Showing preview only (3,087K chars total). Download the full file or copy to clipboard to get everything.
Repository: jianchang512/clone-voice
Branch: main
Commit: c541b8a9589e
Files: 48
Total size: 2.9 MB
Directory structure:
gitextract_l1kjskog/
├── .dockerignore
├── .github/
│ ├── FUNDING.yml
│ └── workflows/
│ └── docker-image-tag-commit.yml
├── .gitignore
├── .vscode/
│ ├── launch.json
│ └── tasks.json
├── LICENSE
├── README.md
├── README_EN.md
├── app.py
├── appdingzhi.py
├── change.md
├── clone/
│ ├── __init__.py
│ ├── cfg.py
│ ├── character.json
│ └── logic.py
├── code_dev.py
├── docker/
│ ├── build@source/
│ │ └── dockerfile
│ ├── up@cpu/
│ │ ├── .models.json
│ │ └── docker-compose.yml
│ └── up@gpu/
│ ├── .models.json
│ └── docker-compose.yml
├── environment.yml
├── models/
│ ├── faster/
│ │ └── models--Systran--faster-whisper-medium/
│ │ ├── refs/
│ │ │ └── main
│ │ └── snapshots/
│ │ └── ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/
│ │ ├── config.json
│ │ ├── tokenizer.json
│ │ └── vocabulary.txt
│ └── tts/
│ └── run/
│ └── training/
│ └── XTTS_v2.0_original_model_files/
│ ├── config.json
│ └── vocab.json
├── params.json
├── requirements.txt
├── runapp.bat
├── runtrain.bat
├── static/
│ └── js/
│ └── layer/
│ ├── layer.js
│ ├── mobile/
│ │ ├── layer.js
│ │ └── need/
│ │ └── layer.css
│ └── theme/
│ └── default/
│ └── layer.css
├── templates/
│ ├── index.html
│ └── txt.html
├── test.py
├── testapi.py
├── train.py
├── tts/
│ └── 模型目录.txt
├── utils/
│ ├── __init__.py
│ ├── cfg.py
│ └── formatter.py
├── version.json
└── xtts_demo.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
.git/
.github/
.vscode/
cache/
docker/
tts/
.dockerignore
.gitignore
.env
app.log
environment.yml
runapp.bat
runtrain.bat
# Ignore generated files
**/*.pyc
================================================
FILE: .github/FUNDING.yml
================================================
# These are supported funding model platforms
github: # Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [user1, user2]
patreon: # Replace with a single Patreon username
open_collective: # Replace with a single Open Collective username
ko_fi: jianchang512
tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
liberapay: # Replace with a single Liberapay username
issuehunt: # Replace with a single IssueHunt username
otechie: # Replace with a single Otechie username
lfx_crowdfunding: # Replace with a single LFX Crowdfunding project-name e.g., cloud-foundry
custom: # Replace with up to 4 custom sponsorship URLs e.g., ['link1', 'link2']
================================================
FILE: .github/workflows/docker-image-tag-commit.yml
================================================
name: Docker Image Build/Publish tag with commit
on:
push:
branches:
- 'main'
workflow_dispatch:
inputs:
commit_id:
description: clone-voice commit id(like 'main' 'dd668d2')
required: true
default: main
jobs:
build-and-push-docker-image:
name: Build Docker image and push to repositories
runs-on: ubuntu-latest
strategy:
matrix:
BRANCH_CHECKOUT:
- ${{ github.event.inputs.commit_id || 'main' }}
platforms:
- linux/amd64
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Docker Hub
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Login to GitHub Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.repository_owner }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Set env git short head
run: echo "COMMIT_SHORT=$(git rev-parse --short HEAD)" >> $GITHUB_ENV
- name: Meta data image
id: meta
uses: docker/metadata-action@v5
with:
images: |
${{ secrets.DOCKERHUB_USERNAME }}/clone-voice
ghcr.io/${{ github.repository_owner }}/clone-voice
tags: |
type=raw,value=${{ matrix.BRANCH_CHECKOUT }}
type=raw,value=${{ env.COMMIT_SHORT }}
flavor: |
latest=false
- name: Build push image
id: build
uses: docker/build-push-action@v5
with:
context: .
file: ./docker/build@source/dockerfile
platforms: ${{ matrix.platforms }}
push: true
tags: ${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}
- name: Print image digest
run: echo ${{ steps.build.outputs.digest }}
================================================
FILE: .gitignore
================================================
.idea/
*.pyc
*.pyd
.DS_Store
__pycache__
scripts
ku
build
dist
docs
include
Lib
notebooks
recipes
share
venv
tests
dev
ffmpeg.exe
ffprobe.exe
*.zip
*.rar
*.exe
*.log
pyvenv.cfg
setup.cfg
*.pth
*.pt
cn1.wav
sx1.wav
*.spec
tts/tts_models--multilingual--multi-dataset--xtts_v2
tts/voice_conversion_models--multilingual--vctk--freevc24
tts/wavlm
tts/*.7z
tts_cache/*
tts/mymodels/xiaomi
tts/1voice_conversion_models--multilingual--vctk--freevc24
hubconf.py
static/ttslist/*
static/tmp/*.wav
static/ttslist/*.wav
*.pth
*.out
*.bin
*.7z
cache
================================================
FILE: .vscode/launch.json
================================================
{
"version": "0.2.0",
"configurations": [
{
"name": "debugpy: code_dev",
"type": "debugpy",
"request": "launch",
"program": "${workspaceFolder}/code_dev.py",
"console": "integratedTerminal",
"justMyCode": false
},
{
"name": "debugpy: app",
"type": "debugpy",
"request": "launch",
"program": "${workspaceFolder}/app.py",
"console": "integratedTerminal",
"env": {
"WEB_ADDRESS": "0.0.0.0:9988",
"ENABLE_STS": "1",
"DEVICE": "CUDA",
"PATH": "${env:PATH}:${env:CONDA_PREFIX}/envs/clone-voice/bin"
},
"justMyCode": false
},
]
}
================================================
FILE: .vscode/tasks.json
================================================
{
"version": "2.0.0",
"tasks": [
{
"label": "docker: compose up@gpu",
"type": "shell",
"options": {
"cwd": "${workspaceFolder}/docker/up@gpu/"
},
"command": "docker compose -p clone-voice up",
},
{
"label": "docker: compose up@cpu",
"type": "shell",
"options": {
"cwd": "${workspaceFolder}/docker/up@cpu/"
},
"command": "docker compose -p clone-voice up",
},
{
"label": "docker: build main",
"type": "shell",
"command": "docker build -t jianchang512/clone-voice:main -f ./docker/build@source/dockerfile .",
},
{
"label": "conda: run code_dev",
"type": "shell",
"options": {
"cwd": "${workspaceFolder}"
},
"command": "conda run -n clone-voice python code_dev.py",
},
{
"label": "conda: run app",
"type": "shell",
"options": {
"cwd": "${workspaceFolder}",
"env": {
"WEB_ADDRESS": "0.0.0.0:9988",
"ENABLE_STS": "1",
"PATH": "${env:PATH}:${env:CONDA_PREFIX}/envs/clone-voice/bin"
}
},
"command": "conda run -n clone-voice python app.py"
},
{
"label": "huggingface-cli: download model Voice-Conversion",
"type": "shell",
"options": {
"cwd": "${workspaceFolder}",
"env": {
"HF_ENDPOINT": "https://hf-mirror.com",
"HF_HUB_ETAG_TIMEOUT": "1000",
"HF_HUB_DOWNLOAD_TIMEOUT": "1000"
}
},
"command": [
"huggingface-cli download --revision main --cache-dir ./cache --repo-type space vuxuanhoan/Voice-Conversion",
"&& huggingface-cli download --revision main --cache-dir ./cache --local-dir ./tts --local-dir-use-symlinks False --repo-type space vuxuanhoan/Voice-Conversion --include 'tts_models/*'",
"&& mv ./tts/tts_models/voice_conversion_models--multilingual--vctk--freevc24 ./tts/",
"&& mv ./tts/tts_models/wavlm ./tts/",
]
},
{
"label": "huggingface-cli: download model xtts_v2",
"type": "shell",
"options": {
"cwd": "${workspaceFolder}",
"env": {
"HF_ENDPOINT": "https://hf-mirror.com",
"HF_HUB_ETAG_TIMEOUT": "1000",
"HF_HUB_DOWNLOAD_TIMEOUT": "1000"
}
},
"command": [
"huggingface-cli download --resume-download --revision v2.0.2 --cache-dir ./cache coqui/XTTS-v2",
"&& huggingface-cli download --revision v2.0.2 --cache-dir ./cache --local-dir ./tts/tts_models--multilingual--multi-dataset--xtts_v2 --local-dir-use-symlinks False coqui/XTTS-v2",
]
},
{
"label": "conda: create env",
"type": "shell",
"command": [
"conda env create -f environment.yml"
]
}
]
}
================================================
FILE: LICENSE
================================================
本项目所用模型为[coqui.ai](https://coqui.ai/)出品的xtts_v2,模型开源协议为[Coqui Public Model License 1.0.0](https://coqui.ai/cpml.txt),使用本项目请遵循该协议,协议全文见 https://coqui.ai/cpml.txt
The model used in this project is xtts_v2 produced by [coqui.ai](https://coqui.ai/), and the model open source license is [Coqui Public Model License 1.0.0](https://coqui.ai/cpml.txt) , please follow this agreement when using this project. The full text of the agreement can be found at https://coqui.ai/cpml.txt
----
Coqui Public Model License 1.0.0
https://coqui.ai/cpml.txt
This license allows only non-commercial use of a machine learning model and its outputs.
Acceptance
In order to get any license under these terms, you must agree to them as both strict obligations and conditions to all your licenses.
Licenses
The licensor grants you a copyright license to do everything you might do with the model that would otherwise infringe the licensor's copyright in it, for any non-commercial purpose. The licensor grants you a patent license that covers patent claims the licensor can license, or becomes able to license, that you would infringe by using the model in the form provided by the licensor, for any non-commercial purpose.
Non-commercial Purpose
Non-commercial purposes include any of the following uses of the model or its output, but only so far as you do not receive any direct or indirect payment arising from the use of the model or its output.
Personal use for research, experiment, and testing for the benefit of public knowledge, personal study, private entertainment, hobby projects, amateur pursuits, or religious observance.
Use by commercial or for-profit entities for testing, evaluation, or non-commercial research and development. Use of the model to train other models for commercial use is not a non-commercial purpose.
Use by any charitable organization for charitable purposes, or for testing or evaluation. Use for revenue-generating activity, including projects directly funded by government grants, is not a non-commercial purpose.
Notices
You must ensure that anyone who gets a copy of any part of the model, or any modification of the model, or their output, from you also gets a copy of these terms or the URL for them above.
No Other Rights
These terms do not allow you to sublicense or transfer any of your licenses to anyone else, or prevent the licensor from granting licenses to anyone else. These terms do not imply any other licenses.
Patent Defense
If you make any written claim that the model infringes or contributes to infringement of any patent, your licenses for the model granted under these terms ends immediately. If your company makes such a claim, your patent license ends immediately for work on behalf of your company.
Violations
The first time you are notified in writing that you have violated any of these terms, or done anything with the model or its output that is not covered by your licenses, your licenses can nonetheless continue if you come into full compliance with these terms, and take practical steps to correct past violations, within 30 days of receiving notice. Otherwise, all your licenses end immediately.
No Liability
AS FAR AS THE LAW ALLOWS, THE MODEL AND ITS OUTPUT COME AS IS, WITHOUT ANY WARRANTY OR CONDITION, AND THE LICENSOR WILL NOT BE LIABLE TO YOU FOR ANY DAMAGES ARISING OUT OF THESE TERMS OR THE USE OR NATURE OF THE MODEL OR ITS OUTPUT, UNDER ANY KIND OF LEGAL CLAIM. IF THIS PROVISION IS NOT ENFORCEABLE IN YOUR JURISDICTION, YOUR LICENSES ARE VOID.
Definitions
The licensor is the individual or entity offering these terms, and the model is the model the licensor makes available under these terms, including any documentation or similar information about the model.
You refers to the individual or entity agreeing to these terms.
Your company is any legal entity, sole proprietorship, or other kind of organization that you work for, plus all organizations that have control over, are under the control of, or are under common control with that organization. Control means ownership of substantially all the assets of an entity, or the power to direct its management and policies by vote, contract, or otherwise. Control can be direct or indirect.
Your licenses are all the licenses granted to you under these terms.
Use means anything you do with the model or its output requiring one of your licenses.
We collect and process your personal information for visitor statistics and browsing behavior. 🍪
================================================
FILE: README.md
================================================
[English README](./README_EN.md) / [捐助项目](https://github.com/jianchang512/pyvideotrans/issues/80) / [Discord](https://discord.gg/7ZWbwKGMcx)
# CV声音克隆工具
> 本项目所用模型为[coqui.ai](https://coqui.ai/)出品的xtts_v2,模型开源协议为[Coqui Public Model License 1.0.0](https://coqui.ai/cpml.txt),使用本项目请遵循该协议,协议全文见 https://coqui.ai/cpml.txt
这是一个声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。
使用非常简单,没有N卡GPU也可以使用,下载预编译版本,双击 app.exe 打开一个web界面,鼠标点点就能用。
支持 **中、英、日、韩、法、德、意等16种语言**,可在线从麦克风录制声音。
为保证合成效果,建议录制时长5秒到20秒,发音清晰准确,不要存在背景噪声。
英文效果很棒,中文效果还凑合。
# 视频演示
https://github.com/jianchang512/clone-voice/assets/3378335/4e63f2ac-cc68-4324-a4d9-ecf4d4f81acd
# window预编译版使用方法(其他系统可源码部署)
1. [点击此处打开Releases下载页面](https://github.com/jianchang512/clone-voice/releases),下载预编译版主文件(1.7G) 和 模型(3G)
2. 下载后解压到某处,比如 E:/clone-voice 下
3. 双击 app.exe ,等待自动打开web窗口,**请仔细阅读cmd窗口的文字提示**,如有错误,均会在此显示
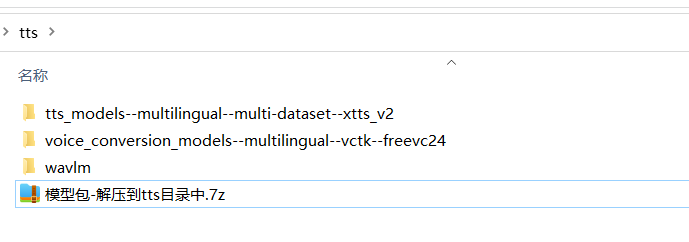
4. 模型下载后解压到软件目录下的 `tts` 文件夹内,解压后效果如图
5. 转换操作步骤
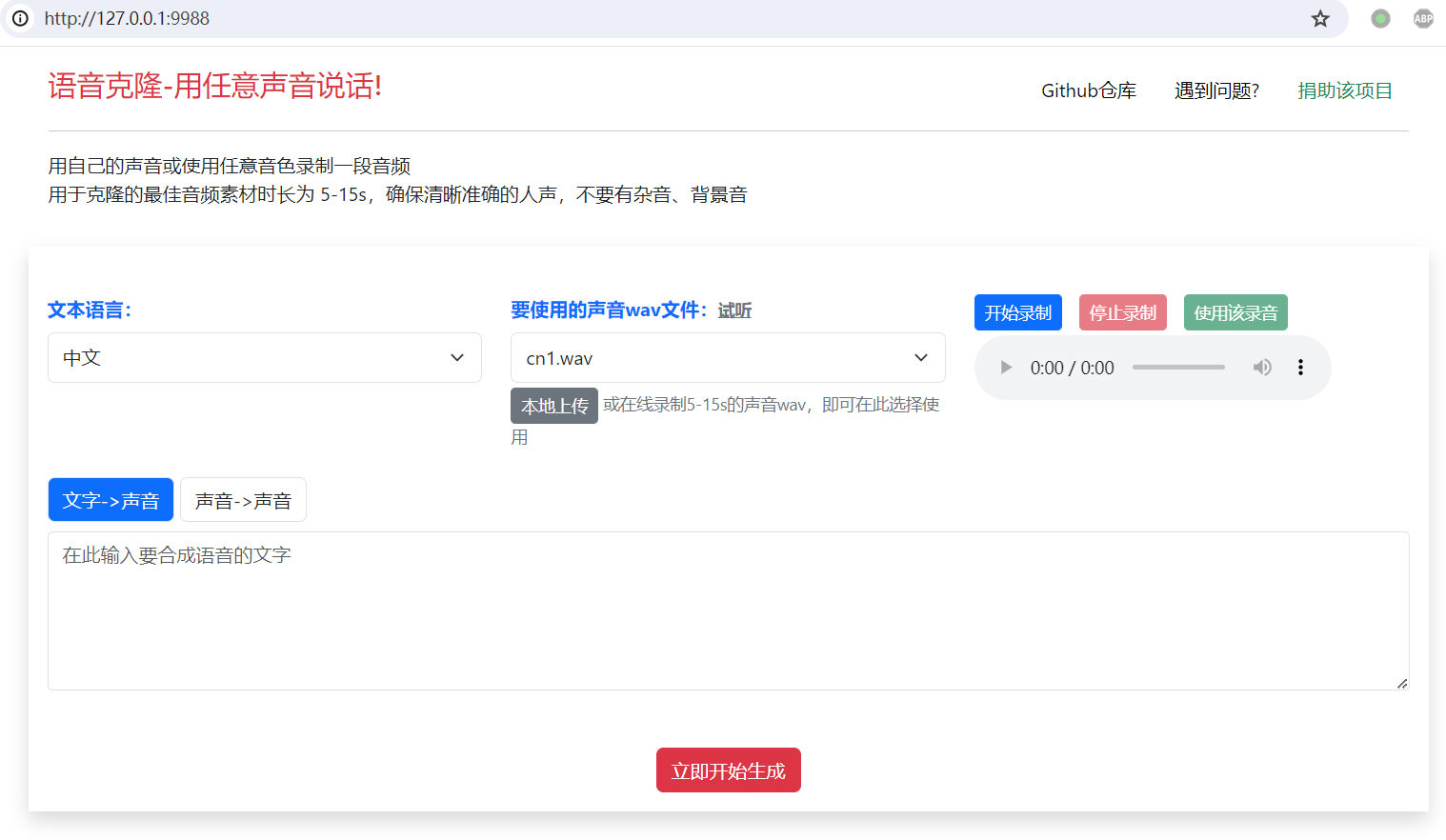
- 选择【文字->声音】按钮,在文本框中输入文字、或点击导入srt字幕文件,然后点击“立即开始”。
- 选择【声音->声音】按钮,点击或拖拽要转换的音频文件(mp3/wav/flac),然后从“要使用的声音文件”下拉框中选择要克隆的音色,如果没有满意的,也可以点击“本地上传”按钮,选择已录制好的5-20s的wav/mp3/flac声音文件。或者点击“开始录制”按钮,在线录制你自己的声音5-20s,录制完成点击使用。然后点击“立即开始”按钮
6. 如果机器拥有N卡GPU,并正确配置了CUDA环境,将自动使用CUDA加速
# 源码部署(linux mac window)
**源码版需要在 .env 中 HTTP_PROXY=设置代理(比如http://127.0.0.1:7890),要从 https://huggingface.co https://github.com 下载模型,而这个网址国内无法访问,必须保证代理稳定可靠,否则大模型下载可能中途失败**
0. 要求 python 3.9->3.11, 并且提前安装好 git-cmd 工具,[下载地址](https://github.com/git-for-windows/git/releases/download/v2.44.0.windows.1/Git-2.44.0-64-bit.exe)
1. 创建空目录,比如 E:/clone-voice, 在这个目录下打开 cmd 窗口,方法是地址栏中输入 `cmd`, 然后回车。
使用git拉取源码到当前目录 ` git clone git@github.com:jianchang512/clone-voice.git . `
2. 创建虚拟环境 `python -m venv venv`
3. 激活环境,win下 `E:/clone-voice/venv/scripts/activate`,
4. 安装依赖: `pip install -r requirements.txt --no-deps`,
windows 和 linux 如果要启用cuda加速,继续执行 `pip uninstall -y torch` 卸载,然后执行`pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121`。(必须有N卡并且配置好CUDA环境)
5. win下解压 ffmpeg.7z,将其中的`ffmpeg.exe`和`app.py`在同一目录下, linux和mac 到 [ffmpeg官网](https://ffmpeg.org/download.html)下载对应版本ffmpeg,解压其中的`ffmpeg`程序到根目录下,必须将可执行二进制文件 `ffmpeg` 和app.py放在同一目录下。

6. **首先运行** `python code_dev.py `,在提示同意协议时,输入 `y`,然后等待模型下载完毕。


下载模型需要挂全局代理,模型非常大,如果代理不够稳定可靠,可能会遇到很多错误,大部分的错误均是代理问题导致。
如果显示下载多个模型均成功了,但最后还是提示“Downloading WavLM model”错误,则需要修改库包文件 `\venv\Lib\site-packages\aiohttp\client.py`, 在大约535行附近,`if proxy is not None:` 上面一行添加你的代理地址,比如 `proxy="http://127.0.0.1:10809"`.
7. 下载完毕后,再启动 `python app.py`
8. **【训练说明】** 如果想训练,执行 `python train.py`, 训练参数在 `param.json`中调整,调整后重新执行训练脚本`python train.py`
8. 每次启动都会连接墙外检测或更新模型,请耐心等待。如果不想每次启动都检测或更新,需手动修改依赖包下文件,打开 \venv\Lib\site-packages\TTS\utils\manage.py ,大约 389 行附近,def download_model 方法中,注释掉如下代码
```
if md5sum is not None:
md5sum_file = os.path.join(output_path, "hash.md5")
if os.path.isfile(md5sum_file):
with open(md5sum_file, mode="r") as f:
if not f.read() == md5sum:
print(f" > {model_name} has been updated, clearing model cache...")
self.create_dir_and_download_model(model_name, model_item, output_path)
else:
print(f" > {model_name} is already downloaded.")
else:
print(f" > {model_name} has been updated, clearing model cache...")
self.create_dir_and_download_model(model_name, model_item, output_path)
```
9. 源码版启动时可能频繁遇到错误,基本都是代理问题导致无法从墙外下载模型或下载中断不完整。建议使用稳定的代理,全局开启。如果始终无法完整下载,建议使用预编译版。
# 常见问题
**模型xtts仅可用于学习研究,不可用于商业**
0. 源码版需要在 .env 中 HTTP_PROXY=设置代理(比如http://127.0.0.1:7890),要从 https://huggingface.co https://github.com 下载模型,而这个网址国内无法访问,必须保证代理稳定可靠,否则大模型下载可能中途失败
1. 启动后需要冷加载模型,会消耗一些时间,请耐心等待显示出`http://127.0.0.1:9988`, 并自动打开浏览器页面后,稍等两三分钟后再进行转换
2. 功能有:
文字到语音:即输入文字,用选定的音色生成声音。
声音到声音:即从本地选择一个音频文件,用选定的音色生成另一个音频文件.
3. 如果打开的cmd窗口很久不动,需要在上面按下回车才继续输出,请在cmd左上角图标上单击,选择“属性”,然后取消“快速编辑”和“插入模式”的复选框


4. 预编译版 声音-声音线程启动失败
首先确认模型已正确下载放置。tts文件夹内有3个文件夹,如下图

如果已正确放置了,但仍错误,[点击下载 extra-to-tts_cache.zip](https://github.com/jianchang512/clone-voice/releases/download/v0.0.1/extra-to-tts_cache.zip) ,将解压后得到的2个文件,复制到软件根目录的 tts_cache 文件夹内
如果上述方法无效,在 .env 文件中 HTTP_PROXY后填写代理地址比如 `HTTP_PROXY=http://127.0.0.1:7890`,可解决该问题,必须确保代理稳定,填写端口正确
5. 提示 “The text length exceeds the character limit of 182/82 for language”
这是因为由句号分隔的句子太长导致的,建议将太长的语句使用句号隔开,而不是大量使用逗号,或者你也可以打开 clone/character.json文件,手动修改限制
6. 提示"symbol not found __svml_cosf8_ha"
打开网页 https://www.dll-files.com/svml_dispmd.dll.html ,点击红色"Download"下载字样,下载后解压,将里面的dll文件复制粘贴到"C:\Windows\System32"
# CUDA 加速支持
**安装CUDA工具** [详细安装方法](https://juejin.cn/post/7318704408727519270)
如果你的电脑拥有 Nvidia 显卡,先升级显卡驱动到最新,然后去安装对应的
[CUDA Toolkit 11.8](https://developer.nvidia.com/cuda-downloads) 和 [cudnn for CUDA11.X](https://developer.nvidia.com/rdp/cudnn-archive)。
安装完成成,按`Win + R`,输入 `cmd`然后回车,在弹出的窗口中输入`nvcc --version`,确认有版本信息显示,类似该图

然后继续输入`nvidia-smi`,确认有输出信息,并且能看到cuda版本号,类似该图
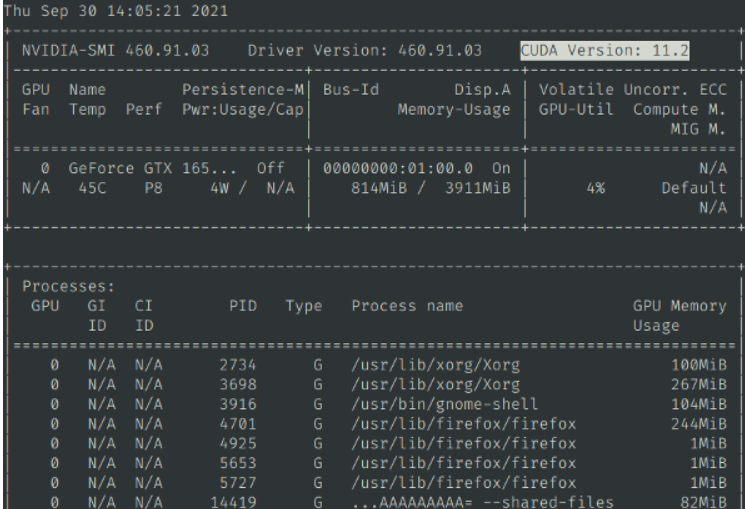
说明安装正确,可以cuda加速了,否则需重新安装
# 相关联项目
[视频翻译配音工具:翻译字幕并配音](https://github.com/jianchang512/pyvideotrans)
[语音识别工具:本地离线的语音识别转文字工具](https://github.com/jianchang512/stt)
[人声背景乐分离:极简的人声和背景音乐分离工具,本地化网页操作](https://github.com/jianchang512/vocal-separate)
# [Youtube演示视频](https://youtu.be/CC227GXOJLk)
================================================
FILE: README_EN.md
================================================
[简体中文](./README.md) / [Discord](https://discord.gg/TMCM2PfHzQ) / [Buy me a coffee](https://ko-fi.com/jianchang512) / [Twitter](https://twitter.com/mortimer_wang)
# CV Voice Clone Tool
> The model used in this project is xtts_v2 produced by [coqui.ai](https://coqui.ai/), and the model open source license is [Coqui Public Model License 1.0.0](https://coqui.ai/cpml.txt) , please follow this agreement when using this project. The full text of the agreement can be found at https://coqui.ai/cpml.txt
This is a voice cloning tool that can use any human voice to synthesize a piece of text into a voice using that voice, or to convert one voice into another using that voice.
It's very easy to use, even without an N-series GPU. Download the precompiled version and double click on app.exe to open a web interface, and it can be used with a few mouse clicks.
Supports **Chinese English Japanese Korean eg. total 16 languages**, and can record voices online through a microphone.
To ensure the synthesized effect, it's recommended to record for 5 to 20 seconds, pronounce clearly and accurately, and don't have background noise.
# Video Demonstration
https://github.com/jianchang512/clone-voice/assets/3378335/813d46dd-7634-43d1-97ae-1531369c471f

# How to use the precompiled version under win (other systems can deploy source code)
1. Download the 'precompiled version of the main file(1.7G) and Model(3G) separately from [Releases](https://github.com/jianchang512/clone-voice/releases) on the right.
2. After downloading, unzip it to somewhere, for example E:/clone-voice.
3. Double click app.exe, wait for the web window to open automatically, **Please read the text prompts in the CMD window carefully**, if there are errors, they will be displayed here.
4. After the model download, unzip it to the tts folder under the software directory, the effect after unzipping is as shown in the picture

5. Conversion operation steps:
- Enter the text in the text box, or import the SRT file, or select "Voice-> Voice", choose the voice wav format file you want to convert.
- Then select the voice you want to use from the drop-down box under "Voice wav file to use", if you are not satisfied, you can also click the "Upload locally" button, select a recorded 5-20s wav voice file. Or click the "Start recording" button to record your own voice for 5-20 seconds online, after recording, click to use.
- Click the "Start Generating Now" button and wait patiently for completion.
6. If the machine has an N card GPU and CUDA environment is correctly configured, CUDA acceleration will be used automatically.
# Source Code Deployment (linux mac window) / Example: window
**If your area can't access google and huggingface, you'll need a global proxy because models need to be downloaded from github and huggingface**
0. Required python 3.9-> 3.11, and enable a global proxy, ensure the proxy is stable
1. Create an empty directory, such as E:/clone-voice, open a cmd window in this directory, the method is to type `cmd` in the address bar, then press Enter.
and exec git pull source code `git clone git@github.com:jianchang512/clone-voice.git . `
2. Create a virtual environment `python -m venv venv`
3. Activate the environment `E:/clone-voice/venv/scripts/activate`, linux and Mac exec `source ./venv/bin/activate`
4. Install dependencies: `pip install -r requirements.txt`
5. Unzip the ffmpeg.7z to the project root directory;for Linux and Mac, download the corresponding version of ffmpeg from the [ffmpeg official website](https://ffmpeg.org/download.html), unzip it to the root directory, and make sure to place the executable file ffmepg directly in the root directory.

6. **First run** `python code_dev.py`, enter `y` when prompted to accept the agreement, then wait for the model to be downloaded completely.

7. After downloading, restart `python app.py`.
8. Every startup will connect to the foreign Internet to check or update the model, please be patient and wait. If you don't want to check or update every time you start, you need to manually modify the files under the dependent package, open \venv\Lib\site-packages\TTS\utils\manage.py, around line 389, def download_model method, comment out the following code.
```
if md5sum is not None:
md5sum_file = os.path.join(output_path, "hash.md5")
if os.path.isfile(md5sum_file):
with open(md5sum_file, mode="r") as f:
if not f.read() == md5sum:
print(f" > {model_name} has been updated, clearing model cache...")
self.create_dir_and_download_model(model_name, model_item, output_path)
else:
print(f" > {model_name} is already downloaded.")
else:
print(f" > {model_name} has been updated, clearing model cache...")
self.create_dir_and_download_model(model_name, model_item, output_path)
```
9. The startup of the source code version may frequently encounter errors, which are basically due to proxy problems that prevent the download of models from the walls or the download is interrupted and not complete. It is recommended to use a stable proxy and open it globally. If you can't download completely all the time, it's recommended to use the precompiled version.
# CUDA Acceleration Support
**Installation of CUDA tools**
If your computer has Nvidia graphics card, upgrade the graphics card driver to the latest, then go to install the corresponding [CUDA Toolkit 11.8](https://developer.nvidia.com/cuda-downloads) and [cudnn for CUDA11.X](https://developer.nvidia.com/rdp/cudnn-archive).
When installation is complete, press `Win + R`, type `cmd` then press Enter, in the pop-up window type `nvcc --version`, confirm the version information display, similar to this image

Then continue to type `nvidia-smi`, confirm there's output information, and you can see the cuda version number, similar to this image

That means the installation is correct, you can cuda accelerate now, otherwise you need to reinstall.
# Precautions
The model xtts can only be used for study and research, not for commerical use
0. The source code version requires global proxy, because it needs to download models from https://huggingface.co, and this website can't be accessed in China, the source code version may frequently encounter errors when starting, basically proxy problems lead to unable to download models from overseas or download interruption incomplete. It's recommended to use a stable proxy, open it globally. If you can't download completely all the time, it's recommended to use the precompiled version.
1. It will consume some time to load the model coldly after starting, please wait patiently for `http://127.0.0.1:9988` to be displayed, and automatically open the browser page, wait for two or three minutes before converting.
2. Functions include:
Text to voice: that is, enter the text, generate voice with the selected voice.
Voice to Voice: that is, select an audio file from the local area, generate another audio file with the selected voice.
3. If the cmd window opened for a long time doesn't move, you need to press Enter on it to continue output, please click on the icon in the upper left corner of cmd, select "Properties", then uncheck the "Quick Edit" and "Insert Mode" checkboxes
4. “The text length exceeds the character limit of 182/82 for language”
This is because sentences separated by periods are too long. It is recommended to use periods to separate sentences that are too long, rather than excessive use of commas,
# [Youtube Demo Video](https://youtu.be/NL5cIoJ9Gjo)
================================================
FILE: app.py
================================================
import datetime
import logging
import queue
import re
import threading
import time
import sys
from flask import Flask, request, render_template, jsonify, send_file, send_from_directory
import os
import glob
import hashlib
from logging.handlers import RotatingFileHandler
import clone
from clone import cfg
from clone.cfg import ROOT_DIR, TTS_DIR, VOICE_MODEL_EXITS, TMP_DIR, VOICE_DIR, TEXT_MODEL_EXITS, langlist
from clone.logic import ttsloop, stsloop, create_tts, openweb, merge_audio_segments, get_subtitle_from_srt, updatecache
from clone import logic
import shutil
import subprocess
from dotenv import load_dotenv
from waitress import serve
load_dotenv()
web_address = os.getenv('WEB_ADDRESS', '127.0.0.1:9988')
enable_sts = int(os.getenv('ENABLE_STS', '0'))
updatecache()
# 配置日志
# 禁用 Werkzeug 默认的日志处理器
log = logging.getLogger('werkzeug')
log.handlers[:] = []
log.setLevel(logging.WARNING)
app = Flask(__name__, static_folder=os.path.join(ROOT_DIR, 'static'), static_url_path='/static',
template_folder=os.path.join(ROOT_DIR, 'templates'))
root_log = logging.getLogger() # Flask的根日志记录器
root_log.handlers = []
root_log.setLevel(logging.WARNING)
app.logger.setLevel(logging.WARNING) # 设置日志级别为 INFO
# 创建 RotatingFileHandler 对象,设置写入的文件路径和大小限制
file_handler = RotatingFileHandler(os.path.join(ROOT_DIR, 'app.log'), maxBytes=1024 * 1024, backupCount=5)
# 创建日志的格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 设置文件处理器的级别和格式
file_handler.setLevel(logging.WARNING)
file_handler.setFormatter(formatter)
# 将文件处理器添加到日志记录器中
app.logger.addHandler(file_handler)
app.jinja_env.globals.update(enumerate=enumerate)
@app.route('/static/<path:filename>')
def static_files(filename):
return send_from_directory(app.config['STATIC_FOLDER'], filename)
@app.route('/')
def index():
return render_template("index.html",
text_model=TEXT_MODEL_EXITS,
voice_model=VOICE_MODEL_EXITS,
version=clone.ver,
mymodels=cfg.MYMODEL_OBJS,
language=cfg.LANG,
langlist=cfg.langlist,
root_dir=ROOT_DIR.replace('\\', '/'))
# 上传音频
@app.route('/upload', methods=['POST'])
@app.route('/upload', methods=['POST'])
def upload():
try:
# 获取上传的文件
audio_file = request.files['audio']
save_dir = request.form.get("save_dir")
save_dir = VOICE_DIR if not save_dir else os.path.join(ROOT_DIR, f'static/{save_dir}')
app.logger.info(f"[upload]{audio_file.filename=},{save_dir=}")
# 检查文件是否存在且是 WAV/mp3格式
noextname, ext = os.path.splitext(os.path.basename(audio_file.filename.lower()))
noextname = noextname.replace(' ', '')
if audio_file and ext in [".wav", ".mp3", ".flac"]:
# 保存文件到服务器指定目录
name = f'{noextname}{ext}'
if os.path.exists(os.path.join(save_dir, f'{noextname}{ext}')):
name = f'{datetime.datetime.now().strftime("%m%d-%H%M%S")}-{noextname}{ext}'
# mp3 or wav
tmp_wav = os.path.join(TMP_DIR, "tmp_" + name)
audio_file.save(tmp_wav)
# save to wav
if ext != '.wav':
name = f"{name[:-len(ext)]}.wav"
savename = os.path.join(save_dir, name)
subprocess.run(['ffmpeg', '-hide_banner', '-y', '-i', tmp_wav, savename], check=True)
try:
os.unlink(tmp_wav)
except:
pass
# 返回成功的响应
return jsonify({'code': 0, 'msg': 'ok', "data": name})
else:
# 返回错误的响应
return jsonify({'code': 1, 'msg': 'not wav'})
except Exception as e:
app.logger.error(f'[upload]error: {e}')
return jsonify({'code': 2, 'msg': 'error'})
# 从 voicelist 目录获取可用的 wav 声音列表
@app.route('/init')
def init():
wavs = glob.glob(f"{VOICE_DIR}/*.wav")
result = []
for it in wavs:
if os.path.getsize(it) > 0:
result.append(os.path.basename(it))
result.extend(cfg.MYMODEL_OBJS.keys())
return jsonify(result)
# 判断线程是否启动
@app.route('/isstart', methods=['GET', 'POST'])
def isstart():
return jsonify(cfg.MYMODEL_OBJS)
# 外部接口
@app.route('/apitts', methods=['GET', 'POST'])
def apitts():
'''
audio:原始声音wav,作为音色克隆源
voice:已有的声音名字,如果存在 voice则先使用,否则使用audio
text:文字一行
language:语言代码
Returns:
'''
try:
langcodelist = ["zh-cn", "en", "ja", "ko", "es", "de", "fr", "it", "tr", "ru", "pt", "pl", "nl", "ar", "hu", "cs"]
text = request.form.get("text","").strip()
model = request.form.get("model","").strip()
text = text.replace("\n", ' . ')
language = request.form.get("language", "").lower()
if language.startswith("zh"):
language = "zh-cn"
if language not in langcodelist:
return jsonify({"code": 1, "msg": f" {language} dont support language "})
md5_hash = hashlib.md5()
audio_name = request.form.get('voice','')
voicename=""
model=""
# 存在传来的声音文件名字
print(f'1,{text=},{model=},{audio_name=},{language=}')
if audio_name and audio_name.lower().endswith('.wav'):
voicename = os.path.join(VOICE_DIR, audio_name)
if not os.path.exists(voicename):
return jsonify({"code": 2, "msg": f"{audio_name} 不存在"})
if os.path.isdir(voicename):
model=audio_name
voicename=""
elif audio_name:
#存在,是新模型
model=audio_name
elif not audio_name: # 不存在,原声复制 clone 获取上传的文件
audio_file = request.files['audio']
print(f'{audio_file.filename}')
# 保存临时上传过来的声音文件
audio_name = f'video_{audio_file.filename}.wav'
voicename = os.path.join(TMP_DIR, audio_name)
audio_file.save(voicename)
print(f'22={text=},{model=},{audio_name=},{language=}')
md5_hash.update(f"{text}-{language}-{audio_name}-{model}".encode('utf-8'))
app.logger.info(f"[apitts]{voicename=}")
if re.match(r'^[~`!@#$%^&*()_+=,./;\':\[\]{}<>?\\|",。?;‘:“”’{【】}!·¥、\s\n\r -]*$', text):
return jsonify({"code": 3, "msg": "lost text for translate"})
if not text or not language:
return jsonify({"code": 4, "msg": "text & language params lost"})
app.logger.info(f"[apitts]{text=},{language=}")
# 存放结果
# 合成后的语音文件, 以wav格式存放和返回
filename = md5_hash.hexdigest() + ".wav"
app.logger.info(f"[apitts]{filename=}")
# 合成语音
rs = create_tts(text=text,model=model, speed=1.0, voice=voicename, language=language, filename=filename)
# 已有结果或错误,直接返回
if rs is not None:
print(f'{rs=}')
result = rs
else:
# 循环等待 最多7200s
time_tmp = 0
while filename not in cfg.global_tts_result:
time.sleep(3)
time_tmp += 3
if time_tmp % 30 == 0:
app.logger.info(f"[apitts][tts]{time_tmp=},{filename=}")
if time_tmp>3600:
return jsonify({"code": 5, "msg": f'error:{text}'})
# 当前行已完成合成
target_wav = os.path.normpath(os.path.join(TTS_DIR, filename))
if not os.path.exists(target_wav):
msg = {"code": 6, "msg": cfg.global_tts_result[filename] if filename in cfg.global_tts_result else "error"}
else:
msg = {"code": 0, "filename": target_wav, 'name': filename}
app.logger.info(f"[apitts][tts] {filename=},{msg=}")
try:
cfg.global_tts_result.pop(filename)
except:
pass
result = msg
app.logger.info(f"[apitts]{msg=}")
if result['code'] == 0:
result['url'] = f'http://{web_address}/static/ttslist/{filename}'
return jsonify(result)
except Exception as e:
msg = f'{str(e)} {str(e.args)}'
app.logger.error(f"[apitts]{msg}")
return jsonify({'code': 7, 'msg': msg})
# 根据文本返回tts结果,返回 name=文件名字,filename=文件绝对路径
# 请求端根据需要自行选择使用哪个
# params
# text:待合成文字
# voice:声音文件
# language:语言代码
@app.route('/tts', methods=['GET', 'POST'])
def tts():
# 原始字符串
text = request.form.get("text","").strip()
voice = request.form.get("voice",'')
speed = 1.0
try:
speed = float(request.form.get("speed",1))
except:
pass
language = request.form.get("language",'')
model = request.form.get("model","")
app.logger.info(f"[tts][tts]recev {text=}\n{voice=},{language=}\n")
if re.match(r'^[~`!@#$%^&*()_+=,./;\':\[\]{}<>?\\|",。?;‘:“”’{【】}!·¥、\s\n\r -]*$', text):
return jsonify({"code": 1, "msg": "no text"})
if not text or not voice or not language:
return jsonify({"code": 1, "msg": "text/voice/language params lost"})
# 判断是否是srt
text_list = get_subtitle_from_srt(text)
app.logger.info(f"[tts][tts]{text_list=}")
is_srt = True
# 不是srt格式,则按行分割
if text_list is None:
is_srt = False
text_list = []
for it in text.split("\n"):
text_list.append({"text": it.strip()})
app.logger.info(f"[tts][tts] its not srt")
num = 0
while num < len(text_list):
t = text_list[num]
# 换行符改成 .
t['text'] = t['text'].replace("\n", ' . ')
md5_hash = hashlib.md5()
md5_hash.update(f"{t['text']}-{voice}-{language}-{speed}-{model}".encode('utf-8'))
filename = md5_hash.hexdigest() + ".wav"
app.logger.info(f"[tts][tts]{filename=}")
# 合成语音
rs = create_tts(text=t['text'], model=model,speed=speed, voice=os.path.join(cfg.VOICE_DIR, voice), language=language, filename=filename)
# 已有结果或错误,直接返回
if rs is not None:
text_list[num]['result'] = rs
num += 1
continue
# 循环等待 最多7200s
time_tmp = 0
# 生成的目标音频
target_wav = os.path.normpath(os.path.join(TTS_DIR, filename))
msg=None
while filename not in cfg.global_tts_result and not os.path.exists(target_wav):
time.sleep(3)
time_tmp += 3
if time_tmp % 30 == 0:
app.logger.info(f"[tts][tts]{time_tmp=},{filename=}")
if time_tmp>3600:
msg={"code": 1, "msg":f'{filename} error'}
text_list[num]['result'] = msg
num+=1
break
if msg is not None:
continue
# 当前行已完成合成
if not os.path.exists(target_wav):
msg = {"code": 1, "msg": "not exists"}
else:
if speed != 1.0 and speed > 0 and speed <= 2.0:
# 生成的加速音频
speed_tmp = os.path.join(TMP_DIR, f'speed_{time.time()}.wav')
p = subprocess.run(
['ffmpeg', '-hide_banner', '-ignore_unknown', '-y', '-i', target_wav, '-af', f"atempo={speed}",
os.path.normpath(speed_tmp)], encoding="utf-8", capture_output=True)
if p.returncode != 0:
return jsonify({"code": 1, "msg": str(p.stderr)})
shutil.copy2(speed_tmp, target_wav)
msg = {"code": 0, "filename": target_wav, 'name': filename}
app.logger.info(f"[tts][tts] {filename=},{msg=}")
try:
cfg.global_tts_result.pop(filename)
except:
pass
text_list[num]['result'] = msg
app.logger.info(f"[tts][tts]{num=}")
num += 1
filename, errors = merge_audio_segments(text_list, is_srt=is_srt)
app.logger.info(f"[tts][tts]is srt,{filename=},{errors=}")
if filename and os.path.exists(filename) and os.path.getsize(filename) > 0:
res = {"code": 0, "filename": filename, "name": os.path.basename(filename), "msg": errors}
else:
res = {"code": 1, "msg": f"error:{filename=},{errors=}"}
app.logger.info(f"[tts][tts]end result:{res=}")
return jsonify(res)
# s to s wav->wav
# params
# voice: 声音文件
# filename: 上传的原始声音
@app.route('/sts', methods=['GET', 'POST'])
def sts():
try:
# 保存文件到服务器指定目录
# 目标
voice = request.form.get("voice",'')
filename = request.form.get("name",'')
app.logger.info(f"[sts][sts]sts {voice=},{filename=}\n")
if not voice:
return jsonify({"code": 1, "msg": "voice params lost"})
obj = {"filename": filename, "voice": voice}
# 压入队列,准备转换语音
app.logger.info(f"[sts][sts]push sts")
cfg.q_sts.put(obj)
# 已有结果或错误,直接返回
# 循环等待 最多7200s
time_tmp = 0
while filename not in cfg.global_sts_result:
time.sleep(3)
time_tmp += 3
if time_tmp % 30 == 0:
app.logger.info(f"{time_tmp=},{filename=}")
# 当前行已完成合成
if cfg.global_sts_result[filename] != 1:
msg = {"code": 1, "msg": cfg.global_sts_result[filename]}
app.logger.error(f"[sts][sts]error,{msg=}")
else:
msg = {"code": 0, "filename": os.path.join(TTS_DIR, filename), 'name': filename}
app.logger.info(f"[sts][sts]ok,{msg=}")
cfg.global_sts_result.pop(filename)
return jsonify(msg)
except Exception as e:
app.logger.error(f"[sts][sts]error:{str(e)}")
return jsonify({'code': 2, 'msg': f'voice->voice:{str(e)}'})
# 启动或关闭模型
@app.route('/onoroff',methods=['GET','POST'])
def onoroff():
name = request.form.get("name",'')
status_new = request.form.get("status_new",'')
if status_new=='on':
if name not in cfg.MYMODEL_OBJS or not cfg.MYMODEL_OBJS[name] or isinstance(cfg.MYMODEL_OBJS[name],str):
try:
print(f'start {name}...')
res=logic.load_model(name)
print(f'{res=}')
return jsonify({"code":0,"msg":res})
except Exception as e:
return jsonify({"code":1,"msg":str(e)})
elif cfg.MYMODEL_OBJS[name] in ['error','no']:
return jsonify({"code":0,"msg":"模型启动出错或不存在"})
return jsonify({"code":0,"msg":"已启动"})
else:
#关闭
cfg.MYMODEL_OBJS[name]=None
#删除队列
cfg.MYMODEL_QUEUE[name]=None
return jsonify({"code":0,"msg":"已停止"})
@app.route('/checkupdate', methods=['GET', 'POST'])
def checkupdate():
return jsonify({'code': 0, "msg": cfg.updatetips})
@app.route('/stsstatus', methods=['GET', 'POST'])
def stsstatus():
return jsonify({'code': 0, "msg": "start" if cfg.sts_status else "stop"})
if __name__ == '__main__':
tts_thread = None
sts_thread = None
try:
if 'app.py' == sys.argv[0] and 'app.py' == os.path.basename(__file__):
print(langlist["lang1"])
threading.Thread(target=logic.checkupdate).start()
# 如果存在默认模型则启动
if TEXT_MODEL_EXITS:
print("\n"+langlist['lang2'])
tts_thread = threading.Thread(target=ttsloop)
tts_thread.start()
else:
app.logger.error(
f"\n{langlist['lang3']}: {cfg.download_address}\n")
input(f"\n{langlist['lang3']}: {cfg.download_address}\n")
sys.exit()
if enable_sts==1 and VOICE_MODEL_EXITS:
print(langlist['lang4'])
sts_thread = threading.Thread(target=stsloop)
sts_thread.start()
#else:
# app.logger.error(
# f"\n{langlist['lang5']}: {cfg.download_address}\n")
print(langlist['lang7'])
try:
host = web_address.split(':')
threading.Thread(target=openweb, args=(web_address,)).start()
serve(app,host=host[0], port=int(host[1]))
finally:
print('exit')
except Exception as e:
print("error:" + str(e))
app.logger.error(f"[app]start error:{str(e)}")
time.sleep(30)
sys.exit()
================================================
FILE: appdingzhi.py
================================================
import datetime
import logging
import re
import threading
import time
import sys
from flask import Flask, request, render_template, jsonify, send_file, send_from_directory
import os
from gevent.pywsgi import WSGIServer, WSGIHandler
import glob
import hashlib
from logging.handlers import RotatingFileHandler
import clone
from clone import cfg
from clone.cfg import ROOT_DIR, TTS_DIR, VOICE_MODEL_EXITS, TMP_DIR, VOICE_DIR, TEXT_MODEL_EXITS, langlist
from clone.logic import ttsloop, stsloop, create_tts, openweb, merge_audio_segments, get_subtitle_from_srt, updatecache
from clone import logic
from gevent.pywsgi import LoggingLogAdapter
import shutil
import subprocess
from dotenv import load_dotenv
load_dotenv()
web_address = os.getenv('WEB_ADDRESS', '127.0.0.1:9988')
class CustomRequestHandler(WSGIHandler):
def log_request(self):
pass
#updatecache()
# 配置日志
# 禁用 Werkzeug 默认的日志处理器
log = logging.getLogger('werkzeug')
log.handlers[:] = []
log.setLevel(logging.WARNING)
app = Flask(__name__, static_folder=os.path.join(ROOT_DIR, 'static'), static_url_path='/static',
template_folder=os.path.join(ROOT_DIR, 'templates'))
root_log = logging.getLogger() # Flask的根日志记录器
root_log.handlers = []
root_log.setLevel(logging.WARNING)
app.logger.setLevel(logging.INFO) # 设置日志级别为 INFO
# 创建 RotatingFileHandler 对象,设置写入的文件路径和大小限制
file_handler = RotatingFileHandler(os.path.join(ROOT_DIR, 'app.log'), maxBytes=1024 * 1024, backupCount=5)
# 创建日志的格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 设置文件处理器的级别和格式
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
# 将文件处理器添加到日志记录器中
app.logger.addHandler(file_handler)
@app.route('/static/<path:filename>')
def static_files(filename):
return send_from_directory(app.config['STATIC_FOLDER'], filename)
@app.route('/')
def index():
return render_template("index.html",
text_model=TEXT_MODEL_EXITS,
voice_model=VOICE_MODEL_EXITS,
version=clone.ver,
language=cfg.LANG,
root_dir=ROOT_DIR.replace('\\', '/'))
@app.route('/txt')
def txt():
return render_template("txt.html",
text_model=True,#TEXT_MODEL_EXITS,
version=clone.ver,
language=cfg.LANG,
root_dir=ROOT_DIR.replace('\\', '/'))
# 上传音频
@app.route('/upload', methods=['POST'])
def upload():
try:
# 获取上传的文件
audio_file = request.files['audio']
save_dir = request.form.get("save_dir")
save_dir = VOICE_DIR if not save_dir else os.path.join(ROOT_DIR, f'static/{save_dir}')
app.logger.info(f"[upload]{audio_file.filename=},{save_dir=}")
# 检查文件是否存在且是 WAV/mp3格式
noextname, ext = os.path.splitext(os.path.basename(audio_file.filename.lower()))
noextname = noextname.replace(' ', '')
if audio_file and ext in [".wav", ".mp3", ".flac"]:
# 保存文件到服务器指定目录
name = f'{noextname}{ext}'
if os.path.exists(os.path.join(save_dir, f'{noextname}{ext}')):
name = f'{datetime.datetime.now().strftime("%m%d-%H%M%S")}-{noextname}{ext}'
# mp3 or wav
tmp_wav = os.path.join(TMP_DIR, "tmp_" + name)
audio_file.save(tmp_wav)
# save to wav
if ext != '.wav':
name = f"{name[:-len(ext)]}.wav"
savename = os.path.join(save_dir, name)
subprocess.run(['ffmpeg', '-hide_banner', '-y', '-i', tmp_wav, savename], check=True)
try:
os.unlink(tmp_wav)
except:
pass
# 返回成功的响应
return jsonify({'code': 0, 'msg': 'ok', "data": name})
else:
# 返回错误的响应
return jsonify({'code': 1, 'msg': 'not wav'})
except Exception as e:
app.logger.error(f'[upload]error: {e}')
return jsonify({'code': 2, 'msg': 'error'})
# 从 voicelist 目录获取可用的 wav 声音列表
@app.route('/init')
def init():
wavs = glob.glob(f"{VOICE_DIR}/*.wav")
result = []
for it in wavs:
if os.path.getsize(it) > 0:
result.append(os.path.basename(it))
return jsonify(result)
# 判断线程是否启动
@app.route('/isstart', methods=['GET', 'POST'])
def isstart():
total = cfg.tts_n + cfg.sts_n
return jsonify({"code": 0, "msg": total, "tts": cfg.langlist['lang15'] if cfg.tts_n < 1 else "",
"sts": cfg.langlist['lang16'] if cfg.sts_n < 1 else ""})
# 外部接口
@app.route('/apitts', methods=['GET', 'POST'])
def apitts():
'''
audio:原始声音wav,作为音色克隆源
voice:已有的声音名字,如果存在 voice则先使用,否则使用audio
text:文字一行
language:语言代码
Returns:
'''
try:
langcodelist=["zh-cn","en","ja","ko","es","de","fr","it","tr","ru","pt","pl","nl","ar","hu","cs"]
text = request.form.get("text").strip()
text = text.replace("\n", ' . ')
language = request.form.get("language","").lower()
if language.startswith("zh"):
language="zh-cn"
if language not in langcodelist:
return jsonify({"code":1,"msg":f"dont support language {language}"})
md5_hash = hashlib.md5()
audio_name = request.form.get('voice')
# 存在传来的声音文件名字
if audio_name:
voicename = os.path.join(VOICE_DIR, audio_name)
else: # 获取上传的文件
audio_file = request.files['audio']
print(f'{audio_file.filename}')
# 保存临时上传过来的声音文件
audio_name = f'video_{audio_file.filename}.wav'
voicename = os.path.join(TMP_DIR, audio_name)
audio_file.save(voicename)
md5_hash.update(f"{text}-{language}-{audio_name}".encode('utf-8'))
app.logger.info(f"[apitts]{voicename=}")
if re.match(r'^[~`!@#$%^&*()_+=,./;\':\[\]{}<>?\\|",。?;‘:“”’{【】}!·¥、\s\n\r -]*$', text):
return jsonify({"code": 1, "msg": "lost text for translate"})
if not text or not language:
return jsonify({"code": 1, "msg": "text & language params lost"})
app.logger.info(f"[apitts]{text=},{language=}")
# 存放结果
# 合成后的语音文件, 以wav格式存放和返回
filename = md5_hash.hexdigest() + ".wav"
app.logger.info(f"[apitts]{filename=}")
# 合成语音
rs = create_tts(text=text, speed=1.0, voice=voicename, language=language, filename=filename)
# 已有结果或错误,直接返回
if rs is not None:
result = rs
else:
# 循环等待 最多7200s
time_tmp = 0
while filename not in cfg.global_tts_result:
time.sleep(3)
time_tmp += 3
if time_tmp % 30 == 0:
app.logger.info(f"[apitts][tts]{time_tmp=},{filename=}")
# 当前行已完成合成
if cfg.global_tts_result[filename] != 1:
msg = {"code": 1, "msg": cfg.global_tts_result[filename]}
else:
target_wav = os.path.normpath(os.path.join(TTS_DIR, filename))
msg = {"code": 0, "filename": target_wav, 'name': filename}
app.logger.info(f"[apitts][tts] {filename=},{msg=}")
cfg.global_tts_result.pop(filename)
result = msg
app.logger.info(f"[apitts]{msg=}")
if result['code'] == 0:
result['url'] = f'http://{web_address}/static/ttslist/{filename}'
return jsonify(result)
except Exception as e:
msg=f'{str(e)} {str(e.args)}'
app.logger.error(f"[apitts]{msg}")
return jsonify({'code': 2, 'msg': msg})
chuliing={"name":"","line":0,"end":False}
# 获取进度
@app.route('/ttslistjindu',methods=['GET', 'POST'])
def ttslistjindu():
return jsonify(chuliing)
# 具体起一个新线程执行
def detail_task(*pams):
global chuliing
chuliing={"name":"","line":0,"end":False}
voice, src, dst, speed, language=pams
# 遍历所有txt文件
for t in os.listdir(src):
if not t.lower().endswith('.txt'):
continue
concat_txt=os.path.join(cfg.TTS_DIR, re.sub(r'[ \s\[\]\{\}\(\)<>\?\, :]+','', t, re.I) + '.txt')
app.logger.info(f'####开始处理文件:{t}, 每行结果保存在:{concat_txt}')
with open(concat_txt,'w',encoding='utf-8') as f:
f.write("")
#需要等待执行完毕的数据 [{}, {}]
waitlist=[]
#已执行完毕的 {1:{}, 2:{}}
result={}
with open(os.path.join(src,t),'r',encoding='utf-8') as f:
num=0
for line in f.readlines():
num+=1
line=line.strip()
if re.match(r'^[~`!@#$%^&*()_+=,./;\':\[\]{}<>?\\|",。?;‘:“”’{【】}!·¥、\s\n\r -]*$', line):
app.logger.info(f'\t第{num}不存在有效文字,跳过')
continue
md5_hash = hashlib.md5()
md5_hash.update(f"{line}-{voice}-{language}-{speed}".encode('utf-8'))
filename = md5_hash.hexdigest() + ".wav"
app.logger.info(f'\t开始合成第{num}行声音:{filename=}')
# 合成语音
rs = create_tts(text=line, speed=speed, voice=voice, language=language, filename=filename)
# 已有结果或错误,直接返回
if rs is not None and rs['code']==1:
app.logger.error(f'\t{t}:文件内容第{num}行【 {line} 】出错了,跳过')
continue
if rs is not None and rs['code']==0:
#已存在直接使用
result[f'{num}']={"filename":filename, "num":num}
chuliing['name']=t
chuliing['line']=num
app.logger.info(f'\t第{num}行合成完毕:{filename=}')
continue
waitlist.append({"filename":filename, "num":num, "t":t})
#for it in waitlist:
time_tmp = 0
chuliing['name']=t
if len(waitlist)>0:
chuliing['line']=waitlist[0]['num']
while len(waitlist)>0:
it=waitlist.pop(0)
filename, num, t=it.values()
#需要等待
if time_tmp>7200:
continue
# 当前行已完成合成
if filename in cfg.global_tts_result and cfg.global_tts_result[filename] != 1:
#出错了
app.logger.error(f'\t{t}:文件内容第{num}行出错了,{cfg.global_tts_result[filename]}, 跳过')
continue
if os.path.exists(os.path.join(cfg.TTS_DIR, filename)):
chuliing['name']=t
chuliing['line']=num
app.logger.info(f'\t第{num}行合成完毕:{filename}')
#成功了
result[f'{num}']={"filename":filename, "num":num}
continue
#未完成,插入重新开
waitlist.append(it)
time_tmp+=1
time.sleep(1)
if len(result.keys())<1:
app.logger.error(f'\t该文件合成失败,没有生成任何声音')
continue
sorted_result = {k: result[k] for k in sorted(result, key=lambda x: int(x))}
for i, it in sorted_result.items():
theaudio = os.path.normpath(os.path.join(cfg.TTS_DIR, it['filename']))
with open(concat_txt, 'a', encoding='utf-8') as f:
f.write(f"file '{theaudio}'\n")
#当前txt执行完成 合并音频
target_mp3=os.path.normpath((os.path.join(dst,f'{t}.mp3')))
p=subprocess.run(['ffmpeg',"-hide_banner", "-ignore_unknown", '-y', '-f', 'concat', '-safe', '0', '-i', concat_txt, target_mp3])
if p.returncode!=0:
app.logger.error(f'\t处理文件:{t},将所有音频连接一起时出错')
continue
app.logger.info(f'\t已生成完整音频:{target_mp3}')
if speed != 1.0 and speed > 0 and speed <= 2.0:
p= subprocess.run(['ffmpeg', '-hide_banner', '-ignore_unknown', '-y', '-i', target_mp3, '-af', f"atempo={speed}",f'{target_mp3}-speed{speed}.mp3'], encoding="utf-8", capture_output=True)
if p.returncode != 0:
app.logger.error(f'\t处理文件{t}:将{target_mp3}音频改变速度{speed}倍时失败')
continue
os.unlink(target_mp3)
target_mp3=f'{target_mp3}-speed{speed}.mp3'
app.logger.info(f'\t文件:{t} 处理完成,mp3:{target_mp3}')
app.logger.info('所有文件处理完毕')
chuliing['end']=True
@app.route('/ttslist',methods=['GET', 'POST'])
def ttslist():
voice = request.form.get("voice")
src = request.form.get("src")
dst = request.form.get("dst")
speed = 1.0
try:
speed = float(request.form.get("speed"))
except:
pass
language = request.form.get("language")
#根据src获取所有txt
src=os.path.normpath(src)
print(f'{src=},{dst=},{language=},{speed=},{voice=}')
if not src or not dst or not os.path.exists(src) or not os.path.exists(dst):
return jsonify({"code":1,"msg":"必须正确填写txt所在目录以及目标目录的完整路径"})
threading.Thread(target=detail_task, args=(voice, src, dst, speed, language)).start()
return jsonify({"code":0,"msg":"ok"})
# 根据文本返回tts结果,返回 name=文件名字,filename=文件绝对路径
# 请求端根据需要自行选择使用哪个
# params
# text:待合成文字
# voice:声音文件
# language:语言代码
@app.route('/tts', methods=['GET', 'POST'])
def tts():
# 原始字符串
text = request.form.get("text").strip()
voice = request.form.get("voice")
speed = 1.0
try:
speed = float(request.form.get("speed"))
except:
pass
language = request.form.get("language")
app.logger.info(f"[tts][tts]recev {text=}\n{voice=},{language=}\n")
if re.match(r'^[~`!@#$%^&*()_+=,./;\':\[\]{}<>?\\|",。?;‘:“”’{【】}!·¥、\s\n\r -]*$', text):
return jsonify({"code": 1, "msg": "no text"})
if not text or not voice or not language:
return jsonify({"code": 1, "msg": "text/voice/language params lost"})
# 判断是否是srt
text_list = get_subtitle_from_srt(text)
app.logger.info(f"[tts][tts]{text_list=}")
is_srt = True
# 不是srt格式,则按行分割
if text_list is None:
is_srt = False
text_list = []
for it in text.split("\n"):
text_list.append({"text": it.strip()})
app.logger.info(f"[tts][tts] its not srt")
num = 0
while num < len(text_list):
t = text_list[num]
# 换行符改成 .
t['text'] = t['text'].replace("\n", ' . ')
md5_hash = hashlib.md5()
md5_hash.update(f"{t['text']}-{voice}-{language}-{speed}".encode('utf-8'))
filename = md5_hash.hexdigest() + ".wav"
app.logger.info(f"[tts][tts]{filename=}")
# 合成语音
rs = create_tts(text=t['text'], speed=speed, voice=voice, language=language, filename=filename)
# 已有结果或错误,直接返回
if rs is not None:
text_list[num]['result'] = rs
num += 1
continue
# 循环等待 最多7200s
time_tmp = 0
while filename not in cfg.global_tts_result:
time.sleep(3)
time_tmp += 3
if time_tmp % 30 == 0:
app.logger.info(f"[tts][tts]{time_tmp=},{filename=}")
# 当前行已完成合成
if cfg.global_tts_result[filename] != 1:
msg = {"code": 1, "msg": cfg.global_tts_result[filename]}
else:
target_wav = os.path.normpath(os.path.join(TTS_DIR, filename))
if speed != 1.0 and speed > 0 and speed <= 2.0:
# 生成的加速音频
speed_tmp = os.path.join(TMP_DIR, f'speed_{time.time()}.wav')
p = subprocess.run(
['ffmpeg', '-hide_banner', '-ignore_unknown', '-y', '-i', target_wav, '-af', f"atempo={speed}",
os.path.normpath(speed_tmp)], encoding="utf-8", capture_output=True)
if p.returncode != 0:
return jsonify({"code": 1, "msg": str(p.stderr)})
shutil.copy2(speed_tmp, target_wav)
msg = {"code": 0, "filename": target_wav, 'name': filename}
app.logger.info(f"[tts][tts] {filename=},{msg=}")
cfg.global_tts_result.pop(filename)
text_list[num]['result'] = msg
app.logger.info(f"[tts][tts]{num=}")
num += 1
filename, errors = merge_audio_segments(text_list, is_srt=is_srt)
app.logger.info(f"[tts][tts]is srt,{filename=},{errors=}")
if filename and os.path.exists(filename) and os.path.getsize(filename) > 0:
res = {"code": 0, "filename": filename, "name": os.path.basename(filename), "msg": errors}
else:
res = {"code": 1, "msg": f"error:{filename=},{errors=}"}
app.logger.info(f"[tts][tts]end result:{res=}")
return jsonify(res)
# s to s wav->wav
# params
# voice: 声音文件
# filename: 上传的原始声音
@app.route('/sts', methods=['GET', 'POST'])
def sts():
try:
# 保存文件到服务器指定目录
# 目标
voice = request.form.get("voice")
filename = request.form.get("name")
app.logger.info(f"[sts][sts]sts {voice=},{filename=}\n")
if not voice:
return jsonify({"code": 1, "msg": "voice params lost"})
obj = {"filename": filename, "voice": voice}
# 压入队列,准备转换语音
app.logger.info(f"[sts][sts]push sts")
cfg.q_sts.put(obj)
# 已有结果或错误,直接返回
# 循环等待 最多7200s
time_tmp = 0
while filename not in cfg.global_sts_result:
time.sleep(3)
time_tmp += 3
if time_tmp % 30 == 0:
app.logger.info(f"{time_tmp=},{filename=}")
# 当前行已完成合成
if cfg.global_sts_result[filename] != 1:
msg = {"code": 1, "msg": cfg.global_sts_result[filename]}
app.logger.error(f"[sts][sts]error,{msg=}")
else:
msg = {"code": 0, "filename": os.path.join(TTS_DIR, filename), 'name': filename}
app.logger.info(f"[sts][sts]ok,{msg=}")
cfg.global_sts_result.pop(filename)
return jsonify(msg)
except Exception as e:
app.logger.error(f"[sts][sts]error:{str(e)}")
return jsonify({'code': 2, 'msg': f'voice->voice:{str(e)}'})
@app.route('/checkupdate', methods=['GET', 'POST'])
def checkupdate():
return jsonify({'code': 0, "msg": cfg.updatetips})
if __name__ == '__main__':
tts_thread = None
sts_thread = None
try:
if 'app.py' == sys.argv[0] and 'app.py' == os.path.basename(__file__):
print(langlist["lang1"])
# threading.Thread(target=logic.checkupdate).start()
if TEXT_MODEL_EXITS:
print(langlist['lang2'])
tts_thread = threading.Thread(target=ttsloop)
tts_thread.start()
else:
app.logger.error(f"\n{langlist['lang3']}: {cfg.download_address}\n")
if VOICE_MODEL_EXITS:
print(langlist['lang4'])
sts_thread = threading.Thread(target=stsloop)
sts_thread.start()
else:
app.logger.info(
f"\n{langlist['lang5']}: {cfg.download_address}\n")
if not VOICE_MODEL_EXITS and not TEXT_MODEL_EXITS:
print(f"\n{langlist['lang6']}: {cfg.download_address}\n")
input("Press Enter close")
sys.exit()
print("===")
http_server = None
try:
host = web_address.split(':')
print(f'{host=}')
http_server = WSGIServer((host[0], int(host[1])), app, handler_class=CustomRequestHandler)
print(f'@@@@@@@@@@@')
threading.Thread(target=openweb, args=(web_address,)).start()
http_server.serve_forever()
finally:
if http_server:
http_server.stop()
# 设置事件,通知线程退出
cfg.exit_event.set()
# 等待后台线程结束
if tts_thread:
tts_thread.join()
if sts_thread:
sts_thread.join()
except Exception as e:
print("error:" + str(e))
app.logger.error(f"[app]start error:{str(e)}")
sys.exit()
================================================
FILE: change.md
================================================
ffmpeg -y -i cn.mp4 -i cn.wav -map '0:v' -map '1:a' -c:v libx264 -c:a aac cnout.mp4
ffmpeg -y -i en.mp4 -i en.wav -map 0:v -map 1:a -c:v libx264 -c:a aac enout.mp4
0.
\venv\Lib\site-packages\TTS\utils\manage.py ,大约 389 行附近,def download_model 方法中,注释掉如下代码
1. tts/utils/manage.py 532 line _download_zip_file
def _download_zip_file:
proxies=None
if os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'):
proxies = {
"http": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'),
"https": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY')
}
r = requests.get(file_url, stream=True,proxies=proxies)
@staticmethod
def _download_tar_file(file_url, output_folder, progress_bar):
"""Download the github releases"""
# download the file
proxies=None
if os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'):
proxies = {
"http": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'),
"https": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY')
}
r = requests.get(file_url, stream=True,proxies=proxies)
def _download_model_files(file_urls, output_folder, progress_bar):
"""Download the github releases"""
proxies=None
if os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'):
proxies = {
"http": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'),
"https": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY')
}
2. tts/vc/modules/freevc/wavlm
def get_wavlm():
print(f" > Downloading WavLM model to {output_path} ...")
if os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'):
# 创建ProxyHandler对象
proxy_support = urllib.request.ProxyHandler({"http": os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY'),"https":os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY')})
# 创建Opener
opener = urllib.request.build_opener(proxy_support)
# 安装Opener
urllib.request.install_opener(opener)
urllib.request.urlretrieve(model_uri, output_path)
3. E:\python\tts\venv\Lib\site-packages\fsspec\implementations\http.py
async def _get_file(
self, rpath, lpath, chunk_size=5 * 2**20, callback=_DEFAULT_CALLBACK, **kwargs
):
print(f'%%%%%%%%%%%%%%%%%%%{rpath=},{lpath=}')
import os
if os.path.exists(lpath) and os.path.getsize(lpath)>16000:
print('存在')
return True
proxy=os.environ.get('http_proxy') or os.environ.get('HTTP_PROXY')
async with session.get(self.encode_url(rpath), proxy=proxy if proxy else None,**kw) as r:
================================================
FILE: clone/__init__.py
================================================
VERSION=908
ver="0.908"
================================================
FILE: clone/cfg.py
================================================
import locale
import os
import queue
import re
import sys
import threading
import torch
from dotenv import load_dotenv
load_dotenv()
ROOT_DIR = os.getcwd() # os.path.dirname(os.path.abspath(__file__))
os.environ['TTS_HOME'] = ROOT_DIR
print(f"DIR: {ROOT_DIR}")
LANG = "en" if locale.getdefaultlocale()[0].split('_')[0].lower() != 'zh' else "zh"
if sys.platform == 'win32':
os.environ['PATH'] = f'{ROOT_DIR};{ROOT_DIR}\\ffmpeg;' + os.environ['PATH']
else:
os.environ['PATH'] = f'{ROOT_DIR}:{ROOT_DIR}/ffmpeg:' + os.environ['PATH']
def setorget_proxy():
proxy = os.getenv("http_proxy", '') or os.getenv("HTTP_PROXY", '')
if proxy:
os.environ['AIOHTTP_PROXY'] = "http://" + proxy.replace('http://', '')
os.environ['HTTPS_PROXY'] = "http://" + proxy.replace('http://', '')
return proxy
return None
# 存放录制好的素材,5-15s的语音 wav
VOICE_DIR = os.path.join(ROOT_DIR, 'static','voicelist')
# 存放经过tts转录后的wav文件
TTS_DIR = os.path.join(ROOT_DIR, 'static','ttslist')
# 临时目录
TMP_DIR = os.path.join(ROOT_DIR, 'static','tmp')
# 声音转声音 模型是否存在
if os.path.exists(os.path.join(ROOT_DIR, "tts/voice_conversion_models--multilingual--vctk--freevc24/model.pth")):
VOICE_MODEL_EXITS = True
else:
VOICE_MODEL_EXITS = False
if os.path.exists(os.path.join(ROOT_DIR, "tts/tts_models--multilingual--multi-dataset--xtts_v2/model.pth")):
TEXT_MODEL_EXITS = True
else:
TEXT_MODEL_EXITS = False
if not os.path.exists(VOICE_DIR):
os.makedirs(VOICE_DIR)
if not os.path.exists(TTS_DIR):
os.makedirs(TTS_DIR)
if not os.path.exists(TMP_DIR):
os.makedirs(TMP_DIR)
def get_models(path):
objs={}
if not os.path.exists(path):
return {}
dirs=os.listdir(path)
if len(dirs)<1:
return {}
for it in dirs:
if re.match(r'^[0-9a-zA-Z_-]+$',it) and os.path.exists(os.path.join(path,it,'model.pth')):
objs[it]=None
return objs
# 存放所有自定义模型实例
MYMODEL_DIR=os.path.join(ROOT_DIR,'tts','mymodels')
MYMODEL_OBJS=get_models(MYMODEL_DIR)
MYMODEL_QUEUE={}
sts_status=False
device = "cuda" if os.getenv('DEVICE','')=='CUDA' and torch.cuda.is_available() else "cpu"
q = queue.Queue(maxsize=2000)
q_sts = queue.Queue(maxsize=2000)
# 存放tts结果
global_tts_result = {}
#存放sts结果
global_sts_result = {}
# 用于通知线程退出的事件
exit_event = threading.Event()
#文字->声音线程是否启动
tts_n = 0
download_address = 'https://github.com/jianchang512/clone-voice/releases/tag/v0.0.1'
langdict = {
"zh": {
"lang1": "\n=====源码部署须知======\n如果你是源码部署,需要先执行 python code_dev.py 文件,以便同意coqou-ai的授权协议(显示同意协议后输入 y ),然后从下载或更新模型,需要提前配置好全局vpn\n=====\n",
"lang2": "准备启动 【文字->声音】 线程",
"lang3": "不存在 【文字->声音】 模型,下载地址",
"lang4": "准备启动 【声音->声音】 线程",
"lang5": "不存在 【声音->声音】 模型,如果需要 ‘声音转声音’ 功能请下载,否则忽略该提示,下载地址",
"lang6": "不存在任何模型,请先下载模型后,解压到tts目录下",
"lang7": "启动后加载模型可能需要几分钟,请耐心等待浏览器自动打开",
"lang8": "[已打开浏览器窗口,如果未能自动打开,你也可以手动打开地址]",
"lang9": "启动 声音->声音 线程失败,如果不需要 ‘声音转声音’ 功能,可忽略该提示",
"lang10": "启动 声音->声音 线程成功",
"lang11": "代理不可用,请设置正确的代理,以便下载模型",
"lang12": "请在该文件中正确设置 http 代理,以便能下载模型",
"lang13": "启动 文字->声音 线程失败",
"lang14": "启动 文字->声音 线程成功",
"lang15":"[文字->声音]线程还没有启动完毕,若模型已存在,请等待,否则请下载模型. ",
"lang16":"[声音->声音]线程还没有启动完毕,若模型已存在,请等待,否则请下载模型",
"lang17":"已启动",
"lang18":"未启动",
},
"en": {
"lang1": "\n=====Source Code Deployment Notes======\nIf you are deploying from source code, you need to execute the python code_dev.py file first to agree to the coqou-ai license agreement (display agreement and enter y), and then download or update the model. You need to configure the global VPN in advance\n=====\n",
"lang2": "Preparing to start the [Text -> Speech] thread",
"lang3": "No [Text -> Speech] model exists, download address",
"lang4": "Preparing to start the [Speech -> Speech] thread",
"lang5": "No [Speech -> Speech] model exists, download address",
"lang6": "No models exist, please download the models first and unzip them to the tts directory",
"lang7": "It may take a few minutes to load the model after starting, please be patient and wait for the browser to open automatically",
"lang8": "[Browser window opened. If it does not open automatically, you can also open the address manually]",
"lang9": "Failed to start the [Speech -> Speech] thread",
"lang10": "Successfully started the [Speech -> Speech] thread",
"lang11": "Proxy unavailable, please set the correct proxy to download the model",
"lang12": "Please set the http proxy correctly in this file to download the model",
"lang13": "Failed to start the [Text -> Speech] thread",
"lang14": "Successfully started the [Text -> Speech] thread",
"lang15":"[text->speech]not start,if model has downloaded,please wait a moment,else download. ",
"lang16":"[speech->speech]not start,if model has downloaded,please wait a moment,else download",
"lang17":"Runing",
"lang18":"Stoped"
}
}
langlist = langdict[LANG]
updatetips=""
================================================
FILE: clone/character.json
================================================
{
"en": 250,
"de": 253,
"fr": 273,
"es": 239,
"it": 213,
"pt": 203,
"pl": 224,
"zh": 82,
"ar": 166,
"cs": 186,
"ru": 182,
"nl": 251,
"tr": 226,
"ja": 71,
"hu": 224,
"ko": 95
}
================================================
FILE: clone/logic.py
================================================
import hashlib
import json
import os
import re
import shutil
import tempfile
import threading
import time
import webbrowser
import aiohttp
import requests
import torch
import torchaudio
from pydub import AudioSegment
import clone
from clone import cfg
from clone.cfg import langlist
from TTS.api import TTS
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import Xtts
from dotenv import load_dotenv
load_dotenv()
def updatecache():
# 禁止更新,避免无代理时报错
file=os.path.join(cfg.ROOT_DIR,'tts_cache/cache')
if file:
j=json.load(open(file,'r',encoding='utf-8'))
for i,it in enumerate(j):
if "time" in it and "fn" in it:
cache_file=os.path.join(cfg.ROOT_DIR,f'tts_cache/{it["fn"]}')
if os.path.exists(cache_file) and os.path.getsize(cache_file)>17000000:
it['time']=time.time()
j[i]=it
json.dump(j,open(file,'w',encoding='utf-8'))
# 加载自定义模型 /tts/mymodels
# tts 合成线程
def ttsloop():
try:
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(cfg.device)
print(langlist['lang14'])
cfg.tts_n=1
except aiohttp.client_exceptions.ClientOSError as e:
print(f'{langlist["lang13"]}:{str(e)}')
if not cfg.setorget_proxy():
print(f'.env {langlist["lang12"]}')
else:
print("\n"+langlist['lang11']+"\n")
return
except Exception as e:
print(f'{langlist["lang13"]}:{str(e)}')
return
while 1:
try:
obj = cfg.q.get(block=True, timeout=1)
print(f"[tts][ttsloop]start tts,{obj=}")
if not os.path.exists(obj['voice']):
cfg.global_tts_result[obj['filename']] = f'参考声音不存:{obj["voice"]}'
continue
try:
tts.tts_to_file(text=obj['text'], speaker_wav=obj['voice'], language=obj['language'], file_path=os.path.join(cfg.TTS_DIR, obj['filename']))
cfg.global_tts_result[obj['filename']] = 1
print(f"[tts][ttsloop]end: {obj=}")
except Exception as e:
print(f"[tts][ttsloop]error:{str(e)}")
cfg.global_tts_result[obj['filename']] = str(e)
except Exception:
continue
# s t s 线程
def stsloop():
try:
tts = TTS(model_name='voice_conversion_models/multilingual/vctk/freevc24').to(cfg.device)
print("\n"+langlist['lang10']+"\n")
except aiohttp.client_exceptions.ClientOSError as e:
cfg.sts_status=False
print(f'{langlist["lang9"]}:{str(e)}')
if not cfg.setorget_proxy():
print(f'.env {langlist["lang12"]}')
else:
print(f'{os.environ.get("HTTP_PROXY")} {langlist["lang11"]}')
return
except Exception as e:
cfg.sts_status=False
print(f'{langlist["lang9"]}:{str(e)}')
return
else:
cfg.sts_status=True
while 1:
try:
obj = cfg.q_sts.get(block=True, timeout=1)
print(f"[sts][stsloop]start sts,{obj=}")
try:
#split_sentences=True
tts.voice_conversion_to_file(source_wav=os.path.join(cfg.TMP_DIR, obj['filename']),
target_wav=os.path.join(cfg.VOICE_DIR, obj['voice']),
file_path=os.path.join(cfg.TTS_DIR, obj['filename']))
cfg.global_sts_result[obj['filename']] = 1
print(f"[sts][stsloop] end {obj=}")
except Exception as e:
print(f"[sts][stsloop]error:{str(e)}")
cfg.global_sts_result[obj['filename']] = str(e)
except Exception as e:
continue
# 实际启动tts合成的函数
def create_tts(*, text, voice, language, filename, speed=1.0,model=""):
absofilename = os.path.join(cfg.TTS_DIR, filename)
if os.path.exists(absofilename) and os.path.getsize(absofilename) > 0:
print(f"[tts][create_ts]{filename} {speed} has exists")
cfg.global_tts_result[filename] = 1
return {"code": 0, "filename": absofilename, 'name': filename}
try:
print(f"[tts][create_ts] **{text}** {voice=},{model=}")
if not model or model =="default":
cfg.q.put({"voice": voice, "text": text,"speed":speed, "language": language, "filename": filename})
else:
#如果不存在该模型,就先启动
print(f'{model=}')
if model not in cfg.MYMODEL_QUEUE or not cfg.MYMODEL_QUEUE[model]:
run_tts(model)
cfg.MYMODEL_QUEUE[model].put({"text": text,"speed":speed, "language": language, "filename": filename})
except Exception as e:
print(e)
print(f"error,{str(e)}")
return {"code": 10, "msg": str(e)}
return None
# join all short audio to one ,eg name.mp4 name.mp4.wav
def merge_audio_segments(text_list,is_srt=True):
# 获得md5
md5_hash = hashlib.md5()
md5_hash.update(f"{json.dumps(text_list)}".encode('utf-8'))
# 合成后的名字
filename = md5_hash.hexdigest() + ".wav"
absofilename = os.path.join(cfg.TTS_DIR, filename)
if os.path.exists(absofilename):
return (absofilename, "")
segments = []
start_times = []
errors = []
merged_audio = AudioSegment.empty()
print(f'{text_list=}')
for it in text_list:
if "filename" in it['result'] and os.path.exists(it['result']['filename']):
# 存在音频文件
seg=AudioSegment.from_wav(it['result']['filename'])
if "start_time" in it:
start_times.append(it['start_time'])
segments.append(seg)
else:
merged_audio+=seg
try:
os.unlink(it['result']['filename'])
except:
pass
elif "msg" in it['result']:
# 出错
errors.append(str(it['result']['msg']))
#不是srt直接返回
if not is_srt:
print(f'{absofilename=},{errors=}')
merged_audio.export(absofilename, format="wav")
return (absofilename, " | ".join(errors))
# start is not 0
if int(start_times[0]) != 0:
silence_duration = start_times[0]
silence = AudioSegment.silent(duration=silence_duration)
merged_audio += silence
# join
for i in range(len(segments)):
segment = segments[i]
start_time = start_times[i]
# add silence
if i > 0:
previous_end_time = start_times[i - 1] + len(segments[i - 1])
silence_duration = start_time - previous_end_time
# 可能存在字幕 语音对应问题
if silence_duration > 0:
silence = AudioSegment.silent(duration=silence_duration)
merged_audio += silence
merged_audio += segment
merged_audio.export(absofilename, format="wav")
return (absofilename, " | ".join(errors))
def openweb(web_address):
while cfg.tts_n==0:
time.sleep(5)
try:
webbrowser.open("http://"+web_address)
print(f"\n{langlist['lang8']} http://{web_address}")
except Exception as e:
pass
# 判断是否符合字幕格式,如果是,则直接返回
# 从字幕文件获取格式化后的字幕信息
'''
[
{'line': 13, 'time': '00:01:56,423 --> 00:02:06,423', 'text': '因此,如果您准备好停止沉迷于不太理想的解决方案并开始构建下一个
出色的语音产品,我们已准备好帮助您实现这一目标。深度图。没有妥协。唯一的机会..', 'startraw': '00:01:56,423', 'endraw': '00:02:06,423', 'start_time'
: 116423, 'end_time': 126423},
{'line': 14, 'time': '00:02:06,423 --> 00:02:07,429', 'text': '机会..', 'startraw': '00:02:06,423', 'endraw': '00:02
:07,429', 'start_time': 126423, 'end_time': 127429}
]
'''
# 将字符串或者字幕文件内容,格式化为有效字幕数组对象
# 格式化为有效的srt格式
#content是每行内容,按\n分割的,
def format_srt(content):
#去掉空行
content=[it for it in content if it.strip()]
if len(content)<1:
return []
result=[]
maxindex=len(content)-1
# 时间格式
timepat = r'^\s*?\d+:\d+:\d+([\,\.]\d+?)?\s*?-->\s*?\d+:\d+:\d+([\,\.]\d+?)?\s*?$'
textpat=r'^[,./?`!@#$%^&*()_+=\\|\[\]{}~\s \n-]*$'
for i,it in enumerate(content):
#当前空行跳过
if not it.strip():
continue
it=it.strip()
is_time=re.match(timepat,it)
if is_time:
#当前行是时间格式,则添加
result.append({"time":it,"text":[]})
elif i==0:
#当前是第一行,并且不是时间格式,跳过
continue
elif re.match(r'^\s*?\d+\s*?$',it) and i<maxindex and re.match(timepat,content[i+1]):
#当前不是时间格式,不是第一行,并且都是数字,并且下一行是时间格式,则当前是行号,跳过
continue
elif len(result)>0 and not re.match(textpat,it):
#当前不是时间格式,不是第一行,(不是行号),并且result中存在数据,则是内容,可加入最后一个数据
result[-1]['text'].append(it)
#再次遍历,去掉text为空的
result=[it for it in result if len(it['text'])>0]
if len(result)>0:
for i,it in enumerate(result):
result[i]['line']=i+1
result[i]['text']="\n".join(it['text'])
s,e=(it['time'].replace('.',',')).split('-->')
s=s.strip()
e=e.strip()
if s.find(',')==-1:
s+=',000'
if len(s.split(':')[0])<2:
s=f'0{s}'
if e.find(',')==-1:
e+=',000'
if len(e.split(':')[0])<2:
e=f'0{e}'
result[i]['time']=f'{s} --> {e}'
return result
def get_subtitle_from_srt(srtfile):
timepat = r'^\s*?\d+:\d+:\d+(\,\d+?)?\s*?-->\s*?\d+:\d+:\d+(\,\d+?)?\s*?$'
if not re.search(timepat,srtfile,re.I|re.M):
return None
content = srtfile.strip().splitlines()
if len(content)<1:
return None
result=format_srt(content)
if len(result)<1:
return None
new_result = []
line = 1
for it in result:
if "text" in it and len(it['text'].strip()) > 0:
it['line'] = line
startraw, endraw = it['time'].strip().split("-->")
start = startraw.strip().replace(',', '.').replace(',','.').replace(':',':').split(":")
end = endraw.strip().replace(',', '.').replace(',','.').replace(':',':').split(":")
start_time = int(int(start[0]) * 3600000 + int(start[1]) * 60000 + float(start[2]) * 1000)
end_time = int(int(end[0]) * 3600000 + int(end[1]) * 60000 + float(end[2]) * 1000)
it['startraw'] = startraw
it['endraw'] = endraw
it['start_time'] = start_time
it['end_time'] = end_time
new_result.append(it)
line += 1
return new_result
def get_subtitle_from_srt0(txt):
# 行号
line = 0
maxline = len(txt)
# 行格式
linepat = r'^\s*?\d+\s*?$'
# 时间格式
timepat = r'^\s*?\d+:\d+:\d+\,?\d*?\s*?-->\s*?\d+:\d+:\d+\,?\d*?$'
txt = txt.strip().split("\n")
# 先判断是否符合srt格式,不符合返回None
if len(txt) < 3:
return None
if not re.match(linepat, txt[0]) or not re.match(timepat, txt[1]):
return None
result = []
for i, t in enumerate(txt):
# 当前行 小于等于倒数第三行 并且匹配行号,并且下一行匹配时间戳,则是行号
if i < maxline - 2 and re.match(linepat, t) and re.match(timepat, txt[i + 1]):
# 是行
line += 1
obj = {"line": line, "time": "", "text": ""}
result.append(obj)
elif re.match(timepat, t):
# 是时间行
result[line - 1]['time'] = t
elif len(t.strip()) > 0:
# 是内容
result[line - 1]['text'] += t.strip().replace("\n", '')
# 再次遍历,删掉美元text的行
new_result = []
line = 1
for it in result:
if "text" in it and len(it['text'].strip()) > 0 and not re.match(r'^[,./?`!@#$%^&*()_+=\\|\[\]{}~\s \n-]*$',
it['text']):
it['line'] = line
startraw, endraw = it['time'].strip().split(" --> ")
start = startraw.replace(',', '.').split(":")
start_time = int(int(start[0]) * 3600000 + int(start[1]) * 60000 + float(start[2]) * 1000)
end = endraw.replace(',', '.').split(":")
end_time = int(int(end[0]) * 3600000 + int(end[1]) * 60000 + float(end[2]) * 1000)
it['startraw'] = startraw
it['endraw'] = endraw
it['start_time'] = start_time
it['end_time'] = end_time
new_result.append(it)
line += 1
return new_result
def checkupdate():
try:
res=requests.get("https://raw.githubusercontent.com/jianchang512/clone-voice/main/version.json")
#print(f"{res.status_code=}")
if res.status_code==200:
d=res.json()
#print(f"{d=}")
if d['version_num']>clone.VERSION:
cfg.updatetips=f'New version {d["version"]}'
except Exception as e:
pass
def clear_gpu_cache():
# clear the GPU cache
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 加载自定义模型,name是文件夹名, tts/mymodels/name/
def load_model(name):
print(f'load_model,{name=}')
while cfg.MYMODEL_OBJS[name]=="loading":
time.sleep(3)
xtts_checkpoint, xtts_config, xtts_vocab=os.path.join(cfg.MYMODEL_DIR,name,'model.pth'),os.path.join(cfg.MYMODEL_DIR,name,'config.json'),os.path.join(cfg.MYMODEL_DIR,name,'vocab.json')
clear_gpu_cache()
print(f'{xtts_checkpoint=},{xtts_config=},{xtts_vocab=}')
if cfg.MYMODEL_OBJS[name]=="no" or not os.path.exists(xtts_checkpoint) or not os.path.exists(xtts_config) or not os.path.exists(xtts_vocab):
cfg.MYMODEL_OBJS[name]="no"
return "自定义模型下不存在 model.pth或config.json/vocab.json 文件!!"
if cfg.MYMODEL_OBJS[name]=="error":
return "模型启动时出错,请重试"
if cfg.MYMODEL_OBJS[name] and not isinstance(cfg.MYMODEL_OBJS[name],str):
return "已启动"
cfg.MYMODEL_OBJS[name]="loading"
try:
cfg.MYMODEL_QUEUE[name]=queue.Queue(1000)
config = XttsConfig()
config.load_json(xtts_config)
cfg.MYMODEL_OBJS[name] = Xtts.init_from_config(config)
print("Loading XTTS model! ")
cfg.MYMODEL_OBJS[name].load_checkpoint(config, checkpoint_path=xtts_checkpoint, vocab_path=xtts_vocab, use_deepspeed=False)
if torch.cuda.is_available():
cfg.MYMODEL_OBJS[name].cuda()
threading.Thread(target=run_tts,args=(name,)).start()
except Exception as e:
cfg.MYMODEL_QUEUE[name]=None
cfg.MYMODEL_OBJS[name]="error"
return str(e)
return "启动成功!"
def run_tts(name):
while 1:
if not cfg.MYMODEL_OBJS[name]:
load_model(name)
time.sleep(5)
continue
if cfg.MYMODEL_OBJS[name]=='no':
print(f"自定义模型 {name} 下不存在model.pth或config.json/vocab.json文件!!")
break
if cfg.MYMODEL_OBJS[name]=='error':
print(f"加载自定义模型 {name} 时出错!!")
break
if cfg.MYMODEL_OBJS[name]=='loading':
time.sleep(10)
continue
try:
obj = cfg.MYMODEL_QUEUE[name].get(block=True, timeout=1)
except:
time.sleep(1)
continue
try:
print(f'{obj=}')
lang, tts_text, speaker_audio_file=obj['language'],obj['text'],os.path.join(cfg.MYMODEL_DIR,name,'base.wav')
gpt_cond_latent, speaker_embedding = cfg.MYMODEL_OBJS[name].get_conditioning_latents(audio_path=speaker_audio_file, gpt_cond_len=cfg.MYMODEL_OBJS[name].config.gpt_cond_len, max_ref_length=cfg.MYMODEL_OBJS[name].config.max_ref_len, sound_norm_refs=cfg.MYMODEL_OBJS[name].config.sound_norm_refs)
out = cfg.MYMODEL_OBJS[name].inference(
text=tts_text,
language=lang,
gpt_cond_latent=gpt_cond_latent,
speaker_embedding=speaker_embedding,
temperature=cfg.MYMODEL_OBJS[name].config.temperature, # Add custom parameters here
length_penalty=cfg.MYMODEL_OBJS[name].config.length_penalty,
repetition_penalty=cfg.MYMODEL_OBJS[name].config.repetition_penalty,
top_k=cfg.MYMODEL_OBJS[name].config.top_k,
top_p=cfg.MYMODEL_OBJS[name].config.top_p,
)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as fp:
out["wav"] = torch.tensor(out["wav"]).unsqueeze(0)
out_path = fp.name
torchaudio.save(out_path, out["wav"], 24000)
shutil.copy2(out_path,os.path.join(cfg.TTS_DIR, obj['filename']))
cfg.global_tts_result[obj['filename']] = 1
except Exception as e:
#出错了
print(f'run_tts:{name=},{str(e)}')
================================================
FILE: code_dev.py
================================================
import torch
import os
rootdir=os.getcwd()
os.environ['TTS_HOME']=rootdir
from TTS.api import TTS
from dotenv import load_dotenv
load_dotenv()
print("源码部署需要先运行该文件,以便同意coqou-ai协议,当弹出协议时,请输入 y \n同时需要连接墙外下载或更新模型,请在 .env 中 HTTP_PROXY=设置代理地址")
def updatecache():
# 禁止更新,避免无代理时报错
file=os.path.join(rootdir,'tts_cache/cache')
if file:
import json,time
j=json.load(open(file,'r',encoding='utf-8'))
for i,it in enumerate(j):
if "time" in it and "fn" in it:
cache_file=os.path.join(rootdir,f'tts_cache/{it["fn"]}')
if os.path.exists(cache_file) and os.path.getsize(cache_file)>17000000:
it['time']=time.time()
j[i]=it
json.dump(j,open(file,'w',encoding='utf-8'))
updatecache()
device = "cuda" if torch.cuda.is_available() else "cpu"
#ttsv2 = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)
tts = TTS(model_name='voice_conversion_models/multilingual/vctk/freevc24').to(device)
# test
#tts.tts_to_file(text='我是中国人,你呢我的宝贝。今天天气看起来很不错啊', speaker_wav='./cn1.wav',language='zh', file_path='hafalse2.wav', speed=2.0,split_sentences=False)
#tts.tts_to_file(text='我是中国人,你呢我的宝贝。今天天气看起来很不错啊', speaker_wav='./cn1.wav',language='zh', file_path='hafalse0.2.wav', speed=0.2,split_sentences=False)
#target_wav is voice file
# tts.voice_conversion_to_file(source_wav="./cn1.wav", target_wav="./sx1.wav", file_path="./out.wav")
================================================
FILE: docker/build@source/dockerfile
================================================
FROM pytorch/pytorch:2.3.1-cuda12.1-cudnn8-runtime
WORKDIR /app
RUN apt-get update && apt-get install -y \
python3-pip \
libgl1-mesa-glx \
libsm6 \
libxext6 \
libglib2.0-0 \
libxrender-dev \
git \
ffmpeg \
&& rm -rf /var/lib/apt/lists/*
RUN pip3 install --upgrade pip
COPY ./requirements.txt /app/requirements.txt
RUN pip3 install --no-cache-dir -r requirements.txt
COPY . /app
ENV WEB_ADDRESS=0.0.0.0:9988
ENV ENABLE_STS=1
ENV DEVICE=CUDA
ENV PYTHONUNBUFFERED=1
EXPOSE 9988
VOLUME /app/tts
VOLUME /app/tts_cache
CMD ["python", "app.py"]
================================================
FILE: docker/up@cpu/.models.json
================================================
{
"tts_models": {
"multilingual": {
"multi-dataset": {
"xtts_v2": {
"description": "XTTS-v2.0.2 by Coqui with 16 languages.",
"hf_url": [
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/model.pth",
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/config.json",
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/vocab.json",
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/hash.md5"
],
"model_hash": "5ce0502bfe3bc88dc8d9312b12a7558c",
"default_vocoder": null,
"commit": "480a6cdf7",
"license": "CPML",
"contact": "info@coqui.ai",
"tos_required": true
},
"xtts_v1.1": {
"description": "XTTS-v1.1 by Coqui with 14 languages, cross-language voice cloning and reference leak fixed.",
"hf_url": [
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/model.pth",
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/config.json",
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/vocab.json",
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/hash.md5"
],
"model_hash": "7c62beaf58d39b729de287330dc254e7b515677416839b649a50e7cf74c3df59",
"default_vocoder": null,
"commit": "82910a63",
"license": "CPML",
"contact": "info@coqui.ai",
"tos_required": true
},
"your_tts": {
"description": "Your TTS model accompanying the paper https://arxiv.org/abs/2112.02418",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.1_models/tts_models--multilingual--multi-dataset--your_tts.zip",
"default_vocoder": null,
"commit": "e9a1953e",
"license": "CC BY-NC-ND 4.0",
"contact": "egolge@coqui.ai"
},
"bark": {
"description": "🐶 Bark TTS model released by suno-ai. You can find the original implementation in https://github.com/suno-ai/bark.",
"hf_url": [
"https://coqui.gateway.scarf.sh/hf/bark/coarse_2.pt",
"https://coqui.gateway.scarf.sh/hf/bark/fine_2.pt",
"https://app.coqui.ai/tts_model/text_2.pt",
"https://coqui.gateway.scarf.sh/hf/bark/config.json",
"https://coqui.gateway.scarf.sh/hf/bark/hubert.pt",
"https://coqui.gateway.scarf.sh/hf/bark/tokenizer.pth"
],
"default_vocoder": null,
"commit": "e9a1953e",
"license": "MIT",
"contact": "https://www.suno.ai/"
}
}
},
"bg": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--bg--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"cs": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--cs--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"da": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--da--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"et": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--et--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"ga": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--ga--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"en": {
"ek1": {
"tacotron2": {
"description": "EK1 en-rp tacotron2 by NMStoker",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ek1--tacotron2.zip",
"default_vocoder": "vocoder_models/en/ek1/wavegrad",
"commit": "c802255",
"license": "apache 2.0"
}
},
"ljspeech": {
"tacotron2-DDC": {
"description": "Tacotron2 with Double Decoder Consistency.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "bae2ad0f",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"tacotron2-DDC_ph": {
"description": "Tacotron2 with Double Decoder Consistency with phonemes.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--tacotron2-DDC_ph.zip",
"default_vocoder": "vocoder_models/en/ljspeech/univnet",
"commit": "3900448",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"glow-tts": {
"description": "",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--glow-tts.zip",
"stats_file": null,
"default_vocoder": "vocoder_models/en/ljspeech/multiband-melgan",
"commit": "",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"speedy-speech": {
"description": "Speedy Speech model trained on LJSpeech dataset using the Alignment Network for learning the durations.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--speedy-speech.zip",
"stats_file": null,
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "4581e3d",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"tacotron2-DCA": {
"description": "",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--tacotron2-DCA.zip",
"default_vocoder": "vocoder_models/en/ljspeech/multiband-melgan",
"commit": "",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"vits": {
"description": "VITS is an End2End TTS model trained on LJSpeech dataset with phonemes.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--vits.zip",
"default_vocoder": null,
"commit": "3900448",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"vits--neon": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--en--ljspeech--vits.zip",
"default_vocoder": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause",
"contact": null,
"commit": null
},
"fast_pitch": {
"description": "FastPitch model trained on LJSpeech using the Aligner Network",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--fast_pitch.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "b27b3ba",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"overflow": {
"description": "Overflow model trained on LJSpeech",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.0_models/tts_models--en--ljspeech--overflow.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "3b1a28f",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
},
"neural_hmm": {
"description": "Neural HMM model trained on LJSpeech",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.11.0_models/tts_models--en--ljspeech--neural_hmm.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "3b1a28f",
"author": "Shivam Metha @shivammehta25",
"license": "apache 2.0",
"contact": "d83ee8fe45e3c0d776d4a865aca21d7c2ac324c4"
}
},
"vctk": {
"vits": {
"description": "VITS End2End TTS model trained on VCTK dataset with 109 different speakers with EN accent.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--vctk--vits.zip",
"default_vocoder": null,
"commit": "3900448",
"author": "Eren @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
},
"fast_pitch": {
"description": "FastPitch model trained on VCTK dataseset.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--vctk--fast_pitch.zip",
"default_vocoder": null,
"commit": "bdab788d",
"author": "Eren @erogol",
"license": "CC BY-NC-ND 4.0",
"contact": "egolge@coqui.ai"
}
},
"sam": {
"tacotron-DDC": {
"description": "Tacotron2 with Double Decoder Consistency trained with Aceenture's Sam dataset.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--sam--tacotron-DDC.zip",
"default_vocoder": "vocoder_models/en/sam/hifigan_v2",
"commit": "bae2ad0f",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
}
},
"blizzard2013": {
"capacitron-t2-c50": {
"description": "Capacitron additions to Tacotron 2 with Capacity at 50 as in https://arxiv.org/pdf/1906.03402.pdf",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.0_models/tts_models--en--blizzard2013--capacitron-t2-c50.zip",
"commit": "d6284e7",
"default_vocoder": "vocoder_models/en/blizzard2013/hifigan_v2",
"author": "Adam Froghyar @a-froghyar",
"license": "apache 2.0",
"contact": "adamfroghyar@gmail.com"
},
"capacitron-t2-c150_v2": {
"description": "Capacitron additions to Tacotron 2 with Capacity at 150 as in https://arxiv.org/pdf/1906.03402.pdf",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.1_models/tts_models--en--blizzard2013--capacitron-t2-c150_v2.zip",
"commit": "a67039d",
"default_vocoder": "vocoder_models/en/blizzard2013/hifigan_v2",
"author": "Adam Froghyar @a-froghyar",
"license": "apache 2.0",
"contact": "adamfroghyar@gmail.com"
}
},
"multi-dataset": {
"tortoise-v2": {
"description": "Tortoise tts model https://github.com/neonbjb/tortoise-tts",
"github_rls_url": [
"https://app.coqui.ai/tts_model/autoregressive.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/clvp2.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/cvvp.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/diffusion_decoder.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/rlg_auto.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/rlg_diffuser.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/vocoder.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/mel_norms.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/config.json"
],
"commit": "c1875f6",
"default_vocoder": null,
"author": "@neonbjb - James Betker, @manmay-nakhashi Manmay Nakhashi",
"license": "apache 2.0"
}
},
"jenny": {
"jenny": {
"description": "VITS model trained with Jenny(Dioco) dataset. Named as Jenny as demanded by the license. Original URL for the model https://www.kaggle.com/datasets/noml4u/tts-models--en--jenny-dioco--vits",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.0_models/tts_models--en--jenny--jenny.zip",
"default_vocoder": null,
"commit": "ba40a1c",
"license": "custom - see https://github.com/dioco-group/jenny-tts-dataset#important",
"author": "@noml4u"
}
}
},
"es": {
"mai": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--es--mai--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/universal/libri-tts/fullband-melgan",
"commit": "",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
}
},
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--es--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"fr": {
"mai": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--fr--mai--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/universal/libri-tts/fullband-melgan",
"commit": null,
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
}
},
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--fr--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"uk": {
"mai": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--uk--mai--glow-tts.zip",
"author": "@robinhad",
"commit": "bdab788d",
"license": "MIT",
"contact": "",
"default_vocoder": "vocoder_models/uk/mai/multiband-melgan"
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--uk--mai--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"zh-CN": {
"baker": {
"tacotron2-DDC-GST": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--zh-CN--baker--tacotron2-DDC-GST.zip",
"commit": "unknown",
"author": "@kirianguiller",
"license": "apache 2.0",
"default_vocoder": null
}
}
},
"nl": {
"mai": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--nl--mai--tacotron2-DDC.zip",
"author": "@r-dh",
"license": "apache 2.0",
"default_vocoder": "vocoder_models/nl/mai/parallel-wavegan",
"stats_file": null,
"commit": "540d811"
}
},
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--nl--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"de": {
"thorsten": {
"tacotron2-DCA": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--de--thorsten--tacotron2-DCA.zip",
"default_vocoder": "vocoder_models/de/thorsten/fullband-melgan",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.0_models/tts_models--de--thorsten--vits.zip",
"default_vocoder": null,
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--de--thorsten--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/de/thorsten/hifigan_v1",
"description": "Thorsten-Dec2021-22k-DDC",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
}
},
"css10": {
"vits-neon": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--de--css10--vits.zip",
"default_vocoder": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause",
"commit": null
}
}
},
"ja": {
"kokoro": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--ja--kokoro--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/ja/kokoro/hifigan_v1",
"description": "Tacotron2 with Double Decoder Consistency trained with Kokoro Speech Dataset.",
"author": "@kaiidams",
"license": "apache 2.0",
"commit": "401fbd89"
}
}
},
"tr": {
"common-voice": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--tr--common-voice--glow-tts.zip",
"default_vocoder": "vocoder_models/tr/common-voice/hifigan",
"license": "MIT",
"description": "Turkish GlowTTS model using an unknown speaker from the Common-Voice dataset.",
"author": "Fatih Akademi",
"commit": null
}
}
},
"it": {
"mai_female": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_female--glow-tts.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_female--vits.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
}
},
"mai_male": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_male--glow-tts.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_male--vits.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
}
}
},
"ewe": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--ewe--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"hau": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--hau--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"lin": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--lin--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"tw_akuapem": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--tw_akuapem--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"tw_asante": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--tw_asante--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"yor": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--yor--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"hu": {
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--hu--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"el": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--el--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"fi": {
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--fi--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"hr": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--hr--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"lt": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--lt--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"lv": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--lv--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"mt": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--mt--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"pl": {
"mai_female": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--pl--mai_female--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"pt": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--pt--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"ro": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--ro--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"sk": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--sk--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"sl": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--sl--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"sv": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--sv--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"ca": {
"custom": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.1_models/tts_models--ca--custom--vits.zip",
"default_vocoder": null,
"commit": null,
"description": " It is trained from zero with 101460 utterances consisting of 257 speakers, approx 138 hours of speech. We used three datasets;\nFestcat and Google Catalan TTS (both TTS datasets) and also a part of Common Voice 8. It is trained with TTS v0.8.0.\nhttps://github.com/coqui-ai/TTS/discussions/930#discussioncomment-4466345",
"author": "@gullabi",
"license": "CC-BY-4.0"
}
}
},
"fa": {
"custom": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.1_models/tts_models--fa--custom--glow-tts.zip",
"default_vocoder": null,
"commit": null,
"description": "persian-tts-female-glow_tts model for text to speech purposes. Single-speaker female voice Trained on persian-tts-dataset-famale. \nThis model has no compatible vocoder thus the output quality is not very good. \nDataset: https://www.kaggle.com/datasets/magnoliasis/persian-tts-dataset-famale.",
"author": "@karim23657",
"license": "CC-BY-4.0"
}
}
},
"bn": {
"custom": {
"vits-male": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.13.3_models/tts_models--bn--custom--vits_male.zip",
"default_vocoder": null,
"commit": null,
"description": "Single speaker Bangla male model. For more information -> https://github.com/mobassir94/comprehensive-bangla-tts",
"author": "@mobassir94",
"license": "Apache 2.0"
},
"vits-female": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.13.3_models/tts_models--bn--custom--vits_female.zip",
"default_vocoder": null,
"commit": null,
"description": "Single speaker Bangla female model. For more information -> https://github.com/mobassir94/comprehensive-bangla-tts",
"author": "@mobassir94",
"license": "Apache 2.0"
}
}
},
"be": {
"common-voice": {
"glow-tts":{
"description": "Belarusian GlowTTS model created by @alex73 (Github).",
"github_rls_url":"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.16.6/tts_models--be--common-voice--glow-tts.zip",
"default_vocoder": "vocoder_models/be/common-voice/hifigan",
"commit": "c0aabb85",
"license": "CC-BY-SA 4.0",
"contact": "alex73mail@gmail.com"
}
}
}
},
"vocoder_models": {
"universal": {
"libri-tts": {
"wavegrad": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--universal--libri-tts--wavegrad.zip",
"commit": "ea976b0",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"fullband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--universal--libri-tts--fullband-melgan.zip",
"commit": "4132240",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
}
}
},
"en": {
"ek1": {
"wavegrad": {
"description": "EK1 en-rp wavegrad by NMStoker",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ek1--wavegrad.zip",
"commit": "c802255",
"license": "apache 2.0"
}
},
"ljspeech": {
"multiband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ljspeech--multiband-melgan.zip",
"commit": "ea976b0",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"hifigan_v2": {
"description": "HiFiGAN_v2 LJSpeech vocoder from https://arxiv.org/abs/2010.05646.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ljspeech--hifigan_v2.zip",
"commit": "bae2ad0f",
"author": "@erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
},
"univnet": {
"description": "UnivNet model finetuned on TacotronDDC_ph spectrograms for better compatibility.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ljspeech--univnet_v2.zip",
"commit": "4581e3d",
"author": "Eren @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
}
},
"blizzard2013": {
"hifigan_v2": {
"description": "HiFiGAN_v2 LJSpeech vocoder from https://arxiv.org/abs/2010.05646.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.0_models/vocoder_models--en--blizzard2013--hifigan_v2.zip",
"commit": "d6284e7",
"author": "Adam Froghyar @a-froghyar",
"license": "apache 2.0",
"contact": "adamfroghyar@gmail.com"
}
},
"vctk": {
"hifigan_v2": {
"description": "Finetuned and intended to be used with tts_models/en/vctk/sc-glow-tts",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--vctk--hifigan_v2.zip",
"commit": "2f07160",
"author": "Edresson Casanova",
"license": "apache 2.0",
"contact": ""
}
},
"sam": {
"hifigan_v2": {
"description": "Finetuned and intended to be used with tts_models/en/sam/tacotron_DDC",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--sam--hifigan_v2.zip",
"commit": "2f07160",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
}
}
},
"nl": {
"mai": {
"parallel-wavegan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--nl--mai--parallel-wavegan.zip",
"author": "@r-dh",
"license": "apache 2.0",
"commit": "unknown"
}
}
},
"de": {
"thorsten": {
"wavegrad": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--de--thorsten--wavegrad.zip",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"fullband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--de--thorsten--fullband-melgan.zip",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"hifigan_v1": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/vocoder_models--de--thorsten--hifigan_v1.zip",
"description": "HifiGAN vocoder model for Thorsten Neutral Dec2021 22k Samplerate Tacotron2 DDC model",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
}
}
},
"ja": {
"kokoro": {
"hifigan_v1": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--ja--kokoro--hifigan_v1.zip",
"description": "HifiGAN model trained for kokoro dataset by @kaiidams",
"author": "@kaiidams",
"license": "apache 2.0",
"commit": "3900448"
}
}
},
"uk": {
"mai": {
"multiband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--uk--mai--multiband-melgan.zip",
"author": "@robinhad",
"commit": "bdab788d",
"license": "MIT",
"contact": ""
}
}
},
"tr": {
"common-voice": {
"hifigan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--tr--common-voice--hifigan.zip",
"description": "HifiGAN model using an unknown speaker from the Common-Voice dataset.",
"author": "Fatih Akademi",
"license": "MIT",
"commit": null
}
}
},
"be": {
"common-voice": {
"hifigan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.16.6/vocoder_models--be--common-voice--hifigan.zip",
"description": "Belarusian HiFiGAN model created by @alex73 (Github).",
"author": "@alex73",
"license": "CC-BY-SA 4.0",
"commit": "c0aabb85"
}
}
}
},
"voice_conversion_models": {
"multilingual": {
"vctk": {
"freevc24": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.13.0_models/voice_conversion_models--multilingual--vctk--freevc24.zip",
"description": "FreeVC model trained on VCTK dataset from https://github.com/OlaWod/FreeVC",
"author": "Jing-Yi Li @OlaWod",
"license": "MIT",
"commit": null
}
}
}
}
}
================================================
FILE: docker/up@cpu/docker-compose.yml
================================================
services:
clone-voice:
image: jianchang512/clone-voice:main
container_name: clone-voice
environment:
- DEVICE=CPU
- LANG=zh
- PYTHONUNBUFFERED=1
ports:
- "9988:9988"
volumes:
- ./../../tts/tts_models--multilingual--multi-dataset--xtts_v2:/app/tts/tts_models--multilingual--multi-dataset--xtts_v2
- ./../../tts/voice_conversion_models--multilingual--vctk--freevc24:/app/tts/voice_conversion_models--multilingual--vctk--freevc24
- ./../../tts/wavlm:/app/tts/wavlm
- .models.json:/opt/conda/lib/python3.10/site-packages/TTS/.models.json
================================================
FILE: docker/up@gpu/.models.json
================================================
{
"tts_models": {
"multilingual": {
"multi-dataset": {
"xtts_v2": {
"description": "XTTS-v2.0.2 by Coqui with 16 languages.",
"hf_url": [
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/model.pth",
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/config.json",
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/vocab.json",
"https://hf-mirror.com/coqui/XTTS-v2/resolve/v2.0.2/hash.md5"
],
"model_hash": "5ce0502bfe3bc88dc8d9312b12a7558c",
"default_vocoder": null,
"commit": "480a6cdf7",
"license": "CPML",
"contact": "info@coqui.ai",
"tos_required": true
},
"xtts_v1.1": {
"description": "XTTS-v1.1 by Coqui with 14 languages, cross-language voice cloning and reference leak fixed.",
"hf_url": [
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/model.pth",
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/config.json",
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/vocab.json",
"https://hf-mirror.com/coqui/XTTS-v1/resolve/v1.1.2/hash.md5"
],
"model_hash": "7c62beaf58d39b729de287330dc254e7b515677416839b649a50e7cf74c3df59",
"default_vocoder": null,
"commit": "82910a63",
"license": "CPML",
"contact": "info@coqui.ai",
"tos_required": true
},
"your_tts": {
"description": "Your TTS model accompanying the paper https://arxiv.org/abs/2112.02418",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.1_models/tts_models--multilingual--multi-dataset--your_tts.zip",
"default_vocoder": null,
"commit": "e9a1953e",
"license": "CC BY-NC-ND 4.0",
"contact": "egolge@coqui.ai"
},
"bark": {
"description": "🐶 Bark TTS model released by suno-ai. You can find the original implementation in https://github.com/suno-ai/bark.",
"hf_url": [
"https://coqui.gateway.scarf.sh/hf/bark/coarse_2.pt",
"https://coqui.gateway.scarf.sh/hf/bark/fine_2.pt",
"https://app.coqui.ai/tts_model/text_2.pt",
"https://coqui.gateway.scarf.sh/hf/bark/config.json",
"https://coqui.gateway.scarf.sh/hf/bark/hubert.pt",
"https://coqui.gateway.scarf.sh/hf/bark/tokenizer.pth"
],
"default_vocoder": null,
"commit": "e9a1953e",
"license": "MIT",
"contact": "https://www.suno.ai/"
}
}
},
"bg": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--bg--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"cs": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--cs--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"da": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--da--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"et": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--et--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"ga": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--ga--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"en": {
"ek1": {
"tacotron2": {
"description": "EK1 en-rp tacotron2 by NMStoker",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ek1--tacotron2.zip",
"default_vocoder": "vocoder_models/en/ek1/wavegrad",
"commit": "c802255",
"license": "apache 2.0"
}
},
"ljspeech": {
"tacotron2-DDC": {
"description": "Tacotron2 with Double Decoder Consistency.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "bae2ad0f",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"tacotron2-DDC_ph": {
"description": "Tacotron2 with Double Decoder Consistency with phonemes.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--tacotron2-DDC_ph.zip",
"default_vocoder": "vocoder_models/en/ljspeech/univnet",
"commit": "3900448",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"glow-tts": {
"description": "",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--glow-tts.zip",
"stats_file": null,
"default_vocoder": "vocoder_models/en/ljspeech/multiband-melgan",
"commit": "",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"speedy-speech": {
"description": "Speedy Speech model trained on LJSpeech dataset using the Alignment Network for learning the durations.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--speedy-speech.zip",
"stats_file": null,
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "4581e3d",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"tacotron2-DCA": {
"description": "",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--tacotron2-DCA.zip",
"default_vocoder": "vocoder_models/en/ljspeech/multiband-melgan",
"commit": "",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"vits": {
"description": "VITS is an End2End TTS model trained on LJSpeech dataset with phonemes.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--vits.zip",
"default_vocoder": null,
"commit": "3900448",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"vits--neon": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--en--ljspeech--vits.zip",
"default_vocoder": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause",
"contact": null,
"commit": null
},
"fast_pitch": {
"description": "FastPitch model trained on LJSpeech using the Aligner Network",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--ljspeech--fast_pitch.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "b27b3ba",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
},
"overflow": {
"description": "Overflow model trained on LJSpeech",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.0_models/tts_models--en--ljspeech--overflow.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "3b1a28f",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
},
"neural_hmm": {
"description": "Neural HMM model trained on LJSpeech",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.11.0_models/tts_models--en--ljspeech--neural_hmm.zip",
"default_vocoder": "vocoder_models/en/ljspeech/hifigan_v2",
"commit": "3b1a28f",
"author": "Shivam Metha @shivammehta25",
"license": "apache 2.0",
"contact": "d83ee8fe45e3c0d776d4a865aca21d7c2ac324c4"
}
},
"vctk": {
"vits": {
"description": "VITS End2End TTS model trained on VCTK dataset with 109 different speakers with EN accent.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--vctk--vits.zip",
"default_vocoder": null,
"commit": "3900448",
"author": "Eren @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
},
"fast_pitch": {
"description": "FastPitch model trained on VCTK dataseset.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--vctk--fast_pitch.zip",
"default_vocoder": null,
"commit": "bdab788d",
"author": "Eren @erogol",
"license": "CC BY-NC-ND 4.0",
"contact": "egolge@coqui.ai"
}
},
"sam": {
"tacotron-DDC": {
"description": "Tacotron2 with Double Decoder Consistency trained with Aceenture's Sam dataset.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--en--sam--tacotron-DDC.zip",
"default_vocoder": "vocoder_models/en/sam/hifigan_v2",
"commit": "bae2ad0f",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.com"
}
},
"blizzard2013": {
"capacitron-t2-c50": {
"description": "Capacitron additions to Tacotron 2 with Capacity at 50 as in https://arxiv.org/pdf/1906.03402.pdf",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.0_models/tts_models--en--blizzard2013--capacitron-t2-c50.zip",
"commit": "d6284e7",
"default_vocoder": "vocoder_models/en/blizzard2013/hifigan_v2",
"author": "Adam Froghyar @a-froghyar",
"license": "apache 2.0",
"contact": "adamfroghyar@gmail.com"
},
"capacitron-t2-c150_v2": {
"description": "Capacitron additions to Tacotron 2 with Capacity at 150 as in https://arxiv.org/pdf/1906.03402.pdf",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.1_models/tts_models--en--blizzard2013--capacitron-t2-c150_v2.zip",
"commit": "a67039d",
"default_vocoder": "vocoder_models/en/blizzard2013/hifigan_v2",
"author": "Adam Froghyar @a-froghyar",
"license": "apache 2.0",
"contact": "adamfroghyar@gmail.com"
}
},
"multi-dataset": {
"tortoise-v2": {
"description": "Tortoise tts model https://github.com/neonbjb/tortoise-tts",
"github_rls_url": [
"https://app.coqui.ai/tts_model/autoregressive.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/clvp2.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/cvvp.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/diffusion_decoder.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/rlg_auto.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/rlg_diffuser.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/vocoder.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/mel_norms.pth",
"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.1_models/config.json"
],
"commit": "c1875f6",
"default_vocoder": null,
"author": "@neonbjb - James Betker, @manmay-nakhashi Manmay Nakhashi",
"license": "apache 2.0"
}
},
"jenny": {
"jenny": {
"description": "VITS model trained with Jenny(Dioco) dataset. Named as Jenny as demanded by the license. Original URL for the model https://www.kaggle.com/datasets/noml4u/tts-models--en--jenny-dioco--vits",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.14.0_models/tts_models--en--jenny--jenny.zip",
"default_vocoder": null,
"commit": "ba40a1c",
"license": "custom - see https://github.com/dioco-group/jenny-tts-dataset#important",
"author": "@noml4u"
}
}
},
"es": {
"mai": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--es--mai--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/universal/libri-tts/fullband-melgan",
"commit": "",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
}
},
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--es--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"fr": {
"mai": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--fr--mai--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/universal/libri-tts/fullband-melgan",
"commit": null,
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
}
},
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--fr--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"uk": {
"mai": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--uk--mai--glow-tts.zip",
"author": "@robinhad",
"commit": "bdab788d",
"license": "MIT",
"contact": "",
"default_vocoder": "vocoder_models/uk/mai/multiband-melgan"
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--uk--mai--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"zh-CN": {
"baker": {
"tacotron2-DDC-GST": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--zh-CN--baker--tacotron2-DDC-GST.zip",
"commit": "unknown",
"author": "@kirianguiller",
"license": "apache 2.0",
"default_vocoder": null
}
}
},
"nl": {
"mai": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--nl--mai--tacotron2-DDC.zip",
"author": "@r-dh",
"license": "apache 2.0",
"default_vocoder": "vocoder_models/nl/mai/parallel-wavegan",
"stats_file": null,
"commit": "540d811"
}
},
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--nl--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"de": {
"thorsten": {
"tacotron2-DCA": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--de--thorsten--tacotron2-DCA.zip",
"default_vocoder": "vocoder_models/de/thorsten/fullband-melgan",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.0_models/tts_models--de--thorsten--vits.zip",
"default_vocoder": null,
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--de--thorsten--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/de/thorsten/hifigan_v1",
"description": "Thorsten-Dec2021-22k-DDC",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
}
},
"css10": {
"vits-neon": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--de--css10--vits.zip",
"default_vocoder": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause",
"commit": null
}
}
},
"ja": {
"kokoro": {
"tacotron2-DDC": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--ja--kokoro--tacotron2-DDC.zip",
"default_vocoder": "vocoder_models/ja/kokoro/hifigan_v1",
"description": "Tacotron2 with Double Decoder Consistency trained with Kokoro Speech Dataset.",
"author": "@kaiidams",
"license": "apache 2.0",
"commit": "401fbd89"
}
}
},
"tr": {
"common-voice": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--tr--common-voice--glow-tts.zip",
"default_vocoder": "vocoder_models/tr/common-voice/hifigan",
"license": "MIT",
"description": "Turkish GlowTTS model using an unknown speaker from the Common-Voice dataset.",
"author": "Fatih Akademi",
"commit": null
}
}
},
"it": {
"mai_female": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_female--glow-tts.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_female--vits.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
}
},
"mai_male": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_male--glow-tts.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
},
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/tts_models--it--mai_male--vits.zip",
"default_vocoder": null,
"description": "GlowTTS model as explained on https://github.com/coqui-ai/TTS/issues/1148.",
"author": "@nicolalandro",
"license": "apache 2.0",
"commit": null
}
}
},
"ewe": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--ewe--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"hau": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--hau--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"lin": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--lin--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"tw_akuapem": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--tw_akuapem--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"tw_asante": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--tw_asante--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"yor": {
"openbible": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.2_models/tts_models--yor--openbible--vits.zip",
"default_vocoder": null,
"license": "CC-BY-SA 4.0",
"description": "Original work (audio and text) by Biblica available for free at www.biblica.com and open.bible.",
"author": "@coqui_ai",
"commit": "1b22f03"
}
}
},
"hu": {
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--hu--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"el": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--el--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"fi": {
"css10": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--fi--css10--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"hr": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--hr--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"lt": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--lt--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"lv": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--lv--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"mt": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--mt--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"pl": {
"mai_female": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--pl--mai_female--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"pt": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--pt--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"ro": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--ro--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"sk": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--sk--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"sl": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--sl--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"sv": {
"cv": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/tts_models--sv--cv--vits.zip",
"default_vocoder": null,
"commit": null,
"author": "@NeonGeckoCom",
"license": "bsd-3-clause"
}
}
},
"ca": {
"custom": {
"vits": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.1_models/tts_models--ca--custom--vits.zip",
"default_vocoder": null,
"commit": null,
"description": " It is trained from zero with 101460 utterances consisting of 257 speakers, approx 138 hours of speech. We used three datasets;\nFestcat and Google Catalan TTS (both TTS datasets) and also a part of Common Voice 8. It is trained with TTS v0.8.0.\nhttps://github.com/coqui-ai/TTS/discussions/930#discussioncomment-4466345",
"author": "@gullabi",
"license": "CC-BY-4.0"
}
}
},
"fa": {
"custom": {
"glow-tts": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.10.1_models/tts_models--fa--custom--glow-tts.zip",
"default_vocoder": null,
"commit": null,
"description": "persian-tts-female-glow_tts model for text to speech purposes. Single-speaker female voice Trained on persian-tts-dataset-famale. \nThis model has no compatible vocoder thus the output quality is not very good. \nDataset: https://www.kaggle.com/datasets/magnoliasis/persian-tts-dataset-famale.",
"author": "@karim23657",
"license": "CC-BY-4.0"
}
}
},
"bn": {
"custom": {
"vits-male": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.13.3_models/tts_models--bn--custom--vits_male.zip",
"default_vocoder": null,
"commit": null,
"description": "Single speaker Bangla male model. For more information -> https://github.com/mobassir94/comprehensive-bangla-tts",
"author": "@mobassir94",
"license": "Apache 2.0"
},
"vits-female": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.13.3_models/tts_models--bn--custom--vits_female.zip",
"default_vocoder": null,
"commit": null,
"description": "Single speaker Bangla female model. For more information -> https://github.com/mobassir94/comprehensive-bangla-tts",
"author": "@mobassir94",
"license": "Apache 2.0"
}
}
},
"be": {
"common-voice": {
"glow-tts":{
"description": "Belarusian GlowTTS model created by @alex73 (Github).",
"github_rls_url":"https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.16.6/tts_models--be--common-voice--glow-tts.zip",
"default_vocoder": "vocoder_models/be/common-voice/hifigan",
"commit": "c0aabb85",
"license": "CC-BY-SA 4.0",
"contact": "alex73mail@gmail.com"
}
}
}
},
"vocoder_models": {
"universal": {
"libri-tts": {
"wavegrad": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--universal--libri-tts--wavegrad.zip",
"commit": "ea976b0",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"fullband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--universal--libri-tts--fullband-melgan.zip",
"commit": "4132240",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
}
}
},
"en": {
"ek1": {
"wavegrad": {
"description": "EK1 en-rp wavegrad by NMStoker",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ek1--wavegrad.zip",
"commit": "c802255",
"license": "apache 2.0"
}
},
"ljspeech": {
"multiband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ljspeech--multiband-melgan.zip",
"commit": "ea976b0",
"author": "Eren Gölge @erogol",
"license": "MPL",
"contact": "egolge@coqui.com"
},
"hifigan_v2": {
"description": "HiFiGAN_v2 LJSpeech vocoder from https://arxiv.org/abs/2010.05646.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ljspeech--hifigan_v2.zip",
"commit": "bae2ad0f",
"author": "@erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
},
"univnet": {
"description": "UnivNet model finetuned on TacotronDDC_ph spectrograms for better compatibility.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--ljspeech--univnet_v2.zip",
"commit": "4581e3d",
"author": "Eren @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
}
},
"blizzard2013": {
"hifigan_v2": {
"description": "HiFiGAN_v2 LJSpeech vocoder from https://arxiv.org/abs/2010.05646.",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.7.0_models/vocoder_models--en--blizzard2013--hifigan_v2.zip",
"commit": "d6284e7",
"author": "Adam Froghyar @a-froghyar",
"license": "apache 2.0",
"contact": "adamfroghyar@gmail.com"
}
},
"vctk": {
"hifigan_v2": {
"description": "Finetuned and intended to be used with tts_models/en/vctk/sc-glow-tts",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--vctk--hifigan_v2.zip",
"commit": "2f07160",
"author": "Edresson Casanova",
"license": "apache 2.0",
"contact": ""
}
},
"sam": {
"hifigan_v2": {
"description": "Finetuned and intended to be used with tts_models/en/sam/tacotron_DDC",
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--en--sam--hifigan_v2.zip",
"commit": "2f07160",
"author": "Eren Gölge @erogol",
"license": "apache 2.0",
"contact": "egolge@coqui.ai"
}
}
},
"nl": {
"mai": {
"parallel-wavegan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--nl--mai--parallel-wavegan.zip",
"author": "@r-dh",
"license": "apache 2.0",
"commit": "unknown"
}
}
},
"de": {
"thorsten": {
"wavegrad": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--de--thorsten--wavegrad.zip",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"fullband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--de--thorsten--fullband-melgan.zip",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
},
"hifigan_v1": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.8.0_models/vocoder_models--de--thorsten--hifigan_v1.zip",
"description": "HifiGAN vocoder model for Thorsten Neutral Dec2021 22k Samplerate Tacotron2 DDC model",
"author": "@thorstenMueller",
"license": "apache 2.0",
"commit": "unknown"
}
}
},
"ja": {
"kokoro": {
"hifigan_v1": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--ja--kokoro--hifigan_v1.zip",
"description": "HifiGAN model trained for kokoro dataset by @kaiidams",
"author": "@kaiidams",
"license": "apache 2.0",
"commit": "3900448"
}
}
},
"uk": {
"mai": {
"multiband-melgan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--uk--mai--multiband-melgan.zip",
"author": "@robinhad",
"commit": "bdab788d",
"license": "MIT",
"contact": ""
}
}
},
"tr": {
"common-voice": {
"hifigan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.6.1_models/vocoder_models--tr--common-voice--hifigan.zip",
"description": "HifiGAN model using an unknown speaker from the Common-Voice dataset.",
"author": "Fatih Akademi",
"license": "MIT",
"commit": null
}
}
},
"be": {
"common-voice": {
"hifigan": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.16.6/vocoder_models--be--common-voice--hifigan.zip",
"description": "Belarusian HiFiGAN model created by @alex73 (Github).",
"author": "@alex73",
"license": "CC-BY-SA 4.0",
"commit": "c0aabb85"
}
}
}
},
"voice_conversion_models": {
"multilingual": {
"vctk": {
"freevc24": {
"github_rls_url": "https://ghp.ci/https://github.com/coqui-ai/TTS/releases/download/v0.13.0_models/voice_conversion_models--multilingual--vctk--freevc24.zip",
"description": "FreeVC model trained on VCTK dataset from https://github.com/OlaWod/FreeVC",
"author": "Jing-Yi Li @OlaWod",
"license": "MIT",
"commit": null
}
}
}
}
}
================================================
FILE: docker/up@gpu/docker-compose.yml
================================================
services:
clone-voice:
image: jianchang512/clone-voice:main
container_name: clone-voice
environment:
- DEVICE=CUDA
- LANG=zh
- PYTHONUNBUFFERED=1
ports:
- "9988:9988"
volumes:
- ./../../tts/tts_models--multilingual--multi-dataset--xtts_v2:/app/tts/tts_models--multilingual--multi-dataset--xtts_v2
- ./../../tts/voice_conversion_models--multilingual--vctk--freevc24:/app/tts/voice_conversion_models--multilingual--vctk--freevc24
- ./../../tts/wavlm:/app/tts/wavlm
- .models.json:/opt/conda/lib/python3.10/site-packages/TTS/.models.json
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [ gpu ]
================================================
FILE: environment.yml
================================================
name: clone-voice
channels:
- conda-forge
- pytorch
- nvidia
dependencies:
- python=3.10
- pytorch==2.5.1
- pytorch-cuda==12.4
- ffmpeg==7.1.0
- pip:
- huggingface-hub
- -r ./requirements.txt
================================================
FILE: models/faster/models--Systran--faster-whisper-medium/refs/main
================================================
ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66
================================================
FILE: models/faster/models--Systran--faster-whisper-medium/snapshots/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/config.json
================================================
{
"alignment_heads": [
[
3,
1
],
[
4,
2
],
[
4,
3
],
[
4,
7
],
[
5,
1
],
[
5,
2
],
[
5,
4
],
[
5,
6
]
],
"lang_ids": [
50259,
50260,
50261,
50262,
50263,
50264,
50265,
50266,
50267,
50268,
50269,
50270,
50271,
50272,
50273,
50274,
50275,
50276,
50277,
50278,
50279,
50280,
50281,
50282,
50283,
50284,
50285,
50286,
50287,
50288,
50289,
50290,
50291,
50292,
50293,
50294,
50295,
50296,
50297,
50298,
50299,
50300,
50301,
50302,
50303,
50304,
50305,
50306,
50307,
50308,
50309,
50310,
50311,
50312,
50313,
50314,
50315,
50316,
50317,
50318,
50319,
50320,
50321,
50322,
50323,
50324,
50325,
50326,
50327,
50328,
50329,
50330,
50331,
50332,
50333,
50334,
50335,
50336,
50337,
50338,
50339,
50340,
50341,
50342,
50343,
50344,
50345,
50346,
50347,
50348,
50349,
50350,
50351,
50352,
50353,
50354,
50355,
50356,
50357
],
"suppress_ids": [
1,
2,
7,
8,
9,
10,
14,
25,
26,
27,
28,
29,
31,
58,
59,
60,
61,
62,
63,
90,
91,
92,
93,
359,
503,
522,
542,
873,
893,
902,
918,
922,
931,
1350,
1853,
1982,
2460,
2627,
3246,
3253,
3268,
3536,
3846,
3961,
4183,
4667,
6585,
6647,
7273,
9061,
9383,
10428,
10929,
11938,
12033,
12331,
12562,
13793,
14157,
14635,
15265,
15618,
16553,
16604,
18362,
18956,
20075,
21675,
22520,
26130,
26161,
26435,
28279,
29464,
31650,
32302,
32470,
36865,
42863,
47425,
49870,
50254,
50258,
50358,
50359,
50360,
50361,
50362
],
"suppress_ids_begin": [
220,
50257
]
}
================================================
FILE: models/faster/models--Systran--faster-whisper-medium/snapshots/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/tokenizer.json
================================================
{
"version": "1.0",
"truncation": null,
"padding": null,
"added_tokens": [
{
"id": 50257,
"content": "<|endoftext|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50258,
"content": "<|startoftranscript|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50259,
"content": "<|en|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50260,
"content": "<|zh|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50261,
"content": "<|de|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50262,
"content": "<|es|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50263,
"content": "<|ru|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50264,
"content": "<|ko|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50265,
"content": "<|fr|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50266,
"content": "<|ja|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50267,
"content": "<|pt|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50268,
"content": "<|tr|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50269,
"content": "<|pl|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50270,
"content": "<|ca|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50271,
"content": "<|nl|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50272,
"content": "<|ar|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50273,
"content": "<|sv|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50274,
"content": "<|it|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50275,
"content": "<|id|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50276,
"content": "<|hi|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50277,
"content": "<|fi|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50278,
"content": "<|vi|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50279,
"content": "<|he|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50280,
"content": "<|uk|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50281,
"content": "<|el|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50282,
"content": "<|ms|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50283,
"content": "<|cs|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50284,
"content": "<|ro|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50285,
"content": "<|da|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50286,
"content": "<|hu|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50287,
"content": "<|ta|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50288,
"content": "<|no|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50289,
"content": "<|th|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50290,
"content": "<|ur|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50291,
"content": "<|hr|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50292,
"content": "<|bg|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50293,
"content": "<|lt|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50294,
"content": "<|la|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50295,
"content": "<|mi|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50296,
"content": "<|ml|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50297,
"content": "<|cy|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50298,
"content": "<|sk|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50299,
"content": "<|te|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50300,
"content": "<|fa|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50301,
"content": "<|lv|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50302,
"content": "<|bn|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50303,
"content": "<|sr|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50304,
"content": "<|az|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50305,
"content": "<|sl|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50306,
"content": "<|kn|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
},
{
"id": 50307,
"content": "<|et|>",
gitextract_l1kjskog/ ├── .dockerignore ├── .github/ │ ├── FUNDING.yml │ └── workflows/ │ └── docker-image-tag-commit.yml ├── .gitignore ├── .vscode/ │ ├── launch.json │ └── tasks.json ├── LICENSE ├── README.md ├── README_EN.md ├── app.py ├── appdingzhi.py ├── change.md ├── clone/ │ ├── __init__.py │ ├── cfg.py │ ├── character.json │ └── logic.py ├── code_dev.py ├── docker/ │ ├── build@source/ │ │ └── dockerfile │ ├── up@cpu/ │ │ ├── .models.json │ │ └── docker-compose.yml │ └── up@gpu/ │ ├── .models.json │ └── docker-compose.yml ├── environment.yml ├── models/ │ ├── faster/ │ │ └── models--Systran--faster-whisper-medium/ │ │ ├── refs/ │ │ │ └── main │ │ └── snapshots/ │ │ └── ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/ │ │ ├── config.json │ │ ├── tokenizer.json │ │ └── vocabulary.txt │ └── tts/ │ └── run/ │ └── training/ │ └── XTTS_v2.0_original_model_files/ │ ├── config.json │ └── vocab.json ├── params.json ├── requirements.txt ├── runapp.bat ├── runtrain.bat ├── static/ │ └── js/ │ └── layer/ │ ├── layer.js │ ├── mobile/ │ │ ├── layer.js │ │ └── need/ │ │ └── layer.css │ └── theme/ │ └── default/ │ └── layer.css ├── templates/ │ ├── index.html │ └── txt.html ├── test.py ├── testapi.py ├── train.py ├── tts/ │ └── 模型目录.txt ├── utils/ │ ├── __init__.py │ ├── cfg.py │ └── formatter.py ├── version.json └── xtts_demo.py
SYMBOL INDEX (72 symbols across 10 files)
FILE: app.py
function static_files (line 60) | def static_files(filename):
function index (line 65) | def index():
function upload (line 79) | def upload():
function init (line 118) | def init():
function isstart (line 130) | def isstart():
function apitts (line 136) | def apitts():
function tts (line 241) | def tts():
function sts (line 345) | def sts():
function onoroff (line 387) | def onoroff():
function checkupdate (line 410) | def checkupdate():
function stsstatus (line 414) | def stsstatus():
FILE: appdingzhi.py
class CustomRequestHandler (line 29) | class CustomRequestHandler(WSGIHandler):
method log_request (line 30) | def log_request(self):
function static_files (line 62) | def static_files(filename):
function index (line 67) | def index():
function txt (line 76) | def txt():
function upload (line 87) | def upload():
function init (line 126) | def init():
function isstart (line 137) | def isstart():
function apitts (line 145) | def apitts():
function ttslistjindu (line 225) | def ttslistjindu():
function detail_task (line 229) | def detail_task(*pams):
function ttslist (line 332) | def ttslist():
function tts (line 367) | def tts():
function sts (line 457) | def sts():
function checkupdate (line 496) | def checkupdate():
FILE: clone/cfg.py
function setorget_proxy (line 24) | def setorget_proxy():
function get_models (line 57) | def get_models(path):
FILE: clone/logic.py
function updatecache (line 26) | def updatecache():
function ttsloop (line 43) | def ttsloop():
function stsloop (line 78) | def stsloop():
function create_tts (line 116) | def create_tts(*, text, voice, language, filename, speed=1.0,model=""):
function merge_audio_segments (line 139) | def merge_audio_segments(text_list,is_srt=True):
function openweb (line 200) | def openweb(web_address):
function format_srt (line 224) | def format_srt(content):
function get_subtitle_from_srt (line 274) | def get_subtitle_from_srt(srtfile):
function get_subtitle_from_srt0 (line 305) | def get_subtitle_from_srt0(txt):
function checkupdate (line 353) | def checkupdate():
function clear_gpu_cache (line 365) | def clear_gpu_cache():
function load_model (line 373) | def load_model(name):
function run_tts (line 407) | def run_tts(name):
FILE: code_dev.py
function updatecache (line 12) | def updatecache():
FILE: static/js/layer/layer.js
function e (line 2) | function e(){var e=a.cancel&&a.cancel(t.index,n);e===!1||r.close(t.index)}
function o (line 2) | function o(e,t,i){var n=new Image;return n.src=e,n.complete?t(n):(n.onlo...
FILE: test.py
function get_models (line 6) | def get_models(path):
FILE: train.py
function clear_gpu_cache (line 42) | def clear_gpu_cache():
function load_model (line 48) | def load_model(xtts_checkpoint, xtts_config, xtts_vocab):
function run_tts (line 65) | def run_tts(lang, tts_text, speaker_audio_file):
class Logger (line 98) | class Logger:
method __init__ (line 99) | def __init__(self, filename="log.out"):
method write (line 104) | def write(self, message):
method flush (line 108) | def flush(self):
method isatty (line 112) | def isatty(self):
function read_logs (line 130) | def read_logs():
function openweb (line 135) | def openweb(port):
function train_model (line 284) | def train_model(language, train_text, eval_text,trainfile,evalfile):
function preprocess_dataset (line 325) | def preprocess_dataset(audio_path, language, progress=gr.Progress(track...
function move_to_clone (line 359) | def move_to_clone(model_name,model_file,vocab,cfg,audio_file):
FILE: utils/formatter.py
function list_audios (line 26) | def list_audios(basePath, contains=None):
function list_files (line 30) | def list_files(basePath, validExts=None, contains=None):
function format_audio_list (line 49) | def format_audio_list(audio_files, target_language="en", out_path=None, ...
FILE: xtts_demo.py
function clear_gpu_cache (line 23) | def clear_gpu_cache():
function load_model (line 29) | def load_model(xtts_checkpoint, xtts_config, xtts_vocab):
function run_tts (line 45) | def run_tts(lang, tts_text, speaker_audio_file):
class Logger (line 73) | class Logger:
method __init__ (line 74) | def __init__(self, filename="log.out"):
method write (line 79) | def write(self, message):
method flush (line 83) | def flush(self):
method isatty (line 87) | def isatty(self):
function read_logs (line 105) | def read_logs():
function train_model (line 206) | def train_model(language, train_csv, eval_csv, num_epochs, batch_size, g...
function preprocess_dataset (line 228) | def preprocess_dataset(audio_path, language, progress=gr.Progress(track...
Condensed preview — 48 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (3,501K chars).
[
{
"path": ".dockerignore",
"chars": 171,
"preview": ".git/\r\n.github/\r\n.vscode/\r\ncache/\r\ndocker/\r\ntts/\r\n.dockerignore\r\n.gitignore\r\n.env\r\napp.log\r\nenvironment.yml\r\nrunapp.bat\r"
},
{
"path": ".github/FUNDING.yml",
"chars": 777,
"preview": "# These are supported funding model platforms\n\ngithub: # Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [u"
},
{
"path": ".github/workflows/docker-image-tag-commit.yml",
"chars": 2126,
"preview": "\nname: Docker Image Build/Publish tag with commit\n\non:\n push:\n branches:\n - 'main'\n workflow_dispatch:\n inp"
},
{
"path": ".gitignore",
"chars": 541,
"preview": ".idea/\n*.pyc\n*.pyd\n.DS_Store\n__pycache__\nscripts\n\nku\nbuild\ndist\ndocs\ninclude\nLib\nnotebooks\nrecipes\nshare\nvenv\ntests\ndev\n"
},
{
"path": ".vscode/launch.json",
"chars": 824,
"preview": "{\r\n \"version\": \"0.2.0\",\r\n \"configurations\": [\r\n {\r\n \"name\": \"debugpy: code_dev\",\r\n \"t"
},
{
"path": ".vscode/tasks.json",
"chars": 3349,
"preview": "{\n \"version\": \"2.0.0\",\n \"tasks\": [\n {\n \"label\": \"docker: compose up@gpu\",\n \"type\": \"s"
},
{
"path": "LICENSE",
"chars": 4492,
"preview": "本项目所用模型为[coqui.ai](https://coqui.ai/)出品的xtts_v2,模型开源协议为[Coqui Public Model License 1.0.0](https://coqui.ai/cpml.txt),使用本"
},
{
"path": "README.md",
"chars": 5923,
"preview": "[English README](./README_EN.md) / [捐助项目](https://github.com/jianchang512/pyvideotrans/issues/80) / [Discord](https://d"
},
{
"path": "README_EN.md",
"chars": 8168,
"preview": "[简体中文](./README.md) / [Discord](https://discord.gg/TMCM2PfHzQ) / [Buy me a coffee](https://ko-fi.com/jianchang512) / [Tw"
},
{
"path": "app.py",
"chars": 16161,
"preview": "import datetime\nimport logging\nimport queue\nimport re\nimport threading\nimport time\nimport sys\nfrom flask import Flask, r"
},
{
"path": "appdingzhi.py",
"chars": 19899,
"preview": "import datetime\nimport logging\nimport re\nimport threading\nimport time\nimport sys\nfrom flask import Flask, request, rende"
},
{
"path": "change.md",
"chars": 2824,
"preview": "ffmpeg -y -i cn.mp4 -i cn.wav -map '0:v' -map '1:a' -c:v libx264 -c:a aac cnout.mp4\nffmpeg -y -i en.mp4 -i en.wav -map "
},
{
"path": "clone/__init__.py",
"chars": 23,
"preview": "VERSION=908\nver=\"0.908\""
},
{
"path": "clone/cfg.py",
"chars": 5121,
"preview": "import locale\nimport os\nimport queue\nimport re\nimport sys\nimport threading\n\nimport torch\nfrom dotenv import load_dotenv\n"
},
{
"path": "clone/character.json",
"chars": 207,
"preview": "{\n \"en\": 250,\n \"de\": 253,\n \"fr\": 273,\n \"es\": 239,\n \"it\": 213,\n \"pt\": 203,\n \"pl\": 224,\n \"zh\": 82,\n \"ar\": 166,\n "
},
{
"path": "clone/logic.py",
"chars": 16570,
"preview": "import hashlib\nimport json\nimport os\nimport re\nimport shutil\nimport tempfile\nimport threading\nimport time\nimport webbrow"
},
{
"path": "code_dev.py",
"chars": 1460,
"preview": "import torch\nimport os\nrootdir=os.getcwd()\nos.environ['TTS_HOME']=rootdir\n\nfrom TTS.api import TTS\nfrom dotenv import lo"
},
{
"path": "docker/build@source/dockerfile",
"chars": 618,
"preview": "\r\nFROM pytorch/pytorch:2.3.1-cuda12.1-cudnn8-runtime\r\n\r\nWORKDIR /app\r\n\r\nRUN apt-get update && apt-get install -y \\\r\n "
},
{
"path": "docker/up@cpu/.models.json",
"chars": 47011,
"preview": "{\n \"tts_models\": {\n \"multilingual\": {\n \"multi-dataset\": {\n \"xtts_v2\": {\n "
},
{
"path": "docker/up@cpu/docker-compose.yml",
"chars": 623,
"preview": "\r\n\r\nservices:\r\n clone-voice:\r\n image: jianchang512/clone-voice:main\r\n container_name: clone-voice\r\n environmen"
},
{
"path": "docker/up@gpu/.models.json",
"chars": 47011,
"preview": "{\n \"tts_models\": {\n \"multilingual\": {\n \"multi-dataset\": {\n \"xtts_v2\": {\n "
},
{
"path": "docker/up@gpu/docker-compose.yml",
"chars": 765,
"preview": "\r\n\r\nservices:\r\n clone-voice:\r\n image: jianchang512/clone-voice:main\r\n container_name: clone-voice\r\n environmen"
},
{
"path": "environment.yml",
"chars": 235,
"preview": "name: clone-voice\r\nchannels:\r\n - conda-forge\r\n - pytorch\r\n - nvidia\r\ndependencies:\r\n - python=3.10\r\n\r\n - pytorch==2"
},
{
"path": "models/faster/models--Systran--faster-whisper-medium/refs/main",
"chars": 40,
"preview": "ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66"
},
{
"path": "models/faster/models--Systran--faster-whisper-medium/snapshots/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/config.json",
"chars": 2309,
"preview": "{\n \"alignment_heads\": [\n [\n 3,\n 1\n ],\n [\n 4,\n 2\n ],\n [\n 4,\n 3\n ],\n ["
},
{
"path": "models/faster/models--Systran--faster-whisper-medium/snapshots/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/tokenizer.json",
"chars": 2028970,
"preview": "{\n \"version\": \"1.0\",\n \"truncation\": null,\n \"padding\": null,\n \"added_tokens\": [\n {\n \"id\": 50257,\n \"conte"
},
{
"path": "models/faster/models--Systran--faster-whisper-medium/snapshots/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/vocabulary.txt",
"chars": 372645,
"preview": "!\n\"\n#\n$\n%\n&\n'\n(\n)\n*\n+\n,\n-\n.\n/\n0\n1\n2\n3\n4\n5\n6\n7\n8\n9\n:\n;\n<\n=\n>\n?\n@\nA\nB\nC\nD\nE\nF\nG\nH\nI\nJ\nK\nL\nM\nN\nO\nP\nQ\nR\nS\nT\nU\nV\nW\nX\nY\nZ\n[\n\\\n"
},
{
"path": "models/tts/run/training/XTTS_v2.0_original_model_files/config.json",
"chars": 4368,
"preview": "{\n \"output_path\": \"output\",\n \"logger_uri\": null,\n \"run_name\": \"run\",\n \"project_name\": null,\n \"run_descrip"
},
{
"path": "models/tts/run/training/XTTS_v2.0_original_model_files/vocab.json",
"chars": 347870,
"preview": "{\n \"version\": \"1.0\",\n \"truncation\": null,\n \"padding\": null,\n \"added_tokens\": [\n {\n \"id\": 0"
},
{
"path": "params.json",
"chars": 101,
"preview": "{\n\"port\":5003,\n\"out_path\":\"\",\n\"num_epochs\":4,\n\"batch_size\":2,\n\"grad_acumm\":1,\n\"max_audio_length\":10\n}"
},
{
"path": "requirements.txt",
"chars": 3390,
"preview": "absl-py==2.0.0\naiofiles==23.2.1\naiohttp==3.9.1\naiosignal==1.3.1\naltair==5.2.0\naltgraph==0.17.4\nannotated-types==0.6.0\nan"
},
{
"path": "runapp.bat",
"chars": 58,
"preview": "@echo off\n\n%cd%\\venv\\scripts\\python.exe %cd%\\app.py\n\npause"
},
{
"path": "runtrain.bat",
"chars": 44,
"preview": "@echo off\n.\\venv\\scripts\\python.exe train.py"
},
{
"path": "static/js/layer/layer.js",
"chars": 22724,
"preview": "/*! layer-v3.5.1 Web 通用弹出层组件 MIT License */\n ;!function(e,t){\"use strict\";var i,n,a=e.layui&&layui.define,o={getPath:fun"
},
{
"path": "static/js/layer/mobile/layer.js",
"chars": 3256,
"preview": "/*! layer mobile-v2.0.0 Web 通用弹出层组件 MIT License */\n ;!function(e){\"use strict\";var t=document,n=\"querySelectorAll\",i=\"ge"
},
{
"path": "static/js/layer/mobile/need/layer.css",
"chars": 5260,
"preview": ".layui-m-layer{position:relative;z-index:19891014}.layui-m-layer *{-webkit-box-sizing:content-box;-moz-box-sizing:conten"
},
{
"path": "static/js/layer/theme/default/layer.css",
"chars": 14271,
"preview": ".layui-layer-imgbar,.layui-layer-imgtit a,.layui-layer-tab .layui-layer-title span,.layui-layer-title{text-overflow:elli"
},
{
"path": "templates/index.html",
"chars": 32757,
"preview": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width"
},
{
"path": "templates/txt.html",
"chars": 20180,
"preview": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width"
},
{
"path": "test.py",
"chars": 232,
"preview": "\nimport os\nimport re\n\n\ndef get_models(path):\n objs={}\n for it in os.listdir(path):\n if re.match(r'^[0-9a-zA"
},
{
"path": "testapi.py",
"chars": 307,
"preview": "import requests\nimport os\n#\n# res=requests.post(\"http://127.0.0.1:9988/apitts\",data={\"text\":\"hello,everyone,you are my f"
},
{
"path": "train.py",
"chars": 15137,
"preview": "import argparse\nimport os\nimport sys\nimport tempfile\nimport threading\nimport webbrowser\nimport time\n\nimport gradio as gr"
},
{
"path": "tts/模型目录.txt",
"chars": 168,
"preview": "该目录下有3个模型文件夹,如下,源码版首先执行 python code_dev.py 将自动下载模型到此。需全局代理\ntts_models--multilingual--multi-dataset--xtts_v2\nvoice_conver"
},
{
"path": "utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "utils/cfg.py",
"chars": 544,
"preview": "import os,sys\nrootdir=os.getcwd()\n\nZH_PROMPT=\"生亦何欢,生亦何哀,不亦快哉。\"\n\nTTSMODEL_DIR=os.path.join(rootdir,'models','tts')\nif not"
},
{
"path": "utils/formatter.py",
"chars": 7601,
"preview": "import os\nimport gc\nimport torchaudio\nimport pandas\nfrom faster_whisper import WhisperModel\nfrom glob import glob\n\nfrom "
},
{
"path": "version.json",
"chars": 42,
"preview": "{\n\"version\":\"v0.907\",\n\"version_num\":907\n}\n"
},
{
"path": "xtts_demo.py",
"chars": 11716,
"preview": "import argparse\nimport os\nimport sys\nimport tempfile\n\nimport gradio as gr\nimport librosa.display\nimport numpy as np\n\nimp"
}
]
About this extraction
This page contains the full source code of the jianchang512/clone-voice GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 48 files (2.9 MB), approximately 772.0k tokens, and a symbol index with 72 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.