总数量不同。
- 题目数据保证对于给定的输入至少存在一个有效答案。
**示例**:
- 示例 1:
```python
输入:aliceSizes = [1,1], bobSizes = [2,2]
输出:[1,2]
```
- 示例 2:
```python
输入:aliceSizes = [1,2], bobSizes = [2,3]
输出:[1,2]
```
## 解题思路
### 思路 1:哈希表 + 数学
这道题要求找到一对糖果盒,使得交换后两人的糖果总数相等。
设爱丽丝的糖果总数为 $sumA$,鲍勃的糖果总数为 $sumB$。交换后两人糖果总数相等,即:
$$sumA - x + y = sumB - y + x$$
其中 $x$ 是爱丽丝交换出去的糖果数,$y$ 是鲍勃交换出去的糖果数。
化简得:$y = x + \frac{sumB - sumA}{2}$
算法步骤:
1. 计算爱丽丝和鲍勃的糖果总数 $sumA$ 和 $sumB$。
2. 计算差值 $diff = \frac{sumB - sumA}{2}$。
3. 将鲍勃的糖果数存入哈希表,方便快速查找。
4. 遍历爱丽丝的糖果盒,对于每个 $x$,检查 $y = x + diff$ 是否在鲍勃的糖果盒中。
5. 如果找到,返回 $[x, y]$。
### 思路 1:代码
```python
class Solution:
def fairCandySwap(self, aliceSizes: List[int], bobSizes: List[int]) -> List[int]:
# 计算爱丽丝和鲍勃的糖果总数
sumA = sum(aliceSizes)
sumB = sum(bobSizes)
# 计算差值
diff = (sumB - sumA) // 2
# 将鲍勃的糖果数存入哈希表
bobSet = set(bobSizes)
# 遍历爱丽丝的糖果盒
for x in aliceSizes:
y = x + diff
# 如果 y 在鲍勃的糖果盒中,返回结果
if y in bobSet:
return [x, y]
return []
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 和 $m$ 分别是 $\text{aliceSizes}$ 和 $\text{bobSizes}$ 的长度。需要遍历两个数组。
- **空间复杂度**:$O(m)$,需要使用哈希表存储鲍勃的糖果数。
================================================
FILE: docs/solutions/0800-0899/find-and-replace-in-string.md
================================================
# [0833. 字符串中的查找与替换](https://leetcode.cn/problems/find-and-replace-in-string/)
- 标签:数组、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [0833. 字符串中的查找与替换 - 力扣](https://leetcode.cn/problems/find-and-replace-in-string/)
## 题目大意
**描述**:
给定一个字符串 $s$ (索引从 0 开始),你必须对它执行 $k$ 个替换操作。替换操作以三个长度均为 $k$ 的并行数组给出:$indices$, $sources$, $targets$。
要完成第 $i$ 个替换操作:
1. 检查「子字符串 $sources[i]$」是否出现在「原字符串 $s$」的索引 $indices[i]$ 处。
2. 如果没有出现,什么也不做。
3. 如果出现,则用 $targets[i]$「替换」该子字符串。
例如,如果 `s = "abcd"`, `indices[i] = 0`, `sources[i] = "ab"`,`targets[i] = "eee"`,那么替换的结果将是 `"eeecd"`。
所有替换操作必须「同时」发生,这意味着替换操作不应该影响彼此的索引。测试用例保证元素间不会重叠 。
- 例如,一个 `s = "abc"`,`indices = [0,1]`,`sources = ["ab","bc"]` 的测试用例将不会生成,因为 `"ab"` 和 `"bc"` 替换重叠。
**要求**:
在对 $s$ 执行所有替换操作后返回「结果字符串」。
**说明**:
- 「子字符串」是字符串中连续的字符序列。
- $1 \le s.length \le 10^{3}$。
- $k == indices.length == sources.length == targets.length$。
- $1 \le k \le 10^{3}$。
- $0 \le indices[i] \lt s.length$。
- $1 \le sources[i].length, targets[i].length \le 50$。
- $s$ 仅由小写英文字母组成。
- $sources[i]$ 和 $targets[i]$ 仅由小写英文字母组成。
**示例**:
- 示例 1:

```python
输入:s = "abcd", indices = [0,2], sources = ["a","cd"], targets = ["eee","ffff"]
输出:"eeebffff"
解释:
"a" 从 s 中的索引 0 开始,所以它被替换为 "eee"。
"cd" 从 s 中的索引 2 开始,所以它被替换为 "ffff"。
```
- 示例 2:
```python
输入:s = "abcd", indices = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"]
输出:"eeecd"
解释:
"ab" 从 s 中的索引 0 开始,所以它被替换为 "eee"。
"ec" 没有从原始的 S 中的索引 2 开始,所以它没有被替换。
```
## 解题思路
### 思路 1:排序 + 模拟
这道题要求对字符串进行多次替换操作,关键是所有替换操作必须同时发生,不能相互影响。
1. 将所有替换操作按照索引从大到小排序,这样从后往前替换时,前面的索引不会受到影响。
2. 对于每个替换操作,检查在指定位置 $indices[i]$ 处是否匹配 $sources[i]$。
3. 如果匹配,则用 $targets[i]$ 替换该子串;否则跳过。
4. 由于从后往前处理,可以直接在原字符串上进行替换操作。
### 思路 1:代码
```python
class Solution:
def findReplaceString(self, s: str, indices: List[int], sources: List[str], targets: List[str]) -> str:
# 将替换操作按索引从大到小排序,从后往前替换不会影响前面的索引
operations = sorted(zip(indices, sources, targets), reverse=True)
# 将字符串转为列表,方便操作
s_list = list(s)
for idx, source, target in operations:
# 检查在位置 idx 处是否匹配 source
if s[idx:idx + len(source)] == source:
# 替换:删除原来的子串,插入新的子串
s_list[idx:idx + len(source)] = list(target)
return ''.join(s_list)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(k \log k + n)$,其中 $k$ 是替换操作的数量,$n$ 是字符串 $s$ 的长度。排序需要 $O(k \log k)$,每次替换操作最多需要 $O(n)$。
- **空间复杂度**:$O(n)$,需要将字符串转换为列表进行操作。
================================================
FILE: docs/solutions/0800-0899/find-and-replace-pattern.md
================================================
# [0890. 查找和替换模式](https://leetcode.cn/problems/find-and-replace-pattern/)
- 标签:数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0890. 查找和替换模式 - 力扣](https://leetcode.cn/problems/find-and-replace-pattern/)
## 题目大意
**描述**:
你有一个单词列表 $words$ 和一个模式 $pattern$,你想知道 $words$ 中的哪些单词与模式匹配。
如果存在字母的排列 $p$ ,使得将模式中的每个字母 $x$ 替换为 $p$($x$) 之后,我们就得到了所需的单词,那么单词与模式是匹配的。(回想一下,字母的排列是从字母到字母的双射:每个字母映射到另一个字母,没有两个字母映射到同一个字母。)
**要求**:
返回 $words$ 中与给定模式匹配的单词列表。
你可以按任何顺序返回答案。
**说明**:
- $1 \le words.length \le 50$。
- $1 \le pattern.length = words[i].length \le 20$。
**示例**:
- 示例 1:
```python
示例:
输入:words = ["abc","deq","mee","aqq","dkd","ccc"], pattern = "abb"
输出:["mee","aqq"]
解释:
"mee" 与模式匹配,因为存在排列 {a -> m, b -> e, ...}。
"ccc" 与模式不匹配,因为 {a -> c, b -> c, ...} 不是排列。
因为 a 和 b 映射到同一个字母。
```
## 解题思路
### 思路 1:哈希表 + 双射映射
这道题要求找出与给定模式匹配的单词。单词与模式匹配的条件是:存在一个字母的排列(双射),使得将模式中的每个字母替换后得到该单词。
双射的含义是:
- 模式中的每个字母映射到单词中的唯一字母。
- 单词中的每个字母也只能由模式中的唯一字母映射而来。
算法步骤:
1. 对于每个单词,检查它是否与模式匹配。
2. 使用两个哈希表分别记录从模式到单词、从单词到模式的映射关系。
3. 遍历模式和单词的每个字符:
- 如果模式字符已有映射,检查是否与当前单词字符一致。
- 如果单词字符已有映射,检查是否与当前模式字符一致。
- 如果不一致,说明不匹配。
4. 如果所有字符都匹配,将该单词加入结果。
### 思路 1:代码
```python
class Solution:
def findAndReplacePattern(self, words: List[str], pattern: str) -> List[str]:
def match(word, pattern):
# 检查 word 是否与 pattern 匹配
if len(word) != len(pattern):
return False
# 两个哈希表分别记录双向映射
map_p_to_w = {} # 模式到单词的映射
map_w_to_p = {} # 单词到模式的映射
for w_char, p_char in zip(word, pattern):
# 检查模式到单词的映射
if p_char in map_p_to_w:
if map_p_to_w[p_char] != w_char:
return False
else:
map_p_to_w[p_char] = w_char
# 检查单词到模式的映射
if w_char in map_w_to_p:
if map_w_to_p[w_char] != p_char:
return False
else:
map_w_to_p[w_char] = p_char
return True
# 筛选出与模式匹配的单词
result = []
for word in words:
if match(word, pattern):
result.append(word)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是单词列表的长度,$m$ 是单词的平均长度。需要遍历每个单词并检查是否匹配。
- **空间复杂度**:$O(m)$,需要使用两个哈希表存储映射关系。
================================================
FILE: docs/solutions/0800-0899/find-eventual-safe-states.md
================================================
# [0802. 找到最终的安全状态](https://leetcode.cn/problems/find-eventual-safe-states/)
- 标签:深度优先搜索、广度优先搜索、图、拓扑排序
- 难度:中等
## 题目链接
- [0802. 找到最终的安全状态 - 力扣](https://leetcode.cn/problems/find-eventual-safe-states/)
## 题目大意
**描述**:给定一个有向图 $graph$,其中 $graph[i]$ 是与节点 $i$ 相邻的节点列表,意味着从节点 $i$ 到节点 $graph[i]$ 中的每个节点都有一条有向边。
**要求**:找出图中所有的安全节点,将其存入数组作为答案返回,答案数组中的元素应当按升序排列。
**说明**:
- **终端节点**:如果一个节点没有连出的有向边,则它是终端节点。或者说,如果没有出边,则节点为终端节点。
- **安全节点**:如果从该节点开始的所有可能路径都通向终端节点,则该节点为安全节点。
- $n == graph.length$。
- $1 \le n \le 10^4$。
- $0 \le graph[i].length \le n$。
- $0 \le graph[i][j] \le n - 1$。
- $graph[i]$ 按严格递增顺序排列。
- 图中可能包含自环。
- 图中边的数目在范围 $[1, 4 \times 10^4]$ 内。
**示例**:
- 示例 1:
```python
输入:graph = [[1,2],[2,3],[5],[0],[5],[],[]]
输出:[2,4,5,6]
解释:示意图如上。
节点 5 和节点 6 是终端节点,因为它们都没有出边。
从节点 2、4、5 和 6 开始的所有路径都指向节点 5 或 6。
```
- 示例 2:
```python
输入:graph = [[1,2,3,4],[1,2],[3,4],[0,4],[]]
输出:[4]
解释:
只有节点 4 是终端节点,从节点 4 开始的所有路径都通向节点 4。
```
## 解题思路
### 思路 1:拓扑排序
1. 根据题意可知,安全节点所对应的终点,一定是出度为 $0$ 的节点。而安全节点一定能在有限步内到达终点,则说明安全节点一定不在「环」内。
2. 我们可以利用拓扑排序来判断顶点是否在环中。
3. 为了找出安全节点,可以采取逆序建图的方式,将所有边进行反向。这样出度为 $0$ 的终点就变为了入度为 $0$ 的点。
4. 然后通过拓扑排序不断移除入度为 $0$ 的点之后,如果不在「环」中的点,最后入度一定为 $0$,这些点也就是安全节点。而在「环」中的点,最后入度一定不为 $0$。
5. 最后将所有安全的起始节点存入数组作为答案返回。
### 思路 1:代码
```python
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingKahn(self, graph: dict):
indegrees = {u: 0 for u in graph} # indegrees 用于记录所有节点入度
for u in graph:
for v in graph[u]:
indegrees[v] += 1 # 统计所有节点入度
# 将入度为 0 的顶点存入集合 S 中
S = collections.deque([u for u in indegrees if indegrees[u] == 0])
while S:
u = S.pop() # 从集合中选择一个没有前驱的顶点 0
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
indegrees[v] -= 1 # 删除从顶点 u 出发的有向边
if indegrees[v] == 0: # 如果删除该边后顶点 v 的入度变为 0
S.append(v) # 将其放入集合 S 中
res = []
for u in indegrees:
if indegrees[u] == 0:
res.append(u)
return res
def eventualSafeNodes(self, graph: List[List[int]]) -> List[int]:
graph_dict = {u: [] for u in range(len(graph))}
for u in range(len(graph)):
for v in graph[u]:
graph_dict[v].append(u) # 逆序建图
return self.topologicalSortingKahn(graph_dict)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是图中节点数目,$m$ 是图中边数目。
- **空间复杂度**:$O(n + m)$。
================================================
FILE: docs/solutions/0800-0899/flipping-an-image.md
================================================
# [0832. 翻转图像](https://leetcode.cn/problems/flipping-an-image/)
- 标签:数组、双指针、矩阵、模拟
- 难度:简单
## 题目链接
- [0832. 翻转图像 - 力扣](https://leetcode.cn/problems/flipping-an-image/)
## 题目大意
给定一个二进制矩阵 `A` 代表图像,先将矩阵进行水平翻转,再进行翻转(将 0 变为 1,1 变为 0)。
## 解题思路
两重 for 循环,第二层 for 循环遍历到一半即可。对于 `image[i][j]`、`image[i][n-1-j]` 先水平翻转操作,再进行翻转。
## 代码
```python
class Solution:
def flipAndInvertImage(self, image: List[List[int]]) -> List[List[int]]:
n = len(image)
for i in range(n):
for j in range((n+1)//2):
image[i][j], image[i][n-1-j] = image[i][n-1-j], image[i][j]
image[i][j] = 0 if image[i][j] == 1 else 1
if j != n-1-j:
image[i][n-1-j] = 0 if image[i][n-1-j] == 1 else 1
return image
```
================================================
FILE: docs/solutions/0800-0899/friends-of-appropriate-ages.md
================================================
# [0825. 适龄的朋友](https://leetcode.cn/problems/friends-of-appropriate-ages/)
- 标签:数组、双指针、二分查找、排序
- 难度:中等
## 题目链接
- [0825. 适龄的朋友 - 力扣](https://leetcode.cn/problems/friends-of-appropriate-ages/)
## 题目大意
**描述**:
在社交媒体网站上有 $n$ 个用户。给你一个整数数组 $ages$,其中 $ages[i]$ 是第 $i$ 个用户的年龄。
如果下述任意一个条件为真,那么用户 $x$ 将不会向用户 $y$($x \ne y$)发送好友请求:
- $ages[y] \le 0.5 \times ages[x] + 7$
- $ages[y] > ages[x]$
- $ages[y] > 100 && ages[x] < 100$
否则,$x$ 将会向 $y$ 发送一条好友请求。
注意,如果 $x$ 向 $y$ 发送一条好友请求,$y$ 不必也向 $x$ 发送一条好友请求。另外,用户不会向自己发送好友请求。
**要求**:
返回在该社交媒体网站上产生的好友请求总数。
**说明**:
- $n == ages.length$。
- $1 \le n \le 2 \times 10^{4}$。
- $1 \le ages[i] \le 120$。
**示例**:
- 示例 1:
```python
输入:ages = [16,16]
输出:2
解释:2 人互发好友请求。
```
- 示例 2:
```python
输入:ages = [16,17,18]
输出:2
解释:产生的好友请求为 17 -> 16 ,18 -> 17 。
```
## 解题思路
### 思路 1:计数 + 数学
这道题要求计算好友请求的总数。根据题意,用户 $x$ 不会向用户 $y$ 发送好友请求的条件是:
1. $ages[y] \le 0.5 \times ages[x] + 7$
2. $ages[y] > ages[x]$
3. $ages[y] > 100$ 且 $ages[x] < 100$
反过来,$x$ 会向 $y$ 发送好友请求的条件是:
- $0.5 \times ages[x] + 7 < ages[y] \le ages[x]$
由于年龄范围只有 $1$ 到 $120$,我们可以使用计数数组来统计每个年龄的人数,然后枚举所有可能的年龄对。
算法步骤:
1. 使用计数数组 $count$ 统计每个年龄的人数。
2. 枚举所有可能的年龄对 $(ageX, ageY)$。
3. 如果满足发送好友请求的条件,累加请求数:
- 如果 $ageX == ageY$,则请求数为 $count[ageX] \times (count[ageX] - 1)$(同年龄的人互相发送,但不向自己发送)。
- 如果 $ageX \ne ageY$,则请求数为 $count[ageX] \times count[ageY]$。
### 思路 1:代码
```python
class Solution:
def numFriendRequests(self, ages: List[int]) -> int:
# 统计每个年龄的人数
count = [0] * 121
for age in ages:
count[age] += 1
result = 0
# 枚举所有可能的年龄对
for ageX in range(1, 121):
if count[ageX] == 0:
continue
for ageY in range(1, 121):
if count[ageY] == 0:
continue
# 判断 x 是否会向 y 发送好友请求
if ageY <= 0.5 * ageX + 7:
continue
if ageY > ageX:
continue
if ageY > 100 and ageX < 100:
continue
# 累加请求数
if ageX == ageY:
result += count[ageX] * (count[ageX] - 1)
else:
result += count[ageX] * count[ageY]
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + C^2)$,其中 $n$ 是数组 $ages$ 的长度,$C = 120$ 是年龄的范围。需要遍历数组统计年龄,然后枚举所有年龄对。
- **空间复杂度**:$O(C)$,需要使用计数数组存储每个年龄的人数。
================================================
FILE: docs/solutions/0800-0899/goat-latin.md
================================================
# [0824. 山羊拉丁文](https://leetcode.cn/problems/goat-latin/)
- 标签:字符串
- 难度:简单
## 题目链接
- [0824. 山羊拉丁文 - 力扣](https://leetcode.cn/problems/goat-latin/)
## 题目大意
**描述**:给定一个由若干单词组成的句子 $sentence$,单词之间由空格分隔。每个单词仅由大写和小写字母组成。
**要求**:将句子转换为「山羊拉丁文(Goat Latin)」,并返回将 $sentence$ 转换为山羊拉丁文后的句子。
**说明**:
- 山羊拉丁文的规则如下:
- 如果单词以元音开头(`a`,`e`,`i`,`o`,`u`),在单词后添加 `"ma"`。
- 例如,单词 `"apple"` 变为 `"applema"`。
- 如果单词以辅音字母开头(即,非元音字母),移除第一个字符并将它放到末尾,之后再添加 `"ma"`。
- 例如,单词 `"goat"` 变为 `"oatgma"`。
- 根据单词在句子中的索引,在单词最后添加与索引相同数量的字母 `a`,索引从 $1$ 开始。
- 例如,在第一个单词后添加 `"a"` ,在第二个单词后添加 `"aa"`,以此类推。
- $1 \le sentence.length \le 150$。
- $sentence$ 由英文字母和空格组成。
- $sentence$ 不含前导或尾随空格。
- $sentence$ 中的所有单词由单个空格分隔。
**示例**:
- 示例 1:
```python
输入:sentence = "I speak Goat Latin"
输出:"Imaa peaksmaaa oatGmaaaa atinLmaaaaa"
```
- 示例 2:
```python
输入:sentence = "The quick brown fox jumped over the lazy dog"
输出:"heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa"
```
## 解题思路
### 思路 1:模拟
1. 使用集合 $vowels$ 存储元音字符,然后将 $sentence$ 按照空格分隔成单词数组 $words$。
2. 遍历单词数组 $words$,对于当前单词 $word$,根据山羊拉丁文的规则,将其转为山羊拉丁文的单词,并存入答案数组 $res$ 中。
3. 遍历完之后将答案数组拼接为字符串并返回。
### 思路 1:代码
```python
class Solution:
def toGoatLatin(self, sentence: str) -> str:
vowels = set(['a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U'])
words = sentence.split(' ')
res = []
for i in range(len(words)):
word = words[i]
ans = ""
if word[0] in vowels:
ans += word + "ma"
else:
ans += word[1:] + word[0] + "ma"
ans += 'a' * (i + 1)
res.append(ans)
return " ".join(res)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/groups-of-special-equivalent-strings.md
================================================
# [0893. 特殊等价字符串组](https://leetcode.cn/problems/groups-of-special-equivalent-strings/)
- 标签:数组、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [0893. 特殊等价字符串组 - 力扣](https://leetcode.cn/problems/groups-of-special-equivalent-strings/)
## 题目大意
**描述**:
给定一个字符串数组 $words$。
一步操作中,你可以交换字符串 $words[i]$ 的任意两个偶数下标对应的字符或任意两个奇数下标对应的字符。
对两个字符串 $words[i]$ 和 $words[j]$ 而言,如果经过任意次数的操作,$words[i] == words[j]$,那么这两个字符串是 特殊等价 的。
- 例如,$words[i] = "zzxy"$ 和 $words[j] = "xyzz"$ 是一对「特殊等价」字符串,因为可以按 `"zzxy"` -> `"xzzy"` -> `"xyzz"` 的操作路径使 $words[i] == words[j]$。
现在规定,$words$ 的「一组特殊等价字符串」就是 $words$ 的一个同时满足下述条件的非空子集:
- 该组中的每一对字符串都是 特殊等价 的
- 该组字符串已经涵盖了该类别中的所有特殊等价字符串,容量达到理论上的最大值(也就是说,如果一个字符串不在该组中,那么这个字符串就 不会 与该组内任何字符串特殊等价)
**要求**:
返回 $words$ 中「特殊等价字符串组」的数量。
**说明**:
- $1 \le words.length \le 10^{3}$。
- $1 \le words[i].length \le 20$。
- 所有 $words[i]$ 都只由小写字母组成。
- 所有 $words[i]$ 都具有相同的长度。
**示例**:
- 示例 1:
```python
输入:words = ["abcd","cdab","cbad","xyzz","zzxy","zzyx"]
输出:3
解释:
其中一组为 ["abcd", "cdab", "cbad"],因为它们是成对的特殊等价字符串,且没有其他字符串与这些字符串特殊等价。
另外两组分别是 ["xyzz", "zzxy"] 和 ["zzyx"]。特别需要注意的是,"zzxy" 不与 "zzyx" 特殊等价。
```
- 示例 2:
```python
输入:words = ["abc","acb","bac","bca","cab","cba"]
输出:3
解释:3 组 ["abc","cba"],["acb","bca"],["bac","cab"]
```
## 解题思路
### 思路 1:哈希表
这道题要求统计特殊等价字符串组的数量。两个字符串特殊等价的条件是:可以任意交换偶数位置的字符,也可以任意交换奇数位置的字符。
关键观察:
- 如果两个字符串特殊等价,那么它们的偶数位置字符集合相同,奇数位置字符集合也相同。
- 可以将字符串的偶数位置字符排序后和奇数位置字符排序后拼接,作为该字符串的"签名"。
- 特殊等价的字符串具有相同的签名。
算法步骤:
1. 对于每个字符串,提取偶数位置和奇数位置的字符。
2. 分别对偶数位置和奇数位置的字符排序。
3. 将排序后的字符拼接作为签名。
4. 使用哈希集合统计不同签名的数量。
### 思路 1:代码
```python
class Solution:
def numSpecialEquivGroups(self, words: List[str]) -> int:
def get_signature(word):
# 提取偶数位置和奇数位置的字符
even_chars = []
odd_chars = []
for i, char in enumerate(word):
if i % 2 == 0:
even_chars.append(char)
else:
odd_chars.append(char)
# 排序后拼接作为签名
even_chars.sort()
odd_chars.sort()
return ''.join(even_chars) + '|' + ''.join(odd_chars)
# 使用哈希集合统计不同签名的数量
signatures = set()
for word in words:
signatures.add(get_signature(word))
return len(signatures)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m \log m)$,其中 $n$ 是字符串数组的长度,$m$ 是字符串的平均长度。需要遍历每个字符串并对其字符排序。
- **空间复杂度**:$O(n \times m)$,需要使用哈希集合存储签名。
================================================
FILE: docs/solutions/0800-0899/guess-the-word.md
================================================
# [0843. 猜猜这个单词](https://leetcode.cn/problems/guess-the-word/)
- 标签:数组、数学、字符串、博弈、交互
- 难度:困难
## 题目链接
- [0843. 猜猜这个单词 - 力扣](https://leetcode.cn/problems/guess-the-word/)
## 题目大意
**描述**:
给定一个由「不同」字符串组成的单词列表 $words$,其中 $words[i]$ 长度均为 6。$words$ 中的一个单词将被选作秘密单词 $secret$。
另给你一个辅助对象 Master,你可以调用 `Master.guess(word)` 来猜单词,其中参数 $word$ 长度为 6 且必须是 $words$ 中的字符串。
`Master.guess(word)` 将会返回如下结果:
- 如果 $word$ 不是 $words$ 中的字符串,返回 -1,或者
- 一个整数,表示你所猜测的单词 $word$ 与「秘密单词 $secret$」的准确匹配(值和位置同时匹配)的数目。
每组测试用例都会包含一个参数 $allowedGuesses$,其中 $allowedGuesses$ 是你可以调用 `Master.guess(word)` 的最大次数。
**要求**:
对于每组测试用例,如果在不超过允许猜测的次数的前提下:
- 如果能够通过调用 `Master.guess` 来猜出秘密单词,则返回 `"You guessed the secret word correctly."`。
- 如果猜不出或者超过允许猜测的次数,则返回 `"Either you took too many guesses, or you did not find the secret word."`。
**说明**:
- 生成的测试用例保证你可以利用某种合理的策略(而不是暴力)猜到秘密单词。
- $1 \le words.length \le 10^{3}$。
- $words[i].length == 6$。
- $words[i]$ 仅由小写英文字母组成。
- $words$ 中所有字符串「互不相同」。
- $secret$ 存在于 $words$ 中。
- $10 \le allowedGuesses \le 30$。
**示例**:
- 示例 1:
```python
输入:secret = "acckzz", words = ["acckzz","ccbazz","eiowzz","abcczz"], allowedGuesses = 10
输出:You guessed the secret word correctly.
解释:
master.guess("aaaaaa") 返回 -1 ,因为 "aaaaaa" 不在 words 中。
master.guess("acckzz") 返回 6 ,因为 "acckzz" 是秘密单词 secret ,共有 6 个字母匹配。
master.guess("ccbazz") 返回 3 ,因为 "ccbazz" 共有 3 个字母匹配。
master.guess("eiowzz") 返回 2 ,因为 "eiowzz" 共有 2 个字母匹配。
master.guess("abcczz") 返回 4 ,因为 "abcczz" 共有 4 个字母匹配。
一共调用 5 次 master.guess ,其中一个为秘密单词,所以通过测试用例。
```
- 示例 2:
```python
输入:secret = "hamada", words = ["hamada","khaled"], allowedGuesses = 10
输出:You guessed the secret word correctly.
解释:共有 2 个单词,且其中一个为秘密单词,可以通过测试用例。
```
## 解题思路
### 思路 1:MinMax 策略 + 预计算匹配矩阵
这道题要求通过调用 API 猜测秘密单词。关键是设计一个好的策略来选择每次猜测的单词。
**核心思想**:
- 每次猜测后,根据返回的匹配数,可以过滤掉大量不可能的候选单词。
- 我们希望选择一个单词,使得无论返回什么匹配数,剩余的候选单词数量都尽可能少。
- 这是一个 MinMax 策略:最小化最坏情况下的候选单词数量。
**关键优化**:
1. **预计算匹配矩阵**:提前计算所有单词对之间的匹配数,避免重复计算。
2. **排除已猜单词**:在选择猜测单词时,排除已经猜过的单词。
3. **MinMax 选择**:对于每个候选单词,统计不同匹配数对应的候选单词分组,选择最大分组最小的单词。
**算法步骤**:
1. 预计算所有单词对之间的匹配数矩阵 $H[i][j]$,表示单词 $i$ 和单词 $j$ 的匹配数。
2. 初始化候选单词索引列表和已猜单词集合。
3. 每次使用 MinMax 策略选择最优的猜测单词:
- 对于每个未猜过的候选单词,统计不同匹配数对应的候选单词分组。
- 选择最大分组最小的单词(即最坏情况下剩余候选单词最少的单词)。
4. 调用 `master.guess()` 获取匹配数。
5. 如果匹配数为 $6$,说明猜中,直接返回。
6. 否则,过滤候选单词:只保留与猜测单词有相同匹配数的单词。
7. 重复步骤 3-6,直到猜中。
### 思路 1:代码
```python
# """
# This is Master's API interface.
# You should not implement it, or speculate about its implementation
# """
# class Master:
# def guess(self, word: str) -> int:
class Solution:
def findSecretWord(self, words: List[str], master: 'Master') -> None:
n = len(words)
# 预计算所有单词对之间的匹配数矩阵
H = [[sum(a == b for a, b in zip(words[i], words[j]))
for j in range(n)] for i in range(n)]
# 候选单词索引列表
possible = list(range(n))
# 已猜单词集合
guessed = set()
while possible:
# 使用 MinMax 策略选择最优单词
guess_idx = self.solve(H, possible, guessed)
# 猜测单词
matches = master.guess(words[guess_idx])
# 如果猜中,直接返回
if matches == len(words[0]):
return
# 将当前猜测加入已猜集合
guessed.add(guess_idx)
# 过滤候选单词:只保留与猜测单词有相同匹配数的单词
possible = [j for j in possible if H[guess_idx][j] == matches]
def solve(self, H, possible, guessed):
# 如果候选单词数量很少,直接返回第一个
if len(possible) <= 2:
return possible[0]
min_max_group_size = float('inf')
best_guess = possible[0]
# 遍历所有未猜过的单词
for guess_idx in range(len(H)):
if guess_idx in guessed:
continue
# 统计不同匹配数对应的候选单词分组
groups = [[] for _ in range(7)] # 匹配数从 0 到 6
for j in possible:
if j != guess_idx:
groups[H[guess_idx][j]].append(j)
# 找到最大的分组(最坏情况)
max_group = max(groups, key=len)
# 选择最坏情况最好的单词
if len(max_group) < min_max_group_size:
min_max_group_size = len(max_group)
best_guess = guess_idx
return best_guess
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times m + n^2 \times k)$,其中 $n$ 是单词数量,$m$ 是单词长度,$k$ 是猜测次数(最多 $10$ 次)。预计算匹配矩阵需要 $O(n^2 \times m)$ 时间,每次选择最优单词需要 $O(n^2)$ 时间。
- **空间复杂度**:$O(n^2)$,需要存储匹配矩阵。
================================================
FILE: docs/solutions/0800-0899/hand-of-straights.md
================================================
# [0846. 一手顺子](https://leetcode.cn/problems/hand-of-straights/)
- 标签:贪心、数组、哈希表、排序
- 难度:中等
## 题目链接
- [0846. 一手顺子 - 力扣](https://leetcode.cn/problems/hand-of-straights/)
## 题目大意
**描述**:`Alice` 手中有一把牌,她想要重新排列这些牌,分成若干组,使每一组的牌都是顺子(即由连续的牌构成),并且每一组的牌数都是 `groupSize`。现在给定一个整数数组 `hand`,其中 `hand[i]` 是表示第 `i` 张牌的数值,和一个整数 `groupSize`。
**要求**:如果 `Alice` 能将这些牌重新排列成若干组、并且每组都是 `goupSize` 张牌的顺子,则返回 `True`;否则,返回 `False`。
**说明**:
- $1 \le hand.length \le 10^4$。
- $0 \le hand[i] \le 10^9$。
- $1 \le groupSize \le hand.length$。
**示例**:
- 示例 1:
```python
输入:hand = [1,2,3,6,2,3,4,7,8], groupSize = 3
输出:True
解释:Alice 手中的牌可以被重新排列为 [1,2,3],[2,3,4],[6,7,8]。
```
## 解题思路
### 思路 1:哈希表 + 排序
1. 使用哈希表存储每个数出现的次数。
2. 将哈希表中每个键从小到大排序。
3. 从哈希表中最小的数开始,以它作为当前顺子的开头,然后依次判断顺子里的数是否在哈希表中,如果在的话,则将哈希表中对应数的数量减 `1`。不在的话,说明无法满足题目要求,直接返回 `False`。
4. 重复执行 2 ~ 3 步,直到哈希表为空。最后返回 `True`。
### 思路 1:哈希表 + 排序代码
```python
class Solution:
def isPossibleDivide(self, nums: List[int], k: int) -> bool:
hand_map = collections.defaultdict(int)
for i in range(len(nums)):
hand_map[nums[i]] += 1
for key in sorted(hand_map.keys()):
value = hand_map[key]
if value == 0:
continue
count = 0
for i in range(k):
hand_map[key + count] -= value
if hand_map[key + count] < 0:
return False
count += 1
return True
```
================================================
FILE: docs/solutions/0800-0899/image-overlap.md
================================================
# [0835. 图像重叠](https://leetcode.cn/problems/image-overlap/)
- 标签:数组、矩阵
- 难度:中等
## 题目链接
- [0835. 图像重叠 - 力扣](https://leetcode.cn/problems/image-overlap/)
## 题目大意
**描述**:
给定两个图像 $img1$ 和 $img2$,两个图像的大小都是 $n \times n$,用大小相同的二进制正方形矩阵表示。二进制矩阵仅由若干 0 和若干 1 组成。
「转换」其中一个图像,将所有的 1 向左,右,上,或下滑动任何数量的单位;然后把它放在另一个图像的上面。该转换的「重叠」是指两个图像「都」具有 1 的位置的数目。
请注意,转换「不包括」向任何方向旋转。越过矩阵边界的 1 都将被清除。
**要求**:
计算最大可能的重叠数量。
**说明**:
- $n == img1.length == img1[i].length$。
- $n == img2.length == img2[i].length$。
- $1 \le n \le 30$。
- $img1[i][j]$ 为 0 或 1。
- $img2[i][j]$ 为 0 或 1。
**示例**:
- 示例 1:
```python
输入:img1 = [[1,1,0],[0,1,0],[0,1,0]], img2 = [[0,0,0],[0,1,1],[0,0,1]]
输出:3
解释:将 img1 向右移动 1 个单位,再向下移动 1 个单位。
```
```python
两个图像都具有 1 的位置的数目是 3(用红色标识)。
```
- 示例 2:
```python
输入:img1 = [[1]], img2 = [[1]]
输出:1
```
## 解题思路
### 思路 1:哈希表 + 偏移量统计
这道题要求计算两个二进制矩阵的最大重叠数。可以通过平移其中一个矩阵来实现重叠。
关键观察:
- 只有值为 $1$ 的位置才会对重叠产生贡献。
- 可以枚举 $img1$ 中所有值为 $1$ 的位置和 $img2$ 中所有值为 $1$ 的位置,计算它们之间的偏移量。
- 相同偏移量出现的次数就是该偏移下的重叠数。
算法步骤:
1. 提取 $img1$ 和 $img2$ 中所有值为 $1$ 的位置。
2. 对于 $img1$ 中的每个 $1$ 和 $img2$ 中的每个 $1$,计算偏移量 $(dx, dy)$。
3. 使用哈希表统计每个偏移量出现的次数。
4. 返回最大的出现次数。
### 思路 1:代码
```python
class Solution:
def largestOverlap(self, img1: List[List[int]], img2: List[List[int]]) -> int:
n = len(img1)
# 提取 img1 和 img2 中所有值为 1 的位置
ones1 = []
ones2 = []
for i in range(n):
for j in range(n):
if img1[i][j] == 1:
ones1.append((i, j))
if img2[i][j] == 1:
ones2.append((i, j))
# 统计每个偏移量出现的次数
offset_count = {}
for x1, y1 in ones1:
for x2, y2 in ones2:
# 计算偏移量
dx = x1 - x2
dy = y1 - y2
offset = (dx, dy)
offset_count[offset] = offset_count.get(offset, 0) + 1
# 返回最大重叠数
return max(offset_count.values()) if offset_count else 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^4)$,其中 $n$ 是矩阵的边长。最坏情况下,两个矩阵都全为 $1$,需要枚举 $O(n^2) \times O(n^2)$ 对位置。
- **空间复杂度**:$O(n^2)$,需要存储所有值为 $1$ 的位置和偏移量统计。
================================================
FILE: docs/solutions/0800-0899/increasing-order-search-tree.md
================================================
# [0897. 递增顺序搜索树](https://leetcode.cn/problems/increasing-order-search-tree/)
- 标签:栈、树、深度优先搜索、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [0897. 递增顺序搜索树 - 力扣](https://leetcode.cn/problems/increasing-order-search-tree/)
## 题目大意
给定一棵二叉搜索树的根节点 `root`。
要求:按中序遍历顺序将其重新排列为一棵递增顺序搜索树,使树中最左边的节点成为树的根节点,并且每个节点没有左子节点,只有一个右子节点。
## 解题思路
可以分为两步:
1. 中序遍历二叉搜索树,将节点先存储到列表中。
2. 将列表中的节点构造成一棵递增顺序搜索树。
中序遍历直接按照 `左 -> 根 -> 右` 的顺序递归遍历,然后将遍历的节点存储到 `res` 中。
构造递增顺序搜索树,则用 `head` 保存头节点位置。遍历列表中的每个节点,将其左右指针先置空,再将其连接在上一个节点的右子节点上。
最后返回 `head.right` 即可。
## 代码
```python
class Solution:
def inOrder(self, root, res):
if not root:
return
self.inOrder(root.left, res)
res.append(root)
self.inOrder(root.right, res)
def increasingBST(self, root: TreeNode) -> TreeNode:
res = []
self.inOrder(root, res)
if not res:
return
head = TreeNode(-1)
cur = head
for node in res:
node.left = node.right = None
cur.right = node
cur = cur.right
return head.right
```
================================================
FILE: docs/solutions/0800-0899/index.md
================================================
## 本章内容
- [0800. 相似 RGB 颜色](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/similar-rgb-color.md)
- [0801. 使序列递增的最小交换次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/minimum-swaps-to-make-sequences-increasing.md)
- [0802. 找到最终的安全状态](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/find-eventual-safe-states.md)
- [0803. 打砖块](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/bricks-falling-when-hit.md)
- [0804. 唯一摩尔斯密码词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/unique-morse-code-words.md)
- [0805. 数组的均值分割](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/split-array-with-same-average.md)
- [0806. 写字符串需要的行数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/number-of-lines-to-write-string.md)
- [0807. 保持城市天际线](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/max-increase-to-keep-city-skyline.md)
- [0808. 分汤](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/soup-servings.md)
- [0809. 情感丰富的文字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/expressive-words.md)
- [0810. 黑板异或游戏](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/chalkboard-xor-game.md)
- [0811. 子域名访问计数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/subdomain-visit-count.md)
- [0812. 最大三角形面积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/largest-triangle-area.md)
- [0813. 最大平均值和的分组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/largest-sum-of-averages.md)
- [0814. 二叉树剪枝](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/binary-tree-pruning.md)
- [0815. 公交路线](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/bus-routes.md)
- [0816. 模糊坐标](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/ambiguous-coordinates.md)
- [0817. 链表组件](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/linked-list-components.md)
- [0818. 赛车](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/race-car.md)
- [0819. 最常见的单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/most-common-word.md)
- [0820. 单词的压缩编码](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/short-encoding-of-words.md)
- [0821. 字符的最短距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/shortest-distance-to-a-character.md)
- [0822. 翻转卡片游戏](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/card-flipping-game.md)
- [0823. 带因子的二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/binary-trees-with-factors.md)
- [0824. 山羊拉丁文](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/goat-latin.md)
- [0825. 适龄的朋友](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/friends-of-appropriate-ages.md)
- [0826. 安排工作以达到最大收益](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/most-profit-assigning-work.md)
- [0827. 最大人工岛](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/making-a-large-island.md)
- [0828. 统计子串中的唯一字符](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/count-unique-characters-of-all-substrings-of-a-given-string.md)
- [0829. 连续整数求和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/consecutive-numbers-sum.md)
- [0830. 较大分组的位置](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/positions-of-large-groups.md)
- [0831. 隐藏个人信息](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/masking-personal-information.md)
- [0832. 翻转图像](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/flipping-an-image.md)
- [0833. 字符串中的查找与替换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/find-and-replace-in-string.md)
- [0834. 树中距离之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/sum-of-distances-in-tree.md)
- [0835. 图像重叠](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/image-overlap.md)
- [0836. 矩形重叠](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/rectangle-overlap.md)
- [0837. 新 21 点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/new-21-game.md)
- [0838. 推多米诺](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/push-dominoes.md)
- [0839. 相似字符串组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/similar-string-groups.md)
- [0840. 矩阵中的幻方](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/magic-squares-in-grid.md)
- [0841. 钥匙和房间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/keys-and-rooms.md)
- [0842. 将数组拆分成斐波那契序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/split-array-into-fibonacci-sequence.md)
- [0843. 猜猜这个单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/guess-the-word.md)
- [0844. 比较含退格的字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/backspace-string-compare.md)
- [0845. 数组中的最长山脉](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/longest-mountain-in-array.md)
- [0846. 一手顺子](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/hand-of-straights.md)
- [0847. 访问所有节点的最短路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/shortest-path-visiting-all-nodes.md)
- [0848. 字母移位](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/shifting-letters.md)
- [0849. 到最近的人的最大距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/maximize-distance-to-closest-person.md)
- [0850. 矩形面积 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/rectangle-area-ii.md)
- [0851. 喧闹和富有](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/loud-and-rich.md)
- [0852. 山脉数组的峰顶索引](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/peak-index-in-a-mountain-array.md)
- [0853. 车队](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/car-fleet.md)
- [0854. 相似度为 K 的字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/k-similar-strings.md)
- [0855. 考场就座](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/exam-room.md)
- [0856. 括号的分数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/score-of-parentheses.md)
- [0857. 雇佣 K 名工人的最低成本](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/minimum-cost-to-hire-k-workers.md)
- [0858. 镜面反射](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/mirror-reflection.md)
- [0859. 亲密字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/buddy-strings.md)
- [0860. 柠檬水找零](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/lemonade-change.md)
- [0861. 翻转矩阵后的得分](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/score-after-flipping-matrix.md)
- [0862. 和至少为 K 的最短子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/shortest-subarray-with-sum-at-least-k.md)
- [0863. 二叉树中所有距离为 K 的结点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/all-nodes-distance-k-in-binary-tree.md)
- [0864. 获取所有钥匙的最短路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/shortest-path-to-get-all-keys.md)
- [0865. 具有所有最深节点的最小子树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/smallest-subtree-with-all-the-deepest-nodes.md)
- [0866. 回文质数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/prime-palindrome.md)
- [0867. 转置矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/transpose-matrix.md)
- [0868. 二进制间距](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/binary-gap.md)
- [0869. 重新排序得到 2 的幂](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/reordered-power-of-2.md)
- [0870. 优势洗牌](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/advantage-shuffle.md)
- [0871. 最低加油次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/minimum-number-of-refueling-stops.md)
- [0872. 叶子相似的树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/leaf-similar-trees.md)
- [0873. 最长的斐波那契子序列的长度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/length-of-longest-fibonacci-subsequence.md)
- [0874. 模拟行走机器人](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/walking-robot-simulation.md)
- [0875. 爱吃香蕉的珂珂](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/koko-eating-bananas.md)
- [0876. 链表的中间结点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/middle-of-the-linked-list.md)
- [0877. 石子游戏](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/stone-game.md)
- [0878. 第 N 个神奇数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/nth-magical-number.md)
- [0879. 盈利计划](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/profitable-schemes.md)
- [0880. 索引处的解码字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/decoded-string-at-index.md)
- [0881. 救生艇](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/boats-to-save-people.md)
- [0882. 细分图中的可到达节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/reachable-nodes-in-subdivided-graph.md)
- [0883. 三维形体投影面积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/projection-area-of-3d-shapes.md)
- [0884. 两句话中的不常见单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/uncommon-words-from-two-sentences.md)
- [0885. 螺旋矩阵 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/spiral-matrix-iii.md)
- [0886. 可能的二分法](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/possible-bipartition.md)
- [0887. 鸡蛋掉落](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/super-egg-drop.md)
- [0888. 公平的糖果交换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/fair-candy-swap.md)
- [0889. 根据前序和后序遍历构造二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/construct-binary-tree-from-preorder-and-postorder-traversal.md)
- [0890. 查找和替换模式](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/find-and-replace-pattern.md)
- [0891. 子序列宽度之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/sum-of-subsequence-widths.md)
- [0892. 三维形体的表面积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/surface-area-of-3d-shapes.md)
- [0893. 特殊等价字符串组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/groups-of-special-equivalent-strings.md)
- [0894. 所有可能的真二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/all-possible-full-binary-trees.md)
- [0895. 最大频率栈](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/maximum-frequency-stack.md)
- [0896. 单调数列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/monotonic-array.md)
- [0897. 递增顺序搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/increasing-order-search-tree.md)
- [0898. 子数组按位或操作](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/bitwise-ors-of-subarrays.md)
- [0899. 有序队列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/orderly-queue.md)
================================================
FILE: docs/solutions/0800-0899/k-similar-strings.md
================================================
# [0854. 相似度为 K 的字符串](https://leetcode.cn/problems/k-similar-strings/)
- 标签:广度优先搜索、哈希表、字符串
- 难度:困难
## 题目链接
- [0854. 相似度为 K 的字符串 - 力扣](https://leetcode.cn/problems/k-similar-strings/)
## 题目大意
**描述**:
对于某些非负整数 $k$,如果交换 $s1$ 中两个字母的位置恰好 $k$ 次,能够使结果字符串等于 $s2$ ,则认为字符串 $s1$ 和 $s2$ 的 相似度为 $k$ 。
给你两个字母异位词 $s1$ 和 $s2$。
**要求**:
返回 $s1$ 和 $s2$ 的相似度 $k$ 的最小值。
**说明**:
- $1 \le s1.length \le 20$。
- $s2.length == s1.length$。
- $s1$ 和 $s2$ 只包含集合 `{'a', 'b', 'c', 'd', 'e', 'f'}` 中的小写字母。
- $s2$ 是 $s1$ 的一个字母异位词。
**示例**:
- 示例 1:
```python
输入:s1 = "ab", s2 = "ba"
输出:1
```
- 示例 2:
```python
输入:s1 = "abc", s2 = "bca"
输出:2
```
## 解题思路
### 思路 1:BFS(广度优先搜索)
这道题要求计算将字符串 $s1$ 通过最少的交换次数变成 $s2$。这是一个典型的 BFS 最短路径问题。
算法步骤:
1. 使用 BFS 从 $s1$ 开始搜索,每次尝试交换两个字符。
2. 使用哈希集合记录已访问的字符串,避免重复搜索。
3. 优化:只交换能让字符串更接近 $s2$ 的位置,即只交换那些当前位置字符与 $s2$ 不匹配的位置。
4. 当搜索到 $s2$ 时,返回交换次数。
具体优化:
- 对于当前字符串,找到第一个与 $s2$ 不匹配的位置 $i$。
- 尝试将位置 $i$ 与后面所有位置 $j$ 交换,其中 $s[j] == s2[i]$ 且 $s[i] \ne s2[j]$(避免无效交换)。
### 思路 1:代码
```python
class Solution:
def kSimilarity(self, s1: str, s2: str) -> int:
from collections import deque
if s1 == s2:
return 0
# BFS
queue = deque([(s1, 0)]) # (当前字符串, 交换次数)
visited = {s1}
while queue:
curr, swaps = queue.popleft()
# 找到第一个与 s2 不匹配的位置
i = 0
while i < len(curr) and curr[i] == s2[i]:
i += 1
# 尝试交换位置 i 与后面的位置
for j in range(i + 1, len(curr)):
# 只交换能让位置 i 匹配的字符
if curr[j] == s2[i]:
# 交换位置 i 和 j
next_str = list(curr)
next_str[i], next_str[j] = next_str[j], next_str[i]
next_str = ''.join(next_str)
# 如果到达目标字符串
if next_str == s2:
return swaps + 1
# 如果未访问过,加入队列
if next_str not in visited:
visited.add(next_str)
queue.append((next_str, swaps + 1))
return -1 # 理论上不会到达这里
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times n!)$,其中 $n$ 是字符串的长度。最坏情况下需要遍历所有可能的字符串排列,但实际上由于剪枝和字符集较小,运行时间会快很多。
- **空间复杂度**:$O(n!)$,需要存储访问过的字符串。
================================================
FILE: docs/solutions/0800-0899/keys-and-rooms.md
================================================
# [0841. 钥匙和房间](https://leetcode.cn/problems/keys-and-rooms/)
- 标签:深度优先搜索、广度优先搜索、图
- 难度:中等
## 题目链接
- [0841. 钥匙和房间 - 力扣](https://leetcode.cn/problems/keys-and-rooms/)
## 题目大意
**描述**:有 `n` 个房间,编号为 `0` ~ `n - 1`,每个房间都有若干把钥匙,每把钥匙上都有一个编号,可以开启对应房间号的门。最初,除了 `0` 号房间外其他房间的门都是锁着的。
现在给定一个二维数组 `rooms`,`rooms[i][j]` 表示第 `i` 个房间的第 `j` 把钥匙所能开启的房间号。
**要求**:判断是否能开启所有房间的门。如果能开启,则返回 `True`。否则返回 `False`。
**说明**:
- $n == rooms.length$。
- $2 \le n \le 1000$。
- $0 \le rooms[i].length \le 1000$。
- $1 \le sum(rooms[i].length) \le 3000$。
- $0 \le rooms[i][j] < n$。
- 所有 $rooms[i]$ 的值互不相同。
**示例**:
- 示例 1:
```python
输入:rooms = [[1],[2],[3],[]]
输出:True
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。
```
- 示例 2:
```python
输入:rooms = [[1,3],[3,0,1],[2],[0]]
输出:False
解释:我们不能进入 2 号房间。
```
## 解题思路
### 思路 1:深度优先搜索
当 `x` 号房间有 `y` 号房间的钥匙时,就可以认为我们可以通过 `x` 号房间去往 `y` 号房间。现在把 `n` 个房间看做是拥有 `n` 个节点的图,则上述关系可以看做是 `x` 与 `y` 点之间有一条有向边。
那么问题就变为了给定一张有向图,从 `0` 节点开始出发,问是否能到达所有的节点。
我们可以使用深度优先搜索的方式来解决这道题,具体做法如下:
1. 使用 set 集合变量 `visited` 来统计遍历到的节点个数。
2. 从 `0` 节点开始,使用深度优先搜索的方式遍历整个图。
3. 将当前节点 `x` 加入到集合 `visited` 中,遍历当前节点的邻接点。
1. 如果邻接点不再集合 `visited` 中,则继续递归遍历。
4. 最后深度优先搜索完毕,判断一下遍历到的节点个数是否等于图的节点个数(即集合 `visited` 中的元素个数是否等于节点个数)。
1. 如果等于,则返回 `True`
2. 如果不等于,则返回 `False`。
### 思路 1:代码
```python
class Solution:
def canVisitAllRooms(self, rooms: List[List[int]]) -> bool:
def dfs(x):
visited.add(x)
for key in rooms[x]:
if key not in visited:
dfs(key)
visited = set()
dfs(0)
return len(visited) == len(rooms)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是房间的数量,$m$ 是所有房间中的钥匙数量的总数。
- **空间复杂度**:$O(n)$,递归调用的栈空间深度不超过 $n$。
================================================
FILE: docs/solutions/0800-0899/koko-eating-bananas.md
================================================
# [0875. 爱吃香蕉的珂珂](https://leetcode.cn/problems/koko-eating-bananas/)
- 标签:数组、二分查找
- 难度:中等
## 题目链接
- [0875. 爱吃香蕉的珂珂 - 力扣](https://leetcode.cn/problems/koko-eating-bananas/)
## 题目大意
**描述**:给定一个数组 $piles$ 代表 $n$ 堆香蕉。其中 $piles[i]$ 表示第 $i$ 堆香蕉的个数。再给定一个整数 $h$ ,表示最多可以在 $h$ 小时内吃完所有香蕉。珂珂决定以速度每小时 $k$(未知)根的速度吃香蕉。每一个小时,她讲选择其中一堆香蕉,从中吃掉 $k$ 根。如果这堆香蕉少于 $k$ 根,珂珂将在这一小时吃掉这堆的所有香蕉,并且这一小时不会再吃其他堆的香蕉。
**要求**:返回珂珂可以在 $h$ 小时内吃掉所有香蕉的最小速度 $k$($k$ 为整数)。
**说明**:
- $1 \le piles.length \le 10^4$。
- $piles.length \le h \le 10^9$。
- $1 \le piles[i] \le 10^9$。
**示例**:
- 示例 1:
```python
输入:piles = [3,6,7,11], h = 8
输出:4
```
- 示例 2:
```python
输入:piles = [30,11,23,4,20], h = 5
输出:30
```
## 解题思路
### 思路 1:二分查找算法
先来看 $k$ 的取值范围,因为 $k$ 是整数,且速度肯定不能为 $0$ 吧,为 $0$ 的话就永远吃不完了。所以$k$ 的最小值可以取 $1$。$k$ 的最大值根香蕉中最大堆的香蕉个数有关,因为 $1$ 个小时内只能选择一堆吃,不能再吃其他堆的香蕉,则 $k$ 的最大值取香蕉堆的最大值即可。即 $k$ 的最大值为 $max(piles)$。
我们的目标是求出 $h$ 小时内吃掉所有香蕉的最小速度 $k$。现在有了区间「$[1, max(piles)]$」,有了目标「最小速度 $k$」。接下来使用二分查找算法来查找「最小速度 $k$」。至于计算 $h$ 小时内能否以 $k$ 的速度吃完香蕉,我们可以再写一个方法 $canEat$ 用于判断。如果能吃完就返回 $True$,不能吃完则返回 $False$。下面说一下算法的具体步骤。
- 使用两个指针 $left$、$right$。令 $left$ 指向 $1$,$right$ 指向 $max(piles)$。代表待查找区间为 $[left, right]$
- 取两个节点中心位置 $mid$,判断是否能在 $h$ 小时内以 $k$ 的速度吃完香蕉。
- 如果不能吃完,则将区间 $[left, mid]$ 排除掉,继续在区间 $[mid + 1, right]$ 中查找。
- 如果能吃完,说明 $k$ 还可以继续减小,则继续在区间 $[left, mid]$ 中查找。
- 当 $left == right$ 时跳出循环,返回 $left$。
### 思路 1:代码
```python
class Solution:
def canEat(self, piles, hour, speed):
time = 0
for pile in piles:
time += (pile + speed - 1) // speed
return time <= hour
def minEatingSpeed(self, piles: List[int], h: int) -> int:
left, right = 1, max(piles)
while left < right:
mid = left + (right - left) // 2
if not self.canEat(piles, h, mid):
left = mid + 1
else:
right = mid
return left
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log max(piles))$,$n$ 表示数组 $piles$ 中的元素个数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/largest-sum-of-averages.md
================================================
# [0813. 最大平均值和的分组](https://leetcode.cn/problems/largest-sum-of-averages/)
- 标签:数组、动态规划、前缀和
- 难度:中等
## 题目链接
- [0813. 最大平均值和的分组 - 力扣](https://leetcode.cn/problems/largest-sum-of-averages/)
## 题目大意
**描述**:
给定数组 $nums$ 和一个整数 $k$。我们将给定的数组 $nums$ 分成「最多 $k$ 个非空子数组」,且数组内部是连续的 。
「分数」由每个子数组内的平均值的总和构成。
注意我们必须使用 $nums$ 数组中的每一个数进行分组,并且分数不一定需要是整数。
**要求**:
返回我们所能得到的最大 分数 是多少。答案误差在 $10^{-6}$ 内被视为是正确的。
**说明**:
- $1 \le nums.length \le 10^{3}$。
- $1 \le nums[i] \le 10^{4}$。
- $1 \le k \le nums.length$。
**示例**:
- 示例 1:
```python
输入: nums = [9,1,2,3,9], k = 3
输出: 20.00000
解释:
nums 的最优分组是[9], [1, 2, 3], [9]. 得到的分数是 9 + (1 + 2 + 3) / 3 + 9 = 20.
我们也可以把 nums 分成[9, 1], [2], [3, 9].
这样的分组得到的分数为 5 + 2 + 6 = 13, 但不是最大值.
```
- 示例 2:
```python
输入: nums = [1,2,3,4,5,6,7], k = 4
输出: 20.50000
```
## 解题思路
### 思路 1:动态规划
这道题要求将数组分成最多 $k$ 个连续子数组,使得每个子数组的平均值之和最大。
定义状态:
- $dp[i][j]$ 表示将前 $i$ 个元素分成 $j$ 个子数组时的最大平均值和。
状态转移方程:
- $dp[i][j] = \max(dp[p][j-1] + \frac{\sum_{t=p+1}^{i} nums[t]}{i-p})$,其中 $j-1 \le p < i$。
边界条件:
- $dp[i][1] = \frac{\sum_{t=1}^{i} nums[t]}{i}$,即前 $i$ 个元素分成 $1$ 个子数组。
为了优化计算,可以使用前缀和数组 $prefix$ 来快速计算子数组的和。
算法步骤:
1. 计算前缀和数组 $prefix$。
2. 初始化 $dp$ 数组。
3. 填充 $dp$ 数组,枚举分组数 $j$ 和元素数 $i$,以及分割点 $p$。
4. 返回 $dp[n][k]$。
### 思路 1:代码
```python
class Solution:
def largestSumOfAverages(self, nums: List[int], k: int) -> float:
n = len(nums)
# 计算前缀和
prefix = [0] * (n + 1)
for i in range(n):
prefix[i + 1] = prefix[i] + nums[i]
# 初始化 dp 数组
dp = [[0.0] * (k + 1) for _ in range(n + 1)]
# 边界条件:前 i 个元素分成 1 个子数组
for i in range(1, n + 1):
dp[i][1] = prefix[i] / i
# 状态转移
for j in range(2, k + 1): # 枚举分组数
for i in range(j, n + 1): # 枚举元素数(至少需要 j 个元素)
for p in range(j - 1, i): # 枚举分割点
# 前 p 个元素分成 j-1 组,后面 i-p 个元素作为第 j 组
avg = (prefix[i] - prefix[p]) / (i - p)
dp[i][j] = max(dp[i][j], dp[p][j - 1] + avg)
return dp[n][k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times k)$,其中 $n$ 是数组的长度。需要填充 $n \times k$ 个状态,每个状态需要枚举 $O(n)$ 个分割点。
- **空间复杂度**:$O(n \times k)$,需要使用 $dp$ 数组存储状态。
================================================
FILE: docs/solutions/0800-0899/largest-triangle-area.md
================================================
# [0812. 最大三角形面积](https://leetcode.cn/problems/largest-triangle-area/)
- 标签:几何、数组、数学
- 难度:简单
## 题目链接
- [0812. 最大三角形面积 - 力扣](https://leetcode.cn/problems/largest-triangle-area/)
## 题目大意
**描述**:
给定一个由 X-Y 平面上的点组成的数组 $points$,其中 $points[i] = [xi, yi]$。
**要求**:
从其中取任意三个不同的点组成三角形,返回能组成的最大三角形的面积。与真实值误差在 $10^{-5}$ 内的答案将会视为正确答案。
**说明**:
- $3 \le points.length \le 50$。
- $-50 \le xi, yi \le 50$。
- 给出的所有点「互不相同」。
**示例**:
- 示例 1:
```python
输入:points = [[0,0],[0,1],[1,0],[0,2],[2,0]]
输出:2.00000
解释:输入中的 5 个点如上图所示,红色的三角形面积最大。
```
- 示例 2:
```python
输入:points = [[1,0],[0,0],[0,1]]
输出:0.50000
```
## 解题思路
### 思路 1:枚举 + 几何
这道题要求计算由给定点组成的最大三角形面积。
对于三个点 $(x_1, y_1)$、$(x_2, y_2)$、$(x_3, y_3)$,三角形的面积可以用以下公式计算(鞋带公式):
$$S = \frac{1}{2} |x_1(y_2 - y_3) + x_2(y_3 - y_1) + x_3(y_1 - y_2)|$$
算法步骤:
1. 枚举所有可能的三个点的组合。
2. 对于每个组合,使用鞋带公式计算三角形面积。
3. 记录最大面积。
### 思路 1:代码
```python
class Solution:
def largestTriangleArea(self, points: List[List[int]]) -> float:
n = len(points)
max_area = 0
# 枚举所有可能的三个点
for i in range(n):
for j in range(i + 1, n):
for k in range(j + 1, n):
# 获取三个点的坐标
x1, y1 = points[i]
x2, y2 = points[j]
x3, y3 = points[k]
# 使用鞋带公式计算三角形面积
area = 0.5 * abs(x1 * (y2 - y3) + x2 * (y3 - y1) + x3 * (y1 - y2))
# 更新最大面积
max_area = max(max_area, area)
return max_area
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是点的数量。需要枚举所有三个点的组合。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/leaf-similar-trees.md
================================================
# [0872. 叶子相似的树](https://leetcode.cn/problems/leaf-similar-trees/)
- 标签:树、深度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0872. 叶子相似的树 - 力扣](https://leetcode.cn/problems/leaf-similar-trees/)
## 题目大意
将一棵二叉树树上所有的叶子,按照从左到右的顺序排列起来就形成了一个「叶值序列」。如果两棵二叉树的叶值序列是相同的,我们就认为它们是叶相似的。
现在给定两棵二叉树的根节点 `root1`、`root2`。如果两棵二叉是叶相似的,则返回 `True`,否则返回 `False`。
## 解题思路
分别 DFS 遍历两棵树,得到对应的叶值序列,判断两个叶值序列是否相等。
## 代码
```python
class Solution:
def leafSimilar(self, root1: TreeNode, root2: TreeNode) -> bool:
def dfs(node: TreeNode, res: List[int]):
if not node:
return
if not node.left and not node.right:
res.append(node.val)
dfs(node.left, res)
dfs(node.right, res)
res1 = []
dfs(root1, res1)
res2 = []
dfs(root2, res2)
return res1 == res2
```
================================================
FILE: docs/solutions/0800-0899/lemonade-change.md
================================================
# [0860. 柠檬水找零](https://leetcode.cn/problems/lemonade-change/)
- 标签:贪心、数组
- 难度:简单
## 题目链接
- [0860. 柠檬水找零 - 力扣](https://leetcode.cn/problems/lemonade-change/)
## 题目大意
**描述**:一杯柠檬水的售价是 $5$ 美元。现在有 $n$ 个顾客排队购买柠檬水,每人只能购买一杯。顾客支付的钱面额有 $5$ 美元、$10$ 美元、$20$ 美元。必须给每个顾客正确找零(就是每位顾客需要向你支付 $5$ 美元,多出的钱要找还回顾客)。
现在给定 $n$ 个顾客支付的钱币面额数组 `bills`。
**要求**:如果能给每位顾客正确找零,则返回 `True`,否则返回 `False`。
**说明**:
- 一开始的时候手头没有任何零钱。
- $1 \le bills.length \le 10^5$。
- `bills[i]` 不是 $5$ 就是 $10$ 或是 $20$。
**示例**:
- 示例 1:
```python
输入:bills = [5,5,5,10,20]
输出:True
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 True。
```
- 示例 2:
```python
输入:bills = [5,5,10,10,20]
输出:False
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 False。
```
## 解题思路
### 思路 1:贪心算法
由于顾客只能给我们 $5$、$10$、$20$ 三种面额的钞票,且一开始我们手头没有任何钞票,所以我们手中所能拥有的钞票面额只能是 $5$、$10$、$20$。因此可以采取下面的策略:
1. 如果顾客支付 $5$ 美元,直接收下。
2. 如果顾客支付 $10$ 美元,如果我们手头有 $5$ 美元面额的钞票,则找给顾客,否则无法正确找零,返回 `False`。
3. 如果顾客支付 $20$ 美元,如果我们手头有 $1$ 张 $10$ 美元和 $1$ 张 $5$ 美元的钞票,或者有 $3$ 张 $5$ 美元的钞票,则可以找给顾客。如果两种组合方式同时存在,倾向于第 $1$ 种方式找零,因为使用 $5$ 美元的场景比使用 $10$ 美元的场景多,要尽可能的保留 $5$ 美元的钞票。如果这两种组合方式都不通知,则无法正确找零,返回 `False`。
所以,我们可以使用两个变量 `five` 和 `ten` 来维护手中 $5$ 美元、$10$ 美团的钞票数量, 然后遍历一遍根据上述条件分别判断即可。
### 思路 1:代码
```python
class Solution:
def lemonadeChange(self, bills: List[int]) -> bool:
five, ten, twenty = 0, 0, 0
for bill in bills:
if bill == 5:
five += 1
if bill == 10:
if five <= 0:
return False
ten += 1
five -= 1
if bill == 20:
if five > 0 and ten > 0:
five -= 1
ten -= 1
twenty += 1
elif five >= 3:
five -= 3
twenty += 1
else:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 `bill` 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/length-of-longest-fibonacci-subsequence.md
================================================
# [0873. 最长的斐波那契子序列的长度](https://leetcode.cn/problems/length-of-longest-fibonacci-subsequence/)
- 标签:数组、哈希表、动态规划
- 难度:中等
## 题目链接
- [0873. 最长的斐波那契子序列的长度 - 力扣](https://leetcode.cn/problems/length-of-longest-fibonacci-subsequence/)
## 题目大意
**描述**:给定一个严格递增的正整数数组 $arr$。
**要求**:从数组 $arr$ 中找出最长的斐波那契式的子序列的长度。如果不存斐波那契式的子序列,则返回 0。
**说明**:
- **斐波那契式序列**:如果序列 $X_1, X_2, ..., X_n$ 满足:
- $n \ge 3$;
- 对于所有 $i + 2 \le n$,都有 $X_i + X_{i+1} = X_{i+2}$。
则称该序列为斐波那契式序列。
- **斐波那契式子序列**:从序列 $A$ 中挑选若干元素组成子序列,并且子序列满足斐波那契式序列,则称该序列为斐波那契式子序列。例如:$A = [3, 4, 5, 6, 7, 8]$。则 $[3, 5, 8]$ 是 $A$ 的一个斐波那契式子序列。
- $3 \le arr.length \le 1000$。
- $1 \le arr[i] < arr[i + 1] \le 10^9$。
**示例**:
- 示例 1:
```python
输入: arr = [1,2,3,4,5,6,7,8]
输出: 5
解释: 最长的斐波那契式子序列为 [1,2,3,5,8]。
```
- 示例 2:
```python
输入: arr = [1,3,7,11,12,14,18]
输出: 3
解释: 最长的斐波那契式子序列有 [1,11,12]、[3,11,14] 以及 [7,11,18]。
```
## 解题思路
### 思路 1: 暴力枚举(超时)
假设 $arr[i]$、$arr[j]$、$arr[k]$ 是序列 $arr$ 中的 $3$ 个元素,且满足关系:$arr[i] + arr[j] == arr[k]$,则 $arr[i]$、$arr[j]$、$arr[k]$ 就构成了 $arr$ 的一个斐波那契式子序列。
通过 $arr[i]$、$arr[j]$,我们可以确定下一个斐波那契式子序列元素的值为 $arr[i] + arr[j]$。
因为给定的数组是严格递增的,所以对于一个斐波那契式子序列,如果确定了 $arr[i]$、$arr[j]$,则可以顺着 $arr$ 序列,从第 $j + 1$ 的元素开始,查找值为 $arr[i] + arr[j]$ 的元素 。找到 $arr[i] + arr[j]$ 之后,然后再顺着查找子序列的下一个元素。
简单来说,就是确定了 $arr[i]$、$arr[j]$,就能尽可能的得到一个长的斐波那契式子序列,此时我们记录下子序列长度。然后对于不同的 $arr[i]$、$arr[j]$,统计不同的斐波那契式子序列的长度。
最后将这些长度进行比较,其中最长的长度就是答案。
### 思路 1:代码
```python
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
ans = 0
for i in range(size):
for j in range(i + 1, size):
temp_ans = 0
temp_i = i
temp_j = j
k = j + 1
while k < size:
if arr[temp_i] + arr[temp_j] == arr[k]:
temp_ans += 1
temp_i = temp_j
temp_j = k
k += 1
if temp_ans > ans:
ans = temp_ans
if ans > 0:
return ans + 2
else:
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 为数组 $arr$ 的元素个数。
- **空间复杂度**:$O(1)$。
### 思路 2:哈希表
对于 $arr[i]$、$arr[j]$,要查找的元素 $arr[i] + arr[j]$ 是否在 $arr$ 中,我们可以预先建立一个反向的哈希表。键值对关系为 $value : idx$,这样就能在 $O(1)$ 的时间复杂度通过 $arr[i] + arr[j]$ 的值查找到对应的 $arr[k]$,而不用像原先一样线性查找 $arr[k]$ 了。
### 思路 2:代码
```python
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
ans = 0
idx_map = dict()
for idx, value in enumerate(arr):
idx_map[value] = idx
for i in range(size):
for j in range(i + 1, size):
temp_ans = 0
temp_i = i
temp_j = j
while arr[temp_i] + arr[temp_j] in idx_map:
temp_ans += 1
k = idx_map[arr[temp_i] + arr[temp_j]]
temp_i = temp_j
temp_j = k
if temp_ans > ans:
ans = temp_ans
if ans > 0:
return ans + 2
else:
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为数组 $arr$ 的元素个数。
- **空间复杂度**:$O(n)$。
### 思路 3:动态规划 + 哈希表
###### 1. 阶段划分
按照斐波那契式子序列相邻两项的结尾位置进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 表示为:以 $arr[i]$、$arr[j]$ 为结尾的斐波那契式子序列的最大长度。
###### 3. 状态转移方程
以 $arr[j]$、$arr[k]$ 结尾的斐波那契式子序列的最大长度 = 满足 $arr[i] + arr[j] = arr[k]$ 条件下,以 $arr[i]$、$arr[j]$ 结尾的斐波那契式子序列的最大长度加 $1$。即状态转移方程为:$dp[j][k] = max_{(A[i] + A[j] = A[k], i < j < k)}(dp[i][j] + 1)$。
###### 4. 初始条件
默认状态下,数组中任意相邻两项元素都可以作为长度为 $2$ 的斐波那契式子序列,即 $dp[i][j] = 2$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][j]$ 表示为:以 $arr[i]$、$arr[j]$ 为结尾的斐波那契式子序列的最大长度。那为了计算出最大的最长递增子序列长度,则需要在进行状态转移时,求出最大值 $ans$ 即为最终结果。
因为题目定义中,斐波那契式中 $n \ge 3$,所以只有当 $ans \ge 3$ 时,返回 $ans$。如果 $ans < 3$,则返回 $0$。
> **注意**:在进行状态转移的同时,我们应和「思路 2:哈希表」一样采用哈希表优化的方式来提高效率,降低算法的时间复杂度。
### 思路 3:代码
```python
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
dp = [[0 for _ in range(size)] for _ in range(size)]
ans = 0
# 初始化 dp
for i in range(size):
for j in range(i + 1, size):
dp[i][j] = 2
idx_map = {}
# 将 value : idx 映射为哈希表,这样可以快速通过 value 获取到 idx
for idx, value in enumerate(arr):
idx_map[value] = idx
for i in range(size):
for j in range(i + 1, size):
if arr[i] + arr[j] in idx_map:
# 获取 arr[i] + arr[j] 的 idx,即斐波那契式子序列下一项元素
k = idx_map[arr[i] + arr[j]]
dp[j][k] = max(dp[j][k], dp[i][j] + 1)
ans = max(ans, dp[j][k])
if ans >= 3:
return ans
return 0
```
### 思路 3:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为数组 $arr$ 的元素个数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0800-0899/linked-list-components.md
================================================
# [0817. 链表组件](https://leetcode.cn/problems/linked-list-components/)
- 标签:数组、哈希表、链表
- 难度:中等
## 题目链接
- [0817. 链表组件 - 力扣](https://leetcode.cn/problems/linked-list-components/)
## 题目大意
**描述**:
给定链表头结点 $head$,该链表上的每个结点都有一个「唯一的整型值」。同时给定列表 $nums$,该列表是上述链表中整型值的一个子集。
**要求**:
返回列表 $nums$ 中组件的个数,这里对组件的定义为:链表中一段最长连续结点的值(该值必须在列表 $nums$ 中)构成的集合。
**说明**:
- 链表中节点数为n。
- $1 \le n \le 10^{4}$。
- $0 \le Node.val \lt n$。
- Node.val 中所有值 不同。
- $1 \le nums.length \le n$。
- $0 \le nums[i] \lt n$。
- $nums$ 中所有值「不同」。
**示例**:
- 示例 1:

```python
输入: head = [0,1,2,3], nums = [0,1,3]
输出: 2
解释: 链表中,0 和 1 是相连接的,且 nums 中不包含 2,所以 [0, 1] 是 nums 的一个组件,同理 [3] 也是一个组件,故返回 2。
```
- 示例 2:

```python
输入: head = [0,1,2,3,4], nums = [0,3,1,4]
输出: 2
解释: 链表中,0 和 1 是相连接的,3 和 4 是相连接的,所以 [0, 1] 和 [3, 4] 是两个组件,故返回 2。
```
## 解题思路
### 思路 1:哈希表 + 链表遍历
这道题要求统计链表中组件的数量。组件是链表中连续的、值都在 $nums$ 中的节点序列。
算法步骤:
1. 将 $nums$ 转换为哈希集合,方便快速查找。
2. 遍历链表,统计组件数量:
- 如果当前节点的值在 $nums$ 中,且前一个节点的值不在 $nums$ 中(或当前是第一个节点),则组件数加 $1$。
- 换句话说,每次遇到一个新组件的开始时,计数器加 $1$。
### 思路 1:代码
```python
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def numComponents(self, head: Optional[ListNode], nums: List[int]) -> int:
# 将 nums 转换为哈希集合
num_set = set(nums)
count = 0
in_component = False # 标记当前是否在组件中
# 遍历链表
curr = head
while curr:
if curr.val in num_set:
# 如果当前节点在 nums 中
if not in_component:
# 如果之前不在组件中,说明这是一个新组件的开始
count += 1
in_component = True
else:
# 如果当前节点不在 nums 中,标记不在组件中
in_component = False
curr = curr.next
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是链表的长度,$m$ 是数组 $nums$ 的长度。需要遍历链表和构建哈希集合。
- **空间复杂度**:$O(m)$,需要使用哈希集合存储 $nums$ 中的元素。
================================================
FILE: docs/solutions/0800-0899/longest-mountain-in-array.md
================================================
# [0845. 数组中的最长山脉](https://leetcode.cn/problems/longest-mountain-in-array/)
- 标签:数组、双指针、动态规划、枚举
- 难度:中等
## 题目链接
- [0845. 数组中的最长山脉 - 力扣](https://leetcode.cn/problems/longest-mountain-in-array/)
## 题目大意
**描述**:给定一个整数数组 $arr$。
**要求**:返回最长山脉子数组的长度。如果不存在山脉子数组,返回 $0$。
**说明**:
- **山脉数组**:符合下列属性的数组 $arr$ 称为山脉数组。
- $arr.length \ge 3$。
- 存在下标 $i(0 < i < arr.length - 1)$ 满足:
- $arr[0] < arr[1] < … < arr[i]$
- $arr[i] > arr[i + 1] > … > arr[arr.length - 1]$
- $1 \le arr.length \le 10^4$。
- $0 \le arr[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:arr = [2,1,4,7,3,2,5]
输出:5
解释:最长的山脉子数组是 [1,4,7,3,2],长度为 5。
```
- 示例 2:
```python
输入:arr = [2,2,2]
输出:0
解释:不存在山脉子数组。
```
## 解题思路
### 思路 1:快慢指针
1. 使用变量 $ans$ 保存最长山脉长度。
2. 遍历数组,假定当前节点为山峰。
3. 使用双指针 $left$、$right$ 分别向左、向右查找山脉的长度。
4. 如果当前山脉的长度比最长山脉长度更长,则更新最长山脉长度。
5. 最后输出 $ans$。
### 思路 1:代码
```python
class Solution:
def longestMountain(self, arr: List[int]) -> int:
size = len(arr)
res = 0
for i in range(1, size - 1):
if arr[i] > arr[i - 1] and arr[i] > arr[i + 1]:
left = i - 1
right = i + 1
while left > 0 and arr[left - 1] < arr[left]:
left -= 1
while right < size - 1 and arr[right + 1] < arr[right]:
right += 1
if right - left + 1 > res:
res = right - left + 1
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $arr$ 中的元素数量。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/loud-and-rich.md
================================================
# [0851. 喧闹和富有](https://leetcode.cn/problems/loud-and-rich/)
- 标签:深度优先搜索、图、拓扑排序、数组
- 难度:中等
## 题目链接
- [0851. 喧闹和富有 - 力扣](https://leetcode.cn/problems/loud-and-rich/)
## 题目大意
**描述**:有一组 `n` 个人作为实验对象,从 `0` 到 `n - 1` 编号,其中每个人都有不同数目的钱,以及不同程度的安静值 `quietness`。
现在给定一个数组 `richer`,其中 `richer[i] = [ai, bi]` 表示第 `ai` 个人比第 `bi` 个人更有钱。另给你一个整数数组 `quiet`,其中 `quiet[i]` 是第 `i` 个人的安静值。数组 `richer` 中所给出的数据逻辑自洽(也就是说,在第 `ai` 个人比第 `bi` 个人更有钱的同时,不会出现第 `bi` 个人比第 `ai` 个人更有钱的情况 )。
**要求**:返回一个长度为 `n` 的整数数组 `answer` 作为答案,其中 `answer[i]` 表示在所有比第 `i` 个人更有钱或者和他一样有钱的人中,安静值最小的那个人的编号。
**说明**:
- $n == quiet.length$
- $1 \le n \le 500$。
- $0 \le quiet[i] \le n$。
- $quiet$ 的所有值互不相同。
- $0 \le richer.length \le n * (n - 1) / 2$。
- $0 \le ai, bi < n$。
- $ai != bi$。
- $richer$ 中的所有数对 互不相同。
- 对 $richer$ 的观察在逻辑上是一致的。
**示例**:
- 示例 1:
```python
输入:richer = [[1,0],[2,1],[3,1],[3,7],[4,3],[5,3],[6,3]], quiet = [3,2,5,4,6,1,7,0]
输出:[5,5,2,5,4,5,6,7]
解释:
answer[0] = 5,
person 5 比 person 3 有更多的钱,person 3 比 person 1 有更多的钱,person 1 比 person 0 有更多的钱。
唯一较为安静(有较低的安静值 quiet[x])的人是 person 7,
但是目前还不清楚他是否比 person 0 更有钱。
answer[7] = 7,
在所有拥有的钱肯定不少于 person 7 的人中(这可能包括 person 3,4,5,6 以及 7),
最安静(有较低安静值 quiet[x])的人是 person 7。
其他的答案也可以用类似的推理来解释。
```
## 解题思路
### 思路 1:拓扑排序
对于第 `i` 个人,我们要求解的是比第 `i` 个人更有钱或者和他一样有钱的人中,安静值最小的那个人的编号。
我们可以建立一张有向无环图,由富人指向穷人。这样,对于任意一点来说(比如 `x`),通过有向边链接的点(比如 `y`),拥有的钱都没有 `x` 多。则我们可以根据 `answer[x]` 去更新所有 `x` 能连接到的点的 `answer` 值。
我们可以先将数组 `answer` 元素初始化为当前元素编号。然后对建立的有向无环图进行拓扑排序,按照拓扑排序的顺序去更新 `x` 能连接到的点的 `answer` 值。
### 思路 1:拓扑排序代码
```python
import collections
class Solution:
def loudAndRich(self, richer: List[List[int]], quiet: List[int]) -> List[int]:
size = len(quiet)
indegrees = [0 for _ in range(size)]
edges = collections.defaultdict(list)
for x, y in richer:
edges[x].append(y)
indegrees[y] += 1
res = [i for i in range(size)]
queue = collections.deque([])
for i in range(size):
if not indegrees[i]:
queue.append(i)
while queue:
x = queue.popleft()
size -= 1
for y in edges[x]:
if quiet[res[x]] < quiet[res[y]]:
res[y] = res[x]
indegrees[y] -= 1
if not indegrees[y]:
queue.append(y)
return res
```
================================================
FILE: docs/solutions/0800-0899/magic-squares-in-grid.md
================================================
# [0840. 矩阵中的幻方](https://leetcode.cn/problems/magic-squares-in-grid/)
- 标签:数组、哈希表、数学、矩阵
- 难度:中等
## 题目链接
- [0840. 矩阵中的幻方 - 力扣](https://leetcode.cn/problems/magic-squares-in-grid/)
## 题目大意
**描述**:
$3 \times 3$ 的幻方是一个填充有 从 1 到 9 的不同数字的 $3 \times 3$ 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。
给定一个由整数组成的 $row \times col$ 的 $grid$。
**要求**:
计算其中有多少个 $3 \times 3$ 的「幻方」子矩阵。
注意:虽然幻方只能包含 1 到 9 的数字,但 $grid$ 可以包含最多 15 的数字。
**说明**:
- $row == grid.length$。
- $col == grid[i].length$。
- $1 \le row, col \le 10$。
- $0 \le grid[i][j] \le 15$。
**示例**:
- 示例 1:
```python
输入: grid = [[4,3,8,4],[9,5,1,9],[2,7,6,2]
输出: 1
解释:
下面的子矩阵是一个 3 x 3 的幻方:
```
```python
而这一个不是:
```
```python
总的来说,在本示例所给定的矩阵中只有一个 3 x 3 的幻方子矩阵。
```
- 示例 2:
```python
输入: grid = [[8]]
输出: 0
```
## 解题思路
### 思路 1:枚举 + 模拟
这道题要求统计矩阵中 $3 \times 3$ 幻方的数量。幻方需要满足:
1. 包含 $1$ 到 $9$ 的所有数字,且每个数字只出现一次。
2. 每行、每列、两条对角线的和都相等(都等于 $15$)。
算法步骤:
1. 枚举所有可能的 $3 \times 3$ 子矩阵的左上角位置。
2. 对于每个子矩阵,检查是否为幻方:
- 检查是否包含 $1$ 到 $9$ 的所有数字。
- 检查每行、每列、两条对角线的和是否都等于 $15$。
3. 统计满足条件的幻方数量。
### 思路 1:代码
```python
class Solution:
def numMagicSquaresInside(self, grid: List[List[int]]) -> int:
def is_magic(square):
# 检查是否为幻方
# 1. 检查是否包含 1 到 9 的所有数字
nums = []
for row in square:
for num in row:
if num < 1 or num > 9:
return False
nums.append(num)
if sorted(nums) != list(range(1, 10)):
return False
# 2. 检查每行、每列、两条对角线的和是否都等于 15
# 检查行
for row in square:
if sum(row) != 15:
return False
# 检查列
for col in range(3):
if sum(square[row][col] for row in range(3)) != 15:
return False
# 检查对角线
if sum(square[i][i] for i in range(3)) != 15:
return False
if sum(square[i][2 - i] for i in range(3)) != 15:
return False
return True
rows = len(grid)
cols = len(grid[0])
count = 0
# 枚举所有可能的 3x3 子矩阵
for i in range(rows - 2):
for j in range(cols - 2):
# 提取 3x3 子矩阵
square = [grid[i + r][j:j + 3] for r in range(3)]
if is_magic(square):
count += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$ 和 $n$ 分别是矩阵的行数和列数。需要枚举所有可能的 $3 \times 3$ 子矩阵,每个子矩阵的检查时间为常数。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/making-a-large-island.md
================================================
# [0827. 最大人工岛](https://leetcode.cn/problems/making-a-large-island/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、矩阵
- 难度:困难
## 题目链接
- [0827. 最大人工岛 - 力扣](https://leetcode.cn/problems/making-a-large-island/)
## 题目大意
**描述**:
给定一个大小为 $n \times n$ 二进制矩阵 $grid$。最多 只能将一格 0 变成 1 。
**要求**:
返回执行此操作后,$grid$ 中最大的岛屿面积是多少?
**说明**:
- 「岛屿」由一组上、下、左、右四个方向相连的 1 形成。
- $n == grid.length$。
- $n == grid[i].length$。
- $1 \le n \le 500$。
- grid[i][j] 为 0 或 1。
**示例**:
- 示例 1:
```python
输入: grid = [[1, 0], [0, 1]]
输出: 3
解释: 将一格0变成1,最终连通两个小岛得到面积为 3 的岛屿。
```
- 示例 2:
```python
输入: grid = [[1, 1], [1, 0]]
输出: 4
解释: 将一格0变成1,岛屿的面积扩大为 4。
```
## 解题思路
### 思路 1:DFS(深度优先搜索)+ 并查集
这道题要求在最多将一个 $0$ 变成 $1$ 的情况下,计算最大的岛屿面积。
算法步骤:
1. 使用 DFS 标记每个岛屿,并计算每个岛屿的面积。
2. 为每个岛屿分配一个唯一的 ID。
3. 遍历所有的 $0$,尝试将其变成 $1$:
- 统计该位置四周相邻的不同岛屿。
- 计算将该 $0$ 变成 $1$ 后的总面积($1$ + 相邻岛屿面积之和)。
4. 返回最大面积。
5. 特殊情况:如果没有 $0$,返回整个网格的面积。
### 思路 1:代码
```python
class Solution:
def largestIsland(self, grid: List[List[int]]) -> int:
n = len(grid)
# 四个方向
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
# DFS 标记岛屿并计算面积
def dfs(i, j, island_id):
if i < 0 or i >= n or j < 0 or j >= n or grid[i][j] != 1:
return 0
grid[i][j] = island_id # 标记为岛屿 ID
area = 1
for di, dj in directions:
ni, nj = i + di, j + dj
area += dfs(ni, nj, island_id)
return area
# 标记所有岛屿并记录面积
island_id = 2 # 从 2 开始,因为 0 和 1 已被使用
area_map = {} # 记录每个岛屿的面积
for i in range(n):
for j in range(n):
if grid[i][j] == 1:
area = dfs(i, j, island_id)
area_map[island_id] = area
island_id += 1
# 如果没有 0,返回整个网格的面积
max_area = max(area_map.values()) if area_map else 0
# 尝试将每个 0 变成 1
for i in range(n):
for j in range(n):
if grid[i][j] == 0:
# 统计相邻的不同岛屿
adjacent_islands = set()
for di, dj in directions:
ni, nj = i + di, j + dj
if 0 <= ni < n and 0 <= nj < n and grid[ni][nj] > 1:
adjacent_islands.add(grid[ni][nj])
# 计算总面积
total_area = 1 + sum(area_map[island] for island in adjacent_islands)
max_area = max(max_area, total_area)
return max_area
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是网格的边长。需要遍历网格两次,一次标记岛屿,一次尝试填充 $0$。
- **空间复杂度**:$O(n^2)$,递归调用栈的深度最多为 $O(n^2)$。
================================================
FILE: docs/solutions/0800-0899/masking-personal-information.md
================================================
# [0831. 隐藏个人信息](https://leetcode.cn/problems/masking-personal-information/)
- 标签:字符串
- 难度:中等
## 题目链接
- [0831. 隐藏个人信息 - 力扣](https://leetcode.cn/problems/masking-personal-information/)
## 题目大意
**描述**:
给定一条个人信息字符串 $s$,可能表示一个「邮箱地址」,也可能表示一串「电话号码」。
一个「有效」的电子邮件地址由以下部分组成:
- 一个 `名字`,由大小写英文字母组成,后面跟着
- 一个 `'@'` 字符,后面跟着
- 一个 `域名`,由大小写英文字母和一个位于中间的 `'.'` 字符组成。`'.'` 不会是域名的第一个或者最后一个字符。
要想隐藏电子邮件地址中的个人信息:
- `名字` 和 `域名` 部分的大写英文字母应当转换成小写英文字母。
- `名字` 中间的字母(即,除第一个和最后一个字母外)必须用 5 个 `"*****"` 替换。
一个「有效」的电话号码应当按下述格式组成:
- 电话号码可以由 $10 \sim 13$ 位数字组成
- 后 10 位构成 本地号码
- 前面剩下的 $0 \sim 3$ 位,构成「国家代码」
- 利用 `{'+', '-', '(', ')', ' '}` 这些「分隔字符」按某种形式对上述数字进行分隔
要想隐藏电话号码中的个人信息:
- 移除所有 `分隔字符`
- 隐藏个人信息后的电话号码应该遵从这种格式:
- `"***-***-XXXX"` 如果国家代码为 0 位数字
- `"+*-***-***-XXXX"` 如果国家代码为 1 位数字
- `"+**-***-***-XXXX"` 如果国家代码为 2 位数字
- `"+***-***-***-XXXX"` 如果国家代码为 3 位数字
- `"XXXX"` 是最后 4 位 本地号码
**要求**:
返回按规则「隐藏」个人信息后的结果。
**说明**:
- $s$ 是一个「有效」的电子邮件或者电话号码。
- 如果 $s$ 是一个电子邮件:
- $8 \le s.length \le 40$。
- s 是由大小写英文字母,恰好一个 `'@'` 字符,以及 `'.'` 字符组成。
- 如果 $s$ 是一个电话号码:
- $10 \le s.length \le 20$。
- s 是由数字、空格、字符 `'('`、`')'`、`'-'` 和 `'+'` 组成。
**示例**:
- 示例 1:
```python
输入:s = "LeetCode@LeetCode.com"
输出:"l*****e@leetcode.com"
解释:s 是一个电子邮件地址。
名字和域名都转换为小写,名字的中间用 5 个 * 替换。
```
- 示例 2:
```python
输入:s = "AB@qq.com"
输出:"a*****b@qq.com"
解释:s 是一个电子邮件地址。
名字和域名都转换为小写,名字的中间用 5 个 * 替换。
注意,尽管 "ab" 只有两个字符,但中间仍然必须有 5 个 * 。
```
## 解题思路
### 思路 1:字符串处理 + 模拟
这道题要求根据规则隐藏个人信息。需要分别处理邮箱和电话号码两种情况。
**邮箱处理规则**:
1. 将名字和域名转换为小写。
2. 名字中间的字母用 $5$ 个 `*` 替换(保留首尾字母)。
**电话号码处理规则**:
1. 移除所有分隔字符,只保留数字。
2. 后 $10$ 位是本地号码,前面的是国家代码。
3. 根据国家代码位数格式化输出。
算法步骤:
1. 判断是邮箱还是电话号码(包含 `@` 则为邮箱)。
2. 根据类型应用相应的处理规则。
### 思路 1:代码
```python
class Solution:
def maskPII(self, s: str) -> str:
if '@' in s:
# 处理邮箱
s = s.lower()
name, domain = s.split('@')
# 名字首尾字母 + 5个* + 域名
return name[0] + '*****' + name[-1] + '@' + domain
else:
# 处理电话号码
# 移除所有非数字字符
digits = ''.join(c for c in s if c.isdigit())
# 本地号码是后 10 位
local = digits[-10:]
# 国家代码是前面的部分
country_code_len = len(digits) - 10
# 格式化本地号码
masked_local = '***-***-' + local[-4:]
# 根据国家代码位数添加前缀
if country_code_len == 0:
return masked_local
else:
return '+' + '*' * country_code_len + '-' + masked_local
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串的长度。需要遍历字符串进行处理。
- **空间复杂度**:$O(n)$,需要存储处理后的字符串。
================================================
FILE: docs/solutions/0800-0899/max-increase-to-keep-city-skyline.md
================================================
# [0807. 保持城市天际线](https://leetcode.cn/problems/max-increase-to-keep-city-skyline/)
- 标签:贪心、数组、矩阵
- 难度:中等
## 题目链接
- [0807. 保持城市天际线 - 力扣](https://leetcode.cn/problems/max-increase-to-keep-city-skyline/)
## 题目大意
**描述**:
给定一座由 $n \times n$ 个街区组成的城市,每个街区都包含一座立方体建筑。给你一个下标从 0 开始的 $n \times n$ 整数矩阵 $grid$,其中 $grid[r][c]$ 表示坐落于 $r$ 行 $c$ 列的建筑物的「高度」。
城市的「天际线」是从远处观察城市时,所有建筑物形成的外部轮廓。从东、南、西、北四个主要方向观测到的「天际线」可能不同。
我们被允许为「任意数量的建筑物」的高度增加「任意增量(不同建筑物的增量可能不同)」。高度为 0 的建筑物的高度也可以增加。然而,增加的建筑物高度「不能影响」从任何主要方向观察城市得到的「天际线」。
**要求**:
在「不改变」从任何主要方向观测到的城市「天际线」的前提下,返回建筑物可以增加的「最大高度增量总和」。
**说明**:
- $n == grid.length$。
- $n == grid[r].length$。
- $2 \le n \le 50$。
- $0 \le grid[r][c] \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:grid = [[3,0,8,4],[2,4,5,7],[9,2,6,3],[0,3,1,0]]
输出:35
解释:建筑物的高度如上图中心所示。
用红色绘制从不同方向观看得到的天际线。
在不影响天际线的情况下,增加建筑物的高度:
gridNew = [ [8, 4, 8, 7],
[7, 4, 7, 7],
[9, 4, 8, 7],
[3, 3, 3, 3] ]
```
- 示例 2:
```python
输入:grid = [[0,0,0],[0,0,0],[0,0,0]]
输出:0
解释:增加任何建筑物的高度都会导致天际线的变化。
```
## 解题思路
### 思路 1:贪心 + 矩阵
这道题要求在不改变天际线的前提下,计算建筑物可以增加的最大高度增量总和。
关键观察:
- 从东西方向看,天际线由每行的最大值决定。
- 从南北方向看,天际线由每列的最大值决定。
- 对于位置 $(i, j)$ 的建筑物,它的最大高度不能超过第 $i$ 行的最大值和第 $j$ 列的最大值中的较小值。
算法步骤:
1. 计算每行的最大值 $row\_max[i]$。
2. 计算每列的最大值 $col\_max[j]$。
3. 对于每个位置 $(i, j)$,建筑物可以增加的高度为 $\min(row\_max[i], col\_max[j]) - grid[i][j]$。
4. 累加所有位置的增量。
### 思路 1:代码
```python
class Solution:
def maxIncreaseKeepingSkyline(self, grid: List[List[int]]) -> int:
n = len(grid)
# 计算每行的最大值
row_max = [max(grid[i]) for i in range(n)]
# 计算每列的最大值
col_max = [max(grid[i][j] for i in range(n)) for j in range(n)]
# 计算总增量
total_increase = 0
for i in range(n):
for j in range(n):
# 当前位置的最大高度
max_height = min(row_max[i], col_max[j])
# 累加增量
total_increase += max_height - grid[i][j]
return total_increase
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是矩阵的边长。需要遍历矩阵计算行列最大值和增量。
- **空间复杂度**:$O(n)$,需要存储每行和每列的最大值。
================================================
FILE: docs/solutions/0800-0899/maximize-distance-to-closest-person.md
================================================
# [0849. 到最近的人的最大距离](https://leetcode.cn/problems/maximize-distance-to-closest-person/)
- 标签:数组
- 难度:中等
## 题目链接
- [0849. 到最近的人的最大距离 - 力扣](https://leetcode.cn/problems/maximize-distance-to-closest-person/)
## 题目大意
**描述**:
给定一个数组 $seats$ 表示一排座位,其中 $seats[i] = 1$ 代表有人坐在第 i 个座位上,$seats[i] = 0$ 代表座位 $i$ 上是空的(下标从 0 开始)。
至少有一个空座位,且至少有一人已经坐在座位上。
亚历克斯希望坐在一个能够使他与离他最近的人之间的距离达到最大化的座位上。
**要求**:
返回他到离他最近的人的最大距离。
**说明**:
- $2 \le seats.length \le 2 * 10^{4}$。
- $seats[i]$ 为 0 或 1。
- 至少有一个「空座位」。
- 至少有一个「座位上有人」。
**示例**:
- 示例 1:
```python
输入:seats = [1,0,0,0,1,0,1]
输出:2
解释:
如果亚历克斯坐在第二个空位(seats[2])上,他到离他最近的人的距离为 2 。
如果亚历克斯坐在其它任何一个空位上,他到离他最近的人的距离为 1 。
因此,他到离他最近的人的最大距离是 2 。
```
- 示例 2:
```python
输入:seats = [1,0,0,0]
输出:3
解释:
如果亚历克斯坐在最后一个座位上,他离最近的人有 3 个座位远。
这是可能的最大距离,所以答案是 3 。
```
## 解题思路
### 思路 1:一次遍历
这道题要求找到使亚历克斯到最近的人的距离最大化的座位。
关键观察:
- 最大距离可能出现在三种情况:
1. 两个有人座位之间的中点。
2. 最左边的空座位(如果最左边是空的)。
3. 最右边的空座位(如果最右边是空的)。
算法步骤:
1. 遍历座位数组,记录上一个有人座位的位置 $prev$。
2. 对于每个空座位:
- 如果 $prev == -1$(左边没有人),距离为当前位置到第一个有人座位的距离。
- 否则,距离为 $(i - prev) // 2$(两个有人座位之间的中点)。
3. 特殊处理最右边的空座位。
4. 返回最大距离。
### 思路 1:代码
```python
class Solution:
def maxDistToClosest(self, seats: List[int]) -> int:
n = len(seats)
max_dist = 0
prev = -1 # 上一个有人座位的位置
for i in range(n):
if seats[i] == 1:
# 如果当前座位有人
if prev == -1:
# 如果左边没有人,距离为从开始到当前位置
max_dist = i
else:
# 否则,距离为两个有人座位之间的中点
max_dist = max(max_dist, (i - prev) // 2)
prev = i
# 特殊处理最右边的空座位
max_dist = max(max_dist, n - 1 - prev)
return max_dist
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是座位数组的长度。只需遍历一次数组。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/maximum-frequency-stack.md
================================================
# [0895. 最大频率栈](https://leetcode.cn/problems/maximum-frequency-stack/)
- 标签:栈、设计、哈希表、有序集合
- 难度:困难
## 题目链接
- [0895. 最大频率栈 - 力扣](https://leetcode.cn/problems/maximum-frequency-stack/)
## 题目大意
**要求**:
设计一个类似堆栈的数据结构,将元素推入堆栈,并从堆栈中弹出出现频率最高的元素。
实现 FreqStack 类:
- `FreqStack$()` 构造一个空的堆栈。
- `void push(int val)` 将一个整数 $val$ 压入栈顶。
- `int pop()` 删除并返回堆栈中出现频率最高的元素。
- 如果出现频率最高的元素不只一个,则移除并返回最接近栈顶的元素。
**说明**:
- $0 \le val \le 10^{9}$。
- `push` 和 `pop` 的操作数不大于 $2 \times 10^{4}$。
- 输入保证在调用 `pop` 之前堆栈中至少有一个元素。
**示例**:
- 示例 1:
```python
输入:
["FreqStack","push","push","push","push","push","push","pop","pop","pop","pop"],
[[],[5],[7],[5],[7],[4],[5],[],[],[],[]]
输出:[null,null,null,null,null,null,null,5,7,5,4]
解释:
FreqStack = new FreqStack();
freqStack.push (5);//堆栈为 [5]
freqStack.push (7);//堆栈是 [5,7]
freqStack.push (5);//堆栈是 [5,7,5]
freqStack.push (7);//堆栈是 [5,7,5,7]
freqStack.push (4);//堆栈是 [5,7,5,7,4]
freqStack.push (5);//堆栈是 [5,7,5,7,4,5]
freqStack.pop ();//返回 5 ,因为 5 出现频率最高。堆栈变成 [5,7,5,7,4]。
freqStack.pop ();//返回 7 ,因为 5 和 7 出现频率最高,但7最接近顶部。堆栈变成 [5,7,5,4]。
freqStack.pop ();//返回 5 ,因为 5 出现频率最高。堆栈变成 [5,7,4]。
freqStack.pop ();//返回 4 ,因为 4, 5 和 7 出现频率最高,但 4 是最接近顶部的。堆栈变成 [5,7]。
```
## 解题思路
### 思路 1:哈希表 + 频率栈
这道题要求设计一个数据结构,支持 `push` 和 `pop` 操作,其中 `pop` 操作返回频率最高的元素(如果有多个,返回最接近栈顶的)。
关键数据结构:
1. $freq$ 哈希表:记录每个元素的出现频率。
2. $group$ 哈希表:记录每个频率对应的元素栈。$group[f]$ 存储所有频率为 $f$ 的元素。
3. $max\_freq$:记录当前最大频率。
算法步骤:
- **push 操作**:
1. 更新元素的频率 $freq[val]$。
2. 将元素加入对应频率的栈 $group[freq[val]]$。
3. 更新最大频率 $max\_freq$。
- **pop 操作**:
1. 从最大频率的栈 $group[max\_freq]$ 中弹出元素。
2. 更新该元素的频率 $freq[val]$。
3. 如果最大频率的栈为空,减小 $max\_freq$。
### 思路 1:代码
```python
class FreqStack:
def __init__(self):
self.freq = {} # 记录每个元素的频率
self.group = {} # 记录每个频率对应的元素栈
self.max_freq = 0 # 当前最大频率
def push(self, val: int) -> None:
# 更新元素的频率
self.freq[val] = self.freq.get(val, 0) + 1
f = self.freq[val]
# 将元素加入对应频率的栈
if f not in self.group:
self.group[f] = []
self.group[f].append(val)
# 更新最大频率
self.max_freq = max(self.max_freq, f)
def pop(self) -> int:
# 从最大频率的栈中弹出元素
val = self.group[self.max_freq].pop()
# 更新元素的频率
self.freq[val] -= 1
# 如果最大频率的栈为空,减小最大频率
if not self.group[self.max_freq]:
self.max_freq -= 1
return val
# Your FreqStack object will be instantiated and called as such:
# obj = FreqStack()
# obj.push(val)
# param_2 = obj.pop()
```
### 思路 1:复杂度分析
- **时间复杂度**:`push` 和 `pop` 操作的时间复杂度都是 $O(1)$。
- **空间复杂度**:$O(n)$,其中 $n$ 是元素的总数。需要存储频率和分组信息。
================================================
FILE: docs/solutions/0800-0899/middle-of-the-linked-list.md
================================================
# [0876. 链表的中间结点](https://leetcode.cn/problems/middle-of-the-linked-list/)
- 标签:链表、双指针
- 难度:简单
## 题目链接
- [0876. 链表的中间结点 - 力扣](https://leetcode.cn/problems/middle-of-the-linked-list/)
## 题目大意
**描述**:给定一个单链表的头节点 `head`。
**要求**:返回链表的中间节点。如果有两个中间节点,则返回第二个中间节点。
**说明**:
- 给定链表的结点数介于 `1` 和 `100` 之间。
**示例**:
- 示例 1:
```python
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
解释:返回的结点值为 3 。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
```
- 示例 2:
```python
输入:[1,2,3,4,5,6]
输出:此列表中的结点 4 (序列化形式:[4,5,6])
解释:由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
```
## 解题思路
### 思路 1:单指针
先遍历一遍链表,统计一下节点个数为 `n`,再遍历到 `n / 2` 的位置,返回中间节点。
### 思路 1:代码
```python
class Solution:
def middleNode(self, head: ListNode) -> ListNode:
n = 0
curr = head
while curr:
n += 1
curr = curr.next
k = 0
curr = head
while k < n // 2:
k += 1
curr = curr.next
return curr
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
### 思路 2:快慢指针
使用步长不一致的快慢指针进行一次遍历找到链表的中间节点。具体做法如下:
1. 使用两个指针 `slow`、`fast`。`slow`、`fast` 都指向链表的头节点。
2. 在循环体中将快、慢指针同时向右移动。其中慢指针每次移动 `1` 步,即 `slow = slow.next`。快指针每次移动 `2` 步,即 `fast = fast.next.next`。
3. 等到快指针移动到链表尾部(即 `fast == Node`)时跳出循环体,此时 `slow` 指向链表中间位置。
4. 返回 `slow` 指针。
### 思路 2:代码
```python
class Solution:
def middleNode(self, head: ListNode) -> ListNode:
fast = head
slow = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/minimum-cost-to-hire-k-workers.md
================================================
# [0857. 雇佣 K 名工人的最低成本](https://leetcode.cn/problems/minimum-cost-to-hire-k-workers/)
- 标签:贪心、数组、排序、堆(优先队列)
- 难度:困难
## 题目链接
- [0857. 雇佣 K 名工人的最低成本 - 力扣](https://leetcode.cn/problems/minimum-cost-to-hire-k-workers/)
## 题目大意
**描述**:
有 $n$ 名工人。 给定两个数组 $quality$ 和 $wage$ ,其中,$quality[i]$ 表示第 $i$ 名工人的工作质量,其最低期望工资为 $wage[i]$。
现在我们想雇佣 $k$ 名工人组成一个 工资组。在雇佣 一组 $k$ 名工人时,我们必须按照下述规则向他们支付工资:
1. 对工资组中的每名工人,应当按其工作质量与同组其他工人的工作质量的比例来支付工资。
2. 工资组中的每名工人至少应当得到他们的最低期望工资。
给定整数 $k$。
**要求**:
返回「组成满足上述条件的付费群体所需的最小金额」。与实际答案误差相差在 $10^{-5}$ 以内的答案将被接受。
**说明**:
- $n == quality.length == wage.length$。
- $1 \le k \le n \le 10^{4}$。
- $1 \le quality[i], wage[i] \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入: quality = [10,20,5], wage = [70,50,30], k = 2
输出: 105.00000
解释: 我们向 0 号工人支付 70,向 2 号工人支付 35。
```
- 示例 2:
```python
输入: quality = [3,1,10,10,1], wage = [4,8,2,2,7], k = 3
输出: 30.66667
解释: 我们向 0 号工人支付 4,向 2 号和 3 号分别支付 13.33333。
```
## 解题思路
### 思路 1:贪心 + 堆
关键观察:如果我们选定了某个工人作为"基准",其工资恰好等于最低期望工资,那么其他工人的工资由他们的工作质量比例决定。
设基准工人的工资期望比为 $r = \frac{wage}{quality}$,那么所有工人的工资期望比都不能超过 $r$,否则无法满足最低工资要求。
算法步骤:
1. 计算每个工人的工资期望比 $ratio[i] = \frac{wage[i]}{quality[i]}$
2. 按照 $ratio$ 从小到大排序
3. 枚举每个工人作为工资期望比最大的工人(基准)
4. 对于当前基准,选择前面 $k-1$ 个工作质量最小的工人,使用大顶堆维护
5. 计算总成本:$ratio \times \sum quality$
### 思路 1:代码
```python
class Solution:
def mincostToHireWorkers(self, quality: List[int], wage: List[int], k: int) -> float:
import heapq
n = len(quality)
# 计算每个工人的工资期望比,并按比例排序
workers = sorted([(wage[i] / quality[i], quality[i]) for i in range(n)])
min_cost = float('inf')
quality_sum = 0 # 当前选中的工人的工作质量之和
max_heap = [] # 大顶堆,存储工作质量(取负数实现大顶堆)
for ratio, q in workers:
# 将当前工人加入堆
heapq.heappush(max_heap, -q)
quality_sum += q
# 如果堆中元素超过 k 个,移除工作质量最大的
if len(max_heap) > k:
quality_sum += heapq.heappop(max_heap) # 注意是负数,所以用加法
# 如果堆中恰好有 k 个工人,计算成本
if len(max_heap) == k:
min_cost = min(min_cost, ratio * quality_sum)
return min_cost
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是工人数量。排序需要 $O(n \log n)$,每个工人最多入堆出堆一次,堆操作需要 $O(n \log k)$。
- **空间复杂度**:$O(n)$,需要存储排序后的工人信息和堆。
================================================
FILE: docs/solutions/0800-0899/minimum-number-of-refueling-stops.md
================================================
# [0871. 最低加油次数](https://leetcode.cn/problems/minimum-number-of-refueling-stops/)
- 标签:贪心、数组、动态规划、堆(优先队列)
- 难度:困难
## 题目链接
- [0871. 最低加油次数 - 力扣](https://leetcode.cn/problems/minimum-number-of-refueling-stops/)
## 题目大意
**描述**:
汽车从起点出发驶向目的地,该目的地位于出发位置东面 $target$ 英里处。
沿途有加油站,用数组 $stations$ 表示。其中 $stations[i] = [position_i, fuel_i] 表示第 $i$ 个加油站位于出发位置东面 $position_i$ 英里处,并且有 $fuel_i$ 升汽油。
假设汽车油箱的容量是无限的,其中最初有 $startFuel$ 升燃料。它每行驶 1 英里就会用掉 1 升汽油。当汽车到达加油站时,它可能停下来加油,将所有汽油从加油站转移到汽车中。
**要求**:
为了到达目的地,汽车所必要的最低加油次数是多少?如果无法到达目的地,则返回 -1。
**说明**:
- 注意:如果汽车到达加油站时剩余燃料为 0,它仍然可以在那里加油。如果汽车到达目的地时剩余燃料为 0,仍然认为它已经到达目的地。
- $1 \le target, startFuel \le 10^{9}$。
- $0 \le stations.length \le 500$。
- $1 \le position_i \lt position_i+1 \lt target$。
- $1 \le fuel_i \lt 10^{9}$。
**示例**:
- 示例 1:
```python
输入:target = 1, startFuel = 1, stations = []
输出:0
解释:可以在不加油的情况下到达目的地。
```
- 示例 2:
```python
输入:target = 100, startFuel = 10, stations = [[10,60],[20,30],[30,30],[60,40]]
输出:2
解释:
出发时有 10 升燃料。
开车来到距起点 10 英里处的加油站,消耗 10 升燃料。将汽油从 0 升加到 60 升。
然后,从 10 英里处的加油站开到 60 英里处的加油站(消耗 50 升燃料),
并将汽油从 10 升加到 50 升。然后开车抵达目的地。
沿途在两个加油站停靠,所以返回 2 。
```
## 解题思路
### 思路 1:贪心 + 堆(优先队列)
这道题要求计算到达目的地所需的最低加油次数。
贪心策略:
- 尽可能少加油,每次加油时选择之前经过的加油站中油量最多的。
- 使用最大堆记录经过的加油站的油量。
算法步骤:
1. 初始化当前位置 $pos = 0$,当前油量 $fuel = startFuel$,加油次数 $count = 0$。
2. 使用最大堆存储经过的加油站的油量。
3. 遍历加油站:
- 如果当前油量不足以到达下一个加油站,从堆中取出最大油量加油,直到能到达或堆为空。
- 如果堆为空仍无法到达,返回 $-1$。
- 将当前加油站的油量加入堆。
4. 检查是否能到达目的地,如果不能,继续加油。
5. 返回加油次数。
### 思路 1:代码
```python
class Solution:
def minRefuelStops(self, target: int, startFuel: int, stations: List[List[int]]) -> int:
import heapq
# 最大堆(Python 的 heapq 是最小堆,所以存储负值)
max_heap = []
fuel = startFuel
count = 0
prev = 0
# 遍历所有加油站
for position, gas in stations:
# 尝试到达当前加油站
fuel -= (position - prev)
# 如果油量不足,从之前经过的加油站中选择油量最多的加油
while fuel < 0 and max_heap:
fuel += -heapq.heappop(max_heap)
count += 1
# 如果仍然无法到达,返回 -1
if fuel < 0:
return -1
# 将当前加油站的油量加入堆
heapq.heappush(max_heap, -gas)
prev = position
# 尝试到达目的地
fuel -= (target - prev)
while fuel < 0 and max_heap:
fuel += -heapq.heappop(max_heap)
count += 1
# 如果仍然无法到达,返回 -1
if fuel < 0:
return -1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是加油站的数量。每个加油站最多入堆和出堆一次。
- **空间复杂度**:$O(n)$,需要使用堆存储加油站的油量。
================================================
FILE: docs/solutions/0800-0899/minimum-swaps-to-make-sequences-increasing.md
================================================
# [0801. 使序列递增的最小交换次数](https://leetcode.cn/problems/minimum-swaps-to-make-sequences-increasing/)
- 标签:数组、动态规划
- 难度:困难
## 题目链接
- [0801. 使序列递增的最小交换次数 - 力扣](https://leetcode.cn/problems/minimum-swaps-to-make-sequences-increasing/)
## 题目大意
给定两个长度相等的整形数组 A 和 B。可以交换两个数组相同位置上的元素,比如 A[i] 与 B[i] 交换,可以交换多个位置,但要保证交换之后保证数组 A和数组 B 是严格递增的。
要求:返回使得数组 A和数组 B 保持严格递增状态的最小交换次数。假设给定的输入一定有效。
## 解题思路
可以用动态规划来做。
对于两个数组每一个位置上的元素 A[i] 和 B[i] 来说,只有两种情况:换或者不换。
动态规划的状态 `dp[i][j]` 表示为:第 i 个位置元素,不交换(j = 0)、交换(j = 1)状态时的最小交换次数。
如果数组元素个数只有一个,则:
- `dp[0][0] = 0` ,第 0 个元素不做交换,交换次数为 0。
- `dp[0][1] = 1`,第 0 个元素做交换,交换次数为 1。
如果有 2 个元素,为了保证两个数组中的相邻元素都为递增元素,则第 2 个元素交换与否与第 1 个元素有关。同理如果有多个元素,那么第 i 个元素交换与否,只与第 i - 1 个元素有关。现在来考虑第 i 个元素与第 i - 1 的元素的情况。
先按原本数组当前是否满足递增关系来划分,可以划分为:
- 原本数组都满足递增关系,即 `A[i - 1] < A[i]` 并且 `B[i - 1] < B[i]`。
- 不满足上述递增关系的情况,即 `A[i - 1] >= A[i]` 或者 `B[i - 1] >= B[i]`。
可以看出,不满足递增关系的情况下是肯定要交换的。只需要考虑交换第 i 位元素,还是第 i - 1 位元素。
- `dp[i][0] = dp[i - 1][1]`,第 i 位如果不交换,则第 i - 1 位必须交换。
- `dp[i][1] = dp[i - 1][0] + 1`,第 i 位交换,则第 i - 1 位不能交换。
下面再来考虑原本数组都满足递增关系的情况。考虑两个数组间相邻元素的关系。
- `A[i - 1] < B[i]` 并且 `B[i - 1] < A[i]`。
- `A[i - 1] >= B[i]` 或者 `B[i - 1] >= A[i]`。
如果是 `A[i - 1] < B[i]` 并且 `B[i - 1] < A[i]` 情况下,第 i 位交换,与第 i - 1 位交换与否无关,则 `dp[i][j]` 只需取 `dp[i-1][j]` 上较小结果进行计算即可,即:
- `dp[i][0] = min(dp[i-1][0], dp[i-1][1])`
- `dp[i][1] = min(dp[i-1][0], dp[i-1][1]) + 1`
如果是 `A[i - 1] >= B[i]` 或者 `B[i - 1] >= A[i]` 情况下,则如果第 i 位交换,则第 i - 1 位必须跟着交换。如果第 i 位不交换,则第 i - 1 为也不能交换,即:
- `dp[i][0] = dp[i - 1][0]`,如果第 i 位不交换,则第 i - 1 位也不交换。
- `dp[i][1] = dp[i - 1][1] + 1`,如果第 i 位交换,则第 i - 1 位也必须交换。
这样就考虑了所有的情况,最终返回最后一个元素,(交换、不交换)状态下的最小值即可。
## 代码
```python
class Solution:
def minSwap(self, nums1: List[int], nums2: List[int]) -> int:
size = len(nums1)
dp = [[0 for _ in range(size)] for _ in range(size)]
dp[0][1] = 1
for i in range(1, size):
if nums1[i - 1] < nums1[i] and nums2[i - 1] < nums2[i]:
if nums1[i - 1] < nums2[i] and nums2[i - 1] < nums1[i]:
# 第 i 位交换,与第 i - 1 位交换与否无关
dp[i][0] = min(dp[i-1][0], dp[i-1][1])
dp[i][1] = min(dp[i-1][0], dp[i-1][1]) + 1
else:
# 如果第 i 位不交换,则第 i - 1 位也不交换
# 如果第 i 位交换,则第 i - 1 位也必须交换
dp[i][0] = dp[i - 1][0]
dp[i][1] = dp[i - 1][1] + 1
else:
dp[i][0] = dp[i - 1][1] # 如果第 i 位如果不交换,则第 i - 1 位必须交换
dp[i][1] = dp[i - 1][0] + 1 # 如果第 i 位交换,则第 i - 1 位不能交换
return min(dp[size - 1][0], dp[size - 1][1])
```
================================================
FILE: docs/solutions/0800-0899/mirror-reflection.md
================================================
# [0858. 镜面反射](https://leetcode.cn/problems/mirror-reflection/)
- 标签:几何、数学、数论
- 难度:中等
## 题目链接
- [0858. 镜面反射 - 力扣](https://leetcode.cn/problems/mirror-reflection/)
## 题目大意
**描述**:
有一个特殊的正方形房间,每面墙上都有一面镜子。除西南角以外,每个角落都放有一个接受器,编号为 0, 1,以及 2。
正方形房间的墙壁长度为 $p$,一束激光从西南角射出,首先会与东墙相遇,入射点到接收器 0 的距离为 $q$。
**要求**:
返回光线最先遇到的接收器的编号(保证光线最终会遇到一个接收器)。
**说明**:
- $1 \le q \le p \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:p = 2, q = 1
输出:2
解释:这条光线在第一次被反射回左边的墙时就遇到了接收器 2 。
```
- 示例 2:
```python
输入:p = 3, q = 1
输入:1
```
## 解题思路
### 思路 1:数学 + 最大公约数
这道题要求计算激光在正方形房间中经过镜面反射后最先遇到的接收器编号。
关键观察:
- 可以将镜面反射问题转换为"展开"问题:将房间沿着镜面展开,激光沿直线传播。
- 激光从 $(0, 0)$ 出发,斜率为 $\frac{q}{p}$,最终会到达某个点 $(m \times p, n \times q)$,其中 $m$ 和 $n$ 是整数。
- 需要找到最小的 $m$ 和 $n$,使得 $(m \times p, n \times q)$ 对应某个接收器。
接收器位置:
- 接收器 $0$:东南角 $(p, 0)$,对应 $m$ 为奇数,$n$ 为偶数。
- 接收器 $1$:东北角 $(p, p)$,对应 $m$ 和 $n$ 都为奇数。
- 接收器 $2$:西北角 $(0, p)$,对应 $m$ 为偶数,$n$ 为奇数。
算法步骤:
1. 计算 $p$ 和 $q$ 的最大公约数 $g$。
2. 化简 $m = \frac{p}{g}$,$n = \frac{q}{g}$。
3. 根据 $m$ 和 $n$ 的奇偶性判断接收器编号。
### 思路 1:代码
```python
class Solution:
def mirrorReflection(self, p: int, q: int) -> int:
from math import gcd
# 计算最大公约数
g = gcd(p, q)
# 化简
m = p // g # 水平方向的反射次数
n = q // g # 垂直方向的反射次数
# 根据奇偶性判断接收器编号
if m % 2 == 1 and n % 2 == 1:
return 1 # 东北角
elif m % 2 == 1 and n % 2 == 0:
return 0 # 东南角
else: # m % 2 == 0 and n % 2 == 1
return 2 # 西北角
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log \min(p, q))$,计算最大公约数的时间复杂度。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/monotonic-array.md
================================================
# [0896. 单调数列](https://leetcode.cn/problems/monotonic-array/)
- 标签:数组
- 难度:简单
## 题目链接
- [0896. 单调数列 - 力扣](https://leetcode.cn/problems/monotonic-array/)
## 题目大意
**描述**:
如果数组是单调递增或单调递减的,那么它是「单调」的。
如果对于所有 $i \le j$,$nums[i] \le nums[j]$,那么数组 $nums$ 是单调递增的。如果对于所有 $i \le j$,$nums[i] \ge nums[j]$,那么数组 $nums$ 是单调递减的。
**要求**:
当给定的数组 $nums$ 是单调数组时返回 true,否则返回 false。
**说明**:
- $1 \le nums.length \le 10^{5}$。
- $-10^{5} \le nums[i] \le 10^{5}$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,2,3]
输出:true
```
- 示例 2:
```python
输入:nums = [6,5,4,4]
输出:true
```
## 解题思路
### 思路 1:一次遍历
这道题要求判断数组是否单调(单调递增或单调递减)。
算法步骤:
1. 使用两个布尔变量 $increasing$ 和 $decreasing$ 分别表示数组是否单调递增和单调递减,初始值都为 $True$。
2. 遍历数组,比较相邻元素:
- 如果 $nums[i] > nums[i-1]$,说明不是单调递减,设置 $decreasing = False$。
- 如果 $nums[i] < nums[i-1]$,说明不是单调递增,设置 $increasing = False$。
3. 最后返回 $increasing$ 或 $decreasing$ 是否为 $True$。
### 思路 1:代码
```python
class Solution:
def isMonotonic(self, nums: List[int]) -> bool:
n = len(nums)
if n <= 1:
return True
# 标记是否单调递增和单调递减
increasing = True
decreasing = True
# 遍历数组,比较相邻元素
for i in range(1, n):
if nums[i] > nums[i - 1]:
decreasing = False # 不是单调递减
if nums[i] < nums[i - 1]:
increasing = False # 不是单调递增
# 只要满足其中一个条件即可
return increasing or decreasing
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组的长度。只需遍历一次数组。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/most-common-word.md
================================================
# [0819. 最常见的单词](https://leetcode.cn/problems/most-common-word/)
- 标签:哈希表、字符串、计数
- 难度:简单
## 题目链接
- [0819. 最常见的单词 - 力扣](https://leetcode.cn/problems/most-common-word/)
## 题目大意
**描述**:给定一个字符串 $paragraph$ 表示段落,再给定搞一个禁用单词列表 $banned$。
**要求**:返回出现次数最多,同时不在禁用列表中的单词。
**说明**:
- 题目保证至少有一个词不在禁用列表中,而且答案唯一。
- 禁用列表 $banned$ 中的单词用小写字母表示,不含标点符号。
- 段落 $paragraph$ 只包含字母、空格和下列标点符号`!?',;.`
- 段落中的单词不区分大小写。
- $1 \le \text{段落长度} \le 1000$。
- $0 \le \text{禁用单词个数} \le 100$。
- $1 \le \text{禁用单词长度} \le 10$。
- 答案是唯一的,且都是小写字母(即使在 $paragraph$ 里是大写的,即使是一些特定的名词,答案都是小写的)。
- 不存在没有连字符或者带有连字符的单词。
- 单词里只包含字母,不会出现省略号或者其他标点符号。
**示例**:
- 示例 1:
```python
输入:
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
banned = ["hit"]
输出: "ball"
解释:
"hit" 出现了3次,但它是一个禁用的单词。
"ball" 出现了2次 (同时没有其他单词出现2次),所以它是段落里出现次数最多的,且不在禁用列表中的单词。
注意,所有这些单词在段落里不区分大小写,标点符号需要忽略(即使是紧挨着单词也忽略, 比如 "ball,"),
"hit"不是最终的答案,虽然它出现次数更多,但它在禁用单词列表中。
```
- 示例 2:
```python
输入:
paragraph = "a."
banned = []
输出:"a"
```
## 解题思路
### 思路 1:哈希表
1. 将禁用词列表转为集合 $banned\_set$。
2. 遍历段落 $paragraph$,获取段落中的所有单词。
3. 判断当前单词是否在禁用词集合中,如果不在禁用词集合中,则使用哈希表对该单词进行计数。
4. 遍历完,找出哈希表中频率最大的单词,将该单词作为答案进行返回。
### 思路 1:代码
```python
class Solution:
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
banned_set = set(banned)
cnts = Counter()
word = ""
for ch in paragraph:
if ch.isalpha():
word += ch.lower()
else:
if word and word not in banned_set:
cnts[word] += 1
word = ""
if word and word not in banned_set:
cnts[word] += 1
max_cnt, ans = 0, ""
for word, cnt in cnts.items():
if cnt > max_cnt:
max_cnt = cnt
ans = word
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 为段落 $paragraph$ 的长度,$m$ 是禁用词 $banned$ 的长度。
- **空间复杂度**:$O(n + m)$。
================================================
FILE: docs/solutions/0800-0899/most-profit-assigning-work.md
================================================
# [0826. 安排工作以达到最大收益](https://leetcode.cn/problems/most-profit-assigning-work/)
- 标签:贪心、数组、双指针、二分查找、排序
- 难度:中等
## 题目链接
- [0826. 安排工作以达到最大收益 - 力扣](https://leetcode.cn/problems/most-profit-assigning-work/)
## 题目大意
**描述**:
你有 $n$ 个工作和 $m$ 个工人。给定三个数组:$difficulty$, $profit$ 和 $worker$,其中:
- $difficulty[i]$ 表示第 $i$ 个工作的难度,$profit[i]$ 表示第 $i$ 个工作的收益。
- $worker[i]$ 是第 $i$ 个工人的能力,即该工人只能完成难度小于等于 $worker[i]$ 的工作。
每个工人「最多」只能安排「一个」工作,但是一个工作可以「完成多次」。
- 举个例子,如果 3 个工人都尝试完成一份报酬为 1 的同样工作,那么总收益为 $3$。如果一个工人不能完成任何工作,他的收益为 0。
**要求**:
返回「在把工人分配到工作岗位后,我们所能获得的最大利润」。
**说明**:
- $n == difficulty.length$。
- $n == profit.length$。
- $m == worker.length$。
- $1 \le n, m \le 10^{4}$。
- $1 \le difficulty[i], profit[i], worker[i] \le 10^{5}$。
**示例**:
- 示例 1:
```python
输入: difficulty = [2,4,6,8,10], profit = [10,20,30,40,50], worker = [4,5,6,7]
输出: 100
解释: 工人被分配的工作难度是 [4,4,6,6] ,分别获得 [20,20,30,30] 的收益。
```
- 示例 2:
```python
输入: difficulty = [85,47,57], profit = [24,66,99], worker = [40,25,25]
输出: 0
```
## 解题思路
### 思路 1:贪心 + 排序 + 双指针
这道题要求安排工人完成工作以达到最大收益。每个工人只能完成一个工作,且工作难度不能超过工人能力。
贪心策略:
- 对于每个工人,选择他能完成的工作中收益最大的。
算法步骤:
1. 将工作按难度排序,同时记录对应的收益。
2. 预处理:对于每个难度,记录到该难度为止的最大收益(因为难度更高的工作收益不一定更高)。
3. 将工人按能力排序。
4. 使用双指针遍历工人和工作:
- 对于每个工人,找到他能完成的所有工作中收益最大的。
- 累加收益。
### 思路 1:代码
```python
class Solution:
def maxProfitAssignment(self, difficulty: List[int], profit: List[int], worker: List[int]) -> int:
# 将工作按难度排序
jobs = sorted(zip(difficulty, profit))
# 预处理:记录到每个难度为止的最大收益
max_profit = 0
for i in range(len(jobs)):
max_profit = max(max_profit, jobs[i][1])
jobs[i] = (jobs[i][0], max_profit)
# 将工人按能力排序
worker.sort()
total_profit = 0
job_idx = 0
# 遍历每个工人
for ability in worker:
# 找到该工人能完成的所有工作中收益最大的
while job_idx < len(jobs) and jobs[job_idx][0] <= ability:
job_idx += 1
# 如果该工人能完成至少一个工作
if job_idx > 0:
total_profit += jobs[job_idx - 1][1]
return total_profit
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n + m \log m)$,其中 $n$ 是工作数量,$m$ 是工人数量。需要对工作和工人排序。
- **空间复杂度**:$O(n)$,需要存储排序后的工作列表。
================================================
FILE: docs/solutions/0800-0899/new-21-game.md
================================================
# [0837. 新 21 点](https://leetcode.cn/problems/new-21-game/)
- 标签:数学、动态规划、滑动窗口、概率与统计
- 难度:中等
## 题目链接
- [0837. 新 21 点 - 力扣](https://leetcode.cn/problems/new-21-game/)
## 题目大意
**描述**:
爱丽丝参与一个大致基于纸牌游戏「21点」规则的游戏,描述如下:
爱丽丝以 0 分开始,并在她的得分少于 $k$ 分时抽取数字。 抽取时,她从 $[1, maxPts]$ 的范围中随机获得一个整数作为分数进行累计,其中 $maxPts$ 是一个整数。每次抽取都是独立的,其结果具有相同的概率。
当爱丽丝获得 $k$ 分或更多分时,她就停止抽取数字。
**要求**:
计算爱丽丝的分数不超过 $n$ 的概率。
**说明**:
- 与实际答案误差不超过 $10^{-5}$ 的答案将被视为正确答案。
- $0 \le k \le n \le 10^{4}$。
- $1 \le maxPts \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:n = 10, k = 1, maxPts = 10
输出:1.00000
解释:爱丽丝得到一张牌,然后停止。
```
- 示例 2:
```python
输入:n = 6, k = 1, maxPts = 10
输出:0.60000
解释:爱丽丝得到一张牌,然后停止。 在 10 种可能性中的 6 种情况下,她的得分不超过 6 分。
```
## 解题思路
### 思路 1:动态规划 + 滑动窗口
定义 $dp[x]$ 表示从分数为 $x$ 的情况开始,最终得分不超过 $n$ 的概率。
状态转移:
- 当 $x \ge k$ 时,游戏停止,如果 $x \le n$,则 $dp[x] = 1$,否则 $dp[x] = 0$
- 当 $x < k$ 时,可以抽取 $[1, maxPts]$ 中的任意数字,每个数字的概率为 $\frac{1}{maxPts}$:
$$dp[x] = \frac{1}{maxPts} \sum_{i=1}^{maxPts} dp[x+i]$$
为了优化计算,我们可以维护一个滑动窗口的和 $sum$,表示 $\sum_{i=x+1}^{x+maxPts} dp[i]$。
### 思路 1:代码
```python
class Solution:
def new21Game(self, n: int, k: int, maxPts: int) -> float:
# 特判:如果 k = 0 或 n >= k + maxPts - 1,概率为 1
if k == 0 or n >= k + maxPts - 1:
return 1.0
# dp[x] 表示从分数 x 开始,最终得分不超过 n 的概率
dp = [0.0] * (n + 1)
dp[0] = 1.0
# sum 表示滑动窗口的和
window_sum = 1.0
for x in range(1, n + 1):
# 当前分数的概率
dp[x] = window_sum / maxPts
if x < k:
# 如果还可以继续抽牌,将当前概率加入窗口
window_sum += dp[x]
# 移除窗口左边界
if x >= maxPts:
window_sum -= dp[x - maxPts]
# 答案是从 0 分开始,最终得分在 [k, n] 范围内的概率
return dp[0] if k == 0 else sum(dp[k:n+1]) / maxPts * maxPts if k > 0 else dp[0]
```
实际上,我们需要重新理解题意。让我重写:
```python
class Solution:
def new21Game(self, n: int, k: int, maxPts: int) -> float:
# 特判
if k == 0 or n >= k + maxPts - 1:
return 1.0
# dp[x] 表示得分为 x 时,最终得分不超过 n 的概率
dp = [0.0] * (k + maxPts)
# 初始化:得分在 [k, n] 范围内的概率为 1
for i in range(k, min(n + 1, k + maxPts)):
dp[i] = 1.0
# 滑动窗口和
window_sum = min(n - k + 1, maxPts)
# 从 k-1 倒推到 0
for x in range(k - 1, -1, -1):
dp[x] = window_sum / maxPts
# 更新窗口:加入 dp[x+1],移除 dp[x+maxPts+1]
window_sum += dp[x]
if x + maxPts < len(dp):
window_sum -= dp[x + maxPts]
return dp[0]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(k + maxPts)$,需要计算 $k + maxPts$ 个状态。
- **空间复杂度**:$O(k + maxPts)$,需要存储 $dp$ 数组。
================================================
FILE: docs/solutions/0800-0899/nth-magical-number.md
================================================
# [0878. 第 N 个神奇数字](https://leetcode.cn/problems/nth-magical-number/)
- 标签:数学、二分查找
- 难度:困难
## 题目链接
- [0878. 第 N 个神奇数字 - 力扣](https://leetcode.cn/problems/nth-magical-number/)
## 题目大意
**描述**:
- 一个正整数如果能被 $a$ 或 $b$ 整除,那么它是神奇的。
给定三个整数 $n$ , $a$, $b$。
**要求**:
返回第 $n$ 个神奇的数字。因为答案可能很大,所以返回答案对 $10^9 + 7$ 取模后的值。
**说明**:
- $1 \le n \le 10^{9}$。
- $2 \le a, b \le 4 \times 10^{4}$。
**示例**:
- 示例 1:
```python
输入:n = 1, a = 2, b = 3
输出:2
```
- 示例 2:
```python
输入:n = 4, a = 2, b = 3
输出:6
```
## 解题思路
### 思路 1:二分查找 + 容斥原理
要找第 $n$ 个神奇数字,我们可以使用二分查找。关键是如何计算不超过 $x$ 的神奇数字个数。
根据容斥原理,不超过 $x$ 的神奇数字个数为:
$$count(x) = \lfloor \frac{x}{a} \rfloor + \lfloor \frac{x}{b} \rfloor - \lfloor \frac{x}{lcm(a,b)} \rfloor$$
其中 $lcm(a,b)$ 是 $a$ 和 $b$ 的最小公倍数,可以通过 $lcm(a,b) = \frac{a \times b}{gcd(a,b)}$ 计算。
二分查找的范围:
- 左边界:$1$
- 右边界:$n \times \min(a, b)$
### 思路 1:代码
```python
class Solution:
def nthMagicalNumber(self, n: int, a: int, b: int) -> int:
import math
MOD = 10**9 + 7
# 计算最小公倍数
lcm = a * b // math.gcd(a, b)
# 计算不超过 x 的神奇数字个数
def count(x):
return x // a + x // b - x // lcm
# 二分查找
left, right = 1, n * min(a, b)
while left < right:
mid = (left + right) // 2
if count(mid) < n:
left = mid + 1
else:
right = mid
return left % MOD
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log(n \times \min(a, b)))$,二分查找的时间复杂度。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/number-of-lines-to-write-string.md
================================================
# [0806. 写字符串需要的行数](https://leetcode.cn/problems/number-of-lines-to-write-string/)
- 标签:数组、字符串
- 难度:简单
## 题目链接
- [0806. 写字符串需要的行数 - 力扣](https://leetcode.cn/problems/number-of-lines-to-write-string/)
## 题目大意
**描述**:给定一个数组 $widths$,其中 $words[0]$ 代表 `'a'` 需要的单位,$words[1]$ 代表 `'b'` 需要的单位,…,$words[25]$ 代表 `'z'` 需要的单位。再给定一个字符串 $s$,现在需要将字符串 $s$ 从左到右写到每一行上,每一行的最大宽度为 $100$ 个单位,如果在写某个字符的时候使改行超过了 $100$ 个单位,那么我们应该将这个字母写到下一行。
**要求**:计算出能放下 $s$ 的最少行数,以及最后一行使用的宽度单位。
**说明**:
- 字符串 $s$ 的长度在 $[1, 1000]$ 的范围。
- $s$ 只包含小写字母。
- $widths$ 是长度为 $26$ 的数组。
- $widths[i]$ 值的范围在 $[2, 10]$。
**示例**:
- 示例 1:
```python
输入:
widths = [10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]
S = "abcdefghijklmnopqrstuvwxyz"
输出: [3, 60]
解释:
所有的字符拥有相同的占用单位10。所以书写所有的26个字母,
我们需要2个整行和占用60个单位的一行。
```
- 示例 2:
```python
输入:
widths = [4,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]
S = "bbbcccdddaaa"
输出: [2, 4]
解释:
除去字母'a'所有的字符都是相同的单位10,并且字符串 "bbbcccdddaa" 将会覆盖 9 * 10 + 2 * 4 = 98 个单位.
最后一个字母 'a' 将会被写到第二行,因为第一行只剩下2个单位了。
所以,这个答案是2行,第二行有4个单位宽度。
```
## 解题思路
### 思路 1:模拟
1. 使用变量 $line\_cnt$ 记录行数,使用变量 $last\_cnt$ 记录最后一行使用的单位数。
2. 遍历字符串,如果当前最后一行使用的单位数 + 当前字符需要的单位超过了 $100$,则:
1. 另起一行填充字符。(即行数加 $1$,最后一行使用的单位数为当前字符宽度)。
3. 如果当前最后一行使用的单位数 + 当前字符需要的单位没有超过 $100$,则:
1. 在当前行填充字符。(即最后一行使用的单位数累加上当前字符宽度)。
### 思路 1:代码
```python
class Solution:
def numberOfLines(self, widths: List[int], s: str) -> List[int]:
line_cnt, last_cnt = 1, 0
for ch in s:
width = widths[ord(ch) - ord('a')]
if last_cnt + width > 100:
line_cnt += 1
last_cnt = width
else:
last_cnt += width
return [line_cnt, last_cnt]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/orderly-queue.md
================================================
# [0899. 有序队列](https://leetcode.cn/problems/orderly-queue/)
- 标签:数学、字符串、排序
- 难度:困难
## 题目链接
- [0899. 有序队列 - 力扣](https://leetcode.cn/problems/orderly-queue/)
## 题目大意
**描述**:
给定一个字符串 $s$ 和一个整数 $k$。你可以从 $s$ 的前 $k$ 个字母中选择一个,并把它加到字符串的末尾。
**要求**:
返回在应用上述步骤的任意数量的移动后,字典序最小的字符串。
**说明**:
- $1 \le k \le S.length \le 10^{3}$。
- $s$ 只由小写字母组成。
**示例**:
- 示例 1:
```python
输入:s = "cba", k = 1
输出:"acb"
解释:
在第一步中,我们将第一个字符(“c”)移动到最后,获得字符串 “bac”。
在第二步中,我们将第一个字符(“b”)移动到最后,获得最终结果 “acb”。
```
- 示例 2:
```python
输入:s = "baaca", k = 3
输出:"aaabc"
解释:
在第一步中,我们将第一个字符(“b”)移动到最后,获得字符串 “aacab”。
在第二步中,我们将第三个字符(“c”)移动到最后,获得最终结果 “aaabc”。
```
## 解题思路
### 思路 1:数学 + 排序
这道题的关键在于分析 $k$ 的不同取值:
1. **当 $k = 1$ 时**:只能将第一个字符移到末尾,相当于字符串的循环移位。我们需要枚举所有可能的循环移位,找到字典序最小的。
2. **当 $k \ge 2$ 时**:可以实现任意两个字符的交换,因此可以得到任意排列。此时答案就是将字符串排序后的结果。
证明 $k \ge 2$ 时可以交换任意两个字符:
- 假设要交换位置 $i$ 和 $j$ 的字符($i < j$)
- 可以通过一系列操作,将这两个字符移到相邻位置,然后交换它们
### 思路 1:代码
```python
class Solution:
def orderlyQueue(self, s: str, k: int) -> str:
if k == 1:
# k = 1 时,枚举所有循环移位
result = s
for i in range(len(s)):
# 将前 i 个字符移到末尾
rotated = s[i:] + s[:i]
if rotated < result:
result = rotated
return result
else:
# k >= 2 时,可以得到任意排列,返回排序后的字符串
return ''.join(sorted(s))
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是字符串的长度。当 $k = 1$ 时,需要枚举 $n$ 种循环移位,每次比较需要 $O(n)$;当 $k \ge 2$ 时,排序需要 $O(n \log n)$。
- **空间复杂度**:$O(n)$,需要存储结果字符串。
================================================
FILE: docs/solutions/0800-0899/peak-index-in-a-mountain-array.md
================================================
# [0852. 山脉数组的峰顶索引](https://leetcode.cn/problems/peak-index-in-a-mountain-array/)
- 标签:数组、二分查找
- 难度:中等
## 题目链接
- [0852. 山脉数组的峰顶索引 - 力扣](https://leetcode.cn/problems/peak-index-in-a-mountain-array/)
## 题目大意
**描述**:给定由整数组成的山脉数组 $arr$。
**要求**:返回任何满足 $arr[0] < arr[1] < ... arr[i - 1] < arr[i] > arr[i + 1] > ... > arr[len(arr) - 1] $ 的下标 $i$。
**说明**:
- **山脉数组**:满足以下属性的数组:
1. $len(arr) \ge 3$;
2. 存在 $i$($0 < i < len(arr) - 1$),使得:
1. $arr[0] < arr[1] < ... arr[i-1] < arr[i]$;
2. $arr[i] > arr[i+1] > ... > arr[len(arr) - 1]$。
- $3 <= arr.length <= 105$
- $0 <= arr[i] <= 106$
- 题目数据保证 $arr$ 是一个山脉数组
**示例**:
- 示例 1:
```python
输入:arr = [0,1,0]
输出:1
```
- 示例 2:
```python
输入:arr = [0,2,1,0]
输出:1
```
## 解题思路
### 思路 1:二分查找
1. 使用两个指针 $left$、$right$ 。$left$ 指向数组第一个元素,$right$ 指向数组最后一个元素。
2. 取区间中间节点 $mid$,并比较 $nums[mid]$ 和 $nums[mid + 1]$ 的值大小。
1. 如果 $nums[mid]< nums[mid + 1]$,则右侧存在峰值,令 `left = mid + 1`。
2. 如果 $nums[mid] \ge nums[mid + 1]$,则左侧存在峰值,令 `right = mid`。
3. 最后,当 $left == right$ 时,跳出循环,返回 $left$。
### 思路 1:代码
```python
class Solution:
def peakIndexInMountainArray(self, arr: List[int]) -> int:
left = 0
right = len(arr) - 1
while left < right:
mid = left + (right - left) // 2
if arr[mid] < arr[mid + 1]:
left = mid + 1
else:
right = mid
return left
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/positions-of-large-groups.md
================================================
# [0830. 较大分组的位置](https://leetcode.cn/problems/positions-of-large-groups/)
- 标签:字符串
- 难度:简单
## 题目链接
- [0830. 较大分组的位置 - 力扣](https://leetcode.cn/problems/positions-of-large-groups/)
## 题目大意
**描述**:给定由小写字母构成的字符串 $s$。字符串 $s$ 包含一些连续的相同字符所构成的分组。
**要求**:找到每一个较大分组的区间,按起始位置下标递增顺序排序后,返回结果。
**说明**:
- **较大分组**:我们称所有包含大于或等于三个连续字符的分组为较大分组。
**示例**:
- 示例 1:
```python
输入:s = "abbxxxxzzy"
输出:[[3,6]]
解释:"xxxx" 是一个起始于 3 且终止于 6 的较大分组。
```
- 示例 2:
```python
输入:s = "abc"
输出:[]
解释:"a","b" 和 "c" 均不是符合要求的较大分组。
```
## 解题思路
### 思路 1:简单模拟
遍历字符串 $s$,统计出所有大于等于 $3$ 个连续字符的子字符串的开始位置与结束位置。具体步骤如下:
1. 令 $cnt = 1$,然后从下标 $1$ 位置开始遍历字符串 $s$。
1. 如果 $s[i - 1] == s[i]$,则令 $cnt$ 加 $1$。
2. 如果 $s[i - 1] \ne s[i]$,说明出现了不同字符,则判断之前连续字符个数 $cnt$ 是否大于等于 $3$。
3. 如果 $cnt \ge 3$,则将对应包含 $cnt$ 个连续字符的子字符串的开始位置与结束位置存入答案数组中。
4. 令 $cnt = 1$,重新开始记录连续字符个数。
2. 遍历完字符串 $s$,输出答案数组。
### 思路 1:代码
```python
class Solution:
def largeGroupPositions(self, s: str) -> List[List[int]]:
res = []
cnt = 1
size = len(s)
for i in range(1, size):
if s[i] == s[i - 1]:
cnt += 1
else:
if cnt >= 3:
res.append([i - cnt, i - 1])
cnt = 1
if cnt >= 3:
res.append([size - cnt, size - 1])
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/possible-bipartition.md
================================================
# [0886. 可能的二分法](https://leetcode.cn/problems/possible-bipartition/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [0886. 可能的二分法 - 力扣](https://leetcode.cn/problems/possible-bipartition/)
## 题目大意
把 n 个人(编号为 1, 2, ... , n)分为任意大小的两组。每个人都可能不喜欢其他人,那么他们不应该属于同一组。
给定表示不喜欢关系的数组 `dislikes`,其中 `dislikes[i] = [a, b]` 表示 `a` 和 `b` 互相不喜欢,不允许将编号 `a` 和 `b` 的人归入同一组。
要求:如果可以以这种方式将所有人分为两组,则返回 `True`;如果不能则返回 `False`。
## 解题思路
先构建图,对于 `dislikes[i] = [a, b]`,在节点 `a` 和 `b` 之间建立一条无向边,然后判断该图是否为二分图。具体做法如下:
- 找到一个没有染色的节点 `u`,将其染成红色。
- 然后遍历该节点直接相连的节点 `v`,如果该节点没有被染色,则将该节点直接相连的节点染成蓝色,表示两个节点不是同一集合。如果该节点已经被染色并且颜色跟 `u` 一样,则说明该图不是二分图,直接返回 `False`。
- 从上面染成蓝色的节点 `v` 出发,遍历该节点直接相连的节点。。。依次类推的递归下去。
- 如果所有节点都顺利染上色,则说明该图为二分图,可以将所有人分为两组,返回 `True`。否则,如果在途中不能顺利染色,不能将所有人分为两组,则返回 `False`。
## 代码
```python
class Solution:
def dfs(self, graph, colors, i, color):
colors[i] = color
for j in graph[i]:
if colors[j] == colors[i]:
return False
if colors[j] == 0 and not self.dfs(graph, colors, j, -color):
return False
return True
def possibleBipartition(self, n: int, dislikes: List[List[int]]) -> bool:
graph = [[] for _ in range(n + 1)]
colors = [0 for _ in range(n + 1)]
for x, y in dislikes:
graph[x].append(y)
graph[y].append(x)
for i in range(1, n + 1):
if colors[i] == 0 and not self.dfs(graph, colors, i, 1):
return False
return True
```
================================================
FILE: docs/solutions/0800-0899/prime-palindrome.md
================================================
# [0866. 回文质数](https://leetcode.cn/problems/prime-palindrome/)
- 标签:数学、数论
- 难度:中等
## 题目链接
- [0866. 回文质数 - 力扣](https://leetcode.cn/problems/prime-palindrome/)
## 题目大意
**描述**:
给定一个整数 $n$。
**要求**:
返回大于或等于 $n$ 的最小 回文质数。
**说明**:
- 一个整数如果恰好有两个除数:1 和它本身,那么它是「质数」。注意,1 不是质数。
- 例如,2、3、5、7、11 和 13 都是质数。
- 一个整数如果从左向右读和从右向左读是相同的,那么它是「回文数」。
- 例如,101 和 12321 都是回文数。
- 测试用例保证答案总是存在,并且在 $[2, 2 \times 10^8]$ 范围内。
- $1 \le n \le 10^{8}$。
**示例**:
- 示例 1:
```python
输入:n = 6
输出:7
```
- 示例 2:
```python
输入:n = 8
输出:11
```
## 解题思路
### 思路 1:数学 + 枚举
关键观察:除了 11 之外,所有偶数位的回文数都能被 11 整除,因此不是质数。
所以我们只需要检查奇数位的回文数即可。
1. 编写判断质数的函数 `is_prime(x)`。
2. 编写判断回文数的函数 `is_palindrome(x)`。
3. 从 $n$ 开始枚举:
- 如果当前数是偶数位且大于 11,直接跳到下一个奇数位的起始位置
- 否则检查是否同时是回文数和质数
4. 返回第一个满足条件的数。
### 思路 1:代码
```python
class Solution:
def primePalindrome(self, n: int) -> int:
# 判断是否为质数
def is_prime(x):
if x < 2:
return False
if x == 2:
return True
if x % 2 == 0:
return False
# 只需检查到 sqrt(x)
i = 3
while i * i <= x:
if x % i == 0:
return False
i += 2
return True
# 判断是否为回文数
def is_palindrome(x):
s = str(x)
return s == s[::-1]
# 特判
if n == 1:
return 2
# 从 n 开始枚举
x = n
while True:
# 如果是偶数位且大于 11,跳到下一个奇数位
s = str(x)
if len(s) % 2 == 0 and x > 11:
# 跳到下一个奇数位的起始位置
x = 10 ** len(s)
continue
# 检查是否同时是回文数和质数
if is_palindrome(x) and is_prime(x):
return x
x += 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(N \sqrt{N})$,其中 $N$ 是答案的大小。需要枚举并检查每个数是否为质数。
- **空间复杂度**:$O(\log N)$,字符串转换需要的空间。
================================================
FILE: docs/solutions/0800-0899/profitable-schemes.md
================================================
# [0879. 盈利计划](https://leetcode.cn/problems/profitable-schemes/)
- 标签:数组、动态规划
- 难度:困难
## 题目链接
- [0879. 盈利计划 - 力扣](https://leetcode.cn/problems/profitable-schemes/)
## 题目大意
**描述**:
集团里有 $n$ 名员工,他们可以完成各种各样的工作创造利润。
第 $i$ 种工作会产生 $profit[i]$ 的利润,它要求 $group[i]$ 名成员共同参与。如果成员参与了其中一项工作,就不能参与另一项工作。
工作的任何至少产生 $minProfit$ 利润的子集称为「盈利计划」。并且工作的成员总数最多为 $n$。
**要求**:
计算出有多少种计划可以选择?因为答案很大,所以 返回结果模 $10^9 + 7$ 的值。
**说明**:
- $1 \le n \le 10^{3}$。
- $0 \le minProfit \le 10^{3}$。
- $1 \le group.length \le 10^{3}$。
- $1 \le group[i] \le 10^{3}$。
- $profit.length == group.length$。
- $0 \le profit[i] \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:n = 5, minProfit = 3, group = [2,2], profit = [2,3]
输出:2
解释:至少产生 3 的利润,该集团可以完成工作 0 和工作 1 ,或仅完成工作 1 。
总的来说,有两种计划。
```
- 示例 2:
```python
输入:n = 10, minProfit = 5, group = [2,3,5], profit = [6,7,8]
输出:7
解释:至少产生 5 的利润,只要完成其中一种工作就行,所以该集团可以完成任何工作。
有 7 种可能的计划:(0),(1),(2),(0,1),(0,2),(1,2),以及 (0,1,2) 。
```
## 解题思路
### 思路 1:三维动态规划
这是一个多维约束的 01 背包问题。我们需要在员工数量不超过 $n$ 的约束下,选择若干工作,使得利润至少为 $minProfit$。
**状态定义**:
定义 $dp[i][j][k]$ 表示考虑前 $i$ 个工作,使用了 $j$ 个员工,获得的利润至少为 $k$ 的方案数。
**状态转移**:
对于第 $i$ 个工作(需要 $group[i-1]$ 个员工,产生 $profit[i-1]$ 利润):
1. **不选择第 $i$ 个工作**:$dp[i][j][k] = dp[i-1][j][k]$
2. **选择第 $i$ 个工作**(前提是 $j \ge group[i-1]$):
- 需要从 $dp[i-1][j-group[i-1]][k-profit[i-1]]$ 转移过来
- 注意:当 $k - profit[i-1] \le 0$ 时,说明利润已经足够,应该从 $dp[i-1][j-group[i-1]][0]$ 转移
- 因此:$dp[i][j][k] += dp[i-1][j-group[i-1]][\max(0, k-profit[i-1])]$
**初始状态**:
$dp[0][0][0] = 1$,表示不选择任何工作,使用 0 个员工,获得 0 利润的方案数为 1。
**答案**:
$\sum_{j=0}^{n} dp[length][j][minProfit]$,即考虑所有工作后,使用不超过 $n$ 个员工,获得至少 $minProfit$ 利润的方案数之和。
### 思路 1:代码
```python
class Solution:
def profitableSchemes(self, n: int, minProfit: int, group: List[int], profit: List[int]) -> int:
MOD = 10**9 + 7
length = len(group)
# dp[i][j][k] 表示考虑前 i 个工作,使用 j 个员工,获得至少 k 利润的方案数
dp = [[[0] * (minProfit + 1) for _ in range(n + 1)] for _ in range(length + 1)]
# 初始状态:不选择任何工作,使用 0 个员工,获得 0 利润
dp[0][0][0] = 1
# 枚举每个工作
for i in range(1, length + 1):
members = group[i - 1] # 第 i 个工作需要的员工数
earn = profit[i - 1] # 第 i 个工作产生的利润
# 枚举员工数
for j in range(n + 1):
# 枚举利润
for k in range(minProfit + 1):
# 不选择第 i 个工作
dp[i][j][k] = dp[i - 1][j][k]
# 选择第 i 个工作(需要足够的员工)
if j >= members:
# 利润超过 minProfit 的部分都算作 minProfit
prev_profit = max(0, k - earn)
dp[i][j][k] = (dp[i][j][k] + dp[i - 1][j - members][prev_profit]) % MOD
# 统计答案:使用不超过 n 个员工,获得至少 minProfit 利润的方案数
result = 0
for j in range(n + 1):
result = (result + dp[length][j][minProfit]) % MOD
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(length \times n \times minProfit)$,其中 $length$ 是工作数量。需要填充三维 $dp$ 数组。
- **空间复杂度**:$O(length \times n \times minProfit)$,需要存储三维 $dp$ 数组。可以使用滚动数组优化到 $O(n \times minProfit)$。
================================================
FILE: docs/solutions/0800-0899/projection-area-of-3d-shapes.md
================================================
# [0883. 三维形体投影面积](https://leetcode.cn/problems/projection-area-of-3d-shapes/)
- 标签:几何、数组、数学、矩阵
- 难度:简单
## 题目链接
- [0883. 三维形体投影面积 - 力扣](https://leetcode.cn/problems/projection-area-of-3d-shapes/)
## 题目大意
**描述**:
在 $n \times n$ 的网格 $grid$ 中,我们放置了一些与 $x$,$y$,$z$ 三轴对齐的 $1 \times 1 \times 1$ 立方体。
每个值 $v = grid[i][j]$ 表示有一列 $v$ 个正方体叠放在格子 $(i, j)$ 上。
现在,我们查看这些立方体在 $xy$、$yz$ 和 $zx$ 平面上的投影。
「投影」就像影子,将「三维」形体映射到一个「二维」平面上。从顶部、前面和侧面看立方体时,我们会看到「影子」。
**要求**:
返回「所有三个投影的总面积」。
**说明**:
- $n == grid.length == grid[i].length$。
- $1 \le n \le 50$。
- $0 \le grid[i][j] \le 50$。
**示例**:
- 示例 1:
```python
输入:[[1,2],[3,4]]
输出:17
解释:这里有该形体在三个轴对齐平面上的三个投影(“阴影部分”)。
```
- 示例 2:
```python
输入:grid = [[2]]
输出:5
```
## 解题思路
### 思路 1:数学 + 模拟
三维形体在三个平面上的投影面积分别为:
1. **xy 平面(俯视图)**:每个非零格子贡献 1 的面积,即统计非零格子的个数。
2. **yz 平面(正视图)**:每一行的最大值之和,因为从前面看,每一行的高度由该行最高的立方体决定。
3. **zx 平面(侧视图)**:每一列的最大值之和,因为从侧面看,每一列的高度由该列最高的立方体决定。
### 思路 1:代码
```python
class Solution:
def projectionArea(self, grid: List[List[int]]) -> int:
n = len(grid)
xy_area = 0 # xy 平面投影面积
yz_area = 0 # yz 平面投影面积
zx_area = 0 # zx 平面投影面积
for i in range(n):
row_max = 0 # 第 i 行的最大值
col_max = 0 # 第 i 列的最大值
for j in range(n):
# 统计非零格子
if grid[i][j] > 0:
xy_area += 1
# 更新行最大值
row_max = max(row_max, grid[i][j])
# 更新列最大值
col_max = max(col_max, grid[j][i])
yz_area += row_max
zx_area += col_max
return xy_area + yz_area + zx_area
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是网格的边长。需要遍历整个网格。
- **空间复杂度**:$O(1)$,只使用常数额外空间。
================================================
FILE: docs/solutions/0800-0899/push-dominoes.md
================================================
# [0838. 推多米诺](https://leetcode.cn/problems/push-dominoes/)
- 标签:双指针、字符串、动态规划
- 难度:中等
## 题目链接
- [0838. 推多米诺 - 力扣](https://leetcode.cn/problems/push-dominoes/)
## 题目大意
**描述**:
$n$ 张多米诺骨牌排成一行,将每张多米诺骨牌垂直竖立。在开始时,同时把一些多米诺骨牌向左或向右推。
每过一秒,倒向左边的多米诺骨牌会推动其左侧相邻的多米诺骨牌。同样地,倒向右边的多米诺骨牌也会推动竖立在其右侧的相邻多米诺骨牌。
如果一张垂直竖立的多米诺骨牌的两侧同时有多米诺骨牌倒下时,由于受力平衡,「该骨牌仍然保持不变」。
就这个问题而言,我们会认为一张正在倒下的多米诺骨牌不会对其它正在倒下或已经倒下的多米诺骨牌施加额外的力。
给定一个字符串 $dominoes$ 表示这一行多米诺骨牌的初始状态,其中:
- $dominoes[i] = 'L'$,表示第 $i$ 张多米诺骨牌被推向左侧,
- $dominoes[i] = 'R'$,表示第 $i$ 张多米诺骨牌被推向右侧,
- $dominoes[i] = '.'$,表示没有推动第 $i$ 张多米诺骨牌。
**要求**:
返回表示最终状态的字符串。
**说明**:
- $n == dominoes.length$。
- $1 \le n \le 10^{5}$。
- $dominoes[i]$ 为 `'L'`、`'R'` 或 `'.'`。
**示例**:
- 示例 1:
```python
输入:dominoes = "RR.L"
输出:"RR.L"
解释:第一张多米诺骨牌没有给第二张施加额外的力。
```
- 示例 2:
```python
输入:dominoes = ".L.R...LR..L.."
输出:"LL.RR.LLRRLL.."
```
## 解题思路
### 思路 1:双指针 + 模拟
多米诺骨牌的最终状态取决于相邻的 `R` 和 `L` 之间的关系。我们可以用双指针来标记相邻的两个非 `.` 字符,然后根据它们的组合来决定中间部分的状态。
1. 在字符串首尾分别添加虚拟的 `L` 和 `R`,方便处理边界情况。
2. 使用两个指针 $left$ 和 $right$,分别指向相邻的两个非 `.` 字符。
3. 根据 $dominoes[left]$ 和 $dominoes[right]$ 的组合,分四种情况处理:
- `R...R`:中间全部变为 `R`
- `L...L`:中间全部变为 `L`
- `R...L`:中间部分向两边倒,中心位置保持不变(如果距离为奇数)
- `L...R`:中间部分保持不变
### 思路 1:代码
```python
class Solution:
def pushDominoes(self, dominoes: str) -> str:
# 在首尾添加虚拟字符,方便处理边界
dominoes = 'L' + dominoes + 'R'
n = len(dominoes)
res = []
left = 0 # 左指针
for right in range(1, n):
# 找到下一个非 '.' 的字符
if dominoes[right] == '.':
continue
# 计算中间 '.' 的个数
middle = right - left - 1
# 添加左边界字符(跳过最开始的虚拟 'L')
if left > 0:
res.append(dominoes[left])
# 根据左右字符的组合处理中间部分
if dominoes[left] == dominoes[right]:
# R...R 或 L...L,中间全部变为相同字符
res.append(dominoes[left] * middle)
elif dominoes[left] == 'R' and dominoes[right] == 'L':
# R...L,向中间倒
res.append('R' * (middle // 2))
if middle % 2 == 1:
res.append('.') # 中心位置保持不变
res.append('L' * (middle // 2))
else:
# L...R,中间保持不变
res.append('.' * middle)
left = right
return ''.join(res)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串 $dominoes$ 的长度。只需遍历一次字符串。
- **空间复杂度**:$O(n)$,需要存储结果字符串。
================================================
FILE: docs/solutions/0800-0899/race-car.md
================================================
# [0818. 赛车](https://leetcode.cn/problems/race-car/)
- 标签:动态规划
- 难度:困难
## 题目链接
- [0818. 赛车 - 力扣](https://leetcode.cn/problems/race-car/)
## 题目大意
**描述**:
你的赛车可以从位置 0 开始,并且速度为 +1,在一条无限长的数轴上行驶。赛车也可以向负方向行驶。赛车可以按照由加速指令 `'A'` 和倒车指令 `'R'` 组成的指令序列自动行驶。
- 当收到指令 `'A'` 时,赛车这样行驶:
- $position += speed$
- $speed *= 2$
- 当收到指令 `'R'` 时,赛车这样行驶:
- 如果速度为正数,那么 $speed = -1$
- 否则 $speed = 1$
当前所处位置不变。
例如,在执行指令 `"AAR"` 后,赛车位置变化为 $0 \rightarrow 1 \rightarrow 3 \rightarrow 3$,速度变化为 $1 \rightarrow 2 \rightarrow 4 \rightarrow -1$。
给定一个目标位置 $target$。
**要求**:
返回能到达目标位置的最短指令序列的长度。
**说明**:
- $1 \le target \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:target = 3
输出:2
解释:
最短指令序列是 "AA" 。
位置变化 0 --> 1 --> 3 。
```
- 示例 2:
```python
输入:target = 6
输出:5
解释:
最短指令序列是 "AAARA" 。
位置变化 0 --> 1 --> 3 --> 7 --> 7 --> 6 。
```
## 解题思路
### 思路 1:动态规划
定义 $dp[i]$ 表示到达位置 $i$ 所需的最少指令数。
对于位置 $target$,有两种策略:
1. **直接到达或超过**:连续执行 $n$ 次 `A`,可以到达位置 $2^n - 1$。
- 如果 $2^n - 1 = target$,则 $dp[target] = n$
- 如果 $2^n - 1 > target$,需要先到达 $2^n - 1$,然后倒车回到 $target$
2. **先前进再倒车**:先执行 $n$ 次 `A` 到达 $2^n - 1$,然后执行 `R` 倒车,再执行 $m$ 次 `A` 后退 $2^m - 1$,最后再执行 `R` 前进,到达剩余距离。
- 总指令数为:$n + 1 + m + 1 + dp[2^n - 1 - (2^m - 1) - target]$
### 思路 1:代码
```python
class Solution:
def racecar(self, target: int) -> int:
dp = [0] * (target + 1)
for i in range(1, target + 1):
# 找到最小的 n,使得 2^n - 1 >= i
n = i.bit_length()
# 情况 1:恰好到达
if (1 << n) - 1 == i:
dp[i] = n
continue
# 情况 2:超过后倒车回来
# 先走 n 步到达 2^n - 1,然后倒车,再走到 i
dp[i] = n + 1 + dp[(1 << n) - 1 - i]
# 情况 3:先走 n-1 步,然后倒车,再前进
# 枚举倒车时前进的步数 m
for m in range(n - 1):
# 先走 n-1 步到达 2^(n-1) - 1
# 倒车(R)
# 前进 m 步到达 2^(n-1) - 1 - (2^m - 1)
# 再倒车(R)
# 继续前进到 i
pos = (1 << (n - 1)) - 1 - ((1 << m) - 1)
dp[i] = min(dp[i], (n - 1) + 1 + m + 1 + dp[i - pos])
return dp[target]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(target \log target)$,对于每个位置,需要枚举 $O(\log target)$ 种倒车策略。
- **空间复杂度**:$O(target)$,需要存储 $dp$ 数组。
================================================
FILE: docs/solutions/0800-0899/reachable-nodes-in-subdivided-graph.md
================================================
# [0882. 细分图中的可到达节点](https://leetcode.cn/problems/reachable-nodes-in-subdivided-graph/)
- 标签:图、最短路、堆(优先队列)
- 难度:困难
## 题目链接
- [0882. 细分图中的可到达节点 - 力扣](https://leetcode.cn/problems/reachable-nodes-in-subdivided-graph/)
## 题目大意
**描述**:
给定一个无向图(原始图),图中有 $n$ 个节点,编号从 0 到 $n - 1$ 。你决定将图中的每条边「细分」为一条节点链,每条边之间的新节点数各不相同。
图用由边组成的二维数组 $edges$ 表示,其中 $edges[i] = [u_i, v_i, cnt_i]$ 表示原始图中节点 $u_i$ 和 $v_i$ 之间存在一条边,$cnt_i$ 是将边「细分」后的新节点总数。注意,$cnt_i == 0$ 表示边不可细分。
要「」边 $[u_i, v_i]$ ,需要将其替换为 $(cnt_i + 1)$ 条新边,和 $cnt_i$ 个新节点。新节点为 $x1, x2, ..., xcnt_i$,新边为 $[ui, x1], [x1, x2], [x2, x3], ..., [xcnt_i-1, xcnt_i], [xcnt_i, v_i]$。
现在得到一个「新的细分图」,请你计算从节点 0 出发,可以到达多少个节点?如果节点间距离是 $maxMoves$ 或更少,则视为 可以到达。
给定原始图和 $maxMoves$。
**要求**:
返回「新的细分图中从节点 0 出发 可到达的节点数」。
**说明**:
- $0 \le edges.length \le min(n \times (n - 1) / 2, 10^{4})$。
- $edges[i].length == 3$。
- $0 \le u_i \lt v_i \lt n$。
- 图中「不存在平行边」。
- $0 \le cnt_i \le 10^{4}$。
- $0 \le maxMoves \le 10^{9}$。
- $1 \le n \le 3000$。
**示例**:
- 示例 1:
```python
输入:edges = [[0,1,10],[0,2,1],[1,2,2]], maxMoves = 6, n = 3
输出:13
解释:边的细分情况如上图所示。
可以到达的节点已经用黄色标注出来。
```
- 示例 2:
```python
输入:edges = [[0,1,4],[1,2,6],[0,2,8],[1,3,1]], maxMoves = 10, n = 4
输出:23
```
## 解题思路
### 思路 1:Dijkstra 最短路
这道题的关键是:从节点 0 出发,在 $maxMoves$ 步内能到达多少个节点(包括原始节点和细分后的新节点)。
使用 Dijkstra 算法计算从节点 0 到其他所有节点的最短距离。对于每条边:
- 如果能从两端都到达这条边,需要避免重复计数中间的新节点
- 从节点 $u$ 出发,能到达边上的新节点数为 $\min(cnt, maxMoves - dist[u])$
- 从节点 $v$ 出发,能到达边上的新节点数为 $\min(cnt, maxMoves - dist[v])$
- 这条边上能到达的新节点总数为 $\min(cnt, \text{从u到达的数量} + \text{从v到达的数量})$
### 思路 1:代码
```python
class Solution:
def reachableNodes(self, edges: List[List[int]], maxMoves: int, n: int) -> int:
import heapq
from collections import defaultdict
# 构建图
graph = defaultdict(dict)
for u, v, cnt in edges:
graph[u][v] = cnt
graph[v][u] = cnt
# Dijkstra 算法
dist = [float('inf')] * n
dist[0] = 0
heap = [(0, 0)] # (距离, 节点)
visited = set()
while heap:
d, u = heapq.heappop(heap)
if u in visited:
continue
visited.add(u)
# 更新相邻节点的距离
for v, cnt in graph[u].items():
# 到达节点 v 需要的步数:到达 u 的步数 + 边上的新节点数 + 1
new_dist = d + cnt + 1
if new_dist < dist[v]:
dist[v] = new_dist
heapq.heappush(heap, (new_dist, v))
# 统计可到达的节点数
result = 0
# 统计原始节点
for i in range(n):
if dist[i] <= maxMoves:
result += 1
# 统计边上的新节点
for u, v, cnt in edges:
# 从 u 出发能到达的新节点数
from_u = max(0, maxMoves - dist[u]) if dist[u] <= maxMoves else 0
# 从 v 出发能到达的新节点数
from_v = max(0, maxMoves - dist[v]) if dist[v] <= maxMoves else 0
# 这条边上能到达的新节点总数(避免重复计数)
result += min(cnt, from_u + from_v)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O((n + m) \log n)$,其中 $n$ 是节点数,$m$ 是边数。Dijkstra 算法的时间复杂度。
- **空间复杂度**:$O(n + m)$,需要存储图和距离数组。
================================================
FILE: docs/solutions/0800-0899/rectangle-area-ii.md
================================================
# [0850. 矩形面积 II](https://leetcode.cn/problems/rectangle-area-ii/)
- 标签:线段树、数组、有序集合、扫描线
- 难度:困难
## 题目链接
- [0850. 矩形面积 II - 力扣](https://leetcode.cn/problems/rectangle-area-ii/)
## 题目大意
**描述**:给定一个二维矩形列表 `rectangles`,其中 `rectangle[i] = [x1, y1, x2, y2]` 表示第 `i` 个矩形,`(x1, y1)` 是第 `i` 个矩形左下角的坐标,`(x2, y2)` 是第 `i` 个矩形右上角的坐标。。
**要求**:计算 `rectangles` 中所有矩形所覆盖的总面积,并返回总面积。
**说明**:
- 任何被两个或多个矩形覆盖的区域应只计算一次 。
- 因为答案可能太大,返回 $10^9 + 7$ 的模。
- $1 \le rectangles.length \le 200$。
- $rectanges[i].length = 4$。
- $0 \le x_1, y_1, x_2, y_2 \le 10^9$。
- 矩形叠加覆盖后的总面积不会超越 $2^63 - 1$,这意味着可以用一个 $64$ 位有符号整数来保存面积结果。
**示例**:
- 示例 1:
```python
输入:rectangles = [[0,0,2,2],[1,0,2,3],[1,0,3,1]]
输出:6
解释:如图所示,三个矩形覆盖了总面积为6的区域。
从 (1,1) 到 (2,2),绿色矩形和红色矩形重叠。
从 (1,0) 到 (2,3),三个矩形都重叠。
```
## 解题思路
### 思路 1:扫描线 + 动态开点线段树
### 思路 1:扫描线 + 动态开点线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, cnt=0, height=0, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.cnt = cnt # 节点值(区间值)
self.height = height # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self):
self.tree = SegTreeNode(0, int(1e9))
# 区间更新接口:将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 以下为内部实现方法
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, node):
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
node.cnt += val # 当前节点所在区间每个元素值改为 val
self.__pushup(node)
return
self.__pushdown(node)
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询实现方法:在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.height # 直接返回节点值
self.__pushdown(node)
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, node.mid, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(node.mid + 1, q_right, node.rightNode)
return res_left + res_right # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新 node 节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.cnt > 0:
node.height = node.right - node.left + 1
else:
if node.leftNode and node.rightNode:
node.height = node.leftNode.height + node.rightNode.height
else:
node.height = 0
# 向下更新实现方法:更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
class Solution:
def rectangleArea(self, rectangles) -> int:
# lines 存储每个矩阵的上下两条边
lines = []
for rectangle in rectangles:
x1, y1, x2, y2 = rectangle
lines.append([x1, y1 + 1, y2, 1])
lines.append([x2, y1 + 1, y2, -1])
lines.sort(key=lambda line: line[0])
# 建立线段树
self.STree = SegmentTree()
ans = 0
mod = 10 ** 9 + 7
prev_x = lines[0][0]
for i in range(len(lines)):
x, y1, y2, val = lines[i]
height = self.STree.query_interval(0, int(1e9))
ans += height * (x - prev_x)
ans %= mod
self.STree.update_interval(y1, y2, val)
prev_x = x
return ans
```
## 参考资料
- 【文章】[【hdu1542】线段树求矩形面积并 - 拦路雨偏似雪花](https://www.cnblogs.com/KonjakJuruo/p/6024266.html)
================================================
FILE: docs/solutions/0800-0899/rectangle-overlap.md
================================================
# [0836. 矩形重叠](https://leetcode.cn/problems/rectangle-overlap/)
- 标签:几何、数学
- 难度:简单
## 题目链接
- [0836. 矩形重叠 - 力扣](https://leetcode.cn/problems/rectangle-overlap/)
## 题目大意
给定两个矩形的左下角、右上角坐标:[x1, y1, x2, y2]。[x1, y1] 表示左下角坐标,[x2, y2] 表示右上角坐标。如果两个矩形相交面积大于 0,则称两矩形重叠。
要求:根据给定的矩形 rec1 和 rec2 的左下角、右上角坐标,如果重叠,则返回 True,否则返回 False。
## 解题思路
如果两个矩形重叠,则两个矩形的水平边投影到 x 轴上的线段会有交集,同理竖直边投影到 y 轴上的线段也会有交集。因此我们可以把问题看做是:判断两条线段是否有交集。
矩形 rec1 和 rec2 水平边投影到 x 轴上的线段为 `(rec1[0], rec1[2])` 和 `(rec2[0], rec2[2])`。如果两条线段有交集,则 `min(rec1[2], rec2[2]) > max(rec1[0], rec2[0])`。
矩形 rec1 和 rec2 竖直边投影到 y 轴上的线段为 `(rec1[1], rec1[3])` 和 `(rec2[1], rec2[3])`。如果两条线段有交集,则 `min(rec1[3], rec2[3]) > max(rec1[1], rec2[1])`。
判断是否满足上述条件,如果满足则说明两个矩形重叠,返回 True,如果不满足则返回 False。
## 代码
```python
class Solution:
def isRectangleOverlap(self, rec1: List[int], rec2: List[int]) -> bool:
return min(rec1[2], rec2[2]) > max(rec1[0], rec2[0]) and min(rec1[3], rec2[3]) > max(rec1[1], rec2[1])
```
================================================
FILE: docs/solutions/0800-0899/reordered-power-of-2.md
================================================
# [0869. 重新排序得到 2 的幂](https://leetcode.cn/problems/reordered-power-of-2/)
- 标签:哈希表、数学、计数、枚举、排序
- 难度:中等
## 题目链接
- [0869. 重新排序得到 2 的幂 - 力扣](https://leetcode.cn/problems/reordered-power-of-2/)
## 题目大意
**描述**:
给定正整数 $n$,我们按任何顺序(包括原始顺序)将数字重新排序,注意其前导数字不能为零。
**要求**:
如果我们可以通过上述方式得到 2 的幂,返回 true;否则,返回 false。
**说明**:
- $1 \le n \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:n = 1
输出:true
```
- 示例 2:
```python
输入:n = 10
输出:false
```
## 解题思路
### 思路 1:计数 + 枚举
判断一个数能否重新排列成 2 的幂,关键在于判断它的数字组成是否与某个 2 的幂相同。
由于 $1 \le n \le 10^9$,所以 2 的幂最多到 $2^{29} = 536870912$。我们可以:
1. 统计 $n$ 中每个数字出现的次数。
2. 枚举所有在范围内的 2 的幂 $2^i$($i = 0, 1, 2, \ldots, 29$)。
3. 统计每个 2 的幂中各数字出现的次数。
4. 如果某个 2 的幂的数字计数与 $n$ 的数字计数完全相同,返回 `True`。
### 思路 1:代码
```python
class Solution:
def reorderedPowerOf2(self, n: int) -> bool:
# 统计 n 中每个数字出现的次数
def count_digits(num):
cnt = [0] * 10
while num > 0:
cnt[num % 10] += 1
num //= 10
return cnt
n_count = count_digits(n)
# 枚举所有可能的 2 的幂(2^0 到 2^29)
for i in range(30):
power = 1 << i # 2^i
if count_digits(power) == n_count:
return True
return False
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n + 30 \times \log C)$,其中 $C = 10^9$。统计 $n$ 的数字需要 $O(\log n)$,枚举 30 个 2 的幂并统计数字需要 $O(30 \times \log C)$。
- **空间复杂度**:$O(1)$,只需要常数大小的数组来存储数字计数。
================================================
FILE: docs/solutions/0800-0899/score-after-flipping-matrix.md
================================================
# [0861. 翻转矩阵后的得分](https://leetcode.cn/problems/score-after-flipping-matrix/)
- 标签:贪心、位运算、数组、矩阵
- 难度:中等
## 题目链接
- [0861. 翻转矩阵后的得分 - 力扣](https://leetcode.cn/problems/score-after-flipping-matrix/)
## 题目大意
**描述**:给定一个二维矩阵 `A`,其中每个元素的值为 `0` 或 `1`。
我们可以选择任一行或列,并转换该行或列中的每一个值:将所有 `0` 都更改为 `1`,将所有 `1` 都更改为 `0`。
在做出任意次数的移动后,将该矩阵的每一行都按照二进制数来解释,矩阵的得分就是这些数字的总和。
**要求**:返回尽可能高的分数。
**说明**:
- $1 \le A.length \le 20$。
- $1 \le A[0].length \le 20$。
- `A[i][j]` 值为 `0` 或 `1`。
**示例**:
- 示例 1:
```python
输入:[[0,0,1,1],[1,0,1,0],[1,1,0,0]]
输出:39
解释:
转换为 [[1,1,1,1],[1,0,0,1],[1,1,1,1]]
0b1111 + 0b1001 + 0b1111 = 15 + 9 + 15 = 39
```
## 解题思路
### 思路 1:贪心算法
对于一个二进制数来说,应该优先保证高位(靠前的列)尽可能的大,也就是保证高位尽可能值为 `1`。
- 我们先来看矩阵的第一列数,只要第一列的某一行为 `0`,则将这一行的值进行翻转。这样就保证了最高位一定为 `1`。
- 接下来,我们再来关注除了第一列的其他列,这里因为有最高位限制,所以我们不能随意再将某一行的值进行翻转,只能选择某一列进行翻转。
- 为了保证当前位上有尽可能多的 `1`。我们可以用两个变量 `one_cnt`、`zeo_cnt` 来记录当前列上 `1` 的个数和 `0` 的个数。如果 `0` 的个数多于 `1` 的个数,那么我们就将当前列进行翻转。从而保证当前位上有尽可能多的 `1`。
- 当所有列都遍历完成后,我们会得到加和最大的情况。
### 思路 1:贪心算法代码
```python
class Solution:
def matrixScore(self, grid: List[List[int]]) -> int:
zero_cnt, one_cnt = 0, 0
res = 0
rows, cols = len(grid), len(grid[0])
for col in range(cols):
for row in range(rows):
if col == 0 and grid[row][col] == 0:
for j in range(cols):
grid[row][j] = 1 - grid[row][j]
else:
if grid[row][col] == 1:
one_cnt += 1
else:
zero_cnt += 1
if zero_cnt > one_cnt:
for row in range(rows):
grid[row][col] = 1 - grid[row][col]
for row in range(rows):
if grid[row][col] == 1:
res += pow(2, cols - col - 1)
zero_cnt = 0
one_cnt = 0
return res
```
================================================
FILE: docs/solutions/0800-0899/score-of-parentheses.md
================================================
# [0856. 括号的分数](https://leetcode.cn/problems/score-of-parentheses/)
- 标签:栈、字符串
- 难度:中等
## 题目链接
- [0856. 括号的分数 - 力扣](https://leetcode.cn/problems/score-of-parentheses/)
## 题目大意
**描述**:
给定一个平衡括号字符串 $S$,按下述规则计算该字符串的分数:
- `()` 得 1 分。
- `AB` 得 $A + B$ 分,其中 $A$ 和 $B$ 是平衡括号字符串。
- `(A)` 得 $2 \times A$ 分,其中 $A$ 是平衡括号字符串。
**要求**:
返回该字符串的分数。
**说明**:
- $S$ 是平衡括号字符串,且只含有 `(` 和 `)`。
- $2 \le S.length \le 50$。
**示例**:
- 示例 1:
```python
输入: "()()"
输出: 2
```
- 示例 2:
```python
输入: "(()(()))"
输出: 6
```
## 解题思路
### 思路 1:栈
根据题意,括号的分数计算规则为:
- `()` 得 1 分
- `AB` 得 $A + B$ 分
- `(A)` 得 $2 \times A$ 分
我们可以使用栈来模拟这个过程:
1. 遍历字符串 $s$,用栈来记录每一层的分数。
2. 遇到 `(` 时,将 0 压入栈中,表示新的一层开始。
3. 遇到 `)` 时:
- 弹出栈顶元素 $cur$
- 如果 $cur = 0$,说明是 `()`,得 1 分
- 否则说明是 `(A)`,得 $2 \times cur$ 分
- 将得分加到新的栈顶(上一层)
4. 最后栈中只剩一个元素,即为总分数。
### 思路 1:代码
```python
class Solution:
def scoreOfParentheses(self, s: str) -> int:
stack = [0] # 初始化栈,栈底为 0
for ch in s:
if ch == '(':
# 遇到左括号,新的一层开始
stack.append(0)
else:
# 遇到右括号,计算当前层的分数
cur = stack.pop()
if cur == 0:
# () 的情况,得 1 分
score = 1
else:
# (A) 的情况,得 2 * A 分
score = 2 * cur
# 将分数加到上一层
stack[-1] += score
return stack[0]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。需要遍历一次字符串。
- **空间复杂度**:$O(n)$,栈的空间复杂度最坏情况下为 $O(n)$。
================================================
FILE: docs/solutions/0800-0899/shifting-letters copy.md
================================================
# [0848. 字母移位](https://leetcode.cn/problems/shifting-letters/)
- 标签:数组、字符串、前缀和
- 难度:中等
## 题目链接
- [0848. 字母移位 - 力扣](https://leetcode.cn/problems/shifting-letters/)
## 题目大意
**描述**:
有一个由小写字母组成的字符串 $s$,和一个长度相同的整数数组 $shifts$。
我们将字母表中的下一个字母称为原字母的「移位 `shift()`」 (由于字母表是环绕的, `'z'` 将会变成 `'a'`)。
- 例如,`shift('a') = 'b'`, `shift('t') = 'u'`, 以及 `shift('z') = 'a'`。
对于每个 $shifts[i] = x$,我们会将 $s$ 中的前 $i + 1$ 个字母移位 $x$ 次。
**要求**:
返回「将所有这些移位都应用到 $s$ 后最终得到的字符串」。
**说明**:
- $1 \le s.length \le 10^{5}$。
- $s$ 由小写英文字母组成。
- $shifts.length == s.length$。
- $0 \le shifts[i] \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:s = "abc", shifts = [3,5,9]
输出:"rpl"
解释:
我们以 "abc" 开始。
将 S 中的第 1 个字母移位 3 次后,我们得到 "dbc"。
再将 S 中的前 2 个字母移位 5 次后,我们得到 "igc"。
最后将 S 中的这 3 个字母移位 9 次后,我们得到答案 "rpl"。
```
- 示例 2:
```python
输入:
输出:
```
## 解题思路
### 思路 1:后缀和
根据题意,对于位置 $i$ 的字符,它需要移位的总次数为 $\sum_{j=i}^{n-1} shifts[j]$。
如果直接计算每个位置的移位次数,时间复杂度为 $O(n^2)$,会超时。我们可以使用后缀和来优化:
1. 从后向前遍历 $shifts$ 数组,计算后缀和 $total$。
2. 对于位置 $i$,其移位次数为 $total$。
3. 将字符 $s[i]$ 移位 $total \bmod 26$ 次(因为字母表是循环的)。
4. 更新 $total$ 为下一个位置的后缀和。
### 思路 1:代码
```python
class Solution:
def shiftingLetters(self, s: str, shifts: List[int]) -> str:
n = len(s)
res = []
total = 0 # 后缀和
# 从后向前遍历
for i in range(n - 1, -1, -1):
total += shifts[i]
# 计算移位后的字符
# ord(s[i]) - ord('a') 得到字符相对于 'a' 的偏移量
# 加上移位次数后对 26 取模,得到新的偏移量
new_char = chr((ord(s[i]) - ord('a') + total) % 26 + ord('a'))
res.append(new_char)
# 因为是从后向前遍历,需要反转结果
return ''.join(res[::-1])
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。只需遍历一次数组。
- **空间复杂度**:$O(n)$,需要存储结果字符串。
================================================
FILE: docs/solutions/0800-0899/shifting-letters.md
================================================
# [0848. 字母移位](https://leetcode.cn/problems/shifting-letters/)
- 标签:数组、字符串、前缀和
- 难度:中等
## 题目链接
- [0848. 字母移位 - 力扣](https://leetcode.cn/problems/shifting-letters/)
## 题目大意
**描述**:
有一个由小写字母组成的字符串 $s$,和一个长度相同的整数数组 $shifts$。
我们将字母表中的下一个字母称为原字母的「移位 `shift()`」 (由于字母表是环绕的, `'z'` 将会变成 `'a'`)。
- 例如,`shift('a') = 'b'`, `shift('t') = 'u'`, 以及 `shift('z') = 'a'`。
对于每个 $shifts[i] = x$,我们会将 $s$ 中的前 $i + 1$ 个字母移位 $x$ 次。
**要求**:
返回「将所有这些移位都应用到 $s$ 后最终得到的字符串」。
**说明**:
- $1 \le s.length \le 10^{5}$。
- $s$ 由小写英文字母组成。
- $shifts.length == s.length$。
- $0 \le shifts[i] \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:s = "abc", shifts = [3,5,9]
输出:"rpl"
解释:
我们以 "abc" 开始。
将 S 中的第 1 个字母移位 3 次后,我们得到 "dbc"。
再将 S 中的前 2 个字母移位 5 次后,我们得到 "igc"。
最后将 S 中的这 3 个字母移位 9 次后,我们得到答案 "rpl"。
```
- 示例 2:
```python
输入:
输出:
```
## 解题思路
### 思路 1:后缀和
根据题意,对于位置 $i$ 的字符,它需要移位的总次数为 $\sum_{j=i}^{n-1} shifts[j]$。
如果直接计算每个位置的移位次数,时间复杂度为 $O(n^2)$,会超时。我们可以使用后缀和来优化:
1. 从后向前遍历 $shifts$ 数组,计算后缀和 $total$。
2. 对于位置 $i$,其移位次数为 $total$。
3. 将字符 $s[i]$ 移位 $total \bmod 26$ 次(因为字母表是循环的)。
4. 更新 $total$ 为下一个位置的后缀和。
### 思路 1:代码
```python
class Solution:
def shiftingLetters(self, s: str, shifts: List[int]) -> str:
n = len(s)
res = []
total = 0 # 后缀和
# 从后向前遍历
for i in range(n - 1, -1, -1):
total += shifts[i]
# 计算移位后的字符
# ord(s[i]) - ord('a') 得到字符相对于 'a' 的偏移量
# 加上移位次数后对 26 取模,得到新的偏移量
new_char = chr((ord(s[i]) - ord('a') + total) % 26 + ord('a'))
res.append(new_char)
# 因为是从后向前遍历,需要反转结果
return ''.join(res[::-1])
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。只需遍历一次数组。
- **空间复杂度**:$O(n)$,需要存储结果字符串。
================================================
FILE: docs/solutions/0800-0899/short-encoding-of-words.md
================================================
# [0820. 单词的压缩编码](https://leetcode.cn/problems/short-encoding-of-words/)
- 标签:字典树、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0820. 单词的压缩编码 - 力扣](https://leetcode.cn/problems/short-encoding-of-words/)
## 题目大意
给定一个单词数组 `words`。要求对 `words` 进行编码成一个助记字符串,用来帮助记忆。`words` 中拥有相同字符后缀的单词可以合并成一个单词,比如`time` 和 `me` 可以合并成 `time`。同时每个不能再合并的单词末尾以 `#` 为结束符,将所有合并后的单词排列起来就是一个助记字符串。
要求:返回对 `words` 进行编码的最小助记字符串 `s` 的长度。
## 解题思路
构建一个字典树。然后对字符串长度进行从小到大排序。
再依次将去重后的所有单词插入到字典树中。如果出现比当前单词更长的单词,则将短单词的结尾置为 `False`,意为替换掉短单词。
然后再依次在字典树中查询所有单词,「单词长度 + 1」就是当前不能在合并的单词,累加起来就是答案。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = False
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
trie_tree = Trie()
words = list(set(words))
words.sort(key=lambda i: len(i))
ans = 0
for word in words:
trie_tree.insert(word[::-1])
for word in words:
if trie_tree.search(word[::-1]):
ans += len(word) + 1
return ans
```
================================================
FILE: docs/solutions/0800-0899/shortest-distance-to-a-character.md
================================================
# [0821. 字符的最短距离](https://leetcode.cn/problems/shortest-distance-to-a-character/)
- 标签:数组、双指针、字符串
- 难度:简单
## 题目链接
- [0821. 字符的最短距离 - 力扣](https://leetcode.cn/problems/shortest-distance-to-a-character/)
## 题目大意
**描述**:给定一个字符串 $s$ 和一个字符 $c$,并且 $c$ 是字符串 $s$ 中出现过的字符。
**要求**:返回一个长度与字符串 $s$ 想通的整数数组 $answer$,其中 $answer[i]$ 是字符串 $s$ 中从下标 $i$ 到离下标 $i$ 最近的字符 $c$ 的距离。
**说明**:
- 两个下标 $i$ 和 $j$ 之间的 **距离** 为 $abs(i - j)$ ,其中 $abs$ 是绝对值函数。
- $1 \le s.length \le 10^4$。
- $s[i]$ 和 $c$ 均为小写英文字母
- 题目数据保证 $c$ 在 $s$ 中至少出现一次。
**示例**:
- 示例 1:
```python
输入:s = "loveleetcode", c = "e"
输出:[3,2,1,0,1,0,0,1,2,2,1,0]
解释:字符 'e' 出现在下标 3、5、6 和 11 处(下标从 0 开始计数)。
距下标 0 最近的 'e' 出现在下标 3,所以距离为 abs(0 - 3) = 3。
距下标 1 最近的 'e' 出现在下标 3,所以距离为 abs(1 - 3) = 2。
对于下标 4,出现在下标 3 和下标 5 处的 'e' 都离它最近,但距离是一样的 abs(4 - 3) == abs(4 - 5) = 1。
距下标 8 最近的 'e' 出现在下标 6,所以距离为 abs(8 - 6) = 2。
```
- 示例 2:
```python
输入:s = "aaab", c = "b"
输出:[3,2,1,0]
```
## 解题思路
### 思路 1:两次遍历
第一次从左到右遍历,记录每个 $i$ 左边最近的 $c$ 的位置,并将其距离记录到 $answer[i]$ 中。
第二次从右到左遍历,记录每个 $i$ 右侧最近的 $c$ 的位置,并将其与第一次遍历左侧最近的 $c$ 的位置相比较,并将较小的距离记录到 $answer[i]$ 中。
### 思路 1:代码
```python
class Solution:
def shortestToChar(self, s: str, c: str) -> List[int]:
size = len(s)
ans = [size + 1 for _ in range(size)]
pos = -1
for i in range(size):
if s[i] == c:
pos = i
if pos != -1:
ans[i] = i - pos
pos = -1
for i in range(size - 1, -1, -1):
if s[i] == c:
pos = i
if pos != -1:
ans[i] = min(ans[i], pos - i)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/shortest-path-to-get-all-keys.md
================================================
# [0864. 获取所有钥匙的最短路径](https://leetcode.cn/problems/shortest-path-to-get-all-keys/)
- 标签:位运算、广度优先搜索、数组、矩阵
- 难度:困难
## 题目链接
- [0864. 获取所有钥匙的最短路径 - 力扣](https://leetcode.cn/problems/shortest-path-to-get-all-keys/)
## 题目大意
**描述**:
给定一个二维网格 $grid$,其中:
- `'.'` 代表一个空房间
- `'#'` 代表一堵墙
- `'@'` 是起点
- 小写字母代表钥匙
- 大写字母代表锁
我们从起点开始出发,一次移动是指向四个基本方向之一行走一个单位空间。我们不能在网格外面行走,也无法穿过一堵墙。如果途经一个钥匙,我们就把它捡起来。除非我们手里有对应的钥匙,否则无法通过锁。
假设 $k$ 为 钥匙/锁 的个数,且满足 $1 \le k \le 6$,字母表中的前 $k$ 个字母在网格中都有自己对应的一个小写和一个大写字母。换言之,每个锁有唯一对应的钥匙,每个钥匙也有唯一对应的锁。另外,代表钥匙和锁的字母互为大小写并按字母顺序排列。
**要求**:
返回获取所有钥匙所需要的移动的最少次数。如果无法获取所有钥匙,返回 -1。
**说明**:
- $m == grid.length$。
- $n == grid[i].length$。
- $1 \le m, n \le 30$。
- $grid[i][j]$ 只含有 `'.'`, `'#'`, `'@'`, `'a'-'f'` 以及 `'A'-'F'`。
- 钥匙的数目范围是 $[1, 6]$。
- 每个钥匙都对应一个「不同」的字母。
- 每个钥匙正好打开一个对应的锁。
**示例**:
- 示例 1:
```python
输入:grid = ["@.a..","###.#","b.A.B"]
输出:8
解释:目标是获得所有钥匙,而不是打开所有锁。
```
- 示例 2:
```python
输入:grid = ["@..aA","..B#.","....b"]
输出:6
```
## 解题思路
### 思路 1:BFS + 状态压缩
这是一个带状态的最短路径问题。状态包括:当前位置 $(x, y)$ 和已收集的钥匙集合。
由于钥匙最多 6 个,可以用 6 位二进制数表示钥匙的收集状态,第 $i$ 位为 1 表示已收集第 $i$ 把钥匙。
算法步骤:
1. 找到起点位置和钥匙总数
2. 使用 BFS,状态为 $(x, y, keys)$,其中 $keys$ 是钥匙的二进制状态
3. 对于每个状态,尝试向四个方向移动:
- 如果是墙,不能通过
- 如果是锁,需要有对应的钥匙才能通过
- 如果是钥匙,收集它并更新状态
4. 当收集到所有钥匙时,返回步数
### 思路 1:代码
```python
class Solution:
def shortestPathAllKeys(self, grid: List[str]) -> int:
from collections import deque
m, n = len(grid), len(grid[0])
start_x, start_y = 0, 0
key_count = 0
# 找到起点和钥匙总数
for i in range(m):
for j in range(n):
if grid[i][j] == '@':
start_x, start_y = i, j
elif grid[i][j].islower():
key_count += 1
# 所有钥匙都收集完的状态
all_keys = (1 << key_count) - 1
# BFS
queue = deque([(start_x, start_y, 0, 0)]) # (x, y, keys, steps)
visited = set()
visited.add((start_x, start_y, 0))
directions = [(0, 1), (0, -1), (1, 0), (-1, 0)]
while queue:
x, y, keys, steps = queue.popleft()
# 如果收集到所有钥匙,返回步数
if keys == all_keys:
return steps
# 尝试四个方向
for dx, dy in directions:
nx, ny = x + dx, y + dy
# 检查边界
if nx < 0 or nx >= m or ny < 0 or ny >= n:
continue
cell = grid[nx][ny]
# 如果是墙,跳过
if cell == '#':
continue
# 如果是锁,检查是否有钥匙
if cell.isupper():
key_bit = ord(cell.lower()) - ord('a')
if not (keys & (1 << key_bit)):
continue
# 更新钥匙状态
new_keys = keys
if cell.islower():
key_bit = ord(cell) - ord('a')
new_keys = keys | (1 << key_bit)
# 如果状态未访问过,加入队列
if (nx, ny, new_keys) not in visited:
visited.add((nx, ny, new_keys))
queue.append((nx, ny, new_keys, steps + 1))
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n \times 2^k)$,其中 $m$ 和 $n$ 是网格的大小,$k$ 是钥匙的数量。每个状态最多访问一次。
- **空间复杂度**:$O(m \times n \times 2^k)$,需要存储访问状态。
================================================
FILE: docs/solutions/0800-0899/shortest-path-visiting-all-nodes.md
================================================
# [0847. 访问所有节点的最短路径](https://leetcode.cn/problems/shortest-path-visiting-all-nodes/)
- 标签:位运算、广度优先搜索、图、动态规划、状态压缩
- 难度:困难
## 题目链接
- [0847. 访问所有节点的最短路径 - 力扣](https://leetcode.cn/problems/shortest-path-visiting-all-nodes/)
## 题目大意
**描述**:存在一个由 $n$ 个节点组成的无向连通图,图中节点编号为 $0 \sim n - 1$。现在给定一个数组 $graph$ 表示这个图。其中,$graph[i]$ 是一个列表,由所有与节点 $i$ 直接相连的节点组成。
**要求**:返回能够访问所有节点的最短路径长度。可以在任一节点开始和停止,也可以多次重访节点,并且可以重用边。
**说明**:
- $n == graph.length$。
- $1 \le n \le 12$。
- $0 \le graph[i].length < n$。
- $graph[i]$ 不包含 $i$。
- 如果 $graph[a]$ 包含 $b$,那么 $graph[b]$ 也包含 $a$。
- 输入的图总是连通图。
**示例**:
- 示例 1:
```python
输入:graph = [[1,2,3],[0],[0],[0]]
输出:4
解释:一种可能的路径为 [1,0,2,0,3]
```
- 示例 2:
```python
输入:graph = [[1],[0,2,4],[1,3,4],[2],[1,2]]
输出:4
解释:一种可能的路径为 [0,1,4,2,3]
```
## 解题思路
### 思路 1:状态压缩 + 广度优先搜索
题目需要求解的是「能够访问所有节点的最短路径长度」,并且每个节点都可以作为起始点。
如果对于一个特定的起点,我们可以将该起点放入队列中,然后对其进行广度优先搜索,并使用访问数组 $visited$ 标记访问过的节点,直到所有节点都已经访问过时,返回路径长度即为「从某点开始出发,所能够访问所有节点的最短路径长度」。
而本题中,每个节点都可以作为起始点,则我们可以直接将所有节点放入队列中,然后对所有节点进行广度优先搜索。
因为本题中节点数目 $n$ 的范围为 $[1, 12]$,所以我们可以采用「状态压缩」的方式,标记节点的访问情况。每个点的初始状态可以表示为 `(u, 1 << u)`。当状态 $state == 1 \text{ <}\text{< } n - 1$ 时,表示所有节点都已经访问过了,此时返回其对应路径长度即为「能够访问所有节点的最短路径长度」。
为了方便在广度优先搜索的同事,记录当前的「路径长度」以及「节点的访问情况」。我们可以使用一个三元组 $(u, state, dist)$ 来表示当前节点情况,其中:
- $u$:表示当前节点编号。
- $state$:一个 $n$ 位的二进制数,表示 $n$ 个节点的访问情况。$state$ 第 $i$ 位为 $0$ 时表示未访问过,$state$ 第 $i$ 位为 $1$ 时表示访问过。
- $dist$ 表示当前的「路径长度」。
同时为了避免重复搜索同一个节点 $u$ 以及相同节点的访问情况,我们可以使用集合记录 $(u, state)$ 是否已经被搜索过。
整个算法步骤如下:
1. 将所有节点的 `(节点编号, 起始状态, 路径长度)` 作为三元组存入队列,并使用集合 $visited$ 记录所有节点的访问情况。
2. 对所有点开始进行广度优先搜索:
1. 从队列中弹出队头节点。
2. 判断节点的当前状态,如果所有节点都已经访问过,则返回答案。
3. 如果没有全访问过,则遍历当前节点的邻接节点。
4. 将邻接节点的访问状态标记为访问过。
5. 如果节点即当前路径没有访问过,则加入队列继续遍历,并标记为访问过。
3. 重复进行第 $2$ 步,直到队列为空。
### 思路 1:代码
```python
import collections
class Solution:
def shortestPathLength(self, graph: List[List[int]]) -> int:
size = len(graph)
queue = collections.deque([])
visited = set()
for u in range(size):
queue.append((u, 1 << u, 0)) # 将 (节点编号, 起始状态, 路径长度) 存入队列
visited.add((u, 1 << u)) # 标记所有节点的节点编号,以及当前状态
while queue: # 对所有点开始进行广度优先搜索
u, state, dist = queue.popleft() # 弹出队头节点
if state == (1 << size) - 1: # 所有节点都访问完,返回答案
return dist
for v in graph[u]: # 遍历邻接节点
next_state = state | (1 << v) # 标记邻接节点的访问状态
if (v, next_state) not in visited: # 如果节点即当前路径没有访问过,则加入队列继续遍历,并标记为访问过
queue.append((v, next_state, dist + 1))
visited.add((v, next_state))
return 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times 2^n)$,其中 $n$ 为图的节点数量。
- **空间复杂度**:$O(n \times 2^n)$。
================================================
FILE: docs/solutions/0800-0899/shortest-subarray-with-sum-at-least-k.md
================================================
# [0862. 和至少为 K 的最短子数组](https://leetcode.cn/problems/shortest-subarray-with-sum-at-least-k/)
- 标签:队列、数组、二分查找、前缀和、滑动窗口、单调队列、堆(优先队列)
- 难度:困难
## 题目链接
- [0862. 和至少为 K 的最短子数组 - 力扣](https://leetcode.cn/problems/shortest-subarray-with-sum-at-least-k/)
## 题目大意
**描述**:给定一个整数数组 $nums$ 和一个整数 $k$。
**要求**:找出 $nums$ 中和至少为 $k$ 的最短非空子数组,并返回该子数组的长度。如果不存在这样的子数组,返回 $-1$。
**说明**:
- **子数组**:数组中连续的一部分。
- $1 \le nums.length \le 10^5$。
- $-10^5 \le nums[i] \le 10^5$。
- $1 \le k \le 10^9$。
**示例**:
- 示例 1:
```python
输入:nums = [1], k = 1
输出:1
```
- 示例 2:
```python
输入:nums = [1,2], k = 4
输出:-1
```
## 解题思路
### 思路 1:前缀和 + 单调队列
题目要求得到满足和至少为 $k$ 的子数组的最短长度。
先来考虑暴力做法。如果使用两重循环分别遍历子数组的开始和结束位置,则可以直接求出所有满足条件的子数组,以及对应长度。但是这种做法的时间复杂度为 $O(n^2)$。我们需要对其进行优化。
#### 1. 前缀和优化
首先对于子数组和,我们可以使用「前缀和」的方式,方便快速的得到某个子数组的和。
对于区间 $[left, right]$,通过 $pre\_sum[right + 1] - prefix\_cnts[left]$ 即可快速求解出区间 $[left, right]$ 的子数组和。
此时问题就转变为:是否能找到满足 $i > j$ 且 $pre\_sum[i] - pre\_sum[j] \ge k$ 两个条件的子数组 $[j, i)$?如果能找到,则找出 $i - j$ 差值最小的作为答案。
#### 2. 单调队列优化
对于区间 $[j, i)$ 来说,我们应该尽可能的减少不成立的区间枚举。
1. 对于某个区间 $[j, i)$ 来说,如果 $pre\_sum[i] - pre\_sum[j] \ge k$,那么大于 $i$ 的索引值就不用再进行枚举了,不可能比 $i - j$ 的差值更优了。此时我们应该尽可能的向右移动 $j$,从而使得 $i - j$ 更小。
2. 对于某个区间 $[j, i)$ 来说,如果 $pre\_sum[j] \ge pre\_sum[i]$,对于任何大于等于 $i$ 的索引值 $r$ 来说,$pre\_sum[r] - pre\_sum[i]$ 一定比 $pre\_sum[i] - pre\_sum[j]$ 更小且长度更小,此时 $pre\_sum[j]$ 可以直接忽略掉。
因此,我们可以使用单调队列来维护单调递增的前缀数组 $pre\_sum$。其中存放了下标 $x:x_0, x_1, …$,满足 $pre\_sum[x_0] < pre\_sum[x_1] < …$ 单调递增。
1. 使用一重循环遍历位置 $i$,将当前位置 $i$ 存入倒掉队列中。
2. 对于每一个位置 $i$,如果单调队列不为空,则可以判断其之前存入在单调队列中的 $pre\_sum[j]$ 值,如果 $pre\_sum[i] - pre\_sum[j] \ge k$,则更新答案,并将 $j$ 从队头位置弹出。直到不再满足 $pre\_sum[i] - pre\_sum[j] \ge k$ 时为止(即 $pre\_sum[i] - pre\_sum[j] < k$)。
3. 如果队尾 $pre\_sum[j] \ge pre\_sum[i]$,那么说明以后无论如何都不会再考虑 $pre\_sum[j]$ 了,则将其从队尾弹出。
4. 最后遍历完返回答案。
### 思路 1:代码
```Python
class Solution:
def shortestSubarray(self, nums: List[int], k: int) -> int:
size = len(nums)
# 优化 1
pre_sum = [0 for _ in range(size + 1)]
for i in range(size):
pre_sum[i + 1] = pre_sum[i] + nums[i]
ans = float('inf')
queue = collections.deque()
for i in range(size + 1):
# 优化 2
while queue and pre_sum[i] - pre_sum[queue[0]] >= k:
ans = min(ans, i - queue.popleft())
while queue and pre_sum[queue[-1]] >= pre_sum[i]:
queue.pop()
queue.append(i)
if ans == float('inf'):
return -1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(n)$。
## 参考资料
- 【题解】[862. 和至少为 K 的最短子数组 - 力扣](https://leetcode.cn/problems/shortest-subarray-with-sum-at-least-k/solutions/1925036/liang-zhang-tu-miao-dong-dan-diao-dui-li-9fvh/)
- 【题解】[Leetcode 862:和至少为 K 的最短子数组 - 掘金](https://juejin.cn/post/7076316608460750856)
- 【题解】[LeetCode 862. 和至少为 K 的最短子数组 - AcWing](https://www.acwing.com/solution/leetcode/content/612/)
- 【题解】[0862. Shortest Subarray With Sum at Least K | LeetCode Cookbook](https://books.halfrost.com/leetcode/ChapterFour/0800~0899/0862.Shortest-Subarray-with-Sum-at-Least-K/)
================================================
FILE: docs/solutions/0800-0899/similar-rgb-color.md
================================================
# [0800. 相似 RGB 颜色](https://leetcode.cn/problems/similar-rgb-color/)
- 标签:数学、字符串、枚举
- 难度:简单
## 题目链接
- [0800. 相似 RGB 颜色 - 力扣](https://leetcode.cn/problems/similar-rgb-color/)
## 题目大意
**描述**:RGB 颜色 `"#AABBCC"` 可以简写成 `"#ABC"` 。例如,`"#1155cc"` 可以简写为 `"#15c"`。现在给定一个按 `"#ABCDEF"` 形式定义的字符串 `color` 表示 RGB 颜色。
**要求**:返回一个与 `color` 相似度最大并且可以简写的颜色。
**说明**:
- 两个颜色 `"#ABCDEF"` 和 `"#UVWXYZ"` 的相似度计算公式为:$-(AB - UV)^2 - (CD - WX)^2 - (EF - YZ)^2$。
**示例**:
- 示例 1:
```python
输入 color = "#09f166"
输出 "#11ee66"
解释: 因为相似度计算得出 -(0x09 - 0x11)^2 -(0xf1 - 0xee)^2 - (0x66 - 0x66)^2 = -64 -9 -0 = -73,这是所有可以简写的颜色中与 color 最相似的颜色
```
## 解题思路
### 思路 1:枚举算法
所有可以简写的颜色范围是 `"#000"` ~ `"#fff"`,共 $16^3 = 4096$ 种颜色。因此,我们可以枚举这些可以简写的颜色,并计算出其与 $color$的相似度,从而找出与 $color$ 最相似的颜色。具体做法如下:
- 将 $color$ 转换为十六进制数,即 `hex_color = int(color[1:], 16)`。
- 三重循环遍历 $R$、$G$、$B$ 三个通道颜色,每一重循环范围为 $0 \sim 15$。
- 计算出每一种可以简写的颜色对应的十六进制,即 $17 \times R \times (1 << 16) + 17 \times G \times (1 << 8) + 17 \times B$,$17$ 是 $0x11 = 16 + 1 = 17$,$(1 << 16)$ 为 $R$ 左移的位数,$17 \times R \times (1 << 16)$ 就表示 $R$ 通道上对应的十六进制数。$(1 << 8)$ 为 $G$ 左移的位数,$17 \times G \times (1 << 8)$ 就表示 $G$ 通道上对应的十六进制数。$17 \times B$ 就表示 $B$ 通道上对应的十六进制数。
- 然后我们根据 $color$ 的十六进制数,与每一个可以简写的颜色对应的十六进制数,计算出相似度,并找出大相似对应的颜色。将其转换为字符串,并输出。
### 思路 1:枚举算法代码
```python
class Solution:
def similar(self, hex1, hex2):
r1, g1, b1 = hex1 >> 16, (hex1 >> 8) % 256, hex1 % 256
r2, g2, b2 = hex2 >> 16, (hex2 >> 8) % 256, hex2 % 256
return - (r1 - r2) ** 2 - (g1 - g2) ** 2 - (b1 - b2) ** 2
def similarRGB(self, color: str) -> str:
ans = 0
hex_color = int(color[1:], 16)
for r in range(16):
for g in range(16):
for b in range(16):
hex_cur = 17 * r * (1 << 16) + 17 * g * (1 << 8) + 17 * b
if self.similar(hex_color, hex_cur) > self.similar(hex_color, ans):
ans = hex_cur
return "#{:06x}".format(ans)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(16^3)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/similar-string-groups.md
================================================
# [0839. 相似字符串组](https://leetcode.cn/problems/similar-string-groups/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、哈希表、字符串
- 难度:困难
## 题目链接
- [0839. 相似字符串组 - 力扣](https://leetcode.cn/problems/similar-string-groups/)
## 题目大意
**描述**:
如果交换字符串 $X$ 中的两个不同位置的字母,使得它和字符串 $Y$ 相等,那么称 $X$ 和 $Y$ 两个字符串相似。如果这两个字符串本身是相等的,那它们也是相似的。
例如,`"tars"` 和 `"rats"` 是相似的 (交换 0 与 2 的位置); `"rats"` 和 `"arts"` 也是相似的,但是 `"star"` 不与 `"tars"`,`"rats"`,或 `"arts"` 相似。
总之,它们通过相似性形成了两个关联组:`{"tars", "rats", "arts"}` 和 `{"star"}`。注意,`"tars"` 和 `"arts"` 是在同一组中,即使它们并不相似。形式上,对每个组而言,要确定一个单词在组中,只需要这个词和该组中至少一个单词相似。
给你一个字符串列表 $strs$。列表中的每个字符串都是 $strs$ 中其它所有字符串的一个字母异位词。
**要求**:
计算 $strs$ 中有多少个相似字符串组。
**说明**:
- $1 \le strs.length \le 300$。
- $1 \le strs[i].length \le 300$。
- $strs[i]$ 只包含小写字母。
- $strs$ 中的所有单词都具有相同的长度,且是彼此的字母异位词。
**示例**:
- 示例 1:
```python
输入:strs = ["tars","rats","arts","star"]
输出:2
```
- 示例 2:
```python
输入:strs = ["omv","ovm"]
输出:1
```
## 解题思路
### 思路 1:并查集
判断两个字符串是否相似:只需检查它们有多少个位置的字符不同。如果不同位置的个数为 0 或 2,则相似。
使用并查集来维护相似字符串组:
1. 初始化并查集,每个字符串自成一组
2. 遍历所有字符串对,如果两个字符串相似,将它们合并到同一组
3. 最后统计并查集中有多少个不同的根节点
### 思路 1:代码
```python
class Solution:
def numSimilarGroups(self, strs: List[str]) -> int:
n = len(strs)
# 并查集
parent = list(range(n))
def find(x):
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def union(x, y):
root_x = find(x)
root_y = find(y)
if root_x != root_y:
parent[root_x] = root_y
# 判断两个字符串是否相似
def is_similar(s1, s2):
diff_count = 0
for i in range(len(s1)):
if s1[i] != s2[i]:
diff_count += 1
if diff_count > 2:
return False
# 相同或恰好两个位置不同
return diff_count == 0 or diff_count == 2
# 遍历所有字符串对
for i in range(n):
for j in range(i + 1, n):
if is_similar(strs[i], strs[j]):
union(i, j)
# 统计不同的根节点数量
return len(set(find(i) for i in range(n)))
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times m + n \times \alpha(n))$,其中 $n$ 是字符串数量,$m$ 是字符串长度,$\alpha$ 是并查集的反阿克曼函数。需要检查 $O(n^2)$ 对字符串,每次比较需要 $O(m)$。
- **空间复杂度**:$O(n)$,并查集需要 $O(n)$ 空间。
================================================
FILE: docs/solutions/0800-0899/smallest-subtree-with-all-the-deepest-nodes.md
================================================
# [0865. 具有所有最深节点的最小子树](https://leetcode.cn/problems/smallest-subtree-with-all-the-deepest-nodes/)
- 标签:树、深度优先搜索、广度优先搜索、哈希表、二叉树
- 难度:中等
## 题目链接
- [0865. 具有所有最深节点的最小子树 - 力扣](https://leetcode.cn/problems/smallest-subtree-with-all-the-deepest-nodes/)
## 题目大意
**描述**:
给定一个根为 $root$ 的二叉树,每个节点的深度是「该节点到根的最短距离」。
**要求**:
返回包含原始树中所有「最深节点」的「最小子树」。
**说明**:
- 如果一个节点在「整个树」的任意节点之间具有最大的深度,则该节点是「最深的」。
- 一个节点的「子树」是该节点加上它的所有后代的集合。
- 树中节点的数量在 $[1, 500]$ 范围内。
- $0 \le Node.val \le 500$。
- 每个节点的值都是「独一无二」的。
- 注意:本题与力扣 1123 重复:https://leetcode-cn.com/problems/lowest-common-ancestor-of-deepest-leaves [https://leetcode-cn.com/problems/lowest-common-ancestor-of-deepest-leaves/]
**示例**:
- 示例 1:
```python
输入:root = [3,5,1,6,2,0,8,null,null,7,4]
输出:[2,7,4]
解释:
我们返回值为 2 的节点,在图中用黄色标记。
在图中用蓝色标记的是树的最深的节点。
注意,节点 5、3 和 2 包含树中最深的节点,但节点 2 的子树最小,因此我们返回它。
```
- 示例 2:
```python
输入:root = [1]
输出:[1]
解释:根节点是树中最深的节点。
```
## 解题思路
### 思路 1:DFS
对于每个节点,我们需要知道:
1. 左子树的最大深度
2. 右子树的最大深度
如果左右子树的最大深度相同,说明当前节点就是包含所有最深节点的最小子树的根。
递归函数返回:(节点, 深度),表示以当前节点为根的子树中,包含所有最深节点的最小子树的根节点和深度。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def subtreeWithAllDeepest(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
def dfs(node):
# 返回 (包含所有最深节点的最小子树根节点, 深度)
if not node:
return None, 0
# 递归处理左右子树
left_node, left_depth = dfs(node.left)
right_node, right_depth = dfs(node.right)
# 如果左右子树深度相同,当前节点就是答案
if left_depth == right_depth:
return node, left_depth + 1
# 如果左子树更深,答案在左子树中
elif left_depth > right_depth:
return left_node, left_depth + 1
# 如果右子树更深,答案在右子树中
else:
return right_node, right_depth + 1
return dfs(root)[0]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是树中节点的数量。需要遍历每个节点一次。
- **空间复杂度**:$O(h)$,其中 $h$ 是树的高度。递归栈的深度为树的高度。
================================================
FILE: docs/solutions/0800-0899/soup-servings.md
================================================
# [0808. 分汤](https://leetcode.cn/problems/soup-servings/)
- 标签:数学、动态规划、概率与统计
- 难度:中等
## 题目链接
- [0808. 分汤 - 力扣](https://leetcode.cn/problems/soup-servings/)
## 题目大意
**描述**:
你有两种汤,A 和 B,每种初始为 $n$ 毫升。在每一轮中,会随机选择以下四种操作中的一种,每种操作的概率为 0.25,且与之前的所有轮次 无关:
1. 从汤 A 取 100 毫升,从汤 B 取 0 毫升
2. 从汤 A 取 75 毫升,从汤 B 取 25 毫升
3. 从汤 A 取 50 毫升,从汤 B 取 50 毫升
4. 从汤 A 取 25 毫升,从汤 B 取 75 毫升
注意:
- 不存在从汤 A 取 0ml 和从汤 B 取 100ml 的操作。
- 汤 A 和 B 在每次操作中同时被取出。
- 如果一次操作要求你取出比剩余的汤更多的量,请取出该汤剩余的所有部分。
操作过程在任何回合中任一汤被取完后立即停止。
**要求**:
返回汤 A 在 B 前取完的概率,加上两种汤在「同一回合」取完概率的一半。返回值在正确答案 $10^{-5}$ 的范围内将被认为是正确的。
**说明**:
- $0 \le n \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:n = 50
输出:0.62500
解释:
如果我们选择前两个操作,A 首先将变为空。
对于第三个操作,A 和 B 会同时变为空。
对于第四个操作,B 首先将变为空。
所以 A 变为空的总概率加上 A 和 B 同时变为空的概率的一半是 0.25 *(1 + 1 + 0.5 + 0)= 0.625。
```
- 示例 2:
```python
输入:n = 100
输出:0.71875
解释:
如果我们选择第一个操作,A 首先将变为空。
如果我们选择第二个操作,A 将在执行操作 [1, 2, 3] 时变为空,然后 A 和 B 在执行操作 4 时同时变空。
如果我们选择第三个操作,A 将在执行操作 [1, 2] 时变为空,然后 A 和 B 在执行操作 3 时同时变空。
如果我们选择第四个操作,A 将在执行操作 1 时变为空,然后 A 和 B 在执行操作 2 时同时变空。
所以 A 变为空的总概率加上 A 和 B 同时变为空的概率的一半是 0.71875。
```
## 解题思路
### 思路 1:动态规划 + 记忆化搜索
定义 $dp(a, b)$ 表示汤 A 剩余 $a$ 毫升、汤 B 剩余 $b$ 毫升时,满足条件的概率。
状态转移:
- 如果 $a \le 0$ 且 $b \le 0$,返回 $0.5$(同时取完)
- 如果 $a \le 0$,返回 $1$(A 先取完)
- 如果 $b \le 0$,返回 $0$(B 先取完)
- 否则:
$$dp(a, b) = 0.25 \times [dp(a-100, b) + dp(a-75, b-25) + dp(a-50, b-50) + dp(a-25, b-75)]$$
优化:
1. 由于每次操作都是 25 的倍数,可以将 $n$ 除以 25 来缩小规模。
2. 当 $n$ 很大时($n \ge 5000$),概率会非常接近 1,可以直接返回 1。
### 思路 1:代码
```python
class Solution:
def soupServings(self, n: int) -> float:
# 当 n >= 5000 时,概率非常接近 1
if n >= 5000:
return 1.0
# 将 n 转换为以 25 为单位(向上取整)
n = (n + 24) // 25
# 记忆化搜索
memo = {}
def dp(a, b):
# 如果已经计算过,直接返回
if (a, b) in memo:
return memo[(a, b)]
# 边界条件
if a <= 0 and b <= 0:
return 0.5
if a <= 0:
return 1.0
if b <= 0:
return 0.0
# 状态转移
result = 0.25 * (
dp(a - 4, b) + # 操作 1: A 取 100ml, B 取 0ml
dp(a - 3, b - 1) + # 操作 2: A 取 75ml, B 取 25ml
dp(a - 2, b - 2) + # 操作 3: A 取 50ml, B 取 50ml
dp(a - 1, b - 3) # 操作 4: A 取 25ml, B 取 75ml
)
memo[(a, b)] = result
return result
return dp(n, n)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是转换后的汤的容量。需要计算 $O(n^2)$ 个状态。
- **空间复杂度**:$O(n^2)$,记忆化搜索需要存储 $O(n^2)$ 个状态。
================================================
FILE: docs/solutions/0800-0899/spiral-matrix-iii.md
================================================
# [0885. 螺旋矩阵 III](https://leetcode.cn/problems/spiral-matrix-iii/)
- 标签:数组、矩阵、模拟
- 难度:中等
## 题目链接
- [0885. 螺旋矩阵 III - 力扣](https://leetcode.cn/problems/spiral-matrix-iii/)
## 题目大意
**描述**:
在 $rows \times cols$ 的网格上,你从单元格 $(rStart, cStart)$ 面朝东面开始。网格的西北角位于第一行第一列,网格的东南角位于最后一行最后一列。
你需要以顺时针按螺旋状行走,访问此网格中的每个位置。每当移动到网格的边界之外时,需要继续在网格之外行走(但稍后可能会返回到网格边界)。
最终,我们到过网格的所有 $rows \times cols$ 个空间。
**要求**:
按照访问顺序返回表示网格位置的坐标列表。
**说明**:
- $1 \le rows, cols \le 10^{3}$。
- $0 \le rStart \lt rows$。
- $0 \le cStart \lt cols$。
**示例**:
- 示例 1:
```python
输入:rows = 1, cols = 4, rStart = 0, cStart = 0
输出:[[0,0],[0,1],[0,2],[0,3]]
```
- 示例 2:
```python
输入:rows = 5, cols = 6, rStart = 1, cStart = 4
输出:[[1,4],[1,5],[2,5],[2,4],[2,3],[1,3],[0,3],[0,4],[0,5],[3,5],[3,4],[3,3],[3,2],[2,2],[1,2],[0,2],[4,5],[4,4],[4,3],[4,2],[4,1],[3,1],[2,1],[1,1],[0,1],[4,0],[3,0],[2,0],[1,0],[0,0]]
```
## 解题思路
### 思路 1:模拟
按照螺旋顺序模拟机器人的行走过程:
1. 螺旋行走的规律是:向右走 1 步,向下走 1 步,向左走 2 步,向上走 2 步,向右走 3 步,向下走 3 步...
2. 可以发现,每个方向走的步数规律为:1, 1, 2, 2, 3, 3, 4, 4...
3. 方向顺序为:东、南、西、北,循环往复。
4. 在行走过程中,如果当前位置在网格内,就将其加入结果。
5. 当结果数组的长度等于 $rows \times cols$ 时,说明已经访问完所有格子。
### 思路 1:代码
```python
class Solution:
def spiralMatrixIII(self, rows: int, cols: int, rStart: int, cStart: int) -> List[List[int]]:
# 方向数组:东、南、西、北
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
result = [[rStart, cStart]] # 起始位置
if rows * cols == 1:
return result
r, c = rStart, cStart
steps = 1 # 当前方向要走的步数
while len(result) < rows * cols:
# 每两个方向,步数增加 1
for i in range(4):
dr, dc = directions[i]
# 在当前方向走 steps 步
for _ in range(steps):
r += dr
c += dc
# 如果在网格内,加入结果
if 0 <= r < rows and 0 <= c < cols:
result.append([r, c])
if len(result) == rows * cols:
return result
# 每走完两个方向,步数加 1
if i % 2 == 1:
steps += 1
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\max(rows, cols)^2)$,最坏情况下需要走出网格很远才能访问完所有格子。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间。
================================================
FILE: docs/solutions/0800-0899/split-array-into-fibonacci-sequence.md
================================================
# [0842. 将数组拆分成斐波那契序列](https://leetcode.cn/problems/split-array-into-fibonacci-sequence/)
- 标签:字符串、回溯
- 难度:中等
## 题目链接
- [0842. 将数组拆分成斐波那契序列 - 力扣](https://leetcode.cn/problems/split-array-into-fibonacci-sequence/)
## 题目大意
**描述**:
给定一个数字字符串 $num$,比如 `"123456579"`,我们可以将它分成「斐波那契式」的序列 $[123, 456, 579]$。
形式上,「斐波那契式」序列是一个非负整数列表 $f$,且满足:
- $0 \le f[i] < 2^{31}$,(也就是说,每个整数都符合 32 位 有符号整数类型)
- $f.length \ge 3$
- 对于所有的 $0 \le i < f.length - 2$,都有 $f[i] + f[i + 1] = f[i + 2]$
另外,请注意,将字符串拆分成小块时,每个块的数字一定不要以零开头,除非这个块是数字 0 本身。
**要求**:
返回从 $num$ 拆分出来的任意一组斐波那契式的序列块,如果不能拆分则返回 []。
**说明**:
- $1 \le num.length \le 200$。
- $num$ 中只含有数字。
**示例**:
- 示例 1:
```python
输入:num = "1101111"
输出:[11,0,11,11]
解释:输出 [110,1,111] 也可以。
```
- 示例 2:
```python
输入: num = "112358130"
输出: []
解释: 无法拆分。
```
## 解题思路
### 思路 1:回溯
斐波那契序列的特点是:前两个数确定后,后续所有数都确定了。因此我们可以:
1. 枚举前两个数的所有可能划分。
2. 对于每种划分,尝试按照斐波那契规则继续划分剩余部分。
3. 如果能成功划分完整个字符串,返回结果;否则尝试下一种划分。
注意事项:
- 数字不能有前导零(除非数字本身是 0)
- 每个数必须在 32 位有符号整数范围内($< 2^{31}$)
- 序列至少要有 3 个数
### 思路 1:代码
```python
class Solution:
def splitIntoFibonacci(self, num: str) -> List[int]:
n = len(num)
def backtrack(index, path):
# 如果已经遍历完字符串且序列长度 >= 3,返回 True
if index == n and len(path) >= 3:
return True
# 枚举当前数字的长度
for i in range(index, n):
# 如果有前导零,只能是单独的 0
if num[index] == '0' and i > index:
break
# 截取当前数字
cur_str = num[index:i+1]
cur_num = int(cur_str)
# 检查是否超过 32 位整数范围
if cur_num >= 2**31:
break
# 如果序列长度 < 2,直接加入
if len(path) < 2:
path.append(cur_num)
if backtrack(i + 1, path):
return True
path.pop()
# 如果序列长度 >= 2,检查是否满足斐波那契规则
elif cur_num == path[-1] + path[-2]:
path.append(cur_num)
if backtrack(i + 1, path):
return True
path.pop()
# 如果当前数字已经大于前两数之和,后面更长的数字更不可能满足
elif cur_num > path[-1] + path[-2]:
break
return False
path = []
if backtrack(0, path):
return path
return []
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是字符串的长度。最坏情况下需要枚举前两个数的所有可能组合,每种组合最多需要 $O(n)$ 时间验证。
- **空间复杂度**:$O(n)$,递归栈的深度最多为 $O(n)$。
================================================
FILE: docs/solutions/0800-0899/split-array-with-same-average.md
================================================
# [0805. 数组的均值分割](https://leetcode.cn/problems/split-array-with-same-average/)
- 标签:位运算、数组、数学、动态规划、状态压缩
- 难度:困难
## 题目链接
- [0805. 数组的均值分割 - 力扣](https://leetcode.cn/problems/split-array-with-same-average/)
## 题目大意
**描述**:
给定你一个整数数组 $nums$。
我们要将 $nums$ 数组中的每个元素移动到 A 数组 或者 B 数组中,使得 A 数组和 B 数组不为空,并且 `average(A) == average(B)`。
**要求**:
如果可以完成则返回 true,否则返回 false。
**说明**:
- 注意:对于数组 $arr$, `average(arr)` 是 $arr$ 的所有元素的和除以 $arr$ 长度。
- $1 \le nums.length \le 30$。
- $0 \le nums[i] \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入: nums = [1,2,3,4,5,6,7,8]
输出: true
解释: 我们可以将数组分割为 [1,4,5,8] 和 [2,3,6,7], 他们的平均值都是4.5。
```
- 示例 2:
```python
输入: nums = [3,1]
输出: false
```
## 解题思路
### 思路 1:动态规划 + 状态压缩
设数组总和为 $sum$,长度为 $n$。如果能将数组分成两部分 $A$ 和 $B$,使得它们的平均值相等,则:
$$\frac{\sum A}{|A|} = \frac{\sum B}{|B|} = \frac{sum}{n}$$
即:$\sum A \times n = sum \times |A|$
因此,我们需要找到一个子集 $A$,使得 $\sum A = \frac{sum \times |A|}{n}$。
枚举子集大小 $k$(从 1 到 $n/2$),使用动态规划判断是否存在大小为 $k$、和为 $\frac{sum \times k}{n}$ 的子集。
定义 $dp[k]$ 为所有大小为 $k$ 的子集的和的集合。
### 思路 1:代码
```python
class Solution:
def splitArraySameAverage(self, nums: List[int]) -> bool:
n = len(nums)
total = sum(nums)
# 特判
if n == 1:
return False
# dp[k] 存储所有大小为 k 的子集的和
dp = [set() for _ in range(n // 2 + 1)]
dp[0].add(0)
for num in nums:
# 倒序遍历,避免重复使用
for k in range(n // 2, 0, -1):
for s in list(dp[k - 1]):
dp[k].add(s + num)
# 检查是否存在满足条件的子集
for k in range(1, n // 2 + 1):
# 检查 sum * k 是否能被 n 整除
if (total * k) % n == 0:
target = (total * k) // n
if target in dp[k]:
return True
return False
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times sum)$,其中 $n$ 是数组长度,$sum$ 是数组总和。需要枚举所有子集。
- **空间复杂度**:$O(n \times sum)$,需要存储所有可能的子集和。
================================================
FILE: docs/solutions/0800-0899/stone-game.md
================================================
# [0877. 石子游戏](https://leetcode.cn/problems/stone-game/)
- 标签:数组、数学、动态规划、博弈
- 难度:中等
## 题目链接
- [0877. 石子游戏 - 力扣](https://leetcode.cn/problems/stone-game/)
## 题目大意
亚历克斯和李在玩石子游戏。总共有偶数堆石子,每堆都有正整数颗石子 `piles[i]`,总共的石子数为奇数 。每回合,玩家从开始位置或者结束位置取走一整堆石子。直到没有石子堆为止结束游戏,最终手中石子颗数多的玩家获胜。假设亚历克斯和李每回合都能发挥出最佳水平,并且亚历克斯先开始。
给定代表每个位置石子颗数的数组 `piles`。
要求:判断亚历克斯是否能赢得比赛。如果亚历克斯赢得比赛,则返回 `True`。如果李赢得比赛返回 `False`。
## 解题思路
能取的次数是偶数个,总数是奇数个。
- 如果亚历克斯开始取了开始偶数位置 `0`,那么李只能取奇数位置 `1` 或者末尾位置 `len(piles) - 1`。然后亚历克斯可以j接着取偶数位。
- 或者亚历克斯开始取了最后奇数位置 `len(piles) - 1`,那么李只能取偶数位置 `0` 或 `len(piles) - 2`。然后亚历克斯可以接着取奇数位。
- 这样亚历克斯只要一开始计算好奇数位置上的石子总数多,还是偶数位置上的石子总数多,然后就可以选择一开始取奇数位置还是偶数位置。所以最后肯定会赢
- 游戏一开始,其实就没李啥事了。。。
## 代码
```python
class Solution:
def stoneGame(self, piles: List[int]) -> bool:
return True
```
================================================
FILE: docs/solutions/0800-0899/subdomain-visit-count.md
================================================
# [0811. 子域名访问计数](https://leetcode.cn/problems/subdomain-visit-count/)
- 标签:数组、哈希表、字符串、计数
- 难度:中等
## 题目链接
- [0811. 子域名访问计数 - 力扣](https://leetcode.cn/problems/subdomain-visit-count/)
## 题目大意
**描述**:网站域名是由多个子域名构成的。
- 例如 `"discuss.leetcode.com"` 的顶级域名为 `"com"`,二级域名为 `"leetcode.com"`,三级域名为 `"discuss.leetcode.com"`。
当访问 `"discuss.leetcode.com"` 时,也会隐式访问其父域名 `"leetcode.com"` 以及 `"com"`。
计算机配对域名的格式为 `"rep d1.d2.d3"` 或 `"rep d1.d2"`。其中 `rep` 表示访问域名的次数,`d1.d2.d3` 或 `d1.d2` 为域名本身。
- 例如:`"9001 discuss.leetcode.com"` 就是一个 计数配对域名 ,表示 `discuss.leetcode.com` 被访问了 `9001` 次。
现在给定一个由计算机配对域名组成的数组 `cpdomains`。
**要求**:解析每一个计算机配对域名,计算出所有域名的访问次数,并以数组形式返回。可以按任意顺序返回答案。
## 解题思路
这道题求解的是不同层级的域名的次数汇总,很容易想到使用哈希表。我们可以使用哈希表来统计不同层级的域名访问次数。具体做如下:
1. 如果数组 `cpdomains` 为空,直接返回空数组。
2. 使用哈希表 `times_dict` 存储不同层级的域名访问次数。
3. 遍历数组 `cpdomains`。对于每一个计算机配对域名 `cpdomain`:
1. 先将计算机配对域名的访问次数 `times` 和域名 `domain` 进行分割。
2. 然后将域名转为子域名数组 `domain_list`,逆序拼接不同等级的子域名 `sub_domain`。
3. 如果子域名 `sub_domain` 没有出现在哈希表 `times_dict` 中,则在哈希表中存入 `sub_domain` 和访问次数 `times` 的键值对。
4. 如果子域名 `sub_domain` 曾经出现在哈希表 `times_dict` 中,则在哈希表对应位置加上 `times`。
4. 遍历完之后,遍历哈希表 `times_dict`,将所有域名和访问次数拼接为字符串,存入答案数组中。
5. 最后返回答案数组。
## 代码
```python
class Solution:
def subdomainVisits(self, cpdomains: List[str]) -> List[str]:
if not cpdomains:
return []
times_dict = dict()
for cpdomain in cpdomains:
tiems, domain = cpdomain.split()
tiems = int(tiems)
domain_list = domain.split('.')
for i in range(len(domain_list) - 1, -1, -1):
sub_domain = '.'.join(domain_list[i:])
if sub_domain not in times_dict:
times_dict[sub_domain] = tiems
else:
times_dict[sub_domain] += tiems
res = []
for key in times_dict.keys():
res.append(str(times_dict[key]) + ' ' + key)
return res
```
================================================
FILE: docs/solutions/0800-0899/sum-of-distances-in-tree.md
================================================
# [0834. 树中距离之和](https://leetcode.cn/problems/sum-of-distances-in-tree/)
- 标签:树、深度优先搜索、图、动态规划
- 难度:困难
## 题目链接
- [0834. 树中距离之和 - 力扣](https://leetcode.cn/problems/sum-of-distances-in-tree/)
## 题目大意
**描述**:给定一个无向、连通的树。树中有 $n$ 个标记为 $0 \sim n - 1$ 的节点以及 $n - 1$ 条边 。
给定整数 $n$ 和数组 $edges$,其中 $edges[i] = [ai, bi]$ 表示树中的节点 $ai$ 和 $bi$ 之间有一条边。
**要求**:返回长度为 $n$ 的数组 $answer$,其中 $answer[i]$ 是树中第 $i$ 个节点与所有其他节点之间的距离之和。
**说明**:
- $1 \le n \le 3 \times 10^4$。
- $edges.length == n - 1$。
- $edges[i].length == 2$。
- $0 \le ai, bi < n$。
- $ai \ne bi$。
- 给定的输入保证为有效的树。
**示例**:
- 示例 1:
```python
输入: n = 6, edges = [[0,1],[0,2],[2,3],[2,4],[2,5]]
输出: [8,12,6,10,10,10]
解释: 树如图所示。
我们可以计算出 dist(0,1) + dist(0,2) + dist(0,3) + dist(0,4) + dist(0,5)
也就是 1 + 1 + 2 + 2 + 2 = 8。 因此,answer[0] = 8,以此类推。
```
- 示例 2:
```python
输入: n = 2, edges = [[1,0]]
输出: [1,1]
```
## 解题思路
### 思路 1:树形 DP + 二次遍历换根法
最容易想到的做法是:枚举 $n$ 个节点,以每个节点为根节点进行树形 DP。
对于节点 $u$,定义 $dp[u]$ 为:以节点 $u$ 为根节点的树,它的所有子节点到它的距离之和。
然后进行一轮深度优先搜索,在搜索的过程中得到以节点 $v$ 为根节点的树,节点 $v$ 与所有其他子节点之间的距离之和 $dp[v]$。还能得到子树的节点个数 $sizes[v]$。
对于节点 $v$ 来说,其对 $dp[u]$ 的贡献为:节点 $v$ 与所有其他子节点之间的距离之和,再加上需要经过 $u \rightarrow v$ 这条边的节点个数,即 $dp[v] + sizes[v]$。
可得到状态转移方程为:$dp[u] = \sum_{v \in graph[u]}(dp[v] + sizes[v])$。
这样,对于 $n$ 个节点来说,需要进行 $n$ 次树形 DP,这种做法的时间复杂度为 $O(n^2)$,而 $n$ 的范围为 $[1, 3 \times 10^4]$,这样做会导致超时,因此需要进行优化。
我们可以使用「二次遍历换根法」进行优化,从而在 $O(n)$ 的时间复杂度内解决这道题。
以编号为 $0$ 的节点为根节点,进行两次深度优先搜索。
1. 第一次遍历:从编号为 $0$ 的根节点开始,自底向上地计算出节点 $0$ 到其他的距离之和,记录在 $ans[0]$ 中。并且统计出以子节点为根节点的子树节点个数 $sizes[v]$。
2. 第二次遍历:从编号为 $0$ 的根节点开始,自顶向下地枚举每个点,计算出将每个点作为新的根节点时,其他节点到根节点的距离之和。如果当前节点为 $v$,其父节点为 $u$,则自顶向下计算出 $ans[u]$ 之后,我们将根节点从 $u$ 换为节点 $v$,子树上的点到新根节点的距离比原来都小了 $1$,非子树上剩下所有点到新根节点的距离比原来都大了 $1$。则可以据此计算出节点 $v$ 与其他节点的距离和为:$ans[v] = ans[u] + n - 2 \times sizes[u]$。
### 思路 1:代码
```python
class Solution:
def sumOfDistancesInTree(self, n: int, edges: List[List[int]]) -> List[int]:
graph = [[] for _ in range(n)]
for u, v in edges:
graph[u].append(v)
graph[v].append(u)
ans = [0 for _ in range(n)]
sizes = [1 for _ in range(n)]
def dfs(u, fa, depth):
ans[0] += depth
for v in graph[u]:
if v == fa:
continue
dfs(v, u, depth + 1)
sizes[u] += sizes[v]
def reroot(u, fa):
for v in graph[u]:
if v == fa:
continue
ans[v] = ans[u] + n - 2 * size[v]
reroot(v, u)
dfs(0, -1, 0)
reroot(0, -1)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为树的节点个数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0800-0899/sum-of-subsequence-widths.md
================================================
# [0891. 子序列宽度之和](https://leetcode.cn/problems/sum-of-subsequence-widths/)
- 标签:数组、数学、排序
- 难度:困难
## 题目链接
- [0891. 子序列宽度之和 - 力扣](https://leetcode.cn/problems/sum-of-subsequence-widths/)
## 题目大意
**描述**:
一个序列的「宽度」定义为该序列中最大元素和最小元素的差值。
给定一个整数数组 $nums$。
**要求**:
返回 $nums$ 的所有非空「子序列」的「宽度之和」。由于答案可能非常大,请返回对 $10^9 + 7$ 取余后的结果。
**说明**:
- 「子序列」定义为从一个数组里删除一些(或者不删除)元素,但不改变剩下元素的顺序得到的数组。例如,$[3,6,2,7]$ 就是数组 $[0,3,1,6,2,2,7]$ 的一个子序列。
- $1 \le nums.length \le 10^{5}$。
- $1 \le nums[i] \le 10^{5}$。
**示例**:
- 示例 1:
```python
输入:nums = [2,1,3]
输出:6
解释:子序列为 [1], [2], [3], [2,1], [2,3], [1,3], [2,1,3] 。
相应的宽度是 0, 0, 0, 1, 1, 2, 2 。
宽度之和是 6 。
```
- 示例 2:
```python
输入:nums = [2]
输出:0
```
## 解题思路
### 思路 1:排序 + 数学
关键观察:子序列的宽度只与最大值和最小值有关,与中间元素无关。
对数组排序后,对于元素 $nums[i]$:
- 作为最大值时,有 $2^i$ 个子序列(从前 $i$ 个元素中任选)
- 作为最小值时,有 $2^{n-1-i}$ 个子序列(从后 $n-1-i$ 个元素中任选)
因此,元素 $nums[i]$ 对答案的贡献为:
$$nums[i] \times (2^i - 2^{n-1-i})$$
总答案为:
$$\sum_{i=0}^{n-1} nums[i] \times (2^i - 2^{n-1-i})$$
### 思路 1:代码
```python
class Solution:
def sumSubseqWidths(self, nums: List[int]) -> int:
MOD = 10**9 + 7
n = len(nums)
# 排序
nums.sort()
# 预计算 2 的幂次
pow2 = [1] * n
for i in range(1, n):
pow2[i] = (pow2[i - 1] * 2) % MOD
result = 0
# 计算每个元素的贡献
for i in range(n):
# 作为最大值的贡献 - 作为最小值的贡献
contribution = (nums[i] * pow2[i] - nums[i] * pow2[n - 1 - i]) % MOD
result = (result + contribution) % MOD
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组长度。排序需要 $O(n \log n)$,计算贡献需要 $O(n)$。
- **空间复杂度**:$O(n)$,需要存储 2 的幂次数组。
================================================
FILE: docs/solutions/0800-0899/super-egg-drop.md
================================================
# [0887. 鸡蛋掉落](https://leetcode.cn/problems/super-egg-drop/)
- 标签:数学、二分查找、动态规划
- 难度:困难
## 题目链接
- [0887. 鸡蛋掉落 - 力扣](https://leetcode.cn/problems/super-egg-drop/)
## 题目大意
**描述**:给定一个整数 `k` 和整数 `n`,分别代表 `k` 枚鸡蛋和可以使用的一栋从第 `1` 层到第 `n` 层楼的建筑。
已知存在楼层 `f`,满足 `0 <= f <= n`,任何从高于 `f` 的楼层落下的鸡蛋都会碎,从 `f` 楼层或比它低的楼层落下的鸡蛋都不会碎。
每次操作,你可以取一枚没有碎的鸡蛋并把它从任一楼层 `x` 扔下(满足 `1 <= x <= n`),如果鸡蛋碎了,就不能再次使用它。如果鸡蛋没碎,则可以再次使用。
**要求**:计算并返回要确定 `f` 确切值的最小操作次数是多少。
**说明**:
- $1 \le k \le 100$。
- $1 \le n \le 10^4$。
**示例**:
- 示例 1:
```python
输入:k = 1, n = 2
输入:2
解释:鸡蛋从 1 楼掉落。如果它碎了,肯定能得出 f = 0。否则,鸡蛋从 2 楼掉落。如果它碎了,肯定能得出 f = 1。如果它没碎,那么肯定能得出 f = 2。因此,在最坏的情况下我们需要移动 2 次以确定 f 是多少。
```
## 解题思路
这道题目的题意不是很容易理解,我们先把题目简化一下,忽略一些限制条件,理解简单情况下的题意。然后再一步步增加限制条件,从而弄明白这道题目的意思,以及思考清楚这道题的解题思路。
我们先忽略 `k` 个鸡蛋这个条件,假设有无限个鸡蛋。
现在有 `1` ~ `n` 一共 `n` 层楼。已知存在楼层 `f`,低于等于 `f` 层的楼层扔下去的鸡蛋都不会碎,高于 `f` 的楼层扔下去的鸡蛋都会碎。
当然这个楼层 `f` 的确切值题目没有给出,需要我们一次次去测试鸡蛋最高会在哪一层不会摔碎。
在每次操作中,我们可以选定一个楼层,将鸡蛋扔下去:
- 如果鸡蛋没摔碎,则可以继续选择其他楼层进行测试。
- 如果鸡蛋摔碎了,则该鸡蛋无法继续测试。
现在题目要求:**已知有 `n` 层楼,无限个鸡蛋,求出至少需要扔几次鸡蛋,才能保证无论 `f` 是多少层,都能将 `f` 找出来?**
最简单且直观的想法:
1. 从第 `1` 楼开始扔鸡蛋。`1` 楼不碎,再去 `2` 楼扔。
2. `2` 楼还不碎,就去 `3` 楼扔。
3. ……
4. 直到鸡蛋碎了,也就找到了鸡蛋不会摔碎的最高层 `f`。
用这种方法,最坏情况下,鸡蛋在第 `n` 层也没摔碎。这种情况下我们总共试了 `n` 次才确定鸡蛋不会摔碎的最高楼层 `f`。
下面再来说一下比 `n` 次要少的情况。
如果我们可以通过二分查找的方法,先从 `1` ~ `n` 层的中间层开始扔鸡蛋。
- 如果鸡蛋碎了,则从第 `1` 层到中间层这个区间中去扔鸡蛋。
- 如果鸡蛋没碎,则从中间层到第 `n` 层这个区间中去扔鸡蛋。
每次扔鸡蛋都从区间的中间层去扔,这样每次都能排除当前区间一半的答案,从而最终确定鸡蛋不会摔碎的最高楼层 `f`。
通过这种二分查找的方法,可以优化到 $\log n$ 次就能确定鸡蛋不会摔碎的最高楼层 `f`。
因为 $\log n \le n$,所以通过二分查找的方式,「至少」比线性查找的次数要少。
同样,我们还可以通过三分查找、五分查找等等方式减少次数。
这是在不限制鸡蛋个数的情况下,现在我们来限制一下鸡蛋个数为 `k`。
现在题目要求:**已知有 `n` 层楼,`k` 个鸡蛋,求出至少需要扔几次鸡蛋,才能保证无论 `f` 是多少层,都能将 `f` 找出来?**
如果鸡蛋足够多(大于等于 $\log_2 n$ 个),可以通过二分查找的方法来测试。如果鸡蛋不够多,可能二分查找过程中,鸡蛋就用没了,则不能通过二分查找的方法来测试。
那么这时候为了找出 `f` ,我们应该如何求出最少的扔鸡蛋次数?
### 思路 1:动态规划(超时)
可以这样考虑。题目限定了 `n` 层楼,`k` 个鸡蛋。
如果我们尝试在 `1` ~ `n` 层中的任意一层 `x` 扔鸡蛋:
1. 如果鸡蛋没碎,则说明 `1` ~ `x` 层都不用再考虑了,我们需要用 `k` 个鸡蛋去考虑剩下的 `n - x` 层,问题就从 `(n, k)` 转变为了 `(n - x, k)`。
2. 如果鸡蛋碎了,则说明 `x + 1` ~ `n` 层都不用再考虑了,我们需要去剩下的 `k - 1` 个鸡蛋考虑剩下的 `x - 1` 层,问题就从 `(n, k)` 转变为了 `(x - 1, k - 1)`。
这样一来,我们就可以根据上述关系使用动态规划方法来解决这道题目了。具体步骤如下:
###### 1. 阶段划分
按照楼层数量、剩余鸡蛋个数进行阶段划分。
###### 2. 定义状态
定义状态 `dp[i][j]` 表示为:一共有 `i` 层楼,`j` 个鸡蛋的条件下,为了找出 `f` ,最坏情况下的最少扔鸡蛋次数。
###### 3. 状态转移方程
根据之前的描述,`dp[i][j]` 有两个来源,其状态转移方程为:
$dp[i][j] = min_{1 \le x \le n} (max(dp[i - x][j], dp[x - 1][j - 1])) + 1$
###### 4. 初始条件
给定鸡蛋 `k` 的取值范围为 `[1, 100]`,`f` 值取值范围为 `[0, n]`,初始化时,可以考虑将所有值设置为当前拥有的楼层数。
- 当鸡蛋数为 `1` 时,`dp[i][1] = i`。这是如果唯一的蛋碎了,则无法测试了。只能从低到高,一步步进行测试,最终最少测试数为当前拥有的楼层数(如果刚开始初始化时已经将所有值设置为当前拥有的楼层数,其实这一步可省略)。
- 当楼层为 `1` 时,在 `1` 层扔鸡蛋,`dp[1][j] = 1`。这是因为:
- 如果在 `1` 层扔鸡蛋碎了,则 `f < 1`。同时因为 `f` 的取值范围为 `[0, n]`。所以能确定 `f = 0`。
- 如果在 `1` 层扔鸡蛋没碎,则 `f >= 1`。同时因为 `f` 的取值范围为 `[0, n]`。所以能确定 `f = 0`。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i][j]` 表示为:一共有 `i` 层楼,`j` 个鸡蛋的条件下,为了找出 `f` ,最坏情况下的最少扔鸡蛋次数。则最终结果为 `dp[n][k]`。
### 思路 1:代码
```python
class Solution:
def superEggDrop(self, k: int, n: int) -> int:
dp = [[0 for _ in range(k + 1)] for i in range(n + 1)]
for i in range(1, n + 1):
for j in range(1, k + 1):
dp[i][j] = i
# for i in range(1, n + 1):
# dp[i][1] = i
for j in range(1, k + 1):
dp[1][j] = 1
for i in range(2, n + 1):
for j in range(2, k + 1):
for x in range(1, i + 1):
dp[i][j] = min(dp[i][j], max(dp[i - x][j], dp[x - 1][j - 1]) + 1)
return dp[n][k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times k)$。三重循环的时间复杂度为 $O(n^2 \times k)$。
- **空间复杂度**:$O(n \times k)$。
### 思路 2:动态规划优化
上一步中时间复杂度为 $O(n^2 \times k)$。根据 $n$ 的规模,提交上去不出意外的超时了。
我们可以观察一下上面的状态转移方程:$dp[i][j] = min_{1 \le x \le n} (max(dp[i - x][j], dp[x - 1][j - 1])) + 1$ 。
这里最外两层循环的 `i`、`j` 分别为状态的阶段,可以先将 `i`、`j` 看作固定值。最里层循环的 `x` 代表选择的任意一层 `x` ,值从 `1` 遍历到 `i`。
此时我们把 `dp[i - x][j]` 和 `dp[x - 1][j - 1]` 分别单独来看。可以看出:
- 对于 `dp[i - x][j]`:当 `x` 增加时,`i - x` 的值减少,`dp[i - x][j]` 的值跟着减小。自变量 `x` 与函数 `dp[i - x][j]` 是一条单调非递增函数。
- 对于 `dp[x - 1][j - 1]`:当 `x` 增加时, `x - 1` 的值增加,`dp[x - 1][j - 1]` 的值跟着增加。自变量 `x` 与函数 `dp[x - 1][j - 1]` 是一条单调非递减函数。
两条函数的交点处就是两个函数较大值的最小值位置。即 `dp[i][j]` 所取位置。而这个位置可以通过二分查找满足 `dp[x - 1][j - 1] >= dp[i - x][j]` 最大的那个 `x`。这样时间复杂度就从 $O(n^2 \times k)$ 优化到了 $O(n \log n \times k)$。
### 思路 2:代码
```python
class Solution:
def superEggDrop(self, k: int, n: int) -> int:
dp = [[0 for _ in range(k + 1)] for i in range(n + 1)]
for i in range(1, n + 1):
for j in range(1, k + 1):
dp[i][j] = i
# for i in range(1, n + 1):
# dp[i][1] = i
for j in range(1, k + 1):
dp[1][j] = 1
for i in range(2, n + 1):
for j in range(2, k + 1):
left, right = 1, i
while left < right:
mid = left + (right - left) // 2
if dp[mid - 1][j - 1] < dp[i - mid][j]:
left = mid + 1
else:
right = mid
dp[i][j] = max(dp[left - 1][j - 1], dp[i - left][j]) + 1
return dp[n][k]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \log n \times k)$。两重循环的时间复杂度为 $O(n \times k)$,二分查找的时间复杂度为 $O(\log n)$。
- **空间复杂度**:$O(n \times k)$。
### 思路 3:动态规划 + 逆向思维
再看一下我们现在的题目要求:已知有 `n` 层楼,`k` 个鸡蛋,求出至少需要扔几次鸡蛋,才能保证无论 `f` 是多少层,都能将 `f` 找出来?
我们可以逆向转换一下思维,将题目转变为:**已知有 `k` 个鸡蛋,最多扔 `x` 次鸡蛋(碎没碎都算 `1` 次),求最多可以检测的多少层?**
我们把未知条件「扔鸡蛋的次数」变为了已知条件,将「检测的楼层个数」变为了未知条件。
这样如果求出来的「检测的楼层个数」大于等于 `n`,则说明 `1` ~ `n` 层楼都考虑全了,`f` 值也就明确了。我们只需要从符合条件的情况中,找出「扔鸡蛋次数」最少的次数即可。
动态规划的具体步骤如下:
###### 1. 阶段划分
按照鸡蛋个数、扔鸡蛋的次数进行阶段划分。
###### 2. 定义状态
定义状态 `dp[i][j]` 表示为:一共有 `i` 个鸡蛋,最多扔 `j` 次鸡蛋(碎没碎都算 `1` 次)的条件下,最多可以检测的楼层个数。
###### 3. 状态转移方程
我们现在有 `i` 个鸡蛋,`j` 次扔鸡蛋的机会,现在尝试在 `1` ~ `n` 层中的任意一层 `x` 扔鸡蛋:
1. 如果鸡蛋没碎,剩下 `i` 个鸡蛋,还有 `j - 1` 次扔鸡蛋的机会,最多可以检测 `dp[i][j - 1]` 层楼层。
2. 如果鸡蛋碎了,剩下 `i - 1` 个鸡蛋,还有 `j - 1` 次扔鸡蛋的机会,最多可以检测 `dp[i - 1][j - 1]` 层楼层。
3. 再加上我们扔鸡蛋的第 `x` 层,`i` 个鸡蛋,`j` 次扔鸡蛋的机会最多可以检测 `dp[i][j - 1] + dp[i - 1][j - 1] + 1` 层。
则状态转移方程为:$dp[i][j] = dp[i][j - 1] + dp[i - 1][j - 1] + 1$。
###### 4. 初始条件
- 当鸡蛋数为 `1` 时,只有 `1` 次扔鸡蛋的机会时,最多可以检测 `1` 层,即 `dp[1][1] = 1`。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i][j]` 表示为:一共有 `i` 个鸡蛋,最多扔 `j` 次鸡蛋(碎没碎都算 `1` 次)的条件下,最多可以检测的楼层个数。则我们需要从满足 `i == k` 并且 `dp[i][j] >= n`(即 `k` 个鸡蛋,`j` 次扔鸡蛋,一共检测出 `n` 层楼)的情况中,找出最小的 ` j`,将其返回。
### 思路 3:代码
```python
class Solution:
def superEggDrop(self, k: int, n: int) -> int:
dp = [[0 for _ in range(n + 1)] for i in range(k + 1)]
dp[1][1] = 1
for i in range(1, k + 1):
for j in range(1, n + 1):
dp[i][j] = dp[i][j - 1] + dp[i - 1][j - 1] + 1
if i == k and dp[i][j] >= n:
return j
return n
```
### 思路 3:复杂度分析
- **时间复杂度**:$O(n \times k)$。两重循环的时间复杂度为 $O(n \times k)$。
- **空间复杂度**:$O(n \times k)$。
## 参考资料
- 【题解】[题目理解 + 基本解法 + 进阶解法 - 鸡蛋掉落 - 力扣](https://leetcode.cn/problems/super-egg-drop/solution/ji-ben-dong-tai-gui-hua-jie-fa-by-labuladong/)
- 【题解】[动态规划(只解释官方题解方法一)(Java) - 鸡蛋掉落 - 力扣](https://leetcode.cn/problems/super-egg-drop/solution/dong-tai-gui-hua-zhi-jie-shi-guan-fang-ti-jie-fang/)
- 【题解】[动态规划 & 记忆化搜索 2000ms -> 32ms 的过程 - 鸡蛋掉落 - 力扣](https://leetcode.cn/problems/super-egg-drop/solution/python-dong-tai-gui-hua-ji-yi-hua-sou-su-hnj9/)
================================================
FILE: docs/solutions/0800-0899/surface-area-of-3d-shapes.md
================================================
# [0892. 三维形体的表面积](https://leetcode.cn/problems/surface-area-of-3d-shapes/)
- 标签:几何、数组、数学、矩阵
- 难度:简单
## 题目链接
- [0892. 三维形体的表面积 - 力扣](https://leetcode.cn/problems/surface-area-of-3d-shapes/)
## 题目大意
**描述**:给定一个 $n \times n$ 的网格 $grid$,上面放置着一些 $1 \times 1 \times 1$ 的正方体。每个值 $v = grid[i][j]$ 表示 $v$ 个正方体叠放在对应单元格 $(i, j)$ 上。
放置好正方体后,任何直接相邻的正方体都会互相粘在一起,形成一些不规则的三维形体。
**要求**:返回最终这些形体的总面积。
**说明**:
- 每个形体的底面也需要计入表面积中。
**示例**:
- 示例 1:

```python
输入:grid = [[1,2],[3,4]]
输出:34
```
- 示例 2:
```python
输入:grid = [[1,1,1],[1,0,1],[1,1,1]]
输出:32
```
## 解题思路
### 思路 1:模拟
使用二重循环遍历所有的正方体,计算每一个正方体所贡献的表面积,将其累积起来即为答案。
而每一个正方体所贡献的表面积,可以通过枚举当前正方体前后左右相邻四个方向上的正方体的个数,从而通过判断计算得出。
- 如果当前位置 $(row, col)$ 存在正方体,则正方体在上下位置上起码贡献了 $2$ 的表面积。
- 如果当前位置 $(row, col)$ 的相邻位置 $(new\_row, new\_col)$ 上不存在正方体,说明当前正方体在该方向为最外侧,则 $(row, col)$ 位置所贡献的表面积为当前位置上的正方体个数,即 $grid[row][col]$。
- 如果当前位置 $(row, col)$ 的相邻位置 $(new\_row, new\_col)$ 上存在正方体:
- 如果 $grid[row][col] > grid[new\_row][new\_col]$,说明 $grid[row][col]$ 在该方向上底面一部分被 $grid[new\_row][new\_col]$ 遮盖了,则 $(row, col)$ 位置所贡献的表面积为 $grid[row][col] - grid[new_row][new_col]$。
- 如果 $grid[row][col] \le grid[new\_row][new\_col]$,说明 $grid[row][col]$ 在该方向上完全被 $grid[new\_row][new\_col]$ 遮盖了,则 $(row, col)$ 位置所贡献的表面积为 $0$。
### 思路 1:代码
```Python
class Solution:
def surfaceArea(self, grid: List[List[int]]) -> int:
directions = [(-1, 0), (0, 1), (1, 0), (0, -1)]
size = len(grid)
ans = 0
for row in range(size):
for col in range(size):
if grid[row][col]:
# 底部、顶部贡献表面积
ans += 2
for direction in directions:
new_row = row + direction[0]
new_col = col + direction[1]
if 0 <= new_row < size and 0 <= new_col < size:
if grid[row][col] > grid[new_row][new_col]:
add = grid[row][col] - grid[new_row][new_col]
else:
add = 0
else:
add = grid[row][col]
ans += add
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为二位数组 $grid$ 的行数或列数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0800-0899/transpose-matrix.md
================================================
# [0867. 转置矩阵](https://leetcode.cn/problems/transpose-matrix/)
- 标签:数组、矩阵、模拟
- 难度:简单
## 题目链接
- [0867. 转置矩阵 - 力扣](https://leetcode.cn/problems/transpose-matrix/)
## 题目大意
给定一个二维数组 matrix。返回 matrix 的转置矩阵。
## 解题思路
直接模拟求解即可。先求出 matrix 的规模。如果 matrix 是 m * n 的矩阵。则创建一个 n * m 大小的矩阵 transposed。根据转置的规则对 transposed 的每个元素进行赋值。最终返回 transposed。
## 代码
```python
class Solution:
def transpose(self, matrix: List[List[int]]) -> List[List[int]]:
m = len(matrix)
n = len(matrix[0])
transposed = [[0 for _ in range(m)] for _ in range(n)]
for i in range(m):
for j in range(n):
transposed[j][i] = matrix[i][j]
return transposed
```
================================================
FILE: docs/solutions/0800-0899/uncommon-words-from-two-sentences.md
================================================
# [0884. 两句话中的不常见单词](https://leetcode.cn/problems/uncommon-words-from-two-sentences/)
- 标签:哈希表、字符串
- 难度:简单
## 题目链接
- [0884. 两句话中的不常见单词 - 力扣](https://leetcode.cn/problems/uncommon-words-from-two-sentences/)
## 题目大意
**描述**:给定两个字符串 $s1$ 和 $s2$ ,分别表示两个句子。
**要求**:返回所有不常用单词的列表。返回列表中单词可以按任意顺序组织。
**说明**:
- **句子**:是一串由空格分隔的单词。
- **单词**:仅由小写字母组成的子字符串。
- **不常见单词**:如果某个单词在其中一个句子中恰好出现一次,在另一个句子中却没有出现,那么这个单词就是不常见的。
- $1 \le s1.length, s2.length \le 200$。
- $s1$ 和 $s2$ 由小写英文字母和空格组成。
- $s1$ 和 $s2$ 都不含前导或尾随空格。
- $s1$ 和 $s2$ 中的所有单词间均由单个空格分隔。
**示例**:
- 示例 1:
```python
输入:s1 = "this apple is sweet", s2 = "this apple is sour"
输出:["sweet","sour"]
```
- 示例 2:
```python
输入:s1 = "apple apple", s2 = "banana"
输出:["banana"]
```
## 解题思路
### 思路 1:哈希表
题目要求找出在其中一个句子中恰好出现一次,在另一个句子中却没有出现的单词,其实就是找出在两个句子中只出现过一次的单词,我们可以用哈希表统计两个句子中每个单词的出现频次,然后将出现频次为 $1$ 的单词就是不常见单词,将其加入答案数组即可。
具体步骤如下:
1. 遍历字符串 $s1$、$s2$,使用哈希表 $table$ 统计字符串 $s1$、$s2$ 各个单词的出现频次。
2. 遍历哈希表,找出出现频次为 $1$ 的单词,将其加入答案数组 $res$ 中。
3. 遍历完返回答案数组 $res$。
### 思路 1:代码
```python
class Solution:
def uncommonFromSentences(self, s1: str, s2: str) -> List[str]:
table = dict()
for word in s1.split(' '):
if word not in table:
table[word] = 1
else:
table[word] += 1
for word in s2.split(' '):
if word not in table:
table[word] = 1
else:
table[word] += 1
res = []
for word in table:
if table[word] == 1:
res.append(word)
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m + n)$,其中 $m$、$n$ 分别为字符串 $s1$、$s2$ 的长度。
- **空间复杂度**:$O(m + n)$。
================================================
FILE: docs/solutions/0800-0899/unique-morse-code-words.md
================================================
# [0804. 唯一摩尔斯密码词](https://leetcode.cn/problems/unique-morse-code-words/)
- 标签:数组、哈希表、字符串
- 难度:简单
## 题目链接
- [0804. 唯一摩尔斯密码词 - 力扣](https://leetcode.cn/problems/unique-morse-code-words/)
## 题目大意
**描述**:国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如:
- `'a'` 对应 `".-"`,
- `'b'` 对应 `"-..."`,
- `'c'` 对应 `"-.-."` ,以此类推。
为了方便,所有 $26$ 个英文字母的摩尔斯密码表如下:
`[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]`
给定一个字符串数组 $words$,每个单词可以写成每个字母对应摩尔斯密码的组合。
- 例如,`"cab"` 可以写成 `"-.-..--..."` ,(即 `"-.-."` + `".-"` + `"-..."` 字符串的结合)。我们将这样一个连接过程称作单词翻译。
**要求**:对 $words$ 中所有单词进行单词翻译,返回不同单词翻译的数量。
**说明**:
- $1 \le words.length \le 100$。
- $1 \le words[i].length \le 12$。
- $words[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入: words = ["gin", "zen", "gig", "msg"]
输出: 2
解释:
各单词翻译如下:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
共有 2 种不同翻译, "--...-." 和 "--...--.".
```
- 示例 2:
```python
输入:words = ["a"]
输出:1
```
## 解题思路
### 思路 1:模拟 + 哈希表
1. 根据题目要求,将所有单词都转换为对应摩斯密码。
2. 使用哈希表存储所有转换后的摩斯密码。
3. 返回哈希表中不同的摩斯密码个数(脊哈希表的长度)作为答案。
### 思路 1:代码
```Python
class Solution:
def uniqueMorseRepresentations(self, words: List[str]) -> int:
table = [".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
word_set = set()
for word in words:
word_mose = ""
for ch in word:
word_mose += table[ord(ch) - ord('a')]
word_set.add(word_mose)
return len(word_set)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(s)$,其中 $s$ 为数组 $words$ 中所有单词的长度之和。
- **空间复杂度**:$O(s)$。
================================================
FILE: docs/solutions/0800-0899/walking-robot-simulation.md
================================================
# [0874. 模拟行走机器人](https://leetcode.cn/problems/walking-robot-simulation/)
- 标签:数组、哈希表、模拟
- 难度:中等
## 题目链接
- [0874. 模拟行走机器人 - 力扣](https://leetcode.cn/problems/walking-robot-simulation/)
## 题目大意
**描述**:
机器人在一个无限大小的 XY 网格平面上行走,从点 $(0, 0)$ 处开始出发,面向北方。该机器人可以接收以下三种类型的命令 $commands$:
- $-2$:向左转 90 度
- $-1$:向右转 90 度
- $1 \le x \le 9$:向前移动 $x$ 个单位长度
在网格上有一些格子被视为障碍物 $obstacles$。第 $i$ 个障碍物位于网格点 $obstacles[i] = (xi, yi)$。
机器人无法走到障碍物上,它将会停留在障碍物的前一个网格方块上,并继续执行下一个命令。
**要求**:
返回机器人距离原点的「最大欧式距离」的「平方」。(即,如果距离为 5 ,则返回 25 )
**说明**:
- 注意:
- 北方表示 +Y 方向。
- 东方表示 +X 方向。
- 南方表示 -Y 方向。
- 西方表示 -X 方向。
- 原点 $[0,0]$ 可能会有障碍物。
- $1 \le commands.length \le 10^{4}$。
- $commands[i]$ 的值可以取 -2、-1 或者是范围 $[1, 9]$ 内的一个整数。
- $0 \le obstacles.length \le 10^{4}$。
- $-3 \times 10^{4} \le xi, yi \le 3 \times 10^{4}$。
- 答案保证小于 $2^{31}$。
**示例**:
- 示例 1:
```python
输入:commands = [4,-1,3], obstacles = []
输出:25
解释:
机器人开始位于 (0, 0):
1. 向北移动 4 个单位,到达 (0, 4)
2. 右转
3. 向东移动 3 个单位,到达 (3, 4)
距离原点最远的是 (3, 4) ,距离为 32 + 42 = 25
```
- 示例 2:
```python
输入:commands = [4,-1,4,-2,4], obstacles = [[2,4]]
输出:65
解释:机器人开始位于 (0, 0):
1. 向北移动 4 个单位,到达 (0, 4)
2. 右转
3. 向东移动 1 个单位,然后被位于 (2, 4) 的障碍物阻挡,机器人停在 (1, 4)
4. 左转
5. 向北走 4 个单位,到达 (1, 8)
距离原点最远的是 (1, 8) ,距离为 12 + 82 = 65
```
## 解题思路
### 思路 1:模拟 + 哈希表
模拟机器人的行走过程:
1. 用方向数组表示四个方向:北(0, 1)、东(1, 0)、南(0, -1)、西(-1, 0)。
2. 用变量 $direction$ 表示当前方向的索引。
3. 将障碍物坐标存入哈希集合,方便快速查询。
4. 遍历命令:
- 如果是 -2(左转),方向索引减 1
- 如果是 -1(右转),方向索引加 1
- 如果是移动命令,逐步移动,每次移动一格并检查是否有障碍物
5. 记录过程中距离原点的最大欧式距离的平方。
### 思路 1:代码
```python
class Solution:
def robotSim(self, commands: List[int], obstacles: List[List[int]]) -> int:
# 方向数组:北、东、南、西
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
direction = 0 # 初始方向为北
# 将障碍物转换为集合,方便查询
obstacle_set = set(map(tuple, obstacles))
x, y = 0, 0 # 初始位置
max_dist = 0 # 最大距离的平方
for cmd in commands:
if cmd == -2:
# 左转
direction = (direction - 1) % 4
elif cmd == -1:
# 右转
direction = (direction + 1) % 4
else:
# 前进 cmd 步
dx, dy = directions[direction]
for _ in range(cmd):
# 尝试移动一步
next_x, next_y = x + dx, y + dy
# 检查是否有障碍物
if (next_x, next_y) not in obstacle_set:
x, y = next_x, next_y
# 更新最大距离
max_dist = max(max_dist, x * x + y * y)
else:
# 遇到障碍物,停止移动
break
return max_dist
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(N + K)$,其中 $N$ 是命令数组的长度,$K$ 是所有移动命令的步数之和。将障碍物加入集合需要 $O(M)$,其中 $M$ 是障碍物数量。
- **空间复杂度**:$O(M)$,需要存储障碍物的哈希集合。
================================================
FILE: docs/solutions/0900-0999/3sum-with-multiplicity.md
================================================
# [0923. 三数之和的多种可能](https://leetcode.cn/problems/3sum-with-multiplicity/)
- 标签:数组、哈希表、双指针、计数、排序
- 难度:中等
## 题目链接
- [0923. 三数之和的多种可能 - 力扣](https://leetcode.cn/problems/3sum-with-multiplicity/)
## 题目大意
**描述**:
给定一个整数数组 $arr$,以及一个整数 $target$ 作为目标值。
**要求**:
返回满足 $i < j < k$ 且 $arr[i] + arr[j] + arr[k] == target$ 的元组 $i, j, k$ 的数量。
由于结果会非常大,请返回 $10^9 + 7$ 的模。
**说明**:
- $3 \le arr.length \le 3000$。
- $0 \le arr[i] \le 10^{3}$。
- $0 \le target \le 300$。
**示例**:
- 示例 1:
```python
输入:arr = [1,1,2,2,3,3,4,4,5,5], target = 8
输出:20
解释:
按值枚举(arr[i], arr[j], arr[k]):
(1, 2, 5) 出现 8 次;
(1, 3, 4) 出现 8 次;
(2, 2, 4) 出现 2 次;
(2, 3, 3) 出现 2 次。
```
- 示例 2:
```python
输入:arr = [1,1,2,2,2,2], target = 5
输出:12
解释:
arr[i] = 1, arr[j] = arr[k] = 2 出现 12 次:
我们从 [1,1] 中选择一个 1,有 2 种情况,
从 [2,2,2,2] 中选出两个 2,有 6 种情况。
```
## 解题思路
### 思路 1:哈希表 + 双指针
#### 思路
这道题要求统计满足 $i < j < k$ 且 $arr[i] + arr[j] + arr[k] = target$ 的三元组数量。
由于数组元素范围较小($0 \le arr[i] \le 100$),我们可以使用哈希表统计每个数字的出现次数,然后枚举所有可能的三元组:
1. **统计频次**:使用哈希表 $count$ 统计每个数字的出现次数。
2. **枚举三元组**:枚举所有可能的 $(i, j, k)$ 组合,其中 $i \le j \le k$:
- 如果 $i + j + k = target$,计算该组合的方案数。
- 方案数的计算需要考虑三个数是否相同:
- 如果三个数都相同:$C(count[i], 3) = \frac{count[i] \times (count[i] - 1) \times (count[i] - 2)}{6}$
- 如果两个数相同:$C(count[i], 2) \times count[k] = \frac{count[i] \times (count[i] - 1)}{2} \times count[k]$
- 如果三个数都不同:$count[i] \times count[j] \times count[k]$
3. 返回总方案数对 $10^9 + 7$ 取模的结果。
#### 代码
```python
class Solution:
def threeSumMulti(self, arr: List[int], target: int) -> int:
MOD = 10**9 + 7
from collections import Counter
# 统计每个数字的出现次数
count = Counter(arr)
res = 0
# 枚举所有可能的三元组 (i, j, k),其中 i <= j <= k
for i in range(101):
for j in range(i, 101):
k = target - i - j
if k < 0 or k > 100:
continue
if i == j == k:
# 三个数都相同:C(count[i], 3)
res += count[i] * (count[i] - 1) * (count[i] - 2) // 6
elif i == j:
# 前两个数相同:C(count[i], 2) * count[k]
if k > j:
res += count[i] * (count[i] - 1) // 2 * count[k]
elif j == k:
# 后两个数相同:count[i] * C(count[j], 2)
if k > i:
res += count[i] * count[j] * (count[j] - 1) // 2
else:
# 三个数都不同
if k > j:
res += count[i] * count[j] * count[k]
res %= MOD
return res
```
#### 复杂度分析
- **时间复杂度**:$O(n + C^2)$,其中 $n$ 是数组长度,$C = 101$ 是数字的范围。统计频次需要 $O(n)$,枚举三元组需要 $O(C^2)$。
- **空间复杂度**:$O(C)$,需要哈希表存储每个数字的频次。
================================================
FILE: docs/solutions/0900-0999/add-to-array-form-of-integer.md
================================================
# [0989. 数组形式的整数加法](https://leetcode.cn/problems/add-to-array-form-of-integer/)
- 标签:数组、数学
- 难度:简单
## 题目链接
- [0989. 数组形式的整数加法 - 力扣](https://leetcode.cn/problems/add-to-array-form-of-integer/)
## 题目大意
**描述**:
整数的「数组形式」$num$ 是按照从左到右的顺序表示其数字的数组。
- 例如,对于 $num = 1321$ ,数组形式是 $[1,3,2,1]$。
给定 $num$,整数的「数组形式」,和整数 $k$。
**要求**:
返回 整数 $num + k$ 的「数组形式」。
**说明**:
- $1 \le num.length \le 10^{4}$。
- $0 \le num[i] \le 9$。
- $num$ 不包含任何前导零,除了零本身。
- $1 \le k \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:num = [1,2,0,0], k = 34
输出:[1,2,3,4]
解释:1200 + 34 = 1234
```
- 示例 2:
```python
输入:num = [2,7,4], k = 181
输出:[4,5,5]
解释:274 + 181 = 455
```
## 解题思路
### 思路 1:模拟加法
#### 思路
这道题要求将数组形式的整数与整数 $k$ 相加,返回数组形式的结果。我们可以模拟加法的过程:
1. 从数组 $num$ 的最后一位开始,与 $k$ 的个位相加。
2. 计算当前位的和以及进位。
3. 将当前位的结果插入到结果数组的开头。
4. 更新 $k$ 为进位值($k$ 除以 $10$)。
5. 继续处理下一位,直到数组遍历完且 $k$ 为 $0$。
#### 代码
```python
class Solution:
def addToArrayForm(self, num: List[int], k: int) -> List[int]:
res = []
n = len(num)
i = n - 1 # 从数组最后一位开始
# 当数组还有位数或 k 不为 0 时继续
while i >= 0 or k > 0:
# 获取当前位的数字
digit = num[i] if i >= 0 else 0
# 计算当前位的和
total = digit + k % 10
# 将当前位结果插入到结果数组开头
res.append(total % 10)
# 计算进位
k = k // 10 + total // 10
i -= 1
# 结果是逆序的,需要反转
return res[::-1]
```
#### 复杂度分析
- **时间复杂度**:$O(\max(n, \log k))$,其中 $n$ 是数组 $num$ 的长度,$\log k$ 是整数 $k$ 的位数。需要遍历所有位数。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/array-of-doubled-pairs.md
================================================
# [0954. 二倍数对数组](https://leetcode.cn/problems/array-of-doubled-pairs/)
- 标签:贪心、数组、哈希表、排序
- 难度:中等
## 题目链接
- [0954. 二倍数对数组 - 力扣](https://leetcode.cn/problems/array-of-doubled-pairs/)
## 题目大意
**描述**:
给定一个长度为偶数的整数数组 $arr$。
**要求**:
只有对 $arr$ 进行重组后可以满足「对于每个 $0 \le i < len(arr) / 2$,都有 $arr[2 \times i + 1] = 2 \times arr[2 \times i]$」时,返回 true;否则,返回 false。
**说明**:
- $0 \le arr.length \le 3 \times 10^{4}$。
- $arr.length$ 是偶数。
- $-10^{5} \le arr[i] \le 10^{5}$。
**示例**:
- 示例 1:
```python
输入:arr = [3,1,3,6]
输出:false
```
- 示例 2:
```python
输入:arr = [2,1,2,6]
输出:false
```
## 解题思路
### 思路 1:贪心 + 哈希表
#### 思路
这道题要求判断数组能否重组为二倍数对的形式,即 $arr[2 \times i + 1] = 2 \times arr[2 \times i]$。
我们可以使用贪心策略:
1. **统计频次**:使用哈希表统计每个数字出现的次数。
2. **排序**:按绝对值从小到大排序。这样可以保证先处理较小的数,避免遗漏。
3. **贪心匹配**:对于每个数 $x$,如果它还有剩余次数,就尝试找它的二倍 $2x$:
- 如果 $2x$ 的次数不足,返回 `False`。
- 否则,将 $x$ 和 $2x$ 的次数都减 $1$。
4. 如果所有数都能成功匹配,返回 `True`。
**注意**:需要按绝对值排序,因为负数的二倍关系是 $-4$ 和 $-2$,而不是 $-2$ 和 $-4$。
#### 代码
```python
class Solution:
def canReorderDoubled(self, arr: List[int]) -> bool:
from collections import Counter
# 统计每个数字的出现次数
count = Counter(arr)
# 按绝对值从小到大排序
for x in sorted(count, key=abs):
# 如果 x 还有剩余次数
if count[x] > 0:
# 检查 2x 的次数是否足够
if count[2 * x] < count[x]:
return False
# 匹配 x 和 2x
count[2 * x] -= count[x]
return True
```
#### 复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组长度。主要时间消耗在排序上。
- **空间复杂度**:$O(n)$,需要哈希表存储每个数字的频次。
================================================
FILE: docs/solutions/0900-0999/available-captures-for-rook.md
================================================
# [0999. 可以被一步捕获的棋子数](https://leetcode.cn/problems/available-captures-for-rook/)
- 标签:数组、矩阵、模拟
- 难度:简单
## 题目链接
- [0999. 可以被一步捕获的棋子数 - 力扣](https://leetcode.cn/problems/available-captures-for-rook/)
## 题目大意
**描述**:在一个 $8 \times 8$ 的棋盘上,有一个白色的车(Rook),用字符 `'R'` 表示。棋盘上还可能存在空方块,白色的象(Bishop)以及黑色的卒(pawn),分别用字符 `'.'`,`'B'` 和 `'p'` 表示。不难看出,大写字符表示的是白棋,小写字符表示的是黑棋。
**要求**:你现在可以控制车移动一次,请你统计有多少敌方的卒处于你的捕获范围内(即,可以被一步捕获的棋子数)。
**说明**:
- 车按国际象棋中的规则移动。东,西,南,北四个基本方向任选其一,然后一直向选定的方向移动,直到满足下列四个条件之一:
- 棋手选择主动停下来。
- 棋子因到达棋盘的边缘而停下。
- 棋子移动到某一方格来捕获位于该方格上敌方(黑色)的卒,停在该方格内。
- 车不能进入/越过已经放有其他友方棋子(白色的象)的方格,停在友方棋子前。
- $board.length == board[i].length == 8$
- $board[i][j]$ 可以是 `'R'`,`'.'`,`'B'` 或 `'p'`。
- 只有一个格子上存在 $board[i][j] == 'R'$。
**示例**:
- 示例 1:

```python
输入:[[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".","R",".",".",".","p"],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."]]
输出:3
解释:在本例中,车能够捕获所有的卒。
```
- 示例 2:

```python
输入:[[".",".",".",".",".",".",".","."],[".","p","p","p","p","p",".","."],[".","p","p","B","p","p",".","."],[".","p","B","R","B","p",".","."],[".","p","p","B","p","p",".","."],[".","p","p","p","p","p",".","."],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."]]
输出:0
解释:象阻止了车捕获任何卒。
```
## 解题思路
### 思路 1:模拟
1. 双重循环遍历确定白色车的位置 $(pos\_i,poss\_j)$。
2. 让车向上、下、左、右四个方向进行移动,直到超出边界 / 碰到白色象 / 碰到卒为止。使用计数器 $cnt$ 记录捕获的卒的数量。
3. 返回答案 $cnt$。
### 思路 1:代码
```Python
class Solution:
def numRookCaptures(self, board: List[List[str]]) -> int:
directions = {(1, 0), (-1, 0), (0, 1), (0, -1)}
pos_i, pos_j = -1, -1
for i in range(len(board)):
if pos_i != -1 and pos_j != -1:
break
for j in range(len(board[i])):
if board[i][j] == 'R':
pos_i, pos_j = i, j
break
cnt = 0
for direction in directions:
setp = 0
while True:
new_i = pos_i + setp * direction[0]
new_j = pos_j + setp * direction[1]
if new_i < 0 or new_i >= 8 or new_j < 0 or new_j >= 8 or board[new_i][new_j] == 'B':
break
if board[new_i][new_j] == 'p':
cnt += 1
break
setp += 1
return cnt
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为棋盘的边长。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0900-0999/bag-of-tokens.md
================================================
# [0948. 令牌放置](https://leetcode.cn/problems/bag-of-tokens/)
- 标签:贪心、数组、双指针、排序
- 难度:中等
## 题目链接
- [0948. 令牌放置 - 力扣](https://leetcode.cn/problems/bag-of-tokens/)
## 题目大意
**描述**:
你的初始「能量」为 $power$,初始「分数」为 0,只有一包令牌以整数数组 $tokens$ 给出。其中 $tokens[i]$ 是第 $i$ 个令牌的值(下标从 0 开始)。
你的目标是通过有策略地使用这些令牌以「最大化」总「分数」。在一次行动中,你可以用两种方式中的一种来使用一个 未被使用的 令牌(但不是对同一个令牌使用两种方式):
- 朝上:如果你当前「至少」有 $tokens[i]$ 点 能量 ,可以使用令牌 $i$,失去 $tokens[i]$ 点「能量」,并得到 1 分。
- 朝下:如果你当前至少有 1 分,可以使用令牌 $i$ ,获得 $tokens[i]$ 点「能量」,并失去 1 分。
**要求**:
在使用「任意」数量的令牌后,返回我们可以得到的最大「分数」。
**说明**:
- $0 \le tokens.length \le 10^{3}$。
- $0 \le tokens[i], power \lt 10^{4}$。
**示例**:
- 示例 1:
```python
输入:tokens = [100], power = 50
输出:0
解释:因为你的初始分数为 0,无法使令牌朝下。你也不能使令牌朝上因为你的能量(50)比 tokens[0] 少(100)。
```
- 示例 2:
```python
输入:tokens = [200,100], power = 150
输出:1
解释:使令牌 1 正面朝上,能量变为 50,分数变为 1 。
不必使用令牌 0,因为你无法使用它来提高分数。可得到的最大分数是 1。
```
## 解题思路
### 思路 1:贪心 + 双指针
#### 思路
这道题要求通过使用令牌来最大化分数。我们有两种操作:
- **朝上**:消耗 $tokens[i]$ 点能量,获得 $1$ 分。
- **朝下**:消耗 $1$ 分,获得 $tokens[i]$ 点能量。
贪心策略:
1. **排序**:将令牌按值从小到大排序。
2. **双指针**:使用左右指针分别指向最小和最大的令牌。
3. **策略**:
- 优先使用能量较少的令牌朝上(左指针),获得分数。
- 当能量不足时,如果有分数,可以使用能量较大的令牌朝下(右指针),获得能量。
- 记录过程中的最大分数。
#### 代码
```python
class Solution:
def bagOfTokensScore(self, tokens: List[int], power: int) -> int:
tokens.sort() # 排序
left, right = 0, len(tokens) - 1
score = 0 # 当前分数
max_score = 0 # 最大分数
while left <= right:
if power >= tokens[left]:
# 能量足够,使用最小的令牌朝上
power -= tokens[left]
score += 1
max_score = max(max_score, score)
left += 1
elif score > 0:
# 能量不足但有分数,使用最大的令牌朝下
power += tokens[right]
score -= 1
right -= 1
else:
# 能量不足且没有分数,无法继续
break
return max_score
```
#### 复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是令牌数量。主要时间消耗在排序上。
- **空间复杂度**:$O(1)$,只使用了常数个额外变量(不考虑排序的空间)。
================================================
FILE: docs/solutions/0900-0999/beautiful-array.md
================================================
# [0932. 漂亮数组](https://leetcode.cn/problems/beautiful-array/)
- 标签:数组、数学、分治
- 难度:中等
## 题目链接
- [0932. 漂亮数组 - 力扣](https://leetcode.cn/problems/beautiful-array/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:返回长度为 $n$ 的任一漂亮数组。
**说明**:
- **漂亮数组**(长度为 $n$ 的数组 $nums$ 满足下述条件):
- $nums$ 是由范围 $[1, n]$ 的整数组成的一个排列。
- 对于每个 $0 \le i < j < n$,均不存在下标 $k$($i < k < j$)使得 $2 \times nums[k] == nums[i] + nums[j]$。
- $1 \le n \le 1000$。
- 本题保证对于给定的 $n$ 至少存在一个有效答案。
**示例**:
- 示例 1:
```python
输入:n = 4
输出:[2,1,4,3]
```
- 示例 2:
```python
输入:n = 5
输出:[3,1,2,5,4]
```
## 解题思路
### 思路 1:分治算法
根据题目要求,我们可以得到以下信息:
1. 题目要求 $2 \times nums[k] == nums[i] + nums[j], (0 \le i < k < j < n)$ 不能成立,可知:等式左侧必为偶数,只要右侧和为奇数则等式不成立。
2. 已知:奇数 + 偶数 = 奇数,则令 $nums[i]$ 和 $nums[j]$ 其中一个为奇数,另一个为偶数,即可保证 $nums[i] + nums[j]$ 一定为奇数。这里我们不妨令 $nums[i]$ 为奇数,令 $nums[j]$ 为偶数。
3. 如果数组 $nums$ 是漂亮数组,那么对数组 $nums$ 的每一位元素乘以一个常数或者加上一个常数之后,$nums$ 仍是漂亮数组。
- 即如果 $[a_1, a_2, ..., a_n]$ 是一个漂亮数组,那么 $[k \times a_1 + b, k \times a_2 + b, ..., k \times a_n + b]$ 也是漂亮数组。
那么,我们可以按照下面的规则构建长度为 $n$ 的漂亮数组。
1. 当 $n = 1$ 时,返回 $[1]$。此时数组 $nums$ 中仅有 $1$ 个元素,并且满足漂亮数组的条件。
2. 当 $n > 1$ 时,我们将 $nums$ 分解为左右两个部分:`left_nums`、`right_nums`。如果左右两个部分满足:
1. 数组 `left_nums` 中元素全为奇数(可以通过 `nums[i] * 2 - 1` 将 `left_nums` 中元素全部映射为奇数)。
2. 数组 `right_nums` 中元素全为偶数(可以通过 `nums[i] * 2` 将 `right_nums` 中元素全部映射为偶数)。
3. `left_nums` 和 `right_nums` 都是漂亮数组。
3. 那么 `left_nums + right_nums` 构成的数组一定也是漂亮数组,即 $nums$ 为漂亮数组,将 $nums$ 返回即可。
### 思路 1:代码
```python
class Solution:
def beautifulArray(self, n: int) -> List[int]:
if n == 1:
return [1]
nums = [0 for _ in range(n)]
left_cnt = (n + 1) // 2
right_cnt = n - left_cnt
left_nums = self.beautifulArray(left_cnt)
right_nums = self.beautifulArray(right_cnt)
for i in range(left_cnt):
nums[i] = 2 * left_nums[i] - 1
for i in range(right_cnt):
nums[left_cnt + i] = 2 * right_nums[i]
return nums
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(n \times \log n)$。
================================================
FILE: docs/solutions/0900-0999/binary-subarrays-with-sum.md
================================================
# [0930. 和相同的二元子数组](https://leetcode.cn/problems/binary-subarrays-with-sum/)
- 标签:数组、哈希表、前缀和、滑动窗口
- 难度:中等
## 题目链接
- [0930. 和相同的二元子数组 - 力扣](https://leetcode.cn/problems/binary-subarrays-with-sum/)
## 题目大意
**描述**:
给定一个二元数组 $nums$,和一个整数 $goal$。
**要求**:
请你统计并返回有多少个和为 $goal$ 的「非空」子数组。
**说明**:
- 「子数组」是数组的一段连续部分。
- $1 \le nums.length \le 3 * 10^{4}$。
- $nums[i]$ 不是 0 就是 1。
- $0 \le goal \le nums.length$。
**示例**:
- 示例 1:
```python
输入:nums = [1,0,1,0,1], goal = 2
输出:4
解释:
有 4 个满足题目要求的子数组:[1,0,1]、[1,0,1,0]、[0,1,0,1]、[1,0,1]
```
- 示例 2:
```python
输入:nums = [0,0,0,0,0], goal = 0
输出:15
```
## 解题思路
### 思路 1:前缀和 + 哈希表
#### 思路
这道题要求统计和为 $goal$ 的非空子数组数量。我们可以使用前缀和的思想:
1. **前缀和**:定义 $preSum[i]$ 为数组前 $i$ 个元素的和。
2. **子数组和**:子数组 $[i, j]$ 的和为 $preSum[j] - preSum[i - 1]$。
3. **转化问题**:要找满足 $preSum[j] - preSum[i - 1] = goal$ 的 $(i, j)$ 对数,即找满足 $preSum[i - 1] = preSum[j] - goal$ 的数量。
4. **哈希表优化**:使用哈希表 $count$ 记录每个前缀和出现的次数,遍历数组时:
- 如果 $preSum - goal$ 在哈希表中,说明存在以当前位置为结尾、和为 $goal$ 的子数组,累加对应的次数。
- 将当前前缀和加入哈希表。
#### 代码
```python
class Solution:
def numSubarraysWithSum(self, nums: List[int], goal: int) -> int:
from collections import defaultdict
# 哈希表记录前缀和出现的次数
count = defaultdict(int)
count[0] = 1 # 前缀和为 0 的情况,初始化为 1
preSum = 0 # 当前前缀和
res = 0 # 结果
for num in nums:
preSum += num
# 如果 preSum - goal 存在,说明存在和为 goal 的子数组
if preSum - goal in count:
res += count[preSum - goal]
# 记录当前前缀和
count[preSum] += 1
return res
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组长度。只需要遍历一次数组。
- **空间复杂度**:$O(n)$,哈希表最多存储 $n$ 个不同的前缀和。
================================================
FILE: docs/solutions/0900-0999/binary-tree-cameras.md
================================================
# [0968. 监控二叉树](https://leetcode.cn/problems/binary-tree-cameras/)
- 标签:树、深度优先搜索、动态规划、二叉树
- 难度:困难
## 题目链接
- [0968. 监控二叉树 - 力扣](https://leetcode.cn/problems/binary-tree-cameras/)
## 题目大意
给定一个二叉树,需要在树的节点上安装摄像头。节点上的每个摄影头都可以监视其父节点、自身及其直接子节点。
计算监控树的所有节点所需的最小摄像头数量。
- 示例 1:
```
输入:[0,0,null,0,0]
输出:1
解释:如图所示,一台摄像头足以监控所有节点。
```
- 示例 2:
```
输入:[0,0,null,0,null,0,null,null,0]
输出:2
解释:需要至少两个摄像头来监视树的所有节点。 上图显示了摄像头放置的有效位置之一。
```
## 解题思路
根据题意可知,一个摄像头的有效范围为 3 层:父节点、自身及其直接子节点。而约是下层的节点就越多,所以摄像头应该优先满足下层节点。可以使用后序遍历的方式遍历二叉树的节点,这样就可以优先遍历叶子节点。
对于每个节点,利用贪心思想,可以确定三种状态:
- 第一种状态:该节点无覆盖
- 第二种状态:该节点已经装上了摄像头
- 第三种状态:该节点已经覆盖
为了让摄像头数量最少,我们要尽量让叶⼦节点的⽗节点安装摄像头,这样才能摄像头的数量最少。对此我们应当分析当前节点和左右两侧子节点的覆盖情况。
先来考虑空节点,空节点应该算作已经覆盖状态。
再来考虑左右两侧子覆盖情况:
- 如果左节点或者右节点都无覆盖,则当前节点需要装上摄像头,答案 res 需要 + 1。
- 如果左节点已经覆盖或者右节点已经装上了摄像头,则当前节点已经覆盖。
- 如果左节点右节点都已经覆盖,则当前节点无覆盖。
根据以上条件就可以写出对应的后序遍历代码。
## 代码
```python
class Solution:
res = 0
def traversal(self, cur: TreeNode) -> int:
if not cur:
return 3
left = self.traversal(cur.left)
right = self.traversal(cur.right)
if left == 1 or right == 1:
self.res += 1
return 2
if left == 2 or right == 2:
return 3
if left == 3 and right == 3:
return 1
return -1
def minCameraCover(self, root: TreeNode) -> int:
self.res = 0
if self.traversal(root) == 1:
self.res += 1
return self.res
```
================================================
FILE: docs/solutions/0900-0999/broken-calculator.md
================================================
# [0991. 坏了的计算器](https://leetcode.cn/problems/broken-calculator/)
- 标签:贪心、数学
- 难度:中等
## 题目链接
- [0991. 坏了的计算器 - 力扣](https://leetcode.cn/problems/broken-calculator/)
## 题目大意
**描述**:
在显示着数字 $startValue$ 的坏计算器上,我们可以执行以下两种操作:
- 双倍(Double):将显示屏上的数字乘 2;
- 递减(Decrement):将显示屏上的数字减 1。
给定两个整数 $startValue$ 和 $target$。
**要求**:
返回显示数字 $target$ 所需的最小操作数。
**说明**:
- $1 \le startValue, target \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:startValue = 2, target = 3
输出:2
解释:先进行双倍运算,然后再进行递减运算 {2 -> 4 -> 3}.
```
- 示例 2:
```python
输入:startValue = 5, target = 8
输出:2
解释:先递减,再双倍 {5 -> 4 -> 8}.
```
## 解题思路
### 思路 1:逆向贪心
#### 思路
这道题可以进行两种操作:乘 $2$(Double)和减 $1$(Decrement),要求从 $startValue$ 到 $target$ 的最少操作数。
如果正向思考,每一步有两种选择,会导致搜索空间很大。我们可以 **逆向思考**:
- 从 $target$ 出发,逆向操作回到 $startValue$。
- 逆向操作为:除以 $2$(对应正向的乘 $2$)和加 $1$(对应正向的减 $1$)。
贪心策略:
1. 如果 $target \le startValue$,只能一直减 $1$,操作数为 $startValue - target$。
2. 如果 $target$ 是偶数,除以 $2$ 更优(一次操作减少一半)。
3. 如果 $target$ 是奇数,必须先加 $1$ 变成偶数,然后再除以 $2$。
#### 代码
```python
class Solution:
def brokenCalc(self, startValue: int, target: int) -> int:
count = 0
# 从 target 逆向到 startValue
while target > startValue:
if target % 2 == 0:
# target 是偶数,除以 2
target //= 2
else:
# target 是奇数,加 1
target += 1
count += 1
# 如果 target < startValue,需要减 1 操作
count += startValue - target
return count
```
#### 复杂度分析
- **时间复杂度**:$O(\log target)$,每次除以 $2$ 会使 $target$ 减半,最多需要 $O(\log target)$ 次操作。
- **空间复杂度**:$O(1)$,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/cat-and-mouse.md
================================================
# [0913. 猫和老鼠](https://leetcode.cn/problems/cat-and-mouse/)
- 标签:图、拓扑排序、记忆化搜索、数学、动态规划、博弈
- 难度:困难
## 题目链接
- [0913. 猫和老鼠 - 力扣](https://leetcode.cn/problems/cat-and-mouse/)
## 题目大意
**描述**:
两位玩家分别扮演猫和老鼠,在一张「无向」图上进行游戏,两人轮流行动。
图的形式是:$graph[a]$ 是一个列表,由满足 $ab$ 是图中的一条边的所有节点 $b$ 组成。
老鼠从节点 1 开始,第一个出发;猫从节点 2 开始,第二个出发。在节点 0 处有一个洞。
在每个玩家的行动中,他们 必须 沿着图中与所在当前位置连通的一条边移动。例如,如果老鼠在节点 1 ,那么它必须移动到 $graph[1]$ 中的任一节点。
此外,猫无法移动到洞中(节点 0)。
然后,游戏在出现以下三种情形之一时结束:
- 如果猫和老鼠出现在同一个节点,猫获胜。
- 如果老鼠到达洞中,老鼠获胜。
- 如果某一位置重复出现(即,玩家的位置和移动顺序都与上一次行动相同),游戏平局。
给定一张图 $graph$ ,并假设两位玩家都都以最佳状态参与游戏。
**要求**:
- 如果老鼠获胜,则返回 1;
- 如果猫获胜,则返回 2;
- 如果平局,则返回 0 。
**说明**:
- $3 \le graph.length \le 50$。
- $1 \le graph[i].length \lt graph.length$。
- $0 \le graph[i][j] \lt graph.length$。
- $graph[i][j] \ne i$。
- $graph[i]$ 互不相同。
- 猫和老鼠在游戏中总是可以移动。
**示例**:
- 示例 1:
```python
输入:graph = [[2,5],[3],[0,4,5],[1,4,5],[2,3],[0,2,3]]
输出:0
```
- 示例 2:
```python
输入:graph = [[1,3],[0],[3],[0,2]]
输出:1
```
## 解题思路
### 思路 1:博弈论 + 拓扑排序
#### 思路
这是一个博弈问题,需要判断在双方都采取最优策略的情况下,谁会获胜。
我们可以使用 **拓扑排序 + 博弈状态** 来解决:
- 状态定义:$(mouse, cat, turn)$ 表示老鼠在位置 $mouse$,猫在位置 $cat$,当前轮到 $turn$($1$ 表示老鼠,$2$ 表示猫)。
- 状态结果:
- $0$:平局
- $1$:老鼠获胜
- $2$:猫获胜
使用逆向思维,从已知结果的状态开始,逐步推导其他状态:
1. **初始化必胜/必败状态**:
- 老鼠到达洞口($mouse = 0$):老鼠获胜。
- 猫抓到老鼠($mouse = cat$):猫获胜。
2. **拓扑排序**:从已知状态出发,更新前驱状态:
- 如果某个状态的所有后继状态都对对手有利,则该状态对当前玩家不利。
- 如果某个状态存在一个后继状态对当前玩家有利,则该状态对当前玩家有利。
3. **返回初始状态**:$(1, 2, 1)$ 的结果。
#### 代码
```python
class Solution:
def catMouseGame(self, graph: List[List[int]]) -> int:
n = len(graph)
DRAW, MOUSE_WIN, CAT_WIN = 0, 1, 2
# 状态:(mouse, cat, turn),turn=1 表示老鼠,turn=2 表示猫
# 结果:0=平局,1=老鼠赢,2=猫赢
result = [[[DRAW] * 3 for _ in range(n)] for _ in range(n)]
degree = [[[0] * 3 for _ in range(n)] for _ in range(n)]
# 计算每个状态的出度
for mouse in range(n):
for cat in range(n):
degree[mouse][cat][1] = len(graph[mouse])
degree[mouse][cat][2] = len([node for node in graph[cat] if node != 0])
# 初始化队列:已知结果的状态
from collections import deque
queue = deque()
for cat in range(n):
for turn in [1, 2]:
# 老鼠到达洞口,老鼠赢
result[0][cat][turn] = MOUSE_WIN
queue.append((0, cat, turn))
# 猫抓到老鼠(但猫不能在洞口),猫赢
if cat > 0:
result[cat][cat][turn] = CAT_WIN
queue.append((cat, cat, turn))
# 拓扑排序
while queue:
mouse, cat, turn = queue.popleft()
current_result = result[mouse][cat][turn]
if turn == 1: # 当前是老鼠的回合,推导上一步猫的状态
for prev_cat in graph[cat]:
if prev_cat == 0: # 猫不能进洞
continue
if result[mouse][prev_cat][2] != DRAW:
continue
if current_result == CAT_WIN:
# 如果老鼠这步后猫赢,说明猫的上一步可以导致猫赢
result[mouse][prev_cat][2] = CAT_WIN
queue.append((mouse, prev_cat, 2))
else:
# 否则,减少出度
degree[mouse][prev_cat][2] -= 1
if degree[mouse][prev_cat][2] == 0:
# 所有后继状态都对猫不利,猫输
result[mouse][prev_cat][2] = MOUSE_WIN
queue.append((mouse, prev_cat, 2))
else: # 当前是猫的回合,推导上一步老鼠的状态
for prev_mouse in graph[mouse]:
if result[prev_mouse][cat][1] != DRAW:
continue
if current_result == MOUSE_WIN:
# 如果猫这步后老鼠赢,说明老鼠的上一步可以导致老鼠赢
result[prev_mouse][cat][1] = MOUSE_WIN
queue.append((prev_mouse, cat, 1))
else:
# 否则,减少出度
degree[prev_mouse][cat][1] -= 1
if degree[prev_mouse][cat][1] == 0:
# 所有后继状态都对老鼠不利,老鼠输
result[prev_mouse][cat][1] = CAT_WIN
queue.append((prev_mouse, cat, 1))
return result[1][2][1]
```
#### 复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是图中节点的数量。需要遍历所有状态和边。
- **空间复杂度**:$O(n^2)$,需要存储所有状态的结果和出度。
================================================
FILE: docs/solutions/0900-0999/check-completeness-of-a-binary-tree.md
================================================
# [0958. 二叉树的完全性检验](https://leetcode.cn/problems/check-completeness-of-a-binary-tree/)
- 标签:树、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0958. 二叉树的完全性检验 - 力扣](https://leetcode.cn/problems/check-completeness-of-a-binary-tree/)
## 题目大意
**描述**:给定一个二叉树的根节点 `root`。
**要求**:判断该二叉树是否是一个完全二叉树。
**说明**:
- **完全二叉树**:
- 树的结点数在范围 $[1, 100]$ 内。
- $1 \le Node.val \le 1000$。
**示例**:
- 示例 1:
```python
输入:root = [1,2,3,4,5,6]
输出:true
解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。
```
- 示例 2:
```python
输入:root = [1,2,3,4,5,null,7]
输出:false
解释:值为 7 的结点没有尽可能靠向左侧。
```
## 解题思路
### 思路 1:广度优先搜索
对于一个完全二叉树,按照「层序遍历」的顺序进行广度优先搜索,在遇到第一个空节点之后,整个完全二叉树的遍历就已结束了。不应该在后续遍历过程中再次出现非空节点。
如果在遍历过程中在遇到第一个空节点之后,又出现了非空节点,则该二叉树不是完全二叉树。
利用这一点,我们可以在广度优先搜索的过程中,维护一个布尔变量 `is_empty` 用于标记是否遇见了空节点。
### 思路 1:代码
```python
class Solution:
def isCompleteTree(self, root: Optional[TreeNode]) -> bool:
if not root:
return False
queue = collections.deque([root])
is_empty = False
while queue:
size = len(queue)
for _ in range(size):
cur = queue.popleft()
if not cur:
is_empty = True
else:
if is_empty:
return False
queue.append(cur.left)
queue.append(cur.right)
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为二叉树的节点数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0900-0999/complete-binary-tree-inserter.md
================================================
# [0919. 完全二叉树插入器](https://leetcode.cn/problems/complete-binary-tree-inserter/)
- 标签:树、广度优先搜索、设计、二叉树
- 难度:中等
## 题目链接
- [0919. 完全二叉树插入器 - 力扣](https://leetcode.cn/problems/complete-binary-tree-inserter/)
## 题目大意
要求:设计一个用完全二叉树初始化的数据结构 `CBTInserter`,并支持以下几种操作:
- `CBTInserter(TreeNode root)` 使用根节点为 `root` 的给定树初始化该数据结构;
- `CBTInserter.insert(int v)` 向树中插入一个新节点,节点类型为 `TreeNode`,值为 `v`。使树保持完全二叉树的状态,并返回插入的新节点的父节点的值;
- `CBTInserter.get_root()` 返回树的根节点。
## 解题思路
使用数组标记完全二叉树中节点的序号,初始化数组为 `[None]`。完全二叉树中节点的序号从 `1` 开始,对于序号为 `k` 的节点,其左子节点序号为 `2k`,右子节点的序号为 `2k + 1`,其父节点的序号为 `k // 2`。
然后在初始化和插入节点的同时,按顺序向数组中插入节点。
## 代码
```python
class CBTInserter:
def __init__(self, root: TreeNode):
self.queue = [root]
self.nodelist = [None]
while self.queue:
node = self.queue.pop(0)
self.nodelist.append(node)
if node.left:
self.queue.append(node.left)
if node.right:
self.queue.append(node.right)
def insert(self, v: int) -> int:
self.nodelist.append(TreeNode(v))
index = len(self.nodelist) - 1
father = self.nodelist[index // 2]
if index % 2 == 0:
father.left = self.nodelist[-1]
else:
father.right = self.nodelist[-1]
return father.val
def get_root(self) -> TreeNode:
return self.nodelist[1]
```
================================================
FILE: docs/solutions/0900-0999/cousins-in-binary-tree.md
================================================
# [0993. 二叉树的堂兄弟节点](https://leetcode.cn/problems/cousins-in-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0993. 二叉树的堂兄弟节点 - 力扣](https://leetcode.cn/problems/cousins-in-binary-tree/)
## 题目大意
给定一个二叉树,和两个值 x,y。从二叉树中找出 x 和 y 对应的节点 node_x,node_y。如果两个节点是堂兄弟节点,则返回 True,否则返回 False。
- 堂兄弟节点:两个节点的深度相同,父节点不同。
## 解题思路
广度优先搜索或者深度优先搜索都可。以深度优先搜索为例,递归遍历查找节点值为 x,y 的两个节点。在递归的同时,需要传入递归函数当前节点的深度和父节点信息。如果找到对应的节点,则保存两节点对应深度和父节点信息。最后判断两个节点是否是深度相同,父节点不同。如果是,则返回 True,不是则返回 False。
## 代码
```python
class Solution:
def isCousins(self, root: TreeNode, x: int, y: int) -> bool:
depths = [0, 0]
parents = [None, None]
def dfs(node, depth, parent):
if not node:
return
if node.val == x:
depths[0] = depth
parents[0] = parent
elif node.val == y:
depths[1] = depth
parents[1] = parent
dfs(node.left, depth+1, node)
dfs(node.right, depth+1, node)
dfs(root, 0, None)
return depths[0] == depths[1] and parents[0] != parents[1]
```
================================================
FILE: docs/solutions/0900-0999/delete-columns-to-make-sorted-ii.md
================================================
# [0955. 删列造序 II](https://leetcode.cn/problems/delete-columns-to-make-sorted-ii/)
- 标签:贪心、数组、字符串
- 难度:中等
## 题目链接
- [0955. 删列造序 II - 力扣](https://leetcode.cn/problems/delete-columns-to-make-sorted-ii/)
## 题目大意
**描述**:
给定由 $n$ 个字符串组成的数组 $strs$,其中每个字符串长度相等。
选取一个删除索引序列,对于 $strs$ 中的每个字符串,删除对应每个索引处的字符。
比如,有 $strs = ["abcdef", "uvwxyz"]$,删除索引序列 ${0, 2, 3}$,删除后 $strs$ 为 $["bef", "vyz"]$。
假设,我们选择了一组删除索引 $answer$,那么在执行删除操作之后,最终得到的数组的元素是按 字典序($strs[0] \le strs[1] \le strs[2] ... \le strs[n - 1]$)排列的。
**要求**:
返回 $answer.length$ 的最小可能值。
**说明**:
- $n == strs.length$。
- $1 \le n \le 10^{3}$。
- $1 \le strs[i].length \le 10^{3}$。
- $strs[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:strs = ["ca","bb","ac"]
输出:1
解释:
删除第一列后,strs = ["a", "b", "c"]。
现在 strs 中元素是按字典排列的 (即,strs[0] <= strs[1] <= strs[2])。
我们至少需要进行 1 次删除,因为最初 strs 不是按字典序排列的,所以答案是 1。
```
- 示例 2:
```python
输入:strs = ["xc","yb","za"]
输出:0
解释:
strs 的列已经是按字典序排列了,所以我们不需要删除任何东西。
注意 strs 的行不需要按字典序排列。
也就是说,strs[0][0] <= strs[0][1] <= ... 不一定成立。
```
## 解题思路
### 思路 1:贪心算法
#### 思路
这道题要求删除最少的列,使得删除后的字符串数组按字典序排列。与删列造序 I 不同,这里要求的是整个字符串的字典序,而不是每一列的字典序。
我们可以使用贪心策略:
1. 维护一个数组 $sorted$,记录每一行是否已经确定了字典序关系(即前面的列已经使得该行严格小于下一行)。
2. 遍历每一列:
- 检查该列是否会破坏字典序:对于未确定字典序的相邻行,如果当前列使得前一行大于后一行,则需要删除该列。
- 如果该列不需要删除,更新 $sorted$ 数组:对于未确定字典序的相邻行,如果当前列使得前一行小于后一行,则标记为已确定。
3. 返回删除的列数。
#### 代码
```python
class Solution:
def minDeletionSize(self, strs: List[str]) -> int:
n = len(strs) # 行数
m = len(strs[0]) # 列数
count = 0 # 需要删除的列数
# sorted[i] 表示第 i 行和第 i+1 行是否已经确定了字典序关系
sorted_rows = [False] * (n - 1)
# 遍历每一列
for j in range(m):
# 检查当前列是否需要删除
need_delete = False
for i in range(n - 1):
# 如果该行还未确定字典序,且当前列破坏了字典序
if not sorted_rows[i] and strs[i][j] > strs[i + 1][j]:
need_delete = True
break
if need_delete:
# 删除当前列
count += 1
else:
# 更新已确定字典序的行
for i in range(n - 1):
if strs[i][j] < strs[i + 1][j]:
sorted_rows[i] = True
return count
```
#### 复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是字符串数组的长度,$m$ 是每个字符串的长度。需要遍历所有字符。
- **空间复杂度**:$O(n)$,需要一个长度为 $n - 1$ 的数组记录字典序关系。
================================================
FILE: docs/solutions/0900-0999/delete-columns-to-make-sorted-iii.md
================================================
# [0960. 删列造序 III](https://leetcode.cn/problems/delete-columns-to-make-sorted-iii/)
- 标签:数组、字符串、动态规划
- 难度:困难
## 题目链接
- [0960. 删列造序 III - 力扣](https://leetcode.cn/problems/delete-columns-to-make-sorted-iii/)
## 题目大意
**描述**:
给定由 $n$ 个小写字母字符串组成的数组 $strs$,其中每个字符串长度相等。
选取一个删除索引序列,对于 $strs$ 中的每个字符串,删除对应每个索引处的字符。
比如,有 $strs = ["abcdef","uvwxyz"]$,删除索引序列 ${0, 2, 3}$,删除后为 $["bef", "vyz"]$。
假设,我们选择了一组删除索引 $answer$,那么在执行删除操作之后,最终得到的数组的行中的「每个元素」都是按字典序排列的(即 ($strs[0][0] \le strs[0][1] \le ... \le strs[0][strs[0].length - 1]$) 和 ($strs[1][0] \le strs[1][1] \le ... \le strs[1][strs[1].length - 1]$),依此类推)。
**要求**:
请返回 $answer.length$ 的最小可能值。
**说明**:
- $n == strs.length$。
- $1 \le n \le 10^{3}$。
- $1 \le strs[i].length \le 10^{3}$。
- $strs[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:strs = ["babca","bbazb"]
输出:3
解释:
删除 0、1 和 4 这三列后,最终得到的数组是 strs = ["bc", "az"]。
这两行是分别按字典序排列的(即,strs[0][0] <= strs[0][1] 且 strs[1][0] <= strs[1][1])。
注意,strs[0] > strs[1] —— 数组 strs 不一定是按字典序排列的。
```
- 示例 2:
```python
输入:strs = ["edcba"]
输出:4
解释:如果删除的列少于 4 列,则剩下的行都不会按字典序排列。
```
## 解题思路
### 思路 1:动态规划 + 最长公共子序列(LCS)
#### 思路
这道题要求删除最少的列,使得删除后每一行都按字典序非严格递增。这等价于保留最多的列,使得保留的列满足条件。
我们可以使用动态规划求解最长递增子序列(LIS)的变体:
- 定义 $dp[j]$ 表示以第 $j$ 列结尾的最长合法列数。
- 对于每一列 $j$,检查它能否接在之前的某一列 $i$ 后面:
- 如果对于所有行,都有 $strs[row][i] \le strs[row][j]$,则可以接在后面。
- $dp[j] = \max(dp[j], dp[i] + 1)$
- 最终答案为 $m - \max(dp)$,其中 $m$ 是列数。
#### 代码
```python
class Solution:
def minDeletionSize(self, strs: List[str]) -> int:
n = len(strs) # 行数
m = len(strs[0]) # 列数
# dp[j] 表示以第 j 列结尾的最长合法列数
dp = [1] * m
# 对于每一列 j
for j in range(1, m):
# 检查能否接在之前的某一列 i 后面
for i in range(j):
# 检查所有行是否满足 strs[row][i] <= strs[row][j]
valid = True
for row in range(n):
if strs[row][i] > strs[row][j]:
valid = False
break
if valid:
dp[j] = max(dp[j], dp[i] + 1)
# 最少删除的列数 = 总列数 - 最长合法列数
return m - max(dp)
```
#### 复杂度分析
- **时间复杂度**:$O(n \times m^2)$,其中 $n$ 是字符串数组的长度,$m$ 是每个字符串的长度。需要枚举所有列对,并检查所有行。
- **空间复杂度**:$O(m)$,需要一个长度为 $m$ 的 $dp$ 数组。
================================================
FILE: docs/solutions/0900-0999/delete-columns-to-make-sorted.md
================================================
# [0944. 删列造序](https://leetcode.cn/problems/delete-columns-to-make-sorted/)
- 标签:数组、字符串
- 难度:简单
## 题目链接
- [0944. 删列造序 - 力扣](https://leetcode.cn/problems/delete-columns-to-make-sorted/)
## 题目大意
**描述**:
给定由 $n$ 个小写字母字符串组成的数组 $strs$,其中每个字符串长度相等。
这些字符串可以每个一行,排成一个网格。例如,$strs = [$"abc", "bce", "cae"] 可以排列为:
```python
abc
bce
cae
```
你需要找出并删除「不是按字典序非严格递增排列的」列。在上面的例子(下标从 0 开始)中,列 0 `('a', 'b', 'c')`和列 2 `('c', 'e', 'e')` 都是按字典序非严格递增排列的,而列 1 `('b', 'c', 'a')` 不是,所以要删除列 1。
**要求**:
返回你需要删除的列数。
**说明**:
- $n == strs.length$。
- $1 \le n \le 10^{3}$。
- $1 \le strs[i].length \le 10^{3}$。
- $strs[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:strs = ["cba","daf","ghi"]
输出:1
解释:网格示意如下:
cba
daf
ghi
列 0 和列 2 按升序排列,但列 1 不是,所以只需要删除列 1 。
```
- 示例 2:
```python
输入:strs = ["a","b"]
输出:0
解释:网格示意如下:
a
b
只有列 0 这一列,且已经按升序排列,所以不用删除任何列。
```
## 解题思路
### 思路 1:模拟
#### 思路
这道题要求找出不按字典序非严格递增排列的列数。我们可以逐列检查,对于每一列,从上到下遍历,如果发现某个字符小于前一个字符,说明这一列不满足要求,需要删除。
1. 遍历每一列(列索引从 $0$ 到 $m - 1$,其中 $m$ 是字符串长度)。
2. 对于每一列,遍历每一行(行索引从 $1$ 到 $n - 1$,其中 $n$ 是字符串数组长度)。
3. 如果当前行的字符小于前一行的字符,说明这一列不满足递增要求,计数器加 $1$,并跳出内层循环。
4. 返回需要删除的列数。
#### 代码
```python
class Solution:
def minDeletionSize(self, strs: List[str]) -> int:
n = len(strs) # 行数
m = len(strs[0]) # 列数
count = 0 # 需要删除的列数
# 遍历每一列
for j in range(m):
# 检查当前列是否按字典序递增
for i in range(1, n):
if strs[i][j] < strs[i - 1][j]:
# 当前列不满足递增要求
count += 1
break
return count
```
#### 复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是字符串数组的长度,$m$ 是每个字符串的长度。需要遍历所有字符。
- **空间复杂度**:$O(1)$,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/di-string-match.md
================================================
# [0942. 增减字符串匹配](https://leetcode.cn/problems/di-string-match/)
- 标签:贪心、数组、双指针、字符串
- 难度:简单
## 题目链接
- [0942. 增减字符串匹配 - 力扣](https://leetcode.cn/problems/di-string-match/)
## 题目大意
**描述**:
由范围 $[0, n]$ 内所有整数组成的 $n + 1$ 个整数的排列序列可以表示为长度为 $n$ 的字符串 $s$,其中:
- 如果 $perm[i] < perm[i + 1]$,那么 $s[i] == 'I'$
- 如果 $perm[i] > perm[i + 1]$,那么 $s[i] == 'D'$
给定一个字符串 $s$。
**要求**:
重构排列 $perm$ 并返回它。如果有多个有效排列 $perm$,则返回其中任何一个。
**说明**:
- $1 \le s.length \le 10^{5}$。
- $s$ 只包含字符 `"I"` 或 `"D"`。
**示例**:
- 示例 1:
```python
输入:s = "IDID"
输出:[0,4,1,3,2]
```
- 示例 2:
```python
输入:s = "III"
输出:[0,1,2,3]
```
## 解题思路
### 思路 1:贪心算法
#### 思路
这道题要求根据字符串 $s$ 构造一个排列 $perm$,使得相邻元素的大小关系符合 $s$ 中的 `I`(递增)和 `D`(递减)。
我们可以使用贪心策略:
- 维护两个指针 $low$ 和 $high$,分别指向当前可用的最小值和最大值。
- 遍历字符串 $s$:
- 如果遇到 `I`,说明下一个数要比当前数大,我们选择当前最小的可用数 $low$,然后 $low$ 加 $1$。
- 如果遇到 `D`,说明下一个数要比当前数小,我们选择当前最大的可用数 $high$,然后 $high$ 减 $1$。
- 最后还剩一个数,此时 $low$ 和 $high$ 相等,将其加入结果。
#### 代码
```python
class Solution:
def diStringMatch(self, s: str) -> List[int]:
n = len(s)
low, high = 0, n # 初始化最小值和最大值
res = []
# 遍历字符串 s
for ch in s:
if ch == 'I':
# 递增,选择当前最小值
res.append(low)
low += 1
else:
# 递减,选择当前最大值
res.append(high)
high -= 1
# 最后剩下一个数,low 和 high 相等
res.append(low)
return res
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串 $s$ 的长度。只需要遍历一次字符串。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/distinct-subsequences-ii.md
================================================
# [0940. 不同的子序列 II](https://leetcode.cn/problems/distinct-subsequences-ii/)
- 标签:字符串、动态规划
- 难度:困难
## 题目链接
- [0940. 不同的子序列 II - 力扣](https://leetcode.cn/problems/distinct-subsequences-ii/)
## 题目大意
**描述**:
给定一个字符串 $s$。
**要求**:
计算 $s$ 的 不同非空子序列 的个数。因为结果可能很大,所以返回答案需要对 $10^9 + 7$ 取余。
**说明**:
- 字符串的「子序列」是经由原字符串删除一些(也可能不删除)字符但不改变剩余字符相对位置的一个新字符串。
- 例如,`"ace"` 是 `"abcde"` 的一个子序列,但 `"aec"` 不是。
- $1 \le s.length \le 2000$。
- $s$ 仅由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:s = "abc"
输出:7
解释:7 个不同的子序列分别是 "a", "b", "c", "ab", "ac", "bc", 以及 "abc"。
```
- 示例 2:
```python
输入:s = "aba"
输出:6
解释:6 个不同的子序列分别是 "a", "b", "ab", "ba", "aa" 以及 "aba"。
```
## 解题思路
### 思路 1:动态规划
#### 思路
这道题要求计算字符串 $s$ 的不同非空子序列的个数。
我们可以使用动态规划:
- 定义 $dp[i]$ 表示字符串前 $i$ 个字符的不同子序列个数。
- 对于第 $i$ 个字符 $s[i]$:
- 如果不选择 $s[i]$,子序列个数为 $dp[i - 1]$。
- 如果选择 $s[i]$,可以将 $s[i]$ 添加到前面所有子序列的末尾,得到 $dp[i - 1]$ 个新子序列,再加上单独的 $s[i]$,共 $dp[i - 1] + 1$ 个。
- 但如果 $s[i]$ 之前出现过(在位置 $j$),那么以 $s[i]$ 结尾的子序列中,有 $dp[j - 1]$ 个是重复的,需要减去。
状态转移方程:
- $dp[i] = dp[i - 1] \times 2 + 1$(不考虑重复)
- 如果 $s[i]$ 在位置 $j$ 出现过,$dp[i] = dp[i - 1] \times 2 + 1 - dp[j - 1] - 1 = dp[i - 1] \times 2 - dp[j - 1]$
#### 代码
```python
class Solution:
def distinctSubseqII(self, s: str) -> int:
MOD = 10**9 + 7
n = len(s)
# last[c] 记录字符 c 最后一次出现时的 dp 值
last = {}
dp = 0 # 当前的不同子序列个数(不包括空序列)
for ch in s:
# 新增的子序列个数
new_dp = (dp * 2 + 1) % MOD
# 如果字符之前出现过,减去重复的部分
if ch in last:
new_dp = (new_dp - last[ch]) % MOD
# 记录当前字符的 dp 值
last[ch] = dp + 1
dp = new_dp
return dp
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串长度。只需要遍历一次字符串。
- **空间复杂度**:$O(|\Sigma|)$,其中 $|\Sigma|$ 是字符集大小(这里是 $26$)。需要哈希表记录每个字符的最后出现位置。
================================================
FILE: docs/solutions/0900-0999/distribute-coins-in-binary-tree.md
================================================
# [0979. 在二叉树中分配硬币](https://leetcode.cn/problems/distribute-coins-in-binary-tree/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0979. 在二叉树中分配硬币 - 力扣](https://leetcode.cn/problems/distribute-coins-in-binary-tree/)
## 题目大意
**描述**:
给定一个有 $n$ 个结点的二叉树的根结点 $root$,其中树中每个结点 $node$ 都对应有 $node$.$val$ 枚硬币。整棵树上一共有 $n$ 枚硬币。
在一次移动中,我们可以选择两个相邻的结点,然后将一枚硬币从其中一个结点移动到另一个结点。移动可以是从父结点到子结点,或者从子结点移动到父结点。
**要求**:
返回使每个结点上「只有」一枚硬币所需的「最少」移动次数。
**说明**:
- 树中节点的数目为 $n$。
- $1 \le n \le 10^{3}$。
- $0 \le Node.val \le n$。
- 所有 $Node.val$ 的值之和是 $n$。
**示例**:
- 示例 1:
```python
输入:root = [3,0,0]
输出:2
解释:一枚硬币从根结点移动到左子结点,一枚硬币从根结点移动到右子结点。
```
- 示例 2:
```python
输入:root = [0,3,0]
输出:3
解释:将两枚硬币从根结点的左子结点移动到根结点(两次移动)。然后,将一枚硬币从根结点移动到右子结点。
```
## 解题思路
### 思路 1:深度优先搜索(DFS)
#### 思路
这道题要求计算使每个节点都恰好有一枚硬币所需的最少移动次数。
关键观察:对于每个节点,我们需要计算它的「盈余」或「亏损」:
- 如果一个节点有 $k$ 枚硬币,它需要 $1$ 枚,那么它有 $k - 1$ 枚盈余(或 $k - 1$ 枚亏损)。
- 这些盈余或亏损需要通过父节点传递给其他节点。
我们可以使用后序遍历(先处理子节点,再处理父节点):
1. 对于每个节点,计算其左右子树的盈余/亏损。
2. 当前节点的盈余 / 亏损 = 左子树盈余 + 右子树盈余 + 当前节点硬币数 - 1。
3. 移动次数 = 所有盈余 / 亏损的绝对值之和(因为每次移动都需要经过边)。
#### 代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def distributeCoins(self, root: Optional[TreeNode]) -> int:
self.moves = 0 # 记录移动次数
def dfs(node):
"""返回当前节点的盈余/亏损"""
if not node:
return 0
# 递归处理左右子树
left_surplus = dfs(node.left)
right_surplus = dfs(node.right)
# 计算移动次数:左右子树的盈余/亏损都需要通过当前节点传递
self.moves += abs(left_surplus) + abs(right_surplus)
# 返回当前节点的盈余/亏损
# = 左子树盈余 + 右子树盈余 + 当前节点硬币数 - 1
return left_surplus + right_surplus + node.val - 1
dfs(root)
return self.moves
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是树中节点的数量。每个节点被访问一次。
- **空间复杂度**:$O(h)$,其中 $h$ 是树的高度。递归调用栈的深度最多为树的高度。
================================================
FILE: docs/solutions/0900-0999/equal-rational-numbers.md
================================================
# [0972. 相等的有理数](https://leetcode.cn/problems/equal-rational-numbers/)
- 标签:数学、字符串
- 难度:困难
## 题目链接
- [0972. 相等的有理数 - 力扣](https://leetcode.cn/problems/equal-rational-numbers/)
## 题目大意
**描述**:
给定两个字符串 $s$ 和 $t$,每个字符串代表一个非负有理数。
有理数 最多可以用三个部分来表示:整数部分 ``、小数非重复部分 `` 和小数重复部分 `<(><)>`。数字可以用以下三种方法之一来表示:
- ` `
- 例: 0, 12 和 123
- `<.>`
- 例: 0.5, 1., 2.12 和 123.0001
- `<.><(><)>`
- 例: 0.1(6), 1.(9), 123.00(1212)
十进制展开的重复部分通常在一对圆括号内表示。例如:
`1 / 6 = 0.16666666... = 0.1(6) = 0.1666(6) = 0.166(66)`
**要求**:
只有当它们表示相同的数字时才返回 true,否则返回 false。字符串中可以使用括号来表示有理数的重复部分。
**说明**:
- 每个部分仅由数字组成。
- 整数部分 `` 不会以零开头。(零本身除外)
- $1 \le$ `.length` $\le 4$。
- $0 \le$ `.length` $\le 4$。
- $1 \le$ `.length` $\le 4$。
**示例**:
- 示例 1:
```python
输入:s = "0.(52)", t = "0.5(25)"
输出:true
解释:因为 "0.(52)" 代表 0.52525252...,而 "0.5(25)" 代表 0.52525252525.....,则这两个字符串表示相同的数字。
```
- 示例 2:
```python
输入:s = "0.1666(6)", t = "0.166(66)"
输出:true
```
## 解题思路
### 思路 1:数学 + 字符串处理
#### 思路
这道题要求判断两个有理数字符串是否相等。有理数可以表示为:整数部分 + 非重复小数部分 + 重复小数部分。
关键思路:
1. **解析字符串**:将字符串解析为整数部分、非重复部分和重复部分。
2. **转换为分数**:将有理数转换为分数形式进行比较。
- 对于重复小数,可以使用数学公式:$0.\overline{abc} = \frac{abc}{999}$,$0.d\overline{abc} = \frac{d}{10} + \frac{abc}{9990}$
3. **比较**:将两个分数化简后比较是否相等。
由于实现较复杂,我们可以使用一个简化的方法:将有理数展开为足够长的小数(例如 $20$ 位),然后比较。
#### 代码
```python
class Solution:
def isRationalEqual(self, s: str, t: str) -> bool:
def parse(s):
"""将有理数字符串转换为浮点数"""
# 查找小数点和括号
if '.' not in s:
return float(s)
integer_part, decimal_part = s.split('.')
if '(' not in decimal_part:
# 没有重复部分
return float(s)
# 有重复部分
non_repeat, repeat = decimal_part.split('(')
repeat = repeat.rstrip(')')
# 构造足够长的小数(20 位)
# 重复部分重复多次
repeat_count = (20 - len(non_repeat)) // len(repeat) + 1
full_decimal = non_repeat + repeat * repeat_count
full_decimal = full_decimal[:20] # 截取 20 位
return float(integer_part + '.' + full_decimal)
# 比较两个有理数(使用足够小的误差)
return abs(parse(s) - parse(t)) < 1e-9
```
#### 复杂度分析
- **时间复杂度**:$O(1)$,字符串长度有限,处理时间为常数。
- **空间复杂度**:$O(1)$,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/find-the-shortest-superstring.md
================================================
# [0943. 最短超级串](https://leetcode.cn/problems/find-the-shortest-superstring/)
- 标签:位运算、数组、字符串、动态规划、状态压缩
- 难度:困难
## 题目链接
- [0943. 最短超级串 - 力扣](https://leetcode.cn/problems/find-the-shortest-superstring/)
## 题目大意
**描述**:
给定一个字符串数组 $words$。
我们可以假设 $words$ 中没有字符串是 $words$ 中另一个字符串的子字符串。
**要求**:
找到以 $words$ 中每个字符串作为子字符串的最短字符串。如果有多个有效最短字符串满足题目条件,返回其中「任意一个」即可。
**说明**:
- $1 \le words.length \le 12$。
- $1 \le words[i].length \le 20$。
- $words[i]$ 由小写英文字母组成。
- $words$ 中的所有字符串互不相同。
**示例**:
- 示例 1:
```python
输入:words = ["alex","loves","leetcode"]
输出:"alexlovesleetcode"
解释:"alex","loves","leetcode" 的所有排列都会被接受。
```
- 示例 2:
```python
输入:words = ["catg","ctaagt","gcta","ttca","atgcatc"]
输出:"gctaagttcatgcatc"
```
## 解题思路
### 思路 1:状态压缩动态规划
#### 思路
这道题要求找到包含所有字符串的最短超级串。这是一个 NP 难问题,但由于字符串数量最多只有 $12$ 个,我们可以使用状态压缩动态规划。
核心思想:
1. **预处理**:计算任意两个字符串的重叠长度 $overlap[i][j]$,表示将字符串 $j$ 接在字符串 $i$ 后面时可以节省的长度。
2. **状态压缩 DP**:
- 定义 $dp[mask][i]$ 表示已经使用了 $mask$ 中的字符串,且最后一个字符串是 $i$ 时的最短长度。
- 状态转移:$dp[mask | (1 << j)][j] = \min(dp[mask | (1 << j)][j], dp[mask][i] + len(words[j]) - overlap[i][j])$
3. **路径重建**:记录转移路径,最后重建最短超级串。
#### 代码
```python
class Solution:
def shortestSuperstring(self, words: List[str]) -> str:
n = len(words)
# 计算重叠长度
overlap = [[0] * n for _ in range(n)]
for i in range(n):
for j in range(n):
if i != j:
# 计算 words[j] 接在 words[i] 后面的重叠长度
max_overlap = min(len(words[i]), len(words[j]))
for k in range(max_overlap, 0, -1):
if words[i][-k:] == words[j][:k]:
overlap[i][j] = k
break
# 状态压缩 DP
# dp[mask][i] 表示使用了 mask 中的字符串,最后一个是 i 时的最短长度
INF = float('inf')
dp = [[INF] * n for _ in range(1 << n)]
parent = [[-1] * n for _ in range(1 << n)]
# 初始化:只使用一个字符串
for i in range(n):
dp[1 << i][i] = len(words[i])
# 状态转移
for mask in range(1, 1 << n):
for i in range(n):
if not (mask & (1 << i)) or dp[mask][i] == INF:
continue
for j in range(n):
if mask & (1 << j):
continue
new_mask = mask | (1 << j)
new_len = dp[mask][i] + len(words[j]) - overlap[i][j]
if new_len < dp[new_mask][j]:
dp[new_mask][j] = new_len
parent[new_mask][j] = i
# 找到最短长度和对应的最后一个字符串
full_mask = (1 << n) - 1
min_len = INF
last = -1
for i in range(n):
if dp[full_mask][i] < min_len:
min_len = dp[full_mask][i]
last = i
# 重建路径
path = []
mask = full_mask
while last != -1:
path.append(last)
new_last = parent[mask][last]
mask ^= (1 << last)
last = new_last
path.reverse()
# 构建结果
result = words[path[0]]
for i in range(1, len(path)):
prev = path[i - 1]
curr = path[i]
result += words[curr][overlap[prev][curr]:]
return result
```
#### 复杂度分析
- **时间复杂度**:$O(n^2 \times 2^n + n^2 \times L)$,其中 $n$ 是字符串数量,$L$ 是字符串的平均长度。预处理重叠需要 $O(n^2 \times L)$,DP 需要 $O(n^2 \times 2^n)$。
- **空间复杂度**:$O(n \times 2^n)$,需要存储 DP 数组和路径信息。
================================================
FILE: docs/solutions/0900-0999/find-the-town-judge.md
================================================
# [0997. 找到小镇的法官](https://leetcode.cn/problems/find-the-town-judge/)
- 标签:图、数组、哈希表
- 难度:简单
## 题目链接
- [0997. 找到小镇的法官 - 力扣](https://leetcode.cn/problems/find-the-town-judge/)
## 题目大意
**描述**:
小镇里有 $n$ 个人,按从 1 到 $n$ 的顺序编号。传言称,这些人中有一个暗地里是小镇法官。
如果小镇法官真的存在,那么:
1. 小镇法官不会信任任何人。
2. 每个人(除了小镇法官)都信任这位小镇法官。
3. 只有一个人同时满足属性 1 和属性 2。
给你一个数组 $trust$,其中 $trust[i] = [ai, bi]$ 表示编号为 $ai$ 的人信任编号为 $bi$ 的人。
**要求**:
如果小镇法官存在并且可以确定他的身份,请返回该法官的编号;否则,返回 -1。
**说明**:
- $1 \le n \le 10^{3}$。
- $0 \le trust.length \le 10^{4}$。
- $trust[i].length == 2$。
- $trust$ 中的所有 $trust[i] = [ai, bi]$ 互不相同。
- $ai \ne bi$。
- $1 \le ai, bi \le n$。
**示例**:
- 示例 1:
```python
输入:n = 2, trust = [[1,2]]
输出:2
```
- 示例 2:
```python
输入:n = 3, trust = [[1,3],[2,3]]
输出:3
```
## 解题思路
### 思路 1:入度和出度统计
#### 思路
这道题可以看作一个有向图问题。法官的特点是:
1. 法官不信任任何人(出度为 $0$)。
2. 所有其他人都信任法官(入度为 $n - 1$)。
我们可以用一个数组 $degree$ 来统计每个人的「信任度」:
- 如果 $a$ 信任 $b$,则 $degree[a]$ 减 $1$(出度),$degree[b]$ 加 $1$(入度)。
- 最后遍历数组,找到 $degree$ 值为 $n - 1$ 的人,即为法官。
#### 代码
```python
class Solution:
def findJudge(self, n: int, trust: List[List[int]]) -> int:
# degree[i] 表示 i 的信任度(入度 - 出度)
degree = [0] * (n + 1)
# 统计每个人的信任度
for a, b in trust:
degree[a] -= 1 # a 信任别人,出度 +1
degree[b] += 1 # b 被信任,入度 +1
# 查找法官:信任度为 n - 1 的人
for i in range(1, n + 1):
if degree[i] == n - 1:
return i
return -1
```
#### 复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 是人数,$m$ 是信任关系的数量。需要遍历所有信任关系和所有人。
- **空间复杂度**:$O(n)$,需要一个长度为 $n + 1$ 的数组来存储信任度。
================================================
FILE: docs/solutions/0900-0999/flip-binary-tree-to-match-preorder-traversal.md
================================================
# [0971. 翻转二叉树以匹配先序遍历](https://leetcode.cn/problems/flip-binary-tree-to-match-preorder-traversal/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0971. 翻转二叉树以匹配先序遍历 - 力扣](https://leetcode.cn/problems/flip-binary-tree-to-match-preorder-traversal/)
## 题目大意
**描述**:
给定一棵二叉树的根节点 $root$,树中有 $n$ 个节点,每个节点都有一个不同于其他节点且处于 1 到 $n$ 之间的值。
另给你一个由 $n$ 个值组成的行程序列 $voyage$,表示「预期」的二叉树「先序遍历」结果。
通过交换节点的左右子树,可以「翻转」该二叉树中的任意节点。例,翻转节点 1 的效果如下:
请翻转「最少」的树中节点,使二叉树的「先序遍历」与预期的遍历行程 $voyage$ 相匹配。
**要求**:
如果可以,则返回「翻转的」所有节点的值的列表。你可以按任何顺序返回答案。如果不能,则返回列表 $[-1]$。
**说明**:
- 树中的节点数目为 n。
- $n == voyage.length$。
- $1 \le n \le 10^{3}$。
- $1 \le Node.val, voyage[i] \le n$。
- 树中的所有值 互不相同。
- voyage 中的所有值 互不相同。
**示例**:
- 示例 1:

```python
输入:root = [1,2], voyage = [2,1]
输出:[-1]
解释:翻转节点无法令先序遍历匹配预期行程。
```
- 示例 2:

```python
输入:root = [1,2,3], voyage = [1,3,2]
输出:[1]
解释:交换节点 2 和 3 来翻转节点 1 ,先序遍历可以匹配预期行程。
```
## 解题思路
### 思路 1:深度优先搜索(DFS)
#### 思路
这道题要求翻转二叉树的某些节点,使得先序遍历结果与给定的 $voyage$ 匹配。
我们可以使用深度优先搜索,同时维护一个指针 $index$ 指向 $voyage$ 中当前应该匹配的位置:
1. **基本情况**:如果当前节点为空,返回 `True`。
2. **检查值**:如果当前节点的值与 $voyage[index]$ 不匹配,返回 `False`。
3. **递归处理**:
- 如果左子节点存在且值与 $voyage[index + 1]$ 匹配,按正常顺序遍历(先左后右)。
- 否则,需要翻转当前节点(先右后左),并记录当前节点的值。
4. 如果任何一步失败,返回 `[-1]`。
#### 代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def flipMatchVoyage(self, root: Optional[TreeNode], voyage: List[int]) -> List[int]:
self.flipped = [] # 记录翻转的节点
self.index = 0 # 当前匹配的位置
def dfs(node):
if not node:
return True
# 检查当前节点的值是否匹配
if node.val != voyage[self.index]:
return False
self.index += 1
# 如果左子节点存在且值不匹配,需要翻转
if node.left and node.left.val != voyage[self.index]:
# 记录翻转的节点
self.flipped.append(node.val)
# 先遍历右子树,再遍历左子树
return dfs(node.right) and dfs(node.left)
# 正常顺序:先左后右
return dfs(node.left) and dfs(node.right)
# 如果匹配失败,返回 [-1]
if dfs(root):
return self.flipped
else:
return [-1]
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是树中节点的数量。每个节点最多被访问一次。
- **空间复杂度**:$O(h)$,其中 $h$ 是树的高度。递归调用栈的深度最多为树的高度。
================================================
FILE: docs/solutions/0900-0999/flip-equivalent-binary-trees.md
================================================
# [0951. 翻转等价二叉树](https://leetcode.cn/problems/flip-equivalent-binary-trees/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [0951. 翻转等价二叉树 - 力扣](https://leetcode.cn/problems/flip-equivalent-binary-trees/)
## 题目大意
**描述**:
我们可以为二叉树 $T$ 定义一个「翻转操作」,如下所示:选择任意节点,然后交换它的左子树和右子树。
只要经过一定次数的翻转操作后,能使 $X$ 等于 $Y$,我们就称二叉树 $X$ 翻转「等价」于二叉树 $Y$。
这些树由根节点 $root1$ 和 $root2$ 给出。
**要求**:
如果两个二叉树是否是翻转「等价」的树,则返回 true,否则返回 false。
**说明**:
- 每棵树节点数在 $[0, 10^{3}]$ 范围内。
- 每棵树中的每个值都是唯一的、在 $[0, 99]$ 范围内的整数。
**示例**:
- 示例 1:
```python
输入:root1 = [1,2,3,4,5,6,null,null,null,7,8], root2 = [1,3,2,null,6,4,5,null,null,null,null,8,7]
输出:true
解释:我们翻转值为 1,3 以及 5 的三个节点。
```
- 示例 2:
```python
输入: root1 = [], root2 = []
输出: true
```
## 解题思路
### 思路 1:深度优先搜索(DFS)
#### 思路
这道题要求判断两棵二叉树是否翻转等价。翻转等价的定义是:通过若干次翻转操作(交换左右子树),可以使两棵树相同。
我们可以使用递归的方式判断:
1. **基本情况**:
- 如果两个节点都为空,返回 `True`。
- 如果只有一个节点为空,或者两个节点的值不同,返回 `False`。
2. **递归情况**:对于两个节点,有两种可能:
- **不翻转**:左子树对应左子树,右子树对应右子树。
- **翻转**:左子树对应右子树,右子树对应左子树。
- 只要其中一种情况成立,就返回 `True`。
#### 代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def flipEquiv(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> bool:
# 基本情况:两个节点都为空
if not root1 and not root2:
return True
# 只有一个节点为空,或者值不同
if not root1 or not root2 or root1.val != root2.val:
return False
# 递归判断:不翻转或翻转
# 不翻转:左对左,右对右
no_flip = self.flipEquiv(root1.left, root2.left) and self.flipEquiv(root1.right, root2.right)
# 翻转:左对右,右对左
flip = self.flipEquiv(root1.left, root2.right) and self.flipEquiv(root1.right, root2.left)
return no_flip or flip
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是树中节点的数量。每个节点最多被访问一次。
- **空间复杂度**:$O(h)$,其中 $h$ 是树的高度。递归调用栈的深度最多为树的高度。
================================================
FILE: docs/solutions/0900-0999/flip-string-to-monotone-increasing.md
================================================
# [0926. 将字符串翻转到单调递增](https://leetcode.cn/problems/flip-string-to-monotone-increasing/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [0926. 将字符串翻转到单调递增 - 力扣](https://leetcode.cn/problems/flip-string-to-monotone-increasing/)
## 题目大意
**描述**:
如果一个二进制字符串,是以一些 0(可能没有 0)后面跟着一些 1(也可能没有 1)的形式组成的,那么该字符串是「单调递增」的。
给定一个二进制字符串 $s$,你可以将任何 0 翻转为 1 或者将 1 翻转为 0。
**要求**:
返回使 $s$ 单调递增的最小翻转次数。
**说明**:
- $1 \le s.length \le 10^{5}$。
- $s[i]$ 为 `'0'` 或 `'1'`。
**示例**:
- 示例 1:
```python
输入:s = "00110"
输出:1
解释:翻转最后一位得到 00111.
```
- 示例 2:
```python
输入:s = "010110"
输出:2
解释:翻转得到 011111,或者是 000111。
```
## 解题思路
### 思路 1:动态规划
#### 思路
这道题要求将二进制字符串翻转为单调递增(先 $0$ 后 $1$)的最小翻转次数。
我们可以使用动态规划:
- 定义 $dp0$ 表示当前位置结尾为 $0$ 的最小翻转次数。
- 定义 $dp1$ 表示当前位置结尾为 $1$ 的最小翻转次数。
状态转移:
- 如果当前字符是 `'0'`:
- $dp0$ 不变(不需要翻转)。
- $dp1 = dp1 + 1$(需要将 `'0'` 翻转为 `'1'`)。
- 如果当前字符是 `'1'`:
- $dp0 = dp0 + 1$(需要将 `'1'` 翻转为 `'0'`,但这会破坏单调性,所以实际上不能再添加 $0$)。
- $dp1 = \min(dp0, dp1)$(可以保持 `'1'` 不变,或者从前面的 $0$ 序列转换过来)。
最终答案是 $\min(dp0, dp1)$,但由于单调递增的字符串可以全是 $0$ 或全是 $1$,所以答案是 $dp1$。
#### 代码
```python
class Solution:
def minFlipsMonoIncr(self, s: str) -> int:
dp0 = 0 # 以 0 结尾的最小翻转次数
dp1 = 0 # 以 1 结尾的最小翻转次数
for ch in s:
if ch == '0':
# 当前是 0,保持 0 不需要翻转,变成 1 需要翻转
dp1 = min(dp0, dp1) + 1
# dp0 不变
else:
# 当前是 1,变成 0 需要翻转(但会破坏单调性),保持 1 不需要翻转
dp1 = min(dp0, dp1)
dp0 = dp0 + 1
return min(dp0, dp1)
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串长度。只需要遍历一次字符串。
- **空间复杂度**:$O(1)$,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/fruit-into-baskets.md
================================================
# [0904. 水果成篮](https://leetcode.cn/problems/fruit-into-baskets/)
- 标签:数组、哈希表、滑动窗口
- 难度:中等
## 题目链接
- [0904. 水果成篮 - 力扣](https://leetcode.cn/problems/fruit-into-baskets/)
## 题目大意
给定一个数组 `fruits`。其中 `fruits[i]` 表示第 `i` 棵树会产生 `fruits[i]` 型水果。
你可以从你选择的任何树开始,然后重复执行以下步骤:
- 把这棵树上的水果放进你的篮子里。如果你做不到,就停下来。
- 移动到当前树右侧的下一棵树。如果右边没有树,就停下来。
- 请注意,在选择一棵树后,你没有任何选择:你必须执行步骤 1,然后执行步骤 2,然后返回步骤 1,然后执行步骤 2,依此类推,直至停止。
你有 `2` 个篮子,每个篮子可以携带任何数量的水果,但你希望每个篮子只携带一种类型的水果。
要求:返回你能收集的水果树的最大总量。
## 解题思路
只有 `2` 个篮子,要求在连续子数组中装最多 `2` 种不同水果。可以理解为维护一个水果种类数为 `2` 的滑动数组,求窗口中最大的水果树数目。具体做法如下:
- 用滑动窗口 `window` 来维护不同种类水果树数目。`window` 为哈希表类型。`ans` 用来维护能收集的水果树的最大总量。设定两个指针:`left`、`right`,分别指向滑动窗口的左右边界,保证窗口中水果种类数不超过 `2` 种。
- 一开始,`left`、`right` 都指向 `0`。
- 将最右侧数组元素 `fruits[right]` 加入当前窗口 `window` 中,该水果树数目 +1。
- 如果该窗口中该水果树种类多于 `2` 种,即 `len(window) > 2`,则不断右移 `left`,缩小滑动窗口长度,并更新窗口中对应水果树的个数,直到 `len(window) <= 2`。
- 维护更新能收集的水果树的最大总量。然后右移 `right`,直到 `right >= len(fruits)` 结束。
- 输出能收集的水果树的最大总量。
## 代码
```python
class Solution:
def totalFruit(self, fruits: List[int]) -> int:
window = dict()
window_size = 2
ans = 0
left, right = 0, 0
while right < len(fruits):
if fruits[right] in window:
window[fruits[right]] += 1
else:
window[fruits[right]] = 1
while len(window) > window_size:
window[fruits[left]] -= 1
if window[fruits[left]] == 0:
del window[fruits[left]]
left += 1
ans = max(ans, right - left + 1)
right += 1
return ans
```
================================================
FILE: docs/solutions/0900-0999/index.md
================================================
## 本章内容
- [0900. RLE 迭代器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/rle-iterator.md)
- [0901. 股票价格跨度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/online-stock-span.md)
- [0902. 最大为 N 的数字组合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/numbers-at-most-n-given-digit-set.md)
- [0903. DI 序列的有效排列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/valid-permutations-for-di-sequence.md)
- [0904. 水果成篮](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/fruit-into-baskets.md)
- [0905. 按奇偶排序数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/sort-array-by-parity.md)
- [0906. 超级回文数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/super-palindromes.md)
- [0907. 子数组的最小值之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/sum-of-subarray-minimums.md)
- [0908. 最小差值 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/smallest-range-i.md)
- [0909. 蛇梯棋](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/snakes-and-ladders.md)
- [0910. 最小差值 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/smallest-range-ii.md)
- [0911. 在线选举](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/online-election.md)
- [0912. 排序数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/sort-an-array.md)
- [0913. 猫和老鼠](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/cat-and-mouse.md)
- [0914. 卡牌分组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/x-of-a-kind-in-a-deck-of-cards.md)
- [0915. 分割数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/partition-array-into-disjoint-intervals.md)
- [0916. 单词子集](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/word-subsets.md)
- [0917. 仅仅反转字母](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/reverse-only-letters.md)
- [0918. 环形子数组的最大和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/maximum-sum-circular-subarray.md)
- [0919. 完全二叉树插入器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/complete-binary-tree-inserter.md)
- [0920. 播放列表的数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/number-of-music-playlists.md)
- [0921. 使括号有效的最少添加](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-add-to-make-parentheses-valid.md)
- [0922. 按奇偶排序数组 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/sort-array-by-parity-ii.md)
- [0923. 三数之和的多种可能](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/3sum-with-multiplicity.md)
- [0924. 尽量减少恶意软件的传播](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimize-malware-spread.md)
- [0925. 长按键入](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/long-pressed-name.md)
- [0926. 将字符串翻转到单调递增](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/flip-string-to-monotone-increasing.md)
- [0927. 三等分](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/three-equal-parts.md)
- [0928. 尽量减少恶意软件的传播 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimize-malware-spread-ii.md)
- [0929. 独特的电子邮件地址](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/unique-email-addresses.md)
- [0930. 和相同的二元子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/binary-subarrays-with-sum.md)
- [0931. 下降路径最小和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-falling-path-sum.md)
- [0932. 漂亮数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/beautiful-array.md)
- [0933. 最近的请求次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/number-of-recent-calls.md)
- [0934. 最短的桥](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/shortest-bridge.md)
- [0935. 骑士拨号器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/knight-dialer.md)
- [0936. 戳印序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/stamping-the-sequence.md)
- [0937. 重新排列日志文件](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/reorder-data-in-log-files.md)
- [0938. 二叉搜索树的范围和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/range-sum-of-bst.md)
- [0939. 最小面积矩形](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-area-rectangle.md)
- [0940. 不同的子序列 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/distinct-subsequences-ii.md)
- [0941. 有效的山脉数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/valid-mountain-array.md)
- [0942. 增减字符串匹配](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/di-string-match.md)
- [0943. 最短超级串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/find-the-shortest-superstring.md)
- [0944. 删列造序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/delete-columns-to-make-sorted.md)
- [0945. 使数组唯一的最小增量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-increment-to-make-array-unique.md)
- [0946. 验证栈序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/validate-stack-sequences.md)
- [0947. 移除最多的同行或同列石头](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/most-stones-removed-with-same-row-or-column.md)
- [0948. 令牌放置](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/bag-of-tokens.md)
- [0949. 给定数字能组成的最大时间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/largest-time-for-given-digits.md)
- [0950. 按递增顺序显示卡牌](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/reveal-cards-in-increasing-order.md)
- [0951. 翻转等价二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/flip-equivalent-binary-trees.md)
- [0952. 按公因数计算最大组件大小](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/largest-component-size-by-common-factor.md)
- [0953. 验证外星语词典](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/verifying-an-alien-dictionary.md)
- [0954. 二倍数对数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/array-of-doubled-pairs.md)
- [0955. 删列造序 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/delete-columns-to-make-sorted-ii.md)
- [0956. 最高的广告牌](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/tallest-billboard.md)
- [0957. N 天后的牢房](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/prison-cells-after-n-days.md)
- [0958. 二叉树的完全性检验](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/check-completeness-of-a-binary-tree.md)
- [0959. 由斜杠划分区域](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/regions-cut-by-slashes.md)
- [0960. 删列造序 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/delete-columns-to-make-sorted-iii.md)
- [0961. 在长度 2N 的数组中找出重复 N 次的元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/n-repeated-element-in-size-2n-array.md)
- [0962. 最大宽度坡](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/maximum-width-ramp.md)
- [0963. 最小面积矩形 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-area-rectangle-ii.md)
- [0964. 表示数字的最少运算符](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/least-operators-to-express-number.md)
- [0965. 单值二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/univalued-binary-tree.md)
- [0966. 元音拼写检查器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/vowel-spellchecker.md)
- [0967. 连续差相同的数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/numbers-with-same-consecutive-differences.md)
- [0968. 监控二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/binary-tree-cameras.md)
- [0969. 煎饼排序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/pancake-sorting.md)
- [0970. 强整数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/powerful-integers.md)
- [0971. 翻转二叉树以匹配先序遍历](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/flip-binary-tree-to-match-preorder-traversal.md)
- [0972. 相等的有理数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/equal-rational-numbers.md)
- [0973. 最接近原点的 K 个点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/k-closest-points-to-origin.md)
- [0974. 和可被 K 整除的子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/subarray-sums-divisible-by-k.md)
- [0975. 奇偶跳](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/odd-even-jump.md)
- [0976. 三角形的最大周长](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/largest-perimeter-triangle.md)
- [0977. 有序数组的平方](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/squares-of-a-sorted-array.md)
- [0978. 最长湍流子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/longest-turbulent-subarray.md)
- [0979. 在二叉树中分配硬币](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/distribute-coins-in-binary-tree.md)
- [0980. 不同路径 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/unique-paths-iii.md)
- [0981. 基于时间的键值存储](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/time-based-key-value-store.md)
- [0982. 按位与为零的三元组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/triples-with-bitwise-and-equal-to-zero.md)
- [0983. 最低票价](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-cost-for-tickets.md)
- [0984. 不含 AAA 或 BBB 的字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/string-without-aaa-or-bbb.md)
- [0985. 查询后的偶数和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/sum-of-even-numbers-after-queries.md)
- [0986. 区间列表的交集](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/interval-list-intersections.md)
- [0987. 二叉树的垂序遍历](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/vertical-order-traversal-of-a-binary-tree.md)
- [0988. 从叶结点开始的最小字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/smallest-string-starting-from-leaf.md)
- [0989. 数组形式的整数加法](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/add-to-array-form-of-integer.md)
- [0990. 等式方程的可满足性](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/satisfiability-of-equality-equations.md)
- [0991. 坏了的计算器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/broken-calculator.md)
- [0992. K 个不同整数的子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/subarrays-with-k-different-integers.md)
- [0993. 二叉树的堂兄弟节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/cousins-in-binary-tree.md)
- [0994. 腐烂的橘子](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/rotting-oranges.md)
- [0995. K 连续位的最小翻转次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/minimum-number-of-k-consecutive-bit-flips.md)
- [0996. 平方数组的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/number-of-squareful-arrays.md)
- [0997. 找到小镇的法官](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/find-the-town-judge.md)
- [0998. 最大二叉树 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/maximum-binary-tree-ii.md)
- [0999. 可以被一步捕获的棋子数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/available-captures-for-rook.md)
================================================
FILE: docs/solutions/0900-0999/interval-list-intersections.md
================================================
# [0986. 区间列表的交集](https://leetcode.cn/problems/interval-list-intersections/)
- 标签:数组、双指针、扫描线
- 难度:中等
## 题目链接
- [0986. 区间列表的交集 - 力扣](https://leetcode.cn/problems/interval-list-intersections/)
## 题目大意
**描述**:
给定两个由一些「闭区间」组成的列表,$firstList$ 和 $secondList$,其中 $firstList[i] = [start_i, end_i]$ 而 $secondList[j] = [start_j, end_j]$。每个区间列表都是成对「不相交」的,并且「已经排序」。
**要求**:
返回这 两个区间列表的交集 。
**说明**:
- 形式上,闭区间 $[a, b]$(其中 $a \le b$)表示实数 $x$ 的集合,而 $a \le x \le b$。
- 两个闭区间的「交集」是一组实数,要么为空集,要么为闭区间。例如,$[1, 3]$ 和 $[2, 4]$ 的交集为 $[2, 3]$。
- $0 \le firstList.length, secondList.length \le 10^{3}$。
- $firstList.length + secondList.length \ge 1$。
- $0 \le start_i \lt end_i \le 10^{9}$。
- $end_i \lt start_i+1$。
- $0 \le start_j \lt end_j \le 10^{9}$。
- $end_j \lt start_j+1$。
**示例**:
- 示例 1:
```python
输入:firstList = [[0,2],[5,10],[13,23],[24,25]], secondList = [[1,5],[8,12],[15,24],[25,26]]
输出:[[1,2],[5,5],[8,10],[15,23],[24,24],[25,25]]
```
- 示例 2:
```python
输入:firstList = [[1,3],[5,9]], secondList = []
输出:[]
```
## 解题思路
### 思路 1:双指针
#### 思路
这道题要求找到两个区间列表的交集。我们可以使用双指针分别遍历两个列表:
1. 初始化两个指针 $i$ 和 $j$,分别指向 $firstList$ 和 $secondList$ 的起始位置。
2. 对于当前的两个区间 $[start1, end1]$ 和 $[start2, end2]$:
- 计算交集:$[\max(start1, start2), \min(end1, end2)]$。
- 如果交集有效(即 $\max(start1, start2) \le \min(end1, end2)$),将其加入结果。
- 移动指针:如果 $end1 < end2$,说明第一个区间已经处理完,移动 $i$;否则移动 $j$。
3. 返回所有交集区间。
#### 代码
```python
class Solution:
def intervalIntersection(self, firstList: List[List[int]], secondList: List[List[int]]) -> List[List[int]]:
res = []
i, j = 0, 0
# 双指针遍历两个列表
while i < len(firstList) and j < len(secondList):
start1, end1 = firstList[i]
start2, end2 = secondList[j]
# 计算交集
start = max(start1, start2)
end = min(end1, end2)
# 如果交集有效,加入结果
if start <= end:
res.append([start, end])
# 移动指针:结束时间较早的区间已经处理完
if end1 < end2:
i += 1
else:
j += 1
return res
```
#### 复杂度分析
- **时间复杂度**:$O(m + n)$,其中 $m$ 和 $n$ 分别是两个列表的长度。每个区间最多被访问一次。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/k-closest-points-to-origin.md
================================================
# [0973. 最接近原点的 K 个点](https://leetcode.cn/problems/k-closest-points-to-origin/)
- 标签:几何、数组、数学、分治、快速选择、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [0973. 最接近原点的 K 个点 - 力扣](https://leetcode.cn/problems/k-closest-points-to-origin/)
## 题目大意
给定一个由由平面上的点组成的列表 `points`,再给定一个整数 `K`。
要求:从中找出 `K` 个距离原点` (0, 0)` 最近的点。(这里,平面上两点之间的距离是欧几里德距离。)可以按任何顺序返回答案。除了点坐标的顺序之外,答案确保是唯一的。
## 解题思路
1. 使用二叉堆构建优先队列,优先级为距离原点的距离。此时堆顶元素即为距离原点最近的元素。
2. 将堆顶元素加入到答案数组中,进行出队操作。时间复杂度 $O(log{n})$。
- 出队操作:交换堆顶元素与末尾元素,将末尾元素已移出堆。继续调整大顶堆。
3. 不断重复第 2 步,直到 `K` 次结束。
## 代码
```python
class Heapq:
def compare(self, a, b):
dist_a = a[0] * a[0] + a[1] * a[1]
dist_b = b[0] * b[0] + b[1] * b[1]
if dist_a < dist_b:
return -1
elif dist_a == dist_b:
return 0
else:
return 1
# 堆调整方法:调整为小顶堆
def heapAdjust(self, nums: [int], index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子结点
max_index = index
if self.compare(nums[left], nums[max_index]) == -1:
max_index = left
if right <= end and self.compare(nums[right], nums[max_index]) == -1:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 将数组构建为二叉堆
def heapify(self, nums: [int]):
size = len(nums)
# (size - 2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
# 调用调整堆函数
self.heapAdjust(nums, i, size - 1)
# 入队操作
def heappush(self, nums: list, value):
nums.append(value)
size = len(nums)
i = size - 1
# 寻找插入位置
while (i - 1) // 2 >= 0:
cur_root = (i - 1) // 2
# value 大于当前根节点,则插入到当前位置
if self.compare(nums[cur_root], value) == -1:
break
# 继续向上查找
nums[i] = nums[cur_root]
i = cur_root
# 找到插入位置或者到达根位置,将其插入
nums[i] = value
# 出队操作
def heappop(self, nums: list) -> int:
size = len(nums)
nums[0], nums[-1] = nums[-1], nums[0]
# 得到最小值(堆顶元素)然后调整堆
top = nums.pop()
if size > 0:
self.heapAdjust(nums, 0, size - 2)
return top
# 升序堆排序
def heapSort(self, nums: [int]):
self.heapify(nums)
size = len(nums)
for i in range(size):
nums[0], nums[size - i - 1] = nums[size - i - 1], nums[0]
self.heapAdjust(nums, 0, size - i - 2)
return nums
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
heap = Heapq()
queue = []
for point in points:
heap.heappush(queue, point)
res = []
for i in range(k):
res.append(heap.heappop(queue))
return res
```
================================================
FILE: docs/solutions/0900-0999/knight-dialer.md
================================================
# [0935. 骑士拨号器](https://leetcode.cn/problems/knight-dialer/)
- 标签:动态规划
- 难度:中等
## 题目链接
- [0935. 骑士拨号器 - 力扣](https://leetcode.cn/problems/knight-dialer/)
## 题目大意
**描述**:象棋骑士可以垂直移动两个方格,水平移动一个方格,或者水平移动两个方格,垂直移动一个方格(两者都形成一个 $L$ 的形状),如下图所示。
现在我们有一个象棋其实和一个电话垫,如下图所示,骑士只能站在一个数字单元格上($0 \sim 9$)。
现在给定一个整数 $n$。
**要求**:返回我们可以拨多少个长度为 $n$ 的不同电话号码。因为答案可能很大,所以最终答案需要对 $10^9 + 7$ 进行取模。
**说明**:
- 可以将骑士放在任何数字单元格上,然后执行 $n - 1$ 次移动来获得长度为 $n$ 的电话号码。
- $1 \le n \le 5000$。
**示例**:
- 示例 1:
```python
输入:n = 1
输出:10
解释:我们需要拨一个长度为1的数字,所以把骑士放在10个单元格中的任何一个数字单元格上都能满足条件。
```
- 示例 2:
```python
输入:n = 2
输出:20
解释:我们可以拨打的所有有效号码为[04, 06, 16, 18, 27, 29, 34, 38, 40, 43, 49, 60, 61, 67, 72, 76, 81, 83, 92, 94]
```
## 解题思路
### 思路 1:动态规划
根据象棋骑士的跳跃规则,以及电话键盘的样式,我们可以预先处理一下象棋骑士当前位置与下一步能跳跃到的位置关系,将其存入哈希表中,方便查询。
接下来我们可以用动态规划的方式,计算出跳跃 $n - 1$ 次总共能得到多少个长度为 $n$ 的不同电话号码。
###### 1. 阶段划分
按照步数、所处数字位置进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][v]$ 表示为:第 $i$ 步到达键位 $u$ 总共能到的长度为 $i + 1$ 的不同电话号码个数。
###### 3. 状态转移方程
第 $i$ 步到达键位 $v$ 所能得到的不同电话号码个数,取决于 $i - 1$ 步中所有能到达 $v$ 的键位 $u$ 的不同电话号码个数总和。
呢状态转移方程为:$dp[i][v] = \sum dp[i - 1][u]$(可以从 $u$ 跳到 $v$)。
###### 4. 初始条件
- 第 $0$ 步(位于开始位置)所能得到的电话号码个数为 $1$,因为开始时可以将骑士放在任何数字单元格上,所以所有的 $dp[0][v] = 1$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][v]$ 表示为:第 $i$ 步到达键位 $u$ 总共能到的长度为 $i + 1$ 的不同电话号码个数。 所以最终结果为第 $n - 1$ 行所有的 $dp[n - 1][v]$ 的总和。
### 思路 1:代码
```python
class Solution:
def knightDialer(self, n: int) -> int:
graph = {
0: [4, 6],
1: [6, 8],
2: [7, 9],
3: [4, 8],
4: [0, 3, 9],
5: [],
6: [0, 1, 7],
7: [2, 6],
8: [1, 3],
9: [2, 4]
}
MOD = 10 ** 9 + 7
dp = [[0 for _ in range(10)] for _ in range(n)]
for v in range(10):
dp[0][v] = 1
for i in range(1, n):
for u in range(10):
for v in graph[u]:
dp[i][v] = (dp[i][v] + dp[i - 1][u]) % MOD
return sum(dp[n - 1]) % MOD
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times 10)$,其中 $n$ 为给定整数。
- **空间复杂度**:$O(n \times 10)$。
================================================
FILE: docs/solutions/0900-0999/largest-component-size-by-common-factor.md
================================================
# [0952. 按公因数计算最大组件大小](https://leetcode.cn/problems/largest-component-size-by-common-factor/)
- 标签:并查集、数组、哈希表、数学、数论
- 难度:困难
## 题目链接
- [0952. 按公因数计算最大组件大小 - 力扣](https://leetcode.cn/problems/largest-component-size-by-common-factor/)
## 题目大意
**描述**:
给定一个由不同正整数的组成的非空数组 $nums$,考虑下面的图:
- 有 $nums.length$ 个节点,按从 $nums[0]$ 到 $nums[nums.length - 1]$ 标记;
- 只有当 $nums[i]$ 和 $nums[j]$ 共用一个大于 1 的公因数时,$nums[i]$ 和 $nums[j]$ 之间才有一条边。
**要求**:
返回「图中最大连通组件的大小」。
**说明**:
- $1 \le nums.length \le 2 * 10^{4}$。
- $1 \le nums[i] \le 10^{5}$。
- $nums$ 中所有值都不同。
**示例**:
- 示例 1:

```python
输入:nums = [4,6,15,35]
输出:4
```
- 示例 2:

```python
输入:nums = [20,50,9,63]
输出:2
```
## 解题思路
### 思路 1:并查集
#### 思路
这道题要求找到图中最大连通组件的大小,其中两个数如果有大于 $1$ 的公因数,则它们之间有边。
直接判断两两之间的公因数会超时。我们可以通过 **质因数分解** 来优化:
- 如果两个数有公因数 $p$,那么它们都能被 $p$ 整除。
- 我们可以将每个数分解为质因数,然后将所有包含相同质因数的数连接起来。
使用并查集:
1. 对每个数进行质因数分解。
2. 将每个数与其所有质因数连接(使用并查集的 $union$ 操作)。
3. 统计每个连通分量的大小,返回最大值。
为了避免直接连接数字和质因数(范围不同),我们可以用一个哈希表记录每个质因数第一次出现时对应的数字,后续出现相同质因数的数字都与这个数字连接。
#### 代码
```python
class Solution:
def largestComponentSize(self, nums: List[int]) -> int:
# 并查集
parent = {}
def find(x):
if x not in parent:
parent[x] = x
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def union(x, y):
root_x = find(x)
root_y = find(y)
if root_x != root_y:
parent[root_x] = root_y
# 质因数分解
def get_prime_factors(n):
factors = []
# 处理因子 2
if n % 2 == 0:
factors.append(2)
while n % 2 == 0:
n //= 2
# 处理奇数因子
i = 3
while i * i <= n:
if n % i == 0:
factors.append(i)
while n % i == 0:
n //= i
i += 2
# 如果 n 是质数
if n > 2:
factors.append(n)
return factors
# prime_to_num[p] 记录质因数 p 第一次出现时对应的数字
prime_to_num = {}
# 对每个数进行质因数分解,并连接
for num in nums:
primes = get_prime_factors(num)
for prime in primes:
if prime in prime_to_num:
union(num, prime_to_num[prime])
else:
prime_to_num[prime] = num
# 统计每个连通分量的大小
from collections import Counter
count = Counter(find(num) for num in nums)
return max(count.values())
```
#### 复杂度分析
- **时间复杂度**:$O(n \sqrt{m})$,其中 $n$ 是数组长度,$m$ 是数组中的最大值。每个数的质因数分解需要 $O(\sqrt{m})$ 时间。
- **空间复杂度**:$O(n + k)$,其中 $k$ 是不同质因数的数量。需要并查集和哈希表存储。
================================================
FILE: docs/solutions/0900-0999/largest-perimeter-triangle.md
================================================
# [0976. 三角形的最大周长](https://leetcode.cn/problems/largest-perimeter-triangle/)
- 标签:贪心、数组、数学、排序
- 难度:简单
## 题目链接
- [0976. 三角形的最大周长 - 力扣](https://leetcode.cn/problems/largest-perimeter-triangle/)
## 题目大意
**描述**:给定一些由正数(代表长度)组成的数组 `nums`。
**要求**:返回由其中 `3` 个长度组成的、面积不为 `0` 的三角形的最大周长。如果不能形成任何面积不为 `0` 的三角形,则返回 `0`。
**说明**:
- $3 \le nums.length \le 10^4$。
- $1 \le nums[i] \le 10^6$。
**示例**:
- 示例 1:
```python
输入:nums = [2,1,2]
输出:5
解释:长度为 2, 1, 2 的边组成的三角形周长为 5,为最大周长
```
## 解题思路
### 思路 1:
要想三角形的周长最大,则每一条边都要尽可能的长,并且还要满足三角形的边长条件,即 `a + b > c`,其中 `a`、`b`、`c` 分别是三角形的 `3` 条边长。
所以,我们可以先对所有边长进行排序。然后倒序枚举最长边 `nums[i]`,判断前两个边长相加是否大于最长边,即 `nums[i - 2] + nums[i - 1] > nums[i]`。如果满足,则返回 `3` 条边长的和,否则的话继续枚举最长边。
## 代码
### 思路 1 代码:
```python
class Solution:
def largestPerimeter(self, nums: List[int]) -> int:
nums.sort()
for i in range(len(nums) - 1, 1, -1):
if nums[i - 2] + nums[i - 1] > nums[i]:
return nums[i - 2] + nums[i - 1] + nums[i]
return 0
```
================================================
FILE: docs/solutions/0900-0999/largest-time-for-given-digits.md
================================================
# [0949. 给定数字能组成的最大时间](https://leetcode.cn/problems/largest-time-for-given-digits/)
- 标签:数组、字符串、回溯、枚举
- 难度:中等
## 题目链接
- [0949. 给定数字能组成的最大时间 - 力扣](https://leetcode.cn/problems/largest-time-for-given-digits/)
## 题目大意
**描述**:
24 小时格式为 `"HH:MM"`,其中 $HH$ 在 00 到 23 之间,$MM$ 在 00 到 59 之间。最小的 24 小时制时间是 `00:00`,而最大的是 `23:59`。从 `00:00` (午夜)开始算起,过得越久,时间越大。
给定一个由 4 位数字组成的数组。
**要求**:
返回可以设置的符合 24 小时制的最大时间。
长度为 5 的字符串,按 `"HH:MM"` 格式返回答案。如果不能确定有效时间,则返回空字符串。
**说明**:
- $arr.length == 4$。
- $0 \le arr[i] \le 9$。
**示例**:
- 示例 1:
```python
输入:arr = [1,2,3,4]
输出:"23:41"
解释:有效的 24 小时制时间是 "12:34","12:43","13:24","13:42","14:23","14:32","21:34","21:43","23:14" 和 "23:41" 。这些时间中,"23:41" 是最大时间。
```
- 示例 2:
```python
输入:arr = [5,5,5,5]
输出:""
解释:不存在有效的 24 小时制时间,因为 "55:55" 无效。
```
## 解题思路
### 思路 1:枚举
#### 思路
这道题要求用 $4$ 个数字组成符合 $24$ 小时制的最大时间。由于只有 $4$ 个数字,我们可以枚举所有可能的排列(共 $4! = 24$ 种),然后检查每个排列是否能组成有效的时间,并记录最大的时间。
有效时间的条件:
- 小时部分:$00 \sim 23$,即第一位 $\le 2$,如果第一位是 $2$,第二位 $\le 3$。
- 分钟部分:$00 \sim 59$,即第三位 $\le 5$。
#### 代码
```python
class Solution:
def largestTimeFromDigits(self, arr: List[int]) -> str:
from itertools import permutations
max_time = -1 # 记录最大时间(用分钟数表示)
# 枚举所有排列
for perm in permutations(arr):
hour = perm[0] * 10 + perm[1]
minute = perm[2] * 10 + perm[3]
# 检查是否是有效时间
if hour < 24 and minute < 60:
# 转换为分钟数进行比较
time_in_minutes = hour * 60 + minute
max_time = max(max_time, time_in_minutes)
# 如果没有有效时间,返回空字符串
if max_time == -1:
return ""
# 将分钟数转换为时间格式
hour = max_time // 60
minute = max_time % 60
return f"{hour:02d}:{minute:02d}"
```
#### 复杂度分析
- **时间复杂度**:$O(1)$,因为数组长度固定为 $4$,排列数固定为 $24$。
- **空间复杂度**:$O(1)$,只使用了常数个额外变量。
================================================
FILE: docs/solutions/0900-0999/least-operators-to-express-number.md
================================================
# [0964. 表示数字的最少运算符](https://leetcode.cn/problems/least-operators-to-express-number/)
- 标签:记忆化搜索、数学、动态规划
- 难度:困难
## 题目链接
- [0964. 表示数字的最少运算符 - 力扣](https://leetcode.cn/problems/least-operators-to-express-number/)
## 题目大意
**描述**:
给定一个正整数 $x$,我们将会写出一个形如 $x (op1) x (op2) x (op3) x ...$ 的表达式,其中每个运算符 $op1, op2, …$ 可以是加、减、乘、除(`+`,`-`,`*`,或是 `/`)之一。例如,对于 $x = 3$,我们可以写出表达式 $3 * 3 / 3 + 3 - 3$,该式的值为 3。
在写这样的表达式时,我们需要遵守下面的惯例:
- 除运算符(`/`)返回有理数。
- 任何地方都没有括号。
- 我们使用通常的操作顺序:乘法和除法发生在加法和减法之前。
- 不允许使用一元否定运算符(`-`)。例如,$x - x$ 是一个有效的表达式,因为它只使用减法,但是 $-x + x$ 不是,因为它使用了否定运算符。
我们希望编写一个能使表达式等于给定的目标值 $target$ 且运算符最少的表达式。
**要求**:
返回所用运算符的最少数量。
**说明**:
- $2 \le x \le 10^{3}$。
- $1 \le target \le 2 * 10^{8}$。
**示例**:
- 示例 1:
```python
输入:x = 3, target = 19
输出:5
解释:3 * 3 + 3 * 3 + 3 / 3 。表达式包含 5 个运算符。
```
- 示例 2:
```python
输入:x = 5, target = 501
输出:8
解释:5 * 5 * 5 * 5 - 5 * 5 * 5 + 5 / 5 。表达式包含 8 个运算符。
```
## 解题思路
### 思路 1:记忆化搜索 + 动态规划
#### 思路
这道题要求用最少的运算符表示目标数字 $target$。我们可以将 $target$ 看作 $x$ 进制数,每一位可以是 $0$ 到 $x$(允许进位)。
**关键观察**:
- $x^0 = 1$ 需要 $x / x$,即 $2$ 个运算符(一个除号一个乘号,但连接时算作 $2$ 个代价)。
- $x^1 = x$ 不需要运算符(直接使用 $x$,但连接时需要 $1$ 个加号/减号)。
- $x^i$ 需要 $i$ 个运算符($i - 1$ 个乘号 + $1$ 个加号/减号用于连接)。
**状态定义**:
- 定义 $dp(i, target)$ 表示用 $x^i$ 及更高次幂表示 $target$ 的最少运算符数。
- 对于每个位置 $i$,计算 $target$ 除以 $x$ 的商 $q$ 和余数 $r$:
- **方案 1**:使用 $r$ 个 $x^i$,然后递归处理 $q$。
- **方案 2**:使用 $(x - r)$ 个 $-x^i$(相当于凑到下一个 $x^{i+1}$),然后递归处理 $q + 1$。
**代价计算**:
- 预先计算 $cost[i]$,表示使用一个 $x^i$ 需要的运算符数:
- $cost[0] = 2$($x / x$ 需要 $2$ 个运算符)
- $cost[i] = i$($i \ge 1$ 时,$x^i$ 需要 $i$ 个运算符)
#### 代码
```python
class Solution:
def leastOpsExpressTarget(self, x: int, target: int) -> int:
from functools import lru_cache
# cost[i] 表示使用一个 x^i 需要的运算符数
# cost[0] = 2 (x/x),cost[i] = i (i >= 1)
cost = [2] + list(range(1, 40))
@lru_cache(None)
def dp(i, targ):
"""用 x^i 及更高次幂表示 targ 的最少运算符数"""
# 基本情况
if targ == 0:
return 0
if targ == 1:
return cost[i]
if i >= 39: # 防止溢出
return float('inf')
# 计算 targ 除以 x 的商和余数
quotient, remainder = divmod(targ, x)
# 方案 1:使用 remainder 个 x^i,然后处理 quotient
# 每个 x^i 需要 cost[i] 个运算符
ans1 = remainder * cost[i] + dp(i + 1, quotient)
# 方案 2:使用 (x - remainder) 个 -x^i,然后处理 quotient + 1
# 相当于凑到下一个 x^(i+1)
ans2 = (x - remainder) * cost[i] + dp(i + 1, quotient + 1)
return min(ans1, ans2)
# 从 x^0 开始,最后减 1 是因为最外层不需要加号
return dp(0, target) - 1
```
#### 复杂度分析
- **时间复杂度**:$O(\log_x target \times \log target)$,递归深度最多为 $O(\log_x target)$,每个状态最多被计算一次。
- **空间复杂度**:$O(\log_x target \times \log target)$,记忆化搜索的缓存空间。
================================================
FILE: docs/solutions/0900-0999/long-pressed-name.md
================================================
# [0925. 长按键入](https://leetcode.cn/problems/long-pressed-name/)
- 标签:双指针、字符串
- 难度:简单
## 题目链接
- [0925. 长按键入 - 力扣](https://leetcode.cn/problems/long-pressed-name/)
## 题目大意
**描述**:你的朋友正在使用键盘输入他的名字 $name$。偶尔,在键入字符时,按键可能会被长按,而字符可能被输入 $1$ 次或多次。
现在给定代表名字的字符串 $name$,以及实际输入的字符串 $typed$。
**要求**:检查键盘输入的字符 $typed$。如果它对应的可能是你的朋友的名字(其中一些字符可能被长按),就返回 `True`。否则返回 `False`。
**说明**:
- $1 \le name.length, typed.length \le 1000$。
- $name$ 和 $typed$ 的字符都是小写字母。
**示例**:
- 示例 1:
```python
输入:name = "alex", typed = "aaleex"
输出:true
解释:'alex' 中的 'a' 和 'e' 被长按。
```
- 示例 2:
```python
输入:name = "saeed", typed = "ssaaedd"
输出:false
解释:'e' 一定需要被键入两次,但在 typed 的输出中不是这样。
```
## 解题思路
### 思路 1:分离双指针
这道题目的意思是在 $typed$ 里边匹配 $name$,同时要考虑字符重复问题,以及不匹配的情况。可以使用分离双指针来做。具体做法如下:
1. 使用两个指针 $left\_1$、$left\_2$,$left\_1$ 指向字符串 $name$ 开始位置,$left\_2$ 指向字符串 $type$ 开始位置。
2. 如果 $name[left\_1] == name[left\_2]$,则将 $left\_1$、$left\_2$ 同时右移。
3. 如果 $nmae[left\_1] \ne name[left\_2]$,则:
1. 如果 $typed[left\_2]$ 和前一个位置元素 $typed[left\_2 - 1]$ 相等,则说明出现了重复元素,将 $left\_2$ 右移,过滤重复元素。
2. 如果 $typed[left\_2]$ 和前一个位置元素 $typed[left\_2 - 1]$ 不等,则说明出现了多余元素,不匹配。直接返回 `False` 即可。
4. 当 $left\_1 == len(name)$ 或者 $left\_2 == len(typed)$ 时跳出循环。然后过滤掉 $typed$ 末尾的重复元素。
5. 最后判断,如果 $left\_1 == len(name)$ 并且 $left\_2 == len(typed)$,则说明匹配,返回 `True`,否则返回 `False`。
### 思路 1:代码
```python
class Solution:
def isLongPressedName(self, name: str, typed: str) -> bool:
left_1, left_2 = 0, 0
while left_1 < len(name) and left_2 < len(typed):
if name[left_1] == typed[left_2]:
left_1 += 1
left_2 += 1
elif left_2 > 0 and typed[left_2 - 1] == typed[left_2]:
left_2 += 1
else:
return False
while 0 < left_2 < len(typed) and typed[left_2] == typed[left_2 - 1]:
left_2 += 1
if left_1 == len(name) and left_2 == len(typed):
return True
else:
return False
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$。其中 $n$、$m$ 分别为字符串 $name$、$typed$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0900-0999/longest-turbulent-subarray.md
================================================
# [0978. 最长湍流子数组](https://leetcode.cn/problems/longest-turbulent-subarray/)
- 标签:数组、动态规划、滑动窗口
- 难度:中等
## 题目链接
- [0978. 最长湍流子数组 - 力扣](https://leetcode.cn/problems/longest-turbulent-subarray/)
## 题目大意
**描述**:给定一个数组 $arr$。当 $arr$ 的子数组 $arr[i]$,$arr[i + 1]$,$...$, $arr[j]$ 满足下列条件时,我们称其为湍流子数组:
- 如果 $i \le k < j$,当 $k$ 为奇数时, $arr[k] > arr[k + 1]$,且当 $k$ 为偶数时,$arr[k] < arr[k + 1]$;
- 或如果 $i \le k < j$,当 $k$ 为偶数时,$arr[k] > arr[k + 1]$ ,且当 $k$ 为奇数时,$arr[k] < arr[k + 1]$。
- 也就是说,如果比较符号在子数组中的每个相邻元素对之间翻转,则该子数组是湍流子数组。
**要求**:返回给定数组 $arr$ 的最大湍流子数组的长度。
**说明**:
- $1 \le arr.length \le 4 \times 10^4$。
- $0 \le arr[i] \le 10^9$。
**示例**:
- 示例 1:
```python
输入:arr = [9,4,2,10,7,8,8,1,9]
输出:5
解释:arr[1] > arr[2] < arr[3] > arr[4] < arr[5]
```
- 示例 2:
```python
输入:arr = [4,8,12,16]
输出:2
```
## 解题思路
### 思路 1:快慢指针
湍流子数组实际上像波浪一样,比如 $arr[i - 2] > arr[i - 1] < arr[i] > arr[i + 1] < arr[i + 2]$。所以我们可以使用双指针的做法。具体做法如下:
- 使用两个指针 $left$、$right$。$left$ 指向湍流子数组的左端,$right$ 指向湍流子数组的右端。
- 如果 $arr[right - 1] == arr[right]$,则更新 `left = right`,重新开始计算最长湍流子数组大小。
- 如果 $arr[right - 2] < arr[right - 1] < arr[right]$,此时为递增数组,则 $left$ 从 $right - 1$ 开始重新计算最长湍流子数组大小。
- 如果 $arr[right - 2] > arr[right - 1] > arr[right]$,此时为递减数组,则 $left$ 从 $right - 1$ 开始重新计算最长湍流子数组大小。
- 其他情况(即 $arr[right - 2] < arr[right - 1] > arr[right]$ 或 $arr[right - 2] > arr[right - 1] < arr[right]$)时,不用更新 $left$值。
- 更新最大湍流子数组的长度,并向右移动 $right$。直到 $right \ge len(arr)$ 时,返回答案 $ans$。
### 思路 1:代码
```python
class Solution:
def maxTurbulenceSize(self, arr: List[int]) -> int:
left, right = 0, 1
ans = 1
while right < len(arr):
if arr[right - 1] == arr[right]:
left = right
elif right != 1 and arr[right - 2] < arr[right - 1] and arr[right - 1] < arr[right]:
left = right - 1
elif right != 1 and arr[right - 2] > arr[right - 1] and arr[right - 1] > arr[right]:
left = right - 1
ans = max(ans, right - left + 1)
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $arr$ 中的元素数量。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0900-0999/maximum-binary-tree-ii.md
================================================
# [0998. 最大二叉树 II](https://leetcode.cn/problems/maximum-binary-tree-ii/)
- 标签:树、二叉树
- 难度:中等
## 题目链接
- [0998. 最大二叉树 II - 力扣](https://leetcode.cn/problems/maximum-binary-tree-ii/)
## 题目大意
**描述**:
「最大树」定义:一棵树,并满足:其中每个节点的值都大于其子树中的任何其他值。
给你最大树的根节点 $root$ 和一个整数 $val$。
就像 [之前的问题](https://leetcode.cn/problems/maximum-binary-tree/) 那样,给定的树是利用 `Construct(a)` 例程从列表 $a$(`root = Construct(a)`)递归地构建的:
- 如果 $a$ 为空,返回 $null$。
- 否则,令 $a[i]$ 作为 $a$ 的最大元素。创建一个值为 $a[i]$ 的根节点 $root$。
- $root$ 的左子树将被构建为 `Construct([a[0], a[1], ..., a[i - 1]])`。
- $root$ 的右子树将被构建为 `Construct([a[i + 1], a[i + 2], ..., a[a.length - 1]])`。
- 返回 $root$。
请注意,题目没有直接给出 $a$,只是给出一个根节点 `root = Construct(a)`。
假设 $b$ 是 $a$ 的副本,并在末尾附加值 $val$。题目数据保证 $b$ 中的值互不相同。
**要求**:
返回 `Construct(b)`。
**说明**:
- 树中节点数目在范围 $[1, 10^{3}]$ 内。
- $1 \le Node.val \le 10^{3}$。
- 树中的所有值「互不相同」。
- $1 \le val \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:root = [4,1,3,null,null,2], val = 5
输出:[5,4,null,1,3,null,null,2]
解释:a = [1,4,2,3], b = [1,4,2,3,5]
```
- 示例 2:
```python
输入:root = [5,2,4,null,1], val = 3
输出:[5,2,4,null,1,null,3]
解释:a = [2,1,5,4], b = [2,1,5,4,3]
```
## 解题思路
### 思路 1:递归
#### 思路
这道题要求在最大二叉树的末尾插入一个新值 $val$。根据最大二叉树的构造规则:
- 如果 $val$ 大于根节点的值,那么 $val$ 应该成为新的根节点,原来的树成为新根的左子树。
- 如果 $val$ 小于根节点的值,那么 $val$ 应该插入到右子树中(因为 $val$ 是在数组末尾添加的)。
我们可以使用递归的方式:
1. 如果当前节点为空,创建一个新节点返回。
2. 如果 $val$ 大于当前节点的值,创建新节点作为根,当前节点作为左子树。
3. 否则,递归地将 $val$ 插入到右子树中。
#### 代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def insertIntoMaxTree(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
# 如果当前节点为空,创建新节点
if not root:
return TreeNode(val)
# 如果 val 大于当前节点的值,val 成为新的根节点
if val > root.val:
new_root = TreeNode(val)
new_root.left = root
return new_root
# 否则,递归地插入到右子树
root.right = self.insertIntoMaxTree(root.right, val)
return root
```
#### 复杂度分析
- **时间复杂度**:$O(h)$,其中 $h$ 是树的高度。最坏情况下需要遍历到最右边的叶子节点。
- **空间复杂度**:$O(h)$,递归调用栈的深度最多为树的高度。
================================================
FILE: docs/solutions/0900-0999/maximum-sum-circular-subarray.md
================================================
# [0918. 环形子数组的最大和](https://leetcode.cn/problems/maximum-sum-circular-subarray/)
- 标签:队列、数组、分治、动态规划、单调队列
- 难度:中等
## 题目链接
- [0918. 环形子数组的最大和 - 力扣](https://leetcode.cn/problems/maximum-sum-circular-subarray/)
## 题目大意
给定一个环形整数数组 nums,数组 nums 的尾部和头部是相连状态。求环形数组 nums 的非空子数组的最大和(子数组中每个位置元素最多出现一次)。
## 解题思路
构成环形整数数组 nums 的非空子数组的最大和的子数组有两种情况:
- 最大和的子数组为一个子区间:$nums[i] + nums[i+1] + nums[i+2] + ... + num[j]$。
- 最大和的子数组为首尾的两个子区间:$(nums[0] + nums[1] + ... + nums[i]) + (nums[j] + nums[j+1] + ... + num[N-1])$。
第一种情况其实就是无环情况下的整数数组的非空子数组最大和问题,跟「[53. 最大子序和](https://leetcode.cn/problems/maximum-subarray/)」问题是一致的,我们假设求解结果为 `max_num`。
下来来思考第二种情况,第二种情况下,要使首尾两个子区间的和尽可能的大,则中间的子区间的和应该尽可能的小。
使得中间子区间的和尽可能小的问题,可以转变为求解:整数数组 nums 的非空子数组最小和问题。求解思路跟上边是相似的,只不过最大变为了最小。我们假设求解结果为 `min_num`。
而首尾两个区间和尽可能大的结果为数组 nums 的和减去中间最小子数组和,即 `sum(nums) - min_num`。
最终的结果就是比较 `sum(nums) - min_num` 和 `max_num`的大小,返回较大值即可。
## 代码
```python
class Solution:
def maxSubarraySumCircular(self, nums: List[int]) -> int:
size = len(nums)
dp_max, dp_min = nums[0], nums[0]
max_num, min_num = nums[0], nums[0]
for i in range(1, size):
dp_max = max(dp_max + nums[i], nums[i])
dp_min = min(dp_min + nums[i], nums[i])
max_num = max(dp_max, max_num)
min_num = min(dp_min, min_num)
sum_num = sum(nums)
if max_num < 0:
return max_num
return max(sum_num - min_num, max_num)
```
================================================
FILE: docs/solutions/0900-0999/maximum-width-ramp.md
================================================
# [0962. 最大宽度坡](https://leetcode.cn/problems/maximum-width-ramp/)
- 标签:栈、数组、双指针、单调栈
- 难度:中等
## 题目链接
- [0962. 最大宽度坡 - 力扣](https://leetcode.cn/problems/maximum-width-ramp/)
## 题目大意
**描述**:
给定一个整数数组 A,坡是元组 $(i, j)$,其中 $i < j$ 且 $A[i] \le A[j]$。这样的坡的宽度为 $j - i$。
**要求**:
找出 A 中的坡的最大宽度,如果不存在,返回 0。
**说明**:
- $2 \le A.length \le 50000$。
- $0 \le A[i] \le 50000$。
**示例**:
- 示例 1:
```python
输入:[6,0,8,2,1,5]
输出:4
解释:
最大宽度的坡为 (i, j) = (1, 5): A[1] = 0 且 A[5] = 5.
```
- 示例 2:
```python
输入:[9,8,1,0,1,9,4,0,4,1]
输出:7
解释:
最大宽度的坡为 (i, j) = (2, 9): A[2] = 1 且 A[9] = 1.
```
## 解题思路
### 思路 1:单调栈
#### 思路
这道题要求找到最大宽度的坡,即满足 $i < j$ 且 $nums[i] \le nums[j]$ 的最大 $j - i$。
我们可以使用单调栈来解决:
1. **构建单调递减栈**:从左到右遍历数组,将索引压入栈中,保持栈中索引对应的值单调递减。这样栈中存储的是可能作为坡起点的候选位置。
2. **从右向左查找最大宽度**:从右向左遍历数组,对于每个位置 $j$,尝试从栈顶弹出满足 $nums[stack[-1]] \le nums[j]$ 的索引 $i$,计算宽度 $j - i$ 并更新最大值。
为什么从右向左遍历?因为对于栈顶的索引 $i$,我们希望找到最远的 $j$ 使得 $nums[i] \le nums[j]$,从右向左可以保证找到的是最大宽度。
#### 代码
```python
class Solution:
def maxWidthRamp(self, nums: List[int]) -> int:
n = len(nums)
stack = [] # 单调递减栈,存储索引
# 构建单调递减栈
for i in range(n):
if not stack or nums[i] < nums[stack[-1]]:
stack.append(i)
max_width = 0
# 从右向左遍历,寻找最大宽度
for j in range(n - 1, -1, -1):
# 当栈不为空且当前值大于等于栈顶索引对应的值
while stack and nums[j] >= nums[stack[-1]]:
i = stack.pop()
max_width = max(max_width, j - i)
return max_width
```
#### 复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组长度。每个元素最多入栈和出栈各一次。
- **空间复杂度**:$O(n)$,栈的空间最多存储 $n$ 个元素。
================================================
FILE: docs/solutions/0900-0999/minimize-malware-spread-ii.md
================================================
# [0928. 尽量减少恶意软件的传播 II](https://leetcode.cn/problems/minimize-malware-spread-ii/)
- 标签:深度优先搜索、广度优先搜索、并查集、图、数组、哈希表
- 难度:困难
## 题目链接
- [0928. 尽量减少恶意软件的传播 II - 力扣](https://leetcode.cn/problems/minimize-malware-spread-ii/)
## 题目大意
**描述**:
给定一个由 $n$ 个节点组成的网络,用 $n$ $x$ $n$ 个邻接矩阵 $graph$ 表示。在节点网络中,只有当 $graph[i][j] = 1$ 时,节点 $i$ 能够直接连接到另一个节点 $j$。
一些节点 $initial$ 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 $M(initial)$ 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
我们可以从 $initial$ 中 删除一个节点,并完全移除该节点以及从该节点到任何其他节点的任何连接。
**要求**:
请返回移除后能够使 $M(initial)$ 最小化的节点。如果有多个节点满足条件,返回索引「最小的节点」。
**说明**:
- $n == graph.length$。
- $n == graph[i].length$。
- $2 \le n \le 300$。
- $graph[i][j]$ 是 $0$ 或 $1$。
- $graph[i][j] == graph[j][i]$。
- $graph[i][i] == 1$。
- $1 \le initial.length \lt n$。
- $0 \le initial[i] \le n - 1$。
- $initial$ 中每个整数都不同。
**示例**:
- 示例 1:
```python
输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1]
输出:0
```
- 示例 2:
```python
输入:graph = [[1,1,0],[1,1,1],[0,1,1]], initial = [0,1]
输出:1
```
## 解题思路
### 思路 1:并查集
这道题与 0924 类似,但区别在于删除节点后,该节点不会传播病毒。
1. **枚举删除节点**:对于每个初始感染节点,假设删除它,计算剩余节点的感染范围。
2. **BFS/DFS 计算感染范围**:从剩余的初始感染节点开始,使用 BFS 或 DFS 计算能感染的节点数。
3. **选择最优节点**:选择删除后感染节点数最少的节点,如果有多个,选择索引最小的。
**优化**:可以使用并查集预处理连通分量,然后对每个初始感染节点计算影响。
### 思路 1:代码
```python
class Solution:
def minMalwareSpread(self, graph: List[List[int]], initial: List[int]) -> int:
n = len(graph)
def bfs(removed):
"""计算删除 removed 节点后的感染节点数"""
infected = set()
queue = collections.deque()
# 将剩余的初始感染节点加入队列
for node in initial:
if node != removed:
queue.append(node)
infected.add(node)
# BFS 扩散
while queue:
curr = queue.popleft()
for next_node in range(n):
if next_node != removed and graph[curr][next_node] == 1 and next_node not in infected:
infected.add(next_node)
queue.append(next_node)
return len(infected)
# 枚举删除每个初始感染节点
min_infected = n + 1
result = min(initial)
for node in sorted(initial):
infected_count = bfs(node)
if infected_count < min_infected:
min_infected = infected_count
result = node
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n^2)$,其中 $m$ 是初始感染节点数量,$n$ 是节点总数。对于每个初始感染节点,需要进行一次 BFS,每次 BFS 需要 $O(n^2)$ 时间。
- **空间复杂度**:$O(n)$,需要使用队列和集合存储访问状态。
================================================
FILE: docs/solutions/0900-0999/minimize-malware-spread.md
================================================
# [0924. 尽量减少恶意软件的传播](https://leetcode.cn/problems/minimize-malware-spread/)
- 标签:深度优先搜索、广度优先搜索、并查集、图、数组、哈希表
- 难度:困难
## 题目链接
- [0924. 尽量减少恶意软件的传播 - 力扣](https://leetcode.cn/problems/minimize-malware-spread/)
## 题目大意
**描述**:
给定一个由 $n$ 个节点组成的网络,用 $n \times n$ 个邻接矩阵图 $graph$ 表示。在节点网络中,当 $graph[i][j] = 1$ 时,表示节点 $i$ 能够直接连接到另一个节点 $j$。
一些节点 $initial$ 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 $M(initial)$ 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
**要求**:
如果从 $initial$ 中移除某一节点能够最小化 $M(initial)$,返回该节点。如果有多个节点满足条件,就返回索引最小的节点。
**说明**:
- 注意:如果某个节点已从受感染节点的列表 $initial$ 中删除,它以后仍有可能因恶意软件传播而受到感染。
- $n == graph.length$。
- $n == graph[i].length$。
- $2 \le n \le 300$。
- $graph[i][j] == 0$ 或 $1$。
- $graph[i][j] == graph[j][i]$。
- $graph[i][i] == 1$。
- $1 \le initial.length \le n$。
- $0 \le initial[i] \le n - 1$。
- $initial$ 中所有整数均不重复。
**示例**:
- 示例 1:
```python
输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1]
输出:0
```
- 示例 2:
```python
输入:graph = [[1,0,0],[0,1,0],[0,0,1]], initial = [0,2]
输出:0
```
## 解题思路
### 思路 1:并查集
这道题的关键是找到删除哪个初始感染节点能最大程度减少感染范围。
1. **构建连通分量**:使用并查集将所有节点连接起来,形成连通分量。
2. **统计影响**:对于每个连通分量,统计其中包含的初始感染节点数量和连通分量大小。
3. **选择最优节点**:
- 如果一个连通分量只包含一个初始感染节点,删除该节点可以拯救整个连通分量
- 如果一个连通分量包含多个初始感染节点,删除任何一个都无法拯救它
- 选择能拯救最多节点的初始感染节点,如果有多个,选择索引最小的
### 思路 1:代码
```python
class Solution:
def minMalwareSpread(self, graph: List[List[int]], initial: List[int]) -> int:
n = len(graph)
initial_set = set(initial)
# 并查集
parent = list(range(n))
def find(x):
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def union(x, y):
px, py = find(x), find(y)
if px != py:
parent[px] = py
# 将所有相连的节点连接起来
for i in range(n):
for j in range(i + 1, n):
if graph[i][j] == 1:
union(i, j)
# 统计每个连通分量的大小和包含的初始感染节点
component_size = collections.defaultdict(int)
component_malware = collections.defaultdict(list)
for i in range(n):
root = find(i)
component_size[root] += 1
if i in initial_set:
component_malware[root].append(i)
# 统计删除每个初始感染节点能拯救的节点数
saved = collections.defaultdict(int)
for root, malware_list in component_malware.items():
# 只有一个初始感染节点时,删除它可以拯救整个连通分量(除了它自己)
if len(malware_list) == 1:
m = malware_list[0]
saved[m] = component_size[root]
# 选择能拯救最多节点的初始感染节点
initial.sort()
max_saved = max(saved.values()) if saved else 0
for node in initial:
if saved[node] == max_saved:
return node
return initial[0]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是节点数量。需要遍历邻接矩阵构建并查集。
- **空间复杂度**:$O(n)$,需要使用并查集和哈希表存储信息。
================================================
FILE: docs/solutions/0900-0999/minimum-add-to-make-parentheses-valid.md
================================================
# [0921. 使括号有效的最少添加](https://leetcode.cn/problems/minimum-add-to-make-parentheses-valid/)
- 标签:栈、贪心、字符串
- 难度:中等
## 题目链接
- [0921. 使括号有效的最少添加 - 力扣](https://leetcode.cn/problems/minimum-add-to-make-parentheses-valid/)
## 题目大意
**描述**:给定一个括号字符串 `s`,可以在字符串的任何位置插入一个括号。
**要求**:返回为使结果字符串 `s` 有效而必须添加的最少括号数。
**说明**:
- $1 \le s.length \le 1000$。
- `s` 只包含 `'('` 和 `')'` 字符。
只有满足下面几点之一,括号字符串才是有效的:
- 它是一个空字符串,或者
- 它可以被写成 AB (A 与 B 连接), 其中 A 和 B 都是有效字符串,或者
- 它可以被写作 (A),其中 A 是有效字符串。
例如,如果 `s = "()))"`,你可以插入一个开始括号为 `"(()))"` 或结束括号为 `"())))"`。
**示例**:
- 示例 1:
```python
输入:s = "())"
输出:1
```
## 解题思路
### 思路 1:贪心算法
为了最终添加的最少括号数,我们应该尽可能将当前能够匹配的括号先进行配对。则剩余的未完成配对的括号数量就是答案。
我们使用变量 `left_cnt` 来记录当前左括号的数量。使用 `res` 来记录添加的最少括号数量。
- 遍历字符串,判断当前字符。
- 如果当前字符为左括号 `(`,则令 `left_cnt` 加 `1`。
- 如果当前字符为右括号 `)`,则令 `left_cnt` 减 `1`。如果 `left_cnt` 减到 `-1`,说明当前有右括号不能完成匹配,则答案数量 `res` 加 `1`,并令 `left_cnt` 重新赋值为 `0`。
- 遍历完之后,令 `res` 加上剩余不匹配的 `left_cnt` 数量。
- 最后输出 `res`。
### 思路 1:贪心算法代码
```python
class Solution:
def minAddToMakeValid(self, s: str) -> int:
res = 0
left_cnt = 0
for ch in s:
if ch == '(':
left_cnt += 1
elif ch == ')':
left_cnt -= 1
if left_cnt == -1:
left_cnt = 0
res += 1
res += left_cnt
return res
```
================================================
FILE: docs/solutions/0900-0999/minimum-area-rectangle-ii.md
================================================
# [0963. 最小面积矩形 II](https://leetcode.cn/problems/minimum-area-rectangle-ii/)
- 标签:几何、数组、哈希表、数学
- 难度:中等
## 题目链接
- [0963. 最小面积矩形 II - 力扣](https://leetcode.cn/problems/minimum-area-rectangle-ii/)
## 题目大意
**描述**:
给定一个 X-Y 平面上的点数组 $points$,其中 $points[i] = [x_i, y_i]$。
**要求**:
返回由这些点形成的任意矩形的最小面积,矩形的边「不一定」平行于 X 轴和 Y 轴。如果不存在这样的矩形,则返回 0。
答案只需在$10^{-5}$ 的误差范围内即可被视作正确答案。
**说明**:
- $1 \le points.length \le 50$。
- $points[i].length == 2$。
- $0 \le x_i, y_i \le 4 \times 10^{4}$。
- 所有给定的点都是「唯一」的。
**示例**:
- 示例 1:

```python
输入: points = [[1,2],[2,1],[1,0],[0,1]]
输出: 2.00000
解释: 最小面积矩形由 [1,2]、[2,1]、[1,0]、[0,1] 组成,其面积为 2。
```
- 示例 2:

```python
输入: points = [[0,1],[2,1],[1,1],[1,0],[2,0]]
输出: 1.00000
解释: 最小面积矩形由 [1,0]、[1,1]、[2,1]、[2,0] 组成,其面积为 1。
```
## 解题思路
### 思路 1:哈希表 + 几何
对于任意矩形,可以由对角线的两个点和中心点唯一确定。我们可以枚举所有点对作为对角线,然后检查是否存在另外两个点构成矩形。
1. **枚举对角线**:枚举所有点对 $(p_1, p_2)$ 作为对角线。
2. **计算中心和边长**:
- 中心点:$(\frac{x_1 + x_2}{2}, \frac{y_1 + y_2}{2})$
- 对角线长度:$d = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2}$
3. **哈希存储**:使用哈希表存储 (中心点, 对角线长度) 到点对的映射。
4. **验证矩形**:对于相同中心和对角线长度的两对点,验证它们是否构成矩形(对角线互相垂直)。
5. **计算面积**:使用向量叉积计算矩形面积。
### 思路 1:代码
```python
class Solution:
def minAreaFreeRect(self, points: List[List[int]]) -> float:
from collections import defaultdict
n = len(points)
if n < 4:
return 0.0
# 哈希表:(中心点, 对角线长度平方) -> [(点1, 点2), ...]
diagonals = defaultdict(list)
# 枚举所有点对作为对角线
for i in range(n):
for j in range(i + 1, n):
x1, y1 = points[i]
x2, y2 = points[j]
# 计算中心点(使用 2 倍坐标避免浮点数)
cx, cy = x1 + x2, y1 + y2
# 计算对角线长度的平方
dist_sq = (x2 - x1) ** 2 + (y2 - y1) ** 2
# 存储到哈希表
diagonals[(cx, cy, dist_sq)].append((i, j))
min_area = float('inf')
# 检查相同中心和对角线长度的点对
for key, pairs in diagonals.items():
if len(pairs) < 2:
continue
# 枚举所有点对组合
for k in range(len(pairs)):
for l in range(k + 1, len(pairs)):
i1, j1 = pairs[k]
i2, j2 = pairs[l]
# 获取四个点
p1, p2 = points[i1], points[j1]
p3, p4 = points[i2], points[j2]
# 计算两条边的向量
v1 = (p3[0] - p1[0], p3[1] - p1[1])
v2 = (p4[0] - p1[0], p4[1] - p1[1])
# 检查是否垂直(点积为 0)
if v1[0] * v2[0] + v1[1] * v2[1] == 0:
# 计算面积
len1 = (v1[0] ** 2 + v1[1] ** 2) ** 0.5
len2 = (v2[0] ** 2 + v2[1] ** 2) ** 0.5
area = len1 * len2
min_area = min(min_area, area)
return min_area if min_area != float('inf') else 0.0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 + m^2)$,其中 $n$ 是点的数量,$m$ 是相同中心和对角线长度的点对数量。枚举点对需要 $O(n^2)$,验证矩形需要 $O(m^2)$。
- **空间复杂度**:$O(n^2)$,哈希表最多存储 $O(n^2)$ 个点对。
================================================
FILE: docs/solutions/0900-0999/minimum-area-rectangle.md
================================================
# [0939. 最小面积矩形](https://leetcode.cn/problems/minimum-area-rectangle/)
- 标签:几何、数组、哈希表、数学、排序
- 难度:中等
## 题目链接
- [0939. 最小面积矩形 - 力扣](https://leetcode.cn/problems/minimum-area-rectangle/)
## 题目大意
**描述**:
给定一个 X-Y 平面上的点数组 $points$,其中 $points[i] = [x_i, y_i]$。
**要求**:
返回由这些点形成的矩形的最小面积,矩形的边与 X 轴和 Y 轴平行。如果不存在这样的矩形,则返回 0。
**说明**:
- $1 \le points.length \le 500$。
- $points[i].length == 2$。
- $0 \le x_i, y_i \le 4 \times 10^{4}$。
- 所有给定的点都是「唯一」的。
**示例**:
- 示例 1:
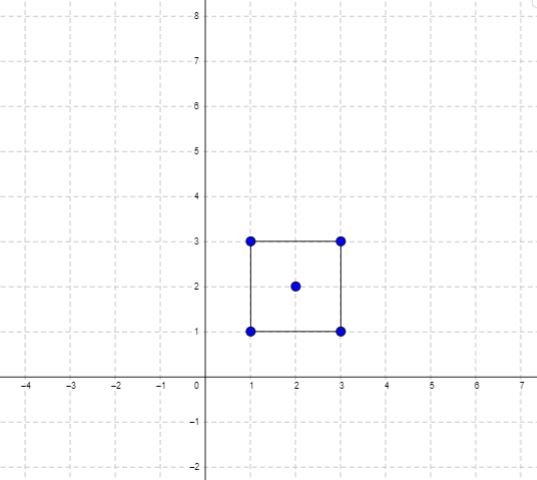
```python
输入: points = [[1,1],[1,3],[3,1],[3,3],[2,2]]
输出: 4
```
- 示例 2:
```python
输入: points = [[1,1],[1,3],[3,1],[3,3],[4,1],[4,3]]
输出: 2
```
## 解题思路
### 思路 1:哈希表
要找到边平行于坐标轴的最小面积矩形,我们需要找到四个点构成的矩形。
1. **枚举对角线**:矩形可以由对角线上的两个点确定。对于边平行于坐标轴的矩形,对角线的两个点 $(x_1, y_1)$ 和 $(x_2, y_2)$ 满足 $x_1 \ne x_2$ 且 $y_1 \ne y_2$。
2. **验证矩形**:对于每对对角线点,检查另外两个点 $(x_1, y_2)$ 和 $(x_2, y_1)$ 是否存在。
3. **计算面积**:如果四个点都存在,计算面积 $|x_2 - x_1| \times |y_2 - y_1|$,更新最小值。
4. **优化**:使用哈希集合存储所有点,快速判断点是否存在。
### 思路 1:代码
```python
class Solution:
def minAreaRect(self, points: List[List[int]]) -> int:
point_set = set(map(tuple, points))
min_area = float('inf')
# 枚举所有点对作为对角线
for i in range(len(points)):
x1, y1 = points[i]
for j in range(i + 1, len(points)):
x2, y2 = points[j]
# 必须是对角线(不在同一行或同一列)
if x1 != x2 and y1 != y2:
# 检查另外两个点是否存在
if (x1, y2) in point_set and (x2, y1) in point_set:
area = abs(x2 - x1) * abs(y2 - y1)
min_area = min(min_area, area)
return min_area if min_area != float('inf') else 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是点的数量,需要枚举所有点对。
- **空间复杂度**:$O(n)$,需要使用哈希集合存储所有点。
================================================
FILE: docs/solutions/0900-0999/minimum-cost-for-tickets.md
================================================
# [0983. 最低票价](https://leetcode.cn/problems/minimum-cost-for-tickets/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [0983. 最低票价 - 力扣](https://leetcode.cn/problems/minimum-cost-for-tickets/)
## 题目大意
**描述**:
在一个火车旅行很受欢迎的国度,你提前一年计划了一些火车旅行。在接下来的一年里,你要旅行的日子将以一个名为 $days$ 的数组给出。每一项是一个从 1 到 365 的整数。
火车票有「三种不同的销售方式」:
- 一张「为期一天」的通行证售价为 $costs[0]$ 美元;
- 一张「为期七天」的通行证售价为 $costs[1]$ 美元;
- 一张「为期三十天」的通行证售价为 $costs[2]$ 美元。
通行证允许数天无限制的旅行。例如,如果我们在第 2 天获得一张 为期 7 天 的通行证,那么我们可以连着旅行 7 天:第 2 天、第 3 天、第 4 天、第 5 天、第 6 天、第 7 天和第 8 天。
**要求**:
返回你想要完成在给定的列表 $days$ 中列出的每一天的旅行所需要的最低消费。
**说明**:
- $1 \le days.length \le 365$。
- $1 \le days[i] \le 365$。
- $days$ 按顺序严格递增。
- $costs.length == 3$。
- $1 \le costs[i] \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:days = [1,4,6,7,8,20], costs = [2,7,15]
输出:11
解释:
例如,这里有一种购买通行证的方法,可以让你完成你的旅行计划:
在第 1 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 1 天生效。
在第 3 天,你花了 costs[1] = $7 买了一张为期 7 天的通行证,它将在第 3, 4, ..., 9 天生效。
在第 20 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 20 天生效。
你总共花了 $11,并完成了你计划的每一天旅行。
```
- 示例 2:
```python
输入:days = [1,2,3,4,5,6,7,8,9,10,30,31], costs = [2,7,15]
输出:17
解释:
例如,这里有一种购买通行证的方法,可以让你完成你的旅行计划:
在第 1 天,你花了 costs[2] = $15 买了一张为期 30 天的通行证,它将在第 1, 2, ..., 30 天生效。
在第 31 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 31 天生效。
你总共花了 $17,并完成了你计划的每一天旅行。
```
## 解题思路
### 思路 1:动态规划
这是一个经典的动态规划问题,需要考虑三种购票方案的最优组合。
1. **状态定义**:$dp[i]$ 表示到第 $i$ 天为止的最低消费。
2. **状态转移**:对于旅行日 $days[i]$,可以选择三种购票方案:
- 购买 $1$ 天通行证:$dp[i] = dp[i-1] + costs[0]$
- 购买 $7$ 天通行证:$dp[i] = dp[j] + costs[1]$,其中 $j$ 是 $7$ 天前的最后一个旅行日
- 购买 $30$ 天通行证:$dp[i] = dp[k] + costs[2]$,其中 $k$ 是 $30$ 天前的最后一个旅行日
3. **优化**:可以使用数组索引而不是日期作为状态,避免处理非旅行日。
### 思路 1:代码
```python
class Solution:
def mincostTickets(self, days: List[int], costs: List[int]) -> int:
n = len(days)
dp = [0] * n
for i in range(n):
# 方案 1:购买 1 天通行证
dp[i] = (dp[i - 1] if i > 0 else 0) + costs[0]
# 方案 2:购买 7 天通行证
j = i
while j >= 0 and days[i] - days[j] < 7:
j -= 1
cost_7 = (dp[j] if j >= 0 else 0) + costs[1]
dp[i] = min(dp[i], cost_7)
# 方案 3:购买 30 天通行证
k = i
while k >= 0 and days[i] - days[k] < 30:
k -= 1
cost_30 = (dp[k] if k >= 0 else 0) + costs[2]
dp[i] = min(dp[i], cost_30)
return dp[n - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \cdot d)$,其中 $n$ 是旅行天数,$d$ 是通行证的最大天数($30$)。对于每个旅行日,最多向前查找 $30$ 天。
- **空间复杂度**:$O(n)$,需要使用数组存储 DP 状态。
================================================
FILE: docs/solutions/0900-0999/minimum-falling-path-sum.md
================================================
# [0931. 下降路径最小和](https://leetcode.cn/problems/minimum-falling-path-sum/)
- 标签:数组、动态规划、矩阵
- 难度:中等
## 题目链接
- [0931. 下降路径最小和 - 力扣](https://leetcode.cn/problems/minimum-falling-path-sum/)
## 题目大意
**描述**:
给定一个 $n \times n$ 的方形整数数组 $matrix$。
**要求**:
请你找出并返回通过 $matrix$ 的下降路径的「最小和」。
**说明**:
- 「下降路径」可以从第一行中的任何元素开始,并从每一行中选择一个元素。在下一行选择的元素和当前行所选元素最多相隔一列(即位于正下方或者沿对角线向左或者向右的第一个元素)。具体来说,位置 $(row, col)$ 的下一个元素应当是 $(row + 1, col - 1)$、$(row + 1, col)$ 或者 $(row + 1, col + 1)$。
- $n == matrix.length == matrix[i].length$。
- $1 \le n \le 10^{3}$。
- $-10^{3} \le matrix[i][j] \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:matrix = [[2,1,3],[6,5,4],[7,8,9]]
输出:13
解释:如图所示,为和最小的两条下降路径
```
- 示例 2:
```python
输入:matrix = [[-19,57],[-40,-5]]
输出:-59
解释:如图所示,为和最小的下降路径
```
## 解题思路
### 思路 1:动态规划
这是一个经典的动态规划问题,类似于"最小路径和"。
1. **状态定义**:$dp[i][j]$ 表示到达位置 $(i, j)$ 的最小路径和。
2. **状态转移**:对于位置 $(i, j)$,可以从三个位置转移而来:
- 正上方:$(i-1, j)$
- 左上方:$(i-1, j-1)$
- 右上方:$(i-1, j+1)$
转移方程:$dp[i][j] = matrix[i][j] + \min(dp[i-1][j-1], dp[i-1][j], dp[i-1][j+1])$
3. **初始化**:第一行的值就是 $matrix[0][j]$。
4. **边界处理**:注意处理列的边界情况。
5. **返回结果**:最后一行的最小值。
**空间优化**:可以直接在原数组上修改,或使用滚动数组优化空间。
### 思路 1:代码
```python
class Solution:
def minFallingPathSum(self, matrix: List[List[int]]) -> int:
n = len(matrix)
# 从第二行开始,逐行计算最小路径和
for i in range(1, n):
for j in range(n):
# 计算从上一行三个位置转移的最小值
min_prev = matrix[i - 1][j] # 正上方
if j > 0: # 左上方
min_prev = min(min_prev, matrix[i - 1][j - 1])
if j < n - 1: # 右上方
min_prev = min(min_prev, matrix[i - 1][j + 1])
# 更新当前位置的最小路径和
matrix[i][j] += min_prev
# 返回最后一行的最小值
return min(matrix[n - 1])
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是矩阵的边长,需要遍历整个矩阵。
- **空间复杂度**:$O(1)$,直接在原数组上修改。如果不能修改原数组,需要 $O(n^2)$ 的额外空间。
================================================
FILE: docs/solutions/0900-0999/minimum-increment-to-make-array-unique.md
================================================
# [0945. 使数组唯一的最小增量](https://leetcode.cn/problems/minimum-increment-to-make-array-unique/)
- 标签:贪心、数组、计数、排序
- 难度:中等
## 题目链接
- [0945. 使数组唯一的最小增量 - 力扣](https://leetcode.cn/problems/minimum-increment-to-make-array-unique/)
## 题目大意
**描述**:
给定一个整数数组 $nums$。每次 $move$ 操作将会选择任意一个满足 $0 \le i < nums.length$ 的下标 $i$,并将 $nums[i]$ 递增 1。
**要求**:
返回使 $nums$ 中的每个值都变成唯一的所需要的最少操作次数。
**说明**:
- 生成的测试用例保证答案在 32 位整数范围内。
- $1 \le nums.length \le 10^{5}$。
- $0 \le nums[i] \le 10^{5}$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,2]
输出:1
解释:经过一次 move 操作,数组将变为 [1, 2, 3]。
```
- 示例 2:
```python
输入:nums = [3,2,1,2,1,7]
输出:6
解释:经过 6 次 move 操作,数组将变为 [3, 4, 1, 2, 5, 7]。
可以看出 5 次或 5 次以下的 move 操作是不能让数组的每个值唯一的。
```
## 解题思路
### 思路 1:贪心 + 排序
要使数组中的每个值都唯一,我们可以先排序,然后从左到右遍历,确保每个元素都大于前一个元素。
1. **排序**:首先对数组进行排序。
2. **贪心策略**:从左到右遍历,对于每个元素:
- 如果当前元素小于或等于前一个元素,需要将其增加到 $\text{prev} + 1$
- 累加操作次数
3. **维护最大值**:使用变量 $\text{need}$ 记录当前位置需要的最小值。
### 思路 1:代码
```python
class Solution:
def minIncrementForUnique(self, nums: List[int]) -> int:
nums.sort()
moves = 0
need = 0 # 当前位置需要的最小值
for num in nums:
# 如果当前数字小于需要的最小值,需要增加
if num < need:
moves += need - num
need += 1
else:
# 当前数字已经足够大,更新需要的最小值
need = num + 1
return moves
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组长度,主要是排序的时间复杂度。
- **空间复杂度**:$O(\log n)$,排序所需的栈空间。
================================================
FILE: docs/solutions/0900-0999/minimum-number-of-k-consecutive-bit-flips.md
================================================
# [0995. K 连续位的最小翻转次数](https://leetcode.cn/problems/minimum-number-of-k-consecutive-bit-flips/)
- 标签:位运算、队列、数组、前缀和、滑动窗口
- 难度:困难
## 题目链接
- [0995. K 连续位的最小翻转次数 - 力扣](https://leetcode.cn/problems/minimum-number-of-k-consecutive-bit-flips/)
## 题目大意
**描述**:给定一个仅包含 $0$ 和 $1$ 的数组 $nums$,再给定一个整数 $k$。进行一次 $k$ 位翻转包括选择一个长度为 $k$ 的(连续)子数组,同时将子数组中的每个 $0$ 更改为 $1$,而每个 $1$ 更改为 $0$。
**要求**:返回所需的 $k$ 位翻转的最小次数,以便数组没有值为 $0$ 的元素。如果不可能,返回 $-1$。
**说明**:
- **子数组**:数组的连续部分。
- $1 <= nums.length <= 105$。
- $1 <= k <= nums.length$。
**示例**:
- 示例 1:
```python
输入:nums = [0,1,0], K = 1
输出:2
解释:先翻转 A[0],然后翻转 A[2]。
```
- 示例 2:
```python
输入:nums = [0,0,0,1,0,1,1,0], K = 3
输出:3
解释:
翻转 A[0],A[1],A[2]: A变成 [1,1,1,1,0,1,1,0]
翻转 A[4],A[5],A[6]: A变成 [1,1,1,1,1,0,0,0]
翻转 A[5],A[6],A[7]: A变成 [1,1,1,1,1,1,1,1]
```
## 解题思路
### 思路 1:滑动窗口
每次需要翻转的起始位置肯定是遇到第一个元素为 $0$ 的位置开始反转,如果能够使得整个数组不存在 $0$,即返回 $ans$ 作为反转次数。
同时我们还可以发现:
- 如果某个元素反转次数为奇数次,元素会由 $0 \rightarrow 1$,$1 \rightarrow 0$。
- 如果某个元素反转次数为偶数次,元素不会发生变化。
每个第 $i$ 位置上的元素只会被前面 $[i - k + 1, i - 1]$ 的元素影响。所以我们只需要知道前面 $k - 1$ 个元素翻转次数的奇偶性就可以了。
同时如果我们知道了前面 $k - 1$ 个元素的翻转次数就可以直接修改 $nums[i]$ 了。
我们使用 $flip\_count$ 记录第 $i$ 个元素之前 $k - 1$ 个位置总共被反转了多少次,或者 $flip\_count$ 是大小为 $k - 1$ 的滑动窗口。
- 如果前面第 $k - 1$ 个元素翻转了奇数次,则如果 $nums[i] == 1$,则 $nums[i]$ 也被翻转成了 $0$,需要再翻转 $1$ 次。
- 如果前面第 $k - 1$ 个元素翻转了偶数次,则如果 $nums[i] == 0$,则 $nums[i]$ 也被翻转成为了 $0$,需要再翻转 $1$ 次。
这两句写成判断语句可以写为:`if (flip_count + nums[i]) % 2 == 0:`。
因为 $0 <= nums[i] <= 1$,所以我们可以用 $0$ 和 $1$ 以外的数,比如 $2$ 来标记第 $i$ 个元素发生了翻转,即 `nums[i] = 2`。这样在遍历到第 $i$ 个元素时,如果有 $nums[i - k] == 2$,则说明 $nums[i - k]$ 发生了翻转。同时根据 $flip\_count$ 和 $nums[i]$ 来判断第 $i$ 位是否需要进行翻转。
整个算法的具体步骤如下:
- 使用 $res$ 记录最小翻转次数。使用 $flip\_count$ 记录窗口内前 $k - 1 $ 位元素的翻转次数。
- 遍历数组 $nums$,对于第 $i$ 位元素:
- 如果 $i - k >= 0$,并且 $nums[i - k] == 2$,需要缩小窗口,将翻转次数减一。(此时窗口范围为 $[i - k + 1, i - 1]$)。
- 如果 $(flip\_count + nums[i]) \mod 2 == 0$,则说明 $nums[i]$ 还需要再翻转一次,将 $nums[i]$ 标记为 $2$,同时更新窗口内翻转次数 $flip\_count$ 和答案最小翻转次数 $ans$。
- 遍历完之后,返回 $res$。
### 思路 1:代码
```python
class Solution:
def minKBitFlips(self, nums: List[int], k: int) -> int:
ans = 0
flip_count = 0
for i in range(len(nums)):
if i - k >= 0 and nums[i - k] == 2:
flip_count -= 1
if (flip_count + nums[i]) % 2 == 0:
if i + k > len(nums):
return -1
nums[i] = 2
flip_count += 1
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0900-0999/most-stones-removed-with-same-row-or-column.md
================================================
# [0947. 移除最多的同行或同列石头](https://leetcode.cn/problems/most-stones-removed-with-same-row-or-column/)
- 标签:深度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [0947. 移除最多的同行或同列石头 - 力扣](https://leetcode.cn/problems/most-stones-removed-with-same-row-or-column/)
## 题目大意
**描述**:二维平面中有 $n$ 块石头,每块石头都在整数坐标点上,且每个坐标点上最多只能有一块石头。如果一块石头的同行或者同列上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 $n$ 的数组 $stones$ ,其中 $stones[i] = [xi, yi]$ 表示第 $i$ 块石头的位置。
**要求**:返回可以移除的石子的最大数量。
**说明**:
- $1 \le stones.length \le 1000$。
- $0 \le xi, yi \le 10^4$。
- 不会有两块石头放在同一个坐标点上。
**示例**:
- 示例 1:
```python
输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
输出:5
解释:一种移除 5 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,1] 同行。
2. 移除石头 [2,1] ,因为它和 [0,1] 同列。
3. 移除石头 [1,2] ,因为它和 [1,0] 同行。
4. 移除石头 [1,0] ,因为它和 [0,0] 同列。
5. 移除石头 [0,1] ,因为它和 [0,0] 同行。
石头 [0,0] 不能移除,因为它没有与另一块石头同行/列。
```
- 示例 2:
```python
输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
输出:3
解释:一种移除 3 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,0] 同行。
2. 移除石头 [2,0] ,因为它和 [0,0] 同列。
3. 移除石头 [0,2] ,因为它和 [0,0] 同行。
石头 [0,0] 和 [1,1] 不能移除,因为它们没有与另一块石头同行/列。
```
## 解题思路
### 思路 1:并查集
题目「求最多可以移走的石头数目」也可以换一种思路:「求最少留下的石头数目」。
- 如果两个石头 $A$、$B$ 处于同一行或者同一列,我们就可以删除石头 $A$ 或 $B$,最少留下 $1$ 个石头。
- 如果三个石头 $A$、$B$、$C$,其中 $A$、$B$ 处于同一行,$B$、$C$ 处于同一列,则我们可以先删除石头 $A$,再删除石头 $C$,最少留下 $1$ 个石头。
- 如果有 $n$ 个石头,其中每个石头都有一个同行或者同列的石头,则我们可以将 $n - 1$ 个石头都删除,最少留下 $1$ 个石头。
通过上面的分析,我们可以利用并查集,将同行、同列的石头都加入到一个集合中。这样「最少可以留下的石头」就是并查集中集合的个数。
则答案为:**最多可以移走的石头数目 = 所有石头个数 - 最少可以留下的石头(并查集的集合个数)**。
因为石子坐标是二维的,在使用并查集的时候要区分横纵坐标,因为 $0 <= xi, yi <= 10^4$,可以取 $n = 10010$,将纵坐标映射到 $[n, n + 10000]$ 的范围内,这样就可以得到所有节点的标号。
最后计算集合个数,可以使用 set 集合去重,然后统计数量。
整体步骤如下:
1. 定义一个 $10010 \times 2$ 大小的并查集。
2. 遍历每块石头的横纵坐标:
1. 将纵坐标映射到 $[10010, 10010 + 10000]$ 的范围内。
2. 然后将当前石头的横纵坐标相连接(加入到并查集中)。
3. 建立一个 set 集合,查找每块石头横坐标所在集合对应的并查集编号,将编号加入到 set 集合中。
4. 最后,返回「所有石头个数 - 并查集集合个数」即为答案。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def removeStones(self, stones: List[List[int]]) -> int:
size = len(stones)
n = 10010
union_find = UnionFind(n * 2)
for i in range(size):
union_find.union(stones[i][0], stones[i][1] + n)
stones_set = set()
for i in range(size):
stones_set.add(union_find.find(stones[i][0]))
return size - len(stones_set)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \alpha(n))$。其中 $n$ 是石子个数。$\alpha$ 是反 Ackerman 函数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0900-0999/n-repeated-element-in-size-2n-array.md
================================================
# [0961. 在长度 2N 的数组中找出重复 N 次的元素](https://leetcode.cn/problems/n-repeated-element-in-size-2n-array/)
- 标签:数组、哈希表
- 难度:简单
## 题目链接
- [0961. 在长度 2N 的数组中找出重复 N 次的元素 - 力扣](https://leetcode.cn/problems/n-repeated-element-in-size-2n-array/)
## 题目大意
**描述**:
给定一个整数数组 $nums$,该数组具有以下属性:
- $nums.length == 2 \times n$。
- $nums$ 包含 $n + 1$ 个「不同的」元素。
- $nums$ 中恰有一个元素重复 $n$ 次。
**要求**:
找出并返回重复了 $n$ 次的那个元素。
**说明**:
- $2 \le n \le 5000$。
- $nums.length == 2 \times n$。
- $0 \le nums[i] \le 10^{4}$。
- $nums$ 由 $n + 1$ 个「不同的」元素组成,且其中一个元素恰好重复 $n$ 次。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,3]
输出:3
```
- 示例 2:
```python
输入:nums = [2,1,2,5,3,2]
输出:2
```
## 解题思路
### 思路 1:哈希表
由于数组长度为 $2 \times n$,包含 $n+1$ 个不同元素,且恰有一个元素重复 $n$ 次,所以只需要找到出现次数最多的元素即可。
1. **使用哈希表**:遍历数组,统计每个元素的出现次数。
2. **返回结果**:返回出现次数为 $n$ 的元素。
**优化**:由于重复元素占据了一半的位置,我们可以使用更简单的方法:只要发现某个元素出现第二次,就返回它。
### 思路 1:代码
```python
class Solution:
def repeatedNTimes(self, nums: List[int]) -> int:
seen = set()
for num in nums:
if num in seen:
return num
seen.add(num)
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组长度,最多遍历一次数组。
- **空间复杂度**:$O(n)$,需要使用哈希集合存储已访问的元素。
================================================
FILE: docs/solutions/0900-0999/number-of-music-playlists.md
================================================
# [0920. 播放列表的数量](https://leetcode.cn/problems/number-of-music-playlists/)
- 标签:数学、动态规划、组合数学
- 难度:困难
## 题目链接
- [0920. 播放列表的数量 - 力扣](https://leetcode.cn/problems/number-of-music-playlists/)
## 题目大意
**描述**:
你的音乐播放器里有 $n$ 首不同的歌,在旅途中,你计划听 $goal$ 首歌(不一定不同,即,允许歌曲重复)。你将会按如下规则创建播放列表:
- 每首歌「至少播放一次」。
- 一首歌只有在其他 $k$ 首歌播放完之后才能再次播放。
给定 $n$、$goal$ 和 $k$。
**要求**:
返回可以满足要求的播放列表的数量。由于答案可能非常大,请返回对 $10^9 + 7$ 取余 的结果。
**说明**:
- $0 \le k \lt n \le goal \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:n = 3, goal = 3, k = 1
输出:6
解释:有 6 种可能的播放列表。[1, 2, 3],[1, 3, 2],[2, 1, 3],[2, 3, 1],[3, 1, 2],[3, 2, 1] 。
```
- 示例 2:
```python
输入:n = 2, goal = 3, k = 0
输出:6
解释:有 6 种可能的播放列表。[1, 1, 2],[1, 2, 1],[2, 1, 1],[2, 2, 1],[2, 1, 2],[1, 2, 2] 。
```
## 解题思路
### 思路 1:动态规划
这是一个经典的组合计数问题,需要使用动态规划来解决。
1. **状态定义**:$dp[i][j]$ 表示长度为 $i$、包含 $j$ 首不同歌曲的播放列表数量。
2. **状态转移**:对于 $dp[i][j]$,考虑第 $i$ 首歌的选择:
- **选择新歌**:从剩余的 $n - j + 1$ 首歌中选择,转移方程:$dp[i][j] = dp[i-1][j-1] \times (n - j + 1)$
- **选择旧歌**:必须是 $k$ 首歌之前播放过的,即至少有 $j - k$ 首歌可选,转移方程:$dp[i][j] = dp[i-1][j] \times \max(j - k, 0)$
3. **初始化**:$dp[0][0] = 1$(空播放列表)。
4. **返回结果**:$dp[goal][n]$。
### 思路 1:代码
```python
class Solution:
def numMusicPlaylists(self, n: int, goal: int, k: int) -> int:
MOD = 10**9 + 7
# dp[i][j] 表示长度为 i、包含 j 首不同歌曲的播放列表数量
dp = [[0] * (n + 1) for _ in range(goal + 1)]
dp[0][0] = 1
for i in range(1, goal + 1):
for j in range(1, min(i, n) + 1):
# 选择新歌:从 n - j + 1 首歌中选择
dp[i][j] = dp[i - 1][j - 1] * (n - j + 1) % MOD
# 选择旧歌:从已播放的 j 首歌中选择(需要满足 k 首歌的限制)
if j > k:
dp[i][j] = (dp[i][j] + dp[i - 1][j] * (j - k)) % MOD
return dp[goal][n]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(goal \times n)$,需要填充 $goal \times n$ 的 DP 表。
- **空间复杂度**:$O(goal \times n)$,需要使用二维数组存储 DP 状态。可以优化为 $O(n)$(滚动数组)。
================================================
FILE: docs/solutions/0900-0999/number-of-recent-calls.md
================================================
# [0933. 最近的请求次数](https://leetcode.cn/problems/number-of-recent-calls/)
- 标签:设计、队列、数据流
- 难度:简单
## 题目链接
- [0933. 最近的请求次数 - 力扣](https://leetcode.cn/problems/number-of-recent-calls/)
## 题目大意
要求:实现一个用来计算特定时间范围内的最近请求的 `RecentCounter` 类:
- `RecentCounter()` 初始化计数器,请求数为 0 。
- `int ping(int t)` 在时间 `t` 时添加一个新请求,其中 `t` 表示以毫秒为单位的某个时间,并返回在 `[t-3000, t]` 内发生的请求数。
## 解题思路
使用一个队列,用于存储 `[t - 3000, t]` 范围内的请求。
获取请求数时,将队首所有小于 `t - 3000` 时间的请求将其从队列中移除,然后返回队列的长度即可。
## 代码
```python
class RecentCounter:
def __init__(self):
self.queue = []
def ping(self, t: int) -> int:
self.queue.append(t)
while self.queue[0] < t - 3000:
self.queue.pop(0)
return len(self.queue)
```
================================================
FILE: docs/solutions/0900-0999/number-of-squareful-arrays.md
================================================
# [0996. 平方数组的数目](https://leetcode.cn/problems/number-of-squareful-arrays/)
- 标签:位运算、数组、哈希表、数学、动态规划、回溯、状态压缩
- 难度:困难
## 题目链接
- [0996. 平方数组的数目 - 力扣](https://leetcode.cn/problems/number-of-squareful-arrays/)
## 题目大意
**描述**:
如果一个数组的任意两个相邻元素之和都是「完全平方数」,则该数组称为「平方数组」。
给定一个整数数组 $nums$。
**要求**:
返回所有属于「平方数组」的 $nums$ 的排列数量。
**说明**:
- 如果存在某个索引 $i$ 使得 $perm1[i] \ne perm2[i]$,则认为两个排列 $perm1$ 和 $perm2$ 不同。
- $1 \le nums.length \le 12$。
- $0 \le nums[i] \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:nums = [1,17,8]
输出:2
解释:[1,8,17] 和 [17,8,1] 是有效的排列。
```
- 示例 2:
```python
输入:nums = [2,2,2]
输出:1
```
## 解题思路
### 思路 1:回溯 + 剪枝
这道题需要找到所有满足条件的排列,可以使用回溯算法。
1. **判断完全平方数**:首先实现一个函数判断两个数之和是否为完全平方数。
2. **回溯搜索**:
- 使用回溯算法生成所有排列
- 在添加新元素时,检查与前一个元素的和是否为完全平方数
- 使用访问标记避免重复使用元素
3. **剪枝优化**:
- 对数组进行排序,方便去重
- 如果当前元素与前一个元素相同且前一个元素未被使用,跳过(避免重复排列)
- 预先计算哪些数字对可以相邻,构建图结构
### 思路 1:代码
```python
class Solution:
def numSquarefulPerms(self, nums: List[int]) -> int:
import math
def is_square(n):
"""判断是否为完全平方数"""
root = int(math.sqrt(n))
return root * root == n
nums.sort()
n = len(nums)
visited = [False] * n
self.count = 0
def backtrack(path):
if len(path) == n:
self.count += 1
return
for i in range(n):
# 跳过已使用的元素
if visited[i]:
continue
# 去重:如果当前元素与前一个元素相同,且前一个元素未被使用,跳过
if i > 0 and nums[i] == nums[i - 1] and not visited[i - 1]:
continue
# 检查是否满足平方数条件
if path and not is_square(path[-1] + nums[i]):
continue
# 选择当前元素
visited[i] = True
path.append(nums[i])
backtrack(path)
# 撤销选择
path.pop()
visited[i] = False
backtrack([])
return self.count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n! \times n)$,其中 $n$ 是数组长度。最坏情况下需要遍历所有排列,每次检查需要 $O(n)$ 时间。
- **空间复杂度**:$O(n)$,递归栈和访问标记数组的空间。
================================================
FILE: docs/solutions/0900-0999/numbers-at-most-n-given-digit-set.md
================================================
# [0902. 最大为 N 的数字组合](https://leetcode.cn/problems/numbers-at-most-n-given-digit-set/)
- 标签:数组、数学、字符串、二分查找、动态规划
- 难度:困难
## 题目链接
- [0902. 最大为 N 的数字组合 - 力扣](https://leetcode.cn/problems/numbers-at-most-n-given-digit-set/)
## 题目大意
**描述**:给定一个按非递减序列排列的数字数组 $digits$。我们可以使用任意次数的 $digits[i]$ 来写数字。例如,如果 `digits = ["1", "3", "5"]`,我们可以写数字,如 `"13"`, `"551"`, 和 `"1351315"`。
**要求**:返回可以生成的小于等于给定整数 $n$ 的正整数个数。
**说明**:
- $1 \le digits.length \le 9$。
- $digits[i].length == 1$。
- $digits[i]$ 是从 `'1'` 到 `'9'` 的数。
- $digits$ 中的所有值都不同。
- $digits$ 按非递减顺序排列。
- $1 \le n \le 10^9$。
**示例**:
- 示例 1:
```python
输入:digits = ["1","3","5","7"], n = 100
输出:20
解释:
可写出的 20 个数字是:
1, 3, 5, 7, 11, 13, 15, 17, 31, 33, 35, 37, 51, 53, 55, 57, 71, 73, 75, 77。
```
- 示例 2:
```python
输入:digits = ["1","4","9"], n = 1000000000
输出:29523
解释:
我们可以写 3 个一位数字,9 个两位数字,27 个三位数字,
81 个四位数字,243 个五位数字,729 个六位数字,
2187 个七位数字,6561 个八位数字和 19683 个九位数字。
总共,可以使用D中的数字写出 29523 个整数。
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
数位 DP 模板的应用。因为这道题目中可以使用任意次数的 $digits[i]$,所以不需要用状态压缩的方式来表示数字集合。
这道题的具体步骤如下:
将 $n$ 转换为字符串 $s$,定义递归函数 `def dfs(pos, isLimit, isNum):` 表示构造第 $pos$ 位及之后所有数位的合法方案数。接下来按照如下步骤进行递归。
1. 从 `dfs(0, True, False)` 开始递归。 `dfs(0, True, False)` 表示:
1. 从位置 $0$ 开始构造。
2. 开始时受到数字 $n$ 对应最高位数位的约束。
3. 开始时没有填写数字。
2. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:
1. 如果 $isNum == True$,说明当前方案符合要求,则返回方案数 $1$。
2. 如果 $isNum == False$,说明当前方案不符合要求,则返回方案数 $0$。
3. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
4. 如果遇到 $isNum == False$,说明之前位数没有填写数字,当前位可以跳过,这种情况下方案数等于 $pos + 1$ 位置上没有受到 $pos$ 位的约束,并且之前没有填写数字时的方案数,即:`ans = dfs(i + 1, False, False)`。
5. 如果 $isNum == True$,则当前位必须填写一个数字。此时:
1. 根据 $isNum$ 和 $isLimit$ 来决定填当前位数位所能选择的最大数字($maxX$)。
2. 然后枚举 $digits$ 数组中所有能够填入的数字 $d$。
3. 如果 $d$ 超过了所能选择的最大数字 $maxX$ 则直接跳出循环。
4. 如果 $d$ 是合法数字,则方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, isLimit and d == maxX, True)`。
1. `isLimit and d == maxX` 表示 $pos + 1$ 位受到之前位限制和 $pos$ 位限制。
2. $isNum == True$ 表示 $pos$ 位选择了数字。
6. 最后的方案数为 `dfs(0, True, False)`,将其返回即可。
### 思路 1:代码
```python
class Solution:
def atMostNGivenDigitSet(self, digits: List[str], n: int) -> int:
# 将 n 转换为字符串 s
s = str(n)
@cache
# pos: 第 pos 个数位
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
# isNum: 表示 pos 前面的数位是否填了数字。
# 如果为真,则当前位不可跳过;如果为假,则当前位可跳过。
def dfs(pos, isLimit, isNum):
if pos == len(s):
# isNum 为 True,则表示当前方案符合要求
return int(isNum)
ans = 0
if not isNum:
# 如果 isNumb 为 False,则可以跳过当前数位
ans = dfs(pos + 1, False, False)
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = s[pos] if isLimit else '9'
# 枚举可选择的数字
for d in digits:
if d > maxX:
break
ans += dfs(pos + 1, isLimit and d == maxX, True)
return ans
return dfs(0, True, False)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times \log n)$,其中 $m$ 是数组 $digits$ 的长度,$\log n$ 是 $n$ 转为字符串之后的位数长度。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/0900-0999/numbers-with-same-consecutive-differences.md
================================================
# [0967. 连续差相同的数字](https://leetcode.cn/problems/numbers-with-same-consecutive-differences/)
- 标签:广度优先搜索、回溯
- 难度:中等
## 题目链接
- [0967. 连续差相同的数字 - 力扣](https://leetcode.cn/problems/numbers-with-same-consecutive-differences/)
## 题目大意
**描述**:
给定两个整数 $n$ 和 $k$。
**要求**:
返回所有长度为 $n$ 且满足其每两个连续位上的数字之间的差的绝对值为 $k$ 的 非负整数。
你可以按「任何顺序」返回答案。
**说明**:
- 注意:除了「数字 0」本身之外,答案中的每个数字都「不能」有前导零。例如,01 有一个前导零,所以是无效的;但 0 是有效的。
- $2 \le n \le 9$。
- $0 \le k \le 9$。
**示例**:
- 示例 1:
```python
输入:n = 3, k = 7
输出:[181,292,707,818,929]
解释:注意,070 不是一个有效的数字,因为它有前导零。
```
- 示例 2:
```python
输入:n = 2, k = 1
输出:[10,12,21,23,32,34,43,45,54,56,65,67,76,78,87,89,98]
```
## 解题思路
### 思路 1:广度优先搜索
使用 BFS 逐层构建满足条件的数字。
1. **初始化**:从 $1 \sim 9$ 开始(不能有前导零),将它们加入队列。
2. **BFS 扩展**:对于队列中的每个数字,尝试在末尾添加新的数字:
- 新数字与当前数字的最后一位的差的绝对值必须等于 $k$
- 即可以添加 $\text{lastDigit} + k$ 或 $\text{lastDigit} - k$(如果在 $[0, 9]$ 范围内)
3. **长度控制**:当数字长度达到 $n$ 时,加入结果集。
4. **去重**:注意当 $k = 0$ 时,$\text{lastDigit} + k$ 和 $\text{lastDigit} - k$ 相同,需要避免重复添加。
### 思路 1:代码
```python
class Solution:
def numsSameConsecDiff(self, n: int, k: int) -> List[int]:
# 初始化:从 1-9 开始
queue = list(range(1, 10))
# BFS 构建 n 位数
for _ in range(n - 1):
next_queue = []
for num in queue:
last_digit = num % 10
# 尝试添加 last_digit + k
if last_digit + k <= 9:
next_queue.append(num * 10 + last_digit + k)
# 尝试添加 last_digit - k(避免重复)
if k != 0 and last_digit - k >= 0:
next_queue.append(num * 10 + last_digit - k)
queue = next_queue
return queue
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(2^n)$,每个数字最多可以扩展出 $2$ 个新数字,最多有 $n$ 层。
- **空间复杂度**:$O(2^n)$,队列中最多存储 $O(2^n)$ 个数字。
================================================
FILE: docs/solutions/0900-0999/odd-even-jump.md
================================================
# [0975. 奇偶跳](https://leetcode.cn/problems/odd-even-jump/)
- 标签:栈、数组、动态规划、有序集合、排序、单调栈
- 难度:困难
## 题目链接
- [0975. 奇偶跳 - 力扣](https://leetcode.cn/problems/odd-even-jump/)
## 题目大意
**描述**:
给定一个整数数组 $arr$,你可以从某一起始索引出发,跳跃一定次数。在你跳跃的过程中,第 1、3、5... 次跳跃称为奇数跳跃,而第 2、4、6... 次跳跃称为偶数跳跃。
你可以按以下方式从索引 $i$ 向后跳转到索引 $j$(其中 $i < j$):
- 在进行奇数跳跃时(如,第 1,3,5... 次跳跃),你将会跳到索引 $j$,使得 $arr[i] \le arr[j]$,且 $arr[j]$ 的值尽可能小。如果存在多个这样的索引 $j$,你只能跳到满足要求的最小索引 $j$ 上。
- 在进行偶数跳跃时(如,第 2,4,6... 次跳跃),你将会跳到索引 $j$,使得 $arr[i] \ge arr[j]$,且 $arr[j]$ 的值尽可能大。如果存在多个这样的索引 $j$,你只能跳到满足要求的最小索引 $j$ 上。
- (对于某些索引 $i$,可能无法进行合乎要求的跳跃。)
如果从某一索引开始跳跃一定次数(可能是 0 次或多次),就可以到达数组的末尾(索引 $arr.length - 1$),那么该索引就会被认为是好的起始索引。
**要求**:
返回好的起始索引的数量。
**说明**:
- $1 \le arr.length \le 20000$。
- $0 \le arr[i] \lt 10^{0000}$。
**示例**:
- 示例 1:
```python
输入:[10,13,12,14,15]
输出:2
解释:
从起始索引 i = 0 出发,我们可以跳到 i = 2,(因为 arr[2] 是 arr[1],arr[2],arr[3],arr[4] 中大于或等于 arr[0] 的最小值),然后我们就无法继续跳下去了。
从起始索引 i = 1 和 i = 2 出发,我们可以跳到 i = 3,然后我们就无法继续跳下去了。
从起始索引 i = 3 出发,我们可以跳到 i = 4,到达数组末尾。
从起始索引 i = 4 出发,我们已经到达数组末尾。
总之,我们可以从 2 个不同的起始索引(i = 3, i = 4)出发,通过一定数量的跳跃到达数组末尾。
```
- 示例 2:
```python
输入:[2,3,1,1,4]
输出:3
解释:
从起始索引 i=0 出发,我们依次可以跳到 i = 1,i = 2,i = 3:
在我们的第一次跳跃(奇数)中,我们先跳到 i = 1,因为 arr[1] 是(arr[1],arr[2],arr[3],arr[4])中大于或等于 arr[0] 的最小值。
在我们的第二次跳跃(偶数)中,我们从 i = 1 跳到 i = 2,因为 arr[2] 是(arr[2],arr[3],arr[4])中小于或等于 arr[1] 的最大值。arr[3] 也是最大的值,但 2 是一个较小的索引,所以我们只能跳到 i = 2,而不能跳到 i = 3。
在我们的第三次跳跃(奇数)中,我们从 i = 2 跳到 i = 3,因为 arr[3] 是(arr[3],arr[4])中大于或等于 arr[2] 的最小值。
我们不能从 i = 3 跳到 i = 4,所以起始索引 i = 0 不是好的起始索引。
类似地,我们可以推断:
从起始索引 i = 1 出发, 我们跳到 i = 4,这样我们就到达数组末尾。
从起始索引 i = 2 出发, 我们跳到 i = 3,然后我们就不能再跳了。
从起始索引 i = 3 出发, 我们跳到 i = 4,这样我们就到达数组末尾。
从起始索引 i = 4 出发,我们已经到达数组末尾。
总之,我们可以从 3 个不同的起始索引(i = 1, i = 3, i = 4)出发,通过一定数量的跳跃到达数组末尾。
```
## 解题思路
### 思路 1:动态规划 + 单调栈
这是一道困难的动态规划问题,需要结合单调栈来优化。
1. **状态定义**:
- $odd[i]$:从位置 $i$ 开始,第一次跳跃是奇数跳,能否到达终点
- $even[i]$:从位置 $i$ 开始,第一次跳跃是偶数跳,能否到达终点
2. **状态转移**:
- 奇数跳:跳到满足 $arr[j] \ge arr[i]$ 且 $arr[j]$ 最小的位置 $j$
- 偶数跳:跳到满足 $arr[j] \le arr[i]$ 且 $arr[j]$ 最大的位置 $j$
3. **单调栈优化**:使用单调栈预处理每个位置的下一跳位置。
4. **从后向前 DP**:从最后一个位置开始,逐步计算每个位置的状态。
### 思路 1:代码
```python
class Solution:
def oddEvenJumps(self, arr: List[int]) -> int:
n = len(arr)
# 计算下一跳位置
def make_next(sorted_indices):
"""使用单调栈计算下一跳位置"""
result = [None] * n
stack = []
for i in sorted_indices:
while stack and i > stack[-1]:
result[stack.pop()] = i
stack.append(i)
return result
# 奇数跳:按值升序,索引升序排序
odd_next = make_next(sorted(range(n), key=lambda i: (arr[i], i)))
# 偶数跳:按值降序,索引升序排序
even_next = make_next(sorted(range(n), key=lambda i: (-arr[i], i)))
# DP:从后向前计算
odd = [False] * n
even = [False] * n
odd[n - 1] = even[n - 1] = True
for i in range(n - 2, -1, -1):
if odd_next[i] is not None:
odd[i] = even[odd_next[i]]
if even_next[i] is not None:
even[i] = odd[even_next[i]]
# 统计从奇数跳开始能到达终点的位置数
return sum(odd)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组长度。排序需要 $O(n \log n)$,单调栈和 DP 都是 $O(n)$。
- **空间复杂度**:$O(n)$,需要存储下一跳位置和 DP 状态。
================================================
FILE: docs/solutions/0900-0999/online-election.md
================================================
# [0911. 在线选举](https://leetcode.cn/problems/online-election/)
- 标签:设计、数组、哈希表、二分查找
- 难度:中等
## 题目链接
- [0911. 在线选举 - 力扣](https://leetcode.cn/problems/online-election/)
## 题目大意
**描述**:
给定两个整数数组 $persons$ 和 $times$。在选举中,第 $i$ 张票是在时刻为 $times[i]$ 时投给候选人 $persons[i]$ 的。
对于发生在时刻 $t$ 的每个查询,需要找出在 $t$ 时刻在选举中领先的候选人的编号。
在 $t$ 时刻投出的选票也将被计入我们的查询之中。在平局的情况下,最近获得投票的候选人将会获胜。
**要求**:
实现 TopVotedCandidate 类:
- `TopVotedCandidate(int[] persons, int[] times)` 使用 $persons$ 和 $times$ 数组初始化对象。
- `int q(int t)` 根据前面描述的规则,返回在时刻 $t$ 在选举中领先的候选人的编号。
**说明**:
- $1 \le persons.length \le 5000$。
- $times.length == persons.length$。
- $0 \le persons[i] \lt persons.length$。
- $0 \le times[i] \le 10^{9}$。
- $times$ 是一个严格递增的有序数组。
- $times[0] \le t \le 10^{9}$。
- 每个测试用例最多调用 $10^{4}$ 次 `q`。
**示例**:
- 示例 1:
```python
输入:
["TopVotedCandidate", "q", "q", "q", "q", "q", "q"]
[[[0, 1, 1, 0, 0, 1, 0], [0, 5, 10, 15, 20, 25, 30]], [3], [12], [25], [15], [24], [8]]
输出:
[null, 0, 1, 1, 0, 0, 1]
解释:
TopVotedCandidate topVotedCandidate = new TopVotedCandidate([0, 1, 1, 0, 0, 1, 0], [0, 5, 10, 15, 20, 25, 30]);
topVotedCandidate.q(3); // 返回 0 ,在时刻 3 ,票数分布为 [0] ,编号为 0 的候选人领先。
topVotedCandidate.q(12); // 返回 1 ,在时刻 12 ,票数分布为 [0,1,1] ,编号为 1 的候选人领先。
topVotedCandidate.q(25); // 返回 1 ,在时刻 25 ,票数分布为 [0,1,1,0,0,1] ,编号为 1 的候选人领先。(在平局的情况下,1 是最近获得投票的候选人)。
topVotedCandidate.q(15); // 返回 0
topVotedCandidate.q(24); // 返回 0
topVotedCandidate.q(8); // 返回 1
```
## 解题思路
### 思路 1:预处理 + 二分查找
这道题需要快速查询某个时刻的领先候选人,可以通过预处理和二分查找来优化。
1. **预处理**:在初始化时,遍历所有投票记录,计算每个时刻的领先候选人。
- 使用哈希表记录每个候选人的票数
- 维护当前领先的候选人和最高票数
- 在平局时,选择最近获得投票的候选人
2. **二分查找**:查询时,使用二分查找找到不超过 $t$ 的最大时刻,返回该时刻的领先候选人。
### 思路 1:代码
```python
class TopVotedCandidate:
def __init__(self, persons: List[int], times: List[int]):
self.times = times
self.leaders = [] # 记录每个时刻的领先者
vote_count = collections.defaultdict(int)
leader = -1
max_votes = 0
for person in persons:
vote_count[person] += 1
# 票数更多,或票数相同但是最近获得投票
if vote_count[person] >= max_votes:
leader = person
max_votes = vote_count[person]
self.leaders.append(leader)
def q(self, t: int) -> int:
# 二分查找:找到不超过 t 的最大时刻
left, right = 0, len(self.times) - 1
while left < right:
mid = (left + right + 1) // 2
if self.times[mid] <= t:
left = mid
else:
right = mid - 1
return self.leaders[left]
# Your TopVotedCandidate object will be instantiated and called as such:
# obj = TopVotedCandidate(persons, times)
# param_1 = obj.q(t)
```
### 思路 1:复杂度分析
- **时间复杂度**:初始化 $O(n)$,查询 $O(\log n)$,其中 $n$ 是投票记录的数量。
- **空间复杂度**:$O(n)$,需要存储每个时刻的领先者。
================================================
FILE: docs/solutions/0900-0999/online-stock-span.md
================================================
# [0901. 股票价格跨度](https://leetcode.cn/problems/online-stock-span/)
- 标签:栈、设计、数据流、单调栈
- 难度:中等
## 题目链接
- [0901. 股票价格跨度 - 力扣](https://leetcode.cn/problems/online-stock-span/)
## 题目大意
要求:编写一个 `StockSpanner` 类,用于收集某些股票的每日报价,并返回该股票当日价格的跨度。
- 今天股票价格的跨度:股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
例如:如果未来 7 天股票的价格是 `[100, 80, 60, 70, 60, 75, 85]`,那么股票跨度将是 `[1, 1, 1, 2, 1, 4, 6]`。
## 解题思路
「求解小于或等于今天价格的最大连续日」等价于「求出左侧第一个比当前股票价格大的股票,并计算距离」。求出左侧第一个比当前股票价格大的股票我们可以使用「单调递减栈」来做。具体步骤如下:
- 初始化方法:初始化一个空栈,即 `self.stack = []`
- 求解今天股票价格的跨度:
- 初始化跨度 `span` 为 `1`。
- 如果今日股票价格 `price` 大于等于栈顶元素 `self.stack[-1][0]`,则:
- 将其弹出,即 `top = self.stack.pop()`。
- 跨度累加上弹出栈顶元素的跨度,即 `span += top[1]`。
- 继续判断,直到遇到一个今日股票价格 `price` 小于栈顶元素的元素位置,再将 `[price, span]` 压入栈中。
- 如果今日股票价格 `price` 小于栈顶元素 `self.stack[-1][0]`,则直接将 `[price, span]` 压入栈中。
- 最后输出今天股票价格的跨度 `span`。
## 代码
```python
class StockSpanner:
def __init__(self):
self.stack = []
def next(self, price: int) -> int:
span = 1
while self.stack and price >= self.stack[-1][0]:
top = self.stack.pop()
span += top[1]
self.stack.append([price, span])
return span
```
================================================
FILE: docs/solutions/0900-0999/pancake-sorting.md
================================================
# [0969. 煎饼排序](https://leetcode.cn/problems/pancake-sorting/)
- 标签:贪心、数组、双指针、排序
- 难度:中等
## 题目链接
- [0969. 煎饼排序 - 力扣](https://leetcode.cn/problems/pancake-sorting/)
## 题目大意
**描述**:
给定一个整数数组 $arr$,请使用「煎饼翻转」完成对数组的排序。
一次煎饼翻转的执行过程如下:
- 选择一个整数 $k$,$1 \le k \le arr$.length$。
- 反转子数组 $arr[...k-1]$(下标从 0 开始)。
例如,$arr = [3,2,1,4]$,选择 $k = 3$ 进行一次煎饼翻转,反转子数组 $[3,2,1]$,得到 $arr = [1,2,3,4]$。
**要求**:
以数组形式返回能使 $arr$ 有序的煎饼翻转操作所对应的 $k$ 值序列。任何将数组排序且翻转次数在 $10 \times arr.length$ 范围内的有效答案都将被判断为正确。
**说明**:
- $1 \le arr.length \le 10^{3}$。
- $1 \le arr[i] \le arr.length$。
- $arr$ 中的所有整数互不相同(即,$arr$ 是从 $1$ 到 $arr.length$ 整数的一个排列)。
**示例**:
- 示例 1:
```python
输入:[3,2,4,1]
输出:[4,2,4,3]
解释:
我们执行 4 次煎饼翻转,k 值分别为 4,2,4,和 3。
初始状态 arr = [3, 2, 4, 1]
第一次翻转后(k = 4):arr = [1, 4, 2, 3]
第二次翻转后(k = 2):arr = [4, 1, 2, 3]
第三次翻转后(k = 4):arr = [3, 2, 1, 4]
第四次翻转后(k = 3):arr = [1, 2, 3, 4],此时已完成排序。
```
- 示例 2:
```python
输入:[1,2,3]
输出:[]
解释:
输入已经排序,因此不需要翻转任何内容。
请注意,其他可能的答案,如 [3,3] ,也将被判断为正确。
```
## 解题思路
### 思路 1:贪心
煎饼排序的核心思想是:每次找到未排序部分的最大值,将其翻转到最前面,再翻转到正确的位置。
1. **从后向前排序**:从数组末尾开始,每次将最大的未排序元素放到正确位置。
2. **两次翻转**:
- 第一次翻转:将最大元素翻转到数组开头(翻转 $[0, maxIndex]$)
- 第二次翻转:将最大元素翻转到目标位置(翻转 $[0, i]$)
3. **重复过程**:对剩余未排序部分重复上述过程。
**优化**:如果当前最大元素已经在正确位置,则跳过。
### 思路 1:代码
```python
class Solution:
def pancakeSort(self, arr: List[int]) -> List[int]:
result = []
n = len(arr)
# 从后向前排序
for target in range(n, 0, -1):
# 找到目标值的位置
max_index = arr.index(target)
# 如果已经在正确位置,跳过
if max_index == target - 1:
continue
# 如果不在开头,先翻转到开头
if max_index != 0:
result.append(max_index + 1)
arr[:max_index + 1] = arr[:max_index + 1][::-1]
# 翻转到目标位置
result.append(target)
arr[:target] = arr[:target][::-1]
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是数组长度。外层循环 $O(n)$ 次,每次查找和翻转需要 $O(n)$ 时间。
- **空间复杂度**:$O(1)$,不考虑返回结果的空间。
================================================
FILE: docs/solutions/0900-0999/partition-array-into-disjoint-intervals.md
================================================
# [0915. 分割数组](https://leetcode.cn/problems/partition-array-into-disjoint-intervals/)
- 标签:数组
- 难度:中等
## 题目链接
- [0915. 分割数组 - 力扣](https://leetcode.cn/problems/partition-array-into-disjoint-intervals/)
## 题目大意
**描述**:
给定一个数组 $nums$,将其划分为两个连续子数组 $left$ 和 $right$,使得:
- $left$ 中的每个元素都小于或等于 $right$ 中的每个元素。
- $left$ 和 $right$ 都是非空的。
- $left$ 的长度要尽可能小。
**要求**:
在完成这样的分组后返回 $left$ 的「长度」。
用例可以保证存在这样的划分方法。
**说明**:
- $2 \le nums.length \le 10^{5}$。
- $0 \le nums[i] \le 10^{6}$。
- 可以保证至少有一种方法能够按题目所描述的那样对 $nums$ 进行划分。
**示例**:
- 示例 1:
```python
输入:nums = [5,0,3,8,6]
输出:3
解释:left = [5,0,3],right = [8,6]
```
- 示例 2:
```python
输入:nums = [1,1,1,0,6,12]
输出:4
解释:left = [1,1,1,0],right = [6,12]
```
## 解题思路
### 思路 1:前缀最大值 + 后缀最小值
要满足 $left$ 中的每个元素都小于或等于 $right$ 中的每个元素,即 $left$ 的最大值要小于或等于 $right$ 的最小值。
1. **预处理**:
- 计算前缀最大值数组 $max\_left[i]$:表示 $[0, i]$ 范围内的最大值
- 计算后缀最小值数组 $min\_right[i]$:表示 $[i, n-1]$ 范围内的最小值
2. **查找分割点**:从左到右遍历,找到第一个满足 $max\_left[i] \le min\_right[i+1]$ 的位置 $i$,返回 $i+1$(即 $left$ 的长度)。
### 思路 1:代码
```python
class Solution:
def partitionDisjoint(self, nums: List[int]) -> int:
n = len(nums)
# 计算前缀最大值
max_left = [0] * n
max_left[0] = nums[0]
for i in range(1, n):
max_left[i] = max(max_left[i - 1], nums[i])
# 计算后缀最小值
min_right = [0] * n
min_right[n - 1] = nums[n - 1]
for i in range(n - 2, -1, -1):
min_right[i] = min(min_right[i + 1], nums[i])
# 查找分割点
for i in range(n - 1):
if max_left[i] <= min_right[i + 1]:
return i + 1
return n - 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组长度,需要遍历三次数组。
- **空间复杂度**:$O(n)$,需要存储前缀最大值和后缀最小值数组。
================================================
FILE: docs/solutions/0900-0999/powerful-integers.md
================================================
# [0970. 强整数](https://leetcode.cn/problems/powerful-integers/)
- 标签:哈希表、数学、枚举
- 难度:中等
## 题目链接
- [0970. 强整数 - 力扣](https://leetcode.cn/problems/powerful-integers/)
## 题目大意
**描述**:
给定三个整数 $x$、$y$ 和 $bound$。
**要求**:
返回值小于或等于 $bound$ 的所有「强整数」组成的列表。
**说明**:
- 如果某一整数可以表示为 $x^i + y^j$ ,其中整数 $i \le 0$ 且 $j \le 0$,那么我们认为该整数是一个「强整数」。
- 你可以按任何顺序返回答案。在你的回答中,每个值「最多」出现一次。
- $1 \le x, y \le 10^{3}$。
- $0 \le bound \le 10^{6}$。
**示例**:
- 示例 1:
```python
输入:x = 2, y = 3, bound = 10
输出:[2,3,4,5,7,9,10]
解释:
2 = 20 + 30
3 = 21 + 30
4 = 20 + 31
5 = 21 + 31
7 = 22 + 31
9 = 23 + 30
10 = 20 + 32
```
- 示例 2:
```python
输入:x = 3, y = 5, bound = 15
输出:[2,4,6,8,10,14]
```
## 解题思路
### 思路 1:枚举
根据题意,强整数可以表示为 $x^i + y^j$,其中 $i \ge 0$,$j \ge 0$。由于结果要小于等于 $bound$,我们可以枚举所有可能的 $i$ 和 $j$。
1. **确定枚举范围**:
- 当 $x = 1$ 时,$x^i = 1$(对所有 $i$)
- 当 $x > 1$ 时,$x^i$ 最多枚举到 $\log_x(bound)$
- 同理,$y^j$ 也有类似的范围
2. **枚举所有组合**:使用两层循环枚举所有可能的 $i$ 和 $j$,计算 $x^i + y^j$。
3. **去重**:使用集合存储结果,自动去重。
4. **边界处理**:当 $x = 1$ 或 $y = 1$ 时,只需要枚举一次即可。
### 思路 1:代码
```python
class Solution:
def powerfulIntegers(self, x: int, y: int, bound: int) -> List[int]:
result = set()
# 确定 x 的幂次上限
x_limit = 20 if x > 1 else 1 # x^20 > 10^6
y_limit = 20 if y > 1 else 1 # y^20 > 10^6
# 枚举所有可能的 i 和 j
for i in range(x_limit):
x_power = x ** i
if x_power > bound:
break
for j in range(y_limit):
y_power = y ** j
total = x_power + y_power
if total <= bound:
result.add(total)
# 如果 y = 1,只需要枚举一次
if y == 1:
break
# 如果 x = 1,只需要枚举一次
if x == 1:
break
return list(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log^2 \text{bound})$,最多枚举 $\log_x(\text{bound}) \times \log_y(\text{bound})$ 次。
- **空间复杂度**:$O(\log^2 \text{bound})$,集合中最多存储 $O(\log^2 \text{bound})$ 个元素。
================================================
FILE: docs/solutions/0900-0999/prison-cells-after-n-days.md
================================================
# [0957. N 天后的牢房](https://leetcode.cn/problems/prison-cells-after-n-days/)
- 标签:位运算、数组、哈希表、数学
- 难度:中等
## 题目链接
- [0957. N 天后的牢房 - 力扣](https://leetcode.cn/problems/prison-cells-after-n-days/)
## 题目大意
**描述**:
监狱中 8 间牢房排成一排,每间牢房可能被占用或空置。
每天,无论牢房是被占用或空置,都会根据以下规则进行变更:
- 如果一间牢房的两个相邻的房间都被占用或都是空的,那么该牢房就会被占用。
- 否则,它就会被空置。
注意:由于监狱中的牢房排成一行,所以行中的第一个和最后一个牢房不存在两个相邻的房间。
给你一个整数数组 $cells$,用于表示牢房的初始状态:如果第 $i$ 间牢房被占用,则 $cell[i]==1$,否则 $cell[i]==0$。另给你一个整数 $n$。
**要求**:
请你返回 $n$ 天后监狱的状况(即,按上文描述进行 $n$ 次变更)。
**说明**:
- $cells.length == 8$。
- $cells[i]$ 为 0 或 1。
- $1 \le n \le 10^{9}$。
**示例**:
- 示例 1:
```python
输入:cells = [0,1,0,1,1,0,0,1], n = 7
输出:[0,0,1,1,0,0,0,0]
解释:下表总结了监狱每天的状况:
Day 0: [0, 1, 0, 1, 1, 0, 0, 1]
Day 1: [0, 1, 1, 0, 0, 0, 0, 0]
Day 2: [0, 0, 0, 0, 1, 1, 1, 0]
Day 3: [0, 1, 1, 0, 0, 1, 0, 0]
Day 4: [0, 0, 0, 0, 0, 1, 0, 0]
Day 5: [0, 1, 1, 1, 0, 1, 0, 0]
Day 6: [0, 0, 1, 0, 1, 1, 0, 0]
Day 7: [0, 0, 1, 1, 0, 0, 0, 0]
```
- 示例 2:
```python
输入:cells = [1,0,0,1,0,0,1,0], n = 1000000000
输出:[0,0,1,1,1,1,1,0]
```
## 解题思路
### 思路 1:哈希表 + 找规律
由于牢房只有 $8$ 间,状态数量有限(最多 $2^8 = 256$ 种),必然会出现循环。我们可以利用这个特性来优化。
1. **模拟变化**:按照规则模拟牢房状态的变化。
2. **检测循环**:使用哈希表记录每个状态第一次出现的天数,当出现重复状态时,说明进入循环。
3. **计算结果**:
- 如果 $n$ 天内没有循环,直接返回第 $n$ 天的状态
- 如果出现循环,计算循环周期,通过取模快速得到第 $n$ 天的状态
4. **边界处理**:注意第一个和最后一个牢房始终为空。
### 思路 1:代码
```python
class Solution:
def prisonAfterNDays(self, cells: List[int], n: int) -> List[int]:
def next_day(cells):
"""计算下一天的状态"""
new_cells = [0] * 8
for i in range(1, 7):
# 两个相邻房间状态相同,则被占用
new_cells[i] = 1 if cells[i - 1] == cells[i + 1] else 0
return new_cells
seen = {}
day = 0
while day < n:
# 将状态转换为元组(可哈希)
state = tuple(cells)
# 检测循环
if state in seen:
# 计算循环周期
cycle_length = day - seen[state]
# 跳过完整的循环
remaining_days = (n - day) % cycle_length
# 继续模拟剩余天数
for _ in range(remaining_days):
cells = next_day(cells)
return cells
# 记录当前状态
seen[state] = day
# 模拟下一天
cells = next_day(cells)
day += 1
return cells
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\min(n, 2^k))$,其中 $k = 8$ 是牢房数量。最多模拟 $2^8 = 256$ 天就会出现循环。
- **空间复杂度**:$O(2^k)$,哈希表最多存储 $256$ 个状态。
================================================
FILE: docs/solutions/0900-0999/range-sum-of-bst.md
================================================
# [0938. 二叉搜索树的范围和](https://leetcode.cn/problems/range-sum-of-bst/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [0938. 二叉搜索树的范围和 - 力扣](https://leetcode.cn/problems/range-sum-of-bst/)
## 题目大意
给定一个二叉搜索树,和一个范围 [low, high]。求范围 [low, high] 之间所有节点的值的和。
## 解题思路
二叉搜索树的定义:
- 如果左子树不为空,则左子树上所有节点值均小于它的根节点值;
- 如果右子树不为空,则右子树上所有节点值均大于它的根节点值;
- 任意节点的左、右子树也分别为二叉搜索树。
这道题求解 [low, high] 之间所有节点的值的和,需要递归求解。
- 当前节点为 None 时返回 0;
- 当前节点值 val > high 时,则返回左子树之和;
- 当前节点值 val < low 时,则返回右子树之和;
- 当前节点 val <= high,且 val >= low 时,则返回当前节点值 + 左子树之和 + 右子树之和。
## 代码
```python
class Solution:
def rangeSumBST(self, root: TreeNode, low: int, high: int) -> int:
if not root:
return 0
if root.val > high:
return self.rangeSumBST(root.left, low, high)
if root.val < low:
return self.rangeSumBST(root.right, low, high)
return root.val + self.rangeSumBST(root.left, low, high) + self.rangeSumBST(root.right, low, high)
```
================================================
FILE: docs/solutions/0900-0999/regions-cut-by-slashes.md
================================================
# [0959. 由斜杠划分区域](https://leetcode.cn/problems/regions-cut-by-slashes/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [0959. 由斜杠划分区域 - 力扣](https://leetcode.cn/problems/regions-cut-by-slashes/)
## 题目大意
**描述**:在由 $1 \times 1$ 方格组成的 $n \times n$ 网格 $grid$ 中,每个 $1 \times 1$ 方块由 `'/'`、`'\'` 或 `' '` 构成。这些字符会将方块划分为一些共边的区域。
现在给定代表网格的二维数组 $grid$。
**要求**:返回区域的数目。
**说明**:
- 反斜杠字符是转义的,因此 `'\'` 用 `'\\'` 表示。
- $n == grid.length == grid[i].length$。
- $1 \le n \le 30$。
- $grid[i][j]$ 是 `'/'`、`'\'` 或 `' '`。
**示例**:
- 示例 1:

```python
输入:grid = [" /","/ "]
输出:2
```
- 示例 2:

```python
输入:grid = ["/\\","\\/"]
输出:5
解释:回想一下,因为 \ 字符是转义的,所以 "/\\" 表示 /\,而 "\\/" 表示 \/。
```
## 解题思路
### 思路 1:并查集
我们把一个 $1 \times 1$ 的单元格分割成逻辑上的 $4$ 个部分,则 `' '`、`'/'`、`'\'` 可以将 $1 \times 1$ 的方格分割为以下三种形态:
在进行遍历的时候,需要将联通的部分进行合并,并统计出联通的块数。这就需要用到了并查集。
遍历二维数组 $gird$,然后在「单元格内」和「单元格间」进行合并。
现在我们为单元格的每个小三角部分按顺时针方向都编上编号,起始位置为左边。然后单元格间的编号按照从左到右,从上到下的位置进行编号,如下图所示:

假设当前单元格的起始位置为 $index$,则合并策略如下:
- 如果是单元格内:
- 如果是空格:合并 $index$、$index + 1$、$index + 2$、$index + 3$。
- 如果是 `'/'`:合并 $index$ 和 $index + 1$,合并 $index + 2$ 和 $index + 3$。
- 如果是 `'\'`:合并 $index$ 和 $index + 3$,合并 $index + 1$ 和 $index + 2$。
- 如果是单元格间,则向下向右进行合并:
- 向下:合并 $index + 3$ 和 $index + 4 * size + 1 $。
- 向右:合并 $index + 2$ 和 $index + 4$。
最后合并完成之后,统计并查集中连通分量个数即为答案。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def regionsBySlashes(self, grid: List[str]) -> int:
size = len(grid)
m = 4 * size * size
union_find = UnionFind(m)
for i in range(size):
for j in range(size):
index = 4 * (i * size + j)
ch = grid[i][j]
if ch == '/':
union_find.union(index, index + 1)
union_find.union(index + 2, index + 3)
elif ch == '\\':
union_find.union(index, index + 3)
union_find.union(index + 1, index + 2)
else:
union_find.union(index, index + 1)
union_find.union(index + 1, index + 2)
union_find.union(index + 2, index + 3)
if j + 1 < size:
union_find.union(index + 2, index + 4)
if i + 1 < size:
union_find.union(index + 3, index + 4 * size + 1)
return union_find.count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times \alpha(n^2))$,其中 $\alpha$ 是反 `Ackerman` 函数。
- **空间复杂度**:$O(n^2)$。
================================================
FILE: docs/solutions/0900-0999/reorder-data-in-log-files.md
================================================
# [0937. 重新排列日志文件](https://leetcode.cn/problems/reorder-data-in-log-files/)
- 标签:数组、字符串、排序
- 难度:中等
## 题目链接
- [0937. 重新排列日志文件 - 力扣](https://leetcode.cn/problems/reorder-data-in-log-files/)
## 题目大意
**描述**:
给定一个日志数组 $logs$。每条日志都是以空格分隔的字串,其第一个字为字母与数字混合的「标识符」。
有两种不同类型的日志:
- 字母日志:除标识符之外,所有字均由小写字母组成
- 数字日志:除标识符之外,所有字均由数字组成
请按下述规则将日志重新排序:
- 所有「字母日志」都排在「数字日志」之前。
- 「字母日志」在内容不同时,忽略标识符后,按内容字母顺序排序;在内容相同时,按标识符排序。
- 「数字日志」应该保留原来的相对顺序。
**要求**:
返回日志的最终顺序。
**说明**:
- $1 \le logs.length \le 10^{3}$。
- $3 \le logs[i].length \le 10^{3}$。
- $logs[i]$ 中,字与字之间都用 单个 空格分隔。
- 题目数据保证 $logs[i]$ 都有一个标识符,并且在标识符之后至少存在一个字。
**示例**:
- 示例 1:
```python
输入:logs = ["dig1 8 1 5 1","let1 art can","dig2 3 6","let2 own kit dig","let3 art zero"]
输出:["let1 art can","let3 art zero","let2 own kit dig","dig1 8 1 5 1","dig2 3 6"]
解释:
字母日志的内容都不同,所以顺序为 "art can", "art zero", "own kit dig" 。
数字日志保留原来的相对顺序 "dig1 8 1 5 1", "dig2 3 6" 。
```
- 示例 2:
```python
输入:logs = ["a1 9 2 3 1","g1 act car","zo4 4 7","ab1 off key dog","a8 act zoo"]
输出:["g1 act car","a8 act zoo","ab1 off key dog","a1 9 2 3 1","zo4 4 7"]
```
## 解题思路
### 思路 1:自定义排序
根据题目要求,需要对日志进行自定义排序。
1. **分类日志**:将日志分为字母日志和数字日志。
2. **排序规则**:
- 字母日志排在数字日志之前
- 字母日志按内容排序,内容相同时按标识符排序
- 数字日志保持原有顺序
3. **实现方式**:使用自定义排序函数,返回排序键。
### 思路 1:代码
```python
class Solution:
def reorderLogFiles(self, logs: List[str]) -> List[str]:
def sort_key(log):
identifier, content = log.split(' ', 1)
# 判断是字母日志还是数字日志
if content[0].isalpha():
# 字母日志:返回 (0, 内容, 标识符)
return (0, content, identifier)
else:
# 数字日志:返回 (1,),保持原有顺序
return (1,)
return sorted(logs, key=sort_key)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n \cdot m)$,其中 $n$ 是日志数量,$m$ 是日志的平均长度。排序需要 $O(n \log n)$ 次比较,每次比较需要 $O(m)$ 时间。
- **空间复杂度**:$O(n \cdot m)$,排序需要的额外空间。
================================================
FILE: docs/solutions/0900-0999/reveal-cards-in-increasing-order.md
================================================
# [0950. 按递增顺序显示卡牌](https://leetcode.cn/problems/reveal-cards-in-increasing-order/)
- 标签:队列、数组、排序、模拟
- 难度:中等
## 题目链接
- [0950. 按递增顺序显示卡牌 - 力扣](https://leetcode.cn/problems/reveal-cards-in-increasing-order/)
## 题目大意
**描述**:
给定一个数组 $A$ 代表牌组。牌组中的每张卡牌都对应有一个唯一的整数。你可以按你想要的顺序对这套卡片进行排序。
最初,这些卡牌在牌组里是正面朝下的(即,未显示状态)。
现在,重复执行以下步骤,直到显示所有卡牌为止:
1. 从牌组顶部抽一张牌,显示它,然后将其从牌组中移出。
2. 如果牌组中仍有牌,则将下一张处于牌组顶部的牌放在牌组的底部。
3. 如果仍有未显示的牌,那么返回步骤 1。否则,停止行动。
**要求**:
返回能以递增顺序显示卡牌的牌组顺序。
答案中的第一张牌被认为处于牌堆顶部。
**说明**:
- $1 \le A.length \le 10^{3}$。
- $1 \le A[i] \le 10^6$。
- 对于所有的 $i \ne j$,$A[i] \ne A[j]$。
**示例**:
- 示例 1:
```python
输入:[17,13,11,2,3,5,7]
输出:[2,13,3,11,5,17,7]
解释:
我们得到的牌组顺序为 [17,13,11,2,3,5,7](这个顺序不重要),然后将其重新排序。
重新排序后,牌组以 [2,13,3,11,5,17,7] 开始,其中 2 位于牌组的顶部。
我们显示 2,然后将 13 移到底部。牌组现在是 [3,11,5,17,7,13]。
我们显示 3,并将 11 移到底部。牌组现在是 [5,17,7,13,11]。
我们显示 5,然后将 17 移到底部。牌组现在是 [7,13,11,17]。
我们显示 7,并将 13 移到底部。牌组现在是 [11,17,13]。
我们显示 11,然后将 17 移到底部。牌组现在是 [13,17]。
我们展示 13,然后将 17 移到底部。牌组现在是 [17]。
我们显示 17。
由于所有卡片都是按递增顺序排列显示的,所以答案是正确的。
```
## 解题思路
### 思路 1:队列模拟
这道题需要逆向思考:从最终的递增顺序反推初始的牌组顺序。
1. **逆向模拟**:
- 将排序后的牌从小到大依次放入结果
- 模拟逆向操作:如果正向是"抽牌、移底",逆向就是"放底、移顶"
2. **使用队列**:
- 初始化一个索引队列 $[0, 1, 2, ..., n-1]$
- 模拟抽牌过程,记录每次抽牌的位置
- 将排序后的牌按照抽牌顺序放入对应位置
3. **具体步骤**:
- 每次从队列头部取出一个索引(对应抽牌位置)
- 如果队列不为空,将队列头部的下一个索引移到队列尾部(对应移底操作)
### 思路 1:代码
```python
class Solution:
def deckRevealedIncreasing(self, deck: List[int]) -> List[int]:
n = len(deck)
deck.sort() # 先排序
# 使用队列模拟索引
queue = collections.deque(range(n))
result = [0] * n
for card in deck:
# 当前卡牌放到队列头部对应的位置
idx = queue.popleft()
result[idx] = card
# 如果队列不为空,将下一个索引移到队列尾部
if queue:
queue.append(queue.popleft())
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是牌的数量。排序需要 $O(n \log n)$,模拟过程需要 $O(n)$。
- **空间复杂度**:$O(n)$,需要使用队列存储索引。
================================================
FILE: docs/solutions/0900-0999/reverse-only-letters.md
================================================
# [0917. 仅仅反转字母](https://leetcode.cn/problems/reverse-only-letters/)
- 标签:双指针、字符串
- 难度:简单
## 题目链接
- [0917. 仅仅反转字母 - 力扣](https://leetcode.cn/problems/reverse-only-letters/)
## 题目大意
**描述**:
给定一个字符串 $s$ ,根据下述规则反转字符串:
- 所有非英文字母保留在原有位置。
- 所有英文字母(小写或大写)位置反转。
**要求**:
返回反转后的 $s$。
**说明**:
- $1 \le s.length \le 100$
- $s$ 仅由 ASCII 值在范围 $[33, 122]$ 的字符组成
- $s$ 不含 `'\"'` 或 `'\\'`
**示例**:
- 示例 1:
```python
输入:s = "ab-cd"
输出:"dc-ba"
```
- 示例 2:
```python
输入:s = "a-bC-dEf-ghIj"
输出:"j-Ih-gfE-dCba"
```
## 解题思路
### 思路 1:双指针
使用双指针分别从字符串的两端向中间移动,只交换英文字母,跳过非英文字母。
1. **初始化**:将字符串转换为列表(Python 字符串不可变),使用左右指针 $left$ 和 $right$。
2. **双指针移动**:
- 如果 $s[left]$ 不是字母,$left$ 右移
- 如果 $s[right]$ 不是字母,$right$ 左移
- 如果两者都是字母,交换它们,然后同时移动
3. **返回结果**:将列表转换回字符串。
### 思路 1:代码
```python
class Solution:
def reverseOnlyLetters(self, s: str) -> str:
s = list(s)
left, right = 0, len(s) - 1
while left < right:
# 左指针找到字母
if not s[left].isalpha():
left += 1
# 右指针找到字母
elif not s[right].isalpha():
right -= 1
# 交换两个字母
else:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
return ''.join(s)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是字符串长度,每个字符最多访问一次。
- **空间复杂度**:$O(n)$,需要将字符串转换为列表。
================================================
FILE: docs/solutions/0900-0999/rle-iterator.md
================================================
# [0900. RLE 迭代器](https://leetcode.cn/problems/rle-iterator/)
- 标签:设计、数组、计数、迭代器
- 难度:中等
## 题目链接
- [0900. RLE 迭代器 - 力扣](https://leetcode.cn/problems/rle-iterator/)
## 题目大意
**描述**:我们可以使用游程编码(即 RLE)来编码一个整数序列。在偶数长度 $encoding$ ( 从 $0$ 开始 )的游程编码数组中,对于所有偶数 $i$,$encoding[i]$ 告诉我们非负整数 $encoding[i + 1]$ 在序列中重复的次数。
- 例如,序列 $arr = [8,8,8,5,5]$ 可以被编码为 $encoding =[3,8,2,5]$。$encoding =[3,8,0,9,2,5]$ 和 $encoding =[2,8,1,8,2,5]$ 也是 $arr$ 有效的 RLE。
给定一个游程长度的编码数组 $encoding$。
**要求**:设计一个迭代器来遍历它。
实现 `RLEIterator` 类:
- `RLEIterator(int[] encoded)` 用编码后的数组初始化对象。
- `int next(int n)` 以这种方式耗尽后 $n$ 个元素并返回最后一个耗尽的元素。如果没有剩余的元素要耗尽,则返回 $-1$。
**说明**:
- $2 \le encoding.length \le 1000$。
- $encoding.length$ 为偶。
- $0 \le encoding[i] \le 10^9$。
- $1 \le n \le 10^9$。
- 每个测试用例调用 `next` 不高于 $1000$ 次。
**示例**:
- 示例 1:
```python
输入:
["RLEIterator","next","next","next","next"]
[[[3,8,0,9,2,5]],[2],[1],[1],[2]]
输出:
[null,8,8,5,-1]
解释:
RLEIterator rLEIterator = new RLEIterator([3, 8, 0, 9, 2, 5]); // 这映射到序列 [8,8,8,5,5]。
rLEIterator.next(2); // 耗去序列的 2 个项,返回 8。现在剩下的序列是 [8, 5, 5]。
rLEIterator.next(1); // 耗去序列的 1 个项,返回 8。现在剩下的序列是 [5, 5]。
rLEIterator.next(1); // 耗去序列的 1 个项,返回 5。现在剩下的序列是 [5]。
rLEIterator.next(2); // 耗去序列的 2 个项,返回 -1。 这是由于第一个被耗去的项是 5,
但第二个项并不存在。由于最后一个要耗去的项不存在,我们返回 -1。
```
## 解题思路
### 思路 1:模拟
1. 初始化时:
1. 保存数组 $encoding$ 作为成员变量。
2. 保存当前位置 $index$,表示当前迭代器指向元素 $encoding[index + 1]$。初始化赋值为 $0$。
3. 保存当前指向元素 $encoding[index + 1]$ 已经被删除的元素个数 $d\_cnt$。初始化赋值为 $0$。
2. 调用 `next(n)` 时:
1. 对于当前元素,先判断当前位置是否超出 $encoding$ 范围,超过则直接返回 $-1$。
2. 如果未超过,再判断当前元素剩余个数 $encoding[index] - d\_cnt$ 是否小于 $n$ 个。
1. 如果小于 $n$ 个,则删除当前元素剩余所有个数,并指向下一位置继续删除剩余元素。
2. 如果等于大于等于 $n$ 个,则令当前指向元素 $encoding[index + 1]$ 已经被删除的元素个数 $d\_cnt$ 加上 $n$。
### 思路 1:代码
```Python
class RLEIterator:
def __init__(self, encoding: List[int]):
self.encoding = encoding
self.index = 0
self.d_cnt = 0
def next(self, n: int) -> int:
while self.index < len(self.encoding):
if self.d_cnt + n > self.encoding[self.index]:
n -= self.encoding[self.index] - self.d_cnt
self.d_cnt = 0
self.index += 2
else:
self.d_cnt += n
return self.encoding[self.index + 1]
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 为数组 $encoding$ 的长度,$m$ 是调用 `next(n)` 的次数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0900-0999/rotting-oranges.md
================================================
# [0994. 腐烂的橘子](https://leetcode.cn/problems/rotting-oranges/)
- 标签:广度优先搜索、数组、矩阵
- 难度:中等
## 题目链接
- [0994. 腐烂的橘子 - 力扣](https://leetcode.cn/problems/rotting-oranges/)
## 题目大意
**描述**:
$m \times n$ 网格 $grid$ 中,每个单元格可以有以下三个值之一:
- 值 0 代表空单元格;
- 值 1 代表新鲜橘子;
- 值 2 代表腐烂的橘子。
每分钟,腐烂的橘子「周围 4 个方向上相邻」的新鲜橘子都会腐烂。
**要求**:
返回直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1。
**说明**:
- $m == grid.length$。
- $n == grid[i].length$。
- $1 \le m, n \le 10$。
- $grid[i][j]$ 仅为 0、1 或 2。
**示例**:
- 示例 1:
```python
输入:grid = [[2,1,1],[1,1,0],[0,1,1]]
输出:4
```
- 示例 2:
```python
输入:grid = [[2,1,1],[0,1,1],[1,0,1]]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
```
## 解题思路
### 思路 1:广度优先搜索
这是一个多源 BFS 问题,所有腐烂的橘子同时开始扩散。
1. **初始化**:
- 遍历矩阵,统计新鲜橘子的数量
- 将所有腐烂橘子的位置加入队列
2. **BFS 扩展**:
- 每一轮 BFS 代表一分钟
- 从队列中取出所有腐烂橘子,向四个方向扩散
- 如果相邻位置是新鲜橘子,将其变为腐烂,加入队列,新鲜橘子数量减 $1$
3. **判断结果**:
- 如果最后还有新鲜橘子,返回 $-1$
- 否则返回经过的分钟数
### 思路 1:代码
```python
class Solution:
def orangesRotting(self, grid: List[List[int]]) -> int:
m, n = len(grid), len(grid[0])
queue = collections.deque()
fresh_count = 0
# 统计新鲜橘子数量,收集腐烂橘子位置
for i in range(m):
for j in range(n):
if grid[i][j] == 1:
fresh_count += 1
elif grid[i][j] == 2:
queue.append((i, j))
# 如果没有新鲜橘子,直接返回 0
if fresh_count == 0:
return 0
# BFS 扩散
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
minutes = 0
while queue:
size = len(queue)
for _ in range(size):
x, y = queue.popleft()
for dx, dy in directions:
nx, ny = x + dx, y + dy
# 如果相邻位置是新鲜橘子
if 0 <= nx < m and 0 <= ny < n and grid[nx][ny] == 1:
grid[nx][ny] = 2 # 变为腐烂
fresh_count -= 1
queue.append((nx, ny))
# 如果队列不为空,说明这一轮有橘子腐烂
if queue:
minutes += 1
# 如果还有新鲜橘子,返回 -1
return minutes if fresh_count == 0 else -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$ 和 $n$ 是矩阵的行数和列数,每个格子最多访问一次。
- **空间复杂度**:$O(m \times n)$,队列中最多存储所有格子。
================================================
FILE: docs/solutions/0900-0999/satisfiability-of-equality-equations.md
================================================
# [0990. 等式方程的可满足性](https://leetcode.cn/problems/satisfiability-of-equality-equations/)
- 标签:并查集、图、数组、字符串
- 难度:中等
## 题目链接
- [0990. 等式方程的可满足性 - 力扣](https://leetcode.cn/problems/satisfiability-of-equality-equations/)
## 题目大意
**描述**:给定一个由字符串方程组成的数组 `equations`,每个字符串方程 `equations[i]` 的长度为 `4`,有以下两种形式组成:`a==b` 或 `a!=b`。`a` 和 `b` 是小写字母,表示单字母变量名。
**要求**:判断所有的字符串方程是否能同时满足,如果能同时满足,返回 `True`,否则返回 `False`。
**说明**:
- $1 \le equations.length \le 500$。
- $equations[i].length == 4$。
- $equations[i][0]$ 和 $equations[i][3]$ 是小写字母。
- $equations[i][1]$ 要么是 `'='`,要么是 `'!'`。
- `equations[i][2]` 是 `'='`。
**示例**:
- 示例 1:
```python
输入:["a==b","b!=a"]
输出:False
解释:如果我们指定,a = 1 且 b = 1
那么可以满足第一个方程,但无法满足第二个方程。
没有办法分配变量同时满足这两个方程。
```
## 解题思路
### 思路 1:并查集
字符串方程只有 `==` 或者 `!=`,可以考虑将相等的遍历划分到相同集合中,然后再遍历所有不等式方程,看方程的两个变量是否在之前划分的相同集合中,如果在则说明不满足。
这就需要用到并查集,具体操作如下:
- 遍历所有等式方程,将等式两边的单字母变量顶点进行合并。
- 遍历所有不等式方程,检查不等式两边的单字母遍历是不是在一个连通分量中,如果在则返回 `False`,否则继续扫描。如果所有不等式检查都没有矛盾,则返回 `True`。
### 思路 1:并查集代码
```python
class UnionFind:
def __init__(self, n): # 初始化
self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引
def __find(self, x): # 查找元素根节点的集合编号内部实现方法
while self.fa[x] != x: # 递归查找元素的父节点,直到根节点
self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化
x = self.fa[x]
return x # 返回元素根节点的集合编号
def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点
root_x = self.__find(x)
root_y = self.__find(y)
if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合
return False
self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点
return True
def is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合
return self.__find(x) == self.__find(y)
class Solution:
def equationsPossible(self, equations: List[str]) -> bool:
union_find = UnionFind(26)
for eqation in equations:
if eqation[1] == "=":
index1 = ord(eqation[0]) - 97
index2 = ord(eqation[3]) - 97
union_find.union(index1, index2)
for eqation in equations:
if eqation[1] == "!":
index1 = ord(eqation[0]) - 97
index2 = ord(eqation[3]) - 97
if union_find.is_connected(index1, index2):
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + C \times \log C)$。其中 $n$ 是方程组 $equations$ 中的等式数量。$C$ 是字母变量的数量。本题中变量都是小写字母,即 $C \le 26$。
- **空间复杂度**:$O(C)$。
================================================
FILE: docs/solutions/0900-0999/shortest-bridge.md
================================================
# [0934. 最短的桥](https://leetcode.cn/problems/shortest-bridge/)
- 标签:深度优先搜索、广度优先搜索、数组、矩阵
- 难度:中等
## 题目链接
- [0934. 最短的桥 - 力扣](https://leetcode.cn/problems/shortest-bridge/)
## 题目大意
**描述**:
给定一个大小为 $n \times n$ 的二元矩阵 $grid$,其中 1 表示陆地,0 表示水域。
「岛」是由四面相连的 1 形成的一个最大组,即不会与非组内的任何其他 1 相连。$grid$ 中 恰好存在两座岛 。
你可以将任意数量的 0 变为 1,以使两座岛连接起来,变成「一座岛」。
**要求**:
返回必须翻转的 0 的最小数目。
**说明**:
- $n == grid.length == grid[i].length$。
- $2 \le n \le 10^{3}$。
- $grid[i][j]$ 为 0 或 1。
- $grid$ 中恰有两个岛。
**示例**:
- 示例 1:
```python
输入:grid = [[0,1],[1,0]]
输出:1
```
- 示例 2:
```python
输入:grid = [[0,1,0],[0,0,0],[0,0,1]]
输出:2
```
## 解题思路
### 思路 1:广度优先搜索
这道题需要找到连接两个岛屿的最短桥,可以分为两步:
1. **找到第一个岛屿**:使用 DFS 找到第一个岛屿的所有格子,并将它们加入队列。
2. **BFS 扩展**:从第一个岛屿的所有格子开始,使用 BFS 向外扩展,直到遇到第二个岛屿。
**具体步骤**:
- 遍历矩阵,找到第一个值为 $1$ 的格子,从这里开始 DFS
- DFS 标记第一个岛屿的所有格子(改为 $2$),并将它们加入队列
- BFS 从队列中的所有格子开始扩展,每次将水域($0$)改为 $2$,直到遇到第二个岛屿($1$)
### 思路 1:代码
```python
class Solution:
def shortestBridge(self, grid: List[List[int]]) -> int:
n = len(grid)
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
# DFS 找到第一个岛屿
def dfs(i, j):
if i < 0 or i >= n or j < 0 or j >= n or grid[i][j] != 1:
return
grid[i][j] = 2 # 标记为第一个岛屿
queue.append((i, j))
for di, dj in directions:
dfs(i + di, j + dj)
# 找到第一个岛屿并标记
queue = collections.deque()
found = False
for i in range(n):
if found:
break
for j in range(n):
if grid[i][j] == 1:
dfs(i, j)
found = True
break
# BFS 扩展,寻找第二个岛屿
steps = 0
while queue:
size = len(queue)
for _ in range(size):
x, y = queue.popleft()
for dx, dy in directions:
nx, ny = x + dx, y + dy
if 0 <= nx < n and 0 <= ny < n:
if grid[nx][ny] == 1: # 找到第二个岛屿
return steps
elif grid[nx][ny] == 0: # 水域,继续扩展
grid[nx][ny] = 2
queue.append((nx, ny))
steps += 1
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是矩阵的边长。DFS 和 BFS 都最多访问每个格子一次。
- **空间复杂度**:$O(n^2)$,队列和递归栈的空间。
================================================
FILE: docs/solutions/0900-0999/smallest-range-i.md
================================================
# [0908. 最小差值 I](https://leetcode.cn/problems/smallest-range-i/)
- 标签:数组、数学
- 难度:简单
## 题目链接
- [0908. 最小差值 I - 力扣](https://leetcode.cn/problems/smallest-range-i/)
## 题目大意
**描述**:给定一个整数数组 `nums`,和一个整数 `k`。给数组中的每个元素 `nums[i]` 都加上一个任意数字 `x` (`-k <= x <= k`),从而得到一个新数组 `result`。
**要求**:返回数组 `result` 的最大值和最小值之间可能存在的最小差值。
**说明**:
- $1 \le nums.length \le 10^4$。
- $0 \le nums[i] \le 10^4$。
- $0 \le k \le 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [1], k = 0
输出:0
解释:分数是 max(nums) - min(nums) = 1 - 1 = 0。
```
- 示例 2:
```python
输入:nums = [0,10], k = 2
输出:6
解释:将 nums 改为 [2,8]。分数是 max(nums) - min(nums) = 8 - 2 = 6。
```
## 解题思路
### 思路 1:数学
`nums` 中的每个元素可以波动 `[-k, k]`。最小的差值就是「最大值减去 `k`」和「最小值加上 `k`」之间的差值。而如果差值小于 `0`,则说明每个数字都可以波动成相等的数字,此时直接返回 `0` 即可。
### 思路 1:代码
```python
class Solution:
def smallestRangeI(self, nums: List[int], k: int) -> int:
return max(0, max(nums) - min(nums) - 2*k)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/0900-0999/smallest-range-ii.md
================================================
# [0910. 最小差值 II](https://leetcode.cn/problems/smallest-range-ii/)
- 标签:贪心、数组、数学、排序
- 难度:中等
## 题目链接
- [0910. 最小差值 II - 力扣](https://leetcode.cn/problems/smallest-range-ii/)
## 题目大意
**描述**:
给定一个整数数组 $nums$,和一个整数 $k$。
对于每个下标 $i$($0 \le i < nums.length$),将 $nums[i]$ 变成 $nums[i] + k$ 或 $nums[i] - k$。
$nums$ 的「分数」是 $nums$ 中最大元素和最小元素的差值。
**要求**:
在更改每个下标对应的值之后,返回 $nums$ 的最小「分数」。
**说明**:
- $1 \le nums.length \le 10^{4}$。
- $0 \le nums[i] \le 10^{4}$。
- $0 \le k \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:nums = [1], k = 0
输出:0
解释:分数 = max(nums) - min(nums) = 1 - 1 = 0 。
```
- 示例 2:
```python
输入:nums = [0,10], k = 2
输出:6
解释:将数组变为 [2, 8] 。分数 = max(nums) - min(nums) = 8 - 2 = 6 。
```
## 解题思路
### 思路 1:贪心 + 排序
这道题的关键是理解:对于排序后的数组,最优策略是将数组分为两部分,前一部分都加 $k$,后一部分都减 $k$。
1. **排序**:首先对数组进行排序。
2. **贪心策略**:排序后,我们尝试在每个位置 $i$ 进行分割,使得 $[0, i]$ 的元素都加 $k$,$[i+1, n-1]$ 的元素都减 $k$。
3. **计算分数**:对于每个分割点,计算可能的最大值和最小值:
- 最大值可能是 $\text{nums}[i] + k$ 或 $\text{nums}[n-1] - k$
- 最小值可能是 $\text{nums}[0] + k$ 或 $\text{nums}[i+1] - k$
4. **更新答案**:取所有分割点中的最小分数。
**特殊情况**:如果所有元素都加 $k$ 或都减 $k$,分数为 $\text{nums}[n-1] - \text{nums}[0]$。
### 思路 1:代码
```python
class Solution:
def smallestRangeII(self, nums: List[int], k: int) -> int:
nums.sort()
n = len(nums)
# 初始答案:所有元素都加 k 或都减 k
ans = nums[n - 1] - nums[0]
# 尝试在每个位置分割
for i in range(n - 1):
# [0, i] 加 k,[i+1, n-1] 减 k
max_val = max(nums[i] + k, nums[n - 1] - k)
min_val = min(nums[0] + k, nums[i + 1] - k)
ans = min(ans, max_val - min_val)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是数组长度,主要是排序的时间复杂度。
- **空间复杂度**:$O(\log n)$,排序所需的栈空间。
================================================
FILE: docs/solutions/0900-0999/smallest-string-starting-from-leaf.md
================================================
# [0988. 从叶结点开始的最小字符串](https://leetcode.cn/problems/smallest-string-starting-from-leaf/)
- 标签:树、深度优先搜索、字符串、回溯、二叉树
- 难度:中等
## 题目链接
- [0988. 从叶结点开始的最小字符串 - 力扣](https://leetcode.cn/problems/smallest-string-starting-from-leaf/)
## 题目大意
**描述**:
给定一颗根结点为 $root$ 的二叉树,树中的每一个结点都有一个 $[0, 25]$ 范围内的值,分别代表字母 `'a'` 到 `'z'`。
**要求**:
返回「按字典序最小」的字符串,该字符串从这棵树的一个叶结点开始,到根结点结束。
**说明**:
- 注意:字符串中任何较短的前缀在「字典序上」都是「较小」的:
- 例如,在字典序上 `"ab"` 比 `"aba"` 要小。叶结点是指没有子结点的结点。
- 节点的叶节点是没有子节点的节点。
- 给定树的结点数在 $[1, 8500]$ 范围内。
- $0 \le Node.val \le 25$。
**示例**:
- 示例 1:
```python
输入:root = [0,1,2,3,4,3,4]
输出:"dba"
```
- 示例 2:
```python
输入:root = [25,1,3,1,3,0,2]
输出:"adz"
```
## 解题思路
### 思路 1:深度优先搜索
使用 DFS 遍历二叉树,从叶子节点到根节点构建字符串,然后比较所有路径的字典序。
1. **DFS 遍历**:从根节点开始,递归遍历到叶子节点。
2. **构建字符串**:在递归过程中,将节点值转换为字符并拼接。
3. **叶子节点判断**:当到达叶子节点时,将当前路径(反转后)与最小字符串比较。
4. **字典序比较**:使用 Python 的字符串比较功能,更新最小字符串。
**注意**:由于是从叶子到根,需要在递归返回时构建字符串,或者在递归过程中构建后反转。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def smallestFromLeaf(self, root: Optional[TreeNode]) -> str:
self.result = None
def dfs(node, path):
if not node:
return
# 将当前节点值转换为字符并添加到路径
path = chr(ord('a') + node.val) + path
# 如果是叶子节点,更新结果
if not node.left and not node.right:
if self.result is None or path < self.result:
self.result = path
return
# 递归遍历左右子树
if node.left:
dfs(node.left, path)
if node.right:
dfs(node.right, path)
dfs(root, "")
return self.result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是树中节点的数量。需要遍历所有节点,每次字符串拼接需要 $O(n)$ 时间。
- **空间复杂度**:$O(n)$,递归栈的深度最多为树的高度,字符串长度最多为 $n$。
================================================
FILE: docs/solutions/0900-0999/snakes-and-ladders.md
================================================
# [0909. 蛇梯棋](https://leetcode.cn/problems/snakes-and-ladders/)
- 标签:广度优先搜索、数组、矩阵
- 难度:中等
## 题目链接
- [0909. 蛇梯棋 - 力扣](https://leetcode.cn/problems/snakes-and-ladders/)
## 题目大意
**描述**:
给定一个大小为 $n \times n$ 的整数矩阵 $board$,方格按从 1 到 $n^2$ 编号,编号遵循「转行交替方式」,从左下角开始 (即,从 $board[n - 1][0]$ 开始)的每一行改变方向。
你一开始位于棋盘上的方格 1。每一回合,玩家需要从当前方格 $curr$ 开始出发,按下述要求前进:
- 选定目标方格 $next$,目标方格的编号在范围 $[curr + 1, min(curr + 6, n^2)]$。
- 该选择模拟了掷「六面体骰子」的情景,无论棋盘大小如何,玩家最多只能有 6 个目的地。
- 传送玩家:如果目标方格 $next$ 处存在蛇或梯子,那么玩家会传送到蛇或梯子的目的地。否则,玩家传送到目标方格 $next$。
- 当玩家到达编号 $n^2$ 的方格时,游戏结束。
如果 $board[r][c] \ne -1$,位于 $r$ 行 $c$ 列的棋盘格中可能存在「蛇」或「梯子」。那个蛇或梯子的目的地将会是 $board[r][c]$。编号为 1 和 $n^2$ 的方格不是任何蛇或梯子的起点。
注意,玩家在每次掷骰的前进过程中最多只能爬过蛇或梯子一次:就算目的地是另一条蛇或梯子的起点,玩家也 不能 继续移动。
- 举个例子,假设棋盘是 $[[-1,4],[-1,3]]$,第一次移动,玩家的目标方格是 2。那么这个玩家将会顺着梯子到达方格 3,但「不能」顺着方格 3 上的梯子前往方格 4。(简单来说,类似飞行棋,玩家掷出骰子点数后移动对应格数,遇到单向的路径(即梯子或蛇)可以直接跳到路径的终点,但如果多个路径首尾相连,也不能连续跳多个路径)
**要求**:
返回达到编号为 $n^2$ 的方格所需的最少掷骰次数,如果不可能,则返回 -1。
**说明**:
- $n == board.length == board[i].length$。
- $2 \le n \le 20$。
- $board[i][j]$ 的值是 -1 或在范围 $[1, n^2]$ 内。
- 编号为 1 和 $n^2$ 的方格上没有蛇或梯子。
**示例**:
- 示例 1:
```python

输入:board = [[-1,-1,-1,-1,-1,-1],[-1,-1,-1,-1,-1,-1],[-1,-1,-1,-1,-1,-1],[-1,35,-1,-1,13,-1],[-1,-1,-1,-1,-1,-1],[-1,15,-1,-1,-1,-1]]
输出:4
解释:
首先,从方格 1 [第 5 行,第 0 列] 开始。
先决定移动到方格 2 ,并必须爬过梯子移动到到方格 15 。
然后决定移动到方格 17 [第 3 行,第 4 列],必须爬过蛇到方格 13 。
接着决定移动到方格 14 ,且必须通过梯子移动到方格 35 。
最后决定移动到方格 36 , 游戏结束。
可以证明需要至少 4 次移动才能到达最后一个方格,所以答案是 4 。
```
- 示例 2:
```python
输入:board = [[-1,-1],[-1,3]]
输出:1
```
## 解题思路
### 思路 1:广度优先搜索
这道题是一个典型的最短路径问题,可以使用广度优先搜索(BFS)来解决。
1. **坐标转换**:首先需要将编号转换为二维坐标。由于棋盘是"牛耕式转行"编号,即奇数行从左到右,偶数行从右到左。
2. **BFS 搜索**:从方格 $1$ 开始,每次可以移动 $1 \sim 6$ 步(模拟掷骰子),如果目标方格有蛇或梯子,则传送到对应位置。
3. **记录步数**:使用队列记录当前位置和步数,使用集合记录已访问的方格,避免重复访问。
4. **终止条件**:当到达方格 $n^2$ 时,返回当前步数。
### 思路 1:代码
```python
class Solution:
def snakesAndLadders(self, board: List[List[int]]) -> int:
n = len(board)
# 将编号转换为坐标
def num_to_pos(num):
num -= 1 # 转换为 0 索引
row = n - 1 - num // n # 从下往上
col = num % n
# 奇数行(从下往上数)需要反转列
if (n - 1 - row) % 2 == 1:
col = n - 1 - col
return row, col
# BFS
queue = collections.deque([(1, 0)]) # (当前位置, 步数)
visited = {1}
while queue:
curr, steps = queue.popleft()
# 尝试掷骰子 1-6
for i in range(1, 7):
next_num = curr + i
if next_num > n * n:
break
# 获取目标位置
row, col = num_to_pos(next_num)
# 如果有蛇或梯子,传送到目标位置
if board[row][col] != -1:
next_num = board[row][col]
# 到达终点
if next_num == n * n:
return steps + 1
# 未访问过则加入队列
if next_num not in visited:
visited.add(next_num)
queue.append((next_num, steps + 1))
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是棋盘的边长。每个方格最多访问一次。
- **空间复杂度**:$O(n^2)$,需要使用队列和集合存储访问状态。
================================================
FILE: docs/solutions/0900-0999/sort-an-array.md
================================================
# [0912. 排序数组](https://leetcode.cn/problems/sort-an-array/)
- 标签:数组、分治、桶排序、计数排序、基数排序、排序、堆(优先队列)、归并排序
- 难度:中等
## 题目链接
- [0912. 排序数组 - 力扣](https://leetcode.cn/problems/sort-an-array/)
## 题目大意
**描述**:给定一个整数数组 $nums$。
**要求**:将该数组升序排列。
**说明**:
- $1 \le nums.length \le 5 * 10^4$。
- $-5 * 10^4 \le nums[i] \le 5 * 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [5,2,3,1]
输出:[1,2,3,5]
```
- 示例 2:
```python
输入:nums = [5,1,1,2,0,0]
输出:[0,0,1,1,2,5]
```
## 解题思路
这道题是一道用来复习排序算法,测试算法时间复杂度的好题。我试过了十种排序算法。得到了如下结论:
- 超时算法(时间复杂度为 $O(n^2)$):冒泡排序、选择排序、插入排序。
- 通过算法(时间复杂度为 $O(n \times \log n)$):希尔排序、归并排序、快速排序、堆排序。
- 通过算法(时间复杂度为 $O(n)$):计数排序、桶排序。
- 解答错误算法(普通基数排序只适合非负数):基数排序。
### 思路 1:冒泡排序(超时)
> **冒泡排序(Bubble Sort)基本思想**:经过多次迭代,通过相邻元素之间的比较与交换,使值较小的元素逐步从后面移到前面,值较大的元素从前面移到后面。
假设数组的元素个数为 $n$ 个,则冒泡排序的算法步骤如下:
1. 第 $1$ 趟「冒泡」:对前 $n$ 个元素执行「冒泡」,从而使第 $1$ 个值最大的元素放置在正确位置上。
1. 先将序列中第 $1$ 个元素与第 $2$ 个元素进行比较,如果前者大于后者,则两者交换位置,否则不交换。
2. 然后将第 $2$ 个元素与第 $3$ 个元素比较,如果前者大于后者,则两者交换位置,否则不交换。
3. 依次类推,直到第 $n - 1$ 个元素与第 $n$ 个元素比较(或交换)为止。
4. 经过第 $1$ 趟排序,使得 $n$ 个元素中第 $i$ 个值最大元素被安置在第 $n$ 个位置上。
2. 第 $2$ 趟「冒泡」:对前 $n - 1$ 个元素执行「冒泡」,从而使第 $2$ 个值最大的元素放置在正确位置上。
1. 先将序列中第 $1$ 个元素与第 $2$ 个元素进行比较,如果前者大于后者,则两者交换位置,否则不交换。
2. 然后将第 $2$ 个元素与第 $3$ 个元素比较,如果前者大于后者,则两者交换位置,否则不交换。
3. 依次类推,直到第 $n - 2$ 个元素与第 $n - 1$ 个元素比较(或交换)为止。
4. 经过第 $2$ 趟排序,使得数组中第 $2$ 个值最大元素被安置在第 $n$ 个位置上。
3. 依次类推,重复上述「冒泡」过程,直到某一趟排序过程中不出现元素交换位置的动作,则排序结束。
### 思路 1:代码
```python
class Solution:
def bubbleSort(self, nums: [int]) -> [int]:
# 第 i 趟「冒泡」
for i in range(len(nums) - 1):
flag = False # 是否发生交换的标志位
# 对数组未排序区间 [0, n - i - 1] 的元素执行「冒泡」
for j in range(len(nums) - i - 1):
# 相邻两个元素进行比较,如果前者大于后者,则交换位置
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
flag = True
if not flag: # 此趟遍历未交换任何元素,直接跳出
break
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.bubbleSort(nums)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(1)$。
### 思路 2:选择排序(超时)
>**选择排序(Selection Sort)基本思想**:将数组分为两个区间,左侧为已排序区间,右侧为未排序区间。每趟从未排序区间中选择一个值最小的元素,放到已排序区间的末尾,从而将该元素划分到已排序区间。
假设数组的元素个数为 $n$ 个,则选择排序的算法步骤如下:
1. 初始状态下,无已排序区间,未排序区间为 $[0, n - 1]$。
2. 第 $1$ 趟选择:
1. 遍历未排序区间 $[0, n - 1]$,使用变量 $min\_i$ 记录区间中值最小的元素位置。
2. 将 $min\_i$ 与下标为 $0$ 处的元素交换位置。如果下标为 $0$ 处元素就是值最小的元素位置,则不用交换。
3. 此时,$[0, 0]$ 为已排序区间,$[1, n - 1]$(总共 $n - 1$ 个元素)为未排序区间。
3. 第 $2$ 趟选择:
1. 遍历未排序区间 $[1, n - 1]$,使用变量 $min\_i$ 记录区间中值最小的元素位置。
2. 将 $min\_i$ 与下标为 $1$ 处的元素交换位置。如果下标为 $1$ 处元素就是值最小的元素位置,则不用交换。
3. 此时,$[0, 1]$ 为已排序区间,$[2, n - 1]$(总共 $n - 2$ 个元素)为未排序区间。
4. 依次类推,对剩余未排序区间重复上述选择过程,直到所有元素都划分到已排序区间,排序结束。
### 思路 2:代码
```python
class Solution:
def selectionSort(self, nums: [int]) -> [int]:
for i in range(len(nums) - 1):
# 记录未排序区间中最小值的位置
min_i = i
for j in range(i + 1, len(nums)):
if nums[j] < nums[min_i]:
min_i = j
# 如果找到最小值的位置,将 i 位置上元素与最小值位置上的元素进行交换
if i != min_i:
nums[i], nums[min_i] = nums[min_i], nums[i]
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.selectionSort(nums)
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(1)$。
### 思路 3:插入排序(超时)
>**插入排序(Insertion Sort)基本思想**:将数组分为两个区间,左侧为有序区间,右侧为无序区间。每趟从无序区间取出一个元素,然后将其插入到有序区间的适当位置。
假设数组的元素个数为 $n$ 个,则插入排序的算法步骤如下:
1. 初始状态下,有序区间为 $[0, 0]$,无序区间为 $[1, n - 1]$。
2. 第 $1$ 趟插入:
1. 取出无序区间 $[1, n - 1]$ 中的第 $1$ 个元素,即 $nums[1]$。
2. 从右到左遍历有序区间中的元素,将比 $nums[1]$ 小的元素向后移动 $1$ 位。
3. 如果遇到大于或等于 $nums[1]$ 的元素时,说明找到了插入位置,将 $nums[1]$ 插入到该位置。
4. 插入元素后有序区间变为 $[0, 1]$,无序区间变为 $[2, n - 1]$。
3. 第 $2$ 趟插入:
1. 取出无序区间 $[2, n - 1]$ 中的第 $1$ 个元素,即 $nums[2]$。
2. 从右到左遍历有序区间中的元素,将比 $nums[2]$ 小的元素向后移动 $1$ 位。
3. 如果遇到大于或等于 $nums[2]$ 的元素时,说明找到了插入位置,将 $nums[2]$ 插入到该位置。
4. 插入元素后有序区间变为 $[0, 2]$,无序区间变为 $[3, n - 1]$。
4. 依次类推,对剩余无序区间中的元素重复上述插入过程,直到所有元素都插入到有序区间中,排序结束。
### 思路 3:代码
```python
class Solution:
def insertionSort(self, nums: [int]) -> [int]:
# 遍历无序区间
for i in range(1, len(nums)):
temp = nums[i]
j = i
# 从右至左遍历有序区间
while j > 0 and nums[j - 1] > temp:
# 将有序区间中插入位置右侧的所有元素依次右移一位
nums[j] = nums[j - 1]
j -= 1
# 将该元素插入到适当位置
nums[j] = temp
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.insertionSort(nums)
```
### 思路 3:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(1)$。
### 思路 4:希尔排序(通过)
> **希尔排序(Shell Sort)基本思想**:将整个数组切按照一定的间隔取值划分为若干个子数组,每个子数组分别进行插入排序。然后逐渐缩小间隔进行下一轮划分子数组和对子数组进行插入排序。直至最后一轮排序间隔为 $1$,对整个数组进行插入排序。
假设数组的元素个数为 $n$ 个,则希尔排序的算法步骤如下:
1. 确定一个元素间隔数 $gap$。
2. 将参加排序的数组按此间隔数从第 $1$ 个元素开始一次分成若干个子数组,即分别将所有位置相隔为 $gap$ 的元素视为一个子数组。
3. 在各个子数组中采用某种排序算法(例如插入排序算法)进行排序。
4. 减少间隔数,并重新将整个数组按新的间隔数分成若干个子数组,再分别对各个子数组进行排序。
5. 依次类推,直到间隔数 $gap$ 值为 $1$,最后进行一次排序,排序结束。
### 思路 4:代码
```python
class Solution:
def shellSort(self, nums: [int]) -> [int]:
size = len(nums)
gap = size // 2
# 按照 gap 分组
while gap > 0:
# 对每组元素进行插入排序
for i in range(gap, size):
# temp 为每组中无序数组第 1 个元素
temp = nums[i]
j = i
# 从右至左遍历每组中的有序数组元素
while j >= gap and nums[j - gap] > temp:
# 将每组有序数组中插入位置右侧的元素依次在组中右移一位
nums[j] = nums[j - gap]
j -= gap
# 将该元素插入到适当位置
nums[j] = temp
# 缩小 gap 间隔
gap = gap // 2
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.shellSort(nums)
```
### 思路 4:复杂度分析
- **时间复杂度**:介于 $O(n \times \log n)$ 与 $O(n^2)$ 之间。
- **空间复杂度**:$O(1)$。
### 思路 5:归并排序(通过)
> **归并排序(Merge Sort)基本思想**:采用经典的分治策略,先递归地将当前数组平均分成两半,然后将有序数组两两合并,最终合并成一个有序数组。
假设数组的元素个数为 $n$ 个,则归并排序的算法步骤如下:
1. **分解过程**:先递归地将当前数组平均分成两半,直到子数组长度为 $1$。
1. 找到数组中心位置 $mid$,从中心位置将数组分成左右两个子数组 $left\_nums$、$right\_nums$。
2. 对左右两个子数组 $left\_nums$、$right\_nums$ 分别进行递归分解。
3. 最终将数组分解为 $n$ 个长度均为 $1$ 的有序子数组。
2. **归并过程**:从长度为 $1$ 的有序子数组开始,依次将有序数组两两合并,直到合并成一个长度为 $n$ 的有序数组。
1. 使用数组变量 $nums$ 存放合并后的有序数组。
2. 使用两个指针 $left\_i$、$right\_i$ 分别指向两个有序子数组 $left\_nums$、$right\_nums$ 的开始位置。
3. 比较两个指针指向的元素,将两个有序子数组中较小元素依次存入到结果数组 $nums$ 中,并将指针移动到下一位置。
4. 重复步骤 $3$,直到某一指针到达子数组末尾。
5. 将另一个子数组中的剩余元素存入到结果数组 $nums$ 中。
6. 返回合并后的有序数组 $nums$。
### 思路 5:代码
```python
class Solution:
# 合并过程
def merge(self, left_nums: [int], right_nums: [int]):
nums = []
left_i, right_i = 0, 0
while left_i < len(left_nums) and right_i < len(right_nums):
# 将两个有序子数组中较小元素依次插入到结果数组中
if left_nums[left_i] < right_nums[right_i]:
nums.append(left_nums[left_i])
left_i += 1
else:
nums.append(right_nums[right_i])
right_i += 1
# 如果左子数组有剩余元素,则将其插入到结果数组中
while left_i < len(left_nums):
nums.append(left_nums[left_i])
left_i += 1
# 如果右子数组有剩余元素,则将其插入到结果数组中
while right_i < len(right_nums):
nums.append(right_nums[right_i])
right_i += 1
# 返回合并后的结果数组
return nums
# 分解过程
def mergeSort(self, nums: [int]) -> [int]:
# 数组元素个数小于等于 1 时,直接返回原数组
if len(nums) <= 1:
return nums
mid = len(nums) // 2 # 将数组从中间位置分为左右两个数组
left_nums = self.mergeSort(nums[0: mid]) # 递归将左子数组进行分解和排序
right_nums = self.mergeSort(nums[mid:]) # 递归将右子数组进行分解和排序
return self.merge(left_nums, right_nums) # 把当前数组组中有序子数组逐层向上,进行两两合并
def sortArray(self, nums: [int]) -> [int]:
return self.mergeSort(nums)
```
### 思路 5:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(n)$。
### 思路 6:快速排序(通过)
> **快速排序(Quick Sort)基本思想**:采用经典的分治策略,选择数组中某个元素作为基准数,通过一趟排序将数组分为独立的两个子数组,一个子数组中所有元素值都比基准数小,另一个子数组中所有元素值都比基准数大。然后再按照同样的方式递归的对两个子数组分别进行快速排序,以达到整个数组有序。
假设数组的元素个数为 $n$ 个,则快速排序的算法步骤如下:
1. **哨兵划分**:选取一个基准数,将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。
1. 从当前数组中找到一个基准数 $pivot$(这里以当前数组第 $1$ 个元素作为基准数,即 $pivot = nums[low]$)。
2. 使用指针 $i$ 指向数组开始位置,指针 $j$ 指向数组末尾位置。
3. 从右向左移动指针 $j$,找到第 $1$ 个小于基准值的元素。
4. 从左向右移动指针 $i$,找到第 $1$ 个大于基准数的元素。
5. 交换指针 $i$、指针 $j$ 指向的两个元素位置。
6. 重复第 $3 \sim 5$ 步,直到指针 $i$ 和指针 $j$ 相遇时停止,最后将基准数放到两个子数组交界的位置上。
2. **递归分解**:完成哨兵划分之后,对划分好的左右子数组分别进行递归排序。
1. 按照基准数的位置将数组拆分为左右两个子数组。
2. 对每个子数组分别重复「哨兵划分」和「递归分解」,直到各个子数组只有 $1$ 个元素,排序结束。
### 思路 6:代码
```python
import random
class Solution:
# 随机哨兵划分:从 nums[low: high + 1] 中随机挑选一个基准数,并进行移位排序
def randomPartition(self, nums: [int], low: int, high: int) -> int:
# 随机挑选一个基准数
i = random.randint(low, high)
# 将基准数与最低位互换
nums[i], nums[low] = nums[low], nums[i]
# 以最低位为基准数,然后将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上
return self.partition(nums, low, high)
# 哨兵划分:以第 1 位元素 nums[low] 为基准数,然后将比基准数小的元素移动到基准数左侧,将比基准数大的元素移动到基准数右侧,最后将基准数放到正确位置上
def partition(self, nums: [int], low: int, high: int) -> int:
# 以第 1 位元素为基准数
pivot = nums[low]
i, j = low, high
while i < j:
# 从右向左找到第 1 个小于基准数的元素
while i < j and nums[j] >= pivot:
j -= 1
# 从左向右找到第 1 个大于基准数的元素
while i < j and nums[i] <= pivot:
i += 1
# 交换元素
nums[i], nums[j] = nums[j], nums[i]
# 将基准数放到正确位置上
nums[j], nums[low] = nums[low], nums[j]
return j
def quickSort(self, nums: [int], low: int, high: int) -> [int]:
if low < high:
# 按照基准数的位置,将数组划分为左右两个子数组
pivot_i = self.partition(nums, low, high)
# 对左右两个子数组分别进行递归快速排序
self.quickSort(nums, low, pivot_i - 1)
self.quickSort(nums, pivot_i + 1, high)
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.quickSort(nums, 0, len(nums) - 1)
```
### 思路 6:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(n)$。
### 思路 7:堆排序(通过)
> **堆排序(Heap sort)基本思想**:借用「堆结构」所设计的排序算法。将数组转化为大顶堆,重复从大顶堆中取出数值最大的节点,并让剩余的堆结构继续维持大顶堆性质。
假设数组的元素个数为 $n$ 个,则堆排序的算法步骤如下:
1. **构建初始大顶堆**:
1. 定义一个数组实现的堆结构,将原始数组的元素依次存入堆结构的数组中(初始顺序不变)。
2. 从数组的中间位置开始,从右至左,依次通过「下移调整」将数组转换为一个大顶堆。
2. **交换元素,调整堆**:
1. 交换堆顶元素(第 $1$ 个元素)与末尾(最后 $1$ 个元素)的位置,交换完成后,堆的长度减 $1$。
2. 交换元素之后,由于堆顶元素发生了改变,需要从根节点开始,对当前堆进行「下移调整」,使其保持堆的特性。
3. **重复交换和调整堆**:
1. 重复第 $2$ 步,直到堆的大小为 $1$ 时,此时大顶堆的数组已经完全有序。
### 思路 7:代码
```python
class Solution:
# 调整为大顶堆
def heapify(self, arr, index, end):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子节点
max_index = index
if arr[left] > arr[max_index]:
max_index = left
if right <= end and arr[right] > arr[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
arr[index], arr[max_index] = arr[max_index], arr[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 初始化大顶堆
def buildMaxHeap(self, arr):
size = len(arr)
# (size-2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
self.heapify(arr, i, size - 1)
return arr
# 升序堆排序,思路如下:
# 1. 先建立大顶堆
# 2. 让堆顶最大元素与最后一个交换,然后调整第一个元素到倒数第二个元素,这一步获取最大值
# 3. 再交换堆顶元素与倒数第二个元素,然后调整第一个元素到倒数第三个元素,这一步获取第二大值
# 4. 以此类推,直到最后一个元素交换之后完毕。
def maxHeapSort(self, arr):
self.buildMaxHeap(arr)
size = len(arr)
for i in range(size):
arr[0], arr[size-i-1] = arr[size-i-1], arr[0]
self.heapify(arr, 0, size-i-2)
return arr
def sortArray(self, nums: List[int]) -> List[int]:
return self.maxHeapSort(nums)
```
### 思路 7:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(1)$。
### 思路 8:计数排序(通过)
> **计数排序(Counting Sort)基本思想**:通过统计数组中每个元素在数组中出现的次数,根据这些统计信息将数组元素有序的放置到正确位置,从而达到排序的目的。
假设数组的元素个数为 $n$ 个,则计数排序的算法步骤如下:
1. **计算排序范围**:遍历数组,找出待排序序列中最大值元素 $nums\_max$ 和最小值元素 $nums\_min$,计算出排序范围为 $nums\_max - nums\_min + 1$。
2. **定义计数数组**:定义一个大小为排序范围的计数数组 $counts$,用于统计每个元素的出现次数。其中:
1. 数组的索引值 $num - nums\_min$ 表示元素的值为 $num$。
2. 数组的值 $counts[num - nums\_min]$ 表示元素 $num$ 的出现次数。
3. **对数组元素进行计数统计**:遍历待排序数组 $nums$,对每个元素在计数数组中进行计数,即将待排序数组中「每个元素值减去最小值」作为索引,将「对计数数组中的值」加 $1$,即令 $counts[num - nums\_min]$ 加 $1$。
4. **生成累积计数数组**:从 $counts$ 中的第 $1$ 个元素开始,每一项累家前一项和。此时 $counts[num - nums\_min]$ 表示值为 $num$ 的元素在排序数组中最后一次出现的位置。
5. **逆序填充目标数组**:逆序遍历数组 $nums$,将每个元素 $num$ 填入正确位置。
6. 将其填充到结果数组 $res$ 的索引 $counts[num - nums\_min]$ 处。
7. 放入后,令累积计数数组中对应索引减 $1$,从而得到下个元素 $num$ 的放置位置。
### 思路 8:代码
```python
class Solution:
def countingSort(self, nums: [int]) -> [int]:
# 计算待排序数组中最大值元素 nums_max 和最小值元素 nums_min
nums_min, nums_max = min(nums), max(nums)
# 定义计数数组 counts,大小为 最大值元素 - 最小值元素 + 1
size = nums_max - nums_min + 1
counts = [0 for _ in range(size)]
# 统计值为 num 的元素出现的次数
for num in nums:
counts[num - nums_min] += 1
# 生成累积计数数组
for i in range(1, size):
counts[i] += counts[i - 1]
# 反向填充目标数组
res = [0 for _ in range(len(nums))]
for i in range(len(nums) - 1, -1, -1):
num = nums[i]
# 根据累积计数数组,将 num 放在数组对应位置
res[counts[num - nums_min] - 1] = num
# 将 num 的对应放置位置减 1,从而得到下个元素 num 的放置位置
counts[nums[i] - nums_min] -= 1
return res
def sortArray(self, nums: [int]) -> [int]:
return self.countingSort(nums)
```
### 思路 8:复杂度分析
- **时间复杂度**:$O(n + k)$。其中 $k$ 代表待排序序列的值域。
- **空间复杂度**:$O(k)$。其中 $k$ 代表待排序序列的值域。
### 思路 9:桶排序(通过)
> **桶排序(Bucket Sort)基本思想**:将待排序数组中的元素分散到若干个「桶」中,然后对每个桶中的元素再进行单独排序。
假设数组的元素个数为 $n$ 个,则桶排序的算法步骤如下:
1. **确定桶的数量**:根据待排序数组的值域范围,将数组划分为 $k$ 个桶,每个桶可以看做是一个范围区间。
2. **分配元素**:遍历待排序数组元素,将每个元素根据大小分配到对应的桶中。
3. **对每个桶进行排序**:对每个非空桶内的元素单独排序(使用插入排序、归并排序、快排排序等算法)。
4. **合并桶内元素**:将排好序的各个桶中的元素按照区间顺序依次合并起来,形成一个完整的有序数组。
### 思路 9:代码
```python
class Solution:
def insertionSort(self, nums: [int]) -> [int]:
# 遍历无序区间
for i in range(1, len(nums)):
temp = nums[i]
j = i
# 从右至左遍历有序区间
while j > 0 and nums[j - 1] > temp:
# 将有序区间中插入位置右侧的元素依次右移一位
nums[j] = nums[j - 1]
j -= 1
# 将该元素插入到适当位置
nums[j] = temp
return nums
def bucketSort(self, nums: [int], bucket_size=5) -> [int]:
# 计算待排序序列中最大值元素 nums_max、最小值元素 nums_min
nums_min, nums_max = min(nums), max(nums)
# 定义桶的个数为 (最大值元素 - 最小值元素) // 每个桶的大小 + 1
bucket_count = (nums_max - nums_min) // bucket_size + 1
# 定义桶数组 buckets
buckets = [[] for _ in range(bucket_count)]
# 遍历待排序数组元素,将每个元素根据大小分配到对应的桶中
for num in nums:
buckets[(num - nums_min) // bucket_size].append(num)
# 对每个非空桶内的元素单独排序,排序之后,按照区间顺序依次合并到 res 数组中
res = []
for bucket in buckets:
self.insertionSort(bucket)
res.extend(bucket)
# 返回结果数组
return res
def sortArray(self, nums: [int]) -> [int]:
return self.bucketSort(nums)
```
### 思路 9:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n + m)$。$m$ 为桶的个数。
### 思路 10:基数排序(提交解答错误,普通基数排序只适合非负数)
> **基数排序(Radix Sort)基本思想**:将整数按位数切割成不同的数字,然后从低位开始,依次到高位,逐位进行排序,从而达到排序的目的。
我们以最低位优先法为例,讲解一下基数排序的算法步骤。
1. **确定排序的最大位数**:遍历数组元素,获取数组最大值元素,并取得对应位数。
2. **从最低位(个位)开始,到最高位为止,逐位对每一位进行排序**:
1. 定义一个长度为 $10$ 的桶数组 $buckets$,每个桶分别代表 $0 \sim 9$ 中的 $1$ 个数字。
2. 按照每个元素当前位上的数字,将元素放入对应数字的桶中。
3. 清空原始数组,然后按照桶的顺序依次取出对应元素,重新加入到原始数组中。
### 思路 10:代码
```python
class Solution:
def radixSort(self, nums: [int]) -> [int]:
# 桶的大小为所有元素的最大位数
size = len(str(max(nums)))
# 从最低位(个位)开始,逐位遍历每一位
for i in range(size):
# 定义长度为 10 的桶数组 buckets,每个桶分别代表 0 ~ 9 中的 1 个数字。
buckets = [[] for _ in range(10)]
# 遍历数组元素,按照每个元素当前位上的数字,将元素放入对应数字的桶中。
for num in nums:
buckets[num // (10 ** i) % 10].append(num)
# 清空原始数组
nums.clear()
# 按照桶的顺序依次取出对应元素,重新加入到原始数组中。
for bucket in buckets:
for num in bucket:
nums.append(num)
# 完成排序,返回结果数组
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.radixSort(nums)
```
### 思路 10:复杂度分析
- **时间复杂度**:$O(n \times k)$。其中 $n$ 是待排序元素的个数,$k$ 是数字位数。$k$ 的大小取决于数字位的选择(十进制位、二进制位)和待排序元素所属数据类型全集的大小。
- **空间复杂度**:$O(n + k)$。
================================================
FILE: docs/solutions/0900-0999/sort-array-by-parity-ii.md
================================================
# [0922. 按奇偶排序数组 II](https://leetcode.cn/problems/sort-array-by-parity-ii/)
- 标签:数组、双指针、排序
- 难度:简单
## 题目链接
- [0922. 按奇偶排序数组 II - 力扣](https://leetcode.cn/problems/sort-array-by-parity-ii/)
## 题目大意
**描述**:
给定一个非负整数数组 $nums$,$nums$ 中一半整数是「奇数」,一半整数是「偶数」。
对数组进行排序,以便当 $nums[i]$ 为奇数时,i 也是「奇数」;当 $nums[i]$ 为偶数时, $i$ 也是「偶数」。
**要求**:
你可以返回「任何满足上述条件的数组作为答案」。
**说明**:
- $2 \le nums.length \le 2 * 10^{4}$。
- $nums.length$ 是偶数。
- $nums$ 中一半是偶数。
- $0 \le nums[i] \le 10^{3}$。
- 进阶:可以不使用额外空间解决问题吗?
**示例**:
- 示例 1:
```python
输入:nums = [4,2,5,7]
输出:[4,5,2,7]
解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
```
- 示例 2:
```python
输入:nums = [2,3]
输出:[2,3]
```
## 解题思路
### 思路 1:双指针
使用两个指针 $even$ 和 $odd$,分别指向偶数索引和奇数索引。
1. $even$ 指针从 $0$ 开始,每次移动 $2$ 步,寻找偶数索引上的奇数。
2. $odd$ 指针从 $1$ 开始,每次移动 $2$ 步,寻找奇数索引上的偶数。
3. 当 $even$ 指向奇数且 $odd$ 指向偶数时,交换两个元素。
4. 重复上述过程,直到遍历完整个数组。
### 思路 1:代码
```python
class Solution:
def sortArrayByParityII(self, nums: List[int]) -> List[int]:
n = len(nums)
even, odd = 0, 1 # even 指向偶数索引,odd 指向奇数索引
while even < n and odd < n:
# 偶数索引找到奇数
while even < n and nums[even] % 2 == 0:
even += 2
# 奇数索引找到偶数
while odd < n and nums[odd] % 2 == 1:
odd += 2
# 交换位置不对的元素
if even < n and odd < n:
nums[even], nums[odd] = nums[odd], nums[even]
return nums
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0900-0999/sort-array-by-parity.md
================================================
# [0905. 按奇偶排序数组](https://leetcode.cn/problems/sort-array-by-parity/)
- 标签:数组、双指针、排序
- 难度:简单
## 题目链接
- [0905. 按奇偶排序数组 - 力扣](https://leetcode.cn/problems/sort-array-by-parity/)
## 题目大意
**描述**:
给定一个整数数组 $nums$,将 $nums$ 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。
**要求**:
返回满足此条件的「任一数组」作为答案。
**说明**:
- $1 \le nums.length \le 5000$。
- $0 \le nums[i] \le 5000$。
**示例**:
- 示例 1:
```python
输入:nums = [3,1,2,4]
输出:[2,4,3,1]
解释:[4,2,3,1]、[2,4,1,3] 和 [4,2,1,3] 也会被视作正确答案。
```
- 示例 2:
```python
输入:nums = [0]
输出:[0]
```
## 解题思路
### 思路 1:双指针
使用双指针法,一个指针 $left$ 指向数组开头,一个指针 $right$ 指向数组末尾。
1. 当 $left$ 指向的元素为偶数时,$left$ 右移。
2. 当 $right$ 指向的元素为奇数时,$right$ 左移。
3. 当 $left$ 指向奇数且 $right$ 指向偶数时,交换两个元素。
4. 重复上述过程,直到 $left \ge right$。
### 思路 1:代码
```python
class Solution:
def sortArrayByParity(self, nums: List[int]) -> List[int]:
left, right = 0, len(nums) - 1
# 双指针,左边放偶数,右边放奇数
while left < right:
# 左指针找到奇数
while left < right and nums[left] % 2 == 0:
left += 1
# 右指针找到偶数
while left < right and nums[right] % 2 == 1:
right -= 1
# 交换奇数和偶数
if left < right:
nums[left], nums[right] = nums[right], nums[left]
left += 1
right -= 1
return nums
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0900-0999/squares-of-a-sorted-array.md
================================================
# [0977. 有序数组的平方](https://leetcode.cn/problems/squares-of-a-sorted-array/)
- 标签:数组、双指针、排序
- 难度:简单
## 题目链接
- [0977. 有序数组的平方 - 力扣](https://leetcode.cn/problems/squares-of-a-sorted-array/)
## 题目大意
**描述**:给定一个按「非递减顺序」排序的整数数组 $nums$。
**要求**:返回「每个数字的平方」组成的新数组,要求也按「非递减顺序」排序。
**说明**:
- 要求使用时间复杂度为 $O(n)$ 的算法解决本问题。
- $1 \le nums.length \le 10^4$。
- $-10^4 \le nums[i] \le 10^4$。
- $nums$ 已按非递减顺序排序。
**示例**:
- 示例 1:
```python
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
```
- 示例 2:
```python
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
```
## 解题思路
### 思路 1:对撞指针
原数组是按「非递减顺序」排序的,可能会存在负数元素。但是无论是否存在负数,数字的平方最大值一定在原数组的两端。题目要求返回的新数组也要按照「非递减顺序」排序。那么,我们可以利用双指针,从两端向中间移动,然后不断将数的平方最大值填入数组。具体做法如下:
- 使用两个指针 $left$、$right$。$left$ 指向数组第一个元素位置,$right$ 指向数组最后一个元素位置。再定义 $index = len(nums) - 1$ 作为答案数组填入顺序的索引值。$res$ 作为答案数组。
- 比较 $nums[left]$ 与 $nums[right]$ 的绝对值大小。大的就是平方最大的的那个数。
- 如果 $abs(nums[right])$ 更大,则将其填入答案数组对应位置,并令 `right -= 1`。
- 如果 $abs(nums[left])$ 更大,则将其填入答案数组对应位置,并令 `left += 1`。
- 令 $index -= 1$。
- 直到 $left == right$,最后将 $nums[left]$ 填入答案数组对应位置。
返回答案数组 $res$。
### 思路 1:代码
```python
class Solution:
def sortedSquares(self, nums: List[int]) -> List[int]:
size = len(nums)
left, right = 0, size - 1
index = size - 1
res = [0 for _ in range(size)]
while left < right:
if abs(nums[left]) < abs(nums[right]):
res[index] = nums[right] * nums[right]
right -= 1
else:
res[index] = nums[left] * nums[left]
left += 1
index -= 1
res[index] = nums[left] * nums[left]
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 中的元素数量。
- **空间复杂度**:$O(1)$,不考虑最终返回值的空间占用。
### 思路 2:排序算法
可以通过各种排序算法来对平方后的数组进行排序。以快速排序为例,具体步骤如下:
1. 遍历数组,将数组中各个元素变为平方项。
2. 从数组中找到一个基准数。
3. 然后将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧,从而把数组拆分为左右两个部分。
4. 再对左右两个部分分别重复第 2、3 步,直到各个部分只有一个数,则排序结束。
### 思路 2:代码
```python
import random
class Solution:
def randomPartition(self, arr: [int], low: int, high: int):
i = random.randint(low, high)
arr[i], arr[high] = arr[high], arr[i]
return self.partition(arr, low, high)
def partition(self, arr: [int], low: int, high: int):
i = low - 1
pivot = arr[high]
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quickSort(self, arr, low, high):
if low < high:
pi = self.randomPartition(arr, low, high)
self.quickSort(arr, low, pi - 1)
self.quickSort(arr, pi + 1, high)
return arr
def sortedSquares(self, nums: List[int]) -> List[int]:
for i in range(len(nums)):
nums[i] = nums[i] * nums[i]
return self.quickSort(nums, 0, len(nums) - 1)
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 为数组 $nums$ 中的元素数量。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/0900-0999/stamping-the-sequence.md
================================================
# [0936. 戳印序列](https://leetcode.cn/problems/stamping-the-sequence/)
- 标签:栈、贪心、队列、字符串
- 难度:困难
## 题目链接
- [0936. 戳印序列 - 力扣](https://leetcode.cn/problems/stamping-the-sequence/)
## 题目大意
**描述**:
你想要用小写字母组成一个目标字符串 $target$。
开始的时候,序列由 $target.length$ 个 `'?'` 记号组成。而你有一个小写字母印章 $stamp$。
在每个回合,你可以将印章放在序列上,并将序列中的每个字母替换为印章上的相应字母。你最多可以进行 $10 \times target.length$ 个回合。
举个例子,如果初始序列为 `"?????"`,而你的印章 $stamp$ 是 `"abc"`,那么在第一回合,你可以得到 `"abc??"`、`"?abc?"`、`"??abc"`。(请注意,印章必须完全包含在序列的边界内才能盖下去。)
**要求**:
如果可以印出序列,那么返回一个数组,该数组由每个回合中被印下的最左边字母的索引组成。如果不能印出序列,就返回一个空数组。
例如,如果序列是 `"ababc"`,印章是 `"abc"`,那么我们就可以返回与操作 `"?????"` -> `"abc??"` -> `"ababc"` 相对应的答案 $[0, 2]$;
另外,如果可以印出序列,那么需要保证可以在 $10 \times target.length$ 个回合内完成。任何超过此数字的答案将不被接受。
**说明**:
- $1 \le stamp.length \le target.length \le 10^{3}$
- $stamp$ 和 $target$ 只包含小写字母。
**示例**:
- 示例 1:
```python
输入:stamp = "abc", target = "ababc"
输出:[0,2]
([1,0,2] 以及其他一些可能的结果也将作为答案被接受)
```
- 示例 2:
```python
输入:stamp = "abca", target = "aabcaca"
输出:[3,0,1]
```
## 解题思路
### 思路 1:逆向思维 + 贪心
这道题正向思考比较困难,我们可以逆向思考:从目标字符串 $target$ 逆推回全 `?` 的初始状态。
1. 将 $target$ 转换为字符数组,方便修改。
2. 从后往前,每次找到一个可以被"擦除"的位置(即该位置的字符可以被替换为 `?`)。
3. 一个位置可以被擦除的条件是:该位置的字符与 $stamp$ 匹配,或者已经是 `?`。
4. 每次擦除后,记录擦除的起始位置。
5. 重复上述过程,直到所有字符都变成 `?`。
6. 最后将记录的位置反转,即为答案。
### 思路 1:代码
```python
class Solution:
def movesToStamp(self, stamp: str, target: str) -> List[int]:
m, n = len(stamp), len(target)
target = list(target) # 转换为列表方便修改
result = []
visited = [False] * n # 标记是否已经被戳印覆盖
stars = 0 # 记录 '?' 的数量
# 检查从位置 pos 开始是否可以戳印
def canStamp(pos):
changed = False
for i in range(m):
if target[pos + i] == '?':
continue
if target[pos + i] != stamp[i]:
return False
changed = True
return changed
# 从位置 pos 开始戳印(将字符替换为 '?')
def doStamp(pos):
nonlocal stars
for i in range(m):
if target[pos + i] != '?':
target[pos + i] = '?'
stars += 1
# 不断尝试戳印,直到所有字符都变成 '?'
while stars < n:
stamped = False
for i in range(n - m + 1):
if not visited[i] and canStamp(i):
doStamp(i)
result.append(i)
visited[i] = True
stamped = True
# 如果一轮下来没有任何戳印,说明无法完成
if not stamped:
return []
# 反转结果(因为是逆向推导)
return result[::-1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times (n - m))$,其中 $n$ 是 $target$ 的长度,$m$ 是 $stamp$ 的长度。最多需要 $n$ 次戳印,每次需要检查 $O(n - m)$ 个位置。
- **空间复杂度**:$O(n)$,需要存储 $target$ 的字符数组和访问标记数组。
================================================
FILE: docs/solutions/0900-0999/string-without-aaa-or-bbb.md
================================================
# [0984. 不含 AAA 或 BBB 的字符串](https://leetcode.cn/problems/string-without-aaa-or-bbb/)
- 标签:贪心、字符串
- 难度:中等
## 题目链接
- [0984. 不含 AAA 或 BBB 的字符串 - 力扣](https://leetcode.cn/problems/string-without-aaa-or-bbb/)
## 题目大意
**描述**:
给定两个整数 $a$ 和 $b$。
**要求**:
返回 任意 字符串 $s$,要求满足:
- $s$ 的长度为 $a + b$,且正好包含 $a$ 个 `'a'` 字母与 $b$ 个 `'b'` 字母;
- 子串 `'aaa'` 没有出现在 $s$ 中;
- 子串 `'bbb'` 没有出现在 $s$ 中。
**说明**:
- $0 \le a, b \le 10^{3}$。
- 对于给定的 $a$ 和 $b$,保证存在满足要求的 $s$。
**示例**:
- 示例 1:
```python
输入:a = 1, b = 2
输出:"abb"
解释:"abb", "bab" 和 "bba" 都是正确答案。
```
- 示例 2:
```python
输入:a = 4, b = 1
输出:"aabaa"
```
## 解题思路
### 思路 1:贪心
使用贪心策略构造字符串:优先放置数量较多的字符,但要避免连续三个相同字符。
1. 每次选择剩余数量较多的字符。
2. 如果该字符已经连续出现两次,则必须放置另一个字符。
3. 否则,如果该字符数量较多,可以连续放置两个;如果数量相近,则只放置一个。
4. 重复上述过程,直到所有字符都放置完毕。
### 思路 1:代码
```python
class Solution:
def strWithout3a3b(self, a: int, b: int) -> str:
result = []
while a > 0 or b > 0:
# 判断是否需要写入 'a'
write_a = False
n = len(result)
# 如果最后两个字符是 'bb',必须写 'a'
if n >= 2 and result[-1] == result[-2] == 'b':
write_a = True
# 如果最后两个字符是 'aa',不能写 'a'
elif n >= 2 and result[-1] == result[-2] == 'a':
write_a = False
# 否则,选择剩余数量较多的字符
else:
write_a = a >= b
if write_a:
result.append('a')
a -= 1
else:
result.append('b')
b -= 1
return ''.join(result)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(a + b)$,需要构造长度为 $a + b$ 的字符串。
- **空间复杂度**:$O(1)$,不考虑结果字符串的空间。
================================================
FILE: docs/solutions/0900-0999/subarray-sums-divisible-by-k.md
================================================
# [974. 和可被 K 整除的子数组](https://leetcode.cn/problems/subarray-sums-divisible-by-k/)
- 标签:数组、哈希表、前缀和
- 难度:中等
## 题目链接
- [974. 和可被 K 整除的子数组 - 力扣](https://leetcode.cn/problems/subarray-sums-divisible-by-k/)
## 题目大意
给定一个整数数组 `nums` 和一个整数 `k`。
要求:返回其中元素之和可被 `k` 整除的(连续、非空)子数组的数目。
## 解题思路
先考虑暴力计算子数组和,外层两重循环,遍历所有连续子数组,然后最内层再计算一下子数组的和。部分代码如下:
```python
for i in range(len(nums)):
for j in range(i + 1):
sum = countSum(i, j)
```
这样下来时间复杂度就是 $O(n^3)$ 了。下一步是想办法降低时间复杂度。
先用一重循环遍历数组,计算出数组 `nums` 中前 i 个元素的和(前缀和),保存到一维数组 `pre_sum` 中,那么对于任意 `[j..i]` 的子数组 的和为 `pre_sum[i] - pre_sum[j - 1]`。这样计算子数组和的时间复杂度降为了 $O(1)$。总体时间复杂度为 $O(n^2)$。
由于我们只关心和为 `k` 出现的次数,不关心具体的解,可以使用哈希表来加速运算。
`pre_sum[i]` 的定义是前 `i` 个元素和,则 `[j..i]` 子数组和可以被 `k` 整除可以转换为:`(pre_sum[i] - pre_sum[j - 1])% k == 0`。再转换一下:`pre_sum[i] % k == pre_sum[j - 1] % k`。
所以,我们只需要统计满足 `pre_sum[i] % k == pre_sum[j - 1] % k` 条件的组合个数。具体做法如下:
使用 `pre_sum` 变量记录前缀和(代表 `pre_sum[i]`)。使用哈希表 `pre_dic` 记录 `pre_sum[i] % k` 出现的次数。键值对为 `pre_sum[i] : count`。
- 从左到右遍历数组,计算当前前缀和并对 `k` 取余,即 `pre_sum = (pre_sum + nums[i]) % k`。
- 如果 `pre_sum` 在哈希表中,则答案个数累加上 `pre_dic[pre_sum]`。同时 `pre_sum` 个数累加 1,即 `pre_dic[pre_sum] += 1`。
- 如果 `pre_sum` 不在哈希表中,则 `pre_sum` 个数记为 1,即 `pre_dic[pre_sum] += 1`。
- 最后输出答案个数。
## 代码
```python
class Solution:
def subarraysDivByK(self, nums: List[int], k: int) -> int:
pre_sum = 0
ans = 0
nums_dict = {0: 1}
for i in range(len(nums)):
pre_sum = (pre_sum + nums[i]) % k
if pre_sum < 0:
pre_sum += k
if pre_sum in nums_dict:
ans += nums_dict[pre_sum]
nums_dict[pre_sum] += 1
else:
nums_dict[pre_sum] = 1
return ans
```
================================================
FILE: docs/solutions/0900-0999/subarrays-with-k-different-integers.md
================================================
# [0992. K 个不同整数的子数组](https://leetcode.cn/problems/subarrays-with-k-different-integers/)
- 标签:数组、哈希表、计数、滑动窗口
- 难度:困难
## 题目链接
- [0992. K 个不同整数的子数组 - 力扣](https://leetcode.cn/problems/subarrays-with-k-different-integers/)
## 题目大意
给定一个正整数数组 `nums`,再给定一个整数 `k`。如果 `nums` 的某个子数组中不同整数的个数恰好为 `k`,则称 `nums` 的这个连续、不一定不同的子数组为「好子数组」。
- 例如,`[1, 2, 3, 1, 2]` 中有 3 个不同的整数:`1`,`2` 以及 `3`。
要求:返回 `nums` 中好子数组的数目。
## 解题思路
这道题转换一下思路会更简单。
恰好包含 `k` 个不同整数的连续子数组数量 = 包含小于等于 `k` 个不同整数的连续子数组数量 - 包含小于等于 `k - 1` 个不同整数的连续子数组数量
可以专门写一个方法计算包含小于等于 `k` 个不同整数的连续子数组数量。
计算包含小于等于 `k` 个不同整数的连续子数组数量的方法具体步骤如下:
用滑动窗口 `windows` 来记录不同的整数个数,`windows` 为哈希表类型。
设定两个指针:`left`、`right`,分别指向滑动窗口的左右边界,保证窗口内不超过 `k` 个不同整数。
- 一开始,`left`、`right` 都指向 `0`。
- 将最右侧整数 `nums[right]` 加入当前窗口 `windows` 中,记录该整数个数。
- 如果该窗口中该整数的个数多于 `k` 个,即 `len(windows) > k`,则不断右移 `left`,缩小滑动窗口长度,并更新窗口中对应整数的个数,直到 `len(windows) <= k`。
- 维护更新包含小于等于 `k` 个不同整数的连续子数组数量。每次累加数量为 `right - left + 1`,表示以 `nums[right]` 为结尾的小于等于 `k` 个不同整数的连续子数组数量。
- 然后右移 `right`,直到 `right >= len(nums)` 结束。
- 返回包含小于等于 `k` 个不同整数的连续子数组数量。
## 代码
```python
class Solution:
def subarraysMostKDistinct(self, nums, k):
windows = dict()
left, right = 0, 0
ans = 0
while right < len(nums):
if nums[right] in windows:
windows[nums[right]] += 1
else:
windows[nums[right]] = 1
while len(windows) > k:
windows[nums[left]] -= 1
if windows[nums[left]] == 0:
del windows[nums[left]]
left += 1
ans += right - left + 1
right += 1
return ans
def subarraysWithKDistinct(self, nums: List[int], k: int) -> int:
return self.subarraysMostKDistinct(nums, k) - self.subarraysMostKDistinct(nums, k - 1)
```
================================================
FILE: docs/solutions/0900-0999/sum-of-even-numbers-after-queries.md
================================================
# [0985. 查询后的偶数和](https://leetcode.cn/problems/sum-of-even-numbers-after-queries/)
- 标签:数组、模拟
- 难度:中等
## 题目链接
- [0985. 查询后的偶数和 - 力扣](https://leetcode.cn/problems/sum-of-even-numbers-after-queries/)
## 题目大意
**描述**:
给定一个整数数组 A 和一个查询数组 $queries$。
对于第 $i$ 次查询,有 $val = queries[i][0]$, $index = queries[i][1]$,我们会把 $val$ 加到 $A[index]$ 上。然后,第 $i$ 次查询的答案是 A 中偶数值的和。
(此处给定的 $index = queries[i][1]$ 是从 0 开始的索引,每次查询都会永久修改数组 A。)
**要求**:
返回所有查询的答案。你的答案应当以数组 $answer$ 给出,$answer[i]$ 为第 $i$ 次查询的答案。
**说明**:
- $1 \le A.length \le 10^{000}$。
- $-10^{000} \le A[i] \le 10^{000}$。
- $1 \le queries.length \le 10^{000}$。
- $-10^{000} \le queries[i][0] \le 10^{000}$。
- $0 \le queries[i][1] \lt A.length$。
**示例**:
- 示例 1:
```python
输入:A = [1,2,3,4], queries = [[1,0],[-3,1],[-4,0],[2,3]]
输出:[8,6,2,4]
解释:
开始时,数组为 [1,2,3,4]。
将 1 加到 A[0] 上之后,数组为 [2,2,3,4],偶数值之和为 2 + 2 + 4 = 8。
将 -3 加到 A[1] 上之后,数组为 [2,-1,3,4],偶数值之和为 2 + 4 = 6。
将 -4 加到 A[0] 上之后,数组为 [-2,-1,3,4],偶数值之和为 -2 + 4 = 2。
将 2 加到 A[3] 上之后,数组为 [-2,-1,3,6],偶数值之和为 -2 + 6 = 4。
```
## 解题思路
### 思路 1:模拟
先计算初始的偶数和,然后对每次查询进行模拟。
1. 先遍历数组 $nums$,计算初始的偶数和 $even\_sum$。
2. 对于每次查询 $[val, index]$:
- 如果 $nums[index]$ 是偶数,从 $even\_sum$ 中减去它。
- 更新 $nums[index] = nums[index] + val$。
- 如果更新后的 $nums[index]$ 是偶数,将它加到 $even\_sum$ 中。
- 将当前的 $even\_sum$ 加入结果数组。
3. 返回结果数组。
### 思路 1:代码
```python
class Solution:
def sumEvenAfterQueries(self, nums: List[int], queries: List[List[int]]) -> List[int]:
# 计算初始偶数和
even_sum = sum(x for x in nums if x % 2 == 0)
result = []
for val, index in queries:
# 如果原来是偶数,先从和中减去
if nums[index] % 2 == 0:
even_sum -= nums[index]
# 更新值
nums[index] += val
# 如果更新后是偶数,加到和中
if nums[index] % 2 == 0:
even_sum += nums[index]
result.append(even_sum)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + q)$,其中 $n$ 是数组 $nums$ 的长度,$q$ 是查询数组 $queries$ 的长度。
- **空间复杂度**:$O(1)$,不考虑结果数组的空间。
================================================
FILE: docs/solutions/0900-0999/sum-of-subarray-minimums.md
================================================
# [0907. 子数组的最小值之和](https://leetcode.cn/problems/sum-of-subarray-minimums/)
- 标签:栈、数组、动态规划、单调栈
- 难度:中等
## 题目链接
- [0907. 子数组的最小值之和 - 力扣](https://leetcode.cn/problems/sum-of-subarray-minimums/)
## 题目大意
**描述**:
给定一个整数数组 $arr$。
**要求**:
找到 `min(b)` 的总和,其中 $b$ 的范围为 $arr$ 的每个(连续)子数组。
由于答案可能很大,因此 返回答案模 $10^9 + 7$。
**说明**:
- $1 \le arr.length \le 3 \times 10^{4}$。
- $1 \le arr[i] \le 3 \times 10^{4}$。
**示例**:
- 示例 1:
```python
输入:arr = [3,1,2,4]
输出:17
解释:
子数组为 [3],[1],[2],[4],[3,1],[1,2],[2,4],[3,1,2],[1,2,4],[3,1,2,4]。
最小值为 3,1,2,4,1,1,2,1,1,1,和为 17。
```
- 示例 2:
```python
输入:arr = [11,81,94,43,3]
输出:444
```
## 解题思路
### 思路 1:单调栈
对于每个元素 $arr[i]$,我们需要找到它作为最小值的所有子数组。使用单调栈可以高效地找到每个元素左边和右边第一个比它小的元素。
1. 使用单调栈找到每个元素 $arr[i]$ 左边第一个比它小的元素位置 $left[i]$。
2. 使用单调栈找到每个元素 $arr[i]$ 右边第一个比它小的元素位置 $right[i]$。
3. 对于元素 $arr[i]$,它作为最小值的子数组个数为 $(i - left[i]) \times (right[i] - i)$。
4. 累加所有元素的贡献:$arr[i] \times (i - left[i]) \times (right[i] - i)$。
### 思路 1:代码
```python
class Solution:
def sumSubarrayMins(self, arr: List[int]) -> int:
MOD = 10**9 + 7
n = len(arr)
# left[i] 表示左边第一个小于 arr[i] 的位置
left = [-1] * n
# right[i] 表示右边第一个小于 arr[i] 的位置
right = [n] * n
# 单调递增栈,找左边第一个更小的元素
stack = []
for i in range(n):
while stack and arr[stack[-1]] > arr[i]:
stack.pop()
if stack:
left[i] = stack[-1]
stack.append(i)
# 单调递增栈,找右边第一个更小的元素
stack = []
for i in range(n - 1, -1, -1):
while stack and arr[stack[-1]] >= arr[i]: # 注意这里用 >= 避免重复计算
stack.pop()
if stack:
right[i] = stack[-1]
stack.append(i)
# 计算每个元素的贡献
result = 0
for i in range(n):
# arr[i] 作为最小值的子数组个数
count = (i - left[i]) * (right[i] - i)
result = (result + arr[i] * count) % MOD
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $arr$ 的长度。每个元素最多入栈和出栈各一次。
- **空间复杂度**:$O(n)$,需要使用栈和辅助数组。
================================================
FILE: docs/solutions/0900-0999/super-palindromes.md
================================================
# [0906. 超级回文数](https://leetcode.cn/problems/super-palindromes/)
- 标签:数学、字符串、枚举
- 难度:困难
## 题目链接
- [0906. 超级回文数 - 力扣](https://leetcode.cn/problems/super-palindromes/)
## 题目大意
**描述**:
如果一个正整数自身是回文数,而且它也是一个回文数的平方,那么我们称这个数为「超级回文数」。
现在,给定两个以字符串形式表示的正整数 $left$ 和 $right$,
**要求**:
统计并返回区间 $[left, right]$ 中的「超级回文数」的数目。
**说明**:
- $1 \le left.length, right.length \le 18$。
- $left$ 和 $right$ 仅由数字(0 - 9)组成。
- $left$ 和 $right$ 不含前导零。
- $left$ 和 $right$ 表示的整数在区间 $[1, 10^{18} - 1]$ 内。
- $left$ 小于等于 $right$。
**示例**:
- 示例 1:
```python
输入:left = "4", right = "1000"
输出:4
解释:4、9、121 和 484 都是超级回文数。
注意 676 不是超级回文数:26 * 26 = 676 ,但是 26 不是回文数。
```
- 示例 2:
```python
输入:left = "1", right = "2"
输出:1
```
## 解题思路
### 思路 1:枚举 + 回文数构造
超级回文数是回文数的平方,且平方后仍是回文数。我们可以枚举所有可能的回文数,然后检查其平方是否也是回文数。
1. 由于 $left$ 和 $right$ 最大为 $10^{18}$,所以回文数最大为 $\sqrt{10^{18}} = 10^9$。
2. 我们可以通过构造前半部分来生成回文数,这样只需要枚举到 $10^5$ 左右。
3. 对于每个构造的回文数,计算其平方,检查是否在范围内且是回文数。
### 思路 1:代码
```python
class Solution:
def superpalindromesInRange(self, left: str, right: str) -> int:
L, R = int(left), int(right)
# 判断是否为回文数
def is_palindrome(x):
s = str(x)
return s == s[::-1]
count = 0
# 枚举回文数的前半部分(长度为 1 到 5)
for length in range(1, 6):
# 枚举前半部分的所有可能值
for i in range(10**(length - 1), 10**length):
s = str(i)
# 构造奇数长度的回文数
for root in [int(s + s[-2::-1]), int(s + s[::-1])]:
square = root * root
# 检查平方是否在范围内且是回文数
if L <= square <= R and is_palindrome(square):
count += 1
return count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\sqrt[4]{R})$,其中 $R$ 是右边界。需要枚举所有可能的回文数根。
- **空间复杂度**:$O(\log R)$,用于存储字符串。
================================================
FILE: docs/solutions/0900-0999/tallest-billboard.md
================================================
# [0956. 最高的广告牌](https://leetcode.cn/problems/tallest-billboard/)
- 标签:数组、动态规划
- 难度:困难
## 题目链接
- [0956. 最高的广告牌 - 力扣](https://leetcode.cn/problems/tallest-billboard/)
## 题目大意
**描述**:
你正在安装一个广告牌,并希望它高度最大。这块广告牌将有两个钢制支架,两边各一个。每个钢支架的高度必须相等。
你有一堆可以焊接在一起的钢筋 $rods$。举个例子,如果钢筋的长度为 1、2 和 3,则可以将它们焊接在一起形成长度为 6 的支架。
**要求**:
返回「广告牌的最大可能安装高度」。如果没法安装广告牌,请返回 0。
**说明**:
- $0 \le rods.length \le 20$。
- $1 \le rods[i] \le 10^{3}$。
- $sum(rods[i]) \le 5000$。
**示例**:
- 示例 1:
```python
输入:[1,2,3,6]
输出:6
解释:我们有两个不相交的子集 {1,2,3} 和 {6},它们具有相同的和 sum = 6。
```
- 示例 2:
```python
输入:[1,2,3,4,5,6]
输出:10
解释:我们有两个不相交的子集 {2,3,5} 和 {4,6},它们具有相同的和 sum = 10。
```
## 解题思路
### 思路 1:动态规划
这道题可以转化为:将钢筋分成两组,使得两组的和相等,求最大的和。
使用动态规划,$dp[diff]$ 表示当两组差值为 $diff$ 时,较小组的最大高度。
1. 初始化 $dp[0] = 0$,表示差值为 $0$ 时,较小组高度为 $0$。
2. 对于每根钢筋 $rod$,有三种选择:
- 不选:不更新 $dp$。
- 放入较大组:$dp[diff + rod] = \max(dp[diff + rod], dp[diff])$。
- 放入较小组:$dp[|diff - rod|] = \max(dp[|diff - rod|], dp[diff] + \min(diff, rod))$。
3. 最终答案为 $dp[0]$。
### 思路 1:代码
```python
class Solution:
def tallestBillboard(self, rods: List[int]) -> int:
# dp[diff] 表示差值为 diff 时,较小组的最大高度
dp = {0: 0}
for rod in rods:
new_dp = dp.copy()
for diff, smaller in dp.items():
# 将 rod 加到较大组
new_diff = diff + rod
new_dp[new_diff] = max(new_dp.get(new_diff, 0), smaller)
# 将 rod 加到较小组
if rod > diff:
# 较小组变成较大组
new_diff = rod - diff
new_smaller = smaller + diff
else:
# 较小组仍是较小组
new_diff = diff - rod
new_smaller = smaller + rod
new_dp[new_diff] = max(new_dp.get(new_diff, 0), new_smaller)
dp = new_dp
return dp[0]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times S)$,其中 $n$ 是钢筋数量,$S$ 是所有钢筋长度之和。
- **空间复杂度**:$O(S)$,需要存储所有可能的差值状态。
================================================
FILE: docs/solutions/0900-0999/three-equal-parts.md
================================================
# [0927. 三等分](https://leetcode.cn/problems/three-equal-parts/)
- 标签:数组、数学
- 难度:困难
## 题目链接
- [0927. 三等分 - 力扣](https://leetcode.cn/problems/three-equal-parts/)
## 题目大意
**描述**:
给定一个由 0 和 1 组成的数组 $arr$ ,将数组分成 3 个非空的部分 ,使得所有这些部分表示相同的二进制值。
**要求**:
如果可以做到,请返回任何 $[i, j]$,其中 $i+1 < j$,这样一来:
- $arr[0], arr[1], ..., arr[i]$ 为第一部分;
- $arr[i + 1], arr[i + 2], ..., arr[j - 1]$ 为第二部分;
- $arr[j], arr[j + 1], ..., arr[arr.length - 1]$ 为第三部分。
- 这三个部分所表示的二进制值相等。
如果无法做到,就返回 $[-1, -1]$。
注意,在考虑每个部分所表示的二进制时,应当将其看作一个整体。例如,$[1,1,0]$ 表示十进制中的 6,而不会是 3。此外,前导零也是被允许的,所以 $[0,1,1]$ 和 $[1,1]$ 表示相同的值。
**说明**:
- $3 \le arr.length \le 3 * 10^{4}$。
- $arr[i]$ 是 0 或 1。
**示例**:
- 示例 1:
```python
输入:arr = [1,0,1,0,1]
输出:[0,3]
```
- 示例 2:
```python
输入:arr = [1,1,0,1,1]
输出:[-1,-1]
示例 3:
输入:arr = [1,1,0,0,1]
输出:[0,2]
```
## 解题思路
### 思路 1:数学 + 双指针
要将数组分成三个表示相同二进制值的部分,首先需要统计 $1$ 的个数。
1. 统计数组中 $1$ 的总个数 $ones$。
2. 如果 $ones$ 不能被 $3$ 整除,返回 $[-1, -1]$。
3. 如果 $ones = 0$,说明全是 $0$,返回 $[0, n - 1]$。
4. 每部分应该有 $ones / 3$ 个 $1$。
5. 找到三部分的起始位置(第一个 $1$ 的位置)。
6. 从最后一部分的第一个 $1$ 开始,向前匹配三部分,确保它们表示相同的二进制值。
7. 最后一部分的尾部 $0$ 决定了前两部分的尾部 $0$ 的数量。
### 思路 1:代码
```python
class Solution:
def threeEqualParts(self, arr: List[int]) -> List[int]:
n = len(arr)
ones = sum(arr)
# 如果 1 的个数不能被 3 整除,无法分成三等分
if ones % 3 != 0:
return [-1, -1]
# 如果全是 0,任意分割都可以
if ones == 0:
return [0, n - 1]
# 每部分应该有 k 个 1
k = ones // 3
# 找到三部分的第一个 1 的位置
first = second = third = -1
count = 0
for i in range(n):
if arr[i] == 1:
count += 1
if count == 1:
first = i
elif count == k + 1:
second = i
elif count == 2 * k + 1:
third = i
break
# 从第三部分开始,向前匹配
while third < n:
if arr[first] != arr[second] or arr[second] != arr[third]:
return [-1, -1]
first += 1
second += 1
third += 1
# 返回分割点
return [first - 1, second]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $arr$ 的长度。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0900-0999/time-based-key-value-store.md
================================================
# [0981. 基于时间的键值存储](https://leetcode.cn/problems/time-based-key-value-store/)
- 标签:设计、哈希表、字符串、二分查找
- 难度:中等
## 题目链接
- [0981. 基于时间的键值存储 - 力扣](https://leetcode.cn/problems/time-based-key-value-store/)
## 题目大意
**描述**:
设计一个基于时间的键值数据结构,该结构可以在不同时间戳存储对应同一个键的多个值,并针对特定时间戳检索键对应的值。
**要求**:
实现 TimeMap 类:
- `TimeMap()` 初始化数据结构对象
- `void set(String key, String value, int timestamp)` 存储给定时间戳 $timestamp$ 时的键 $key$ 和值 $value$。
- `String get(String key, int timestamp)` 返回一个值,该值在之前调用了 `set`,其中 $timestamp\_prev \le timestamp$。如果有多个这样的值,它将返回与最大 $timestamp\_prev$ 关联的值。如果没有值,则返回空字符串(`""`)。
**说明**:
- $1 \le key.length, value.length \le 10^{3}$。
- key 和 value 由小写英文字母和数字组成。
- $1 \le timestamp \le 10^{7}$。
- `set` 操作中的时间戳 timestamp 都是严格递增的。
- 最多调用 `set` 和 `get` 操作 $2 \times 10^{5}$ 次。
**示例**:
- 示例 1:
```python
输入:
["TimeMap", "set", "get", "get", "set", "get", "get"]
[[], ["foo", "bar", 1], ["foo", 1], ["foo", 3], ["foo", "bar2", 4], ["foo", 4], ["foo", 5]]
输出:
[null, null, "bar", "bar", null, "bar2", "bar2"]
解释:
TimeMap timeMap = new TimeMap();
timeMap.set("foo", "bar", 1); // 存储键 "foo" 和值 "bar" ,时间戳 timestamp = 1
timeMap.get("foo", 1); // 返回 "bar"
timeMap.get("foo", 3); // 返回 "bar", 因为在时间戳 3 和时间戳 2 处没有对应 "foo" 的值,所以唯一的值位于时间戳 1 处(即 "bar") 。
timeMap.set("foo", "bar2", 4); // 存储键 "foo" 和值 "bar2" ,时间戳 timestamp = 4
timeMap.get("foo", 4); // 返回 "bar2"
timeMap.get("foo", 5); // 返回 "bar2"
```
## 解题思路
### 思路 1:哈希表 + 二分查找
使用哈希表存储每个键对应的时间戳和值的列表,由于时间戳是递增的,可以使用二分查找。
1. 使用哈希表 $data$,键为字符串 $key$,值为列表,列表中每个元素是 $(timestamp, value)$ 元组。
2. `set` 操作:将 $(timestamp, value)$ 添加到 $data[key]$ 的列表末尾。
3. `get` 操作:在 $data[key]$ 的列表中二分查找小于等于 $timestamp$ 的最大时间戳。
### 思路 1:代码
```python
class TimeMap:
def __init__(self):
# 哈希表,key -> [(timestamp, value), ...]
self.data = collections.defaultdict(list)
def set(self, key: str, value: str, timestamp: int) -> None:
# 直接添加到列表末尾(时间戳递增)
self.data[key].append((timestamp, value))
def get(self, key: str, timestamp: int) -> str:
if key not in self.data:
return ""
pairs = self.data[key]
# 二分查找小于等于 timestamp 的最大时间戳
left, right = 0, len(pairs) - 1
result = ""
while left <= right:
mid = (left + right) // 2
if pairs[mid][0] <= timestamp:
result = pairs[mid][1]
left = mid + 1
else:
right = mid - 1
return result
# Your TimeMap object will be instantiated and called as such:
# obj = TimeMap()
# obj.set(key,value,timestamp)
# param_2 = obj.get(key,timestamp)
```
### 思路 1:复杂度分析
- **时间复杂度**:`set` 操作为 $O(1)$,`get` 操作为 $O(\log n)$,其中 $n$ 是该键对应的时间戳数量。
- **空间复杂度**:$O(N)$,其中 $N$ 是所有 `set` 操作的总次数。
================================================
FILE: docs/solutions/0900-0999/triples-with-bitwise-and-equal-to-zero.md
================================================
# [0982. 按位与为零的三元组](https://leetcode.cn/problems/triples-with-bitwise-and-equal-to-zero/)
- 标签:位运算、数组、哈希表
- 难度:困难
## 题目链接
- [0982. 按位与为零的三元组 - 力扣](https://leetcode.cn/problems/triples-with-bitwise-and-equal-to-zero/)
## 题目大意
**描述**:给定一个整数数组 $nums$。
**要求**:返回其中「按位与三元组」的数目。
**说明**:
- **按位与三元组**:由下标 $(i, j, k)$ 组成的三元组,并满足下述全部条件:
- $0 \le i < nums.length$。
- $0 \le j < nums.length$。
- $0 \le k < nums.length$。
- $nums[i] \text{ \& } nums[j] \text{ \& } nums[k] == 0$ ,其中 $\text{ \& }$ 表示按位与运算符。
- $1 \le nums.length \le 1000$。
- $0 \le nums[i] < 2^{16}$。
**示例**:
- 示例 1:
```python
输入:nums = [2,1,3]
输出:12
解释:可以选出如下 i, j, k 三元组:
(i=0, j=0, k=1) : 2 & 2 & 1
(i=0, j=1, k=0) : 2 & 1 & 2
(i=0, j=1, k=1) : 2 & 1 & 1
(i=0, j=1, k=2) : 2 & 1 & 3
(i=0, j=2, k=1) : 2 & 3 & 1
(i=1, j=0, k=0) : 1 & 2 & 2
(i=1, j=0, k=1) : 1 & 2 & 1
(i=1, j=0, k=2) : 1 & 2 & 3
(i=1, j=1, k=0) : 1 & 1 & 2
(i=1, j=2, k=0) : 1 & 3 & 2
(i=2, j=0, k=1) : 3 & 2 & 1
(i=2, j=1, k=0) : 3 & 1 & 2
```
- 示例 2:
```python
输入:nums = [0,0,0]
输出:27
```
## 解题思路
### 思路 1:枚举
最直接的方法是使用三重循环直接枚举 $(i, j, k)$,然后再判断 $nums[i] \text{ \& } nums[j] \text{ \& } nums[k]$ 是否为 $0$。但是这样做的时间复杂度为 $O(n^3)$。
从题目中可以看出 $nums[i]$ 的值域范围为 $[0, 2^{16}]$,而 $2^{16} = 65536$。所以我们可以按照下面步骤优化时间复杂度:
1. 先使用两重循环枚举 $(i, j)$,计算出 $nums[i] \text{ \& } nums[j]$ 的值,将其存入一个大小为 $2^{16}$ 的数组或者哈希表 $cnts$ 中,并记录每个 $nums[i] \text{ \& } nums[j]$ 值出现的次数。
2. 然后遍历该数组或哈希表,再使用一重循环遍历 $k$,找出所有满足 $nums[k] \text{ \& } x == 0$ 的 $x$,并将其对应数量 $cnts[x]$ 累积到答案 $ans$ 中。
3. 最后返回答案 $ans$ 即可。
### 思路 1:代码
```python
class Solution:
def countTriplets(self, nums: List[int]) -> int:
states = 1 << 16
cnts = [0 for _ in range(states)]
for num_x in nums:
for num_y in nums:
cnts[num_x & num_y] += 1
ans = 0
for num in nums:
for x in range(states):
if num & x == 0:
ans += cnts[x]
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 + 2^{16} \times n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(2^{16})$。
### 思路 2:枚举 + 优化
第一步跟思路 1 一样,我们先使用两重循环枚举 $(i, j)$,计算出 $nums[i] \text{ \& } nums[j]$ 的值,将其存入一个大小为 $2^{16}$ 的数组或者哈希表 $cnts$ 中,并记录每个 $nums[i] \text{ \& } nums[j]$ 值出现的次数。
接下来我们对思路 1 中的第二步进行优化,在思路 1 中,我们是通过枚举数组或哈希表的方式得到 $x$ 的,这里我们换一种方法。
使用一重循环遍历 $k$,对于 $nums[k]$,我们先计算出 $nums[k]$ 的补集,即将 $nums[k]$ 与 $2^{16} - 1$(二进制中 $16$ 个 $1$)进行按位异或操作,得到 $nums[k]$ 的补集 $com$。如果 $nums[k] \text{ \& } x == 0$,则 $x$ 一定是 $com$ 的子集。
换句话说,$x$ 中 $1$ 的位置一定与 $nums[k]$ 中 $1$ 的位置不同,如果 $nums[k]$ 中第 $m$ 位为 $1$,则 $x$ 中第 $m$ 位一定为 $0$。
接下来我们通过下面的方式来枚举子集:
1. 定义子集为 $sub$,初始时赋值为 $com$,即:$sub = com$。
2. 令 $sub$ 减 $1$,然后与 $com$ 做按位与操作,得到下一个子集,即:$sub = (sub - 1) \text{ \& } com$。
3. 不断重复第 $2$ 步,直到 $sub$ 为空集时为止。
这种方法能枚举子集的原理是:$sub$ 减 $1$ 会将最低位的 $1$ 改为 $0$,而比这个 $1$ 更低位的 $0$ 都改为了 $1$。此时再与 $com$ 做按位与操作,就会过保留原本高位上的 $1$,滤掉当前最低位的 $1$,并且保留比这个 $1$ 更低位上的原有的 $1$,也就得到嘞下一个子集。
举个例子,比如补集 $com$ 为 $(00010110)_2$:
1. 初始 $sub = (00010110)_2$。
2. 令其减 $1$ 后为 $(00010101)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00010100)_2$,即:$(00010101)_2 \text{ \& } (00010110)_2$)。
3. 令其减 $1$ 后为 $(00010011)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00010010)_2$,即: $(00010011)_2 \text{ \& } (00010110)_2$。
4. 令其减 $1$ 后为 $(00010001)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00010000)_2$,即:$(00010001)_2 \text{ \& } (00010110)_2$。
5. 令其减 $1$ 后为 $(00001111)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00000110)_2$,即:$(00001111)_2 \text{ \& } (00010110)_2$。
6. 令其减 $1$ 后为 $(00000101)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00000100)_2$,即:$(00000101)_2 \text{ \& } (00010110)_2$。
7. 令其减 $1$ 后为 $(00000011)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00000010)_2$,即:$(00000011)_2 \text{ \& } (00010110)_2$。
8. 令其减 $1$ 后为 $(00000001)_2$,然后与 $com$ 做按位与操作,得到下一个子集 $sub = (00000000)_2$,即:$(00000001)_2 \text{ \& } (00010110)_2$。
9. $sub$ 变为了空集。
### 思路 2:代码
```python
class Solution:
def countTriplets(self, nums: List[int]) -> int:
states = 1 << 16
cnts = [0 for _ in range(states)]
for num_x in nums:
for num_y in nums:
cnts[num_x & num_y] += 1
ans = 0
for num in nums:
com = num ^ 0xffff # com: num 的补集
sub = com # sub: 子集
while True:
ans += cnts[sub]
if sub == 0:
break
sub = (sub - 1) & com
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^2 + 2^{16} \times n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(2^{16})$。
## 参考资料
- 【题解】[按位与为零的三元组 - 按位与为零的三元组](https://leetcode.cn/problems/triples-with-bitwise-and-equal-to-zero/solution/an-wei-yu-wei-ling-de-san-yuan-zu-by-lee-gjud/)
- 【题解】[有技巧的枚举 + 常数优化(Python/Java/C++/Go) - 按位与为零的三元组](https://leetcode.cn/problems/triples-with-bitwise-and-equal-to-zero/solution/you-ji-qiao-de-mei-ju-chang-shu-you-hua-daxit/)
================================================
FILE: docs/solutions/0900-0999/unique-email-addresses.md
================================================
# [0929. 独特的电子邮件地址](https://leetcode.cn/problems/unique-email-addresses/)
- 标签:数组、哈希表、字符串
- 难度:简单
## 题目链接
- [0929. 独特的电子邮件地址 - 力扣](https://leetcode.cn/problems/unique-email-addresses/)
## 题目大意
**描述**:
每个「有效电子邮件地址」都由一个「本地名」和一个「域名」组成,以 `'@'` 符号分隔。除小写字母之外,电子邮件地址还可以含有一个或多个 `'.'` 或 `'+'`。
- 例如,在 `alice@leetcode.com` 中, $alice$ 是 本地名 ,而 `leetcode.com` 是「域名」。
如果在电子邮件地址的「本地名」部分中的某些字符之间添加句点(`'.'`),则发往那里的邮件将会转发到本地名中没有点的同一地址。请注意,此规则「不适用于域名」。
- 例如,`"alice.z@leetcode.com"` 和 `"alicez@leetcode.com"` 会转发到同一电子邮件地址。
如果在「本地名」中添加加号(`'+'`),则会忽略第一个加号后面的所有内容。这允许过滤某些电子邮件。同样,此规则「不适用于域名」。
- 例如 `m.y+name@email.com` 将转发到 `my@email.com`。
可以同时使用这两个规则。
给定一个字符串数组 $emails$,我们会向每个 $emails[i]$ 发送一封电子邮件。
**要求**:
返回实际收到邮件的不同地址数目。
**说明**:
- $1 \le emails.length \le 10^{3}$。
- $1 \le emails[i].length \le 10^{3}$。
- $emails[i]$ 由小写英文字母、`'+'`、`'.'` 和 `'@'` 组成。
- 每个 $emails[i]$ 都包含有且仅有一个 `'@'` 字符。
- 所有本地名和域名都不为空。
- 本地名不会以 `'+'` 字符作为开头。
- 域名以 `".com"` 后缀结尾。
- 域名在 `".com"` 后缀前至少包含一个字符。
**示例**:
- 示例 1:
```python
输入:emails = ["test.email+alex@leetcode.com","test.e.mail+bob.cathy@leetcode.com","testemail+david@lee.tcode.com"]
输出:2
解释:实际收到邮件的是 "testemail@leetcode.com" 和 "testemail@lee.tcode.com"。
```
- 示例 2:
```python
输入:emails = ["a@leetcode.com","b@leetcode.com","c@leetcode.com"]
输出:3
```
## 解题思路
### 思路 1:哈希表 + 字符串处理
对每个邮箱地址进行规范化处理,然后使用哈希表统计不同的邮箱地址数量。
1. 将邮箱地址按 `@` 分割成本地名和域名。
2. 对本地名进行处理:
- 遇到 `+` 时,忽略 `+` 及其后面的所有字符。
- 忽略所有 `.` 字符。
3. 将处理后的本地名和域名组合成规范化的邮箱地址。
4. 使用哈希表统计不同的邮箱地址数量。
### 思路 1:代码
```python
class Solution:
def numUniqueEmails(self, emails: List[str]) -> int:
unique_emails = set()
for email in emails:
# 分割本地名和域名
local, domain = email.split('@')
# 处理本地名
# 1. 遇到 '+' 时截断
if '+' in local:
local = local[:local.index('+')]
# 2. 移除所有 '.'
local = local.replace('.', '')
# 组合规范化的邮箱地址
normalized = local + '@' + domain
unique_emails.add(normalized)
return len(unique_emails)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$ 是邮箱地址的数量,$m$ 是每个邮箱地址的平均长度。
- **空间复杂度**:$O(n \times m)$,需要存储所有规范化后的邮箱地址。
================================================
FILE: docs/solutions/0900-0999/unique-paths-iii.md
================================================
# [0980. 不同路径 III](https://leetcode.cn/problems/unique-paths-iii/)
- 标签:位运算、数组、回溯、矩阵
- 难度:困难
## 题目链接
- [0980. 不同路径 III - 力扣](https://leetcode.cn/problems/unique-paths-iii/)
## 题目大意
**描述**:
在二维网格 $grid$ 上,有 4 种类型的方格:
- 1 表示起始方格。且只有一个起始方格。
- 2 表示结束方格,且只有一个结束方格。
- 0 表示我们可以走过的空方格。
- -1 表示我们无法跨越的障碍。
**要求**:
返回在四个方向(上、下、左、右)上行走时,从起始方格到结束方格的不同路径的数目。
**说明**:
- 每一个无障碍方格都要通过一次,但是一条路径中不能重复通过同一个方格。
- $1 \le grid.length \times grid[0].length \le 20$。
**示例**:
- 示例 1:
```python
输入:[[1,0,0,0],[0,0,0,0],[0,0,2,-1]]
输出:2
解释:我们有以下两条路径:
1. (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2)
2. (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2)
```
- 示例 2:
```python
输入:[[1,0,0,0],[0,0,0,0],[0,0,0,2]]
输出:4
解释:我们有以下四条路径:
1. (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2),(2,3)
2. (0,0),(0,1),(1,1),(1,0),(2,0),(2,1),(2,2),(1,2),(0,2),(0,3),(1,3),(2,3)
3. (0,0),(1,0),(2,0),(2,1),(2,2),(1,2),(1,1),(0,1),(0,2),(0,3),(1,3),(2,3)
4. (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2),(2,3)
```
## 解题思路
### 思路 1:回溯
使用回溯法遍历所有可能的路径,统计从起点到终点且经过所有空方格的路径数量。
1. 首先遍历网格,找到起点位置,统计空方格的数量(包括起点和终点)。
2. 从起点开始进行深度优先搜索(DFS):
- 标记当前方格为已访问。
- 如果到达终点,检查是否经过了所有空方格。
- 否则,向四个方向继续搜索。
- 回溯时,恢复当前方格的状态。
3. 返回满足条件的路径数量。
### 思路 1:代码
```python
class Solution:
def uniquePathsIII(self, grid: List[List[int]]) -> int:
m, n = len(grid), len(grid[0])
start_x = start_y = 0
empty_count = 0
# 找到起点,统计空方格数量
for i in range(m):
for j in range(n):
if grid[i][j] == 1:
start_x, start_y = i, j
if grid[i][j] != -1:
empty_count += 1
self.result = 0
def dfs(x, y, count):
# 到达终点
if grid[x][y] == 2:
# 检查是否经过了所有空方格
if count == empty_count:
self.result += 1
return
# 标记为已访问
temp = grid[x][y]
grid[x][y] = -1
# 向四个方向搜索
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if 0 <= nx < m and 0 <= ny < n and grid[nx][ny] != -1:
dfs(nx, ny, count + 1)
# 回溯
grid[x][y] = temp
dfs(start_x, start_y, 1)
return self.result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(4^{m \times n})$,其中 $m$ 和 $n$ 是网格的行数和列数。最坏情况下需要遍历所有可能的路径。
- **空间复杂度**:$O(m \times n)$,递归调用栈的深度最多为网格中方格的数量。
================================================
FILE: docs/solutions/0900-0999/univalued-binary-tree.md
================================================
# [0965. 单值二叉树](https://leetcode.cn/problems/univalued-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [0965. 单值二叉树 - 力扣](https://leetcode.cn/problems/univalued-binary-tree/)
## 题目大意
**描述**:
给定一棵二叉树的根节点 $root$。如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
**要求**:
如果给定的树是单值二叉树,返回 true;否则返回 false。
**说明**:
- 给定树的节点数范围是 $[1, 10^{3}]$。
- 每个节点的值都是整数,范围为 $[0, 99]$。
**示例**:
- 示例 1:
```python
输入:[1,1,1,1,1,null,1]
输出:true
```
- 示例 2:
```python
输入:[2,2,2,5,2]
输出:false
```
## 解题思路
### 思路 1:深度优先搜索
使用深度优先搜索遍历整棵树,检查每个节点的值是否与根节点的值相同。
1. 如果当前节点为空,返回 $True$。
2. 如果当前节点的值与根节点的值不同,返回 $False$。
3. 递归检查左子树和右子树。
4. 只有当左右子树都是单值二叉树时,整棵树才是单值二叉树。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isUnivalTree(self, root: Optional[TreeNode]) -> bool:
if not root:
return True
def dfs(node, val):
# 空节点返回 True
if not node:
return True
# 当前节点值不等于目标值,返回 False
if node.val != val:
return False
# 递归检查左右子树
return dfs(node.left, val) and dfs(node.right, val)
return dfs(root, root.val)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是二叉树的节点数量。需要遍历所有节点。
- **空间复杂度**:$O(h)$,其中 $h$ 是二叉树的高度。递归调用栈的深度为树的高度。
================================================
FILE: docs/solutions/0900-0999/valid-mountain-array.md
================================================
# [0941. 有效的山脉数组](https://leetcode.cn/problems/valid-mountain-array/)
- 标签:数组
- 难度:简单
## 题目链接
- [0941. 有效的山脉数组 - 力扣](https://leetcode.cn/problems/valid-mountain-array/)
## 题目大意
**描述**:
如果 $arr$ 满足下述条件,那么它是一个山脉数组:
- $arr.length \ge 3$
- 在 0 < i < arr.length - 1$ 条件下,存在 $i$ 使得:
- $arr[0] < arr[1] < ... arr[i-1] < arr[i]$
- $arr[i] > arr[i+1] > ... > arr[arr.length - 1]$
给定一个整数数组 $arr$。
**要求**:
如果 $arr$ 是有效的山脉数组就返回 true,否则返回 false。
**说明**:
- $1 \le arr.length \le 10^{4}$。
- $0 \le arr[i] \le 10^{4}$。
**示例**:
- 示例 1:
```python
输入:arr = [2,1]
输出:false
```
- 示例 2:
```python
输入:arr = [3,5,5]
输出:false
```
## 解题思路
### 思路 1:双指针
使用双指针分别从左右两端向中间移动,找到山峰位置。
1. 如果数组长度小于 $3$,直接返回 $False$。
2. 使用指针 $left$ 从左向右移动,找到第一个不再递增的位置。
3. 使用指针 $right$ 从右向左移动,找到第一个不再递减的位置。
4. 检查 $left$ 和 $right$ 是否相等,且不在数组的两端(必须有上升和下降部分)。
### 思路 1:代码
```python
class Solution:
def validMountainArray(self, arr: List[int]) -> bool:
n = len(arr)
# 长度小于 3,不可能是山脉数组
if n < 3:
return False
left = 0
# 从左向右找到山峰
while left < n - 1 and arr[left] < arr[left + 1]:
left += 1
# 山峰不能在两端
if left == 0 or left == n - 1:
return False
# 从山峰向右检查是否递减
while left < n - 1 and arr[left] > arr[left + 1]:
left += 1
# 如果到达数组末尾,说明是有效的山脉数组
return left == n - 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是数组 $arr$ 的长度。
- **空间复杂度**:$O(1)$,只使用了常数级别的额外空间。
================================================
FILE: docs/solutions/0900-0999/valid-permutations-for-di-sequence.md
================================================
# [0903. DI 序列的有效排列](https://leetcode.cn/problems/valid-permutations-for-di-sequence/)
- 标签:字符串、动态规划、前缀和
- 难度:困难
## 题目链接
- [0903. DI 序列的有效排列 - 力扣](https://leetcode.cn/problems/valid-permutations-for-di-sequence/)
## 题目大意
**描述**:
给定一个长度为 $n$ 的字符串 $s$,其中 $s[i]$ 是:
- `"D"` 意味着减少,或者
- `"I"` 意味着增加
「有效排列」是对有 $n + 1$ 个在 $[0, n]$ 范围内的整数的一个排列 $perm$,使得对所有的 $i$:
- 如果 $s[i] == 'D'$,那么 $perm[i] > perm[i+1]$,以及;
- 如果 $s[i] == 'I'$,那么 $perm[i] < perm[i+1]$。
**要求**:
返回「有效排列 $perm$」的数量。因为答案可能很大,所以请返回你的答案对 $10^9 + 7$ 取余。
**说明**:
- $n == s.length$。
- $1 \le n \le 200$。
- $s[i]$ 不是 `'I'` 就是 `'D'`。
**示例**:
- 示例 1:
```python
输入:s = "DID"
输出:5
解释:
(0, 1, 2, 3) 的五个有效排列是:
(1, 0, 3, 2)
(2, 0, 3, 1)
(2, 1, 3, 0)
(3, 0, 2, 1)
(3, 1, 2, 0)
```
- 示例 2:
```python
输入: s = "D"
输出: 1
```
## 解题思路
### 思路 1:动态规划
使用动态规划,$dp[i][j]$ 表示长度为 $i + 1$ 的排列中,最后一个数字在这 $i + 1$ 个数字中排名第 $j$(从小到大排序后的位置)的方案数。
关键理解:
- 对于长度为 $i + 1$ 的排列,我们只关心相对大小关系,可以用 $0$ 到 $i$ 的排列表示。
- $dp[i][j]$ 表示前 $i + 1$ 个位置,最后一个位置的数字在这 $i + 1$ 个数字中排第 $j$ 小的方案数。
状态转移:
- 如果 $s[i - 1] == 'D'$(第 $i - 1$ 个位置大于第 $i$ 个位置):
- 前一个位置的数字必须大于当前位置,即前一个位置排名 $\ge j$
- $dp[i][j] = \sum_{k=j}^{i-1} dp[i-1][k]$
- 如果 $s[i - 1] == 'I'$(第 $i - 1$ 个位置小于第 $i$ 个位置):
- 前一个位置的数字必须小于当前位置,即前一个位置排名 $< j$
- $dp[i][j] = \sum_{k=0}^{j-1} dp[i-1][k]$
### 思路 1:代码
```python
class Solution:
def numPermsDISequence(self, s: str) -> int:
MOD = 10**9 + 7
n = len(s)
# dp[i][j] 表示长度为 i+1 的排列,最后一个数字排名第 j 的方案数
dp = [[0] * (n + 2) for _ in range(n + 2)]
dp[0][0] = 1 # 长度为 1 的排列,只有一个数字,排名第 0
for i in range(n):
for j in range(i + 2): # 长度为 i+2 的排列,排名范围是 0 到 i+1
if s[i] == 'D':
# 前一个位置的数字要大于当前位置
# 前一个位置排名 >= j(因为插入新数字后,排名会变化)
for k in range(j, i + 1):
dp[i + 1][j] = (dp[i + 1][j] + dp[i][k]) % MOD
else: # s[i] == 'I'
# 前一个位置的数字要小于当前位置
# 前一个位置排名 < j
for k in range(j):
dp[i + 1][j] = (dp[i + 1][j] + dp[i][k]) % MOD
# 统计所有可能的结果
result = 0
for j in range(n + 1):
result = (result + dp[n][j]) % MOD
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是字符串 $s$ 的长度。
- **空间复杂度**:$O(n^2)$,需要存储动态规划数组。
### 思路 2:动态规划 + 前缀和优化
在思路 1 的基础上,使用前缀和优化求和过程,将时间复杂度降低到 $O(n^2)$。
### 思路 2:代码
```python
class Solution:
def numPermsDISequence(self, s: str) -> int:
MOD = 10**9 + 7
n = len(s)
# dp[j] 表示当前长度的排列,最后一个数字排名第 j 的方案数
dp = [1] # 初始长度为 1,只有一种方案
for i in range(n):
new_dp = [0] * (i + 2)
if s[i] == 'D':
# 从右向左累加(前缀和)
cumsum = 0
for j in range(i, -1, -1):
cumsum = (cumsum + dp[j]) % MOD
new_dp[j] = cumsum
else: # s[i] == 'I'
# 从左向右累加(前缀和)
cumsum = 0
for j in range(i + 1):
cumsum = (cumsum + dp[j]) % MOD
new_dp[j + 1] = cumsum
dp = new_dp
# 返回所有方案数之和
return sum(dp) % MOD
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 是字符串 $s$ 的长度。
- **空间复杂度**:$O(n)$,使用滚动数组优化空间。
================================================
FILE: docs/solutions/0900-0999/validate-stack-sequences.md
================================================
# [0946. 验证栈序列](https://leetcode.cn/problems/validate-stack-sequences/)
- 标签:栈、数组、模拟
- 难度:中等
## 题目链接
- [0946. 验证栈序列 - 力扣](https://leetcode.cn/problems/validate-stack-sequences/)
## 题目大意
**描述**:给定两个整数序列 `pushed` 和 `popped`,每个序列中的值都不重复。
**要求**:如果第一个序列为空栈的压入顺序,而第二个序列 `popped` 为该栈的压出序列,则返回 `True`,否则返回 `False`。
**说明**:
- $1 \le pushed.length \le 1000$。
- $0 \le pushed[i] \le 1000$。
- $pushed$ 的所有元素互不相同。
- $popped.length == pushed.length$。
- $popped$ 是 $pushed$ 的一个排列。
**示例**:
- 示例 1:
```python
输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1]
输出:true
解释:我们可以按以下顺序执行:
push(1), push(2), push(3), push(4), pop() -> 4,
push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1
```
- 示例 2:
```python
输入:pushed = [1,2,3,4,5], popped = [4,3,5,1,2]
输出:false
解释:1 不能在 2 之前弹出。
```
## 解题思路
### 思路 1:栈
借助一个栈来模拟压入、压出的操作。检测最后是否能模拟成功。
### 思路 1:代码
```python
class Solution:
def validateStackSequences(self, pushed: List[int], popped: List[int]) -> bool:
stack = []
index = 0
for item in pushed:
stack.append(item)
while (stack and stack[-1] == popped[index]):
stack.pop()
index += 1
return len(stack) == 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/0900-0999/verifying-an-alien-dictionary.md
================================================
# [0953. 验证外星语词典](https://leetcode.cn/problems/verifying-an-alien-dictionary/)
- 标签:数组、哈希表、字符串
- 难度:简单
## 题目链接
- [0953. 验证外星语词典 - 力扣](https://leetcode.cn/problems/verifying-an-alien-dictionary/)
## 题目大意
给定一组用外星语书写的单词字符串数组 `words`,以及表示外星字母表的顺序的字符串 `order` 。
要求:判断 `words` 中的单词是否都是按照 `order` 来排序的。如果是,则返回 `True`,否则返回 `False`。
## 解题思路
如果所有单词是按照 `order` 的规则升序排列,则所有单词都符合规则。而判断所有单词是升序排列,只需要两两比较相邻的单词即可。所以我们可以先用哈希表存储所有字母的顺序,然后对所有相邻单词进行两两比较,如果最终是升序排列,则符合要求。具体步骤如下:
- 使用哈希表 `order_map` 存储字母的顺序。
- 遍历单词数组 `words`,比较相邻单词 `word1` 和 `word2` 中所有字母在 `order_map` 中的下标,看是否满足 `word1 <= word2`。
- 如果全部满足,则返回 `True`。如果有不满足的情况,则直接返回 `False`。
## 代码
```python
class Solution:
def isAlienSorted(self, words: List[str], order: str) -> bool:
order_map = dict()
for i in range(len(order)):
order_map[order[i]] = i
for i in range(len(words) - 1):
word1 = words[i]
word2 = words[i + 1]
flag = True
for j in range(min(len(word1), len(word2))):
if word1[j] != word2[j]:
if order_map[word1[j]] > order_map[word2[j]]:
return False
else:
flag = False
break
if flag and len(word1) > len(word2):
return False
return True
```
================================================
FILE: docs/solutions/0900-0999/vertical-order-traversal-of-a-binary-tree.md
================================================
# [0987. 二叉树的垂序遍历](https://leetcode.cn/problems/vertical-order-traversal-of-a-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、哈希表、二叉树、排序
- 难度:困难
## 题目链接
- [0987. 二叉树的垂序遍历 - 力扣](https://leetcode.cn/problems/vertical-order-traversal-of-a-binary-tree/)
## 题目大意
**描述**:
给定二叉树的根结点 $root$ ,请你设计算法计算二叉树的「垂序遍历」序列。
对位于 $(row, col)$ 的每个结点而言,其左右子结点分别位于 $(row + 1, col - 1)$ 和 $(row + 1, col + 1)$。树的根结点位于 $(0, 0)$。
二叉树的「垂序遍历」从最左边的列开始直到最右边的列结束,按列索引每一列上的所有结点,形成一个按出现位置从上到下排序的有序列表。如果同行同列上有多个结点,则按结点的值从小到大进行排序。
**要求**:
返回二叉树的「垂序遍历」序列。
**说明**:
- 树中结点数目总数在范围 $[1, 10^{3}]$ 内。
- $0 \le Node.val \le 10^{3}$。
**示例**:
- 示例 1:
```python
输入:root = [3,9,20,null,null,15,7]
输出:[[9],[3,15],[20],[7]]
解释:
列 -1 :只有结点 9 在此列中。
列 0 :只有结点 3 和 15 在此列中,按从上到下顺序。
列 1 :只有结点 20 在此列中。
列 2 :只有结点 7 在此列中。
```
- 示例 2:
```python
输入:root = [1,2,3,4,5,6,7]
输出:[[4],[2],[1,5,6],[3],[7]]
解释:
列 -2 :只有结点 4 在此列中。
列 -1 :只有结点 2 在此列中。
列 0 :结点 1 、5 和 6 都在此列中。
1 在上面,所以它出现在前面。
5 和 6 位置都是 (2, 0) ,所以按值从小到大排序,5 在 6 的前面。
列 1 :只有结点 3 在此列中。
列 2 :只有结点 7 在此列中。
```
## 解题思路
### 思路 1:深度优先搜索 + 排序
使用深度优先搜索遍历二叉树,记录每个节点的位置 $(row, col)$ 和值,然后按照题目要求排序。
1. 使用 DFS 遍历二叉树,记录每个节点的 $(col, row, val)$。
2. 按照以下规则排序:
- 首先按列 $col$ 从小到大排序。
- 列相同时,按行 $row$ 从小到大排序。
- 行和列都相同时,按值 $val$ 从小到大排序。
3. 将排序后的节点按列分组,返回结果。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def verticalTraversal(self, root: Optional[TreeNode]) -> List[List[int]]:
nodes = [] # 存储 (col, row, val)
def dfs(node, row, col):
if not node:
return
nodes.append((col, row, node.val))
dfs(node.left, row + 1, col - 1)
dfs(node.right, row + 1, col + 1)
dfs(root, 0, 0)
# 按照 col, row, val 排序
nodes.sort()
# 按列分组
result = []
prev_col = float('-inf')
for col, row, val in nodes:
if col != prev_col:
result.append([])
prev_col = col
result[-1].append(val)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \log n)$,其中 $n$ 是二叉树的节点数量。需要遍历所有节点并排序。
- **空间复杂度**:$O(n)$,需要存储所有节点的位置信息。
================================================
FILE: docs/solutions/0900-0999/vowel-spellchecker.md
================================================
# [0966. 元音拼写检查器](https://leetcode.cn/problems/vowel-spellchecker/)
- 标签:数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0966. 元音拼写检查器 - 力扣](https://leetcode.cn/problems/vowel-spellchecker/)
## 题目大意
**描述**:
在给定单词列表 $wordlist$ 的情况下,我们希望实现一个拼写检查器,将查询单词转换为正确的单词。
对于给定的查询单词 $query$,拼写检查器将会处理两类拼写错误:
- 大小写:如果查询匹配单词列表中的某个单词(不区分大小写),则返回的正确单词与单词列表中的大小写相同。
- 例如:`wordlist = ["yellow"]`, `query = "YellOw"`: `correct = "yellow"`
- 例如:`wordlist = ["yellow"]`, `query = "yellow"`: `correct = "Yellow"`
- 例如:`wordlist = ["yellow"]`, `query = "yellow"`: `correct = "yellow"`
- 元音错误:如果在将查询单词中的元音 (`'a'`, `'e'`, `'i'`, `'o'`, `'u'`) 分别替换为任何元音后,能与单词列表中的单词匹配(不区分大小写),则返回的正确单词与单词列表中的匹配项大小写相同。
- 例如:`wordlist = ["yellow"]`, `query = "yollow"`: `correct = "YellOw"`
- 例如:`wordlist = ["yellow"]`, `query = "yeellow"`: `correct = ""` (无匹配项)
- 例如:`wordlist = ["yellow"]`, `query = "yllw"`: `correct = ""` (无匹配项)
此外,拼写检查器还按照以下优先级规则操作:
- 当查询完全匹配单词列表中的某个单词(区分大小写)时,应返回相同的单词。
- 当查询匹配到大小写问题的单词时,您应该返回单词列表中的第一个这样的匹配项。
- 当查询匹配到元音错误的单词时,您应该返回单词列表中的第一个这样的匹配项。
- 如果该查询在单词列表中没有匹配项,则应返回空字符串。
给定一些查询 $queries$。
**要求**:
返回一个单词列表 $answer$,其中 $answer[i]$ 是由查询 $query = queries[i]$ 得到的正确单词。
**说明**:
- $1 \le wordlist.length, queries.length \le 5000$。
- $1 \le wordlist[i].length, queries[i].length \le 7$。
- $wordlist[i]$ 和 $queries[i]$ 只包含英文字母。
**示例**:
- 示例 1:
```python
输入:wordlist = ["KiTe","kite","hare","Hare"], queries = ["kite","Kite","KiTe","Hare","HARE","Hear","hear","keti","keet","keto"]
输出:["kite","KiTe","KiTe","Hare","hare","","","KiTe","","KiTe"]
```
- 示例 2:
```python
输入:wordlist = ["yellow"], queries = ["YellOw"]
输出:["yellow"]
```
## 解题思路
### 思路 1:哈希表
使用三个哈希表分别处理三种匹配情况:完全匹配、大小写匹配、元音匹配。
1. 建立三个哈希表:
- $exact$:存储完全匹配的单词。
- $lower$:存储小写形式的单词(用于大小写匹配)。
- $vowel$:存储元音替换后的单词(用于元音匹配)。
2. 对于每个查询,按优先级依次查找:
- 首先查找完全匹配。
- 其次查找大小写匹配。
- 最后查找元音匹配。
3. 如果都没有匹配,返回空字符串。
### 思路 1:代码
```python
class Solution:
def spellchecker(self, wordlist: List[str], queries: List[str]) -> List[str]:
# 将元音替换为统一字符
def devowel(word):
return ''.join('*' if c in 'aeiouAEIOU' else c for c in word)
# 三个哈希表
exact = set(wordlist) # 完全匹配
lower = {} # 大小写匹配
vowel = {} # 元音匹配
for word in wordlist:
lower_word = word.lower()
vowel_word = devowel(lower_word)
# 只保留第一个匹配的单词
if lower_word not in lower:
lower[lower_word] = word
if vowel_word not in vowel:
vowel[vowel_word] = word
result = []
for query in queries:
# 1. 完全匹配
if query in exact:
result.append(query)
# 2. 大小写匹配
elif query.lower() in lower:
result.append(lower[query.lower()])
# 3. 元音匹配
elif devowel(query.lower()) in vowel:
result.append(vowel[devowel(query.lower())])
# 4. 无匹配
else:
result.append("")
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m + q \times m)$,其中 $n$ 是单词列表的长度,$q$ 是查询列表的长度,$m$ 是单词的平均长度。
- **空间复杂度**:$O(n \times m)$,需要存储所有单词的不同形式。
================================================
FILE: docs/solutions/0900-0999/word-subsets.md
================================================
# [0916. 单词子集](https://leetcode.cn/problems/word-subsets/)
- 标签:数组、哈希表、字符串
- 难度:中等
## 题目链接
- [0916. 单词子集 - 力扣](https://leetcode.cn/problems/word-subsets/)
## 题目大意
**描述**:
给定两个字符串数组 $words1$ 和 $words2$。
现在,如果 $b$ 中的每个字母都出现在 $a$ 中,包括重复出现的字母,那么称字符串 $b$ 是字符串 $a$ 的「子集」。
- 例如,`"wrr"` 是 `"warrior"` 的子集,但不是 `"world"` 的子集。
如果对 $words2$ 中的每一个单词 $b$,$b$ 都是 $a$ 的子集,那么我们称 $words1$ 中的单词 $a$ 是「通用单词」。
**要求**:
以数组形式返回 $words1$ 中所有的「通用」单词。你可以按任意顺序返回答案。
**说明**:
- $1 \le words1.length, words2.length \le 10^{4}$。
- $1 \le words1[i].length, words2[i].length \le 10$。
- $words1[i]$ 和 $words2[i]$ 仅由小写英文字母组成。
- $words1$ 中的所有字符串「互不相同」。
**示例**:
- 示例 1:
```python
输入:words1 = ["amazon","apple","facebook","google","leetcode"], words2 = ["e","o"]
输出:["facebook","google","leetcode"]
```
- 示例 2:
```python
输入:words1 = ["amazon","apple","facebook","google","leetcode"], words2 = ["lc","eo"]
输出:["leetcode"]
```
## 解题思路
### 思路 1:哈希表
对于 $words1$ 中的每个单词,检查它是否包含 $words2$ 中所有单词的字母(包括重复)。
1. 首先统计 $words2$ 中每个字母的最大需求量(对所有单词取并集)。
2. 对于 $words1$ 中的每个单词,统计其字母频率。
3. 检查该单词是否满足 $words2$ 的所有字母需求。
4. 如果满足,将该单词加入结果列表。
### 思路 1:代码
```python
class Solution:
def wordSubsets(self, words1: List[str], words2: List[str]) -> List[str]:
# 统计 words2 中每个字母的最大需求量
max_freq = collections.Counter()
for word in words2:
freq = collections.Counter(word)
for char, count in freq.items():
max_freq[char] = max(max_freq[char], count)
result = []
# 检查 words1 中的每个单词
for word in words1:
freq = collections.Counter(word)
# 检查是否满足所有字母需求
is_universal = True
for char, count in max_freq.items():
if freq[char] < count:
is_universal = False
break
if is_universal:
result.append(word)
return result
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n_1 \times m_1 + n_2 \times m_2)$,其中 $n_1$ 和 $n_2$ 分别是 $words1$ 和 $words2$ 的长度,$m_1$ 和 $m_2$ 是单词的平均长度。
- **空间复杂度**:$O(1)$,字母表大小固定为 $26$。
================================================
FILE: docs/solutions/0900-0999/x-of-a-kind-in-a-deck-of-cards.md
================================================
# [0914. 卡牌分组](https://leetcode.cn/problems/x-of-a-kind-in-a-deck-of-cards/)
- 标签:数组、哈希表、数学、计数、数论
- 难度:简单
## 题目链接
- [0914. 卡牌分组 - 力扣](https://leetcode.cn/problems/x-of-a-kind-in-a-deck-of-cards/)
## 题目大意
**描述**:
给定一副牌,每张牌上都写着一个整数。
此时,你需要选定一个数字 $X$,使我们可以将整副牌按下述规则分成 1 组或更多组:
- 每组都有 $X$ 张牌。
- 组内所有的牌上都写着相同的整数。
**要求**:
仅当你可选的 $X \ge 2$ 时返回 true,否则返回 false。
**说明**:
- $1 \le deck.length \le 10^{4}$。
- $0 \le deck[i] \lt 10^{4}$。
**示例**:
- 示例 1:
```python
输入:deck = [1,2,3,4,4,3,2,1]
输出:true
解释:可行的分组是 [1,1],[2,2],[3,3],[4,4]
```
- 示例 2:
```python
输入:deck = [1,1,1,2,2,2,3,3]
输出:false
解释:没有满足要求的分组。
```
## 解题思路
### 思路 1:最大公约数
要将卡牌分组,每组有 $X$ 张牌且组内所有牌相同,$X \ge 2$。这等价于找到所有牌的出现次数的最大公约数,且该最大公约数 $\ge 2$。
1. 使用哈希表统计每张牌的出现次数。
2. 计算所有出现次数的最大公约数 $g$。
3. 如果 $g \ge 2$,返回 $True$;否则返回 $False$。
### 思路 1:代码
```python
class Solution:
def hasGroupsSizeX(self, deck: List[int]) -> bool:
from math import gcd
from functools import reduce
# 统计每张牌的出现次数
count = collections.Counter(deck)
# 计算所有出现次数的最大公约数
g = reduce(gcd, count.values())
# 最大公约数至少为 2
return g >= 2
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + k \log C)$,其中 $n$ 是卡牌数量,$k$ 是不同卡牌的种类数,$C$ 是最大的出现次数。
- **空间复杂度**:$O(k)$,需要存储每张牌的出现次数。
================================================
FILE: docs/solutions/1000-1099/best-sightseeing-pair.md
================================================
# [1014. 最佳观光组合](https://leetcode.cn/problems/best-sightseeing-pair/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [1014. 最佳观光组合 - 力扣](https://leetcode.cn/problems/best-sightseeing-pair/)
## 题目大意
给你一个正整数数组 `values`,其中 `values[i]` 表示第 `i` 个观光景点的评分,并且两个景点 `i` 和 `j` 之间的距离 为 `j - i`。一对景点(`i < j`)组成的观光组合的得分为 `values[i] + values[j] + i - j`,也就是景点的评分之和减去它们两者之间的距离。
要求:返回一对观光景点能取得的最高分。
## 解题思路
求解的是 `ans = max(values[i] + values[j] + i - j)`。对于当前第 `j` 个位置上的元素来说,`values[j] - j` 的值是固定的,求解 `ans` 就是在求解 `values[i] + i` 的最大值。我们使用一个变量 `max_score` 来存储当前第 `j` 个位置元素之前 `values[i] + i` 的最大值。然后遍历数组,求出每一个元素位置之前 `values[i] + i` 的最大值,并找出其中最大的 `ans`。
## 代码
```python
class Solution:
def maxScoreSightseeingPair(self, values: List[int]) -> int:
ans = 0
max_score = values[0]
for i in range(1, len(values)):
ans = max(ans, max_score + values[i] - i)
max_score = max(max_score, values[i] + i)
return ans
```
================================================
FILE: docs/solutions/1000-1099/binary-search-tree-to-greater-sum-tree.md
================================================
# [1038. 从二叉搜索树到更大和树](https://leetcode.cn/problems/binary-search-tree-to-greater-sum-tree/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [1038. 从二叉搜索树到更大和树 - 力扣](https://leetcode.cn/problems/binary-search-tree-to-greater-sum-tree/)
## 题目大意
给定一棵二叉搜索树(BST)的根节点,且二叉搜索树的节点值各不相同。
要求:将它的每个节点的值替换成树中大于或者等于该节点值的所有节点值之和。
二叉搜索树的定义:
- 如果左子树不为空,则左子树上所有节点值均小于它的根节点值;
- 如果右子树不为空,则右子树上所有节点值均大于它的根节点值;
- 任意节点的左、右子树也分别为二叉搜索树。
## 解题思路
题目要求将每个节点的值修改为原来的节点值加上大于它的节点值之和。已知二叉搜索树的中序遍历可以得到一个升序数组。
题目就可以变为:修改升序数组中每个节点值为末尾元素累加和。由于末尾元素累加和的求和过程和遍历顺序相反,所以我们可以考虑换种思路。
二叉搜索树的中序遍历顺序为:左 -> 根 -> 右,从而可以得到一个升序数组,那么我们将左右反着遍历,即顺序为:右 -> 根 -> 左,就可以得到一个降序数组,这样就可以在遍历的同时求前缀和。
当然我们在计算前缀和的时候,需要用到前一个节点的值,所以需要用变量 `pre` 存储前一节点的值。
## 代码
```python
class Solution:
pre = 0
def createBinaryTree(self, root: TreeNode):
if not root:
return
self.createBinaryTree(root.right)
root.val += self.pre
self.pre = root.val
self.createBinaryTree(root.left)
def bstToGst(self, root: TreeNode) -> TreeNode:
self.pre = 0
self.createBinaryTree(root)
return root
```
================================================
FILE: docs/solutions/1000-1099/camelcase-matching.md
================================================
# [1023. 驼峰式匹配](https://leetcode.cn/problems/camelcase-matching/)
- 标签:字典树、双指针、字符串、字符串匹配
- 难度:中等
## 题目链接
- [1023. 驼峰式匹配 - 力扣](https://leetcode.cn/problems/camelcase-matching/)
## 题目大意
**描述**:给定待查询列表 `queries`,和模式串 `pattern`。如果我们可以将小写字母(0 个或多个)插入模式串 `pattern` 中间(任意位置)得到待查询项 `queries[i]`,那么待查询项与给定模式串匹配。如果匹配,则对应答案为 `True`,否则为 `False`。
**要求**:将匹配结果存入由布尔值组成的答案列表中,并返回。
**说明**:
- $1 \le queries.length \le 100$。
- $1 \le queries[i].length \le 100$。
- $1 \le pattern.length \le 100$。
- 所有字符串都仅由大写和小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FB"
输出:[true,false,true,true,false]
示例:
"FooBar" 可以这样生成:"F" + "oo" + "B" + "ar"。
"FootBall" 可以这样生成:"F" + "oot" + "B" + "all".
"FrameBuffer" 可以这样生成:"F" + "rame" + "B" + "uffer".
```
- 示例 2:
```python
输入:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FoBa"
输出:[true,false,true,false,false]
解释:
"FooBar" 可以这样生成:"Fo" + "o" + "Ba" + "r".
"FootBall" 可以这样生成:"Fo" + "ot" + "Ba" + "ll".
```
## 解题思路
### 思路 1:字典树
构建一棵字典树,将 `pattern` 存入字典树中。
1. 对于 `queries[i]` 中的每个字符串。逐个字符与 `pattern` 进行匹配。
1. 如果遇见小写字母,直接跳过。
2. 如果遇见大写字母,但是不能匹配,返回 `False`。
3. 如果遇见大写字母,且可以匹配,继续查找。
4. 如果到达末尾仍然匹配,则返回 `True`。
2. 最后将所有结果存入答案数组中返回。
### 思路 1:代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ord(ch) > 96:
if ch not in cur.children:
continue
else:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class Solution:
def camelMatch(self, queries: List[str], pattern: str) -> List[bool]:
trie_tree = Trie()
trie_tree.insert(pattern)
res = []
for query in queries:
res.append(trie_tree.search(query))
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times |T| + |pattern|)$。其中 $n$ 是待查询项的数目,$|T|$ 是最长的待查询项的字符串长度,$|pattern|$ 是字符串 `pattern` 的长度。
- **空间复杂度**:$O(|pattern|)$。
================================================
FILE: docs/solutions/1000-1099/capacity-to-ship-packages-within-d-days.md
================================================
# [1011. 在 D 天内送达包裹的能力](https://leetcode.cn/problems/capacity-to-ship-packages-within-d-days/)
- 标签:数组、二分查找
- 难度:中等
## 题目链接
- [1011. 在 D 天内送达包裹的能力 - 力扣](https://leetcode.cn/problems/capacity-to-ship-packages-within-d-days/)
## 题目大意
**描述**:传送带上的包裹必须在 $D$ 天内从一个港口运送到另一个港口。给定所有包裹的重量数组 $weights$,货物必须按照给定的顺序装运。且每天船上装载的重量不会超过船的最大运载重量。
**要求**:求能在 $D$ 天内将所有包裹送达的船的最低运载量。
**说明**:
- $1 \le days \le weights.length \le 5 * 10^4$。
- $1 \le weights[i] \le 500$。
**示例**:
- 示例 1:
```python
输入:weights = [1,2,3,4,5,6,7,8,9,10], days = 5
输出:15
解释:
船舶最低载重 15 就能够在 5 天内送达所有包裹,如下所示:
第 1 天:1, 2, 3, 4, 5
第 2 天:6, 7
第 3 天:8
第 4 天:9
第 5 天:10
请注意,货物必须按照给定的顺序装运,因此使用载重能力为 14 的船舶并将包装分成 (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) 是不允许的。
```
- 示例 2:
```python
输入:weights = [3,2,2,4,1,4], days = 3
输出:6
解释:
船舶最低载重 6 就能够在 3 天内送达所有包裹,如下所示:
第 1 天:3, 2
第 2 天:2, 4
第 3 天:1, 4
```
## 解题思路
### 思路 1:二分查找
船最小的运载能力,最少也要等于或大于最重的那件包裹,即 $max(weights)$。最多的话,可以一次性将所有包裹运完,即 $sum(weights)$。船的运载能力介于 $[max(weights), sum(weights)]$ 之间。
我们现在要做的就是从这个区间内,找到满足可以在 $D$ 天内运送完所有包裹的最小载重量。
可以通过二分查找的方式,找到满足要求的最小载重量。
### 思路 1:代码
```python
class Solution:
def shipWithinDays(self, weights: List[int], D: int) -> int:
left = max(weights)
right = sum(weights)
while left < right:
mid = (left + right) >> 1
days = 1
cur = 0
for weight in weights:
if cur + weight > mid:
days += 1
cur = 0
cur += weight
if days <= D:
right = mid
else:
left = mid + 1
return left
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。二分查找算法的时间复杂度为 $O(\log n)$。
- **空间复杂度**:$O(1)$。只用到了常数空间存放若干变量。
================================================
FILE: docs/solutions/1000-1099/coloring-a-border.md
================================================
# [1034. 边界着色](https://leetcode.cn/problems/coloring-a-border/)
- 标签:深度优先搜索、广度优先搜索、数组、矩阵
- 难度:中等
## 题目链接
- [1034. 边界着色 - 力扣](https://leetcode.cn/problems/coloring-a-border/)
## 题目大意
给定一个二维整数矩阵 `grid`,其中 `grid[i][j]` 表示矩阵第 `i` 行、第 `j` 列上网格块的颜色值。再给定一个起始位置 `(row, col)`,以及一个目标颜色 `color`。
要求:对起始位置 `(row, col)` 所在的连通分量边界填充颜色为 `color`。并返回最终的二维整数矩阵 `grid`。
- 连通分量:当两个相邻(上下左右四个方向上)网格块的颜色值相同时,它们属于同一连通分量。
- 连通分量边界:当前连通分量最外圈的所有网格块,这些网格块与连通分量的颜色相同,与其他周围网格块颜色不同。边界上的网格块也是连通分量边界。
## 解题思路
深度优先搜索。使用二维数组 `visited` 标记访问过的节点。遍历上、下、左、右四个方向上的点。如果下一个点位置越界,或者当前位置与下一个点位置颜色不一样,则对该节点进行染色。
在遍历的过程中注意使用 `visited` 标记访问过的节点,以免重复遍历。
## 代码
```python
class Solution:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
def dfs(self, grid, i, j, origin_color, color, visited):
rows, cols = len(grid), len(grid[0])
for direct in self.directs:
new_i = i + direct[0]
new_j = j + direct[1]
# 下一个位置越界,则当前点在边界,对其进行着色
if new_i < 0 or new_i >= rows or new_j < 0 or new_j >= cols:
grid[i][j] = color
continue
# 如果访问过,则跳过
if visited[new_i][new_j]:
continue
# 如果下一个位置颜色与当前颜色相同,则继续搜索
if grid[new_i][new_j] == origin_color:
visited[new_i][new_j] = True
self.dfs(grid, new_i, new_j, origin_color, color, visited)
# 下一个位置颜色与当前颜色不同,则当前位置为连通区域边界,对其进行着色
else:
grid[i][j] = color
def colorBorder(self, grid: List[List[int]], row: int, col: int, color: int) -> List[List[int]]:
if not grid:
return grid
rows, cols = len(grid), len(grid[0])
visited = [[False for _ in range(cols)] for _ in range(rows)]
visited[row][col] = True
self.dfs(grid, row, col, grid[row][col], color, visited)
return grid
```
================================================
FILE: docs/solutions/1000-1099/complement-of-base-10-integer.md
================================================
# [1009. 十进制整数的反码](https://leetcode.cn/problems/complement-of-base-10-integer/)
- 标签:位运算
- 难度:简单
## 题目链接
- [1009. 十进制整数的反码 - 力扣](https://leetcode.cn/problems/complement-of-base-10-integer/)
## 题目大意
**描述**:给定一个十进制数 $n$。
**要求**:返回其二进制表示的反码对应的十进制整数。
**说明**:
- $0 \le N < 10^9$。
**示例**:
- 示例 1:
```python
输入:5
输出:2
解释:5 的二进制表示为 "101",其二进制反码为 "010",也就是十进制中的 2 。
```
- 示例 2:
```python
输入:7
输出:0
解释:7 的二进制表示为 "111",其二进制反码为 "000",也就是十进制中的 0 。
```
## 解题思路
### 思路 1:模拟
1. 将十进制数 $n$ 转为二进制 $binary$。
2. 遍历二进制 $binary$ 的每一个数位 $digit$。
1. 如果 $digit$ 为 $0$,则将其转为 $1$,存入答案 $res$ 中。
2. 如果 $digit$ 为 $1$,则将其转为 $0$,存入答案 $res$ 中。
3. 返回答案 $res$。
### 思路 1:代码
```python
class Solution:
def bitwiseComplement(self, n: int) -> int:
binary = ""
while n:
binary += str(n % 2)
n //= 2
if binary == "":
binary = "0"
else:
binary = binary[::-1]
res = 0
for digit in binary:
if digit == '0':
res = res * 2 + 1
else:
res = res * 2
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(len(n))$,其中 $len(n)$ 为 $n$ 对应二进制的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1000-1099/construct-binary-search-tree-from-preorder-traversal.md
================================================
# [1008. 前序遍历构造二叉搜索树](https://leetcode.cn/problems/construct-binary-search-tree-from-preorder-traversal/)
- 标签:栈、树、二叉搜索树、数组、二叉树、单调栈
- 难度:中等
## 题目链接
- [1008. 前序遍历构造二叉搜索树 - 力扣](https://leetcode.cn/problems/construct-binary-search-tree-from-preorder-traversal/)
## 题目大意
给定一棵二叉搜索树的前序遍历结果 `preorder`。
要求:返回与给定前序遍历 `preorder` 相匹配的二叉搜索树的根节点。题目保证,对于给定的测试用例,总能找到满足要求的二叉搜索树。
## 解题思路
二叉搜索树的中序遍历是升序序列。而题目又给了我们二叉搜索树的前序遍历,那么通过对前序遍历结果的排序,我们也可以得到二叉搜索树的中序遍历结果。这样就能根据二叉树的前序、中序遍历序列构造二叉树了。就变成了了「[0105. 从前序与中序遍历序列构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)」题。
此外,我们还有另一种方法求解。前序遍历的顺序是:根 -> 左 -> 右。并且在二叉搜索树中,左子树的值小于根节点,右子树的值大于根节点。
根据以上性质,我们可以递归地构造二叉搜索树。
首先,以前序遍历的开始位置元素构造为根节点。从开始位置的下一个位置开始,找到序列中第一个大于等于根节点值的位置 `mid`。该位置左侧的值都小于根节点,右侧的值都大于等于根节点。以此位置为中心,递归的构造左子树和右子树。
最后再将根节点进行返回。
## 代码
```python
class Solution:
def buildTree(self, preorder, start, end):
if start == end:
return None
root = preorder[start]
mid = start + 1
while mid < end and preorder[mid] < root:
mid += 1
node = TreeNode(root)
node.left = self.buildTree(preorder, start + 1, mid)
node.right = self.buildTree(preorder, mid, end)
return node
def bstFromPreorder(self, preorder: List[int]) -> TreeNode:
return self.buildTree(preorder, 0, len(preorder))
```
================================================
FILE: docs/solutions/1000-1099/divisor-game.md
================================================
# [1025. 除数博弈](https://leetcode.cn/problems/divisor-game/)
- 标签:脑筋急转弯、数学、动态规划、博弈
- 难度:简单
## 题目链接
- [1025. 除数博弈 - 力扣](https://leetcode.cn/problems/divisor-game/)
## 题目大意
爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。最初,黑板上有一个数字 `n`。在每个玩家的回合,玩家需要执行以下操作:
- 选出任一 `x`,满足 `0 < x < n` 且 `n % x == 0`。
- 用 `n - x` 替换黑板上的数字 `n` 。
- 如果玩家无法执行这些操作,就会输掉游戏。
只有在爱丽丝在游戏中取得胜利时才返回 `True`,否则返回 `False`。假设两个玩家都以最佳状态参与游戏。
## 解题思路
- 如果 `n` 为奇数,则 `n` 的约数必然都是奇数;如果 `n` 为偶数,则 `n` 的约数可能为奇数也可能为偶数。
- 无论 `n` 为奇数还是偶数,都可以选择 `1` 作为约数。
- 无论 `n` 初始为多大的数,游戏到最终只能到 `n == 2` 结束,只要谁先到 `n == 2`,谁就赢得胜利。
- 当初始 `n` 为偶数时,爱丽丝只要一直选 `1`,那么鲍勃必然会一直面临 `n` 为奇数的情况,这样最后爱丽丝肯定能先到 `n == 2`,稳赢。
- 当初始 `n` 为奇数时,因为奇数的约数只能是奇数,奇数 - 奇数 必然是偶数,所以给鲍勃的数一定是偶数,鲍勃只需一直选 `1` 就会稳赢,此时爱丽丝稳输。
所以,当 `n` 为偶数时,爱丽丝稳赢。当 `n` 为奇数时,爱丽丝稳输。
## 代码
```python
class Solution:
def divisorGame(self, n: int) -> bool:
return n & 1 == 0
```
================================================
FILE: docs/solutions/1000-1099/duplicate-zeros.md
================================================
# [1089. 复写零](https://leetcode.cn/problems/duplicate-zeros/)
- 标签:数组、双指针
- 难度:简单
## 题目链接
- [1089. 复写零 - 力扣](https://leetcode.cn/problems/duplicate-zeros/)
## 题目大意
**描述**:给定搞一个长度固定的整数数组 $arr$。
**要求**:键改改数组中出现的每一个 $0$ 都复写一遍,并将其余的元素向右平移。
**说明**:
- 注意:不要在超过该数组长度的位置写上元素。请对输入的数组就地进行上述修改,不要从函数返回任何东西。
- $1 \le arr.length \le 10^4$。
- $0 \le arr[i] \le 9$。
**示例**:
- 示例 1:
```python
输入:arr = [1,0,2,3,0,4,5,0]
输出:[1,0,0,2,3,0,0,4]
解释:调用函数后,输入的数组将被修改为:[1,0,0,2,3,0,0,4]
```
- 示例 2:
```python
输入:arr = [1,2,3]
输出:[1,2,3]
解释:调用函数后,输入的数组将被修改为:[1,2,3]
```
## 解题思路
### 思路 1:两次遍历 + 快慢指针
因为数组中出现的 $0$ 需要复写为 $00$,占用空间从一个单位变成两个单位空间,那么右侧必定会有一部分元素丢失。我们可以先遍历一遍数组,找出复写后需要保留的有效数字部分与需要丢失部分的分界点。则从分界点开始,分界点右侧的元素都可以丢失。
我们再次逆序遍历数组,
1. 使用两个指针 $slow$、$fast$,$slow$ 表示当前有效字符位置,$fast$ 表示当前遍历字符位置。一开始 $slow$ 和 $fast$ 都指向数组开始位置。
2. 正序扫描数组:
1. 如果遇到 $arr[slow] == 0$,则让 $fast$ 指针多走一步。
2. 然后 $fast$、$slow$ 各自向右移动 $1$ 位,直到 $fast$ 指针移动到数组末尾。此时 $slow$ 左侧数字 $arr[0]... arr[slow - 1]$ 为需要保留的有效数字部分, $arr[slow]...arr[fast - 1]$ 为需要丢失部分。
3. 令 $slow$、$fast$ 分别左移 $1$ 位,此时 $slow$ 指向最后一个有效数字,$fast$ 指向丢失部分的最后一个数字。此时 $fast$ 可能等于 $size - 1$,也可能等于 $size$(比如输入 $[0, 0, 0]$)。
4. 逆序遍历数组:
1. 将 $slow$ 位置元素移动到 $fast$ 位置。
2. 如果遇到 $arr[slow] == 0$,则令 $fast$ 减 $1$,然后再复制 $1$ 个 $0$ 到 $fast$ 位置。
3. 令 $slow$、$fast$ 分别左移 $1$ 位。
### 思路 1:代码
```python
class Solution:
def duplicateZeros(self, arr: List[int]) -> None:
"""
Do not return anything, modify arr in-place instead.
"""
size = len(arr)
slow, fast = 0, 0
while fast < size:
if arr[slow] == 0:
fast += 1
slow += 1
fast += 1
slow -= 1 # slow 指向最后一个有效数字
fast -= 1 # fast 指向丢失部分的最后一个数字(可能在减 1 之后为 size,比如输入 [0, 0, 0])
while slow >= 0:
if fast < size: # 防止 fast 越界
arr[fast] = arr[slow] # 将 slow 位置元素移动到 fast 位置
if arr[slow] == 0 and fast >= 0: # 遇见 0 则复制 0 到 fast - 1 位置
fast -= 1
arr[fast] = arr[slow]
fast -= 1
slow -= 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $arr$ 中的元素个数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1000-1099/find-common-characters.md
================================================
# [1002. 查找共用字符](https://leetcode.cn/problems/find-common-characters/)
- 标签:数组、哈希表、字符串
- 难度:简单
## 题目链接
- [1002. 查找共用字符 - 力扣](https://leetcode.cn/problems/find-common-characters/)
## 题目大意
**描述**:给定一个字符串数组 $words$。
**要求**:找出所有在 $words$ 的每个字符串中都出现的公用字符(包括重复字符),并以数组形式返回。可以按照任意顺序返回答案。
**说明**:
- $1 \le words.length \le 100$。
- $1 \le words[i].length \le 100$。
- $words[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:words = ["bella","label","roller"]
输出:["e","l","l"]
```
- 示例 2:
```python
输入:words = ["cool","lock","cook"]
输出:["c","o"]
```
## 解题思路
### 思路 1:哈希表
如果某个字符 $ch$ 在所有字符串中都出现了 $k$ 次以上,则最终答案中需要包含 $k$ 个 $ch$。因此,我们可以使用哈希表 $minfreq[ch]$ 记录字符 $ch$ 在所有字符串中出现的最小次数。具体步骤如下:
1. 定义长度为 $26$ 的哈希表 $minfreq$,初始化所有字符出现次数为无穷大,$minfreq[ch] = float('inf')$。
2. 遍历字符串数组中的所有字符串 $word$,对于字符串 $word$:
1. 记录 $word$ 中所有字符串的出现次数 $freq[ch]$。
2. 取 $freq[ch]$ 与 $minfreq[ch]$ 中的较小值更新 $minfreq[ch]$。
3. 遍历完之后,再次遍历 $26$ 个字符,将所有最小出现次数大于零的字符按照出现次数存入答案数组中。
4. 最后将答案数组返回。
### 思路 1:代码
```python
class Solution:
def commonChars(self, words: List[str]) -> List[str]:
minfreq = [float('inf') for _ in range(26)]
for word in words:
freq = [0 for _ in range(26)]
for ch in word:
freq[ord(ch) - ord('a')] += 1
for i in range(26):
minfreq[i] = min(minfreq[i], freq[i])
res = []
for i in range(26):
while minfreq[i]:
res.append(chr(i + ord('a')))
minfreq[i] -= 1
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times (|\sum| + m))$,其中 $n$ 为字符串数组 $words$ 的长度,$m$ 为每个字符串的平均长度,$|\sum|$ 为字符集。
- **空间复杂度**:$O(|\sum|)$。
================================================
FILE: docs/solutions/1000-1099/find-in-mountain-array.md
================================================
# [1095. 山脉数组中查找目标值](https://leetcode.cn/problems/find-in-mountain-array/)
- 标签:数组、二分查找、交互
- 难度:困难
## 题目链接
- [1095. 山脉数组中查找目标值 - 力扣](https://leetcode.cn/problems/find-in-mountain-array/)
## 题目大意
**描述**:给定一个山脉数组 $mountainArr$。
**要求**:返回能够使得 `mountainArr.get(index)` 等于 $target$ 最小的下标 $index$ 值。如果不存在这样的下标 $index$,就请返回 $-1$。
**说明**:
- 山脉数组:满足以下属性的数组:
- $len(arr) \ge 3$;
- 存在 $i$($0 < i < len(arr) - 1$),使得:
- $arr[0] < arr[1] < ... arr[i-1] < arr[i]$;
- $arr[i] > arr[i+1] > ... > arr[len(arr) - 1]$。
- 不能直接访问该山脉数组,必须通过 `MountainArray` 接口来获取数据:
- `MountainArray.get(index)`:会返回数组中索引为 $k$ 的元素(下标从 $0$ 开始)。
- `MountainArray.length()`:会返回该数组的长度。
- 对 `MountainArray.get` 发起超过 $100$ 次调用的提交将被视为错误答案。
- $3 \le mountain_arr.length() \le 10000$。
- $0 \le target \le 10^9$。
- $0 \le mountain_arr.get(index) \le 10^9$。
**示例**:
- 示例 1:
```python
输入:array = [1,2,3,4,5,3,1], target = 3
输出:2
解释:3 在数组中出现了两次,下标分别为 2 和 5,我们返回最小的下标 2。
```
- 示例 2:
```python
输入:array = [0,1,2,4,2,1], target = 3
输出:-1
解释:3 在数组中没有出现,返回 -1。
```
## 解题思路
### 思路 1:二分查找
因为题目要求不能对 `MountainArray.get` 发起超过 $100$ 次调用。所以遍历数组进行查找是不可行的。
根据山脉数组的性质,我们可以把山脉数组分为两部分:「前半部分的升序数组」和「后半部分的降序数组」。在有序数组中查找目标值可以使用二分查找来减少查找次数。
而山脉的峰顶元素索引也可以通过二分查找来做。所以这道题我们可以分为三步:
1. 通过二分查找找到山脉数组的峰顶元素索引。
2. 通过二分查找在前半部分的升序数组中查找目标元素。
3. 通过二分查找在后半部分的降序数组中查找目标元素。
最后,通过对查找结果的判断来输出最终答案。
### 思路 1:代码
```python
#class MountainArray:
# def get(self, index: int) -> int:
# def length(self) -> int:
class Solution:
def binarySearchPeak(self, mountain_arr) -> int:
left, right = 0, mountain_arr.length() - 1
while left < right:
mid = left + (right - left) // 2
if mountain_arr.get(mid) < mountain_arr.get(mid + 1):
left = mid + 1
else:
right = mid
return left
def binarySearchAscending(self, mountain_arr, left, right, target):
while left < right:
mid = left + (right - left) // 2
if mountain_arr.get(mid) < target:
left = mid + 1
else:
right = mid
return left if mountain_arr.get(left) == target else -1
def binarySearchDescending(self, mountain_arr, left, right, target):
while left < right:
mid = left + (right - left) // 2
if mountain_arr.get(mid) > target:
left = mid + 1
else:
right = mid
return left if mountain_arr.get(left) == target else -1
def findInMountainArray(self, target: int, mountain_arr: 'MountainArray') -> int:
size = mountain_arr.length()
peek_i = self.binarySearchPeak(mountain_arr)
res_left = self.binarySearchAscending(mountain_arr, 0, peek_i, target)
res_right = self.binarySearchDescending(mountain_arr, peek_i + 1, size - 1, target)
return res_left if res_left != -1 else res_right
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1000-1099/grumpy-bookstore-owner.md
================================================
# [1052. 爱生气的书店老板](https://leetcode.cn/problems/grumpy-bookstore-owner/)
- 标签:数组、滑动窗口
- 难度:中等
## 题目链接
- [1052. 爱生气的书店老板 - 力扣](https://leetcode.cn/problems/grumpy-bookstore-owner/)
## 题目大意
**描述**:书店老板有一家店打算试营业 $len(customers)$ 分钟。每一分钟都有一些顾客 $customers[i]$ 会进入书店,这些顾客会在这一分钟结束后离开。
在某些时候,书店老板会生气。如果书店老板在第 $i$ 分钟生气,则 `grumpy[i] = 1`,如果第 $i$ 分钟不生气,则 `grumpy[i] = 0`。当书店老板生气时,这一分钟的顾客会不满意。当书店老板不生气时,这一分钟的顾客是满意的。
假设老板知道一个秘密技巧,能保证自己连续 $minutes$ 分钟不生气,但只能使用一次。
现在给定代表每分钟进入书店的顾客数量的数组 $customes$,和代表老板生气状态的数组 $grumpy$,以及老板保证连续不生气的分钟数 $minutes$。
**要求**:计算出试营业下来,最多有多少客户能够感到满意。
**说明**:
- $n == customers.length == grumpy.length$。
- $1 \le minutes \le n \le 2 \times 10^4$。
- $0 \le customers[i] \le 1000$。
- $grumpy[i] == 0 \text{ or } 1$。
**示例**:
- 示例 1:
```python
输入:customers = [1,0,1,2,1,1,7,5], grumpy = [0,1,0,1,0,1,0,1], minutes = 3
输出:16
解释:书店老板在最后 3 分钟保持冷静。
感到满意的最大客户数量 = 1 + 1 + 1 + 1 + 7 + 5 = 16.
```
- 示例 2:
```python
输入:customers = [1], grumpy = [0], minutes = 1
输出:1
```
## 解题思路
### 思路 1:滑动窗口
固定长度的滑动窗口题目。我们可以维护一个窗口大小为 $minutes$ 的滑动窗口。使用 $window_count$ 记录当前窗口内生气的顾客人数。然后滑动求出窗口中最大顾客数,然后累加上老板未生气时的顾客数,就是答案。具体做法如下:
1. $ans$ 用来维护答案数目。$window\_count$ 用来维护窗口中生气的顾客人数。
2. $left$ 、$right$ 都指向序列的第一个元素,即:`left = 0`,`right = 0`。
3. 如果书店老板生气,则将这一分钟的顾客数量加入到 $window\_count$ 中,然后向右移动 $right$。
4. 当窗口元素个数大于 $minutes$ 时,即:$right - left + 1 > count$ 时,如果最左侧边界老板处于生气状态,则向右移动 $left$,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为小于 $minutes$。
5. 重复 $3 \sim 4$ 步,直到 $right$ 到达数组末尾。
6. 然后累加上老板未生气时的顾客数,最后输出答案。
### 思路 1:代码
```python
class Solution:
def maxSatisfied(self, customers: List[int], grumpy: List[int], minutes: int) -> int:
left = 0
right = 0
window_count = 0
ans = 0
while right < len(customers):
if grumpy[right] == 1:
window_count += customers[right]
if right - left + 1 > minutes:
if grumpy[left] == 1:
window_count -= customers[left]
left += 1
right += 1
ans = max(ans, window_count)
for i in range(len(customers)):
if grumpy[i] == 0:
ans += customers[i]
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $coustomer$、$grumpy$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1000-1099/height-checker.md
================================================
# [1051. 高度检查器](https://leetcode.cn/problems/height-checker/)
- 标签:数组、计数排序、排序
- 难度:简单
## 题目链接
- [1051. 高度检查器 - 力扣](https://leetcode.cn/problems/height-checker/)
## 题目大意
**描述**:学校打算为全体学生拍一张年度纪念照。根据要求,学生需要按照 非递减 的高度顺序排成一行。
排序后的高度情况用整数数组 $expected$ 表示,其中 $expected[i]$ 是预计排在这一行中第 $i$ 位的学生的高度(下标从 $0$ 开始)。
给定一个整数数组 $heights$ ,表示当前学生站位的高度情况。$heights[i]$ 是这一行中第 $i$ 位学生的高度(下标从 $0$ 开始)。
**要求**:返回满足 $heights[i] \ne expected[i]$ 的下标数量 。
**说明**:
- $1 \le heights.length \le 100$。
- $1 \le heights[i] \le 100$。
**示例**:
- 示例 1:
```python
输入:heights = [1,1,4,2,1,3]
输出:3
解释:
高度:[1,1,4,2,1,3]
预期:[1,1,1,2,3,4]
下标 2 、4 、5 处的学生高度不匹配。
```
- 示例 2:
```python
输入:heights = [5,1,2,3,4]
输出:5
解释:
高度:[5,1,2,3,4]
预期:[1,2,3,4,5]
所有下标的对应学生高度都不匹配。
```
## 解题思路
### 思路 1:排序算法
1. 将数组 $heights$ 复制一份,记为 $expected$。
2. 对数组 $expected$ 进行排序。
3. 排序之后,对比并统计 $heights[i] \ne expected[i]$ 的下标数量,记为 $ans$。
4. 返回 $ans$。
### 思路 1:代码
```Python
class Solution:
def heightChecker(self, heights: List[int]) -> int:
expected = sorted(heights)
ans = 0
for i in range(len(heights)):
if expected[i] != heights[i]:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组 $heights$ 的长度。
- **空间复杂度**:$O(n)$。
### 思路 2:计数排序
题目中 $heights[i]$ 的数据范围为 $[1, 100]$,所以我们可以使用计数排序。
### 思路 2:代码
```python
class Solution:
def heightChecker(self, heights: List[int]) -> int:
# 待排序数组中最大值元素 heights_max = 100 和最小值元素 heights_min = 1
heights_min, heights_max = 1, 100
# 定义计数数组 counts,大小为 最大值元素 - 最小值元素 + 1
size = heights_max - heights_min + 1
counts = [0 for _ in range(size)]
# 统计值为 height 的元素出现的次数
for height in heights:
counts[height - heights_min] += 1
ans = 0
idx = 0
# 从小到大遍历 counts 的元素值范围
for height in range(heights_min, heights_max + 1):
while counts[height - heights_min]:
# 对于每个元素值,判断是否与对应位置上的 heights[idx] 相等
if heights[idx] != height:
ans += 1
idx += 1
counts[height - heights_min] -= 1
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n + k)$,其中 $n$ 为数组 $heights$ 的长度,$k$ 为数组 $heights$ 的值域范围。
- **空间复杂度**:$O(k)$。
================================================
FILE: docs/solutions/1000-1099/index-pairs-of-a-string.md
================================================
# [1065. 字符串的索引对](https://leetcode.cn/problems/index-pairs-of-a-string/)
- 标签:字典树、数组、字符串、排序
- 难度:简单
## 题目链接
- [1065. 字符串的索引对 - 力扣](https://leetcode.cn/problems/index-pairs-of-a-string/)
## 题目大意
给定字符串 `text` 和单词列表 `words`。
要求:在 `text` 中找出所有属于单词列表 `words` 中的单词,并返回该单词在 `text` 中的索引对位置 `[i, j]`。将所有索引对存入列表中返回,并且返回的索引对可以交叉。
## 解题思路
构建字典树,将所有单词存入字典树中。
然后一重循环遍历 `text`,表示从第 `i` 位置开始的字符串 `text[i:]`。然后在字符串前缀中搜索对应的单词,将所有符合要求的单词末尾位置存入列表中,返回所有位置列表。对于列表中每个单词末尾位置 `index` 和 `text` 来说,每个 `[i, i + index]` 都构成了单词在 `text` 中的索引对位置,将其存入答案数组并返回即可。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, text: str) -> list:
"""
Returns if the word is in the trie.
"""
cur = self
res = []
for i in range(len(text)):
ch = text[i]
if ch not in cur.children:
return res
cur = cur.children[ch]
if cur.isEnd:
res.append(i)
return res
class Solution:
def indexPairs(self, text: str, words: List[str]) -> List[List[int]]:
trie_tree = Trie()
for word in words:
trie_tree.insert(word)
res = []
for i in range(len(text)):
for index in trie_tree.search(text[i:]):
res.append([i, i + index])
return res
```
================================================
FILE: docs/solutions/1000-1099/index.md
================================================
## 本章内容
- [1000. 合并石头的最低成本](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/minimum-cost-to-merge-stones.md)
- [1002. 查找共用字符](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/find-common-characters.md)
- [1004. 最大连续1的个数 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/max-consecutive-ones-iii.md)
- [1005. K 次取反后最大化的数组和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/maximize-sum-of-array-after-k-negations.md)
- [1008. 前序遍历构造二叉搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/construct-binary-search-tree-from-preorder-traversal.md)
- [1009. 十进制整数的反码](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/complement-of-base-10-integer.md)
- [1011. 在 D 天内送达包裹的能力](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/capacity-to-ship-packages-within-d-days.md)
- [1012. 至少有 1 位重复的数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/numbers-with-repeated-digits.md)
- [1014. 最佳观光组合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/best-sightseeing-pair.md)
- [1020. 飞地的数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/number-of-enclaves.md)
- [1021. 删除最外层的括号](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/remove-outermost-parentheses.md)
- [1023. 驼峰式匹配](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/camelcase-matching.md)
- [1025. 除数博弈](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/divisor-game.md)
- [1028. 从先序遍历还原二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/recover-a-tree-from-preorder-traversal.md)
- [1029. 两地调度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/two-city-scheduling.md)
- [1032. 字符流](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/stream-of-characters.md)
- [1034. 边界着色](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/coloring-a-border.md)
- [1035. 不相交的线](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/uncrossed-lines.md)
- [1037. 有效的回旋镖](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/valid-boomerang.md)
- [1038. 从二叉搜索树到更大和树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/binary-search-tree-to-greater-sum-tree.md)
- [1039. 多边形三角剖分的最低得分](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/minimum-score-triangulation-of-polygon.md)
- [1041. 困于环中的机器人](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/robot-bounded-in-circle.md)
- [1047. 删除字符串中的所有相邻重复项](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/remove-all-adjacent-duplicates-in-string.md)
- [1049. 最后一块石头的重量 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/last-stone-weight-ii.md)
- [1051. 高度检查器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/height-checker.md)
- [1052. 爱生气的书店老板](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/grumpy-bookstore-owner.md)
- [1065. 字符串的索引对](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/index-pairs-of-a-string.md)
- [1079. 活字印刷](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/letter-tile-possibilities.md)
- [1081. 不同字符的最小子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/smallest-subsequence-of-distinct-characters.md)
- [1089. 复写零](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/duplicate-zeros.md)
- [1091. 二进制矩阵中的最短路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/shortest-path-in-binary-matrix.md)
- [1095. 山脉数组中查找目标值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/find-in-mountain-array.md)
- [1099. 小于 K 的两数之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/two-sum-less-than-k.md)
================================================
FILE: docs/solutions/1000-1099/last-stone-weight-ii.md
================================================
# [1049. 最后一块石头的重量 II](https://leetcode.cn/problems/last-stone-weight-ii/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [1049. 最后一块石头的重量 II - 力扣](https://leetcode.cn/problems/last-stone-weight-ii/)
## 题目大意
**描述**:有一堆石头,用整数数组 $stones$ 表示,其中 $stones[i]$ 表示第 $i$ 块石头的重量。每一回合,从石头中选出任意两块石头,将这两块石头一起粉碎。假设石头的重量分别为 $x$ 和 $y$。且 $x \le y$,则结果如下:
- 如果 $x = y$,则两块石头都会被完全粉碎;
- 如果 $x < y$,则重量为 $x$ 的石头被完全粉碎,而重量为 $y$ 的石头新重量为 $y - x$。
**要求**:最后,最多只会剩下一块石头,返回此石头的最小可能重量。如果没有石头剩下,则返回 $0$。
**说明**:
- $1 \le stones.length \le 30$。
- $1 \le stones[i] \le 100$。
**示例**:
- 示例 1:
```python
输入:stones = [2,7,4,1,8,1]
输出:1
解释:
组合 2 和 4,得到 2,所以数组转化为 [2,7,1,8,1],
组合 7 和 8,得到 1,所以数组转化为 [2,1,1,1],
组合 2 和 1,得到 1,所以数组转化为 [1,1,1],
组合 1 和 1,得到 0,所以数组转化为 [1],这就是最优值。
```
- 示例 2:
```python
输入:stones = [31,26,33,21,40]
输出:5
```
## 解题思路
### 思路 1:动态规划
选取两块石头,重新放回去的重量是两块石头的差值绝对值。重新放回去的石头还会进行选取,然后进行粉碎,直到最后只剩一块或者不剩石头。
这个问题其实可以转化为:把一堆石头尽量平均的分成两对,求两堆石头重量差的最小值。
这就和「[0416. 分割等和子集](https://leetcode.cn/problems/partition-equal-subset-sum/)」有点相似。两堆石头的重量要尽可能的接近数组总数量和的一半。
进一步可以变为:「0-1 背包问题」。
1. 假设石头总重量和为 $sum$,将一堆石头放进载重上限为 $sum / 2$ 的背包中,获得的最大价值为 $max\_weight$(即其中一堆石子的重量)。另一堆石子的重量为 $sum - max\_weight$。
2. 则两者的差值为 $sum - 2 \times max\_weight$,即为答案。
###### 1. 阶段划分
按照石头的序号进行阶段划分。
###### 2. 定义状态
定义状态 $dp[w]$ 表示为:将石头放入载重上限为 $w$ 的背包中可以获得的最大价值。
###### 3. 状态转移方程
$dp[w] = max \lbrace dp[w], dp[w - stones[i - 1]] + stones[i - 1] \rbrace$。
###### 4. 初始条件
- 无论背包载重上限为多少,只要不选择石头,可以获得的最大价值一定是 $0$,即 $dp[w] = 0, 0 \le w \le W$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[w]$ 表示为:将石头放入载重上限为 $w$ 的背包中可以获得的最大价值,即第一堆石头的价值为 $dp[size]$,第二堆石头的价值为 $sum - dp[size]$,最终答案为两者的差值,即 $sum - dp[size] \times 2$。
### 思路 1:代码
```python
class Solution:
def lastStoneWeightII(self, stones: List[int]) -> int:
W = 1500
size = len(stones)
dp = [0 for _ in range(W + 1)]
target = sum(stones) // 2
for i in range(1, size + 1):
for w in range(target, stones[i - 1] - 1, -1):
dp[w] = max(dp[w], dp[w - stones[i - 1]] + stones[i - 1])
return sum(stones) - dp[target] * 2
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times W)$,其中 $n$ 为数组 $stones$ 的元素个数,$W$ 为数组 $stones$ 中元素和的一半。
- **空间复杂度**:$O(W)$。
================================================
FILE: docs/solutions/1000-1099/letter-tile-possibilities.md
================================================
# [1079. 活字印刷](https://leetcode.cn/problems/letter-tile-possibilities/)
- 标签:哈希表、字符串、回溯、计数
- 难度:中等
## 题目链接
- [1079. 活字印刷 - 力扣](https://leetcode.cn/problems/letter-tile-possibilities/)
## 题目大意
**描述**:给定一个代表活字字模的字符串 $tiles$,其中 $tiles[i]$ 表示第 $i$ 个字模上刻的字母。
**要求**:返回你可以印出的非空字母序列的数目。
**说明**:
- 本题中,每个活字字模只能使用一次。
- $1 <= tiles.length <= 7$。
- $tiles$ 由大写英文字母组成。
**示例**:
- 示例 1:
```python
输入:"AAB"
输出:8
解释:可能的序列为 "A", "B", "AA", "AB", "BA", "AAB", "ABA", "BAA"。
```
- 示例 2:
```python
输入:"AAABBC"
输出:188
```
## 解题思路
### 思路 1:哈希表 + 回溯算法
1. 使用哈希表存储每个字符的个数。
2. 然后依次从哈希表中取出对应字符,统计排列个数,并进行回溯。
3. 如果当前字符个数为 $0$,则不再进行回溯。
4. 回溯之后将状态回退。
### 思路 1:代码
```python
class Solution:
ans = 0
def backtrack(self, tile_map):
for key, value in tile_map.items():
if value == 0:
continue
self.ans += 1
tile_map[key] -= 1
self.backtrack(tile_map)
tile_map[key] += 1
def numTilePossibilities(self, tiles: str) -> int:
tile_map = dict()
for tile in tiles:
if tile not in tile_map:
tile_map[tile] = 1
else:
tile_map[tile] += 1
self.backtrack(tile_map)
return self.ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times n!)$,其中 $n$ 表示 $tiles$ 的长度最小值。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1000-1099/max-consecutive-ones-iii.md
================================================
# [1004. 最大连续1的个数 III](https://leetcode.cn/problems/max-consecutive-ones-iii/)
- 标签:数组、二分查找、前缀和、滑动窗口
- 难度:中等
## 题目链接
- [1004. 最大连续1的个数 III - 力扣](https://leetcode.cn/problems/max-consecutive-ones-iii/)
## 题目大意
**描述**:给定一个由 $0$、$1$ 组成的数组 $nums$,再给定一个整数 $k$。最多可以将 $k$ 个值从 $0$ 变到 $1$。
**要求**:返回仅包含 $1$ 的最长连续子数组的长度。
**说明**:
- $1 \le nums.length \le 10^5$。
- $nums[i]$ 不是 $0$ 就是 $1$。
- $0 \le k \le nums.length$。
**示例**:
- 示例 1:
```python
输入:nums = [1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0], K = 2
输出:6
解释:[1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1]
将 nums[5]、nums[10] 从 0 翻转到 1,最长的子数组长度为 6。
```
- 示例 2:
```python
输入:nums = [0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1], K = 3
输出:10
解释:[0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1]
将 nums[4]、nums[5]、nums[9] 从 0 翻转到 1,最长的子数组长度为 10。
```
## 解题思路
### 思路 1:滑动窗口(不定长度)
1. 使用两个指针 $left$、$right$ 指向数组开始位置。使用 $max\_count$ 来维护仅包含 $1$ 的最长连续子数组的长度。
2. 不断右移 $right$ 指针,扩大滑动窗口范围,并统计窗口内 $0$ 元素的个数。
3. 直到 $0$ 元素的个数超过 $k$ 时将 $left$ 右移,缩小滑动窗口范围,并减小 $0$ 元素的个数,同时维护 $max\_count$。
4. 最后输出最长连续子数组的长度 $max\_count$。
### 思路 1:代码
```python
class Solution:
def longestOnes(self, nums: List[int], k: int) -> int:
max_count = 0
zero_count = 0
left, right = 0, 0
while right < len(nums):
if nums[right] == 0:
zero_count += 1
right += 1
if zero_count > k:
if nums[left] == 0:
zero_count -= 1
left += 1
max_count = max(max_count, right - left)
return max_count
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1000-1099/maximize-sum-of-array-after-k-negations.md
================================================
# [1005. K 次取反后最大化的数组和](https://leetcode.cn/problems/maximize-sum-of-array-after-k-negations/)
- 标签:贪心、数组、排序
- 难度:简单
## 题目链接
- [1005. K 次取反后最大化的数组和 - 力扣](https://leetcode.cn/problems/maximize-sum-of-array-after-k-negations/)
## 题目大意
给定一个整数数组 nums 和一个整数 k。只能用下面的方法修改数组:
- 将数组上第 i 个位置上的值取相反数,即将 `nums[i]` 变为 `-nums[i]`。
用这种方式进行 K 次修改(可以多次修改同一个位置 i) 后,返回数组可能的最大和。
## 解题思路
- 先将数组按绝对值大小进行排序
- 从绝对值大的数开始遍历数组,如果 nums[i] < 0,并且 k > 0:
- 则对 nums[i] 取相反数,并将 k 值 -1。
- 如果最后 k 还有余值,则判断奇偶性:
- 如果 k 为奇数,则将数组绝对值最小的数进行取反。
- 如果 k 为偶数,则说明可将某一位数进行偶数次取反,和原数值一致,则不需要进行操作。
- 最后返回数组和。
## 代码
```python
class Solution:
def largestSumAfterKNegations(self, nums: List[int], k: int) -> int:
nums.sort(key=lambda x: abs(x), reverse = True)
for i in range(len(nums)):
if nums[i] < 0 and k > 0:
nums[i] *= -1
k -= 1
if k % 2 == 1:
nums[-1] *= -1
return sum(nums)
```
================================================
FILE: docs/solutions/1000-1099/minimum-cost-to-merge-stones.md
================================================
# [1000. 合并石头的最低成本](https://leetcode.cn/problems/minimum-cost-to-merge-stones/)
- 标签:数组、动态规划、前缀和
- 难度:困难
## 题目链接
- [1000. 合并石头的最低成本 - 力扣](https://leetcode.cn/problems/minimum-cost-to-merge-stones/)
## 题目大意
**描述**:给定一个代表 $n$ 堆石头的整数数组 $stones$,其中 $stones[i]$ 代表第 $i$ 堆中的石头个数。再给定一个整数 $k$, 每次移动需要将连续的 $k$ 堆石头合并为一堆,而这次移动的成本为这 $k$ 堆中石头的总数。
**要求**:返回把所有石头合并成一堆的最低成本。如果无法合并成一堆,则返回 $-1$。
**说明**:
- $n == stones.length$。
- $1 \le n \le 30$。
- $1 \le stones[i] \le 100$。
- $2 \le k \le 30$。
**示例**:
- 示例 1:
```python
输入:stones = [3,2,4,1], K = 2
输出:20
解释:
从 [3, 2, 4, 1] 开始。
合并 [3, 2],成本为 5,剩下 [5, 4, 1]。
合并 [4, 1],成本为 5,剩下 [5, 5]。
合并 [5, 5],成本为 10,剩下 [10]。
总成本 20,这是可能的最小值。
```
- 示例 2:
```python
输入:stones = [3,5,1,2,6], K = 3
输出:25
解释:
从 [3, 5, 1, 2, 6] 开始。
合并 [5, 1, 2],成本为 8,剩下 [3, 8, 6]。
合并 [3, 8, 6],成本为 17,剩下 [17]。
总成本 25,这是可能的最小值。
```
## 解题思路
### 思路 1:动态规划 + 前缀和
每次将 $k$ 堆连续的石头合并成 $1$ 堆,石头堆数就会减少 $k - 1$ 堆。总共有 $n$ 堆石子,则:
1. 当 $(n - 1) \mod (k - 1) == 0$ 时,一定可以经过 $\frac{n - 1}{k - 1}$ 次合并,将 $n$ 堆石头合并为 $1$ 堆。
2. 当 $(n - 1) \mod (k - 1) \ne 0$ 时,则无法将所有的石头合并成一堆。
根据以上情况,我们可以先将无法将所有的石头合并成一堆的情况排除出去,接下来只考虑合法情况。
由于每次合并石头的成本为合并的 $k$ 堆的石子总数,即数组 $stones$ 中长度为 $k$ 的连续子数组和,因此为了快速计算数组 $stones$ 的连续子数组和,我们可以使用「前缀和」的方式,预先计算出「前 $i$ 堆的石子总数」,从而可以在 $O(1)$ 的时间复杂度内得到数组 $stones$ 的连续子数组和。
$k$ 堆石头合并为 $1$ 堆石头的过程,可以看做是长度为 $k$ 的连续子数组合并为长度为 $1$ 的子数组的过程,也可以看做是将长度为 $k$ 的区间合并为长度为 $1$ 的区间。
接下来我们就可以按照「区间 DP 问题」的基本思路来做。
###### 1. 阶段划分
按照区间长度进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j][m]$ 表示为:将区间 $[i, j]$ 的石堆合并成 $m$ 堆的最低成本,其中 $m$ 的取值为 $[1,k]$。
###### 3. 状态转移方程
我们将区间 $[i, j]$ 的石堆合并成 $m$ 堆,可以枚举 $i \le n \le j$,将区间 $[i, j]$ 拆分为两个区间 $[i, n]$ 和 $[n + 1, j]$。然后将 $[i, n]$ 中的石头合并为 $1$ 堆,将 $[n + 1, j]$ 中的石头合并成 $m - 1$ 堆。最后将 $1$ 堆石头和 $m - 1$ 堆石头合并成 $1$ 堆,这样就可以将 $[i, j]$ 的石堆合并成 $k$ 堆。则状态转移方程为:$dp[i][j][m] = min_{i \le n < j} \lbrace dp[i][n][1] + dp[n + 1][j][m - 1] \rbrace$。
我们再将区间 $[i, j]$ 的 $k$ 堆石头合并成 $1$ 堆,其成本为 区间 $[i, j]$ 的石堆合并成 $k$ 堆的成本,加上将这 $k$ 堆石头合并成 $1$ 堆的成本,即状态转移方程为:$dp[i][j][1] = dp[i][j][k] + \sum_{t = i}^{t = j} stones[t]$。
###### 4. 初始条件
- 长度为 $1$ 的区间 $[i, i]$ 合并为 $1$ 堆成本为 $0$,即:$dp[i][i][1] = 0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][j][m]$ 表示为:将区间 $[i, j]$ 的石堆合并成 $m$ 堆的最低成本,其中 $m$ 的取值为 $[1,k]$。 所以最终结果为 $dp[1][size][1]$,其中 $size$ 为数组 $stones$ 的长度。
### 思路 1:代码
```python
class Solution:
def mergeStones(self, stones: List[int], k: int) -> int:
size = len(stones)
if (size - 1) % (k - 1) != 0:
return -1
prefix = [0 for _ in range(size + 1)]
for i in range(1, size + 1):
prefix[i] = prefix[i - 1] + stones[i - 1]
dp = [[[float('inf') for _ in range(k + 1)] for _ in range(size)] for _ in range(size)]
for i in range(size):
dp[i][i][1] = 0
for l in range(2, size + 1):
for i in range(size):
j = i + l - 1
if j >= size:
break
for m in range(2, k + 1):
for n in range(i, j, k - 1):
dp[i][j][m] = min(dp[i][j][m], dp[i][n][1] + dp[n + 1][j][m - 1])
dp[i][j][1] = dp[i][j][k] + prefix[j + 1] - prefix[i]
return dp[0][size - 1][1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3 \times k)$,其中 $n$ 是数组 $stones$ 的长度。
- **空间复杂度**:$O(n^2 \times k)$。
### 思路 2:动态规划 + 状态优化
在思路 1 中,我们使用定义状态 $dp[i][j][m]$ 表示为:将区间 $[i, j]$ 的石堆合并成 $m$ 堆的最低成本,其中 $m$ 的取值为 $[1,k]$。
事实上,对于固定区间 $[i, j]$,初始时堆数为 $j - i + 1$,每次合并都会减少 $k - 1$ 堆,合并到无法合并时的堆数固定为 $(j - i) \mod (k - 1) + 1$。
所以,我们可以直接定义状态 $dp[i][j]$ 表示为:将区间 $[i, j]$ 的石堆合并到无法合并时的最低成本。
具体步骤如下:
###### 1. 阶段划分
按照区间长度进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 表示为:将区间 $[i, j]$ 的石堆合并到无法合并时的最低成本。
###### 3. 状态转移方程
枚举 $i \le n \le j$,将区间 $[i, j]$ 拆分为两个区间 $[i, n]$ 和 $[n + 1, j]$。然后将区间 $[i, n]$ 合并成 $1$ 堆,$[n + 1, j]$ 合并成 $m$ 堆。
$dp[i][j] = min_{i \le n < j} \lbrace dp[i][n] + dp[n + 1][j] \rbrace$。
如果 $(j - i) \mod (k - 1) == 0$,则说明区间 $[i, j]$ 能狗合并为 1 堆,则加上区间子数组和,即 $dp[i][j] += prefix[j + 1] - prefix[i]$。
###### 4. 初始条件
- 长度为 $1$ 的区间 $[i, i]$ 合并到无法合并时的最低成本为 $0$,即:$dp[i][i] = 0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][j]$ 表示为:将区间 $[i, j]$ 的石堆合并到无法合并时的最低成本。所以最终结果为 $dp[0][size - 1]$,其中 $size$ 为数组 $stones$ 的长度。
### 思路 2:代码
```python
class Solution:
def mergeStones(self, stones: List[int], k: int) -> int:
size = len(stones)
if (size - 1) % (k - 1) != 0:
return -1
prefix = [0 for _ in range(size + 1)]
for i in range(1, size + 1):
prefix[i] = prefix[i - 1] + stones[i - 1]
dp = [[float('inf') for _ in range(size)] for _ in range(size)]
for i in range(size):
dp[i][i] = 0
for l in range(2, size + 1):
for i in range(size):
j = i + l - 1
if j >= size:
break
# 遍历每一个可以组成 k 堆石子的分割点 n,每次递增 k - 1 个
for n in range(i, j, k - 1):
# 判断 [i, n] 到 [n + 1, j] 是否比之前花费小
dp[i][j] = min(dp[i][j], dp[i][n] + dp[n + 1][j])
# 如果 [i, j] 能狗合并为 1 堆,则加上区间子数组和
if (l - 1) % (k - 1) == 0:
dp[i][j] += prefix[j + 1] - prefix[i]
return dp[0][size - 1]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是数组 $stones$ 的长度。
- **空间复杂度**:$O(n^2)$。
## 参考资料
- 【题解】[一题一解:动态规划(区间 DP)+ 前缀和(清晰题解) - 合并石头的最低成本](https://leetcode.cn/problems/minimum-cost-to-merge-stones/solution/python3javacgo-yi-ti-yi-jie-dong-tai-gui-lr9q/)
================================================
FILE: docs/solutions/1000-1099/minimum-score-triangulation-of-polygon.md
================================================
# [1039. 多边形三角剖分的最低得分](https://leetcode.cn/problems/minimum-score-triangulation-of-polygon/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [1039. 多边形三角剖分的最低得分 - 力扣](https://leetcode.cn/problems/minimum-score-triangulation-of-polygon/)
## 题目大意
**描述**:有一个凸的 $n$ 边形,其每个顶点都有一个整数值。给定一个整数数组 $values$,其中 $values[i]$ 是第 $i$ 个顶点的值(即顺时针顺序)。
现在要将 $n$ 边形剖分为 $n - 2$ 个三角形,对于每个三角形,该三角形的值是顶点标记的乘积,$n$ 边形三角剖分的分数是进行三角剖分后所有 $n - 2$ 个三角形的值之和。
**要求**:返回多边形进行三角剖分可以得到的最低分。
**说明**:
- $n == values.length$。
- $3 \le n \le 50$。
- $1 \le values[i] \le 100$。
**示例**:
- 示例 1:
```python
输入:values = [1,2,3]
输出:6
解释:多边形已经三角化,唯一三角形的分数为 6。
```
- 示例 2:
```python
输入:values = [3,7,4,5]
输出:144
解释:有两种三角剖分,可能得分分别为:3*7*5 + 4*5*7 = 245,或 3*4*5 + 3*4*7 = 144。最低分数为 144。
```
## 解题思路
### 思路 1:动态规划
对于 $0 \sim n - 1$ 个顶点组成的凸多边形进行三角剖分,我们可以在 $[0, n - 1]$ 中任选 $1$ 个点 $k$,从而将凸多边形划分为:
1. 顶点 $0 \sim k$ 组成的凸多边形。
2. 顶点 $0$、$k$、$n - 1$ 组成的三角形。
3. 顶点 $k \sim n - 1$ 组成的凸多边形。
对于顶点 $0$、$k$、$n - 1$ 组成的三角形,我们可以直接计算对应的三角剖分分数为 $values[0] \times values[k] \times values[n - 1]$。
而对于顶点 $0 \sim k$ 组成的凸多边形和顶点 $k \sim n - 1$ 组成的凸多边形,我们可以利用递归或者动态规划的思想,定义一个 $dp[i][j]$ 用于计算顶点 $i$ 到顶点 $j$ 组成的多边形三角剖分的最小分数。
具体做法如下:
###### 1. 阶段划分
按照区间长度进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 表示为:区间 $[i, j]$ 内三角剖分后的最小分数。
###### 3. 状态转移方程
对于区间 $[i, j]$,枚举分割点 $k$,最小分数为 $min(dp[i][k] + dp[k][j] + values[i] \times values[k] \times values[j])$,即:$dp[i][j] = min(dp[i][k] + dp[k][j] + values[i] \times values[k] \times values[j])$。
###### 4. 初始条件
- 默认情况下,所有区间 $[i, j]$ 的最小分数为无穷大。
- 当区间 $[i, j]$ 长度小于 $3$ 时,无法进行三角剖分,其最小分数为 $0$。
- 当区间 $[i, j]$ 长度等于 $3$ 时,其三角剖分的最小分数为 $values[i] * values[i + 1] * values[i + 2]$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][j]$ 表示为:区间 $[i, j]$ 内三角剖分后的最小分数。。 所以最终结果为 $dp[0][size - 1]$。
### 思路 1:代码
```python
class Solution:
def minScoreTriangulation(self, values: List[int]) -> int:
size = len(values)
dp = [[float('inf') for _ in range(size)] for _ in range(size)]
for l in range(1, size + 1):
for i in range(size):
j = i + l - 1
if j >= size:
break
if l < 3:
dp[i][j] = 0
elif l == 3:
dp[i][j] = values[i] * values[i + 1] * values[i + 2]
else:
for k in range(i + 1, j):
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j] + values[i] * values[j] * values[k])
return dp[0][size - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 为顶点个数。
- **空间复杂度**:$O(n^2)$。
================================================
FILE: docs/solutions/1000-1099/number-of-enclaves.md
================================================
# [1020. 飞地的数量](https://leetcode.cn/problems/number-of-enclaves/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、矩阵
- 难度:中等
## 题目链接
- [1020. 飞地的数量 - 力扣](https://leetcode.cn/problems/number-of-enclaves/)
## 题目大意
**描述**:给定一个二维数组 `grid`,每个单元格为 `0`(代表海)或 `1`(代表陆地)。我们可以从一个陆地走到另一个陆地上(朝四个方向之一),然后从边界上的陆地离开网络的边界。
**要求**:返回网格中无法在任意次数的移动中离开网格边界的陆地单元格的数量。
**说明**:
- $m == grid.length$。
- $n == grid[i].length$。
- $1 \le m, n \le 500$。
- $grid[i][j]$ 的值为 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入:grid = [[0,0,0,0],[1,0,1,0],[0,1,1,0],[0,0,0,0]]
输出:3
解释:有三个 1 被 0 包围。一个 1 没有被包围,因为它在边界上。
```
- 示例 2:
```python
输入:grid = [[0,1,1,0],[0,0,1,0],[0,0,1,0],[0,0,0,0]]
输出:0
解释:所有 1 都在边界上或可以到达边界。
```
## 解题思路
### 思路 1:深度优先搜索
与四条边界相连的陆地单元是肯定能离开网络边界的。
我们可以先通过深度优先搜索将与四条边界相关的陆地全部变为海(赋值为 `0`)。
然后统计网格中 `1` 的数量,即为答案。
### 思路 1:代码
```python
class Solution:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
def dfs(self, grid, i, j):
rows = len(grid)
cols = len(grid[0])
if i < 0 or i >= rows or j < 0 or j >= cols or grid[i][j] == 0:
return
grid[i][j] = 0
for direct in self.directs:
new_i = i + direct[0]
new_j = j + direct[1]
self.dfs(grid, new_i, new_j)
def numEnclaves(self, grid: List[List[int]]) -> int:
rows = len(grid)
cols = len(grid[0])
for i in range(rows):
if grid[i][0] == 1:
self.dfs(grid, i, 0)
if grid[i][cols - 1] == 1:
self.dfs(grid, i, cols - 1)
for j in range(cols):
if grid[0][j] == 1:
self.dfs(grid, 0, j)
if grid[rows - 1][j] == 1:
self.dfs(grid, rows - 1, j)
ans = 0
for i in range(rows):
for j in range(cols):
if grid[i][j] == 1:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$。其中 $m$ 和 $n$ 分别为行数和列数。
- **空间复杂度**:$O(m \times n)$。
================================================
FILE: docs/solutions/1000-1099/numbers-with-repeated-digits.md
================================================
# [1012. 至少有 1 位重复的数字](https://leetcode.cn/problems/numbers-with-repeated-digits/)
- 标签:数学、动态规划
- 难度:困难
## 题目链接
- [1012. 至少有 1 位重复的数字 - 力扣](https://leetcode.cn/problems/numbers-with-repeated-digits/)
## 题目大意
**描述**:给定一个正整数 $n$。
**要求**:返回在 $[1, n]$ 范围内具有至少 $1$ 位重复数字的正整数的个数。
**说明**:
- $1 \le n \le 10^9$。
**示例**:
- 示例 1:
```python
输入:n = 20
输出:1
解释:具有至少 1 位重复数字的正数(<= 20)只有 11。
```
- 示例 2:
```python
输入:n = 100
输出:10
解释:具有至少 1 位重复数字的正数(<= 100)有 11,22,33,44,55,66,77,88,99 和 100。
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
正向求解在 $[1, n]$ 范围内具有至少 $1$ 位重复数字的正整数的个数不太容易,我们可以反向思考,先求解出在 $[1, n]$ 范围内各位数字都不重复的正整数的个数 $ans$,然后 $n - ans$ 就是题目答案。
将 $n$ 转换为字符串 $s$,定义递归函数 `def dfs(pos, state, isLimit, isNum):` 表示构造第 $pos$ 位及之后所有数位的合法方案数。接下来按照如下步骤进行递归。
1. 从 `dfs(0, 0, True, False)` 开始递归。 `dfs(0, 0, True, False)` 表示:
1. 从位置 $0$ 开始构造。
2. 初始没有使用数字(即前一位所选数字集合为 $0$)。
3. 开始时受到数字 $n$ 对应最高位数位的约束。
4. 开始时没有填写数字。
2. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:
1. 如果 $isNum == True$,说明当前方案符合要求,则返回方案数 $1$。
2. 如果 $isNum == False$,说明当前方案不符合要求,则返回方案数 $0$。
3. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
4. 如果遇到 $isNum == False$,说明之前位数没有填写数字,当前位可以跳过,这种情况下方案数等于 $pos + 1$ 位置上没有受到 $pos$ 位的约束,并且之前没有填写数字时的方案数,即:`ans = dfs(i + 1, state, False, False)`。
5. 如果 $isNum == True$,则当前位必须填写一个数字。此时:
1. 根据 $isNum$ 和 $isLimit$ 来决定填当前位数位所能选择的最小数字($minX$)和所能选择的最大数字($maxX$),
2. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
3. 如果之前没有选择 $d$,即 $d$ 不在之前选择的数字集合 $state$ 中,则方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, state | (1 << d), isLimit and d == maxX, True)`。
1. `state | (1 << d)` 表示之前选择的数字集合 $state$ 加上 $d$。
2. `isLimit and d == maxX` 表示 $pos + 1$ 位受到之前位限制和 $pos$ 位限制。
3. $isNum == True$ 表示 $pos$ 位选择了数字。
6. 最后的方案数为 `n - dfs(0, 0, True, False)`,将其返回即可。
### 思路 1:代码
```python
class Solution:
def numDupDigitsAtMostN(self, n: int) -> int:
# 将 n 转换为字符串 s
s = str(n)
@cache
# pos: 第 pos 个数位
# state: 之前选过的数字集合。
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
# isNum: 表示 pos 前面的数位是否填了数字。
# 如果为真,则当前位不可跳过;如果为假,则当前位可跳过。
def dfs(pos, state, isLimit, isNum):
if pos == len(s):
# isNum 为 True,则表示当前方案符合要求
return int(isNum)
ans = 0
if not isNum:
# 如果 isNumb 为 False,则可以跳过当前数位
ans = dfs(pos + 1, state, False, False)
# 如果前一位没有填写数字,则最小可选择数字为 0,否则最少为 1(不能含有前导 0)。
minX = 0 if isNum else 1
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = int(s[pos]) if isLimit else 9
# 枚举可选择的数字
for d in range(minX, maxX + 1):
# d 不在选择的数字集合中,即之前没有选择过 d
if (state >> d) & 1 == 0:
ans += dfs(pos + 1, state | (1 << d), isLimit and d == maxX, True)
return ans
return n - dfs(0, 0, True, False)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n \times 10 \times 2^{10})$。
- **空间复杂度**:$O(\log n \times 2^{10})$。
================================================
FILE: docs/solutions/1000-1099/recover-a-tree-from-preorder-traversal.md
================================================
# [1028. 从先序遍历还原二叉树](https://leetcode.cn/problems/recover-a-tree-from-preorder-traversal/)
- 标签:树、深度优先搜索、字符串、二叉树
- 难度:困难
## 题目链接
- [1028. 从先序遍历还原二叉树 - 力扣](https://leetcode.cn/problems/recover-a-tree-from-preorder-traversal/)
## 题目大意
对一棵二叉树进行深度优先搜索。在遍历的过程中,遇到节点,先输出与该节点深度相同数量的短线,再输出该节点的值。如果节点深度为 `D`,则子节点深度为 `D + 1`。根节点的深度为 `0`。如果节点只有一个子节点,则该子节点一定为左子节点。
现在给定深度优先搜索输出的字符串 `traversal`。
要求:还原二叉树,并返回其根节点 `root`。
## 解题思路
用栈存储需要构建子树的节点。并记录下上一节点深度和当前节点深度。
然后遍历深度优先搜索的输出字符串。
- 先将开始部分的数字作为根节点值,构建一个根节点 `root`,并将根节点插入到栈中。
- 如果遇到 `-`,则更新当前节点深度。
- 然后如果遇到数字,则将数字逐位转为整数。并且在最后进行判断。
- 如果当前节点深度 > 前一节点深度:
- 将栈顶节点出栈。
- 构建一个新节点,值为当前整数。将新节点插入到栈顶节点的左子树上。
- 将当前节点和新节点插入到栈中。
- 如果当前节点深度 <= 前一节点深度:
- 将当前节点深度个数的节点从栈中弹出。
- 构建一个新节点,值为当前整数。并将新节点插入到最后弹出节点的右子树上。
- 将当前节点和新节点插入到栈中。
- 最后输出根节点 `root`。
## 代码
```python
class Solution:
def recoverFromPreorder(self, traversal: str) -> Optional[TreeNode]:
stack = []
index, num = 0, 0
pre_level, cur_level = 0, 0
size = len(traversal)
while index < size and traversal[index] != '-':
num = num * 10 + ord(traversal[index]) - ord('0')
index += 1
root = TreeNode(num)
stack.append(root)
while index < size:
if traversal[index] == '-':
cur_level += 1
index += 1
else:
num = 0
while index < size and traversal[index] != '-':
num = num * 10 + ord(traversal[index]) - ord('0')
index += 1
if cur_level > pre_level:
node = stack.pop()
node.left = TreeNode(num)
stack.append(node)
stack.append(node.left)
pre_level = cur_level
cur_level = 0
else:
while len(stack) > cur_level:
stack.pop()
node = stack.pop()
node.right = TreeNode(num)
stack.append(node)
stack.append(node.right)
pre_level = cur_level
cur_level = 0
return root
```
================================================
FILE: docs/solutions/1000-1099/remove-all-adjacent-duplicates-in-string.md
================================================
# [1047. 删除字符串中的所有相邻重复项](https://leetcode.cn/problems/remove-all-adjacent-duplicates-in-string/)
- 标签:栈、字符串
- 难度:简单
## 题目链接
- [1047. 删除字符串中的所有相邻重复项 - 力扣](https://leetcode.cn/problems/remove-all-adjacent-duplicates-in-string/)
## 题目大意
给定一个全部由小写字母组成的字符串 S,重复的删除相邻且相同的字母,直到相邻字母不再有相同的。
比如 "abbaca"。先删除相邻且相同的字母 "bb",变为 "aaca",再删除相邻且相同的字母 "aa",变为 "ca",无相邻且相同的字母,即 "ca" 为最终结果。
## 解题思路
跟括号匹配有点类似。我们可以利用「栈」来做这道题。遍历字符串,如果当前字符与栈顶字符相同,则将栈顶所有相同字符删除,否则就将当前字符入栈。
## 代码
```python
class Solution:
def removeDuplicates(self, S: str) -> str:
stack = []
for ch in S:
if stack and stack[-1] == ch:
stack.pop()
else:
stack.append(ch)
return "".join(stack)
```
================================================
FILE: docs/solutions/1000-1099/remove-outermost-parentheses.md
================================================
# [1021. 删除最外层的括号](https://leetcode.cn/problems/remove-outermost-parentheses/)
- 标签:栈、字符串
- 难度:简单
## 题目链接
- [1021. 删除最外层的括号 - 力扣](https://leetcode.cn/problems/remove-outermost-parentheses/)
## 题目大意
**描述**:有效括号字符串为空 `""`、`"("` + $A$ + `")"` 或 $A + B$ ,其中 $A$ 和 $B$ 都是有效的括号字符串,$+$ 代表字符串的连接。
- 例如,`""`,`"()"`,`"(())()"` 和 `"(()(()))"` 都是有效的括号字符串。
如果有效字符串 $s$ 非空,且不存在将其拆分为 $s = A + B$ 的方法,我们称其为原语(primitive),其中 $A$ 和 $B$ 都是非空有效括号字符串。
给定一个非空有效字符串 $s$,考虑将其进行原语化分解,使得:$s = P_1 + P_2 + ... + P_k$,其中 $P_i$ 是有效括号字符串原语。
**要求**:对 $s$ 进行原语化分解,删除分解中每个原语字符串的最外层括号,返回 $s$。
**说明**:
- $1 \le s.length \le 10^5$。
- $s[i]$ 为 `'('` 或 `')'`。
- $s$ 是一个有效括号字符串。
**示例**:
- 示例 1:
```python
输入:s = "(()())(())"
输出:"()()()"
解释:
输入字符串为 "(()())(())",原语化分解得到 "(()())" + "(())",
删除每个部分中的最外层括号后得到 "()()" + "()" = "()()()"。
```
- 示例 2:
```python
输入:s = "(()())(())(()(()))"
输出:"()()()()(())"
解释:
输入字符串为 "(()())(())(()(()))",原语化分解得到 "(()())" + "(())" + "(()(()))",
删除每个部分中的最外层括号后得到 "()()" + "()" + "()(())" = "()()()()(())"。
```
## 解题思路
### 思路 1:计数遍历
题目要求我们对 $s$ 进行原语化分解,并且删除分解中每个原语字符串的最外层括号。
通过观察可以发现,每个原语其实就是一组有效的括号对(左右括号匹配时),此时我们需要删除这组有效括号对的最外层括号。
我们可以使用一个计数器 $cnt$ 来进行原语化分解,并删除每个原语的最外层括号。
当计数器遇到左括号时,令计数器 $cnt$ 加 $1$,当计数器遇到右括号时,令计数器 $cnt$ 减 $1$。这样当计数器为 $0$ 时表示当前左右括号匹配。
为了删除每个原语的最外层括号,当遇到每个原语最外侧的左括号时(此时 $cnt$ 必然等于 $0$,因为之前字符串为空或者为上一个原语字符串),因为我们不需要最外层的左括号,所以此时我们不需要将其存入答案字符串中。只有当 $cnt > 0$ 时,才将其存入答案字符串中。
同理,当遇到每个原语最外侧的右括号时(此时 $cnt$ 必然等于 $1$,因为之前字符串差一个右括号匹配),因为我们不需要最外层的右括号,所以此时我们不需要将其存入答案字符串中。只有当 $cnt > 1$ 时,才将其存入答案字符串中。
具体步骤如下:
1. 遍历字符串 $s$。
2. 如果遇到 `'('`,判断当前计数器是否大于 $0$:
1. 如果 $cnt > 0$,则将 `'('` 存入答案字符串中,并令计数器加 $1$,即:`cnt += 1`。
2. 如果 $cnt == 0$,则令计数器加 $1$,即:`cnt += 1`。
3. 如果遇到 `')'`,判断当前计数器是否大于 $1$:
1. 如果 $cnt > 1$,则将 `')'` 存入答案字符串中,并令计数器减 $1$,即:`cnt -= 1`。
2. 如果 $cnt == 1$,则令计数器减 $1$,即:`cnt -= 1`。
4. 遍历完返回答案字符串 $ans$。
### 思路 1:代码
```Python
class Solution:
def removeOuterParentheses(self, s: str) -> str:
cnt, ans = 0, ""
for ch in s:
if ch == '(':
if cnt > 0:
ans += ch
cnt += 1
else:
if cnt > 1:
ans += ch
cnt -= 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1000-1099/robot-bounded-in-circle.md
================================================
# [1041. 困于环中的机器人](https://leetcode.cn/problems/robot-bounded-in-circle/)
- 标签:数学、字符串、模拟
- 难度:中等
## 题目链接
- [1041. 困于环中的机器人 - 力扣](https://leetcode.cn/problems/robot-bounded-in-circle/)
## 题目大意
**描述**:在无限的平面上,机器人最初位于 $(0, 0)$ 处,面朝北方。注意:
- 北方向 是 $y$ 轴的正方向。
- 南方向 是 $y$ 轴的负方向。
- 东方向 是 $x$ 轴的正方向。
- 西方向 是 $x$ 轴的负方向。
机器人可以接受下列三条指令之一:
- `"G"`:直走 $1$ 个单位
- `"L"`:左转 $90$ 度
- `"R"`:右转 $90$ 度
给定一个字符串 $instructions$,机器人按顺序执行指令 $instructions$,并一直重复它们。
**要求**:只有在平面中存在环使得机器人永远无法离开时,返回 $True$。否则,返回 $False$。
**说明**:
- $1 \le instructions.length \le 100$。
- $instructions[i]$ 仅包含 `'G'`,`'L'`,`'R'`。
**示例**:
- 示例 1:
```python
输入:instructions = "GGLLGG"
输出:True
解释:机器人最初在(0,0)处,面向北方。
“G”:移动一步。位置:(0,1)方向:北。
“G”:移动一步。位置:(0,2).方向:北。
“L”:逆时针旋转90度。位置:(0,2).方向:西。
“L”:逆时针旋转90度。位置:(0,2)方向:南。
“G”:移动一步。位置:(0,1)方向:南。
“G”:移动一步。位置:(0,0)方向:南。
重复指令,机器人进入循环:(0,0)——>(0,1)——>(0,2)——>(0,1)——>(0,0)。
在此基础上,我们返回 True。
```
- 示例 2:
```python
输入:instructions = "GG"
输出:False
解释:机器人最初在(0,0)处,面向北方。
“G”:移动一步。位置:(0,1)方向:北。
“G”:移动一步。位置:(0,2).方向:北。
重复这些指示,继续朝北前进,不会进入循环。
在此基础上,返回 False。
```
## 解题思路
### 思路 1:模拟
设定初始位置为 $(0, 0)$,初始方向 $direction = 0$,假设按照给定字符串 $instructions$ 执行一遍之后,位于 $(x, y)$ 处,且方向为 $direction$,则可能出现的所有情况为:
1. 方向不变($direction == 0$),且 $(x, y) == (0, 0)$,则会一直在原点,无法走出去。
2. 方向不变($direction == 0$),且 $(x, y) \ne (0, 0)$,则可以走出去。
3. 方向相反($direction == 2$),无论是否产生位移,则再执行 $1$ 遍将会回到原点。
4. 方向逆时针 / 顺时针改变 $90°$($direction == 1 \text{ or } 3$),无论是否产生位移,则再执行 $3$ 遍将会回到原点。
综上所述,最多模拟 $4$ 次即可知道能否回到原点。
从上面也可以等出结论:如果不产生位移,则一定会回到原点。如果改变方向,同样一定会回到原点。
我们只需要根据以上结论,按照 $instructions$ 执行一遍之后,通过判断是否产生位移和改变方向,即可判断是否一定会回到原点。
### 思路 1:代码
```Python
class Solution:
def isRobotBounded(self, instructions: str) -> bool:
# 分别代表北、东、南、西
directions = [(0, 1), (-1, 0), (0, -1), (1, 0)]
x, y = 0, 0
# 初始方向为北
direction = 0
for step in instructions:
if step == 'G':
x += directions[direction][0]
y += directions[direction][1]
elif step == 'L':
direction = (direction + 1) % 4
else:
direction = (direction + 3) % 4
return (x == 0 and y == 0) or direction != 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串 $instructions$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1000-1099/shortest-path-in-binary-matrix.md
================================================
# [1091. 二进制矩阵中的最短路径](https://leetcode.cn/problems/shortest-path-in-binary-matrix/)
- 标签:广度优先搜索、数组、矩阵
- 难度:中等
## 题目链接
- [1091. 二进制矩阵中的最短路径 - 力扣](https://leetcode.cn/problems/shortest-path-in-binary-matrix/)
## 题目大意
给定一个 `n * n` 的二进制矩阵 `grid`。 `grid` 中只含有 `0` 或者 `1`。`grid` 中的畅通路径是一条从左上角 `(0, 0)` 位置上到右下角 `(n - 1, n - 1)`位置上的路径。该路径同时满足以下要求:
- 路径途径的所有单元格的值都是 `0`。
- 路径中所有相邻的单元格应该在 `8` 个方向之一上连通(即相邻两单元格之间彼此不同且共享一条边或者一个角)。
- 畅通路径的长度是该路径途径的单元格总数。
要求:计算出矩阵中最短畅通路径的长度。如果不存在这样的路径,返回 `-1`。
## 解题思路
使用广度优先搜索查找最短路径。具体做法如下:
1. 使用队列 `queue` 存放当前节点位置,使用 set 集合 `visited` 存放遍历过的节点位置。使用 `count` 记录最短路径。将起始位置 `(0, 0)` 加入到 `queue` 中,并标记为访问过。
2. 如果队列不为空,则令 `count += 1`,并将队列中的节点位置依次取出。对于每一个节点位置:
- 先判断是否为右下角节点,即 `(n - 1, n - 1)`。如果是则返回当前最短路径长度 `count`。
- 如果不是,则继续遍历 `8` 个方向上、没有访问过、并且值为 `0` 的相邻单元格。
- 将其加入到队列 `queue` 中,并标记为访问过。
3. 重复进行第 2 步骤,直到队列为空时,返回 `-1`。
## 代码
```python
class Solution:
def shortestPathBinaryMatrix(self, grid: List[List[int]]) -> int:
if grid[0][0] == 1:
return -1
size = len(grid)
directions = {(1, 0), (1, -1), (0, -1), (-1, -1), (-1, 0), (-1, 1), (0, 1), (1, 1)}
visited = set((0, 0))
queue = [(0, 0)]
count = 0
while queue:
count += 1
for _ in range(len(queue)):
row, col = queue.pop(0)
if row == size - 1 and col == size - 1:
return count
for direction in directions:
new_row = row + direction[0]
new_col = col + direction[1]
if 0 <= new_row < size and 0 <= new_col < size and grid[new_row][new_col] == 0 and (new_row, new_col) not in visited:
queue.append((new_row, new_col))
visited.add((new_row, new_col))
return -1
```
================================================
FILE: docs/solutions/1000-1099/smallest-subsequence-of-distinct-characters.md
================================================
# [1081. 不同字符的最小子序列](https://leetcode.cn/problems/smallest-subsequence-of-distinct-characters/)
- 标签:栈、贪心、字符串、单调栈
- 难度:中等
## 题目链接
- [1081. 不同字符的最小子序列 - 力扣](https://leetcode.cn/problems/smallest-subsequence-of-distinct-characters/)
## 题目大意
**描述**:给定一个字符串 `s`。
**要求**:去除字符串中重复的字母,使得每个字母只出现一次。需要保证 **「返回结果的字典序最小(要求不能打乱其他字符的相对位置)」**。
**说明**:
- $1 \le s.length \le 10^4$。
- `s` 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:s = "bcabc"
输出:"abc"
```
- 示例 2:
```python
输入:s = "cbacdcbc"
输出:"acdb"
```
## 解题思路
### 思路 1:哈希表 + 单调栈
针对题目的三个要求:去重、不能打乱其他字符顺序、字典序最小。我们来一一分析。
1. **去重**:可以通过 **「使用哈希表存储字母出现次数」** 的方式,将每个字母出现的次数统计起来,再遍历一遍,去除重复的字母。
2. **不能打乱其他字符顺序**:按顺序遍历,将非重复的字母存储到答案数组或者栈中,最后再拼接起来,就能保证不打乱其他字符顺序。
3. **字典序最小**:意味着字典序小的字母应该尽可能放在前面。
1. 对于第 `i` 个字符 `s[i]` 而言,如果第 `0` ~ `i - 1` 之间的某个字符 `s[j]` 在 `s[i]` 之后不再出现了,那么 `s[j]` 必须放到 `s[i]` 之前。
2. 而如果 `s[j]` 在之后还会出现,并且 `s[j]` 的字典序大于 `s[i]`,我们则可以先舍弃 `s[j]`,把 `s[i]` 尽可能的放到前面。后边再考虑使用 `s[j]` 所对应的字符。
要满足第 3 条需求,我们可以使用 **「单调栈」** 来解决。我们使用单调栈存储 `s[i]` 之前出现的非重复、并且字典序最小的字符序列。整个算法步骤如下:
1. 先遍历一遍字符串,用哈希表 `letter_counts` 统计出每个字母出现的次数。
2. 然后使用单调递减栈保存当前字符之前出现的非重复、并且字典序最小的字符序列。
3. 当遍历到 `s[i]` 时,如果 `s[i]` 没有在栈中出现过:
1. 比较 `s[i]` 和栈顶元素 `stack[-1]` 的字典序。如果 `s[i]` 的字典序小于栈顶元素 `stack[-1]`,并且栈顶元素之后的出现次数大于 `0`,则将栈顶元素弹出。
2. 然后继续判断 `s[i]` 和栈顶元素 `stack[-1]`,并且知道栈顶元素出现次数为 `0` 时停止弹出。此时将 `s[i]` 添加到单调栈中。
4. 从哈希表 `letter_counts` 中减去 `s[i]` 出现的次数,继续遍历。
5. 最后将单调栈中的字符依次拼接为答案字符串,并返回。
### 思路 1:代码
```python
class Solution:
def removeDuplicateLetters(self, s: str) -> str:
stack = []
letter_counts = dict()
for ch in s:
if ch in letter_counts:
letter_counts[ch] += 1
else:
letter_counts[ch] = 1
for ch in s:
if ch not in stack:
while stack and ch < stack[-1] and stack[-1] in letter_counts and letter_counts[stack[-1]] > 0:
stack.pop()
stack.append(ch)
letter_counts[ch] -= 1
return ''.join(stack)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(|\sum|)$,其中 $\sum$ 为字符集合,$|\sum|$ 为字符种类个数。由于栈中字符不能重复,因此栈中最多有 $|\sum|$ 个字符。
## 参考资料
- 【题解】[去除重复数组 - 去除重复字母 - 力扣(LeetCode)](https://leetcode.cn/problems/remove-duplicate-letters/solution/qu-chu-zhong-fu-shu-zu-by-lu-shi-zhe-sokp/)
================================================
FILE: docs/solutions/1000-1099/stream-of-characters.md
================================================
# [1032. 字符流](https://leetcode.cn/problems/stream-of-characters/)
- 标签:设计、字典树、数组、字符串、数据流
- 难度:困难
## 题目链接
- [1032. 字符流 - 力扣](https://leetcode.cn/problems/stream-of-characters/)
## 题目大意
**描述**:设计一个算法:接收一个字符流,并检查这些字符的后缀是否是字符串数组 $words$ 中的一个字符串。
**要求**:
按下述要求实现 StreamChecker 类:
- `StreamChecker(String[] words):` 构造函数,用字符串数组 $words$ 初始化数据结构。
- `boolean query(char letter):` 从字符流中接收一个新字符,如果字符流中的任一非空后缀能匹配 $words$ 中的某一字符串,返回 $True$;否则,返回 $False$。
**说明**:
- $1 \le words.length \le 2000$。
- $1 <= words[i].length <= 200$。
- $words[i]$ 由小写英文字母组成。
- $letter$ 是一个小写英文字母。
- 最多调用查询 $4 \times 10^4$ 次。
**示例**:
- 示例 1:
```python
输入:
["StreamChecker", "query", "query", "query", "query", "query", "query", "query", "query", "query", "query", "query", "query"]
[[["cd", "f", "kl"]], ["a"], ["b"], ["c"], ["d"], ["e"], ["f"], ["g"], ["h"], ["i"], ["j"], ["k"], ["l"]]
输出:
[null, false, false, false, true, false, true, false, false, false, false, false, true]
解释:
StreamChecker streamChecker = new StreamChecker(["cd", "f", "kl"]);
streamChecker.query("a"); // 返回 False
streamChecker.query("b"); // 返回 False
streamChecker.query("c"); // 返回n False
streamChecker.query("d"); // 返回 True ,因为 'cd' 在 words 中
streamChecker.query("e"); // 返回 False
streamChecker.query("f"); // 返回 True ,因为 'f' 在 words 中
streamChecker.query("g"); // 返回 False
streamChecker.query("h"); // 返回 False
streamChecker.query("i"); // 返回 False
streamChecker.query("j"); // 返回 False
streamChecker.query("k"); // 返回 False
streamChecker.query("l"); // 返回 True ,因为 'kl' 在 words 中
```
## 解题思路
这道题要求设计一个数据结构,能够实时检查字符流中的后缀是否匹配给定的单词集合。由于字符流是动态的,我们需要高效地处理每个新字符的查询。
### 思路 1:字典树 + 字符串反转
**问题分析**:
- 需要检查字符流中的后缀是否匹配单词集合中的任意单词
- 字符流是动态添加的,直接存储所有可能的后缀会非常低效
- 字典树适合前缀匹配,但我们需要后缀匹配
**核心思想**:
将后缀匹配问题转化为前缀匹配问题:将所有单词反转后插入字典树,这样检查后缀就变成了检查前缀。
**算法步骤**:
1. **初始化**:将所有单词反转后插入字典树中
2. **查询处理**:每次接收到新字符时,将其添加到字符流的前面
3. **匹配检查**:在字典树中搜索当前字符流,找到匹配的单词就返回 `True`
**关键优化**:
- 使用反转的单词构建字典树,将后缀匹配转化为前缀匹配
- 在搜索过程中,一旦找到匹配的单词就立即返回,避免不必要的继续搜索
**示例分析**:
- 单词集合:`["cd", "f", "kl"]` → 插入字典树:`["dc", "f", "lk"]`
- 字符流 `"cd"` → 检查 `"dc"` 是否在字典树中 → 匹配成功,返回 `True`
### 思路 1:代码
```python
class Node: # 字符节点
def __init__(self): # 初始化字符节点
self.children = dict() # 初始化子节点
self.isEnd = False # isEnd 用于标记单词结束
class Trie: # 字典树
# 初始化字典树
def __init__(self): # 初始化字典树
self.root = Node() # 初始化根节点(根节点不保存字符)
# 向字典树中插入一个单词
def insert(self, word: str) -> None:
cur = self.root
for ch in word: # 遍历单词中的字符
if ch not in cur.children: # 如果当前节点的子节点中,不存在键为 ch 的节点
cur.children[ch] = Node() # 建立一个节点,并将其保存到当前节点的子节点
cur = cur.children[ch] # 令当前节点指向新建立的节点,继续处理下一个字符
cur.isEnd = True # 单词处理完成时,将当前节点标记为单词结束
# 查找字典树中是否存在一个单词
def search(self, word: str) -> bool:
cur = self.root
for ch in word: # 遍历单词中的字符
if ch not in cur.children: # 如果当前节点的子节点中,不存在键为 ch 的节点
return False # 直接返回 False
cur = cur.children[ch] # 令当前节点指向新建立的节点,然后继续查找下一个字符
if cur.isEnd:
return True
return False
# 查找字典树中是否存在一个前缀
def startsWith(self, prefix: str) -> bool:
cur = self.root
for ch in prefix: # 遍历前缀中的字符
if ch not in cur.children: # 如果当前节点的子节点中,不存在键为 ch 的节点
return False # 直接返回 False
cur = cur.children[ch] # 令当前节点指向新建立的节点,然后继续查找下一个字符
return cur is not None # 判断当前节点是否为空,不为空则查找成功
class StreamChecker:
def __init__(self, words: List[str]):
self.trie = Trie()
self.stream = ""
for word in words:
self.trie.insert(word[::-1])
def query(self, letter: str) -> bool:
self.stream = letter + self.stream
size = len(letter)
return self.trie.search(self.stream)
# Your StreamChecker object will be instantiated and called as such:
# obj = StreamChecker(words)
# param_1 = obj.query(letter)
```
### 思路 1:复杂度分析
- **时间复杂度**:
- 初始化:$O(m \times n)$,其中 $m$ 是单词数量,$n$ 是单词的平均长度。
- 查询:$O(k)$,其中 $k$ 是当前字符流的长度。最坏情况下,每次查询都需要遍历整个字符流。
- **空间复杂度**:$O(m \times n)$,字典树的空间复杂度,其中 $m$ 是单词数量,$n$ 是单词的平均长度。
### 思路 2:AC 自动机
**问题分析**:
- 需要处理多模式串匹配问题,适合使用 AC 自动机
- 字符流查询频率高,需要优化查询时间复杂度
- 不需要存储完整的字符流历史,只需要维护当前匹配状态
**核心思想**:
使用 AC 自动机(Aho-Corasick Automaton)进行多模式串匹配:
1. 将所有单词构建成AC自动机,利用字典树共享公共前缀
2. 为每个节点设置失配指针,实现匹配失败时的快速跳转
3. 维护当前匹配状态,每次接收新字符时更新状态并检查匹配
**算法步骤**:
1. **构建AC自动机**:将所有单词插入字典树,并构建失配指针
2. **维护匹配状态**:使用变量记录当前在AC自动机中的位置
3. **字符流处理**:每次接收新字符时,沿着AC自动机进行状态转移
4. **匹配检测**:检查当前状态及其失配链上是否有单词结尾
**关键优势**:
- **时间复杂度优秀**:构建 $O(m)$,查询平均 $O(1)$
- **空间效率高**:共享公共前缀,节省存储空间
- **适合流式处理**:不需要存储整个字符流历史
### 思路 2:代码
```python
class TrieNode:
def __init__(self):
self.children = {} # 子节点,key 为字符,value 为 TrieNode
self.fail = None # 失配指针,指向当前节点最长可用后缀的节点
self.is_end = False # 是否为某个模式串的结尾
self.word = "" # 如果是结尾,存储完整的单词
class AC_Automaton:
def __init__(self):
self.root = TrieNode() # 初始化根节点
def add_word(self, word):
"""
向Trie树中插入一个模式串
"""
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode() # 新建子节点
node = node.children[char]
node.is_end = True # 标记单词结尾
node.word = word # 存储完整单词
def build_fail_pointers(self):
"""
构建失配指针(fail指针),采用BFS广度优先遍历
"""
from collections import deque
queue = deque()
# 1. 根节点的所有子节点的 fail 指针都指向根节点
for child in self.root.children.values():
child.fail = self.root
queue.append(child)
# 2. 广度优先遍历,依次为每个节点建立 fail 指针
while queue:
current = queue.popleft()
for char, child in current.children.items():
# 从当前节点的 fail 指针开始,向上寻找有无相同字符的子节点
fail = current.fail
while fail and char not in fail.children:
fail = fail.fail
# 如果找到了,child的fail指针指向该节点,否则指向根节点
child.fail = fail.children[char] if fail and char in fail.children else self.root
queue.append(child)
class StreamChecker:
def __init__(self, words):
self.ac = AC_Automaton()
# 将所有单词插入AC自动机
for word in words:
self.ac.add_word(word)
# 构建失配指针
self.ac.build_fail_pointers()
# 当前匹配状态
self.current_node = self.ac.root
def query(self, letter):
"""
处理新字符,检查是否匹配到任何单词
"""
# 如果当前节点没有该字符的子节点,则沿 fail 指针向上跳转
while self.current_node is not self.ac.root and letter not in self.current_node.children:
self.current_node = self.current_node.fail
# 如果有该字符的子节点,则转移到该子节点
if letter in self.current_node.children:
self.current_node = self.current_node.children[letter]
# 否则仍然停留在根节点
# 检查当前节点以及沿 fail 链上的所有节点是否为单词结尾
temp = self.current_node
while temp is not self.ac.root:
if temp.is_end:
return True # 找到匹配的单词
temp = temp.fail
return False # 没有找到匹配的单词
# Your StreamChecker object will be instantiated and called as such:
# obj = StreamChecker(words)
# param_1 = obj.query(letter)
```
### 思路 2:复杂度分析
- **时间复杂度**:
- 初始化:$O(m)$,其中 $m$ 是所有单词的总长度。构建字典树和失配指针都是线性时间。
- 查询:$O(1)$ 平均情况,$O(k)$ 最坏情况,其中 $k$ 是单词的最大长度。由于失配指针的存在,大部分情况下可以快速跳转。
- **空间复杂度**:$O(m)$,其中 $m$ 是所有单词的总长度。AC自动机的空间复杂度主要由字典树决定。
================================================
FILE: docs/solutions/1000-1099/two-city-scheduling.md
================================================
# [1029. 两地调度](https://leetcode.cn/problems/two-city-scheduling/)
- 标签:贪心、数组、排序
- 难度:中等
## 题目链接
- [1029. 两地调度 - 力扣](https://leetcode.cn/problems/two-city-scheduling/)
## 题目大意
**描述**:公司计划面试 `2 * n` 人。给你一个数组 `costs`,其中 `costs[i] = [aCosti, bCosti]`,表示第 `i` 人飞往 `a` 市的费用为 `aCosti` ,飞往 `b` 市的费用为 `bCosti`。
**要求**:返回将每个人都飞到 `a`、`b` 中某座城市的最低费用,要求每个城市都有 `n` 人抵达。
**说明**:
- $2 * n == costs.length$。
- $2 \le costs.length \le 100$。
- $costs.length$ 为偶数。
- $1 \le aCosti, bCosti \le 1000$。
**示例**:
- 示例 1:
```python
输入:costs = [[10,20],[30,200],[400,50],[30,20]]
输出:110
解释:
第一个人去 a 市,费用为 10。
第二个人去 a 市,费用为 30。
第三个人去 b 市,费用为 50。
第四个人去 b 市,费用为 20。
最低总费用为 10 + 30 + 50 + 20 = 110,每个城市都有一半的人在面试。
```
## 解题思路
### 思路 1:贪心算法
我们先假设所有人都去了城市 `a`。然后令一半的人再去城市 `b`。现在的问题就变成了,让一半的人改变城市去向,从原本的 `a` 城市改成 `b` 城市的最低费用为多少。
已知第 `i` 个人更换去向的费用为「去城市 `b` 的费用 - 去城市 `a` 的费用」。所以我们可以根据「去城市 `b` 的费用 - 去城市 `a` 的费用」对数组 `costs` 进行排序,让前 `n` 个改变方向去城市 `b`,后 `n` 个人去城市 `a`。
最后统计所有人员的费用,将其返回即可。
### 思路 1:贪心算法代码
```python
class Solution:
def twoCitySchedCost(self, costs: List[List[int]]) -> int:
costs.sort(key=lambda x:x[1] - x[0])
cost = 0
size = len(costs) // 2
for i in range(size):
cost += costs[i][ 1]
cost += costs[i + size][0]
return cost
```
================================================
FILE: docs/solutions/1000-1099/two-sum-less-than-k.md
================================================
# [1099. 小于 K 的两数之和](https://leetcode.cn/problems/two-sum-less-than-k/)
- 标签:数组、双指针、二分查找、排序
- 难度:简单
## 题目链接
- [1099. 小于 K 的两数之和 - 力扣](https://leetcode.cn/problems/two-sum-less-than-k/)
## 题目大意
**描述**:给定一个整数数组 $nums$ 和整数 $k$。
**要求**:返回最大和 $sum$,满足存在 $i < j$ 使得 $nums[i] + nums[j] = sum$ 且 $sum < k$。如果没有满足此等式的 $i$, $j$ 存在,则返回 $-1$。
**说明**:
- $1 \le nums.length \le 100$。
- $1 \le nums[i] \le 1000$。
- $1 \le k \le 2000$。
**示例**:
- 示例 1:
```python
输入:nums = [34,23,1,24,75,33,54,8], k = 60
输出:58
解释:34 和 24 相加得到 58,58 小于 60,满足题意。
```
- 示例 2:
```python
输入:nums = [10,20,30], k = 15
输出:-1
解释:我们无法找到和小于 15 的两个元素。
```
## 解题思路
### 思路 1:对撞指针
常规暴力枚举时间复杂度为 $O(n^2)$。可以通过双指针降低时间复杂度。具体做法如下:
- 先对数组进行排序(时间复杂度为 $O(n \log n$),使用 $res$ 记录答案,初始赋值为最小值 `float('-inf')`。
- 使用两个指针 $left$、$right$。$left$ 指向第 $0$ 个元素位置,$right$ 指向数组的最后一个元素位置。
- 计算 $nums[left] + nums[right]$,与 $k$ 进行比较。
- 如果 $nums[left] + nums[right] \ge k$,则将 $right$ 左移,继续查找。
- 如果 $nums[left] + nums[rigth] < k$,则将 $left$ 右移,并更新答案值。
- 当 $left == right$ 时,区间搜索完毕,判断 $res$ 是否等于 `float('-inf')`,如果等于,则返回 $-1$,否则返回 $res$。
### 思路 1:代码
```python
class Solution:
def twoSumLessThanK(self, nums: List[int], k: int) -> int:
nums.sort()
res = float('-inf')
left, right = 0, len(nums) - 1
while left < right:
total = nums[left] + nums[right]
if total >= k:
right -= 1
else:
res = max(res, total)
left += 1
return res if res != float('-inf') else -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为数组中元素的个数。
- **空间复杂度**:$O(\log n)$,排序需要 $\log n$ 的栈空间。
================================================
FILE: docs/solutions/1000-1099/uncrossed-lines.md
================================================
# [1035. 不相交的线](https://leetcode.cn/problems/uncrossed-lines/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [1035. 不相交的线 - 力扣](https://leetcode.cn/problems/uncrossed-lines/)
## 题目大意
有两条独立平行的水平线,按照给定的顺序写下 `nums1` 和 `nums2` 的整数。
现在,我们可以绘制一些直线,只要满足以下要求:
- `nums1[i] == nums2[j]`。
- 绘制的直线不与其他任何直线相交。
例如:
现在要求:计算出能绘制的最大直线数目。
## 解题思路
动态规划求解。
定义状态 `dp[i][j]` 表示:`nums1` 中前 `i` 个数与 `nums2` 中前 `j` 个数的最大连接数,则:
状态转移方程为:
- 如果 `nums1[i] == nums[j]`,则 `nums1[i]` 与 `nums2[j]` 可连线,此时 `dp[i][j] = dp[i - 1][j - 1] + 1`。
- 如果 `nums1[i] != nums[j]`,则 `nums1[i]` 与 `nums2[j]` 不可连线,此时最大连线数取决于 `dp[i - 1][j]` 和 `dp[i][j - 1]` 的较大值,即:`dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])`。
最后输出 `dp[size1][size2]` 即可。
## 代码
```python
class Solution:
def maxUncrossedLines(self, nums1: List[int], nums2: List[int]) -> int:
size1 = len(nums1)
size2 = len(nums2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if nums1[i - 1] == nums2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[size1][size2]
```
================================================
FILE: docs/solutions/1000-1099/valid-boomerang.md
================================================
# [1037. 有效的回旋镖](https://leetcode.cn/problems/valid-boomerang/)
- 标签:几何、数组、数学
- 难度:简单
## 题目链接
- [1037. 有效的回旋镖 - 力扣](https://leetcode.cn/problems/valid-boomerang/)
## 题目大意
**描述**:给定一个数组 $points$,其中 $points[i] = [xi, yi]$ 表示平面上的一个点。
**要求**:如果这些点构成一个回旋镖,则返回 `True`,否则,则返回 `False`。
**说明**:
- **回旋镖**:定义为一组三个点,这些点各不相同且不在一条直线上。
- $points.length == 3$。
- $points[i].length == 2$。
- $0 \le xi, yi \le 100$。
**示例**:
- 示例 1:
```python
输入:points = [[1,1],[2,3],[3,2]]
输出:True
```
- 示例 2:
```python
输入:points = [[1,1],[2,2],[3,3]]
输出:False
```
## 解题思路
### 思路 1:
设三点坐标为 $A = (x1, y1)$,$B = (x2, y2)$,$C = (x3, y3)$,则向量 $\overrightarrow{AB} = (x2 - x1, y2 - y1)$,$\overrightarrow{BC} = (x3 - x2, y3 - y2)$。
如果三点共线,则应满足:$\overrightarrow{AB} \times \overrightarrow{BC} = (x2 − x1) \times (y3 − y2) - (x3 − x2) \times (y2 − y1) = 0$。
如果三点不共线,则应满足:$\overrightarrow{AB} \times \overrightarrow{BC} = (x2 − x1) \times (y3 − y2) - (x3 − x2) \times (y2 − y1) \ne 0$。
### 思路 1:代码
```python
class Solution:
def isBoomerang(self, points: List[List[int]]) -> bool:
x1, y1 = points[0]
x2, y2 = points[1]
x3, y3 = points[2]
cross1 = (x2 - x1) * (y3 - y2)
cross2 = (x3 - x2) * (y2 - y1)
return cross1 - cross2 != 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1100-1199/corporate-flight-bookings.md
================================================
# [1109. 航班预订统计](https://leetcode.cn/problems/corporate-flight-bookings/)
- 标签:数组、前缀和
- 难度:中等
## 题目链接
- [1109. 航班预订统计 - 力扣](https://leetcode.cn/problems/corporate-flight-bookings/)
## 题目大意
**描述**:给定整数 `n`,代表 `n` 个航班。再给定一个包含三元组的数组 `bookings`,代表航班预订表。表中第 `i` 条预订记录 $bookings[i] = [first_i, last_i, seats_i]$ 意味着在从 $first_i$ 到 $last_i$ (包含 $first_i$ 和 $last_i$)的 每个航班上预订了 $seats_i$ 个座位。
**要求**:返回一个长度为 `n` 的数组 `answer`,里面元素是每个航班预定的座位总数。
**说明**:
- $1 \le n \le 2 * 10^4$。
- $1 \le bookings.length \le 2 * 10^4$。
- $bookings[i].length == 3$。
- $1 \le first_i \le last_i \le n$。
- $1 \le seats_i \le 10^4$
**示例**:
- 示例 1:
```python
给定 n = 5。初始 answer = [0, 0, 0, 0, 0]
航班编号 1 2 3 4 5
预订记录 1 : 10 10
预订记录 2 : 20 20
预订记录 3 : 25 25 25 25
总座位数: 10 55 45 25 25
最终 answer = [10, 55, 45, 25, 25]
```
## 解题思路
### 思路 1:线段树
- 初始化一个长度为 `n`,值全为 `0` 的 `nums` 数组。
- 然后根据 `nums` 数组构建一棵线段树。每个线段树的节点类存储当前区间的左右边界和该区间的和。并且线段树使用延迟标记。
- 然后遍历三元组操作,进行区间累加运算。
- 最后从线段树中查询数组所有元素,返回该数组即可。
这样构建线段树的时间复杂度为 $O(\log n)$,单次区间更新的时间复杂度为 $O(\log n)$,单次区间查询的时间复杂度为 $O(\log n)$。总体时间复杂度为 $O(\log n)$。
### 思路 1 线段树代码:
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=0):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
self.lazy_tag = None # 区间和问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, nums, function):
self.size = len(nums)
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
self.nums = nums # 原始数据
self.function = function # function 是一个函数,左右区间的聚合方法
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.nums[i] = val
self.__update_point(i, val, 0)
# 区间更新接口:将区间为 [q_left, q_right] 上的所有元素值加上 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self):
for i in range(self.size):
self.nums[i] = self.query_interval(i, i)
return self.nums
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = self.nums[left]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.__pushup(index) # 向上更新节点的区间值
# 单点更新实现方法:将 nums[i] 更改为 val,节点的存储下标为 index
def __update_point(self, i, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left == right:
self.tree[index].val = val # 叶子节点,节点值修改为 val
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if i <= mid: # 在左子树中更新节点值
self.__update_point(i, val, left_index)
else: # 在右子树中更新节点值
self.__update_point(i, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if self.tree[index].lazy_tag is not None:
self.tree[index].lazy_tag += val # 将当前节点的延迟标记增加 val
else:
self.tree[index].lazy_tag = val # 将当前节点的延迟标记增加 val
interval_size = (right - left + 1) # 当前节点所在区间大小
self.tree[index].val += val * interval_size # 当前节点所在区间每个元素值增加 val
return
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
self.__pushdown(index) # 向下更新节点的区间值
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if q_left <= mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, left_index)
if q_right > mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间查询实现方法:在线段树中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(index)
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新下标为 index 的节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, index):
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[index].val = self.function(self.tree[left_index].val, self.tree[right_index].val)
# 向下更新实现方法:更新下标为 index 的节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, index):
lazy_tag = self.tree[index].lazy_tag
if lazy_tag is None:
return
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if self.tree[left_index].lazy_tag is not None:
self.tree[left_index].lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
self.tree[left_index].lazy_tag = lazy_tag
left_size = (self.tree[left_index].right - self.tree[left_index].left + 1)
self.tree[left_index].val += lazy_tag * left_size # 左子节点每个元素值增加 lazy_tag
if self.tree[right_index].lazy_tag is not None:
self.tree[right_index].lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
self.tree[right_index].lazy_tag = lazy_tag
right_size = (self.tree[right_index].right - self.tree[right_index].left + 1)
self.tree[right_index].val += lazy_tag * right_size # 右子节点每个元素值增加 lazy_tag
self.tree[index].lazy_tag = None # 更新当前节点的懒惰标记
class Solution:
def corpFlightBookings(self, bookings: List[List[int]], n: int) -> List[int]:
nums = [0 for _ in range(n)]
self.STree = SegmentTree(nums, lambda x, y: x + y)
for booking in bookings:
self.STree.update_interval(booking[0] - 1, booking[1] - 1, booking[2])
return self.STree.get_nums()
```
================================================
FILE: docs/solutions/1100-1199/defanging-an-ip-address.md
================================================
# [1108. IP 地址无效化](https://leetcode.cn/problems/defanging-an-ip-address/)
- 标签:字符串
- 难度:简单
## 题目链接
- [1108. IP 地址无效化 - 力扣](https://leetcode.cn/problems/defanging-an-ip-address/)
## 题目大意
**描述**:给定一个有效的 IPv4 的地址 `address`。。
**要求**:返回这个 IP 地址的无效化版本。
**说明**:
- **无效化 IP 地址**:其实就是用 `"[.]"` 代替了每个 `"."`。
**示例**:
- 示例 1:
```python
输入:address = "255.100.50.0"
输出:"255[.]100[.]50[.]0"
```
## 解题思路
### 思路 1:字符串替换
依次将字符串 `address` 中的 `"."` 替换为 `"[.]"`。这里为了方便,直接调用了 `replace` 方法。
### 思路 1:字符串替换代码
```python
class Solution:
def defangIPaddr(self, address: str) -> str:
return address.replace('.', '[.]')
```
================================================
FILE: docs/solutions/1100-1199/delete-nodes-and-return-forest.md
================================================
# [1110. 删点成林](https://leetcode.cn/problems/delete-nodes-and-return-forest/)
- 标签:树、深度优先搜索、数组、哈希表、二叉树
- 难度:中等
## 题目链接
- [1110. 删点成林 - 力扣](https://leetcode.cn/problems/delete-nodes-and-return-forest/)
## 题目大意
**描述**:给定二叉树的根节点 $root$,树上每个节点都有一个不同的值。
如果节点值在 $to\_delete$ 中出现,我们就把该节点从树上删去,最后得到一个森林(一些不相交的树构成的集合)。
**要求**:返回森林中的每棵树。你可以按任意顺序组织答案。
**说明**:
- 树中的节点数最大为 $1000$。
- 每个节点都有一个介于 $1$ 到 $1000$ 之间的值,且各不相同。
- $to\_delete.length \le 1000$。
- $to\_delete$ 包含一些从 $1$ 到 $1000$、各不相同的值。
**示例**:
- 示例 1:
```python
输入:root = [1,2,3,4,5,6,7], to_delete = [3,5]
输出:[[1,2,null,4],[6],[7]]
```
- 示例 2:
```python
输入:root = [1,2,4,null,3], to_delete = [3]
输出:[[1,2,4]]
```
## 解题思路
### 思路 1:深度优先搜索
将待删除节点数组 $to\_delete$ 转为集合 $deletes$,则每次能以 $O(1)$ 的时间复杂度判断节点值是否在待删除节点数组中。
如果当前节点值在待删除节点数组中,则删除当前节点后,我们还需要判断其左右子节点是否也在待删除节点数组中。
以此类推,还需要判断左右子节点的左右子节点。。。
因此,我们应该递归遍历处理完所有的左右子树,再判断当前节点的左右子节点是否在待删除节点数组中。如果在,则将其加入到答案数组中。
为此我们可以写一个深度优先搜索算法,具体步骤如下:
1. 如果当前根节点为空,则返回 `None`。
2. 递归遍历处理完当前根节点的左右子树,更新当前节点的左右子树(子节点被删除的情况下需要更新当前根节点的左右子树)。
3. 如果当前根节点值在待删除节点数组中:
1. 如果当前根节点的左子树没有在被删除节点数组中,将左子树节点加入到答案数组中。
2. 如果当前根节点的右子树没有在被删除节点数组中,将右子树节点加入到答案数组中。
3. 返回 `None`,表示当前节点被删除。
4. 如果当前根节点值不在待删除节点数组中:
1. 返回根节点,表示当前节点没有被删除。
### 思路 1:代码
```Python
class Solution:
def delNodes(self, root: Optional[TreeNode], to_delete: List[int]) -> List[TreeNode]:
forest = []
deletes = set(to_delete)
def dfs(root):
if not root:
return None
root.left = dfs(root.left)
root.right = dfs(root.right)
if root.val in deletes:
if root.left:
forest.append(root.left)
if root.right:
forest.append(root.right)
return None
else:
return root
if dfs(root):
forest.append(root)
return forest
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为二叉树中节点个数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1100-1199/diet-plan-performance.md
================================================
# [1176. 健身计划评估](https://leetcode.cn/problems/diet-plan-performance/)
- 标签:数组、滑动窗口
- 难度:简单
## 题目链接
- [1176. 健身计划评估 - 力扣](https://leetcode.cn/problems/diet-plan-performance/)
## 题目大意
**描述**:好友给自己制定了一份健身计划。想请你帮他评估一下这份计划是否合理。
给定一个数组 $calories$,其中 $calories[i]$ 代表好友第 $i$ 天需要消耗的卡路里总量。再给定 $lower$ 代表较低消耗的卡路里,$upper$ 代表较高消耗的卡路里。再给定一个整数 $k$,代表连续 $k$ 天。
- 如果你的好友在这一天以及之后连续 $k$ 天内消耗的总卡路里 $T$ 小于 $lower$,则这一天的计划相对糟糕,并失去 $1$ 分。
- 如果你的好友在这一天以及之后连续 $k$ 天内消耗的总卡路里 $T$ 高于 $upper$,则这一天的计划相对优秀,并得到 $1$ 分。
- 如果你的好友在这一天以及之后连续 $k$ 天内消耗的总卡路里 $T$ 大于等于 $lower$,并且小于等于 $upper$,则这份计划普普通通,分值不做变动。
**要求**:输出最后评估的得分情况。
**说明**:
- $1 \le k \le calories.length \le 10^5$。
- $0 \le calories[i] \le 20000$。
- $0 \le lower \le upper$。
**示例**:
- 示例 1:
```python
输入:calories = [1,2,3,4,5], k = 1, lower = 3, upper = 3
输出:0
解释:calories[0], calories[1] < lower 而 calories[3], calories[4] > upper, 总分 = 0.
```
- 示例 2:
```python
输入:calories = [3,2], k = 2, lower = 0, upper = 1
输出:1
解释:calories[0] + calories[1] > upper, 总分 = 1.
```
## 解题思路
### 思路 1:滑动窗口
固定长度为 $k$ 的滑动窗口题目。具体做法如下:
1. $score$ 用来维护得分情况,初始值为 $0$。$window\_sum$ 用来维护窗口中卡路里总量。
2. $left$ 、$right$ 都指向数组的第一个元素,即:`left = 0`,`right = 0`。
3. 向右移动 $right$,先将 $k$ 个元素填入窗口中。
4. 当窗口元素个数为 $k$ 时,即:$right - left + 1 \ge k$ 时,计算窗口内的卡路里总量,并判断和 $upper$、$lower$ 的关系。同时维护得分情况。
5. 然后向右移动 $left$,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 $k$。
6. 重复 $4 \sim 5$ 步,直到 $right$ 到达数组末尾。
最后输出得分情况 $score$。
### 思路 1:代码
```python
class Solution:
def dietPlanPerformance(self, calories: List[int], k: int, lower: int, upper: int) -> int:
left, right = 0, 0
window_sum = 0
score = 0
while right < len(calories):
window_sum += calories[right]
if right - left + 1 >= k:
if window_sum < lower:
score -= 1
elif window_sum > upper:
score += 1
window_sum -= calories[left]
left += 1
right += 1
return score
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $calories$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1100-1199/distance-between-bus-stops.md
================================================
# [1184. 公交站间的距离](https://leetcode.cn/problems/distance-between-bus-stops/)
- 标签:数组
- 难度:简单
## 题目链接
- [1184. 公交站间的距离 - 力扣](https://leetcode.cn/problems/distance-between-bus-stops/)
## 题目大意
**描述**:环形公交路线上有 $n$ 个站,序号为 $0 \sim n - 1$。给定一个数组 $distance$ 表示每一对相邻公交站之间的距离,其中 $distance[i]$ 表示编号为 $i$ 的车站与编号为 $(i + 1) \mod n$ 的车站之间的距离。再给定乘客的出发点编号 $start$ 和目的地编号 $destination$。
**要求**:返回乘客从出发点 $start$ 到目的地 $destination$ 之间的最短距离。
**说明**:
- $1 \le n \le 10^4$。
- $distance.length == n$。
- $0 \le start, destination < n$。
- $0 \le distance[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:distance = [1,2,3,4], start = 0, destination = 1
输出:1
解释:公交站 0 和 1 之间的距离是 1 或 9,最小值是 1。
```
- 示例 2:
```python
输入:distance = [1,2,3,4], start = 0, destination = 2
输出:3
解释:公交站 0 和 2 之间的距离是 3 或 7,最小值是 3。
```
## 解题思路
### 思路 1:简单模拟
1. 因为 $start$ 和 $destination$ 的先后顺序不影响结果,为了方便计算,我们先令 $start \le destination$。
2. 遍历数组 $distance$,计算出 $[start, destination]$ 之间的距离和 $dist$。
3. 计算出环形路线中 $[destination, start]$ 之间的距离和为 $sum(distance) - dist$。
4. 比较 $2 \sim 3$ 中两个距离的大小,将距离最小值作为答案返回。
### 思路 1:代码
```python
class Solution:
def distanceBetweenBusStops(self, distance: List[int], start: int, destination: int) -> int:
start, destination = min(start, destination), max(start, destination)
dist = 0
for i in range(len(distance)):
if start <= i < destination:
dist += distance[i]
return min(dist, sum(distance) - dist)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1100-1199/distribute-candies-to-people.md
================================================
# [1103. 分糖果 II](https://leetcode.cn/problems/distribute-candies-to-people/)
- 标签:数学、模拟
- 难度:简单
## 题目链接
- [1103. 分糖果 II - 力扣](https://leetcode.cn/problems/distribute-candies-to-people/)
## 题目大意
**描述**:给定一个整数 $candies$,代表糖果的数量。再给定一个整数 $num\_people$,代表小朋友的数量。
现在开始分糖果,给第 $1$ 个小朋友分 $1$ 颗糖果,第 $2$ 个小朋友分 $2$ 颗糖果,以此类推,直到最后一个小朋友分 $n$ 颗糖果。
然后回到第 $1$ 个小朋友,给第 $1$ 个小朋友分 $n + 1$ 颗糖果,第 $2$ 个小朋友分 $n + 2$ 颗糖果,一次类推,直到最后一个小朋友分 $n + n$ 颗糖果。
重复上述过程(每次都比上一次多给出 $1$ 颗糖果,当分完第 $n$ 个小朋友时回到第 $1$ 个小朋友),直到我们分完所有的糖果。
> 注意:如果我们手中剩下的糖果数不够(小于等于前一次发的糖果数),则将剩下的糖果全部发给当前的小朋友。
**要求**:返回一个长度为 $num\_people$、元素之和为 $candies$ 的数组,以表示糖果的最终分发情况(即 $ans[i]$ 表示第 $i$ 个小朋友分到的糖果数)。
**说明**:
- $1 \le candies \le 10^9$。
- $1 \le num\_people \le 1000$。
**示例**:
- 示例 1:
```python
输入:candies = 7, num_people = 4
输出:[1,2,3,1]
解释:
第一次,ans[0] += 1,数组变为 [1,0,0,0]。
第二次,ans[1] += 2,数组变为 [1,2,0,0]。
第三次,ans[2] += 3,数组变为 [1,2,3,0]。
第四次,ans[3] += 1(因为此时只剩下 1 颗糖果),最终数组变为 [1,2,3,1]。
```
- 示例 2:
```python
输入:candies = 10, num_people = 3
输出:[5,2,3]
解释:
第一次,ans[0] += 1,数组变为 [1,0,0]。
第二次,ans[1] += 2,数组变为 [1,2,0]。
第三次,ans[2] += 3,数组变为 [1,2,3]。
第四次,ans[0] += 4,最终数组变为 [5,2,3]。
```
## 解题思路
### 思路 1:暴力模拟
不断遍历数组,将对应糖果数分给当前小朋友,直到糖果数为 $0$ 时停止。
### 思路 1:代码
```python
class Solution:
def distributeCandies(self, candies: int, num_people: int) -> List[int]:
ans = [0 for _ in range(num_people)]
idx = 0
while candies:
ans[idx % num_people] += min(idx + 1, candies)
candies -= min(idx + 1, candies)
idx += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(max(\sqrt{m}, n))$,其中 $m$ 为糖果数量,$n$ 为小朋友数量。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1100-1199/find-k-length-substrings-with-no-repeated-characters.md
================================================
# [1100. 长度为 K 的无重复字符子串](https://leetcode.cn/problems/find-k-length-substrings-with-no-repeated-characters/)
- 标签:哈希表、字符串、滑动窗口
- 难度:中等
## 题目链接
- [1100. 长度为 K 的无重复字符子串 - 力扣](https://leetcode.cn/problems/find-k-length-substrings-with-no-repeated-characters/)
## 题目大意
**描述**:给定一个字符串 `s`。
**要求**:找出所有长度为 `k` 且不含重复字符的子串,返回全部满足要求的子串的数目。
**说明**:
- $1 \le s.length \le 10^4$。
- $s$ 中的所有字符均为小写英文字母。
- $1 <= k <= 10^4$。
**示例**:
- 示例 1:
```python
输入:s = "havefunonleetcode", k = 5
输出:6
解释:
这里有 6 个满足题意的子串,分别是:'havef','avefu','vefun','efuno','etcod','tcode'。
```
- 示例 2:
```python
输入:s = "home", K = 5
输出:0
解释:
注意:k 可能会大于 s 的长度。在这种情况下,就无法找到任何长度为 k 的子串。
```
## 解题思路
### 思路 1:滑动窗口
固定长度滑动窗口的题目。维护一个长度为 `k` 的滑动窗口。用 `window_count` 来表示窗口内所有字符个数。可以用字典、数组来实现,也可以直接用 `collections.Counter()` 实现。然后不断向右滑动,然后进行比较。如果窗口内字符无重复,则答案数目 + 1。然后继续滑动。直到末尾时。整个解题步骤具体如下:
1. `window_count` 用来维护窗口中 `2` 对应子串的各个字符数量。
2. `left` 、`right` 都指向序列的第一个元素,即:`left = 0`,`right = 0`。
3. 向右移动 `right`,先将 `k` 个元素填入窗口中。
4. 当窗口元素个数为 `k` 时,即:`right - left + 1 >= k` 时,判断窗口内各个字符数量 `window_count` 是否等于 `k`。
1. 如果等于,则答案 + 1。
2. 如果不等于,则向右移动 `left`,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 `k`。
5. 重复 3 ~ 4 步,直到 `right` 到达数组末尾。返回答案。
### 思路 1:代码
```python
import collections
class Solution:
def numKLenSubstrNoRepeats(self, s: str, k: int) -> int:
left, right = 0, 0
window_count = collections.Counter()
ans = 0
while right < len(s):
window_count[s[right]] += 1
if right - left + 1 >= k:
if len(window_count) == k:
ans += 1
window_count[s[left]] -= 1
if window_count[s[left]] == 0:
del window_count[s[left]]
left += 1
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(|\sum|)$,其中 $\sum$ 是字符集。
================================================
FILE: docs/solutions/1100-1199/index.md
================================================
## 本章内容
- [1100. 长度为 K 的无重复字符子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/find-k-length-substrings-with-no-repeated-characters.md)
- [1103. 分糖果 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/distribute-candies-to-people.md)
- [1108. IP 地址无效化](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/defanging-an-ip-address.md)
- [1109. 航班预订统计](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/corporate-flight-bookings.md)
- [1110. 删点成林](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/delete-nodes-and-return-forest.md)
- [1122. 数组的相对排序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/relative-sort-array.md)
- [1136. 并行课程](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/parallel-courses.md)
- [1137. 第 N 个泰波那契数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/n-th-tribonacci-number.md)
- [1143. 最长公共子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/longest-common-subsequence.md)
- [1151. 最少交换次数来组合所有的 1](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/minimum-swaps-to-group-all-1s-together.md)
- [1155. 掷骰子等于目标和的方法数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/number-of-dice-rolls-with-target-sum.md)
- [1161. 最大层内元素和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/maximum-level-sum-of-a-binary-tree.md)
- [1176. 健身计划评估](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/diet-plan-performance.md)
- [1184. 公交站间的距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/distance-between-bus-stops.md)
================================================
FILE: docs/solutions/1100-1199/longest-common-subsequence.md
================================================
# [1143. 最长公共子序列](https://leetcode.cn/problems/longest-common-subsequence/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [1143. 最长公共子序列 - 力扣](https://leetcode.cn/problems/longest-common-subsequence/)
## 题目大意
**描述**:给定两个字符串 $text1$ 和 $text2$。
**要求**:返回两个字符串的最长公共子序列的长度。如果不存在公共子序列,则返回 $0$。
**说明**:
- **子序列**:原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- **公共子序列**:两个字符串所共同拥有的子序列。
- $1 \le text1.length, text2.length \le 1000$。
- $text1$ 和 $text2$ 仅由小写英文字符组成。
**示例**:
- 示例 1:
```python
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace",它的长度为 3。
```
- 示例 2:
```python
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc",它的长度为 3。
```
## 解题思路
### 思路 1:动态规划
###### 1. 阶段划分
按照两个字符串的结尾位置进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 表示为:「以 $text1$ 中前 $i$ 个元素组成的子字符串 $str1$ 」与「以 $text2$ 中前 $j$ 个元素组成的子字符串 $str2$」的最长公共子序列长度为 $dp[i][j]$。
###### 3. 状态转移方程
双重循环遍历字符串 $text1$ 和 $text2$,则状态转移方程为:
1. 如果 $text1[i - 1] = text2[j - 1]$,说明两个子字符串的最后一位是相同的,所以最长公共子序列长度加 $1$。即:$dp[i][j] = dp[i - 1][j - 1] + 1$。
2. 如果 $text1[i - 1] \ne text2[j - 1]$,说明两个子字符串的最后一位是不同的,则 $dp[i][j]$ 需要考虑以下两种情况,取两种情况中最大的那种:$dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])$。
1. 「以 $text1$ 中前 $i - 1$ 个元素组成的子字符串 $str1$ 」与「以 $text2$ 中前 $j$ 个元素组成的子字符串 $str2$」的最长公共子序列长度,即 $dp[i - 1][j]$。
2. 「以 $text1$ 中前 $i$ 个元素组成的子字符串 $str1$ 」与「以 $text2$ 中前 $j - 1$ 个元素组成的子字符串 $str2$」的最长公共子序列长度,即 $dp[i][j - 1]$。
###### 4. 初始条件
1. 当 $i = 0$ 时,$str1$ 表示的是空串,空串与 $str2$ 的最长公共子序列长度为 $0$,即 $dp[0][j] = 0$。
2. 当 $j = 0$ 时,$str2$ 表示的是空串,$str1$ 与 空串的最长公共子序列长度为 $0$,即 $dp[i][0] = 0$。
###### 5. 最终结果
根据状态定义,最后输出 $dp[sise1][size2]$(即 $text1$ 与 $text2$ 的最长公共子序列长度)即可,其中 $size1$、$size2$ 分别为 $text1$、$text2$ 的字符串长度。
### 思路 1:代码
```python
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
size1 = len(text1)
size2 = len(text2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[size1][size2]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m)$,其中 $n$、$m$ 分别是字符串 $text1$、$text2$ 的长度。两重循环遍历的时间复杂度是 $O(n \times m)$,所以总的时间复杂度为 $O(n \times m)$。
- **空间复杂度**:$O(n \times m)$。用到了二维数组保存状态,所以总体空间复杂度为 $O(n \times m)$。
================================================
FILE: docs/solutions/1100-1199/maximum-level-sum-of-a-binary-tree.md
================================================
# [1161. 最大层内元素和](https://leetcode.cn/problems/maximum-level-sum-of-a-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [1161. 最大层内元素和 - 力扣](https://leetcode.cn/problems/maximum-level-sum-of-a-binary-tree/)
## 题目大意
**描述**:给你一个二叉树的根节点 $root$。设根节点位于二叉树的第 $1$ 层,而根节点的子节点位于第 $2$ 层,依此类推。
**要求**:返回层内元素之和最大的那几层(可能只有一层)的层号,并返回其中层号最小的那个。
**说明**:
- 树中的节点数在 $[1, 10^4]$ 范围内。
- $-10^5 \le Node.val \le 10^5$。
**示例**:
- 示例 1:
```python
输入:root = [1,7,0,7,-8,null,null]
输出:2
解释:
第 1 层各元素之和为 1,
第 2 层各元素之和为 7 + 0 = 7,
第 3 层各元素之和为 7 + -8 = -1,
所以我们返回第 2 层的层号,它的层内元素之和最大。
```
- 示例 2:
```python
输入:root = [989,null,10250,98693,-89388,null,null,null,-32127]
输出:2
```
## 解题思路
### 思路 1:二叉树的层序遍历
1. 利用广度优先搜索,在二叉树的层序遍历的基础上,统计每一层节点和,并存入数组 $levels$ 中。
2. 遍历 $levels$ 数组,从 $levels$ 数组中找到最大层和 $max\_sum$。
3. 再次遍历 $levels$ 数组,找出等于最大层和 $max\_sum$ 的那一层,并返回该层序号。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:
return []
queue = [root]
levels = []
while queue:
level = 0
size = len(queue)
for _ in range(size):
curr = queue.pop(0)
level += curr.val
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
levels.append(level)
return levels
def maxLevelSum(self, root: Optional[TreeNode]) -> int:
levels = self.levelOrder(root)
max_sum = max(levels)
for i in range(len(levels)):
if levels[i] == max_sum:
return i + 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。其中 $n$ 是二叉树的节点数目。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1100-1199/minimum-swaps-to-group-all-1s-together.md
================================================
# [1151. 最少交换次数来组合所有的 1](https://leetcode.cn/problems/minimum-swaps-to-group-all-1s-together/)
- 标签:数组、滑动窗口
- 难度:中等
## 题目链接
- [1151. 最少交换次数来组合所有的 1 - 力扣](https://leetcode.cn/problems/minimum-swaps-to-group-all-1s-together/)
## 题目大意
**描述**:给定一个二进制数组 $data$。
**要求**:通过交换位置,将数组中任何位置上的 $1$ 组合到一起,并返回所有可能中所需的最少交换次数。c
**说明**:
- $1 \le data.length \le 10^5$。
- $data[i] == 0 \text{ or } 1$。
**示例**:
- 示例 1:
```python
输入: data = [1,0,1,0,1]
输出: 1
解释:
有三种可能的方法可以把所有的 1 组合在一起:
[1,1,1,0,0],交换 1 次;
[0,1,1,1,0],交换 2 次;
[0,0,1,1,1],交换 1 次。
所以最少的交换次数为 1。
```
- 示例 2:
```python
输入:data = [0,0,0,1,0]
输出:0
解释:
由于数组中只有一个 1,所以不需要交换。
```
## 解题思路
### 思路 1:滑动窗口
将数组中任何位置上的 $1$ 组合到一起,并要求最少的交换次数。也就是说交换之后,某个连续子数组中全是 $1$,数组其他位置全是 $0$。为此,我们可以维护一个固定长度为 $1$ 的个数的滑动窗口,找到滑动窗口中 $0$ 最少的个数,这样最终交换出去的 $0$ 最少,交换次数也最少。
求最少交换次数,也就是求滑动窗口中最少的 $0$ 的个数。具体做法如下:
1. 统计 $1$ 的个数,并设置为窗口长度 $window\_size$。使用 $window\_count$ 维护窗口中 $0$ 的个数。使用 $ans$ 维护窗口中最少的 $0$ 的个数,也可以叫做最少交换次数。
2. 如果 $window\_size$ 为 $0$,则说明不用交换,直接返回 $0$。
3. 使用两个指针 $left$、$right$。$left$、$right$ 都指向数组的第一个元素,即:`left = 0`,`right = 0`。
4. 如果 $data[right] == 0$,则更新窗口中 $0$ 的个数,即 `window_count += 1`。然后向右移动 $right$。
5. 当窗口元素个数为 $window\_size$ 时,即:$right - left + 1 \ge window\_size$ 时,更新窗口中最少的 $0$ 的个数。
6. 然后如果左侧 $data[left] == 0$,则更新窗口中 $0$ 的个数,即 `window_count -= 1`。然后向右移动 $left$,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 $window\_size$。
7. 重复 4 ~ 6 步,直到 $right$ 到达数组末尾。返回答案 $ans$。
### 思路 1:代码
```python
class Solution:
def minSwaps(self, data: List[int]) -> int:
window_size = 0
for item in data:
if item == 1:
window_size += 1
if window_size == 0:
return 0
left, right = 0, 0
window_count = 0
ans = float('inf')
while right < len(data):
if data[right] == 0:
window_count += 1
if right - left + 1 >= window_size:
ans = min(ans, window_count)
if data[left] == 0:
window_count -= 1
left += 1
right += 1
return ans if ans != float('inf') else 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $data$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1100-1199/n-th-tribonacci-number.md
================================================
# [1137. 第 N 个泰波那契数](https://leetcode.cn/problems/n-th-tribonacci-number/)
- 标签:记忆化搜索、数学、动态规划
- 难度:简单
## 题目链接
- [1137. 第 N 个泰波那契数 - 力扣](https://leetcode.cn/problems/n-th-tribonacci-number/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:返回第 $n$ 个泰波那契数。
**说明**:
- **泰波那契数**:$T_0 = 0, T_1 = 1, T_2 = 1$,且在 $n >= 0$ 的条件下,$T_{n + 3} = T_{n} + T_{n+1} + T_{n+2}$。
- $0 \le n \le 37$。
- 答案保证是一个 32 位整数,即 $answer \le 2^{31} - 1$。
**示例**:
- 示例 1:
```python
输入:n = 4
输出:4
解释:
T_3 = 0 + 1 + 1 = 2
T_4 = 1 + 1 + 2 = 4
```
- 示例 2:
```python
输入:n = 25
输出:1389537
```
## 解题思路
### 思路 1:记忆化搜索
1. 问题的状态定义为:第 $n$ 个泰波那契数。其状态转移方程为:$T_0 = 0, T_1 = 1, T_2 = 1$,且在 $n >= 0$ 的条件下,$T_{n + 3} = T_{n} + T_{n+1} + T_{n+2}$。
2. 定义一个长度为 $n + 1$ 数组 `memo` 用于保存一斤个计算过的泰波那契数。
3. 定义递归函数 `my_tribonacci(n, memo)`。
1. 当 $n = 0$ 或者 $n = 1$,或者 $n = 2$ 时直接返回结果。
2. 当 $n > 2$ 时,首先检查是否计算过 $T(n)$,即判断 $memo[n]$ 是否等于 $0$。
1. 如果 $memo[n] \ne 0$,说明已经计算过 $T(n)$,直接返回 $memo[n]$。
2. 如果 $memo[n] = 0$,说明没有计算过 $T(n)$,则递归调用 `my_tribonacci(n - 3, memo)`、`my_tribonacci(n - 2, memo)`、`my_tribonacci(n - 1, memo)`,并将计算结果存入 $memo[n]$ 中,并返回 $memo[n]$。
### 思路 1:代码
```python
class Solution:
def tribonacci(self, n: int) -> int:
# 使用数组保存已经求解过的 T(k) 的结果
memo = [0 for _ in range(n + 1)]
return self.my_tribonacci(n, memo)
def my_tribonacci(self, n: int, memo: List[int]) -> int:
if n == 0:
return 0
if n == 1 or n == 2:
return 1
if memo[n] != 0:
return memo[n]
memo[n] = self.my_tribonacci(n - 3, memo) + self.my_tribonacci(n - 2, memo) + self.my_tribonacci(n - 1, memo)
return memo[n]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
### 思路 2:动态规划
###### 1. 阶段划分
我们可以按照整数顺序进行阶段划分,将其划分为整数 $0 \sim n$。
###### 2. 定义状态
定义状态 `dp[i]` 为:第 `i` 个泰波那契数。
###### 3. 状态转移方程
根据题目中所给的泰波那契数的定义:$T_0 = 0, T_1 = 1, T_2 = 1$,且在 $n >= 0$ 的条件下,$T_{n + 3} = T_{n} + T_{n+1} + T_{n+2}$。,则直接得出状态转移方程为 $dp[i] = dp[i - 3] + dp[i - 2] + dp[i - 1]$(当 $i > 2$ 时)。
###### 4. 初始条件
根据题目中所给的初始条件 $T_0 = 0, T_1 = 1, T_2 = 1$ 确定动态规划的初始条件,即 `dp[0] = 0, dp[1] = 1, dp[2] = 1`。
###### 5. 最终结果
根据状态定义,最终结果为 `dp[n]`,即第 `n` 个泰波那契数为 `dp[n]`。
### 思路 2:代码
```python
class Solution:
def tribonacci(self, n: int) -> int:
if n == 0:
return 0
if n == 1 or n == 2:
return 1
dp = [0 for _ in range(n + 1)]
dp[1] = dp[2] = 1
for i in range(3, n + 1):
dp[i] = dp[i - 3] + dp[i - 2] + dp[i - 1]
return dp[n]
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1100-1199/number-of-dice-rolls-with-target-sum.md
================================================
# [1155. 掷骰子等于目标和的方法数](https://leetcode.cn/problems/number-of-dice-rolls-with-target-sum/)
- 标签:动态规划
- 难度:中等
## 题目链接
- [1155. 掷骰子等于目标和的方法数 - 力扣](https://leetcode.cn/problems/number-of-dice-rolls-with-target-sum/)
## 题目大意
**描述**:有 $n$ 个一样的骰子,每个骰子上都有 $k$ 个面,分别标号为 $1 \sim k$。现在给定三个整数 $n$、$k$ 和 $target$,滚动 $n$ 个骰子。
**要求**:计算出使所有骰子正面朝上的数字和等于 $target$ 的方案数量。
**说明**:
- $1 \le n, k \le 30$。
- $1 \le target \le 1000$。
**示例**:
- 示例 1:
```python
输入:n = 1, k = 6, target = 3
输出:1
解释:你扔一个有 6 个面的骰子。
得到 3 的和只有一种方法。
```
- 示例 2:
```python
输入:n = 2, k = 6, target = 7
输出:6
解释:你扔两个骰子,每个骰子有 6 个面。
得到 7 的和有 6 种方法 1+6 2+5 3+4 4+3 5+2 6+1。
```
## 解题思路
### 思路 1:动态规划
我们可以将这道题转换为「分组背包问题」中求方案总数的问题。将每个骰子看做是一组物品,骰子每一个面上的数值当做是每组物品中的一个物品。这样问题就转换为:用 $n$ 个骰子($n$ 组物品)进行投掷,投掷出总和(总价值)为 $target$ 的方案数。
###### 1. 阶段划分
按照总价值 $target$ 进行阶段划分。
###### 2. 定义状态
定义状态 $dp[w]$ 表示为:用 $n$ 个骰子($n$ 组物品)进行投掷,投掷出总和(总价值)为 $w$ 的方案数。
###### 3. 状态转移方程
用 $n$ 个骰子($n$ 组物品)进行投掷,投掷出总和(总价值)为 $w$ 的方案数,等于用 $n$ 个骰子($n$ 组物品)进行投掷,投掷出总和(总价值)为 $w - d$ 的方案数累积值,其中 $d$ 为当前骰子掷出的价值,即:$dp[w] = dp[w] + dp[w - d]$。
###### 4. 初始条件
- 用 $n$ 个骰子($n$ 组物品)进行投掷,投掷出总和(总价值)为 $0$ 的方案数为 $1$。
###### 5. 最终结果
根据我们之前定义的状态, $dp[w]$ 表示为:用 $n$ 个骰子($n$ 组物品)进行投掷,投掷出总和(总价值)为 $w$ 的方案数。则最终结果为 $dp[target]$。
### 思路 1:代码
```python
class Solution:
def numRollsToTarget(self, n: int, k: int, target: int) -> int:
dp = [0 for _ in range(target + 1)]
dp[0] = 1
MOD = 10 ** 9 + 7
# 枚举前 i 组物品
for i in range(1, n + 1):
# 逆序枚举背包装载重量
for w in range(target, -1, -1):
dp[w] = 0
# 枚举第 i - 1 组物品能取个数
for d in range(1, k + 1):
if w >= d:
dp[w] = (dp[w] + dp[w - d]) % MOD
return dp[target] % MOD
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times m \times target)$。
- **空间复杂度**:$O(target)$。
================================================
FILE: docs/solutions/1100-1199/parallel-courses.md
================================================
# [1136. 并行课程](https://leetcode.cn/problems/parallel-courses/)
- 标签:图、拓扑排序
- 难度:中等
## 题目链接
- [1136. 并行课程 - 力扣](https://leetcode.cn/problems/parallel-courses/)
## 题目大意
有 N 门课程,分别以 1 到 N 进行编号。现在给定一份课程关系表 `relations[i] = [X, Y]`,用以表示课程 `X` 和课程 `Y` 之间的先修关系:课程 `X` 必须在课程 `Y` 之前修完。假设在一个学期里,你可以学习任何数量的课程,但前提是你已经学习了将要学习的这些课程的所有先修课程。
要求:返回学完全部课程所需的最少学期数。如果没有办法做到学完全部这些课程的话,就返回 `-1`。
## 解题思路
拓扑排序。具体解法如下:
1. 使用列表 `edges` 存放课程关系图,并统计每门课程节点的入度,存入入度列表 `indegrees`。使用 `ans` 表示学期数。
2. 借助队列 `queue`,将所有入度为 `0` 的节点入队。
3. 将队列中所有节点依次取出,学期数 +1。对于取出的每个节点:
1. 对应课程数 -1。
2. 将该顶点以及该顶点为出发点的所有边的另一个节点入度 -1。如果入度 -1 后的节点入度不为 0,则将其加入队列 `queue`。
4. 重复 3~4 的步骤,直到队列中没有节点。
5. 最后判断剩余课程数是否为 0,如果为 0,则返回 `ans`,否则,返回 `-1`。
## 代码
```python
import collections
class Solution:
def minimumSemesters(self, n: int, relations: List[List[int]]) -> int:
indegrees = [0 for _ in range(n + 1)]
edges = collections.defaultdict(list)
for x, y in relations:
edges[x].append(y)
indegrees[y] += 1
queue = collections.deque([])
for i in range(1, n + 1):
if not indegrees[i]:
queue.append(i)
ans = 0
while queue:
size = len(queue)
for i in range(size):
x = queue.popleft()
n -= 1
for y in edges[x]:
indegrees[y] -= 1
if not indegrees[y]:
queue.append(y)
ans += 1
return ans if n == 0 else -1
```
================================================
FILE: docs/solutions/1100-1199/relative-sort-array.md
================================================
# [1122. 数组的相对排序](https://leetcode.cn/problems/relative-sort-array/)
- 标签:数组、哈希表、计数排序、排序
- 难度:简单
## 题目链接
- [1122. 数组的相对排序 - 力扣](https://leetcode.cn/problems/relative-sort-array/)
## 题目大意
**描述**:给定两个数组,$arr1$ 和 $arr2$,其中 $arr2$ 中的元素各不相同,$arr2$ 中的每个元素都出现在 $arr1$ 中。
**要求**:对 $arr1$ 中的元素进行排序,使 $arr1$ 中项的相对顺序和 $arr2$ 中的相对顺序相同。未在 $arr2$ 中出现过的元素需要按照升序放在 $arr1$ 的末尾。
**说明**:
- $1 \le arr1.length, arr2.length \le 1000$。
- $0 \le arr1[i], arr2[i] \le 1000$。
**示例**:
- 示例 1:
```python
输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
输出:[2,2,2,1,4,3,3,9,6,7,19]
```
- 示例 2:
```python
输入:arr1 = [28,6,22,8,44,17], arr2 = [22,28,8,6]
输出:[22,28,8,6,17,44]
```
## 解题思路
### 思路 1:计数排序
因为元素值范围在 $[0, 1000]$,所以可以使用计数排序的思路来解题。
1. 使用数组 $count$ 统计 $arr1$ 各个元素个数。
2. 遍历 $arr2$ 数组,将对应元素$num2$ 按照个数 $count[num2]$ 添加到答案数组 $ans$ 中,同时在 $count$ 数组中减去对应个数。
3. 然后在处理 $count$ 中剩余元素,将 $count$ 中大于 $0$ 的元素下标依次添加到答案数组 $ans$ 中。
4. 最后返回答案数组 $ans$。
### 思路 1:代码
```python
class Solution:
def relativeSortArray(self, arr1: List[int], arr2: List[int]) -> List[int]:
# 计算待排序序列中最大值元素 arr_max 和最小值元素 arr_min
arr1_min, arr1_max = min(arr1), max(arr1)
# 定义计数数组 counts,大小为 最大值元素 - 最小值元素 + 1
size = arr1_max - arr1_min + 1
counts = [0 for _ in range(size)]
# 统计值为 num 的元素出现的次数
for num in arr1:
counts[num - arr1_min] += 1
res = []
for num in arr2:
while counts[num - arr1_min] > 0:
res.append(num)
counts[num - arr1_min] -= 1
for i in range(size):
while counts[i] > 0:
num = i + arr1_min
res.append(num)
counts[i] -= 1
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m + n + max(arr_1))$。其中 $m$ 是数组 $arr_1$ 的长度,$n$ 是数组 $arr_2$ 的长度,$max(arr_1)$ 是数组 $arr_1$ 的最大值。
- **空间复杂度**:$O(max(arr_1))$。
================================================
FILE: docs/solutions/1200-1299/airplane-seat-assignment-probability.md
================================================
# [1227. 飞机座位分配概率](https://leetcode.cn/problems/airplane-seat-assignment-probability/)
- 标签:脑筋急转弯、数学、动态规划、概率与统计
- 难度:中等
## 题目链接
- [1227. 飞机座位分配概率 - 力扣](https://leetcode.cn/problems/airplane-seat-assignment-probability/)
## 题目大意
**描述**:给定一个整数 $n$,代表 $n$ 位乘客即将登飞机。飞机上刚好有 $n$ 个座位。第一位乘客的票丢了,他随便选择了一个座位坐下。则剩下的乘客将会:
- 如果自己的座位还空着,就坐到自己的座位上。
- 如果自己的座位被占用了,就随机选择其他座位。
**要求**:计算出第 $n$ 位乘客坐在自己座位上的概率是多少。
**说明**:
- $1 \le n \le 10^5$。
**示例**:
- 示例 1:
```python
输入:n = 1
输出:1.00000
解释:第一个人只会坐在自己的位置上。
```
- 示例 2:
```python
输入: n = 2
输出: 0.50000
解释:在第一个人选好座位坐下后,第二个人坐在自己的座位上的概率是 0.5。
```
## 解题思路
### 思路 1:数学
我们按照乘客的登机顺序为乘客编下号:$1 \sim n$,我们用 $f(n)$ 来表示第 $n$ 位乘客登机时,坐在自己座位上的概率。先从简单的情况开始考虑:
当 $n = 1$ 时:
- 第 $1$ 位乘客只能坐在第 $1$ 个座位上,$f(1) = 1$。
当 $n = 2$ 时:
- 第 $1$ 位乘客有 $\frac{1}{2}$ 的概率选中自己的位置,第 $2$ 位乘客一定能坐到自己的位置上,则第 $2$ 位乘客坐在自己座位上的概率为 $\frac{1}{2} * 1.0$。
- 第 $1$ 位乘客有 $\frac{1}{2}$ 的概率坐在第 $2$ 位乘客的位置上,第 $2$ 位乘客只能坐到第 $1$ 位乘客的位置上,那么第 $2$ 位乘客坐在自己座位上的概率为 $\frac{1}{2} * 0.0$。
- 综上,$f(2) = \frac{1}{2} * 1.0 + \frac{1}{2} * 0.0 = 0.5$。
当 $n \ge 3$ 时:
- 先来考虑第 $1$ 位乘客登机情况:
- 第 $1$ 位乘客有 $\frac{1}{n}$ 的概率选择坐在自己位置上,这样第 $1$ 位到第 $n - 1$ 位乘客的座位都不会被占,第 n 位乘客一定能坐到自己位置上。那么第 n 位乘客坐在自己座位上的概率为 $\frac{1}{n} * 1.0$。
- 第 $1$ 位乘客有 $\frac{1}{n}$ 的概率选择坐在第 $n$ 位乘客的位置上,这样第 $2$ 位到第 $n - 1$ 位乘客的座位都不会被占,第 $n$ 位乘客只能坐到第 $1$ 位乘客的位置上,那么第 $n$ 位乘客坐在自己座位上的概率为 $\frac{1}{n} * 0.0$。
- 第 $1$ 位乘客有 $\frac{n-2}{n}$ 的概率坐在第 $i$ 号座位上,$2 \le i \le n - 1$,每个座位被选中概率为 $\frac{1}{n}$。这样第 $2$ 位到第 $i - 1$ 位乘客的座位都不会被占。此时第 $i$ 位乘客,会在剩下的 $n - (i - 1)$ 个座位中进行选择:
- 坐在第 $1$ 位乘客的位置上,这样后面的乘客座位都不会被占,第 $n$ 位乘客一定能坐到自己位置上。
- 坐在第 $n$ 个乘客的位置上,这样第 $n$ 个乘客肯定无法坐到自己的位置上。
- 在第 $[i + 1, n - 1]$ 之间找个位置坐。
- 再来考虑第 $i$ 位乘客登机情况:
- 第 $i$ 为乘客所面临的情况跟第 $1$ 位乘客所面临的情况类似,只不过问题的规模数从 $n$ 减小到了 $n - (i - 1)$。
那么综合上面情况,可以得到 $f(n),(n \ge 3)$ 的递推式:
$\begin{aligned} f(n) & = \frac{1}{n} * 1.0 + \frac{1}{n} * 0.0 + \frac{1}{n} * \sum_{i = 2}^{n-1} f(n - i + 1) \cr & = \frac{1}{n} (1.0 + \sum_{i = 2}^{n-1} f(n - i + 1)) \end{aligned}$
接下来我们从等式中寻找规律,消去 $\sum_{i = 2}^{n-1} f(n - i + 1)$ 部分。
将 $n$ 换为 $n - 1$,得:
$\begin{aligned} f(n - 1) & = \frac{1}{n - 1} * 1.0 + \frac{1}{n - 1} * 0.0 + \frac{1}{n - 1} * \sum_{i = 2}^{n-2} f(n - i) \cr & = \frac{1}{n - 1} (1.0 + \sum_{i = 2}^{n-2} f(n - i)) \end{aligned} $
将 $f(n) * n$ 与 $f(n - 1) * (n - 1)$ 进行比较:
$\begin{aligned} f(n) * n & = 1.0 + \sum_{i = 2}^{n-1} f(n - i + 1) & (1) \cr f(n - 1) * (n - 1) & = 1.0 + \sum_{i = 2}^{n-2} f(n - i) & (2) \end{aligned}$
将上述 (1)、(2) 式相减得:
$\begin{aligned} & f(n) * n - f(n - 1) * (n - 1) & \cr = & \sum_{i = 2}^{n-1} f(n - i + 1) - \sum_{i = 2}^{n-2} f(n - i) \cr = & f(n-1) \end{aligned}$
整理后得:$f(n) = f(n - 1)$。
已知 $f(1) = 1$,$f(2) = 0.5$,因此当 $n \ge 3$ 时,$f(n) = 0.5$。
所以可以得出结论:
$f(n) = \begin{cases} 1.0 & n = 1 \cr 0.5 & n \ge 2 \end{cases}$
### 思路 1:代码
```python
class Solution:
def nthPersonGetsNthSeat(self, n: int) -> float:
if n == 1:
return 1.0
else:
return 0.5
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
## 参考资料
- [飞机座位分配概率 - 力扣(LeetCode)](https://leetcode.cn/problems/airplane-seat-assignment-probability/solution/fei-ji-zuo-wei-fen-pei-gai-lu-by-leetcod-gyw4/)
================================================
FILE: docs/solutions/1200-1299/check-if-it-is-a-straight-line.md
================================================
# [1232. 缀点成线](https://leetcode.cn/problems/check-if-it-is-a-straight-line/)
- 标签:几何、数组、数学
- 难度:简单
## 题目链接
- [1232. 缀点成线 - 力扣](https://leetcode.cn/problems/check-if-it-is-a-straight-line/)
## 题目大意
给定一系列的二维坐标点的坐标 `(xi, yi)`,判断这些点是否属于同一条直线。如果属于同一条直线,则返回 True,否则返回 False。
## 解题思路
如果根据斜率来判断点是否处于同一条直线,需要处理斜率不存在(无穷大)的情况。我们可以使用叉乘来判断三个点构成的两个向量是否处于同一条直线上。
叉乘原理:
设向量 P 为 `(x1, y1)` 向量,Q 为 `(x2, y2)`,则向量 P、Q 的叉积定义为:$P × Q = x_1y_2 - x_2y_1$,其几何意义表示为如果以向量 P 和向量 Q 为边构成一个平行四边形,那么这两个向量叉乘的模长与这个平行四边形的正面积相等。
- 如果 `P × Q = 0`,则 P 与 Q 共线,有可能同向,也有可能反向。
- 如果 `P × Q > 0`,则 P 在 Q 的顺时针方向。
- 如果 `P × Q < 0`,则 P 在 Q 的逆时针方向。
具体求解方法:
- 先求出第一个坐标与第二个坐标构成的向量 P。
- 遍历所有坐标,求出所有坐标与第一个坐标构成的向量 Q。
- 如果 `P × Q ≠ 0`,则返回 False。
- 如果遍历完仍没有发现 `P × Q ≠ 0`,则返回 True。
## 代码
```python
class Solution:
def checkStraightLine(self, coordinates: List[List[int]]) -> bool:
x1 = coordinates[1][0] - coordinates[0][0]
y1 = coordinates[1][1] - coordinates[0][1]
for i in range(len(coordinates)):
x2 = coordinates[i][0] - coordinates[0][0]
y2 = coordinates[i][1] - coordinates[0][1]
if x1 * y2 != x2 * y1:
return False
return True
```
================================================
FILE: docs/solutions/1200-1299/count-vowels-permutation.md
================================================
# [1220. 统计元音字母序列的数目](https://leetcode.cn/problems/count-vowels-permutation/)
- 标签:动态规划
- 难度:困难
## 题目链接
- [1220. 统计元音字母序列的数目 - 力扣](https://leetcode.cn/problems/count-vowels-permutation/)
## 题目大意
**描述**:给定一个整数 `n`,我们可以按照以下规则生成长度为 `n` 的字符串:
- 字符串中的每个字符都应当是小写元音字母(`'a'`、`'e'`、`'i'`、`'o'`、`'u'`)。
- 每个元音 `'a'` 后面都只能跟着 `'e'`。
- 每个元音 `'e'` 后面只能跟着 `'a'` 或者是 `'i'`。
- 每个元音 `'i'` 后面不能再跟着另一个 `'i'`。
- 每个元音 `'o'` 后面只能跟着 `'i'` 或者是 `'u'`。
- 每个元音 `'u'` 后面只能跟着 `'a'`。
**要求**:统计一下我们可以按上述规则形成多少个长度为 `n` 的字符串。由于答案可能会很大,所以请返回模 $10^9 + 7$ 之后的结果。
**说明**:
- $1 \le n \le 2 * 10^4$。
**示例**:
- 示例 1:
```python
输入:n = 2
输出:10
解释:所有可能的字符串分别是:"ae", "ea", "ei", "ia", "ie", "io", "iu", "oi", "ou" 和 "ua"。
```
## 解题思路
### 思路 1:动态规划
根据题目给定的字符串规则,我们可以将其整理一下:
- 元音字母 `'a'` 前面只能跟着 `'e'`、`'i'`、`'u'`。
- 元音字母 `'e'` 前面只能跟着 `'a'`、`'i'`。
- 元音字母 `'i'` 前面只能跟着 `'e'`、`'o'`。
- 元音字母 `'o'` 前面只能跟着 `'i'`。
- 元音字母 `'u'` 前面只能跟着 `'o'`、`'i'`。
现在我们可以按照字符串的长度以及字符结尾进行阶段划分,并按照上述规则推导状态转移方程。
###### 1. 阶段划分
按照字符串的结尾位置和结尾位置上的字符进行阶段划分。
###### 2. 定义状态
定义状态 `dp[i][j]` 表示为:长度为 `i` 并且以字符 `j` 结尾的字符串数量。这里 $j = 0, 1, 2, 3, 4$ 分别代表元音字母 `'a'`、`'e'`、`'i'`、`'o'`、`'u'`。
###### 3. 状态转移方程
通过上面的字符规则,可以得到状态转移方程为:
$\begin{cases} dp[i][0] = dp[i - 1][1] + dp[i - 1][2] + dp[i - 1][4] \cr dp[i][1] = dp[i - 1][0] + dp[i - 1][2] \cr dp[i][2] = dp[i - 1][1] + dp[i - 1][3] \cr dp[i][3] = dp[i - 1][2] \cr dp[i][4] = dp[i - 1][2] + dp[i - 1][3] \end{cases}$
###### 4. 初始条件
- 长度为 `1` 并且以字符 `j` 结尾的字符串数量为 `1`,即 `dp[1][j] = 1`。
###### 5. 最终结果
根据我们之前定义的状态,`dp[i]` 表示为:长度为 `i` 并且以字符 `j` 结尾的字符串数量。则将 `dp[n]` 行所有列相加,就是长度为 `n` 的字符串数量。
### 思路 1:动态规划代码
```python
class Solution:
def countVowelPermutation(self, n: int) -> int:
mod = 10 ** 9 + 7
dp = [[0 for _ in range(5)] for _ in range(n + 1)]
for j in range(5):
dp[1][j] = 1
for i in range(2, n + 1):
dp[i][0] = (dp[i - 1][1] + dp[i - 1][2] + dp[i - 1][4]) % mod
dp[i][1] = (dp[i - 1][0] + dp[i - 1][2]) % mod
dp[i][2] = (dp[i - 1][1] + dp[i - 1][3]) % mod
dp[i][3] = dp[i - 1][2] % mod
dp[i][4] = (dp[i - 1][2] + dp[i - 1][3]) % mod
ans = 0
for j in range(5):
ans += dp[n][j] % mod
ans %= mod
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1200-1299/divide-array-in-sets-of-k-consecutive-numbers.md
================================================
# [1296. 划分数组为连续数字的集合](https://leetcode.cn/problems/divide-array-in-sets-of-k-consecutive-numbers/)
- 标签:贪心、数组、哈希表、排序
- 难度:中等
## 题目链接
- [1296. 划分数组为连续数字的集合 - 力扣](https://leetcode.cn/problems/divide-array-in-sets-of-k-consecutive-numbers/)
## 题目大意
**描述**:给定一个整数数组 `nums` 和一个正整数 `k`。
**要求**:判断是否可以把这个数组划分成一些由 `k` 个连续数字组成的集合。如果可以,则返回 `True`;否则,返回 `False`。
**说明**:
- $1 \le k \le nums.length \le 10^5$。
- $1 \le nums[i] \le 10^9$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,3,4,4,5,6], k = 4
输出:True
解释:数组可以分成 [1,2,3,4] 和 [3,4,5,6]。
```
## 解题思路
### 思路 1:哈希表 + 排序
1. 使用哈希表存储每个数出现的次数。
2. 将哈希表中每个键从小到大排序。
3. 从哈希表中最小的数开始,以它作为当前连续数字的开头,然后依次判断连续的 `k` 个数是否在哈希表中,如果在的话,则将哈希表中对应数的数量减 `1`。不在的话,说明无法满足题目要求,直接返回 `False`。
4. 重复执行 2 ~ 3 步,直到哈希表为空。最后返回 `True`。
### 思路 1:哈希表 + 排序代码
```python
class Solution:
def isPossibleDivide(self, nums: List[int], k: int) -> bool:
hand_map = collections.defaultdict(int)
for i in range(len(nums)):
hand_map[nums[i]] += 1
for key in sorted(hand_map.keys()):
value = hand_map[key]
if value == 0:
continue
count = 0
for i in range(k):
hand_map[key + count] -= value
if hand_map[key + count] < 0:
return False
count += 1
return True
```
================================================
FILE: docs/solutions/1200-1299/find-elements-in-a-contaminated-binary-tree.md
================================================
# [1261. 在受污染的二叉树中查找元素](https://leetcode.cn/problems/find-elements-in-a-contaminated-binary-tree/)
- 标签:树、深度优先搜索、广度优先搜索、设计、哈希表、二叉树
- 难度:中等
## 题目链接
- [1261. 在受污染的二叉树中查找元素 - 力扣](https://leetcode.cn/problems/find-elements-in-a-contaminated-binary-tree/)
## 题目大意
**描述**:给出一满足下属规则的二叉树的根节点 $root$:
1. $root.val == 0$。
2. 如果 $node.val == x$ 且 $node.left \ne None$,那么 $node.left.val == 2 \times x + 1$。
3. 如果 $node.val == x$ 且 $node.right \ne None$,那么 $node.left.val == 2 \times x + 2$。
现在这个二叉树受到「污染」,所有的 $node.val$ 都变成了 $-1$。
**要求**:请你先还原二叉树,然后实现 `FindElements` 类:
- `FindElements(TreeNode* root)` 用受污染的二叉树初始化对象,你需要先把它还原。
- `bool find(int target)` 判断目标值 $target$ 是否存在于还原后的二叉树中并返回结果。
**说明**:
- $node.val == -1$
- 二叉树的高度不超过 $20$。
- 节点的总数在 $[1, 10^4]$ 之间。
- 调用 `find()` 的总次数在 $[1, 10^4]$ 之间。
- $0 \le target \le 10^6$。
**示例**:
- 示例 1:
```python
输入:
["FindElements","find","find"]
[[[-1,null,-1]],[1],[2]]
输出:
[null,false,true]
解释:
FindElements findElements = new FindElements([-1,null,-1]);
findElements.find(1); // return False
findElements.find(2); // return True
```
- 示例 2:
```python
输入:
["FindElements","find","find","find"]
[[[-1,-1,-1,-1,-1]],[1],[3],[5]]
输出:
[null,true,true,false]
解释:
FindElements findElements = new FindElements([-1,-1,-1,-1,-1]);
findElements.find(1); // return True
findElements.find(3); // return True
findElements.find(5); // return False
```
## 解题思路
### 思路 1:哈希表 + 深度优先搜索
1. 从根节点开始进行还原。
2. 然后使用深度优先搜索的方式,依次递归还原左右两个孩子节点。
3. 递归还原的同时,将还原之后的所有节点值,存入集合 $val\_set$ 中。
这样就可以在 $O(1)$ 的时间复杂度内判断目标值 $target$ 是否在还原后的二叉树中了。
### 思路 1:代码
```Python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class FindElements:
def __init__(self, root: Optional[TreeNode]):
self.val_set = set()
def dfs(node, val):
if not node:
return
self.val_set.add(val)
dfs(node.left, val * 2 + 1)
dfs(node.right, val * 2 + 2)
dfs(root, 0)
def find(self, target: int) -> bool:
return target in self.val_set
# Your FindElements object will be instantiated and called as such:
# obj = FindElements(root)
# param_1 = obj.find(target)
```
### 思路 1:复杂度分析
- **时间复杂度**:还原二叉树:$O(n)$,其中 $n$ 为二叉树中的节点个数。查找目标值:$O(1)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1200-1299/get-equal-substrings-within-budget.md
================================================
# [1208. 尽可能使字符串相等](https://leetcode.cn/problems/get-equal-substrings-within-budget/)
- 标签:字符串、二分查找、前缀和、滑动窗口
- 难度:中等
## 题目链接
- [1208. 尽可能使字符串相等 - 力扣](https://leetcode.cn/problems/get-equal-substrings-within-budget/)
## 题目大意
**描述**:给定两个长度相同的字符串,$s$ 和 $t$。将 $s$ 中的第 $i$ 个字符变到 $t$ 中的第 $i$ 个字符需要 $| s[i] - t[i] |$ 的开销(开销可能为 $0$),也就是两个字符的 ASCII 码值的差的绝对值。用于变更字符串的最大预算是 $maxCost$。在转化字符串时,总开销应当小于等于该预算,这也意味着字符串的转化可能是不完全的。
**要求**:如果你可以将 $s$ 的子字符串转化为它在 $t$ 中对应的子字符串,则返回可以转化的最大长度。如果 $s$ 中没有子字符串可以转化成 $t$ 中对应的子字符串,则返回 $0$。
**说明**:
- $1 \le s.length, t.length \le 10^5$。
- $0 \le maxCost \le 10^6$。
- $s$ 和 $t$ 都只含小写英文字母。
**示例**:
- 示例 1:
```python
输入:s = "abcd", t = "bcdf", maxCost = 3
输出:3
解释:s 中的 "abc" 可以变为 "bcd"。开销为 3,所以最大长度为 3。
```
- 示例 2:
```python
输入:s = "abcd", t = "cdef", maxCost = 3
输出:1
解释:s 中的任一字符要想变成 t 中对应的字符,其开销都是 2。因此,最大长度为 1。
```
## 解题思路
### 思路 1:滑动窗口
维护一个滑动窗口 $window\_sum$ 用于记录窗口内的开销总和,保证窗口内的开销总和小于等于 $maxCost$。使用 $ans$ 记录可以转化的最大长度。具体做法如下:
使用两个指针 $left$、$right$。分别指向滑动窗口的左右边界,保证窗口内所有元素转化开销总和小于等于 $maxCost$。
- 先统计出 $s$ 中第 $i$ 个字符变为 $t$ 的第 $i$ 个字符的开销,用数组 $costs$ 保存。
- 一开始,$left$、$right$ 都指向 $0$。
- 将最右侧字符的转变开销填入窗口中,向右移动 $right$。
- 直到窗口内开销总和 $window\_sum$ 大于 $maxCost$。则不断右移 $left$,缩小窗口长度。直到 $window\_sum \le maxCost$ 时,更新可以转换的最大长度 $ans$。
- 向右移动 $right$,直到 $right \ge len(s)$ 为止。
- 输出答案 $ans$。
### 思路 1:代码
```python
class Solution:
def equalSubstring(self, s: str, t: str, maxCost: int) -> int:
size = len(s)
costs = [0 for _ in range(size)]
for i in range(size):
costs[i] = abs(ord(s[i]) - ord(t[i]))
left, right = 0, 0
ans = 0
window_sum = 0
while right < size:
window_sum += costs[right]
while window_sum > maxCost:
window_sum -= costs[left]
left += 1
ans = max(ans, right - left + 1)
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:
- **空间复杂度**:
================================================
FILE: docs/solutions/1200-1299/index.md
================================================
## 本章内容
- [1202. 交换字符串中的元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/smallest-string-with-swaps.md)
- [1208. 尽可能使字符串相等](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/get-equal-substrings-within-budget.md)
- [1217. 玩筹码](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/minimum-cost-to-move-chips-to-the-same-position.md)
- [1220. 统计元音字母序列的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/count-vowels-permutation.md)
- [1227. 飞机座位分配概率](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/airplane-seat-assignment-probability.md)
- [1229. 安排会议日程](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/meeting-scheduler.md)
- [1232. 缀点成线](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/check-if-it-is-a-straight-line.md)
- [1245. 树的直径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/tree-diameter.md)
- [1247. 交换字符使得字符串相同](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/minimum-swaps-to-make-strings-equal.md)
- [1253. 重构 2 行二进制矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/reconstruct-a-2-row-binary-matrix.md)
- [1254. 统计封闭岛屿的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/number-of-closed-islands.md)
- [1261. 在受污染的二叉树中查找元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/find-elements-in-a-contaminated-binary-tree.md)
- [1266. 访问所有点的最小时间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/minimum-time-visiting-all-points.md)
- [1268. 搜索推荐系统](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/search-suggestions-system.md)
- [1281. 整数的各位积和之差](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/subtract-the-product-and-sum-of-digits-of-an-integer.md)
- [1296. 划分数组为连续数字的集合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/divide-array-in-sets-of-k-consecutive-numbers.md)
================================================
FILE: docs/solutions/1200-1299/meeting-scheduler.md
================================================
# [1229. 安排会议日程](https://leetcode.cn/problems/meeting-scheduler/)
- 标签:数组、双指针、排序
- 难度:中等
## 题目链接
- [1229. 安排会议日程 - 力扣](https://leetcode.cn/problems/meeting-scheduler/)
## 题目大意
**描述**:给定两位客户的空闲时间表:$slots1$ 和 $slots2$,再给定会议的预计持续时间 $duration$。
其中 $slots1[i] = [start_i, end_i]$ 表示空闲时间第从 $start_i$ 开始,到 $end_i$ 结束。$slots2$ 也是如此。
**要求**:为他们安排合适的会议时间,如果有合适的会议时间,则返回该时间的起止时刻。如果没有满足要求的会议时间,就请返回一个 空数组。
**说明**:
- **会议时间**:两位客户都有空参加,并且持续时间能够满足预计时间 $duration$ 的最早的时间间隔。
- 题目保证数据有效。同一个人的空闲时间不会出现交叠的情况,也就是说,对于同一个人的两个空闲时间 $[start1, end1]$ 和 $[start2, end2]$,要么 $start1 > end2$,要么 $start2 > end1$。
- $1 \le slots1.length, slots2.length \le 10^4$。
- $slots1[i].length, slots2[i].length == 2$。
- $slots1[i][0] < slots1[i][1]$。
- $slots2[i][0] < slots2[i][1]$。
- $0 \le slots1[i][j], slots2[i][j] \le 10^9$。
- $1 \le duration \le 10^6$。
**示例**:
- 示例 1:
```python
输入:slots1 = [[10,50],[60,120],[140,210]], slots2 = [[0,15],[60,70]], duration = 8
输出:[60,68]
```
- 示例 2:
```python
输入:slots1 = [[10,50],[60,120],[140,210]], slots2 = [[0,15],[60,70]], duration = 12
输出:[]
```
## 解题思路
### 思路 1:分离双指针
题目保证了同一个人的空闲时间不会出现交叠。那么可以先直接对两个客户的空间时间表按照开始时间从小到大排序。然后使用分离双指针来遍历两个数组,求出重合部分,并判断重合区间是否大于等于 $duration$。具体做法如下:
1. 先对两个数组排序。
2. 然后使用两个指针 $left\_1$、$left\_2$。$left\_1$ 指向第一个数组开始位置,$left\_2$ 指向第二个数组开始位置。
3. 遍历两个数组。计算当前两个空闲时间区间的重叠范围。
1. 如果重叠范围大于等于 $duration$,直接返回当前重叠范围开始时间和会议结束时间,即 $[start, start + duration]$,$start$ 为重叠范围开始时间。
2. 如果第一个客户的空闲结束时间小于第二个客户的空闲结束时间,则令 $left\_1$ 右移,即 `left_1 += 1`,继续比较重叠范围。
3. 如果第一个客户的空闲结束时间大于等于第二个客户的空闲结束时间,则令 $left\_2$ 右移,即 `left_2 += 1`,继续比较重叠范围。
4. 直到 $left\_1 == len(slots1)$ 或者 $left\_2 == len(slots2)$ 时跳出循环,返回空数组 $[]$。
### 思路 1:代码
```python
class Solution:
def minAvailableDuration(self, slots1: List[List[int]], slots2: List[List[int]], duration: int) -> List[int]:
slots1.sort()
slots2.sort()
size1 = len(slots1)
size2 = len(slots2)
left_1, left_2 = 0, 0
while left_1 < size1 and left_2 < size2:
start_1, end_1 = slots1[left_1]
start_2, end_2 = slots2[left_2]
start = max(start_1, start_2)
end = min(end_1, end_2)
if end - start >= duration:
return [start, start + duration]
if end_1 < end_2:
left_1 += 1
else:
left_2 += 1
return []
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n + m \times \log m)$,其中 $n$、$m$ 分别为数组 $slots1$、$slots2$ 中的元素个数。
- **空间复杂度**:$O(\log n + \log m)$。
================================================
FILE: docs/solutions/1200-1299/minimum-cost-to-move-chips-to-the-same-position.md
================================================
# [1217. 玩筹码](https://leetcode.cn/problems/minimum-cost-to-move-chips-to-the-same-position/)
- 标签:贪心、数组、数学
- 难度:简单
## 题目链接
- [1217. 玩筹码 - 力扣](https://leetcode.cn/problems/minimum-cost-to-move-chips-to-the-same-position/)
## 题目大意
**描述**:给定一个数组 $position$ 代表 $n$ 个筹码的位置,其中 $position[i]$ 代表第 $i$ 个筹码的位置。现在需要把所有筹码移到同一个位置。在一步中,我们可以将第 $i$ 个芯片的位置从 $position[i]$ 改变为:
- $position[i] + 2$ 或 $position[i] - 2$,此时 $cost = 0$;
- $position[i] + 1$ 或 $position[i] - 1$,此时 $cost = 1$。
即移动偶数位长度的代价为 $0$,移动奇数位长度的代价为 $1$。
**要求**:返回将所有筹码移动到同一位置上所需要的 最小代价 。
**说明**:
- $1 \le chips.length \le 100$。
- $1 \le chips[i] \le 10^9$。
**示例**:
- 示例 1:
```python
输入:position = [2,2,2,3,3]
输出:2
解释:我们可以把位置3的两个芯片移到位置 2。每一步的成本为 1。总成本 = 2。
```
## 解题思路
### 思路 1:贪心算法
题目中移动偶数位长度是不需要代价的,所以奇数位移动到奇数位不需要代价,偶数位移动到偶数位也不需要代价。
则我们可以想将所有偶数位都移动到下标为 $0$ 的位置,奇数位都移动到下标为 $1$ 的位置。
这样,所有的奇数位、偶数位上的人都到相同或相邻位置了。
我们只需要统计一下奇数位和偶数位的数字个数。将少的数移动到多的数上边就是最小代价。
则这道题就可以通过以下步骤求解:
- 遍历数组,统计数组中奇数个数和偶数个数。
- 返回奇数个数和偶数个数中较小的数即为答案。
### 思路 1:贪心算法代码
```python
class Solution:
def minCostToMoveChips(self, position: List[int]) -> int:
odd, even = 0, 0
for p in position:
if p & 1:
odd += 1
else:
even += 1
return min(odd, even)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $poition$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1200-1299/minimum-swaps-to-make-strings-equal.md
================================================
# [1247. 交换字符使得字符串相同](https://leetcode.cn/problems/minimum-swaps-to-make-strings-equal/)
- 标签:贪心、数学、字符串
- 难度:中等
## 题目链接
- [1247. 交换字符使得字符串相同 - 力扣](https://leetcode.cn/problems/minimum-swaps-to-make-strings-equal/)
## 题目大意
**描述**:给定两个长度相同的字符串 $s1$ 和 $s2$,并且两个字符串中只含有字符 `'x'` 和 `'y'`。现在需要通过「交换字符」的方式使两个字符串相同。
- 每次「交换字符」,需要分别从两个字符串中各选一个字符进行交换。
- 「交换字符」只能发生在两个不同的字符串之间,不能发生在同一个字符串内部。
**要求**:返回使 $s1$ 和 $s2$ 相同的最小交换次数,如果没有方法能够使得这两个字符串相同,则返回 $-1$。
**说明**:
- $1 \le s1.length, s2.length \le 1000$。
- $s1$、$s2$ 只包含 `'x'` 或 `'y'`。
**示例**:
- 示例 1:
```python
输入:s1 = "xy", s2 = "yx"
输出:2
解释:
交换 s1[0] 和 s2[0],得到 s1 = "yy",s2 = "xx" 。
交换 s1[0] 和 s2[1],得到 s1 = "xy",s2 = "xy" 。
注意,你不能交换 s1[0] 和 s1[1] 使得 s1 变成 "yx",因为我们只能交换属于两个不同字符串的字符。
```
## 解题思路
### 思路 1:贪心算法
- 如果 $s1 == s2$,则不需要交换。
- 如果 `s1 = "xx"`,`s2 = "yy"`,则最少需要交换一次,才可以使两个字符串相等。
- 如果 `s1 = "yy"`,`s2 = "xx"`,则最少需要交换一次,才可以使两个字符串相等。
- 如果 `s1 = "xy"`,`s2 = "yx"`,则最少需要交换两次,才可以使两个字符串相等。
- 如果 `s1 = "yx"`,`s2 = "xy"`,则最少需要交换两次,才可以使两个字符串相等。
则可以总结为:
- `"xx"` 与 `"yy"`、`"yy"` 与 `"xx"` 只需要交换一次。
- `"xy"` 与 `"yx"`、`"yx"` 与 `"xy"` 需要交换两次。
我们把这两种情况分别进行统计。
- 当遇到 $s1[i] == s2[i]$ 时直接跳过。
- 当遇到 $s1[i] \ne s2[i]$ 时:
- 如果 `s1[i] == 'x'`,`s2[i] == 'y'`,则统计数量到变量 $xyCnt$ 中。
- 如果 `s1[i] == 'y'`,`s2[i] == 'y'`,则统计数量到变量 $yxCnt$ 中。
则最后我们只需要判断 $xyCnt$ 和 $yxCnt$ 的个数即可。
- 如果 $xyCnt + yxCnt$ 是奇数,则说明最终会有一个位置上的两个字符无法通过交换相匹配。
- 如果 $xyCnt + yxCnt$ 是偶数,并且 $xyCnt$ 为偶数,则 $yxCnt$ 也为偶数。则优先交换 `"xx"` 与 `"yy"`、`"yy"` 与 `"xx"`。即每两个 $xyCnt$ 对应一次交换,每两个 $yxCnt$ 对应交换一次,则结果为 $xyCnt \div 2 + yxCnt \div 2$。
- 如果 $xyCnt + yxCnt$ 是偶数,并且 $xyCnt$ 为奇数,则 $yxCnt$ 也为奇数。则优先交换 `"xx"` 与 `"yy"`、`"yy"` 与 `"xx"`。即每两个 $xyCnt$ 对应一次交换,每两个 $yxCnt$ 对应交换一次,则结果为 $xyCnt \div 2 + yxCnt \div 2$。最后还剩一组 `"xy"` 与 `"yx"` 或者 `"yx"` 与 `"xy"`,则再交换一次,则结果为 $xyCnt \div 2 + yxCnt \div 2 + 2$。
以上结果可以统一写成 $xyCnt \div 2 + yxCnt \div 2 + xyCnt \mod 2 \times 2$。
### 思路 1:贪心算法代码
```python
class Solution:
def minimumSwap(self, s1: str, s2: str) -> int:
xyCnt, yxCnt = 0, 0
for i in range(len(s1)):
if s1[i] == s2[i]:
continue
if s1[i] == 'x':
xyCnt += 1
else:
yxCnt += 1
if (xyCnt + yxCnt) & 1:
return -1
return xyCnt // 2 + yxCnt // 2 + (xyCnt % 2 * 2)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1200-1299/minimum-time-visiting-all-points.md
================================================
# [1266. 访问所有点的最小时间](https://leetcode.cn/problems/minimum-time-visiting-all-points/)
- 标签:几何、数组、数学
- 难度:简单
## 题目链接
- [1266. 访问所有点的最小时间 - 力扣](https://leetcode.cn/problems/minimum-time-visiting-all-points/)
## 题目大意
**描述**:给定 $n$ 个点的整数坐标数组 $points$。其中 $points[i] = [xi, yi]$,表示第 $i$ 个点坐标为 $(xi, yi)$。可以按照以下规则在平面上移动:
1. 每一秒内,可以:
1. 沿着水平方向移动一个单位长度。
2. 沿着竖直方向移动一个单位长度。
3. 沿着对角线移动 $\sqrt 2$ 个单位长度(可看做在一秒内沿着水平方向和竖直方向各移动一个单位长度)。
2. 必须按照坐标数组 $points$ 中的顺序来访问这些点。
3. 在访问某个点时,可以经过该点后面出现的点,但经过的那些点不算作有效访问。
**要求**:计算出访问这些点需要的最小时间(以秒为单位)。
**说明**:
- $points.length == n$。
- $1 \le n \le 100$。
- $points[i].length == 2$。
- $-1000 \le points[i][0], points[i][1] \le 1000$。
**示例**:
- 示例 1:
```python
输入:points = [[1,1],[3,4],[-1,0]]
输出:7
解释:一条最佳的访问路径是: [1,1] -> [2,2] -> [3,3] -> [3,4] -> [2,3] -> [1,2] -> [0,1] -> [-1,0]
从 [1,1] 到 [3,4] 需要 3 秒
从 [3,4] 到 [-1,0] 需要 4 秒
一共需要 7 秒
```
```python
输入:points = [[3,2],[-2,2]]
输出:5
```
## 解题思路
### 思路 1:数学
根据题意,每一秒可以沿着水平方向移动一个单位长度、或者沿着竖直方向移动一个单位长度、或者沿着对角线移动 $\sqrt 2$ 个单位长度。而沿着对角线移动 $\sqrt 2$ 个单位长度可以看做是先沿着水平方向移动一个单位长度,又沿着竖直方向移动一个单位长度,算是一秒走了两步距离。
现在假设从 A 点(坐标为 $(x1, y1)$)移动到 B 点(坐标为 $(x2, y2)$)。
那么从 A 点移动到 B 点如果要想得到最小时间,我们应该计算出沿着水平方向走的距离为 $dx = |x2 - x1|$,沿着竖直方向走的距离为 $dy = |y2 - y1|$。
然后比较沿着水平方向的移动距离和沿着竖直方向的移动距离。
- 如果 $dx > dy$,则我们可以先沿着对角线移动 $dy$ 次,再水平移动 $dx - dy$ 次,总共 $dx$ 次。
- 如果 $dx == dy$,则我们可以直接沿着对角线移动 $dx$ 次,总共 $dx$ 次。
- 如果 $dx < dy$,则我们可以先沿着对角线移动 $dx$ 次,再水平移动 $dy - dx$ 次,,总共 $dy$ 次。
根据上面观察可以发现:最小时间取决于「走的步数较多的那个方向所走的步数」,即 $max(dx, dy)$。
根据题目要求,需要按照坐标数组 $points$ 中的顺序来访问这些点,则我们需要按顺序遍历整个数组,计算出相邻点之间的 $max(dx, dy)$,将其累加到答案中。
最后将答案输出即可。
### 思路 1:代码
```python
class Solution:
def minTimeToVisitAllPoints(self, points: List[List[int]]) -> int:
ans = 0
x1, y1 = points[0]
for point in points:
x2, y2 = point
ans += max(abs(x2 - x1), abs(y2 - y1))
x1, y1 = point
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1200-1299/number-of-closed-islands.md
================================================
# [1254. 统计封闭岛屿的数目](https://leetcode.cn/problems/number-of-closed-islands/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、矩阵
- 难度:中等
## 题目链接
- [1254. 统计封闭岛屿的数目 - 力扣](https://leetcode.cn/problems/number-of-closed-islands/)
## 题目大意
**描述**:给定一个二维矩阵 `grid`,每个位置要么是陆地(记号为 `0`)要么是水域(记号为 `1`)。
我们从一块陆地出发,每次可以往上下左右 `4` 个方向相邻区域走,能走到的所有陆地区域,我们将其称为一座「岛屿」。
如果一座岛屿完全由水域包围,即陆地边缘上下左右所有相邻区域都是水域,那么我们将其称为「封闭岛屿」。
**要求**:返回封闭岛屿的数目。
**说明**:
- $1 \le grid.length, grid[0].length \le 100$。
- $0 \le grid[i][j] \le 1$。
**示例**:
- 示例 1:
```python
输入:grid = [[1,1,1,1,1,1,1,0],[1,0,0,0,0,1,1,0],[1,0,1,0,1,1,1,0],[1,0,0,0,0,1,0,1],[1,1,1,1,1,1,1,0]]
输出:2
解释:灰色区域的岛屿是封闭岛屿,因为这座岛屿完全被水域包围(即被 1 区域包围)。
```
- 示例 2:
```python
输入:grid = [[0,0,1,0,0],[0,1,0,1,0],[0,1,1,1,0]]
输出:1
```
## 解题思路
### 思路 1:深度优先搜索
1. 从 `grid[i][j] == 0` 的位置出发,使用深度优先搜索的方法遍历上下左右四个方向上相邻区域情况。
1. 如果上下左右都是 `grid[i][j] == 1`,则返回 `True`。
2. 如果有一个以上方向的 `grid[i][j] == 0`,则返回 `False`。
3. 遍历之后将当前陆地位置置为 `1`,表示该位置已经遍历过了。
2. 最后统计出上下左右都满足 `grid[i][j] == 1` 的情况数量,即为答案。
### 思路 1:代码
```python
class Solution:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
def dfs(self, grid, i, j):
n, m = len(grid), len(grid[0])
if i < 0 or i >= n or j < 0 or j >= m:
return False
if grid[i][j] == 1:
return True
grid[i][j] = 1
res = True
for direct in self.directs:
new_i = i + direct[0]
new_j = j + direct[1]
if not self.dfs(grid, new_i, new_j):
res = False
return res
def closedIsland(self, grid: List[List[int]]) -> int:
res = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == 0 and self.dfs(grid, i, j):
res += 1
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$。其中 $m$ 和 $n$ 分别为行数和列数。
- **空间复杂度**:$O(m \times n)$。
================================================
FILE: docs/solutions/1200-1299/reconstruct-a-2-row-binary-matrix.md
================================================
# [1253. 重构 2 行二进制矩阵](https://leetcode.cn/problems/reconstruct-a-2-row-binary-matrix/)
- 标签:贪心、数组、矩阵
- 难度:中等
## 题目链接
- [1253. 重构 2 行二进制矩阵 - 力扣](https://leetcode.cn/problems/reconstruct-a-2-row-binary-matrix/)
## 题目大意
**描述**:给定一个 $2$ 行 $n$ 列的二进制数组:
- 矩阵是一个二进制矩阵,这意味着矩阵中的每个元素不是 $0$ 就是 $1$。
- 第 $0$ 行的元素之和为 $upper$。
- 第 $1$ 行的元素之和为 $lowe$r。
- 第 $i$ 列(从 $0$ 开始编号)的元素之和为 $colsum[i]$,$colsum$ 是一个长度为 $n$ 的整数数组。
**要求**:你需要利用 $upper$,$lower$ 和 $colsum$ 来重构这个矩阵,并以二维整数数组的形式返回它。
**说明**:
- 如果有多个不同的答案,那么任意一个都可以通过本题。
- 如果不存在符合要求的答案,就请返回一个空的二维数组。
- $1 \le colsum.length \le 10^5$。
- $0 \le upper, lower \le colsum.length$。
- $0 \le colsum[i] \le 2$。
**示例**:
- 示例 1:
```python
输入:upper = 2, lower = 1, colsum = [1,1,1]
输出:[[1,1,0],[0,0,1]]
解释:[[1,0,1],[0,1,0]] 和 [[0,1,1],[1,0,0]] 也是正确答案。
```
- 示例 2:
```python
输入:upper = 2, lower = 3, colsum = [2,2,1,1]
输出:[]
```
## 解题思路
### 思路 1:贪心算法
1. 先构建一个 $2 \times n$ 的答案数组 $ans$,其中 $ans[0]$ 表示矩阵的第 $0$ 行,$ans[1]$ 表示矩阵的第 $1$ 行。
2. 遍历数组 $colsum$,对于当前列的和 $colsum[i]$ 来说:
1. 如果 $colsum[i] == 2$,则需要将 $ans[0][i]$ 和 $ans[1][i]$ 都置为 $1$,此时 $upper$ 和 $lower$ 各自减去 $1$。
2. 如果 $colsum[i] == 1$,则需要将 $ans[0][i]$ 置为 $1$ 或将 $ans[1][i]$ 置为 $1$。我们优先使用元素和多的那一项。
1. 如果 $upper > lower$,则优先使用 $upper$,将 $ans[0][i]$ 置为 $1$,并且令 $upper$ 减去 $1$。
2. 如果 $upper \le lower$,则优先使用 $lower$,将 $ans[1][i]$ 置为 $1$,并且令 $lower$ 减去 $1$。
3. 如果 $colsum[i] == 0$,则需要将 $ans[0][i]$ 和 $ans[1][i]$ 都置为 $0$。
3. 在遍历过程中,如果出现 $upper < 0$ 或者 $lower < 0$,则说明无法构造出满足要求的矩阵,则直接返回空数组。
4. 遍历结束后,如果 $upper$ 和 $lower$ 都为 $0$,则返回答案数组 $ans$;否则返回空数组。
### 思路 1:代码
```Python
class Solution:
def reconstructMatrix(self, upper: int, lower: int, colsum: List[int]) -> List[List[int]]:
size = len(colsum)
ans = [[0 for _ in range(size)] for _ in range(2)]
for i in range(size):
if colsum[i] == 2:
ans[0][i] = ans[1][i] = 1
upper -= 1
lower -= 1
elif colsum[i] == 1:
if upper > lower:
ans[0][i] = 1
upper -= 1
else:
ans[1][i] = 1
lower -= 1
if upper < 0 or lower < 0:
return []
if lower != 0 or upper != 0:
return []
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1200-1299/search-suggestions-system.md
================================================
# [1268. 搜索推荐系统](https://leetcode.cn/problems/search-suggestions-system/)
- 标签:字典树、数组、字符串
- 难度:中等
## 题目链接
- [1268. 搜索推荐系统 - 力扣](https://leetcode.cn/problems/search-suggestions-system/)
## 题目大意
给定一个产品数组 `products` 和一个字符串 `searchWord` ,`products` 数组中每个产品都是一个字符串。
要求:设计一个推荐系统,在依次输入单词 `searchWord` 的每一个字母后,推荐 `products` 数组中前缀与 `searchWord` 相同的最多三个产品(如果前缀相同的可推荐产品超过三个,请按字典序返回最小的三个)。
- 请你以二维列表的形式,返回在输入 `searchWord` 每个字母后相应的推荐产品的列表。
## 解题思路
先将产品数组按字典序排序。
然后使用字典树结构存储每个产品,并在字典树中维护一个数组,用于表示当前前缀所对应的产品列表(只保存最多 3 个产品)。
在查询的时候,将不同前缀所对应的产品列表加入到答案数组中。
最后输出答案数组。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
self.words = list()
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
if len(cur.words) < 3:
cur.words.append(word)
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
res = []
flag = False
for ch in word:
if flag or ch not in cur.children:
res.append([])
flag = True
else:
cur = cur.children[ch]
res.append(cur.words)
return res
class Solution:
def suggestedProducts(self, products: List[str], searchWord: str) -> List[List[str]]:
products.sort()
trie_tree = Trie()
for product in products:
trie_tree.insert(product)
return trie_tree.search(searchWord)
```
================================================
FILE: docs/solutions/1200-1299/smallest-string-with-swaps.md
================================================
# [1202. 交换字符串中的元素](https://leetcode.cn/problems/smallest-string-with-swaps/)
- 标签:深度优先搜索、广度优先搜索、并查集、哈希表、字符串
- 难度:中等
## 题目链接
- [1202. 交换字符串中的元素 - 力扣](https://leetcode.cn/problems/smallest-string-with-swaps/)
## 题目大意
**描述**:给定一个字符串 `s`,再给定一个数组 `pairs`,其中 `pairs[i] = [a, b]` 表示字符串的第 `a` 个字符可以跟第 `b` 个字符交换。只要满足 `pairs` 中的交换关系,可以任意多次交换字符串中的字符。
**要求**:返回 `s` 经过若干次交换之后,可以变成的字典序最小的字符串。
**说明**:
- $1 \le s.length \le 10^5$。
- $0 \le pairs.length \le 10^5$。
- $0 \le pairs[i][0], pairs[i][1] < s.length$。
- `s` 中只含有小写英文字母。
**示例**:
- 示例 1:
```python
输入:s = "dcab", pairs = [[0,3],[1,2]]
输出:"bacd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[1] 和 s[2], s = "bacd"
```
- 示例 2:
```python
输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]]
输出:"abcd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[0] 和 s[2], s = "acbd"
交换 s[1] 和 s[2], s = "abcd"
```
## 解题思路
### 思路 1:并查集
如果第 `a` 个字符可以跟第 `b` 个字符交换,第 `b` 个字符可以跟第 `c` 个字符交换,那么第 `a` 个字符、第 `b` 个字符、第 `c` 个字符之间就可以相互交换。我们可以把可以相互交换的「位置」都放入一个集合中。然后对每个集合中的字符进行排序。然后将其放置回在字符串中原有位置即可。
### 思路 1:代码
```python
import collections
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def smallestStringWithSwaps(self, s: str, pairs: List[List[int]]) -> str:
size = len(s)
union_find = UnionFind(size)
for pair in pairs:
union_find.union(pair[0], pair[1])
mp = collections.defaultdict(list)
for i, ch in enumerate(s):
mp[union_find.find(i)].append(ch)
for vec in mp.values():
vec.sort(reverse=True)
ans = []
for i in range(size):
x = union_find.find(i)
ans.append(mp[x][-1])
mp[x].pop()
return "".join(ans)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log_2 n + m * \alpha(n))$。其中 $n$ 是字符串的长度,$m$ 为 $pairs$ 的索引对数量,$\alpha$ 是反 `Ackerman` 函数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1200-1299/subtract-the-product-and-sum-of-digits-of-an-integer.md
================================================
# [1281. 整数的各位积和之差](https://leetcode.cn/problems/subtract-the-product-and-sum-of-digits-of-an-integer/)
- 标签:数学
- 难度:简单
## 题目链接
- [1281. 整数的各位积和之差 - 力扣](https://leetcode.cn/problems/subtract-the-product-and-sum-of-digits-of-an-integer/)
## 题目大意
**描述**:给定一个整数 `n`。
**要求**:计算并返回该整数「各位数字之积」与「各位数字之和」的差。
**说明**:
- $1 <= n <= 10^5$。
**示例**:
- 示例 1:
```python
输入:n = 234
输出:15
解释:
各位数之积 2 * 3 * 4 = 24
各位数之和 2 + 3 + 4 = 9
结果 24 - 9 = 15
```
## 解题思路
### 思路 1:数学
- 通过取模运算得到 `n` 的最后一位,即 `n %= 10`。
- 然后去除 `n` 的最后一位,及`n //= 10`。
- 一次求出各位数字之积与各位数字之和,并返回其差值。
### 思路 1:数学代码
```python
class Solution:
def subtractProductAndSum(self, n: int) -> int:
product = 1
total = 0
while n:
digit = n % 10
product *= digit
total += digit
n //= 10
return product - total
```
================================================
FILE: docs/solutions/1200-1299/tree-diameter.md
================================================
# [1245. 树的直径](https://leetcode.cn/problems/tree-diameter/)
- 标签:树、深度优先搜索、广度优先搜索、图、拓扑排序
- 难度:中等
## 题目链接
- [1245. 树的直径 - 力扣](https://leetcode.cn/problems/tree-diameter/)
## 题目大意
**描述**:给定一个数组 $edges$,用来表示一棵无向树。其中 $edges[i] = [u, v]$ 表示节点 $u$ 和节点 $v$ 之间的双向边。书上的节点编号为 $0 \sim edges.length$,共 $edges.length + 1$ 个节点。
**要求**:求出这棵无向树的直径。
**说明**:
- $0 \le edges.length < 10^4$。
- $edges[i][0] \ne edges[i][1]$。
- $0 \le edges[i][j] \le edges.length$。
- $edges$ 会形成一棵无向树。
**示例**:
- 示例 1:
```python
输入:edges = [[0,1],[0,2]]
输出:2
解释:
这棵树上最长的路径是 1 - 0 - 2,边数为 2。
```
- 示例 2:
```python
输入:edges = [[0,1],[1,2],[2,3],[1,4],[4,5]]
输出:4
解释:
这棵树上最长的路径是 3 - 2 - 1 - 4 - 5,边数为 4。
```
## 解题思路
### 思路 1:树形 DP + 深度优先搜索
对于根节点为 $u$ 的树来说:
1. 如果其最长路径经过根节点 $u$,则:**最长路径长度 = 某子树中的最长路径长度 + 另一子树中的最长路径长度 + 1**。
2. 如果其最长路径不经过根节点 $u$,则:**最长路径长度 = 某个子树中的最长路径长度**。
即:**最长路径长度 = max(某子树中的最长路径长度 + 另一子树中的最长路径长度 + 1,某个子树中的最长路径长度)**。
对此,我们可以使用深度优先搜索递归遍历 $u$ 的所有相邻节点 $v$,并在递归遍历的同时,维护一个全局最大路径和变量 $ans$,以及当前节点 $u$ 的最大路径长度变量 $u\_len$。
1. 先计算出从相邻节点 $v$ 出发的最长路径长度 $v\_len$。
2. 更新维护全局最长路径长度为 $self.ans = max(self.ans, \quad u\_len + v\_len + 1)$。
3. 更新维护当前节点 $u$ 的最长路径长度为 $u\_len = max(u\_len, \quad v\_len + 1)$。
> 注意:在遍历邻接节点的过程中,为了避免造成重复遍历,我们在使用深度优先搜索时,应过滤掉父节点。
### 思路 1:代码
```python
class Solution:
def __init__(self):
self.ans = 0
def dfs(self, graph, u, fa):
u_len = 0
for v in graph[u]:
if v != fa:
v_len = self.dfs(graph, v, u)
self.ans = max(self.ans, u_len + v_len + 1)
u_len = max(u_len, v_len + 1)
return u_len
def treeDiameter(self, edges: List[List[int]]) -> int:
size = len(edges) + 1
graph = [[] for _ in range(size)]
for u, v in edges:
graph[u].append(v)
graph[v].append(u)
self.dfs(graph, 0, -1)
return self.ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为无向树中的节点个数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1300-1399/all-elements-in-two-binary-search-trees.md
================================================
# [1305. 两棵二叉搜索树中的所有元素](https://leetcode.cn/problems/all-elements-in-two-binary-search-trees/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树、排序
- 难度:中等
## 题目链接
- [1305. 两棵二叉搜索树中的所有元素 - 力扣](https://leetcode.cn/problems/all-elements-in-two-binary-search-trees/)
## 题目大意
**描述**:给定两棵二叉搜索树的根节点 $root1$ 和 $root2$。
**要求**:返回一个列表,其中包含两棵树中所有整数并按升序排序。
**说明**:
- 每棵树的节点数在 $[0, 5000]$ 范围内。
- $-10^5 \le Node.val \le 10^5$。
**示例**:
- 示例 1:
```python
输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
```
- 示例 2:
```python
输入:root1 = [1,null,8], root2 = [8,1]
输出:[1,1,8,8]
```
## 解题思路
### 思路 1:二叉树的中序遍历 + 快慢指针
根据二叉搜索树的特性,如果我们以中序遍历的方式遍历整个二叉搜索树时,就会得到一个有序递增列表。我们按照这样的方式分别对两个二叉搜索树进行中序遍历,就得到了两个有序数组,那么问题就变成了:两个有序数组的合并问题。
两个有序数组的合并可以参考归并排序中的归并过程,使用快慢指针将两个有序数组合并为一个有序数组。
具体步骤如下:
1. 分别使用中序遍历的方式遍历两个二叉搜索树,得到两个有序数组 $nums1$、$nums2$。
2. 使用两个指针 $index1$、$index2$ 分别指向两个有序数组的开始位置。
3. 比较两个指针指向的元素,将两个有序数组中较小元素依次存入结果数组 $nums$ 中,并将指针移动到下一个位置。
4. 重复步骤 $3$,直到某一指针到达数组末尾。
5. 将另一个数组中的剩余元素依次存入结果数组 $nums$ 中。
6. 返回结果数组 $nums$。
### 思路 1:代码
```python
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
res = []
def inorder(root):
if not root:
return
inorder(root.left)
res.append(root.val)
inorder(root.right)
inorder(root)
return res
def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
nums1 = self.inorderTraversal(root1)
nums2 = self.inorderTraversal(root2)
nums = []
index1, index2 = 0, 0
while index1 < len(nums1) and index2 < len(nums2):
if nums1[index1] < nums2[index2]:
nums.append(nums1[index1])
index1 += 1
else:
nums.append(nums2[index2])
index2 += 1
while index1 < len(nums1):
nums.append(nums1[index1])
index1 += 1
while index2 < len(nums2):
nums.append(nums2[index2])
index2 += 1
return nums
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m)$,其中 $n$ 和 $m$ 分别为两棵二叉搜索树的节点个数。
- **空间复杂度**:$O(n + m)$。
================================================
FILE: docs/solutions/1300-1399/angle-between-hands-of-a-clock.md
================================================
# [1344. 时钟指针的夹角](https://leetcode.cn/problems/angle-between-hands-of-a-clock/)
- 标签:数学
- 难度:中等
## 题目链接
- [1344. 时钟指针的夹角 - 力扣](https://leetcode.cn/problems/angle-between-hands-of-a-clock/)
## 题目大意
**描述**:给定两个数 $hour$ 和 $minutes$。
**要求**:请你返回在时钟上,由给定时间的时针和分针组成的较小角的角度($60$ 单位制)。
**说明**:
- $1 \le hour \le 12$。
- $0 \le minutes \le 59$。
- 与标准答案误差在 $10^{-5}$ 以内的结果都被视为正确结果。
**示例**:
- 示例 1:
```python
输入:hour = 12, minutes = 30
输出:165
```
- 示例 2:
```python
输入:hour = 3, minutes = 30
输出;75
```
## 解题思路
### 思路 1:数学
1. 我们以 $00:00$ 为基准,分别计算出分针与 $00:00$ 中垂线的夹角,以及时针与 $00:00$ 中垂线的夹角。
2. 然后计算出两者差值的绝对值 $diff$。当前差值可能为较小的角(小于 $180°$ 的角),也可能为较大的角(大于等于 $180°$ 的角)。
3. 将差值的绝对值 $diff$ 与 $360 - diff$ 进行比较,取较小值作为答案。
### 思路 1:代码
```Python
class Solution:
def angleClock(self, hour: int, minutes: int) -> float:
mins_angle = 6 * minutes
hours_angle = (hour % 12 + minutes / 60) * 30
diff = abs(hours_angle - mins_angle)
return min(diff, 360 - diff)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1300-1399/closest-divisors.md
================================================
# [1362. 最接近的因数](https://leetcode.cn/problems/closest-divisors/)
- 标签:数学
- 难度:中等
## 题目链接
- [1362. 最接近的因数 - 力扣](https://leetcode.cn/problems/closest-divisors/)
## 题目大意
**描述**:给定一个整数 $num$。
**要求**:找出同时满足下面全部要求的两个整数:
- 两数乘积等于 $num + 1$ 或 $num + 2$。
- 以绝对差进行度量,两数大小最接近。
你可以按照任意顺序返回这两个整数。
**说明**:
- $1 \le num \le 10^9$。
**示例**:
- 示例 1:
```python
输入:num = 8
输出:[3,3]
解释:对于 num + 1 = 9,最接近的两个因数是 3 & 3;对于 num + 2 = 10, 最接近的两个因数是 2 & 5,因此返回 3 & 3。
```
- 示例 2:
```python
输入:num = 123
输出:[5,25]
```
## 解题思路
### 思路 1:数学
对于整数的任意一个范围在 $[\sqrt{n}, n]$ 的因数而言,一定存在一个范围在 $[1, \sqrt{n}]$ 的因数与其对应。因此,我们在遍历整数因数时,我们只需遍历 $[1, \sqrt{n}]$ 范围内的因数即可。
则这道题的具体解题步骤如下:
1. 对于整数 $num + 1$、从 $\sqrt{num + 1}$ 的位置开始,到 $1$ 为止,以递减的顺序在 $[1, \sqrt{num + 1}]$ 范围内找到最接近的小因数 $a1$,并根据 $num // a1$ 获得另一个因数 $a2$。
2. 用同样的方式,对于整数 $num + 2$、从 $\sqrt{num + 2}$ 的位置开始,到 $1$ 为止,以递减的顺序在 $[1, \sqrt{num + 2}]$ 范围内找到最接近的小因数 $b1$,并根据 $num // b1$ 获得另一个因数 $b2$。
3. 判断 $abs(a1 - a2)$ 与 $abs(b1 - b2)$ 的大小,返回差值绝对值较小的一对因子数作为答案。
### 思路 1:代码
```Python
class Solution:
def disassemble(self, num):
for i in range(int(sqrt(num) + 1), 1, -1):
if num % i == 0:
return (i, num // i)
return (1, num)
def closestDivisors(self, num: int) -> List[int]:
a1, a2 = self.disassemble(num + 1)
b1, b2 = self.disassemble(num + 2)
if abs(a1 - a2) <= abs(b1 - b2):
return [a1, a2]
return [b1, b2]
```
### 思路 1:复杂度分析
- **时间复杂度**:$(\sqrt{n})$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1300-1399/convert-integer-to-the-sum-of-two-no-zero-integers.md
================================================
# [1317. 将整数转换为两个无零整数的和](https://leetcode.cn/problems/convert-integer-to-the-sum-of-two-no-zero-integers/)
- 标签:数学
- 难度:简单
## 题目链接
- [1317. 将整数转换为两个无零整数的和 - 力扣](https://leetcode.cn/problems/convert-integer-to-the-sum-of-two-no-zero-integers/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:返回一个由两个整数组成的列表 $[A, B]$,满足:
- $A$ 和 $B$ 都是无零整数。
- $A + B = n$。
**说明**:
- **无零整数**:十进制表示中不含任何 $0$ 的正整数。
- 题目数据保证至少一个有效的解决方案。
- 如果存在多个有效解决方案,可以返回其中任意一个。
- $2 \le n \le 10^4$。
**示例**:
- 示例 1:
```python
输入:n = 2
输出:[1,1]
解释:A = 1, B = 1. A + B = n 并且 A 和 B 的十进制表示形式都不包含任何 0。
```
- 示例 2:
```python
输入:n = 11
输出:[2,9]
```
## 解题思路
### 思路 1:枚举
1. 由于给定的 $n$ 范围为 $[1, 10000]$,比较小,我们可以直接在 $[1, n)$ 的范围内枚举 $A$,并通过 $n - A$ 得到 $B$。
2. 在判断 $A$ 和 $B$ 中是否都不包含 $0$。如果都不包含 $0$,则返回 $[A, B]$。
### 思路 1:代码
```python
class Solution:
def getNoZeroIntegers(self, n: int) -> List[int]:
for A in range(1, n):
B = n - A
if '0' not in str(A) and '0' not in str(B):
return [A, B]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1300-1399/decompress-run-length-encoded-list.md
================================================
# [1313. 解压缩编码列表](https://leetcode.cn/problems/decompress-run-length-encoded-list/)
- 标签:数组
- 难度:简单
## 题目链接
- [1313. 解压缩编码列表 - 力扣](https://leetcode.cn/problems/decompress-run-length-encoded-list/)
## 题目大意
**描述**:给定一个以行程长度编码压缩的整数列表 $nums$。
考虑每对相邻的两个元素 $[freq, val] = [nums[2 \times i], nums[2 \times i + 1]]$ (其中 $i \ge 0$ ),每一对都表示解压后子列表中有 $freq$ 个值为 $val$ 的元素,你需要从左到右连接所有子列表以生成解压后的列表。
**要求**:返回解压后的列表。
**说明**:
- $2 \le nums.length \le 100$。
- $nums.length \mod 2 == 0$。
- $1 \le nums[i] \le 100$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,4]
输出:[2,4,4,4]
解释:第一对 [1,2] 代表着 2 的出现频次为 1,所以生成数组 [2]。
第二对 [3,4] 代表着 4 的出现频次为 3,所以生成数组 [4,4,4]。
最后将它们串联到一起 [2] + [4,4,4] = [2,4,4,4]。
```
- 示例 2:
```python
输入:nums = [1,1,2,3]
输出:[1,3,3]
```
## 解题思路
### 思路 1:模拟
1. 以步长为 $2$,遍历数组 $nums$。
2. 对于遍历到的元素 $nums[i]$、$nnums[i + 1]$,将 $nums[i]$ 个 $nums[i + 1]$ 存入答案数组中。
3. 返回答案数组。
### 思路 1:代码
```Python
class Solution:
def decompressRLElist(self, nums: List[int]) -> List[int]:
res = []
for i in range(0, len(nums), 2):
cnts = nums[i]
for cnt in range(cnts):
res.append(nums[i + 1])
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + s)$,其中 $n$ 为数组 $nums$ 的长度,$s$ 是数组 $nums$ 中所有偶数下标对应元素之和。
- **空间复杂度**:$O(s)$。
================================================
FILE: docs/solutions/1300-1399/design-a-stack-with-increment-operation.md
================================================
# [1381. 设计一个支持增量操作的栈](https://leetcode.cn/problems/design-a-stack-with-increment-operation/)
- 标签:栈、设计、数组
- 难度:中等
## 题目链接
- [1381. 设计一个支持增量操作的栈 - 力扣](https://leetcode.cn/problems/design-a-stack-with-increment-operation/)
## 题目大意
**要求**:设计一个支持对其元素进行增量操作的栈。
实现自定义栈类 $CustomStack$:
- `CustomStack(int maxSize)`:用 $maxSize$ 初始化对象,$maxSize$ 是栈中最多能容纳的元素数量。
- `void push(int x)`:如果栈还未增长到 $maxSize$,就将 $x$ 添加到栈顶。
- `int pop()`:弹出栈顶元素,并返回栈顶的值,或栈为空时返回 $-1$。
- `void inc(int k, int val)`:栈底的 $k$ 个元素的值都增加 $val$。如果栈中元素总数小于 $k$,则栈中的所有元素都增加 $val$。
**说明**:
- $1 \le maxSize, x, k \le 1000$。
- $0 \le val \le 100$。
- 每种方法 `increment`,`push` 以及 `pop` 分别最多调用 $1000$ 次。
**示例**:
- 示例 1:
```python
输入:
["CustomStack","push","push","pop","push","push","push","increment","increment","pop","pop","pop","pop"]
[[3],[1],[2],[],[2],[3],[4],[5,100],[2,100],[],[],[],[]]
输出:
[null,null,null,2,null,null,null,null,null,103,202,201,-1]
解释:
CustomStack stk = new CustomStack(3); // 栈是空的 []
stk.push(1); // 栈变为 [1]
stk.push(2); // 栈变为 [1, 2]
stk.pop(); // 返回 2 --> 返回栈顶值 2,栈变为 [1]
stk.push(2); // 栈变为 [1, 2]
stk.push(3); // 栈变为 [1, 2, 3]
stk.push(4); // 栈仍然是 [1, 2, 3],不能添加其他元素使栈大小变为 4
stk.increment(5, 100); // 栈变为 [101, 102, 103]
stk.increment(2, 100); // 栈变为 [201, 202, 103]
stk.pop(); // 返回 103 --> 返回栈顶值 103,栈变为 [201, 202]
stk.pop(); // 返回 202 --> 返回栈顶值 202,栈变为 [201]
stk.pop(); // 返回 201 --> 返回栈顶值 201,栈变为 []
stk.pop(); // 返回 -1 --> 栈为空,返回 -1
```
## 解题思路
### 思路 1:模拟
1. 初始化:
1. 使用空数组 $stack$ 用于表示栈。
2. 使用 $size$ 用于表示当前栈中元素个数,
3. 使用 $maxSize$ 用于表示栈中允许的最大元素个数。
4. 使用另一个空数组 $increments$ 用于增量操作。
2. `push(x)` 操作:
1. 判断当前元素个数与栈中允许的最大元素个数关系。
2. 如果当前元素个数小于栈中允许的最大元素个数,则:
1. 将 $x$ 添加到数组 $stack$ 中,即:`self.stack.append(x)`。
2. 当前元素个数加 $1$,即:`self.size += 1`。
3. 将 $0$ 添加到增量数组 $increments$ 中,即:`self.increments.append(0)`。
3. `increment(k, val)` 操作:
1. 如果增量数组不为空,则取 $k$ 与元素个数 `self.size` 的较小值,令增量数组对应位置加上 `val`(等 `pop()` 操作时,再计算出准确值)。
4. `pop()` 操作:
1. 如果当前元素个数为 $0$,则直接返回 $-1$。
2. 如果当前元素个数大于等于 $2$,则更新弹出元素后的增量数组(保证剩余元素弹出时能够正确计算出),即:`self.increments[-2] += self.increments[-1]`
3. 令元素个数减 $1$,即:`self.size -= 1`。
4. 弹出数组 $stack$ 中的栈顶元素和增量数组 $increments$ 中的栈顶元素,令其相加,即为弹出元素值,将其返回。
### 思路 1:代码
```python
class CustomStack:
def __init__(self, maxSize: int):
self.maxSize = maxSize
self.stack = []
self.increments = []
self.size = 0
def push(self, x: int) -> None:
if self.size < self.maxSize:
self.stack.append(x)
self.increments.append(0)
self.size += 1
def pop(self) -> int:
if self.size == 0:
return -1
if self.size >= 2:
self.increments[-2] += self.increments[-1]
self.size -= 1
val = self.stack.pop() + self.increments.pop()
return val
def increment(self, k: int, val: int) -> None:
if self.increments:
self.increments[min(k, self.size) - 1] += val
# Your CustomStack object will be instantiated and called as such:
# obj = CustomStack(maxSize)
# obj.push(x)
# param_2 = obj.pop()
# obj.increment(k,val)
```
### 思路 1:复杂度分析
- **时间复杂度**:初始化、`push` 操作、`pop` 操作、`increment` 操作的时间复杂度为 $O(1)$。
- **空间复杂度**:$O(maxSize)$。
================================================
FILE: docs/solutions/1300-1399/index.md
================================================
## 本章内容
- [1300. 转变数组后最接近目标值的数组和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/sum-of-mutated-array-closest-to-target.md)
- [1305. 两棵二叉搜索树中的所有元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/all-elements-in-two-binary-search-trees.md)
- [1310. 子数组异或查询](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/xor-queries-of-a-subarray.md)
- [1313. 解压缩编码列表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/decompress-run-length-encoded-list.md)
- [1317. 将整数转换为两个无零整数的和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/convert-integer-to-the-sum-of-two-no-zero-integers.md)
- [1319. 连通网络的操作次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/number-of-operations-to-make-network-connected.md)
- [1324. 竖直打印单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/print-words-vertically.md)
- [1338. 数组大小减半](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/reduce-array-size-to-the-half.md)
- [1343. 大小为 K 且平均值大于等于阈值的子数组数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/number-of-sub-arrays-of-size-k-and-average-greater-than-or-equal-to-threshold.md)
- [1344. 时钟指针的夹角](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/angle-between-hands-of-a-clock.md)
- [1347. 制造字母异位词的最小步骤数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/minimum-number-of-steps-to-make-two-strings-anagram.md)
- [1349. 参加考试的最大学生数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/maximum-students-taking-exam.md)
- [1358. 包含所有三种字符的子字符串数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/number-of-substrings-containing-all-three-characters.md)
- [1362. 最接近的因数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/closest-divisors.md)
- [1381. 设计一个支持增量操作的栈](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/design-a-stack-with-increment-operation.md)
================================================
FILE: docs/solutions/1300-1399/maximum-students-taking-exam.md
================================================
# [1349. 参加考试的最大学生数](https://leetcode.cn/problems/maximum-students-taking-exam/)
- 标签:位运算、数组、动态规划、状态压缩、矩阵
- 难度:困难
## 题目链接
- [1349. 参加考试的最大学生数 - 力扣](https://leetcode.cn/problems/maximum-students-taking-exam/)
## 题目大意
**描述**:给定一个 $m \times n$ 大小的矩阵 $seats$ 表示教室中的座位分布,其中如果座位是坏的(不可用),就用 `'#'` 表示,如果座位是好的,就用 `'.'` 表示。
学生可以看到左侧、右侧、左上方、右上方这四个方向上紧邻他的学生答卷,但是看不到直接坐在他前面或者后面的学生答卷。
**要求**:计算并返回该考场可以容纳的一期参加考试且无法作弊的最大学生人数。
**说明**:
- 学生必须坐在状况良好的座位上。
- $seats$ 只包含字符 `'.'` 和 `'#'`。
- $m == seats.length$。
- $n == seats[i].length$。
- $1 \le m \le 8$。
- $1 \le n \le 8$。
**示例**:
- 示例 1:
```python
输入:seats = [["#",".","#","#",".","#"],
[".","#","#","#","#","."],
["#",".","#","#",".","#"]]
输出:4
解释:教师可以让 4 个学生坐在可用的座位上,这样他们就无法在考试中作弊。
```
- 示例 2:
```python
输入:seats = [[".","#"],
["#","#"],
["#","."],
["#","#"],
[".","#"]]
输出:3
解释:让所有学生坐在可用的座位上。
```
## 解题思路
### 思路 1:状态压缩 DP
题目中给定的 $m$、$n$ 范围为 $1 \le m, n \le 8$,每一排最多有 $8$ 个座位,那么我们可以使用一个 $8$ 位长度的二进制数来表示当前排座位的选择情况(也就是「状态压缩」的方式)。
同时从题目中可以看出,当前排的座位与当前行左侧、右侧座位有关,并且也与上一排中左上方、右上方的座位有关,则我们可以使用一个二维数组来表示状态。其中第一维度为排数,第二维度为当前排的座位选择情况。
具体做法如下:
###### 1. 阶段划分
按照排数、当前排的座位选择情况进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][state]$ 表示为:前 $i$ 排,并且最后一排座位选择状态为 $state$ 时,可以参加考试的最大学生数。
###### 3. 状态转移方程
因为学生可以看到左侧、右侧、左上方、右上方这四个方向上紧邻他的学生答卷,所以对于当前排的某个座位来说,其左侧、右侧、左上方、右上方都不应有人坐。我们可以根据当前排的座位选取状态 $cur\_state$,并通过枚举的方式,找出符合要求的上一排座位选取状态 $pre\_state$,并计算出当前排座位选择个数,即 $f(cur\_state)$,则状态转移方程为:
$dp[i][state] = \max \lbrace dp[i - 1][pre\_state] \rbrace + f(state)$
因为所给座位中还有坏座位(不可用)的情况,我们可以使用一个 $8$ 位的二进制数 $bad\_seat$ 来表示当前排的坏座位情况,如果 $cur\_state \text{ \& } bad\_seat == 1$,则说明当前状态下,选择了坏椅子,则可直接跳过这种状态。
我们还可以通过 $cur\_state \text{ \& } (cur\_state \text{ <}\text{< } 1)$ 和 $cur\_state \& (cur\_state \text{ >}\text{> } 1)$ 来判断当前排选择状态下,左右相邻座位上是否有人,如果有人,则可直接跳过这种状态。
同理,我们还可以通过 $cur\_state \text{ \& } (pre\_state \text{ <}\text{< } 1)$ 和 $cur\_state \text{ \& } (pre\_state \text{ >}\text{> } 1)$ 来判断当前排选择状态下,上一行左上、右上相邻座位上是否有人,如果有人,则可直接跳过这种状态。
###### 4. 初始条件
- 默认情况下,前 $0$ 排所有选择状态下,可以参加考试的最大学生数为 $0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][state]$ 表示为:前 $i$ 排,并且最后一排座位选择状态为 $state$ 时,可以参加考试的最大学生数。 所以最终结果为最后一排 $dp[rows]$ 中的最大值。
### 思路 1:代码
```python
class Solution:
def maxStudents(self, seats: List[List[str]]) -> int:
rows, cols = len(seats), len(seats[0])
states = 1 << cols
dp = [[0 for _ in range(states)] for _ in range(rows + 1)]
for i in range(1, rows + 1): # 模拟 1 ~ rows 排分配座位
bad_seat = 0 # 当前排的坏座位情况
for j in range(cols):
if seats[i - 1][j] == '#': # 记录坏座位情况
bad_seat |= 1 << j
for cur_state in range(states): # 枚举当前排的座位选取状态
if cur_state & bad_seat: # 当前排的座位选择了换座位,跳过
continue
if cur_state & (cur_state << 1): # 当前排左侧座位有人,跳过
continue
if cur_state & (cur_state >> 1): # 当前排右侧座位有人,跳过
continue
count = bin(cur_state).count('1') # 计算当前排最多可以坐多少人
for pre_state in range(states): # 枚举前一排情况
if cur_state & (pre_state << 1): # 左上座位有人,跳过
continue
if cur_state & (pre_state >> 1): # 右上座位有人,跳过
continue
# dp[i][cur_state] 取自上一排分配情况为 pre_state 的最大值 + 当前排最多可以坐的人数
dp[i][cur_state] = max(dp[i][cur_state], dp[i - 1][pre_state] + count)
return max(dp[rows])
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times 2^{2n})$,其中 $m$、$n$ 分别为所给矩阵的行数、列数。
- **空间复杂度**:$O(m \times 2^n)$。
================================================
FILE: docs/solutions/1300-1399/minimum-number-of-steps-to-make-two-strings-anagram.md
================================================
# [1347. 制造字母异位词的最小步骤数](https://leetcode.cn/problems/minimum-number-of-steps-to-make-two-strings-anagram/)
- 标签:哈希表、字符串、计数
- 难度:中等
## 题目链接
- [1347. 制造字母异位词的最小步骤数 - 力扣](https://leetcode.cn/problems/minimum-number-of-steps-to-make-two-strings-anagram/)
## 题目大意
**描述**:给定两个长度相等的字符串 $s$ 和 $t$。每一个步骤中,你可以选择将 $t$ 中任一个字符替换为另一个字符。
**要求**:返回使 $t$ 成为 $s$ 的字母异位词的最小步骤数。
**说明**:
- **字母异位词**:指字母相同,但排列不同(也可能相同)的字符串。
- $1 \le s.length \le 50000$。
- $s.length == t.length$。
- $s$ 和 $t$ 只包含小写英文字母。
**示例**:
- 示例 1:
```python
输出:s = "bab", t = "aba"
输出:1
提示:用 'b' 替换 t 中的第一个 'a',t = "bba" 是 s 的一个字母异位词。
```
- 示例 2:
```python
输出:s = "leetcode", t = "practice"
输出:5
提示:用合适的字符替换 t 中的 'p', 'r', 'a', 'i' 和 'c',使 t 变成 s 的字母异位词。
```
## 解题思路
### 思路 1:哈希表
题目要求使 $t$ 成为 $s$ 的字母异位词,则只需要 $t$ 和 $s$ 对应的每种字符数量相一致即可,无需考虑字符位置。
因为每一次转换都会减少一个字符,并增加另一个字符。
1. 我们使用两个哈希表 $cnts\_s$、$cnts\_t$ 分别对 $t$ 和 $s$ 中的字符进行计数,并求出两者的交集。
2. 遍历交集中的字符种类,以及对应的字符数量。
3. 对于当前字符 $key$,如果当前字符串 $s$ 中的字符 $key$ 的数量小于字符串 $t$ 中字符 $key$ 的数量,即 $cnts\_s[key] < cnts\_t[key]$。则 $s$ 中需要补齐的字符数量就是需要的最小步数,将其累加到答案中。
4. 遍历完返回答案。
### 思路 1:代码
```Python
class Solution:
def minSteps(self, s: str, t: str) -> int:
cnts_s, cnts_t = Counter(s), Counter(t)
cnts = cnts_s | cnts_t
ans = 0
for key, cnt in cnts.items():
if cnts_s[key] < cnts_t[key]:
ans += cnts_t[key] - cnts_s[key]
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m + n)$,其中 $m$、$n$ 分别为字符串 $s$、$t$ 的长度。
- **空间复杂度**:$O(|\sum|)$,其中 $\sum$ 是字符集,本题中 $| \sum | = 26$。
================================================
FILE: docs/solutions/1300-1399/number-of-operations-to-make-network-connected.md
================================================
# [1319. 连通网络的操作次数](https://leetcode.cn/problems/number-of-operations-to-make-network-connected/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [1319. 连通网络的操作次数 - 力扣](https://leetcode.cn/problems/number-of-operations-to-make-network-connected/)
## 题目大意
**描述**:$n$ 台计算机通过网线连接成一个网络,计算机的编号从 $0$ 到 $n - 1$。线缆用 $comnnections$ 表示,其中 $connections[i] = [a, b]$ 表示连接了计算机 $a$ 和 $b$。
给定这个计算机网络的初始布线 $connections$,可以拔除任意两台直接相连的计算机之间的网线,并用这根网线连接任意一对未直接连接的计算机。
**要求**:计算并返回使所有计算机都连通所需的最少操作次数。如果不可能,则返回 $-1$。
**说明**:
- $1 \le n \le 10^5$。
- $1 \le connections.length \le min( \frac{n \times (n-1)}{2}, 10^5)$。
- $connections[i].length == 2$。
- $0 \le connections[i][0], connections[i][1] < n$。
- $connections[i][0] != connections[i][1]$。
- 没有重复的连接。
- 两台计算机不会通过多条线缆连接。
**示例**:
- 示例 1:
```python
输入:n = 4, connections = [[0,1],[0,2],[1,2]]
输出:1
解释:拔下计算机 1 和 2 之间的线缆,并将它插到计算机 1 和 3 上。
```
- 示例 2:
```python
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]]
输出:2
```
## 解题思路
### 思路 1:并查集
$n$ 台计算机至少需要 $n - 1$ 根线才能进行连接,如果网线的数量少于 $n - 1$,那么就不可能将其连接。接下来计算最少操作次数。
把 $n$ 台计算机看做是 $n$ 个节点,每条网线看做是一条无向边。维护两个变量:多余电线数 $removeCount$、需要电线数 $needConnectCount$。初始 $removeCount = 1, needConnectCount = n - 1$。
遍历网线数组,将相连的节点 $a$ 和 $b$ 利用并查集加入到一个集合中(调用 `union` 操作)。
- 如果 $a$ 和 $b$ 已经在同一个集合中,说明该连接线多余,多余电线数加 $1$。
- 如果 $a$ 和 $b$ 不在一个集合中,则将其合并,则 $a$ 和 $b$ 之间不再需要用额外的电线连接了,所以需要电线数减 $1$。
最后,判断多余的电线数是否满足需要电线数,不满足返回 $-1$,如果满足,则返回需要电线数。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return False
self.parent[root_x] = root_y
return True
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def makeConnected(self, n: int, connections: List[List[int]]) -> int:
union_find = UnionFind(n)
removeCount = 0
needConnectCount = n - 1
for connection in connections:
if union_find.union(connection[0], connection[1]):
needConnectCount -= 1
else:
removeCount += 1
if removeCount < needConnectCount:
return -1
return needConnectCount
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times \alpha(n))$,其中 $m$ 是数组 $connections$ 的长度,$\alpha$ 是反 `Ackerman` 函数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1300-1399/number-of-sub-arrays-of-size-k-and-average-greater-than-or-equal-to-threshold.md
================================================
# [1343. 大小为 K 且平均值大于等于阈值的子数组数目](https://leetcode.cn/problems/number-of-sub-arrays-of-size-k-and-average-greater-than-or-equal-to-threshold/)
- 标签:数组、滑动窗口
- 难度:中等
## 题目链接
- [1343. 大小为 K 且平均值大于等于阈值的子数组数目 - 力扣](https://leetcode.cn/problems/number-of-sub-arrays-of-size-k-and-average-greater-than-or-equal-to-threshold/)
## 题目大意
**描述**:给定一个整数数组 $arr$ 和两个整数 $k$ 和 $threshold$。
**要求**:返回长度为 $k$ 且平均值大于等于 $threshold$ 的子数组数目。
**说明**:
- $1 \le arr.length \le 10^5$。
- $1 \le arr[i] \le 10^4$。
- $1 \le k \le arr.length$。
- $0 \le threshold \le 10^4$。
**示例**:
- 示例 1:
```python
输入:arr = [2,2,2,2,5,5,5,8], k = 3, threshold = 4
输出:3
解释:子数组 [2,5,5],[5,5,5] 和 [5,5,8] 的平均值分别为 4,5 和 6 。其他长度为 3 的子数组的平均值都小于 4 (threshold 的值)。
```
- 示例 2:
```python
输入:arr = [11,13,17,23,29,31,7,5,2,3], k = 3, threshold = 5
输出:6
解释:前 6 个长度为 3 的子数组平均值都大于 5 。注意平均值不是整数。
```
## 解题思路
### 思路 1:滑动窗口(固定长度)
这道题目是典型的固定窗口大小的滑动窗口题目。窗口大小为 `k`。具体做法如下:
1. `ans` 用来维护答案数目。`window_sum` 用来维护窗口中元素的和。
2. `left` 、`right` 都指向序列的第一个元素,即:`left = 0`,`right = 0`。
3. 向右移动 `right`,先将 `k` 个元素填入窗口中。
4. 当窗口元素个数为 `k` 时,即:`right - left + 1 >= k` 时,判断窗口内的元素和平均值是否大于等于阈值 `threshold`。
1. 如果满足,则答案数目 + 1。
2. 然后向右移动 `left`,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 `k`。
5. 重复 3 ~ 4 步,直到 `right` 到达数组末尾。
6. 最后输出答案数目。
### 思路 1:代码
```python
class Solution:
def numOfSubarrays(self, arr: List[int], k: int, threshold: int) -> int:
left = 0
right = 0
window_sum = 0
ans = 0
while right < len(arr):
window_sum += arr[right]
if right - left + 1 >= k:
if window_sum >= k * threshold:
ans += 1
window_sum -= arr[left]
left += 1
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1300-1399/number-of-substrings-containing-all-three-characters.md
================================================
# [1358. 包含所有三种字符的子字符串数目](https://leetcode.cn/problems/number-of-substrings-containing-all-three-characters/)
- 标签:哈希表、字符串、滑动窗口
- 难度:中等
## 题目链接
- [1358. 包含所有三种字符的子字符串数目 - 力扣](https://leetcode.cn/problems/number-of-substrings-containing-all-three-characters/)
## 题目大意
给你一个字符串 `s` ,`s` 只包含三种字符 `a`, `b` 和 `c`。
请你返回 `a`,`b` 和 `c` 都至少出现过一次的子字符串数目。
## 解题思路
只要找到首个 `a`、`b`、`c` 同时存在的子字符串,则在该子字符串后面追加字符构成的新字符串还是满足题意的。假设该子串末尾字母的位置为 `i`,则以此字符串构建的新字符串有 `len(s) - i`个。所以题目可以转换为找出 `a`、`b`、`c` 同时存在的最短子串,并记录所有满足题意的字符串数量。具体做法如下:
用滑动窗口 `window` 来记录各个字符个数,`window` 为哈希表类型。用 `ans` 来维护 `a`,`b` 和 `c` 都至少出现过一次的子字符串数目。
设定两个指针:`left`、`right`,分别指向滑动窗口的左右边界,保证窗口中不超过 `k` 种字符。
- 一开始,`left`、`right` 都指向 `0`。
- 将最右侧字符 `s[right]` 加入当前窗口 `window_counts` 中,记录该字符个数,向右移动 `right`。
- 如果该窗口中字符的种数大于等于 `3` 种,即 `len(window) >= 3`,则累积答案个数为 `len(s) - right`,并不断右移 `left`,缩小滑动窗口长度,并更新窗口中对应字符的个数,直到 `len(window) < 3`。
- 然后继续右移 `right`,直到 `right >= len(nums)` 结束。
- 输出答案 `ans`。
## 代码
```python
class Solution:
def numberOfSubstrings(self, s: str) -> int:
window = dict()
ans = 0
left, right = 0, 0
while right < len(s):
if s[right] in window:
window[s[right]] += 1
else:
window[s[right]] = 1
while len(window) >= 3:
ans += len(s) - right
window[s[left]] -= 1
if window[s[left]] == 0:
del window[s[left]]
left += 1
right += 1
return ans
```
================================================
FILE: docs/solutions/1300-1399/print-words-vertically.md
================================================
# [1324. 竖直打印单词](https://leetcode.cn/problems/print-words-vertically/)
- 标签:数组、字符串、模拟
- 难度:中等
## 题目链接
- [1324. 竖直打印单词 - 力扣](https://leetcode.cn/problems/print-words-vertically/)
## 题目大意
**描述**:给定一个字符串 $s$。
**要求**:按照单词在 $s$ 中出现顺序将它们全部竖直返回。
**说明**:
- 单词应该以字符串列表的形式返回,必要时用空格补位,但输出尾部的空格需要删除(不允许尾随空格)。
- 每个单词只能放在一列上,每一列中也只能有一个单词。
- $1 \le s.length \le 200$。
- $s$ 仅含大写英文字母。
- 题目数据保证两个单词之间只有一个空格。
**示例**:
- 示例 1:
```python
输入:s = "HOW ARE YOU"
输出:["HAY","ORO","WEU"]
解释:每个单词都应该竖直打印。
"HAY"
"ORO"
"WEU"
```
- 示例 2:
```python
输入:s = "TO BE OR NOT TO BE"
输出:["TBONTB","OEROOE"," T"]
解释:题目允许使用空格补位,但不允许输出末尾出现空格。
"TBONTB"
"OEROOE"
" T"
```
## 解题思路
### 思路 1:模拟
1. 将字符串 $s$ 按空格分割为单词数组 $words$。
2. 计算出单词数组 $words$ 中单词的最大长度 $max\_len$。
3. 第一重循环遍历竖直单词的每个单词位置 $i$,第二重循环遍历当前第 $j$ 个单词。
1. 如果当前单词没有第 $i$ 个字符(当前单词的长度超过了单词位置 $i$),则将空格插入到竖直单词中。
2. 如果当前单词有第 $i$ 个字符,泽讲当前单词的第 $i$ 个字符插入到竖直单词中。
4. 第二重循环遍历完,将竖直单词去除尾随空格,并加入到答案数组中。
5. 第一重循环遍历完,则返回答案数组。
### 思路 1:代码
```Python
class Solution:
def printVertically(self, s: str) -> List[str]:
words = s.split(' ')
max_len = 0
for word in words:
max_len = max(len(word), max_len)
res = []
for i in range(max_len):
ans = ""
for j in range(len(words)):
if i + 1 > len(words[j]):
ans += ' '
else:
ans += words[j][i]
res.append(ans.rstrip())
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times max(|word|))$,其中 $n$ 为字符串 $s$ 中的单词个数,$max(|word|)$ 是最长的单词长度。。
- **空间复杂度**:$O(n \times max(|word|))$。
================================================
FILE: docs/solutions/1300-1399/reduce-array-size-to-the-half.md
================================================
- [1338. 数组大小减半](https://leetcode.cn/problems/reduce-array-size-to-the-half/)
- 标签:贪心、数组、哈希表、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [1338. 数组大小减半 - 力扣](https://leetcode.cn/problems/reduce-array-size-to-the-half/)
## 题目大意
**描述**:给定过一个整数数组 $arr$。你可以从中选出一个整数集合,并在数组 $arr$ 删除所有整数集合对应的数。
**要求**:返回至少能删除数组中的一半整数的整数集合的最小大小。
**说明**:
- $1 \le arr.length \le 10^5$。
- $arr.length$ 为偶数。
- $1 \le arr[i] \le 10^5$。
**示例**:
- 示例 1:
```python
输入:arr = [3,3,3,3,5,5,5,2,2,7]
输出:2
解释:选择 {3,7} 使得结果数组为 [5,5,5,2,2]、长度为 5(原数组长度的一半)。
大小为 2 的可行集合有 {3,5},{3,2},{5,2}。
选择 {2,7} 是不可行的,它的结果数组为 [3,3,3,3,5,5,5],新数组长度大于原数组的二分之一。
```
- 示例 2:
```python
输入:arr = [7,7,7,7,7,7]
输出:1
解释:我们只能选择集合 {7},结果数组为空。
```
## 解题思路
### 思路 1:贪心算法
对于选出的整数集合中每一个数 $x$ 来说,我们会删除数组 $arr$ 中所有值为 $x$ 的整数。
因为题目要求我们选出的整数集合最小,所以在每一次选择整数 $x$ 加入整数集合时,我们都应该选择数组 $arr$ 中出现次数最多的数。
因此,我们可以统计出数组 $arr$ 中每个整数的出现次数,用哈希表存储,并依照出现次数进行降序排序。
然后,依次选择出现次数最多的数进行删除,并统计个数,直到删除了至少一半的数时停止。
最后,将统计个数作为答案返回。
### 思路 1:代码
```Python
class Solution:
def minSetSize(self, arr: List[int]) -> int:
cnts = Counter(arr)
ans, cnt = 0, 0
for num, freq in cnts.most_common():
cnt += freq
ans += 1
if cnt * 2 >= len(arr):
break
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组 $arr$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1300-1399/sum-of-mutated-array-closest-to-target.md
================================================
# [1300. 转变数组后最接近目标值的数组和](https://leetcode.cn/problems/sum-of-mutated-array-closest-to-target/)
- 标签:数组、二分查找、排序
- 难度:中等
## 题目链接
- [1300. 转变数组后最接近目标值的数组和 - 力扣](https://leetcode.cn/problems/sum-of-mutated-array-closest-to-target/)
## 题目大意
**描述**:给定一个整数数组 $arr$ 和一个目标值 $target$。
**要求**:返回一个整数 $value$,使得将数组中所有大于 $value$ 的值变成 $value$ 后,数组的和最接近 $target$(最接近表示两者之差的绝对值最小)。如果有多种使得和最接近 $target$ 的方案,请你返回这些整数中的最小值。
**说明**:
- 答案 $value$ 不一定是 $arr$ 中的数字。
- $1 \le arr.length \le 10^4$。
- $1 \le arr[i], target \le 10^5$。
**示例**:
- 示例 1:
```python
输入:arr = [4,9,3], target = 10
输出:3
解释:当选择 value 为 3 时,数组会变成 [3, 3, 3],和为 9 ,这是最接近 target 的方案。
```
- 示例 2:
```python
输入:arr = [60864,25176,27249,21296,20204], target = 56803
输出:11361
```
## 解题思路
### 思路 1:二分查找
题目可以理解为:在 $[0, max(arr)]$ 的区间中,查找一个值 $value$。使得「转变后的数组和」与 $target$ 最接近。
- 转变规则:将数组中大于 $value$ 的值变为 $value$。
在 $[0, max(arr)]$ 的区间中,查找一个值 $value$ 可以使用二分查找答案的方式减少时间复杂度。但是这个最接近 $target$ 应该怎么理解,或者说怎么衡量接近程度。
最接近 $target$ 的肯定是数组和等于 $target$ 的时候。不过更可能是出现数组和恰好比 $target$ 大一点,或数组和恰好比 $target$ 小一点。我们可以将 $target$ 上下两个值相对应的数组和与 $target$ 进行比较,输出差值更小的那一个 $value$。
在根据查找的值 $value$ 计算数组和时,也可以通过二分查找方法查找出数组刚好大于等于 $value$ 元素下标。还可以根据事先处理过的前缀和数组,快速得到转变后的数组和。
最后输出使得数组和与 $target$ 差值更小的 $value$。
整个算法步骤如下:
- 先对数组排序,并计算数组的前缀和 $pre\_sum$。
- 通过二分查找在 $[0, arr[-1]]$ 中查找使得转变后数组和刚好大于等于 $target$ 的值 $value$。
- 计算 $value$ 对应的数组和 $sum\_1$,以及 $value - 1$ 对应的数组和 $sum\_2$。并分别计算与 $target$ 的差值 $diff\_1$、$diff\_2$。
- 输出差值小的那个值。
### 思路 1:代码
```python
class Solution:
# 计算 value 对应的转变后的数组
def calc_sum(self, arr, value, pre_sum):
size = len(arr)
left, right = 0, size - 1
while left < right:
mid = left + (right - left) // 2
if arr[mid] < value:
left = mid + 1
else:
right = mid
return pre_sum[left] + (size - left) * value
# 查找使得转变后的数组和刚好大于等于 target 的 value
def binarySearchValue(self, arr, target, pre_sum):
left, right = 0, arr[-1]
while left < right:
mid = left + (right - left) // 2
if self.calc_sum(arr, mid, pre_sum) < target:
left = mid + 1
else:
right = mid
return left
def findBestValue(self, arr: List[int], target: int) -> int:
size = len(arr)
arr.sort()
pre_sum = [0 for _ in range(size + 1)]
for i in range(size):
pre_sum[i + 1] = pre_sum[i] + arr[i]
value = self.binarySearchValue(arr, target, pre_sum)
sum_1 = self.calc_sum(arr, value, pre_sum)
sum_2 = self.calc_sum(arr, value - 1, pre_sum)
diff_1 = abs(sum_1 - target)
diff_2 = abs(sum_2 - target)
return value if diff_1 < diff_2 else value - 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O((n + k) \times \log n)$。其中 $n$ 是数组 $arr$ 的长度,$k$ 是数组 $arr$ 中的最大值。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1300-1399/xor-queries-of-a-subarray.md
================================================
# [1310. 子数组异或查询](https://leetcode.cn/problems/xor-queries-of-a-subarray/)
- 标签:位运算、数组、前缀和
- 难度:中等
## 题目链接
- [1310. 子数组异或查询 - 力扣](https://leetcode.cn/problems/xor-queries-of-a-subarray/)
## 题目大意
**描述**:给定一个正整数数组 `arr`,再给定一个对应的查询数组 `queries`,其中 `queries[i] = [Li, Ri]`。
**要求**:对于每个查询 `queries[i]`,要求计算从 `Li` 到 `Ri` 的异或值(即 `arr[Li] ^ arr[Li+1] ^ ... ^ arr[Ri]`)作为本次查询的结果。并返回一个包含给定查询 `queries` 所有结果的数组。
**说明**:
- $1 \le arr.length \le 3 * 10^4$。
- $1 \le arr[i] \le 10^9$。
- $1 \le queries.length \le 3 * 10^4$。
- $queries[i].length == 2$。
- $0 \le queries[i][0] \le queries[i][1] < arr.length$。
**示例**:
- 示例 1:
```python
输入:arr = [1,3,4,8], queries = [[0,1],[1,2],[0,3],[3,3]]
输出:[2,7,14,8]
解释
数组中元素的二进制表示形式是:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
查询的 XOR 值为:
[0,1] = 1 xor 3 = 2
[1,2] = 3 xor 4 = 7
[0,3] = 1 xor 3 xor 4 xor 8 = 14
[3,3] = 8
```
## 解题思路
### 思路 1:线段树
- 使用数组 `res` 作为答案数组,用于存放每个查询的结果值。
- 根据 `nums` 数组构建一棵线段树。
- 然后遍历查询数组 `queries`。对于每个查询 `queries[i]`,在线段树中查询对应区间的异或值,将其结果存入答案数组 `res` 中。
- 返回答案数组 `res` 即可。
这样构建线段树的时间复杂度为 $O(\log n)$,单次区间查询的时间复杂度为 $O(\log n)$。总体时间复杂度为 $O(k * \log n)$,其中 $k$ 是查询次数。
### 思路 1:线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=0):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
self.lazy_tag = None # 区间和问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, nums, function):
self.size = len(nums)
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
self.nums = nums # 原始数据
self.function = function # function 是一个函数,左右区间的聚合方法
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.nums[i] = val
self.__update_point(i, val, 0)
# 区间更新接口:将区间为 [q_left, q_right] 上的所有元素值加上 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self):
for i in range(self.size):
self.nums[i] = self.query_interval(i, i)
return self.nums
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = self.nums[left]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.__pushup(index) # 向上更新节点的区间值
# 区间查询实现方法:在线段树中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新下标为 index 的节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, index):
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[index].val = self.function(self.tree[left_index].val, self.tree[right_index].val)
class Solution:
def xorQueries(self, arr: List[int], queries: List[List[int]]) -> List[int]:
self.STree = SegmentTree(arr, lambda x, y: (x ^ y))
res = []
for query in queries:
ans = self.STree.query_interval(query[0], query[1])
res.append(ans)
return res
```
================================================
FILE: docs/solutions/1400-1499/average-salary-excluding-the-minimum-and-maximum-salary.md
================================================
# [1491. 去掉最低工资和最高工资后的工资平均值](https://leetcode.cn/problems/average-salary-excluding-the-minimum-and-maximum-salary/)
- 标签:数组、排序
- 难度:简单
## 题目链接
- [1491. 去掉最低工资和最高工资后的工资平均值 - 力扣](https://leetcode.cn/problems/average-salary-excluding-the-minimum-and-maximum-salary/)
## 题目大意
**描述**:给定一个整数数组 `salary`,数组中的每一个数都是唯一的,其中 `salary[i]` 是第 `i` 个员工的工资。
**要求**:返回去掉最低工资和最高工资之后,剩下员工工资的平均值。
**说明**:
- $3 \le salary.length \le 100$。
- $10^3 \le salary[i] \le 10^6$。
- $salary[i]$ 是唯一的。
- 与真实值误差在 $10^{-5}$ 以内的结果都将视为正确答案。
**示例**:
- 示例 1:
```python
给定 salary = [1000,2000,3000]
输出 2000.00000
解释 最低工资为 1000,最高工资为 3000,去除最低工资和最高工资之后,剩下员工工资的平均值为 2000 / 1 = 2000
```
## 解题思路
### 思路 1:
因为给定 $salary.length \ge 3$,并且 $salary[i]$ 是唯一的,所以无需考虑最低工资和最高工资是同一个。接下来就是按照题意模拟过程:
- 计算出最小工资为 `min_s`,即 `min_s = min(salary)`。
- 计算出最大工资为 `max_s`,即 `max_s = max(salary)`。
- 计算出所有工资和之后再减去最小工资和最大工资,即 `total = sum(salary) - min_s - max_s`。
- 求剩下工资的平均值,并返回,即 `return total / (len(salary) - 2)`。
## 代码
### 思路 1 代码:
```python
class Solution:
def average(self, salary: List[int]) -> float:
min_s, max_s = min(salary), max(salary)
total = sum(salary) - min_s - max_s
return total / (len(salary) - 2)
```
================================================
FILE: docs/solutions/1400-1499/consecutive-characters.md
================================================
# [1446. 连续字符](https://leetcode.cn/problems/consecutive-characters/)
- 标签:字符串
- 难度:简单
## 题目链接
- [1446. 连续字符 - 力扣](https://leetcode.cn/problems/consecutive-characters/)
## 题目大意
给你一个字符串 `s` ,字符串的「能量」定义为:只包含一种字符的最长非空子字符串的长度。
要求:返回字符串的能量。
注意:
- `1 <= s.length <= 500`
- `s` 只包含小写英文字母。
## 解题思路
使用 `count` 统计连续不重复子串的长度,使用 `ans` 记录最长连续不重复子串的长度。
## 代码
```python
class Solution:
def maxPower(self, s: str) -> int:
ans = 1
count = 1
for i in range(1, len(s)):
if s[i] == s[i - 1]:
count += 1
else:
count = 1
ans = max(ans, count)
return ans
```
================================================
FILE: docs/solutions/1400-1499/construct-k-palindrome-strings.md
================================================
# [1400. 构造 K 个回文字符串](https://leetcode.cn/problems/construct-k-palindrome-strings/)
- 标签:贪心、哈希表、字符串、计数
- 难度:中等
## 题目链接
- [1400. 构造 K 个回文字符串 - 力扣](https://leetcode.cn/problems/construct-k-palindrome-strings/)
## 题目大意
**描述**:给定一个字符串 $s$ 和一个整数 $k$。
**要求**:用 $s$ 字符串中所有字符构造 $k$ 个非空回文串。如果可以用 $s$ 中所有字符构造 $k$ 个回文字符串,那么请你返回 `True`,否则返回 `False`。
**说明**:
- $1 \le s.length \le 10^5$。
- $s$ 中所有字符都是小写英文字母。
- $1 \le k \le 10^5$。
**示例**:
- 示例 1:
```python
输入:s = "annabelle", k = 2
输出:True
解释:可以用 s 中所有字符构造 2 个回文字符串。
一些可行的构造方案包括:"anna" + "elble","anbna" + "elle","anellena" + "b"
```
## 解题思路
### 思路 1:贪心算法
- 用字符串 $s$ 中所有字符构造回文串最多可以构造 $len(s)$ 个(将每个字符当做一个回文串)。所以如果 $len(s) < k$,则说明字符数量不够,无法构成 $k$ 个回文串,直接返回 `False`。
- 如果 $len(s) == k$,则可以直接使用单个字符构建回文串,直接返回 `True`。
- 如果 $len(s) > k$,则需要判断一下字符串 $s$ 中每个字符的个数。因为当字符是偶数个时,可以直接构造成回文串。所以我们只需要考虑个数为奇数的字符即可。如果个位为奇数的字符种类小于等于 $k$,则说明可以构造 $k$ 个回文串,返回 `True`。如果个位为奇数的字符种类大于 $k$,则说明无法构造 $k$ 个回文串,返回 `Fasle`。
### 思路 1:贪心算法代码
```python
import collections
class Solution:
def canConstruct(self, s: str, k: int) -> bool:
size = len(s)
if size < k:
return False
if size == k:
return True
letter_dict = dict()
for i in range(size):
if s[i] in letter_dict:
letter_dict[s[i]] += 1
else:
letter_dict[s[i]] = 1
odd = 0
for key in letter_dict:
if letter_dict[key] % 2 == 1:
odd += 1
return odd <= k
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + |\sum|)$,其中 $n$ 为字符串 $s$ 的长度,$\sum$ 是字符集,本题中 $|\sum| = 26$。
- **空间复杂度**:$O(|\sum|)$。
================================================
FILE: docs/solutions/1400-1499/form-largest-integer-with-digits-that-add-up-to-target.md
================================================
# [1449. 数位成本和为目标值的最大数字](https://leetcode.cn/problems/form-largest-integer-with-digits-that-add-up-to-target/)
- 标签:数组、动态规划
- 难度:困难
## 题目链接
- [1449. 数位成本和为目标值的最大数字 - 力扣](https://leetcode.cn/problems/form-largest-integer-with-digits-that-add-up-to-target/)
## 题目大意
**描述**:给定一个整数数组 $cost$ 和一个整数 $target$。现在从 `""` 开始,不断通过以下规则得到一个新的整数:
1. 给当前结果添加一个数位($i + 1$)的成本为 $cost[i]$($cost$ 数组下标从 $0$ 开始)。
2. 总成本必须恰好等于 $target$。
3. 添加的数位中没有数字 $0$。
**要求**:找到按照上述规则可以得到的最大整数。
**说明**:
- 由于答案可能会很大,请你以字符串形式返回。
- 如果按照上述要求无法得到任何整数,请你返回 `"0"`。
- $cost.length == 9$。
- $1 \le cost[i] \le 5000$。
- $1 \le target \le 5000$。
**示例**:
- 示例 1:
```python
输入:cost = [4,3,2,5,6,7,2,5,5], target = 9
输出:"7772"
解释:添加数位 '7' 的成本为 2 ,添加数位 '2' 的成本为 3 。所以 "7772" 的代价为 2*3+ 3*1 = 9 。 "977" 也是满足要求的数字,但 "7772" 是较大的数字。
数字 成本
1 -> 4
2 -> 3
3 -> 2
4 -> 5
5 -> 6
6 -> 7
7 -> 2
8 -> 5
9 -> 5
```
- 示例 2:
```python
输入:cost = [7,6,5,5,5,6,8,7,8], target = 12
输出:"85"
解释:添加数位 '8' 的成本是 7 ,添加数位 '5' 的成本是 5 。"85" 的成本为 7 + 5 = 12。
数字 成本
1 -> 7
2 -> 6
3 -> 5
4 -> 5
5 -> 5
6 -> 6
7 -> 8
8 -> 7
9 -> 8
```
## 解题思路
把每个数位($1 \sim 9$)看做是一件物品,$cost[i]$ 看做是物品的重量,一共有无数件物品可以使用,$target$ 看做是背包的载重上限,得到的最大整数可以看做是背包的最大价值。那么问题就变为了「完全背包问题」中的「恰好装满背包的最大价值问题」。
因为答案可能会很大,要求以字符串形式返回。这里我们可以直接令 $dp[w]$ 为字符串形式,然后定义一个 `def maxInt(a, b):` 方法用于判断两个字符串代表的数字大小。
### 思路 1:动态规划
###### 1. 阶段划分
按照背包载重上限进行阶段划分。
###### 2. 定义状态
定义状态 $dp[w]$ 表示为:将物品装入一个最多能装重量为 $w$ 的背包中,恰好装满背包的情况下,能装入背包的最大整数。
###### 3. 状态转移方程
$dp[w] = maxInt(dp[w], str(i) + dp[w - cost[i - 1]])$
###### 4. 初始条件
1. 只有载重上限为 $0$ 的背包,在不放入物品时,能够恰好装满背包(有合法解),此时背包所含物品的最大价值为空字符串,即 `dp[0] = ""`。
2. 其他载重上限下的背包,在放入物品的时,都不能恰好装满背包(都没有合法解),此时背包所含物品的最大价值属于未定义状态,值为自定义字符 `"#"`,即 ,`dp[w] = "#"`,$0 \le w \le target$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[w]$ 表示为:将物品装入一个最多能装重量为 $w$ 的背包中,恰好装满背包的情况下,能装入背包的最大价值总和。 所以最终结果为 $dp[target]$。
### 思路 1:代码
```python
class Solution:
def largestNumber(self, cost: List[int], target: int) -> str:
def maxInt(a, b):
if len(a) == len(b):
return max(a, b)
if len(a) > len(b):
return a
return b
size = len(cost)
dp = ["#" for _ in range(target + 1)]
dp[0] = ""
for i in range(1, size + 1):
for w in range(cost[i - 1], target + 1):
if dp[w - cost[i - 1]] != "#":
dp[w] = maxInt(dp[w], str(i) + dp[w - cost[i - 1]])
if dp[target] == "#":
return "0"
return dp[target]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times target)$,其中 $n$ 为数组 $cost$ 的元素个数,$target$ 为所给整数。
- **空间复杂度**:$O(target)$。
================================================
FILE: docs/solutions/1400-1499/index.md
================================================
## 本章内容
- [1400. 构造 K 个回文字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/construct-k-palindrome-strings.md)
- [1408. 数组中的字符串匹配](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/string-matching-in-an-array.md)
- [1422. 分割字符串的最大得分](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/maximum-score-after-splitting-a-string.md)
- [1423. 可获得的最大点数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/maximum-points-you-can-obtain-from-cards.md)
- [1438. 绝对差不超过限制的最长连续子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit.md)
- [1446. 连续字符](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/consecutive-characters.md)
- [1447. 最简分数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/simplified-fractions.md)
- [1449. 数位成本和为目标值的最大数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/form-largest-integer-with-digits-that-add-up-to-target.md)
- [1450. 在既定时间做作业的学生人数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/number-of-students-doing-homework-at-a-given-time.md)
- [1451. 重新排列句子中的单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/rearrange-words-in-a-sentence.md)
- [1456. 定长子串中元音的最大数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/maximum-number-of-vowels-in-a-substring-of-given-length.md)
- [1476. 子矩形查询](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/subrectangle-queries.md)
- [1480. 一维数组的动态和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/running-sum-of-1d-array.md)
- [1482. 制作 m 束花所需的最少天数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/minimum-number-of-days-to-make-m-bouquets.md)
- [1486. 数组异或操作](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/xor-operation-in-an-array.md)
- [1491. 去掉最低工资和最高工资后的工资平均值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/average-salary-excluding-the-minimum-and-maximum-salary.md)
- [1493. 删掉一个元素以后全为 1 的最长子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/longest-subarray-of-1s-after-deleting-one-element.md)
- [1496. 判断路径是否相交](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/path-crossing.md)
================================================
FILE: docs/solutions/1400-1499/longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit.md
================================================
# [1438. 绝对差不超过限制的最长连续子数组](https://leetcode.cn/problems/longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit/)
- 标签:队列、数组、有序集合、滑动窗口、单调队列、堆(优先队列)
- 难度:中等
## 题目链接
- [1438. 绝对差不超过限制的最长连续子数组 - 力扣](https://leetcode.cn/problems/longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit/)
## 题目大意
给定一个整数数组 `nums`,和一个表示限制的整数 `limit`。
要求:返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 `limit`。
如果不存在满足条件的子数组,则返回 `0`。
## 解题思路
求最长连续子数组,可以使用滑动窗口来解决。这道题目的难点在于如何维护滑动窗口内的最大值和最小值的差值。遍历滑动窗口求最大值和最小值,每次计算的时间复杂度为 $O(k)$,时间复杂度过高。考虑使用特殊的数据结构来降低时间复杂度。可以使用堆(优先队列)来解决。这里使用 `Python` 中 `heapq` 实现。具体做法如下:
- 使用 `left`、`right` 两个指针,分别指向滑动窗口的左右边界,保证窗口中最大值和最小值的差值不超过 `limit`。
- 一开始,`left`、`right` 都指向 `0`。
- 向右移动 `right`,将最右侧元素加入当前窗口和大顶堆、小顶堆中。
- 如果大顶堆堆顶元素和小顶堆堆顶元素大于 `limit`,则不断右移 `left`,缩小滑动窗口长度,并更新窗口内的大顶堆、小顶堆。
- 如果大顶堆堆顶元素和小顶堆堆顶元素小于等于 `limit`,则更新最长连续子数组长度。
- 然后继续右移 `right`,直到 `right >= len(nums)` 结束。
- 输出答案。
## 代码
```python
import heapq
class Solution:
def longestSubarray(self, nums: List[int], limit: int) -> int:
size = len(nums)
heap_max = []
heap_min = []
ans = 0
left, right = 0, 0
while right < size:
heapq.heappush(heap_max, [-nums[right], right])
heapq.heappush(heap_min, [nums[right], right])
while -heap_max[0][0] - heap_min[0][0] > limit:
while heap_min[0][1] <= left:
heapq.heappop(heap_min)
while heap_max[0][1] <= left:
heapq.heappop(heap_max)
left += 1
ans = max(ans, right - left + 1)
right += 1
return ans
```
================================================
FILE: docs/solutions/1400-1499/longest-subarray-of-1s-after-deleting-one-element.md
================================================
# [1493. 删掉一个元素以后全为 1 的最长子数组](https://leetcode.cn/problems/longest-subarray-of-1s-after-deleting-one-element/)
- 标签:数组、动态规划、滑动窗口
- 难度:中等
## 题目链接
- [1493. 删掉一个元素以后全为 1 的最长子数组 - 力扣](https://leetcode.cn/problems/longest-subarray-of-1s-after-deleting-one-element/)
## 题目大意
**描述**:给定一个二进制数组 $nums$,需要从数组中删掉一个元素。
**要求**:返回最长的且只包含 $1$ 的非空子数组的长度。如果不存在这样的子数组,请返回 $0$。
**说明**:
- $1 \le nums.length \le 10^5$。
- $nums[i]$ 要么是 $0$ 要么是 $1$。
**示例**:
- 示例 1:
```python
输入:nums = [1,1,0,1]
输出:3
解释:删掉位置 2 的数后,[1,1,1] 包含 3 个 1。
```
- 示例 2:
```python
输入:nums = [0,1,1,1,0,1,1,0,1]
输出:5
解释:删掉位置 4 的数字后,[0,1,1,1,1,1,0,1] 的最长全 1 子数组为 [1,1,1,1,1]。
```
## 解题思路
### 思路 1:滑动窗口
维护一个元素值为 $0$ 的元素数量少于 $1$ 个的滑动窗口。则答案为滑动窗口长度减去窗口内 $0$ 的个数求最大值。具体做法如下:
设定两个指针:$left$、$right$,分别指向滑动窗口的左右边界,保证窗口 $0$ 的个数小于 $1$ 个。使用 $window\_count$ 记录窗口中 $0$ 的个数,使用 $ans$ 记录删除一个元素后,最长的只包含 $1$ 的非空子数组长度。
- 一开始,$left$、$right$ 都指向 $0$。
- 如果最右侧元素等于 $0$,则 `window_count += 1` 。
- 如果 $window\_count > 1$ ,则不断右移 $left$,缩小滑动窗口长度。并更新当前窗口中 $0$ 的个数,直到 $window\_count \le 1$。
- 更新答案值,然后向右移动 $right$,直到 $right \ge len(nums)$ 结束。
- 输出答案 $ans$。
### 思路 1:代码
```python
class Solution:
def longestSubarray(self, nums: List[int]) -> int:
left, right = 0, 0
window_count = 0
ans = 0
while right < len(nums):
if nums[right] == 0:
window_count += 1
while window_count > 1:
if nums[left] == 0:
window_count -= 1
left += 1
ans = max(ans, right - left + 1 - window_count)
right += 1
if ans == len(nums):
return len(nums) - 1
else:
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1400-1499/maximum-number-of-vowels-in-a-substring-of-given-length.md
================================================
# [1456. 定长子串中元音的最大数目](https://leetcode.cn/problems/maximum-number-of-vowels-in-a-substring-of-given-length/)
- 标签:字符串、滑动窗口
- 难度:中等
## 题目链接
- [1456. 定长子串中元音的最大数目 - 力扣](https://leetcode.cn/problems/maximum-number-of-vowels-in-a-substring-of-given-length/)
## 题目大意
**描述**:给定字符串 $s$ 和整数 $k$。
**要求**:返回字符串 $s$ 中长度为 $k$ 的单个子字符串中可能包含的最大元音字母数。
**说明**:
- 英文中的元音字母为($a$, $e$, $i$, $o$, $u$)。
- $1 <= s.length <= 10^5$。
- $s$ 由小写英文字母组成。
- $1 <= k <= s.length$。
**示例**:
- 示例 1:
```python
输入:s = "abciiidef", k = 3
输出:3
解释:子字符串 "iii" 包含 3 个元音字母。
```
- 示例 2:
```python
输入:s = "aeiou", k = 2
输出:2
解释:任意长度为 2 的子字符串都包含 2 个元音字母。
```
## 解题思路
### 思路 1:滑动窗口
固定长度的滑动窗口题目。维护一个长度为 $k$ 的窗口,并统计滑动窗口中最大元音字母数。具体做法如下:
1. $ans$ 用来维护长度为 $k$ 的单个字符串中最大元音字母数。$window\_count$ 用来维护窗口中元音字母数。集合 $vowel\_set$ 用来存储元音字母。
2. $left$ 、$right$ 都指向字符串 $s$ 的第一个元素,即:$left = 0$,$right = 0$。
3. 判断 $s[right]$ 是否在元音字母集合中,如果在则用 $window\_count$ 进行计数。
4. 当窗口元素个数为 $k$ 时,即:$right - left + 1 \ge k$ 时,更新 $ans$。然后判断 $s[left]$ 是否为元音字母,如果是则 `window_count -= 1`,并向右移动 $left$,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 $k$。
5. 重复 $3 \sim 4$ 步,直到 $right$ 到达数组末尾。
6. 最后输出 $ans$。
### 思路 1:代码
```python
class Solution:
def maxVowels(self, s: str, k: int) -> int:
left, right = 0, 0
ans = 0
window_count = 0
vowel_set = ('a','e','i','o','u')
while right < len(s):
if s[right] in vowel_set:
window_count += 1
if right - left + 1 >= k:
ans = max(ans, window_count)
if s[left] in vowel_set:
window_count -= 1
left += 1
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1400-1499/maximum-points-you-can-obtain-from-cards.md
================================================
# [1423. 可获得的最大点数](https://leetcode.cn/problems/maximum-points-you-can-obtain-from-cards/)
- 标签:数组、前缀和、滑动窗口
- 难度:中等
## 题目链接
- [1423. 可获得的最大点数 - 力扣](https://leetcode.cn/problems/maximum-points-you-can-obtain-from-cards/)
## 题目大意
**描述**:将卡牌排成一行,给定每张卡片的点数数组 $cardPoints$,其中 $cardPoints[i]$ 表示第 $i$ 张卡牌对应点数。
每次行动,可以从行的开头或者末尾拿一张卡牌,最终保证正好拿到了 $k$ 张卡牌。所得点数就是你拿到手中的所有卡牌的点数之和。
现在给定一个整数数组 $cardPoints$ 和整数 $k$。
**要求**:返回可以获得的最大点数。
**说明**:
- $1 \le cardPoints.length \le 10^5$。
- $1 \le cardPoints[i] \le 10^4$
- $1 \le k \le cardPoints.length$。
**示例**:
- 示例 1:
```python
输入:cardPoints = [1,2,3,4,5,6,1], k = 3
输出:12
解释:第一次行动,不管拿哪张牌,你的点数总是 1 。但是,先拿最右边的卡牌将会最大化你的可获得点数。最优策略是拿右边的三张牌,最终点数为 1 + 6 + 5 = 12。
```
- 示例 2:
```python
输入:cardPoints = [2,2,2], k = 2
输出:4
解释:无论你拿起哪两张卡牌,可获得的点数总是 4。
```
## 解题思路
### 思路 1:滑动窗口
可以用固定长度的滑动窗口来做。
由于只能从开头或末尾位置拿 $k$ 张牌,则最后剩下的肯定是连续的 $len(cardPoints) - k$ 张牌。要求求出 $k$ 张牌可以获得的最大收益,我们可以反向先求出连续 $len(cardPoints) - k$ 张牌的最小点数。则答案为 $sum(cardPoints) - min\_sum$。维护一个固定长度为 $len(cardPoints) - k$ 的滑动窗口,求最小和。具体做法如下:
1. $window\_sum$ 用来维护窗口内的元素和,初始值为 $0$。$min\_sum$ 用来维护滑动窗口元素的最小和。初始值为 $sum(cardPoints)$。滑动窗口的长度为 $window\_size$,值为 $len(cardPoints) - k$。
2. 使用双指针 $left$、$right$。$left$ 、$right$ 都指向序列的第一个元素,即:`left = 0`,`right = 0`。
3. 向右移动 $right$,先将 $window\_size$ 个元素填入窗口中。
4. 当窗口元素个数为 $window\_size$ 时,即:$right - left + 1 \ge window\_size$ 时,计算窗口内的元素和,并维护子数组最小和 $min\_sum$。
5. 然后向右移动 $left$,从而缩小窗口长度,即 `left += 1`,使得窗口大小始终保持为 $k$。
6. 重复 4 ~ 5 步,直到 $right$ 到达数组末尾。
7. 最后输出 $sum(cardPoints) - min\_sum$ 即为答案。
注意:如果 $window\_size$ 为 $0$ 时需要特殊判断,此时答案为数组和 $sum(cardPoints)$。
### 思路 1:代码
```python
class Solution:
def maxScore(self, cardPoints: List[int], k: int) -> int:
window_size = len(cardPoints) - k
window_sum = 0
cards_sum = sum(cardPoints)
min_sum = cards_sum
left, right = 0, 0
if window_size == 0:
return cards_sum
while right < len(cardPoints):
window_sum += cardPoints[right]
if right - left + 1 >= window_size:
min_sum = min(window_sum, min_sum)
window_sum -= cardPoints[left]
left += 1
right += 1
return cards_sum - min_sum
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $cardPoints$ 中的元素数量。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1400-1499/maximum-score-after-splitting-a-string.md
================================================
# [1422. 分割字符串的最大得分](https://leetcode.cn/problems/maximum-score-after-splitting-a-string/)
- 标签:字符串
- 难度:简单
## 题目链接
- [1422. 分割字符串的最大得分 - 力扣](https://leetcode.cn/problems/maximum-score-after-splitting-a-string/)
## 题目大意
**描述**:给定一个由若干 $0$ 和 $1$ 组成的字符串。将字符串分割成两个非空子字符串的得分为:左子字符串中 $0$ 的数量 + 右子字符串中 $1$ 的数量。
**要求**:计算并返回该字符串分割成两个非空子字符串(即左子字符串和右子字符串)所能获得的最大得分。
**说明**:
- $2 \le s.length \le 500$。
- 字符串 $s$ 仅由字符 $0$ 和 $1$ 组成。
**示例**:
- 示例 1:
```python
输入:s = "011101"
输出:5
解释:
将字符串 s 划分为两个非空子字符串的可行方案有:
左子字符串 = "0" 且 右子字符串 = "11101",得分 = 1 + 4 = 5
左子字符串 = "01" 且 右子字符串 = "1101",得分 = 1 + 3 = 4
左子字符串 = "011" 且 右子字符串 = "101",得分 = 1 + 2 = 3
左子字符串 = "0111" 且 右子字符串 = "01",得分 = 1 + 1 = 2
左子字符串 = "01110" 且 右子字符串 = "1",得分 = 2 + 1 = 3
```
- 示例 2:
```python
输入:s = "00111"
输出:5
解释:当 左子字符串 = "00" 且 右子字符串 = "111" 时,我们得到最大得分 = 2 + 3 = 5
```
## 解题思路
### 思路 1:前缀和
1. 遍历字符串 $s$,使用前缀和数组来记录每个前缀子字符串中 $1$ 的个数。
2. 再次遍历字符串 $s$,枚举每个分割点,利用前缀和数组计算出当前分割出的左子字符串中 $1$ 的个数与右子字符串中 $0$ 的个数,并计算当前得分,然后更新最大得分。
3. 返回最大得分作为答案。
### 思路 1:代码
```python
class Solution:
def maxScore(self, s: str) -> int:
size = len(s)
one_cnts = [0 for _ in range(size + 1)]
for i in range(1, size + 1):
if s[i - 1] == '1':
one_cnts[i] = one_cnts[i - 1] + 1
else:
one_cnts[i] = one_cnts[i - 1]
ans = 0
for i in range(1, size):
left_score = i - one_cnts[i]
right_score = one_cnts[size] - one_cnts[i]
ans = max(ans, left_score + right_score)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1400-1499/minimum-number-of-days-to-make-m-bouquets.md
================================================
# [1482. 制作 m 束花所需的最少天数](https://leetcode.cn/problems/minimum-number-of-days-to-make-m-bouquets/)
- 标签:数组、二分查找
- 难度:中等
## 题目链接
- [1482. 制作 m 束花所需的最少天数 - 力扣](https://leetcode.cn/problems/minimum-number-of-days-to-make-m-bouquets/)
## 题目大意
**描述**:给定一个整数数组 $bloomDay$,以及两个整数 $m$ 和 $k$。$bloomDay$ 代表花朵盛开的时间,$bloomDay[i]$ 表示第 $i$ 朵花的盛开时间。盛开后就可以用于一束花中。
现在需要制作 $m$ 束花。制作花束时,需要使用花园中相邻的 $k$ 朵花 。
**要求**:返回从花园中摘 $m$ 束花需要等待的最少的天数。如果不能摘到 $m$ 束花则返回 $-1$。
**说明**:
- $bloomDay.length == n$。
- $1 \le n \le 10^5$。
- $1 \le bloomDay[i] \le 10^9$。
- $1 \le m \le 10^6$。
- $1 \le k \le n$。
**示例**:
- 示例 1:
```python
输入:bloomDay = [1,10,3,10,2], m = 3, k = 1
输出:3
解释:让我们一起观察这三天的花开过程,x 表示花开,而 _ 表示花还未开。
现在需要制作 3 束花,每束只需要 1 朵。
1 天后:[x, _, _, _, _] // 只能制作 1 束花
2 天后:[x, _, _, _, x] // 只能制作 2 束花
3 天后:[x, _, x, _, x] // 可以制作 3 束花,答案为 3
```
- 示例 2:
```python
输入:bloomDay = [1,10,3,10,2], m = 3, k = 2
输出:-1
解释:要制作 3 束花,每束需要 2 朵花,也就是一共需要 6 朵花。而花园中只有 5 朵花,无法满足制作要求,返回 -1。
```
## 解题思路
### 思路 1:二分查找算法
这道题跟「[0875. 爱吃香蕉的珂珂](https://leetcode.cn/problems/koko-eating-bananas/)」、「[1011. 在 D 天内送达包裹的能力](https://leetcode.cn/problems/capacity-to-ship-packages-within-d-days/)」有点相似。
根据题目可知:
- 制作花束最少使用时间跟花朵开花最短时间有关系,即 $min(bloomDay)$。
- 制作花束最多使用时间跟花朵开花最长时间有关系,即 $max(bloomDay)$。
- 则制作花束所需要的天数就变成了一个区间 $[min(bloomDay), max(bloomDay)]$。
那么,我们就可以根据这个区间,利用二分查找算法找到一个符合题意的最少天数。而判断某个天数下能否摘到 $m$ 束花则可以写个方法判断。具体步骤如下:
- 遍历数组 $bloomDay$。
- 如果 $bloomDay[i] \le days$。就将花朵数量加 $1$。
- 当能摘的花朵数等于 $k$ 时,能摘的花束数目加 $1$,花朵数量置为 $0$。
- 如果 $bloomDay[i] > days$。就将花朵数置为 $0$。
- 最后判断能摘的花束数目是否大于等于 $m$。
整个算法的步骤如下:
- 如果 $m \times k > len(bloomDay)$,说明无法满足要求,直接返回 $-1$。
- 使用两个指针 $left$、$right$。令 $left$ 指向 $min(bloomDay)$,$right$ 指向 $max(bloomDay)$。代表待查找区间为 $[left, right]$。
- 取两个节点中心位置 $mid$,判断是否能在 $mid$ 天制作 $m$ 束花。
- 如果不能,则将区间 $[left, mid]$ 排除掉,继续在区间 $[mid + 1, right]$ 中查找。
- 如果能,说明天数还可以继续减少,则继续在区间 $[left, mid]$ 中查找。
- 当 $left == right$ 时跳出循环,返回 $left$。
### 思路 1:代码
```python
class Solution:
def canMake(self, bloomDay, days, m, k):
count = 0
flower = 0
for i in range(len(bloomDay)):
if bloomDay[i] <= days:
flower += 1
if flower == k:
count += 1
flower = 0
else:
flower = 0
return count >= m
def minDays(self, bloomDay: List[int], m: int, k: int) -> int:
if m > len(bloomDay) / k:
return -1
left, right = min(bloomDay), max(bloomDay)
while left < right:
mid = left + (right - left) // 2
if not self.canMake(bloomDay, mid, m, k):
left = mid + 1
else:
right = mid
return left
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log (max(bloomDay) - min(bloomDay)))$。
- **空间复杂度**:$O(1)$。
## 参考资料
- 【题解】[【赤小豆】为什么是二分法,思路及模板 python - 制作 m 束花所需的最少天数 - 力扣(LeetCode)](https://leetcode.cn/problems/minimum-number-of-days-to-make-m-bouquets/solution/chi-xiao-dou-python-wei-shi-yao-shi-er-f-24p7/)
================================================
FILE: docs/solutions/1400-1499/number-of-students-doing-homework-at-a-given-time.md
================================================
# [1450. 在既定时间做作业的学生人数](https://leetcode.cn/problems/number-of-students-doing-homework-at-a-given-time/)
- 标签:数组
- 难度:简单
## 题目链接
- [1450. 在既定时间做作业的学生人数 - 力扣](https://leetcode.cn/problems/number-of-students-doing-homework-at-a-given-time/)
## 题目大意
**描述**:给你两个长度相等的整数数组,一个表示开始时间的数组 $startTime$ ,另一个表示结束时间的数组 $endTime$。再给定一个整数 $queryTime$ 作为查询时间。已知第 $i$ 名学生在 $startTime[i]$ 时开始写作业并于 $endTime[i]$ 时完成作业。
**要求**:返回在查询时间 $queryTime$ 时正在做作业的学生人数。即能够使 $queryTime$ 处于区间 $[startTime[i], endTime[i]]$ 的学生人数。
**说明**:
- $startTime.length == endTime.length$。
- $1\le startTime.length \le 100$。
- $1 \le startTime[i] \le endTime[i] \le 1000$。
- $1 \le queryTime \le 1000$。
**示例**:
- 示例 1:
```python
输入:startTime = [4], endTime = [4], queryTime = 4
输出:1
解释:在查询时间只有一名学生在做作业。
```
## 解题思路
### 思路 1:枚举算法
- 维护一个用于统计在查询时间 $queryTime$ 时正在做作业的学生人数的变量 $cnt$。然后遍历所有学生的开始时间和结束时间。
- 如果 $queryTime$ 在区间 $[startTime[i], endTime[i]]$ 之间,即 $startTime[i] <= queryTime <= endTime[i]$,则令 $cnt$ 加 $1$。
- 遍历完输出统计人数 $cnt$。
### 思路 1:枚举算法代码
```python
class Solution:
def busyStudent(self, startTime: List[int], endTime: List[int], queryTime: int) -> int:
cnt = 0
size = len(startTime)
for i in range(size):
if startTime[i] <= queryTime <= endTime[i]:
cnt += 1
return cnt
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组中的元素个数。
- **空间复杂度**:$O(1)$。
### 思路 2:线段树
- 因为 $1 \le startTime[i] \le endTime[i] \le 1000$,所以我们可以维护一个区间为 $[0, 1000]$ 的线段树,初始化所有区间值都为 $0$。
- 然后遍历所有学生的开始时间和结束时间,并将区间 $[startTime[i], endTime[i]]$ 值加 $1$。
- 在线段树中查询 $queryTime$ 对应的单点区间 $[queryTime, queryTime]$ 的最大值为多少。
### 思路 2:线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, val=0):
self.left = -1 # 区间左边界
self.right = -1 # 区间右边界
self.val = val # 节点值(区间值)
self.lazy_tag = None # 区间和问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, nums, function):
self.size = len(nums)
self.tree = [SegTreeNode() for _ in range(4 * self.size)] # 维护 SegTreeNode 数组
self.nums = nums # 原始数据
self.function = function # function 是一个函数,左右区间的聚合方法
if self.size > 0:
self.__build(0, 0, self.size - 1)
# 单点更新接口:将 nums[i] 更改为 val
def update_point(self, i, val):
self.nums[i] = val
self.__update_point(i, val, 0)
# 区间更新接口:将区间为 [q_left, q_right] 上的所有元素值加上 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, 0)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, 0)
# 获取 nums 数组接口:返回 nums 数组
def get_nums(self):
for i in range(self.size):
self.nums[i] = self.query_interval(i, i)
return self.nums
# 以下为内部实现方法
# 构建线段树实现方法:节点的存储下标为 index,节点的区间为 [left, right]
def __build(self, index, left, right):
self.tree[index].left = left
self.tree[index].right = right
if left == right: # 叶子节点,节点值为对应位置的元素值
self.tree[index].val = self.nums[left]
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.__build(left_index, left, mid) # 递归创建左子树
self.__build(right_index, mid + 1, right) # 递归创建右子树
self.__pushup(index) # 向上更新节点的区间值
# 单点更新实现方法:将 nums[i] 更改为 val,节点的存储下标为 index
def __update_point(self, i, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left == right:
self.tree[index].val = val # 叶子节点,节点值修改为 val
return
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if i <= mid: # 在左子树中更新节点值
self.__update_point(i, val, left_index)
else: # 在右子树中更新节点值
self.__update_point(i, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
if self.tree[index].lazy_tag is not None:
self.tree[index].lazy_tag += val # 将当前节点的延迟标记增加 val
else:
self.tree[index].lazy_tag = val # 将当前节点的延迟标记增加 val
interval_size = (right - left + 1) # 当前节点所在区间大小
self.tree[index].val += val * interval_size # 当前节点所在区间每个元素值增加 val
return
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
self.__pushdown(index) # 向下更新节点的区间值
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if q_left <= mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, left_index)
if q_right > mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, right_index)
self.__pushup(index) # 向上更新节点的区间值
# 区间查询实现方法:在线段树中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, index):
left = self.tree[index].left
right = self.tree[index].right
if left >= q_left and right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return self.tree[index].val # 直接返回节点值
if right < q_left or left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(index)
mid = left + (right - left) // 2 # 左右节点划分点
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, left_index)
if q_right > mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, right_index)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新下标为 index 的节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, index):
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
self.tree[index].val = self.function(self.tree[left_index].val, self.tree[right_index].val)
# 向下更新实现方法:更新下标为 index 的节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, index):
lazy_tag = self.tree[index].lazy_tag
if lazy_tag is None:
return
left_index = index * 2 + 1 # 左子节点的存储下标
right_index = index * 2 + 2 # 右子节点的存储下标
if self.tree[left_index].lazy_tag is not None:
self.tree[left_index].lazy_tag += lazy_tag # 更新左子节点懒惰标记
else:
self.tree[left_index].lazy_tag = lazy_tag
left_size = (self.tree[left_index].right - self.tree[left_index].left + 1)
self.tree[left_index].val += lazy_tag * left_size # 左子节点每个元素值增加 lazy_tag
if self.tree[right_index].lazy_tag is not None:
self.tree[right_index].lazy_tag += lazy_tag # 更新右子节点懒惰标记
else:
self.tree[right_index].lazy_tag = lazy_tag
right_size = (self.tree[right_index].right - self.tree[right_index].left + 1)
self.tree[right_index].val += lazy_tag * right_size # 右子节点每个元素值增加 lazy_tag
self.tree[index].lazy_tag = None # 更新当前节点的懒惰标记
class Solution:
def busyStudent(self, startTime: List[int], endTime: List[int], queryTime: int) -> int:
nums = [0 for _ in range(1010)]
self.STree = SegmentTree(nums, lambda x, y: max(x, y))
size = len(startTime)
for i in range(size):
self.STree.update_interval(startTime[i], endTime[i], 1)
return self.STree.query_interval(queryTime, queryTime)
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组元素的个数。
- **空间复杂度**:$O(n)$。
### 思路 3:树状数组
- 因为 $1 \le startTime[i] \le endTime[i] \le 1000$,所以我们可以维护一个区间为 $[0, 1000]$ 的树状数组。
- 注意:
- 树状数组中 $update(self, index, delta):$ 指的是将对应元素 $nums[index] $ 加上 $delta$。
- $query(self, index):$ 指的是 $index$ 位置之前的元素和,即前缀和。
- 然后遍历所有学生的开始时间和结束时间,将树状数组上 $startTime[i]$ 的值增加 $1$,再将树状数组上$endTime[i]$ 的值减少 $1$。
- 则查询 $queryTime$ 位置的前缀和即为答案。
### 思路 3:树状数组代码
```python
class BinaryIndexTree:
def __init__(self, n):
self.size = n
self.tree = [0 for _ in range(n + 1)]
def lowbit(self, index):
return index & (-index)
def update(self, index, delta):
while index <= self.size:
self.tree[index] += delta
index += self.lowbit(index)
def query(self, index):
res = 0
while index > 0:
res += self.tree[index]
index -= self.lowbit(index)
return res
class Solution:
def busyStudent(self, startTime: List[int], endTime: List[int], queryTime: int) -> int:
bit = BinaryIndexTree(1010)
size = len(startTime)
for i in range(size):
bit.update(startTime[i], 1)
bit.update(endTime[i] + 1, -1)
return bit.query(queryTime)
```
### 思路 3:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组元素的个数。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1400-1499/path-crossing.md
================================================
# [1496. 判断路径是否相交](https://leetcode.cn/problems/path-crossing/)
- 标签:哈希表、字符串
- 难度:简单
## 题目链接
- [1496. 判断路径是否相交 - 力扣](https://leetcode.cn/problems/path-crossing/)
## 题目大意
**描述**:给定一个字符串 $path$,其中 $path[i]$ 的值可以是 `'N'`、`'S'`、`'E'` 或者 `'W'`,分别表示向北、向南、向东、向西移动一个单位。
你从二维平面上的原点 $(0, 0)$ 处开始出发,按 $path$ 所指示的路径行走。
**要求**:如果路径在任何位置上与自身相交,也就是走到之前已经走过的位置,请返回 $True$;否则,返回 $False$。
**说明**:
- $1 \le path.length \le 10^4$。
- $path[i]$ 为 `'N'`、`'S'`、`'E'` 或 `'W'`。
**示例**:
- 示例 1:
```python
输入:path = "NES"
输出:false
解释:该路径没有在任何位置相交。
```
- 示例 2:
```python
输入:path = "NESWW"
输出:true
解释:该路径经过原点两次。
```
## 解题思路
### 思路 1:哈希表 + 模拟
1. 使用哈希表将 `'N'`、`'S'`、`'E'`、`'W'` 对应横纵坐标轴上的改变表示出来。
2. 使用集合 $visited$ 存储走过的坐标元组。
3. 遍历 $path$,按照 $path$ 所指示的路径模拟行走,并将所走过的坐标使用 $visited$ 存储起来。
4. 如果在 $visited$ 遇到已经走过的坐标,则返回 $True$。
5. 如果遍历完仍未发现已经走过的坐标,则返回 $False$。
### 思路 1:代码
```Python
class Solution:
def isPathCrossing(self, path: str) -> bool:
directions = {
"N" : (-1, 0),
"S" : (1, 0),
"W" : (0, -1),
"E" : (0, 1),
}
x, y = 0, 0
visited = set()
visited.add((x, y))
for ch in path:
x += directions[ch][0]
y += directions[ch][1]
if (x, y) in visited:
return True
visited.add((x, y))
return False
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $path$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1400-1499/rearrange-words-in-a-sentence.md
================================================
# [1451. 重新排列句子中的单词](https://leetcode.cn/problems/rearrange-words-in-a-sentence/)
- 标签:字符串、排序
- 难度:中等
## 题目链接
- [1451. 重新排列句子中的单词 - 力扣](https://leetcode.cn/problems/rearrange-words-in-a-sentence/)
## 题目大意
**描述**:「句子」是一个用空格分隔单词的字符串。给定一个满足下述格式的句子 $text$:
- 句子的首字母大写。
- $text$ 中的每个单词都用单个空格分隔。
**要求**:重新排列 $text$ 中的单词,使所有单词按其长度的升序排列。如果两个单词的长度相同,则保留其在原句子中的相对顺序。
请同样按上述格式返回新的句子。
**说明**:
- $text$ 以大写字母开头,然后包含若干小写字母以及单词间的单个空格。
- $1 \le text.length \le 10^5$。
**示例**:
- 示例 1:
```python
输入:text = "Leetcode is cool"
输出:"Is cool leetcode"
解释:句子中共有 3 个单词,长度为 8 的 "Leetcode" ,长度为 2 的 "is" 以及长度为 4 的 "cool"。
输出需要按单词的长度升序排列,新句子中的第一个单词首字母需要大写。
```
- 示例 2:
```python
输入:text = "Keep calm and code on"
输出:"On and keep calm code"
解释:输出的排序情况如下:
"On" 2 个字母。
"and" 3 个字母。
"keep" 4 个字母,因为存在长度相同的其他单词,所以它们之间需要保留在原句子中的相对顺序。
"calm" 4 个字母。
"code" 4 个字母。
```
## 解题思路
### 思路 1:模拟
1. 将 $text$ 按照 `" "` 进行分割为单词数组 $words$。
2. 将单词数组按照「单词长度」进行升序排序。
3. 将单词数组用 `" "` 连接起来,并将首字母转为大写字母,其他字母转为小写字母,将结果存入答案字符串 $ans$ 中。
4. 返回答案字符串 $ans$。
### 思路 1:代码
```Python
class Solution:
def arrangeWords(self, text: str) -> str:
words = text.split(' ')
words.sort(key=lambda word:len(word))
ans = " ".join(words).capitalize()
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为字符串 $text$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1400-1499/running-sum-of-1d-array.md
================================================
# [1480. 一维数组的动态和](https://leetcode.cn/problems/running-sum-of-1d-array/)
- 标签:数组、前缀和
- 难度:简单
## 题目链接
- [1480. 一维数组的动态和 - 力扣](https://leetcode.cn/problems/running-sum-of-1d-array/)
## 题目大意
**描述**:给定一个数组 $nums$。
**要求**:返回数组 $nums$ 的动态和。
**说明**:
- **动态和**:数组前 $i$ 项元素和构成的数组,计算公式为 $runningSum[i] = \sum_{x = 0}^{x = i}(nums[i])$。
- $1 \le nums.length \le 1000$。
- $-10^6 \le nums[i] \le 10^6$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,4]
输出:[1,3,6,10]
解释:动态和计算过程为 [1, 1+2, 1+2+3, 1+2+3+4]。
```
- 示例 2:
```python
输入:nums = [1,1,1,1,1]
输出:[1,2,3,4,5]
解释:动态和计算过程为 [1, 1+1, 1+1+1, 1+1+1+1, 1+1+1+1+1]。
```
## 解题思路
### 思路 1:递推
根据动态和的公式 $runningSum[i] = \sum_{x = 0}^{x = i}(nums[i])$,可以推导出:
$runningSum = \begin{cases} nums[0], & i = 0 \cr runningSum[i - 1] + nums[i], & i > 0\end{cases}$
则解决过程如下:
1. 新建一个长度等于 $nums$ 的数组 $res$ 用于存放答案。
2. 初始化 $res[0] = nums[0]$。
3. 从下标 $1$ 开始遍历数组 $nums$,递推更新 $res$,即:`res[i] = res[i - 1] + nums[i]`。
4. 遍历结束,返回 $res$ 作为答案。
### 思路 1:代码
```python
class Solution:
def runningSum(self, nums: List[int]) -> List[int]:
size = len(nums)
res = [0 for _ in range(size)]
for i in range(size):
if i == 0:
res[i] = nums[i]
else:
res[i] = res[i - 1] + nums[i]
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。一重循环遍历的时间复杂度为 $O(n)$。
- **空间复杂度**:$O(n)$。如果算上答案数组的空间占用,则空间复杂度为 $O(n)$。不算上则空间复杂度为 $O(1)$。
================================================
FILE: docs/solutions/1400-1499/simplified-fractions.md
================================================
# [1447. 最简分数](https://leetcode.cn/problems/simplified-fractions/)
- 标签:数学、字符串、数论
- 难度:中等
## 题目链接
- [1447. 最简分数 - 力扣](https://leetcode.cn/problems/simplified-fractions/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:返回所有 $0$ 到 $1$ 之间(不包括 $0$ 和 $1$)满足分母小于等于 $n$ 的最简分数。分数可以以任意顺序返回。
**说明**:
- $1 \le n \le 100$。
**示例**:
- 示例 1:
```python
输入:n = 2
输出:["1/2"]
解释:"1/2" 是唯一一个分母小于等于 2 的最简分数。
```
- 示例 2:
```python
输入:n = 4
输出:["1/2","1/3","1/4","2/3","3/4"]
解释:"2/4" 不是最简分数,因为它可以化简为 "1/2"。
```
## 解题思路
### 思路 1:数学
如果分子和分母的最大公约数为 $1$ 时,则当前分数为最简分数。
而 $n$ 的数据范围为 $(1, 100)$。因此我们可以使用两重遍历,分别枚举分子和分母,然后通过判断分子和分母是否为最大公约数,来确定当前分数是否为最简分数。
### 思路 1:代码
```python
class Solution:
def simplifiedFractions(self, n: int) -> List[str]:
res = []
for i in range(1, n):
for j in range(i + 1, n + 1):
if math.gcd(i, j) == 1:
res.append(str(i) + "/" + str(j))
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times \log n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1400-1499/string-matching-in-an-array.md
================================================
# [1408. 数组中的字符串匹配](https://leetcode.cn/problems/string-matching-in-an-array/)
- 标签:数组、字符串、字符串匹配
- 难度:简单
## 题目链接
- [1408. 数组中的字符串匹配 - 力扣](https://leetcode.cn/problems/string-matching-in-an-array/)
## 题目大意
**描述**:给定一个字符串数组 `words`,数组中的每个字符串都可以看作是一个单词。如果可以删除 `words[j]` 最左侧和最右侧的若干字符得到 `word[i]`,那么字符串 `words[i]` 就是 `words[j]` 的一个子字符串。
**要求**:按任意顺序返回 `words` 中是其他单词的子字符串的所有单词。
**说明**:
- $1 \le words.length \le 100$。
- $1 \le words[i].length \le 30$
- `words[i]` 仅包含小写英文字母。
- 题目数据保证每个 `words[i]` 都是独一无二的。
**示例**:
- 示例 1:
```python
输入:words = ["mass","as","hero","superhero"]
输出:["as","hero"]
解释:"as" 是 "mass" 的子字符串,"hero" 是 "superhero" 的子字符串。此外,["hero","as"] 也是有效的答案。
```
## 解题思路
### 思路 1:KMP 算法
1. 先按照字符串长度从小到大排序,使用数组 `res` 保存答案。
2. 使用两重循环遍历,对于 `words[i]` 和 `words[j]`,使用 `KMP` 匹配算法,如果 `wrods[j]` 包含 `words[i]`,则将其加入到答案数组中,并跳出最里层循环。
3. 返回答案数组 `res`。
### 思路 1:代码
```python
class Solution:
# 生成 next 数组
# next[j] 表示下标 j 之前的模式串 p 中,最长相等前后缀的长度
def generateNext(self, p: str):
m = len(p)
next = [0 for _ in range(m)] # 初始化数组元素全部为 0
left = 0 # left 表示前缀串开始所在的下标位置
for right in range(1, m): # right 表示后缀串开始所在的下标位置
while left > 0 and p[left] != p[right]: # 匹配不成功, left 进行回退, left == 0 时停止回退
left = next[left - 1] # left 进行回退操作
if p[left] == p[right]: # 匹配成功,找到相同的前后缀,先让 left += 1,此时 left 为前缀长度
left += 1
next[right] = left # 记录前缀长度,更新 next[right], 结束本次循环, right += 1
return next
# KMP 匹配算法,T 为文本串,p 为模式串
def kmp(self, T: str, p: str) -> int:
n, m = len(T), len(p)
next = self.generateNext(p) # 生成 next 数组
j = 0 # j 为模式串中当前匹配的位置
for i in range(n): # i 为文本串中当前匹配的位置
while j > 0 and T[i] != p[j]: # 如果模式串前缀匹配不成功, 将模式串进行回退, j == 0 时停止回退
j = next[j - 1]
if T[i] == p[j]: # 当前模式串前缀匹配成功,令 j += 1,继续匹配
j += 1
if j == m: # 当前模式串完全匹配成功,返回匹配开始位置
return i - j + 1
return -1 # 匹配失败,返回 -1
def stringMatching(self, words: List[str]) -> List[str]:
words.sort(key=lambda x:len(x))
res = []
for i in range(len(words) - 1):
for j in range(i + 1, len(words)):
if self.kmp(words[j], words[i]) != -1:
res.append(words[i])
break
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2 \times m)$,其中字符串数组长度为 $n$,字符串数组中最长字符串长度为 $m$。
- **空间复杂度**:$O(m)$。
================================================
FILE: docs/solutions/1400-1499/subrectangle-queries.md
================================================
# [1476. 子矩形查询](https://leetcode.cn/problems/subrectangle-queries/)
- 标签:设计、数组、矩阵
- 难度:中等
## 题目链接
- [1476. 子矩形查询 - 力扣](https://leetcode.cn/problems/subrectangle-queries/)
## 题目大意
**要求**:实现一个类 SubrectangleQueries,它的构造函数的参数是一个 $rows \times cols $的矩形(这里用整数矩阵表示),并支持以下两种操作:
1. `updateSubrectangle(int row1, int col1, int row2, int col2, int newValue)`:用 $newValue$ 更新以 $(row1,col1)$ 为左上角且以 $(row2,col2)$ 为右下角的子矩形。
2. `getValue(int row, int col)`:返回矩形中坐标 (row,col) 的当前值。
**说明**:
- 最多有 $500$ 次 `updateSubrectangle` 和 `getValue` 操作。
- $1 <= rows, cols <= 100$。
- $rows == rectangle.length$。
- $cols == rectangle[i].length$。
- $0 <= row1 <= row2 < rows$。
- $0 <= col1 <= col2 < cols$。
- $1 <= newValue, rectangle[i][j] <= 10^9$。
- $0 <= row < rows$。
- $0 <= col < cols$。
**示例**:
- 示例 1:
```python
输入:
["SubrectangleQueries","getValue","updateSubrectangle","getValue","getValue","updateSubrectangle","getValue","getValue"]
[[[[1,2,1],[4,3,4],[3,2,1],[1,1,1]]],[0,2],[0,0,3,2,5],[0,2],[3,1],[3,0,3,2,10],[3,1],[0,2]]
输出:
[null,1,null,5,5,null,10,5]
解释:
SubrectangleQueries subrectangleQueries = new SubrectangleQueries([[1,2,1],[4,3,4],[3,2,1],[1,1,1]]);
// 初始的 (4x3) 矩形如下:
// 1 2 1
// 4 3 4
// 3 2 1
// 1 1 1
subrectangleQueries.getValue(0, 2); // 返回 1
subrectangleQueries.updateSubrectangle(0, 0, 3, 2, 5);
// 此次更新后矩形变为:
// 5 5 5
// 5 5 5
// 5 5 5
// 5 5 5
subrectangleQueries.getValue(0, 2); // 返回 5
subrectangleQueries.getValue(3, 1); // 返回 5
subrectangleQueries.updateSubrectangle(3, 0, 3, 2, 10);
// 此次更新后矩形变为:
// 5 5 5
// 5 5 5
// 5 5 5
// 10 10 10
subrectangleQueries.getValue(3, 1); // 返回 10
subrectangleQueries.getValue(0, 2); // 返回 5
```
- 示例 2:
```python
输入:
["SubrectangleQueries","getValue","updateSubrectangle","getValue","getValue","updateSubrectangle","getValue"]
[[[[1,1,1],[2,2,2],[3,3,3]]],[0,0],[0,0,2,2,100],[0,0],[2,2],[1,1,2,2,20],[2,2]]
输出:
[null,1,null,100,100,null,20]
解释:
SubrectangleQueries subrectangleQueries = new SubrectangleQueries([[1,1,1],[2,2,2],[3,3,3]]);
subrectangleQueries.getValue(0, 0); // 返回 1
subrectangleQueries.updateSubrectangle(0, 0, 2, 2, 100);
subrectangleQueries.getValue(0, 0); // 返回 100
subrectangleQueries.getValue(2, 2); // 返回 100
subrectangleQueries.updateSubrectangle(1, 1, 2, 2, 20);
subrectangleQueries.getValue(2, 2); // 返回 20
```
## 解题思路
### 思路 1:暴力
矩形最大为 $row \times col == 100 \times 100$,则每次更新最多需要更新 $10000$ 个值,更新次数最多为 $500$ 次。
用暴力更新的方法最多需要更新 $5000000$ 次,我们可以尝试一下用暴力更新的方法解决本题(提交后发现可以通过)。
### 思路 1:代码
```Python
class SubrectangleQueries:
def __init__(self, rectangle: List[List[int]]):
self.rectangle = rectangle
def updateSubrectangle(self, row1: int, col1: int, row2: int, col2: int, newValue: int) -> None:
for row in range(row1, row2 + 1):
for col in range(col1, col2 + 1):
self.rectangle[row][col] = newValue
def getValue(self, row: int, col: int) -> int:
return self.rectangle[row][col]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(row \times col \times 500)$。
- **空间复杂度**:$O(row \times col)$。
================================================
FILE: docs/solutions/1400-1499/xor-operation-in-an-array.md
================================================
# [1486. 数组异或操作](https://leetcode.cn/problems/xor-operation-in-an-array/)
- 标签:位运算、数学
- 难度:简单
## 题目链接
- [1486. 数组异或操作 - 力扣](https://leetcode.cn/problems/xor-operation-in-an-array/)
## 题目大意
给定两个整数 n、start。数组 nums 定义为:nums[i] = start + 2*i(下标从 0 开始)。n 为数组长度。返回数组 nums 中所有元素按位异或(XOR)后得到的结果。
## 解题思路
### 1. 模拟
直接按照题目要求模拟即可。
### 2. 规律
- $x \oplus x = 0$;
- $x \oplus y = y \oplus x$(交换律);
- $(x \oplus y) \oplus z = x \oplus (y \oplus z)$(结合律);
- $x \oplus y \oplus y = x$(自反性);
- $\forall i \in Z$,有 $4i \oplus (4i+1) \oplus (4i+2) \oplus (4i+3) = 0$;
- $\forall i \in Z$,有 $2i \oplus (2i+1) = 1$;
- $\forall i \in Z$,有 $2i \oplus 1 = 2i+1$。
本题中计算的是 $start \oplus (start + 2) \oplus (start + 4) \oplus (start + 6) \oplus … \oplus (start+(2*(n-1)))$。
可以看出,如果 start 为奇数,则 $start+2, start + 4, …, start + (2 \times(n - 1))$ 都为奇数。如果 start 为偶数,则 $start + 2, start + 4, …, start + (2 \times(n - 1))$ 都为偶数。则它们对应二进制的最低位相同,则我们可以将最低位提取处理单独处理。从而将公式转换一下。
令 $s = \frac{start}{2}$,则等式变为 $(s) \oplus (s+1) \oplus (s+2) \oplus (s+3) \oplus … \oplus (s+(n-1)) * 2 + e$,e 表示运算结果的最低位。
根据自反性,$(s) \oplus (s+1) \oplus (s+2) \oplus (s+3) \oplus … \oplus (s+(n-1)) = \\ (1 \oplus 2 \oplus … \oplus (s-1)) \oplus (1 \oplus 2 \oplus … \oplus (s-1) \oplus (s) \oplus (s+1) \oplus … \oplus (s+(n-1)))$
例如: $3 \oplus 4 \oplus 5 \oplus 6 \oplus 7 = (1 \oplus 2) \oplus (1 \oplus 2 \oplus 3 \oplus 4 \oplus 5 \oplus 6 \oplus7)$
就变为了计算前 n 项序列的异或值。假设我们定义一个函数 sumXor(x) 用于计算前 n 项数的异或结果,通过观察可得出:
$sumXor(x) = \begin{cases} \begin{array} \ x, & x = 4i, k \in Z \cr (x-1) \oplus x, & x = 4i+1, k \in Z \cr (x-2) \oplus (x-1) \oplus x, & x = 4i+2, k \in Z \cr (x-3) \oplus (x-2) \oplus (x-3) \oplus x, & x = 4i+3, k \in Z \end{array} \end{cases}$
继续化简得:
$sumXor(x) = \begin{cases} \begin{array} \ x, & x = 4i, k \in Z \cr 1, & x = 4i+1, k \in Z \cr x+1, & x = 4i+2, k \in Z \cr 0, & x = 4i+3, k \in Z \end{array} \end{cases}$
则最终结果为 $sumXor(s-1) \oplus sumXor(s+n-1) * 2 + e$。
下面还有最后一位 e 的计算。
- 如果 start 为偶数,则最后一位 e 为 0。
- 如果 start 为奇数,最后一位 e 跟 n 有关,如果 n 为奇数,则最后一位 e 为 1,如果 n 为偶数,则最后一位 e 为 0。
总结下来就是 `e = start & n & 1`。
## 代码
1. 模拟
```python
class Solution:
def xorOperation(self, n: int, start: int) -> int:
ans = 0
for i in range(n):
ans ^= (start + i * 2)
return ans
```
2. 规律
```python
class Solution:
def sumXor(self, x):
if x % 4 == 0:
return x
if x % 4 == 1:
return 1
if x % 4 == 2:
return x + 1
return 0
def xorOperation(self, n: int, start: int) -> int:
s = start >> 1
e = n & start & 1
ans = self.sumXor(s-1) ^ self.sumXor(s + n - 1)
return ans << 1 | e
```
================================================
FILE: docs/solutions/1500-1599/can-make-arithmetic-progression-from-sequence.md
================================================
# [1502. 判断能否形成等差数列](https://leetcode.cn/problems/can-make-arithmetic-progression-from-sequence/)
- 标签:数组、排序
- 难度:简单
## 题目链接
- [1502. 判断能否形成等差数列 - 力扣](https://leetcode.cn/problems/can-make-arithmetic-progression-from-sequence/)
## 题目大意
**描述**:给定一个数字数组 `arr`。如果一个数列中,任意相邻两项的差总等于同一个常数,那么这个数序就称为等差数列。
**要求**:如果数组 `arr` 通过重新排列可以形成等差数列,则返回 `True`;否则返回 `False`。
**说明**:
- $2 \le arr.length \le 1000$
- $-10^6 \le arr[i] \le 10^6$
**示例**:
- 示例 1:
```python
输入:arr = [3,5,1]
输出:True
解释:数组重新排序后得到 [1,3,5] 或者 [5,3,1],任意相邻两项的差分别为 2 或 -2 ,可以形成等差数列。
```
## 解题思路
### 思路 1:
- 如果数组元素个数小于等于 `2`,则数组肯定可以形成等差数列,直接返回 `True`。
- 对数组进行排序。
- 从下标为 `2` 的元素开始,遍历相邻的 `3` 个元素 `arr[i]` 、`arr[i - 1]`、`arr[i - 2]`。判断 `arr[i] - arr[i - 1]` 是否等于 `arr[i - 1] - arr[i - 2]`。如果不等于,则数组无法形成等差数列,返回 `False`。
- 如果遍历完数组,则说明数组可以形成等差数列,返回 `True`。
## 代码
### 思路 1 代码:
```python
class Solution:
def canMakeArithmeticProgression(self, arr: List[int]) -> bool:
size = len(arr)
if size <= 2:
return True
arr.sort()
for i in range(2, size):
if arr[i] - arr[i - 1] != arr[i - 1] - arr[i - 2]:
return False
return True
```
================================================
FILE: docs/solutions/1500-1599/count-good-triplets.md
================================================
# [1534. 统计好三元组](https://leetcode.cn/problems/count-good-triplets/)
- 标签:数组、枚举
- 难度:简单
## 题目链接
- [1534. 统计好三元组 - 力扣](https://leetcode.cn/problems/count-good-triplets/)
## 题目大意
**描述**:给定一个整数数组 $arr$,以及 $a$、$b$、$c$ 三个整数。
**要求**:统计其中好三元组的数量。
**说明**:
- **好三元组**:如果三元组($arr[i]$、$arr[j]$、$arr[k]$)满足下列全部条件,则认为它是一个好三元组。
- $0 \le i < j < k < arr.length$。
- $| arr[i] - arr[j] | \le a$。
- $| arr[j] - arr[k] | \le b$。
- $| arr[i] - arr[k] | \le c$。
- $3 \le arr.length \le 100$。
- $0 \le arr[i] \le 1000$。
- $0 \le a, b, c \le 1000$。
**示例**:
- 示例 1:
```python
输入:arr = [3,0,1,1,9,7], a = 7, b = 2, c = 3
输出:4
解释:一共有 4 个好三元组:[(3,0,1), (3,0,1), (3,1,1), (0,1,1)]。
```
- 示例 2:
```python
输入:arr = [1,1,2,2,3], a = 0, b = 0, c = 1
输出:0
解释:不存在满足所有条件的三元组。
```
## 解题思路
### 思路 1:枚举
- 使用三重循环依次枚举所有的 $(i, j, k)$,判断对应 $arr[i]$、$arr[j]$、$arr[k]$ 是否满足条件。
- 然后统计出所有满足条件的三元组的数量。
### 思路 1:代码
```python
class Solution:
def countGoodTriplets(self, arr: List[int], a: int, b: int, c: int) -> int:
size = len(arr)
ans = 0
for i in range(size):
for j in range(i + 1, size):
for k in range(j + 1, size):
if abs(arr[i] - arr[j]) <= a and abs(arr[j] - arr[k]) <= b and abs(arr[i] - arr[k]) <= c:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^3)$,其中 $n$ 是数组 $arr$ 的长度。
- **空间复杂度**:$O(1)$。
### 思路 2:枚举优化 + 前缀和
我们可以先通过二重循环遍历二元组 $(j, k)$,找出所有满足 $| arr[j] - arr[k] | \le b$ 的二元组。
然后在 $| arr[j] - arr[k] | \le b$ 的条件下,我们需要找到满足以下要求的 $arr[i]$ 数量:
1. $i < j$。
2. $| arr[i] - arr[j] | \le a$。
3. $| arr[i] - arr[k] | \le c$。
4. $0 \le arr[i] \le 1000$。
其中 $2$、$3$ 去除绝对值之后可变为:
1. $arr[j] - a \le arr[i] \le arr[j] + a$。
2. $arr[k] - c \le arr[i] \le arr[k] + c$。
将这两个条件再结合第 $4$ 个条件综合一下就变为:$max(0, arr[j] - a, arr[k] - c) \le arr[i] \le min(arr[j] + a, arr[k] + c, 1000)$。
假如定义 $left = max(0, arr[j] - a, arr[k] - c)$,$right = min(arr[j] + a, arr[k] + c, 1000)$。
现在问题就转变了如何快速获取在值域区间 $[left, right]$ 中,有多少个 $arr[i]$。
我们可以利用前缀和数组,先计算出 $[0, 1000]$ 范围中,满足 $arr[i] < num$ 的元素个数,即为 $prefix\_cnts[num]$。
然后对于区间 $[left, right]$,通过 $prefix\_cnts[right] - prefix\_cnts[left - 1]$ 即可快速求解出区间 $[left, right]$ 内 $arr[i]$ 的个数。
因为 $i < j < k$,所以我们可以在每次 $j$ 向右移动一位的时候,更新 $arr[j]$ 对应的前缀和数组,保证枚举到 $j$ 时,$prefix\_cnts$ 存储对应元素值的个数足够正确。
### 思路 2:代码
```python
class Solution:
def countGoodTriplets(self, arr: List[int], a: int, b: int, c: int) -> int:
size = len(arr)
ans = 0
prefix_cnts = [0 for _ in range(1010)]
for j in range(size):
for k in range(j + 1, size):
if abs(arr[j] - arr[k]) <= b:
left_j, right_j = arr[j] - a, arr[j] + a
left_k, right_k = arr[k] - c, arr[k] + c
left, right = max(0, left_j, left_k), min(1000, right_j, right_k)
if left <= right:
if left == 0:
ans += prefix_cnts[right]
else:
ans += prefix_cnts[right] - prefix_cnts[left - 1]
for k in range(arr[j], 1001):
prefix_cnts[k] += 1
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n^2 + n \times S)$,其中 $n$ 是数组 $arr$ 的长度,$S$ 为数组的值域上限。
- **空间复杂度**:$O(S)$。
================================================
FILE: docs/solutions/1500-1599/count-odd-numbers-in-an-interval-range.md
================================================
# [1523. 在区间范围内统计奇数数目](https://leetcode.cn/problems/count-odd-numbers-in-an-interval-range/)
- 标签:数学
- 难度:简单
## 题目链接
- [1523. 在区间范围内统计奇数数目 - 力扣](https://leetcode.cn/problems/count-odd-numbers-in-an-interval-range/)
## 题目大意
**描述**:给定两个非负整数 `low` 和 `high`。
**要求**:返回 `low` 与 `high` 之间(包括二者)的奇数数目。
**说明**:
- $0 \le low \le high \le 10^9$。
**示例**:
- 示例 1:
```python
输入:low = 3, high = 7
输出:3
解释:3 到 7 之间奇数数字为 [3,5,7]
```
## 解题思路
### 思路 1:
暴力枚举 `[low, high]` 之间的奇数可能会超时。我们可以通过公式直接计算出 `[0, low - 1]` 之间的奇数个数和 `[0, high]` 之间的奇数个数,然后将两者相减即为答案。
计算奇数个数的公式为:$pre(x) = \lfloor \frac{x + 1}{2} \rfloor$。
## 代码
### 思路 1 代码:
```python
class Solution:
def pre(self, val):
return (val + 1) >> 1
def countOdds(self, low: int, high: int) -> int:
return self.pre(high) - self.pre(low - 1)
```
================================================
FILE: docs/solutions/1500-1599/index.md
================================================
## 本章内容
- [1502. 判断能否形成等差数列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/can-make-arithmetic-progression-from-sequence.md)
- [1507. 转变日期格式](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/reformat-date.md)
- [1523. 在区间范围内统计奇数数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/count-odd-numbers-in-an-interval-range.md)
- [1534. 统计好三元组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/count-good-triplets.md)
- [1547. 切棍子的最小成本](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/minimum-cost-to-cut-a-stick.md)
- [1551. 使数组中所有元素相等的最小操作数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/minimum-operations-to-make-array-equal.md)
- [1556. 千位分隔数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/thousand-separator.md)
- [1561. 你可以获得的最大硬币数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/maximum-number-of-coins-you-can-get.md)
- [1567. 乘积为正数的最长子数组长度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/maximum-length-of-subarray-with-positive-product.md)
- [1582. 二进制矩阵中的特殊位置](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/special-positions-in-a-binary-matrix.md)
- [1584. 连接所有点的最小费用](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/min-cost-to-connect-all-points.md)
- [1593. 拆分字符串使唯一子字符串的数目最大](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/split-a-string-into-the-max-number-of-unique-substrings.md)
- [1595. 连通两组点的最小成本](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/minimum-cost-to-connect-two-groups-of-points.md)
================================================
FILE: docs/solutions/1500-1599/maximum-length-of-subarray-with-positive-product.md
================================================
# [1567. 乘积为正数的最长子数组长度](https://leetcode.cn/problems/maximum-length-of-subarray-with-positive-product/)
- 标签:贪心、数组、动态规划
- 难度:中等
## 题目链接
- [1567. 乘积为正数的最长子数组长度 - 力扣](https://leetcode.cn/problems/maximum-length-of-subarray-with-positive-product/)
## 题目大意
给定一个整数数组 `nums`。
要求:求出乘积为正数的最长子数组的长度。
- 子数组:是由原数组中零个或者更多个连续数字组成的数组。
## 解题思路
使用动态规划来做。使用数组 `pos` 表示以下标 `i` 结尾的乘积为正数的最长子数组长度。使用数组 `neg` 表示以下标 `i` 结尾的乘积为负数的最长子数组长度。
- 先初始化 `pos[0]`、`neg[0]`。
- 如果 `nums[0] == 0`,则 `pos[0] = 0, neg[0] = 0`。
- 如果 `nums[0] > 0`,则 `pos[0] = 1, neg[0] = 0`。
- 如果 `nums[0] < 0`,则 `pos[0] = 0, neg[0] = 1`。
- 然后从下标 `1` 开始递推遍历数组 `nums`,对于 `nums[i - 1]` 和 `nums[i]`:
- 如果 `nums[i - 1] == 0`,显然有 `pos[i] = 0`,`neg[i] = 0`。表示:以`i` 结尾的乘积为正数的最长子数组长度为 `0`,以`i` 结尾的乘积为负数数的最长子数组长度也为 `0`。
- 如果 `nums[i - 1] > 0`,则 `pos[i] = pos[i - 1] + 1`。而 `neg[i]` 需要进行判断,如果 `neg[i - 1] > 0`,则再乘以当前 `nums[i]` 后仍为负数,此时长度 +1,即 `neg[i] = neg[i - 1] + 1 `。而如果 `neg[i - 1] == 0`,则 `neg[i] = 0`。
- 如果 `nums[i - 1] < 0`,则 `pos[i]` 需要进行判断,如果 `neg[i - 1] > 0`,再乘以当前 `nums[i]` 后变为正数,此时长度 +1,即 `pos[i] = neg[i - 1] + 1`。而如果 `neg[i - 1] = 0`,则 `pos[i] = 0`。
- 更新 `ans` 答案为 `pos[i]` 最大值。
- 最后输出答案 `ans`。
## 代码
```python
class Solution:
def getMaxLen(self, nums: List[int]) -> int:
size = len(nums)
pos = [0 for _ in range(size + 1)]
neg = [0 for _ in range(size + 1)]
if nums[0] == 0:
pos[0], neg[0] = 0, 0
elif nums[0] > 0:
pos[0], neg[0] = 1, 0
else:
pos[0], neg[0] = 0, 1
ans = pos[0]
for i in range(1, size):
if nums[i] == 0:
pos[i] = 0
neg[i] = 0
elif nums[i] > 0:
pos[i] = pos[i - 1] + 1
neg[i] = neg[i - 1] + 1 if neg[i - 1] > 0 else 0
elif nums[i] < 0:
pos[i] = neg[i - 1] + 1 if neg[i - 1] > 0 else 0
neg[i] = pos[i - 1] + 1
ans = max(ans, pos[i])
return ans
```
## 参考资料
- 【题解】[递推就完事了,巨好理解~ - 乘积为正数的最长子数组长度 - 力扣](https://leetcode.cn/problems/maximum-length-of-subarray-with-positive-product/solution/di-tui-jiu-wan-shi-liao-ju-hao-li-jie-by-time-limi/)
================================================
FILE: docs/solutions/1500-1599/maximum-number-of-coins-you-can-get.md
================================================
# [1561. 你可以获得的最大硬币数目](https://leetcode.cn/problems/maximum-number-of-coins-you-can-get/)
- 标签:贪心、数组、数学、博弈、排序
- 难度:中等
## 题目链接
- [1561. 你可以获得的最大硬币数目 - 力扣](https://leetcode.cn/problems/maximum-number-of-coins-you-can-get/)
## 题目大意
有 `3*n` 堆数目不一的硬币,三个人按照下面的规则分硬币:
- 每一轮选出任意 3 堆硬币。
- Alice 拿走硬币数量最多的那一堆。
- 我们自己拿走硬币数量第二多的那一堆。
- Bob 拿走最后一堆。
- 重复这个过程,直到没有更多硬币。
现在给定一个整数数组 `piles`,代表 `3*n` 堆硬币,其中 `piles[i]` 表示第 `i` 堆中硬币的数目。
## 解题思路
每次 `3` 堆,总共取 `n` 次。Bob 每次总是选择最少的一堆,所以最终 Bob 得到 `3*n` 堆中最少的 `n` 堆才能使得另外两个人获得更多。所以先对硬币堆进行排序。Bob 拿走最少的 `n` 堆。我们接着分剩下的 `2*n` 堆。
按照大小顺序,每次都选取硬币数目最多的两堆, Alice 取得较大的一堆,我们取较小的一堆。
然后继续在剩余堆中选取硬币数目最多的两堆,同样 Alice 取得较大的一堆,我们取较小的一堆。
只有这样才能在满足规则的情况下,使我们所获得硬币数最多。
最后统计我们所获取的硬币数,并返回结果。
## 代码
```python
class Solution:
def maxCoins(self, piles: List[int]) -> int:
piles.sort()
ans = 0
for i in range(len(piles) // 3, len(piles), 2):
ans += piles[i]
return ans
```
================================================
FILE: docs/solutions/1500-1599/min-cost-to-connect-all-points.md
================================================
# [1584. 连接所有点的最小费用](https://leetcode.cn/problems/min-cost-to-connect-all-points/)
- 标签:并查集、图、数组、最小生成树
- 难度:中等
## 题目链接
- [1584. 连接所有点的最小费用 - 力扣](https://leetcode.cn/problems/min-cost-to-connect-all-points/)
## 题目大意
**描述**:给定一个 $points$ 数组,表示 2D 平面上的一些点,其中 $points[i] = [x_i, y_i]$。
链接点 $[x_i, y_i]$ 和点 $[x_j, y_j]$ 的费用为它们之间的 **曼哈顿距离**:$|x_i - x_j| + |y_i - y_j|$。其中 $|val|$ 表示 $val$ 的绝对值。
**要求**:返回将所有点连接的最小总费用。
**说明**:
- 只有任意两点之间有且仅有一条简单路径时,才认为所有点都已连接。
- $1 \le points.length \le 1000$。
- $-10^6 \le x_i, y_i \le 10^6$。
- 所有点 $(x_i, y_i)$ 两两不同。
**示例**:
- 示例 1:

```python
输入:points = [[0,0],[2,2],[3,10],[5,2],[7,0]]
输出:20
解释:我们可以按照上图所示连接所有点得到最小总费用,总费用为 20 。
注意到任意两个点之间只有唯一一条路径互相到达。
```
- 示例 2:
```python
输入:points = [[3,12],[-2,5],[-4,1]]
输出:18
```
## 解题思路
将所有点之间的费用看作是边,则所有点和边可以看作是一个无向图。每两个点之间都存在一条无向边,边的权重为两个点之间的曼哈顿距离。将所有点连接的最小总费用,其实就是求无向图的最小生成树。对此我们可以使用 Prim 算法或者 Kruskal 算法。
### 思路 1:Prim 算法
每次选择最短边来扩展最小生成树,从而保证生成树的总权重最小。算法通过不断扩展小生成树的顶点集合 $MST$,逐步构建出最小生成树。
### 思路 1:代码
```Python
class Solution:
def distance(self, point1, point2):
return abs(point1[0] - point2[0]) + abs(point1[1] - point2[1])
def Prim(self, points, start):
size = len(points)
vis = set()
dis = [float('inf') for _ in range(size)]
ans = 0 # 最小生成树的边权值
dis[start] = 0 # 起始位置到起始位置的边权值初始化为 0
for i in range(1, size):
dis[i] = self.distance(points[start], points[i])
vis.add(start)
for _ in range(size - 1): # 进行 n 轮迭代
min_dis = float('inf')
min_dis_i = -1
for i in range(size):
if i not in vis and dis[i] < min_dis:
min_dis = dis[i]
min_dis_i = i
if min_dis_i == -1:
return -1
ans += min_dis
vis.add(min_dis_i)
for i in range(size):
if i not in vis:
dis[i] = min(dis[i], self.distance(points[i], points[min_dis_i]))
return ans
def minCostConnectPoints(self, points: List[List[int]]) -> int:
return self.Prim(points, 0)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(n^2)$。
### 思路 2:Kruskal 算法
通过依次选择权重最小的边并判断其两个端点是否连接在同一集合中,从而逐步构建最小生成树。这个过程保证了最终生成的树是无环的,并且总权重最小。
### 思路 2:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def Kruskal(self, edges, size):
union_find = UnionFind(size)
edges.sort(key=lambda x: x[2])
ans, cnt = 0, 0
for x, y, dist in edges:
if union_find.is_connected(x, y):
continue
ans += dist
cnt += 1
union_find.union(x, y)
if cnt == size - 1:
return ans
return ans
def minCostConnectPoints(self, points: List[List[int]]) -> int:
size = len(points)
edges = []
for i in range(size):
xi, yi = points[i]
for j in range(i + 1, size):
xj, yj = points[j]
dist = abs(xi - xj) + abs(yi - yj)
edges.append([i, j, dist])
ans = self.Kruskal(edges, size)
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(m \times \log(n))$。其中 $m$ 为边数,$n$ 为节点数,本题中 $m = n^2$。
- **空间复杂度**:$O(n^2)$。
================================================
FILE: docs/solutions/1500-1599/minimum-cost-to-connect-two-groups-of-points.md
================================================
# [1595. 连通两组点的最小成本](https://leetcode.cn/problems/minimum-cost-to-connect-two-groups-of-points/)
- 标签:位运算、数组、动态规划、状态压缩、矩阵
- 难度:困难
## 题目链接
- [1595. 连通两组点的最小成本 - 力扣](https://leetcode.cn/problems/minimum-cost-to-connect-two-groups-of-points/)
## 题目大意
**描述**:有两组点,其中一组中有 $size_1$ 个点,第二组中有 $size_2$ 个点,且 $size_1 \ge size_2$。现在给定一个大小为 $size_1 \times size_2$ 的二维数组 $cost$ 用于表示两组点任意两点之间的链接成本。其中 $cost[i][j]$ 表示第一组中第 $i$ 个点与第二组中第 $j$ 个点的链接成本。
如果两个组中每个点都与另一个组中的一个或多个点连接,则称这两组点是连通的。
**要求**:返回连通两组点所需的最小成本。
**说明**:
- $size_1 == cost.length$。
- $size_2 == cost[i].length$。
- $1 \le size_1, size_2 \le 12$。
- $size_1 \ge size_2$。
- $0 \le cost[i][j] \le 100$。
**示例**:
- 示例 1:
```python
输入:cost = [[15, 96], [36, 2]]
输出:17
解释:连通两组点的最佳方法是:
1--A
2--B
总成本为 17。
```
- 示例 2:
```python
输入:cost = [[1, 3, 5], [4, 1, 1], [1, 5, 3]]
输出:4
解释:连通两组点的最佳方法是:
1--A
2--B
2--C
3--A
最小成本为 4。
请注意,虽然有多个点连接到第一组中的点 2 和第二组中的点 A ,但由于题目并不限制连接点的数目,所以只需要关心最低总成本。
```
## 解题思路
### 思路 1:状压 DP
### 思路 1:代码
```python
class Solution:
def connectTwoGroups(self, cost: List[List[int]]) -> int:
m, n = len(cost), len(cost[0])
states = 1 << n
dp = [[float('inf') for _ in range(states)] for _ in range(m + 1)]
dp[0][0] = 0
for i in range(1, m + 1):
for state in range(states):
for j in range(n):
dp[i][state | (1 << j)] = min(dp[i][state | (1 << j)], dp[i - 1][state] + cost[i - 1][j], dp[i][state] + cost[i - 1][j])
return dp[m][states - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:
- **空间复杂度**:
================================================
FILE: docs/solutions/1500-1599/minimum-cost-to-cut-a-stick.md
================================================
# [1547. 切棍子的最小成本](https://leetcode.cn/problems/minimum-cost-to-cut-a-stick/)
- 标签:数组、动态规划、排序
- 难度:困难
## 题目链接
- [1547. 切棍子的最小成本 - 力扣](https://leetcode.cn/problems/minimum-cost-to-cut-a-stick/)
## 题目大意
**描述**:给定一个整数 $n$,代表一根长度为 $n$ 个单位的木根,木棍从 $0 \sim n$ 标记了若干位置。例如,长度为 $6$ 的棍子可以标记如下:
再给定一个整数数组 $cuts$,其中 $cuts[i]$ 表示需要将棍子切开的位置。
我们可以按照顺序完成切割,也可以根据需要更改切割顺序。
每次切割的成本都是当前要切割的棍子的长度,切棍子的总成本是所有次切割成本的总和。对棍子进行切割将会把一根木棍分成两根较小的木棍(这两根小木棍的长度和就是切割前木棍的长度)。
**要求**:返回切棍子的最小总成本。
**说明**:
- $2 \le n \le 10^6$。
- $1 \le cuts.length \le min(n - 1, 100)$。
- $1 \le cuts[i] \le n - 1$。
- $cuts$ 数组中的所有整数都互不相同。
**示例**:
- 示例 1:
```python
输入:n = 7, cuts = [1,3,4,5]
输出:16
解释:按 [1, 3, 4, 5] 的顺序切割的情况如下所示。
第一次切割长度为 7 的棍子,成本为 7 。第二次切割长度为 6 的棍子(即第一次切割得到的第二根棍子),第三次切割为长度 4 的棍子,最后切割长度为 3 的棍子。总成本为 7 + 6 + 4 + 3 = 20 。而将切割顺序重新排列为 [3, 5, 1, 4] 后,总成本 = 16(如示例图中 7 + 4 + 3 + 2 = 16)。
```
- 示例 2:
```python
输入:n = 9, cuts = [5,6,1,4,2]
输出:22
解释:如果按给定的顺序切割,则总成本为 25。总成本 <= 25 的切割顺序很多,例如,[4, 6, 5, 2, 1] 的总成本 = 22,是所有可能方案中成本最小的。
```
## 解题思路
### 思路 1:动态规划
我们可以预先在数组 $cuts$ 种添加位置 $0$ 和位置 $n$,然后对数组 $cuts$ 进行排序。这样待切割的木棍就对应了数组中连续元素构成的「区间」。
###### 1. 阶段划分
按照区间长度进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][j]$ 表示为:切割区间为 $[i, j]$ 上的小木棍的最小成本。
###### 3. 状态转移方程
假设位置 $i$ 与位置 $j$ 之间最后一个切割的位置为 $k$,则 $dp[i][j]$ 取决与由 $k$ 作为切割点分割出的两个区间 $[i, k]$ 与 $[k, j]$ 上的最小成本 + 切割位置 $k$ 所带来的成本。
而切割位置 $k$ 所带来的成本是这段区间所代表的小木棍的长度,即 $cuts[j] - cuts[i]$。
则状态转移方程为:$dp[i][j] = min \lbrace dp[i][k] + dp[k][j] + cuts[j] - cuts[i] \rbrace, \quad i < k < j$
###### 4. 初始条件
- 相邻位置之间没有切割点,不需要切割,最小成本为 $0$,即 $dp[i - 1][i] = 0$。
- 其余位置默认为最小成本为一个极大值,即 $dp[i][j] = \infty, \quad i + 1 \ne j$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[i][j]$ 表示为:切割区间为 $[i, j]$ 上的小木棍的最小成本。 所以最终结果为 $dp[0][size - 1]$。
### 思路 1:代码
```python
class Solution:
def minCost(self, n: int, cuts: List[int]) -> int:
cuts.append(0)
cuts.append(n)
cuts.sort()
size = len(cuts)
dp = [[float('inf') for _ in range(size)] for _ in range(size)]
for i in range(1, size):
dp[i - 1][i] = 0
for l in range(3, size + 1): # 枚举区间长度
for i in range(size): # 枚举区间起点
j = i + l - 1 # 根据起点和长度得到终点
if j >= size:
continue
dp[i][j] = float('inf')
for k in range(i + 1, j): # 枚举区间分割点
# 状态转移方程,计算合并区间后的最优值
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j] + cuts[j] - cuts[i])
return dp[0][size - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m^3)$,其中 $m$ 为数组 $cuts$ 的元素个数。
- **空间复杂度**:$O(m^2)$。
================================================
FILE: docs/solutions/1500-1599/minimum-operations-to-make-array-equal.md
================================================
# [1551. 使数组中所有元素相等的最小操作数](https://leetcode.cn/problems/minimum-operations-to-make-array-equal/)
- 标签:数学
- 难度:中等
## 题目链接
- [1551. 使数组中所有元素相等的最小操作数 - 力扣](https://leetcode.cn/problems/minimum-operations-to-make-array-equal/)
## 题目大意
**描述**:存在一个长度为 $n$ 的数组 $arr$,其中 $arr[i] = (2 \times i) + 1$,$(0 \le i < n)$。
在一次操作中,我们可以选出两个下标,记作 $x$ 和 $y$($0 \le x, y < n$),并使 $arr[x]$ 减去 $1$,$arr[y]$ 加上 $1$)。最终目标是使数组中所有元素都相等。
现在给定一个整数 $n$,即数组 $arr$ 的长度。
**要求**:返回使数组 $arr$ 中所有元素相等所需要的最小操作数。
**说明**:
- 题目测试用例将会保证:在执行若干步操作后,数组中的所有元素最终可以全部相等。
- $1 \le n \le 10^4$。
**示例**:
- 示例 1:
```python
输入:n = 3
输出:2
解释:arr = [1, 3, 5]
第一次操作选出 x = 2 和 y = 0,使数组变为 [2, 3, 4]
第二次操作继续选出 x = 2 和 y = 0,数组将会变成 [3, 3, 3]
```
- 示例 2:
```python
输入:n = 6
输出:9
```
## 解题思路
### 思路 1:贪心
通过观察可以发现,数组中所有元素构成了一个等差数列,为了使所有元素相等,在每一次操作中,尽可能让较小值增大,让较大值减小,直到到达平均值为止,这样才能得到最小操作次数。
在一次操作中,我们可以同时让第 $i$ 个元素增大与第 $n - 1 - i$ 个元素减小。这样,我们只需要统计出数组前半部分元素变化幅度即可。
### 思路 1:代码
```python
class Solution:
def minOperations(self, n: int) -> int:
ans = 0
for i in range(n // 2):
ans += n - 1 - 2 * i
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
### 思路 2:贪心 + 优化
数组前半部分元素变化幅度的计算可以看做是一个等差数列求和,所以我们可以直接根据高斯求和公式求出结果。
$\lbrace n - 1 + [n - 1 - 2 * (n \div 2 - 1)]\rbrace \times (n \div 2) \div 2 = n \times n \div 4$
### 思路 2:代码
```python
class Solution:
def minOperations(self, n: int) -> int:
return n * n // 4
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1500-1599/reformat-date.md
================================================
# [1507. 转变日期格式](https://leetcode.cn/problems/reformat-date/)
- 标签:字符串
- 难度:简单
## 题目链接
- [1507. 转变日期格式 - 力扣](https://leetcode.cn/problems/reformat-date/)
## 题目大意
**描述**:给定一个字符串 $date$,它的格式为 `Day Month Year` ,其中:
- $Day$ 是集合 `{"1st", "2nd", "3rd", "4th", ..., "30th", "31st"}` 中的一个元素。
- $Month$ 是集合 `{"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}` 中的一个元素。
- $Year$ 的范围在 $[1900, 2100]$ 之间。
**要求**:将字符串转变为 `YYYY-MM-DD` 的格式,其中:
- $YYYY$ 表示 $4$ 位的年份。
- $MM$ 表示 $2$ 位的月份。
- $DD$ 表示 $2$ 位的天数。
**说明**:
- 给定日期保证是合法的,所以不需要处理异常输入。
**示例**:
- 示例 1:
```python
输入:date = "20th Oct 2052"
输出:"2052-10-20"
```
- 示例 2:
```python
输入:date = "6th Jun 1933"
输出:"1933-06-06"
```
## 解题思路
### 思路 1:模拟
1. 将字符串分割为三部分,分别按照以下规则得到日、月、年:
1. 日:去掉末尾两位英文字母,将其转为整型数字,并且进行补零操作,使其宽度为 $2$。
2. 月:使用哈希表将其映射为对应两位数字。
3. 年:直接赋值。
2. 将得到的年、月、日使用 `"-"` 进行链接并返回。
### 思路 1:代码
```python
class Solution:
def reformatDate(self, date: str) -> str:
months = {
"Jan" : "01", "Feb" : "02", "Mar" : "03", "Apr" : "04", "May" : "05", "Jun" : "06",
"Jul" : "07", "Aug" : "08", "Sep" : "09", "Oct" : "10", "Nov" : "11", "Dec" : "12"
}
date_list = date.split(' ')
day = "{:0>2d}".format(int(date_list[0][: -2]))
month = months[date_list[1]]
year = date_list[2]
return year + "-" + month + "-" + day
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1500-1599/special-positions-in-a-binary-matrix.md
================================================
# [1582. 二进制矩阵中的特殊位置](https://leetcode.cn/problems/special-positions-in-a-binary-matrix/)
- 标签:数组、矩阵
- 难度:简单
## 题目链接
- [1582. 二进制矩阵中的特殊位置 - 力扣](https://leetcode.cn/problems/special-positions-in-a-binary-matrix/)
## 题目大意
**描述**:给定一个 $m \times n$ 的二进制矩阵 $mat$。
**要求**:返回矩阵 $mat$ 中特殊位置的数量。
**说明**:
- **特殊位置**:如果位置 $(i, j)$ 满足 $mat[i][j] == 1$ 并且行 $i$ 与列 $j$ 中的所有其他元素都是 $0$(行和列的下标从 $0$ 开始计数),那么它被称为特殊位置。
- $m == mat.length$。
- $n == mat[i].length$。
- $1 \le m, n \le 100$。
- $mat[i][j]$ 是 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入:mat = [[1,0,0],[0,0,1],[1,0,0]]
输出:1
解释:位置 (1, 2) 是一个特殊位置,因为 mat[1][2] == 1 且第 1 行和第 2 列的其他所有元素都是 0。
```
- 示例 2:
```python
输入:mat = [[1,0,0],[0,1,0],[0,0,1]]
输出:3
解释:位置 (0, 0),(1, 1) 和 (2, 2) 都是特殊位置。
```
## 解题思路
### 思路 1:模拟
1. 按照行、列遍历二位数组 $mat$。
2. 使用数组 $row\_cnts$、$col\_cnts$ 分别记录每行和每列所含 $1$ 的个数。
3. 再次按照行、列遍历二维数组 $mat$。
4. 统计满足 $mat[row][col] == 1$ 并且 $row\_cnts[row] == col\_cnts[col] == 1$ 的位置个数。
5. 返回答案。
### 思路 1:代码
```Python
class Solution:
def numSpecial(self, mat: List[List[int]]) -> int:
rows, cols = len(mat), len(mat[0])
row_cnts = [0 for _ in range(rows)]
col_cnts = [0 for _ in range(cols)]
for row in range(rows):
for col in range(cols):
row_cnts[row] += mat[row][col]
col_cnts[col] += mat[row][col]
ans = 0
for row in range(rows):
for col in range(cols):
if mat[row][col] == 1 and row_cnts[row] == 1 and col_cnts[col] == 1:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$,其中 $m$、$n$ 分别为数组 $mat$ 的行数和列数。
- **空间复杂度**:$O(m + n)$。
================================================
FILE: docs/solutions/1500-1599/split-a-string-into-the-max-number-of-unique-substrings.md
================================================
# [1593. 拆分字符串使唯一子字符串的数目最大](https://leetcode.cn/problems/split-a-string-into-the-max-number-of-unique-substrings/)
- 标签:哈希表、字符串、回溯
- 难度:中等
## 题目链接
- [1593. 拆分字符串使唯一子字符串的数目最大 - 力扣](https://leetcode.cn/problems/split-a-string-into-the-max-number-of-unique-substrings/)
## 题目大意
**描述**:给定一个字符串 $s$。将字符串 $s$ 拆分后可以得到若干非空子字符串,这些子字符串连接后应当能够还原为原字符串。但是拆分出来的每个子字符串都必须是唯一的 。
**要求**:拆分该字符串,并返回拆分后唯一子字符串的最大数目。
**说明**:
- 子字符串是字符串中的一个连续字符序列。
- $1 \le s.length \le 16$。
- $s$ 仅包含小写英文字母。
**示例**:
- 示例 1:
```python
输入:s = "ababccc"
输出:5
解释:一种最大拆分方法为 ['a', 'b', 'ab', 'c', 'cc'] 。像 ['a', 'b', 'a', 'b', 'c', 'cc'] 这样拆分不满足题目要求,因为其中的 'a' 和 'b' 都出现了不止一次。
```
- 示例 2:
```python
输入:s = "aba"
输出:2
解释:一种最大拆分方法为 ['a', 'ba']。
```
## 解题思路
### 思路 1:回溯算法
维护一个全局变量 $ans$ 用于记录拆分后唯一子字符串的最大数目。并使用集合 $s\_set$ 记录不重复的子串。
- 从下标为 $0$ 开头的子串回溯。
- 对于下标为 $index$ 开头的子串,我们可以在 $index + 1$ 开始到 $len(s) - 1$ 的位置上,分别进行子串拆分,将子串拆分为 $s[index: i + 1]$。
- 如果当前子串不在 $s\_set$ 中,则将其存入 $s\_set$ 中,然后记录当前拆分子串个数,并从 $i + 1$ 的位置进行下一层递归拆分。然后在拆分完,对子串进行回退操作。
- 如果拆到字符串 $s$ 的末尾,则记录并更新 $ans$。
- 在开始位置还可以进行以下剪枝:如果剩余字符个数 + 当前子串个数 <= 当前拆分后子字符串的最大数目,则直接返回。
最后输出 $ans$。
### 思路 1:代码
```python
class Solution:
ans = 0
def backtrack(self, s, index, count, s_set):
if len(s) - index + count <= self.ans:
return
if index >= len(s):
self.ans = max(self.ans, count)
return
for i in range(index, len(s)):
sub_s = s[index: i + 1]
if sub_s not in s_set:
s_set.add(sub_s)
self.backtrack(s, i + 1, count + 1, s_set)
s_set.remove(sub_s)
def maxUniqueSplit(self, s: str) -> int:
s_set = set()
self.ans = 0
self.backtrack(s, 0, 0, s_set)
return self.ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times 2^n)$,其中 $n$ 为字符串的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1500-1599/thousand-separator.md
================================================
# [1556. 千位分隔数](https://leetcode.cn/problems/thousand-separator/)
- 标签:字符串
- 难度:简单
## 题目链接
- [1556. 千位分隔数 - 力扣](https://leetcode.cn/problems/thousand-separator/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:每隔三位田间点(即 `"."` 符号)作为千位分隔符,并将结果以字符串格式返回。
**说明**:
- $0 \le n \le 2^{31}$。
**示例**:
- 示例 1:
```python
输入:n = 987
输出:"987"
```
- 示例 2:
```python
输入:n = 123456789
输出:"123.456.789"
```
## 解题思路
### 思路 1:模拟
1. 使用字符串变量 $ans$ 用于存储答案,使用一个计数器 $idx$ 来记录当前位数的个数。
2. 将 $n$ 转为字符串 $s$ 后,从低位向高位遍历。
3. 将当前数字 $s[i]$ 存入 $ans$ 中,计数器加 $1$,当计数器为 $3$ 的整数倍并且当前数字位不是最高位时,将 `"."` 存入 $ans$ 中。
4. 遍历完成后,将 $ans$ 翻转后返回。
### 思路 1:代码
```python
class Solution:
def thousandSeparator(self, n: int) -> str:
s = str(n)
ans = ""
idx = 0
for i in range(len(s) - 1, -1, -1):
ans += s[i]
idx += 1
if idx % 3 == 0 and i != 0:
ans += "."
return ''.join(reversed(ans))
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/1600-1699/count-sorted-vowel-strings.md
================================================
# [1641. 统计字典序元音字符串的数目](https://leetcode.cn/problems/count-sorted-vowel-strings/)
- 标签:数学、动态规划、组合数学
- 难度:中等
## 题目链接
- [1641. 统计字典序元音字符串的数目 - 力扣](https://leetcode.cn/problems/count-sorted-vowel-strings/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:返回长度为 $n$、仅由原音($a$、$e$、$i$、$o$、$u$)组成且按字典序排序的字符串数量。
**说明**:
- 字符串 $a$ 按字典序排列需要满足:对于所有有效的 $i$,$s[i]$ 在字母表中的位置总是与 $s[i + 1]$ 相同或在 $s[i+1] $之前。
- $1 \le n \le 50$。
**示例**:
- 示例 1:
```python
输入:n = 1
输出:5
解释:仅由元音组成的 5 个字典序字符串为 ["a","e","i","o","u"]
```
- 示例 2:
```python
输入:n = 2
输出:15
解释:仅由元音组成的 15 个字典序字符串为
["aa","ae","ai","ao","au","ee","ei","eo","eu","ii","io","iu","oo","ou","uu"]
注意,"ea" 不是符合题意的字符串,因为 'e' 在字母表中的位置比 'a' 靠后
```
## 解题思路
### 思路 1:组和数学
题目要求按照字典序排列,则如果确定了每个元音的出现次数可以确定一个序列。
对于长度为 $n$ 的序列,$a$、$e$、$i$、$o$、$u$ 出现次数加起来为 $n$ 次,且顺序为 $a…a \rightarrow e…e \rightarrow i…i \rightarrow o…o \rightarrow u…u$。
我们可以看作是将 $n$ 分隔成了 $5$ 份,每一份对应一个原音字母的数量。
我们可以使用「隔板法」的方式,看作有 $n$ 个球,$4$ 个板子,将 $n$ 个球分隔成 $5$ 份。
则一共有 $n + 4$ 个位置可以放板子,总共需要放 $4$ 个板子,则答案为 $C_{n + 4}^4$,其中 $C$ 为组和数。
### 思路 1:代码
```Python
class Solution:
def countVowelStrings(self, n: int) -> int:
return comb(n + 4, 4)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(| \sum |)$,其中 $\sum$ 为字符集,本题中 $| \sum | = 5$ 。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1600-1699/count-subtrees-with-max-distance-between-cities.md
================================================
# [1617. 统计子树中城市之间最大距离](https://leetcode.cn/problems/count-subtrees-with-max-distance-between-cities/)
- 标签:位运算、树、动态规划、状态压缩、枚举
- 难度:困难
## 题目链接
- [1617. 统计子树中城市之间最大距离 - 力扣](https://leetcode.cn/problems/count-subtrees-with-max-distance-between-cities/)
## 题目大意
**描述**:给定一个整数 $n$,代表 $n$ 个城市,城市编号为 $1 \sim n$。同时给定一个大小为 $n - 1$ 的数组 $edges$,其中 $edges[i] = [u_i, v_i]$ 表示城市 $u_i$ 和 $v_i$ 之间有一条双向边。题目保证任意城市之间只有唯一的一条路径。换句话说,所有城市形成了一棵树。
**要求**:返回一个大小为 $n - 1$ 的数组,其中第 $i$ 个元素(下标从 $1$ 开始)是城市间距离恰好等于 $i$ 的子树数目。
**说明**:
- **两个城市间距离**:定义为它们之间需要经过的边的数目。
- **一棵子树**:城市的一个子集,且子集中任意城市之间可以通过子集中的其他城市和边到达。两个子树被认为不一样的条件是至少有一个城市在其中一棵子树中存在,但在另一棵子树中不存在。
- $2 \le n \le 15$。
- $edges.length == n - 1$。
- $edges[i].length == 2$。
- $1 \le u_i, v_i \le n$。
- 题目保证 $(ui, vi)$ 所表示的边互不相同。
**示例**:
- 示例 1:
```python
输入:n = 4, edges = [[1,2],[2,3],[2,4]]
输出:[3,4,0]
解释:
子树 {1,2}, {2,3} 和 {2,4} 最大距离都是 1 。
子树 {1,2,3}, {1,2,4}, {2,3,4} 和 {1,2,3,4} 最大距离都为 2 。
不存在城市间最大距离为 3 的子树。
```
- 示例 2:
```python
输入:n = 2, edges = [[1,2]]
输出:[1]
```
## 解题思路
### 思路 1:树形 DP + 深度优先搜索
因为题目中给定 $n$ 的范围为 $2 \le n \le 15$,范围比较小,我们可以通过类似「[0078. 子集](https://leetcode.cn/problems/subsets/)」中二进制枚举的方式,得到所有子树的子集。
而对于一个确定的子树来说,求子树中两个城市间距离就是在求子树的直径,这就跟 [「1245. 树的直径」](https://leetcode.cn/problems/tree-diameter/) 和 [「2246. 相邻字符不同的最长路径」](https://leetcode.cn/problems/longest-path-with-different-adjacent-characters/) 一样了。
那么这道题的思路就变成了:
1. 通过二进制枚举的方式,得到所有子树。
2. 对于当前子树,通过树形 DP + 深度优先搜索的方式,计算出当前子树的直径。
3. 统计所有子树直径中经过的不同边数个数,将其放入答案数组中。
### 思路 1:代码
```python
class Solution:
def countSubgraphsForEachDiameter(self, n: int, edges: List[List[int]]) -> List[int]:
graph = [[] for _ in range(n)] # 建图
for u, v in edges:
graph[u - 1].append(v - 1)
graph[v - 1].append(u - 1)
def dfs(mask, u):
nonlocal visited, diameter
visited |= 1 << u # 标记 u 访问过
u_len = 0 # u 节点的最大路径长度
for v in graph[u]: # 遍历 u 节点的相邻节点
if (visited >> v) & 1 == 0 and mask >> v & 1: # v 没有访问过,且在子集中
v_len = dfs(mask, v) # 相邻节点的最大路径长度
diameter = max(diameter, u_len + v_len + 1) # 维护最大路径长度
u_len = max(u_len, v_len + 1) # 更新 u 节点的最大路径长度
return u_len
ans = [0 for _ in range(n - 1)]
for mask in range(3, 1 << n): # 二进制枚举子集
if mask & (mask - 1) == 0: # 子集至少需要两个点
continue
visited = 0
diameter = 0
u = mask.bit_length() - 1
dfs(mask, u) # 在子集 mask 中递归求树的直径
if visited == mask:
ans[diameter - 1] += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times 2^n)$,其中 $n$ 为给定的城市数目。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1600-1699/design-parking-system.md
================================================
# [1603. 设计停车系统](https://leetcode.cn/problems/design-parking-system/)
- 标签:设计、计数、模拟
- 难度:简单
## 题目链接
- [1603. 设计停车系统 - 力扣](https://leetcode.cn/problems/design-parking-system/)
## 题目大意
给一个停车场设计一个停车系统。停车场总共有三种尺寸的车位:大、中、小,每种尺寸的车位分别有固定数目。
现在要求实现 `ParkingSystem` 类:
- `ParkingSystem(big, medium, small)`:初始化 ParkingSystem 类,三个参数分别对应三种尺寸车位的数目。
- `addCar(carType) -> bool:`:检测是否有 `carType` 对应的停车位,如果有,则将车停入车位,并返回 `True`,否则返回 `False`。
## 解题思路
使用不同成员变量存放车位数目。并根据给定操作进行判断。
## 代码
```python
class ParkingSystem:
def __init__(self, big: int, medium: int, small: int):
self.park = [0, big, medium, small]
def addCar(self, carType: int) -> bool:
if self.park[carType] == 0:
return False
self.park[carType] -= 1
return True
```
================================================
FILE: docs/solutions/1600-1699/determine-if-two-strings-are-close.md
================================================
# [1657. 确定两个字符串是否接近](https://leetcode.cn/problems/determine-if-two-strings-are-close/)
- 标签:哈希表、字符串、排序
- 难度:中等
## 题目链接
- [1657. 确定两个字符串是否接近 - 力扣](https://leetcode.cn/problems/determine-if-two-strings-are-close/)
## 题目大意
**描述**:如果可以使用以下操作从一个字符串得到另一个字符串,则认为两个字符串 接近 :
- 操作 1:交换任意两个现有字符。
- 例如,`abcde` -> `aecdb`。
- 操作 2:将一个 现有 字符的每次出现转换为另一个现有字符,并对另一个字符执行相同的操作。
- 例如,`aacabb` -> `bbcbaa`(所有 `a` 转化为 `b`,而所有的 `b` 转换为 `a` )。
给定两个字符串,$word1$ 和 $word2$。
**要求**:如果 $word1$ 和 $word2$ 接近 ,就返回 $True$;否则,返回 $False$。
**说明**:
- $1 \le word1.length, word2.length \le 10^5$。
- $word1$ 和 $word2$ 仅包含小写英文字母。
**示例**:
- 示例 1:
```python
输入:word1 = "abc", word2 = "bca"
输出:True
解释:2 次操作从 word1 获得 word2 。
执行操作 1:"abc" -> "acb"
执行操作 1:"acb" -> "bca"
```
- 示例 2:
```python
输入:word1 = "a", word2 = "aa"
输出:False
解释:不管执行多少次操作,都无法从 word1 得到 word2 ,反之亦然。
```
## 解题思路
### 思路 1:模拟
无论是操作 1,还是操作 2,只是对字符位置进行交换,而不会产生或者删除字符。
则我们只需要检查两个字符串的字符种类以及每种字符的个数是否相同即可。
具体步骤如下:
1. 分别使用哈希表 $cnts1$、$cnts2$ 统计每个字符串中的字符种类,每种字符的个数。
2. 判断两者的字符种类是否相等,并且判断每种字符的个数是否相同。
3. 如果字符种类相同,且每种字符的个数完全相同,则返回 $True$,否则,返回 $False$。
### 思路 1:代码
```Python
class Solution:
def closeStrings(self, word1: str, word2: str) -> bool:
cnts1 = Counter(word1)
cnts2 = Counter(word2)
return cnts1.keys() == cnts2.keys() and sorted(cnts1.values()) == sorted(cnts2.values())
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(max(n1, n2) + |\sum| \times \log | \sum |)$,其中 $n1$、$n2$ 分别为字符串 $word1$、$word2$ 的长度,$\sum$ 为字符集,本题中 $| \sum | = 26$。
- **空间复杂度**:$O(| \sum |)$。
================================================
FILE: docs/solutions/1600-1699/find-valid-matrix-given-row-and-column-sums.md
================================================
# [1605. 给定行和列的和求可行矩阵](https://leetcode.cn/problems/find-valid-matrix-given-row-and-column-sums/)
- 标签:贪心、数组、矩阵
- 难度:中等
## 题目链接
- [1605. 给定行和列的和求可行矩阵 - 力扣](https://leetcode.cn/problems/find-valid-matrix-given-row-and-column-sums/)
## 题目大意
**描述**:给你两个非负整数数组 `rowSum` 和 `colSum` ,其中 `rowSum[i]` 是二维矩阵中第 `i` 行元素的和,`colSum[j]` 是第 `j` 列元素的和。换句话说,我们不知道矩阵里的每个元素,只知道每一行的和,以及每一列的和。
**要求**:找到并返回一个大小为 `rowSum.length * colSum.length` 的任意非负整数矩阵,且该矩阵满足 `rowSum` 和 `colSum` 的要求。
**说明**:
- 返回任意一个满足题目要求的二维矩阵即可,题目保证存在至少一个可行矩阵。
- $1 \le rowSum.length, colSum.length \le 500$。
- $0 \le rowSum[i], colSum[i] \le 10^8$。
- $sum(rows) == sum(columns)$。
**示例**:
- 示例 1:
```python
输入:rowSum = [3,8], colSum = [4,7]
输出:[[3,0],
[1,7]]
解释
第 0 行:3 + 0 = 3 == rowSum[0]
第 1 行:1 + 7 = 8 == rowSum[1]
第 0 列:3 + 1 = 4 == colSum[0]
第 1 列:0 + 7 = 7 == colSum[1]
行和列的和都满足题目要求,且所有矩阵元素都是非负的。
另一个可行的矩阵为 [[1,2],
[3,5]]
```
## 解题思路
### 思路 1:贪心算法
题目要求找出一个满足要求的非负整数矩阵,矩阵中元素值可以为 `0`。所以我们可以尽可能将大的值填入前面的行和列中,然后剩余位置用 `0` 补齐即可。具体做法如下:
1. 使用二维数组 `board` 来保存答案,初始情况下,`board` 中元素全部赋值为 `0`。
2. 遍历二维数组的每一行,每一列。当前位置下的值为当前行的和与当前列的和的较小值,即 `board[row][col] = min(rowSum[row], colSum[col])`。
3. 更新当前行的和,将当前行的和减去 `board[row][col]`。
4. 更新当前列的和,将当前列的和减去 `board[row][col]`。
5. 遍历完返回二维数组 `board`。
### 思路 1:贪心算法代码
```python
class Solution:
def restoreMatrix(self, rowSum: List[int], colSum: List[int]) -> List[List[int]]:
rows, cols = len(rowSum), len(colSum)
board = [[0 for _ in range(cols)] for _ in range(rows)]
for row in range(rows):
for col in range(cols):
board[row][col] = min(rowSum[row], colSum[col])
rowSum[row] -= board[row][col]
colSum[col] -= board[row][col]
return board
```
================================================
FILE: docs/solutions/1600-1699/get-maximum-in-generated-array.md
================================================
# [1646. 获取生成数组中的最大值](https://leetcode.cn/problems/get-maximum-in-generated-array/)
- 标签:数组、动态规划、模拟
- 难度:简单
## 题目链接
- [1646. 获取生成数组中的最大值 - 力扣](https://leetcode.cn/problems/get-maximum-in-generated-array/)
## 题目大意
**描述**:给定一个整数 $n$,按照下述规则生成一个长度为 $n + 1$ 的数组 $nums$:
- $nums[0] = 0$。
- $nums[1] = 1$。
- 当 $2 \le 2 \times i \le n$ 时,$nums[2 \times i] = nums[i]$。
- 当 $2 \le 2 \times i + 1 \le n$ 时,$nums[2 \times i + 1] = nums[i] + nums[i + 1]$。
**要求**:返回生成数组 $nums$ 中的最大值。
**说明**:
- $0 \le n \le 100$。
**示例**:
- 示例 1:
```python
输入:n = 7
输出:3
解释:根据规则:
nums[0] = 0
nums[1] = 1
nums[(1 * 2) = 2] = nums[1] = 1
nums[(1 * 2) + 1 = 3] = nums[1] + nums[2] = 1 + 1 = 2
nums[(2 * 2) = 4] = nums[2] = 1
nums[(2 * 2) + 1 = 5] = nums[2] + nums[3] = 1 + 2 = 3
nums[(3 * 2) = 6] = nums[3] = 2
nums[(3 * 2) + 1 = 7] = nums[3] + nums[4] = 2 + 1 = 3
因此,nums = [0,1,1,2,1,3,2,3],最大值 3
```
- 示例 2:
```python
输入:n = 2
输出:1
解释:根据规则,nums[0]、nums[1] 和 nums[2] 之中的最大值是 1
```
## 解题思路
### 思路 1:模拟
1. 按照题目要求,定义一个长度为 $n + 1$ 的数组 $nums$。
2. 按照规则模拟生成对应的 $nums$ 数组元素。
3. 求出数组 $nums$ 中最大值,并作为答案返回。
### 思路 1:代码
```python
class Solution:
def getMaximumGenerated(self, n: int) -> int:
if n <= 1:
return n
nums = [0 for _ in range(n + 1)]
nums[1] = 1
for i in range(n):
if 2 * i <= n:
nums[2 * i] = nums[i]
if 2 * i + 1 <= n:
nums[2 * i + 1] = nums[i] + nums[i + 1]
ans = max(nums)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1600-1699/index.md
================================================
## 本章内容
- [1603. 设计停车系统](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/design-parking-system.md)
- [1605. 给定行和列的和求可行矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/find-valid-matrix-given-row-and-column-sums.md)
- [1614. 括号的最大嵌套深度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/maximum-nesting-depth-of-the-parentheses.md)
- [1617. 统计子树中城市之间最大距离](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/count-subtrees-with-max-distance-between-cities.md)
- [1631. 最小体力消耗路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/path-with-minimum-effort.md)
- [1641. 统计字典序元音字符串的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/count-sorted-vowel-strings.md)
- [1646. 获取生成数组中的最大值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/get-maximum-in-generated-array.md)
- [1647. 字符频次唯一的最小删除次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/minimum-deletions-to-make-character-frequencies-unique.md)
- [1657. 确定两个字符串是否接近](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/determine-if-two-strings-are-close.md)
- [1658. 将 x 减到 0 的最小操作数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/minimum-operations-to-reduce-x-to-zero.md)
- [1672. 最富有客户的资产总量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/richest-customer-wealth.md)
- [1695. 删除子数组的最大得分](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/maximum-erasure-value.md)
- [1698. 字符串的不同子字符串个数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/number-of-distinct-substrings-in-a-string.md)
================================================
FILE: docs/solutions/1600-1699/maximum-erasure-value.md
================================================
# [1695. 删除子数组的最大得分](https://leetcode.cn/problems/maximum-erasure-value/)
- 标签:数组、哈希表、滑动窗口
- 难度:中等
## 题目链接
- [1695. 删除子数组的最大得分 - 力扣](https://leetcode.cn/problems/maximum-erasure-value/)
## 题目大意
**描述**:给定一个正整数数组 $nums$,从中删除一个含有若干不同元素的子数组。删除子数组的「得分」就是子数组各元素之和 。
**要求**:返回只删除一个子数组可获得的最大得分。
**说明**:
- **子数组**:如果数组 $b$ 是数组 $a$ 的一个连续子序列,即如果它等于 $a[l],a[l+1],...,a[r]$ ,那么它就是 $a$ 的一个子数组。
- $1 \le nums.length \le 10^5$。
- $1 \le nums[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [4,2,4,5,6]
输出:17
解释:最优子数组是 [2,4,5,6]
```
- 示例 2:
```python
输入:nums = [5,2,1,2,5,2,1,2,5]
输出:8
解释:最优子数组是 [5,2,1] 或 [1,2,5]
```
## 解题思路
### 思路 1:滑动窗口
题目要求的是含有不同元素的连续子数组最大和,我们可以用滑动窗口来做,维护一个不包含重复元素的滑动窗口,计算最大的窗口和。具体方法如下:
- 用滑动窗口 $window$ 来记录不重复的元素个数,$window$ 为哈希表类型。用 $window\_sum$ 来记录窗口内子数组元素和,$ans$ 用来维护最大子数组和。设定两个指针:$left$、$right$,分别指向滑动窗口的左右边界,保证窗口中没有重复元素。
- 一开始,$left$、$right$ 都指向 $0$。
- 将最右侧数组元素 $nums[right]$ 加入当前窗口 $window$ 中,记录该元素个数。
- 如果该窗口中该元素的个数多于 $1$ 个,即 $window[s[right]] > 1$,则不断右移 $left$,缩小滑动窗口长度,并更新窗口中对应元素的个数,直到 $window[s[right]] \le 1$。
- 维护更新无重复元素的最大子数组和。然后右移 $right$,直到 $right \ge len(nums)$ 结束。
- 输出无重复元素的最大子数组和。
### 思路 1:代码
```python
class Solution:
def maximumUniqueSubarray(self, nums: List[int]) -> int:
window_sum = 0
left, right = 0, 0
window = dict()
ans = 0
while right < len(nums):
window_sum += nums[right]
if nums[right] not in window:
window[nums[right]] = 1
else:
window[nums[right]] += 1
while window[nums[right]] > 1:
window[nums[left]] -= 1
window_sum -= nums[left]
left += 1
ans = max(ans, window_sum)
right += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1600-1699/maximum-nesting-depth-of-the-parentheses.md
================================================
# [1614. 括号的最大嵌套深度](https://leetcode.cn/problems/maximum-nesting-depth-of-the-parentheses/)
- 标签:栈、字符串
- 难度:简单
## 题目链接
- [1614. 括号的最大嵌套深度 - 力扣](https://leetcode.cn/problems/maximum-nesting-depth-of-the-parentheses/)
## 题目大意
**描述**:给你一个有效括号字符串 $s$。
**要求**:返回该字符串 $s$ 的嵌套深度 。
**说明**:
- 如果字符串满足以下条件之一,则可以称之为 有效括号字符串(valid parentheses string,可以简写为 VPS):
- 字符串是一个空字符串 `""`,或者是一个不为 `"("` 或 `")"` 的单字符。
- 字符串可以写为 $AB$($A$ 与 B 字符串连接),其中 $A$ 和 $B$ 都是有效括号字符串 。
- 字符串可以写为 ($A$),其中 $A$ 是一个有效括号字符串。
- 类似地,可以定义任何有效括号字符串 $s$ 的 嵌套深度 $depth(s)$:
- `depth("") = 0`。
- `depth(C) = 0`,其中 $C$ 是单个字符的字符串,且该字符不是 `"("` 或者 `")"`。
- `depth(A + B) = max(depth(A), depth(B))`,其中 $A$ 和 $B$ 都是 有效括号字符串。
- `depth("(" + A + ")") = 1 + depth(A)`,其中 A 是一个 有效括号字符串。
- $1 \le s.length \le 100$。
- $s$ 由数字 $0 \sim 9$ 和字符 `'+'`、`'-'`、`'*'`、`'/'`、`'('`、`')'` 组成。
- 题目数据保证括号表达式 $s$ 是有效的括号表达式。
**示例**:
- 示例 1:
```python
输入:s = "(1+(2*3)+((8)/4))+1"
输出:3
解释:数字 8 在嵌套的 3 层括号中。
```
- 示例 2:
```python
输入:s = "(1)+((2))+(((3)))"
输出:3
```
## 解题思路
### 思路 1:模拟
我们可以使用栈来进行模拟括号匹配。遍历字符串 $s$,如果遇到左括号,则将其入栈,如果遇到右括号,则弹出栈中的左括号,与当前右括号进行匹配。在整个过程中栈的大小的最大值,就是我们要求的 $s$ 的嵌套深度,其实也是求最大的连续左括号的数量(跳过普通字符,并且与右括号匹配后)。具体步骤如下:
1. 使用 $ans$ 记录最大的连续左括号数量,使用 $cnt$ 记录当前栈中左括号的数量。
2. 遍历字符串 $s$:
1. 如果遇到左括号,则令 $cnt$ 加 $1$。
2. 如果遇到右括号,则令 $cnt$ 减 $1$。
3. 将 $cnt$ 与答案进行比较,更新最大的连续左括号数量。
3. 遍历完字符串 $s$,返回答案 $ans$。
### 思路 1:代码
```Python
class Solution:
def maxDepth(self, s: str) -> int:
ans, cnt = 0, 0
for ch in s:
if ch == '(':
cnt += 1
elif ch == ')':
cnt -= 1
ans = max(ans, cnt)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1600-1699/minimum-deletions-to-make-character-frequencies-unique.md
================================================
# [1647. 字符频次唯一的最小删除次数](https://leetcode.cn/problems/minimum-deletions-to-make-character-frequencies-unique/)
- 标签:贪心、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [1647. 字符频次唯一的最小删除次数 - 力扣](https://leetcode.cn/problems/minimum-deletions-to-make-character-frequencies-unique/)
## 题目大意
**描述**:给定一个字符串 $s$。
**要求**:返回使 $s$ 成为优质字符串需要删除的最小字符数。
**说明**:
- **频次**:指的是该字符在字符串中的出现次数。例如,在字符串 `"aab"` 中,`'a'` 的频次是 $2$,而 `'b'` 的频次是 $1$。
- **优质字符串**:如果字符串 $s$ 中不存在两个不同字符频次相同的情况,就称 $s$ 是优质字符串。
- $1 \le s.length \le 10^5$。
- $s$ 仅含小写英文字母。
**示例**:
- 示例 1:
```python
输入:s = "aab"
输出:0
解释:s 已经是优质字符串。
```
- 示例 2:
```python
输入:s = "aaabbbcc"
输出:2
解释:可以删除两个 'b' , 得到优质字符串 "aaabcc" 。
另一种方式是删除一个 'b' 和一个 'c' ,得到优质字符串 "aaabbc"。
```
## 解题思路
### 思路 1:贪心算法 + 哈希表
1. 使用哈希表 $cnts$ 统计每字符串中每个字符出现次数。
2. 然后使用集合 $s\_set$ 保存不同的出现次数。
3. 遍历哈希表中所偶出现次数:
1. 如果当前出现次数不在集合 $s\_set$ 中,则将该次数添加到集合 $s\_set$ 中。
2. 如果当前出现次数在集合 $s\_set$ 中,则不断减少该次数,直到该次数不在集合 $s\_set$ 中停止,将次数添加到集合 $s\_set$ 中,同时将减少次数累加到答案 $ans$ 中。
4. 遍历完哈希表后返回答案 $ans$。
### 思路 1:代码
```Python
class Solution:
def minDeletions(self, s: str) -> int:
cnts = Counter(s)
s_set = set()
ans = 0
for key, value in cnts.items():
while value > 0 and value in s_set:
value -= 1
ans += 1
s_set.add(value)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1600-1699/minimum-operations-to-reduce-x-to-zero.md
================================================
# [1658. 将 x 减到 0 的最小操作数](https://leetcode.cn/problems/minimum-operations-to-reduce-x-to-zero/)
- 标签:数组、哈希表、二分查找、前缀和、滑动窗口
- 难度:中等
## 题目链接
- [1658. 将 x 减到 0 的最小操作数 - 力扣](https://leetcode.cn/problems/minimum-operations-to-reduce-x-to-zero/)
## 题目大意
**描述**:给定一个整数数组 $nums$ 和一个整数 $x$ 。每一次操作时,你应当移除数组 $nums$ 最左边或最右边的元素,然后从 $x$ 中减去该元素的值。请注意,需要修改数组以供接下来的操作使用。
**要求**:如果可以将 $x$ 恰好减到 $0$,返回最小操作数;否则,返回 $-1$。
**说明**:
- $1 \le nums.length \le 10^5$。
- $1 \le nums[i] \le 10^4$。
- $1 \le x \le 10^9$。
**示例**:
- 示例 1:
```python
输入:nums = [1,1,4,2,3], x = 5
输出:2
解释:最佳解决方案是移除后两个元素,将 x 减到 0。
```
- 示例 2:
```python
输入:nums = [3,2,20,1,1,3], x = 10
输出:5
解释:最佳解决方案是移除后三个元素和前两个元素(总共 5 次操作),将 x 减到 0。
```
## 解题思路
### 思路 1:滑动窗口
将 $x$ 减到 $0$ 的最小操作数可以转换为求和等于 $sum(nums) - x$ 的最长连续子数组长度。我们可以维护一个区间和为 $sum(nums) - x$ 的滑动窗口,求出最长的窗口长度。具体做法如下:
令 `target = sum(nums) - x`,使用 $max\_len$ 维护和等于 $target$ 的最长连续子数组长度。然后用滑动窗口 $window\_sum$ 来记录连续子数组的和,设定两个指针:$left$、$right$,分别指向滑动窗口的左右边界,保证窗口中的和刚好等于 $target$。
- 一开始,$left$、$right$ 都指向 $0$。
- 向右移动 $right$,将最右侧元素加入当前窗口和 $window\_sum$ 中。
- 如果 $window\_sum > target$,则不断右移 $left$,缩小滑动窗口长度,并更新窗口和的最小值,直到 $window\_sum \le target$。
- 如果 $window\_sum == target$,则更新最长连续子数组长度。
- 然后继续右移 $right$,直到 $right \ge len(nums)$ 结束。
- 输出 $len(nums) - max\_len$ 作为答案。
- 注意判断题目中的特殊情况。
### 思路 1:代码
```python
class Solution:
def minOperations(self, nums: List[int], x: int) -> int:
target = sum(nums) - x
size = len(nums)
if target < 0:
return -1
if target == 0:
return size
left, right = 0, 0
window_sum = 0
max_len = float('-inf')
while right < size:
window_sum += nums[right]
while window_sum > target:
window_sum -= nums[left]
left += 1
if window_sum == target:
max_len = max(max_len, right - left + 1)
right += 1
return len(nums) - max_len if max_len != float('-inf') else -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1600-1699/number-of-distinct-substrings-in-a-string.md
================================================
# [1698. 字符串的不同子字符串个数](https://leetcode.cn/problems/number-of-distinct-substrings-in-a-string/)
- 标签:字典树、字符串、后缀数组、哈希函数、滚动哈希
- 难度:中等
## 题目链接
- [1698. 字符串的不同子字符串个数 - 力扣](https://leetcode.cn/problems/number-of-distinct-substrings-in-a-string/)
## 题目大意
给定一个字符串 `s`。
要求:返回 `s` 的不同子字符串的个数。
注意:字符串的「子字符串」是由原字符串删除开头若干个字符(可能是 0 个)并删除结尾若干个字符(可能是 0 个)形成的字符串。
## 解题思路
构建一颗字典树。分别将原字符串删除开头若干个字符的子字符串依次插入到字典树中。
每次插入过程中碰到字典树中没有的字符节点时,说明此时插入的字符串可作为新的子字符串。
我们可以通过统计插入过程中新建字符节点的次数的方式来获取不同子字符串的个数。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> int:
"""
Inserts a word into the trie.
"""
cur = self
cnt = 0
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cnt += 1
cur = cur.children[ch]
cur.isEnd = True
return cnt
class Solution:
def countDistinct(self, s: str) -> int:
trie_tree = Trie()
cnt = 0
for i in range(len(s)):
cnt += trie_tree.insert(s[i:])
return cnt
```
================================================
FILE: docs/solutions/1600-1699/path-with-minimum-effort.md
================================================
# [1631. 最小体力消耗路径](https://leetcode.cn/problems/path-with-minimum-effort/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、二分查找、矩阵、堆(优先队列)
- 难度:中等
## 题目链接
- [1631. 最小体力消耗路径 - 力扣](https://leetcode.cn/problems/path-with-minimum-effort/)
## 题目大意
**描述**:给定一个 $rows \times cols$ 大小的二维数组 $heights$,其中 $heights[i][j]$ 表示为位置 $(i, j)$ 的高度。
现在要从左上角 $(0, 0)$ 位置出发,经过方格的一些点,到达右下角 $(n - 1, n - 1)$ 位置上。其中所经过路径的花费为「这条路径上所有相邻位置的最大高度差绝对值」。
**要求**:计算从 $(0, 0)$ 位置到 $(n - 1, n - 1)$ 的最优路径的花费。
**说明**:
- **最优路径**:路径上「所有相邻位置最大高度差绝对值」最小的那条路径。
- $rows == heights.length$。
- $columns == heights[i].length$。
- $1 \le rows, columns \le 100$。
- $1 \le heights[i][j] \le 10^6$。
**示例**:
- 示例 1:
```python
输入:heights = [[1,2,2],[3,8,2],[5,3,5]]
输出:2
解释:路径 [1,3,5,3,5] 连续格子的差值绝对值最大为 2 。
这条路径比路径 [1,2,2,2,5] 更优,因为另一条路径差值最大值为 3。
```
- 示例 2:
```python
输入:heights = [[1,2,3],[3,8,4],[5,3,5]]
输出:1
解释:路径 [1,2,3,4,5] 的相邻格子差值绝对值最大为 1 ,比路径 [1,3,5,3,5] 更优。
```
## 解题思路
### 思路 1:并查集
将整个网络抽象为一个无向图,每个点与相邻的点(上下左右)之间都存在一条无向边,边的权重为两个点之间的高度差绝对值。
我们要找到左上角到右下角的最优路径,可以遍历所有的点,将所有的边存储到数组中,每条边的存储格式为 $[x, y, h]$,意思是编号 $x$ 的点和编号为 $y$ 的点之间的权重为 $h$。
然后按照权重从小到大的顺序,对所有边进行排序。
再按照权重大小遍历所有边,将其依次加入并查集中。并且每次都需要判断 $(0, 0)$ 点和 $(n - 1, n - 1)$ 点是否连通。
如果连通,则该边的权重即为答案。
### 思路 1:代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def minimumEffortPath(self, heights: List[List[int]]) -> int:
row_size = len(heights)
col_size = len(heights[0])
size = row_size * col_size
edges = []
for row in range(row_size):
for col in range(col_size):
if row < row_size - 1:
x = row * col_size + col
y = (row + 1) * col_size + col
h = abs(heights[row][col] - heights[row + 1][col])
edges.append([x, y, h])
if col < col_size - 1:
x = row * col_size + col
y = row * col_size + col + 1
h = abs(heights[row][col] - heights[row][col + 1])
edges.append([x, y, h])
edges.sort(key=lambda x: x[2])
union_find = UnionFind(size)
for edge in edges:
x, y, h = edge[0], edge[1], edge[2]
union_find.union(x, y)
if union_find.is_connected(0, size - 1):
return h
return 0
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n \times \log(m \times n))$,其中 $m$ 和 $n$ 分别为矩阵的行数和列数。主要耗时在于对所有边进行排序,排序复杂度为 $O(m \times n \times \log(m \times n))$,并查集的合并与查找操作均摊为常数级。
- **空间复杂度**:$O(m \times n)$。
================================================
FILE: docs/solutions/1600-1699/richest-customer-wealth.md
================================================
# [1672. 最富有客户的资产总量](https://leetcode.cn/problems/richest-customer-wealth/)
- 标签:数组、矩阵
- 难度:简单
## 题目链接
- [1672. 最富有客户的资产总量 - 力扣](https://leetcode.cn/problems/richest-customer-wealth/)
## 题目大意
**描述**:给定一个 $m \times n$ 的整数网格 $accounts$,其中 $accounts[i][j]$ 是第 $i$ 位客户在第 $j$ 家银行托管的资产数量。
**要求**:返回最富有客户所拥有的资产总量。
**说明**:
- 客户的资产总量:指的是他们在各家银行托管的资产数量之和。
- 最富有客户:资产总量最大的客户。
- $m == accounts.length$。
- $n == accounts[i].length$。
- $1 \le m, n \le 50$。
- $1 \le accounts[i][j] \le 100$。
**示例**:
- 示例 1:
```python
输入:accounts = [[1,2,3],[3,2,1]]
输出:6
解释:
第 1 位客户的资产总量 = 1 + 2 + 3 = 6
第 2 位客户的资产总量 = 3 + 2 + 1 = 6
两位客户都是最富有的,资产总量都是 6 ,所以返回 6。
```
- 示例 2:
```python
输入:accounts = [[1,5],[7,3],[3,5]]
输出:10
解释:
第 1 位客户的资产总量 = 6
第 2 位客户的资产总量 = 10
第 3 位客户的资产总量 = 8
第 2 位客户是最富有的,资产总量是 10,随意返回 10。
```
## 解题思路
### 思路 1:直接模拟
1. 使用变量 $max\_ans$ 存储最富有客户所拥有的资产总量。
2. 遍历所有客户,对于当前客户 $accounts[i]$,统计其拥有的资产总量。
3. 将当前客户的资产总量与 $max\_ans$ 进行比较,如果大于 $max\_ans$,则更新 $max\_ans$ 的值。
4. 遍历完所有客户,最终返回 $max\_ans$ 作为结果。
### 思路 1:代码
```python
class Solution:
def maximumWealth(self, accounts: List[List[int]]) -> int:
max_ans = 0
for i in range(len(accounts)):
total = 0
for j in range(len(accounts[i])):
total += accounts[i][j]
if total > max_ans:
max_ans = total
return max_ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$。其中 $m$ 和 $n$ 分别为二维数组 $accounts$ 的行数和列数。两重循环遍历的时间复杂度为 $O(m * n)$ 。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1700-1799/calculate-money-in-leetcode-bank.md
================================================
# [1716. 计算力扣银行的钱](https://leetcode.cn/problems/calculate-money-in-leetcode-bank/)
- 标签:数学
- 难度:简单
## 题目链接
- [1716. 计算力扣银行的钱 - 力扣](https://leetcode.cn/problems/calculate-money-in-leetcode-bank/)
## 题目大意
**描述**:Hercy 每天都往力扣银行里存钱。
最开始,他在周一的时候存入 $1$ 块钱。从周二到周日,他每天都比前一天多存入 $1$ 块钱。在接下来的每个周一,他都会比前一个周一多存入 $1$ 块钱。
给定一个整数 $n$。
**要求**:计算在第 $n$ 天结束的时候,Hercy 在力扣银行中总共存了多少块钱。
**说明**:
- $1 \le n \le 1000$。
**示例**:
- 示例 1:
```python
输入:n = 4
输出:10
解释:第 4 天后,总额为 1 + 2 + 3 + 4 = 10。
```
- 示例 2:
```python
输入:n = 10
输出:37
解释:第 10 天后,总额为 (1 + 2 + 3 + 4 + 5 + 6 + 7) + (2 + 3 + 4) = 37 。注意到第二个星期一,Hercy 存入 2 块钱。
```
## 解题思路
### 思路 1:暴力模拟
1. 记录当前周 $week$ 和当前周的当前天数 $day$。
2. 按照题目要求,每天增加 $1$ 块钱,每周一比上周一增加 $1$ 块钱。这样,每天存钱数为 $week + day - 1$。
3. 将每天存的钱数累加起来即为答案。
### 思路 1:代码
```python
class Solution:
def totalMoney(self, n: int) -> int:
weak, day = 1, 1
ans = 0
for i in range(n):
ans += weak + day - 1
day += 1
if day == 8:
day = 1
weak += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
### 思路 2:等差数列计算优化
每周一比上周一增加 $1$ 块钱,则每周七天存钱总数比上一周多 $7$ 块钱。所以每周存的钱数是一个等差数列。我们可以通过高斯求和公式求出所有整周存的钱数,再计算出剩下天数存的钱数,两者相加即为答案。
### 思路 2:代码
```python
class Solution:
def totalMoney(self, n: int) -> int:
week_cnt = n // 7
weak_first_money = (1 + 7) * 7 // 2
weak_last_money = weak_first_money + 7 * (week_cnt - 1)
week_ans = (weak_first_money + weak_last_money) * week_cnt // 2
day_cnt = n % 7
day_first_money = 1 + week_cnt
day_last_money = day_first_money + day_cnt - 1
day_ans = (day_first_money + day_last_money) * day_cnt // 2
return week_ans + day_ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1700-1799/check-if-one-string-swap-can-make-strings-equal.md
================================================
# [1790. 仅执行一次字符串交换能否使两个字符串相等](https://leetcode.cn/problems/check-if-one-string-swap-can-make-strings-equal/)
- 标签:哈希表、字符串、计数
- 难度:简单
## 题目链接
- [1790. 仅执行一次字符串交换能否使两个字符串相等 - 力扣](https://leetcode.cn/problems/check-if-one-string-swap-can-make-strings-equal/)
## 题目大意
**描述**:给定两个长度相等的字符串 `s1` 和 `s2`。
已知一次「字符串交换操作」步骤如下:选出某个字符串中的两个下标(不一定要相同),并交换这两个下标所对应的字符。
**要求**:如果对其中一个字符串执行最多一次字符串交换可以使两个字符串相等,则返回 `True`;否则返回 `False`。
**说明**:
- $1 \le s1.length, s2.length \le 100$。
- $s1.length == s2.length$。
- `s1` 和 `s2` 仅由小写英文字母组成。
**示例**:
- 示例 1:
```python
给定:s1 = "bank", s2 = "kanb"
输出:True
解释:交换 s1 中的第一个和最后一个字符可以得到 "kanb",与 s2 相同
```
## 解题思路
### 思路 1:
- 用一个变量 `diff_cnt` 记录两个字符串中对应位置上出现不同字符的次数。用 `c1`、`c2` 记录第一次出现不同字符时两个字符串对应位置上的字符。
- 遍历两个字符串,对于第 `i` 个位置的字符 `s1[i]` 和 `s2[i]`:
- 如果 `s1[i] == s2[i]`,继续判断下一个位置。
- 如果 `s1[i] != s2[i]`,则出现不同字符的次数加 `1`。
- 如果出现不同字符的次数等于 `1`,则记录第一次出现不同字符时两个字符串对应位置上的字符。
- 如果出现不同字符的次数等于 `2`,则判断第一次出现不同字符时两个字符串对应位置上的字符与当前位置字符交换之后是否相等。如果不等,则说明交换之后 `s1` 和 `s2` 不相等,返回 `False`。如果相等,则继续判断下一个位置。
- 如果出现不同字符的次数超过 `2`,则不符合最多一次字符串交换的要求,返回 `False`。
- 如果遍历完,出现不同字符的次数为 `0` 或者 `2`,为 `0` 说明无需交换,本身 `s1` 和 `s2` 就是相等的,为 `2` 说明交换一次字符串之后 `s1` 和 `s2` 相等,此时返回 `True`。否则返回 `False`。
## 代码
### 思路 1 代码:
```python
class Solution:
def areAlmostEqual(self, s1: str, s2: str) -> bool:
size = len(s1)
diff_cnt = 0
c1, c2 = None, None
for i in range(size):
if s1[i] == s2[i]:
continue
diff_cnt += 1
if diff_cnt == 1:
c1 = s1[i]
c2 = s2[i]
elif diff_cnt == 2:
if c1 != s2[i] or c2 != s1[i]:
return False
else:
return False
return diff_cnt == 0 or diff_cnt == 2
```
================================================
FILE: docs/solutions/1700-1799/decode-xored-array.md
================================================
# [1720. 解码异或后的数组](https://leetcode.cn/problems/decode-xored-array/)
- 标签:位运算、数组
- 难度:简单
## 题目链接
- [1720. 解码异或后的数组 - 力扣](https://leetcode.cn/problems/decode-xored-array/)
## 题目大意
n 个非负整数构成数组 arr,经过编码后变为长度为 n-1 的整数数组 encoded,其中 `encoded[i] = arr[i] XOR arr[i+1]`。例如 arr = [1, 0, 2, 1] 经过编码后变为 encoded = [1, 2, 3]。
现在给定编码后的数组 encoded 和原数组 arr 的第一个元素 arr[0]。要求返回原数组 arr。
## 解题思路
首先要了解异或的性质:
- 异或运算满足交换律和结合律。
- 交换律:`a^b = b^a`
- 结合律:`(a^b)^c = a^(b^c)`
- 任何整数和自身做异或运算结果都为 0,即 `x^x = 0`。
- 任何整数和 0 做异或运算结果都为其本身,即 `x^0 = 0`。
已知当 $1 \le i \le n$ 时,有 `encoded[i-1] = arr[i-1] XOR arr[i]`。两边同时「异或」上 arr[i-1]。得:
- `encoded[i-1] XOR arr[i-1] = arr[i-1] XOR arr[i] XOR arr[i-1]`
- `encoded[i-1] XOR arr[i-1] = arr[i] XOR 0`
- `encoded[i-1] XOR arr[i-1] = arr[i]`
所以就可以根据所得结论 `arr[i] = encoded[i-1] XOR arr[i-1]` 模拟得出原数组 arr。
## 代码
```python
class Solution:
def decode(self, encoded: List[int], first: int) -> List[int]:
n = len(encoded) + 1
arr = [0] * n
arr[0] = first
for i in range(1, n):
arr[i] = encoded[i-1] ^ arr[i-1]
return arr
```
================================================
FILE: docs/solutions/1700-1799/find-center-of-star-graph.md
================================================
# [1791. 找出星型图的中心节点](https://leetcode.cn/problems/find-center-of-star-graph/)
- 标签:图
- 难度:简单
## 题目链接
- [1791. 找出星型图的中心节点 - 力扣](https://leetcode.cn/problems/find-center-of-star-graph/)
## 题目大意
**描述**:有一个无向的行型图,由 $n$ 个编号 $1 \sim n$ 的节点组成。星型图有一个中心节点,并且恰好有 $n - 1$ 条边将中心节点与其他每个节点连接起来。
给定一个二维整数数组 $edges$,其中 $edges[i] = [u_i, v_i]$ 表示节点 $u_i$ 与节点 $v_i$ 之间存在一条边。
**要求**:找出并返回该星型图的中心节点。
**说明**:
- $3 \le n \le 10^5$。
- $edges.length == n - 1$。
- $edges[i].length == 2$。
- $1 \le ui, vi \le n$。
- $ui \ne vi$。
- 题目数据给出的 $edges$ 表示一个有效的星型图。
**示例**:
- 示例 1:
```python
输入:edges = [[1,2],[2,3],[4,2]]
输出:2
解释:如上图所示,节点 2 与其他每个节点都相连,所以节点 2 是中心节点。
```
- 示例 2:
```python
输入:edges = [[1,2],[5,1],[1,3],[1,4]]
输出:1
```
## 解题思路
### 思路 1:求度数
根据题意可知:中心节点恰好有 $n - 1$ 条边将中心节点与其他每个节点连接起来,那么中心节点的度数一定为 $n - 1$。则我们可以遍历边集数组 $edges$,统计出每个节点 $u$ 的度数 $degrees[u]$。最后返回度数为 $n - 1$ 的节点编号。
### 思路 1:代码
```python
class Solution:
def findCenter(self, edges: List[List[int]]) -> int:
n = len(edges) + 1
degrees = collections.Counter()
for u, v in edges:
degrees[u] += 1
degrees[v] += 1
for i in range(1, n + 1):
if degrees[i] == n - 1:
return i
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1700-1799/find-nearest-point-that-has-the-same-x-or-y-coordinate.md
================================================
# [1779. 找到最近的有相同 X 或 Y 坐标的点](https://leetcode.cn/problems/find-nearest-point-that-has-the-same-x-or-y-coordinate/)
- 标签:数组
- 难度:简单
## 题目链接
- [1779. 找到最近的有相同 X 或 Y 坐标的点 - 力扣](https://leetcode.cn/problems/find-nearest-point-that-has-the-same-x-or-y-coordinate/)
## 题目大意
**描述**:给定两个整数 `x` 和 `y`,表示笛卡尔坐标系下的 `(x, y)` 点。再给定一个数组 `points`,其中 `points[i] = [ai, bi]`,表示在 `(ai, bi)` 处有一个点。当一个点与 `(x, y)` 拥有相同的 `x` 坐标或者拥有相同的 `y` 坐标时,我们称这个点是有效的。
**要求**:返回数组中距离 `(x, y)` 点出曼哈顿距离最近的有效点在 `points` 中的下标位置。如果有多个最近的有效点,则返回下标最小的一个。如果没有有效点,则返回 `-1`。
**说明**:
- **曼哈顿距离**:`(x1, y1)` 和 `(x2, y2)` 之间的曼哈顿距离为 `abs(x1 - x2) + abs(y1 - y2)` 。
- $1 \le points.length \le 10^4$。
- $points[i].length == 2$。
- $1 \le x, y, ai, bi \le 10^4$。
**示例**:
- 示例 1:
```python
输入:x = 3, y = 4, points = [[1, 2], [3, 1], [2, 4], [2, 3], [4, 4]]
输出:2
解释:在所有点中 [3, 1]、[2, 4]、[4, 4] 为有效点。其中 [2, 4]、[4, 4] 距离 [3, 4] 曼哈顿距离最近,都为 1。[2, 4] 下标最小,所以返回 2。
```
## 解题思路
### 思路 1:
- 使用 `min_dist` 记录下有效点中最近的曼哈顿距离,初始化为 `float('inf')`。使用 `min_index` 记录下符合要求的最小下标。
- 遍历 `points` 数组,遇到有效点之后计算一下当前有效点与 `(x, y)` 的曼哈顿距离,并判断更新一下有效点中最近的曼哈顿距离 `min_dist` 和符合要求的最小下标 `min_index`。
- 遍历完之后,判断一下 `min_dist` 是否等于 `float('inf')`。如果等于,说明没有找到有效点,则返回 `-1`。如果不等于,则返回符合要求的最小下标 `min_index`。
## 代码
### 思路 1 代码:
```python
class Solution:
def nearestValidPoint(self, x: int, y: int, points: List[List[int]]) -> int:
min_dist = float('inf')
min_index = 0
for i in range(len(points)):
if points[i][0] == x or points[i][1] == y:
dist = abs(points[i][0] - x) + abs(points[i][1] - y)
if dist < min_dist:
min_dist = dist
min_index = i
if min_dist == float('inf'):
return -1
return min_index
```
================================================
FILE: docs/solutions/1700-1799/index.md
================================================
## 本章内容
- [1710. 卡车上的最大单元数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/maximum-units-on-a-truck.md)
- [1716. 计算力扣银行的钱](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/calculate-money-in-leetcode-bank.md)
- [1720. 解码异或后的数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/decode-xored-array.md)
- [1726. 同积元组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/tuple-with-same-product.md)
- [1736. 替换隐藏数字得到的最晚时间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/latest-time-by-replacing-hidden-digits.md)
- [1742. 盒子中小球的最大数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/maximum-number-of-balls-in-a-box.md)
- [1749. 任意子数组和的绝对值的最大值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/maximum-absolute-sum-of-any-subarray.md)
- [1763. 最长的美好子字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/longest-nice-substring.md)
- [1779. 找到最近的有相同 X 或 Y 坐标的点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/find-nearest-point-that-has-the-same-x-or-y-coordinate.md)
- [1790. 仅执行一次字符串交换能否使两个字符串相等](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/check-if-one-string-swap-can-make-strings-equal.md)
- [1791. 找出星型图的中心节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/find-center-of-star-graph.md)
================================================
FILE: docs/solutions/1700-1799/latest-time-by-replacing-hidden-digits.md
================================================
# [1736. 替换隐藏数字得到的最晚时间](https://leetcode.cn/problems/latest-time-by-replacing-hidden-digits/)
- 标签:贪心、字符串
- 难度:简单
## 题目链接
- [1736. 替换隐藏数字得到的最晚时间 - 力扣](https://leetcode.cn/problems/latest-time-by-replacing-hidden-digits/)
## 题目大意
**描述**:给定一个字符串 $time$,格式为 `hh:mm`(小时:分钟),其中某几位数字被隐藏(用 `?` 表示)。
**要求**:替换 $time$ 中隐藏的数字,返回你可以得到的最晚有效时间。
**说明**:
- **有效时间**: `00:00` 到 `23:59` 之间的所有时间,包括 `00:00` 和 `23:59`。
- $time$ 的格式为 `hh:mm`。
- 题目数据保证你可以由输入的字符串生成有效的时间。
**示例**:
- 示例 1:
```python
输入:time = "2?:?0"
输出:"23:50"
解释:以数字 '2' 开头的最晚一小时是 23 ,以 '0' 结尾的最晚一分钟是 50。
```
- 示例 2:
```python
输入:time = "0?:3?"
输出:"09:39"
```
## 解题思路
### 思路 1:贪心算法
为了使有效时间尽可能晚,我们可以从高位到低位依次枚举所有符号为 `?` 的字符。在保证时间有效的前提下,每一位上取最大值,并进行保存。具体步骤如下:
- 如果第 $1$ 位为 `?`:
- 如果第 $2$ 位已经确定,并且范围在 $[4, 9]$ 中间,则第 $1$ 位最大为 $1$;
- 否则第 $1$ 位最大为 $2$。
- 如果第 $2$ 位为 `?`:
- 如果第 $1$ 位上值为 $2$,则第 $2$ 位最大可以为 $3$;
- 否则第 $2$ 位最大为 $9$。
- 如果第 $3$ 位为 `?`:
- 第 $3$ 位最大可以为 $5$。
- 如果第 $4$ 位为 `?`:
- 第 $4$ 位最大可以为 $9$。
### 思路 1:代码
```python
class Solution:
def maximumTime(self, time: str) -> str:
time_list = list(time)
if time_list[0] == '?':
if '4' <= time_list[1] <= '9':
time_list[0] = '1'
else:
time_list[0] = '2'
if time_list[1] == '?':
if time_list[0] == '2':
time_list[1] = '3'
else:
time_list[1] = '9'
if time_list[3] == '?':
time_list[3] = '5'
if time_list[4] == '?':
time_list[4] = '9'
return "".join(time_list)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1700-1799/longest-nice-substring.md
================================================
# [1763. 最长的美好子字符串](https://leetcode.cn/problems/longest-nice-substring/)
- 标签:位运算、哈希表、字符串、分治、滑动窗口
- 难度:简单
## 题目链接
- [1763. 最长的美好子字符串 - 力扣](https://leetcode.cn/problems/longest-nice-substring/)
## 题目大意
**描述**: 给定一个字符串 $s$。
**要求**:返回 $s$ 最长的美好子字符串。
**说明**:
- **美好字符串**:当一个字符串 $s$ 包含的每一种字母的大写和小写形式同时出现在 $s$ 中,就称这个字符串 $s$ 是美好字符串。
- $1 \le s.length \le 100$。
**示例**:
- 示例 1:
```python
输入:s = "YazaAay"
输出:"aAa"
解释:"aAa" 是一个美好字符串,因为这个子串中仅含一种字母,其小写形式 'a' 和大写形式 'A' 也同时出现了。
"aAa" 是最长的美好子字符串。
```
- 示例 2:
```python
输入:s = "Bb"
输出:"Bb"
解释:"Bb" 是美好字符串,因为 'B' 和 'b' 都出现了。整个字符串也是原字符串的子字符串。
```
## 解题思路
### 思路 1:枚举
字符串 $s$ 的范围为 $[1, 100]$,长度较小,我们可以枚举所有的子串,判断该子串是否为美好字符串。
由于大小写英文字母各有 $26$ 位,则我们可以利用二进制来标记某字符是否在子串中出现过,我们使用 $lower$ 标记子串中出现过的小写字母,使用 $upper$ 标记子串中出现过的大写字母。如果满足 $lower == upper$,则说明该子串为美好字符串。
具体解法步骤如下:
1. 使用二重循环遍历字符串。对于子串 $s[i]…s[j]$,使用 $lower$ 标记子串中出现过的小写字母,使用 $upper$ 标记子串中出现过的大写字母。
2. 如果 $s[j]$ 为小写字母,则 $lower$ 对应位置标记为出现过该小写字母,即:`lower |= 1 << (ord(s[j]) - ord('a'))`。
3. 如果 $s[j]$ 为大写字母,则 $upper$ 对应位置标记为出现过该小写字母,即:`upper |= 1 << (ord(s[j]) - ord('A'))`。
4. 判断当前子串对应 $lower$ 和 $upper$ 是否相等,如果相等,并且子串长度大于记录的最长美好字符串长度,则更新最长美好字符串长度。
5. 遍历完返回记录的最长美好字符串长度。
### 思路 1:代码
```Python
class Solution:
def longestNiceSubstring(self, s: str) -> str:
size = len(s)
max_pos, max_len = 0, 0
for i in range(size):
lower, upper = 0, 0
for j in range(i, size):
if s[j].islower():
lower |= 1 << (ord(s[j]) - ord('a'))
else:
upper |= 1 << (ord(s[j]) - ord('A'))
if lower == upper and j - i + 1 > max_len:
max_len = j - i + 1
max_pos = i
return s[max_pos: max_pos + max_len]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 为字符串 $s$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1700-1799/maximum-absolute-sum-of-any-subarray.md
================================================
# [1749. 任意子数组和的绝对值的最大值](https://leetcode.cn/problems/maximum-absolute-sum-of-any-subarray/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [1749. 任意子数组和的绝对值的最大值 - 力扣](https://leetcode.cn/problems/maximum-absolute-sum-of-any-subarray/)
## 题目大意
**描述**:给定一个整数数组 $nums$。
**要求**:找出 $nums$ 中「和的绝对值」最大的任意子数组(可能为空),并返回最大值。
**说明**:
- **子数组 $[nums_l, nums_{l+1}, ..., nums_{r-1}, nums_{r}]$ 的和的绝对值**:$abs(nums_l + nums_{l+1} + ... + nums_{r-1} + nums_{r})$。
- $abs(x)$ 定义如下:
- 如果 $x$ 是负整数,那么 $abs(x) = -x$。
- 如果 $x$ 是非负整数,那么 $abs(x) = x$。
- $1 \le nums.length \le 10^5$。
- $-10^4 \le nums[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [1,-3,2,3,-4]
输出:5
解释:子数组 [2,3] 和的绝对值最大,为 abs(2+3) = abs(5) = 5。
```
- 示例 2:
```python
输入:nums = [2,-5,1,-4,3,-2]
输出:8
解释:子数组 [-5,1,-4] 和的绝对值最大,为 abs(-5+1-4) = abs(-8) = 8。
```
## 解题思路
### 思路 1:动态规划
子数组和的绝对值的最大值,可能来自于「连续子数组的最大和」,也可能来自于「连续子数组的最小和」。
而求解「连续子数组的最大和」,我们可以参考「[0053. 最大子数组和](https://leetcode.cn/problems/maximum-subarray/)」的做法,使用一个变量 $mmax$ 来表示以第 $i$ 个数结尾的连续子数组的最大和。使用另一个变量 $mmin$ 来表示以第 $i$ 个数结尾的连续子数组的最小和。然后取两者绝对值的最大值为答案 $ans$。
具体步骤如下:
1. 遍历数组 $nums$,对于当前元素 $nums[i]$:
1. 如果 $mmax < 0$,则「第 $i - 1$ 个数结尾的连续子数组的最大和」+「第 $i$ 个数的值」<「第 $i$ 个数的值」,所以 $mmax$ 应取「第 $i$ 个数的值」,即:$mmax = nums[i]$。
2. 如果 $mmax \ge 0$ ,则「第 $i - 1$ 个数结尾的连续子数组的最大和」 +「第 $i$ 个数的值」 >= 第 $i$ 个数的值,所以 $mmax$ 应取「第 $i - 1$ 个数结尾的连续子数组的最大和」 +「第 $i$ 个数的值」,即:$mmax = mmax + nums[i]$。
3. 如果 $mmin > 0$,则「第 $i - 1$ 个数结尾的连续子数组的最大和」+「第 $i$ 个数的值」>「第 $i$ 个数的值」,所以 $mmax$ 应取「第 $i$ 个数的值」,即:$mmax = nums[i]$。
4. 如果 $mmin \le 0$ ,则「第 $i - 1$ 个数结尾的连续子数组的最大和」 +「第 $i$ 个数的值」 <= 第 $i$ 个数的值,所以 $mmax$ 应取「第 $i - 1$ 个数结尾的连续子数组的最大和」 +「第 $i$ 个数的值」,即:$mmin = mmin + nums[i]$。
5. 维护答案 $ans$,将 $mmax$ 和 $mmin$ 绝对值的最大值与 $ans$ 进行比较,并更新 $ans$。
2. 遍历完返回答案 $ans$。
### 思路 1:代码
```python
class Solution:
def maxAbsoluteSum(self, nums: List[int]) -> int:
ans = 0
mmax, mmin = 0, 0
for num in nums:
mmax = max(mmax, 0) + num
mmin = min(mmin, 0) + num
ans = max(ans, mmax, -mmin)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1700-1799/maximum-number-of-balls-in-a-box.md
================================================
# [1742. 盒子中小球的最大数量](https://leetcode.cn/problems/maximum-number-of-balls-in-a-box/)
- 标签:哈希表、数学、计数
- 难度:简单
## 题目链接
- [1742. 盒子中小球的最大数量 - 力扣](https://leetcode.cn/problems/maximum-number-of-balls-in-a-box/)
## 题目大意
**描述**:给定两个整数 $lowLimit$ 和 $highLimt$,代表 $n$ 个小球的编号(包括 $lowLimit$ 和 $highLimit$,即 $n == highLimit = lowLimit + 1$)。另外有无限个盒子。
现在的工作是将每个小球放入盒子中,其中盒子的编号应当等于小球编号上每位数字的和。例如,编号 $321$ 的小球应当放入编号 $3 + 2 + 1 = 6$ 的盒子,而编号 $10$ 的小球应当放入编号 $1 + 0 = 1$ 的盒子。
**要求**:返回放有最多小球的盒子中的小球数量。如果有多个盒子都满足放有最多小球,只需返回其中任一盒子的小球数量。
**说明**:
- $1 \le lowLimit \le highLimit \le 10^5$。
**示例**:
- 示例 1:
```python
输入:lowLimit = 1, highLimit = 10
输出:2
解释:
盒子编号:1 2 3 4 5 6 7 8 9 10 11 ...
小球数量:2 1 1 1 1 1 1 1 1 0 0 ...
编号 1 的盒子放有最多小球,小球数量为 2。
```
- 示例 2:
```python
输入:lowLimit = 5, highLimit = 15
输出:2
解释:
盒子编号:1 2 3 4 5 6 7 8 9 10 11 ...
小球数量:1 1 1 1 2 2 1 1 1 0 0 ...
编号 5 和 6 的盒子放有最多小球,每个盒子中的小球数量都是 2。
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
将 $lowLimit$、$highLimit$ 转为字符串 $s1$、$s2$,并将 $s1$ 补上前导 $0$,令其与 $s2$ 长度一致。定义递归函数 `def dfs(pos, remainTotal, isMaxLimit, isMinLimit):` 表示构造第 $pos$ 位及之后剩余数位和为 $remainTotal$ 的合法方案数。
因为数据范围为 $[1, 10^5]$,对应数位和范围为 $[1, 45]$。因此我们可以枚举所有的数位和,并递归调用 `dfs(i, remainTotal, isMaxLimit, isMinLimit)`,求出不同数位和对应的方案数,并求出最大方案数。
接下来按照如下步骤进行递归。
1. 从 `dfs(0, i, True, True)` 开始递归。 `dfs(0, i, True, True)` 表示:
1. 从位置 $0$ 开始构造。
2. 剩余数位和为 $i$。
3. 开始时当前数位最大值受到最高位数位的约束。
4. 开始时当前数位最小值受到最高位数位的约束。
2. 如果剩余数位和小于 $0$,说明当前方案不符合要求,则返回方案数 $0$。
3. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:
1. 如果剩余数位和 $remainTotal$ 等于 $0$,说明当前方案符合要求,则返回方案数 $1$。
2. 如果剩余数位和 $remainTotal$ 不等于 $0$,说明当前方案不符合要求,则返回方案数 $0$。
4. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
5. 如果遇到 $isNum == False$,说明之前位数没有填写数字,当前位可以跳过,这种情况下方案数等于 $pos + 1$ 位置上没有受到 $pos$ 位的约束,并且之前没有填写数字时的方案数,即:`ans = dfs(i + 1, state, False, False)`。
6. 根据 $isMaxLimit$ 和 $isMinLimit$ 来决定填当前位数位所能选择的最小数字($minX$)和所能选择的最大数字($maxX$)。
7. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
8. 方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, remainTotal - d, isMaxLimit and d == maxX, isMinLimit and d == minX)`。
1. `remainTotal - d` 表示当前剩余数位和减去 $d$。
2. `isMaxLimit and d == maxX` 表示 $pos + 1$ 位最大值受到之前 $pos$ 位限制。
3. `isMinLimit and d == maxX` 表示 $pos + 1$ 位最小值受到之前 $pos$ 位限制。
9. 最后返回所有 `dfs(0, i, True, True)` 中最大的方案数即可。
### 思路 1:代码
```python
class Solution:
def countBalls(self, lowLimit: int, highLimit: int) -> int:
s1, s2 = str(lowLimit), str(highLimit)
m, n = len(s1), len(s2)
if m < n:
s1 = '0' * (n - m) + s1
@cache
# pos: 第 pos 个数位
# remainTotal: 表示剩余数位和
# isMaxLimit: 表示是否受到上限选择限制。如果为真,则第 pos 位填入数字最多为 s2[pos];如果为假,则最大可为 9。
# isMinLimit: 表示是否受到下限选择限制。如果为真,则第 pos 位填入数字最小为 s1[pos];如果为假,则最小可为 0。
def dfs(pos, remainTotal, isMaxLimit, isMinLimit):
if remainTotal < 0:
return 0
if pos == n:
# remainTotal 为 0,则表示当前方案符合要求
return int(remainTotal == 0)
ans = 0
# 如果前一位没有填写数字,或受到选择限制,则最小可选择数字为 s1[pos],否则最少为 0(可以含有前导 0)。
minX = int(s1[pos]) if isMinLimit else 0
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = int(s2[pos]) if isMaxLimit else 9
# 枚举可选择的数字
for d in range(minX, maxX + 1):
ans += dfs(pos + 1, remainTotal - d, isMaxLimit and d == maxX, isMinLimit and d == minX)
return ans
ans = 0
for i in range(46):
ans = max(ans, dfs(0, i, True, True))
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n \times 45)$。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/1700-1799/maximum-units-on-a-truck.md
================================================
# [1710. 卡车上的最大单元数](https://leetcode.cn/problems/maximum-units-on-a-truck/)
- 标签:贪心、数组、排序
- 难度:简单
## 题目链接
- [1710. 卡车上的最大单元数 - 力扣](https://leetcode.cn/problems/maximum-units-on-a-truck/)
## 题目大意
**描述**:现在需要将一些箱子装在一辆卡车上。给定一个二维数组 $boxTypes$,其中 $boxTypes[i] = [numberOfBoxesi, numberOfUnitsPerBoxi]$。
$numberOfBoxesi$ 是类型 $i$ 的箱子的数量。$numberOfUnitsPerBoxi$ 是类型 $i$ 的每个箱子可以装载的单元数量。
再给定一个整数 $truckSize$ 表示一辆卡车上可以装载箱子的最大数量。只要箱子数量不超过 $truckSize$,你就可以选择任意箱子装到卡车上。
**要求**:返回卡车可以装载的最大单元数量。
**说明**:
- $1 \le boxTypes.length \le 1000$。
- $1 \le numberOfBoxesi, numberOfUnitsPerBoxi \le 1000$。
- $1 \le truckSize \le 106$。
**示例**:
- 示例 1:
```python
输入:boxTypes = [[1,3],[2,2],[3,1]], truckSize = 4
输出:8
解释
箱子的情况如下:
- 1 个第一类的箱子,里面含 3 个单元。
- 2 个第二类的箱子,每个里面含 2 个单元。
- 3 个第三类的箱子,每个里面含 1 个单元。
可以选择第一类和第二类的所有箱子,以及第三类的一个箱子。
单元总数 = (1 * 3) + (2 * 2) + (1 * 1) = 8
```
- 示例 2:
```python
输入:boxTypes = [[5,10],[2,5],[4,7],[3,9]], truckSize = 10
输出:91
```
## 解题思路
### 思路 1:贪心算法
题目中,一辆卡车上可以装载箱子的最大数量是固定的($truckSize$),那么如果想要使卡车上装载的单元数量最大,就应该优先选取装载单元数量多的箱子。
所以,从贪心算法的角度来考虑,我们应该按照每个箱子可以装载的单元数量对数组 $boxTypes$ 从大到小排序。然后优先选取装载单元数量多的箱子。
下面我们使用贪心算法三步走的方法解决这道题。
1. **转换问题**:将原问题转变为,在 $truckSize$ 的限制下,当选取完装载单元数量最多的箱子 $box$ 之后,再解决剩下箱子($truckSize - box[0]$)的选择问题(子问题)。
2. **贪心选择性质**:对于当前 $truckSize$,优先选取装载单元数量最多的箱子。
3. **最优子结构性质**:在上面的贪心策略下,当前 $truckSize$ 的贪心选择 + 剩下箱子的子问题最优解,就是全局最优解。也就是说在贪心选择的方案下,能够使得卡车可以装载的单元数量达到最大。
使用贪心算法的解决步骤描述如下:
1. 对数组 $boxTypes$ 按照每个箱子可以装载的单元数量从大到小排序。使用变量 $res$ 记录卡车可以装载的最大单元数量。
2. 遍历数组 $boxTypes$,对于当前种类的箱子 $box$:
1. 如果 $truckSize > box[0]$,说明当前种类箱子可以全部装载。则答案数量加上该种箱子的单元总数,即 $box[0] \times box[1]$,并且最大数量 $truckSize$ 减去装载的箱子数。
2. 如果 $truckSize \le box[0]$,说明当前种类箱子只能部分装载。则答案数量加上 $truckSize \times box[1]$,并跳出循环。
3. 最后返回答案 $res$。
### 思路 1:代码
```python
class Solution:
def maximumUnits(self, boxTypes: List[List[int]], truckSize: int) -> int:
boxTypes.sort(key=lambda x:x[1], reverse=True)
res = 0
for box in boxTypes:
if truckSize > box[0]:
res += box[0] * box[1]
truckSize -= box[0]
else:
res += truckSize * box[1]
break
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 是数组 $boxTypes$ 的长度。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/1700-1799/tuple-with-same-product.md
================================================
# [1726. 同积元组](https://leetcode.cn/problems/tuple-with-same-product/)
- 标签:数组、哈希表
- 难度:中等
## 题目链接
- [1726. 同积元组 - 力扣](https://leetcode.cn/problems/tuple-with-same-product/)
## 题目大意
**描述**:给定一个由不同正整数组成的数组 $nums$。
**要求**:返回满足 $a \times b = c \times d$ 的元组 $(a, b, c, d)$ 的数量。其中 $a$、$b$、$c$ 和 $d$ 都是 $nums$ 中的元素,且 $a \ne b \ne c \ne d$。
**说明**:
- $1 \le nums.length \le 1000$。
- $1 \le nums[i] \le 10^4$。
- $nums$ 中的所有元素互不相同。
**示例**:
- 示例 1:
```python
输入:nums = [2,3,4,6]
输出:8
解释:存在 8 个满足题意的元组:
(2,6,3,4) , (2,6,4,3) , (6,2,3,4) , (6,2,4,3)
(3,4,2,6) , (4,3,2,6) , (3,4,6,2) , (4,3,6,2)
```
- 示例 2:
```python
输入:nums = [1,2,4,5,10]
输出:16
解释:存在 16 个满足题意的元组:
(1,10,2,5) , (1,10,5,2) , (10,1,2,5) , (10,1,5,2)
(2,5,1,10) , (2,5,10,1) , (5,2,1,10) , (5,2,10,1)
(2,10,4,5) , (2,10,5,4) , (10,2,4,5) , (10,2,5,4)
(4,5,2,10) , (4,5,10,2) , (5,4,2,10) , (5,4,10,2)
```
## 解题思路
### 思路 1:哈希表 + 数学
1. 二重循环遍历数组 $nums$,使用哈希表 $cnts$ 记录下所有不同 $nums[i] \times nums[j]$ 的结果。
2. 因为满足 $a \times b = c \times d$ 的元组 $(a, b, c, d)$ 可以按照不同顺序进行组和,所以对于 $x$ 个 $nums[i] \times nums[j]$,就有 $C_x^2$ 种组和方法。
3. 遍历哈希表 $cnts$ 中所有值 $value$,将不同组和的方法数累积到答案 $ans$ 中。
4. 遍历完返回答案 $ans$。
### 思路 1:代码
```Python
class Solution:
def tupleSameProduct(self, nums: List[int]) -> int:
cnts = Counter()
size = len(nums)
for i in range(size):
for j in range(i + 1, size):
product = nums[i] * nums[j]
cnts[product] += 1
ans = 0
for key, value in cnts.items():
ans += value * (value - 1) * 4
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$,其中 $n$ 表示数组 $nums$ 的长度。
- **空间复杂度**:$O(n^2)$。
================================================
FILE: docs/solutions/1800-1899/check-if-all-the-integers-in-a-range-are-covered.md
================================================
# [1893. 检查是否区域内所有整数都被覆盖](https://leetcode.cn/problems/check-if-all-the-integers-in-a-range-are-covered/)
- 标签:数组、哈希表、前缀和
- 难度:简单
## 题目链接
- [1893. 检查是否区域内所有整数都被覆盖 - 力扣](https://leetcode.cn/problems/check-if-all-the-integers-in-a-range-are-covered/)
## 题目大意
**描述**:给定一个二维整数数组 $ranges$ 和两个整数 $left$ 和 $right$。每个 $ranges[i] = [start_i, end_i]$ 表示一个从 $start_i$ 到 $end_i$ 的 闭区间 。
**要求**:如果闭区间 $[left, right]$ 内每个整数都被 $ranges$ 中至少一个区间覆盖,那么请你返回 $True$ ,否则返回 $False$。
**说明**:
- $1 \le ranges.length \le 50$。
- $1 \le start_i \le end_i \le 50$。
- $1 \le left \le right \le 50$。
**示例**:
- 示例 1:
```python
输入:ranges = [[1,2],[3,4],[5,6]], left = 2, right = 5
输出:True
解释:2 到 5 的每个整数都被覆盖了:
- 2 被第一个区间覆盖。
- 3 和 4 被第二个区间覆盖。
- 5 被第三个区间覆盖。
```
- 示例 2:
```python
输入:ranges = [[1,10],[10,20]], left = 21, right = 21
输出:False
解释:21 没有被任何一个区间覆盖。
```
## 解题思路
### 思路 1:暴力
区间的范围为 $[1, 50]$,所以我们可以使用一个长度为 $51$ 的标志数组 $flags$ 用于标记区间内的所有整数。
1. 遍历数组 $ranges$ 中的所有区间 $[l, r]$。
2. 对于区间 $[l, r]$ 和区间 $[left, right]$,将两区间相交部分标记为 $True$。
3. 遍历区间 $[left, right]$ 上的所有整数,判断对应标志位是否为 $False$。
4. 如果对应标志位出现 $False$,则返回 $False$。
5. 如果遍历完所有标志位都为 $True$,则返回 $True$。
### 思路 1:代码
```Python
class Solution:
def isCovered(self, ranges: List[List[int]], left: int, right: int) -> bool:
flags = [False for _ in range(51)]
for l, r in ranges:
for i in range(max(l, left), min(r, right) + 1):
flags[i] = True
for i in range(left, right + 1):
if not flags[i]:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(50 \times n)$。
- **空间复杂度**:$O(50)$。
================================================
FILE: docs/solutions/1800-1899/index.md
================================================
## 本章内容
- [1822. 数组元素积的符号](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/sign-of-the-product-of-an-array.md)
- [1827. 最少操作使数组递增](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/minimum-operations-to-make-the-array-increasing.md)
- [1833. 雪糕的最大数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/maximum-ice-cream-bars.md)
- [1844. 将所有数字用字符替换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/replace-all-digits-with-characters.md)
- [1858. 包含所有前缀的最长单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/longest-word-with-all-prefixes.md)
- [1859. 将句子排序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/sorting-the-sentence.md)
- [1876. 长度为三且各字符不同的子字符串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/substrings-of-size-three-with-distinct-characters.md)
- [1877. 数组中最大数对和的最小值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/minimize-maximum-pair-sum-in-array.md)
- [1879. 两个数组最小的异或值之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/minimum-xor-sum-of-two-arrays.md)
- [1893. 检查是否区域内所有整数都被覆盖](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/check-if-all-the-integers-in-a-range-are-covered.md)
- [1897. 重新分配字符使所有字符串都相等](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/redistribute-characters-to-make-all-strings-equal.md)
================================================
FILE: docs/solutions/1800-1899/longest-word-with-all-prefixes.md
================================================
# [1858. 包含所有前缀的最长单词](https://leetcode.cn/problems/longest-word-with-all-prefixes/)
- 标签:深度优先搜索、字典树
- 难度:中等
## 题目链接
- [1858. 包含所有前缀的最长单词 - 力扣](https://leetcode.cn/problems/longest-word-with-all-prefixes/)
## 题目大意
给定一个字符串数组 `words`。
要求:找出 `words` 中所有前缀从都在 `words` 中的最长字符串。如果存在多个符合条件相同长度的字符串,则输出字典序中最小的字符串。如果不存在这样的字符串,返回 `' '`。
- 例如:令 `words = ["a", "app", "ap"]`。字符串 `"app"` 含前缀 `"ap"` 和 `"a"` ,都在 `words` 中。
## 解题思路
使用字典树存储所有单词,再将字典中单词按照长度从大到小、字典序从小到大排序。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
if not cur.isEnd:
return False
return True
class Solution:
def longestWord(self, words: List[str]) -> str:
tire_tree = Trie()
for word in words:
tire_tree.insert(word)
words.sort(key=lambda x:(-len(x), x))
for word in words:
if tire_tree.search(word):
return word
return ''
```
================================================
FILE: docs/solutions/1800-1899/maximum-ice-cream-bars.md
================================================
# [1833. 雪糕的最大数量](https://leetcode.cn/problems/maximum-ice-cream-bars/)
- 标签:贪心、数组、排序
- 难度:中等
## 题目链接
- [1833. 雪糕的最大数量 - 力扣](https://leetcode.cn/problems/maximum-ice-cream-bars/)
## 题目大意
**描述**:给定一个数组 $costs$ 表示不同雪糕的定价,其中 $costs[i]$ 表示第 $i$ 支雪糕的定价。再给定一个整数 $coins$ 表示 Tony 一共有的现金数量。
**要求**:计算并返回 Tony 用 $coins$ 现金能够买到的雪糕的最大数量。
**说明**:
- $costs.length == n$。
- $1 \le n \le 10^5$。
- $1 \le costs[i] \le 10^5$。
- $1 \le coins \le 10^8$。
**示例**:
- 示例 1:
```python
输入:costs = [1,3,2,4,1], coins = 7
输出:4
解释:Tony 可以买下标为 0、1、2、4 的雪糕,总价为 1 + 3 + 2 + 1 = 7
```
- 示例 2:
```python
输入:costs = [10,6,8,7,7,8], coins = 5
输出:0
解释:Tony 没有足够的钱买任何一支雪糕。
```
## 解题思路
### 思路 1:排序 + 贪心
贪心思路,如果想尽可能买到多的雪糕,就应该优先选择价格便宜的雪糕。具体步骤如下:
1. 对数组 $costs$ 进行排序。
2. 按照雪糕价格从低到高开始买雪糕,并记录下购买雪糕的数量,知道现有钱买不起雪糕为止。
3. 输出购买雪糕的数量作为答案。
### 思路 1:代码
```python
class Solution:
def maxIceCream(self, costs: List[int], coins: int) -> int:
costs.sort()
ans = 0
for cost in costs:
if coins >= cost:
ans += 1
coins -= cost
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log_2n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1800-1899/minimize-maximum-pair-sum-in-array.md
================================================
# [1877. 数组中最大数对和的最小值](https://leetcode.cn/problems/minimize-maximum-pair-sum-in-array/)
- 标签:贪心、数组、双指针、排序
- 难度:中等
## 题目链接
- [1877. 数组中最大数对和的最小值 - 力扣](https://leetcode.cn/problems/minimize-maximum-pair-sum-in-array/)
## 题目大意
**描述**:一个数对 $(a, b)$ 的数对和等于 $a + b$。最大数对和是一个数对数组中最大的数对和。
- 比如,如果我们有数对 $(1, 5)$,$(2, 3)$ 和 $(4, 4)$,最大数对和为 $max(1 + 5, 2 + 3, 4 + 4) = max(6, 5, 8) = 8$。
给定一个长度为偶数 $n$ 的数组 $nums$,现在将 $nums$ 中的元素分为 $n / 2$ 个数对,使得:
- $nums$ 中每个元素恰好在一个数对中。
- 最大数对和的值最小。
**要求**:在最优数对划分的方案下,返回最小的最大数对和。
**说明**:
- $n == nums.length$。
- $2 \le n \le 10^5$。
- $n$ 是偶数。
- $1 \le nums[i] \le 10^5$。
**示例**:
- 示例 1:
```python
输入:nums = [3,5,2,3]
输出:7
解释:数组中的元素可以分为数对 (3,3) 和 (5,2)。
最大数对和为 max(3+3, 5+2) = max(6, 7) = 7。
```
- 示例 2:
```python
输入:nums = [3,5,4,2,4,6]
输出:8
解释:数组中的元素可以分为数对 (3,5),(4,4) 和 (6,2)。
最大数对和为 max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8。
```
## 解题思路
### 思路 1:排序 + 贪心
为了使最大数对和的值尽可能的小,我们应该尽可能的让数组中最大值与最小值组成一对,次大值与次小值组成一对。而其他任何方案都会使得最大数对和的值更大。
那么,我们可以先将数组进行排序,然后首尾依次进行组对,并计算这种方案下的最大数对和即为答案。
### 思路 1:代码
```python
class Solution:
def minPairSum(self, nums: List[int]) -> int:
nums.sort()
ans, size = 0, len(nums)
for i in range(len(nums) // 2):
ans = max(ans, nums[i] + nums[size - 1 - i])
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/1800-1899/minimum-operations-to-make-the-array-increasing.md
================================================
# [1827. 最少操作使数组递增](https://leetcode.cn/problems/minimum-operations-to-make-the-array-increasing/)
- 标签:贪心、数组
- 难度:简单
## 题目链接
- [1827. 最少操作使数组递增 - 力扣](https://leetcode.cn/problems/minimum-operations-to-make-the-array-increasing/)
## 题目大意
**描述**:给定一个整数数组 $nums$(下标从 $0$ 开始)。每一次操作中,你可以选择数组中的一个元素,并将它增加 $1$。
- 比方说,如果 $nums = [1,2,3]$,你可以选择增加 $nums[1]$ 得到 $nums = [1,3,3]$。
**要求**:请你返回使 $nums$ 严格递增的最少操作次数。
**说明**:
- 我们称数组 $nums$ 是严格递增的,当它满足对于所有的 $0 \le i < nums.length - 1$ 都有 $nums[i] < nums[i + 1]$。一个长度为 $1$ 的数组是严格递增的一种特殊情况。
- $1 \le nums.length \le 5000$。
- $1 \le nums[i] \le 10^4$。
**示例**:
- 示例 1:
```python
输入:nums = [1,1,1]
输出:3
解释:你可以进行如下操作:
1) 增加 nums[2] ,数组变为 [1,1,2]。
2) 增加 nums[1] ,数组变为 [1,2,2]。
3) 增加 nums[2] ,数组变为 [1,2,3]。
```
- 示例 2:
```python
输入:nums = [1,5,2,4,1]
输出:14
```
## 解题思路
### 思路 1:贪心算法
题目要求使 $nums$ 严格递增的最少操作次数。当遇到 $nums[i - 1] \ge nums[i]$ 时,我们应该在满足要求的同时,尽可能使得操作次数最少,则 $nums[i]$ 应增加到 $nums[i - 1] + 1$ 时,此时操作次数最少,并且满足 $nums[i - 1] < nums[i]$。
具体操作步骤如下:
1. 从左到右依次遍历数组元素。
2. 如果遇到 $nums[i - 1] \ge nums[i]$ 时:
1. 本次增加的最少操作次数为 $nums[i - 1] + 1 - nums[i]$,将其计入答案中。
2. 将 $nums[i]$ 变为 $nums[i - 1] + 1$。
3. 遍历完返回答案 $ans$。
### 思路 1:代码
```Python
class Solution:
def minOperations(self, nums: List[int]) -> int:
ans = 0
for i in range(1, len(nums)):
if nums[i - 1] >= nums[i]:
ans += nums[i - 1] + 1 - nums[i]
nums[i] = nums[i - 1] + 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1800-1899/minimum-xor-sum-of-two-arrays.md
================================================
# [1879. 两个数组最小的异或值之和](https://leetcode.cn/problems/minimum-xor-sum-of-two-arrays/)
- 标签:位运算、数组、动态规划、状态压缩
- 难度:困难
## 题目链接
- [1879. 两个数组最小的异或值之和 - 力扣](https://leetcode.cn/problems/minimum-xor-sum-of-two-arrays/)
## 题目大意
**描述**:给定两个整数数组 $nums1$ 和 $nums2$,两个数组长度都为 $n$。
**要求**:将 $nums2$ 中的元素重新排列,使得两个数组的异或值之和最小。并返回重新排列之后的异或值之和。
**说明**:
- **两个数组的异或值之和**:$(nums1[0] \oplus nums2[0]) + (nums1[1] \oplus nums2[1]) + ... + (nums1[n - 1] \oplus nums2[n - 1])$(下标从 $0$ 开始)。
- 举个例子,$[1, 2, 3]$ 和 $[3,2,1]$ 的异或值之和 等于 $(1 \oplus 3) + (2 \oplus 2) + (3 \oplus 1) + (3 \oplus 1) = 2 + 0 + 2 = 4$。
- $n == nums1.length$。
- $n == nums2.length$。
- $1 \le n \le 14$。
- $0 \le nums1[i], nums2[i] \le 10^7$。
**示例**:
- 示例 1:
```python
输入:nums1 = [1,2], nums2 = [2,3]
输出:2
解释:将 nums2 重新排列得到 [3,2] 。
异或值之和为 (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2。
```
- 示例 2:
```python
输入:nums1 = [1,0,3], nums2 = [5,3,4]
输出:8
解释:将 nums2 重新排列得到 [5,4,3] 。
异或值之和为 (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8。
```
## 解题思路
### 思路 1:状态压缩 DP
由于数组 $nums2$ 可以重新排列,所以我们可以将数组 $nums1$ 中的元素顺序固定,然后将数组 $nums1$ 中第 $i$ 个元素与数组 $nums2$ 中所有还没被选择的元素进行组合,找到异或值之和最小的组合。
同时因为两个数组长度 $n$ 的大小范围只有 $[1, 14]$,所以我们可以采用「状态压缩」的方式来表示 $nums2$ 中当前元素的选择情况。
「状态压缩」指的是使用一个 $n$ 位的二进制数 $state$ 来表示排列中数的选取情况。
如果二进制数 $state$ 的第 $i$ 位为 $1$,说明数组 $nums2$ 第 $i$ 个元素在该状态中被选取。反之,如果该二进制的第 $i$ 位为 $0$,说明数组 $nums2$ 中第 $i$ 个元素在该状态中没有被选取。
举个例子:
1. $nums2 = \lbrace 1, 2, 3, 4 \rbrace$,$state = (1001)_2$,表示选择了第 $1$ 个元素和第 $4$ 个元素,也就是 $1$、$4$。
2. $nums2 = \lbrace 1, 2, 3, 4, 5, 6 \rbrace$,$state = (011010)_2$,表示选择了第 $2$ 个元素、第 $4$ 个元素、第 $5$ 个元素,也就是 $2$、$4$、$5$。
这样,我们就可以通过动态规划的方式来解决这道题。
###### 1. 阶段划分
按照数组 $nums$ 中元素选择情况进行阶段划分。
###### 2. 定义状态
定义当前数组 $nums2$ 中元素选择状态为 $state$,$state$ 对应选择的元素个数为 $count(state)$。
则可以定义状态 $dp[state]$ 表示为:当前数组 $nums2$ 中元素选择状态为 $state$,并且选择了 $nums1$ 中前 $count(state)$ 个元素的情况下,可以组成的最小异或值之和。
###### 3. 状态转移方程
对于当前状态 $dp[state]$,肯定是从比 $state$ 少选一个元素的状态中递推而来。我们可以枚举少选一个元素的状态,找到可以组成的异或值之和最小值,赋值给 $dp[state]$。
举个例子 $nums2 = \lbrace 1, 2, 3, 4 \rbrace$,$state = (1001)_2$,表示选择了第 $1$ 个元素和第 $4$ 个元素,也就是 $1$、$4$。那么 $state$ 只能从 $(1000)_2$ 和 $(0001)_2$ 这两个状态转移而来,我们只需要枚举这两种状态,并求出转移过来的异或值之和最小值。
即状态转移方程为:$dp[state] = min(dp[state], \quad dp[state \oplus (1 \text{ <}\text{< } i)] + (nums1[i] \oplus nums2[one\_cnt - 1]))$,其中 $state$ 第 $i$ 位一定为 $1$,$one\_cnt$ 为 $state$ 中 $1$ 的个数。
###### 4. 初始条件
- 既然是求最小值,不妨将所有状态初始为最大值。
- 未选择任何数时,异或值之和为 $0$,所以初始化 $dp[0] = 0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[state]$ 表示为:当前数组 $nums2$ 中元素选择状态为 $state$,并且选择了 $nums1$ 中前 $count(state)$ 个元素的情况下,可以组成的最小异或值之和。 所以最终结果为 $dp[states - 1]$,其中 $states = 1 \text{ <}\text{< } n$。
### 思路 1:代码
```python
class Solution:
def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:
ans = float('inf')
size = len(nums1)
states = 1 << size
dp = [float('inf') for _ in range(states)]
dp[0] = 0
for state in range(states):
one_cnt = bin(state).count('1')
for i in range(size):
if (state >> i) & 1:
dp[state] = min(dp[state], dp[state ^ (1 << i)] + (nums1[i] ^ nums2[one_cnt - 1]))
return dp[states - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(2^n \times n)$,其中 $n$ 是数组 $nums1$、$nums2$ 的长度。
- **空间复杂度**:$O(2^n)$。
================================================
FILE: docs/solutions/1800-1899/redistribute-characters-to-make-all-strings-equal.md
================================================
# [1897. 重新分配字符使所有字符串都相等](https://leetcode.cn/problems/redistribute-characters-to-make-all-strings-equal/)
- 标签:哈希表、字符串、计数
- 难度:简单
## 题目链接
- [1897. 重新分配字符使所有字符串都相等 - 力扣](https://leetcode.cn/problems/redistribute-characters-to-make-all-strings-equal/)
## 题目大意
**描述**:给定一个字符串数组 $words$(下标从 $0$ 开始计数)。
在一步操作中,需先选出两个 不同 下标 $i$ 和 $j$,其中 $words[i]$ 是一个非空字符串,接着将 $words[i]$ 中的任一字符移动到 $words[j]$ 中的 任一 位置上。
**要求**:如果执行任意步操作可以使 $words$ 中的每个字符串都相等,返回 $True$;否则,返回 $False$。
**说明**:
- $1 <= words.length <= 100$。
- $1 <= words[i].length <= 100$
- $words[i]$ 由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:words = ["abc","aabc","bc"]
输出:true
解释:将 words[1] 中的第一个 'a' 移动到 words[2] 的最前面。
使 words[1] = "abc" 且 words[2] = "abc"。
所有字符串都等于 "abc" ,所以返回 True。
```
- 示例 2:
```python
输入:words = ["ab","a"]
输出:False
解释:执行操作无法使所有字符串都相等。
```
## 解题思路
### 思路 1:哈希表
如果通过重新分配字符能够使所有字符串都相等,则所有字符串的字符需要满足:
1. 每个字符串中字符种类相同,
2. 每个字符串中各种字符的个数相同。
则我们可以使用哈希表来统计字符串中字符种类及个数。具体步骤如下:
1. 遍历单词数组 $words$ 中的所有单词 $word$。
2. 遍历所有单词 $word$ 中的所有字符 $ch$。
3. 使用哈希表 $cnts$ 统计字符种类及个数。
4. 如果所有字符个数都是单词个数的倍数,则说明通过重新分配字符能够使所有字符串都相等,则返回 $True$。
5. 否则返回 $False$。
### 思路 1:代码
```Python
class Solution:
def makeEqual(self, words: List[str]) -> bool:
size = len(words)
cnts = Counter()
for word in words:
for ch in word:
cnts[ch] += 1
return all(value % size == 0 for key, value in cnts.items())
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(s + |\sum|)$,其中 $s$ 为数组 $words$ 中所有单词的长度之和,$\sum$ 是字符集,本题中 $|\sum| = 26$。
- **空间复杂度**:$O(|\sum|)$。
================================================
FILE: docs/solutions/1800-1899/replace-all-digits-with-characters.md
================================================
# [1844. 将所有数字用字符替换](https://leetcode.cn/problems/replace-all-digits-with-characters/)
- 标签:字符串
- 难度:简单
## 题目链接
- [1844. 将所有数字用字符替换 - 力扣](https://leetcode.cn/problems/replace-all-digits-with-characters/)
## 题目大意
**描述**:给定一个下标从 $0$ 开始的字符串 $s$。字符串 $s$ 的偶数下标处为小写英文字母,奇数下标处为数字。
定义一个函数 `shift(c, x)`,其中 $c$ 是一个字符且 $x$ 是一个数字,函数返回字母表中 $c$ 后边第 $x$ 个字符。
- 比如,`shift('a', 5) = 'f'`,`shift('x', 0) = 'x'`。
对于每个奇数下标 $i$,我们需要将数字 $s[i]$ 用 `shift(s[i - 1], s[i])` 替换。
**要求**:替换字符串 $s$ 中所有数字以后,将字符串 $s$ 返回。
**说明**:
- 题目保证 `shift(s[i - 1], s[i])` 不会超过 `'z'`。
- $1 \le s.length \le 100$。
- $s$ 只包含小写英文字母和数字。
- 对所有奇数下标处的 $i$,满足 `shift(s[i - 1], s[i]) <= 'z'` 。
**示例**:
- 示例 1:
```python
输入:s = "a1c1e1"
输出:"abcdef"
解释:数字被替换结果如下:
- s[1] -> shift('a',1) = 'b'
- s[3] -> shift('c',1) = 'd'
- s[5] -> shift('e',1) = 'f'
```
- 示例 2:
```python
输入:s = "a1b2c3d4e"
输出:"abbdcfdhe"
解释:数字被替换结果如下:
- s[1] -> shift('a',1) = 'b'
- s[3] -> shift('b',2) = 'd'
- s[5] -> shift('c',3) = 'f'
- s[7] -> shift('d',4) = 'h'
```
## 解题思路
### 思路 1:模拟
1. 先定义一个 `shift(ch, x)` 用于替换 `s[i]`。
2. 将字符串转为字符串列表,定义为 $res$。
3. 以两个字符为一组遍历字符串,对 $res[i]$ 进行修改。
4. 将字符串列表连接起来,作为答案返回。
### 思路 1:代码
```python
class Solution:
def replaceDigits(self, s: str) -> str:
def shift(ch, x):
return chr(ord(ch) + x)
res = list(s)
for i in range(1, len(s), 2):
res[i] = shift(res[i - 1], int(res[i]))
return "".join(res)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1800-1899/sign-of-the-product-of-an-array.md
================================================
# [1822. 数组元素积的符号](https://leetcode.cn/problems/sign-of-the-product-of-an-array/)
- 标签:数组、数学
- 难度:简单
## 题目链接
- [1822. 数组元素积的符号 - 力扣](https://leetcode.cn/problems/sign-of-the-product-of-an-array/)
## 题目大意
**描述**:已知函数 `signFunc(x)` 会根据 `x` 的正负返回特定值:
- 如果 `x` 是正数,返回 `1`。
- 如果 `x` 是负数,返回 `-1`。
- 如果 `x` 等于 `0`,返回 `0`。
现在给定一个整数数组 `nums`。令 `product` 为数组 `nums` 中所有元素值的乘积。
**要求**:返回 `signFun(product)` 的值。
**说明**:
- $1 \le nums.length \le 1000$。
- $-100 \le nums[i] \le 100$。
**示例**:
- 示例 1:
```python
输入 nums = [-1,-2,-3,-4,3,2,1]
输出 1
解释 数组中所有值的乘积是 144,且 signFunc(144) = 1
```
## 解题思路
### 思路 1:
题目要求的是数组所有值乘积的正负性,但是我们没必要将所有数乘起来再判断正负性。只需要统计出数组中负数的个数,再加以判断即可。
- 使用变量 `minus_count` 记录数组中负数个数。
- 然后遍历数组 `nums`,对于当前元素 `num`:
- 如果为 `0`,则最终乘积肯定为 `0`,直接返回 `0`。
- 如果小于 `0`,负数个数加 `1`。
- 最终统计出数组中负数的个数为 `minus_count`。
- 如果 `minus_count` 是 `2` 的倍数,则说明最终乘积为正数,返回 `1`。
- 如果 `minus_count` 不是 `2` 的倍数,则说明最终乘积为负数,返回 `-1`。
## 代码
### 思路 1 代码:
```python
class Solution:
def arraySign(self, nums: List[int]) -> int:
minus_count = 0
for num in nums:
if num < 0:
minus_count += 1
elif num == 0:
return 0
if minus_count % 2 == 0:
return 1
else:
return -1
```
================================================
FILE: docs/solutions/1800-1899/sorting-the-sentence.md
================================================
# [1859. 将句子排序](https://leetcode.cn/problems/sorting-the-sentence/)
- 标签:字符串、排序
- 难度:简单
## 题目链接
- [1859. 将句子排序 - 力扣](https://leetcode.cn/problems/sorting-the-sentence/)
## 题目大意
**描述**:给定一个句子 $s$,句子中包含的单词不超过 $9$ 个。并且句子 $s$ 中每个单词末尾添加了「从 $1$ 开始的单词位置索引」,并且将句子中所有单词打乱顺序。
举个例子,句子 `"This is a sentence"` 可以被打乱顺序得到 `"sentence4 a3 is2 This1"` 或者 `"is2 sentence4 This1 a3"` 。
**要求**:重新构造并得到原本顺序的句子。
**说明**:
- **一个句子**:指的是一个序列的单词用单个空格连接起来,且开头和结尾没有任何空格。每个单词都只包含小写或大写英文字母。
- $2 \le s.length \le 200$。
- $s$ 只包含小写和大写英文字母、空格以及从 $1$ 到 $9$ 的数字。
- $s$ 中单词数目为 $1$ 到 $9$ 个。
- $s$ 中的单词由单个空格分隔。
- $s$ 不包含任何前导或者后缀空格。
**示例**:
- 示例 1:
```python
输入:s = "is2 sentence4 This1 a3"
输出:"This is a sentence"
解释:将 s 中的单词按照初始位置排序,得到 "This1 is2 a3 sentence4" ,然后删除数字。
```
- 示例 2:
```python
输入:s = "Myself2 Me1 I4 and3"
输出:"Me Myself and I"
解释:将 s 中的单词按照初始位置排序,得到 "Me1 Myself2 and3 I4" ,然后删除数字。
```
## 解题思路
### 思路 1:模拟
1. 将句子 $s$ 按照空格分隔成数组 $s\_list$。
2. 遍历数组 $s\_list$ 中的单词:
1. 从单词中分割出对应单词索引 $idx$ 和对应单词 $word$。
2. 将单词 $word$ 存入答案数组 $res$ 对应位置 $idx - 1$ 上,即:$res[int(idx) - 1] = word$。
3. 将答案数组用空格拼接成句子字符串,并返回。
### 思路 1:代码
```python
class Solution:
def sortSentence(self, s: str) -> str:
s_list = s.split()
size = len(s_list)
res = ["" for _ in range(size)]
for sub in s_list:
idx = ""
word = ""
for ch in sub:
if '1' <= ch <= '9':
idx += ch
else:
word += ch
res[int(idx) - 1] = word
return " ".join(res)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m)$,其中 $m$ 为给定句子 $s$ 的长度。
- **空间复杂度**:$O(m)$。
================================================
FILE: docs/solutions/1800-1899/substrings-of-size-three-with-distinct-characters.md
================================================
# [1876. 长度为三且各字符不同的子字符串](https://leetcode.cn/problems/substrings-of-size-three-with-distinct-characters/)
- 标签:哈希表、字符串、计数、滑动窗口
- 难度:简单
## 题目链接
- [1876. 长度为三且各字符不同的子字符串 - 力扣](https://leetcode.cn/problems/substrings-of-size-three-with-distinct-characters/)
## 题目大意
**描述**:给定搞一个字符串 $s$。
**要求**:返回 $s$ 中长度为 $3$ 的好子字符串的数量。如果相同的好子字符串出现多次,则每一次都应该被记入答案之中。
**说明**:
- **子字符串**:指的是一个字符串中连续的字符序列。
- **好子字符串**:如果一个字符串中不含有任何重复字符,则称这个字符串为好子字符串。
- $1 \le s.length \le 100$。
- $s$ 只包含小写英文字母。
**示例**:
- 示例 1:
```python
输入:s = "xyzzaz"
输出:1
解释:总共有 4 个长度为 3 的子字符串:"xyz","yzz","zza" 和 "zaz" 。
唯一的长度为 3 的好子字符串是 "xyz" 。
```
- 示例 2:
```python
输入:s = "aababcabc"
输出:4
解释:总共有 7 个长度为 3 的子字符串:"aab","aba","bab","abc","bca","cab" 和 "abc" 。
好子字符串包括 "abc","bca","cab" 和 "abc" 。
```
## 解题思路
### 思路 1:模拟
1. 遍历字符串 $s$ 中长度为 3 的子字符串。
2. 判断子字符串中的字符是否有重复。如果没有重复,则答案进行计数。
3. 遍历完输出答案。
### 思路 1:代码
```python
class Solution:
def countGoodSubstrings(self, s: str) -> int:
ans = 0
for i in range(2, len(s)):
if s[i - 2] != s[i - 1] and s[i - 1] != s[i] and s[i - 2] != s[i]:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1900-1999/add-minimum-number-of-rungs.md
================================================
# [1936. 新增的最少台阶数](https://leetcode.cn/problems/add-minimum-number-of-rungs/)
- 标签:贪心、数组
- 难度:中等
## 题目链接
- [1936. 新增的最少台阶数 - 力扣](https://leetcode.cn/problems/add-minimum-number-of-rungs/)
## 题目大意
**描述**:给定一个严格递增的整数数组 $rungs$,用于表示梯子上每一台阶的高度。当前你正站在高度为 $0$ 的地板上,并打算爬到最后一个台阶。
另给定一个整数 $dist$。每次移动中,你可以到达下一个距离当前位置(地板或台阶)不超过 $dist$ 高度的台阶。当前,你也可以在任何正整数高度插入尚不存在的新台阶。
**要求**:返回爬到最后一阶时必须添加到梯子上的最少台阶数。
**说明**:
-
**示例**:
- 示例 1:
```python
输入:rungs = [1,3,5,10], dist = 2
输出:2
解释:
现在无法到达最后一阶。
在高度为 7 和 8 的位置增设新的台阶,以爬上梯子。
梯子在高度为 [1,3,5,7,8,10] 的位置上有台阶。
```
- 示例 2:
```python
输入:rungs = [3,4,6,7], dist = 2
输出:1
解释:
现在无法从地板到达梯子的第一阶。
在高度为 1 的位置增设新的台阶,以爬上梯子。
梯子在高度为 [1,3,4,6,7] 的位置上有台阶。
```
## 解题思路
### 思路 1:贪心算法 + 模拟
1. 遍历梯子的每一层台阶。
2. 计算每一层台阶与上一层台阶之间的差值 $diff$。
3. 每层最少需要新增的台阶数为 $\lfloor \frac{diff - 1}{dist} \rfloor$,将其计入答案 $ans$ 中。
4. 遍历完返回答案。
### 思路 1:代码
```Python
class Solution:
def addRungs(self, rungs: List[int], dist: int) -> int:
ans, cur = 0, 0
for h in rungs:
diff = h - cur
ans += (diff - 1) // dist
cur = h
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $rungs$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1900-1999/check-if-all-characters-have-equal-number-of-occurrences.md
================================================
# [1941. 检查是否所有字符出现次数相同](https://leetcode.cn/problems/check-if-all-characters-have-equal-number-of-occurrences/)
- 标签:哈希表、字符串、计数
- 难度:简单
## 题目链接
- [1941. 检查是否所有字符出现次数相同 - 力扣](https://leetcode.cn/problems/check-if-all-characters-have-equal-number-of-occurrences/)
## 题目大意
**描述**:给定一个字符串 $s$。如果 $s$ 中出现过的所有字符的出现次数相同,那么我们称字符串 $s$ 是「好字符串」。
**要求**:如果 $s$ 是一个好字符串,则返回 `True`,否则返回 `False`。
**说明**:
- $1 \le s.length \le 1000$。
- $s$ 只包含小写英文字母。
**示例**:
- 示例 1:
```python
输入:s = "abacbc"
输出:true
解释:s 中出现过的字符为 'a','b' 和 'c' 。s 中所有字符均出现 2 次。
```
- 示例 2:
```python
输入:s = "aaabb"
输出:false
解释:s 中出现过的字符为 'a' 和 'b' 。
'a' 出现了 3 次,'b' 出现了 2 次,两者出现次数不同。
```
## 解题思路
### 思路 1:哈希表
1. 使用哈希表记录字符串 $s$ 中每个字符的频数。
2. 然后遍历哈希表中的键值对,检测每个字符的频数是否相等。
3. 如果发现频数不相等,则直接返回 `False`。
4. 如果检查完发现所有频数都相等,则返回 `True`。
### 思路 1:代码
```python
class Solution:
def areOccurrencesEqual(self, s: str) -> bool:
counter = Counter(s)
flag = -1
for key in counter:
if flag == -1:
flag = counter[key]
else:
if flag != counter[key]:
return False
return True
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1900-1999/concatenation-of-array.md
================================================
# [1929. 数组串联](https://leetcode.cn/problems/concatenation-of-array/)
- 标签:数组
- 难度:简单
## 题目链接
- [1929. 数组串联 - 力扣](https://leetcode.cn/problems/concatenation-of-array/)
## 题目大意
**描述**:给定一个长度为 $n$ 的整数数组 $nums$。
**要求**:构建一个长度为 $2 \times n$ 的答案数组 $ans$,答案数组下标从 $0$ 开始计数 ,对于所有 $0 \le i < n$ 的 $i$ ,满足下述所有要求:
- $ans[i] == nums[i]$。
- $ans[i + n] == nums[i]$。
具体而言,$ans$ 由两个 $nums$ 数组「串联」形成。
**说明**:
- $n == nums.length$。
- $1 \le n \le 1000$。
- $1 \le nums[i] \le 1000$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,1]
输出:[1,2,1,1,2,1]
解释:数组 ans 按下述方式形成:
- ans = [nums[0],nums[1],nums[2],nums[0],nums[1],nums[2]]
- ans = [1,2,1,1,2,1]
```
- 示例 2:
```python
输入:nums = [1,3,2,1]
输出:[1,3,2,1,1,3,2,1]
解释:数组 ans 按下述方式形成:
- ans = [nums[0],nums[1],nums[2],nums[3],nums[0],nums[1],nums[2],nums[3]]
- ans = [1,3,2,1,1,3,2,1]
```
## 解题思路
### 思路 1:按要求模拟
1. 定义一个数组变量(列表)$ans$ 作为答案数组。
2. 然后按顺序遍历两次数组 $nums$ 中的元素,并依次添加到 $ans$ 的尾部。最后返回 $ans$。
### 思路 1:代码
```python
class Solution:
def getConcatenation(self, nums: List[int]) -> List[int]:
ans = []
for num in nums:
ans.append(num)
for num in nums:
ans.append(num)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(n)$。如果算上答案数组的空间占用,则空间复杂度为 $O(n)$。不算上则空间复杂度为 $O(1)$。
### 思路 2:利用运算符
Python 中可以直接利用 `+` 号运算符将两个列表快速进行串联。即 `return nums + nums`。
### 思路 2:代码
```python
class Solution:
def getConcatenation(self, nums: List[int]) -> List[int]:
return nums + nums
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(n)$。如果算上答案数组的空间占用,则空间复杂度为 $O(n)$。不算上则空间复杂度为 $O(1)$。
================================================
FILE: docs/solutions/1900-1999/count-square-sum-triples.md
================================================
# [1925. 统计平方和三元组的数目](https://leetcode.cn/problems/count-square-sum-triples/)
- 标签:数学、枚举
- 难度:简单
## 题目链接
- [1925. 统计平方和三元组的数目 - 力扣](https://leetcode.cn/problems/count-square-sum-triples/)
## 题目大意
**描述**:给你一个整数 $n$。
**要求**:请你返回满足 $1 \le a, b, c \le n$ 的平方和三元组的数目。
**说明**:
- **平方和三元组**:指的是满足 $a^2 + b^2 = c^2$ 的整数三元组 $(a, b, c)$。
- $1 \le n \le 250$。
**示例**:
- 示例 1:
```python
输入 n = 5
输出 2
解释 平方和三元组为 (3,4,5) 和 (4,3,5)。
```
- 示例 2:
```python
输入:n = 10
输出:4
解释:平方和三元组为 (3,4,5),(4,3,5),(6,8,10) 和 (8,6,10)。
```
## 解题思路
### 思路 1:枚举算法
我们可以在 $[1, n]$ 区间中枚举整数三元组 $(a, b, c)$ 中的 $a$ 和 $b$。然后判断 $a^2 + b^2$ 是否小于等于 $n$,并且是完全平方数。
在遍历枚举的同时,我们维护一个用于统计平方和三元组数目的变量 `cnt`。如果符合要求,则将计数 `cnt` 加 $1$。最终,我们返回该数目作为答案。
利用枚举算法统计平方和三元组数目的时间复杂度为 $O(n^2)$。
- 注意:在计算中,为了防止浮点数造成的误差,并且两个相邻的完全平方正数之间的距离一定大于 $1$,所以我们可以用 $\sqrt{a^2 + b^2 + 1}$ 来代替 $\sqrt{a^2 + b^2}$。
### 思路 1:代码
```python
class Solution:
def countTriples(self, n: int) -> int:
cnt = 0
for a in range(1, n + 1):
for b in range(1, n + 1):
c = int(sqrt(a * a + b * b + 1))
if c <= n and a * a + b * b == c * c:
cnt += 1
return cnt
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1900-1999/eliminate-maximum-number-of-monsters.md
================================================
# [1921. 消灭怪物的最大数量](https://leetcode.cn/problems/eliminate-maximum-number-of-monsters/)
- 标签:贪心、数组、排序
- 难度:中等
## 题目链接
- [1921. 消灭怪物的最大数量 - 力扣](https://leetcode.cn/problems/eliminate-maximum-number-of-monsters/)
## 题目大意
**描述**:你正在玩一款电子游戏,在游戏中你需要保护城市免受怪物侵袭。给定一个下标从 $0$ 开始且大小为 $n$ 的整数数组 $dist$,其中 $dist[i]$ 是第 $i$ 个怪物与城市的初始距离(单位:米)。
怪物以恒定的速度走向城市。每个怪物的速度都以一个长度为 $n$ 的整数数组 $speed$ 表示,其中 $speed[i]$ 是第 $i$ 个怪物的速度(单位:千米/分)。
你有一种武器,一旦充满电,就可以消灭 一个 怪物。但是,武器需要 一分钟 才能充电。武器在游戏开始时是充满电的状态,怪物从 第 $0$ 分钟时开始移动。
一旦任一怪物到达城市,你就输掉了这场游戏。如果某个怪物 恰好 在某一分钟开始时到达城市(距离表示为 $0$),这也会被视为输掉 游戏,在你可以使用武器之前,游戏就会结束。
**要求**:返回在你输掉游戏前可以消灭的怪物的最大数量。如果你可以在所有怪物到达城市前将它们全部消灭,返回 $n$。
**说明**:
-
**示例**:
- 示例 1:
```python
输入:dist = [1,3,4], speed = [1,1,1]
输出:3
解释:
第 0 分钟开始时,怪物的距离是 [1,3,4],你消灭了第一个怪物。
第 1 分钟开始时,怪物的距离是 [X,2,3],你消灭了第二个怪物。
第 3 分钟开始时,怪物的距离是 [X,X,2],你消灭了第三个怪物。
所有 3 个怪物都可以被消灭。
```
- 示例 2:
```python
输入:dist = [1,1,2,3], speed = [1,1,1,1]
输出:1
解释:
第 0 分钟开始时,怪物的距离是 [1,1,2,3],你消灭了第一个怪物。
第 1 分钟开始时,怪物的距离是 [X,0,1,2],所以你输掉了游戏。
你只能消灭 1 个怪物。
```
## 解题思路
### 思路 1:排序 + 贪心算法
对于第 $i$ 个怪物,最晚可被消灭的时间为 $times[i] = \lfloor \frac{dist[i] - 1}{speed[i]} \rfloor$。我们可以根据以上公式,将所有怪物最晚可被消灭时间存入数组 $times$ 中,然后对 $times$ 进行升序排序。
然后遍历数组 $times$,对于第 $i$ 个怪物:
1. 如果 $times[i] < i$,则说明第 $i$ 个怪物无法被消灭,直接返回 $i$ 即可。
2. 如果 $times[i] \ge i$,则说明第 $i$ 个怪物可以被消灭,继续向下遍历。
如果遍历完数组 $times$,则说明所有怪物都可以被消灭,则返回 $n$。
### 思路 1:代码
```Python
class Solution:
def eliminateMaximum(self, dist: List[int], speed: List[int]) -> int:
times = []
for d, s in zip(dist, speed):
time = (d - 1) // s
times.append(time)
times.sort()
size = len(times)
for i in range(size):
if times[i] < i:
return i
return size
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组 $dist$ 的长度。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/1900-1999/find-the-middle-index-in-array.md
================================================
# [1991. 找到数组的中间位置](https://leetcode.cn/problems/find-the-middle-index-in-array/)
- 标签:数组、前缀和
- 难度:简单
## 题目链接
- [1991. 找到数组的中间位置 - 力扣](https://leetcode.cn/problems/find-the-middle-index-in-array/)
## 题目大意
**描述**:给定一个下标从 $0$ 开始的整数数组 $nums$。
**要求**:返回最左边的中间位置 $middleIndex$(也就是所有可能中间位置下标做小的一个)。如果找不到这样的中间位置,则返回 $-1$。
**说明**:
- **中间位置 $middleIndex$**:满足 $nums[0] + nums[1] + … + nums[middleIndex - 1] == nums[middleIndex + 1] + nums[middleIndex + 2] + … + nums[nums.length - 1]$ 的数组下标。
- 如果 $middleIndex == 0$,左边部分的和定义为 $0$。类似的,如果 $middleIndex == nums.length - 1$,右边部分的和定义为 $0$。
**示例**:
- 示例 1:
```python
输入:nums = [2,3,-1,8,4]
输出:3
解释:
下标 3 之前的数字和为:2 + 3 + -1 = 4
下标 3 之后的数字和为:4 = 4
```
- 示例 2:
```python
输入:nums = [1,-1,4]
输出:2
解释:
下标 2 之前的数字和为:1 + -1 = 0
下标 2 之后的数字和为:0
```
## 解题思路
### 思路 1:前缀和
1. 先遍历一遍数组,求出数组中全部元素和为 $total$。
2. 再遍历一遍数组,使用变量 $prefix\_sum$ 为前 $i$ 个元素和。
3. 当遍历到第 $i$ 个元素时,其数组左侧元素之和为 $prefix\_sum$,右侧元素和为 $total - prefix\_sum - nums[i]$。
1. 如果左右元素之和相等,即 $prefix\_sum == total - prefix\_sum - nums[i]$($2 \times prefix\_sum + nums[i] == total$) 时,$i$ 为中间位置。此时返回 $i$。
2. 如果不满足,则继续累加当前元素到 $prefix\_sum$ 中,继续向后遍历。
4. 如果找不到符合要求的中间位置,则返回 $-1$。
### 思路 1:代码
```python
class Solution:
def findMiddleIndex(self, nums: List[int]) -> int:
total = sum(nums)
prefix_sum = 0
for i in range(len(nums)):
if 2 * prefix_sum + nums[i] == total:
return i
prefix_sum += nums[i]
return -1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1900-1999/index.md
================================================
## 本章内容
- [1903. 字符串中的最大奇数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/largest-odd-number-in-string.md)
- [1921. 消灭怪物的最大数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/eliminate-maximum-number-of-monsters.md)
- [1925. 统计平方和三元组的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/count-square-sum-triples.md)
- [1929. 数组串联](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/concatenation-of-array.md)
- [1930. 长度为 3 的不同回文子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/unique-length-3-palindromic-subsequences.md)
- [1936. 新增的最少台阶数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/add-minimum-number-of-rungs.md)
- [1941. 检查是否所有字符出现次数相同](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/check-if-all-characters-have-equal-number-of-occurrences.md)
- [1947. 最大兼容性评分和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/maximum-compatibility-score-sum.md)
- [1984. 学生分数的最小差值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/minimum-difference-between-highest-and-lowest-of-k-scores.md)
- [1986. 完成任务的最少工作时间段](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/minimum-number-of-work-sessions-to-finish-the-tasks.md)
- [1991. 找到数组的中间位置](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/find-the-middle-index-in-array.md)
- [1994. 好子集的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/the-number-of-good-subsets.md)
================================================
FILE: docs/solutions/1900-1999/largest-odd-number-in-string.md
================================================
# [1903. 字符串中的最大奇数](https://leetcode.cn/problems/largest-odd-number-in-string/)
- 标签:贪心、数学、字符串
- 难度:简单
## 题目链接
- [1903. 字符串中的最大奇数 - 力扣](https://leetcode.cn/problems/largest-odd-number-in-string/)
## 题目大意
**描述**:给定一个字符串 $num$,表示一个大整数。
**要求**:在字符串 $num$ 的所有非空子字符串中找出值最大的奇数,并以字符串形式返回。如果不存在奇数,则返回一个空字符串 `""`。
**说明**:
- **子字符串**:指的是字符串中一个连续的字符序列。
- $1 \le num.length \le 10^5$
- $num$ 仅由数字组成且不含前导零。
**示例**:
- 示例 1:
```python
输入:num = "52"
输出:"5"
解释:非空子字符串仅有 "5"、"2" 和 "52" 。"5" 是其中唯一的奇数。
```
- 示例 2:
```python
输入:num = "4206"
输出:""
解释:在 "4206" 中不存在奇数。
```
## 解题思路
### 思路 1:贪心算法
如果某个数 $x$ 为奇数,则 $x$ 末尾位上的数字一定为奇数。那么我们只需要在末尾为奇数的字符串中考虑最大的奇数即可。显而易见的是,最大的奇数一定是长度最长的那个。所以我们只需要逆序遍历字符串,找到第一个奇数,从整个字符串开始位置到该奇数位置所代表的整数,就是最大的奇数。具体步骤如下:
1. 逆序遍历字符串 $s$。
2. 找到第一个奇数位置 $i$,则 $num[0: i + 1]$ 为最大的奇数,将其作为答案返回。
### 思路 1:代码
```python
class Solution:
def largestOddNumber(self, num: str) -> str:
for i in range(len(num) - 1, -1, -1):
if int(num[i]) % 2 == 1:
return num[0: i + 1]
return ""
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1900-1999/maximum-compatibility-score-sum.md
================================================
# [1947. 最大兼容性评分和](https://leetcode.cn/problems/maximum-compatibility-score-sum/)
- 标签:位运算、数组、动态规划、回溯、状态压缩
- 难度:中等
## 题目链接
- [1947. 最大兼容性评分和 - 力扣](https://leetcode.cn/problems/maximum-compatibility-score-sum/)
## 题目大意
**描述**:有一份由 $n$ 个问题组成的调查问卷,每个问题的答案只有 $0$ 或 $1$。将这份调查问卷分发给 $m$ 名学生和 $m$ 名老师,学生和老师的编号都是 $0 \sim m - 1$。现在给定一个二维整数数组 $students$ 表示 $m$ 名学生给出的答案,其中 $studuents[i][j]$ 表示第 $i$ 名学生第 $j$ 个问题给出的答案。再给定一个二维整数数组 $mentors$ 表示 $m$ 名老师给出的答案,其中 $mentors[i][j]$ 表示第 $i$ 名导师第 $j$ 个问题给出的答案。
每个学生要和一名导师互相配对。配对的学生和导师之间的兼容性评分等于学生和导师答案相同的次数。
- 例如,学生答案为 $[1, 0, 1]$,而导师答案为 $[0, 0, 1]$,那么他们的兼容性评分为 $2$,因为只有第 $2$ 个和第 $3$ 个答案相同。
**要求**:找出最优的学生与导师的配对方案,以最大程度上提高所有学生和导师的兼容性评分和。然后返回可以得到的最大兼容性评分和。
**说明**:
- $m == students.length == mentors.length$。
- $n == students[i].length == mentors[j].length$。
- $1 \le m, n \le 8$。
- $students[i][k]$ 为 $0$ 或 $1$。
- $mentors[j][k]$ 为 $0$ 或 $1$。
**示例**:
- 示例 1:
```python
输入:students = [[1,1,0],[1,0,1],[0,0,1]], mentors = [[1,0,0],[0,0,1],[1,1,0]]
输出:8
解释:按下述方式分配学生和导师:
- 学生 0 分配给导师 2 ,兼容性评分为 3。
- 学生 1 分配给导师 0 ,兼容性评分为 2。
- 学生 2 分配给导师 1 ,兼容性评分为 3。
最大兼容性评分和为 3 + 2 + 3 = 8。
```
- 示例 2:
```python
输入:students = [[0,0],[0,0],[0,0]], mentors = [[1,1],[1,1],[1,1]]
输出:0
解释:任意学生与导师配对的兼容性评分都是 0。
```
## 解题思路
### 思路 1:状压 DP
因为 $m$、$n$ 的范围都是 $[1, 8]$,所以我们可以使用「状态压缩」的方式来表示学生的分配情况。即使用一个 $m$ 位长度的二进制数 $state$ 来表示每一位老师是否被分配了学生。如果 $state$ 的第 $i$ 位为 $1$,表示第 $i$ 位老师被分配了学生,如果 $state$ 的第 $i$ 位为 $0$,则表示第 $i$ 位老师没有分配到学生。
这样,我们就可以通过动态规划的方式来解决这道题。
###### 1. 阶段划分
按照学生的分配情况进行阶段划分。
###### 2. 定义状态
定义当前学生的分配情况为 $state$,$state$ 中包含 $count(state)$ 个 $1$,表示有 $count(state)$ 个老师被分配了学生。
则可以定义状态 $dp[state]$ 表示为:当前老师被分配学生的状态为 $state$,其中有 $count(state)$ 个老师被分配了学生的情况下,可以得到的最大兼容性评分和。
###### 3. 状态转移方程
对于当前状态 $state$,肯定是从比 $state$ 少选一个老师被分配的状态中递推而来。我们可以枚举少选一个元素的状态,找到可以得到的最大兼容性评分和,赋值给 $dp[state]$。
即状态转移方程为:$dp[state] = max(dp[state], \quad dp[state \oplus (1 \text{ <}\text{< } i)] + score[i][one\_cnt - 1])$,其中:
1. $state$ 第 $i$ 位一定为 $1$。
2. $state \oplus (1 \text{ <}\text{< } i)$ 为比 $state$ 少选一个元素的状态。
3. $scores[i][one\_cnt - 1]$ 为第 $i$ 名老师分配到第 $one\_cnt - 1$ 名学生的兼容性评分。
关于每位老师与每位同学之间的兼容性评分,我们可以事先通过一个 $m \times m \times n$ 的三重循环计算得出,并且存入到 $m \times m$ 大小的二维矩阵 $scores$ 中。
###### 4. 初始条件
- 初始每个老师都没有分配到学生的状态下,可以得到的最兼容性评分和为 $0$,即 $dp[0] = 0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[state]$ 表示为:当前老师被分配学生的状态为 $state$,其中有 $count(state)$ 个老师被分配了学生的情况下,可以得到的最大兼容性评分和。所以最终结果为 $dp[states - 1]$,其中 $states = 1 \text{ <}\text{< } m$。
### 思路 1:代码
```python
class Solution:
def maxCompatibilitySum(self, students: List[List[int]], mentors: List[List[int]]) -> int:
m, n = len(students), len(students[0])
scores = [[0 for _ in range(m)] for _ in range(m)]
for i in range(m):
for j in range(m):
for k in range(n):
scores[i][j] += (students[i][k] == mentors[j][k])
states = 1 << m
dp = [0 for _ in range(states)]
for state in range(states):
one_cnt = bin(state).count('1')
for i in range(m):
if (state >> i) & 1:
dp[state] = max(dp[state], dp[state ^ (1 << i)] + scores[i][one_cnt - 1])
return dp[states - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m^2 \times n + m \times 2^m)$。
- **空间复杂度**:$O(2^m)$。
================================================
FILE: docs/solutions/1900-1999/minimum-difference-between-highest-and-lowest-of-k-scores.md
================================================
# [1984. 学生分数的最小差值](https://leetcode.cn/problems/minimum-difference-between-highest-and-lowest-of-k-scores/)
- 标签:数组、排序、滑动窗口
- 难度:简单
## 题目链接
- [1984. 学生分数的最小差值 - 力扣](https://leetcode.cn/problems/minimum-difference-between-highest-and-lowest-of-k-scores/)
## 题目大意
**描述**:给定一个下标从 $0$ 开始的整数数组 $nums$,其中 $nums[i]$ 表示第 $i$ 名学生的分数。另给定一个整数 $k$。
**要求**:从数组中选出任意 $k$ 名学生的分数,使这 $k$ 个分数间最高分和最低分的差值达到最小化。返回可能的最小差值 。
**说明**:
- $1 \le k \le nums.length \le 1000$。
- $0 \le nums[i] \le 10^5$。
**示例**:
- 示例 1:
```python
输入:nums = [90], k = 1
输出:0
解释:选出 1 名学生的分数,仅有 1 种方法:
- [90] 最高分和最低分之间的差值是 90 - 90 = 0
可能的最小差值是 0
```
- 示例 2:
```python
输入:nums = [9,4,1,7], k = 2
输出:2
解释:选出 2 名学生的分数,有 6 种方法:
- [9,4,1,7] 最高分和最低分之间的差值是 9 - 4 = 5
- [9,4,1,7] 最高分和最低分之间的差值是 9 - 1 = 8
- [9,4,1,7] 最高分和最低分之间的差值是 9 - 7 = 2
- [9,4,1,7] 最高分和最低分之间的差值是 4 - 1 = 3
- [9,4,1,7] 最高分和最低分之间的差值是 7 - 4 = 3
- [9,4,1,7] 最高分和最低分之间的差值是 7 - 1 = 6
可能的最小差值是 2
```
## 解题思路
### 思路 1:排序 + 滑动窗口
如果想要最小化选择的 $k$ 名学生中最高分与最低分的差值,我们应该在排序后的数组中连续选择 $k$ 名学生。这是因为如果将连续 $k$ 名学生中的某位学生替换成不连续的学生,其最高分 / 最低分一定会发生变化,并且一定会使最高分变得最高 / 最低分变得最低。从而导致差值增大。
因此,最优方案一定是在排序后的数组中连续选择 $k$ 名学生中的所有情况中的其中一种。
这样,我们可以先对数组 $nums$ 进行升序排序。然后使用一个固定长度为 $k$ 的滑动窗口计算连续选择 $k$ 名学生的最高分与最低分的差值。并记录下最小的差值 $ans$,最后作为答案并返回结果。
### 思路 1:代码
```Python
class Solution:
def minimumDifference(self, nums: List[int], k: int) -> int:
nums.sort()
ans = float('inf')
for i in range(k - 1, len(nums)):
ans = min(ans, nums[i] - nums[i - k + 1])
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$,其中 $n$ 为数组 $nums$ 的长度。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/1900-1999/minimum-number-of-work-sessions-to-finish-the-tasks.md
================================================
# [1986. 完成任务的最少工作时间段](https://leetcode.cn/problems/minimum-number-of-work-sessions-to-finish-the-tasks/)
- 标签:位运算、数组、动态规划、回溯、状态压缩
- 难度:中等
## 题目链接
- [1986. 完成任务的最少工作时间段 - 力扣](https://leetcode.cn/problems/minimum-number-of-work-sessions-to-finish-the-tasks/)
## 题目大意
**描述**:给定一个整数数组 $tasks$ 代表需要完成的任务。 其中 $tasks[i]$ 表示第 $i$ 个任务需要花费的时长(单位为小时)。再给定一个整数 $sessionTime$,代表在一个工作时段中,最多可以连续工作的小时数。在连续工作至多 $sessionTime$ 小时后,需要进行休息。
现在需要按照如下条件完成给定任务:
1. 如果你在某一个时间段开始一个任务,你需要在同一个时间段完成它。
2. 完成一个任务后,你可以立马开始一个新的任务。
3. 你可以按任意顺序完成任务。
**要求**:按照上述要求,返回完成所有任务所需要的最少数目的工作时间段。
**说明**:
- $n == tasks.length$。
- $1 \le n \le 14$。
- $1 \le tasks[i] \le 10$。
- $max(tasks[i]) \le sessionTime \le 15$。
**示例**:
- 示例 1:
```python
输入:tasks = [1,2,3], sessionTime = 3
输出:2
解释:你可以在两个工作时间段内完成所有任务。
- 第一个工作时间段:完成第一和第二个任务,花费 1 + 2 = 3 小时。
- 第二个工作时间段:完成第三个任务,花费 3 小时。
```
- 示例 2:
```python
输入:tasks = [3,1,3,1,1], sessionTime = 8
输出:2
解释:你可以在两个工作时间段内完成所有任务。
- 第一个工作时间段:完成除了最后一个任务以外的所有任务,花费 3 + 1 + 3 + 1 = 8 小时。
- 第二个工作时间段,完成最后一个任务,花费 1 小时。
```
## 解题思路
### 思路 1:状压 DP
### 思路 1:代码
```python
class Solution:
def minSessions(self, tasks: List[int], sessionTime: int) -> int:
size = len(tasks)
states = 1 << size
prefix_sum = [0 for _ in range(states)]
for state in range(states):
for i in range(size):
if (state >> i) & 1:
prefix_sum[state] = prefix_sum[state ^ (1 << i)] + tasks[i]
break
dp = [float('inf') for _ in range(states)]
dp[0] = 0
for state in range(states):
sub = state
while sub > 0:
if prefix_sum[sub] <= sessionTime:
dp[state] = min(dp[state], dp[state ^ sub] + 1)
sub = (sub - 1) & state
return dp[states - 1]
```
### 思路 1:复杂度分析
- **时间复杂度**:
- **空间复杂度**:
================================================
FILE: docs/solutions/1900-1999/the-number-of-good-subsets.md
================================================
# [1994. 好子集的数目](https://leetcode.cn/problems/the-number-of-good-subsets/)
- 标签:位运算、数组、数学、动态规划、状态压缩
- 难度:困难
## 题目链接
- [1994. 好子集的数目 - 力扣](https://leetcode.cn/problems/the-number-of-good-subsets/)
## 题目大意
**描述**:给定一个整数数组 $nums$。
**要求**:返回 $nums$ 中不同的好子集的数目对 $10^9 + 7$ 取余的结果。
**说明**:
- **子集**:通过删除 $nums$ 中一些(可能一个都不删除,也可能全部都删除)元素后剩余元素组成的数组。如果两个子集删除的下标不同,那么它们被视为不同的子集。
- **好子集**:如果 $nums$ 的一个子集中,所有元素的乘积可以表示为一个或多个互不相同的质数的乘积,那么我们称它为好子集。
- 比如,如果 $nums = [1, 2, 3, 4]$:
- $[2, 3]$,$[1, 2, 3]$ 和 $[1, 3]$ 是好子集,乘积分别为 $6 = 2 \times 3$ ,$6 = 2 \times 3$ 和 $3 = 3$。
- $[1, 4]$ 和 $[4]$ 不是好子集,因为乘积分别为 $4 = 2 \times 2$ 和 $4 = 2 \times 2$。
- $1 \le nums.length \le 10^5$。
- $1 \le nums[i] \le 30$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,4]
输出:6
解释:好子集为:
- [1,2]:乘积为 2,可以表示为质数 2 的乘积。
- [1,2,3]:乘积为 6,可以表示为互不相同的质数 2 和 3 的乘积。
- [1,3]:乘积为 3,可以表示为质数 3 的乘积。
- [2]:乘积为 2,可以表示为质数 2 的乘积。
- [2,3]:乘积为 6,可以表示为互不相同的质数 2 和 3 的乘积。
- [3]:乘积为 3,可以表示为质数 3 的乘积。
```
- 示例 2:
```python
输入:nums = [4,2,3,15]
输出:5
解释:好子集为:
- [2]:乘积为 2,可以表示为质数 2 的乘积。
- [2,3]:乘积为 6,可以表示为互不相同质数 2 和 3 的乘积。
- [2,15]:乘积为 30,可以表示为互不相同质数 2,3 和 5 的乘积。
- [3]:乘积为 3,可以表示为质数 3 的乘积。
- [15]:乘积为 15,可以表示为互不相同质数 3 和 5 的乘积。
```
## 解题思路
### 思路 1:状态压缩 DP
根据题意可以看出:
1. 虽然 $nums$ 的长度是 $[1, 10^5]$,但是其值域范围只有 $[1, 30]$,则我们可以将 $[1, 30]$ 的数分为 $3$ 类:
1. 质数:$[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]$(共 $10$ 个数)。由于好子集的乘积拆解后的质因子只能包含这 $10$ 个,我们可以使用一个数组 $primes$ 记录下这 $10$ 个质数,将好子集的乘积拆解为质因子后,每个 $primes[i]$ 最多出现一次。
2. 非质数:$[4, 6, 8, 9, 10, 12, 14, 16, 18, 20, 21, 22, 24, 25, 26, 27, 28, 30]$。非质数肯定不会出现在好子集的乘积拆解后的质因子中。
3. 特殊的数:$[1]$。对于一个好子集而言,无论向中间添加多少个 $1$,得到的新子集仍是好子集。
2. 分类完成后,由于 $[1, 30]$ 中只有 $10$ 个质数,因此我们可以使用一个长度为 $10$ 的二进制数 $state$ 来表示 $primes$ 中质因数的选择情况。其中,如果 $state$ 第 $i$ 位为 $1$,则说明第 $i$ 个质因数 $primes[i]$ 被使用过;如果 $state$ 第 $i$ 位为 $0$,则说明第 $i$ 个质因数 $primes[i]$ 没有被使用过。
3. 题目规定值相同,但是下标不同的子集视为不同子集,那么我们可先统计出 $nums$ 中每个数 $nums[i]$ 的出现次数,将其存入 $cnts$ 数组中,其中 $cnts[num]$ 表示 $num$ 出现的次数。这样在统计方案时,直接计算出 $num$ 的方案数,再乘以 $cnts[num]$ 即可。
接下来,我们就可以使用「动态规划」的方式来解决这道题目了。
###### 1. 阶段划分
按照质因数的选择情况进行阶段划分。
###### 2. 定义状态
定义状态 $dp[state]$ 表示为:当质因数选择的情况为 $state$ 时,好子集的数目。
###### 3. 状态转移方程
对于 $nums$ 中的每个数 $num$,其对应出现次数为 $cnt$。我们可以通过试除法,将 $num$ 分解为不同的质因数,并使用「状态压缩」的方式,用一个二进制数 $cur\_state$ 来表示当前数 $num$ 中使用了哪些质因数。然后枚举所有状态,找到与 $cur\_state$ 不冲突的状态 $state$(也就是除了 $cur\_state$ 中选择的质因数外,选择的其他质因数情况,比如 $cur\_state$ 选择了 $2$ 和 $5$,则枚举不选择 $2$ 和 $5$ 的状态)。
此时,状态转移方程为:$dp[state | cur\_state] = \sum (dp[state] \times cnt) \mod MOD , \quad state \text{ \& } cur\_state == 0$
###### 4. 初始条件
- 当 $state == 0$,所选质因数为空时,空集为好子集,则 $dp[0] = 1$。同时,对于一个好子集而言,无论向中间添加多少个 $1$,得到的新子集仍是好子集,所以对于空集来说,可以对应出 $2^{cnts[1]}$ 个方案,则最终 $dp[0] = 2^{cnts[1]}$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[state]$ 表示为:当质因数的选择的情况为 $state$ 时,好子集的数目。 所以最终结果为所有状态下的好子集数目累积和。所以我们可以枚举所有状态,并记录下所有好子集的数目和,就是最终结果。
### 思路 1:代码
```python
class Solution:
def numberOfGoodSubsets(self, nums: List[int]) -> int:
MOD = 10 ** 9 + 7
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
cnts = Counter(nums)
dp = [0 for _ in range(1 << len(primes))]
dp[0] = pow(2, cnts[1], MOD) # 计算 1
# num 分解质因数
for num, cnt in cnts.items(): # 遍历 nums 中所有数及其频数
if num == 1: # 跳过 1
continue
flag = True # 检查 num 的质因数是否都不超过 1
cur_num = num
cur_state = 0
for i, prime in enumerate(primes): # 对 num 进行试除
cur_cnt = 0
while cur_num % prime == 0:
cur_cnt += 1
cur_state |= 1 << i
cur_num //= prime
if cur_cnt > 1: # 当前质因数超过 1,则 num 不能添加到子集中,跳过
flag = False
break
if not flag:
continue
for state in range(1 << len(primes)):
if state & cur_state == 0: # 只有当前选择状态与前一状态不冲突时,才能进行动态转移
dp[state | cur_state] = (dp[state | cur_state] + dp[state] * cnt) % MOD
ans = 0 # 统计所有非空集合的方案数
for i in range(1, 1 << len(primes)):
ans = (ans + dp[i]) % MOD
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n + m \times 2^p)$,其中 $n$ 为数组 $nums$ 的元素个数,$m$ 为 $nums$ 的最大值,$p$ 为 $[1, 30]$ 中的质数个数。
- **空间复杂度**:$O(2^p)$。
================================================
FILE: docs/solutions/1900-1999/unique-length-3-palindromic-subsequences.md
================================================
# [1930. 长度为 3 的不同回文子序列](https://leetcode.cn/problems/unique-length-3-palindromic-subsequences/)
- 标签:哈希表、字符串、前缀和
- 难度:中等
## 题目链接
- [1930. 长度为 3 的不同回文子序列 - 力扣](https://leetcode.cn/problems/unique-length-3-palindromic-subsequences/)
## 题目大意
**描述**:给定一个人字符串 $s$。
**要求**:返回 $s$ 中长度为 $s$ 的不同回文子序列的个数。即便存在多种方法来构建相同的子序列,但相同的子序列只计数一次。
**说明**:
- **回文**:指正着读和反着读一样的字符串。
- **子序列**:由原字符串删除其中部分字符(也可以不删除)且不改变剩余字符之间相对顺序形成的一个新字符串。
- 例如,`"ace"` 是 `"abcde"` 的一个子序列。
- $3 \le s.length \le 10^5$。
- $s$ 仅由小写英文字母组成。
**示例**:
- 示例 1:
```python
输入:s = "aabca"
输出:3
解释:长度为 3 的 3 个回文子序列分别是:
- "aba" ("aabca" 的子序列)
- "aaa" ("aabca" 的子序列)
- "aca" ("aabca" 的子序列)
```
- 示例 2:
```python
输入:s = "bbcbaba"
输出:4
解释:长度为 3 的 4 个回文子序列分别是:
- "bbb" ("bbcbaba" 的子序列)
- "bcb" ("bbcbaba" 的子序列)
- "bab" ("bbcbaba" 的子序列)
- "aba" ("bbcbaba" 的子序列)
```
## 解题思路
### 思路 1:枚举 + 哈希表
字符集只包含 $26$ 个小写字母,所以我们可以枚举这 $26$ 个小写字母。
对于每个小写字母,使用对撞双指针,找到字符串 $s$ 首尾两侧与小写字母相同的最左位置和最右位置。
如果两个位置不同,则我们可以将两个位置中间不重复的字符当作是长度为 $3$ 的子序列最中间的那个字符。
则我们可以统计出两个位置中间不重复字符的个数,将其累加到答案中。
遍历完,返回答案。
### 思路 1:代码
```Python
class Solution:
def countPalindromicSubsequence(self, s: str) -> int:
size = len(s)
ans = 0
for i in range(26):
left, right = 0, size - 1
while left < size and ord(s[left]) - ord('a') != i:
left += 1
while right >= 0 and ord(s[right]) - ord('a') != i:
right -= 1
if right - left < 2:
continue
char_set = set()
for j in range(left + 1, right):
char_set.add(s[j])
ans += len(char_set)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$n \times | \sum | + | \sum |^2$,其中 $n$ 为字符串 $s$ 的长度,$\sum$ 为字符集,本题中 $| \sum | = 26$。
- **空间复杂度**:$O(| \sum |)$。
================================================
FILE: docs/solutions/2000-2099/final-value-of-variable-after-performing-operations.md
================================================
# [2011. 执行操作后的变量值](https://leetcode.cn/problems/final-value-of-variable-after-performing-operations/)
- 标签:数组、字符串、模拟
- 难度:简单
## 题目链接
- [2011. 执行操作后的变量值 - 力扣](https://leetcode.cn/problems/final-value-of-variable-after-performing-operations/)
## 题目大意
存在一种支持 `4` 种操作和 `1` 个变量 `X` 的编程语言:
- `++X` 和 `x++` 使得变量 `X` 值加 `1`。
- `--X` 和 `X--` 使得变脸 `X ` 值减 `1`。
`X` 的初始值是 `0`。现在给定一个字符串数组 `operations`,这是由操作组成的一个列表。
要求:返回执行所有操作后,`X` 的最终值。
## 解题思路
思路很简单,初始答案 `res` 赋值为 `0`。
然后遍历操作列表 `operations`,判断每一个操作 `operation` 的符号。如果操作中含有 `+`,则让答案加 `1`,否则,则让答案减 `1`。最后输出答案。
## 代码
```python
def finalValueAfterOperations(self, operations):
"""
:type operations: List[str]
:rtype: int
"""
res = 0
for opration in operations:
res += 1 if '+' in opration else -1
return res
```
================================================
FILE: docs/solutions/2000-2099/index.md
================================================
## 本章内容
- [2011. 执行操作后的变量值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2000-2099/final-value-of-variable-after-performing-operations.md)
- [2023. 连接后等于目标字符串的字符串对](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2000-2099/number-of-pairs-of-strings-with-concatenation-equal-to-target.md)
- [2050. 并行课程 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2000-2099/parallel-courses-iii.md)
================================================
FILE: docs/solutions/2000-2099/number-of-pairs-of-strings-with-concatenation-equal-to-target.md
================================================
# [2023. 连接后等于目标字符串的字符串对](https://leetcode.cn/problems/number-of-pairs-of-strings-with-concatenation-equal-to-target/)
- 标签:数组、字符串
- 难度:中等
## 题目链接
- [2023. 连接后等于目标字符串的字符串对 - 力扣](https://leetcode.cn/problems/number-of-pairs-of-strings-with-concatenation-equal-to-target/)
## 题目大意
**描述**:给定一个数字字符串数组 `nums` 和一个数字字符串 `target`。
**要求**:返回 `nums[i] + nums[j]` (两个字符串连接,其中 `i != j`)结果等于 `target` 的下标 `(i, j)` 的数目。
**说明**:
- $2 \le nums.length \le 100$。
- $1 \le nums[i].length \le 100$。
- $2 \le target.length \le 100$。
- `nums[i]` 和 `target` 只包含数字。
- `nums[i]` 和 `target` 不含有任何前导 $0$。
**示例**:
- 示例 1:
```python
输入:nums = ["777","7","77","77"], target = "7777"
输出:4
解释:符合要求的下标对包括:
- (0, 1):"777" + "7"
- (1, 0):"7" + "777"
- (2, 3):"77" + "77"
- (3, 2):"77" + "77"
```
- 示例 2:
```python
输入:nums = ["123","4","12","34"], target = "1234"
输出:2
解释:符合要求的下标对包括
- (0, 1):"123" + "4"
- (2, 3):"12" + "34"
```
## 解题思路
### 思路 1:暴力枚举
1. 双重循环遍历所有的 `i` 和 `j`,满足 `i != j` 并且 `nums[i] + nums[j] == target` 时,记入到答案数目中。
2. 遍历完,返回答案数目。
### 思路 1:代码
```python
class Solution:
def numOfPairs(self, nums: List[str], target: str) -> int:
res = 0
for i in range(len(nums)):
for j in range(len(nums)):
if i != j and nums[i] + nums[j] == target:
res += 1
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(1)$。
### 思路 2:哈希表
1. 使用哈希表记录字符串数组 `nums` 中所有数字字符串的数量。
2. 遍历哈希表中的键 `num`。
3. 将 `target` 根据 `num` 的长度分为前缀 `prefix` 和 `suffix`。
4. 如果 `num` 等于 `prefix`,则判断后缀 `suffix` 是否在哈希表中,如果在哈希表中,则说明 `prefix` 和 `suffix` 能够拼接为 `target`。
1. 如果 `num` 等于 `suffix`,此时 `perfix == suffix`,则答案数目累积为 `table[prefix] * (table[suffix] - 1)`。
2. 如果 `num` 不等于 `suffix`,则答案数目累积为 `table[prefix] * table[suffix]`。
5. 最后输出答案数目。
### 思路 2:代码
```python
class Solution:
def numOfPairs(self, nums: List[str], target: str) -> int:
res = 0
table = collections.defaultdict(int)
for num in nums:
table[num] += 1
for num in table:
size = len(num)
prefix, suffix = target[ :size], target[size: ]
if num == prefix and suffix in table:
if num == suffix:
res += table[prefix] * (table[suffix] - 1)
else:
res += table[prefix] * table[suffix]
return res
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/2000-2099/parallel-courses-iii.md
================================================
# [2050. 并行课程 III](https://leetcode.cn/problems/parallel-courses-iii/)
- 标签:图、拓扑排序、数组、动态规划
- 难度:困难
## 题目链接
- [2050. 并行课程 III - 力扣](https://leetcode.cn/problems/parallel-courses-iii/)
## 题目大意
**描述**:给定一个整数 $n$,表示有 $n$ 节课,课程编号为 $1 \sim n$。
再给定一个二维整数数组 $relations$,其中 $relations[j] = [prevCourse_j, nextCourse_j]$,表示课程 $prevCourse_j$ 必须在课程 $nextCourse_j$ 之前完成(先修课的关系)。
再给定一个下标从 $0$ 开始的整数数组 $time$,其中 $time[i]$ 表示完成第 $(i + 1)$ 门课程需要花费的月份数。
现在根据以下规则计算完成所有课程所需要的最少月份数:
- 如果一门课的所有先修课都已经完成,则可以在任意时间开始这门课程。
- 可以同时上任意门课程。
**要求**:返回完成所有课程所需要的最少月份数。
**说明**:
- $1 \le n \le 5 * 10^4$。
- $0 \le relations.length \le min(n * (n - 1) / 2, 5 \times 10^4)$。
- $relations[j].length == 2$。
- $1 \le prevCourse_j, nextCourse_j \le n$。
- $prevCourse_j != nextCourse_j$。
- 所有的先修课程对 $[prevCourse_j, nextCourse_j]$ 都是互不相同的。
- $time.length == n$。
- $1 \le time[i] \le 10^4$。
- 先修课程图是一个有向无环图。
**示例**:
- 示例 1:

```python
输入:n = 3, relations = [[1,3],[2,3]], time = [3,2,5]
输出:8
解释:上图展示了输入数据所表示的先修关系图,以及完成每门课程需要花费的时间。
你可以在月份 0 同时开始课程 1 和 2 。
课程 1 花费 3 个月,课程 2 花费 2 个月。
所以,最早开始课程 3 的时间是月份 3 ,完成所有课程所需时间为 3 + 5 = 8 个月。
```
- 示例 2:
```python
输入:n = 5, relations = [[1,5],[2,5],[3,5],[3,4],[4,5]], time = [1,2,3,4,5]
输出:12
解释:上图展示了输入数据所表示的先修关系图,以及完成每门课程需要花费的时间。
你可以在月份 0 同时开始课程 1 ,2 和 3 。
在月份 1,2 和 3 分别完成这三门课程。
课程 4 需在课程 3 之后开始,也就是 3 个月后。课程 4 在 3 + 4 = 7 月完成。
课程 5 需在课程 1,2,3 和 4 之后开始,也就是在 max(1,2,3,7) = 7 月开始。
所以完成所有课程所需的最少时间为 7 + 5 = 12 个月。
```
## 解题思路
### 思路 1:拓扑排序 + 动态规划
1. 使用邻接表 $graph$ 存放课程关系图,并统计每门课程节点的入度,存入入度列表 $indegrees$。定义 $dp[i]$ 为完成第 $i$ 门课程所需要的最少月份数。使用 $ans$ 表示完成所有课程所需要的最少月份数。
2. 借助队列 $queue$,将所有入度为 $0$ 的节点入队。
3. 将队列中入度为 $0$ 的节点依次取出。对于取出的每个节点 $u$:
1. 遍历该节点的相邻节点 $v$,更新相邻节点 $v$ 所需要的最少月份数,即:$dp[v] = max(dp[v], dp[u] + time[v - 1])$。
2. 更新完成所有课程所需要的最少月份数 $ans$,即:$ans = max(ans, dp[v])$。
3. 相邻节点 $v$ 的入度减 $1$,如果入度减 $1$ 后的节点入度为 0,则将其加入队列 $queue$。
4. 重复 $3$ 的步骤,直到队列中没有节点。
5. 最后返回 $ans$。
### 思路 1:代码
```python
class Solution:
def minimumTime(self, n: int, relations: List[List[int]], time: List[int]) -> int:
graph = [[] for _ in range(n + 1)]
indegrees = [0 for _ in range(n + 1)]
for u, v in relations:
graph[u].append(v)
indegrees[v] += 1
queue = collections.deque()
dp = [0 for _ in range(n + 1)]
ans = 0
for i in range(1, n + 1):
if indegrees[i] == 0:
queue.append(i)
dp[i] = time[i - 1]
ans = max(ans, time[i - 1])
while queue:
u = queue.popleft()
for v in graph[u]:
dp[v] = max(dp[v], dp[u] + time[v - 1])
ans = max(ans, dp[v])
indegrees[v] -= 1
if indegrees[v] == 0:
queue.append(v)
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m + n)$,其中 $m$ 为数组 $relations$ 的长度。
- **空间复杂度**:$O(m + n)$。
================================================
FILE: docs/solutions/2100-2199/find-substring-with-given-hash-value.md
================================================
# [2156. 查找给定哈希值的子串](https://leetcode.cn/problems/find-substring-with-given-hash-value/)
- 标签:字符串、滑动窗口、哈希函数、滚动哈希
- 难度:困难
## 题目链接
- [2156. 查找给定哈希值的子串 - 力扣](https://leetcode.cn/problems/find-substring-with-given-hash-value/)
## 题目大意
**描述**:如果给定整数 `p` 和 `m`,一个长度为 `k` 且下标从 `0` 开始的字符串 `s` 的哈希值按照如下函数计算:
- $hash(s, p, m) = (val(s[0]) * p^0 + val(s[1]) * p^1 + ... + val(s[k-1]) * p^{k-1}) mod m$.
其中 `val(s[i])` 表示 `s[i]` 在字母表中的下标,从 `val('a') = 1` 到 `val('z') = 26`。
现在给定一个字符串 `s` 和整数 `power`,`modulo`,`k` 和 `hashValue` 。
**要求**:返回 `s` 中 第一个 长度为 `k` 的 子串 `sub`,满足 `hash(sub, power, modulo) == hashValue`。
**说明**:
- 子串:定义为一个字符串中连续非空字符组成的序列。
- $1 \le k \le s.length \le 2 * 10^4$。
- $1 \le power, modulo \le 10^9$。
- $0 \le hashValue < modulo$。
- `s` 只包含小写英文字母。
- 测试数据保证一定存在满足条件的子串。
**示例**:
- 示例 1:
```python
输入:s = "leetcode", power = 7, modulo = 20, k = 2, hashValue = 0
输出:"ee"
解释:"ee" 的哈希值为 hash("ee", 7, 20) = (5 * 1 + 5 * 7) mod 20 = 40 mod 20 = 0 。
"ee" 是长度为 2 的第一个哈希值为 0 的子串,所以我们返回 "ee" 。
```
## 解题思路
### 思路 1:Rabin Karp 算法、滚动哈希算法
这道题目的思想和 Rabin Karp 字符串匹配算法中用到的滚动哈希思想是一样的。不过两者计算的公式是相反的。
- 本题目中的子串哈希计算公式:$hash(s, p, m) = (val(s[i]) * p^0 + val(s[i+1]) * p^1 + ... + val(s[i+k-1]) * p^{k-1}) \mod m$.
- RK 算法中的子串哈希计算公式:$hash(s, p, m) = (val(s[i]) * p^{k-1} + val(s[i+1]) * p^{k-2} + ... + val(s[i+k-1]) * p^0) \mod m$.
可以看出两者的哈希计算公式是反的。
在 RK 算法中,下一个子串的哈希值计算方式为:$Hash(s_{[i + 1, i + k]}) = \{[Hash(s_{[i, i + k - 1]}) - s_i \times d^{k - 1}] \times d + s_{i + k} \times d^{0} \} \mod m$。其中 $Hash(s_{[i, i + k - 1]}$ 为当前子串的哈希值,$Hash(s_{[i + 1, i + k]})$ 为下一个子串的哈希值。
这个公式也可以用文字表示为:**在计算完当前子串的哈希值后,向右滚动字符串,即移除当前子串中最左侧字符的哈希值($val(s[i]) * p^{k-1}$)之后,再将整体乘以 $p$,再移入最右侧字符的哈希值 $val(s[i+k])$**。
我们可以参考 RK 算法中滚动哈希的计算方式,将其应用到本题中。
因为两者的哈希计算公式相反,所以本题中,我们可以从右侧想左侧逆向遍历字符串,当计算完当前子串的哈希值后,移除当前子串最右侧字符的哈希值($ val(s[i+k-1]) * p^{k-1}$)之后,再整体乘以 $p$,再移入最左侧字符的哈希值 $val(s[i - 1])$。
在本题中,对应的下一个逆向子串的哈希值计算方式为:$Hash(s_{[i - 1, i + k - 2]}) = \{ [Hash(s_{[i, i + k - 1]}) - s_{i + k - 1} \times d^{k - 1}] \times d + s_{i - 1} \times d^{0} \} \mod m$。其中 $Hash(s_{[i, i + k - 1]})$ 为当前子串的哈希值,$Hash(s_{[i - 1, i + k - 2]})$ 是下一个逆向子串的哈希值。
利用取模运算的两个公式:
- $(a \times b) \mod m = ((a \mod m) \times (b \mod m)) \mod m$
- $(a + b) \mod m = (a \mod m + b \mod m) \mod m$
我们可以把上面的式子转变为:
$$\begin{aligned} Hash(s_{[i - 1, i + k - 2]}) &= \{[Hash(s_{[i, i + k - 1]}) - s_{i + k - 1} \times d^{k - 1}] \times d + s_{i - 1} \times d^{0} \} \mod m \cr &= \{[Hash(s_{[i, i + k - 1]}) - s_{i + k - 1} \times d^{k - 1}] \times d \mod m + s_{i - 1} \times d^{0} \mod m \} \mod m \cr &= \{[Hash(s_{[i, i + k - 1]}) - s_{i + k - 1} \times d^{k - 1}] \mod m \times d \mod m + s_{i - 1} \times d^{0} \mod m \} \mod m \end{aligned}$$
> 注意:这里之所以用了「反向迭代」而不是「正向迭代」是因为如果使用了正向迭代,那么每次移除的最左侧字符哈希值为 $val(s[i]) * p^0$,之后整体需要除以 $p$,再移入最右侧字符哈希值为($val(s[i+k]) * p^{k-1})$)。
>
> 这样就用到了「除法」。而除法是不满足取模运算对应的公式的,所以这里不能用这种方法进行迭代。
>
> 而反向迭代,用到的是乘法。在整个过程中是满足取模运算相关的公式。乘法取余不影响最终结果。
### 思路 1:代码
```python
class Solution:
def subStrHash(self, s: str, power: int, modulo: int, k: int, hashValue: int) -> str:
hash_t = 0
n = len(s)
for i in range(n - 1, n - k - 1, -1):
hash_t = (hash_t * power + (ord(s[i]) - ord('a') + 1)) % modulo # 计算最后一个子串的哈希值
h = pow(power, k - 1) % modulo # 计算最高位项,方便后续移除操作
ans = ""
if hash_t == hashValue:
ans = s[n - k: n]
for i in range(n - k - 1, -1, -1): # 反向迭代,滚动计算子串的哈希值
hash_t = (hash_t - h * (ord(s[i + k]) - ord('a') + 1)) % modulo # 移除 s[i + k] 的哈希值
hash_t = (hash_t * power % modulo + (ord(s[i]) - ord('a') + 1) % modulo) % modulo # 添加 s[i] 的哈希值
if hash_t == hashValue: # 如果子串哈希值等于 hashValue,则为答案
ans = s[i: i + k]
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。其中字符串 $s$ 的长度为 $n$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/2100-2199/index.md
================================================
## 本章内容
- [2156. 查找给定哈希值的子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2100-2199/find-substring-with-given-hash-value.md)
- [2172. 数组的最大与和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2100-2199/maximum-and-sum-of-array.md)
================================================
FILE: docs/solutions/2100-2199/maximum-and-sum-of-array.md
================================================
# [2172. 数组的最大与和](https://leetcode.cn/problems/maximum-and-sum-of-array/)
- 标签:位运算、数组、动态规划、状态压缩
- 难度:困难
## 题目链接
- [2172. 数组的最大与和 - 力扣](https://leetcode.cn/problems/maximum-and-sum-of-array/)
## 题目大意
**描述**:给定一个长度为 $n$ 的整数数组 $nums$ 和一个整数 $numSlots$ 满足 $2 \times numSlots \ge n$。一共有 $numSlots$ 个篮子,编号为 $1 \sim numSlots$。
现在需要将所有 $n$ 个整数分到这些篮子中,且每个篮子最多有 $2$ 个整数。
**要求**:返回将 $nums$ 中所有数放入 $numSlots$ 个篮子中的最大与和。
**说明**:
- **与和**:当前方案中,每个数与它所在篮子编号的按位与运算结果之和。
- 比如,将数字 $[1, 3]$ 放入篮子 $1$ 中,$[4, 6]$ 放入篮子 $2$ 中,这个方案的与和为 $(1 \text{ AND } 1) + (3 \text{ AND } 1) + (4 \text{ AND } 2) + (6 \text{ AND } 2) = 1 + 1 + 0 + 2 = 4$。
- $n == nums.length$。
- $1 \le numSlots \le 9$。
- $1 \le n \le 2 \times numSlots$。
- $1 \le nums[i] \le 15$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,4,5,6], numSlots = 3
输出:9
解释:一个可行的方案是 [1, 4] 放入篮子 1 中,[2, 6] 放入篮子 2 中,[3, 5] 放入篮子 3 中。
最大与和为 (1 AND 1) + (4 AND 1) + (2 AND 2) + (6 AND 2) + (3 AND 3) + (5 AND 3) = 1 + 0 + 2 + 2 + 3 + 1 = 9。
```
- 示例 2:
```python
输入:nums = [1,3,10,4,7,1], numSlots = 9
输出:24
解释:一个可行的方案是 [1, 1] 放入篮子 1 中,[3] 放入篮子 3 中,[4] 放入篮子 4 中,[7] 放入篮子 7 中,[10] 放入篮子 9 中。
最大与和为 (1 AND 1) + (1 AND 1) + (3 AND 3) + (4 AND 4) + (7 AND 7) + (10 AND 9) = 1 + 1 + 3 + 4 + 7 + 8 = 24 。
注意,篮子 2 ,5 ,6 和 8 是空的,这是允许的。
```
## 解题思路
### 思路 1:状压 DP
每个篮子最多可分 $2$ 个整数,则我们可以将 $1$ 个篮子分成两个篮子,这样总共有 $2 \times numSlots$ 个篮子,每个篮子中最多可以装 $1$ 个整数。
同时因为 $numSlots$ 的范围为 $[1, 9]$,$2 \times numSlots$ 的范围为 $[2, 19]$,范围不是很大,所以我们可以用「状态压缩」的方式来表示每个篮子中的整数放取情况。
即使用一个 $n \times numSlots$ 位的二进制数 $state$ 来表示每个篮子中的整数放取情况。如果 $state$ 的第 $i$ 位为 $1$,表示第 $i$ 个篮子里边放了整数,如果 $state$ 的第 $i$ 位为 $0$,表示第 $i$ 个篮子为空。
这样,我们就可以通过动态规划的方式来解决这道题。
###### 1. 阶段划分
按照 $2 \times numSlots$ 个篮子中的整数放取情况进行阶段划分。
###### 2. 定义状态
定义当前每个篮子中的整数放取情况为 $state$,$state$ 对应选择的整数个数为 $count(state)$。
则可以定义状态 $dp[state]$ 表示为:将前 $count(state)$ 个整数放到篮子里,并且每个篮子中的整数放取情况为 $state$ 时,可以获得的最大与和。
###### 3. 状态转移方程
对于当前状态 $dp[state]$,肯定是从比 $state$ 少选一个元素的状态中递推而来。我们可以枚举少选一个元素的状态,找到可以获得的最大与和,赋值给 $dp[state]$。
即状态转移方程为:$dp[state] = min(dp[state], dp[state \oplus (1 \text{ <}\text{< } i)] + (i // 2 + 1) \text{ \& } nums[one\_cnt - 1])$,其中:
1. $state$ 第 $i$ 位一定为 $1$。
2. $state \oplus (1 \text{ <}\text{< } i)$ 为比 $state$ 少选一个元素的状态。
3. $i // 2 + 1$ 为篮子对应编号
4. $nums[one\_cnt - 1]$ 为当前正在考虑的数组元素。
###### 4. 初始条件
- 初始每个篮子中都没有放整数的情况下,可以获得的最大与和为 $0$,即 $dp[0] = 0$。
###### 5. 最终结果
根据我们之前定义的状态,$dp[state]$ 表示为:将前 $count(state)$ 个整数放到篮子里,并且每个篮子中的整数放取情况为 $state$ 时,可以获得的最大与和。所以最终结果为 $max(dp)$。
> 注意:当 $one\_cnt > len(nums)$ 时,无法通过递推得到 $dp[state]$,需要跳过。
### 思路 1:代码
```python
class Solution:
def maximumANDSum(self, nums: List[int], numSlots: int) -> int:
states = 1 << (numSlots * 2)
dp = [0 for _ in range(states)]
for state in range(states):
one_cnt = bin(state).count('1')
if one_cnt > len(nums):
continue
for i in range(numSlots * 2):
if (state >> i) & 1:
dp[state] = max(dp[state], dp[state ^ (1 << i)] + ((i // 2 + 1) & nums[one_cnt - 1]))
return max(dp)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(2^m \times m)$,其中 $m = 2 \times numSlots$。
- **空间复杂度**:$O(2^m)$。
================================================
FILE: docs/solutions/2200-2299/add-two-integers.md
================================================
# [2235. 两整数相加](https://leetcode.cn/problems/add-two-integers/)
- 标签:数学
- 难度:简单
## 题目链接
- [2235. 两整数相加 - 力扣](https://leetcode.cn/problems/add-two-integers/)
## 题目大意
**描述**:给定两个整数 $num1$ 和 $num2$。
**要求**:返回这两个整数的和。
**说明**:
- $-100 \le num1, num2 \le 100$。
**示例**:
- 示例 1:
```python
示例 1:
输入:num1 = 12, num2 = 5
输出:17
解释:num1 是 12,num2 是 5,它们的和是 12 + 5 = 17,因此返回 17。
```
- 示例 2:
```python
输入:num1 = -10, num2 = 4
输出:-6
解释:num1 + num2 = -6,因此返回 -6。
```
## 解题思路
### 思路 1:直接计算
1. 直接计算整数 $num1$ 与 $num2$ 的和,返回 $num1 + num2$ 即可。
### 思路 1:代码
```python
class Solution:
def sum(self, num1: int, num2: int) -> int:
return num1 + num2
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/2200-2299/count-integers-in-intervals.md
================================================
# [2276. 统计区间中的整数数目](https://leetcode.cn/problems/count-integers-in-intervals/)
- 标签:设计、线段树、有序集合
- 难度:困难
## 题目链接
- [2276. 统计区间中的整数数目 - 力扣](https://leetcode.cn/problems/count-integers-in-intervals/)
## 题目大意
**描述**:给定一个区间的空集。
**要求**:设计并实现满足要求的数据结构:
- 新增:添加一个区间到这个区间集合中。
- 统计:计算出现在 至少一个 区间中的整数个数。
实现 CountIntervals 类:
- `CountIntervals()` 使用区间的空集初始化对象
- `void add(int left, int right)` 添加区间 `[left, right]` 到区间集合之中。
- `int count()` 返回出现在 至少一个 区间中的整数个数。
**说明**:
- 区间 `[left, right]` 表示满足 $left \le x \le right$ 的所有整数 `x`。
- $1 \le left \le right \le 10^9$。
- 最多调用 `add` 和 `count` 方法 **总计** $10^5$ 次。
- 调用 `count` 方法至少一次。
**示例**:
- 示例 1:
```python
输入:
["CountIntervals", "add", "add", "count", "add", "count"]
[[], [2, 3], [7, 10], [], [5, 8], []]
输出:
[null, null, null, 6, null, 8]
解释:
CountIntervals countIntervals = new CountIntervals(); // 用一个区间空集初始化对象
countIntervals.add(2, 3); // 将 [2, 3] 添加到区间集合中
countIntervals.add(7, 10); // 将 [7, 10] 添加到区间集合中
countIntervals.count(); // 返回 6
// 整数 2 和 3 出现在区间 [2, 3] 中
// 整数 7、8、9、10 出现在区间 [7, 10] 中
countIntervals.add(5, 8); // 将 [5, 8] 添加到区间集合中
countIntervals.count(); // 返回 8
// 整数 2 和 3 出现在区间 [2, 3] 中
// 整数 5 和 6 出现在区间 [5, 8] 中
// 整数 7 和 8 出现在区间 [5, 8] 和区间 [7, 10] 中
// 整数 9 和 10 出现在区间 [7, 10] 中
```
## 解题思路
### 思路 1:动态开点线段树
这道题可以使用线段树来做。
因为区间的范围是 $[1, 10^9]$,普通数组构成的线段树不满足要求。需要用到动态开点线段树。具体做法如下:
- 初始化方法,构建一棵线段树。每个线段树的节点类存储当前区间中保存的元素个数。
- 在 `add` 方法中,将区间 `[left, right]` 上的每个元素值赋值为 `1`,则区间值为 `right - left + 1`。
- 在 `count` 方法中,返回区间 $[0, 10^9]$ 的区间值(即区间内元素个数)。
### 思路 1:动态开点线段树代码
```python
# 线段树的节点类
class SegTreeNode:
def __init__(self, left=-1, right=-1, val=0, lazy_tag=None, leftNode=None, rightNode=None):
self.left = left # 区间左边界
self.right = right # 区间右边界
self.mid = left + (right - left) // 2
self.leftNode = leftNode # 区间左节点
self.rightNode = rightNode # 区间右节点
self.val = val # 节点值(区间值)
self.lazy_tag = lazy_tag # 区间问题的延迟更新标记
# 线段树类
class SegmentTree:
# 初始化线段树接口
def __init__(self, function):
self.tree = SegTreeNode(0, int(1e9))
self.function = function # function 是一个函数,左右区间的聚合方法
# 区间更新接口:将区间为 [q_left, q_right] 上的元素值修改为 val
def update_interval(self, q_left, q_right, val):
self.__update_interval(q_left, q_right, val, self.tree)
# 区间查询接口:查询区间为 [q_left, q_right] 的区间值
def query_interval(self, q_left, q_right):
return self.__query_interval(q_left, q_right, self.tree)
# 以下为内部实现方法
# 区间更新实现方法
def __update_interval(self, q_left, q_right, val, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
node.lazy_tag = val # 将当前节点的延迟标记标记为 val
interval_size = (node.right - node.left + 1) # 当前节点所在区间大小
node.val = val * interval_size # 当前节点所在区间每个元素值改为 val
return
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
if q_left <= node.mid: # 在左子树中更新区间值
self.__update_interval(q_left, q_right, val, node.leftNode)
if q_right > node.mid: # 在右子树中更新区间值
self.__update_interval(q_left, q_right, val, node.rightNode)
self.__pushup(node)
# 区间查询实现方法:在线段树的 [left, right] 区间范围中搜索区间为 [q_left, q_right] 的区间值
def __query_interval(self, q_left, q_right, node):
if node.left >= q_left and node.right <= q_right: # 节点所在区间被 [q_left, q_right] 所覆盖
return node.val # 直接返回节点值
if node.right < q_left or node.left > q_right: # 节点所在区间与 [q_left, q_right] 无关
return 0
self.__pushdown(node) # 向下更新节点所在区间的左右子节点的值和懒惰标记
res_left = 0 # 左子树查询结果
res_right = 0 # 右子树查询结果
if q_left <= node.mid: # 在左子树中查询
res_left = self.__query_interval(q_left, q_right, node.leftNode)
if q_right > node.mid: # 在右子树中查询
res_right = self.__query_interval(q_left, q_right, node.rightNode)
return self.function(res_left, res_right) # 返回左右子树元素值的聚合计算结果
# 向上更新实现方法:更新 node 节点区间值 等于 该节点左右子节点元素值的聚合计算结果
def __pushup(self, node):
if node.leftNode and node.rightNode:
node.val = self.function(node.leftNode.val, node.rightNode.val)
# 向下更新实现方法:更新 node 节点所在区间的左右子节点的值和懒惰标记
def __pushdown(self, node):
if node.leftNode is None:
node.leftNode = SegTreeNode(node.left, node.mid)
if node.rightNode is None:
node.rightNode = SegTreeNode(node.mid + 1, node.right)
lazy_tag = node.lazy_tag
if node.lazy_tag is None:
return
node.leftNode.lazy_tag = lazy_tag # 更新左子节点懒惰标记
left_size = (node.leftNode.right - node.leftNode.left + 1)
node.leftNode.val = lazy_tag * left_size # 更新左子节点值
node.rightNode.lazy_tag = lazy_tag # 更新右子节点懒惰标记
right_size = (node.rightNode.right - node.rightNode.left + 1)
node.rightNode.val = lazy_tag * right_size # 更新右子节点值
node.lazy_tag = None # 更新当前节点的懒惰标记
class CountIntervals:
def __init__(self):
self.STree = SegmentTree(lambda x, y: x + y)
self.left = 10 ** 9
self.right = 0
def add(self, left: int, right: int) -> None:
self.STree.update_interval(left, right, 1)
def count(self) -> int:
return self.STree.query_interval(0, int(1e9))
# Your CountIntervals object will be instantiated and called as such:
# obj = CountIntervals()
# obj.add(left,right)
# param_2 = obj.count()
```
================================================
FILE: docs/solutions/2200-2299/count-lattice-points-inside-a-circle.md
================================================
# [2249. 统计圆内格点数目](https://leetcode.cn/problems/count-lattice-points-inside-a-circle/)
- 标签:几何、数组、哈希表、数学、枚举
- 难度:中等
## 题目链接
- [2249. 统计圆内格点数目 - 力扣](https://leetcode.cn/problems/count-lattice-points-inside-a-circle/)
## 题目大意
**描述**:给定一个二维整数数组 `circles`。其中 `circles[i] = [xi, yi, ri]` 表示网格上圆心为 `(xi, yi)` 且半径为 `ri` 的第 $i$ 个圆。
**要求**:返回出现在至少一个圆内的格点数目。
**说明**:
- **格点**:指的是整数坐标对应的点。
- 圆周上的点也被视为出现在圆内的点。
- $1 \le circles.length \le 200$。
- $circles[i].length == 3$。
- $1 \le xi, yi \le 100$。
- $1 \le ri \le min(xi, yi)$。
**示例**:
- 示例 1:
```python
输入:circles = [[2,2,1]]
输出:5
解释:
给定的圆如上图所示。
出现在圆内的格点为 (1, 2)、(2, 1)、(2, 2)、(2, 3) 和 (3, 2),在图中用绿色标识。
像 (1, 1) 和 (1, 3) 这样用红色标识的点,并未出现在圆内。
因此,出现在至少一个圆内的格点数目是 5。
```
- 示例 2:
```python
输入:circles = [[2,2,2],[3,4,1]]
输出:16
解释:
给定的圆如上图所示。
共有 16 个格点出现在至少一个圆内。
其中部分点的坐标是 (0, 2)、(2, 0)、(2, 4)、(3, 2) 和 (4, 4)。
```
## 解题思路
### 思路 1:枚举算法
题目要求中 $1 \le xi, yi \le 100$,$1 \le ri \le min(xi, yi)$。则圆中点的范围为 $1 \le x, y \le 200$。
我们可以枚举所有坐标和所有圆,检测该坐标是否在圆中。
为了优化枚举范围,我们可以先遍历一遍所有圆,计算最小、最大的 $x$、$y$ 范围,再枚举所有坐标和所有圆,并进行检测。
### 思路 1:代码
```python
class Solution:
def countLatticePoints(self, circles: List[List[int]]) -> int:
min_x, min_y = 200, 200
max_x, max_y = 0, 0
for circle in circles:
if circle[0] + circle[2] > max_x:
max_x = circle[0] + circle[2]
if circle[0] - circle[2] < min_x:
min_x = circle[0] - circle[2]
if circle[1] + circle[2] > max_y:
max_y = circle[1] + circle[2]
if circle[1] - circle[2] < min_y:
min_y = circle[1] - circle[2]
ans = 0
for x in range(min_x, max_x + 1):
for y in range(min_y, max_y + 1):
for xi, yi, ri in circles:
if (xi - x) * (xi - x) + (yi - y) * (yi - y) <= ri * ri:
ans += 1
break
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(x \times y)$,其中 $x$、$y$ 分别为横纵坐标的个数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/2200-2299/index.md
================================================
## 本章内容
- [2235. 两整数相加](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2200-2299/add-two-integers.md)
- [2246. 相邻字符不同的最长路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2200-2299/longest-path-with-different-adjacent-characters.md)
- [2249. 统计圆内格点数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2200-2299/count-lattice-points-inside-a-circle.md)
- [2276. 统计区间中的整数数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2200-2299/count-integers-in-intervals.md)
================================================
FILE: docs/solutions/2200-2299/longest-path-with-different-adjacent-characters.md
================================================
# [2246. 相邻字符不同的最长路径](https://leetcode.cn/problems/longest-path-with-different-adjacent-characters/)
- 标签:树、深度优先搜索、图、拓扑排序、数组、字符串
- 难度:困难
## 题目链接
- [2246. 相邻字符不同的最长路径 - 力扣](https://leetcode.cn/problems/longest-path-with-different-adjacent-characters/)
## 题目大意
**描述**:给定一个长度为 $n$ 的数组 $parent$ 来表示一棵树(即一个连通、无向、无环图)。该树的节点编号为 $0 \sim n - 1$,共 $n$ 个节点,其中根节点的编号为 $0$。其中 $parent[i]$ 表示节点 $i$ 的父节点,由于节点 $0$ 是根节点,所以 $parent[0] == -1$。再给定一个长度为 $n$ 的字符串,其中 $s[i]$ 表示分配给节点 $i$ 的字符。
**要求**:找出路径上任意一对相邻节点都没有分配到相同字符的最长路径,并返回该路径的长度。
**说明**:
- $n == parent.length == s.length$。
- $1 \le n \le 10^5$。
- 对所有 $i \ge 1$ ,$0 \le parent[i] \le n - 1$ 均成立。
- $parent[0] == -1$。
- $parent$ 表示一棵有效的树。
- $s$ 仅由小写英文字母组成。
**示例**:
- 示例 1:

```python
输入:parent = [-1,0,0,1,1,2], s = "abacbe"
输出:3
解释:任意一对相邻节点字符都不同的最长路径是:0 -> 1 -> 3 。该路径的长度是 3 ,所以返回 3。
可以证明不存在满足上述条件且比 3 更长的路径。
```
- 示例 2:

```python
输入:parent = [-1,0,0,0], s = "aabc"
输出:3
解释:任意一对相邻节点字符都不同的最长路径是:2 -> 0 -> 3 。该路径的长度为 3 ,所以返回 3。
```
## 解题思路
### 思路 1:树形 DP + 深度优先搜索
因为题目给定的是表示父子节点的 $parent$ 数组,为了方便递归遍历相邻节点,我们可以根据 $partent$ 数组,建立一个由父节点指向子节点的有向图 $graph$。
如果不考虑相邻节点是否为相同字符这一条件,那么这道题就是在求树的直径(树的最长路径长度)中的节点个数。
对于根节点为 $u$ 的树来说:
1. 如果其最长路径经过根节点 $u$,则 **最长路径长度 = 某子树中的最长路径长度 + 另一子树中的最长路径长度 + 1**。
2. 如果其最长路径不经过根节点 $u$,则 **最长路径长度 = 某个子树中的最长路径长度**。
即:**最长路径长度 = max(某子树中的最长路径长度 + 另一子树中的最长路径长度 + 1,某个子树中的最长路径长度)**。
对此,我们可以使用深度优先搜索递归遍历 $u$ 的所有相邻节点 $v$,并在递归遍历的同时,维护一个全局最大路径和变量 $ans$,以及当前节点 $u$ 的最大路径长度变量 $u\_len$。
1. 先计算出从相邻节点 $v$ 出发的最长路径长度 $v\_len$。
2. 更新维护全局最长路径长度为 $self.ans = max(self.ans, \quad u\_len + v\_len + 1)$。
3. 更新维护当前节点 $u$ 的最长路径长度为 $u\_len = max(u\_len, \quad v\_len + 1)$。
因为题目限定了「相邻节点字符不同」,所以在更新全局最长路径长度和当前节点 $u$ 的最长路径长度时,我们需要判断一下节点 $u$ 与相邻节点 $v$ 的字符是否相同,只有在字符不同的条件下,才能够更新维护。
最后,因为题目要求的是树的直径(树的最长路径长度)中的节点个数,而:**路径的节点 = 路径长度 + 1**,所以最后我们返回 $self.ans + 1$ 作为答案。
### 思路 1:代码
```python
class Solution:
def longestPath(self, parent: List[int], s: str) -> int:
size = len(parent)
# 根据 parent 数组,建立有向图
graph = [[] for _ in range(size)]
for i in range(1, size):
graph[parent[i]].append(i)
ans = 0
def dfs(u):
nonlocal ans
u_len = 0 # u 节点的最大路径长度
for v in graph[u]: # 遍历 u 节点的相邻节点
v_len = dfs(v) # 相邻节点的最大路径长度
if s[u] != s[v]: # 相邻节点字符不同
ans = max(ans, u_len + v_len + 1) # 维护最大路径长度
u_len = max(u_len, v_len + 1) # 更新 u 节点的最大路径长度
return u_len # 返回 u 节点的最大路径长度
dfs(0)
return ans + 1
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 是树的节点数目。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/2300-2399/count-special-integers.md
================================================
# [2376. 统计特殊整数](https://leetcode.cn/problems/count-special-integers/)
- 标签:数学、动态规划
- 难度:困难
## 题目链接
- [2376. 统计特殊整数 - 力扣](https://leetcode.cn/problems/count-special-integers/)
## 题目大意
**描述**:给定一个正整数 $n$。
**要求**:求区间 $[1, n]$ 内的所有整数中,特殊整数的数目。
**说明**:
- **特殊整数**:如果一个正整数的每一个数位都是互不相同的,则称它是特殊整数。
- $1 \le n \le 2 \times 10^9$。
**示例**:
- 示例 1:
```python
输入:n = 20
输出:19
解释:1 到 20 之间所有整数除了 11 以外都是特殊整数。所以总共有 19 个特殊整数。
```
- 示例 2:
```python
输入:n = 5
输出:5
解释:1 到 5 所有整数都是特殊整数。
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
将 $n$ 转换为字符串 $s$,定义递归函数 `def dfs(pos, state, isLimit, isNum):` 表示构造第 $pos$ 位及之后所有数位的合法方案数。接下来按照如下步骤进行递归。
1. 从 `dfs(0, 0, True, False)` 开始递归。 `dfs(0, 0, True, False)` 表示:
1. 从位置 $0$ 开始构造。
2. 初始没有使用数字(即前一位所选数字集合为 $0$)。
3. 开始时受到数字 $n$ 对应最高位数位的约束。
4. 开始时没有填写数字。
2. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:
1. 如果 $isNum == True$,说明当前方案符合要求,则返回方案数 $1$。
2. 如果 $isNum == False$,说明当前方案不符合要求,则返回方案数 $0$。
3. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
4. 如果遇到 $isNum == False$,说明之前位数没有填写数字,当前位可以跳过,这种情况下方案数等于 $pos + 1$ 位置上没有受到 $pos$ 位的约束,并且之前没有填写数字时的方案数,即:`ans = dfs(i + 1, state, False, False)`。
5. 如果 $isNum == True$,则当前位必须填写一个数字。此时:
1. 根据 $isNum$ 和 $isLimit$ 来决定填当前位数位所能选择的最小数字($minX$)和所能选择的最大数字($maxX$),
2. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
3. 如果之前没有选择 $d$,即 $d$ 不在之前选择的数字集合 $state$ 中,则方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, state | (1 << d), isLimit and d == maxX, True)`。
1. `state | (1 << d)` 表示之前选择的数字集合 $state$ 加上 $d$。
2. `isLimit and d == maxX` 表示 $pos + 1$ 位受到之前 $pos$ 位限制。
3. $isNum == True$ 表示 $pos$ 位选择了数字。
6. 最后的方案数为 `dfs(0, 0, True, False)`,将其返回即可。
### 思路 1:代码
```python
class Solution:
def countSpecialNumbers(self, n: int) -> int:
# 将 n 转换为字符串 s
s = str(n)
@cache
# pos: 第 pos 个数位
# state: 之前选过的数字集合。
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
# isNum: 表示 pos 前面的数位是否填了数字。
# 如果为真,则当前位不可跳过;如果为假,则当前位可跳过。
def dfs(pos, state, isLimit, isNum):
if pos == len(s):
# isNum 为 True,则表示当前方案符合要求
return int(isNum)
ans = 0
if not isNum:
# 如果 isNum 为 False,则可以跳过当前数位
ans = dfs(pos + 1, state, False, False)
# 如果前一位没有填写数字,则最小可选择数字为 0,否则最少为 1(不能含有前导 0)。
minX = 0 if isNum else 1
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = int(s[pos]) if isLimit else 9
# 枚举可选择的数字
for d in range(minX, maxX + 1):
# d 不在选择的数字集合中,即之前没有选择过 d
if (state >> d) & 1 == 0:
ans += dfs(pos + 1, state | (1 << d), isLimit and d == maxX, True)
return ans
return dfs(0, 0, True, False)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n \times 10 \times 2^{10})$,其中 $n$ 为给定整数。
- **空间复杂度**:$O(\log n \times 2^{10})$。
================================================
FILE: docs/solutions/2300-2399/index.md
================================================
## 本章内容
- [2376. 统计特殊整数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2300-2399/count-special-integers.md)
================================================
FILE: docs/solutions/2400-2499/index.md
================================================
## 本章内容
- [2427. 公因子的数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2400-2499/number-of-common-factors.md)
================================================
FILE: docs/solutions/2400-2499/number-of-common-factors.md
================================================
# [2427. 公因子的数目](https://leetcode.cn/problems/number-of-common-factors/)
- 标签:数学、枚举、数论
- 难度:简单
## 题目链接
- [2427. 公因子的数目 - 力扣](https://leetcode.cn/problems/number-of-common-factors/)
## 题目大意
**描述**:给定两个正整数 $a$ 和 $b$。
**要求**:返回 $a$ 和 $b$ 的公因子数目。
**说明**:
- **公因子**:如果 $x$ 可以同时整除 $a$ 和 $b$,则认为 $x$ 是 $a$ 和 $b$ 的一个公因子。
- $1 \le a, b \le 1000$。
**示例**:
- 示例 1:
```python
输入:a = 12, b = 6
输出:4
解释:12 和 6 的公因子是 1、2、3、6。
```
- 示例 2:
```python
输入:a = 25, b = 30
输出:2
解释:25 和 30 的公因子是 1、5。
```
## 解题思路
### 思路 1:枚举算法
最直接的思路就是枚举所有 $[1, min(a, b)]$ 之间的数,并检查是否能同时整除 $a$ 和 $b$。
当然,因为 $a$ 与 $b$ 的公因子肯定不会超过 $a$ 与 $b$ 的最大公因数,则我们可以直接枚举 $[1, gcd(a, b)]$ 之间的数即可,其中 $gcd(a, b)$ 是 $a$ 与 $b$ 的最大公约数。
### 思路 1:代码
```python
class Solution:
def commonFactors(self, a: int, b: int) -> int:
ans = 0
for i in range(1, math.gcd(a, b) + 1):
if a % i == 0 and b % i == 0:
ans += 1
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\sqrt{min(a, b)})$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/2500-2599/difference-between-maximum-and-minimum-price-sum.md
================================================
# [2538. 最大价值和与最小价值和的差值](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/)
- 标签:树、深度优先搜索、数组、动态规划
- 难度:困难
## 题目链接
- [2538. 最大价值和与最小价值和的差值 - 力扣](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/)
## 题目大意
**描述**:给定一个整数 $n$ 和一个长度为 $n - 1$ 的二维整数数组 $edges$ 用于表示一个 $n$ 个节点的无向无根图,节点编号为 $0 \sim n - 1$。其中 $edges[i] = [ai, bi]$ 表示树中节点 $ai$ 和 $bi$ 之间有一条边。再给定一个整数数组 $price$,其中 $price[i]$ 表示图中节点 $i$ 的价值。
一条路径的价值和是这条路径上所有节点的价值之和。
你可以选择树中任意一个节点作为根节点 $root$。选择 $root$ 为根的开销是以 $root$ 为起点的所有路径中,价值和最大的一条路径与最小的一条路径的差值。
**要求**:返回所有节点作为根节点的选择中,最大的开销为多少。
**说明**:
- $1 \le n \le 10^5$。
- $edges.length == n - 1$。
- $0 \le ai, bi \le n - 1$。
- $edges$ 表示一棵符合题面要求的树。
- $price.length == n$。
- $1 \le price[i] \le 10^5$。
**示例**:
- 示例 1:
```python
输入:n = 6, edges = [[0,1],[1,2],[1,3],[3,4],[3,5]], price = [9,8,7,6,10,5]
输出:24
解释:上图展示了以节点 2 为根的树。左图(红色的节点)是最大价值和路径,右图(蓝色的节点)是最小价值和路径。
- 第一条路径节点为 [2,1,3,4]:价值为 [7,8,6,10] ,价值和为 31 。
- 第二条路径节点为 [2] ,价值为 [7] 。
最大路径和与最小路径和的差值为 24 。24 是所有方案中的最大开销。
```
- 示例 2:
```python
输入:n = 3, edges = [[0,1],[1,2]], price = [1,1,1]
输出:2
解释:上图展示了以节点 0 为根的树。左图(红色的节点)是最大价值和路径,右图(蓝色的节点)是最小价值和路径。
- 第一条路径包含节点 [0,1,2]:价值为 [1,1,1] ,价值和为 3 。
- 第二条路径节点为 [0] ,价值为 [1] 。
最大路径和与最小路径和的差值为 2 。2 是所有方案中的最大开销。
```
## 解题思路
### 思路 1:树形 DP + 深度优先搜索
1. 因为 $price$ 数组中元素都为正数,所以价值和最小的一条路径一定为「单个节点」,也就是根节点 $root$ 本身。
2. 因为价值和最大的路径是从根节点 $root$ 出发的价值和最大的一条路径,所以「最大的开销」等于「从根节点 $root$ 出发的价值和最大的一条路径」与「路径中一个端点值」 的差值。
3. 价值和最大的路径的两个端点中,一个端点为根节点 $root$,另一个节点为叶子节点。
这样问题就变为了求树中一条路径,使得路径的价值和减去其中一个端点值的权值最大。
对此我们可以使用深度优先搜索递归遍历二叉树,并在递归遍历的同时,维护一个最大开销变量 $ans$。
然后定义函数 ` def dfs(self, u, father):` 计算以节点 $u$ 为根节点的子树中,带端点的最大路径和 $max\_s1$,以及去掉端点的最大路径和 $max\_s2$,其中 $father$ 表示节点 $u$ 的根节点,用于遍历邻接节点的过程中过滤父节点,避免重复遍历。
初始化带端点的最大路径和 $max\_s1$ 为 $price[u]$,表示当前只有一个节点,初始化去掉端点的最大路径和 $max\_s2$ 为 $0$,表示当前没有节点。
然后在遍历节点 $u$ 的相邻节点 $v$ 时,递归调用 $dfs(v, u)$,获取以节点 $v$ 为根节点的子树中,带端点的最大路径和 $s1$,以及去掉端点的最大路径和 $s2$。此时最大开销变量 $self.ans$ 有两种情况:
1. $u$ 的子树中带端点的最大路径和,加上 $v$ 的子树中不带端点的最大路径和,即:$max\_s1 + s2$。
2. $u$ 的子树中去掉端点的最大路径和,加上 $v$ 的子树中带端点的最大路径和,即:$max\_s2 + s1$。
此时我们更新最大开销变量 $self.ans$,即:$self.ans = max(self.ans, \quad max\_s1 + s2, \quad max\_s2 + s1)$。
然后更新 $u$ 的子树中带端点的最大路径和 $max\_s1$,即:$max\_s1= max(max\_s1, \quad s1 + price[u])$。
再更新 $u$ 的子树中去掉端点的最大路径和 $max\_s2$,即:$max\_s2 = max(max\_s2, \quad s2 + price[u])$。
最后返回带端点 $u$ 的最大路径和 $max\_s1$,以及去掉端点 $u$ 的最大路径和 $。
最终,最大开销变量 $self.ans$ 即为答案。
### 思路 1:代码
```python
class Solution:
def __init__(self):
self.ans = 0
def dfs(self, graph, price, u, father):
max_s1 = price[u]
max_s2 = 0
for v in graph[u]:
if v == father: # 过滤父节点,避免重复遍历
continue
s1, s2 = self.dfs(graph, price, v, u)
self.ans = max(self.ans, max_s1 + s2, max_s2 + s1)
max_s1 = max(max_s1, s1 + price[u])
max_s2 = max(max_s2, s2 + price[u])
return max_s1, max_s2
def maxOutput(self, n: int, edges: List[List[int]], price: List[int]) -> int:
graph = [[] for _ in range(n)]
for u, v in edges:
graph[u].append(v)
graph[v].append(u)
self.dfs(graph, price, 0, -1)
return self.ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为树中节点个数。
- **空间复杂度**:$O(n)$。
## 参考链接
- 【题解】[二维差分模板 双指针 树形DP 树的直径【力扣周赛 328】](https://www.bilibili.com/video/BV1QT41127kJ/)
- 【题解】[2538. 最大价值和与最小价值和的差值 题解](https://github.com/doocs/leetcode/blob/main/solution/2500-2599/2538.Difference Between Maximum and Minimum Price Sum/README.md)
================================================
FILE: docs/solutions/2500-2599/index.md
================================================
## 本章内容
- [2538. 最大价值和与最小价值和的差值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2500-2599/difference-between-maximum-and-minimum-price-sum.md)
- [2585. 获得分数的方法数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2500-2599/number-of-ways-to-earn-points.md)
================================================
FILE: docs/solutions/2500-2599/number-of-ways-to-earn-points.md
================================================
# [2585. 获得分数的方法数](https://leetcode.cn/problems/number-of-ways-to-earn-points/)
- 标签:数组、动态规划
- 难度:困难
## 题目链接
- [2585. 获得分数的方法数 - 力扣](https://leetcode.cn/problems/number-of-ways-to-earn-points/)
## 题目大意
**描述**:考试中有 $n$ 种类型的题目。给定一个整数 $target$ 和一个下标从 $0$ 开始的二维整数数组 $types$,其中 $types[i] = [count_i, marks_i]$ 表示第 $i$ 种类型的题目有 $count_i$ 道,每道题目对应 $marks_i$ 分。
**要求**:返回你在考试中恰好得到 $target$ 分的方法数。由于答案可能很大,结果需要对 $10^9 + 7$ 取余。
**说明**:
- 同类型题目无法区分。比如说,如果有 $3$ 道同类型题目,那么解答第 $1$ 和第 $2$ 道题目与解答第 $1$ 和第 $3$ 道题目或者第 $2$ 和第 $3$ 道题目是相同的。
- $1 \le target \le 1000$。
- $n == types.length$。
- $1 \le n \le 50$。
- $types[i].length == 2$。
- $1 \le counti, marksi \le 50$。
**示例**:
- 示例 1:
```python
输入:target = 6, types = [[6,1],[3,2],[2,3]]
输出:7
解释:要获得 6 分,你可以选择以下七种方法之一:
- 解决 6 道第 0 种类型的题目:1 + 1 + 1 + 1 + 1 + 1 = 6
- 解决 4 道第 0 种类型的题目和 1 道第 1 种类型的题目:1 + 1 + 1 + 1 + 2 = 6
- 解决 2 道第 0 种类型的题目和 2 道第 1 种类型的题目:1 + 1 + 2 + 2 = 6
- 解决 3 道第 0 种类型的题目和 1 道第 2 种类型的题目:1 + 1 + 1 + 3 = 6
- 解决 1 道第 0 种类型的题目、1 道第 1 种类型的题目和 1 道第 2 种类型的题目:1 + 2 + 3 = 6
- 解决 3 道第 1 种类型的题目:2 + 2 + 2 = 6
- 解决 2 道第 2 种类型的题目:3 + 3 = 6
```
- 示例 2:
```python
输入:target = 5, types = [[50,1],[50,2],[50,5]]
输出:4
解释:要获得 5 分,你可以选择以下四种方法之一:
- 解决 5 道第 0 种类型的题目:1 + 1 + 1 + 1 + 1 = 5
- 解决 3 道第 0 种类型的题目和 1 道第 1 种类型的题目:1 + 1 + 1 + 2 = 5
- 解决 1 道第 0 种类型的题目和 2 道第 1 种类型的题目:1 + 2 + 2 = 5
- 解决 1 道第 2 种类型的题目:5
```
## 解题思路
### 思路 1:动态规划
###### 1. 阶段划分
按照进行阶段划分。
###### 2. 定义状态
定义状态 $dp[i][w]$ 表示为:前 $i$ 种题目恰好组成 $w$ 分的方案数。
###### 3. 状态转移方程
前 $i$ 种题目恰好组成 $w$ 分的方案数,等于前 $i - 1$ 种问题恰好组成 $w - k \times marks_i$ 分的方案数总和,即状态转移方程为:$dp[i][w] = \sum_{k = 0} dp[i - 1][w - k \times marks_i]$。
###### 4. 初始条件
- 前 $0$ 种题目恰好组成 $0$ 分的方案数为 $1$。
###### 5. 最终结果
根据我们之前定义的状态, $dp[i][w]$ 表示为:前 $i$ 种题目恰好组成 $w$ 分的方案数。 所以最终结果为 $dp[size][target]$。
### 思路 1:代码
```python
class Solution:
def waysToReachTarget(self, target: int, types: List[List[int]]) -> int:
size = len(types)
group_count = [types[i][0] for i in range(len(types))]
weight = [[(types[i][1] * k) for k in range(types[i][0] + 1)] for i in range(len(types))]
mod = 1000000007
dp = [[0 for _ in range(target + 1)] for _ in range(size + 1)]
dp[0][0] = 1
# 枚举前 i 组物品
for i in range(1, size + 1):
# 枚举背包装载重量
for w in range(target + 1):
# 枚举第 i 组物品能取个数
dp[i][w] = dp[i - 1][w]
for k in range(1, group_count[i - 1] + 1):
if w >= weight[i - 1][k]:
dp[i][w] += dp[i - 1][w - weight[i - 1][k]]
dp[i][w] %= mod
return dp[size][target]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times target \times m)$,其中 $n$ 为题目种类数,$target$ 为目标分数,$m$ 为每种题目的最大分数。
- **空间复杂度**:$O(n \times target)$。
================================================
FILE: docs/solutions/2700-2799/count-of-integers.md
================================================
# [2719. 统计整数数目](https://leetcode.cn/problems/count-of-integers/)
- 标签:数学、字符串、动态规划
- 难度:困难
## 题目链接
- [2719. 统计整数数目 - 力扣](https://leetcode.cn/problems/count-of-integers/)
## 题目大意
**描述**:给定两个数字字符串 $num1$ 和 $num2$,以及两个整数 $max\_sum$ 和 $min\_sum$。
**要求**:返回好整数的数目。答案可能很大,请返回答案对 $10^9 + 7$ 取余后的结果。
**说明**:
- **好整数**:如果一个整数 $x$ 满足一下条件,我们称它是一个好整数:
- $num1 \le x \le num2$。
- $num\_sum \le digit\_sum(x) \le max\_sum$。
- $digit\_sum(x)$ 表示 $x$ 各位数字之和。
- $1 \le num1 \le num2 \le 10^{22}$。
- $1 \le min\_sum \le max\_sum \le 400$。
**示例**:
- 示例 1:
```python
输入:num1 = "1", num2 = "12", min_num = 1, max_num = 8
输出:11
解释:总共有 11 个整数的数位和在 1 到 8 之间,分别是 1,2,3,4,5,6,7,8,10,11 和 12 。所以我们返回 11。
```
- 示例 2:
```python
输入:num1 = "1", num2 = "5", min_num = 1, max_num = 5
输出:5
解释:数位和在 1 到 5 之间的 5 个整数分别为 1,2,3,4 和 5 。所以我们返回 5。
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
将 $num1$ 补上前导 $0$,补到和 $num2$ 长度一致,定义递归函数 `def dfs(pos, total, isMaxLimit, isMinLimit):` 表示构造第 $pos$ 位及之后所有数位的合法方案数。接下来按照如下步骤进行递归。
1. 从 `dfs(0, 0, True, True)` 开始递归。 `dfs(0, 0, True, True)` 表示:
1. 从位置 $0$ 开始构造。
2. 初始数位和为 $0$。
3. 开始时当前数位最大值受到最高位数位的约束。
4. 开始时当前数位最小值受到最高位数位的约束。
2. 如果 $total > max\_sum$,说明当前方案不符合要求,则返回方案数 $0$。
3. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:
1. 如果 $min\_sum \le total \le max\_sum$,说明当前方案符合要求,则返回方案数 $1$。
2. 如果不满足,则当前方案不符合要求,则返回方案数 $0$。
4. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
5. 根据 $isMaxLimit$ 和 $isMinLimit$ 来决定填当前位数位所能选择的最小数字($minX$)和所能选择的最大数字($maxX$)。
6. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
7. 方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, total + d, isMaxLimit and d == maxX, isMinLimit and d == minX)`。
1. `total + d` 表示当前数位和 $total$ 加上 $d$。
2. `isMaxLimit and d == maxX` 表示 $pos + 1$ 位最大值受到之前 $pos$ 位限制。
3. `isMinLimit and d == maxX` 表示 $pos + 1$ 位最小值受到之前 $pos$ 位限制。
8. 最后的方案数为 `dfs(0, 0, True, True) % MOD`,将其返回即可。
### 思路 1:代码
```python
class Solution:
def count(self, num1: str, num2: str, min_sum: int, max_sum: int) -> int:
MOD = 10 ** 9 + 7
# 将 num1 补上前导 0,补到和 num2 长度一致
m, n = len(num1), len(num2)
if m < n:
num1 = '0' * (n - m) + num1
@cache
# pos: 第 pos 个数位
# total: 表示数位和
# isMaxLimit: 表示是否受到上限选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
# isMaxLimit: 表示是否受到下限选择限制。如果为真,则第 pos 位填入数字最小为 s[pos];如果为假,则最小可为 0。
def dfs(pos, total, isMaxLimit, isMinLimit):
if total > max_sum:
return 0
if pos == n:
# 当 min_sum <= total <= max_sum 时,当前方案符合要求
return int(total >= min_sum)
ans = 0
# 如果受到选择限制,则最小可选择数字为 num1[pos],否则最大可选择数字为 0。
minX = int(num1[pos]) if isMinLimit else 0
# 如果受到选择限制,则最大可选择数字为 num2[pos],否则最大可选择数字为 9。
maxX = int(num2[pos]) if isMaxLimit else 9
# 枚举可选择的数字
for d in range(minX, maxX + 1):
ans += dfs(pos + 1, total + d, isMaxLimit and d == maxX, isMinLimit and d == minX)
return ans % MOD
return dfs(0, 0, True, True) % MOD
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times 10)$,其中 $n$ 为数组 $nums2$ 的长度。
- **空间复杂度**:$O(n \times max\_sum)$。
================================================
FILE: docs/solutions/2700-2799/index.md
================================================
## 本章内容
- [2719. 统计整数数目](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2700-2799/count-of-integers.md)
================================================
FILE: docs/solutions/LCR/0H97ZC.md
================================================
# [LCR 075. 数组的相对排序](https://leetcode.cn/problems/0H97ZC/)
- 标签:数组、哈希表、计数排序、排序
- 难度:简单
## 题目链接
- [LCR 075. 数组的相对排序 - 力扣](https://leetcode.cn/problems/0H97ZC/)
## 题目大意
给定两个数组,`arr1` 和 `arr2`,其中 `arr2` 中的元素各不相同,`arr2` 中的每个元素都出现在 `arr1` 中。
要求:对 `arr1` 中的元素进行排序,使 `arr1` 中项的相对顺序和 `arr2` 中的相对顺序相同。未在 `arr2` 中出现过的元素需要按照升序放在 `arr1` 的末尾。
注意:
- `1 <= arr1.length, arr2.length <= 1000`。
- `0 <= arr1[i], arr2[i] <= 1000`。
## 解题思路
因为元素值范围在 `[0, 1000]`,所以可以使用计数排序的思路来解题。
使用数组 `count` 统计 `arr1` 各个元素个数。
遍历 `arr2` 数组,将对应元素`num2` 按照个数 `count[num2]` 添加到答案数组 `ans` 中,同时在 `count` 数组中减去对应个数。
然后在处理 `count` 中剩余元素,将 `count` 中大于 `0` 的元素下标依次添加到答案数组 `ans` 中。
## 代码
```python
class Solution:
def relativeSortArray(self, arr1: List[int], arr2: List[int]) -> List[int]:
count = [0 for _ in range(1010)]
for num1 in arr1:
count[num1] += 1
res = []
for num2 in arr2:
while count[num2] > 0:
res.append(num2)
count[num2] -= 1
for num in range(len(count)):
while count[num] > 0:
res.append(num)
count[num] -= 1
return res
```
================================================
FILE: docs/solutions/LCR/0on3uN.md
================================================
# [LCR 087. 复原 IP 地址](https://leetcode.cn/problems/0on3uN/)
- 标签:字符串、回溯
- 难度:中等
## 题目链接
- [LCR 087. 复原 IP 地址 - 力扣](https://leetcode.cn/problems/0on3uN/)
## 题目大意
给定一个只包含数字的字符串,用来表示一个 IP 地址。
要求:返回所有由 `s` 构成的有效 IP 地址,可以按任何顺序返回答案。
- 有效 IP 地址:正好由四个整数(每个整数由 0~255 的数构成,且不能含有前导 0),整数之间用 `.` 分割。
例如:`0.1.2.201` 和 `192.168.1.1` 是有效 IP 地址,但是 `0.011.255.245`、`192.168.1.312` 和 `192.168@1.1` 是 无效 IP 地址。
## 解题思路
回溯算法。使用 `res` 存储所有有效 IP 地址。用 `point_num` 表示当前 IP 地址的 `.` 符号个数。
定义回溯方法,从 `start_index` 位置开始遍历字符串。
- 如果字符串中添加的 `.` 符号数量为 `3`,则判断当前字符串是否为有效 IP 地址,如果为有效 IP 地址则加入到 `res` 数组中。直接返回。
- 然后在 `[start_index, len(s) - 1]` 范围循环遍历,判断 `[start_index, i]` 范围所代表的子串是否合法。如果合法:
- 则 `point_num += 1`。
- 然后在 i 位置后边增加 `.` 符号,继续回溯遍历。
- 最后 `point_num -= 1` 进行回退。
- 不符合则直接跳出循环。
- 最后返回 `res`。
## 代码
```python
class Solution:
res = []
def backstrack(self, s: str, start_index: int, point_num: int):
if point_num == 3:
if self.isValid(s, start_index, len(s) - 1):
self.res.append(s)
return
for i in range(start_index, len(s)):
if self.isValid(s, start_index, i):
point_num += 1
self.backstrack(s[:i + 1] + '.' + s[i + 1:], i + 2, point_num)
point_num -= 1
else:
break
def isValid(self, s: str, start: int, end: int):
if start > end:
return False
if s[start] == '0' and start != end:
return False
num = 0
for i in range(start, end + 1):
if s[i] > '9' or s[i] < '0':
return False
num = num * 10 + ord(s[i]) - ord('0')
if num > 255:
return False
return True
def restoreIpAddresses(self, s: str) -> List[str]:
self.res.clear()
if len(s) > 12:
return self.res
self.backstrack(s, 0, 0)
return self.res
```
================================================
FILE: docs/solutions/LCR/0ynMMM.md
================================================
# [LCR 039. 柱状图中最大的矩形](https://leetcode.cn/problems/0ynMMM/)
- 标签:栈、数组、单调栈
- 难度:困难
## 题目链接
- [LCR 039. 柱状图中最大的矩形 - 力扣](https://leetcode.cn/problems/0ynMMM/)
## 题目大意
给定一个非负整数数组 `heights` ,`heights[i]` 用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
要求:计算出在该柱状图中,能够勾勒出来的矩形的最大面积。
## 解题思路
思路一:枚举「宽度」。一重循环枚举所有柱子,第二重循环遍历柱子右侧的柱子,所得的宽度就是两根柱子形成区间的宽度,高度就是这段区间中的最小高度。然后计算出对应面积,记录并更新最大面积。这样下来,时间复杂度为 $O(n^2)$。
思路二:枚举「高度」。一重循环枚举所有柱子,以柱子高度为当前矩形高度,然后向两侧延伸,遇到小于当前矩形高度的情况就停止。然后计算当前矩形面积,记录并更新最大面积。这样下来,时间复杂度也是 $O(n^2)$。
思路三:利用「单调栈」减少两侧延伸的复杂度。
- 枚举所有柱子。
- 如果当前柱子高度较大,大于等于栈顶柱体的高度,则直接将当前柱体入栈。
- 如果当前柱体高度较小,小于栈顶柱体的高度,则一直出栈,直到当前柱体大于等于栈顶柱体高度。
- 出栈后,说明当前柱体是出栈柱体向右找到的第一个小于当前柱体高度的柱体,那么就可以向右将宽度扩展到当前柱体。
- 出栈后,说明新的栈顶柱体是出栈柱体向左找到的第一个小于新的栈顶柱体高度的柱体,那么就可以向左将宽度扩展到新的栈顶柱体。
- 以新的栈顶柱体为左边界,当前柱体为右边界,以出栈柱体为高度。计算矩形面积,然后记录并更新最大面积。
## 代码
```python
class Solution:
def largestRectangleArea(self, heights: List[int]) -> int:
heights.append(0)
ans = 0
stack = []
for i in range(len(heights)):
while stack and heights[stack[-1]] >= heights[i]:
cur = stack.pop(-1)
left = stack[-1] + 1 if stack else 0
right = i - 1
ans = max(ans, (right - left + 1) * heights[cur])
stack.append(i)
return ans
```
================================================
FILE: docs/solutions/LCR/1fGaJU.md
================================================
# [LCR 007. 三数之和](https://leetcode.cn/problems/1fGaJU/)
- 标签:数组、双指针、排序
- 难度:中等
## 题目链接
- [LCR 007. 三数之和 - 力扣](https://leetcode.cn/problems/1fGaJU/)
## 题目大意
给定一个包含 `n` 个整数的数组 `nums`,判断 `nums` 中是否存在三个元素 `a`、`b`、`c`,满足 `a + b + c = 0`。
要求:找出所有满足要求的不重复的三元组。
## 解题思路
直接三重遍历查找 a、b、c 的时间复杂度是:$O(n^3)$。我们可以通过一些操作来降低复杂度。
先将数组进行排序,以保证按顺序查找 a、b、c 时,元素值为升序,从而保证所找到的三个元素是不重复的。同时也方便下一步使用双指针减少一重遍历。时间复杂度为:$O(nlogn)$
第一重循环遍历 a,对于每个 a 元素,从 a 元素的下一个位置开始,使用双指针 left,right。left 指向 a 元素的下一个位置,right 指向末尾位置。先将 left 右移、right 左移去除重复元素,再进行下边的判断。
- 如果 `nums[a] + nums[left] + nums[right] = 0`,则得到一个解,将其加入答案数组中,并继续将 left 右移,right 左移;
- 如果 `nums[a] + nums[left] + nums[right] > 0`,说明 nums[right] 值太大,将 right 向左移;
- 如果 `nums[a] + nums[left] + nums[right] < 0`,说明 nums[left] 值太小,将 left 右移。
## 代码
```python
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
nums.sort()
ans = []
for i in range(n):
if i > 0 and nums[i] == nums[i - 1]:
continue
left = i + 1
right = n - 1
while left < right:
while left < right and left > i + 1 and nums[left] == nums[left - 1]:
left += 1
while left < right and right < n - 1 and nums[right + 1] == nums[right]:
right -= 1
if left < right and nums[i] + nums[left] + nums[right] == 0:
ans.append([nums[i], nums[left], nums[right]])
left += 1
right -= 1
elif nums[i] + nums[left] + nums[right] > 0:
right -= 1
else:
left += 1
return ans
```
================================================
FILE: docs/solutions/LCR/21dk04.md
================================================
# [LCR 097. 不同的子序列](https://leetcode.cn/problems/21dk04/)
- 标签:字符串、动态规划
- 难度:困难
## 题目链接
- [LCR 097. 不同的子序列 - 力扣](https://leetcode.cn/problems/21dk04/)
## 题目大意
给定两个字符串 `s` 和 `t`。
要求:计算在 `s` 的子序列中 `t` 出现的个数。
## 解题思路
动态规划求解。
定义状态 `dp[i][j]`表示为:以 `i - 1` 为结尾的 `s` 子序列中出现以 `j - 1` 为结尾的 `t` 的个数。
则状态转移方程为:
- 如果 `s[i - 1] == t[j - 1]`,则:`dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]`。即 `dp[i][j]` 来源于两部分:
- 使用 `s[i - 1]` 匹配 `t[j - 1]`,则 `dp[i][j]` 取源于以 `i - 2` 为结尾的 `s` 子序列中出现以 `j - 2` 为结尾的 `t` 的个数,即 `dp[i - 1][j - 1]`。
- 不使用 `s[i - 1]` 匹配 `t[j - 1]`,则 `dp[i][j]` 取源于以 `i - 2` 为结尾的 `s` 子序列中出现以 `j - 1` 为结尾的 `t` 的个数,即 `dp[i - 1][j]`。
- 如果 `s[i - 1] != t[j - 1]`,那么肯定不能用 `s[i - 1]` 匹配 `t[j - 1]`,则 `dp[i][j]` 取源于 `dp[i - 1][j]`。
下面来看看初始化:
- `dp[i][0]` 表示以 `i - 1` 为结尾的 `s` 子序列中出现空字符串的个数。把 `s` 中的元素全删除,出现空字符串的个数就是 `1`,则 `dp[i][0] = 1`。
- `dp[0][j]` 表示空字符串中出现以 `j - 1` 结尾的 `t` 的个数,空字符串无论怎么变都不会变成 `t`,则 `dp[0][j] = 0`
- `dp[0][0]` 表示空字符串中出现空字符串的个数,这个应该是 `1`,即 `dp[0][0] = 1`。
然后递推求解,最后输出 `dp[size_s][size_t]`。
## 代码
```python
class Solution:
def numDistinct(self, s: str, t: str) -> int:
size_s = len(s)
size_t = len(t)
dp = [[0 for _ in range(size_t + 1)] for _ in range(size_s + 1)]
for i in range(size_s):
dp[i][0] = 1
for i in range(1, size_s + 1):
for j in range(1, size_t + 1):
if s[i - 1] == t[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]
else:
dp[i][j] = dp[i - 1][j]
return dp[size_s][size_t]
```
================================================
FILE: docs/solutions/LCR/2AoeFn.md
================================================
# [LCR 098. 不同路径](https://leetcode.cn/problems/2AoeFn/)
- 标签:数学、动态规划、组合数学
- 难度:中等
## 题目链接
- [LCR 098. 不同路径 - 力扣](https://leetcode.cn/problems/2AoeFn/)
## 题目大意
给定一个 `m * n` 的棋盘, 机器人在左上角的位置,机器人每次只能向右、或者向下移动一步。
要求:求出到达棋盘右下角共有多少条不同的路径。
## 解题思路
可以用动态规划求解,设 `dp[i][j]` 是从 `(0, 0)`到 `(i, j)` 的不同路径数。显然 `dp[i][j] = dp[i-1][j] + dp[i][j-1]`。对于第一行、第一列,因为只能超一个方向走,所以 `dp[i][0] = 1`,`dp[0][j] = 1`。
## 代码
```python
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
dp = [1 for _ in range(n)]
for i in range(1, m):
for j in range(1, n):
dp[j] += dp[j - 1]
return dp[-1]
```
================================================
FILE: docs/solutions/LCR/2VG8Kg.md
================================================
# [LCR 008. 长度最小的子数组](https://leetcode.cn/problems/2VG8Kg/)
- 标签:数组、二分查找、前缀和、滑动窗口
- 难度:中等
## 题目链接
- [LCR 008. 长度最小的子数组 - 力扣](https://leetcode.cn/problems/2VG8Kg/)
## 题目大意
给定一个只包含正整数的数组 `nums` 和一个正整数 `target`。
要求:找出数组中满足和大于等于 `target` 的长度最小的「连续子数组」,并返回其长度。
## 解题思路
最直接的做法是暴力枚举,时间复杂度为 $O(n^2)$。但是我们可以利用滑动窗口的方法,在时间复杂度为 $O(n)$ 的范围内解决问题。
定义两个指针 `start` 和 `end`。`start` 代表滑动窗口开始位置,`end` 代表滑动窗口结束位置。再定义一个变量 `sum` 用来存储滑动窗口中的元素和,一个变量 `ans` 来存储满足提议的最小长度。
先不断移动 `end`,直到 `sum ≥ target`,则更新最小长度值 `ans`。然后再将滑动窗口的起始位置从滑动窗口中移出去,直到 `sum ≤ target`,在移出的期间,同样要更新最小长度值 `ans`。
然后等满足 `sum ≤ target` 时,再移动 `end`,重复上一步,直到遍历到数组末尾。
## 代码
```python
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
if not nums:
return 0
n = len(nums)
start = 0
end = 0
sum = 0
ans = n + 1
while end < n:
sum += nums[end]
while sum >= target:
ans = min(ans, end - start + 1)
sum -= nums[start]
start += 1
end += 1
if ans == n + 1:
return 0
else:
return ans
```
================================================
FILE: docs/solutions/LCR/2bCMpM.md
================================================
# [LCR 107. 01 矩阵](https://leetcode.cn/problems/2bCMpM/)
- 标签:广度优先搜索、数组、动态规划、矩阵
- 难度:中等
## 题目链接
- [LCR 107. 01 矩阵 - 力扣](https://leetcode.cn/problems/2bCMpM/)
## 题目大意
给定一个由 `0` 和 `1` 组成的矩阵,两个相邻元素间的距离为 `1` 。
要求:找出每个元素到最近的 `0` 的距离,并输出为矩阵。
## 解题思路
题目要求的是每个 `1` 到 `0`的最短曼哈顿距离。换句话也可以求每个 `0` 到 `1` 的最短曼哈顿距离。这样做的好处是,可以从所有值为 `0` 的元素开始进行搜索,可以不断累积距离,直到遇到值为 `1` 的元素时,可以直接将累积距离直接赋值。
具体操作如下:将所有值为 `0` 的元素坐标加入访问集合中,对所有值为`0` 的元素上下左右进行搜索。每进行一次上下左右搜索,更新新位置的距离值,并把新的位置坐标加入队列和访问集合中,直到遇见值为 `1` 的元素停止搜索。
## 代码
```python
class Solution:
def updateMatrix(self, mat: List[List[int]]) -> List[List[int]]:
row_count = len(mat)
col_count = len(mat[0])
dist_map = [[0 for _ in range(col_count)] for _ in range(row_count)]
zeroes_pos = []
for i in range(row_count):
for j in range(col_count):
if mat[i][j] == 0:
zeroes_pos.append((i, j))
directions = {(1, 0), (-1, 0), (0, 1), (0, -1)}
queue = collections.deque(zeroes_pos)
visited = set(zeroes_pos)
while queue:
i, j = queue.popleft()
for direction in directions:
new_i = i + direction[0]
new_j = j + direction[1]
if 0 <= new_i < row_count and 0 <= new_j < col_count and (new_i, new_j) not in visited:
dist_map[new_i][new_j] = dist_map[i][j] + 1
queue.append((new_i, new_j))
visited.add((new_i, new_j))
return dist_map
```
================================================
FILE: docs/solutions/LCR/3Etpl5.md
================================================
# [LCR 049. 求根节点到叶节点数字之和](https://leetcode.cn/problems/3Etpl5/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 049. 求根节点到叶节点数字之和 - 力扣](https://leetcode.cn/problems/3Etpl5/)
## 题目大意
给定一个二叉树的根节点 `root`,树中每个节点都存放有一个 `0` 到 `9` 之间的数字。每条从根节点到叶节点的路径都代表一个数字。例如,从根节点到叶节点的路径是 `1` -> `2` -> `3`,表示数字 `123`。
要求:计算从根节点到叶节点生成的所有数字的和。
## 解题思路
使用深度优先搜索,记录下路径上所有节点构成的数字,使用 `pretotal` 保存下当前路径上构成的数字。如果遇到叶节点直接返回当前数字,否则递归遍历左右子树,并累加对应结果。
## 代码
```python
class Solution:
def dfs(self, root, pretotal):
if not root:
return 0
total = pretotal * 10 + root.val
if not root.left and not root.right:
return total
return self.dfs(root.left, total) + self.dfs(root.right, total)
def sumNumbers(self, root: TreeNode) -> int:
return self.dfs(root, 0)
```
================================================
FILE: docs/solutions/LCR/3u1WK4.md
================================================
# [LCR 023. 相交链表](https://leetcode.cn/problems/3u1WK4/)
- 标签:哈希表、链表、双指针
- 难度:简单
## 题目链接
- [LCR 023. 相交链表 - 力扣](https://leetcode.cn/problems/3u1WK4/)
## 题目大意
给定 `A`、`B` 两个链表。
要求:判断两个链表是否相交,返回相交的起始点。如果不相交,则返回 `None`。
比如:链表 A 为 [4, 1, 8, 4, 5],链表 B 为 [5, 0, 1, 8, 4, 5]。则如下图所示,两个链表相交的起始节点为 8,则输出结果为 8。

## 解题思路
如果两个链表相交,那么从相交位置开始,到结束,必有一段等长且相同的节点。假设链表 A 的长度为 m、链表 B 的长度为 n,他们的相交序列有 k 个,则相交情况可以如下如所示:
现在问题是如何找到 m-k 或者 n-k 的位置。
考虑将链表 A 的末尾拼接上链表 B,链表 B 的末尾拼接上链表 A。
然后使用两个指针 pA 、PB,分别从链表 A、链表 B 的头节点开始遍历,如果走到共同的节点,则返回该节点。
否则走到两个链表末尾,返回 None。

## 代码
```python
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
if headA == None or headB == None:
return None
pA = headA
pB = headB
while pA != pB:
pA = pA.next if pA != None else headB
pB = pB.next if pB != None else headA
return pA
```
================================================
FILE: docs/solutions/LCR/4sjJUc.md
================================================
# [LCR 082. 组合总和 II](https://leetcode.cn/problems/4sjJUc/)
- 标签:数组、回溯
- 难度:中等
## 题目链接
- [LCR 082. 组合总和 II - 力扣](https://leetcode.cn/problems/4sjJUc/)
## 题目大意
给定一个数组 `candidates` 和一个目标数 `target`。
要求:找出 `candidates` 中所有可以使数字和为目标数 `target` 的组合。
数组 `candidates` 中的数字在每个组合中只能使用一次,且 `1 ≤ candidates[i] ≤ 50`。
## 解题思路
本题不能有重复组合,关键步骤在于去重。
在回溯遍历的时候,下一层递归的 `start_index` 要从当前节点的后一位开始遍历,即 `i + 1` 位开始。而且统一递归层不能使用相同的元素,即需要增加一句判断 `if i > start_index and candidates[i] == candidates[i - 1]: continue`。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, candidates: List[int], target: int, sum: int, start_index: int):
if sum > target:
return
if sum == target:
self.res.append(self.path[:])
return
for i in range(start_index, len(candidates)):
if sum + candidates[i] > target:
break
if i > start_index and candidates[i] == candidates[i - 1]:
continue
sum += candidates[i]
self.path.append(candidates[i])
self.backtrack(candidates, target, sum, i + 1)
sum -= candidates[i]
self.path.pop()
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
self.res.clear()
self.path.clear()
candidates.sort()
self.backtrack(candidates, target, 0, 0)
return self.res
```
================================================
FILE: docs/solutions/LCR/4ueAj6.md
================================================
# [LCR 029. 循环有序列表的插入](https://leetcode.cn/problems/4ueAj6/)
- 标签:链表
- 难度:中等
## 题目链接
- [LCR 029. 循环有序列表的插入 - 力扣](https://leetcode.cn/problems/4ueAj6/)
## 题目大意
给定循环升序链表中的一个节点 `head` 和一个整数 `insertVal`。
要求:将整数 `insertVal` 插入循环升序链表中,并且满足链表仍为循环升序链表。最终返回原先给定的节点。
## 解题思路
- 先判断所给节点 `head` 是否为空,为空直接创建一个值为 `insertVal` 的新节点,并指向自己,返回即可。
- 如果 `head` 不为空,把 `head` 赋值给 `node` ,方便最后返回原节点 `head`。
- 然后遍历 `node`,判断插入值 `insertVal` 与 `node.val` 和 `node.next.val` 的关系,找到插入位置,具体判断如下:
- 如果新节点值在两个节点值中间, 即 `node.val <= insertVal <= node.next.val`。则说明新节点值在最大值最小值中间,应将新节点插入到当前位置,则应将 `insertVal` 插入到这个位置。
- 如果新节点值比当前节点值和当前节点下一节点值都大,并且当前节点值比当前节点值的下一节点值大,即 `node.next.val < node.val <= insertVal`,则说明 `insertVal` 比链表最大值都大,应插入最大值后边。
- 如果新节点值比当前节点值和当前节点下一节点值都小,并且当前节点值比当前节点值的下一节点值大,即 `insertVal < node.next.val < node.val`,则说明 `insertVal` 比链表中最小值都小,应插入最小值前边。
- 找到插入位置后,跳出循环,在插入位置插入值为 `insertVal` 的新节点。
## 代码
```python
class Solution:
def insert(self, head: 'Node', insertVal: int) -> 'Node':
if not head:
node = Node(insertVal)
node.next = node
return node
node = head
while node.next != head:
if node.val <= insertVal <= node.next.val:
break
elif node.next.val < node.val <= insertVal:
break
elif insertVal < node.next.val < node.val:
break
else:
node = node.next
insert_node = Node(insertVal)
insert_node.next = node.next
node.next = insert_node
return head
```
================================================
FILE: docs/solutions/LCR/569nqc.md
================================================
# [LCR 035. 最小时间差](https://leetcode.cn/problems/569nqc/)
- 标签:数组、数学、字符串、排序
- 难度:中等
## 题目链接
- [LCR 035. 最小时间差 - 力扣](https://leetcode.cn/problems/569nqc/)
## 题目大意
给定一个 24 小时制形式(小时:分钟 "HH:MM")的时间列表 `timePoints`。
要求:找出列表中任意两个时间的最小时间差并以分钟数表示。
## 解题思路
- 遍历时间列表 `timePoints`,将每个时间转换为以分钟计算的整数形式,比如时间 `14:20`,将其转换为 `14 * 60 + 20 = 860`,存放到新的时间列表 `times` 中。
- 为了处理最早时间、最晚时间之间的时间间隔,我们将 `times` 中最小时间添加到列表末尾一起进行排序。
- 然后将新的时间列表 `times` 按照升序排列。
- 遍历排好序的事件列表 `times` ,找出相邻两个时间的最小间隔值即可。
## 代码
```python
class Solution:
def changeTime(self, timePoint: str):
hours, minutes = timePoint.split(':')
return int(hours) * 60 + int(minutes)
def findMinDifference(self, timePoints: List[str]) -> int:
if not timePoints or len(timePoints) > 24 * 60:
return 0
times = sorted(self.changeTime(time) for time in timePoints)
times.append(times[0] + 24 * 60)
res = times[-1]
for i in range(1, len(times)):
res = min(res, times[i] - times[i - 1])
return res
```
================================================
FILE: docs/solutions/LCR/6eUYwP.md
================================================
# [LCR 050. 路径总和 III](https://leetcode.cn/problems/6eUYwP/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 050. 路径总和 III - 力扣](https://leetcode.cn/problems/6eUYwP/)
## 题目大意
## 解题思路
## 代码
```python
class Solution:
prefixsum_count = dict()
def dfs(self, root, prefixsum_count, target_sum, cur_sum):
if not root:
return 0
res = 0
cur_sum += root.val
res += prefixsum_count.get(cur_sum - target_sum, 0)
prefixsum_count[cur_sum] = prefixsum_count.get(cur_sum, 0) + 1
res += self.dfs(root.left, prefixsum_count, target_sum, cur_sum)
res += self.dfs(root.right, prefixsum_count, target_sum, cur_sum)
prefixsum_count[cur_sum] -= 1
return res
def pathSum(self, root: TreeNode, targetSum: int) -> int:
if not root:
return 0
prefixsum_count = dict()
prefixsum_count[0] = 1
return self.dfs(root, prefixsum_count, targetSum, 0)
```
================================================
FILE: docs/solutions/LCR/7LpjUW.md
================================================
# [LCR 118. 冗余连接](https://leetcode.cn/problems/7LpjUW/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [LCR 118. 冗余连接 - 力扣](https://leetcode.cn/problems/7LpjUW/)
## 题目大意
一个 `n` 个节点的树(节点值为 `1~n`)添加一条边后就形成了图,添加的这条边不属于树中已经存在的边。图的信息记录存储与长度为 `n` 的二维数组 `edges`,`edges[i] = [ai, bi]` 表示图中在 `ai` 和 `bi` 之间存在一条边。
现在给定代表边信息的二维数组 `edges`。
要求:找到一条可以山区的边,使得删除后的剩余部分是一个有着 `n` 个节点的树。如果有多个答案,则返回数组 `edges` 中最后出现的边。
## 解题思路
树可以看做是无环的图,这道题就是要找出那条添加边之后成环的边。可以考虑用并查集来做。
从前向后遍历每一条边,如果边的两个节点不在同一个集合,就加入到一个集合(链接到同一个根节点)。如果边的节点已经出现在同一个集合里,说明边的两个节点已经连在一起了,再加入这条边一定会出现环,则这条边就是所求答案。
## 代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
self.parent[root_x] = root_y
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:
size = len(edges)
union_find = UnionFind(size + 1)
for edge in edges:
if union_find.is_connected(edge[0], edge[1]):
return edge
union_find.union(edge[0], edge[1])
return None
```
================================================
FILE: docs/solutions/LCR/7WHec2.md
================================================
# [LCR 077. 排序链表](https://leetcode.cn/problems/7WHec2/)
- 标签:链表、双指针、分治、排序、归并排序
- 难度:中等
## 题目链接
- [LCR 077. 排序链表 - 力扣](https://leetcode.cn/problems/7WHec2/)
## 题目大意
给定链表的头节点 `head`。
要求:按照升序排列并返回排序后的链表。
## 解题思路
归并排序。
1. 利用快慢指针找到链表的中点,以中点为界限将链表拆分成两个子链表。
2. 然后对两个子链表分别递归排序。
3. 将排序后的子链表进行归并排序,得到完整的排序后的链表。
## 代码
```python
class Solution:
def merge_sort(self, head: ListNode, tail: ListNode) -> ListNode:
if not head:
return head
if head.next == tail:
head.next = None
return head
slow = fast = head
while fast != tail:
slow = slow.next
fast = fast.next
if fast != tail:
fast = fast.next
mid = slow
return self.merge(self.merge_sort(head, mid), self.merge_sort(mid, tail))
def merge(self, a: ListNode, b: ListNode) -> ListNode:
root = ListNode(-1)
cur = root
while a and b:
if a.val < b.val:
cur.next = a
a = a.next
else:
cur.next = b
b = b.next
cur = cur.next
if a:
cur.next = a
if b:
cur.next = b
return root.next
def sortList(self, head: ListNode) -> ListNode:
return self.merge_sort(head, None)
```
================================================
FILE: docs/solutions/LCR/7WqeDu.md
================================================
# [LCR 057. 存在重复元素 III](https://leetcode.cn/problems/7WqeDu/)
- 标签:数组、桶排序、有序集合、排序、滑动窗口
- 难度:中等
## 题目链接
- [LCR 057. 存在重复元素 III - 力扣](https://leetcode.cn/problems/7WqeDu/)
## 题目大意
给定一个整数数组 `nums`,以及两个整数 `k`、`t`。判断数组中是否存在两个不同下标的 `i` 和 `j`,其对应元素满足 `abs(nums[i] - nums[j]) <= t`,同时满足 `abs(i - j) <= k`。如果满足条件则返回 `True`,不满足条件返回 `False`。
## 解题思路
对于第 `i` 个元素 `nums[i]`,需要查找的区间为 `[i - t, i + t]`。可以利用桶排序的思想。
桶的大小设置为 `t + 1`。我们将元素按照大小依次放入不同的桶中。
遍历数组 `nums` 中的元素,对于元素 `nums[i]` :
- 如果 `nums[i]` 放入桶之前桶里已经有元素了,那么这两个元素必然满足 `abs(nums[i] - nums[j]) <= t`,
- 如果之前桶里没有元素,那么就将 `nums[i]` 放入对应桶中。
- 然后再判断左右桶的左右两侧桶中是否有元素满足 `abs(nums[i] - nums[j]) <= t`。
- 然后将 `nums[i - k]` 之前的桶清空,因为这些桶中的元素与 `nums[i]` 已经不满足 `abs(i - j) <= k` 了。
最后上述满足条件的情况就返回 `True`,最终遍历完仍不满足条件就返回 `False`。
## 代码
```python
class Solution:
def containsNearbyAlmostDuplicate(self, nums: List[int], k: int, t: int) -> bool:
bucket_dict = dict()
for i in range(len(nums)):
# 将 nums[i] 划分到大小为 t + 1 的不同桶中
num = nums[i] // (t + 1)
# 桶中已经有元素了
if num in bucket_dict:
return True
# 把 nums[i] 放入桶中
bucket_dict[num] = nums[i]
# 判断左侧桶是否满足条件
if (num - 1) in bucket_dict and abs(bucket_dict[num - 1] - nums[i]) <= t:
return True
# 判断右侧桶是否满足条件
if (num + 1) in bucket_dict and abs(bucket_dict[num + 1] - nums[i]) <= t:
return True
# 将 i-k 之前的旧桶清除,因为之前的桶已经不满足条件了
if i >= k:
bucket_dict.pop(nums[i - k] // (t + 1))
return False
```
================================================
FILE: docs/solutions/LCR/7p8L0Z.md
================================================
# [LCR 084. 全排列 II](https://leetcode.cn/problems/7p8L0Z/)
- 标签:数组、回溯
- 难度:中等
## 题目链接
- [LCR 084. 全排列 II - 力扣](https://leetcode.cn/problems/7p8L0Z/)
## 题目大意
给定一个可包含重复数字的序列 `nums` 。
要求:按任意顺序返回所有不重复的全排列。
## 解题思路
这道题跟「[LCR 083. 全排列](https://leetcode.cn/problems/VvJkup/)」不一样的地方在于增加了序列中的元素可重复这一条件。这就涉及到了去重。先对 `nums` 进行排序,然后使用 visited 数组标记该元素在当前排列中是否被访问过。如果未被访问过则将其加入排列中,并在访问后将该元素变为未访问状态。
然后再递归遍历下一层元素之前,增加一句语句进行判重:`if i > 0 and nums[i] == nums[i - 1] and not visited[i - 1]: continue`。
然后进行回溯遍历。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, nums: List[int], visited: List[bool]):
if len(self.path) == len(nums):
self.res.append(self.path[:])
return
for i in range(len(nums)):
if i > 0 and nums[i] == nums[i - 1] and not visited[i - 1]:
continue
if not visited[i]:
visited[i] = True
self.path.append(nums[i])
self.backtrack(nums, visited)
self.path.pop()
visited[i] = False
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
self.res.clear()
self.path.clear()
nums.sort()
visited = [False for _ in range(len(nums))]
self.backtrack(nums, visited)
return self.res
```
================================================
FILE: docs/solutions/LCR/8Zf90G.md
================================================
# [LCR 036. 逆波兰表达式求值](https://leetcode.cn/problems/8Zf90G/)
- 标签:栈、数组、数学
- 难度:中等
## 题目链接
- [LCR 036. 逆波兰表达式求值 - 力扣](https://leetcode.cn/problems/8Zf90G/)
## 题目大意
给定一个字符串数组 `tokens`,表示「逆波兰表达式」,求解表达式的值。
## 解题思路
栈的典型应用。遍历字符串数组。遇到操作字符的时候,取出栈顶两个元素,进行运算之后,再将结果入栈。遇到数字,则直接入栈。
## 代码
```python
class Solution:
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for token in tokens:
if token == '+':
stack.append(stack.pop() + stack.pop())
elif token == '-':
stack.append(-stack.pop() + stack.pop())
elif token == '*':
stack.append(stack.pop() * stack.pop())
elif token == '/':
stack.append(int(1 / stack.pop() * stack.pop()))
else:
stack.append(int(token))
return stack.pop()
```
================================================
FILE: docs/solutions/LCR/A1NYOS.md
================================================
# [LCR 011. 连续数组](https://leetcode.cn/problems/A1NYOS/)
- 标签:数组、哈希表、前缀和
- 难度:中等
## 题目链接
- [LCR 011. 连续数组 - 力扣](https://leetcode.cn/problems/A1NYOS/)
## 题目大意
给定一个二进制数组 `nums`。
要求:找到含有相同数量 `0` 和 `1` 的最长连续子数组,并返回该子数组的长度。
## 解题思路
「`0` 和 `1` 数量相同」等价于「`1` 的数量减去 `0` 的数量等于 `0`」。
我们可以使用一个变量 `pre_diff` 来记录下前 `i` 个数中,`1` 的数量比 `0` 的数量多多少个。我们把这个 `pre_diff`叫做「`1` 和 `0` 数量差」,也可以理解为变种的前缀和。
然后我们再用一个哈希表 `pre_dic` 来记录「`1` 和 `0` 数量差」第一次出现的下标。
那么,如果我们在遍历的时候,发现 `pre_diff` 相同的数量差已经在之前出现过了,则说明:这两段之间相减的 `1` 和 `0` 数量差为 `0`。
什么意思呢?
比如说:`j < i`,前 `j` 个数中第一次出现 `pre_diff == 2` ,然后前 `i` 个数中个第二次又出现了 `pre_diff == 2`。那么这两段形成的子数组 `nums[j + 1: i]` 中 `1` 比 `0` 多 `0` 个,则 `0` 和 `1` 数量相同的子数组长度为 `i - j`。
而第二次之所以又出现 `pre_diff == 2` ,是因为前半段子数组 `nums[0: j]` 贡献了相同的差值。
接下来还有一个小问题,如何计算「`1` 和 `0` 数量差」?
我们可以把数组中的 `1` 记为贡献 `+1`,`0` 记为贡献 `-1`。然后使用一个变量 `count`,只要出现 `1` 就让 `count` 加上 `1`,意思是又多出了 `1` 个 `1`。只要出现 `0`,将让 `count` 减去 `1`,意思是 `0` 和之前累积的 `1` 个 `1` 相互抵消掉了。这样遍历完数组,也就计算出了对应的「`1` 和 `0` 数量差」。
整个思路的具体做法如下:
- 创建一个哈希表,键值对关系为「`1` 和 `0` 的数量差:最早出现的下标 `i`」。
- 使用变量 `pre_diff` 来计算「`1` 和 `0` 数量差」,使用变量 `count` 来记录 `0` 和 `1` 数量相同的连续子数组的最长长度,然后遍历整个数组。
- 如果 `nums[i] == 1`,则让 `pre_diff += 1`;如果 `nums[i] == 0`,则让 `pre_diff -= 1`。
- 如果在哈希表中发现了相同的 `pre_diff`,则计算相应的子数组长度,与 `count` 进行比较并更新 `count` 值。
- 如果在哈希表中没有发现相同的 `pre_diff`,则在哈希表中记录下第一次出现 `pre_diff` 的下标 `i`。
- 最后遍历完输出 `count`。
> 注意:初始化哈希表为:`pre_dic = {0: -1}`,意思为空数组时,默认「`1` 和 `0` 数量差」为 `0`,且第一次出现的下标为 `-1`。
>
> 之所以这样做,是因为在遍历过程中可能会直接出现 `pre_diff == 0` 的情况,这种情况下说明 `nums[0: i]` 中 `0` 和 `1` 数量相同,如果像上边这样初始化后,就可以直接计算出此时子数组长度为 `i - (-1) = i + 1`。
## 代码
```python
class Solution:
def findMaxLength(self, nums: List[int]) -> int:
pre_dic = {0: -1}
count = 0
pre_sum = 0
for i in range(len(nums)):
if nums[i]:
pre_sum += 1
else:
pre_sum -= 1
if pre_sum in pre_dic:
count = max(count, i - pre_dic[pre_sum])
else:
pre_dic[pre_sum] = i
return count
```
================================================
FILE: docs/solutions/LCR/D0F0SV.md
================================================
# [LCR 104. 组合总和 Ⅳ](https://leetcode.cn/problems/D0F0SV/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [LCR 104. 组合总和 Ⅳ - 力扣](https://leetcode.cn/problems/D0F0SV/)
## 题目大意
给定一个由不同整数组成的数组 `nums` 和一个目标整数 `target`。
要求:从 `nums` 中找出并返回总和为 `target` 的元素组合个数。
## 解题思路
完全背包问题。题目求解的是组合数。
动态规划的状态 `dp[i]` 可以表示为:凑成总和 `i` 的组合数。
动态规划的状态转移方程为:`dp[i] = dp[i] + dp[i - nums[j]]`,意思为凑成总和为 `i` 的组合数 = 「不使用当前 `nums[j]`,只使用之前整数凑成和为 `i` 的组合数」+「使用当前 `nums[j]` 凑成金额 `i - nums[j]` 的方案数」。
最终输出 `dp[target]`。
## 代码
```python
class Solution:
def combinationSum4(self, nums: List[int], target: int) -> int:
dp = [0 for _ in range(target + 1)]
dp[0] = 1
size = len(nums)
for i in range(target + 1):
for j in range(size):
if i - nums[j] >= 0:
dp[i] += dp[i - nums[j]]
return dp[target]
```
================================================
FILE: docs/solutions/LCR/FortPu.md
================================================
# [LCR 030. O(1) 时间插入、删除和获取随机元素](https://leetcode.cn/problems/FortPu/)
- 标签:设计、数组、哈希表、数学、随机化
- 难度:中等
## 题目链接
- [LCR 030. O(1) 时间插入、删除和获取随机元素 - 力扣](https://leetcode.cn/problems/FortPu/)
## 题目大意
设计一个数据结构 ,支持时间复杂度为 $O(1)$ 的以下操作:
- `insert(val)`:当元素 val 不存在时,向集合中插入该项。
- `remove(val)`:元素 val 存在时,从集合中移除该项。
- `getRandom`:随机返回现有集合中的一项。每个元素应该有相同的概率被返回。
## 解题思路
普通动态数组进行访问操作,需要线性时间查找解决。我们可以利用哈希表记录下每个元素的下标,这样在访问时可以做到常数时间内访问元素了。对应的插入、删除、后去随机元素需要做相应的变化。
- 插入操作:将元素直接插入到数组尾部,并用哈希表记录插入元素的下标位置。
- 删除操作:使用哈希表找到待删除元素所在位置,将其与数组末尾位置元素相互交换,更新哈希表中交换后元素的下标值,并将末尾元素删除。
- 获取随机元素:使用` random.choice` 获取。
## 代码
```python
import random
class RandomizedSet:
def __init__(self):
"""
Initialize your data structure here.
"""
self.dict = dict()
self.list = list()
def insert(self, val: int) -> bool:
"""
Inserts a value to the set. Returns true if the set did not already contain the specified element.
"""
if val in self.dict:
return False
self.dict[val] = len(self.list)
self.list.append(val)
return True
def remove(self, val: int) -> bool:
"""
Removes a value from the set. Returns true if the set contained the specified element.
"""
if val in self.dict:
idx = self.dict[val]
last = self.list[-1]
self.list[idx] = last
self.dict[last] = idx
self.list.pop()
self.dict.pop(val)
return True
return False
def getRandom(self) -> int:
"""
Get a random element from the set.
"""
return random.choice(self.list)
```
================================================
FILE: docs/solutions/LCR/Gu0c2T.md
================================================
# [LCR 089. 打家劫舍](https://leetcode.cn/problems/Gu0c2T/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [LCR 089. 打家劫舍 - 力扣](https://leetcode.cn/problems/Gu0c2T/)
## 题目大意
给定一个数组 `nums`,`num[i]` 代表第 `i` 间房屋存放的金额。相邻的房屋装有防盗系统,假如相邻的两间房屋同时被偷,系统就会报警。假如你是一名专业的小偷。
要求:计算在不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
## 解题思路
可以用动态规划来解决问题,关键点在于找到状态转移方程。
先考虑最简单的情况。假如只有一间房,则直接偷这间屋子就能偷到最高金额,即 `dp[0] = nums[i]`。假如只有两间房屋,那么就选择金额最大的那间屋进行偷窃,就可以偷到最高金额,即 `dp[1] = max(nums[0], nums[1])`。
如果房屋大于两间,则偷窃第 `i` 间房屋的时候,就有两种状态:
- 偷窃第 `i` 间房屋,那么第 `i - 1` 间房屋就不能偷窃了,偷窃的最高金额为:前 `i - 2` 间房屋的最高总金额 + 第 `i` 间房屋的金额,即 `dp[i] = dp[i-2] + nums[i]`;
- 不偷窃第 `i` 间房屋,那么第 `i - 1` 间房屋可以偷窃,偷窃的最高金额为:前 `i - 1` 间房屋的最高总金额,即 `dp[i] = dp[i-1]`。
然后这两种状态取最大值即可,即 `dp[i] = max(dp[i-2] + nums[i], dp[i-1])`。
总结下就是:
$dp[i] = \begin{cases} \begin{array} {**lr**} nums[0] & i = 0 \cr max( nums[0], nums[1]) & i = 1 \cr max( dp[i-2] + nums[i], dp[i-1]) & i \ge 2 \end{array} \end{cases}$
## 代码
```python
class Solution:
def rob(self, nums: List[int]) -> int:
size = len(nums)
dp = [0 for _ in range(size)]
for i in range(size):
if i == 0:
dp[i] = nums[i]
elif i == 1:
dp[i] = max(nums[i - 1], nums[i])
else:
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1])
return dp[size - 1]
```
================================================
FILE: docs/solutions/LCR/GzCJIP.md
================================================
# [LCR 088. 使用最小花费爬楼梯](https://leetcode.cn/problems/GzCJIP/)
- 标签:数组、动态规划
- 难度:简单
## 题目链接
- [LCR 088. 使用最小花费爬楼梯 - 力扣](https://leetcode.cn/problems/GzCJIP/)
## 题目大意
给定一个数组 `cost` 代表一段楼梯,`cost[i]` 代表爬上第 `i` 阶楼梯醒酒药花费的体力值(下标从 `0` 开始)。
每爬上一个阶梯都要花费对应的体力值,一旦支付了相应的体力值,你就可以选择向上爬一个阶梯或者爬两个阶梯。
要求:找出达到楼层顶部的最低花费。在开始时,你可以选择从下标为 `0` 或 `1` 的元素作为初始阶梯。
## 解题思路
使用动态规划方法。
状态 `dp[i]` 表示为:到达第 `i` 个台阶所花费的最少体⼒。
则状态转移方程为: `dp[i] = min(dp[i - 1], dp[i - 2]) + cost[i]`。
表示为:到达第 `i` 个台阶所花费的最少体⼒ = 到达第 `i - 1` 个台阶所花费的最小体力 与 到达第 `i - 2` 个台阶所花费的最小体力中的最小值 + 到达第 `i` 个台阶所需要花费的体力值。
## 代码
```python
class Solution:
def minCostClimbingStairs(self, cost: List[int]) -> int:
size = len(cost)
dp = [0 for _ in range(size + 1)]
for i in range(2, size + 1):
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2])
return dp[size]
```
================================================
FILE: docs/solutions/LCR/H8086Q.md
================================================
# [LCR 042. 最近的请求次数](https://leetcode.cn/problems/H8086Q/)
- 标签:设计、队列、数据流
- 难度:简单
## 题目链接
- [LCR 042. 最近的请求次数 - 力扣](https://leetcode.cn/problems/H8086Q/)
## 题目大意
要求:实现一个用来计算特定时间范围内的最近请求的 `RecentCounter` 类:
- `RecentCounter()` 初始化计数器,请求数为 0 。
- `int ping(int t)` 在时间 `t` 时添加一个新请求,其中 `t` 表示以毫秒为单位的某个时间,并返回在 `[t-3000, t]` 内发生的请求数。
## 解题思路
使用一个队列,用于存储 `[t - 3000, t]` 范围内的请求。
获取请求数时,将队首所有小于 `t - 3000` 时间的请求将其从队列中移除,然后返回队列的长度即可。
## 代码
```python
class RecentCounter:
def __init__(self):
self.queue = []
def ping(self, t: int) -> int:
self.queue.append(t)
while self.queue[0] < t - 3000:
self.queue.pop(0)
return len(self.queue)
```
================================================
FILE: docs/solutions/LCR/IDBivT.md
================================================
# [LCR 085. 括号生成](https://leetcode.cn/problems/IDBivT/)
- 标签:字符串、动态规划、回溯
- 难度:中等
## 题目链接
- [LCR 085. 括号生成 - 力扣](https://leetcode.cn/problems/IDBivT/)
## 题目大意
给定一个整数 `n`。
要求:生成所有有可能且有效的括号组合。
## 解题思路
通过回溯算法生成所有答案。为了生成的括号组合是有效的,回溯的时候,使用一个标记变量 `symbol` 来表示是否当前组合是否成对匹配。
如果在当前组合中增加一个 `(`,则 `symbol += 1`,如果增加一个 `)`,则 `symbol -= 1`。显然只有在 `symbol < n` 的时候,才能增加 `(`,在 `symbol > 0` 的时候,才能增加 `)`。
如果最终生成 `2 * n` 的括号组合,并且 `symbol == 0`,则说明当前组合是有效的,将其加入到最终答案数组中。
最终输出最终答案数组。
## 代码
```python
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
def backtrack(parenthesis, symbol, index):
if n * 2 == index:
if symbol == 0:
parentheses.append(parenthesis)
else:
if symbol < n:
backtrack(parenthesis + '(', symbol + 1, index + 1)
if symbol > 0:
backtrack(parenthesis + ')', symbol - 1, index + 1)
parentheses = list()
backtrack("", 0, 0)
return parentheses
```
================================================
FILE: docs/solutions/LCR/JFETK5.md
================================================
# [LCR 002. 二进制求和](https://leetcode.cn/problems/JFETK5/)
- 标签:位运算、数学、字符串、模拟
- 难度:简单
## 题目链接
- [LCR 002. 二进制求和 - 力扣](https://leetcode.cn/problems/JFETK5/)
## 题目大意
给定两个二进制数的字符串 `a`、`b`。
要求:计算 `a` 和 `b` 的和,返回结果也用二进制表示。
## 解题思路
这道题可以直接将 `a`、`b` 转换为十进制数,相加后再转换为二进制数。
也可以利用位运算的一些知识,直接求和。
因为 `a`、`b` 为二进制的字符串,先将其转换为二进制数。
本题用到的位运算知识:
- 异或运算 `x ^ y` :可以获得 `x + y` 无进位的加法结果。
- 与运算 `x & y`:对应位置为 `1`,说明 `x`、`y` 该位置上原来都为 `1`,则需要进位。
- 座椅运算 `x << 1`:将 a 对应二进制数左移 `1` 位。
这样,通过 `x ^ y` 运算,我们可以得到相加后无进位结果,再根据 `(x & y) << 1`,计算进位后结果。
进行 `x ^ y` 和 `(x & y) << 1`操作之后判断进位是否为 `0`,如果不为 `0`,则继续上一步操作,直到进位为 `0`。
最后将其结果转为 `2` 进制返回。
## 代码
```python
class Solution:
def addBinary(self, a: str, b: str) -> str:
x = int(a, 2)
y = int(b, 2)
while y:
carry = ((x & y) << 1)
x ^= y
y = carry
return bin(x)[2:]
```
================================================
FILE: docs/solutions/LCR/LGjMqU.md
================================================
# [LCR 026. 重排链表](https://leetcode.cn/problems/LGjMqU/)
- 标签:栈、递归、链表、双指针
- 难度:中等
## 题目链接
- [LCR 026. 重排链表 - 力扣](https://leetcode.cn/problems/LGjMqU/)
## 题目大意
给定一个单链表 `L` 的头节点 `head`,单链表 `L` 表示为:$L_0$ -> $L_1$ -> $L_2$ -> ... -> $L_{n-1}$ -> $L_n$。
要求:将单链表 `L` 重新排列为:$L_0$ -> $L_n$ -> $L_1$ -> $L_{n-1}$ -> $L_2$ -> $L_{n-2}$ -> $L_3$ -> $L_{n-3}$ -> ...。
注意:需要将实际节点进行交换。
## 解题思路
链表不能像数组那样直接进行随机访问。所以我们可以先将链表转为线性表。然后直接按照提要要求的排列顺序访问对应数据元素,重新建立链表。
## 代码
```python
class Solution:
def reorderList(self, head: ListNode) -> None:
"""
Do not return anything, modify head in-place instead.
"""
if not head:
return
vec = []
node = head
while node:
vec.append(node)
node = node.next
left, right = 0, len(vec) - 1
while left < right:
vec[left].next = vec[right]
left += 1
if left == right:
break
vec[right].next = vec[left]
right -= 1
vec[left].next = None
```
================================================
FILE: docs/solutions/LCR/LwUNpT.md
================================================
# [LCR 045. 找树左下角的值](https://leetcode.cn/problems/LwUNpT/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 045. 找树左下角的值 - 力扣](https://leetcode.cn/problems/LwUNpT/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:找出该二叉树 「最底层」的「最左边」节点的值。
## 解题思路
这个问题拆开来看,一是如何找到「最底层」,而是在「最底层」如何找到最左边的节点。
通过层序遍历,我们可以直接确定最底层节点。而「最底层」的「最左边」节点可以改变层序遍历的左右节点访问顺序。
每层元素先访问右节点,在访问左节点,则最后一个遍历的元素就是「最底层」的「最左边」节点,即左下角的节点,返回该点对应的值即可。
## 代码
```python
import collections
class Solution:
def findBottomLeftValue(self, root: TreeNode) -> int:
if not root:
return -1
queue = collections.deque()
queue.append(root)
while queue:
cur = queue.popleft()
if cur.right:
queue.append(cur.right)
if cur.left:
queue.append(cur.left)
return cur.val
```
================================================
FILE: docs/solutions/LCR/M1oyTv.md
================================================
# [LCR 017. 最小覆盖子串](https://leetcode.cn/problems/M1oyTv/)
- 标签:哈希表、字符串、滑动窗口
- 难度:困难
## 题目链接
- [LCR 017. 最小覆盖子串 - 力扣](https://leetcode.cn/problems/M1oyTv/)
## 题目大意
给定一个字符串 `s`、一个字符串 `t`。
要求:返回 `s` 中涵盖 `t` 所有字符的最小子串。如果 `s` 中不存在涵盖 `t` 所有字符的子串,则返回空字符串 `""`。如果存在多个符合条件的子字符串,返回任意一个。
## 解题思路
使用滑动窗口求解。
`left`、`right` 表示窗口的边界,一开始都位于下标 `0` 处。`need` 用于记录短字符串需要的字符数。`window` 记录当前窗口内的字符数。
将 `right` 右移,直到出现了 `t` 中全部字符,开始右移 `left`,减少滑动窗口的大小,并记录下最小覆盖子串的长度和起始位置。最后输出结果。
## 代码
```python
class Solution:
def minWindow(self, s: str, t: str) -> str:
need = collections.defaultdict(int)
window = collections.defaultdict(int)
for ch in t:
need[ch] += 1
left, right = 0, 0
valid = 0
start = 0
size = len(s) + 1
while right < len(s):
insert_ch = s[right]
right += 1
if insert_ch in need:
window[insert_ch] += 1
if window[insert_ch] == need[insert_ch]:
valid += 1
while valid == len(need):
if right - left < size:
start = left
size = right - left
remove_ch = s[left]
left += 1
if remove_ch in need:
if window[remove_ch] == need[remove_ch]:
valid -= 1
window[remove_ch] -= 1
if size == len(s) + 1:
return ''
return s[start:start + size]
```
================================================
FILE: docs/solutions/LCR/M99OJA.md
================================================
# [LCR 086. 分割回文串](https://leetcode.cn/problems/M99OJA/)
- 标签:深度优先搜索、广度优先搜索、图、哈希表
- 难度:中等
## 题目链接
- [LCR 086. 分割回文串 - 力扣](https://leetcode.cn/problems/M99OJA/)
## 题目大意
给定一个字符串 `s`将 `s` 分割成一些子串,保证每个子串都是「回文串」。
要求:返回 `s` 所有可能的分割方案。
## 解题思路
回溯算法,建立两个数组 `res`、`path`。`res` 用于存放所有满足题意的组合,`path` 用于存放当前满足题意的一个组合。
在回溯的时候判断当前子串是否为回文串,如果不是则跳过,如果是则继续向下一层遍历。
定义判断是否为回文串的方法和回溯方法,从 `start_index = 0` 的位置开始回溯。
- 如果 `start_index >= len(s)`,则将 `path` 中的元素加入到 `res` 数组中。
- 然后对 `[start_index, len(s) - 1]` 范围内的子串进行遍历取值。
- 如果字符串 `s` 在范围 `[start_index, i]` 所代表的子串是回文串,则将其加入 `path` 数组。
- 递归遍历 `[i + 1, len(s) - 1]` 范围上的子串。
- 然后将遍历的范围 `[start_index, i]` 所代表的子串进行回退。
- 最终返回 `res` 数组。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, s: str, start_index: int):
if start_index >= len(s):
self.res.append(self.path[:])
return
for i in range(start_index, len(s)):
if self.ispalindrome(s, start_index, i):
self.path.append(s[start_index: i + 1])
self.backtrack(s, i + 1)
self.path.pop()
def ispalindrome(self, s: str, start: int, end: int):
i, j = start, end
while i < j:
if s[i] != s[j]:
return False
i += 1
j -= 1
return True
def partition(self, s: str) -> List[List[str]]:
self.res.clear()
self.path.clear()
self.backtrack(s, 0)
return self.res
```
================================================
FILE: docs/solutions/LCR/N6YdxV.md
================================================
# [LCR 068. 搜索插入位置](https://leetcode.cn/problems/N6YdxV/)
- 标签:数组、二分查找
- 难度:简单
## 题目链接
- [LCR 068. 搜索插入位置 - 力扣](https://leetcode.cn/problems/N6YdxV/)
## 题目大意
给定一个排好序的数组 `nums`,以及一个目标值 `target`。
要求:在数组中找到目标值,并返回下标。如果找不到,则返回目标值按顺序插入数组的位置。
## 解题思路
二分查找法。利用两个指针 `left` 和 `right`,分别指向数组首尾位置。每次用 `left` 和 `right` 中间位置上的元素值与目标值做比较,如果等于目标值,则返回当前位置。如果小于目标值,则更新 `left` 位置为 `mid + 1`,继续查找。如果大于目标值,则更新 `right` 位置为 `mid - 1`,继续查找。直到查找到目标值,或者 `left > right` 值时停止查找。然后返回 `left` 所在位置,即是代插入数组的位置。
## 代码
```python
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
n = len(nums)
left = 0
right = n - 1
while left <= right:
mid = left + (right - left) // 2
if nums[mid] == target:
return mid
elif nums[mid] < target:
left = mid + 1
else:
right = mid - 1
return left
```
================================================
FILE: docs/solutions/LCR/NUPfPr.md
================================================
# [LCR 101. 分割等和子集](https://leetcode.cn/problems/NUPfPr/)
- 标签:数学、字符串、模拟
- 难度:简单
## 题目链接
- [LCR 101. 分割等和子集 - 力扣](https://leetcode.cn/problems/NUPfPr/)
## 题目大意
给定一个只包含正整数的非空数组 `nums`。
要求:判断是否可以将这个数组分成两个子集,使得两个子集的元素和相等。
## 解题思路
动态规划求解。
如果两个子集和相等,则两个子集元素和刚好等于整个数组元素和的一半。这就相当于 `0-1` 背包问题。
定义 `dp[i][j]` 表示从 `[0, i]` 个数中任意选取一些数,放进容量为 j 的背包中,价值总和最大为多少。则 `dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - nums[i]] + nums[i])`。
转换为一维 dp 就是:`dp[j] = max(dp[j], dp[j - nums[i]] + nums[i])`。
然后进行递归求解。最后判断 `dp[target]` 和 `target` 是否相等即可。
## 代码
```python
class Solution:
def canPartition(self, nums: List[int]) -> bool:
size = 100010
dp = [0 for _ in range(size)]
sum_nums = sum(nums)
if sum_nums & 1:
return False
target = sum_nums // 2
for i in range(len(nums)):
for j in range(target, nums[i] - 1, -1):
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i])
if dp[target] == target:
return True
return False
```
================================================
FILE: docs/solutions/LCR/NYBBNL.md
================================================
# [LCR 052. 递增顺序搜索树](https://leetcode.cn/problems/NYBBNL/)
- 标签:栈、树、深度优先搜索、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [LCR 052. 递增顺序搜索树 - 力扣](https://leetcode.cn/problems/NYBBNL/)
## 题目大意
给定一棵二叉搜索树的根节点 `root`。
要求:按中序遍历顺序将其重新排列为一棵递增顺序搜索树,使树中最左边的节点成为树的根节点,并且每个节点没有左子节点,只有一个右子节点。
## 解题思路
可以分为两步:
1. 中序遍历二叉搜索树,将节点先存储到列表中。
2. 将列表中的节点构造成一棵递增顺序搜索树。
中序遍历直接按照 `左 -> 根 -> 右` 的顺序递归遍历,然后将遍历的节点存储到 `res` 中。
构造递增顺序搜索树,则用 `head` 保存头节点位置。遍历列表中的每个节点,将其左右指针先置空,再将其连接在上一个节点的右子节点上。
最后返回 `head.right` 即可。
## 代码
```python
class Solution:
def inOrder(self, root, res):
if not root:
return
self.inOrder(root.left, res)
res.append(root)
self.inOrder(root.right, res)
def increasingBST(self, root: TreeNode) -> TreeNode:
res = []
self.inOrder(root, res)
if not res:
return
head = TreeNode(-1)
cur = head
for node in res:
node.left = node.right = None
cur.right = node
cur = cur.right
return head.right
```
================================================
FILE: docs/solutions/LCR/NaqhDT.md
================================================
# [LCR 043. 完全二叉树插入器](https://leetcode.cn/problems/NaqhDT/)
- 标签:树、广度优先搜索、设计、二叉树
- 难度:中等
## 题目链接
- [LCR 043. 完全二叉树插入器 - 力扣](https://leetcode.cn/problems/NaqhDT/)
## 题目大意
要求:设计一个用完全二叉树初始化的数据结构 `CBTInserter`,并支持以下几种操作:
- `CBTInserter(TreeNode root)` 使用根节点为 `root` 的给定树初始化该数据结构;
- `CBTInserter.insert(int v)` 向树中插入一个新节点,节点类型为 `TreeNode`,值为 `v`。使树保持完全二叉树的状态,并返回插入的新节点的父节点的值;
- `CBTInserter.get_root()` 返回树的根节点。
## 解题思路
使用数组标记完全二叉树中节点的序号,初始化数组为 `[None]`。完全二叉树中节点的序号从 `1` 开始,对于序号为 `k` 的节点,其左子节点序号为 `2k`,右子节点的序号为 `2k + 1`,其父节点的序号为 `k // 2`。
然后在初始化和插入节点的同时,按顺序向数组中插入节点。
## 代码
```python
class CBTInserter:
def __init__(self, root: TreeNode):
self.queue = [root]
self.nodelist = [None]
while self.queue:
node = self.queue.pop(0)
self.nodelist.append(node)
if node.left:
self.queue.append(node.left)
if node.right:
self.queue.append(node.right)
def insert(self, v: int) -> int:
self.nodelist.append(TreeNode(v))
index = len(self.nodelist) - 1
father = self.nodelist[index // 2]
if index % 2 == 0:
father.left = self.nodelist[-1]
else:
father.right = self.nodelist[-1]
return father.val
def get_root(self) -> TreeNode:
return self.nodelist[1]
```
================================================
FILE: docs/solutions/LCR/O4NDxx.md
================================================
# [LCR 013. 二维区域和检索 - 矩阵不可变](https://leetcode.cn/problems/O4NDxx/)
- 标签:设计、数组、矩阵、前缀和
- 难度:中等
## 题目链接
- [LCR 013. 二维区域和检索 - 矩阵不可变 - 力扣](https://leetcode.cn/problems/O4NDxx/)
## 题目大意
给定一个二维矩阵 `matrix`。
要求:满足以下多个请求:
- ` def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:`计算以 `(row1, col1)` 为左上角、`(row2, col2)` 为右下角的子矩阵中各个元素的和。
- `def __init__(self, matrix: List[List[int]]):` 对二维矩阵 `matrix` 进行初始化操作。
## 解题思路
在进行初始化的时候做预处理,这样在多次查询时可以减少重复计算,也可以减少时间复杂度。
在进行初始化的时候,使用一个二维数组 `pre_sum` 记录下以 `(0, 0)` 为左上角,以当前 `(row, col)` 为右下角的子数组各个元素和,即 `pre_sum[row + 1][col + 1]`。
则在查询时,以 `(row1, col1)` 为左上角、`(row2, col2)` 为右下角的子矩阵中各个元素的和就等于以 `(0, 0)` 到 `(row2, col2)` 的大子矩阵减去左边 `(0, 0)` 到 `(row2, col1 - 1)`的子矩阵,再减去上边 `(0, 0)` 到 `(row1 - 1, col2)` 的子矩阵,再加上左上角 `(0, 0)` 到 `(row1 - 1, col1 - 1)` 的子矩阵(因为之前重复减了)。即 `pre_sum[row2 + 1][col2 + 1] - self.pre_sum[row2 + 1][col1] - self.pre_sum[row1][col2 + 1] + self.pre_sum[row1][col1]`。
## 代码
```python
class NumMatrix:
def __init__(self, matrix: List[List[int]]):
rows = len(matrix)
cols = len(matrix[0])
self.pre_sum = [[0 for _ in range(cols + 1)] for _ in range(rows + 1)]
for row in range(rows):
for col in range(cols):
self.pre_sum[row + 1][col + 1] = self.pre_sum[row + 1][col] + self.pre_sum[row][col + 1] - self.pre_sum[row][col] + matrix[row][col]
def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:
return self.pre_sum[row2 + 1][col2 + 1] - self.pre_sum[row2 + 1][col1] - self.pre_sum[row1][col2 + 1] + self.pre_sum[row1][col1]
```
================================================
FILE: docs/solutions/LCR/OrIXps.md
================================================
# [LCR 031. LRU 缓存](https://leetcode.cn/problems/OrIXps/)
- 标签:设计、哈希表、链表、双向链表
- 难度:中等
## 题目链接
- [LCR 031. LRU 缓存 - 力扣](https://leetcode.cn/problems/OrIXps/)
## 题目大意
要求:实现一个 `LRU(最近最少使用)缓存机制`,并且在 `O(1)` 时间复杂度内完成 `get`、`put` 操作。
实现 `LRUCache` 类:
- `LRUCache(int capacity)` 以正整数作为容量 `capacity` 初始化 LRU 缓存。
- `int get(int key)` 如果关键字 `key` 存在于缓存中,则返回关键字的值,否则返回 `-1`。
- `void put(int key, int value)` 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
## 解题思路
LRU(最近最少使用缓存)是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。LRU 更新和插入新页面都发生在链表首,删除页面都发生在链表尾。
## 代码
```python
class Node:
def __init__(self, key=None, val=None, prev=None, next=None):
self.key = key
self.val = val
self.prev = prev
self.next = next
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.hashmap = dict()
self.head = Node()
self.tail = Node()
self.head.next = self.tail
self.tail.prev = self.head
def get(self, key: int) -> int:
if key not in self.hashmap:
return -1
node = self.hashmap[key]
self.move_node(node)
return node.val
def put(self, key: int, value: int) -> None:
if key in self.hashmap:
node = self.hashmap[key]
node.val = value
self.move_node(node)
return
if len(self.hashmap) == self.capacity:
self.hashmap.pop(self.head.next.key)
self.remove_node(self.head.next)
node = Node(key=key, val=value)
self.hashmap[key] = node
self.add_node(node)
def remove_node(self, node):
node.prev.next = node.next
node.next.prev = node.prev
def add_node(self, node):
self.tail.prev.next = node
node.prev = self.tail.prev
node.next = self.tail
self.tail.prev = node
def move_node(self, node):
self.remove_node(node)
self.add_node(node)
```
================================================
FILE: docs/solutions/LCR/P5rCT8.md
================================================
# [LCR 053. 二叉搜索树中的中序后继](https://leetcode.cn/problems/P5rCT8/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [LCR 053. 二叉搜索树中的中序后继 - 力扣](https://leetcode.cn/problems/P5rCT8/)
## 题目大意
给定一棵二叉搜索树的根节点 `root` 和其中一个节点 `p`。
要求:找到该节点在树中的中序后继,即按照中序遍历的顺序节点 `p` 的下一个节点。
## 解题思路
递归遍历,具体步骤如下:
- 如果 `root.val` 小于等于 `p.val`,则直接从 `root` 的右子树递归查找比 `p.val` 大的节点,从而找到中序后继。
- 如果 `root.val` 大于 `p.val`,则 `root` 有可能是中序后继,也有可能是 `root` 的左子树。则从 `root` 的左子树递归查找更接近(更小的)。如果查找的值为 `None`,则当前 `root` 就是中序后继,否则继续递归查找,从而找到中序后继。
## 代码
```python
class Solution:
def inorderSuccessor(self, root: 'TreeNode', p: 'TreeNode') -> 'TreeNode':
if not p or not root:
return None
if root.val <= p.val:
node = self.inorderSuccessor(root.right, p)
else:
node = self.inorderSuccessor(root.left, p)
if not node:
node = root
return node
```
================================================
FILE: docs/solutions/LCR/PzWKhm.md
================================================
# [LCR 090. 打家劫舍 II](https://leetcode.cn/problems/PzWKhm/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [LCR 090. 打家劫舍 II - 力扣](https://leetcode.cn/problems/PzWKhm/)
## 题目大意
给定一个数组 `nums`,`num[i]` 代表第 `i` 间房屋存放的金额,假设房屋可以围成一圈,首尾相连。相邻的房屋装有防盗系统,假如相邻的两间房屋同时被偷,系统就会报警。假如你是一名专业的小偷。
要求:计算在不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
## 解题思路
「[LCR 089. 打家劫舍](https://leetcode.cn/problems/Gu0c2T/)」的升级版。可以用动态规划来解决问题,关键点在于找到状态转移方程。
先来考虑最简单的情况。
假如只有一间房屋,则直接偷这间房屋就能偷到最高金额,即 $dp[0] = nums[i]$。假如有两间房屋,那么就选择金额最大的那间房屋进行偷窃,就可以偷到最高金额,即 $dp[1] = max(nums[0], nums[1])$。
两间屋子以下,最多只能偷窃一间房屋,则不用考虑首尾相连的情况。如果三个屋子以上,偷窃了第一间房屋,则不能偷窃最后一间房屋。同样偷窃了最后一间房屋则不能偷窃第一间房屋。
假设总共房屋数量为 N,这种情况可以转换为分别求解 $[0, N - 2]$ 和 $[1, N - 1]$ 范围下首尾不相连的房屋所能偷窃的最高金额,这就变成了「[LCR 089. 打家劫舍](https://leetcode.cn/problems/Gu0c2T/)」的求解问题。
「[LCR 089. 打家劫舍](https://leetcode.cn/problems/Gu0c2T/)」求解思路如下:
如果房屋大于两间,则偷窃第 `i` 间房屋的时候,就有两种状态:
- 偷窃第 `i` 间房屋,那么第 `i - 1` 间房屋就不能偷窃了,偷窃的最高金额为:前 `i - 2` 间房屋的最高总金额 + 第 `i` 间房屋的金额,即 $dp[i] = dp[i-2] + nums[i]$;
- 不偷窃第 `i` 间房屋,那么第 `i - 1` 间房屋可以偷窃,偷窃的最高金额为:前 `i - 1` 间房屋的最高总金额,即 $dp[i] = dp[i-1]$。
然后这两种状态取最大值即可,即 $dp[i] = max( dp[i-2] + nums[i], dp[i-1])$。
总结下就是:
$dp[i] = \begin{cases} nums[0], & i = 0 \cr max( nums[0], nums[1]) & i = 1 \cr max( dp[i-2] + nums[i], dp[i-1]) & i \ge 2 \end{cases}$
## 代码
```python
class Solution:
def rob(self, nums: List[int]) -> int:
def helper(nums):
size = len(nums)
if size == 1:
return nums[0]
dp = [0 for _ in range(size)]
for i in range(size):
if i == 0:
dp[i] = nums[0]
elif i == 1:
dp[i] = max(nums[i - 1], nums[i])
else:
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1])
return dp[-1]
if len(nums) == 1:
return nums[0]
else:
return max(helper(nums[1:]), helper(nums[:-1]))
```
================================================
FILE: docs/solutions/LCR/Q91FMA.md
================================================
# [LCR 093. 最长的斐波那契子序列的长度](https://leetcode.cn/problems/Q91FMA/)
- 标签:数组、哈希表、动态规划
- 难度:中等
## 题目链接
- [LCR 093. 最长的斐波那契子序列的长度 - 力扣](https://leetcode.cn/problems/Q91FMA/)
## 题目大意
给定一个严格递增的正整数数组 `arr`。
要求:从 `arr` 中找出最长的斐波那契式的子序列的长度。如果不存斐波那契式的子序列,则返回 `0`。
- 斐波那契式序列:如果序列 $X_1, X_2, ..., X_n$ 满足:
- $n \ge 3$;
- 对于所有 $i + 2 \le n$,都有 $X_i + X_{i+1} = X_{i+2}$。
则称该序列为斐波那契式序列。
- 斐波那契式子序列:从序列 `arr` 中挑选若干元素组成子序列,并且子序列满足斐波那契式序列,则称该序列为斐波那契式子序列。例如:`arr = [3, 4, 5, 6, 7, 8]`。则 `[3, 5, 8]` 是 `arr` 的一个斐波那契式子序列。
## 解题思路
我们先从最简单的暴力做法思考。
**1. 暴力做法:**
我们先来考虑暴力做法怎么做。
假设 `arr[i]`、`arr[j]`、`arr[k]` 是序列 `arr` 中的 3 个元素,且满足关系:`arr[i] + arr[j] == arr[k]`,则 `arr[i]`、`arr[j]`、`arr[k]` 就构成了 A 的一个斐波那契式子序列。
通过 `arr[i]`、`arr[j]`,我们可以确定下一个斐波那契式子序列元素的值为 `arr[i] + arr[j]`。
因为给定的数组是严格递增的,所以对于一个斐波那契式子序列,如果确定了 `arr[i]`、`arr[j]`,则可以顺着 `arr` 序列,从第 `j + 1` 的元素开始,查找值为 `arr[i] + arr[j]` 的元素 。找到 `arr[i] + arr[j]` 之后,然后在顺着查找子序列的下一个元素。
简单来说,就是确定了 `arr[i]`、`arr[j]`,就能尽可能的得到一个长的斐波那契式子序列,此时我们记录下子序列长度。然后对于不同的 `arr[i]`、`arr[j]`,统计不同的斐波那契式子序列的长度。将这些长度进行比较,其中最长的长度就是答案。
下面是暴力做法的代码:
```python
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
ans = 0
for i in range(size):
for j in range(i + 1, size):
temp_ans = 0
temp_i = i
temp_j = j
k = j + 1
while k < size:
if arr[temp_i] + arr[temp_j] == arr[k]:
temp_ans += 1
temp_i = temp_j
temp_j = k
k += 1
if temp_ans > ans:
ans = temp_ans
if ans > 0:
return ans + 2
else:
return ans
```
毫无意外的,超出时间限制了。
那么我们怎么来优化呢?
**2. 使用哈希表优化做法:**
我们注意到:对于 `arr[i]`、`arr[j]`,要查找的元素 `arr[i] + arr[j]` 是否在 `arr` 中,我们可以预先建立一个反向的哈希表。键值对关系为 `value : idx`,这样就能在 `O(1)` 的时间复杂度通过 `arr[i] + arr[j]` 的值查找到对应的 `k` 值,而不用像原先一样线性查找 `arr[k]` 了。
使用哈希表优化之后的代码如下:
```python
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
ans = 0
idx_map = dict()
for idx, value in enumerate(arr):
idx_map[value] = idx
for i in range(size):
for j in range(i + 1, size):
temp_ans = 0
temp_i = i
temp_j = j
while arr[temp_i] + arr[temp_j] in idx_map:
temp_ans += 1
k = idx_map[arr[temp_i] + arr[temp_j]]
temp_i = temp_j
temp_j = k
if temp_ans > ans:
ans = temp_ans
if ans > 0:
return ans + 2
else:
return ans
```
再次提交,通过了。
但是,这道题我们还可以用动态规划来做。
**3. 动态规划做法:**
这道题用动态规划来做,难点在于如何「定义状态」和「定义状态转移方程」。
- 定义状态:`dp[i][j]` 表示以 `arr[i]`、`arr[j]` 为结尾的斐波那契式子序列的最大长度。
- 定义状态转移方程:$dp[j][k] = max_{(arr[i] + arr[j] = arr[k], i < j < k)}(dp[i][j] + 1)$
- 意思为:以 `arr[j]`、`arr[k]` 结尾的斐波那契式子序列的最大长度 = 满足 `arr[i] + arr[j] = arr[k]` 条件下,以 `arr[i]`、`arr[j]` 结尾的斐波那契式子序列的最大长度 + 1。
但是直接这样做其实跟 **1. 暴力解法** 一样仍会超时,所以我们依旧采用哈希表优化的方式来提高效率,降低算法的时间复杂度。
具体代码如下:
## 代码
```python
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
# 初始化 dp
dp = [[0 for _ in range(size)] for _ in range(size)]
ans = 0
idx_map = {}
# 将 value : idx 映射为哈希表,这样可以快速通过 value 获取到 idx
for idx, value in enumerate(arr):
idx_map[value] = idx
for i in range(size):
for j in range(i + 1, size):
if arr[i] + arr[j] in idx_map:
# 获取 arr[i] + arr[j] 的 idx,即斐波那契式子序列下一项元素
k = idx_map[arr[i] + arr[j]]
dp[j][k] = max(dp[j][k], dp[i][j] + 1)
ans = max(ans, dp[j][k])
if ans > 0:
return ans + 2
else:
return ans
```
================================================
FILE: docs/solutions/LCR/QA2IGt.md
================================================
# [LCR 113. 课程表 II](https://leetcode.cn/problems/QA2IGt/)
- 标签:深度优先搜索、广度优先搜索、图、拓扑排序
- 难度:中等
## 题目链接
- [LCR 113. 课程表 II - 力扣](https://leetcode.cn/problems/QA2IGt/)
## 题目大意
给定一个整数 `numCourses`,代表这学期必须选修的课程数量,课程编号为 `0` 到 `numCourses - 1`。再给定一个数组 `prerequisites` 表示先修课程关系,其中 `prerequisites[i] = [ai, bi]` 表示如果要学习课程 `ai` 则必须要学习课程 `bi`。
要求:返回学完所有课程所安排的学习顺序。如果有多个正确的顺序,只要返回其中一种即可。如果无法完成所有课程,则返回空数组。
## 解题思路
拓扑排序。这道题是「[0207. 课程表](https://leetcode.cn/problems/course-schedule/)」的升级版,只需要在上一题的基础上增加一个答案数组即可。
1. 使用列表 `edges` 存放课程关系图,并统计每门课程节点的入度,存入入度列表 `indegrees`。
2. 借助队列 `queue`,将所有入度为 `0` 的节点入队。
3. 从队列中选择一个节点,并将其加入到答案数组 `res` 中,再让课程数 -1。
4. 将该顶点以及该顶点为出发点的所有边的另一个节点入度 -1。如果入度 -1 后的节点入度不为 `0`,则将其加入队列 `queue`。
5. 重复 3~4 的步骤,直到队列中没有节点。
6. 最后判断剩余课程数是否为 `0`,如果为 `0`,则返回答案数组 `res`,否则,返回空数组。
## 代码
```python
class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
indegrees = [0 for _ in range(numCourses)]
edges = collections.defaultdict(list)
res = []
for x, y in prerequisites:
edges[y].append(x)
indegrees[x] += 1
queue = collections.deque([])
for i in range(numCourses):
if not indegrees[i]:
queue.append(i)
while queue:
y = queue.popleft()
res.append(y)
numCourses -= 1
for x in edges[y]:
indegrees[x] -= 1
if not indegrees[x]:
queue.append(x)
if not numCourses:
return res
else:
return []
```
================================================
FILE: docs/solutions/LCR/QC3q1f.md
================================================
# [LCR 062. 实现 Trie (前缀树)](https://leetcode.cn/problems/QC3q1f/)
- 标签:设计、字典树、哈希表、字符串
- 难度:中等
## 题目链接
- [LCR 062. 实现 Trie (前缀树) - 力扣](https://leetcode.cn/problems/QC3q1f/)
## 题目大意
要求:实现前缀树数据结构的相关类 `Trie` 类。
`Trie` 类:
- `Trie()` 初始化前缀树对象。
- `void insert(String word)` 向前缀树中插入字符串 `word`。
- `boolean search(String word)` 如果字符串 `word` 在前缀树中,返回 `True`(即,在检索之前已经插入);否则,返回 `False`。
- `boolean startsWith(String prefix)` 如果之前已经插入的字符串 `word` 的前缀之一为 `prefix`,返回 `True`;否则,返回 `False`。
## 解题思路
前缀树(字典树)是一棵多叉数,其中每个节点包含指向子节点的指针数组 `children`,以及布尔变量 `isEnd`。`children` 用于存储当前字符节点,一般长度为所含字符种类个数,也可以使用哈希表代替指针数组。`isEnd` 用于判断该节点是否为字符串的结尾。
下面依次讲解插入、查找前缀的具体步骤:
插入字符串:
- 从根节点开始插入字符串。对于待插入的字符,有两种情况:
- 如果该字符对应的节点存在,则沿着指针移动到子节点,继续处理下一个字符。
- 如果该字符对应的节点不存在,则创建一个新的节点,保存在 `children` 中对应位置上,然后沿着指针移动到子节点,继续处理下一个字符。
- 重复上述步骤,直到最后一个字符,然后将该节点标记为字符串的结尾。
查找前缀:
- 从跟姐点开始查找前缀,对于待查找的字符,有两种情况:
- 如果该字符对应的节点存在,则沿着指针移动到子节点,继续查找下一个字符。
- 如果该字符对应的节点不存在,则说明字典树中不包含该前缀,直接返回空指针。
- 重复上述步骤,直到最后一个字符搜索完毕,则说明字典树中存在该前缀。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
def startsWith(self, prefix: str) -> bool:
"""
Returns if there is any word in the trie that starts with the given prefix.
"""
cur = self
for ch in prefix:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None
```
================================================
FILE: docs/solutions/LCR/QTMn0o.md
================================================
# [LCR 010. 和为 K 的子数组](https://leetcode.cn/problems/QTMn0o/)
- 标签:数组、哈希表、前缀和
- 难度:中等
## 题目链接
- [LCR 010. 和为 K 的子数组 - 力扣](https://leetcode.cn/problems/QTMn0o/)
## 题目大意
给定一个整数数组 `nums` 和一个整数 `k`。
要求:找到该数组中和为 `k` 的连续子数组的个数。
## 解题思路
看到题目的第一想法是通过滑动窗口求解。但是做下来发现有些数据样例无法通过。发现这道题目中的整数不能保证都为正数,则无法通过滑动窗口进行求解。
先考虑暴力做法,外层两重循环,遍历所有连续子数组,然后最内层再计算一下子数组的和。部分代码如下:
```python
for i in range(len(nums)):
for j in range(i + 1):
sum = countSum(i, j)
```
这样下来时间复杂度就是 $O(n^3)$ 了。下一步是想办法降低时间复杂度。
先用一重循环遍历数组,计算出数组 `nums` 中前 i 个元素的和(前缀和),保存到一维数组 `pre_sum` 中,那么对于任意 `[j..i]` 的子数组 的和为 `pre_sum[i] - pre_sum[j - 1]`。这样计算子数组和的时间复杂度降为了 $O(1)$。总体时间复杂度为 $O(n^3)$。
但是还是超时了。。
由于我们只关心和为 `k` 出现的次数,不关心具体的解,可以使用哈希表来加速运算。
`pre_sum[i]` 的定义是前 `i` 个元素和,则 `pre_sum[i]` 可以由 `pre_sum[i - 1]` 递推而来,即:`pre_sum[i] = pre_sum[i - 1] + sum[i]`。 `[j..i]` 子数组和为 `k` 可以转换为:`pre_sum[i] - pre_sum[j - 1] == k`。
综合一下,可得:`pre_sum[j - 1] == pre_sum[i] - k `。
所以,当我们考虑以 `i` 结尾和为 `k` 的连续子数组个数时,只需要统计有多少个前缀和为 `pre_sum[i] - k` (即 `pre_sum[j - 1]`)的个数即可。具体做法如下:
- 使用 `pre_sum` 变量记录前缀和(代表 `pre_sum[i]`)。
- 使用哈希表 `pre_dic` 记录 `pre_sum[i]` 出现的次数。键值对为 `pre_sum[i] : pre_sum_count`。
- 从左到右遍历数组,计算当前前缀和 `pre_sum`。
- 如果 `pre_sum - k` 在哈希表中,则答案个数累加上 `pre_dic[pre_sum - k]`。
- 如果 `pre_sum` 在哈希表中,则前缀和个数累加 1,即 `pre_dic[pre_sum] += 1`。
- 最后输出答案个数。
## 代码
```python
class Solution:
def subarraySum(self, nums: List[int], k: int) -> int:
pre_dic = {0: 1}
pre_sum = 0
count = 0
for num in nums:
pre_sum += num
if pre_sum - k in pre_dic:
count += pre_dic[pre_sum - k]
if pre_sum in pre_dic:
pre_dic[pre_sum] += 1
else:
pre_dic[pre_sum] = 1
return count
```
================================================
FILE: docs/solutions/LCR/Qv1Da2.md
================================================
# [LCR 028. 扁平化多级双向链表](https://leetcode.cn/problems/Qv1Da2/)
- 标签:深度优先搜索、链表、双向链表
- 难度:中等
## 题目链接
- [LCR 028. 扁平化多级双向链表 - 力扣](https://leetcode.cn/problems/Qv1Da2/)
## 题目大意
给定一个带子链表指针 `child` 的双向链表。
要求:将 `child` 的子链表进行扁平化处理,使所有节点出现在单级双向链表中。
扁平化处理如下:
```
原链表:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
扁平化之后:
1---2---3---7---8---11---12---9---10---4---5---6--NULL
```
## 解题思路
递归处理多层链表的扁平化。遍历链表,找到 `child` 非空的节点, 将其子链表链接到当前节点的 `next` 位置(自身扁平化处理)。然后继续向后遍历,不断找到 `child` 节点,并进行链接。直到处理到尾部位置。
## 代码
```python
class Solution:
def dfs(self, node: 'Node'):
# 找到链表的尾节点或 child 链表不为空的节点
while node.next and not node.child:
node = node.next
tail = None
if node.child:
# 如果 child 链表不为空,将 child 链表扁平化
tail = self.dfs(node.child)
# 将扁平化的 child 链表链接在该节点之后
temp = node.next
node.next = node.child
node.next.prev = node
node.child = None
tail.next = temp
if temp:
temp.prev = tail
# 链接之后,从 child 链表的尾节点继续向后处理链表
return self.dfs(tail)
# child 链表为空,则该节点是尾节点,直接返回
return node
def flatten(self, head: 'Node') -> 'Node':
if not head:
return head
self.dfs(head)
return head
```
================================================
FILE: docs/solutions/LCR/RQku0D.md
================================================
# [LCR 019. 验证回文串 II](https://leetcode.cn/problems/RQku0D/)
- 标签:贪心、双指针、字符串
- 难度:简单
## 题目链接
- [LCR 019. 验证回文串 II - 力扣](https://leetcode.cn/problems/RQku0D/)
## 题目大意
给定一个非空字符串 `s`。
要求:判断如果最多从字符串中删除一个字符能否得到一个回文字符串。
## 解题思路
双指针 + 贪心算法。
- 用两个指针 `left`、`right` 分别指向字符串的开始和结束位置。
- 判断 `s[left]` 是否等于 `s[right]`。
- 如果等于,则 `left` 右移、`right`左移。
- 如果不等于,则判断 `s[left: right - 1]` 或 `s[left + 1, right]` 是为回文串。
- 如果是则返回 `True`。
- 如果不是则返回 `False`,然后继续判断。
- 如果 `right >= left`,则说明字符串 `s` 本身就是回文串,返回 `True`。
## 代码
```python
class Solution:
def checkPalindrome(self, s: str, left: int, right: int):
i, j = left, right
while i < j:
if s[i] != s[j]:
return False
i += 1
j -= 1
return True
def validPalindrome(self, s: str) -> bool:
left, right = 0, len(s) - 1
while left < right:
if s[left] == s[right]:
left += 1
right -= 1
else:
return self.checkPalindrome(s, left + 1, right) or self.checkPalindrome(s, left, right - 1)
return True
```
================================================
FILE: docs/solutions/LCR/SLwz0R.md
================================================
# [LCR 021. 删除链表的倒数第 N 个结点](https://leetcode.cn/problems/SLwz0R/)
- 标签:链表、双指针
- 难度:中等
## 题目链接
- [LCR 021. 删除链表的倒数第 N 个结点 - 力扣](https://leetcode.cn/problems/SLwz0R/)
## 题目大意
给你一个链表的头节点 `head` 和一个整数 `n`。
要求:删除链表的倒数第 `n` 个节点,并且返回链表的头节点。并且要求使用一次遍历实现。
## 解题思路
常规思路是遍历一遍链表,求出链表长度,再遍历一遍到对应位置,删除该位置上的节点。
如果用一次遍历实现的话,可以使用快慢指针。让快指针先走 n 步,然后快慢指针、慢指针再同时走,每次一步,这样等快指针遍历到链表尾部的时候,慢指针就刚好遍历到了倒数第 n 个节点位置。将该位置上的节点删除即可。
需要注意的是要删除的节点可能包含了头节点。我们可以考虑在遍历之前,新建一个头节点,让其指向原来的头节点。这样,最终如果删除的是头节点,则删除原头节点即可。返回结果的时候,可以直接返回新建头节点的下一位节点。
## 代码
```python
class Solution:
def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
newHead = ListNode(0, head)
fast = head
slow = newHead
while n:
fast = fast.next
n -= 1
while fast:
fast = fast.next
slow = slow.next
slow.next = slow.next.next
return newHead.next
```
================================================
FILE: docs/solutions/LCR/SsGoHC.md
================================================
# [LCR 074. 合并区间](https://leetcode.cn/problems/SsGoHC/)
- 标签:数组、排序
- 难度:中等
## 题目链接
- [LCR 074. 合并区间 - 力扣](https://leetcode.cn/problems/SsGoHC/)
## 题目大意
给定一个数组 `intervals` 表示若干个区间的集合,`intervals[i] = [starti, endi]` 表示单个区间。
要求:合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需要恰好覆盖原数组中的所有区间。
## 解题思路
设定一个数组 `ans` 用于表示最终不重叠的区间数组,然后对原始区间先按照区间左端点大小从小到大进行排序。
遍历所有区间。先将第一个区间加入 `ans` 数组中。然后依次考虑后边的区间,如果第 `i` 个区间左端点在前一个区间右端点右侧,则这两个区间不会重合,直接将该区间加入 `ans` 数组中。否则的话,这两个区间重合,判断一下两个区间的右区间值,更新前一个区间的右区间值为较大值,然后继续考虑下一个区间,以此类推。
## 代码
```python
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
intervals.sort(key=lambda x: x[0])
ans = []
for interval in intervals:
if not ans or ans[-1][1] < interval[0]:
ans.append(interval)
else:
ans[-1][1] = max(ans[-1][1], interval[1])
return ans
```
================================================
FILE: docs/solutions/LCR/TVdhkn.md
================================================
# [LCR 079. 子集](https://leetcode.cn/problems/TVdhkn/)
- 标签:位运算、数组、回溯
- 难度:中等
## 题目链接
- [LCR 079. 子集 - 力扣](https://leetcode.cn/problems/TVdhkn/)
## 题目大意
给定一个整数数组 `nums`,数组中的元素互不相同。
要求:返回该数组所有可能的不重复子集。
## 解题思路
回溯算法,遍历数组 `nums`。为了使得子集不重复,每次遍历从当前位置的下一个位置进行下一层遍历。
## 代码
```python
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
def backtrack(size, subset, index):
res.append(subset)
for i in range(index, size):
backtrack(size, subset + [nums[i]], i + 1)
size = len(nums)
res = list()
backtrack(size, [], 0)
return res
```
================================================
FILE: docs/solutions/LCR/UHnkqh.md
================================================
# [LCR 024. 反转链表](https://leetcode.cn/problems/UHnkqh/)
- 标签:递归、链表
- 难度:简单
## 题目链接
- [LCR 024. 反转链表 - 力扣](https://leetcode.cn/problems/UHnkqh/)
## 题目大意
**描述**:给定一个单链表的头节点 `head`。
**要求**:将其进行反转,并返回反转后的链表的头节点。
## 解题思路
### 思路 1. 迭代
1. 使用两个指针 `cur` 和 `pre` 进行迭代。`pre` 指向 `cur` 前一个节点位置。初始时,`pre` 指向 `None`,`cur` 指向 `head`。
2. 将 `pre` 和 `cur` 的前后指针进行交换,指针更替顺序为:
1. 使用 `next` 指针保存当前节点 `cur` 的后一个节点,即 `next = cur.next`;
2. 断开当前节点 `cur` 的后一节点链接,将 `cur` 的 `next` 指针指向前一节点 `pre`,即 `cur.next = pre`;
3. `pre` 向前移动一步,移动到 `cur` 位置,即 `pre = cur`;
4. `cur` 向前移动一步,移动到之前 `next` 指针保存的位置,即 `cur = next`。
3. 继续执行第 2 步中的 1、2、3、4。
4. 最后等到 `cur` 遍历到链表末尾,即 `cur == None`,时,`pre` 所在位置就是反转后链表的头节点,返回新的头节点 `pre`。
使用迭代法反转链表的示意图如下所示:
### 思路 2. 递归
具体做法如下:
- 首先定义递归函数含义为:将链表反转,并返回反转后的头节点。
- 然后从 `head.next` 的位置开始调用递归函数,即将 `head.next` 为头节点的链表进行反转,并返回该链表的头节点。
- 递归到链表的最后一个节点,将其作为最终的头节点,即为 `new_head`。
- 在每次递归函数返回的过程中,改变 `head` 和 `head.next` 的指向关系。也就是将 `head.next` 的`next` 指针先指向当前节点 `head`,即 `head.next.next = head `。
- 然后让当前节点 `head` 的 `next` 指针指向 `None`,从而实现从链表尾部开始的局部反转。
- 当递归从末尾开始顺着递归栈的退出,从而将整个链表进行反转。
- 最后返回反转后的链表头节点 `new_head`。
使用递归法反转链表的示意图如下所示:
## 代码
1. 迭代
```python
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
pre = None
cur = head
while cur != None:
next = cur.next
cur.next = pre
pre = cur
cur = next
return pre
```
2. 递归
```python
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
if head == None or head.next == None:
return head
new_head = self.reverseList(head.next)
head.next.next = head
head.next = None
return new_head
```
## 参考资料
- 【题解】[反转链表 - 反转链表 - 力扣](https://leetcode.cn/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-by-leetcode-solution-d1k2/)
- 【题解】[【反转链表】:双指针,递归,妖魔化的双指针 - 反转链表 - 力扣(LeetCode)](https://leetcode.cn/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-shuang-zhi-zhen-di-gui-yao-mo-/)
================================================
FILE: docs/solutions/LCR/US1pGT.md
================================================
# [LCR 064. 实现一个魔法字典](https://leetcode.cn/problems/US1pGT/)
- 标签:设计、字典树、哈希表、字符串
- 难度:中等
## 题目链接
- [LCR 064. 实现一个魔法字典 - 力扣](https://leetcode.cn/problems/US1pGT/)
## 题目大意
要求:设计一个使用单词表进行初始化的数据结构。单词表中的单词互不相同。如果给出一个单词,要求判定能否将该单词中的一个字母替换成另一个字母,是的所形成的新单词已经在够构建的单词表中。
实现 MagicDictionary 类:
- `MagicDictionary()` 初始化对象。
- `void buildDict(String[] dictionary)` 使用字符串数组 `dictionary` 设定该数据结构,`dictionary` 中的字符串互不相同。
- `bool search(String searchWord)` 给定一个字符串 `searchWord`,判定能否只将字符串中一个字母换成另一个字母,使得所形成的新字符串能够与字典中的任一字符串匹配。如果可以,返回 `True`;否则,返回 `False`。
## 解题思路
- 初始化使用字典树结构。
- `buildDict` 方法中将所有单词存入字典树中。
- `search` 方法中替换 `searchWord` 每一个位置上的字符,然后在字典树中查询。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class MagicDictionary:
def __init__(self):
"""
Initialize your data structure here.
"""
self.trie_tree = Trie()
def buildDict(self, dictionary: List[str]) -> None:
for word in dictionary:
self.trie_tree.insert(word)
def search(self, searchWord: str) -> bool:
size = len(searchWord)
for i in range(size):
for j in range(26):
new_ch = chr(ord('a') + j)
if searchWord[i] != new_ch:
new_word = searchWord[:i] + new_ch + searchWord[i + 1:]
if self.trie_tree.search(new_word):
return True
return False
```
================================================
FILE: docs/solutions/LCR/UhWRSj.md
================================================
# [LCR 063. 单词替换](https://leetcode.cn/problems/UhWRSj/)
- 标签:字典树、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [LCR 063. 单词替换 - 力扣](https://leetcode.cn/problems/UhWRSj/)
## 题目大意
给定一个由许多词根组成的字典列表 `dictionary`,以及一个句子字符串 `sentence`。
要求:将句子中有词根的单词用词根替换掉。如果单词有很多词根,则用最短的词根替换掉他。最后输出替换之后的句子。
## 解题思路
将所有的词根存入到前缀树(字典树)中。然后在树上查找每个单词的最短词根。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> str:
"""
Returns if the word is in the trie.
"""
cur = self
index = 0
for ch in word:
if ch not in cur.children:
return word
cur = cur.children[ch]
index += 1
if cur.isEnd:
break
return word[:index]
class Solution:
def replaceWords(self, dictionary: List[str], sentence: str) -> str:
trie_tree = Trie()
for word in dictionary:
trie_tree.insert(word)
words = sentence.split(" ")
size = len(words)
for i in range(size):
word = words[i]
words[i] = trie_tree.search(word)
return ' '.join(words)
```
================================================
FILE: docs/solutions/LCR/VvJkup.md
================================================
# [LCR 083. 全排列](https://leetcode.cn/problems/VvJkup/)
- 标签:数组、回溯
- 难度:中等
## 题目链接
- [LCR 083. 全排列 - 力扣](https://leetcode.cn/problems/VvJkup/)
## 题目大意
给定一个不含重复数字的数组 `nums` 。
要求:返回其有可能的全排列,可以按任意顺序返回。
## 解题思路
回溯算法递归遍历 `nums` 元素。同时使用 `visited` 数组来标记该元素在当前排列中是否被访问过。如果未被访问过则将其加入排列中,并在访问后将该元素变为未访问状态。
## 代码
```python
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
def backtrack(size, arrange, index):
if index == size:
res.append(arrange)
return
for i in range(size):
if visited[i] == True:
continue
visited[i] = True
backtrack(size, arrange + [nums[i]], index + 1)
visited[i] = False
size = len(nums)
res = list()
visited = [False for _ in range(size)]
backtrack(size, [], 0)
return res
```
================================================
FILE: docs/solutions/LCR/WGki4K.md
================================================
# [LCR 004. 只出现一次的数字 II](https://leetcode.cn/problems/WGki4K/)
- 标签:位运算、数组
- 难度:中等
## 题目链接
- [LCR 004. 只出现一次的数字 II - 力扣](https://leetcode.cn/problems/WGki4K/)
## 题目大意
给定一个整数数组 `nums`,除了某个元素仅出现一次外,其余每个元素恰好出现三次。
要求:找到并返回那个只出现了一次的元素。
## 解题思路
### 1. 哈希表
朴素解法就是利用哈希表。统计出每个元素的出现次数。再遍历哈希表,找到仅出现一次的元素。
### 2. 位运算
将出现三次的元素换成二进制形式放在一起,其二进制对应位置上,出现 `1` 的个数一定是 `3` 的倍数(包括 `0`)。此时,如果在放进来只出现一次的元素,则某些二进制位置上出现 `1` 的个数就不是 `3` 的倍数了。
将这些二进制位置上出现 `1` 的个数不是 `3` 的倍数位置值置为 `1`,是 `3` 的倍数则置为 `0`。这样对应下来的二进制就是答案所求。
注意:因为 Python 的整数没有位数限制,所以不能通过最高位确定正负。所以 Python 中负整数的补码会被当做正整数。所以在遍历到最后 `31` 位时进行 `ans -= (1 << 31)` 操作,目的是将负数的补码转换为「负号 + 原码」的形式。这样就可以正常识别二进制下的负数。参考:[Two's Complement Binary in Python? - Stack Overflow](https://stackoverflow.com/questions/12946116/twos-complement-binary-in-python/12946226)
## 代码
1. 哈希表
```python
class Solution:
def singleNumber(self, nums: List[int]) -> int:
nums_dict = dict()
for num in nums:
if num in nums_dict:
nums_dict[num] += 1
else:
nums_dict[num] = 1
for key in nums_dict:
value = nums_dict[key]
if value == 1:
return key
return 0
```
2. 位运算
```python
class Solution:
def singleNumber(self, nums: List[int]) -> int:
ans = 0
for i in range(32):
count = 0
for j in range(len(nums)):
count += (nums[j] >> i) & 1
if count % 3 != 0:
if i == 31:
ans -= (1 << 31)
else:
ans = ans | 1 << i
return ans
```
================================================
FILE: docs/solutions/LCR/WNC0Lk.md
================================================
# [LCR 046. 二叉树的右视图](https://leetcode.cn/problems/WNC0Lk/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 046. 二叉树的右视图 - 力扣](https://leetcode.cn/problems/WNC0Lk/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:按照从顶部到底部的顺序,返回从右侧能看到的节点值。
## 解题思路
二叉树的层次遍历,不过遍历每层节点的时候,只需要将最后一个节点加入结果数组即可。
## 代码
```python
class Solution:
def rightSideView(self, root: TreeNode) -> List[int]:
if not root:
return []
queue = [root]
order = []
while queue:
level = []
size = len(queue)
for i in range(size):
curr = queue.pop(0)
level.append(curr.val)
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
if i == size - 1:
order.append(curr.val)
return order
```
================================================
FILE: docs/solutions/LCR/WhsWhI.md
================================================
# [LCR 119. 最长连续序列](https://leetcode.cn/problems/WhsWhI/)
- 标签:并查集、数组、哈希表
- 难度:中等
## 题目链接
- [LCR 119. 最长连续序列 - 力扣](https://leetcode.cn/problems/WhsWhI/)
## 题目大意
给定一个未排序的整数数组 `nums`。
要求:找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。并且要用时间复杂度为 $O(n)$ 的算法解决此问题。
## 解题思路
暴力做法有两种思路。第 1 种思路是先排序再依次判断,这种做法时间复杂度最少是 $O(n \log n)$。第 2 种思路是枚举数组中的每个数 `num`,考虑以其为起点,不断尝试匹配 `num + 1`、`num + 2`、`...` 是否存在,最长匹配次数为 `len(nums)`。这样下来时间复杂度为 $O(n^2)$。但是可以使用集合或哈希表优化这个步骤。
- 先将数组存储到集合中进行去重,然后使用 `curr_streak` 维护当前连续序列长度,使用 `ans` 维护最长连续序列长度。
- 遍历集合中的元素,对每个元素进行判断,如果该元素不是序列的开始(即 `num - 1` 在集合中),则跳过。
- 如果 `num - 1` 不在集合中,说明 `num` 是序列的开始,判断 `num + 1` 、`nums + 2`、`...` 是否在哈希表中,并不断更新当前连续序列长度 `curr_streak`。并在遍历结束之后更新最长序列的长度。
- 最后输出最长序列长度。
将数组存储到集合中进行去重的操作的时间复杂度是 $O(n)$。查询每个数是否在集合中的时间复杂度是 $O(1)$ ,并且跳过了所有不是起点的元素。更新当前连续序列长度 `curr_streak` 的时间复杂度是 $O(n)$,所以最终的时间复杂度是 $O(n)$。符合题意要求。
## 代码
```python
class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
ans = 0
nums_set = set(nums)
for num in nums_set:
if num - 1 not in nums_set:
curr_num = num
curr_streak = 1
while curr_num + 1 in nums_set:
curr_num += 1
curr_streak += 1
ans = max(ans, curr_streak)
return ans
```
================================================
FILE: docs/solutions/LCR/XagZNi.md
================================================
# [LCR 037. 行星碰撞](https://leetcode.cn/problems/XagZNi/)
- 标签:栈、数组
- 难度:中等
## 题目链接
- [LCR 037. 行星碰撞 - 力扣](https://leetcode.cn/problems/XagZNi/)
## 题目大意
给定一个整数数组 `asteroids`,表示在同一行的小行星。
数组中的每一个元素,其绝对值表示小行星的大小,正负表示小行星的移动方向(正表示向右移动,负表示向左移动)。每一颗小行星以相同的速度移动。小行星按照下面的规则发生碰撞。
- 碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
要求:找出碰撞后剩下的所有小行星,将答案存入数组并返回。
## 解题思路
用栈模拟小行星碰撞,具体步骤如下:
- 遍历数组 `asteroids`。
- 如果栈为空或者当前元素 `asteroid` 为正数,将其压入栈。
- 如果当前栈不为空并且当前元素 `asteroid` 为负数:
- 与栈中元素发生碰撞,判断当前元素和栈顶元素的大小和方向,如果栈顶元素为正数,并且当前元素的绝对值大于栈顶元素,则将栈顶元素弹出,并继续与栈中元素发生碰撞。
- 碰撞完之后,如果栈为空并且栈顶元素为负数,则将当前元素 `asteroid` 压入栈,表示碰撞完剩下了 `asteroid`。
- 如果栈顶元素恰好与当前元素值大小相等、方向相反,则弹出栈顶元素,表示碰撞完两者都爆炸了。
- 最后返回栈作为答案。
## 代码
```python
class Solution:
def asteroidCollision(self, asteroids: List[int]) -> List[int]:
stack = []
for asteroid in asteroids:
if not stack or asteroid > 0:
stack.append(asteroid)
else:
while stack and 0 < stack[-1] < -asteroid:
stack.pop()
if not stack or stack[-1] < 0:
stack.append(asteroid)
elif stack[-1] == -asteroid:
stack.pop()
return stack
```
================================================
FILE: docs/solutions/LCR/XltzEq.md
================================================
# [LCR 018. 验证回文串](https://leetcode.cn/problems/XltzEq/)
- 标签:双指针、字符串
- 难度:简单
## 题目链接
- [LCR 018. 验证回文串 - 力扣](https://leetcode.cn/problems/XltzEq/)
## 题目大意
给定一个字符串 `s`。
要求:判断是否为回文串。(只考虑字符串中的字母和数字字符,并且忽略字母的大小写)
## 解题思路
左右两个指针 `start` 和 `end`,左指针 `start` 指向字符串头部,右指针 `end` 指向字符串尾部。先过滤掉除字母和数字字符以外的字符,在判断 `s[start]` 和 `s[end]` 是否相等。不相等返回 `False`,相等则继续过滤和判断。
## 代码
```python
class Solution:
def isPalindrome(self, s: str) -> bool:
n = len(s)
start = 0
end = n - 1
while start < end:
if not s[start].isalnum():
start += 1
continue
if not s[end].isalnum():
end -= 1
continue
if s[start].lower() == s[end].lower():
start += 1
end -= 1
else:
return False
return True
```
================================================
FILE: docs/solutions/LCR/YaVDxD.md
================================================
# [LCR 102. 目标和](https://leetcode.cn/problems/YaVDxD/)
- 标签:数组、动态规划、回溯
- 难度:中等
## 题目链接
- [LCR 102. 目标和 - 力扣](https://leetcode.cn/problems/YaVDxD/)
## 题目大意
给定一个整数数组 `nums` 和一个整数 `target`。数组长度不超过 `20`。向数组中每个整数前加 `+` 或 `-`。然后串联起来构造成一个表达式。
要求:返回通过上述方法构造的、运算结果等于 `target` 的不同表达式数目。
## 解题思路
暴力方法就是使用深度优先搜索对每位数字遍历 `+`、`-`,并统计符合要求的表达式数目。但是实际发现超时了。所以采用动态规划的方法来做。
假设数组中所有元素和为 `sum`,数组中所有符号为 `+` 的元素为 `sum_x`,符号为 `-` 的元素和为 `sum_y`。则 `target = sum_x - sum_y`。
而 `sum_x + sum_y = sum`。根据两个式子可以求出 `2 * sum_x = target + sum `,即 `sum_x = (target + sum) / 2`。
那么这道题就变成了,如何在数组中找到一个集合,使集合中元素和为 `(target + sum) / 2`。这就变为了求容量为 `(target + sum) / 2` 的 `01` 背包问题。
动态规划的状态 `dp[i]` 表示为:填满容量为 `i` 的背包,有 `dp[i]` 种方法。
动态规划的状态转移方程为:`dp[i] = dp[i] + dp[i-num]`,意思为填满容量为 `i` 的背包的方法数 = 不使用当前 `num`,只使用之前元素填满容量为 `i` 的背包的方法数 + 填满容量 `i - num` 的包的方法数,再填入 `num` 的方法数。
## 代码
```python
class Solution:
def findTargetSumWays(self, nums: List[int], target: int) -> int:
sum_nums = sum(nums)
if target > sum_nums or (target + sum_nums) % 2 == 1:
return 0
size = (target + sum_nums) // 2
dp = [0 for _ in range(size + 1)]
dp[0] = 1
for num in nums:
for i in range(size, num - 1, -1):
dp[i] = dp[i] + dp[i - num]
return dp[size]
```
================================================
FILE: docs/solutions/LCR/Ygoe9J.md
================================================
# [LCR 081. 组合总和](https://leetcode.cn/problems/Ygoe9J/)
- 标签:数组、回溯
- 难度:中等
## 题目链接
- [LCR 081. 组合总和 - 力扣](https://leetcode.cn/problems/Ygoe9J/)
## 题目大意
给定一个无重复元素的正整数数组 `candidates` 和一个正整数 `target`。
要求:找出 `candidates` 中所有可以使数字和为目标数 `target` 的唯一组合。
注意:数组 `candidates` 中的数字可以无限重复选取,且 `1 ≤ candidates[i] ≤ 200`。
## 解题思路
回溯算法,因为 `1 ≤ candidates[i] ≤ 200`,所以即便是 `candidates[i]` 值为 `1`,重复选取也会等于或大于 target,从而终止回溯。
建立两个数组 `res`、`path`。`res` 用于存放所有满足题意的组合,`path` 用于存放当前满足题意的一个组合。
定义回溯方法,`start_index = 1` 开始进行回溯。
- 如果 `sum > target`,则直接返回。
- 如果 `sum == target`,则将 `path` 中的元素加入到 `res` 数组中。
- 然后对 `[start_index, n]` 范围内的数进行遍历取值。
- 如果 `sum + candidates[i] > target`,可以直接跳出循环。
- 将和累积,即 `sum += candidates[i]`,然后将当前元素 `i` 加入 `path` 数组。
- 递归遍历 `[start_index, n]` 上的数。
- 加之前的和回退,即 `sum -= candidates[i]`,然后将遍历的 `i` 元素进行回退。
- 最终返回 `res` 数组。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, candidates: List[int], target: int, sum: int, start_index: int):
if sum > target:
return
if sum == target:
self.res.append(self.path[:])
return
for i in range(start_index, len(candidates)):
if sum + candidates[i] > target:
break
sum += candidates[i]
self.path.append(candidates[i])
self.backtrack(candidates, target, sum, i)
sum -= candidates[i]
self.path.pop()
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
self.res.clear()
self.path.clear()
candidates.sort()
self.backtrack(candidates, target, 0, 0)
return self.res
```
================================================
FILE: docs/solutions/LCR/ZL6zAn.md
================================================
# [LCR 105. 岛屿的最大面积](https://leetcode.cn/problems/ZL6zAn/)
- 标签:深度优先搜索、广度优先搜索、并查集、数组、矩阵
- 难度:中等
## 题目链接
- [LCR 105. 岛屿的最大面积 - 力扣](https://leetcode.cn/problems/ZL6zAn/)
## 题目大意
给定一个只包含 `0`、`1` 元素的二维数组,`1` 代表岛屿,`0` 代表水。一座岛的面积就是上下左右相邻相邻的 `1` 所组成的连通块的数目。找到最大的岛屿面积。
## 解题思路
使用深度优先搜索方法。遍历二维数组的每一个元素,对于每个值为 `1` 的元素,记下其面积。然后将该值置为 `0`(防止二次重复计算),再递归其上下左右四个位置,并将深度优先搜索搜到的值为 `1` 的元素个数,进行累积统计。
## 代码
```python
class Solution:
def dfs(self, grid, i, j):
size_n = len(grid)
size_m = len(grid[0])
if i < 0 or i >= size_n or j < 0 or j >= size_m or grid[i][j] == 0:
return 0
ans = 1
grid[i][j] = 0
ans += self.dfs(grid, i + 1, j)
ans += self.dfs(grid, i, j + 1)
ans += self.dfs(grid, i - 1, j)
ans += self.dfs(grid, i, j - 1)
return ans
def maxAreaOfIsland(self, grid: List[List[int]]) -> int:
ans = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == 1:
ans = max(ans, self.dfs(grid, i, j))
return ans
```
================================================
FILE: docs/solutions/LCR/ZVAVXX.md
================================================
# [LCR 009. 乘积小于 K 的子数组](https://leetcode.cn/problems/ZVAVXX/)
- 标签:数组、滑动窗口
- 难度:中等
## 题目链接
- [LCR 009. 乘积小于 K 的子数组 - 力扣](https://leetcode.cn/problems/ZVAVXX/)
## 题目大意
给定一个正整数数组 `nums` 和一个整数 `k`。
要求:找出该数组内乘积小于 `k` 的连续子数组的个数。
## 解题思路
滑动窗口求解。
设定两个指针:`left`、`right`,分别指向滑动窗口的左右边界,保证窗口内所有数的乘积 `product` 都小于 `k`。
- 一开始,`left`、`right` 都指向 `0`。
- 向右移动 `right`,将最右侧元素加入当前子数组乘积 `product` 中。
- 如果 `product >= k` ,则不断右移 `left`,缩小滑动窗口,并更新当前乘积值 `product` 直到 `product < k`。
- 累积答案个数 += 1,继续右移 `right`,直到 `right >= len(nums)` 结束。
- 输出累积答案个数。
## 代码
```python
class Solution:
def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:
if k <= 1:
return 0
size = len(nums)
left, right = 0, 0
count = 0
product = 1
while right < size:
product *= nums[right]
right += 1
while product >= k:
product /= nums[left]
left += 1
count += (right - left)
return count
```
================================================
FILE: docs/solutions/LCR/a7VOhD.md
================================================
# [LCR 020. 回文子串](https://leetcode.cn/problems/a7VOhD/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [LCR 020. 回文子串 - 力扣](https://leetcode.cn/problems/a7VOhD/)
## 题目大意
给定一个字符串 `s`。
要求:计算 `s` 中有多少个回文子串。
## 解题思路
动态规划求解。
先定义状态 `dp[i][j]` 表示为区间 `[i, j]` 的子串是否为回文子串,如果是,则 `dp[i][j] = True`,如果不是,则 `dp[i][j] = False`。
接下来确定状态转移共识:
如果 `s[i] == s[j]`,分为以下几种情况:
- `i == j`,单字符肯定是回文子串,`dp[i][j] == True`。
- `j - i == 1`,比如 `aa` 肯定也是回文子串,`dp[i][j] = True`。
- 如果 `j - i > 1`,则需要看 `[i + 1, j - 1]` 区间是不是回文子串,`dp[i][j] = dp[i + 1][j - 1]`。
如果 `s[i] != s[j]`,那肯定不是回文子串,`dp[i][j] = False`。
下一步确定遍历方向。
由于 `dp[i][j]` 依赖于 `dp[i + 1][j - 1]`,所以我们可以从左下角向右上角遍历。
同时,在递推过程中记录下 `dp[i][j] == True` 的个数,即为最后结果。
## 代码
```python
class Solution:
def countSubstrings(self, s: str) -> int:
size = len(s)
dp = [[False for _ in range(size)] for _ in range(size)]
res = 0
for i in range(size - 1, -1, -1):
for j in range(i, size):
if s[i] == s[j]:
if j - i <= 1:
dp[i][j] = True
else:
dp[i][j] = dp[i + 1][j - 1]
else:
dp[i][j] = False
if dp[i][j]:
res += 1
return res
```
================================================
FILE: docs/solutions/LCR/aMhZSa.md
================================================
# [LCR 027. 回文链表](https://leetcode.cn/problems/aMhZSa/)
- 标签:栈、递归、链表、双指针
- 难度:简单
## 题目链接
- [LCR 027. 回文链表 - 力扣](https://leetcode.cn/problems/aMhZSa/)
## 题目大意
给定一个链表的头节点 `head`。
要求:判断该链表是否为回文链表。
## 解题思路
利用数组,将链表元素依次存入。然后再使用两个指针,一个指向数组开始位置,一个指向数组结束位置,依次判断首尾对应元素是否相等,如果都相等,则为回文链表。如果不相等,则不是回文链表。
## 代码
```python
class Solution:
def isPalindrome(self, head: ListNode) -> bool:
nodes = []
p1 = head
while p1 != None:
nodes.append(p1.val)
p1 = p1.next
return nodes == nodes[::-1]
```
================================================
FILE: docs/solutions/LCR/aseY1I.md
================================================
# [LCR 005. 最大单词长度乘积](https://leetcode.cn/problems/aseY1I/)
- 标签:位运算、数组、字符串
- 难度:中等
## 题目链接
- [LCR 005. 最大单词长度乘积 - 力扣](https://leetcode.cn/problems/aseY1I/)
## 题目大意
给定一个字符串数组 `words`。字符串中只包含英语的小写字母。
要求:计算当两个字符串 `words[i]` 和 `words[j]` 不包含相同字符时,它们长度的乘积的最大值。如果没有不包含相同字符的一对字符串,返回 0。
## 解题思路
这道题的核心难点是判断任意两个字符串之间是否包含相同字符。最直接的做法是先遍历第一个字符串的每个字符,再遍历第二个字符串查看是否有相同字符。但是这样做的话,时间复杂度过高。考虑怎么样可以优化一下。
题目中说字符串中只包含英语的小写字母,也就是 `26` 种字符。一个 `32` 位的 `int` 整数每一个二进制位都可以表示一种字符的有无,那么我们就可以通过一个整数来表示一个字符串中所拥有的字符种类。延伸一下,我们可以用一个整数数组来表示一个字符串数组中,每个字符串所拥有的字符种类。
接下来事情就简单了,两重循环遍历整数数组,遇到两个字符串不包含相同字符的情况,就计算一下他们长度的乘积,并维护一个乘积最大值。最后输出最大值即可。
## 代码
```python
class Solution:
def maxProduct(self, words: List[str]) -> int:
size = len(words)
arr = [0 for _ in range(size)]
for i in range(size):
word = words[i]
len_word = len(word)
for j in range(len_word):
arr[i] |= 1 << (ord(word[j]) - ord('a'))
ans = 0
for i in range(size):
for j in range(i + 1, size):
if arr[i] & arr[j] == 0:
k = len(words[i]) * len(words[j])
ans = k if ans < k else ans
return ans
```
================================================
FILE: docs/solutions/LCR/bLyHh0.md
================================================
# [LCR 116. 省份数量](https://leetcode.cn/problems/bLyHh0/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [LCR 116. 省份数量 - 力扣](https://leetcode.cn/problems/bLyHh0/)
## 题目大意
一个班上有 `n` 个同学,其中一些彼此是朋友,另一些不是。如果 `a` 与 `b` 是直接朋友,且 `b` 与 `c` 也是直接朋友,那么 `a` 与 `c` 是间接朋友。
现在定义「朋友圈」是由一组直接或间接朋友组成的集合。
现在给定一个 `n * n` 的矩阵 `isConnected` 表示班上的朋友关系。其中 `isConnected[i][j] = 1` 表示第 `i` 个同学和第 `j` 个同学是直接朋友,`isConnected[i][j] = 0` 表示第 `i` 个同学和第 `j` 个同学不是直接朋友。
要求:根据给定的同学关系,返回「朋友圈」的数量。
## 解题思路
可以利用并查集来做。具体做法如下:
遍历矩阵 `isConnected`。如果 `isConnected[i][j] = 1`,将 `i` 节点和 `j` 节点相连。然后判断每个同学节点的根节点,然后统计不重复的根节点有多少个,即为「朋友圈」的数量。
## 代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.count = n
def find(self, x):
while x != self.parent[x]:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.count -= 1
def is_connected(self, x, y):
return self.find(x) == self.find(y)
class Solution:
def findCircleNum(self, isConnected: List[List[int]]) -> int:
size = len(isConnected)
union_find = UnionFind(size)
for i in range(size):
for j in range(i + 1, size):
if isConnected[i][j] == 1:
union_find.union(i, j)
return union_find.count
```
================================================
FILE: docs/solutions/LCR/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof.md
================================================
# [LCR 165. 解密数字](https://leetcode.cn/problems/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [LCR 165. 解密数字 - 力扣](https://leetcode.cn/problems/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof/)
## 题目大意
给定一个数字 `num`,按照如下规则将其翻译为字符串:`0` 翻译为 `a`,`1` 翻译为 `b`,…,`11` 翻译为 `l`,…,`25` 翻译为 `z`。
要求:计算出共有多少种可能的翻译方案。
## 解题思路
可用动态规划来做。
将数字 `nums` 转为字符串 `s`。设 `dp[i]` 表示字符串 `s` 前 `i` 个数字 `s[0: i]` 的翻译方案数。`dp[i]` 的来源有两种情况:
1. 第 `i - 1`、`i - 2` 构成的数字在 `[10, 25]`之间,则 `dp[i]` 来源于: `s[i - 1]` 单独翻译的方案数(即 `dp[i - 1]`) + `s[i - 2]` 和 `s[i - 1]` 连起来进行翻译的方案数(即 `dp[i - 2]`)。
2. 第 `i - 1`、`i - 2` 构成的数字在 `[10, 25]`之外,则 `dp[i]` 来源于:`s[i]` 单独翻译的方案数。
## 代码
```python
class Solution:
def translateNum(self, num: int) -> int:
s = str(num)
size = len(s)
dp = [0 for _ in range(size + 1)]
dp[0] = 1
dp[1] = 1
for i in range(2, size + 1):
temp = int(s[i-2:i])
if temp >= 10 and temp <= 25:
dp[i] = dp[i - 1] + dp[i - 2]
else:
dp[i] = dp[i - 1]
return dp[size]
```
================================================
FILE: docs/solutions/LCR/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof.md
================================================
# [LCR 164. 破解闯关密码](https://leetcode.cn/problems/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof/)
- 标签:贪心、字符串、排序
- 难度:中等
## 题目链接
- [LCR 164. 破解闯关密码 - 力扣](https://leetcode.cn/problems/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof/)
## 题目大意
**描述**:给定一个非负整数数组 $nums$。
**要求**:将数组中的数字拼接起来排成一个数,打印能拼接出的所有数字中的最小的一个。
**说明**:
- $0 < nums.length \le 100$。
- 输出结果可能非常大,所以你需要返回一个字符串而不是整数。
- 拼接起来的数字可能会有前导 $0$,最后结果不需要去掉前导 $0$。
**示例**:
- 示例 1:
```python
输入: [10,2]
输出: "102"
```
- 示例 2:
```python
输入:[3,30,34,5,9]
输出:"3033459"
```
## 解题思路
### 思路 1:自定义排序
本质上是给数组进行排序。假设 $x$、$y$ 是数组 $nums$ 中的两个元素。则排序的判断规则如下所示:
- 如果拼接字符串 $x + y > y + x$,则 $x$ 大于 $y$,$y$ 应该排在 $x$ 前面,从而使拼接起来的数字尽可能的小。
- 反之,如果拼接字符串 $x + y < y + x$,则 $x$ 小于 $y$,$x$ 应该排在 $y$ 前面,从而使拼接起来的数字尽可能的小。
按照上述规则,对原数组进行排序。这里使用了 `functools.cmp_to_key` 自定义排序函数。
### 思路 1:自定义排序代码
```python
import functools
class Solution:
def minNumber(self, nums: List[int]) -> str:
def cmp(a, b):
if a + b == b + a:
return 0
elif a + b > b + a:
return 1
else:
return -1
nums_s = list(map(str, nums))
nums_s.sort(key=functools.cmp_to_key(cmp))
return ''.join(nums_s)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。排序算法的时间复杂度为 $O(n \times \log n)$。
- **空间复杂度**:$O(1)$。
## 参考资料
- 【题解】[LCR 164. 破解闯关密码(自定义排序,清晰图解) - 把数组排成最小的数 - 力扣](https://leetcode.cn/problems/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof/solution/mian-shi-ti-45-ba-shu-zu-pai-cheng-zui-xiao-de-s-4/)
================================================
FILE: docs/solutions/LCR/ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof.md
================================================
# [LCR 192. 把字符串转换成整数 (atoi)](https://leetcode.cn/problems/ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof/)
- 标签:字符串
- 难度:中等
## 题目链接
- [LCR 192. 把字符串转换成整数 (atoi) - 力扣](https://leetcode.cn/problems/ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof/)
## 题目大意
给定一个字符串 `str`。
要求:使其能换成一个 32 位有符号整数。并且该方法满足以下要求:
- 丢弃开头无用的空格字符,直到找到第一个非空格字符为止。
- 当找到的第一个非空字符为正负号时,将该符号与后面尽可能多的连续数组组合起来,作为该整数的正负号。如果第一个非空字符为数字,则直接将其与之后连续的数字字符组合起来,形成整数。
- 该字符串中除了有效的整数部分之后也可能会存在多余字符,可直接将这些字符忽略,不会对函数造成影响。
- 如果第一个非空格字符不是一个有效整数字符、或者字符串为空、字符串仅包含空白字符时,函数不需要进行转换。
- 需要检测有效性,无法读取返回 0。
- 所有整数范围为 $[-2^{31}, 2^{31} - 1]$,超过这个范围,则返回 $2^{31} - 1$ 或者 $-2^{31}$。
## 解题思路
根据题意直接模拟即可。
1. 先去除前后空格。
2. 检测正负号。
3. 读入数字,并用字符串存储数字结果
4. 将数字字符串转为整数,并根据正负号转换整数结果。
5. 判断整数范围,并返回最终结果。
## 代码
```python
class Solution:
def strToInt(self, str: str) -> int:
num_str = ""
positive = True
start = 0
s = str.lstrip()
if not s:
return 0
if s[0] == '-':
positive = False
start = 1
elif s[0] == '+':
positive = True
start = 1
elif not s[0].isdigit():
return 0
for i in range(start, len(s)):
if s[i].isdigit():
num_str += s[i]
else:
break
if not num_str:
return 0
num = int(num_str)
if not positive:
num = -num
return max(num, -2 ** 31)
else:
return min(num, 2 ** 31 - 1)
```
================================================
FILE: docs/solutions/LCR/bao-han-minhan-shu-de-zhan-lcof.md
================================================
# [LCR 147. 最小栈](https://leetcode.cn/problems/bao-han-minhan-shu-de-zhan-lcof/)
- 标签:栈、设计
- 难度:简单
## 题目链接
- [LCR 147. 最小栈 - 力扣](https://leetcode.cn/problems/bao-han-minhan-shu-de-zhan-lcof/)
## 题目大意
要求:设计一个「栈」,实现 `push` ,`pop` ,`top` ,`min` 操作,并且操作时间复杂度都是 `O(1)`。
## 解题思路
使用一个栈,栈元素中除了保存当前值之外,再保存一个当前最小值。
- `push` 操作:如果栈不为空,则判断当前值与栈顶元素所保存的最小值,并更新当前最小值,将新元素保存到栈中。
- `pop`操作:正常出栈
- `top` 操作:返回栈顶元素保存的值。
- `min` 操作:返回栈顶元素保存的最小值。
## 代码
```python
class MinStack:
def __init__(self):
"""
initialize your data structure here.
"""
self.stack = []
class Node:
def __init__(self, x):
self.val = x
self.min = x
def push(self, x: int) -> None:
node = self.Node(x)
if len(self.stack) == 0:
self.stack.append(node)
else:
topNode = self.stack[-1]
if node.min > topNode.min:
node.min = topNode.min
self.stack.append(node)
def pop(self) -> None:
self.stack.pop()
def top(self) -> int:
return self.stack[-1].val
def min(self) -> int:
return self.stack[-1].min
```
================================================
FILE: docs/solutions/LCR/bu-ke-pai-zhong-de-shun-zi-lcof.md
================================================
# [LCR 186. 文物朝代判断](https://leetcode.cn/problems/bu-ke-pai-zhong-de-shun-zi-lcof/)
- 标签:数组、排序
- 难度:简单
## 题目链接
- [LCR 186. 文物朝代判断 - 力扣](https://leetcode.cn/problems/bu-ke-pai-zhong-de-shun-zi-lcof/)
## 题目大意
给定一个 `5` 位数的数组 `nums` 代表扑克牌中的 `5` 张牌。其中 `2~10` 为数字本身,`A` 用 `1` 表示,`J` 用 `11` 表示,`Q` 用 `12` 表示,`K` 用 `13` 表示,大小王用 `0` 表示,且大小王可以替换任意数字。
要求:判断给定的 `5` 张牌是否是一个顺子,即是否为连续的`5` 个数。
## 解题思路
先不考虑牌中有大小王,如果 `5` 个数是连续的,则这 `5` 个数中最大值最小值的关系为:`最大值 - 最小值 = 4`。如果牌中有大小王可以替换这 `5` 个数中的任意数字,则除大小王之外剩下数的最大值最小值关系为 `最大值 - 最小值 <= 4`。而且剩余数不能有重复数字。于是可以这样进行判断。
遍历 `5` 张牌:
- 如果出现大小王,则跳过。
- 判断 `5` 张牌中是否有重复数,如果有则直接返回 `False`,如果没有则将其加入集合。
- 计算 `5` 张牌的最大值,最小值。
最后判断 `最大值 - 最小值 <= 4` 是否成立。如果成立,返回 `True`,否则返回 `False`。
## 代码
```python
class Solution:
def isStraight(self, nums: List[int]) -> bool:
max_num, min_num = 0, 14
repeat = set()
for num in nums:
if num == 0:
continue
if num in repeat:
return False
repeat.add(num)
max_num = max(max_num, num)
min_num = min(min_num, num)
return max_num - min_num <= 4
```
================================================
FILE: docs/solutions/LCR/bu-yong-jia-jian-cheng-chu-zuo-jia-fa-lcof.md
================================================
# [LCR 190. 加密运算](https://leetcode.cn/problems/bu-yong-jia-jian-cheng-chu-zuo-jia-fa-lcof/)
- 标签:位运算、数学
- 难度:简单
## 题目链接
- [LCR 190. 加密运算 - 力扣](https://leetcode.cn/problems/bu-yong-jia-jian-cheng-chu-zuo-jia-fa-lcof/)
## 题目大意
给定两个整数 `a`、`b`。
要求:不能使用运算符 `+`、`-`、`*`、`/`,计算两整数 `a` 、`b` 之和。
## 解题思路
需要用到位运算的一些知识。
- 异或运算 a ^ b :可以获得 a + b 无进位的加法结果。
- 与运算 a & b:对应位置为 1,说明 a、b 该位置上原来都为 1,则需要进位。
- 座椅运算 a << 1:将 a 对应二进制数左移 1 位。
这样,通过 a^b 运算,我们可以得到相加后无进位结果,再根据 (a&b) << 1,计算进位后结果。
进行 a^b 和 (a&b) << 1操作之后判断进位是否为 0,如果不为 0,则继续上一步操作,直到进位为 0。
> 注意:
>
> Python 的整数类型是无限长整数类型,负数不确定符号位是第几位。所以我们可以将输入的数字手动转为 32 位无符号整数。
>
> 通过 a &= 0xFFFFFFFF 即可将 a 转为 32 位无符号整数。最后通过对 a 的范围判断,将其结果映射为有符号整数。
## 代码
```python
class Solution:
def getSum(self, a: int, b: int) -> int:
MAX_INT = 0x7FFFFFFF
MASK = 0xFFFFFFFF
a &= MASK
b &= MASK
while b:
carry = ((a & b) << 1) & MASK
a ^= b
b = carry
if a <= MAX_INT:
return a
else:
return ~(a ^ MASK)
```
================================================
FILE: docs/solutions/LCR/c32eOV.md
================================================
# [LCR 022. 环形链表 II](https://leetcode.cn/problems/c32eOV/)
- 标签:哈希表、链表、双指针
- 难度:中等
## 题目链接
- [LCR 022. 环形链表 II - 力扣](https://leetcode.cn/problems/c32eOV/)
## 题目大意
给定一个链表的头节点 `head`。
要求:判断链表中是否有环,如果有环则返回入环的第一个节点,无环则返回 `None`。
## 解题思路
利用两个指针,一个慢指针每次前进一步,快指针每次前进两步(两步或多步效果是等价的)。如果两个指针在链表头节点以外的某一节点相遇(即相等)了,那么说明链表有环,否则,如果(快指针)到达了某个没有后继指针的节点时,那么说明没环。
如果有环,则再定义一个指针,和慢指针一起每次移动一步,两个指针相遇的位置即为入口节点。
这是因为:假设入环位置为 A,快慢指针在在 B 点相遇,则相遇时慢指针走了 a + b 步,快指针走了 $a + n(b+c) + b$ 步。
$2(a + b) = a + n(b + c) + b$。可以推出:$a = c + (n-1)(b + c)$。
我们可以发现:从相遇点到入环点的距离 $c$ 加上 $n-1$ 圈的环长 $b + c$ 刚好等于从链表头部到入环点的距离。
## 代码
```python
class Solution:
def detectCycle(self, head: ListNode) -> ListNode:
fast, slow = head, head
while True:
if not fast or not fast.next:
return None
fast = fast.next.next
slow = slow.next
if fast == slow:
break
ans = head
while ans != slow:
ans, slow = ans.next, slow.next
return ans
```
================================================
FILE: docs/solutions/LCR/chou-shu-lcof.md
================================================
# [LCR 168. 丑数](https://leetcode.cn/problems/chou-shu-lcof/)
- 标签:哈希表、数学、动态规划、堆(优先队列)
- 难度:中等
## 题目链接
- [LCR 168. 丑数 - 力扣](https://leetcode.cn/problems/chou-shu-lcof/)
## 题目大意
给定一个整数 `n`。
要求:找出并返回第 `n` 个丑数。
- 丑数:只包含质因数 `2`、`3`、`5` 的正整数。
## 解题思路
动态规划求解。
定义状态 `dp[i]` 表示第 `i` 个丑数。
状态转移方程为:`dp[i] = min(dp[p2] * 2, dp[p3] * 3, dp[p5] * 5)` ,其中 `p2`、`p3`、`p5` 分别表示当前 `i` 中 `2`、`3`、`5` 的质因子数量。
## 代码
```python
class Solution:
def nthUglyNumber(self, n: int) -> int:
dp = [1 for _ in range(n)]
p2, p3, p5 = 0, 0, 0
for i in range(1, n):
dp[i] = min(dp[p2] * 2, dp[p3] * 3, dp[p5] * 5)
if dp[i] == dp[p2] * 2:
p2 += 1
if dp[i] == dp[p3] * 3:
p3 += 1
if dp[i] == dp[p5] * 5:
p5 += 1
return dp[n - 1]
```
================================================
FILE: docs/solutions/LCR/cong-shang-dao-xia-da-yin-er-cha-shu-ii-lcof.md
================================================
# [LCR 150. 彩灯装饰记录 II](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-ii-lcof/)
- 标签:树、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [LCR 150. 彩灯装饰记录 II - 力扣](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-ii-lcof/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
## 解题思路
广度优先搜索,需要增加一些变化。普通广度优先搜索只取一个元素,变化后的广度优先搜索每次取出第 i 层上所有元素。
具体步骤如下:
- 根节点入队。
- 当队列不为空时,求出当前队列长度 $s_i$。
- 依次从队列中取出这 $s_i$ 个元素,并将其左右子节点入队,遍历完之后将这层节点数组加入答案数组中,然后继续迭代。
- 当队列为空时,结束。
## 代码
```python
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:
return []
queue = [root]
order = []
while queue:
level = []
size = len(queue)
for _ in range(size):
curr = queue.pop(0)
level.append(curr.val)
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
if level:
order.append(level)
return order
```
================================================
FILE: docs/solutions/LCR/cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof.md
================================================
# [LCR 151. 彩灯装饰记录 III](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof/)
- 标签:树、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 151. 彩灯装饰记录 III - 力扣](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:返回其之字形层序遍历。
- 之字形层序遍历:从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行。
## 解题思路
广度优先搜索,在二叉树的层序遍历的基础上需要增加一些变化。
普通广度优先搜索只取一个元素,变化后的广度优先搜索每次取出第 i 层上所有元素。
新增一个变量 odd,用于判断当前层数是奇数层,还是偶数层。从而判断元素遍历方向。
存储每层元素的 level 列表改用双端队列,如果是奇数层,则从末尾添加元素。如果是偶数层,则从头部添加元素。
具体步骤如下:
- 根节点入队。
- 当队列不为空时,求出当前队列长度 $s_i$,并判断当前层数的奇偶性。
- 依次从队列中取出这 $s_i$ 个元素。
- 如果为奇数层,如果是奇数层,则从 level 末尾添加元素。
- 如果是偶数层,则从 level头部添加元素。
- 然后保存将其左右子节点入队,然后继续迭代。
- 当队列为空时,结束。
## 代码
```python
import collections
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:
return []
queue = [root]
order = []
odd = True
while queue:
level = collections.deque()
size = len(queue)
for _ in range(size):
curr = queue.pop(0)
if odd:
level.append(curr.val)
else:
level.appendleft(curr.val)
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
if level:
order.append(list(level))
odd = not odd
return order
```
================================================
FILE: docs/solutions/LCR/cong-shang-dao-xia-da-yin-er-cha-shu-lcof.md
================================================
# [LCR 149. 彩灯装饰记录 I](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-lcof/)
- 标签:树、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 149. 彩灯装饰记录 I - 力扣](https://leetcode.cn/problems/cong-shang-dao-xia-da-yin-er-cha-shu-lcof/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
## 解题思路
广度优先搜索。
具体步骤如下:
- 根节点入队。
- 当队列不为空时,求出当前队列长度 $s_i$。
- 依次从队列中取出这 $s_i$ 个元素,将其加入答案数组,并将其左右子节点入队,然后继续迭代。
- 当队列为空时,结束。
## 代码
```python
class Solution:
def levelOrder(self, root: TreeNode) -> List[int]:
if not root:
return []
queue = [root]
order = []
while queue:
size = len(queue)
for _ in range(size):
curr = queue.pop(0)
order.append(curr.val)
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
return order
```
================================================
FILE: docs/solutions/LCR/cong-wei-dao-tou-da-yin-lian-biao-lcof.md
================================================
# [LCR 123. 图书整理 I](https://leetcode.cn/problems/cong-wei-dao-tou-da-yin-lian-biao-lcof/)
- 标签:栈、递归、链表、双指针
- 难度:简单
## 题目链接
- [LCR 123. 图书整理 I - 力扣](https://leetcode.cn/problems/cong-wei-dao-tou-da-yin-lian-biao-lcof/)
## 题目大意
给定一个链表的头节点 `head`。
要求:从尾到头反过来返回每个节点的值(用数组返回)。
## 解题思路
- 定义数组 `res`,从头到尾遍历链表。
- 将每个节点值存入数组中。
- 直接返回倒序数组。
## 代码
```python
class Solution:
def reversePrint(self, head: ListNode) -> List[int]:
res = []
while head:
res.append(head.val)
head = head.next
return res[::-1]
```
================================================
FILE: docs/solutions/LCR/dKk3P7.md
================================================
# [LCR 032. 有效的字母异位词](https://leetcode.cn/problems/dKk3P7/)
- 标签:哈希表、字符串、排序
- 难度:简单
## 题目链接
- [LCR 032. 有效的字母异位词 - 力扣](https://leetcode.cn/problems/dKk3P7/)
## 题目大意
给定两个字符串 `s` 和 `t`。
要求:判断 `t` 和 `s` 是否使用了相同的字符构成(字符出现的种类和数目都相同,字符顺序不完全相同)。
## 解题思路
1. 先判断字符串 `s` 和 `t` 的长度,不一样直接返回 `False`;
2. 如果 `s` 和 `t` 相等,则直接返回 `False`,因为变位词的字符顺序不完全相同;
3. 分别遍历字符串 `s` 和 `t`。先遍历字符串 `s`,用哈希表存储字符串 `s` 中字符出现的频次;
4. 再遍历字符串 `t`,哈希表中减去对应字符的频次,出现频次小于 `0` 则输出 `False`;
5. 如果没出现频次小于 `0`,则输出 `True`。
## 代码
```python
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
if len(s) != len(t) or s == t:
return False
strDict = dict()
for ch in s:
if ch in strDict:
strDict[ch] += 1
else:
strDict[ch] = 1
for ch in t:
if ch in strDict:
strDict[ch] -= 1
if strDict[ch] < 0:
return False
else:
return False
return True
```
================================================
FILE: docs/solutions/LCR/da-yin-cong-1dao-zui-da-de-nwei-shu-lcof.md
================================================
# [LCR 135. 报数](https://leetcode.cn/problems/da-yin-cong-1dao-zui-da-de-nwei-shu-lcof/)
- 标签:数组、数学
- 难度:简单
## 题目链接
- [LCR 135. 报数 - 力扣](https://leetcode.cn/problems/da-yin-cong-1dao-zui-da-de-nwei-shu-lcof/)
## 题目大意
给定一个数字 `n`。
要求:按顺序打印从 `1` 到最大 `n` 位的十进制数。
## 解题思路
直接枚举 $1 \sim 10^{n} - 1$,生成列表并返回。
## 代码
```python
class Solution:
def printNumbers(self, n: int) -> List[int]:
return [i for i in range(1, 10 ** n)]
```
================================================
FILE: docs/solutions/LCR/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof.md
================================================
# [LCR 169. 招式拆解 II](https://leetcode.cn/problems/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof/)
- 标签:队列、哈希表、字符串、计数
- 难度:简单
## 题目链接
- [LCR 169. 招式拆解 II - 力扣](https://leetcode.cn/problems/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof/)
## 题目大意
给定一个字符串 `s`。
要求:从字符串 `s` 中找到第一个只出现一次的字符。如果没有,则返回空格 ` `。
## 解题思路
遍历字符串 `s`,使用哈希表存储每个字符频数。
再次遍历字符串 `s`,返回第一个频数为 `1` 的字符。
## 代码
```python
class Solution:
def firstUniqChar(self, s: str) -> str:
dic = dict()
for ch in s:
if ch in dic:
dic[ch] += 1
else:
dic[ch] = 1
for ch in s:
if ch in dic and dic[ch] == 1:
return ch
return ' '
```
================================================
FILE: docs/solutions/LCR/diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof.md
================================================
# [LCR 139. 训练计划 I](https://leetcode.cn/problems/diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof/)
- 标签:数组、双指针、排序
- 难度:简单
## 题目链接
- [LCR 139. 训练计划 I - 力扣](https://leetcode.cn/problems/diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof/)
## 题目大意
**描述**:给定一个整数数组 $nums$。
**要求**:将奇数元素位于数组的前半部分,偶数元素位于数组的后半部分。
**说明**:
- $0 \le nums.length \le 50000$。
- $0 \le nums[i] \le 10000$。
**示例**:
- 示例 1:
```python
输入:nums = [1,2,3,4,5]
输出:[1,3,5,2,4]
解释:为正确答案之一
```
## 解题思路
### 思路 1:快慢指针
定义快慢指针 $slow$、$fast$,开始时都指向 $0$。
- $fast$ 向前搜索奇数位置,$slow$ 指向下一个奇数应当存放的位置。
- $fast$ 不断进行右移,当遇到奇数时,将该奇数与 $slow$ 指向的元素进行交换,并将 $slow$ 进行右移。
- 重复上面操作,直到 $fast$ 指向数组末尾。
### 思路 1:代码
```python
class Solution:
def exchange(self, nums: List[int]) -> List[int]:
slow, fast = 0, 0
while fast < len(nums):
if nums[fast] % 2 == 1:
nums[slow], nums[fast] = nums[fast], nums[slow]
slow += 1
fast += 1
return nums
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为数组 $nums$ 中的元素个数。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/LCR/dui-cheng-de-er-cha-shu-lcof.md
================================================
# [LCR 145. 判断对称二叉树](https://leetcode.cn/problems/dui-cheng-de-er-cha-shu-lcof/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [LCR 145. 判断对称二叉树 - 力扣](https://leetcode.cn/problems/dui-cheng-de-er-cha-shu-lcof/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:检查这课二叉树是否是左右对称的。
## 解题思路
递归遍历左右子树, 然后判断当前节点的左右子节点。如果可以直接判断的情况,则跳出递归,直接返回结果。如果无法直接判断结果,则递归检测左右子树的外侧节点是否相等,同理再递归检测左右子树的内侧节点是否相等。
## 代码
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root:
return True
return self.check(root.left, root.right)
def check(self, left: TreeNode, right: TreeNode):
if not left and not right:
return True
elif not left and right:
return False
elif left and not right:
return False
elif left.val != right.val:
return False
return self.check(left.left, right.right) and self.check(left.right, right.left)
```
================================================
FILE: docs/solutions/LCR/dui-lie-de-zui-da-zhi-lcof.md
================================================
# [LCR 184. 设计自助结算系统](https://leetcode.cn/problems/dui-lie-de-zui-da-zhi-lcof/)
- 标签:设计、队列、单调队列
- 难度:中等
## 题目链接
- [LCR 184. 设计自助结算系统 - 力扣](https://leetcode.cn/problems/dui-lie-de-zui-da-zhi-lcof/)
## 题目大意
要求:设计一个「队列」,实现 `max_value` 函数,可通过 `max_value` 得到大年队列的最大值。并且要求 `max_value`、`push_back`、`pop_front` 的均摊时间复杂度都是 `O(1)`。
## 解题思路
利用空间换时间,使用两个队列。其中一个为原始队列 `queue`,另一个为递减队列 `deque`,`deque` 用来保存队列的最大值,具体做法如下:
- `push_back` 操作:如果 `deque` 队尾元素小于即将入队的元素 `value`,则将小于 `value` 的元素全部出队,再将 `valuew` 入队。否则直接将 `value` 直接入队,这样 `deque` 队首元素保存的就是队列的最大值。
- `pop_front` 操作:先判断 `deque`、`queue` 是否为空,如果 `deque` 或者 `queue` 为空,则说明队列为空,直接返回 `-1`。如果都不为空,从 `queue` 中取出一个元素,并跟 `deque` 队首元素进行比较,如果两者相等则需要将 `deque` 队首元素弹出。
- `max_value` 操作:如果 `deque` 不为空,则返回 `deque` 队首元素。否则返回 `-1`。
## 代码
```python
import collections
import queue
class MaxQueue:
def __init__(self):
self.queue = queue.Queue()
self.deque = collections.deque()
def max_value(self) -> int:
if self.deque:
return self.deque[0]
else:
return -1
def push_back(self, value: int) -> None:
while self.deque and self.deque[-1] < value:
self.deque.pop()
self.deque.append(value)
self.queue.put(value)
def pop_front(self) -> int:
if not self.deque or not self.queue:
return -1
ans = self.queue.get()
if ans == self.deque[0]:
self.deque.popleft()
return ans
```
================================================
FILE: docs/solutions/LCR/er-cha-shu-de-jing-xiang-lcof.md
================================================
# [LCR 144. 翻转二叉树](https://leetcode.cn/problems/er-cha-shu-de-jing-xiang-lcof/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [LCR 144. 翻转二叉树 - 力扣](https://leetcode.cn/problems/er-cha-shu-de-jing-xiang-lcof/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:将其进行左右翻转。
## 解题思路
从根节点开始遍历,然后从叶子节点向上递归交换左右子树位置。
## 代码
```python
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root:
return root
left = self.mirrorTree(root.left)
right = self.mirrorTree(root.right)
root.left = right
root.right = left
return root
```
================================================
FILE: docs/solutions/LCR/er-cha-shu-de-shen-du-lcof.md
================================================
# [LCR 175. 计算二叉树的深度](https://leetcode.cn/problems/er-cha-shu-de-shen-du-lcof/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:简单
## 题目链接
- [LCR 175. 计算二叉树的深度 - 力扣](https://leetcode.cn/problems/er-cha-shu-de-shen-du-lcof/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:找出树的深度。
- 深度:从根节点到叶节点一次经过的节点形成一条路径,最长路径的长度为树的深度。
## 解题思路
递归遍历,先递归遍历左右子树,返回左右子树的高度,则当前节点的高度为左右子树最大深度 + 1。即 `max(left_height, right_height) + 1`。
## 代码
```python
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if root == None:
return 0
left_height = self.maxDepth(root.left)
right_height = self.maxDepth(root.right)
return max(left_height, right_height) + 1
```
================================================
FILE: docs/solutions/LCR/er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof.md
================================================
# [LCR 194. 二叉树的最近公共祖先](https://leetcode.cn/problems/er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof/)
- 标签:树、深度优先搜索、二叉树
- 难度:简单
## 题目链接
- [LCR 194. 二叉树的最近公共祖先 - 力扣](https://leetcode.cn/problems/er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof/)
## 题目大意
给定一个二叉树的根节点 `root`,再给定两个指定节点 `p`、`q`。
要求:找到两个指定节点 `p`、`q` 的最近公共祖先。
- 祖先:如果节点 `p` 在节点 `node` 的左子树或右子树中,或者 `p == node`,则称 `node` 是 `p` 的祖先。
- 最近公共祖先:对于树的两个节点 `p`、`q`,最近公共祖先表示为一个节点 `lca_node`,满足 `lca_node` 是 `p`、`q` 的祖先且 `lca_node` 的深度尽可能大(一个节点也可以是自己的祖先)
## 解题思路
设 `lca_node` 为节点 `p`、`q` 的最近公共祖先。则 `lca_node` 只能是下面几种情况:
- `p`、`q` 在 `lca_node` 的子树中,且分别在 `lca_node` 的两侧子树中。
- `p = lca_node`,且 `q` 在 `lca_node` 的左子树或右子树中。
- `q = lca_node`,且 `p` 在 `lca_node` 的左子树或右子树中。
下面递归求解 `lca_node`。递归需要满足以下条件:
- 如果 `p`、`q` 都不为空,则返回 `p`、`q` 的公共祖先。
- 如果 `p`、`q` 只有一个存在,则返回存在的一个。
- 如果 `p`、`q` 都不存在,则返回存在的一个。
具体思路为:
- 如果当前节点 `node` 为 `None`,则说明 `p`、`q` 不在 `node` 的子树中,不可能为公共祖先,直接返回 `None`。
- 如果当前节点 `node` 等于 `p` 或者 `q`,那么 `node` 就是 `p`、`q` 的最近公共祖先,直接返回 `node`
- 递归遍历左子树、右子树,并判断左右子树结果。
- 如果左子树为空,则返回右子树。
- 如果右子树为空,则返回左子树。
- 如果左右子树都不为空,则说明 `p`、`q` 在当前根节点的两侧,当前根节点就是他们的最近公共祖先。
- 如果左右子树都为空,则返回空。
## 代码
```python
class Solution:
def lowestCommonAncestor(self, root: TreeNode, p: TreeNode, q: TreeNode) -> TreeNode:
if root == p or root == q:
return root
if root:
node_left = self.lowestCommonAncestor(root.left, p, q)
node_right = self.lowestCommonAncestor(root.right, p, q)
if node_left and node_right:
return root
elif not node_left:
return node_right
else:
return node_left
return None
```
================================================
FILE: docs/solutions/LCR/er-cha-shu-zhong-he-wei-mou-yi-zhi-de-lu-jing-lcof.md
================================================
# [LCR 153. 二叉树中和为目标值的路径](https://leetcode.cn/problems/er-cha-shu-zhong-he-wei-mou-yi-zhi-de-lu-jing-lcof/)
- 标签:树、深度优先搜索、回溯、二叉树
- 难度:中等
## 题目链接
- [LCR 153. 二叉树中和为目标值的路径 - 力扣](https://leetcode.cn/problems/er-cha-shu-zhong-he-wei-mou-yi-zhi-de-lu-jing-lcof/)
## 题目大意
给定一棵二叉树的根节点 `root` 和一个整数 `target`。
要求:打印出二叉树中各节点的值的和为 `target` 的所有路径。从根节点开始往下一直到叶节点所经过的节点形成一条路径。
## 解题思路
回溯求解。在回溯的同时,记录下当前路径。同时维护 `target`,每遍历到一个节点,就减去该节点值。如果遇到叶子节点,并且 `target == 0` 时,将当前路径加入答案数组中。然后递归遍历左右子树,并回退当前节点,继续遍历。
## 代码
```python
class Solution:
def pathSum(self, root: TreeNode, target: int) -> List[List[int]]:
res = []
path = []
def dfs(root: TreeNode, target: int):
if not root:
return
path.append(root.val)
target -= root.val
if not root.left and not root.right and target == 0:
res.append(path[:])
dfs(root.left, target)
dfs(root.right, target)
path.pop()
dfs(root, target)
return res
```
================================================
FILE: docs/solutions/LCR/er-cha-sou-suo-shu-de-di-kda-jie-dian-lcof.md
================================================
# [LCR 174. 寻找二叉搜索树中的目标节点](https://leetcode.cn/problems/er-cha-sou-suo-shu-de-di-kda-jie-dian-lcof/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [LCR 174. 寻找二叉搜索树中的目标节点 - 力扣](https://leetcode.cn/problems/er-cha-sou-suo-shu-de-di-kda-jie-dian-lcof/)
## 题目大意
**描述**:给定一棵二叉搜索树的根节点 $root$,以及一个整数 $k$。
**要求**:找出二叉搜索树书第 $k$ 大的节点。
**说明**:
-
**示例**:
- 示例 1:
```python
输入:root = [7, 3, 9, 1, 5], cnt = 2
7
/ \
3 9
/ \
1 5
输出:7
```
- 示例 2:
```python
输入: root = [10, 5, 15, 2, 7, null, 20, 1, null, 6, 8], cnt = 4
10
/ \
5 15
/ \ \
2 7 20
/ / \
1 6 8
输出: 8
```
## 解题思路
### 思路 1:遍历
已知中序遍历「左 -> 根 -> 右」能得到递增序列。逆中序遍历「右 -> 根 -> 左」可以得到递减序列。
则根据「右 -> 根 -> 左」递归遍历 k 次,找到第 $k$ 个节点位置,并记录答案。
### 思路 1:代码
```python
class Solution:
res = 0
k = 0
def dfs(self, root):
if not root:
return
self.dfs(root.right)
if self.k == 0:
return
self.k -= 1
if self.k == 0:
self.res = root.val
return
self.dfs(root.left)
def kthLargest(self, root: TreeNode, k: int) -> int:
self.res = 0
self.k = k
self.dfs(root)
return self.res
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$,其中 $n$ 为树中节点数量。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/LCR/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof.md
================================================
# [LCR 152. 验证二叉搜索树的后序遍历序列](https://leetcode.cn/problems/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof/)
- 标签:栈、树、二叉搜索树、递归、二叉树、单调栈
- 难度:中等
## 题目链接
- [LCR 152. 验证二叉搜索树的后序遍历序列 - 力扣](https://leetcode.cn/problems/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof/)
## 题目大意
**描述**:给定一个整数数组 $postorder$。数组的任意两个数字都互不相同。
**要求**:判断该数组是不是某二叉搜索树的后序遍历结果。如果是,则返回 `True`,否则返回 `False`。
**说明**:
- 数组长度 <= 1000。
- $postorder$ 中无重复数字。
**示例**:
- 示例 1:
```python
输入: postorder = [4,9,6,9,8]
输出: false
解释:从上图可以看出这不是一颗二叉搜索树
```
- 示例 2:
```python
输入: postorder = [4,6,5,9,8]
输出: true
解释:可构建的二叉搜索树如上图
```
## 解题思路
### 思路 1:递归分治
后序遍历的顺序为:左 -> 右 -> 根。而二叉搜索树的定义是:左子树所有节点值 < 根节点值,右子树所有节点值 > 根节点值。
所以,可以把数组最右侧元素作为二叉搜索树的根节点值。然后判断数组的左右两侧是否符合左侧值都小于该节点值,右侧值都大于该节点值。如果不满足,则说明不是某二叉搜索树的后序遍历结果。
找到左右分界线位置,然后递归左右数组继续查找。
终止条件为数组 开始位置 > 结束位置,此时该树的子节点数目小于等于 $1$,直接返回 `True` 即可。
### 思路 1:代码
```python
class Solution:
def verifyPostorder(self, postorder: List[int]) -> bool:
def verify(left, right):
if left >= right:
return True
index = left
while postorder[index] < postorder[right]:
index += 1
mid = index
while postorder[index] > postorder[right]:
index += 1
return index == right and verify(left, mid - 1) and verify(mid, right - 1)
if len(postorder) <= 2:
return True
return verify(0, len(postorder) - 1)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n^2)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/LCR/er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof.md
================================================
# [LCR 193. 二叉搜索树的最近公共祖先](https://leetcode.cn/problems/er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:简单
## 题目链接
- [LCR 193. 二叉搜索树的最近公共祖先 - 力扣](https://leetcode.cn/problems/er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof/)
## 题目大意
给定一棵二叉搜索树的根节点 `root` 和两个指定节点 `p`、`q`。
要求:找到该树中两个指定节点 `p`、`q` 的最近公共祖先。
- 祖先:如果节点 `p` 在节点 `node` 的左子树或右子树中,或者 `p == node`,则称 `node` 是 `p` 的祖先。
- 最近公共祖先:对于树的两个节点 `p`、`q`,最近公共祖先表示为一个节点 `lca_node`,满足 `lca_node` 是 `p`、`q` 的祖先且 `lca_node` 的深度尽可能大(一个节点也可以是自己的祖先)
## 解题思路
对于节点 `p`、节点 `q`,最近公共祖先就是从根节点分别到它们路径上的分岔点,也是路径中最后一个相同的节点,现在我们的问题就是求这个分岔点。
使用递归遍历查找最近公共祖先。
- 从根节点开始遍历;
- 如果当前节点的值大于 `p`、`q` 的值,说明 `p` 和 `q` 应该在当前节点的左子树,因此将当前节点移动到它的左子节点,继续遍历;
- 如果当前节点的值小于 `p`、`q` 的值,说明 `p` 和 `q` 应该在当前节点的右子树,因此将当前节点移动到它的右子节点,继续遍历;
- 如果当前节点不满足上面两种情况,则说明 `p` 和 `q` 分别在当前节点的左右子树上,则当前节点就是分岔点,直接返回该节点即可。
## 代码
```python
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
ancestor = root
while True:
if ancestor.val > p.val and ancestor.val > q.val:
ancestor = ancestor.left
elif ancestor.val < p.val and ancestor.val < q.val:
ancestor = ancestor.right
else:
break
return ancestor
```
================================================
FILE: docs/solutions/LCR/er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof.md
================================================
# [LCR 155. 将二叉搜索树转化为排序的双向链表](https://leetcode.cn/problems/er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof/)
- 标签:栈、树、深度优先搜索、二叉搜索树、链表、二叉树、双向链表
- 难度:中等
## 题目链接
- [LCR 155. 将二叉搜索树转化为排序的双向链表 - 力扣](https://leetcode.cn/problems/er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:将这棵二叉树转换为一个排序的循环双向链表。要求不能创建新的节点,只能调整树中节点指针的指向。
## 解题思路
通过中序递归遍历可以将二叉树升序排列输出。这道题需要在中序遍历的同时,将节点的左右指向进行改变。使用 `head`、`tail` 存放双向链表的头尾节点,然后从根节点开始,进行中序递归遍历。
具体做法如下:
- 如果当前节点为空,直接返回。
- 如果当前节点不为空:
- 递归遍历左子树。
- 如果尾节点不为空,则将尾节点与当前节点进行连接。
- 如果尾节点为空,则初始化头节点。
- 将当前节点标记为尾节点。
- 递归遍历右子树。
- 最后将头节点和尾节点进行连接。
## 代码
```python
class Solution:
def treeToDoublyList(self, root: 'Node') -> 'Node':
def dfs(node: 'Node'):
if not node:
return
dfs(node.left)
if self.tail:
self.tail.right = node
node.left = self.tail
else:
self.head = node
self.tail = node
dfs(node.right)
if not root:
return None
self.head, self.tail = None, None
dfs(root)
self.head.left = self.tail
self.tail.right = self.head
return self.head
```
================================================
FILE: docs/solutions/LCR/er-jin-zhi-zhong-1de-ge-shu-lcof.md
================================================
# [LCR 133. 位 1 的个数](https://leetcode.cn/problems/er-jin-zhi-zhong-1de-ge-shu-lcof/)
- 标签:位运算
- 难度:简单
## 题目链接
- [LCR 133. 位 1 的个数 - 力扣](https://leetcode.cn/problems/er-jin-zhi-zhong-1de-ge-shu-lcof/)
## 题目大意
给定一个无符号整数 `n`。
要求:统计其对应二进制表达式中 `1` 的个数。
## 解题思路
### 1. 循环按位计算
对整数 n 的每一位进行按位与运算,并统计结果。
### 2. 改进位运算
利用 $n \text{ \& } (n-1)$ 。这个运算刚好可以将 n 的二进制中最低位的 $1$ 变为 $0$。 比如 $n = 6$ 时,$6 = (110)_2$,$6 - 1 = (101)_2$,$(110)_2 \text{ \& } (101)_2 = (100)_2$ 。
利用这个位运算,不断的将 $n$ 中最低位的 $1$ 变为 $0$,直到 $n$ 变为 $0$ 即可,其变换次数就是我们要求的结果。
## 代码
1. 循环按位计算
```python
class Solution:
def hammingWeight(self, n: int) -> int:
ans = 0
while n:
ans += (n & 1)
n = n >> 1
return ans
```
2. 改进位运算
```python
class Solution:
def hammingWeight(self, n: int) -> int:
ans = 0
while n:
n &= n-1
ans += 1
return ans
```
================================================
FILE: docs/solutions/LCR/er-wei-shu-zu-zhong-de-cha-zhao-lcof.md
================================================
# [LCR 121. 寻找目标值 - 二维数组](https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/)
- 标签:数组、二分查找、分治、矩阵
- 难度:中等
## 题目链接
- [LCR 121. 寻找目标值 - 二维数组 - 力扣](https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/)
## 题目大意
给定一个 `m * n` 大小的有序整数矩阵 `matrix`。每行元素从左到右升序排列,每列元素从上到下升序排列。再给定一个目标值 `target`。
要求:判断矩阵中是否可以找到 `target`,如果找到 `target`,返回 `True`,否则返回 `False`。
## 解题思路
矩阵是有序的,可以考虑使用二分搜索来进行查找。
迭代对角线元素,假设对角线元素的坐标为 `(row, col)`。把数组元素按对角线分为右上角部分和左下角部分。
则对于当前对角线元素右侧第 `row` 行、对角线元素下侧第 `col` 列进行二分查找。
- 如果找到目标,直接返回 `True`。
- 如果找不到目标,则缩小范围,继续查找。
- 直到所有对角线元素都遍历完,依旧没找到,则返回 `False`。
## 代码
```python
class Solution:
def diagonalBinarySearch(self, matrix, diagonal, target):
left = 0
right = diagonal
while left < right:
mid = left + (right - left) // 2
if matrix[mid][mid] < target:
left = mid + 1
else:
right = mid
return left
def rowBinarySearch(self, matrix, begin, cols, target):
left = begin
right = cols
while left < right:
mid = left + (right - left) // 2
if matrix[begin][mid] < target:
left = mid + 1
elif matrix[begin][mid] > target:
right = mid - 1
else:
left = mid
break
return begin <= left <= cols and matrix[begin][left] == target
def colBinarySearch(self, matrix, begin, rows, target):
left = begin + 1
right = rows
while left < right:
mid = left + (right - left) // 2
if matrix[mid][begin] < target:
left = mid + 1
elif matrix[mid][begin] > target:
right = mid - 1
else:
left = mid
break
return begin <= left <= rows and matrix[left][begin] == target
def findNumberIn2DArray(self, matrix: List[List[int]], target: int) -> bool:
rows = len(matrix)
if rows == 0:
return False
cols = len(matrix[0])
if cols == 0:
return False
min_val = min(rows, cols)
index = self.diagonalBinarySearch(matrix, min_val - 1, target)
if matrix[index][index] == target:
return True
for i in range(index + 1):
row_search = self.rowBinarySearch(matrix, i, cols - 1, target)
col_search = self.colBinarySearch(matrix, i, rows - 1, target)
if row_search or col_search:
return True
return False
```
================================================
FILE: docs/solutions/LCR/fan-zhuan-dan-ci-shun-xu-lcof.md
================================================
# [LCR 181. 字符串中的单词反转](https://leetcode.cn/problems/fan-zhuan-dan-ci-shun-xu-lcof/)
- 标签:双指针、字符串
- 难度:简单
## 题目链接
- [LCR 181. 字符串中的单词反转 - 力扣](https://leetcode.cn/problems/fan-zhuan-dan-ci-shun-xu-lcof/)
## 题目大意
给定一个字符串 `s`。
要求:逐个翻转字符串中所有的单词。
说明:
- 数组字符串 `s` 可以再前面、后面或者单词间包含多余的空格。
- 翻转后的单词应当只有一个空格分隔。
- 翻转后的字符串不应该包含额外的空格。
## 解题思路
最简单的就是调用 API 进行切片,翻转。复杂一点的也可以根据 API 的思路写出模拟代码。
## 代码
```python
class Solution:
def reverseWords(self, s: str) -> str:
return " ".join(reversed(s.split()))
```
================================================
FILE: docs/solutions/LCR/fan-zhuan-lian-biao-lcof.md
================================================
# [LCR 141. 训练计划 III](https://leetcode.cn/problems/fan-zhuan-lian-biao-lcof/)
- 标签:递归、链表
- 难度:简单
## 题目链接
- [LCR 141. 训练计划 III - 力扣](https://leetcode.cn/problems/fan-zhuan-lian-biao-lcof/)
## 题目大意
**描述**:给定一个链表的头节点 `head`。
**要求**:将该链表反转并输出反转后链表的头节点。
## 解题思路
### 思路 1. 迭代
1. 使用两个指针 `cur` 和 `pre` 进行迭代。`pre` 指向 `cur` 前一个节点位置。初始时,`pre` 指向 `None`,`cur` 指向 `head`。
2. 将 `pre` 和 `cur` 的前后指针进行交换,指针更替顺序为:
1. 使用 `next` 指针保存当前节点 `cur` 的后一个节点,即 `next = cur.next`;
2. 断开当前节点 `cur` 的后一节点链接,将 `cur` 的 `next` 指针指向前一节点 `pre`,即 `cur.next = pre`;
3. `pre` 向前移动一步,移动到 `cur` 位置,即 `pre = cur`;
4. `cur` 向前移动一步,移动到之前 `next` 指针保存的位置,即 `cur = next`。
3. 继续执行第 2 步中的 1、2、3、4。
4. 最后等到 `cur` 遍历到链表末尾,即 `cur == None`,时,`pre` 所在位置就是反转后链表的头节点,返回新的头节点 `pre`。
使用迭代法反转链表的示意图如下所示:

### 思路 2. 递归
具体做法如下:
- 首先定义递归函数含义为:将链表反转,并返回反转后的头节点。
- 然后从 `head.next` 的位置开始调用递归函数,即将 `head.next` 为头节点的链表进行反转,并返回该链表的头节点。
- 递归到链表的最后一个节点,将其作为最终的头节点,即为 `new_head`。
- 在每次递归函数返回的过程中,改变 `head` 和 `head.next` 的指向关系。也就是将 `head.next` 的`next` 指针先指向当前节点 `head`,即 `head.next.next = head `。
- 然后让当前节点 `head` 的 `next` 指针指向 `None`,从而实现从链表尾部开始的局部反转。
- 当递归从末尾开始顺着递归栈的退出,从而将整个链表进行反转。
- 最后返回反转后的链表头节点 `new_head`。
使用递归法反转链表的示意图如下所示:

## 代码
1. 迭代
```python
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
pre = None
cur = head
while cur != None:
next = cur.next
cur.next = pre
pre = cur
cur = next
return pre
```
2. 递归
```python
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
if head == None or head.next == None:
return head
new_head = self.reverseList(head.next)
head.next.next = head
head.next = None
return new_head
```
## 参考资料
- 【题解】[反转链表 - 反转链表 - 力扣](https://leetcode.cn/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-by-leetcode-solution-d1k2/)
- 【题解】[【反转链表】:双指针,递归,妖魔化的双指针 - 反转链表 - 力扣(LeetCode)](https://leetcode.cn/problems/reverse-linked-list/solution/fan-zhuan-lian-biao-shuang-zhi-zhen-di-gui-yao-mo-/)
================================================
FILE: docs/solutions/LCR/fei-bo-na-qi-shu-lie-lcof.md
================================================
# [LCR 126. 斐波那契数](https://leetcode.cn/problems/fei-bo-na-qi-shu-lie-lcof/)
- 标签:记忆化搜索、数学、动态规划
- 难度:简单
## 题目链接
- [LCR 126. 斐波那契数 - 力扣](https://leetcode.cn/problems/fei-bo-na-qi-shu-lie-lcof/)
## 题目大意
给定一个整数 `n`。
要求:计算斐波那契数列的第 `n` 项。
注意:答案需对 `1000000007` 进行取余操作。
## 解题思路
斐波那契的递推公式为:`F(n) = F(n-1) + F(n-2)`。
直接根据递推公式求解即可。注意答案需要取余。
## 代码
```python
class Solution:
def fib(self, n: int) -> int:
if n < 2:
return n
f1 = 0
f2 = 0
f3 = 1
for i in range(2, n + 1):
f1, f2 = f2, f3
f3 = (f1 + f2) % 1000000007
return f3
```
================================================
FILE: docs/solutions/LCR/fpTFWP.md
================================================
# [LCR 112. 矩阵中的最长递增路径](https://leetcode.cn/problems/fpTFWP/)
- 标签:深度优先搜索、广度优先搜索、图、拓扑排序、记忆化搜索、数组、动态规划、矩阵
- 难度:困难
## 题目链接
- [LCR 112. 矩阵中的最长递增路径 - 力扣](https://leetcode.cn/problems/fpTFWP/)
## 题目大意
给定一个 `m * n` 大小的整数矩阵 `matrix`。要求:找出其中最长递增路径的长度。
对于每个单元格,可以往上、下、左、右四个方向移动,不能向对角线方向移动或移动到边界外。
## 解题思路
深度优先搜索。使用二维数组 `record` 存储遍历过的单元格最大路径长度,已经遍历过的单元格就不需要再次遍历了。
## 代码
```python
class Solution:
max_len = 0
directions = {(1, 0), (-1, 0), (0, 1), (0, -1)}
def longestIncreasingPath(self, matrix: List[List[int]]) -> int:
if not matrix:
return 0
rows, cols = len(matrix), len(matrix[0])
record = [[0 for _ in range(cols)] for _ in range(rows)]
def dfs(i, j):
record[i][j] = 1
for direction in self.directions:
new_i, new_j = i + direction[0], j + direction[1]
if 0 <= new_i < rows and 0 <= new_j < cols and matrix[new_i][new_j] > matrix[i][j]:
if record[new_i][new_j] == 0:
dfs(new_i, new_j)
record[i][j] = max(record[i][j], record[new_i][new_j] + 1)
self.max_len = max(self.max_len, record[i][j])
for i in range(rows):
for j in range(cols):
if record[i][j] == 0:
dfs(i, j)
return self.max_len
```
================================================
FILE: docs/solutions/LCR/fu-za-lian-biao-de-fu-zhi-lcof.md
================================================
# [LCR 154. 复杂链表的复制](https://leetcode.cn/problems/fu-za-lian-biao-de-fu-zhi-lcof/)
- 标签:哈希表、链表
- 难度:中等
## 题目链接
- [LCR 154. 复杂链表的复制 - 力扣](https://leetcode.cn/problems/fu-za-lian-biao-de-fu-zhi-lcof/)
## 题目大意
给定一个链表,每个节点除了 `next` 指针之后,还包含一个随机指针 `random`,该指针可以指向链表中的任何节点或者空节点。
要求:将该链表进行深拷贝。
## 解题思路
遍历链表,利用哈希表,以旧节点:新节点为映射关系,将节点关系存储下来。
再次遍历链表,将新链表的 `next` 和 `random` 指针设置好。
## 代码
```python
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
if not head:
return None
node_dict = dict()
curr = head
while curr:
new_node = Node(curr.val, None, None)
node_dict[curr] = new_node
curr = curr.next
curr = head
while curr:
if curr.next:
node_dict[curr].next = node_dict[curr.next]
if curr.random:
node_dict[curr].random = node_dict[curr.random]
curr = curr.next
return node_dict[head]
```
================================================
FILE: docs/solutions/LCR/g5c51o.md
================================================
# [LCR 060. 前 K 个高频元素](https://leetcode.cn/problems/g5c51o/)
- 标签:数组、哈希表、分治、桶排序、计数、快速选择、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [LCR 060. 前 K 个高频元素 - 力扣](https://leetcode.cn/problems/g5c51o/)
## 题目大意
给定一个整数数组 `nums` 和一个整数 `k`。
要求:返回出现频率前 `k` 高的元素。可以按任意顺序返回答案。
## 解题思路
- 使用哈希表记录下数组中各个元素的频数。时间复杂度 $O(n)$,空间复杂度 $O(n)$。
- 然后将哈希表中的元素去重,转换为新数组。时间复杂度 $O(n)$,空间复杂度 $O(n)$。
- 利用建立大顶堆,此时堆顶元素即为频数最高的元素。时间复杂度 $O(n)$,空间复杂度 $O(n)$。
- 将堆顶元素加入到答案数组中,并交换堆顶元素与末尾元素,此时末尾元素已移出堆。继续调整大顶堆。时间复杂度 $O(log{n})$。
- 调整玩大顶堆之后,此时堆顶元素为频数第二高的元素,和上一步一样,将其加入到答案数组中,继续交换堆顶元素与末尾元素,继续调整大顶堆。
- 不断重复上步,直到 k 次结束。调整 k 次的时间复杂度 $O(nlog{n})$。
总体时间复杂度 $O(nlog{n})$。
因为用的是大顶堆,堆的规模是 N 个元素,调整 k 次,所以时间复杂度是 $O(nlog{n})$。
如果用小顶堆,只需维护 k 个元素的小顶堆,不断向堆中替换元素即可,时间复杂度为 $O(nlog{k})$。
## 代码
```python
class Solution:
# 调整为大顶堆
def heapify(self, nums, nums_dict, index, end):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子节点
max_index = index
if nums_dict[nums[left]] > nums_dict[nums[max_index]]:
max_index = left
if right <= end and nums_dict[nums[right]] > nums_dict[nums[max_index]]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 初始化大顶堆
def buildMaxHeap(self, nums, nums_dict):
size = len(nums)
# (size-2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
self.heapify(nums, nums_dict, i, size - 1)
return nums
# 堆排序方法(本题未用到)
def maxHeapSort(self, nums, nums_dict):
self.buildMaxHeap(nums)
size = len(nums)
for i in range(size):
nums[0], nums[size - i - 1] = nums[size - i - 1], nums[0]
self.heapify(nums, nums_dict, 0, size - i - 2)
return nums
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
# 统计元素频数
nums_dict = dict()
for num in nums:
if num in nums_dict:
nums_dict[num] += 1
else:
nums_dict[num] = 1
# 使用 set 方法去重,得到新数组
new_nums = list(set(nums))
size = len(new_nums)
# 初始化大顶堆
self.buildMaxHeap(new_nums, nums_dict)
res = list()
for i in range(k):
# 堆顶元素为当前堆中频数最高的元素,将其加入答案中
res.append(new_nums[0])
# 交换堆顶和末尾元素,继续调整大顶堆
new_nums[0], new_nums[size - i - 1] = new_nums[size - i - 1], new_nums[0]
self.heapify(new_nums, nums_dict, 0, size - i - 2)
return res
```
================================================
FILE: docs/solutions/LCR/gaM7Ch.md
================================================
# [LCR 103. 零钱兑换](https://leetcode.cn/problems/gaM7Ch/)
- 标签:广度优先搜索、数组、动态规划
- 难度:中等
## 题目链接
- [LCR 103. 零钱兑换 - 力扣](https://leetcode.cn/problems/gaM7Ch/)
## 题目大意
给定不同面额的硬币 `coins` 和一个总金额 `amount`。
乔秋:计算出凑成总金额所需的最少的硬币个数。如果无法凑出,则返回 `-1`。
## 解题思路
完全背包问题。
可以转换为有 `n` 枚不同的硬币,每种硬币可以无限次使用。凑成总金额为 `amount` 的背包,最少需要多少硬币。
动态规划的状态 `dp[i]` 可以表示为:凑成总金额为 `i` 的组合中,至少有 `dp[i]` 枚硬币。
动态规划的状态转移方程为:`dp[i] = min(dp[i], + dp[i-coin] + 1`,意思为凑成总金额为 `i` 最少硬币数量 = 「不使用当前 `coin`,只使用之前硬币凑成金额 `i` 的最少硬币数量」和「凑成金额 `i - num` 的最少硬币数量,再加上当前硬币」两者的较小值。
## 代码
```python
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
dp = [float('inf') for _ in range(amount + 1)]
dp[0] = 0
for coin in coins:
for i in range(coin, amount + 1):
dp[i] = min(dp[i], dp[i - coin] + 1)
if dp[amount] != float('inf'):
return dp[amount]
else:
return -1
```
================================================
FILE: docs/solutions/LCR/gou-jian-cheng-ji-shu-zu-lcof.md
================================================
# [LCR 191. 按规则计算统计结果](https://leetcode.cn/problems/gou-jian-cheng-ji-shu-zu-lcof/)
- 标签:数组、前缀和
- 难度:中等
## 题目链接
- [LCR 191. 按规则计算统计结果 - 力扣](https://leetcode.cn/problems/gou-jian-cheng-ji-shu-zu-lcof/)
## 题目大意
给定一个数组 `A`。
要求:构建一个数组 `B`,其中 `B[i]` 为数组 `A` 中除了 `A[i]` 之外的其他所有元素乘积。
要求不能使用除法。
## 解题思路
构造一个答案数组 `B`,长度和数组 `A` 长度一致。先从左到右遍历一遍 `A` 数组,将 `A[i]` 左侧的元素乘积累积起来,存储到 `B` 数组中。再从右到左遍历一遍,将 `A[i]` 右侧的元素乘积累积起来,再乘以原本 `B[i]` 的值,即为 `A` 中除了 `A[i]` 之外的其他所有元素乘积。
## 代码
```python
class Solution:
def constructArr(self, a: List[int]) -> List[int]:
size = len(a)
b = [1 for _ in range(size)]
left = 1
for i in range(size):
b[i] *= left
left *= a[i]
right = 1
for i in range(size - 1, -1, -1):
b[i] *= right
right *= a[i]
return b
```
================================================
FILE: docs/solutions/LCR/gu-piao-de-zui-da-li-run-lcof.md
================================================
# [LCR 188. 买卖芯片的最佳时机](https://leetcode.cn/problems/gu-piao-de-zui-da-li-run-lcof/)
- 标签:数组、动态规划
- 难度:中等
## 题目链接
- [LCR 188. 买卖芯片的最佳时机 - 力扣](https://leetcode.cn/problems/gu-piao-de-zui-da-li-run-lcof/)
## 题目大意
给定一个数组 `nums`,`nums[i]` 表示一支给定股票第 `i` 天的价格。选择某一天买入这只股票,并选择在未来的某一个不同的日子卖出该股票。求能获取的最大利润。
## 解题思路
最简单的思路当然是两重循环暴力枚举,寻找不同天数下的最大利润。
但更好的做法是进行一次遍历。设置两个变量 `minprice`(用来记录买入的最小值)、`maxprofit`(用来记录可获取的最大利润)。
进行一次遍历,遇到当前价格比 `minprice` 还要小的,就更新 `minprice`。如果单签价格大于或者等于 `minprice`,则判断一下以当前价格卖出的话能卖多少,如果比 `maxprofit` 还要大,就更新 `maxprofit`。
## 代码
```python
class Solution:
def maxProfit(self, prices: List[int]) -> int:
minprice = 10010
maxprofit = 0
for price in prices:
if price < minprice:
minprice = price
elif price - minprice > maxprofit:
maxprofit = price - minprice
return maxprofit
```
================================================
FILE: docs/solutions/LCR/h54YBf.md
================================================
# [LCR 048. 二叉树的序列化与反序列化](https://leetcode.cn/problems/h54YBf/)
- 标签:树、深度优先搜索、广度优先搜索、设计、字符串、二叉树
- 难度:困难
## 题目链接
- [LCR 048. 二叉树的序列化与反序列化 - 力扣](https://leetcode.cn/problems/h54YBf/)
## 题目大意
要求:设计一个算法,来实现二叉树的序列化与反序列化。
## 解题思路
### 1. 序列化:将二叉树转为字符串数据表示
按照前序递归遍历二叉树,并将根节点跟左右子树的值链接起来(中间用 `,` 隔开)。
注意:如果遇到空节点,则标记为 'None',这样在反序列化时才能唯一确定一棵二叉树。
### 2. 反序列化:将字符串数据转为二叉树结构
先将字符串按 `,` 分割成数组。然后递归处理每一个元素。
- 从数组左侧取出一个元素。
- 如果当前元素为 'None',则返回 None。
- 如果当前元素不为空,则新建一个二叉树节点作为根节点,保存值为当前元素值。并递归遍历左右子树,不断重复从数组中取出元素,进行判断。
- 最后返回当前根节点。
## 代码
```python
class Codec:
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
if not root:
return 'None'
return str(root.val) + ',' + str(self.serialize(root.left)) + ',' + str(self.serialize(root.right))
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
def dfs(datalist):
val = datalist.pop(0)
if val == 'None':
return None
root = TreeNode(int(val))
root.left = dfs(datalist)
root.right = dfs(datalist)
return root
datalist = data.split(',')
return dfs(datalist)
```
================================================
FILE: docs/solutions/LCR/hPov7L.md
================================================
# [LCR 044. 在每个树行中找最大值](https://leetcode.cn/problems/hPov7L/)
- 标签:树、深度优先搜索、广度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 044. 在每个树行中找最大值 - 力扣](https://leetcode.cn/problems/hPov7L/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:找出二叉树中每一层的最大值。
## 解题思路
利用队列进行层序遍历,并记录下每一层的最大值,将其存入答案数组中。
## 代码
```python
class Solution:
def largestValues(self, root: TreeNode) -> List[int]:
queue = []
res = []
if root:
queue.append(root)
while queue:
max_level = float('-inf')
size_level = len(queue)
for i in range(size_level):
node = queue.pop(0)
max_level = max(max_level, node.val)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
res.append(max_level)
return res
```
================================================
FILE: docs/solutions/LCR/he-bing-liang-ge-pai-xu-de-lian-biao-lcof.md
================================================
# [LCR 142. 训练计划 IV](https://leetcode.cn/problems/he-bing-liang-ge-pai-xu-de-lian-biao-lcof/)
- 标签:递归、链表
- 难度:简单
## 题目链接
- [LCR 142. 训练计划 IV - 力扣](https://leetcode.cn/problems/he-bing-liang-ge-pai-xu-de-lian-biao-lcof/)
## 题目大意
给定两个升序链表。
要求:将其合并为一个升序链表。
## 解题思路
利用归并排序的思想。
创建一个新的链表节点作为头节点(记得保存),然后判断 l1和 l2 头节点的值,将较小值的节点添加到新的链表中。
当一个节点添加到新的链表中之后,将对应的 l1 或 l2 链表向后移动一位。
然后继续判断当前 l1 节点和当前 l2 节点的值,继续将较小值的节点添加到新的链表中,然后将对应的链表向后移动一位。
这样,当 l1 或 l2 遍历到最后,最多有一个链表还有节点未遍历,则直接将该节点链接到新的链表尾部即可。
## 代码
```python
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
newHead = ListNode(-1)
curr = newHead
while l1 and l2:
if l1.val <= l2.val:
curr.next = l1
l1 = l1.next
else:
curr.next = l2
l2 = l2.next
curr = curr.next
curr.next = l1 if l1 is not None else l2
return newHead.next
```
================================================
FILE: docs/solutions/LCR/he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof.md
================================================
# [LCR 180. 文件组合](https://leetcode.cn/problems/he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof/)
- 标签:数学、双指针、枚举
- 难度:简单
## 题目链接
- [LCR 180. 文件组合 - 力扣](https://leetcode.cn/problems/he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof/)
## 题目大意
**描述**:给定一个正整数 `target`。
**要求**:输出所有和为 `target` 的连续正整数序列(至少含有两个数)。序列中的数字由小到大排列,不同序列按照首个数字从小到大排列。
**说明**:
- $1 \le target \le 10^5$。
**示例**:
- 示例 1:
```python
输入:target = 9
输出:[[2,3,4],[4,5]]
```
- 示例 2:
```python
输入:target = 15
输出:[[1,2,3,4,5],[4,5,6],[7,8]]
```
## 解题思路
### 思路 1:枚举算法
连续正整数序列中元素的最小值大于等于 `1`,而最大值不会超过 `target`。所以我们可以枚举可行的区间,并计算出区间和,将其与 `target` 进行比较,如果相等则将对应的区间元素加入答案数组中,最终返回答案数组。
因为题目要求至少含有两个数,则序列开始元素不会超过 `target` 的一半,所以序列开始元素可以从 `1` 开始,枚举到 `target // 2` 即可。
具体步骤如下:
1. 使用列表变量 `res` 作为答案数组。
2. 使用一重循环 `i`,用于枚举序列开始位置,枚举范围为 `[1, target // 2]`。
3. 使用变量 `cur_sum` 维护当前区间的区间和,`cur_sum` 初始为 `0`。
4. 使用第 `2` 重循环 `j`,用于枚举序列的结束位置,枚举范围为 `[i, target - 1]`,并累积计算当前区间的区间和,即 `cur_sum += j`。
1. 如果当前区间的区间和大于 `target`,则跳出循环。
2. 如果当前区间的区间和等于 `target`,则将区间上的元素保存为列表,并添加到答案数组中,然后跳出第 `2` 重循环。
5. 遍历完返回答案数组。
### 思路 1:代码
```python
class Solution:
def findContinuousSequence(self, target: int) -> List[List[int]]:
res = []
for i in range(1, target // 2 + 1):
cur_sum = 0
for j in range(i, target):
cur_sum += j
if cur_sum > target:
break
if cur_sum == target:
cur_res = []
for k in range(i, j + 1):
cur_res.append(k)
res.append(cur_res)
break
return res
```
### 思路 1:复杂度分析
- **时间复杂度**:$target \times \sqrt{target}$。
- **空间复杂度**:$O(1)$。
### 思路 2:滑动窗口
具体做法如下:
- 初始化窗口,令 `left = 1`,`right = 2`。
- 计算 `sum = (left + right) * (right - left + 1) // 2`。
- 如果 `sum == target`,时,将其加入答案数组中。
- 如果 `sum < target` 时,说明需要扩大窗口,则 `right += 1`。
- 如果 `sum > target` 时,说明需要缩小窗口,则 `left += 1`。
- 直到 `left >= right` 时停止,返回答案数组。
### 思路 2:滑动窗口代码
```python
class Solution:
def findContinuousSequence(self, target: int) -> List[List[int]]:
left, right = 1, 2
res = []
while left < right:
sum = (left + right) * (right - left + 1) // 2
if sum == target:
arr = []
for i in range(0, right - left + 1):
arr.append(i + left)
res.append(arr)
left += 1
elif sum < target:
right += 1
else:
left += 1
return res
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(target)$。
- **空间复杂度**:$O(1)$。
================================================
FILE: docs/solutions/LCR/he-wei-sde-liang-ge-shu-zi-lcof.md
================================================
# [LCR 179. 查找总价格为目标值的两个商品](https://leetcode.cn/problems/he-wei-sde-liang-ge-shu-zi-lcof/)
- 标签:数组、双指针、二分查找
- 难度:简单
## 题目链接
- [LCR 179. 查找总价格为目标值的两个商品 - 力扣](https://leetcode.cn/problems/he-wei-sde-liang-ge-shu-zi-lcof/)
## 题目大意
给定一个升序数组 `nums`,以及一个目标整数 `target`。
要求:在数组中查找两个数,使它们的和刚好等于 `target`。
## 解题思路
因为数组是升序的,可以使用双指针。`left`、`right` 分别指向数组首尾位置。
- 计算 `sum = nums[left] + nums[right]`。
- 如果 `sum > target`,则 `right` 进行左移。
- 如果 `sum < target`,则 `left` 进行右移。
- 如果 `sum == target`,则返回 `[nums[left], nums[right]]`。
## 代码
```python
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
left, right = 0, len(nums) - 1
while left < right:
sum = nums[left] + nums[right]
if sum > target:
right -= 1
elif sum < target:
left += 1
else:
return nums[left], nums[right]
return []
```
================================================
FILE: docs/solutions/LCR/hua-dong-chuang-kou-de-zui-da-zhi-lcof.md
================================================
# [LCR 183. 望远镜中最高的海拔](https://leetcode.cn/problems/hua-dong-chuang-kou-de-zui-da-zhi-lcof/)
- 标签:队列、滑动窗口、单调队列、堆(优先队列)
- 难度:困难
## 题目链接
- [LCR 183. 望远镜中最高的海拔 - 力扣](https://leetcode.cn/problems/hua-dong-chuang-kou-de-zui-da-zhi-lcof/)
## 题目大意
给定一个整数数组 `nums` 和滑动窗口的大小 `k`。表示为大小为 `k` 的滑动窗口从数组的最左侧移动到数组的最右侧。我们只能看到滑动窗口内的 `k` 个数字,滑动窗口每次只能向右移动一位。
要求:返回滑动窗口中的最大值。
## 解题思路
暴力求解的话,二重循环,时间复杂度为 $O(n * k)$。
我们可以使用优先队列,每次窗口移动时想优先队列中增加一个节点,并删除一个节点。将窗口中的最大值加入到答案数组中。
## 代码
```python
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
size = len(nums)
if size == 0:
return []
q = [(-nums[i], i) for i in range(k)]
heapq.heapify(q)
res = [-q[0][0]]
for i in range(k, size):
heapq.heappush(q, (-nums[i], i))
while q[0][1] <= i - k:
heapq.heappop(q)
res.append(-q[0][0])
return res
```
================================================
FILE: docs/solutions/LCR/iIQa4I.md
================================================
# [LCR 038. 每日温度](https://leetcode.cn/problems/iIQa4I/)
- 标签:栈、数组、单调栈
- 难度:中等
## 题目链接
- [LCR 038. 每日温度 - 力扣](https://leetcode.cn/problems/iIQa4I/)
## 题目大意
给定一个列表 `temperatures`,每一个位置对应每天的气温。要求输出一个列表,列表上每个位置代表如果要观测到更高的气温,至少需要等待的天数。如果之后的气温不再升高,则用 `0` 来代替。
## 解题思路
题目的意思实际上就是给定一个数组,每个位置上有整数值。对于每个位置,在该位置后侧找到第一个比当前值更高的值。求该点与该位置的距离,将所有距离保存为数组返回结果。
很简单的思路是对于每个温度值,向后依次进行搜索,找到比当前温度更高的值。
更好的方式使用「递减栈」。栈中保存元素的下标。
首先,将答案数组全部赋值为 0。然后遍历数组每个位置元素。
- 如果栈为空,则将当前元素的下标入栈。
- 如果栈不为空,且当前数字大于栈顶元素对应数字,则栈顶元素出栈,并计算下标差。
- 此时当前元素就是栈顶元素的下一个更高值,将其下标差存入答案数组中保存起来,判断栈顶元素。
- 直到当前数字小于或等于栈顶元素,则停止出栈,将当前元素下标入栈。
## 代码
```python
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
n = len(temperatures)
stack = []
ans = [0 for _ in range(n)]
for i in range(n):
while stack and temperatures[i] > temperatures[stack[-1]]:
index = stack.pop()
ans[index] = (i - index)
stack.append(i)
return ans
```
================================================
FILE: docs/solutions/LCR/iSwD2y.md
================================================
# [LCR 065. 单词的压缩编码](https://leetcode.cn/problems/iSwD2y/)
- 标签:字典树、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [LCR 065. 单词的压缩编码 - 力扣](https://leetcode.cn/problems/iSwD2y/)
## 题目大意
给定一个单词数组 `words`。要求对 `words` 进行编码成一个助记字符串,用来帮助记忆。`words` 中拥有相同字符后缀的单词可以合并成一个单词,比如`time` 和 `me` 可以合并成 `time`。同时每个不能再合并的单词末尾以 `#` 为结束符,将所有合并后的单词排列起来就是一个助记字符串。
要求:返回对 `words` 进行编码的最小助记字符串 `s` 的长度。
## 解题思路
构建一个字典树。然后对字符串长度进行从小到大排序。
再依次将去重后的所有单词插入到字典树中。如果出现比当前单词更长的单词,则将短单词的结尾置为 `False`,意为替换掉短单词。
然后再依次在字典树中查询所有单词,「单词长度 + 1」就是当前不能在合并的单词,累加起来就是答案。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = False
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
trie_tree = Trie()
words = list(set(words))
words.sort(key=lambda i: len(i))
ans = 0
for word in words:
trie_tree.insert(word[::-1])
for word in words:
if trie_tree.search(word[::-1]):
ans += len(word) + 1
return ans
```
================================================
FILE: docs/solutions/LCR/index.md
================================================
## 本章内容
- [LCR 001. 两数相除](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/xoh6Oh.md)
- [LCR 002. 二进制求和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/JFETK5.md)
- [LCR 003. 比特位计数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/w3tCBm.md)
- [LCR 004. 只出现一次的数字 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/WGki4K.md)
- [LCR 005. 最大单词长度乘积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/aseY1I.md)
- [LCR 006. 两数之和 II - 输入有序数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/kLl5u1.md)
- [LCR 007. 三数之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/1fGaJU.md)
- [LCR 008. 长度最小的子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/2VG8Kg.md)
- [LCR 009. 乘积小于 K 的子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ZVAVXX.md)
- [LCR 010. 和为 K 的子数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/QTMn0o.md)
- [LCR 011. 连续数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/A1NYOS.md)
- [LCR 012. 寻找数组的中心下标](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/tvdfij.md)
- [LCR 013. 二维区域和检索 - 矩阵不可变](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/O4NDxx.md)
- [LCR 016. 无重复字符的最长子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/wtcaE1.md)
- [LCR 017. 最小覆盖子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/M1oyTv.md)
- [LCR 018. 验证回文串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/XltzEq.md)
- [LCR 019. 验证回文串 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/RQku0D.md)
- [LCR 020. 回文子串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/a7VOhD.md)
- [LCR 021. 删除链表的倒数第 N 个结点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/SLwz0R.md)
- [LCR 022. 环形链表 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/c32eOV.md)
- [LCR 023. 相交链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/3u1WK4.md)
- [LCR 024. 反转链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/UHnkqh.md)
- [LCR 025. 两数相加 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/lMSNwu.md)
- [LCR 026. 重排链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/LGjMqU.md)
- [LCR 027. 回文链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/aMhZSa.md)
- [LCR 028. 扁平化多级双向链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/Qv1Da2.md)
- [LCR 029. 循环有序列表的插入](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/4ueAj6.md)
- [LCR 030. O(1) 时间插入、删除和获取随机元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/FortPu.md)
- [LCR 031. LRU 缓存](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/OrIXps.md)
- [LCR 032. 有效的字母异位词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/dKk3P7.md)
- [LCR 033. 字母异位词分组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/sfvd7V.md)
- [LCR 034. 验证外星语词典](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/lwyVBB.md)
- [LCR 035. 最小时间差](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/569nqc.md)
- [LCR 036. 逆波兰表达式求值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/8Zf90G.md)
- [LCR 037. 行星碰撞](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/XagZNi.md)
- [LCR 038. 每日温度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/iIQa4I.md)
- [LCR 039. 柱状图中最大的矩形](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/0ynMMM.md)
- [LCR 041. 数据流中的移动平均值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/qIsx9U.md)
- [LCR 042. 最近的请求次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/H8086Q.md)
- [LCR 043. 完全二叉树插入器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/NaqhDT.md)
- [LCR 044. 在每个树行中找最大值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/hPov7L.md)
- [LCR 045. 找树左下角的值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/LwUNpT.md)
- [LCR 046. 二叉树的右视图](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/WNC0Lk.md)
- [LCR 047. 二叉树剪枝](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/pOCWxh.md)
- [LCR 048. 二叉树的序列化与反序列化](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/h54YBf.md)
- [LCR 049. 求根节点到叶节点数字之和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/3Etpl5.md)
- [LCR 050. 路径总和 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/6eUYwP.md)
- [LCR 051. 二叉树中的最大路径和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/jC7MId.md)
- [LCR 052. 递增顺序搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/NYBBNL.md)
- [LCR 053. 二叉搜索树中的中序后继](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/P5rCT8.md)
- [LCR 054. 把二叉搜索树转换为累加树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/w6cpku.md)
- [LCR 055. 二叉搜索树迭代器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/kTOapQ.md)
- [LCR 056. 两数之和 IV - 输入二叉搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/opLdQZ.md)
- [LCR 057. 存在重复元素 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/7WqeDu.md)
- [LCR 059. 数据流中的第 K 大元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/jBjn9C.md)
- [LCR 060. 前 K 个高频元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/g5c51o.md)
- [LCR 062. 实现 Trie (前缀树)](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/QC3q1f.md)
- [LCR 063. 单词替换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/UhWRSj.md)
- [LCR 064. 实现一个魔法字典](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/US1pGT.md)
- [LCR 065. 单词的压缩编码](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/iSwD2y.md)
- [LCR 066. 键值映射](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/z1R5dt.md)
- [LCR 067. 数组中两个数的最大异或值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ms70jA.md)
- [LCR 068. 搜索插入位置](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/N6YdxV.md)
- [LCR 072. x 的平方根](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/jJ0w9p.md)
- [LCR 073. 爱吃香蕉的狒狒](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/nZZqjQ.md)
- [LCR 074. 合并区间](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/SsGoHC.md)
- [LCR 075. 数组的相对排序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/0H97ZC.md)
- [LCR 076. 数组中的第 K 个最大元素](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/xx4gT2.md)
- [LCR 077. 排序链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/7WHec2.md)
- [LCR 078. 合并 K 个升序链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/vvXgSW.md)
- [LCR 079. 子集](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/TVdhkn.md)
- [LCR 080. 组合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/uUsW3B.md)
- [LCR 081. 组合总和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/Ygoe9J.md)
- [LCR 082. 组合总和 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/4sjJUc.md)
- [LCR 083. 全排列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/VvJkup.md)
- [LCR 084. 全排列 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/7p8L0Z.md)
- [LCR 085. 括号生成](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/IDBivT.md)
- [LCR 086. 分割回文串](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/M99OJA.md)
- [LCR 087. 复原 IP 地址](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/0on3uN.md)
- [LCR 088. 使用最小花费爬楼梯](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/GzCJIP.md)
- [LCR 089. 打家劫舍](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/Gu0c2T.md)
- [LCR 090. 打家劫舍 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/PzWKhm.md)
- [LCR 093. 最长的斐波那契子序列的长度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/Q91FMA.md)
- [LCR 095. 最长公共子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/qJnOS7.md)
- [LCR 097. 不同的子序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/21dk04.md)
- [LCR 098. 不同路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/2AoeFn.md)
- [LCR 101. 分割等和子集](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/NUPfPr.md)
- [LCR 102. 目标和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/YaVDxD.md)
- [LCR 103. 零钱兑换](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/gaM7Ch.md)
- [LCR 104. 组合总和 Ⅳ](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/D0F0SV.md)
- [LCR 105. 岛屿的最大面积](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ZL6zAn.md)
- [LCR 106. 判断二分图](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/vEAB3K.md)
- [LCR 107. 01 矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/2bCMpM.md)
- [LCR 108. 单词接龙](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/om3reC.md)
- [LCR 109. 打开转盘锁](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zlDJc7.md)
- [LCR 111. 除法求值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/vlzXQL.md)
- [LCR 112. 矩阵中的最长递增路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/fpTFWP.md)
- [LCR 113. 课程表 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/QA2IGt.md)
- [LCR 116. 省份数量](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/bLyHh0.md)
- [LCR 118. 冗余连接](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/7LpjUW.md)
- [LCR 119. 最长连续序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/WhsWhI.md)
- [LCR 120. 寻找文件副本](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-zu-zhong-zhong-fu-de-shu-zi-lcof.md)
- [LCR 121. 寻找目标值 - 二维数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-wei-shu-zu-zhong-de-cha-zhao-lcof.md)
- [LCR 122. 路径加密](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ti-huan-kong-ge-lcof.md)
- [LCR 123. 图书整理 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/cong-wei-dao-tou-da-yin-lian-biao-lcof.md)
- [LCR 124. 推理二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zhong-jian-er-cha-shu-lcof.md)
- [LCR 125. 图书整理 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/yong-liang-ge-zhan-shi-xian-dui-lie-lcof.md)
- [LCR 126. 斐波那契数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/fei-bo-na-qi-shu-lie-lcof.md)
- [LCR 127. 跳跃训练](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/qing-wa-tiao-tai-jie-wen-ti-lcof.md)
- [LCR 128. 库存管理 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof.md)
- [LCR 129. 字母迷宫](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ju-zhen-zhong-de-lu-jing-lcof.md)
- [LCR 130. 衣橱整理](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ji-qi-ren-de-yun-dong-fan-wei-lcof.md)
- [LCR 131. 砍竹子 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/jian-sheng-zi-lcof.md)
- [LCR 133. 位 1 的个数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-jin-zhi-zhong-1de-ge-shu-lcof.md)
- [LCR 134. Pow(x, n)](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-zhi-de-zheng-shu-ci-fang-lcof.md)
- [LCR 135. 报数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/da-yin-cong-1dao-zui-da-de-nwei-shu-lcof.md)
- [LCR 136. 删除链表的节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shan-chu-lian-biao-de-jie-dian-lcof.md)
- [LCR 139. 训练计划 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof.md)
- [LCR 140. 训练计划 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof.md)
- [LCR 141. 训练计划 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/fan-zhuan-lian-biao-lcof.md)
- [LCR 142. 训练计划 IV](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/he-bing-liang-ge-pai-xu-de-lian-biao-lcof.md)
- [LCR 143. 子结构判断](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-de-zi-jie-gou-lcof.md)
- [LCR 144. 翻转二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-shu-de-jing-xiang-lcof.md)
- [LCR 145. 判断对称二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/dui-cheng-de-er-cha-shu-lcof.md)
- [LCR 146. 螺旋遍历二维数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shun-shi-zhen-da-yin-ju-zhen-lcof.md)
- [LCR 147. 最小栈](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/bao-han-minhan-shu-de-zhan-lcof.md)
- [LCR 148. 验证图书取出顺序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zhan-de-ya-ru-dan-chu-xu-lie-lcof.md)
- [LCR 149. 彩灯装饰记录 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/cong-shang-dao-xia-da-yin-er-cha-shu-lcof.md)
- [LCR 150. 彩灯装饰记录 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/cong-shang-dao-xia-da-yin-er-cha-shu-ii-lcof.md)
- [LCR 151. 彩灯装饰记录 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/cong-shang-dao-xia-da-yin-er-cha-shu-iii-lcof.md)
- [LCR 152. 验证二叉搜索树的后序遍历序列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof.md)
- [LCR 153. 二叉树中和为目标值的路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-shu-zhong-he-wei-mou-yi-zhi-de-lu-jing-lcof.md)
- [LCR 154. 复杂链表的复制](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/fu-za-lian-biao-de-fu-zhi-lcof.md)
- [LCR 155. 将二叉搜索树转化为排序的双向链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-sou-suo-shu-yu-shuang-xiang-lian-biao-lcof.md)
- [LCR 156. 序列化与反序列化二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/xu-lie-hua-er-cha-shu-lcof.md)
- [LCR 157. 套餐内商品的排列顺序](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zi-fu-chuan-de-pai-lie-lcof.md)
- [LCR 158. 库存管理 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof.md)
- [LCR 159. 库存管理 III](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zui-xiao-de-kge-shu-lcof.md)
- [LCR 160. 数据流中的中位数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-ju-liu-zhong-de-zhong-wei-shu-lcof.md)
- [LCR 161. 连续天数的最高销售额](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/lian-xu-zi-shu-zu-de-zui-da-he-lcof.md)
- [LCR 163. 找到第 k 位数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof.md)
- [LCR 164. 破解闯关密码](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof.md)
- [LCR 165. 解密数字](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof.md)
- [LCR 166. 珠宝的最高价值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/li-wu-de-zui-da-jie-zhi-lcof.md)
- [LCR 167. 招式拆解 I](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof.md)
- [LCR 168. 丑数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/chou-shu-lcof.md)
- [LCR 169. 招式拆解 II](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof.md)
- [LCR 170. 交易逆序对的总数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-zu-zhong-de-ni-xu-dui-lcof.md)
- [LCR 171. 训练计划 V](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof.md)
- [LCR 172. 统计目标成绩的出现次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof.md)
- [LCR 173. 点名](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/que-shi-de-shu-zi-lcof.md)
- [LCR 174. 寻找二叉搜索树中的目标节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-sou-suo-shu-de-di-kda-jie-dian-lcof.md)
- [LCR 175. 计算二叉树的深度](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-shu-de-shen-du-lcof.md)
- [LCR 176. 判断是否为平衡二叉树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ping-heng-er-cha-shu-lcof.md)
- [LCR 177. 撞色搭配](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof.md)
- [LCR 179. 查找总价格为目标值的两个商品](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/he-wei-sde-liang-ge-shu-zi-lcof.md)
- [LCR 180. 文件组合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/he-wei-sde-lian-xu-zheng-shu-xu-lie-lcof.md)
- [LCR 181. 字符串中的单词反转](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/fan-zhuan-dan-ci-shun-xu-lcof.md)
- [LCR 182. 动态口令](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/zuo-xuan-zhuan-zi-fu-chuan-lcof.md)
- [LCR 183. 望远镜中最高的海拔](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/hua-dong-chuang-kou-de-zui-da-zhi-lcof.md)
- [LCR 184. 设计自助结算系统](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/dui-lie-de-zui-da-zhi-lcof.md)
- [LCR 186. 文物朝代判断](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/bu-ke-pai-zhong-de-shun-zi-lcof.md)
- [LCR 187. 破冰游戏](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof.md)
- [LCR 188. 买卖芯片的最佳时机](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/gu-piao-de-zui-da-li-run-lcof.md)
- [LCR 189. 设计机械累加器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/qiu-12n-lcof.md)
- [LCR 190. 加密运算](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/bu-yong-jia-jian-cheng-chu-zuo-jia-fa-lcof.md)
- [LCR 191. 按规则计算统计结果](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/gou-jian-cheng-ji-shu-zu-lcof.md)
- [LCR 192. 把字符串转换成整数 (atoi)](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/ba-zi-fu-chuan-zhuan-huan-cheng-zheng-shu-lcof.md)
- [LCR 193. 二叉搜索树的最近公共祖先](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-sou-suo-shu-de-zui-jin-gong-gong-zu-xian-lcof.md)
- [LCR 194. 二叉树的最近公共祖先](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/er-cha-shu-de-zui-jin-gong-gong-zu-xian-lcof.md)
================================================
FILE: docs/solutions/LCR/jBjn9C.md
================================================
# [LCR 059. 数据流中的第 K 大元素](https://leetcode.cn/problems/jBjn9C/)
- 标签:树、设计、二叉搜索树、二叉树、数据流、堆(优先队列)
- 难度:简单
## 题目链接
- [LCR 059. 数据流中的第 K 大元素 - 力扣](https://leetcode.cn/problems/jBjn9C/)
## 题目大意
设计一个 ` KthLargest` 类,用于找到数据流中第 `k` 大元素。
- `KthLargest(int k, int[] nums)`:使用整数 `k` 和整数流 `nums` 初始化对象。
- `int add(int val)`:将 `val` 插入数据流 `nums` 后,返回当前数据流中第 `k` 大的元素。
## 解题思路
- 建立大小为 `k` 的大顶堆,堆中元素保证不超过 k 个。
- 每次 `add` 操作时,将新元素压入堆中,如果堆中元素超出了 `k` 个,则将堆中最小元素(堆顶)移除。
- 此时堆中最小元素(堆顶)就是整个数据流中的第 `k` 大元素。
## 代码
```python
import heapq
class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.min_heap = []
self.k = k
for num in nums:
heapq.heappush(self.min_heap, num)
if len(self.min_heap) > k:
heapq.heappop(self.min_heap)
def add(self, val: int) -> int:
heapq.heappush(self.min_heap, val)
if len(self.min_heap) > self.k:
heapq.heappop(self.min_heap)
return self.min_heap[0]
```
================================================
FILE: docs/solutions/LCR/jC7MId.md
================================================
# [LCR 051. 二叉树中的最大路径和](https://leetcode.cn/problems/jC7MId/)
- 标签:树、深度优先搜索、动态规划、二叉树
- 难度:困难
## 题目链接
- [LCR 051. 二叉树中的最大路径和 - 力扣](https://leetcode.cn/problems/jC7MId/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:返回其最大路径和。
- 路径:从树中的任意节点出发,沿父节点——子节点连接,到达任意节点的序列。同一个节点在一条路径序列中至多出现一次。该路径至少包含一个节点,且不一定经过根节点。
- 路径和:路径中各节点值的总和。
## 解题思路
深度优先搜索遍历二叉树。递归的同时,维护一个最大路径和变量。定义函数 `dfs(self, root)` 计算二叉树中以该节点为根节点,并且经过该节点的最大贡献值。
计算的结果可能的情况有 2 种:
- 经过空节点的最大贡献值等于 `0`。
- 经过非空节点的最大贡献值等于 当前节点值 + 左右子节点的最大贡献值中较大的一个。
在递归时,我们先计算左右子节点的最大贡献值,再更新维护当前最大路径和变量。
最终 `max_sum` 即为答案。
## 代码
```python
class Solution:
def __init__(self):
self.max_sum = float('-inf')
def dfs(self, root):
if not root:
return 0
left_max = max(self.dfs(root.left), 0)
right_max = max(self.dfs(root.right), 0)
self.max_sum = max(self.max_sum, root.val + left_max + right_max)
return root.val + max(left_max, right_max)
def maxPathSum(self, root: TreeNode) -> int:
self.dfs(root)
return self.max_sum
```
================================================
FILE: docs/solutions/LCR/jJ0w9p.md
================================================
# [LCR 072. x 的平方根](https://leetcode.cn/problems/jJ0w9p/)
- 标签:数学、二分查找
- 难度:简单
## 题目链接
- [LCR 072. x 的平方根 - 力扣](https://leetcode.cn/problems/jJ0w9p/)
## 题目大意
要求:实现 `int sqrt(int x)` 函数。计算并返回 `x` 的平方根(只保留整数部分),其中 `x` 是非负整数。
## 解题思路
因为求解的是 x 开方的整数部分。所以我们可以从 0~x 的范围进行遍历,找到 k^2 <= x 的最大结果。
为了减少时间复杂度,使用二分查找的方式来搜索答案。
## 代码
```python
class Solution:
def mySqrt(self, x: int) -> int:
left = 0
right = x
ans = -1
while left <= right:
mid = (left + right) // 2
if mid * mid <= x:
ans = mid
left = mid + 1
else:
right = mid - 1
return ans
```
================================================
FILE: docs/solutions/LCR/ji-qi-ren-de-yun-dong-fan-wei-lcof.md
================================================
# [LCR 130. 衣橱整理](https://leetcode.cn/problems/ji-qi-ren-de-yun-dong-fan-wei-lcof/)
- 标签:深度优先搜索、广度优先搜索、动态规划
- 难度:中等
## 题目链接
- [LCR 130. 衣橱整理 - 力扣](https://leetcode.cn/problems/ji-qi-ren-de-yun-dong-fan-wei-lcof/)
## 题目大意
**描述**:有一个 `m * n` 大小的方格,坐标从 `(0, 0)` 到 `(m - 1, n - 1)`。一个机器人从 `(0, 0)` 处的格子开始移动,每次可以向上、下、左、右移动一格(不能移动到方格外),也不能移动到行坐标和列坐标的数位之和大于 `k` 的格子。现在给定 `3` 个整数 `m`、`n`、`k`。
**要求**:计算并输出该机器人能够达到多少个格子。
**说明**:
- $1 \le n, m \le 100$。
- $0 \le k \le 20$。
**示例**:
- 示例 1:
```python
输入:m = 2, n = 3, k = 1
输出:3
```
- 示例 2:
```python
输入:m = 3, n = 1, k = 0
输出:1
```
## 解题思路
### 思路 1:广度优先搜索
先定义一个计算数位和的方法 `digitsum`,该方法输入一个整数,返回该整数各个数位的总和。
然后我们使用广度优先搜索方法,具体步骤如下:
- 将 `(0, 0)` 加入队列 `queue` 中。
- 当队列不为空时,每次将队首坐标弹出,加入访问集合 `visited` 中。
- 再将满足行列坐标的数位和不大于 `k` 的格子位置加入到队列中,继续弹出队首位置。
- 直到队列为空时停止。输出访问集合的长度。
### 思路 1:代码
```python
import collections
class Solution:
def digitsum(self, n: int):
ans = 0
while n:
ans += n % 10
n //= 10
return ans
def movingCount(self, m: int, n: int, k: int) -> int:
queue = collections.deque([(0, 0)])
visited = set()
while queue:
x, y = queue.popleft()
if (x, y) not in visited and self.digitsum(x) + self.digitsum(y) <= k:
visited.add((x, y))
for dx, dy in [(1, 0), (0, 1)]:
nx = x + dx
ny = y + dy
if 0 <= nx < m and 0 <= ny < n:
queue.append((nx, ny))
return len(visited)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m \times n)$。其中 $m$ 为方格的行数,$n$ 为方格的列数。
- **空间复杂度**:$O(m \times n)$。
================================================
FILE: docs/solutions/LCR/jian-sheng-zi-lcof.md
================================================
# [LCR 131. 砍竹子 I](https://leetcode.cn/problems/jian-sheng-zi-lcof/)
- 标签:数学、动态规划
- 难度:中等
## 题目链接
- [LCR 131. 砍竹子 I - 力扣](https://leetcode.cn/problems/jian-sheng-zi-lcof/)
## 题目大意
给定一根长度为 `n` 的绳子,将绳子剪成整数长度的 `m` 段,每段绳子长度即为 `k[0]`、`k[1]`、...、`k[m - 1]`。
要求:计算出 `k[0] * k[1] * ... * k[m - 1]` 可能的最大乘积。
## 解题思路
可以使用动态规划求解。
定义状态 `dp[i]` 为:拆分长度为 `i` 的绳子,可以获得的最大乘积为 `dp[i]`。
将 `j` 从 `1` 遍历到 `i - 1`,通过两种方式得到 `dp[i]`:
- `(i - j) * j` ,直接将长度为 `i` 的绳子分割为 `i - j` 和 `j`,获取两者乘积。
- `dp[i - j] * j`,将长度为 `i`的绳子 中的 `i - j` 部分拆分,得到 `dp[i - j]`,和 `j` ,获取乘积。
则 `dp[i]` 取两者中的最大值。遍历 `j`,得到 `dp[i]` 的最大值。
则状态转移方程为:`dp[i] = max(dp[i], (i - j) * j, dp[i - j] * j)`。
最终输出 `dp[n]`。
## 代码
```python
class Solution:
def cuttingRope(self, n: int) -> int:
dp = [0 for _ in range(n + 1)]
dp[1] = 1
for i in range(2, n + 1):
for j in range(1, i):
dp[i] = max(dp[i], dp[i - j] * j, (i - j) * j)
return dp[n]
```
================================================
FILE: docs/solutions/LCR/ju-zhen-zhong-de-lu-jing-lcof.md
================================================
# [LCR 129. 字母迷宫](https://leetcode.cn/problems/ju-zhen-zhong-de-lu-jing-lcof/)
- 标签:数组、回溯、矩阵
- 难度:中等
## 题目链接
- [LCR 129. 字母迷宫 - 力扣](https://leetcode.cn/problems/ju-zhen-zhong-de-lu-jing-lcof/)
## 题目大意
给定一个 `m * n` 大小的二维字符矩阵 `board` 和一个字符串单词 `word`。如果 `word` 存在于网格中,返回 `True`,否则返回 `False`。
- 单词必须按照字母顺序通过上下左右相邻的单元格字母构成。且同一个单元格内的字母不允许被重复使用。
## 解题思路
回溯算法在二维矩阵 `board` 中按照上下左右四个方向递归搜索。设函数 `backtrack(i, j, index)` 表示从 `board[i][j]` 出发,能否搜索到单词字母 `word[index]`,以及 `index` 位置之后的后缀子串。如果能搜索到,则返回 `True`,否则返回 `False`。`backtrack(i, j, index)` 执行步骤如下:
- 如果 $board[i][j] = word[index]$,而且 `index` 已经到达 `word` 字符串末尾,则返回 `True`。
- 如果 $board[i][j] = word[index]$,而且 `index` 未到达 `word` 字符串末尾,则遍历当前位置的所有相邻位置。如果从某个相邻位置能搜索到后缀子串,则返回 `True`,否则返回 `False`。
- 如果 $board[i][j] \ne word[index]$,则当前字符不匹配,返回 `False`。
## 代码
```python
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
rows = len(board)
if rows == 0:
return False
cols = len(board[0])
visited = [[False for _ in range(cols)] for _ in range(rows)]
def backtrack(i, j, index):
if index == len(word) - 1:
return board[i][j] == word[index]
if board[i][j] == word[index]:
visited[i][j] = True
for direct in directs:
new_i = i + direct[0]
new_j = j + direct[1]
if 0 <= new_i < rows and 0 <= new_j < cols and visited[new_i][new_j] == False:
if backtrack(new_i, new_j, index + 1):
return True
visited[i][j] = False
return False
for i in range(rows):
for j in range(cols):
if backtrack(i, j, 0):
return True
return False
```
================================================
FILE: docs/solutions/LCR/kLl5u1.md
================================================
# [LCR 006. 两数之和 II - 输入有序数组](https://leetcode.cn/problems/kLl5u1/)
- 标签:数组、双指针、二分查找
- 难度:简单
## 题目链接
- [LCR 006. 两数之和 II - 输入有序数组 - 力扣](https://leetcode.cn/problems/kLl5u1/)
## 题目大意
给定一个升序数组:`numbers` 和一个目标值 `target`。
要求:从数组中找出满足相加之和等于 `target` 的两个数,并返回两个数在数组中下的标值。
## 解题思路
因为数组是有序的,所以我们可以使用两个指针 low,high。low 指向数组开始较小元素位置,high 指向数组较大元素位置。判断两个位置上的元素和,如果和等于目标值,则返回两个元素位置。如果和大于目标值,则 high 左移,继续检测。如果和小于目标值,则 low 右移,继续检测。直到 low 和 high 移动到相同位置停止检测。如果最终仍没找到,则返回 [0, 0]。
## 代码
```python
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
low = 0
high = len(numbers) - 1
while low < high:
total = numbers[low] + numbers[high]
if total == target:
return [low, high]
elif total < target:
low += 1
else:
high -= 1
return [0, 0]
```
================================================
FILE: docs/solutions/LCR/kTOapQ.md
================================================
# [LCR 055. 二叉搜索树迭代器](https://leetcode.cn/problems/kTOapQ/)
- 标签:栈、树、设计、二叉搜索树、二叉树、迭代器
- 难度:中等
## 题目链接
- [LCR 055. 二叉搜索树迭代器 - 力扣](https://leetcode.cn/problems/kTOapQ/)
## 题目大意
要求:实现一个二叉搜索树的迭代器 `BSTIterator`。表示一个按中序遍历二叉搜索树(BST)的迭代器:
- `def __init__(self, root: TreeNode):`:初始化 `BSTIterator` 类的一个对象,会给出二叉搜索树的根节点。
- `def hasNext(self) -> bool:`:如果向右指针遍历存在数字,则返回 `True`,否则返回 `False`。
- `def next(self) -> int:`:将指针向右移动,返回指针处的数字。
## 解题思路
中序遍历的顺序是:左、根、右。我们使用一个栈来保存节点,以便于迭代的时候取出对应节点。
- 初始的遍历当前节点的左子树,将其路径上的节点存储到栈中。
- 调用 next 方法的时候,从栈顶取出节点,因为之前已经将路径上的左子树全部存入了栈中,所以此时该节点的左子树为空,这时候取出节点右子树,再将右子树的左子树进行递归遍历,并将其路径上的节点存储到栈中。
- 调用 hasNext 的方法的时候,直接判断栈中是否有值即可。
## 代码
```python
class BSTIterator:
def __init__(self, root: TreeNode):
self.stack = []
self.in_order(root)
def in_order(self, node):
while node:
self.stack.append(node)
node = node.left
def next(self) -> int:
node = self.stack.pop()
if node.right:
self.in_order(node.right)
return node.val
def hasNext(self) -> bool:
return len(self.stack) != 0
```
================================================
FILE: docs/solutions/LCR/lMSNwu.md
================================================
# [LCR 025. 两数相加 II](https://leetcode.cn/problems/lMSNwu/)
- 标签:栈、链表、数学
- 难度:中等
## 题目链接
- [LCR 025. 两数相加 II - 力扣](https://leetcode.cn/problems/lMSNwu/)
## 题目大意
给定两个非空链表的头节点 `l1` 和 `l2` 来代表两个非负整数。数字最高位位于链表开始位置。每个节点只储存一位数字。除了数字 `0` 之外,这两个链表代表的数字都不会以 `0` 开头。
要求:将这两个数相加会返回一个新的链表。
## 解题思路
链表中最高位位于链表开始位置,最低位位于链表结束位置。这与我们做加法的数位顺序是相反的。为了将链表逆序,从而从低位开始处理数位,我们可以借用两个栈:将链表中所有数字分别压入两个栈中,再依次取出相加。
同时,在相加的时候,还要考虑进位问题。具体步骤如下:
- 将链表 `l1` 中所有节点值压入 `stack1` 栈中,再将链表 `l2` 中所有节点值压入 `stack2` 栈中。
- 使用 `res` 存储新的结果链表,一开始指向 `None`,`carry` 记录进位。
- 如果 `stack1` 或 `stack2` 不为空,或着进位 `carry` 不为 `0`,则:
- 从 `stack1` 中取出栈顶元素 `num1`,如果 `stack1` 为空,则 `num1 = 0`。
- 从 `stack2` 中取出栈顶元素 `num2`,如果 `stack2` 为空,则 `num2 = 0`。
- 计算相加结果,并计算进位。
- 建立新节点,存储进位后余下的值,并令其指向 `res`。
- `res` 指向新节点,继续判断。
- 如果 `stack1`、`stack2` 都为空,并且进位 `carry` 为 `0`,则输出 `res`。
## 代码
```python
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
stack1, stack2 = [], []
while l1:
stack1.append(l1.val)
l1 = l1.next
while l2:
stack2.append(l2.val)
l2 = l2.next
res = None
carry = 0
while stack1 or stack2 or carry != 0:
num1 = stack1.pop() if stack1 else 0
num2 = stack2.pop() if stack2 else 0
cur_sum = num1 + num2 + carry
carry = cur_sum // 10
cur_sum %= 10
cur_node = ListNode(cur_sum)
cur_node.next = res
res = cur_node
return res
```
================================================
FILE: docs/solutions/LCR/li-wu-de-zui-da-jie-zhi-lcof.md
================================================
# [LCR 166. 珠宝的最高价值](https://leetcode.cn/problems/li-wu-de-zui-da-jie-zhi-lcof/)
- 标签:数组、动态规划、矩阵
- 难度:中等
## 题目链接
- [LCR 166. 珠宝的最高价值 - 力扣](https://leetcode.cn/problems/li-wu-de-zui-da-jie-zhi-lcof/)
## 题目大意
给定一个 `m * n` 大小的二维矩阵 `grid` 代表棋盘,棋盘的每一格都放有一个礼物,每个礼物有一定的价值(价值大于 `0`)。`grid[i][j]` 表示棋盘第 `i` 行第 `j` 列的礼物价值。我们可以从左上角的格子开始拿礼物,每次只能向右或者向下移动一格,直到到达棋盘的右下角。
要求:计算出最多能拿多少价值的礼物。
## 解题思路
可以用动态规划求解,设 `dp[i][j]` 是从 `(0, 0)` 到 `(i - 1, j - 1)` 能得礼物的最大价值。
显然 `dp[i][j] = max(dp[i - 1][j] + dp[i][j - 1]) + grid[i][j]`。
因为是自上而下递推 `dp[i-1][j]` 可以用 `dp[j]` 来表示,所以也可以将二维改为一位。状态转移公式为: `dp[j] = max(dp[j], dp[j - 1]) + grid[i][j]`。
## 代码
```python
class Solution:
def maxValue(self, grid: List[List[int]]) -> int:
if not grid:
return 0
size_m = len(grid)
size_n = len(grid[0])
dp = [0 for _ in range(size_n + 1)]
for i in range(size_m):
for j in range(size_n):
dp[j + 1] = max(dp[j], dp[j + 1]) + grid[i][j]
return dp[size_n]
```
================================================
FILE: docs/solutions/LCR/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof.md
================================================
# [LCR 140. 训练计划 II](https://leetcode.cn/problems/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof/)
- 标签:链表、双指针
- 难度:简单
## 题目链接
- [LCR 140. 训练计划 II - 力扣](https://leetcode.cn/problems/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof/)
## 题目大意
给定一个链表的头节点 `head`,以及一个整数 `k`。
要求返回链表的倒数第 `k` 个节点。
## 解题思路
常规思路是遍历一遍链表,求出链表长度,再遍历一遍到对应位置,返回该位置上的节点。
如果用一次遍历实现的话,可以使用快慢指针。让快指针先走 `k` 步,然后快慢指针、慢指针再同时走,每次一步,这样等快指针遍历到链表尾部的时候,慢指针就刚好遍历到了倒数第 `k` 个节点位置。返回该该位置上的节点即可。
## 代码
```python
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
slow = head
fast = head
for _ in range(k):
if fast == None:
return fast
fast = fast.next
while fast:
slow = slow.next
fast = fast.next
return slow
```
================================================
FILE: docs/solutions/LCR/lian-xu-zi-shu-zu-de-zui-da-he-lcof.md
================================================
# [LCR 161. 连续天数的最高销售额](https://leetcode.cn/problems/lian-xu-zi-shu-zu-de-zui-da-he-lcof/)
- 标签:数组、分治、动态规划
- 难度:简单
## 题目链接
- [LCR 161. 连续天数的最高销售额 - 力扣](https://leetcode.cn/problems/lian-xu-zi-shu-zu-de-zui-da-he-lcof/)
## 题目大意
给定一个整数数组 `nums` 。
要求:找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和,要求时间复杂度为 `O(n)`。
## 解题思路
动态规划的方法,关键点是要找到状态转移方程。
假设 f(i) 表示第 i 个数结尾的「连续子数组的最大和」,那么 $max_{0 < i \le n-1} {f(i)} = max(f(i-1) + nums[i], nums[i])$
即将之前累加和加上当前值与当前值做比较。
- 如果将之前累加和加上当前值 > 当前值,那么加上当前值。
- 如果将之前累加和加上当前值 < 当前值,那么 $f(i) = nums[i]$。
## 代码
```python
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
max_ans = nums[0]
ans = 0
for num in nums:
ans = max(ans + num, num)
max_ans = max(max_ans, ans)
return max_ans
```
================================================
FILE: docs/solutions/LCR/liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof.md
================================================
# [LCR 171. 训练计划 V](https://leetcode.cn/problems/liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof/)
- 标签:哈希表、链表、双指针
- 难度:简单
## 题目链接
- [LCR 171. 训练计划 V - 力扣](https://leetcode.cn/problems/liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof/)
## 题目大意
给定 A、B 两个链表,判断两个链表是否相交,返回相交的起始点。如果不相交,则返回 None。
比如:链表 A 为 [4, 1, 8, 4, 5],链表 B 为 [5, 0, 1, 8, 4, 5]。则如下图所示,两个链表相交的起始节点为 8,则输出结果为 8。

## 解题思路
如果两个链表相交,那么从相交位置开始,到结束,必有一段等长且相同的节点。假设链表 A 的长度为 m、链表 B 的长度为 n,他们的相交序列有 k 个,则相交情况可以如下如所示:

现在问题是如何找到 m-k 或者 n-k 的位置。
考虑将链表 A 的末尾拼接上链表 B,链表 B 的末尾拼接上链表 A。
然后使用两个指针 pA 、PB,分别从链表 A、链表 B 的头节点开始遍历,如果走到共同的节点,则返回该节点。
否则走到两个链表末尾,返回 None。

## 代码
```python
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
if not headA or not headB:
return None
pA = headA
pB = headB
while pA != pB:
pA = pA.next if pA else headB
pB = pB.next if pB else headA
return pA
```
================================================
FILE: docs/solutions/LCR/lwyVBB.md
================================================
# [LCR 034. 验证外星语词典](https://leetcode.cn/problems/lwyVBB/)
- 标签:数组、哈希表、字符串
- 难度:简单
## 题目链接
- [LCR 034. 验证外星语词典 - 力扣](https://leetcode.cn/problems/lwyVBB/)
## 题目大意
给定一组用外星语书写的单词字符串数组 `words`,以及表示外星字母表的顺序的字符串 `order` 。
要求:判断 `words` 中的单词是否都是按照 `order` 来排序的。如果是,则返回 `True`,否则返回 `False`。
## 解题思路
如果所有单词是按照 `order` 的规则升序排列,则所有单词都符合规则。而判断所有单词是升序排列,只需要两两比较相邻的单词即可。所以我们可以先用哈希表存储所有字母的顺序,然后对所有相邻单词进行两两比较,如果最终是升序排列,则符合要求。具体步骤如下:
- 使用哈希表 `order_map` 存储字母的顺序。
- 遍历单词数组 `words`,比较相邻单词 `word1` 和 `word2` 中所有字母在 `order_map` 中的下标,看是否满足 `word1 <= word2`。
- 如果全部满足,则返回 `True`。如果有不满足的情况,则直接返回 `False`。
## 代码
```python
class Solution:
def isAlienSorted(self, words: List[str], order: str) -> bool:
order_map = dict()
for i in range(len(order)):
order_map[order[i]] = i
for i in range(len(words) - 1):
word1 = words[i]
word2 = words[i + 1]
flag = True
for j in range(min(len(word1), len(word2))):
if word1[j] != word2[j]:
if order_map[word1[j]] > order_map[word2[j]]:
return False
else:
flag = False
break
if flag and len(word1) > len(word2):
return False
return True
```
================================================
FILE: docs/solutions/LCR/ms70jA.md
================================================
# [LCR 067. 数组中两个数的最大异或值](https://leetcode.cn/problems/ms70jA/)
- 标签:位运算、字典树、数组、哈希表
- 难度:中等
## 题目链接
- [LCR 067. 数组中两个数的最大异或值 - 力扣](https://leetcode.cn/problems/ms70jA/)
## 题目大意
给定一个整数数组 `nums`。
要求:返回 `num[i] XOR nums[j]` 的最大运算结果。其中 `0 ≤ i ≤ j < n`。
## 解题思路
最直接的想法暴力求解。两层循环计算两两之间的异或结果,记录并更新最大异或结果。
更好的做法可以减少一重循环。首先,要取得异或结果的最大值,那么从二进制的高位到低位,尽可能的让每一位异或结果都为 `1`。
将数组中所有数字的二进制形式从高位到低位依次存入字典树中。然后是利用异或运算交换律:如果 `a ^ b = max` 成立,那么 `a ^ max = b` 与 `b ^ max = a` 均成立。这样当我们知道 `a` 和 `max` 时,可以通过交换律求出 `b`。`a` 是我们遍历的每一个数,`max` 是我们想要尝试的最大值,从 `111111...` 开始,从高位到低位依次填 `1`。
对于 `a` 和 `max`,如果我们所求的 `b` 也在字典树中,则表示 `max` 是可以通过 `a` 和 `b` 得到的,那么 `max` 就是所求最大的异或。如果 `b` 不在字典树中,则减小 `max` 值继续判断,或者继续查询下一个 `a`。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, num: int, max_bit: int) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for i in range(max_bit, -1, -1):
bit = num >> i & 1
if bit not in cur.children:
cur.children[bit] = Trie()
cur = cur.children[bit]
cur.isEnd = True
def search(self, num: int, max_bit: int) -> int:
"""
Returns if the word is in the trie.
"""
cur = self
res = 0
for i in range(max_bit, -1, -1):
bit = num >> i & 1
if 1 - bit not in cur.children:
res = res * 2
cur = cur.children[bit]
else:
res = res * 2 + 1
cur = cur.children[1 - bit]
return res
class Solution:
def findMaximumXOR(self, nums: List[int]) -> int:
trie_tree = Trie()
max_bit = len(format(max(nums), 'b')) - 1
ans = 0
for num in nums:
trie_tree.insert(num, max_bit)
ans = max(ans, trie_tree.search(num, max_bit))
return ans
```
================================================
FILE: docs/solutions/LCR/nZZqjQ.md
================================================
# [LCR 073. 爱吃香蕉的狒狒](https://leetcode.cn/problems/nZZqjQ/)
- 标签:数组、二分查找
- 难度:中等
## 题目链接
- [LCR 073. 爱吃香蕉的狒狒 - 力扣](https://leetcode.cn/problems/nZZqjQ/)
## 题目大意
给定一个数组 `piles` 代表 `n` 堆香蕉。其中 `piles[i]` 表示第 `i` 堆香蕉的个数。再给定一个整数 `h` ,表示最多可以在 `h` 小时内吃完所有香蕉。狒狒决定以速度每小时 `k`(未知)根的速度吃香蕉。每一个小时,她将选择其中一堆香蕉,从中吃掉 `k` 根。如果这堆香蕉少于 `k` 根,狒狒将在这一小时吃掉这堆的所有香蕉,并且这一小时不会再吃其他堆的香蕉。
要求:返回狒狒可以在 `h` 小时内吃掉所有香蕉的最小速度 `k`(`k` 为整数)。
## 解题思路
先来看 `k` 的取值范围,因为 `k` 是整数,且速度肯定不能为 `0` 吧,为 `0` 的话就永远吃不完了。所以`k` 的最小值可以取 `1`。`k` 的最大值根香蕉中最大堆的香蕉个数有关,因为 `1` 个小时内只能选择一堆吃,不能再吃其他堆的香蕉,则 `k` 的最大值取香蕉堆的最大值即可。即 `k` 的最大值为 `max(piles)`。
我们的目标是求出 `h` 小时内吃掉所有香蕉的最小速度 `k`。现在有了区间「`[1, max(piles)]`」,有了目标「最小速度 `k`」。接下来使用二分查找算法来查找「最小速度 `k`」。至于计算 `h` 小时内能否以 `k` 的速度吃完香蕉,我们可以再写一个方法 `canEat` 用于判断。如果能吃完就返回 `True`,不能吃完则返回 `False`。下面说一下算法的具体步骤。
- 使用两个指针 `left`、`right`。令 `left` 指向 `1`,`right` 指向 `max(piles)`。代表待查找区间为 `[left, right]`
- 取两个节点中心位置 `mid`,判断是否能在 `h` 小时内以 `k` 的速度吃完香蕉。
- 如果不能吃完,则将区间 `[left, mid]` 排除掉,继续在区间 `[mid + 1, right]` 中查找。
- 如果能吃完,说明 `k` 还可以继续减小,则继续在区间 `[left, mid]` 中查找。
- 当 `left == right` 时跳出循环,返回 `left`。
## 代码
```python
class Solution:
def canEat(self, piles, hour, speed):
time = 0
for pile in piles:
time += (pile + speed - 1) // speed
return time <= hour
def minEatingSpeed(self, piles: List[int], h: int) -> int:
left, right = 1, max(piles)
while left < right:
mid = left + (right - left) // 2
if not self.canEat(piles, h, mid):
left = mid + 1
else:
right = mid
return left
```
================================================
FILE: docs/solutions/LCR/om3reC.md
================================================
# [LCR 108. 单词接龙](https://leetcode.cn/problems/om3reC/)
- 标签:广度优先搜索、哈希表、字符串
- 难度:困难
## 题目链接
- [LCR 108. 单词接龙 - 力扣](https://leetcode.cn/problems/om3reC/)
## 题目大意
给定两个单词 `beginWord` 和 `endWord`,以及一个字典 `wordList`。找到从 `beginWord` 到 `endWord` 的最短转换序列中的单词数目。如果不存在这样的转换序列,则返回 0。
转换需要遵守的规则如下:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须为字典中的单词。
## 解题思路
广度优先搜索。使用队列存储将要遍历的单词和单词数目。
从 `beginWord` 开始变换,把单词的每个字母都用 `a ~ z` 变换一次,变换后的单词是否是 `endWord`,如果是则直接返回。
否则查找变换后的词是否在 `wordList` 中。如果在 `wordList` 中找到就加入队列,找不到就输出 `0`。然后按照广度优先搜索的算法急需要遍历队列中的节点,直到所有单词都出队时结束。
## 代码
```python
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
if not wordList or endWord not in wordList:
return 0
word_set = set(wordList)
if beginWord in word_set:
word_set.remove(beginWord)
queue = collections.deque()
queue.append((beginWord, 1))
while queue:
word, level = queue.popleft()
if word == endWord:
return level
for i in range(len(word)):
for j in range(26):
new_word = word[:i] + chr(ord('a') + j) + word[i + 1:]
if new_word in word_set:
word_set.remove(new_word)
queue.append((new_word, level + 1))
return 0
```
================================================
FILE: docs/solutions/LCR/opLdQZ.md
================================================
# [LCR 056. 两数之和 IV - 输入二叉搜索树](https://leetcode.cn/problems/opLdQZ/)
- 标签:树、深度优先搜索、广度优先搜索、二叉搜索树、哈希表、双指针、二叉树
- 难度:简单
## 题目链接
- [LCR 056. 两数之和 IV - 输入二叉搜索树 - 力扣](https://leetcode.cn/problems/opLdQZ/)
## 题目大意
给定一个二叉搜索树的根节点 `root` 和一个整数 `k`。
要求:判断该二叉搜索树是否存在两个节点值的和等于 `k`。如果存在,则返回 `True`,不存在则返回 `False`。
## 解题思路
二叉搜索树中序遍历的结果是从小到大排序,所以我们可以先对二叉搜索树进行中序遍历,将中序遍历结果存储到列表中。再使用左右指针查找节点值和为 `k` 的两个节点。
## 代码
```python
class Solution:
def inOrder(self, root, nums):
if not root:
return
self.inOrder(root.left, nums)
nums.append(root.val)
self.inOrder(root.right, nums)
def findTarget(self, root: TreeNode, k: int) -> bool:
nums = []
self.inOrder(root, nums)
left, right = 0, len(nums) - 1
while left < right:
sum = nums[left] + nums[right]
if sum == k:
return True
elif sum < k:
left += 1
else:
right -= 1
return False
```
================================================
FILE: docs/solutions/LCR/pOCWxh.md
================================================
# [LCR 047. 二叉树剪枝](https://leetcode.cn/problems/pOCWxh/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 047. 二叉树剪枝 - 力扣](https://leetcode.cn/problems/pOCWxh/)
## 题目大意
给定一棵二叉树的根节点 `root`,树的每个节点值要么是 `0`,要么是 `1`。
要求:剪除该二叉树中所有节点值为 `0` 的子树。
- 节点 `node` 的子树为: `node` 本身,以及所有 `node` 的后代。
## 解题思路
定义辅助方法 `containsOnlyZero(root)` 递归判断以 `root` 为根的子树中是否只包含 `0`。如果子树中只包含 `0`,则返回 `True`。如果子树中含有 `1`,则返回 `False`。当 `root` 为空时,也返回 `True`。
然后递归遍历二叉树,判断当前节点 `root` 是否只包含 `0`。如果只包含 `0`,则将其置空,返回 `None`。否则递归遍历左右子树,并设置对应的左右指针。
最后返回根节点 `root`。
## 代码
```python
class Solution:
def containsOnlyZero(self, root: TreeNode):
if not root:
return True
if root.val == 1:
return False
return self.containsOnlyZero(root.left) and self.containsOnlyZero(root.right)
def pruneTree(self, root: TreeNode) -> TreeNode:
if not root:
return root
if self.containsOnlyZero(root):
return None
root.left = self.pruneTree(root.left)
root.right = self.pruneTree(root.right)
return root
```
================================================
FILE: docs/solutions/LCR/ping-heng-er-cha-shu-lcof.md
================================================
# [LCR 176. 判断是否为平衡二叉树](https://leetcode.cn/problems/ping-heng-er-cha-shu-lcof/)
- 标签:树、深度优先搜索、二叉树
- 难度:简单
## 题目链接
- [LCR 176. 判断是否为平衡二叉树 - 力扣](https://leetcode.cn/problems/ping-heng-er-cha-shu-lcof/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:判断该树是不是平衡二叉树。如果是平衡二叉树,返回 `True`,否则,返回 `False`。
- 平衡二叉树:任意节点的左右子树深度不超过 `1`。
## 解题思路
递归遍历二叉树。先递归遍历左右子树,判断左右子树是否平衡,再判断以当前节点为根节点的左右子树是否平衡。
如果遍历的子树是平衡的,则返回它的高度,否则返回 `-1`。
只要出现不平衡的子树,则该二叉树一定不是平衡二叉树。
## 代码
```python
class Solution:
def isBalanced(self, root: TreeNode) -> bool:
def height(root: TreeNode) -> int:
if root == None:
return False
leftHeight = height(root.left)
rightHeight = height(root.right)
if leftHeight == -1 or rightHeight == -1 or abs(leftHeight - rightHeight) > 1:
return -1
else:
return max(leftHeight, rightHeight) + 1
return height(root) >= 0
```
================================================
FILE: docs/solutions/LCR/qIsx9U.md
================================================
# [LCR 041. 数据流中的移动平均值](https://leetcode.cn/problems/qIsx9U/)
- 标签:设计、队列、数组、数据流
- 难度:简单
## 题目链接
- [LCR 041. 数据流中的移动平均值 - 力扣](https://leetcode.cn/problems/qIsx9U/)
## 题目大意
**描述**:给定一个整数数据流和一个窗口大小 `size`。
**要求**:根据滑动窗口的大小,计算滑动窗口里所有数字的平均值。要求实现 `MovingAverage` 类:
- `MovingAverage(int size)`:用窗口大小 `size` 初始化对象。
- `double next(int val)`:成员函数 `next` 每次调用的时候都会往滑动窗口增加一个整数,请计算并返回数据流中最后 `size` 个值的移动平均值,即滑动窗口里所有数字的平均值。
**说明**:
- $1 \le size \le 1000$。
- $-10^5 \le val \le 10^5$。
- 最多调用 `next` 方法 $10^4$ 次。
**示例**:
- 示例 1:
```python
输入:
inputs = ["MovingAverage", "next", "next", "next", "next"]
inputs = [[3], [1], [10], [3], [5]]
输出:
[null, 1.0, 5.5, 4.66667, 6.0]
解释:
MovingAverage movingAverage = new MovingAverage(3);
movingAverage.next(1); // 返回 1.0 = 1 / 1
movingAverage.next(10); // 返回 5.5 = (1 + 10) / 2
movingAverage.next(3); // 返回 4.66667 = (1 + 10 + 3) / 3
movingAverage.next(5); // 返回 6.0 = (10 + 3 + 5) / 3
```
## 解题思路
### 思路 1:队列
1. 使用队列保存滑动窗口的元素,并记录对应窗口大小和元素和。
2. 当队列长度小于窗口大小的时候,直接向队列中添加元素,并记录当前窗口中的元素和。
3. 当队列长度等于窗口大小的时候,先将队列头部元素弹出,再添加元素,并记录当前窗口中的元素和。
4. 然后根据元素和和队列中元素个数计算出平均值。
### 思路 1:代码
```python
class MovingAverage:
def __init__(self, size: int):
"""
Initialize your data structure here.
"""
self.queue = []
self.size = size
self.sum = 0
def next(self, val: int) -> float:
if len(self.queue) < self.size:
self.queue.append(val)
else:
if self.queue:
self.sum -= self.queue[0]
self.queue.pop(0)
self.queue.append(val)
self.sum += val
return self.sum / len(self.queue)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(1)$。初始化方法和每次调用 `next` 方法的时间复杂度都是 $O(1)$。
- **空间复杂度**:$O(size)$。其中 $size$ 就是给定的滑动窗口的大小。
================================================
FILE: docs/solutions/LCR/qJnOS7.md
================================================
# [LCR 095. 最长公共子序列](https://leetcode.cn/problems/qJnOS7/)
- 标签:字符串、动态规划
- 难度:中等
## 题目链接
- [LCR 095. 最长公共子序列 - 力扣](https://leetcode.cn/problems/qJnOS7/)
## 题目大意
给定两个字符串 `text1` 和 `text2`。
要求:返回两个字符串的最长公共子序列的长度。如果不存在公共子序列,则返回 `0`。
- 子序列:原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 公共子序列:两个字符串所共同拥有的子序列。
## 解题思路
用动态规划来做。
动态规划的状态 `dp[i][j]` 表示为:前 `i` 个字符组成的字符串 `str1` 与前 `j` 个字符组成的字符串 `str2` 的最长公共子序列长度为 `dp[i][j]`。
遍历字符串 `text1` 和 `text2`,则状态转移方程为:
- 如果 `text1[i - 1] == text2[j - 1]`,则找到了一个公共元素,则 `dp[i][j] = dp[i - 1][j - 1] + 1`。
- 如果 `text1[i - 1] != text2[j - 1]`,则 `dp[i][j]` 需要考虑两种情况,取其中最大的那种:
- `text1` 前 `i - 1` 个字符组成的字符串 `str1` 与 `text2` 前 `j` 个字符组成的 `str2` 的最长公共子序列长度,即 `dp[i - 1][j]`。
- `text1` 前 `i` 个字符组成的字符串 `str1` 与 `text2` 前 `j - 1` 个字符组成的 `str2` 的最长公共子序列长度,即 `dp[i][j - 1]`。
最后输出 `dp[sise1][size2]` 即可,`size1`、`size2` 分别为 `text1`、`text2` 的字符串长度。
## 代码
```python
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
size1 = len(text1)
size2 = len(text2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[size1][size2]
```
================================================
FILE: docs/solutions/LCR/qing-wa-tiao-tai-jie-wen-ti-lcof.md
================================================
# [LCR 127. 跳跃训练](https://leetcode.cn/problems/qing-wa-tiao-tai-jie-wen-ti-lcof/)
- 标签:记忆化搜索、数学、动态规划
- 难度:简单
## 题目链接
- [LCR 127. 跳跃训练 - 力扣](https://leetcode.cn/problems/qing-wa-tiao-tai-jie-wen-ti-lcof/)
## 题目大意
一直青蛙一次可以跳上 `1` 级台阶,也可以跳上 `2` 级台阶。
要求:求该青蛙跳上 `n` 级台阶共有多少中跳法。答案需要对 `1000000007` 取余。
## 解题思路
先来看一下规律:
第 0 级台阶:1 种方法(比较特殊)
第 1 级台阶:1 种方法(从 0 阶爬 1 阶)
第 2 阶台阶:2 种方法(从 0 阶爬 2 阶,从 1 阶爬 1 阶)
第 i 阶台阶:从第 i-1 阶台阶爬 1 阶,或者从第 i-2 阶台阶爬 2 阶。
则推出递推公式为:
- 当 `n = 0` 时,`F(i) = 1`。
- 当 `n > 0` 时,`F(i) = F(i-1) + F(i-2)`。
## 代码
```python
class Solution:
def numWays(self, n: int) -> int:
if n == 0:
return 1
f1, f2, f3 = 0, 1, 1
for i in range(2, n + 1):
f1, f2 = f2, f3
f3 = (f1 + f2) % 1000000007
return f3
```
================================================
FILE: docs/solutions/LCR/qiu-12n-lcof.md
================================================
# [LCR 189. 设计机械累加器](https://leetcode.cn/problems/qiu-12n-lcof/)
- 标签:位运算、递归、脑筋急转弯
- 难度:中等
## 题目链接
- [LCR 189. 设计机械累加器 - 力扣](https://leetcode.cn/problems/qiu-12n-lcof/)
## 题目大意
给定一个整数 `n`。
要求:计算 `1 + 2 + ... + n`,并且不能使用乘除法、for、while、if、else、switch、case 等关键字及条件判断语句(A?B:C)。
## 解题思路
Python 中的逻辑运算最终返回的是最后一个非空值。比如 `3 and 2 and 'a'` 最终返回的是 `'a'`。利用这个特性可以递归求解。
## 代码
```python
class Solution:
def sumNums(self, n: int) -> int:
return n and n + self.sumNums(n - 1)
```
================================================
FILE: docs/solutions/LCR/que-shi-de-shu-zi-lcof.md
================================================
# [LCR 173. 点名](https://leetcode.cn/problems/que-shi-de-shu-zi-lcof/)
- 标签:位运算、数组、哈希表、数学、二分查找
- 难度:简单
## 题目链接
- [LCR 173. 点名 - 力扣](https://leetcode.cn/problems/que-shi-de-shu-zi-lcof/)
## 题目大意
给定一个 `n - 1` 个数的升序数组,数组中元素值都在 `0 ~ n - 1` 之间。 `nums` 中有且只有一个数字不在该数组中。
要求:找出这个缺失的数字。
## 解题思路
可以用二分查找解决。
对于中间值,判断元素值与索引值是否一致,如果一致,则说明缺失数字在索引的右侧。如果不一致,则可能为当前索引或者索引的左侧。
## 代码
```python
class Solution:
def missingNumber(self, nums: List[int]) -> int:
if len(nums) == 0:
return 0
left, right = 0, len(nums) - 1
while left < right:
mid = left + (right - left) // 2
if mid == nums[mid]:
left = mid + 1
else:
right = mid
if left == nums[left]:
return left + 1
else:
return left
```
================================================
FILE: docs/solutions/LCR/sfvd7V.md
================================================
# [LCR 033. 字母异位词分组](https://leetcode.cn/problems/sfvd7V/)
- 标签:数组、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [LCR 033. 字母异位词分组 - 力扣](https://leetcode.cn/problems/sfvd7V/)
## 题目大意
给定一个字符串数组 `strs`。
要求:将包含字母相同的字符串组合在一起,不需要考虑输出顺序。
## 解题思路
使用哈希表记录字母相同的字符串。对每一个字符串进行排序,按照 排序字符串:字母相同的字符串数组 的键值顺序进行存储。最终将哈希表的值转换为对应数组返回结果。
## 代码
```python
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
str_dict = dict()
res = []
for s in strs:
sort_s = str(sorted(s))
if sort_s in str_dict:
str_dict[sort_s] += [s]
else:
str_dict[sort_s] = [s]
for sort_s in str_dict:
res += [str_dict[sort_s]]
return res
```
================================================
FILE: docs/solutions/LCR/shan-chu-lian-biao-de-jie-dian-lcof.md
================================================
# [LCR 136. 删除链表的节点](https://leetcode.cn/problems/shan-chu-lian-biao-de-jie-dian-lcof/)
- 标签:链表
- 难度:简单
## 题目链接
- [LCR 136. 删除链表的节点 - 力扣](https://leetcode.cn/problems/shan-chu-lian-biao-de-jie-dian-lcof/)
## 题目大意
给定一个链表。
要求:删除链表中值为 `val` 的节点,并返回新的链表头节点。
## 解题思路
用两个指针 `prev` 和 `curr`。`prev` 指向前一节点和当前节点,`curr` 指向当前节点。从前向后遍历链表,遇到值为 `val` 的节点时,将 `prev` 指向当前节点的下一个节点,继续递归遍历。遇不到则更新 `prev` 指针,并继续遍历。
需要注意的是要删除的节点可能包含了头节点。我们可以考虑在遍历之前,新建一个头节点,让其指向原来的头节点。这样,最终如果删除的是头节点,则删除原头节点即可。返回结果的时候,可以直接返回新建头节点的下一位节点。
## 代码
```python
class Solution:
def deleteNode(self, head: ListNode, val: int) -> ListNode:
newHead = ListNode(0, head)
newHead.next = head
prev, curr = newHead, head
while curr:
if curr.val == val:
prev.next = curr.next
else:
prev = curr
curr = curr.next
return newHead.next
```
================================================
FILE: docs/solutions/LCR/shu-de-zi-jie-gou-lcof.md
================================================
# [LCR 143. 子结构判断](https://leetcode.cn/problems/shu-de-zi-jie-gou-lcof/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [LCR 143. 子结构判断 - 力扣](https://leetcode.cn/problems/shu-de-zi-jie-gou-lcof/)
## 题目大意
给定两棵二叉树的根节点 `A`、`B`。
要求:判断 `B` 是不是 `A` 的子结构。(空树不是任意一棵树的子结构)。
- `B` 是 `A` 的子结构:`A` 中有出现和 `B` 相同的结构和节点值。
## 解题思路
深度优先搜索。
- 先判断特例,如果 `A`、`B` 都为空树,则直接返回 `False`。
- 然后递归判断 `A`、`B` 是否相等。
- 如果 `A`、`B` 相等,则返回 `True`。
- 如果 `A`、`B` 不相等,则递归判断 `B` 是否是 `A` 的左子树的子结构,或者 `B` 是否是 `A` 的右子树的子结构,如果有一种满足,则返回 `True`,如果都不满足,则返回 `False`。
递归判断 `A`、`B` 是否相等的具体方法如下:
- 如果 `B` 为空树,则直接返回 `False`,因为空树不是任意一棵树的子结构。
- 如果 `A` 为空树或者 `A` 节点的值不等于 `B` 节点的值,则返回 `False`。
- 如果 `A`、`B` 都不为空,且节点值相同,则递归判断 `A` 的左子树和 `B` 的左子树是否相等,判断 `A` 的右子树和 `B` 的右子树是否相等。如果都相等,则返回 `True`,否则返回 `False`。
## 代码
```python
class Solution:
def hasSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
if not B:
return True
if not A or A.val != B.val:
return False
return self.hasSubStructure(A.left, B.left) and self.hasSubStructure(A.right, B.right)
def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
if not A or not B:
return False
if self.hasSubStructure(A, B):
return True
return self.isSubStructure(A.left, B) or self.isSubStructure(A.right, B)
```
================================================
FILE: docs/solutions/LCR/shu-ju-liu-zhong-de-zhong-wei-shu-lcof.md
================================================
# [LCR 160. 数据流中的中位数](https://leetcode.cn/problems/shu-ju-liu-zhong-de-zhong-wei-shu-lcof/)
- 标签:设计、双指针、数据流、排序、堆(优先队列)
- 难度:困难
## 题目链接
- [LCR 160. 数据流中的中位数 - 力扣](https://leetcode.cn/problems/shu-ju-liu-zhong-de-zhong-wei-shu-lcof/)
## 题目大意
要求:设计一个支持一下两种操作的数组结构:
- `void addNum(int num)`:从数据流中添加一个整数到数据结构中。
- `double findMedian()`:返回目前所有元素的中位数。
## 解题思路
使用一个大顶堆 `queMax` 记录大于中位数的数,使用一个小顶堆 `queMin` 小于中位数的数。
- 当添加元素数量为偶数: `queMin` 和 `queMax` 中元素数量相同,则中位数为它们队头的平均值。
- 当添加元素数量为奇数:`queMin` 中的数比 `queMax` 多一个,此时中位数为 `queMin` 的队头。
为了满足上述条件,在进行 `addNum` 操作时,我们应当分情况处理:
- `num > max{queMin}`:此时 `num` 大于中位数,将该数添加到大顶堆 `queMax` 中。新的中位数将大于原来的中位数,所以可能需要将 `queMax` 中的最小数移动到 `queMin` 中。
- `num ≤ max{queMin}`:此时 `num` 小于中位数,将该数添加到小顶堆 `queMin` 中。新的中位数将小于等于原来的中位数,所以可能需要将 `queMin` 中最大数移动到 `queMax` 中。
## 代码
```python
import heapq
class MedianFinder:
def __init__(self):
"""
initialize your data structure here.
"""
self.queMin = list()
self.queMax = list()
def addNum(self, num: int) -> None:
if not self.queMin or num < -self.queMin[0]:
heapq.heappush(self.queMin, -num)
if len(self.queMax) + 1 < len(self.queMin):
heapq.heappush(self.queMax, -heapq.heappop(self.queMin))
else:
heapq.heappush(self.queMax, num)
if len(self.queMax) > len(self.queMin):
heapq.heappush(self.queMin, -heapq.heappop(self.queMax))
def findMedian(self) -> float:
if len(self.queMin) > len(self.queMax):
return -self.queMin[0]
return (-self.queMin[0] + self.queMax[0]) / 2
```
================================================
FILE: docs/solutions/LCR/shu-zhi-de-zheng-shu-ci-fang-lcof.md
================================================
# [LCR 134. Pow(x, n)](https://leetcode.cn/problems/shu-zhi-de-zheng-shu-ci-fang-lcof/)
- 标签:递归、数学
- 难度:中等
## 题目链接
- [LCR 134. Pow(x, n) - 力扣](https://leetcode.cn/problems/shu-zhi-de-zheng-shu-ci-fang-lcof/)
## 题目大意
给定浮点数 `x` 和整数 `n`。
要求:实现 `pow(x, n)`,即计算 $x^n$,不能使用库函数,不需要考虑大数问题。
## 解题思路
常规方法是直接将 x 累乘 n 次得出结果,时间复杂度为 $O(n)$。可以利用快速幂来减少时间复杂度。
如果 n 为偶数,$x^n = x^{n/2} * x^{n/2}$。如果 n 为奇数,$x^n = x * x^{(n-1)/2} * x^{(n-1)/2}$。
$x^(n/2)$ 又可以继续向下递归划分。则我们可以利用低纬度的幂计算结果,来得到高纬度的幂计算结果。
这样递归求解,时间复杂度为 $O(logn)$,并且递归也可以转为递推来做。
需要注意如果 n 为负数,可以转换为 $\frac{1}{x} ^{(-n)}$。
## 代码
```python
class Solution:
def myPow(self, x: float, n: int) -> float:
if x == 0.0:
return 0.0
res = 1
if n < 0:
x = 1 / x
n = -n
while n:
if n & 1:
res *= x
x *= x
n >>= 1
return res
```
================================================
FILE: docs/solutions/LCR/shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof.md
================================================
# [LCR 163. 找到第 k 位数字](https://leetcode.cn/problems/shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof/)
- 标签:数学、二分查找
- 难度:中等
## 题目链接
- [LCR 163. 找到第 k 位数字 - 力扣](https://leetcode.cn/problems/shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof/)
## 题目大意
数字以 `0123456789101112131415…` 的格式序列化到一个字符序列中。在这个序列中,第 `5` 位(从下标 `0` 开始计数)是 `5`,第 `13` 位是 `1`,第 `19` 位是 `4`,等等。
要求:返回任意第 `n` 位对应的数字。
## 解题思路
根据题意中的字符串,找数学规律:
- `123456789`:是 `9` 个 `1` 位数字。
- `10111213...9899`:是 `90` 个 `2` 位数字。
- `100...999`:是 `900` 个 `3` 位数字。
- `1000...9999` 是 `9000` 个 `4` 位数字。
- 我们可以先找到对应的数字对应的位数 `digits`。
- 然后找到该位数 `digits` 的起始数字 `start`。
- 再计算出 `n` 所在的数字 `number`。`number` 等于从起始数字 `start` 开始的第 $\lfloor(n - 1) / digits\rfloor$ 个数字。即 `number = start + (n - 1) // digits`。
- 然后确定 `n` 对应的是数字 `number` 中的哪一位。即 `idx = (n - 1) % digits`。
- 最后返回结果。
## 代码
```python
class Solution:
def findNthDigit(self, n: int) -> int:
digits = 1
start = 1
base = 9
while n > base:
n -= base
digits += 1
start *= 10
base = start * digits * 9
number = start + (n - 1) // digits
idx = (n - 1) % digits
return int(str(number)[idx])
```
## 参考资料
- 【题解】[面试题44. 数字序列中某一位的数字(迭代 + 求整 / 求余,清晰图解) - 数字序列中某一位的数字 - 力扣](https://leetcode.cn/problems/shu-zi-xu-lie-zhong-mou-yi-wei-de-shu-zi-lcof/solution/mian-shi-ti-44-shu-zi-xu-lie-zhong-mou-yi-wei-de-6/)
================================================
FILE: docs/solutions/LCR/shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof.md
================================================
# [LCR 158. 库存管理 II](https://leetcode.cn/problems/shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof/)
- 标签:数组、哈希表、分治、计数、排序
- 难度:简单
## 题目链接
- [LCR 158. 库存管理 II - 力扣](https://leetcode.cn/problems/shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof/)
## 题目大意
给定一个数组 `nums`,其中有一个数字出现次数超过数组长度一半。
要求:找到出现次数超过数组长度一半的数字。
## 解题思路
可以利用哈希表。遍历一遍数组 `nums`,用哈希表统计每个元素 `num` 出现的次数,再遍历一遍哈希表,找出元素个数最多的元素即可。
## 代码
```python
class Solution:
def majorityElement(self, nums: List[int]) -> int:
numDict = dict()
for num in nums:
if num in numDict:
numDict[num] += 1
else:
numDict[num] = 1
max = 0
max_index = -1
for num in numDict:
if numDict[num] > max:
max = numDict[num]
max_index = num
return max_index
```
================================================
FILE: docs/solutions/LCR/shu-zu-zhong-de-ni-xu-dui-lcof.md
================================================
# [LCR 170. 交易逆序对的总数](https://leetcode.cn/problems/shu-zu-zhong-de-ni-xu-dui-lcof/)
- 标签:树状数组、线段树、数组、二分查找、分治、有序集合、归并排序
- 难度:困难
## 题目链接
- [LCR 170. 交易逆序对的总数 - 力扣](https://leetcode.cn/problems/shu-zu-zhong-de-ni-xu-dui-lcof/)
## 题目大意
**描述**:给定一个数组 $nums$。
**要求**:计算出数组中的逆序对的总数。
**说明**:
- **逆序对**:在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。
- $0 \le nums.length \le 50000$。
**示例**:
- 示例 1:
```python
输入: [7,5,6,4]
输出: 5
```
## 解题思路
### 思路 1:归并排序
归并排序主要分为:「分解过程」和「合并过程」。其中「合并过程」实质上是两个有序数组的合并过程。
每当遇到 左子数组当前元素 > 右子树组当前元素时,意味着「左子数组从当前元素开始,一直到左子数组末尾元素」与「右子树组当前元素」构成了若干个逆序对。
比如上图中的左子数组 $[0, 3, 5, 7]$ 与右子树组 $[1, 4, 6, 8]$,遇到左子数组中元素 $3$ 大于右子树组中元素 $1$。则左子数组从 $3$ 开始,经过 $5$ 一直到 $7$,与右子数组当前元素 $1$ 都构成了逆序对。即 $[3, 1]$、$[5, 1]$、$[7, 1]$ 都构成了逆序对。
因此,我们可以在合并两个有序数组的时候计算逆序对。具体做法如下:
1. 使用全局变量 $cnt$ 来存储逆序对的个数。然后进行归并排序。
2. **分割过程**:先递归地将当前序列平均分成两半,直到子序列长度为 $1$。
1. 找到序列中心位置 $mid$,从中心位置将序列分成左右两个子序列 $left\_arr$、$right\_arr$。
2. 对左右两个子序列 $left\_arr$、$right\_arr$ 分别进行递归分割。
3. 最终将数组分割为 $n$ 个长度均为 $1$ 的有序子序列。
3. **归并过程**:从长度为 $1$ 的有序子序列开始,依次进行两两归并,直到合并成一个长度为 $n$ 的有序序列。
1. 使用数组变量 $arr$ 存放归并后的有序数组。
2. 使用两个指针 $left\_i$、$right\_i$ 分别指向两个有序子序列 $left\_arr$、$right\_arr$ 的开始位置。
3. 比较两个指针指向的元素:
1. 如果 $left\_arr[left\_i] \le right\_arr[right\_i]$,则将 $left\_arr[left\_i]$ 存入到结果数组 $arr$ 中,并将指针移动到下一位置。
2. 如果 $left\_arr[left\_i] > right\_arr[right\_i]$,则 **记录当前左子序列中元素与当前右子序列元素所形成的逆序对的个数,并累加到 $cnt$ 中,即 `self.cnt += len(left_arr) - left_i`**,然后将 $right\_arr[right\_i]$ 存入到结果数组 $arr$ 中,并将指针移动到下一位置。
4. 重复步骤 $3$,直到某一指针到达子序列末尾。
5. 将另一个子序列中的剩余元素存入到结果数组 $arr$ 中。
6. 返回归并后的有序数组 $arr$。
4. 返回数组中的逆序对的总数,即 $self.cnt$。
### 思路 1:代码
```python
class Solution:
cnt = 0
def merge(self, left_arr, right_arr): # 归并过程
arr = []
left_i, right_i = 0, 0
while left_i < len(left_arr) and right_i < len(right_arr):
# 将两个有序子序列中较小元素依次插入到结果数组中
if left_arr[left_i] <= right_arr[right_i]:
arr.append(left_arr[left_i])
left_i += 1
else:
self.cnt += len(left_arr) - left_i
arr.append(right_arr[right_i])
right_i += 1
while left_i < len(left_arr):
# 如果左子序列有剩余元素,则将其插入到结果数组中
arr.append(left_arr[left_i])
left_i += 1
while right_i < len(right_arr):
# 如果右子序列有剩余元素,则将其插入到结果数组中
arr.append(right_arr[right_i])
right_i += 1
return arr # 返回排好序的结果数组
def mergeSort(self, arr): # 分割过程
if len(arr) <= 1: # 数组元素个数小于等于 1 时,直接返回原数组
return arr
mid = len(arr) // 2 # 将数组从中间位置分为左右两个数组。
left_arr = self.mergeSort(arr[0: mid]) # 递归将左子序列进行分割和排序
right_arr = self.mergeSort(arr[mid:]) # 递归将右子序列进行分割和排序
return self.merge(left_arr, right_arr) # 把当前序列组中有序子序列逐层向上,进行两两合并。
def reversePairs(self, nums: List[int]) -> int:
self.cnt = 0
self.mergeSort(nums)
return self.cnt
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(n)$。
### 思路 2:树状数组
数组 $tree[i]$ 表示数字 $i$ 是否在序列中出现过,如果数字 $i$ 已经存在于序列中,$tree[i] = 1$,否则 $tree[i] = 0$。
1. 按序列从左到右将值为 $nums[i]$ 的元素当作下标为$nums[i]$,赋值为 $1$ 插入树状数组里,这时,比 $nums[i]$ 大的数个数就是 $i + 1 - query(a)$。
2. 将全部结果累加起来就是逆序数了。
### 思路 2:代码
```python
import bisect
class BinaryIndexTree:
def __init__(self, n):
self.size = n
self.tree = [0 for _ in range(n + 1)]
def lowbit(self, index):
return index & (-index)
def update(self, index, delta):
while index <= self.size:
self.tree[index] += delta
index += self.lowbit(index)
def query(self, index):
res = 0
while index > 0:
res += self.tree[index]
index -= self.lowbit(index)
return res
class Solution:
def reversePairs(self, nums: List[int]) -> int:
size = len(nums)
sort_nums = sorted(nums)
for i in range(size):
nums[i] = bisect.bisect_left(sort_nums, nums[i]) + 1
bit = BinaryIndexTree(size)
ans = 0
for i in range(size):
bit.update(nums[i], 1)
ans += (i + 1 - bit.query(nums[i]))
return ans
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n \times \log n)$。
- **空间复杂度**:$O(n)$。
================================================
FILE: docs/solutions/LCR/shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof.md
================================================
# [LCR 177. 撞色搭配](https://leetcode.cn/problems/shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof/)
- 标签:位运算、数组
- 难度:中等
## 题目链接
- [LCR 177. 撞色搭配 - 力扣](https://leetcode.cn/problems/shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof/)
## 题目大意
给定一个整型数组 `nums` 。`nums` 里除两个数字之外,其他数字都出现了两次。
要求:找出这两个只出现一次的数字。要求时间复杂度是 $O(n)$,空间复杂度是 $O(1)$。
## 解题思路
- 求解这道题之前,我们先来看看如何求解「一个数组中除了某个元素只出现一次以外,其余每个元素均出现两次。」即「[136. 只出现一次的数字](https://leetcode.cn/problems/single-number/)」问题。我们可以对所有数不断进行异或操作,最终可得到单次出现的元素。
- 如果数组中有两个数字只出现一次,其余每个元素均出现两次。那么经过全部异或运算。我们可以得到只出现一次的两个数字的异或结果。
- 根据异或结果的性质,异或运算中如果某一位上为 `1`,则说明异或的两个数在该位上是不同的。根据这个性质,我们将数字分为两组:一组是和该位为 `0` 的数字,另一组是该位为 `1` 的数字。然后将这两组分别进行异或运算,就可以得到最终要求的两个数字。
## 代码
```python
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
all_xor = 0
for num in nums:
all_xor ^= num
# 获取所有异或中最低位的 1
mask = 1
while all_xor & mask == 0:
mask <<= 1
a_xor, b_xor = 0, 0
for num in nums:
if num & mask == 0:
a_xor ^= num
else:
b_xor ^= num
return a_xor, b_xor
```
================================================
FILE: docs/solutions/LCR/shu-zu-zhong-zhong-fu-de-shu-zi-lcof.md
================================================
# [LCR 120. 寻找文件副本](https://leetcode.cn/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
- 标签:数组、哈希表、排序
- 难度:简单
## 题目链接
- [LCR 120. 寻找文件副本 - 力扣](https://leetcode.cn/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
## 题目大意
给定一个包含 `n + 1` 个整数的数组 `nums`,里边包含的值都在 `1 ~ n` 之间。假设 `nums` 中只存在一个重复的整数,要求找出这个重复的数。
## 解题思路
使用哈希表存储数组每个元素,遇到重复元素则直接返回该元素。
## 代码
```python
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
nums_dict = dict()
for num in nums:
if num in nums_dict:
return num
nums_dict[num] = 1
return -1
```
================================================
FILE: docs/solutions/LCR/shun-shi-zhen-da-yin-ju-zhen-lcof.md
================================================
# [LCR 146. 螺旋遍历二维数组](https://leetcode.cn/problems/shun-shi-zhen-da-yin-ju-zhen-lcof/)
- 标签:数组、矩阵、模拟
- 难度:简单
## 题目链接
- [LCR 146. 螺旋遍历二维数组 - 力扣](https://leetcode.cn/problems/shun-shi-zhen-da-yin-ju-zhen-lcof/)
## 题目大意
给定一个 `m * n` 大小的二维矩阵 `matrix`。
要求:按照顺时针旋转的顺序,返回矩阵中的所有元素。
## 解题思路
按照题意进行模拟。可以实现定义一下上、下、左、右的边界,然后按照逆时针的顺序从边界上依次访问元素。
当访问完当前边界之后,要更新一下边界位置,缩小范围,方便下一轮进行访问。
## 代码
```python
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
size_m = len(matrix)
if size_m == 0:
return []
size_n = len(matrix[0])
if size_n == 0:
return []
up, down, left, right = 0, size_m - 1, 0, size_n - 1
ans = []
while True:
for i in range(left, right + 1):
ans.append(matrix[up][i])
up += 1
if up > down:
break
for i in range(up, down + 1):
ans.append(matrix[i][right])
right -= 1
if right < left:
break
for i in range(right, left - 1, -1):
ans.append(matrix[down][i])
down -= 1
if down < up:
break
for i in range(down, up - 1, -1):
ans.append(matrix[i][left])
left += 1
if left > right:
break
return ans
```
================================================
FILE: docs/solutions/LCR/ti-huan-kong-ge-lcof.md
================================================
# [LCR 122. 路径加密](https://leetcode.cn/problems/ti-huan-kong-ge-lcof/)
- 标签:字符串
- 难度:简单
## 题目链接
- [LCR 122. 路径加密 - 力扣](https://leetcode.cn/problems/ti-huan-kong-ge-lcof/)
## 题目大意
给定一个字符串 `s`。
要求:将字符串 `s` 中的每个空格换成 `%20`。
## 解题思路
Python 的字符串是不可变类型,所以需要先用数组存储答案,再将其转为字符串返回。具体操作如下。
- 定义数组 `res`,遍历字符串 `s`。
- 如果当前字符 `ch` 为空格,则将 ` %20` 加入到数组中。
- 如果当前字符 `ch` 不为空格,则直接加入到数组中。
- 遍历完之后,通过 `join` 将其转为字符串返回。
## 代码
```python
class Solution:
def replaceSpace(self, s: str) -> str:
res = []
for ch in s:
if ch == ' ':
res.append("%20")
else:
res.append(ch)
return "".join(res)
```
================================================
FILE: docs/solutions/LCR/tvdfij.md
================================================
# [LCR 012. 寻找数组的中心下标](https://leetcode.cn/problems/tvdfij/)
- 标签:数组、前缀和
- 难度:简单
## 题目链接
- [LCR 012. 寻找数组的中心下标 - 力扣](https://leetcode.cn/problems/tvdfij/)
## 题目大意
给定一个数组 `nums`。
要求:找到「左侧元素和」与「右侧元素和相等」的位置,如果找不到,则返回 `-1`。
## 解题思路
两次遍历,第一次遍历先求出数组全部元素和。第二次遍历找到左侧元素和恰好为全部元素和一半的位置。
## 代码
```python
class Solution:
def pivotIndex(self, nums: List[int]) -> int:
sum = 0
for i in range(len(nums)):
sum += nums[i]
curr_sum = 0
for i in range(len(nums)):
if curr_sum * 2 + nums[i] == sum:
return i
curr_sum += nums[i]
return -1
```
================================================
FILE: docs/solutions/LCR/uUsW3B.md
================================================
# [LCR 080. 组合](https://leetcode.cn/problems/uUsW3B/)
- 标签:数组、回溯
- 难度:中等
## 题目链接
- [LCR 080. 组合 - 力扣](https://leetcode.cn/problems/uUsW3B/)
## 题目大意
给定两个整数 `n` 和 `k`。
要求:返回范围 `[1, n]` 中所有可能的 `k` 个数的组合。可以按任何顺序返回答案。
## 解题思路
组合问题通常可以用回溯算法来解决。定义两个数组 `res`、`path`。`res` 用来存放最终答案,`path` 用来存放当前符合条件的一个结果。再使用一个变量 `start_index` 来表示从哪一个数开始遍历。
定义回溯方法,`start_index = 1` 开始进行回溯。
- 如果 `path` 数组的长度等于 `k`,则将 `path` 中的元素加入到 `res` 数组中。
- 然后对 `[start_index, n]` 范围内的数进行遍历取值。
- 将当前元素 `i` 加入 `path` 数组。
- 递归遍历 `[start_index, n]` 上的数。
- 将遍历的 `i` 元素进行回退。
- 最终返回 `res` 数组。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, n: int, k: int, start_index: int):
if len(self.path) == k:
self.res.append(self.path[:])
return
for i in range(start_index, n - (k - len(self.path)) + 2):
self.path.append(i)
self.backtrack(n, k, i + 1)
self.path.pop()
def combine(self, n: int, k: int) -> List[List[int]]:
self.res.clear()
self.path.clear()
self.backtrack(n, k, 1)
return self.res
```
================================================
FILE: docs/solutions/LCR/vEAB3K.md
================================================
# [LCR 106. 判断二分图](https://leetcode.cn/problems/vEAB3K/)
- 标签:深度优先搜索、广度优先搜索、并查集、图
- 难度:中等
## 题目链接
- [LCR 106. 判断二分图 - 力扣](https://leetcode.cn/problems/vEAB3K/)
## 题目大意
给定一个代表 n 个节点的无向图的二维数组 `graph`,其中 `graph[u]` 是一个节点数组,由节点 `u` 的邻接节点组成。对于 `graph[u]` 中的每个 `v`,都存在一条位于节点 `u` 和节点 `v` 之间的无向边。
该无向图具有以下属性:
- 不存在自环(`graph[u]` 不包含 `u`)。
- 不存在平行边(`graph[u]` 不包含重复值)。
- 如果 `v` 在 `graph[u]` 内,那么 `u` 也应该在 `graph[v]` 内(该图是无向图)。
- 这个图可能不是连通图,也就是说两个节点 `u` 和 `v` 之间可能不存在一条连通彼此的路径。
要求:判断该图是否是二分图,如果是二分图,则返回 `True`;否则返回 `False`。
- 二分图:如果能将一个图的节点集合分割成两个独立的子集 `A` 和 `B`,并使图中的每一条边的两个节点一个来自 `A` 集合,一个来自 `B` 集合,就将这个图称为 二分图 。
## 解题思路
对于图中的任意节点 `u` 和 `v`,如果 `u` 和 `v` 之间有一条无向边,那么 `u` 和 `v` 必然属于不同的集合。
我们可以通过在深度优先搜索中对邻接点染色标记的方式,来识别该图是否是二分图。具体做法如下:
- 找到一个没有染色的节点 `u`,将其染成红色。
- 然后遍历该节点直接相连的节点 `v`,如果该节点没有被染色,则将该节点直接相连的节点染成蓝色,表示两个节点不是同一集合。如果该节点已经被染色并且颜色跟 `u` 一样,则说明该图不是二分图,直接返回 `False`。
- 从上面染成蓝色的节点 `v` 出发,遍历该节点直接相连的节点。。。依次类推的递归下去。
- 如果所有节点都顺利染上色,则说明该图为二分图,返回 `True`。否则,如果在途中不能顺利染色,则返回 `False`。
## 代码
```python
class Solution:
def dfs(self, graph, colors, i, color):
colors[i] = color
for j in graph[i]:
if colors[j] == colors[i]:
return False
if colors[j] == 0 and not self.dfs(graph, colors, j, -color):
return False
return True
def isBipartite(self, graph: List[List[int]]) -> bool:
size = len(graph)
colors = [0 for _ in range(size)]
for i in range(size):
if colors[i] == 0 and not self.dfs(graph, colors, i, 1):
return False
return True
```
================================================
FILE: docs/solutions/LCR/vlzXQL.md
================================================
# [LCR 111. 除法求值](https://leetcode.cn/problems/vlzXQL/)
- 标签:深度优先搜索、广度优先搜索、并查集、图、数组、最短路
- 难度:中等
## 题目链接
- [LCR 111. 除法求值 - 力扣](https://leetcode.cn/problems/vlzXQL/)
## 题目大意
给定一个变量对数组 `equations` 和一个实数数组 `values` 作为已知条件,其中 `equations[i] = [Ai, Bi]` 和 `values[i]` 共同表示 `Ai / Bi = values[i]`。每个 `Ai` 或 `Bi` 是一个表示单个变量的字符串。
再给定一个表示多个问题的数组 `queries`,其中 `queries[j] = [Cj, Dj]` 表示第 `j` 个问题,要求:根据已知条件找出 `Cj / Dj = ?` 的结果作为答案。返回所有问题的答案。如果某个答案无法确定,则用 `-1.0` 代替,如果问题中出现了给定的已知条件中没有出现的表示变量的字符串,则也用 `-1.0` 代替这个答案。
## 解题思路
在「[等式方程的可满足性](https://leetcode.cn/problems/satisfiability-of-equality-equations)」的基础上增加了倍数关系。在「[等式方程的可满足性](https://leetcode.cn/problems/satisfiability-of-equality-equations)」中我们处理传递关系使用了并查集,这道题也是一样,不过在使用并查集的同时还要维护倍数关系。
举例说明:
- `a / b = 2.0`:说明 `a = 2b`,`a` 和 `b` 在同一个集合。
- `b / c = 3.0`:说明 `b = 3c`,`b` 和 `c` 在同一个集合。
根据上述两式可得:`a`、`b`、`c` 都在一个集合中,且 `a = 2b = 6c`。
我们可以将同一集合中的变量倍数关系都转换为与根节点变量的倍数关系,比如上述例子中都转变为与 `a` 的倍数关系。
具体操作如下:
- 定义并查集结构,并在并查集中定义一个表示倍数关系的 `multiples` 数组。
- 遍历 `equations` 数组、`values` 数组,将每个变量按顺序编号,并使用 `union` 将其并入相同集合。
- 遍历 `queries` 数组,判断两个变量是否在并查集中,并且是否在同一集合。如果找到对应关系,则将计算后的倍数关系存入答案数组,否则则将 `-1` 存入答案数组。
- 最终输出答案数组。
并查集中维护倍数相关方法说明:
- `find` 方法:
- 递推寻找根节点,并将倍数累乘,然后进行路径压缩,并且更新当前节点的倍数关系。
- `union` 方法:
- 如果两个节点属于同一集合,则直接返回。
- 如果两个节点不属于同一个集合,合并之前当前节点的倍数关系更新,然后再进行更新。
- `is_connect` 方法:
- 如果两个节点不属于同一集合,返回 `-1`。
- 如果两个节点属于同一集合,则返回倍数关系。
## 代码
```python
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.multiples = [1 for _ in range(n)]
def find(self, x):
multiple = 1.0
origin = x
while x != self.parent[x]:
multiple *= self.multiples[x]
x = self.parent[x]
self.parent[origin] = x
self.multiples[origin] = multiple
return x
def union(self, x, y, multiple):
root_x = self.find(x)
root_y = self.find(y)
if root_x == root_y:
return
self.parent[root_x] = root_y
self.multiples[root_x] = multiple * self.multiples[y] / self.multiples[x]
return
def is_connected(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
return -1.0
return self.multiples[x] / self.multiples[y]
class Solution:
def calcEquation(self, equations: List[List[str]], values: List[float], queries: List[List[str]]) -> List[float]:
equations_size = len(equations)
hash_map = dict()
union_find = UnionFind(2 * equations_size)
id = 0
for i in range(equations_size):
equation = equations[i]
var1, var2 = equation[0], equation[1]
if var1 not in hash_map:
hash_map[var1] = id
id += 1
if var2 not in hash_map:
hash_map[var2] = id
id += 1
union_find.union(hash_map[var1], hash_map[var2], values[i])
queries_size = len(queries)
res = []
for i in range(queries_size):
query = queries[i]
var1, var2 = query[0], query[1]
if var1 not in hash_map or var2 not in hash_map:
res.append(-1.0)
else:
id1 = hash_map[var1]
id2 = hash_map[var2]
res.append(union_find.is_connected(id1, id2))
return res
```
================================================
FILE: docs/solutions/LCR/vvXgSW.md
================================================
# [LCR 078. 合并 K 个升序链表](https://leetcode.cn/problems/vvXgSW/)
- 标签:链表、分治、堆(优先队列)、归并排序
- 难度:困难
## 题目链接
- [LCR 078. 合并 K 个升序链表 - 力扣](https://leetcode.cn/problems/vvXgSW/)
## 题目大意
给定一个链表数组 `lists`,每个链表都已经按照升序排列。
要求:将所有链表合并到一个升序链表中,返回合并后的链表。
## 解题思路
分而治之的思想。将链表数组不断二分,转为规模为二分之一的子问题,然后再进行归并排序。
## 代码
```python
class Solution:
def merge_sort(self, lists: List[ListNode], left: int, right: int) -> ListNode:
if left == right:
return lists[left]
mid = left + (right - left) // 2
node_left = self.merge_sort(lists, left, mid)
node_right = self.merge_sort(lists, mid + 1, right)
return self.merge(node_left, node_right)
def merge(self, a: ListNode, b: ListNode) -> ListNode:
root = ListNode(-1)
cur = root
while a and b:
if a.val < b.val:
cur.next = a
a = a.next
else:
cur.next = b
b = b.next
cur = cur.next
if a:
cur.next = a
if b:
cur.next = b
return root.next
def mergeKLists(self, lists: List[ListNode]) -> ListNode:
if not lists:
return None
size = len(lists)
return self.merge_sort(lists, 0, size - 1)
```
================================================
FILE: docs/solutions/LCR/w3tCBm.md
================================================
# [LCR 003. 比特位计数](https://leetcode.cn/problems/w3tCBm/)
- 标签:位运算、动态规划
- 难度:简单
## 题目链接
- [LCR 003. 比特位计数 - 力扣](https://leetcode.cn/problems/w3tCBm/)
## 题目大意
给定一个整数 `n`。
要求:对于 `0 ≤ i ≤ n` 的每一个 `i`,计算其二进制表示中 `1` 的个数,返回一个长度为 `n + 1` 的数组 `ans` 作为答案。
## 解题思路
可以根据整数的二进制特点将其分为两类:
- 奇数:一定比前面相邻的偶数多一个 `1`。
- 偶数:一定和除以 `2` 之后的数一样多。
- 边界 `0`:`1` 的个数为 `0`。
于是可以根据规律,从 `0` 开始到 `n` 进行递推求解。
## 代码
```python
class Solution:
def countBits(self, n: int) -> List[int]:
dp = [0 for _ in range(n + 1)]
for i in range(1, n + 1):
if i % 2 == 1:
dp[i] = dp[i - 1] + 1
else:
dp[i] = dp[i // 2]
return dp
```
================================================
FILE: docs/solutions/LCR/w6cpku.md
================================================
# [LCR 054. 把二叉搜索树转换为累加树](https://leetcode.cn/problems/w6cpku/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [LCR 054. 把二叉搜索树转换为累加树 - 力扣](https://leetcode.cn/problems/w6cpku/)
## 题目大意
给定一棵二叉搜索树(BST)的根节点 `root`,且二叉搜索树的节点值各不相同。要求将其转化为「累加树」,使其每个节点 `node` 的新值等于原树中大于或等于 `node.val` 的值之和。
二叉搜索树的定义:
- 如果左子树不为空,则左子树上所有节点值均小于它的根节点值;
- 如果右子树不为空,则右子树上所有节点值均大于它的根节点值;
- 任意节点的左、右子树也分别为二叉搜索树。
## 解题思路
题目要求将每个节点的值修改为原来的节点值加上大于它的节点值之和。已知二叉搜索树的中序遍历可以得到一个升序数组。
题目就可以变为:修改升序数组中每个节点值为末尾元素累加和。由于末尾元素累加和的求和过程和遍历顺序相反,所以我们可以考虑换种思路。
二叉搜索树的中序遍历顺序为:左 -> 根 -> 右,从而可以得到一个升序数组,那么我们将左右反着遍历,即顺序为:右 -> 根 -> 左,就可以得到一个降序数组,这样就可以在遍历的同时求前缀和。
当然我们在计算前缀和的时候,需要用到前一个节点的值,所以需要用变量 `pre` 存储前一节点的值。
## 代码
```python
class Solution:
pre = 0
def createBinaryTree(self, root: TreeNode):
if not root:
return
self.createBinaryTree(root.right)
root.val += self.pre
self.pre = root.val
self.createBinaryTree(root.left)
def convertBST(self, root: TreeNode) -> TreeNode:
self.pre = 0
self.createBinaryTree(root)
return root
```
================================================
FILE: docs/solutions/LCR/wtcaE1.md
================================================
# [LCR 016. 无重复字符的最长子串](https://leetcode.cn/problems/wtcaE1/)
- 标签:哈希表、字符串、滑动窗口
- 难度:中等
## 题目链接
- [LCR 016. 无重复字符的最长子串 - 力扣](https://leetcode.cn/problems/wtcaE1/)
## 题目大意
给定一个字符串 `s`。
要求:找出其中不含有重复字符的 最长子串 的长度。
## 解题思路
利用集合来存储不重复的字符。用两个指针分别指向最长子串的左右节点。遍历字符串,右指针不断右移,利用集合来判断有没有重复的字符,如果没有,就持续向右扩大右边界。如果出现重复字符,就缩小左侧边界。每次移动终止,都要计算一下当前不含重复字符的子串长度,并判断一下是否需要更新最大长度。
## 代码
```python
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if not s:
return 0
letterSet = set()
right = 0
ans = 0
for i in range(len(s)):
if i != 0:
letterSet.remove(s[i - 1])
while right < len(s) and s[right] not in letterSet:
letterSet.add(s[right])
right += 1
ans = max(ans, right - i)
return ans
```
================================================
FILE: docs/solutions/LCR/xoh6Oh.md
================================================
# [LCR 001. 两数相除](https://leetcode.cn/problems/xoh6Oh/)
- 标签:位运算、数学
- 难度:简单
## 题目链接
- [LCR 001. 两数相除 - 力扣](https://leetcode.cn/problems/xoh6Oh/)
## 题目大意
给定两个整数,被除数 dividend 和除数 divisor。要求返回两数相除的商,并且不能使用乘法,除法和取余运算。取值范围在 $[-2^{31}, 2^{31}-1]$。如果结果溢出,则返回 $2^{31} - 1$。
## 解题思路
题目要求不能使用乘法,除法和取余运算。
可以把被除数和除数当做二进制,这样进行运算的时候,就可以通过移位运算来实现二进制的乘除。
- 先将除数不断左移,移位到位数大于或等于被除数。记录其移位次数 count。
- 然后再将除数右移 count 次,模拟二进制除法运算。
- 如果当前被除数大于等于除数,则将 1 左移 count 位,即为当前位的商,并将其累加答案上。再用除数减去被除数,进行下一次运算。
## 代码
```python
添加备注
class Solution:
def divide(self, a: int, b: int) -> int:
MIN_INT, MAX_INT = -2147483648, 2147483647
symbol = True if (a ^ b) < 0 else False
if a < 0:
a = -a
if b < 0:
b = -b
# 除数不断左移,移位到位数大于或等于被除数
count = 0
while a >= b:
count += 1
b <<= 1
# 向右移位,不断模拟二进制除法运算
res = 0
while count > 0:
count -= 1
b >>= 1
if a >= b:
res += (1 << count)
a -= b
if symbol:
res = -res
if MIN_INT <= res <= MAX_INT:
return res
else:
return MAX_INT
```
================================================
FILE: docs/solutions/LCR/xu-lie-hua-er-cha-shu-lcof.md
================================================
# [LCR 156. 序列化与反序列化二叉树](https://leetcode.cn/problems/xu-lie-hua-er-cha-shu-lcof/)
- 标签:树、深度优先搜索、广度优先搜索、设计、字符串、二叉树
- 难度:困难
## 题目链接
- [LCR 156. 序列化与反序列化二叉树 - 力扣](https://leetcode.cn/problems/xu-lie-hua-er-cha-shu-lcof/)
## 题目大意
给定一棵二叉树的根节点 `root`。
要求:设计一个算法,来实现二叉树的序列化与反序列化。
## 解题思路
1. 序列化:将二叉树转为字符串数据表示
按照前序递归遍历二叉树,并将根节点跟左右子树的值链接起来(中间用 `,` 隔开)。
注意:如果遇到空节点,则标记为 'None',这样在反序列化时才能唯一确定一棵二叉树。
2. 反序列化:将字符串数据转为二叉树结构
先将字符串按 `,` 分割成数组。然后递归处理每一个元素。
- 从数组左侧取出一个元素。
- 如果当前元素为 'None',则返回 None。
- 如果当前元素不为空,则新建一个二叉树节点作为根节点,保存值为当前元素值。并递归遍历左右子树,不断重复从数组中取出元素,进行判断。
- 最后返回当前根节点。
## 代码
```python
class Codec:
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
if not root:
return 'None'
return str(root.val) + ',' + str(self.serialize(root.left)) + ',' + str(self.serialize(root.right))
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
def dfs(datalist):
val = datalist.pop(0)
if val == 'None':
return None
root = TreeNode(int(val))
root.left = dfs(datalist)
root.right = dfs(datalist)
return root
datalist = data.split(',')
return dfs(datalist)
```
================================================
FILE: docs/solutions/LCR/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof.md
================================================
# [LCR 128. 库存管理 I](https://leetcode.cn/problems/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof/)
- 标签:数组、二分查找
- 难度:简单
## 题目链接
- [LCR 128. 库存管理 I - 力扣](https://leetcode.cn/problems/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof/)
## 题目大意
给定一个数组 `numbers`,`numbers` 是有升序数组经过「旋转」得到的。但是旋转次数未知。数组中可能存在重复元素。
要求:找出数组中的最小元素。
- 旋转:将数组整体右移。
## 解题思路
数组经过「旋转」之后,会有两种情况,第一种就是原先的升序序列,另一种是两段升序的序列。
第一种的最小值在最左边。第二种最小值在第二段升序序列的第一个元素。
```
*
*
*
*
*
*
```
```
*
*
*
*
*
*
```
最直接的办法就是遍历一遍,找到最小值。但是还可以有更好的方法。考虑用二分查找来降低算法的时间复杂度。
创建两个指针 left、right,分别指向数组首尾。让后计算出两个指针中间值 mid。将 mid 与右边界进行比较。
1. 如果 `numbers[mid] > numbers[right]`,则最小值不可能在 `mid` 左侧,一定在 `mid` 右侧,则将 `left` 移动到 `mid + 1` 位置,继续查找右侧区间。
2. 如果 `numbers[mid] < numbers[right]`,则最小值一定在 `mid` 左侧,将 `right` 移动到 `mid` 位置上,继续查找左侧区间。
3. 当 `numbers[mid] == numbers[right]`,无法判断在 `mid` 的哪一侧,可以采用 `right = right - 1` 逐步缩小区域。
## 代码
```python
class Solution:
def minArray(self, numbers: List[int]) -> int:
left = 0
right = len(numbers) - 1
while left < right:
mid = left + (right - left) // 2
if numbers[mid] > numbers[right]:
left = mid + 1
elif numbers[mid] < numbers[right]:
right = mid
else:
right = right - 1
return numbers[left]
```
================================================
FILE: docs/solutions/LCR/xx4gT2.md
================================================
# [LCR 076. 数组中的第 K 个最大元素](https://leetcode.cn/problems/xx4gT2/)
- 标签:数组、分治、快速选择、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [LCR 076. 数组中的第 K 个最大元素 - 力扣](https://leetcode.cn/problems/xx4gT2/)
## 题目大意
给定一个未排序的数组 `nums`,从中找到第 `k` 个最大的数字。
## 解题思路
很不错的一道题,面试常考。
直接可以想到的思路是:排序后输出数组上对应第 k 位大的数。所以问题关键在于排序方法的复杂度。
冒泡排序、选择排序、插入排序时间复杂度 $O(n^2)$ 太高了,解答会超时。
可考虑堆排序、归并排序、快速排序。
这道题的要求是找到第 k 大的元素,使用归并排序只有到最后排序完毕才能返回第 k 大的数。而堆排序每次排序之后,就会确定一个元素的准确排名,同理快速排序也是如此。
### 1. 堆排序
升序堆排序的思路如下:
1. 先建立大顶堆
2. 让堆顶最大元素与最后一个交换,然后调整第一个元素到倒数第二个元素,这一步获取最大值
3. 再交换堆顶元素与倒数第二个元素,然后调整第一个元素到倒数第三个元素,这一步获取第二大值
4. 以此类推,直到最后一个元素交换之后完毕。
这道题我们只需进行 1 次建立大顶堆, k-1 次调整即可得到第 k 大的数。
时间复杂度:$O(n^2)$
### 2. 快速排序
快速排序每次调整,都会确定一个元素的最终位置,且以该元素为界限,将数组分成了两个数组,前一个数组元素都比该元素小,后一个元素都比该元素大。
这样,只要某次划分的元素恰好是第 k 个下标就找到了答案。并且我们只需关注 k 元素所在区间的排序情况,与 k 元素无关的区间排序都可以忽略。这样进一步减少了执行步骤。
### 3. 借用标准库(不建议)
提交代码中的最快代码是调用了 Python 的 heapq 库,或者 sort 方法。
这样的确可以通过,但是不建议这样做。借用标准库实现,只能说对这个库的 API 和相关数据结构的用途相对熟悉,而不代表着掌握了这个数据结构。可以问问自己,如果换一种语言,自己还能不能实现对应的数据结构?刷题的本质目的是为了把算法学会学透,而不仅仅是调 API。
## 代码
1. 堆排序
```python
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
# 调整为大顶堆
def heapify(nums, index, end):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子节点
max_index = index
if nums[left] > nums[max_index]:
max_index = left
if right <= end and nums[right] > nums[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 初始化大顶堆
def buildMaxHeap(nums):
size = len(nums)
# (size-2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((size - 2) // 2, -1, -1):
heapify(nums, i, size - 1)
return nums
buildMaxHeap(nums)
size = len(nums)
for i in range(k-1):
nums[0], nums[size-i-1] = nums[size-i-1], nums[0]
heapify(nums, 0, size-i-2)
return nums[0]
```
2. 快速排序
```python
import random
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
def randomPartition(nums, low, high):
i = random.randint(low, high)
nums[i], nums[high] = nums[high], nums[i]
return partition(nums, low, high)
def partition(nums, low, high):
x = nums[high]
i = low-1
for j in range(low, high):
if nums[j] <= nums[high]:
i += 1
nums[i], nums[j] = nums[j], nums[i]
nums[i+1], nums[high] = nums[high], nums[i+1]
return i+1
def quickSort(nums, low, high, k):
n = len(nums)
if low < high:
pi = randomPartition(nums, low, high)
if pi == n-k:
return nums[len(nums)-k]
if pi > n-k:
quickSort(nums, low, pi-1, k)
if pi < n-k:
quickSort(nums, pi+1, high, k)
return nums[len(nums)-k]
return quickSort(nums, 0, len(nums)-1, k)
```
3. 借用标准库
```python
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
nums.sort()
return nums[len(nums)-k]
```
```python
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
res = []
for n in nums:
if len(res) < k:
heapq.heappush(res, n)
elif n > res[0]:
heapq.heappop(res)
heapq.heappush(res, n)
return heapq.heappop(res)
```
================================================
FILE: docs/solutions/LCR/yong-liang-ge-zhan-shi-xian-dui-lie-lcof.md
================================================
# [LCR 125. 图书整理 II](https://leetcode.cn/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof/)
- 标签:栈、设计、队列
- 难度:简单
## 题目链接
- [LCR 125. 图书整理 II - 力扣](https://leetcode.cn/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof/)
## 题目大意
要求:使用两个栈实现先入先出队列。需要实现对应的两个函数:
- `appendTail`:在队列尾部插入整数。
- `deleteHead`:在队列头部删除整数(如果队列中没有元素,`deleteHead` 返回 -1)。
## 解题思路
使用两个栈,inStack 用于输入,outStack 用于输出。
- `appendTail` 操作:将元素压入 inStack 中
- `deleteHead` 操作:
- 先判断 `inStack` 和 `outStack` 是否都为空,如果都为空则说明队列中没有元素,直接返回 `-1`。
- 如果 `outStack` 输出栈为空,将 `inStack` 输入栈元素依次取出,按顺序压入 `outStack` 栈。这样 `outStack` 栈的元素顺序和之前 `inStack` 元素顺序相反,`outStack` 顶层元素就是要取出的队头元素,将其移出,并返回该元素。如果 `outStack` 输出栈不为空,则直接取出顶层元素。
## 代码
```python
class CQueue:
def __init__(self):
self.inStack = []
self.outStack = []
def appendTail(self, value: int) -> None:
self.inStack.append(value)
def deleteHead(self) -> int:
if len(self.outStack) == 0 and len(self.inStack) == 0:
return -1
if (len(self.outStack) == 0):
while (len(self.inStack) != 0):
self.outStack.append(self.inStack[-1])
self.inStack.pop()
top = self.outStack[-1]
self.outStack.pop()
return top
```
================================================
FILE: docs/solutions/LCR/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof.md
================================================
# [LCR 187. 破冰游戏](https://leetcode.cn/problems/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof/)
- 标签:递归、数学
- 难度:简单
## 题目链接
- [LCR 187. 破冰游戏 - 力扣](https://leetcode.cn/problems/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof/)
## 题目大意
**描述**:$0$、$1$、…、$n - 1$ 这 $n$ 个数字排成一个圆圈,从数字 $0$ 开始,每次从圆圈里删除第 $m$ 个数字。现在给定整数 $n$ 和 $m$。
**要求**:求出这个圆圈中剩下的最后一个数字。
**说明**:
- $1 \le num \le 10^5$。
- $1 \le target \le 10^6$。
**示例**:
- 示例 1:
```python
输入:num = 7, target = 4
输出:1
```
- 示例 2:
```python
输入:num = 12, target = 5
输出:0
```
## 解题思路
### 思路 1:枚举 + 模拟
模拟循环删除,需要进行 $n - 1$ 轮,每轮需要对节点进行 $m$ 次访问操作。总体时间复杂度为 $O(n \times m)$。
可以通过找规律来做,以 $n = 5$、$m = 3$ 为例。
- 刚开始为 $0$、$1$、$2$、$3$、$4$。
- 第一次从 $0$ 开始数,数 $3$ 个数,于是 $2$ 出圈,变为 $3$、$4$、$0$、$1$。
- 第二次从 $3$ 开始数,数 $3$ 个数,于是 $0$ 出圈,变为 $1$、$3$、$4$。
- 第三次从 $1$ 开始数,数 $3$ 个数,于是 $4$ 出圈,变为 $1$、$3$。
- 第四次从 $1$ 开始数,数 $3$ 个数,于是 $1$ 出圈,变为 $3$。
- 所以最终为 $3$。
通过上面的流程可以发现:每隔 $m$ 个数就要删除一个数,那么被删除的这个数的下一个数就会成为新的起点。就相当于数组进行左移了 $m$ 位。反过来思考的话,从最后一步向前推,则每一步都向右移动了 $m$ 位(包括胜利者)。
如果用 $f(n, m)$ 表示: $n$ 个数构成环没删除 $m$ 个数后,最终胜利者的位置,则 $f(n, m) = f(n - 1, m) + m$。
即等于 $n - 1$ 个数构成的环没删除 $m$ 个数后最终胜利者的位置,像右移动 $m$ 次。
问题是现在并不是真的进行了右移,因为当前数组右移后超过数组容量的部分应该重新放到数组头部位置。所以公式应为:$f(n, m) = [f(n - 1, m) + m] \mod n$,$n$ 为反过来向前推的时候,每一步剩余的数字个数(比如第二步推回第一步,n $4$),则反过来递推公式为:
- $f(1, m) = 0$。
- $f(2, m) = [f(1, m) + m] \mod 2$。
- $f(3, m) = [f(2, m) + m] \mod 3$。
- 。。。。。。
- $f(n, m) = [f(n - 1, m) + m] \mod n $。
接下来就是递推求解了。
### 思路 1:代码
```python
class Solution:
def lastRemaining(self, n: int, m: int) -> int:
ans = 0
for i in range(2, n + 1):
ans = (m + ans) % i
return ans
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n)$。
- **空间复杂度**:$O(1)$。
## 参考资料:
- [字节题库 - #剑62 - 简单 - 圆圈中最后剩下的数字 - 1刷](https://leetcode.cn/problems/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof/solution/zi-jie-ti-ku-jian-62-jian-dan-yuan-quan-3hlji/)
================================================
FILE: docs/solutions/LCR/z1R5dt.md
================================================
# [LCR 066. 键值映射](https://leetcode.cn/problems/z1R5dt/)
- 标签:设计、字典树、哈希表、字符串
- 难度:中等
## 题目链接
- [LCR 066. 键值映射 - 力扣](https://leetcode.cn/problems/z1R5dt/)
## 题目大意
要求:实现一个 MapSum 类,支持两个方法,`insert` 和 `sum`:
- `MapSum()` 初始化 MapSum 对象。
- `void insert(String key, int val)` 插入 `key-val` 键值对,字符串表示键 `key`,整数表示值 `val`。如果键 `key` 已经存在,那么原来的键值对将被替代成新的键值对。
- `int sum(string prefix)` 返回所有以该前缀 `prefix` 开头的键 `key` 的值的总和。
## 解题思路
可以构造前缀树(字典树)解题。
- 初始化时,构建一棵前缀树(字典树),并增加 `val` 变量。
- 调用插入方法时,用字典树存储 `key`,并在对应字母节点存储对应的 `val`。
- 在调用查询总和方法时,先查找该前缀 `prefix` 对应的前缀树节点,从该节点开始,递归遍历该节点的子节点,并累积子节点的 `val`,进行求和,并返回求和累加结果。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
self.value = 0
def insert(self, word: str, value: int) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
cur.value = value
def search(self, word: str) -> int:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return 0
cur = cur.children[ch]
return self.dfs(cur)
def dfs(self, root) -> int:
if not root:
return 0
res = root.value
for node in root.children.values():
res += self.dfs(node)
return res
class MapSum:
def __init__(self):
"""
Initialize your data structure here.
"""
self.trie_tree = Trie()
def insert(self, key: str, val: int) -> None:
self.trie_tree.insert(key, val)
def sum(self, prefix: str) -> int:
return self.trie_tree.search(prefix)
```
================================================
FILE: docs/solutions/LCR/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof.md
================================================
# [LCR 172. 统计目标成绩的出现次数](https://leetcode.cn/problems/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof/)
- 标签:数组、二分查找
- 难度:简单
## 题目链接
- [LCR 172. 统计目标成绩的出现次数 - 力扣](https://leetcode.cn/problems/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof/)
## 题目大意
给定一个排序数组 `nums`,以及一个整数 `target`。
要求:统计 `target` 在排序数组 `nums` 中出现的次数。
## 解题思路
两次二分查找。
- 先查找 `target` 第一次出现的位置(下标):`left`。
- 再查找 `target` 最后一次出现的位置(下标):`right`。
- 最终答案为 `right - left + 1`。
## 代码
```python
class Solution:
def searchLeft(self, nums, target):
left, right = 0, len(nums) - 1
while left < right:
mid = left + (right - left) // 2
if nums[mid] < target:
left = mid + 1
else:
right = mid
if nums[left] == target:
return left
else:
return -1
def searchRight(self, nums, target):
left, right = 0, len(nums) - 1
while left < right:
mid = left + (right - left + 1) // 2
if nums[mid] <= target:
left = mid
else:
right = mid - 1
return left
def search(self, nums: List[int], target: int) -> int:
if len(nums) == 0:
return 0
left = self.searchLeft(nums, target)
right = self.searchRight(nums, target)
if left == -1:
return 0
return right - left + 1
```
================================================
FILE: docs/solutions/LCR/zhan-de-ya-ru-dan-chu-xu-lie-lcof.md
================================================
# [LCR 148. 验证图书取出顺序](https://leetcode.cn/problems/zhan-de-ya-ru-dan-chu-xu-lie-lcof/)
- 标签:栈、数组、模拟
- 难度:中等
## 题目链接
- [LCR 148. 验证图书取出顺序 - 力扣](https://leetcode.cn/problems/zhan-de-ya-ru-dan-chu-xu-lie-lcof/)
## 题目大意
给定连个整数序列 `pushed` 和 `popped`,其中 `pushed` 表示栈的压入顺序。
要求:判断第二个序列 `popped` 是否为栈的压出序列。
## 解题思路
借助一个栈来模拟压入、压出的操作。检测最后是否能模拟成功。
## 代码
```python
class Solution:
def validateStackSequences(self, pushed: List[int], popped: List[int]) -> bool:
stack = []
index = 0
for item in pushed:
stack.append(item)
while(stack and stack[-1] == popped[index]):
stack.pop()
index += 1
return len(stack) == 0
```
================================================
FILE: docs/solutions/LCR/zhong-jian-er-cha-shu-lcof.md
================================================
# [LCR 124. 推理二叉树](https://leetcode.cn/problems/zhong-jian-er-cha-shu-lcof/)
- 标签:树、数组、哈希表、分治、二叉树
- 难度:中等
## 题目链接
- [LCR 124. 推理二叉树 - 力扣](https://leetcode.cn/problems/zhong-jian-er-cha-shu-lcof/)
## 题目大意
给定一棵二叉树的前序遍历结果和中序遍历结果。
要求:构建该二叉树,并返回其根节点。假设树中没有重复的元素。
## 解题思路
前序遍历的顺序是:根 -> 左 -> 右。中序遍历的顺序是:左 -> 根 -> 右。根据前序遍历的顺序,可以找到根节点位置。然后在中序遍历的结果中可以找到对应的根节点位置,就可以从根节点位置将二叉树分割成左子树、右子树。同时能得到左右子树的节点个数。此时构建当前节点,并递归建立左右子树,在左右子树对应位置继续递归遍历进行上述步骤,直到节点为空,具体操作步骤如下:
- 从前序遍历顺序中当前根节点的位置在 `postorder[0]`。
- 通过在中序遍历中查找上一步根节点对应的位置 `inorder[k]`,从而将二叉树的左右子树分隔开,并得到左右子树节点的个数。
- 从上一步得到的左右子树个数将前序遍历结果中的左右子树分开。
- 构建当前节点,并递归建立左右子树,在左右子树对应位置继续递归遍历并执行上述三步,直到节点为空。
## 代码
```python
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
def createTree(preorder, inorder, n):
if n == 0:
return None
k = 0
while preorder[0] != inorder[k]:
k += 1
node = TreeNode(inorder[k])
node.left = createTree(preorder[1: k + 1], inorder[0: k], k)
node.right = createTree(preorder[k + 1:], inorder[k + 1:], n - k - 1)
return node
return createTree(preorder, inorder, len(inorder))
```
================================================
FILE: docs/solutions/LCR/zi-fu-chuan-de-pai-lie-lcof.md
================================================
# [LCR 157. 套餐内商品的排列顺序](https://leetcode.cn/problems/zi-fu-chuan-de-pai-lie-lcof/)
- 标签:字符串、回溯
- 难度:中等
## 题目链接
- [LCR 157. 套餐内商品的排列顺序 - 力扣](https://leetcode.cn/problems/zi-fu-chuan-de-pai-lie-lcof/)
## 题目大意
给定一个字符串 `s`。
要求:打印出该字符串中字符的所有排列。可以以任意顺序返回这个字符串数组,但里边不能有重复元素。
## 解题思路
因为原字符串可能含有重复元素,所以在回溯的时候需要进行去重。先将字符串 `s` 转为 `list` 列表,再对列表进行排序,然后使用 `visited` 数组标记该元素在当前排列中是否被访问过。如果未被访问过则将其加入排列中,并在访问后将该元素变为未访问状态。
然后再递归遍历下一层元素之前,增加一句语句进行判重:`if i > 0 and nums[i] == nums[i - 1] and not visited[i - 1]: continue`。
然后进行回溯遍历。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, ls, visited):
if len(self.path) == len(ls):
self.res.append(''.join(self.path))
return
for i in range(len(ls)):
if i > 0 and ls[i] == ls[i - 1] and not visited[i - 1]:
continue
if not visited[i]:
visited[i] = True
self.path.append(ls[i])
self.backtrack(ls, visited)
self.path.pop()
visited[i] = False
def permutation(self, s: str) -> List[str]:
self.res.clear()
self.path.clear()
ls = list(s)
ls.sort()
visited = [False for _ in range(len(s))]
self.backtrack(ls, visited)
return self.res
```
================================================
FILE: docs/solutions/LCR/zlDJc7.md
================================================
# [LCR 109. 打开转盘锁](https://leetcode.cn/problems/zlDJc7/)
- 标签:广度优先搜索、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [LCR 109. 打开转盘锁 - 力扣](https://leetcode.cn/problems/zlDJc7/)
## 题目大意
有一把带有四个数字的密码锁,每个位置上有 0~9 共 10 个数字。每次只能将其中一个位置上的数字转动一下。可以向上转,也可以向下转。比如:1 -> 2、2 -> 1。
密码锁的初始数字为:`0000`。现在给定一组表示死亡数字的字符串数组 `deadends`,和一个带有四位数字的目标字符串 `target`。
如果密码锁转动到 `deadends` 中任一字符串状态,则锁就会永久锁定,无法再次旋转。
要求:求出最小的选择次数,使得锁的状态由 `0000` 转动到 `target`。
## 解题思路
使用宽度优先搜索遍历,将`0000` 状态入队。
- 将队列中的元素出队,判断是否为死亡字符串
- 如果为死亡字符串,则跳过该状态,否则继续执行。
- 如果为目标字符串,则返回当前路径长度,否则继续执行。
- 枚举当前状态所有位置所能到达的所有状态,并判断是否访问过该状态。
- 如果之前出现过该状态,则继续执行,否则将其存入队列,并标记访问。
## 代码
```python
class Solution:
def openLock(self, deadends: List[str], target: str) -> int:
queue = collections.deque(['0000'])
visited = set(['0000'])
deadset = set(deadends)
level = 0
while queue:
size = len(queue)
for _ in range(size):
cur = queue.popleft()
if cur in deadset:
continue
if cur == target:
return level
for i in range(len(cur)):
up = self.upward_adjust(cur, i)
if up not in visited:
queue.append(up)
visited.add(up)
down = self.downward_adjust(cur, i)
if down not in visited:
queue.append(down)
visited.add(down)
level += 1
return -1
def upward_adjust(self, s, i):
s_list = list(s)
if s_list[i] == '9':
s_list[i] = '0'
else:
s_list[i] = chr(ord(s_list[i]) + 1)
return "".join(s_list)
def downward_adjust(self, s, i):
s_list = list(s)
if s_list[i] == '0':
s_list[i] = '9'
else:
s_list[i] = chr(ord(s_list[i]) - 1)
return "".join(s_list)
```
================================================
FILE: docs/solutions/LCR/zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof.md
================================================
# [LCR 167. 招式拆解 I](https://leetcode.cn/problems/zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof/)
- 标签:哈希表、字符串、滑动窗口
- 难度:中等
## 题目链接
- [LCR 167. 招式拆解 I - 力扣](https://leetcode.cn/problems/zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof/)
## 题目大意
给定一个字符串 `s`。
要求:找出其中不含有重复字符的最长子串的长度。
## 解题思路
利用集合来存储不重复的字符。用两个指针分别指向最长子串的左右节点。遍历字符串,右指针不断右移,利用集合来判断有没有重复的字符,如果没有,就持续向右扩大右边界。如果出现重复字符,就缩小左侧边界。每次移动终止,都要计算一下当前不含重复字符的子串长度,并判断一下是否需要更新最大长度。
## 代码
```python
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if not s:
return 0
letterSet = set()
right = 0
ans = 0
for i in range(len(s)):
if i != 0:
letterSet.remove(s[i - 1])
while right < len(s) and s[right] not in letterSet:
letterSet.add(s[right])
right += 1
ans = max(ans, right - i)
return ans
```
================================================
FILE: docs/solutions/LCR/zui-xiao-de-kge-shu-lcof.md
================================================
# [LCR 159. 库存管理 III](https://leetcode.cn/problems/zui-xiao-de-kge-shu-lcof/)
- 标签:数组、分治、快速选择、排序、堆(优先队列)
- 难度:简单
## 题目链接
- [LCR 159. 库存管理 III - 力扣](https://leetcode.cn/problems/zui-xiao-de-kge-shu-lcof/)
## 题目大意
**描述**:给定整数数组 $arr$,再给定一个整数 $k$。
**要求**:返回数组 $arr$ 中最小的 $k$ 个数。
**说明**:
- $0 \le k \le arr.length \le 10000$。
- $0 \le arr[i] \le 10000$。
**示例**:
- 示例 1:
```python
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]
```
- 示例 2:
```python
输入:arr = [0,1,2,1], k = 1
输出:[0]
```
## 解题思路
直接可以想到的思路是:排序后输出数组上对应的最小的 k 个数。所以问题关键在于排序方法的复杂度。
冒泡排序、选择排序、插入排序时间复杂度 $O(n^2)$ 太高了,解答会超时。
可考虑堆排序、归并排序、快速排序。
### 思路 1:堆排序(基于大顶堆)
具体做法如下:
1. 使用数组前 $k$ 个元素,维护一个大小为 $k$ 的大顶堆。
2. 遍历数组 $[k, size - 1]$ 的元素,判断其与堆顶元素关系,如果遇到比堆顶元素小的元素,则将与堆顶元素进行交换。再将这 $k$ 个元素调整为大顶堆。
3. 最后输出大顶堆的 $k$ 个元素。
### 思路 1:代码
```python
class Solution:
def heapify(self, nums: [int], index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子节点
max_index = index
if nums[left] > nums[max_index]:
max_index = left
if right <= end and nums[right] > nums[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 初始化大顶堆
def buildMaxHeap(self, nums: [int], k: int):
# (k-2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((k - 2) // 2, -1, -1):
self.heapify(nums, i, k - 1)
return nums
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
size = len(arr)
if k <= 0 or not arr:
return []
if size <= k:
return arr
self.buildMaxHeap(arr, k)
for i in range(k, size):
if arr[i] < arr[0]:
arr[i], arr[0] = arr[0], arr[i]
self.heapify(arr, 0, k - 1)
return arr[:k]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(n\log_2k)$。
- **空间复杂度**:$O(1)$。
### 思路 2:快速排序
使用快速排序在每次调整时,都会确定一个元素的最终位置,且以该元素为界限,将数组分成了左右两个子数组,左子数组中的元素都比该元素小,右子树组中的元素都比该元素大。
这样,只要某次划分的元素恰好是第 $k$ 个元素下标,就找到了数组中最小的 $k$ 个数所对应的区间,即 $[0, k - 1]$。 并且我们只需关注第 $k$ 个最小元素所在区间的排序情况,与第 $k$ 个最小元素无关的区间排序都可以忽略。这样进一步减少了执行步骤。
### 思路 2:代码
```python
import random
class Solution:
# 从 arr[low: high + 1] 中随机挑选一个基准数,并进行移动排序
def randomPartition(self, arr: [int], low: int, high: int):
# 随机挑选一个基准数
i = random.randint(low, high)
# 将基准数与最低位互换
arr[i], arr[low] = arr[low], arr[i]
# 以最低位为基准数,然后将序列中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上
return self.partition(arr, low, high)
# 以最低位为基准数,然后将序列中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上
def partition(self, arr: [int], low: int, high: int):
pivot = arr[low] # 以第 1 为为基准数
i = low + 1 # 从基准数后 1 位开始遍历,保证位置 i 之前的元素都小于基准数
for j in range(i, high + 1):
# 发现一个小于基准数的元素
if arr[j] < pivot:
# 将小于基准数的元素 arr[j] 与当前 arr[i] 进行换位,保证位置 i 之前的元素都小于基准数
arr[i], arr[j] = arr[j], arr[i]
# i 之前的元素都小于基准数,所以 i 向右移动一位
i += 1
# 将基准节点放到正确位置上
arr[i - 1], arr[low] = arr[low], arr[i - 1]
# 返回基准数位置
return i - 1
def quickSort(self, arr, low, high, k):
size = len(arr)
if low < high:
# 按照基准数的位置,将序列划分为左右两个子序列
pi = self.randomPartition(arr, low, high)
if pi == k:
return arr[:k]
if pi > k:
# 对左子序列进行递归快速排序
self.quickSort(arr, low, pi - 1, k)
if pi < k:
# 对右子序列进行递归快速排序
self.quickSort(arr, pi + 1, high, k)
return arr[:k]
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
size = len(arr)
if k >= size:
return arr
return self.quickSort(arr, 0, size - 1, k)
```
### 思路 2:复杂度分析
- **时间复杂度**:$O(n)$。证明过程可参考「算法导论 9.2:期望为线性的选择算法」。
- **空间复杂度**:$O(\log n)$。递归使用栈空间的空间代价期望为 $O(\log n)$。
================================================
FILE: docs/solutions/LCR/zuo-xuan-zhuan-zi-fu-chuan-lcof.md
================================================
# [LCR 182. 动态口令](https://leetcode.cn/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/)
- 标签:数学、双指针、字符串
- 难度:简单
## 题目链接
- [LCR 182. 动态口令 - 力扣](https://leetcode.cn/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/)
## 题目大意
给定一个字符串 `s` 和一个整数 `n`。
要求:将字符串 `s` 每个字符向左旋转 `n` 位。
- 左旋转:将字符串前面的若干字符转移到字符串的尾部。
## 解题思路
- 使用数组 `res` 存放答案。
- 先遍历 `[n, len(s) - 1]` 范围的字符,将其存入数组。
- 再遍历 `[0, n - 1]` 范围的字符,将其存入数组。
- 将数组转为字符串返回。
## 代码
```python
class Solution:
def reverseLeftWords(self, s: str, n: int) -> str:
res = []
for i in range(n, len(s)):
res.append(s[i])
for i in range(n):
res.append(s[i])
return "".join(res)
```
================================================
FILE: docs/solutions/index.md
================================================
## 本章内容
- [第 1 ~ 99 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0001-0099/)
- [第 100 ~ 199 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0100-0199/)
- [第 200 ~ 299 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0200-0299/)
- [第 300 ~ 399 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0300-0399/)
- [第 400 ~ 499 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0400-0499/)
- [第 500 ~ 599 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0500-0599/)
- [第 600 ~ 699 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0600-0699/)
- [第 700 ~ 799 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0700-0799/)
- [第 800 ~ 899 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0800-0899/)
- [第 900 ~ 999 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/0900-0999/)
- [第 1000 ~ 1099 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1000-1099/)
- [第 1100 ~ 1199 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1100-1199/)
- [第 1200 ~ 1299 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1200-1299/)
- [第 1300 ~ 1399 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1300-1399/)
- [第 1400 ~ 1499 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1400-1499/)
- [第 1500 ~ 1599 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1500-1599/)
- [第 1600 ~ 1699 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1600-1699/)
- [第 1700 ~ 1799 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1700-1799/)
- [第 1800 ~ 1899 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1800-1899/)
- [第 1900 ~ 1999 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/1900-1999/)
- [第 2000 ~ 2099 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2000-2099/)
- [第 2100 ~ 2199 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2100-2199/)
- [第 2200 ~ 2299 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2200-2299/)
- [第 2300 ~ 2399 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2300-2399/)
- [第 2400 ~ 2499 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2400-2499/)
- [第 2500 ~ 2599 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2500-2599/)
- [第 2700 ~ 2799 题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/2700-2799/)
- [LCR 系列](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/LCR/)
- [面试题](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/)
================================================
FILE: docs/solutions/interviews/bracket-lcci.md
================================================
# [面试题 08.09. 括号](https://leetcode.cn/problems/bracket-lcci/)
- 标签:字符串、动态规划、回溯
- 难度:中等
## 题目链接
- [面试题 08.09. 括号 - 力扣](https://leetcode.cn/problems/bracket-lcci/)
## 题目大意
给定一个整数 `n`。
要求:生成所有有可能且有效的括号组合。
## 解题思路
通过回溯算法生成所有答案。为了生成的括号组合是有效的,回溯的时候,使用一个标记变量 `symbol` 来表示是否当前组合是否成对匹配。
如果在当前组合中增加一个 `(`,则 `symbol += 1`,如果增加一个 `)`,则 `symbol -= 1`。显然只有在 `symbol < n` 的时候,才能增加 `(`,在 `symbol > 0` 的时候,才能增加 `)`。
如果最终生成 `2 * n` 的括号组合,并且 `symbol == 0`,则说明当前组合是有效的,将其加入到最终答案数组中。
最终输出最终答案数组。
## 代码
```python
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
def backtrack(parenthesis, symbol, index):
if n * 2 == index:
if symbol == 0:
parentheses.append(parenthesis)
else:
if symbol < n:
backtrack(parenthesis + '(', symbol + 1, index + 1)
if symbol > 0:
backtrack(parenthesis + ')', symbol - 1, index + 1)
parentheses = list()
backtrack("", 0, 0)
return parentheses
```
================================================
FILE: docs/solutions/interviews/calculator-lcci.md
================================================
# [面试题 16.26. 计算器](https://leetcode.cn/problems/calculator-lcci/)
- 标签:栈、数学、字符串
- 难度:中等
## 题目链接
- [面试题 16.26. 计算器 - 力扣](https://leetcode.cn/problems/calculator-lcci/)
## 题目大意
给定一个包含正整数、加(`+`)、减(`-`)、乘(`*`)、除(`/`)的算出表达式(括号除外)。表达式仅包含非负整数,`+`、`-`、`*`、`/` 四种运算符和空格 ` `。整数除法仅保留整数部分。
要求:计算其结果。
## 解题思路
计算表达式中,乘除运算优先于加减运算。我们可以先进行乘除运算,再将进行乘除运算后的整数值放入原表达式中相应位置,再依次计算加减。
可以考虑使用一个栈来保存进行乘除运算后的整数值。正整数直接压入栈中,负整数,则将对应整数取负号,再压入栈中。这样最终计算结果就是栈中所有元素的和。
具体做法:
- 遍历字符串 s,使用变量 op 来标记数字之前的运算符,默认为 `+`。
- 如果遇到数字,继续向后遍历,将数字进行累积,得到完整的整数 num。判断当前 op 的符号。
- 如果 op 为 `+`,则将 num 压入栈中。
- 如果 op 为 `-`,则将 -num 压入栈中。
- 如果 op 为 `*`,则将栈顶元素 top 取出,计算 top * num,并将计算结果压入栈中。
- 如果 op 为 `/`,则将栈顶元素 top 取出,计算 int(top / num),并将计算结果压入栈中。
- 如果遇到 `+`、`-`、`*`、`/` 操作符,则更新 op。
- 最后将栈中整数进行累加,并返回结果。
## 代码
```python
class Solution:
def calculate(self, s: str) -> int:
size = len(s)
stack = []
op = '+'
index = 0
while index < size:
if s[index] == ' ':
index += 1
continue
if s[index].isdigit():
num = ord(s[index]) - ord('0')
while index + 1 < size and s[index + 1].isdigit():
index += 1
num = 10 * num + ord(s[index]) - ord('0')
if op == '+':
stack.append(num)
elif op == '-':
stack.append(-num)
elif op == '*':
top = stack.pop()
stack.append(top * num)
elif op == '/':
top = stack.pop()
stack.append(int(top / num))
elif s[index] in "+-*/":
op = s[index]
index += 1
return sum(stack)
```
================================================
FILE: docs/solutions/interviews/color-fill-lcci.md
================================================
# [面试题 08.10. 颜色填充](https://leetcode.cn/problems/color-fill-lcci/)
- 标签:深度优先搜索、广度优先搜索、数组、矩阵
- 难度:简单
## 题目链接
- [面试题 08.10. 颜色填充 - 力扣](https://leetcode.cn/problems/color-fill-lcci/)
## 题目大意
给定一个二维整数矩阵 `image`,其中 `image[i][j]` 表示矩阵第 `i` 行、第 `j` 列上网格块的颜色值。再给定一个起始位置 `(sr, sc)`,以及一个目标颜色 `newColor`。
要求:对起始位置 `(sr, sc)` 所在位置周围区域填充颜色为 `newColor`。并返回填充后的图像 `image`。
- 周围区域:颜色相同且在上、下、左、右四个方向上存在相连情况的若干元素。
## 解题思路
深度优先搜索。使用二维数组 `visited` 标记访问过的节点。遍历上、下、左、右四个方向上的点。如果下一个点位置越界,或者当前位置与下一个点位置颜色不一样,则对该节点进行染色。
在遍历的过程中注意使用 `visited` 标记访问过的节点,以免重复遍历。
## 代码
```python
class Solution:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
def dfs(self, image, i, j, origin_color, color, visited):
rows, cols = len(image), len(image[0])
for direct in self.directs:
new_i = i + direct[0]
new_j = j + direct[1]
# 下一个位置越界,则当前点在边界,对其进行着色
if new_i < 0 or new_i >= rows or new_j < 0 or new_j >= cols:
image[i][j] = color
continue
# 如果访问过,则跳过
if visited[new_i][new_j]:
continue
# 如果下一个位置颜色与当前颜色相同,则继续搜索
if image[new_i][new_j] == origin_color:
visited[new_i][new_j] = True
self.dfs(image, new_i, new_j, origin_color, color, visited)
# 下一个位置颜色与当前颜色不同,则当前位置为连通区域边界,对其进行着色
else:
image[i][j] = color
def floodFill(self, image: List[List[int]], sr: int, sc: int, newColor: int) -> List[List[int]]:
if not image:
return image
rows, cols = len(image), len(image[0])
visited = [[False for _ in range(cols)] for _ in range(rows)]
visited[sr][sc] = True
self.dfs(image, sr, sc, image[sr][sc], newColor, visited)
return image
```
================================================
FILE: docs/solutions/interviews/eight-queens-lcci.md
================================================
# [面试题 08.12. 八皇后](https://leetcode.cn/problems/eight-queens-lcci/)
- 标签:数组、回溯
- 难度:困难
## 题目链接
- [面试题 08.12. 八皇后 - 力扣](https://leetcode.cn/problems/eight-queens-lcci/)
## 题目大意
- n 皇后问题:将 n 个皇后放置在 `n * n` 的棋盘上,并且使得皇后彼此之间不能攻击。
- 皇后彼此不能相互攻击:指的是任何两个皇后都不能处于同一条横线、纵线或者斜线上。
现在给定一个整数 `n`,返回所有不同的「n 皇后问题」的解决方案。每一种解法包含一个不同的「n 皇后问题」的棋子放置方案,该方案中的 `Q` 和 `.` 分别代表了皇后和空位。
## 解题思路
经典的回溯问题。使用 `chessboard` 来表示棋盘,`Q` 代表皇后,`.` 代表空位,初始都为 `.`。然后使用 `res` 存放最终答案。
先定义棋盘合理情况判断方法,判断同一条横线、纵线或者斜线上是否存在两个以上的皇后。
再定义回溯方法,从第一行开始进行遍历。
- 如果当前行 `row` 等于 `n`,则当前棋盘为一个可行方案,将其拼接加入到 `res` 数组中。
- 遍历 `[0, n]` 列元素,先验证棋盘是否可行,如果可行:
- 将当前行当前列尝试换为 `Q`。
- 然后继续递归下一行。
- 再将当前行回退为 `.`。
- 最终返回 `res` 数组。
## 代码
```python
class Solution:
res = []
def backtrack(self, n: int, row: int, chessboard: List[List[str]]):
if row == n:
temp_res = []
for temp in chessboard:
temp_str = ''.join(temp)
temp_res.append(temp_str)
self.res.append(temp_res)
return
for col in range(n):
if self.isValid(n, row, col, chessboard):
chessboard[row][col] = 'Q'
self.backtrack(n, row + 1, chessboard)
chessboard[row][col] = '.'
def isValid(self, n: int, row: int, col: int, chessboard: List[List[str]]):
for i in range(row):
if chessboard[i][col] == 'Q':
return False
i, j = row - 1, col - 1
while i >= 0 and j >= 0:
if chessboard[i][j] == 'Q':
return False
i -= 1
j -= 1
i, j = row - 1, col + 1
while i >= 0 and j < n:
if chessboard[i][j] == 'Q':
return False
i -= 1
j += 1
return True
def solveNQueens(self, n: int) -> List[List[str]]:
self.res.clear()
chessboard = [['.' for _ in range(n)] for _ in range(n)]
self.backtrack(n, 0, chessboard)
return self.res
```
================================================
FILE: docs/solutions/interviews/factorial-zeros-lcci.md
================================================
# [面试题 16.05. 阶乘尾数](https://leetcode.cn/problems/factorial-zeros-lcci/)
- 标签:数学
- 难度:简单
## 题目链接
- [面试题 16.05. 阶乘尾数 - 力扣](https://leetcode.cn/problems/factorial-zeros-lcci/)
## 题目大意
给定一个整数 `n`。
要求:计算 `n` 的阶乘中尾随零的数量。
注意:$0 <= n <= 10^4$。
## 解题思路
阶乘中,末尾 `0` 的来源只有 `2 * 5`。所以尾随 `0` 的个数为 `2` 的倍数个数和 `5` 的倍数个数的最小值。又因为 `2 < 5`,`2` 的倍数个数肯定小于等于 `5` 的倍数,所以直接统计 `5` 的倍数个数即可。
## 代码
```python
class Solution:
def trailingZeroes(self, n: int) -> int:
count = 0
while n > 0:
count += n // 5
n = n // 5
return count
```
================================================
FILE: docs/solutions/interviews/first-common-ancestor-lcci.md
================================================
# [面试题 04.08. 首个共同祖先](https://leetcode.cn/problems/first-common-ancestor-lcci/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [面试题 04.08. 首个共同祖先 - 力扣](https://leetcode.cn/problems/first-common-ancestor-lcci/)
## 题目大意
给定一个二叉树,要求找到该树中指定节点 `p`、`q` 的最近公共祖先:
- 祖先:如果节点 `p` 在节点 `node` 的左子树或右子树中,或者 `p = node`,则称 `node` 是 `p` 的祖先。
- 最近公共祖先:对于树的两个节点 `p`、`q`,最近公共祖先表示为一个节点 `lca_node`,满足 `lca_node` 是 `p`、`q` 的祖先且 `lca_node` 的深度尽可能大(一个节点也可以是自己的祖先)。
## 解题思路
设 `lca_node` 为节点 `p`、`q` 的最近公共祖先。则 `lca_node` 只能是下面几种情况:
- `p`、`q` 在 `lca_node` 的子树中,且分别在 `lca_node` 的两侧子树中。
- `p == lca_node`,且 `q` 在 `lca_node` 的左子树或右子树中。
- `q == lca_node`,且 `p` 在 `lca_node` 的左子树或右子树中。
下面递归求解 `lca_node`。递归需要满足以下条件:
- 如果 `p`、`q` 都不为空,则返回 `p`、`q` 的公共祖先。
- 如果 `p`、`q` 只有一个存在,则返回存在的一个。
- 如果 `p`、`q` 都不存在,则返回存在的一个。
具体思路为:
- 如果当前节点 `node` 为 `None`,则说明 `p`、`q` 不在 `node` 的子树中,不可能为公共祖先,直接返回 `None`。
- 如果当前节点 `node` 等于 `p` 或者 `q`,那么 `node` 就是 `p`、`q` 的最近公共祖先,直接返回 `node`。
- 递归遍历左子树、右子树,并判断左右子树结果。
- 如果左子树为空,则返回右子树。
- 如果右子树为空,则返回左子树。
- 如果左右子树都不为空,则说明 `p`、`q` 在当前根节点的两侧,当前根节点就是他们的最近公共祖先。
- 如果左右子树都为空,则返回空。
## 代码
```python
class Solution:
def lowestCommonAncestor(self, root: TreeNode, p: TreeNode, q: TreeNode) -> TreeNode:
if root == p or root == q:
return root
if root:
node_left = self.lowestCommonAncestor(root.left, p, q)
node_right = self.lowestCommonAncestor(root.right, p, q)
if node_left and node_right:
return root
elif not node_left:
return node_right
else:
return node_left
return None
```
================================================
FILE: docs/solutions/interviews/group-anagrams-lcci.md
================================================
# [面试题 10.02. 变位词组](https://leetcode.cn/problems/group-anagrams-lcci/)
- 标签:数组、哈希表、字符串、排序
- 难度:中等
## 题目链接
- [面试题 10.02. 变位词组 - 力扣](https://leetcode.cn/problems/group-anagrams-lcci/)
## 题目大意
给定一个字符串数组 `strs`。
要求:将所有变位词组合在一起。不需要考虑输出顺序。
- 变位词:字母相同,但排列不同的字符串。
## 解题思路
使用哈希表记录变位词。对每一个字符串进行排序,按照 `排序字符串:变位词数组` 的键值顺序进行存储。
最终将哈希表的值转换为对应数组返回结果。
## 代码
```python
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
str_dict = dict()
res = []
for s in strs:
sort_s = str(sorted(s))
if sort_s in str_dict:
str_dict[sort_s] += [s]
else:
str_dict[sort_s] = [s]
for sort_s in str_dict:
res += [str_dict[sort_s]]
return res
```
================================================
FILE: docs/solutions/interviews/implement-queue-using-stacks-lcci.md
================================================
# [面试题 03.04. 化栈为队](https://leetcode.cn/problems/implement-queue-using-stacks-lcci/)
- 标签:栈、设计、队列
- 难度:简单
## 题目链接
- [面试题 03.04. 化栈为队 - 力扣](https://leetcode.cn/problems/implement-queue-using-stacks-lcci/)
## 题目大意
要求:实现一个 MyQueue 类,要求仅使用两个栈实现先入先出队列。
## 解题思路
使用两个栈,`inStack` 用于输入,`outStack` 用于输出。
- `push` 操作:将元素压入 `inStack` 中。
- `pop` 操作:如果 `outStack` 输出栈为空,将 `inStack` 输入栈元素依次取出,按顺序压入 `outStack` 栈。这样 `outStack` 栈的元素顺序和之前 `inStack` 元素顺序相反,`outStack` 顶层元素就是要取出的队头元素,将其移出,并返回该元素。如果 `outStack` 输出栈不为空,则直接取出顶层元素。
- `peek` 操作:和 `pop` 操作类似,只不过最后一步不需要取出顶层元素,直接将其返回即可。
- `empty` 操作:如果 `inStack` 和 `outStack` 都为空,则队列为空,否则队列不为空。
## 代码
```python
class MyQueue:
def __init__(self):
"""
Initialize your data structure here.
"""
self.inStack = []
self.outStack = []
def push(self, x: int) -> None:
"""
Push element x to the back of queue.
"""
self.inStack.append(x)
def pop(self) -> int:
"""
Removes the element from in front of queue and returns that element.
"""
if (len(self.outStack) == 0):
while (len(self.inStack) != 0):
self.outStack.append(self.inStack[-1])
self.inStack.pop()
top = self.outStack[-1]
self.outStack.pop()
return top
def peek(self) -> int:
"""
Get the front element.
"""
if (len(self.outStack) == 0):
while (len(self.inStack) != 0):
self.outStack.append(self.inStack[-1])
self.inStack.pop()
top = self.outStack[-1]
return top
def empty(self) -> bool:
"""
Returns whether the queue is empty.
"""
return len(self.outStack) == 0 and len(self.inStack) == 0
```
================================================
FILE: docs/solutions/interviews/index.md
================================================
## 本章内容
- [面试题 01.07. 旋转矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/rotate-matrix-lcci.md)
- [面试题 01.08. 零矩阵](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/zero-matrix-lcci.md)
- [面试题 02.02. 返回倒数第 k 个节点](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/kth-node-from-end-of-list-lcci.md)
- [面试题 02.05. 链表求和](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/sum-lists-lcci.md)
- [面试题 02.06. 回文链表](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/palindrome-linked-list-lcci.md)
- [面试题 02.07. 链表相交](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/intersection-of-two-linked-lists-lcci.md)
- [面试题 02.08. 环路检测](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/linked-list-cycle-lcci.md)
- [面试题 03.02. 栈的最小值](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/min-stack-lcci.md)
- [面试题 03.04. 化栈为队](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/implement-queue-using-stacks-lcci.md)
- [面试题 04.02. 最小高度树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/minimum-height-tree-lcci.md)
- [面试题 04.05. 合法二叉搜索树](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/legal-binary-search-tree-lcci.md)
- [面试题 04.06. 后继者](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/successor-lcci.md)
- [面试题 04.08. 首个共同祖先](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/first-common-ancestor-lcci.md)
- [面试题 04.12. 求和路径](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/paths-with-sum-lcci.md)
- [面试题 08.04. 幂集](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/power-set-lcci.md)
- [面试题 08.07. 无重复字符串的排列组合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/permutation-i-lcci.md)
- [面试题 08.08. 有重复字符串的排列组合](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/permutation-ii-lcci.md)
- [面试题 08.09. 括号](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/bracket-lcci.md)
- [面试题 08.10. 颜色填充](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/color-fill-lcci.md)
- [面试题 08.12. 八皇后](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/eight-queens-lcci.md)
- [面试题 10.01. 合并排序的数组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/sorted-merge-lcci.md)
- [面试题 10.02. 变位词组](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/group-anagrams-lcci.md)
- [面试题 10.09. 排序矩阵查找](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/sorted-matrix-search-lcci.md)
- [面试题 16.02. 单词频率](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/words-frequency-lcci.md)
- [面试题 16.05. 阶乘尾数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/factorial-zeros-lcci.md)
- [面试题 16.26. 计算器](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/calculator-lcci.md)
- [面试题 17.06. 2出现的次数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/number-of-2s-in-range-lcci.md)
- [面试题 17.14. 最小K个数](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/smallest-k-lcci.md)
- [面试题 17.15. 最长单词](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/longest-word-lcci.md)
- [面试题 17.17. 多次搜索](https://github.com/ITCharge/AlgoNote/tree/main/docs/solutions/interviews/multi-search-lcci.md)
================================================
FILE: docs/solutions/interviews/intersection-of-two-linked-lists-lcci.md
================================================
# [面试题 02.07. 链表相交](https://leetcode.cn/problems/intersection-of-two-linked-lists-lcci/)
- 标签:哈希表、链表、双指针
- 难度:简单
## 题目链接
- [面试题 02.07. 链表相交 - 力扣](https://leetcode.cn/problems/intersection-of-two-linked-lists-lcci/)
## 题目大意
给定两个链表的头节点 `headA`、`headB`。
要求:找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 `None` 。
比如:链表 A 为 `[4, 1, 8, 4, 5]`,链表 B 为 `[5, 0, 1, 8, 4, 5]`。则如下图所示,两个链表相交的起始节点为 `8`,则输出结果为 `8`。

## 解题思路
如果两个链表相交,那么从相交位置开始,到结束,必有一段等长且相同的节点。假设链表 `A` 的长度为 `m`、链表 `B` 的长度为 `n`,他们的相交序列有 `k` 个,则相交情况可以如下如所示:

现在问题是如何找到 `m - k` 或者 `n - k` 的位置。
考虑将链表 `A` 的末尾拼接上链表 `B`,链表 `B` 的末尾拼接上链表 `A`。
然后使用两个指针 `pA` 、`pB`,分别从链表 `A`、链表 `B` 的头节点开始遍历,如果走到共同的节点,则返回该节点。
否则走到两个链表末尾,返回 `None`。

## 代码
```python
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
if headA == None or headB == None:
return None
pA = headA
pB = headB
while pA != pB :
pA = pA.next if pA != None else headB
pB = pB.next if pB != None else headA
return pA
```
================================================
FILE: docs/solutions/interviews/kth-node-from-end-of-list-lcci.md
================================================
# [面试题 02.02. 返回倒数第 k 个节点](https://leetcode.cn/problems/kth-node-from-end-of-list-lcci/)
- 标签:链表、双指针
- 难度:简单
## 题目链接
- [面试题 02.02. 返回倒数第 k 个节点 - 力扣](https://leetcode.cn/problems/kth-node-from-end-of-list-lcci/)
## 题目大意
给定一个链表的头节点 `head`,以及一个整数 `k`。
要求:返回链表的倒数第 `k` 个节点的值。
## 解题思路
常规思路是遍历一遍链表,求出链表长度,再遍历一遍到对应位置,返回该位置上的节点。
如果用一次遍历实现的话,可以使用快慢指针。让快指针先走 `k` 步,然后快慢指针、慢指针再同时走,每次一步,这样等快指针遍历到链表尾部的时候,慢指针就刚好遍历到了倒数第 `k` 个节点位置。返回该该位置上的节点即可。
## 代码
```python
class Solution:
def kthToLast(self, head: ListNode, k: int) -> int:
slow = head
fast = head
for _ in range(k):
if fast == None:
return fast
fast = fast.next
while fast:
slow = slow.next
fast = fast.next
return slow.val
```
================================================
FILE: docs/solutions/interviews/legal-binary-search-tree-lcci.md
================================================
# [面试题 04.05. 合法二叉搜索树](https://leetcode.cn/problems/legal-binary-search-tree-lcci/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [面试题 04.05. 合法二叉搜索树 - 力扣](https://leetcode.cn/problems/legal-binary-search-tree-lcci/)
## 题目大意
给定一个二叉树的根节点 `root`。
要求:检查该二叉树是否为二叉搜索树。
二叉搜索树特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
## 解题思路
根据题意进行递归遍历即可。前序、中序、后序遍历都可以。
以前序遍历为例,递归函数为:`preorderTraversal(root, min_v, max_v)`
前序遍历时,先判断根节点的值是否在 `(min_v, max_v)` 之间。如果不在则直接返回 `False`。在区间内,则继续递归检测左右子树是否满足,都满足才是一棵二叉搜索树。
递归遍历左子树的时候,要将上界 `max_v` 改为左子树的根节点值,因为左子树上所有节点的值均小于根节点的值。同理,遍历右子树的时候,要将下界 `min_v` 改为右子树的根节点值,因为右子树上所有节点的值均大于根节点。
## 代码
```python
class Solution:
def isValidBST(self, root: TreeNode) -> bool:
def preorderTraversal(root, min_v, max_v):
if root == None:
return True
if root.val >= max_v or root.val <= min_v:
return False
return preorderTraversal(root.left, min_v, root.val) and preorderTraversal(root.right, root.val, max_v)
return preorderTraversal(root, float('-inf'), float('inf'))
```
================================================
FILE: docs/solutions/interviews/linked-list-cycle-lcci.md
================================================
# [面试题 02.08. 环路检测](https://leetcode.cn/problems/linked-list-cycle-lcci/)
- 标签:哈希表、链表、双指针
- 难度:中等
## 题目链接
- [面试题 02.08. 环路检测 - 力扣](https://leetcode.cn/problems/linked-list-cycle-lcci/)
## 题目大意
给定一个链表的头节点 `head`。
要求:判断链表中是否有环,如果有环则返回入环的第一个节点,无环则返回 None。
## 解题思路
利用两个指针,一个慢指针每次前进一步,快指针每次前进两步(两步或多步效果是等价的)。如果两个指针在链表头节点以外的某一节点相遇(即相等)了,那么说明链表有环,否则,如果(快指针)到达了某个没有后继指针的节点时,那么说明没环。
如果有环,则再定义一个指针,和慢指针一起每次移动一步,两个指针相遇的位置即为入口节点。
这是因为:假设入环位置为 A,快慢指针在在 B 点相遇,则相遇时慢指针走了 $a + b$ 步,快指针走了 $a + n(b+c) + b$ 步。
$2(a + b) = a + n(b + c) + b$。可以推出:$a = c + (n-1)(b + c)$。
我们可以发现:从相遇点到入环点的距离 $c$ 加上 $n-1$ 圈的环长 $b + c$ 刚好等于从链表头部到入环点的距离。
## 代码
```python
class Solution:
def detectCycle(self, head: ListNode) -> ListNode:
fast, slow = head, head
while True:
if not fast or not fast.next:
return None
fast = fast.next.next
slow = slow.next
if fast == slow:
break
ans = head
while ans != slow:
ans, slow = ans.next, slow.next
return ans
```
================================================
FILE: docs/solutions/interviews/longest-word-lcci.md
================================================
# [面试题 17.15. 最长单词](https://leetcode.cn/problems/longest-word-lcci/)
- 标签:字典树、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [面试题 17.15. 最长单词 - 力扣](https://leetcode.cn/problems/longest-word-lcci/)
## 题目大意
给定一组单词 `words`。
要求:找出其中的最长单词,且该单词由这组单词中的其他单词组合而成。如果有多个长度相同的结果,返回其中字典序最小的一项,如果没有符合要求的单词则返回空字符串。
## 解题思路
先将所有单词按照长度从长到短排序,相同长度的字典序小的排在前面。然后将所有单词存入字典树中。
然后一重循环遍历所有单词 `word`,二重循环遍历单词中所有字符 `word[i]`。
如果当前遍历的字符为单词末尾,递归判断从 `i + 1` 位置开始,剩余部分是否可以切分为其他单词组合,如果可以切分,则返回当前单词 `word`。如果不可以切分,则返回空字符串 `""`。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
return cur is not None and cur.isEnd
def splitToWord(self, remain):
if not remain or remain == "":
return True
cur = self
for i in range(len(remain)):
ch = remain[i]
if ch not in cur.children:
return False
if cur.children[ch].isEnd and self.splitToWord(remain[i + 1:]):
return True
cur = cur.children[ch]
return False
def dfs(self, words):
for word in words:
cur = self
size = len(word)
for i in range(size):
ch = word[i]
if i < size - 1 and cur.children[ch].isEnd and self.splitToWord(word[i+1:]):
return word
cur = cur.children[ch]
return ""
class Solution:
def longestWord(self, words: List[str]) -> str:
words.sort(key=lambda x: (-len(x), x))
trie_tree = Trie()
for word in words:
trie_tree.insert(word)
ans = trie_tree.dfs(words)
return ans
```
================================================
FILE: docs/solutions/interviews/min-stack-lcci.md
================================================
# [面试题 03.02. 栈的最小值](https://leetcode.cn/problems/min-stack-lcci/)
- 标签:栈、设计
- 难度:简单
## 题目链接
- [面试题 03.02. 栈的最小值 - 力扣](https://leetcode.cn/problems/min-stack-lcci/)
## 题目大意
设计一个「栈」,要求实现 `push` ,`pop` ,`top` ,`getMin` 操作,其中 `getMin` 要求能在常数时间内实现。
## 解题思路
使用一个栈,栈元素中除了保存当前值之外,再保存一个当前最小值。
- `push` 操作:如果栈不为空,则判断当前值与栈顶元素所保存的最小值,并更新当前最小值,将新元素保存到栈中。
- `pop`操作:正常出栈
- `top` 操作:返回栈顶元素保存的值。
- `getMin` 操作:返回栈顶元素保存的最小值。
## 代码
```python
class MinStack:
def __init__(self):
"""
initialize your data structure here.
"""
self.stack = []
class Node:
def __init__(self, x):
self.val = x
self.min = x
def push(self, x: int) -> None:
node = self.Node(x)
if len(self.stack) == 0:
self.stack.append(node)
else:
topNode = self.stack[-1]
if node.min > topNode.min:
node.min = topNode.min
self.stack.append(node)
def pop(self) -> None:
self.stack.pop()
def top(self) -> int:
return self.stack[-1].val
def getMin(self) -> int:
return self.stack[-1].min
```
================================================
FILE: docs/solutions/interviews/minimum-height-tree-lcci.md
================================================
# [面试题 04.02. 最小高度树](https://leetcode.cn/problems/minimum-height-tree-lcci/)
- 标签:树、二叉搜索树、数组、分治、二叉树
- 难度:简单
## 题目链接
- [面试题 04.02. 最小高度树 - 力扣](https://leetcode.cn/problems/minimum-height-tree-lcci/)
## 题目大意
给定一个升序的有序数组 `nums`。
要求:创建一棵高度最小的二叉搜索树(高度平衡的二叉搜索树)。
## 解题思路
直观上,如果把数组的中间元素当做根,那么数组左侧元素都小于根节点,右侧元素都大于根节点,且左右两侧元素个数相同,或最多相差 `1` 个。那么构建的树高度差也不会超过 `1`。所以猜想出:如果左右子树约平均,树就越平衡。这样我们就可以每次取中间元素作为当前的根节点,两侧的元素作为左右子树递归建树,左侧区间 `[L, mid - 1]` 作为左子树,右侧区间 `[mid + 1, R]` 作为右子树。
## 代码
```python
class Solution:
def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
size = len(nums)
if size == 0:
return None
mid = size // 2
root = TreeNode(nums[mid])
root.left = Solution.sortedArrayToBST(self, nums[:mid])
root.right = Solution.sortedArrayToBST(self, nums[mid + 1:])
return root
```
================================================
FILE: docs/solutions/interviews/multi-search-lcci.md
================================================
# [面试题 17.17. 多次搜索](https://leetcode.cn/problems/multi-search-lcci/)
- 标签:字典树、数组、哈希表、字符串、字符串匹配、滑动窗口
- 难度:中等
## 题目链接
- [面试题 17.17. 多次搜索 - 力扣](https://leetcode.cn/problems/multi-search-lcci/)
## 题目大意
给定一个较长字符串 `big` 和一个包含较短字符串的数组 `smalls`。
要求:设计一个方法,根据 `smalls` 中的每一个较短字符串,对 `big` 进行搜索。输出 `smalls` 中的字符串在 `big` 里出现的所有位置 `positions`,其中 `positions[i]` 为 `smalls[i]` 出现的所有位置。
## 解题思路
构建字典树,将 `smalls` 中所有字符串存入字典树中,并在字典树中记录下插入字符串的顺序下标。
然后一重循环遍历 `big`,表示从第 `i` 位置开始的字符串 `big[i:]`。然后在字符串前缀中搜索对应的单词,将所有符合要求的单词插入顺序位置存入列表中,返回列表。
对于列表中每个单词插入下标顺序 `index` 和 `big[i:]` 来说, `i` 就是 `smalls` 中第 `index` 个字符串所对应在 `big` 中的开始位置,将其存入答案数组并返回即可。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
self.index = -1
def insert(self, word: str, index: int) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
cur.index = index
def search(self, text: str) -> list:
"""
Returns if the word is in the trie.
"""
cur = self
res = []
for i in range(len(text)):
ch = text[i]
if ch not in cur.children:
return res
cur = cur.children[ch]
if cur.isEnd:
res.append(cur.index)
return res
class Solution:
def multiSearch(self, big: str, smalls: List[str]) -> List[List[int]]:
trie_tree = Trie()
for i in range(len(smalls)):
word = smalls[i]
trie_tree.insert(word, i)
res = [[] for _ in range(len(smalls))]
for i in range(len(big)):
for index in trie_tree.search(big[i:]):
res[index].append(i)
return res
```
================================================
FILE: docs/solutions/interviews/number-of-2s-in-range-lcci.md
================================================
# [面试题 17.06. 2出现的次数](https://leetcode.cn/problems/number-of-2s-in-range-lcci/)
- 标签:递归、数学、动态规划
- 难度:困难
## 题目链接
- [面试题 17.06. 2出现的次数 - 力扣](https://leetcode.cn/problems/number-of-2s-in-range-lcci/)
## 题目大意
**描述**:给定一个整数 $n$。
**要求**:计算从 $0$ 到 $n$ (包含 $n$) 中数字 $2$ 出现的次数。
**说明**:
- $n \le 10^9$。
**示例**:
- 示例 1:
```python
输入: 25
输出: 9
解释: (2, 12, 20, 21, 22, 23, 24, 25)(注意 22 应该算作两次)
```
## 解题思路
### 思路 1:动态规划 + 数位 DP
将 $n$ 转换为字符串 $s$,定义递归函数 `def dfs(pos, cnt, isLimit):` 表示构造第 $pos$ 位及之后所有数位中数字 $2$ 出现的个数。接下来按照如下步骤进行递归。
1. 从 `dfs(0, 0, True)` 开始递归。 `dfs(0, 0, True)` 表示:
1. 从位置 $0$ 开始构造。
2. 初始数字 $2$ 出现的个数为 $0$。
3. 开始时受到数字 $n$ 对应最高位数位的约束。
2. 如果遇到 $pos == len(s)$,表示到达数位末尾,此时:返回数字 $2$ 出现的个数 $cnt$。
3. 如果 $pos \ne len(s)$,则定义方案数 $ans$,令其等于 $0$,即:`ans = 0`。
4. 如果遇到 $isNum == False$,说明之前位数没有填写数字,当前位可以跳过,这种情况下方案数等于 $pos + 1$ 位置上没有受到 $pos$ 位的约束,并且之前没有填写数字时的方案数,即:`ans = dfs(i + 1, state, False, False)`。
5. 如果 $isNum == True$,则当前位必须填写一个数字。此时:
1. 因为不需要考虑前导 $0$ 所以当前位数位所能选择的最小数字($minX$)为 $0$。
2. 根据 $isLimit$ 来决定填当前位数位所能选择的最大数字($maxX$)。
3. 然后根据 $[minX, maxX]$ 来枚举能够填入的数字 $d$。
4. 方案数累加上当前位选择 $d$ 之后的方案数,即:`ans += dfs(pos + 1, cnt + (d == 2), isLimit and d == maxX)`。
1. `cnt + (d == 2)` 表示之前数字 $2$ 出现的个数加上当前位为数字 $2$ 的个数。
2. `isLimit and d == maxX` 表示 $pos + 1$ 位受到之前位 $pos$ 位限制。
6. 最后的方案数为 `dfs(0, 0, True)`,将其返回即可。
### 思路 1:代码
```python
class Solution:
def numberOf2sInRange(self, n: int) -> int:
# 将 n 转换为字符串 s
s = str(n)
@cache
# pos: 第 pos 个数位
# cnt: 之前数字 2 出现的个数。
# isLimit: 表示是否受到选择限制。如果为真,则第 pos 位填入数字最多为 s[pos];如果为假,则最大可为 9。
def dfs(pos, cnt, isLimit):
if pos == len(s):
return cnt
ans = 0
# 不需要考虑前导 0,则最小可选择数字为 0
minX = 0
# 如果受到选择限制,则最大可选择数字为 s[pos],否则最大可选择数字为 9。
maxX = int(s[pos]) if isLimit else 9
# 枚举可选择的数字
for d in range(minX, maxX + 1):
ans += dfs(pos + 1, cnt + (d == 2), isLimit and d == maxX)
return ans
return dfs(0, 0, True)
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(\log n)$。
- **空间复杂度**:$O(\log n)$。
================================================
FILE: docs/solutions/interviews/palindrome-linked-list-lcci.md
================================================
# [面试题 02.06. 回文链表](https://leetcode.cn/problems/palindrome-linked-list-lcci/)
- 标签:栈、递归、链表、双指针
- 难度:简单
## 题目链接
- [面试题 02.06. 回文链表 - 力扣](https://leetcode.cn/problems/palindrome-linked-list-lcci/)
## 题目大意
给定一个链表的头节点 `head`。
要求:判断该链表是否为回文链表。
## 解题思路
利用数组,将链表元素依次存入。然后再使用两个指针,一个指向数组开始位置,一个指向数组结束位置,依次判断首尾对应元素是否相等,如果都相等,则为回文链表。如果不相等,则不是回文链表。
## 代码
```python
class Solution:
def isPalindrome(self, head: ListNode) -> bool:
nodes = []
p1 = head
while p1 != None:
nodes.append(p1.val)
p1 = p1.next
return nodes == nodes[::-1]
```
================================================
FILE: docs/solutions/interviews/paths-with-sum-lcci.md
================================================
# [面试题 04.12. 求和路径](https://leetcode.cn/problems/paths-with-sum-lcci/)
- 标签:树、深度优先搜索、二叉树
- 难度:中等
## 题目链接
- [面试题 04.12. 求和路径 - 力扣](https://leetcode.cn/problems/paths-with-sum-lcci/)
## 题目大意
给定一个二叉树的根节点 `root`,和一个整数 `targetSum`。
要求:求出该二叉树里节点值之和等于 `targetSum` 的路径的数目。
- 路径:不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
## 解题思路
直观想法是:
以每一个节点 `node` 为起始节点,向下检测延伸的路径。递归遍历每一个节点所有可能的路径,然后将这些路径数目加起来即为答案。
但是这样会存在许多重复计算。我们可以定义节点的前缀和来减少重复计算。
- 节点的前缀和:从根节点到当前节点路径上所有节点的和。
有了节点的前缀和,我们就可以通过前缀和来计算两节点之间的路劲和。即:`则两节点之间的路径和 = 两节点之间的前缀和之差`。
为了计算符合要求的路径数量,我们用哈希表存储「前缀和的节点数量」。哈希表以「当前节点的前缀和」为键,以「该前缀和的节点数量」为值。这样就能通过哈希表直接计算出符合要求的路径数量,从而累加到答案上。
整个算法的具体步骤如下:
- 通过先序遍历方式递归遍历二叉树,计算每一个节点的前缀和 `cur_sum`。
- 从哈希表中取出 `cur_sum - target_sum` 的路径数量(也就是表示存在从前缀和为 `cur_sum - target_sum` 所对应的节点到前缀和为 `cur_sum` 所对应的节点的路径个数)累加到答案 `res` 中。
- 然后以「当前节点的前缀和」为键,以「该前缀和的节点数量」为值,存入哈希表中。
- 递归遍历二叉树,并累加答案值。
- 恢复哈希表「当前前缀和的节点数量」,返回答案。
## 代码
```python
```
================================================
FILE: docs/solutions/interviews/permutation-i-lcci.md
================================================
# [面试题 08.07. 无重复字符串的排列组合](https://leetcode.cn/problems/permutation-i-lcci/)
- 标签:字符串、回溯
- 难度:中等
## 题目链接
- [面试题 08.07. 无重复字符串的排列组合 - 力扣](https://leetcode.cn/problems/permutation-i-lcci/)
## 题目大意
给定一个字符串 `S`。
要求:打印出该字符串中字符的所有排列。可以以任意顺序返回这个字符串数组,但里边不能有重复元素。
## 解题思路
使用 `visited` 数组标记该元素在当前排列中是否被访问过。如果未被访问过则将其加入排列中,并在访问后将该元素变为未访问状态。然后进行回溯遍历。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, S, visited):
if len(self.path) == len(S):
self.res.append(''.join(self.path))
return
for i in range(len(S)):
if not visited[i]:
visited[i] = True
self.path.append(S[i])
self.backtrack(S, visited)
self.path.pop()
visited[i] = False
def permutation(self, S: str) -> List[str]:
self.res.clear()
self.path.clear()
visited = [False for _ in range(len(S))]
self.backtrack(S, visited)
return self.res
```
================================================
FILE: docs/solutions/interviews/permutation-ii-lcci.md
================================================
# [面试题 08.08. 有重复字符串的排列组合](https://leetcode.cn/problems/permutation-ii-lcci/)
- 标签:字符串、回溯
- 难度:中等
## 题目链接
- [面试题 08.08. 有重复字符串的排列组合 - 力扣](https://leetcode.cn/problems/permutation-ii-lcci/)
## 题目大意
给定一个字符串 `s`,字符串中包含有重复字符。
要求:打印出该字符串中字符的所有排列。可以以任意顺序返回这个字符串数组。
## 解题思路
因为原字符串可能含有重复元素,所以在回溯的时候需要进行去重。先将字符串 `s` 转为 `list` 列表,再对列表进行排序,然后使用 `visited` 数组标记该元素在当前排列中是否被访问过。如果未被访问过则将其加入排列中,并在访问后将该元素变为未访问状态。
然后再递归遍历下一层元素之前,增加一句语句进行判重:`if i > 0 and nums[i] == nums[i - 1] and not visited[i - 1]: continue`。
然后进行回溯遍历。
## 代码
```python
class Solution:
res = []
path = []
def backtrack(self, ls, visited):
if len(self.path) == len(ls):
self.res.append(''.join(self.path))
return
for i in range(len(ls)):
if i > 0 and ls[i] == ls[i - 1] and not visited[i - 1]:
continue
if not visited[i]:
visited[i] = True
self.path.append(ls[i])
self.backtrack(ls, visited)
self.path.pop()
visited[i] = False
def permutation(self, S: str) -> List[str]:
self.res.clear()
self.path.clear()
ls = list(S)
ls.sort()
visited = [False for _ in range(len(S))]
self.backtrack(ls, visited)
return self.res
```
================================================
FILE: docs/solutions/interviews/power-set-lcci.md
================================================
# [面试题 08.04. 幂集](https://leetcode.cn/problems/power-set-lcci/)
- 标签:位运算、数组、回溯
- 难度:中等
## 题目链接
- [面试题 08.04. 幂集 - 力扣](https://leetcode.cn/problems/power-set-lcci/)
## 题目大意
给定一个集合 `nums`,集合中不包含重复元素。
压枪欧秋:返回该集合的所有子集。
## 解题思路
回溯算法,遍历集合 `nums`。为了使得子集不重复,每次遍历从当前位置的下一个位置进行下一层遍历。
## 代码
```python
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
def backtrack(size, subset, index):
res.append(subset)
for i in range(index, size):
backtrack(size, subset + [nums[i]], i + 1)
size = len(nums)
res = list()
backtrack(size, [], 0)
return res
```
================================================
FILE: docs/solutions/interviews/rotate-matrix-lcci.md
================================================
# [面试题 01.07. 旋转矩阵](https://leetcode.cn/problems/rotate-matrix-lcci/)
- 标签:数组、数学、矩阵
- 难度:中等
## 题目链接
- [面试题 01.07. 旋转矩阵 - 力扣](https://leetcode.cn/problems/rotate-matrix-lcci/)
## 题目大意
给定一个 `n * n` 大小的二维矩阵用来表示图像,其中每个像素的大小为 4 字节。
要求:设计一种算法,将图像旋转 90 度。并且要不占用额外内存空间。
## 解题思路
题目要求不占用额外内存空间,就是要在原二维矩阵上直接进行旋转操作。我们可以用翻转操作代替旋转操作。具体可以分为两步:
1. 上下翻转。
2. 主对角线翻转。
举个例子:
```
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
```
上下翻转后变为:
```
13 14 15 16
9 10 11 12
5 6 7 8
1 2 3 4
```
在经过主对角线翻转后变为:
```
13 9 5 1
14 10 6 2
15 11 7 3
16 12 8 4
```
## 代码
```python
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
size = len(matrix)
for i in range(size // 2):
for j in range(size):
matrix[i][j], matrix[size - i - 1][j] = matrix[size - i - 1][j], matrix[i][j]
for i in range(size):
for j in range(i):
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
```
================================================
FILE: docs/solutions/interviews/smallest-k-lcci.md
================================================
# [面试题 17.14. 最小K个数](https://leetcode.cn/problems/smallest-k-lcci/)
- 标签:数组、分治、快速选择、排序、堆(优先队列)
- 难度:中等
## 题目链接
- [面试题 17.14. 最小K个数 - 力扣](https://leetcode.cn/problems/smallest-k-lcci/)
## 题目大意
给定整数数组 `arr`,再给定一个整数 `k`。
要求:返回数组 `arr` 中最小的 `k` 个数。
## 解题思路
直接可以想到的思路是:排序后输出数组上对应的最小的 k 个数。所以问题关键在于排序方法的复杂度。
冒泡排序、选择排序、插入排序时间复杂度 $O(n^2)$ 太高了,解答会超时。
可考虑堆排序、归并排序、快速排序。本题使用堆排序。具体做法如下:
1. 利用数组前 `k` 个元素,建立大小为 `k` 的大顶堆。
2. 遍历数组 `[k, size - 1]` 的元素,判断其与堆顶元素关系,如果比堆顶元素小,则将其赋值给堆顶元素,再对大顶堆进行调整。
3. 最后输出前调整过后的大顶堆的前 `k` 个元素。
## 代码
```python
class Solution:
def heapify(self, nums: [int], index: int, end: int):
left = index * 2 + 1
right = left + 1
while left <= end:
# 当前节点为非叶子节点
max_index = index
if nums[left] > nums[max_index]:
max_index = left
if right <= end and nums[right] > nums[max_index]:
max_index = right
if index == max_index:
# 如果不用交换,则说明已经交换结束
break
nums[index], nums[max_index] = nums[max_index], nums[index]
# 继续调整子树
index = max_index
left = index * 2 + 1
right = left + 1
# 初始化大顶堆
def buildMaxHeap(self, nums: [int], k: int):
# (k-2) // 2 是最后一个非叶节点,叶节点不用调整
for i in range((k - 2) // 2, -1, -1):
self.heapify(nums, i, k - 1)
return nums
def smallestK(self, arr: List[int], k: int) -> List[int]:
size = len(arr)
if k <= 0 or not arr:
return []
if size <= k:
return arr
self.buildMaxHeap(arr, k)
for i in range(k, size):
if arr[i] < arr[0]:
arr[i], arr[0] = arr[0], arr[i]
self.heapify(arr, 0, k - 1)
return arr[:k]
```
================================================
FILE: docs/solutions/interviews/sorted-matrix-search-lcci.md
================================================
# [面试题 10.09. 排序矩阵查找](https://leetcode.cn/problems/sorted-matrix-search-lcci/)
- 标签:数组、二分查找、分治、矩阵
- 难度:中等
## 题目链接
- [面试题 10.09. 排序矩阵查找 - 力扣](https://leetcode.cn/problems/sorted-matrix-search-lcci/)
## 题目大意
给定一个 `m * n` 大小的有序整数矩阵。每一行、每一列都按升序排列。再给定一个目标值 `target`。
要求:判断矩阵中是否可以找到 `target`,如果找到 `target`,返回 `True`,否则返回 `False`。
## 解题思路
矩阵是有序的,可以考虑使用二分搜索来进行查找。
迭代对角线元素,假设对角线元素的坐标为 `(row, col)`。把数组元素按对角线分为右上角部分和左下角部分。
则对于当前对角线元素右侧第 `row` 行、对角线元素下侧第 `col` 列进行二分查找。
- 如果找到目标,直接返回 `True`。
- 如果找不到目标,则缩小范围,继续查找。
- 直到所有对角线元素都遍历完,依旧没找到,则返回 `False`。
## 代码
```python
class Solution:
def diagonalBinarySearch(self, matrix, diagonal, target):
left = 0
right = diagonal
while left < right:
mid = left + (right - left) // 2
if matrix[mid][mid] < target:
left = mid + 1
else:
right = mid
return left
def rowBinarySearch(self, matrix, begin, cols, target):
left = begin
right = cols
while left < right:
mid = left + (right - left) // 2
if matrix[begin][mid] < target:
left = mid + 1
elif matrix[begin][mid] > target:
right = mid - 1
else:
left = mid
break
return begin <= left <= cols and matrix[begin][left] == target
def colBinarySearch(self, matrix, begin, rows, target):
left = begin + 1
right = rows
while left < right:
mid = left + (right - left) // 2
if matrix[mid][begin] < target:
left = mid + 1
elif matrix[mid][begin] > target:
right = mid - 1
else:
left = mid
break
return begin <= left <= rows and matrix[left][begin] == target
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
rows = len(matrix)
if rows == 0:
return False
cols = len(matrix[0])
if cols == 0:
return False
min_val = min(rows, cols)
index = self.diagonalBinarySearch(matrix, min_val - 1, target)
if matrix[index][index] == target:
return True
for i in range(index + 1):
row_search = self.rowBinarySearch(matrix, i, cols - 1, target)
col_search = self.colBinarySearch(matrix, i, rows - 1, target)
if row_search or col_search:
return True
return False
```
================================================
FILE: docs/solutions/interviews/sorted-merge-lcci.md
================================================
# [面试题 10.01. 合并排序的数组](https://leetcode.cn/problems/sorted-merge-lcci/)
- 标签:数组、双指针、排序
- 难度:简单
## 题目链接
- [面试题 10.01. 合并排序的数组 - 力扣](https://leetcode.cn/problems/sorted-merge-lcci/)
## 题目大意
**描述**:给定两个排序后的数组 `A` 和 `B`,以及 `A` 的元素数量 `m` 和 `B` 的元素数量 `n`。 `A` 的末端有足够的缓冲空间容纳 `B`。
**要求**:编写一个方法,将 `B` 合并入 `A` 并排序。
**说明**:
- $A.length == n + m$。
**示例**:
- 示例 1:
```python
输入:
A = [1,2,3,0,0,0], m = 3
B = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
```
## 解题思路
### 思路 1:归并排序
可以利用归并排序算法的归并步骤思路。
1. 使用两个指针分别表示`A`、`B` 正在处理的元素下标。
2. 对 `A`、`B` 进行归并操作,将结果存入新数组中。归并之后,再将所有元素赋值到数组 `A` 中。
### 思路 1:代码
```python
class Solution:
def merge(self, A: List[int], m: int, B: List[int], n: int) -> None:
"""
Do not return anything, modify A in-place instead.
"""
arr = []
index_A, index_B = 0, 0
while index_A < m and index_B < n:
if A[index_A] <= B[index_B]:
arr.append(A[index_A])
index_A += 1
else:
arr.append(B[index_B])
index_B += 1
while index_A < m:
arr.append(A[index_A])
index_A += 1
while index_B < n:
arr.append(B[index_B])
index_B += 1
for i in range(m + n):
A[i] = arr[i]
```
### 思路 1:复杂度分析
- **时间复杂度**:$O(m + n)$。
- **空间复杂度**:$O(m + n)$。
================================================
FILE: docs/solutions/interviews/successor-lcci.md
================================================
# [面试题 04.06. 后继者](https://leetcode.cn/problems/successor-lcci/)
- 标签:树、深度优先搜索、二叉搜索树、二叉树
- 难度:中等
## 题目链接
- [面试题 04.06. 后继者 - 力扣](https://leetcode.cn/problems/successor-lcci/)
## 题目大意
给定一棵二叉搜索树的根节点 `root` 和其中一个节点 `p`。
要求:找出该节点在树中的中序后继,即按照中序遍历的顺序节点 `p` 的下一个节点。如果节点 `p` 没有对应的下一个节点,则返回 `None`。
## 解题思路
递归遍历,具体步骤如下:
- 如果 `root.val` 小于等于 `p.val`,则直接从 `root` 的右子树递归查找比 `p.val` 大的节点,从而找到中序后继。
- 如果 `root.val` 大于 `p.val`,则 `root` 有可能是中序后继,也有可能是 `root` 的左子树。则从 `root` 的左子树递归查找更接近(更小的)。如果查找的值为 `None`,则当前 `root` 就是中序后继,否则继续递归查找,从而找到中序后继。
## 代码
```python
class Solution:
def inorderSuccessor(self, root: TreeNode, p: TreeNode) -> TreeNode:
if not p or not root:
return None
if root.val <= p.val:
node = self.inorderSuccessor(root.right, p)
else:
node = self.inorderSuccessor(root.left, p)
if not node:
node = root
return node
```
================================================
FILE: docs/solutions/interviews/sum-lists-lcci.md
================================================
# [面试题 02.05. 链表求和](https://leetcode.cn/problems/sum-lists-lcci/)
- 标签:递归、链表、数学
- 难度:中等
## 题目链接
- [面试题 02.05. 链表求和 - 力扣](https://leetcode.cn/problems/sum-lists-lcci/)
## 题目大意
给定两个非空的链表 `l1` 和 `l2`,表示两个非负整数,每位数字都是按照逆序的方式存储的,每个节点存储一位数字。
要求:计算两个整数的和,并逆序返回表示和的链表。
## 解题思路
模拟大数加法,按位相加,将结果添加到新链表上。需要注意进位和对 `10` 取余。
## 代码
```python
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
head = curr = ListNode(0)
carry = 0
while l1 or l2 or carry:
if l1:
num1 = l1.val
l1 = l1.next
else:
num1 = 0
if l2:
num2 = l2.val
l2 = l2.next
else:
num2 = 0
sum = num1 + num2 + carry
carry = sum // 10
curr.next = ListNode(sum % 10)
curr = curr.next
return head.next
```
================================================
FILE: docs/solutions/interviews/words-frequency-lcci.md
================================================
# [面试题 16.02. 单词频率](https://leetcode.cn/problems/words-frequency-lcci/)
- 标签:设计、字典树、数组、哈希表、字符串
- 难度:中等
## 题目链接
- [面试题 16.02. 单词频率 - 力扣](https://leetcode.cn/problems/words-frequency-lcci/)
## 题目大意
要求:设计一个方法,找出任意指定单词在一本书中的出现频率。
支持如下操作:
- `WordsFrequency(book)` 构造函数,参数为字符串数组构成的一本书。
- `get(word)` 查询指定单词在书中出现的频率。
## 解题思路
使用字典树统计单词频率。
构造函数时,构建一个字典树,并将所有单词存入字典树中,同时在字典树中记录并维护单词频率。
查询时,调用字典树查询方法,查询单词频率。
## 代码
```python
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.children = dict()
self.isEnd = False
self.count = 0
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
cur.children[ch] = Trie()
cur = cur.children[ch]
cur.isEnd = True
cur.count += 1
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
cur = self
for ch in word:
if ch not in cur.children:
return 0
cur = cur.children[ch]
if cur and cur.isEnd:
return cur.count
return 0
class WordsFrequency:
def __init__(self, book: List[str]):
self.tire_tree = Trie()
for word in book:
self.tire_tree.insert(word)
def get(self, word: str) -> int:
return self.tire_tree.search(word)
```
================================================
FILE: docs/solutions/interviews/zero-matrix-lcci.md
================================================
# [面试题 01.08. 零矩阵](https://leetcode.cn/problems/zero-matrix-lcci/)
- 标签:数组、哈希表、矩阵
- 难度:中等
## 题目链接
- [面试题 01.08. 零矩阵 - 力扣](https://leetcode.cn/problems/zero-matrix-lcci/)
## 题目大意
给定一个 `m * n` 大小的二维矩阵 `matrix`。
要求:编写一种算法,如果矩阵中某个元素为 `0`,增将其所在行与列清零。
## 解题思路
直观上可以使用两个数组或者集合来标记行和列出现 `0` 的情况,但更好的做法是不用开辟新的数组或集合,直接原本二维矩阵 `matrix` 的空间。使用数组原本的元素进行记录出现 0 的情况。
设定两个变量 `flag_row0`、`flag_col0` 来标记第一行、第一列是否出现了 `0`。
接下来我们使用数组第一行、第一列来标记 `0` 的情况。
对数组除第一行、第一列之外的每个元素进行遍历,如果某个元素出现 `0` 了,则使用数组的第一行、第一列对应位置来存储 `0` 的标记。
再对数组除第一行、第一列之外的每个元素进行遍历,通过对第一行、第一列的标记 0 情况,进行置为 `0` 的操作。
最后再根据 `flag_row0`、`flag_col0` 的标记情况,对第一行、第一列进行置为 `0` 的操作。
## 代码
```python
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
rows = len(matrix)
cols = len(matrix[0])
flag_col0 = False
flag_row0 = False
for i in range(rows):
if matrix[i][0] == 0:
flag_col0 = True
break
for j in range(cols):
if matrix[0][j] == 0:
flag_row0 = True
break
for i in range(1, rows):
for j in range(1, cols):
if matrix[i][j] == 0:
matrix[i][0] = matrix[0][j] = 0
for i in range(1, rows):
for j in range(1, cols):
if matrix[i][0] == 0 or matrix[0][j] == 0:
matrix[i][j] = 0
if flag_col0:
for i in range(rows):
matrix[i][0] = 0
if flag_row0:
for j in range(cols):
matrix[0][j] = 0
```





